-
Diese
Forschungsarbeit wurde durch eine finanzielle Unterstützung von
der Regierung der Vereinigten Staaten, bereitgestellt von den National
Institutes of Health, gefördert.
Die US-Regierung hat somit bestimmte Rechte an dieser Erfindung
inne.
-
GEBIET DER
ERFINDUNG
-
Die
Erfinder beschreiben hierin eine neue Gruppe von hochaffinen Nucleinsäureliganden,
die sich spezifisch an ein erwünschtes
Targetmolekül
binden. Ein Verfahren wird zur Selektion eines Nucleinsäureliganden präsentiert,
der jegliches erwünschte
Targetmolekül
spezifisch bindet. Das Verfahren wird als SELEX bezeichnet, ein
Akronym für
Systematic Evolution of Ligands by Exponential Enrichment (Systematische
Entwicklung von Liganden durch exponentielle Anreicherung). Das
Verfahren der Erfindung (SELEX) ist nützlich, um einen Nucleinsäureliganden
für ein
erwünschtes
Targetmolekül
zu isolieren. Die Nucleinsäureprodukte
der Erfindung sind für
jeglichen Zweck geeignet, bei dem eine Bindungsreaktion eingesetzt
werden kann, beispielsweise in Testverfahren, Diagnoseverfahren,
Zellsortieren, als Inhibitoren von Targetmolekülfunktion, als Sonden, als Sequestrationsmittel
und dergleichen. Darüber
hinaus können
die Nucleinsäureprodukte
der Erfindung katalytische Aktivität aufweisen. Targetmoleküle umfassen
neutrale und synthetische Polymere einschließlich Proteine, Polysaccharide,
Glykoproteine, Hormone, Rezeptoren und Zelloberflächen und
kleine Moleküle
wie Wirkstoffe, Metabolite, Co-Faktoren, Übergangszustand-Analoga und
Toxine.
-
HINTERGRUND
DER ERFINDUNG
-
Die
meisten Proteine oder kleinen Moleküle sind nicht dafür bekannt,
sich spezifisch an Nucleinsäuren zu
binden. Die bekannten Proteinausnahmen sind jene Regulationsproteine
wie Repressoren, Polymerasen, Aktivatoren und dergleichen, die in
einer Lebendzelle funktionieren, um den Transfer von genetischer
Information, die in den Nucleinsäuren
kodiert sind, in Zellstrukturen und die Replikation des genetischen Materials
zu bewirken. Weiters binden sich kleine Moleküle wie GTP an manche Intron-RNAs.
-
Lebende
Materie entwickelte sich so, dass die Funktion von Nucleinsäuren auf
eine weitgehend informative Rolle eingeschränkt wurde. Das Zentrale Dogma
von Crick schlägt,
sowohl in der ursprünglichen
als auch der erweiterten Version, vor, dass Nucleinsäuren (entweder
RNA oder DNA) als Matrices für
die Synthese anderer Nucleinsäuren über replikative
Prozesse, die die Information in einer Matrix-Nucleinsäure „lesen" und somit komplementäre Nucleinsäuren ergeben,
dienen können.
Sämtliche
experimentelle Paradigma im Bereich Genetik und Genexpression hängen von
diesen Eigenschaften von Nucleinsäuren ab: im Wesentlichen sind
doppelsträngige
Nucleinsäuren
bezüglich
ihrer Information aufgrund des chemischen Konzepts von Basenpaaren
und auch, da Replikationsprozesse in der Lage sind, diese Basenpaarung
in einer relativ fehlerfreien Weise zu verwenden, redundant.
-
Die
einzelnen Komponenten von Proteinen, die zwanzig natürlichen
Aminosäuren,
besitzen ausreichende chemische Unterschiede und Aktivitäten, um
eine enorme Bandbreite an Aktivitäten sowohl für Bindung
als auch für
Katalyse bereitzustellen. Von Nucleinsäuren wird jedoch angenommen,
dass sie enger gefasste chemische Möglichkeiten als Proteine aufweisen,
jedoch auch eine Informationsrolle spielen, die es genetischer Information
ermöglicht,
von Virus zu Virus, Zelle zu Zelle und Organismus zu Organismus übertragen zu
werden. In diesem Zusammenhang müssen
Nucleinsäurekomponenten,
die Nucleotide, nur Oberflächenpaare
aufweisen, die Informationsredundanz innerhalb eines Watson-Crick-Basenpaars
ermöglicht.
Nucleinsäurekomponenten
müssen
keine chemischen Unterschiede und Aktivitäten aufweisen, die entweder
für einen breiten
Bereich von Bindung oder Katalyse ausreichend sind.
-
Manche
Nucleinsäuren
jedoch, die in der Natur zu finden sind, nehmen an der Bindung an
bestimmte Targetmoleküle
teil, und es wurde sogar von einigen wenigen Fällen von Katalyse berichtet.
Der Aktivitätsbereich
dieser Art ist im Vergleich zu Proteinen und insbesondere Antikörpern eng
gefasst. Wo zum Beispiel Nucleinsäuren dafür bekannt sind, sich an manche
Proteintargets mit hoher Affinität
und Spezifität
zu binden, hängt
die Bindung von den exakten Nucleotidsequenzen ab, die den DNA-
oder RNA-Liganden einschließen. Somit
sind kurze doppelsträngige
DNA-Sequenzen bekannt
dafür,
sich an Targetproteine zu binden, die die Transkription sowohl in
Prokaryoten als auch in Eukaryoten unterdrücken oder aktivieren. Andere
kurze doppelsträngige
DNA-Sequenzen sind dafür
bekannt, sich an Restriktionsendonucleasen zu binden, Proteintargets,
die mit hoher Affinität
und Spezifität
selektiert werden können.
Andere kurze DNA-Sequenzen dienen als Centromere und Telomere an
Chromosomen, vermutlich durch Schaffen von Liganden für die Bindung
spezifischer Proteine, die an der Chromosomenmechanik teilnehmen.
Somit weist doppelsträngige
DNA eine durchwegs bekannte Fähigkeit
auf, sich innerhalb der Ecken und Ritzen von Targetproteinen zu
binden, deren Funktionen auf DNA-Bindung ausgerichtet sind. Einzelsträngige DNA
kann sich auch an manche Proteine mit hoher Affinität und Spezifität binden,
wenn auch die Zahl der Beispiele hierzu eher gering ist. Aufgrund
der bekannten Beispiele von doppelsträngigen DNA-Bindungsproteinen
wurde es möglich,
die Bindungswechselwirkungen als solche zu beschreiben, die verschiedene
Proteinmotive einbinden, die Aminosäurenseitenketten aufweisen,
die in die große
Furche von doppelsträngiger
B-Form-DNA vorstehen, was die Sequenzprüfung liefert, die Spezifität ermöglicht.
-
Doppelsträngige RNA
dient gegebenenfalls als ein Ligand für bestimmte Proteine, beispielsweise
die Endonuclease RNase III aus E. coli. Es gibt bekanntere Fälle von
Targetproteinen, die sich an einzelsträngige RNA-Liganden binden,
obwohl in diesen Fällen
die einzelsträngige
RNA häufig
eine komplexe dreidimensionale Form annimmt, die lokale Regionen
von intramolekularer Doppelsträngigkeit
umfasst. Die Aminoacyl-tRNA-Synthetasen binden sich eng an tRNA-Moleküle mit hoher
Spezifität.
Eine kurze Region innerhalb der Genome von RNA-Viren bindet sich
fest und mit hoher Spezifität
an die Virushüllenproteine.
Eine kurze Sequenz von RNA bindet sich an die Bakteriophagen-T4-kodierte
DNA-Polymerase, wiederum mit hoher Affinität und Spezifität. Somit
ist es möglich,
RNA- und DNA-Liganden, entweder doppel- oder einzelsträngig, zu finden,
die als Bindungspartner für
spezifische Proteintargets dienen. Die meisten bekannten DNA-Bindungsproteine
binden sich spezifisch an doppelsträngige DNA, während die
meisten RNA-Bindungsproteine einzelsträngige RNA erkennen. Diese statistische
Vorgabe in der Literatur spiegelt zweifellos die vorliegende statistische
Prädisposition
der Biosphäre
wider, DNA als ein doppelsträngiges
Genom und RNA als eine einzelsträngige
Einheit in den zahlreichen Rollen, die RNA über jene des Genoms hinaus
spielt, zu verwenden. Chemisch gibt es keinen wichtigen Grund, einzelsträngige DNA
als einen völlig
fähigen
Partner für
spezifische Proteinwechselwirkungen fallen zu lassen.
-
Für RNA und
DNA wurde auch erkannt, dass sie sich beide an kleinere Targetmoleküle binden.
Doppelsträngige
DNA bindet sich an verschiedene Antibiotika, wie Actinomycin D.
Eine spezifische einzelsträngige RNA
bindet sich an das Antibiotikum Thiostrepton; spezifische RNA-Sequenzen
und -Strukturen binden sich vermutlich an bestimmte andere Antibiotika,
insbesondere jene, deren Funktionen die Inaktivierung von Ribosomen
in einem Targetorganismus ist. Eine Familie von evolutionär verwandten
RNAs bindet sich mit Spezifität und
dezenter Affinität
an Nucleotide und Nucleoside (B. Bass & T. Cech, Nature 308, 820–826 (1984))
sowie an eine der zwanzig Aminosäuren
(M. Yarus, Science 240, 1751–1758
(1984)). Katalytische RNAs sind nun auch bekannt, wenn auch diese
Moleküle über einen
eng gefassten Bereich chemischer Möglichkeiten Leistung zeigen
und somit größtenteils
mit Phosphodiestertransfer-Reaktionen und Hydrolyse von Nucleinsäuren entfernt
zusammenhängen.
-
Trotz
dieser bekannten Beispiele wird von der großen Mehrheit von Proteinen
und anderen Zellkomponenten angenommen, dass sie sich an Nucleinsäuren unter
physiologischen Bedingungen binden und dass solche Bindung, die
beobachtet werden kann, nicht spezifisch ist. Entweder ist die Fähigkeit
von Nucleinsäuren,
sich an andere Verbindungen zu binden, auf die relativ wenigen Fälle, die
zuvor genannt wurden, eingeschränkt,
oder das chemische Repertoire der Nucleinsäuren für spezifische Bindung wird
in den Strukturen, die in der Natur vorkommen, vermieden (es wird
dagegen selektiert). Die vorliegende Erfindung basiert auf der grundlegenden
Erkenntnis der Erfinder, dass Nucleinsäuren als chemische Verbindungen
eine praktisch uneingeschränkte
Reihe an Formen, Größen und
Konfigurationen bilden kön nen
und in der Lage sind, ein weit größeres Repertoire an Bindungs-
und Katalysefunktionen aufzuweisen als jene, die in biologischen
Systemen vorhanden sind.
-
Die
chemischen Wechselwirkungen wurden in Fällen bestimmter bekannter Beispiele
von Protein-Nucleinsäure-Bindung
untersucht. Die Größe und Sequenz
der RNA-Stelle von
Bakteriophagen-R17-Hüllprotein-Bindung
beispielsweise wurde von Uhlenbeck und Mitarbeitern identifiziert.
Die minimale natürliche RNA-Bindungsstelle
(21 Basen lang) für
das R17-Hüllprotein
wurde durch Untersuchen von markierten Fragmenten der mRNA variabler
Größe durch
Nitrocellulosefilter-Bindungstests, in denen Protein-RNA-Fragment-Komplexe
an den Filter gebunden bleiben, bestimmt (Carey et al., Biochemistry
22, 2601 (1983)). Zahlreiche Sequenzvarianten der minimalen R17-Hüllproteinbindungsstelle
wurden in vitro geschaffen, um die Beteiligung einzelner Nucleinsäuren an
Proteinbindung zu bestimmen (Uhlenbeck et al., J. Biomol. Structure
Dynamics 1, 539 (1983); und Romaniuk et al., Biochemistry 26, 1563
(1987)). Es wurde erkannt, dass die Erhaltung der Haarnadelschleifenstruktur
der Bindungsstelle für
Proteinbindung wesentlich war, darüber hinaus wurde jedoch auch
erkannt, dass Nucleotidsubstitutionen an den meisten der einzelsträngigen Reste
in der Bindungsstelle, einschließlich eines ausgeweiteten Nucleotids
im Haarnadelstamm, die Bindung signifikant beeinflussten. In ähnlichen
Studien wurde die Bindung von Bakteriophagen-Qβ-Hüllprotein an seinen translationalen
Operator untersucht (Witherell & Uhlenbeck,
Biochemistry 28, 71 (1989)). Die Qβ-Hüllprotein-RNA-Bindungsstelle wurde
als eine erkannt, die jener von R17 bezüglich Größe und der vorhergesagten Sekundärstruktur
darin ähnlich
war, dass sie etwa 20 Basen mit einer 8-Basenpaar-Haarnadelstruktur,
die ein ausgeweitetes Nucleotid und eine 3-Basen-Schleife einband, umfasste. Im
Gegensatz zur R17-Hüllprotein-Bindungsstelle
ist nur einer der einzelsträngigen
Reste der Schleife für
Bindung wesentlich, und die Gegenwart des ausgeweiteten Nucleotids
ist nicht erforderlich. Die Protein-RNA-Bindungswechselwirkungen, die in translationale Regulation
eingebunden sind, zeigen signifikante Spezifität.
-
Nucleinsäuren sind
dafür bekannt,
Sekundär-
und Tertiärstrukturen
in Lösung
zu bilden. Die doppelsträngigen
Formen von DNA umfassen die so genannte B-doppelhelikale Form, Z-DNA und Superhelixwindungen
(A. Rich et al., Ann. Rev. Biochem. 53, 791–846 (1984)). Einzelsträngige RNA-Formen
lokalisierten Regionen der Sekundärstruktur wie Haarnadelschleifen
und Pseudoknotenstrukturen (P. Schimmel, Cell 58, 9–12 (1989)).
Wenig ist jedoch bezüglich
der Wirkungen von ungepaarten Schleifen-Nucleotiden auf die Stabilität von Schleifenstruktur,
die Bildungs- und Denaturierungskinetik und Thermodynamik bekannt,
und beinahe nichts ist von Tertiärstrukturen
und dreidimensionaler Form oder von der Kinetik und Thermodynamik
von Tertiärfaltung
in Nucleinsäuren
bekannt (C. Tuerk et al., Proc. Natl. Acad. Sci. USA 85, 1364–1368 (1988)).
-
Von
einem Typ von In-vitro-Entwicklung wurde bei der Replikation des
RNA-Bakteriophagen
Qβ berichtet.
D.R. Mills et al., Proc. Natl. Acad. Sci. USA 58, 217–224 (1967);
R. Levinsohn & S.
Spiegelman, Proc. Natl. Acad. Sci. USA 60, 866–872 (1968); R. Levisohn & S. Spiegelman,
Proc. Natl. Acad. Sci. USA 63, 805–811 (1969); R. Saffhill et
al., J. Mol. Biol. 51, 531–539
(1970); D.L. Kacian et al., Proc. Natl. Acad. Sci. USA 69, 3038–3042 (1972);
D.R. Mills et al., Science 180, 916–927 (1973). Die Phagen-RNA
dient als eine poly-cistronische Messenger-RNA, die Translation
von phagenspezifischen Proteinen steuert, und auch als eine Matrix
für ihre
eigene, durch Qβ-RNA-Replikase
katalysierte Replikation. Für
diese RNA-Replikase wurde gezeigt, dass sie für ihre eigenen RNA-Matrices
hoch spezifisch ist. Während
des Ablaufs der Replikationszyklen in vitro wurden kleine RNA-Varianten
isoliert, die auch durch Qβ-Replikase
repliziert wurden. Geringe Veränderungen
der Bedingungen, unter denen die Replikationszyklen durchgeführt wurden,
resultierten, wie erkannt wurde, in der Akkumulierung verschiedener
RNAs, wahrscheinlich, weil ihre Replikation unter den geänderten
Bedingungen begünstigt
war. In diesen Versuchen musste die selektierte RNA wirksam durch
die Replikase gebunden werden, um Replikation zu initiieren, und
musste als eine kinetisch begünstigte
Matrix während
der Verlängerung
von RNA dienen. Kramer et al., J. Mol. Biol. 89, 719 (1974), berichteten
von der Isolierung einer mutierten RNA-Matrix von Qβ-Replikase,
deren Repli kation gegenüber
Inhibierung durch Ethidiumbromid resistenter war als die natürliche Matrix.
Es wurde vorgeschlagen, dass diese Mutante in der anfänglichen RNA-Population nicht
vorhanden war, jedoch durch sequenzielle Mutation während der
Zyklen von In-vitro-Replikation mit Qβ-Replikase gebildet wurde. Die
einzige Quelle für
Variationen während
der Selektion war die Grundfehlerhäufigkeit während der Verlängerung
durch Qβ-Replikase.
In diesen Untersuchungen trat das, was als „Selektion" bezeichnet wurde, durch präferenzielle
Amplifikation von einer oder mehreren einer eingeschränkten Anzahl
an spontanen Varianten einer anfänglich
homogenen RNA-Sequenz auf. Es gab keine Selektion eines erwünschten
Resultats, nur jene, die der Wirkungsweise von Qβ-Replikase zueigen war.
-
Joyce & Robertson (Joyce,
in: RNA: Catalysis, Splicing, Evolution, Belfort & Shub (Hrsg.),
Elsevier, Amsterdam, 83–87
(1989); und Robertson & Joyce,
Nature 344, 467 (1990)) berichteten von einem Verfahren zur Identifikation
von RNAs, die einzelsträngige
DNA spezifisch spalten. Die Selektion auf katalytische Aktivität basierte
auf der Fähigkeit
des Ribozyms, die Spaltung einer Substrat-ssRNA oder -DNA an einer
spezifischen Position und den Transfer des 3'-Endes des Substrats zum 3'-Ende des Ribozyms zu katalysieren. Das
Produkt der erwünschten
Reaktion wurde unter Verwendung eines Oligodesoxynucleotidprimers
selektiert, der sich nur an das vollständige Produkt über die
Verbindung, die durch die katalytische Reaktion gebildet wurde, hinweg
binden konnte und selektive reverse Transkription der Ribozymsequenz
ermöglichte.
Die selektierten katalytischen Sequenzen wurden durch Bindung des
Promotors von T7-RNA-Polymerase an das 3'-Ende der cDNA, gefolgt von Transkription
zu RNA, amplifiziert. Das Verfahren wurde verwendet, um aus einer
geringen Anzahl an Ribozymvarianten die Variante zu identifizieren,
die für
die Spaltung eines selektierten Substrats am stärksten reaktiv war. Nur eine
eingeschränkte
Reihe von Varianten konnte getestet werden, da Variation von einzelnen
Nucleotidänderungen,
die während
der Amplifikation auftraten, abhing.
-
Oliphant
et al. (Molecular and Cellular Biology, 2944–2949 (Juli 1989)) beschreiben
ein Verfahren zur Definition der Sequenzerkennungseigenschaften
von doppelsträn gigen
DNA-Bindungsproteinen durch Selektieren hochaffiner Bindungsstellen
aus Zufallssequenz-DNA. Insbesondere untersuchten sie das Hefe-Transkriptionsaktivatorprotein
GCN4.
-
Thiesen & Bach (Nucleic
Acids Research, Bd. 18, Nr. 11, 3203–3209) beschreiben ein Verfahren,
das als Target Detection Assay (TDA) bezeichnet wird, um DNA-Bindungsstellen für mutmaßliche doppelsträngige DNA-Bindungsproteine
zu bestimmen.
-
Im
Stand der Technik wurde bis heute nicht mehr als ein eingeschränkter Bereich
chemischer Funktionen für
Nucleinsäuren
in ihren Wechselwirkungen mit anderen Substanzen gelehrt oder vorgeschlagen:
als Targets für
Proteinliganden, die in die Bindung bestimmter spezifischer Oligonucleotidsequenzen
eingebunden sind; und in jüngerer
Vergangenheit als Katalysatoren mit einem eingeschränkten Aktivitätsbereich.
Frühere „Selektions"-Verfahren waren
auf einen engen Bereich von Varianten einer bereits davor beschriebenen
Funktion eingeschränkt.
Nun wird das erste Mal verstanden, dass die Nucleinsäuren in
der Lage sind, enorm viele Funktionen auszuüben, und die Methodik zur Realisierung
dieser Fähigkeit
ist hierin offenbart.
-
ZUSAMMENFASSUNG
DER ERFINDUNG
-
Die
vorliegende Erfindung betrifft nur das Verfahren, das die spezifische
Bindung in vitro von einem Nucleinsäureliganden an ein Targetmolekül, wie es
in den beiliegenden Ansprüchen
definiert ist, umfasst. Es betrifft auch die Verwendung eines Nucleinsäureliganden
wie in den Ansprüchen
definiert.
-
Das
vorliegende Patent beschreibt auch eine Gruppe von Produkten, die
Nucleinsäuremoleküle sind, wobei
jedes eine einmalige Sequenz aufweist, die jeweils die Eigenschaft
besitzt, sich spezifisch an eine erwünschte Targetverbindung oder
ein Targetmolekül
zu binden. Jede beschriebene Verbindung ist ein spezifischer Ligand
eines bestimmten Targetmoleküls.
Die Erfindung basiert auf der einmaligen Erkenntnis, dass Nucleinsäuren über ausreichende
Kapazität
verfügen,
um zahlreiche ver schiedene zwei- und dreidimensionale Strukturen
zu bilden, und über
ausreichende chemische Vielseitigkeit verfügen, die innerhalb ihrer Monomere vorhanden
ist, um mit praktisch jeglicher chemischen Verbindung, unabhängig davon,
ob monomer oder polymer, als Liganden zu wirken (spezifische Bindungspaare
zu bilden). Moleküle
jeglicher Größe können als
Targets dienen. Am üblichsten,
und bevorzugt, für
therapeutische Anwendungen findet Bindung in wässriger Lösung unter Bedingungen in Hinblick
auf Salz, Temperatur und pH, die in der Nähe der annehmbaren physiologischen
Grenzen liegen, statt.
-
Ebenfalls
wird ein Verfahren beschrieben, das im Allgemeinen einsetzbar ist,
um einen Nucleinsäureliganden
für jegliches
erwünschte
Target zu bilden. Das Verfahren umfasst die Selektion aus einem
Gemisch von Kandidaten und schrittweise Wiederholungen struktureller
Verbesserung unter Verwendung desselben allgemeinen Selektionsthemas,
um praktisch jegliches erwünschte
Kriterium von Bindungsaffinität
und -selektivität
zu erreichen. Ausgehend von einem Gemisch von Nucleinsäuren, die
vorzugsweise ein Segment einer randomisierten Sequenz umfassen,
umfasst das Verfahren, das hierin als SELEX bezeichnet wird, Schritte
des Kontaktierens des Gemisches mit dem Target unter Bedingungen,
die für
Bindung günstig
sind, des Abtrennens von nicht gebundenen Nucleinsäuren von
jenen Nucleinsäuren,
die sich an Targetmoleküle
banden, des Dissoziierens der Nucleinsäure-Target-Paare, des Amplifizierens
der Nucleinsäuren,
die von den Nucleinsäure-Target-Paaren
dissoziiert wurden, um ein an Liganden angereichertes Gemisch von
Nucleinsäuren
zu erhalten, und anschließend
das Wiederholen der Schritte der Bindung, Abtrennung, Dissoziation
und Amplifikation in so vielen Zyklen wie erwünscht.
-
Während hier
keine Einschränkung
auf eine bestimmte Theorie zur Herstellung beabsichtigt wird, basiert
SELEX auf der Erkenntnis der Erfinder, dass es innerhalb eines Nucleinsäuregemisches,
das eine große Anzahl
an möglichen
Sequenzen und Strukturen enthält,
einen breiten Bereich an Bindungsaffinitäten für ein bestimmtes Target gibt.
Ein Nucleinsäuregemisch,
das beispielsweise ein randomisiertes Segment mit 20 Nucleotiden
umfasst, kann 420 Möglichkeiten aufweisen. Jene,
die die höheren
Affinitätskonstanten
für das
Target haben, binden sich am wahrscheinlichs ten. Nach dem Trennen,
der Dissoziation und der Amplifikation wird ein zweites Nucleinsäuregemisch
gebildet, das an den Kandidaten mit höherer Bindungsaffinität angereichert
ist. Zusätzliche
Selektionsdurchgänge
begünstigen
schrittweise die besten Liganden, bis sich das resultierende Nucleinsäuregemisch
vorwiegend aus nur einer oder einigen wenigen Sequenzen zusammensetzt.
Diese können
dann kloniert, sequenziert und einzeln auf Bindungsaffinität als reine
Liganden getestet werden.
-
Selektions-
und Amplifikationszyklen werden wiederholt, bis ein erwünschtes
Ziel erreicht ist. Im allgemeinsten Fall wird Selektion/Amplifikation
fortgesetzt, bis keine signifikante Verbesserung bezüglich der
Bindungsstärke
durch Wiederholen des Zyklus mehr erreicht wird. Das Selektions/Amplifikationsverfahren
mit wiederholten Durchgängen
ist empfindlich genug, um Isolierung einer einzelnen Sequenzvariante
in einem Gemisch, das zumindest 65.000 Sequenzvarianten enthält, zu ermöglichen.
Das Verfahren ist sogar in der Lage, eine geringe Anzahl an hochaffinen
Sequenzen in einem Gemisch, das 1014 Sequenzen
enthält,
zu isolieren. Das Verfahren könnte
im Prinzip verwendet werden, um bis zu etwa 1018 verschiedene
Nucleinsäurespezies zu
prüfen.
Die Nucleinsäuren
des Testgemisches umfassen vorzugsweise einen Anteil an randomisierten
Sequenzen sowie an konservierten Sequenzen, die für wirksame
Amplifikation erforderlich sind. Nucleinsäuresequenzvarianten können auf
zahlreiche verschiedene Arten gebildet werden, einschließlich Synthese
randomisierter Nucleinsäuresequenzen
und Größenselektion
aus nach dem Zufallsprinzip gespalteten zellulären Nucleinsäuren. Der
Anteil an variablen Sequenzen kann vollständig oder teilweise Zufallssequenz
enthalten; er kann auch Unterabschnitte konservierter Sequenz, inkorporiert
in randomisierte Sequenz, enthalten. Sequenzvariation in Testnucleinsäuren kann
durch Mutagenese vor oder während
der Selektions/Amplifikations-Wiederholungen eingeführt oder
gesteigert werden.
-
In
einem beschriebenen Beispiel ist das Selektionsverfahren beim Isolieren
jener Nucleinsäureliganden,
die sich am stärksten
an das ausgewählte
Target binden, so wirksam, dass nur ein Selektions- und Amplifikationszyklus
erforderlich ist. Solch eine wirksame Selektion kann beispielsweise
in einem Verfahren vom Chromatographie-Typ auftreten, worin die
Fähigkeit
von Nucleinsäuren,
sich mit Targets zu assoziieren, die an eine Säule gebunden sind, so funktioniert,
dass die Säule
ausreichend in der Lage ist, Trennung und Isolierung der Nucleinsäureliganden
mit höchster
Affinität
zu ermöglichen.
-
In
zahlreichen Fällen
ist es nicht notwendigerweise wünschenswert,
die Wiederholungsschritte von SELEX durchzuführen, bis ein einzelner Nucleinsäureligand
identifiziert wird. Die targetspezifische Nucleinsäureligandenlösung kann
eine Familie von Nucleinsäurestrukturen
oder -motiven umfassen, die zahlreiche konservierte Sequenzen und
zahlreiche Sequenzen aufweist, die substituiert oder zugesetzt werden
können, ohne
die Affinität
der Nucleinsäureliganden
zum Target signifikant zu beeinflussen. Durch Beenden des SELEX-Verfahrens
vor Abschluss ist es möglich,
die Sequenz zahlreicher Mitglieder der Nucleinsäureligandenlösungsfamilie
zu bestimmen, was die Festlegung einer umfassenden Beschreibung
der Nucleinsäureligandenlösung ermöglicht.
-
Nachdem
eine Beschreibung der Nucleinsäureliganden-Familie
durch SELEX festgelegt wurde, kann es in bestimmten Fällen wünschenswert
sein, eine weitere Reihe von SELEX durchzuführen, die durch die Information,
die während
des SELEX-Versuchs
gewonnen wurde, definiert ist. In einer Ausführungsform fixiert die zweite
Reihe von SELEX jene konservierten Regionen der Nucleinsäureliganden-Familie,
während
alle anderen Teile in der Ligandenstruktur randomisiert werden.
In einer alternativen Ausführungsform
kann die Sequenz der repräsentativsten
Mitglieder der Nucleinsäureliganden-Familie
als Grundlage für
ein SELEX-Verfahren verwendet werden, worin der ursprüngliche
Pool an Nucleinsäuresequenzen
nicht vollständig
randomisiert ist, sondern Vorgaben bezüglich des nächsten Liganden enthält. Durch
diese Verfahren ist es möglich,
das SELEX-Verfahren zu optimieren, um die am meisten bevorzugten
Nucleinsäureliganden
zu erlangen.
-
Die
Existenz zahlreicher verschiedener Nucleinsäure-Primär, -Sekundär- und -Tertiärstrukturen
ist bekannt. Die Strukturen oder Motive, für die gezeigt wurde, dass sie
am häufigsten
in Nicht-Watson-Crick-Typ-Wechselwirkungen eingebunden sind, werden
als Haarnadelschleifen, symmetrische und asymmetrische Ausweitungen, Pseudoknoten
und als zahlreiche Kombinationen dieser Konformationen bezeichnet.
Beinahe alle bekannten Fälle
solcher Motive lassen darauf schließen, dass sie in einer Nucleinsäuresequenz
von nicht mehr als 30 Nucleotiden ausgebildet sein können. Aus
diesem Grund wird bevorzugt, dass SELEX-Verfahren mit zusammenhängenden
randomisierten Segmenten mit Nucleinsäuresequenzen begonnen werden,
die ein randomisiertes Segment von zwischen etwa 20–50 Nucleotiden
enthalten. In einem anderen Aspekt umfasst die Erfindung daher ein
Kandidatengemisch, das aus Nucleinsäuren besteht, worin sich diese
Nucleinsäuren
aus einem konservierten Nucleotidsegment und einem randomisierten
Nucleotidsegment zusammensetzen. Vorzugsweise ist das randomisierte
Segment ein zusammenhängender
Strang von zumindest etwa 15 Nucleotiden, noch bevorzugter von zumindest
etwa 25 Nucleotiden, und in den am meisten bevorzugten Ausführungsformen
von zwischen 25 und 40 Nucleotiden. Diese Erfindung umfasst ein
Kandidatengemisch von Ausgangslösung,
die zumindest etwa 109 Nucleinsäuren, vorzugsweise
zumindest etwa 1014 Nucleinsäuren, enthält. Insbesondere
umfasst diese Erfindung Lösungen,
die ein Gemisch von zwischen etwa 109 bis
108 Nucleinsäuresequenzen mit einer zusammenhängenden
randomisierten Sequenz mit einer Länge von zumindest etwa 15 Nucleotiden
umfasst. In der bevorzugten Ausführungsform
ist der randomisierte Sequenzabschnitt durch fixierte oder konservierte
Sequenzen, insbesondere jene, die die Amplifikation der Liganden
erleichtern, flankiert.
-
Im
Fall eines polymeren Targets, wie z.B. eines Proteins, kann die
Ligandenaffinität
durch Anwenden von SELEX an einem Kandidatengemisch, das eine erste
selektierte Sequenz und eine zweite randomisierte Sequenz umfasst,
gesteigert werden. Die Sequenz des ersten selektierten Liganden,
der mit Bindung assoziiert ist, oder Unterabschnitte davon kann
bzw. können
in den randomisierten Abschnitt der Nucleinsäuren eines zweiten Testgemisches
eingeführt
werden. Das SELEX-Verfahren wird mit dem zweiten Testgemisch wiederholt,
um einen zweiten Nucleinsäureliganden
zu isolieren, der zwei für
Bindung an das Target selektierte Sequenzen aufweist und im Vergleich
mit dem ersten isolierten Nucleinsäureliganden erhöhte Bindungsstärke oder
erhöhte
Bindungsspezifität
aufweist. Die Sequenz des zweiten Nucleinsäureliganden, der mit Bindung
an das Target assoziiert ist, kann anschließend in den vari ablen Abschnitt
der Nucleinsäuren
eines dritten Testgemisches eingeführt werden, das nach SELEX-Zyklen
zu einem dritten Nucleinsäureliganden
führt.
Diese Verfahren können
wiederholt werden, bis ein Nucleinsäureligand mit einer erwünschten
Bindungsstärke
oder einer erwünschten
Bindungsspezifität
an das Targetmolekül
erreicht wird. Das Verfahren wiederholter Selektion und Kombination
von Nucleinsäuresequenzelementen,
die sich an ein selektiertes Targetmolekül binden, wird hierin „Walking" genannt, eine Bezeichnung,
die die optimierte Bindung an andere zugängliche Bereiche einer makromolekularen
Targetoberfläche
oder -spalte, ausgehend von einer ersten Bindungsdomäne, impliziert.
Eine Steigerung des Bereichs von Bindungskontakt zwischen Liganden
und Target kann die Affinitätskonstante
der Bindungsreaktion steigern. Diese Walking-Verfahren sind besonders
für die
Isolierung von Nucleinsäure-Antikörpern nützlich,
die für
Bindung an ein bestimmtes Targetmolekül hochspezifisch sind.
