KR20100058541A - 생물학적 활성 폴리펩티드의 특성을 변경하기 위한 조성물 및 방법 - Google Patents
생물학적 활성 폴리펩티드의 특성을 변경하기 위한 조성물 및 방법 Download PDFInfo
- Publication number
- KR20100058541A KR20100058541A KR1020107005458A KR20107005458A KR20100058541A KR 20100058541 A KR20100058541 A KR 20100058541A KR 1020107005458 A KR1020107005458 A KR 1020107005458A KR 20107005458 A KR20107005458 A KR 20107005458A KR 20100058541 A KR20100058541 A KR 20100058541A
- Authority
- KR
- South Korea
- Prior art keywords
- polypeptide
- amino acids
- auxiliary
- glycine
- residues
- Prior art date
Links
Images



















































































Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/30—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants from tumour cells
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P1/00—Drugs for disorders of the alimentary tract or the digestive system
- A61P1/02—Stomatological preparations, e.g. drugs for caries, aphtae, periodontitis
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P1/00—Drugs for disorders of the alimentary tract or the digestive system
- A61P1/04—Drugs for disorders of the alimentary tract or the digestive system for ulcers, gastritis or reflux esophagitis, e.g. antacids, inhibitors of acid secretion, mucosal protectants
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P1/00—Drugs for disorders of the alimentary tract or the digestive system
- A61P1/16—Drugs for disorders of the alimentary tract or the digestive system for liver or gallbladder disorders, e.g. hepatoprotective agents, cholagogues, litholytics
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P11/00—Drugs for disorders of the respiratory system
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
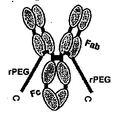
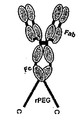
- A61P11/00—Drugs for disorders of the respiratory system
- A61P11/06—Antiasthmatics
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P13/00—Drugs for disorders of the urinary system
- A61P13/12—Drugs for disorders of the urinary system of the kidneys
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P15/00—Drugs for genital or sexual disorders; Contraceptives
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P15/00—Drugs for genital or sexual disorders; Contraceptives
- A61P15/10—Drugs for genital or sexual disorders; Contraceptives for impotence
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P17/00—Drugs for dermatological disorders
- A61P17/02—Drugs for dermatological disorders for treating wounds, ulcers, burns, scars, keloids, or the like
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P17/00—Drugs for dermatological disorders
- A61P17/06—Antipsoriatics
-
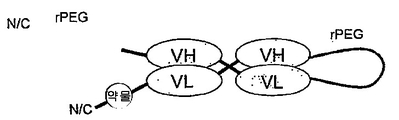
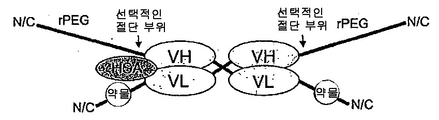
- A—HUMAN NECESSITIES
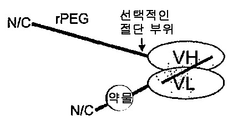
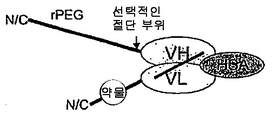
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P19/00—Drugs for skeletal disorders
- A61P19/02—Drugs for skeletal disorders for joint disorders, e.g. arthritis, arthrosis
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P19/00—Drugs for skeletal disorders
- A61P19/08—Drugs for skeletal disorders for bone diseases, e.g. rachitism, Paget's disease
- A61P19/10—Drugs for skeletal disorders for bone diseases, e.g. rachitism, Paget's disease for osteoporosis
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P21/00—Drugs for disorders of the muscular or neuromuscular system
- A61P21/04—Drugs for disorders of the muscular or neuromuscular system for myasthenia gravis
-
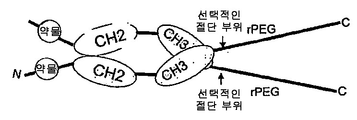
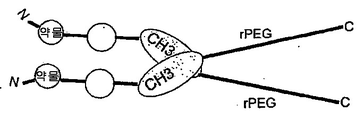
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P25/00—Drugs for disorders of the nervous system
- A61P25/04—Centrally acting analgesics, e.g. opioids
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P25/00—Drugs for disorders of the nervous system
- A61P25/14—Drugs for disorders of the nervous system for treating abnormal movements, e.g. chorea, dyskinesia
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P25/00—Drugs for disorders of the nervous system
- A61P25/28—Drugs for disorders of the nervous system for treating neurodegenerative disorders of the central nervous system, e.g. nootropic agents, cognition enhancers, drugs for treating Alzheimer's disease or other forms of dementia
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P27/00—Drugs for disorders of the senses
- A61P27/02—Ophthalmic agents
- A61P27/06—Antiglaucoma agents or miotics
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P29/00—Non-central analgesic, antipyretic or antiinflammatory agents, e.g. antirheumatic agents; Non-steroidal antiinflammatory drugs [NSAID]
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P3/00—Drugs for disorders of the metabolism
- A61P3/04—Anorexiants; Antiobesity agents
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P3/00—Drugs for disorders of the metabolism
- A61P3/08—Drugs for disorders of the metabolism for glucose homeostasis
- A61P3/10—Drugs for disorders of the metabolism for glucose homeostasis for hyperglycaemia, e.g. antidiabetics
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P31/00—Antiinfectives, i.e. antibiotics, antiseptics, chemotherapeutics
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P31/00—Antiinfectives, i.e. antibiotics, antiseptics, chemotherapeutics
- A61P31/04—Antibacterial agents
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P31/00—Antiinfectives, i.e. antibiotics, antiseptics, chemotherapeutics
- A61P31/12—Antivirals
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P31/00—Antiinfectives, i.e. antibiotics, antiseptics, chemotherapeutics
- A61P31/12—Antivirals
- A61P31/14—Antivirals for RNA viruses
- A61P31/18—Antivirals for RNA viruses for HIV
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
- A61P35/02—Antineoplastic agents specific for leukemia
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P37/00—Drugs for immunological or allergic disorders
- A61P37/08—Antiallergic agents
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P43/00—Drugs for specific purposes, not provided for in groups A61P1/00-A61P41/00
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P5/00—Drugs for disorders of the endocrine system
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P5/00—Drugs for disorders of the endocrine system
- A61P5/24—Drugs for disorders of the endocrine system of the sex hormones
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P7/00—Drugs for disorders of the blood or the extracellular fluid
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P7/00—Drugs for disorders of the blood or the extracellular fluid
- A61P7/02—Antithrombotic agents; Anticoagulants; Platelet aggregation inhibitors
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P7/00—Drugs for disorders of the blood or the extracellular fluid
- A61P7/06—Antianaemics
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P9/00—Drugs for disorders of the cardiovascular system
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P9/00—Drugs for disorders of the cardiovascular system
- A61P9/10—Drugs for disorders of the cardiovascular system for treating ischaemic or atherosclerotic diseases, e.g. antianginal drugs, coronary vasodilators, drugs for myocardial infarction, retinopathy, cerebrovascula insufficiency, renal arteriosclerosis
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P9/00—Drugs for disorders of the cardiovascular system
- A61P9/12—Antihypertensives
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/52—Cytokines; Lymphokines; Interferons
- C07K14/53—Colony-stimulating factor [CSF]
- C07K14/535—Granulocyte CSF; Granulocyte-macrophage CSF
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/52—Cytokines; Lymphokines; Interferons
- C07K14/555—Interferons [IFN]
- C07K14/56—IFN-alpha
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/575—Hormones
- C07K14/61—Growth hormones [GH] (Somatotropin)
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2863—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against receptors for growth factors, growth regulators
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/32—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against translation products of oncogenes
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/40—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against enzymes
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K38/00—Medicinal preparations containing peptides
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/20—Immunoglobulins specific features characterized by taxonomic origin
- C07K2317/22—Immunoglobulins specific features characterized by taxonomic origin from camelids, e.g. camel, llama or dromedary
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/55—Fab or Fab'
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/56—Immunoglobulins specific features characterized by immunoglobulin fragments variable (Fv) region, i.e. VH and/or VL
- C07K2317/569—Single domain, e.g. dAb, sdAb, VHH, VNAR or nanobody®
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/60—Immunoglobulins specific features characterized by non-natural combinations of immunoglobulin fragments
- C07K2317/62—Immunoglobulins specific features characterized by non-natural combinations of immunoglobulin fragments comprising only variable region components
- C07K2317/622—Single chain antibody (scFv)
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/60—Immunoglobulins specific features characterized by non-natural combinations of immunoglobulin fragments
- C07K2317/62—Immunoglobulins specific features characterized by non-natural combinations of immunoglobulin fragments comprising only variable region components
- C07K2317/626—Diabody or triabody
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/33—Fusion polypeptide fusions for targeting to specific cell types, e.g. tissue specific targeting, targeting of a bacterial subspecies
Abstract
본 발명은 하나 이상의 보조적 폴리펩티드에 연결된 생물학적 활성 폴리펩티드에 관한 것이다. 본 발명은 또한 본 발명의 단백질성 물질을 코딩하는 벡터를 포함하는 재조합 폴리펩티드 및 상기 벡터를 포함하는 숙주 세포를 제공한다. 본 발명의 조성물은 다양한 범위의 약학적 용도를 비롯한 각종 유용성을 갖는다.
Description
[관련 출원에 대한 상호 참조]
본원은 2007년 8월 15일자로 출원된 계류중인 미국 가특허 출원 일련번호 제60/956,109호, 2007년 10월 18일자로 출원된 일련번호 제60/981,073호, 및 2007년 11월 8일자로 출원된 일련번호 제60/986,569호(본원에 참고로 이들의 전체가 인용되어 있음)를 기초로 우선권을 주장한다.
재조합 단백질은 신규 치료제의 개발을 위해 매우 관심있는 후보가 되어 왔다. 그러나, 단백질 약제의 생산은 특정 생물학적 활성 폴리펩티드의 충분한 수율을 수득하기 위해 공정들의 상당한 최적화를 필요로 한다. 에스케리치아 콜라이(Escherichia coli)의 세포질에서의 재조합 단백질의 발현, 특히 포유동물 재조합 단백질의 발현은 종종 봉입체(inclusion body)로서 공지된 불용성 응집체의 형성을 초래함이 잘 정립되어 있다. 이. 콜라이의 봉입체로부터 재조합 단백질을 높은 세포 밀도로 발효하고 정제하는 것은 치료학적 단백질의 비용 효과적 생산을 위한 2개의 주요 병목문제(bottleneck)이다(Panda, A.K, 2003, Adv. Biochem. Eng. Biotechnol., 85, 43). 유사하게, 연구 목적을 위해, 수백종의 단백질이 다양한 활성에 대해 스크리닝될 필요가 있는 경우, 가용성 활성 단백질의 발현이 요망되는데, 이로써 먼저 봉입체를 정제하는 단계, 및 이어서 단백질을 각각 별도로 변성시키고 리폴딩(refolding)하는 단계를 방지한다.
이. 콜라이의 세포질 공간에서 발현될 경우 불용성 봉입체를 형성하는 많은 약학적으로 중요한 단백질의 예로는 인간 성장 호르몬(hGH: human growth hormone)(Patra, A.K et al. 2000, Protein Expr. Purif., 18, 182, Khan, R.H, et al. 1998, Biotechnol. Prog., 14, 722), 인간 과립구-콜로니 자극 인자(G-CSF: Granulocyte-Colony Stimulating Factor)(Zaveckas, M. et al 2007, J Chromatogr B Analyt Technol Biomed Life Sci 852, 409; Lee A.Y. et al. 2003, Biotechnol Lett., 25, 205) 및 인터페론(interferon) 알파(IFN-alpha; Valente, C.A et al. 2006, Protein Expr. Purif., 45, 226)가 포함된다. 추가로, 항체 및 이들 단편, 예컨대 도메인 항체 단편(dAb: domain antibody fragment), Fv 단편, 단일쇄 Fv 단편(scFv: single chain Fv fragment), Fab 단편, Fab'2 단편, 및 많은 비-항체 단백질의 면역글로불린 도메인(예컨대 FnIII 도메인)은 일반적으로 박테리아 숙주의 세포질에서 발현시에 봉입체를 형성한다(Kou, G., et al. 2007, Protein Expr. Purif., 52, 131, Cao, P., et al. 2006, Appl Microbiol Biotechnol., 73, 151; Chen, L.H et al. 2006, Protein Expr. Purif., 46, 495).
인간 단백질은 전형적으로 다수의 소수성 아미노산을 포함하는 소수성 코어를 사용하여 폴딩된다. 연구에 따르면, 단백질은, 특히 한 유기체로부터의 유전자가 또 다른 발현 숙주에서 발현되는 경우, 단백질의 고유의 결합 파트너가 존재하지 않아 폴딩 도움이 허용되지 않고 소수성 패치가 노출된 채로 남는 경우 응집하여 봉입체를 형성할 수 있다. 이는 큰 진화적 거리가 교차되는 경우 특히 그러하고; 예를 들면 진핵생물로부터 단리된 cDNA가 원핵생물에서 재조합 유전자로서 발현될 경우 응집되어 봉입체를 형성할 위험이 높다. cDNA는 번역가능한 mRNA에 대해 적절히 코딩될 수 있지만, 생성된 단백질은 외래의 미세환경에서 출현될 것이다. 이는 종종 농도가 충분히 높다면 응집체로서 일반적으로 축적되는 미스폴딩(misfolding)된 불활성 단백질을 생성한다. 다른 효과자, 예컨대 원핵 세포의 내부 미세환경(pH, 삼투압)은 유전자의 본래의 근원과 상이하여 단백질 폴딩에 영향을 줄 수 있다. 단백질을 폴딩하기 위한 기작은 또한 숙주 의존적이고, 따라서 이종기원 숙주에 존재하지 않고, 정상적으로는 소수성 코어의 일부로서 매장되어 있는 소수성 잔기가 대신에 노출되어 다른 단백질 상의 소수성 부위와 상호작용하도록 이용될 수 있다. 발현된 단백질의 내부 펩티드의 절단 및 제거를 위한 가공 시스템 또한 박테리아에 존재하지 않을 수 있다. 또한, 단백질 농도를 낮게 유지시키는 미세 제어가 또한 원핵 세포에는 없을 것이고, 과발현은, 비록 적절히 폴딩될지라도 그의 환경을 포화시킴으로써 침전될 단백질로 세포를 채울 수 있다.
봉입체에서 발견되는 응집된 상태로부터 생물학적 활성 생성물을 회수함은, 카오트로픽(chaotropic) 제제 또는 산에 의해 언폴딩(unfolding)한 후, 최적화된 리폴딩 완충액내로 희석 또는 투석함으로써 전형적으로 달성된다. 그러나, 많은 폴리펩티드(특별히 구조적 복합체 올리고머 단백질 및 다수의 디설파이드 결합을 갖는 폴리펩티드)는 화학적 변성 후에 활성 입체구조(conformation)를 쉽게 취하지 않는다.
1차 구조에서의 작은 변화는, 아마도 폴딩 경로의 변경에 의해 용해도에 영향을 줄 수 있다(Mitraki, A. et al. (1989) Bio/Technology 7, 690; Baneyx, F, et. al. 2004 Nat Biotechnol, 22, 1399; Ventura, S. 2005 Microb Cell Fact, 4, 11). 고밀도 발효 동안에 불용성 응집체의 형성을 감소시키기 위해, 몇몇 그룹들이 관심있는 단백질에 이종기원 융합 단백질을 연결시켰다. 이러한 융합 서열의 예는 글루타티온-S-전이효소(GST: Glutathione-S-Transferase), 단백질 디설파이드 이성화효소(PDI: Protein Disulfide Isomerase), 티오레독신(TRX: Thioredoxin), 말토스 결합 단백질(MBP: Maltose Binding Protein), His6 태그(tag), 키틴 결합 도메인(CBD: Chitin Binding Domain) 및 셀룰로스 결합 도메인(CBD: Cellulose Binding Domain)(Sahadev, S. et al. 2007, Mol. Cell. Biochem.; Dysom, M.R. et al. 2004, BMC Biotechnol, 14, 32)이다. 요약하면, 이들 접근법은, 이들이 모든 단백질에 대해 작용하지 않으므로, 단백질 특이적인 것으로 밝혀졌다.
다양한 융합 단백질이 폴딩을 개선시키기 위해 디자인되었고, 또한 단백질의 화학적 페그화(PEGylation)가 단백질 용해도를 증진시키고, 응집을 감소시키며, 면역원성을 감소시키고, 단백질가수분해를 감소시키는 것으로 보고되었다. 그럼에도 불구하고, 과생산된 폴리펩티드의 적절한 폴딩은, 응집이 농도 의존적 방식으로 초래되는 세포질의 고농도 점성 환경에서 문제가 된다. 박테리아 숙주에서 포유동물 단백질의 발현을 위한 또 다른 접근법은 리더 펩티드를 방지하고 숙주의 세포질에서 활성 단백질을 직접 발현시킨다. 그러나, 이 과정은 응집 및 봉입체 형성을 일으키는 경향이 있다.
박테리아에서 활성 형태로 포유동물 단백질을 발현시키기 위해 널리 사용되는 한 접근법은, 전형적으로 분비를 유도하기 위해 신호- 또는 리더-펩티드를 사용하여 박테리아 숙주, 예컨대 이. 콜라이의 주변세포질 공간(periplasmic space)의 비-환원 환경내로 단백질을 유도하는 것이다. 주변세포질(및 드물게는 배지)로의 분비는 단백질 분비, 폴딩 및 디설파이드 형성과 같은 고유의 진핵생물 과정을 모방하는 것으로 보이고, 종종 활성 단백질을 생성한다. 이러한 접근법은 많은 심각한 단점을 갖는다. 주변세포질은 낮은 수율을 제공하는 경향이 있고; 이러한 과정은 일반적으로 보다 작은 단백질에 제한되며; 이 과정은 단백질 특이적인 경향이 있고; 또한 주변세포질 단백질을 추출하기 위한 절차가 세포질로부터의 추출만큼 확고하지 않고, 이로써 수율이 낮게 된다. 이러한 이유들로, 박테리아의 주변세포질에서의 단백질의 발현은, 전형적으로 효모 또는 포유동물 세포주에서 상업적으로 발현되는 대부분의 약학적 단백질에 적용할 수 없다.
봉입체를 형성하지 않으면서 박테리아의 세포질에서 포유동물 단백질을 발현시키고자 시도된 또 다른 접근법은, 광범위한 생명공학 분야에서 일정 역할을 하는 분자 샤프론(chaperone)과 같은 폴딩-도우미(folding-helper) 단백질을 과별현시키는 것이다(Mogk et al. 2002 Chembiochem 3, 807). 지금까지, 샤프론의 몇몇 상이한 계열이 보고되어 왔다. 이들 모두는 언폴딩되거나 부분적으로 언폴딩된 단백질에 결합하고 바르게 폴딩된 단백질을 박테리아 세포질로 방출시키는 능력을 특징으로 한다. 잘 특징화된 예는 단백질의 열-충격 계열(Hsp: heat-shock family of protein)로서, 이는 문헌[Buchner, J., Faseb J. 1996 10, 10] 및 [Beissinger, M. and Buchner, 1998. J. Biol. Chem. 379, 245]에 기재된 바와 같이 상대 분자량에 따라 표기된다. 많은 박테리아 및 진핵생물의 샤프로닌(chapronin)이 박테리아 및 보다 적은 정도로 포유동물 세포에서 단백질의 과-발현을 위해 시도되었지만, 이러한 접근법은 일반적으로 거의 또는 전혀 효과가 없었고, 이는 발현 최적화를 위해 더 적은 빈도로 실행된다.
따라서 생물학적 활성 단백질을 생산하고 숙주 세포, 예컨대 원핵생물을 이용하는 대규모 생산에 영향을 미치는 이들의 용해도를 개선하기 위한 방법 및 조성물이 상당히 요구되고 있다.
[발명의 요약]
본 발명은 생물학적 활성 폴리펩티드를 생산하는 방법을 제공한다. 이 방법은 전형적으로 a) 숙주 세포에서 보조적 폴리펩티드와 연결된 생물학적 활성 폴리펩티드를 포함하는 변경된 폴리펩티드의 발현이 상기 생물학적 활성 폴리펩티드의 단독(예를 들어, 보조적 폴리펩티드가 없음)의 발현에 비해 상기 생물학적 활성 폴리펩티드의 가용성 형태를 더 많은 양으로 산출하도록 상기 변경된 폴리펩티드를 코딩하는 폴리뉴클레오티드 서열을 제공하는 단계; 및 b) 상기 변경된 폴리펩티드를 상기 숙주 세포에서 발현시킴으로써 생물학적 활성 폴리펩티드를 생산하는 단계를 포함한다. 한 실시양태에서, 생물학적 활성 폴리펩티드의 가용성 활성 형태의 발현은 총 단백질의 약 1%, 5%, 25%, 50%, 75%, 95% 또는 99%이다. 한 실시양태에서, 숙주 세포에서 변경된 폴리펩티드의 발현은 생물학적 활성 폴리펩티드 단독에 비해 생물학적 활성 폴리펩티드의 가용성 형태를 약 2배 이상 산출한다. 또 다른 실시양태에서, 생물학적 활성 폴리펩티드는 프로테이나제(proteinase) 절단 부위를 통해 보조적 폴리펩티드에 연결된다. 요망될 경우, 절단 부위는 TEV 프로테아제(protease), 엔테로키나제(enterokinase), 인자(Factor) Xa, 트롬빈(thrombin), PreScissionTM 프로테아제, 3C 프로테아제, 소르타제(sortase) A, 및 그랜자임(granzyme) B로 구성된 군에서 선택될 수 있다. 몇몇 실시양태에서, 숙주 세포에서 변경된 폴리펩티드의 발현은 가용성 형태의 생물학적 활성 폴리펩티드를 약 2배, 5배, 10배, 30배, 또는 100배 이상 산출한다.
본 발명은 또한 변경된 폴리뉴클레오티드 서열을 발현하기 위한 숙주 세포를 제공한다. 숙주 세포는 전형적으로 제한되지 않지만 이. 콜라이를 비롯한 원핵생물이고, 이는 또한 진핵생물, 예컨대 효모 세포 및 포유동물 세포(예를 들어 CHO 세포)일 수 있다.
본 발명은 또한 보조적 폴리펩티드와 연결되거나 연결되지 않은 생물학적 활성 폴리펩티드를 코딩하는 본 발명의 폴리뉴클레오티드 서열을 포함하는 유전자 운반체(genetic vehicle)를 제공한다.
본 발명에 의해 보조적 폴리펩티드와 연결된 생물학적 활성 폴리펩티드의 가용성 형태를 포함하고, 이때, 상기 보조적 폴리펩티드는, 이것이 생물학적 활성 폴리펩티드와 연결된 경우, 연결된 생물학적 활성 폴리펩티드가 발현되는 숙주 세포의 사이토졸 분획에서 생물학적 활성 폴리펩티드의 용해도를 증가시키는 것인 조성물이 제공된다. 원할 경우, 생물학적 활성 폴리펩티드는 보조적 폴리펩티드에 프로테아제 절단 부위를 통해 연결된다. 절단 부위는 TEV 프로테아제, 엔테로키나제, 인자 Xa, 트롬빈, PreScissionTM 프로테아제, 3C 프로테아제, 소르타제 A, 및 그랜자임 B로 구성된 군에서 선택될 수 있다.
본 방법 또는 조성물에 사용되는 보조적 폴리펩티드는 전체적으로 또는 부분적으로 하기 내용을 특징으로 할 수 있다. 한 실시양태에서, 본 발명의 보조적 폴리펩티드는 아미노산 잔기당 약 +0.025, +0.05, +0.075, +0.1, +0.2, +0.3, +0.4, +0.5, +0.6, +0.7, +0.8, +0.9 또는 더욱이 +1.0 전하의 변경된 생물학적 활성 폴리펩티드의 평균 순 양전하 밀도(net positive charge density)를 제공한다. 또 다른 실시양태에서, 본 발명의 보조적 폴리펩티드는 아미노산 잔기당 약 -0.25, -0.5, -0.075, -0.1, -0.2, -0.3, -0.4, -0.5, -0.6, -0.7, -0.8, -0.9 또는 더욱이 -1.0 평균 순 전하의 변경된 생물학적 활성 폴리펩티드의 평균 순 음전하 밀도(net negative charge density)를 제공한다. 한 실시양태에서, 보조적 폴리펩티드는 약 +3, +4, +5, +6, +7, +8, +9, +10, +12, +14, +16, +18, +20, +25, +30, +35, +40, +50 이상의 변경된 생물학적 활성 폴리펩티드의 순 양전하를 제공한다. 한 실시양태에서, 보조적 폴리펩티드는 약 -3, -4, -5, -6, -7, -8, -9, -10, -12, -14, -16, -18, -20, -25, -30, -35, -40, -50 이상의 변경된 생물학적 활성 폴리펩티드의 순 음전하를 제공한다.
또 다른 실시양태에서, 본 발명의 보조적 폴리펩티드는 약 10, 30, 50 또는 100개보다 많은 아미노산을 포함할 수 있다. 한 실시양태에서, 보조적 폴리펩티드는 40개 이상의 연속된 아미노산을 포함하고, 혈청 단백질에 비특이적으로 결합하는 것이 실질적으로 불가능하다. 몇몇 실시양태에서, 보조적 폴리펩티드에 포함된 글리신(G), 아스파테이트(D), 알라닌(A), 세린(S), 트레오닌(T), 글루타메이트(E) 및 프롤린(P) 및 라이신(K) 잔기의 합은 보조적 폴리펩티드의 총 아미노산의 약 80%를 초과하고/하거나; 초우-파스만 알고리즘(Chou-Fasman algorithm)에 의해 결정할 때, 보조적 폴리펩티드 중의 아미노산의 50% 이상은 2차 구조를 갖지 않는다. 관련된 실시양태에서, 보조적 폴리펩티드 40개 이상의 연속된 아미노산을 포함하고, 보조적 폴리펩티드는 약 4시간, 5시간, 10시간, 15시간 또는 24시간보다 긴 시험관내 혈청 반감기를 갖는다. 추가로, (a) 보조적 폴리펩티드에 포함된 글리신(G), 아스파테이트(D), 알라닌(A), 세린(S), 트레오닌(T), 글루타메이트(E) 및 프롤린(P) 및 라이신(K) 잔기의 합은 보조적 폴리펩티드의 총 아미노산의 약 80%를 초과하고/하거나; 초우-파스만 알고리즘에 의해 결정할 때, 보조적 폴리펩티드 중의 아미노산의 50% 이상은 2차 구조를 갖지 않는다. 몇몇 실시양태에서, 총 아미노산의 80%(또는 50, 60, 70 또는 90%)가 선택되는 아미노산의 집합은 G/S/E/D, G/S/K/R, G/S/E/D/K/R, 또는 G/A/S/T/Q이다.
몇몇 실시양태에서, 보조적 폴리펩티드는 50% 이상의 글리신 잔기를 포함한다(즉, 모든 잔기의 50%가 글리신임). 다르게는, 보조적 폴리펩티드는 50% 미만의 글리신 잔기를 포함할 수 있다. 몇몇 실시양태에서, 보조적 폴리펩티드는 50% 이상의 세린 잔기를 포함한다. 다른 실시양태는 50% 이상의 세린 및 글리신 잔기를 포함하는 보조적 폴리펩티드를 제공한다. 추가의 실시양태는 5% 이상의 글루탐산, 또는 다르게는 10, 20 또는 30% 이상의 글루탐산을 포함하는 보조적 폴리펩티드를 제공한다.
한 실시양태에서, 보조적 폴리펩티드는 또한 (a) 3가지 유형의 아미노산으로 구성되고, 각각의 유형은 알라닌(A), 아스파르트산(D), 글루탐산(E), 글리신(G), 히스티딘(H), 라이신(K), 아스파라긴(N), 프롤린(P), 글루타민(Q), 아르기닌(R), 세린(S), 트레오닌(T) 및 타이로신(Y)으로 구성된 군에서 선택되며; (b) 10, 25, 50, 100개 이상의 아미노산을 포함하는 것을 특징으로 할 수 있다. 관련된 실시양태에서, 보조적 폴리펩티드는 3가지 유형의 아미노산으로 구성되고, 각각의 유형은 D, E, G, K, P, R, S, 및 T로 구성된 군에서 선택된다. 보조적 폴리펩티드는 또한 3가지 유형의 아미노산으로 구성되고, 각각의 유형은 E, G, 및 S로 구성된 군에서 선택된다.
본 발명은 또한: (i) 3가지 유형의 아미노산으로 구성되고, 이중 2가지는 세린(S) 및 글리신(G)이고 나머지 유형은 아스파르트산(D), 글루탐산(E), 라이신(K), 프롤린(P), 아르기닌(R), 글리신(G), 트레오닌(T), 알라닌(A), 히스티딘(H), 아스파라긴(N), 타이로신(Y), 루신(L), 발린(V), 트립토판(W), 메티오닌(M), 페닐알라닌(F), 아이소루신(I), 및 시스테인(C)으로 구성된 군에서 선택되며; (ii) 10개 이상의 아미노산 잔기를 포함하고, 이중 50% 이상이 세린 또는 글리신임을 특징으로 하는 보조적 폴리펩티드를 제공한다.
또 다른 실시양태에서, 보조적 폴리펩티드는 (a) 2가지 유형의 아미노산으로 구성되고, 이 중 하나는 글리신(G)이고 나머지 유형은 아스파르트산(D), 글루탐산(E), 라이신(K), 프롤린(P), 아르기닌(R), 세린(S), 트레오닌(T), 알라닌(A), 히스티딘(H), 아스파라긴(N), 타이로신(Y), 루신(L), 발린(V), 트립토판(W), 메티오닌(M), 페닐알라닌(F), 이소루신(I), 및 시스테인(C)으로 구성된 군에서 선택되며; (b) 10개 이상의 아미노산 잔기를 포함하고, 이중 50% 이하가 글리신임을 특징으로 하는 보조적 폴리펩티드를 제공한다.
다르게는, 보조적 폴리펩티드는 2가지 유형의 아미노산으로 구성되고, 여기서 총 아미노산의 50% 이하는 A, S, T, D, E, K 및 H로 구성된 군에서 선택된다.
또 다른 실시양태에서, 보조적 폴리펩티드는: (a) 50개 이상의 아미노산을 포함하고; (b) 2가지 유형의 아미노산으로 구성되고, (c) 총 아미노산의 50% 이하가 A, S, T, D, E, K 및 H로 구성된 군에서 선택됨을 특징으로 한다.
보조적 폴리펩티드는 1, 2, 5 또는 10개 이상의 반복 모티프(motif)를 포함할 수 있고, 이들 각각은 2∼500개의 아미노산을 포함할 수 있다. 몇몇 경우에, 반복 모티프는 2 또는 3가지 이상의 상이한 유형의 아미노산으로 구성된다. 다수의 보조적 폴리펩티드가 사용될 수 있다. 보조적 폴리펩티드는 또한 하전된 아미노산을 포함할 수 있다.
몇몇 실시양태에서, 보조적 폴리펩티드는 아미노산 서열 (GGEGGS)n을 포함하고, 여기서 n은 2, 3, 4, 5, 6, 7, 8, 9, 10 이상의 정수이다. 다른 실시양태에서, 보조적 폴리펩티드는 아미노산 서열 (GES)n을 포함하고, 여기서 G, E, 및 S는 임의의 순서일 수 있고, n은 2, 3, 4, 5, 6, 7, 8, 9, 10 이상의 정수이다. 다르게는, 보조적 폴리펩티드는 아미노산 서열 (GGSGGE)n을 포함하고, 여기서 G, E, 및 S는 임의의 순서일 수 있고, n은 2, 3, 4, 5, 6, 7, 8, 9, 10 이상의 정수이다. 또 다른 실시양태에서, 보조적 폴리펩티드는 아미노산 서열 (GEGGGEGGE)n을 포함하고, 여기서 n은 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 이상의 정수이다. 또 다른 실시양태에서, 보조적 서열은 아미노산 서열 (GE)n을 포함하고, 여기서 G 및 E는 임의의 순서일 수 있고, n은 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 이상의 정수이다.
몇몇 실시양태에서, 보조적 폴리펩티드는 아미노산 서열 (S)n을 포함하고, 여기서 n은 10, 15 20, 50 이상의 정수이다. 다른 실시양태에서, 보조적 폴리펩티드는 아미노산 서열 (SSSSSSE)n을 포함하고, 여기서 E 및 S는 임의의 순서일 수 있고, n은 2, 3, 4, 5, 6, 7, 8, 9, 10 이상의 정수이다. 다른 실시양태에서, 보조적 폴리펩티드는 아미노산 서열 (SSSSE)n을 포함하고, 여기서 E 및 S 임의의 순서일 수 있고, n은 2, 3, 4, 5, 6, 7, 8, 9, 10 이상의 정수이다. 또한 다른 실시양태에서, 보조적 폴리펩티드는 아미노산 서열 (SESSSESSE)n을 포함하고, 여기서 E 및 S는 임의의 순서일 수 있고, n은 2, 3, 4, 5, 6, 7, 8, 9, 10 이상의 정수이다. 몇몇 실시양태에서, 보조적 폴리펩티드는 아미노산 서열 (SSESSSSESSSE)n을 포함하고, 여기서 E 및 S는 임의의 순서일 수 있고, n은 3 이상의 정수이다. 다른 실시양태에서, 보조적 폴리펩티드는 아미노산 서열 (SSSESSSSSESSSSE)n을 포함하고, 여기서 E 및 S는 임의의 순서일 수 있고, n은 3 이상의 정수이다. 그 외의 다른 실시양태에서, 보조적 폴리펩티드는 아미노산 서열 (SSSSESSSSSSESSSSSE)n을 포함하고, 여기서 E 및 S는 임의의 순서일 수 있고, n은 3 이상의 정수이다.
몇몇 실시양태에서, 보조적 폴리펩티드는 3, 4, 5, 6 또는 7개 아미노산의 펩티드 모티프의 반복 단위로 이루어지지 않거나, 임의의 단일 폴리펩티드 모티프의 반복 단위로 이루어지지 않는다. 몇몇 실시양태에서, 보조적 폴리펩티드는 고정된 길이의 2, 5, 10, 또는 20개보다 많은 상이한 반복 모티프로 이루어진다. 몇몇 실시양태에서, 보조적 폴리펩티드는 임의의 길이의 2, 5, 10, 또는 20개보다 많은 상이한 반복 모티프로 이루어진다.
추가로, 본 발명은: (a) 변경된 폴리펩티드를 제공하는 단계; (b) 상기 변경된 폴리펩티드를 중합체 매트릭스와 혼합하는 단계를 포함하는, 약학적 조성물을 제조하는 방법을 기재한다.
본 방법에 의해 생산되거나 본 조성물에 존재하는 생물학적 활성 폴리펩티드는 인간 성장 호르몬(hGH), 글루카곤(Glucagon) 유사 펩티드-1(GLP-1), 엑세나타이드(exenatide), 프람리타이드(pramlitide), 유리카제(uricase), 과립구-콜로니 자극 인자(G-CSF), 인터페론-알파, 인터페론-베타, 인터페론-감마, 인슐린, 인터류킨 1 수용체 길항물질(IL-1RA: Interleukin 1 receptor antagonist), 에리스로포이에틴 또는 종양 괴사 인자(TFN:tumor necrosis factor)-알파일 수 있다.
본 발명은 (a) 서방형 제제(slow release agent), 및 (b) 보조적 폴리펩티드에 연결된 생물학적 활성 폴리펩티드를 포함하는 변경된 폴리펩티드를 포함하는 약학적 조성물에 관한 것이다. 변경된 폴리펩티드는 1보다 큰 겉보기 분자량 계수를 산출할 수 있다. 겉보기 분자량 계수는 변경된 폴리펩티드의 예상 분자량에 대한, 크기 배제 크로마토그래피에 의해 측정된 변경된 폴리펩티드의 겉보기 분자량으로서 결정될 수 있다. 한 실시양태에서, 변경된 폴리펩티드의 겉보기 분자량 계수는 3보다 크다. 또 다른 실시양태에서, 변경된 폴리펩티드의 겉보기 분자량 계수는 5보다 크다. 또 다른 실시양태에서, 변경된 폴리펩티드의 겉보기 분자량 계수는 7보다 크다. 그 외의 또 다른 실시양태에서, 변경된 폴리펩티드의 겉보기 분자량 계수는 9보다 크다.
보조적 폴리펩티드는 생물학적 활성 폴리펩티드의 혈청 반감기를 증가시킬 수 있다. 다르게는, 보조적 폴리펩티드는 생물학적 활성 폴리펩티드의 프로테아제 내성을 증가시킬 수 있다. 다른 경우에, 보조적 폴리펩티드는 생물학적 활성 폴리펩티드의 용해도를 증가시킬 수 있다. 다른 경우에, 보조적 폴리펩티드는 생물학적 활성 폴리펩티드의 면역원성을 감소시킬 수 있다. 본 발명의 보조적 폴리펩티드는 약 10, 30, 50 또는 100개보다 많은 아미노산을 포함할 수 있다. 몇몇 실시양태에서, 생물학적 활성 폴리펩티드는 인간 성장 호르몬(hGH), 글루카곤 유사 펩티드-1(GLP-1), 엑세나타이드, 프람리타이드, 유리카제, 과립구-콜로니 자극 인자(G-CSF), 인터페론-알파, 인터페론-베타, 인터페론-감마, 인슐린, 인터류킨 1 수용체 길항제(IL-IRA), 에리스로포이에틴 또는 종양 괴사 인자-알파(TFN-알파)일 수 있다.
한 실시양태에서, 보조적 폴리펩티드는 40개 이상의 연속된 아미노산을 포함하고, 혈청 단백질에 비특이적으로 결합하는 것이 실질적으로 불가능하다. 몇몇 실시양태에서, 보조적 폴리펩티드에 포함된 글리신(G), 아스파테이트(D), 알라닌(A), 세린(S), 트레오닌(T), 글루타메이트(E) 및 프롤린(P) 잔기의 합은 보조적 폴리펩티드의 총 아미노산의 약 80%를 초과하고/하거나; 초우-파스만 알고리즘에 의해 결정할 때, 보조적 폴리펩티드 중의 아미노산의 50% 이상은 2차 구조를 갖지 않는다. 관련된 실시양태에서, 보조적 폴리펩티드는 40개 이상의 연속된 아미노산을 포함하고, 보조적 폴리펩티드는 약 4시간, 5시간, 10시간, 15시간 또는 24시간보다 긴 시험관내 혈청 반감기를 갖는다. 추가로, 여기서 (a) 보조적 폴리펩티드에 포함된 글리신(G), 아스파테이트(D), 알라닌(A), 세린(S), 트레오닌(T), 글루타메이트(E) 및 프롤린(P) 잔기의 합은 보조적 폴리펩티드의 총 아미노산의 약 80%를 초과하고/하거나; 초우-파스만 알고리즘에 의해 결정할 때, 보조적 폴리펩티드 중의 아미노산의 50% 이상은 2차 구조를 갖지 않는다.
몇몇 실시양태에서, 보조적 폴리펩티드는 50% 이상의 글리신 잔기를 포함한다(즉, 모든 잔기의 50%가 글리신임). 다르게는, 보조적 폴리펩티드는 50% 미만의 글리신 잔기를 포함할 수 있다. 몇몇 실시양태에서, 보조적 폴리펩티드는 50% 이상의 세린 잔기를 포함할 수 있다. 다른 실시양태는 50% 이상의 세린 및 글리신 잔기를 포함하는 보조적 폴리펩티드를 제공한다. 추가의 실시양태는 5% 이상의 글루탐산, 또는 다르게는 10, 20 또는 30% 이상의 글루탐산을 포함하는 보조적 폴리펩티드를 제공한다.
한 실시양태에서, 보조적 폴리펩티드는 또한 (a) 3가지 유형의 아미노산으로 구성되고, 각각의 유형은 알라닌(A), 아스파르트산(D), 글루탐산(E), 글리신(G), 히스티딘(H), 라이신(K), 아스파라긴(N), 프롤린(P), 글루타민(Q), 아르기닌(R), 세린(S), 트레오닌(T) 및 타이로신(Y)으로 구성된 군에서 선택되며; (b) 10, 25, 50, 100개 이상의 아미노산을 포함하는 것을 특징으로 한다. 관련된 실시양태에서, 보조적 폴리펩티드는 3가지 유형의 아미노산으로 구성되고, 각각의 유형은 D, E, G, K, P, R, S, 및 T로 구성된 군에서 선택된다. 보조적 폴리펩티드는 또한 3가지 유형의 아미노산으로 구성된고, 각각의 유형은 E, G, 및 S로 구성된 군에서 선택된다.
본 발명은 또한: (i) 3가지 유형의 아미노산으로 구성되고, 이중 2가지 유형은 세린(S) 및 글리신(G)이고, 나머지 유형은 아스파르트산(D), 글루탐산(E), 라이신(K), 프롤린(P), 아르기닌(R), 글리신(G), 트레오닌(T), 알라닌(A), 히스티딘(H), 아스파라긴(N), 타이로신(Y), 루신(L), 발린(V), 트립토판(W), 메티오닌(M), 페닐알라닌(F), 이소루신(I), 및 시스테인(C)으로 구성된 군에서 선택되며; (ii) 10개 이상의 아미노산 잔기를 포함하고, 이중 50% 이상이 세린 또는 글리신임을 특징으로 하는 보조적 폴리펩티드를 제공한다.
또 다른 실시양태에서, 보조적 폴리펩티드는: (a) 2가지 유형의 아미노산으로 구성되고, 이 중 하나는 글리신(G)이고 나머지 유형은 아스파르트산(D), 글루탐산(E), 라이신(K), 프롤린(P), 아르기닌(R), 세린(S), 트레오닌(T), 알라닌(A), 히스티딘(H), 아스파라긴(N), 타이로신(Y), 루신(L), 발린(V), 트립토판(W), 메티오닌(M), 페닐알라닌(F), 이소루신(I), 및 시스테인(C)으로 구성된 군에서 선택되며; (b) 10개 이상의 아미노산 잔기를 포함하고, 이중 50% 이하가 글리신임을 특징으로 한다.
다르게는, 보조적 폴리펩티드는 2가지 유형의 아미노산으로 구성되고, 여기서 총 아미노산의 50% 이하는 A, S, T, D, E, 및 H로 구성된 군에서 선택된다.
그 외의 또 다른 실시양태에서, 보조적 폴리펩티드는: (a) 50개 이상의 아미노산을 포함하고; (b) 2가지 유형의 아미노산으로 구성되고, (c) 총 아미노산의 50% 이하가 A, S, T, D, E, 및 H로 구성된 군에서 선택됨을 특징으로 한다.
보조적 폴리펩티드는 1, 2, 5 또는 10개 이상의 반복 모티프를 포함할 수 있고, 이들 각각은 2∼500개의 아미노산을 포함할 수 있다. 몇몇 경우에, 반복 모티프는 2가지 또는 3가지 이상의 상이한 유형의 아미노산으로 구성된다. 다수의 보조적 폴리펩티드가 사용될 수 있다. 보조적 폴리펩티드는 또한 하전된 아미노산을 포함할 수 있다.
몇몇 실시양태에서, 보조적 폴리펩티드는 아미노산 서열 (GGEGGS)n을 포함하고, 여기서 n은 2, 3, 4, 5, 6, 7, 8, 9, 10 이상의 정수이다. 다른 실시양태에서, 보조적 폴리펩티드는 아미노산 서열 (GES)n을 포함하고, 여기서 G, E, 및 S는 임의의 순서일 수 있고, n은 2, 3, 4, 5, 6, 7, 8, 9, 10 이상의 정수이다. 다르게는, 보조적 폴리펩티드는 아미노산 서열 (GGSGGE)n을 포함하고, 여기서 G, E, 및 S는 임의의 순서일 수 있고 n은 2, 3, 4, 5, 6, 7, 8, 9, 10 이상의 정수이다. 또 다른 실시양태에서, 보조적 폴리펩티드는 아미노산 서열 (GEGGGEGGE)n을 포함하고, 여기서 n은 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 이상의 정수이다. 또 다른 실시양태에서, 보조적 서열은 아미노산 서열(GE)n을 포함하고, 여기서 G 및 E는 임의의 순서일 수 있고, n은 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 이상의 정수이다.
몇몇 실시양태에서, 보조적 폴리펩티드는 아미노산 서열 (S)n을 포함하고, 여기서 n은 10, 15, 20, 50 이상의 정수이다. 다른 실시양태에서, 보조적 폴리펩티드는 아미노산 서열 (SSSSSSE)n을 포함하고, 여기서 E 및 S는 임의의 순서일 수 있고, n은 2, 3, 4, 5, 6, 7, 8, 9, 10 이상의 정수이다. 다른 실시양태에서, 보조적 폴리펩티드는 아미노산 서열 (SSSSE)n을 포함하고, 여기서 E 및 S는 임의의 순서일 수 있고, n은 2, 3, 4, 5, 6, 7, 8, 9, 10 이상의 정수이다. 또한 다른 실시양태에서, 보조적 폴리펩티드는 아미노산 서열 (SESSSESSE)n을 포함하고, 여기서 E 및 S는 임의의 순서일 수 있고, n은 2, 3, 4, 5, 6, 7, 8, 9, 10 이상의 정수이다. 몇몇 실시양태에서, 보조적 폴리펩티드는 아미노산 서열 (SSESSSSESSSE)n을 포함하고, 여기서 E 및 S는 임의의 순서일 수 있고 n은 3 이상의 정수이다. 다른 실시양태에서, 보조적 폴리펩티드는 아미노산 서열 (SSSESSSSSESSSSE)n을 포함하고, 여기서 E 및 S는 임의의 순서일 수 있고 n은 3 이상의 정수이다. 그 외의 다른 실시양태에서, 보조적 폴리펩티드는 아미노산 서열 (SSSSESSSSSSESSSSSE)n을 포함하고, 여기서 E 및 S는 임의의 순서일 수 있고 n은 3 이상의 정수이다.
몇몇 실시양태에서 보조적 폴리펩티드는 3, 4, 5, 6 또는 7개 아미노산의 펩티드 모티프의 반복 단위로 이루어지지 않거나, 임의의 단일 폴리펩티드 모티프의 반복 단위로 이루어지지 않는다. 몇몇 실시양태에서 보조적 폴리펩티드는 고정된 길이의 2, 5, 10, 또는 20개 초과의 상이한 반복 모티프로 이루어진다. 몇몇 실시양태에서, 보조적 폴리펩티드는 임의의 길이의 2, 5, 10, 또는 20개 초과의 상이한 반복 모티프로 이루어진다.
서방형 제제로는 중합체 매트릭스가 포함될 수 있다. 몇몇 실시양태에서, 중합체 매트릭스는 하전된다. 특정 실시양태에서, 중합체 매트릭스는 폴리-d,l-락티드(PLA: poly-d,l-lactide), 폴리-(d,l-락티드-코-글리콜리드)(PLGA: poly-(d,l-lactide-co-glycolide)), PLGA-PEG 공중합체, 알기네이트, 덱스트란 및/또는 키토산이다. 경피 패치를 포함하여 서방형 제제가 또한 패키지될 수 있다.
본 발명은 또한 a) 변경된 폴리펩티드를 코딩하는 폴리뉴클레오티드 서열을 제공하는 단계; b) 상기 변경된 폴리펩티드를 숙주에서 발현시켜 상기 변경된 폴리펩티드를 생산하는 단계를 포함하는, 변경된 폴리펩티드의 제조 방법을 제공한다. 변경된 폴리펩티드를 코딩하는 핵산 서열을 포함하는 유전자 운반체, 뿐만 아니라 본 발명의 변경된 폴리펩티드를 발현하는 숙주 세포가 또한 제공된다.
또한, 본 발명은: (a) 변경된 폴리펩티드를 제공하는 단계; (b) 상기 변경된 폴리펩티드를 중합체 매트릭스와 혼합하는 단계를 포함하는, 약학적 조성물의 제조 방법을 기재한다.
본 발명의 약학적 조성물은 a) 서방형 제제, 및 b) 5 kD보다 큰 크기의 PEG 기에 연결된 생물학적 활성 폴리펩티드를 포함하는 변경된 폴리펩티드를 포함할 수 있다.
또한 다른 실시양태에서, 보조적 폴리펩티드는 실질적으로 2차 구조가 갖지 않는다. 그 외의 다른 실시양태에서, 보조적 폴리펩티드는 보조적 폴리펩티드가 없는 상응하는 폴리펩티드에 비해 2배 더 긴 혈청 반감기를 나타낸다. 생물학적 활성 폴리펩티드 및 보조적 폴리펩티드는 펩티드 결합을 통해 연결될 수 있다.
몇몇 실시양태에서, 변경된 폴리펩티드는 추가로 하나 이상의 데포 모듈(depot module)을 포함한다. 데포 모듈은 10개 이상의 아미노산 길이, 바람직하게는 100개 이상의 아미노산 길이를 갖는다. 양으로 하전된 데포 모듈(예를 들어, 라이신 풍부 또는 아르기닌 풍부 폴리펩티드)은 음으로 하전된 중합체와 함께 유용할 수 있다. 음으로 하전된 데포 모듈은 양으로 하전된 중합체와 함께 유용할 수 있다. 폴리-His 서열을 포함하는 데포 모듈은 킬레이팅 하이드로겔(chelating hydrogel)과 함께 사용될 수 있다. 몇몇 경우에, 데포 모듈은 프로테아제 민감성일 수 있고, 예를 들어, 제한없이, 혈청 프로테아제 또는 다른 프로테아제에 감수성이다. 다수의 및/또는 상이한 데포 모듈이 사용될 수 있다. 데포 모듈 생물학적 활성 폴리펩티드 및 보조적 폴리펩티드의 임의의 조합은 잠재적으로 지속 방출형 치료제를 생산하기 위해 사용될 수 있다. 구체적인 실시양태에서, 서방형 제제는 변경된 폴리펩티드에 연결된 데포 모듈이다.
또한, 본 발명의 API를 코딩하는 핵산 서열을 포함하는 유전자 운반체가 제공된다. 또 다른 실시양태에서, 폴리펩티드를 발현하는 숙주 세포가 기재되어 있다.
본 발명은 생물학적 활성 폴리펩티드의 특성을 변경시키기 위해 사용되는 보조적 폴리펩티드에 관한 것이다. 한 실시양태에서, 본 발명은 생물학적 활성 폴리펩티드 및 보조적 폴리펩티드를 포함하는 단리된 폴리펩티드를 제공하고, 여기서 보조적 폴리펩티드는 (i) 3가지 유형의 아미노산으로 구성되고, 각각의 유형은 알라닌(A), 아스파르트산(D), 글루탐산(E), 글리신(G), 히스티딘(H), 라이신(K), 아스파라긴(N), 프롤린(P), 글루타민(Q), 아르기닌(R), 세린(S), 트레오닌(T) 및 타이로신(Y)으로 구성된 군에서 선택되며; (ii) 10개 이상의 아미노산을 포함하는 것을 특징으로 한다. 관련된 실시양태에서, 보조적 폴리펩티드는 3가지 유형의 아미노산으로 구성되고, 각각의 유형은 D, E, G, K, P, R, S, 및 T로 구성된 군에서 선택된다. 또 다른 관련된 실시양태에서, 보조적 폴리펩티드는 3가지 유형의 아미노산으로 구성되고, 각각의 유형은 E, S, G, R, 및 A로 구성된 군에서 선택된다. 또 다른 관련된 실시양태에서, 보조적 폴리펩티드는 3가지 유형의 아미노산으로 구성되고, 각각의 유형은 E, S, G, R, 및 A로 구성된 군에서 선택된다. 또 다른 실시양태에서, 보조적 폴리펩티드는 3가지 유형의 아미노산으로 구성되고, 각각의 유형은 E, G, 및 S로 구성된 군에서 선택된다. 단리된 폴리펩티드는 치료학적 폴리펩티드일 수 있다.
본 발명은 또한 생물학적 활성 폴리펩티드 및 보조적 폴리펩티드를 포함하는 단리된 폴리펩티드를 제공하고, 여기서 보조적 폴리펩티드는: (i) 폴리-세린이고, (ii) 10개 이상의 아미노산을 포함하는 것을 특징으로 한다. 관련된 실시양태에서, 단리된 폴리펩티드는 (i) 2가지 유형의 아미노산으로 구성되고, 이중 대부분은 세린이고, (ii) 10개 이상의 아미노산을 포함하는 것을 특징으로 한다.
또 다른 실시양태에서, 보조적 폴리펩티드는 2가지 유형의 아미노산으로 구성되고, 이 중 하나는 글리신(G)이고, 나머지 유형은 아스파르트산(D), 글루탐산(E), 라이신(K), 프롤린(P), 아르기닌(R), 세린(S), 트레오닌(T), 알라닌(A), 히스티딘(H), 아스파라긴(N), 타이로신(Y), 루신(L), 발린(V), 트립토판(W), 메티오닌(M), 페닐알라닌(F), 이소루신(I), 및 시스테인(C)으로 구성된 군에서 선택되며; (ii) 10개 이상의 아미노산 잔기를 포함하고, 이중 50% 이하가 글리신이다.
본 발명은 또한 보조적 폴리펩티드가 (i) 2가지 유형의 아미노산으로 구성되고, 이 중 하나는 세린(S)이고 나머지 유형은 아스파르트산(D), 글루탐산(E), 라이신(K), 프롤린(P), 아르기닌(R), 글리신(G), 트레오닌(T), 알라닌(A), 히스티딘(H), 아스파라긴(N), 타이로신(Y), 루신(L), 발린(V), 트립토판(W), 메티오닌(M), 페닐알라닌(F), 이소루신(I), 및 시스테인(C)으로 구성된 군에서 선택되며; (ii) 10개 이상의 아미노산 잔기를 포함하고, 이중 50% 이상은 세린임을 특징으로 하는, 생물학적 활성 폴리펩티드 및 보조적 폴리펩티드를 포함하는 단리된 폴리펩티드를 제공한다 .
다르게는, 본 발명은 보조적 폴리펩티드가 (i) 10개 이상의 아미노산을 포함하고; (ii) 2가지 유형의 아미노산으로 구성되고, 여기서 총 아미노산의 50% 이하가 A, S, T, D, E, 및 H로 구성된 군에서 선택됨을 특징으로 하는, 생물학적 활성 폴리펩티드 및 보조적 폴리펩티드를 포함하는 단리된 폴리펩티드를 기재한다.
또 다른 실시양태에서, 본 발명은 보조적 폴리펩티드가 (i) 10개 이상의 아미노산을 포함하고;(ii) 2가지 유형의 아미노산으로 구성되고, 총 아미노산의 50% 이하가 A, G, T, D, E, 및 H로 구성된 군에서 선택됨을 특징으로 하는, 생물학적 활성 폴리펩티드 및 보조적 폴리펩티드를 포함하는 단리된 폴리펩티드를 기재한다.
몇몇 실시양태에서, 보조적 폴리펩티드가 (i) 2가지 유형의 아미노산으로 구성되고, 이 중 하나가 P, R, L, V, Y, W, M, F, I, K, 및 C로 구성된 군에서 선택되며; (ii) 10개 이상의 아미노산을 포함하는 것을 특징으로 하는, 생물학적 활성 폴리펩티드 및 보조적 폴리펩티드를 포함하는 단리된 폴리펩티드가 제공된다.
다른 실시양태에서, 보조적 폴리펩티드가 10개 이상의 아미노산 길이를 갖고, 동일한 수로 나타나는 2가지 상이한 유형의 아미노산으로 구성되는, 생물학적 활성 폴리펩티드 및 보조적 폴리펩티드를 포함하는 단리된 폴리펩티드가 제공된다. 다르게는, 2가지 상이한 유형의 아미노산은 1:2, 2:3, 또는 3:4 비로 나타난다. 보조적 폴리펩티드는 추가로 4개 이상의 반복 모티프를 포함할 수 있고, 이들 각각은 2∼500개의 아미노산을 포함하고, 2가지 상이한 유형의 아미노산으로 이루어진다. 반복 모티프는 8개보다 많은 아미노산을 포함할 수 있고, 몇몇 실시양태에서 4개 이상의 반복 모티프가 동일하다. 4개 이상의 반복 모티프는 상이한 아미노산 서열을 포함할 수 있다. 관련된 실시양태에서, 보조적 폴리펩티드는 10개 이상의 반복 모티프를 포함한다.
또 다른 실시양태는 2차 구조가 실질적으로 갖지 않는 보조적 폴리펩티드로 변경된 생물학적 활성 폴리펩티드를 제공한다. 다르게는, 단리된 폴리펩티드의 겉보기 분자량은 보조적 폴리펩티드가 없는 상응하는 폴리펩티드의 겉보기 분자량보다 크다. 한 구체적인 실시양태에서, 보조적 폴리펩티드의 겉보기 분자량은 그의 실제 분자량에 비해 3배 이상 더 크다. 그 외의 다른 실시양태에서, 보조적 폴리펩티드는 보조적 폴리펩티드가 없는 상응하는 폴리펩티드에 비해 2배 더 긴 혈청 반감기를 나타낸다. 생물학적 활성 폴리펩티드 및 보조적 폴리펩티드는 펩티드 결합을 통해 연결될 수 있다.
몇몇 실시양태에서, 보조적 폴리펩티드는 아미노산 서열 (GGEGGS)n을 포함하고, 여기서 n은 3 이상의 정수이다. 다른 실시양태에서, 보조적 폴리펩티드는 아미노산 서열 (GES)n을 포함하고, 여기서 G, E, 및 S는 임의의 순서일 수 있고, n은 3 이상의 정수이다. 다르게는, 보조적 폴리펩티드는 아미노산 서열 (GGSGGE)n을 포함하고, 여기서 G, E, 및 S는 임의의 순서일 수 있고, n은 3 이상의 정수이다. 또 다른 실시양태에서, 보조적 폴리펩티드는 아미노산 서열 (GGEGGEGGES)n을 포함하고, 여기서 n은 1 이상의 정수이다. 또 다른 실시양태에서, 보조적 서열은 아미노산 서열 (GE)n을 포함하고, 여기서 G 및 E는 임의의 순서일 수 있다.
몇몇 실시양태에서, 보조적 폴리펩티드는 아미노산 서열 (S)n을 포함하고, 여기서 n은 10 이상의 정수이다. 다른 실시양태에서, 보조적 폴리펩티드는 아미노산 서열 (SSSSSSE)n을 포함하고, 여기서 E 및 S는 임의의 순서일 수 있고, n은 2 이상의 정수이다. 또한 다른 실시양태에서, 보조적 폴리펩티드는 아미노산 서열 (SESSSESSE)n 을 포함하고, 여기서 E 및 S는 임의의 순서일 수 있고, n은 3 이상의 정수이다. 몇몇 실시양태에서, 보조적 폴리펩티드는 아미노산 서열 (SSESSSSESSSE)n을 포함하고, 여기서 E 및 S는 임의의 순서일 수 있고, n은 3 이상의 정수이다. 다른 실시양태에서, 보조적 폴리펩티드는 아미노산 서열 (SSSESSSSSESSSSE)n이고, 여기서 E, 및 S는 임의의 순서일 수 있고, n은 3 이상의 정수이다. 그 외의 다른 실시양태에서, 보조적 폴리펩티드는 아미노산 서열 (SSSSESSSSSSESSSSSE)n을 포함하고, 여기서 E 및 S는 임의의 순서일 수 있고, n은 3 이상의 정수이다.
본 발명은 또한: a) 특허청구범위 제1항, 제6항, 제7항, 제8항, 또는 제9항중 어느 한 항의 단리된 폴리펩티드를 코딩하는 폴리뉴클레오티드 서열을 제공하는 단계; b) 상기 폴리펩티드를 숙주 세포에서 발현시킴으로써 상기 폴리펩티드를 생산하는 단계를 포함하는, 단리된 폴리펩티드의 제조 방법을 제공한다.
또한, 본 발명의 단리된 폴리펩티드를 코딩하는 핵산 서열을 포함하는 유전자 운반체가 제공된다. 또 다른 실시양태에서, 본 폴리펩티드를 발현하는 숙주 세포가 기재되어 있다. 본 폴리펩티드의 라이브러리(library)가 또한 구현된다. 구체적인 실시양태에서, 폴리펩티드의 라이브러리는 파지(phage) 입자 상에 디스플레이된다.
참고 인용
본 명세서에 언급된 모든 특허 및 특허출원은, 각각의 개별적 공보 또는 특허출원이 구체적이고 개별적으로 참고로 인용되는 것으로 지시되어 있지만, 동일한 정도로 참고로 본원에 인용되어 있다.
본 발명의 신규 특징은 첨부된 특허청구범위에 구체적으로 제시되어 있다. 본 발명의 특징 및 이점은 본 발명의 원리가 이용되는 예시적인 실시양태를 제시하는 하기 상세한 설명, 및 첨부된 도면에 의해 보다 잘 이해될 것이다.
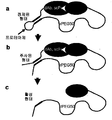
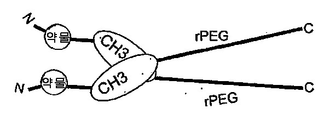
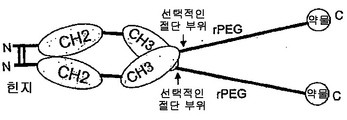
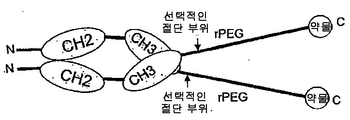
도 1은 생물학적 활성 단백질을 변경하는 보조적 폴리펩티드의 예시적 대표도이다.
도 2 및 3은 본 발명의 변경된 폴리펩티드에서의 포함물에 대한 가능한 모듈을 도시한다: 보조적 폴리펩티드(들), 생물학적 활성 폴리펩티드(들), 선택가능한 데포 모듈(들) 및 선택가능한 중합체 매트릭스 또는 매트릭스들.
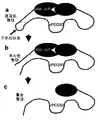
도 4는 다양한 생성물 배열의 예를 도시한다. 모듈은 동일한 생성물에서 수회 사용되어, 예를 들면 생물학적 활성 단백질의 그의 표적에 대한 친화도를 증가시키거나, rPEG 모듈을 연장시킴으로써 반감기를 증가시키거나, 데포 제형(depot formulation)의 특성을 변경시킬 수 있다.
도 5는 부위 특이적 바이오틴화(site-specific biotinylation)를 허용하는 데포 모듈을 포함하는 변경된 사량체 폴리펩티드의 구체적 예를 제시한다. 스트렙타비딘(streptavidin)의 첨가는 매우 안정하지만 비공유적인 변경된 폴리펩티드 사량체의 형성을 유도한다. 다가 폴리펩티드는 또한 다중 모듈을 단일쇄내로 합치거나, 특이적 모듈을 함유하는 다중 단백질 쇄를 화학적으로 연결시킴으로써 생성될 수 있다.
도 6은 알기네이트 미소구체(microsphere)의 중합체 매트릭스내로 혼입될 수 있는 라이신- 또는 아르기닌 풍부 데포 모듈(직사각형으로서 표시됨)을 예시한다. 매트릭스 모듈은 보다 큰 원으로 표시된다. 라이신- 또는 아르기닌 풍부 데포가 생리학적 pH에서 순 양전하를 전달할 것이고, 이 특성은 음으로 하전된 알기네이트 중합체로 변경된 폴리펩티드를 결합시키는데 활용될 수 있다. 결합은 다가 양식으로 초래된다.
도 7은 중합체에 결합된 2가 양이온 Cu2+에 의해 예시화된 2가 양이온 킬레이팅 하이드로겔(매트릭스 모듈)을 나타낸다. 폴리히스티딘 데포 모듈(직사각형 모듈)은 높은 친화도로 Cu2+ 양이온에 결합한다.
도 8은 프로테아제 민감성 다량체 변경 폴리펩티드를 도시한다. 데포 모듈(직사각형으로 표시됨)은 연장된 중합체에서 개별적인 변경된 폴리펩티드 단위를 연결시킨다. 데포 모듈은 혈청 프로테아제에 특이적으로 감수성이도록 디자인된다. 데포 모듈의 프로테아제 절단은 개별적인 변경된 활성 폴리펩티드를 방출한다.
도 9는 발현 벡터 pCW0150의 디자인을 도시한다.
도 10은 GFP에 융합된 보조적 폴리펩티드 rPEG(L288)의 디자인 및 작제를 보여준다.
도 11은 rPEG_L288 폴리펩티드의 아미노산 및 뉴클레오티드 서열을 보여준다.
도 12는 hGH-rPEG(L288) 및 GLP-1-rPEG(L288) 구성물의 디자인을 보여준다.
도 13은 보조적 폴리펩티드에 접합된 생물학적 활성 단백질의 예를 보여준다.
도 14 및 15는 보조적 폴리펩티드의 서열 최적화를 위한 예시적인 지침을 기재한다.
도 16은 GFP에 융합된 rPEG_J288 보조적 폴리펩티드를 포함하는 벡터의 작제를 기재한다.
도 17은 rPEG_J288 폴리펩티드의 아미노산 및 뉴클레오티드 서열을 보여준다.
도 18은 본 발명에 사용하기에 적합한 스터퍼 벡터(stuffer vector)의 디자인을 보여준다.
도 19는 rPEG_J288에 의해 변경된 GFP의 정제를 보여준다.
도 20은 rPEG_J288에 의해 변경된 GFP의 혈청 안정성의 결정을 보여준다.
도 21은 보조제에 의해 변경된 폴리펩티드와 세포 표적의 상호작용을 보여준다.
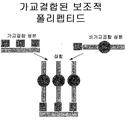
도 22는 가교결합된 보조적 폴리펩티드의 개념을 보여준다.
도 23은 가교결합 성분의 예를 기재한다.
도 24는 가교결합된 보조적 폴리펩티드의 몇몇 예를 열거한다.
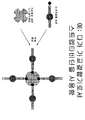
도 25는 스트렙타비딘이 연결기로서 사용된 예를 보여준다.
도 26은 가교결합된 보조적 폴리펩티드를 작제하는 상이한 양식을 기재한다.
도 27은 가교결합된 보조적 폴리펩티드의 몇몇 가능한 형식을 확인하고 예시한다.
도 28은 결합 도메인 또는 다른 기에 의해 추가로 변경된 보조적 폴리펩티드를 기재한다.
도 29는 서방형 보조적 폴리펩티드의 개념을 예시한다.
도 30은 보편적 보조적 폴리펩티드를 보여준다.
도 31은 인간 IgG1으로부터의 항체 Fc 단편을 보여주지만, 이는 또한 IgG2, IgG3, IgG4, IgA, IgD 또는 IgE로부터일 수 있다. 이러한 Fc는 IgG1, IgG2, IgG3, IgG4, IgA, IgD 또는 IgE로부터의 고유 힌지를 가질 수 있다. 힌지 디설파이드의 수에 천연적인 다양성이 존재하지만, 이는 또한 힌지, 특별히 시스테인 잔기의 돌연변이, 결실, 또는 절단(truncation)에 의해 생성될 수 있다. 유용한 변형체는 3개의 디설파이드(도시되지 않음), 2개의 디설파이드, 1개의 디설파이드(IgG1의 제1 또는 제2 천연 디설파이드중 선택)을 갖거나, 디설파이드를 갖지 않는다.
도 32는 친화성 태그, 용해도 태그 및/또는 프로테아제 절단 부위를 포함하는 변경된 폴리펩티드의 다양한 배열을 예시한다.
도 33은 특이적인 보조적 폴리펩티드를 사용하는 변경된 폴리펩티드의 개선된 발현 수준을 예시한다.
도 34는 변경되지 않은 hGH에 대한 보조제 변경 hGH 폴리펩티드의 활성을 예시한다.
도 35는 음이온 교환 및 크기 배제 크로마토그래피에 의한 보조제 변경 폴리펩티드의 정제를 보여준다.
도 36은 SDS-PAGE에 의해 확인될 경우 rPEG 변경 GFP의 정제에 의해 수득된 순수한 생성물을 보여준다.
도 37은 분석용 크기 배제 크로마토그래피에 의해 확인될 경우 rPEG-연결된 GLP1의 순도를 보여준다.
도 38은 분석용 역-상 HPLC에 의해 관찰될 경우 rPEG_L288-GFP 변경된 폴리펩티드의 순도를 보여준다.
도 39는 rPEG_J288-GFP의 질량 분광계이다.
도 40은 비특이적 결합이 변경된 폴리펩티드와 혈청 단백질 사이에 거의 관찰되지 않음을 입증한다.
도 41은 생물학적 활성 폴리펩티드가 보조적 폴리펩티드를 연결시킬 경우 관찰되는 겉보기 분자량에서의 증가를 기재한다.
도 42는 래트 및 인간 혈청에서 변경된 폴리펩티드의 안정성을 보여준다.
도 43은 래트 혈청에서 rPEG_K288-GFP 폴리펩티드의 PK 프로파일을 예시한다.
도 44는 rPEG_J288-GFP, rPEG_K288-GFP 및 rPEG_L288-GFP에 대한 동물 실험에서 결정될 경우 rPEG 폴리펩티드의 면역원성의 상대적 결여를 보여준다.
도 45는 보조적 폴리펩티드에 연결된 생물학적 활성 폴리펩티드를 발현하는 이점을 예시한다.
도 46은 보조제 변경 폴리펩티드의 지속된 방출을 예시한다.
도 47은 크기 배제 크로마토그래피(운행당 다수회 주사)에 의해 결정될 경우 rPEG_J288-GLP1 폴리펩티드의 순도를 보여준다.
도 48은 크기 배제 크로마토그래피(운행당 다수회 주사)에 의해 결정될 경우 rPEG_K288-GLP1 폴리펩티드의 순도를 보여준다.
도 49는 생물학적 활성 폴리펩티드(GLP1)를 rPEG_J288, rPEG_K288, 및 rPEG_L288 보조적 폴리펩티드에 연결시킬 경우 관찰되는 겉보기 분자량에서의 증가를 설명한다.
도 50은 친화성 태그, 보조적 폴리펩티드, 및 생물학적 활성 폴리펩티드(rPEG_K288-hGH)로서의 hGH를 포함하는 폴리펩티드의 프로테아제 절단을 통해 수득된 생성물을 보여준다. 프로테아제는 태그를 제거하는 한편, rPEG_K288 보조적 폴리펩티드에 연결된 hGH인 최종 생성물을 남긴다.
도 51은 프로테아제 절단 및 추가의 정제 이후 rPEG_K288-hGH의 순도를 보여준다.
도 52는 전체 IgG1의 구조를 보여주지만, IgG2, IgG3, IgG4, IgE, IgD, IgA 및 IgM이 출발점으로서 유사하게 사용될 수 있다. dAb-dAb-Fc 융합 단백질은 또한 그의 4원가로 인해 유용하고, 이는 도시되지 않는다.
도 53은 Fc와 항원 결합 도메인을 분리하고 C-말단에 Fc를 갖는 rPEG를 포함하는 구성물을 보여준다: (dAb/scFv)-rPEG-Fc 및 (dAb/scFv)-(dAb/scFv)-rPEG-Fc. 그러나, 동일한 요소를 상이한 순서로 갖는 형식 또한 유용하고, 예컨대 rPEG-Fc-(dAb/scFv), rPEG-Fc-(dAb/scFv)-(dAb/scFv), Fc-rPEG-(dAb/scFv), Fc-rPEG-(dAb/scFv)-(dAb/scFv), Fc-(dAb/scFv)-rPEG, Fc-(dAb/scFv)-(dAb/scFv)-rPEG, dAb/scFv)-Fc-rPEG, 및 (dAb/scFv)-(dAb/scFv)-Fc-rPEG이다. dAb-scFv 또는 scFv-dAb와 같이 scFv 및 dAb를 혼합할 수 있거나, 상이한 표적 특이성의 2개의 scFv 또는 2개의 dAb를 조합할 수 있다: scFv1-scFv2 또는 dAb1-dAb2.
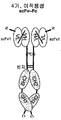
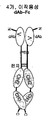
도 53a는 scFv-Fc 융합 단백질을 보여준다. 도 53b는 dAb-Fc 융합 단백질을 보여준다. 도 53c는 4가인 scFv-scFv-Fc 융합 단백질을 보여준다.
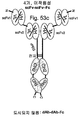
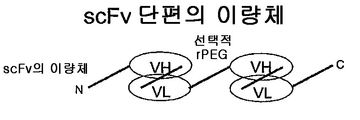
도 54는 scFv 단편의 이량체를 보여준다. 이종이량체 및 동종이량체 둘 다 작제될 수 있다.
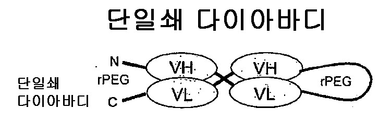
도 55는 단일쇄 다이아바디(diabody)를 보여준다.
도 56은 단일쇄 Fc 단편의 한 예를 보여준다. 경우에 따라, 생물학적 활성 단백질은 이러한 구성물의 말단에 융합될 수 있다.
도 57: 단백질 쇄의 단일 카피로 구성된 생성물
도 58: AFBT의 구조. 58a: 1가 AFBT; 58b: 이특이적 AFBT의 구조
도 59: AFBT의 표적 항원으로의 다가 결합
도 60a: 2개의 모 항체로부터 유도된 항체 단편을 포함하는 다가 AFBT
도 60b: 다이아바디 및 페이로드(payload)를 포함하는 AFBT의 구조
도 61: 반합성 AFBT의 제조
도 62: rPEG50에 융합된 항 Her-2 scFv의 정제, 특징화 및 결합 활성. 62a: 결합 활성. 채워진 다이아몬드: 코팅된 Her-2로의 결합; 빈 다이아몬드: 코팅된 IgG로의 결합. 62b: 크기 배제 크로마토그래피; 62c: 유리 SH 기의 검출.
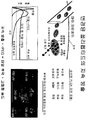
도 63: 항 Her-2 다이아바디, aHer203-rPEG50의 정제, 특징화 및 결합 활성. 63a: 결합 활성. 채워진 다이아몬드: 코팅된 Her-2로의 결합; 빈 다이아몬드: 코팅된 IgG로의 결합. 63b: 다이아바디 aHer203-rPEG50 및 scFv aHer230-rPEG50의 크기 배제 크로마토그래피; 63c: 시간에 대한 aHer203-rPEG50의 SEC는 고급 다량체에서 증가를 나타내지 않는다.
도 64: scFv-rPEG50 융합 단백질의 작제, 서열 및 발현. 64a: 단백질 구축의 밑그림; 64b: Her-2에 대해 특이성을 갖는 AFBT의 서열; 64c: scFv-rPEG50 융합 단백질의 발현을 나타내는 SDS/PAGE; 7d: EGFR에 대한 특이성을 갖는 AFBT의 서열.
도 65: 다이아바디-rPEG50 융합 단백질, aHer203-rPEG의 작제, 서열 및 발현. 65a: 단백질 구축의 밑그림; 65b: 단백질 서열; 65c: 이. 콜라이의 사이토졸에서 융합 단백질의 발현을 입증하는 SDS/PAGE.
도 66: 박테리아 발현을 위한 Fc 도메인의 코돈 최적화: 66a: 공정 및 올리고뉴클레오티드 디자인의 예시. 인간 Fc를 코딩하는 서열은 반-랜덤 올리고뉴클레오티드로부터 조립되고 보고된 바와 같이 작용하는 rPEG25 및 GFP 앞에 클로닝된다. 66b: 라이브러리로부터 선택된 클론의 SDS/PAGE. 화살표는 원하는 융합 단백질의 밴드를 지시한다. 66c: 최적화된 인간 Fc 유전자의 아미노산 및 뉴클레오티드 서열.
도 67: Fab-rPEG 융합 단백질에 대한 발현 구성물을 예시하는 밑그림
도 68: 항혈청으로부터의 AFBT에 대한 발견 과정의 플로우 차트
도 69: GFP-rPEG50의 아미노산 서열. GFP의 서열은 밑줄쳐져 있다.
도 70: 사이노몰구스 원숭이(cynomologos monkey)에서 GFP-rPEG50 및 Ex4-rPEG50의 약물동력학.
도 71a: CDB-Ex4-rPEG50 융합 단백질의 아미노산 서열. 도 71b: 도 14a에 도시된 융합 서열로부터 Ex4-rPEG50을 방출하기 위해 사용되는 공정의 예시.
도 72: 마우스에서 Ex4-rPEG50의 면역원성. 도 72a는 주사의 시간 경과 및 혈액 샘플 분석을 예시한다. 도 72b는 1:500 희석시 혈액 샘플의 ELISA 분석을 보여준다. 도 72c는 1:12,500 희석시 혈액 샘플의 ELISA 분석을 보여준다.
도 73: GFP-rPEG25 및 GFP-rPEG50의 크기 배제 크로마토그래피. 회색선은 구형 단백질을 사용하는 분자량 표준을 지시한다.
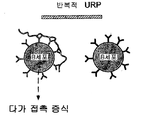
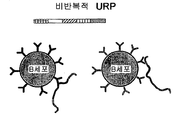
도 74: 반복적 및 비반복적 URP와 B 세포의 상호작용의 비교. 도 74a는 다수의 동일한 서열 반복으로 이루어진 반복적 URP를 보여준다. 이러한 반복적 URP는 반복 서열을 인식하는 B 세포와의 다가 접촉을 형성할 수 있고, 이는 B 세포 증식을 개시할 수 있다. 도 74b는 다수의 상이한 부분서열로 이루어진 비반복적 URP를 보여준다. 각각의 서열은 동족 특이성을 갖는 B-세포의 특별한 하위집합에 의해 인식될 수 있다. 그러나, 비반복적 URP의 개별 분자는 단지 임의의 특별한 B 세포와 하나 또는 소수의 상호작용을 형성할 수 있고, 이는 증식을 개시하지 않을 것이다.
도 75: 아미노산 서열의 반복성을 평가하기 위한 알고리즘.
도 76: 매우 낮은 반복성을 갖는 nrURP를 디자인하는 컴퓨터 알고리즘.
도 77: URP 분절(segment)의 라이브러리로부터 nrURP의 작제.
도 78: rPEG_Y를 작제하기 위해 사용된 아미노산 서열. 이 도면은 또한 분절 라이브러리를 작제하기 위해 사용된 올리고뉴클레오티드의 상대적 농도를 지시한다.
도 79: 합성 올리고뉴클레오티드로부터의 URP 분절의 조립. 도 79a는 결찰 반응을 보여준다. 반복 분절은 인산화된 올리고뉴클레오티드를 부분적으로 중첩시킴으로써 코딩된다. 어닐링된(annealed) 올리고뉴클레오티드의 제2 쌍이 첨가되어 쇄 신장을 종결시킨다. 이들 캡핑(capping) 올리고뉴클레오티드중 하나는 인산화되지 않고, 이는 한쪽 말단에서 결찰을 방지한다.
도 79b는 결찰 반응의 아가로스 겔을 보여준다.
도 80: URP_Y144 서열의 예
도 81: 플라스미드 pCW0279에 의해 코딩된 아미노산 서열. 오픈 리딩 프레임(open reading frame)은 플래그(Flag)-URP_Y576-GFP의 융합 단백질을 코딩한다. URP_Y576의 아미노산 서열은 밑줄쳐져 있다.
도 82는 'rPEG 연결된 결합 쌍'을 제조하는 일반적 방식을 보여주고, 이는 초기 활성이 없어서 돌발 방출 효과가 없고(독성없이 투여될 수 있는 투약량을 증가시킴) 초기 수용체 매개성 제거(clearance)를 감소시킨다는 이점을 갖는다. 일반적 결합 쌍은 수용체-리간드, 항체-리간드, 또는 일반적 결합 단백질 1-결합 단백질 2일 수 있다. 구성물은, 주입 전에 절단될 수 있고 주입 후에(프로테아제에 의해 혈청에서) rPEG가 치료학적 최종 생성물(활성 단백질)(이는 리간드, 수용체 또는 항체일 수 있음)과 함께 있도록 위치될 수 있는 절단 부위를 가질 수 있다.
도 83a는 N-말단에 약물 모듈을 갖고, 뒤에 rPEG가 수반되며, 힌지를 포함하는 항체 Fc 단편에 융합되는 구성물을 보여준다. Fc 단편은 긴 반감기를 제공하고, rPEG는 Fc 단편이 이. 콜라이 세포질에서 가용성 활성 형태로 발현하도록 허용한다.
도 83b는 N-말단에 약물 모듈을 갖고, 뒤에 rPEG가 수반되며, 힌지가 없는 항체 Fc 단편에 융합되는 구성물을 보여준다. Fc 단편은 긴 반감기를 제공하고, rPEG는 Fc 단편이 이. 콜라이 세포질에서 가용성 활성 형태로 발현하도록 허용한다.
도 84a: 다이아바디는 VH 및 VL 도메인 사이의 단일쇄 연결기가 약 10∼20 AA보다 짧은 경우에 형성되어, 단일쇄 Fv 단편의 형성을 방지한다. 다이아바디는 2개의 단백질 쇄를 갖고, 하나 또는 둘 다의 C-말단 말단에, 및/또는 하나 또는 둘 다의 N-말단 말단에 rPEG를 가질 수 있다. 다이아바디는 2개의 결합 부위를 갖고, 이중 0, 1개 또는 2개는 약학적 표적, 또는 반감기 표적(즉, HSA, IgG, 적혈 세포, 콜라겐 등)에 결합하거나, 표적에 전혀 결합하지 않을 수 있다.
도 84b: 다이아바디는 0, 1개 또는 둘 다의 단백질 쇄의 N-말단 말단 또는 C-말단 말단에 위치한 0, 1개 또는 그 이상의 약물 모듈을 함유할 수 있다.
도 85a는 약물 모듈(IFNa, hGH 등과 같음)이 N- 및/또는 C-말단 말단의 하나 또는 둘 다에 융합될 수 있는 단일쇄 Fv 단편을 보여준다. scFv는 하나의 결합 부위를 갖고, 이는 약학적 표적 또는 반감기 표적(즉 HSA(도 85b 참조), IgG, 적혈 세포 등)에 결합하거나 결합하지 않을 수 있다.
도 86은 동일한 복합체에 속하는 2개의 단백질을 회합하기 위한 rPEG의 용도를 보여준다. 이러한 단백질 사이의 친화도는 종종 이들 회합을 유지하기에 불충분하지만, rPEG의 첨가는 이들 상호작용을 안정화시키고, 중합체를 형성하려는 이들의 경향을 감소시킨다.
도 87은 세포-표면 표적으로의 Fab 단편 결합을 보여주고; H 쇄는 Fc(전체 항체에서와 같이)에 또는 매우 다양한 다른 단백질, 도메인 및 펩티드에 융합될 수 있다. VH와 CH 도메인 사이, 및 VL과 CL 도메인 사이에서, 통상 2∼6개 아미노산으로부터 4, 5, 6, 7, 8, 9, 10, 11, 1, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 24, 26, 28, 30, 35, 40, 45, 50, 60,70, 80, 100개 이상의 아미노산으로의 천연 연결기 길이의 연장은, 도메인 스와핑(swapping)에 의해 하나의 Fab가 또 다른 Fab에 가교결합되는 능력을 증가시킴으로써, 보다 높은 결합가를 갖는 결합 복합체를 형성하고, 그 결과 보다 높은 겉보기 친화도(결합활성: avidity)를 생성한다. 연결기는 rPEG 또는 상이한 조성물일 수 있다. 이러한 '연장된 연결기' 형식은 보다 높은 밀도의 표적, 예컨대 종양 세포에 대해 (부분적으로) 종양 특이적 항원을 갖는 부위에 특이적으로 증가된 친화도를 갖는 결합을 허용한다.
도 88은 회합 펩티드, 예컨대 SKVILF(E) 또는 RARADADA(이는 역평행 배향으로 동일한 서열의 또 다른 카피(copy)에 결합함)가 전구약물을 생성하는데 어떻게 사용될 수 있는지를 보여준다. 이러한 경우, 약물은 마지막 제작 단계에서 프로테아제에 의해 절단되지만, 2개의 쇄가 여전히 회합 펩티드에 의해 회합되어 있기 때문에 절단은 약물을 활성화시키지 않는다. 단지 약물이 혈액내로 주사되고 농도가 크게 감소된 후에야만, 작은 비-rPEG 함유 단백질 쇄가 복합체를 떠나서(친화도에 의존하는 속도로, 특별히 오프(off)-속도로) 신장을 통해 제거될 것이고, 이에 따라 r-PEG 함유 약물 모듈을 활성화시킨다.
도 89는 제작된 단일쇄 단백질을 2개의 단백질 쇄의 복합체로 전환시키는 단백질가수분해 절단을 보여준다. 이러한 절단은 마지막 제작 단계(주사 전)로서 초래되거나, 주사 후 환자 혈액중의 프로테아제에 의해 초래될 수 있다.
도 90a는 (경우에 따라) 하나의 말단 상에서 약물 모듈(예를 들어, IFNa, hGH, 등)에 융합되고 (경우에 따라) 다른 말단 상에서 rPEG에 융합된, 힌지 영역을 갖는 항체 Fc 단편을 보여준다. CH2 및 CH3 사이의 서열은, 돌연변이에 의해 기능이 제거되지 않는 한, FcRn, 신생(neonatal) Fc 수용체로의 결합을 중재한다.도 90b는 힌지 영역이 없는 유사 구성물을 보여준다.
도 91a는 CH3 도메인의 짝을 이룬 쌍을 포함하는 단백질 구성물을 보여준다; 이들 쇄중 0, 1개 또는 둘 다는 N-말단 말단 및/또는 C-말단 말단 상에서 rPEG에, 및 나머지 말단에서 0, 1개 또는 그 이상의 약물 모듈에 융합될 수 있다. FcRn 결합 서열은 유지 또는 결실될 수 있고; 보유는 보다 긴 혈청 반감기를 산출해야 한다.
도 91b는 유사 단백질을 보여주지만, CH2는 완전히 제거되어 Fc의 FcRn 수용체로의 결합은 더 이상 작용하지 않아 반감기를 감소시킨다.
도 92a는 힌지, CH2 및 CH3 도메인을 포함하고, c-말단에서 rPEG에 융합되고, C-말단에 위치된 약물/약물분자구조(drug/pharmacophore)를 갖는 완전한 Fc인 단백질을 보여준다.
도 92b는 c-종단부에서 rPEG에 융합되고, C-말단에 위치된 약물/약물분자구조를 갖는, 힌지가 없는 완전한 Fc를 보여주고; 이들 분자는 쇄 스와핑되어, 잠재적으로 이종-이량체를 생성할 수 있다.
도 93a는 절단되었으나 FcRn 결합을 보유하는 CH2를 갖고 C-말단에 위치된 약물/약물분자구조를 갖는, 힌지가 없는 부분적 Fc를 보여준다.
도 93b는 힌지 및 CH2가 없으나 CH3을 보유하고 C-말단에 위치된 약물/약물분자구조를 갖는 부분적 Fc를 보여준다. 이는 FcRn에 결합하지 않지만, CH3 도메인을 통해 이량체화될 수 있다.
도 94a는 동일한 수용체 도메인(또는 동일한 결합 기능을 갖는 도메인, 또는 동일한 표적에 동시에 결합할 수 있는 도메인)에 의해 플랭킹된(flanked) rPEG를 보여준다. 수용체 둘 다가 동시에 표적에 결합할 수 있다면, 하나의 수용체의 결합은 제2 수용체의 결합을 안정화시키고, 유효성/겉보기 친화도/결합활성은 전형적으로 10∼100배, 그외에 3배 이상 증가된다. rPEG는 혈청 반감기를 제공한다. 하나의 선택사항은 생성물에 리간드를 미리 로딩하는 것이다. 이러한 경우, 주사된 생성물은 이것이 리간드에 결합한 상태로 남아있는 한 불활성이다. 이러한 접근법은 최고 용량 독성을 감소시키고, 또한 수용체 매개성 제거를 감소시키며, 따라서 이것이 중요한 적용분야에서 유용할 수 있다.
도 94b는 리간드에 동시에 결합할 수 있는 2종의 상이한 수용체에 의해 플랭킹된 rPEG를 갖는 생성물을 보여주는데, 이는 복합체의 상호 안정성 및 증가된 겉보기 친화도(결합활성)를 초래하고, rPEG는 수용체의 효과적 농도를 증가시키는 결합가 가교로서 작용한다.
도 94c: 하나의 선택사항은 생성물을 리간드로 미리 로딩하는 것이다. 이 경우, 주사된 생성물은 이것이 리간드에 결합한 상태로 남아있는 한 불활성이다. 리간드가 풀리면, 이는 신속히 신장을 통해 제거되어 생성물을 활성화시키는데, 이 생성물은 rPEG 테일(tail)로 인해 증가된 반감기를 갖는다. 이러한 접근법은 최고 용량 독성을 감소시키고, 또한 수용체 매개성 제거를 감소시키며, 따라서 이것이 중요한 적용분야에서 유용할 수 있다.
도 94에서 볼 수 있듯이, 동일한 전구약물 형식은 절단 또는 다른 활성화 부위를 포함할 필요가 없다. 단일 단백질 쇄는 rPEG에 의해 분리된 2개(또는 그 이상)의 약물 모듈을 함유할 수 있고; 이들 모듈은 동일하거나(단일 유형) 2종 이상의 상이한 유형일 수 있다. 모든 약물 모듈은 수용체이거나 모두 리간드이다. 이러한 rPEG를 함유하는 생성물은 제2의 상보성 단백질과 착화되어 수용체-리간드-수용체 상호작용을 형성한다. 이러한 형식에서, 리간드는 이량체 또는 다량체이기 쉽지만, 또한 특별히 2개의 약물 모듈이 상이한 경우 단량체일 수 있다. 양쪽 모듈이 제3의 단백질에 결합한다. X 및 Y는 동일하거나 상이할 수 있고, X 및 Y는 약물 모듈이거나 약물 모듈에 결합할 수 있다. 각 경우에, 도 94에서, X 및 Y(및 rPEG)는 하나의 단백질 쇄를 포함하고, 이들이 결합된 분자는 별도의 분자, 전형적으로 단백질 또는 작은 분자이다. 단일 단백질 쇄에 조합된 2개보다 많은 결합 단백질을 갖는 것이 가능하다. 이러한 생각은 큰 rPEG 함유 단백질 및 비-rPEG 함유 단백질의 복합체가 주사시 불활성이지만, 2∼24시간에 걸쳐 보다 작은 비-rPEG 함유 단백질이 복합체를 떠나고 신장을 통해 배출됨으로써 약물 모듈(들)을 활성화시킨다는 것이다. 이러한 형식의 이점은 약물 농도에서의 초기 스파이크(spike) 및 연관된 안전성 문제를 감소 또는 제거하고, 복합체가 착화되어 있는 동안 수용체 매개성 제거를 최소화하여 혈청 분비 반감기를 증진시킨다는 것이다.
도 95는 VEGF-수용체에 의해 양쪽 측부 상에 플랭킹된 rPEG를 보여준다. VEGF가 이량체이므로, 이는 rPEG의 양쪽 측부 상에 동일한 수용체일 수 있거나 상이한 수용체일 수 있다(바람직하게는 VEGF-R1 및 VEGF-R2, 그러나 VEGFR3도 사용될 수 있음).
도 96은 불활성 전구약물로서 제작되거나(주사 전 절단됨) 투여되는(주사 후 혈액중에서 절단됨) 생성물을 보여준다. 약물의 불활성화는 rPEG에 의해 약물로 연결되는 결합 단백질에 의해 중재되어, 모든 3개의 모듈이 단일 단백질 쇄로서 제작된다. 약물이 수용체라면, 결합 단백질은 수용체의 리간드(펩티드 또는 단백질)이고; 약물이 항체 단편이라면, 결합 부위는 펩티드 또는 단백질 리간드이다. 이들 예에서 약물은 2개의 결합 도메인(X 및 Y로 지칭됨) 사이의 부위의 프로테아제 절단에 의해 활성화된다. 단백질 Y가 활성 생성물이면, Y는 rPEG를 보유해야 하고, 프로테아제 절단 부위는 (X와 Y 사이이지만) X에 가까와야 한다. 단백질 X가 활성 생성물이면, X는 rPEG를 보유해야 하고, 절단 부위는 Y에 가까와야 한다. 청색 크로스바(crossbar)에 의해 보여지듯이 1개 또는 다수의 절단 부위가 존재할 수 있다. 약물 모듈은 수용체, 리간드, 하나 이상의 Ig 도메인, 항체 단편, 펩티드, 미소단백질, 항체에 대한 에피토프(epitope)일 수 있다. 약물 모듈에 결합되는 단백질은 결합 단백질, 수용체, 리간드, 하나 이상의 Ig 도메인, 항체 단편, 펩티드, 미소단백질, 항체에 대한 에피토프일 수 있다.
도 97은 불활성 전구약물이 결합 펩티드를 약물 모듈에 첨가함으로써 어떻게 생성될 수 있는지를 보여준다. 펩티드는 약물의 표적 결합 능력을 무효화시키고, 펩티드는 rPEG 함유 약물에 비해 더 높은 속도로 혈액으로부터 점진적으로 제거된다. 이러한 펩티드는 천연적일 수 있지만 보다 전형적으로 이는 약물 모듈에 대한 랜덤 펩티드 라이브러리의 파지 패닝(panning)에 의해 수득된다. 펩티드는 바람직하게는 합성적으로 만들어지지만, 이는 재조합체일 수 있다.
도 98은 rPEG의 동일한 말단 또는 rPEG의 반대쪽 말단에 있을 수 있는 다수의 생물활성 펩티드를 함유하는 단일쇄 단백질 약물을 보여준다. 이들 펩티드는 동일한 활성 또는 상이한 활성을 가질 수 있다. 단일쇄중에 다수의 펩티드를 갖는 목적은 복잡한 제작과정 없이 결합활성을 통해 이들의 효과적인 효능을 증가시키는 것이다.
도 99는 전구약물-rPEG가 수용체 매개성 제거를 방지함으로써 혈청 반감기를 어떻게 증가시키는지를 보여준다.
도 100은 약물 농도가 정맥내 주사 후 시간에 대해 어떻게 변화하는지를 보여준다. 전형적 치료법에서의 목표는 치료학적 투약량에 비해 높은 농도이지만 독성 투약량에 비해 낮은 농도로 약물을 유지시키는 것이다. 짧은 반감기를 갖는 약물의 전형적 일시주사(bolus injection)(IV, IM, SC, IP 또는 이와 유사함)는 독성 투약량에 비해 매우 높은 피크 농도를 초래하고, 이후 치료학적 투약량 미만으로 신속히 강하하는 약물 농도를 초래하는 제거 상이 수반된다. 이러한 PK 프로필(profile)은 독성 및 장기간의 비효과적 치료를 초래하는 경향이 있는 반면, 약물은 단지 짧은 기간에만 치료학적 농도로 존재한다(청색선). rPEG의 약물로의 첨가는 피크 농도를 감소시켜 독성을 감소시키고, 약물이 치료학적 무독성 투약량으로 존재하는 기간을 증가시킨다. rPEG + 약물 결합 단백질을 첨가하여 전구약물을 생성하면 '돌발 방출' 또는 독성 피크 투여량(적색선)을 방지할 수 있는데, 이는 약물이 수 시간에 걸쳐 점진적으로만 활성화되고, 독성 투약량과 치료학적 투약량 사이의 시간 길이가 다른 형식에 비해 증가되기 때문이다.
도 101은 rPEG 및 C-말단 Fc 단편(힌지를 가짐)이 수반되는 N-말단 약물 모듈을 보여준다. 이는 이. 콜라이 세포질에서 제작될 수 있는 약물 모듈의 반감기 연장을 위해 유용한 형식이다.
도 102a는 Fc 단편을 함유하는 전구약물에 대한 대안의 형식을 보여준다. 이 형식은 도 101에 기재된 바와 유사하고, 약물 서열(적색)에 결합하여 이를 저해하는 저해 서열(청색)이 첨가된다(N-말단에). 이전과 마찬가지로, 약물은 절단 부위에 의해 저해 서열로부터 분리된다. N-말단 저해 결합 서열은 절단 부위를 수반하고, 이는 약물 서열(적색)을 수반한다. 절단 전, 약물은 저해 서열에 결합하고, 따라서 불활성이다(전구약물). 절단 후, 저해 결합 서열(청색)은 점진적으로 방출 및 제거되고, 약물(적색)이 활성인 시간의 양을 점진적으로 증가시킨다.
도 102b는 Fc 단편을 함유하는 대안의 전구약물 형식을 보여준다. 이 형식은 도 101에 기재된 형식과 유사하고, 역시 절단 부위에 의해 약물(청색으로 제시됨)로부터 분리되는 저해 결합 서열(전형적으로 rPEG내에 또는 이의 부근에 위치된 펩티드 또는 도메인(적색으로 제시됨))이 첨가된다. 절단 전, 약물은 저해 서열에 결합하고, 따라서 불활성이다(전구약물). 절단 후, 저해 결합 서열(청색)은 점진적으로 방출 및 제거되고, 약물(적색)이 활성인 시간의 양을 점진적으로 증가시킨다.
도 103a∼d는 손상되지 않은 전체 항체(IgG1, 2, 3, 4, IgE, IgA, IgD, IgM가 포함됨)로의 rPEG에 대한 바람직한 융합 부위를 보여준다. 지시된 이들 부위가 이들 작용성 도메인의 폴딩을 교란시키지 않으면서 구조화된 서열, 예컨대 도메인, 힌지 등의 경계에 있으므로 바람직하다. 따라서 rPEG는 1, 2, 3, 4, 5, 6, 7 또는 8개의 상이한 위치에서 하나의 항체(및 IgM 및 IgG3에 대해 8개보다 많이)에 첨가될 수 있고, 단일 항체는 다양한 위치에서 및 임의로 조합된 도시된 8개 위치에서 1, 2, 3, 4, 5, 6, 7, 8개 이상의 rPEG를 가질 수 있다.
도 103e는 항체(IgG1, 2, 3, 4, IgE, IgA, IgD, IgM)의 도메인 및 단편으로의 rPEG에 대한 바람직한 융합 부위를 보여준다. rPEG의 N-말단 및/또는 C-말단 첨가를 위한 융합 부위는 적색 화살표 또는 적색선으로 도시되어 있다.
도 104는 Fc 단편의 올바른 폴딩에 대한 검정을 보여준다.
도 105는 부위 특이적 프로테아제에 의한, 혈청에서의 또는 주사 전의 불활성 단백질의 활성 단백질로의 전환을 보여준다. 이 예에서, 적색 서열은 활성 치료제이다.
도 106은 부위 특이적 프로테아제에 의한 불활성 약물의 활성 약물로의 전환을 보여준다. 이 예에서, 청색 도메인(dAb, scFv, 기타)은 치료학적 물질이다.
도 1은 생물학적 활성 단백질을 변경하는 보조적 폴리펩티드의 예시적 대표도이다.
도 2 및 3은 본 발명의 변경된 폴리펩티드에서의 포함물에 대한 가능한 모듈을 도시한다: 보조적 폴리펩티드(들), 생물학적 활성 폴리펩티드(들), 선택가능한 데포 모듈(들) 및 선택가능한 중합체 매트릭스 또는 매트릭스들.
도 4는 다양한 생성물 배열의 예를 도시한다. 모듈은 동일한 생성물에서 수회 사용되어, 예를 들면 생물학적 활성 단백질의 그의 표적에 대한 친화도를 증가시키거나, rPEG 모듈을 연장시킴으로써 반감기를 증가시키거나, 데포 제형(depot formulation)의 특성을 변경시킬 수 있다.
도 5는 부위 특이적 바이오틴화(site-specific biotinylation)를 허용하는 데포 모듈을 포함하는 변경된 사량체 폴리펩티드의 구체적 예를 제시한다. 스트렙타비딘(streptavidin)의 첨가는 매우 안정하지만 비공유적인 변경된 폴리펩티드 사량체의 형성을 유도한다. 다가 폴리펩티드는 또한 다중 모듈을 단일쇄내로 합치거나, 특이적 모듈을 함유하는 다중 단백질 쇄를 화학적으로 연결시킴으로써 생성될 수 있다.
도 6은 알기네이트 미소구체(microsphere)의 중합체 매트릭스내로 혼입될 수 있는 라이신- 또는 아르기닌 풍부 데포 모듈(직사각형으로서 표시됨)을 예시한다. 매트릭스 모듈은 보다 큰 원으로 표시된다. 라이신- 또는 아르기닌 풍부 데포가 생리학적 pH에서 순 양전하를 전달할 것이고, 이 특성은 음으로 하전된 알기네이트 중합체로 변경된 폴리펩티드를 결합시키는데 활용될 수 있다. 결합은 다가 양식으로 초래된다.
도 7은 중합체에 결합된 2가 양이온 Cu2+에 의해 예시화된 2가 양이온 킬레이팅 하이드로겔(매트릭스 모듈)을 나타낸다. 폴리히스티딘 데포 모듈(직사각형 모듈)은 높은 친화도로 Cu2+ 양이온에 결합한다.
도 8은 프로테아제 민감성 다량체 변경 폴리펩티드를 도시한다. 데포 모듈(직사각형으로 표시됨)은 연장된 중합체에서 개별적인 변경된 폴리펩티드 단위를 연결시킨다. 데포 모듈은 혈청 프로테아제에 특이적으로 감수성이도록 디자인된다. 데포 모듈의 프로테아제 절단은 개별적인 변경된 활성 폴리펩티드를 방출한다.
도 9는 발현 벡터 pCW0150의 디자인을 도시한다.
도 10은 GFP에 융합된 보조적 폴리펩티드 rPEG(L288)의 디자인 및 작제를 보여준다.
도 11은 rPEG_L288 폴리펩티드의 아미노산 및 뉴클레오티드 서열을 보여준다.
도 12는 hGH-rPEG(L288) 및 GLP-1-rPEG(L288) 구성물의 디자인을 보여준다.
도 13은 보조적 폴리펩티드에 접합된 생물학적 활성 단백질의 예를 보여준다.
도 14 및 15는 보조적 폴리펩티드의 서열 최적화를 위한 예시적인 지침을 기재한다.
도 16은 GFP에 융합된 rPEG_J288 보조적 폴리펩티드를 포함하는 벡터의 작제를 기재한다.
도 17은 rPEG_J288 폴리펩티드의 아미노산 및 뉴클레오티드 서열을 보여준다.
도 18은 본 발명에 사용하기에 적합한 스터퍼 벡터(stuffer vector)의 디자인을 보여준다.
도 19는 rPEG_J288에 의해 변경된 GFP의 정제를 보여준다.
도 20은 rPEG_J288에 의해 변경된 GFP의 혈청 안정성의 결정을 보여준다.
도 21은 보조제에 의해 변경된 폴리펩티드와 세포 표적의 상호작용을 보여준다.
도 22는 가교결합된 보조적 폴리펩티드의 개념을 보여준다.
도 23은 가교결합 성분의 예를 기재한다.
도 24는 가교결합된 보조적 폴리펩티드의 몇몇 예를 열거한다.
도 25는 스트렙타비딘이 연결기로서 사용된 예를 보여준다.
도 26은 가교결합된 보조적 폴리펩티드를 작제하는 상이한 양식을 기재한다.
도 27은 가교결합된 보조적 폴리펩티드의 몇몇 가능한 형식을 확인하고 예시한다.
도 28은 결합 도메인 또는 다른 기에 의해 추가로 변경된 보조적 폴리펩티드를 기재한다.
도 29는 서방형 보조적 폴리펩티드의 개념을 예시한다.
도 30은 보편적 보조적 폴리펩티드를 보여준다.
도 31은 인간 IgG1으로부터의 항체 Fc 단편을 보여주지만, 이는 또한 IgG2, IgG3, IgG4, IgA, IgD 또는 IgE로부터일 수 있다. 이러한 Fc는 IgG1, IgG2, IgG3, IgG4, IgA, IgD 또는 IgE로부터의 고유 힌지를 가질 수 있다. 힌지 디설파이드의 수에 천연적인 다양성이 존재하지만, 이는 또한 힌지, 특별히 시스테인 잔기의 돌연변이, 결실, 또는 절단(truncation)에 의해 생성될 수 있다. 유용한 변형체는 3개의 디설파이드(도시되지 않음), 2개의 디설파이드, 1개의 디설파이드(IgG1의 제1 또는 제2 천연 디설파이드중 선택)을 갖거나, 디설파이드를 갖지 않는다.
도 32는 친화성 태그, 용해도 태그 및/또는 프로테아제 절단 부위를 포함하는 변경된 폴리펩티드의 다양한 배열을 예시한다.
도 33은 특이적인 보조적 폴리펩티드를 사용하는 변경된 폴리펩티드의 개선된 발현 수준을 예시한다.
도 34는 변경되지 않은 hGH에 대한 보조제 변경 hGH 폴리펩티드의 활성을 예시한다.
도 35는 음이온 교환 및 크기 배제 크로마토그래피에 의한 보조제 변경 폴리펩티드의 정제를 보여준다.
도 36은 SDS-PAGE에 의해 확인될 경우 rPEG 변경 GFP의 정제에 의해 수득된 순수한 생성물을 보여준다.
도 37은 분석용 크기 배제 크로마토그래피에 의해 확인될 경우 rPEG-연결된 GLP1의 순도를 보여준다.
도 38은 분석용 역-상 HPLC에 의해 관찰될 경우 rPEG_L288-GFP 변경된 폴리펩티드의 순도를 보여준다.
도 39는 rPEG_J288-GFP의 질량 분광계이다.
도 40은 비특이적 결합이 변경된 폴리펩티드와 혈청 단백질 사이에 거의 관찰되지 않음을 입증한다.
도 41은 생물학적 활성 폴리펩티드가 보조적 폴리펩티드를 연결시킬 경우 관찰되는 겉보기 분자량에서의 증가를 기재한다.
도 42는 래트 및 인간 혈청에서 변경된 폴리펩티드의 안정성을 보여준다.
도 43은 래트 혈청에서 rPEG_K288-GFP 폴리펩티드의 PK 프로파일을 예시한다.
도 44는 rPEG_J288-GFP, rPEG_K288-GFP 및 rPEG_L288-GFP에 대한 동물 실험에서 결정될 경우 rPEG 폴리펩티드의 면역원성의 상대적 결여를 보여준다.
도 45는 보조적 폴리펩티드에 연결된 생물학적 활성 폴리펩티드를 발현하는 이점을 예시한다.
도 46은 보조제 변경 폴리펩티드의 지속된 방출을 예시한다.
도 47은 크기 배제 크로마토그래피(운행당 다수회 주사)에 의해 결정될 경우 rPEG_J288-GLP1 폴리펩티드의 순도를 보여준다.
도 48은 크기 배제 크로마토그래피(운행당 다수회 주사)에 의해 결정될 경우 rPEG_K288-GLP1 폴리펩티드의 순도를 보여준다.
도 49는 생물학적 활성 폴리펩티드(GLP1)를 rPEG_J288, rPEG_K288, 및 rPEG_L288 보조적 폴리펩티드에 연결시킬 경우 관찰되는 겉보기 분자량에서의 증가를 설명한다.
도 50은 친화성 태그, 보조적 폴리펩티드, 및 생물학적 활성 폴리펩티드(rPEG_K288-hGH)로서의 hGH를 포함하는 폴리펩티드의 프로테아제 절단을 통해 수득된 생성물을 보여준다. 프로테아제는 태그를 제거하는 한편, rPEG_K288 보조적 폴리펩티드에 연결된 hGH인 최종 생성물을 남긴다.
도 51은 프로테아제 절단 및 추가의 정제 이후 rPEG_K288-hGH의 순도를 보여준다.
도 52는 전체 IgG1의 구조를 보여주지만, IgG2, IgG3, IgG4, IgE, IgD, IgA 및 IgM이 출발점으로서 유사하게 사용될 수 있다. dAb-dAb-Fc 융합 단백질은 또한 그의 4원가로 인해 유용하고, 이는 도시되지 않는다.
도 53은 Fc와 항원 결합 도메인을 분리하고 C-말단에 Fc를 갖는 rPEG를 포함하는 구성물을 보여준다: (dAb/scFv)-rPEG-Fc 및 (dAb/scFv)-(dAb/scFv)-rPEG-Fc. 그러나, 동일한 요소를 상이한 순서로 갖는 형식 또한 유용하고, 예컨대 rPEG-Fc-(dAb/scFv), rPEG-Fc-(dAb/scFv)-(dAb/scFv), Fc-rPEG-(dAb/scFv), Fc-rPEG-(dAb/scFv)-(dAb/scFv), Fc-(dAb/scFv)-rPEG, Fc-(dAb/scFv)-(dAb/scFv)-rPEG, dAb/scFv)-Fc-rPEG, 및 (dAb/scFv)-(dAb/scFv)-Fc-rPEG이다. dAb-scFv 또는 scFv-dAb와 같이 scFv 및 dAb를 혼합할 수 있거나, 상이한 표적 특이성의 2개의 scFv 또는 2개의 dAb를 조합할 수 있다: scFv1-scFv2 또는 dAb1-dAb2.
도 53a는 scFv-Fc 융합 단백질을 보여준다. 도 53b는 dAb-Fc 융합 단백질을 보여준다. 도 53c는 4가인 scFv-scFv-Fc 융합 단백질을 보여준다.
도 54는 scFv 단편의 이량체를 보여준다. 이종이량체 및 동종이량체 둘 다 작제될 수 있다.
도 55는 단일쇄 다이아바디(diabody)를 보여준다.
도 56은 단일쇄 Fc 단편의 한 예를 보여준다. 경우에 따라, 생물학적 활성 단백질은 이러한 구성물의 말단에 융합될 수 있다.
도 57: 단백질 쇄의 단일 카피로 구성된 생성물
도 58: AFBT의 구조. 58a: 1가 AFBT; 58b: 이특이적 AFBT의 구조
도 59: AFBT의 표적 항원으로의 다가 결합
도 60a: 2개의 모 항체로부터 유도된 항체 단편을 포함하는 다가 AFBT
도 60b: 다이아바디 및 페이로드(payload)를 포함하는 AFBT의 구조
도 61: 반합성 AFBT의 제조
도 62: rPEG50에 융합된 항 Her-2 scFv의 정제, 특징화 및 결합 활성. 62a: 결합 활성. 채워진 다이아몬드: 코팅된 Her-2로의 결합; 빈 다이아몬드: 코팅된 IgG로의 결합. 62b: 크기 배제 크로마토그래피; 62c: 유리 SH 기의 검출.
도 63: 항 Her-2 다이아바디, aHer203-rPEG50의 정제, 특징화 및 결합 활성. 63a: 결합 활성. 채워진 다이아몬드: 코팅된 Her-2로의 결합; 빈 다이아몬드: 코팅된 IgG로의 결합. 63b: 다이아바디 aHer203-rPEG50 및 scFv aHer230-rPEG50의 크기 배제 크로마토그래피; 63c: 시간에 대한 aHer203-rPEG50의 SEC는 고급 다량체에서 증가를 나타내지 않는다.
도 64: scFv-rPEG50 융합 단백질의 작제, 서열 및 발현. 64a: 단백질 구축의 밑그림; 64b: Her-2에 대해 특이성을 갖는 AFBT의 서열; 64c: scFv-rPEG50 융합 단백질의 발현을 나타내는 SDS/PAGE; 7d: EGFR에 대한 특이성을 갖는 AFBT의 서열.
도 65: 다이아바디-rPEG50 융합 단백질, aHer203-rPEG의 작제, 서열 및 발현. 65a: 단백질 구축의 밑그림; 65b: 단백질 서열; 65c: 이. 콜라이의 사이토졸에서 융합 단백질의 발현을 입증하는 SDS/PAGE.
도 66: 박테리아 발현을 위한 Fc 도메인의 코돈 최적화: 66a: 공정 및 올리고뉴클레오티드 디자인의 예시. 인간 Fc를 코딩하는 서열은 반-랜덤 올리고뉴클레오티드로부터 조립되고 보고된 바와 같이 작용하는 rPEG25 및 GFP 앞에 클로닝된다. 66b: 라이브러리로부터 선택된 클론의 SDS/PAGE. 화살표는 원하는 융합 단백질의 밴드를 지시한다. 66c: 최적화된 인간 Fc 유전자의 아미노산 및 뉴클레오티드 서열.
도 67: Fab-rPEG 융합 단백질에 대한 발현 구성물을 예시하는 밑그림
도 68: 항혈청으로부터의 AFBT에 대한 발견 과정의 플로우 차트
도 69: GFP-rPEG50의 아미노산 서열. GFP의 서열은 밑줄쳐져 있다.
도 70: 사이노몰구스 원숭이(cynomologos monkey)에서 GFP-rPEG50 및 Ex4-rPEG50의 약물동력학.
도 71a: CDB-Ex4-rPEG50 융합 단백질의 아미노산 서열. 도 71b: 도 14a에 도시된 융합 서열로부터 Ex4-rPEG50을 방출하기 위해 사용되는 공정의 예시.
도 72: 마우스에서 Ex4-rPEG50의 면역원성. 도 72a는 주사의 시간 경과 및 혈액 샘플 분석을 예시한다. 도 72b는 1:500 희석시 혈액 샘플의 ELISA 분석을 보여준다. 도 72c는 1:12,500 희석시 혈액 샘플의 ELISA 분석을 보여준다.
도 73: GFP-rPEG25 및 GFP-rPEG50의 크기 배제 크로마토그래피. 회색선은 구형 단백질을 사용하는 분자량 표준을 지시한다.
도 74: 반복적 및 비반복적 URP와 B 세포의 상호작용의 비교. 도 74a는 다수의 동일한 서열 반복으로 이루어진 반복적 URP를 보여준다. 이러한 반복적 URP는 반복 서열을 인식하는 B 세포와의 다가 접촉을 형성할 수 있고, 이는 B 세포 증식을 개시할 수 있다. 도 74b는 다수의 상이한 부분서열로 이루어진 비반복적 URP를 보여준다. 각각의 서열은 동족 특이성을 갖는 B-세포의 특별한 하위집합에 의해 인식될 수 있다. 그러나, 비반복적 URP의 개별 분자는 단지 임의의 특별한 B 세포와 하나 또는 소수의 상호작용을 형성할 수 있고, 이는 증식을 개시하지 않을 것이다.
도 75: 아미노산 서열의 반복성을 평가하기 위한 알고리즘.
도 76: 매우 낮은 반복성을 갖는 nrURP를 디자인하는 컴퓨터 알고리즘.
도 77: URP 분절(segment)의 라이브러리로부터 nrURP의 작제.
도 78: rPEG_Y를 작제하기 위해 사용된 아미노산 서열. 이 도면은 또한 분절 라이브러리를 작제하기 위해 사용된 올리고뉴클레오티드의 상대적 농도를 지시한다.
도 79: 합성 올리고뉴클레오티드로부터의 URP 분절의 조립. 도 79a는 결찰 반응을 보여준다. 반복 분절은 인산화된 올리고뉴클레오티드를 부분적으로 중첩시킴으로써 코딩된다. 어닐링된(annealed) 올리고뉴클레오티드의 제2 쌍이 첨가되어 쇄 신장을 종결시킨다. 이들 캡핑(capping) 올리고뉴클레오티드중 하나는 인산화되지 않고, 이는 한쪽 말단에서 결찰을 방지한다.
도 79b는 결찰 반응의 아가로스 겔을 보여준다.
도 80: URP_Y144 서열의 예
도 81: 플라스미드 pCW0279에 의해 코딩된 아미노산 서열. 오픈 리딩 프레임(open reading frame)은 플래그(Flag)-URP_Y576-GFP의 융합 단백질을 코딩한다. URP_Y576의 아미노산 서열은 밑줄쳐져 있다.
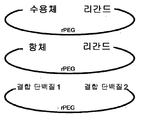
도 82는 'rPEG 연결된 결합 쌍'을 제조하는 일반적 방식을 보여주고, 이는 초기 활성이 없어서 돌발 방출 효과가 없고(독성없이 투여될 수 있는 투약량을 증가시킴) 초기 수용체 매개성 제거(clearance)를 감소시킨다는 이점을 갖는다. 일반적 결합 쌍은 수용체-리간드, 항체-리간드, 또는 일반적 결합 단백질 1-결합 단백질 2일 수 있다. 구성물은, 주입 전에 절단될 수 있고 주입 후에(프로테아제에 의해 혈청에서) rPEG가 치료학적 최종 생성물(활성 단백질)(이는 리간드, 수용체 또는 항체일 수 있음)과 함께 있도록 위치될 수 있는 절단 부위를 가질 수 있다.
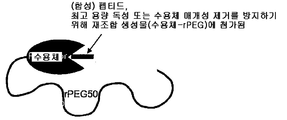
도 83a는 N-말단에 약물 모듈을 갖고, 뒤에 rPEG가 수반되며, 힌지를 포함하는 항체 Fc 단편에 융합되는 구성물을 보여준다. Fc 단편은 긴 반감기를 제공하고, rPEG는 Fc 단편이 이. 콜라이 세포질에서 가용성 활성 형태로 발현하도록 허용한다.
도 83b는 N-말단에 약물 모듈을 갖고, 뒤에 rPEG가 수반되며, 힌지가 없는 항체 Fc 단편에 융합되는 구성물을 보여준다. Fc 단편은 긴 반감기를 제공하고, rPEG는 Fc 단편이 이. 콜라이 세포질에서 가용성 활성 형태로 발현하도록 허용한다.
도 84a: 다이아바디는 VH 및 VL 도메인 사이의 단일쇄 연결기가 약 10∼20 AA보다 짧은 경우에 형성되어, 단일쇄 Fv 단편의 형성을 방지한다. 다이아바디는 2개의 단백질 쇄를 갖고, 하나 또는 둘 다의 C-말단 말단에, 및/또는 하나 또는 둘 다의 N-말단 말단에 rPEG를 가질 수 있다. 다이아바디는 2개의 결합 부위를 갖고, 이중 0, 1개 또는 2개는 약학적 표적, 또는 반감기 표적(즉, HSA, IgG, 적혈 세포, 콜라겐 등)에 결합하거나, 표적에 전혀 결합하지 않을 수 있다.
도 84b: 다이아바디는 0, 1개 또는 둘 다의 단백질 쇄의 N-말단 말단 또는 C-말단 말단에 위치한 0, 1개 또는 그 이상의 약물 모듈을 함유할 수 있다.
도 85a는 약물 모듈(IFNa, hGH 등과 같음)이 N- 및/또는 C-말단 말단의 하나 또는 둘 다에 융합될 수 있는 단일쇄 Fv 단편을 보여준다. scFv는 하나의 결합 부위를 갖고, 이는 약학적 표적 또는 반감기 표적(즉 HSA(도 85b 참조), IgG, 적혈 세포 등)에 결합하거나 결합하지 않을 수 있다.
도 86은 동일한 복합체에 속하는 2개의 단백질을 회합하기 위한 rPEG의 용도를 보여준다. 이러한 단백질 사이의 친화도는 종종 이들 회합을 유지하기에 불충분하지만, rPEG의 첨가는 이들 상호작용을 안정화시키고, 중합체를 형성하려는 이들의 경향을 감소시킨다.
도 87은 세포-표면 표적으로의 Fab 단편 결합을 보여주고; H 쇄는 Fc(전체 항체에서와 같이)에 또는 매우 다양한 다른 단백질, 도메인 및 펩티드에 융합될 수 있다. VH와 CH 도메인 사이, 및 VL과 CL 도메인 사이에서, 통상 2∼6개 아미노산으로부터 4, 5, 6, 7, 8, 9, 10, 11, 1, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 24, 26, 28, 30, 35, 40, 45, 50, 60,70, 80, 100개 이상의 아미노산으로의 천연 연결기 길이의 연장은, 도메인 스와핑(swapping)에 의해 하나의 Fab가 또 다른 Fab에 가교결합되는 능력을 증가시킴으로써, 보다 높은 결합가를 갖는 결합 복합체를 형성하고, 그 결과 보다 높은 겉보기 친화도(결합활성: avidity)를 생성한다. 연결기는 rPEG 또는 상이한 조성물일 수 있다. 이러한 '연장된 연결기' 형식은 보다 높은 밀도의 표적, 예컨대 종양 세포에 대해 (부분적으로) 종양 특이적 항원을 갖는 부위에 특이적으로 증가된 친화도를 갖는 결합을 허용한다.
도 88은 회합 펩티드, 예컨대 SKVILF(E) 또는 RARADADA(이는 역평행 배향으로 동일한 서열의 또 다른 카피(copy)에 결합함)가 전구약물을 생성하는데 어떻게 사용될 수 있는지를 보여준다. 이러한 경우, 약물은 마지막 제작 단계에서 프로테아제에 의해 절단되지만, 2개의 쇄가 여전히 회합 펩티드에 의해 회합되어 있기 때문에 절단은 약물을 활성화시키지 않는다. 단지 약물이 혈액내로 주사되고 농도가 크게 감소된 후에야만, 작은 비-rPEG 함유 단백질 쇄가 복합체를 떠나서(친화도에 의존하는 속도로, 특별히 오프(off)-속도로) 신장을 통해 제거될 것이고, 이에 따라 r-PEG 함유 약물 모듈을 활성화시킨다.
도 89는 제작된 단일쇄 단백질을 2개의 단백질 쇄의 복합체로 전환시키는 단백질가수분해 절단을 보여준다. 이러한 절단은 마지막 제작 단계(주사 전)로서 초래되거나, 주사 후 환자 혈액중의 프로테아제에 의해 초래될 수 있다.
도 90a는 (경우에 따라) 하나의 말단 상에서 약물 모듈(예를 들어, IFNa, hGH, 등)에 융합되고 (경우에 따라) 다른 말단 상에서 rPEG에 융합된, 힌지 영역을 갖는 항체 Fc 단편을 보여준다. CH2 및 CH3 사이의 서열은, 돌연변이에 의해 기능이 제거되지 않는 한, FcRn, 신생(neonatal) Fc 수용체로의 결합을 중재한다.도 90b는 힌지 영역이 없는 유사 구성물을 보여준다.
도 91a는 CH3 도메인의 짝을 이룬 쌍을 포함하는 단백질 구성물을 보여준다; 이들 쇄중 0, 1개 또는 둘 다는 N-말단 말단 및/또는 C-말단 말단 상에서 rPEG에, 및 나머지 말단에서 0, 1개 또는 그 이상의 약물 모듈에 융합될 수 있다. FcRn 결합 서열은 유지 또는 결실될 수 있고; 보유는 보다 긴 혈청 반감기를 산출해야 한다.
도 91b는 유사 단백질을 보여주지만, CH2는 완전히 제거되어 Fc의 FcRn 수용체로의 결합은 더 이상 작용하지 않아 반감기를 감소시킨다.
도 92a는 힌지, CH2 및 CH3 도메인을 포함하고, c-말단에서 rPEG에 융합되고, C-말단에 위치된 약물/약물분자구조(drug/pharmacophore)를 갖는 완전한 Fc인 단백질을 보여준다.
도 92b는 c-종단부에서 rPEG에 융합되고, C-말단에 위치된 약물/약물분자구조를 갖는, 힌지가 없는 완전한 Fc를 보여주고; 이들 분자는 쇄 스와핑되어, 잠재적으로 이종-이량체를 생성할 수 있다.
도 93a는 절단되었으나 FcRn 결합을 보유하는 CH2를 갖고 C-말단에 위치된 약물/약물분자구조를 갖는, 힌지가 없는 부분적 Fc를 보여준다.
도 93b는 힌지 및 CH2가 없으나 CH3을 보유하고 C-말단에 위치된 약물/약물분자구조를 갖는 부분적 Fc를 보여준다. 이는 FcRn에 결합하지 않지만, CH3 도메인을 통해 이량체화될 수 있다.
도 94a는 동일한 수용체 도메인(또는 동일한 결합 기능을 갖는 도메인, 또는 동일한 표적에 동시에 결합할 수 있는 도메인)에 의해 플랭킹된(flanked) rPEG를 보여준다. 수용체 둘 다가 동시에 표적에 결합할 수 있다면, 하나의 수용체의 결합은 제2 수용체의 결합을 안정화시키고, 유효성/겉보기 친화도/결합활성은 전형적으로 10∼100배, 그외에 3배 이상 증가된다. rPEG는 혈청 반감기를 제공한다. 하나의 선택사항은 생성물에 리간드를 미리 로딩하는 것이다. 이러한 경우, 주사된 생성물은 이것이 리간드에 결합한 상태로 남아있는 한 불활성이다. 이러한 접근법은 최고 용량 독성을 감소시키고, 또한 수용체 매개성 제거를 감소시키며, 따라서 이것이 중요한 적용분야에서 유용할 수 있다.
도 94b는 리간드에 동시에 결합할 수 있는 2종의 상이한 수용체에 의해 플랭킹된 rPEG를 갖는 생성물을 보여주는데, 이는 복합체의 상호 안정성 및 증가된 겉보기 친화도(결합활성)를 초래하고, rPEG는 수용체의 효과적 농도를 증가시키는 결합가 가교로서 작용한다.
도 94c: 하나의 선택사항은 생성물을 리간드로 미리 로딩하는 것이다. 이 경우, 주사된 생성물은 이것이 리간드에 결합한 상태로 남아있는 한 불활성이다. 리간드가 풀리면, 이는 신속히 신장을 통해 제거되어 생성물을 활성화시키는데, 이 생성물은 rPEG 테일(tail)로 인해 증가된 반감기를 갖는다. 이러한 접근법은 최고 용량 독성을 감소시키고, 또한 수용체 매개성 제거를 감소시키며, 따라서 이것이 중요한 적용분야에서 유용할 수 있다.
도 94에서 볼 수 있듯이, 동일한 전구약물 형식은 절단 또는 다른 활성화 부위를 포함할 필요가 없다. 단일 단백질 쇄는 rPEG에 의해 분리된 2개(또는 그 이상)의 약물 모듈을 함유할 수 있고; 이들 모듈은 동일하거나(단일 유형) 2종 이상의 상이한 유형일 수 있다. 모든 약물 모듈은 수용체이거나 모두 리간드이다. 이러한 rPEG를 함유하는 생성물은 제2의 상보성 단백질과 착화되어 수용체-리간드-수용체 상호작용을 형성한다. 이러한 형식에서, 리간드는 이량체 또는 다량체이기 쉽지만, 또한 특별히 2개의 약물 모듈이 상이한 경우 단량체일 수 있다. 양쪽 모듈이 제3의 단백질에 결합한다. X 및 Y는 동일하거나 상이할 수 있고, X 및 Y는 약물 모듈이거나 약물 모듈에 결합할 수 있다. 각 경우에, 도 94에서, X 및 Y(및 rPEG)는 하나의 단백질 쇄를 포함하고, 이들이 결합된 분자는 별도의 분자, 전형적으로 단백질 또는 작은 분자이다. 단일 단백질 쇄에 조합된 2개보다 많은 결합 단백질을 갖는 것이 가능하다. 이러한 생각은 큰 rPEG 함유 단백질 및 비-rPEG 함유 단백질의 복합체가 주사시 불활성이지만, 2∼24시간에 걸쳐 보다 작은 비-rPEG 함유 단백질이 복합체를 떠나고 신장을 통해 배출됨으로써 약물 모듈(들)을 활성화시킨다는 것이다. 이러한 형식의 이점은 약물 농도에서의 초기 스파이크(spike) 및 연관된 안전성 문제를 감소 또는 제거하고, 복합체가 착화되어 있는 동안 수용체 매개성 제거를 최소화하여 혈청 분비 반감기를 증진시킨다는 것이다.
도 95는 VEGF-수용체에 의해 양쪽 측부 상에 플랭킹된 rPEG를 보여준다. VEGF가 이량체이므로, 이는 rPEG의 양쪽 측부 상에 동일한 수용체일 수 있거나 상이한 수용체일 수 있다(바람직하게는 VEGF-R1 및 VEGF-R2, 그러나 VEGFR3도 사용될 수 있음).
도 96은 불활성 전구약물로서 제작되거나(주사 전 절단됨) 투여되는(주사 후 혈액중에서 절단됨) 생성물을 보여준다. 약물의 불활성화는 rPEG에 의해 약물로 연결되는 결합 단백질에 의해 중재되어, 모든 3개의 모듈이 단일 단백질 쇄로서 제작된다. 약물이 수용체라면, 결합 단백질은 수용체의 리간드(펩티드 또는 단백질)이고; 약물이 항체 단편이라면, 결합 부위는 펩티드 또는 단백질 리간드이다. 이들 예에서 약물은 2개의 결합 도메인(X 및 Y로 지칭됨) 사이의 부위의 프로테아제 절단에 의해 활성화된다. 단백질 Y가 활성 생성물이면, Y는 rPEG를 보유해야 하고, 프로테아제 절단 부위는 (X와 Y 사이이지만) X에 가까와야 한다. 단백질 X가 활성 생성물이면, X는 rPEG를 보유해야 하고, 절단 부위는 Y에 가까와야 한다. 청색 크로스바(crossbar)에 의해 보여지듯이 1개 또는 다수의 절단 부위가 존재할 수 있다. 약물 모듈은 수용체, 리간드, 하나 이상의 Ig 도메인, 항체 단편, 펩티드, 미소단백질, 항체에 대한 에피토프(epitope)일 수 있다. 약물 모듈에 결합되는 단백질은 결합 단백질, 수용체, 리간드, 하나 이상의 Ig 도메인, 항체 단편, 펩티드, 미소단백질, 항체에 대한 에피토프일 수 있다.
도 97은 불활성 전구약물이 결합 펩티드를 약물 모듈에 첨가함으로써 어떻게 생성될 수 있는지를 보여준다. 펩티드는 약물의 표적 결합 능력을 무효화시키고, 펩티드는 rPEG 함유 약물에 비해 더 높은 속도로 혈액으로부터 점진적으로 제거된다. 이러한 펩티드는 천연적일 수 있지만 보다 전형적으로 이는 약물 모듈에 대한 랜덤 펩티드 라이브러리의 파지 패닝(panning)에 의해 수득된다. 펩티드는 바람직하게는 합성적으로 만들어지지만, 이는 재조합체일 수 있다.
도 98은 rPEG의 동일한 말단 또는 rPEG의 반대쪽 말단에 있을 수 있는 다수의 생물활성 펩티드를 함유하는 단일쇄 단백질 약물을 보여준다. 이들 펩티드는 동일한 활성 또는 상이한 활성을 가질 수 있다. 단일쇄중에 다수의 펩티드를 갖는 목적은 복잡한 제작과정 없이 결합활성을 통해 이들의 효과적인 효능을 증가시키는 것이다.
도 99는 전구약물-rPEG가 수용체 매개성 제거를 방지함으로써 혈청 반감기를 어떻게 증가시키는지를 보여준다.
도 100은 약물 농도가 정맥내 주사 후 시간에 대해 어떻게 변화하는지를 보여준다. 전형적 치료법에서의 목표는 치료학적 투약량에 비해 높은 농도이지만 독성 투약량에 비해 낮은 농도로 약물을 유지시키는 것이다. 짧은 반감기를 갖는 약물의 전형적 일시주사(bolus injection)(IV, IM, SC, IP 또는 이와 유사함)는 독성 투약량에 비해 매우 높은 피크 농도를 초래하고, 이후 치료학적 투약량 미만으로 신속히 강하하는 약물 농도를 초래하는 제거 상이 수반된다. 이러한 PK 프로필(profile)은 독성 및 장기간의 비효과적 치료를 초래하는 경향이 있는 반면, 약물은 단지 짧은 기간에만 치료학적 농도로 존재한다(청색선). rPEG의 약물로의 첨가는 피크 농도를 감소시켜 독성을 감소시키고, 약물이 치료학적 무독성 투약량으로 존재하는 기간을 증가시킨다. rPEG + 약물 결합 단백질을 첨가하여 전구약물을 생성하면 '돌발 방출' 또는 독성 피크 투여량(적색선)을 방지할 수 있는데, 이는 약물이 수 시간에 걸쳐 점진적으로만 활성화되고, 독성 투약량과 치료학적 투약량 사이의 시간 길이가 다른 형식에 비해 증가되기 때문이다.
도 101은 rPEG 및 C-말단 Fc 단편(힌지를 가짐)이 수반되는 N-말단 약물 모듈을 보여준다. 이는 이. 콜라이 세포질에서 제작될 수 있는 약물 모듈의 반감기 연장을 위해 유용한 형식이다.
도 102a는 Fc 단편을 함유하는 전구약물에 대한 대안의 형식을 보여준다. 이 형식은 도 101에 기재된 바와 유사하고, 약물 서열(적색)에 결합하여 이를 저해하는 저해 서열(청색)이 첨가된다(N-말단에). 이전과 마찬가지로, 약물은 절단 부위에 의해 저해 서열로부터 분리된다. N-말단 저해 결합 서열은 절단 부위를 수반하고, 이는 약물 서열(적색)을 수반한다. 절단 전, 약물은 저해 서열에 결합하고, 따라서 불활성이다(전구약물). 절단 후, 저해 결합 서열(청색)은 점진적으로 방출 및 제거되고, 약물(적색)이 활성인 시간의 양을 점진적으로 증가시킨다.