-
Eine
Variante des Walking-Verfahrens verwendet einen Nicht-Nucleinsäureliganden,
der als „Anker" bezeichnet wird
und sich an das Targetmolekül
als eine erste Bindungsdomäne
bindet (siehe 9). Dieses Ankermolekül kann im
Prinzip jegliches Nicht-Nucleinsäuremolekül sein,
das sich an das Targetmolekül
bindet und das kovalent direkt oder indirekt an eine Nucleinsäure gebunden
werden kann. Ist das Targetmolekül
ein Enzym, so kann das Ankermolekül beispielsweise ein Inhibitor
oder Substrat von diesem Enzym sein. Der Anker kann auch ein Antikörper oder
Antikörperfragment
sein, der bzw. das für
das Target spezifisch ist. Das Ankermolekül ist kovalent an ein Nucleinsäureoligomer
mit bekannter Sequenz gebunden, um ein Verbrückungsmolekül zu bilden. Das Oligomer besteht
vorzugsweise aus zumindest etwa 3 bis 10 Basen. Ein Testgemisch aus
Kandidaten-Nucleinsäuren
wird dann hergestellt, das einen randomisierten Abschnitt und eine
Sequenz, die zur bekannten Sequenz des Verbrückungsmoleküls komplementär ist, umfasst.
Das Verbrückungsmolekül bildet
mit dem Targetmolekül
einen Komplex. SELEX wird dann angewandt, um Nucleinsäuren zu
selektieren, die sich an den Komplex aus dem Verbrückungsmolekül und dem
Targetmolekül
binden. Nucleinsäureliganden,
die sich an den Komplex binden, werden isoliert. Walking-Verfahren
wie zuvor beschrieben können
dann angewendet werden, um Nucleinsäureliganden mit erhöhter Bindungsstärke oder
erhöhter
Bindungsspezifität zum
Komplex zu erhalten. Walking-Verfahren könnten Selektionen auf Bindung
an den Komplex oder das Target selbst verwenden. Dieses Verfahren
ist besonders nützlich,
um Nucleinsäureliganden
zu isolieren, die sich an eine bestimmte Stelle innerhalb des Targetmoleküls binden.
Die Komplementärsequenz
im Testgemisch wirkt zur Sicherstellung der Isolierung von Nucleinsäuresequenzen,
die sich an das Targetmolekül
an oder in der Nähe
der Bindungsstelle des Verbrückungsmoleküls binden.
Wird das Verbrückungsmolekül von einem
Inhibitor des Targetmoleküls
abgeleitet, so resultiert dieses Verfahren wahrscheinlich in einem
Nucleinsäureliganden,
der die Funktion des Targetmoleküls
inhibiert. Es ist beispielsweise zur Isolierung von Nucleinsäuren, die
Proteinfunktion aktivieren oder inhibieren, besonders nützlich.
Die Kombination von Ligand und Target kann eine neue oder gesteigerte
Funktion aufweisen.
-
Die
hierin beschriebenen Nucleinsäureliganden
können
zahlreiche Ligandenkomponenten enthalten. Wie zuvor beschrieben
können
Nucleinsäureliganden,
die aus Walking-Verfahren abgeleitet werden, als welche betrachtet
werden, die mehr als eine Nucleinsäureliganden-Komponente aufweisen.
Auch werden in dieser Erfindung Nucleinsäure-Antikörper beschrieben, die basierend
auf den Resultaten, die durch SELEX gewonnen werden, konstruiert
werden, wobei sie jedoch nicht zu einem Nucleinsäureliganden, wie er durch SELEX
definiert wird, identisch sind. Ein Nucleinsäure-Antikörper kann beispielsweise konstruiert
werden, wobei zahlreiche identische Ligandenstrukturen Teile einer
einzelnen Nucleinsäure
bilden. In einer anderen Ausführungsform
kann SELEX mehr als eine Familie von Nucleinsäureliganden zu einem bestimmten
Target identifizieren. In solch einem Fall kann ein einzelner Nucleinsäure-Antikörper konstruiert
werden, der zahlreiche verschiedene Ligandenstrukturen enthält. Auch
SELEX-Versuche können
durchgeführt
werden, in denen fixierte identische oder unterschiedliche Ligandenstrukturen
durch randomisierte Nucleotidregionen und/oder Regionen mit variierender
Distanz zwischen den fixierten Ligandenstrukturen verbunden werden,
um die besten Nucleinsäure-Antikörper zu
identifizieren.
-
Screens,
Selektionen oder Tests zur Bewertung der Wirkung von Bindung eines
Nucleinsäureliganden auf
die Funktion des Targetmoleküls
können
leicht mit den SELEX-Verfahren kombiniert werden. Insbesondere Screens
zur Inhibierung oder Aktivierung von Enzymaktivität können mit
den SELEX-Verfahren kombiniert werden.
-
In
spezifischeren Beispielen liefert das SELEX-Verfahren ein rasches
Mittel zur Isolierung und Identifizierung von Nucleinsäureliganden,
die sich an Proteine binden, einschließlich Nucleinsäure-Bindungsproteine
und Proteine, die nicht dafür
bekannt sind, Nucleinsäuren
als Teil ihrer biologischen Funktion zu binden. Nucleinsäure-Bindungsproteine
umfassen unter anderem Polymerasen und Umkehrtranskriptasen. Die
Verfahren können
auch leicht an Proteinen angewandt werden, die Nucleotide, Nucleoside,
Nucleotid-Cofaktoren und strukturell verwandte Moleküle binden.
-
In
einem Aspekt stellt die vorliegende Erfindung ein Verfahren zur
Detektion der Gegenwart oder Abwesenheit von einem Targetmolekül und/oder
zum Messen der Menge eines Targetmoleküls in einer Probe bereit, worin
das Verfahren einen Nucleinsäureliganden
verwendet, der durch die hierin beschriebenen Verfahren isoliert
werden kann. Detektion des Targetmoleküls wird durch seine Bindung
an einen Nucleinsäureliganden, der
für dieses
Targetmolekül
spezifisch ist, vermittelt. Der Nucleinsäureligand kann markiert, z.B.
radioaktiv markiert, werden, um qualitative oder quantitative Detektion
zu ermöglichen.
Das Detektionsverfahren ist für Targetmoleküle, die
Proteine sind, besonders nützlich.
Das Verfahren ist insbesondere zur Detektion von Proteinen, die
nicht dafür
bekannt sind, als Teil ihrer biologischen Funktion Nucleinsäuren zu
binden, nützlich.
Somit können
Nucleinsäureliganden
der vorliegenden Erfindung in Diagnoseverfahren in ähnlicher
Weise wie in herkömmlichen
Antikörper-basierten
Diagnoseverfahren verwendet werden. Ein Vorteil von Nucleinsäureliganden
gegenüber
herkömmlichen
Antikörpern
in solch einem Detektionsverfahren und Diagnoseverfahren ist, dass
Nucleinsäuren
in der Lage sind, leicht in vitro amplifiziert zu werden, beispielsweise
unter Verwendung von PCR-Amplifikation oder ähnlichen Verfahren. Ein anderer
Vorteil ist, dass das gesamte SELEX-Verfahren in vitro ausgeführt wird
und die Immunisierung von Testtieren nicht erfordert. Weiters kann
die Bindungsaffinität von
Nucleinsäureliganden
an die Bedürfnisse
des Benutzers angepasst werden.
-
Nucleinsäureliganden
von niedermolekularen Targets sind als diagnostische Testreagenzien
nützlich und
weisen therapeutische Verwendungen als Maskierungsmittel, Wirkstoffzufuhrvehikel
und Modifikatoren von Hormonwirkung auf. Katalytische Nucleinsäuren sind
nachweisbare Produkte dieser Erfindung. Durch Selektieren auf Bindung
an Übergangszustands-Analoga
einer Enzym-katalysierten Reaktion beispielsweise können katalytische
Nucleinsäuren
selektiert werden.
-
In
wiederum einem anderen Aspekt stellt die vorliegende Erfindung ein
Verfahren zur Modifikation der Funktion eines Targetmoleküls unter
Verwendung von Nucleinsäureliganden
bereit, die durch SELEX isoliert werden können. Nucleinsäureliganden,
die sich an ein Targetmolekül
binden, werden gescreent, um jene zu selektieren, die die Funktion
des Targetmoleküls
spezifisch modifizieren, beispielsweise um Inhibitoren oder Aktivatoren
der Funktion des Targetmoleküls
zu selektieren. Eine Menge des selektierten Nucleinsäureliganden,
der zur Modifikation der Funktion des Targets wirksam ist, wird
mit dem Targetmolekül
kombiniert, um die erwünschte
funktionelle Modifikation zu erreichen. Dieses Verfahren ist besonders
auf Targetmoleküle
anwendbar, die Proteine sind. Eine besonders nützliche Anwendung dieses Verfahrens
ist die Inhibierung von Proteinfunktion, z.B. die Inhibierung von
Rezeptorbindung an einen Effektor oder die Inhibierung von Enzymkatalyse.
In diesem Fall wird eine Menge des selektierten Nucleinsäuremoleküls, die
zur Targetprotein-Inhibierung wirksam ist, mit dem Targetprotein
kombiniert, um die erwünschte
Inhibierung zu erreichen.
-
Folglich
wird in einem Aspekt der vorliegenden Erfindung ein Verfahren bereitgestellt,
das die spezifische Bindung in vitro eines Nucleinsäureliganden
an ein Targetmolekül,
die nicht Bindung zwischen Nucleinsäuren ist, umfasst; worin, wenn
das Targetmolekül
ein Protein ist, es ein Protein ist, das sich nicht an Nucleinsäuren als
Teil seiner biologischen Funktion bindet, und worin der Nucleinsäureligand
durch ein Verfahren identifiziert wurde, das die folgenden Schritte
umfasst:
- (a) Kontaktieren eines Gemisches von
Nucleinsäuren
mit dem Target unter Bedingungen, die für Bindung günstig sind;
- (b) Abtrennen ungebundener Nucleinsäuren von jenen Nucleinsäuren, die
sich an Targetmoleküle
gebunden haben;
- (c) Dissoziieren der Nucleinsäure-Target-Paare;
- (d) Amplifizieren der von den Nucleinsäure-Target-Paaren dissoziierten
Nucleinsäuren,
um ein an Liganden angereichertes Gemisch von Nucleinsäuren zu
erhalten;
- (e) Wiederholen der Schritte von Bindung, Abtrennung, Dissoziierung
und Amplifikation in so vielen Zyklen wie erwünscht,
um den/die
Liganden) zu erhalten, der/die sich spezifisch an das Targetmolekül bindet/binden.
-
In
einem anderen Aspekt der vorliegenden Erfindung wird die Verwendung
eines Nucleinsäureliganden
bei der Herstellung eines therapeutischen oder diagnostischen Mittels
für ein
Therapie- oder Diagnoseverfahren bereitgestellt, das die spezifische
Bindung in vivo des Liganden an ein Targetmolekül, die nicht Bindung zwischen
Nucleinsäuren
ist, umfasst; worin, wenn das Targetmolekül ein Protein ist, es ein Protein
ist, das sich nicht an Nucleinsäuren
als Teil seiner biologischen Funktion bindet, und worin der Nucleinsäureligand durch
ein Verfahren identifiziert wurde, das die folgenden Schritte umfasst:
- (a) Kontaktieren eines Gemisches von Nucleinsäuren mit
dem Target unter Bedingungen, die für Bindung günstig sind;
- (b) Abtrennen ungebundener Nucleinsäuren von jenen Nucleinsäuren, die
sich an Targetmoleküle
gebunden haben;
- (c) Dissoziieren der Nucleinsäure-Target-Paare;
- (d) Amplifizieren der von den Nucleinsäure-Target-Paaren dissoziierten
Nucleinsäuren,
um ein an Liganden angereichertes Gemisch von Nucleinsäuren zu
erhalten;
- (e) Wiederholen der Schritte von Bindung, Abtrennung, Dissoziierung
und Amplifikation in so vielen Zyklen wie erwünscht,
um den/die
Ligand(en) zu erhalten, der/die sich spezifisch an das Targetmolekül bindet/binden.
-
KURZBESCHREIBUNG
DER ZEICHNUNGEN
-
1 ist
ein Diagramm der Ribonucleotidsequenz eines Abschnitts der Gen-43-Messenger-RNA, die für die Bakteriophagen-T4-DNA-Polymerase
kodiert. Gezeigt ist die Sequenz in der Region, die dafür bekannt ist,
sich an gp43 zu binden. Die Großbuchstaben
in Fettdruck bezeichnen das Ausmaß der Information, die für Bindung
von gp43 erforderlich ist. Die 8-Basenpaar-Schleife wurde durch
randomisierte Sequenz ersetzt, um eine Kandidatenpopulation für SELEX
zu erhalten.
-
2 ist
ein schematisches Diagramm des SELEX-Verfahrens, beispielhaft für die Selektion
von Schleifensequenzvarianten für
RNAs, die sich an T4-DNA-Polymerase (gp43) binden, dargestellt.
Eine DNA-Matrix zur Herstellung eines Testgemisches aus RNAs wurde,
wie in Schritt a angegeben, durch Ligation von Oligomeren 3, 4 und
5, deren Sequenzen in Tabelle 1, siehe unten, angegeben sind, hergestellt.
Korrekte Ligation in Schritt a wurde durch Hybridisierung mit den
Oligomeren 1 und 2 sichergestellt, die Komplementärsequenz
aufweisen (in Tabelle 1 angegeben), die die Oligomere 3 und 4 bzw.
4 und 5 verbrückt.
Die resultierende, 110 Basen lange Matrix wurde gelgereinigt, an
Oligo 1 anelliert und in In-vitro-Transkriptionsreaktionen verwendet
(Miligan et al., Nucl. Acids. Res. 15, 8783–8798 (1987)), um ein Start-RNA-Gemisch zu bilden,
das randomisierte Sequenzen der 8-Basen-Schleife enthält, Schritt
b. Die resultierenden Transkripte wurden gelgereinigt und Selektion
an Nitrocellulosefiltern auf Bindung an gp43 unterzogen (Schritt
c), wie in Beispiel 1 beschrieben ist. Selektierte RNAs wurden in
einem Prozess mit drei Schritten amplifiziert: (d) cDNA-Kopien der selektierten
RNAs wurden durch Umkehrtranskriptasesynthese unter Verwendung von
Oligo 5 (Tabelle 1) als Primer gebildet; (e) cDNAs wurden unter
Verwendung von Taq-DNA-Polymerasekettenextension von Oligo 1 (Tabelle
1), das wesentliche T7-Promotorsequenzen trägt, und Oligo 5 (Tabelle 1),
wie in Innis et al., Proc. Natl. Acad. Sci. USA 85, 9436 (1988),
beschrieben, amplifiziert; und (f) doppelsträngige DNA-Amplifikationsprodukte
wurden in vitro transkri biert. Die resultierenden selektierten amplifizierten
RNAs wurden im nächsten
Selektionsdurchgang verwendet.
-
3 ist
eine Zusammensetzung von Autoradiographen von Elektrophorese unterzogenen
Chargensequenzierungsreaktionen der aus SELEX für Bindung von RNA-Schleifenvarianten
an gp43 abgeleiteten In-vitro-Transkripte. Die Figur zeigt die Veränderung
von Schleifensequenzkomponenten als eine Funktion der Anzahl an
Selektionszyklen (für
2, 3 und 4 Zyklen) für
Selektionsbedingungen von Versuch B, in dem die Konzentration von
gp43 3 × 10–8 M
und die Konzentration von RNA etwa 3 × 10–5 in
allen Selektionszyklen betrug. Sequenzierung erfolgte wie in Gauss
et al., Mol. Gen. Genet. 206, 24–34 (1987), beschrieben.
-
4 ist
eine Zusammensetzung von Autoradiographen von Chargen-RNA-Sequenzen von jenen RNAs,
die aus dem vierten Durchgang von SELEX-Amplifikation für Bindung von RNA-Schleifenvarianten
an gp43 unter Verwendung verschiedener Bindungsbedingungen selektiert
wurden. In Versuch A betrug die gp43-Konzentration 3 × 10–8 M
und die RNA-Konzentration etwa 3 × 10–7 M.
In Versuch B betrug gp43 3 × 10–8 M
und RNA etwa 3 × 10–5 M.
In Versuch C betrug gp43 3 × 10–7 M
und RNA etwa 3 × 10–5 M.
-
5 ist
eine Zusammensetzung von Autoradiographen von drei Sequenzierungsgelen
für Schleifenvarianten,
selektiert für
Bindung an gp43 unter den Selektionsbedingungen aus Versuch B (siehe
Beispiel 1). Das linke Sequenzgel ist die Chargensequenzierung selektierter
RNAs nach dem vierten Durchgang von Selektion/Amplifikation. Die
mittleren und rechten Sequenzgele sind doppelsträngige DNA-Sequenzierungsgele von
zwei klonalen Isolaten, abstammend von den Chargen-RNAs. Die selektierte
RNA-Charge setzt sich aus zwei Hauptvarianten zusammen, von denen
eine die Wildtypsequenz ist (mittleres Sequenzgel) und die andere eine
neue Sequenz ist (rechtes Gel).
-
6 ist
ein Diagramm der Prozentsätze
an RNA, die an gp43 gebunden ist, als eine Funktion von gp43-Konzentration
für verschiedene
selektierte RNA-Schleifense quenzvarianten und für RNA mit einer randomisierten
Schleifensequenz. Bindung der Wildtypschleifensequenz AAUAACUC wird
als leere Kreise auf durchgehender Linie angegeben; die Hauptvarianten-Schleifensequenz
AGCAACCU als „x" auf gepunkteter Linie;
die Nebenvarianten-Schleifensequenz AAUAACUU als leere Kästchen auf
durchgehender Linie; die Nebenvarianten-Schleifensequenz AAUGACUC
als volle Kreise auf gepunkteter Linie; die Nebenvarianten-Schleifensequenz
AGCGACCU als Kreuze auf gepunkteter Linie; und die Bindung des randomisierten
Gemisches (NNNNNNNN) von Schleifensequenzen als leere Kreise auf
gepunkteter Linie.
-
7 ist
eine in Bildern dargestellte Zusammenfassung der Resultate, die
nach vier Runden von SELEX erreicht wurden, um eine neue gp43-Bindungs-RNA
aus einer Kandidatenpopulation, die in der 8-Basenpaar-Schleife
randomisiert ist, zu selektieren. SELEX ergab den „offensichtlichen" Consensus nicht,
der aus den in 4 gezeigten Chargensequenzen
erwartet wurde, ergab jedoch stattdessen Wildtyp und eine einzelne
Hauptvariante in etwa gleichen Verhältnissen und drei einzelne
Mutanten. Die Häufigkeiten
von jeder Spezies aus zwanzig klonierten Isolaten werden zusammen
mit den ungefähren
Affinitätskonstanten
(Kd) für
alle Isolate gezeigt, wie sie aus Filterbindungstests, die in 6 gezeigt
sind, gewonnen wurden.
-
8 ist
eine Reihe von Diagrammen, die die Synthese von Kandidaten-Nucleinsäureliganden
unter Verwendung der Enzyme terminale Transferase (TDT) und DNA-Polymerase
(DNA-pol) zeigen. Ein 5'-Primer oder
eine primäre
Ligandensequenz wird mit einem Ende von randomisierter Sequenz durch
Inkubieren mit terminaler Transferase in Gegenwart der vier Desoxynucleotidtriphosphate
(dNTPs) bereitgestellt. Das Zuschneiden von Homopolymer aus dem
randomisierten Segment unter Verwendung desselben Enzyms in Gegenwart
eines einzelnen Desoxynucleotidtriphosphats (z.B. dCTP) stellt eine
Anellierungsstelle für
Poly-G-geschnittene 3'-Primer bereit. Nach
dem Anellieren wird das doppelsträngige Molekül durch die Wirkung von DNA-Polymerase
vervollständigt.
Das Gemisch kann weiter, sofern erwünscht, durch Polymerasekettenreaktion
amplifiziert werden.
-
9 ist
ein Diagramm, das ein Verfahren unter Verwendung von SELEX zur Selektion
eines großen Nucleinsäureliganden
mit zwei räumlich
voneinander getrennten Bindungswechselwirkungen mit einem Targetprotein
zeigt. Das Verfahren wird als „Walking" bezeichnet, da es
zwei Phasen umfasst, wobei die zweite eine Verlängerung der ersten ist. Der
obere Teil der Figur zeigt ein Target („Protein von Interesse") mit einem gebundenen
Nucleinsäureliganden,
der durch einen ersten Durchgang von SELEX selektiert wurde („entwickelter
primärer
Ligand"), der an
das Protein an einer ersten Bindungsstelle gebunden ist. Eine durch
terminale Transferase katalysierte Reaktion verlängert die Länge des entwickelten primären Liganden
und bildet eine neue Reihe von Kandidaten mit randomisierter Sequenz,
die eine konservierte Region aufweisen, die den primären Liganden
enthält.
Der untere Teil der Figur zeigt das Resultat eines zweiten Durchgangs
von SELEX, basierend auf verbesserter Bindung, die aus der sekundären Ligandenwechselwirkung
an der sekundären
Bindungsstelle des Proteins resultiert. Die Bezeichnungen „primär" und „sekundär" sind ausschließlich praktische Bezeichnungen
zur Unterscheidung, die nicht implizieren, dass der eine höhere Affinität als der
andere aufweist.
-
Die 10 und 11 sind
Diagramme eines Selektionsverfahrens unter Verwendung von SELEX
in zwei Phasen. In 10 wird SELEX angewandt, um
Liganden auszuwählen,
die sich an sekundäre
Bindungsstellen an einem Target binden, das mit einem Verbrückungs-Oligonucleotid,
das an einen spezifischen Binder, z.B. einen Inhibitor des Targetproteins,
gebunden ist, einen Komplex bildet. Das Verbrückungs-Oligonucleotid wirkt als ein Leitkörper, um
Selektion von Liganden, die sich an zugängliche sekundäre Bindungsstellen
binden, zu bevorzugen. In 11 wird
ein zweiter SELEX eingesetzt, um Liganden zu entwickeln, die sich
sowohl an die sekundären
Stellen, auf die ursprünglich
selektiert wurde, als auch die primäre Targetdomäne binden. Die
Nucleinsäuren,
die dadurch entwickelt werden, binden sich sehr fest und können selbst
als Inhibitoren des Targetproteins wirken oder gegen Inhibitoren
oder Substrate des Targetproteins konkurrieren.
-
12 zeigt die Sequenz und Anordnung von
Oligomeren, die verwendet werden, um das in Beispiel 2 verwendete
Kandidatengemisch zu konstruieren. Die obere Li nie zeigt die Sequenzen
der Oligomere 1b bzw. 2b von links nach rechts (siehe Tabelle 2,
unten). Die zweite Linie zeigt, von links nach rechts, die Sequenzen der
Oligomere 3b, 4b und 5b (Tabelle 2). Korrekte Ligation der Oligomere
wurde durch Hybridisierung mit Oligomeren 1b und 2b, deren Sequenzen
komplementär
sind, sichergestellt. Die resultierende ligierte Matrix wurde gelgereinigt,
an Oligomer 1b anelliert und in einer In-vitro-Transkriptionsreaktion
verwendet (Milligan et al. (1987)), um ein RNA-Kandidatengemisch
zu bilden, das in der letzten Linie der Figur gezeigt und als „In-vitro-Transkript" markiert ist. Das
Kandidatengemisch enthielt ein 32 Nucleotid langes, randomisiertes
Segment, wie gezeigt.
-
13 zeigt eine hypothetische RNA-Sequenz, die zahlreiche
sekundäre
Strukturen enthält,
die bekanntlich von RNA angenommen werden. Eingebunden sind: A Haarnadelschleifen,
B Ausweitungen, C asymmetrische Ausweitungen und D Pseudoknoten.
-
14 zeigt Nitrocellulosefilter-Bindungstests von
Ligandenaffinität
für HIV-RT.
Gezeigt ist der Prozentsatz von Eingangs-RNA, die an den Nitrocellulosefilter
mit variierenden Konzentrationen von HIV-RT gebunden ist.
-
15 zeigt zusätzliche
Nitrocellulosefilter-Bindungstests von Ligandenaffinität für HIV-RT.
-
16 zeigt Informationsgrenzenbestimmung
für HIV-1-RT-Liganden
1.1 und 1.3a.
- a) 3'-Grenzenbestimmung. RNAs wurden 5'-endmarkiert, partieller
alkalischer Hydrolyse und Selektion an Nitrocellulosefiltern unterzogen,
an einem denaturierendem 8%igen Polyacrylamidgel getrennt und Autoradiographie
unterzogen. Etwa 90 pmol von markierter RNA und 80 pmol von HIV-1-RT
wurden in 0,5, 2,5 und 5 ml Puffer vermischt und vor dem Waschen
durch ein Nitrocellulosefilter 5 min lang bei 37°C inkubiert. Die eluierten RNAs
werden unter den Endkonzentrationen von HIV-1-RT, die in jedem Versuch
verwendet wurden, gezeigt. Auch gezeigt werden die Produkte eines
teilweisen RNase-T1-Verdaus, der die Identifikation der Informationsgrenze
an der benachbarten Sequenz ermöglicht,
wie durch die Pfeile angezeigt wird.
- b) 5'-Grenzenbestimmung.
Die 5'-Grenze wurde
unter denselben Bedingungen wie zuvor in a) beschrieben bestimmt.
-
17 zeigt die Inhibierung von HIV-1-RT durch RNA-Liganden
1.1. Eine Reihe von dreifachen Verdünnungen von 32N-Kandidatengemisch-RNA
und Ligand-1.1-RNA im Bereich einer Endreaktionskonzentration von
10 μM bis
4,6 nM wurde vorgemischt mit HIV-RT und 5 min lang bei 37°C in 6 μl 200 mM
KOAc, 50 mM Tris-HCl, pH 7,7, 10 mM Dithiothreit, 6 mM Mg(OAc)2 und 0,4 mM NTPS inkubiert. In einer separaten
Röhrchen
wurden RNA-Matrix (transkribiert aus einem PCR-Produkt eines T7-1,
erhalten von U.S. Biochemical Corp., unter Verwendung der Oligos
7 und 9) und markiertes Oligo 9 vermischt und bei 95°C eine Minute
lang erhitzt und auf Eis 15 min lang in 10 mM Tris-HCl, pH 7, 0,1
mM EDTA gekühlt.
Vier μl
dieser Matrix wurden zu allen 6 μl
von Enzym-Inhibitor-Gemisch zugesetzt, um die Reaktion zu starten,
die weitere 5 min bei 37°C inkubiert
und dann gestoppt wurde. Die Endkonzentration von HIV-1-RT betrug
16 nM, von RNA-Matrix 13 nM und von markiertem Primer 150 nM in
allen Reaktionen. Die Extensionsprodukte von jeder Reaktion sind
gezeigt.
-
18 zeigt einen Vergleich von HIV-1-RT-Inhibierung
durch Liganden 1.1 mit den Wirkungen von MMLV-RT und AMV-RT. Versuche
wurden wie in 17 durchgeführt, mit der Ausnahme, dass
5fache Verdünnungen
mit den unten gezeigten resultierenden Konzentrationen hergestellt
wurden. Die Konzentrationen von jeder RT wurden bezogen auf jene
von HIV-RT durch Verdünnungen
und Vergleich von Gelbandenintensität sowohl mit Coomassie-Blau-
als auch Silberfärbungen,
Biorad-Proteinkonzentrationstests
und Aktivitätstests
normalisiert.
-
19 zeigt die Consensus-Sequenzen ausgewählter Haarnadelschleifen,
die die R-17-Hüllproteinligandenlösung darstellen.
Die Nucleotiddarstellung an jeder Position wird in den Gitternetzen
angegeben. Die Spalte mit dem Titel „Bulge" zeigt die Anzahl der Klone mit einem
extrahelikalen Nucleotid an einer oder beiden Seiten des Stamms
zwischen den entsprechenden Stammbasenpaaren an. Die Spalte mit
dem Titel „END" zeigt die Anzahl
der Klone, deren Haarnadel am vorangehenden Basenpaar endet.
-
20 zeigt eine Bindungskurve von 30N-Haupt-RNA
für Bradykinin.
Die Analyse erfolgte unter Verwendung von Zentrifugensäulen; 10
mM KOAc, 10 mM DEM, pH 7,5; RNA-Konzentration 1,5 × 10–8 M.
-
21 zeigt Matrices zur Verwendung bei der Bildung
von Kandidatengemischen, die in bestimmten strukturellen Motiven
angereichert sind. Matrix A ist dafür entworfen, das Kandidatengemisch
an Haarnadelschleifen anzureichern. Matrix B ist dafür entworfen,
das Kandidatengemisch an Pseudoknoten anzureichern.
-
22 ist ein schematisches Diagramm von Stamm-Schleifen-Anordnungen
für die
Motive I und II der HIV-rev-Ligandenlösung. Die gepunkteten Linien
in den Stämmen
1 und 2 zwischen den Schleifen 1 und 3 bezeichnen potenzielle Basenpaare.
-
23 zeigt die gefalteten Sekundärstrukturen von rev-Liganden-Unterdomänen der
Isolate 6a, 1a und 8, um die Motive I, II bzw. III zu zeigen. Auch
zu Vergleichszwecken gezeigt wird die vorhergesagte Faltung der
Wildtyp-RRE-RNA.
-
24 ist ein Diagramm der Prozentsätze von
Eingangszählungen,
gebunden an ein Nitrocellulosefilter, mit verschiedenen Konzentrationen
von HIV-rev-Protein. Auch gezeigt sind die Bindungskurven der 32N-Ausgangspopulation
(#) und der entwickelten Population nach 10 Durchgängen (P)
und der Wildtyp-RRE-Sequenz, die aus einer aus den Oligos 8 und
9 bestehenden Matrix transkribiert wurde (W).
-
25 ist ein Vergleich von Motiv-I(a)-rev-Liganden.
Die Parameter sind wie in 24 gezeigt
festgelegt. Auch eingebunden ist die Bindungskurve des „Consensus"-Konstrukts (C).
-
26 ist ein Vergleich von Motiv-1(b)-rev-Liganden.
Die Parameter sind wie in 24 gezeigt
festgelegt.
-
27 ist ein Vergleich von Motiv-II-rev-Liganden.
Die Parameter sind wie in 24 gezeigt
festgelegt.
-
28 ist ein Vergleich von Motiv-III-rev-Liganden.
Die Parameter sind wie in 24 gezeigt
festgelegt.
-
29 zeigt die Consensus-Nucleinsäureligandenlösung zu
HIV-rev, bezeichnet als Motiv I.
-
30 zeigt die Consensus-Nucleinsäureligandenlösung zu
HIV-rev, bezeichnet als Motiv II.
-
31 ist eine schematische Darstellung eines Pseudoknotens.
Der Pseudoknoten besteht aus zwei Stämmen und drei Schleifen, die
hierin als Stämme
S1 und S2 und als
Schleifen 1, 2 und 3 bezeichnet werden.
-
DETAILLIERTE
BESCHREIBUNG DER ERFINDUNG
-
Die
folgenden Bezeichnungen werden hierin gemäß den Definitionen verwendet.
-
Nucleinsäure bezeichnet
entweder DNA, RNA, einzelsträngig
oder doppelsträngig,
und jegliche chemische Modifikation davon, vorausgesetzt, dass die
Modifikation die Amplifikation von selektierten Nucleinsäuren nicht
stört.
Solche Modifikationen umfassen, sind jedoch nicht beschränkt auf,
Modifikationen an exozyklischen Cytosin-Aminen, Substitution von 5-Bromuracil,
Hauptkettenmodifikationen, Methylierungen, unübliche Basenpaarungskombinationen
und dergleichen.
-
Ligand
bezeichnet eine Nucleinsäure,
die sich an ein anderes Molekül
(Target) bindet. In einer Population von Kandidaten-Nucleinsäuren ist
ein Ligand einer, der sich mit größerer Affinität als jener
der Hauptpopulation bindet. In einem Kandidatengemisch können mehr
als ein Ligand für
ein bestimmtes Target vorhanden sein. Die Li ganden können sich
voneinander in ihren Bindungsaffinitäten für das Targetmolekül unterscheiden.
-
Kandidatengemisch
ist ein Gemisch von Nucleinsäuren
unterschiedlicher Sequenz, aus dem ein erwünschter Ligand selektiert wird.
Die Quelle eines Kandidatengemisches kann in natürlich-vorkommenden Nucleinsäuren oder
Fragmenten davon, chemisch synthetisierten Nucleinsäuren, enzymatisch
synthetisierten Nucleinsäuren
oder Nucleinsäuren,
die durch eine Kombination der obigen Verfahren hergestellt werden,
bestehen.
-
Targetmolekül bezeichnet
jegliche Verbindung von Interesse, für die ein Ligand erwünscht ist.
Ein Targetmolekül
kann, ohne darauf eingeschränkt
zu sein, ein Protein, Peptid, Kohlenhydrat, Polysaccharid, Glykoprotein,
Hormon, Rezeptor, Antigen, Antikörper,
Virus, Substrat, Metabolit, Übergangszustands-Analogon, Co-Faktor,
Inhibitor, Wirkstoff, Farbstoff, Nährstoff, Wachstumsfaktor usw.
sein.