도 102b는 Fc 단편을 함유하는 대안의 전구약물 형식을 보여준다. 이 형식은 도 101에 기재된 형식과 유사하고, 역시 절단 부위에 의해 약물(청색으로 제시됨)로부터 분리되는 저해 결합 서열(전형적으로 rPEG내에 또는 이의 부근에 위치된 펩티드 또는 도메인(적색으로 제시됨))이 첨가된다. 절단 전, 약물은 저해 서열에 결합하고, 따라서 불활성이다(전구약물). 절단 후, 저해 결합 서열(청색)은 점진적으로 방출 및 제거되고, 약물(적색)이 활성인 시간의 양을 점진적으로 증가시킨다.
도 103a∼d는 손상되지 않은 전체 항체(IgG1, 2, 3, 4, IgE, IgA, IgD, IgM가 포함됨)로의 rPEG에 대한 바람직한 융합 부위를 보여준다. 지시된 이들 부위가 이들 작용성 도메인의 폴딩을 교란시키지 않으면서 구조화된 서열, 예컨대 도메인, 힌지 등의 경계에 있으므로 바람직하다. 따라서 rPEG는 1, 2, 3, 4, 5, 6, 7 또는 8개의 상이한 위치에서 하나의 항체(및 IgM 및 IgG3에 대해 8개보다 많이)에 첨가될 수 있고, 단일 항체는 다양한 위치에서 및 임의로 조합된 도시된 8개 위치에서 1, 2, 3, 4, 5, 6, 7, 8개 이상의 rPEG를 가질 수 있다.
도 103e는 항체(IgG1, 2, 3, 4, IgE, IgA, IgD, IgM)의 도메인 및 단편으로의 rPEG에 대한 바람직한 융합 부위를 보여준다. rPEG의 N-말단 및/또는 C-말단 첨가를 위한 융합 부위는 적색 화살표 또는 적색선으로 도시되어 있다.
도 104는 Fc 단편의 올바른 폴딩에 대한 검정을 보여준다.
도 105는 부위 특이적 프로테아제에 의한, 혈청에서의 또는 주사 전의 불활성 단백질의 활성 단백질로의 전환을 보여준다. 이 예에서, 적색 서열은 활성 치료제이다.
도 106은 부위 특이적 프로테아제에 의한 불활성 약물의 활성 약물로의 전환을 보여준다. 이 예에서, 청색 도메인(dAb, scFv, 기타)은 치료학적 물질이다.
본 발명은, 보조적 폴리펩티드로 변경된 생물학적 활성 폴리펩티드가, 이러한 변경이 없는 생물학적 활성 폴리펩티드가 응집되어 봉입체를 형성하는 조건하에, 세포질에서 가용성으로 남아있고 이들의 활성 형태로 폴딩되는 특성을 가질 수 있다는 예기치 못한 발견을 이용한다. 본 발명의 방법은 여러 적용 분야 중에서도, 디자인 상에서의 단백질의 고 산출량 스크리닝, 주변세포질 공간 발현을 현재 필요로하는 단백질의 제작, 예컨대 봉입체를 비롯한 응집체로부터 리폴딩하기 어려운 단백질의 제작에 유용할 수 있다. 본 발명은 보조적 단백질 서열, 변경된 폴리펩티드를 코딩하는 재조합 DNA 분자, 이러한 폴리펩티드를 위한 발현 벡터, 이러한 폴리펩티드의 발현을 위한 숙주 세포 및 정제 공정을 디자인하는 방법을 개시한다. 예를 들면, 긴 친수성 폴리펩티드 서열의 단백질(이는 펩티드, 단백질, 항체 및 백신을 포함할 수 있고, 진핵생물 또는 포유동물 단백질일 수 있음)로의 융합은 세포질에서 활성 형태로 개선된 폴딩을 나타내는 가용성 융합 단백질을 생성한다.
본 발명의 보조적 폴리펩티드는 GCSF, 성장 호르몬, 인터페론 알파 및 항체 단편을 비롯한 약학적 단백질에 연결될 수 있다. 이들 4종의 단백질 또는 단백질의 부류는 이. 콜라이의 세포질에서 발현될 경우 전형적으로 봉입체를 형성한다. 그러나, 긴 친수성 보조적 폴리펩티드 서열에 연결될 경우, 생물학적 활성 폴리펩티드의 폴딩 특성은 크게 개선되어, 보조적 단백질의 부재하에 진핵생물 단백질의 경우 전형적으로 발생되는 즉각적이고 비가역적인 봉입체로의 응집과는 반대로, 세포내에서 활성 단백질로 정확히 폴딩될 수 있는 분율을 크게 증가시킨다. 보조적 폴리펩티드는 또한 이온 교환에 의한 단백질 정제를 위한 친화성 태그를, 단독으로 또는 다른 공지된 정제 태그, 예컨대 키틴 결합 도메인, 셀룰로스 결합 도메인, MBP, GST 또는 His-태그와 함께 포함할 수 있다.
본 발명의 이러한 양태 및 다른 양태는 하기 추가로 상세히 기재될 것이다.
일반적 기법 :
본 발명의 실행은, 달리 지시되지 않는 한, 당분야의 기술에 속하는 면역학, 생화학, 화학, 분자 생물학, 미생물학, 세포 생물학, 유전체학 및 재조합 DNA의 통상의 기법을 사용한다. 문헌[Sambrook, Fritsch and Maniatis, MOLECULAR CLONING: A LABORATORY MANUAL, 2nd edition (1989)]; [CURRENT PROTOCOLS IN MOLECULAR BIOLOGY(F. M. Ausubel, et al. eds., (1987)]; [the series METHODS IN ENZYMOLOGY(Academic Press, Inc.): PCR 2: A PRACTICAL APPROACH(M.J. MacPherson, B.D. Hames and G.R. Taylor eds. (1995))], [Harlow and Lane, eds. (1988) ANTIBODIES, A LABORATORY MANUAL], 및 [ANIMAL CELL CULTURE(R.I. Freshney, ed. (1987))]을 참조한다.
정의 :
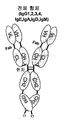
명세서 및 특허청구범위에서 사용될 경우, 단수 형태인 "하나", 및 "그"는 문맥에서 명확히 달리 지시되지 않는 한, 복수 개의 피험체를 포함한다. 예를 들면, "하나의 세포"는 이의 혼합물을 비롯한 복수 개의 세포를 포함한다.
용어 "폴리펩티드", "펩티드", "아미노산 서열" 및 "단백질"은 본원에서 상호교환적으로 사용되어 임의의 길이의 아미노산의 중합체를 지칭한다. 중합체는 선형 또는 분지형일 수 있고, 이는 변경된 아미노산을 포함할 수 있고, 이는 비-아미노산에 의해 차단될 수 있다. 용어는 또한, 변경된, 예를 들면, 디설파이드 결합 형성, 글리코실화, 지질화(lipidation), 아세틸화, 인산화, 또는 임의의 다른 조작, 예컨대 표지화 성분에 의한 접합에 의해 변경된 아미노산 중합체를 내포한다. 본원에서 사용될 경우 용어 "아미노산"은 천연 및/또는 비천연 또는 합성 아미노산을 지칭하고, 제한되지 않지만 글리신 및 D 또는 L 광학 이성체 둘 다, 및 아미노산 유사체 및 펩티드 유사체(peptidomimetics)가 포함된다. 표준의 단일 또는 3문자 코드가 아미노산을 표시하기 위해 사용된다.
용어 "생물학적 활성 폴리펩티드"는, 예컨대 세포, 조직 또는 기관 표적화를 위해, 치료학적 표적 및/또는 보조적 표적일 수 있는 소정의 표적 또는 표적들에 결합 특이성을 나타내는 임의의 길이의 폴리펩티드를 지칭한다. 다르게는, 또는 추가로, 이는 시험관내 또는 생체내에서 사용될 경우 목적하는 생물학적 특징을 나타내는 폴리펩티드를 지칭한다. 예로서, 생물학적 활성 폴리펩티드는 치료학적 또는 진단학적 표적에 결합하는 기능적 치료제 또는 생체내 진단학적 단백질을 포함한다. 용어 "생물학적 활성 폴리펩티드" 및 "결합 모듈" 또는 "BM"은 본원에서 상호교환적으로 사용된다. 생물학적 활성 폴리펩티드는, 예를 들면, 제한없이, 선형 또는 환형 펩티드, 시스테인-구속된(constrained) 펩티드, 미소단백질, 스캐폴드(scaffold) 단백질, 예컨대 피브로넥틴(fibronectin), 안키린(ankyrin), 결정질, 스트렙타비딘, 항체 단편, 도메인 항체, 펩티드성 호르몬, 성장 인자, 사이토킨(cytokines), 또는 임의의 유형의 단백질 도메인, 인간 또는 비-인간, 천연 또는 비-천연일 수 있고, 이들은 천연 스캐폴드에 기초하거나 천연 스캐폴드에 기초하지 않을 수 있거나(즉, 조작되거나 선택됨), 또는 상기 임의의 조합 또는 단편에 기초할 수 있다. 경우에 따라, 생물학적 활성 폴리펩티드는 이들의 결합 특성, 이들의 안정성, 또는 다른 원하는 특성을 증진시키기 위해 하나 또는 다수의 아미노산을 첨가, 제거 또는 대체함으로써 조작될 수 있다. 결합 모듈은 천연 단백질로부터, 디자인 또는 유전자 패키지 디스플레이(genetic package display), 예컨대 파지 디스플레이, 세포 디스플레이, 리보솜 디스플레이 또는 기타 디스플레이 방법에 의해 수득될 수 있다. 결합 모듈은 동일한 표적의 동일한 카피에 결합되어 결합활성을 일으키거나, 이들은 동일한 표적의 상이한 카피에 결합되거나(이는 이들 카피가 예컨대 세포 막에 의해 어느 정도 이어지거나 연결될 경우 결합활성을 초래할 수 있음), 이들은 2개의 관계없는 표적에 결합될 수 있다(이는 이들 표적이 예컨대 막에 의해 어느정도 연결되는 경우 결합활성을 산출할 수 있음). 결합 모듈은 스크리닝에 의해 또는 달리는 펩티드나 단백질의 랜덤 라이브러리를 분석함으로써 동정될 수 있다.
"재조합 PEG", "rPEG" 또는 "rPEG 폴리펩티드" 또는 "재조합 PK 증진 기(Enhancing Group)"는 생물학적 활성 폴리펩티드를 변경하기 위해 사용될 수 있는 폴리펩티드의 부류를 내포하는 일반적 용어이고, 여기서 변경은 생물학적 특성, 예컨대 혈청 반감기 또는 생체내 제거에서 원하는 변화를 초래한다. 일반적으로, rPEG 폴리펩티드는 생물학적 활성 폴리펩티드에 의해 결합된 동일한 소정의 표적으로의 결합 특이성이 결여되어 있다. 몇몇 양태에서, rPEG는 PEG의 공지된 특성의 일부를 모방하지만 전체를 모방할 필요는 없는 PEG의 기능적 유사체이다. 하기 보다 상세히 기재되는 이러한 특성은 수력학적 반경을 증가시키는 증진된 능력, 프로테아제에 대한 증가된 내성, 감소된 면역원성 및 감소된 특이적 활성을 포함한다. rPEG 분자가 PEG와 넓은 구조적 및 기능적 특징, 예컨대 선형성 또는 3차 구조의 결여를 공유하지만, PEG에 의한 엄격한 화학 유사성은 rPEG의 필수적 특징이 아니다.
"보조적 폴리펩티드(accessory polypeptide)" 또는 "보조적 단백질(accessory protein)"은, 생물학적 활성 폴리펩티드와 함께 사용될 경우, 예를 들어 생물학적 활성 폴리펩티드와 연결된 방식으로, 전체 연결된 폴리펩티드의 생물학적 특성에 있어서 원하는 변화를 일으키는 폴리펩티드를 지칭한다. 보조적 폴리펩티드의 비제한적인 예로는 rPEG, 및 수력학적 반경을 증가시키고 혈청 반감기를 연장시키고/시키거나 생체내 제거 속도를 변경할 수 있는 임의의 다른 폴리펩티드가 포함된다. 원할 경우, 보조적 폴리펩티드는 예상 분자량에서 약간의 증가를 일으키지만, 겉보기 분자량에서는 보다 큰 증가를 일으킨다. 상이한 명칭이 상이한 특징을 강조할지라도, 이들은 동일한 모듈을 지칭하고 상호교환적으로 사용될 수 있다.
용어 "변경된 폴리펩티드" 및 "보조제 변경 폴리펩티드(accessory-modified polypeptide)"는 본원에서 상호교환적으로 사용되어 본 발명의 보조적 폴리펩티드로 변경된 생물학적 활성 폴리펩티드를 지칭한다. 이들 용어는 또한 본 발명에 따른 보조적 폴리펩티드로 변경된 생물학적 활성 폴리펩티드를 포함하는 서방형 또는 다른 유형의 제형을 지칭한다.
"반복적 서열" 또는 "반복적 모티프"는 본원에서 상호교환적으로 사용되고, 다수의 서열 모티프의 정방향 반복부, 또는 역방향 반복부 또는 교대 반복부를 형성하는 반복 펩티드 서열("반복부")의 올리고머로서 기재될 수 있는 아미노산 서열을 지칭한다. 이들 반복 올리고머 서열은 서로 동일하거나 상동성일 수 있지만, 다수의 반복된 모티프일 수도 있다. 반복적 서열은 매우 낮은 정보 함량을 특징으로 한다. 반복적 서열은 보조적 폴리펩티드의 필수 특징부가 아니고, 몇몇 경우에 비반복적 서열이 실제로 바람직할 것이다.
아미노산은 이들의 소수성에 기초하여 특징지워질 수 있다. 다수의 척도가 개발되어 왔다. 한 예는 레비트(Levitt, M) 등에 의해 개발된 척도이다(문헌[Levitt, M (1976) J Mol Biol 104, 59, #3233, which is listed in Hopp, TP, et al. (1981) Proc Natl Acad Sci U S A 78, 3824, #3232] 참조). "친수성 아미노산"의 예는 아르기닌, 라이신, 트레오닌, 알라닌, 아스파라긴, 및 글루타민이다. 친수성 아미노산인 아스파테이트, 글루타메이트, 및 세린, 및 글리신이 특히 관심있다. "소수성 아미노산"의 예는 트립토판, 타이로신, 페닐알라닌, 메티오닌, 루신, 이소루신, 및 발린이다.
본원에서 사용될 경우, 용어 "세포 표면 단백질"은 세포의 혈장 막 성분을 지칭한다. 이는 혈장 막을 구성하는 내재(integral) 및 주변 막 단백질, 당단백질, 다당류 및 지질을 내포한다. 내재 막 단백질은 세포의 혈장 막의 지질 2층을 가로질러 연장되는 막간 단백질이다. 전형적인 내재 막 단백질은 소수성 아미노산 잔기를 일반적으로 포함하는 하나 이상의 막 스패닝(spanning) 분절로 구성된다. 주변 막 단백질은 지질 2층의 소수성 내부로 연장되지 않고, 이들은 직접적으로 또는 다른 막 성분에 의해 간접적으로 공유 또는 비공유 상호작용을 통해 막에 결합된다.
세포 단백질에 적용될 경우 용어 "막", "사이토졸성", "핵" 및 "분비된"은 세포 단백질이 주로, 우세하게, 또는 선호적으로 편재하는 세포외 및/또는 하위세포 위치를 구체화한다.
"세포 표면 수용체"는 이들의 개별 리간드에 결합할 수 있는 막 단백질의 하위집합을 나타낸다. 세포 표면 수용체는 세포 혈장 막에 고정되거나 이에 삽입된 분자이다. 이들은 보다 큰 계열의 단백질, 당단백질, 다당류 및 지질을 구성하는데, 이는 혈장 막의 구조적 구성성분으로서 뿐만 아니라 다양한 생물학적 기능을 지배하는 조절 요소로서 작용한다.
단백질에 적용되는 "비-천연적으로 발생된"은 단백질이 상응하는 야생형 또는 고유 단백질과 상이한 하나 이상의 아미노산을 함유함을 의미한다. 비-천연 서열은, BLAST 조사를 수행하여, 예를 들어, BLAST 2.0을 사용하여 유전자은행의 비-과다("nr"; non-redundant) 데이터베이스와 비교될 경우 가장 낮고 작은 합의 가능성을 사용하여(여기서 비교 창은 관심있는 서열(질문됨)의 길이임) 결정될 수 있다. BLAST 2.0 알고리즘은 각각 문헌[Altschul et al. (1990) J. Mol. Biol. 215:403-410]에 기재되어 있다. BLAST 분석을 수행하기 위한 소프트웨어는 국립 생물기술정보센터(National Center for Biotechnology Information)를 통해 공식적으로 입수가능하다.
"숙주 세포"는 벡터에 대한 수용자(recipient)일 수 있거나 수용자인 개별 세포 또는 세포 배양액을 포함한다. 숙주 세포는 단일 숙주 세포의 자손을 포함한다. 자손은, 천연적, 우연적 또는 의도적 돌연변이에 기인하여 본래의 모세포와 완벽히 동일할 필요는 없다(형태학적으로 또는 총 DNA 상보성의 게놈에서). 숙주 세포는 본 발명의 벡터에 의해 생체내에서 형질감염된 세포를 포함한다.
본원에서 사용될 경우, 용어 "단리된"은 폴리뉴클레오티드, 펩티드, 폴리펩티드, 단백질, 항체, 또는 이의 단편이 자연에서 정상적으로 회합되는 구성성분 및 세포 및 기타물질로부터 분리됨을 의미한다. 당분야의 숙련가에게 명백하듯이, 비-천연 발생된 폴리뉴클레오티드, 펩티드, 폴리펩티드, 단백질, 항체, 또는 이의 단편은 이를 이의 천연적으로 발생된 대응물과 구별하기 위해 "단리"할 필요가 없다. 또한, "농축된", "분리된" 또는 "희석된" 폴리뉴클레오티드, 펩티드, 폴리펩티드, 단백질, 항체, 또는 이의 단편은, 부피당 분자의 농도 또는 수가 그의 천연적으로 발생된 대응물의 "농축된" 경우에 비해 더 크거나 "분리된" 경우에 비해 더 작다는 점에서 그의 천연적으로 발생된 대응물로부터 구별가능하다. 일반적으로, 재조합 수단에 의해 제조되고 숙주 세포에서 발현된 폴리펩티드는 "단리된" 것으로 고려된다.
"접합된", "연결된" 및 "융합된" 또는 "융합"은 본원에서 상호교환적으로 사용된다. 이들 용어는 2개 이상의 화학 요소 또는 성분을 화학적 접합 또는 재조합 수단을 비롯한 어떠한 수단에 의해 함께 연합시킴을 지칭한다. "프레임내 융합(in-frame fusion)"은 둘 이상의 오픈 리딩 프레임(ORF)을 연합시켜 본래의 ORF의 정확한 판독 프레임을 유지하는 방식으로 연속적인 보다 긴 ORF를 형성함을 지칭한다. 따라서, 생성된 재조합 융합 단백질은 본래의 ORF에 의해 코딩된 폴리펩티드에 상응하는 둘 이상의 분절을 함유하는 단일 단백질이다(이러한 분절은 정상적으로는 자연적으로 이렇게 연합되지 않음).
폴리펩티드에 관하여, "선형 서열" 또는 "서열"은 아미노에서 카복실 종단부 방향으로의 폴리펩티드중의 아미노산의 순서이고, 여기서 서열중의 서로 이웃한 잔기는 폴리펩티드의 1차 구조에서 접촉한다. "부분적(partial) 서열"은 한 방향 또는 두 방향에서 추가의 잔기를 포함하는 것으로 공지된 폴리펩티드의 일부의 선형 서열이다.
"이종성"은 비교되어지는 실체의 나머지로부터 유전자형으로 별개인 실체로부터 유도됨을 의미한다. 예를 들면, 고유의 코딩 서열로부터 제거되고 고유 서열과는 다른 코딩 서열에 작동적으로(operatively) 연결된 글리신 풍부 서열은 이종성의 글리신 풍부 서열이다. 폴리뉴클레오티드 및 폴리펩티드에 적용될 경우 용어 "이종성"은 폴리뉴클레오티드 또는 폴리펩티드가 비교되어지는 실체의 나머지로부터 유전자형으로 별개인 실체로부터 유도됨을 의미한다.
용어 "폴리뉴클레오티드", "핵산", "뉴클레오티드" 및 "올리고뉴클레오티드"는 상호교환적으로 사용된다. 이들은 임의의 길이의 뉴클레오티드의 중합체 형태, 데옥시리보뉴클레오티드 또는 리보뉴클레오티드, 또는 이의 유사체를 지칭한다. 폴리뉴클레오티드는 임의의 3차원 구조를 가질 수 있고, 공지되거나 비공지된 임의의 기능을 수행할 수 있다. 다음은 폴리뉴클레오티드의 비제한적 예이다: 유전자 또는 유전자 단편의 코딩 또는 비코딩 영역, 연결 분석으로부터 정의된 장소들(장소), 엑손(exon), 인트론(intron), 메신저(messenger) RNA(mRNA), 전이 RNA, 리보솜 RNA, 리보자임(ribozyme), cDNA, 재조합 폴리뉴클레오티드, 분지형 폴리뉴클레오티드, 플라스미드, 벡터, 임의의 서열의 단리된 DNA, 임의의 서열의 단리된 RNA, 핵산 프로브(probe), 및 프라이머. 폴리뉴클레오티드는 변경된 뉴클레오티드, 예컨대 메틸화된 뉴클레오티드 및 뉴클레오티드 유사체를 포함할 수 있다. 존재할 경우, 뉴클레오티드 구조로의 변경이 중합체의 조립 전후에 부여될 수 있다. 뉴클레오티드의 서열은 비-뉴클레오티드 성분에 의해 차단될 수 있다. 폴리뉴클레오티드는 중합 후, 예컨대 표지 성분과의 접합에 의해 추가로 변경될 수 있다.
폴리뉴클레오티드에 적용될 경우 "재조합"은 클로닝, 제한, 및/또는 결찰 단계, 및 숙주 세포에서 잠재적으로 발현될 수 있는 구성물을 생성하는 다른 절차와의 다양한 조합에 의한 생성물이다.
용어 "유전자" 또는 "유전자 단편"은 본원에서 상호교환적으로 사용된다. 이들은 전사 및 번역 후 특정 단백질을 코딩할 수 있는 하나 이상의 오픈 리딩 프레임을 함유하는 폴리뉴클레오티드를 지칭한다. 유전자 또는 유전자 단편은, 폴리뉴클레오티드가 하나 이상의 오픈 리딩 프레임을 포함하는 한, 게놈 또는 cDNA일 수 있고, 이는 전체 코딩 영역 또는 이의 분절을 포함할 수 있다. "융합 유전자"는 함께 연결된 둘 이상의 이종성 폴리뉴클레오티드로 구성된 유전자이다.
"벡터"는 바람직하게는 자가 복제하는 핵산 분자로서, 삽입된 핵산 분자를 숙주 세포 내로 및/또는 사이로 전달한다. 이 용어는 일차적으로 DNA 또는 RNA를 세포내로 삽입하는 기능을 하는 벡터, 일차적으로 DNA 또는 RNA를 복제하는 기능을 하는 복제 벡터, 및 DNA 또는 RNA의 전사 및/또는 번역 기능을 하는 발현 벡터를 포함한다. 또한 상기 기능 중 하나보다 많은 기능을 제공하는 벡터가 포함된다. "발현 벡터"는, 적절한 숙주 세포내로 도입될 경우 폴리펩티드(들)로 전사 및 번역될 수 있는 폴리뉴클레오티드이다. "발현 시스템"은 통상적으로 원하는 발현 생성물을 산출할 수 있는 발현 벡터로 이루어진 적합한 숙주 세포를 암시한다.
보조적 폴리펩티드와 관련하여 사용될 경우 "표적"은 생물학적 활성 폴리펩티드가 결합될 수 있고 이때 결합이 원하는 생물학적 활성을 초래하는 생화학적 분자 또는 구조물이다. 표적은 t 단백질에 의해 저해되거나, 활성화되거나, 달리는 작용되는 단백질 리간드 또는 수용체일 수 있다. 표적의 예는 호르몬, 사이토킨, 항체 또는 항체 단편, 세포 표면 수용체, 키나제, 성장 호르몬, 및 생물학적 활성을 갖는 다른 생화학적 구조물이다.
"혈청 분해 내성" - 단백질은 혈청 또는 혈장에서 전형적으로 프로테아제를 포함하는 혈액에서 분해에 의해 제거될 수 있다. 혈청 분해 내성은 단백질을 인간(또는 적절한 경우 마우스, 래트, 원숭이) 혈청 또는 혈장과, 전형적으로 일정 범위의 기간동안(즉 0.25, 0.5, 1, 2, 4, 8, 16 일) 37℃에서 합함으로써 측정된다. 이들 시점을 위한 샘플은 웨스턴 검정(Western assay)으로 수행되고, 단백질은 항체로 검출된다. 항체는 단백질 중의 태그일 수 있다. 단백질은 웨스턴 상에서 단일 밴드를 나타내고, 여기서 단백질의 크기는 주사된 단백질의 크기와 동일하고, 이어서 분해는 전혀 일어나지 않는다. 웨스턴 블롯(Western Blot) 또는 동등한 기법에 의해 판단될 경우 50%의 단백질이 분해되는 시점은 단백질의 반감기 또는 "혈청 반감기"이다.
"겉보기 분자량 계수(apparent molecular weight factor)" 또는 "겉보기 분자량"은 특정 아미노산 서열에 의해 나타난 겉보기 분자량에서의 상대적 증가 또는 감소의 측정값을 지칭하는 관련된 용어이다. 겉보기 분자량은 구형 단백질 표준물을 사용하여 계산될 수 있는 크기 배제 칼럼을 사용하여 결정되고 "겉보기 KD" 유닛으로 측정된다. 겉보기 분자량 계수는 구형 단백질로 보정된 크기 배제 칼럼상에서 결정될 경우, 겉보기 분자량과 실제 분자량 사이의 비로서 측정된다(즉, 아미노산 조성물 중 각각의 유형의 아미노산의 계산된 분자량을 아미노산 조성물에 기초하여 더함으로써 예측됨). 예를 들면, 20 KD 폴리-글리신 서열은 크기 배제 크로마토그래피에 의해 200 kD의 겉보기 분자량을 갖고, 이는 10x의 겉보기 분자량 계수에 상응한다. '고유 수력학적 반경'은 단위 분자량(kD)당 수력학적 반경이고, 반감기 연장제의 성능에 대한 측정값으로서, 이는 단위 질량당 혈청 분비 반감기(kD당 시간)으로서 측정된다. 이들 측정값 둘 다는 보다 직관적 측정값인 '겉보기 분자량 계수'와 상관관계가 있다.
단백질의 "수력학적 반경"은 수성 용액에서의 그의 확산 속도 뿐만 아니라 거대분자의 겔에서의 그의 이동 능력에 영향을 준다. 단백질의 수력학적 반경은 그의 분자량 뿐만 아니라 그의 구조, 예컨대 형상 및 치밀도(compactness)에 의해 결정된다. 대부분의 단백질은 가장 치밀한 3차원 구조인 구형 구조를 갖고, 이때 단백질은 가장 작은 수력학적 반경을 가질 수 있다. 몇몇 단백질은 랜덤하고 개방된 비구조화된 입체구조 또는 '선형' 입체구조를 취하고, 결과로서 유사한 분자량의 전형적인 구형 단백질에 비해 훨씬 더 큰 수력학적 반경을 갖는다.
"생리학적 조건"은 살아있는 피험체의 조건을 모방하는 온도, 염 농도, pH를 비롯한 조건의 집합을 지칭한다. 시험관내 검정에서 사용하기 위한 생리학적으로 연관된 조건의 숙주가 확립되었다. 일반적으로, 생리학적 완충액은 생리학적 농도의 염을 함유하고 약 6.5∼약 7.8, 바람직하게는 약 7.0∼약 7.5 범위의 중성 pH로 조정된다. 다양한 생리학적 완충액은 상기 문헌[Sambrook et al. (1989)]에 열거되어 있고, 따라서 본원에 상세히 기재되지 않는다. 생리학적으로 관련된 온도는 약 25℃∼약 38℃, 바람직하게는 약 30℃∼약 37℃이다.
"반응성 기"는 제2 반응성 기에 커플링될 수 있는 화학 구조물이다. 반응성 기의 예는 아미노 기, 카복실 기, 설프하이드릴 기, 하이드록실 기, 알데히드 기, 아지드 기이다. 몇몇 반응성 기는 활성화되어 제2 반응성 기와의 커플링을 조장할 수 있다. 활성화를 위한 예는 카복실 기와 카보디이미드의 반응, 카복실 기의 활성화된 에스테르로의 전환, 또는 카복실 기의 아지드 작용기로의 전환이다.
"가교결합 성분"은 하나 이상의 반응성 기를 포함하는 화학 구조물을 포함한다. 이들 반응성 기는 이들 화학 구조에서 동일하여 가교결합된 보조적 폴리펩티드의 직접적 작제를 허용할 수 있다. 가교결합 성분은 보호 기에 의해 블로킹된 반응성 기를 함유할 수 있다. 이는 수 개의 상이한 비가교결합 성분을 하나의 가교결합 성분에 제어된 연속 반응으로 접합될 수 있도록 한다. 가교결합 성분은, 구조가 상이하고 상이한 비가교결합 성분과 선택적으로 접합될 수 있는 다수의 반응성 기를 함유할 수 있다. 다수의 고-친화도 결합 부위를 함유하는 단백질은 또한 가교결합제로서 작용할 수 있다. 예는 스트렙타비딘이고, 이는 바이오틴화된 비가교결합 성분의 4개 이하의 분자에 결합될 수 있다. 분지형 다작용성 폴리에틸렌 글리콜(PEG) 분자는 가교결합 성분으로서 작용할 수 있다. 2∼8개의 작용기 및 다양한 길이의 PEG 뿐만 아니라 다양한 반응성 기를 갖는 다양한 시약들이 상업적으로 입수가능하다. 공급업체로는 NOF 아메리카 코포레이션(America Corporation) 및 선바이오(SunBio)가 포함된다.
"비가교결합 성분"은 가교결합 성분에 접합을 허용하는 반응성 기를 포함하는 화학 구조물을 포함한다. 비가교결합 성분은 하나 이상의 생물학적 활성 폴리펩티드 및/또는 하나 이상의 보조적 폴리펩티드를 비롯한 다양한 모듈을 함유할 수 있다. 또한, 비가교결합 성분은 정제 및/또는 검출을 촉진시키는 친화성 태그, 예컨대 플래그-태그, E-태그, Myc-태그, HA-태그, His6-태그, 녹색 형광성 단백질 등을 함유할 수 있다.
"가교결합된 rPEG 폴리펩티드", "가교결합된 보조적 폴리펩티드", "가교결합된 rPEG", "CL-rPEG 폴리펩티드", "CL-rPEG"은 하나 이상의 비가교결합 성분과 가교결합 성분의 접합물을 지칭하는 용어들이다.
"제어 방출형 제제", "서방형 제제", "데포 제형" 또는 "지속 방출형 제제"는 상호교환적으로 사용되어 변경된 폴리펩티드가 제제의 부재하에 투여될 경우 방출 기간에 비해 본 발명의 변경된 폴리펩티드의 방출 기간을 연장시킬 수 있는 제제를 지칭한다. 본 발명의 상이한 실시양태는 상이한 방출 속도를 가짐으로써, 상이한 치료학적 양을 생성할 수 있다.
"vL 도메인"은 항체의 경쇄의 가변성 도메인을 지칭한다.
"vH 도메인" 항체의 중쇄의 가변성 도메인을 지칭한다.
"가변성 단편"(Fv)은 2개의 비공유적으로 회합된 VL 및 VH 도메인을 포함하는 항체의 일부분을 지칭한다.
"단일쇄 가변성 단편"(scFv)은 단일쇄로서 하나의 vL 도메인에 비-천연적 펩티드 연결기를 통해 연결된 하나의 vH를 포함하는 항체의 일부분을 지칭한다. scFv는 vH-연결기-vL 또는 vL-연결기-vH 구조를 가질 수 있고, 여기서 연결기는 다양한 수의 아미노산을 포함하는 임의의 펩티드 서열일 수 있다. scFv는 생리학적 조건하에 바람직하게는 12개보다 많은 아미노산의 펩티드 연결기를 필요로 하는 단량체 구조물로서 우선적으로 발생된다.
항체의 디설파이드 안정화 Fv 단편(dFv)은, VH-VL 이종이량체가 상보성 결정 영역(CDR: complementarity-determining region)으로부터 떨어진 구조적으로 보존된 골격구조 위치 사이에서 조작된 쇄간 디설파이드 결합에 의해 안정화되는 분자를 지칭한다. 이러한 안정화 방법은 많은 항체 Fv의 안정화를 위해 적용가능하다.
"가변성 도메인"은 항체의 항원 결합 부위를 형성하는 도메인을 지칭한다. 가변성 도메인은 vH 또는 vL일 수 있고; 가변성 도메인 간의 차이는 과가변성 영역(HV-1, HV-2 및 HV-3) 또는 CDR1, CDR2 및 CDR3으로서 공지된 3개의 루프 상에 위치한다. CDR은 보존적 골격구조 영역에 의해 가변성 도메인에서 지지된다.
"도메인 항체"(dAb)는 단량체로서 표적에 결합할 수 있는 항체의 일부분을 지칭한다. 도메인 항체는 항체의 중쇄의 가변성 영역(VH) 또는 경쇄의 가변성 영역(VL)에 상응한다. dAb는 일반적으로 표적 결합을 위한 제2 가변성 도메인(vH 또는 vL)을 필요로 하지 않는다. dAb는 파지 디스플레이 또는 다른 시험관내 방법에 의해 생성될 수 있다. 다르게는, dAb 도메인은 면역화된 카멜리드(camelid) 또는 상어 또는 경쇄가 결여된 항체를 생성하는 다른 종으로부터 수득될 수 있다.
"다이아바디(diabody)"는 하나의 폴리펩티드로부터의 VH 도메인과 쌍을 이룬 또 다른 폴리펩티드로부터의 VL 도메인으로 각각 구성된 2개의 Fv 헤드(head)를 갖는 재조합 항체를 지칭한다. 다이아바디는 전형적으로 2개의 vH-vL(또는 vL-vH) 쇄를 함유한다. 다이아바디는 펩티드 연결기에 의해 항체의 vL 및 vH 도메인을 연결함으로써 작제될 수 있다. 펩티드 연결기 길이는 다양한 수의 아미노산, 바람직하게는 2∼12개의 아미노산을 포함한다. 다이아바디는 일특이적이거나 이특이적일 수 있다.
"트리아바디(triabody)"는 하나의 폴리펩티드로부터의 VH 도메인과 쌍을 이룬 또 다른 폴리펩티드로부터의 VL 도메인으로 각각 구성된 3개의 Fv 헤드를 갖는 재조합 항체를 지칭한다. 트리아바디는 3개의 vH-vL(또는 vL-vH) 쇄를 함유한다. 트리아바디는 펩티드 연결기에 의해 항체의 vL 및 vH 도메인을 연결함으로써 작제될 수 있다. 펩티드 연결기 길이는 다양한 수의 아미노산, 바람직하게는 0∼2개의 아미노산을 포함한다. 다이아바디는 일특이적이거나 이특이적이거나 삼특이적일 수 수 있다.
"테트라바디(tetrabody)"는 4개의 vH-vL(또는 vL-vH) 쇄를 포함한다. 테트라바디는 펩티드 연결기에 의해 항체의 vL 및 vH 도메인을 연결시킴으로써 작제될 수 있다. 펩티드 연결기 길이는 다양한 수의 아미노산, 바람직하게는 0∼2개의 아미노산을 포함한다. 테트라바디는 다양한 수의 아미노산, 바람직하게는 1∼10개의 아미노산을 vL 및 vH 도메인의 연합된 말단으로부터 절단함으로써 수득될 수 있다.
"Fab 단편"은 항원에 결합된 항체 상의 영역을 지칭한다. Fab 단편은 각각의 중쇄 및 경쇄의 불변성 및 가변성 도메인으로 이루어진다. 이들 도메인은 파라토프(paratope)-항원 결합 부위-를 단량체의 아미노 말단에서 형상화한다. 2개의 가변성 도메인은 이들의 특이적 항원 상에서 에피토프에 결합한다. Fab 단편은 C-말단에서 디설파이드 결합에 의해 연결될 수 있다. Fab 단편은 시험관내에서 생성될 수 있다. 효소 파파인(papain)은 면역글로불린 단량체를 2개의 Fab 단편 및 Fc 단편으로 절단하는데 사용될 수 있다. 효소 펩신은 힌지 영역 아래를 절단하여 F(ab')2 단편 및 Fc 단편이 형성된다. 중쇄 및 경쇄의 가변성 영역은 함께 융합되어 단일쇄 가변성 단편(scFv)을 형성하고, 이는 모 면역글로불린의 본래의 특이성을 보유한다
용어 "항체 단편"은 이후 상세히 정의되는 임의의 항원 결합 단위를 포함하는 본 발명에 기재된 모든 단편, 예컨대 임의의 형태의 dAb, Fv, Fab, 및 Fc를 포함하기 위해 사용된다. 항체 단편은 항체의 추가의 도메인을 포함할 수 있다. 항체 단편은 또한 완전한 또는 전체 항체를 내포한다.
용어 "모 항체"은 본원에서 항체 단편의 작제에 기초가 되는 항체를 지칭하기 위해 사용된다.
"항체 단편에 기초한 치료제"(AFBT: antibody fragment based therapeutic)는 본원에 기재된 바와 같은 항체 단편에 기초한 임의의 치료학적 제제 또는 약학적 조성물을 지칭한다. AFBT는 다수의 상이한 모 항체로부터 유도될 수 있는 다수의 항체 단편을 포함할 수 있다. 다특이적 AFBT는 다수의 상이한 에피토프에 대해 특이성을 갖는 다수의 항체 단편을 포함할 수 있다. 이러한 에피토프는 동일한 표적 항원의 부분이거나 다수의 상이한 표적 항원 상에 존재할 수 있다. 이특이적 AFBT는 2개의 상이한 결합 특이성을 갖는 결합 부위(일반적으로 2개 이상, 그러나 1개일 수 있음)를 포함한다.
용어 "항원", "표적 항원" 또는 "면역원"은 본원에서 상호교환적으로 사용되어 항체 단편 또는 항체 단편에 기초한 치료제가 결합하거나 그에 대해 특이성을 갖는 구조물 또는 결합 결정물을 지칭한다.
용어 "도메인 재편성(reassortment)" 및 "도메인 스와핑"은 본원에서 상호교환적으로 사용되어 항체 단편 또는 항체 단편에 기초한 치료제의 결합가를 바꾸는 과정을 지칭한다. 예를 들면, 단일쇄가변성 단편(scFv)은 재편성되어 이량체, 삼량체 등 뿐만 아니라 다이아바디, 트리아바디, 테트라바디 등을 형성할 수 있다. Fab는 전체 쇄를 다른 Fab 또는 심지어 전체 항체로 교환하여, 잠재적으로 미스매칭된(mismatched) 쇄를 산출할 수 있고, 이는 하나 또는 둘 다의 결합 활성의 손실을 초래한다. 벤스-존스(Bence-Jones) 단백질로 지칭되는 경쇄 이량체의 형성은 또 다른 예이다. 재편성의 또 다른 예는 이러한 교환을 방지하는 디설파이드 결합된 힌지를 갖지 않는 IgG4 항체 사이의 중쇄 재편성으로, 이는 이특이적 IgG4 항체를 유도할 수 있다. 도메인 재편성의 속도는 반응 조건, 예컨대 염 농도, pH, 온도 및 표적 항원의존재에 좌우된다.
용어 "페이로드(payload)"는 본원에서 사용될 경우 소분자의 약물분자구조에 대응하는, 생물학적 또는 치료학적 활성을 갖는 단백질 또는 펩티드 서열을 지칭한다. 페이로드의 예로는, 제한되지 않지만, 사이토킨, 효소 및 성장 인자가 포함된다. 페이로드는 유전학적으로 융합되거나 화학적으로 접합된 잔사를 포함할 수 있다. 이러한 화학적으로 접합된 잔사의 예로는, 제한되지 않지만, 화학치료학적 제제, 항바이러스성 화합물 또는 콘트라스트(contrast) 제제가 포함된다. 이들 접합된 잔사는 절단성 또는 비절단성 연결기를 통해 AFBT의 나머지 부분에 연합될 수 있다.
"콜라겐 결합 도메인"(CBD: collagen binding domain)은 콜라겐에 결합하거나 이에 대해 특이성을 갖는 단백질 도메인을 지칭한다. CBD는 임의의 특정 유형의 콜라겐, 예컨대 콜라겐 I에 특이적일 수 있다. 다르게는, CBD는 다양한 콜라겐 유형에 결합될 수 있다. 한 예는 4개의 단백질 도메인이 콜라겐 결합에 충분한 피브로넥틴이다.
폴리펩티드, 예를 들면, 보조적 폴리펩티드 PEG와 관련하여 사용되는 용어 "반복성"은, 펩티드 서열에서의 내부 상동성 정도를 지칭한다. 반복적 서열은 아미노산 서열의 다수의 동일하거나 상동성인 카피를 함유할 수 있다. 반복성은 동일한 부분서열의 빈도를 분석함으로써 측정될 수 있다. 예를 들면, 관심있는 폴리펩티드 서열은 n량체 부분서열로 나눠지고, 동일한 부분서열의 수가 계수될 수 있다. 고도의 반복적 서열은 높은 분율로 동일한 부분서열을 함유한다.
"총 전하 밀도"는 본원에서 사용될 경우 음으로 하전된 아미노산의 수와 양으로 하전된 아미노산의 수를 더하고, 그 합을 폴리펩티드중의 아미노산의 총 수로 나눔으로써 계산된다. 예를 들면: hIgG1 Fc 서열: (MDKTHTCPPCP APELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTIPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSL) 음으로 하전된 잔기의 수: 24; 양으로 하전된 잔기의 수: 22; 잔기의 총 수: 224; Fc 단독의 총 전하 밀도: (22+24)/224=46/224=20.5%
"순 전하 밀도"는 본원에서 사용될 경우 양으로 하전된 아미노산의 수를 음으로 하전된 아미노산의 수로부터 차감하고, 그 차를 폴리펩티드중의 아미노산의 총 수로 나눔으로써 계산된다. 예를 들면: hIgG1 Fc 서열: (MDKTHTCPPCP APELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTIPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSL) 음으로 하전된 잔기의 수: 24; 양으로 하전된 잔기의 수: 22; 잔기의 총 수: 224; Fc 단독의 순 전하 밀도: (24-22)/224=2/224=0.9%.
"예상 용해도"는 본원에서 사용될 경우 폴딩된 단백질의 순 전하를 비구조화된 단백질(예를 들어 rPEG)의 총 전하에 더하고, 그 합을 단백질 중 아미노산의 총 수로 나눔으로써 계산된다. 예를 들면, Fc-rPEG50의 예상 용해도는 (-2 +192)/(224+576)=190/800=23.75%이다.
생물학적 활성 폴리펩티드의 발현 동안 용해도를 개선시키기 위한 보조적 폴리펩티드의 디자인.
가용성 변경된 생물학적 활성 폴리펩티드의 발현은 변경된 폴리펩티드의 순 전하 밀도를 변경시킴으로써 최적화될 수 있다. 몇몇 경우에, 순 전하 밀도는 잔기당 +0.1 초과 또는 -0.1 미만의 전하이다. 다른 경우에, 전하 밀도는 잔기당 +0.2 초과 또는 -0.2 미만의 전하이다. 전하 밀도는 생물학적 활성 폴리펩티드에 연결된 보조적 폴리펩티등중의 하전된 아미노산, 예컨대 아르기닌, 라이신, 글루탐산 및 아스파르트산의 함량을 변경함으로써 제어될 수 있다. 원할 경우, 보조적 폴리펩티드는 하전된 잔기의 짧은 신장부로만 이루어질 수 있다. 다르게는, 보조적 폴리펩티드는 다른 잔기, 예컨대 세린 또는 글리신에 의해 분리된 하전된 잔기를 포함할 수 있고, 이는 보다 나은 발현 또는 정제 행동을 이끌 수 있다. 보다 높은 발현이 수득될 수 있다. 세린의 사용은 보다 높은 발현 수준을 이끈다.
융합 단백질을 가용성으로 만들고 세포질에서 폴딩되도록 만드는 보조적 단백질에 필요한 순 전하는 생물학적 활성 폴리펩티드, 구체적으로 그의 크기 및 순 전하에 좌우된다. 변경된 폴리펩티드의 순 전하는 양성 또는 음성일 수 있다. 몇몇 적용분야에서, 음성 아미노산, 예컨대 글루탐산 또는 아스파르트산이 풍부한 보조적 폴리펩티드 서열이 바람직할 수 있다. 다른 적용분야에서, 양성 아미노산, 예컨대 라이신 또는 아르기닌이 풍부한 보조적 폴리펩티드 서열이 바람직할 수 있다. 양성으로 및 음으로 하전된 아미노산 둘 다의 사용은 전하 중성화를 유도할 수 있고, 이는 본 발명의 이점을 잠재적으로 무력화시킬 수도 있다. 예를 들면, 16%, 25% 또는 33%의 음으로 하전된 잔기를 갖는 288개 아미노산으로 이루어진 보조적 단백질은 96 이하의 총 전하를 제공하고, 이는 960개 이하의 아미노산의 중성 융합 단백질, 또는 672개 아미노산의 비-융합 단백질에 대해 0.1의 전하 밀도를 달성하기에 충분하다. 한 특정 예에서, 33%의 글루탐산 잔기를 포함하는 보조적 폴리펩티드는 매우 크고 발현이 어려운 단백질을 가용성으로 만들기 위해 사용될 수도 있다.
결합 단백질에 용해도를 부여하기 위해, 보조적 폴리펩티드의 순 양성 또는 음전하는 5, 10, 15 또는 20보다 크거나, 30, 40, 50, 60, 70, 80, 90 또는 100보다 클 수 있다. 전하는 5, 10, 15, 20, 25, 30, 40, 50개 아미노산의 짧은 서열에 집중될 수 있거나, 60, 80, 100, 150, 200, 250, 300, 400, 또는 500개 이상의 아미노산의 보다 긴 서열에 걸쳐 확장될 수 있다. 음성 보조적 폴리펩티드의 서열은 대략 5, 10, 15, 25, 30, 40, 50, 60, 70, 80, 90 또는 100%의 글루탐산 또는 아스파르트산을 함유하는 반면, 양성 보조적 폴리펩티드 대략 5, 10, 15, 20, 25, 30, 40, 50, 60, 70, 80, 90 또는 100%의 아르기닌 또는 라이신을 함유한다. 예컨대 비교적 친수성 잔기인 세린 및 글리신과 같은 비-하전된 잔기가 사용될 수 있다.
보조적 폴리펩티드의 디자인에서 추가의 고려사항:
본 발명의 한 양태는 생물학적 활성 폴리펩티드의 변경을 위한 보조적 폴리펩티드, 예를 들어, rPEG 보조적 폴리펩티드 등의 디자인이다(도 1). 보조적 폴리펩티드는 치료학적 및/또는 진단학적 가치를 갖는 재조합 단백질을 생성하기 위해 특히 유용하다.
다양한 보조적 폴리펩티드 서열이 디자인될 수 있고, 이들은 글리신 및/또는 세린, 뿐만 아니라 다른 아미노산, 예컨대 글루타메이트, 아스파테이트, 알라닌 또는 프롤린이 풍부할 수 있다. 보조적 폴리펩티드 서열은 친수성 아미노산이 풍부할 수 있고, 소수성 또는 방향족 아미노산을 낮은 백분율로 함유한다. 보조적 폴리펩티드 서열은 30, 40, 50, 60, 70, 80, 90 또는 100% 이상의 글리신 및/또는 세린 잔기를 갖는 것으로 디자인될 수 있다. 몇몇 경우에, 보조적 폴리펩티드 서열은 50, 55, 60, 65% 이상의 글리신 및/또는 세린을 함유한다. 다른 경우에, 보조적 폴리펩티드 서열은 70, 75, 80, 85, 90% 이상의 글리신 및/또는 세린 잔기를 함유할 수 있다.
본 발명의 조성물은 전형적으로 총 40개 이상의 아미노산으로 구성된 보조적 폴리펩티드 서열을 함유할 것이다. 그러나, 생성물은 다수의 보조적 폴리펩티드 서열을 함유할 수 있고, 이들 개개의 보조적 폴리펩티드 서열의 일부 또는 전부는, 생성물의 모든 보조적 폴리펩티드 서열의 합쳐진 길이가 40개 이상의 아미노산인 한, 40개 아미노산보다 짧을 수 있다. 몇몇 실시양태에서, 단백질에 부착된 보조적 폴리펩티드 서열의 합쳐진 길이는 20, 25, 35, 50, 60, 70, 80, 90, 100, 120, 140, 160, 180, 200, 250, 300, 350, 400, 500, 600, 700, 800, 900 또는 1000 또는 2000개보다 많은 아미노산일 수 있다. 몇몇 변경된 생물학적 활성 폴리펩티드에서, 보조적 폴리펩티드 서열의 합쳐진 길이는 60, 70, 80, 90개 이상의 아미노산을 초과한다. 다른 변경된 폴리펩티드에서, 보조적 폴리펩티드 서열의 합쳐진 길이는 100, 120, 140, 160 또는 180개의 아미노산, 더욱 200, 250, 300, 350, 400, 500, 600, 700, 800개 이상의 아미노산, 더욱 더 1000개보다 많은 아미노산을 초과한다.
하나 또는 수개의 보조적 폴리펩티드 서열은 생물학적 활성 폴리펩티드, 예를 들면 생물학적 활성 폴리펩티드의 N- 또는 C-말단에 융합되거나, 관심있는 폴리펩티드의 루프내로 삽입되어, 변경되지 않은 폴리펩티드에 비해 특성이 개선된 변경된 폴리펩티드를 제공한다. 보조적 서열의 (치료학적) 단백질로의 융합은 변경되지 않은 단백질에 비해 생성된 융합 단백질의 수력학적 반경을 상당히 증가시키고, 이는 예를 들면, 초원심분리, 크기 배제 크로마토그래피, 또는 광 산란에 의해 검출될 수 있다.
보조적 폴리펩티드 서열은 하나 이상의 유형의 아미노산을 방지하여 원하는 특성을 수득하도록 디자인될 수 있다. 예를 들면, 하기 아미노산을 거의 또는 전혀 함유하지 않는 보조적 폴리펩티드 서열을 디자인할 수 있다: 시스테인(디설파이드 형성 및 산화를 방지하기 위함), 메티오닌(산화를 방지하기 위함), 아스파라긴 및 글루타민(탈아미드화를 방지하기 위함) 및 아스파테이트. 보조적 폴리펩티드 서열은 단백질가수분해에 대한 감수성을 감소시키는 경향이 있는 프롤린 잔기를 함유하도록 디자인될 수 있다.
보조적 폴리펩티드 서열은, 예컨대 단백질 생산을 최적화하기 위해 디자인될 수 있다. 이는 코딩 DNA의 반복성을 방지하거나 최소화함으로써 달성될 수 있다. 보조적 폴리펩티드 서열, 예컨대 폴리-글리신 또는 폴리-세린은 매우 원하는 약학적 특성을 가질 수 있지만, 이들의 제작은 폴리-글리신을 코딩하는 DNA 서열의 높은 GC-함량 및 재조합을 유도할 수 있는 반복 DNA 서열의 존재에 기인하여 어려울 수 있다.
G, S 및 E가 풍부한 서열을 다량함유한 풍부한 짧은 반복된 모티프로 이루어진 단순 서열을 포함한 보조적 폴리펩티드는, 이들 서열에 T-세포 에피토프가 존재하지 않을 지라도, 다수의 종에서 >1,000의 비교적 높은 항체 역가를 초래할 수 있다. 이는 보조적 폴리펩티드의 반복적 성질로 초래될 수 있는데, 단백질 응집체, 가교결합된 면역원, 및 반복적 탄수화물을 비롯한 반복된 에피토프를 갖는 면역원이 고도로 면역원성인 것으로 나타났기 때문이다(Johansson, J., et al. (2007) Vaccine, 25: 1676-82, Yankai, Z., et al. (2006) Biochem Biophys Res Commun, 345: 1365-71, Hsu, C. T., et al. (2000) Cancer Res, 60: 3701-5). 5가 IgM 분자를 디스플레이하는 B-세포는, IgM에 대한 면역원의 1가 결합 친화도가 매우 낮을 지라도, 예컨대 마이크로몰 농도일 지라도, 반복적 면역원에 의해 자극된다(도 74). 동일한 분자 또는 동일한 세포에 위치된 다수의 연결된 IgM 도메인으로의 연결된 반복부의 동시적 결합은 상호작용의 겉보기 (효과적) 친화도에서 큰 (천, 백만 또는 아마도 10억 배) 증가를 초래하고, 이는 B-세포를 자극할 수 있다. 이러한 유형의 영향을 방지하기 위해, 보조적 폴리펩티드는 다수 종의 동물(예컨대 래트, 토끼, 마우스, 또는 기니아 피그. 다수 회의 주사가 수행되고, 약물동력학적 특성은 면역화 전후에 동일한 동물에서 측정됨)에서 면역원성(뿐만 아니라 반감기 및 다른 특성)에 대해 스크리닝 될 수 있다. 또한, 보조적 폴리펩티드 서열은 비반복적으로(각각의 서열 모티프중 단지 1개의 동일한 카피를 포함함) 또는 각각의 서열 모티프의 최소한의 수의 카피를 갖도록 디자인될 수 있다. 덜 반복적인 보조적 폴리펩티드 서열은 상이한 IgM에 대한 결합 부위를 포함할 수 있지만, 이들은 동일한 IgM 분자 또는 동일한 B-세포에 다가로 결합할 가능성이 적은데, 그 이유는 각각의 B-세포가 일반적으로 단지 하나의 유형의 IgM을 분비하고, 각각의 IgM이 전형적으로 단지 하나의 유형의 결합 부위를 갖기 때문이다. 이러한 기작은 도 74a 및 b에 예시되어 있다. 몇몇 실시양태에서, 보조적 폴리펩티드는 보조적 폴리펩티드 당 1, 2, 3, 4, 5개 등의 카피에서 초래되는 서열만을 함유할 수 있다. 보다 적은 수의 반복부를 갖는 폴리펩티드는 보다 낮은 예상 결합활성을 가질 수 있고, 실질적인 면역 반응을 유도할 가능성이 낮을 것이다. 이러한 서열은 다수의 유형의 아미노산, 예컨대 2가지 유형(예를 들면, G 및 E 또는 S 및 E), 3가지 유형의 아미노산(예컨대, G, E 및 S) 또는 더욱 4가지 이상의 유형의 아미노산을 포함할 수 있다. 이러한 보조적 폴리펩티드는 또한, 예를 들면, 총 아미노산 조성물의 30∼80%의 글리신, 10∼40%의 세린 및 15∼50%의 글루타메이트를 포함할 수 있다. 이러한 서열은 원하는 특성, 예컨대 발현 수준, 혈청 및 이. 콜라이 프로테아제 내성, 용해도, 응집 및 면역원성의 최적의 균형을 제공할 수 있다.
도 74는 상기 서열에서 에피토프를 인식하는 B 세포와 반복적 보조적 폴리펩티드 서열(74a) 및 비반복적 보조적 폴리펩티드 서열(74b)의 상호작용을 비교한다. 반복적 서열은 비교적 적은 수의 상이한 에피토프를 함유하므로 유기체에서 극소수의 B 세포를 인식할 것이다. 그러나, 반복적 서열은 이들 극소수의 B 세포와 다가 접촉을 형성할 수 있고, 결과로서, 도 74a에 예시된 바와 같이 이들의 증식을 자극할 수 있다. 비반복적 서열은 많은 상이한 에피토프를 함유하므로 많은 상이한 B 세포와 접촉부를 형성할 수 있다. 그러나, 각각의 개별적 B 세포는, 도 74b에 예시된 바와 같이 반복성의 결여로 인해, 개개의 비반복적 보조적 폴리펩티드("nrURP")와 단지 1개 또는 적은 수의 접촉부를 형성할 수 있다. 결과로서, 비반복적 보조적 폴리펩티드는 B 세포의 증식, 및 이에 따른 면역 반응을 자극하는 경향이 매우 적을 수 있다.
반복적 보조적 폴리펩티드에 대한 비반복적 보조적 폴리펩티드의 추가의 이점은 비반복적 보조적 폴리펩티드가 반복적 보조적 폴리펩티드에 비해 항체와 더 약하게 접촉한다는 것이다. 항체는 다가 분자이다. 예를 들면, IgG는 2개의 동일한 결합 부위를 갖고, IgM은 10개의 동일한 결합 부위를 함유한다. 따라서, 반복적 서열에 대한 항체는 높은 결합활성을 갖는 이러한 반복적 서열과 다가 접촉부를 형성할 수 있고, 이는 이러한 반복적 서열의 제거 및/또는 효능에 영향을 줄 수 있다. 반대로, 비반복적 보조적 폴리펩티드는 각각의 에피토프의 반복부를 극소수로 함유하므로 이는 항체와 대부분 1가 상호작용을 형성하는 경향이 있다.
반복성은 펩티드 서열에서의 내부 상동성의 정도를 설명한다. 극한 경우, 반복적 서열은 아미노산 서열의 다수의 동일한 카피를 함유할 수 있다. 반복성은 동일한 부분서열의 빈도를 분석함으로써 측정될 수 있다. 예를 들면, 관심있는 서열을 n량체 부분서열로 나누고, 동일하거나 상동성인 부분서열의 수를 계수할 수 있다. 고도로 반복적인 서열은 동일하거나 상동성인 부분서열을 큰 분율로 함유할 것이다.
유전자의 반복성은 컴퓨터 알고리즘에 의해 측정될 수 있다. 한 예는 도 75에 예시되어 있다. 질문 서열에 기초하여, 특정 길이의 모든 부분서열의 쌍대 비교(pair wise comparison)를 수행할 수 있다. 이들 부분서열은 동일성 또는 상동성에 대해 비교될 수 있다. 도 75의 예는 4개 아미노산의 부분서열을 동일성에 대해 비교한다. 이 예에서, 대부분의 4량체 부분서열은 질문에서 1회 발생되고, 3개의 4량체 부분서열은 2회 발생된다. 유전자에서 반복성을 평균낼 수 있다. 부분서열의 길이는 조정될 수 있다. 원할 경우, 부분서열의 길이는 면역계에 의해 인식될 수 있는 서열 에피토프의 길이를 반영할 수 있다. 4∼15개 아미노산의 부분서열의 분석이 수행될 수 있다. 비반복적 보조적 폴리펩티드를 코딩하는 유전자는 유전자 합성의 표준 기법을 사용하여 올리고뉴클레오티드로부터 조립될 수 있다. 유전자 디자인은 코돈 용법과 아미노산 조성을 최적화하는 알고리즘을 사용하여 수행될 수 있다. 또한, 인간 면역계에 의해 쉽게 인식될 수 있는 에피토프로 알려지거나 프로테아제 민감성인 아미노산 서열을 방지할 수 있다. 컴퓨터 알고리즘은 생성된 아미노산 서열의 반복성을 최소화하기 위해 서열 디자인 동안 적용될 수 있다. 미리 정해진 기준, 예컨대 아미노산 조성, 코돈 용법, 프로테아제 민감성 부분서열의 방지에 부합되는 많은 수의 유전자 디자인의 반복성을 평가할 수 있고, 합성 및 후속적 평가를 위한 최소한의 반복적 서열을 선택할 수 있다.
비반복적 보조적 폴리펩티드 유전자의 디자인에 대한 다른 접근법은, 높은 수준의 발현, 낮은 응집 경향, 높은 용해도 및 프로테아제에 대한 양호한 내성을 나타내는 비반복적 보조적 폴리펩티드의 존재하는 수집물의 서열을 분석하는 것이다. 컴퓨터 알고리즘은 서열 단편의 재-조립에 의해 미리-존재하는 비반복적 보조적 폴리펩티드 서열에 기초하여 비반복적 보조적 폴리펩티드 서열을 디자인할 수 있다. 알고리즘은 이들 비반복적 보조적 폴리펩티드 서열로부터의 부분서열의 수집물을 생성하고, 이러한 부분서열로부터 비반복적 보조적 폴리펩티드 서열을 조립하기 위한 다수의 방식을 평가한다. 이러한 조립된 서열은 반복성에 대해 평가되어, 이전에 동정된 비반복적 보조적 폴리펩티드의 부분서열로만 이루어진 비반복적 보조적 폴리펩티드 서열을 동정할 수 있다.
비반복적 보조적 폴리펩티드-인코딩 유전자는 도 77에 예시된 바와 같은 짧은 보조적 폴리펩티드 분절의 라이브러리로부터 조립될 수 있다. 우선 보조적 폴리펩티드 분절의 큰 라이브러리를 생성할 수 있다. 이러한 라이브러리는 부분적으로 랜덤화된 올리고뉴클레오티드로부터 조립될 수 있다. 랜덤화 계획은 각각의 위치에 대한 아미노산 선택 뿐만 아니라 코돈 용법을 제어하기 위해 최적화될 수 있다. 보조적 폴리펩티드 분절의 라이브러리를 발현 벡터내로 클로닝할 수 있다. 다르게는, 보조적 폴리펩티드 분절의 라이브러리를 GFP와 같은 인디케이터(indicator) 유전자에 융합된 발현 벡터내로 클로닝할 수 있다. 후속적으로, 다수의 특성, 예컨대 발현 수준, 프로테아제 안정성, 항혈청으로의 결합에 대해 라이브러리 구성원을 스크리닝할 수 있다. 특히 원하는 아미노산 조성, 분절 길이를 갖는 분절을 동정하거나, 내부 반복부의 빈도가 낮은 분절을 동정하기 위해 라이브러리 구성원의 아미노산 서열을 결정할 수 있다. 후속적으로, 랜덤 이량체화 또는 다량체화에 의해 보조적 폴리펩티드 분절의 수집물로부터 비반복적 보조적 폴리펩티드 서열을 조립할 수 있다. 이량체화 또는 다량체화는 결찰 또는 PCR 조립에 의해 달성될 수 있다. 이 과정은 최상의 특성을 갖는 비반복적 보조적 폴리펩티드 서열을 동정하기 위해 다수의 특성에 대해 평가될 수 있는 비반복적 보조적 폴리펩티드 서열 라이브러리를 생성한다. 비반복적 보조적 폴리펩티드 서열의 길이를 추가로 증가시키기 위해 이량체화 또는 다량체화 과정을 반복할 수 있다.
한 구체적 실시양태에서, 보조적 폴리펩티드는 다음의 8개 아미노산 모티프의 혼합물을 포함한다: GEGSGEGSE, GEGGSEGSE, GEGSEGSGE, GEGSEGGSE, GEGSGEGGE, GEGGSEGGE, GEGGGEGSE, GEGGEGSGE, GEGGEGGSE, 또는 GEGSEGGGE. 이러한 디자인은 서로에 대한 모티프 수의 비에 따라 평균 33% E 및 11∼22% 세린 함량을 갖는다. 또 다른 구체적인 실시양태에서, 보조적 폴리펩티드는 다음의 12개 아미노산 모티프의 혼합물을 포함한다: GXEGSGEGXGXE, GXEGGSEGXGXE, GXEGSGEGGSGE, GXEGGSEGGSGE, GSGEGXEGXGXE, GGSEGXEGXGXE, GSGEGXEGGSGE 또는 GGSEGXEGGSGE, 여기서 X는 동일한 가능성을 갖는 S 또는 E를 나타낸다. 이러한 디자인은 선택된 고유비에 따라 25% E 및 대략 1% S을 갖는다. 적합한 고유비는 1:1:1:1:1:1:1:1 비이거나 임의의 다른 비율일 수 있고, 조성물을 미세 조정한다.
보조적 폴리펩티드 서열은 아미노산 수준에서 매우 반복적으로, 덜 반복적으로, 또는 비반복적으로 디자인될 수 있다. 예를 들면, 매우 반복적인 보조적 폴리펩티드 서열은 단지 작은 수의 중첩 9량체 펩티드 서열을 함유하고, 이러한 방식으로 면역 반응을 일으킬 위험이 감소될 수 있다.
단일 아미노산 유형의 보조적 폴리펩티드 서열의 예는: 폴리-글리신, 폴리-글루탐산, 폴리-아스파르트산, 폴리-세린, 폴리-트레오닌이고, 여기서 길이는 20개 이상의 잔기이다. 2가지 유형의 아미노산을 갖는 보조적 폴리펩티드의 예는 (GX)n, (SX)n이고, 여기서 G는 글리신이고 S는 세린이고, X는 아스파르트산, 글루탐산, 트레오닌, 또는 프롤린이고, n은 10 이상이다. 또 다른 예는 (GGX)n 또는 (SSX)n이고, 여기서 X는 아스파르트산, 글루탐산, 트레오닌, 또는 프롤린이고, n은 7 이상이다. 또 다른 예는 (GGGX)n 또는 (SSSX)n이고, 여기서 X는 아스파르트산, 글루탐산, 트레오닌, 또는 프롤린이고, n은 5 이상이다. 또 다른 예는 (GGGGX)n 또는 (SSSSX)n이고, 여기서 X는 아스파르트산, 글루탐산, 트레오닌, 또는 프롤린이고, n은 4 이상이다. 다른 실시예는 (GzX)n 및 (SzX)n이고, 여기서 X는 아스파르트산, 글루탐산, 트레오닌, 또는 프롤린이고, n은 10 이상이고, z는 1∼20이다.
이들 반복부의 수는 5∼300 이상의 임의의 수일 수 있다. 본 발명의 생성물은 반-랜덤 서열인 보조적 폴리펩티드 서열을 함유할 수 있다. 예는 30, 40, 50, 60 또는 70% 이상의 글리신을 함유하는 반-랜덤 서열로서, 여기서 글리신은 잘 분산되고 트립토판, 페닐알라닌, 타이로신, 발린, 루신, 및 이소루신의 총 농도는 70, 60, 50, 40, 30, 20, 또는 10% 미만(합쳐진 경우)이다. 한 바람직한 반-랜덤 보조적 폴리펩티드 서열은 40% 이상의 글리신을 함유하고, 트립토판, 페닐알라닌, 타이로신, 발린, 루신, 및 이소루신의 총 농도가 10% 미만이다. 보다 바람직한 랜덤 보조적 폴리펩티드 서열은 50% 이상의 글리신을 함유하고, 트립토판, 페닐알라닌, 타이로신, 발린, 루신, 및 이소루신의 총 농도가 5% 미만이다. 보조적 폴리펩티드 서열은 둘 이상의 보다 짧은 보조적 폴리펩티드 서열 또는 보조적 폴리펩티드 서열의 단편을 조합함으로써 디자인될 수 있다. 이러한 조합은 보조적 폴리펩티드 서열을 함유한 생성물의 약학적 특성을 보다 잘 조정할 수 있도록 하고, 보조적 폴리펩티드 서열을 코딩하는 DNA 서열의 반복성을 감소시켜, 보조적 폴리펩티드 서열-인코딩 서열의 재조합을 감소시키고 발현을 개선시킬 수 있다.
높은 수준의 용해도를 원할 경우, 하전된 잔기의 높은 분율, 바람직하게는 >25% 글루타메이트(E)(나머지는 대부분 글리신 또는 세린임)가 사용될 수 있다. 높은 수준의 발현은 10∼50% 세린(E)을 선호하는데, 이는 세린이 일반적으로 글리신(4 코돈)에 비해 훨씬 높은 발현 수준을 산출하는 6 코돈을 갖기 때문이다. 서열에 높은 글루타메이트 함량을 이용할 경우, 일반적으로 용해도에서의 균형(trade-off) 및 신속한 소가가 존재한다. 원할 경우, 50% 미만, 바람직하게는 30% 미만의 글루타메이트 함량이 사용되어 원하는 용해도를 제공하고 동물에서 신속한 제거를 방지한다.
비-글리신 잔기가 선택되어 특성을 최적화할 수 있다.
글리신 및/또는 세린이 풍부한 보조적 폴리펩티드 서열이 특히 관심을 끈다. 이들 글리신 풍부 또는 세린 풍부 서열에서 비-gly, 비-ser 잔기의 서열이 선택되어 단백질의 특성을 최적화할 수 있다. 예를 들면, 보조적 폴리펩티드의 서열을 최적화하여 특정 조직에 대한 생물학적 활성 폴리펩티드의 선택성을 증진시킬 수 있다. 이러한 조직-선택적 보조적 폴리펩티드 서열은 랜덤 또는 반-랜덤 보조적 폴리펩티드 서열의 라이브러리를 생성하고, 이들을 동물 또는 환자에 주사하고, 조직 샘플에서 원하는 조직 선택성을 갖는 서열을 결정함으로써 수득될 수 있다. 서열 결정은 질량 분광계로 수행될 수 있다. 유사한 방법을 사용하여, 경구, 구강, 소장, 비강, 복강, 폐, 직장 또는 진피 섭취를 촉진하는 보조적 폴리펩티드 서열을 선택할 수 있다. 막을 통한 수송 또는 세포 섭취에 유리한 양으로 하전된 아미노산 아르기닌 또는 라이신이 비교적 풍부한 영역을 함유하는 보조적 폴리펩티드 서열이 특히 관심을 끌고; 이러한 보조적 폴리펩티드는 단백질의 세포내 전달에 유용할 수 있다.
아래에 보다 상세히 기재된 바와 같이, 보조적 폴리펩티드 서열은 1개 또는 수개의 프로페아제 감수성 서열을 함유하도록 디자인될 수 있다. 이러한 보조적 폴리펩티드 서열은 일단 본 발명의 생성물이 그의 표적 위치에 도달되면 절단될 수 있다. 이러한 절단은 약학적 활성 도메인의 효능의 증가(전구약물 활성화)를 개시하거나, 절단 생성물의 수용체로의 결합을 증진시킬 수 있다. 이는 현재 항체에 대해서는 가능하지 않다. 그러나, 페그화되거나 보조적 단백질 변경된 생물학적 활성 폴리펩티드의 경우, 외래 프로테아제, 예컨대 토마토 에치 바이러스 프로테아제(Tomato Etch Virus Protease) 또는 유사한 부위 특이적 비-인간 프로테아제에 대한 절단 부위를 제공할 수 있다. 프로테아제 부위가 보조적 단백질과 치료학적 단백질 사이에 있거나, 치료학적 단백질에 가깝다면, 프로테아제의 주사는 약물로부터 보조적 단백질 테일을 제거하여 반감기를 단축시키고 환자의 전신으로부터의 제거를 초래할 것이다. 혈청중 약물의 농도는 10∼100배 강하되어, 치료를 사실상 종결시킬 것이다. 이는, 예를 들면, 예컨대 TNF-저해 미소단백질(예컨대 TNFa-수용체-rPEG)에 의한 치료 동안의 감염에 기인하여 치료가 갑자기 중단될 필요가 있는 경우 필요하다. 한 예는 보조적 단백질을 절단하는 치료 섭생에 프로테아제를 첨가하여, 단백질의 활성 TNF-저해 부분의 반감기를 급격히 감소시키는 것으로, 이는 이후 신속히 제거된다. 이러한 접근법은 감염을 제어할 수 있을 것이다.
보조적 폴리펩티드 서열은 아스파르트산 또는 글루탐산 잔기를 도입함으로써 과량의 음전하를 전달하도록 디자인될 수 있다. 8, 10, 15, 20, 25, 30, 40 또는 더욱 50%의 글루탐산 및 2% 미만의 라이신 또는 아르기닌을 함유한 보조적 폴리펩티드가 특히 관심을 끈다. 이러한 보조적 폴리펩티드는 높은 순 음전하를 전달하고, 그 결과 이들은 펩티드의 개개 음전하 사이의 정전기적 반발에 기인하여 열린 입체구조를 취하는 경향을 갖는다. 이러한 순 음전하는 이들의 수력학적 반경을 효과적으로 증가시키고, 그 결과 이러한 분자의 신장 제거를 감소시킬 수 있다. 따라서, 보조적 폴리펩티드 서열에서 음으로 하전된 아미노산의 빈도와 분포를 제어함으로써 보조적 폴리펩티드 서열의 효과적인 순 전하 및 수력학적 반경을 조정할 수 있다. 인간 또는 동물에서 대부분의 조직 및 표면은 순 음전하를 갖는다. 순 음전하를 갖도록 보조적 폴리펩티드 서열을 디자인함으로써, 보조적 폴리펩티드-치료학적 단백질과 다양한 표면, 예컨대 혈관, 건강한 조직 따는 다양한 수용체 사이에 비특이적 상호작용을 최소화할 수 있다.
본 발명에 유용한 다른 보조적 폴리펩티드는 하나 이상의 하기의 특징을 나타낸다.
보조적 폴리펩티드는 증진된 수력학적 반경을 특징으로 할 수 있고, 여기서 보조적 폴리펩티드는 이에 연결된 생물학적 활성 폴리펩티드의 겉보기 분자량 계수를 증가시킨다. 겉보기 분자량 계수가 혈청 분비 반감기의 예상 인자이므로(예상 분자량이 일정하다고 가정하여), 보다 높은 겉보기 분자량 계수를 갖는 보조적 폴리펩티드는 보다 긴 혈청 반감기를 나타낼 것으로 예상된다. 몇몇 실시양태에서, 보조적 폴리펩티드를 위한 겉보기 분자량 계수는 3, 5, 7 또는 더욱 9보다 클 수 있다. 겉보기 분자량 계수는, 제한되지 않지만 제어된 기공 크기를 갖는 막을 통한 한외여과를 비롯한 다양한 방법에 의해, 또는 크기 배제 겔 여과(SEC: size exclusion gel filtration)에 의해 측정될 수 있다. 겉보기 분자량 계수는 염 및 다른 용질의 농도에 영향받을 수 있다. 이는 일반적으로 생리학적 조건과 유사한 조건하에, 예컨대 혈액 또는 염수내에서 측정되어야 한다.
보조적 폴리펩티드는 또한 생물학적 활성 폴리펩티드내로 혼입시 보조적 폴리펩티드가 없는 상응하는 단백질에 비해 상기 생물학적 활성 폴리펩티드가 더 긴 혈청 반감기를 나타낸다는 효과를 특징으로 할 수 있다(혈청 반감기를 확인하는 방법은 당분야에 공지되어 있다. 예를 들어, 문헌[Alvarez, P., et al. (2004) J Biol Chem, 279: 3375-81]을 참조한다). 당분야에서 이용가능하거나 본원에 예시된 임의의 방법을 실행함으로써, 생성된 단백질이 변경되지 않은 단백질에 비해 더 긴 혈청 반감기를 갖는지의 여부를 용이하게 결정할 수 있다.
보조적 폴리펩티드는 또한 이에 부착된 단백질의 용해도를 증가시킬 수 있다. 예를 들면, 인간 인터페론-알파, 인간 성장 호르몬 및 인간 G-CSF가 이. 콜라이의 세포질에서 발현될 경우 전형적으로 봉입체를 형성하는 반면, 보조적 폴리펩티드(예컨대 (SSGSSE)48 또는 (SSESSSSESSSE)24, (GEGGGEGGE)36, 또는 기타)의 부착은 발현된 폴리펩티드의 용해도를 증가시켜, 더이상 봉입체를 형성하지 않지만 이것이 활성 형태로 높은 발현 수준 및 효능하에 쉽게 정제될 수 있는 세포질에서 가용성으로 남도록 하여, 봉입체로부터의 리폴딩의 필요성을 방지한다.
보조적 폴리펩티드는 생리학적 조건하에 입체구조적 가요성의 정도가 높을 수 있고, 이들은 유사 분자량의 구형 단백질에 비해 큰 수력학적 반경[스토크 반경(Stokes' radius)]을 가져서, 큰 '비체적(specific volume)'(단위 질량당 부피)을 유도하는 경향이 있다. 따라서, 보조적 폴리펩티드는 생리학적 조건하에 잘 정의된 2차 또는 3차 구조가 결여된 변성 펩티드 서열과 같이 거동할 수 있다. 변성된 입체구조는 펩티드 주쇄의 큰 입체구조적 자유를 특징으로 하는 용액중의 펩티드의 상태를 말한다. 대부분의 펩티드 및 단백질은 높은 농도의 변성물의 존재하에 또는 상승된 온도에서 변성된 입체구조를 취한다. 변성된 입체구조의 펩티드는 특징적 CD 스펙트럼을 갖고, 이들은 NMR에 의해 결정될 경우 긴 범위의 상호작용이 결여됨을 특징으로 한다. "변성된 입체구조" 및 "언폴딩된 입체구조"는 본원에서 동의어로 사용된다. 소정의 폴리펩티드의 2차 및 3차 구조의 존재 또는 부재를 알아내는 다양한 방법들이 당분야에 확립되어 있다. 예를 들면, 폴리펩티드의 2차 구조는 CD 분광계에 의해 "원거리-UV" 스펙트럼 영역(190∼250 nm)에서 결정될 수 있다. 2차 구조 요소, 예컨대 알파-나선(helix), 베타-시이트(sheet), 및 랜덤 코일 구조는 각각 CD 스펙트럼의 특징적 형상 및 크기를 일으킨다. 2차 구조는 또한 특정 컴퓨터 프로그램 또는 알고리즘, 예컨대 초우-파스만 알고리즘을 통해 확인할 수 있다(Chou, P. Y., et al. (1974) Biochemistry, 13: 222-45). 소정의 보조적 서열을 위해, 알고리즘은 2차 구조가 일부 존재하는지 전혀 존재하지 않는지를 예측할 수 있다. 많은 경우에, 보조적 서열은 2차 및 3차 구조 함량이 낮기 때문에 변성된 서열과 닮은 스펙트럼을 가질 것이다. 다른 경우에, 보조적 서열은 2차 구조, 특별히 나선형, 예컨대 알파-나선형, 또는 시이트형, 예컨대 베타-시이트형을 취할 수 있다. 비구조화된 아미노산 중합체가 일반적으로 본 발명을 위해 바람직하지만, 일부 2차 구조, 특히 알파-나선형 및 보다 적게는 베타-시이트형을 취하는 아미노산 서열을 사용하는 것이 가능하다. 3차 구조는 일반적으로 그의 낮은 고유 수력학적 반경으로 인해 바람직하지 않다. 2차 구조를 갖는 서열은 2차 구조가 적은 서열에 비해 적은 수력학적 반경을 가질 것이지만, 이들은 여전히 유용할 수 있다. 보조적 서열이 3차 구조를 취한다면(예컨대 단백질 도메인에서), 수력학적 반경은 더 작을 것으로 예상된다. 폴리글리신이 수력학적 반경 대 질량의 가장 높은 비를 갖는 반면(글리신은 단지 70D임), 구형 단백질은 수력학적 반경 대 질량의 가장 낮은 비를 갖는다. 0, 1, 2, 3 또는 4개의 디설파이드를 갖고 2차 및 3차 구조의 정도가 다양한 펩티드를 보조적 폴리펩티드에 포함하여 혈청-노출된 표적에 결합하여 상이한 기작에 의해 혈청 분비 반감기를 증가시키는 예외가 있다.
보조적 폴리펩티드는 면역원성이 낮은 서열일 수 있다. 낮은 면역원성은 보조적 서열의 입체구조적 가요성의 직접적인 결과일 수 있다. 많은 항체는 단백질 항원에서 소위 입체구조적 에피토프를 인식한다. 입체구조적 에피토프는 단백질 항원의 다수의 불연속 아미노산 서열로 이루어진 단백질 표면 영역에 의해 형성된다. 단백질의 정확한 폴딩은 이들 서열이 항체에 의해 인식될 수 있는 잘 규정된 특별한 배열로 만든다. 바람직한 보조적 폴리펩티드는 입체구조적 에피토프의 형성을 방지하도록 디자인된다. 예를 들면, 수성 용액에서 치밀하게 폴딩된 입체구조를 취하는 경향이 낮은 보조적 서열이 특히 관심을 끈다. 특히, 낮은 면역원성은 항원이 존재하는 세포에서 항원 처리과정에 저항하는 서열을 선택하고/하거나, MHC에 잘 결합하지 않는 서열을 선택하고/하거나, 인간 서열로부터 유도된 서열을 선택함으로써 달성될 수 있다. 보조적 폴리펩티드 서열은 또한 생물학적 활성 폴리펩티드의 면역원성을 감소시킬 수 있다.
보조적 폴리펩티드는 프로테아제 내성도가 높은 서열일 수 있다. 프로테아제 내성은 또한 보조적 서열의 입체구조적 가요성의 결과(예를 들어, 이들의 높은 엔트로피(entropy)로 인함)일 수 있다. 프로테아제 내성은 내부- 및 외부-프로테아제 둘 다에 대한 공지의 프로테아제 인식 부위를 방지하고, 높은 글리신 함량을 포함함으로써 디자인될 수 있다. 다르게는, 프로테아제 내성 서열은 파지 디스플레이 또는 랜덤 또는 반-랜덤 서열 라이브러리로부터의 관련된 기법에 의해 선택될 수 있다. 특수 적용분야, 예컨대 데포 단백질로부터의 저속 방출을 위해 원하는 경우, 혈청 프로테아제 절단 부위는 보조적 폴리펩티드내로 만들어질 수 있다. 이러한 경우에, 본 발명의 조성물은 사용도중 용해 또는 분해될 수 있다(또는 용해 또는 분해되도록 의도될 수 있다). 일반적으로, 생분해성에 기인하는 분해는 중합체의 그의 구성성분으로의 분해를 포함한다(제한없이, 변경된 폴리펩티드 및 생성된 분해 산물이 포함됨). 중합체의 분해 속도는 종종 부분적으로 다양한 인자, 예컨대 중합체를 형성하는 임의의 구성성분의 동일성(예컨대 프로테아제 민감성 부위), 임의의 치환기의 비율, 및 조성물이 형성되거나 처리되는 방식(예를 들어 치환기가 보호되는지의 여부)에 좌우된다. 그러나, 적용분야에 관련된 혈액 및 신체 조직에서 높은 안정성(예를 들어, 긴 혈청 반감기, 체액에 존재하는 프로테아제에 의한 낮은 분열 경향)을 갖는 보조적 서열이 관심을 끈다. 보조적 폴리펩티드는 또한 이들이 프로테아제 공격으로부터 단백질을 방어하므로 단백질의 프로테아제 내성을 개선시킬 수 있다. 3개의 아미노산으로 이루어진 천연 비구조화된 반복적 서열의 한 예는 M13 파지의 pIII 단백질 중의 연결기로서, 이는 반복부 (GGGSE)n을 갖고 광범위한 정렬의 프로테아제에 예외적으로 안정한 것으로 공지되어 있다. 모티프 (GGGSE)n를 갖는 보조적 단백질은 매우 유용할 것으로 예측된다. 긴 서열의 경우, 증가된 길이에 요구될 수 있는 보다 높은 용해도를 달성하기 위해 (GGSE)n이 선호된다.
생리학적 조건하에 물, 혈액 및 기타 체액에서 양호한 용해도를 갖는 보조적 폴리펩티드는 또한 생물이용성을 촉진시키기 위해 요망된다. 이러한 서열은 친수성 아미노산, 예컨대 글리신, 세린, 아스파테이트, 글루타메이트, 라이신, 아르기닌, 트레오닌이 풍부하고 소수성 아미노산, 예컨대 트립토판, 페닐알라닌, 타이로신, 루신, 이소루신, 발린, 메티오닌을 거의 함유하지 않는 서열을 디자인함으로써 수득될 수 있다. 이들 아미노산 조성의 결과로서, 보조적 폴리펩티드는 수성 제형에서 응집체를 형성하는 경향이 낮고, 다른 단백질 또는 펩티드로의 보조적 폴리펩티드의 융합은 이들의 용해도를 증진시키고 응집체를 형성하는 이들의 경향을 감소시키고, 이는 면역원성을 감소시키는 것과 별도의 기작이다.
보조적 폴리펩티드는, 몇몇 경우에, 조직 또는 혈청 단백질에 대한 증진된 비특이적 결합을 나타내고(도 28), 이는 이들의 혈청 반감기를 연장시키는 작용을 한다. 혈청 단백질 결합은 다양한 방법을 사용하여 측정될 수 있다. 결합 검정의 예는 ELISA, 비아코어(Biacore), 키넥사(Kinexa), 또는 포르테 바이오(Forte Bio)이다. 대부분의 동물 조직 표면은 (순) 약한 음전하를 갖고, 순 음전하를 갖는 단백질은 순 양전하를 갖는 단백질에 비해 비특이적 조직 결합을 덜 나타낸다. 음전하를 첨가하거나 양전하를 제거함으로써 약한 순 음전하를 생성하면 단백질은 보다 특이적으로 결합되거나 적어도 비특이적 결합을 감소시킬 수 있다.
그러나, 순 음전하(또는 순 전하 밀도)가 너무 높으면, 양전하의 국소적 패치를 갖는 표면, 예컨대 세포외 기질, 또는 DNA 또는 RNA에 결합된 부분 또는 단백질(예를 들어 VEGF, 히스톤(histone))에 비특이적 결합을 일으킬 수 있다. 반대로, 양전하(예컨대 K, R)를 첨가하거나 음전하를 제거함으로써 순 양전하를 갖는 단백질을 생성하면 단백질이 조직에 비특이적으로 결합되도록 만들 수 있고, 그 결과 반감기를 연장시킨다.
보조적 폴리펩티드 자체의 전하 유형 및 밀도는 변경될 수 있다. 음으로 하전된 아미노산은 E, D, (C)이고, 양으로 하전된 아미노산은 R, K, (H)이다. 변화는 일반적으로 음으로 하전된 잔기를 또 다른 잔기로 교환함을 포함하고, 예컨대 E를 D로 교환하거나 그 반대이다. 몇몇 경우에, E가 바람직한데, 이는 D가 이성화되어 제작에 바람직하지 않은 화학적 불안정성을 유도할 수 있기 때문이다. 양전하에서 음전하로, 또는 그 반대로의 전하 유형에서의 변화는, K 또는 R을 E 또는 D로 대체함을 포함한다(음전하에 의해 대체된 양전하). 전하의 변화는 또한 비-하전되거나 약하게 하전된 아미노산(A, C, F, G, H, I, L, M, N, P, Q, S, T, V, W, Y)을 하전된 아미노산(E, D, K, R)으로 대체하거나 그 반대를 포함한다. "전하 밀도"는 총 잔기의 백분율로서의 하전된 아미노산의 수이다. 전하 밀도의 변화는 총 아미노산의 백분율로서 음으로 하전된 아미노산(구체적으로 E, D) 또는 양으로 하전된 아미노산(K, R)의 증가되거나 감소된 수를 포함한다. 반대로, '순 전하 밀도'는 잔기의 총 수의 백분율로서 모든 양으로 하전된 아미노산의 합에서 모든 음으로 하전된 아미노산을 뺀 값("순 전하")이다.
"순 전하" 및 "순 전하 밀도(AA당 순 전하)"는 보조적 폴리펩티드 및 보조제 변경 폴리펩티드의 용해도, 뿐만 아니라 다른 분자에 결합하는 이의 능력에 영향을 미칠 수 있다. 보조적 폴리펩티드는 융합 단백질의 전하 유형 및 밀도를 변경시킬 수 있고, 이는 혈청 반감기를 증진시킬 수 있고, 원하는 상호작용을 증진시키거나 융합 단백질과 다른 단백질 또는 물질의 원치않는 상호작용을 감소시키도록 이용될 수 있다.
보조적 폴리펩티드는, 몇몇 경우에, 조직 또는 혈청 단백질로의 증진된 비특이적 결합을 나타내고, 이는 이들의 혈청 반감기를 연장시키는 기능을 할 수 있다. 이는 비특이적인 것으로 보이지 않는 보조적 서열과 비교된 혈청 반감기의 연장으로서 측정될 수 있거나, 고 밀도의 반대 전하를 갖는 단백질에 대한 약한 결합 친화도로서 ELISA에 의해 제시될 수 있다.
보조적 폴리펩티드는 부분적으로 또는 전체적으로 단일 아미노산, 예컨대 (E)n, (G)n 또는 (S)n(또한 폴리-E, EEEEE, 폴리-G, GGGGG, 또는 폴리-S, SSSSS로 지칭됨), 또는 A, C, D, F, H, I, K, L, M, N, P, Q, R, S, T, V, W, Y중 하나의 단독중합체(즉, AAAAA)로 구성될 수 있다. 최상의 단일 아미노산 모티프(E,G,S)는 면역학적으로 가장 작은 복합체이지만(단지 9개 아미노산 펩티드 중 하나의 유형만이 생성될 수 있음), 각각은 몇몇 단점을 갖는다. 글리신은 약한 소수성이고 폴리-G는 제한된 용해도를 갖는다. 글리신의 이점은 그의 높은 엔트로피이다. 몇몇 경우에, 세린은 글리신에 비해 바람직할 수 있는데, 이는 상응하는 DNA 서열이 보다 균형을 이룬 GC-비율을 갖기 쉽고 일반적으로 아마도 그의 6개의 코돈으로 인해 보다 높은 발현 수준을 제공하기 때문이다. 글루탐산(E)을 포함한 4개의 하전된 아미노산은 20개의 천연 아미노산 중 최고의 용해도를 갖고, 글리신 및 세린이 뒤따른다. 그러나, 높은 음성 순 전하 밀도에서, 단백질은 양으로 하전된 단백질 및 표면, 예컨대 VEGF(ECM에 결합하는 염기성 엑손), 히스톤, DNA/RNA 결합 단백질 및 또한 골에 비특이적으로 결합하기 시작한다. 다르게는, 폴리-E의 긴 스트링이 원하는 연장된 반감기 대신 감소된 반감기를 초래한다고 보고되어 있다.
세린 및 폴리-세린은 종종 응집의 위험 없이 최상의 코돈 용법 및 발현 수준을 가지면서 높은 용해도를 제공한다. 세린을 위한 6개의 코돈은 종종 균형을 이룬 GC 함량을 제공하지만, 보다 중요하게는, 이들은 폴리-S 또는 S 풍부 서열이 예외적으로 다른 종류의 DNA 서열에 의해 코딩되어 다른 아미노산, 예컨대 폴리-E 또는 폴리-G에 비해 더 큰 정도의 코돈 용법 최적화 및 발현 수준 최적화를 제공한다(도 14 및 15).
보조적 폴리펩티드는 상기 기재된 작용성 변화에 영향을 주기에 필수적인 임의의 길이일 수 있다. 단지 1, 2, 3가지 이상의 유형의 아미노산을 포함하는 보조적 서열의 길이는 10, 12, 14, 16, 18, 20, 25, 30, 35, 40, 45, 50, 60, 70, 80, 90 또는 100개 아미노산의 하한 및 30, 40, 50, 60, 70, 80, 90, 100, 125, 150, 175, 200, 250, 300, 350, 400, 500, 600개 또는 더욱 1000개 아미노산의 상한을 가질 수 있다.
보조적 폴리펩티드의 아미노산 조성은, 생성된 폴리펩티드의 원하는 특성이 최대화되도록 선택될 수 있다. 예를 들면, 혈청 반감기의 연장을 위해, 예상 분자량에 대한 겉보기 분자량의 높은 비가 바람직하다. 동일한 질량에 대해 보다 큰 수력학적 반경을 제공하는 비구조화된 보조적 폴리펩티드는 구조, 예컨대 알파 나선 또는 베타-시이트를 지지하지 않는 아미노산으로 작제된다. 초우-파스만 알고리즘에 의한 아미노산 잔기의 등급평가에 따르면, 잔기 A, D, E, Q, I, L, K, M, F, W, V는 알파-나선 구조를 지지하고, 잔기 C, Q, I, L, M, F, T, W, Y, V는 베타-시이트 구조를 지지한다. 턴(turn)-형성에 의해 초우-파스만 알고리즘에 따라 대부분 비구조화된 것으로 고려되는 아미노산은, 최대로부터 최소한의 비구조화된 순서로 다음과 같다: G, N, P, D, S, C, Y, K. 모든 것을 감안할 때, 구조를 최소한으로 지지하는 잔기는 G, N, P, S이다.
중합체의 특성, 특별히 용해도 및 전하 밀도의 보다 나은 미세 조율을 달성하기 위해, 2개 또는 3개의 아미노산으로 이루어진 보조적 폴리펩티드가 단일 아미노산으로 이루어진 폴리펩티드에 비해 일반적으로 바람직하다. 2 또는 3가지 유형의 아미노산으로 이루어진 보조적 폴리펩티드가 바람직한데, 이는 이들이 최적의 용해도, 프로테아제 내성, 전하 유형 및 밀도, 구조의 부재, 엔트로피, 및 조직으로의 비특이적 결합(이는 바람직하지 않을 수 있지만 또한 반감기 기작으로서 사용될 수 있음)과 함께 면역학적 단순성(MHC 복합체에 결합할 수 있는 상이한 9량체 펩티드 또는 항체 결합을 위한 에피토프를 형성하는 8량체 펩티드를 단직 적은 수로 산출함)의 최상의 균형을 제공하기 때문이다. 일반적으로, 보조적 단백질 서열로부터 생성될 수 있는 비-인간 8량체 또는 9량체 펩티드의 수가 많을수록, 면역원성의 위험이 높아진다. 따라서, 몇몇 양태에서, 보조적 폴리펩티드는 작은 수의 상이한 8량체 또는 9량체를 포함하고, 여기서 이들 펩티드 서열의 모두 또는 대부분은 인간 단백질에서, 바람직하게는 많은 카피를 갖고 발생된다.
원할 경우, 2 또는 3가지 아미노산 유형의 블렌드는 특성들의 원하는 균형을 수득하기 위해 최적화될 수 있다. 20개의 천연 아미노산(AA)은 관련된 특성을 갖는 그룹으로 분리될 수 있다. 잔기 E, D(및 보다 적은 정도로 C)는 생리학적(중성) pH에서 음으로 하전되고, 잔기 K, R 및 보다 적은 정도로 H는 중성 pH에서 양으로 하전된다. 하전된 잔기 E, D, K 및 R의 존재는 긴 폴리펩티드의 수 용해도를 최대화하기 위해 필요할 수 있다. 몇몇 생물학적 적용분야를 위해, 음성 및 양성 잔기의 빈도가 높지만 동일하거나 유사한 것이 바람직하고, 이는 전하 밀도가 높지만 순 전하가 낮은 하전되지 않거나 거의 하전되지 않은 폴리펩티드를 생성하고, 이러한 폴리펩티드는 하전된 중합체, 예컨대 헤파린에 결합하는 수용체와 비특이적 상호상용을 하는 경향이 낮다. 몇몇 생물학적 적용분야에서, (D와 달리) 단일 전하 유형(음성)은 화학적으로 안정하고; 따라서 E(글루타메이트)를 선호한다. 문제는 아미노산의 어느 정도의 백분율이 E이어야 하는지, 비-전하 아미노산의 대부분이 G이어야 하는지 S이어야 하는지, 서열이 매우 반복적이어야 하는지 덜 반복적이어야 하는지이다.
음으로 하전된 잔기 E, D의 높은 빈도는, 많은 수의 양전하를 갖는 분자, 예컨대 DNA 결합 단백질, 히스톤 및 다른 R,K 풍부 서열에 중합체를 결합시키기 쉽다. 양으로 하전된 잔기 K, R의 높은 빈도는, 많은 수의 음전하를 갖는 표면(이는 대부분의 세포 표면을 포함함)에 중합체를 결합시킬 것이다. 세포 표면으로의 결합은 일반적으로 바람직하지 않지만, 낮은 정도의 이러한 비특이적 결합은 반감기를 증가시키는데 유용할 수 있다. 극성, 친수성 아미노산 N, Q, S, T, K, R, H, D, E, 및 추가의 아미노산 C 또는 Y는 비교적 수용성인 보조적 폴리펩티드를 제조하는데 유용할 수 있다. Q 및 N은 글리코실화 부위여서, 수력학적 반경을 증가시키고 이에 따라 반감기를 증가시키는 별도의 기작을 제공할 수 있다. 비-극성, 소수성 잔기, 예컨대 A, V, L, I, P, Y, F, W, M, C는 높은 수용성을 갖는 서열을 생성할 경우 덜 유용하지만, 하나 이상의의 이들 잔기를 낮은 빈도로 혼입하여 이들이 전체의 10∼20% 미만을 구성하도록 하는 것이 요망될 수 있다. 예를 들면, 소수성 잔기의 제한된 수의 치환기은, 혈청-노출된 부위로의 비특이적 결합을 증가시킴으로써 반감기를 증가시킬 수 있다. 유사하게, 시스테인 잔기로부터의 유리 티올은, 다른 유리 티올, 예컨대 인간 혈청 알부민중의 유리 티올에 결합함으로써 반감기 연장을 위한 기작으로서 작용할 수 있다. 또한, 이러한 덜 바람직한 아미노산은 혈청-노출된 단백질에 결합하는 펩티드를 생성하는데 사용되어, 보조적 단백질에 수력학적 반경 이외에 제2 반감기 연장 기작을 부여할 수 있다.
글리신은, 수력학적 반경 대 질량 또는 겉보기 분자량 대 예상 분자량의 높은 비로 인해, 보조적 폴리펩티드에 사용될 수 있는 바람직한 잔기이다. 글리신은 측쇄를 갖지 않고, 따라서 70Da의 가장 작은 잔기이다. 글리신은, 이의 작은 크기로 인해, 최대 회전 자유 및 최대 엔트로피를 제공한다. 이는 보다 높은 빈도로 글리신을 갖는 서열에 단백질이 결합하는 것을 어렵게 만들고, 글리신 풍부 서열은 프로테아제 내성이 높다.
잔기 C, W, N, Q, S, T, Y, K, R, H, D, E는 다른 잔기와 수소 결합을 형성할 수 있고, 이로써 구조를 지지하고(분자간 수소 결합) 다른 단백질에 결합한다(분자간 수소 결합). 이들은 구조물을 원치않는 경우에 배제될 수 있거나, 어느 정도의 결합(특이적 또는 비특이적)이 반감기 연장을 위해 요구되는 경우 포함될 수 있다. 황 함유 잔기 C 및 M은 전형적으로 보조적 폴리펩티드에서 방지되지만, 시스테인은 그의 유리 티올을 통해 반감기를 제공하기 위해 포함될 수 있고, 또한 환형 펩티드에서 낮은-면역원성 결합 요소로서 사용되어 혈청-노출된 단백질로의 결합에 의해 반감기를 연장시키거나 조직 특이적 부위에 결합하여 조직 표적화 또는 조정된 생물분포를 수득할 수 있다.
한 실시양태에서, 보조적 폴리펩티드는 최소한의 반복적 서열을 함유하지 않거나 최소한으로 함유한다. IgM은 5가이고, 반복적 서열을 인식하는 경향을 나타낸다. 더욱이 IgM과의 낮은 친화도 접촉은, IgM의 5가에 기인하여 상당한 겉보기 친화도(결합활성)를 유도한다. 감소된 반복 정도 및 감소된 IgM 결합 경향을 갖는 서열을 만드는 한 방식은 긴 반복 서열(즉, 7, 8, 9, 10, 12, 14, 16, 20, 30, 40, 50, 70, 100, 150, 200개 아미노산의 반복 길이)을 사용하는 것이다. 반복이 감소된 서열의 예는 (SESSSESSE)n, (SSESSSSESSSE)n, (SSSESSSSSESSSSE)n 또는 (SSSSESSSSSSE)n인 반면, 유사한 전체 조성을 갖는 반복적 서열은 (SSE)n, (SSSE)n, (SSSSE)n, (SSSSSE)n 또는 (SSSSSSE)n이다. 또 다른 접근법은 다수의 모티프의 사용 및/또는 동일한 보조적 폴리펩티드에서 상호혼합된 하나 이상의 모티프의 변형(예컨대 모티프의 서열 변형, 공간 변형 및 모티프를 분리하는 서열에서의 변형)을 포함한다. 본 발명의 또 다른 양태는 대부분 비반복적이고 원하는 아미노산 조성을 갖는 긴, 전체 인간 또는 인간화된 서열의 용도를 제공한다. 관련된 실시양태에서, 다른 유형의 아미노산 또는 다른 유형의 아미노산에 기초한 모티프가 산재될 수 있다. 한 예는 다음과 같다: GEGESEGEGEGESEGEGESGE.
3가지 상이한 유형의 아미노산을 포함하는 보조적 폴리펩티드:
한 실시양태에서, 보조적 폴리펩티드는 3가지 상이한 유형의 아미노산을 포함하는 서열을 포함한다. 1 또는 2가지의 아미노산에 비교된 3가지 아미노산의 이점은 의도된 상업적 용도를 위해 생성된 중합체의 특성을 미세-조율하는 능력이 증가된다는 것이다.
본 발명의 한 특별한 실시양태는 3가지 상이한 유형의 아미노산을 포함하는 비반복적 서열을 제공한다. 본 발명의 한 추가의 실시양태는 3가지 상이한 유형의 아미노산이 함유된 비반복적 서열을 제공하고, 여기서 아미노산은 A, D, E, G, H, K, N, P, Q, R, S, T 및 Y로 구성된 군에서 선택된다. 이러한 실시양태의 예시적인 서열은 표 1에 제시되어 있다. 한 바람직한 실시양태에서, 아미노산은 D, E, G, K, P, R, S 및 T로 구성된 군에서 선택된다. 보다 바람직한 실시양태에서, 아미노산은 E, S, G, R 및 A로 구성된 군에서 선택된다. 가장 바람직한 실시양태에서, 아미노산은 E, G 및 S이다. 이러한 단백질에서, 바람직한 조성은 30∼70%(최상: 50∼60%) 범위의 G, 20∼40%(최상: 25∼30%) 범위의 E, 및 10∼25% 범위의 S를 갖고, 바람직하게는 각각의 서열의 단지 1, 2, 3, 4 또는 5개 카피(반복부)만이 9∼15개 초과의 AA를 갖는다.
별도의 실시양태에서, 보조적 폴리펩티드는 반복된 서열 모티프를 함유하는 서열을 포함하고, 여기서 각각의 반복된 서열 모티프는 3가지 상이한 유형의 아미노산을 함유하고, 여기서 아미노산은 A, D, E, G, H, K, N, P, Q, R, S, T 및 Y로 구성된 군에서 선택된다. 상기 실시양태에 대한 예시적 서열은 표 1에 제시되어 있다. 한 실시양태에서, 아미노산은 D, E, G, K, P, R, S 및 T로 구성된 군에서 선택된다. 또 다른 실시양태에서, 아미노산은 E, S, G, R 및 A로 구성된 군에서 선택된다. 또 다른 실시양태에서, 아미노산은 E, G 및 S(임의의 순서로)이다.
관련된 실시양태에서, 본 발명의 보조적 폴리펩티드는 반복적 서열 모티프에 조직화된 3가지 상이한 유형의 아미노산을 함유하고, 여기서 각각의 반복된 서열 모티프는 3개의 연속된 아미노산보다 길다. 이러한 실시양태에 대한 예시적 서열은 표 1에 제시되어 있다. 반복적 서열 모티프는 정방향이거나 역방향일 수 있고, 1, 2, 3, 4가지 이상의 상이한 유형의 모티프는 별도로 또는 동일한 단백질에 상호혼합되어 초래될 수 있다. 1, 2, 3, 4, 5개 이상의 미스매칭된 잔기를 갖는 반복부는 완벽하거나 완벽하지 않을 수 있고, 반복부는 인접하거나 분산될 수 있고, 이는 이들이 동일한 모티프로 이루어지지 않은 다른 관련되지 않은 서열에 의해 분리됨을 의미한다. 몇몇 실시양태에서, 반복적 서열은 보조적 폴리펩티드의 대부분을 구성하는 반면, 비반복적 서열은 다른 실시양태에서 우세하다. 한 특별한 실시양태에서, 반복적 서열은 서열의 엄격한 반복적 성질을 깨는 산재된 단일 아미노산을 포함하는다. 상기 실시양태를 위한 예시적인 서열은 표 1에 제시되어 있다. 또 다른 관련된 실시양태에서, 보조적 폴리펩티드는 주로 반복적 또는 비반복적 서열에 조직화된 3가지 유형의 아미노산을, 적은 수의 상이한 유형의 아미노산과 함께 함유하고, 여기서 상기 3가지 유형의 아미노산은 전체 서열의 50%, 60%, 70%, 80%, 90%, 95%, 98% 초과 또는 >99%를 구성한다.
다수의 유형의 반복된 모티프를 포함하는 서열의 또 다른 예는 GGGGGGGGGGEEEEEEEEEEGGGGGGGGGGEEEEEEEEEE이다. 다른 바람직한 예는 2, 3, 4, 5개 이상의 모티프의 다양한 조합을 갖는 서열이고, 여기서 모티프는 E, S, G, GE, GS, SE, GES, GSE, ESG, EGS, SGE, 및 SEG로부터 선택되고, 조성 (E)n, (S)n, (G)n, (GE)n, (GS)n, (SE)n, (GES)n, (GSE)n, (ESG)n, (EGS)n, (SGE)n, 및 (SEG) 뿐만 아니라 많은 추가의 서열을 유도한다.
모티프 또는 중합체 서열 중 아미노산의 조성은 균형을 이루거나(예를 들면, 50% G 및 50% E; 또는 33% G, 33% E 및 33% S, 및 다른 유사한 예) 균형을 이루지 않을 수 있다(즉, 75% S 및 25% E).
보조적 서열 반복부는 단백질의 N-말단에, 단백질의 C-말단에, 또는 N-말단 또는 C-말단로부터 1, 2, 3, 4, 5, 6, 10, 20, 30개 이상의 아미노산 잔기만큼 떨어져 위치될 수 있다. 폴리아미노산은 2개의 단백질 도메인 사이에 위치될 수도 있다.
폴리아미노산 중 모티프의 반복부의 수는 4, 5, 6, 7, 8, 9, 10, 12, 14, 16, 18, 20, 25, 30, 35, 40, 45, 50, 60, 70, 80, 90, 100개의 하한 및 10, 12, 14, 16, 18, 20, 25, 30, 35, 40, 45, 50, 60, 70, 80, 90, 100, 150, 200, 250, 300, 400, 500, 또는 더욱 600개의 상한을 가질 수 있다.
반복된 모티프는 주된 아미노산 유형 및 부수적인 아미노산 유형을 가질 수 있다. 소정의 반복된 모티프의 경우, 부수적 유형의 잔기에 비해 주된 아미노산 유형의 보다 많은 잔기가 존재한다. 예를 들면, 보조적 폴리펩티드 (GGGEE)n에서, G는 주된 아미노산 유형이고, E는 부수적 아미노산 유형이다. 이들 서열은 정의에 의해 균형을 이루지 않는다. 이러한 모티프에서, 2, 3, 4가지 이상의 유형의 주된 아미노산을 가질 수 있다. 한 바람직한 실시양태에서, 주된 아미노산은 G, E, S이고, 부수적 아미노산은 A, D, E, F, G, H, I, K, L, M, N, P, Q, R, S, T, V, W, Y이고, 동일한 아미노산 유형이 모티프에 존재하는 주된 기 및 부수적 기 둘 다에 존재할 수 없다는 추가의 제한을 갖는다. 이러한 모티프에서 2가지 이상의 유형의 부수적 아미노산을 갖는 것도 가능하고; 한 예는 G가 주된 유형이고 E 및 S가 아미노산의 부수적 유형인 (GGEGGS)n이다. 다른 예는 (EGGSGG)n, (GEGGSG)n, (GGSGGE)n, (SGGEGG)n, (GSGGEG)n, (GEEGSS)n, (GSSGEE)n, (SGSEGE)n, (SSGEEG)n이다.
구체적인 서열과 무관하게, 보조적 서열에서 아미노산 잔기의 총 수는 10, 12, 14, 16, 18, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 45, 50, 55, 60, 65, 70, 75, 80, 85, 90, 95, 100, 120, 140, 160, 180, 200, 250, 또는 300개 아미노산의 하한 및 30, 35, 40, 45, 50, 55, 60, 65, 70, 75, 80, 85, 90, 95, 100, 110, 120, 130, 140, 150, 160, 170, 180, 190, 200, 220, 240, 260, 280, 300, 350, 400, 450, 500, 550개, 또는 더욱 600, 700, 800, 900 또는 1000개 초과의 아미노산의 상한을 갖는다. 이러한 수는 단일의 연속된 서열의 길이, 또는 비연속적으로 발생된 다수의 모티프로 이루어진 다수의 서열에 대한 축적된 총 길이를 지칭할 수 있고, 이는 이들 반복부가 상이한 모티프의 반복부를 포함하는 다른 서열에 의해 분산되고 분리됨을 의미한다.
[표 1]
3가지 상이한 유형의 아미노산을 포함하는 보조적 폴리펩티드 서열

2가지 상이한 유형의 아미노산을 포함하는 보조적 폴리펩티드:
한 실시양태에서, 보조적 폴리펩티드는 2가지 상이한 유형의 아미노산을 포함하는 서열을 포함한다.
구체적인 실시양태에서, 보조적 폴리펩티드는 2가지 상이한 유형의 아미노산을 포함하는 서열을 포함하고, 여기서 아미노산 중 하나는 글리신이고 나머지는 D, E, K, P, R, S, T, A, H, N, Y, L, V, W, M, F, I 또는 C이다. 보다 특이적인 실시양태는, 2가지 상이한 유형의 아미노산을 포함하는 서열을 포함하고, 여기서 아미노산 중 하나가 글리신이고, 이때 글리신이 전체 서열의 0%, 절반, 또는 절반 미만을 구성하는 보조적 폴리펩티드를 제공한다. 관련된 실시양태에서, 보조적 폴리펩티드는 10%, 20%, 30%, 40%, 50%, 60%, 70%, 80%, 90% 또는 더욱 100%의 글리신 잔기를 포함한다.
상이한 실시양태에서, 보조적 폴리펩티드는 2가지 상이한 유형의 아미노산을 포함하는 서열을 포함하고, 여기서 아미노산 중 하나는 세린이고 나머지는 D, E, K, P, R, G, T, A, H, N, Y, L, V, W, M, F, I 또는 C이다. 보다 구체적인 실시양태는 2가지 상이한 유형의 아미노산을 포함하는 서열을 포함하고, 여기서 아미노산 중 하나가 세린이고, 이때 세린이 전체 서열의 0%, 절반, 또는 절반 미만을 구성하는 보조적 폴리펩티드를 제공한다. 관련된 실시양태에서, 보조적 폴리펩티드는 10%, 20%, 30%, 40%, 50%, 60%, 70%, 80%, 90% 또는 더욱 100%의 세린 잔기를 포함한다.
관련된 실시양태에서, 보조적 폴리펩티드는 2가지 상이한 유형의 아미노산을 포함하고, 여기서 아미노산은 동일하거나 대략 동일한 양으로 표시된다(1:1 비). 관련된 실시양태에서, 2가지 유형의 아미노산은 1:2, 1:3, 2:3, 3:4 비로 표시된다. 서열의 예는 표 2에 제시되어 있다.
본 발명의 대안의 실시양태는 2가지 상이한 유형의 아미노산을 포함하는 서열을 포함하고, 여기서 총 아미노산의 절반 또는 절반 미만이 A, T, G, D, E 또는 H인 보조적 폴리펩티드를 제공한다.
본 발명의 대안의 실시양태는, 2가지 상이한 유형의 아미노산을 포함하는 서열을 포함하고, 여기서 아미노산의 절반 이상이 G이고 총 아미노산의 절반 이하가 A, S, T, D, E 또는 H인 보조적 폴리펩티드를 제공한다.
본 발명의 또 다른 실시양태는, 2가지 상이한 유형의 아미노산을 포함하는 서열을 포함하고, 여기서 아미노산의 절반 이상이 S이고 총 아미노산의 절반 이하가A, T, G, D, E 또는 H인 보조적 폴리펩티드를 제공한다.
본 발명의 또 다른 실시양태는 2가지 상이한 유형의 아미노산을 포함하는 서열을 포함하고, 여기서 총 아미노산의 절반 또는 절반 미만이 P, R, L, V, Y, W, M, F, I, K 또는 C인 보조적 폴리펩티드를 제공한다.
반복 서열 모티프를 포함하고, 여기서 서열 모티프가 2, 3, 4, 5, 6, 7, 8, 9개 이상의 아미노산으로 구성될 수 있는 보조적 폴리펩티드가 또한 구현된다.
모티프 또는 중합체 서열 중 아미노산의 조성은 균형을 이루거나(예를 들면, 50% S 및 50% E), 균형을 이루지 않을 수 있다(즉., 75% S 및 25% E).
보조적 폴리펩티드 반복부는 단백질의 N-말단에, 단백질의 C-말단에, 또는 N-말단 또는 C-말단로부터 1, 2, 3, 4, 5, 6, 10, 20, 30개 이상의 아미노산 잔기만큼 떨어져 위치될 수 있다. 폴리아미노산은 또한 2개의 단백질 도메인 사이에 놓일 수 있다.
폴리아미노산 중 모티프의 반복 수는 4, 5, 6, 7, 8, 9, 10, 12, 14, 16, 18, 20, 25, 30, 35, 40, 45, 50, 60, 70, 80, 90, 100개의 상한 및 10, 12, 14, 16, 18, 20, 25, 30, 35, 40, 45, 50, 60, 70, 80, 90, 100, 150, 200, 250, 300, 400, 500, 또는 더욱 600개의 상한을 가질 수 있다.
보조적 폴리펩티드 중 아미노산 잔기의 총 수는 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 34, 35, 36, 37, 38, 39, 40, 45, 50, 55, 60, 65, 70, 75, 80, 85, 90, 95, 100, 120, 140, 160, 180, 200, 250, 또는 300개 아미노산의 하한 및 30, 35, 40, 45, 50, 55, 60, 65, 70, 75, 80, 85, 90, 95, 100, 110, 120, 130, 140, 150, 160, 170, 180, 190, 200, 220, 240, 260, 280, 300, 350, 400, 450, 500, 550개, 또는 더욱 600, 700, 800, 900 또는 1000개 초과의 아미노산의 상한을 가질 수 있다. 이 수는 단일의 연속된 서열의 길이, 또는 비연속적으로 발생된 다수의 서열에 대한 축적된 총 길이를 지칭하고, 이는 이들 반복부가 상이한 모티프의 반복부를 포함하는 다른 서열에 의해 분산되고 분리됨을 의미한다.
2개 아미노산을 포함하는 가능한 모티프는 AD, AE, AF, AG, AH, AI, AK, AL, AM, AN, AP, AQ, AR, AS, AT, AV, AW, AY, DA, DE, DF, DG, DH, DI, DK, DL, DM, DN, DP, DQ, DR, DS, DT, DV, DW, DY, EA, ED, EF, EG, EH, EI, EK, EL, EM, EN, EP, EQ, ER, ES, ET, EV, EW, EY, FA, FD, FE, FG, FH, FI, FK, FL, FM, FN, FP, FQ, FR, FS, FT, FV, FW, FY, GA, GD, GE, GF, GH, GI, GK, GL, GM, GN, GP, GQ, GR, GS, GT, GV, GW, GY, HA, HD, HE, HF, HG, HI, HK, HL, HM, HN, HP, HQ, HR, HS, HT, HV, HW, HY, IA, ID, IE, IF, IG, IH, IK, IL, IM, IN, IP, IQ, IR, IS, IT, IV, IW, IY, KA, KD, KE, KF, KG, KH, KI, KL, KM, KN, KP, KQ, KR, KS, KT, KV, KW, KY, LA, LD, LE, LF, LG, LH, LI, LK, LM, LN, LP, LQ, LR, LS, LT, LV, LW, LY, MA, MD, ME, MF, MG, MH, MI, MK, ML, MN, MP, MQ, MR, MS, MT, MV, MW, MY, NA, ND, NE, NF, NG, NH, NI, NK, NL, NM, NN, NP, NQ, NR, NS, NT, NV, NW, NY, PA, PD, PE, PF, PG, PH, PI, PK, PL, PM, PN, PQ, PR, PS, PT, PV, PW, PY, QA, QD, QE, QF, QG, QH, QI, QK, QL, QM, QN, QP, QR, QS, QT, QV, QW, QY, RA, RD, RE, RF, RG, RH, RI, RK, RL, RM, RN, RP, RQ, RR, RS, RT, RV, RW, RY, SA, SD, SE, SF, SG, SH, SI, SK, SL, SM, SN, SP, SQ, SR, SS, ST, SV, SW, SY, TA, TD, TE, TF, TG, TH, TI, TK, TL, TM, TN, TP, TQ, TR, TS, TV, TW, TY, VA, VD, VE, VF, VG, VH, VI, VK, VL, VM, VN, VP, VQ, VR, VS, VT, VW, VY, WA, WD, WE, WF, WG, WH, WI, WK, WL, WM, WN, WP, WQ, WR, WS, WT, WV, WY, YA, YD, YE, YF, YG, YH, YI, YK, YL, YM, YN, YP, YQ, YR, YS, YT, YV, YW이다. 이들 중, 바람직한 2가지 아미노산 모티프는 EG 및 GE(중합체 EGEGEGEGEGE 및 다른 변형체를 형성함), GS 및 SG(중합체 GSGSGSGSGSGSGS 및 다른 변형체를 형성함), ES 및 SE(중합체 SESESESESESESESES 및 다른 변형체를 형성함)이다. 반복부는 또한 3, 4, 5, 6 또는 7개의 아미노산 잔기를 포함할 수 있다. 또한 반복부가 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20개 또는 더욱 >20개 잔기를 포함하는 것이 가능하다. 이러한 각각의 반복부는 2, 3, 4, 5가지 이상의 유형의 아미노산을, 반복부에 존재하는 잔기의 수 이하로 함유할 수 있다.
보조적 폴리펩티드의 한 바람직한 유형은 단지 2가지 유형의 아미노산을 함유하지만, 잔기의 50% 이상은 바람직한 잔기 중 하나이다(A, S, T, D, E, H). 몇몇 경우에 보조적 폴리펩티드는 단지 2개의 주요 유형의 아미노산을 함유하지만, 보다 낮은 비의 P, R, L, V, Y, W, M, F, I, K 또는 C는 보조적 폴리펩티드의 특성에 대한 최적의 미세 조정을 위해 첨가될 수 있다(표 2 참조).
[표 2a]
2가지 상이한 유형의 아미노산을 포함하는 보조적 폴리펩티드

[표 2b]

[표 2c]

인간 서열에 관련된 보조적 폴리펩티드 서열
인간 단백질의 서열에 매우 관련된 보조적 폴리펩티드 서열은, 이들이 환자에서 면역 반응을 유도하는 위험을 감소시키므로 몇몇 적용분야에서 바람직하다. 이러한 서열은 보조적 폴리펩티드로서 본 발명의 몇몇 실시양태에서 사용될 수 있다. 인간 서열에 대한 보조적 서열의 관계는 인간 게놈에서 상기 보조적 폴리펩티드 서열의 부분적 서열의 다량성을 결정함으로써 평가될 수 있다. 표 3은 8량체 부분 서열의 발생에 대한 한 예를 보여준다. 보조적 폴리펩티드는 표 3에서 예시된 바와 같이 적은 수의 8량체 서열로 절단될 수 있고, 여기서 8량체 서열은 밑줄쳐져 있다. 각각의 8량체 서열을 위해, 인간 단백질 서열의 데이터베이스에서 정합의 수를 식별하기 위해 데이터 베이스 조사를 수행할 수 있다. 유사한 분석이 7량체, 9량체, 1O량체, 11량체, 또는 보다 긴 올리고머에 대해 수행될 수 있다. 이들 부분적 서열의 완전한 정합을 위한 데이터베이스 분석 조사를 수행할 수 있거나, 가까운 상동체에 대해 조사할 수 있다. 따라서, 조사의 엄격성(stringency)은 인간 단백질에 대한 관계를 위해 보조적 폴리펩티드를 등급화할 수 있도록 조율될 수 있다. 표 3에서의 데이터는 인간 단백질에 대한 이들의 밀접한 관련성에 기초하여 선택된 보조적 폴리펩티드의 수개의 예를 보여준다. 서열 (SSSSE)n, (SSSSSSE)n, 및 (SSSSESSSSSSE)n(여기서, 모든 8량체 부분서열은 수개의 인간 단백질에서 발견될 수 있음)의 보조적 단백질이 특히 관심을 끈다.
[표 3]
인간 단백질 서열에 대한 이들의 관련성에 의한 서열의 등급화

비구조화된 재조합 중합체(URP: Unstructured Recombinant Polymer ) :
본 발명의 한 양태는 보조적 폴리펩티드로서의 비구조화된 재조합 중합체(URP)의 용도이다. 본 URP는 치료학적 및/또는 진단학적 가치를 갖는 재조합 단백질을 생성하기에 특히 유용하다. 본 URP는 하나 이상의 하기 특징을 나타낸다.
본 URP는 전형적으로 생리학적 조건하에 변성된 펩티드 서열과 공통점을 공유하는 아미노산 서열을 포함한다. URP 서열은 전형적으로 생리학적 조건하에 변성된 펩티드 서열과 유사한 거동을 한다. URP 서열에는 잘 규정된 2차 및 3차 구조가 생리학적 조건하에 결여되어 있다. 소정의 폴리펩티드의 2차 및 3차 구조를 확인하기 위해 당분야에 다양한 방법이 확립되어 있다. 예를 들면, 폴리펩티드의 2차 구조는 "원거리-UV" 스펙트럼 영역(190∼250 nm)에서 CD 분광계에 의해 결정될 수 있다. 알파-나선, 베타-시이트, 및 랜덤 코일 구조는 각각 CD 스펙트럼의 특징적 형상 및 크기를 일으킨다. 2차 구조는 또한 특정 컴퓨터 프로그램 또는 알고리즘, 예컨대 초우-파스만 알고리즘을 통해 확인할 수도 있다(Chou, P. Y., et al. (1974) Biochemistry, 13: 222-45). 소정의 URP 서열을 위해, 알고리즘은 2차 구조를 어느 정도 나타내는지 전혀 나타내지 않는지를 예측할 수 있다. 일반적으로, URP 서열은 2차 및 3차 구조의 정도가 낮기 때문에 변성된 서열과 유사한 스펙트럼을 가질 것이다. 원할 경우, URP 서열은 생리학적 조건하에 우세하게 변성된 입체구조를 갖도록 디자인될 수 있다. URP 서열은 전형적으로 생리학적 조건하에 고도의 입체구조적 가요성을 갖고, 이들은 유사한 분자량의 구형 단백질에 비해 큰 수력학적 반경(스토크스 반경)을 갖는 경향이 있다. 본원에서 사용될 경우, 생리학적 조건은 생명체의 조건과 유사한 온도, 염 농도, pH를 비롯한 조건의 집합을 지칭한다. 시험관내 검정에서 사용하기 위해 생리학적으로 관련된 조건의 숙주가 확립되어 있다. 일반적으로, 생리학적 완충액은 생리학적 염 농도를 포함하고, 약 6.5∼약 7.8, 바람직하게는 약 7.0∼약 7.5 범위의 중성 pH로 조정된다. 다양한 생리학적 완충액은 상기 문헌[Sambrook et al. (1989)]에 열거되어 있고, 따라서 본원에 상세화되지 않는다. 생리학적으로 관련된 온도는 약 25℃∼약 38℃, 바람직하게는 약 30℃∼약 37℃이다.
본 URP는 낮은 면역원성을 갖는 서열일 수 있다. 낮은 면역원성은 URP 서열의 입체구조적 가요성의 직접적인 결과일 수 있다. 많은 항체는 소위 입체구조적 에피토프를 단백질 항원에서 인식한다. 입체구조적 에피토프는 단백질 항원의 다수의 비연속 아미노산 서열로 구성된 단백질 표면의 영역에 의해 형성된다. 단백질의 정확한 폴딩은 서열을 항체에 의해 인식될 수 있는 잘-규정된 특수 배열로 옮긴다. 바람직한 URP는 입체구조적 에피토프의 형성을 방지하도록 디자인된다. 예를 들면, 수성 용액에서 치밀하게 폴딩된 입체구조를 취하는 경향이 낮은 URP 서열이 특히 관심을 끈다. 특히, 낮은 면역원성은 항원 존재 세포에서 항원 처리에 내성인 서열을 선택하고/하거나, MHC에 잘 결합하지 않는 서열을 선택하고/하거나, 인간 서열로부터 유도된 서열을 선택함으로써 달성될 수 있다.
본 URP는 고도의 프로테아제 내성을 갖는 서열일 수 있다. 프로테아제 내성은 URP 서열의 입체구조적 가요성의 결과일 수 있다. 프로테아제 내성은 공지된 프로테아제 인식 부위를 방지함으로써 디자인될 수 있다. 다르게는, 프로테아제 내성 서열은 파지 디스플레이 또는 관련된 기법에 의해 랜덤 또는 반-랜덤 서열 라이브러리로부터 선택될 수 있다. 특수 적용분야, 예컨대 데포 단백질로부터의 저속 방출을 위해 요망될 경우, 혈청 프로테아제 절단 부위는 URP내로 만들어질 수 있다. 혈액에서 높은 안정성(예를 들어, 긴 혈청 반감기, 체액에 존재하는 프로테아제에 의한 낮은 절단 경향)을 갖는 URP 서열이 특히 관심을 끈다.
본 URP는 또한 이것이 생물학적 활성 폴리펩티드에 혼입될 경우, 변경된 폴리펩티드가 변경되지 않은 생물학적 활성 폴리펩티드에 비해 보다 긴 혈청 반감기 및/또는 보다 높은 용해도를 나타낸다는 효과를 특징으로 할 수 있다. 본 URP는 (a) URP를 포함하는 단백질의 혈청 반감기의 연장; (b) 생성된 단백질의 용해도의 증가; (c) 프로테아제에 대한 증가된 내성; 및/또는 (d) URP를 포함하는 생성된 단백질의 감소된 면역원성을 일으키기에 필요한 임의의 길이일 수 있다. 전형적으로, 본 URP는 약 30, 40, 50, 60, 70, 80, 90, 100, 150, 200, 300, 400개 이상의 연속된 아미노산을 갖는다. 단백질내로 혼입될 경우, URP는 생성된 단백질이 다수의 URP, 또는 URP의 다수의 단편을 함유하도록 단편화될 수 있다. 이들 개개의 URP 서열의 일부 또는 전부는, 생성된 단백질 중의 모든 URP 서열의 합쳐진 길이가 40개 이상의 아미노산이기만 하면 40개 아미노산보다 더 짧을 수 있다. 바람직하게는, 생성된 단백질은 40, 50, 60, 70, 80, 90, 100, 150, 200개 이상의 아미노산을 초과하는 URP 서열의 합쳐진 길이를 갖는다.
URP는 1.0, 1.5, 2.0, 2.5, 3.0, 3.5, 4.0, 4.5, 5.0, 5.5, 6.0, 6.5, 7.0, 7.5, 8.0, 8.5, 9.0, 9.5, 10.0, 10.5, 11.0, 11.5, 12.0, 12.5 또는 더욱 13.0의 등전점(pI: isoelectric point)을 가질 수 있다.
일반적으로, URP 서열은 친수성 아미노산이 풍부하고, 소수성 또는 방향족 아미노산을 낮은 백분율로 함유한다. 적합한 친수성 잔기로는, 제한되지 않지만, 글리신, 세린, 아스파테이트, 글루타메이트, 라이신, 아르기닌, 및 트레오닌이 포함된다. URP의 작제에 덜 우호적인 소수성 잔기로는 트립토판, 페닐알라닌, 타이로신, 루신, 이소루신, 발린, 및 메티오닌이 포함된다. URP 서열은 글리신이 풍부할 수 있지만, URP 서열은 또한 아미노산 글루타메이트, 아스파테이트, 세린, 트레오닌, 알라닌 또는 프롤린이 풍부할 수 있다. 따라서, 우세한 아미노산은 G, E, D, S, T, A 또는 P이다. 프롤린 잔기를 포함하면, 단백질가수분해에 대한 감수성을 감소시키는 경향이 있다.
친수성 잔기의 포함은, 전형적으로 생리학적 조건하에 물 및 수성 매질에서 URP의 용해도를 증가시킨다. 이들 아미노산 조성의 결과로서, URP 서열은 수성 제형에서 응집체를 형성할 경향이 적고, 생물학적으로 활성인 다른 폴리펩티드 또는 펩티드로의 URP 서열의 융합은 이들의 용해도를 증진시키고 응집체를 형성하는 경향을 감소시키고, 이는 면역원성을 감소시키는 것과 별도의 기작이다.
URP 서열은 생물학적 활성 폴리펩티드에 원치않는 특성을 부여하는 특정 아미노산을 방지하도록 디자인될 수 있다. 예를 들면, 하기 아미노산을 거의 또는 전혀 함유하지 않는 URP 서열을 디자인할 수 있다: 시스테인(디설파이드 형성 및 산화를 방지하기 위함), 메티오닌(산화를 방지하기 위함), 아스파라긴 및 글루타민(탈아미드화를 방지하기 위함).
글리신 풍부
URP
:
한 실시양태에서, 본 URP는 글리신 풍부 서열(GRS:glycine rich sequence)을 포함한다. 예를 들면, 글리신은 이것이 관심있는 서열에 존재하는 가장 우세한 잔기이도록 우세하게 존재할 수 있다. 또 다른 예에서, URP 서열은 글리신 잔기가 총 아미노산의 약 30%, 35%, 40%, 45%, 50%, 55%, 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%, 100%를 구성하도록 디자인될 수 있다. URP는 또한 100%의 글리신을 함유할 수 있다. 또 다른 예에서, URP은 30% 이상의 글리신을 함유하고, 트립토판, 페닐알라닌, 타이로신, 발린, 루신, 및 이소루신의 총 농도는 20% 미만이다. 또 다른 예에서, URP는 40% 이상의 글리신을 함유하고, 트립토판, 페닐알라닌, 타이로신, 발린, 루신, 및 이소루신의 총 농도는 10% 미만이다. 또 다른 예에서, URP는 약 50% 이상의 글리신을 함유하고, 트립토판, 페닐알라닌, 타이로신, 발린, 루신, 및 이소루신의 총 농도는 5% 미만이다.
GRS의 길이는 약 5개 아미노산∼200개 이상의 아미노산 사이에서 다양할 수 있다. 예를 들면, 단일의 연속된 GRS의 길이는 5, 10, 15, 20, 25, 30, 35, 40, 45, 50, 55, 60, 70, 80, 90, 100, 120, 140, 160, 180, 200, 240, 280, 320 또는 400개 이상의 아미노산을 함유할 수 있다. GRS는 양쪽 말단에 글리신 잔기를 포함할 수 있다.
GRS는 또한 상당량의 다른 아미노산, 예를 들면 Ser, Thr, Ala, 또는 Pro를 가질 수 있다. GRS는 제한되지 않지만 Asp 및 Glu을 비롯한 음으로 하전된 아미노산을 상당한 분율로 함유할 수 있다. GRS는 제한되지 않지만 Arg 또는 Lys을 비롯한 양으로 하전된 아미노산을 상당한 분율로 함유할 수 있다. 원할 경우, URP는, 일반적으로 대부분의 20가지 유형의 아미노산으로 이루어진 전형적인 단백질 및 전형적인 연결기와는 대조적으로, 단지 단일 유형의 아미노산(즉, Gly 또는 Glu), 때때로 단지 소수의 유형의 아미노산, 예를 들어, 2∼5가지 유형의 아미노산(예를 들어, G, E, D, S, T, A 및 P로부터 선택됨)을 함유하도록 디자인될 수 있다. URP는 음으로 하전된 잔기(Asp, Glu)를 아미노산 위치의 30, 25, 20, 15, 12, 10, 9, 8, 7, 6, 5, 4, 3, 2, 또는 1 퍼센트로 함유할 수 있다.
전형적으로, 본 GRS 함유 URP는 약 30, 40, 50, 60, 70, 80, 90, 100개 이상의 연속된 아미노산을 갖는다. 생물학적 활성 폴리펩티드내로 혼입될 경우, URP는 생성된 변경된 폴리펩티드가 다수의 URP, 또는 URP의 다수의 단편을 함유하도록 단편화될 수 있다. 이들 개개의 URP 서열의 일부 또는 전부는, 생성된 폴리펩티드중의 모든 URP 서열의 합쳐진 길이가 30개 이상의 아미노산이기만 하면 40개 아미노산에 비해 더 짧을 수 있다. 바람직하게는, 생성된 폴리펩티드는 40, 50, 60, 70, 80, 90, 100개 이상의 아미노산을 초과하는 URP 서열의 합쳐진 길이를 갖는다.