-
Abtrennung
bezeichnet jegliches Verfahren, durch das Liganden, die an Targetmoleküle gebunden sind,
was hierin als Liganden-Target-Paar bezeichnet wird, von Nucleinsäuren, die
nicht an Targetmoleküle
gebunden sind, getrennt werden können.
Das Abtrennen kann durch verschiedene Verfahren, die auf dem Gebiet der
Erfindung bekannt sind, durchgeführt
werden. Nucleinsäure-Protein-Paare
können
an Nitrocellulosefilter gebunden sein, während ungebundene Nucleinsäuren dies
nicht können.
Säulen,
die Liganden-Target-Paare spezifisch festhalten (oder gebundenen
Liganden, der mit einem gebundenen Target einen Komplex bildet, spezifisch
festhalten), können
zum Abtrennen verwendet werden. Flüssig-Flüssig-Abtrennung kann auch verwendet
werden wie auch Filtrationsgel-Retardierung und Dichtegradienten-Zentrifugation. Die
Wahl des Abtrennungsverfahrens hängt
von den Eigenschaften des Targets und von den Liganden-Target-Paaren
ab und kann gemäß den Prinzipien
und Eigenschaften durchgeführt
werden, die Fachleuten bekannt sind.
-
Amplifikation
bezeichnet jegliches Verfahren oder jegliche Kombination von Verfahrensschritten,
das bzw. die die Menge oder Anzahl von Kopien eines Moleküls oder einer
Klasse von Molekülen
erhöht.
Amplifikation von RNA-Molekülen
in den offenbarten Beispielen wurde durch eine Abfolge von drei
Reaktionen durchgeführt:
Herstellen von cDNA-Kopien von selektierten RNAs unter Verwendung
von Polymerasekettenreaktion, um die Kopienanzahl von jeder cDNA
zu erhöhen,
und Transkribieren der cDNA-Kopien, um RNA-Moleküle mit denselben Sequenzen
wie die selektierten RNAs zu erhalten. Jegliche Reaktion oder Kombination
von Reaktionen, die auf dem Gebiet der Erfindung bekannt sind, kann
je nach Bedarf verwendet werden, einschließlich direkter DNA-Replikation,
direkter RNA-Amplifikation und dergleichen, wie Fachleuten bekannt
sein wird. Das Amplifikationsverfahren sollte in den Verhältnissen
des amplifizierten Gemisches resultieren, die für die Verhältnisse unterschiedlicher Sequenzen
im Ausgangsgemisch im Wesentlichen repräsentativ sind.
-
Spezifische
Bindung ist eine Bezeichnung, die von Fall zu Fall unterschiedlich
definiert wird. In Zusammenhang mit einer bestimmten Wechselwirkung
zwischen einem bestimmten Liganden und einem bestimmten Target wird
eine Bindungswechselwirkung von Liganden und Target mit höherer Affinität als jene,
die zwischen dem Target und dem Kandidaten-Ligandengemisch vorhanden
ist, beobachtet. Um Bindungsaffinitäten zu vergleichen, müssen die
Bedingungen beider Bindungsreaktionen dieselben sein und sollten
mit den Bedingungen des beabsichtigen Verwendungszwecks vergleichbar
sein. Für
die exaktesten Vergleiche werden Messungen durchgeführt, die
die Wechselwirkung zwischen Liganden als Ganzes und Target als Ganzes
widerspiegeln. Die Nucleinsäureliganden
der Erfindung können
selektiert werden, um so spezifisch wie nötig zu sein, entweder durch
Festlegen von Selektionsbedingungen, die die erforderliche Spezifität während SELEX
bedingen, oder durch Zuschneiden und Modifizieren des Liganden durch „Walking" und andere Modifikationen
unter Verwendung der Wechselwirkungen von SELEX.
-
Randomisiert
ist eine Bezeichnung, um ein Segment einer Nucleinsäure zu beschreiben,
das im Prinzip jegliche mögliche
Sequenz über
eine bestimmte Länge
aufweist. Randomisierte Sequenzen weisen verschiedene Längen auf,
die, je nach Belieben, im Bereich von etwa 8 bis mehr als 100 Nucleotiden
liegen. Die chemischen oder enzymatischen Reaktionen, durch die
Zufallssequenzsegmente gebildet werden, können aufgrund von unbekannten
Vorgaben oder Nucleotidpräferenzen,
die vorhanden sein können,
keine mathematisch zufälligen
Sequenzen ergeben. Die Bezeichnung „randomisiert" wird anstelle von „zufällig" verwendet, um die
Möglichkeit
solcher Abweichungen vom Nicht-Idealfall auszudrücken. In den zur Zeit bekannten
Verfahren, beispielsweise bei sequenzieller chemischer Synthese,
ist nicht bekannt, dass große
Abweichungen auftreten. Für
kürzere
Segmente von 20 Nucleotiden oder weniger würde jegliche geringfügige Vorgabe,
die vorhanden sein könnte,
Konsequenzen haben, die zu vernachlässigen wären. Je länger die Sequenzen einer einzelnen
Synthese, desto größer die
Wirkung irgendeiner Vorgabe.
-
Eine
Vorgabe kann absichtlich in randomisierte Sequenz eingeführt werden,
beispielsweise durch Verändern
der Mol-Verhältnisse
von Vorläufer-Nucleosid-
(oder -Desoxynucleosid-) Triphosphaten der Synthesereaktion. Eine
absichtliche Vorgabe kann erwünscht
sein, beispielsweise um die Verhältnisse
der einzelnen Basen in einem bestimmten Organismus anzunähern oder
um die Sekundärstruktur
zu beeinflussen.
-
SELEXION
bezieht sich auf eine mathematische Analyse und Computersimulation,
die verwendet wird, um die enorme Fähigkeit von SELEX darzustellen,
Nucleinsäureliganden
zu identifizieren, und vorherzusagen, welche Variationen im SELEX-Verfahren die größte Wirkung
auf die Optimierung des Verfahrens haben. SELEXION ist ein Akronym
für Systematic
Evolution of Ligands by Exponential Enrichment with Integrated Optimization
by Nonlinear Analysis (Systematische Entwicklung von Liganden durch
exponentielle Anreicherung mit integrierter Optimierung durch nichtlineare
Analyse).
-
Nucleinsäure-Antikörper ist
eine Bezeichnung, die verwendet wird, um auf eine Klasse von Nucleinsäureliganden
Bezug zu nehmen, die sich aus einzelnen Nucleinsäurestrukturen oder -motiven
zusammensetzt, die sich selektiv an Targetmoleküle binden. Nucleinsäure-Antikörper können aus
doppel- oder einzelsträngiger
RNA oder DNA gebildet werden. Die Nucleinsäure-Antikörper werden synthetisiert und
werden in einer bevorzugten Ausführungsform
basierend auf einer Ligandenlösung
oder -lösungen
konstruiert, die für
ein bestimmtes Target durch das SELEX-Verfahren erhalten wurde(n).
In zahlreichen Fällen
treten die Nucleinsäure-Antikörper der
vorliegenden Erfindung nicht natürlich
in der Natur auf, während
sie in anderen Situationen signifikante Ähnlichkeit zu einer in der
Natur vorkommenden Nucleinsäuresequenz
zeigen können.
-
Die
Nucleinsäure-Antikörper der
vorliegenden Erfindung umfassen alle Nucleinsäuren, die eine spezifische
Bindungsaffinität
für ein
Target aufweisen, während
sie jene Fälle
nicht einbinden, in denen das Target ein Polynucleotid ist, das
sich an die Nucleinsäure
durch einen Mechanismus bindet, der vorwiegend von Watson/Crick-Basenpaarung oder
Tripelhelix-Mitteln abhängt
(siehe M. Riordan et al., Nature 350, 442–443 (1991)); vorausgesetzt
jedoch, dass, wenn der Nucleinsäure-Antikörper doppelsträngige DNA
ist, das Target ein nicht in der Natur vorkommendes Protein ist,
dessen physiologische Funktion von spezifischer Bindung an doppelsträngige DNA
abhängt.
-
RNA-Motive
ist eine Bezeichnung, die im Allgemeinen verwendet wird, um die
Sekundär-
oder Tertiärstruktur
von RNA-Molekülen
zu beschreiben. Die Primärsequenz
einer RNA ist ein spezifischer Strang von Nucleotiden (A, C, G oder
U) in einer Dimension. Die Primärsequenz
gibt dem ersten Eindruck nach bezüglich der dreidimensionalen
Konfiguration der RNA keine Information ab, wenn auch es die Primärsequenz
ist, die die dreidimensionale Konfiguration festlegt. In bestimmten
Fällen
kann die Ligandenlösung,
die nach Durchführung
von SELEX an einem bestimmten Target erhalten wurde, am besten als
eine Primärsequenz
dargestellt werden. Obwohl Konformationsinformation in Bezug auf
solch eine Ligandenlösung
basierend auf den durch SELEX erhaltenen Resultaten nicht immer
feststellbar ist, sollte die Darstellung einer Ligandenlösung als
Primärsequenz
nicht als ein Nicht-Anerkennung der Existenz einer integralen Tertiärstruktur
verstanden werden.
-
Die
Sekundärstruktur
eines RNA-Motivs wird durch Kontakt in zwei Dimensionen zwischen
spezifischen Nucleotiden dargestellt. Die am leichtesten zu erkennenden
Sekundärstrukturmotive
bestehen aus Watson/Crick-Basenpaaren A:U und C:G.
-
Nicht-Watson/Crick-Basenpaare,
häufig
mit geringerer Stabilität,
wurden auch bereits erkannt und umfassen die Paare G:U, A:C, G:A
und U:U. (Basenpaare sind einmal gezeigt; in RNA-Molekülen steht
das Basenpaar X:Y per definitionem für eine Sequenz, in der X 5' zu Y steht, während das
Basenpaar Y:X ebenfalls zulässig
ist.) In 13 ist eine Reihe von Sekundärstrukturen,
gebunden durch einzelsträngige
Regionen, gezeigt; die herkömmliche
Nomenklatur für
die Sekundärstrukturen
umfasst Haarnadelschleifen, asymmetrische ausgeweitete Haarnadelschleifen,
symmetrische Haarnadelschleifen und Pseudoknoten.
-
Wenn
Nucleotide, die in der Primärsequenz
voneinander beabstandet sind und von denen nicht angenommen wird,
dass sie durch Watson/Crick- und Nicht-Watson/Crick-Basenpaare wechselwirken,
tatsächlich jedoch
wechselwirken, so sind diese Wechselwirkungen (die häufig zweidimensional
dargestellt sind) auch Teil der Sekundärstruktur.
-
Die
dreidimensionale Struktur eines RNA-Motivs ist lediglich die räumliche
Beschreibung der Atome des RNA-Motivs. Doppelsträngige RNA, vollständig basengepaart
durch Watson/Crick-Paarung, weist eine reguläre Struktur in drei Dimensionen
auf, wenn auch die exakten Positionen von allen Atomen der helikalen Hauptkette
von der exakten Sequenz von Basen in der RNA abhängen könnten. Viel Fachliteratur befasst
sich mit Sekundärstrukturen
von RNA-Motiven, und von jenen Sekundärstrukturen, die Watson/Crick-Basenpaare enthalten,
wird häufig
angenommen, dass sie A-förmige
doppelsträngige
Helices bilden.
-
Ausgehend
von A-förmigen
Helices kann auf die anderen dreidimensionalen Motive übergegangen werden.
Nicht-Watson/Crick-Basenpaare, Haarnadelschleifen, Ausweitungen
und Pseudoknoten sind Strukturen, die innerhalb und auf Helices
gebildet werden. Die Konstruktion dieser zusätzlichen Motive wird ausführlicher
in der nachstehenden Beschreibung erläutert.
-
Die
tatsächliche
Struktur einer RNA umfasst alle Atome des Nucleotids des Moleküls in den
drei Dimensionen. Eine vollständig
aufgelöste
Struktur würde
Wasser und an organische Atome umfassen sowie binden, obwohl solch
eine Auflösung
von Forschern selten erreicht wird. Aufgelöste RNA-Strukturen in den drei Dimensionen
umfassen alle Sekundärstrukturelemente
(dargestellt als dreidimensionale Strukturen) und fixierte Positionen
für die
Atome von Nucleotiden, die nicht durch Sekundärstrukturelemente eingeschränkt sind; aufgrund
von Basenschichtung und anderen Kräften können umfassende einzelsträngige Domänen fixierte Strukturen
aufweisen.
-
Primärsequenzen
von RNAs schränken
die möglichen
dreidimensionalen Strukturen ein, wie dies auch die fixierten Sekundärstrukturen
machen. Die dreidimensionalen Strukturen einer RNA sind durch die spezifischen
Kontakte zwischen Atomen in zwei Dimensionen eingeschränkt, und
sie sind weiters durch Energieminimierung, die Kapazität eines
Moleküls,
alle frei rotierbaren Bindungen zu rotieren, sodass das resultierende
Molekül
stabiler ist als andere Konformere mit derselben Primär- und Sekundärsequenz
und -struktur, eingeschränkt.
-
Am
wichtigsten gilt festzuhalten, dass RNA-Moleküle dreidimensionale Strukturen
aufweisen, die sich aus einer Reihe von RNA-Motiven, einschließlich jeglicher
Anzahl an Motiven, die in 13 gezeigt
sind, zusammensetzen.
-
Daher
umfassen RNA-Motive alle Arten, in denen es möglich ist, allgemein die stabilsten
Gruppen von Konformationen zu beschreiben, die eine Nucleinsäureverbindung
bilden kann. Für
ein bestimmtes Target kann die Ligandenlösung und der Nucleinsäure-Antikörper eines
der hierin beschriebenen RNA-Motive oder eine gewisse Kombination
von mehreren RNA-Motiven sein.
-
Ligandenlösungen sind
definiert als die dreidimensionale Struktur, die sie gemeinsam aufweisen,
oder als eine Familie, die die konservierten, durch SELEX identifizierten
Komponenten definiert. Die für
ein bestimmtes Target identifizierten Liganden beispielsweise können eine
Primärsequenz
enthalten, die sie gemeinsam haben (NNNCGNAANUCGN'N'N), die durch eine Haarnadel in zwei
Dimensionen durch:
dargestellt werden kann.
-
Die
dreidimensionale Struktur würde
somit gegenüber
der exakten Sequenz von drei der fünf Basenpaare und von zwei
der fünf
Schleifennucleotide unempfindlich sein und würde in allen oder in den meisten Versionen
der Sequenz/Struktur ein geeigneter Ligand für die weitere Verwendung sein.
Somit sollen Ligandenlösungen
für eine
potenziell große
Sammlung an geeigneten Sequenz/Strukturen stehen, wovon jede durch
die Familienbeschreibung, die ausschließlich für alle exakten Sequenz/Struktur-Lösungen sind,
identifiziert wird. Weiters wird durch diese Definition erwogen,
dass Ligandenlösungen
nicht nur Elemente mit exakter numerischer Äquivalenz zwischen den verschiedenen
Komponenten eines RNA-Motivs umfassen dürfen. Manche Liganden können Schleifen
beispielsweise mit fünf
Nucleotiden aufweisen, während
andere Liganden für
dasselbe Target weniger oder mehr Nucleotide in der äquivalenten
Schleife enthalten können
und dennoch in die Beschreibung der Ligandenlösung fallen.
-
Obwohl
die durch SELEX hergeleitete Ligandenlösung eine relativ große Anzahl
an potenziellen Elementen umfassen kann, sind die Ligandenlösungen targetspezifisch,
und im Großteil
der Fälle
kann jedes Element der Ligandenlösungsfamilie
als ein Nucleinsäure-Antikörper zum
Target verwendet werden. Die Selektion eines spezifischen Elements
aus einer Familie von Ligandenlösungen,
das als ein Nucleinsäure-Antikörper zu verwenden
ist, kann wie in der Beschreibung erläutert durchgeführt werden
und kann durch zahlreiche praktische Überlegungen beeinflusst werden,
die für
Fachleute selbstverständlich
ersichtlich sind.
-
Das
Verfahren der vorliegenden Erfindung wird in Verbindungen mit Untersuchungen
von Translationsregulation in Bakteriophagen-T4-Infektion entwickelt.
Autoregulation der Synthese bestimmter viraler Proteine, wie der
Bakteriophagen-T4-DNA-Polymerase
(gp43), umfasst die Bindung des Proteins an seine eigene Nachricht, wodurch
seine Translation blockiert wird. Das SELEX-Verfahren wurde verwendet,
um die Sequenz- und Strukturerfordernisse der gp43-RNA-Bindungsstelle
zu hinterleuchten. SELEX ermöglichte
die rasche Selektion bevorzugter Bindungssequenzen aus einer Population
zufälliger
Nucleinsäuresequenzen.
Während dies
durch die Isolierung und Identifikation von Nucleinsäuresequenzen,
die sich an Proteine binden, die sich bekanntlich an RNA binden,
beispielhaft dargestellt wird, ist das Verfahren der vorliegenden
Erfindung im Allgemeinen auf die Selektion einer Nucleinsäure anwendbar,
die in der Lage ist, jegliches gegebene Protein zu binden. Das Verfahren
ist auf Selektion von Nucleinsäuren
anwendbar, die sich an Proteine binden, die sich nicht (oder nicht
bekanntlich) an Nucleinsäure
als Teil ihrer natürlichen
Aktivität
oder biologischen Funktion binden. Das SELEX-Verfahren erfordert
kein Wissen der Struktur oder Sequenz einer Bindungsstelle und kein Wissen
der Struktur oder Sequenz des Targetproteins. Das Verfahren hängt nicht
von gereinigtem Targetprotein für
Selektionen ab. Im Allgemeinen reichert die Anwendung von SELEX
Liganden des am häufigsten
vorhandenen Targets an. Bei einem Gemisch von Liganden sind Verfahren
zur Isolierung des Liganden eines bestimmten Targets verfügbar. Beispielsweise
ein anderer Ligand (z.B. Substrat, Inhibitor, Antikörper) des
erwünschten
Targets kann verwendet werden, um spezifisch um Bindung an das Target
zu konkurrieren, sodass der erwünschte
Nucleinsäureligand
aus Liganden von anderen Targets abgetrennt werden kann.
-
In
der bevorzugten Ausführungsform
bestehen Liganden, die durch SELEX hergeleitet werden, aus einzelsträngigen RNA-Sequenzen.
Es ist ein maßgebliches
Element dieser Erfindung, dass die Erfinder in der Lage waren, Schlussfolgerungen
bezüglich
RNA zu ziehen, die zu jenen Annahmen, die bisher auf dem Gebiet der
Erfindung vorherrschten, konträr
sind, und diese Schlussfolgerungen zu verwenden, um das SELEX-Verfahren
zu verändern,
um Nucleinsäure-Antikörper zu
gewinnen, die aus Ligandenlösungen
stammen.
-
RNA
wurde zuerst als ein Informationsmessenger zwischen den DNA-Sequenzen,
die die Gene sind, und den Proteinsequenzen, die innerhalb von Enzymen
und anderen Proteinen zu finden sind, definiert. Von Beginn an,
nachdem Watson und Crick die Struktur von DNA und die Verbindung
zwischen DNA-Sequenz und Proteinsequenz beschrieben, wurden die
Mittel, durch die Proteine synthetisiert wurden, in zahlreichen
Bereichen der experimentellen Biochemie zu zentralen Elementen.
Schließlich
wurde Messenger-RNA (mRNA) als das chemische Zwischenprodukt zwischen
Genen und Proteinen identifiziert. Die Mehrzahl von RNA-Spezies, die
in Organismen vorhanden sind, sind mRNAs, und somit wird RNA weiterhin
umfassend als ein Informationsmolekül betrachtet. RNA erfüllt seine
Rolle als Informationsmolekül
vor allem durch die Primärsequenz
von Nucleotiden, in derselben Weise, wie DNA ihre Funktion als das
Material von Genen durch die Primärsequenz von Nucleotiden erfüllt; das
heißt,
dass Information in Nucleinsäuren
eindimensional dargestellt werden kann.
-
Als
die Biochemie von Genexpression untersucht wurde, wurden mehrere
RNA-Moleküle innerhalb von
Zellen entdeckt, deren Rollen keine informativen waren. Ribosomen
wurden als die Einheiten entdeckt, über die mRNAs in Proteine translatiert
werden, und es wurde erkannt, dass Ribosomen essenzielle RNA (ribosomale
RNAs oder rRNAs) enthielten. rRNAs wurden über zahlreiche Jahre hinweg
als strukturell erachtet, eine Art von Gerüst, auf das die Proteinkomponenten
des Ribosoms „aufgehängt" wurden, sodass die
Proteinkomponenten des Ribosoms die proteinsynthetische Wirkung
des Ribosoms darbringen konnten. Eine zusätzliche große Klasse von RNAs, die Transfer-RNAs
(tRNAs), wurden vorausgesagt und gefunden. tRNAs sind die chemisch
bifunktionellen Adaptoren, die Codons innerhalb von mRNA erkennen
und die Aminosäuren tragen,
die zu Protein kondensiert werden. Sehr interessant ist auch, dass,
auch wenn eine tRNA-Struktur im Jahr 1974 durch Röntgenanalyse
bestimmt wurde, die RNAs ein weiteres Jahrzehnt lang als primär eindimensionale „Stränge" betrachtet wurden.
rRNA hatte unter der Forschungsgemeinschaft eine sonderbare Position eingenommen.
Lange Zeit erahnte kaum jemand den Grund der umfassenden Ähnlichkeiten
zwischen den rRNAs aus den verschiedenen Spezies und auch nicht
die tatsächliche
chemische Fähigkeit
von RNA-Molekülen.
Mehrere Forscher postulierten, dass RNA einst möglicherweise eine enzymatische
und nicht eine informative Rolle spielte, doch diese Annahmen waren
nie als Vorhersagen bezüglich
der aktuellen Funktionen von RNA beabsichtigt.
-
Die
Arbeit von Tom Cech über
Ribozyme – eine
neue Klasse von RNA-Molekülen – erweiterte
das Wissen über
die funktionelle Fähigkeit
von RNA. Die Gruppe-I-Intronen
sind in der Lage, autokatalytisch zu spleißen, und somit liegt zumindest
eine gewisse eingeschränkte
Katalyse im Bereich von RNA. Innerhalb dieses Bereichs von Katalyse
liegt die Aktivität
der RNA-Komponente von RNase P, eine Aktivität, die durch Altman und Pace
entdeckt wurde. Cech und Altman erhielten der Nobelpreis für Chemie
für ihre
Arbeit, die die früheren Einschränkungen
für RNA-Moleküle ausschließlich auf
Informationsrollen revolutionierte. rRNAs werden nun, dank der Arbeit
von Cech und Altman, von manchen als das katalytische Zentrum des
Ribosoms betrachtet und werden nicht länger als ausschließlich strukturell
gesehen.
-
Es
ist eine zentrale Aussage dieser Erfindung, dass RNA-Moleküle in Hinblick
auf Bindung und andere Fähigkeiten
von der Forschungsgemeinschaft stets unterschätzt sind. Während das Interesse an Ribozymen zu
einer beachtlichen Verstärkung
der Forschung auf dem Gebiet der RNA-Funktionen führte, zieht
die vorliegende Anmeldung in Betracht, dass die Formmöglichkeiten
für RNA-Moleküle (und
vielleicht auch für
DNA) eine Gelegenheit bieten, SELEX zu verwenden, um RNAs mit praktisch
jeder beliebigen Bindungsfunktion zu finden. Weiters wird angenommen,
dass der Bereich von katalytischen Funktionen, der für RNA möglich ist, weit über das
aktuelle herkömmliche
Wissen hinausgeht, wenn er auch nicht notwendigerweise so breit
wie jener von Proteinen ist.
-
Die
dreidimensionalen Formen von manchen RNAs sind entweder direkt aus
Röntgenbeugung
oder aus NMR-Verfahren bekannt. Die bestehende Datenreihe ist eher
spärlich.
Die Strukturen von vier tRNAs konnten bisher aufgelöst werden,
sowie drei kleinere RNA-Moleküle:
zwei kleine Haarnadeln und ein kleiner Pseudoknoten. Die verschiedenen
tRNAs, wenn sie auch verwandt sind, weisen Elemente einer einmaligen Struktur
auf; beispielsweise sind die Anticodon-Basen der Verlängerungs-tRNAs
in Richtung des Lösungsmittels
ausgerichtet, während
die Anticodon-Basen einer Initiator-tRNA eher weg vom Lösungsmittel
zeigen. Manche dieser Unterschiede können aus Kristallgitter-Packungskräften resultieren,
doch manche sind zweifellos auch ein Resultat von idiosynkratischer
Energieminimierung durch verschiedene ein zelsträngige Sequenzen innerhalb homologer
sekundärer
und dreidimensionaler Strukturen.
-
Sequenzvariationen
sind natürlich
umfassend. Enthält
eine einzelsträngige
Schleife einer RNA-Haarnadel acht Nucleotide, so umfassen 65.536
verschiedene Sequenzen den gesättigten
Sequenz-„Raum". Wenn hier auch
keine Einschränkung
auf die Theorie dieser Feststellung beabsichtigt ist, so nehmen
die Erfinder dieser Erfindung doch an, dass jedes Element dieser
Reihe durch Energieminimierung eine äußerst stabile Struktur aufweist
und dass der Hauptteil jener Strukturen geringfügig unterschiedliche chemische
Oberflächen
gegenüber
dem Lösungsmittel
oder gegenüber
potenziellen wechselwirkenden Targetmolekülen wie Proteinen aufweist.
Wurden alle 65.536 Sequenzen innerhalb eines bestimmten strukturellen
Motivs gegen die Bakteriophagen-T4-DNA-Polymerase getestet, so banden
sich zwei Sequenzen dieser Reihe besser als alle anderen. Dies lässt darauf
schließen,
dass strukturelle Aspekte dieser zwei Sequenzen für dieses
Target speziell sind und dass die übrigen 65.534 Sequenzen nicht
so gut für
Bindung an das Target geeignet sind. Es ist beinahe gewiss, dass
innerhalb jener 65.536 Sequenzen auch andere einzelne Elemente oder
Reihen von Elementen vorhanden sind, die für Wechselwirkung mit anderen
Targets am besten geeignet sind.
-
Eine
zentrale Idee in dieser Beschreibung von RNA-Strukturen ist, dass
jede Sequenz ihre stabilste Struktur findet, auch wenn RNAs häufig in
einer Form gezeichnet werden, die auf ein Zufallsknäuel oder
ein schlappes unstrukturiertes Element schließen lassen würden. Für Homopolymere
von RNA, die nicht in der Lage sind, Watson/Crick-Basenpaare zu
formen, wird häufig
erkannt, dass sie eine nicht-zufällige Struktur
aufweisen, die dem „Stapeln" von Energie zuzuschreiben
ist, die aus dem Fixieren der Positionen von benachbarten Basen übereinander
gewonnen wird. Eindeutig können
Sequenzen, die alle vier Nucleotide einbinden, lokale Regionen mit
fixierter Struktur aufweisen, und sogar ohne Watson/Crick-Basenpaare
kann eine nicht gleichförmige
Sequenz mehr Struktur aufweisen, als vorerst angenommen wird. Das
Auftreten fixierter Strukturen in RNA-Schleifen ist sogar noch häufiger.
Die Anticodon-Schleifen von tRNAs weisen eine Struktur auf, und
dies gilt – wahrschein lich – auch für die zwei
gewinnenden Sequenzen, die sich am besten an T4-DNA-Polymerase binden.
-
Antiparallele
Stränge
von komplementärer
Sequenz in RNA ergeben A-förmige
Helices, aus denen Schleifensequenzen hervortreten und wieder zum
Ausgangspunkt zurückkehren.
Auch wenn die Schleifensequenzen kein starkes Potenzial aufweisen,
wechselzuwirken, ist Energieminimierung eine energetisch freie Strukturoptimierung
(das heißt,
keine ersichtlichen Aktivierungsenergien blockieren Energieminimierung
einer Schleifensequenz). Ein kinetisch wahrscheinlicher Ausgangspunkt
für Optimierung
kann das Schleifen-schließende
Basenpaar eines RNA-Stamms sein, das eine flache Oberfläche aufweist,
auf der optimale Stapelung von Schleifennucleotiden und -basen auftreten
kann. Schleifen von RNA sind im Prinzip mit Schleifen von Proteinen,
die antiparallele alpha-Helices oder beta-Stränge verbinden, gleichwertig.
Obwohl diese Proteinschleifen häufig
als Zufallsknäuel
bezeichnet werden, sind sie weder zufällig noch gedreht. Solche Schleifen
werden als „omega"-Strukturen bezeichnet,
was zeigt, dass die Schleife an Positionen hervortritt und zurückkehrt,
die in relativ großer
Nähe zueinander
liegen (siehe J. Leszczynski & G.
Rose et al., Science 234, 849–855
(1986)); solche Positionen in einem Protein entsprechen konzeptuell
dem Schleifen-schließenden
Basenpaar einer RNA-Haarnadel.
-
Zahlreiche
omega-Strukturen wurden durch Röntgenbeugung
aufgelöst
und als idiosynkratisch erkannt. Eindeutig jede Struktur ist das
Resultat einer einmaligen Energieminimierung, die auf eine Schleife
wirkt, deren Enden nahe beieinander liegen. Sowohl in Proteinen
als auch in RNAs minimieren jene Schleifen Energie ohne Information
aus der übrigen
Struktur mit Ausnahme, nach einer ersten Annäherung, des Schleifen-schließenden Paars
von Aminosäuren
oder Basenpaaren. Sowohl im Fall von Protein-omega-Schleifen als auch
von RNA-Haarnadelschleifen sind alle frei rotierbaren Bindungen
am Versuch beteiligt, die freie Energie zu minimieren. RNA, so scheint
es, reagiert eher auf Elektrostatik als Proteine, während Proteine
viel mehr Freiheitsgrade aufweisen als RNAs. Somit ergeben Berechnungen
von RNA-Strukturen
durch Energieminimierung eher exakte Lösungsstrukturen als vergleichbare
Berechnungen für
Proteine.
-
Einzelsträngige Regionen
sowohl von RNAs als auch von Protein können so gehalten werden, dass sie
die mögliche
Struktur verlängern.
Das heißt,
dass, wenn eine einzelsträngige
Schleife in einer Proteinstruktur aus parallelen Strängen von
alpha-Helix oder
beta-Strängen
hervortritt und zurückkehrt,
die Punkte des Hervortretens und Zurückkehrens weiter voneinander
entfernt sind als im Fall der omega-Strukturen. Weiters kann die Distanz,
die vom Peptideinzelstrang überspannt
wird, durch die Längen
von paralleler/m alpha-Helix oder beta-Strang verändert werden.
-
Im
Fall jener Proteinstrukturen, in denen der Einzelstrang über einer
fixierten Proteinsekundärstruktur liegt,
könnte
die resultierende Energieminimierung im Prinzip Wechselwirkungen
zwischen der einzelsträngigen
Domäne
und der zugrundeliegenden Struktur ermöglichen. Es ist wahrscheinlich,
dass Aminosäureseitenketten,
die Salzbrücken
in Sekundärstrukturen
bilden können,
dasselbe in verlängerten
Einzelsträngen
machen könnten,
die an der Spitze von regulären
Sekundärstrukturen
liegen. Somit sind die exakten Strukturen von solchen Proteinregionen
wiederum idiosynkratisch und sehr stark sequenzabhängig. In
diesem Fall umfasst die Sequenzabhängigkeit sowohl den Einzelstrang
als auch die zugrundeliegende Sequenz der Sekundärstruktur.
-
Interessanterweise
ist eine RNA-Struktur, die als ein Pseudoknoten bekannt ist, analog
zu diesen verlängerten
Proteinmotiven und kann dazu dienen, in Richtung Lösungsmittel
oder Targetmoleküle
verlängerte Einzelstränge von
RNA aufzuweisen, deren Basen idiosynkratisch entweder in Richtung
des Lösungsmittels/Targets
oder in Richtung einer zugrundeliegenden RNA-Sekundärstruktur
angeordnet sind. Pseudoknoten haben, wie Proteinmotive, die auf
Schleifen zwischen Parallelsträngen
basieren, die Fähigkeit,
die Länge
von Einzelstrang und die Sequenz der Helix, auf der er liegt, zu
verändern.
-
Somit
ist es, exakt wie in Proteinmotiven, durch Kovariation mit Sequenzen
in der zugrundeliegenden Sekundärstruktur
möglich,
einzelsträngige
Nucleotide und Basen entweder in Richtung des Lösungsmittels oder der zugrundeliegenden
Struktur zu präsentieren
und somit die Elektrostatik und die funktionellen chemischen Gruppen, die
mit Targets wechselwirken, zu verändern. Es ist wichtig anzumerken,
dass solche Strukturvarianten aus Energieminimierungen resultieren,
doch nur eine Pseudoknotenstruktur ist bekannt, sogar bei geringer
Auflösung.
Nichtsdestoweniger entsteht der Wert dieser Erfindung aus der Erkenntnis,
dass die Form und die funktionellen Displays, die aus Pseudoknoten
möglich
sind, bezüglich
ihrer einmaligen Qualitäten
als beinahe unendlich erkannt werden.
-
Sowohl
Haarnadelschleifen als auch die einzelsträngige Domäne von Pseudoknoten werden
auf antiparallele RNA-Helices aufgebaut. Helices aus RNA können Unregelmäßigkeiten
aufweisen, die als Ausweitungen bezeichnet werden. Ausweitungen
können
in einem Strang einer Helix oder in beiden vorhanden sein und liefern
idiosynkratische strukturelle Eigenschaften, die zur Targeterkennung
nützlich
sind. Darüber
hinaus können
Helix-Unregelmäßigkeiten
winkelige Verbindungen zwischen regulären Helices liefern.
-
Eine
große
Ausweitung (siehe 13) an einem Strang von RNA
kann mit Haarnadelschleifen verglichen werden, mit der Ausnahme,
dass das Schleifen-schließende
Basenpaar durch die zwei die Ausweitung flankierenden Basenpaare
ersetzt ist.
-
Asymmetrische
Ausweitungen (siehe 13) können eine verlängerte und
unregelmäßige Struktur bereitstellen,
die durch Nucleotidkontakte quer über die Ausweitung stabilisiert
wird. Diese Kontakte können Watson/Crick-Wechselwirkungen
oder jegliche andere stabilisierende Anordnung umfassen, einschließlich anderer
Wasserstoffbindungen und Basenstapelung.
-
Schließlich ist
es, wenn fixierte RNA-Formen oder -Motive in Betracht gezogen werden,
sehr aufschlussreich zu berücksichtigen,
welche grundsätzlichen
Unterschiede zwischen RNA und Proteinen bestehen. Da von Protein
angenommen wird, dass es im Laufe der Evolution RNA bezüglich jener
Aktivitäten,
die nun beinahe vollständig
von Proteinen und Peptiden ausgeführt werden, einschließlich Katalyse
und hochspezifische Erkennung, ersetzt hat, wird von den chemischen
Eigenschaften von Proteinen angenommen, dass sie zur Konstruktion
verschiedener Formen und Aktivi täten
nützlicher
als RNA sind. Die hauptsächliche
Argumentation bezieht sich auf die Existenz von 20 Aminosäuren gegenüber nur
vier Nucleotiden, die stark ionischen Qualitäten von Lysin, Arginin, Asparaginsäure und
Glutaminsäure,
die in den RNA-Basen
kein Gegenstück
haben, die relative Neutralität
der Peptidhauptkette im Vergleich zur stark negativen Zucker-Phosphat-Hauptkette
von Nucleinsäuren,
die Existenz von Histidin mit einem pK-Wert nahe der Neutralität, die Tatsache,
dass die Seitenketten der Aminosäuren
in Richtung des Lösungsmittels
sowohl in alpha-Helices als auch in beta-Strängen zeigt, und die regulären Sekundärstrukturen
von Proteinen. In den doppelsträngigen Nucleinsäuren, einschließlich RNA,
sind in Basenpaaren die Basen gegeneinander ausgerichtet und verwenden
viel der chemischen Information, die auf der eindimensionalen Ebene
vorhanden ist. Aus jedem bis heute bekannten Betrachtungswinkel
der möglichen
Einbindung in Formdiversität
und Funktion kann angenommen werden, dass Proteine den Nucleinsäuren, einschließlich RNA,
stark überlegene
chemische Bestandteil sind. Im Laufe der Evolution wurden Proteine,
und nicht RNA, für
Erkennung und Katalyse ausgewählt,
was die zur Zeit weitverbreitete Betrachtungsweise untermauert.
-
Umgekehrt,
was für
diese Erfindung auch maßgeblich
ist, ermöglicht
die enorme Anzahl an Sequenzen und Formen, die für RNA möglich sind, denkbar jede erwünschte Funktion
und Bindungsaffinität,
insbesondere in Bezug auf Sequenzen, die während der gesamten Evolutionsgeschichte
nie getestet wurden, auch wenn RNA aus nur vier Nucleotiden besteht
und auch wenn die Hauptkette einer RNA so stark geladen ist. Das
heißt,
dass die zuvor beschriebenen RNA-Motive mit geeigneter Sequenzspezifizierung
im Raum jene chemischen Funktionen ergeben, die erforderlich sind,
um feste und spezifische Bindung an die meisten Targets bereitzustellen.
Es mag vorgeschlagen werden, dass RNA so vielseitig wie das Immunsystem
ist. Das heißt,
dass, während
das Immunsystem eine passende Antwort auf jegliches erwünschte Target
liefert, RNA dieselben Möglichkeiten
liefert. Die hierin beschriebene ausführbare Methodik kann 1018 Sequenzen verwenden und somit eine enorme
Anzahl an Strukturen durchprobieren, sodass, welche innewohnenden
Vorteile Proteine oder spezifische Antikörper auch gegenüber RNA
aufweisen mögen,
diese durch den Umfang des möglichen „Pools", aus dem RNA-Liganden
selektiert werden, kompensiert werden. Darüber hinaus kann mit der Verwendung
modifizierter Nucleotide RNA verwendet werden, die in sich chemisch
stärker
variiert ist als natürliche
RNAs.
-
Das
SELEX-Verfahren umfasst die Kombination einer Selektion von Nucleinsäureliganden,
die sich an ein Targetmolekül,
beispielsweise ein Protein, binden, mit Amplifikation jener selektierten
Nucleinsäuren.
Wiederholtes Zyklieren der Selektions/Amplifikationsschritte ermöglicht die
Selektion einer oder einer geringen Anzahl von Nucleinsäure(n),
die sich am stärksten
an das Target aus einem Pool bindet/n, der eine sehr große Anzahl
an Nucleinsäuren
enthält.
-
Zyklieren
des Selektions/Amplifikationsverfahrens wird fortgesetzt, bis ein
selektiertes Ziel erreicht wurde. Beispielsweise kann das Zyklieren
fortgesetzt werden, bis ein erwünschter
Grad an Bindung der Nucleinsäuren
im Testgemisch erreicht wurde oder bis eine Mindestanzahl an Nucleinsäurekomponenten
des Gemisches erreicht wurde (im äußersten Fall, bis eine einzelne
Spezies im Testgemisch verbleibt). In zahlreichen Fällen wird
erwünscht,
Zyklieren fortzusetzen, bis keine weitere Verbesserung von Bindung
mehr erreicht wird. Es kann vorkommen, dass bestimmte Testgemische
von Nucleinsäuren
eine geringfügige
Verbesserung von Bindung gegenüber
Hintergrundniveaus während
des Zyklierens von Selektion/Amplifikation aufzeigen. In solchen
Fällen
sollte die Sequenzvariation im Testgemisch gesteigert werden und
mehr der möglichen
Sequenzvarianten umfassen, oder die Länge der Sequenzrandomisierten
Region sollte gesteigert werden, bis Verbesserungen von Bindung
erreicht wurden. Verankerungs-Arbeitsvorschriften und/oder Walking-Verfahren
können auch
verwendet werden.
-
Insbesondere
erfordert das Verfahren die anfängliche
Herstellung eines Testgemisches von Kandidaten-Nucleinsäuren. Die
einzelnen Test-Nucleinsäuren
können
eine randomisierte Region enthalten, die durch Sequenzen flankiert
ist, die in allen Nucleinsäuren
im Gemisch konserviert sind. Die konservierten Regionen werden bereitgestellt,
um Amplifikation selektierter Nucleinsäuren zu erleichtern. Da es
zahlreiche solche Sequenzen gibt, die auf dem Gebiet der Erfindung
bekannt sind, ist die Sequenzauswahl von durchschnittlichen Fachleuten
unter Berücksichtigung
des er wünschten
Amplifikationsverfahrens durchführbar.
Die randomisierte Region kann eine vollständig oder teilweise randomisierte
Sequenz aufweisen. Alternativ dazu kann dieser Abschnitt der Nucleinsäure Untereinheiten
enthalten, die randomisiert sind, zusammen mit Untereinheiten, die
in allen Nucleinsäurespezies
im Gemisch konstant gehalten werden. Beispielsweise können die
Sequenzregionen, die dafür
bekannt sind, das Targetprotein zu binden, oder für Bindung
an das Targetprotein ausgewählt werden,
in randomisierte Regionen integriert werden, um verbesserte Bindung
oder verbesserte Bindungsspezifität zu erreichen. Sequenzvariabilität im Testgemisch
kann auch durch Bilden von Mutationen in den Nucleinsäuren im
Testgemisch während
des Selektions/Amplifikationsverfahrens eingeführt oder erhöht werden.
Im Prinzip können
die Nucleinsäuren,
die im Testgemisch verwendet werden, jegliche Länge aufweisen, solange sie
amplifiziert werden können.
Das Verfahren der vorliegenden Erfindung wird am praktischsten für Selektion aus
einer großen
Anzahl an Sequenzvarianten verwendet. Somit wird erwogen, dass das
vorliegende Verfahren vorzugsweise verwendet wird, um Bindung von
Nucleinsäuresequenzen
zu bewerten, die eine Länge
im Bereich von etwa vier Basen bis hin zu jeglicher erreichbaren
Größe aufweisen.
-
Der
randomisierte Abschnitt der Nucleinsäuren im Testgemisch kann auf
zahlreiche Weisen hergeleitet werden. Beispielsweise kann vollständige oder
teilweise Randomisierung leicht durch direkte chemische Synthese
der Nucleinsäure
(oder eines Teils davon) oder durch Synthese einer Matrix, aus der
die Nucleinsäure
(oder Teile davon) unter Verwendung von geeigneten Enzymen hergestellt
werden kann, erreicht werden. Endhinzufügen, katalysiert durch Terminal-Transferase
in Gegenwart von nicht einschränkenden
Konzentrationen aller vier Nucleotidtriphosphate, kann eine randomisierte
Sequenz zu einem Segment hinzufügen.
Sequenzvariabilität
in den Testnucleinsäuren
kann auch durch Verwenden von größenselektierten
Fragmenten von teilweise verdauten (oder anders gespalteten) Präparaten
aus großen,
natürlichen
Nucleinsäuren,
wie genomischen DNA-Präparaten
oder zellulären
RNA-Präparaten,
erreicht werden. In diesen Fällen,
in denen randomisierte Sequenz verwendet wird, ist es nicht erforderlich
(oder aus langen randomisierten Segmenten möglich), dass das Testgemisch
alle möglichen
Sequenzvarianten enthält.
Es wird im Allgemeinen bevorzugt, dass das Testgemisch eine so große Anzahl
an möglichen
Sequenzvarianten enthält,
wie dies für
Selektion praktisch ist, um sicherzustellen, dass eine maximale
Anzahl an potenziellen Bindungssequenzen identifiziert wird. Eine
randomisierte Sequenz von 30 Nucleotiden enthält berechnete 1018 verschiedene
Kandidatensequenzen. Praktisch gesehen ist es besser, nur etwa 1018 Kandidaten in einer einzelnen Selektion
zu prüfen.
Praktische Überlegungen
umfassen die Anzahl an Matrices an der DNA-Synthesesäule und
die Löslichkeit
von RNA und dem Target in Lösung.
(Natürlich
gibt es keine theoretische Einschränkung für die Anzahl an Sequenzen im Targetgemisch.)
Daher enthalten Kandidatengemische, die randomisierte Segmente mit
einer Länge
von mehr als 30 aufweisen, zu viele mögliche Sequenzen, als dass
alle auf praktische Weise in einer Selektion geprüft werden
könnten.
Es ist nicht erforderlich, alle möglichen Sequenzen eines Kandidatengemisches
zu prüfen, um
einen Nucleinsäureliganden
der Erfindung zu selektieren. Es ist eine Grundlage des Verfahrens,
dass die Nucleinsäuren
des Testgemisches in der Lage sind, amplifiziert zu werden. Somit
wird bevorzugt, dass jegliche konservierten Regionen, die in den
Testnucleinsäuren
verwendet werden, keine Sequenzen enthalten, die Amplifikation stören.
-
Die
verschiedenen, zuvor beschriebenen RNA-Motive können fast immer durch ein Polynucleotid
definiert werden, das etwa 30 Nucleotide enthält. Aufgrund der physikalischen
Einschränkungen
des SELEX-Verfahrens ist ein randomisiertes Gemisch, das etwa 30
Nucleotide enthält,
auch etwa das längste
zusammenhängende
randomisierte Segment, das verwendet werden kann, wobei es in der
Lage ist, im Wesentlichen alle der potenziellen Varianten zu testen.
Es ist daher eine bevorzugte Ausführungsform dieser Erfindung,
eine randomisierte Sequenz von zumindest 15 Nucleotiden zu verwenden,
die zumindest etwa 109 Nucleinsäuren enthält, und
in der am meisten bevorzugten Ausführungsform zumindest 25 Nucleotide
enthält,
wenn ein Kandidatengemisch mit einer zusammenhängenden randomisierten Region
verwendet wird.
-
Diese
Erfindung umfasst Kandidatengemische, die alle möglichen Varianten eines zusammenhängenden
randomisierten Segments von zumindest 15 Nucleotiden ent halten.
Jedes einzelne Element im Kandidatengemisch kann auch aus fixierten
Sequenzen bestehen, die das randomisierte Segment flankieren, das
die Amplifikation der selektierten Nucleinsäuresequenzen unterstützt.
-
Kandidatengemische
können
auch hergestellt werden, die sowohl randomisierte Sequenzen als
auch fixierte Sequenzen enthalten, worin die fixierten Sequenzen
zusätzlich
zum Amplifikationsverfahren eine weitere Funktion erfüllen. In
einer Ausführungsform
der Erfindung können
die fixierten Sequenzen in einem Kandidatengemisch selektiert werden,
um den Prozentsatz von Nucleinsäuren
im Kandidatengemisch zu steigern, das ein gegebenes Nucleinsäuremotiv
oder eine gegebene Tertiärstruktur
aufweist. Beispielsweise ermöglicht es
die Einbindung der geeigneten fixierten Nucleotide, den Prozentsatz
von Pseudoknoten oder Haarnadelschleifen in einem Kandidatengemisch
zu steigern. Ein Kandidatengemisch, das einschließlich fixierter
Sequenzen hergestellt wurde, die den Prozentsatz eines gegebenen
strukturellen Nucleinsäuremotivs
steigern, ist daher ein Teil dieser Erfindung. Fachleute werden
auf Grundlage einer Routineuntersuchung zahlreicher verschiedener,
hierin beschriebener Nuclein-Antikörper in der Lage sein, ohne übermäßiges Experimentieren solch
ein Kandidatengemisch zu konstruieren. Die nachstehenden Beispiele
2 und 8 beschreiben spezifische Beispiele für Kandidatengemische, die verändert werden,
um bevorzugte RNA-Motive zu maximieren.
-
Kandidatengemische,
die verschiedene fixierte Sequenzen enthalten oder eine zweckvolle,
teilweise randomisierte Sequenz verwenden, können auch eingesetzt werden,
nachdem eine Ligandenlösung
oder eine teilweise Ligandenlösung
durch SELEX erhalten wurde. Ein neues SELEX-Verfahren kann dann
mit einem Kandidatengemisch initiiert werden, das durch die Ligandenlösung Information
enthält.
-
Polymerasekettenreaktion
(PCR) ist ein beispielhaftes Verfahren zur Amplifikation von Nucleinsäuren. Beschreibungen
von PCR-Verfahren sind beispielsweise in Saiki et al., Science 230,
1350–1354
(1985); Saiki et al., Nature 324, 163–166 (1986); Scharf et al.,
Science 233, 1076–1078
(1986); Innis et al., Proc. Natl. Acad. Sci. 85, 9436–9440 (1988);
und im US-Patent Nr. 4.683.195 (Multis et al.) und im US-Patent Nr.
4.683.202 (Multis et al.) zu finden. In seiner Grundform umfasst
PCR-Amplifikation
wiederholte Zyklen von Replikation einer erwünschten einzelsträngigen DNA
(oder cDNA-Kopie einer RNA) unter Verwendung spezifischer Oligonucleotidprimer,
die zu den 3'- und
5'-Enden der ssDNA
komplementär
sind, Primerextension mit einer DNA-Polymerase und DNA-Denaturierung.
Produkte, die durch Extension aus einem Primer gebildet werden, dienen
als Matrices für
Extension aus dem anderen Primer. Ein verwandtes Amplifikationsverfahren,
das in der veröffentlichten
PCT-Anmeldung WO 89/01050 (Burg et al.) beschrieben wird, erfordert
die Gegenwart oder Einführung
einer Promotorsequenz stromauf der zu amplifizierenden Sequenz,
um ein doppelsträngiges
Zwischenprodukt zu ergeben. Mehrfach-RNA-Kopien des doppelsträngigen Promotor enthaltenden
Zwischenprodukts werden dann unter Verwendung von RNA-Polymerase
produziert. Die resultierenden RNA-Kopien werden mit reverser Transkriptase
behandelt, um zusätzliche,
doppelsträngigen
Promotor enthaltende Zwischenprodukte zu bilden, die dann einem
weiteren Amplifikationsdurchgang mit RNA-Polymerase unterzogen werden
können.
Alternative Amplifikationsverfahren umfassen unter anderem das Klonieren
selektierter DNAs oder cDNA-Kopien selektierter RNAs in einen geeigneten
Vektor und das Einführen
dieses Vektors in einen Wirtsorganismus, wo der Vektor und die klonierten
DNAs repliziert und somit amplifiziert werden (J.C. Guatelli et
al., Proc. Natl. Acad. Sci. 87, 1874 (1990)). Im Allgemeinen kann
jegliches Mittel, das zuverlässige,
wirksame Amplifikation selektierter Nucleinsäuresequenzen ermöglicht,
im Verfahren der vorliegenden Erfindung verwendet werden. Es ist
nur notwendig, dass die proportionale Darstellung von Sequenzen
nach der Amplifikation zumindest ungefähr den relativen Proportionen
von Sequenzen im Gemisch vor der Amplifikation entspricht.
-
Spezifische
Verfahren zur Amplifikation der hierin beschriebenen RNAs wurden
aufbauend auf Innis et al. (1988), s.o., entwickelt. Die RNA-Moleküle und Targetmoleküle im Testgemisch
wurden so entworfen, dass sie nach Amplifikation und PCR wesentliche
T7-Promotorsequenzen in ihren 5'-Abschnitten
bereitstellen. VolllängencDNA-Kopien
von selektierten RNA-Molekülen
wurden unter Verwendung von reverser Transkriptase, geprimt mit
einem Oligomer, das zu den 3'-Sequenzen
der selektierten RNAs komplementär
ist, gebildet. Die resultierenden cDNAs wurden durch Taq-DNA-Polymerasekettenextension
amplifiziert, was die T7-Promotorsequenzen in den selektierten DNAs
lieferte. Doppelsträngige
Produkte dieses Amplifikationsverfahrens wurden dann in vitro transkribiert.
Die Transkripte wurden im nächsten
Selektions/Amplifikationszyklus verwendet. Das Verfahren kann gegebenenfalls
geeignete Nucleinsäure-Reinigungsschritte
umfassen.
-
Im
Allgemeinen kann jegliche Arbeitsvorschrift, die die Selektion von
Nucleinsäuren
basierend auf ihrer Fähigkeit,
sich spezifisch an ein anderes Molekül, d.h. an ein Protein oder
ganz allgemein gesprochen an jegliches Targetmolekül, zu binden,
ermöglicht,
im Verfahren der vorliegenden Erfindung verwendet werden. Es ist
nur erforderlich, dass die Selektion Nucleinsäuren abtrennt, die in der Lage
sind, amplifiziert zu werden. Bei einer Filterbindungsselektion
beispielsweise, wie sie in Beispiel 1 beschrieben wird, in der ein
Testnucleinsäuregemisch
mit Targetprotein inkubiert wird, wird dann das Nucleinsäure/Proteingemisch
durch ein Nitrocellulosefilter filtriert und mit geeignetem Puffer
gewaschen, um freie Nucleinsäuren
zu entfernen. Protein/Nucleinsäure
bleiben häufig
am Filter gebunden. Die relativen Konzentrationen von Protein zum
Testen von Nucleinsäure
im inkubierten Gemisch beeinflusst die Stärke von Bindung, auf die selektiert
wird. Ist Nucleinsäure
im Überschuss
vorhanden, so tritt Konkurrenz um freie Bindungsstellen ein, und
jene Nucleinsäuren,
die sich am stärksten
binden, werden selektiert. Umgekehrt wird erwartet, dass, wenn ein Überschuss
von Protein verwendet wird, jede Nucleinsäure, die sich an das Protein
bindet, selektiert wird. Die relativen verwendeten Konzentrationen
von Protein zu Nucleinsäure,
um die erwünschte
Selektion zu erreichen, hängt
vom Typ des Proteins, der Stärke
der Bindungswechselwirkung und dem Grad jeglicher vorhandener Hintergrundbindung
ab. Die relativen Konzentrationen, die erforderlich sind, um das
erwünschte
Selektionsresultat zu erreichen, können empirisch leicht und ohne übermäßiges Experimentieren
bestimmt werden. In ähnlicher
Weise kann es erforderlich sein, das Filterwaschverfahren zu optimieren,
um Hintergrundbindung zu minimieren. Solch eine Optimierung der
Filterwaschverfahren liegt wiederum im Kompetenzbereich durchschnittlicher
Fachleute.
-
Die
Erfinder der vorliegenden Erfindung verwendeten eine mathematische
Evaluierung von SELEX, die als SELEXION bezeichnet wird. Anhang
A dieser Anmeldung umfasst einen kurzen Überblick zur mathematischen
Analyse, die verwendet wurde, um allgemeine Feststellungen bezüglich SELEX,
abgeleitet von SELEXION, zu erhalten.
-
Die
aus SELEXION abgeleiteten Generalisierungen sind die folgenden:
1) Die Wahrscheinlichkeit, die best-bindende RNA in jedem Durchgang
von SELEX zu erhalten, steigt mit der Anzahl solcher vorhandenen Moleküle, mit
ihrem Bindungsvorteil gegenüber
dem Haupt-RNA-Pool und mit der Gesamtmenge an verwendetem Protein.
Obwohl es intuitiv nicht immer einfach ist, im Vorhinein zu wissen,
wie die Bindungsdifferenz maximiert werden kann, kann die Wahrscheinlichkeit,
die am besten bindende RNA zu finden, dennoch durch Maximieren der
Anzahl an überprüften RNA-Molekülen und
Target-Molekülen
gesteigert werden; 2) die idealen Nucleinsäure- und Proteinkonzentrationen,
die in den verschiedenen Durchgängen
von SELEX zu verwenden sind, hängen
von mehreren Faktoren ab. Die Versuchsparameter, die von SELEXION
vorgeschlagen werden, gleichen jenen, die in den Beispielen hierin
verwendet werden. Ist beispielsweise die relative Affinität der letztlichen
Ligandenlösung
nicht bekannt – was
fast unumgänglich
der Fall ist, wenn SELEX durchgeführt wird –, so wird bevorzugt, dass
die Konzentrationen von Protein und Nucleinsäure-Kandidatengemisch so ausgewählt werden,
dass eine Bindung zwischen etwa 3 und 7 % der gesamten Nucleinsäuren an
das Proteintarget erreicht wird. Unter Einhaltung dieses Kriteriums
kann erwartet werden, dass eine zehnfache bis zwanzigfache Anreicherung
an hochaffinen Liganden in jeder Runde von SELEX erreicht wird.
-
Die
Versuchsbedingungen, die verwendet werden, um Nucleinsäureliganden
zu Targets in der bevorzugten Ausführungsform zu selektieren,
werden so ausgewählt,
dass die Umgebung, in der das Target in vivo gefunden wurde, nachgeahmt
wird. Beispiel 10 unten zeigt auf, wie eine Veränderung der Selektionsbedingungen
die Ligandenlösung,
die zu einem bestimmten Target erhalten wird, beeinflusst. Obwohl
die Ligandenlösung
zu NGF signifikante Ähnlichkeiten
unter hohen und niedrigen Salzbedingungen aufzeigte, wurden auch Unterschiede
beobachtet. Veränderbare Bedingungen,
die verändert
werden können,
um die In-vivo-Umgebung des Targets exakter widerzuspiegeln, umfassen,
sind jedoch nicht beschränkt
auf, die Gesamtionenstärke,
die Konzentration an zweiwertigen Kationen und den pH der Lösung. Fachleute
werden problemlos in der Lage sein, die geeigneten Trennungsbedingungen
basierend auf der Kenntnis des gegebenen Targets auszuwählen.
-
Um
zum Amplifikationsschritt überzugehen,
müssen
selektierte Nucleinsäuren
aus dem Target nach dem Abtrennen freigesetzt werden. Dieses Verfahren
muss ohne chemischen Abbau der selektierten Nucleinsäuren erfolgen
und muss amplifizierbare Nucleinsäuren ergeben. In einer spezifischen
Ausführungsform
werden selektierte RNA-Moleküle
aus Nitrocellulosefiltern unter Verwendung von frisch hergestellter
Lösung,
die 200 μl
von 7 M Harnstoff, 20 mM Natriumcitrat (pH 5,0), 1 mM EDTA-Lösung, kombiniert mit 500 μl Phenol (äquilibriert
mit 0,1 M Natriumacetat, pH 5,2) enthält, eluiert. Eine Lösung von
200 μl 7
M Harnstoff mit 500 μl Phenol
wurde bereits erfolgreich verwendet. Die eluierte Lösung von
selektierter RNA wurde dann mit Ether extrahiert, Ethanol-gefällt, und
der Niederschlag wurde in Wasser resuspendiert. Zahlreiche verschiedene
Pufferbedingungen zur Elution von selektierter RNA aus den Filtern
können
verwendet werden. Beispielsweise können, ohne darauf eingeschränkt zu sein,
nicht-oberflächenaktive
wässrige
Protein-denaturierende Mittel wie Guanidiniumchlorid, Guanidiniumthiocyanat
usw., die nach dem Stand der Technik bekannt sind, verwendet werden.
Die spezifische Lösung,
die zur Elution von Nucleinsäuren
aus dem Filter verwendet werden, kann von durchschnittlichen Fachleuten
routinemäßig ausgewählt werden.
-
Alternativ
dazu sind Abtrennungsarbeitsvorschriften zum Abtrennen von Nucleinsäuren, die
an Targets, insbesondere Proteine, gebunden sind, auf dem Gebiet
der Erfindung verfügbar.
Zum Beispiel können Bindung
und Abtrennung mittels Durchführung
des Testnucleinsäuregemisches
durch eine Säule,
die das Targetmolekül,
gebunden an ein festes Trägermaterial,
enthält,
erreicht werden. Jene Nucleinsäuren,
die sich an das Target binden, werden an der Säule festgehalten, und nicht
gebundene Nucleinsäuren
werden von der Säule
abgewaschen.
-
In
dieser gesamten Anmeldung wurde das SELEX-Verfahren als ein sich
wiederholender Prozess definiert, worin Selektion und Amplifikation
wiederholt werden, bis eine erwünschte
Selektivität
erreicht wurde. In einer Ausführungsform
der Erfindung kann das Selektionsverfahren ausreichend wirksam sein,
um eine Ligandenlösung
nach nur einem Abtrennungsschritt bereitzustellen. Theoretisch sollte
beispielsweise eine Säule, die
das Target trägt
und durch die das Kandidatengemisch – unter den geeigneten Bedingungen
und mit einer ausreichend langen Säule – eingeführt wird, in der Lage sein,
Nucleinsäuren
basierend auf Affinität
zum Target ausreichend abzutrennen, um eine Ligandenlösung zu
erhalten. In dem Maße,
in dem der ursprüngliche
Selektionsschritt ausreichend selektiv ist, um eine Ligandenlösung nach
nur einem Schritt zu erhalten, ist solch ein Verfahren auch im Schutzumfang
dieser Erfindung eingebunden.
-
In
einer Ausführungsform
wird SELEX wiederholt durchgeführt,
bis ein einzelner Nucleinsäureligand oder
eine eingeschränkte
kleine Anzahl an Nucleinsäureliganden
im Kandidatengemisch nach Amplifikation zurückbleibt/zurückbleiben.
In solchen Fällen
wird die Ligandenlösung
als eine einzelne Nucleinsäuresequenz dargestellt
und umfasst nicht eine Familie von Sequenzen, die vergleichbare
Bindungsaffinitäten
zum Target aufweisen.
-
In
einer alternativen Ausführungsform
der Erfindung werden die SELEX-Wiederholungen zu einem bestimmten
Punkt unterbrochen, zu dem das Kandidatengemisch an Nucleinsäureliganden
mit höherer
Bindungsaffinität
angereichert ist, jedoch stets eine relativ große Anzahl an unterschiedlichen
Sequenzen aufweist. Dieser Punkt kann von Fachleuten durch periodisches
Analysieren der Sequenzrandomisierung des Hauptteils des Kandidatengemisches
oder durch Testen der Affinität
des Hauptteils zum Target bestimmt werden.
-
Zu
diesem Zeitpunkt wird SELEX bestimmt, und Klone werden hergestellt
und sequenziert. Natürlich gibt
es eine beinahe uneingeschränkte
Anzahl an Klonen, die sequenziert werden könnten. Wie in den Beispielen
unten gesehen werden kann, ist es jedoch nach dem Sequenzieren von
zwischen 20 und 50 Klonen im Allgemeinen möglich, die am häufigsten
vorhandenen Sequenzen nachzuweisen und die Eigenschaften der Ligandenlösung zu
definieren. In einem theoretischen Beispiel wird nach dem Klonieren
von 30 Sequenzen erkannt werden, dass 6 Sequenzen identisch sind,
während
bestimmte Sequenzabschnitte von 20 der anderen Sequenzen eng mit
den Sequenzen innerhalb der „gewinnenden" Sequenzen verwandt
sind. Wenn auch die am häufigsten
vorkommende Sequenz als eine Ligandenlösung zu jenem Target betrachtet
werden kann, ist es häufig
geeigneter, eine Ligandenlösung
zu konstruieren oder zu beschreiben, die aus einer Familie von Sequenzen
besteht, die die allgemeinen Eigenschaften zahlreicher der klonierten
Sequenzen umfasst.
-
In
einem weiteren Beispiel kann eine Ligandenlösung, die als eine Familie
von Sequenzen dargestellt wird, die zahlreiche definierende Eigenschaften
aufweisen (z.B. wenn die Ligandenlösung AAGUNNGUNNCNNNN ist, worin
N offensichtlich jedes der vier Nucleotide sein kann), verwendet
werden, um ein zusätzliches SELEX-Verfahren zu beginnen.
In dieser Ausführungsform
würde sich
das Kandidatengemisch aus teilweise fixierten und teilweise zufälligen Nucleotiden
zusammensetzen, wobei die fixierten Nucleotide basierend auf der
im anfänglichen
SELEX-Verfahren erhaltenen Ligandenlösung selektiert werden. Auf
diese Weise wird, wenn es eine einzelne Nucleotidsequenz gibt, die
sich besser als die anderen Mitglieder der Ligandenlösungsfamilie
bindet, diese rasch identifiziert werden.
-
In
einer alternativen Ausführungsform
wird auch ein zweiter SELEX-Versuch basierend auf der in einem SELEX-Verfahren
erhaltenen Ligandenlösung
verwendet. In dieser Ausführungsform
wird die einzelne, am häufigsten
vorkommende Sequenz (z.B. AAGUCCGUAACACAC) verwendet, um das zweite
SELEX-Verfahren zu informieren. In diesem zweiten SELEX-Verfahren
wird das Kandidatengemisch hergestellt, um Sequenzen basierend auf
dem ausgewählten
Gewinner zu erhalten, während
sichergestellt wird, dass es an jeder der Sequenzen ausreichende
Randomisierung gibt. Dieses Kandidatengemisch kann unter Verwendung
von Nucleotid-Ausgangsmaterialien
gebildet werden, die eher durch Vorgabe bestimmt als randomisiert
sind. Die A-Lösung
enthält
beispielsweise 75 % A und 25 % U, C und G. Obwohl der Nucleinsäure-Syntheseautomat
so eingestellt ist, dass er das vorherr schende Nucleotid ergibt,
führt die
Gegenwart der anderen Nucleotide in der A-Lösung
zu Nucleinsäuresequenzen,
die vorwiegend A aufweisen, jedoch auch Variationen in dieser Position ergeben
werden. Wiederum wird dieser zweite SELEX-Durchgang, informiert durch die im anfänglichen
SELEX-Verfahren erhaltenen Resultate, die Wahrscheinlichkeit, die
beste Ligandenlösung
zu einem gegebenen Target zu erhalten, maximieren. Auch hier muss
angemerkt werden, dass die Ligandenlösung aus einem einzelnen bevorzugten
Nucleinsäureliganden
bestehen kann oder dass sie aus einer Familie von strukturell verwandten
Sequenzen mit wesentlich ähnlichen
Bindungsaffinitäten
bestehen kann.
-
In
der Praxis kann gegebenenfalls bevorzugt werden, dass das SELEX-Verfahren
nicht durchgeführt wird,
bis eine einzelne Sequenz erhalten wird. Das SELEX-Verfahren enthält mehrere
Vorgabepunkte, die das Überwiegen
bestimmter Sequenzen in einem Kandidatengemisch nach mehreren SELEX-Durchgängen beeinflussen
können,
die mit der Bindungsaffinität
von jener Sequenz zum Target nicht in Verbindung stehen. Eine Vorgabe
für oder
gegen bestimmte Sequenzen kann beispielsweise während der Herstellung von cDNA aus
der nach der Selektion gewonnen RNA auftreten oder auch während des
Amplifikationsverfahrens. Die Wirkungen von solchen nicht vorhersagbaren
Vorgaben können
durch das Anhalten von SELEX vor dem Zeitpunkt, zu dem nur eine
Sequenz oder eine geringe Anzahl an Sequenzen, die im Reaktionsgemisch
vorwiegend vorhanden ist bzw. sind, minimiert werden.