GRS 함유 URP는, 부분적으로, 글리신 함유 펩티드의 증가된 입체구조적 자유로 인하여 특히 관심을 끈다. 용액 중 변성된 펩티드는 고도의 입체구조적 자유를 갖는다. 이러한 입체구조적 자유의 대부분은 수용체, 항체, 또는 프로테아제와 같은 표적에 상기 펩티드가 결합될 때 손실된다. 이러한 엔트로피의 손실은 펩티드와 그의 표적 사이의 상호작용 에너지에 의해 상쇄될 필요가 있다. 변성된 펩티드의 입체구조적 자유도는 그의 아미노산 서열에 의존한다. 작은 측쇄를 갖는 아미노산을 많이 함유하는 펩티드는 보다 큰 측쇄를 갖는 아미노산으로 이루어진 펩티드에 비해 보다 큰 입체구조적 자유를 갖는 경향이 있다. 아미노산 글리신을 함유하는 펩티드는 특히 큰 자유도를 갖는다. 글리신 함유 펩티드 결합이 상응하는 알라닌 함유 서열에 비해 용액 중에 약 3.4배 더 큰 엔트로피를 갖는 것으로 추정되었다(D'Aquino, J. A., et al. (1996) Proteins, 25: 143-56). 이러한 인자는 서열 중 글리신 잔기의 수에 따라 증가한다. 그 결과, 이러한 펩티드는 표적으로 결합될 때 엔트로피를 더 손실하는 경향이 있고, 이는 다른 단백질과 상호작용하는 전체 능력 뿐만 아니라 규정된 3차원 구조를 취하는 이들의 능력을 감소시킨다. 글리신-펩티드 결합의 큰 입체구조적 가요성은, 글리신펩티드 결합이 다른 펩티드 결합에 의해 거의 차지되지 않는 영역을 차지하는 단백질 구조의 라마챈드란 플롯(Ramachandran plot)을 분석할 경우 또한 입증된다(Venkatachalam, C. M., et al. (1969) Annu Rev Biochem, 38: 45-82). 스티테스(Stites) 등은 61개 비상동성, 고 해상 결정 구조로부터의 12,320개 잔기의 데이터베이스를 연구하여 20개 아이노산 각각의 파이(phi), 싸이(psi) 입체구조적 선호도를 결정하였다. 단백질의 고유 상태에서 관찰된 분포는 또한 변성된 상태에서 발견되는 분포를 반영하도록 추정된다. 이 분포는 각각의 잔기에 대한 에너지 표면을 추정하는데 사용되어, 글리신에 대한 각각의 잔기에 대한 상대적인 입체구조적 엔트로피를 계산할 수 있도록 한다. 글리신의 프롤린에 의한 대체라는 가장 극한 경우에, 입체구조적 엔트로피 변화는 -0.82 +/- 0.08 kcal/몰로 20℃에서 변성된 상태에 대한 고유 상태를 안정화시킬 것이다(Stites, W. E., et al. (1995) Proteins, 22. 132). 이러한 관찰은 20개의 천연 아미노산 중 글리신의 특별한 역할을 확인시킨다.
본 URP의 디자인시, 천연 또는 비-천연 서열이 사용될 수 있다. 예를 들면, 글리신 함량이 높은 천연 서열의 숙주는 표 4, 표 5, 표 6, 및 표 7에 제공되어 있다. 당분야의 숙련가라면 URP로서의 서열중 임의의 하나를 채택하거나, 이 서열을 변경시켜 의도된 특성을 달성할 수 있을 것이다. 숙주 피험체로의 면역원성이 고려되는 경우, 숙주로부터 유도된 글리신 풍부 서열에 기초한 GRS 함유 URP를 디자인하는 것이 바람직하다. 바람직한 GRS 함유 URP는, 인간 단백질로부터의 서열이거나, 또는 참고 인간 단백질에서 상응하는 글리신 풍부 서열에 대한 실질적인 상동성을 공유하는 서열이다.
| 글리신 풍부 서열을 함유하는 단백질의 구조적 분석 | ||
| PDB 파일 | 단백질 융합 | 글리신 풍부 서열 |
| 1K3V | 돼지 파보바이러스 캡시드 (Porcine Parvovirus capsid) |
sgggggggggrgagg |
| 1FPV | 범백혈구감소증 바이러스 (Feline Panleukopenia Virus) |
tgsgngsgggggggsgg |
| 1IJS | CpV 균주 D, 돌연변이체 A300d | tgsgngsgggggggsgg |
| 1MVM | Mvm(균주 I) 바이러스 | ggsggggsgggg |
| 300개 이상의 글리신 잔기를 갖는 GRS를 코딩하는 오픈 리딩 프레임 | |||||
| 수탁번호 | 유기체 | Gly(%) | GRS 길이 |
유전자 길이 | 예측된 기능 |
| NP_974499 | 아라비돕시스 탈리아나 (Arabidopsis thaliana) |
64 | 509 | 579 | 비공지됨 |
| ZP_00458077 | 부르크홀데리아 세노코파시아 (Burkholderia cenocopacia) |
66 | 373 | 518 | 추정적 지단백질 |
| XP_477841 | 오리자 사티바(Oryza sativa) | 74 | 371 | 422 | 비공지됨 |
| NP_910409 | 오리자 사티바 | 75 | 368 | 400 | 추정적 세포벽 전구체 |
| NP_610660 | 드로소필라 멜라노가스터 (Drosophila melanogaster) |
66 | 322 | 610 | 이동가능한 요소 |
| 인간 GRS의 예 | |||||
| 수탁번호 | Gly(%) | GRS 길이 | 유전자 길이 | 소수성 | 예측된 기능 |
| NP_000217 | 62 | 135 | 622 | 있음 | 케라틴 9 |
| NP_631961 | 61 | 73 | 592 | 있음 | TBP 관련 인자 15 이소형 1 |
| NP_476429 | 65 | 70 | 629 | 있음 | 케라틴 3 |
| NP_000418 | 70 | 66 | 316 | 있음 | 로리크린(loricrin), 세포 외피 |
| NP_056932 | 60 | 66 | 638 | 있음 | 사이토케라틴 2 |
| 인간 GRS의 추가의 예 | ||
| 수탁번호 | 서열 | 아미노산의 수 |
| NP_006228 | GPGGGGGPGGGGGPGGGGPGGGGGGGPGGGGGGPGGG | 37 |
| NP_787059 | GAGGGGGGGGGGGGGSGGGGGGGGAGAGGAGAG | 33 |
| NP_009060 | GGGSGSGGAGGGSGGGSGSGGGGGGAGGGGGG | 32 |
| NP_031393 | GDGGGAGGGGGGGGSGGGGSGGGGGGG | 27 |
| NP_005850 | GSGSGSGGGGGGGGGGGGSGGGGGG | 25 |
| NP_061856 | GGGRGGRGGGRGGGGRGGGRGGG | 22 |
| NP_787059 | GAGGGGGGGGGGGGGSGGGGGGGGAGAGGAGAG | 33 |
| NP_009060 | GGGSGSGGAGGGSGGGSGSGGGGGGAGGGGGG | 32 |
| NP_031393 | GDGGGAGGGGGGGGSGGGGSGGGGGGG | 27 |
| NP_115818 | GSGGSGGSGGGPGPGPGGGGG | 21 |
| XP_376532 | GEGGGGGGEGGGAGGGSG | 18 |
| NP_065104 | GGGGGGGGDGGG | 12 |
GGGSGSGGAGGGSGGGSGSGGGGGGAGGGGGGSSGGGSGTAGGHSG
POU 도메인, 부류 4, 전사 인자 1[호모 사피엔스(Homo sapiens)]
GPGGGGGPGGGGGPGGGGPGGGGGGGPGGGGGGPGGG
YEATS 도메인 함유 2[호모 사피엔스]
GGSGAGGGGGGGGGGGSGSGGGGSTGGGGGTAGGG
AT 풍부 상호작용 도메인 1B(SWI1 유사) 이소형 3; BRG1 결합 단백질 ELD/OSA1; Eld(눈꺼풀)/Osa 단백질[호모 사피엔스]
GAGGGGGGGGGGGGGSGGGGGGGGAGAGGAGAG
AT 풍부 상호작용 도메인 1B(SWI1 유사) 이소형 2; BRG1 결합 단백질 ELD/OSA1; Eld(눈꺼풀)/Osa 단백질[호모 사피엔스]
GAGGGGGGGGGGGGGSGGGGGGGGAGAGGAGAG
AT 풍부 상호작용 도메인 1B(SWI1 유사) 이소형 1; BRG1 결합 단백질 ELD/OSA1; Eld(눈꺼풀)/Osa 단백질[호모 사피엔스]
GAGGGGGGGGGGGGGSGGGGGGGGAGAGGAGAG
퓨린 풍부 요소 결합 단백질 A; 퓨린 풍부 단일 가닥 DNA 결합 단백질 알파;전사 활성화제 단백질 PUR-알파[호모 사피엔스]
GHPGSGSGSGGGGGGGGGGGGSGGGGGGAPGG
조절 인자 X1; 트랜스-작용 조절 인자 1; 인핸서(enhancer) 인자 C; MHC 부류 II 조절 인자 RFX[호모 사피엔스]
GGGGSGGGGGGGGGGGGGGSGSTGGGGSGAG
백혈병에서 교란되는 브로모 도메인 함유 단백질[호모 사피엔스]
GGRGRGGRGRGSRGRGGGGTRGRGRGRGGRG
공지되지 않은 단백질[호모 사피엔스]
GSGGSGGSGGGPGPGPGGGGGPSGSGSGPG
예측: 가상 단백질(hypothetical protein) XP_059256[호모 사피엔스]
GGGGGGGGGGGRGGGGRGGGRGGGGEGGG
아연 핑거(finger) 단백질 281; ZNP-99 전사 인자[호모 사피엔스]
GGGGTGSSGGSGSGGGGSGGGGGGGSSG
RNA 결합 단백질(자기항원성, hnRNP-레탈 옐로우(lethal yellow)와 연관됨) 짧은 이소형; RNA 결합 단백질(자기항원성); RNA 결합 단백질(자기항원성, hnRNP-레탈 옐로우와 연관됨)[호모 사피엔스]
GDGGGAGGGGGGGGSGGGGSGGGGGGG
신호 인식 입자 68kDa[호모 사피엔스]
GGGGGGGSGGGGGSGGGGSGGGRGAGG
KIAA0265 단백질[호모 사피엔스]
GGGAAGAGGGGSGAGGGSGGSGGRGTG
인그레일드(engrailed) 상동체 2; 인그레일드-2[호모 사피엔스]
GAGGGRGGGAGGEGGASGAEGGGGAGG
RNA 결합 단백질(자기항원성, hnRNP-레탈 옐로우와 연관됨) 긴 이소형; RNA 결합 단백질(자기항원성); RNA 결합 단백질(자기항원성, hnRNP-레탈 옐로우와 연관됨)[호모 사피엔스]
GDGGGAGGGGGGGGSGGGGSGGGGGGG
안드로겐(androgen) 수용체; 디하이드로테트토스테론(dihydrotestosterone) 수용체[호모 사피엔스]
GGGGGGGGGGGGGGGGGGGGGGGEAG
호메오 박스(homeo box) D11; 호메오 박스 4F; Hox-4.6, 마우스, 상동체; 호메오박스 단백질 Hox-D11[호모 사피엔스]
GGGGGGSAGGGSSGGGPGGGGGGAGG
프리즐드(frizzled) 8; 프리즐드 (초파리) 상동체 8[호모 사피엔스]
GGGGGPGGGGGGGPGGGGGPGGGGG
안구 발달 관련 유전자[호모 사피엔스]
GRGGAGSGGAGSGAAGGTGSSGGGG
호메오 박스 B3; 호메오 박스 2G; 호메오박스 단백질 Hox-B3[호모 사피엔스]
GGGGGGGGGGGSGGSGGGGGGGGGG
염색체 2 오픈 리딩 프레임 29[호모 사피엔스]
GGSGGGRGGASGPGSGSGGPGGPAG
DKFZP564F0522 단백질[호모 사피엔스]
GGHHGDRGGGRGGRGGRGGRGGRAG
예측: 호메오박스 균일-스킵된(skipped) 상동체 단백질 2(EVX-2)와 유사함[호모 사피엔스]
GSRGGGGGGGGGGGGGGGGAGAGGG
ras 상동체 유전자 계열, 구성원 U; Ryu GTP아제; Wnt-1 응답성 Cdc42 상동체; 2310026M05Rik; 유사 GTP 결합 단백질 유사체 1; CDC42 유사 GTP아제[호모 사피엔스]
GGRGGRGPGEPGGRGRAGGAEGRG
스크래치(scratch) 2 단백질; 전사 억제제 스크래치 2; 스크래치(초파리 상동체) 2, 아연 핑거 단백질[호모 사피엔스]
GGGGGDAGGSGDAGGAGGRAGRAG
핵인(nucleolar) 단백질 계열 A, 구성원 1; GAR1 단백질[호모 사피엔스]
GGGRGGRGGGRGGGGRGGGRGGG
케라틴 1; 케라틴-1; 사이토케라틴 1; 헤어 알파 단백질[호모 사피엔스]
GGSGGGGGGSSGGRGSGGGSSGG
가상 단백질 FLJ31413[호모 사피엔스]
GSGPGTGGGGSGSGGGGGGSGGG
원컷(one cut) 도메인, 계열 구성원 2; 원컷 2[호모 사피엔스]
GARGGGSGGGGGGGGGGGGGGPG
POU 도메인, 부류 3, 전사 인자 2[호모 사피엔스]
GGGGGGGGGGGGGGGGGGGGGDG
예측: THO 복합체 서브유닛 4(Tho4)과 유사함(RNA 및 유출 인자 결합 단백질 1)(REF1-I)(AML-1 및 LEF-1의 연합)(Aly/REF)[호모 사피엔스]
GGTRGGTRGGTRGGDRGRGRGAG
예측: THO 복합체 서브유닛 4(Tho4)와 유사함(RNA 및 유출 인자 결합 단백질 1)(REF1-I)(AML-1 및 LEF-1의 연합)(Aly/REF)[호모 사피엔스]
GGTRGGTRGGTRGGDRGRGRGAG
POU 도메인, 부류 3, 전사 인자 3[호모 사피엔스]
GAGGGGGGGGGGGGGGAGGGGGG
핵인 단백질 계열 A, 구성원 1; GAR1 단백질[호모 사피엔스]
GGGRGGRGGGRGGGGRGGGRGGG
피브릴아린(fibrillarin); 34 kD 핵인 경피증 항원; RNA, U3 작은 핵인 상호작용 단백질 1[호모 사피엔스]
GRGRGGGGGGGGGGGGGRGGGG
아연 핑거 단백질 579[호모 사피엔스]
GRGRGRGRGRGRGRGRGRGGAG
칼페인(calpain), 작은 서브유닛 1; 칼슘 활성화된 중성 프로테이나제; 칼페인, 작은 폴리펩티드; 칼페인 4, 작은 서브유닛(30K); 칼슘 의존성 프로테아제, 작은 서브유닛[호모 사피엔스]
GAGGGGGGGGGGGGGGGGGGGG
케라틴 9[호모 사피엔스]
GGGSGGGHSGGSGGGHSGGSGG
포크헤드 박스(forkhead box) D1; 포크헤드 관련 활성화제 4; 포크헤드, 초파리, 상동체 유사 8; 포크헤드(초파리) 유사 8[호모 사피엔스]
GAGAGGGGGGGGAGGGGSAGSG
예측: RIKEN cDNA C230094B15와 유사함[호모 사피엔스]
GGPGTGSGGGGAGTGGGAGGPG
GGGGGGGGGAGGAGGAGSAGGG
카드헤린(카드헤린) 22 전구체; 래트 PB-카드헤린의 오쏠로그(ortholog)[호모 사피엔스]
GGDGGGSAGGGAGGGSGGGAG
AT 결합 전사 인자 1; AT 모티프 결합 인자 1[호모 사피엔스]
GGGGGGSGGGGGGGGGGGGGG
에오메소더민(eomesodermin); t 박스, 뇌, 2; 에오메소더민[제노푸스 라에비스(Xenopus laevis) 상동체[호모 사피엔스]
GPGAGAGSGAGGSSGGGGGPG
포스파티딜이노시톨(phosphatidylinositol) 전달 단백질, 막 관련 2; PYK2 N-말단 도메인 상호작용 수용체 3; 레티날(retinal) 분해 B 알파 2(초파리)[호모 사피엔스]
GGGGGGGGGGGSSGGGGSSGG
정자 연관된 항원 8 이소형 2; 정자 막 단백질 1[호모 사피엔스]
GSGSGPGPGSGPGSGPGHGSG
예측: RNA 결합 모티프 단백질 27[호모 사피엔스]
GPGPGPGPGPGPGPGPGPGPG
AP1 감마 서브유닛 결합 단백질 1 이소형 1; 감사-시너긴(synergin);어댑터(adaptor) 관련 단백질 복합체 1 감마 서브유닛 결합 단백질 1[호모 사피엔스]
GAGSGGGGAAGAGAGSAGGGG
AP1 감마 서브유닛 결합 단백질 1 이소형 2; 감마-시너긴; 어댑터 관련 단백질 복합체 1 감마 서브유닛 결합 단백질 1[호모 사피엔스]
GAGSGGGGAAGAGAGSAGGGG
안키린(ankyrin) 반복부 및 멸균 알파 모티프 도메인 함유 1; 안키린 반복부 및 SAM 도메인 함유 1[호모 사피엔스]
GGGGGGGSGGGGGGSGGGGGG
메틸-CpG 결합 도메인 단백질 2 이소형 1[호모 사피엔스]
GRGRGRGRGRGRGRGRGRGRG
3중 기능 도메인(PTPRF 상호작용)[호모 사피엔스]
GGGGGGGSGGSGGGGGSGGGG
포크헤드 박스 D3[호모 사피엔스]
GGEEGGASGGGPGAGSGSAGG
정자 연관된 항원 8 이소형 1; 정자 막 단백질 1[호모 사피엔스]
GSGSGPGPGSGPGSGPGHGSG
메틸-CpG 결합 도메인 단백질 2 고환 특이적 이소형[호모 사피엔스]
GRGRGRGRGRGRGRGRGRGRG
세포 사멸 조절자 아벤(aven); 프로그램화된 세포 사멸 12[호모 사피엔스]
GGGGGGGGDGGGRRGRGRGRG
넌센스 전사(nonsense transcript) 1의 조절자; 델타 헬리카아제(delta helicase); 상향-프레임전이(up-frameshift) 돌연변이 1 상동체(에스. 세레비지아(S. cerevisiae)); 넌센스 mRNA 감소 인자 1; 효모 Upf1p 상동체[호모 사피엔스]
GGPGGPGGGGAGGPGGAGAG
작은 전도성 칼슘 활성화된 칼륨 채널 단백질 2 이소형 a; 아파민(apamin)-감수성 작은 전도성 Ca2+ 활성화된 칼륨 채널[호모 사피엔스]
GTGGGGSTGGGGGGGGSGHG
SRY(성 결정 영역 Y)-박스 1; SRY 관련 HMG-박스 유전자 1[호모 사피엔스]
GPAGAGGGGGGGGGGGGGGG
전사 인자 20 이소형 2; 스트롬리신(stromelysin)-1 혈소판 유래 성장 인자 반응 요소 결합 단백질; 스트롬리신 1 PDGF 반응 요소 결합 단백질; SPRE 결합 단백질; 핵 인자 SPBP[호모 사피엔스]
GGTGGSSGSSGSGSGGGRRG
전사 인자 20 이소형 1; 스트롬리신-1 혈소판 유래 성장 인자 반응 요소 결합 단백질; 스트롬리신 1 PDGF 반응 요소 결합 단백질; SPRE 결합 단백질; 핵 인자 SPBP[호모 사피엔스]
GGTGGSSGSSGSGSGGGRRG
Ras-상호작용 단백질 1[호모 사피엔스]
GSGTGTTGSSGAGGPGTPGG
BMP-2 유도성 키나제 이소형 b[호모 사피엔스]
GGSGGGAAGGGAGGAGAGAG
BMP-2 유도성 키나제 이소형 a[호모 사피엔스]
GGSGGGAAGGGAGGAGAGAG
포크헤드 박스 C1; 포크헤드 관련 활성화제 3; 포크헤드, 초파리, 상동체 유사 7; 포크헤드(초파리) 유사 7; 이리도고니도디스제네시스(iridogoniodysgenesis) 유형 1[호모 사피엔스]
GSSGGGGGGAGAAGGAGGAG
스플라이싱 인자 p54; 아르기닌 풍부 54 kDa 핵 단백질[호모 사피엔스]
GPGPSGGPGGGGGGGGGGGG
v-maf 근건막성 섬유육종 종양유전자 상동체; 조류 근건막성 섬유육종(MAF: musculoaponeurotic fibrosarcoma) 원형종양유전자; v-maf 근건막성 섬유육종(조류) 종양유전자 상동체[호모 사피엔스]
GGGGGGGGGGGGGGAAGAGG
소형 핵 리보핵단백질 D1 폴리펩티드 16kDa; snRNP 코어 단백질 D1; Sm-D 자기항원(autoantigen); 소핵 리보핵단백질 D1 폴리펩티드(16kD)[호모 사피엔스]
GRGRGRGRGRGRGRGRGRGG
가상 단백질 H41[호모 사피엔스]
GSAGGSSGAAGAAGGGAGAG
비-글리신 잔기(NGR: non-glycine residue)를 포함하는
URP
:
이들 GRS에서 비-글리신 잔기의 서열은 URP의 특성, 및 이에 따라 원하는 URP를 함유하는 생물학적 활성 폴리펩티드의 특성을 최적화하기 위해 선택될 수 있다. 예를 들면, 특정 조직, 특이적 세포 유형 또는 세포 계보(lineage)를 위한 생성된 변경된 폴리펩티드의 선택성을 증진시키도록 URP의 서열을 최적화할 수 있다. 예를 들면, 흔하게 발현되지 않고 오히려 하나 이상의 신체 조직, 예컨대 심장, 간, 전립선, 폐, 신장, 골수, 혈액, 피부, 방광, 뇌, 근육, 신경, 및 질환, 예컨대 감염성 질환, 자가면역 질환, 신장, 신경세포, 심장 질환 및 암에 의해 영향받는 선택된 조직에서 차별적으로 발현되는 단백질 서열을 혼입할 수 있다. 특정 발달 기점의 대표적인 서열, 예컨대 다세포 유기체에서 외배엽, 내배엽 또는 중배엽 형성 동안 배아 또는 성체에서 발현되는 서열을 사용할 수 있다. 또한, 제한되지 않지만 세포 주기 조절, 세포 분화, 아폽토시스, 주화성, 세포 운동성 및 세포골격 재정렬을 비롯한 특정 생물학적 과정에 관여된 서열을 사용할 수 있다. 또한, 생성된 단백질을 특정 하위세포 위치, 즉 세포외 기질, 핵, 세포질, 세포골격, 혈장 및/또는 제한되지 않지만 코팅된 막공(pit), 골지체(Golgi apparatus), 소포체, 엔도솜(endosome), 리소좀(lysosome) 및 미토콘드리아를 비롯한 세포내 막 구조물로 향하게 하는 다른 비-편재되어 발현된 단백질 서열을 이용할 수 있다.
다양한 이들 조직 특이적, 세포 유형 특이적, 하위세포 위치 특이적 서열은 공지되어 있고 다수의 단백질 데이터베이스로부터 이용가능하다. 이러한 선택적 URP 서열은 랜덤 또는 반-랜덤 URP 서열의 라이브러리를 생성하고, 이들을 동물 또는 환자에게 주사하고, 원하는 조직 선택성을 갖는 서열을 조직 샘플에서 결정함으로써 수득될 수 있다. 서열 결정은 질량 분광계에 의해 수행될 수 있다. 유사한 방법을 사용하여, 경구, 구강, 소장, 비강, 포막, 복강, 폐, 직장 또는 피부 섭취를 조장하는 URP 서열을 선택할 수 있다.
막을 통한 수송 또는 세포 섭취에 우호적인 양으로 하전된 아미노산인 아르기닌 또는 라이신이 비교적 풍부한 영역을 함유하는 URP 서열이 특히 관심을 끈다. URP 서열은 한개 또는 수개의 프로테아제-감수성 서열을 함유하도록 디자인될 수 있다. 이러한 URP 서열은 일단 본 발명의 생성물이 그의 표적 위치에 도달하면 절단될 수 있다. 이러한 절단은 약학적 활성 도메인(전구약물 활성화)의 효능 증가를 개시할 수 있거나, 절단 생성물의 수용체로의 결합을 증진시킬 수 있다. URP 서열은 아스파르트산 또는 글루탐산 잔기를 도입함으로써 과량의 음전하를 전달하도록 디자인될 수 있다. 5% 초과, 6%, 7%, 8%, 9%, 10%, 15%, 30% 이상 초과된 글루탐산 및 2% 미만의 라이신 또는 아르기닌을 함유하는 URP가 특히 관심을 끈다. 이러한 URP는 과량의 음전하를 운반하고, 결과로서 이들은 펩티드의 개별 음전하 사이의 정전기적 반발에 기인하여 개방 입체구조를 취하는 경향을 갖는다. 이러한 과량의 음전하는 이들의 수력학적 반경을 효과적으로 증가시키고, 결과로서 이는 이러한 분자의 신장 제거를 감소시킬 수 있다. 따라서, URP 서열중 음으로 하전된 아미노산의 빈도 및 분포를 제어함으로써 URP 서열의 효과적인 순 전하 및 수력학적 반경을 조정할 수 있다. 인간 또는 동물에서 대부분의 조직 및 표면은 과량의 음전하를 운반한다. 과량의 음전하를 운반하는 URP 서열을 디자인함으로써, URP를 포함하는 생성된 변경된 폴리펩티드와 다양한 표면, 예컨대 혈관, 건강한 조직, 또는 다양한 수용체 사이의 비특이적 상호작용을 최소화할 수 있다.
URP는 형식 (모티프)x의 반복적 아미노산 서열을 가질 수 있고, 여기서 서열 모티프는 정방향 반복부(즉, ABCABCABCABC) 또는 역방향 반복부(ABCCBAABCCBA)를 형성하고, 이들 반복부의 수는 2, 3, 4, 5, 6, 7, 8, 9, 10, 12, 14, 16, 18, 20, 22, 24, 26, 28, 30, 35, 40, 50개 이상일 수 있다. URP 또는 URP 내의 반복부는 종종 단지 1, 2, 3, 4, 5 또는 6가지 상이한 유형의 아미노산만을 함유한다. URP는 전형적으로 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 22, 24, 26, 28, 30, 32, 34, 36개 이상의 아미노산 길이의 인간 아미노산 서열의 반복부로 구성되지만, URP는 20, 22, 24, 26, 28, 30, 32, 34, 36, 38, 40, 42, 44, 46, 48, 50개의 아미노산 길이의 비-인간 아미노산 서열로 구성될 수도 있다.
인간 서열로부터 유도된 URP:
URP는 인간 서열로부터 유도될 수 있다. 인간 게놈은 하나의 특정 아미노산이 풍부한 많은 부분서열을 함유한다. 친수성 아미노산, 예컨대 세린, 트레오닌, 글루타메이트, 아스파테이트, 또는 글리신이 풍부한 이러한 아미노산 서열이 특히 관심을 끈다. 극소수의 소수성 아미노산을 포함하는 이러한 부분서열이 특히 관심을 끈다. 이러한 부분서열은 수성 용액에서 비구조화되고 매우 가용성인 것으로 예측된다. 이러한 인간 부분서열은 변경되어 추가로 이들의 이용성을 개선시킬 수 있다. 예를 들면, 덴틴 시알로포스포단백질(dentin sialophosphoprotein)은 670개-아미노산 부분서열을 함유하고, 여기서 64%의 잔기는 세린이고, 대부분의 다른 위치는 친수성 아미노산, 예컨대 아스파테이트, 아스파라긴, 및 글루타메이트이다. 서열은 극히 반복적이고, 결과로서 이는 낮은 정보 함량을 갖는다. 이러한 인간 단백질의 부분서열을 직접적으로 사용할 수 있다. 원할 경우, 서열의 전체 특징을 보존하지만 이를 약학적 적용분야에 보다 적합하게 만들도록 서열을 변경할 수 있다. 덴틴 시알로포스포단백질과 관련된 서열의 예는 (SSD)n, (SSDSSN)n, (SSE)n이고, 여기서 n은 약 4∼200이다.
인간 단백질로부터의 서열의 사용은 인간 피험체에서 감소된 면역원성을 갖는 URP의 디자인에서 특히 바람직하다. 외래 단백질에 대한 면역 반응을 이끌어내는 핵심 단계는 MHC 부류 II 수용체에 의한 상기 단백질의 펩티드 단편의 제공이다. 이들 MHCII 결합 단편은 T 세포 수용체에 의해 검출될 수 있는데, 이는 T 헬퍼 세포의 증식을 개시하고 면역 반응을 개시한다. 약학적 단백질로부터의 T 세포 에피토프의 제거는 면역 반응을 이끌어낼 위험을 감소시키는 수단으로 인식되어 왔다(Stickler, M., et al. (2003) J Immunol Methods, 281: 95-108). MHCII 수용체는 전형적으로 예를 들어, 디스플레이된 펩티드의 9개-아미노산 길이의 영역과 상호작용한다. 따라서, 단백질의 가능한 9량체 서열중 모두 또는 대부분이 인간 단백질에서 발견될 수 있다면, 이에 따라 이들 서열 및 이들 서열의 반복부가 외래 서열로서 환자에 의해 인식되지 않는 다면, 환자에서 단백질에 대한 면역 반응을 이끌어낼 위험을 감소시킬 수 있다. 적합한 아미노산 조성을 갖는 인간 서열을 올리고머화하거나 연쇄시킴으로써 URP 서열의 디자인내로 인간 서열을 혼입할 수 있다. 이들은 정방향 반복부 또는 역방향 반복부 또는 상이한 반복부의 혼합물일 수 있다. 예를 들면, 표 5에 제시된 서열을 올리고머화할 수 있다. 이러한 올리고머는 면역원성의 위험을 감소시킨다. 그러나, 단량체 단위 사이의 합류지점 서열은 면역 반응을 개시할 수 있는 T 세포 에피토프를 여전히 함유할 수 있다. 추가로 다수의 중첩 인간 서열에 기초한 URP 서열을 디자인함으로써 면역 반응을 이끌어낼 위험을 감소시킬 수 있다. URP 서열은, 올리고머의 각각의 9량체 부분서열이 인간 단백질에서 발견될 수 있도록 다수의 인간 서열에 기초한 올리고머로서 디자인될 수 있다. 이들 디자인에서, 모든 9량체 부분서열은 모두 인간 서열이다. 예를 들면, URP 서열은 3개의 인간 서열에 기초할 수 있다. 올리고머성 URP 서열에서 모든 가능한 9량체 부분서열이 동일한 인간 단백질에서 초래되도록 단일 인간 서열에 기초하여 URP 서열을 디자인할 수도 있다. 비-올리고머성 URP 서열은 또한 인간 단백질에 기초하여 디자인될 수 있다. 우선적 조건은 모든 9량체 부분서열이 인간 서열에서 발견될 수 있다는 것이다. 서열의 아미노산 조성은, 바람직하게는 소수성 잔기를 거의 함유하지 않는다. 인간 서열에 기초하여 디자인되고 글리신 잔기를 큰 분율로 함유하는 URP 서열이 특히 관심을 끈다.
이러한 또는 유사한 계획을 사용하여, 관심있는 숙주로의 면역원성이 낮은 반복 서열을 포함하는 URP 부류를 디자인할 수 있다. 관심있는 숙주는 척추동물 및 무척추동물을 비롯한 임의의 동물일 수 있다. 바람직한 숙주는 포유동물, 예컨대 영장류(예를 들어 침팬지 및 인간), 고래목 동물(예를 들어 고래 및 돌고래), 익수류(예를 들어 박쥐), 기제류(perrisodactyl)(예를 들어 말 및 코뿔소), 설치류(예를 들어 래트), 및 특정 종류의 식충동물, 예컨대 뾰족뒤지, 두더쥐 및 고슴도치이다. 인간이 숙주로 선택될 경우, URP는 전형적으로 반복 서열 또는 단위의 다수의 카피를 함유하고, 약 6∼약 15개의 연속된 아미노산을 포함하는 분절의 대부분은 하나 이상의 고유 인간 단백질에 존재한다. 또한 약 9∼약 15개의 연속된 아미노산을 포함하는 분절의 대부분이 하나 이상의 고유 인간 단백질에서 발견되는 URP를 디자인할 수 있다. 본원에서 사용될 경우, 분절의 대부분은 약 50% 초과, 바람직하게는 60%, 바람직하게는 70%, 바람직하게는 80%, 바람직하게는 90%, 바람직하게는 100%를 지칭한다. 원할 경우, 반복 단위에서 약 6∼15개 아미노산, 바람직하게는 약 9∼15개 아미노산 사이의 가능한 각각의 분절은 하나 이상의 고유의 인간 단백질에 존재한다. URP는 다수의 반복 단위 또는 서열, 예를 들면 2, 3, 4, 5, 6, 7, 8, 9, 10개 이상의 반복 단위를 포함할 수 있다.
인간 T-세포 에피토프가 실질적으로 존재하지 않는
URP
의 디자인:
URP 서열은 인간 T 세포에 의해 인식된 에피토프가 실질적으로 존재하지 않도록 디자인될 수 있다. 예를 들면, 변성된, 비구조화된 입체구조를 선호하는 아미노산 조성을 갖는 일련의 반-랜덤 서열을 합성하고, 이들 서열을 인간 T 세포 에피토프의 존재 및 이들이 인간 서열인지 아닌지에 대해 평가할 수 있다. 인간 T 세포 에피토프에 대한 검정이 기재되어 있다(Stickler, M., et al. (2003) J Immunol Methods, 281: 95-108). T 세포 에피토프 또는 비-인간 서열을 생성하지 않으면서 올리고머화될 수 있는 펩티드 서열이 특히 관심을 끈다. 이는 이들 서열의 정방향 반복부를 T-세포 에피토프의 존재 및 인간이 아닌 6∼15량체, 특히 9량체 부분서열의 발생에 대해 시험함으로써 달성된다. 한 대안은 인간 서열의 조립에 대해 이전 섹션에서 기재된 바와 같은 반복 단위로 조립될 수 있는 다수의 펩티드 서열을 평가하는 것이다. 또 다른 대안은 TEPITOPE와 같은 에피토프 예측 알고리즘을 사용하여 낮은 점수를 생성하는 서열을 디자인하는 것이다(Sturniolo, T., et al. (1999) Nat Biotechnol, 17: 555-61). T-세포 에피토프를 방지하기 위한 또 다른 시도는 MHC 상의 펩티드 디스플레이 동안 고정 잔기로서 작용할 수 있는 아미노산, 예컨대 M, I, L, V, F를 방지하는 것이다. 소수성 아미노산 및 양으로 하전된 아미노산은 종종 이러한 고정 잔기로서 작용할 수 있고, URP 서열에서 이들의 빈도를 최소화하면 T-세포 에피토프를 생성하여 면역 반응을 이끌어내는 변화를 감소시킨다. 선택된 URP는 일반적으로 하나 이상의 인간 단백질에서 발견되는 부분서열을 함유하고, 소수성 아미노산을 보다 낮은 함량으로 갖는다.
URP 서열은 단백질 생산을 최적화하도록 디자인될 수 있다. 이는 코딩 DNA의 반복성을 방지 또는 최소화함으로써 달성될 수 있다. URP 서열, 예컨대 폴리-글리신은 매우 바람직한 약학적 특성을 가질 수 있지만, 이들의 제작은 GRS를 코딩하는 DNA 서열의 높은 GC-함량 및 재조합을 유도할 수 있는 반복 DNA 서열의 존재에 기인하여 어려울 수 있다.
상기 주지된 바와 같이, URP 서열은 아미노산 수준에서 고도로 반복적이도록 디자인될 수 있다. 결과로서, URP 서열은 매우 낮은 정보 함량을 갖고, 면역 반응을 이끌어내는 위험이 감소될 수 있다.
반복 아미노산을 포함하는 URP의 비제한적 예는 다음과 같다: 폴리-글리신, 폴리-글루탐산, 폴리-아스파르트산, 폴리-세린, 폴리-트레오닌, (GX)n(여기서 G는 글리신이고, X는 세린, 아스파르트산, 글루탐산, 트레오닌, 또는 프롤린이고, n은 20 이상임), (GGX)n(여기서 X는 세린, 아스파르트산, 글루탐산, 트레오닌, 또는 프롤린이고, n은 13 이상임), (GGGX)n(여기서 X는 세린, 아스파르트산, 글루탐산, 트레오닌, 또는 프롤린이고, n은 10 이상임), (GGGGX)n(여기서 X는 세린, 아스파르트산, 글루탐산, 트레오닌, 또는 프롤린이고, n은 8 이상임), (GzX)n(여기서 X는 세린, 아스파르트산, 글루탐산, 트레오닌, 또는 프롤린이고, n은 15 이상이고, z는 1∼20임).
이들 반복부의 수는 10∼100 사이의 임의의 수일 수 있다. 본 발명의 생성물은 반-랜덤 서열인 URP 서열을 함유할 수 있다. 예는 30, 40, 50, 60 또는 70% 이상의 글리신을 함유하는 반-랜덤 서열이고, 여기서 글리신은 잘 분산되어 있고, 트립토판, 페닐알라닌, 타이로신, 발린, 루신, 및 이소루신의 총 농도는 합쳤을 때 70, 60, 50, 40, 30, 20, 또는 10% 미만이다. 바람직한 반-랜덤 URP 서열은 40% 이상의 글리신을 함유하고, 트립토판, 페닐알라닌, 타이로신, 발린, 루신, 및 이소루신의 총 농도는 10% 미만이다. 보다 바람직한 랜덤 URP 서열은 50% 이상의 글리신을 함유하고, 트립토판, 페닐알라닌, 타이로신, 발린, 루신, 및 이소루신의 총 농도는 5% 미만이다. URP 서열은 둘 이상의 보다 짧은 URP 서열의 서열 또는 URP 서열의 단편을 조합함으로써 디자인될 수 있다. 이러한 조합은 URP 서열을 함유하는 생성물의 약학적 특성을 보다 잘 조정할 수 있도록 하고, URP 서열을 코딩하는 DNA 서열의 반복성을 감소시켜, 발현을 개선시키고 URP 코딩 서열의 재조합을 감소시킬 수 있도록 한다.
URP 서열은 하기 수개의 원하는 특성을 갖도록 디자인되고 선택될 수 있다: a) 생산 숙주에서 코딩 서열의 높은 유전적 안정성, b) 높은 발현 수준, c) 낮은 (예상치/계산치) 면역원성, d) 혈청 프로테아제 및/또는 다른 조직 프로테아제의 존재시 높은 안정성, e) 생리학적 조건하에 큰 수력학적 반경. 다수의 기준을 충족하는 URP 서열을 수득하기 위한 한 예시적인 접근법은 후보 서열의 라이브러리를 작제하고 적합한 부분서열을 라이브러리로부터 동정하는 것이다. 라이브러리는 랜덤 및/또는 반-랜덤 서열을 포함할 수 있다. 동일한 아미노산 잔기를 위해 다수의 코돈을 함유한 DNA 분자의 라이브러리인 코돈 라이브러리가 특히 유용하다. 코돈 랜덤화는 특정 유형의 선택된 아미노산 위치에 또는 대부분 또는 모든 위치에 적용될 수 있다. 실제 코돈 라이브러리는 단일 아미노산 서열만을 코딩하지만, 이들은 쉽게 아미노산 라이브러리와 조합될 수 있고, 이는 동일한 잔기 위치에서 (관련된 또는 관련되지 않은) 아미노산의 혼합물을 코딩하는 DNA 분자의 모집단이다. 코돈 라이브러리는 DNA 수준에서 비교적 낮은 반복성을 갖지만 매우 반복적인 아미노산 서열을 코딩하는 유전자의 동정을 허용한다. 이는, 반복적 DNA 서열이 재조합하여 불안정성을 유도하는 경향이 있으므로 유용하다. 또한 제한된 아미노산 다양성을 코딩하는 코돈 라이브러리를 작제할 수 있다. 이러한 라이브러리는 서열의 몇몇 위치에 제한된 수의 아미노산의 도입을 허용하는 한편, 다른 위치는 코돈 다양성을 허용하지만, 모든 코돈은 동일한 아미노산을 코딩한다. 뉴클레오티드의 혼합물을 동일한 위치에 올리고뉴클레오티드 합성 동안 혼입함으로써 부분적 랜덤 올리고뉴클레오티드를 합성할 수 있다. 이러한 부분적 랜덤 올리고뉴클레오티드는 중첩 PCR 또는 결찰에 기초한 접근법에 의해 융합될 수 있다. 특히, 글리신 풍부 서열을 코딩하는 반-랜덤 올리고뉴클레오티드를 다량체화할 수 있다. 이들 올리고뉴클레오티드는 길이, 및 서열 및 코돈 용법이 상이할 수 있다. 결과로서, 후보 URP 서열의 라이브러리를 수득한다. 라이브러리를 생성하는 또 다른 방법은 출발 서열을 합성한 후 상기 서열을 부분적 랜덤화하는 것이다. 이는 URP 서열을 코딩하는 유전자를 돌연변이유발 균주에서 배양하거나 코딩 유전자를 돌연변이 조건하에 증폭시킴으로써 수행될 수 있다(Leung, D., et al. (1989) Technique, 1 : 11-15). 원하는 특성을 갖는 URP 서열은 다양한 방법을 사용하여 라이브러리로부터 동정될 수 있다. 고도의 유전적 안정성을 갖는 서열은 생산 숙주에서 라이브러리를 배양함으로써 강화될 수 있다. 불안정한 서열은 돌연변이를 축적할 것이고, 이는 DNA 서열화에 의해 동정될 수 있다. 높은 농도로 발현될 수 있는 URP 서열의 변형체는 당분야의 숙련가에게 공지된 다수의 프로토콜을 사용하여 스크리닝 또는 선택에 의해 동정될 수 있다. 예를 들면, 라이브러리로부터의 다수의 단리물을 배양하고 발현 수준을 비교할 수 있다. 발현 수준은 겔 분석, 분석용 크로마토그래피, 또는 다양한 ELISA 기반 방법에 의해 측정될 수 있다. 개별 서열 변형체의 발현 수준의 결정은 후보 URP 서열의 라이브러리를 서열 태그, 예컨대 myc-태그, His-태그, HA-태그에 융합시킴으로써 촉진될 수 있다. 또 다른 접근법은 라이브러리를 효소 또는 녹색 형광성 단백질과 같은 다른 리포터(reporter) 단백질에 융합시키는 것이다. 라이브러리의 선택가능한 마커, 예컨대 베타-락타마아제(lactamase) 또는 카나마이신-아실 전이효소(kanamycin-acyl transferase)로의 융합이 특히 관심을 끈다. 고농도로 발현되고 유전적 안정성이 양호한 변형체를 강화시키기 위해 항생물질 선택을 사용할 수 있다. 양호한 프로테아제 내성을 갖는 변형체는 프로테아제와의 항온처리 후 손상되지 않은 서열을 스크리닝함으로써 동정될 수 있다. 프로테아제 내성 URP-서열을 동정하기 위한 한 효과적인 방식은 박테리아 파지 디스플레이 또는 관련된 디스플레이 방법이다. 신속히 단백질가수분해되는 서열이 파지 디스플레이에 의해 강화될 수 있는 다수의 시스템이 기재되어 있다. 이들 방법은 프로테아제 내성 서열을 강화시키기 위해 쉽게 채택될 수 있다. 예를 들면, 친화성 태그와 M13 파지의 pIII 단백질 사이의 후보 URP 서열의 라이브러리를 클로닝할 수 있다. 이어서, 라이브러리는 프로테아제 또는 프로테아제 함유 생물학적 샘플, 예컨대 혈액 또는 리소좀 제조물에 노출될 수 있다. 프로테아제 내성 서열을 함유하는 파지는 친화성 태그로의 결합에 의해 프로테아제 처리 후 포획될 수 있다. 리소좀 제조물에 의한 분해에 내성인 서열이 특히 관심을 끄는데, 이는 리소좀 분해가 수지상 세포 및 기타 항원 제공 세포에서 항원 제공 동안의 핵심 단계이기 때문이다. 파지 디스플레이는 낮은 면역원성을 갖는 URP 서열을 동정하기 위해 특정 면역 혈청에 결합되지 않는 후보 URP 서열을 동정하기 위해 이용될 수 있다. 동물을 후보 URP 서열 또는 라이브러리중 URP 서열에 대해 항체를 일으키는 URP 서열의 라이브러리로 면역화시킬 수 있다. 이어서 생성된 혈청은 파지 패닝에 사용되어 생성된 면역 혈청에서 항체에 의해 인식되는 서열을 제거 또는 동정할 수 있다. 박테리아 디스플레이, 효모 디스플레이, 리보솜성 디스플레이와 같은 다른 방법이 사용되어 원하는 특성을 갖는 URP 서열의 변형체를 동정할 수 있다. 또 다른 접근법은 질량 분광계에 의한 URP 서열의 동정이다. 예를 들면, 후보 URP 서열의 라이브러리를 프로테아제 또는 관심있는 생물학적 샘플과 항온처리하고, 질량 분광계에 의해 분해에 저항하는 서열을 동정한다. 유사한 접근법에서, 경구 섭취를 촉진하는 URP 서열을 동정할 수 있다. 후보 URP 서열의 혼합물을 동물 또는 인간에게 공급하고, 몇몇 조직 장벽(즉, 피부 등)을 가로질러 가장 높은 전달 또는 섭취 유효성을 갖는 변형체를 질량 분광계에 의해 동정할 수 있다. 유사한 방식으로, 다른 섭취 기작, 예컨대 폐, 비강내, 직장, 경피 전달을 선호하는 URP 서열을 동정할 수 있다. 또한 세포 섭취를 선호하는 URP 서열 또는 세포 섭취에 저항하는 URP 서열을 동정할 수 있다.
URP 서열은, 상기 기재된 임의의 방법에 의해 디자인될 수 있는 URP 서열 또는 URP 서열의 단편을 조합함으로써 디자인될 수 있다. 또한, 반-랜덤 접근법을 적용하여 상기 기재된 규칙에 기초하여 디자인된 서열을 최적화시킬 수 있다. 증진된 폴리펩티드의 발현을 개선시키고 생산 숙주에서 코딩 유전자의 유전적 안정성을 개선시키는 목표를 갖는 코돈 최적화가 관심을 끈다. 코돈 최적화는 글리신이 풍부하고 매우 반복적인 아미노산 서열을 갖는 URP 서열을 위해 특히 중요하다. 코돈 최적화는 컴퓨터 프로그램을 사용하여 수행될 수 있고(Gustafsson, C, et al. (2004) Trends Biotechnol, 22: 346-53), 이중 일부는 리보솜 휴지기를 최소화한다(Coda Genomics Inc.). URP 서열을 디자인할 때, 다수의 특성을 고려할 수 있다. 코딩 DNA 서열에서의 반복성을 최소화할 수 있다. 또한, 생산 숙주에 의해 잘 사용되지 않는 코돈(즉, 이. 콜라이중 AGG 및 AGA 아르기닌 코돈, 및 루신 코돈)의 사용을 방지 또는 최소화할 수 있다. 높은 수준의 글리신을 갖는 DNA 서열은 높은 GC 함량을 갖는 경향이 있어, 불안정성 또는 낮은 발현 수준을 유도할 수 있다. 따라서, 가능할 경우, URP-인코딩 서열의 GC-함량이 URP를 제작하기 위해 사용될 생산 유기체에 적합하도록 코돈을 선택하는 것이 바람직하다.
URP 코딩 유전자는, 하나 이상의 단계로, 완전히 합성적으로 또는 효소 공정과 조합된 합성에 의해, 예컨대 제한 효소 매개성 클로닝, PCR 및 중첩 연장에 의해 만들어질 수 있다. URP 보조적 폴리펩티드는, URP 보조적 폴리펩티드-인코딩 유전자가 낮은 반복성을 갖는 반면 코딩된 아미노산 서열이 고도의 반복성을 갖도록 작제될 수 있다. 제1 단계로서, 비교적 짧은 URP 서열의 라이브러리를 작제한다. 이는 각각의 라이브러리 구성원이 동일한 아미노산 서열을 갖지만 많은 상이한 코딩 서열이 가능하도록 순수 코돈 라이브러리일 수 있다. 잘-발현하는 라이브러리 구성원의 동정을 촉진하기 위해, 리포터 단백질의 융합물로서 라이브러리를 작제할 수 있다. 적합한 리포터 유전자의 예는 녹색 형광성 단백질, 루시퍼라세(luciferace), 알칼리성 포스파타제, 베타-갈락토시다제이다. 스크리닝에 의해, 선택된 숙주 유기체에서 고농도로 발현될 수 있는 짧은 URP 서열을 동정할 수 있다. 후속적으로, 랜덤 URP 이량체의 라이브러리를 생성하고, 높은 수준의 발현을 위해 스크리닝을 반복할 수 있다. 이량체화는 결찰, 중첩 연장 또는 유사한 클로닝 기법에 의해 수행될 수 있다. 이량체화 및 후속적인 스크리닝의 이러한 과정은 생성된 URP 서열이 원하는 길이에 도달될 때까지 다수회 반복될 수 있다. 경우에 따라, 원치않는 서열을 함유한 단리물을 제거하기 위해 라이브러리에서 서열 클로닝을 할 수 있다. 짧은 URP 서열의 초기 라이브러리는 아미노산 서열에서의 일부 변형을 허용할 수 있다. 예를 들어, 몇몇 코돈을 랜덤화하여 다수의 친수성 아미노산을 상기 위치에서 발생될 수있도록 한다. 되풀이되는 다량체화의 과정 동안, 높은 수준의 발현에 대한 스크리닝에 더하여 다른 특징, 예컨대 용해도 또는 프로테아제 내성에 대해 라이브러리 구성원을 스크리닝 할 수 있다. URP 서열을 이량체화하는 대신에, 또한 보다 긴 다량체를 생성할 수 있다. 이는 URP 보조적 폴리펩티드의 길이를 보다 빨리 증가시킬 수 있도록 한다.
많은 URP 서열은 높은 분율로 특정 아미노산을 포함하는다. 이러한 서열은 재조합 기법에 의해 생산하기 어려울 수 있는데, 이들의 코딩 유전자가 재조합되는 반복적 서열을 함유할 수 있기 때문이다. 추가로, 매우 높은 빈도로 특정 코돈을 함유하는 유전자는 발현을 제한할 수 있는데, 이는 생산 숙주에 개별적으로 로딩되는 tRNA가 제한되기 때문이다. 한 예는 GRS의 재조합 생산이다. 글리신 잔기는 4개의 삼중체(triplet), GGG, GGC, GGA, 및 GGT에 의해 코딩된다. 결과로서, GRS를 코딩하는 유전자는 높은 GC-함량을 갖고, 특히 반복적인 경향이 있다. 추가의 챌린지(challenge)는 생산 숙주의 코돈 바이어스(bias)로부터 생성된다. 이. 콜라이의 경우, 2개의 글리신 코돈, GGA 및 GGG는 고도로 발현된 단백질에서 흔히 사용되지 않는다. 따라서, URP 서열을 코딩하는 유전자의 코돈 최적화는 매우 요망될 수 있다. 생산 숙주의 코돈 바이어스를 고려하는 컴퓨터 프로그램을 사용함으로써 코돈 용법을 최적화할 수 있다(Gustafsson, C., et al. (2004) Trends Biotechnol, 22: 346-53). 대안으로서, 라이브러리의 모든 구성원이 동일 아미노산 서열을 코딩하지만, 코돈 용법이 상이한 코돈 라이브러리를 작제할 수 있다. 이러한 라이브러리는 URP 함유 생성물의 대규모 생산에 특히 적합한 유전적으로 안정하고 고도로 발현되는 구성원에 대해 스크리닝될 수 있다.
다가의 비구조화된 재조합 단백질(MURP: Multivalent Unstructured Recombinant Protein):
주지된 바와 같이, 본 URP는 생물학적 활성 폴리펩티드의 변경을 위한 보조적 폴리펩티드로서 특히 유용하다. 따라서, 본 발명은 하나 이상의 본 URP를 포함하는 단백질을 제공한다. 이러한 단백질은 본원에 다가의 비구조화된 재조합 단백질(MURP)로 명명된다.
MURP를 작제하기 위해, 하나 이상의 URP 서열은 단백질의 N-말단 또는 C-말단에 융합되거나 단백질의 중간, 예를 들어, 단백질의 루프 내로 또는 관심있는 생물학적 활성 폴리펩티드의 모듈 사이에 삽입되어 변경되지 않은 단백질에 비해 개선된 특성을 갖는 변경된 폴리펩티드를 생성할 수 있다. 단백질에 부착된 URP 서열의 합쳐진 길이는 40, 50, 60, 70, 80, 90, 100, 150, 200개 이상의 아미노산일 수 있다.
본 MURP는 이후 상세화되는 바와 같이 하나 이상의 개선된 특성을 나타낸다.
개선된 반감기:
URP 서열을 생물학적 활성 폴리펩티드에 첨가하면 그 단백질의 많은 특성을 개선시킬 수 있다. 특히, 긴 URP 서열의 첨가는 단백질의 혈청 반감기를 크게 증가시킬 수 있다. 이러한 URP는 전형적으로 약 40, 50, 60, 70, 80, 90, 100, 150, 200개 이상의 아미노산의 아미노산 서열을 함유한다.
URP는 생성된 단백질이 다수의 URP, 또는 URP의 다수의 단편을 함유하도록 단편화될 수 있다. 이들 개개의 URP 서열의 일부 또는 전부는, 생성된 단백질 중 모든 URP 서열의 합쳐진 길이가 30개 이상의 아미노산이기만 하면 40개 아미노산보다 짧을 수 있다. 바람직하게는, 생성된 단백질은 40, 50, 60, 70, 80, 90, 100, 150, 200개 이상의 아미노산을 초과하는 URP 서열의 합쳐진 길이를 갖는다. 한 양태에서, 융합된 URP는 단백질의 수력학적 반경을 증가시키고, 신장에 의한 혈액으로부터의 이의 제거를 감소시킬 수 있다. 변경되지 않은 단백질에 비해 생성된 융합 단백질의 수력학적 반경이 증가함은 초원심분리, 크기 배제 크로마토그래피, 또는 광 산란에 의해 검출될 수 있다.
개선된 조직 선택성:
또한, 수력학적 반경을 증가시키는 것은 조직내로의 침투를 감소시킬 수 있고, 이는 생물학적 활성 폴리펩티드의 부작용을 최소화시키도록 활용될 수 있다. 친수성 중합체는 종양 조직에서 선택적으로 축적되는 경향을 갖고, 이는 증진된 투과성 및 보유(EPR: enhanced permeability and retention) 효과에 의해 야기된다는 것이 문서화되어 있다. EPR 효과의 근원적 원인은 종양 맥관구조의 유출 성질(McDonald, D. M., et al. (2002) Cancer Res, 62: 5381-5) 및 종양 조직에서의 림프 배수(lymphatic drainage)의 결여이다. 따라서, 종양 조직에 대한 생물학적 활성 폴리펩티드의 선택성은 친수성 중합체를 첨가함으로써 증진될 수 있다. 이와 같이, 소정의 생물학적 활성 폴리펩티드의 치료학적 지수는 본 URP를 혼입함으로써 증가될 수 있다.
분해로부터의 보호 및 감소된 면역원성:
URP 서열의 첨가는 단백질의 프로테아제 내성을 상당히 개선시킬 수 있다. URP 서열 그 자체는 프로테아제 내성이도록 디자인될 수 있고, 이들을 단백질에 부착시킴으로써 그 단백질을 분해 효소의 접근으로부터 보호한다. URP 서열은 단백질과 다른 수용체 또는 표면의 원치않는 상호작용을 감소시킬 목적을 갖고 생물학적 활성 폴리펩티드에 첨가될 수 있다. 이를 달성하기 위해, 이러한 원치않는 접촉부를 만드는 단백질의 부위와 근접하여 URP 서열을 생물학적 활성 폴리펩티드에 첨가하는 것이 유리할 수 있다. 특히, 면역계의 임의의 성분과의 상호작용을 감소시켜 본 발명의 생성물에 대한 면역 반응을 방지하는 목표를 갖고 URP 서열을 생물학적 활성 폴리펩티드에 첨가할 수 있다. URP 서열을 생물학적 활성 폴리펩티드에 첨가하는 것은 미리-존재하는 항체 또는 B-세포 수용체와의 상호작용을 감소시킬 수 있다. 추가로, URP 서열의 첨가는 항원 제공 세포에 의해 본 발명의 생성물의 섭취 및 처리를 감소시킬 수 있다. 하나 이상의 URP 서열을 단백질에 첨가함은 이의 면역원성을 감소시키는 바람직한 방식인데, 이는 많은 종에서 면역 반응을 억제하여 동물 데이터에 기초하여 환자에서 생성물의 기대되는 면역원성을 예측할 수 있기 때문이다. 이러한 종 독립적 면역원성 시험은, 인간 T 세포 에피토의 동정 및 제거, 또는 인간 서열과의 서열 비교에 기초하는 접근법에 대해서는 가능하지 않다.
T 세포 에피토프의 차단:
URP 서열은 T 세포 에피토프를 차단하기 위해 단백질내로 도입될 수 있다. 이는 다수의 별도의 작용성 모듈을 조합하는 단백질의 경우 특히 유용하다. T 세포 에피토프의 형성은 단백질 항원의 펩티드 단편이 MHC로 결합되는 것을 필요로 한다. MHC 분자는 아미노산의 짧은 분절, 전형적으로 제공된 펩티드의 9개의 연속된 잔기와 상호작용한다. 단백질 분자에서 상이한 결합 모듈의 직접적 융합은 2개의 이웃한 도메인을 스패닝하는 T 세포 에피토프를 유도할 수 있다. URP에 의해 작용성 모듈을 분리함으로써, 보조적 폴리펩티드는 이러한 모듈-스패닝 T 세포 에피토프의 생성을 방지한다. 작용성 모듈 사이에 URP 서열을 삽입하면 또한 항원 제공 세포에서 단백질가수분해 처리과정을 간섭하여, 면역원성의 추가의 감소를 유도할 수 있다.
개선된 용해도
:
단백질의 작용성 모듈은 제한된 용해도를 가질 수 있다. 특히, 결합 모듈은 이들의 용해도를 제한하여 응집을 유도할 수 있는 소수성 잔기를 이들의 표면상에서 운반하는 경향이 있다. 이러한 작용성 모듈을 URP 보조적 폴리펩티드에 의해 이격시키거나 플랭킹함으로써, 생성된 생성물의 전체 용해도를 개선시킬 수 있다. 이는 상당한 백분율의 친수성 또는 하전된 잔기를 운반하는 URP 보조적 폴리펩티드의 경우 특히 적용된다. 작용성 모듈을 가용성 URP 모듈로 분리시킴으로써, 이들 작용성 모듈 사이의 분자내 상호작용을 감소시킬 수 있다.
생성물 전하의 개선된 pH 프로필 및 균일성:
URP 서열은 과량의 음성 또는 양전하를 운반하도록 디자인될 수 있다. 결과로서, 이들은 임의의 융합 파트너에 정전기장을 부여하고, 이는 효소의 pH 프로필 또는 결합 상호작용을 전이하기 위해 사용될 수 있다. 추가로, 하전된 URP 서열의 정전기장은 단백질 생성물의 표면 전하의 pKa 값의 균일성을 증가시킬 수 있고, 이는 리간드 상호작용의 pH 프로필을 예리하게 하고 등전성 포커싱(focusing) 또는 크로마토포커싱(chromatofocusing)에 의한 분리를 예리하게 한다.
보다 예리한 생성물 pKa에 기인한 개선된 정제 특성:
용액중 각각의 아미노산은 그 자체로 단일한 고정된 pKa(이는 그의 작용기의 절반이 양성자화되는 pH임)를 갖는다. 전형적인 단백질에서, 많은 유형의 잔기가 존재하고, 근위 및 단백질 호흡 효과로 인해, 이들은 또한 다양한 방식으로 서로의 유효 pKa를 변화시킨다. 이로 인하여, 광범위한 pH 조건하에, 전형적인 단백질은 수백개의 상이하게 이온화된 종을 채택할 수 있는데, 이들 각각은 하전된 아미노산 잔기와 중성 아미노산 잔기의 다수의 조합으로 인해 상이한 분자량 및 순 전하를 갖는다. 이는 넓은 이온화 스펙트럼으로 지칭되고, 이러한 단백질의 분석(예: 질량 분광계에 의함) 및 정제를 보다 어렵게 만든다.
PEG는 하전되지 않고, 이것이 부착된 단백질의 이온화 스펙트럼에 영향을 주지 않아, 넓은 이온화 스펙트럼을 갖는다. 그러나, 원칙적으로 Gly 및 Glu을 높은 함량으로 갖는 URP는 단지 2가지 상태로 존재한다: pH가 글루타메이트의 pKa 미만인 경우 중성(-COOH), 및 pH가 글루타메이트의 pKa보다 높은 경우 음으로 하전됨(-COO"). URP 보조적 폴리펩티드는 분자의 균질하게 이온화된 단일 유형을 형성할 수 있고, 질량 분광계에서 단일 질량을 산출할 수 있다.
원할 경우, MURP는 URP 보조적 폴리펩티드를 통해 일정한 간격으로 분포된 전하(Glu)의 단일 유형을 갖는 URP와의 융합물로서 발현될 수 있다. 2O kD의 URP 당 25∼50개의 Glu 잔기를 혼입하도록 선택될 수 있고, 이들 모든 25∼50개 잔기는 매우 유사한 pKa를 가질 것이다.
또한, 작은 단백질, 예컨대 IFN, hGH 또는 GCSF(단지 20개의 하전된 잔기를 가짐)로의 25∼50의 음전하를 첨가함은 생성물의 전하 균일성을 증가시키고, 그의 등전점을 예리하게 할 수 있고, 이는 유리 글루타메이트의 pKa와 매우 비슷할 것이다.
단백질 모집단의 균일성의 증가는, 전통적인 페그화에 비해, 예컨대 이온 교환, 등전성 포커싱, 질량 분광계에서 우호적인 처리과정 특성을 갖는다.
생물학적 활성 폴리펩티드
보조적 폴리펩티드에 연결될 수 있는 적합한 폴리펩티드로는, 소정의 표적에 결합 특이성을 나타내거나 시험관내 또는 생체내에서 사용될 경우 또 다른 원하는 생물학적 특징을 나타내는 모든 생물학적 활성 폴리펩티드가 포함된다. 특히, 치료학적 또는 진단학적으로 관심을 끄는 임의의 단백질은 보조적 폴리펩티드에 의해 변경될 수 있다. 어떤 특성들, 예컨대 혈청 반감기 또는 생체내 제거의 변경이 요망되는 폴리펩티드가 특히 관심을 끈다. 이러한 변경은 치료학적 적용분야와 관련되어, 예를 들면 투여된 단백질 치료 약물의 반감기를 연장시키고자 할 경우 구현될 수 있다. 보조적 폴리펩티드에 의한 변경은 진단학적 적용분야에서, 예를 들면 진단학적 단백질 또는 영상화제의 다른 분자로의 비특이적 결합을 감소시키기 위해 유용성을 나타낼 수 있다.
생물학적 활성 폴리펩티드는, 제한되지 않지만, 사이토킨(cytokine), 케모카인(chemokine), 림포카인(lymphokine), 리간드, 수용체, 호르몬, 효소, 항체 및 항체 단편, 및 성장 인자가 포함된다. 수용체의 예로는 TNF 유형 I 수용체, IL-1 수용체 유형 II, IL-1 수용체 길항물질, IL-4 수용체 및 임의의 화학적으로 또는 유전학적으로 변경된 가용성 수용체가 포함된다. 효소의 예로는 활성화된 단백질 C, 인자 VII, 콜라게나제(예를 들어, 어드밴스 바이오팩츄어스 코포레이션(Advance Biofactures Corporation)에 의해 산틸(Santyl: 등록상표)하에 시판됨); 아갈시다제(agalsidase)-베타(예를 들어, 진자임(Genzyme)에 의해 파브라자임(Fabrazyme: 등록상표)하에 시판됨); 도나제(dornase)-알파(예를 들어, 진테크(Genentech)에 의해 풀모자임(Pulmozyme: 등록상표)하에 시판됨); 알테플라제(alteplase)(예를 들어, 진테크하에 액티바아제(Activase: 등록상표)하에 시판됨); 페그화된-아스파라기나제(asparaginase)(예를 들어, 엔존(Enzon)에 의해 온카스파(Oncaspar: 등록상표)하에 시판됨); 아스파라기나제(예를 들어, 메르크(Merck)에 의해 엘스파(Elspar: 등록상표)하에 시판됨); 및 이미글루세라제(imiglucerase)(예를 들어, 진자임에 의해 세레다제(Ceredase: 등록상표)하에 시판됨)가 포함된다. 특이적 폴리펩티드 또는 단백질의 예로는, 제한되지 않지만, 과립구 대식세포 콜로니 자극 인자(GM-CSF: granulocyte macrophage colony stimulating factor), 과립구 콜로니 자극 인자(G-CSF), 대식세포 콜로니 자극 인자(M-CSF), 콜로니 자극 인자(CSF), 인터페론 베타(IFN-β), 인터페론 감마(IFNγ), 인터페론 감마 유도 인자 I(IGIF), 형질전환 성장 인자 베타(TGF-β: transforming growth factor-β), RANTES(활성화시 조절됨, 정상 T-세포 발현되고 짐작컨대 분비됨), 대식세포 염증성 단백질(예를 들어, MIP-1-α 및 MIP-1-β), 리슈마니아 신장 개시 인자(LEIF: Leishmania elongation initiating factor), 혈소판 유도된 성장 인자 (PDGF: platelet derived growth factor), 종양 괴사 인자(TNF), 성장 인자, 예를 들어, 상피 성장 인자(EGF: epidermal growth factor), 혈관 내피 성장 인자(VEGF: vascular endothelial growth factor), 섬유아세포 성장 인자(FGF: fibroblast growth factor), 신경 성장 인자(NGF: nerve growth factor), 뇌 유도된 신경친화성 인자(BDNF: brain derived neurotrophic factor), 뉴로트로핀(neurotrophin)-2(NT-2), 뉴로트로핀-3(NT-3), 뉴로트로핀-4(NT-4), 뉴로트로핀-5(NT-5), 신경교세포주 유래 신경친화성 인자(GDNF: glial cell line-derived neurotrophic factor), 모양체 신경친화성 인자(CNTF: ciliary neurotrophic factor), TNF α 유형 II 수용체, 에리스로포이에틴(EPO: Erythropoietin), 인슐린 및 가용성 당단백질, 예를 들어, gp120 및 gp160 당단백질이 포함된다. gp120 당단백질은 인간 면역결핍 바이러스(HIV: human immunodeficiency virus) 외피 단백질이고, gp160 당단백질은 gp120 당단백질에 대한 공지된 전구체이다.
예로서, 본 발명에 따른 변경에 적합한 생물학적 활성 폴리펩티드의 몇몇 예는 다음과 같다.
한 실시양태에서, 생물학적 활성 폴리펩티드는 GLP-1이다. GLP-1은 당뇨병의 가능한 치료제로서 현재 연구되고 있는 대략 30개의 아미노산 폴리펩티드이다. GLP-1은 글루카곤 방출을 억제하고, 인슐린 방출을 증가시킨다. GLP-1에 대한 양쪽 응답 결과 글루코스의 혈청 농도를 감소시킨다. GLP-1은 신속히 신체에서 디펩티딜 펩티다제-4에 의해 절단되고, 결과로서 극히 짧은 혈청 반감기(∼2분)를 갖는다. GLP-1의 치료학적 단백질로서의 성공적인 개발은 단백질의 전달 및 혈청 반감기를 증가시키는 제형을 필요로 한다. 이러한 예는 rPEG(L288)에 기초한 rPEG-GLP-1 융합 단백질의 제조, 및 치료학적 용도를 위한 GLP-1의 반감기를 개선시키기 위한 중합체 매트릭스로의 이의 캡슐화를 설명한다.
또 다른 실시양태에서, 생물학적 활성 폴리펩티드는 네시리티드(nesiritide), 즉 인간 B-유형 나트륨이뇨 펩티드(hBNP: human B-type natriuretic peptide)이다. 네시리티드는 재조합 DNA 기법을 사용하여 이. 콜라이에서 제작될 수 있다. 특정 실시양태에서, 네시리티드는 3464 g/몰의 분자량을 갖는 32개의 아미노산 서열로 구성된다.
또 다른 실시양태에서, 생물학적 활성 폴리펩티드는 세크레틴(secretin)이고, 이는 27개의 아미노산으로 구성된 천연 발생 돼지 세크레틴과 동일한 아미노산 서열로 이루어진 펩티드 호르몬이다. 0.4 mcg/kg의 변경되지 않은 폴리펩티드의 정맥내 일시주사 투여후, 합성 인간 세크레틴 농도는 기선 세크레틴 수준으로 90∼120분 이내에 신속히 감소한다. 합성 인간 세크레틴(보조적 폴리펩티드로 변경되지 않음)의 제거 반감기는 대략 45분이다.
대안의 실시양태에서, 생물학적 활성 폴리펩티드는 HIV-1과 CD4+ 세포의 융합에 대한 저해제인, 선형 36-아미노산 합성 폴리펩티드, 엔푸비르티드(enfuvirtide)이다
추가의 실시양태에서, 생물학적 활성 폴리펩티드는 특이적이고 가역적인 직접적 트롬빈 저해제인 비발리루딘(bivalirudin)이다. 보다 구체적인 실시양태는 분자량이 1280 돌턴인 20개의 합성 아미노산 펩티드인 생물학적 활성 폴리펩티드를 제공한다.
다르게는, 항혈우병 인자(AHF: Antihemophilic factor)가 생물학적 활성 폴리펩티드로서 선택될 수 있다. AHF는 유전학적으로 조작된 차이니즈 햄스터 난소(CHO: Chinese Hamster Ovary) 세포주에서 합성되는 당단백질이다. 이는 또한 HEMOFIL M(등록상표) AHF(박스터(Baxter)) 또는 항혈우병 인자(인간)[AHF(인간)]로 공지되어 있다. HEMOFIL M(등록상표) AHF의 평균 생체내 반감기는 14.7±5.1시간 (n=61)이다.
또 다른 실시양태에서, 에리스로포이에틴은 생물학적 활성 폴리펩티드이다. 에리스로포이에틴은 재조합 DNA 기법에 의해 제작될 수 있는 165개 아미노산 당단백질이고, 내생성 에리스로포이에틴과 동일한 생물학적 효과를 갖는다. 구체적인 실시양태에서, 에리스로포이에틴은 30,400 돌턴의 분자량을 갖고, 인간 에리스로포이에틴 유전자가 도입되는 포유동물 세포에 의해 생산된다. 생성물은 단리된 천연 에리스로포이에틴과 동일한 아미노산 서열을 함유할 수 있다. 만성 신부전을 앓는 성인 및 소아 환자에서, 변경되지 않은 혈장 에리스로포이에틴의 정맥내 투여후의 제거 반감기는 4∼13시간의 범위로 공지되어 있다.
그 외의 또 다른 실시양태에서, 생물학적 활성 폴리펩티드는 레테플라제(Reteplase)이다. 레테플라제는 조직 플라스미노겐 활성화제(tPA: tissue plasminogen activator)의 비-글리코실화된 결실 돌연변이단백질로서, 크린글(kringle) 2 및 인간 tPA의 프로테아제 도메인을 포함한다. 레테플라제는 고유의 tPA의 527개 아미노산 중 355개(아미노산 1∼3 및 176∼527)를 함유한다. 폴리펩티드는 이. 콜라이에서 재조합 DNA 기법에 의해 생산되고, 이. 콜라이로부터의 불활성 봉입체로서 단리되고, 시험관내 폴딩 공정에 의해 그의 활성 형태로 전환되고, 크로마토그래피 분리에 의해 정제될 수 있다. 변경되지 않은 레테플라제의 분자량은 39,571 돌턴이다. 혈전용해 활성의 측정값에 기초하여, 변경되지 않은 레테플라제의 실제 반감기는 대략 15분으로 공지되어 있다.
추가의 실시양태는 인간 인터류킨-1 수용체 길항물질(IL-1Ra: interleukin-1 receptor antagonist)의 재조합 비글리코실화된 형태, 아나킨라(Anakinra)인 생물학적 활성 폴리펩티드를 제공한다. 한 경우에, 아나킨라는 153개의 아미노산으로 구성되고, 17.3 킬로돌턴의 분자량을 갖는다. 이는 재조합 DNA 기법에 의해 이. 콜라이 박테리아 발현 시스템을 이용하여 생산될 수 있다. 변경되지 않은 아나킨라의 생체내 반감기는 4∼6시간의 범위로 공지되어 있다.
베카플러민(Becaplermin)은 또한 생물학적 활성 폴리펩티드로서 선택될 수 있다. 베카플러민은 국소 투여용의 재조합 인간 혈소판 유래 성장 인자(rhPDGF-BB: recombinant human platelet-derived growth factor)이다. 베카플러민은 재조합 DNA 기법에 의해 혈소판 유래 성장 인자(PDGF: platelet derived growth factor)의 B 쇄를 위한 유전자를 효모 균주 사카로마이세스 세레비지아(Saccharomyces cerevisiae)내로 삽입함으로써 생산될 수 있다. 베카플러민의 한 형태는 대략 25 kD의 분자량을 갖고, 디설파이드 결합에 의해 함께 결합되는 2개의 동일한 폴리펩티드로 이루어진 동종이량체이다.
생물학적 활성 폴리펩티드는 재조합 DNA 기법에 의해 에스케리치아 콜라이(이. 콜라이)에서 생산되는 인터류킨 11(IL-11)의 재조합 형태인 오프렐베킨(Oprelvekin)일 수 있다. 한 실시양태에서, 선택된 생물학적 활성 폴리펩티드는 대략 19,000 돌턴의 분자 질량을 갖고, 비-글리코실화된다. 폴리펩티드는 177개 아미노산 길이이고, 단지 아미노 말단 프롤린 잔기가 결여된 것만 고유의 IL-11의 178개 아미노산 길이와 상이하고, 이는 시험관내 또는 생체내에서 생물활성에 측정가능한 차이를 생성하지 않는 것으로 공지되어 있다. 변경되지 않은 오프렐베킨의 최종 반감기는 대략 7시간인 것으로 공지되어 있다.
또 다른 실시양태는 혈액 글루코스를 증가시키고 위장관의 평활근을 이완시키는 인간 글루카곤과 동일한 폴리펩티드 호르몬, 글루카곤인 생물학적 활성 폴리펩티드를 제공한다. 글루카곤은, 이를 위한 유전자를 첨가하여 유전학적으로 변경된 이. 콜라이 박테리아의 특수 비-병원성 실험실 균주에서 합성될 수 있다. 구체적인 실시양태에서, 글루카곤은 29개의 아미노산 잔기를 함유하고 3,483의 분자량을 갖는 단일쇄 폴리펩티드이다. 생체내 반감기는 8∼18분의 범위로 짧은 것으로 공지되어 있다.
G-CSF는 생물학적 활성 폴리펩티드로서 선택될 수 있다. 재조합 과립구-콜로니 자극 인자 또는 G-CSF는 백혈 세포의 회복을 자극하기 위한 하기 다양한 화학치료법에 사용된다. 재조합 G-CSF의 보고된 반감기는 단지 3.5시간이다.
다르게는, 생물학적 활성 폴리펩티드는 인터페론 알파(IFN 알파)이다. 화학적으로 PEG 변경 인터페론-알파 2a는 C형 간염의 치료에 임상적으로 인증되어 있다. 페그화된 단백질은 매주 주사가 필요하고, 보다 긴 반감기를 갖는 서방형 제형이 요망된다.
보조적 폴리펩티드로 변경될 수 있거나, 생물학적 활성 폴리펩티드가 표적화할 수 있는 추가의 세포 단백질은 VEGF, VEGF-R1, VEGF-R2, VEGF-R3, Her-1, Her-2, Her-3, EGF-1, EGF-2, EGF-3, 알파3, cMet, ICOS, CD40L, LFA-1, c-Met, ICOS, LFA-1, IL-6, B7.1, B7.2, OX40, IL-1b,. TACI, IgE, BAFF or BLys, TPO-R, CD19, CD20, CD22, CD33, CD28, IL-1-R1, TNFα, TRAIL-R1, 보체(Complement) 수용체 1, FGFa, 오스테오폰틴(Osteopontin), 비트로넥틴(Vitronectin), 에프린(Ephrin) A1-A5, 에프린 B1-B3, 알파-2-매크로글로불린, CCL1, CCL2, CCL3, CCL4, CCL5, CCL6, CCL7, CXCL8, CXCL9, CXCL1O, CXCL11, CXCL12, CCL13, CCL14, CCL15, CXCL16, CCL16, CCL17, CCL18, CCL19, CCL20, CCL21, CCL22, PDGF, TGFb, GMCSF, SCF, p40 (IL12/IL23), IL1b, IL1a, IL1ra, IL2, IL3, IL4, IL5, IL6, IL8, ILlO, IL12, IL15, IL23, Fas, FasL, Flt3 리간드, 41BB, ACE, ACE-2, KGF, FGF-7, SCF, 네트린(Netrin)1, 2, IFNa, b, g, 카스파아제(Caspase)2, 3, 7, 8, 10, ADAM S1, S5, 8, 9, 15, TS1, TS5; 아디포넥틴(Adiponectin), ALCAM, ALK-1, APRIL, 아넥신(Annexin) V, 안지오게닌(Angiogenin), 암피레귤린(Amphiregulin), 안지오포이에틴(Angiopoietin)1, 2, 4, B7-1/CD80, B7-2/CD86, B7-H1, B7-H2, B7-H3, Bcl-2, BACE-I, BAK, BCAM, BDNF, bNGF, bECGF, BMP 2, 3, 4, 5, 6, 7, 8; CRP, 카드헤린(cadherin)6, 8, 11; 카텝신(cathepsin) A, B, C, D, E, L, S, V, X; CD11a/LFA-1, LFA-3, GP2b3a, GH 수용체, RSV F 단백질, IL-23(p40, p19), IL-12, CD80, CD86, CD28, CTLA-4, α4β1, α4β7, TNF/림포톡신(Lymphotoxin), IgE, CD3, CD20, IL-6, IL-6R, BLYS/BAFF, IL-2R, HER2, EGFR, CD33, CD52, 디곡신(Digoxin), Rho(D), 바리셀라(Varicella), 헤파티티스(Hepatitis), CMV, 테타너스(Tetanus), 바시니아(Vaccinia), 안티베놈(Antivenom), 보툴리넘(Botulinum), Trail-R1, Trail-R2, cMet, TNF-R 계열, 예컨대 LA NGF-R, CD27, CD30, CD40, CD95, 림포톡신 a/b 수용체, Ws1-1, TL1A/TNFSF15, BAFF, BAFF-R/TNFRSF13C, TRAIL R2/TNFRSF10B, TRAIL R2/TNFRSF10B, Fas/TNFRSF6 CD27/TNFRSF7, DR3/TNFRSF25, HVEM/TNFRSF14, TROY/TNFRSF19, CD40 리간드/TNFSF5, BCMA/TNFRSF17, CD30/TNFRSF8, LIGHT/TNFSF14, 4-1BB/TNFRSF9, CD40/TNFRSF5, GITR/TNFRSF18, 오스테오프로테게린(Osteoprotegerin)/TNFRSF11B, RANK/TNFRSF11A, TRAIL R3/TNFRSF10C, TRAIL/TNFSF10, TRANCE/RANK L/TNFSF11, 4-1BB 리간드/TNFSF9, TWEAK/TNFSF12, CD40 리간드/TNFSFS, Fas 리간드/TNFSF6, RELT/TNFRSF19L, APRIL/TNFSF13, DcR3/TNFRSF6B, TNF RI/TNFRSF1A, TRAIL R1/TNFRSF1OA, TRAIL R4/TNFRSF10D, CD30 리간드/TNFSF8, GITR 리간드/TNFSF18, TNFSF18, TACI/TNFRSF13B, NGF R/TNFRSF16, OX40 리간드/TNFSF4, TRAIL R2/TNFRSF10B, TRAIL R3/TNFRSF10C, TWEAK R/TNFRSF12, BAFF/BLyS/TNFSF13, DR6/TNFRSF21, TNF-알파/TNFSF1A, 프로-TNF-알파/TNFSF1A, 림포톡신 베타 R/TNFRSF3, 림포톡신 베타 R(LTbR)/Fc 키메라(Chimera), TNF RI/TNFRSF1A, TNF-베타/TNFSF1B, PGRP-S, TNF RI/TNFRSF1A, TNF RII/TNFRSF1B, EDA-A2, TNF-알파/TNFSF1A, EDAR, XEDAR, TNF RI/TNFRSF1A이다.
정제된 형태로 상업적으로 입수가능한 인간 표적 단백질 뿐만 아니라 이들 표적 단백질에 결합된 단백질이 관심을 끈다. 예는 다음과 같다: 4EBP1, 14-3-3 제타, 53BP1, 2B4/SLAMF4, CCL21/6Ckine, 4-1BB/TNFRSF9, 8D6A, 4-1BB 리간드/TNFSF9, 8-옥소-dG, 4-아미노-1,8-나프탈이미드, A2B5, 아미노펩티다제(Aminopeptidase) LRAP/ERAP2, A33, 아미노펩티다제 N/ANPEP, Aag, 아미노펩티다제 P2/XPNPEP2, ABCG2, 아미노펩티다제 P1/XPNPEP1, ACE, 아미노펩티다제 PILS/ARTS1, ACE-2, 암니온레스(Amnionless), 액틴(Actin), 암피레귤린(Amphiregulin), 베타-액틴, AMPK 알파 1/2, 액티빈(Activin) A, AMPK 알파 1, 액티빈 AB, AMPK 알파 2, 액티빈 B, AMPK 베타 1, 액티빈 C, AMPK 베타 2, 액티빈 RIA/ALK-2, 안드로겐(Androgen) R/NR3C4, 액티빈 RIB/ALK-4, 안지오제닌(Angiogenin), 액티빈 RIIA, 안지오포이에틴-1, 액티빈 RIIB, 안지오포이에틴-2, ADAM8, 안지오포이에틴-3, ADAM9, 안지오포이에틴-4, ADAM1O, 안지오포이에틴 유사 1, ADAM12, 안지오포이에틴 유사 2, ADAM15, 안지오포이에틴 유사 3, TACE/ADAM17, 안지오포이에틴 유사 4, ADAM19, 안지오포이에틴 유사 7/CDT6, ADAM33, 안지오스타틴(Angiostatin), ADAMTS4, 아넥신(Annexin) A1/아넥신 I, ADAMTS5, 아넥신 A7, ADAMTS1, 아넥신 A1O, ADAMTSL-1/펀크틴(Punctin), 아넥신 V, 아디포넥틴/Acrp30, ANP, AEBSF, AP 부위, 아그레칸(Aggrecan), APAF-1, 아그린(Agrin), APC, AgRP, APE, AGTR-2, APJ, AIF, APLP-1, Akt, APLP-2, Akt1, 아포지단백질 AI, Akt2, 아포지단백질 B, Akt3, APP, 혈청 알부민, APRIL/TNFSF13, ALCAM, ARC, ALK-1, 아르테민(Artemin), ALK-7, 아릴설파타제(Arylsulfatase) A/ARSA, 알칼리성 포스파타제, ASAH2/N-아실스핀고신 아미도하이드롤라제(acylsphingosine Amidohydrolase)-2, 알파 2u-글로불린, ASC, 알파-1-산 당단백질, ASGR1, 알파-페토(Feto)단백질, ASK1, ALS, ATM, 에나멜아세포 ATRIP, AMICA/JAML, 오로라(Aurora) A, AMIGO, 오로라 B, AMIG02, 악신(Axin)-1, AMIG03, AxI, 아미노아실라제/ACY1, 아주로시딘(Azurocidin)/CAP37/HBP, 아미노펩티다제 A/ENPEP, B4GALT1, BIM, B7-1/CD80, 6-바이오틴-17-NAD, B7-2/CD86, BLAME/SLAMF8, B7-H1/PD-L1, CXCL13/BLC/BCA-1, B7-H2, BLIMP1, B7-H3, Blk, B7-H4, BMI-1, BACE-1, BMP-1/PCP, BACE-2, BMP-2, 배드(Bad), BMP-3, BAFF/TNFSF13B, BMP-3b/GDF-10, BAFF R/TNFRSF 13C, BMP-4, Bag-1, BMP-5, BAK, BMP-6, BAMBI/NMA, BMP-7, BARD1, BMP-8, Bax, BMP-9, BCAM, BMP-10, Bcl-10, BMP-15/GDF-9B, Bcl-2, BMPR-IA/ALK-3, Bc1-2 관련 단백질 A1, BMPR-IB/ALK-6, Bcl-w, BMPR-II, Bcl-x, BNIP3L, Bcl-xL, BOC, BCMA/TNFRSF17, BOK, BDNF, BPDE, 벤즈아미드(Benzamide), 브라키우리(Brachyury), 통상의 베타 쇄, B-Raf, 베타 IG-H3, CXCL14/BRAK, 베타셀룰린(Betacellulin), BRCA1, 베타-데펜신(Defensin) 2, BRCA2, BID, BTLA, 비글리칸(Biglycan), Bub-1, Bik 유사 킬러(Killer) 단백질, c-jun, CD90/Thy1, c-Rel, CD94, CCL6/C10, CD97, C1q R1/CD93, CD151, C1qTNFl, CD160, ClqTNF4, CD163, ClqTNF5, CD164, 보체 성분 C1r, CD200, 보체 성분 C1s, CD200 R1, 보체 성분 C2, CD229/SLAMF3, 보체 성분 C3a, CD23/Fc 엡실론 RII, 보체 성분 C3d, CD2F-10/SLAMF9, 보체 성분 C5a, CD5L, 카드헤린-4/R-카드헤린, CD69, 카드헤린-6, CDC2, 카드헤린-8, CDC25A, 카드헤린-11, CDC25B, 카드헤린-12, CDCP1, 카드헤린-13, CDO, 카드헤린-17, CDX4, E-카드헤린, CEACAM-1/CD66a, N-카드헤린, CEACAM-6, P-카드헤린, 세베루스(Cerberus) 1, VE-카드헤린, CFTR, 칼빈딘(Calbindin) D, cGMP, 칼시뉴린(Calcineurin) A, 켐(Chem) R23, 칼시뉴린 B, 케메린(Chemerin), 칼렉티큘린(Calreticulin)-2, 케모카인 샘플러 팩(Sampler Pack), CaM 키나제 II, 키티나제(Chitinase) 3 유사 1, cAMP, 키토트리오시다제(Chitotriosidase)/CHIT1, 카나비노이드(Cannabinoid) R1, Chk1, 카나비노이드(Cannabinoid) R2/CB2/CNR2, Chk2, CAR/NR1I3, CHL-1/LlCAM-2, 탄산 탈수효소 I, 콜린 아세틸전이효소(Choline Acetyltransferase)/CbAT, 탄산 탈수효소 II, 콘드로렉틴(Chondrolectin), 탄산 탈수효소 III, 코르딘(Chordin), 탄산 탈수효소 IV, 코르딘 유사 1, 탄산 탈수효소 VA, 코르딘 유사 2, 탄산 탈수효소 VB, CINC-1, 탄산 탈수효소 VI, CINC-2, 탄산 탈수효소 VII, CINC-3, 탄산 탈수효소 VIII, 클라스핀(Claspin), 탄산 탈수효소 IX, 클라우딘(Claudin)-6, 탄산 탈수효소 X, CLC, 탄산 탈수효소 XII, CLEC-1, 탄산 탈수효소 XIII, CLEC-2, 탄산 탈수효소 XIV, CLECSF13/CLEC4F, 카복시멜틸 라이신, CLECSF8, 카복시펩티다제(Carboxypeptidase) A1/CPA1, CLF-1, 카복시펩티다제 A2, CL-P1/COLEC12, 카복시펩티다제 A4, 클러스테린(Clusterin), 카복시펩티다제 B1, 클러스테린 유사 1, 카복시펩티다제 E/CPE, CMG-2, 카복시펩티다제 X1, CMV UL146, 카리도트로핀(Cardiotrophin)-1, CMV UL147, 카르노신 디펩티다제(Carnosine Dipeptidase) 1, CNP, 카로네이트(Caronte), CNTF, CART, CNTF R 알파, 카스파아제, 응집 인자 II/트롬빈, 카스파아제-1, 응집 인자 III/조직 인자, 카스파아제-2, 응집 인자 VII, 카스파아제-3, 응집 인자 X, 카스파아제-4, 응집 인자 XI, 카스파아제-6, 응집 인자 XIV/단백질 C, 카스파아제-7, COCO, 카스파아제-8, 코헤신(Cohesin), 카스파아제-9, 콜라겐 I, 카스파아제-10, 콜라겐 II, 카스파아제-12, 콜라겐 IV, 카스파아제-13, 통상의 감마 쇄/IL-2 R 감마, 카스파아제 펩티드 저해제, COMP/트롬보스폰딘(Thrombospondin)-5, 카탈라제(Catalase), 보체 성분 C1rLP, 베타-카테닌(Catenin), 보체 성분 C1qA, 카텝신(Cathepsin) 1, 보체 성분 C1qC, 카텝신 3, 보체 인자 D, 카텝신 6, 보체 인자 I, 카텝신 A, 보체 MASP3, 카텝신 B, 코넥신(Connexin) 43, 카텝신 C/DPPI, 콘탁틴(Contactin)-1, 카텝신 D, 콘탁틴-2/TAGl, 카텝신 E, 콘탁틴-4, 카텝신 F, 콘탁틴-5, 카텝신 H, 코린(Corin), 카텝신 L, 코르눌린(Cornulin), 카텝신 O, CORS26/ClqTNF,3, 카텝신 S, 래트 피질 줄기 세포, 카텝신 V, 코르티졸(Cortisol), 카텝신 X/Z/P, COUP-TFI/NR2F1, CBP, COUP-TFII/NR2F2, CCI, COX-1, CCK-A R, COX-2, CCL28, CRACC/SLAMF7, CCR1, C 반응성 단백질, CCR2, 크레아틴 키나제, 근육/CKMM, CCR3, 크레아티닌, CCR4, CREB, CCR5, CREG, CCR6, CRELD1, CCR7, CRELD2, CCR8, CRHBP, CCR9, CRHR-1, CCR1O, CRIM1, CD155/PVR, 크립토(Cripto), CD2, CRISP-2, CD3, CRISP-3, CD4, 크로스베인레스(Crossveinless)-2, CD4+/45RA-, CRTAM, CD4+/45RO-, CRTH-2, CD4+/CD62L-/CD44, CRY1, CD4+/CD62L+/CD44, 크립틱(Cryptic), CD5, CSB/ERCC6, CD6, CCL27/CTACK, CD8, CTGF/CCN2, CD8+/45RA-, CTLA-4, CD8+/45RO-, 쿠빌린(Cubilin), CD9, CX3CR1, CD14, CXADR, CD27/TNFRSF7, CXCL16, CD27 리간드/TNFSF7, CXCR3, CD28, CXCR4, CD30/TNFRSF8, CXCR5, CD30 리간드/TNFSF8, CXCR6, CD31/PECAM-1, 사이클로필린(Cyclophilin) A, CD34, Cyr61/CCN1, CD36/SR-B3, 시스타틴(Cystatin) A, CD38, 시스타틴 B, CD40/TNFRSF5, 시스타틴 C, CD40 리간드/TNFSF5, 시스타틴 D, CD43, 시스타틴 E/M, CD44, 시스타틴 F, CD45, 시스타틴 H, CD46, 시스타틴 H2, CD47, 시스타틴 S, CD48/SLAMF2, 시스타틴 SA, CD55/DAF, 시스타틴 SN, CD58/LFA-3, 사이토크롬(Cytochrome) c, CD59, 아포사이토크롬 c, CD68, 홀로사이토크롬 c, CD72, 사이토케라틴 8, CD74, 사이토케라틴 14, CD83, 사이토케라틴 19, CD84/SLAMF5, 사이토닌(Cytonin), D6, DISP1, DAN, Dkk-1, DANCE, Dkk-2, DARPP-32, Dkk-3, DAX1/NR0B1, Dkk-4, DCC, DLEC, DCIR/CLEC4A, DLL1, DCAR, DLL4, DcR3/TNFRSF6B, d-루시페린(Luciferin), DC-SIGN, DNA 리가제(Ligase) IV, DC-SIGNR/CD299, DNA 폴리머라제 베타, DcTRAIL R1/TNFRSF23, DNAM-1, DcTRAIL R2/TNFRSF22, DNA-PKcs, DDR1, DNER, DDR2, 도파 데카복실라제(Dopa Decarboxylase)/DDC, DEC-205, DPCR-1, 데카펜타플레직(Decapentaplegic), DPP6, 데코린(Decorin), DPPA4, 덱틴(Dectin)-1/CLEC7A, DPPA5/ESG1, 덱틴-2/CLEC6A, DPPII/QPP/DPP7, DEP-1/CD148, DPPIV/CD26, 데저트 헤지호그(Desert Hedgehog), DR3/TNFRSF25, 데스민(Desmin), DR6/TNFRSF21, 데스모그레인(Desmoglein)-1, DSCAM, 데스모그레인-2, DSCAM-L1, 데스모그레인-3, DSPG3, 디쉐벨드(Dishevelled)-1, Dtk, 디쉐벨드-3, 다이나민(Dynamin), EAR2/NR2F6, EphA5, ECE-1, EphA6, ECE-2, EphA7, ECF-L/CHI3L3, EphA8, ECM-1, EphB1, 에코틴(Ecotin), EphB2, EDA, EphB3, EDA-A2, EphB4, EDAR, EphB6, EDG-1, 에프린(Ephrin), EDG-5, 에프린-A1, EDG-8, 에프린-A2, eEF-2, 에프린-A3, EGF, 에프린-A4, EGF R, 에프린-A5, EGR1, 에프린-B, EG-VEGF/PK1, 에프린-B1, eIF2 알파, 에프린-B2, eIF4E, 에프린-B3, EIk-1, 에피겐(Epigen), EMAP-II, 에피모핀(Epimorphin)/신탁신(Syntaxin) 2, EMMPRIN/CD147, 에피레귤린(Epiregulin), CXCL5/ENA, EPR-1/Xa 수용체, 엔도칸(Endocan), ErbB2, 엔도글린(Endoglin)/CD105, ErbB3, 엔도글리칸(Endoglycan), ErbB4, 엔도뉴클레아제(Endonuclease) III, ERCC1, 엔도뉴클레아제 IV, ERCC3, 엔도뉴클레아제 V, ERK1/ERK2, 엔도뉴클레아제 VIII, ERK1, 엔도레펠린(Endorepellin)/퍼레칸(Perlecan), ERK2, 엔도스타틴(Endostatin), ERK3, 엔도텔린(Endothelin)-1, ERK5/BMK1, 인그레일드-2, ERR 알파/NR3B1, EN-RAGE, ERR 베타/NR3B2, 엔테로펩티다제(Enteropeptidase)/엔테로키나제(Enterokinase), ERR 감마/NR3B3, CCL11/에오탁신(Eotaxin), 에리스로포이에틴, CCL24/에오탁신-2, 에리스로포이에틴 R, CCL26/에오탁신-3, ESAM, EpCAM/TROP-1, ER 알파/NR3A1, EPCR, ER 베타/NR3A2, Eph, 엑소뉴클레아제(Exonuclease) III, EphA1, 엑소스토신(Exostosin) 유사 2/EXTL2, EphA2, 엑소스토신 유사 3/EXTL3, EphA3, FABP1, FGF-BP, FABP2, FGF R1-4, FABP3, FGF R1, FABP4, FGF R2, FABP5, FGF R3, FABP7, FGF R4, FABP9, FGF R5, 보체 인자 B, Fgr, FADD, FHR5, FAM3A, 피브로넥틴, FAM3B, 피콜린-2, FAM3C, 피콜린-3, FAM3D, FITC, 섬유아세포 활성화 단백질 알파/FAP, FKBP38, Fas/TNFRSF6, Flap, Fas 리간드/TNFSF6, FLIP, FATP1, FLRG, FATP4, FLRT1, FATP5, FLRT2, Fc 감마 RI/CD64, FLRT3, Fc 감마 RIIB/CD32b, Flt-3, Fc 감마 RIIC/CD32c, Flt-3 리간드, Fc 감마 RIIA/CD32a, 폴리스타틴(Follistatin), Fc 감마 RIII/CD16, 폴리스타틴 유사 1, FcRH1/IRTA5, FosB/G0S3, FcRH2/IRTA4, FoxD3, FcRH4/IRTA1, FoxJ1, FcRH5/IRTA2, FoxP3, Fc 수용체 유사 3/CD16-2, Fpg, FEN-1, FPR1, 페투인(Fetuin) A, FPRL1, 페투인 B, FPRL2, FGF 산성, CX3CL1/프랙탈킨(Fractalkine), FGF 염기성, 프리즐드-1, FGF-3, 프리즐드-2, FGF-4, 프리즐드-3, FGF-5, 프리즐드-4, FGF-6, 프리즐드-5, FGF-8, 프리즐드-6, FGF-9, 프리즐드-7, FGF-1O, 프리즐드-8, FGF-11, 프리즐드-9, FGF-12, Frk, FGF-13, sFRP-1, FGF-16, sFRP-2, FGF-17, sFRP-3, FGF-19, sFRP-4, FGF-20, 퓨린(Furin), FGF-21, FXR/NR1H4, FGF-22, Fyn, FGF-23, G9a/EHMT2, GFR 알파-3/GDNF R 알파-3, GABA-A-R 알파 1, GFR 알파-4/GDNF R 알파-4, GABA-A-R 알파 2, GITR/TNFRSF18, GABA-A-R 알파 4, GITR 리간드/TNFSF18, GABA-A-R 알파 5, GLI-1, GABA-A-R 알파 6, GLI-2, GABA-A-R 베타 1, GLP/EHMT1, GABA-A-R 베타 2, GLP-1 R, GABA-A-R 베타 3, 글루카곤, GABA-A-R 감마 2, 글루코사민(Glucosamine) (N-아세틸)-6-설파타제(Sulfatase)/GNS, GABA-B-R2, GluR1, GAD1/GAD67, GluR2/3, GAD2/GAD65, GluR2, GADD45 알파, GluR3, GADD45 베타, Glut1, GADD45 감마, Glut2, 갈렉틴(Galectin)-1, Glut3, 갈렉틴-2, Glut4, 갈렉틴-3, Glut5, 갈렉틴-3 BP, 글루타레독신(Glutaredoxin) 1, 갈렉틴-4, 글리신 R, 갈렉틴-7, 글리코포린(Glycophorin) A, 갈렉틴-8, 글리피칸(Glypican) 2, 갈렉틴-9, 글리피칸 3, GalNAc4S-6ST, 글리피칸 5, GAP-43, 글리피칸 6, GAPDH, GM-CSF, Gas1, GM-CSF R 알파, Gas6, GMF-베타, GASP-1/WFIKKNRP, gp130, GASP-2/WFIKKN, 글리코겐 포스포릴라제(Glycogen Phosphorylase) BB/GPBB, GATA-1, GPR15, GATA-2, GPR39, GATA-3, GPVI, GATA-4, GR/NR3C1, GATA-5, Gr-1/Ly-6G, GATA-6, 그래뉼리신(Granulysin), GBL, 그랜자임 A, GCNF/NR6A1, 그랜자임 B, CXCL6/GCP-2, 그랜자임 D, G-CSF, 그랜자임 G, G-CSF R, 그랜자임 H, GDF-1, GRASP, GDF-3 GRB2, GDF-5, 그렘린(Gremlin), GDF-6, GRO, GDF-7, CXCL1/GRO 알파, GDF-8, CXCL2/GRO 베타, GDF-9, CXCL3/GRO 감마, GDF-11, 성장 호르몬, GDF-15, 성장 호르몬 R, GDNF, GRP75/HSPA9B, GFAP, GSK-3 알파/베타, GFI-1, GSK-3 알파, GFR 알파-1/GDNF R 알파-1, GSK-3 베타, GFR 알파-2/GDNF R 알파-2, EZFIT, H2AX, 히스티딘, H60, HM74A, HAI-1, HMGA2, HAI-2, HMGB1, HAI-2A, TCF-2/HNF-1 베타, HAI-2B, HNF-3 베타/FoxA2, HAND1, HNF-4 알파/NR2A1, HAPLN1, HNF-4 감마/NR2A2, 기도(Airway) 트립신 유사 프로테아제/HAT, HO-1/HMOX1/HSP32, HB-EGF, HO-2/HMOX2, CCL 14a/HCC-1, HPRG, CCL14b/HCC-3, Hrk, CCL16/HCC-4, HRP-1, 알파 HCG, HS6ST2, Hck, HSD-1, HCR/CRAM-A/B, HSD-2, HDGF, HSP10/EPF, 헤모글로빈(Hemoglobin), HSP27, 헤파소신(Hepassocin), HSP60, HES-1, HSP70, HES-4, HSP90, HGF, HTRA/프로테아제 Do, HGF 활성화제, HTRA1/PRSS11, HGF R, HTRA2/0mi, HIF-1 알파, HVEM/TNFRSF14, HIF-2 알파, 하이알유로난(Hyaluronan), HIN-1/세크레토글로불린(Secretoglobulin) 3A1, 4-하이드록시노네날(Hydroxynonenal), Hip, CCL1/I-309/TCA-3, IL-1O, cIAP(pan), IL-1OR 알파, cIAP-1/HIAP-2, IL-1OR 베타, cIAP-2/HIAP-1, IL-11, IBSP/시알로(Sialo)단백질 II, EL-11 R 알파, ICAM-1/CD54, IL-12, ICAM-2/CD102, IL-12/IL-23 p40, ICAM-3/CD50, IL-12 R 베타 1, ICAM-5, IL-12 R 베타 2, ICAT, IL-13, ICOS, IL-13 R 알파 1, 이듀로네이트(Iduronate) 2-설파타제/IDS, IL-13 R 알파 2, IFN, IL-15, IFN-알파, IL-15 R 알파, IFN-알파 1, IL-16, IFN-알파 2, IL-17, IFN-알파 4b, IL-17 R, IFN-알파 A, IL-17 RC, IFN-알파 B2, IL-17 RD, IFN-알파 C, IL-17B, IFN-알파 D, IL-17B R, IFN-알파 F, IL-17C, IFN-알파 G, IL-17D, IFN-알파 H2, IL-17E, IFN-알파 I, IL-17F, IFN-알파 J1, IL-18/IL-1F4, IFN-알파 K, IL-18 BPa, IFN-알파 WA, IL-18 BPc, IFN-알파/베타 R1, IL-18 BPd, IFN-알파/베타 R2, IL-18 R 알파/IL-1 R5, IFN-베타, IL-18 R 베타/IL-1 R7, IFN-감마, IL-19, IFN-감마 R1, IL-20, IFN-감마 R2, IL-20 R 알파, IFN-오메가, IL-20 R 베타, IgE, IL-21, IGFBP-1, IL-21 R, IGFBP-2, IL-22, IGFBP-3, IL-22 R, IGFBP-4, IL-22BP, IGFBP-5, IL-23, IGFBP-6, IL-23 R, IGFBP-L1, IL-24, IGFBP-rpl/IGFBP-7, IL-26/AK155, IGFBP-rP1O, IL-27, IGF-I, EL-28A, IGF-I R, IL-28B, IGF-II, IL-29/IFN-람다 1, IGF-II R, IL-31, IgG, EL-31 RA, IgM, IL-32 알파, IGSF2, IL-33, IGSF4A/SynCAM, ILT2/CD85j, IGSF4B, ILT3/CD85k, IGSF8, ILT4/CD85d, IgY, ILT5/CD85a, IkB-베타, ILT6/CD85e, IKK 알파, 인디안 헤지호그(Indian Hedgehog), IKK 엡실론, INSRR, EKK 감마, 인슐린, IL-1 알파/IL-IF1, 인슐린 R/CD220, IL-1 베타/IL-1F2, 프로인슐린, IL-1ra/IL-1F3, 인슐리신(Insulysin)/IDE, IL-1F5/FIL1 델타, 인테그린(Integrin) 알파 2/CD49b, IL-1F6/FIL1 엡실론, 인테그린 알파 3/CD49c, IL-1F7/FIL1 제타, 인테그린 알파 3 베타 1/VLA-3, IL-1F8/FIL1 에타, 인테그린 알파 4/CD49d, IL-1F9/IL-1 H1, 인테그린 알파 5/CD49e, IL-1F10/IL-1HY2, 인테그린 알파 5 베타 1, IL-1 RI, 인테그린 알파 6/CD49f, IL-1 RII, 인테그린 알파 7, IL-1 R3/IL-1 R AcP, 인테그린 알파 9, IL-1 R4/ST2, 인테그린 알파 E/CD103, IL-1 R6/IL-1 R rp2, 인테그린 알파 L/CD11a, IL-1 R8, 인테그린 알파 L 베타 2, IL-1 R9, 인테그린 알파 M/CD11b, IL-2, 인테그린 알파 M 베타 2, IL-2 R 알파, 인테그린 알파 V/CD51, IL-2 R 베타, 인테그린 알파 V 베타 5, IL-3, 인테그린 알파 V 베타 3, IL-3 R 알파, 인테그린 알파 V 베타 6, IL-3 R 베타, 인테그린 알파 XJCD11c, IL-4, 인테그린 베타 1/CD29, IL-4 R, 인테그린 베타 2/CD18, IL-5, 인테그린 베타 3/CD61, IL-5 R 알파, 인테그린 베타 5, IL-6, 인테그린 베타 6, IL-6 R, 인테그린 베타 7, IL-7, CXCL10/EP-10/CRG-2, IL-7 R 알파/CD127, IRAK1, CXCR1/IL-8 RA, IRAK4, CXCR2/IL-8 RB, ERS-1, CXCL8/IL-8, 아일렛(Islet)-1, IL-9, CXCL11/I-TAC, IL-9 R, 잭드(Jagged) 1, JAM-4/IGSF5, 잭드 2, JNK, JAM-A, JNK1/JNK2, JAM-B/VE-JAM, JNK1, JAM-C, JNK2, 키니노겐(Kininogen), 칼리크레인(Kallikrein) 3/PSA, 키니노스타틴(Kininostatin), 칼리크레인 4, KIR/CD158, 칼리크레인 5, KIR2DL1, 칼리크레인 6/뉴로신(Neurosin), KIR2DL3, 칼리크레인 7, KIR2DL4/CD158d, 칼리크레인 8/뉴롭신(Neuropsin), KIR2DS4, 칼리크레인 9, KIR3DL1, 혈장 칼리크레인/KLKB1, KIR3DL2, 칼리크레인 10, 키렐(Kirrel)2, 칼리크레인 11, KLF4, 칼리크레인 12, KLF5, 칼리크레인 13, KLF6, 칼리크레인 14, 클로쏘(Klotho), 칼리크레인 15, 클로쏘 베타, KC, KOR, 키프(Keap)1, 크레먼(Kremen)-1, Kell, 크레멘(Kremen)-2, KGF/FGF-7, LAG-3, LINGO-2, LAIR1, 리핀(Lipin) 2, LAIR2, 리포칼린(Lipocalin)-1, 라미닌(Laminin) 알파 4, 리포칼린(Lipocalin)-2/NGAL, 라미닌 감마 1, 5-리폭시게나제(Lipoxygenase), 라미닌 I, LXR 알파/NR1H3, 라미닌 S, LXR 베타/NR1H2, 라미닌-1, 리빈(Livin), 라미닌-5, LEX, LAMP, LMIR1/CD300A, 란게린(Langerin), LMIR2/CD300c, LAR, LMIR3/CD300LF, 라텍신(Latexin), LMIR5/CD300LB, 레이일린(Layilin), LMIR6/CD300LE, LBP, LMO2, LDL R, LOX-1/SR-E1, LECT2, LRH-1/NR5A2, LEDGF, LRIG1, 레프티(Lefty), LRIG3, 레프티-1, LRP-1, 레프티-A, LRP-6, 레구메인(Legumain), LSECtin/CLEC4G, 렙틴(Leptin), 루미칸(Lumican), 렙틴 R, CXCL15/렁킨(Lungkine), 류코트리엔(Leukotriene) B4, XCL1/림포탁틴(Lymphotactin), 류코트리엔 B4 R1, 림포톡신(Lymphotoxin), LIF, 림포톡신 베타/TNFSF3, LIF R 알파, 림포톡신 베타 R/TNFRSF3, LIGHT/TNFSF14, Lyn, 리미틴(Limitin), Lyp, LIMPII/SR-B2, 라이실 산화효소 상동체 2, LIN-28, LYVE-1, LINGO-1, 알파 2-매크로글로불린, CXCL9/MIG, MAD2L1, 미메칸(Mimecan), MAdCAM-1, 민딘(Mindin), MafB, 미네랄로코르티코이드(Mineralocorticoid) R/NR3C2, MafF, CCL3L1/MIP-1 알파 이소형 LD78 베타, MafG, CCL3/MIP-1 알파, MafK, CCL4L1/LAG-1, MAG/시글렉(Siglec)-4a, CCL4/MIP-1 베타, MANF, CCL15/MIP-1 델타, MAP2, CCL9/10/MIP-1 감마, MAPK, MIP-2, 마랍신(Marapsin)/판크레아신(Pancreasin), CCL19/MIP-3 베타, MARCKS, CCL20/MIP-3 알파, MARCO, MIP-I, Mash1, MIP-II, 마트릴린(Matrilin)-2, MIP-III, 마트릴린-3, MIS/AMH, 마트릴린-4, MIS RII, 마트립타제(Matriptase)/ST14, MIXL1, MBL, MKK3/MKK6, MBL-2, MKK3, 멜라노코르틴(Melanocortin) 3R/MC3R, MKK4, MCAM/CD146, MKK6, MCK-2, MKK7, Mcl-1, MKP-3, MCP-6, MLH-1, CCL2/MCP-1, MLK4 알파, MCP-11, MMP, CCL8/MCP-2, MMP-1, CCL7/MCP-3/MARC, MMP-2, CCL13/MCP-4, MMP-3, CCL12/MCP-5, MMP-7, M-CSF, MMP-8, M-CSF R, MMP-9, MCV-유형 II, MMP-1O, MD-1, MMP-11, MD-2, MMP-12, CCL22/MDC, MMP-13, MDL-1/CLEC5A, MMP-14, MDM2, MMP-15, MEA-1, MMP-16/MT3-MMP, MEK1/MEK2, MMP-24/MT5-MMP, MEK1, MMP-25/MT6-MMP, MEK2, MMP-26, 멜루신(Melusin), MMR, MEPE, MOG, 메프린(Meprin) 알파, CCL23/MPIF-1, 메프린 베타, M-Ras/R-Ras3, Mer, Mre11, 메소텔린(Mesothelin), MRP1 메테오린(Meteorin), MSK1/MSK2, 메티오닌 아미노펩티다제 1, MSK1, 메티오닌아미노펩티다제, MSK2, 메티오닌아미노펩티다제 2, MSP, MFG-E8, MSP R/Ron, MFRP, Mug, MgcRacGAP, MULT-1, MGL2, 무사쉬(Musashi)-1, MGMT, 무사쉬-2, MIA, MuSK, MICA, MutY DNA 글리코실라제, MICB, MyD88, MICL/CLEC12A, 미엘로퍼옥시다제(Myeloperoxidase), 베타 2 마이크로글로불린, 마이오카딘(Myocardin), 미드킨(Midkine), 미오실린(Myocilin), MIF, 미오글로빈(Myoglobin), NAIP NGFI-B 감마/NR4A3, 나노그(Nanog), NgR2/NgRH1, CXCL7/NAP-2, NgR3/NgRH2, Nbs1, 니도겐(Nidogen)-1/엔탁틴(Entactin), NCAM-1/CD56, 니도겐-2, NCAM-L1, 산화질소, 넥틴(Nectin)-1, 니트로타이로신, 넥틴-2/CD112, NKG2A, 넥틴-3, NKG2C, 넥틴-4, NKG2D, 네오게닌(Neogenin), NKp30, 네프릴리신(Neprilysin)/CD1O, NKp44, 네프리리신-2/MMEL1/MMEL2, NKp46/NCR1, 네스틴(Nestin), NKp80/KLRF1, NETO2, NKX2.5, 네트린(Netrin)-1, NMDA R, NR1 서브유닛, 네트린-2, NMDA R, NR2A 서브유닛, 네트린-4, NMDA R, NR2B 서브유닛, 네트린-Gla, NMDA R, NR2C 서브유닛, 네트린-G2a, N-Me-6,7-디OH-TIQ, 뉴레귤린(Neuregulin)-1/NRG1, 노달(Nodal), 뉴레귤린-3/NRG3, 노긴(Noggin), 뉴리틴(Neuritin), 노고(Nogo) 수용체, 뉴로(Neuro)D1, 노고(Nogo)-A, 뉴로파신(Neurofascin), NOMO, 뉴로게닌(Neurogenin)-1, 노프(Nope), 뉴로게닌-2, 노린(Norrin), 뉴로게닌-3, eNOS, 뉴로리신, iNOS, 뉴로피신(Neurophysin) II, nNOS, 뉴로필린(Neuropilin)-1, 노취(Notch)-1, 뉴로필린-2, 노취-2, 뉴로포이에틴(Neuropoietin), 노취-3, 뉴로트리민(Neurotrimin), 노취-4, 뉴르튜린(Neurturin), NOV/CCN3, NFAM1, NRAGE, NF-H, NrCAM, NFkBl, NRL, NFkB2, NT-3, NF-L, NT-4, NF-M, NTB-A/SLAMF6, NG2/MCSP, NTH1, NGF R/TNFRSF16, 뉴클레오스테민(Nucleostemin), 베타-NGF, Nurr-1/NR4A2, NGFI-B 알파/NR4A1, OAS2, 오렉신(Orexin) B, OBCAM, OSCAR, OCAM, OSF-2/페리오스틴(Periostin), OCIL/CLEC2d, 온코스타틴(Oncostatin) M/OSM, OCILRP2/CLEC2i, OSM R 베타, Oct-3/4, 오스테오액티빈/GPNMB, OGG1, 오스테오아드헤린(Osteoadherin), 올리그(Olig)1, 2, 3, 오스테오칼신(Osteocalcin), 올리그1, 오스테오크린(Osteocrin), 올리그2, 오스테오폰틴(Osteopontin), 올리그3, 오스테오프로테게린/TNFRSF11B, 올리고덴드로사이트(Oligodendrocyte) 마커 01, Otx2, 올리고덴드로사이트 마커 O4, OV-6, OMgp, OX40/TNFRSF4, 옵티신(Opticin), OX40 리간드/TNFSF4, 오렉신(Orexin) A, OAS2, 오렉신 B, OBCAM, OSCAR, OCAM, OSF-2/페리오스틴(Periostin), 0CIL/CLEC2d, 온코스타틴(Oncostatin) M/OSM, OCILRP2/CLEC2i, OSM R 베타, Oct-3/4, 오스테오액티빈/GPNMB, OGG1, 오스테오아드헤린(Osteoadherin), 올리그 1, 2, 3, 오스테오칼신(Osteocalcin), 올리그1, 오스테오크린(Osteocrin), 올리그2, 오스테오폰틴(Osteopontin), 올리그3, 오스테오프로테게린(Osteoprotegerin)/TNFRSF11B, 올리고덴드로사이트 마커 O1, Otx2, 올리고덴드로사이트 마커 04, OV-6, OMgp, OX40/TNFRSF4, 옵티신(Opticin), OX40 리간드/TNFSF4, 오렉신 A, RACK1, Ret, Rad1, REV-ERB 알파/NRlD1, Radl7, REV-ERB 베타/NRlD2, Rad51, Rex-1, Rae-1, RGM-A, Rae-1 알파, RGM-B, Rae-1 베타, RGM-C, Rae-1 델타, Rheb, Rae-1 엡실론, 리보솜 단백질 S6, Rae-1 감마, RIP1, Raf-1, ROBOl, RAGE, R0B02, RalA/RalB, R0B03, RalA, ROBO4, RalB, R0R/NR1F1-3(pan), RANK/TNFRSF11A, ROR 알파/NRlF1, CCL5/RANTES, ROR 감마/NRlF3, Rap1A/B, RTK 유사 오펀(Orphan) 수용체 1/ROR1, RAR 알파/NRlB1, RTK 유사 오펀 수용체 2/ROR2, RAR 베타/NRlB2, RP105, RAR 감마/NRlB3, RPA2, Ras, RSK(pan), RBP4, RSK1/RSK2, RECK, RSK1, Reg2/PAP, RSK2, Reg I, RSK3, Reg II, RSK4, Reg III, R-스폰딘(Spondin) 1, Reg IIIa, R-스폰딘 2, Reg IV, R-스폰딘 3, 릴랙신(Relaxin)-1, RUNX1/CBFA2, 릴랙신-2, RUNX2/CBFA1, 릴랙신-3, RUNX3/CBFA3, RELM 알파, RXR 알파/NR2B1, RELM 베타, RXR 베타/NR2B2, RELT/TNFRSF19L, RXR 감마/NR2B3, 레지스틴(Resistin), S1OOA1O, SLITRK5, S100A8, SLPI, S100A9, SMAC/디아블로(Diablo), S1OOB, Smad1, S1OOP, Smad2, SALL1, Smad3, 델타-사코글리칸(Sarcoglycan), Smad4, Sca-1/Ly6, Smad5, SCD-1, Smad7, SCF, Smad8, SCF R/c-키트, SMC1, SCGF, 알파-평활근 액틴, SCL/Tall, SMUG1, SCP3/SYCP3, 스네일(Snail), CXCL12/SDF-1, 나트륨 칼슘 교환기 1, SDNSF/MCFD2, 소기(Soggy)-1, 알파-세크레타제(Secretase), 소닉 헤지호그(Sonic Hedgehog), 감마-세크레타제, SorCS1, 베타-세크레타제, SorCS3, E-셀렉틴(Selectin), 소르틸린(Sortilin), L-셀렉틴, SOST, P-셀렉틴, SOX1, 세마포린(Semaphorin) 3A, SOX2, 세마포린 3C, SOX3, 세마포린 3E, SOX7, 세마포린 3F, SOX9, 세마포린 6A, SOX1O, 세마포린 6B, SOX17, 세마포린 6C, SOX21 세마포린 6D, SPARC, 세마포린 7A, SPARC 유사 1, 세파라제(Separase), SP-D, 세린/트레오닌 포스파타제 기질 I, 스피네신(Spinesin), 세르핀(Serpin) A1, F-스폰딘, 세르핀 A3, SR-AI/MSR, 세르핀 A4/칼리스타틴(Kallistatin), Src, 세르핀 A5/단백질 C 저해제, SREC-I/SR-F1, 세르핀 A8/안지오텐시노겐, SREC-II, 세르핀 B5, SSEA-1, 세르핀 C1/안티트롬빈-III, SSEA-3, 세르핀 D1/헤파린 보조인자 II, SSEA-4, 세르핀 E1/PAI-1, ST7/LRP12, 세르핀 E2, 스타빌린(Stabilin)-1, 세르핀 F1, 스타빌린-2, 세르핀 F2, 스탄니오칼신(Stanniocalcin) 1, 세르핀 G1/C1 저해제, 스탄니노칼신 2, 세르핀 I2, STAT1, 혈청 아밀로이드 A1, STAT2, SF-1/NR5A1, STAT3, SGK, STAT4, SHBG, STAT5a/b, SHIP, STAT5a, SHP/NR0B2, STAT5b, SHP-1, STAT6, SHP-2, VE-스타틴(Statin), SIGIRR, 스텔라(Stella)/Dppa3, 시글렉(Siglec)-2/CD22, STRO-1, 시글렉-3/CD33, 물질 P, 시글렉-5, 설파미다제(Sulfamidase)/SGSH, 시글렉-6, 설파타제 변경 인자 1/SUMFl, 시글렉-7, 설파타제 변경 인자 2/SUMF2, 시글렉-9, SUMO1, 시글렉-10, SUMO2/3/4, 시글렉-11, SUMO3, 시글렉-F, 수퍼옥시드 디스뮤타제(Superoxide Dismutase), SIGNR1/CD209, 수퍼옥시드 디스뮤타제-1 /Cu-Zn SOD, SIGNR4, 수퍼옥시드 디스뮤타제-2/Mn-SOD, SIRP 베타 1, 수퍼옥시드 디스뮤타제-3/EC-SOD, SKI, 서비빈(Survivin), SLAM/CD150, 시냅신(Synapsin) I, 슬리핑 뷰티 트랜스포사아제(Sleeping Beauty Transposase), 신데칸(Syndecan)-I/CD138, 슬릿(Slit)3, 신데칸-2, SLITRK1, 신데칸-3, SLITRK2, 신데칸-4, SLITRK4, TACI/TNFRSF13B, TMEFF1/토모레귤린(Tomoregulin)-1, TAO2, TMEFF2, TAPP1, TNF-알파/TNFSF1A, CCL17/TARC, TNF-베타/TNFSF1B, Tau, TNFRI/TNFRSFIA, TC21/R-Ras2, TNF RII/TNFRSF1B, TCAM-1, TOR, TCCR/WSX-1, TP-1, TC-PTP, TP63/TP73L, TDG, TR, CCL25/TECK, TR 알파/NR1A1, 테나신(Tenascin) C, TR 베타 1/NR1A2, 테나신 R, TR2/NR2C1, TER-119, TR4/NR2C2, TERT, TRA-1-85, 테스티칸(Testican) 1/SPOCK1, TRADD, 테스티칸 2/SPOCK2, TRAF-1, 테스티칸 3/SPOCK3, TRAF-2, TFPI, TRAF-3, TFPI-2, TRAF-4, TGF-알파, TRAF-6, TGF-베타, TRAIL/TNFSF10, TGF-베타 1, TRAIL R1/TNFRSF1OA, LAP(TGF-베타 1), TRAIL R2/TNFRSF10B, 잠복성(Latent) TGF-베타 1, TRAIL R3/TNFRSF10C, TGF-베타 1.2, TRAIL R4/TNFRSF10D, TGF-베타 2, TRANCE/TNFSF11, TGF-베타 3, TfR(트랜스페린(Transferrin) R), TGF-베타 5, Apo-트랜스페린, 잠복성 TGF-베타 bp 1, 홀로-트랜스페린, 잠복성 TGF-베타 bp2, 트랩핀(Trappin)-2/엘라핀(Elafin), 잠복성 TGF-베타 bp4, TREM-1, TGF-베타 RI/ALK-5, TREM-2, TGF-베타 RII, TREM-3, TGF-베타 RIIb, TREML1/TLT-1, TGF-베타 RIII, TRF-1, 써모리신(Thermolysin), TRF-2, 티오레독신-1, TRH-분해 엑토엔자임(Ectoenzyme)/TRHDE, 티오레독신-2, TRIM5, 티오레독신-80, 트리펩티딜-펩티다제 I, 티오레독신 유사 5/TRP14, TrkA, THOP1, TrkB, 트롬보모듈린(Thrombomodulin)/CD141, TrkC, 혈소판형성인자(Thrombopoietin), TROP-2, 혈소판형성인자 R, 트로포닌(Troponin) I 펩티드 3, 트롬보스폰딘-1, 트로포닌 T, 트롬보스폰딘-2, TROY/TNFRSF19, 트롬보스폰딘-4, 트립신 1, 티모포이에틴(Thymopoietin), 트립신 2/PRSS2, 티머스 케모카인(Thymus chemokine)-1, 트립신 3/PRSS3, 타이(Tie)-1, 트립타제(Tryptase)-5/Prss32, 타이-2, 트립타제 알파/TPS1, TIM-1/KIM-1/HAVCR, 트립타제 베타-1/MCPT-7, TIM-2, 트립타제 베타-2/TPSB2, TIM-3, 트립타제 엡실론/BSSP-4, TIM-4, 트립타제 감마-1/TPSG1, TIM-5, 트립토판하이드록실라제, TIM-6, TSC22, TIMP-1, TSG, TIMP-2, TSG-6, TIMP-3, TSK, TIMP-4, TSLP, TL1A/TNFSF15, TSLP R, TLR1, TSP50, TLR2, 베타-III 튜불린, TLR3, TWEAK/TNFSF12, TLR4, TWEAK R/TNFRSF12, TLR5, Tyk2, TLR6, 포스포-타이로신, TLR9, 타이로신하이드록실라제, TLX/NR2E1, 타이로신 포스파타제 기질 I, 유비퀴틴(Ubiquitin), UNC5H3, Ugi, UNC5H4, UGRP1, UNG, ULBP-1, uPA, ULBP-2, uPAR, ULBP-3, URB, UNC5H1, UVDE, UNC5H2, 바닐로이드(Vanilloid) R1, VEGFR, VASA, VEGF R1/Flt-1, 바소히빈(Vasohibin), VEGF R2/KDR/Flk-1, 바소린(Vasorin), VEGF R3/Flt-4, 바소스타틴(Vasostatin), 베르시칸(Versican), Vav-1, VG5Q, VCAM-1, VHR, VDR/NR1I1, 비멘틴(Vimentin), VEGF, 비트로넥틴, VEGF-B, VLDLR, VEGF-C, vWF-A2, VEGF-D, 사이누클레인(Synuclein)-알파, Ku70, WASP, Wnt-7b, WIF-1, Wnt-8a WISP-1/CCN4, Wnt-8b, WNK1, Wnt-9a, Wnt-1, Wnt-9b, Wnt-3a, Wnt-lOa, Wnt-4, Wnt-10b, Wnt-5a, Wnt-11, Wnt-5b, wnvNS3, Wnt7a, XCR1, XPE/DDB1, XEDAR, XPE/DDB2, Xg, XPF, XIAP, XPG, XPA, XPV, XPD, XRCC1, Yes, YY1, EphA4.
다수의 인간 이온 채널은 특히 관심을 끄는 표적이다. 비제한적 예로는 5-하이드록시트립타민(hydroxytryptamine) 3 수용체 B 서브유닛, 5-하이드록시트립타민 3 수용체 전구체, 5-하이드록시트립타민 수용체 3 서브유닛 C, AAD114 단백질, 아세틸콜린(Acetylcholine) 수용체 단백질, 알파 서브유닛 전구체, 아세틸콜린 수용체 단백질, 베타 서브유닛 전구체, 아세틸콜린 수용체 단백질, 델타 서브유닛 전구체, 아세틸콜린 수용체 단백질, 엡실론 서브유닛 전구체, 아세틸콜린 수용체 단백질, 감마 서브유닛 전구체, 산 감지 이온 채널 3 스플라이스(splice) 변형체 b, 산 감지 이온 채널 3 스플라이스 변형체 c, 산 감지 이온 채널 4, ADP-리보스피로포스파타제(ribosepyrophosphatase), 미토콘드리아 전구체, 알파1A-전압 의존성 칼슘 채널, 연령 의존성 칼슘 채널, 아밀로이드-감수성 양이온 채널 1, 뉴런성(neuronal), 아밀로이드-감수성 양이온 채널 2, 뉴런성 아밀로이드-감수성 양이온 채널 4, 이소형 2, 아밀로이드-감수성 나트륨 채널, 아밀로이드-감수성 나트륨 채널 알파-서브유닛, 아밀로이드-감수성 나트륨 채널 베타-서브유닛, 아밀로이드-감수성 나트륨 채널 델타-서브유닛, 아밀로이드-감수성 나트륨 채널 감마-서브유닛, 아넥신 A7, 설첨(Apical) 유사 단백질, ATP-감수성 내부 개정자(rectifier) 칼륨 채널 1, ATP-감수성 내부 개정자 칼륨 채널 10, ATP-감수성 내부 개정자 칼륨 채널 11, ATP-감수성 내부 개정자 칼륨 채널 14, ATP-감수성 내부 개정자 칼륨 채널 15, ATP-감수성 내부 개정자 칼륨 채널 8, 칼슘 채널 알파12.2 서브유닛, 칼슘 채널 알파12.2 서브유닛, 칼슘 채널 알파1E 서브유닛, 델타19 델타40 델타46 스플라이스 변형체, 칼슘 활성화된 칼륨 채널 알파 서브유닛 1, 칼슘 활성화된 칼륨 채널 베타 서브유닛 1, 칼슘 활성화된 칼륨 채널 베타 서브유닛 2, 칼슘 활성화된 칼륨 채널 베타 서브유닛 3, 칼슘 의존성 클로라이드 채널-1, 양이온 채널 TRPM4B, CDNA FLJ90453 fis, 클론 NT2RP3001542, 칼륨 채널 4량체화 도메인 함유 6와 매우 유사함, CDNA FLJ90663 fis, 클론 PLACE1005031, 클로라이드 세포내 채널 단백질 5와 매우 유사함, CGMP-게이티드(gated) 양이온 채널 베타 서브유닛, 클로라이드 채널 단백질, 클로라이드 채널 단백질 2, 클로라이드 채널 단백질 3, 클로라이드 채널 단백질 4, 클로라이드 채널 단백질 5, 클로라이드 채널 단백질 6, 클로라이드 채널 단백질 ClC-Ka, 클로라이드 채널 단백질 ClC-Kb, 클로라이드 채널 단백질, 골격근, 클로라이드 세포내 채널 6, 클로라이드 세포내 채널 단백질 3, 클로라이드 세포내 채널 단백질 4, 클로라이드 세포내 채널 단백질 5, CHRNA3 단백질, Clcn3e 단백질, CLCNKB 단백질, CNGA4 단백질, 쿨린(Cullin)-5, 환형 GMP 게이티드 칼륨 채널, 환형-뉴클레오티드-게이티드 양이온 채널 4, 환형-뉴클레오티드-게이티드 양이온 채널 알파 3, 환형-뉴클레오티드-게이티드 양이온 채널 베타 3, 환형-뉴클레오티드-게이티드 후각 채널, 낭포성 섬유증 막 전도 조절자(Cystic fibrosis transmembrane conductance regulator), 사이토크롬 B-245 중쇄, 디하이드로피리딘-감수성 L-유형, 칼슘 채널 알파-2/델타 서브유닛 전구체, FXYD 도메인 함유 이온 수송 조절자 3 전구체, FXYD 도메인 함유 이온 수송 조절자 5 전구체, FXYD 도메인 함유 이온 수송 조절자 6 전구체, FXYD 도메인 함유 이온 수송 조절자 7, FXYD 도메인 함유 이온 수송 조절자 8 전구체, G 단백질 활성화된 내부 개정자 칼륨 채널 1, G 단백질 활성화된 내부 개정자 칼륨 채널 2, G 단백질 활성화된 내부 개정자 칼륨 채널 3, G 단백질 활성화된 내부 개정자 칼륨 채널 4, 감마-아미노부티르산 수용체 알파-1 서브유닛 전구체, 감마-아미노부티르산 수용체 알파-2 서브유닛 전구체, 감마-아미노부티르산 수용체 알파-3 서브유닛 전구체, 감마-아미노부티르산 수용체 알파-4 서브유닛 전구체, 감마-아미노부티르산 수용체 알파-5 서브유닛 전구체, 감마-아미노부티르산 수용체 알파-6 서브유닛 전구체, 감마-아미노부티르산 수용체 베타-1 서브유닛 전구체, 감마-아미노부티르산 수용체 베타-2 서브유닛 전구체, 감마-아미노부티르산 수용체 베타-3 서브유닛 전구체, 감마-아미노부티르산 수용체 델타 서브유닛 전구체, 감마-아미노부티르산 수용체 엡실론 서브유닛 전구체, 감마-아미노부티르산 수용체 감마-1 서브유닛 전구체, 감마-아미노부티르산 수용체 감마-3 서브유닛 전구체, 감마-아미노부티르산 수용체 파이 서브유닛 전구체, 감마-아미노부티르산 수용체 rho-1 서브유닛 전구체, 감마-아미노부티르산 수용체 rho-2 서브유닛 전구체, 감마-아미노부티르산 수용체 쎄타 서브유닛 전구체, GluR6 카이네이트 수용체, 글루타메이트 수용체 1 전구체, 글루타메이트 수용체 2 전구체, 글루타메이트 수용체 3 전구체, 글루타메이트 수용체 4 전구체, 글루타메이트 수용체 7, 글루타메이트 수용체 B, 글루타메이트 수용체 델타-1 서브유닛 전구체, 글루타메이트 수용체, 이오노트로픽(ionotropic) 카이네이트 1 전구체, 글루타메이트 수용체, 이오노트로픽 카이네이트 2 전구체, 글루타메이트 수용체, 이오노트로픽 카이네이트 3 전구체, 글루타메이트 수용체, 이오노트로픽 카이네이트 4 전구체, 글루타메이트 수용체, 이오노트로픽 카이네이트 5 전구체, 글루타메이트 [NMDA] 수용체 서브유닛 3A 전구체, 글루타메이트 [NMDA] 수용체 서브유닛 3B 전구체, 글루타메이트 [NMDA] 수용체 서브유닛 엡실론 1 전구체, 글루타메이트 [NMDA] 수용체 서브유닛 엡실론 2 전구체, 글루타메이트 [NMDA] 수용체 서브유닛 엡실론 4 전구체, 글루타메이트 [NMDA] 수용체 서브유닛 제타 1 전구체, 글리신수용체 알파-1 쇄 전구체, 글리신수용체 알파-2 쇄 전구체, 글리신수용체 알파-3 쇄 전구체, 글리신수용체 베타 쇄 전구체, H/ACA 리보뉴클레오단백질 복합체 서브유닛 1, 고친화도 면역글로불린 엡실론 수용체 베타-서브유닛, 가상 단백질 DKFZp31310334, 가상 단백질 DKFZp761M1724, 가상 단백질 FLJ12242, 가상 단백질 FLJ14389, 가상 단백질 FLJ14798, 가상 단백질 FLJ14995, 가상 단백질 FLJ16180, 가상 단백질 FLJ16802, 가상 단백질 FLJ32069, 가상 단백질 FLJ37401, 가상 단백질 FLJ38750, 가상 단백질 FLJ40162, 가상 단백질 FLJ41415, 가상 단백질 FLJ90576, 가상 단백질 FLJ90590, 가상 단백질 FLJ90622, 가상 단백질 KCTD15, 가상 단백질 MGC15619, 이노시톨(Inositol) 1,4,5-트리포스페이트 수용체 유형 1, 이노시톨 1,4,5-트리포스페이트 수용체 유형 2, 이노시톨 1,4,5-트리포스페이트 수용체 유형 3, 중간체 전도 칼슘 활성화된 칼륨 채널 단백질 4, 내부 개정자 칼륨 채널 13, 내부 개정자 칼륨 채널 16, 내부 개정자 칼륨 채널 4, 내부 개정 K(+) 채널 음성 조절자 Kir2.2v, 카이네이트 수용체 서브유닛 KA2a, KCNH5 단백질, KCTD17 단백질, KCTD2 단백질, 케라티노사이트 연결된 막간 단백질 1, Kv 채널-상호작용 단백질 4, 멜라스타틴(Melastatin) 1, 막 단백질 MLC1, MGC15619 단백질, 뮤콜리핀(Mucolipin)-1, 뮤콜리핀-2, 뮤콜리핀-3, 다중약물 내성 관련 단백질 4, N-메틸-D-아스파테이트 수용체 2C 서브유닛 전구체, NADPH 산화효소 상동체 1, Navl.5, 뉴런성 아세틸콜린 수용체 단백질, 알파-10 서브유닛 전구체, 뉴런성 아세틸콜린 수용체 단백질, 알파-2 서브유닛 전구체, 뉴런성 아세틸콜린 수용체 단백질, 알파-3 서브유닛 전구체, 뉴런성 아세틸콜린 수용체 단백질, 알파-4 서브유닛 전구체, 뉴런성 아세틸콜린 수용체 단백질, 알파-5 서브유닛 전구체, 뉴런성 아세틸콜린 수용체 단백질, 알파-6 서브유닛 전구체, 뉴런성 아세틸콜린 수용체 단백질, 알파-7 서브유닛 전구체, 뉴런성 아세틸콜린 수용체 단백질, 알파-9 서브유닛 전구체, 뉴런성 아세틸콜린 수용체 단백질, 베타-2 서브유닛 전구체, 뉴런성 아세틸콜린 수용체 단백질, 베타-3 서브유닛 전구체, 뉴런성 아세틸콜린 수용체 단백질, 베타-4 서브유닛 전구체, 뉴런성 전압 의존성 칼슘 채널 알파 2D 서브유닛, P2X 퓨리노셉터(purinoceptor) 1, P2X 퓨리노셉터 2, P2X 퓨리노셉터 3, P2X 퓨리노셉터 4, P2X 퓨리노셉터 5, P2X 퓨리노셉터 6, P2X 퓨리노셉터 7, 췌장 칼륨 채널 TALK-1b, 췌장 칼륨 채널 TALK-1c, 췌장 칼륨 채널 TALK-1d, 포스폴만(Phospholemman) 전구체, 플라스모리핀(Plasmolipin), 다낭포성 신장 질환 2 관련된 단백질, 다낭포성 신장 질환 2 유사 1 단백질, 다낭포성 신장 질환 2 유사 2 단백질, 에그 젤리(egg jelly) 관련된 단백질 전구체를 위한 다낭포성 신장 질환 및 수용체, 칼륨 채널 조절자, 칼륨 채널 하위계열 K 구성원 1, 칼륨 채널 하위계열 K 구성원 10, 칼륨 채널 하위계열 K 구성원 12, 칼륨 채널 하위계열 K 구성원 13, 칼륨 채널 하위계열 K 구성원 15, 칼륨 채널 하위계열 K 구성원 16, 칼륨 채널 하위계열 K 구성원 17, 칼륨 채널 하위계열 K 구성원 2, 칼륨 채널 하위계열 K 구성원 3, 칼륨 채널 하위계열 K 구성원 4, 칼륨 채널 하위계열 K 구성원 5, 칼륨 채널 하위계열 K 구성원 6, 칼륨 채널 하위계열 K 구성원 7, 칼륨 채널 하위계열 K 구성원 9, 칼륨 채널 사량체화 도메인 함유 3, 칼륨 채널 사량체화 도메인 함유 단백질 12, 칼륨 채널 사량체화 도메인 함유 단백질 14, 칼륨 채널 사량체화 도메인 함유 단백질 2, 칼륨 채널 사량체화 도메인 함유 단백질 4, 칼륨 채널 사량체화 도메인 함유 단백질 5, 칼륨 채널 사량체화 도메인 함유 10, 칼륨 채널 사량체화 도메인 함유 단백질 13, 칼륨 채널 사량체화 도메인 함유 1, 칼륨 전압 게이팅 채널 하위계열 A 구성원 1, 칼륨 전압 게이팅 채널 하위계열 A 구성원 2, 칼륨 전압 게이팅 채널 하위계열 A 구성원 4, 칼륨 전압 게이팅 채널 하위계열 A 구성원 5, 칼륨 전압 게이팅 채널 하위계열 A 구성원 6, 칼륨 전압 게이팅 채널 하위계열 B 구성원 1, 칼륨 전압 게이팅 채널 하위계열 B 구성원 2, 칼륨 전압 게이팅 채널 하위계열 C 구성원 1, 칼륨 전압 게이팅 채널 하위계열 C 구성원 3, 칼륨 전압 게이팅 채널 하위계열 C 구성원 4, 칼륨 전압 게이팅 채널 하위계열 D 구성원 1, 칼륨 전압 게이팅 채널 하위계열 D 구성원 2, 칼륨 전압 게이팅 채널 하위계열 D 구성원 3, 칼륨 전압 게이팅 채널 하위계열 E 구성원 1, 칼륨 전압 게이팅 채널 하위계열 E 구성원 2, 칼륨 전압 게이팅 채널 하위계열 E 구성원 3, 칼륨 전압 게이팅 채널 하위계열 E 구성원 4, 칼륨 전압 게이팅 채널 하위계열 F 구성원 1, 칼륨 전압 게이팅 채널 하위계열 G 구성원 1, 칼륨 전압 게이팅 채널 하위계열 G 구성원 2, 칼륨 전압 게이팅 채널 하위계열 G 구성원 3, 칼륨 전압 게이팅 채널 하위계열 G 구성원 4, 칼륨 전압 게이팅 채널 하위계열 H 구성원 1, 칼륨 전압 게이팅 채널 하위계열 H 구성원 2, 칼륨 전압 게이팅 채널 하위계열 H 구성원 3, 칼륨 전압 게이팅 채널 하위계열 H 구성원 4, 칼륨 전압 게이팅 채널 하위계열 H 구성원 5, 칼륨 전압 게이팅 채널 하위계열 H 구성원 6, 칼륨 전압 게이팅 채널 하위계열 H 구성원 7, 칼륨 전압 게이팅 채널 하위계열 H 구성원 8, 칼륨 전압 게이팅 채널 하위계열 KQT 구성원 1, 칼륨 전압 게이팅 채널 하위계열 KQT 구성원 2, 칼륨 전압 게이팅 채널 하위계열 KQT 구성원 3, 칼륨 전압 게이팅 채널 하위계열 KQT 구성원 4, 칼륨 전압 게이팅 채널 하위계열 KQT 구성원 5, 칼륨 전압 게이팅 채널 하위계열 S 구성원 1, 칼륨 전압 게이팅 채널 하위계열 S 구성원 2, 칼륨 전압 게이팅 채널 하위계열 S 구성원 3, 칼륨 전압 게이팅 채널 하위계열 V 구성원 2, 칼륨 전압 게이팅 채널, 하위계열 H, 구성원 7, 이소형 2, 칼륨/나트륨 과분극화 활성화된 환형 뉴클레오티드-게이티드 채널 1, 칼륨/나트륨 과분극화 활성화된 환형 뉴클레오티드-게이티드 채널 2, 칼륨/나트륨 과분극화 활성화된 환형 뉴클레오티드-게이티드 채널 3, 칼륨/나트륨 과분극화 활성화된 환형 뉴클레오티드-게이티드 채널 4, 가능한 미토콘드리아 유입 수용체 서브유닛 TOM40 상동체, 퓨린성(Purinergic) 수용체 P2X5, 이소형 A, 추정적 4 반복전압 게이팅 이온 채널, 추정적 클로라이드 채널 단백질 7, 추정적 GluR6 카이네이트 수용체, 추정적 이온 채널 단백질 CATSPER2 변형체 1, 추정적 이온 채널 단백질 CATSPER2 변형체 2, 추정적 이온 채널 단백질 CATSPER2 변형체 3, 칼륨 채널 단백질 변형체 1의 추정적 조절자, 추정적 타이로신-단백질 포스파타제 TPTE, 리아노딘(Ryanodine) 수용체 1, 리아노딘 수용체 2, 리아노딘 수용체 3, SH3KBP1 결합 단백질 1, 짧은 일과성 수용체 전위 채널 1, 짧은 일과성 수용체 전위 채널 4, 짧은 일과성 수용체 전위 채널 5, 짧은 일과성 수용체 전위 채널 6, 짧은 일과성 수용체 전위 채널 7, 작은 전도성 칼슘 활성화된 칼륨 채널 단백질 1, 작은 전도성 칼슘 활성화된 칼륨 채널 단백질 2, 이소형 b, 작은 전도성 칼슘 활성화된 칼륨 채널 단백질 3, 이소형 b, 작은 전도성 칼슘 활성화된 칼륨 채널 SK2, 작은 전도성 칼슘 활성화된 칼륨 채널 SK3, 나트륨 채널, 나트륨 채널 베타-1 서브유닛 전구체, 나트륨 채널 단백질 유형 II 알파 서브유닛, 나트륨 채널 단백질 유형 III 알파 서브유닛, 나트륨 채널 단백질 유형 IV 알파 서브유닛, 나트륨 채널 단백질 유형 IX 알파 서브유닛, 나트륨 채널 단백질 유형 V 알파 서브유닛, 나트륨 채널 단백질 유형 VII 알파 서브유닛, 나트륨 채널 단백질 유형 VIII 알파 서브유닛, 나트륨 채널 단백질 유형 X 알파 서브유닛, 나트륨 채널 단백질 유형 XI 알파 서브유닛, 나트륨-및 클로라이드 활성화된 ATP-감수성 칼륨 채널, 나트륨/칼륨-수송 ATP아제(ATPase) 감마 쇄, 정자 관련 양이온 채널 1, 정자 관련 양이온 채널 2, 이소형 4, 신탁신(Syntaxin)-1B1, 일과성 수용체 전위 양이온 채널 하위계열 A 구성원 1, 일과성 수용체 전위 양이온 채널 하위계열 M 구성원 2, 일과성 수용체 전위 양이온 채널 하위계열 M 구성원 3, 일과성 수용체 전위 양이온 채널 하위계열 M 구성원 6, 일과성 수용체 전위 양이온 채널 하위계열 M 구성원 7, 일과성 수용체 전위 양이온 채널 하위계열 V 구성원 1, 일과성 수용체 전위 양이온 채널 하위계열 V 구성원 2, 일과성 수용체 전위 양이온 채널 하위계열 V 구성원 3, 일과성 수용체 전위 양이온 채널 하위계열 V 구성원 4, 일과성 수용체 전위 양이온 채널 하위계열 V 구성원 5, 일과성 수용체 전위 양이온 채널 하위계열 V 구성원 6, 일과성 수용체 전위 채널 4 엡실론 스플라이스 변형체, 일과성 수용체 전위 채널 4 제타 스플라이스 변형체, 일과성 수용체 전위 채널 7 감마 스플라이스 변형체, 종양 괴사 인자, 알파 유래 단백질 1, 내피성, 2-기공 칼슘 채널 단백질 2, VDAC4 단백질, 전압 게이티드 칼륨 채널 Kv3.2b, 전압 게이티드 나트륨 채널 베타1B 서브유닛, 전압 의존성 음이온 채널, 전압 의존성 음이온 채널 2, 전압 의존성 음이온-선택적 채널 단백질 1, 전압 의존성 음이온-선택적 채널 단백질 2, 전압 의존성 음이온-선택적 채널 단백질 3, 전압 의존성 칼슘 채널 감마-1 서브유닛, 전압 의존성 칼슘 채널 감마-2 서브유닛, 전압 의존성 칼슘 채널 감마-3 서브유닛, 전압 의존성 칼슘 채널 감마-4 서브유닛, 전압 의존성 칼슘 채널 감마-5 서브유닛, 전압 의존성 칼슘 채널 감마-6 서브유닛, 전압 의존성 칼슘 채널 감마-7 서브유닛, 전압 의존성 칼슘 채널 감마-8 서브유닛, 전압 의존성 L-유형 칼슘 채널 알파-1C 서브유닛, 전압 의존성 L-유형 칼슘 채널 알파-1D 서브유닛, 전압 의존성 L-유형 칼슘 채널 알파-1S 서브유닛, 전압 의존성 L-유형 칼슘 채널 베타-1 서브유닛, 전압 의존성 L-유형 칼슘 채널 베타-2 서브유닛, 전압 의존성 L-유형 칼슘 채널 베타-3 서브유닛, 전압 의존성 L-유형 칼슘 채널 베타-4 서브유닛, 전압 의존성 N-유형 칼슘 채널 알파-1B 서브유닛, 전압 의존성 P/Q-유형 칼슘 채널 알파-1A 서브유닛, 전압 의존성 R-유형 칼슘 채널 알파-1E 서브유닛, 전압 의존성 T-유형 칼슘 채널 알파-1G 서브유닛, 전압 의존성 T-유형 칼슘 채널 알파-1H 서브유닛, 전압 의존성 T-유형 칼슘 채널 알파-1I 서브유닛, 전압 게이팅 L-유형 칼슘 채널 알파-1 서브유닛, 전압 게이팅 칼륨 채널 베타-1 서브유닛, 전압 게이팅 칼륨 채널 베타-2 서브유닛, 전압 게이팅 칼륨 채널 베타-3 서브유닛, 전압 게이팅 칼륨 채널 KCNA7이 포함된다. 인간 전압 게이팅 나트륨 채널의 Nav1.x 계열 또한 특히 유망한 표적이다. 이러한 계열로는, 예를 들면, 채널 Nav1.6 및 Nav1.8이 포함된다.
본원에서 스캐폴드로서 사용되는 많은 미소단백질은 G-단백질 커플링된 수용체(GPCR: G-Protein Coupled Receptor)에 대한 고유 활성을 갖고, 신규 GPCR 조정자(작용물질, 길항물질, 및 GPCR의 임의의 특성의 조정자를 포함함)를 생성하는 이상적 출발점을 제공한다. 예시적 GPCR로는, 제한되지 않지만, 부류 A 로돕신(Rhodopsin) 유사 수용체, 예컨대 무스카티닉(Muscatinic)(Muse.) 아세틸콜린 척추동물 유형 1, Muse. 아세틸콜린 척추동물 유형 2, Muse. 아세틸콜린 척추동물 유형 3, Muse. 아세틸콜린 척추동물 유형 4; 아드레날린수용체(Adrenoceptor)(알파 아드레날린수용체 유형 1, 알파 아드레날린수용체 유형 2, 베타 아드레날린수용체 유형 1, 베타 아드레날린수용체 유형 2, 베타 아드레날린수용체 유형 3), 도파민(Dopamine) 척추동물 유형 1, 도파민 척추동물 유형 2, 도파민 척추동물 유형 3, 도파민 척추동물 유형 4, 히스타민(Histamine) 유형 1, 히스타민 유형 2, 히스타민 유형 3, 히스타민 유형 4, 세로토닌(Serotonin) 유형 1, 세로토닌 유형 2, 세로토닌 유형 3, 세로토닌 유형 4, 세로토닌 유형 5, 세로토닌 유형 6, 세로토닌 유형 7, 세로토닌 유형 8, 다른 세로토닌 유형, 미량 아민, 안지오텐신(Angiotensin) 유형 1, 안지오텐신 유형 2, 봄베신(Bombesin), 브라드키닌(Bradykinin), C5a 아나필라톡신(anaphylatoxin), Fmet-leu-phe, APJ 유사체, 인터류킨-8 유형 A, 인터류킨-8 유형 B, 다른 인터류킨-8 유형, C-C 케모카인 유형 1∼유형 11 및 다른 유형, C-X-C 케모카인(유형 2∼6 및 다른 유형), C-X3-C 케모카인, 콜레시스토키닌(Cholecystokinin) CCK, CCK 유형 A, CCK 유형 B, 다른 CCK 유형, 엔도텔린, 멜라노코르틴(멜라닌형성세포 자극 호르몬, 부신피질자극(Adrenocorticotropic) 호르몬, 멜라노코르틴 호르몬), 더피(Duffy) 항원, 프로락틴(Prolactin) 방출 펩티드(GPR1O), 신경펩티드 Y(유형 1∼7), 신경펩티드 Y, 기타 신경펩티드 Y, 뉴로텐신(Neurotensin), 오피오이드(Opioid)(유형 D, K, M, X), 소마토스타틴(Somatostatin)(유형 1∼5), 타키키닌(Tachykinin)(물질 P(NK1), 물질 K(NK2), 뉴로메딘(Neuromedin) K(NK3), 타키키닌 유사체 1, 타키키닌 유사체 2, 바소프레신(Vasopressin)/바소토신(vasotocin)(유형 1∼2), 바소토신, 옥시토신(Oxytocin)/메조토신(mesotocin), 코노프레신(Conopressin), 갈라닌(Galanin) 유사체, 프로테이나제 활성화된 유사체, 오렉신(Orexin) & 신경펩티드 FF, QRFP, 케모카인 수용체 유사체, 뉴로메딘 U 유사체(뉴로메딘 U, PRX아미드), 호르몬 단백질(폴리클(Follicle) 자극 호르몬, 루트로핀-코리오고나도트로픽(Lutropin-choriogonadotropic) 호르몬, 갑상선자극호르몬(Thyrotropine), 고나도트로핀(Gonadotropin) 유형 I, 고나도트로핀 유형 II), (로드)옵신, 로돕신 척추동물 (유형 1∼5), 로돕신 척추동물 유형 5, 로돕신 절지동물, 로돕신 절지동물 유형 1, 로돕신 절지동물 유형 2, 로돕신 절지동물 유형 3, 로돕신 연체동물, 로돕신, 후각 (후각 II fam 1∼13), 프로스타글란딘(Prostaglandin)(프로스타글란딘 E2 하위유형 EP1, 프로스타글란딘 E2/D2 하위유형 EP2, 프로스타글란딘 E2 하위유형 EP3, 프로스타글란딘 E2 하위유형 EP4, 프로스타글란딘 F2-알파, 프로스타사이클린(Prostacyclin), 트롬복산(Thromboxane), 아데노신 유형 1∼3, 퓨리노셉터, 퓨리노셉터 P2RY1-4,6,11 GPR91, 퓨리노셉터 P2RY5, 8, 9, 10 GPR35, 92, 174, 퓨리노셉터 P2RY12-14 GPR87(UDP-글루코스), 카나비노이드(Cannabinoid), 혈소판 활성화 인자, 고나도트로핀 방출 호르몬, 고나도트로핀 방출 호르몬 유형 I, 고나도트로핀 방출 호르몬 유형 II, 아디포키네틱(Adipokinetic) 호르몬 유사체, 코라조닌(Corazonin), 갑상선자극호르몬 방출 호르몬 & 세크레타고그(Secretagogue), 갑상선자극호르몬 방출 호르몬, 성장 호르몬 세크레타고그, 성장 호르몬 세크레타고그 유사체, 탈각 개시 호르몬(ETHR: Ecdysis-triggering hormone), 멜라토닌(Melatonin), 리소스핀고리피드(Lysosphingolipid) & LPA(EDG), 스핀고신(Sphingosine) 1-포스페이트 Edg-1, 리소포스파티딘산(Lysophosphatidic acid) Edg-2, 스핀고신 1-포스페이트 Edg-3, 리소포스파티딘산 Edg-4, 스핀고신 1-포스페이트 Edg-5, 스핀고신 1-포스페이트 Edg-6, 리소포스파티딘산 Edg-7, 스핀고신 1-포스페이트 Edg-8, Edg 기타 류코트리엔 B4 수용체, 류코트리엔 B4 수용체 BLT1, 류코트리엔 B4 수용체 BLT2, 부류 A 오펀/기타, 추정적 신경전달자, SREB, Mas 원형-종양유전자 & Mas 관련된(MRG), GPR45 유사체, 시스테이닐 류코트리엔, G-단백질 커플링된 담즙산 수용체, 유리 지방산 수용체(GP40, GP41, GP43), 부류 B 세크레틴 유사체, 칼시토닌(Calcitonin), 코르티코트로핀 방출 인자, 위 저해성 펩티드, 글루카곤, 성장 호르몬 방출 호르몬, 부갑상선 호르몬, PACAP, 세크레틴, 혈관작용 장성 폴리펩티드, 라트로필린(Latrophilin), 라트로필린 유형 1, 라트로필린 유형 2, 라트로필린 유형 3, ETL 수용체, 뇌 특이적 신생혈관형성 저해제(BAI: Brain-specific angiogenesis inhibitor), 므두셀라(Methuselah) 유사 단백질(MTH), 카드헤린 EGF LAG(CELSR), 매우 큰 G-단백질 커플링된 수용체, 부류 C 대사성(Metabotropic) 글루타메이트/페로몬, 대사성 글루타메이트 그룹 I∼III, 칼슘-감지 유사체, 세포외 칼슘-감지, 페로몬, 기타 칼슘-감지 유사체, 추정적 페로몬 수용체, GABA-B, GABA-B 하위유형 1, GABA-B 하위유형 2, GABA-B 유사체, 오펀 GPRC5, 오펀 GPCR6, 브라이드 오브 세븐리스 단백질(BOSS: Bride of sevenless protein), 미각 수용체(TlR), 부류 D 진균류 페로몬, 진균류 페로몬 A-인자 유사체(STE2, STE3), 진균류 페로몬 B 유사체(BAR, BBR, RCB, PRA), 부류 E cAMP 수용체, 안구 백색증 단백질, 프리즐드/평활화된 계열, 프리즐드 그룹 A(Fz 1&2&4&5&7∼9), 프리즐드 그룹 B (Fz 3&6), 프리즐드 그룹 C(기타), 서비골(Vomeronasal) 수용체, 선충 화학수용체, 곤충 냄새 수용체, 및 부류 Z 고세균성(Archaeal)/박테리아성/진균류성 옵신(opsin)이 포함된다.
보조적 서열의 임의의 하기 활성 폴리펩티드로의 융합이 특히 유용하다: 보톡스(BOTOX), 마이오블록(Myobloc), 뉴로블록(Neurobloc), 디스포트(Dysport)(또는 보툴리넘(botulinum) 신경독소의 다른 혈청형), 알글루코시다제(alglucosidase) alfa, 답토마이신(daptomycin), YH-16, 코리오고나도트로핀 alfa, 필그라스팀(filgrastim), 세트로렐릭스(cetrorelix), 인터류킨-2, 알데스류킨(aldesleukin), 테셀류킨(teceleukin), 데니류킨 디프티톡스(denileukin diftitox), 인터페론 alfa-n3(주사), 인터페론 alfa-n1, DL-8234, 인터페론, 선토리(Suntory)(감마-1a), 인터페론 감마, 티모신(thymosin) 알파 1, 타소너민(tasonermin), DigiFab, ViperaTAb, EchiTAb, CroFab, 네시리티드(nesiritide), 어바타셉트(abatacept), 알레파셉트(alefacept), 레비프(Rebif), 엡토터민(eptotermin) alfa, 테리파라티드(teriparatide)(골다공증), 칼시토닌(calcitonin)(주사가능; 골 질환), 칼시토닌(비강, 골다공증), 에타너셉트(etanercept), 헤모글로빈 글루타머(glutamer) 250(소), 드로트레코긴(drotrecogin) alfa, 콜라게나제, 카퍼리티드(carperitide), 재조합 인간 상피 성장 인자(국소용 겔, 상처 치유), DWP-401, 다베포에틴(darbepoetin) alfa, 에포에틴(epoetin) 오메가, 에포에틴 베타, 에포에틴 alfa, 데시루딘(desirudin), 레피루딘(lepirudin), 비발리루딘(bivalirudin), 노나코그(nonacog) 알파, 모노닌(Mononine), 엡타코그(eptacog) alfa(활성화됨), 재조합 인자 VIII+VWF, 재조합체, 재조합 인자 VIII, 인자 VIII(재조합체), 알파네이트(Alphanate), 옥토코그(octocog) alfa, 인자 VIII, 팔리퍼민(palifermin), 인디키나제(Indikinase), 테넥테플라제(tenecteplase), 알테플라제(alteplase), 파미테플라제(pamiteplase), 레테플라제(reteplase), 나테플라제(nateplase), 몬테플라제(monteplase), 폴리트로핀(follitropin) alfa, rFSH, hpFSH, 미카펀긴(micafungin), 페그필그라스팀(pegfilgrastim), 레노그라스팀(lenograstim), 나토그라스팀(nartograstim), 세르모렐린(sermorelin), 글루카곤, 엑세나타이드, 프람린티드, 이미글루세라제(imiglucerase), 갈설파아제(galsulfase), 류코트로핀, 몰그라모스팀(molgramostim), 트립토렐린(triptorelin) 아세테이트, 히스트렐린(histrelin)(피하 이식물, 하이드론(Hydron)), 데스로렐린(deslorelin), 히스트렐린, 나파렐린(nafarelin), 류프롤리드 지속된 방출 데포(ATRIGEL), 류프롤리드 이식물(DUROS), 고세렐린(goserelin), 소마트로핀(somatropin), 유트로핀(Eutropin), KP-102 프로그램, 소마트로핀, 소마트로핀, 메카세르민(mecasermin)(성장 부전), 엔푸비르티드(enfuvirtide), Org-33408, 인슐린 글라르긴(glargine), 인슐린 글루리신(glulisine), 인슐린(흡입), 인슐린 리스프로(lispro), 인슐린 데테미르(detemir), 인슐린(구강, 래피드미스트(RapidMist)), 메카세르민 린파베이트(mecasermin rinfabate), 아나킨라(anakinra), 셀모류킨(celmoleukin), 99mTc-앱시티드(apcitide) 주사, 미엘로피드(myelopid), 베타세론(betaseron), 글라티라머(glatiramer) 아세테이트, 게폰(Gepon), 사그라모스팀(sargramostim), 오프렐베킨(oprelvekin), 인간 백혈구 유래 알파 인터페론, 빌리브(Bilive), 인슐린(재조합체), 재조합 인간 인슐린, 인슐린 아스파트(aspart), 메카세르민(mecasermin), 로페론(Roferon)-A, 인터페론-알파 2, 알파페론(Alfaferone), 인터페론 알파콘(alfacon)-1, 인터페론 알파, 아보넥스(Avonex') 재조합 인간 루테인화 호르몬, 도르나사(dornase) alfa, 트라페르민(trafermin), 지코노티드(ziconotide), 탈티렐린(taltirelin), 디보테르민(dibotermin) alfa, 아토시반(atosiban), 베카플러민, 엡티피바티드(eptifibatide), 제마이라(Zemaira), CTC-111, 샨백(Shanvac)-B, HPV 백신(4가), NOV-002, 옥트레오티드(octreotide), 란레오티드(Lanreotide), 안세스팀(ancestim), 아갈시다제 베타, 아갈시다제 alfa, 라로니다제(laronidase), 프레자티드(prezatide) 구리 아세테이트(국소용 겔), 라스부리카아제(rasburicase), 라니비주맵(ranibizumab), 악티뮨, PEG-인트론, 트리코민(Tricomin), 재조합 집먼지 진드기 알러지 탈감작 주사, 재조합 인간 부갑상선 호르몬(PTH: parathyroid hormone) 1-84(피하, 골다공증), 에포에틴 델타, 유전자이식 항트롬빈 III, 그랜디트로핀(Granditropin), 비트라제(Vitrase), 재조합 인슐린, 인터페론-알파(경구 로젠지), GEM-21S, 바프레오티드(vapreotide), 이더설파제(idursulfase), 오마파트리라트(omapatrilat), 재조합 혈청 알부민, 세르톨리주맵 페골(certolizumab pegol), 글루카피다제(glucarpidase), 인간 재조합 C1 에스터라제 저해제(혈관신경부종), 라노테플라제(lanoteplase), 재조합 인간 성장 호르몬, 엔푸비르티드(enfuvirtide)(침이 없는 주사, 바이오젝터(Biojector) 2000), VGV-1, 인터페론 (알파), 루시낙탄트(lucinactant), 아빕타딜(aviptadil)(흡입, 폐 질환), 이카티반트(icatibant), 에칼란티드(ecallantide), 오미가난(omiganan), 아우로그랩(Aurograb), 펙시가난(pexiganan) 아세테이트, ADI-PEG-20, LDI-200, 데가렐릭스(degarelix), 신트레데킨 베수도톡스(cintredekin besudotox), FavId, MDX-1379, ISAtx-247, 리라글루티드(liraglutide), 테리파라티드(teriparatide)(골다공증), 티파코긴(tifacogin), AA-4500, T4N5 리포솜 로션, 카투맥소맵(catumaxomab), DWP-413, ART-123, 크리살린(Chrysalin), 메스모테플라제(desmoteplase), 아메디플라제(amediplase), 코리폴리트로핀(corifollitropin) 알파, TH-9507, 테두글루티드(teduglutide), 디아미드(Diamyd), DWP-412, 성장 호르몬(지속된 방출 주사), 재조합 G-CSF, 인슐린(흡입, AIR), 인슐린 (흡입, 테크노스피어(Technosphere)), 인슐린(흡입, AERx), RGN-303, DiaPep277, 인터페론 베타(C형 간염 바이러스성 감염(HCV: hepatitis C viral infection)), 인터페론 알파-n3(경구), 벨라타셉트(belatacept), 경피 인슐린 패치, AMG-531, MBP-8298, 세레셉트(Xerecept), 오페바칸(opebacan), AIDSVAX, GV-1001, 림포스캔(LymphoScan), 란피나제(ranpirnase), 리폭시산(Lipoxysan), 루서풀티드(lusupultide), MP52 (베타-트리칼슘포스페이트 전달제, 골 재생), 흑색종 백신, 시풀류셀(sipuleucel)-T, CTP-37, 인세기아(Insegia), 비테스펜(vitespen), 인간 트롬빈(동결, 수술 출혈), 트롬빈, 트랜스MID, 알피메프라제(alfimeprase), 퓨리카아제(Puricase), 터리프레신(terlipressin)(정맥내, 간신성 증후군), EUR-1008M, 재조합 FGF-1(주사가능, 혈관 질환), BDM-E, 로티갭티드(rotigaptide), ETC-216, P-113, MBI-594AN, 듀라마이신(duramycin)(흡입, 낭포성 섬유증), SCV-07, OPI-45, 엔도스타틴(Endostatin), 안지오스타틴(Angiostatin), ABT-510, 바우만 브릭(Bowman Birk) 저해제 농축액, XMP-629, 99mTc-하이닉(Hynic)-아넥신(Annexin) V, 카할라리드(kahalalide) F, CTCE-9908, 테베렐릭스(teverelix)(연장된 방출), 오자렐릭스(ozarelix), 로미뎁신(romidepsin), BAY-50-4798, 인터류킨-4, PRX-321, 펩스칸(Pepscan), 이복타데킨(iboctadekin), rh 락토페린, TRU-015, IL-21, ATN-161, 시렌기티드(cilengitide), 알부페론(Albuferon), 비파식스(Biphasix), IRX-2, 오메가 인터페론, PCK-3145, CAP-232, 파시레오티드(pasireotide), huN901-DM1, 난소암 면역치료학적 백신, SB-249553, 온코백스(Oncovax)-CL, 온코백스-P, BLP-25, 세르백스(CerVax)-16, 다중-에피토프 펩티드 흑색종 백신(MART-1, gp1OO, 티로시나제(tyrosinase)), 네미피티드(nemifitide), rAAT(흡입), rAAT(피부학적), CGRP(흡입, 천식), 페그수너셉트(pegsunercept), 티모신(thymosin) 베타-4, 플리티뎁신(plitidepsin), GTP-200, 라모플라닌(ramoplanin), GRASPA, OBI-1, AC-100, 연어 칼시토닌(calcitonin)(경구, 엘리겐(eligen)), 칼시토닌(경구, 골다공증), 엑사모렐린(examorelin), 카프로모렐린(capromorelin), 카데바(Cardeva), 벨라페르민(velafermin), 1311-TM-601, KK-220, TP-10, 율라리티드(ularitide), 데펠레스타트(depelestat), 헤마티드(hematide), 키르살린(kirsaline)(국소용), rNAPc2, 재조합 인자 VIII(페그화된 리포솜성), bFGF, 페그화된 재조합 스타필로키나제(staphylokinase) 변형체, V-10153, 소노라이시스 프롤리즈(SonoLysis Prolyse), 뉴로백스(NeuroVax), CZEN-002, 섬 세포 신생 치료법, rGLP-1, BIM-51077, LY-548806, 엑세나타이드(제어 방출형, 메디소브(Medisorb)), AVE-0010, GA-GCB, 아보렐린(avorelin), AOD-9604, 리나콜티드(linaclotide) 아세테이트, CETi-1, 헤모스판(Hemospan), VAL(주사가능), 신속-작용 인슐린(주사가능, 비아델(Viadel)), 비강내 인슐린, 인슐린(흡입), 인슐린(경구, 엘리겐), 재조합 메티오닐 인간 렙틴, 피트라킨라(pitrakinra)(피하 주사, 습진), 피트라킨라(흡입 건조 분말, 천식), 멀티킨(Multikine), RG-1068, MM-093, NBI-6024, AT-001, PI-0824, Org-39141, CpnlO(자가면역 질환/염증), 타락토페린(talactoferrin)(국소용), rEV-131(안과용), rEV-131(호흡기 질환), 경구 재조합 인간 인슐린(당뇨병), RPI-78M, 오프렐베킨(oprelvekin)(경구), CYT-99007 CTLA4-Ig, DTY-001, 발라테그라스트(valategrast), 인터페론 alfa-n3(국소용), IRX-3, RDP-58, 타우페론(Tauferon), 담즙 염 자극된 리파아제, 메리스파아제(Merispase), 알칼리성 포스파타제(alkaline phosphatase), EP-2104R, 멜라노탄(Melanotan)-II, 브렘라노티드(bremelanotide), ATL-104, 재조합 인간 마이크로플라스민(microplasmin), AX-200, SEMAX, ACV-1, Xen-2174, CJC-1008, 다이노핀(dynorphin) A, SI-6603, LAB GHRH, AER-002, BGC-728, 말라리아 백신(비로솜(virosome), 페비프로(PeviPRO)), ALTU-135, 파보바이러스(parvovirus) B 19 백신, 인플루엔자 백신(재조합 뉴라미니다제(neuraminidase)), 말라리아/HBV 백신, 안트락스(anthrax) 백신, Vacc-5q, Vacc-4x, HIV 백신(경구), HPV 백신, 타트 톡소이드(Tat Toxoid), YSPSL, CHS-13340, PTH(1-34) 리포솜 크림(노바솜(Novasome)), 오스타볼린(Ostabolin)-C, PTH 유사체(국소용, 건선), MBRI-93.02, MTB72F 백신(결핵), MVA-Ag85 A 백신(결핵), FAR-404, BA-210, 재조합 플라크 FlV 백신, AG-702, 옥소드롤(OxSODrol), rBetV1, Der-p1/Der-p2/Der-p7 알러지항원-표적화 백신(먼지 진드기 알러지), PR1 펩티드 항원(백혈병), 돌연변이체 ras 백신, HPV-16 E7 리포펩티드 백신, 라비린틴(labyrinthin) 백신(선암), CML 백신, WT1-펩티드 백신(암), IDD-5, CDX-110, 펜트리스(Pentrys), 노렐린(Norelin), CytoFab, P-9808, VT-111, 이크로캅티드(icrocaptide), 텔베르민(telbermin)(피부학적, 당뇨병성 족부 궤양), 루핀트리비르(rupintrivir), 레티큘로스(reticulose), rGRF, P1A, 알파-갈락토시다제 A, ACE-011, ALTU-140, CGX-1160, 안지오텐신 치료학적 백신, D-4F, ETC-642, APP-018, rhMBL, SCV-07(경구, 결핵), DRF-7295, ABT-828, ErbB2 특이적 면역독소(항암), DT388IL-3, TST-10088, PRO-1762, 콤보톡스(Combotox), 콜레시스토키닌(cholecystokinin)-B/가스트린(gastrin)-수용체 결합 펩티드, 111In-hEGF, AE-37, 트라스투주맵(trastuzumab)-DM1, 길항물질 G, IL-12(재조합체), PM-02734, IMP-321, rhIGF-BP3, BLX-883, CUV-1647(국소용), L-19 기초 방사선면역치료제(암), Re-188-P-2045, AMG-386, DC/I540/KLH 백신(암), VX-001, AVE-9633, AC-9301, NY-ESO-1 백신(펩티드), NA17.A2 펩티드, 흑색종 백신(진동화된 항원 치료제), 전립선 암 백신, CBP-501, 재조합 인간 락토페린(건조한 눈), FX-06, AP-214, WAP-8294A2(주사가능), ACP-HIP, SUN-11031, 펩티드 YY[3-36](비만, 비강내), FGLL, 아타시셉트(atacicept), BR3-Fc, BN-003, BA-058, 인간 부갑상선 호르몬 1-34(비강, 골다공증), F-18-CCR1, AT-1001(소아 지방변증/당뇨병), JPD-003, PTH(7-34) 리포솜 크림(노바솜), 듀라마이신(안과용, 건조한 눈), CAB-2, CTCE-0214, 당페그화된 에리스로포이에틴, EPO-Fc, CNTO-528, AMG-114, JR-013, 인자 XIII, 아미노칸딘(aminocandin), PN-951, 716155, SUN-E7001, TH-0318, BAY-73-7977, 테베렐릭스(teverelix)(즉각 방출), EP-51216, hGH(제어 방출형, 바이오스피어(Biosphere)), OGP-I, 시푸비르티드(sifuvirtide), TV-4710, ALG-889, Org-41259, rhCC1O, F-991, 티모펜틴(thymopentin)(폐 질환), r(m)CRP, 간(hepato)선택적 인슐린, 수발린, L19-IL-2 융합 단백질, 엘라핀(elafin), NMK-150, ALTU-139, EN-122004, rhTPO, 혈소판형성인자 수용체 작용물질(혈소판감소 장애), AL-108, AL-208, 신경 성장 인자 길항물질(통증), SLV-317, CGX-1007, INNO-105, 경구 테리파라티드(teriparatide)(엘리겐), GEM-OS1, AC-162352, PRX-302, LFn-p24 융합 백신(테라포어(Therapore)), EP-1043, S 뉴모니아 소아 백신, 말라리아 백신, 수막염균(Neisseria meningitidis) 그룹 B 백신, 신생 그룹 B 스트렙토코커스 백신, 탄저병 백신, HCV 백신(gpE1+gpE2+MF-59), 중이염 치료제, HCV 백신(코어 항원+ISCOMATRIX), hPTH(1-34)(경피, 비아덤(ViaDerm)), 768974, SYN-101, PGN-0052, 아비스쿠민(aviscumine), BIM-23190, 결핵 백신, 다중-에피토프 티로시나제 펩티드, 암 백신, 엔카스팀(enkastim), APC-8024, GI-5005, ACC-OOl, TTS-CD3, 혈관-표적화된 TNF(고체 종양), 데스모프레신(desmopressin)(구강 제어형 방출), 오너셉트(onercept), TP-9201.
비반복적 URP(nrURP: Non-repetitive URP)
본 발명은 또한 비반복적 URP(nrURP)를 내포한다. nrURP는 주로 작은 친수성 아미노산으로 이루어지고 생체내에서 2차 구조를 형성하는 경향이 낮은 아미노산 서열이다. nrURP는 생리학적 조건하에 잘 정의된 2차 및 3차 구조의 결여, 이들의 입체구조적 가요성에 대한 기여; 고도의 프로테아제 내성; 생물학적 활성 폴리펩티드내로 URP의 혼입시 생물학적 활성 폴리펩티드의 용해도 및/또는 반감기를 증가시키는 능력을 비롯한 URP의 특징을 소유한다. nrURP의 구체적인 특성은 이들의 내부 반복성의 정도가 낮다. nrURP는 다수의 상이한 펩티드 부분서열을 포함한다. 이들 부분서열은 URP 유사 아미노산 조성을 갖지만, 이들 아미노산 서열 및 길이에 있어서 서로 상이하다.
nrURP는 유사한 아미노산 조성을 갖는 반복적 URP(rURP)와 비교하여 개선된 용해도를 갖는 경향이 있다. 일반적으로, 반복적 아미노산 서열은 천연 반복적 서열, 예컨대 콜라겐 및 루신 지퍼(zipper)로 예시되는 바와 같이 응집하는 경향을 갖는다. 반복적 서열은 보다 정렬된 구조를 형성하여 유사한 접촉부로부터의 동일한 부분서열이 결정질 또는 의사결정질 구조를 생성하도록 할 수 있다. nrURP는, 이러한 의사-결정질 구조를 형성하는 경향이 상당히 낮은데, 이는 이들이 임의의 반복적인 보다 고도의 정렬 구조의 형성을 방지하는 다수의 상이한 부분서열을 함유하기 때문이다. 비반복적 서열이 응집하는 낮은 경향으로 인해 반복적 URP에서 응집하기 쉬운 하전된 아미노산의 빈도가 비교적 낮은 URP를 디자인할 수 있다. nrURP의 낮은 응집 경향은 nrURP-포함 약학적 제제의 형성을 촉진시키고, 특히 100 mg/ml를 초과하는 특히 높은 약물 농도를 갖는 제제를 가능하게 한다.
(a) nrURP는 낮은 면역원성을 갖는다
상기 서열에서 에피토프를 인식하는 B 세포와 반복적 및 비반복적 URP 서열의 상호작용은 도 74에서 비교되고 예시된다. rURP는 유기체에서 극소수의 B 세포에 의해 인식되는데, 이는 비교적 적은 수의 상이한 에피토프를 함유하기 때문이다. 그러나, rURP는 이들 B 세포와 다가 접촉부를 형성할 수 있고, 결과로서, 도 74a에 예시된 바와 같이 이는 B 세포 증식을 자극할 수 있다. 반대로, nrURP는 많은 상이한 에피토프를 함유하므로 많은 상이한 B 세포와 접촉부를 형성할 수 있다. 그러나, 각각의 개별적 B 세포는 도 74b에 예시된 바와 같이 반복성의 결여로 인해 개별적 nrURP와 1개 또는 적은 수의 접촉부만을 형성할 수 있다. 결과로서, nrURP는 B 세포의 증식, 및 이에 따라 면역 반응을 자극하는 경향이 매우 낮다.
nrURP의 rURP에 대한 추가의 이점은, nrURP가 rURP에 비해 항체와 보다 약한 접촉부를 형성한다는 것이다. 항체는 다가 분자이다. 예를 들면, IgG는 2개의 동일한 결합 부위를 갖고, IgM은 10개의 동일한 결합 부위를 함유한다. 따라서, 반복적 서열에 대한 항체는 높은 결합활성을 갖는 이러한 반복적 서열과 다가 접촉부를 형성할 수 있고, 이는 이러한 반복적 서열의 효능 및/또는 제거에 영향을 줄 수 있다. 반대로, nrURP에 대한 항체는, 이러한 nrURP가 각각의 에피토프의 반복부를 극소수로 함유하므로 항체와 주로 1가 상호작용을 형성한다.
(b) 반복성의 검출
유전자의 반복성은 컴퓨터 알고리즘에 의해 측정될 수 있다. 한 예는 도 75에 예시되어 있다. 질문 서열에 기초하여, 특정 길이의 모든 부분서열의 쌍대 비교가 수행될 수 있다. 이들 부분서열은 동일성 또는 상동성에 대해 비교될 수 있다. 도 75에서의 예는 4개 아미노산의 부분서열을 동일성에 대해 비교한다. 이 예에서, 대부분의 4량체 부분서열은 질문 서열에서 1회 발생되고, 3,4량체 부분서열은 2회 발생된다. 유전자에서의 반복성은 평균될 수 있다. 부분서열의 길이는 조정될 수 있다. 부분서열의 길이는 면역계에 의해 인식될 수 있는 서열 에피토프의 길이를 반영한다. 따라서, 4∼15개 아미노산의 부분서열의 분석이 가장 유용할 수 있다.
(c) nrURP 서열의 디자인
nrURP를 코딩하는 유전자는 유전자 합성의 표준 기법을 사용하여 올리고뉴클레오티드로부터 조립될 수 있다. 유전자 디자인은 코돈 용법 및 아미노산 조성을 최적화하는 알고리즘을 사용하여 수행될 수 있다. 또한, 프로테아제 민감성이거나 인간 면역계에 의해 쉽게 인식될 수 있는 에피토프를 함유하는 것으로 공지된 아미노산 서열을 방지할 수 있다. 컴퓨터 알고리즘은 서열 디자인 동안 적용되어 생성된 아미노산 서열의 반복성을 최소화시킨다. 예정된 기준, 예컨대 아미노산 조성, 코돈 용법, 프로테아제 민감성 부분서열의 방지, 에피토프의 방지에 부합되는 다수의 유전자 디자인의 반복성을 평가하고, 합성 및 후속적 평가를 위한 최소한의 반복적 서열을 선택할 수 있다.
nrURP 유전자의 디자인에 대한 대안의 접근법은 높은 수준의 발현, 낮은 응집 경향, 높은 용해도, 및 프로테아제에 대한 양호한 내성을 나타내는 nrURP의 현존하는 수집물의 서열을 분석하는 것이다. 컴퓨터 알고리즘은 도 76에 예시된 바와 같은 서열 단편의 재-조립에 의해 이러한 미리-존재하는 nrURP 서열에 기초하여 nrURP 서열을 디자인할 수 있다. 알고리즘은 이들 nrURP 서열로부터의 부분서열의 수집물을 생성하고, 이어서 다중 방식으로 평가하여 이러한 부분서열로부터 nrURP 서열을 조립한다. 이전에 동정된 nrURP의 부분서열로만 이루어지지만, 모든 모 nrURP에 비해 반복성이 감소된 nrURP를 동정하기 위해 이들 조립된 서열은 반복성에 대해 평가될 수 있다.
(d) 라이브러리로부터의 nrURP 서열의 작제
nrURP-인코딩 유전자는 도 77에 예시된 바와 같이 짧은 URP 분절의 라이브러리로부터 조립될 수 있다. 우선 URP 분절의 큰 라이브러리를 생성할 수 있다. 이러한 라이브러리는 부분적으로 랜덤화된 올리고뉴클레오티드로부터 조립될 수 있다. 랜덤화 계획은, 각각의 위치에 대한 아미노산 선택, 뿐만 아니라 코돈 용법 및 서열 길이를 제어하기 위해 최적화될 수 있다. 한 실시양태에서, URP 분절의 라이브러리는 발현 벡터내로 클로닝된다. 또 다른 실시양태에서, URP 분절의 라이브러리는 GFP와 같은 인디케이터 유전자에 융합된 발현 벡터내로 클로닝된다. 후속적으로, 다수의 특성, 예컨대 발현 수준, 프로테아제 안정성, 혈청 단백질로의 결합에 대해 라이브러리 구성원을 스크리닝할 수 있다. 항혈청으로의 결합에 대해 URP 분절을 스크리닝하여 상기 혈청에 높은 친화도를 갖는 분절을 제거할 수 있다. 구체적으로, 라이브러리 구성원을 스크리닝하여 동정하고, URP 서열에 반응성을 갖는 항혈청으로의 결합을 방지할 수 있다. 라이브러리 구성원의 아미노산 서열은, 특히 원하는 아미노산 조성, 분절 길이를 갖는 분절을 동정하거나 내부 반복부의 빈도가 낮은 분절을 동정하기 위해 결정될 수 있다. 후속적으로, nrURP 서열은 랜덤 이량체화 또는 다량체화에 의해 URP 분절의 수집물로부터 조립될 수 있다. 이량체화 또는 다량체화는 결찰 또는 PCR 조립에 의해 달성될 수 있다. 이러한 공정은 가장 원하는 특성을 갖는 nrURP 서열을 동정하기 위해 다수의 특성에 대해 평가될 수 있는 nrURP 서열의 라이브러리를 생성한다. 이량체화 또는 다량체화의 과정은 반복되어 추가로 nrURP 서열의 길이를 증가시킨다.
가교결합된 보조적 폴리펩티드의 디자인
본 발명은 또한 가교결합된 보조적 폴리펩티드를 포함하는 증진된 특성(예컨대 증가된 수력학적 반경 또는 연장된 혈청 반감기)을 갖는 폴리펩티드에 관한 것이다. 가교결합된 보조적 폴리펩티드는 하나 이상의 비가교결합 성분 및 하나 이상의 가교결합 성분을 접합시킴으로써 생성될 수 있다.
이러한 접근법의 이점은, 고도로 발현된 중간 길이의 보조적 폴리펩티드를 사용하여 원하는 특성을 갖는 보다 큰 분자를 효과적으로 생성할 수 있다는 것이다. 예를 들면, 화학적 커플링을 사용하여, 단일 단백질로서 발현되는 1종의 1000개 아미노산 길이의 폴리펩티드에 비해 단일한 5종의 200개 아미노산 길이 단위를 포함하는 분자를 훨씬 더 효과적으로 생성할 수 있다.
임의의 수의 비가교결합 성분, 예컨대 2, 3, 4, 5, 6, 7, 8, 9, 10개 이상의 성분이 함께 연결될 수 있다. 이들 성분은 동일하거나 2, 3, 4, 5, 6, 7, 8, 9 또는 10종 이상의 상이한 종류일 수 있다. 한 바람직한 실시양태에서, 각각의 성분은 결정된 결합 특이성을 갖고, 이는 각 성분에 대해 동일하거나 2, 3, 4, 5, 6, 7, 8, 9, 또는 10종 이상의 상이한 유형일 수 있다. 비가교결합 성분의 서열은 또한 동일하거나 1∼10종의 상이한 서열을 포함할 수 있다.
본 발명의 한 바람직한 실시양태는 단일반응성 비가교결합 성분의 1, 2, 3, 4, 5, 6, 7, 8개 이상의 카피를 다중반응성 가교결합 성분의 1개의 카피와 반응시킴을 제공하고, 이는 경우에 따라 폴리에틸렌글리콜, 보조적 폴리펩티드 또는 또 다른 수용성 중합체를 함유하여, 정확히 (예를 들면) 비가교결합 성분의 4개의 카피(이러한 카피는 가교결합제에 연결됨)를 함유하는 미리-규정된 중합체를 생성한다. 비가교결합 성분은 경우에 따라 결합 특이성을 갖는 도메인을 포함한다.
다양한 결합 화학이 접합을 위해 사용될 수 있다. 한 바람직한 실시양태에서, 표준 아미노-카복실 커플링 및 특별히 라이신 기 또는 N-말단의 아미노 기를 통한 결합, 글루타메이트 또는 C-말단의 카복실 기를 통한 결합은 특별히 가교결합된 보조적 폴리펩티드의 가교결합에 특히 유용하다.
몇몇 실시양태에서, 가교결합 성분은 합성 폴리펩티드일 수 있다. 예를 들면, 이러한 폴리펩티드는, 경우에 따라 카복실 기 사이에 삽입된 서열('연결 펩티드')에 의해 이격된 5개의 카복시 잔기(즉, 4 글루타메이트+C-말단 카복시)를 포함할 수 있다. 이러한 연결 펩티드의 아미노-종단부는, 예를 들면 아미드화에 의해 블로킹되어, 추가의 변형체의 형성을 예방할 수 있다(도 27). 제2 반응성 기는 보조적 폴리펩티드를 함유하는 단백질의 아미노-종단부이다. 경우에 따라, 연결 펩티드에서 카복실로의 커플링을 위해 하나 이상의 라이신을 비축할 수 있다. 완전한 화학 연결 후, 균일한 단일 생성물을 수득할 수 있고, 이는 5개의 보조적 폴리펩티드(경우에 따라 결합 도메인 함유), 뿐만 아니라 연결 펩티드를 함유하는 분자이다. 변형은 연결 펩티드가 아미노 기를 함유하고 다른 단백질(이는 전형적으로 결합 도메인을 운반함)에 카복실을 사용하는 것이다.
이러한 분지화된 구조에 더하여, 또한 한 단백질의 아미노-종단부를 또 다른 단백질의 카복시-종단부에 연결시킴으로써 2, 3, 4, 5, 6, 7, 8개 이상의 별도로 발현된 폴리펩티드의 선형 중합체를 생성하는 것이 가능하다. 다시, 이들 폴리펩티드는 상기 기재된 바와 같이 동일하거나 상이할 수 있다.
바람직한 연결은 아미노-대-카복시이다. 커플링에 사용되는 아미노 기는, 사용되는 카복실 기가 화학적 가교결합기 상에 위치된다면 재조합 단백질 상에 위치된다. 다르게는, 커플링을 위해 사용되는 아미노 기는, 사용되는 카복실 기가 재조합 단백질 상에 위치된다면 화학적 가교결합기 상에 위치된다.
가교결합기 상에 사용된 커플링 부위의 수는, 생성물이 1, 2, 3, 4, 5, 6, 7, 8, 9 또는 10개 이상의 재조합 단백질(각각 전형적으로 1, 2, 3, 4, 5개 이상의 결합 도메인을 함유함)을 함유하는지의 여부를 결정한다. 가교결합 성분은 전형적으로 작은, FDA-승인된 케미칼(chemical)이지만, 또한 재조합 폴리펩티드일 수 있고, 경우에 따라 반복된 모티프의 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 20, 30, 40, 50, 75, 100개 이상의 단위, 및 반복된 모티프의 10, 20, 30, 40, 50, 75, 100, 150, 200, 250, 300, 350, 400, 450 또는 500개 이하의 단위를 함유한다.
상이한 조건하에 차등적으로 제거될 수 있는 보호기를 사용하여, 각각 상이한 단백질을 접합에 첨가하는 수개의 접합 단계를 가질 수 있다. 이는 예비-디자인된 화학량론으로 다수의 상이한 단백질과의 접합 생성을 허용한다. 1개의 연결가능한 위치(예: N-말단)를 갖는 2개의 단백질 쇄와의 2가 가교결합기의 접합은 이량체를 생성한다. 2개의 연결기 부위를 갖는 단백질의 가교결합은 선형 중합체를 생성한다. 양쪽 말단에 연결기 부위를 갖는 단백질과 3가 가교결합기의 가교결합은 덴드리머(dendrimer)를 생성한다(도 26).
몇몇 실시양태에서, 비가교결합 성분은 표적 수용체에 친화도를 갖는 하나 이상의 생물학적 활성 폴리펩티드를 포함한다. 이들 생물학적 활성 폴리펩티드는 상이한 표적 수용체에 결합하여, 수개의 상이한 표적 수용체의 수개의 카피에 결합하는 가교결합된 보조적 폴리펩티드의 생성을 허용한다. 다르게는, 비가교결합 성분은 동일한 표적 수용체의 수개의 상이한 에피토프에 결합하는 다수의 생물학적 활성 폴리펩티드를 포함할 수 있다. 생성된 가교결합된 보조적 폴리펩티드는 표적 수용체의 다수의 카피에 결합하는 한편, 각각의 표적 수용체와 다수의 결합 접촉부를 만들어 매우 높은 결합활성을 생성한다. 또 다른 선택사항은 매우 많은 수의 동일한 결합 부위를 갖는 가교결합된 보조적 폴리펩티드를 작제하기 위해 다수의 동일한 결합 요소를 함유하는 비가교결합 성분을 사용하는 것이다.
다른 실시양태에서, 비가교결합 성분은 1개 또는 다수의 보조적 폴리펩티드 모듈을 포함할 수 있다. 이들 rPEG 모듈은 생성된 가교결합된 보조적 폴리펩티드에게 큰 수력학적 반경, 및 이에 따른 낮은 속도의 신장 제거를 제공한다. 또한, 보조적 폴리펩티드 모듈은 생성된 가교결합된 보조적 폴리펩티드내의 다양한 도메인의 이동성을 증가시킨다. 이는 다수의 적용성을 가질 수 있다. 예를 들면, 입체구조적 이동성은, 표적 수용체가 서로에 대해 가깝게 위치되지 않은 경우에도, 가교결합된 보조적 폴리펩티드가 표적, 예컨대 세포, 조직 또는 전염성 제제 상에서 다수의 표적 수용체에 결합할 수 있도록 허용할 수 있다. 보조적 폴리펩티드 모듈은 또한 가교결합된 보조적 폴리펩티드의 조직 분포를 조정하기 위해 작용할 수도 있다. 예를 들면, 보조적 폴리펩티드 모듈을 가교결합된 보조적 폴리펩티드에 포함시켜, 큰 단백질에 대한 낮은 투과성을 갖는 손상되지 않은 맥관을 특징으로 하는 건강한 조직으로 가교결합된 보조적 폴리펩티드가 침투하는 것을 제한할 수 있다.
또한 다른 실시양태에서, 비가교결합 성분은 생성된 가교결합된 보조적 폴리펩티드의 혈청 반감기를 증가시키는 결합 요소를 함유할 수 있다. 이러한 결합 요소는 1개 또는 다수의 혈청 성분, 예컨대 HSA, IgG, 적색 세포, 또는 고농도로 발견되는 다른 혈청 성분에 결합될 수 있다.
그 외의 다른 실시양태에서, 비가교결합 성분은 하나 이상의 작은 약물 분자에 접합될 수 있다. 유용한 약물 분자의 예는 독소루비신(doxorubicin), 멜팔란(melphalan), 파크리탁셀(paclitaxel), 마이탄신스(maytansines), 두오카마이신스(duocarmycines), 칼리키아마이신(calicheamycin), 아우리스타틴(auristatin) 및 다른 세포독성, 세포정지성, 항전염성 약물이다.
몇몇 실시양태에서, 비가교결합 성분은 친화성 태그를 포함할 수 있다. 유용한 친화성 태그의 예는 플래그(Flag), HA-태그, 헥사-히스티딘이다. 이러한 친화성 태그는 비가교결합 성분 뿐만 아니라 생성된 가교결합된 보조적 폴리펩티드의 정제를 촉진시킨다. 또한, 친화성 태그는 생물학적 샘플에서 가교결합된 보조적 폴리펩티드의 검출을 촉진시킨다. 구체적으로, 친화성 태그는 환자 또는 동물에서 가교결합된 보조적 폴리펩티드의 혈청 반감기 및/또는 조직 분포의 모니터링에 유용하다.
다른 실시양태에서, 비가교결합 성분은 결합 도메인, 활성 약물, 또는 생물학적 활성을 갖는 다른 부분서열의 저속 방출을 허용하는 프로테아제 부위를 포함할 수 있다.
라이신 잔기가 없는 비가교결합 성분이 특히 유용하다. 이러한 서열은 이들의 N-말단에 단일 아미노 기를 함유하고, 이는 가교결합 성분에 접합하기에 유용하다. 유리 시스테인 잔기를 함유하는 비가교결합 성분은 또한 유용한데, 이는 유리 시스테인 잔기의 측쇄로의 제어된 접합을 허용하는 많은 이용가능한 화학성이 존재하기 때문이다. 또 다른 접근법은 비가교결합 성분의 C-말단 카복실 기를 반응성 기로서 이용하는 것이다.
다수의 반응성 기를 포함하는 많은 분자는 유용한 가교결합 성분으로서 작용할 수 있다. 많은 유용한 가교결합 제제는 시그마-알드리치(Sigma-Aldrich), 또는 피어스(Pierce)와 같은 회사로부터 상업적으로 입수가능하다. 활성화된 형태로 이용가능하고 접합을 위해 직접 사용될 수 있는 가교결합 성분이 특히 유용하다. 예는 도 22에 제시되어 있다. 가교결합 성분은 유사하거나 동일한 화학적 구조를 갖는 다수의 반응성 기를 포함할 수 있다(도 23). 이러한 반응성 기는 동시에 활성화되고 다수의 동일한 비가교결합 성분에 커플링되어 동종다량체 생성물을 직접적으로 형성할 수 있다. 다수의 유사한 반응성 기를 갖는 가교결합 성분의 예는 시트르산, EDTA, TSAT이다. 다수의 동일한 반응성 기를 함유하는 분지형 PEG 분자가 특히 관심을 끈다.
하기 소수의 염기성 반응식에 기초하여 작용하는 다수의 특이적 화학 생성물이 존재하고, 이들 모두는 www.piercenet.com에 상세히 기재되어 있다. 유용한 가교결합제의 예는 이미도에스테르, 활성 할로겐, 말레이미드, 피리딜 디설파이드, 및 NHS-에스테르이다. 동종이작용성 가교결합 제제는 2개의 동일한 반응성 기를 갖고, 종종 1단계 화학 가교결합 절차에 사용된다. 예는 BS3(비절단성의 수용성 DSS 유사체), BSOCOES(염기-가역성), DMA (다이메틸 아디피미데이트-2HCl), DMP(다이메틸 피멜리미데이트-2HCl), DMS(다이메틸 서버이미데이트-2HCl), DSG(DSS의 5-탄소 유사체), DSP(로만트 시약: Lomant's reagent), DSS(비절단성), DST(산화제에 의해 절단가능함), DTBP(디메틸 3,3'-디티오비스프로피온이미데이트-2HCl), DTSSP, EGS, 설포-EGS, THPP, TSAT, DFDNB(1,5-디플루오로-2,4-디니트로벤젠)이고, 이는 작은 공간 거리 사이의 가교결합을 위해 특히 유용하다(Kornblatt, J.A. and Lake, D.F. (1980). Cross-linking of cytochrome oxidase subunits with difluorodinitrobenzene. Can J. Biochem. 58, 219-224).
설프하이드릴 반응성 동종이작용성 가교결합 제제는 설프하이드릴과 반응하고 종종 말레이미드에 기초하는 동종이작용성 단백질 가교결합기이고, 이는 -SH 기와 pH 6.5∼7.5에서 반응하여 안정한 티오에테르 연결을 형성한다. BM[PEO]3은 8-원자 폴리에스테르 이격자로서, 이는 설프하이드릴-대-설프하이드릴 가교결합 적용시 접합 침전을 위해 전위를 감소시킨다. BM[PEO]4는 유사하지만, 11-원자 이격자를 갖는다. BMB는 4-탄소 이격자를 갖는 비절단성 가교결합기이다. BMDB는 페리오데이트에 의해 절단될 수 있는 연결부를 만든다. BMH는 널리 사용되는 동종이작용성 설프하이드릴 반응성 가교결합기이다. BMOE는 특별히 짧은 연결기이다. DPDPB 및 DTME는 절단가능한 가교결합기이다. HVBS는 멜레이미드의 가수분해 전위를 갖지 않는다. TMEA는 또 다른 선택사항이다. 이종-이작용성 가교결합 제제는 2가지 상이한 반응성 기를 갖는다. 예는 EDC 활성화를 경유한 NHS-에스테르 및 아민/하이드라진, AEDP, ASBA(광반응성, 요오드화가능), EDC(수용성 카보디이미드)이다. 아민-설프하이드릴 반응성 이작용성 가교결합기는 AMAS, APDP, BMPS, EMCA, EMCS, GMBS, KMUA, LC-SMCC, LC-SPDP, MBS, SBAP, SIA(극히 짧음), SIAB, SMCC, SMPB, SMPH, SMPT, SPDP, 설포-EMCS, 설포-GMBS, 설포-KMUS, 설포-LC-SMPT, 설포-LC-SPDP, 설포-MBS, 설포-SIAB, 설포-SMCC, 설포-SMPB이다. 아미노-기 반응성 이종이작용성 가교결합 제제는 ANB-NOS, MSA, NHS-ASA, SADP, SAED, SAND, SANPAH, SASD, SFAD, 설포-HSAB, 설포-NHS-LC-ASA, 설포-SADP, 설포-SANPAH, TFCS이다. 아르기닌 반응성 가교결합 제제는 예를 들면 pH 7∼8에서 아르기닌과 특이적으로 반응하는 APG이다.
폴리펩티드는 가교결합 성분으로서 작용하도록 디자인될 수 있다. 이러한 폴리펩티드는 화학적 합성에 의해 또는 재조합 기법을 사용하여 생성될 수 있다. 예는 다수의 아스파테이트 또는 글루타메이트 잔기를 함유하는 폴리펩티드이다. 이들 잔기의 측쇄 뿐만 아니라 C-말단 카복실 기는 비가교결합 성분에 커플링하기 위해 사용될 수 있다. 아스파테이트 또는 글루타메이트 잔기 사이에 1개 또는 수개의 아미노산을 첨가함으로써 반응성 기 사이의 거리를 조절할 수 있고, 이는 접합의 효능 뿐만 아니라 생성된 가교결합된 보조적 폴리펩티드의 전체 특성에 영향을 줄 수 있다. 다수의 아스파테이트 또는 글루타메이트 잔기를 함유하고 이들의 N-말단 아미노 기에서 보호기를 운반하는 폴리펩티드가 특히 유용하다. 적합한 보호 계획의 예는 아세틸화, 석시닐화, 및 펩티드의 N-말단 아미노 기의 반응성을 감소시키는 다른 변경이다.
덴드리머 구성물이 가교결합 성분으로서 특히 유용하다. 많은 덴드리머 구조는 당분야에 공지되어 있고, 이들은 많은 수의 반응성 기를 함유하도록 디자인될 수 있다. 가교결합된 보조적 폴리펩티드의 예는 도 24에 예시되어 있다.
보조적 폴리펩티드의 추가의 변경
추가의 기작은 보조적 폴리펩티드, 뿐만 아니라 혈청-노출된 분자에 대한 결합 친화도를 갖는 펩티드로 중재된 가교결합된 보조적 폴리펩티드에 활용될 수 있다. 이러한 표적으로의 결합에 의해, 본 발명의 폴리펩티드의 반감기는 추가로 증가된다. 예를 들면, 가교결합된 보조적 폴리펩티드는 혈청-노출된 표적에 결합 친화도를 갖는 폴리펩티드를 포함하는 비가교결합 단위를 포함할 수 있다. 다르게는, 보조적 폴리펩티드는 이러한 결합 친화도를 갖는 폴리펩티드를 코딩하는 서열을 포함할 수 있다. 펩티드 또는 단백질 도메인이 반감기 증진을 위해 결합될 수 있는 바람직한 혈청-노출된 표적은 (인간, 마우스, 래트, 원숭이) 혈청 알부민, 면역글로불린 예컨대 IgG(IgG1, 2, 3, 4), IgM, IgA, IgE 뿐만 아니라 적혈 세포(RBC: red blood cell), 또는 내피 세포이다. 보조적 폴리펩티드는 또한 예로서 세포외 기질을 표적화하고 막으로 삽입되는 서열, 또는 다른 표적화 펩티드 및 도메인을 포함할 수 있다(도 28).
또 다른 실시양태에서, 보조적 폴리펩티드 또는 가교결합된 보조적 폴리펩티드는 수개의 분리된 생물학적 활성 폴리펩티드, 뿐만 아니라 혈청 프로테아제에 대한 특이적 절단 부위를 포함하는 서열을 포함할 수 있다(도 29). 혈청으로의 노출 또는 투여 후, 혈청 프로테아제는 절단 부위에 작용하여 점진적 단백질가수분해, 및 생물학적 활성 폴리펩티드 또는 보조적 폴리펩티드의 혈액내로의 방출을 유도한다.
보조적 폴리펩티드 또는 가교결합된 보조적 폴리펩티드는 또한 합성후 변경될 수 있다. 한 실시양태에서, 하나 이상의 라이신 잔기를 포함하는 보조적 폴리펩티드가 발현된다(도 30). 발현 후, 폴리펩티드는 하나 이상의 제2 작용성 단위(이는 예를 들면 생물학적 활성 폴리펩티드일 수 있음)에 부착된 Lys 반응성 잔기와 반응한다. 관련된 실시양태에서, 작용성 단위는 혈청-노출된 표적, 예컨대 혈청 알부민, 면역글로불린, 예컨대 IgG(IgG1, 2, 3, 4), IgM, IgA, IgE 뿐만 아니라 적혈 세포(RBC) 또는 내피 세포에 대한 결합 친화도를 갖는 폴리펩티드이다.
항원 결합 단위에 연결된 보조적 폴리펩티드
본 발명은 항원 결합 단위에 연결된 보조적 폴리펩티드를 구현한다. 용어 "항원 결합 단위"는 총체적으로 면역글로불린 분자 및 면역글로불린 분자의 면역학적 활성 부분의 임의의 형태, 즉, 항원에 특이적으로 결합하거나 이와 면역반응하는 항원 결합 부위를 함유한 분자를 지칭한다. 구조적으로, 가장 단순한 천연 발생 항체(예를 들어, IgG)는 4개의 폴리펩티드 쇄, 즉 2개의 중(H)쇄 및 2개의 경(L)쇄(디설파이드 결합에 의해 상호-연결됨)를 포함한다. 면역글로불린은 수종의 유형의 분자, 예컨대 IgD, IgG, IgA, IgM 및 IgE를 포함하는 분자의 큰 계열을 나타낸다. 용어 "면역글로불린 분자"는, 예를 들면, 하이브리드 항체, 또는 변형된 항체, 및 이의 단편을 포함한다. 항체 결합 단위는 넓게 "단일쇄"("Sc": single-chain) 및 "비단일쇄"("Nsc": non-single-chain) 유형으로 나뉠 수 있고, 이는, 제한되지 않지만, Fv, scFv, dFv, dAb, 다이아바디, 트리아바디, 테트라바디, 도메인 Ab, Fab 단편, Fab', (Fab')2, 이특이적 Ab 및 다특이적 Ab가 포함된다.
또한 용어 "항원 결합 단위"내에 무척추동물 및 척추동물을 비롯한 다양한 종 기원의 면역글로불린 분자가 내포된다. 항원 결합 단위에 적용될 경우 용어 "인간"은 인간 유전자 또는 이의 단편에 의해 발현된 면역글로불린 분자를 지칭한다. 비-인간(예를 들어 설치류 또는 영장류) 항체에 적용될 경우 용어 "인간화된"은 비-인간 면역글로불린으로부터 유도된 최소한의 서열을 함유하는 하이브리드 면역글로불린, 면역글로불린 쇄 또는 이의 단편이다. 대부분의 경우, 인간화된 항체는 인간 면역글로불린(수령자 항체)이고, 여기서 수령자의 상보성 결정 영역(CDR: complementary determining region)으로부터의 잔기는 원하는 특이성, 친화도 및 능력을 갖는 비-인간 종(공여자 항체), 예컨대 마우스, 래트, 래빗 또는 영장류의 잔기로부터의 CDR에 의해 대체된다. 몇몇 경우에, 인간 면역글로불린의 Fv 골격구조 영역(FR: framework region) 잔기는 상응하는 비-인간 잔기에 의해 대체된다. 추가로, 인간화된 항체는 수령자 항체에서 또는 유입된 CDR 또는 골격구조 서열에서 발견되지 않는 잔기를 포함할 수 있다. 이들 변경은 인체에 도입될 경우 추가로 항체 성능을 정련 및 최적화하고 면역원성을 최소화하도록 이루어진다. 일반적으로, 인간화된 항체는 실질적으로 모든 하나 이상, 전형적으로 2개의 가변성 도메인을 포함하고, 여기서 모든 또는 실질적으로 모든 CDR 영역은 비-인간 면역글로불린의 영역에 상응하고, 모든 또는 실질적으로 모든 FR 영역은 인간 면역글로불린 서열의 영역이다. 인간화된 항체는 또한 면역글로불린 불변 영역(Fc), 전형적으로 인간 면역글로불린의 불변 영역의 적어도 일부를 포함할 수 있다.
"비단일쇄 항원 결합 단위"는 경쇄 폴리펩티드 및 중쇄 폴리펩티드를 포함하는 이종다량체이다. 비단일쇄 항원 결합 단위의 예는, 제한되지 않지만, (i) VL 및 VH 영역으로 이루어지고, VL 및 VH 영역과 프레임내에서 융합된 제1 및 제2 이종이량체화 서열의 쌍대 친화도를 통해 이량체화한 이량체 단백질인 ccFv 단편; (ii) 하나 이상의 ccFv 단편을 포함하는 임의의 다른 1가 및 다가 분자; (iii) VL, VH, CL 및 CH1 도메인으로 구성된 Fab 단편; (iv) VH 및 CH1 도메인으로 구성된 Fd 단편; (v) 항체의 단일 암(arm)의 VL 및 VH 도메인으로 구성된 Fv 단편; (vi) 힌지 영역에서 디설파이드 가교에 의해 연결된 2개의 Fab 단편을 포함하는 2가 단편인 F(ab')2 단편; (vii) 다이아바디; 및 (viii) 당분야에 기재되고 공지된 임의의 다른 비단일쇄 항원 결합 단위가 포함된다.
주지된 바와 같이, 비단일쇄 항원 결합 단위는 "1가" 또는 "다가"일 수 있다. 전자가 항원 결합 단위당 1개의 결합 부위를 갖는 반면, 후자는 동일하거나 상이한 종류의 하나보다 많은 항원에 결합할 수 있는 다중 결합 부위를 함유한다. 결합 부위의 수에 의존하여, 비단일쇄 항원 결합 단위는 2가(2개의 항원 결합 부위를 가짐), 3가(3개의 항원 결합 부위를 가짐), 4가(4개의 항원 결합 부위를 가짐) 등일 수 있다. 다가 비-단일쇄 항원 결합 단위는 이들의 결합 특이성에 기초하여 추가로 분류될 수 있다. "일특이적" 비단일쇄 항원 결합 단위는 동일한 종류의 하나 이상의 항원에 결합할 수 있는 분자이다. "다특이적" 비단일쇄 항원 결합 단위는 2개 이상의 상이한 항원에 대한 결합 특이성을 갖는 분자이다. 이러한 분자는 정상적으로 단지 2개의 별개의 항원인 반면, 이러한 삼특이적 항체와 같은 추가의 특이성을 갖는 항체는 본 발명에 의해 내포된다.
"단일쇄 항원 결합 단위"는 단량체 항원 결합 단위를 지칭한다. Fv 단편의 2개의 도메인이 별도의 유전자에 의해 코딩되지만, 합성 연결기는 재조합 방법에 의해 단일 단백질 쇄(즉 문헌[Bird et al. (1988) Science 242:423-426 and Huston et al. (1988) PNAS 85:5879-5883]에 기재된 바와 같은 단일쇄 Fv("scFv"))로서 제조되도록 할 수 있는 합성 연결기가 제조될 수 있다. 다른 단일쇄 항원 결합 단위는 본 이종이량체 서열에 의해 안정화된 항원 결합 분자, 및 VH 도메인과 단리된 상보성 결정 영역(CDR)으로 구성된 dAb 단편(Ward et al. (1989) Nature 341:544-546)을 포함한다. 바람직한 단일쇄 항원 결합 단위는 함께 연결되고 한 쌍의 이종이량체 서열에 의해 안정화된 VL 및 VH 영역을 함유한다. scFv는 임의의 순서로, 예를 들면, VH--(제1 이종이량체화 서열)-(제2 이종이량체화 서열)--VL 또는 V.sub.L --(제1 이종이량체화 서열)-(제2 이종이량체화 서열)--VH로 조립될 수 있다.
항원 결합 단위는, 이것이 폴리펩티드 또는 다른 물질을 비롯한 다른 참고 항원에 결합하는 것보다 더 큰 친화도 또는 결합활성을 갖고 결합한다면, 항원에 특이적으로 결합하거나 이와 면역반응성이다. 항원 결합 단위는 숙주 세포의 외부 표면에 직접적으로 부착될 수 있거나, 숙주 세포 결합된 유전적 패키지, 예컨대 파지 입자를 통해 숙주 세포에 간접적으로 부착될 수 있다.
항원 결합 단위에 연결된 보조적 폴리펩티드로는, 제한되지 않지만, rPEG, nrPEG, 및 수력학적 반경을 증가시키고, 혈청 반감기를 연장시키고/거나, 생체내 제거 속도를 변경시킬 수 있는 임의의 다른 폴리펩티드가 포함된다. 원할 경우, 보조적 폴리펩티드는 예상 분자량을 약간 증가시키지만, 겉보기 분자량은 보다 많이 증가시킨다.
본 발명의 또 다른 실시양태는 보조적 폴리펩티드, 예컨대 양쪽 말단에서 결합 쌍에 연결된 rPEG를 포함한다. 이러한 결합 쌍은 rPEG를 통해 연결된 결합 단백질 1 및 결합 단백질 2로 일반적으로 구성된다. 이러한 결합 쌍의 예로는, 제한되지 않지만, 수용체-리간드 쌍, 항체-항원 쌍, 또는 서로 상호작용할 수 있는 임의의 2개의 폴리펩티드가 포함된다. 도 82는 이러한 rPEG 연결된 결합 쌍을 제조하는 일반적 방식을 보여주는데, 이는 초기 활성이 없고, 이에 따라 돌발 방출 효과가 없으며(독성을 일이키지 않고 투여될 수 있는 용량을 증가시킴), 초기 수용체 매개성 제거가 감소된다는 이점을 갖는다. 일반적 결합 쌍은 수용체-리간드, 항체-리간드, 또는 일반적인 결합 단백질 1-결합 단백질 2일 수 있다. 구성물은 절단 부위를 가질 수 있고, 이는 주사 전에 절단될 수 있으며, 주사 후에(프로테아제에 의해 혈청에서) rPEG가 치료학적 최종 생성물(활성 단백질)(이는 리간드, 수용체 또는 항체일 수 있음)과 함께 존재하도록 위치될 수 있다.
항체 단편에 기초한 치료제(AFBT:
Antibody
fragment
-
based
therapeutics
)
본 발명의 또 다른 실시양태는 항체 단편에 기초한 치료제(AFBT)를 포함한다. AFBT는 하나 이상의 항원 결합 단위또는 항체 단편 및 하나의 보조적 폴리펩티드 예컨대, rPEG 도메인을 포함한다. AFBT는 또한 하나 이상의 페이로드를 포함할 수 있고, 이는 생물학적 활성을 갖는 잔사, 예컨대 사이토킨, 효소 및 성장 인자, 뿐만 아니라 치료학적 잠재성을 가질 수 있는 제제, 예컨대 세포독성 제제, 화학치료제, 항바이러스성 화합물, 또는 대비제(contrast agent)를 포함한다. AFBT는 또한 추가의 도메인, 예를 들면, 다량체화 도메인, 예컨대 Fc 영역 또는 루신 지퍼를 포함할 수 있다. 도 58a는 AFBT의 주 성분을 예시하는 AFBT의 일예를 보여준다. 항체 단편은 표적 항원에 대한 특이성을 갖는 AFBT를 제공한다(또한 도 21에 일반적으로 예시되어 있음). rPEG 도메인은 항체 단편 뿐만 아니라 페이로드에 다양한 이점을 제공한다. 이러한 이점으로는, 제한되지 않지만, 연장된 생체내 반감기, 증가된 용해도, 증가된 열 안정성, 증가된 프로테아제 안정성, 개선된 단백질 폴딩, 감소된 쇄 재편성, 페이로드의 감소된 면역원성, 및 화학 PEG에 대한 미리존재하는 면역 응답의 방지가 포함된다. rPEG 도메인은 또한 생산 및 정제를 촉진한다. rPEG 도메인의 높은 용해도는 AFBT를 높은 용해도로 만들어 응집을 형성하는 경향이 낮으면서 높은 농도로 제형화될 수 있도록 한다. AFBT는 상기 도면에서 특별히 예시되지 않은 추가의 성분을 함유할 수 있는 것으로 이해되어야 한다.
vH/vL 도메인에 기초한 구조
본 발명의 한 실시양태에서, AFBT는 또한 하나 이상의 항체에 의해 유도된 면역글로불린(Ig) 도메인 또는 단편, 예컨대 단일쇄 가변성 단편(scFv)을 포함한다. scFv는 vH와 vL 도메인 사이의 펩티드 연결기를 통해 vL 도메인에 연결된 vH 도메인으로 구성된다. scFv중 연결기는 총-길이, 즉 총 항체(도 52)에 비해, scFv, 다이아바디, 트리아바디, 또는 테트라바디(도 53, 54, 55)를 포함하는 단일 분자 종을 형성하도록 선택된다. 전형적으로 생성된 AFBT의 결합가는 보다 높은 결합가가 배제되지 않지만 1∼4이다. 단일의 균질한 종을 우세하게 형성하는 디자인이 바람직하다. Fv 단편은 접촉된 vH 및 vL 도메인 사이의 디설파이드 결합을 포함하여 도메인 재편성의 위험을 감소시킨다. 달성될 수 있는 원하는 종의 분율은 항체 단편 혼합물의 1%∼100% 미만의 범위이다. 1차 제어는 포맷을 지시하는 연결기 길이, 및 항체 단편 쇄 재편성을 감소시키는 rPEG이다. 바람직한 실시양태로는 12개 이상의 아미노산의 연결기를 사용하는 단일 vH-vL 쇄로부터 단량체 scFv를 형성함을 포함한다. 보다 바람직한 실시양태는 15개 이상, 20개 이상, 30개 이상, 50개 이상, 100개 이상, 200개 이상, 또는 288개 이상의 아미노산의 연결기를 포함한다. 10∼20개 미만의 아미노산, 바람직하게는 1, 2, 3, 4, 5, 6, 7, 8, 9 또는 10개 아미노산의 연결기를 필요로 하는 다이아바디를 우선적으로 형성하는 vH-vL 쇄가 특히 유용하다(도 84). 다이아바디는 2개의 단백질 쇄를 갖고, 한쪽 또는 양쪽 C-말단 말단, 및/또는 한쪽 또는 양쪽 N-말단 말단에 rPEG를 가질 수 있다. 다이아바디는 2개의 결합 부위를 갖고, 이중 0, 1 또는 2개는 약학적 표적, 또는 반감기 표적(예를 들어 HSA, IgG, 적혈 세포, 콜라겐, 등)에 결합하거나 어떤 표적에도 결합하지 않는다. 다이아바디는 0, 1 또는 양쪽 단백질 쇄의 N-말단 또는 C-말단 말단에 위치된 약물 분자를 0, 1개 또는 그 이상 함유할 수 있다. 다이아바디 함유 AFBT는 그의 이량체 구조에 기인하여 증가된 분자량을 갖고, 이는 신장 제거를 둔화시킨다. 한 실시양태에서, 1종에서 다른 종으로의 항체 단편 쇄 재편성의 정도는 고정된 온도(예를 들어 4℃, 25℃ 또는 37℃)에서 1일 또는 1주당 단백질 질량의 50%, 40%, 30%, 20% 또는 10% 미만, 바람직하게는 5%, 2%, 1% 또는 0.1% 미만이다.
또 다른 실시양태에서, AFBT는 트리아바디를 포함하고, 이는 3개의 폴리펩티드 쇄를 함유하고, 각각 10개 미만의 아미노산, 바람직하게는 5개 미만의 아미노산의 연결기를 통해 연결된 vH 및 vL 도메인을 함유한다. 트리아바디의 빈도는, vH 및 vL 도메인의 하나 또는 양쪽 연결 말단으로부터 하나 또는 소수의 아미노산을 제거하고, 연결 서열을 단축시켜 트리아바디가 우호적으로 형성되게 함으로써 증가될 수 있다. 항체의 융합된 말단의 하나 또는 둘 다로부터 제거된 잔기의 수는 1∼10개 아미노산 범위일 수 있다.
또 다른 실시양태에서, AFBT는 4개의 폴리펩티드 쇄를 함유하는 테트라바디를 포함하고, 각각은 5개 미만의 아미노산의 짧은 연결기를 통해 연결되거나, 또는 항체의 융합된 말단의 한쪽 또는 양쪽으로부터의 1∼10개 잔기를 제거한 결과로서 vH 도메인 및 vL 도메인을 갖는다. vH 및 vL 도메인의 한쪽 또는 양쪽 말단으로부터 제거하기 위한 아미노산의 수는 가장 원하는 결과를 확보하기 위해 조정될 수 있다.
폴리펩티드 쇄의 단일 카피로 구성된 단일쇄(scFv) 조합의 다양한 유형의 예로는, 제한되지 않지만, scFv-scFv, scFab-scFc, dAb-scFc, scFc-scFc, scFc-scFab, 및 scFc-dAb(도 57)가 포함된다. scFv 단편은 N- 및/또는 C-말단 말단의 한쪽 또는 양쪽에서 약물 분자, 예컨대 IFNα, hGH 등에 융합될 수 있다(도 85). scFv는 하나의 결합 부위를 갖고, 이는 약학적 표적, 또는 반감기 표적, 예를 들어 HSA(도 85b), IgG, 적색 세포 등에 결합하거나 결합하지 않을 수 있다.
Ig 도메인을 함유한 AFBT는 다양한 구조를 가질 수 있다. 특히 유용한 구성물로는, 제한되지 않지만, 다음이 포함된다: vL-연결기-vH-rPEG, vH-연결기-vL-rPEG, vL-연결기-vH-rPEG-페이로드, vH-연결기-vL-rPEG-페이로드, vL-연결기-vH-페이로드-rPEG, vH-연결기-vL-페이로드-rPEG, rPEG-vL-연결기-vH, rPEG-vH-연결기-vL, 페이로드-rPEG-vL-연결기-vH, 페이로드-rPEG-vH-연결기-vL, rPEG-페이로드-vL-연결기-vH, rPEG-페이로드-vH-연결기-vL. 이들 AFBT는 도메인 사이에, 또는 rPEG 도메인으로의 임의의 위치에 삽입될 수 있는 추가의 도메인을 함유할 수 있다 . 또한 수개의 페이로드 모듈이 존재할 수 있다.
vH 및 vL을 연결하는 연결기 서열는 최적의 단백질 폴딩 및 안정성, 뿐만 아니라 원하는 종의 높은 수준의 발현 및 큰 분율을 달성하기 위해 최적화될 수 있다. 바람직한 실시양태로는 글리신 및 기타 소량의 친수성 아미노산, 예컨대 세린, 트레오닌, 글루탐산, 아스파르트산, 라이신, 아르기닌, 및 알라닌이 풍부한(예를 들어 50% 초과) 연결기 서열이 포함된다. rPEG는 vH과 vL 도메인 사이의 연결기로서 특히 적합하다. 개선된 특성을 갖는 연결기는 라이브러리의 선택 또는 스크리닝에 의해 수득될 수 있다.
rPEG
연결기를
갖는
scFv
또 다른 실시양태에서, scFv는 rPEG 서열을 연결기로서 vH 및 vL 도메인 사이에 포함한다. 바람직한 실시양태는 상당한 음성 순 전하를 함유하여 scFv 도메인의 용해도 및 폴딩을 개선시키는 rPEG 연결기를 포함한다. 바람직한 실시양태는 15개 이상, 20개 이상, 30개 이상, 50개 이상, 100개 이상, 200개 이상, 또는 288개 이상의 잔기를 갖는 연결기를 포함한다.
AFBT
의 안정한 항체 단편을 생성하는 방법
본 발명은 또한 AFBT의 항원 결합 단위를 생성 및 조작하는 방법에 관한 것이다. 많은 방법은 표적 항원에 대한 특이성을 갖는 항체를 생성하는 것으로 공지되어 있다. 예로는, 특히 인간 항체를 생산하는 유전자도입 동물에서의 단일클론성 항체; Fab 또는 scFv 라이브러리의 파지 디스플레이; 리보솜 디스플레이; 및 단일클론성 항체의 인간화가 포함된다. scFv의 안정성을 조작하기 위한 다수의 방법은 또한 문헌[Worn, A., et al. (2001) J Mol Biol, 305: 989]에 기재되어 있다. scFv의 vH 및 vL 도메인 사이의 디설파이드 결합을 첨가하는 것이 상당한 안정화를 유도할 수 있는 것으로 제시되었다[Dooley, H, et al. (1998) Biotechnol Appl Biochem 28 (Pt 1), 77, #2802]. 한 대안은 컨센서스(consensus) 돌연변이의 도입이다. 항체 골격구조 잔기에서 다양한 위치에서의 아미노산 빈도가 분석되었다. 볼츠만(Boltzmann) 식은 몇몇 컨센서스 돌연변이의 안정화 효과를 예측할 수 있는 것으로 제시되었다[Steipe, B, et al. (1994) J Mol Biol 240, 188, #2026]. 단일쇄 항체 단편내로 다수의 컨센서스 돌연변이의 동시 도입을 허용하는 조합 접근법이 기재되어 있다[Roberge, M., et al. (2006) Protein Eng Des Sel, 19: 141]. 보다 안정한 항체 단편을 생산하는 것은 생체내 표적화를 개선시켰다[Worn, A., et al. (2000) J Biol Chem, 275: 2795].
몇몇 scFv는 이. 콜라이의 사이토졸에서 가용성 형태로 발현되었다. 일반적으로, 디설파이드 결합은 사이토졸에 형성되지 않지만, 이들은 세포 용해후 자발적으로 형성될 수 있다[Tavladoraki, P., et al. (1999) Eur J Biochem, 262: 617]. 일반적으로, 항체의 사이토졸 발현은 항체 안정성과 매우 상관관계가 있다[Worn, A., et al. (2001) J Mol Biol, 305: 989]. 항체 단편의 돌연변이 라이브러리는 개선된 사이토졸 발현을 위해 선택될 수 있다[Martineau, P., et al. (1998) J Mol Biol, 280: 117].
이. 콜라이의 레독스(Redox) 조작된 균주는 Fab 단편의 사이토졸 발현을 개선시키기 위해 사용될 수 있다[Levy, R., et al. (2007) J Immunol Methods, 321: 164]. 배양 조건은 이. 콜라이의 사이토졸에서의 가용성 scFv의 발현을 개선시키기 위해 최적화되어 35 mg/L 까지의 배양액의 발현 수준을 일으킬 수 있다[Padiolleau-Lefevre, S., et al. (2007) Mol Immunol, 44: 1888]. scFv의 사이토졸 발현을 개선시키기 위한 또 다른 접근법은 샤프론(chaperone) 또는 발현을 촉진하는 다른 인자를 동정할 목적을 갖고 게놈 라이브러리를 스크리닝 또는 선택하는 것이다. 이러한 접근법은 람다 파지를 사용하여 평가되었다. scFv에서의 디설파이드 결합은 성공적으로 제거되어 인트라바디를 형성하였다. 이러한 인트라바디의 변형체는 동정되어 개선된 사이토졸 발현을 일으킬 수 있다[der Maur, A. A., et al. (2002) J Biol Chem, 277: 45075]. 그러나, 디설파이드 결합은 대부분의 항체 단편의 전체 안정성을 위해 중요하고, 대부분의 경우 인트라바디는 제한된 유용성을 갖는다.
상보성 결정 영역(
CDR
) 그래프팅(
grafting
)
항체 또는 항체 단편과 이들 표적 사이의 결합 상호작용은 주로 상보성 결정영역(CDR)에 의해 결정된다. CDR은 상이한 항체의 가변성 도메인 사이에 그라프팅될 수 있는 것으로 제시되었다[Jones, P. T., et al. (1986) Nature, 321: 522]. 많은 경우에, 항체 골격구조중 다른 잔기는 항원 결합을 보유하기 위해 CDR 잔기에 추가로 그래프팅될 필요가 있다. CDR 그래프팅은 CDR을 덜 안정한 가변성 도메인으로부터 더 안정한 가변성 도메인으로 그래프팅함으로써 항체의 안정성을 개선시키기 위해 유용할 수 있다. 한 예는 플루오레세인(fluorescein) 결합 scFv로부터 '스캐폴드'로서 사용되는 잘-발현된 scFv로의 CDR의 그라프팅으로서, 이는 발현을 개선시키고 폴딩 안정성을 증가시킨다[Jung, S., et al. (1997) Protein Eng, 10: 959]. 항체 단편으로의 CDR 그라프팅의 추가의 예는 문헌[Leong, S. R., et al. (2001) Cytokine, 16: 106] 및 [Werther, W. A., et al. (1996) J Immunol, 157: 4986]에 기재되어 있다. CDR 그라프팅은 뮤린 항체로부터 인간 골격구조 잔기에 CDR을 그래프팅함으로써 환자에서 항체의 면역원성을 감소시키기 위해 사용될 수 있다[Winter, G., et al. (1993) Trends Pharmacol Sci, 14: 139].
AFBT
의 항원 결합 단위의 친화도
본 발명은 또한 AFBT의 항원 결합 단위의 친화도를 개선하는 방법을 구현한다. 개선된 친화도를 갖는 항체 및 항체 단편의 동정을 허용하는 다중 접근법이 기재되어 있다. 예를 들어 파스탄(Pastan)은 천연적으로 과돌연변이되는 경향이 있는 핫 스팟(hot spot) 상에 집중된 1000∼10000개 클론의 미니 라이브러리를 제조하였다. 파지 패닝은 15∼55배 개선된 변형체를 제공하였다[Chowdhury, PS, et al. (1999) Nat Biotechnol 17, 568, #2800]. 개선된 친화도를 갖는 항체 단편의 변형체를 동정하기 위해 파지 디스플레이 및 다른 디스플레이 방법이 이용될 수 있다[Corisdeo, S., et al. (2004) Protein Expr Purif, 34: 270]. 항원 결합에 관여된 잔기는 알라닌 스캐닝 돌연변이생성을 사용하여 동정될 수 있다. 후속적으로, 이들 위치는 돌연변이생성에 표적화되어 개선된 친화도를 갖는 변형체를 동정할 수 있다[Leong, S. R., et al. (2001) Cytokine, 16: 106]. 또 다른 전략은 CDR 워킹(walking) 돌연변이생성으로, 이는 높은 표적 결합 친화도를 갖는 항체 단편을 동정할 수 있다[Yang, W. P., et al. (1995) J Mol Biol, 254: 392]. 개선된 친화도는 항체 단편의 개선된 종양-선택성을 일으킬 수 있다[Adams, G. P., et al. (1998) Cancer Res, 58: 485]. 고친화도는 scFv의 종양 침투를 제한할 수 있다[Adams, G. P., et al. (2001) Cancer Res, 61: 4750] [Graff, C. P., et al. (2003) Cancer Res, 63: 1288]. 친화도가 개선된 항체 단편은 효모 디스플레이를 FACS 분류와 함께 조합하여 동정될 수 있다[Boder, E. T., et al. (2000) Proc Natl Acad Sci USA, 97: 10701].
다양한
IgG
도메인
AFBT는 다양한 면역글로불린 도메인을 함유할 수 있다. 이들 도메인은 단백질 발현, 다량체화에 영향을 주고, 이펙터(effector)로서 작용할 수 있다. Ig 도메인의 다양성을 예시하기 위한 예를 제공하는 하기 목록(여지가 있음)은, 인간을 비롯한 임의의 종으로부터의 IgG1, IgG2, IgG3, IgG4, IgE, IgM, IgA, 및 IgD를 비롯한 임의의 항체 이소형으로의 융합에 적용가능하다. rPEG의 면역글로불린-계열 서열로의 융합을 위한 부위는 제한되지 않지만 다음과 같다:
o CL1 도메인으로의 N-말단, 쇄간 시스테인 앞
o CL1 도메인으로의 N-말단, 쇄간 시스테인 뒤
o CL1 도메인으로의 C-말단, 쇄간 시스테인 앞
o CL1 도메인으로의 C-말단, 쇄간 시스테인 뒤
o CH1 도메인으로의 N-말단, 쇄간 시스테인 앞
o CH1 도메인으로의 N-말단, 쇄간 시스테인 뒤
o CH1 도메인으로의 C-말단, 쇄간 시스테인 앞
o CH1 도메인으로의 C-말단, 힌지 시스테인(들) 앞
o CH1 도메인으로의 C-말단, 힌지 시스테인(들) 뒤
o 힌지 시스테인(들)으로의 N-말단
o 힌지 시스테인(들)으로의 C-말단, CH2 앞
o CH2 도메인으로의 N-말단
o CH2 도메인로의 C-말단
o CH3 도메인으로의 N-말단
o CH3 도메인으로의 C-말단
o CH4 도메인으로의 N-말단
o CH4 도메인으로의 C-말단
o CDRH1-3 및/또는 CDRL1-3으로부터 유도된 펩티드로의 N-말단(람다 및 카파)
o CDRH1-3 및/또는 CDRL1-3로부터 유도된 펩티드로의 N-말단(람다 및 카파)
Fab
도메인에 기초한
AFBT
본 발명의 또 다른 실시양태는 Fab 도메인에 기초한 AFBT를 포함한다(도 56). Fab 도메인은 2개의 펩티드 쇄를 포함하고, 이 중 하나는 항체의 중쇄 및 경쇄로부터 유도된다. rPEG 및 페이로드 및 다른 도메인은 Fab 단편의 쇄에 융합될 수 있다. 다르게는, rPEG 및 페이로드는 Fab의 양쪽 쇄에 융합될 수 있다. Fab 도메인은 생성된 단백질의 이량체화를 촉진시켜 최종 단백질이 4개의 펩티드 쇄를 함유하도록 디자인될 수 있다. 다음은 하나 이상의 Fab 도메인을 포함하는 AFBT의 목록이다:


전장(
Full
length
) 항체
rPEG 및 페이로드 및 다른 도메인은 항체의 경쇄 또는 중쇄, 또는 항체의 양쪽 쇄에 융합될 수 있다. 하기 표는 전장 항체에 기초한 AFBT의 몇몇 예를 예시한다:


본원에 정의된 바와 같은 전장 항체 또는 항체 단편상의 특정 부위는 rPEG에 대한 전장 항체(IgG1, 2, 3, 4, IgE, IgA, IgD, 및 IgM을 포함함) 또는 항체 단편으로의 바람직한 융합 부위이다. 이들 바람직한 부위는 구조화된 서열의 경계, 예컨대 도메인, 힌지 등에, 이들 작용성 도메인의 폴딩을 방해하지 않으면서 위치한다. rPEG는 1, 2, 3, 4, 5, 6, 7 또는 더욱 8개의 상이한 위치에서 항체(및, IgM 및 IgG3에 대해 8개 초과)에 첨가되고, 단일 항체는 1, 2, 3, 4, 5, 6, 7, 8개 이상의 rPEG를 도 103에 도시된 8개 위치의 임의의 조합 및 다양한 위치에서 가질 수 있다. 도 103e는 rPEG에 대한 항체의 도메인 및 단편으로의 바람직한 융합 부위를 보여준다.
도메인 항체에 기초한 AFBT
또 다른 실시양태에서, rPEG 및 페이로드 및 다른 도메인은 도메인 항체(dAb)에 융합될 수 있다. 적합한 결합 특성을 갖는 도메인 항체를 생성하기 위해, 경쇄가 천연적으로 결여된 카멜리드 및 상어의 면역 목록에서 발견되는 천연 단량체 vH 도메인(vHH로 지칭됨)을 사용할 수 있다[Hamers-Casterman, C, et al. (1993) Nature, 363: 446]. 다르게는, 용해도를 개선시키고 이량체화 및 응집을 감소시키기 위해 인간 vH 또는 vL 도메인의 vH-vL 계면을 조작할 수 있다. 이러한 돌연변이는 생성된 도메인 항체의 면역원성을 증가시킨다는 위험을 수반한다. 본 발명은 인간 vH 또는 vL Ig 도메인을 rPEG에 융합함을 기재하고, 이는 용해도 및 폴딩을 개선시키고, 응집을 감소시키고, 인간 골격구조 잔기의 돌연변이생성에 의해 개시되는 면역 응답을 유도하지 않는다. dAb 도메인에 기초한 AFBT의 예로는, 제한되지 않지만, dAb-rPEG, dAb-rPEG-페이로드, dAb-페이로드-rPEG, rPEG-dAb, 페이로드-rPEG-dAb, rPEG-페이로드-dAb가 포함된다. dAb 도메인은 항체 분자의 vH 또는 vL 도메인으로부터 유도될 수 있다.
다특이적
AFBT
본 발명은 또한 상이한 결합 특이성을 갖는 다수의 상이한 항체로부터 유도된 단편을 포함하는 AFBT를 구현한다. 한 예는 58b에 제시되어 있다. 이러한 AFBT는 2개 이상의 모 항체의 결합 특이성을 조합한다. 모 항체는 다수의 상이한 표적 항원에 생성된 AFBT가 결합하도록 선택될 수 있다. 다르게는, 모 항체는 동일한 표적 항원의 상이한 에피토프에 결합할 수 있다. AFBT는, 이들이 도 59에 예시된 바와 같이 동일한 표적 항원 상에서 다수의 부위에 결합함으로써 다가 상호작용을 형성할 경우, 표적에 매우 밀착되어 결합된다. 다특이적 AFBT는 동일한 단백질 쇄의 다량체를 형성할 수 있다. 예를 들면, 도 58b는 vH-vL 쇄 A에 기초한 2개의 결합 부위 및 vH-vL 쇄 B에 기초한 2개의 추가의 결합 부위를 함유하는 2개의 폴리펩티드 쇄의 이량체인 다특이적 AFBT를 예시한다. 당분야의 숙련가는 결합 도메인 또는 결합 모듈의 많은 상이한 조합물을 함유하는 다특이적 AFBT를 생성할 가능성을 인식할 수 있다. 상이한 가변성 도메인에 더하여, 다가 AFBT는 하나 이상의 페이로드 도메인, rPEG 모듈, 및 치료학적 유용성 또는 생산 및 정제를 증진시키도록 선택될 수 있는 다른 단백질 도메인을 포함한다. 한 실시양태는 동일한 질환 증후, 발병과정의 동일한 병원체 및 원인, 또는 동일한 생리학적 경로 및 과정과 관련된 다수의 표적 항원과 상호작용하는 다특이적 AFBT를 포함한다. 이러한 다특이적 AFBT의 예로는, 제한되지 않지만, 관련된 생물학적 과정에 관여된 다수의 사이토킨을 차단하는 다특이적 AFBT가 포함된다. 바람직한 실시양태는 신생혈관형성에 관여된 다수의 성장 인자, 예컨대 VEGF, PDGF, 및 PIGF를 차단하는 다특이적 AFBT를 포함한다. 도 95는 VEGF-수용체에 의해 양쪽 측부 상에 플랭킹된 rPEG를 보여준다. VEGF는 이량체이므로, 이는 rPEG의 양쪽 측부상의 동일한 수용체, 또는 상이한 수용체, 바람직하게는 VEGF-R1 및 VEGF-R2일 수 있지만, VEGFR3이 또한 사용될 수 있다. 또 다른 바람직한 실시양태로는 염증성 질환에 관여된 다수의 사이토킨, 예컨대 TNF-α, IL-1, IL-6, IL12, IL-13, IL17, 및 IL-23을 차단하는 다특이적 AFBT를 포함한다. 또 다른 바람직한 실시양태로는 다수의 종양 항원, 예컨대 Her1, Her2, Her3, EGFR, TF 항원, CEA, A33, PSMA, MUC1, αv/β3 인테그린, αv/ β5 인테그린, 및 α5/β1 인테그린에 결합하는 다특이적 AFBT를 포함한다. 또 다른 바람직한 양태로는 감염성 질환에 관련된 다수의 항원에 결합하는 다특이적 AFBT가 포함된다. 상기 다특이적 AFBT는 감염성 제제와 다가 상호작용을 형성하여 개선된 치료학적 유효성을 일으킬 수 있다. 다특이적 AFBT는 종양 항원에 대한 결합 부위 및 항원에 대한 제2 결합 부위를 면역 세포 상에 포함하도록 조작될 수 있다. 예로는 종양 항원 및 CD3 또는 CD16에 결합하는 AFBT가 포함되고, 이는 중성 킬러(NK: natural killer) 세포를 모집하고 활성화시킬 수 있다. 추가로 효능을 증가시키기 위해, 사이토킨 도메인, 예컨대 IL-2는 종양 세포의 부근에서 면역 세포를 활성화시키기 위해 포함될 수 있다.
동일한 항체의 다수의 단편을 함유한 AFBT
AFBT는 각각의 폴리펩티드 쇄가 동일한 모 항체의 다수의 가변성 단편을 함유하도록 조작될 수 있다. 이들 단편은 이들 서열과 동일하거나 적절한 도메인 조립을 촉진하도록 조작될 수 있다. 한 예는 도 60a에 예시되어 있다. 이러한 AFBT는 다이아바디 도메인 및 1가 scFv 도메인(동일한 모 항체에 기초함)을 함유한다. 결과로서, AFBT는 총 4개의 등가 표적 결합 부위를 함유한 이량체 구조물 내로 조립된다. 이러한 다가 AFBT는 결합활성에 기인한 개선된 효능을 가질 수 있다.
다이아바디에 기초한 이특이적 AFBT
AFBT는 하나의 다이아바디, 하나의 가변성 도메인 및 하나 이상의 rPEG 도메인을 조합하여 작제될 수 있다. 작제물은 이량체를 형성하고 총 4개의 항원 결합 부위를 함유한다. 도 58b는 이특이적 AFBT의 한 예를 예시한다. 이러한 구성물에서 가변성 도메인 A는 scFv 도메인 또는 dAb 도메인일 수 있다. 가변성 도메인 A는 다이아바디 도메인 B의 C-말단 측부에 존재할 수 있다. 다르게는, 가변성 도메인 A는 다이아바디 도메인 B의 N-말단 측부에 존재할 수 있다. 이특이적 AFBT는 추가의 rPEG 도메인 또는 다른 도메인, 예컨대 호르몬, 사이토킨 또는 효소를 함유할 수 있다. 이특이적 AFBT에서 가변성 도메인이 scFv 도메인이라면, scFv 도메인은 배열 vH-연결기-vL 또는 배열 vL-연결기-vH를 가질 수 있다.
한 바람직한 실시양태에서, 이특이적 AFBT는 다이아바디 B 및 scFv A를 포함하고, 여기서 다이아바디 및 scFv 도메인은 최적화되어 이들 구성물에서 4개 Ig 도메인의 비정확한 짝형성을 감소시킨다. 도메인은 vL-A 및 vH-A 뿐만 아니라 vL-B 및 vH-B가 비정확한 짝형성 vL-A 및 vH-B 및 vL-B 및 vH-A에 비해 보다 치밀한 상호작용을 형성하도록 최적화될 수 있다. scFv 도메인 A의 vH/vL 접촉 표면이 다이아바디 도메인 B의 vH/vL 접촉 표면과 상당한 구조적 차이를 갖도록 두 vH 및 vL 도메인의 골격구조를 선택함으로써 달성될 수 있다. 추가로, scFv 도메인 A 및 다이아바디 도메인 B의 vH/vL 접촉 영역을 조작함으로써 이러한 차이를 증진시켜 원치않는 접촉 기회를 최소화할 수 있다. 예를 들면, 이온 쌍이 정확한 vH/vL 짝형성을 위해 형성되지만 동일한 이온 쌍이 이특이적 AFBT에서 vH 및 vL 도메인의 비정확한 짝형성 동안 형성될 수 없도록 전하 차이를 조작할 수 있다. 또 다른 접근법은, vH 및 vL 도메인의 비정확한 짝형성에서 형성될 수 없는 원하는 vH/vL 접촉 표면으로 수소 결합 파트너를 도입하는 것이다. 또 다른 접근법은 비정확한 vL/vH 짝형성이 불안정화되도록 vL/vH 접촉 표면의 형상을 변경하는 것이다.
다이아바디에 기초한 이특이적 AFBT는, 이들이 2가 복합체당 2개의 rPEG 도메인을 함유하여 감소된 신장 여과 및 개선된 생체내 반감기을 일으키므로 특히 유용하다. AFBT는 폴리펩티드 쇄 당 하나의 다이아바디 도메인 및 2개의 추가의 가변성 도메인을 함유하도록 조작될 수 있다. 이러한 단백질은 총 6개의 항원 결합 부위를 포함하는 이량체 복합체를 형성할 수 있다. 추가로 가변성 단편 또는 페이로드 도메인은 효능을 증가시키기 위해 첨가될 수 있다.
페이로드를 함유한 이량체 AFBT
도 60b는 다이아바디 도메인 및 페이로드 도메인을 함유하는 이량체 AFBT를 예시한다. 이러한 단백질은 각각의 복합체가 표적 결합 부위, 2개의 rPEG, 및 2개의 페이로드 도메인을 함유하도록 이량체 복합체를 형성한다. 추가의 단백질 도메인은 이용성을 증가시키도록 첨가될 수 있다. 단백질 복합체당 2개의 rPEG를 갖는 것은 신장 여과를 감소시키고 생체내 반감기를 증가시킨다. 2개의 페이로드 도메인을 갖는 것은 효능을 증가시킨다. 다이아바디 도메인의 표적 결합 부위는, 혈액 성분, 예컨대 적혈 세포, 인간 혈청 알부민, IgG, 콜라겐, 또는 다른 단백질, 또는 혈액중의 세포에 결합시킴으로써 조작되어 추가로 생체내 반감기를 증가시킬 수 있다.
항체 단편 및 페이로드의 조합
본 발명은 하나 이상의 페이로드를 포함하는 AFBT를 구현한다. 한 바람직한 실시양태는 단백질 도메인이고, AFBT를 포함하는 다른 도메인에 직접 융합될 수 있는 페이로드를 포함한다. 페이로드 도메인의 예로는, 제한되지 않지만, 사이토킨, 호르몬, 성장 인자, 및 효소가 포함된다. 이러한 AFBT는 항체의 특이성을 페이로드의 효능과 조합하는 한편, rPEG 도메인은 반감기를 제공하고 생산 및 제형화를 촉진시킨다. 또 다른 바람직한 실시양태로는 특정 조직에 대해 특이성을 갖는 항체 단편을 동일한 조직에서 활성을 나타내는 페이로드와 조합한 AFBT를 포함한다. 한 예는 세포정지 또는 세포독성 페이로드와 조합된 종양에 대한 특이성을 갖는 항체 단편을 포함한다. 또 다른 예는 항-감염성 페이로드와 조합된, 감염된 세포 또는 감염성 제제에 대해 특이성을 갖는 항체 단편을 포함한다. 또 다른 유용한 조합은 항-염증성 활성을 갖는 페이로드와 조합된, 염증이 생긴 조직에 대해 특이성을 갖는 항체 단편을 포함한다. 보조적 폴리펩티드에 연결된 항체로는, 제한되지 않지만, 아브식시맵(abciximab), 아달리뮤맵(adalimumab), 알렘투주맵(alemtuzumab), 바실릭시맵(basiliximab), 베바시주맵(bevacizumab), 세툭시맵(cetuximab), 달시주맵(daclizumab), 에쿨리주맵(eculizumab), 에팔리주맵(efalizumab), 이브리투모맵(ibritumomab), 티욱세탄(tiuxetan), 인플릭시맵(infliximab), 뮤로노냅(muromonab)-CD3, 나탈리주맵(natalizumab), 오말리주맵(omalizumab), 팔리비주맵(palivizumab), 파니투뮤맵(panitumumab), 라니비주맵(ranibizumab), 겜투주맵(gemtuzumab), 오조감미신(ozogamicin), 리툭시맵(rituximab), 토시투모맵(tositumomab), 트라스투주맵(trastuzumab), 및 보체 C5, CBL, CD147, IL8, gp120, VLA4, CD11a, CD18, VEGF, CD40L, 항-Id, ICAM1, CD2, EGFR, TGF-β2, TNFα, E-셀렉틴, FactII, Her2/neu, F gp, CD11/18, CD14, CD80, ICAM3, CD4, CD23, β2-인테그린, α4β7, CD52, CD22, HLA-DR, CD64(FcR), TCRαβ, CD3, Hep B, CD125, EpCAM, gpIIbIIIa, IgE, CD20, IL5, IL4, CD25, CD33, HLA, F gp, 및 VNR인테그린을 비롯한 항원에 대해 특이적인 임의의 항체 단편이 포함된다.
효소는 종양 특이적 AFBT를 위한 페이로드로서 사용될 수 있다. 효소는 종양 환경으로부터의 필요한 영양분 또는 대사산물을 제거하기 위해 선택될 수 있고, 예컨대 아스파라기나아세(asparaginase), 아르기나제(arginase), 히스티디나제(histidinase), 또는 메티오니나제(methioninase)이다. 다르게는, 세포독성 활성을 나타내는 효소를 이용할 수 있다. 한 예로는 종양 특이적 항체 단편, 및 세포로의 내재화시 아폽토시스를 유도하는 RAN아제를 포함하는 AFBT가 포함된다.
항암, 항미생물 및/또는 항-염증성 치료제로서 유용한 페이로드로는, 독소 예컨대 슈도모나스(Pseudomonas) 외독소, 리신, 보툴리넘 독소, 및 기타 식물 또는 박테리아 독소가 포함된다. 다른 생물학적 독소로는, 제한되지 않지만, 아브린(abrin), 아에로리신(aerolysin), 보툴리닌(botulinin) 독소 A, B, C1, C2, D, E, F, b-분가로톡신(bungarotoxin), 카에룰에오톡신(Caeruleotoxin), 세레오리신(Cereolysin), 콜레라(Cholera) 독소, 클로스트리디움 디피실레(Clostridium difficile) 장독소 A 및 B, 클로스트리디움 페르프린겐스(Clostridium perfringens) 레시티나제(lecithinase), 클로스트리디움 페르프린겐스 카파 독소, 클로스트리디움 페르프린겐스 페르프린고리신(perfringolysin) O, 클로스트리디움 페르프린겐스 장독소, 클로스트리디움 페르프린겐스 베타 독소, 클로스트리디움 페르프린겐스 델타 독소, 클로스트리디움 페르프린겐스 엡실론 독소, 코노톡신(Conotoxin), 크로톡신(Crotoxin), 디프테리아(Diphtheria) 독소, 리스테리오리신(Listeriolysin), 류코시딘(Leucocidin), 모데신(Modeccin), 네마토시스트(Nematocyst) 독소, 노텍신(Notexin), 퍼투시스(Pertussis) 독소, 뉴모리신(Pneumolysin), 슈도모나스 아에루기노사(Pseudomonas aeruginosa) 독소 A, 삭시톡신(Saxitoxin), 쉬가(Shiga) 독소, 쉬겔라 디센테리아(Shigella dysenteriae) 신경독소, 스트렙토리신(Streptolysin) O, 스타필로코커스(Staphylococcus) 장독소 B 및 F, 스트렙토리신 S, 타이폭신(Taipoxin), 테타누스(Tetanus) 독소, 테트로도톡신(Tetrodotoxin), 비스커민(Viscuminm), 볼켄신(Volkensin), 및 예르시니아 페스티스(Yersinia pestis) 뮤린 독소가 포함된다.
페이로드는 독성 대사산물을 제거하기 위해 선택될 수 있다. 예는 통풍 치료를 위한 요산염 산화효소, 및 페닐케톤뇨증의 치료를 위한 페닐알라닌 암모니아 라이아제(lyase)이다. 페이로드는 또한 화학적으로 접합된 작은 분자를 포함할 수 있다. 이러한 페이로드는 AFBT로 접합되어 반합성 AFBT를 생성한다. 반합성 AFBT의 단백질 부분은 도 61에 예시된 바와 같은 완벽한 커플링을 통해 제어된 화학 접합을 촉진하도록 조작될 수 있다. 단백질 부분은 한정된 수의 커플링 부위를 갖도록 조작될 수 있다. 이는 커플링 부위의 농도에 과량으로 커플링 시약을 사용하여, 커플링 유효성이 완료에 가까와져 규정된 커플링 생성물을 제공할 수 있도록 한다. 유용한 커플링 부위는 아미노 기일 수 있다. 이러한 반합성 AFBT의 단백질 부분은 항체 단편중의 모든 또는 대부분의 라이신 잔기가 폴딩 및 표적 결합과 화합성인 다른 잔기로 대체되도록 조작될 수 있다. 많은 단백질에서, 라이신 잔기를 아르기닌, 글루타메이트, 아스파테이트, 세린, 트레오닌 또는 또 다른 아미노산으로 대체할 수 있다. 표시된 커플링 부위는 단백질의 rPEG 도메인 또는 임의의 다른 단백질 부분내로 혼입될 수 있다. 또한, 각각의 단백질 쇄의 N-말단는 공액 부위로서 작용할 수 있다. 시스테인 잔기는 또한 공액 부위로서 작용할 수 있다. AFBT로 접합될 수 있는 페이로드의 예로는 세포독성 약물, 예컨대 독소루비신, 아우리스타틴, 마이탄신 및 종양 특이적 항체 단편에 의해 AFBT에 융합될 수 있는 관련 분자가 포함된다. 접합을 위해 관심을 끄는 다른 페이로드로는 항바이러스성 화합물, 이미지화 시약, 및 킬레이트 시약(방사성핵종으로 표지화되어 방사선치료를 위한 이미지화 시약 또는 AFBT를 생성할 수 있음)이 포함된다.
rPEG 테일에서의 티올
본 발명의 또 다른 실시양태는 1개 또는 다수의 시스테인 잔기를 함유하는 rPEG 서열을 포함하는 AFBT가 포함된다. 이들 시스테인 측쇄는 환자로의 주사 후 다른 단백질과 디설파이드 가교를 형성할 수 있다. 이들 디설파이드 가교는 생체내 반감기를 증가시킬 수 있다. 다른 실시양태에서, 디설파이드 결합 형성은 주사 부위에서 AFBT의 연장된 보유를 일으켜 서방형 PK 프로필을 초래할 수 있다. 유리 시스테인을 함유하는 AFBT는 또한 경구, 비강내, 및 피부내 투여된 AFBT에 대한 개선된 생물이용성을 위해 조작될 수 있다. 이는 내피 세포의 표면에서 단백질과의 디설파이드 가교를 형성함으로써 달성되어 AFBT의 증진된 섭취를 초래할 수 있다.
rPEG 중의 RGD-펩티드
AFBT는 또한 하나 또는 다수의 RGD 서열 또는 인테그린 뿐만 아니라 외세포 매트릭스의 성분과 상호작용하는 것으로 공지된 관련된 서열을 함유할 수 있다. 이들 RGD 관련 서열은 시스테인 잔기와 플랭킹되어 디설파이드 매개성 환화를 초래할 수 있다. 다르게는, RGD 관련 서열은 특정 인테그린과의 상호작용에 대한 친화도 및/또는 특이성을 증진시키기 위해 선택될 수 있는 추가의 아미노산에 의해 플랭킹된다. 한 바람직한 실시양태는 RGD 서열을 함유하고 인테그린 αγβ3, αγβ5, α5β1(다양한 종양 세포 상에서 과발현됨)과 상호작용하며, AFBT를 포함한다.
반감기를 증가시키는 항체 단편
본 발명은 또한 AFBT의 생체내 반감기를 증가시키는 항체 단편을 함유하는 AFBT를 구현한다. 이는 긴 생체내 반감기를 갖는 표적에 결합하는 항체 단편을 혼입함으로써 달성될 수 있다. 생체내 반감기를 증가시키는 이러한 표적의 예로는, 제한되지 않지만, 혈청 단백질, 구체적으로, 혈청 알부민, 면역글로불린, 및 다른 고도로 풍부한 단백질이 포함된다. AFBT는 또한 혈액 세포 또는 혈관 벽에 대한 특이성을 갖는 항체 단편을 혼입할 수 있다. 극히 풍부하고, 대략 4개월의 평균 수명 기간을 갖고, 최소 대사 활성을 특징으로 하는 적혈 세포(RBC)가 특히 관심을 끈다. AFBT는 RBC의 표면 상에서 임의의 단백질에 결합하도록 조작될 수 있다. 한 바람직한 실시양태는 RBC의 표면 상에 고농도로 발현되는 글리코포린 A에 결합하는 AFBT를 포함한다. AFBT는 생체내 AFBT와 접촉하여 AFBT의 연장된 보유를 이끌 수 있는 임의의 세포 표면 표적에 결합하도록 조작될 수 있다. 또 다른 실시양태는 세포외 기질(ECM: extracellular matrix)의 성분에 결합하는 AFBT를 포함한다. ECM은 많은 단백질을 함유하고, 제한되지 않지만, 아그린, 알파 엘스틴(elstin), 아미신(amisyn), 베스트로핀(bestrophin), 콜라겐, 콘탁틴 1, CRIPT, 드레브린(drebrin), 엔탁틴(entactin), 페투인(fetuin) A, HAS3, HCAP-G, 신데칸, KAL1, 1 아파딘(Afadin), 라미닌, Mint3, MMP24, NCAM, 뉴로칸(neurocan), 니도겐(nidogen) 2, 옵티메딘(optimedin), 프로콜라겐 유형 IIA, PSCDBP, 릴린(reelin), SIRP, 시냅토태그민(synaptotagmin), synCAM, 신데칸, 신트로핀(syntrophin), TAG1, 테나신(tenascin) C, 및 자익신(zyxin)이 포함된다. 또 다른 실시양태로는 흡수된 AFBT의 재생을 초래하는 FcRn 수용체에 결합하는 항체 단편을 포함하는 AFBT가 포함된다. 예로는 항체 단편이 대략 중성 pH에서는 FcRn에 낮은 친화도를 갖고 결합하지만 더 낮은 pH, 예를 들어 pH 5(이는 리소좀 격실에서 우세하게 발견되는 pH 범위내임)에서는 높은 친화도록 결합하도록, FcRn으로의 pH 의존성 결합을 나타내는 항체 단편이 포함된다. 증가된 반감기를 제공하는 AFBT는 도 58a 및 60b에 예시되어 있다. 페이로드 도메인 및 반감기 연장을 제공하는 항체 단편을 포함하는 많은 다른 배열이 디자인될 수 있음을 주지해야 한다.
본 발명은 또한 rPEG에 융합된 Fc 단편을 포함하는 융합 단백질을 구현한다. 도 83은 N-말단에 약물 모듈을 갖고, rPEG에 의해 후속되고, 힌지의 존재 또는 부재하에 항체 Fc 단편에 융합되는 구성물을 보여준다. Fc 단편은 긴 반감기를 제공하고, rPEG는 Fc 단편이 가용성 및 활성 형태로 이. 콜라이 세포질에서 발현되도록 허용한다. 또 다른 실시양태에서, 힌지의 존재 또는 부재하에 항체 Fc 단편은 경우에 따라 한쪽 말단 상에서 약물 모듈(예를 들어 IFNa, hGH, 등)에 융합되고, 경우에 따라 다른 말단 상에서 rPEG에 융합된다. CH2와 CH3 사이의 서열은 FcRn, 신생 Fc 수용체로의 결합을 중재한다(도 90). 또 다른 실시양태로는 한 쌍의 CH3 도메인을 포함하는 단백질 구성물을 포함한다(도 91). 2개의 폴리펩티드 쇄중 0, 1개 또는 둘 다는 rPEG에 N-말단 및/또는 C-말단 말단 상에서융합되고, 다른 말단에서 0, 1개 또는 그 이상의 약물 모듈에 융합된다. FcRn 결합 서열은 보유 또는 결실될 수 있다. FcRn 결합 서열의 보유는 보다 긴 혈청 반감기를 산출한다. 또 다른 실시양태는 C-말단에 위치된 약물/약물분자구조를 갖는 rPEG로 C-말단에서 융합된, CH2 및 CH3 도메인을 포함하는 전체 Fc인 단백질을 기재한다(도 92). 폴리펩티드 쇄 스와핑을 할 수 있어서, 이종이량체를 생성하는 분자가 존재한다. 또 다른 실시양태는 절단되지만 FcRn 결합을 보유하는 CH2 도메인 및 C-말단에 위치된 약물/약물분자구조를 갖고 힌지가 존재하지 않는 부분적 Fc를 기재한다(도 93a). 도 93b는 힌지 및 CH2 도메인이 존재하지 않지만, CH3 도메인을 보유하고 C-말단에 위치된 약물/약물분자구조를 갖는 부분적 Fc를 예시한다. 이러한 Fc 단편은 FcRn에 결합하지 않지만, CH3 도메인을 통해 이량체화될 수 있다.
또 다른 실시양태는 rPEG가 수반된 N-말단 약물 모듈 및 힌지를 갖는 C-말단 Fc 단편을 사용한다(도 101). 이는 이. 콜라이 세포질에서 제작될 수 있는 약물 모듈의 반감기 연장을 위해 유용한 포맷이다. Fc 단편을 함유한 전구약물을 위한 대안의 형식이 본원에 기재되어 있다(도 102). 이 형식은 도 101에 기재된 바와 유사하고, 약물 서열에 결합하여 이를 저해하는 저해 서열을 첨가한다. 약물은 절단 부위에 의해 저해 서열로부터 분리된다. N-말단 저해 결합 서열에 절단 부위가 수반되고, 여기에 약물 서열이 수반된다. 절단 전에, 전구약물은 저해 서열에 결합되고, 따라서 이는 불활성이다. 절단시, 저해 결합 서열은 점진적으로 방출되고 제거되어, 약물이 활성인 시간의 양을 점진적으로 증가시킨다. rPEG에 융합되는 Fc 단편의 정확한 폴딩을 평가하기 위한 검정, 예컨대 힌지 디설파이드 형성에 대한 SDS-PAGE 및 CH3 이량체화에 대한 크기 배제 크로마토그래피가 도 104에 도시되어 있다.
저속 방출을 일으키는 항체 단편
AFBT는 주사 부위로부터 천천히 방출되어 장기간 약물 노출을 일으키도록 조작될 수 있다. 본 발명의 한 실시양태는 주사 부위에서 높은 농도로 발현되는 분자에 결합하는 항체 단편의 혼입을 포함한다. 예를 들면, 이러한 항체 단편은 제한되지 않지만 콜라겐, 히알루론산, 헤파란 설페이트, 라미닌, 엘라스틴, 콘드로이틴 설페이트, 케라탄 설페이트, 피브로넥틴, 및 인테그린을 비롯한 표적 항원에 결합될 수 있다. 항체 단편의 이의 표적 항원에 대한 친화도 및/또는 결합활성을 조작함으로써, 주사 부위로부터의 AFBT 방출 속도가 제어될 수 있다. 또 다른 실시양태는 주사 부위에서 AFBT 방출의 속도를 제어하기 위해 주사 부위에서 프로테아제에 의해 절단될 수 있는 1개 또는 수개의 프로테아제 부위의 도입을 포함한다.
조직 분포에 영향을 주는 항체 단편
본 발명은 또한 특정 세포 또는 조직 또는 조직의 특정 세트에 존재하는 표적 항원에 결합하는 항체 단편을 혼입한 AFBT를 포함한다. 이들 구성물은 AFBT의 국부적 조직 특이적 축적을 달성함으로써 활성 약물의 치료학적 윈도우를 증가시킬 수 있다. 예로는 종양 조직 또는 종양 미세환경, 예컨대 종양 맥관구조에서 과발현되는 종양 항원에 대한 특이성을 갖는 항체 단편을 함유하는 AFBT가 포함된다. 세포내 활성을 갖는 페이로드를 포함하는 AFBT에 대한 표적으로서 세포에 의해 효과적으로 내재화된 종양 항원을 선택할 수 있다. 예를 들면, AFBT는 결합시 내재화가능한 종양 항원에 대해 특이성을 갖는 항체 단편 및 세포독성 페이로드를 포함한다. 다른 예로는 바이러스성 표적에 대해 특이성을 갖는 AFBT가 포함된다.
콜라겐 결합 도메인(CBD: Collagen binding domain)
본 발명의 또 다른 실시양태는 AFBT 및 기타 단백질 약물에서 도메인으로서의 CBD의 용도를 포함한다. 콜라겐은 많은 조직에서, 특히 세포외 공간에서 매우 풍부하다. CBD를 포함하는 단백질 약제는 주사 부위 또는 주사 부위의 부근에서 콜라겐에 결합되어, AFBT가 느리게 방출되는 데포를 형성할 수 있다. 방출 속도는 프로테아제 부위를 도입함으로써 또는 콜라겐으로의 적합한 친화도를 갖는 CBD를 선택함으로써 제어될 수 있다. 콜라겐에 대한 친화도가 낮은 CBD를 선택함으로써, AFBT의 방출 속도가 증가된다. 다르게는, AFBT 방출 속도는 콜라겐에 매우 높은 친화도록 결합하는 CBD를 포함시키거나 다수의 CBD를 AFBT에 포함시켜 결합활성을 달성함으로써 둔화될 수 있다. CBD 서열은 천연 발생 CBD로부터 수득될 수 있다. 콜라겐에 결합하고 CBD를 포함하는 단백질의 예로는, 제한되지 않지만, 인테그린, 구체적으로 α1β1 인테그린, α2β1 인테그린, αγβ3 인테그린, 신생혈관형성 저해제, 콜라겐 V, C-프로테이나제, 데코린(decorin), 피브로넥틴, 인터류킨-2, 기질 메탈로프로테아제 1, 2, 9, 및 13, 포스포포린(phosphophoryn), 트롬보스폰딘, 비글리칸, 비릴루딘(bilirubin), BM40/SPARC, MRP8, MRP-14, 거머리로부터의 칼린, DDR1, DDR2, 피브로모듈린(fibromodulin), GIa 단백질, 당단백질 46, 열 충격(heat shock) 단백질 47, 루미칸(lumican), 미엘린(myelin) 연관된 당단백질, 혈소판 수용체, 스타필로코커스 아우레어스 표면 분자 및 다른 미생물 접착 분자, 신데칸-1, 테나신(tenascin)-C, 비트로넥틴(vitronectin), 폰 윌브랜드(von Willebrand) 인자, 및 인자 XII가 포함된다. 콜라겐에 결합하고 CBD을 함유하는 추가의 단백질의 예는 문헌[Di Lullo, G. A., et al. (2002) J Biol Chem, 111: 4223]에 열거되어 있다. 천연 단백질로부터의 CBD는 추가로 조작되어 이들 치료학적 유용성을 증가시키고 이들의 안정성을 개선시킬 수 있다. CBD 함유 단백질의 면역원성은 B 및/또는 T 세포에 의해 인식되는 에피토프를 제거함으로써 감소될 수 있다. CBD 서열은 또한 단백질 생산을 최대화하고/하거나 단백질 용해도를 개선시키도록 최적화될 수 있다.
테일 중 HSA 결합 펩티드
생체내 반감기를 증가시키는 펩티드 서열을 포함하는 AFBT는 또한 혈청 단백질 또는 혈액 세포의 표면에 결합하는 펩티드 서열을 이용함으로써 달성될 수 있다. 예로는 인간 혈청 알부민(HSA)에 결합하는 펩티드 서열이 포함된다. 이러한 서열은 랜덤 펩티드 서열의 파지 디스플레이 또는 스크리닝 접근법의 유사한 선택에 의해 수득될 수 있다. AFBT는 이러한 펩티드 서열의 하나 이상의, 동일하거나 상이한 카피를 함유할 수 있다.