-
Wie
zuvor erwähnt
kann Sequenzvariation im Testnucleinsäuregemisch durch Mutation erreicht
oder gesteigert werden. Es wurde beispielsweise ein Verfahren für wirksame
Mutagenese von Nucleinsäuresequenzen
während
PCR-Amplifikation beschrieben (Leung et al., 1989). Dieses Verfahren
oder funktionell äquivalente
Verfahren können
in der vorliegenden Erfindung gegebenenfalls mit Amplifikationsverfahren
kombiniert werden.
-
Alternativ
dazu können
herkömmliche
Verfahren von DNA-Mutagenese in das Nucleinsäure-Amplifikationsverfahren
eingebunden werden. Anwendbare Mutagenese verfahren umfassen unter
anderem chemisch induzierte Mutagenese und ortsgerichtete Oligonucleotidmutagenese.
-
Die
vorliegende Erfindung kann auch auf die Verwendung zusätzlicher
interessanter Fähigkeiten
von Nucleinsäuren
und die Weise, in der sie bekanntlich mit Targets wie Proteinen
wechselwirken, oder die Weise, die erst für die Wechselwirkungen dieser
Nucleinsäuren
erkannt werden muss, erweitert werden. Beispielsweise kann ein SELEX-Verfahren
verwendet werden, um auf Liganden zu screenen, die Michael-Addukte mit Proteinen
bilden. Pyrimidine, wenn sie an der korrekten Stelle innerhalb eines
Proteins sitzen, üblicherweise
benachbart zu einem maßgeblichen
Cystein oder anderen Nucleophil, können mit diesem Nucleophil
reagieren, um ein Michael-Addukt
zu bilden. Der Mechanismus, durch den Michael-Addukte gebildet werden,
bindet einen nucleophilen Angriff an der 6-Position der Pyrimidinbase
ein, um ein vorübergehendes
(jedoch sich langsam umkehrendes) Zwischenprodukt zu schaffen, das
tatsächlich
ein 5,6-Dihydropyrimidin ist. Es ist möglich, auf die Gegenwart solcher
Zwischenprodukte durch Beobachten, ob Bindung zwischen einer RNA
und einem Proteintarget eintritt, auch nachdem das Protein mit jeglichem
geeigneten Denaturierungsmittel denaturiert wurde, zu testen. Das
heißt,
es wird nach einer kontinuierlichen kovalenten Wechselwirkung gesucht,
wenn die Bindungstasche des Targets zerstört wurde. Michael-Addukte sind
jedoch häufig
reversibel, und manchmal so rasch, dass nicht stattgefundene Identifikation
eines Michael-Addukts durch diesen Test kein Hinweis darauf ist,
dass ein solches nicht zu einem früheren Zeitpunkt schon vorhanden
war.
-
SELEX
kann so erfolgen, dass von Michael-Adduktbildung profitiert wird,
um Beinah-Suizidsubstrate für ein Enzym
oder ein anderes Proteintarget mit sehr hoher Affinität zu schaffen.
Man stelle sich vor, dass nach Bindung zwischen einem randomisierten
Gemisch von RNAs und dem Target, vor dem Abtrennen an einem Filter
oder durch andere Mittel, das Target denaturiert wird. Darauf folgendes
Abtrennen, gefolgt von Umkehren des Michael-Addukts und cDNA-Synthese
an der freigesetzten RNA, gefolgt vom übrigen SELEX-Zyklus, schafft
eine Anreicherung an RNAs, die sich vor der Denaturierung an ein
Target binden, sich jedoch weiterhin kovalent binden, bis das Michael-Addukt
durch den Wissenschafter umgekehrt wird. Dieser Ligand würde in vivo
die Eigenschaft permanenter Inhibierung des Targetproteins aufweisen.
Die Protein-tRNA-Uracil-Methyl-Transferase (RUMT) bindet Substrat-tRNAs
durch ein Michael-Addukt. Wird RUMT bei hohen Konzentrationen in
E. coli exprimiert, so wird das Enzym hauptsächlich kovalent an RNA gebunden
vorzufinden sein, was sehr stark darauf schließen lässt, dass annähernd irreversible
Inhibitoren durch SELEX gefunden werden können.
-
Das
Verfahren der vorliegenden Erfindung hat zahlreiche Anwendungsgebiete.
Das Verfahren kann beispielsweise verwendet werden, um die Identifikation
und Charakterisierung von jeglicher Proteinbindungsstelle für DNA oder
RNA zu unterstützen.
Solche Bindungsstellen funktionieren bei der Transkriptions- oder Translationsregulierung
von Genexpression, beispielsweise als Bindungsstellen für Transkriptionsaktivatoren oder
-repressoren, Transkriptionskomplexe an Promotorstellen, Replikationszusatzproteine
und DNA-Polymerasen an oder in der Nähe von Replikationsursprüngen und
Ribosomen und Translationsrepressoren an Ribosombindungsstellen.
Sequenzinformation von solchen Bindungsstellen kann verwendet werden,
um Regulationsregionen zu isolieren und zu identifizieren und dadurch
arbeitsaufwendige Verfahren zur Charakterisierung solcher Regionen
zu umgehen. Isolierte DNA-Regulationsregionen
können
beispielsweise in heterologen Konstrukten verwendet werden, um Genexpression
selektiv zu verändern.
-
Es
ist ein wichtiger und unerwarteter Aspekt der vorliegenden Erfindung,
dass die hierin beschriebenen Verfahren verwendet werden können, um
Nucleinsäuremoleküle zu identifizieren,
isolieren oder produzieren, die sich spezifisch an jegliches erwünschtes
Targetmolekül
binden. Somit können
die vorliegenden Verfahren verwendet werden, um Nucleinsäuren zu
produzieren, die für
Bindung an ein bestimmtes Target spezifisch sind. Solch ein Nucleinsäureligand
ist in vielerlei Hinsicht einem Antikörper ähnlich. Nucleinsäureliganden,
die Bindungsfunktionen aufweisen, die jenen von Antikörpern ähnlich sind,
können
durch die Verfahren der vorliegenden Erfindung isoliert werden.
Solche Nucleinsäureliganden
werden hierin als Nucleinsäure-Antikörper bezeichnet
und sind im Allgemeinen in Anwendungen nützlich, in denen polyklonale
oder monoklonale Antikörper
zum Einsatz kommen. Nucleinsäure-Antikörper können im
Allgemeinen anstelle von Antikörpern
in jeglicher In-vitro- oder In-vivo-Anwendung eingesetzt werden.
Es ist lediglich notwendig, dass unter den Bedingungen, unter denen
der Nucleinsäure-Antikörper verwendet
wird, die Nucleinsäure
im Wesentlichen resistent gegenüber
Abbau ist. Anwendungen von Nucleinsäure-Antikörpern umfassen die spezifische
qualitative oder quantitative Detektion von Targetmolekülen aus
jeder beliebigen Quelle; Reinigung von Targetmolekülen basierend
auf ihrer spezifischen Bindung an die Nucleinsäure; und verschiedene therapeutische
Verfahren, die auf dem spezifischen Richten eines Toxins oder anderen
therapeutischen Mittels auf eine spezifische Targetstelle beruhen.
-
Targetmoleküle sind
vorzugsweise Proteine, können
jedoch unter anderem auch andere Kohlenhydrate, Peptidglycane und
zahlreiche verschiedene kleine Moleküle umfassen. Wie im Fall von
herkömmlichen proteinartigen
Antikörpern
können
Nucleinsäure-Antikörper verwendet
werden, um auf biologische Strukturen, wie z.B. Zelloberflächen oder
Viren, durch spezifische Wechselwirkung mit einem Molekül, das ein
integrativer Bestandteil dieser biologischen Struktur ist, gerichtet
zu werden. Nucleinsäure-Antikörper sind
darin von Vorteil, dass sie nicht durch Selbsttoleranz eingeschränkt sind,
wie dies bei herkömmlichen
Antikörpern
der Fall ist. Auch erfordern Nucleinsäure-Antikörper keine Tier- oder Zellkulturen
für die
Synthese oder Produktion, da SELEX ein Verfahren ist, das vollständig in
vitro durchgeführt
wird. Wie bekannt ist, können
sich Nucleinsäuren an
komplementäre
Nucleinsäuresequenzen
binden. Diese Eigenschaft von Nucleinsäuren wurde bereits ausführlich für die Detektion,
Quantifizierung und Isolierung von Nucleinsäuremolekülen verwendet. Somit ist es nicht
beabsichtigt, dass die Verfahren der vorliegenden Erfindung diese
durchwegs bekannten Bindungsfähigkeiten
zwischen Nucleinsäuren
umfassen. Insbesondere sollen die Verfahren der vorliegenden Erfindung,
die mit der Verwendung von Nucleinsäure-Antikörpern in Verbindung stehen,
nicht bekannte Bindungsaffinitäten zwischen
Nucleinsäuremolekülen umfassen.
Zahlreiche Proteine sind dafür
bekannt, dass sie über
Bindung an Nucleinsequenzen funktionieren, wie z.B. Regulationsproteine,
die sich an Nucleinsäure-Operatorsequenzen
binden. Die bekannte Fähigkeit
von bestimmten Nucleinsäure-Bindungsproteinen,
sich an ihre natürlichen Stellen
zu binden, wurde beispielsweise bereits zur Detektion, Quantifizierung,
Isolierung und Reinigung solcher Proteine verwendet. Die Verfahren
der vorliegenden Erfindung, die mit der Verwendung von Nucleinsäure-Antikörpern in
Zusammenhang stehen, sollen nicht die bekannte Bindungsaffinität zwischen
Nucleinsäure-Bindungsproteinen
und Nucleinsäuresequenzen,
an die sie sich bekanntlich binden, umfassen. Neue, nicht natürlich vorkommende
Sequenzen jedoch, die sich an dieselben Nucleinsäure-Bindungsproteine binden,
können
unter Verwendung von SELEX entwickelt werden. Es gilt anzumerken,
dass SELEX sehr rasche Bestimmung von Nucleinsäuresequenzen, die sich an ein
Protein binden, erlaubt und somit leicht verwendet werden kann,
um die Struktur von unbekannten Operator- und Bindungsstellensequenzen
zu bestimmen, worin diese Sequenzen anschließend für hierin beschriebene Anwendungen
verwendet werden können.
Es wird angenommen, dass die vorliegende Erfindung die erste Offenbarung
der allgemeinen Verwendung von Nucleinsäuremolekülen für die Detektion, Quantifizierung,
Isolierung und Reinigung von Proteinen ist, die nicht dafür bekannt
sind, Nucleinsäuren
zu binden. Wie nachstehend erläutert
wird, können
bestimmte Nucleinsäure-Antikörper, die
durch SELEX isoliert werden können,
auch verwendet werden, um die Funktion von spezifischen Targetmolekülen oder
-strukturen zu beeinflussen, beispielsweise zu inhibieren, zu steigern
oder zu aktivieren. Insbesondere können die Nucleinsäure-Antikörper verwendet
werden, um die Funktion von Proteinen zu inhibieren, steigern oder
aktivieren.
-
Proteine,
die eine bekannte Fähigkeit
aufweisen, sich an Nucleinsäuren
zu binden (wie DNA-Polymerasen, andere Replikasen und Proteine,
die Stellen an RNA erkennen, jedoch nicht in weitere katalytische
Wirkung einbinden), ergeben über
SELEX hochaffine RNA-Liganden, die sich an die aktive Stelle des
Targetproteins binden. Somit blockiert im Fall von HIV-1-Umkehrtranskriptase
der resultierende RNA-Ligand (genannt 1.1 in Beispiel 2) cDNA-Synthese
in Gegenwart einer Primer-DNA, einer RNA-Matrix und der vier Desoxynucleotidtriphosphate.
-
Die
Theorie der Erfinder über
RNA-Strukturen lässt
darauf schließen,
dass beinahe jedes Protein als ein Target für SELEX dient. Die anfänglichen
Versuche gegen Nicht-Nucleinsäure-Bindungsproteine
wurden mit drei Proteinen durchgeführt, von denen nicht angenommen
wurde, dass sie mit Nucleinsäuren
im Allgemeinen oder mit RNA im Besonderen wechselwirken. Die drei
Proteine waren Gewebeplasminogenaktivator (tPA), Nervenwachstumsfaktor
(NGF) und die extrazelluläre
Domäne
des Wachstumsfaktorrezeptors (gfR-Xtra). Alle diese Proteine wurden
getestet, um zu erkennen, ob sie gemischte randomisierte RNAs an
einem Nitrocellulosefilter zurückhalten
würden.
tPA und NGF zeigten Affinität
für randomisierte
RNA mit Kds knapp unter μM. gfR-Xtra
band sich nicht mit messbarer Affinität, was darauf schließen lässt, dass,
wenn ein RNA-Antikörper für dieses
Protein existiert, sich dieser an einer Stelle binden muss, die
keine Affinität
für die
meisten anderen RNAs aufweist.
-
tPA
und NGF wurden dem strengen SELEX-Verfahren unter Verwendung von
RNAs mit 30 randomisierten Positionen unterzogen. Sowohl tPA als
auch NGF ergaben Ligandenlösungen
im SELEX-Verfahren, was darauf schließen lässt, dass eine gewisse Stelle
an jedem Protein die gewinnenden Sequenzen fester banden als jene
Stelle (oder eine andere Stelle), die andere RNAs band. Die Gewinner-Sequenzen
sind für
die beiden Proteine verschieden.
-
Da
tPA und NGF im SELEX-Verfahren so gut funktionierten, wurde eine
zufällige
Sammlung von Proteinen und Peptiden getestet, um zu sehen, ob sie
irgendeine Affinität
für RNA
aufwiesen. Es wurde erörtert, dass,
wenn ein Protein eine Affinität
für RNA
aufweist, das SELEX-Verfahren, durchschnittlich, Sequenzen mit höherer Affinität ergeben
wird, die dieselbe Region des Targets kontaktieren, welche die geringe,
verallgemeinerte Affinität
bereitstellt. Eine Reihe von Proteinen und Peptiden wurde getestet,
um zu sehen, ob randomisierte RNAs (die 40 randomisierte Abschnitte
enthalten) an Nitrocellulosefiltern festgehalten werden würden. Etwa
zwei Drittel der getesteten Proteine banden RNA, und einige wenige
Proteine banden RNA sehr fest. Siehe Beispiel 9.
-
Proteine,
die RNA nicht an Nitrocellulosefilter binden, können aus sehr banalen Gründen ausfallen,
die nichts mit der Wahrscheinlichkeit zu tun haben, RNA-Antikörper hervorzubringen.
Ein Beispiel, Bradykinin, kann sich nicht an Nitrocellulosefilter
binden und würde
somit im obigen Versuch seinen Zweck nicht erfüllen. Ein Bradykinin, das durch
den Amino-Terminus des Peptids an eine feste Matrix gebunden ist,
wurde hergestellt, und dann wurde erkannt, dass sich randomisierte
RNA fest an die Matrix band (siehe Beispiel 7). Somit binden in
den anfänglichen
Versuchen zwei kurze Peptide, Bradykinin und Bombesin, randomisierte
RNAs relativ fest. Jeglicher hochaffine RNA-Ligand, der durch SELEX
mit diesen Peptidtargets erhalten wird, würde vielleicht ein Antagonist
dieser aktiven Peptide sein und könnte therapeutisch nützlich sein.
Es ist schwierig, sich eine RNA mit etwa 30 Nucleotiden vorzustellen,
die sich an ein sehr kleines Peptid bindet, ohne dieses Peptid bezüglich praktisch
jeglicher Aktivität
zu deaktivieren.
-
Wie
nachstehend in den Beispielen 4, 7, 9 und 10 beschrieben wird, wurde
für Proteine,
von denen nicht angenommen wurde, dass sie in der Natur mit Nucleinsäuren wechselwirken,
erkannt, dass sie sich in einem nicht zu vernachlässigenden
Ausmaß an
ein zufälliges
Gemisch von Nucleinsäuren
binden. Es wurde weiters gezeigt, dass für solche Proteine, für die erkannt
wurde, dass sie sich nicht-spezifisch an RNA-Gemische binden, eine Ligandenlösung nach
SELEX gewonnen werden kann. Es ist daher vielleicht wertvoll, vor der
Durchführung
von SELEX einen Screen durchzuführen,
um zu bestimmen, ob ein gegebenes Target irgendeine Art von Bindung
an ein zufälliges
Gemisch von Nucleinsäuren
aufweist.
-
Ein
zweiter wichtiger und unerwarteter Aspekt der vorliegenden Erfindung
ist, dass die hierin beschriebenen Verfahren verwendet werden können, um
Nucleinsäuremoleküle zu identifizieren,
isolieren oder produzieren, die sich spezifisch an ein bestimmtes
Targetmolekül
binden und die Funktion dieses Moleküls beeinflussen. In diesem
Aspekt sind die Targetmoleküle
wiederum vorzugsweise Proteine, können jedoch auch, unter anderem,
Kohlenhydrate und verschiedene kleine Moleküle umfassen, an die spezifische
Nucleinsäurebindung
erreicht werden kann. Nucleinsäureliganden,
die sich an kleine Moleküle
binden, können
ihre Funktion durch Sequestrieren von ihnen oder durch Unterbinden
einer Wechselwirkung von ihnen mit ihren natürlichen Liganden beeinflussen.
Die Aktivität
eines Enzyms kann beispielsweise durch einen Nucleinsäureliganden
beeinflusst werden, der sich an das Substrat des Enzyms bindet.
Nucleinsäureliganden,
d.h. Nucleinsäure-Antikörper, von
kleinen Mo lekülen
sind besonders als Reagenzien für
Diagnosetests (oder andere quantitative Tests) nützlich. Beispielsweise kann
die Gegenwart gesteuerter Substanzen, gebundener Metabolite oder anormaler
Mengen normaler Metabolite unter Verwendung von Nucleinsäureliganden
der Erfindung nachgewiesen und gemessen werden. Ein Nucleinsäureligand
mit katalytischer Aktivität
kann die Funktion eines kleinen Moleküls durch Katalysieren einer
chemischen Änderung
im Target beeinflussen. Der Bereich möglicher katalytischer Aktivitäten ist
zumindest so breit wie jener, den Proteine aufweisen. Das Durchführen von
Selektion eines Liganden für
ein Übergangszustands-Analogon
einer erwünschten
Reaktion ist ein Verfahren, durch das katalytische Nucleinsäureliganden
selektiert werden können.
-
Es
wird angenommen, dass die vorliegende Beschreibung zum ersten Mal
die allgemeine Verwendung von Nucleinsäuremolekülen offenbart, um Proteinfunktion
zu beeinflussen, inhibieren oder steigern. Die Bindungsselektionsverfahren
der vorliegenden Erfindung können
leicht mit sekundärer
Selektion oder Screeningverfahren zur Modifikation von Targetmolekülfunktion
auf Bindung an selektierte Nucleinsäuren kombiniert werden. Die
große
Population von verschiedenen Nucleinsäuresequenzen, die durch SELEX
getestet werden können,
steigert die Wahrscheinlichkeit, dass Nucleinsäuresequenzen gefunden werden
können,
die eine erwünschte
Bindungsfähigkeit
und -funktion aufweisen, um Targetmolekülaktivität zu modifizieren. Die Verfahren der
vorliegenden Erfindung sind zur Selektion von Nucleinsäureliganden
nützlich,
die die Funktion von jeglichem Targetprotein, einschließlich Proteine,
die Nucleinsäuren
als Teil ihrer natürlichen
biologischen Aktivität binden,
und von jenen Proteinen, die nicht dafür bekannt sind, Nucleinsäure als
Teil ihrer biologischen Funktion zu binden, selektiv beeinflussen
können.
Die hierin beschriebenen Verfahren können verwendet werden, um Nucleinsäureliganden
zu isolieren oder bilden, die sich an jegliches Protein binden und
dessen Funktion modifizieren, das sich an eine Nucleinsäure, entweder
DNA oder RNA, entweder einzel- oder doppelsträngig; ein Nucleosid oder Nucleotid,
einschließlich
jener, die Purin- oder Pyrimidinbasen oder Basen, die davon abstammen,
aufweisen, insbesondere einschließlich jener, die Adenin-, Thymin-,
Guanin-, Uracil-, Cytosin- und Hyopxanthinbasen und Derivate, insbesondere
methylierte Derivate, davon aufweisen; und Coenzym-Nucleotide, einschließlich u.a.
Nicotinamid-Nucleotide, Flavin-Adenin-Dinucleotide und Coenzym A,
bindet. Es wird erwogen, dass das Verfahren der vorliegenden Erfindung
verwendet werden kann, um Nucleinsäuremoleküle zu identifizieren, isolieren
oder bilden, die die katalytische Aktivität von Targetenzymen beeinflussen,
d.h. Katalyse inhibieren oder Substratbindung modifizieren, die
Funktionalität
von Proteinrezeptoren beeinflussen, d.h. Bindung an Rezeptoren inhibieren
oder die Spezifität
von Bindung an Rezeptoren modifizieren; die Bildung von Proteinmultimeren
beeinflussen, d.h. Quartärstruktur
von Proteinuntereinheiten zerstören;
und Transporteigenschaften von Protein modifizieren, d.h. Transport
von kleinen Molekülen
oder Ionen durch Proteine stören.
-
Das
SELEX-Verfahren wird hierin als die sich wiederholende Selektion
und Amplifikation eines Kandidatengemisches von Nucleinsäuresequenzen,
bis eine Ligandenlösung
erhalten wurde, definiert. Ein weiterer Schritt in diesem Verfahren
ist die Bildung von Nucleinsäure-Antikörpern gegen
ein gegebenes Target. Auch wenn die Ligandenlösung, die für ein bestimmtes Verfahren
abgeleitet wurde, eine einzelne Sequenz ist, muss der Nucleinsäure-Antikörper, der
nur die Ligandenlösung
enthält,
synthetisiert werden. Ein SELEX-Versuch kann beispielsweise eine
bevorzugte einzelne Ligandenlösung
hervorbringen, die nur aus 20 der 30 randomisierten Nucleotidsequenzen,
die im SELEX-Kandidatengemisch verwendet wurden, besteht. Der therapeutisch
wertvolle Nucleinsäure-Antikörper würde vorzugsweise
die 10 nicht maßgeblichen
Nucleotide oder die fixierten Sequenzen, die für den Amplifikationsschritt
von SELEX erforderlich sind, nicht enthalten. Nachdem die erwünschte Struktur
des Nucleinsäure-Antikörpers basierend
auf der Ligandenlösung
bestimmt wurde, wird die tatsächliche
Synthese des Nucleinsäure-Antikörpers gemäß zahlreichen
verschiedenen Verfahren, die auf dem Gebiet der Erfindung bekannt
sind, durchgeführt.
-
Der
Nucleinsäure-Antikörper kann
auch basierend auf einer Ligandenlösung für ein bestimmtes Target konstruiert
werden, das aus einer Familie von Sequenzen besteht. In solch einem
Fall wird ein Routineversuch zeigen, dass eine bestimmte Sequenz
aufgrund von Umständen,
die mit der relativen Affinität
der Ligandenlösung zum
Target nicht in Verbindung stehen, bevorzugt wird. Solche Überlegungen
sind für
durchschnittliche Fachleute offensichtlich.
-
In
einer anderen Ausführungsform
der vorliegenden Erfindung kann der Nucleinsäure-Antikörper aus einer Vielzahl von
targetspezifischen Liganden bestehen, von denen mehr als einer identische
Liganden sein können.
Vorzugsweise besteht er aus zumindest zwei unterschiedlichen targetspezifischen
Liganden. Er kann eine Vielzahl von Nucleinsäureliganden für dasselbe
Target enthalten. Beispielsweise kann SELEX zwei unterschiedliche
Ligandenlösungen
identifizieren. Da die zwei Ligandenlösungen das Target an verschiedenen Orten
binden können,
kann der Nucleinsäure-Antikörper vorzugsweise
beide Ligandenlösungen
enthalten. In einer anderen Ausführungsform
kann der Nucleinsäure-Antikörper mehr
als eine einzelne Ligandenlösung
enthalten. Solche mehrwertigen Nucleinsäure-Antikörper weisen erhöhte Bindungsaffinität zum Target
auf, die für einen äquivalenten
Nucleinsäure-Antikörper, der
nur einen Liganden aufweist, nicht verfügbar ist.
-
Darüber hinaus
kann der Nucleinsäure-Antikörper auch
aus einem Nicht-Nucleinsäure-Element,
insbesondere aus einem targetspezifischen Liganden, bestehen. Somit
kann er andere Elemente enthalten, die 1) unabhängige Affinität für das Target
zum Nucleinsäure-Antikörper hinzufügen; 2)
in unabhängiger
Weise die Affinität
des Nucleinsäureliganden
zum Target steigern; 3) den Nucleinsäure-Antikörper auf die geeignete Stelle
in vivo, wo Behandlung erwünscht
ist, richten oder dort anordnen; oder 4) die Spezifität für den Nucleinsäureliganden
für das
Target verwenden, um eine gewisse zusätzliche Reaktion an dieser
Stelle zu bewirken.
-
Die
hierin beschriebenen Verfahren sind für die Gewinnung von Nucleinsäuren nützlich,
die die Funktion eines Targetproteins inhibieren, und sind besonders
für die
Gewinnung von Nucleinsäuren
nützlich,
die die Funktion von Proteinen inhibieren, deren Funktion Bindung
an Nucleinsäure,
Nucleotide, Nucleoside und Derivate und Analoge davon einbindet.
Die Verfahren der vorliegenden Erfindung können Nucleinsäure-Inhibitoren,
beispielsweise von Polymerasen, reversen Transkriptasen und an deren
Enzymen, in denen eine Nucleinsäure,
ein Nucleotid oder Nucleosid ein Substrat oder Co-Faktor ist, bereitstellen.
-
Sekundäre Selektionsverfahren,
die mit SELEX kombiniert werden können, umfassen unter anderem Selektionen
oder Screens auf Enzyminhibierung, Veränderung von Substratbindung,
Verlust von Funktionalität,
Störung
von Struktur und dergleichen. Fachleute sind in der Lage, unter
verschiedenen Möglichkeiten
jene Selektions- oder Screeningverfahren auszuwählen, die mit den hierin beschriebenen
Verfahren vereinbar sind.
-
Es
wird Fachleuten leicht ersichtlich sein, dass es in manchen Fällen, d.h.
für bestimmte
Targetmoleküle
oder für
bestimmte Anwendungen, bevorzugt sein kann, eher RNA-Moleküle, und
nicht DNA-Moleküle, als
Liganden zu verwenden, während
in anderen Fällen
DNA-Liganden RNA-Liganden vorgezogen werden können.
-
Die
hierin beschriebenen Selektionsverfahren können auch verwendet werden,
um Nucleinsäuren auszuwählen, die
sich spezifisch an einen Molekülkomplex,
beispielsweise an einen Substrat/Protein- oder Inhibitor/Protein-Komplex,
binden. Unter diesen Nucleinsäuren,
die sich spezifisch an die Komplexmoleküle, jedoch nicht an die unvollendeten
Moleküle,
binden, gibt es Nucleinsäuren,
die die Bildung des Komplexes inhibieren. Beispielsweise gibt es
unter jenen Nucleinsäureliganden,
die für
spezifische Bindung an einen Substrat/Enzym-Komplex selektiert werden,
Nucleinsäuren,
die leicht selektiert werden können
und die Substratbindung an das Enzym inhibieren und somit Katalyse
durch dasselbe Enzym inhibieren oder stören.
-
Eine
Ausführungsform
der vorliegenden Erfindung, die besonders zur Identifikation oder
Isolierung von Nucleinsäuren,
die sich an eine bestimmte funktionelle oder aktive Stelle in einem
Protein oder einem anderen Targetmolekül binden, nützlich ist, verwendet ein Molekül, das für Bindung
an eine erwünschte
Stelle innerhalb des Targetproteins bekannt ist oder dafür selektiert
wird, um das Selektions/Amplifikationsverfahren auf eine Untergruppe
von Nucleinsäureliganden
zu richten, die sich an der oder in der Nähe der erwünschten Stelle innerhalb des
Targetmoleküls
bin den. In einem einfachen Beispiel wird eine Nucleinsäuresequenz,
die dafür bekannt
ist, sich an eine erwünschte
Stelle in einem Targetmolekül
zu binden, in der Nähe
der randomisierten Region aller Nucleinsäuren, die auf Bindung getestet
werden, inkorporiert. SELEX wird dann verwendet (9),
um jene Varianten zu selektieren, von denen alle die bekannte Bindungssequenz
enthalten, die sich am festesten an das Targetmolekül bindet.
Eine längere
Bindungssequenz, von der angenommen wird, dass sie sich entweder
fester an das Targetmolekül
oder spezifischer an das Target bindet, kann somit selektiert werden.
Die längere
Bindungssequenz kann dann in der Nähe der randomisierten Region
des Nucleinsäure-Testgemisches
eingeführt
und die Selektions/Amplifikationsschritte können wiederholt werden, um
eine noch längere
Bindungssequenz zu selektieren. Eine Wiederholung dieser Schritte
(d.h. Inkorporation von selektierter Sequenz in Testgemische, gefolgt
von Selektion/Amplifikation auf verbesserte oder spezifischere Bindung)
kann wiederholt werden, bis ein erwünschtes Niveau von Bindungsstärke oder
-spezifität
erreicht wird. Dieses sich wiederholende „Walking"-Verfahren ermöglicht die Selektion von Nucleinsäuren, die
für ein
bestimmtes Targetmolekül
oder eine bestimmte Stelle innerhalb eines Targetmoleküls hochspezifisch
sind. Eine andere Ausführungsform
solch eines sich wiederholenden „Walking"-Verfahrens verwendet ein „Anker"-Molekül, das nicht
notwendigerweise eine Nucleinsäure
ist (siehe die 10 und 11).
In dieser Ausführungsform
wird ein Molekül,
das sich an ein erwünschtes
Target bindet, beispielsweise ein Substrat oder ein Inhibitor eines
Targetenzyms, chemisch modifiziert, sodass es kovalent an ein Oligonucleotid
mit bekannter Sequenz (das „Führungs"-Oligonucleotid aus 10) gebunden werden kann. Das chemisch an das „Anker"-Molekül gebundene Führungs-Oligonucleotid,
das sich an das Target bindet, bindet sich auch an das Targetmolekül. Das Sequenzkomplement
von Führungs-Oligonucleotid wird
in der Nähe
der randomisierten Region des Test-Nucleinsäuregemisches inkorporiert.
Anschließend
wird SELEX durchgeführt,
um auf jene Sequenzen zu selektieren, die sich am stärksten an
den Targetmolekül/Anker-Komplex
binden. Das sich wiederholende Walking-Verfahren kann dann verwendet
werden, um längere
und längere
Nucleinsäuremoleküle mit gesteigerter Bindungsstärke oder
Bindungsspezifität
zum Target zu selektieren oder zu bilden. Von der Verwendung des „Anker"-Verfahrens wird
erwartet, dass es eine raschere Isolierung von Nuclein säureliganden,
die sich an oder in der Nähe
einer erwünschten
Stelle innerhalb des Targetmoleküls
binden, ermöglicht.
Insbesondere wird erwartet, dass das „Anker"-Verfahren
in Kombination mit sich wiederholenden „Walking"-Verfahren zu Nucleinsäuren führt, die
höher spezifische
Inhibitoren von Proteinfunktion sind (11).
-
In
bestimmten Ausführungsformen
der Durchführung
von SELEX ist es wünschenswert,
plus/minus-Screening in Verbindung mit dem Selektionsverfahren durchzuführen, um
sicherzustellen, dass das Selektionsverfahren nicht durch irgendeinen
Faktor verzerrt wird, der in keiner Verbindung mit der Affinität der Nucleinsäuresequenzen
zum Taget steht. Wird beispielsweise Selektion durch Protein-bindende
Nitrocellulose durchgeführt,
so wurde beobachtet, dass bestimmte Nucleinsäuresequenzen vorzugsweise durch
Nitrocellulose zurückgehalten
werden und während
des SELEX-Verfahrens
selektiert werden können.
Diese Sequenzen können
aus dem Kandidatengemisch durch Einbinden zusätzlicher Schritte entfernt
werden, worin das oben genannte SELEX-Gemisch durch Nitrocellulose
geführt
wird, um jene Sequenzen selektiv zu entfernen, die ausschließlich für diese
Eigenschaft selektiert wurden. Derartiges Screenen und derartige
Selektion können durchgeführt werden,
sobald das Target Unreinheiten enthält oder das Selektionsverfahren
Vorgaben einführt, die
mit Affinität
zum Target nicht in Verbindung stehen.