표적 항원
본 발명의 또 다른 실시양태는 치료학적 또는 진단학적 관련성을 갖는 표적 항원에 결합하는 항체 단편을 내포한다. 도 87은 세포-표면 표적에 결합하는 Fab 단편을 예시한다. VH와 CH 도메인, 및 VL과 CL 도메인 사이에서의 보통 2∼6개 아미노산∼4∼100개 이상의 아미노산으로부터의 천연 연결기의 길이의 연장은 Fab가 또 다른 Fab에 도메인 스와핑에 의해 가교결합되는 능력을 증가시킴으로써, 보다 높은 결합가를 갖는 결합 복합체를 형성하여 보다 높은 겉보기 친화도(결합활성)를 생성할 수 있다. 연결기는 rPEG 또는 상이한 조성물일 수 있다. 연장된 연결기 형식은 보다 높은 밀도의 표적을 갖는 부위에서 특이적으로 증가된 친화도를 갖고 결합하는 것을 허용한다. AFBT의 항체 단편은 혈액 성분에 결합하여 순환되는 AFPT의 반감기를 증가시킬 수 있다. AFBT의 항체 단편은 또한 리소좀 재순환을 촉진시키는 수용체에 결합할 수 있다. 한 예는 리소좀 재순환을 촉진시키는 수용체에 결합할 수 있다. 한 예는 리소좀 섭취후 단백질을 재-유출할 수 있는 FcRn 수용체이다. 항체 단편이 리소좀에서 발견되는 조건하에서 높은 친화도로 결합하지만 세포 표면에서 발견되는 조건하에서 동일한 수용체에 낮은 친화도로 결합하도록 리소좀 재순환을 촉진시킬 수 있는 수용체에 대해 공간적으로 또는 일시적 의존성 친화도로 결합하는 항체 단편이 특히 관심을 끈다. AFBT의 항체 단편은 질환 관련 조직에서 우세하게 발견되는 표적 항원에 결합할 수 있다. 결과로서 이러한 AFBT는 특히 질병 관련 조직에서 축적될 수 있다. 예로는 종양 조직 또는 바이러스 감염 조직에 결합하는 AFBT를 포함한다. AFBT의 항체 단편은 질환 관련 조직에서 세포 내재화를 촉진하는 표적 항원에 결합할 수 있다. AFBT의 항체 단편은 또한 신체의 특정 구간내로 AFBT의 섭취를 촉진시키는 표적 항원, 예를 들면, AFBT의 경구, 비강내, 점막, 또는 폐 섭취를 촉진시키는 표적 항원, 및 혈뇌 장벽을 가로질러 AFBT의 수송을 촉진시키는 표적 항원에 결합할 수 있다. 특히 관심을 끄는 표적 항원의 예로는, 제한되지 않지만, IL1, IL4, IL6, IL12, IL13, IL17, IL23, CD22, BAFF, 및 TNFα가 포함된다.
AFBT에서 rPEG의 이점
AFBT는 rPEG 및 항체 단편의 유용한 특성을 조합한다. AFBT의 rPEG 부분은 AFBT의 낮은 전체 면역원성을 초래한다. 이는 AFBT의 항체 단편 및 다른 잠재적인 면역원성 부분을 rPEG에 의해 입체적으로 방어함으로써 달성된다. rPEG는 매우 가요성이고, 결과로서 이들은 입체구조적 에피토프가 결여되어 있다. 이들의 높은 친수성 및 높은 엔트로피에 기인하여, rPEG는 매우 낮은 고유의 면역원성 전위를 가진다.
AFBT의 rPEG 부분은 또한 다른 AFBT 도메인의 안정화를 초래한다. 이들의 친수성 성질에 기인하여, rPEG 도메인은 AFBT의 응집을 감소시킨다. 이는 AFBT에 대한 제형화 진행을 크게 단순화시킨다. 또한, rPEG에 의한 입체적 방어는 단백질가수분해로부터 AFBT의 다른 부분을 보호한다. 이는 단백질가수분해 경향이 있는 페이로드 및 항체 단편에 대해 특히 중요하다.
전장 항체에 비해 AFBT를 사용하는 또 다른 이점은 전장 항체와 연관된 원치않는 이펙터 작용의 최소화 또는 제거이다. 전장 항체 분자는 다수의 이펙터 작용, 예컨대 항체 의존성 세포 매개성 세포독성(ADCC: antibody-dependent cell-mediated cytotoxicity) 뿐만 아니라 이펙터 작용이 바람직하지 않은 경우 증상을 위한 이들의 치료학적 용도를 크게 제한하는 보체 활성화(CDC: complement activation)를 갖는다. 예를 들면, 많은 증상은 분자, 예컨대 사이토킨 또는 호르몬에 결합하거나 이를 격리시키는 제제를 필요로 한다. 일반적으로 이러한 증상을 위해 항체를 이용하는 것은 바람직하지 않은데, 이들의 이펙터 작용이 원치않는 독성을 일으키기 때문이다. 많은 항체 의존성 이펙터 작용은 Fc 부위를 통해 중재된다. 본원에 기재된 많은 실시양태에서, AFBT는 이펙터 작용을 담당하는 Fc 부위를 대체하면서, 표적 결합을 담당하는 항체의 가변성 도메인을 이용한다. AFBT는 세포 표면 수용체, 예컨대 사멸 수용체 DR4 및 DR5에 결합하여 이를 활성화시키도록 조작될 수 있다. 활성화는 수용체 다량체화에 의해 달성될 수 있다. 전장 항체가 이러한 수용체를 활성화시킬 수 있지만, 이들은 또한 동일한 표적 수용체를 발현하는 건강한 세포로의 항체 결합에 의해 야기되는 독성을 유도한다. AFBT는 독성을 일으키는 이펙터 작용을 유도하지 않으면서 세포 표면 수용체를 활성화시킬 수 있다.
rPEG의 또 다른 이점은, 도 86에 예시된 바와 같이, 동일한 복합체에 속하는 2개의 단백질을 회합시키는 것을 돕는다는 것이다. 이러한 단백질 사이의 친화도는 종종 이들을 회합시키기에 불충분하지만, rPEG의 첨가는 이들의 상호작용을 안정화시키고 중합체를 형성하는 이들의 경향을 감소시킨다.
AFBT의 제작/생산
본 발명은 또한 AFBT의 생산에 관한 것이다. AFBT중 rPEG 도메인은 단백질 폴딩을 촉진시키고 단백질 응집을 감소시킨다. 이러한 특성은 AFBT의 미생물 생산을 촉진시킨다. 문헌에 기재된 대부분의 항체 단편은 봉입체로부터의 리폴딩 또는 주변세포질 공간내로의 분비를 필요로 하고, 그 결과 낮은 생산 수율을 초래한다. 반대로, 대부분의 AFBT는 미생물 발현 숙주의 사이토졸에서 고농도로 가용성 형태로 생산될 수 있다. AFBT를 위한 바람직한 발현 숙주는 이. 콜라이이다(도 45). 그러나, AFBT의 특성은 이들이 대부분의 미생물 뿐만 아니라 진핵생물 발현 시스템에서 발현하기에 적합하도록 만든다. AFBT의 N-말단 서열은 번역후 처리과정을 제어하도록 최적화될 수 있다. 특히, 출발 코돈을 뒤따르는 아미노산은 N-말단 메티오닌의 후속적 처리과정을 결정할 수 있다[Hirel, P. H., et al. (1989) Proc Natl Acad Sci USA, 86: 8247]. 한 실시양태는 균일한 생성물을 생성하는 N-말단 서열을 포함한다. N-말단 met을 뒤따르는 아미노산으로서 gly, ala, pro, ser, thr, 또는 val을 선택함으로써, N-말단 met의 유효한 처리과정 및 제거가 달성될 수 있다. 또 다른 실시양태는 N-말단 met을 뒤따르는 아미노산으로서 his, gin, glu, phe, met, lys, tyr, trp, 또는 arg을 포함하고, 이는 N-말단 met의 제거를 방지하고 균질한 생성물을 생성한다. AFBT는 또한 변경되지 않은 대부분의 단백질이 응집체를 산출하는 높은 단백질 농도의 조건하에 리폴딩을 촉진시킨다. AFBT를 제작하는 동안 rPEG의 이점이 중요한데, 이는 AFBT가 응집체를 형성하는 경향이 있는 다수의 단백질 도메인을 함유하기 때문이다. 이러한 단백질 도메인은 AFBT에서 rPEG 서열에 의해 분리되어 폴딩 동안 개별 단백질 도메인 사이의 응집을 최소화 한다.
질환 관련 및/또는 환자 특이적 AFBT의 생성 및 생산
본 발명은 또한 질환 관련 AFBT, 즉 보조적 폴리펩티드에 융합된 항체 단편, 예컨대 rPEG의 생성 및 생산을 구현한다. 항체 유전자는 감염되거나 달리는 노출된 환자로부터 직접 단리될 수 있다[Wrammert, J., et al. (2008) Nature]. rPEG에 융합된 항체 단편의 다양한 형식은 이러한 항체 유전자로부터 신속히 생성될 수 있다. 생성된 융합 단백질은 표준 프로토콜에 의해 생산 및 정제되어, 질환 관련 AFBT의 신속한 생성을 가능하게 한다. 과정의 한 예는 도 68에 예시되어 있다. 신속한 발견 과정은 급성 질환 발생, 예컨대 박테리아나 바이러스 감염에 대응하는 특정 치료의 발견 및 준비를 가능하게 한다. 항체 단편과 rPEG 사이의 융합 단백질의 신속한 생성은 또한 환자 특이적 치료를 가능하게 하고, 이는 제한되지 않지만 환자로부터의 면역 세포의 단리; 면역 세포로부터 질환 특이적 항체 유전자의 클로닝; 항체 단편-rPEG 융합물의 작제 및 후속적 제작(즉 질환 관련 AFBT); 및 질환을 앓는 환자의 치료를 포함한다.
다클론성 및 복합클론성 AFBT
본 발명은 또한 하나보다 많은 AFBT를 포함하는 약학적 조성물에 관한 것이다. AFBT 혼합물의 이러한 조성물은 개별 AFBT에 비해 개선된 성능을 갖는다. AFBT에 기초한 생성물은 이들이 2개, 3개 또는 그 이상의 규정된 AFBT를 함유하도록 복합클론성일 수 있다. 다르게는, AFBT는 다수의 AFBT를 함유하는 다클론성일 수 있다. 이러한 다클론성 AFBT는 유용한 특이성을 갖는 항체 또는 항체 단편이 풍부한 공급원으로부터 항체 단편을 클로닝함으로써 생성될 수 있다. 한 예는 감염된 환자로부터의 항체 단편 목록의 클로닝이다. 또 다른 예는 관심있는 표적에 대한 패닝에 의해 풍부해진 디스플레이 라이브러리를 포함한다.
rPEG 융합 생성물
한 실시양태에서, rPEG 서열은, 생물학적 시스템(예를 들어 에스케리치아 콜라이, 피키아 파스토리스(Pichia pastoris), CHO-S 등)에서 고 수준 단백질 발현을 위하여 적절한 전사 및 번역 서열의 제어하에 인간 성장 호르몬(hGH) 또는 인간 성장 호르몬 수용체(hGH-R) 유전자의 N- 또는 C-말단에 유전학적으로 융합된다. 단백질 발현은 이용된 발현 시스템에 대해 당분야에 공지된 표준 기법을 사용하여 유도되고, 표준 절차(예를 들어 이온 교환 크로마토그래피, 크기 배제 크로마토그래피, 친화도 크로마토그래피, 차등 침전, 상 추출 등)를 사용하여 정제된다. 이어서 정제된 단백질은 제한되지 않지만 하기를 포함하는 증상의 치료를 위해 인간 환자에게 투여될 수 있다: 성인 성장 호르몬 결핍, 소아 성장 호르몬 결핍, 터너 증후군(Turner syndrome), 만성 신부전, 특발성 저신장증, 이식후 성장 부전, 저인산혈성 구루병, 염증성 장질환, 누난 증후군(Noonan syndrome), 소아 만성 소화 장애증, AIDS 소모증후, 비만, 노화, 또는 치료학적 이점을 제공하기 위해 변경되지 않은 단백질이 제시되는 다른 증상. rPEG 서열의 첨가는 연장된 혈청 반감기, 개선된 환자 노출/유효성, 및/또는 개선된 제작 유효성의 특성을 제공한다.
한 실시양태에서, rPEG 서열은 생물학적 시스템(예를 들어 에스케리치아 콜라이, 피키아 파스토리스, CHO-S 등)에서 고 수준 단백질 발현을 위하여 적절한 전사 및 번역 서열의 제어하에 인간 성장 호르몬 단편 176-191 또는 177-191 유전자의 N- 또는 C-말단에 유전학적으로 융합된다. 단백질 발현은 이용된 발현 시스템에 대한 표준기법을 사용하여 유도되고, 당분야의 숙련가에게 공지된 표준 절차(예를 들어 이온 교환 크로마토그래피, 크기 배제 크로마토그래피, 친화도 크로마토그래피, 차등 침전, 상 추출 등)를 사용하여 정제된다. 이어서 정제된 단백질은 제한되지 않지만 하기를 포함하는 증상의 치료를 위해 인간 환자에게 투여될 수 있다: 성인 성장 호르몬 결핍, 소아 성장 호르몬 결핍, 터너 증후군, 만성 신부전, 특발성 저신장증, 이식후 성장 부전, 저인산혈성 구루병, 염증성 장질환, 누난 증후군, 소아 만성 소화 장애증, AIDS 소모증후, 비만, 노화, 또는 치료학적 이점을 제공하기 위해 변경되지 않은 단백질이 제시되는 다른 증상. rPEG 서열의 첨가는 연장된 혈청 반감기, 개선된 환자 노출/유효성, 및/또는 개선된 제작 유효성의 특성을 제공한다.
한 실시양태에서, rPEG 서열은 생물학적 시스템(예를 들어 에스케리치아 콜라이, 피키아 파스토리스, CHO-S 등)에서 고 수준 단백질 발현을 위하여 적절한 전사 및 번역 서열의 제어하에 엑세나타이드 유전자의 N- 또는 C-말단에 유전학적으로 융합된다. 단백질 발현은 이용된 발현 시스템에 대한 표준기법을 사용하여 유도되고, 당분야의 숙련가에게 공지된 표준 절차(예를 들어 이온 교환 크로마토그래피, 크기 배제 크로마토그래피, 친화도 크로마토그래피, 차등 침전, 상 추출 등)를 사용하여 정제된다. 이어서 정제된 단백질은 하기를 포함하는 증상의 치료를 위해 인간 환자에게 투여될 수 있다: 유형 II 당뇨병, 또는 치료학적 이점을 제공하기 위해 변경되지 않은 단백질이 제시되는 다른 증상. rPEG 서열의 첨가는 연장된 혈청 반감기, 개선된 환자 노출/유효성, 및/또는 개선된 제작 유효성의 특성을 제공한다. 생체내 효험을 유지하는데 대한 엑세나타이드의 N-말단의 감수성에 기인하여, 재조합체 발현 및 정제시 고유 N-말단 구조를 유지하기 위해 특별한 고려사항이 필요할 수 있고, 바람직한 실시양태는 엑세나타이드 서열의 C-말단로의 rPEG의 융합을 포함한다. 시험관내 또는 생체내에서 프로테아제에 의해 절단될 수 있는 N-말단 리더 서열은 제작 수율을 개선시키고/시키거나 생체내 활성 분자의 전달을 개선시키기 위해 사용될 수 있다. 대안의 전략은 엑세나타이드의 내부 메티오닌을 화합성 아미노산(예를 들어 GLP-1 서열중 상동성 위치에 존재하는 루신)으로 돌연변이시키고, 브롬화시아노겐 또는 유사한 화학법을 사용하여 N-말단 리더 서열을 제거하여 고유 엑세나타이드 N-말단를 생성함을 포함한다.
한 실시양태에서, rPEG 서열은 생물학적 시스템(예를 들어 에스케리치아 콜라이, 피키아 파스토리스, CHO-S 등)에서 고 수준 단백질 발현을 위하여 적절한 전사 및 번역 서열의 제어하에 GLP-1 유전자의 N- 또는 C-말단에 유전학적으로 융합된다. 단백질 발현은 이용된 발현 시스템에 대한 표준기법을 사용하여 유도되고, 당분야의 숙련가에게 공지된 표준 절차(예를 들어 이온 교환 크로마토그래피, 크기 배제 크로마토그래피, 친화도 크로마토그래피, 차등 침전, 상 추출 등)를 사용하여 정제된다. 이어서 정제된 단백질은 하기를 포함하는 증상의 치료를 위해 인간 환자에게 투여될 수 있다: 유형 II 당뇨병, 또는 치료학적 이점을 제공하기 위해 변경되지 않은 단백질이 제시되는 다른 증상. rPEG 서열의 첨가는 연장된 혈청 반감기, 개선된 환자 노출/유효성, 및/또는 개선된 제작 유효성의 특성을 제공한다. 생체내 효험을 유지하는데 대한 GLP-1의 N-말단의 감수성에 기인하여, 재조합체 발현 및 정제시 고유 N-말단 구조를 유지하기 위해 특별한 고려사항이 필요할 수 있고, 바람직한 실시양태는 GLP-1 서열의 C-말단로의 rPEG의 융합을 포함한다. 시험관내 또는 생체내에서 프로테아제에 의해 절단될 수 있는 N-말단 리더 서열은 제작 수율을 개선시키고/시키거나 생체내 활성 분자의 전달을 개선시키기 위해 사용될 수 있다.
한 실시양태에서, rPEG 서열은 생물학적 시스템(예를 들어 에스케리치아 콜라이, 피키아 파스토리스, CHO-S 등)에서 고 수준 단백질 발현을 위하여 적절한 전사 및 번역 서열의 제어하에 IL1-RA 유전자의 N- 또는 C-말단에 유전학적으로 융합된다. 단백질 발현은 이용된 발현 시스템에 대한 표준기법을 사용하여 유도되고, 당분야의 숙련가에게 공지된 표준 절차(예를 들어 이온 교환 크로마토그래피, 크기 배제 크로마토그래피, 친화도 크로마토그래피, 차등 침전, 상 추출 등)를 사용하여 정제된다. 이어서 정제된 단백질은 제한되지 않지만 하기를 포함하는 증상의 치료를 위해 인간 환자에게 투여될 수 있다: 류마티스 관절염, 건선성 관절염, 건선, 염증성 장 질환, 크론병(Crohn's disease), 또는 치료학적 이점을 제공하기 위해 변경되지 않은 단백질이 제시되는 다른 증상. rPEG 서열의 첨가는 연장된 혈청 반감기, 개선된 환자 노출/유효성, 및/또는 개선된 제작 유효성의 특성을 제공한다.
한 실시양태에서, rPEG 서열은 생물학적 시스템(예를 들어 에스케리치아 콜라이, 피키아 파스토리스, CHO-S 등)에서 고 수준 단백질 발현을 위하여 적절한 전사 및 번역 서열의 제어하에 인터페론 알파, 베타, 또는 감마 유전자의 N- 또는 C-말단에 유전학적으로 융합된다. 단백질 발현은 이용된 발현 시스템에 대한 표준기법을 사용하여 유도되고, 당분야의 숙련가에게 공지된 표준 절차(예를 들어 이온 교환 크로마토그래피, 크기 배제 크로마토그래피, 친화도 크로마토그래피, 차등 침전, 상 추출 등)를 사용하여 정제된다. 이어서 정제된 단백질은 제한되지 않지만 하기를 포함하는 증상의 치료를 위해 인간 환자에게 투여될 수 있다: 털세포 백혈병(hairy cell leukemia), AIDS 관련 카포시 증후군(Kaposi's syndrome), pH 염색체 양성 CML, 만성 C형 간염, 첨형 콘딜로마(condylomata acuminate), 만성 B형 간염, 악성 흑색종, 여포성 림프종, 다발성 경화증, 비-호지킨스(Hodgkins) 림프종, 골화석증, 만성 육아종 질환 관련 감염, 폐 다중약물 내성 결핵, 또는 치료학적 이점을 제공하기 위해 변경되지 않은 단백질이 제시되는 다른 증상. rPEG 서열의 첨가는 연장된 혈청 반감기, 개선된 환자 노출/유효성, 및/또는 개선된 제작 유효성의 특성을 제공한다.
한 실시양태에서, rPEG 서열은 생물학적 시스템(예를 들어 에스케리치아 콜라이, 피키아 파스토리스, CHO-S 등)에서 고 수준 단백질 발현을 위하여 적절한 전사 및 번역 서열의 제어하에 G-CSF 유전자의 N- 또는 C-말단에 유전학적으로 융합된다. 단백질 발현은 이용된 발현 시스템에 대한 표준기법을 사용하여 유도되고, 당분야의 숙련가에게 공지된 표준 절차(예를 들어 이온 교환 크로마토그래피, 크기 배제 크로마토그래피, 친화도 크로마토그래피, 차등 침전, 상 추출 등)를 사용하여 정제된다. 이어서 정제된 단백질은 제한되지 않지만 하기를 포함하는 증상의 치료를 위해 인간 환자에게 투여될 수 있다: 화학치료법에 기인한 열성 호중구감소증(febrile neutropenia), 골수 이식, 울혈성 호중구감소증, 환형 호중구감소증, 특발성 호중구감소증, AIDS 관련 호중구감소증, 골수이형성증후군(myelodysplastic syndrome), 또는 치료학적 이점을 제공하기 위해 변경되지 않은 단백질이 제시되는 다른 증상. rPEG 서열의 첨가는 연장된 혈청 반감기, 개선된 환자 노출/유효성, 및/또는 개선된 제작 유효성의 특성을 제공한다.
한 실시양태에서, rPEG 서열은 생물학적 시스템(예를 들어 에스케리치아 콜라이, 피키아 파스토리스, CHO-S 등)에서 고 수준 단백질 발현을 위하여 적절한 전사 및 번역 서열의 제어하에 FGF21 유전자의 N- 또는 C-말단에 유전학적으로 융합된다. 단백질 발현은 이용된 발현 시스템에 대한 표준기법을 사용하여 유도되고, 당분야의 숙련가에게 공지된 표준 절차(예를 들어 이온 교환 크로마토그래피, 크기 배제 크로마토그래피, 친화도 크로마토그래피, 차등 침전, 상 추출 등)를 사용하여 정제된다. 이어서 정제된 단백질은 제한되지 않지만 하기를 포함하는 증상의 치료를 위해 인간 환자에게 투여될 수 있다: 당뇨병, 비만, 또는 치료학적 이점을 제공하기 위해 변경되지 않은 단백질이 제시되는 다른 증상. rPEG 서열의 첨가는 연장된 혈청 반감기, 개선된 환자 노출/유효성, 및/또는 개선된 제작 유효성의 특성을 제공한다.
한 실시양태에서, rPEG 서열은 생물학적 시스템(예를 들어 에스케리치아 콜라이, 피키아 파스토리스, CHO-S 등)에서 고 수준 단백질 발현을 위하여 적절한 전사 및 번역 서열의 제어하에 칼시토닌 유전자의 N- 또는 C-말단에 유전학적으로 융합된다. 단백질 발현은 이용된 발현 시스템에 대한 표준기법을 사용하여 유도되고, 당분야의 숙련가에게 공지된 표준 절차(예를 들어 이온 교환 크로마토그래피, 크기 배제 크로마토그래피, 친화도 크로마토그래피, 차등 침전, 상 추출 등)를 사용하여 정제된다. 이어서 정제된 단백질은 제한되지 않지만 하기를 포함하는 증상의 치료를 위해 인간 환자에게 투여될 수 있다: 폐경후 골다공증, 페이젯병, 고칼슘혈증, 또는 치료학적 이점을 제공하기 위해 변경되지 않은 단백질이 제시되는 다른 증상. rPEG 서열의 첨가는 연장된 혈청 반감기, 개선된 환자 노출/유효성, 및/또는 개선된 제작 유효성의 특성을 제공한다.
한 실시양태에서, rPEG 서열은 생물학적 시스템(예를 들어 에스케리치아 콜라이, 피키아 파스토리스, CHO-S 등)에서 고 수준 단백질 발현을 위하여 적절한 전사 및 번역 서열의 제어하에 부갑상선 호르몬(PTH) 유전자의 N- 또는 C-말단에 유전학적으로 융합된다. 단백질 발현은 이용된 발현 시스템에 대한 표준기법을 사용하여 유도되고, 당분야의 숙련가에게 공지된 표준 절차(예를 들어 이온 교환 크로마토그래피, 크기 배제 크로마토그래피, 친화도 크로마토그래피, 차등 침전, 상 추출 등)를 사용하여 정제된다. 이어서 정제된 단백질은 하기를 포함하는 증상의 치료를 위해 인간 환자에게 투여될 수 있다: 골다공증, 또는 치료학적 이점을 제공하기 위해 변경되지 않은 단백질이 제시되는 다른 증상. rPEG 서열의 첨가는 연장된 혈청 반감기, 개선된 환자 노출/유효성, 및/또는 개선된 제작 유효성의 특성을 제공한다.
한 실시양태에서, rPEG 서열은 생물학적 시스템(예를 들어 에스케리치아 콜라이, 피키아 파스토리스, CHO-S 등)에서 고 수준 단백질 발현을 위하여 적절한 전사 및 번역 서열의 제어하에 인간 융모막 고나도트로핀(hCG: human chorionic gonadotropin) 유전자의 N- 또는 C-말단에 유전학적으로 융합된다. 단백질 발현은 이용된 발현 시스템에 대한 표준기법을 사용하여 유도되고, 당분야의 숙련가에게 공지된 표준 절차(예를 들어 이온 교환 크로마토그래피, 크기 배제 크로마토그래피, 친화도 크로마토그래피, 차등 침전, 상 추출 등)를 사용하여 정제된다. 이어서 정제된 단백질은 제한되지 않지만 하기를 포함하는 증상의 치료를 위해 인간 환자에게 투여될 수 있다: 불임, 카포시 육종, 천식, 동맥병증(arteriopathy), 지중해빈혈, 골감소증, 녹내장, 또는 치료학적 이점을 제공하기 위해 변경되지 않은 단백질이 제시되는 다른 증상. rPEG 서열의 첨가는 연장된 혈청 반감기, 개선된 환자 노출/유효성, 및/또는 개선된 제작 유효성의 특성을 제공한다.
한 실시양태에서, rPEG 서열은 생물학적 시스템(예를 들어 에스케리치아 콜라이, 피키아 파스토리스, CHO-S 등)에서 고 수준 단백질 발현을 위하여 적절한 전사 및 번역 서열의 제어하에 푸제온(Fuzeon(엔푸비티드: enfurvitide)) 유전자의 N- 또는 C-말단에 유전학적으로 융합된다. 단백질 발현은 이용된 발현 시스템에 대한 표준기법을 사용하여 유도되고, 당분야의 숙련가에게 공지된 표준 절차(예를 들어 이온 교환 크로마토그래피, 크기 배제 크로마토그래피, 친화도 크로마토그래피, 차등 침전, 상 추출 등)를 사용하여 정제된다. 이어서 정제된 단백질은 하기를 포함하는 증상의 치료를 위해 인간 환자에게 투여될 수 있다: HIV-1 감염, 또는 치료학적 이점을 제공하기 위해 변경되지 않은 단백질이 제시되는 다른 증상. rPEG 서열의 첨가는 연장된 혈청 반감기, 개선된 환자 노출/유효성, 및/또는 개선된 제작 유효성의 특성을 제공한다.
한 실시양태에서, rPEG 서열은 생물학적 시스템(예를 들어 에스케리치아 콜라이, 피키아 파스토리스, CHO-S 등)에서 고 수준 단백질 발현을 위하여 적절한 전사 및 번역 서열의 제어하에 렙틴(leptin) 또는 렙틴 수용체 유전자의 N- 또는 C-말단에 유전학적으로 융합된다. 단백질 발현은 이용된 발현 시스템에 대한 표준기법을 사용하여 유도되고, 당분야의 숙련가에게 공지된 표준 절차(예를 들어 이온 교환 크로마토그래피, 크기 배제 크로마토그래피, 친화도 크로마토그래피, 차등 침전, 상 추출 등)를 사용하여 정제된다. 이어서 정제된 단백질은 제한되지 않지만 하기를 포함하는 증상의 치료를 위해 인간 환자에게 투여될 수 있다: 유방암, 골관절염, 골다공증, 패혈성 관절염, 비만, 또는 치료학적 이점을 제공하기 위해 변경되지 않은 단백질이 제시되는 다른 증상. rPEG 서열의 첨가는 연장된 혈청 반감기, 개선된 환자 노출/유효성, 및/또는 개선된 제작 유효성의 특성을 제공한다.
한 실시양태에서, rPEG 서열은 생물학적 시스템(예를 들어 에스케리치아 콜라이, 피키아 파스토리스, CHO-S 등)에서 고 수준 단백질 발현을 위하여 적절한 전사 및 번역 서열의 제어하에 TNF 결합 단백질 1(TNF-BP1; p55) 유전자의 N- 또는 C-말단에 유전학적으로 융합된다. 단백질 발현은 이용된 발현 시스템에 대한 표준기법을 사용하여 유도되고, 당분야의 숙련가에게 공지된 표준 절차(예를 들어 이온 교환 크로마토그래피, 크기 배제 크로마토그래피, 친화도 크로마토그래피, 차등 침전, 상 추출 등)를 사용하여 정제된다. 이어서 정제된 단백질은 제한되지 않지만 하기를 포함하는 증상의 치료를 위해 인간 환자에게 투여될 수 있다: 류마티스 관절염, 건선성 관절염, 건선, 염증성 장 질환, 크론병, 또는 치료학적 이점을 제공하기 위해 변경되지 않은 단백질이 제시되는 다른 증상. rPEG 서열의 첨가는 연장된 혈청 반감기, 개선된 환자 노출/유효성, 및/또는 개선된 제작 유효성의 특성을 제공한다.
한 실시양태에서, rPEG 서열은 생물학적 시스템(예를 들어 에스케리치아 콜라이, 피키아 파스토리스, CHO-S 등)에서 고 수준 단백질 발현을 위하여 적절한 전사 및 번역 서열의 제어하에 글루카곤 유전자의 N- 또는 C-말단에 유전학적으로 융합된다. 단백질 발현은 이용된 발현 시스템에 대한 표준기법을 사용하여 유도되고, 당분야의 숙련가에게 공지된 표준 절차(예를 들어 이온 교환 크로마토그래피, 크기 배제 크로마토그래피, 친화도 크로마토그래피, 차등 침전, 상 추출 등)를 사용하여 정제된다. 이어서 정제된 단백질은 제한되지 않지만 하기를 포함하는 증상의 치료를 위해 인간 환자에게 투여될 수 있다: 유형 II 당뇨병, 청소년 당뇨병, 또는 치료학적 이점을 제공하기 위해 변경되지 않은 단백질이 제시되는 다른 증상. rPEG 서열의 첨가는 연장된 혈청 반감기, 개선된 환자 노출/유효성, 및/또는 개선된 제작 유효성의 특성을 제공한다. 생체내 효험을 유지하는데 대한 글루카곤의 N-말단의 감수성에 기인하여, 재조합체 발현 및 정제시 고유 N-말단 구조를 유지하기 위해 특별한 고려사항이 필요할 수 있고, 바람직한 실시양태는 GLP-1 서열의 C-말단로의 rPEG의 융합을 포함한다. 시험관내 또는 생체내에서 프로테아제에 의해 절단될 수 있는 N-말단 리더 서열은 제작 수율을 개선시키고/시키거나 생체내 활성 분자의 전달을 개선시키기 위해 사용될 수 있다.
한 실시양태에서, rPEG 서열은 생물학적 시스템(예를 들어 에스케리치아 콜라이, 피키아 파스토리스, CHO-S 등)에서 고 수준 단백질 발현을 위하여 적절한 전사 및 번역 서열의 제어하에 IGF-1 유전자의 N- 또는 C-말단에 유전학적으로 융합된다. 단백질 발현은 이용된 발현 시스템에 대한 표준기법을 사용하여 유도되고, 당분야의 숙련가에게 공지된 표준 절차(예를 들어 이온 교환 크로마토그래피, 크기 배제 크로마토그래피, 친화도 크로마토그래피, 차등 침전, 상 추출 등)를 사용하여 정제된다. 이어서 정제된 단백질은 제한되지 않지만 하기를 포함하는 증상의 치료를 위해 인간 환자에게 투여될 수 있다: IGF-1 결핍, hGH 결핍(유전자 결실 또는 항-GH 항체 형성에 의해 야기됨), 또는 치료학적 이점을 제공하기 위해 변경되지 않은 단백질이 제시되는 다른 증상. rPEG 서열의 첨가는 연장된 혈청 반감기, 개선된 환자 노출/유효성, 및/또는 개선된 제작 유효성의 특성을 제공한다.
데포 모듈
본 발명의 조성물은 경우에 따라 데포 모듈을 포함한다. 데포 모듈은 천연 발생 폴리펩티드, 인공 폴리펩티드 또는 파지 디스플레이에 의해 선택된 폴리펩티드일 수 있다. 한 실시양태에서, 데포 모듈은 하기 지칭된 중합체 매트릭스에 직접 결합될 수 있다. 데포 모듈은 변경된 폴리펩티드내로 임의의 위치에서 혼입될 수 있고, 도 2 및 3에서 지시된 바와 같이 하나 또는 다수의 카피로 존재할 수 있다.
데포 모듈은 변경된 폴리펩티드에 다양한 방식으로 부착될 수 있다. 예를 들면, 한 실시양태에서(도 4), 변경된 폴리펩티드는 다음과 같은 반복 단위를 포함한다: 보조적 폴리펩티드-생물학적 활성 폴리펩티드-데포 모듈, 생물학적 활성 폴리펩티드-보조적 폴리펩티드-데포 모듈, 데포 모듈-보조적 폴리펩티드-생물학적 활성 폴리펩티드, 또는 데포 모듈-생물학적 활성 폴리펩티드-보조적 폴리펩티드.
본 발명의 또 다른 양태에서, 데포 모듈은 혈청 프로테아제에 특별히 감수성인 폴리펩티드를 포함한다(도 8). 데포 모듈의 프로테아제 절단은 생물학적 활성 폴리펩티드를 방출한다. 프로테아제 부위는 특정 프로테아제, 예컨대 혈청 프로테아제에 감수성이거나, 프로테아제 절단의 상이한 속도를 나타내도록 조작될 수 있다. 따라서, 방출 속도 또는 부위는 데포 모듈의 프로테아제 절단 부위의 조작을 통해 제어될 수 있다. 이렇게 조작되어 변경된 폴리펩티드는 본원에 기재된 중합체 매트릭스와 제형화될 수 있다.
본 발명의 추가의 양태에서, 데포 모듈은 또한 높은 결합활성의 결합 모듈을 생산하도록 변경될 수 있다. 이는 몇몇 프로테아제 민감성 모듈을 프로테아제 내성 모듈로 대체함으로써 달성될 수 있다. 예를 들면, 4번째 마다 생물학적 활성 폴리펩티드 사이에 프로테아제-감수성 데포 모듈을 갖는 보조적 폴리펩티드-생물학적 활성 폴리펩티드 융합 단백질을 생산함으로써, 융합 단백질의 단백질가수분해는 4가 결합 모듈을 방출할 것이다. 4가 종은 단량체 결합 모듈에 비해 상당히 증가된 표적 결합활성을 갖고, 세포 표면 수용체를 표적화하는데 특히 바람직하다(도 53a∼c).
본 발명의 추가의 양태에서, 데포 모듈은 4가 보조적 단백질-생물학적 활성 폴리펩티드 융합 단백질을 제공하도록, 예를 들면 표적 결합활성을 증가시키고/시키거나 서방형 적용분야를 위해 디자인된다. 데포 모듈은 작은 분자 바이오틴의 부위 특이적 접합을 위해 아미노산 또는 아미노산들을 함유하도록 디자인된다. 바이오틴은 처방전없이 살 수 있는 영양 보충제에서 발견되는 흔한 비타민다. 이는 지방산의 생합성에 관여하는 효소를 비롯한 수 개의 효소를 위한 "보조-인자"로서 작용한다. 바이오틴은 또한 생명공학 분야에 넓게 사용되는데, 바이오틴이 단백질 아비딘, 뉴트라비딘, 및 스트렙타비딘과 매우 높은 친화도 복합체를 형성하기 때문이다. 이러한 실시양태에서, 각각 바이오틴의 4개 분자에 결합하는 아비딘, 스트렙타비딘, 또는 뉴트라비딘이 사용되어 매우 안정한 보조적 폴리펩티드-생물학적 활성 폴리펩티드 융합 단백질 사량체를 형성할 수 있다(도 5).
라이신(K) 및 시스테인(C) 잔기는, 각각, 온화한 조건하에 높은 수율 및 특이성을 갖고, 석시디미딜 에스테르 또는 말레이미드와의 화학 반응에 의해 개별적으로 변경될 수 있다. 보조적 폴리펩티드는 임의의 라이신(K) 또는 시스테인(C) 잔기를 함유하지 않을 경우, 이들은 용이하게 데포 모듈내로 혼입될 수 있다. 데포 모듈은 1개, 2개, 또는 그 이상의 라이신 또는 시스테인 잔기를 포함할 수 있다.
데포 모듈은 또한 부위 특이적 변경을 확보하기 위해 "핫(hot) 시스테인"의 사용을 포함한다. "핫 시스테인"은 라이신 잔기, 예를 들면 (KCKK)(여기서, K는 라이신이고 C는 시스테인임)에 의해 플랭킹된다. 근위 라이신 잔기는 시스테인의 pKa를 전이시켜, 그의 친핵성을 증가시키고 이러한 잔기를 보다 반응성으로 만든다. 수 개의 기는, "핫 시스테인"이 동일한 단백질에 존재하는 23개의 다른 시스테인 잔기의 배경에서 조차 우선적으로 변경될 수 있음을 보여주었다[Okten, Z., et al. (2004) Nat Struct Mol Biol, 11:884-7]. 따라서, 데포 모듈은 시험관내에서 보조적 폴리펩티드 또는 보조적 폴리펩티드-생물학적 활성 폴리펩티드 융합물의 부위 특이적인 유효한 변경을 산출할 수 있다. 이들 반응성 기에 접합된 바이오틴은 상업적으로 이용가능하다.
바이오틴 결합 단백질, 예컨대 아비딘, 스트렙타비딘, 또는 뉴트라비딘의 첨가는 매우 안정한 보조적 폴리펩티드 결합 단백질 폴리펩티드 사량체의 형성을 유도할 수 있다. 이어서 보조적 폴리펩티드 결합 단백질 폴리펩티드 사량체는 이후 기재된 바와 같이 중합체 매트릭스와 제형화될 수 있다(예를 들어, 미소구체내로 캡슐화됨). 보조적 폴리펩티드 결합 단백질 폴리펩티드 사량체는 매우 큰 수력학적 반경을 나타내어, 중합체 매트릭스, 예를 들어, 미소구체로부터의 저속 방출을 확보한다. 보조적 폴리펩티드 결합 단백질 폴리펩티드 사량체는 또한 그의 생물학적 표적으로의 증가된 결합활성을 가질 것이다. 보조적 폴리펩티드 결합 단백질 폴리펩티드 사량체가 4개의 표적 분자와, 예를 들면 세포의 혈장 막 상에서 상호작용할 수 있으므로, 보조적 폴리펩티드 결합 단백질 폴리펩티드의 오프-속도(off-rate)는 극적으로 감소될 것이다. 증가된 결합활성은 생물학적 활성을 증진시키거나 보조적 폴리펩티드 결합 단백질 폴리펩티드의 필요한 투약량을 감소시킬 것이다.
본 발명의 추가의 양태에서, 동일한 활성 잔기를 갖는 데포 모듈은 반응성 바이오틴 대신에 폴리-에틸렌 글리콜로 변경될 수 있다. 4개 및 8개 암(arm)을 갖는 PEG 분자가 특히 관심을 끈다. 이들 PEG 분자는 본원에 기재된 데포 모듈에 공유적으로 결합될 수 있어서, 균질한 사량체 및 8량체 종을 생성할 수 있다. 이러한 방식으로 접합된 단백질 치료제는 이들의 생물학적 표적, 특별히 세포 표면 단백질에 대해 상당히 증진된 결합활성을 가질 것이다.
단백질 침전을 위한 반대이온
본 발명은 관심있는 단백질의 용해도를 조절하기 위해, 즉 데포 제형을 위해 단백질을 침전시키기 위해 반대이온을 이용함에 관한 것이다. 반대이온은, 이의 존재로 인해 전체적으로 중성으로 하전된 종의 형성을 허용하는 이온이다. 예를 들면, (중성) 종 NaCl에서 나트륨 양이온은 클로라이드 음이온에 의해 중화되고, 또한 그 반대이다. 양이온 교환기에 의한 불량한 수불용성 염 형성의 기작은 하기 식으로 도시된다: rPEGn+ + nC- → rPEG·Cn(불용성)(여기서 rPEGn+는 양으로 하전된 펩티드 이온을 나타내는 반면, C-는 음으로 하전된 반대이온을 나타냄). 이 반응에서 참여 아미노산 잔기는 Arg, Lys 및 N-말단를 포함한다. 음이온 교환기에 의한 불량한 수용성 염 형성의 기작은 하기 식으로 도시된다: rPEGn- + nC+ → rPEG·Cn(불용성)(여기서 rPEGn-는 음으로 하전된 펩티드 이온을 나타내는 반면, C+는 양으로 하전된 반대이온을 나타냄). 이 반응에서 참여 아미노산 잔기는 Asp, Glu 및 C-말단를 포함한다.
한 바람직한 실시양태에서, 반대이온은 혼합된 소수성 및 이온성 특징을 나타낸다. 따라서, 반대이온의 전하가 관심있는 단백질과의 복합체 형성에 의해 중화되기만 하면, 반대이온의 소수성 성질이 생성된 복합체를 지배하여, 그의 수성 용해도를 크게 감소시킨다. 또한, 반대이온은 급성 및 만성 독성, 발암성, 생식성 효과 등에 관하여 관심있는 단백질에 대해 의도되는 임상적 증상내에서 생체내 투여와 화합성이어야 한다. 이러한 용도에 적합한 혼합된 반대이온의 비제한적 예는 아래에 제공된다:
■ 음이온:
▣ 베헤네이트
▣ 콜레스테릴 설페이트
▣ 데옥시콜레이트
▣ 도데칸 설포네이트
▣ 에피갈로카테킨 갈레이트(Epigallocatechin gallate)
▣ 헥사데칸 설포네이트
▣ 파모에이트
▣ 펜타갈로일 글루코스
▣ 스테아레이트
▣ 타네이트
■ 양이온:
▣ 콜린 유도체
▣ 펩티드 반대이온: 예를 들어, H-Lys-(Leu)n-NH2; H-(Leu)n-NH2
■ 지질:
▣ 포스파티딜콜린
■ 중합체 물질:
▣ 키토산
▣ 콜라겐
▣ 히알루론산
▣ 폴리 β-아미노 에스테르
▣ PLA/PLGA
▣ 폴리(에틸렌 글리콜) 비스 (2-아미노에틸)
한 실시양태에서, 관심있는 단백질은 상기 기재된 바와 같이 소수성 및 하전된 특징을 포함하는 반대이온과 규정된 비로 혼합된다. 상호작용시, 단백질 및 반대이온은 용액으로부터 침전하는 불용성 복합체를 형성한다. 한 바람직한 실시양태에서, 총 단백질의 20%, 40%, 60%, 또는 80% 이상은 이러한 조건하에 침전된고, 이는 용액중에 남아있는 단백질의 정량적 검정에 의해 평가될 수 있다. 단백질:반대이온 비의 최적화, 유기 용매의 포함, pH 조정, 이온 강도, 및/또는 온도 조정은 침전 반응의 유효성을 조정하기 위해 사용될 수 있다. 침전물은 액상으로부터 표준 방법(즉, 여과, 원심분리)에 의해 분리될 수 있고, 건조 형태로 또는 불활성 완충액중 현탁액으로서 저장될 수 있다. 약학적 조성물을 위해, 저장시 단백질 안정성은 소정의 제형의 실행가능성을 결정하기 위한 중요한 파라미터이다. 한 실시양태에서, 단백질은 규정된 저장 조건 및 제형하에 1, 2, 3, 6, 12, 18, 또는 24 개월 넘게 안정하다.
본 발명은 또한 피험체의 생체내로 상기 기재된 단백질 복합체를 투여하는 방법을 구현한다. 본 발명의 화합물은 약학적 제형, 예컨대 경구(구강 및 설하가 포함됨), 직장, 비강, 국소, 경피 패치, 폐, 질, 좌제, 또는 비경구(근육내, 동맥내, 포막내, 피부내, 복강내, 피하 및 정맥내가 포함됨) 투여에 적합한 제형으로서, 또는 에어로졸화, 흡입 또는 취입에 의한 투여에 적합한 형태로 투여될 수 있다. 한 바람직한 실시양태에서, 단백질 복합체는 피험체에게 비경구 주사를 통해 투여된다. 본원에 사용될 경우, 용어 "비경구"는 소장을 통하지 않고 정맥내(i.v.), 동맥내(i.a.), 복강내(i.p.), 근육내(i.m.), 뇌실내, 기관지내, 및 피하(s.c.) 경로를 통해 신체내로 복합체를 도입함을 지칭한다. 비경구 주사(예를 들어 일시주사 또는 연속 주입)를 통해 투여되기 위해, 침전물은 투여 경로와 화합성인 완충액에 재현탁된다. 바람직한 실시양태에서, 침전물은 최소로 폐색된 18, 22, 25, 26, 27, 또는 28 게이지 침을 통해 통과할 수 있는 균질한 현탁액으로서 재현탁된다. 재현탁 특성을 개선시킬 뿐만 아니라 보다 높은 게이지 침을 통해 효과적으로 통과할 수 있는 입자의 크기를 감소시키기 위해 제분 또는 유사 처리과정이 수행될 수 있다. 용액의 표면 장력, 점도 또는 습윤 특성을 변경시킬 수 있는 청정제(detergent) 또는 다른 부형제가 또한 주사용 침전 현탁액의 균질성을 개선시키는데 유용할 수 있다.
본 발명은 또한 예를 들면 비경구 주사를 통해 생체내 환경으로 침전물을 도입할 때 데포 제형에서의 단백질 방출 속도에 관한 것이다. 단백질 방출 속도는 등장성 완충액(예를 들어, 포스페이트 완충된 염수)에 단백질:반대이온의 침전물을 현탁시키고, 시간에 대한 가용성 단백질의 농도를 측정함으로써 시험관내에서 추정될 수 있다. 바람직한 실시양태는 생체내 조건을 보다 잘 모방하기 위해 생리학적 온도를 사용하지만, 실험적 설비에 따른 재용해 속도를 변경하기 위해 보다 높거나 낮은 온도가 사용될 수도 있다. 소정의 단백질에 대한 최적 방출 속도는 그의 생체내 제거 속도 및 기작, 뿐만 아니라 생체내 효력을 위해 필요한 노출에 좌우된다. 단백질의 상당한 축적을 달성하기 위해, 재용해 속도는 천연 제거 속도에 비해 빨라야 한다. 단백질의 혈청 농도는 제거 속도에 대한 재용해 속도의 비에 비례하는 것으로 예상된다. 단백질 복합체의 그의 가용성 상태와 침전물 상태 사이의 동력학은 하기 수학식 1로 표시된다:
[수학식 1]

복합체 내로의 재침전 속도는 무시되는 것으로 가정함: [단백질]은 대략 k용해/k제거(즉, 제거 속도에 대한 재용해의 비)와 동일함.
생체내에서 달성된 실제 혈청 농도는 또한 주사된 복합체의 총량, 침전물 입자의 표면 영역, 단백질 흡수 속도, 단백질의 그의 동족 수용체로의 결합, 및 재순환 기작을 비롯한 다수의 다른 인자에 좌우된다.
침전물의 재용해 특성은 침전물의 다양한 처리에 의해 변경될 수 있다. 예를 들면, 반대이온의 열 처리 또는 자외선 가교결합은 침전물의 화학적(및 재용해) 특성을 변경시키기 위해 사용될 수 있다. 침전물은 또한 용매의 집접적인 제거(예를 들어, 분사 건조, 동결건조)에 이어, 목적하는 데포 특징을 달성하기 위해 반대이온 또는 코팅 물질로 처리함으로써 형성될 수 있다.
부형제는 복합체 형성의 속도 및 유효성을 제어할 뿐만 아니라, 생체내 환경으로 전달시 단백질:반대이온 복합체의 재용해 속도를 조정하기 위해 복합체 형성 반응에 포함될 수 있다. 부형제는 전형적으로 하전되지 않은 불활성 분자로서, 이는 복합체 형성 반응 완충액에 포함되고 다양한 정도의 최종 침전물 양을 포함한다. 부형제는 용매에 대한 침전물 입자의 표면 면적을 조절하여 단백질의 재용해 속도 및/또는 안정성을 조절하는 작용을 하는 침전물 입자의 표면에 적용되는 코팅물을 포함할 수도 있다. 부형제의 예로는, 제한되지 않지만, 다음이 포함된다:
■ 중합체
▣ 폴리에틸렌 글리콜 500
▣ 폴리에틸렌 글리콜 2000
▣ 폴리에틸렌 글리콜 5000
▣ 폴리에틸렌 글리콜 8000
▣ 폴리에틸렌 글리콜 20000
▣ 폴리라이신
▣ PLA/PLGA
■ 청정제
▣ 폴리소르베이트 20(트윈 20)
▣ 폴리소르베이트 80(트윈 80)
▣ 트리톤 X-100
■ 당/폴리알코올
▣ 글루코스
▣ 글리세린
▣ 글리세롤
▣ 만니톨
▣ 만노스
▣ 소르비톨
▣ 수크로스
▣ 트레할로스
본 발명의 또 다른 실시양태는 데포 형성이 주사시 제자리에서 초래되도록 하는 제형을 포함한다. 예를 들면, 단백질 및 반대이온은 침전물이 생리학적 pH(즉 pH 7.4) 근처에서 형성되도록 선택된다. 단백질 및 반대이온은 서로에 대한 최적 농도 비에서, 그러나 생리학적 pH(예를 들어 pH 4 또는 pH 10)와 충분히 상이한 pH에서 제형화되어 복합체 형성이 초래되지 않도록 한다. 비경구 주사시, 바람직하게는 피하 또는 근육내 주사시, 조직의 고유의 완충 능력은 용액을 pH 7.4로 조정하여, 주사 부위에서 단백질:반대이온 복합체의 침전, 및 이에 따른 저속 방출을 일으킨다. 주사시 온도 변화 및 생체내에서 발견되는 천연 반대이온과 주사된 단백질의 복합체 형성은, 서방형 단백질 데포가 제자리에서 형성될 수 있는 방법이다.
보조제 연결 폴리펩티드의 생산
본 발명은, a) 숙주 세포에서 보조적 폴리펩티드와 연결된 생물학적 활성 폴리펩티드를 포함하는 변경된 폴리펩티드의 발현이 상기 생물학적 활성 폴리펩티드 단독의 발현에 비해 상기 생물학적 활성 폴리펩티드의 가용성 형태를 더 많은 양으로 산출하도록 상기 변경된 폴리펩티드를 코딩하는 폴리뉴클레오티드 서열을 제공하는 단계; 및 b) 상기 변경된 폴리펩티드를 상기 숙주 세포에서 발현시켜, 생물학적 활성 폴리펩티드를 생산하는 단계를 포함하는, 생물학적 활성 폴리펩티드의 제조 방법을 제공한다. 상기 변경된 생물학적 활성 폴리펩티드의 발현은 상기 생물학적 활성 폴리펩티드 단독의 발현에 비해 약 100%, 200%, 500% 또는 1000% 이상의 생물학적 활성 폴리펩티드의 가용성 형태를 산출할 수 있다. 몇몇 실시양태에서, 상기 변경된 생물학적 활성 폴리펩티드의 발현은 상기 생물학적 활성 폴리펩티드 단독의 발현에 비해 100%∼1000% 이상의 생물학적 활성 폴리펩티드의 가용성 형태를 산출할 수 있다.
본 발명의 방법은 DNA가 발현되는 조건하에 보조적 폴리펩티드를 코딩하는 키메라성 DNA 분자로 형질전환된 세포를 배양함으로써 보조제 연결 폴리펩티드를 생산하는 단계; 및 세포 또는 배양 배지로부터 키메라성 DNA 분자의 발현 생성물을 추출하는 단계를 포함한다.
분자 생물학에서 표준 재조합 기법이 본 발명의 보조제 연결 폴리펩티드를 제조하기 위해 사용될 수 있다. 한 실시양태에서, 우선 보조적 폴리펩티드에 상응하는 DNA 서열을 함유한 구성물이 제조된다. 예를 들면, 우선 생물학적 활성 단백질을 코딩하는 유전자 또는 폴리뉴클레오티드가 플리스미드 또는 다른 벡터일 수 있는 구성물내로 클로닝될 수 있다. 이후 단계에서, 보조적 폴리펩티드를 코딩하는 제2 유전자 또는 폴리뉴클레오티드가, 생물학적 활성 폴리펩티드를 코딩하는 유전자와 인접하여 프레임내에 위치하는 구성물내로 클로닝된다. 이러한 제2 단계는 결찰 또는 다량체화 단계를 통해 일어날 수 있다.
이러한 방식으로, 변경된 폴리펩티드를 코딩하는 키메라성 DNA 분자가 구성물내에 생성된다. 경우에 따라, 이러한 키메라성 DNA 분자는 보다 적절한 발현 벡터인 또 다른 구성물내로 전달되거나 클로닝될 수 있다. 이 시점에, 키메라성 DNA 분자를 발현할 수 있는 숙주 세포는 키메라성 DNA 분자에 의해 형질전환된다. 형질전환은 담체, 예컨대 발현 벡터를 이용하거나 이용하지 않고 일어날 수 있다. 이어서, 형질전환된 숙주 세포는 키메라성 DNA 분자의 발현에 적합한 조건하에 배양되어, 보조적 폴리펩티드의 코딩을 일으킨다. 본 발명에서 유용한 결찰 또는 다량체화의 방법은 잘 공지되어 있다. 문헌[Joseph Sambrook, et al., Molecular Cloning: A Laboratory Manual, 2nd ed., 1.53 (Cold Spring Harbor Laboratory Press 1989)]을 참조한다.
본 발명을 수행하기에 적합한 몇몇 클로닝 전략이 구현되어 있고, 이들중 대부분은 본 발명의 보조적 폴리펩티드를 코딩하는 유전자를 포함하는 구성물을 생성하기 위해 사용될 수 있다.
관심있는 DNA 분절을 함유한 벡터는 세포성 숙주의 유형에 의존하여 잘 공지된 방법에 의해 숙주 세포내로 전달될 수 있다. 예를 들면, 칼슘 클로라이드 형질감염이 원핵 세포를 위해 통상적으로 사용되는 반면, 칼슘 포스페이트 처리, 리포펙션(lipofection), 또는 전기천공법이 다른 세포성 숙주를 위해 사용될 수 있다. 포유동물 세포를 형질전환시키기 위한 다른 방법으로는 폴리브렌(polybrene), 원형질체 융합, 리포솜, 전기천공법, 및 마이크로주사가 포함된다(일반적으로, 상기 문헌[Sambrook et al.] 참조). 원핵 또는 진핵 세포가 숙주로서 구현된다. 보조적 폴리펩티드는 원핵 및 진핵 시스템을 비롯한 다양한 발현 시스템에서 생산될 수 있다. 적합한 발현 숙주는, 예를 들어 효모, 진균류, 포유동물 세포 배양물, 및 곤충류 세포이다.
사용될 수 있는 유용한 발현 벡터로는, 예를 들면, 염색체성, 비염색체성, 및 합성 DNA 서열이 포함된다. 적합한 벡터로는, 제한되지 않지만, SV40 및 pcDNA의 유도체, 및 공지된 박테리아 플라스미드, 예컨대 col EI, pCRl, pBR322, pMal-C2, pET, pGEX(문헌[Smith, et al., Gene 57:31-40 (1988)]에 기재된 바와 같음), pMB9 및 이의 유도체, 플라스미드, 예컨대 RP4, 파지 DNA, 예컨대 파지 I의 다수의 유도체, 예컨대 NM98 9, 뿐만 아니라 다른 파지 DNA, 예컨대 M13 및 필라멘트형 단일 가닥 파지 DNA; 효모 플라스미드, 예컨대 2 미크론 플라스미드 또는 2m 플라스미드의 유도체, 뿐만 아니라 센토머성(centomeric) 및 통합성 효모 셔틀(shuttle) 벡터; 진핵 세포에 유용한 벡터, 예컨대 곤충류 또는 포유동물 세포에 유용한 벡터; 플라스미드 및 파지 DNA의 조합물, 예컨대 파지 DNA 또는 발현 제어 서열을 이용하도록 변경된 플라스미드로부터 유도된 벡터; 등이 포함된다. 필수사항은 벡터가 선택된 숙주 세포내에서 복제가능하고 생존가능해야 한다는 것이다. 원할 경우 보다 낮거나 높은 카피 수의 벡터가 사용될 수 있다.
예를 들면 바큘로바이러스(baculovirus) 발현 시스템에서, 비-융합 전달 벡터, 예컨대, 제한되지 않지만, pVL941(BamHI 클로닝 부위, 문헌[Summers, et al., Virology 84:390-402 (1978)]로 부터 이용가능함), pVL1393(BamHI, Smal, Xbal, EcoRI, IVotl, XmaIII, BgIII 및 Pstl 클로닝 부위; 인비트로겐(Invitrogen)), pVL1392(BgIII, Pstl, NotI, XmaIII, EcoRI, Xball, Smal 및 BamHI 클로닝 부위; Summers, et al., Virology 84:390-402 (1978); 인비트로겐) 및 pBlueBacIII (BamHI, BgIII, Pstl, NcoI 및 Hindi II 클로닝 부위, 블루/화이트(blue/white) 재조합 스크리닝에 의함, 인비트로겐), 및 융합 전달 벡터, 예컨대, 제한되지 않지만, pAc700(BamHI 및 KpnI 클로닝 부위, 여기서 BamHI 인식 부위는 개시 코돈으로 시작함; Summers, et al., Virology 84:390-402 (1978)), pAc701 및 pAc70-2(pAc700과 동일함, 상이한 판독 프레임을 가짐), pAc360[BamHI 클로닝 부위, 폴리헤드린 개시 코돈의 36개 염기쌍 다운스트림; 인비트로겐(1995)) 및 pBlueBacHisA, B, C(BamHI, BgIII, Pstl, Nco1 및 Hind III 클로닝 부위를 갖는 3개의 상이한 판독 프레임, 플라크의 프로본드(ProBond) 정제 및 블루/화이트 재조합 스크리닝을 위한 N-말단 펩티드; 인비트로겐(220))가 사용될 수 있다.
포유동물 발현 벡터는 복제 기점, 적합한 프로모터 및 인핸서, 및 임의의 필수 리보솜 결합 부위, 폴리아데닐화 부위, 스플라이스 공여자 및 수여자 부위, 전사 종결 서열, 및 5' 플랭킹 비전사된 서열을 포함할 수 있다. SV40 스플라이스로부터 유도된 DNA 서열, 및 폴리아데닐화 부위는 필요한 비전사된 유전자 요소를 제공하도록 사용될 수 있다. 본 발명에서 사용하기 위해 고려되는 포유동물 발현 벡터로는 유도성 프로모터, 예컨대 디하드로폴레이트 환원효소 프로모터를 갖는 벡터, DHFR 발현 카세트(cassette)를 갖는 임의의 발현 벡터 또는 DHFR/메토트렉세이트 공-증폭 벡터, 예컨대 pED(Pstl, Sail, Sbal, Smal 및 EcoRI 클로닝 부위, 클로닝된 유전자 및 DHFR 둘 다를 발현하는 벡터; Randal J. Kaufman, 1991, Randal J. Kaufman, Current Protocols in Molecular Biology, 16,12 (1991))가 포함된다. 다르게는 글루타민 신테타제(synthetase)/메티오닌설폭시이민 공-증폭 벡터, 예컨대 pEE14(HindIII, Xball, Smal, Sbal, EcoRI 및 Sell 클로닝 부위, 여기서 벡터는 글루타민 신테타제 및 클로닝된 유전자를 발현함;셀테크(Celltech))이다. 엡스타인 바르 바이러스(EBV: Epstein Barr Virus) 또는 핵 항원(EBNA)의 제어하에 에피솜 발현을 유도하는 벡터, 예컨대 pREP4(BamHI r SfH, Xhol, Notl, Nhel, Hindi II, NheI, PvuII 및 KpnI 클로닝 부위, 구성적 RSV-LTR 프로모터, 하이그로마이신 선택가능한 마커; 인비트로겐), pCEP4(BamHI, SfH, Xhol, NotI, Nhel, HindIII, Nhel, PvuII 및 KpnI 클로닝 부위, 구성적 hCMV 조기 반응(immediate early) 유전자 프로모터, 하이그로마이신 선택가능한 마커; 인비트로겐), pMEP4(.KpnI, Pvul, Nhel, HindIII, NotI, Xhol, Sfil, BamHI 클로닝 부위, 유도성 메탈로트비오네인(methallotbionein) H a 유전자 프로모터, 하이그로마이신 선택가능한 마커, 인비트로겐), pREP8(BamHI, Xhol, NotI, HindIII, Nhel 및 KpnI 클로닝 부위, RSV-LTR 프로모터, 히스티디놀 선택가능한 마커; 인비트로겐), pREP9(KpnI, Nhel, HindIII, NotI, Xho 1, Sfi 1, BamH I 클로닝 부위, RSV-LTR 프로모터, G418 선택가능한 마커; 인비트로겐), 및 pEBVHis (RSV-LTR 프로모터, 하이그로마이신 선택가능한 마커, 프로본드 수지를 통해 정제가능하고 엔테로키나제에 의해 절단되는 N-말단 펩티드; 인비트로겐)가 사용될 수 있다.
본 발명에 사용하기 위해 선택가능한 포유동물 발현 벡터로는, 제한되지 않지만, pRc/CMV(HindIII, BstXI, NotI, Sbal 및 Apal 클로닝 부위, G418 선택, 인비트로겐), pRc/RSV(Hind II, Spel, BstXI, NotI, Xbal 클로닝 부위, G418 선택, 인비트로겐) 등이 포함된다. 본 발명에 사용될 수 있는 우두(vaccinia) 바이러스 포유동물 발현 벡터(예를 들면, 문헌[Randall J. Kaufman, Current Protocols in Molecular Biology 16.12 (Frederick M. Ausubel, et al., eds. Wiley 1991] 참조)로는, 제한되지 않지만, pSC11(Smal 클로닝 부위, TK- 및 베타-gal 선택), pMJ601 (Sal 1, Sma 1, A fll, Narl, BspMlI, BamHI, Apal, Nhel, SacII, KpnI 및 HindIII 클로닝 부위; TK- 및 -gal 선택), pTKgptFIS(EcoRI, Pstl, SaIII, Accl, HindII, Sbal, BamHI 및 Hpa 클로닝 부위, TK 또는 XPRT 선택) 등이 포함된다.
본 발명에 사용될 수 있는 효모 발현 시스템으로는, 제한되지 않지만, 비-융합 pYES2 벡터(XJbal, Sphl, Shol, NotI, GstXI, EcoRI, BstXI, BamHI, Sad, KpnI 및 HindIII 클로닝 부위, 인비트로겐), 융합 pYESHisA, B, C(Xball, Sphl, Shol, NotI, BstXI, EcoRI, BamHI, Sad, KpnI 및 Hindi II 클로닝 부위, 프로본드 수지에 의해 정제되고 엔테로키나제에 의해 절단되는 N-말단 펩티드; 인비트로겐), pRS 벡터 등이 포함된다.
또한, 키메라성 DNA 분자를 함유하는 발현 벡터는 약물 선택 마커를 포함한다. 이러한 마커는 키메라성 DNA 분자를 함유하는 벡터의 클로닝 및 선택 또는 동정에 도움을 준다. 예를 들면, 네오마이신(neomycin), 퓨로마이신(puromycin), 하이그로마이신(hygromycin), 디하이드로폴레이트 환원효소(DHFR: dihydrofolate reductase), 구아닌 포스포리보실 전이효소(GPT: guanine phosphoribosyl transferase), 제오신(zeocin), 및 히스티디놀(histidinol)에 대한 내성을 부여하는 유전자가 유용한 선택가능한 마커이다. 다르게는, 효소, 예컨대 단순포진(herpes simplex) 바이러스 티미딘 키나제(tk: thymidine kinase) 또는 클로람페니콜 아세틸교환효소(CAT: chloramphenicol acetyltransferase)가 이용될 수 있다. 면역원성 마커가 또한 사용될 수 있다. 임의의 공지된 선택가능한 마커는, 이것이 유전자 생성물을 코딩하는 핵산과 동시에 발현될 수 있는 한, 사용될 수 있다. 선택가능한 마커의 추가의 예는 당분야의 숙련가에게 잘 공지되어 있고, 리포터(reporter), 예컨대 증진된 녹색 형광성 단백질(EGFP: enhanced green fluorescent protein), 베타-갈락토시다제(β-gal) 또는 클로람페니콜 아세틸교환효소(CAT)가 포함된다.
결과적으로, 포유동물 및 전형적으로 인간 세포, 뿐만 아니라 박테리아, 효모, 진균류, 곤충, 선충 그리고 식물세포가 본 발명에서 숙주 세포로서 사용될 수 있고, 본원에 정의된 바와같은 발현 벡터에 의해 형질전환된다.
적합한 세포의 예로는, 제한되지 않지만, VERO 세포, HELA 세포, 예컨대 ATCC No. CCL2, CHO 세포주, COS 세포, WI38 세포, BHK 세포, HepG2 세포, 3T3 세포, A549 세포, PC12 세포, K562 세포, 293 세포, Sf9 세포 및 CvI 세포가 포함된다.
본 발명에 사용될 수 있는 다른 적합한 세포로는, 제한되지 않지만, 원핵 숙주 세포 균주, 예컨대 에스케리치아 콜라이(예를 들어, 균주 DH5-α), 바실러스 서브틸리스(Bacillus subtilis), 살모넬라 티피뮤리엄(Salmonella typhimurium), 또는 슈도모나스(Pseudomonas), 스트렙토마이세스 및 스타필로코커스(Staphylococcus) 속 균주가 포함된다. 적합한 원핵생물의 비제한적 예로는 하기의 속이 포함된다: 악티노플레네스(Actinoplanes); 아카에오글로부스(Archaeoglobus); 브델로비브리오(Bdellovibrio); 보렐리아(Borrelia); 클로로플렉서스(Chloroflexus); 엔테로코쿠스(Enterococcus); 에스케리치아; 락토바실러스( Lactobacillus); 리스테리아(Listeria); 오세아노바실러스(Oceanobacillus); 파라코커스(Paracoccus); 슈도모나스; 스타필로코커스; 스트렙토코커스(Streptococcus); 스트렙토마이세스; 써모플라스마(Thermoplasma); 및 비브리오(Vibrio). 특정 균주의 비제한적 예로는 다음이 포함된다: 아카에오글로부스 펄지더스(Archaeoglobus fulgidus); 브델로비브리오 박테리오바이러스(Bdellovibrio bacteriovorus); 보렐리아 버그도페리(Borrelia burgdorferi); 클로로플렉서스 아우란티아커스(Chloroflexus aurantiacus); 엔테로코커스 파에칼리스(Enterococcus faecalis); 엔테로코커스 파에시움(Enterococcus faecium); 락토바실러스 존소니(Lactobacillus johnsonii); 락토바실러스 플랜타룸(Lactobacillus plantarum); 락토코커스 락티스(Lactococcus lactis); 리스테리아 이노쿠아(Listeria innocua); 리스테리아 모노사이토겐스(Listeria monocytogenes); 오세아노바실러스 이헤옌시스(Oceanobacillus iheyensis); 파라코커스 제아산티니파시엔스(Paracoccus zeaxanthinifaciens); 슈도모나스 메발로니(Pseudomonas mevalonii); 스타필로코커스 아우레어스; 스타필로코커스 에피더미디스(Staphylococcus epidermidis); 스타필로코커스 하에모리티커스(Staphylococcus haemolyticus); 스트렙토코커스 아가락티아(Streptococcus agalactiae); 스트렙토마이세스 그리세오로스포레어스(Streptomyces griseolosporeus); 스트렙토코커스 뮤탄스(Streptococcus mutans); 스트렙토코커스 뉴모니아(Streptococcus pneumoniae); 스트렙토코커스 피오게네스(Streptococcus pyogenes); 써모플라스마 아시도필럼(Thermoplasma acidophilum); 써모플라스마 볼카니움(Thermoplasma volcanium); 비브리오 콜레라(Vibrio cholerae); 비브리오 파라하에모리티커스(Vibrio parahaemolyticus); 및 비브리오 불니피커스(Vibrio vulnificus).
본 발명에 사용될 수 있는 추가의 적합한 세포들로는 효모 세포, 예컨대 사카로마이세스, 예컨대 사카로마이세스 세레비지아의 세포가 포함된다.
본 발명을 수행하기 위한 박테리아 발현의 핵심적인 이점은 글리코실화의 부재이다. 보조적 폴리펩티드의 글리코실화는 그의 분자량을 증가시키고 일반적으로 그의 혈청 반감기를 증가시키는 한편, 글리코실화된 생성물의 품질 조절은 수행되기 극히 어렵다. 많은 글리코실화 부위가 존재하고 단백질 발현 수준이 높은 경우, 글리코실화 기작은 유지될 수 없고 글리코실화는 불완전한 처리과정에 기인하여 불안정하기 쉬워서, 비균질한 탄수화물 구조를 생성하고, 이는 정제, 특성 분석, 품질 조절 및 재생산을 복잡하게 한다.
단백질이 박테리아에서 어떻게 발현되는지에 따라서(배지로, 주변세포질로 분비, 세포질에서 가용성, 또는 세포질에서 불용성 봉입체로서), 생성물 또는 중간체는 포밀화된 N-말단를 함유한다.
본 발명의 보조적 폴리펩티드 또는 보조제 변경 폴리펩티드가 영향받기 쉬운 추가의 번역후 변경로는, 제한되지 않지만 아실화, 아세틸화, 알킬화, 탈메틸화, 아미드화, 비오티닐화, 포밀화, 감마-카복실화, 글루타밀화, 글리코실화, 글리실화, 헴(heme) 잔기의 부착, 하이드록실화, 요오드화, 이소프레닐화, 리포일화(lipoylation), 프레닐화, 미리스토일화(myristoylation), 파네실화(farnesylation), 게라닐게라닐화(geranylgeranylation), ADP-리보실화, 플라빈 부착, 산화, 페그화, 포스파티딜이노시톨의 부착, 포스포판테티에닐화, 포스포릴화, 피로글루타메이트 형성, 프롤릴 이성화효소에 의한 프롤린의 라세미화, 아미노산의 tRNA 매개 첨가, 예컨대 아르기닌화, 황산화 및 셀레노일화(selenoylation)가 포함된다.
관심있는 폴리뉴클레오티드를 함유하는 숙주 세포는, 프로모터를 활성화하거나, 형질전환체를 선택하거나, 유전자를 증폭시키기 위해 적절히 변경된 종래의 영양 배지(예를 들어, 햄(Ham)의 영양 배지)에서 배양될 수 있다. 배양 조건, 예컨대 온도, pH 등은 발현을 위해 선택된 숙주 세포와 함께 이전에 사용된 것이고, 통상의 숙련가에게 명백할 것이다. 세포는 전형적으로 원심분리에 의해 수확되고, 물리적 또는 화학적 수단에 의해 분쇄되고, 생성된 조질의 추출물은 추가의 정제를 위해 보유된다. 단백질의 발현에 사용된 미생물 세포는 동결-해동 순환, 음파처리, 기계적 분쇄,또는 세포 용해제의 사용(이들 모두는 당분야의 숙련가에게 공지됨)을 비롯한 임의의 편리한 방법에 의해 분쇄될 수 있다. 세포 용해를 포함하는 실시양태는 키메라성 DNA 분자의 발현 후에 분해를 제한하는 프로테아제 저해제를 함유하는 완충액의 사용을 수반한다. 적합한 프로테아제 저해제로는 류펩틴(leupeptin), 펩스타틴(pepstatin) 또는 아프로티닌(aprotinin)이 포함된다. 이어서 상청액은 연속적으로 증가하는 농도의 포화 암모늄 설페이트중에서 침전될 수 있다.
보조적 폴리펩티드 생성물은 당분야의 숙련가에게 공지된 방법을 통해 정제될 수 있다. 절차, 예컨대 겔 여과, 친화도 정제, 염 분별화, 이온 교환 크로마토그래피, 크기 배제 크로마토그래피, 하이드록실아파타이트 흡착 크로마토그래피, 소수성 상호작용 크로마토그래피 및 겔 전기이동이 사용될 수 있다. 몇몇 보조적 폴리펩티드는 리폴딩을 요구할 수 있다. 정제 방법은 문헌[Robert K. Scopes, Protein Purification: Principles and Practice(Charles R. Castor, ed., Springer-Verlag 1994)] 및 문헌[Joseph Sammbrook, Molecular Cloning: A Laboratory Manual, 2nd edition (Cold Spring Harbor Laboratory Press 1989)]에 기재되어 있다. 다단계 정제 분리는 또한 문헌[Baron, et al., Crit. Rev. Biotechnol. 10: 179-90 (1990)] 및 [Below, et al., J. Chromatogr. A. 679:67-83 (1994)]에 기재되어 있다.
가교결합된 보조적 폴리펩티드의 정제
가교결합된 보조적 폴리펩티드는 다양한 방법들에 의해 생산될 수 있다. 비가교결합 및 가교결합 성분 둘 다는 화학적 합성에 의해 또는 재조합 기법을 사용하여 생성될 수 있다. 비가교결합 성분의 재조합 제작이 특히 유용한데, 이는 다양한 미생물 뿐만 아니라 진핵 발현 시스템, 예를 들면 상기 기재된 바와 같은 시스템에서 달성될 수 있다. 비가교결합 성분은 가교결합 전에 정제되어 부산물의 간섭 및 오염을 제거할 수 있다. 커플링을 위해 활성화될 수 있는 화학 가교결합기가 특히 유용하다. 예는 도 22에 제시되어 있다. 생성된 커플링 생성물은 다양한 방법, 특히 크기 배제 크로마토그래피 및 이온 교환 크로마토그래피에 의해 추가로 정제될 수 있다.
다수의 상이한 비가교결합 성분은 생성물 구조를 제어할 수 있는 방법을 사용하여 가교결합 성분에 접합될 수 있다. 예를 들어 수 개의 상이한 반응성 기를 운반하여 상이한 배열 화학을 허용하는 가교결합 성분을 사용할 수 있다. 다르게는, 이들의 반응성 기중 일부 상에 보호기를 운반하는 가교결합 성분을 사용할 수 있다. 이러한 부분적으로-보호된 가교결합 성분은 하나 이상의 비가교결합 성분에 커플링된다. 후속적으로, 가교결합 성분으로부터 보호기를 제거하고, 추가의 비가교결합 성분을 가교결합 성분으로 접합시킨다. 이 과정은 선택적 제거를 허용하는 다수의 상이한 보호기를 사용하여 반복될 수 있다.
본 발명의 또 다른 실시양태에서, 재조합 가교결합 성분이 사용될 수 있다. 가교결합 성분은 다양한 발현 시스템을 사용하여 재조합 기술에 의해 제조될 수 있는 아미노산 서열일 수 있다. 예를 들면, 비가교결합 성분의 서열에 혼입된 fMet 아미노산은 재조합 가교결합 성분에서 아미노 기에 접합될 수 있다.
한 바람직한 실시양태는 하나 이상의 글루타메이트 및/또는 아스파테이트 잔기를 포함하는 가교결합 성분을 제공하고, 이는 반응성 기로서 작용할 수 있는 측쇄를 함유하고, 반응성 기로서 유리 아미노 기를 갖는 비가교결합 성분에 효과적으로 접합될 수 있다. 다양한 카보디이미드는 유리 카복실 기를 활성화시키기 위해 사용될 수 있지만, 보다 많은 화학성분이 적합하다. 재조합 가교결합 성분중 유리 아미노 기는 아세틸화 또는 석시닐화에 의해 블로킹될 수 있다.
다르게는, 가교결합 성분은 다수의 고-친화도 결합 부위를 갖는 단백질일 수 있다. 예는 아비딘, 스트렙타비딘, IgG 또는 IgM이다. 예를 들어 비오티닐화된 비가교결합 성분과 스트렙타비딘을 접촉시킴으로써 가교결합된 보조적 폴리펩티드를 형성할 수 있고, 이는 4가 복합체의 형성을 유도할 것이다. 이 과정은 도 25에 예시되어 있다. 유사한 방식으로, 예를 들어 펩티드 에피토프를 포함하는 비가교결합 성분과 함께 펩티드 에피토프에 대한 특이성을 갖는 IgM 또는 IgG를 사용할 수 있다.
본 발명의 보조적 폴리펩티드는 생물학적 활성 폴리펩티드에 대한 효과를 경정하기 위해 검정될 수 있다. 생물학적 활성 폴리펩티드를 검정하는 방법은 당분야에 흔히 공지되어 있다. 예를 들면, 혈청 반감기는 단백질을 인간(또는 적절한 경우 마우스, 래트, 원숭이) 혈청 또는 혈장과, 전형적으로 37℃에서 일정 범위의 날 동안(즉, 0.25, 0.5, 1, 2, 4, 8, 16일) 합함으로써 측정될 수 있다. 이들 시점에서의 샘플은 웨스턴 검정에서 수행될 수 있고, 단백질은 항체로 검출된다. 항체는 단백질에서 태그일 수 있다. 단백질은 웨스턴 상에 단일 밴드를 나타내고, 여기서 단백질의 크기는 주사된 단백질의 크기와 동일하고, 이후 분해는 일어나지 않았다. 웨스턴 블롯 또는 동등한 기법에 의해 판단될 경우 50%의 단백질이 분해되는 시점은, 단백질의 혈청 분해 반감기 또는 "혈청 반감기"인 것으로 결정된다.
본 발명의 보조적 폴리펩티드는, 제한없이 "생물학적 활성 폴리펩티드" 섹션에서 지칭된 것을 비롯하여, 다양한 세포 표적의 발현 또는 활성을 조정하기 위해 사용될 수 있다. 몇몇 실시양태에서, 표적의 발현은 보조적 폴리펩티드의 투여에 의해 감소될 것인 반면, 다른 실시양태에서는, 이는 증가될 것이다. 보조적 폴리펩티드는 표적 상의 작용성 부위와 상호작용함으로써 세포 표적의 활성에 간섭할 수 있다.
서방형 제제
본 발명의 변경된 폴리펩티드는, 조성물내로 혼입되거나, 캡슐화되거나, 제형화되거나 달리 포함되어 원하는 적용분야에서 폴리펩티드의 제어 방출을 허용한다. 일반적으로, 본 발명의 변경된 폴리펩티드는, 제한되지 않지만 공유 결합, 이온성 상호작용, 또는 중합체 또는 제형내로의 캡슐화를 비롯한 다양한 방식으로 본 발명의 서방형 제제와 상호작용할 수 있다.
본 발명에 사용하기에 적합한 다양한 유형의 서방형 제제가 하기에 기재되어 있다.
중합체 매트릭스
일반적으로, 미소구체는 약 1 이상∼약 1000 미크론 이하의 크기 범위를 갖는 실질적으로 구형인 콜로이드성 구조이다. 마이크로캡슐은 물질, 예컨대, 중합체 제형이 몇몇 유형의 코팅물에 의해 덮혀진 구조로서 총칭적으로 설명된다. 용어 "미립자"는 상기 두 범주내에 또는 이들 둘 다에 대한 총칭적 용어로서 쉽게 위치되지 않는 구조를 설명하기 위해 사용될 수 있다. 직경이 약 1 미크론 미만인 구조의 경우, 상응하는 용어 "나노구체," "나노캡슐" 및 "나노입자"가 이용될 수 있지만, 이들은 용어 "미소구체", "미소캡슐" 및 "미립자"에 각각 내포된다. 특정 실시양태에서, 나노구체, 나노캡슐 또는 나노입자는 약 500, 200, 100, 50 또는 10 nm의 크기를 갖는다.
본 발명의 서방형 제형은 또한 미립자의 형태를 취할 수 있고, 이는 미소캡슐 또는 미소구체를 포함할 수 있다.
미립자에서, 변경된 폴리펩티드는 중합체 분자에 의해 형성되는 막내에 중심에 위치되거나, 미립자 전체에 분산될 수 있다. 내부 구조물은 변경된 폴리펩티드 및 중합체 부형제의 매트릭스를 포함할 수 있다. 전형적으로, 미소구체의 외부 표면은 물에 투과성이고, 이는 수성 유체가 미소구체내로 들어가도록 허용할 뿐만 아니라, 가용화된 변경된 폴리펩티드 및 중합체가 미소구체를 빠져나가도록 허용한다. 한 실시양태에서, 중합체 막은 가교결합된 중합체를 포함한다. 변경된 폴리펩티드는 중합체 막의 확산 및/또는 분해에 의해 방출될 수 있다.
미립자의 외부 층을 위해 가능한 물질로는 중합체의 다음의 범주가 포함된다: (1) 탄수화물에 기초한 중합체, 예컨대 메틸셀룰로스, 카복시메틸 셀룰로스에 기초한 중합체, 덱스트란, 폴리덱스트로즈, 키틴, 키토산, 및 전분(헤타스타치(hetastarch))가 포함됨), 및 이의 유도체; (2) 폴리지방족 알코올, 예컨대 폴리에틸렌 옥사이드 및 이의 유도체, 예컨대 폴리에틸렌 글리콜(PEG), PEG-아크릴레이트, 폴리에틸렌이민, 폴리비닐 아세테이트, 및 이의 유도체; (3) 폴리(비닐) 중합체, 예컨대 폴리(비닐) 알코올, 폴리(비닐) 피롤리돈, 폴리(비닐)포스페이트, 폴리(비닐)포스폰산, 및 이의 유도체; (4) 폴리아크릴산 및 이의 유도체; (5) 폴리유기산, 예컨대 폴리말레산, 및 이의 유도체; (6) 폴리아미노산, 예컨대 폴리라이신, 및 폴리-이미노산, 예컨대 폴리이미노 타이로신, 및 이의 유도체; (7) 공-중합체 및 블록 공중합체, 예컨대 폴록사머(poloxamer) 407 또는 플루로닉(Pluronic) L-101(등록상표). 중합체, 및 이의 유도체; (8) 3급-중합체 및 이의 유도체; (9) 폴리에테르, 예컨대 폴리(테트라메틸렌 에테르 글리콜), 및 이의 유도체; (10) 천연 발생 중합체, 예컨대 제인(zein), 키토산(chitosan) 및 풀루란(pullulan), 및 이의 유도체; (11) 폴리이미드, 예컨대 폴리 n-트리스(하이드록시메틸) 메틸메타크릴레이트, 및 이의 유도체; (12) 계면활성제, 예컨대 폴리옥시에틸렌 소르비탄, 및 이의 유도체; (13) 폴리에스테르, 예컨대 폴리(에틸렌 글리콜) (n) 모노메틸 에테르 모노(석신이미딜 석시네이트)에스테르, 및 이의 유도체; (14) 분지형 및 사이클로-중합체, 예컨대 분지형 PEG 및 사이클로덱스트린, 및 이의 유도체; 및 (15) 폴리알데히드, 예컨대 폴리(퍼플루오로프로필렌 옥사이드-b-퍼플루오로포름알데히드), 및 이의 유도체(본원에 참고로 내용이 인용된 미국 특허 제6,268,053호에 개시된 바와 같음). 당분야의 숙련가에게 공지된 다른 전형적인 중합체로는 폴리(락티드-코-글리콜리드, 폴리락티드 단독중합체; 폴리글리콜리드 단독중합체; 폴리카프로락톤; 폴리하이드록시부티레이트-폴리하이드록시발러레이트 공중합체; 폴리(락티드-코-카프로락톤); 폴리에스테르아미드; 폴리오르토에스테르; 폴리 13-하이드록시부티르산; 및 폴리무수물(본원에 참고로 내용이 인용된 미국 특허 제6,517,859호에 기재된 바와 같음)이 포함된다. 몇몇 실시양태에서, 중합체는 알기네이트 중합체를 포함할 수 있고, (하이드록시에틸)메타크릴레이트화 덱스트란 중합체, 또는 키토산 중합체가 사용될 수 있다.
본 발명의 변경된 폴리펩티드는, 동결건조된 케이크 또는 수성 용액 형태로, 생리학적으로 허용가능한 담체, 부형제 또는 안정화제와 혼합될 수 있다(Remington's Pharmaceutical Sciences, 16th edition, Oslo, A., Ed., 1980). 미립자의 제조를 위해 허용가능한 담체, 부형제 또는 안정화제는 사용되는 투여량 및 농도에서 수령자에게 무독성이고, 이는 완충액, 예컨대 포스페이트, 시트레이트 및 다른 유기 산; 아스코르브산을 비롯한 항산화제; 낮은 분자량(약 10 잔기 미만)의 폴리펩티드; 단백질, 예컨대 혈청 알부민, 젤라틴, 또는 면역글로빈; 친수성 중합체, 예컨대 올리비닐피롤리돈; 아미노산, 예컨대 글리신, 글루타민, 아스파라긴, 아르기닌 또는 라이신; 단당류, 이당류, 및 글루코스, 만노스 또는 덱스트린을 비롯한 다른 탄수화물; 킬레이트제, 예컨대 EDTA; 당 알코올, 예컨대 만니톨 또는 소르비톨; 염-형성 반대이온, 예컨대 나트륨; 및/또는 비-이온성 계면활성제, 예컨대 트윈(Tween), 플루로닉스, 또는 폴리에틸렌 글리콜(PEG)을 포함한다.
본 발명의 미소구체는 표준 기법에 의해 제조된다. 예를 들면, 한 실시양태에서, 부피 배제는 미국 특허 제6,268,053호에 개시된 바와 같이 입자 형성을 위해 충분한 양의 시간 동안 에너지 공급원의 존재하에 용액중의 활성화제를 용액중의 중합체 또는 중합체의 혼합물과 혼합함으로써 수행된다. 용액의 pH는 원하는 pH로 조정된다. 그런 다음, 용액은 에너지 공급원, 예컨대 열, 방사선, 또는 이온화에 단독으로, 또는 음파처리, 와동, 혼합 또는 교반과 조합되어 노출되어 미립자를 형성한다. 이어서 생성된 미립자는 당분야에 공지된 물리적 분리 방법에 의해 용액에 존재하는 임의의 혼입되지 않은 성분으로부터 분리된 후, 세척된다.
몇몇 실시양태에서, 미립자의 현탁액은 변경된 폴리펩티드를 함유한 수성 용액 및 중합체가 용해되는 유기 용액(전형적으로 디클로로메탄)을 격렬히 혼합함으로써 제조된다. 이어서, 유중수적형 현탁액은 유화제(전형적으로 폴리-비닐알코올)가 함유된 수성 완충액내로 희석된다. 최종적으로, 미소구체는 이러한 수중 유중수적형(W/O/W: water-in-oil-in-water) 유화로부터 제거되고, 동결-건조된다. 이러한 공지되고 시험된 W/O/W 공정은 일반적으로 0.1∼100 ㎛ 직경의 미소구체를 산출한다. 이러한 직경의 미소구체는 피하 주사를 위한 현탁액으로서 쉽게 제조된다. 다르게는, 미소구체는 단일 유화액 용매 추출/증발(O/W), 고체/오일/오일(S/O/0: solid/oil/oil) 방법, 및 문헌에 기재된 이들 방법의 모든 변형법에 의해 제조될 수 있다.
공지된 제작 절차는 또한 미국 특허 제6,669,961호; 제6,517,859호; 제6,458,387호; 제6,395,302호; 제6,303,148호; 제6,268,053호; 제6,090,925호; 제6,024,983호; 제5,942,252호; 제5,981,719호; 제5,578,709호; 제5,554,730호; 제5,407,609호; 제4,897,268호; 및 제4,542,025호(이의 내용은 참고로 그의 전체가 인용됨)에 기재되어 있다. 미립자의 제조 및 제형은 하기 문헌에도 기재되어 있다: (Bittner, B., et al. (1998) Eur J Pharm Biopharm, 45:295-305; Rosa, G. D., et al. (2000) J Control Release, 69:283-95; Kissel, T., et al. (2002) Adv Drug Deliv Rev, 54:99-134; Kwon, Y. M. and Kim, S. W. (2004) Pharm Res, 21:339-43;Lane, M. E., et al. (2006) Int J Pharm, 307:16-22; Jackson, J. K., et al. (2007) Int J Pharm).
미립자는 또한 잘 공지되어 있고, 연장된 방출 약물 전달을 위한 이러한 기법을 제공하는데 경험이 있는 회사들로부터 당분야의 숙련가에게 이용가능하다. 예를 들면, 에픽(Epic) 치료제, 박스터 헬쓰케어 코포레이션(Baxter Healthcare Corp.)의 자회사 개발된 PROMAXX(등록상표), 전체적으로 수계 공정에서 생물부식성 단백질 미소구체를 생산하는 단백질-매트릭스 약물 전달 시스템; 옥토플러스(OctoPlus) 개발된 OctoDEX(등록상표), 표면 부식에 기초하기 보다는 매트릭스의 벌크(bulk) 분해에 기초하여 활성 구성성분을 방출하는 가교결합된 덱스트란 미소구체이고; 브룩우드 파마슈티칼스(Brookwood Pharmaceuticals)는 약물 전달을 위한 그의 미소구체 기법의 이용성을 광고한다.
특허, 공개 특허 출원 및 관련된 문헌의 조사는 또한 이러한 개시내용을 읽은 당분야의 숙련가에게 상당한 가능성 있는 미소구체 기법을 제공할 것이다. 예를 들면, 미국 특허 제6,669,961호; 제6,517,859호; 제6,458,387호; 제6,395,302호; 제6,303,148호; 제6,268,053호; 제6,090,925호; 제6,024,983호; 제5,942,252호; 제5,981,719호; 제5,578,709호; 제5,554,730호; 제5,407,609호; 제4,897,268호; 및 제4,542,025호(이의 내용은 참고로 그의 전체가 인용됨)는, 미소구체 및 이들의 제작 방법을 기재한다. 본 발명의 개시내용 및 이들 다른 특허의 개시내용 둘 다를 고려하는 당분야의 숙련가라면 본 발명의 변경된 폴리펩티드의 연장된 방출을 위한 미립자를 제조하고 사용할 수 있을 것이다.
추가의 변경이 본 발명에 의해 제공된다. 미립자, 예컨대 PLGA 비드가 투여후 여전히 약물의 상당한 수준을 즉시 방출하므로, 본 발명은 상기 기재된 바와 같은 보조적 폴리펩티드 및 변경된 폴리펩티드의 일부로서의 선택적 데포 모듈을 포함함으로써 이러한 일시 효과를 경감하는 방법을 제공한다.
원할 경우, 치료학적 단백질의 방출은 2개 이상의 층을 갖는 미립자가 사용될 경우 추가로 제어될 수 있다. 한 실시양태에서, 미소구체는 내부 층 뿐만 아니라 외부 층을 갖는다. 외부 층의 조성 또는 두께는 비드의 변경된-폴리펩티드 함유 중심을 노출시키는데 걸리는 시간에 차이를 도입하기 위해 변경될 수 있다. 한 실시양태에서, 미소구체는 변경된 폴리펩티드를 고농도로 함유한 내부층을 가지는 반면, 외부 층은 변경된 폴리펩티드를 저농도로 함유하거나 변경된 폴리펩티드 함유하지 않을 수 있다. 다르게는, 외부 층은 상이한 미소구체 사이에서 두께가 상이하다. 얇은 외부 층을 갖는 미소구체는 변경된 폴리펩티드를 보다 빨리(예를 들면, 1∼5일부터) 방출하는 반면, 중간 두께의 외부 층을 갖는 비드는 변경된 폴리펩티드를 보다 느린 시간에(예를 들면, 4∼8일부터) 방출하고, 보다 두꺼운 외부 층을 갖는 비드는 변경된 폴리펩티드를 더욱 늦게(예를 들면, 7∼11) 방출한다. 따라서, 보다 일정한 속도의 방출이 이러한 실시양태에서 수득된다.
중합체 매트릭스 제형으로부터의 약물 방출 속도는 생물학적 활성 펩티드에 부착된 보조적 폴리펩티드에 따라 좌우된다. 보조적 폴리펩티드는 변경된 폴리펩티드의 수력학적 반경을 크게 증가시킨다. 따라서 보조적 폴리펩티드 모듈은 미소구체로부터의 약물 방출의 속도를 제어하기 위한 수단을 제공한다. 본원에 기재된 임의의 보조적 폴리펩티드는 중합체 매트릭스와 제형화되어 제어된 방출, 혈청 반감기 안정성, 및 본원에 기재된 다른 원하는 특성에 유리한 이점을 달성할 수 있다.
본 발명의 추가의 양태에서, 본원에 기재된 데포 모듈은 보조적 폴리펩티드-생물학적 활성 폴리펩티드와 중합체 매트릭스 사이에 비공유 상호작용을 증진시키고 매트릭스 비드로부터 변경된 폴리펩티드의 방출 속도를 둔화시키도록 디자인될 수 있다. 예를 들면, 알기네이트는 만뉴론산(mannuronic acid) 및 굴루론산(guluronic acid)으로 구성된 중합체이고, 알기네이트 미소구체는 PLGA 미소구체의 제조와 유사하게 유중수적형 유화 방법을 통해 제조될 수 있다[Srivastava, R., et al. (2005) J Microencapsul, 22: 397-411]. PLGA 미소구체와는 달리, 알기네이트는 단백질 방출이 수일내에 통상적으로 완료되는 매우 다공질의 미소구체를 형성한다. 이러한 본 발명은 부피 증진 모듈과 연관된 데포 모듈 및 알기네이트 미소구체내의 융합 단백질의 보유를 증가시키는 생물학적 활성 폴리펩티드의 용도를 제공한다.
알기네이트 중합체 매트릭스의 각각의 단위는 생리학적 pH에서 -1 전하를 갖는 카복실 기를 함유한다. 따라서 알기네이트 중합체는 생리학적 조건하에 큰 순 음전하를 갖는다. 데포 모듈은 염기성 등전점을 갖도록(생리학적 pH에서 양으로 하전되도록) 디자인되고, 따라서 알기네이트 미소구체내에 더 오래 보유될 것이다(도 6). 이러한 데포 모듈은 예를 들면 다수의 라이신(K) 및/또는 아르기닌(R) 잔기를 함유하는 인간 폴리펩티드를 포함한다. 생리학적 pH에서, 라이신 아미노산은 순 양전하를 전달하여, 알기네이트 중합체에 그의 비공유 결합을 증가시킬 것이다. 데포 모듈은 천연 발생 폴리펩티드 또는 디자인/조작되거나 선택된 폴리펩티드를 포함한다. 잠재적 데포 모듈은 알기네이트와 상호작용하는 그의 능력에 대해 신속히 평가될 수 있다. 추가로, 알기네이트에 매우 약하게 결합된 폴리펩티드는 조합되어 중합체와의 상호작용을 강화시키기 위해 반복되는 데포 모듈 단위를 형성한다.
본 발명의 추가의 실시양태에서, 2가 양이온 킬레이트 중합체 매트릭스(예를 들어 하이드로겔; Lin, C. C. and Metters, A. T. (2007) J Biomed Mater Res A)는 2가 양이온에 결합하는 데포 모듈과 함께 사용된다. 예를 들면, 데포 모듈과 킬레이트 중합체 매트릭스 둘 다는 Cu2+, Co2+ 및 Ni2+ 양이온에 결합하고, 데포 모듈과 2가 양이온 사이의 강한 비공유 상호작용은 하이드로겔로부터의 치료학적 단백질의 지속된 방출을 달성하기 위해 유효한 기작으로서 작용한다(도 7). 도 46은 보조제 변경 폴리펩티드의 지속된 방출을 예시한다. 예를 들면, 데포 모듈은 폴리-히스티딘 태깅된 단백질을 혼입할 수 있다. 폴리-히스티딘서열은 일상적으로 정제 태그로서 사용되는데, 이러한 서열이 고체 지지체 상의 Ni2+ 양이온에 단단히 결합하기 때문이다. 대안의 데포 모듈은 상기 교시내용의 견지에서 유사하게 디자인될 수 있다. 데포 모듈은, 폴리-히스티딘 서열이 치료학적 폴리펩티드의 생물학적 활성에 간섭하기 쉽다면, 생물학적 활성 폴리펩티드 대신에 보조적 폴리펩티드에 직접 결합될 수 있다.
따라서, 중합체 매트릭스, 보조적 폴리펩티드, 데포 모듈 및/또는 생물학적 활성 폴리펩티드를 임의의 수로 변형 및 선택하여 조합함으로써 환자에서 원하는 효과를 달성할 수 있다.
본 발명은 변경된 폴리펩티드를 포함하는 약학적 조성물을 제공한다. 이들은 경구로, 비강내로, 비경구로, 또는 흡입 치료법에 의해 투여될 수 있고, 정제, 로젠지, 과립, 캡슐, 환제, 앰퓰, 좌제 또는 에어로졸 형태를 취할 수 있다. 이들은 또한 수성 또는 비수성 희석제중의 활성 구성성분의 현탁액, 용액 및 유화액, 시럽, 과립 또는 분말의 형태를 취할 수 있다. 또한, 약학적 조성물은 다른 약학적으로 활성인 화합물 또는 본 발명의 복수의 화합물을 함유할 수도 있다.
본 발명의 조성물은 다양한 액상 담체, 예컨대 멸균 또는 수성 용액, 약학적으로 허용가능한 담체, 현탁액 및 유화액과 조합될 수도 있다. 비수성 용매의 예로는 프로필 에틸렌 글리콜, 폴리에틸렌 글리콜 및 식물성 오일이 포함된다.
보다 구체적으로, 본 약학적 조성물은 경구, 직장, 비강, 국소(경피, 에어로졸, 구강 및 설하가 포함됨), 질, 비경구(피하, 근육내, 정맥내 및 피부내가 포함됨) 및 폐를 비롯한 임의의 적합한 경로에 의해 치료를 위해 투여될 수 있다. 바람직한 경로는 수령자의 증상 및 연령, 및 치료될 질환에 의해 달라질 것이다.
본 발명에 유용한 연장된 방출 제형은 매트릭스 및 코팅 조성물을 포함한 경구용 제형일 수 있다. 적합한 매트릭스 물질로는 왁스(예를 들어, 카마우바(camauba), 밀납, 파라핀 왁스, 세레신(ceresine), 쉘락 왁스(shellac wax), 지방산, 및 지방 알코올), 오일, 경화유 또는 지방(예를 들어, 경화된 채종유(rapeseed oil), 피마자유, 우지, 야자유, 및 대두유), 및 중합체(예를 들어, 하이드록시프로필 셀룰로스, 폴리비닐피롤리돈, 하이드록시프로필 메틸 셀룰로스, 및 폴리에틸렌 글리콜)이 포함된다. 다른 적합한 매트릭스 정제제조 물질은 다른 담체 및 충전제를 갖는 미정질 셀룰로스, 분말화된 셀룰로스, 하이드록시프로필 셀룰로스, 에틸 셀룰로스이다. 정제는 또한 과립, 코팅된 분말, 또는 펠릿을 함유할 수 있다. 정제는 또한 다층화될 수 있다. 다층화된 정제는, 활성 구성성분들이 현저히 상이한 약물동력학적 프로필을 갖는 경우 특별히 바람직하다. 경우에 따라, 마감처리된 정제는 코팅되거나 코팅되지 않을 수 있다.
코팅 조성물은 불용성 매트릭스 중합체 및/또는 수용성 물질을 포함할 수 있다. 수용성 물질은 중합체, 예컨대 폴리에틸렌 글리콜, 하이드록시프로필 셀룰로스, 하이드록시프로필 메틸 셀룰로스, 폴리비닐피롤리돈, 폴리비닐 알코올, 또는 단량체 물질, 예컨대 당(예를 들어, 유당, 자당, 과당, 만니톨 등), 염(예를 들어, 소듐 클로라이드, 칼륨 클로라이드 등), 유기산(예를 들어, 푸마르산, 석신산, 락트산 및 타타르산), 및 이의 혼합물일 수 있다. 경우에 따라, 장성(enteric) 중합체가 코팅 조성물에 혼입될 수 있다. 적합한 장성 중합체로는 하이드록시프로필 메틸 셀룰로스, 아세테이트 석시네이트, 하이드록시프로필 메틸 셀룰로스, 프탈레이트, 폴리비닐 아세테이트 프탈레이트, 셀룰로스 아세테이트 프탈레이트, 셀룰로스 아세테이트 트리멜리테이트, 쉘락, 제인, 및 카복실 기 함유 폴리메타크릴레이트가 포함된다. 코팅 조성물은 적합한 가소화제, 예컨대, 예를 들면, 디에틸 프탈레이트, 시트레이트 에스테르, 폴리에틸렌 글리콜, 글리세롤, 아세틸화된 글리세라이드, 아세틸화된 시트레이트 에스테르, 디부틸세바케이트, 및 피마자유를 첨가함으로써 가소화될 수 있다. 코팅 조성물은 또한 불용성 물질인 충전제를 포함할 수 있고, 예컨대 이산화규소, 이산화티탄, 활석, 카올린, 알루미나, 전분, 분말화된 셀룰로스, MCC, 또는 폴아크릴린 칼륨이다. 코팅 조성물은 유기 용매 또는 수성 용매 또는 이의 혼합물중의 용액 또는 라텍스로서 적용될 수 있다. 용매, 예컨대 물, 저급 알코올, 저급 염소처리된 탄화수소, 케톤, 또는 이의 혼합물이 사용될 수 있다.
본 발명의 변경된 폴리펩티드는 다양한 부형제를 사용하여 제형화될 수 있다. 적합한 부형제로는 미정질 셀룰로스(예를 들어 아비셀(Avicel) PH102, 아비셀 PH1O1), 폴리메타크릴레이트, 폴리(에틸 아크릴레이트, 메틸 메타크릴레이트, 트리메틸아미노에틸 메타크릴레이트 클로라이드)(예컨대 유드라짓(Eudragit) RS-30D), 하이드록시프로필 메틸셀룰로스(메토셀(Methocel) K1OOM, 프리미엄(Premium) CR 메토셀 K1OOM, 메토셀 E5, 오파드리(Opadry: 등록상표), 마그네슘 스테아레이트, 활석, 트리에틸 시트레이트, 수성 에틸셀룰로스 분산액(슈어릴리즈(Surelease): 등록상표)가 포함된다. 서방형 제제는 또한 담체를 포함하고, 이는 예를 들면, 용매, 분산 매질, 코팅물, 항박테리아 및 항진균류 제제, 등장성 및 흡수 지속 제제를 포함할 수 있다. 약학적으로 허용가능한 염이 또한 이들 서방형 제제에 사용될 수 있고, 예를 들면, 미네랄 염, 예컨대 하이드로클로라이드, 하이드로브로마이드, 포스페이트, 또는 설페이트, 뿐만 아니라 유기 산의 염, 예컨대 아세테이트, 프로피오네이트, 말로네이트, 또는 벤조에이트이다. 조성물은 또한 액체, 예컨대 물, 염수, 글리세롤, 및 에탄올, 뿐만 아니라 물질, 예컨대 습윤제, 유화제, 또는 pH 완충제를 함유할 수 있다. 리포솜은 또한 담체로서 사용될 수 있다.
경피 제형을 경유한 투여는, 일반적으로, 예를 들어, 미국 특허 제5,186,938호, 제6,183,770호, 제4,861,800호, 제6,743,211호, 제6,945,952호, 제4,284,444호, 및 WO 제89/09051호(본원에 이의 전체가 참고로 인용됨)에 기재된 방법을 비롯하여 당분야에 공지된 방법을 사용하여 수행될 수 있다. 경피 패치는 흡수 문제점을 갖는 폴리펩티드에 특히 유용한 실시양태에다. 패치는 12시간, 24시간, 3일, 및 7일 기간에 걸쳐 피부 투과성 활성 구성성분의 방출을 제어하도록 제조될 수 있다. 한 예에서, 본 발명의 폴리펩티드의 2배 일일 과량은 비휘발성 유체에 위치된다. 본 발명의 조성물은 점성의 비-휘발성 액체의 형태로 제공된다. 특정 제형의 피부를 통한 투과는 당분야의 표준 방법에 의해 측정될 수 있다(예를 들면, 문헌 [Franz et al., J. Invest. Derm. 64: 194-195 (1975)]). 적합한 패치의 예는 수동적 전달 피부 패치, 이온영동(iontophoretic) 피부 패치, 또는 미소침(microneedle)을 갖는 패치, 예컨대 니코덤(Nicoderm)이다.
다른 실시양태에서, 조성물은 비강, 구강, 또는 설하 경로를 통해 뇌로 전달되어 활성 제제를 후각 통로를 통해 CNS로 전달시키고 전신 투여를 감소시킨다. 이러한 투여 경로를 위해 흔히 사용되는 장치는 미국 특허 제6,715,485호에 포함되어 있다. 이러한 경로를 통해 전달된 조성물은 CNS 투약량을 증가시키거나, 전체 신체 부담을 감소시켜 특정 약물과 연관된 전신성 독성 위험을 감소시킨다. 피하로 이식가능한 장치에서 전달하기 위한 약학적 조성물의 제조는 당분야에 공지된 방법을 사용하여, 예컨대, 예를 들어, 미국 특허 제3,992,518호; 제5,660,848호; 및 제5,756,115호에 기재된 방법을 사용하여 수행될 수 있다.
삼투 펌프가 정제, 환제, 캡슐 또는 이식가능한 장치의 형태에서 서방형 제제로서 사용될 수 있다. 삼투 펌프는 당분야에 공지되어 있고, 연장된 방출 약물 전달을 위한 삼투 펌프를 제공하는데 경험이 있는 회사들로부터 당분야의 숙련가에게 쉽게 이용가능하다. 예는 알자(ALZA)의 듀로스(DUROS: 등록상표); 알자의 오로스(OROS: 등록상표); 오스모티카 파마슈티칼(Osmotica Pharmaceutical)의 오스모덱스(Osmodex: 등록상표) 시스템; 쉬어 래보래이토리스(Shire Laboratories)의 엔소트롤(EnSoTrol: 등록상표) 시스템; 및 알제트(Alzet: 등록상표)이다. 삼투 펌프 기술을 설명하는 특허는 미국 특허 제6,890,918호; 제6,838,093호; 제6,814,979호; 제6,713,086호; 제6,534,090호; 제6,514,532호; 제6,361,796호; 제6,352,721호; 제6,294,201호; 제6,284,276호; 제6,110,498호; 제5,573,776호; 제4,200,0984호; 및 제4,088,864호(이의 내용은 본원에 참고로 인용됨)이다. 본 발명의 개시내용 및 이들 다른 특허의 개시내용을 고려하여, 당분야의 숙련가는 본 발명의 폴리펩티드의 연장된 방출을 위한 삼투 펌프를 생산할 수 있다.
주사기 펌프(syringe pump)가 또한 서방형 제제로서 사용될 수 있다. 주사기 펌프는 당분야의 숙련가에게 공지되어 있고, 쉽게 이용가능하다. 이러한 장치는 미국 특허 제4,976,696호; 제4,933,185호; 제5,017,378호; 제6,309,370호; 제6,254,573호; 제4,435,173호; 제4,398,908호; 제6,572,585호; 제5,298,022호; 제5,176,502호; 제5,492,534호; 제5,318,540호; 제4,988,337호에 기재되어 있고, 이의 내용은 본원에 참고로 인용된다. 본 발명의 개시내용 및 이들 다른 특허의 개시내용을 고려하여, 당분야의 숙련가는 본 발명의 폴리펩티드의 연장된 방출을 위한 주사기 펌프를 생산할 수 있다.
또 다른 실시양태에서, 본 발명의 변경된 폴리펩티드는 리포솜내에 캡슐화되고, 이는 시간의 연장된 기간에 걸쳐 제어된 방식으로 유리한 활성 제제를 전달하는데 있어서의 유용성을 입증하였다. 리포솜은 인트래핑된(entrapped) 수성 공간을 갖는 폐쇄된 이중층 막이다. 리포솜은 또한 단일 막 이중층을 갖는 단일판형(unilamellar) 소낭이거나 다수의 막 이중층을 갖는 다중판형(multilamellar) 소낭일 수 있고, 각각은 수성 층에 의해 다음 층과 분리된다. 생성된 막 이중층의 구조는 지질의 소수성(비-극성) 테일이 이중층의 중심을 향해 배향되는 반면, 친수성(극성) 헤드가 수성 상을 향해 배향되도록 한다. 한 실시양태에서, 리포솜은 단핵 식세포 시스템의 기관, 주로 간 및 비장에 의한 섭취를 방지하는 가요성의 수용성 중합체로 코팅될 수 있다. 리포솜을 둘러싸기에 적합한 친수성 중합체로는, 제한되지 않지만, PEG, 폴리비닐피롤리돈, 폴리비닐메틸에테르, 폴리메틸옥사졸린, 폴리에틸옥사졸린, 폴리하이드록시프로필옥사졸린, 폴리하이드록시프로필메타크릴아미드, 폴리메타크릴아미드, 폴리디메틸아크릴아미드, 폴리하이드록시프로필메타크릴레이트, 폴리하이드록시에틸아크릴레이트, 하이드록시메틸셀룰로스 하이드록시에틸셀룰로스, 폴리에틸렌글리콜, 폴리아스파타미드, 및 미국 특허 제6,316,024호; 제6,126,966호; 제6,056,973호; 제6,043,094호(이의 내용은 전체가 참고로 인용됨)에 기재된 바와 같은 친수성 펩티드 서열이 포함된다.
리포솜은 당분야에 공지된 임의의 액체 또는 액체 조합물로 이루어질 수 있다. 예를 들면, 소낭-형성 지질은 천연-발생 또는 합성 지질, 예를 들면 인지질, 예컨대 포스파티딜콜린, 포스파티딜에탄올아민, 포스파티드산, 포스파티딜세린, 포스파티딜글리세롤, 포스파티딜이노시톨, 및 스핀고미엘린이고, 이는 미국 특허 제6,056,973호 및 제5,874,104호에 기재된 바와 같다. 소낭-형성 지질은 또한 당지질, 세레브로시드(cerebroside), 또는 양이온성 지질, 예컨대 1,2-디올레일옥시-3-(트리메틸아미노)프로판(DOTAP); N-[1-(2,3,-디테트라데실옥시)프로필]-N,N-디메틸-N-하이드록시에틸암모늄 브로마이드(DMRIE); N-[1-[(2,3,-디올레일옥시)프로필]-N',N'-디메틸-N-하이드록시에틸암모늄 브로마이드(DORIE); N-[1-(2,3,-디올레일옥시)프로필]-N,N,N-트리메틸암모늄 클로라이드(DOTMA); 3[N-(N',N'-디메틸아미노에탄)카바모일]콜레스테롤(DC-Chol); 또는 디메틸디옥타데실암모늄(DDAB)(또한 미국 특허 제6,056,973호에 개시된 바와 같음)일 수 있다. 콜레스테롤은 또한 미국 특허 제5,916,588호 및 제5,874,104호에 개시된 바와 같이 적절한 범위내로 존재하여 소낭에 안정성을 부여할 수 있다.
리포솜은 또한 당분야에 공지되어 있고 연장된 방출 약물 전달을 위한 리포솜을 제공하는데 경험이 있는 회사로부터 쉽게 이용가능하다. 예를 들면, 정맥내 약물 전달을 위한 알자(이전에 세쿠스 파마슈티칼스(Sequus Pharmaceuticals))의 스틸쓰(STEALTH: 등록상표)의 리포솜 기술은 면역계에 의한 인식을 피하기 위해 리포솜 상에 폴리에틸렌 글리콜 코팅물을 사용하고; 질레드 사이언스(Gilead Sciences)(이전에 넥스스타(Nexstar))의 리포솜 기술은 암비오솜(AmBisome: 등록상표) 및 진균류 감염을 위한 FDA 승인된 치료제에 혼입되고; 엔오에프 코포레이션(NOF Corp.)은 매우 다양한 GMP-등급 인지질, 인지질 유도체, 및 PEG-인지질을 상품명 코트솜(COATSOME: 등록상표) 및 선브라이트(SUNBRIGHT: 등록상표)하에 제공한다.
추가로 가능한 리포솜 기술은 미국 특허 제6,759,057호; 제6,406,713호; 제6,352,716호; 제6,316,024호; 제6,294,191호; 제6,126,966호; 제6,056,973호; 제6,043,094호; 제5,965,156호; 제5,916,588호; 제5,874,104호; 제5,215,680호; 및 제4,684,479호에 기재되어 있고, 이의 내용은 본원에 참고로 인용되어 있다. 이들은 리포솜 및 지질-코팅된 마이크로버블(microbubble), 및 이들의 제조 방법을 기재한다. 따라서, 본 발명의 개시내용 및 이들 다른 특허의 개시내용을 고려하여, 당분야의 숙련가는 본 발명의 폴리펩티드의 연장된 방출을 위한 리포솜을 생산할 수 있다.
본 발명의 조성물을 투여하여 치료할 수 있는 질환으로는, 제한없이, 암, 염증성 질환, 관절염, 골다공증, 감염, 특히 간염, 박테리아 감염, 바이러스 감염, 유전적 질환, 폐 질환, 당뇨병, 호르몬 관련 질환, 알츠하이머병(Alzheimer's disease), 심장 질환, 심근 경색, 심부 정맥 혈전증, 순환계 질환, 고혈압, 저혈압, 알러지, 통증 경감, 왜소증 및 다른 성장 장애, 중독, 블롯 클로팅 질환(blot clotting diseases), 선천적 면역계 질환, 색전증, 상처 치유, 화상 치유, 크론병, 천식, 궤양, 패혈증, 녹내장, 뇌혈관 허혈, 호흡 장애 증후군, 각막 궤양, 신장 질환, 당뇨병성 족부 궤양, 빈혈, 인자 IX 결핍, 인자 VIII 결핍, 인자 VII 결핍, 뮤코스티스(mucositis), 연하곤란, 혈소판 장애, 폐 색전증, 불임, 성선기능저하증, 백혈구감소증, 호중구감소증, 자궁내막증, 고셔병(Gaucher disease), 비만, 리소좀 저장 질환, AIDS, 월경전 증후군, 터너 증후군, 악액질, 근위축, 헌팅톤무도병(Huntington's disease), 대장염, SARS, 카포시 육종, 간 종양, 유방 종양, 신경교종, 비-호지킨 림프종, 만성 골수성 백혈병, 털세포 백혈병; 신장 세포 암종; 간 종양; 림프종; 흑색종, 다발성 경화증, 카포시 육종, 유두종 바이러스, 폐기종, 기관지염, 치주 질환, 치매, 분만, 비소세포(non small cell) 폐암, 췌장 종양, 전립선 종양, 말단비대증, 건선, 난소 종양, 파브리병(Fabry disease), 리소좀 저장 질환이 포함된다.
임의의 제제(단백질 또는 리포터 제제 또는 기타 제제)의 분비 반감기를 미세-조율하는 능력 및 조직 분포를 조절하는 능력은 체내 진단학적 적용분야, 예컨대 PET에 의한 영상화, 초음파, NMR, 컴퓨터 단층촬영, 또는 방사선핵 영상화를 위해 특히 관심을 끈다. 따라서, 본 발명의 조성물은 또한 영상화 제제를 생성하기 위해 사용될 수 있다. 예는 위장관 영상화, 심근 관류 영상화 제제, MRI 영상화 제제, 가돌리늄 킬레이트, 심장 벽 움직임 비정상성에 대한 초음파 제제 및 기타 초음파 적용분야를 위한 제제, 또는 콘트라스트 증진된 컴퓨터 단층촬영을 위한 시약이다.
변경된 폴리펩티드의 생산을 위한 최적화
추가로, 본 발명의 보조적 폴리펩티드는 발현 동안 개선된 폴딩 또는 정제를 허용하는 추가의 서열을 포함할 수 있다. 이러한 개념은 일반적으로 도 32에 설명되어 있다. 예를 들면, 보조적 폴리펩티드는 정제에 도움을 주는 친화도 또는 용해도 태그에 연결된다. 비제한적 예로는 His-태그, 플래그(FLAG), 스트렙태그(Streptag) II, HA-태그, 소프태그(Softag) 1, 소프태그 3, c-myc, T7-태그, S-태그, 엘라스틴 유사 펩티드, 키틴 결합 도메인, 티오레독신, 자일라나제(Xylanase) 1OA, 글루타티온 S-전환효소(GST: Glutathion S-transferase), 말토즈 결합 단백질(MBP: Maltose binding protein), NusA, 및 셀룰로스 결합 단백질이 포함된다.
보조적 폴리펩티드는 또한 변경된 폴리펩티드가 절단뒤 발현되도록 허용하는 프로테아제 절단 부위 또는 다른 서열을 포함할 수 있다. 이러한 부위 또는 부위들은 변경된 폴리펩티드내의 어디에나 위치될 수 있다. 예를 들면, 프로테아제 절단 부위는 용해도를 개선시키는 서열과 친화성 태그를 포함하는 또 다른 서열 사이에 도입되어, 친화성 태그가 프로테아제 처리에 의해 제거되도록 한다. 다르게는, 절단 부위는 생물학적 활성 단백질과 보조적 폴리펩티드 사이에 위치하여, 특정 프로테아제가 전체 보조적 폴리펩티드 서열을 절단해 내도록 한다. 단백질을 절단하기 위한 다양한 효소적 방법이 공지되어 있다. 이러한 방법으로는 엔테로키나제(DDDK), 인자 Xa(IDGR), 트롬빈(LVPR/GS), PreScissionTM(LEVLFQ/GP), TEV 프로테아제(EQLYFQ/G), 3C 프로테아제(ETLFQ/GP), 소르타제(Sortase) A(LPET/G), 그랜자임 B(D/X, N/X, M/N 또는 S/X), 인테인(intein), SUMO, DAP아제(TAGZyme: 등록상표), 에어로모나스(Aeromonas) 아미노펩티다제, 아미노펩티다제 M, 및 카복시펩티다제 A 및 B가 포함된다. 추가의 방법은 문헌[Arnau et al. Prot Expr and Purif (2006) 48, 1-13]에 개시되어 있다.
단백질 발현의 분석
발현된 단백질의 활성은 정확한 폴딩의 정도를 확인하기 위해 측정될 수 있다. 이러한 검정은 발현된 특정의 변경된 폴리펩티드에 따라 당분야에 공지되어 있다. 이러한 검정으로는 세포 기반 검정, 예컨대 증식, 세포 사멸, 아폽토시스 및 세포 이동에 대한 검정이 포함된다. 다른 가능한 검정은 발현된 폴리펩티드의 수용체 결합을 결정할 수 있고, 여기서 검정은 가용성 수용체 분자를 포함하거나 세포-발현된 수용체로의 결합을 결정할 수 있다. 추가로, 유세포분석기(flow cytometry) 또는 표면 플라스몬 공명(surface plasmon resonance)과 같은 기법이 결합을 검출하기 위해 사용될 수 있다. 특정한 생체내 생물학적 검정이 본 발명의 각각의 생물학적 활성 폴리펩티드의 활성을 평가하기 위해 사용될 수 있다. 예를 들면, hGH의 특성은 ESTA 생검에 의해, 또는 다르게는 rhGH 유도된 투약량 관련 체중 증가 및 골 성장, 또는 수용체 결합을 측정함으로써 결정될 수 있다. 추가의 방법은 문헌[Dattani, M. T., et al. (1996) Horm Res, 46: 64-73; Alam, K. S., et al. (1998) J Biotechnol, 65: 183-90; Clark, R., et al. (1996) J Biol Chem, 271: 21969-77; Clarg RG et al. (1996) Endocrinology. 137:4308-15]에 개시되어 있다.
발현된 단백질의 물리적 특성을 특정하기 위한 특정 검정들이 이후 기재되어 있다. 단백질 응집, 폴딩 상태, 용융 특성, 오염 및 물 함량과 같은 특성을 결정하기 위한 다양한 방법이 당분야에 공지되어 있고, 본 발명에 적용될 수 있다. 이러한 방법으로는 분석용 원심분리, EPR, HPLC-이온 교환, HPLC-크기 배제, HPLC-역상, 광 산란, 모세관 전기이동, 원편광 이색성, 차등 주사 열량계, 형광, HPLC-이온 교환, HPLC-크기 배제, IR, NMR, 라만(Raman) 분광계, 굴절계, 및 UV/가시성 분광계가 포함된다. 추가의 방법은 문헌[Arnau et al. Prot Expr and Purif (2006) 48, 1-13]에 개시되어 있다. 이 방법들을 본 발명에 적용하는 것은 당분야의 숙련가라면 잘 알 것이다.
보다 구체적으로, 본 발명의 발현된 폴리펩티드의 세포 편재화는 상기 지칭된 임의의 방법에 의해 결정될 수 있다. 예를 들면, 관심있는 폴리펩티드를 발현하는 세포로부터 수득된 조질의 용해물은 원심분리되어 봉입체중의 불용성 단백질로부터 사이토졸 분획 중의 가용성의 발현된 단백질을 분리할 수 있다. 원할 경우, 가용성(사이토졸성) 및 불용성(봉입체) 분별물은 이후 웨스턴 블롯 또는 유사한 기법에 의해 분석되어 가용성 단백질 대 불용성 단백질의 발현비를 결정할 수 있다.
용해물중 가용성 단백질은 추가로 음이온 교환 또는 크기 배제 크로마토그래피와 같은 기법, 예비적 또는 분석적으로 적용될 수 있는 기법에 의해 정제될 수 있다(도 35∼39, 47, 48, 50 및 51). 최종 생성물의 순도의 확인은 당분야에 공지된 기법, 예컨대 SDS-PAGE, HPLC(예를 들어 역상 또는 크기 배제) 또는 질량 분광계에 의해 수득될 수 있다. 정제 단계는 친화도/용해도 태그 및/또는 보조적 폴리펩티드 또는 이들 둘 다를 제거하기 위한 프로테아제 절단 단계에 선행 또는 후행될 수 있다. 상기 개략화된 임의의 방법에 의한 추가의 정제 단계는, 예를 들면, 사용된 프로테아제를 분해 혼합물로부터 제거하기 위해 요구될 수 있다. 이러한 단계는 당분야의 숙련가라면 잘 알 것이다. 몇몇 이러한 방법은 또한 실시예 섹션에서 보다 상세히 설명된다.
rPEG 융합 생성물의 제형화, 약물동력학 및 투여
본 발명은 피험체에 투여하기 위한 rPEG 융합 생성물을 조작하는 방법 및 조성물에 관한 것이다. 동일한 서열의 또 다른 카피에 역평행 배향으로 결합되는 회합 펩티드, 예컨대 SKVILF(E) 또는 RARADADA는 도 88a∼c에 도시된 바와 같이 전구약물을 생성하기 위해 사용될 수 있다. 한 실시양태에서, 이 약물은 제작의 마지막 단계에서 프로테아제에 의해 절단되지만, 2개의 쇄가 여전히 회합 펩티드에 의해 회합되어 있어 절단은 약물을 활성화시키지 않는다. 약물이 피험체에게 주사되고 농도가 크게 감소된후, 작은 비-rPEG 함유 단백질 쇄는 친화도에 의존하는 속도로 복합체를 떠나고, 신장을 통해 제거되기 쉽고, 이에 따라 r-PEG 함유 약물 모듈을 활성화시킨다.
또 다른 실시양태에서, rPEG50은 단백질 가수분해 부위를 함유하고, 단백질 가수분해적 절단은 제작된 단일쇄 단백질을 2개의 단백질 쇄의 복합체로 전환시킨다(도 89a∼c). 이러한 절단은 피험체로의 주사 전에 마지막 제작 단계로서 발생하거나, 이는 피험체로 주사된 후 피험체에 존재하는 프로테아제에 의해 발생할 수 있다.
또 다른 실시양태는 동일한 수용체 도메인 또는 동일한 결합 기능을 갖는 도메인, 또는 동일한 표적으로 동시에 결합할 수 있는 도메인에 의해 플랭킹된 rPEG를 포함한다(도 94a∼c). 수용체 둘 다가 표적에 동시에 결합할 수 있다면, 하나의 수용체의 결합은 제2 수용체의 결합을 안정화시켜, 복합체의 상호 안정성을 초래함으로써 겉보기 친화도(결합활성)를 전형적으로 10∼100배, 그러나 적어도 3배 이상 증가시키고, 이때 rPEG는 수용체의 효과적 농도를 증가시키는 결합가 가교로서 작용한다(도 94b). 한 실시양태에서, rPEG 생성물은 리간드로 미리 로딩된다(도 94c). 피험체에게 투여될 경우, 주사된 생성물은 리간드에 결합되어 있는 한 불활성이다. 리간드가 해리될 경우, 이는 신장을 통해 신속히 제거되기 쉬워서, 생성물의 활성화를 일으키고, 이는 rPEG 테일에 의한 긴 반감기를 갖는다. 이러한 접근법은 최고 용량 독성 및 수용체 매개성 제거를 감소시킴으로써, 도 99에 예시된 바와 같이 혈청 분비 반감기를 연장시킨다.
도 94에 도시된 바와 같이, 몇몇 전구약물 형식은 절단 부위 또는 다른 활성화 부위를 필요로하지 않는다. 단일 단백질 쇄는 rPEG에 의해 분리된 2개 이상의 약물 모듈을 함유할 수 있다. 이들 모듈은 단일 유형이거나 2종 이상의 상이한 유형일 수 있다. 이러한 rPEG 함유 생성물은 제2의 상보성 단백질과 착화되어 수용체-리간드-수용체 상호작용을 일으킨다. 이러한 형식에서, 리간드는 이량체이거나 다량체일 수 있지만, 특히 2개의 약물 분자가 상이한 경우 단량체일 수도 있다. 모듈 둘 다가 제3의 단백질에 결합된다. X 및 Y는 동일하거나 상이할 수 있고, X 및 Y는 약물 모듈일 수 있거나 약물 모듈에 결합할 수 있다. 도 94a∼c에서 각각의 경우, X 및 Y(및 rPEG)는 하나의 단백질 쇄를 포함하고, 이들이 결합된 분자는 별도의 분자이고, 전형적으로 단백질 또는 소분자이다. 단일 단백질 쇄에 조합된 2개보다 많은 결합 단백질을 가질 수 있다.
약물이 치료학적 투약량에 비해 높지만 독성 투약량에 비해 낮은 농도로 유지되는 것이 치료법에서 일반적으로 바람직하다. 짧은 반감기를 갖는 약물의 전형적인 일시주사(IV, IM, SC, IP 또는 유사한 주사)는 독성 투약량에 비해 더 높은 피크 농도를 초래하고, 이후 약물 농도를 치료학적 투약량 미만으로 신속히 강하시키는 제거 상이 뒤따른다. 도 100은 rPEG에 연결된 약물과 비교하여 약물 단독의 정맥내 주사 후의 시간에 대한 약물 농도 변화를 예시한다. 약물은 단독으로 단지 짧은 시간 동안 치료학적 농도로 존재한다(청색 선). rPEG를 약물에 첨가한 경우 피크 농도가 감소하고, 이에 따라 독성을 감소시키고, 약물이 치료학적 비-독성 투약량으로 존재하는 시간의 기간을 증가시킨다. rPEG + 약물 결합 단백질을 첨가하여 전구약물을 생성하는 것은 "돌발 방출" 또는 독성 최고 용량을 방지할 수 있는데(적색 선), 이는 약물이 시간에 걸쳐 점진적으로만 활성화되고 독성 투약량과 치료학적 투약량 사이의 시간 길이가 다른 형식에 비해 증가되기 때문이다.
또 다른 실시양태에서, rPEG 융합 생성물은 피험체에게 투여되기 전 절단되거나 불활성 전구약물로서 투여된다(즉 피험체에게 투여된후 절단되고 생체내에서 활성화된다). 이러한 공정은 도 96 a∼h에 예시되어 있다. 약물의 불활성화는, 모든 3개의 모듈이 단일 단백질 쇄로서 제작되도록 rPEG에 의해 약물에 연결된 결합 단백질에 의해 중재된다. 약물이 수용체라면, 결합 단백질은 수용체의 리간드일 수 있고; 약물이 항체 단편이라면, 결합 부위는 항원일 수 있다. 이들 예에서, 약물은 2개의 결합 도메인(여기서 X 및 Y로 지칭됨) 사이의 부위의 프로테아제 절단에 의해 활성화된다. 단백질 Y가 활성 생성물이라면, Y는 rPEG를 보유하고, 프로테아제 절단 부위는 X에 가까워야 한다. 단백질 X가 활성 생성물이라면, X는 rPEG를 보유하고 절단 부위는 Y와 가까워야 한다. 청색 크로스바에 의해 도시된 바와 같이 하나 또는 다수의 절단 부위가 존재할 수 있다(도 96a∼g). 약물 모듈로는, 제한되지 않지만, 수용체, 리간드, 하나 이상의 Ig 도메인, 항체 단편, 펩티드, 미소단백질, 또는 항체에 대한 에피토프가 포함된다. 약물 모듈에 결합하는 단백질로는, 제한되지 않지만, 결합 단백질, 수용체, 리간드, 하나 이상의 Ig 도메인, 항체 단편, 펩티드, 미소단백질, 또는 항체에 대한 에피토프가 포함된다. 도 105 및 106은 피험체의 혈청에 존재하거나 또는 피험체로 투여하기 전에 제공된 부위 특이적 프로테아제에 의한 불활성-단백질(즉, 전구약물)의 활성 단백질(즉, 활성 펩티드 또는 dAb 또는 scFv)로의 전환을 예시한다.
또 다른 실시양태는 결합 펩티드를 약물 모듈에 첨가함으로써 생성된 불활성 전구약물을 설명한다(도 97). 펩티드는 약물의 표적 결합 능력을 무효화시키고, 펩티드는 전구약물이 투여된 피험체의 전신으로부터 rPEG 함유 약물에 비해 더 높은 속도로 점진적으로 제거된다. 이러한 펩티드는 천연적이거나, 약물 모듈에 대한 랜덤 펩티드 라이브러리의 파지 패닝에 의해 수득될 수 있다. 펩티드는 바람직하게는 합성적으로 제조되지만, 재조합 펩티드일 수 있다.
단일쇄 단백질 약물은 또한 다수의 생물-활성 펩티드를 함유할 수 있고, 이는 rPEG의 동일한 말단 또는 rPEG의 반대편 말단에 위치할 수 있다(도 98). 이들 펩티드는 동일한 활성 또는 상이한 활성을 가질 수 있다. 단일쇄에 다수의 펩티드가 존재하면 제작을 복잡하게 하지 않으면서 결합활성을 통해 이들의 유효한 효능을 증가시킨다.
실시예
실시예 1: 보조적 폴리펩티드에 융합된 인간 성장 호르몬(
hGH
)의 디자인
본 실시예는 활성, 세포질 수율이 증가되고 혈청 반감기가 개선된 rPEG-hGH 융합 단백질의 제조를 기재한다. 인간 성장 호르몬 생성물은, 혈청중 hGH의 반감기가 단지 약 30분이기 때문에, 전형적으로 1일 주사 또는 1일 2회 주사가 필요하다. 페그화를 통한 반감기 연장은, hGH가 치료학적 활성을 위해 필요한 다수의 라이신을 함유하고 이들이 접합에 사용될 수 없으므로 실현불가능하다. hGH는 전형적으로 이. 콜라이의 세포질에서의 발현에 의해 제작되고, 여기서 이는 응집되어 불활성 단백질을 함유하는 봉입체를 형성한다. 전형적으로, 이러한 봉입체는 가용화되고, 단백질은 리폴딩되어 활성 단백질을 수득한다. 본 실시예에서, rPEG-hGH는 가용성 활성 형태로 세포질내에서 발현되어, 봉입체로부터의 리폴딩 단계를 방지한다.
본 실험에 사용된 hGH의 아미노산 서열은 다음과 같다:
FPTIPLSRLFDNAMLRAHRLHQLAFDTYQEFEEAYIPKEQKYSFLQNPQTSLCFSESIPTPSNREETQQKSNLELLRISLLLIQSWLEPVQFLRSVFANSLVYGASDSNVYDLLKDLEEGIQTLMGRLEDGSPRTGQIFKQTYSKFDTNSHNDDALLKNYGLLYCFRKDMDKVETFLRIVQCRSVEGSCGF.
hGH는 191개의 아미노산을 함유하고, 5.27의 pI 및 22.130 kD의 분자량을 갖는다. hGH는 13개의 글루타메이트 잔기, 11개의 아스파테이트 잔기(총 24개의 음성 잔기), 8개의 라이신 잔기 및 11개의 아르기닌 잔기(총 19개의 양성 잔기)를 함유하여, 순 전하는 -5이고 순 전하 밀도는 -0.026이다(-5/191개 아미노산으로 계산됨). 이러한 순 전하 밀도는 5.27의 실험적 pI 값과 상관관계가 있다.
다양한 hGH-rPEG 융합 단백질은 다음과 같이 디자인된다.
디자인 1. 순 전하 밀도가 -0.1인 rPEG 변경 hGH의 작제
이러한 디자인은 짧은 길이의 보조적 폴리펩티드로 변경되고 순 전하 밀도가 -0.1인 폴리펩티드를 설명한다.
이러한 디자인의 목표는 순 전하 밀도가 -0.1이지만 단지 소수의 아미노산을 첨가한 단백질을 생성하는 것이다. 순 전하 밀도가 -0.1인 hGH 단백질을 생성하기에 필요한 전하의 수는, 첨가된 하전된 아미노산으로부터 생성된 총 길이의 증가를 고려하지 않고, 14.1(19.1-5=14.1)이다. 16개의 음으로 하전된 아미노산의 첨가는 변경된 hGH 폴리펩티드의 순 전하 밀도를 -0.1로 옮긴다((16+5)/(191+16) 아미노산으로 계산됨).
디자인 2. 순 전하 밀도가 -0.2인 rPEG 변경 hGH의 작제
이러한 디자인은 짧은 길이의 보조적 폴리펩티드로 변경되고 순 전하 밀도가 -0.2인 폴리펩티드를 설명한다.
이러한 디자인은 41개의 음전하를 갖는 보조적 단백질을 혼입하여, 총 46개의 조합된 음으로 하전된 아미노산 잔기가 전체 폴리펩티드에 존재하도록 한다. 변경된 폴리펩티드의 총 길이는 232개 아미노산이다(191+41개 아미노산으로 개산됨). 결과적으로, -0.2의 전하 밀도는 총 46개의 음으로 하전된 아미노산 잔기를 필요로 하고(0.2x232개 아미노산으로 계산됨), 이는 보조적 단백질이 41개의 음으로 하전된 잔기를 함유함을 의미한다(46-5로 계산됨).
디자인 3. 순 전하 밀도가 +0.1인 rPEG 변경 hGH의 작제
이러한 디자인은 짧은 길이의 보조적 폴리펩티드로 변경되고 순 전하 밀도가 +0.1인 폴리펩티드를 설명한다.
양으로 하전된 아미노산을 갖는 보조적 단백질은 +0.1의 순 전하 밀도에 도달하도록 디자인될 수 있다. 이러한 융합 단백질은 +22의 순 양전하를 갖고, 이는 27개의 양전하를 함유한 보조적 단백질의 첨가에 의해 달성되어(27-5=22개 아미노산으로 계산됨), 287개 아미노산의 조합된 폴리펩티드 길이를 생성한다(191+27개 아미노산으로 계산됨).
디자인 4. rPEG_J288-GFP, rPEG_J288-hGH 및 rPEG_J288-GLP1 변경된 폴리펩티드의 작제
이러한 디자인은 16.6% 글루타메이트 잔기를 포함하는 288개 아미노산의 긴 친수성 보조적 폴리펩티드로 변경된 폴리펩티드를 설명한다.
rPEG_J288은 서열 (GGSGGE)48을 갖고 48개의 E 잔기를 함유한다(도 17). rPEG_J288이 hGH에 첨가될 경우, 변경된 폴리펩티드의 총 길이는 479개 아미노산이 되고(191+288로 계산됨) 순 전하는 53이 되어(48+5로 계산됨), 순 전하 밀도를 산출한다(53/479=0.11로 계산됨). 이러한 디자인에서, 보조적 폴리펩티드 그 자체는 많은 글리신 및 세린 잔기의 존재에 기인하여 16%의 순 전하 밀도를 갖는 반면, 디자인 1에서는 보조적 폴리펩티드가 하전된 잔기로 전체적으로 이루어진다. 실험 결과로 입증되듯이, 이러한 디자인은 매우 가용성의 활성 폴리펩티드를 산출한다. -0.11의 순 전하 밀도는, 전하가 세린 및/또는 글리신의 첨가에 의해 확산된다면, 용액중에 단백질을 유지시키기에 충절단 수 있는 것으로 보인다.
본 실시예는 144개 아미노산의 보조적 폴리펩티드 및 서열 (GGSGGE)48을 코딩하는 융합 유전자의 작제를 기재한다. 스터퍼 벡터 pCW0051은 도 16에 도시된 바와 같이 작제된다. pCW0051중의 발현 카세트의 서열은 도 18에 도시되어 있다. 인서트는 본질적으로 rPEG_L288에 대해 하기 기재된 바와 같지만, KpnI 부위로의 어댑터를 코딩하는 한 쌍의 올리고뉴클레오티드와 함께 rPEG 서열 rPEG_J288(도11)을 코딩하는 합성 올리고뉴클레오티드를 어닐링(annealing)함으로써 수득된다. 하기 올리고뉴클레오티드는 정방향 및 역방향 프라이머로서 사용된다:
pr_LCW0057정방향: AGGTAGTGGWGGWGARGGWGGWTCYGGWGGAGAAGG,
pr_LCW0057역방향: ACCTCCTTCTCCWCCRGAWCCWCCYTCWCCWCCACT,
하기 올리고뉴클레오티드는 스토퍼(stopper) 프라이머로서 사용된다:
pr_3KpnI스토퍼정방향: AGGTTCGTCTTCACTCGAGGGTAC,
pr_3KpnI스토퍼역방향: CCTCGAGTGAAGACGA.
스토퍼 프라이머로의 정방향/역방향 프라이머의 비를 바꿔줌으로써, 생성된 PCR 생성물의 크기를 제어할 수 있다. 인서트를 사용하여 rPEG_J288 변경 GFP를 코딩하는 플라스미드, 및 이러한 플라스미드를 rPEG_L288 변경 GFP와 유사한 방식으로 발현하는 세포를 생성하였다(도 10). 유사한 인서트를 사용하여 rPEG_J288 변경 hGH 및 rPEG_J288 변경 GLP1을 코딩하는 플라스미드, 및 rPEG_L288 변경 GFP와 유사한 방식으로 상기 플라스미드를 발현하는 세포를 생성하였다(도 12).
rPEG_J288 변경 GFP의 순도를 SDS-PAGE(도 36), 분석용 크기 배제 크로마토그래피(도 37 참조), 질량 분광계(도 39)에 의해 확인하였다. rPEG_J288 변경 GFP의 겉보기 분자량도 이전에 기재된 바와 같이 측정하였다(도 41). 도 49는 생물학적 활성 폴리펩티드(GLP1)를 rPEG_J288 보조적 폴리펩티드에 연결할 때 관찰되는 겉보기 분자량의 증가를 예시한다. 생체내 실험에서 면역원성은 상기 폴리펩티드에 의해 거의 관찰되지 않았다(도 44).
디자인 5. rPEG_L288-GFP, rPEG_L288-hGH 및 rPEG_L288-GLP1 변경된 폴리펩티드의 작제
이러한 디자인은 25% 글루타메이트 잔기를 포함하는 288개 아미노산의 긴 친수성 보조적 폴리펩티드로 변경된 폴리펩티드를 설명한다. rPEG_L288은 서열 (SSESSSSESSSE)24을 갖고 72개의 E 잔기를 함유한다. rPEG_L288를 hGH에 첨가하면, 융합물의 총 길이는 479개 아미노산이 되고(191+288개 아미노산으로 계산됨) 순 전하는 77이 되어(72+5개로 계산됨), 0.16의 순 전하 밀도를 산출한다(77/479개 아미노산으로 계산됨). 하기 실험 결과로 입증되듯이, -0.16의 순 전하 밀도를 갖는 이러한 디자인은 탁월한 용해도를 나타내었고, 단백질은 활성이었다. 일부 겔 형성이 낮은 온도에서 관찰되었지만, 이는 문제가 되지 않았다.
본 섹션은 보조적 폴리펩티드를 코딩하는 코돈 최적화된 유전자인, 288개 아미노산 및 서열 (SSSESSESSSSE)24을 갖는 rPEG_L288의 작제를 기재한다. pET 벡터에 기초하고 T7 프로모터를 포함하는 스터퍼 벡터 pCW0150은 도 9에 도시된 바와 같이 작제된다. 벡터는 플래그 서열을 코딩하고, 이후 BsaI, BbsI, 및 KpnI 부위에 의해 플랭킹된 스터퍼 서열을 코딩한다. 스터퍼 서열에 His6 태그 및 녹색 형광성 단백질(GFP)의 유전자가 후속된다. GFP는 생물학적 활성 단백질로서 선택되고, 영상화 적용분야에서 또는 선택 마커로서 사용될 수 있다. 스터퍼 서열은 종결 코돈을 함유하고, 따라서 스터퍼 플라스미드 pCW0150을 운반하는 이. 콜라이 세포는 비-형광성 콜로니를 형성한다. 스터퍼 벡터 pCW0150을 BsaI 및 KpnI에 의해 분해하였다. 36개 아미노산 길이의 보조적 폴리펩티드를 코딩하는 코돈 라이브러리를 작제하였다. 보조적 폴리펩티드는 지정된 rPEG_L36이였고, 아미노산 서열 (SSSESSESSSSE)3을 가졌다. 아미노산 서열 SSESSESSSSES를 코딩하는 합성 올리고뉴클레오티드 쌍 뿐만 아니라 KpnI 부위로의 어댑터를 코딩하는 올리고뉴클레오티드 쌍을 어닐링함으로써 인서트를 수득하였다. 하기의 올리고뉴클레오티드를 정방향 및 역방향 프라이머로서 사용하였다:
pr_LCW0148정방향: TTCTAGTGARTCYAGYGARTCYAGYTCYAGYGAATC,
pr_LCW0148역방향: AGAAGATTCRCTRGARCTRGAYTCRCTRGAYTCACT,
하기 올리고뉴클레오티드를 스토퍼 프라이머로서 사용한다:
pr_3KpnI스토퍼정방향TTCT: TTCTTCGTCTTCACTCGAGGGTAC,
pr_3KpnI스토퍼역방향: CCTCGAGTGAAGACGA.
스토퍼 프라이머로의 정방향/역방향 프라이머의 비를 바꿔줌으로써, 생성된 PCR 생성물의 크기를 제어할 수 있다. 어닐링된 올리고뉴클레오티드 쌍을 결찰시키고, 이로써 다양한 수의 (SSSESSESSSSE) 반복부를 나타내는 다양한 길이의 생성물의 혼합물을 생성하였다. rPEG_L36의 길이에 상응하는 생성물을 혼합물로부터 아가로스 겔 전기이동에 의해 단리하고, BsaI/KpnI 분해된 스터퍼 벡터 pCWO15O내로 결찰시켰다. 벡터에 의해 형질전환된 세포는 유도후 녹색 형광을 나타내었고, 이는 rPEG_L36의 서열이 GFP 유전자와 프레임내에서 결찰되었음을 보여준다. 생성된 라이브러리는 지정된 LCW0148이였다. 라이브러리 LCW0148로부터의 단리물(예를 들어, 312개 단리물)을 고농도의 형광성에 대해 스크리닝하였다. 강한 형광성을 갖는 단리물(예를 들어, 70개 단리물)을 PCR로 분석하여 rPEG_L 분절의 길이를 입증하고, rPEG_L36의 예상된 길이를 갖는 34개의 클론을 동정하였다. 이러한 과정에 의해 높은 발현을 나타내고 이들의 코돈 용법이 상이한 rPEG_L36의 34개의 단리물의 수집물을 생성하였다. 플라스미드 혼합물을 BsaI/NcoI으로 분해하고, rPEG_L36 서열 및 GFP의 일부를 포함하는 단편을 단리하였다. 동일한 플라스미드 혼합물을 또한 BbsI/NcoI으로 분해하고, rPEG_L36, 대부분의 플라스미드 벡터, 및 GFP 유전자의 나머지를 포함한 벡터 단편을 단리하였다. 두 단편을 혼합하고, 결찰시키고, BL21골드(Gold)(DE3)내로 형질전환시키고, 단리물을 형광성에 대해 스크리닝하였다. 이량체화의 이러한 과정을 2회 초과하여 반복하였다. 각각의 수행 동안, rPEG_L 유전자의 길이는 2배가 되었고, 궁극적으로 rPEG_L288을 코딩하는 유전자의 수집물을 수득하였다. rPEG_L288 모듈은 동일한 아미노산 서열을 가짐에도 불구하고 뉴클레오티드 서열이 상이한 rPEG_L36의 분절을 함유한다. 따라서 유전자중의 내부 상동성은 최소화되고, 결과로서 자발적 재조합의 위험은 감소된다. rPEG_L288을 코딩하는 플라스미드를 갖는 이. 콜라이 BL21골드(DE3)을 20배 이상 배가시키기 위해 배양하였고, 자발적 재조합은 관찰되지 않았다.
rPEG_L288을 코딩하는 플라스미드를 갖는 이. 콜라이 BL21골드(DE3) 세포를 하룻밧 터리픽 브로쓰(TB: Terrific Broth)에서 성장시키고, 다음날 신선한 TB내로 200배 희석하였다. 배양액이 A600 nm=0.6에 도달할 때, rPEG_L288-GFP의 발현을 IPTG의 첨가에 의해 0.2 mM 최종 농도로 유도하였다. 세포를 18시간 동안 26℃에서 수거하고, 추가의 처리과정까지 -80℃에서 저장하였다. 세포를 박테리아 배양액 1 리터당 90 ㎖의 50 mM 트리스(Tris)-HCl, 200 mM 소듐 클로라이드, 0.1% 트윈-20, 10% 글리세롤, pH 8.0에 재현탁하였다. 프로테아제 저해제, 리소자임(최종 20 ug/ml), 및 벤조나제 뉴클레아제를 용해 이전에 박테리아 현탁액에 첨가하였다. 세포를 얼음 상에서 4분 동안 음파처리한 후 80℃에서 20분 동안 열 처리하여 용해시켰다. 용해물을 후속적으로 얼음 상에서 냉각시키고, 20분 동안 15000 rpm으로 소발(Sorvall) SS-34 회전자에서 원심분리하였다. 가용성 재조합 단백질을 상청액의 고정화된 금속 이온 친화도 크로마토그래피(IMAC: immobilized metal ion affinity chromatography)에 의해 정제하였다. 단백질을 추가로 이온 교환 크로마토그래피(IEC: ion exchange chromatography) 및 겔 여과 크로마토그래피로 정제하였다. 경우에 따라, 단백질은 표준 기법을 사용하여 고정화된 항-플래그 항체를 갖는 칼럼에 의해 추가로 정제될 수 있다. 단백질의 순도 및 균일성을 SDS-PAGE, 고유-PAGE, 분석용 겔 여과 크로마토그래피, 광 산란, 및 질량 분광계를 비롯한 표준 생화학적 방법에 의해 평가하였다. 90% 이상의 순도가 수득되었다. 또한, 변경된 폴리펩티드 rPEG_L288-hGH 및 rPEG_L288-GLP1을 유사한 방식으로 수득하였다.
rPEG_L288 변경 GFP의 순도를 SDS-PAGE(도 36), 분석용 역상 HPLC(도 38)로 확인하였다. rPEG_L288 변경 GFP의 겉보기 분자량을 또한 이전에 기재된 바와 같이 측정하였다(도 41). 도 49는 생물학적 활성 폴리펩티드(GLP1)가 rPEG_L288 보조적 폴리펩티드에 연결될 때 관찰되는 겉보기 분자량의 증가를 예시한다. 래트 및 인간 혈청에서 생체내 안정성을 도 42에 도시된 바와 같이 결정하였다. rPEG는 래트 및 인간 혈청에서 안정하고, rPEG288은 래트에서 약 10∼20시간의 반감기를 갖는다(도 43). 이러한 폴리펩티드에 의해 생체내 실험에서 면역원성은 거의 관찰되지 않았다(도 44).
디자인 6. rPEG_K288-GFP, rPEG_K288-hGH 및 rPEG_K288-GLP1 보조적 폴리펩티드의 작제
이러한 디자인은 33% 글루타메이트 잔기를 포함하는 288개 아미노산의 긴 친수성 보조적 폴리펩티드로 변경된 폴리펩티드를 설명한다. rPEG_K288은 서열 (GEGGGEGGE)32을 갖고 96개의 E 잔기를 함유한다. rPEG_K288을 hGH에 첨가할 경우, 융합물의 총 길이는 479개 아미노산이 되고(191+288로 계산됨) 순 전하는 101이 되어(96+5로 계산됨), 0.21의 순 전하 밀도를 산출한다(101/479로 계산됨). 아래에 기재된 실험 결과에 의해 예측되고 확인되듯이, -0.21의 순 전하 밀도를 갖는 상기 디자인은 최고의 용해도를 나타내고, 단백질은 활성이었다. 겔 형성은 시험된 온도 또는 염 농도에서 관찰되지 않았다.
본 섹션은 서열 (GEGGGEGGE)32의 보조적 폴리펩티드를 코딩하는 융합 유전자의 작제를 기재한다. 인서트는 본질적으로 rPEG_L288에 대해 기재된 바와 같으나 KpnI 부위로의 어댑터를 코딩하는 한 쌍의 올리고뉴클레오티드와 함께 rPEG 서열 rPEG_K288을 코딩하는 합성 올리고뉴클레오티드를 어닐링함으로써 수득된다. 하기 올리고뉴클레오티드를 정방향 및 역방향 프라이머로서 사용하였다:
pr_LCW0147정방향: AGGTGAAGGWGARGGWGGWGGWGAAGG
pr_LCW0147역방향: ACCTCCTTCWCCWCCWCCYTCWCCTTC
하기 올리고뉴클레오티드를 스토퍼 프라이머로서 사용한다:
pr_3KpnI스토퍼정방향: AGGTTCGTCTTCACTCGAGGGTAC
pr_3KpnI스토퍼역방향: CCTCGAGTGAAGACGA.
스토퍼 프라이머로의 정방향/역방향 프라이머의 비를 바꿔줌으로써, 생성된 PCR 생성물의 크기를 제어할 수 있다. 인서트를 사용하여 rPEG_K288 변경 GFP를 코딩하는 플라스미드, 및 이러한 플라스미드를 rPEG_L288 변경 GFP와 유사한 방식으로 발현하는 세포를 생성한다. 추가로, rPEG_K288-hGH 및 rPEG_K288-GLP1을 유사한 방식으로 수득하였다.
rPEG_K288 변경 GFP의 순도를 SDS-PAGE(도 36), 및 분석용 크기 배제 크로마토그래피(도 37 참조)에 의해 확인하였다. rPEG_K288 변경 GFP의 겉보기 분자량도 이전에 기재된 바와 같이 측정하였다(도 41). 도 49는 생물학적 활성 폴리펩티드(GLP1)를 rPEG_K288 보조적 폴리펩티드에 연결할 때 관찰되는 겉보기 분자량의 증가를 예시한다. 래트및 인간 혈청에서 생체내 안정성을 도 42에 도시된 바와 같이 결정하였고, 생체내 약물동력학적 특성은 도 43에 지시되어 있다. rPEG는 래트 및 인간 혈청에서 안정하고, rPEG288은 래트에서 약 10∼20시간의 반감기를 가진다(도 43). 생체내 실험에서 면역원성은 상기 폴리펩티드에 의해 거의 관찰되지 않았다(도 44).
단백질 발현
하기와 같이 디자인 4, 5 및 6을 작제하고, 단백질을 발현하고 특성 분석하였다. 간단히, T7 프로모터를 갖는 플라스미드의 rPEG 서열 및 상기 기재된 rPEG-J, -K 또는 -L(개별적으로 디자인 4, 5 또는 6)의 288개 아미노산의 코딩 서열에 hGH 유전자를 융합시켜, GFP 유전자를 대체하였다. 이러한 실시예에서, rPEG에 hGH를 위한 유전자가 뒤따르지만, 다른 형식, 예컨대 변경된 폴리펩티드의 C 말단에 rPEG를 갖는 형식이 구현될 수 있다. 플라스미드를 BL21(DE3)-스타(star) 이. 콜라이 균주(노바겐: Novagen)내로 옮기고, 적절한 항생제를 갖는 LB-한천 플레이트에 플레이팅하고, 하룻밤 37℃에서 성장시켰다. 단일 콜로니를 5 ㎖의 TB 125 배지내로 접종하고, 하룻밤 37℃에서 성장시켰다. 다음날, 접종물을 500 ㎖의 TB 125가 함유된 2ℓ용기내로 형질전환시키고, OD=0.6가 도달될 때까지 성장시킨 후, 26℃에서 16시간 동안 10O mM IPTG와 함께 연속 성장시켰다.
세포를 원심분리에 의해 수집하고, 세포 펠릿을 5O mM 트리스 pH=8.0, 10O mM NaCl, 프로테아제 저해제, 10% (v/v) 글리세롤, 0.1% 트리톤 X-100 및 DNA 분해효소가 함유된 50 ㎖ 완충액에 재현탁시켰다. 세포를 초음파 처리기 세포 분쇄기로 분쇄하고, 세포 잔해를 15000 RPM으로 4℃에서 원심분리하여 제거하였다. 세포 상청액을 음이온-교환기(Q-세파로즈(sepharose), 파마시아(Pharmacia)) 상에 적용하고, 완충액 A(25 mM 트리스 pH=8.0)로 세척하고, 1 M NaCl에 의해 동일한 완충액의 선형 구배를 사용하여 칼럼으로부터 용출하였다. 단백질은 약 500 mM NaCl에서 용출되었다. 용출된 융합 단백질을 모으고, 투석하고, 음이온-교환기(Q-세파로즈, 파마시아) 상에 로딩하고, 완충액 A(25 mM 트리스 pH=8.0)로 세척하고, 1 M NaCl에 의해 동일한 완충액의 얕은 선형 구배를 사용하여 칼럼으로부터 용출하였다. 용출된 융합 단백질을 모으고, 완충액 A에 대해 투석하고, 농축하고, 최종 정제로서 크기 배제 크로마토그래피(SEC)로 정제하였다. 단백질 순도는 98% 초과인 것으로 추정되었는데, 이는 이온 교환만을 고려하여 예측되지 않았고, SEC를 사용하여 전체 세포로부터 단백질을 rPEG 특이적 방식으로 정제하였다. 용출된 융합 단백질의 양을 SDS-PAGE 분석 및 총 단백질 농도의 측정에 의해 결정하였다. 용출된 융합 단백질의 높은 양은 hGH 단독에 비해 융합 단백질의 용해도가 더 높음을 반영한다.
hGH 수용체 결합 검정에서 보조적 폴리펩티드 변경 hGH의 시험
정제된 hGH-rPEG_K288이 그의 활성 고유 입체구조로 존재하는지의 여부를 결정하기 위해, 인간 성장 호르몬 수용체에 결합하는 그의 능력을 시험하였다. 간단히, 포스페이트 완충액 염수(PBS)에 용해된 500 ng의 재조합 hGH 수용체(알&디 시스템스(R&D Systems)로부터 구입)를 마이크로플레이트의 웰에 하룻밤 4℃에서 흡수시켰다. 결합되지 않은 수용체를 후속적으로 0.5% 트윈-20(PBST)이 함유된 PBS로 세척하여 제거하였다. 추가로 비특이적 결합을 PBS 중 1% 소 혈청 알부민(결합 완충액)의 첨가에 의해 블로킹하였다. PBST로 추가로 세척하고, 결합 완충액에 희석된 200 nM의 hGH-rPEG_K288 또는 재조합 hGH(알&디 시스템스로부터 구입)를 hGH 수용체 코팅된 웰에 첨가하였다. 결합된 hGH-rPEG_K288 및 hGH를 다클론성 토끼 항-hGH 항체 및 양고추냉이 퍼옥시다제(HRP: horseradish peroxidase) 접합된 항-토끼 2차 항체로 검출하였다. HRP 기질, 2,2'-아지노-비스(3-에틸벤즈티아졸린-6-설폰산)을 첨가하고 405 nm에서의 흡광도를 30분 후에 측정하였다. 도 34에 도시된 바와 같이, hGH-rPEG_K288는 hGH 수용체 뿐만 아니라 재조합 hGH에 결합되었다. 이 결과는, hGH가 세포질에서 rPEG 융합 단백질로 발현된 경우 가용성이고, 정확히 폴딩되고 그의 활성 입체구조로 존재함을 입증한다. 이 결과는 전형적으로 이. 콜라이의 세포질에서 불활성 단백질로 이루어진 봉입체를 형성하고, 활성이 되기 위해 언폴딩되거나 리폴딩되어야하는 고유 인간 성장 호르몬(hGH)과 대조적이다. 이는 hGH가 rPEG 폴리펩티드에 융합될 경우 이. 콜라이의 세포질에서 가용성 활성 형태로 발현될 수 있음을 보여준다. 이 데이터는 0.1 전하/AA의 순 전하 밀도(hGH-rPEG_J288에의해)가 융합 단백질을 가용성으로 만들기 충분하고, hGH-rPEG_L288에 의해 수득되는 0.16의 순 전하 밀도가 보다 가용성인 단백질을 산출하고, hGH-rPEG_K288에 의해 수득되는 0.21의 순 전하 밀도가 유사하게 용해도를 개선시킴을 보여준다.
디자인 1, 2 및 3은 유사하게 제조되지만, 16개의 음으로 하전된 아미노산(모든 3가지 경우 글루타메이트), 41개의 음으로 하전된 아미노산 또는 27개의 양으로 하전된 아미노산을, 개별적으로, rPEG-J, -K 및 -L 서열 대신 포함하고, 개선된 용해도 특성을 가질 수 있다.
보조적 폴리펩티드 서열을 디자인하는데 있어서, 치료학적 단백질의 원하는 전체 특성, 예를 들면, 혈청 안정성, 발현 수준 및 면역원성이 고려되어야 하고, 이는 상기 기재된 바와 같이 보조적 폴리펩티드내로 혼입된 아미노산의 선택에 영향을 받을 수 있다.
실시예 2: 인간 성장 호르몬(hGH) - 절단가능한 rPEG 변경 폴리펩티드의 발현
도 13에 예시된 바와 같은 본 실시예는 치료학적 단백질과 보조적 폴리펩티드 사이에 프로테아제 절단 서열을 갖는 rPEG_K288-연결된 인간 성장 호르몬 폴리펩티드의 제조를 기재한다. 보조적 폴리펩티드 잔사는, 활성 단백질이 다량으로 쉽게 단리되면서도 프로테아제 절단 부위가 프로테아제 분해에 의해 rPEG를 선택가능하게 제거할 수 있는 정도로 재조합 발현 동안 용해도를 개선시킨다. 최종 단백질 생성물은 순수하고 활성인 hGH이다.
rPEG-K288의 288개 아미노산에 N-말단에 융합된 hGH를 함유하고, 반복적 서열 (GEGGGEGGE)32 및 TEV 프로테아제 절단 부위(ENLYFQ/X)를 갖고, T7 프로모터를 수반하는(즉 T7 프로모터-hGH-TEV-rPEG_K288) 플라스미드를 BL21(DE3)-스타 이. 콜라이 균주내로 형질전환시키고, 상기 기재된 바와 같이 성장시킨다. 세포를 원심분리에 의해 수집하고, 세포 펠릿을 5O mM 트리스 pH=8.0, 10O mM NaCl, 프로테아제 저해제, 10%(v/v) 글리세롤, 0.1% 트리톤 X-100 및 DNA 분해효소를 함유하는 50 ㎖ 완충액에 재현탁시킨다. 세포를 초음파 처리기, 세포 분쇄기로 분쇄하고, 세포 잔해를 15000 RPM으로 4℃에서 원심분리하여 제거한다. 세포 상청액을 음이온-교환기(Q-세파로즈, 파마시아) 상에 적용하고, 완충액 A(25mM 트리스 pH=8.0)로 세척하고, 1 M NaCl에 의해 동일한 완충액의 선형 구배를 사용하여 칼럼으로부터 용출하였다. 단백질은 약 500 mM NaCl에서 용출된다. 용출된 융합 단백질을 모으고, 투석하고, TEV 분해한다. 분해 혼합물을 음이온-교환기(Q-세파로즈, 파마시아) 상에 재로딩하고, 완충액 A(25mM 트리스 pH=8.0)으로 세척하고, 1 M NaCl에 의해 동일한 완충액의 얕은 선형 구배를 사용하여 칼럼으로부터 용출한다. 용출된 hGH 단백질을 모으고, 완충액 A에 대해 투석하고, 농축하고, 최종 정제로서 크기 크로마토그래피(SEC)에 의해 정제한다. 단백질 순도는 98%을 초과하는 것으로 추정된다.
실시예 3: CBD 및 rPEG_K288에 융합된 인간 성장 호르몬(
hGH
)의 발현
본 실시예는 CBD-TEV-rPEG_K288-hGH 융합 단백질의 제조를 기재한다. TEV 프로테아제에 의해 분해하고 정제한 후, 최종 단백질 생성물은 rPEG_K288-hGH이다.
pET-시리즈 벡터를 T7 프로모터로 작제하였고, 이는 셀룰로스 결합 도메인(CBD)을 N-말단에 함유하고, 토마토 부식 바이러스(TEV: Tomato Etch Virus) 프로테아제 절단 부위가 수반되고, 이어 hGH 코딩 서열, 및 rPEG_K288 코딩 서열이 수반된 단백질(CBD-TEV-rPEG_K288-hGH)을 발현한다. rPEG_K288은 반복적 서열(GEGGGEGGE)32을 갖는다. 사용된 CBD 서열은 스위스프로트 파일(Swissprot file) Q06851에 제시되고, CBD 융합 단백질의 정제는 문헌[Ofir, K. et al. (2005) Proteomics 5: 1806]에 기재되어 있다. TEV 절단 부위의 서열은 ENLYFQ/X이고; G는 X 위치에 사용되었다. 이러한 작제물을 BL21(DE3)-스타 이. 콜라이 균주내로 형질전환시키고, CBD 서열을 rPEG 서열의 N-말단로 도입함을 제외하고 본질적으로 상기 기재된 바와 같이 성장시켰다. 세포를 수집하고 본질적으로 상기 기재된 바와 같이 분쇄하였다. 세포 상청액을 비딩된(beaded) 셀룰로스 수지(퍼로자(Perloza) 100)에 적용하고, 완충액 A(25 mM 트리스 pH=8.0)로 세척하고, 2O mM NaOH에 의해 칼럼으로부터 용출하였다. 1 M 트리스 완충액 pH=8.0에 의해 샘플을 재이용함으로써 pH를 조정하였다. 단백질 순도는 90%를 초과하는 것으로 추정되었다.
실시예 2에 기재된 바와 같이 TEV 분해를 적용한 후, 분해된 샘플을 비딩된 셀룰로스 수지(퍼로자 100)에 적용하였고, 여기서 CBD는 칼럼상에 보유되고, rPEG_K288-hGH는 칼럼 유출물에서 발견되었다. 모아진 유출물을 음이온-교환기(Q-세파로즈, 파마시아) 상에 로딩하고, 완충액 A(25 mM 트리스 pH=8.0)로 세척하고, 1 M NaCl에 의해 동일한 완충액의 얕은 선형 구배를 사용하여 칼럼으로부터 용출하였다. 용출된 융합 단백질을 모으고, 완충액 A에 대해 투석하고, 농축하고, 최종 정제로서 크기 배제 크로마토그래피(SEC)로 정제하였다. 단백질 순도는 98%를 초과하는 것으로 추정되었다(도 50 및 51). 최종 단백질은 rPEG_K288-hGH이다.
실시예 4: rPEG_K288에 융합된 CBD-인간 성장 호르몬(
hGH
)의 발현
본 실시예는 CBD-rPEG_K288-TEV-hGH, 융합 단백질의 제조를 기재한다. TEV 프로테아제 분해 및 정제 이후, 최종 단백질 생성물은 순수한 hGH이다.
CBD-rPEG_K288-TEV-hGH를 함유한 벡터를 생성하도록, TEV 프로테아제 인식 부위에 N-말단에 융합되고, T7 프로모터가 수반된 CBD에 융합되며, 또한, 반복적 서열 (GEGGGEGGE)32을 갖는 rPEG-K288에 C-말단에 융합되는, hGH를 갖는 플라스미드를, BL21(DE3)-스타 이. 콜라이 균주(노바겐)내로 형질전환시키고, 본질적으로 실시예 3에 기재된 바와 같이 성장시켰다. 세포를 수집하고 본질적으로 실시예 3에 기재된 바와 같이 분쇄하고, 세포 상청액을 비딩된 셀룰로스 수지(퍼로자 100; 이온토소브 인크.(Iontosorb Inc.)) 상에 적용하고, 완충액 A(25 mM 트리스 pH=8.0)로 세척하였다. 본질적으로 실시예 3에 기재된 바와 같이 수행된 TEV 분해를 적용한 후, hGH는 칼럼 유출물에서 발견되는 반면, CBD-rPEG_K288은 칼럼 상에 잔류하였다. 모아진 유출물을 음이온-교환기(Q-세파로즈, 파마시아) 상에 로딩하고, 완충액 A(25 mM 트리스 pH=8.0)로 세척하고, 1 M NaCl에 의해 동일한 완충액의 얕은 선형 구배를 사용하여 칼럼으로부터 용출하였다. 용출된 hGH 단백질을 모으고, 완충액 A에 대해 투석하고, 농축하고, 최종 정제로서 크기 배제 크로마토그래피(SEC)로 정제하였다. 단백질 순도는 98%를 초과하는 것으로 추정된다. 최종 단백질 생성물은 순수하고 활성인 hGH이다.
실시예 5: 리소자임에 결합하는 도메인 항체,
rPEG
_
K288
-
VHH
의 발현
본 실시예는 VHH 도메인 항체(dAb)에 융합되는 rPEG_K288의 제조를 기재한다.
rPEG-K의 288개 아미노산에 N-말단로 융합되고, 반복적 서열 (GEGGGEGGE)32을 가지며 T7 프로모터가 수반되는, hGH를 갖는 플라스미드를 본질적으로 실시예 1에 기재된 바와 같이 제조하지만, hGH 코딩 서열을 도메인 항체 코딩 서열로 대체한다. 도메인 항체 코딩 서열은 문헌[Dumoulin, M. et al., Protein Science 11:500-505 (2002)]에 제공되어 있다. 클론 dAb-Lys3의 아미노산 잔기 1∼113을 rPEG 구성물내로 혼입한다. 이 서열은 계란 리소자임에 11nM의 Kd로 결합된 도메인 항체이다. 이러한 도메인 항체 서열은 추가의 용해도 증진 서열의 부재하에 이. 콜라이의 세포질에서 발현될 경우 불활성 단백질로 이루어진 봉입체만을 산출하고; 다르게는 리더 서열에 의해 지시된다면 주변세포질에서 활성 형태로 발현될 수 있다. VHH dAb 서열을 rPEG_K288 서열의 업스트림에 삽입하고, 생성된 플라스미드를 BL21(DE3)-스타 이. 콜라이 균주(노바겐)내로 형질전환시킨다. 세포를 성장시키고, 수집하고, 본질적으로 상기 기재된 바와 같이 분쇄한다. 세포 상청액을 음이온 교환기(Q-세파로즈, 파마시아) 상에 로딩하고, 완충액 A(25 mM 트리스 pH=8.0)로 세척하고, 단백질을 1 M NaCl에 의해 동일한 완충액의 선형 구배를 사용하여 칼럼으로부터 용출한다. 단백질은 약 50O mM NaCl에서 용출된다. 용출된 융합 단백질을 모으고, 투석하고, 음이온-교환기(Q-세파로즈, 파마시아) 상에 로딩하고, 완충액 A(25 mM 트리스 pH=8.0)로 세척하고, 1 M NaCl에 의해 동일한 완충액의 얕은 선형 구배를 사용하여 칼럼으로부터 용출하였다. 용출된 융합 단백질을 모으고, 완충액 A에 대해 투석하고, 농축하고, 최종 정제로서 크기 배제 크로마토그래피(SEC)로 정제한다. 단백질 순도는 98%를 초과하는 것으로 추정된다.
생성된 VHH-rPEG_K288 단백질을 그의 표적, 계란 리소자임(시그마: Sigma)에 결합하는 능력에 대해 ELISA로 검정한다. 단백질은 리소자임에는 특이적으로 결합하지만 3가지 대조 단백질에는 결합하지 않는 것으로 보였고, 이는 rPEG_K288를 VHH에 첨가함으로써 이. 콜라이의 세포질에서 가용성 활성 형태로 이를 발현시킴을 입증한다.
실시예 6: IFNa2a-rPEG의 발현
본 실시예는 IFNa2a-rPEG 융합 단백질의 제조를 기재한다.
인터페론 알파 2a는 165개의 아미노산을 갖고, pI가 5.99이고, 분자량이 19241.62이며, 하기 서열에 상응한다:
CDLPQTHSLGSRRTLMLLAQMRKISLFSCLKDRHDFGFPQEEFGNQFQKAETIPVLHEMIQQIFNLFSTKDSSAAWDETLLDKFYTELYQQLNDLEACVIQGVGVTETPLMKEDSILAVRKYFQRITLYLKEKKYSPCAWEVVRAEIMRSFSLSTNLQESLRSKE
폴리펩티드는 14개의 글루타메이트 잔기 및 8개의 아스파테이트 잔기를 가져, 총 22개의 음성 잔기가 된다. 유사하게, 11개의 라이신 및 8개의 아르기닌 잔기가 단백질에 총 19개의 양성 잔기를 더하여, -3의 순 전하를 일으킨다. 따라서, 전하 밀도는 -0.018(-3/165개 아미노산으로 계산됨)이다. 이러한 순 전하 밀도는 5.99의 실험적 pI 값과 상관관계를 형성한다. 개선된 용해도를 위해 원하는 전하 밀도는 0.1 음전하/아미노산으로 선택되었다. 이 전하 밀도를 달성하기 위해, (16.5-3)으로 계산된 추가의 13.5 음전하가 필요하다.
15개의 음으로 하전된 아미노산을 인터페론 알파에 첨가하면 융합 단백질의 순 전하 밀도는 -0.1((15+3)/(165+15)로 계산됨)이 되고, 이는 증가된 용해도를 위해 바람직하다. -0.2 전하/아미노산의 보다 높은 전하 밀도는, 총 41개의 음으로 하전된 아미노산 잔기를 위해 약 26개의 추가의 음으로 하전된 아미노산 잔기를 단백질에 포함시킴으로써 수득된다. 조합된 길이는 206개 아미노산(165+41로 계산됨)이고, -0.2의 전하 밀도는 총 41개의 음으로 하전된 아미노산 잔기를 필요로 하고(0.2x205개 아미노산으로 계산됨), 이는 보조적 단백질이 38개의 음으로 하전된 잔기를 포함할 수 있음을 의미한다(41-3으로 계산됨).
유사한 이유로 인해, +0.1의 순 전하 밀도에 도달하기 위해, 보조적 폴리펩티드는 15+6=21개의 양으로 하전된 아미노산을 포함할 수 있다.
rPEG_J288은 서열 GGSGGE를 갖고, 48개의 E 잔기를 가지며, 따라서 IFNa2a의 전하 밀도를 증가시키기 위해 사용될 수 있다. rPEG_J288이 IFNa2a에 첨가될 경우, 융합 단백질의 총 길이는 453개 아미노산이고(165+288개 아미노산으로 계산됨) 순 전하는 51(48+3)이어서, 0.11의 순 전하 밀도를 산출하고(51/453으로 계산됨), 이는 세포질에서 IFNa2a가 가용성 활성 형태로 발현될 수 있도록 한다. 구성물, 발현, 및 정제 방법이 본질적으로 실시예 1에 기재된 바와 같이 제조되고 실행된다. 융합 단백질은 가용성 및 활성으로 입증되었지만, 응집되는 일부 경향이 일부 조건하에서 여전히 관찰될 수 있었다. 이는 순 전하 밀도를 증가시켜 용액중 단백질을 유지시킴으로써 극복될 수 있다. 동일한 크기이나 전하가 더 큰 rPEG, 예컨대 rPEG_L(288AA, 25% E) 및 rPEG K(288AA, 33% E)는, IFNa2a-rPEG 융합 단백질을 완전히 가용화되고 활성적으로 폴딩되도록 만들 수 있다. IFNa2a-rPEG_K288의 경우, 보조적 폴리펩티드 중 음으로 하전된 아미노산 잔기의 수는 96이어서, 융합 단백질의 총 순 전하가 99이도록 하고(96+3로 계산됨), 이는 순 전하 밀도가 0.218(99/(288+165)로 계산됨)임을 의미한다.
실시예 7: G-CSF-rPEGJ-288의 발현
본 실시예는 G-CSF-rPEG 융합 단백질의 제조를 기재한다.
G-CSF는 174개의 아미노산 길이를 갖고, pI가 5.65이며, 분자량이 18672.29이고, 하기 서열에 상응한다:
TPLGPASSLPQSFLLKCLEQVRKIQGDGAALQEKLCATYKLCHPEELVLLGHSLGIPWAPLSSCPSQALQLAGCLSQLHSGLFLYQGLLQALEGISPELGPTLDTLQLDVADFATTIWQQMEELGMAPALQPTQGAMPAFASAFQRRAGGVLVASHLQSFLEVSYRVLRHLAQP.
폴리펩티드는 9개의 글루타메이트 잔기 및 4개의 아스파테이트 잔기를 가져, 총 13개의 음성 잔기가 된다. 유사하게, 4개의 라이신 및 5개의 아르기닌 잔기가 단백질에 총 9개의 양성 잔기를 더하여, -4의 순 전하를 일으킨다. 따라서, 전하 밀도는 -0.023(-4/174개 아미노산으로 계산됨)이다. 이러한 순 전하 밀도는 5.65의 실험적 pI 값과 상관관계를 형성한다.
개선된 용해도를 위해 원하는 전하 밀도는 0.1 음전하/아미노산로 선택되었다. 이 전하 밀도를 달성하기 위해, 추가의 13.4개의 음으로 하전된 아미노산 잔기가 필요하다(17.4-4로 계산됨).
GCSF의 경우, 14개의 음으로 하전된 아미노산의 첨가는 융합 단백질의 순 전하 밀도를 약 -0.1로 옮기고((14+4)/(174+14)로 계산됨), 이는 전형적으로 용해도를 위해 바람직하다. -0.2의 바람직한 전하 밀도는 총 41개의 음으로 하전된 아미노산 잔기를 위해 약 26개의 추가의 음으로 하전된 아미노산 잔기를 필요로 하는데, 조합된 길이가 217개 아미노산이기 때문이다(174+43으로 계산됨). 달리 선택된 전하 -0.2의 밀도는 총 43개의 음으로 하전된 아미노산 잔기를 필요로 하고(0.2x217개 아미노산으로 계산됨), 이는 보조적 단백질이 39개의 음으로 하전된 잔기를 함유해야 함을 의미한다(43-4로 계산됨).
또 다른 대안의 디자인에서, +0.1의 순 전하 밀도를 달성하기 위해 양으로 하전된 아미노산을 갖는 보조적 단백질이 요망되고, 이는 +21의 순 양전하를 필요로 한다. 이는 25의 양전하를 함유하는 보조적 단백질을 첨가함으로써 달성되어(25-4=21로 계산됨), 209개 아미노산의 조합된 융합 단백질 길이를 생성한다.
실험 결과:
rPEG_J288은 서열 GGSGGE를 갖고 48개의 E 잔기를 함유한다. rPEG_J288이 GCSF에 첨가될 경우, 융합물의 총 길이는 174+288=462개 아미노산이 되고, 순 전하는 48+3=51이 되어, 0.11의 순 전하 밀도를 산출한다(51/462로 계산됨). 이 전하는 GCSF를 >80% 응집으로부터 >80% 가용성 단백질로 전환시키기에 충분한 것으로 예상된다. 0.15 또는 0.2의 보다 높은 전하 밀도가 또한 사용될 수 있다.
표준 분자 생물학적 기법을 사용하여, 상기 제공된 임의의 예는 치료학적 단백질에 융합된 상이한 rPEG 모듈을 사용하도록 변경될 수 있다. 본 발명은 0.1의 순 전하 밀도가 세포질에서 단백질(예를 들어, GFP, hGH 및 IFNa2a)의 용해도를 개선시키는 한편, 약 0.2의 순 전하 밀도가 응집되는 경향이 전혀 없는 매우 가용성의 단백질을 제공함을 보여주었다.
실시예 8: 이. 콜라이의 세포질에서 재조합적으로 발현될 경우 GFP에 융합된 상이한 rPEG 서열의 용해도
하기 단백질 서열을 본 실험에서 제조 및 시험하였다.
rPEG_J288-GFP-는 GFP 단백질 서열에 융합된 반복적 서열 (GSGGEG)48로 이루어진 단백질 서열을 나타낸다. .
rPEG_K288-GFP-는 GFP 단백질 서열에 융합된 반복적 서열 (GEGEGGGEG)32로 이루어진 단백질 서열을 나타낸다.
rPEG_L288-GFP-는 GFP 단백질 서열에 융합된 반복적 서열 (SSESSESSSSES)24로 이루어진 단백질 서열을 나타낸다.
rPEG_O336-GFP-는 GFP 단백질 서열에 융합된 반복적 서열 (SSSSSESSSSSSES)24로 이루어진 단백질 서열을 나타낸다.
rPEG_P320-GFP-는 GFP 단백질 서열에 융합된 반복적 서열 (SSSESSSSES)32로 이루어진 단백질 서열을 나타낸다.
각각 GFP의 N-말단에 융합된 rPEG J288, K288, L288, O336 및 P320을 이. 콜라이 균주 BL21-스타내로 접종하고, LB-Kan 한천 플레이트 상에서 성장시키고, 16시간 동안 37℃에서 항온처리하였다. 다음날, 각각의 구성물의 단일 콜로니를 2 ㎖의 TB 125 성장 배지내로 접종하고 5시간 동안 성장시켰다. 1OO ul의 각각의 박테리아 브로쓰를 TB 125 배지+Kan이 함유된 10 ㎖ 플라스크에 옮기고, OD60O이 ∼0.6에 도달될 때까지 성장시켰다. 성장 플라스크를 26℃로 옮기고, 16시간 동안 진탕시키면서 lOO uM IPTG로 유도하였다. 박테리아 세포를 원심분리하고, 10 ㎖의 PBS에 재현탁시키고, 이후 음파처리로 분쇄하였다. 각각의 샘플의 100 ㎕ 분취량을 원심분리하고 이들의 상청액을 수집하였다. 최종적으로, 100 ㎕의 세포 용해물 및 가용성 분별물을 GFP 형광성에 대해 판독하고 비교하였다.
결과는 도 33에 제시되어 있다. rPEG 보조적 폴리펩티드 J, K 및 L로 변경된 GFP는 GFP 신호의 대부분을 가용성 형태로 갖는 반면, 실질적 분율의 GFP 형광성은 rPEG O 및 rPEG P 융합 서열에서 불용성 형태로 보유되었다. 추가로, Ser 풍부 rPEG 서열에 융합된 GEP는 Gly 풍부 서열을 더 잘 발현하는 반면, Gly 풍부 rPEG 서열은 대부분의 GFP 형광성을 가용성 형태로 보유하였다.
실시예 9: 보조제 연결 폴리펩티드의 특성 측정
보조제 연결 폴리펩티드의 혈청 안정성 측정
도 19에 도시된 바와 같이 정제되고, 녹색 형광성 단백질의 N-말단에 융합된 보조적 서열 rPEG_J288 및 N-말단 플래그 태그를 함유한 융합 단백질 플래그-rPEG_J288-H6-GFP를 50% 마우스 혈청중에서 37℃에서 3일 동안 항온처리한다. 샘플을 다양한 시점에 취하여 SDS PAGE로 분석한 후, 웨스턴 분석에 의해 검출한다. N-말단 플래그 태그에 대한 항체를 웨스텀 검출을 위해 사용한다. 도 20에 따르면, 보조적 단백질은 3일 이상 동안 혈청에서 안정하다.
보조제 연결 폴리펩티드의 혈장 반감기 측정
보조제 연결 폴리펩티드의 혈장 반감기는 보조적 폴리펩티드를 본질적으로 문헌[Pepinsky, R. B., et al. (2001) J Pharmacol Exp Ther, 297: 1059-66]에 기재된 바와 같이 카테터화된(catheterized) 래트내로 정맥내 또는 복강내 주사한 후에 측정될 수 있다. 혈액 샘플을 다양한 시점(5분, 15분, 30분, 1시간, 3시간, 5시간, 1일, 2일, 3일)에 취하고, 보조적 폴리펩티드의 혈장 농도를 ELISA에 의해 측정할 수 있다. 약물동력학적 매개변수는 윈놀린(WinNonlin) 버전 2.0(사이언티픽 컨설팅 인크.(Scientific Consulting Inc.); 노쓰캐롤라이나주 아펙스 소재)에 의해 계산될 수 있다. rPEG-연결된 폴리펩티드의 효과를 분석하기 위해, rPEG 폴리펩티드를 함유한 단백질의 혈장 반감기를 rPEG 폴리펩티드가 결여된 동일 단백질의 혈장 반감기와 비교할 수 있다.
LCW0057 및 LCW0066의 생체내 반감기를 래트에서 연구하였다. 단백질 둘 다를 래트에 정맥내로 주사하였다. 혈청 샘플을 주사 후 5분∼3일 사이에 GFP의 존재에 대해 분석하였다. LCW0057이 주사된 래트의 경우, 단백질 주사 24시간 후에 GFP가 검출되지 않았다. 이는 단백질의 반감기가 1∼3시간임을 암시한다. 반대로, LCW0066은 주사 48시간 이후에도 검출되었고, 한마리 래트는 주사 3일 후에도 검출가능한 GFP를 나타내었다. 이는 LCW0066이 래트에서 약 10시간의 혈청 반감기를 가짐을 보여주고, 이는 52 kDa의 계산된 분자량을 갖는 단백질에 대해 기대되는 것보다 훨씬 더 길다.
보조제 연결된 폴리펩티드의 용해도 시험
보조제 연결된 폴리펩티드의 용해도는 포스페이트 완충된 염수와 같은 생리학적 완충액에서 보조제 연결 폴리펩티드의 정제된 샘플을 0.01 ㎎/㎖∼10 ㎎/㎖ 범위의 다양한 농도로 농축시킴으로써 결정될 수 있다. 샘플을 수 주 동안 항온처리할 수 있다. 농도가 보조제 연결 폴리펩티드의 용해도를 초과하는 샘플은 혼탁도에 의해 지시되는 바와 같이 침전을 나타내고, 이는 흡광 판독기에서 측정될 수 있다. 침전된 물질을 원심분리 또는 여과에 의해 제거하고, 상청액중 남은 단백질의 농도를 브래드포드(Bradford) 검정과 같은 단백질 검정을 사용하여 또는 280nm에서 흡광도를 측정함으로써 측정할 수 있다. 용해도 연구는 샘플을 -20℃에서 동결시키고 이후 해동함으로써 가속화될 수 있다. 이 과정은 종종 불량한 가용성 단백질의 침전을 유도한다.
보조적 폴리펩티드로 변경된 GFP의 크기 배제 크로마토그래피
서열 (GGSGGE)48을 갖는 rPEG를 녹색 형광성 단백질(GFP)에 융합시켜 클론 LCW0066을 산출하였다. 융합 단백질은 또한 N-말단 플래그 태그 및 His6 태그를 rPEG와 GFP 사이에 운반하였다. 융합 단백질을 표준 T7 발현 벡터의 사용에 의해 이. 콜라이에서 발현시켰다. 세포를 LB 배지에서 배양하고, 발현을 IPTG로 유도하였다. 발현 후, 펠릿을 70℃에서 15분 동안 가열함으로써 세포를 용해시켰다. 대부분의 이. 콜라이 단백질은 이러한 가열 단계에서 변성되었고, 원심분리에 의해 제거할 수 있었다. 융합 단백질을 IMAC 크로마토그래피에 의해 상청액으로부터 정제하고, 이어서 고정화된 항-플래그(시그마)에 의해 정제하였다. 10/30 수퍼덱스(Superdex)-200(GE, 아머샴)을 사용하여 크기 배제 크로마토그래피(SEC)에 의해 융합 단백질을 분석하였다. 칼럼을 구형 단백질(다이아몬드)로 보정하였다. 칼럼으로부터 상당히 초기에 용출된 rPEG_J288 및 GFP를 포함하는 융합 단백질을 그의 계산된 분자량에 기초하여 예측하였다. 구형 단백질에 의한 보정에 기초하여, SEC는 융합 단백질의 겉보기 분자량을 243 kDa으로 측정하였고, 이는 52 kDa의 계산된 분자량에 비해 거의 5배 이상 더 크다. 관련된 융합 단백질(LCW0057)은 rPEG36을 함유하였고, 55 kDa의 겉보기 분자량 대 32 kDa의 계산된 분자량을 가졌다. LCW0066과 LCW0057의 비교는 189 kDa의 겉보기 분자량에서의 차이를 나타내고, 이는 20 kDa의 계산된 분자량을 갖는 rPEG 쇄의 첨가에 의해 야기된다. 따라서, 20 kDa의 계산된 분자량을 갖는 rPEG 테일의 첨가가 189 kDa의 분자량의 증가를 유도한 것으로 계산할 수 있다.
실시예 10: 변경된 폴리펩티드의 제어 방출형 제형
rPEG-GFP 융합 단백질의 마이크로캡슐화
리소머(Resomer)-PEG 공중합체는 상업적으로 입수가능하다(예를 들어, 베링거-인겔하임: Boehringer-Ingelheim). rPEG(L288)-GFP 또는 GFP를 단독으로 함유하는 미소구체를 2중 유화액 용매 추출/증발(W/O/W, 수중-유중-수적형) 방법에 의해 제조한다. 단백질(1% 중량/부피) 및 리소머-PEG 공중합체(9% 중량/부피)를 디클로로메탄에 용해시킨다. 따라서 이론적 미소구체 로딩 효율은 10% 중량/중량 단백질이다. 이어서 단백질 중합체 혼합물을 5분 동안 격렬히 와동시킨다. 혼합물을 1% 폴리비닐알코올이 함유된 수성 용액내로 50배로 희석하고, 실온에서 수 시간 동안 격렬히 교반한다. 경화된 미소구체를 초순수(ultrapure water)로 수회 세척하고, 건조시키고, 4℃에서 데시케이터(dessicator)에 저장한다.
이러한 프로토콜에 대한 다양한 변형이 이루어질 수 있는데, 예컨대 단백질:공중합체 비를 바꾸고, 동결건조된 단백질 샘플 대신 수성 용액중의 단백질 샘플을 사용하고, 경화된 미소구체를 동결-건조시키는 것이 포함된다. 예를 들면 리소머-PEG 공중합체를 이블록(PLGA-PEG) 또는 삼블록(PLGA-PEG-PLGA) 공중합체로 대체함으로써 상이한 중합체 매트릭스가 또한 이용될 수 있다. 유사하게, 미소구체는 다양한 조건하에, 예를 들면 -20℃ 또는 -80℃에서 저장될 수 있다. 약물 농도 구배를 갖기 위해 입자의 다수의 코팅물이 또한 이용되어, 보다 적은 표면적을 갖는 내부 층이 약물의 보다 높은 농도에 기인하여 단위 시간 당 동일한 약물 방출을 산출하도록 한다.
캡슐화 유효성의 측정
rPEG(L288)-GFP의 미소구체로의 캡슐화 유효성을 평가하기 위해, 200 ㎎의 미소구체를 디클로로메탄에 용해시킨다. 이어서 rPEG(L288)-GFP를 3 부피의 포스페이트 완충된 염수(PBS)에서 추출한다. 미소구체로부터 추출된 rPEG(L288)-GFP의 양은 샌드위치 ELISA 검정에 의해, 정제된 재조합 rPEG(L288)-GFP를 표준물로서 사용하여 측정된다. 간단히, 방출된 rPEG(L288)-GFP를 α-플래그 항체로 코팅된 미량적정(microtiter) 플레이트 웰에 포획시킨다. 포획된 단백질을 양고추냉이 퍼옥시다제(HRP)에 접합된 2차 항체 및 다클론성 α-GFP 항체로 검출한다. 웰중의 단백질의 양을 정제된 rPEG(L288)-GFP에 의해 생성된 표준 곡선과 비교하여 정량하였다.
미소구체로부터의 rPEG-GFP의 시험관내 방출 측정
rPEG-GFP 융합물 및 GFP의 시험관내 방출을 하기 절차에 의해 측정한다. 우선, 미소구체(200 ㎎)를 1 ㎖의 PBS에 현탁시킨다. 미소구체의 현탁액을 37℃에서 부드럽게 교반하며 항온처리한다. 이어서 분취량(10∼100 ㎕)을 2주 이상 동안 매 24시간 마다 제거한다. 방출된 rPEG-GFP 및 GFP의 양을 상기 기재된 바와 같이 샌드위치 ELISA에 의해 정량한다. 이러한 절차에 대해 가능한 변형으로는 혈청 또는 혈청/PBS 혼합물에 현탁된 비드로부터 rPEG-GFP의 방출을 측정함이 포함된다.
캡슐화된 단백질의 피하 주사 후 rPEG-GFP의 혈청 농도의 측정
rPEG-GFP와 GFP의 혈청 농도는, 개별적으로, rPEG-GFP 미소구체 또는 GFP 미소구체의 단일 피하 주사를 실험실 모델 유기체에서 수행하여 시험될 수 있다. 캡슐화된 rPEG-GFP 혹은 캡슐화된 GFP를 마우스, 래트, 토끼, 또는 다른 동물 모델 유기체에 주사하여(1 ㎖/kg 체중) 생체내 방출 속도를 평가한다. 혈청 샘플을 한 달 동안 매일 수집한다. 혈청 농도 또는 rPEG-GFP를 상기 기재된 샌드위치 ELISA 검정에 의해 측정한다. rPEG-GFP 융합 폴리펩티드는, 미소구체로부터의 저속 방출 및 더 긴 후속적 반감기에 기인하여 GFP에 비해 훨씬 높은 농도로 존재한다.
실시예 11: 보조적 폴리펩티드에 연결된 중합체 캡슐화된 인터페론-알파 (IFN-알파)
본 실시예는 본 폴리펩티드의 투약 간격을 연장시킬 수 있는 rPEG-IFN-알파의 데포 제형을 기재한다. GLP-1 코딩 서열을 IFN-알파 코딩 서열로 대체함을 제외하고, 본질적으로 실시예 3에서 hGH-rPEG 융합 구성물에 대해 기재된 바와 같이 rPEG-융합된 IFN-알파를 작제한다. 캡슐화 방법을 비롯한 모든 다른 방법 및 기법은 본질적으로 실시예 10에 기재된 바와 같다.
표준 분자 생물학적 기법을 사용하여, 본원에 제공된 임의의 실시예는 생물학적 활성 폴리펩티드에 융합된 상이한 보조적 폴리펩티드를 사용하도록 변형될 수 있다. 보조적 폴리펩티드는 이전에 기재된 임의의 서열을 포함할 수 있고, 수 백개 까지의 아미노산 길이일 수 있다. 유사하게, 실시예는 본원에 기재된 임의의 치료학적 단백질, 예컨대, 제한없이, rPEG-인슐린, rPEG-IFN-베타, rPEG-에리스로포이에틴 및 rPEG-종양 괴사 인자-알파를 적용하도록 변형될 수 있다. 이들 실시예에 기재된 재조합 단백질을 표준 생화학적 기법에 따라 이. 콜라이에서 발현시키고 이로부터 정제할 수 있다. 당분야의 숙련가에게 명백하듯이, 예를 들면, rPEG-에리스로포이에틴 및 rPEG-종양 괴사 인자-알파는 번역후 글리코실화를 필요로 하고, 따라서 인간 조직 배양 세포에서 생산되어야 한다. 이러한 경우, 보조적 폴리펩티드는 인간 세포에서 발현될 수 있고, 인간 세포에서 더 잘 발현되기 위해 코돈-최적화될 수 있다. 코돈-최적화는 표준 분자 생물학 방법을 사용하여 수행될 수 있다.
실시예 12: 비반복적 보조적 폴리펩티드의 작제
본 실시예는 합성 올리고뉴클레오티드로부터의 보조적 폴리펩티드 분절의 라이브러리의 작제를 기재한다. 도 78은 합성 올리고뉴클레오티드에 의해 코딩된 아미노산 서열을 열거한다. 각각의 아미노산 서열의 경우, 2개의 상보성 올리고뉴클레오티드를 사용하였다. 서열을 코돈 라이브러리로서 디자인하였고, 즉 다수의 상이한 코돈이 허용되었지만, 모든 서열은 단지 하나의 아미노산 서열을 코딩하였다. 상보성 올리고뉴클레오티드를 열에 의해, 이어서 냉각시켜 어닐링하였다. 도 79에 예시된 바와 같이 어닐링 동안 4개의 염기-쌍 중첩을 생성하도록, 올리고뉴클레오티드를 디자인하였다. 결찰 반응에 의한 다량체화 동안 터미네이터(terminator)로서 작용하는 2개의 추가의 어닐링된 올리고뉴클레오티드를 또한 첨가하였다. 도 79는 다양한 길이의 보조적 폴리펩티드 분절을 코딩하는 유전자 단편을 산출하는 어닐링된 올리고뉴클레오티드의 결찰을 보여준다. 생성된 결찰 혼합물을 도 79에 도시된 바와 같이 전기이동에 의해 분리하고, URP36을 코딩하는 결찰 생성물을 단리하였다. 결찰 생성물을 발현 벡터내로 결찰시키고, URP36 분절의 라이브러리를 GFP로의 융합 단백질로서 발현시켰다.
이러한 방식으로 제조된 보조적 폴리펩티드 서열은 도 80에 제시되어 있다. 추가의 서열은 아래에 개시되어 있다:
LCW0219.040
GEGSGEGSEGEGSEGSGEGEGSEGSGEGEGGSEGSEGEGGSEGSEGEGGSEGSEGEGSGEGSEGEGGSEGSEGEGSGEGSEGEGSEGGSEGEGGSEGSEGEGSGEGSEGEGGEGGSEGEGSEGSGEGEGSGEGSEGEGSEGSGEGEGSGEGSEGEGSEGSGEGEGSEGSGEGEGGSEGSEGEGSEGSGEGEGGEGSGEGEGSGEGSEGEGGGEGSEGEGSGEGGEGEGSEGGSEGEGGSEGGEGEGSEGSGEGEGSEGGSEGEGSEGGSEGEGSEGSGEGEGSEGSGE
LCW0219.068
GEGSGEGSEGEGSEGSGEGEGSEGGSEGEGSEGSGEGEGSEGSGEGEGGEGSGEGEGSGEGSEGEGGGEGSEGEGGSEGSEGEGGSEGSEGEGGEGSGEGEGSEGSGEGEGSGEGSEGEGSEGSGEGEGSEGSGEGEGGSEGSEGEGSGEGSEGEGSEGSGEGEGSEGSGEGEGGSEGSEGEGGSEGSEGEGGSEGSEGEGSGEGSEGEGGSEGSEGEGSGEGSEGEGSEGGSEGEGGSEGSEGEGSGEGSEGEGGEGGSEGEGSEGSGEGEGSGEGSEGEGSEGSGE
LCW0220.038
SEGESEESSESGGESSSGGGSEESSEEGSGGGSEGEGEESSGSEGGGGSGEGSEGGSEEGSEESSEGESEESSESGGESSSGGGSEESSEEGSGGGSGESGSGSSGSESEGGSEGESEESSGGGGSEGSEGESEESSESGGESSSGGGSEESSEEGSGGGSEEESGEGSGEGSEGSSGEGSEESSGGSEGGGSGGSGGEGSGESGSGSSGSESEGGSEGESEESSGGGGSEGSSEESGGSSEEGSEGSSGGESEESSEGESGGGSGGGSEGS
LCW0220.055
SEGESEESSESGGESSSGGGSEESSEEGSGGGSEGESEESSESGGESSSGGGSEESSEEGSGGGSGESGSGSSGSESEGGSEGESEESSGGGGSEGSESEGEEGSEEGSGEGSGEGGGESSEEGESESSGESGSGSSGSESEGGSEGESEESSGGGGSEGSGESGSGSSGSESEGGSEGESEESSGGGGSEGSGESGSGSSGSESEGGSEGESEESSGGGGSEGSSEESGGSSEEGSEGSSGGESEESSEGESGGGSGGGSEGS
LCW0220.064
SEGESEESSESGGESSSGGGSEESSEEGSGGGSEGEGEESSGSEGGGGSGEGSEGGSEEGSEESSEGESEESSESGGESSSGGGSEESSEEGSGGGSGESGSGSSGSESEGGSEGESEESSGGGGSEGSGESGSGSSGSESEGGSEGESEESSGGGGSEGSESEGEEGSEEGSGEGSGEGGGESSEEGESESSEGESEESSESGGESSSGGGSEESSEEGSGGGSSEESGGSSEEGSEGSSGGESEESSEGESGGGSGGGSEGS
LCW0220.093
SEGESEESSESGGESSSGGGSEESSEEGSGGGSGESGSGSSGSESEGGSEGESEESSGGGGSEGSEGESEESSESGGESSSGGGSEESSEEGSGGGSEEGSGESSGGSESEGSGGESEGGSGGEGGEGSGESGSGSSGSESEGGSEGESEESSGGGGSEGSSEESGGSSEEGSGGGSESGEESGSGEESEGGSGGSGGEGSGESGSGSSGSESEGGSEGESEESSGGGGSEGSSGEGEESSEGEGGESSEEGSGGSSEEGSGEG
실시예 13: rPEG_Y576의 작제
본 실시예는 합성 올리고뉴클레오티드로부터 URP 분절의 라이브러리의 작제를 기재한다. 도 78은 합성 올리고뉴클레오티드에 의해 코딩된 아미노산 서열을 열거한다. 각각의 아미노산 서열 경우, 2개의 상보성 올리고뉴클레오티드를 사용하였다. 서열을 코돈 라이브러리로서 디자인하였고, 즉 다수의 상이한 코돈이 허용되었지만, 모든 서열은 단지 하나의 아미노산 서열을 코딩하였다. 상보성 올리고뉴클레오티드를 열에 의해, 이어서 냉각시켜 어닐링하였다. 올리고뉴클레오티드를 디자인하여 도 79a에 예시된 바와 같이 어닐링 동안 4개의 염기-쌍 중첩을 생성하였다. 결찰 반응에 의해 다량체화 동안 터미네이터로서 작용하는 2개의 추가의 어닐링된 올리고뉴클레오티드를 또한 첨가하였다. 도 79b는 다양한 길이의 URP 분절을 코딩하는 유전자 단편을 산출하는 어닐링된 올리고뉴클레오티드의 결찰을 예시한다. 생성된 결찰 혼합물을 도 79b에 도시된 바와 같이 전기이동에 의해 분리하고, URP36을 코딩하는 결찰 생성물을 단리하였다. 결찰 생성물을 발현 벡터내로 결찰시키고, URP36 분절의 라이브러리를 GFP로의 융합 단백질로서 발현시켰다(도 81). 양호한 발현을 하는 라이브러리 구성원을 그의 강한 형광성 강도에 대해 동정하였다.
URP36의 라이브러리 막을 이량체화하고, URP72의 생성된 라이브러리를 높은 발현 수준에 대해 스크리닝하였다. 이량체화 및 스크리닝의 이러한 과정을 1회보다 많이 반복하여 URP144를 생성하였다. 도 80은 서열의 수집물을 보여준다. 서열은 라이브러리의 디자인에 순응하지만, 대부분의 라이브러리 구성원은 이들의 실제 서열이 상이하다. URP_Y144의 수집물은 2회보다 많이 이량체화하여 URP_Y288 및 URP_Y576의 수집물을 생성하였다. URP_Y576의 하나의 단리물의 아미노산 서열이 도 80에 제시되어 있다. 생성된 단리물을 발현, 응집 및 면역원성에 대해 평가하여 약물 단백질에 융합하기에 가장 적합한 URP를 동정하였다.
실시예 14: scFv-rPEG50 융합물의 작제
항-Her2와 항-EGFR의 작제
본 실시예는 scFv-rPEG50 융합물의 작제를 기재한다. 2개의 scFv를 제조하였고, 하나는 Her2에 결합하고 하나는 상피 성장 인자 수용체(EGFR)에 결합한다. 각각의 scFv를 각각 유전학적으로 rPEG50의 N-말단에 융합시켰다. scFv 구성물을 T7 프로모터를 갖고 rPEG50-플랴그-태그-헥사히스티딘을 코딩하는 발현 벡터내로 클로닝하여, scFv-rPEG50-플래그-His6을 발현하는 구성물을 생성하였다. 스터퍼 단편을 NdeI 및 BsaI 엔도뉴클레아제에 의해 제한 분해하여 제거하였다. 합성 scFv 단편을 폴리머라제 쇄 반응(PCR)에 의해 증폭시켰고, 이는 스터퍼 구성물에 화합성인 NdeI 및 BbsI 제한 부위를 도입하였다. 제한 분해된 scFv 단편 및 스터퍼 구성물을 T4 DNA 리가제(ligase)로 결찰시키고, 이. 콜라이 BL21(DE3) 골드내로 전기형질전환시켰다. 생성된 DNA 구성물은 도 64a에 제시되어 있고, 여기서 경쇄(vL) 및 중쇄(vH) 가변성 단편은 rPEGY30, 30개의 아미노산 서열 (SGEGSEGEGGGEGSEGEGSGEGGEGEGS)에 의해 분리된다. vL과 vH 사이의 연결기 서열의 편리한 제거 및 대체를 위해 Y30-아미노산-인코딩 서열을 AgeI 및 KpnI 제한 부위에 의해 플랭킹하였다. 구성물을 DNA 서열화로 확인하였다. aHer230-rPEG(M.W.=80,044 Da) 또는 aEGFR30-rPEG(M.W.=80,102 Da) 구성물에 대한 단백질 서열은 도 64b 및 d에 각각 제시되어 있다.
이. 콜라이 BL21(DE3) 골드에서 항-Her230-rPEG 및 aEGFR30-rPEG 융합물을 0.2 mM 이소프로필 β-D-1 티오갈락토피라노시드(IPTG: isopropyl β-D-1 thiogalactopyranoside)에 의해 유도하여 발현시켰다. 세포를 원심분리로 수확하고 포스페이트 완충된 염수중 버그버스터(BugBuster)+벤조나제(Benzonase)에서 용해시켰다. 용해물을 원심분리에 의해 투명화시키고, 상청액(가용성 분별물)을 4∼12% SDS PAGE 겔에 로딩하였다. scFv-rPEG 융합물은 과발현되고, 이. 콜라이 용해물에서 대략 80 kDa으로 가시화된다(도 64c).
실시예 15: scFv-rPEG50 융합물 aHer230-rPEG의
특성 분석
정제
Her2 수용체를 표적화하는 단일쇄 단편 가변성(scFv) 항체 단편은 rPEG에 융합되어 aHer230-rPEG를 산출하였고, 이를 이. 콜라이의 사이토졸에서 발현시켜 이로부터 정제하였다. aHer230-rPEG 플라스미드를 BL21(DE3)-골드내로 형질전환시키고, 재조합 항체 단편의 발현을 0.2 mM 이소프로필 β-D-1 티오갈락토피라노시드(IPTG)로 20℃에서 유도하였다. 세포를 원심분리에 의해 수확하고, 30 mM 소듐 포스페이트, 0.3 M 소듐 클로라이드, 10% 글리세롤, 및 20 mM 이미다졸, pH 7.5에 재현탁시켰다. 용해를 음파처리에 의해 달성하고, 고정화 금속 친화도 크로마토그래피(IMAC), 소수성 상호작용 크로마토그래피(HIC), 및 이온 교환 크로마토그래피(IEC)를 비롯한 표준 크로마토그래피 방법에 의해 가용성 단백질을 정제하였다.
결합
표적(Her2) 결합을 평가하기 위해, aHer230-rPEG를 상기 기재된 바와 같은BL21(DE3)-골드에서 발현시켰다. 세포를 버그버스터 시약 및 5 U/㎖의 벤조나제(노바겐)가 함유된 포스페이트 완충 염수(PBS)에서 재현탁하여 용해시켰다. 현탁액을 20분 동안 실온에서 항온처리한 후, 10000 rpm에서 10분 동안 원심분리하였다. 이어서 가용성 분별물을 1% 소 혈청 알부민(BSA) 및 0.05% 트윈-20이 함유된 PBS내로 연속적으로 5배 희석하였다. 연속적으로 희석된 aHer230-rPEG를 Her2-Fc 융합 단백질(알&디 시스템스)이 코팅되고 1% BSA로 블로킹된 96웰 플레이트의 웰에 첨가하였다. 결합 반응물을 실온에서 2시간 동안 온화한 교반하에 항온처리하였다. 웰을 0.05% 트윈-20이 함유된 PBS로 철저히 세척하고, 결합된 aHer230-rPEG를 HRP-접합된 항-플래그 항체(시그마)로 검출하였다. 도 62a는 aHer230-rPEG가 Her2-Fc 융합 단백질에 결합하고 인간 IgG에 비특이적으로 결합하지 않음을 보여준다. 결합 데이터는 샘플 희석의 함수로서 제시된다. 50% 최대 결합(EC50)은 대략 10 nM aHer230-rPEG에서 달성된 것으로 추정된다.
정제된 aHer230-rPEG를 크기 배제 HPLC(SE-HPLC)로 분석하여 그의 올리고머화 상태를 결정하였다. aHer230-rPEG의 SE-HPLC 분석을 TSK-겔 G4000SWXL 칼럼 상에서 수행하였다. aHer230-rPEG는 도 62b에 제시된 바와 같이 단량체만을 형성하였다. rPEG 보조적 폴리펩티드의 항-Her2 scFv로의 첨가는 비-rPEG 융합된 scFv에 대해 흔히 관찰되는 이량체의 형성을 효과적으로 제거한다.
SS 결합 산화
이. 콜라이의 세포질내에서의 디설파이드 함유 단백질의 발현은 디설파이드 형성을 억제하는 세포질의 고도의 환원 성질에 기인하여 종종 실패한다. 그러나, 단백질이 보다 산화적인 조건에 노출될 경우 디설파이드 결합이 형성되어 세포 용해를 일으킨다. 상기 입증된 바와 같이, 이. 콜라이에서 발현된 aHer230-rPEG는 그의 표적, Her2에 결합하고, 이는 단백질이 적절히 폴딩됨을 암시한다. aHer230-rPEG의 2개의 디설파이드 결합(각각 vH 및 vL 도메인에 존재)이 정제된 단백질에서 적절히 형성되었는지의 여부를 시험하기 위해, 변성된 정제된 단백질에서 유리 설프하이드릴의 수를 scFv의 완전히 환원된 형태와 비교하였다. 정제된 aHer230-rPEG를 6 M 우레아 또는 10 mM 트리스[2-카복시에틸]포스핀(TCEP: Tris[2-carboxyethyl]phosphine)이 보충된 6 M 우레아에서 1시간 동안 실온에서 변성시켰다. 이어서 샘플을 세파덱스 G-25 수지 상에서 탈염시켜 우레아 및 TCEP를 제거하였다. 즉각적으로, 엘만(Ellman)의 시약(5,5'-디티오-비스-[2-니트로벤조산])을 20 mM의 최종 농도로 첨가하고, 반응을 15분 동안 진행시켰다. 최종적으로, 각각의 용액의 흡광도를 412 nm에서 측정하였다. 변성된 aHer230-rPEG는 거의 흡광도를 나타내지 않고, 이는 정제된 샘플이 완전히 산화됨을 암시한다(도 62c). 변성되고 환원된 반응물(도 62c)은, aHer230-rPEG 중의 모든 시스테인이 환원 상태로 존재할 경우 예상되는 신호를 나타낸다. 따라서, 항-Her2 scFv중의 모든 디설파이드는 적절히 형성되었다.
실시예 16: 다이아바디 aHer203-rPEG의 작제
다이아바디는 vH 및 vL 도메인을 10개 미만의 아미노산 연결기에 의해 연결시킴으로써 형성될 수 있다. 짧은 연결기는 scFv 형성을 허용하지 않고, 결과로서 vH 및 vL 도메인은 상보성, 제2 vH-vL 쇄에 결합하여, 4-도메인, 2 쇄 5OkD 복합체를 형성한다. 다이아바디를 Her2에 결합하는 단일쇄 단편 가변성(scFv) 항체 단편으로부터 작제하였고, 이는 유전학적으로 rPEG50의 N-말단에 융합된다. 실시예 1로부터의 Y30 scFv 연결기 서열을 3개의 아미노산(SGE)으로 대체함으로써 구성물을 생성하여 다이아바디 형식을 허용하였다(도 65a). SGE 서열을 폴리머라제 쇄 반응(PCR)에 의해 도입하였고, 또한 rPEG 스터퍼 구성물과 화합성인 NdeI 및 BbsI 제한 부위를 도입하였다. 이어서 다이아바디-인코딩 단편을 실시예 1에서와 같이 클로닝하였다. 구성물을 DNA 서열화에 의해 확인하였다. aHer203-rPEG 다이아바디를 위한 단백질 서열(다이아바디로서 M.W.=156,598 Da, rPEG를 비롯한 단량체 서열로서 M.W.=78,299 Da)은 도 65b에 제시되어 있다.
BL21(DE3) 골드에서 aHer203-rPEG를 20℃에서 0.2 mM 이소프로필 β-D-1 티오갈락토피라노시드(IPTG)로 유도하여 발현시켰다. 세포를 원심분리에 의해 수확하고, 포스페이트 완충된 염수중 버그버스터/벤조나제에서 용해시켰다. 용해물을 원심분리에 의해 투명하게 만들고, 상청액(가용성 분별물)을 4∼12% SDS PAGE 겔 상으로 로딩하였다. aHer203-rPEG 다이아바디는 이. 콜라이 용해물에서 대략 90 kDa으로 검출되었다(도 65c).
실시예 17: 다이아바디-rPEG50 융합물 aHer203-rPEG의
특성 분석
정제
다이아바디는 vH 및 vL 도메인을 10개 미만의 아미노산 연결기에 의해 연결시킴으로써 형성될 수 있다. 짧은 연결기는 scFv 형성을 허용하지 않고, 결과로서 vH 및 vL 도메인은 상보성 vH-vL 쇄에 결합한다. 다이아바디는 2가의, 가능하게는 이특이적인 치료학적 결여 이펙터 Fc 기능을 생성한다.
Her2에 결합하는 다이아바디를 상기와 같이 디자인하였다. 표적(Her2) 결합을 평가하기 위해, 재조합 aHer203-rPEG 다이아바디를 aHer230-rPEG에 대해 기재된 바와 같이 발현 및 정제하였다. aHer203-rEPG50을 BL21(DE3)-골드 내로 형질전환시키고, 재조합 항체 단편의 발현을 0.2 mM 이소프로필 β-D-1 티오갈락토피라노시드(IPTG)로 20℃에서 유도하였다. 세포를 원심분리에 의해 수확하고, 30 mM 소듐 포스페이트, 0.3 M 소듐 클로라이드, 10% 글리세롤, 20 mM 이미다졸, pH 7.5에 재현탁시켰다. 음파처리로 용해를 달성하고, 가용성 단백질을 고정화 금속 친화도 크로마토그래피(IMAC), 소수성 상호작용 크로마토그래피(HIC), 및 이온 교환 크로마토그래피(IEC)를 비롯한 표준 크로마토그래피 방법에 의해 정제하였다.
결합
aHer203-rPEG 다이아바디의 그의 표적으로의 결합을 aHer230-rPEG에 대해 기재된 바와 같이 수행하였다. 세포를 버그버스터 시약 및 5 U/㎖의 벤조나제(노바겐)가 함유된 포스페이트 완충 염수(PBS)에서 재현탁하여 용해시켰다. 현탁액을 20분 동안 실온에서 항온처리한 후, 10000 rpm에서 10분 동안 원심분리하였다. 이어서 가용성 분별물을 1% 소 혈청 알부민(BSA) 및 0.05% 트윈-20이 함유된 PBS(이후 ELISA 결합 완충액으로 지칭됨)내로 연속적으로 5배 희석하였다. 연속적으로 희석된 aHer230-rPEG 다이아바디를 Her2-Fc 융합 단백질(알&디 시스템스)이 코팅되고 1% BSA로 블로킹된 96웰 플레이트의 웰에 첨가하였다. 결합 반응물을 실온에서 2시간 동안 온화한 교반하에 항온처리하였다. 웰을 0.05% 트윈-20이 함유된 PBS로 철저히 세척하고, 결합된 aHer230-rPEG 다이아바디를 HRP-접합된 항-플래그 항체(M2, 시그마)로 검출하였다. 도 63a는 aHer230-rPEG 다이아바디가 Her2-Fc 융합 단백질에 결합하고 인간 IgG에 비특이적으로 결합하지 않음을 보여준다. 결합 데이터는 샘플 희석의 함수로서 제시된다. 50% 최대 결합(EC50)은 대략 10 nM aHer230-rPEG에서 달성된 것으로 추정된다. 따라서 rPEG 보조적 폴리펩티드를 갖는 기능적 aHer203 다이아바디는 이. 콜라이의 사이토졸에서 발현될 수 있다.
SE-HPLC
다이아바디는 잠재적 2가 치료제로서 조사되어 왔지만, 이들이 보다 높은 차수의 올리고머-삼량체, 사량체 등-으로 재편성되는 경향은 이들의 이용성을 제한하였다. 재편성은 특히 제작시 문제가 되는데, 이는 단량체 scFv를 정제한 후, 액체 형태로 저장할 때 이는 느리지만 예측가능하게 재편성하여 이량체, 및 고급 다량체를 산출하기 때문이다. 이는 최종적으로 수득될 수 있는 정확한 형식의 단백질의 양에 큰 손실을 초래할 뿐만 아니라, 저장시 생성물의 불균일성 및 약물동력학 및 효력에 있어서의 불균일성을 초래한다. scFv의 단량체와 다량체 사이의 평형은 vH와 vL 도메인 사이의 연결기의 길이에 영향을 받을 수 있다. 일반적으로, 12∼14개 초과의 아미노산 길이의 연결기를 갖는 구성물은 우세하게 단량체 형태로 발생되는 반면, 12개 미만의 아미노산 길이의 연결기를 갖는 scFv는 대부분 다량체 형태로 발생된다[Desplancq, D., et al. (1994) Protein Eng, 7: 1027] [Whitlow, M., et al. (1994) Protein Eng, 7: 1017] [Hudson, P. J., et al. (1999) J Immunol Methods, 231: 177]. vH와 vL 사이의 연결기 길이가 30개 아미노산으로 증가하면 평형이 단량체 방향으로 전이된다[Desplancq, D., et al. (1994) Protein Eng, 7: 1027]. 3∼7개 아미노산 사이의 연결기 길이는 다이아바디의 형성을 선호한다[Dolezal, O., et al. (2000) Protein Eng, 13: 565] [Kortt, A. A., et al. (1997) Protein Eng, 10: 423]. 5∼10개 아미노산의 연결기는 대부분 이량체를 초래한다. 항원 존재 및 이온 강도는 단량체-이량체 전이에 영향을 줄 수 있다[Arndt, K. M., et al. (1998) Biochemistry, 37: 12918]. 3개 미만의 아미노산 길이의 연결기는 트리아바디 및 테트라바디의 형성을 선호한다[Le Gall, F., et al. (1999) FEBS Lett, 453: 164] [Dolezal, O., et al. (2000) Protein Eng, 13: 565] [Kortt, A. A., et al. (1997) Protein Eng, 10: 423].
SE-HPLC에 의해 aHer203-rPEG 다이아바디의 올리고머화 상태를 평가하였고, 이는 재편성되지 않음을 입증하였다. 도 63b는 aHer230-rPEG 단일쇄와 aHer203-rPEG 다이아바디의 크기 배제 크로마토그램을 보여준다. 이는 다이아바디가 대부분 이량체이고, 중요하게는, 이는 3% 미만의 삼량체 또는 사량체 형태를 함유함을 입증한다. aHer203-rPEG 다이아바디의 올리고머화 상태를 4℃에서 저장 동안 모니터링하였고, 재편성은 관찰되지 않았다(도 63c). rPEG 보조적 폴리펩티드는 다이아바디의 재편성을 방지하고, 따라서 균일한 생성물의 정제 및 형성을 가능하게 한다.
실시예 18: 박테리아 발현을 위한 Fc 도메인의 코돈 최적화
도 66a에 제시된 바와 같이, 인간 IgG1 불변성 단편(Fc)을 합성하고 rPEG25-녹색 형광성 단백질(GFP)에 융합시켜 Fc-rPEG25-GFP를 산출하였다. Fc 서열을 코딩하는 DNA를 이. 콜라이 최적화된 코돈을 사용하여 시험관내에서 작제하였다. 20개의 뉴클레오티드 중첩(어닐링) 영역을 갖는 60량체 올리고뉴클레오티드를 사용하여 Fc 코돈 라이브러리를 조립하였다. 다수의 코돈을 합성 올리고뉴클레오티드의 비-중첩 영역에 도입하였다. 모든 뉴클레오티드 서열이 목적하는 Fc 서열을 코딩하도록, 생성된 코돈 라이브러리는 대략 10,000의 이론적 크기를 갖는다. 총 18개의 올리고뉴클레오티드를 dNTP 및 DNA 폴리머라제의 존재하에 684 bp의 최종 크기로 조립하였다. NdeI 및 BbsI 화합성 말단을 생성하는 프라이머를 사용하여 PCR에 의해 Fc 코돈 라이브러리를 증폭시켰다. DNA 단편을 제한 분해하고 rPEG25-GFP 벡터내로 NdeI 및 BsaI 제한 분해 부위에서 결찰시켰다. 결찰된 DNA를 BL21(DE3) 골드내로 형질전환시켰다. 총 1000개의 클론을 단리하고, 96웰 형식에서 성장시키고, 0.2 mM IPTG가 함유된 플레이트로 복제하여 발현을 유도하였다. 잘 발현된 구성물은 자외선하에 높은 수준의 형광성을 나타내었다. 총 17개의 클론이 고도의 형광을 특징적으로 나타내었다. 이들 클론을 0.2 mM IPTG를 사용하여 1 ㎖ 배양액에서 발현시키고, 세포를 원심분리에 의해 수확하고, 포스페이트 완충된 염수중 버그버스터+벤조나제로 용해시켰다. 가용성 분별물을 4∼12% SDS PAGE 겔 상에 로딩하였다(도 66b). 재조합 Fc-rPEG 융합물은 SDS-PAGE 상에서 대략 80∼90 kDa의 관찰된 분자량을 가진다(예상 MW는 약 80이지만, rPEG가 단백질 분자량을 증가시킴). 코돈 최적화된 Fc의 DNA 서열은 도 66c에 제시되어 있다.
실시예 19: Fc-rPEG 융합 단백질의 발현 및
특성 분석
IgG1의 Fc 단편을 실시예 5에 상세화된 바와 같이 rPEG에 융합시키고(변형체는 도 31에 예시됨), 이. 콜라이의 세포질에서 발현시켰다. 융합 단백질을 발현하는 세포를 완충액에 재현탁시키고(이 경우 20 mM 소듐 포스페이트 pH 7.0 사용), 세포를 음파처리로 용해시켰다. 불용성 물질을 원심분리에 의해 제거하고, Fc-rPEG-GFP를 가용성 분별물로부터 정제하였다. 손상되지 않은 폴딩된 Fc 단편은 단백질 A에 결합하고, 따라서 친화도 크로마토그래피에 의해 고정화된 재조합 단백질 A를 사용하여 편리하게 정제될 수 있다. Fc 융합물을 함유한 가용성 용해물을 단백질 A 칼럼(GE 헬쓰케어)에 적용하고, 미생물 단백질을 포스페이트 완충액으로 광범위하게 세척하여 제거하였다. Fc-rPEG-GFP 융합 단백질을 단백질 A 칼럼으로부터 글리신 완충액 또는 시트르산나트륨 완충액 pH 3.0을 사용하여 용출하였다. 용출 분별물의 pH를 동량의 트리스 완충액 pH 8.5으로 즉시 조정하였다. 정제된 단백질을 환원 및 산화 조건하에 SDS-PAGE로 분석하였다. 대략 80 kDa의 단일 밴드는 환원 조건하에 검출된 반면, 160 kDa(산화된 힌지) 및 80 kDa(환원된 힌지)에서의 밴드는 산화 조건하에 검출되었다. CuSO4, 데하이드로아스코브산, 또는 다른 산화 제제를 첨가하여 힌지 시스테인의 완전한 산화를 촉매화하였다.
실시예 20: Fab-rPEG 융합 단백질의 작제 및 박테리아 발현
본 실시예는 Fab-rPEG 융합 단백질의 작제 및 박테리아 발현을 기재한다. IgG의 항원 결합(Fab) 단편을 가용성 Fab 발현 뿐만 아니라 반감기 연장을 개선시키는 수단으로서 rPEG에 융합시킬 수 있다. 발현 구성물은 유도성 아라비노즈 프로모터의 제어하에 있는 디자인된 비시스트로닉(bicistronic) RNA 메세지였다(도 67). 비시스트로닉 메세지는 헤어핀(hairpin) 터미네이터, 예컨대 T7 터미네이터 서열에서 종결된다. 각각의 시스트론(cistron) 또는 유전자는 리보솜 결합 부위(RBS: ribosomal binding site)를 가져서 변역 및 종결 코돈(TAA, TGA, 또는 TAG)을 개시하고 번역을 중단한다. 경쇄(vL/cL) 또는 중쇄(vH/cH) 서열을 유전학적으로 rPEG에 융합시키고, 이후 친화성 태그 예컨대 HA(혈구응집소바이러스: hemagglutinin), H(헥사히스티딘), 및/또는 플래그 태그에 융합시킨다. DNA 구성물은 도 67에 도시된 바와 같이 중쇄 첫번째 또는 경쇄 마지막(HL) 또는 경쇄 첫번째 및 중쇄 마지막(LH)을 코딩할 수 있다. 이러한 유형의 구성물로부터의 단백질 발현은 대략 100 kDa 크기의 전체 Fab 단편(이는 rPEG 서열의 총 50 kDa을 포함함)을 형성하는 2개의 대략 50 kDa 쇄를 산출한다.
실시예 21: GFP-rPEG50의 PK 분석
GFP-rPEG50의 아미노산 서열은 도 69에 제시되어 있다. 단백질을 실시예 1과 유사하게 T7 프로모터에 의해 BL21(DE3)에서 발현시켰다. 단백질을 이온 교환 크로마토그래피에 의해, 이어서 소수성 상호작용 크로마토그래피에 의해 정제하였다. GFP-rPEG50의 약물동력학은 피하 및 정맥내 주사를 받은 사이노몰구스 짧은꼬리원숭이에서 연구하였다. 3마리 사이노몰구스 짧은꼬리원숭이를 2개의 그룹으로 나누었고, 2마리 동물에게 정맥내로, 한마리에게 피하로 0.15 ㎎/kg의 GFP-rPEG50을 투약하였다. 일련의 혈액 샘플을 각각의 원숭이에서 취하고, 혈장을 분리하고, 시험 조항(test article) 혈장 농도를 ELISA 검정으로 측정하였다. 정맥내 투약된 동물의 경우 반감기는 17.4시간이었고, 피하 투여된 동물의 경우 13.8시간이었다. 시험 조항에 대한 생물이용성은 도 70에 제시된 바와 같이 대략 54.6%였다.
실시예 22: Ex4-rPEG50의 PK 분석
Ex4-rPEG50은 엑센딘(exendin)-4와 rPEG50 사이의 융합 단백질이다. 이는 셀룰로스 결합 도메인(CBD)을 갖는 융합 단백질로서 생산되었고, 이 도메인은 도 71b에 예시된 바와 같이 TEV 프로테아제에 의한 절단에 의해 제거되도록 디자인되었다. 융합 단백질의 아미노산 서열은 도 71에 제시되어 있다. 발현 플라스미드와 정제 단백질은 실시예 1에서와 유사하게 TEV 단백질가수분해를 위한 단계가 추가되었다. 절단된 CBD를 비딩된 셀룰로스와 함께 항온처리하여 제거하였다. Ex4-rPEG50의 약물동력학을 사이노몰구스 원숭이에서 연구하였다. 4마리 사이노몰구스 짧은꼬리원숭이를 2개의 그룹으로 나누었고, 그룹당 2마리 동물에게 피하 및 정맥내로 0.15 ㎎/kg의 Ex4-rPEG50을 투약하였다. 일련의 혈액 샘플을 각각의 원숭이에서 취하고, 시험 조항 혈장 농도를 ELISA 검정으로 측정하였다. 반감기는 도 70에 제시된 바와 같이 피하 및 정맥내 투약에 대해 각각 9.5시간 및 9.1시간이었다.
실시예 23: 설치류에서 GFP-rPEG50의 PK 분석
본 실시예는 GFP-rPEG25와 GFP-rPEG50의 피하 및 정맥내 약물동력학을 비교한다. 15마리의 래트를 5개의 그룹으로 나누고, 그룹당 3마리의 래트에 피하 및 정맥내 둘 다로 1.67 ㎎/kg의 GFP-rPEGY25 또는 GFP-rPEG_Y288를 투약하였다. GFP-rPEG25는 피하 주사시 대략 8∼9시간의 t0.5를 가졌고 GFP-rPEG50의 경우 11∼15시간의 t0.5를 가졌다. GFP-rPEG25는 대략 25%의 피하 생물이용성이었고, GFP-rPEG50의 경우 11%의 피하 생물이용성이었다. 마우스에서, 125I-GFP-rPEG50을 누드 마우스에 투약하였다. 반감기는 13.4시간이었다.
실시예 24: rPEG50에 융합된 인간 성장 호르몬의
PK
분석
rPEG50을 인간 성장 호르몬(hGH)의 C- 또는 N-말단에 융합시켰다. 단백질을 실시예 8에 기재된 바와 같이 정제하였다. 약물동력학을 사이노몰구스 원숭이에서 연구하였다. 2마리의 사이노몰구스 짧은꼬리원숭이를 2개의 그룹으로 나누고, 그룹당 1마리였다. 각각의 원숭이에게 0.15 ㎎/kg의 성장 호르몬 구성물, hGH-rPEG50 또는 rPEG50-hGH를 정맥내로 투약하였다. 2가지 성장 호르몬 구성물은 각각 7 및 10.5시간의 반감기를 가졌다.
실시예 25: Ex4-rPEG50의 마우스 면역원성 및 독성 연구
본 실시예는 마우스내로 50 μg 투약량의 Ex4-rPEG50(1/주)의 10회 피하 주사와 연관된 면역원성 및 잠재적 독성을 기재한다. 도 72a에 예시된 바와 같이, 총 20마리의 마우스(스위스 웹스터: Swiss Webster)에 있어서, 그룹당 10마리의 마우스(그룹당 5마리의 수컷 및 5마리의 암컷)에 각각 30∼4O g의 Ex4-rPEG50 또는 ELSPAR(대조군으로서 작용함)을 매주 투약하였다. 각각의 투약후, 혈액 샘플을 취하고, IgG를 도 72b 및 72c에 제시된 바와 같이 ELISA 검정으로 측정하였다. ELSPAR는 시간에 대해 증가된 상당한 면역 반응을 일으켰다. 반대로 Ex4-rPEG50은 6회의 항원 주사 후 최대를 나타내고 10회의 항원 주사 후 수득된 샘플에서 감소되는 매우 약한 응답을 제공하였다. 모든 마우스는 연구 동안 체중이 증가되었고, 독성의 징후를 보이지 않았으며, 부검 결과 기관 형태에 대한 어떠한 비이상성도 발견되지 않았다. 생존시 혈액 샘플의 완료 후, 독성 분석을 위해 혈액 도말표본, 혈장 및 조직 샘플을 RADIL(미주리주 콜롬비아 소재)에 옮겼다. 조직학적 분석 결과 원위 또는 근위 세관에 뚜렷한 세포질 액포 형성이 존재하지 않았고, 이는 PEG와의 화학 접합에 대한 주요 관심사이다. 간 조직학의 평가 결과 모든 4개의 분석 샘플에서 약간의 염증을 나타내었다. 이는 명백히 건강한 동물의 간에서 흔히 발견되는 것이다. 비장의 분석 결과 모든 4마리의 마우스가 중간 내지 심각한 혈소판기능억제(megakaryocytosis) 및 중간 정도의 조혈작용(hematopoiesis)을 나타내었다. 임상 화학 결과 ALT 및 ALP 수준이 동물중 한마리에 대해 약간 높았고, 이는 간세포의 손상/괴사를 지시한다. 이는 관찰에 근거하여 위중하거나 만성적이 아니다. 혈액학적 검사 결과, 모든 4마리의 마우스는 하나 이상의 약하게 상승된 혈액 세포 계수, 헤모글로빈, 적혈구 용적률, 또는 혈액 총 단백질 농도를 가졌다. 전체적으로, rPEG 융합 단백질의 다수회의 주사는 매우 미미한 면역원성 및 독성을 일으킨다.
실시예 26: GFP-rPEG 융합 단백질의 크기 배제 크로마토그래피
rPEG_Y25 및 rPEG_Y50에 융합된 GFP를 실시예 8에서 논의된 바와 같이 발현시켰다. 도 73에 도시된 바와 같이, 분석용 SEC에 의해 TSK G4000 SWXL(토소(Tosoh), 오하이오주 그로브 시티 소재)을 사용하여 단백질을 분석하였다. 칼럼을 구형 단백질의 상업용 표준물에 의해 보정하였고, 대조군의 분자량은 도 73에 제시되어 있다. GFP-rPEG25는 500 kDa의 겉보기 분자량에서 용출된 반면, GFP-rPEG50은 1500 kDa의 겉보기 분자량에서 용출되었다.
실시예 27: GFP-rPEGY 융합 단백질의 제형화 및
생체내
투여
PBS 중 10 ㎎/㎖의 GFP-rPEGY의 용액을 동 부피의 PBS 중 5 ㎎/㎖의 키토산과 혼합하고, 실온에서 30분 동안 항온처리한다. 침전물을 5,000 x g에서 10분 동안 원심분리하여 수집하고, 0.1 부피의 멸균 PBS로 신속히 1회 세척한다. 이어서 침전물을 동결건조시켜 과량의 유체를 제거하고 미세 분말로 미분한다. 이어서 15 ㎎의 분말을 1 ㎖의 멸균 PBS에 재현탁시키고, 아래 위로 피페팅(pipetting)하여 균질화시킨다. 균질물을 37℃에서 2주 동안 회전하에 저장하고, 10 uL의 샘플을 규칙적 간격으로 제거한다. 불용성 물질을 제거하기 위해 즉시 원심분리하여 샘플을 제조하고, 재용해된 단백질을 상척액에서 GFP 형광성, 광학 밀도, 및 rPEGY ELISA에 의해 정량한다. 상청액 농도를 시간의 함수로서 플로팅하고, 재용해 속도를 결정하기 위해 단일 지수(exponential) 공정에 정합시켰다. 생체내 방출 속도를 결정하기 위해, 스프라그-다울리(Sprague-Dawly) 래트에게 20 ㎎ 분말/1 ㎖ PBS의 신선하게 제조된 현탁액을 1 ㎖/kg(5 ㎎/kg 효과적 용량)의 투여량으로 피하 주사한다. 착화되지 않은 GFP-rPEGY를 5 ㎎/kg으로 동물의 비의존성 코호트(cohort)에 동시에 정맥내 및 피하 주사한다. 혈액 샘플을 규칙적으로 취하고, 단백질의 혈청 농도를 GFP와 rPEGY ELISA에 의해 결정한다. 약물동력학적 파라미터, 예컨대 제거 속도, C최대값, Css, VD, AUC 및 혈청 반감기를 표준 방법에 의해 결정한다(즉, 윈놀린 분석). 피하 및 데포 제형에 대한 생물이용성 및 효과적 투약량을 정맥내 투약과 비교하여 결정한다.
따라서, 본 발명의 바람직한 실시양태가 본원에 제시되고 기재되었지만, 이러한 실시양태가 단지 예로서 제공됨은 당분야의 숙련가에게 명백할 것이다. 이제 본 발명에서 벗어나지 않고 당분야의 숙련가는 다수의 변형, 변경 및 치환을 수행할 것이다. 본원에 기재된 본 발명의 실시양태에 대한 다수의 대안이 본 발명의 실행시 이용될 수 있음을 알아야 한다. 하기 특허청구범위는 본 발명의 범주를 규정하고, 이들 특허청구범위의 범주내의 방법 및 구조물, 및 이들의 대등물이 이에 의해 포함되는 것으로 의도된다.
SEQUENCE LISTING
<110> AMUNIX, INC.