-
SELEX
wurde durch die Anwendung zur Isolierung von RNA-Molekülen demonstriert,
die sich an Bakteriophagen-T4-DNA-Polymerase, auch als gp43 bezeichnet,
binden und ihre Funktion inhibieren. Der neue RNA-Ligand von T4-DNA-Polymerase
ist als ein spezifisches Testreagens für T4-DNA-Polymerase nützlich. Die
Synthese von T4-DNA-Polymerase
ist autogen reguliert. In Abwesenheit von funktionellem Protein
werden Amber-Fragmente und mutierte Proteine im Vergleich zur Syntheserate
von Wildtyp-Protein in replikationsdefizienten Infektionen überexprimiert
(Russel, J. Mol. Biol. 79, 83–94
(1973)). In-vitro-Translation eines N-terminalen Fragments von gp43
wird durch den Zusatz von gereinigter gp43 spezifisch unterdrückt, und
gp43 schützt
einen einzelnen Abschnitt der mRNA in der Nähe ihrer Ribosombindungsstelle
vor Nuclease-Angriff (Andrake et al., Proc. Natl. Acad. Sci. USA
85, 7942–7946
(1988)). Die Größe und Sequenz
des RNA-Translationsoperators, an den sich gp43 bindet, und die
Stärke
dieser Bindung wurden bereits festgestellt. Die minimale Größe des gp43-Operators
ist eine Sequenz von etwa 36 Nucleotiden, wie in 1 gezeigt,
von der vorhergesagt wird, dass sie eine Haarnadelschleifenstruktur
wie hierin angegeben aufweist. Die minimale Größe des Operators wurde durch
Analyse von Bindung von endmarkierten Hydrolysefragmenten des Operators an
gp43 bestimmt. Eine Analyse der Bindung von Operatormutanten in
der Haarnadel- und Schleifensequenz weist darauf hin, dass gp43-Bindung
an den Operator auf primäre
Basenänderungen
in der Helix empfindlich ist. Bindung an die Polymerase wurde durch Änderungen,
die die Haarnadelstabilität
signifikant reduzieren, sogar noch stärker reduziert. Operatorbindung
wurde als sehr empfindlich gegenüber
der Schleifensequenz erkannt. Es wurde auch erkannt, dass Replikation
und Operatorbindung bei gp43 sich gegenseitig ausschließende Aktivitäten sind.
Für den
Zusatz von mikromolaren Mengen von gereinigten RNAs, die intakten
Operator enthalten, wurde erkannt, dass er In-vitro-Replikation durch gp43 stark inhibierte.
-
Der
Wildtyp-gp43-Operator, 1, wurde als Grundlage für den Entwurf
eines anfänglichen
Gemisches von RNA-Molekülen
verwendet, die eine Region mit randomisierter Sequenz enthielten,
um die Fähigkeit
des Selektions/Amplifikationsverfahrens zu bewerten, Nucleinsäuremoleküle zu isolieren,
die sich an ein Protein binden. Das RNA-Testgemisch wurde durch
In-vitro-Transkription aus einer 110 Basen langen, einzelsträngigen DNA-Matrix
hergestellt. Die Matrix wurde, wie in 1 gezeigt,
hergestellt, um für
den Großteil
der Wildtyp-Operatorsequenz, mit Ausnahme der Schleifensequenz,
zu kodieren. Die 8-Basen-Schleifensequenz wurde durch eine Region
mit randomisierter Sequenz ersetzt, die synthetisiert wurde, um
an jeder Base zur Gänze
zufällig
zu sein. Die Matrix enthielt auch Sequenzen, die für wirksame
Amplifikation erforderlich waren: eine Sequenz an ihrem 3'-Ende, die komplementär zu einem
Primer für
reverse Transkription und Amplifikation in Polymerasekettenreaktionen
ist, und eine Sequenz an ihrem 5'-Ende,
das für
T7-RNA-Polymerasetranskriptionsinitiation erforderlich ist, und
eine ausreichende Sequenz, die zur cDNA des In-vitro-Transkripts komplementär ist. Die
DNA-Matrix ist dieses eine Gemisch aus allen Schleifensequenzvarianten,
das theoretisch 65.536 einzelne Spezies enthält.
-
Für die Dissoziationskonstante
für die
Wildtyp-Schleifen-RNA wurde ein Wert von etwa 5 × 10–9 M
erkannt. Die Dissoziationskonstante für die Population von Schleifensequenzvarianten
wurde auf etwa 2,5 × 10–7 gemessen.
Randomisierung der Schleifensequenz reduzierte Bindungsaffinität um das
50fache.
-
In-vitro-Transkripte,
die die Schleifensequenzvarianten enthielten, wurden mit gereinigter
gp43 vermischt und inkubiert. Das Gemisch wurde durch ein Nitrocellulosefilter
filtriert. Protein-RNA-Komplexe werden am Filter zurückgehalten,
ungebundene RNA nicht. Selektierte RNA wurde dann aus den Filtern
wie in Beispiel 1 beschrieben eluiert. Selektierte RNAs wurden mit
AMV-Umkehrtranskriptase in Gegenwart von 3'-Primer,
wie in Gauss et al. (1987), s.o., beschrieben, verlängert. Die
resultierende cDNA wurde mit Taq-DNA-Polymerase in Gegenwart von
5'-Primer 30 Zyklen
lang, wie in Innis et al. (1986), s.o., beschrieben, amplifiziert.
Die selektierte amplifizierte DNA diente als Matrix für In-vitro-Transkription,
um selektierte amplifizierte RNA-Transkripte herzustellen,
die dann einem weiteren Durchgang von Bindungsselektion/Amplifikation
unterzogen wurden. Das RNA/Protein-Verhältnis im Bindungsselektionsgemisch
wurde über
die gesamten Selektionszyklen hinweg konstant gehalten. Die sich
wiederholende Selektion/Amplifikation wurde unter Verwendung mehrerer
verschiedener RNA/Protein-Molverhältnisse durchgeführt. In
allen Versuchen war RNA im Überschuss
vorhanden: Versuch A verwendete ein RNA/gp43-Verhältnis von
10/1 (mol/mol); Versuch B verwendete ein RNA/gp43-Verhältnis von
1.000/1; und Versuch C verwendete ein RNA/gp43-Verhältnis von
100/1.
-
Der
Fortschritt des Selektionsverfahrens wurde durch Filterbindungstests
an markierten Transkripten von amplifizierter cDNA bei dem Abschluss
jedes Zyklus des Verfahrens beobachtet. Chargen-Sequenzieren der
RNA-Produkte aus jeder Runde für
Versuch B erfolgte auch, um den Fortschritt der Selektion zu beobachten.
-
Autoradiogramme
von Sequenzierungsgelen von RNA-Produkten nach 2, 3 und 4 Durchgängen von Selektion/Amplifikation
sind in 3 gezeigt. Es ist eindeutig,
dass es keine eindeutige Schleifensequenzvorgabe gab, die bis nach
der dritten Selektion eingeführt
wurde. Nach dem vierten Selektionsdurchgang ist eine offensichtliche Consensus-Sequenz
für die
8-Basen-Schleifensequenz erkennbar als: A(a/g)(u/c)AAC(u/c)(u/c).
Chargen-Sequenzierung von selektierter RNA nach dem vierten Selektionsdurchgang
für die
Versuche A, B und C wird in 4 verglichen.
Alle drei unabhängigen
SELEX-Verfahren unter Verwendung verschiedener RNA/Protein-Verhältnisse
ergaben ähnliche
offensichtliche Consensus-Sequenzen. Es gab jedoch manche sichtbare
Vorgaben für
Wildtyp-Schleifensequenz (AAUAACUC) in der selektierten RNA aus
den Versuchen A und C.
-
Um
zu bestimmen, welche zulässigen
Sequenzkombinationen tatsächlich
in den selektierten RNAs vorhanden waren, wurden einzelne DNAs aus
selektierten RNAs nach dem vierten Selektionsdurchgang in Versuch
B kloniert. Das Chargensequenzresultat aus Versuch B schien eine
gleichmäßige Verteilung
der zwei zulässigen
Nucleotide anzugeben, die jeweils die vier variablen Abschnitte
der Schleifensequenz bildeten. Einzelne wurden in pUC18, wie von
J. Sambrook et al., Molecular Cloning: A Laboratory Manual, Cold
Spring Harbor, N.Y., Abschnitte 1.13; 1.85–1.86 (1989), beschrieben,
kloniert. Zwanzig einzelne Klone, die durch Koloniefilterhybridisierung
an den 3'-Primer
identifiziert wurden, wurden sequenziert. Keiner der sequenzierten
Klone war an irgendeiner Stelle in der Operatorsequenz außerhalb
der Schleifensequenz mutiert. Es wurden, wie in 7 gezeigt,
nur fünf
variable Sequenzen wurden beobachtet, und überraschenderweise waren nur
zwei Sequenzvarianten die Hauptkomponenten des selektierten Gemisches.
Die Häufigkeiten
von jeder Sequenz in den 20 einzelnen sequenzierten Isolaten sind
ebenfalls in 7 angegeben. Die Wildtyp-Sequenz
AAUAACUC und die Schleife AGCAACCU waren in etwa gleichen Mengen
in der selektierten RNA von Versuch B vorhanden. Die anderen selektierten
Varianten waren 1-Basen-Mutanten der zwei Hauptvarianten. Die Bindungsstärke der
Sequenzvarianten wurde in Filterbindungstests unter Verwendung markierter
In-vitro-Transkripte, die aus jedem der gereinigten klonalen Isolate
stammten, verglichen. Wie in 6 gezeigt,
wurde eine ungefähre
Korrelation zwischen Bindungsaffinität einer RNA zu gp43 und der
Häufigkeit
der selektierten Sequenz beobachtet. Die zwei Haupt-Schleifensequenzvarianten
zeigten etwa gleiche Bindungsaffinitäten zu gp43.
-
Die
in 7 gezeigten, durch das Selektions/Amplifikationsverfahren
isolierten Schleifensequenzvarianten-RNAs können alle als Inhibitoren von
gp43-Polymeraseaktivität
wirken, wie für
die Wildtyp-Operatorsequenz gezeigt wurde.
-
Ein
Beispiel für
die Verwendung von SELEX wurde bereits durch Selektion eines neuen
RNA-Liganden von Bakteriophagen-T4-DNA-Polymerase (gp43) bereitgestellt
(Andrake et al., Proc. Natl. Acad. Sci. USA 85, 7942–7946 (1988)).
-
Die
vorliegende Erfindung umfasst spezifische Ligandenlösungen,
hergeleitet über
das SELEX-Verfahren, für
die gezeigt wurde, dass sie eine erhöhte Affinität zu HIV-1-Umkehrtranskriptase, R17-Hüllprotein, HIV-1-rev-Protein,
HSV-DNA-Polymerase, E.-coli-Ribosomenprotein S1, tPA und NGF aufweisen.
Diese Ligandenlösungen
können
von Fachleuten verwendet werden, um Nucleinsäure-Antikörper gegen die verschiedenen
Targets zu synthetisieren.
-
Die
folgenden Beispiele beschreiben die erfolgreiche Anwendung von SELEX
an einer breiten Palette an Targets. Die Targets können im
Allgemeinen in zwei Kategorien eingeteilt werden: jene, die Nucleinsäure-Bindungsproteine
sind, und jene Proteine, die nicht dafür bekannt sind, mit Nucleinsäuren wechselzuwirken. In
jedem Fall wird eine Ligandenlösung
erhalten. In manchen Fällen
ist es möglich,
die Ligandenlösung
als ein Nucleinsäuremotiv
wie z.B. eine Haarnadelschleife, eine asymmetrische Ausweitung oder
einen Pseudoknoten darzustellen. In anderen Beispielen wird die
Ligandenlösung
als eine Primärsequenz
dargestellt. In solchen Fällen
soll jedoch nicht impliziert werden, dass die Ligandenlösung keine
definitive Tertiärstruktur
enthält.
-
Zusätzlich zur
T4-DNA-Polymerase umfassen Targets, an denen SELEX erfolgreich durchgeführt wurde,
Bakteriophagen-R17-Hüllprotein,
HIV-Umkehrtranskriptase (HIV-RT), HIV-1-rev-Protein, HSV-DNA-Polymerase
plus oder minus Co-Faktor, E.-coli-Ribosomenprotein
S1, tPA und NGF. Die folgenden Versuche beschreiben auch eine Arbeitsvorschrift
zum Testen der Hauptbindungsaffinität eines randomisierten Nucleinsäure-Kandidatengemisches
zu zahlreichen verschiedenen Proteinen. Bei spiel 7 beschreibt auch
die Immobilisierung von Bradykinin und die Resultate von Untersuchungen
zur Bindung des Hauptteils randomisierter Nucleinsäuren an
Bradykinin.
-
Die
Beispiele und Veranschaulichungen sollen in keiner Weise als Einschränkung betrachtet
werden. Die grundlegende Erkenntnis, die dieser Erfindung zugrunde
liegt, ist, dass Nucleinsäuren
als chemische Verbindungen eine praktisch grenzenlose Vielzahl an
Größen, Formen
und Konfigurationen bilden können
und zu enorm vielen verschiedenen Bindungs- und Katalysefunktionen
fähig sind,
von denen jene, deren Existenz in biologischen Systemen bis heute
bekannt ist, nur einen kleinen Einblick gewähren.
-
BEISPIELE
-
Die
folgenden Materialien und Verfahren wurden in den gesamten Beispielen
verwendet.
-
Der
Transkriptionsvektor pT7-2 ist im Handel erhältlich (U.S. Biochemical Company,
Cleveland, OH). Plasmid pUC18 wird von Norrander et al., Gene 24,
15–27
(1983), beschrieben und ist ebenfalls im Handel bei New England
Biolabs erhältlich.
Alle Manipulationen von DNA zur Schaffung neuer rekombinanter Plasmide erfolgten
wie in Maniatis et al., Molecular Cloning: A Laboratory Manual,
Cold Spring Harbor Laboratory, Cold Spring Harbor, New York (1982),
beschrieben, außer
anders angemerkt. DNA-Oligonucleotide wurden wie von Gauss et al.,
Mol. Gen. Genet. 206, 24–34
(1987), beschrieben synthetisiert und gereinigt.
-
In-vitro-Transkriptionen
mit T7-RNA-Polymerase und RNA-Gelreinigung erfolgten, wie es in
Milligan et al., Nucl. Acids Res. 15, 8783–8798 (1987), beschrieben wird,
mit der Ausnahme, dass in den Markierungsreaktionen die Konzentrationen
von ATP, CTP und GTP jeweils 0,5 mM betrugen und die UTP-Konzentration 0,05
mM betrug. Das UTP wurde an der alpha-Position mit 32P
mit einer spezifischen Aktivität
von etwa 20 Ci/mmol markiert. Rohe mRNA-Präparate aus T4-Infektionen,
Markieren von Oligos und Primerextension mit AMV-Umkehrtranskriptase
waren bzw. erfolgten gemäß Gauss
et al. (1987), s.o.
-
Verdünnungen
von markierter, gelgereinigter RNA und gereinigter gp43 wurden in
200 mM Kaliumacetat, 50 mM Tris-HCl, pH 7,7, bei 4°C hergestellt.
In Nitrocellulosefilter-Bindungstests wurde gereinigte gp43 seriell
verdünnt,
und 30-μl-Aliquoten
von jeder Proteinverdünnung
wurden zu 30-μl-Aliquoten
von verdünnter, markierter,
gelgereinigter RNA zugesetzt. Die RNA-Verdünnung (50 μl) wurde auf ein frisches Nitrocellulosefilter
aufgetragen, getrocknet und gezählt,
um Eingangszählungen
pro Röhrchen
zu bestimmen. Die Konzentration von Protein in den Reaktionen lag
im Bereich von 10–10 M bis 10–8 M,
und die Konzentration der RNAs in jedem Versuch betrug etwa 10–12 M.
Nach 30-minütiger
Inkubation bei 4°C
wurde jedes Röhrchen
3 min lang unter 37°C
gesetzt, und 50 μl
von jeder Probe wurden durch vorbenetzte Nitrocellulosefilter (Millipore
#HAWP 025 00) filtriert und mit 3 ml von 200 mM Kaliumacetat, 50
mM Tris-HCl, pH 7,7, gewaschen. Die Filter wurden getrocknet und
in EcolumeTM-Szintillationsflüssigkeit
(ICN Biomedicals, Inc.) gezählt.
Kontrollen erfolgten in Abwesenheit von gp43, woraus der Hintergrund
(stets weniger als etwa 5 der Eingangszählungen) bestimmt wurde. Von
jeder Messungsreihe wurde der Hintergrund subtrahiert, und der Prozentsatz
von Gesamteingangszählungen,
die auf den Filtern verblieben, wurde berechnet. Aus jeder Reihe
dieser Datenpunkte wurde eine theoretische bimolekulare Bindungskurve
der besten Übereinstimmung
(„best
fit") unter Verwendung
einer Version eines veröffentlichten
Programms (Caceci & Cacheris
(1984), s.o.) gebildet, das modifiziert wurde, um eine Kurve zu
konstruieren, die durch die Gleichung θ = A[gp43]/(Kd
+ [gp43])beschrieben wird, worin θ die Fraktion der Gesamt-RNA
ist, die an den Filter gebunden ist, A der Prozentsatz von RNA ist,
bei dem Bindung sättigt
(etwa 60 % für
diese Protein-RNA-Wechselwirkung), [gp43] die Eingangs-gp43-Konzentration
ist und Kd die Dissoziationskonstante für die bimolekulare Reaktion
ist. Diese Gleichung ist eine algebraische Neugestaltung der Gleichung
[1–5]
von Bisswanger, Theorie und Methoden der Enzymkinetik, Verlag Chemie,
Weinheim, BRD, 9 (1979), mit der verein fachenden Annahme, dass die
Konzentration des Proteins die Konzentration von RNA-Proteinkomplexen
weitaus überschreitet,
eine Annahme, die in den beschriebenen Versuchen richtig ist.
-
Beispiel 1: Selektion
von RNA-Inhibitoren von T4-DNA-Polymerase
-
Eine
110 Basen lange, einzelsträngige
DNA-Matrix für
In-vitro-Transkription wurde wie in 2 gezeigt
durch Ligation von drei synthetischen Oligonucleotiden (Tabellen
1, 3, 4 und 5) in Gegenwart von zwei Capping-Oligonucleotiden (Tabellen
1 und 2) geschaffen. Eines der Matrix-bildenden Oligos wurde auch
als der 3'-Primer
in reverser Transkription des In-vitro-Transkripts und der darauf
folgenden Amplifikation in Polymerasekettenreaktionen (PCRs) verwendet
(Innis et al., Proc. Natl. Acad. Sci. USA 85, 9436–9440 (1988)). Eines
der Capping-Oligos (1) enthält
die Information, die für
T7-RNA-Polymerasetranskriptionsinitiation erforderlich ist, und
ausreichende Sequenzkomplementarität zur cDNA des In-vitro-Transkripts,
um als 5'-Primer
in den PCR-Amplifikationsschritten zu dienen. Die DNA-Matrix kodierte
für eine
RNA, die die gesamte RNA-Erkennungsstelle für T4-DNA-Polymerase enthielt,
mit der Ausnahme, dass eine vollständig zufällige Sequenz anstelle der
Sequenz, die für
die Wildtyp-Schleifensequenz AAUAACUC kodieren würde, eingesetzt wurde. Die
zufällige
Sequenz wurde durch herkömmliche
chemische Synthese unter Verwendung eines handelsüblichen
DNA-Syntheseautomaten (Applied Biosystems) eingeführt, mit
der Ausnahme, dass alle vier dNTPs in äquimolaren Mengen im Reaktionsgemisch
für jede
Position, die in der Sequenz von Oligonucleotid Nr. 4 mit N bezeichnet
ist (Tabelle 1), vorhanden waren. Die zufällige Sequenz wird durch Primeranellierungs-Sequenzinformation
für die
5'- und 3'-Oligos flankiert,
die in PCR verwendet wurden. Die DNA-Matrix ist somit ein Gemisch
von allen Schleifensequenzvarianten, das theoretisch 65.536 einzelne
Spezies enthält.
Die Dissoziationskonstante für
die Wildtyp-Schleifenvarianten-RNA-Sequenz
beträgt
etwa 5 × 10–9 M,
und für
die Population von Sequenzen wurde eine Kd von
etwa 2,5 × 10–7 M
gemessen, eine 50fach niedrigere Bindungsaffinität.
-
-
In-vitro-Transkripte,
die die Schleifensequenzvarianten enthielten, wurden in allen Selektionsdurchgängen mit
gereinigter gp43 in drei verschiedenen RNA-Protein-Verhältnissen
vermischt. (Für
A und B betrug die Konzentration von gp43 3 × 10–8 M, „wenig
Protein", und für C betrug
die Konzentration von gp43 3 × 10–7 M, „viel Protein". Für A betrug
die Konzentration von RNA etwa 3 × 10–7, „wenig
RNA", und für B und
C betrug die Konzentration von RNA etwa 3 × 10–5 M, „viel RNA".) Ein Durchgang
bestand aus den folgenden Schritten:
-
1)
Selektion. Die RNA und das Protein wurden in den erwünschten
Verhältnissen,
wie zuvor beschrieben, vermischt, bei 37°C inkubiert, durch ein Nitrocellulosefilter
gewaschen, und RNA wurde aus den Filtern wie zuvor beschrieben eluiert.
-
2.
Amplifikation. Die aus den Filtern eluierte RNA wurde mit AMV-Umkehrtranskriptase
in Gegenwart von 50 pmol von 3'-Primer
in einer 50-μl-Reaktion
unter Bedingungen, wie sie von Gauss et al. (1987), s.o., beschrieben
wurden, verlängert.
Zur resultierenden cDNA-Synthese wurden 50 pmol von 5'-Primer in einem Reaktionsvolumen
von 100 μl
zugesetzt und wurden mit Taq-DNA-Polymerase wie in Innis (1988),
s.o., beschrieben für
30 Zyklen amplifiziert.
-
3.
Transkription. In-vitro-Transkription erfolgt an den selektierten
amplifizierten Matrices, wie von Milligan et al. (1987), s.o., beschrieben,
wonach DNasel zugesetzt wird, um die DNA-Matrix zu entfernen. Die
resultierenden selektierten RNA-Transkripte
wurden dann in Schritt 1 des nächsten
Durchgangs verwendet. Nur ein Zwanzigstel der Produkte, die in jedem
Schritt des Zyklus gebildet wurden, wurde in den darauf folgenden Zyklen
verwendet, sodass die Abfolge der Selektion zurückverfolgt werden konnte. Der
Fortschritt des Selektionsverfahrens wurde durch Filterbindungstests
von markierten Transkripten aus jeder PCR-Reaktion beobachtet. Nach
dem vierten Selektions- und Amplifikationsdurchgang produzierten
die markierten selektierten RNA-Produkte Bindung an gp43, die jener
von Wildtyp-Kontroll-RNA entsprach. Die RNA-Produkte aus jedem Durchgang
für einen
Versuch (B) und aus dem vierten Durchgang für alle drei Versuche wurden
gelgereinigt und sequenziert. In 3 zeigen
die Erfinder die Sequenz der gereinigten In-vitro-Transkripte, abgeleitet
aus den zweiten, dritten und vierten Durchgängen von Selektion und Amplifikation
für Versuch
B. Es ist eindeutig, dass es keine offensichtliche Schleifensequenzvorgabe
gab, die bis nach der dritten Selektion eingeführt wurde. Zu diesem Zeitpunkt
der Selektion gab es eine nachweisbare Vorgabe, die mit dem vierten
Durchgang für die
ersichtliche Consensus-Sequenz A(a/g)(u/c)AAC(u/c)(u/c) vollständig war.
Chargen-Sequenzierung
der RNA, die nach der vierten Selektion und Amplifikation für die Versuche
A, B und C transkribiert wurde, ist in 4 gezeigt.
Alle drei unabhängigen
Versuche mit verschiedenen Protein/RNA-Verhältnissen ergaben ähnliche
Resultate. Es gibt eine ersichtliche Vorgabe für Wildtyp-Sequenz an jeder
der vier „variablen" Positionen in den
Versuchen A und C.
-
Um
herauszufinden, welche zulässigen
Kombinationen tatsächlich
existierten, verwendeten die Erfinder zwei „Klonierungs"-Oligonucleotide,
die Restriktionsstelleninformation enthielten, um Sequenzen aus
RNA aus dem vierten Durchgang von Versuch B zu amplifizieren, aus
dem einzelne in pUC18 wie beschrieben (Sambrook et al. (1989), s.o.;
Innis et al. (1988), s.o.) kloniert wurden. Die selektierten Chargen
aus Versuch B wurden zur weiteren Untersuchung ausgewählt, da
es eine ausgeglichene Verteilung der zwei zulässigen Nucleotide zu geben
schien, die jeweils die vier „variablen" Positionen bildeten.
Zwanzig einzelne Klone, die durch Koloniefilterhybridisierung an
den 3'-Primer identifiziert
wurden, wurden sequenziert. Keiner dieser einzelnen Klone waren
an irgendeiner Stelle in der Operatorsequenz außerhalb der Schlei fensequenzpositionen, die
absichtlich variiert waren, mutiert. Die Sequenzverteilungen sind
in 7 zusammengefasst. Überraschenderweise bestand
das selektierte RNA-Gemisch tatsächlich
aus zwei Hauptschleifensequenzen. Eine war die Wildtyp-Sequenz, AAUAACUC,
von der 9 von 20 isoliert wurden. Die andere, AGCAACCU, war an vier
Positionen mutiert und in 8 der 20 Klone vorhanden (siehe 7).
Die anderen drei detektierten Schleifensequenzen waren einzelne
Mutationen dieser zwei Hauptsequenzen. Filterbindungsversuche mit
markierten In-vitro-Transkripten, die aus jedem dieser klonalen
Isolate abstammten, wiesen darauf hin, dass eine ungefähre Korrelation
zwischen Bindungsaffinität
einer RNA für
gp43 und selektierter Häufigkeit
bestand (siehe 7).
-
Beispiel 2: Isolierung
eines spezifischen RNA-Liganden für HIV-Umkehrtranskriptase
-
Die
Umkehrtranskriptasen-Aktivität
von HIV-1 setzt sich aus einem Heterodimer aus zwei Untereinheiten
(p51 und p66) zusammen, die Amino-Termini gemeinsam haben. Die zusätzliche
carboxyterminale Region des größeren Peptids
umfasst die RNaseH-Domäne
von reverser Transkriptase; die Struktur dieser Domäne wurde
erst jüngst
in hoher Auflösung
bestimmt.
-
Es
wurde bereits davor gezeigt, dass diese HIV-1-Umkehrtranskriptase
direkt und spezifisch mit ihrem zugehörigen Primer tRNALys3 wechselwirkt,
mit dem sie in einem Versuch an der Anticodon-Schleife und dem Anticodon-Stamm
vernetzt war. Auch wurde erkannt, dass nur das Heterodimer diese
spezifische RNA-Erkennung aufwies; keine der homodimeren Spezies
von reverser Transkriptase band sich mit Spezifität an diese tRNA.
-
Zwei
Matrixpopulationen (mit etwa 1014 verschiedenen
Sequenzen jeweils) wurden zur Verwendung in SELEX durch Ligation
geschaffen. Eine Matrixpopulation wurde über 32 Nucleotidpositionen
hinweg randomisiert, wobei fixierte Sequenzen an den Enden der randomisierten
Region verwendet wurden, um cDNA-Synthese und PCR-Amplifikation zu
gewähren.
Die zweite Matrixpopulation wies, als zusätzliche fixierte Sequenz am
5'-Ende der RNA,
die Anticodon-Schleife und den Anticodon-Stamm von tRNALys3 auf.
(Alle in dieser Arbeit verwendeten Oligos sind in Tabelle 2 gezeigt.)
Es gab keinen Unterschied in der Affinität der zwei randomisierten Populationen
zu HIV-1-Umkehrtranskriptase [RT] (und, wie gezeigt wird, die RNAs,
die selektiert wurden, verwendeten auch keine 5'-Region zur spezifischen Bindung). Neun
Durchgänge
von SELEX mit jeder Population wurden unter Verwendung des Heterodimers
HIV-RT als Targetprotein durchgeführt.
-
Der
Mechanismus, durch den die randomisierte DNA unter Verwendung von
Ligationen und Verbrückungs-Oligonucleotiden
hergestellt wurde, wurde bereits zuvor beschrieben. Solch eine Vorgehensweise kann
die Gesamtanzahl an verschiedenen Sequenzen in der Ausgangspopulation
von der theoretischen Grenze weg, die durch DNA-Synthese mit μmol-Maßstab auferlegt
wird, reduzieren.
-
In
diesen Ligationsreaktionen wurde etwa 1 nmol von jedem Oligonucleotid
verwendet. Das Ligationsprodukt wurde bei einer Ausbeute von etwa
50 % gelgereinigt. Diese gereinigte Matrix wurde mit T7-RNA-Polymerase
wie zuvor beschrieben transkribiert. Es wurde erkannt, dass HIV-RT
diese zufällige
Population auf sättigungsfähige Weise
binden konnte, wobei eine halbmaximale Bindung bei etwa 7 × 10–7 M
eintrat, wie durch Nitrocellulosetests bestimmt wurde. Alle RNA-Protein-Bindungsreaktionen
erfolgten in einem Bindungspuffer aus 200 mM KOAc, 50 mM Tris-HCl,
pH 7,7, 10 mM Dithiothreit. RNA und Proteinverdünnungen wurden vermischt und
auf Eis 30 min lang gelagert und anschließend auf 37°C für 5 min transferiert. (In den
Bindungstests beträgt
das Reaktionsvolumen 60 μl,
von denen 50 μl
getestet werden; in SELEX-Durchgängen
beträgt das
Reaktionsvolumen 100 μl.)
Jede Reaktion wird durch ein (mit Bindungspuffer) vorbenetztes Nitrocellulosefilter
gesaugt und mit 3 ml Bindungspuffer gespült, wonach sie getrocknet und
für Tests
gezählt
oder Elution als Teil der SELEX-Arbeitsvorschrift unterzogen werden.
Neun Durchgänge
wurden durchgeführt.
Die RNA-Konzentration für
alle neun Durchgänge
betrug etwa 3 × 10–5 M.
HIV-RT betrug 2 × 10–8 M
bei der ersten Selektion und 1 × 10–8 in
den Selektionen 2–9.
-
Der
Versuch unter Verwendung von RNA, die die tRNALys3-Anticodon-Schleife
und den -stamm enthält, wurde
zuerst abgeschlossen. Nitrocellulosefilter-Bindungstests, die im
neunten Durchgang durchgeführt
wurden, zeigten, dass die RNA-Population im Vergleich zum Ausgangskandidatengemisch
um etwa das 100fache erhöhte
Affinität
zu NIV-1-RT aufwies, dass jedoch die Hintergrundbindung an Nitrocellulosefilter
in Abwesenheit von Protein von etwa 2 % von Eingangs-RNA auf 15
% gestiegen war. Einzelne Sequenzen wurden aus dieser Population
kloniert (nach Filtration durch Nitrocellulosefilter, um einen Teil
des hohen Hintergrunds von potenziellen Sequenzen, die auf Zurückhaltung
durch die Filter alleine selektiert wurden, zu zerstören) und sind
in Tabelle 3 aufgelistet. Nitrocellulosefilter-Bindungstests zur
Affinität
von selektierten Sequenzen zu HIV-RT sind in 14 gezeigt.
Manche der Sequenzen wurden als Liganden für HIV-RT selektiert, wie durch die
Bindungskurven der Liganden 1.1 und 1.3a beispielhaft gezeigt wird,
und weisen gewisse Sequenzhomologie auf, wie in den Tabellen 4 und
5 veranschaulicht wird. Manche der Ligandensequenzen weisen signifikante
Zurückhaltung
an Nitrocellulosefiltern in Abwesenheit von Protein auf, wofür Ligand
1.4 als Beispiel steht (14),
und scheinen durch eine lange Helix mit einer Schleife aus Purin-Wiederholungselementen
charakterisiert zu sein (wie in Tabelle 4 gezeigt). Trotz der geringen
und späten
Bemühungen
der Erfinder, sie in diesem Versuch vor dem Klonieren zu zerstören, stellten
diese Sequenzen einen signifikanten Teil von jenen dar, die aus
diesem Versuch abgenommen wurden.
-
Folglich
wurde Versuch 2 (der eine unterschiedliche 5'-fixierte Sequenz einband) durch Nitrocellulose vor
dem ersten, dritten, sechsten und neunten Selektionsdurchgang vorfiltriert.
Die aus diesem Versuch abgenommenen Sequenzen sind in Tabelle 6
gezeigt. Wiederum gibt es zahlreiche Sequenzen mit Homologie zu jenen
mit hoher Affinität
aus Versuch 1, wie in den Tabellen 4 und 5 gezeigt ist. Es gibt
jedoch viel weniger, wenn überhaupt,
Sequenzen, die mit dem Motiv von Sequenzen übereinstimmen, die durch Nitrocellulosefilter alleine
zurückgehalten
werden. Nitrocellulose-Bindungstests
von selektierten Ligandensequenzen aus diesem Versuch, verglichen
mit jenen von Ligand 1.1, sind in 15 gezeigt.
-
Hochaffine
Liganden-RNAs mit der häufigsten
Sequenz (1.1) und einer ähnlichen
Sequenz (1.3a) wurden näher
analysiert, um die Informationsgrenzen zu bestimmen, die für hochaffine
Bindung an HIV-1-RT erforderlich sind. Die Resultate aus diesen
Versuchen sind in 16 gezeigt. Diese
Versuche stellen fest, dass das Motiv, das diese Sequenzen gemein
haben, UUCCGNNNNNNNNCGGGAAA, innerhalb der Erkennungsdomäne ähnlich positioniert
ist. Die Sequenzen UUCCG und CGGGA aus diesem Motiv können Basenpaare formen,
um eine RNA-Helix mit einer 8-Basen-Schleife zu bilden. Um zu entdecken,
was neben diesen fixierten Sequenzen zu hochaffiner Bindung an HIV-1-RT
betragen könnte,
wurde eine Kandidatengemischmatrix geschaffen, die zufällige Inkorporation
an den Nucleotidpositionen enthielt, die sich von diesen zwei Sequenzen unterscheiden,
wie in Tabelle 7 gezeigt ist. Nach acht SELEX-Durchgängen wurden
einzelne Sequenzen kloniert und sequenziert. Die 46 Sequenzen sind
in Tabelle 7 gezeigt. Eine Untersuchung dieser Sequenzen zeigt umfassende
Basenpaarung zwischen der zentralen variablen 8n-Region und der
variablen 4n-Stromab-Region und flankierenden Sequenzen; Basenpaarung,
die in Kombination mit jener zuvor erläuterten auf einen RNA-Pseudoknoten
hinweisen würde.