<120> COMPOSITIONS AND METHODS FOR IMPROVING PRODUCTION OF
RECOMBINANT POLYPEPTIDES
<130> 32808-707.601
<140> PCT/US2008/009787
<141> 2008-08-15
<150> 60/956,109
<151> 2007-08-15
<150> 60/981,073
<151> 2007-10-18
<150> 60/986,569
<151> 2007-11-08
<160> 524
<170> PatentIn version 3.5
<210> 1
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
6x His tag
<400> 1
His His His His His His
1 5
<210> 2
<211> 60
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<220>
<223> This sequence may encompass 2 to 10
"Gly Gly Glu Gly Gly Ser" repeating units
<400> 2
Gly Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu Gly
1 5 10 15
Gly Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly Gly
20 25 30
Glu Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly Ser
35 40 45
Gly Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly Ser
50 55 60
<210> 3
<211> 90
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<220>
<223> This sequence may encompass 1 to 10
"Gly Glu Gly Gly Gly Glu Gly Gly Glu" repeating units
<400> 3
Gly Glu Gly Gly Gly Glu Gly Gly Glu Gly Glu Gly Gly Gly Glu Gly
1 5 10 15
Gly Glu Gly Glu Gly Gly Gly Glu Gly Gly Glu Gly Glu Gly Gly Gly
20 25 30
Glu Gly Gly Glu Gly Glu Gly Gly Gly Glu Gly Gly Glu Gly Glu Gly
35 40 45
Gly Gly Glu Gly Gly Glu Gly Glu Gly Gly Gly Glu Gly Gly Glu Gly
50 55 60
Glu Gly Gly Gly Glu Gly Gly Glu Gly Glu Gly Gly Gly Glu Gly Gly
65 70 75 80
Glu Gly Glu Gly Gly Gly Glu Gly Gly Glu
85 90
<210> 4
<211> 50
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<220>
<223> This sequence may encompass 10, 15, 20 or 50
"Ser" repeating residues
<400> 4
Ser Ser Ser Ser Ser Ser Ser Ser Ser Ser Ser Ser Ser Ser Ser Ser
1 5 10 15
Ser Ser Ser Ser Ser Ser Ser Ser Ser Ser Ser Ser Ser Ser Ser Ser
20 25 30
Ser Ser Ser Ser Ser Ser Ser Ser Ser Ser Ser Ser Ser Ser Ser Ser
35 40 45
Ser Ser
50
<210> 5
<211> 18
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 5
Gly Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu Gly
1 5 10 15
Gly Ser
<210> 6
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 6
Gly Gly Glu Gly Gly Glu Gly Gly Glu Ser
1 5 10
<210> 7
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 7
Ser Ser Ser Ser Ser Ser Ser Ser Ser Ser
1 5 10
<210> 8
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<220>
<221> MOD_RES
<222> (7)..(7)
<223> May or may not be present
<400> 8
Ser Lys Val Ile Leu Phe Glu
1 5
<210> 9
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 9
Arg Ala Arg Ala Asp Ala Asp Ala
1 5
<210> 10
<211> 224
<212> PRT
<213> Homo sapiens
<400> 10
Met Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu
1 5 10 15
Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu
20 25 30
Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser
35 40 45
His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu
50 55 60
Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr
65 70 75 80
Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn
85 90 95
Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro
100 105 110
Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln
115 120 125
Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val
130 135 140
Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val
145 150 155 160
Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Ile Pro
165 170 175
Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr
180 185 190
Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val
195 200 205
Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu
210 215 220
<210> 11
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 11
Gly Glu Gly Ser Gly Glu Gly Ser Glu
1 5
<210> 12
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 12
Gly Glu Gly Gly Ser Glu Gly Ser Glu
1 5
<210> 13
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 13
Gly Glu Gly Ser Glu Gly Ser Gly Glu
1 5
<210> 14
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 14
Gly Glu Gly Ser Glu Gly Gly Ser Glu
1 5
<210> 15
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 15
Gly Glu Gly Ser Gly Glu Gly Gly Glu
1 5
<210> 16
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 16
Gly Glu Gly Gly Ser Glu Gly Gly Glu
1 5
<210> 17
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 17
Gly Glu Gly Gly Gly Glu Gly Ser Glu
1 5
<210> 18
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 18
Gly Glu Gly Gly Glu Gly Ser Gly Glu
1 5
<210> 19
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 19
Gly Glu Gly Gly Glu Gly Gly Ser Glu
1 5
<210> 20
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 20
Gly Glu Gly Ser Glu Gly Gly Gly Glu
1 5
<210> 21
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<220>
<221> MOD_RES
<222> (2)..(2)
<223> Ser or Glu
<220>
<221> MOD_RES
<222> (9)..(9)
<223> Ser or Glu
<220>
<221> MOD_RES
<222> (11)..(11)
<223> Ser or Glu
<400> 21
Gly Xaa Glu Gly Ser Gly Glu Gly Xaa Gly Xaa Glu
1 5 10
<210> 22
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<220>
<221> MOD_RES
<222> (2)..(2)
<223> Ser or Glu
<220>
<221> MOD_RES
<222> (9)..(9)
<223> Ser or Glu
<220>
<221> MOD_RES
<222> (11)..(11)
<223> Ser or Glu
<400> 22
Gly Xaa Glu Gly Gly Ser Glu Gly Xaa Gly Xaa Glu
1 5 10
<210> 23
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<220>
<221> MOD_RES
<222> (2)..(2)
<223> Ser or Glu
<400> 23
Gly Xaa Glu Gly Ser Gly Glu Gly Gly Ser Gly Glu
1 5 10
<210> 24
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<220>
<221> MOD_RES
<222> (2)..(2)
<223> Ser or Glu
<400> 24
Gly Xaa Glu Gly Gly Ser Glu Gly Gly Ser Gly Glu
1 5 10
<210> 25
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<220>
<221> MOD_RES
<222> (6)..(6)
<223> Ser or Glu
<220>
<221> MOD_RES
<222> (9)..(9)
<223> Ser or Glu
<220>
<221> MOD_RES
<222> (11)..(11)
<223> Ser or Glu
<400> 25
Gly Ser Gly Glu Gly Xaa Glu Gly Xaa Gly Xaa Glu
1 5 10
<210> 26
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<220>
<221> MOD_RES
<222> (6)..(6)
<223> Ser or Glu
<220>
<221> MOD_RES
<222> (9)..(9)
<223> Ser or Glu
<220>
<221> MOD_RES
<222> (11)..(11)
<223> Ser or Glu
<400> 26
Gly Gly Ser Glu Gly Xaa Glu Gly Xaa Gly Xaa Glu
1 5 10
<210> 27
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<220>
<221> MOD_RES
<222> (6)..(6)
<223> Ser or Glu
<400> 27
Gly Ser Gly Glu Gly Xaa Glu Gly Gly Ser Gly Glu
1 5 10
<210> 28
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<220>
<221> MOD_RES
<222> (6)..(6)
<223> Ser or Glu
<400> 28
Gly Gly Ser Glu Gly Xaa Glu Gly Gly Ser Gly Glu
1 5 10
<210> 29
<211> 20
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<220>
<221> MOD_RES
<222> (2)..(2)
<223> Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (4)..(4)
<223> Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (6)..(6)
<223> Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (8)..(8)
<223> Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (10)..(10)
<223> Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (12)..(12)
<223> Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (14)..(14)
<223> Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (16)..(16)
<223> Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (18)..(18)
<223> Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (20)..(20)
<223> Asp, Glu, Thr or Pro
<400> 29
Gly Xaa Gly Xaa Gly Xaa Gly Xaa Gly Xaa Gly Xaa Gly Xaa Gly Xaa
1 5 10 15
Gly Xaa Gly Xaa
20
<210> 30
<211> 20
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<220>
<221> MOD_RES
<222> (2)..(2)
<223> Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (4)..(4)
<223> Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (6)..(6)
<223> Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (8)..(8)
<223> Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (10)..(10)
<223> Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (12)..(12)
<223> Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (14)..(14)
<223> Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (16)..(16)
<223> Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (18)..(18)
<223> Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (20)..(20)
<223> Asp, Glu, Thr or Pro
<400> 30
Ser Xaa Ser Xaa Ser Xaa Ser Xaa Ser Xaa Ser Xaa Ser Xaa Ser Xaa
1 5 10 15
Ser Xaa Ser Xaa
20
<210> 31
<211> 21
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<220>
<221> MOD_RES
<222> (3)..(3)
<223> Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (6)..(6)
<223> Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (9)..(9)
<223> Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (12)..(12)
<223> Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (15)..(15)
<223> Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (18)..(18)
<223> Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (21)..(21)
<223> Asp, Glu, Thr or Pro
<400> 31
Gly Gly Xaa Gly Gly Xaa Gly Gly Xaa Gly Gly Xaa Gly Gly Xaa Gly
1 5 10 15
Gly Xaa Gly Gly Xaa
20
<210> 32
<211> 21
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<220>
<221> MOD_RES
<222> (3)..(3)
<223> Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (6)..(6)
<223> Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (9)..(9)
<223> Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (12)..(12)
<223> Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (15)..(15)
<223> Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (18)..(18)
<223> Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (21)..(21)
<223> Asp, Glu, Thr or Pro
<400> 32
Ser Ser Xaa Ser Ser Xaa Ser Ser Xaa Ser Ser Xaa Ser Ser Xaa Ser
1 5 10 15
Ser Xaa Ser Ser Xaa
20
<210> 33
<211> 20
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<220>
<221> MOD_RES
<222> (4)..(4)
<223> Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (8)..(8)
<223> Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (12)..(12)
<223> Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (16)..(16)
<223> Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (20)..(20)
<223> Asp, Glu, Thr or Pro
<400> 33
Gly Gly Gly Xaa Gly Gly Gly Xaa Gly Gly Gly Xaa Gly Gly Gly Xaa
1 5 10 15
Gly Gly Gly Xaa
20
<210> 34
<211> 20
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<220>
<221> MOD_RES
<222> (4)..(4)
<223> Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (8)..(8)
<223> Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (12)..(12)
<223> Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (16)..(16)
<223> Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (20)..(20)
<223> Asp, Glu, Thr or Pro
<400> 34
Ser Ser Ser Xaa Ser Ser Ser Xaa Ser Ser Ser Xaa Ser Ser Ser Xaa
1 5 10 15
Ser Ser Ser Xaa
20
<210> 35
<211> 20
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<220>
<221> MOD_RES
<222> (5)..(5)
<223> Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (10)..(10)
<223> Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (15)..(15)
<223> Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (20)..(20)
<223> Asp, Glu, Thr or Pro
<400> 35
Gly Gly Gly Gly Xaa Gly Gly Gly Gly Xaa Gly Gly Gly Gly Xaa Gly
1 5 10 15
Gly Gly Gly Xaa
20
<210> 36
<211> 20
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<220>
<221> MOD_RES
<222> (5)..(5)
<223> Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (10)..(10)
<223> Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (15)..(15)
<223> Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (20)..(20)
<223> Asp, Glu, Thr or Pro
<400> 36
Ser Ser Ser Ser Xaa Ser Ser Ser Ser Xaa Ser Ser Ser Ser Xaa Ser
1 5 10 15
Ser Ser Ser Xaa
20
<210> 37
<211> 210
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<220>
<221> MOD_RES
<222> (1)..(20)
<223> This region may encompass 1 to 20
"Gly" repeating residues
<220>
<221> MOD_RES
<222> (21)..(21)
<223> Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (22)..(41)
<223> This region may encompass 1 to 20
"Gly" repeating residues
<220>
<221> MOD_RES
<222> (42)..(42)
<223> Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (43)..(62)
<223> This region may encompass 1 to 20
"Gly" repeating residues
<220>
<221> MOD_RES
<222> (63)..(63)
<223> Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (64)..(83)
<223> This region may encompass 1 to 20
"Gly" repeating residues
<220>
<221> MOD_RES
<222> (84)..(84)
<223> Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (85)..(104)
<223> This region may encompass 1 to 20
"Gly" repeating residues
<220>
<221> MOD_RES
<222> (105)..(105)
<223> Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (106)..(125)
<223> This region may encompass 1 to 20
"Gly" repeating residues
<220>
<221> MOD_RES
<222> (126)..(126)
<223> Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (127)..(146)
<223> This region may encompass 1 to 20
"Gly" repeating residues
<220>
<221> MOD_RES
<222> (147)..(147)
<223> Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (148)..(167)
<223> This region may encompass 1 to 20
"Gly" repeating residues
<220>
<221> MOD_RES
<222> (168)..(168)
<223> Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (169)..(188)
<223> This region may encompass 1 to 20
"Gly" repeating residues
<220>
<221> MOD_RES
<222> (189)..(189)
<223> Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (190)..(209)
<223> This region may encompass 1 to 20
"Gly" repeating residues
<220>
<221> MOD_RES
<222> (210)..(210)
<223> Asp, Glu, Thr or Pro
<400> 37
Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly
1 5 10 15
Gly Gly Gly Gly Xaa Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly
20 25 30
Gly Gly Gly Gly Gly Gly Gly Gly Gly Xaa Gly Gly Gly Gly Gly Gly
35 40 45
Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Xaa Gly
50 55 60
Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly
65 70 75 80
Gly Gly Gly Xaa Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly
85 90 95
Gly Gly Gly Gly Gly Gly Gly Gly Xaa Gly Gly Gly Gly Gly Gly Gly
100 105 110
Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Xaa Gly Gly
115 120 125
Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly
130 135 140
Gly Gly Xaa Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly
145 150 155 160
Gly Gly Gly Gly Gly Gly Gly Xaa Gly Gly Gly Gly Gly Gly Gly Gly
165 170 175
Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Xaa Gly Gly Gly
180 185 190
Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly
195 200 205
Gly Xaa
210
<210> 38
<211> 210
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<220>
<221> MOD_RES
<222> (21)..(21)
<223> Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (22)..(41)
<223> This region may encompass 1 to 20
"Ser" repeating residues
<220>
<221> MOD_RES
<222> (42)..(42)
<223> Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (43)..(62)
<223> This region may encompass 1 to 20
"Ser" repeating residues
<220>
<221> MOD_RES
<222> (63)..(63)
<223> Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (64)..(83)
<223> This region may encompass 1 to 20
"Ser" repeating residues
<220>
<221> MOD_RES
<222> (84)..(84)
<223> Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (85)..(104)
<223> This region may encompass 1 to 20
"Ser" repeating residues
<220>
<221> MOD_RES
<222> (105)..(105)
<223> Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (106)..(125)
<223> This region may encompass 1 to 20
"Ser" repeating residues
<220>
<221> MOD_RES
<222> (126)..(126)
<223> Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (127)..(146)
<223> This region may encompass 1 to 20
"Ser" repeating residues
<220>
<221> MOD_RES
<222> (147)..(147)
<223> Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (148)..(167)
<223> This region may encompass 1 to 20
"Ser" repeating residues
<220>
<221> MOD_RES
<222> (168)..(168)
<223> Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (169)..(187)
<223> This region may encompass 1 to 20
"Ser" repeating residues
<220>
<221> MOD_RES
<222> (189)..(189)
<223> Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (190)..(209)
<223> This region may encompass 1 to 20
"Ser" repeating residues
<220>
<221> MOD_RES
<222> (210)..(210)
<223> Asp, Glu, Thr or Pro
<400> 38
Ser Ser Ser Ser Ser Ser Ser Ser Ser Ser Ser Ser Ser Ser Ser Ser
1 5 10 15
Ser Ser Ser Ser Xaa Ser Ser Ser Ser Ser Ser Ser Ser Ser Ser Ser
20 25 30
Ser Ser Ser Ser Ser Ser Ser Ser Ser Xaa Ser Ser Ser Ser Ser Ser
35 40 45
Ser Ser Ser Ser Ser Ser Ser Ser Ser Ser Ser Ser Ser Ser Xaa Ser
50 55 60
Ser Ser Ser Ser Ser Ser Ser Ser Ser Ser Ser Ser Ser Ser Ser Ser
65 70 75 80
Ser Ser Ser Xaa Ser Ser Ser Ser Ser Ser Ser Ser Ser Ser Ser Ser
85 90 95
Ser Ser Ser Ser Ser Ser Ser Ser Xaa Ser Ser Ser Ser Ser Ser Ser
100 105 110
Ser Ser Ser Ser Ser Ser Ser Ser Ser Ser Ser Ser Ser Xaa Ser Ser
115 120 125
Ser Ser Ser Ser Ser Ser Ser Ser Ser Ser Ser Ser Ser Ser Ser Ser
130 135 140
Ser Ser Xaa Ser Ser Ser Ser Ser Ser Ser Ser Ser Ser Ser Ser Ser
145 150 155 160
Ser Ser Ser Ser Ser Ser Ser Xaa Ser Ser Ser Ser Ser Ser Ser Ser
165 170 175
Ser Ser Ser Ser Ser Ser Ser Ser Ser Ser Ser Ser Xaa Ser Ser Ser
180 185 190
Ser Ser Ser Ser Ser Ser Ser Ser Ser Ser Ser Ser Ser Ser Ser Ser
195 200 205
Ser Xaa
210
<210> 39
<211> 288
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 39
Ser Ser Gly Ser Ser Glu Ser Ser Gly Ser Ser Glu Ser Ser Gly Ser
1 5 10 15
Ser Glu Ser Ser Gly Ser Ser Glu Ser Ser Gly Ser Ser Glu Ser Ser
20 25 30
Gly Ser Ser Glu Ser Ser Gly Ser Ser Glu Ser Ser Gly Ser Ser Glu
35 40 45
Ser Ser Gly Ser Ser Glu Ser Ser Gly Ser Ser Glu Ser Ser Gly Ser
50 55 60
Ser Glu Ser Ser Gly Ser Ser Glu Ser Ser Gly Ser Ser Glu Ser Ser
65 70 75 80
Gly Ser Ser Glu Ser Ser Gly Ser Ser Glu Ser Ser Gly Ser Ser Glu
85 90 95
Ser Ser Gly Ser Ser Glu Ser Ser Gly Ser Ser Glu Ser Ser Gly Ser
100 105 110
Ser Glu Ser Ser Gly Ser Ser Glu Ser Ser Gly Ser Ser Glu Ser Ser
115 120 125
Gly Ser Ser Glu Ser Ser Gly Ser Ser Glu Ser Ser Gly Ser Ser Glu
130 135 140
Ser Ser Gly Ser Ser Glu Ser Ser Gly Ser Ser Glu Ser Ser Gly Ser
145 150 155 160
Ser Glu Ser Ser Gly Ser Ser Glu Ser Ser Gly Ser Ser Glu Ser Ser
165 170 175
Gly Ser Ser Glu Ser Ser Gly Ser Ser Glu Ser Ser Gly Ser Ser Glu
180 185 190
Ser Ser Gly Ser Ser Glu Ser Ser Gly Ser Ser Glu Ser Ser Gly Ser
195 200 205
Ser Glu Ser Ser Gly Ser Ser Glu Ser Ser Gly Ser Ser Glu Ser Ser
210 215 220
Gly Ser Ser Glu Ser Ser Gly Ser Ser Glu Ser Ser Gly Ser Ser Glu
225 230 235 240
Ser Ser Gly Ser Ser Glu Ser Ser Gly Ser Ser Glu Ser Ser Gly Ser
245 250 255
Ser Glu Ser Ser Gly Ser Ser Glu Ser Ser Gly Ser Ser Glu Ser Ser
260 265 270
Gly Ser Ser Glu Ser Ser Gly Ser Ser Glu Ser Ser Gly Ser Ser Glu
275 280 285
<210> 40
<211> 288
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 40
Ser Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Glu Ser Ser Glu Ser
1 5 10 15
Ser Ser Ser Glu Ser Ser Ser Glu Ser Ser Glu Ser Ser Ser Ser Glu
20 25 30
Ser Ser Ser Glu Ser Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Glu
35 40 45
Ser Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Glu Ser Ser Glu Ser
50 55 60
Ser Ser Ser Glu Ser Ser Ser Glu Ser Ser Glu Ser Ser Ser Ser Glu
65 70 75 80
Ser Ser Ser Glu Ser Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Glu
85 90 95
Ser Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Glu Ser Ser Glu Ser
100 105 110
Ser Ser Ser Glu Ser Ser Ser Glu Ser Ser Glu Ser Ser Ser Ser Glu
115 120 125
Ser Ser Ser Glu Ser Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Glu
130 135 140
Ser Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Glu Ser Ser Glu Ser
145 150 155 160
Ser Ser Ser Glu Ser Ser Ser Glu Ser Ser Glu Ser Ser Ser Ser Glu
165 170 175
Ser Ser Ser Glu Ser Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Glu
180 185 190
Ser Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Glu Ser Ser Glu Ser
195 200 205
Ser Ser Ser Glu Ser Ser Ser Glu Ser Ser Glu Ser Ser Ser Ser Glu
210 215 220
Ser Ser Ser Glu Ser Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Glu
225 230 235 240
Ser Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Glu Ser Ser Glu Ser
245 250 255
Ser Ser Ser Glu Ser Ser Ser Glu Ser Ser Glu Ser Ser Ser Ser Glu
260 265 270
Ser Ser Ser Glu Ser Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Glu
275 280 285
<210> 41
<211> 324
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 41
Gly Glu Gly Gly Gly Glu Gly Gly Glu Gly Glu Gly Gly Gly Glu Gly
1 5 10 15
Gly Glu Gly Glu Gly Gly Gly Glu Gly Gly Glu Gly Glu Gly Gly Gly
20 25 30
Glu Gly Gly Glu Gly Glu Gly Gly Gly Glu Gly Gly Glu Gly Glu Gly
35 40 45
Gly Gly Glu Gly Gly Glu Gly Glu Gly Gly Gly Glu Gly Gly Glu Gly
50 55 60
Glu Gly Gly Gly Glu Gly Gly Glu Gly Glu Gly Gly Gly Glu Gly Gly
65 70 75 80
Glu Gly Glu Gly Gly Gly Glu Gly Gly Glu Gly Glu Gly Gly Gly Glu
85 90 95
Gly Gly Glu Gly Glu Gly Gly Gly Glu Gly Gly Glu Gly Glu Gly Gly
100 105 110
Gly Glu Gly Gly Glu Gly Glu Gly Gly Gly Glu Gly Gly Glu Gly Glu
115 120 125
Gly Gly Gly Glu Gly Gly Glu Gly Glu Gly Gly Gly Glu Gly Gly Glu
130 135 140
Gly Glu Gly Gly Gly Glu Gly Gly Glu Gly Glu Gly Gly Gly Glu Gly
145 150 155 160
Gly Glu Gly Glu Gly Gly Gly Glu Gly Gly Glu Gly Glu Gly Gly Gly
165 170 175
Glu Gly Gly Glu Gly Glu Gly Gly Gly Glu Gly Gly Glu Gly Glu Gly
180 185 190
Gly Gly Glu Gly Gly Glu Gly Glu Gly Gly Gly Glu Gly Gly Glu Gly
195 200 205
Glu Gly Gly Gly Glu Gly Gly Glu Gly Glu Gly Gly Gly Glu Gly Gly
210 215 220
Glu Gly Glu Gly Gly Gly Glu Gly Gly Glu Gly Glu Gly Gly Gly Glu
225 230 235 240
Gly Gly Glu Gly Glu Gly Gly Gly Glu Gly Gly Glu Gly Glu Gly Gly
245 250 255
Gly Glu Gly Gly Glu Gly Glu Gly Gly Gly Glu Gly Gly Glu Gly Glu
260 265 270
Gly Gly Gly Glu Gly Gly Glu Gly Glu Gly Gly Gly Glu Gly Gly Glu
275 280 285
Gly Glu Gly Gly Gly Glu Gly Gly Glu Gly Glu Gly Gly Gly Glu Gly
290 295 300
Gly Glu Gly Glu Gly Gly Gly Glu Gly Gly Glu Gly Glu Gly Gly Gly
305 310 315 320
Glu Gly Gly Glu
<210> 42
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 42
Gly Gly Gly Ser Glu
1 5
<210> 43
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 43
Gly Gly Ser Glu
1
<210> 44
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 44
Glu Glu Glu Glu Glu
1 5
<210> 45
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 45
Gly Gly Gly Gly Gly
1 5
<210> 46
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 46
Ser Ser Ser Ser Ser
1 5
<210> 47
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 47
Ala Ala Ala Ala Ala
1 5
<210> 48
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 48
Ser Glu Ser Ser Ser Glu Ser Ser Glu
1 5
<210> 49
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 49
Ser Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Glu
1 5 10
<210> 50
<211> 15
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 50
Ser Ser Ser Glu Ser Ser Ser Ser Ser Glu Ser Ser Ser Ser Glu
1 5 10 15
<210> 51
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 51
Ser Ser Ser Ser Glu Ser Ser Ser Ser Ser Ser Glu
1 5 10
<210> 52
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 52
Ser Ser Ser Glu
1
<210> 53
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 53
Ser Ser Ser Ser Glu
1 5
<210> 54
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 54
Ser Ser Ser Ser Ser Glu
1 5
<210> 55
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 55
Ser Ser Ser Ser Ser Ser Glu
1 5
<210> 56
<211> 21
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 56
Gly Glu Gly Glu Ser Glu Gly Glu Gly Glu Gly Glu Ser Glu Gly Glu
1 5 10 15
Gly Glu Ser Gly Glu
20
<210> 57
<211> 40
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 57
Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Glu Glu Glu Glu Glu Glu
1 5 10 15
Glu Glu Glu Glu Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Glu Glu
20 25 30
Glu Glu Glu Glu Glu Glu Glu Glu
35 40
<210> 58
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 58
Gly Gly Gly Glu Glu
1 5
<210> 59
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 59
Gly Gly Glu Gly Gly Ser
1 5
<210> 60
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 60
Glu Gly Gly Ser Gly Gly
1 5
<210> 61
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 61
Gly Glu Gly Gly Ser Gly
1 5
<210> 62
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 62
Gly Gly Ser Gly Gly Glu
1 5
<210> 63
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 63
Ser Gly Gly Glu Gly Gly
1 5
<210> 64
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 64
Gly Ser Gly Gly Glu Gly
1 5
<210> 65
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 65
Gly Glu Glu Gly Ser Ser
1 5
<210> 66
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 66
Gly Ser Ser Gly Glu Glu
1 5
<210> 67
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 67
Ser Gly Ser Glu Gly Glu
1 5
<210> 68
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 68
Ser Ser Gly Glu Glu Gly
1 5
<210> 69
<211> 20
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 69
Glu Glu Glu Gly Gly Gly Ser Ser Ser Gly Glu Gly Gly Ser Ser Ser
1 5 10 15
Gly Ser Glu Glu
20
<210> 70
<211> 20
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 70
Glu Ser Gly Gly Ser Ser Glu Gly Ser Ser Glu Glu Ser Gly Ser Ser
1 5 10 15
Glu Gly Ser Glu
20
<210> 71
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 71
Glu Glu Glu Ser Ser Ser Gly Gly Gly
1 5
<210> 72
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 72
Glu Glu Ser Ser Gly Gly
1 5
<210> 73
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 73
Glu Ser Gly Ser Glu
1 5
<210> 74
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 74
Glu Glu Ser Gly Ser
1 5
<210> 75
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 75
Glu Ser Gly Gly Ser Glu
1 5
<210> 76
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 76
Glu Ser Gly Glu Glu Ser Gly
1 5
<210> 77
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 77
Glu Ser Gly Pro Glu Ser Gly
1 5
<210> 78
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 78
Glu Gly Glu Gly Glu Gly Glu Gly Glu Gly Glu
1 5 10
<210> 79
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 79
Gly Ser Gly Ser Gly Ser Gly Ser Gly Ser Gly Ser Gly Ser
1 5 10
<210> 80
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 80
Ser Glu Ser Glu Ser Glu Ser Glu Ser Glu Ser Glu Ser Glu Ser Glu
1 5 10 15
Ser
<210> 81
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 81
Asp Asp Asp Glu Glu
1 5
<210> 82
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 82
Asp Asp Asp Gly Gly
1 5
<210> 83
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 83
Asp Asp Asp Lys Lys
1 5
<210> 84
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 84
Asp Asp Asp Pro Pro
1 5
<210> 85
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 85
Asp Asp Asp Arg Arg
1 5
<210> 86
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 86
Asp Asp Asp Ser Ser
1 5
<210> 87
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 87
Asp Asp Asp Thr Thr
1 5
<210> 88
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 88
Glu Glu Glu Asp Asp
1 5
<210> 89
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 89
Glu Glu Glu Gly Gly
1 5
<210> 90
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 90
Glu Glu Glu Lys Lys
1 5
<210> 91
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 91
Glu Glu Glu Pro Pro
1 5
<210> 92
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 92
Glu Glu Glu Arg Arg
1 5
<210> 93
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 93
Glu Glu Glu Ser Ser
1 5
<210> 94
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 94
Glu Glu Glu Thr Thr
1 5
<210> 95
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 95
Gly Gly Gly Asp Asp
1 5
<210> 96
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 96
Gly Gly Gly Glu Glu
1 5
<210> 97
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 97
Gly Gly Gly Lys Lys
1 5
<210> 98
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 98
Gly Gly Gly Pro Pro
1 5
<210> 99
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 99
Gly Gly Gly Arg Arg
1 5
<210> 100
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 100
Lys Lys Lys Asp Asp
1 5
<210> 101
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 101
Lys Lys Lys Glu Glu
1 5
<210> 102
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 102
Lys Lys Lys Gly Gly
1 5
<210> 103
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 103
Lys Lys Lys Pro Pro
1 5
<210> 104
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 104
Lys Lys Lys Arg Arg
1 5
<210> 105
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 105
Lys Lys Lys Ser Ser
1 5
<210> 106
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 106
Lys Lys Lys Thr Thr
1 5
<210> 107
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 107
Pro Pro Pro Asp Asp
1 5
<210> 108
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 108
Pro Pro Pro Glu Glu
1 5
<210> 109
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 109
Pro Pro Pro Gly Gly
1 5
<210> 110
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 110
Pro Pro Pro Lys Lys
1 5
<210> 111
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 111
Pro Pro Pro Arg Arg
1 5
<210> 112
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 112
Pro Pro Pro Ser Ser
1 5
<210> 113
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 113
Pro Pro Pro Thr Thr
1 5
<210> 114
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 114
Arg Arg Arg Asp Asp
1 5
<210> 115
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 115
Arg Arg Arg Glu Glu
1 5
<210> 116
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 116
Arg Arg Arg Gly Gly
1 5
<210> 117
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 117
Arg Arg Arg Lys Lys
1 5
<210> 118
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 118
Arg Arg Arg Pro Pro
1 5
<210> 119
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 119
Arg Arg Arg Ser Ser
1 5
<210> 120
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 120
Arg Arg Arg Thr Thr
1 5
<210> 121
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 121
Ser Ser Ser Asp Asp
1 5
<210> 122
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 122
Ser Ser Ser Glu Glu
1 5
<210> 123
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 123
Ser Ser Ser Gly Gly
1 5
<210> 124
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 124
Ser Ser Ser Lys Lys
1 5
<210> 125
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 125
Ser Ser Ser Pro Pro
1 5
<210> 126
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 126
Ser Ser Ser Arg Arg
1 5
<210> 127
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 127
Ser Ser Ser Thr Thr
1 5
<210> 128
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 128
Thr Thr Thr Asp Asp
1 5
<210> 129
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 129
Thr Thr Thr Glu Glu
1 5
<210> 130
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 130
Thr Thr Thr Gly Gly
1 5
<210> 131
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 131
Thr Thr Thr Lys Lys
1 5
<210> 132
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 132
Thr Thr Thr Pro Pro
1 5
<210> 133
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 133
Thr Thr Thr Arg Arg
1 5
<210> 134
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 134
Thr Thr Thr Ser Ser
1 5
<210> 135
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 135
Asp Asp Asp Asp Glu Glu Glu
1 5
<210> 136
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 136
Asp Asp Asp Asp Gly Gly Gly
1 5
<210> 137
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 137
Asp Asp Asp Asp Lys Lys Lys
1 5
<210> 138
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 138
Asp Asp Asp Asp Pro Pro Pro
1 5
<210> 139
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 139
Asp Asp Asp Asp Arg Arg Arg
1 5
<210> 140
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 140
Asp Asp Asp Asp Ser Ser Ser
1 5
<210> 141
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 141
Asp Asp Asp Asp Thr Thr Thr
1 5
<210> 142
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 142
Glu Glu Glu Glu Asp Asp Asp
1 5
<210> 143
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 143
Glu Glu Glu Glu Gly Gly Gly
1 5
<210> 144
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 144
Glu Glu Glu Glu Lys Lys Lys
1 5
<210> 145
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 145
Glu Glu Glu Glu Pro Pro Pro
1 5
<210> 146
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 146
Glu Glu Glu Glu Arg Arg Arg
1 5
<210> 147
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 147
Glu Glu Glu Glu Ser Ser Ser
1 5
<210> 148
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 148
Glu Glu Glu Glu Thr Thr Thr
1 5
<210> 149
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 149
Lys Lys Lys Lys Asp Asp Asp
1 5
<210> 150
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 150
Lys Lys Lys Lys Glu Glu Glu
1 5
<210> 151
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 151
Lys Lys Lys Lys Gly Gly Gly
1 5
<210> 152
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 152
Lys Lys Lys Lys Pro Pro Pro
1 5
<210> 153
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 153
Lys Lys Lys Lys Arg Arg Arg
1 5
<210> 154
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 154
Lys Lys Lys Ser Ser Ser Ser
1 5
<210> 155
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 155
Lys Lys Lys Lys Thr Thr Thr
1 5
<210> 156
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 156
Pro Pro Pro Pro Asp Asp Asp
1 5
<210> 157
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 157
Pro Pro Pro Pro Glu Glu Glu
1 5
<210> 158
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 158
Pro Pro Pro Pro Gly Gly Gly
1 5
<210> 159
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 159
Pro Pro Pro Lys Lys Lys Lys
1 5
<210> 160
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 160
Pro Pro Pro Pro Arg Arg Arg
1 5
<210> 161
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 161
Pro Pro Pro Pro Ser Ser Ser
1 5
<210> 162
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 162
Pro Pro Pro Thr Thr Thr
1 5
<210> 163
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 163
Arg Arg Arg Arg Asp Asp Asp
1 5
<210> 164
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 164
Arg Arg Arg Arg Glu Glu Glu
1 5
<210> 165
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 165
Arg Arg Arg Arg Gly Gly Gly
1 5
<210> 166
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 166
Arg Arg Arg Arg Lys Lys Lys
1 5
<210> 167
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 167
Arg Arg Arg Arg Pro Pro Pro
1 5
<210> 168
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 168
Arg Arg Arg Arg Ser Ser Ser
1 5
<210> 169
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 169
Arg Arg Arg Arg Thr Thr Thr
1 5
<210> 170
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 170
Ser Ser Ser Ser Asp Asp Asp
1 5
<210> 171
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 171
Ser Ser Ser Ser Glu Glu Glu
1 5
<210> 172
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 172
Ser Ser Ser Ser Gly Gly Gly
1 5
<210> 173
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 173
Ser Ser Ser Ser Lys Lys Lys
1 5
<210> 174
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 174
Ser Ser Ser Ser Pro Pro Pro
1 5
<210> 175
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 175
Ser Ser Ser Ser Arg Arg Arg
1 5
<210> 176
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 176
Ser Ser Ser Ser Thr Thr Thr
1 5
<210> 177
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 177
Thr Thr Thr Thr Asp Asp Asp
1 5
<210> 178
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 178
Thr Thr Thr Thr Glu Glu Glu
1 5
<210> 179
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 179
Thr Thr Thr Thr Gly Gly Gly
1 5
<210> 180
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 180
Thr Thr Thr Thr Lys Lys Lys
1 5
<210> 181
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 181
Thr Thr Thr Thr Pro Pro Pro
1 5
<210> 182
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 182
Thr Thr Thr Thr Arg Arg Arg
1 5
<210> 183
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 183
Thr Thr Thr Thr Ser Ser Ser
1 5
<210> 184
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 184
Asp Asp Glu Glu
1
<210> 185
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 185
Asp Asp Gly Gly
1
<210> 186
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 186
Asp Asp Lys Lys
1
<210> 187
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 187
Asp Asp Pro Pro
1
<210> 188
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 188
Asp Asp Arg Arg
1
<210> 189
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 189
Asp Asp Ser Ser
1
<210> 190
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 190
Asp Asp Thr Thr
1
<210> 191
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 191
Glu Glu Asp Asp
1
<210> 192
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 192
Glu Glu Gly Gly
1
<210> 193
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 193
Glu Glu Lys Lys
1
<210> 194
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 194
Glu Glu Pro Pro
1
<210> 195
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 195
Glu Glu Arg Arg
1
<210> 196
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 196
Glu Glu Ser Ser
1
<210> 197
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 197
Glu Glu Thr Thr
1
<210> 198
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 198
Gly Gly Asp Asp
1
<210> 199
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 199
Gly Gly Glu Glu
1
<210> 200
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 200
Gly Gly Lys Lys
1
<210> 201
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 201
Gly Gly Pro Pro
1
<210> 202
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 202
Gly Gly Arg Arg
1
<210> 203
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 203
Gly Gly Ser Ser
1
<210> 204
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 204
Gly Gly Thr Thr
1
<210> 205
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 205
Lys Lys Asp Asp
1
<210> 206
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 206
Lys Lys Glu Glu
1
<210> 207
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 207
Lys Lys Gly Gly
1
<210> 208
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 208
Lys Lys Pro Pro
1
<210> 209
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 209
Lys Lys Arg Arg
1
<210> 210
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 210
Lys Lys Ser Ser
1
<210> 211
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 211
Lys Lys Thr Thr
1
<210> 212
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 212
Pro Pro Asp Asp
1
<210> 213
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 213
Pro Pro Glu Glu
1
<210> 214
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 214
Pro Pro Gly Gly
1
<210> 215
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 215
Pro Pro Lys Lys
1
<210> 216
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 216
Pro Pro Arg Arg
1
<210> 217
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 217
Pro Pro Ser Ser
1
<210> 218
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 218
Pro Pro Thr Thr
1
<210> 219
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 219
Arg Arg Asp Asp
1
<210> 220
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 220
Arg Arg Glu Glu
1
<210> 221
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 221
Arg Arg Gly Gly
1
<210> 222
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 222
Arg Arg Lys Lys
1
<210> 223
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 223
Arg Arg Pro Pro
1
<210> 224
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 224
Arg Arg Ser Ser
1
<210> 225
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 225
Arg Arg Thr Thr
1
<210> 226
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 226
Ser Ser Asp Asp
1
<210> 227
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 227
Ser Ser Glu Glu
1
<210> 228
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 228
Ser Ser Gly Gly
1
<210> 229
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 229
Ser Ser Lys Lys
1
<210> 230
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 230
Ser Ser Pro Pro
1
<210> 231
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 231
Ser Ser Arg Arg
1
<210> 232
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 232
Ser Ser Thr Thr
1
<210> 233
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 233
Thr Thr Asp Asp
1
<210> 234
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 234
Thr Thr Glu Glu
1
<210> 235
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 235
Thr Thr Gly Gly
1
<210> 236
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 236
Thr Thr Lys Lys
1
<210> 237
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 237
Thr Thr Pro Pro
1
<210> 238
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 238
Thr Thr Arg Arg
1
<210> 239
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 239
Thr Thr Ser Ser
1
<210> 240
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 240
Gly Gly Gly Ser Ser
1 5
<210> 241
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 241
Gly Gly Gly Thr Thr
1 5
<210> 242
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 242
Asp Asp Glu Glu Glu
1 5
<210> 243
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 243
Asp Asp Gly Gly Gly
1 5
<210> 244
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 244
Asp Asp Lys Lys Lys
1 5
<210> 245
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 245
Asp Asp Pro Pro Pro
1 5
<210> 246
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 246
Asp Asp Arg Arg Arg
1 5
<210> 247
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 247
Asp Asp Ser Ser Ser
1 5
<210> 248
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 248
Asp Asp Thr Thr Thr
1 5
<210> 249
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 249
Glu Glu Asp Asp Asp
1 5
<210> 250
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 250
Glu Glu Gly Gly Gly
1 5
<210> 251
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 251
Glu Glu Lys Lys Lys
1 5
<210> 252
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 252
Glu Glu Pro Pro Pro
1 5
<210> 253
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 253
Glu Glu Arg Arg Arg
1 5
<210> 254
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 254
Glu Glu Ser Ser Ser
1 5
<210> 255
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 255
Glu Glu Thr Thr Thr
1 5
<210> 256
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 256
Gly Gly Asp Asp Asp
1 5
<210> 257
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 257
Gly Gly Glu Glu Glu
1 5
<210> 258
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 258
Gly Gly Lys Lys Lys
1 5
<210> 259
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 259
Gly Gly Pro Pro Pro
1 5
<210> 260
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 260
Gly Gly Arg Arg Arg
1 5
<210> 261
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 261
Gly Gly Ser Ser Ser
1 5
<210> 262
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 262
Gly Gly Thr Thr Thr
1 5
<210> 263
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 263
Lys Lys Asp Asp Asp
1 5
<210> 264
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 264
Lys Lys Glu Glu Glu
1 5
<210> 265
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 265
Lys Lys Gly Gly Gly
1 5
<210> 266
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 266
Lys Lys Pro Pro Pro
1 5
<210> 267
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 267
Lys Lys Arg Arg Arg
1 5
<210> 268
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 268
Lys Lys Ser Ser Ser
1 5
<210> 269
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 269
Lys Lys Thr Thr Thr
1 5
<210> 270
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 270
Pro Pro Asp Asp Asp
1 5
<210> 271
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 271
Pro Pro Glu Glu Glu
1 5
<210> 272
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 272
Pro Pro Gly Gly Gly
1 5
<210> 273
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 273
Pro Pro Lys Lys Lys
1 5
<210> 274
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 274
Pro Pro Arg Arg Arg
1 5
<210> 275
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 275
Pro Pro Ser Ser Ser
1 5
<210> 276
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 276
Pro Pro Thr Thr Thr
1 5
<210> 277
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 277
Arg Arg Asp Asp Asp
1 5
<210> 278
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 278
Arg Arg Glu Glu Glu
1 5
<210> 279
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 279
Arg Arg Gly Gly Gly
1 5
<210> 280
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 280
Arg Arg Lys Lys Lys
1 5
<210> 281
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 281
Arg Arg Pro Pro Pro
1 5
<210> 282
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 282
Arg Arg Ser Ser Ser
1 5
<210> 283
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 283
Arg Arg Thr Thr Thr
1 5
<210> 284
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 284
Ser Ser Asp Asp Asp
1 5
<210> 285
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 285
Ser Ser Glu Glu Glu
1 5
<210> 286
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 286
Ser Ser Gly Gly Gly
1 5
<210> 287
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 287
Ser Ser Lys Lys Lys
1 5
<210> 288
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 288
Ser Ser Pro Pro Pro
1 5
<210> 289
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 289
Ser Ser Arg Arg Arg
1 5
<210> 290
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 290
Ser Ser Thr Thr Thr
1 5
<210> 291
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 291
Thr Thr Asp Asp Asp
1 5
<210> 292
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 292
Thr Thr Glu Glu Glu
1 5
<210> 293
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 293
Thr Thr Gly Gly Gly
1 5
<210> 294
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 294
Thr Thr Lys Lys Lys
1 5
<210> 295
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 295
Thr Thr Pro Pro Pro
1 5
<210> 296
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 296
Thr Thr Arg Arg Arg
1 5
<210> 297
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 297
Thr Thr Ser Ser Ser
1 5
<210> 298
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 298
Asp Asp Asp Glu Glu Glu
1 5
<210> 299
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 299
Asp Asp Asp Gly Gly Gly
1 5
<210> 300
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 300
Asp Asp Asp Lys Lys Lys
1 5
<210> 301
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 301
Asp Asp Asp Pro Pro Pro
1 5
<210> 302
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 302
Asp Asp Asp Arg Arg Arg
1 5
<210> 303
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 303
Asp Asp Asp Ser Ser Ser
1 5
<210> 304
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 304
Asp Asp Asp Thr Thr Thr
1 5
<210> 305
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 305
Glu Glu Glu Asp Asp Asp
1 5
<210> 306
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 306
Glu Glu Glu Gly Gly Gly
1 5
<210> 307
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 307
Glu Glu Glu Lys Lys Lys
1 5
<210> 308
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 308
Glu Glu Glu Pro Pro Pro
1 5
<210> 309
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 309
Glu Glu Glu Arg Arg Arg
1 5
<210> 310
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 310
Glu Glu Glu Ser Ser Ser
1 5
<210> 311
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 311
Glu Glu Glu Thr Thr Thr
1 5
<210> 312
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 312
Gly Gly Gly Asp Asp Asp
1 5
<210> 313
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 313
Gly Gly Gly Glu Glu Glu
1 5
<210> 314
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 314
Gly Gly Gly Lys Lys Lys
1 5
<210> 315
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 315
Gly Gly Gly Pro Pro Pro
1 5
<210> 316
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 316
Gly Gly Gly Arg Arg Arg
1 5
<210> 317
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 317
Gly Gly Gly Ser Ser Ser
1 5
<210> 318
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 318
Gly Gly Gly Thr Thr Thr
1 5
<210> 319
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 319
Lys Lys Lys Asp Asp Asp
1 5
<210> 320
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 320
Lys Lys Lys Glu Glu Glu
1 5
<210> 321
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 321
Lys Lys Lys Gly Gly Gly
1 5
<210> 322
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 322
Lys Lys Lys Pro Pro Pro
1 5
<210> 323
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 323
Lys Lys Lys Arg Arg Arg
1 5
<210> 324
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 324
Lys Lys Lys Ser Ser Ser
1 5
<210> 325
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 325
Lys Lys Lys Thr Thr Thr
1 5
<210> 326
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 326
Pro Pro Pro Asp Asp Asp
1 5
<210> 327
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 327
Pro Pro Pro Glu Glu Glu
1 5
<210> 328
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 328
Pro Pro Pro Gly Gly Gly
1 5
<210> 329
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 329
Pro Pro Pro Lys Lys Lys
1 5
<210> 330
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 330
Pro Pro Pro Arg Arg Arg
1 5
<210> 331
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 331
Pro Pro Pro Ser Ser Ser
1 5
<210> 332
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 332
Pro Pro Pro Thr Thr Thr
1 5
<210> 333
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 333
Arg Arg Arg Asp Asp Asp
1 5
<210> 334
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 334
Arg Arg Arg Glu Glu Glu
1 5
<210> 335
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 335
Arg Arg Arg Gly Gly Gly
1 5
<210> 336
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 336
Arg Arg Arg Lys Lys Lys
1 5
<210> 337
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 337
Arg Arg Arg Pro Pro Pro
1 5
<210> 338
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 338
Arg Arg Arg Ser Ser Ser
1 5
<210> 339
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 339
Arg Arg Arg Thr Thr Thr
1 5
<210> 340
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 340
Ser Ser Ser Asp Asp Asp
1 5
<210> 341
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 341
Ser Ser Ser Glu Glu Glu
1 5
<210> 342
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 342
Ser Ser Ser Gly Gly Gly
1 5
<210> 343
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 343
Ser Ser Ser Lys Lys Lys
1 5
<210> 344
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 344
Ser Ser Ser Pro Pro Pro
1 5
<210> 345
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 345
Ser Ser Ser Arg Arg Arg
1 5
<210> 346
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 346
Ser Ser Ser Thr Thr Thr
1 5
<210> 347
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 347
Thr Thr Thr Asp Asp Asp
1 5
<210> 348
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 348
Thr Thr Thr Glu Glu Glu
1 5
<210> 349
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 349
Thr Thr Thr Gly Gly Gly
1 5
<210> 350
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 350
Thr Thr Thr Lys Lys Lys
1 5
<210> 351
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 351
Thr Thr Thr Pro Pro Pro
1 5
<210> 352
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 352
Thr Thr Thr Arg Arg Arg
1 5
<210> 353
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 353
Thr Thr Thr Ser Ser Ser
1 5
<210> 354
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 354
Gly Gly Gly Gly Asp Asp Asp
1 5
<210> 355
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 355
Gly Gly Gly Gly Glu Glu Glu
1 5
<210> 356
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 356
Gly Gly Gly Gly Lys Lys Lys
1 5
<210> 357
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 357
Gly Gly Gly Gly Pro Pro Pro
1 5
<210> 358
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 358
Gly Gly Gly Gly Arg Arg Arg
1 5
<210> 359
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 359
Gly Gly Gly Gly Ser Ser Ser
1 5
<210> 360
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 360
Gly Gly Gly Gly Thr Thr Thr
1 5
<210> 361
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 361
Pro Pro Pro Pro Thr Thr Thr
1 5
<210> 362
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 362
Ser Ser Ser Glu Ser Ser Glu Ser Ser Ser Ser Glu
1 5 10
<210> 363
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 363
Gly Gly Glu Gly Glu Gly Gly Gly Glu
1 5
<210> 364
<211> 24
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 364
Ser Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Glu Ser Ser Glu Ser
1 5 10 15
Ser Ser Ser Glu Ser Ser Ser Glu
20
<210> 365
<211> 15
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 365
Ser Ser Ser Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Ser Glu
1 5 10 15
<210> 366
<211> 18
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 366
Ser Ser Ser Ser Ser Glu Ser Ser Ser Ser Ser Glu Ser Ser Ser Ser
1 5 10 15
Ser Glu
<210> 367
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 367
Ser Ser Ser Ser Ser Ser Glu Ser Ser Ser Ser Ser Ser Glu
1 5 10
<210> 368
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 368
Ser Ser Ser Ser Ser Ser Glu Ser Ser Ser Ser Glu
1 5 10
<210> 369
<211> 24
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 369
Ser Ser Ser Ser Ser Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Ser
1 5 10 15
Ser Ser Glu Ser Ser Ser Ser Glu
20
<210> 370
<211> 15
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 370
Ser Gly Gly Gly Gly Gly Gly Gly Gly Gly Arg Gly Ala Gly Gly
1 5 10 15
<210> 371
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 371
Thr Gly Ser Gly Asn Gly Ser Gly Gly Gly Gly Gly Gly Gly Ser Gly
1 5 10 15
Gly
<210> 372
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 372
Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
1 5 10
<210> 373
<211> 37
<212> PRT
<213> Homo sapiens
<400> 373
Gly Pro Gly Gly Gly Gly Gly Pro Gly Gly Gly Gly Gly Pro Gly Gly
1 5 10 15
Gly Gly Pro Gly Gly Gly Gly Gly Gly Gly Pro Gly Gly Gly Gly Gly
20 25 30
Gly Pro Gly Gly Gly
35
<210> 374
<211> 33
<212> PRT
<213> Homo sapiens
<400> 374
Gly Ala Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Ser
1 5 10 15
Gly Gly Gly Gly Gly Gly Gly Gly Ala Gly Ala Gly Gly Ala Gly Ala
20 25 30
Gly
<210> 375
<211> 32
<212> PRT
<213> Homo sapiens
<400> 375
Gly Gly Gly Ser Gly Ser Gly Gly Ala Gly Gly Gly Ser Gly Gly Gly
1 5 10 15
Ser Gly Ser Gly Gly Gly Gly Gly Gly Ala Gly Gly Gly Gly Gly Gly
20 25 30
<210> 376
<211> 27
<212> PRT
<213> Homo sapiens
<400> 376
Gly Asp Gly Gly Gly Ala Gly Gly Gly Gly Gly Gly Gly Gly Ser Gly
1 5 10 15
Gly Gly Gly Ser Gly Gly Gly Gly Gly Gly Gly
20 25
<210> 377
<211> 25
<212> PRT
<213> Homo sapiens
<400> 377
Gly Ser Gly Ser Gly Ser Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly
1 5 10 15
Gly Gly Ser Gly Gly Gly Gly Gly Gly
20 25
<210> 378
<211> 23
<212> PRT
<213> Homo sapiens
<400> 378
Gly Gly Gly Arg Gly Gly Arg Gly Gly Gly Arg Gly Gly Gly Gly Arg
1 5 10 15
Gly Gly Gly Arg Gly Gly Gly
20
<210> 379
<211> 21
<212> PRT
<213> Homo sapiens
<400> 379
Gly Ser Gly Gly Ser Gly Gly Ser Gly Gly Gly Pro Gly Pro Gly Pro
1 5 10 15
Gly Gly Gly Gly Gly
20
<210> 380
<211> 18
<212> PRT
<213> Homo sapiens
<400> 380
Gly Glu Gly Gly Gly Gly Gly Gly Glu Gly Gly Gly Ala Gly Gly Gly
1 5 10 15
Ser Gly
<210> 381
<211> 12
<212> PRT
<213> Homo sapiens
<400> 381
Gly Gly Gly Gly Gly Gly Gly Gly Asp Gly Gly Gly
1 5 10
<210> 382
<211> 46
<212> PRT
<213> Homo sapiens
<400> 382
Gly Gly Gly Ser Gly Ser Gly Gly Ala Gly Gly Gly Ser Gly Gly Gly
1 5 10 15
Ser Gly Ser Gly Gly Gly Gly Gly Gly Ala Gly Gly Gly Gly Gly Gly
20 25 30
Ser Ser Gly Gly Gly Ser Gly Thr Ala Gly Gly His Ser Gly
35 40 45
<210> 383
<211> 35
<212> PRT
<213> Homo sapiens
<400> 383
Gly Gly Ser Gly Ala Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly
1 5 10 15
Ser Gly Ser Gly Gly Gly Gly Ser Thr Gly Gly Gly Gly Gly Thr Ala
20 25 30
Gly Gly Gly
35
<210> 384
<211> 32
<212> PRT
<213> Homo sapiens
<400> 384
Gly His Pro Gly Ser Gly Ser Gly Ser Gly Gly Gly Gly Gly Gly Gly
1 5 10 15
Gly Gly Gly Gly Gly Ser Gly Gly Gly Gly Gly Gly Ala Pro Gly Gly
20 25 30
<210> 385
<211> 31
<212> PRT
<213> Homo sapiens
<400> 385
Gly Gly Gly Gly Ser Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly
1 5 10 15
Gly Gly Gly Ser Gly Ser Thr Gly Gly Gly Gly Ser Gly Ala Gly
20 25 30
<210> 386
<211> 31
<212> PRT
<213> Homo sapiens
<400> 386
Gly Gly Arg Gly Arg Gly Gly Arg Gly Arg Gly Ser Arg Gly Arg Gly
1 5 10 15
Gly Gly Gly Thr Arg Gly Arg Gly Arg Gly Arg Gly Gly Arg Gly
20 25 30
<210> 387
<211> 30
<212> PRT
<213> Homo sapiens
<400> 387
Gly Ser Gly Gly Ser Gly Gly Ser Gly Gly Gly Pro Gly Pro Gly Pro
1 5 10 15
Gly Gly Gly Gly Gly Pro Ser Gly Ser Gly Ser Gly Pro Gly
20 25 30
<210> 388
<211> 29
<212> PRT
<213> Homo sapiens
<400> 388
Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Arg Gly Gly Gly Gly
1 5 10 15
Arg Gly Gly Gly Arg Gly Gly Gly Gly Glu Gly Gly Gly
20 25
<210> 389
<211> 28
<212> PRT
<213> Homo sapiens
<400> 389
Gly Gly Gly Gly Thr Gly Ser Ser Gly Gly Ser Gly Ser Gly Gly Gly
1 5 10 15
Gly Ser Gly Gly Gly Gly Gly Gly Gly Ser Ser Gly
20 25
<210> 390
<211> 27
<212> PRT
<213> Homo sapiens
<400> 390
Gly Gly Gly Gly Gly Gly Gly Ser Gly Gly Gly Gly Gly Ser Gly Gly
1 5 10 15
Gly Gly Ser Gly Gly Gly Arg Gly Ala Gly Gly
20 25
<210> 391
<211> 27
<212> PRT
<213> Homo sapiens
<400> 391
Gly Gly Gly Ala Ala Gly Ala Gly Gly Gly Gly Ser Gly Ala Gly Gly
1 5 10 15
Gly Ser Gly Gly Ser Gly Gly Arg Gly Thr Gly
20 25
<210> 392
<211> 27
<212> PRT
<213> Homo sapiens
<400> 392
Gly Ala Gly Gly Gly Arg Gly Gly Gly Ala Gly Gly Glu Gly Gly Ala
1 5 10 15
Ser Gly Ala Glu Gly Gly Gly Gly Ala Gly Gly
20 25
<210> 393
<211> 26
<212> PRT
<213> Homo sapiens
<400> 393
Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly
1 5 10 15
Gly Gly Gly Gly Gly Gly Gly Glu Ala Gly
20 25
<210> 394
<211> 26
<212> PRT
<213> Homo sapiens
<400> 394
Gly Gly Gly Gly Gly Gly Ser Ala Gly Gly Gly Ser Ser Gly Gly Gly
1 5 10 15
Pro Gly Gly Gly Gly Gly Gly Ala Gly Gly
20 25
<210> 395
<211> 25
<212> PRT
<213> Homo sapiens
<400> 395
Gly Gly Gly Gly Gly Pro Gly Gly Gly Gly Gly Gly Gly Pro Gly Gly
1 5 10 15
Gly Gly Gly Pro Gly Gly Gly Gly Gly
20 25
<210> 396
<211> 25
<212> PRT
<213> Homo sapiens
<400> 396
Gly Arg Gly Gly Ala Gly Ser Gly Gly Ala Gly Ser Gly Ala Ala Gly
1 5 10 15
Gly Thr Gly Ser Ser Gly Gly Gly Gly
20 25
<210> 397
<211> 25
<212> PRT
<213> Homo sapiens
<400> 397
Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Ser Gly Gly Ser Gly
1 5 10 15
Gly Gly Gly Gly Gly Gly Gly Gly Gly
20 25
<210> 398
<211> 25
<212> PRT
<213> Homo sapiens
<400> 398
Gly Gly Ser Gly Gly Gly Arg Gly Gly Ala Ser Gly Pro Gly Ser Gly
1 5 10 15
Ser Gly Gly Pro Gly Gly Pro Ala Gly
20 25
<210> 399
<211> 25
<212> PRT
<213> Homo sapiens
<400> 399
Gly Gly His His Gly Asp Arg Gly Gly Gly Arg Gly Gly Arg Gly Gly
1 5 10 15
Arg Gly Gly Arg Gly Gly Arg Ala Gly
20 25
<210> 400
<211> 25
<212> PRT
<213> Homo sapiens
<400> 400
Gly Ser Arg Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly
1 5 10 15
Gly Gly Gly Ala Gly Ala Gly Gly Gly
20 25
<210> 401
<211> 24
<212> PRT
<213> Homo sapiens
<400> 401
Gly Gly Arg Gly Gly Arg Gly Pro Gly Glu Pro Gly Gly Arg Gly Arg
1 5 10 15
Ala Gly Gly Ala Glu Gly Arg Gly
20
<210> 402
<211> 24
<212> PRT
<213> Homo sapiens
<400> 402
Gly Gly Gly Gly Gly Asp Ala Gly Gly Ser Gly Asp Ala Gly Gly Ala
1 5 10 15
Gly Gly Arg Ala Gly Arg Ala Gly
20
<210> 403
<211> 23
<212> PRT
<213> Homo sapiens
<400> 403
Gly Gly Ser Gly Gly Gly Gly Gly Gly Ser Ser Gly Gly Arg Gly Ser
1 5 10 15
Gly Gly Gly Ser Ser Gly Gly
20
<210> 404
<211> 23
<212> PRT
<213> Homo sapiens
<400> 404
Gly Ser Gly Pro Gly Thr Gly Gly Gly Gly Ser Gly Ser Gly Gly Gly
1 5 10 15
Gly Gly Gly Ser Gly Gly Gly
20
<210> 405
<211> 23
<212> PRT
<213> Homo sapiens
<400> 405
Gly Ala Arg Gly Gly Gly Ser Gly Gly Gly Gly Gly Gly Gly Gly Gly
1 5 10 15
Gly Gly Gly Gly Gly Pro Gly
20
<210> 406
<211> 23
<212> PRT
<213> Homo sapiens
<400> 406
Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly
1 5 10 15
Gly Gly Gly Gly Gly Asp Gly
20
<210> 407
<211> 23
<212> PRT
<213> Homo sapiens
<400> 407
Gly Gly Thr Arg Gly Gly Thr Arg Gly Gly Thr Arg Gly Gly Asp Arg
1 5 10 15
Gly Arg Gly Arg Gly Ala Gly
20
<210> 408
<211> 23
<212> PRT
<213> Homo sapiens
<400> 408
Gly Ala Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly
1 5 10 15
Ala Gly Gly Gly Gly Gly Gly
20
<210> 409
<211> 22
<212> PRT
<213> Homo sapiens
<400> 409
Gly Arg Gly Arg Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly
1 5 10 15
Gly Arg Gly Gly Gly Gly
20
<210> 410
<211> 22
<212> PRT
<213> Homo sapiens
<400> 410
Gly Arg Gly Arg Gly Arg Gly Arg Gly Arg Gly Arg Gly Arg Gly Arg
1 5 10 15
Gly Arg Gly Gly Ala Gly
20
<210> 411
<211> 22
<212> PRT
<213> Homo sapiens
<400> 411
Gly Ala Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly
1 5 10 15
Gly Gly Gly Gly Gly Gly
20
<210> 412
<211> 22
<212> PRT
<213> Homo sapiens
<400> 412
Gly Gly Gly Ser Gly Gly Gly His Ser Gly Gly Ser Gly Gly Gly His
1 5 10 15
Ser Gly Gly Ser Gly Gly
20
<210> 413
<211> 22
<212> PRT
<213> Homo sapiens
<400> 413
Gly Ala Gly Ala Gly Gly Gly Gly Gly Gly Gly Gly Ala Gly Gly Gly
1 5 10 15
Gly Ser Ala Gly Ser Gly
20
<210> 414
<211> 22
<212> PRT
<213> Homo sapiens
<400> 414
Gly Gly Pro Gly Thr Gly Ser Gly Gly Gly Gly Ala Gly Thr Gly Gly
1 5 10 15
Gly Ala Gly Gly Pro Gly
20
<210> 415
<211> 22
<212> PRT
<213> Homo sapiens
<400> 415
Gly Gly Gly Gly Gly Gly Gly Gly Gly Ala Gly Gly Ala Gly Gly Ala
1 5 10 15
Gly Ser Ala Gly Gly Gly
20
<210> 416
<211> 21
<212> PRT
<213> Homo sapiens
<400> 416
Gly Gly Asp Gly Gly Gly Ser Ala Gly Gly Gly Ala Gly Gly Gly Ser
1 5 10 15
Gly Gly Gly Ala Gly
20
<210> 417
<211> 21
<212> PRT
<213> Homo sapiens
<400> 417
Gly Gly Gly Gly Gly Gly Ser Gly Gly Gly Gly Gly Gly Gly Gly Gly
1 5 10 15
Gly Gly Gly Gly Gly
20
<210> 418
<211> 21
<212> PRT
<213> Homo sapiens
<400> 418
Gly Pro Gly Ala Gly Ala Gly Ser Gly Ala Gly Gly Ser Ser Gly Gly
1 5 10 15
Gly Gly Gly Pro Gly
20
<210> 419
<211> 21
<212> PRT
<213> Homo sapiens
<400> 419
Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Ser Ser Gly Gly Gly
1 5 10 15
Gly Ser Ser Gly Gly
20
<210> 420
<211> 21
<212> PRT
<213> Homo sapiens
<400> 420
Gly Ser Gly Ser Gly Pro Gly Pro Gly Ser Gly Pro Gly Ser Gly Pro
1 5 10 15
Gly His Gly Ser Gly
20
<210> 421
<211> 21
<212> PRT
<213> Homo sapiens
<400> 421
Gly Pro Gly Pro Gly Pro Gly Pro Gly Pro Gly Pro Gly Pro Gly Pro
1 5 10 15
Gly Pro Gly Pro Gly
20
<210> 422
<211> 21
<212> PRT
<213> Homo sapiens
<400> 422
Gly Ala Gly Ser Gly Gly Gly Gly Ala Ala Gly Ala Gly Ala Gly Ser
1 5 10 15
Ala Gly Gly Gly Gly
20
<210> 423
<211> 21
<212> PRT
<213> Homo sapiens
<400> 423
Gly Gly Gly Gly Gly Gly Gly Ser Gly Gly Gly Gly Gly Gly Ser Gly
1 5 10 15
Gly Gly Gly Gly Gly
20
<210> 424
<211> 21
<212> PRT
<213> Homo sapiens
<400> 424
Gly Arg Gly Arg Gly Arg Gly Arg Gly Arg Gly Arg Gly Arg Gly Arg
1 5 10 15
Gly Arg Gly Arg Gly
20
<210> 425
<211> 21
<212> PRT
<213> Homo sapiens
<400> 425
Gly Gly Gly Gly Gly Gly Gly Ser Gly Gly Ser Gly Gly Gly Gly Gly
1 5 10 15
Ser Gly Gly Gly Gly
20
<210> 426
<211> 21
<212> PRT
<213> Homo sapiens
<400> 426
Gly Gly Glu Glu Gly Gly Ala Ser Gly Gly Gly Pro Gly Ala Gly Ser
1 5 10 15
Gly Ser Ala Gly Gly
20
<210> 427
<211> 21
<212> PRT
<213> Homo sapiens
<400> 427
Gly Gly Gly Gly Gly Gly Gly Gly Asp Gly Gly Gly Arg Arg Gly Arg
1 5 10 15
Gly Arg Gly Arg Gly
20
<210> 428
<211> 20
<212> PRT
<213> Homo sapiens
<400> 428
Gly Gly Pro Gly Gly Pro Gly Gly Gly Gly Ala Gly Gly Pro Gly Gly
1 5 10 15
Ala Gly Ala Gly
20
<210> 429
<211> 20
<212> PRT
<213> Homo sapiens
<400> 429
Gly Thr Gly Gly Gly Gly Ser Thr Gly Gly Gly Gly Gly Gly Gly Gly
1 5 10 15
Ser Gly His Gly
20
<210> 430
<211> 20
<212> PRT
<213> Homo sapiens
<400> 430
Gly Pro Ala Gly Ala Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly
1 5 10 15
Gly Gly Gly Gly
20
<210> 431
<211> 20
<212> PRT
<213> Homo sapiens
<400> 431
Gly Gly Thr Gly Gly Ser Ser Gly Ser Ser Gly Ser Gly Ser Gly Gly
1 5 10 15
Gly Arg Arg Gly
20
<210> 432
<211> 20
<212> PRT
<213> Homo sapiens
<400> 432
Gly Ser Gly Thr Gly Thr Thr Gly Ser Ser Gly Ala Gly Gly Pro Gly
1 5 10 15
Thr Pro Gly Gly
20
<210> 433
<211> 20
<212> PRT
<213> Homo sapiens
<400> 433
Gly Gly Ser Gly Gly Gly Ala Ala Gly Gly Gly Ala Gly Gly Ala Gly
1 5 10 15
Ala Gly Ala Gly
20
<210> 434
<211> 20
<212> PRT
<213> Homo sapiens
<400> 434
Gly Ser Ser Gly Gly Gly Gly Gly Gly Ala Gly Ala Ala Gly Gly Ala
1 5 10 15
Gly Gly Ala Gly
20
<210> 435
<211> 20
<212> PRT
<213> Homo sapiens
<400> 435
Gly Pro Gly Pro Ser Gly Gly Pro Gly Gly Gly Gly Gly Gly Gly Gly
1 5 10 15
Gly Gly Gly Gly
20
<210> 436
<211> 20
<212> PRT
<213> Homo sapiens
<400> 436
Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Ala Ala
1 5 10 15
Gly Ala Gly Gly
20
<210> 437
<211> 20
<212> PRT
<213> Homo sapiens
<400> 437
Gly Ser Ala Gly Gly Ser Ser Gly Ala Ala Gly Ala Ala Gly Gly Gly
1 5 10 15
Ala Gly Ala Gly
20
<210> 438
<211> 600
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<220>
<223> This sequence may encompass 4 to 200
"Ser Ser Asp" repeating units
<400> 438
Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser
1 5 10 15
Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser
20 25 30
Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp
35 40 45
Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser
50 55 60
Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser
65 70 75 80
Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp
85 90 95
Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser
100 105 110
Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser
115 120 125
Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp
130 135 140
Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser
145 150 155 160
Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser
165 170 175
Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp
180 185 190
Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser
195 200 205
Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser
210 215 220
Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp
225 230 235 240
Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser
245 250 255
Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser
260 265 270
Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp
275 280 285
Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser
290 295 300
Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser
305 310 315 320
Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp
325 330 335
Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser
340 345 350
Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser
355 360 365
Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp
370 375 380
Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser
385 390 395 400
Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser
405 410 415
Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp
420 425 430
Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser
435 440 445
Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser
450 455 460
Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp
465 470 475 480
Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser
485 490 495
Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser
500 505 510
Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp
515 520 525
Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser
530 535 540
Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser
545 550 555 560
Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp
565 570 575
Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser Ser Asp Ser
580 585 590
Ser Asp Ser Ser Asp Ser Ser Asp
595 600
<210> 439
<211> 1200
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<220>
<223> This sequence may encompass 4 to 200
"Ser Ser Asp Ser Ser Asn" repeating units
<400> 439
Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser
1 5 10 15
Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser
20 25 30
Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn
35 40 45
Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser
50 55 60
Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser
65 70 75 80
Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn
85 90 95
Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser
100 105 110
Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser
115 120 125
Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn
130 135 140
Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser
145 150 155 160
Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser
165 170 175
Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn
180 185 190
Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser
195 200 205
Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser
210 215 220
Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn
225 230 235 240
Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser
245 250 255
Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser
260 265 270
Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn
275 280 285
Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser
290 295 300
Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser
305 310 315 320
Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn
325 330 335
Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser
340 345 350
Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser
355 360 365
Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn
370 375 380
Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser
385 390 395 400
Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser
405 410 415
Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn
420 425 430
Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser
435 440 445
Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser
450 455 460
Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn
465 470 475 480
Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser
485 490 495
Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser
500 505 510
Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn
515 520 525
Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser
530 535 540
Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser
545 550 555 560
Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn
565 570 575
Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser
580 585 590
Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser
595 600 605
Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn
610 615 620
Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser
625 630 635 640
Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser
645 650 655
Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn
660 665 670
Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser
675 680 685
Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser
690 695 700
Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn
705 710 715 720
Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser
725 730 735
Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser
740 745 750
Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn
755 760 765
Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser
770 775 780
Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser
785 790 795 800
Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn
805 810 815
Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser
820 825 830
Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser
835 840 845
Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn
850 855 860
Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser
865 870 875 880
Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser
885 890 895
Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn
900 905 910
Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser
915 920 925
Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser
930 935 940
Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn
945 950 955 960
Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser
965 970 975
Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser
980 985 990
Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn
995 1000 1005
Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser Asp
1010 1015 1020
Ser Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn
1025 1030 1035
Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser Asp
1040 1045 1050
Ser Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn
1055 1060 1065
Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser Asp
1070 1075 1080
Ser Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn
1085 1090 1095
Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser Asp
1100 1105 1110
Ser Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn
1115 1120 1125
Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser Asp
1130 1135 1140
Ser Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn
1145 1150 1155
Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser Asp
1160 1165 1170
Ser Ser Asn Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn
1175 1180 1185
Ser Ser Asp Ser Ser Asn Ser Ser Asp Ser Ser Asn
1190 1195 1200
<210> 440
<211> 600
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<220>
<223> This sequence may encompass 4 to 200
"Ser Ser Glu" repeating units
<400> 440
Ser Ser Glu Ser Ser Glu Ser Ser Glu Ser Ser Glu Ser Ser Glu Ser
1 5 10 15
Ser Glu Ser Ser Glu Ser Ser Glu Ser Ser Glu Ser Ser Glu Ser Ser
20 25 30
Glu Ser Ser Glu Ser Ser Glu Ser Ser Glu Ser Ser Glu Ser Ser Glu
35 40 45
Ser Ser Glu Ser Ser Glu Ser Ser Glu Ser Ser Glu Ser Ser Glu Ser
50 55 60
Ser Glu Ser Ser Glu Ser Ser Glu Ser Ser Glu Ser Ser Glu Ser Ser
65 70 75 80
Glu Ser Ser Glu Ser Ser Glu Ser Ser Glu Ser Ser Glu Ser Ser Glu
85 90 95
Ser Ser Glu Ser Ser Glu Ser Ser Glu Ser Ser Glu Ser Ser Glu Ser
100 105 110
Ser Glu Ser Ser Glu Ser Ser Glu Ser Ser Glu Ser Ser Glu Ser Ser
115 120 125
Glu Ser Ser Glu Ser Ser Glu Ser Ser Glu Ser Ser Glu Ser Ser Glu
130 135 140
Ser Ser Glu Ser Ser Glu Ser Ser Glu Ser Ser Glu Ser Ser Glu Ser
145 150 155 160
Ser Glu Ser Ser Glu Ser Ser Glu Ser Ser Glu Ser Ser Glu Ser Ser
165 170 175
Glu Ser Ser Glu Ser Ser Glu Ser Ser Glu Ser Ser Glu Ser Ser Glu
180 185 190
Ser Ser Glu Ser Ser Glu Ser Ser Glu Ser Ser Glu Ser Ser Glu Ser
195 200 205
Ser Glu Ser Ser Glu Ser Ser Glu Ser Ser Glu Ser Ser Glu Ser Ser
210 215 220
Glu Ser Ser Glu Ser Ser Glu Ser Ser Glu Ser Ser Glu Ser Ser Glu
225 230 235 240
Ser Ser Glu Ser Ser Glu Ser Ser Glu Ser Ser Glu Ser Ser Glu Ser
245 250 255
Ser Glu Ser Ser Glu Ser Ser Glu Ser Ser Glu Ser Ser Glu Ser Ser
260 265 270
Glu Ser Ser Glu Ser Ser Glu Ser Ser Glu Ser Ser Glu Ser Ser Glu
275 280 285
Ser Ser Glu Ser Ser Glu Ser Ser Glu Ser Ser Glu Ser Ser Glu Ser
290 295 300
Ser Glu Ser Ser Glu Ser Ser Glu Ser Ser Glu Ser Ser Glu Ser Ser
305 310 315 320
Glu Ser Ser Glu Ser Ser Glu Ser Ser Glu Ser Ser Glu Ser Ser Glu
325 330 335
Ser Ser Glu Ser Ser Glu Ser Ser Glu Ser Ser Glu Ser Ser Glu Ser
340 345 350
Ser Glu Ser Ser Glu Ser Ser Glu Ser Ser Glu Ser Ser Glu Ser Ser
355 360 365
Glu Ser Ser Glu Ser Ser Glu Ser Ser Glu Ser Ser Glu Ser Ser Glu
370 375 380
Ser Ser Glu Ser Ser Glu Ser Ser Glu Ser Ser Glu Ser Ser Glu Ser
385 390 395 400
Ser Glu Ser Ser Glu Ser Ser Glu Ser Ser Glu Ser Ser Glu Ser Ser
405 410 415
Glu Ser Ser Glu Ser Ser Glu Ser Ser Glu Ser Ser Glu Ser Ser Glu
420 425 430
Ser Ser Glu Ser Ser Glu Ser Ser Glu Ser Ser Glu Ser Ser Glu Ser
435 440 445
Ser Glu Ser Ser Glu Ser Ser Glu Ser Ser Glu Ser Ser Glu Ser Ser
450 455 460
Glu Ser Ser Glu Ser Ser Glu Ser Ser Glu Ser Ser Glu Ser Ser Glu
465 470 475 480
Ser Ser Glu Ser Ser Glu Ser Ser Glu Ser Ser Glu Ser Ser Glu Ser
485 490 495
Ser Glu Ser Ser Glu Ser Ser Glu Ser Ser Glu Ser Ser Glu Ser Ser
500 505 510
Glu Ser Ser Glu Ser Ser Glu Ser Ser Glu Ser Ser Glu Ser Ser Glu
515 520 525
Ser Ser Glu Ser Ser Glu Ser Ser Glu Ser Ser Glu Ser Ser Glu Ser
530 535 540
Ser Glu Ser Ser Glu Ser Ser Glu Ser Ser Glu Ser Ser Glu Ser Ser
545 550 555 560
Glu Ser Ser Glu Ser Ser Glu Ser Ser Glu Ser Ser Glu Ser Ser Glu
565 570 575
Ser Ser Glu Ser Ser Glu Ser Ser Glu Ser Ser Glu Ser Ser Glu Ser
580 585 590
Ser Glu Ser Ser Glu Ser Ser Glu
595 600
<210> 441
<211> 40
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<220>
<221> MOD_RES
<222> (2)..(2)
<223> Ser, Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (4)..(4)
<223> Ser, Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (6)..(6)
<223> Ser, Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (8)..(8)
<223> Ser, Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (10)..(10)
<223> Ser, Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (12)..(12)
<223> Ser, Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (14)..(14)
<223> Ser, Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (16)..(16)
<223> Ser, Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (18)..(18)
<223> Ser, Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (20)..(20)
<223> Ser, Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (22)..(22)
<223> Ser, Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (24)..(24)
<223> Ser, Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (26)..(26)
<223> Ser, Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (28)..(28)
<223> Ser, Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (30)..(30)
<223> Ser, Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (32)..(32)
<223> Ser, Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (34)..(34)
<223> Ser, Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (36)..(36)
<223> Ser, Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (38)..(38)
<223> Ser, Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (40)..(40)
<223> Ser, Asp, Glu, Thr or Pro
<400> 441
Gly Xaa Gly Xaa Gly Xaa Gly Xaa Gly Xaa Gly Xaa Gly Xaa Gly Xaa
1 5 10 15
Gly Xaa Gly Xaa Gly Xaa Gly Xaa Gly Xaa Gly Xaa Gly Xaa Gly Xaa
20 25 30
Gly Xaa Gly Xaa Gly Xaa Gly Xaa
35 40
<210> 442
<211> 39
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<220>
<221> MOD_RES
<222> (3)..(3)
<223> Ser, Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (6)..(6)
<223> Ser, Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (9)..(9)
<223> Ser, Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (12)..(12)
<223> Ser, Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (15)..(15)
<223> Ser, Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (18)..(18)
<223> Ser, Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (21)..(21)
<223> Ser, Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (24)..(24)
<223> Ser, Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (27)..(27)
<223> Ser, Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (30)..(30)
<223> Ser, Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (33)..(33)
<223> Ser, Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (36)..(36)
<223> Ser, Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (39)..(39)
<223> Ser, Asp, Glu, Thr or Pro
<400> 442
Gly Gly Xaa Gly Gly Xaa Gly Gly Xaa Gly Gly Xaa Gly Gly Xaa Gly
1 5 10 15
Gly Xaa Gly Gly Xaa Gly Gly Xaa Gly Gly Xaa Gly Gly Xaa Gly Gly
20 25 30
Xaa Gly Gly Xaa Gly Gly Xaa
35
<210> 443
<211> 40
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<220>
<221> MOD_RES
<222> (4)..(4)
<223> Ser, Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (8)..(8)
<223> Ser, Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (12)..(12)
<223> Ser, Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (16)..(16)
<223> Ser, Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (20)..(20)
<223> Ser, Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (24)..(24)
<223> Ser, Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (28)..(28)
<223> Ser, Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (32)..(32)
<223> Ser, Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (36)..(36)
<223> Ser, Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (40)..(40)
<223> Ser, Asp, Glu, Thr or Pro
<400> 443
Gly Gly Gly Xaa Gly Gly Gly Xaa Gly Gly Gly Xaa Gly Gly Gly Xaa
1 5 10 15
Gly Gly Gly Xaa Gly Gly Gly Xaa Gly Gly Gly Xaa Gly Gly Gly Xaa
20 25 30
Gly Gly Gly Xaa Gly Gly Gly Xaa
35 40
<210> 444
<211> 40
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<220>
<221> MOD_RES
<222> (5)..(5)
<223> Ser, Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (10)..(10)
<223> Ser, Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (15)..(15)
<223> Ser, Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (20)..(20)
<223> Ser, Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (25)..(25)
<223> Ser, Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (30)..(30)
<223> Ser, Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (35)..(35)
<223> Ser, Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (40)..(40)
<223> Ser, Asp, Glu, Thr or Pro
<400> 444
Gly Gly Gly Gly Xaa Gly Gly Gly Gly Xaa Gly Gly Gly Gly Xaa Gly
1 5 10 15
Gly Gly Gly Xaa Gly Gly Gly Gly Xaa Gly Gly Gly Gly Xaa Gly Gly
20 25 30
Gly Gly Xaa Gly Gly Gly Gly Xaa
35 40
<210> 445
<211> 315
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<220>
<221> MOD_RES
<222> (21)..(21)
<223> Ser, Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (22)..(41)
<223> This region may encompass 1 to 20
"Gly" repeating residues
<220>
<221> MOD_RES
<222> (42)..(42)
<223> Ser, Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (43)..(62)
<223> This region may encompass 1 to 20
"Gly" repeating residues
<220>
<221> MOD_RES
<222> (63)..(63)
<223> Ser, Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (64)..(83)
<223> This region may encompass 1 to 20
"Gly" repeating residues
<220>
<221> MOD_RES
<222> (84)..(84)
<223> Ser, Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (85)..(104)
<223> This region may encompass 1 to 20
"Gly" repeating residues
<220>
<221> MOD_RES
<222> (105)..(105)
<223> Ser, Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (106)..(125)
<223> This region may encompass 1 to 20
"Gly" repeating residues
<220>
<221> MOD_RES
<222> (126)..(126)
<223> Ser, Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (127)..(146)
<223> This region may encompass 1 to 20
"Gly" repeating residues
<220>
<221> MOD_RES
<222> (147)..(147)
<223> Ser, Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (148)..(167)
<223> This region may encompass 1 to 20
"Gly" repeating residues
<220>
<221> MOD_RES
<222> (168)..(168)
<223> Ser, Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (169)..(187)
<223> This region may encompass 1 to 20
"Gly" repeating residues
<220>
<221> MOD_RES
<222> (189)..(189)
<223> Ser, Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (190)..(209)
<223> This region may encompass 1 to 20
"Gly" repeating residues
<220>
<221> MOD_RES
<222> (210)..(210)
<223> Ser, Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (211)..(230)
<223> This region may encompass 1 to 20
"Gly" repeating residues
<220>
<221> MOD_RES
<222> (231)..(231)
<223> Ser, Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (232)..(251)
<223> This region may encompass 1 to 20
"Gly" repeating residues
<220>
<221> MOD_RES
<222> (252)..(252)
<223> Ser, Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (253)..(272)
<223> This region may encompass 1 to 20
"Gly" repeating residues
<220>
<221> MOD_RES
<222> (273)..(273)
<223> Ser, Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (274)..(293)
<223> This region may encompass 1 to 20
"Gly" repeating residues
<220>
<221> MOD_RES
<222> (294)..(294)
<223> Ser, Asp, Glu, Thr or Pro
<220>
<221> MOD_RES
<222> (295)..(314)
<223> This region may encompass 1 to 20
"Gly" repeating residues
<220>
<221> MOD_RES
<222> (315)..(315)
<223> Ser, Asp, Glu, Thr or Pro
<400> 445
Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly
1 5 10 15
Gly Gly Gly Gly Xaa Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly
20 25 30
Gly Gly Gly Gly Gly Gly Gly Gly Gly Xaa Gly Gly Gly Gly Gly Gly
35 40 45
Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Xaa Gly
50 55 60
Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly
65 70 75 80
Gly Gly Gly Xaa Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly
85 90 95
Gly Gly Gly Gly Gly Gly Gly Gly Xaa Gly Gly Gly Gly Gly Gly Gly
100 105 110
Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Xaa Gly Gly
115 120 125
Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly
130 135 140
Gly Gly Xaa Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly
145 150 155 160
Gly Gly Gly Gly Gly Gly Gly Xaa Gly Gly Gly Gly Gly Gly Gly Gly
165 170 175
Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Xaa Gly Gly Gly
180 185 190
Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly
195 200 205
Gly Xaa Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly
210 215 220
Gly Gly Gly Gly Gly Gly Xaa Gly Gly Gly Gly Gly Gly Gly Gly Gly
225 230 235 240
Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Xaa Gly Gly Gly Gly
245 250 255
Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly
260 265 270
Xaa Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly
275 280 285
Gly Gly Gly Gly Gly Xaa Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly
290 295 300
Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Xaa
305 310 315
<210> 446
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 446
Lys Cys Lys Lys
1
<210> 447
<211> 4
<212> PRT
<213> Homo sapiens
<400> 447
Asp Asp Asp Lys
1
<210> 448
<211> 4
<212> PRT
<213> Homo sapiens
<400> 448
Ile Asp Gly Arg
1
<210> 449
<211> 6
<212> PRT
<213> Homo sapiens
<400> 449
Leu Val Pro Arg Gly Ser
1 5
<210> 450
<211> 8
<212> PRT
<213> Homo sapiens
<400> 450
Leu Glu Val Leu Phe Gln Gly Pro
1 5
<210> 451
<211> 7
<212> PRT
<213> Homo sapiens
<400> 451
Glu Gln Leu Tyr Phe Gln Gly
1 5
<210> 452
<211> 7
<212> PRT
<213> Homo sapiens
<400> 452
Glu Thr Leu Phe Gln Gly Pro
1 5
<210> 453
<211> 5
<212> PRT
<213> Homo sapiens
<400> 453
Leu Pro Glu Thr Gly
1 5
<210> 454
<211> 191
<212> PRT
<213> Homo sapiens
<400> 454
Phe Pro Thr Ile Pro Leu Ser Arg Leu Phe Asp Asn Ala Met Leu Arg
1 5 10 15
Ala His Arg Leu His Gln Leu Ala Phe Asp Thr Tyr Gln Glu Phe Glu
20 25 30
Glu Ala Tyr Ile Pro Lys Glu Gln Lys Tyr Ser Phe Leu Gln Asn Pro
35 40 45
Gln Thr Ser Leu Cys Phe Ser Glu Ser Ile Pro Thr Pro Ser Asn Arg
50 55 60
Glu Glu Thr Gln Gln Lys Ser Asn Leu Glu Leu Leu Arg Ile Ser Leu
65 70 75 80
Leu Leu Ile Gln Ser Trp Leu Glu Pro Val Gln Phe Leu Arg Ser Val
85 90 95
Phe Ala Asn Ser Leu Val Tyr Gly Ala Ser Asp Ser Asn Val Tyr Asp
100 105 110
Leu Leu Lys Asp Leu Glu Glu Gly Ile Gln Thr Leu Met Gly Arg Leu
115 120 125
Glu Asp Gly Ser Pro Arg Thr Gly Gln Ile Phe Lys Gln Thr Tyr Ser
130 135 140
Lys Phe Asp Thr Asn Ser His Asn Asp Asp Ala Leu Leu Lys Asn Tyr
145 150 155 160
Gly Leu Leu Tyr Cys Phe Arg Lys Asp Met Asp Lys Val Glu Thr Phe
165 170 175
Leu Arg Ile Val Gln Cys Arg Ser Val Glu Gly Ser Cys Gly Phe
180 185 190
<210> 455
<211> 288
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 455
Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly
1 5 10 15
Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly
20 25 30
Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu
35 40 45
Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly
50 55 60
Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly
65 70 75 80
Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu
85 90 95
Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly
100 105 110
Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly
115 120 125
Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu
130 135 140
Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly
145 150 155 160
Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly
165 170 175
Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu
180 185 190
Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly
195 200 205
Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly
210 215 220
Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu
225 230 235 240
Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly
245 250 255
Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly
260 265 270
Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu
275 280 285
<210> 456
<211> 36
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
primer
<400> 456
aggtagtggw ggwgarggwg gwtcyggwgg agaagg 36
<210> 457
<211> 36
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
primer
<400> 457
acctccttct ccwccrgawc cwccytcwcc wccact 36
<210> 458
<211> 24
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
primer
<400> 458
aggttcgtct tcactcgagg gtac 24
<210> 459
<211> 16
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
primer
<400> 459
cctcgagtga agacga 16
<210> 460
<211> 288
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 460
Ser Ser Ser Glu Ser Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Glu
1 5 10 15
Ser Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Glu Ser Ser Glu Ser
20 25 30
Ser Ser Ser Glu Ser Ser Ser Glu Ser Ser Glu Ser Ser Ser Ser Glu
35 40 45
Ser Ser Ser Glu Ser Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Glu
50 55 60
Ser Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Glu Ser Ser Glu Ser
65 70 75 80
Ser Ser Ser Glu Ser Ser Ser Glu Ser Ser Glu Ser Ser Ser Ser Glu
85 90 95
Ser Ser Ser Glu Ser Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Glu
100 105 110
Ser Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Glu Ser Ser Glu Ser
115 120 125
Ser Ser Ser Glu Ser Ser Ser Glu Ser Ser Glu Ser Ser Ser Ser Glu
130 135 140
Ser Ser Ser Glu Ser Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Glu
145 150 155 160
Ser Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Glu Ser Ser Glu Ser
165 170 175
Ser Ser Ser Glu Ser Ser Ser Glu Ser Ser Glu Ser Ser Ser Ser Glu
180 185 190
Ser Ser Ser Glu Ser Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Glu
195 200 205
Ser Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Glu Ser Ser Glu Ser
210 215 220
Ser Ser Ser Glu Ser Ser Ser Glu Ser Ser Glu Ser Ser Ser Ser Glu
225 230 235 240
Ser Ser Ser Glu Ser Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Glu
245 250 255
Ser Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Glu Ser Ser Glu Ser
260 265 270
Ser Ser Ser Glu Ser Ser Ser Glu Ser Ser Glu Ser Ser Ser Ser Glu
275 280 285
<210> 461
<211> 36
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 461
Ser Ser Ser Glu Ser Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Glu
1 5 10 15
Ser Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Glu Ser Ser Glu Ser
20 25 30
Ser Ser Ser Glu
35
<210> 462
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 462
Ser Ser Glu Ser Ser Glu Ser Ser Ser Ser Glu Ser
1 5 10
<210> 463
<211> 36
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
primer
<400> 463
ttctagtgar tcyagygart cyagytcyag ygaatc 36
<210> 464
<211> 36
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
primer
<400> 464
agaagattcr ctrgarctrg aytcrctrga ytcact 36
<210> 465
<211> 24
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
primer
<400> 465
ttcttcgtct tcactcgagg gtac 24
<210> 466
<211> 288
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 466
Gly Glu Gly Gly Gly Glu Gly Gly Glu Gly Glu Gly Gly Gly Glu Gly
1 5 10 15
Gly Glu Gly Glu Gly Gly Gly Glu Gly Gly Glu Gly Glu Gly Gly Gly
20 25 30
Glu Gly Gly Glu Gly Glu Gly Gly Gly Glu Gly Gly Glu Gly Glu Gly
35 40 45
Gly Gly Glu Gly Gly Glu Gly Glu Gly Gly Gly Glu Gly Gly Glu Gly
50 55 60
Glu Gly Gly Gly Glu Gly Gly Glu Gly Glu Gly Gly Gly Glu Gly Gly
65 70 75 80
Glu Gly Glu Gly Gly Gly Glu Gly Gly Glu Gly Glu Gly Gly Gly Glu
85 90 95
Gly Gly Glu Gly Glu Gly Gly Gly Glu Gly Gly Glu Gly Glu Gly Gly
100 105 110
Gly Glu Gly Gly Glu Gly Glu Gly Gly Gly Glu Gly Gly Glu Gly Glu
115 120 125
Gly Gly Gly Glu Gly Gly Glu Gly Glu Gly Gly Gly Glu Gly Gly Glu
130 135 140
Gly Glu Gly Gly Gly Glu Gly Gly Glu Gly Glu Gly Gly Gly Glu Gly
145 150 155 160
Gly Glu Gly Glu Gly Gly Gly Glu Gly Gly Glu Gly Glu Gly Gly Gly
165 170 175
Glu Gly Gly Glu Gly Glu Gly Gly Gly Glu Gly Gly Glu Gly Glu Gly
180 185 190
Gly Gly Glu Gly Gly Glu Gly Glu Gly Gly Gly Glu Gly Gly Glu Gly
195 200 205
Glu Gly Gly Gly Glu Gly Gly Glu Gly Glu Gly Gly Gly Glu Gly Gly
210 215 220
Glu Gly Glu Gly Gly Gly Glu Gly Gly Glu Gly Glu Gly Gly Gly Glu
225 230 235 240
Gly Gly Glu Gly Glu Gly Gly Gly Glu Gly Gly Glu Gly Glu Gly Gly
245 250 255
Gly Glu Gly Gly Glu Gly Glu Gly Gly Gly Glu Gly Gly Glu Gly Glu
260 265 270
Gly Gly Gly Glu Gly Gly Glu Gly Glu Gly Gly Gly Glu Gly Gly Glu
275 280 285
<210> 467
<211> 27
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
primer
<400> 467
aggtgaaggw garggwggwg gwgaagg 27
<210> 468
<211> 27
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
primer
<400> 468
acctccttcw ccwccwccyt cwccttc 27
<210> 469
<211> 7
<212> PRT
<213> Homo sapiens
<220>
<221> MOD_RES
<222> (7)..(7)
<223> Any amino acid
<400> 469
Glu Asn Leu Tyr Phe Gln Xaa
1 5
<210> 470
<211> 165
<212> PRT
<213> Homo sapiens
<400> 470
Cys Asp Leu Pro Gln Thr His Ser Leu Gly Ser Arg Arg Thr Leu Met
1 5 10 15
Leu Leu Ala Gln Met Arg Lys Ile Ser Leu Phe Ser Cys Leu Lys Asp
20 25 30
Arg His Asp Phe Gly Phe Pro Gln Glu Glu Phe Gly Asn Gln Phe Gln
35 40 45
Lys Ala Glu Thr Ile Pro Val Leu His Glu Met Ile Gln Gln Ile Phe
50 55 60
Asn Leu Phe Ser Thr Lys Asp Ser Ser Ala Ala Trp Asp Glu Thr Leu
65 70 75 80
Leu Asp Lys Phe Tyr Thr Glu Leu Tyr Gln Gln Leu Asn Asp Leu Glu
85 90 95
Ala Cys Val Ile Gln Gly Val Gly Val Thr Glu Thr Pro Leu Met Lys
100 105 110
Glu Asp Ser Ile Leu Ala Val Arg Lys Tyr Phe Gln Arg Ile Thr Leu
115 120 125
Tyr Leu Lys Glu Lys Lys Tyr Ser Pro Cys Ala Trp Glu Val Val Arg
130 135 140
Ala Glu Ile Met Arg Ser Phe Ser Leu Ser Thr Asn Leu Gln Glu Ser
145 150 155 160
Leu Arg Ser Lys Glu
165
<210> 471
<211> 174
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 471
Thr Pro Leu Gly Pro Ala Ser Ser Leu Pro Gln Ser Phe Leu Leu Lys
1 5 10 15
Cys Leu Glu Gln Val Arg Lys Ile Gln Gly Asp Gly Ala Ala Leu Gln
20 25 30
Glu Lys Leu Cys Ala Thr Tyr Lys Leu Cys His Pro Glu Glu Leu Val
35 40 45
Leu Leu Gly His Ser Leu Gly Ile Pro Trp Ala Pro Leu Ser Ser Cys
50 55 60
Pro Ser Gln Ala Leu Gln Leu Ala Gly Cys Leu Ser Gln Leu His Ser
65 70 75 80
Gly Leu Phe Leu Tyr Gln Gly Leu Leu Gln Ala Leu Glu Gly Ile Ser
85 90 95
Pro Glu Leu Gly Pro Thr Leu Asp Thr Leu Gln Leu Asp Val Ala Asp
100 105 110
Phe Ala Thr Thr Ile Trp Gln Gln Met Glu Glu Leu Gly Met Ala Pro
115 120 125
Ala Leu Gln Pro Thr Gln Gly Ala Met Pro Ala Phe Ala Ser Ala Phe
130 135 140
Gln Arg Arg Ala Gly Gly Val Leu Val Ala Ser His Leu Gln Ser Phe
145 150 155 160
Leu Glu Val Ser Tyr Arg Val Leu Arg His Leu Ala Gln Pro
165 170
<210> 472
<211> 288
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 472
Gly Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly Gly
1 5 10 15
Glu Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly Ser
20 25 30
Gly Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu Gly
35 40 45
Gly Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly Gly
50 55 60
Glu Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly Ser
65 70 75 80
Gly Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu Gly
85 90 95
Gly Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly Gly
100 105 110
Glu Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly Ser
115 120 125
Gly Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu Gly
130 135 140
Gly Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly Gly
145 150 155 160
Glu Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly Ser
165 170 175
Gly Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu Gly
180 185 190
Gly Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly Gly
195 200 205
Glu Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly Ser
210 215 220
Gly Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu Gly
225 230 235 240
Gly Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly Gly
245 250 255
Glu Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly Ser
260 265 270
Gly Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu Gly
275 280 285
<210> 473
<211> 288
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 473
Gly Glu Gly Glu Gly Gly Gly Glu Gly Gly Glu Gly Glu Gly Gly Gly
1 5 10 15
Glu Gly Gly Glu Gly Glu Gly Gly Gly Glu Gly Gly Glu Gly Glu Gly
20 25 30
Gly Gly Glu Gly Gly Glu Gly Glu Gly Gly Gly Glu Gly Gly Glu Gly
35 40 45
Glu Gly Gly Gly Glu Gly Gly Glu Gly Glu Gly Gly Gly Glu Gly Gly
50 55 60
Glu Gly Glu Gly Gly Gly Glu Gly Gly Glu Gly Glu Gly Gly Gly Glu
65 70 75 80
Gly Gly Glu Gly Glu Gly Gly Gly Glu Gly Gly Glu Gly Glu Gly Gly
85 90 95
Gly Glu Gly Gly Glu Gly Glu Gly Gly Gly Glu Gly Gly Glu Gly Glu
100 105 110
Gly Gly Gly Glu Gly Gly Glu Gly Glu Gly Gly Gly Glu Gly Gly Glu
115 120 125
Gly Glu Gly Gly Gly Glu Gly Gly Glu Gly Glu Gly Gly Gly Glu Gly
130 135 140
Gly Glu Gly Glu Gly Gly Gly Glu Gly Gly Glu Gly Glu Gly Gly Gly
145 150 155 160
Glu Gly Gly Glu Gly Glu Gly Gly Gly Glu Gly Gly Glu Gly Glu Gly
165 170 175
Gly Gly Glu Gly Gly Glu Gly Glu Gly Gly Gly Glu Gly Gly Glu Gly
180 185 190
Glu Gly Gly Gly Glu Gly Gly Glu Gly Glu Gly Gly Gly Glu Gly Gly
195 200 205
Glu Gly Glu Gly Gly Gly Glu Gly Gly Glu Gly Glu Gly Gly Gly Glu
210 215 220
Gly Gly Glu Gly Glu Gly Gly Gly Glu Gly Gly Glu Gly Glu Gly Gly
225 230 235 240
Gly Glu Gly Gly Glu Gly Glu Gly Gly Gly Glu Gly Gly Glu Gly Glu
245 250 255
Gly Gly Gly Glu Gly Gly Glu Gly Glu Gly Gly Gly Glu Gly Gly Glu
260 265 270
Gly Glu Gly Gly Gly Glu Gly Gly Glu Gly Glu Gly Gly Gly Glu Gly
275 280 285
<210> 474
<211> 288
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 474
Ser Ser Glu Ser Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Glu Ser
1 5 10 15
Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Glu Ser Ser Glu Ser Ser
20 25 30
Ser Ser Glu Ser Ser Ser Glu Ser Ser Glu Ser Ser Ser Ser Glu Ser
35 40 45
Ser Ser Glu Ser Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Glu Ser
50 55 60
Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Glu Ser Ser Glu Ser Ser
65 70 75 80
Ser Ser Glu Ser Ser Ser Glu Ser Ser Glu Ser Ser Ser Ser Glu Ser
85 90 95
Ser Ser Glu Ser Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Glu Ser
100 105 110
Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Glu Ser Ser Glu Ser Ser
115 120 125
Ser Ser Glu Ser Ser Ser Glu Ser Ser Glu Ser Ser Ser Ser Glu Ser
130 135 140
Ser Ser Glu Ser Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Glu Ser
145 150 155 160
Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Glu Ser Ser Glu Ser Ser
165 170 175
Ser Ser Glu Ser Ser Ser Glu Ser Ser Glu Ser Ser Ser Ser Glu Ser
180 185 190
Ser Ser Glu Ser Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Glu Ser
195 200 205
Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Glu Ser Ser Glu Ser Ser
210 215 220
Ser Ser Glu Ser Ser Ser Glu Ser Ser Glu Ser Ser Ser Ser Glu Ser
225 230 235 240
Ser Ser Glu Ser Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Glu Ser
245 250 255
Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Glu Ser Ser Glu Ser Ser
260 265 270
Ser Ser Glu Ser Ser Ser Glu Ser Ser Glu Ser Ser Ser Ser Glu Ser
275 280 285
<210> 475
<211> 336
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 475
Ser Ser Ser Ser Ser Glu Ser Ser Ser Ser Ser Ser Glu Ser Ser Ser
1 5 10 15
Ser Ser Ser Glu Ser Ser Ser Ser Ser Ser Glu Ser Ser Ser Ser Ser
20 25 30
Ser Glu Ser Ser Ser Ser Ser Ser Glu Ser Ser Ser Ser Ser Ser Glu
35 40 45
Ser Ser Ser Ser Ser Ser Glu Ser Ser Ser Ser Ser Ser Glu Ser Ser
50 55 60
Ser Ser Ser Ser Glu Ser Ser Ser Ser Ser Ser Glu Ser Ser Ser Ser
65 70 75 80
Ser Ser Glu Ser Ser Ser Ser Ser Ser Glu Ser Ser Ser Ser Ser Ser
85 90 95
Glu Ser Ser Ser Ser Ser Ser Glu Ser Ser Ser Ser Ser Ser Glu Ser
100 105 110
Ser Ser Ser Ser Ser Glu Ser Ser Ser Ser Ser Ser Glu Ser Ser Ser
115 120 125
Ser Ser Ser Glu Ser Ser Ser Ser Ser Ser Glu Ser Ser Ser Ser Ser
130 135 140
Ser Glu Ser Ser Ser Ser Ser Ser Glu Ser Ser Ser Ser Ser Ser Glu
145 150 155 160
Ser Ser Ser Ser Ser Ser Glu Ser Ser Ser Ser Ser Ser Glu Ser Ser
165 170 175
Ser Ser Ser Ser Glu Ser Ser Ser Ser Ser Ser Glu Ser Ser Ser Ser
180 185 190
Ser Ser Glu Ser Ser Ser Ser Ser Ser Glu Ser Ser Ser Ser Ser Ser
195 200 205
Glu Ser Ser Ser Ser Ser Ser Glu Ser Ser Ser Ser Ser Ser Glu Ser
210 215 220
Ser Ser Ser Ser Ser Glu Ser Ser Ser Ser Ser Ser Glu Ser Ser Ser
225 230 235 240
Ser Ser Ser Glu Ser Ser Ser Ser Ser Ser Glu Ser Ser Ser Ser Ser
245 250 255
Ser Glu Ser Ser Ser Ser Ser Ser Glu Ser Ser Ser Ser Ser Ser Glu
260 265 270
Ser Ser Ser Ser Ser Ser Glu Ser Ser Ser Ser Ser Ser Glu Ser Ser
275 280 285
Ser Ser Ser Ser Glu Ser Ser Ser Ser Ser Ser Glu Ser Ser Ser Ser
290 295 300
Ser Ser Glu Ser Ser Ser Ser Ser Ser Glu Ser Ser Ser Ser Ser Ser
305 310 315 320
Glu Ser Ser Ser Ser Ser Ser Glu Ser Ser Ser Ser Ser Ser Glu Ser
325 330 335
<210> 476
<211> 320
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 476
Ser Ser Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Ser Glu Ser Ser
1 5 10 15
Ser Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser
20 25 30
Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Ser
35 40 45
Glu Ser Ser Ser Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Ser Glu
50 55 60
Ser Ser Ser Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Ser Glu Ser
65 70 75 80
Ser Ser Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Ser Glu Ser Ser
85 90 95
Ser Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser
100 105 110
Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Ser
115 120 125
Glu Ser Ser Ser Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Ser Glu
130 135 140
Ser Ser Ser Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Ser Glu Ser
145 150 155 160
Ser Ser Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Ser Glu Ser Ser
165 170 175
Ser Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser
180 185 190
Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Ser
195 200 205
Glu Ser Ser Ser Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Ser Glu
210 215 220
Ser Ser Ser Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Ser Glu Ser
225 230 235 240
Ser Ser Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Ser Glu Ser Ser
245 250 255
Ser Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser
260 265 270
Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Ser
275 280 285
Glu Ser Ser Ser Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Ser Glu
290 295 300
Ser Ser Ser Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Ser Glu Ser
305 310 315 320
<210> 477
<211> 288
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 477
Gly Glu Gly Ser Gly Glu Gly Ser Glu Gly Glu Gly Ser Glu Gly Ser
1 5 10 15
Gly Glu Gly Glu Gly Ser Glu Gly Ser Gly Glu Gly Glu Gly Gly Ser
20 25 30
Glu Gly Ser Glu Gly Glu Gly Gly Ser Glu Gly Ser Glu Gly Glu Gly
35 40 45
Gly Ser Glu Gly Ser Glu Gly Glu Gly Ser Gly Glu Gly Ser Glu Gly
50 55 60
Glu Gly Gly Ser Glu Gly Ser Glu Gly Glu Gly Ser Gly Glu Gly Ser
65 70 75 80
Glu Gly Glu Gly Ser Glu Gly Gly Ser Glu Gly Glu Gly Gly Ser Glu
85 90 95
Gly Ser Glu Gly Glu Gly Ser Gly Glu Gly Ser Glu Gly Glu Gly Gly
100 105 110
Glu Gly Gly Ser Glu Gly Glu Gly Ser Glu Gly Ser Gly Glu Gly Glu
115 120 125
Gly Ser Gly Glu Gly Ser Glu Gly Glu Gly Ser Glu Gly Ser Gly Glu
130 135 140
Gly Glu Gly Ser Gly Glu Gly Ser Glu Gly Glu Gly Ser Glu Gly Ser
145 150 155 160
Gly Glu Gly Glu Gly Ser Glu Gly Ser Gly Glu Gly Glu Gly Gly Ser
165 170 175
Glu Gly Ser Glu Gly Glu Gly Ser Glu Gly Ser Gly Glu Gly Glu Gly
180 185 190
Gly Glu Gly Ser Gly Glu Gly Glu Gly Ser Gly Glu Gly Ser Glu Gly
195 200 205
Glu Gly Gly Gly Glu Gly Ser Glu Gly Glu Gly Ser Gly Glu Gly Gly
210 215 220
Glu Gly Glu Gly Ser Glu Gly Gly Ser Glu Gly Glu Gly Gly Ser Glu
225 230 235 240
Gly Gly Glu Gly Glu Gly Ser Glu Gly Ser Gly Glu Gly Glu Gly Ser
245 250 255
Glu Gly Gly Ser Glu Gly Glu Gly Ser Glu Gly Gly Ser Glu Gly Glu
260 265 270
Gly Ser Glu Gly Ser Gly Glu Gly Glu Gly Ser Glu Gly Ser Gly Glu
275 280 285
<210> 478
<211> 288
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 478
Gly Glu Gly Ser Gly Glu Gly Ser Glu Gly Glu Gly Ser Glu Gly Ser
1 5 10 15
Gly Glu Gly Glu Gly Ser Glu Gly Gly Ser Glu Gly Glu Gly Ser Glu
20 25 30
Gly Ser Gly Glu Gly Glu Gly Ser Glu Gly Ser Gly Glu Gly Glu Gly
35 40 45
Gly Glu Gly Ser Gly Glu Gly Glu Gly Ser Gly Glu Gly Ser Glu Gly
50 55 60
Glu Gly Gly Gly Glu Gly Ser Glu Gly Glu Gly Gly Ser Glu Gly Ser
65 70 75 80
Glu Gly Glu Gly Gly Ser Glu Gly Ser Glu Gly Glu Gly Gly Glu Gly
85 90 95
Ser Gly Glu Gly Glu Gly Ser Glu Gly Ser Gly Glu Gly Glu Gly Ser
100 105 110
Gly Glu Gly Ser Glu Gly Glu Gly Ser Glu Gly Ser Gly Glu Gly Glu
115 120 125
Gly Ser Glu Gly Ser Gly Glu Gly Glu Gly Gly Ser Glu Gly Ser Glu
130 135 140
Gly Glu Gly Ser Gly Glu Gly Ser Glu Gly Glu Gly Ser Glu Gly Ser
145 150 155 160
Gly Glu Gly Glu Gly Ser Glu Gly Ser Gly Glu Gly Glu Gly Gly Ser
165 170 175
Glu Gly Ser Glu Gly Glu Gly Gly Ser Glu Gly Ser Glu Gly Glu Gly
180 185 190
Gly Ser Glu Gly Ser Glu Gly Glu Gly Ser Gly Glu Gly Ser Glu Gly
195 200 205
Glu Gly Gly Ser Glu Gly Ser Glu Gly Glu Gly Ser Gly Glu Gly Ser
210 215 220
Glu Gly Glu Gly Ser Glu Gly Gly Ser Glu Gly Glu Gly Gly Ser Glu
225 230 235 240
Gly Ser Glu Gly Glu Gly Ser Gly Glu Gly Ser Glu Gly Glu Gly Gly
245 250 255
Glu Gly Gly Ser Glu Gly Glu Gly Ser Glu Gly Ser Gly Glu Gly Glu
260 265 270
Gly Ser Gly Glu Gly Ser Glu Gly Glu Gly Ser Glu Gly Ser Gly Glu
275 280 285
<210> 479
<211> 272
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 479
Ser Glu Gly Glu Ser Glu Glu Ser Ser Glu Ser Gly Gly Glu Ser Ser
1 5 10 15
Ser Gly Gly Gly Ser Glu Glu Ser Ser Glu Glu Gly Ser Gly Gly Gly
20 25 30
Ser Glu Gly Glu Gly Glu Glu Ser Ser Gly Ser Glu Gly Gly Gly Gly
35 40 45
Ser Gly Glu Gly Ser Glu Gly Gly Ser Glu Glu Gly Ser Glu Glu Ser
50 55 60
Ser Glu Gly Glu Ser Glu Glu Ser Ser Glu Ser Gly Gly Glu Ser Ser
65 70 75 80
Ser Gly Gly Gly Ser Glu Glu Ser Ser Glu Glu Gly Ser Gly Gly Gly
85 90 95
Ser Gly Glu Ser Gly Ser Gly Ser Ser Gly Ser Glu Ser Glu Gly Gly
100 105 110
Ser Glu Gly Glu Ser Glu Glu Ser Ser Gly Gly Gly Gly Ser Glu Gly
115 120 125
Ser Glu Gly Glu Ser Glu Glu Ser Ser Glu Ser Gly Gly Glu Ser Ser
130 135 140
Ser Gly Gly Gly Ser Glu Glu Ser Ser Glu Glu Gly Ser Gly Gly Gly
145 150 155 160
Ser Glu Glu Glu Ser Gly Glu Gly Ser Gly Glu Gly Ser Glu Gly Ser
165 170 175
Ser Gly Glu Gly Ser Glu Glu Ser Ser Gly Gly Ser Glu Gly Gly Gly
180 185 190
Ser Gly Gly Ser Gly Gly Glu Gly Ser Gly Glu Ser Gly Ser Gly Ser
195 200 205
Ser Gly Ser Glu Ser Glu Gly Gly Ser Glu Gly Glu Ser Glu Glu Ser
210 215 220
Ser Gly Gly Gly Gly Ser Glu Gly Ser Ser Glu Glu Ser Gly Gly Ser
225 230 235 240
Ser Glu Glu Gly Ser Glu Gly Ser Ser Gly Gly Glu Ser Glu Glu Ser
245 250 255
Ser Glu Gly Glu Ser Gly Gly Gly Ser Gly Gly Gly Ser Glu Gly Ser
260 265 270
<210> 480
<211> 264
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 480
Ser Glu Gly Glu Ser Glu Glu Ser Ser Glu Ser Gly Gly Glu Ser Ser
1 5 10 15
Ser Gly Gly Gly Ser Glu Glu Ser Ser Glu Glu Gly Ser Gly Gly Gly
20 25 30
Ser Glu Gly Glu Ser Glu Glu Ser Ser Glu Ser Gly Gly Glu Ser Ser
35 40 45
Ser Gly Gly Gly Ser Glu Glu Ser Ser Glu Glu Gly Ser Gly Gly Gly
50 55 60
Ser Gly Glu Ser Gly Ser Gly Ser Ser Gly Ser Glu Ser Glu Gly Gly
65 70 75 80
Ser Glu Gly Glu Ser Glu Glu Ser Ser Gly Gly Gly Gly Ser Glu Gly
85 90 95
Ser Glu Ser Glu Gly Glu Glu Gly Ser Glu Glu Gly Ser Gly Glu Gly
100 105 110
Ser Gly Glu Gly Gly Gly Glu Ser Ser Glu Glu Gly Glu Ser Glu Ser
115 120 125
Ser Gly Glu Ser Gly Ser Gly Ser Ser Gly Ser Glu Ser Glu Gly Gly
130 135 140
Ser Glu Gly Glu Ser Glu Glu Ser Ser Gly Gly Gly Gly Ser Glu Gly
145 150 155 160
Ser Gly Glu Ser Gly Ser Gly Ser Ser Gly Ser Glu Ser Glu Gly Gly
165 170 175
Ser Glu Gly Glu Ser Glu Glu Ser Ser Gly Gly Gly Gly Ser Glu Gly
180 185 190
Ser Gly Glu Ser Gly Ser Gly Ser Ser Gly Ser Glu Ser Glu Gly Gly
195 200 205
Ser Glu Gly Glu Ser Glu Glu Ser Ser Gly Gly Gly Gly Ser Glu Gly
210 215 220
Ser Ser Glu Glu Ser Gly Gly Ser Ser Glu Glu Gly Ser Glu Gly Ser
225 230 235 240
Ser Gly Gly Glu Ser Glu Glu Ser Ser Glu Gly Glu Ser Gly Gly Gly
245 250 255
Ser Gly Gly Gly Ser Glu Gly Ser
260
<210> 481
<211> 264
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 481
Ser Glu Gly Glu Ser Glu Glu Ser Ser Glu Ser Gly Gly Glu Ser Ser
1 5 10 15
Ser Gly Gly Gly Ser Glu Glu Ser Ser Glu Glu Gly Ser Gly Gly Gly
20 25 30
Ser Glu Gly Glu Gly Glu Glu Ser Ser Gly Ser Glu Gly Gly Gly Gly
35 40 45
Ser Gly Glu Gly Ser Glu Gly Gly Ser Glu Glu Gly Ser Glu Glu Ser
50 55 60
Ser Glu Gly Glu Ser Glu Glu Ser Ser Glu Ser Gly Gly Glu Ser Ser
65 70 75 80
Ser Gly Gly Gly Ser Glu Glu Ser Ser Glu Glu Gly Ser Gly Gly Gly
85 90 95
Ser Gly Glu Ser Gly Ser Gly Ser Ser Gly Ser Glu Ser Glu Gly Gly
100 105 110
Ser Glu Gly Glu Ser Glu Glu Ser Ser Gly Gly Gly Gly Ser Glu Gly
115 120 125
Ser Gly Glu Ser Gly Ser Gly Ser Ser Gly Ser Glu Ser Glu Gly Gly
130 135 140
Ser Glu Gly Glu Ser Glu Glu Ser Ser Gly Gly Gly Gly Ser Glu Gly
145 150 155 160
Ser Glu Ser Glu Gly Glu Glu Gly Ser Glu Glu Gly Ser Gly Glu Gly
165 170 175
Ser Gly Glu Gly Gly Gly Glu Ser Ser Glu Glu Gly Glu Ser Glu Ser
180 185 190
Ser Glu Gly Glu Ser Glu Glu Ser Ser Glu Ser Gly Gly Glu Ser Ser
195 200 205
Ser Gly Gly Gly Ser Glu Glu Ser Ser Glu Glu Gly Ser Gly Gly Gly
210 215 220
Ser Ser Glu Glu Ser Gly Gly Ser Ser Glu Glu Gly Ser Glu Gly Ser
225 230 235 240
Ser Gly Gly Glu Ser Glu Glu Ser Ser Glu Gly Glu Ser Gly Gly Gly
245 250 255
Ser Gly Gly Gly Ser Glu Gly Ser
260
<210> 482
<211> 264
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 482
Ser Glu Gly Glu Ser Glu Glu Ser Ser Glu Ser Gly Gly Glu Ser Ser
1 5 10 15
Ser Gly Gly Gly Ser Glu Glu Ser Ser Glu Glu Gly Ser Gly Gly Gly
20 25 30
Ser Gly Glu Ser Gly Ser Gly Ser Ser Gly Ser Glu Ser Glu Gly Gly
35 40 45
Ser Glu Gly Glu Ser Glu Glu Ser Ser Gly Gly Gly Gly Ser Glu Gly
50 55 60
Ser Glu Gly Glu Ser Glu Glu Ser Ser Glu Ser Gly Gly Glu Ser Ser
65 70 75 80
Ser Gly Gly Gly Ser Glu Glu Ser Ser Glu Glu Gly Ser Gly Gly Gly
85 90 95
Ser Glu Glu Gly Ser Gly Glu Ser Ser Gly Gly Ser Glu Ser Glu Gly
100 105 110
Ser Gly Gly Glu Ser Glu Gly Gly Ser Gly Gly Glu Gly Gly Glu Gly
115 120 125
Ser Gly Glu Ser Gly Ser Gly Ser Ser Gly Ser Glu Ser Glu Gly Gly
130 135 140
Ser Glu Gly Glu Ser Glu Glu Ser Ser Gly Gly Gly Gly Ser Glu Gly
145 150 155 160
Ser Ser Glu Glu Ser Gly Gly Ser Ser Glu Glu Gly Ser Gly Gly Gly
165 170 175
Ser Glu Ser Gly Glu Glu Ser Gly Ser Gly Glu Glu Ser Glu Gly Gly
180 185 190
Ser Gly Gly Ser Gly Gly Glu Gly Ser Gly Glu Ser Gly Ser Gly Ser
195 200 205
Ser Gly Ser Glu Ser Glu Gly Gly Ser Glu Gly Glu Ser Glu Glu Ser
210 215 220
Ser Gly Gly Gly Gly Ser Glu Gly Ser Ser Gly Glu Gly Glu Glu Ser
225 230 235 240
Ser Glu Gly Glu Gly Gly Glu Ser Ser Glu Glu Gly Ser Gly Gly Ser
245 250 255
Ser Glu Glu Gly Ser Gly Glu Gly
260
<210> 483
<211> 28
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 483
Ser Gly Glu Gly Ser Glu Gly Glu Gly Gly Gly Glu Gly Ser Glu Gly
1 5 10 15
Glu Gly Ser Gly Glu Gly Gly Glu Gly Glu Gly Ser
20 25
<210> 484
<211> 864
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<220>
<221> CDS
<222> (1)..(864)
<400> 484
tct agt gag tcc agt gaa tcc agc tcc agc gaa tct tct agt gaa tcc 48
Ser Ser Glu Ser Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Glu Ser
1 5 10 15
agc gag tct agc tct agc gaa tct tct agt gag tcc agt gag tcc agt 96
Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Glu Ser Ser Glu Ser Ser
20 25 30
tcc agt gaa tct tct agt gag tcc agt gaa tct agc tcc agt gaa tct 144
Ser Ser Glu Ser Ser Ser Glu Ser Ser Glu Ser Ser Ser Ser Glu Ser
35 40 45
tct agt gag tct agc gaa tct agc tcc agc gaa tct tct agt gaa tcc 192
Ser Ser Glu Ser Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Glu Ser
50 55 60
agc gaa tcc agc tct agt gaa tct tct agt gaa tct agc gag tcc agc 240
Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Glu Ser Ser Glu Ser Ser
65 70 75 80
tcc agt gaa tct tct agt gag tcc agt gag tcc agt tct agt gaa tct 288
Ser Ser Glu Ser Ser Ser Glu Ser Ser Glu Ser Ser Ser Ser Glu Ser
85 90 95
tct agt gaa tct agt gag tcc agc tcc agc gaa tct tct agt gaa tct 336
Ser Ser Glu Ser Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Glu Ser
100 105 110
agc gag tcc agt tcc agt gaa tct tct agt gaa tct agt gaa tct agc 384
Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Glu Ser Ser Glu Ser Ser
115 120 125
tct agc gaa tct tct agt gag tcc agc gaa tcc agt tct agt gaa tct 432
Ser Ser Glu Ser Ser Ser Glu Ser Ser Glu Ser Ser Ser Ser Glu Ser
130 135 140
tct agt gag tcc agc gag tcc agc tct agt gaa tct tct agt gaa tcc 480
Ser Ser Glu Ser Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Glu Ser
145 150 155 160
agc gag tcc agt tcc agt gaa tct tct agt gaa tct agt gag tcc agt 528
Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Glu Ser Ser Glu Ser Ser
165 170 175
tct agt gaa tct tct agt gag tcc agc gag tcc agc tct agt gaa tct 576
Ser Ser Glu Ser Ser Ser Glu Ser Ser Glu Ser Ser Ser Ser Glu Ser
180 185 190
tct agt gaa tcc agc gag tcc agt tcc agt gaa tct tct agt gaa tct 624
Ser Ser Glu Ser Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Glu Ser
195 200 205
agt gag tcc agt tct agt gaa tct tct agt gaa tct agt gag tcc agt 672
Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Glu Ser Ser Glu Ser Ser
210 215 220
tcc agt gaa tct tct agt gaa tct agt gaa tcc agt tct agc gaa tct 720
Ser Ser Glu Ser Ser Ser Glu Ser Ser Glu Ser Ser Ser Ser Glu Ser
225 230 235 240
tct agt gag tcc agt gag tcc agc tct agt gaa tct tct agt gaa tcc 768
Ser Ser Glu Ser Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Glu Ser
245 250 255
agc gaa tcc agc tct agc gaa tct tct agt gag tcc agc gag tct agt 816
Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Glu Ser Ser Glu Ser Ser
260 265 270
tcc agt gaa tct tct agt gaa tcc agc gaa tct agc tcc agc gaa tct 864
Ser Ser Glu Ser Ser Ser Glu Ser Ser Glu Ser Ser Ser Ser Glu Ser
275 280 285
<210> 485
<211> 288
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 485
Ser Ser Glu Ser Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Glu Ser
1 5 10 15
Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Glu Ser Ser Glu Ser Ser
20 25 30
Ser Ser Glu Ser Ser Ser Glu Ser Ser Glu Ser Ser Ser Ser Glu Ser
35 40 45
Ser Ser Glu Ser Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Glu Ser
50 55 60
Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Glu Ser Ser Glu Ser Ser
65 70 75 80
Ser Ser Glu Ser Ser Ser Glu Ser Ser Glu Ser Ser Ser Ser Glu Ser
85 90 95
Ser Ser Glu Ser Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Glu Ser
100 105 110
Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Glu Ser Ser Glu Ser Ser
115 120 125
Ser Ser Glu Ser Ser Ser Glu Ser Ser Glu Ser Ser Ser Ser Glu Ser
130 135 140
Ser Ser Glu Ser Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Glu Ser
145 150 155 160
Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Glu Ser Ser Glu Ser Ser
165 170 175
Ser Ser Glu Ser Ser Ser Glu Ser Ser Glu Ser Ser Ser Ser Glu Ser
180 185 190
Ser Ser Glu Ser Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Glu Ser
195 200 205
Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Glu Ser Ser Glu Ser Ser
210 215 220
Ser Ser Glu Ser Ser Ser Glu Ser Ser Glu Ser Ser Ser Ser Glu Ser
225 230 235 240
Ser Ser Glu Ser Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Glu Ser
245 250 255
Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Glu Ser Ser Glu Ser Ser
260 265 270
Ser Ser Glu Ser Ser Ser Glu Ser Ser Glu Ser Ser Ser Ser Glu Ser
275 280 285
<210> 486
<211> 26
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 486
Gly Glu Gly Glu Gly Glu Gly Glu Gly Glu Gly Glu Gly Glu Gly Glu
1 5 10 15
Gly Glu Gly Glu Gly Glu Gly Glu Gly Glu
20 25
<210> 487
<211> 26
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 487
Gly Glu Gly Gly Gly Glu Gly Gly Glu Gly Glu Gly Gly Gly Glu Gly
1 5 10 15
Gly Glu Gly Glu Gly Gly Gly Glu Gly Gly
20 25
<210> 488
<211> 27
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 488
Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly
1 5 10 15
Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly Ser
20 25
<210> 489
<211> 29
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 489
Ser Glu Ser Ser Ser Glu Ser Ser Glu Ser Glu Ser Ser Ser Glu Ser
1 5 10 15
Ser Glu Ser Glu Ser Ser Ser Glu Ser Ser Glu Ser Glu
20 25
<210> 490
<211> 13
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 490
Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly
1 5 10
<210> 491
<211> 24
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 491
Gly Gly Ser Gly Gly Ser Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly
1 5 10 15
Gly Ser Gly Gly Ser Gly Gly Glu
20
<210> 492
<211> 24
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 492
Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly
1 5 10 15
Gly Glu Gly Gly Ser Gly Gly Glu
20
<210> 493
<211> 24
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 493
Gly Glu Gly Gly Gly Glu Gly Gly Glu Gly Glu Gly Gly Gly Glu Gly
1 5 10 15
Gly Glu Gly Glu Gly Gly Gly Glu
20
<210> 494
<211> 18
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 494
Gly Glu Gly Glu Gly Glu Gly Glu Gly Glu Gly Glu Gly Glu Gly Glu
1 5 10 15
Gly Glu
<210> 495
<211> 13
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 495
Glu Glu Glu Glu Glu Glu Glu Glu Glu Glu Glu Glu Glu
1 5 10
<210> 496
<211> 22
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 496
Ser Ser Ser Ser Ser Glu Ser Ser Ser Ser Ser Glu Ser Ser Ser Ser
1 5 10 15
Ser Glu Ser Ser Ser Ser
20
<210> 497
<211> 24
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 497
Ser Ser Ser Glu Ser Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Glu
1 5 10 15
Ser Ser Glu Ser Ser Ser Ser Glu
20
<210> 498
<211> 18
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 498
Ser Ser Ser Ser Ser Glu Ser Ser Ser Ser Glu Ser Ser Ser Ser Ser
1 5 10 15
Ser Glu
<210> 499
<211> 864
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<220>
<221> CDS
<222> (1)..(864)
<400> 499
ggt ggt tct ggt ggt gaa ggt ggt tct ggt ggt gaa ggt ggt tct ggt 48
Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly
1 5 10 15
ggt gaa ggt ggt tct ggt ggt gaa ggt ggt tct ggt ggt gaa ggt ggt 96
Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly
20 25 30
tct ggt ggt gaa ggt ggt tct ggt ggt gaa ggt ggt tct ggt ggt gaa 144
Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu
35 40 45
ggt ggt tct ggt ggt gaa ggt ggt tct ggt ggt gaa ggt ggt tct ggt 192
Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly
50 55 60
ggt gaa ggt ggt tct ggt ggt gaa ggt ggt tct ggt ggt gaa ggt ggt 240
Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly
65 70 75 80
tct ggt ggt gaa ggt ggt tct ggt ggt gaa ggt ggt tct ggt ggt gaa 288
Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu
85 90 95
ggt ggt tct ggt ggt gaa ggt ggt tct ggt ggt gaa ggt ggt tct ggt 336
Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly
100 105 110
ggt gaa ggt ggt tct ggt ggt gaa ggt ggt tct ggt ggt gaa ggt ggt 384
Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly
115 120 125
tct ggt ggt gaa ggt ggt tct ggt ggt gaa ggt ggt tct ggt ggt gaa 432
Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu
130 135 140
ggt ggt tct ggt ggt gaa ggt ggt tct ggt ggt gaa ggt ggt tct ggt 480
Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly
145 150 155 160
ggt gaa ggt ggt tct ggt ggt gaa ggt ggt tct ggt ggt gaa ggt ggt 528
Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly
165 170 175
tct ggt ggt gaa ggt ggt tct ggt ggt gaa ggt ggt tct ggt ggt gaa 576
Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu
180 185 190
ggt ggt tct ggt ggt gaa ggt ggt tct ggt ggt gaa ggt ggt tct ggt 624
Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly
195 200 205
ggt gaa ggt ggt tct ggt ggt gaa ggt ggt tct ggt ggt gaa ggt ggt 672
Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly
210 215 220
tct ggt ggt gaa ggt ggt tct ggt ggt gaa ggt ggt tct ggt ggt gaa 720
Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu
225 230 235 240
ggt ggt tct ggt ggt gaa ggt ggt tct ggt ggt gaa ggt ggt tct ggt 768
Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly
245 250 255
ggt gaa ggt ggt tct ggt ggt gaa ggt ggt tct ggt ggt gaa ggt ggt 816
Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly
260 265 270
tct ggt ggt gaa ggt ggt tct ggt ggt gaa ggt ggt tct ggt ggt gaa 864
Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu
275 280 285
<210> 500
<211> 288
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 500
Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly
1 5 10 15
Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly
20 25 30
Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu
35 40 45
Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly
50 55 60
Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly
65 70 75 80
Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu
85 90 95
Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly
100 105 110
Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly
115 120 125
Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu
130 135 140
Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly
145 150 155 160
Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly
165 170 175
Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu
180 185 190
Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly
195 200 205
Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly
210 215 220
Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu
225 230 235 240
Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly
245 250 255
Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly
260 265 270
Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu Gly Gly Ser Gly Gly Glu
275 280 285
<210> 501
<211> 126
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<220>
<221> CDS
<222> (1)..(39)
<220>
<221> CDS
<222> (58)..(126)
<400> 501
atg gat tat aaa gac gat gac gat aaa ggg tct cca ggt tagtaaccta 49
Met Asp Tyr Lys Asp Asp Asp Asp Lys Gly Ser Pro Gly
1 5 10
ggtgatag gga ggt tcg tct tca ctc gag ggt acc cat cac cat cac cat 99
Gly Gly Ser Ser Ser Leu Glu Gly Thr His His His His His
15 20 25
cac gag ctc gta ccg gta gaa aaa atg 126
His Glu Leu Val Pro Val Glu Lys Met
30 35
<210> 502
<211> 13
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 502
Met Asp Tyr Lys Asp Asp Asp Asp Lys Gly Ser Pro Gly
1 5 10
<210> 503
<211> 23
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 503
Gly Gly Ser Ser Ser Leu Glu Gly Thr His His His His His His Glu
1 5 10 15
Leu Val Pro Val Glu Lys Met
20
<210> 504
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 504
Lys Lys Lys Lys Lys Lys
1 5
<210> 505
<211> 856
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 505
Met Glu Gly Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala
1 5 10 15
Ser Val Gly Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Asp Val
20 25 30
Asn Thr Ala Val Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys
35 40 45
Leu Leu Ile Tyr Ser Ala Ser Phe Leu Tyr Ser Gly Val Pro Ser Arg
50 55 60
Phe Ser Gly Ser Arg Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser
65 70 75 80
Leu Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln His Tyr Thr
85 90 95
Thr Pro Pro Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Thr Gly
100 105 110
Ser Gly Glu Gly Ser Glu Gly Glu Gly Gly Gly Glu Gly Ser Glu Gly
115 120 125
Glu Gly Ser Gly Glu Gly Gly Glu Gly Glu Gly Ser Gly Thr Glu Val
130 135 140
Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly Ser Leu
145 150 155 160
Arg Leu Ser Cys Ala Ala Ser Gly Phe Asn Ile Lys Asp Thr Tyr Ile
165 170 175
His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val Ala Arg
180 185 190
Ile Tyr Pro Thr Asn Gly Tyr Thr Arg Tyr Ala Asp Ser Val Lys Gly
195 200 205
Arg Phe Thr Ile Ser Ala Asp Thr Ser Lys Asn Thr Ala Tyr Leu Gln
210 215 220
Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ser Arg
225 230 235 240
Trp Gly Gly Asp Gly Phe Tyr Ala Met Asp Tyr Trp Gly Gln Gly Thr
245 250 255
Leu Val Thr Val Ser Gly Gly Glu Gly Ser Gly Glu Gly Ser Glu Gly
260 265 270
Glu Gly Ser Glu Gly Ser Gly Glu Gly Glu Gly Ser Glu Gly Ser Gly
275 280 285
Glu Gly Glu Gly Gly Ser Glu Gly Ser Glu Gly Glu Gly Ser Glu Gly
290 295 300
Ser Gly Glu Gly Glu Gly Gly Glu Gly Ser Gly Glu Gly Glu Gly Ser
305 310 315 320
Gly Glu Gly Ser Glu Gly Glu Gly Gly Gly Glu Gly Ser Glu Gly Glu
325 330 335
Gly Ser Gly Glu Gly Gly Glu Gly Glu Gly Ser Glu Gly Gly Ser Glu
340 345 350
Gly Glu Gly Gly Ser Glu Gly Gly Glu Gly Glu Gly Ser Glu Gly Ser
355 360 365
Gly Glu Gly Glu Gly Ser Glu Gly Gly Ser Glu Gly Glu Gly Ser Glu
370 375 380
Gly Gly Ser Glu Gly Glu Gly Ser Glu Gly Ser Gly Glu Gly Glu Gly
385 390 395 400
Ser Glu Gly Ser Gly Glu Gly Glu Gly Ser Glu Gly Ser Gly Glu Gly
405 410 415
Glu Gly Ser Glu Gly Ser Gly Glu Gly Glu Gly Ser Glu Gly Gly Ser
420 425 430
Glu Gly Glu Gly Gly Ser Glu Gly Ser Glu Gly Glu Gly Ser Gly Glu
435 440 445
Gly Ser Glu Gly Glu Gly Gly Ser Glu Gly Ser Glu Gly Glu Gly Gly
450 455 460
Gly Glu Gly Ser Glu Gly Glu Gly Ser Gly Glu Gly Ser Glu Gly Glu
465 470 475 480
Gly Gly Ser Glu Gly Ser Glu Gly Glu Gly Gly Ser Glu Gly Ser Glu
485 490 495
Gly Glu Gly Gly Glu Gly Ser Gly Glu Gly Glu Gly Ser Glu Gly Ser
500 505 510
Gly Glu Gly Glu Gly Ser Gly Glu Gly Ser Glu Gly Glu Gly Ser Glu
515 520 525
Gly Ser Gly Glu Gly Glu Gly Ser Glu Gly Ser Gly Glu Gly Glu Gly
530 535 540
Gly Ser Glu Gly Ser Glu Gly Glu Gly Ser Gly Glu Gly Ser Glu Gly
545 550 555 560
Glu Gly Ser Glu Gly Ser Gly Glu Gly Glu Gly Ser Glu Gly Ser Gly
565 570 575
Glu Gly Glu Gly Gly Ser Glu Gly Ser Glu Gly Glu Gly Gly Ser Glu
580 585 590
Gly Ser Glu Gly Glu Gly Gly Ser Glu Gly Ser Glu Gly Glu Gly Gly
595 600 605
Glu Gly Ser Gly Glu Gly Glu Gly Ser Glu Gly Ser Gly Glu Gly Glu
610 615 620
Gly Ser Gly Glu Gly Ser Glu Gly Glu Gly Ser Glu Gly Ser Gly Glu
625 630 635 640
Gly Glu Gly Ser Glu Gly Ser Gly Glu Gly Glu Gly Gly Ser Glu Gly
645 650 655
Ser Glu Gly Glu Gly Ser Glu Gly Ser Gly Glu Gly Glu Gly Gly Glu
660 665 670
Gly Ser Gly Glu Gly Glu Gly Ser Gly Glu Gly Ser Glu Gly Glu Gly
675 680 685
Gly Gly Glu Gly Ser Glu Gly Glu Gly Ser Glu Gly Ser Gly Glu Gly
690 695 700
Glu Gly Ser Glu Gly Ser Gly Glu Gly Glu Gly Ser Glu Gly Gly Ser
705 710 715 720
Glu Gly Glu Gly Gly Ser Glu Gly Ser Glu Gly Glu Gly Ser Glu Gly
725 730 735
Gly Ser Glu Gly Glu Gly Ser Glu Gly Gly Ser Glu Gly Glu Gly Ser
740 745 750
Glu Gly Ser Gly Glu Gly Glu Gly Ser Glu Gly Ser Gly Glu Gly Glu
755 760 765
Gly Ser Gly Glu Gly Ser Glu Gly Glu Gly Gly Ser Glu Gly Gly Glu
770 775 780
Gly Glu Gly Ser Glu Gly Gly Ser Glu Gly Glu Gly Ser Glu Gly Gly
785 790 795 800
Ser Glu Gly Glu Gly Gly Glu Gly Ser Gly Glu Gly Glu Gly Gly Gly
805 810 815
Glu Gly Ser Glu Gly Glu Gly Ser Glu Gly Ser Gly Glu Gly Glu Gly
820 825 830
Ser Gly Glu Gly Ser Glu Gly Asp Tyr Lys Asp Asp Asp Asp Lys Gly
835 840 845
Gly Ser His His His His His His
850 855
<210> 506
<211> 854
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 506
Met Glu Asp Ile Leu Leu Thr Gln Ser Pro Val Ile Leu Ser Val Ser
1 5 10 15
Pro Gly Glu Arg Val Ser Phe Ser Cys Arg Ala Ser Gln Ser Ile Gly
20 25 30
Thr Asn Ile His Trp Tyr Gln Gln Arg Thr Asn Gly Ser Pro Arg Leu
35 40 45
Leu Ile Lys Tyr Ala Ser Glu Ser Ile Ser Gly Ile Pro Ser Arg Phe
50 55 60
Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Ser Ile Asn Ser Val
65 70 75 80
Glu Ser Glu Asp Ile Ala Asp Tyr Tyr Cys Gln Gln Asn Asn Asn Trp
85 90 95
Pro Thr Thr Phe Gly Ala Gly Thr Lys Leu Glu Leu Lys Thr Gly Ser
100 105 110
Gly Glu Gly Ser Glu Gly Glu Gly Gly Gly Glu Gly Ser Glu Gly Glu
115 120 125
Gly Ser Gly Glu Gly Gly Glu Gly Glu Gly Ser Gly Thr Gln Val Gln
130 135 140
Leu Lys Gln Ser Gly Pro Gly Leu Val Gln Pro Ser Gln Ser Leu Ser
145 150 155 160
Ile Thr Cys Thr Val Ser Gly Phe Ser Leu Thr Asn Tyr Gly Val His
165 170 175
Trp Val Arg Gln Ser Pro Gly Lys Gly Leu Glu Trp Leu Gly Val Ile
180 185 190
Trp Ser Gly Gly Asn Thr Asp Tyr Asn Thr Pro Phe Thr Ser Arg Leu
195 200 205
Ser Ile Asn Lys Asp Asn Ser Lys Ser Gln Val Phe Phe Lys Met Asn
210 215 220
Ser Leu Gln Ser Asn Asp Thr Ala Ile Tyr Tyr Cys Ala Arg Ala Leu
225 230 235 240
Thr Tyr Tyr Asp Tyr Glu Phe Ala Tyr Trp Gly Gln Gly Thr Leu Val
245 250 255
Thr Val Ser Gly Gly Glu Gly Ser Gly Glu Gly Ser Glu Gly Glu Gly
260 265 270
Ser Glu Gly Ser Gly Glu Gly Glu Gly Ser Glu Gly Ser Gly Glu Gly
275 280 285
Glu Gly Gly Ser Glu Gly Ser Glu Gly Glu Gly Ser Glu Gly Ser Gly
290 295 300
Glu Gly Glu Gly Gly Glu Gly Ser Gly Glu Gly Glu Gly Ser Gly Glu
305 310 315 320
Gly Ser Glu Gly Glu Gly Gly Gly Glu Gly Ser Glu Gly Glu Gly Ser
325 330 335
Gly Glu Gly Gly Glu Gly Glu Gly Ser Glu Gly Gly Ser Glu Gly Glu
340 345 350
Gly Gly Ser Glu Gly Gly Glu Gly Glu Gly Ser Glu Gly Ser Gly Glu
355 360 365
Gly Glu Gly Ser Glu Gly Gly Ser Glu Gly Glu Gly Ser Glu Gly Gly
370 375 380
Ser Glu Gly Glu Gly Ser Glu Gly Ser Gly Glu Gly Glu Gly Ser Glu
385 390 395 400
Gly Ser Gly Glu Gly Glu Gly Ser Glu Gly Ser Gly Glu Gly Glu Gly
405 410 415
Ser Glu Gly Ser Gly Glu Gly Glu Gly Ser Glu Gly Gly Ser Glu Gly
420 425 430
Glu Gly Gly Ser Glu Gly Ser Glu Gly Glu Gly Ser Gly Glu Gly Ser
435 440 445
Glu Gly Glu Gly Gly Ser Glu Gly Ser Glu Gly Glu Gly Gly Gly Glu
450 455 460
Gly Ser Glu Gly Glu Gly Ser Gly Glu Gly Ser Glu Gly Glu Gly Gly
465 470 475 480
Ser Glu Gly Ser Glu Gly Glu Gly Gly Ser Glu Gly Ser Glu Gly Glu
485 490 495
Gly Gly Glu Gly Ser Gly Glu Gly Glu Gly Ser Glu Gly Ser Gly Glu
500 505 510
Gly Glu Gly Ser Gly Glu Gly Ser Glu Gly Glu Gly Ser Glu Gly Ser
515 520 525
Gly Glu Gly Glu Gly Ser Glu Gly Ser Gly Glu Gly Glu Gly Gly Ser
530 535 540
Glu Gly Ser Glu Gly Glu Gly Ser Gly Glu Gly Ser Glu Gly Glu Gly
545 550 555 560
Ser Glu Gly Ser Gly Glu Gly Glu Gly Ser Glu Gly Ser Gly Glu Gly
565 570 575
Glu Gly Gly Ser Glu Gly Ser Glu Gly Glu Gly Gly Ser Glu Gly Ser
580 585 590
Glu Gly Glu Gly Gly Ser Glu Gly Ser Glu Gly Glu Gly Gly Glu Gly
595 600 605
Ser Gly Glu Gly Glu Gly Ser Glu Gly Ser Gly Glu Gly Glu Gly Ser
610 615 620
Gly Glu Gly Ser Glu Gly Glu Gly Ser Glu Gly Ser Gly Glu Gly Glu
625 630 635 640
Gly Ser Glu Gly Ser Gly Glu Gly Glu Gly Gly Ser Glu Gly Ser Glu
645 650 655
Gly Glu Gly Ser Glu Gly Ser Gly Glu Gly Glu Gly Gly Glu Gly Ser
660 665 670
Gly Glu Gly Glu Gly Ser Gly Glu Gly Ser Glu Gly Glu Gly Gly Gly
675 680 685
Glu Gly Ser Glu Gly Glu Gly Ser Glu Gly Ser Gly Glu Gly Glu Gly
690 695 700
Ser Glu Gly Ser Gly Glu Gly Glu Gly Ser Glu Gly Gly Ser Glu Gly
705 710 715 720
Glu Gly Gly Ser Glu Gly Ser Glu Gly Glu Gly Ser Glu Gly Gly Ser
725 730 735
Glu Gly Glu Gly Ser Glu Gly Gly Ser Glu Gly Glu Gly Ser Glu Gly
740 745 750
Ser Gly Glu Gly Glu Gly Ser Glu Gly Ser Gly Glu Gly Glu Gly Ser
755 760 765
Gly Glu Gly Ser Glu Gly Glu Gly Gly Ser Glu Gly Gly Glu Gly Glu
770 775 780
Gly Ser Glu Gly Gly Ser Glu Gly Glu Gly Ser Glu Gly Gly Ser Glu
785 790 795 800
Gly Glu Gly Gly Glu Gly Ser Gly Glu Gly Glu Gly Gly Gly Glu Gly
805 810 815
Ser Glu Gly Glu Gly Ser Glu Gly Ser Gly Glu Gly Glu Gly Ser Gly
820 825 830
Glu Gly Ser Glu Gly Asp Tyr Lys Asp Asp Asp Asp Lys Gly Gly Ser
835 840 845
His His His His His His
850
<210> 507
<211> 832
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 507
Met Glu Gly Asp Ile His Met Glu Asp Ile Gln Met Thr Gln Ser Pro
1 5 10 15
Ser Ser Leu Ser Ala Ser Val Gly Asp Arg Val Thr Ile Thr Cys Arg
20 25 30
Ala Ser Gln Asp Val Asn Thr Ala Val Ala Trp Tyr Gln Gln Lys Pro
35 40 45
Gly Lys Ala Pro Lys Leu Leu Ile Tyr Ser Ala Ser Phe Leu Tyr Ser
50 55 60
Gly Val Pro Ser Arg Phe Ser Gly Ser Arg Ser Gly Thr Asp Phe Thr
65 70 75 80
Leu Thr Ile Ser Ser Leu Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys
85 90 95
Gln Gln His Tyr Thr Thr Pro Pro Thr Phe Gly Gln Gly Thr Lys Val
100 105 110
Glu Ile Lys Ser Gly Glu Glu Val Gln Leu Val Glu Ser Gly Gly Gly
115 120 125
Leu Val Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly
130 135 140
Phe Asn Ile Lys Asp Thr Tyr Ile His Trp Val Arg Gln Ala Pro Gly
145 150 155 160
Lys Gly Leu Glu Trp Val Ala Arg Ile Tyr Pro Thr Asn Gly Tyr Thr
165 170 175
Arg Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Ala Asp Thr
180 185 190
Ser Lys Asn Thr Ala Tyr Leu Gln Met Asn Ser Leu Arg Ala Glu Asp
195 200 205
Thr Ala Val Tyr Tyr Cys Ser Arg Trp Gly Gly Asp Gly Phe Tyr Ala
210 215 220
Met Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser Gly Gly Glu
225 230 235 240
Gly Ser Gly Glu Gly Ser Glu Gly Glu Gly Ser Glu Gly Ser Gly Glu
245 250 255
Gly Glu Gly Ser Glu Gly Ser Gly Glu Gly Glu Gly Gly Ser Glu Gly
260 265 270
Ser Glu Gly Glu Gly Ser Glu Gly Ser Gly Glu Gly Glu Gly Gly Glu
275 280 285
Gly Ser Gly Glu Gly Glu Gly Ser Gly Glu Gly Ser Glu Gly Glu Gly
290 295 300
Gly Gly Glu Gly Ser Glu Gly Glu Gly Ser Gly Glu Gly Gly Glu Gly
305 310 315 320
Glu Gly Ser Glu Gly Gly Ser Glu Gly Glu Gly Gly Ser Glu Gly Gly
325 330 335
Glu Gly Glu Gly Ser Glu Gly Ser Gly Glu Gly Glu Gly Ser Glu Gly
340 345 350
Gly Ser Glu Gly Glu Gly Ser Glu Gly Gly Ser Glu Gly Glu Gly Ser
355 360 365
Glu Gly Ser Gly Glu Gly Glu Gly Ser Glu Gly Ser Gly Glu Gly Glu
370 375 380
Gly Ser Glu Gly Ser Gly Glu Gly Glu Gly Ser Glu Gly Ser Gly Glu
385 390 395 400
Gly Glu Gly Ser Glu Gly Gly Ser Glu Gly Glu Gly Gly Ser Glu Gly
405 410 415
Ser Glu Gly Glu Gly Ser Gly Glu Gly Ser Glu Gly Glu Gly Gly Ser
420 425 430
Glu Gly Ser Glu Gly Glu Gly Gly Gly Glu Gly Ser Glu Gly Glu Gly
435 440 445
Ser Gly Glu Gly Ser Glu Gly Glu Gly Gly Ser Glu Gly Ser Glu Gly
450 455 460
Glu Gly Gly Ser Glu Gly Ser Glu Gly Glu Gly Gly Glu Gly Ser Gly
465 470 475 480
Glu Gly Glu Gly Ser Glu Gly Ser Gly Glu Gly Glu Gly Ser Gly Glu
485 490 495
Gly Ser Glu Gly Glu Gly Ser Glu Gly Ser Gly Glu Gly Glu Gly Ser
500 505 510
Glu Gly Ser Gly Glu Gly Glu Gly Gly Ser Glu Gly Ser Glu Gly Glu
515 520 525
Gly Ser Gly Glu Gly Ser Glu Gly Glu Gly Ser Glu Gly Ser Gly Glu
530 535 540
Gly Glu Gly Ser Glu Gly Ser Gly Glu Gly Glu Gly Gly Ser Glu Gly
545 550 555 560
Ser Glu Gly Glu Gly Gly Ser Glu Gly Ser Glu Gly Glu Gly Gly Ser
565 570 575
Glu Gly Ser Glu Gly Glu Gly Gly Glu Gly Ser Gly Glu Gly Glu Gly
580 585 590
Ser Glu Gly Ser Gly Glu Gly Glu Gly Ser Gly Glu Gly Ser Glu Gly
595 600 605
Glu Gly Ser Glu Gly Ser Gly Glu Gly Glu Gly Ser Glu Gly Ser Gly
610 615 620
Glu Gly Glu Gly Gly Ser Glu Gly Ser Glu Gly Glu Gly Ser Glu Gly
625 630 635 640
Ser Gly Glu Gly Glu Gly Gly Glu Gly Ser Gly Glu Gly Glu Gly Ser
645 650 655
Gly Glu Gly Ser Glu Gly Glu Gly Gly Gly Glu Gly Ser Glu Gly Glu
660 665 670
Gly Ser Glu Gly Ser Gly Glu Gly Glu Gly Ser Glu Gly Ser Gly Glu
675 680 685
Gly Glu Gly Ser Glu Gly Gly Ser Glu Gly Glu Gly Gly Ser Glu Gly
690 695 700
Ser Glu Gly Glu Gly Ser Glu Gly Gly Ser Glu Gly Glu Gly Ser Glu
705 710 715 720
Gly Gly Ser Glu Gly Glu Gly Ser Glu Gly Ser Gly Glu Gly Glu Gly
725 730 735
Ser Glu Gly Ser Gly Glu Gly Glu Gly Ser Gly Glu Gly Ser Glu Gly
740 745 750
Glu Gly Gly Ser Glu Gly Gly Glu Gly Glu Gly Ser Glu Gly Gly Ser
755 760 765
Glu Gly Glu Gly Ser Glu Gly Gly Ser Glu Gly Glu Gly Gly Glu Gly
770 775 780
Ser Gly Glu Gly Glu Gly Gly Gly Glu Gly Ser Glu Gly Glu Gly Ser
785 790 795 800
Glu Gly Ser Gly Glu Gly Glu Gly Ser Gly Glu Gly Ser Glu Gly Asp
805 810 815
Tyr Lys Asp Asp Asp Asp Lys Gly Gly Ser His His His His His His
820 825 830
<210> 508
<211> 684
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<220>
<221> CDS
<222> (1)..(684)
<400> 508
atg gat aaa act cat act tgc cct cct tgt cca gcg ccc gaa ctg ctg 48
Met Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu
1 5 10 15
ggt ggc ccg tct gtt ttc ctg ttc cca cca aaa cca aaa gac acc ctg 96
Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu
20 25 30
atg att tcc cgt act cct gag gta acc tgt gta gtt gta gac gtt tct 144
Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser
35 40 45
cac gaa gat ccg gaa gtt aaa ttc aac tgg tac gtg gat ggt gtt gag 192
His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu
50 55 60
gtg cat aac gct aaa acc aaa ccg cgc gag gag caa tat aat tcc acc 240
Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr
65 70 75 80
tac cgt gtt gtg tct gtt ctg acc gtc ctg cac caa gat tgg ctg aac 288
Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn
85 90 95
ggc aaa gaa tac aag tgt aaa gtg tcc aac aaa gcc ctg cca gcg ccg 336
Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro
100 105 110
atc gag aaa act att tct aag gcg aaa ggc cag ccg cgc gaa cca caa 384
Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln
115 120 125
gta tat acc ctg ccg ccg tcc cgt gat gaa ctg acc aag aac caa gtt 432
Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val
130 135 140
tcc ctg acc tgc ctg gtg aag ggt ttc tac cca tct gat atc gcc gtc 480
Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val
145 150 155 160
gag tgg gaa tcc aac ggt cag ccg gag aac aat tat aaa act atc cca 528
Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Ile Pro
165 170 175
ccg gtt ctg gac tct gac ggc tcc ttc ttt ctg tat tcc aag ctg acc 576
Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr
180 185 190
gtt gat aaa agc cgt tgg cag cag ggc aac gtt ttc tct tgc tct gta 624
Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val
195 200 205
atg cat gaa gca ctg cac aac cat tac acc cag aaa agc ctg tcc ctg 672
Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu
210 215 220
tcg ccg ggt aag 684
Ser Pro Gly Lys
225
<210> 509
<211> 228
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 509
Met Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu
1 5 10 15
Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu
20 25 30
Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser
35 40 45
His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu
50 55 60
Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr
65 70 75 80
Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn
85 90 95
Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro
100 105 110
Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln
115 120 125
Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val
130 135 140
Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val
145 150 155 160
Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Ile Pro
165 170 175
Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr
180 185 190
Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val
195 200 205
Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu
210 215 220
Ser Pro Gly Lys
225
<210> 510
<211> 806
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 510
Met Ser Lys Gly Glu Glu Leu Phe Thr Gly Val Val Pro Ile Leu Val
1 5 10 15
Glu Leu Asp Gly Asp Val Asn Gly His Lys Phe Ser Val Ser Gly Glu
20 25 30
Gly Glu Gly Asp Ala Thr Tyr Gly Lys Leu Thr Leu Lys Phe Ile Cys
35 40 45
Thr Thr Gly Lys Leu Pro Val Pro Trp Pro Thr Leu Val Thr Thr Phe
50 55 60
Ser Tyr Gly Val Gln Cys Phe Ser Arg Tyr Pro Asp His Met Lys Arg
65 70 75 80
His Asp Phe Phe Lys Ser Ala Met Pro Glu Gly Tyr Val Gln Glu Arg
85 90 95
Thr Ile Ser Phe Lys Asp Asp Gly Asn Tyr Lys Thr Arg Ala Glu Val
100 105 110
Lys Phe Glu Gly Asp Thr Leu Val Asn Arg Ile Glu Leu Lys Gly Ile
115 120 125
Asp Phe Lys Glu Asp Gly Asn Ile Leu Gly His Lys Leu Glu Tyr Asn
130 135 140
Tyr Asn Ser His Asn Val Tyr Ile Thr Ala Asp Lys Gln Lys Asn Gly
145 150 155 160
Ile Lys Ala Asn Phe Lys Ile Arg His Asn Ile Glu Asp Gly Ser Val
165 170 175
Gln Leu Ala Asp His Tyr Gln Gln Asn Thr Pro Ile Gly Asp Gly Pro
180 185 190
Val Leu Leu Pro Asp Asn His Tyr Leu Ser Thr Gln Ser Ala Leu Ser
195 200 205
Lys Asp Pro Asn Glu Lys Arg Asp His Met Val Leu Leu Glu Phe Val
210 215 220
Thr Ala Ala Gly Ile Gly Glu Gly Ser Gly Glu Gly Ser Glu Gly Glu
225 230 235 240
Gly Ser Glu Gly Ser Gly Glu Gly Glu Gly Ser Glu Gly Ser Gly Glu
245 250 255
Gly Glu Gly Gly Ser Glu Gly Ser Glu Gly Glu Gly Ser Glu Gly Ser
260 265 270
Gly Glu Gly Glu Gly Gly Glu Gly Ser Gly Glu Gly Glu Gly Ser Gly
275 280 285
Glu Gly Ser Glu Gly Glu Gly Gly Gly Glu Gly Ser Glu Gly Glu Gly
290 295 300
Ser Gly Glu Gly Gly Glu Gly Glu Gly Ser Glu Gly Gly Ser Glu Gly
305 310 315 320
Glu Gly Gly Ser Glu Gly Gly Glu Gly Glu Gly Ser Glu Gly Ser Gly
325 330 335
Glu Gly Glu Gly Ser Glu Gly Gly Ser Glu Gly Glu Gly Ser Glu Gly
340 345 350
Gly Ser Glu Gly Glu Gly Ser Glu Gly Ser Gly Glu Gly Glu Gly Ser
355 360 365
Glu Gly Ser Gly Glu Gly Glu Gly Ser Glu Gly Ser Gly Glu Gly Glu
370 375 380
Gly Ser Glu Gly Ser Gly Glu Gly Glu Gly Ser Glu Gly Gly Ser Glu
385 390 395 400
Gly Glu Gly Gly Ser Glu Gly Ser Glu Gly Glu Gly Ser Gly Glu Gly
405 410 415
Ser Glu Gly Glu Gly Gly Ser Glu Gly Ser Glu Gly Glu Gly Gly Gly
420 425 430
Glu Gly Ser Glu Gly Glu Gly Ser Gly Glu Gly Ser Glu Gly Glu Gly
435 440 445
Gly Ser Glu Gly Ser Glu Gly Glu Gly Gly Ser Glu Gly Ser Glu Gly
450 455 460
Glu Gly Gly Glu Gly Ser Gly Glu Gly Glu Gly Ser Glu Gly Ser Gly
465 470 475 480
Glu Gly Glu Gly Ser Gly Glu Gly Ser Glu Gly Glu Gly Ser Glu Gly
485 490 495
Ser Gly Glu Gly Glu Gly Ser Glu Gly Ser Gly Glu Gly Glu Gly Gly
500 505 510
Ser Glu Gly Ser Glu Gly Glu Gly Ser Gly Glu Gly Ser Glu Gly Glu
515 520 525
Gly Ser Glu Gly Ser Gly Glu Gly Glu Gly Ser Glu Gly Ser Gly Glu
530 535 540
Gly Glu Gly Gly Ser Glu Gly Ser Glu Gly Glu Gly Gly Ser Glu Gly
545 550 555 560
Ser Glu Gly Glu Gly Gly Ser Glu Gly Ser Glu Gly Glu Gly Gly Glu
565 570 575
Gly Ser Gly Glu Gly Glu Gly Ser Glu Gly Ser Gly Glu Gly Glu Gly
580 585 590
Ser Gly Glu Gly Ser Glu Gly Glu Gly Ser Glu Gly Ser Gly Glu Gly
595 600 605
Glu Gly Ser Glu Gly Ser Gly Glu Gly Glu Gly Gly Ser Glu Gly Ser
610 615 620
Glu Gly Glu Gly Ser Glu Gly Ser Gly Glu Gly Glu Gly Gly Glu Gly
625 630 635 640
Ser Gly Glu Gly Glu Gly Ser Gly Glu Gly Ser Glu Gly Glu Gly Gly
645 650 655
Gly Glu Gly Ser Glu Gly Glu Gly Ser Glu Gly Ser Gly Glu Gly Glu
660 665 670
Gly Ser Glu Gly Ser Gly Glu Gly Glu Gly Ser Glu Gly Gly Ser Glu
675 680 685
Gly Glu Gly Gly Ser Glu Gly Ser Glu Gly Glu Gly Ser Glu Gly Gly
690 695 700
Ser Glu Gly Glu Gly Ser Glu Gly Gly Ser Glu Gly Glu Gly Ser Glu
705 710 715 720
Gly Ser Gly Glu Gly Glu Gly Ser Glu Gly Ser Gly Glu Gly Glu Gly
725 730 735
Ser Gly Glu Gly Ser Glu Gly Glu Gly Gly Ser Glu Gly Gly Glu Gly
740 745 750
Glu Gly Ser Glu Gly Gly Ser Glu Gly Glu Gly Ser Glu Gly Gly Ser
755 760 765
Glu Gly Glu Gly Gly Glu Gly Ser Gly Glu Gly Glu Gly Gly Gly Glu
770 775 780
Gly Ser Glu Gly Glu Gly Ser Glu Gly Ser Gly Glu Gly Glu Gly Ser
785 790 795 800
Gly Glu Gly Ser Glu Gly
805
<210> 511
<211> 797
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 511
Met Ala Asn Thr Pro Val Ser Gly Asn Leu Lys Val Glu Phe Tyr Asn
1 5 10 15
Ser Asn Pro Ser Asp Thr Thr Asn Ser Ile Asn Pro Gln Phe Lys Val
20 25 30
Thr Asn Thr Gly Ser Ser Ala Ile Asp Leu Ser Lys Leu Thr Leu Arg
35 40 45
Tyr Tyr Tyr Thr Val Asp Gly Gln Lys Asp Gln Thr Phe Trp Ala Asp
50 55 60
His Ala Ala Ile Ile Gly Ser Asn Gly Ser Tyr Asn Gly Ile Thr Ser
65 70 75 80
Asn Val Lys Gly Thr Phe Val Lys Met Ser Ser Ser Thr Asn Asn Ala
85 90 95
Asp Thr Tyr Leu Glu Ile Ser Phe Thr Gly Gly Thr Leu Glu Pro Gly
100 105 110
Ala His Val Gln Ile Gln Gly Arg Phe Ala Lys Asn Asp Trp Ser Asn
115 120 125
Tyr Thr Gln Ser Asn Asp Tyr Ser Phe Lys Ser Ala Ser Gln Phe Val
130 135 140
Glu Trp Asp Gln Val Thr Ala Tyr Leu Asn Gly Val Leu Val Trp Gly
145 150 155 160
Lys Glu Pro Gly Gly Ser Val Val Gly Ser Gly Ser Gly Ser Glu Asn
165 170 175
Leu Tyr Phe Gln His Gly Glu Gly Thr Phe Thr Ser Asp Leu Ser Lys
180 185 190
Gln Met Glu Glu Glu Ala Val Arg Leu Phe Ile Glu Trp Leu Lys Asn
195 200 205
Gly Gly Pro Ser Ser Gly Ala Pro Pro Pro Ser Gly Gly Glu Gly Ser
210 215 220
Gly Glu Gly Ser Glu Gly Glu Gly Ser Glu Gly Ser Gly Glu Gly Glu
225 230 235 240
Gly Ser Glu Gly Ser Gly Glu Gly Glu Gly Gly Ser Glu Gly Ser Glu
245 250 255
Gly Glu Gly Ser Glu Gly Ser Gly Glu Gly Glu Gly Gly Glu Gly Ser
260 265 270
Gly Glu Gly Glu Gly Ser Gly Glu Gly Ser Glu Gly Glu Gly Gly Gly
275 280 285
Glu Gly Ser Glu Gly Glu Gly Ser Gly Glu Gly Gly Glu Gly Glu Gly
290 295 300
Ser Glu Gly Gly Ser Glu Gly Glu Gly Gly Ser Glu Gly Gly Glu Gly
305 310 315 320
Glu Gly Ser Glu Gly Ser Gly Glu Gly Glu Gly Ser Glu Gly Gly Ser
325 330 335
Glu Gly Glu Gly Ser Glu Gly Gly Ser Glu Gly Glu Gly Ser Glu Gly
340 345 350
Ser Gly Glu Gly Glu Gly Ser Glu Gly Ser Gly Glu Gly Glu Gly Ser
355 360 365
Glu Gly Ser Gly Glu Gly Glu Gly Ser Glu Gly Ser Gly Glu Gly Glu
370 375 380
Gly Ser Glu Gly Gly Ser Glu Gly Glu Gly Gly Ser Glu Gly Ser Glu
385 390 395 400
Gly Glu Gly Ser Gly Glu Gly Ser Glu Gly Glu Gly Gly Ser Glu Gly
405 410 415
Ser Glu Gly Glu Gly Gly Gly Glu Gly Ser Glu Gly Glu Gly Ser Gly
420 425 430
Glu Gly Ser Glu Gly Glu Gly Gly Ser Glu Gly Ser Glu Gly Glu Gly
435 440 445
Gly Ser Glu Gly Ser Glu Gly Glu Gly Gly Glu Gly Ser Gly Glu Gly
450 455 460
Glu Gly Ser Glu Gly Ser Gly Glu Gly Glu Gly Ser Gly Glu Gly Ser
465 470 475 480
Glu Gly Glu Gly Ser Glu Gly Ser Gly Glu Gly Glu Gly Ser Glu Gly
485 490 495
Ser Gly Glu Gly Glu Gly Gly Ser Glu Gly Ser Glu Gly Glu Gly Ser
500 505 510
Gly Glu Gly Ser Glu Gly Glu Gly Ser Glu Gly Ser Gly Glu Gly Glu
515 520 525
Gly Ser Glu Gly Ser Gly Glu Gly Glu Gly Gly Ser Glu Gly Ser Glu
530 535 540
Gly Glu Gly Gly Ser Glu Gly Ser Glu Gly Glu Gly Gly Ser Glu Gly
545 550 555 560
Ser Glu Gly Glu Gly Gly Glu Gly Ser Gly Glu Gly Glu Gly Ser Glu
565 570 575
Gly Ser Gly Glu Gly Glu Gly Ser Gly Glu Gly Ser Glu Gly Glu Gly
580 585 590
Ser Glu Gly Ser Gly Glu Gly Glu Gly Ser Glu Gly Ser Gly Glu Gly
595 600 605
Glu Gly Gly Ser Glu Gly Ser Glu Gly Glu Gly Ser Glu Gly Ser Gly
610 615 620
Glu Gly Glu Gly Gly Glu Gly Ser Gly Glu Gly Glu Gly Ser Gly Glu
625 630 635 640
Gly Ser Glu Gly Glu Gly Gly Gly Glu Gly Ser Glu Gly Glu Gly Ser
645 650 655
Glu Gly Ser Gly Glu Gly Glu Gly Ser Glu Gly Ser Gly Glu Gly Glu
660 665 670
Gly Ser Glu Gly Gly Ser Glu Gly Glu Gly Gly Ser Glu Gly Ser Glu
675 680 685
Gly Glu Gly Ser Glu Gly Gly Ser Glu Gly Glu Gly Ser Glu Gly Gly
690 695 700
Ser Glu Gly Glu Gly Ser Glu Gly Ser Gly Glu Gly Glu Gly Ser Glu
705 710 715 720
Gly Ser Gly Glu Gly Glu Gly Ser Gly Glu Gly Ser Glu Gly Glu Gly
725 730 735
Gly Ser Glu Gly Gly Glu Gly Glu Gly Ser Glu Gly Gly Ser Glu Gly
740 745 750
Glu Gly Ser Glu Gly Gly Ser Glu Gly Glu Gly Gly Glu Gly Ser Gly
755 760 765
Glu Gly Glu Gly Gly Gly Glu Gly Ser Glu Gly Glu Gly Ser Glu Gly
770 775 780
Ser Gly Glu Gly Glu Gly Ser Gly Glu Gly Ser Glu Gly
785 790 795
<210> 512
<211> 144
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 512
Gly Glu Gly Ser Gly Glu Gly Ser Glu Gly Glu Gly Gly Ser Glu Gly
1 5 10 15
Gly Glu Gly Glu Gly Gly Ser Glu Gly Ser Glu Gly Glu Gly Ser Glu
20 25 30
Gly Gly Ser Glu Gly Glu Gly Ser Gly Glu Gly Ser Glu Gly Glu Gly
35 40 45
Gly Ser Glu Gly Gly Glu Gly Glu Gly Gly Ser Glu Gly Ser Glu Gly
50 55 60
Glu Gly Ser Glu Gly Gly Ser Glu Gly Glu Gly Gly Ser Glu Gly Ser
65 70 75 80
Glu Gly Glu Gly Ser Glu Gly Gly Gly Glu Gly Glu Gly Ser Gly Glu
85 90 95
Gly Ser Glu Gly Glu Gly Gly Ser Glu Gly Ser Glu Gly Glu Gly Ser
100 105 110
Gly Glu Gly Ser Glu Gly Glu Gly Gly Ser Glu Gly Gly Glu Gly Glu
115 120 125
Gly Gly Ser Glu Gly Ser Glu Gly Glu Gly Ser Glu Gly Gly Ser Glu
130 135 140
<210> 513
<211> 144
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 513
Gly Glu Gly Gly Ser Glu Gly Ser Glu Gly Glu Gly Ser Glu Gly Gly
1 5 10 15
Gly Glu Gly Glu Gly Ser Gly Glu Gly Ser Glu Gly Glu Gly Gly Ser
20 25 30
Glu Gly Ser Glu Gly Glu Gly Ser Gly Glu Gly Ser Glu Gly Glu Gly
35 40 45
Gly Ser Glu Gly Gly Glu Gly Glu Gly Gly Ser Glu Gly Ser Glu Gly
50 55 60
Glu Gly Ser Glu Gly Gly Ser Glu Gly Glu Gly Ser Gly Glu Gly Ser
65 70 75 80
Glu Gly Glu Gly Gly Ser Glu Gly Gly Glu Gly Glu Gly Gly Ser Glu
85 90 95
Gly Ser Glu Gly Glu Gly Ser Glu Gly Gly Ser Glu Gly Glu Gly Ser
100 105 110
Gly Glu Gly Ser Glu Gly Glu Gly Gly Ser Glu Gly Gly Glu Gly Glu
115 120 125
Gly Gly Ser Glu Gly Ser Glu Gly Glu Gly Ser Glu Gly Gly Ser Glu
130 135 140
<210> 514
<211> 144
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 514
Gly Glu Gly Gly Ser Glu Gly Ser Glu Gly Glu Gly Ser Glu Gly Gly
1 5 10 15
Gly Glu Gly Glu Gly Ser Gly Glu Gly Ser Glu Gly Glu Gly Gly Ser
20 25 30
Glu Gly Ser Glu Gly Glu Gly Ser Gly Glu Gly Ser Glu Gly Glu Gly
35 40 45
Gly Ser Glu Gly Gly Glu Gly Glu Gly Gly Ser Glu Gly Ser Glu Gly
50 55 60
Glu Gly Ser Glu Gly Gly Ser Glu Gly Glu Gly Ser Gly Glu Gly Ser
65 70 75 80
Glu Gly Glu Gly Gly Ser Glu Gly Gly Glu Gly Glu Gly Gly Ser Glu
85 90 95
Gly Ser Glu Gly Glu Gly Ser Glu Gly Gly Ser Glu Gly Glu Gly Ser
100 105 110
Gly Glu Gly Ser Glu Gly Glu Gly Gly Ser Glu Gly Gly Glu Gly Glu
115 120 125
Gly Gly Ser Glu Gly Ser Glu Gly Glu Gly Ser Glu Gly Gly Ser Glu
130 135 140
<210> 515
<211> 144
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 515
Gly Glu Gly Ser Gly Glu Gly Ser Glu Gly Glu Gly Gly Ser Glu Gly
1 5 10 15
Gly Glu Gly Glu Gly Gly Ser Glu Gly Ser Glu Gly Glu Gly Ser Glu
20 25 30
Gly Gly Ser Glu Gly Glu Gly Ser Gly Glu Gly Ser Glu Gly Glu Gly
35 40 45
Gly Ser Glu Gly Gly Glu Gly Glu Gly Gly Ser Glu Gly Ser Glu Gly
50 55 60
Glu Gly Ser Glu Gly Gly Ser Glu Gly Glu Gly Gly Ser Glu Gly Ser
65 70 75 80
Glu Gly Glu Gly Ser Glu Gly Gly Gly Glu Gly Glu Gly Ser Gly Glu
85 90 95
Gly Ser Glu Gly Glu Gly Gly Ser Glu Gly Ser Glu Gly Glu Gly Ser
100 105 110
Gly Glu Gly Ser Glu Gly Glu Gly Gly Ser Glu Gly Gly Glu Gly Glu
115 120 125
Gly Gly Ser Glu Gly Ser Glu Gly Glu Gly Ser Glu Gly Gly Ser Glu
130 135 140
<210> 516
<211> 144
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 516
Gly Glu Gly Gly Ser Glu Gly Ser Glu Gly Glu Gly Ser Glu Gly Gly
1 5 10 15
Gly Glu Gly Glu Gly Ser Gly Glu Gly Ser Glu Gly Glu Gly Gly Ser
20 25 30
Glu Gly Ser Glu Gly Glu Gly Ser Gly Glu Gly Ser Glu Gly Glu Gly
35 40 45
Gly Ser Glu Gly Gly Glu Gly Glu Gly Gly Ser Glu Gly Ser Glu Gly
50 55 60
Glu Gly Ser Glu Gly Gly Ser Glu Gly Gly Glu Gly Ser Gly Glu Gly
65 70 75 80
Ser Gly Ser Glu Gly Ser Gly Glu Gly Ser Glu Gly Ser Gly Gly Glu
85 90 95
Gly Gly Ser Glu Gly Gly Glu Gly Gly Gly Ser Glu Gly Glu Gly Ser
100 105 110
Gly Glu Gly Ser Glu Gly Glu Gly Ser Glu Gly Gly Ser Glu Gly Glu
115 120 125
Gly Gly Ser Glu Gly Ser Glu Gly Glu Gly Ser Gly Glu Gly Ser Glu
130 135 140
<210> 517
<211> 144
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 517
Gly Glu Gly Ser Gly Glu Gly Ser Glu Gly Glu Gly Gly Ser Glu Gly
1 5 10 15
Ser Glu Gly Glu Gly Gly Gly Glu Gly Ser Glu Gly Glu Gly Ser Gly
20 25 30
Glu Gly Ser Glu Gly Glu Gly Ser Gly Glu Gly Ser Glu Gly Glu Gly
35 40 45
Gly Ser Glu Gly Gly Glu Gly Glu Gly Gly Ser Glu Gly Ser Glu Gly
50 55 60
Glu Gly Ser Glu Gly Gly Ser Glu Gly Glu Gly Ser Gly Glu Gly Ser
65 70 75 80
Glu Gly Glu Gly Ser Glu Gly Ser Gly Glu Gly Glu Gly Ser Glu Gly
85 90 95
Gly Ser Glu Gly Glu Gly Gly Ser Glu Gly Ser Glu Gly Gly Glu Gly
100 105 110
Ser Gly Glu Gly Ser Gly Ser Glu Gly Gly Ser Glu Gly Gly Glu Gly
115 120 125
Gly Gly Gly Glu Gly Ser Glu Gly Ser Gly Glu Gly Gly Gly Gly Glu
130 135 140
<210> 518
<211> 144
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 518
Gly Glu Gly Gly Ser Glu Gly Ser Glu Gly Glu Gly Ser Glu Gly Gly
1 5 10 15
Gly Glu Gly Glu Gly Ser Gly Glu Gly Ser Glu Gly Glu Gly Gly Ser
20 25 30
Glu Gly Ser Glu Gly Glu Gly Ser Gly Glu Gly Ser Glu Gly Glu Gly
35 40 45
Gly Ser Glu Gly Gly Glu Gly Glu Gly Gly Ser Glu Gly Ser Glu Gly
50 55 60
Glu Gly Ser Glu Gly Gly Ser Glu Gly Glu Gly Ser Gly Glu Gly Ser
65 70 75 80
Glu Gly Glu Gly Gly Ser Glu Gly Gly Glu Gly Glu Gly Gly Ser Glu
85 90 95
Gly Ser Glu Gly Glu Gly Ser Glu Gly Gly Ser Glu Gly Glu Gly Ser
100 105 110
Gly Glu Gly Ser Glu Gly Glu Gly Gly Ser Glu Gly Gly Glu Gly Glu
115 120 125
Gly Gly Ser Glu Gly Ser Glu Gly Glu Gly Ser Glu Gly Gly Ser Glu
130 135 140
<210> 519
<211> 144
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 519
Gly Glu Gly Ser Gly Glu Gly Ser Glu Gly Glu Gly Gly Ser Glu Gly
1 5 10 15
Ser Glu Gly Glu Gly Gly Gly Glu Gly Ser Glu Gly Glu Gly Ser Gly
20 25 30
Glu Gly Ser Glu Gly Glu Gly Ser Gly Glu Gly Ser Glu Gly Glu Gly
35 40 45
Gly Ser Glu Gly Gly Glu Gly Glu Gly Gly Ser Glu Gly Ser Glu Gly
50 55 60
Glu Gly Ser Glu Gly Gly Ser Glu Gly Glu Gly Ser Gly Glu Gly Ser
65 70 75 80
Glu Gly Glu Gly Ser Glu Gly Ser Gly Glu Gly Glu Gly Ser Glu Gly
85 90 95
Gly Ser Glu Gly Glu Gly Gly Ser Glu Gly Ser Glu Gly Ser Glu Gly
100 105 110
Ser Gly Glu Gly Ser Gly Ser Glu Gly Ser Gly Glu Gly Gly Glu Gly
115 120 125
Gly Gly Gly Glu Gly Ser Glu Gly Gly Ser Glu Gly Ser Gly Gly Glu
130 135 140
<210> 520
<211> 144
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 520
Gly Glu Gly Gly Ser Glu Gly Ser Glu Gly Glu Gly Ser Glu Gly Gly
1 5 10 15
Gly Glu Gly Glu Gly Ser Gly Glu Gly Ser Glu Gly Glu Gly Gly Ser
20 25 30
Glu Gly Ser Glu Gly Glu Gly Ser Gly Glu Gly Ser Glu Gly Glu Gly
35 40 45
Gly Ser Glu Gly Gly Glu Gly Glu Gly Gly Ser Glu Gly Ser Glu Gly
50 55 60
Glu Gly Ser Glu Gly Gly Ser Glu Gly Glu Gly Ser Gly Glu Gly Ser
65 70 75 80
Glu Gly Glu Gly Gly Ser Glu Gly Gly Glu Gly Glu Gly Gly Ser Glu
85 90 95
Gly Ser Glu Gly Glu Gly Ser Glu Gly Gly Ser Glu Gly Glu Gly Ser
100 105 110
Gly Glu Gly Ser Glu Gly Glu Gly Gly Ser Glu Gly Gly Glu Gly Glu
115 120 125
Gly Gly Ser Glu Gly Ser Glu Gly Glu Gly Ser Glu Gly Gly Ser Glu
130 135 140
<210> 521
<211> 144
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 521
Gly Glu Gly Gly Ser Glu Gly Ser Glu Gly Glu Gly Ser Glu Gly Gly
1 5 10 15
Gly Glu Gly Glu Gly Ser Gly Glu Gly Ser Glu Gly Glu Gly Gly Ser
20 25 30
Glu Gly Ser Glu Gly Glu Gly Ser Gly Glu Gly Ser Glu Gly Glu Gly
35 40 45
Gly Ser Glu Gly Gly Glu Gly Glu Gly Gly Ser Glu Gly Ser Glu Gly
50 55 60
Glu Gly Ser Glu Gly Gly Ser Glu Gly Glu Gly Ser Gly Glu Gly Ser
65 70 75 80
Glu Gly Glu Gly Gly Ser Glu Gly Gly Glu Gly Glu Gly Gly Ser Glu
85 90 95
Gly Ser Glu Gly Glu Gly Ser Glu Gly Gly Ser Glu Gly Glu Gly Ser
100 105 110
Gly Glu Gly Ser Glu Gly Glu Gly Gly Ser Glu Gly Gly Glu Gly Glu
115 120 125
Gly Gly Ser Glu Gly Ser Glu Gly Glu Gly Ser Glu Gly Gly Ser Glu
130 135 140
<210> 522
<211> 826
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 522
Met Asp Tyr Lys Asp Asp Asp Asp Lys Gly Ser Pro Gly Glu Gly Ser
1 5 10 15
Gly Glu Gly Ser Glu Gly Glu Gly Ser Glu Gly Ser Gly Glu Gly Glu
20 25 30
Gly Ser Glu Gly Ser Gly Glu Gly Glu Gly Gly Ser Glu Gly Ser Glu
35 40 45
Gly Glu Gly Ser Glu Gly Ser Gly Glu Gly Glu Gly Gly Glu Gly Ser
50 55 60
Gly Glu Gly Glu Gly Ser Gly Glu Gly Ser Glu Gly Glu Gly Gly Gly
65 70 75 80
Glu Gly Ser Glu Gly Glu Gly Ser Gly Glu Gly Gly Glu Gly Glu Gly
85 90 95
Ser Glu Gly Gly Ser Glu Gly Glu Gly Gly Ser Glu Gly Gly Glu Gly
100 105 110
Glu Gly Ser Glu Gly Ser Gly Glu Gly Glu Gly Ser Glu Gly Gly Ser
115 120 125
Glu Gly Glu Gly Ser Glu Gly Gly Ser Glu Gly Glu Gly Ser Glu Gly
130 135 140
Ser Gly Glu Gly Glu Gly Ser Glu Gly Ser Gly Glu Gly Glu Gly Ser
145 150 155 160
Glu Gly Ser Gly Glu Gly Glu Gly Ser Glu Gly Ser Gly Glu Gly Glu
165 170 175
Gly Ser Glu Gly Gly Ser Glu Gly Glu Gly Gly Ser Glu Gly Ser Glu
180 185 190
Gly Glu Gly Ser Gly Glu Gly Ser Glu Gly Glu Gly Gly Ser Glu Gly
195 200 205
Ser Glu Gly Glu Gly Gly Gly Glu Gly Ser Glu Gly Glu Gly Ser Gly
210 215 220
Glu Gly Ser Glu Gly Glu Gly Gly Ser Glu Gly Ser Glu Gly Glu Gly
225 230 235 240
Gly Ser Glu Gly Ser Glu Gly Glu Gly Gly Glu Gly Ser Gly Glu Gly
245 250 255
Glu Gly Ser Glu Gly Ser Gly Glu Gly Glu Gly Ser Gly Glu Gly Ser
260 265 270
Glu Gly Glu Gly Ser Glu Gly Ser Gly Glu Gly Glu Gly Ser Glu Gly
275 280 285
Ser Gly Glu Gly Glu Gly Gly Ser Glu Gly Ser Glu Gly Glu Gly Ser
290 295 300
Gly Glu Gly Ser Glu Gly Glu Gly Ser Glu Gly Ser Gly Glu Gly Glu
305 310 315 320
Gly Ser Glu Gly Ser Gly Glu Gly Glu Gly Gly Ser Glu Gly Ser Glu
325 330 335
Gly Glu Gly Gly Ser Glu Gly Ser Glu Gly Glu Gly Gly Ser Glu Gly
340 345 350
Ser Glu Gly Glu Gly Gly Glu Gly Ser Gly Glu Gly Glu Gly Ser Glu
355 360 365
Gly Ser Gly Glu Gly Glu Gly Ser Gly Glu Gly Ser Glu Gly Glu Gly
370 375 380
Ser Glu Gly Ser Gly Glu Gly Glu Gly Ser Glu Gly Ser Gly Glu Gly
385 390 395 400
Glu Gly Gly Ser Glu Gly Ser Glu Gly Glu Gly Ser Glu Gly Ser Gly
405 410 415
Glu Gly Glu Gly Gly Glu Gly Ser Gly Glu Gly Glu Gly Ser Gly Glu
420 425 430
Gly Ser Glu Gly Glu Gly Gly Gly Glu Gly Ser Glu Gly Glu Gly Ser
435 440 445
Glu Gly Ser Gly Glu Gly Glu Gly Ser Glu Gly Ser Gly Glu Gly Glu
450 455 460
Gly Ser Glu Gly Gly Ser Glu Gly Glu Gly Gly Ser Glu Gly Ser Glu
465 470 475 480
Gly Glu Gly Ser Glu Gly Gly Ser Glu Gly Glu Gly Ser Glu Gly Gly
485 490 495
Ser Glu Gly Glu Gly Ser Glu Gly Ser Gly Glu Gly Glu Gly Ser Glu
500 505 510
Gly Ser Gly Glu Gly Glu Gly Ser Gly Glu Gly Ser Glu Gly Glu Gly
515 520 525
Gly Ser Glu Gly Gly Glu Gly Glu Gly Ser Glu Gly Gly Ser Glu Gly
530 535 540
Glu Gly Ser Glu Gly Gly Ser Glu Gly Glu Gly Gly Glu Gly Ser Gly
545 550 555 560
Glu Gly Glu Gly Gly Gly Glu Gly Ser Glu Gly Glu Gly Ser Glu Gly
565 570 575
Ser Gly Glu Gly Glu Gly Ser Gly Glu Gly Ser Glu Gly Ser Lys Gly
580 585 590
Glu Glu Leu Phe Thr Gly Val Val Pro Ile Leu Val Glu Leu Asp Gly
595 600 605
Asp Val Asn Gly His Lys Phe Ser Val Ser Gly Glu Gly Glu Gly Asp
610 615 620
Ala Thr Tyr Gly Lys Leu Thr Leu Lys Phe Ile Cys Thr Thr Gly Lys
625 630 635 640
Leu Pro Val Pro Trp Pro Thr Leu Val Thr Thr Phe Ser Tyr Gly Val
645 650 655
Gln Cys Phe Ser Arg Tyr Pro Asp His Met Lys Arg His Asp Phe Phe
660 665 670
Lys Ser Ala Met Pro Glu Gly Tyr Val Gln Glu Arg Thr Ile Ser Phe
675 680 685
Lys Asp Asp Gly Asn Tyr Lys Thr Arg Ala Glu Val Lys Phe Glu Gly
690 695 700
Asp Thr Leu Val Asn Arg Ile Glu Leu Lys Gly Ile Asp Phe Lys Glu
705 710 715 720
Asp Gly Asn Ile Leu Gly His Lys Leu Glu Tyr Asn Tyr Asn Ser His
725 730 735
Asn Val Tyr Ile Thr Ala Asp Lys Gln Lys Asn Gly Ile Lys Ala Asn
740 745 750
Phe Lys Ile Arg His Asn Ile Glu Asp Gly Ser Val Gln Leu Ala Asp
755 760 765
His Tyr Gln Gln Asn Thr Pro Ile Gly Asp Gly Pro Val Leu Leu Pro
770 775 780
Asp Asn His Tyr Leu Ser Thr Gln Ser Ala Leu Ser Lys Asp Pro Asn
785 790 795 800
Glu Lys Arg Asp His Met Val Leu Leu Glu Phe Val Thr Ala Ala Gly
805 810 815
Ile Thr His Gly Met Asp Glu Leu Tyr Lys
820 825
<210> 523
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 523
Ser Lys Val Ile Leu Phe
1 5
<210> 524
<211> 7
<212> PRT
<213> Homo sapiens
<400> 524
Glu Asn Leu Tyr Phe Gln Gly
1 5
Claims (148)
- a) 숙주 세포에서 보조적 폴리펩티드와 연결된 생물학적 활성 폴리펩티드를 포함하는 변경된 폴리펩티드의 발현이 상기 생물학적 활성 폴리펩티드 단독의 발현에 비해 상기 생물학적 활성 폴리펩티드의 가용성 형태를 더 많은 양으로 산출하도록 상기 변경된 폴리펩티드를 코딩하는 폴리뉴클레오티드 서열을 제공하는 단계; 및
b) 변경된 폴리펩티드를 상기 숙주 세포에서 발현시킴으로써 생물학적 활성 폴리펩티드를 생산하는 단계
를 포함하는, 생물학적 활성 폴리펩티드의 제조 방법. - 제1항에 있어서, 숙주 세포에서의 상기 변경된 폴리펩티드의 발현이 상기 생물학적 활성 폴리펩티드 단독의 발현에 비해 생물학적 활성 폴리펩티드의 가용성 형태를 약 2배 이상 더 많이 산출하는 것인 제조 방법.