Dass keine spezifischen Sequenzen in dieser entwickelten Population überwiegen,
lässt darauf
schließen,
dass es keine Selektion auf primärem
Sequenzniveau gibt und dass Selektion ausschließlich auf Grundlage von Sekundärstruktur
stattfindet, das heißt,
dass es zahlreiche Sequenzkombinationen gibt, die ähnliche
Affinitäten
zu HIV-1-RT ergeben und keine davon einen Konkurrenzvorteil aufweist.
Eine Analyse der ersten und zweiten SELEX-Versuche zeigt, dass die
einzelnen Sequenzen, die jene Populationen umfassen, die Homologie
zum UUCCG...CGGGANAA-Motiv aufweisen, auch ein starkes Potenzial
für diese
Pseudoknoten-Basenpaarung aufzeigen.
-
31 zeigt ein schematisches Diagramm davon, was
hierin als Pseudoknoten bezeichnet wird. Ein Pseudoknoten besteht
aus zwei helikalen Abschnitten und drei Schleifenabschnitten. Nicht
alle Pseudoknoten enthalten alle drei Schleifen. Zur Interpretation
der gewonnenen Daten wurden die verschiedenen Abschnitte des Pseudoknotens
wie in 31 gezeigt markiert. In Tabelle
5 beispielsweise sind die in den Versuchen 1 und 2 gewonnenen Sequenzen
gemäß der Pseudoknoten-Konfiguration
aufgelistet, die von den verschiedenen Sequenzen eingenommen wird.
-
Die
Resultate aus den Versuchen 1 und 2, wie in Tabelle 5 definiert,
führten
zu Versuch 3, worin die Sequenzen in S1(a), S1(b) und L3 fixiert
waren. Wiederum wurden die aus SELEX abgeleiteten Nucleinsäuren beinahe
ausschließlich
zu Pseudoknoten konfiguriert. Eine Untersuchung der Resultate in
jedem der Versuche zeigt, dass die Nucleinsäurelösung zu HIV-RT eine relativ
große
Anzahl an Elementen enthält,
wobei der grundlegendste gemeinsame Nenner die Tatsache ist, dass
alle als Pseudoknoten konfiguriert sind.
-
Andere
allgemeine Feststellungen, die die Nucleinsäurelösung für HIV-RT definieren, sind die
folgenden:
- 1) S1(a) umfasst häufig die
Sequenz 5'-UUCCG-3', und S1(b) umfasst
häufig
die Sequenz 5'-CGGGA-3'. Basenpaar-Drehungen
sind jedoch zugelassen, und der Stamm kann gekürzt werden.
- 2) L1 kann kurz oder lang sein, umfasst jedoch häufig zwei
Nucleotide in den am besten bindenden Nucleinsäuren. Das 5'-Nucleotid in L1 ist häufig entweder
ein U oder ein A.
- 3) S2 besteht üblicherweise
aus 5 oder 6 Basenpaaren und scheint sequenzunabhängig zu
sein. Dieser Stamm kann Nicht-Watson/Crick-Paare enthalten.
- 4) L2 kann aus keinen Nucleotiden bestehen, wenn er jedoch daraus
besteht, so sind die Nucleotide vorzugsweise As.
- 5) L3 besteht im Allgemeinen aus 3 oder mehr Nucleotiden, angereichert
an A.
- 6) In den meisten durch SELEX gewonnenen Sequenzen beläuft sich
die Gesamtanzahl von Nucleotiden in L1, S2(a) und L2 auf 8.
-
Eine
primäre
Absicht bei der Durchführung
dieses Versuchs war, Ligandenlösungen
zu HIV-1-RT zu finden. Die Fähigkeit
des erzeugten Ligandenklons 1.1 wurde mit der Fähigkeit der Ausgangspopulation
für Versuch
1 verglichen, Aktivität
von reverser Transkriptase zu inhibieren, und dies wird in 17 gezeigt. Sogar bei gleichen Kon zentrationen
von Inhibitor-RNA und RT wird die reverse Transkriptase durch Ligand
1.1 signifikant inhibiert. Dahingegen gibt es erst bei 10 mM (oder
einem 200fachen Überschuss)
von Ausgangspopulation-RNA eine signifikante Inhibierung der HIV-1-RT. Somit blockiert
der hochaffine Ligand zu HIV-1-RT entweder die katalytische Stelle
des Enzyms oder er wechselwirkt direkt mit dieser Stelle.
-
Um
die Spezifität
dieser Inhibierung zu testen, wurden verschiedene Konzentrationen
von Ligand 1.1 auf Inhibierung von MMLV, AMV und HIV-1-Umkehrtranskriptase
getestet. Die Resultate aus diesem Versuch, die in 18 dargestellt sind, zeigen, dass die Inhibierung
von Ligand 1.1 zu HIV-1-Umkehrtranskriptase spezifisch ist.
-
Beispiel 3: Isolierung
von spezifischem RNA-Liganden für
Bakteriophagen-R17-Hüllprotein
-
SELEX
wurde am Bakteriophagen-R17-Hüllprotein
durchgeführt.
Das Protein wurde wie von Carey et al., Biochemistry 22, 2601 (1983),
beschrieben gereinigt. Der Bindungspuffer war 100 mM Kaliumacetat
plus 10 mM Dithiothreit plus 50 mM Tris-Acetat, pH 7,5. Protein und RNA wurden
zusammen 3 min lang bei 37°C inkubiert
und anschließend
an Nitrocellulosefiltern filtriert, um proteingebundene RNA von
freier RNA zu trennen. Die Filter wurden mit 50 mM Tris-Acetat,
pH 7,5, gewaschen. Protein lag bei 1,2 × 10–7 M
in den ersten vier SELEX-Durchgängen
und bei 4 × 10–8 in
den Durchgängen
5 bis 11.
-
Die
Ausgangs-RNA wurde aus DNA wie zuvor beschrieben transkribiert.
Die DNA-Sequenz
umfasst eine Bakteriophagen-T7-RNA-Polymerase-Promotorsequenz, die
es ermöglicht,
dass RNA gemäß herkömmlichen
Verfahren synthetisiert wird. cDNA-Synthese während der Amplifikationsphase
des SELEX-Zyklus wird mittels einer DNA mit der Sequenz:
cDNA-Primer
(PCR-Primer 1):
5'GTTTCAATAGAGATATAAAATTCTTTCATAG3'
geprimt.
-
Die
DNA-Primer, die zur Amplifikation der cDNA verwendet wurden, waren
somit die Sequenz einschließlich
des T7-Promotors, 32 randomisierte Positionen, ein AT-Dinucleotid und die
fixierte, zu PCR-Primer 1 komplementäre Sequenz. Die RNA, die verwendet
wurde, um den ersten Zyklus von SELEX zu beginnen, hat also die
Sequenz:
pppGGGAGCCAACACCACAAUUCCAAUCAAG-32N-AUCUAUGAAAGAAUUUUAUCUCUAUUGAAAC
-
Eine
Reihe von Klonen von nach dem 11. Durchgang von SELEX wurde gewonnen
und sequenziert. Innerhalb der 38 verschiedenen Sequenzen, die in
den 47 Klonen erhalten wurden, wurden drei mehr als einmal gefunden:
eine Sequenz wurde sechsmal gefunden, eine Sequenz viermal und eine
weitere Sequenz zweimal. Die übrigen
35 Sequenzen wurden jeweils einmal gefunden. Zwei Sequenzen waren
hinsichtlich der Primärsequenzen
oder wahrscheinlichen Sekundärstrukturen
den anderen nicht ähnlich
und wurden nicht näher
analysiert. Sechsunddreißig
Sequenzen wiesen alle die Sequenz ANCA auf, die als eine Tetranucleotidschleife
einer ausgeweiteten Haarnadel angeordnet war; das ausgeweitete Nucleotid
war ein Adenin in allen 36 Fällen.
Die Sequenzen der gesamten Reihe sind in Tabelle 8 angegeben, abgeglichen
mit den vier Nucleotiden der Haarnadelschleife. Die zwei Nucleotide
3' zum randomisierten
Abschnitt der Ausgangs-RNA (ein AU) können verändert oder deletiert werden,
da der cDNA-Primer die komplementären zwei Nucleotide nicht umfasst;
in zahlreichen Klonen ist eines oder beide dieser Nucleotide verändert.
-
Das
Gewinner-RNA-Motiv, das in
19 gezeigt
wird, weist eine direkte Beziehung zur Hüllbindungsstelle auf, die davor
in Studien zu ortsgerichteter Mutagenese und Bindung identifiziert
wurde. Siehe Uhlenbeck et al. (1983), s.o.; Ramaniuk et al. (1987),
s.o. Manche der Sequenzen sind jedoch in dieser Reihe stärker konserviert
als erwartet worden wäre.
Die Schleifensequenz AUCH ist vorwiegend vorhanden, während frühere Bindungsdaten
darauf schließen
lassen hätten
können,
dass ANCA-Sequenzen
alle äquivalent
sind. Die natürliche
Bindungsstelle des R17-Genoms umfasst die nachstehend gezeigte Sequenz
und Struktur:
-
Die
natürliche
Struktur umfasst die Sequenz GGAG, die dazu dient, Ribosomenbindung
und Translationsinitiation der für
R17-Replikase kodierenden Region zu erleichtern. Während SELEX
kommt dieses Erfordernis nicht zu tragen, und die gewinnenden Sequenzen
enthalten rund um die Schleife und die Ausweitung häufiger C:G-Basenpaare als G:C-Basenpaare.
SELEX erleichtert daher die Einschränkungen, die durch Biologie
und Entwicklungsgeschichte auferlegt werden, und führt zu Liganden
mit höheren
Affinitäten
als der natürliche
Ligand. In ähnlicher
Weise ist das Schleifen-Cytidin, das in jeder der 36 Sequenzen zu
finden ist, ein Uridin an der natürlichen Stelle, und es ist
bekannt, dass C höhere
Affinität
als U liefert. Im Laufe der Entwicklungsgeschichte müssen natürliche Stellen
eher eine geeignete Affinität
und nicht die höchste
Affinität
aufgewiesen haben, da die festeste Bindung zu Nachteilen für die Organismen
führen
kann.
-
Beispiel 4: Isolierung
eines Nucleinsäureliganden
für eine
Serinprotease.
-
Serinproteasen
sind Proteinenzyme, die Peptidbindungen innerhalb von Proteinen
spalten. Die Serinproteasen sind Elemente einer Genfamilie von Säugetieren
und sind wichtige Enzyme im Leben von Säugetieren. Serinproteasen sind
nicht dafür
bekannt, sich an Nucleinsäuren
zu binden. Beispiele für
Serinproteasen sind Gewebeplasminogenaktivator, Trypsin, Elastase,
Chymotrypsin, Thrombin und Plasmin. Zahlreiche Erkrankungszustände können mit
Nucleinsäureliganden
behandelt werden, die sich an Serinproteasen binden, beispielsweise
Störungen
der Blutgerinnung und Thrombenbildung. Proteasen, die keine Serinproteasen
sind, sind in der Biologie von Säugetieren
auch wichtig, und würden
ebenfalls Targets für
Nucleinsäureliganden
mit geeigneten Affinitäten
darstellen, die gemäß der Erfindung
wie hierin beschrieben gewonnen werden.
-
Menschlicher
Gewebeplasminogenaktivator (htPA), der bei handelsüblichen
Quellen erhältlich
ist, wurde als eine Serinprotease ausgewählt, die dem SELEX-Verfahren
dieser Erfindung unterzogen werden soll. Das verwendete RNA-Kandidatengemisch
war mit jenem identisch, das in Beispiel 11 unten im HSV-DNA-Polymeraseversuch
beschrieben wird.
-
Bindung
während
SELEX erfolgte in 50 mM NaCl plus 50 mM Tris-Acetat, pH 7,5, 3 min
lang bei 37°C. SELEX
wurde in zehn Durchgängen
durchgeführt.
Das 30N-Kandidatengemisch
band sich an tPA mit einer Affinität (Kd) von 7 × 10
–8 M
in 150 mM NaAc plus 50 mM Tris-Acetat, pH 7,5; die Affinität der nach
neun Durchgängen
von SELEX vorhandenen RNA war etwa dreifach stärker. Neun Klone wurden isoliert,
sequenziert, und die meisten von ihnen wurden auf Bindung an tPA
als reine RNAs getestet. Die Sequenzen der neun bei geringem Salzgehalt
gewonnenen Klone waren die folgenden:
-
Alle
getesteten Sequenzen banden sich zumindest etwas besser als das
Ausgangs-30N-Kandidatengemisch.
Die A-Reihe band sich jedoch besser an Nitrocellulose in Abwesenheit
von tPA als das Kandidatengemisch, als ob das gemeinsame Sequenzmotiv
Zurückhaltung
an der Nitrocellulosematrix durch sich selbst verursachen würde. Dieses
Motiv ist in den oben gezeigten Sequenzen unterstrichen. In anderen
SELEX-Versuchen wurden AGG-Wiederholungen isoliert, als versucht
wurde, eine Ligandenlösung
zu HIV-1-Umkehrtranskriptase, der extrazellulären Domäne von menschlichem Wachstumsfaktorrezeptor
und sogar dem R17-Hüllprotein
in einem ersten Walking-Versuch zu identifizieren. Bei der Durchführung des
Tests zeigen diese Sequenzen bescheidene oder wesentliche Bindung
an Nitrocellulosefilter, und dies ohne Gegenwart des Targetproteins.
Es scheint, dass die AGG-Wiederholungen in Haarnadelschleifen gefunden
werden können.
Da SELEX ein sich wiederholendes Verfahren in den meisten Ausführungsformen
ist, ist es nicht überraschend,
dass solche Bindungsmotive entstehen würden.
-
Die
Existenz von Nitrocellulose-Bindungsmotiven kann durch eine oder
mehrere von einigen naheliegenden Vorgehensweisen vermieden werden.
RNA kann vor SELEX durch die Nitrocellulosefilter filtriert werden,
um solche Motive zu entfernen. Alternative Matrices können in
alternativen Durchgängen
von SELEX verwendet werden, z.B. Glasfaserfilter. Alternative Abtrennungssysteme
können
verwendet werden, z.B. Säulen, Saccharosegradienten
usw. Es ist naheliegend, dass jegliches gegebene einzelne Verfahren
zu Vorgaben im sich wiederholenden Verfahren führen wird, die Motive bevorzugen,
die keine erhöhte
Bindung zum Target aufweisen, jedoch durch das Selektionsverfahren
selektiert werden. Es ist daher wichtig, alternierende Verfahren oder
Screeningverfahren zu verwenden, um diese Motive zu entfernen. Es
wurde gezeigt, dass die AGG-Wiederholungen, wie andere Motive, die
als Vorgaben, die Target-unabhängig
sind, isoliert werden, dazu neigen, am häufigsten aufzutreten, wenn
die Affinitäten
der besten Sequenzen für
das Target eher gering sind oder wenn die Affinitäten der
besten Sequenzen nur geringfügig
besser sind als die Affinität
des Ausgangskandidatengemisches für das Target.
-
Beispiel 5: Isolierung
eines Nucleinsäureliganden
für einen
Säugetierrezeptor
-
Säugetierrezeptoren
sind häufig
Proteine, die innerhalb der zytoplasmatischen Membranen von Zellen liegen
und auf Moleküle
reagieren, die außerhalb
solcher Zellen zirkulieren. Die meisten Rezeptoren sind nicht dafür bekannt,
sich an Nucleinsäuren
zu binden. Der menschliche Wachstumshormonrezeptor reagiert auf
zirkulierendes menschliches Wachstumshormon, während der Insulinrezeptor auf
zirkulierendes Insulin reagiert. Rezeptoren weisen häufig einen
globulären
Teil des Moleküls
an der extrazellulären
Seite der Membran auf, und dieser globuläre Teil bindet sich spezifisch
an das Hormon (das der natürliche
Ligand ist). Zahlreiche Erkrankungszustände können mit Nucleinsäureliganden
behandelt werden, die sich an Rezeptoren binden.
-
Liganden,
die sich an eine lösliche
globuläre
Domäne
des menschlichen Wachstumshormonrezeptors (shGHR) binden, werden
identifiziert und unter Verwendung des Kandidatengemisches aus Beispiel
4 gereinigt. Wiederum sind die Bindungspuffer frei von DTT. Die
lösliche
globuläre
Domäne
des menschlichen Wachstumshormonrezeptors ist im Handel und bei
universitären
Stellen erhältlich
und wird üblicherweise
durch DNA-Rekombinationsverfahren gebildet, die am gesamten Gen,
das für
ein membrangebundenes Rezeptorprotein kodiert, angewandt werden.
SELEX wird wiederholt verwendet, bis Liganden gefunden werden. Die
Liganden werden kloniert und sequenziert, und Bindungsaffinitäten für den löslichen
Rezeptor werden gemessen. Bindungsaffinitäten werden für denselben
Liganden für
verschiedene lösliche
Rezeptoren gemessen, um Spezifität
zu ermitteln, auch wenn die meisten Rezeptoren keine starken Proteinhomologien
zu den extrazellulären
Domänen
anderer Rezeptoren aufweisen. Die Liganden werden verwendet, um
Inhibierung der normalen Bindungsaktivität von shGHR durch Messen kompetitiver
Bindung zwischen dem Nucleinsäureliganden und
dem natürlichen
(Hormon-) Liganden zu bewerten.
-
Beispiel 6: Isolierung
eines Nucleinsäureliganden
für ein
Säugetierhormon
oder einen Säugetierfaktor
-
Säugetierhormone
oder -faktoren sind Proteine, z.B. Wachstumshormon, oder kleine
Moleküle
(z.B. Epinephrin, Schilddrüsenhormon),
die im Tier zirkulieren und ihre Wirkungen durch Kombinieren mit
Rezeptoren, die innerhalb der zytoplasmatischen Membranen von Zellen
liegen, ausführen.
Das menschliche Wachstumshormon beispielsweise stimuliert Zellen
zuerst durch Wechselwirken mit dem menschlichen Wachstumshormonrezeptor,
während
Insulin Zellen zuerst durch Wechselwirkung mit dem Insulinrezeptor
stimuliert. Zahlreiche Wachstumsfaktoren, z.B. Granulozytenkolonie-stimulierender
Faktor (GCSF), einschließlich
mancher, die zelltypspezifisch sind, Wechselwirken zuerst mit Rezeptoren
an den Targetzellen. Hormone und Faktoren sind dann natürliche Liganden
für manche
Rezeptoren. Hormone und Faktoren sind üblicherweise nicht dafür bekannt,
sich an Nucleinsäuren
zu binden. Zahlreiche Erkrankungszustände, beispielsweise Schilddrüsenüberfunktion,
chronische Hypoglykämie,
können
mit Nucleinsäureliganden,
die sich an Hormone oder Faktoren binden, behandelt werden.
-
Liganden,
die sich an menschliches Insulin binden, werden unter Verwendung
des Ausgangsmaterials aus Beispiel 3 identifiziert und gereinigt.
Menschliches Insulin ist bei handelsüblichen Quellen erhältlich und wurde üblicherweise
durch DNA-Rekombinationsverfahren
gebildet. SELEX wird wiederholt verwendet, bis ein Ligand gefunden
wurde. Die Liganden werden kloniert und sequenziert, und die Bindungsaffinitäten für menschliches
Insulin werden gemessen. Bindungsaffinitäten werden für denselben
Liganden zu anderen Hormonen oder Faktoren gemessen, um Spezifität festzustellen,
auch wenn die meisten Hormone und Faktoren keine starken Proteinhomologien
zu menschlichem Insulin aufzeigen. Es bestehen jedoch manche Hormon- und
Faktor-Genfamilien, einschließlich
einer kleinen Familie von IGF oder insulinähnlichen Wachstumsfaktoren.
Die Nucleinsäureliganden
werden verwendet, um Inhibierung der normalen Bindungsaktivität von menschlichem
Insulin zu seinem Rezeptor durch Messen kompetitiver Bindung mit
dem Insulinrezeptor und dem Nucleinsäureliganden in Gegenwart oder
Abwesenheit von menschlichem Insulin, dem natürlichen Liganden, zu bewerten.
-
Beispiel 7: Herstellung
von Säulenmatrix
für SELEX
-
Nach
den in Beispiel 9, unten, beschriebenen Verfahren wurde gezeigt,
dass das Polypeptid Bradykinin durch Nitrocellulose nicht zurückgehalten
wird. Um das SELEX-Verfahren
für Bradykinin
zu ermöglichen, wurde
das Protein an Activated CH Sepharose 4B (Pharmacia LKB) als Trägermatrix
gemäß herkömmlichen Verfahren
gebunden. Die resultierende Matrix wurde durch den Ninhydrintest
auf 2,0 mM Bradykinin bestimmt. Siehe CrestField et al., J. Biol.
Chem., Bd. 238, S. 238, S. 622–627
(1963); Rosen, Arch. Biochem. Biophys. 67, 10–15 (1957). Die aktivierten
Gruppen, die an der Trägermatrix
zurückblieben,
wurden mit Tris blockiert. Siehe Pharmacia, Affinity Chromatography:
Principles and Methods, Ljungforetagen AB, Uppsala, Schweden (1988).
-
Zentrifugensäulentrennung
wurde verwendet, um Lösungen
von Kandidatengemischen mit Perlenmatrix zu kontaktieren. In einem
allgemeinen Verfahren zur Durchführung
eines Selektionsschrittes aus SELEX wurden 40 μl einer 50:50-Aufschlämmung von
Targetsepharose in Reaktionspuffer in ein 0,5-ml-Eppendorf-Röhrchen übertragen.
Das RNA-Kandidatengemisch wurde mit 60 μl Reaktionspuffer zugesetzt,
das Reaktionsgemisch wurde 30 min lang bei 37°C äquilibrieren gelassen. In den
Boden des Röhrchens
wird ein Loch gebohrt, und das Röhrchen
wird innerhalb eines größeren Eppendorf-Röhrchens
platziert, beide Kappen werden entfernt, und die Röhrchen werden
zentrifugiert (1.000 U/min, 10",
21°C), um
das Eluat abzutrennen. Das kleine Röhrchen wird dann in ein neues
größeres Röhrchen transferiert,
und die Inhalte werden viermal durch Schichtung mit 50 μl des selektierten
Waschpuffers und Zentrifugieren gewaschen. Um Bindungstests durchzuführen, wird
das die radioaktive RNA enthaltende Röhrchen in ein neues Eppendorf-Röhrchen transferiert und
bis zur Trockenheit zentrifugiert.
-
Ein
Hauptteil-Bindungsversuch wurde durchgeführt, worin ein RNA-Kandidatengemisch,
das aus einem 30 Nucleinsäuren
langen, randomisierten Segment bestand, auf die Bardykinin-Sepharose-Matrix
aufgetragen wurde. Unter Verwendung des Zentrifugensäulenverfahrens
wurde die Bindung der Haupt-30N-RNA an verschiedene Matrices unter
hohen Salzkonzentrationen bestimmt, um die besten Bedingungen zur
Minimierung von Hintergrundbindung an Sepharose zu ermitteln. Hintergrundbindung
von RNA an Sepharose wurde durch Blockieren von aktivierten Gruppen
an der Sepharose mit Tris und Verwendung eines Bindungspuffers von
10 mM DEM und 10–20
mM KOAc minimiert. Bei dieser Pufferbedingung ergab eine Bindungskurve
der randomisierten Hauptlösung
von RNA eine Haupt-Kd von etwa 1,0 × 10–5.
Siehe 20. Die Kurve wurde durch Verdünnen der
Bradykininsepharose gegen blockierte, aktivierte Sepharose bestimmt.
-
Beispiel 8: Herstellung
von Kandidatengemischen, die gesteigerte RNA-Motivstrukturen aufweisen
-
In
der bevorzugten Ausführungsform
besteht das in SELEX zu verwendende Kandidatengemisch aus einer
zusammenhängenden
Region von zwischen 20 und 50 randomisierten Nucleinsäuren. Das
randomisierte Segment ist durch fixierte Sequenzen flankiert, die
die Amplifikation der selektierten Nucleinsäuren ermöglichen.
-
In
einer alternativen Ausführungsform
werden die Kandidatengemische gebildet, um den Prozentsatz von Nucleinsäuren im
Kandidatengemisch zu erhöhen,
die die gegebenen Nucleinsäuremotive
aufweisen. Obwohl hierin zwei spezifische Beispiele angegeben werden,
ist diese Erfindung nicht darauf beschränkt. Fachleute werden in der
Lage sein, äquivalente
Kandidatengemische zu bilden, um dasselbe allgemeine Resultat zu
erzielen.
-
In
einem spezifischen Beispiel, das als Sequenz A in 21 gezeigt ist, wird das Kandidatengemisch so
hergestellt, dass die meisten der Nucleinsäuren im Kandidatengemisch vorgegeben
werden, um eine Helixregion von zwischen 4 und 8 Basenpaaren und
eine „Schleife" mit entweder 20
oder 21 zusammenhängenden
randomisierten Sequenzen zu bilden. Sowohl das 5'- als auch das 3'-Ende des Sequenzgemisches enthält fixierte
Sequenzen, die für
die Amplifikation der Nucleinsäuren
wesentlich sind. Benachbart zu diesen funktionellen fixierten Sequenzen
liegen fixierte Sequenzen, die ausgewählt werden, um mit fixierten
Sequenzen an der anderen Seite der randomisierten Region Basenpaare
zu bilden. Vom 5'-
zum 3'-Ende der
Sequenzen erstrecken sich 5 unterschiedliche Regionen: 1) fixierte
Sequenzen zur Amplifikation; 2) fixierte Sequenzen zur Bildung einer
Helixstruktur; 3) 20 oder 21 randomisierte Nucleinsäurereste;
4) fixierte Sequenzen zur Bildung einer Helixstruktur mit den Region-2-Sequenzen;
und 5) fixierte Sequenzen zur Amplifikation. Das A-Kandidatengemisch
aus 21 ist mit Haarnadelmotiven
und symmetrischen und asymmetrischen ausgeweiteten Motiven angereichert.
In einer bevorzugten Ausführungsform
enthält
das Kandidatengemisch gleiche Mengen an Sequenzen, in denen die
randomisierte Region 20 und 21 Basen lang ist.
-
Ein
zweites Beispiel, das in 21 als
Sequenz B gezeigt ist, wird entworfen, um das Kandidatengemisch
an Nucleinsäuren
anzureichern, die im Pseudoknotenmotiv gehalten werden. In diesem
Kandidatengemisch flankieren die fixierten Amplifikationssequenzen
drei Regionen von 12 randomisierten Positionen. Die drei randomisierten
Regionen sind durch zwei fixierte Regionen aus vier Nucleotiden
getrennt, und die fixierten Sequenzen sind ausgewählt, um
vorzugsweise eine 4-Basenpaar-Helixstruktur
zu bilden. Vom 5'-
hin zum 3'-Ende
der Sequenz sind 7 unterschiedliche Regionen zu finden: 1) fixierte
Sequenzen zur Amplifikation; 2) 12 randomisierte Nucleotide; 3)
fixierte Sequenzen zur Bildung einer Helixstruktur; 4) 12 randomisierte
Nucleotide; 5) fixierte Sequenzen zur Bildung einer Helixstruktur
mit den Region-3-Nucleotiden;
6) 12 randomisierte Nucleotide; und 7) fixierte Sequenzen zur Amplifikation.
-
In
einem bevorzugten Kandidatengemisch sind die gentechnisch veränderten
helikalen Regionen so entworfen, dass sie alternierende GC-, CG-,
GC-, CG-Basenpaare ergeben. Für
dieses Basenpaarmotiv wurde gezeigt, dass es eine besonders stabile
Helixstruktur ergibt.
-
Beispiel 9: Hauptteil-Bindung
von randomisierten RNA-Sequenzen an Proteine, die nicht für Bindung
an Nucleinsäuren
bekannt sind.
-
Nach
den allgemeinen Nitrocellulose-Selektionsverfahren, wie sie in Beispiel
1 oben für
SELEX beschrieben wurden, wurde eine Gruppe von zufällig selektierten
Proteinen getestet, um zu bestimmen, ob sie irgendeine Affinität zu einem
Hauptkandidatengemisch von RNA-Sequenzen zeigten. Das in jedem Versuch verwendete
Kandidatengemisch bestand aus einer 40N-RNA-Lösung (ein randomisiertes Gemisch
mit einem Segment mit 40 randomisierten Nucleinsäuresegmenten), die radioaktiv
markiert war, um den Prozentsatz von Bindung nachzuweisen. Das Kandidatengemisch
wurde in Bindungspuffer (200 mM KOAc, 50 mM TrisOAc, pH 7,7, 10
mM DTT) verdünnt,
und 30 μl
wurden in einer 60-μl-Bindungsreaktion
verwendet. Zu jeder Reaktion wurden 20 μl, 10 μl oder 1 μl von jedem Protein zugesetzt.
Bindungspuffer wurde zugesetzt, um ein Gesamtvolumen von 60 μl zu erreichen.
Die Reaktionen wurden bei 37°C
5 min lang inkubiert und anschließend Filterbindung unterzogen.
-
Die
getesteten Proteine waren Acetylcholinesterase (MG 230.000); N-Acetyl-β-D-glucosaminidase (MG
180.000); Actin (MG 43.000); Alkoholdehydrogenase (240.000); Aldehyddehydrogenase
(MG 200.000); Angiotensin (MG 1297); Ascorbatoxidase (MW 140.000);
Atrial Natriuretic Factor (MG 3.064); und Bombesin (MG 1.621). Die
Proteine wurden bei Boehringer Ingelheim erworben und wurden in
der Pufferzusammensetzung verwendet, in der sie verkauft wurden.
-
Das
in jedem Versuch verwendete RNA-Kandidatengemisch enthielt 10.726
Counts von Radiomarkierung, und eine Hintergrundbindung von etwa
72 Counts wurde erkannt. Die Resultate sind in Tabelle 9 zusammengefasst.
Für alle
getesteten Proteine unter Ausnahme von Acetylcholinesterase, N-Acetyl-β-D-glucosaminidase
und Actin wurde erkannt, dass sie eine gewisse Hauptteil-RNA-Affinität ergaben.
Aufgrund der geringen Konzentration von N-Acetyl-β-D-glucosaminidase
in Lösung,
wie es gekauft wurde, sind die Resultate für dieses Protein nicht definitiv.
Bindet sich, darüber
hinaus, eines der getesteten Proteine nicht an Nitrocellulose – was für Bradykinin
der Fall ist –,
so würde
in diesem Versuch keine Affinität
detektiert werden. Beispiel 7 oben, das den Fall von säulengetragenem
Bradykinin erläutert,
zeigt, dass nicht vorhandene Hauptteil-Bindung in diesem Versuch
nicht automatisch bedeutet, dass Hauptteil-Bindung für ein gegebenes
Protein prinzipiell nicht existiert.
-
Beispiel 10: Isolierung
von RNA-Ligandenlösung
für Nervenwachstumsfaktor.
-
Nervenwachstumsfaktor
(NGF) ist ein Proteinfaktor, der durch einen Rezeptor an den äußeren Oberflächen von
Targetzellen wirkt. Antagonisten gegen Wachstumsfaktoren und andere
Hormone können
durch Blockieren eines Rezeptors oder durch Titrieren des Faktors
oder Hormons wirken. Im SELEX-Verfahren wurde nach einer RNA gesucht,
die sich direkt an NGF bindet.
-
Die
Ausgangs-RNAs wurden exakt wie im Fall von HSV-DNA-Polymerase hergestellt
(Beispiel 11).
-
Zwei
verschiedene Versuche wurden mit NGF durchgeführt. Der erste war ein SELEX
mit zehn Durchgängen
unter Verwendung von Bindungspuffer mit geringer Salzkonzentration,
Inkubation 3 min lang bei 37°C, und
anschließend
Filtration und Waschen mit demselben Puffer während des Ablaufs von SELEX.
Der Bindungspuffer mit geringer Salzkonzentration war 50 mM NaCl
plus 50 mM Tris-Acetat, pH 7,5. Der zweite Versuch verwendete als
Bindungspuffer 200 mM NaCl plus 50 mM Tris-Acetat, pH 7,5, und dann, nach der Filtration,
einen Waschschritt mit 50 mM Tris-Acetat, pH 7,5; dieser SELEX-Versuch
durchlief nur sieben Durchgänge.
-
Der
Versuch bei geringer Salzkonzentration ergab 36 klonierte Sequenzen.