- 제1항에 있어서, 숙주 세포에서의 상기 변경된 폴리펩티드의 발현이 상기 생물학적 활성 폴리펩티드 단독의 발현에 비해 생물학적 활성 폴리펩티드의 가용성 형태를 약 5배 이상 더 많이 산출하는 것인 제조 방법.
- 제1항에 있어서, 숙주 세포에서의 상기 변경된 폴리펩티드의 발현이 상기 생물학적 활성 폴리펩티드 단독의 발현에 비해 생물학적 활성 폴리펩티드의 가용성 형태를 약 10배 이상 더 많이 산출하는 것인 제조 방법.
- 제1항에 있어서, 숙주 세포에서의 변경된 폴리펩티드의 발현이 상기 생물학적 활성 폴리펩티드 단독의 발현에 비해 생물학적 활성 폴리펩티드의 가용성 형태를 약 2배∼약 10배 더 많이 산출하는 것인 제조 방법.
- 제1항에 있어서, 상기 보조적 폴리펩티드가 약 50개보다 많은 아미노산을 포함하는 것인 제조 방법.
- 제1항에 있어서, 상기 보조적 폴리펩티드가 약 100개보다 많은 아미노산을 포함하는 것인 제조 방법.
- 제1항에 있어서, 상기 생물학적 활성 폴리펩티드가 인간 성장 호르몬(hGH: human growth hormone), 글루카곤 유사 펩티드-1(GLP-1: glucagon-like peptide-1), 과립구-콜로니 자극 인자(G-CSF: granulocyte-colony stimulating factor), 인터페론(interferon)-알파, 인터페론-베타, 인터페론-감마, 인슐린, 에리스로포이에틴(erythropoietin), 종양 괴사 인자-알파(TFN-alpha: tumor necrosis factor alpha), IL-1RA, 엑세나타이드(exenatide), 유리카제(uricase) 및 프람리타이드(pramlitide)로 구성된 군에서 선택되는 것인 제조 방법.
- 제1항에 있어서, 상기 보조적 폴리펩티드가 40개 이상의 연속된 아미노산을 포함하고,
(a) 상기 보조적 폴리펩티드에 포함된 글리신(G), 아스파테이트(D), 알라닌(A), 세린(S), 트레오닌(T), 글루타메이트(E) 및 프롤린(P) 잔기의 합계가 보조적 폴리펩티드의 총 아미노산의 약 80%를 초과하고/하거나;
(b) 초우-파스만 알고리즘(Chou-Fasman algorithm)에 의해 결정할 때, 상기 아미노산의 50% 이상이 2차 구조를 갖지 않는 것인 제조 방법. - 제1항에 있어서, 상기 보조적 폴리펩티드가 40개 이상의 연속된 아미노산을 포함하고, 상기 보조적 폴리펩티드가 피험체에서 약 4 시간보다 긴 시험관내 혈청 반감기를 가지며,
(a) 상기 보조적 폴리펩티드에 포함된 글리신(G), 아스파테이트(D), 알라닌(A), 세린(S), 트레오닌(T), 글루타메이트(E) 및 프롤린(P) 잔기의 합계가 보조적 폴리펩티드의 총 아미노산의 약 80%를 초과하고/하거나;
(b) 초우-파스만 알고리즘에 의해 결정할 때, 상기 아미노산의 50% 이상이 2차 구조를 갖지 않는 것인 제조 방법. - 제1항에 있어서, 상기 보조적 폴리펩티드의 모든 잔기의 50% 이상이 글리신(G) 잔기인 제조 방법.
- 제1항에 있어서, 상기 보조적 폴리펩티드의 모든 잔기의 80% 이상이 글루탐산(E), 글리신(G) 및 세린(S)으로 구성된 군에서 선택되는 것인 제조 방법.
- 제1항에 있어서, 상기 보조적 폴리펩티드의 모든 잔기의 50% 미만이 글리신(G) 잔기인 제조 방법.
- 제1항에 있어서, 상기 보조적 폴리펩티드의 모든 잔기의 50% 이상이 세린(S) 잔기인 제조 방법.
- 제1항에 있어서, 상기 보조적 폴리펩티드의 모든 잔기의 50% 이상이 세린(S) 및 글리신(G) 잔기 중 어느 하나인 제조 방법.
- 제1항에 있어서, 상기 보조적 폴리펩티드가
(a) 3가지 유형의 아미노산으로 구성되고, 각각의 유형이 알라닌(A), 아스파르트산(D), 글루탐산(E), 글리신(G), 히스티딘(H), 라이신(K), 아스파라긴(N), 프롤린(P), 글루타민(Q), 아르기닌(R), 세린(S), 트레오닌(T) 및 타이로신(Y)으로 구성된 군에서 선택되며;
(b) 10개 이상의 아미노산을 포함하는 것을 특징으로 하는 것인 제조 방법. - 제16항에 있어서, 상기 보조적 폴리펩티드가 3가지 유형의 아미노산으로 구성되고, 각각의 유형이 아스파르트산(D), 글루탐산(E), 글리신(G), 라이신(K), 프롤린(P), 아르기닌(R), 세린(S) 및 트레오닌(T)으로 구성된 군에서 선택되는 것인 제조 방법.
- 제16항에 있어서, 상기 보조적 폴리펩티드가 3가지 유형의 아미노산으로 구성되고, 각각의 유형이 글루탐산(E), 글리신(G) 및 세린(S)으로 구성된 군에서 선택되는 것인 제조 방법.
- 제1항에 있어서, 상기 보조적 폴리펩티드가
(a) 2가지 유형의 아미노산으로 구성되고, 이 중 하나가 글리신(G)이고 나머지 유형이 아스파르트산(D), 글루탐산(E), 라이신(K), 프롤린(P), 아르기닌(R), 세린(S), 트레오닌(T), 알라닌(A), 히스티딘(H), 아스파라긴(N), 타이로신(Y), 루신(L), 발린(V), 트립토판(W), 메티오닌(M), 페닐알라닌(F), 이소루신(I) 및 시스테인(C)으로 구성된 군에서 선택되며;
(b) 50% 이하가 글리신인 10개 이상의 아미노산 잔기를 포함하는 것을 특징으로 하는 것인 제조 방법. - 제1항에 있어서, 상기 보조적 폴리펩티드가
(a) 50개 이상의 아미노산을 포함하고;
(b) 2가지 유형의 아미노산으로 구성되며;
(c) 총 아미노산의 50% 이하가 알라닌(A), 세린(S), 트레오닌(T), 아스파르트산(D), 글루탐산(E) 및 히스티딘(H)으로 구성된 군에서 선택되는 것을 특징으로 하는 것인 제조 방법. - 제1항에 있어서, 상기 보조적 폴리펩티드가 10개 이상의 반복 모티프(motif)를 포함하는 것인 제조 방법.
- 제1항에 있어서, 다수의 보조적 폴리펩티드를 포함하는 것인 제조 방법.
- 제1항의 변경된 폴리펩티드를 발현하는 숙주 세포.
- 제1항의 폴리뉴클레오티드 서열을 포함하는 유전자 운반체(genetic vehicle).
- 제1항에 있어서, 상기 보조적 폴리펩티드가 10 카피 이하의 반복 서열로 구성되고, 각각의 반복 서열은 약 8개∼약 12개의 아미노산을 갖는 것인 제조 방법.
- 제1항에 있어서, 상기 변경된 폴리펩티드가 프로테아제 절단 부위를 통해 보조적 단백질에 연결되는 것인 제조 방법.
- 제25항에 있어서, 프로테아제 절단 부위가 생물학적 활성 폴리펩티드를 코딩하는 서열의 일부가 아닌 것인 제조 방법.
- 제26항에 있어서, 상기 프로테아제 절단 부위가 TEV 프로테아제, 엔테로키나제(enterokinase), 인자(Factor) Xa, 트롬빈, PreScissionTM 프로테아제, 3C 프로테아제, 소르타제(sortase) A 및 그랜자임(granzyme) B로 구성된 군에서 선택되는 것인 제조 방법.
- 제1항에 있어서, 상기 보조적 폴리펩티드가 친화성 태그를 포함하는 것인 제조 방법.
- 제28항에 있어서, 친화성 태그가 플래그(FLAG), His-태그, CBD, GST, MBP 및 TRX로 구성된 군에서 선택되는 것인 제조 방법.
- 제1항에 있어서, 상기 숙주 세포가 원핵 세포인 제조 방법.
- 제1항에 있어서, 상기 숙주 세포가 이. 콜라이(E. Coli)인 제조 방법.
- 제1항에 있어서, 상기 숙주 세포가 진핵 세포인 제조 방법.
- 제1항에 있어서, 상기 숙주 세포가 포유동물 세포 및 효모 세포로 구성된 군에서 선택되는 것인 제조 방법.
- 보조적 폴리펩티드와 연결된 생물학적 활성 폴리펩티드의 가용성 형태를 포함하는 조성물로서, 상기 보조적 폴리펩티드는, 이것이 생물학적 활성 폴리펩티드와 연결될 경우, 연결된 생물학적 활성 폴리펩티드가 발현되는 숙주 세포의 사이토졸 분획에서 생물학적 활성 폴리펩티드의 용해도를 증가시키는 것인 조성물.
- 제35항에 있어서, 상기 생물학적 활성 폴리펩티드가 프로테아제 절단 부위를 통해 상기 보조적 폴리펩티드에 연결되는 것인 조성물.
- 제35항에 있어서, 상기 생물학적 활성 폴리펩티드가 인간 성장 호르몬(hGH), 글루카곤 유사 펩티드-1(GLP-1), 과립구-콜로니 자극 인자(G-CSF), 인터페론-알파, 인터페론-베타, 인터페론-감마, 인슐린, 에리스로포이에틴, 종양 괴사 인자-알파(TFN-알파), IL-1RA, 엑세나타이드, 유리카제 및 프람리타이드로 구성된 군에서 선택되는 것인 조성물.
- 제35항에 있어서, 상기 보조적 폴리펩티드가 40개 이상의 연속된 아미노산을 포함하고,
(a) 상기 보조적 폴리펩티드에 포함된 글리신(G), 아스파테이트(D), 알라닌(A), 세린(S), 트레오닌(T), 글루타메이트(E) 및 프롤린(P) 잔기의 합계가 보조적 폴리펩티드의 총 아미노산의 약 80%를 초과하고/하거나;
(b) 초우-파스만 알고리즘에 의해 결정할 때, 상기 아미노산의 50% 이상이 2차 구조를 갖지 않는 것인 조성물. - 제35항에 있어서, 상기 보조적 폴리펩티드가 40개 이상의 연속된 아미노산을 포함하고, 상기 보조적 폴리펩티드가 피험체에서 약 4 시간보다 긴 시험관내 혈청 반감기를 가지며,
(a) 상기 보조적 폴리펩티드에 포함된 글리신(G), 아스파테이트(D), 알라닌(A), 세린(S), 트레오닌(T), 글루타메이트(E) 및 프롤린(P) 잔기의 합계가 보조적 폴리펩티드의 총 아미노산의 약 80%를 초과하고/하거나;
(b) 초우-파스만 알고리즘에 의해 결정할 때, 상기 아미노산의 50% 이상이 2차 구조를 갖지 않는 것인 조성물. - 제35항에 있어서, 상기 보조적 폴리펩티드의 모든 잔기의 50% 이상이 글리신(G) 잔기인 조성물.
- 제35항에 있어서, 상기 보조적 폴리펩티드의 모든 잔기의 80% 이상이 글루탐산(E), 글리신(G) 및 세린(S)으로 구성된 군에서 선택되는 것인 조성물.
- 제35항에 있어서, 상기 보조적 폴리펩티드의 모든 잔기의 50% 미만이 글리신(G) 잔기인 조성물.
- 제35항에 있어서, 상기 보조적 폴리펩티드의 모든 잔기의 50% 이상이 세린(S) 잔기인 조성물.
- 제35항에 있어서, 상기 보조적 폴리펩티드의 모든 잔기의 50% 이상이 세린(S) 및 글리신(G) 잔기 중 어느 하나인 조성물.
- 제35항에 있어서, 상기 보조적 폴리펩티드가
(a) 3가지 유형의 아미노산으로 구성되고, 각각의 유형이 알라닌(A), 아스파르트산(D), 글루탐산(E), 글리신(G), 히스티딘(H), 라이신(K), 아스파라긴(N), 프롤린(P), 글루타민(Q), 아르기닌(R), 세린(S), 트레오닌(T) 및 타이로신(Y)으로 구성된 군에서 선택되며;
(b) 10개 이상의 아미노산을 포함하는 것을 특징으로 하는 것인 조성물. - 제45항에 있어서, 상기 보조적 폴리펩티드가 3가지 유형의 아미노산으로 구성되고, 각각의 유형이 아스파르트산(D), 글루탐산(E), 글리신(G), 라이신(K), 프롤린(P), 아르기닌(R), 세린(S) 및 트레오닌(T)으로 구성된 군에서 선택되는 것인 조성물.
- 제45항에 있어서, 상기 보조적 폴리펩티드가 3가지 유형의 아미노산으로 구성되고, 각각의 유형이 글루탐산(E), 글리신(G) 및 세린(S)으로 구성된 군에서 선택되는 것인 조성물.
- 제35항에 있어서, 상기 보조적 폴리펩티드가
(a) 2가지 유형의 아미노산으로 구성되고, 이 중 하나가 글리신(G)이고 나머지 유형이 아스파르트산(D), 글루탐산(E), 라이신(K), 프롤린(P), 아르기닌(R), 세린(S), 트레오닌(T), 알라닌(A), 히스티딘(H), 아스파라긴(N), 타이로신(Y), 루신(L), 발린(V), 트립토판(W), 메티오닌(M), 페닐알라닌(F), 이소루신(I) 및 시스테인(C)으로 구성된 군에서 선택되며;
(b) 50% 이하가 글리신인 10개 이상의 아미노산 잔기를 포함하는 것을 특징으로 하는 것인 조성물. - 제35항에 있어서, 상기 보조적 폴리펩티드가
(a) 50개 이상의 아미노산을 포함하고;
(b) 2가지 유형의 아미노산으로 구성되며;
(c) 총 아미노산의 50% 이하가 알라닌(A), 세린(S), 트레오닌(T), 아스파르트산(D), 글루탐산(E) 및 히스티딘(H)으로 구성된 군에서 선택되는 것을 특징으로 하는 것인 조성물. - 제35항에 있어서, 상기 보조적 폴리펩티드가 10개 이상의 반복 모티프를 포함하는 것인 조성물.
- 제35항에 있어서, 상기 보조적 폴리펩티드가 약 +0.1 이상의 연결된 생물학적 활성 폴리펩티드의 순 양전하를 제공하는 것인 조성물.
- 제35항에 있어서, 상기 보조적 폴리펩티드가 약 -0.1 이하의 연결된 생물학적 활성 폴리펩티드의 순 음전하를 제공하는 것인 조성물.
- 제1항에 있어서, 상기 보조적 폴리펩티드가 약 +0.1 이상의 변경된 폴리펩티드의 순 양전하를 제공하는 것인 제조 방법.
- 제1항에 있어서, 상기 보조적 폴리펩티드가 약 -0.1 이하의 변경된 폴리펩티드의 순 음전하를 제공하는 것인 제조 방법.
- a) 서방형 제제; 및
b) 보조적 폴리펩티드에 연결된 생물학적 활성 폴리펩티드를 포함하는 변경된 폴리펩티드
를 포함하는 약학적 조성물로서, 상기 보조적 폴리펩티드가 상기 생물학적 활성 폴리펩티드의 프로테아제 내성을 증가시키는 것인 약학적 조성물. - 제55항에 있어서, 상기 변경된 폴리펩티드는 3보다 큰 겉보기 분자량 계수(apparent molecular weight factor)를 산출하며, 상기 겉보기 분자량 계수는, 변경된 폴리펩티드의 예상 분자량에 대한, 크기 배제 크로마토그래피에 의해 측정된 변경된 폴리펩티드의 겉보기 분자량의 비로서 결정되는 것인 약학적 조성물.
- 제55항에 있어서, 상기 변경된 폴리펩티드의 겉보기 분자량 계수가 5보다 큰 것인 약학적 조성물.
- 제55항에 있어서, 상기 변경된 폴리펩티드의 겉보기 분자량 계수가 7보다 큰 것인 약학적 조성물.
- 제55항에 있어서, 상기 변경된 폴리펩티드의 겉보기 분자량 계수가 9보다 큰 것인 약학적 조성물.
- 제55항에 있어서, 상기 보조적 폴리펩티드가 약 50개보다 많은 아미노산을 포함하는 것인 약학적 조성물.
- 제55항에 있어서, 상기 보조적 폴리펩티드가 약 100개보다 많은 아미노산을 포함하는 것인 약학적 조성물.
- 제55항에 있어서, 상기 생물학적 활성 폴리펩티드가 인간 성장 호르몬(hGH), 글루카곤 유사 펩티드-1(GLP-1), 과립구-콜로니 자극 인자(G-CSF), 인터페론-알파, 인터페론-베타, 인터페론-감마, 인슐린, 에리스로포이에틴, 종양 괴사 인자-알파(TFN-알파), IL-1RA, 엑세나타이드, 유리카제 및 프람리타이드로 구성된 군에서 선택되는 것인 약학적 조성물.
- 제55항에 있어서, 상기 보조적 폴리펩티드가 40개 이상의 연속된 아미노산을 포함하고,
(a) 상기 보조적 폴리펩티드에 포함된 글리신(G), 아스파테이트(D), 알라닌(A), 세린(S), 트레오닌(T), 글루타메이트(E) 및 프롤린(P) 잔기의 합계가 상기 보조적 폴리펩티드의 총 아미노산의 약 80%를 초과하고/하거나;
(b) 초우-파스만 알고리즘에 의해 결정할 때, 상기 아미노산의 50% 이상이 2차 구조를 갖지 않는 것인 약학적 조성물. - 제55항에 있어서, 상기 보조적 폴리펩티드가 40개 이상의 연속된 아미노산을 포함하고, 상기 보조적 폴리펩티드가 피험체에서 약 24 시간보다 긴 시험관내 혈청 반감기를 가지며,
(a) 상기 보조적 폴리펩티드에 포함된 글리신(G), 아스파테이트(D), 알라닌(A), 세린(S), 트레오닌(T), 글루타메이트(E) 및 프롤린(P) 잔기의 합계가 상기 보조적 폴리펩티드의 총 아미노산의 약 80%를 초과하고/하거나;
(b) 초우-파스만 알고리즘에 의해 결정할 때, 상기 아미노산의 50% 이상이 2차 구조를 갖지 않는 것인 약학적 조성물. - 제55항에 있어서, 상기 보조적 폴리펩티드의 모든 잔기의 50% 이상이 글리신(G) 잔기인 약학적 조성물.
- 제55항에 있어서, 상기 보조적 폴리펩티드의 모든 잔기의 80% 이상이 글루탐산(E), 글리신(G) 및 세린(S)으로 구성된 군에서 선택되는 것인 약학적 조성물.
- 제55항에 있어서, 상기 보조적 폴리펩티드의 모든 잔기의 50% 미만이 글리신(G) 잔기인 약학적 조성물.
- 제55항에 있어서, 상기 보조적 폴리펩티드의 모든 잔기의 50% 이상이 세린(S) 잔기인 약학적 조성물.
- 제55항에 있어서, 상기 보조적 폴리펩티드의 모든 잔기의 50% 이상이 세린(S) 및 글리신(G) 잔기 중 어느 하나인 약학적 조성물.
- 제55항에 있어서, 상기 보조적 폴리펩티드가
(a) 3가지 유형의 아미노산으로 구성되고, 각각의 유형이 알라닌(A), 아스파르트산(D), 글루탐산(E), 글리신(G), 히스티딘(H), 라이신(K), 아스파라긴(N), 프롤린(P), 글루타민(Q), 아르기닌(R), 세린(S), 트레오닌(T) 및 타이로신(Y)으로 구성된 군에서 선택되며;
(b) 10개 이상의 아미노산을 포함하는 것을 특징으로 하는 것인 약학적 조성물. - 제70항에 있어서, 상기 보조적 폴리펩티드가 3가지 유형의 아미노산으로 구성되고, 각각의 유형이 아스파르트산(D), 글루탐산(E), 글리신(G), 라이신(K), 프롤린(P), 아르기닌(R), 세린(S) 및 트레오닌(T)으로 구성된 군에서 선택되는 것인 약학적 조성물.
- 제70항에 있어서, 상기 보조적 폴리펩티드가 3가지 유형의 아미노산으로 구성되고, 각각의 유형이 글루탐산(E), 글리신(G) 및 세린(S)으로 구성된 군에서 선택되는 것인 약학적 조성물.
- 제55항에 있어서, 상기 보조적 폴리펩티드가
(a) 2가지 유형의 아미노산으로 구성되고, 이 중 하나가 글리신(G)이고 나머지 유형이 아스파르트산(D), 글루탐산(E), 라이신(K), 프롤린(P), 아르기닌(R), 세린(S), 트레오닌(T), 알라닌(A), 히스티딘(H), 아스파라긴(N), 타이로신(Y), 루신(L), 발린(V), 트립토판(W), 메티오닌(M), 페닐알라닌(F), 이소루신(I) 및 시스테인(C)으로 구성된 군에서 선택되며;
(b) 50% 이하가 글리신인 10개 이상의 아미노산 잔기를 포함하는 것을 특징으로 하는 것인 약학적 조성물. - 제55항에 있어서, 상기 보조적 폴리펩티드가
(a) 50개 이상의 아미노산을 포함하고;
(b) 2가지 유형의 아미노산으로 구성되며;
(c) 총 아미노산의 50% 이하가 알라닌(A), 세린(S), 트레오닌(T), 아스파르트산(D), 글루탐산(E) 및 히스티딘(H)으로 구성된 군에서 선택되는 것을 특징으로 하는 것인 약학적 조성물. - 제55항에 있어서, 상기 보조적 폴리펩티드가 10개 이상의 반복 모티프를 포함하는 것인 약학적 조성물.
- 제55항에 있어서, 다수의 보조적 폴리펩티드를 포함하는 약학적 조성물.
- 제55항에 있어서, 상기 서방형 제제가 중합체 매트릭스인 약학적 조성물.
- 제77항에 있어서, 상기 중합체 매트릭스가 폴리-d,l-락티드(PLA), 폴리-(d,l-락티드-코-글리콜리드)(PLGA), PLGA-PEG 공중합체, 알기네이트, 덱스트란 및 키토산으로 구성된 군에서 선택되는 것인 약학적 조성물.
- 제55항에 있어서, 상기 서방형 제제가 경피 패치인 약학적 조성물.
- 제55항에 있어서, 상기 보조적 폴리펩티드가 하전된 아미노산을 포함하는 것인 약학적 조성물.
- 제55항에 있어서, 상기 보조적 폴리펩티드가 하전된 아미노산을 포함하고, 상기 서방형 제제가 하전된 중합체 매트릭스를 포함하는 것인 약학적 조성물.
- (a) 제55항의 변경된 폴리펩티드를 코딩하는 폴리뉴클레오티드 서열을 제공하는 단계; 및
(b) 상기 변경된 폴리펩티드를 숙주 세포에서 발현시킴으로써 상기 변경된 폴리펩티드를 생산하는 단계
를 포함하는, 변경된 폴리펩티드의 제조 방법. - 제55항의 변경된 폴리펩티드를 코딩하는 핵산 서열을 포함하는 유전자 운반체.
- 제55항의 변경된 폴리펩티드를 발현하는 숙주 세포.
- (a) 제55항의 변경된 폴리펩티드를 제공하는 단계; 및
(b) 상기 변경된 폴리펩티드를 중합체 매트릭스와 혼합하는 단계
를 포함하는, 제어 방출형 조성물의 제조 방법. - a) 서방형 제제; 및
b) 보조적 폴리펩티드에 연결된 생물학적 활성 폴리펩티드를 포함하는 변경된 폴리펩티드
를 포함하는 약학적 조성물로서, 상기 보조적 폴리펩티드가 상기 생물학적 활성 폴리펩티드의 용해도를 증가시키는 것인 약학적 조성물. - 제86항에 있어서, 상기 변경된 폴리펩티드가 3보다 큰 겉보기 분자량 계수를 산출하고, 상기 겉보기 분자량 계수는, 변경된 폴리펩티드의 예상 분자량에 대한, 크기 배제 크로마토그래피에 의해 측정된 변경된 폴리펩티드의 겉보기 분자량의 비로서 결정되는 것인 약학적 조성물.
- 제86항에 있어서, 상기 변경된 폴리펩티드의 겉보기 분자량 계수가 5보다 큰 것인 약학적 조성물.
- 제86항에 있어서, 상기 변경된 폴리펩티드의 겉보기 분자량 계수가 7보다 큰 것인 약학적 조성물.
- 제86항에 있어서, 상기 변경된 폴리펩티드의 겉보기 분자량 계수가 9보다 큰 것인 약학적 조성물.
- 제86항에 있어서, 상기 보조적 폴리펩티드가 약 50개보다 많은 아미노산을 포함하는 것인 약학적 조성물.
- 제86항에 있어서, 상기 보조적 폴리펩티드가 약 100개보다 많은 아미노산을 포함하는 것인 약학적 조성물.
- 제86항에 있어서, 상기 생물학적 활성 폴리펩티드가 인간 성장 호르몬(hGH), 글루카곤 유사 펩티드-1(GLP-1), 과립구-콜로니 자극 인자(G-CSF), 인터페론-알파, 인터페론-베타, 인터페론-감마, 인슐린, 에리스로포이에틴, 종양 괴사 인자-알파(TFN-알파), IL-1RA, 엑세나타이드, 유리카제 및 프람리타이드로 구성된 군에서 선택되는 약학적 조성물.
- 제86항에 있어서, 상기 보조적 폴리펩티드가 40개 이상의 연속된 아미노산을 포함하고,
(a) 상기 보조적 폴리펩티드에 포함된 글리신(G), 아스파테이트(D), 알라닌(A), 세린(S), 트레오닌(T), 글루타메이트(E) 및 프롤린(P) 잔기의 합계가 상기 보조적 폴리펩티드의 총 아미노산의 약 80%를 초과하고/하거나;
(b) 초우-파스만 알고리즘에 의해 결정할 때, 상기 아미노산의 50% 이상이 2차 구조를 갖지 않는 것인 약학적 조성물. - 제86항에 있어서, 상기 보조적 폴리펩티드가 40개 이상의 연속된 아미노산을 포함하고, 상기 보조적 폴리펩티드가 피험체에서 약 24 시간보다 긴 시험관내 혈청 반감기를 가지며,
(a) 상기 보조적 폴리펩티드에 포함된 글리신(G), 아스파테이트(D), 알라닌(A), 세린(S), 트레오닌(T), 글루타메이트(E) 및 프롤린(P) 잔기의 합계가 상기 보조적 폴리펩티드의 총 아미노산의 약 80%를 초과하고/하거나;
(b) 초우-파스만 알고리즘에 의해 결정할 때, 상기 아미노산의 50% 이상이 2차 구조를 갖지 않는 것인 약학적 조성물. - 제86항에 있어서, 상기 보조적 폴리펩티드의 모든 잔기의 50% 이상이 글리신(G) 잔기인 약학적 조성물.
- 제86항에 있어서, 상기 보조적 폴리펩티드의 모든 잔기의 80% 이상이 글루탐산(E), 글리신(G) 및 세린(S)으로 구성된 군에서 선택되는 것인 약학적 조성물.
- 제86항에 있어서, 상기 보조적 폴리펩티드의 모든 잔기의 50% 미만이 글리신(G) 잔기인 약학적 조성물.
- 제86항에 있어서, 상기 보조적 폴리펩티드의 모든 잔기의 50% 이상이 세린(S) 잔기인 약학적 조성물.
- 제86항에 있어서, 상기 보조적 폴리펩티드의 모든 잔기의 50% 이상이 세린(S) 및 글리신(G) 잔기 중 어느 하나인 약학적 조성물.
- 제86항에 있어서, 상기 보조적 폴리펩티드가
(a) 3가지 유형의 아미노산으로 구성되고, 각각의 유형이 알라닌(A), 아스파르트산(D), 글루탐산(E), 글리신(G), 히스티딘(H), 라이신(K), 아스파라긴(N), 프롤린(P), 글루타민(Q), 아르기닌(R), 세린(S), 트레오닌(T) 및 타이로신(Y)으로 구성된 군에서 선택되며;
(b) 10개 이상의 아미노산을 포함하는 것을 특징으로 하는 것인 약학적 조성물. - 제101항에 있어서, 상기 보조적 폴리펩티드가 3가지 유형의 아미노산으로 구성되고, 각각의 유형이 아스파르트산(D), 글루탐산(E), 글리신(G), 라이신(K), 프롤린(P), 아르기닌(R), 세린(S) 및 트레오닌(T)으로 구성된 군에서 선택되는 것인 약학적 조성물.
- 제101항에 있어서, 상기 보조적 폴리펩티드가 3가지 유형의 아미노산으로 구성되고, 각각의 유형이 글루탐산(E), 글리신(G) 및 세린(S)으로 구성된 군에서 선택되는 것인 약학적 조성물.
- 제86항에 있어서, 상기 보조적 폴리펩티드가
(a) 2가지 유형의 아미노산으로 구성되고, 이 중 하나가 글리신(G)이고 나머지 유형이 아스파르트산(D), 글루탐산(E), 라이신(K), 프롤린(P), 아르기닌(R), 세린(S), 트레오닌(T), 알라닌(A), 히스티딘(H), 아스파라긴(N), 타이로신(Y), 루신(L), 발린(V), 트립토판(W), 메티오닌(M), 페닐알라닌(F), 이소루신(I) 및 시스테인(C)으로 구성된 군에서 선택되며;
(b) 50% 이하가 글리신인 10개 이상의 아미노산 잔기를 포함하는 것을 특징으로 하는 것인 약학적 조성물. - 제86항에 있어서, 상기 보조적 폴리펩티드가
(a) 50개 이상의 아미노산을 포함하고;
(b) 2가지 유형의 아미노산으로 구성되며;
(c) 총 아미노산의 50% 이하가 알라닌(A), 세린(S), 트레오닌(T), 아스파르트산(D), 글루탐산(E) 및 히스티딘(H)으로 구성된 군에서 선택되는 것을 특징으로 하는 것인 약학적 조성물. - 제86항에 있어서, 상기 보조적 폴리펩티드가 10개 이상의 반복 모티프를 포함하는 것인 약학적 조성물.
- 제86항에 있어서, 다수의 보조적 폴리펩티드를 포함하는 약학적 조성물.
- 제86항에 있어서, 상기 서방형 제제가 중합체 매트릭스인 약학적 조성물.
- 제108항에 있어서, 상기 중합체 매트릭스가 폴리-d,l-락티드(PLA), 폴리-(d,l-락티드-코-글리콜리드)(PLGA), PLGA-PEG 공중합체, 알기네이트, 덱스트란 및 키토산으로 구성된 군에서 선택되는 것인 약학적 조성물.
- 제86항에 있어서, 상기 서방형 제제가 경피 패치인 약학적 조성물.
- 제86항에 있어서, 상기 보조적 폴리펩티드가 하전된 아미노산을 포함하는 것인 약학적 조성물.
- 제86항에 있어서, 상기 보조적 폴리펩티드가 하전된 아미노산을 포함하고, 상기 서방형 제제가 하전된 중합체 매트릭스를 포함하는 것인 약학적 조성물.
- (a) 제86항의 변경된 폴리펩티드를 코딩하는 폴리뉴클레오티드 서열을 제공하는 단계; 및
(b) 상기 변경된 폴리펩티드를 숙주 세포에서 발현시킴으로써 상기 변경된 폴리펩티드를 생산하는 단계
를 포함하는, 변경된 폴리펩티드의 제조 방법. - 제86항의 변경된 폴리펩티드를 코딩하는 핵산 서열을 포함하는 유전자 운반체.
- 제86항의 변경된 폴리펩티드를 발현하는 숙주 세포.
- (a) 제86항의 변경된 폴리펩티드를 제공하는 단계; 및
(b) 상기 변경된 폴리펩티드를 중합체 매트릭스와 혼합하는 단계
를 포함하는, 제어 방출형 조성물의 제조 방법. - 생물학적 활성 폴리펩티드 및 보조적 폴리펩티드를 포함하는 단리된 폴리펩티드로서, 상기 보조적 폴리펩티드가
(i) 3가지 유형의 아미노산으로 구성되고, 각각의 유형이 알라닌(A), 아스파르트산(D), 글루탐산(E), 글리신(G), 히스티딘(H), 라이신(K), 아스파라긴(N), 프롤린(P), 글루타민(Q), 아르기닌(R), 세린(S), 트레오닌(T) 및 타이로신(Y)으로 구성된 군에서 선택되며;
(ii) 10개 이상의 아미노산을 포함하는 것을 특징으로 하는 것인 단리된 폴리펩티드. - 제117항에 있어서, 상기 보조적 폴리펩티드가 3가지 유형의 아미노산으로 구성되고, 각각의 유형이 D, E, G, K, P, R, S 및 T로 구성된 군에서 선택되는 것인 단리된 폴리펩티드.
- 제117항에 있어서, 상기 보조적 폴리펩티드가 3가지 유형의 아미노산으로 구성되고, 각각의 유형이 E, S, G, R 및 A로 구성된 군에서 선택되는 것인 단리된 폴리펩티드.
- 제117항에 있어서, 상기 생물학적 활성 폴리펩티드가 치료학적 폴리펩티드인 단리된 폴리펩티드.
- 제117항에 있어서, 상기 보조적 폴리펩티드가 3가지 유형의 아미노산으로 구성되고, 각각의 유형이 E, G 및 S로 구성된 군에서 선택되는 것인 단리된 폴리펩티드.
- 생물학적 활성 폴리펩티드 및 보조적 폴리펩티드를 포함하는 단리된 폴리펩티드로서, 상기 보조적 폴리펩티드가
(i) 2가지 유형의 아미노산으로 구성되고, 이 중 하나가 글리신(G)이고 나머지 유형이 아스파르트산(D), 글루탐산(E), 라이신(K), 프롤린(P), 아르기닌(R), 세린(S), 트레오닌(T), 알라닌(A), 히스티딘(H), 아스파라긴(N), 타이로신(Y), 루신(L), 발린(V), 트립토판(W), 메티오닌(M), 페닐알라닌(F), 이소루신(I) 및 시스테인(C)으로 구성된 군에서 선택되며;
(ii) 50% 이하가 글리신인 10개 이상의 아미노산 잔기를 포함하는 것을 특징으로 하는 것인 단리된 폴리펩티드. - 생물학적 활성 폴리펩티드 및 보조적 폴리펩티드를 포함하는 단리된 폴리펩티드로서, 상기 보조적 폴리펩티드가
(i) 10개 이상의 아미노산을 포함하고;
(ii) 2가지 유형의 아미노산으로 구성되고, 총 아미노산의 50% 이하가 A, S, T, D, E 및 H로 구성된 군에서 선택되는 것을 특징으로 하는 것인 단리된 폴리펩티드. - 생물학적 활성 폴리펩티드 및 보조적 폴리펩티드를 포함하는 단리된 폴리펩티드로서, 상기 보조적 폴리펩티드가
(i) 2가지 유형의 아미노산으로 구성되고, 이 중 하나가 P, R, L, V, Y, W, M, F, I, K 및 C로 구성된 군에서 선택되며;
(ii) 10개 이상의 아미노산을 포함하는 것을 특징으로 하는 것인 단리된 폴리펩티드. - 생물학적 활성 폴리펩티드 및 보조적 폴리펩티드를 포함하는 단리된 폴리펩티드로서, 상기 보조적 폴리펩티드가 길이가 10개 이상인 아미노산을 포함하고 동일한 수로 나타나는 2가지 상이한 유형의 아미노산으로 구성되는 것인 단리된 폴리펩티드.
- 제121항, 제122항 또는 제123항 중 어느 한 항에 있어서, 상기 2가지 상이한 유형의 아미노산이 1:2의 비로 나타나는 것인 단리된 폴리펩티드.
- 제121항, 제122항 또는 제123항 중 어느 한 항에 있어서, 상기 2가지 상이한 유형의 아미노산이 2:3의 비로 나타나는 것인 단리된 폴리펩티드.
- 제121항, 제122항 또는 제123항 중 어느 한 항에 있어서, 상기 2가지 상이한 유형의 아미노산이 3:4의 비로 나타나는 것인 단리된 폴리펩티드.
- 제128항에 있어서, 상기 보조적 폴리펩티드가 4개 이상의 반복 모티프를 포함하고, 상기 모티프 각각이 2∼500개의 아미노산을 포함하고 2가지 상이한 유형의 아미노산으로 이루어지는 것인 단리된 폴리펩티드.
- 제128항에 있어서, 상기 반복 모티프가 8개보다 많은 아미노산을 포함하는 것인 단리된 폴리펩티드.
- 제128항에 있어서, 4개 이상의 반복 모티프가 동일한 것인 단리된 폴리펩티드.
- 제128항에 있어서, 4개 이상의 반복 모티프가 상이한 아미노산 서열을 포함하는 것인 단리된 폴리펩티드.
- 제128항에 있어서, 상기 보조적 폴리펩티드가 10개 이상의 반복 모티프를 포함하는 것인 단리된 폴리펩티드.
- 제128항에 있어서, 상기 보조적 폴리펩티드가 실질적으로 2차 구조를 갖지 않는 것인 단리된 폴리펩티드.
- 제128항에 있어서, 상기 단리된 폴리펩티드의 겉보기 분자량이 상기 보조적 폴리펩티드가 없는 상응하는 폴리펩티드의 겉보기 분자량보다 더 큰 것인 단리된 폴리펩티드.
- 제128항에 있어서, 상기 보조적 폴리펩티드의 겉보기 분자량이 그 실제 분자량보다 3배 이상 더 큰 것인 단리된 폴리펩티드.
- 제128항에 있어서, 상기 보조적 폴리펩티드가 없는 상응하는 폴리펩티드에 비해 2배 더 긴 혈청 반감기를 나타내는 것인 단리된 폴리펩티드.
- 제128항에 있어서, 상기 생물학적 활성 폴리펩티드와 상기 보조적 폴리펩티드가 펩티드 결합을 통해 연결되는 것인 단리된 폴리펩티드.
- 제117항에 있어서, 상기 보조적 폴리펩티드가 아미노산 서열 (GGEGGS)n(여기서, n은 3 이상의 정수임)을 포함하는 것인 단리된 폴리펩티드.
- 제117항에 있어서, 상기 보조적 폴리펩티드가 아미노산 서열 (GES)n(여기서, G, E 및 S는 임의의 순서일 수 있고 n은 3 이상의 정수임)을 포함하는 것인 단리된 폴리펩티드.
- 제117항에 있어서, 보조적 폴리펩티드가 아미노산 서열 (GGSGGE)n(여기서, G, E 및 S는 임의의 순서일 수 있고 n은 3 이상의 정수임)을 포함하는 것인 단리된 폴리펩티드.
- 제117항에 있어서, 상기 보조적 폴리펩티드가 아미노산 서열 (GGEGGEGGES)n(여기서, n은 1 이상의 정수임)을 포함하는 것인 단리된 폴리펩티드.
- a) 제117항, 제121항, 제122항, 제123항 또는 제124항 중 어느 한 항에 따른 단리된 폴리펩티드를 코딩하는 폴리뉴클레오티드 서열을 제공하는 단계; 및
b) 상기 폴리펩티드를 숙주 세포에서 발현시킴으로써 상기 폴리펩티드를 생산하는 단계
를 포함하는, 단리된 폴리펩티드의 제조 방법. - 제117항, 제121항, 제122항, 제123항 또는 제124항 중 어느 한 항에 따른 단리된 폴리펩티드를 코딩하는 핵산 서열을 포함하는 유전자 운반체.
- 제117항, 제121항, 제122항, 제123항 또는 제124항 중 어느 한 항에 따른 단리된 폴리펩티드를 발현하는 숙주 세포.
- 제117항, 제121항, 제122항, 제123항 또는 제124항 중 어느 한 항에 따른 단리된 폴리펩티드의 라이브러리.
- 제145항에 있어서, 파지(phage) 입자 상에 디스플레이되는 라이브러리.
- a) 서방형 제제; 및
b) 크기가 5 kD보다 큰 PEG 기에 연결된 생물학적 활성 폴리펩티드를 포함하는 변경된 폴리펩티드를 포함하는 변경된 폴리펩티드
를 포함하는 약학적 조성물.
Applications Claiming Priority (6)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US95610907P | 2007-08-15 | 2007-08-15 | |
| US60/956,109 | 2007-08-15 | ||
| US98107307P | 2007-10-18 | 2007-10-18 | |
| US60/981,073 | 2007-10-18 | ||
| US98656907P | 2007-11-08 | 2007-11-08 | |
| US60/986,569 | 2007-11-08 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20100058541A true KR20100058541A (ko) | 2010-06-03 |
Family
ID=40351372
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020107005458A KR20100058541A (ko) | 2007-08-15 | 2008-08-15 | 생물학적 활성 폴리펩티드의 특성을 변경하기 위한 조성물 및 방법 |
Country Status (10)
| Country | Link |
|---|---|
| US (4) | US8933197B2 (ko) |
| EP (1) | EP2185701A4 (ko) |
| JP (1) | JP2010536341A (ko) |
| KR (1) | KR20100058541A (ko) |
| CN (1) | CN103298935A (ko) |
| AU (1) | AU2008287340A1 (ko) |
| BR (1) | BRPI0815416A2 (ko) |
| CA (1) | CA2695374A1 (ko) |
| MX (1) | MX2010001684A (ko) |
| WO (1) | WO2009023270A2 (ko) |
Cited By (15)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2013169077A1 (ko) * | 2012-05-11 | 2013-11-14 | 주식회사 카엘젬백스 | 악액질 예방 또는 치료용 조성물 |
| US9540419B2 (en) | 2012-05-11 | 2017-01-10 | Gemvax & Kael Co., Ltd. | Anti-inflammatory peptides and composition comprising the same |
| US9572858B2 (en) | 2013-10-23 | 2017-02-21 | Gemvax & Kael Co., Ltd. | Composition for treating and preventing benign prostatic hyperplasia |
| US9907838B2 (en) | 2013-04-19 | 2018-03-06 | Gemvax & Kael Co., Ltd. | Composition and methods for treating ischemic damage |
| US9937240B2 (en) | 2014-04-11 | 2018-04-10 | Gemvax & Kael Co., Ltd. | Peptide having fibrosis inhibitory activity and composition containing same |
| US10034922B2 (en) | 2013-11-22 | 2018-07-31 | Gemvax & Kael Co., Ltd. | Peptide having angiogenesis inhibitory activity and composition containing same |
| US10383926B2 (en) | 2013-06-07 | 2019-08-20 | Gemvax & Kael Co., Ltd. | Biological markers useful in cancer immunotherapy |
| US10463708B2 (en) | 2014-12-23 | 2019-11-05 | Gemvax & Kael Co., Ltd. | Peptide for treating ocular diseases and composition for treating ocular diseases comprising same |
| US10561703B2 (en) | 2013-06-21 | 2020-02-18 | Gemvax & Kael Co., Ltd. | Method of modulating sex hormone levels using a sex hormone secretion modulator |
| US10662223B2 (en) | 2014-04-30 | 2020-05-26 | Gemvax & Kael Co., Ltd. | Composition for organ, tissue, or cell transplantation, kit, and transplantation method |
| US10835582B2 (en) | 2015-02-27 | 2020-11-17 | Gemvax & Kael Co. Ltd. | Peptide for preventing hearing loss, and composition comprising same |
| US10898540B2 (en) | 2016-04-07 | 2021-01-26 | Gem Vax & KAEL Co., Ltd. | Peptide having effects of increasing telomerase activity and extending telomere, and composition containing same |
| US10967000B2 (en) | 2012-07-11 | 2021-04-06 | Gemvax & Kael Co., Ltd. | Cell-penetrating peptide, conjugate comprising same and composition comprising same |
| US11015179B2 (en) | 2015-07-02 | 2021-05-25 | Gemvax & Kael Co., Ltd. | Peptide having anti-viral effect and composition containing same |
| US11058744B2 (en) | 2013-12-17 | 2021-07-13 | Gemvax & Kael Co., Ltd. | Composition for treating prostate cancer |
Families Citing this family (240)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8981061B2 (en) | 2001-03-20 | 2015-03-17 | Novo Nordisk A/S | Receptor TREM (triggering receptor expressed on myeloid cells) and uses thereof |
| PL3404102T3 (pl) | 2004-04-21 | 2021-12-13 | Alexion Pharmaceuticals, Inc. | Koniugaty do dostarczania do kości i sposób ich wykorzystania do nakierowywania białek na kość |
| ES2638792T3 (es) * | 2005-07-28 | 2017-10-24 | Carbon Sink Inc. | Eliminación de dióxido de carbono del aire |
| AU2006294644A1 (en) * | 2005-09-27 | 2007-04-05 | Amunix, Inc. | Proteinaceous pharmaceuticals and uses thereof |
| US20090099031A1 (en) * | 2005-09-27 | 2009-04-16 | Stemmer Willem P | Genetic package and uses thereof |
| US7846445B2 (en) * | 2005-09-27 | 2010-12-07 | Amunix Operating, Inc. | Methods for production of unstructured recombinant polymers and uses thereof |
| US7855279B2 (en) * | 2005-09-27 | 2010-12-21 | Amunix Operating, Inc. | Unstructured recombinant polymers and uses thereof |
| US8841255B2 (en) | 2005-12-20 | 2014-09-23 | Duke University | Therapeutic agents comprising fusions of vasoactive intestinal peptide and elastic peptides |
| US20130172274A1 (en) | 2005-12-20 | 2013-07-04 | Duke University | Methods and compositions for delivering active agents with enhanced pharmacological properties |
| WO2007073486A2 (en) | 2005-12-20 | 2007-06-28 | Duke University | Methods and compositions for delivering active agents with enhanced pharmacological properties |
| US7989160B2 (en) | 2006-02-13 | 2011-08-02 | Alethia Biotherapeutics Inc. | Polynucleotides and polypeptide sequences involved in the process of bone remodeling |
| US8168181B2 (en) | 2006-02-13 | 2012-05-01 | Alethia Biotherapeutics, Inc. | Methods of impairing osteoclast differentiation using antibodies that bind siglec-15 |
| KR20100058541A (ko) | 2007-08-15 | 2010-06-03 | 아뮤닉스 인코포레이티드 | 생물학적 활성 폴리펩티드의 특성을 변경하기 위한 조성물 및 방법 |
| US10004799B2 (en) | 2007-08-27 | 2018-06-26 | Longhorn Vaccines And Diagnostics, Llc | Composite antigenic sequences and vaccines |
| EP2772267B1 (en) * | 2007-08-27 | 2016-04-27 | Longhorn Vaccines and Diagnostics, LLC | Immunogenic compositions and methods |
| CA2953975C (en) | 2008-06-27 | 2019-11-26 | Duke University | Therapeutic agents comprising elastin-like peptides |
| AU2009335715B2 (en) | 2008-12-19 | 2016-09-15 | Indiana University Research And Technology Corporation | Amide-based insulin prodrugs |
| JP2012512903A (ja) | 2008-12-19 | 2012-06-07 | インディアナ ユニバーシティー リサーチ アンド テクノロジー コーポレーション | アミド系グルカゴンスーパーファミリーペプチドプロドラッグ |
| US8703717B2 (en) * | 2009-02-03 | 2014-04-22 | Amunix Operating Inc. | Growth hormone polypeptides and methods of making and using same |
| CN116925238A (zh) * | 2009-02-03 | 2023-10-24 | 阿穆尼克斯制药公司 | 延伸重组多肽和包含该延伸重组多肽的组合物 |
| US8680050B2 (en) * | 2009-02-03 | 2014-03-25 | Amunix Operating Inc. | Growth hormone polypeptides fused to extended recombinant polypeptides and methods of making and using same |
| WO2010111414A1 (en) * | 2009-03-24 | 2010-09-30 | Bayer Healthcare Llc | Factor viii variants and methods of use |
| EP3278813A1 (en) * | 2009-06-08 | 2018-02-07 | Amunix Operating Inc. | Growth hormone polypeptides and methods of making and using same |
| KR101813727B1 (ko) | 2009-06-08 | 2018-01-02 | 아뮤닉스 오퍼레이팅 인코포레이티드 | 성장 호르몬 폴리펩타이드 및 이를 제조하고 사용하는 방법 |
| US9849188B2 (en) | 2009-06-08 | 2017-12-26 | Amunix Operating Inc. | Growth hormone polypeptides and methods of making and using same |
| CA2764108A1 (en) | 2009-06-08 | 2010-12-16 | Amunix Operating Inc. | Glucose-regulating polypeptides and methods of making and using same |
| SG176963A1 (en) | 2009-06-22 | 2012-02-28 | Amgen Inc | Refolding proteins using a chemically controlled redox state |
| EP3660032A1 (en) | 2009-06-25 | 2020-06-03 | Amgen, Inc | Capture purification processes for proteins expressed in a non-mammalian system |
| KR101943420B1 (ko) * | 2009-08-14 | 2019-04-17 | 파세비오 파마수티컬스 인코포레이티드 | 변형된 혈관활성 장 펩티드 |
| CN102741422B (zh) * | 2009-08-24 | 2016-06-08 | 阿穆尼克斯运营公司 | 凝血因子ⅶ组合物及其制备和使用方法 |
| WO2011060528A1 (en) * | 2009-11-17 | 2011-05-26 | Universite De Montreal | Heteropeptides useful for reducing nonspecific adsorption |
| EP2507381A4 (en) * | 2009-12-04 | 2016-07-20 | Hoffmann La Roche | PLURISPECIFIC ANTIBODIES, ANTIBODY ANALOGUES, COMPOSITIONS AND METHODS |
| CN102791285A (zh) | 2009-12-06 | 2012-11-21 | 比奥根艾迪克依蒙菲利亚公司 | 因子VIII-Fc嵌合多肽和杂交多肽及其使用方法 |
| WO2011084426A2 (en) * | 2009-12-16 | 2011-07-14 | Oklahoma Medical Research Foundation | Methods and compositions for inhibiting fungal infection and disease |
| US8703701B2 (en) | 2009-12-18 | 2014-04-22 | Indiana University Research And Technology Corporation | Glucagon/GLP-1 receptor co-agonists |
| NZ629256A (en) * | 2009-12-22 | 2016-02-26 | Celldex Therapeutics Inc | Vaccine compositions |
| EP2528618A4 (en) | 2010-01-27 | 2015-05-27 | Univ Indiana Res & Tech Corp | GLUCAGON ANTAGONISTE AND GIP AGONISTS CONJUGATES AND COMPOSITIONS FOR THE TREATMENT OF METABOLISM DISEASES AND ADIPOSITAS |
| EP3095871B1 (en) | 2010-02-08 | 2019-04-10 | Regeneron Pharmaceuticals, Inc. | Common light chain mouse |
| US9796788B2 (en) | 2010-02-08 | 2017-10-24 | Regeneron Pharmaceuticals, Inc. | Mice expressing a limited immunoglobulin light chain repertoire |
| US20130045492A1 (en) | 2010-02-08 | 2013-02-21 | Regeneron Pharmaceuticals, Inc. | Methods For Making Fully Human Bispecific Antibodies Using A Common Light Chain |
| JP5840148B2 (ja) * | 2010-03-04 | 2016-01-06 | フェニックス インク. | 変性させることなく可溶性組換えインターフェロンタンパク質を産生する方法 |
| NZ603033A (en) | 2010-04-01 | 2014-06-27 | Pfenex Inc | Methods for g-csf production in a pseudomonas host cell |
| WO2011123813A2 (en) * | 2010-04-02 | 2011-10-06 | Amunix Operating Inc. | Binding fusion proteins, binding fusion protein-drug conjugates, xten-drug conjugates and methods of making and using same |
| US8557961B2 (en) | 2010-04-02 | 2013-10-15 | Amunix Operating Inc. | Alpha 1-antitrypsin compositions and methods of making and using same |
| EP2569000B1 (en) | 2010-05-13 | 2017-09-27 | Indiana University Research and Technology Corporation | Glucagon superfamily peptides exhibiting nuclear hormone receptor activity |
| CN102260697A (zh) * | 2010-05-26 | 2011-11-30 | 重庆富进生物医药有限公司 | 融合表达重组制备人β干扰素 |
| CN103068842B (zh) | 2010-06-16 | 2016-10-19 | 印第安纳大学研究及科技有限公司 | 对胰岛素受体具有高活性的单链胰岛素激动剂 |
| EP2585102B1 (en) | 2010-06-24 | 2015-05-06 | Indiana University Research and Technology Corporation | Amide-based insulin prodrugs |
| MX2012014576A (es) | 2010-06-24 | 2013-02-21 | Univ Indiana Res & Tech Corp | Profarmacos de peptido de la superfamilia de glucagon basado en amida. |
| CA3171308A1 (en) | 2010-06-25 | 2011-12-29 | Shire Human Genetic Therapies, Inc. | Methods and compositions for cns delivery of iduronate-2-sulfatase |
| JP6073783B2 (ja) | 2010-06-25 | 2017-02-01 | シャイアー ヒューマン ジェネティック セラピーズ インコーポレイテッド | ヘパランn−スルファターゼのcns送達のための方法および組成物 |
| ES2650689T3 (es) | 2010-06-25 | 2018-01-19 | Shire Human Genetic Therapies, Inc. | Administración de agentes terapéuticos al sistema nervioso central |
| CN103282046B (zh) | 2010-06-25 | 2015-05-13 | 夏尔人类遗传性治疗公司 | 芳基硫酸酯酶 a cns 递送的方法和组合物 |
| CN103140237A (zh) | 2010-07-09 | 2013-06-05 | 比奥根艾迪克依蒙菲利亚公司 | 因子ix多肽及其使用方法 |
| WO2012009580A1 (en) | 2010-07-14 | 2012-01-19 | The Trustees Of Columbia University In The City Of New York | Force-clamp spectrometer and methods of use |
| EP2593472B1 (en) * | 2010-07-15 | 2018-05-16 | The Trustees of Columbia University in the City of New York | Ancestral proteins |
| NZ605928A (en) | 2010-07-29 | 2015-02-27 | Eleven Biotherapeutics Inc | Chimeric il-1 receptor type i agonists and antagonists |
| CN103402536A (zh) | 2010-12-22 | 2013-11-20 | 马克迪亚生物科技公司 | 用gip和glp-1受体活性的基于胰高血糖素的肽来治疗代谢异常和肥胖的方法 |
| MA34885B1 (fr) | 2010-12-22 | 2014-02-01 | Indiana Unversity Res And Technology Corp | Analogues du glucagon presentant una ctivite de recepteur de gip |
| CA2823066A1 (en) | 2010-12-27 | 2012-07-05 | Alexion Pharma International Sarl | Compositions comprising natriuretic peptides and methods of use thereof |
| WO2012097313A2 (en) | 2011-01-14 | 2012-07-19 | The Regents Of The University Of California | Therapeutic antibodies against ror-1 protein and methods for use of same |
| WO2012103240A2 (en) | 2011-01-25 | 2012-08-02 | Eleven Biotherapeutics, Inc. | Receptor binding agents |
| US9561262B2 (en) | 2011-06-06 | 2017-02-07 | Phasebio Pharmaceuticals, Inc. | Use of modified vasoactive intestinal peptides in the treatment of hypertension |
| WO2012170969A2 (en) | 2011-06-10 | 2012-12-13 | Biogen Idec Ma Inc. | Pro-coagulant compounds and methods of use thereof |
| US9156902B2 (en) | 2011-06-22 | 2015-10-13 | Indiana University Research And Technology Corporation | Glucagon/GLP-1 receptor co-agonists |
| US9394343B2 (en) | 2011-07-05 | 2016-07-19 | The Regents Of The University Of California | Appetite stimulating protein |
| US10323081B2 (en) * | 2011-07-06 | 2019-06-18 | Genmag A/S | Modulation of complement-dependent cytotoxicity through modifications of the C-terminus of antibody heavy chains |
| EP2729161B1 (en) | 2011-07-08 | 2018-12-19 | Bioverativ Therapeutics Inc. | Factor viii chimeric and hybrid polypeptides, and methods of use thereof |
| EA028914B1 (ru) | 2011-07-25 | 2018-01-31 | Байоджен Хемофилия Инк. | Исследования для мониторинга нарушений свертываемости крови |
| AU2012290379A1 (en) | 2011-07-29 | 2014-02-06 | Eleven Biotherapeutics, Inc. | Purified proteins |
| MY172718A (en) | 2011-08-05 | 2019-12-11 | Regeneron Pharma | Humanized universal light chain mice |
| US20150094387A1 (en) * | 2011-08-11 | 2015-04-02 | Huntsman Petrochemical Llc | Use of Thickening Agents as Polyurethane Amine Catalyst Diluents |
| JP6170047B2 (ja) | 2011-08-31 | 2017-07-26 | ユニバーシティ・オブ・ジョージア・リサーチ・ファウンデイション・インコーポレイテッド | アポトーシス−ターゲティングナノ粒子 |
| US20150119343A1 (en) * | 2011-11-04 | 2015-04-30 | The Texas A & M University System | Production of TSG-6 Protein |
| WO2013067652A1 (en) * | 2011-11-10 | 2013-05-16 | Beijing Advaccine Biotechnology Co., Ltd. | Facilitator-dna combination vaccine |
| CA2847246A1 (en) | 2011-11-17 | 2013-05-23 | Indiana University Research And Technology Corporation | Glucagon superfamily peptides exhibiting glucocorticoid receptor activity |
| CN104114183A (zh) | 2011-12-20 | 2014-10-22 | 印第安纳大学研究及科技有限公司 | 用于治疗糖尿病的基于ctp的胰岛素类似物 |
| WO2013096899A2 (en) | 2011-12-23 | 2013-06-27 | Shire Human Genetic Therapies, Inc. | Stable formulations for cns delivery of arylsulfatase a |
| BR112014017165B1 (pt) * | 2012-01-12 | 2023-05-02 | Bioverativ Therapeutics Inc | Proteína quimérica compreendendo uma proteína de fator viii, composição farmacêutica, e seus usos |
| US20130210747A1 (en) | 2012-02-13 | 2013-08-15 | University Of Southern California | Methods and Therapeutics Comprising Ligand-Targeted ELPs |
| US9550830B2 (en) | 2012-02-15 | 2017-01-24 | Novo Nordisk A/S | Antibodies that bind and block triggering receptor expressed on myeloid cells-1 (TREM-1) |
| JP6256882B2 (ja) | 2012-02-15 | 2018-01-10 | アムニクス オペレーティング インコーポレイテッド | 第viii因子組成物、ならびに組成物の作製方法および用途 |
| SI2814842T1 (sl) | 2012-02-15 | 2018-10-30 | Novo Nordisk A/S | Protitelesa, ki vežejo peptidoglikal prepoznan protein 1 |
| JP6383666B2 (ja) | 2012-02-15 | 2018-08-29 | バイオベラティブ セラピューティクス インコーポレイテッド | 組換え第viii因子タンパク質 |
| PT2814844T (pt) | 2012-02-15 | 2017-09-18 | Novo Nordisk As | Anticorpos que se ligam e bloqueiam recetor de acionamento expresso em células mieloides-1 (trem-1) |
| US10416167B2 (en) | 2012-02-17 | 2019-09-17 | University Of Georgia Research Foundation, Inc. | Nanoparticles for mitochondrial trafficking of agents |
| WO2013130684A1 (en) | 2012-02-27 | 2013-09-06 | Amunix Operating Inc. | Xten-folate conjugate compositions and methods of making same |
| CN104321336B (zh) * | 2012-03-19 | 2021-08-06 | 米勒尤迪斯公司 | 管理哺乳的肽 |
| MX360109B (es) | 2012-04-20 | 2018-10-23 | Merus Nv | Metodos y medios para la produccion de moleculas de tipo ig. |
| US20130302366A1 (en) | 2012-05-09 | 2013-11-14 | Christopher Marshall | Conformationally Specific Viral Immunogens |
| US10052366B2 (en) | 2012-05-21 | 2018-08-21 | Alexion Pharmaceuticsl, Inc. | Compositions comprising alkaline phosphatase and/or natriuretic peptide and methods of use thereof |
| AU2013270683A1 (en) | 2012-06-08 | 2014-12-11 | Biogen Ma Inc. | Chimeric clotting factors |
| WO2013184938A2 (en) * | 2012-06-08 | 2013-12-12 | Alkermes. Inc. | Fusion polypeptides comprising mucin-domain polypeptide linkers |
| JP2015521589A (ja) | 2012-06-08 | 2015-07-30 | バイオジェン・エムエイ・インコーポレイテッドBiogen MA Inc. | プロコアグラント化合物 |
| CA2877358A1 (en) | 2012-06-21 | 2013-12-27 | Indiana University Research And Technology Corporation | Glucagon analogs exhibiting gip receptor activity |
| KR20150039748A (ko) | 2012-06-21 | 2015-04-13 | 인디애나 유니버시티 리서치 앤드 테크놀로지 코퍼레이션 | Gip 수용체 활성을 나타내는 글루카곤의 유사체들 |
| EP2870250B2 (en) | 2012-07-06 | 2022-06-29 | Bioverativ Therapeutics Inc. | Cell line expressing single chain factor viii polypeptides and uses thereof |
| SG10201913893XA (en) | 2012-07-11 | 2020-03-30 | Bioverativ Therapeutics Inc | Factor viii complex with xten and von willebrand factor protein, and uses thereof |
| CA2928851A1 (en) | 2012-07-19 | 2014-01-23 | Alethia Biotherapeutics Inc. | Anti-siglec-15 antibodies |
| WO2014026054A2 (en) | 2012-08-10 | 2014-02-13 | University Of Southern California | CD20 scFv-ELPs METHODS AND THERAPEUTICS |
| BR112015004734A2 (pt) * | 2012-09-07 | 2017-11-21 | Sanofi Sa | proteínas de fusão para tratar uma síndrome metabólica |
| EP2900328A4 (en) | 2012-09-25 | 2016-05-11 | Biogen Ma Inc | PROCESS FOR USE OF FIXED POLYPEPTIDES |
| SI2900694T1 (sl) | 2012-09-27 | 2018-12-31 | Merus N.V. | Bispecifična IGG protitelesa kot vključitelji T-celic |
| WO2014100913A1 (en) * | 2012-12-24 | 2014-07-03 | Beijing Anxinhuaide Biotech. Co., Ltd | Improving the half life of a therapeutic polypeptide by fusing with a trimeric scaffold protein via a spacer |
| JP6450364B2 (ja) | 2013-03-13 | 2019-01-09 | セセン バイオ, インコーポレイテッド | 眼送達のためのキメラサイトカイン製剤 |
| CA2899089C (en) | 2013-03-15 | 2021-10-26 | Biogen Ma Inc. | Factor ix polypeptide formulations |
| CN105555794A (zh) | 2013-07-10 | 2016-05-04 | 哈佛学院院长及董事 | 涉及核酸-蛋白质复合物的组合物和方法 |
| US10383921B2 (en) | 2013-08-13 | 2019-08-20 | President And Fellows Of Harvard College | Leveraging oxidative stress pathways in lactic acid bacteria to promote gut homeostasis |
| WO2015023268A1 (en) * | 2013-08-13 | 2015-02-19 | President And Fellows Of Harvard College | Leveraging oxidative stress pathways in lactic acid bacteria to promote gut homeostasis |
| US10548953B2 (en) | 2013-08-14 | 2020-02-04 | Bioverativ Therapeutics Inc. | Factor VIII-XTEN fusions and uses thereof |
| EP3065769A4 (en) | 2013-11-08 | 2017-05-31 | Biogen MA Inc. | Procoagulant fusion compound |
| CN104711217B (zh) * | 2013-12-13 | 2018-02-27 | 天津科技大学 | 一种新型的促进乳酸菌生长的生物活性肽 |
| WO2015095553A1 (en) * | 2013-12-20 | 2015-06-25 | Nephrogenesis, Llc | Methods and apparatus for kidney dialysis |
| CN103709253A (zh) * | 2013-12-20 | 2014-04-09 | 南开大学 | 一种生物合成制备glp-1及其类似物的方法 |
| RS63583B1 (sr) | 2014-01-10 | 2022-10-31 | Bioverativ Therapeutics Inc | Himerni proteini faktora viii i njihova upotreba |
| CN104844711B (zh) * | 2014-02-18 | 2018-07-06 | 南通表源生物技术有限公司 | 一种多聚体荧光蛋白复合物及其应用 |
| US9999704B2 (en) * | 2014-02-26 | 2018-06-19 | University Of Massachusetts | Amphiphilic degradable polymers for immobilization and sustained delivery of biomolecules |
| US10398663B2 (en) | 2014-03-14 | 2019-09-03 | University Of Georgia Research Foundation, Inc. | Mitochondrial delivery of 3-bromopyruvate |
| SG11201607203XA (en) | 2014-03-21 | 2016-09-29 | Regeneron Pharma | Non-human animals that make single domain binding proteins |
| US10308697B2 (en) | 2014-04-30 | 2019-06-04 | President And Fellows Of Harvard College | Fusion proteins for treating cancer and related methods |
| CA2947982C (en) | 2014-05-08 | 2022-11-29 | Phasebio Pharmaceuticals, Inc. | Methods and compositions for treating cystic fibrosis |
| CN106573032B (zh) * | 2014-05-21 | 2022-03-18 | 哈佛大学的校长及成员们 | Ras抑制肽和其用途 |
| EP3157552B1 (en) * | 2014-06-18 | 2019-10-23 | Albert Einstein College of Medicine | Syntac polypeptides and uses thereof |
| US9272019B2 (en) | 2014-06-24 | 2016-03-01 | Novo Nordisk A/S | MIC-1 fusion proteins and uses thereof |
| US10822596B2 (en) | 2014-07-11 | 2020-11-03 | Alexion Pharmaceuticals, Inc. | Compositions and methods for treating craniosynostosis |
| EP3168297B1 (en) * | 2014-07-11 | 2020-09-16 | Metcela Inc. | Cardiac cell culture material |
| MY178347A (en) | 2014-07-17 | 2020-10-08 | Novo Nordisk As | Site directed mutagenesis of trem-1 antibodies for decreasing viscosity |
| JP6851965B2 (ja) * | 2014-09-26 | 2021-03-31 | サハイ バートナガール ラジェンドラ | 疾患及び障害の治療のためのnfカッパb活性の阻害剤 |
| NZ730563A (en) | 2014-10-14 | 2019-05-31 | Halozyme Inc | Compositions of adenosine deaminase-2 (ada2), variants thereof and methods of using same |
| MA40835A (fr) | 2014-10-23 | 2017-08-29 | Biogen Ma Inc | Anticorps anti-gpiib/iiia et leurs utilisations |
| MA40861A (fr) | 2014-10-31 | 2017-09-05 | Biogen Ma Inc | Anticorps anti-glycoprotéines iib/iiia |
| RU2708068C2 (ru) | 2014-12-05 | 2019-12-04 | Алексион Фармасьютикалз, Инк. | Лечение судорог с использованием рекомбинантной щелочной фосфатазы |
| WO2016094627A1 (en) | 2014-12-10 | 2016-06-16 | S-Aima Holding Company, Llc | Generation of hemoglobin-based oxygen carriers using elastin-like polypeptides |
| WO2016118577A1 (en) * | 2015-01-22 | 2016-07-28 | Medimmune, Llc | Thymosin-beta-four fusion proteins |
| JP6868561B2 (ja) | 2015-01-28 | 2021-05-12 | アレクシオン ファーマシューティカルズ, インコーポレイテッド | アルカリホスファターゼ欠損を有する被験者を治療する方法 |
| AU2016219513B2 (en) | 2015-02-09 | 2021-09-30 | Immunoforge Co., Ltd. | Methods and compositions for treating muscle disease and disorders |
| EP3270945A4 (en) | 2015-03-18 | 2018-09-05 | Massachusetts Institute of Technology | Selective mcl-1 binding peptides |
| CA2979702A1 (en) | 2015-03-19 | 2016-09-22 | Regeneron Pharmaceuticals, Inc. | Non-human animals that select for light chain variable regions that bind antigen |
| ES2784603T3 (es) | 2015-06-02 | 2020-09-29 | Novo Nordisk As | Insulinas con extensiones recombinantes polares |
| EA033342B1 (ru) * | 2015-07-08 | 2019-09-30 | Ресерч Энд Бизнес Фондэйшн Сонгюнгван Юниверсити | Пирролидинкарбоксамидо производные и способы их получения и их применение |
| CN108026174B (zh) | 2015-07-10 | 2023-02-17 | 美勒斯公司 | 人cd3结合抗体 |
| BR112018002150A2 (pt) | 2015-08-03 | 2018-09-18 | Bioverativ Therapeutics Inc | proteínas de fusão do fator ix e métodos de fabricação e uso das mesmas |
| CN108350440A (zh) | 2015-08-17 | 2018-07-31 | 阿雷克森制药公司 | 碱性磷酸酯的制造 |
| MX2018002226A (es) | 2015-08-28 | 2018-03-23 | Amunix Operating Inc | Ensamble de polipeptido quimerico y metodos para hacer y usar el mismo. |
| ES2848478T3 (es) * | 2015-09-11 | 2021-08-09 | Biosceptre Uk Ltd | Receptores quiméricos para antígenos y usos de estos |
| EP3355904A4 (en) | 2015-09-28 | 2019-06-12 | Alexion Pharmaceuticals, Inc. | IDENTIFICATION OF EFFECTIVE DOSE SHEETS FOR TISSUE-SPECIFIC ALKALINE PHOSPHATASE ENZYMERSAT THERAPY OF HYPOPHOSPHATASIA |
| MA43348A (fr) | 2015-10-01 | 2018-08-08 | Novo Nordisk As | Conjugués de protéines |
| US11186615B2 (en) | 2015-10-08 | 2021-11-30 | The Governors Of The University Of Alberta | Hepatitis C virus E1/E2 heterodimers and methods of producing same |
| WO2017074466A1 (en) | 2015-10-30 | 2017-05-04 | Alexion Pharmaceuticals, Inc. | Methods for treating craniosynostosis in a patient |
| WO2017120890A1 (zh) | 2016-01-15 | 2017-07-20 | 江南大学 | 一种利用磷脂酶融合表达以提高外源蛋白表达量的方法 |
| US11065306B2 (en) | 2016-03-08 | 2021-07-20 | Alexion Pharmaceuticals, Inc. | Methods for treating hypophosphatasia in children |
| EP3436052A4 (en) | 2016-04-01 | 2019-10-09 | Alexion Pharmaceuticals, Inc. | TREATMENT OF MUSCLE WEAKNESS USING ALKALINE PHOSPHATASES |
| US10898549B2 (en) | 2016-04-01 | 2021-01-26 | Alexion Pharmaceuticals, Inc. | Methods for treating hypophosphatasia in adolescents and adults |
| CA3019005A1 (en) | 2016-05-18 | 2017-11-23 | Cue Biopharma, Inc. | T-cell modulatory multimeric polypeptides and methods of use thereof |
| JP2019522466A (ja) | 2016-05-18 | 2019-08-15 | アルバート アインシュタイン カレッジ オブ メディシン,インコーポレイティド | 変異pd−l1ポリペプチド、t細胞調節多量体ポリペプチド、及びそれらの使用方法 |
| WO2017214130A1 (en) | 2016-06-06 | 2017-12-14 | Alexion Pharmaceuticals, Inc. | Metal impact on manufacturing of alkaline phosphatases |
| EA037848B1 (ru) * | 2016-07-14 | 2021-05-27 | Общество С Ограниченной Ответственностью "Биохимический Агент" | Гибридный белок, полинуклеотид, генетическая конструкция, продуцент, препарат для регенерации хряща (варианты) |
| WO2018017922A2 (en) | 2016-07-22 | 2018-01-25 | Massachusetts Institute Of Technology | Selective bfl-1 peptides |
| JP7018933B2 (ja) | 2016-08-18 | 2022-02-14 | アレクシオン ファーマシューティカルズ, インコーポレイテッド | 気管気管支軟化症の治療方法 |
| CA3038292A1 (en) | 2016-09-28 | 2018-04-05 | Cohbar, Inc. | Therapeutic mots-c related peptides |
| US10738338B2 (en) | 2016-10-18 | 2020-08-11 | The Research Foundation for the State University | Method and composition for biocatalytic protein-oligonucleotide conjugation and protein-oligonucleotide conjugate |
| CN108061804B (zh) * | 2016-11-09 | 2020-05-12 | 北京大学人民医院 | 用于诊断子宫内膜异位症的生物标志物 |
| CA3043630A1 (en) | 2016-12-22 | 2018-06-28 | Cue Biopharma, Inc. | T-cell modulatory multimeric polypeptides and methods of use thereof |
| EP3565829A4 (en) | 2017-01-09 | 2021-01-27 | Cue Biopharma, Inc. | MULTIMER POLYPEPTIDES T-LYMPHOCYTE MODULATORS AND THEIR METHODS OF USE |
| EP3579848A4 (en) | 2017-02-08 | 2021-03-03 | Dragonfly Therapeutics, Inc. | MULTISPECIFIC BINDING PROTEINS FOR ACTIVATING NATURAL KILLER CELLS AND THEIR THERAPEUTIC USES FOR TREATING CANCER |
| AU2018220736A1 (en) | 2017-02-20 | 2019-09-05 | Dragonfly Therapeutics, Inc. | Proteins binding HER2, NKG2D and CD16 |
| EP3585411A4 (en) * | 2017-02-21 | 2020-12-16 | The Regents Of The University Of Michigan | IL-22BP COMPOSITIONS AND METHODS OF TREATMENT OF DISEASES THEREOF |
| US11117930B2 (en) | 2017-02-23 | 2021-09-14 | Adrx, Inc. | Peptide inhibitors of transcription factor aggregation |
| EP3596100A4 (en) * | 2017-03-15 | 2021-01-13 | Juneau Biosciences, L.L.C. | METHODS OF USING GENETIC MARKERS ASSOCIATED WITH ENDOMETRIOSIS |
| CN111010875B (zh) | 2017-03-15 | 2024-04-05 | 库尔生物制药有限公司 | 用于调节免疫应答的方法 |
| BR112019019720A2 (pt) * | 2017-03-22 | 2020-04-28 | Pharmain Corp | agonistas de npra, composições e usos dos mesmos |
| US11224637B2 (en) | 2017-03-31 | 2022-01-18 | Alexion Pharmaceuticals, Inc. | Methods for treating hypophosphatasia (HPP) in adults and adolescents |
| WO2018185131A2 (en) | 2017-04-05 | 2018-10-11 | Novo Nordisk A/S | Oligomer extended insulin-fc conjugates |
| CN107098978A (zh) * | 2017-05-05 | 2017-08-29 | 中国药科大学 | 一种抗肿瘤和免疫增强双重功效融合蛋白 |
| TWI710377B (zh) | 2017-05-23 | 2020-11-21 | 丹麥商諾佛 儂迪克股份有限公司 | Mic-1化合物及其用途 |
| JP2020523035A (ja) | 2017-06-07 | 2020-08-06 | エーディーアールエックス, インコーポレイテッド | タウ凝集阻害剤 |
| AU2018279728B2 (en) * | 2017-06-08 | 2023-07-20 | The Brigham And Women's Hospital, Inc. | Methods and compositions for identifying epitopes |
| WO2019004213A1 (ja) * | 2017-06-26 | 2019-01-03 | 国立研究開発法人理化学研究所 | 融合タンパク質 |
| CN111051338A (zh) * | 2017-06-29 | 2020-04-21 | 乌雷卡有限公司 | 具有改进的药物学性能的前药肽 |
| US11453701B2 (en) | 2017-08-18 | 2022-09-27 | Adrx, Inc. | Tau aggregation peptide inhibitors |
| US20210139920A1 (en) * | 2017-08-21 | 2021-05-13 | Indiana University Research And Technology Corporation | Solubility enhancing protein expression systems |
| KR20200064085A (ko) | 2017-09-07 | 2020-06-05 | 큐 바이오파마, 인크. | 접합 부위를 갖는 t-세포 조절 다량체 폴리펩타이드 및 이의 사용 방법 |
| KR101930399B1 (ko) * | 2017-09-20 | 2018-12-18 | 한국과학기술연구원 | 종양세포 특이적 감응형 자가조립 나노약물복합체 |
| EP3737689A4 (en) | 2018-01-09 | 2021-12-01 | Cue Biopharma, Inc. | MULTIMERIC T CELL-MODULATING POLYPEPTIDES AND METHOD OF USING THEREOF |
| CN113603794B (zh) * | 2018-01-11 | 2024-01-16 | 安源医药科技(上海)有限公司 | 用于调节血糖和脂质的增效型双功能蛋白 |
| CN112368012A (zh) | 2018-02-08 | 2021-02-12 | 蜻蜓疗法股份有限公司 | 靶向nkg2d受体的抗体可变结构域 |
| WO2019190752A1 (en) | 2018-03-30 | 2019-10-03 | Alexion Pharmaceuticals, Inc. | Manufacturing of glycoproteins |
| US11155618B2 (en) | 2018-04-02 | 2021-10-26 | Bristol-Myers Squibb Company | Anti-TREM-1 antibodies and uses thereof |
| EP3553522A1 (en) * | 2018-04-12 | 2019-10-16 | Koninklijke Philips N.V. | Gingivitis diagnostic methods, uses and kits |
| US11820801B2 (en) * | 2018-04-26 | 2023-11-21 | Good T Cells, Inc. | Fusion protein, and pharmaceutical composition for preventing or treating cancer, containing same |
| WO2019217332A1 (en) * | 2018-05-07 | 2019-11-14 | Dragonfly Therapeutics, Inc. | A protein binding nkg2d, cd16 and a tumor-associated antigen |
| JP2021524756A (ja) * | 2018-05-14 | 2021-09-16 | ウェアウルフ セラピューティクス, インコーポレイテッド | 活性化可能なサイトカインポリペプチド及びその使用方法 |
| CN108373496A (zh) * | 2018-05-17 | 2018-08-07 | 安徽工程大学 | 抗氧化性多肽gtmgavgprg及其制备方法 |
| CN109053862A (zh) * | 2018-08-07 | 2018-12-21 | 复旦大学附属肿瘤医院 | 靶向PD-L1的多肽衍生物及其99mTc配合物的制备和应用 |
| CN116763943A (zh) * | 2018-08-07 | 2023-09-19 | 普渡研究基金会 | 使car t细胞恢复活力 |
| MX2020007072A (es) * | 2018-09-17 | 2020-11-11 | Gi Innovation Inc | Proteina de fusion que comprende proteina il-2 y proteina cd80 y uso de la misma. |
| EP3852783A1 (en) | 2018-09-17 | 2021-07-28 | Massachusetts Institute of Technology | Peptides selective for bcl-2 family proteins |
| EP3864024A4 (en) * | 2018-10-10 | 2022-07-06 | University of Washington | MIXED CHARGE PEPTIDE fusion products and bioconjugates |
| MA54070A (fr) | 2018-10-29 | 2021-09-08 | Biogen Ma Inc | Variants fc5 humanisés et stabilisés pour l'amélioration du transport à travers la barrière hémato-encéphalique |
| CN109374897B (zh) * | 2018-11-22 | 2021-11-02 | 大连大学 | 一种用于肝癌检测的试剂盒 |
| CN109371052B (zh) * | 2018-12-04 | 2022-02-22 | 安徽农业大学 | 提高高gc含量噬铜菌属细菌电转化效率的方法 |
| TW202039542A (zh) | 2018-12-19 | 2020-11-01 | 美商庫爾生物製藥有限公司 | 多聚體t細胞調節多肽及其使用方法 |
| AU2020216135A1 (en) | 2019-01-28 | 2021-08-05 | Cohbar, Inc. | Therapeutic peptides |
| CN111499759B (zh) * | 2019-01-31 | 2022-12-20 | 上海科技大学 | 一种具有细胞穿膜性的锌指蛋白-乳铁蛋白融合蛋白质及其制备与应用 |
| CN109627300B (zh) * | 2019-02-18 | 2022-08-05 | 浙江新银象生物工程有限公司 | Nisin溶液稳定剂开发及应用 |
| EP3935080A4 (en) | 2019-03-06 | 2023-04-05 | Cue Biopharma, Inc. | T-CELL-MODULATING MULTIMERIC POLYPEPTIDES AND METHODS OF USE THEREOF |
| CN110075280A (zh) * | 2019-04-30 | 2019-08-02 | 王丛飞 | 一种层粘连蛋白肽复合口服剂及其制备方法 |
| CN110244053B (zh) * | 2019-05-09 | 2022-03-11 | 北京大学第三医院(北京大学第三临床医学院) | 用于诊断狼疮肾炎并肺动脉高压疾病的分子标志物及其用途 |
| US11767524B2 (en) * | 2019-09-24 | 2023-09-26 | Abclonal Science, Inc. | His-MBP tagged DNA endonuclease for facilitated enzyme removal |
| CN110658296A (zh) * | 2019-10-30 | 2020-01-07 | 海南通用三洋药业有限公司 | 一种醋酸阿托西班注射液中高分子聚合物的检测方法 |
| US20220395553A1 (en) | 2019-11-14 | 2022-12-15 | Cohbar, Inc. | Cxcr4 antagonist peptides |
| CN116925237A (zh) | 2019-12-31 | 2023-10-24 | 北京质肽生物医药科技有限公司 | Glp-1和gdf15的融合蛋白以及其缀合物 |
| CN115322794A (zh) | 2020-01-11 | 2022-11-11 | 北京质肽生物医药科技有限公司 | Glp-1和fgf21的融合蛋白的缀合物 |
| WO2021147886A1 (zh) * | 2020-01-21 | 2021-07-29 | 张晋宇 | 一种药物组合物及其用途 |
| CN111437444B (zh) * | 2020-04-12 | 2021-03-12 | 南方医科大学 | 一种抗肠粘连双层生物凝胶制备方法及双层生物凝胶 |
| JP2023526723A (ja) | 2020-05-12 | 2023-06-23 | キュー バイオファーマ, インコーポレイテッド | 多量体t細胞調節性ポリペプチド及びその使用方法 |
| CN113773400B (zh) * | 2020-06-09 | 2023-08-18 | 宁波鲲鹏生物科技有限公司 | 一种门冬胰岛素衍生物及其应用 |
| CN111620942B (zh) * | 2020-06-12 | 2021-10-15 | 中国科学院昆明动物研究所 | 布氏鼠耳蝠白三烯A4水解酶抑制剂Motistin的成熟肽及其应用 |
| CN111705032B (zh) * | 2020-07-09 | 2022-04-05 | 科赫生物科技(北京)有限公司 | 一种原核表达细胞及其制备方法和应用 |
| CN111870688A (zh) * | 2020-07-09 | 2020-11-03 | 沣潮医药科技(上海)有限公司 | ACE2蛋白与IL-6或TNFα拮抗剂组合及其应用 |
| CN111875711A (zh) * | 2020-07-31 | 2020-11-03 | 广东昭泰体内生物医药科技有限公司 | 一种增强型免疫细胞及其应用 |
| EP4192495A1 (en) | 2020-08-07 | 2023-06-14 | Bristol-Myers Squibb Company | Fgf21 combined with ccr2/5 antagonists for the treatment of fibrosis |
| CN111944021B (zh) * | 2020-08-24 | 2022-03-22 | 郑州大学 | Cd47亲和肽及其应用 |
| WO2022047248A1 (en) * | 2020-08-28 | 2022-03-03 | Torigen Pharmaceuticals, Inc. | Immune memory enhanced preparations and uses thereof |
| CN115925994B (zh) | 2020-09-30 | 2023-09-22 | 北京质肽生物医药科技有限公司 | 多肽缀合物和使用方法 |
| CN112375712A (zh) * | 2020-11-25 | 2021-02-19 | 昆明理工大学 | 一株乳酸乳球菌及其应用 |
| US20240123031A1 (en) | 2020-11-25 | 2024-04-18 | Bristol-Myers Squibb Company | Methods of treating liver diseases |
| CN112457399B (zh) * | 2020-12-19 | 2023-09-01 | 上海佰君生物科技有限公司 | 一种人免疫球蛋白g的提纯方法 |
| CN113243512A (zh) * | 2021-02-10 | 2021-08-13 | 渤海大学 | 一种鲜味肽 |
| CN113024634B (zh) * | 2021-03-01 | 2022-05-10 | 浙江大学 | 类肽化合物及其在制备抗生素中的应用 |
| CN113358866B (zh) * | 2021-04-22 | 2023-06-23 | 四川大学华西医院 | 基于三重并联杂交链式反应的破伤风抗原的均相超灵敏二维可视化和荧光分析方法及应用 |
| WO2022232610A2 (en) * | 2021-04-29 | 2022-11-03 | Seer, Inc. | Peptide decorated nanoparticles for enrichment of specific protein subsets |
| CN113577237B (zh) * | 2021-05-25 | 2023-12-26 | 浙江大学 | 类肽化合物在抗多耐药菌、泛耐药菌或全耐药菌中的应用 |
| CA3227440A1 (en) * | 2021-07-27 | 2023-02-02 | Stand Therapeutics Co., Ltd. | Peptide tag and nucleic acid encoding same |
| CN114133441B (zh) * | 2021-11-15 | 2024-02-06 | 同济大学 | 一种促进牙本质矿化的活性短肽及其应用 |
| CN114380902B (zh) * | 2021-12-29 | 2023-06-16 | 江苏诺泰澳赛诺生物制药股份有限公司 | 一种hgh(176-191)的制备方法 |
| WO2023212293A1 (en) | 2022-04-29 | 2023-11-02 | Broadwing Bio Llc | Complement factor h related 4-specific antibodies and uses thereof |
| WO2023212298A1 (en) | 2022-04-29 | 2023-11-02 | Broadwing Bio Llc | Bispecific antibodies and methods of treating ocular disease |
| WO2023212294A1 (en) | 2022-04-29 | 2023-11-02 | Broadwing Bio Llc | Angiopoietin-related protein 7-specific antibodies and uses thereof |
| CN116218711B (zh) * | 2022-12-21 | 2024-02-06 | 陕西省微生物研究所 | 一株乳酸乳球菌pz1及其在制备富硒低聚肽中的应用 |
Family Cites Families (118)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US3992518A (en) | 1974-10-24 | 1976-11-16 | G. D. Searle & Co. | Method for making a microsealed delivery device |
| GB1478759A (en) | 1974-11-18 | 1977-07-06 | Alza Corp | Process for forming outlet passageways in pills using a laser |
| US4284444A (en) | 1977-08-01 | 1981-08-18 | Herculite Protective Fabrics Corporation | Activated polymer materials and process for making same |
| US4200984A (en) | 1979-03-12 | 1980-05-06 | Fink Ray D | Detachable tool combining bracket and method |
| DE3006377C2 (de) * | 1980-02-20 | 1983-11-24 | Franz Josef 6233 Kelkheim Lang | Etagenturm |
| US4398908A (en) | 1980-11-28 | 1983-08-16 | Siposs George G | Insulin delivery system |
| US4435173A (en) | 1982-03-05 | 1984-03-06 | Delta Medical Industries | Variable rate syringe pump for insulin delivery |
| US4542025A (en) | 1982-07-29 | 1985-09-17 | The Stolle Research And Development Corporation | Injectable, long-acting microparticle formulation for the delivery of anti-inflammatory agents |
| US5916588A (en) | 1984-04-12 | 1999-06-29 | The Liposome Company, Inc. | Peptide-containing liposomes, immunogenic liposomes and methods of preparation and use |
| US5231112A (en) | 1984-04-12 | 1993-07-27 | The Liposome Company, Inc. | Compositions containing tris salt of cholesterol hemisuccinate and antifungal |
| AU576889B2 (en) | 1984-07-24 | 1988-09-08 | Key Pharmaceuticals, Inc. | Adhesive transdermal dosage layer |
| US4684479A (en) | 1985-08-14 | 1987-08-04 | Arrigo Joseph S D | Surfactant mixtures, stable gas-in-liquid emulsions, and methods for the production of such emulsions from said mixtures |
| US6759057B1 (en) | 1986-06-12 | 2004-07-06 | The Liposome Company, Inc. | Methods and compositions using liposome-encapsulated non-steroidal anti-inflammatory drugs |
| IE60901B1 (en) | 1986-08-21 | 1994-08-24 | Vestar Inc | Improved treatment of systemic fungal infections with phospholipid particles encapsulating polyene antifungal antibiotics |
| US4933185A (en) | 1986-09-24 | 1990-06-12 | Massachusetts Institute Of Technology | System for controlled release of biologically active compounds |
| US5811128A (en) | 1986-10-24 | 1998-09-22 | Southern Research Institute | Method for oral or rectal delivery of microencapsulated vaccines and compositions therefor |
| US6406713B1 (en) | 1987-03-05 | 2002-06-18 | The Liposome Company, Inc. | Methods of preparing low-toxicity drug-lipid complexes |
| US4897268A (en) | 1987-08-03 | 1990-01-30 | Southern Research Institute | Drug delivery system and method of making the same |
| US4976696A (en) | 1987-08-10 | 1990-12-11 | Becton, Dickinson And Company | Syringe pump and the like for delivering medication |
| US4861800A (en) | 1987-08-18 | 1989-08-29 | Buyske Donald A | Method for administering the drug deprenyl so as to minimize the danger of side effects |
| AU598958B2 (en) | 1987-11-12 | 1990-07-05 | Vestar, Inc. | Improved amphotericin b liposome preparation |
| US5270176A (en) | 1987-11-20 | 1993-12-14 | Hoechst Aktiengesellschaft | Method for the selective cleavage of fusion proteins with lysostaphin |
| GB8807504D0 (en) | 1988-03-29 | 1988-05-05 | Sandoz Ltd | Improvements in/relating to organic compounds |
| JP2717808B2 (ja) | 1988-08-10 | 1998-02-25 | テルモ株式会社 | シリンジポンプ |
| US5223409A (en) | 1988-09-02 | 1993-06-29 | Protein Engineering Corp. | Directed evolution of novel binding proteins |
| US5017378A (en) | 1989-05-01 | 1991-05-21 | The University Of Virginia Alumni Patents Foundation | Intraorgan injection of biologically active compounds contained in slow-release microcapsules or microspheres |
| EP0471036B2 (en) | 1989-05-04 | 2004-06-23 | Southern Research Institute | Encapsulation process |
| US5599907A (en) | 1989-05-10 | 1997-02-04 | Somatogen, Inc. | Production and use of multimeric hemoglobins |
| US5298022A (en) | 1989-05-29 | 1994-03-29 | Amplifon Spa | Wearable artificial pancreas |
| FR2647677B1 (fr) | 1989-05-31 | 1991-09-27 | Roussel Uclaf | Nouvelles micro-proteines, procede de preparation et application a titre de medicaments de ces nouvelles micro-proteines |
| US7413537B2 (en) | 1989-09-01 | 2008-08-19 | Dyax Corp. | Directed evolution of disulfide-bonded micro-proteins |
| US5492534A (en) | 1990-04-02 | 1996-02-20 | Pharmetrix Corporation | Controlled release portable pump |
| US5318540A (en) | 1990-04-02 | 1994-06-07 | Pharmetrix Corporation | Controlled release infusion device |
| US5176502A (en) | 1990-04-25 | 1993-01-05 | Becton, Dickinson And Company | Syringe pump and the like for delivering medication |
| US6517859B1 (en) | 1990-05-16 | 2003-02-11 | Southern Research Institute | Microcapsules for administration of neuroactive agents |
| US5215680A (en) | 1990-07-10 | 1993-06-01 | Cavitation-Control Technology, Inc. | Method for the production of medical-grade lipid-coated microbubbles, paramagnetic labeling of such microbubbles and therapeutic uses of microbubbles |
| US5089938A (en) * | 1991-04-24 | 1992-02-18 | General Motors Corporation | Component mounting assembly |
| FR2686899B1 (fr) * | 1992-01-31 | 1995-09-01 | Rhone Poulenc Rorer Sa | Nouveaux polypeptides biologiquement actifs, leur preparation et compositions pharmaceutiques les contenant. |
| US5573776A (en) | 1992-12-02 | 1996-11-12 | Alza Corporation | Oral osmotic device with hydrogel driving member |
| DK0674506T3 (da) * | 1992-12-02 | 2001-01-08 | Alkermes Inc | Væksthormonholdige mikrosfærer med styret frigivelse |
| US5554730A (en) | 1993-03-09 | 1996-09-10 | Middlesex Sciences, Inc. | Method and kit for making a polysaccharide-protein conjugate |
| ATE258685T1 (de) | 1993-03-09 | 2004-02-15 | Baxter Int | Makromolekulare mikropartikel und verfahren zur ihrer herstellung |
| US6090925A (en) | 1993-03-09 | 2000-07-18 | Epic Therapeutics, Inc. | Macromolecular microparticles and methods of production and use |
| US5981719A (en) | 1993-03-09 | 1999-11-09 | Epic Therapeutics, Inc. | Macromolecular microparticles and methods of production and use |
| US20020042079A1 (en) | 1994-02-01 | 2002-04-11 | Sanford M. Simon | Methods and agents for measuring and controlling multidrug resistance |
| US5739276A (en) | 1994-10-07 | 1998-04-14 | University Of Utah Research Foundation | Conotoxin peptides |
| US5660848A (en) | 1994-11-02 | 1997-08-26 | The Population Council, Center For Biomedical Research | Subdermally implantable device |
| ATE204468T1 (de) * | 1995-06-07 | 2001-09-15 | Alkermes Inc | Mittel zur verzögerten freisetzung von menschlichem wachstumshormon |
| US7846455B2 (en) | 1996-07-15 | 2010-12-07 | The United States Of America As Represented By The Department Of Health And Human Services | Attenuated chimeric respiratory syncytial virus |
| GB9526733D0 (en) | 1995-12-30 | 1996-02-28 | Delta Biotechnology Ltd | Fusion proteins |
| US6441025B2 (en) | 1996-03-12 | 2002-08-27 | Pg-Txl Company, L.P. | Water soluble paclitaxel derivatives |
| NZ332234A (en) | 1996-03-12 | 2000-06-23 | Pg Txl Company Lp | Water soluble paclitaxel prodrugs formed by conjugating paclitaxel or docetaxel with a polyglutamic acid polymer and use for treating cancer |
| ES2208946T3 (es) | 1996-08-23 | 2004-06-16 | Sequus Pharmaceuticals, Inc. | Liposomas que contienen un compuesto de cisplatino. |
| EP0932390A1 (en) | 1996-10-11 | 1999-08-04 | Sequus Pharmaceuticals, Inc. | Therapeutic liposome composition and method |
| US6056973A (en) | 1996-10-11 | 2000-05-02 | Sequus Pharmaceuticals, Inc. | Therapeutic liposome composition and method of preparation |
| AU725257B2 (en) | 1996-10-15 | 2000-10-12 | Transave, Inc. | N-acyl phosphatidylethanolamine-mediated liposomal drug delivery |
| US6110498A (en) | 1996-10-25 | 2000-08-29 | Shire Laboratories, Inc. | Osmotic drug delivery system |
| US6361796B1 (en) | 1996-10-25 | 2002-03-26 | Shire Laboratories, Inc. | Soluble form osmotic dose delivery system |
| US6395302B1 (en) | 1996-11-19 | 2002-05-28 | Octoplus B.V. | Method for the preparation of microspheres which contain colloidal systems |
| EP0842657A1 (en) | 1996-11-19 | 1998-05-20 | OctoPlus B.V. | Microspheres for controlled release and processes to prepare these microspheres |
| US6294170B1 (en) | 1997-08-08 | 2001-09-25 | Amgen Inc. | Composition and method for treating inflammatory diseases |
| AT405516B (de) | 1997-02-27 | 1999-09-27 | Immuno Ag | Faktor x-analoge mit modifizierter proteasespaltstelle |
| DE19747261A1 (de) | 1997-10-25 | 1999-04-29 | Bayer Ag | Osmotisches Arzneimittelfreisetzungssystem |
| US6309370B1 (en) | 1998-02-05 | 2001-10-30 | Biosense, Inc. | Intracardiac drug delivery |
| JP2002507393A (ja) | 1998-02-11 | 2002-03-12 | マキシジェン, インコーポレイテッド | 抗原ライブラリー免疫 |
| US20050260605A1 (en) | 1998-02-11 | 2005-11-24 | Maxygen, Inc. | Targeting of genetic vaccine vectors |
| US7090976B2 (en) | 1999-11-10 | 2006-08-15 | Rigel Pharmaceuticals, Inc. | Methods and compositions comprising Renilla GFP |
| US20030190740A1 (en) * | 1998-10-13 | 2003-10-09 | The University Of Georgia Research Foundation, Inc | Stabilized bioactive peptides and methods of identification, synthesis, and use |
| US6329186B1 (en) | 1998-12-07 | 2001-12-11 | Novozymes A/S | Glucoamylases with N-terminal extensions |
| US6713086B2 (en) | 1998-12-18 | 2004-03-30 | Abbott Laboratories | Controlled release formulation of divalproex sodium |
| JP4543553B2 (ja) | 1999-03-03 | 2010-09-15 | オプティノーズ アズ | 鼻用の送り込み装置 |
| US6183770B1 (en) | 1999-04-15 | 2001-02-06 | Acutek International | Carrier patch for the delivery of agents to the skin |
| US7666400B2 (en) | 2005-04-06 | 2010-02-23 | Ibc Pharmaceuticals, Inc. | PEGylation by the dock and lock (DNL) technique |
| US6743211B1 (en) | 1999-11-23 | 2004-06-01 | Georgia Tech Research Corporation | Devices and methods for enhanced microneedle penetration of biological barriers |
| CA2376232A1 (en) | 1999-06-14 | 2000-12-21 | Genentech, Inc. | A structured peptide scaffold for displaying turn libraries on phage |
| US6458387B1 (en) | 1999-10-18 | 2002-10-01 | Epic Therapeutics, Inc. | Sustained release microspheres |
| US20030109428A1 (en) | 1999-12-01 | 2003-06-12 | John Bertin | Novel molecules of the card-related protein family and uses thereof |
| US20050287153A1 (en) | 2002-06-28 | 2005-12-29 | Genentech, Inc. | Serum albumin binding peptides for tumor targeting |
| US6352721B1 (en) | 2000-01-14 | 2002-03-05 | Osmotica Corp. | Combined diffusion/osmotic pumping drug delivery system |
| EP1276849A4 (en) * | 2000-04-12 | 2004-06-09 | Human Genome Sciences Inc | ALBUMIN FUSION PROTEINS |
| WO2002013786A2 (en) | 2000-08-15 | 2002-02-21 | Board Of Trustees Of The University Of Illinois | Method of forming microparticles |
| DE10053224A1 (de) | 2000-10-26 | 2002-05-08 | Univ Goettingen Georg August | Verfahren zur Exposition von Peptiden und Polypeptiden auf der Zelloberfläche von Bakterien |
| US20030049689A1 (en) | 2000-12-14 | 2003-03-13 | Cynthia Edwards | Multifunctional polypeptides |
| IN190699B (ko) | 2001-02-02 | 2003-08-16 | Sun Pharmaceutical Ind Ltd | |
| US20020169125A1 (en) | 2001-03-21 | 2002-11-14 | Cell Therapeutics, Inc. | Recombinant production of polyanionic polymers and uses thereof |
| US20050048512A1 (en) | 2001-04-26 | 2005-03-03 | Avidia Research Institute | Combinatorial libraries of monomer domains |
| JP2004528345A (ja) | 2001-04-30 | 2004-09-16 | シャイア ラボラトリーズ,インコーポレイテッド | Ace/nepインヒビターおよびバイオアベイラビリティーエンハンサーを含む薬学的組成物 |
| US6838093B2 (en) | 2001-06-01 | 2005-01-04 | Shire Laboratories, Inc. | System for osmotic delivery of pharmaceutically active agents |
| KR100407467B1 (ko) | 2001-07-12 | 2003-11-28 | 최수봉 | 리모컨 방식의 인슐린 자동주사기 |
| AU2002322394A1 (en) | 2001-07-30 | 2003-02-17 | Eli Lilly And Company | Method for treating diabetes and obesity |
| US7125843B2 (en) | 2001-10-19 | 2006-10-24 | Neose Technologies, Inc. | Glycoconjugates including more than one peptide |
| NZ532027A (en) | 2001-10-10 | 2008-09-26 | Neose Technologies Inc | Remodeling and glycoconjugation of peptides |
| EP1451297A4 (en) | 2001-12-07 | 2006-06-28 | Toolgen Inc | PHENOTYPIC SCANNING OF CHIMERIC PROTEINS |
| US20080167238A1 (en) | 2001-12-21 | 2008-07-10 | Human Genome Sciences, Inc. | Albumin Fusion Proteins |
| US6945952B2 (en) | 2002-06-25 | 2005-09-20 | Theraject, Inc. | Solid solution perforator for drug delivery and other applications |
| US20070161087A1 (en) | 2003-05-29 | 2007-07-12 | Wolfgang Glaesner | Glp-1 fusion proteins |
| JP4644663B2 (ja) | 2003-06-03 | 2011-03-02 | セル ジェネシス インコーポレイテッド | ペプチド開裂部位を用いた単一ベクターからの組換えポリペプチドの高められた発現のための構成と方法 |
| US20050152979A1 (en) | 2003-09-05 | 2005-07-14 | Cell Therapeutics, Inc. | Hydrophobic drug compositions containing reconstitution enhancer |
| EP2932981B1 (en) | 2003-09-19 | 2021-06-16 | Novo Nordisk A/S | Albumin-binding derivatives of GLP-1 |
| US20050123997A1 (en) | 2003-10-30 | 2005-06-09 | Lollar John S. | Modified fVIII having reduced immunogenicity through mutagenesis of A2 and C2 epitopes |
| JP2007511604A (ja) | 2003-11-18 | 2007-05-10 | アイコニック セラピューティクス インコーポレイティッド | キメラタンパク質の均質製剤 |
| WO2005069845A2 (en) * | 2004-01-14 | 2005-08-04 | Ohio University | Methods of producing peptides/proteins in plants and peptides/proteins produced thereby |
| BRPI0507026A (pt) | 2004-02-09 | 2007-04-17 | Human Genome Sciences Inc | proteìnas de fusão de albumina |
| US8076288B2 (en) | 2004-02-11 | 2011-12-13 | Amylin Pharmaceuticals, Inc. | Hybrid polypeptides having glucose lowering activity |
| US7442778B2 (en) | 2004-09-24 | 2008-10-28 | Amgen Inc. | Modified Fc molecules |
| CA2595695A1 (en) | 2005-01-25 | 2006-08-03 | Cell Therapeutics, Inc. | Biologically active protein conjugates comprising (nn[s/t]) peptide repeats and having increased plasma half-life |
| US8263545B2 (en) | 2005-02-11 | 2012-09-11 | Amylin Pharmaceuticals, Inc. | GIP analog and hybrid polypeptides with selectable properties |
| AU2006294644A1 (en) | 2005-09-27 | 2007-04-05 | Amunix, Inc. | Proteinaceous pharmaceuticals and uses thereof |
| US7846445B2 (en) | 2005-09-27 | 2010-12-07 | Amunix Operating, Inc. | Methods for production of unstructured recombinant polymers and uses thereof |
| US20090099031A1 (en) | 2005-09-27 | 2009-04-16 | Stemmer Willem P | Genetic package and uses thereof |
| US7855279B2 (en) | 2005-09-27 | 2010-12-21 | Amunix Operating, Inc. | Unstructured recombinant polymers and uses thereof |
| CA2644712C (en) | 2006-03-06 | 2016-09-13 | Amunix, Inc. | Unstructured recombinant polymers and uses thereof |
| KR20080108147A (ko) | 2006-03-31 | 2008-12-11 | 백스터 인터내셔널 인코포레이티드 | 페질화된 인자 viii |
| JP5290177B2 (ja) | 2006-08-31 | 2013-09-18 | セントカー・インコーポレーテツド | Glp−2ミメティボディ、ポリペプチド、組成物、方法および用途 |
| WO2008049711A1 (en) | 2006-10-27 | 2008-05-02 | Novo Nordisk A/S | Peptide extended insulins |
| ATE502114T1 (de) | 2007-06-21 | 2011-04-15 | Univ Muenchen Tech | Biologisch aktive proteine mit erhöhter in-vivo- und/oder in-vitro-stabilität |
| KR20100058541A (ko) * | 2007-08-15 | 2010-06-03 | 아뮤닉스 인코포레이티드 | 생물학적 활성 폴리펩티드의 특성을 변경하기 위한 조성물 및 방법 |
| CN116925238A (zh) | 2009-02-03 | 2023-10-24 | 阿穆尼克斯制药公司 | 延伸重组多肽和包含该延伸重组多肽的组合物 |
-
2008
- 2008-08-15 KR KR1020107005458A patent/KR20100058541A/ko not_active Application Discontinuation
- 2008-08-15 EP EP08795371A patent/EP2185701A4/en not_active Withdrawn
- 2008-08-15 US US12/228,859 patent/US8933197B2/en active Active
- 2008-08-15 CN CN2008801033448A patent/CN103298935A/zh active Pending
- 2008-08-15 JP JP2010521048A patent/JP2010536341A/ja active Pending
- 2008-08-15 WO PCT/US2008/009787 patent/WO2009023270A2/en active Application Filing
- 2008-08-15 BR BRPI0815416-3A2A patent/BRPI0815416A2/pt not_active IP Right Cessation
- 2008-08-15 CA CA2695374A patent/CA2695374A1/en not_active Abandoned
- 2008-08-15 AU AU2008287340A patent/AU2008287340A1/en not_active Abandoned
- 2008-08-15 MX MX2010001684A patent/MX2010001684A/es active IP Right Grant
-
2009
- 2009-12-23 US US12/646,566 patent/US20100260706A1/en not_active Abandoned
-
2012
- 2012-05-11 US US13/469,902 patent/US20130039884A1/en not_active Abandoned
-
2014
- 2014-10-22 US US14/521,388 patent/US20150259431A1/en not_active Abandoned
Cited By (22)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US10960056B2 (en) | 2012-05-11 | 2021-03-30 | Gemvax & Kael Co., Ltd. | Anti-inflammatory peptides and composition comprising the same |
| US9540419B2 (en) | 2012-05-11 | 2017-01-10 | Gemvax & Kael Co., Ltd. | Anti-inflammatory peptides and composition comprising the same |
| US11857607B2 (en) | 2012-05-11 | 2024-01-02 | Gemvax & Kael Co., Ltd. | Anti-inflammatory peptides and composition comprising the same |
| US9730984B2 (en) | 2012-05-11 | 2017-08-15 | Gemvax & Kael Co., Ltd. | Composition for preventing or treating rheumatoid arthritis |
| US9907837B2 (en) | 2012-05-11 | 2018-03-06 | Gemvax & Kael Co., Ltd. | Composition for preventing or treating cachexia |
| WO2013169077A1 (ko) * | 2012-05-11 | 2013-11-14 | 주식회사 카엘젬백스 | 악액질 예방 또는 치료용 조성물 |
| US11369665B2 (en) | 2012-05-11 | 2022-06-28 | Gemvax & Kael Co., Ltd. | Anti-inflammatory peptides and composition comprising the same |
| US10039811B2 (en) | 2012-05-11 | 2018-08-07 | Gemvax & Kael Co., Ltd. | Anti-inflammatory peptides and composition comprising the same |
| US10967000B2 (en) | 2012-07-11 | 2021-04-06 | Gemvax & Kael Co., Ltd. | Cell-penetrating peptide, conjugate comprising same and composition comprising same |
| US9907838B2 (en) | 2013-04-19 | 2018-03-06 | Gemvax & Kael Co., Ltd. | Composition and methods for treating ischemic damage |
| US10383926B2 (en) | 2013-06-07 | 2019-08-20 | Gemvax & Kael Co., Ltd. | Biological markers useful in cancer immunotherapy |
| US10561703B2 (en) | 2013-06-21 | 2020-02-18 | Gemvax & Kael Co., Ltd. | Method of modulating sex hormone levels using a sex hormone secretion modulator |
| US9572858B2 (en) | 2013-10-23 | 2017-02-21 | Gemvax & Kael Co., Ltd. | Composition for treating and preventing benign prostatic hyperplasia |
| US10034922B2 (en) | 2013-11-22 | 2018-07-31 | Gemvax & Kael Co., Ltd. | Peptide having angiogenesis inhibitory activity and composition containing same |
| US11058744B2 (en) | 2013-12-17 | 2021-07-13 | Gemvax & Kael Co., Ltd. | Composition for treating prostate cancer |
| US9937240B2 (en) | 2014-04-11 | 2018-04-10 | Gemvax & Kael Co., Ltd. | Peptide having fibrosis inhibitory activity and composition containing same |
| US10662223B2 (en) | 2014-04-30 | 2020-05-26 | Gemvax & Kael Co., Ltd. | Composition for organ, tissue, or cell transplantation, kit, and transplantation method |
| US10463708B2 (en) | 2014-12-23 | 2019-11-05 | Gemvax & Kael Co., Ltd. | Peptide for treating ocular diseases and composition for treating ocular diseases comprising same |
| US11077163B2 (en) | 2014-12-23 | 2021-08-03 | Gemvax & Kael Co., Ltd. | Peptide for treating ocular diseases and composition for treating ocular diseases comprising same |
| US10835582B2 (en) | 2015-02-27 | 2020-11-17 | Gemvax & Kael Co. Ltd. | Peptide for preventing hearing loss, and composition comprising same |
| US11015179B2 (en) | 2015-07-02 | 2021-05-25 | Gemvax & Kael Co., Ltd. | Peptide having anti-viral effect and composition containing same |
| US10898540B2 (en) | 2016-04-07 | 2021-01-26 | Gem Vax & KAEL Co., Ltd. | Peptide having effects of increasing telomerase activity and extending telomere, and composition containing same |
Also Published As
| Publication number | Publication date |
|---|---|
| US20150259431A1 (en) | 2015-09-17 |
| JP2010536341A (ja) | 2010-12-02 |
| BRPI0815416A2 (pt) | 2014-10-21 |
| WO2009023270A2 (en) | 2009-02-19 |
| US20100260706A1 (en) | 2010-10-14 |
| EP2185701A2 (en) | 2010-05-19 |
| AU2008287340A1 (en) | 2009-02-19 |
| MX2010001684A (es) | 2010-04-21 |
| CA2695374A1 (en) | 2009-02-19 |
| US8933197B2 (en) | 2015-01-13 |
| US20130039884A1 (en) | 2013-02-14 |
| CN103298935A (zh) | 2013-09-11 |
| WO2009023270A3 (en) | 2009-05-07 |
| EP2185701A4 (en) | 2011-03-02 |
| US20090092582A1 (en) | 2009-04-09 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US8933197B2 (en) | Compositions comprising modified biologically active polypeptides | |
| US11203630B2 (en) | Serum albumin-binding fibronectin type III domains | |
| US20230145413A1 (en) | Fast-off rate serum albumin binding fibronectin type iii domains | |
| AU2011248273B2 (en) | Serum albumin binding molecules | |
| AU2016203044B2 (en) | Serum albumin binding molecules |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| WITN | Application deemed withdrawn, e.g. because no request for examination was filed or no examination fee was paid |