Fünfzehn
der Klone waren beinahe identisch – Nr. 2, 3, 4, 5, 6, 8, 11,
13, 19, 22, 28, 33 und 34 waren identisch. Die Nr. 15 und 25 wiesen einen
einzigen Unterschied auf:
Eine zweite, häufig vorkommende
Sequenz, die sechsmal gefunden wurde, war:
CCUCAGAGCGCAAGAGUCGAACGAAUACAG
(Nr. 12, 20, 27 und 31)
-
Aus
dem SELEX mit hoher Salzkonzentration wurden zehn Klone sequenziert,
wobei jedoch acht von diesen identisch waren und offensichtlich
der häufig
vorkommenden (jedoch unbedeutenderen) zweiten Klasse aus dem Versuch
mit geringer Salzkonzentration angehörten. Die Gewinner-Sequenz
lautet:
----CUCAUGGAGCGCAAGACGAAUAGCUACAUA---
-
Zwischen
den zwei Versuchen wurden insgesamt 14 verschiedene Sequenzen gewonnen
(Sequenzen mit einem Unterschied werden in dieser Analyse zusammengefasst);
sie sind hier aufgelistet, worin die Ähnlichkeiten darüber gekennzeichnet
und die Häufigkeiten
angeführt
sind. ngf.a bis ngf.k stammen aus dem Versuch mit geringer Salzkonzentration,
während
hsngf.a bis hsngf.c aus dem Versuch mit hoher Salzkonzentration
stammen:
-
Während keine
offensichtliche Sekundärstruktur
innerhalb der ähnlichen
Sequenzen eingebunden ist, ist es wahrscheinlich, dass die gewinnenden
Sequenzen maßgebliche
Nucleotide in eine Struktur platzieren, die durch eine NGF-Bindungsstelle
gut angepasst ist.
-
Ein
Bindungstest von Nucleinsäure
hsngf.a an NGF wurde durchgeführt,
und für
diese Nucleinsäure wurde
eine Kd erkannt, die etwa 20- bis 30fach höher als jene des Haupt-30N-Kandidatengemisches
ist. Für dieselbe
Nucleinsäure
wurde auch erkannt, dass sie eine geringere oder gleiche Affinität zu R17-Hüllprotein und
tPA als bzw. wie ein 30N-Kandidatengemisch aufweist. Somit ist der
aus SELEX abgeleitete Nucleinsäureligand
hsngf.a ein selektiver Ligand zu NGF.
-
Beispiel 11: Isolierung
eines Nucleinsäureliganden
für HSV-1-DNA-Polymerase.
-
Herpes-Simplex-Virus
(HSV-1) ist ein DNA-hältiges
Virus von Säugetieren.
HSV-1, wie zahlreiche DNA-hältige
Viren, kodiert für
seine eigene DNA-Polymerase. Die HSV-1-DNA-Polymerase wurde in zwei
Formen gereinigt, die verschiedene Qualitäten aufweisen, wovon jedoch
jede Form DNA-Replikation in vitro katalysiert. Die einfache Form,
die ein Polypeptid ist, wird aus Zellen, die das klonierte Gen exprimieren,
gemäß T.R. Hernandez & I.R. Lehman,
J. Biol. Chem. 265, 11227–11232
(1990), gereinigt. Die zweite Form von DNA-Polymerase, ein Heterodimer,
wird aus HSV-1-infizierten
Zellen gemäß J.J. Crute & I.R. Lehman,
J. Biol. Chem. 264, 19266–19270
(1989), gereinigt; das Heterodimer enthält ein Peptid, das der Polymerase
selbst entspricht, und ein anderes, UL42, für das auch HSV-1 kodiert.
-
SELEX
wurde sowohl am einfachen Polypeptid als auch am Heterodimer durchgeführt. Der
Bindungspuffer war in jedem Fall 50 mM Kaliumacetat plus 50 mM Tris-Acetat, pH 7,5, und
1 mM Dithiothreit. Filtration zu separater gebundener RNA erfolgte
nach vier Minuten Inkubation bei 37°C; die Filter wurden mit Bindungspuffer
minus Dithiothreit gewaschen.
-
Das
RNA-Kandidatengemisch wurde aus DNA wie zuvor beschrieben transkribiert.
Wie im Fall von anderen Ausführungsformen
umfasst die DNA-Sequenz eine Bakteriophagen-T7-RNA-Polymerase-Promotorsequenz,
die es ermöglicht,
RNA gemäß herkömmlichen
Verfahren zu synthetisieren. cDNA-Synthese während der Amplifikationsphase
von SELEX wird durch eine DNA der folgenden Sequenz geprimt:
cDNA-Primer
(PCR-Primer 1): 5'-GCCGGATCCGGGCCTCATGTGAA-3'
-
Die
DNA-Primer, die zur Amplifikation der cDNA in dieser Phase des SELEX-Zyklus
verwendet wurden, umfassen, in einem von ihnen, den T7-Promotor;
dieser PCR-Primer
weist die folgende Sequenz auf:
PCR-Primer 2: 5' CCGAAGCTTAATACGACTCACTATAGGGAGCTCAGAATAAACGCTCAA
3'
-
Die
anfängliche
randomisierte DNA umfasste die Sequenz mit dem T7-Promotor, 30 randomisierte
Positionen und die fixierte Sequenz, die zu PCR-Primer 1 komplementär war. Die
RNA, die verwendet wird, um den ersten Zyklus von SELEX zu beginnen,
weist somit die folgende Sequenz auf:
pppGGGAGCUCAGAAUAAACGCUCAA-30N-UUCGACAUGAGGCCCGGAUCCGGC
-
SELEX
wurde sieben Durchgänge
lang durchgeführt,
wonach cDNA wie zuvor beschrieben hergestellt und kloniert wurde.
Die Reihe von Sequenzen, die in ihrer Benennung „H" tragen, wurde mit der einfachen HSV-DNA-Polymerase
als Target gewonnen, während
die „U"-Reihe mit der heterodimeren
Polymerase gewonnen wurde, die das UL42-Polypeptid enthält.
-
Etwa
25 % der Sequenzen aus der H-Reihe enthält eine exakte Sequenz von
12 Nucleotiden am 5'-Ende
der randomisierten Region (die Großbuchstaben sind der randomisierten
Region zuzuordnen). In manchen Sequenzen betrug die Länge zwischen
den fixierten Primern nicht exakt 30 Nucleotide, und in einem Fall
(H2) wurde eine große
Deletion innerhalb der randomisierten Region gefunden. Die Mitglieder
dieser H-Untergruppe umfassen:
-
Zwei
Elemente der U-Reihe haben dieses Primärsequenzmotiv gemeinsam:
U9:
--cgcucaaUAAGGAGGGCCACAGAUGUAAUGGAAACuucgaca--
U13: --cgcucaaUAAGGAGGCCACAUACAAAAGGAUGAGUAAAAuucgaca--
-
Die
verbleibenden Sequenzen aus den H- und U-Reihen zeigen keine deutliche
gemeinsame Sequenz; darüber
hinaus ließen
sich in keiner der beiden Serien Sequenzen aus den sieben Durchgängen als gewinnende
einzelne Sequenzen erkennen, was darauf schließen lässt, dass mehr SELEX-Durchgänge erforderlich
sein würden,
um die beste Ligandenfamilie zur Inhibierung von HSV-DNA-Polymerase
zu finden.
-
Es
scheint, dass die Primärsequenz
--cgcucaaUAAGGAGGCCAC...
ein
Kandidat für
eine Antagonistenspezies sein kann, doch jene Elemente der Serien
müssen
noch als Inhibitoren von DNA-Synthese getestet werden. Es scheint,
dass die fixierte Sequenz genau 5' zu der UAAGGAGGCCAC am Auftreten dieser
Untergruppe beteiligt sein muss, oder die gemeinsamen 12 Nucleotide
würden
variabel innerhalb der randomisierten Region positioniert worden
sein.
-
Beispiel 12: Isolierung
eines Nucleinsäureliganden
für E.-coli-Ribosomenprotein
S1
-
Das
E.-coli-30S-Ribosomenprotein S1 ist das größte der 21 30S-Proteine. Das
Protein wurde basierend auf seiner hohen Affinität zu Polypyrimidinen gereinigt,
und es wird angenommen, dass es sich eher fest an einzelsträngige Polynucleotide
bindet, die reich an Pyrimidin sind. Es wurde untersucht, ob die
durch SELEX als eine Ligandenlösung
identifizierte RNA in irgendeiner Weise reicher an Information ist
als eine einfache einzelsträngige
RNA, die reich an Pyrimidinen ist.
-
Die
RNAs, DNAs, cDNA-Primer (PCR-Primer 1) und PCR-Primer 2 waren mit
jenen identisch, die für HSV-1-DNA-Polymerase
verwendet wurden (siehe Beispiel 11). Der Bindungspuffer enthielt
100 mM Ammoniumchlorid plus 10 mM Magnesiumchlorid plus 2 mM Dithiothreit
plus 10 mM Tris-Chlorid, pH 7,5. Bindung erfolgte bei Raumtemperatur,
und Komplexe wurden einmal mehr durch Nitrocellulosefilter getrennt.
Das Protein wurde gemäß I. Boni
et al., European J. Biochem. 121, 371 (1982), gereinigt.
-
Nach
13 SELEX-Durchgängen
wurde eine Reihe von 25 Sequenzen erhalten. Mehr als zwanzig dieser Sequenzen
enthielten Pseudoknoten, und jene Pseudoknoten enthalten gemeinsame
Elemente.
-
Die
allgemeine Struktur von Pseudoknoten kann in Diagrammform folgend
dargestellt werden:
STAMM 1a – SCHLEIFE 1 – STAMM
2a – STAMM
1b – SCHLEIFE
2 – STAMM
2b (siehe 31)
-
Die
meisten der S1-Proteinliganden enthalten:
STAMM 1 aus 4 bis
5 Basenpaaren, mit einem G gleich 5' zu SCHLEIFE 1
SCHLEIFE 1 aus etwa
3 Nucleotiden, häufig
ACA
STAMM 2 aus 6 bis 7 Basenpaaren, direkt auf STAMM 1 gestapelt
SCHLEIFE
2 aus 5 bis 7 Nucleotiden, häufig
mit GGAAC am Ende
-
Eine
vernünftige
Interpretation dieser Daten ist, dass sich SCHLEIFE 2 über STAMM
1 erstreckt, sodass diese Schleife starr in einer Form gehalten
wird, die die Bindung des einzelnen Strangs an die aktive Stelle
von Protein S1 erleichtert und fördert.
Eine zweidimensionale Darstellung des Consensus-Pseudoknoten würde wie
folgt aussehen:
-
In
solchen Figuren sind die Basenpaare als Linien und Bindestriche
gezeigt, die Selektionen von Basen aus der randomisierten Region
sind in Großbuchstaben
gezeigt, Y ist ein Pyrimidin, R ist ein Purin, N-N' bezeichnet jedes
beliebige Basenpaar, N bezeichnet jedes beliebige Nucleotid, und
die Kleinbuchstaben stehen für
Elemente der fixierten Sequenz, die für PCR-Amplifikationen verwendet
wird.
-
Es
scheint, dass einzelsträngige
Polynucleotid-Bindungsproteine und Domänen innerhalb der Proteine
häufig,
während
SELEX, einen Pseudoknoten selektierten, der für den verlängerten, starren Einzelstrang, bezeichnet
als SCHLEIFE 2, an der Bindungsstelle des Proteins in einer Weise
steht, die die Wechselwirkungen mit dieser Stelle maximiert. Somit
ist es, wenn sich der HIV-1-RT-Pseudoknoten bereits gebildet hat,
vernünftig,
anzunehmen, dass die einzelsträngige
Domäne
SCHLEIFE 2 innerhalb der Region von RT gebunden ist, die den Matrixstrang
während
der Replikation hält.
Das heißt,
es scheint vernünftig,
dass die meisten Replikationsenzyme (DNA-Polymerase, RNA-Polymerase,
RNA-Replikasen, reverse Transkriptasen) eine Domäne zur Fixierung des Matrixstrangs
aufweisen, die einen Pseudoknoten als ausgewählten Liganden aus dem SELEX-Verfahren
bevorzugen könnte.
-
Beispiel 13: Isolierung
eines Nucleinsäureliganden
zu HIV-1-rev-Protein
-
Die
RNA-Erkennungsstelle des HIV-1-rev-Proteins scheint komplex zu sein,
und ihre Funktion ist für die
produktive Infektion einer epidemischen Viruserkrankung wesentlich.
Siehe Olsen et al., Science, Bd. 247, 845–848 (1990). Das SELEX-Verfahren
an diesem Protein wurde durchgeführt,
um mehr über
das Erkennungselement zu erfahren und um einen Liganden zum Targetprotein
zu isolieren.
-
Ein
Kandidatengemisch wurde mit einer 32 Nucleotide langen Zufallsregion,
wie zuvor in Beispiel 2 beschrieben, gebildet. Es wurde erkannt,
dass das rev-Protein das Ausgangskandidatengemisch mit einer halbmaximalen
Bindung, die bei etwa 1 × 10–7 M
auftrat, wie durch Nitrocellulosetests bestimmt wurde, auf sättigungsfähige Weise
binden konnte. Alle RNA-Protein-Bindungsreaktionen erfolgten in
einem Bindungspuffer von 200 mM KOAc, 50 mM Tris-HCl, pH 7,7, 10
mM Dithiothreit. RNA- und Proteinverdünnungen wurden vermischt und
auf Eis 30 min lang gelagert und anschließend auf 37°C 5 min lang transferiert. (In
Bindungstests beträgt
das Reaktionsvolumen 60 μl,
von denen 50 μl
getestet werden; in SELEX-Durchgängen
beträgt
das Reaktionsvolumen 100 μl.)
Jede Reaktion wird durch ein (mit Bindungspuffer) orbenetztes Nitrocellulosefilter gesaugt
und mit 3 ml Bindungspuffer gespült,
wonach sie getrocknet und für
Tests gezählt
oder Elution als Teil der SELEX-Arbeitsvorschrift
unterzogen werden. Zehn Durchgänge
von SELEX wurden durchgeführt,
unter Verwendung einer RNA-Konzentration von etwa 3 × 10–5 M.
Die Konzentration von rev-Protein betrug 1 × 10–7 im
ersten Durchgang und 2,5 × 10–8 in
allen darauf folgenden Durchgängen.
Das anfängliche
Kandidatengemisch wurde über
ein Nitrocellulosefilter laufen gelassen, um die Anzahl an Sequenzen
zu reduzieren, die eine hohe Affinität für Nitrocellulose aufweisen.
Dieses Verfahren wurde ebenfalls nach den Runden 3, 6 und 9 wiederholt.
Das cDNA-Produkt wurde nach jedem dritten Selektionsdurchgang gereinigt,
um Spezies anormaler Größen, die
typischerweise bei wiederholten Durchgängen von SELEX entstehen, zu
vermeiden. Nach 10 Durchgängen
war die Sequenz in der variablen Region der RNA-Population nicht
zu fällig,
wie durch Didesoxy-Kettenterminationssequenzierung bestimmt wurde.
53 Isolate wurden kloniert und sequenziert.
-
Alle
klonierten Sequenzen sind in Tabelle 10 aufgelistet. Alle Sequenzen
wurden durch das Zucker-RNA-Sekundärstruktur-Vorhersageprogramm
analysiert. Siehe Zucker, Science 244, 48–52 (1989); Jaeger et. al.,
Proc. Natl. Acad. Sci. USA 86, 7706–7710 (1989). Auf der Grundlage
von gemeinsamer Sekundärstruktur
wurden alle Sequenzen drei gemeinsamen Motiven zugeordnet, wie in
Tabelle 11 gezeigt wird. Die Motive I und II weisen eine ähnliche
Konformation auf, einschließlich
einer ausgeweiteten Schleife, die an jedem Ende durch eine Helix
geschlossen ist. Diese allgemein dargestellte Struktur wurde schematisch
in Tabelle 12 veranschaulicht, und die Domänen wurden zum leichteren Verständnis markiert;
betrachtet von 5' zu
3' sind dies Stamm
1a (der mit dem 3'-Stamm
1b Basenpaare bildet), Schleife 1, Stamm 2a, Schleife 3, Stamm 2b, Schleife
2 und Stamm 1b. Die Sequenzen, die in die verschiedenen Domänen passen,
sind für
einzelne Sequenzen in Tabelle 12 aufgelistet. (Es gilt anzumerken,
dass in Sequenz 3a der homologe Abgleich um 180° gedreht ist, sodass es Stamm
1 ist, der mit einer Schleife abgeschlossen ist.) Die Faltungsenergien
des RNA-Moleküls
(einschließlich
der fixierten flankierenden Sequenzen) sind in Tabelle 13 gezeigt.
-
Das
Wildtyp-rev-reaktive Element (RRE), für das bestimmt wurde, dass
es zumindest minimal in Bindung von rev an HIV-1-Transkripte eingebunden
ist, wurde auch mittels dieses Programms gefaltet und ist in den
Tabellen 12 und 13 aufgenommen.
-
Die
Sequenzen wurden durch ein Verfahren, das auf jenem basiert, das
in Hertz et al., Comput. Appl. Biosci. 6, 81–92 (1990), beschrieben wird,
auch auf verwandte Subsequenzen untersucht. Zwei signifikante Muster
wurden identifiziert. Für
jedes Isolat wurde auf Identität
geprüft,
um seine beste Übereinstimmung
mit den Mustern zu identifizieren, und die zugehörigen Resultate sind in Tabelle
13 zu sehen. Die verwandten Subsequenzmotive sind durch die gemeinsamen
Sekundärstrukturen
in ähnlichen
Konformationen dargestellt; das heißt, die erste Sequenz UUGAGAUACA
wird üblicherweise
als Schleife 1 plus das 3'-terminale
CA gefunden, das mit dem UG am 5'-Ende
der zweiten, an Information reichen Sequenz UGGACUC (üblicherweise
Schleife 3) ein Paar bildet. Auch gibt es eine starke Vorhersage
für Basenpaarung
von der GAG von Sequenz I mit der CUC von Sequenz II. Motiv II ist
Motiv I darin ähnlich,
dass die Subsequenz GAUACAG als eine Schleife gegenüber CUGGACAC
mit einer ähnlichen
Paarung von CA mit UG überwiegt.
Motiv II unterscheidet sich in der Größe der Schleifen und in einem
Teil der Sequenz, insbesondere durch die Abwesenheit von vorhergesagter Basenpaarung über die
Schleife hinweg. Eine Domäne
der Wildtyp-RRE ist Motiv II sehr ähnlich. Motiv III ist allen
anderen Sequenzen am wenigsten ähnlich,
wenn es auch durch zwei ausgeweitete Us, die neben den basengepaarten
GA-UC liegen, wie in Motiv I, gekennzeichnet ist. Unglücklicherweise
sind weitere Vergleiche kompliziert, da das Faltungsmuster von Motiv
III die 3'-fixierte Sequenzregion
in maßgeblichen
Sekundärstrukturen
einbindet; da diese Sequenzen invariant sind, gibt es keinen Weg,
die Bedeutung von einem von diesen zu analysieren. Die gefalteten
Sequenzen von Beispielen von jedem Motiv sind in 23 mit der gefalteten Sequenz des Wildtyp-RRE
gezeigt.
-
Die
Sequenzen wurden weiter auf ihre Affinität zum rev-Protein analysiert.
Matrices wurden ausgehend von zahlreichen Klonen PCR unterzogen,
aus denen markierte In-vitro-Transkripte hergestellt und einzeln
auf ihre Fähigkeit,
sich an rev-Protein zu binden, getestet wurden. Diese Bindungskurven
sind in den 24 bis 28 gezeigt.
Markierte Transkripte aus den Oligonucleotidmatrices wurden ebenfalls
synthetisiert, die das oben erläuterte
Wildtyp-RRE enthalten, von dem angenommen wird, dass es das Consensus-Motiv
in einer äußerst stabilen
Konformation ist. Um auf Varianten in den Versuchen zu kontrollieren,
wurde die am besten bindende Sequenz, Isolat 6a, als Standard in
jedem Bindungsversuch getestet. Die RNA-Protein-Gemische wurden
wie zuvor beschrieben behandelt, mit der Ausnahme, dass verdünnte RNAs
auf 90°C
1 min lang erhitzt und auf Eis vor dem Vermischen gekühlt wurden.
Die durchschnittliche Ka für
Isolat 6a betrug 8,5 × 10–8 M,
und die Resultate aus diesem Versuch sind in Tabelle 13 gezeigt.
-
Die
Bindungskurven aus 24 zeigen, dass die erzeugte
Population (P) eine um etwa das 30fache verbesserte Bindung an rev-Protein
im Vergleich zum Ausgangs kandidatengemisch aufwies. Die Bindung
des Wildtyp-RRE ist jener des am häufigsten vorkommenden Klons,
1c, sehr ähnlich.
Dieser Versuch veranschaulicht auch, wie empfindlich die rev-Bindungswechselwirkung
auf Sekundärstruktur
ist. Die Isolate 6a und 6b sind in den Regionen mit hohem Informationsgehalt
identisch, sind jedoch auf der Ebene der Sekundärstruktur sehr unterschiedlich,
was zu Änderungen
an drei Nucleotidpositionen führt.
Diese Änderungen,
die die Basenpaarung von Stamm 1 vorhersagen, reduzieren die Affinität von 6b
um das 24fache. Empfindlichkeit auf Sekundärstrukturanomalien wird durch
die Bindung von Isolat 17 genauer veranschaulicht, wie in 25 gezeigt. Isolat 17 weist das maximale Ergebnis
bezüglich
Information auf, wie in Tabelle 12 gezeigt wird. Es gibt jedoch ein
zusätzliches
ausgeweitetes U am 5'-Ende
von Schleife 1, wie in Tabelle 11 gezeigt wird. Dieses zusätzliche U
resultiert in der reduzierten Affinität von Isolat 17 zu rev im Vergleich
zu anderen Sequenzen mit Motiv I. Dahingegen werden einzelne Nucleotiddeletionen
von Schleife-2-Sequenzen, auch jene, die die Aussicht auf Basenpaarung
quer über
die Aufweitung reduzieren, von der rev-Wechselwirkung gut toleriert.
-
Eine
andere starke Gemeinsamkeit ist die Konservierung der Sequenz ACA
gegenüber
UGG, worin sich die CA mit dem UG paart, um Stamm 2 zu bilden. Diese
Sequenz haben die Motive I und II sowie das Wildtyp-RRE gemeinsam.
Die Sequenzen 11 und 12 weisen eine Basenpaarsubstitution an dieser
Position auf (siehe Tabelle 12), und Sequenz 12 wurde getestet und
wies reduzierte Affinität
im Vergleich mit den meisten der anderen Motiv-I-Sequenzen auf.
-
Die
RNA-Sequenzen, für
die durch SELEX bestimmt wurde, dass sie rev-Liganden sind, können nach Primär- und Sekundärstruktur
klassiert werden. Ein Consensus tritt aus einer asymmetrischen Ausweitung
hervor, die durch zwei Helices flankiert ist, in denen spezifisch
konservierte einzel- und doppelsträngige Nucleotide konfiguriert
sind. Wenn auch Basenpaarung über
die Ausweitung für
zahlreiche der isolierten Sequenzen vorhersagt sind (Motiv I), kann
diese nicht wesentlich oder maßgeblich
für rev-Wechselwirkung
sein. Optimale Größen für Schleife
1 scheinen 8 (Motiv I) oder 6 (Motiv III) zu sein, wobei es einen
beobachteten Nachteil für Größen von
9 oder 3 gibt. Optimale Größen für Schleife
3 sind 5 und 4. Darüber
hinaus kann die Wechselwirkung von rev mit den verschiedenen Domänen dieser
Liganden additiv sein. Motiv II ist Motiv I primär in der Verbindung der Schleifen
1 und 3 an Stamm 2 ähnlich.
Motiv III ist Motiv I an der Verbindung der Schleifen 1 und 3 an
Stamm 1 ähnlich.
Consensus-Diagramme der Nucleinsäurelösungen von
Motiv I und II für
HIV-rev sind in
den 29 und 30 gezeigt.
-
Die
Häufigkeit
von Sequenzen in der klonierten Population steht nicht in enger
Korrelation mit Affinität zu
rev-Protein. Es ist möglich,
dass die Konzentration von rev-Protein,
die im SELEX-Verfahren verwendet wurde, ausreichend war, um einen
signifikanten Prozentsatz von allen diesen Isolaten zu binden. Folglich
kann eine Selektion für
Replizierbarkeit von cDNA und DNA während PCR stattgefunden haben,
die einer Selektion auf Bindung an rev unter geringer Stringenz
hinzugefügt
wurde. Die hochstrukturierte Beschaffenheit dieser Liganden und
die möglichen
Unterschiede der Wirksamkeit von cDNA-Synthese an diesen Matrices
verstärkt diese
potenzielle replikative Vorgabe. Auch gibt es eine gewisse Mutation,
die während
des SELEX-Verfahrens auftritt.
Die Sequenz 6a ist 6b so ähnlich,
dass die beiden einen gemeinsamen Vorgänger haben müssen. Dieses
relativ späte
Auftreten während
der SELEX-Durchgänge
kann die Knappheit dieser Sequenz, unabhängig von ihrer höheren Affinität zum Target,
erklären.
Auf dieselbe Weise können
manche der Liganden, die aufgetreten sind, relativ spät während der
Selektion der Vorläufersequenzen,
die im Anfangskandidatengemisch existieren, jedoch nicht in der
klonierten Population vorhanden sind, mutiert sein.
-
Die
hierin offenbarte Erfindung ist in ihrem Umfang nicht auf die hierin
offenbarten Ausführungsformen eingeschränkt. Wie
offenbart kann die Erfindung von durchschnittlichen Fachleuten auf
zahlreiche Nucleinsäureliganden
und Targets angewandt werden. Geeignete Modifikationen, Anpassungen
und Behelfe zur Anwendung der hierin enthaltenen Erläuterungen
in individuellen Situationen können
im Rahmen des Schutzumfangs der Erfindung, wie er hierin offenbart
und beansprucht ist, von Fachleuten verwendet und verstanden werden. TABELLE
2
TABELLE
3
TABELLE
4
TABELLE
4 (Fortsetzung)
-
Sekundärstrukturen,
vorhergesagt gemäß dem Zucker-Programm,
sind mit Pfeilen über
den Buchstaben angegeben, die die umgekehrten Wiederholungen hervorheben,
die ein Hinweis auf Basenpaarung sind. TABELLE
5
TABELLE
6
TABELLE
6 (Fortsetzung)
TABELLE
7
TABELLE
7 (Fortsetzung)
TABELLE
7 (Fortsetzung)
TABELLE
8
TABELLE
9
TABELLE
9 (Fortsetzung)
TABELLE
10
TABELLE
11 MOTIV
1
MOTIV
II
TABELLE
11 (Fortsetzung) MOTIV
III
TABELLE
12
TABELLE
13
-
ANHANG
-
Selektion.
-
Ein
einfacher kinetischer Mechanismus für reversible Protein-RNA-Komplexbildung in
einer gut gemischten Lösung
kann wie folgt dargestellt werden:
worin
[Pf] die freie Proteinkonzentration ist, [RNAf
i]
die freie RNA-Spezies-i-Konzentration
ist, [P:RNA
i] die Protein-RNA-Spezies-i-Komplexkonzentration
ist, k
+i die Geschwindigkeitskonstante für Assoziation
von freiem Protein und freier RNA der Spezies i ist, k
–i die
Geschwindigkeitskonstante für
Dissoziation von Protein-RNA-Spezies-i-Komplexen
ist und n die Anzahl von RNA-Sequenzen mit einer einmaligen Reihe
von Geschwindigkeitskonstanten ist. Alternative Mechanismen, einschließlich mehrfacher
Bindungsstellen oder Kooperativität, könnten in darauf folgenden Behandlungen
mit geeigneten Extensionen in diesem einfachen Schema in Betracht
gezogen werden.
-
Für jegliches
System, das durch das obige Schema dargestellt werden kann, sind
die grundlegenden chemisch-kinetischen oder Massenwirkungs-Gleichungen,
die die Änderung
der Konzentration von jedem Protein-RNA-Spezies-i-Komplex als eine
Funktion der Zeit beschreiben, die folgenden:
worin [Pf], [RNAf
i] und [P:RNA
i] die
Konzentrationen von freiem Protein, freier RNA der Spezies i und
von Protein-RNA-Spezies-i-Komplex zum Zeitpunkt t sind.
-
Die
freie Proteinkonzentration ist die Differenz zwischen der gesamten
Proteinkonzentration und der Konzentration von allen Protein-RNA-Komplexen
([P]-Σ[P:RNA
k]); in ähnlicher
Weise ist die freie RNA-Spezies-i-Konzentration die Differenz zwischen
der gesamten RNA-Spezies-i-Konzentration und der Protein-RNA-Spezies-i-Komplexkonzentration
([RNA
i]-[P:RNA
i]):
-
Diese
dynamischen Gleichungen können
entweder für
kinetische oder für
Gleichgewichtsanalysen verwendet werden. Die kontinuierliche differenzielle
Form ist gültig,
wenn die mittlere Geschwindigkeit von jedem Vorgang im Vergleich
zur Varianz in diesem Prozess relativ groß ist, oder anders ausgedrückt, Gleichung (3)
trifft exakt für
die Beschreibung eines Pools an RNA mit mehreren Molekülen zu,
die jeweils eine einmalige Reihe von Geschwindigkeitskonstanten
aufweisen. Immer wenn nur ein Molekül oder nur einige wenige Moleküle der am
besten bindenden RNA vorhanden ist bzw. sind, wird eine statistische
Beschreibung von Bindung verwendet, um die Bedingungen zu bestimmen,
die eine hohe Wahrscheinlichkeit zur Gewinnung der am besten bindenden
RNA ergeben. Diese statistischen Formeln sind im folgenden Abschnitt
basierend auf der Erfolgswahrscheinlichkeit abgeleitet.
-
Bei
Gleichgewicht ist die Änderung
der Konzentration von jedem Protein-RNA-Spezies-i-Komplex gleich null:
wobei die Symbole wie in
Gleichung (3) definiert sind und worin Kd
i die
Gleichgewichts-Dissoziationskonstante für Protein-RNA-Spezies-i-Komplex
ist (Kd
i = k
–i/k
+i).
-
Wird
nur eine RNA-Spezies in Betracht gezogen (d.h. n = 1), so ist eine
analytische Lösung
für die Gleichgewichtskonzentration
von Protein-RNA-Komplexen durch Auflösen der folgenden quadratischen
Gleichung möglich:
die zwei reale Wurzeln hat,
eine, die physikalisch umsetzbar ist:
-
Natürlich gibt
es zahlreiche klassische Annäherungen
für Gleichgewichts-
oder Quasi-Gleichgewichts-Konzentrationen von Komplexen, wie jene
im Michaelis-Menten-Formalismus,
doch keine ergibt ausreichende Exaktheit über den Bereich von Gesamt-RNA-
und Protein-Konzentrationen, die in SELEX verwendet werden. (Aufschlussreiche
Erörterungen
zu gewissen Nachteilen und Einschränkungen von klassischer Annäherung sind
in Savageau (1991); Straus & Goldstein
(1943); Webb (1963) zu finden.) Obwohl eine analytische Lösung der
quadratischen Gleichung für
einfache reversible Assoziation einer einzelnen RNA-Spezies mit
einer einzelnen Bindungsstelle am Protein für alle RNA- und Proteinkonzentrationen,
die in SELEX verwendet werden, exakt ist und obwohl die gebundenen
Konzentrationen der zwei konkurrierenden Spezies durch analytische
Lösung
einer Gleichung dritten Grades berechnet werden können, sind
sich iterative numerische Verfahren erforderlich, um Gleichgewichtskonzentrationen
von Protein-RNA-Komplexen zu berechnen, sobald drei oder mehr konkurrierende
RNA-Spezies in Betracht gezogen werden.
-
Die
Erfinder entwickelten ein Computerprogramm, um eine Lösung für die Gleichgewichtskonzentration
von jedem Protein-RNA-Spezies-i-Komplex [P:RNA
i],
für jede
mögliche
Gesamt-Proteinkonzentration [P], jede mögliche Verteilung von RNA-Spezies-i-Konzentrationen
[RNA
i] und jede mögliche Verteilung von Gleichgewichts-Dissoziationskonstanten,
Kd
i, zu finden. Die Jacobi-Matrix (siehe
z.B. Leunberger (1973) für
eine implizite Lösung
von Gleichung (4) durch Newtonsches Verfahren (siehe z.B. Leunberger
(1973); Press et al. (1988)) wird unter Verwendung der folgenden
Formel berechnet:
worin
a
ij das Element in Zeile i, Spalte j, der
Jacobi-Matrix ist, wobei δ
jj = 1 und δ
ij =
0 für i ≠ j.
-
Häufig hängt der
Erfolg des Newtonschen Verfahrens von einer guten anfänglichen
Schätzung
für die Lösung ab
(siehe z.B. Leunberger (1973); Press et al. (1988)), in diesem Fall
von der Gleichgewichtskonzentration von jedem Protein-RNA-Spezies-i-Komplex [P:RNA
i]. Unter Verwendung der Haupt-K
d für den gesamten
RNA-Pool kann die Konzentration von Protein in allen Protein-RNA-Komplexen
geschätzt
werden:
worin
[P:RNA] die Konzentration von allen Protein-RNA-Komplexen ist, [RNA]
die Konzentration des gesamten RNA-Pools ist und <K
d> die Haupt-Gleichgewichtsdissoziationskonstante
für den
gesamten RNA-Pool ist, berechnet unter Verwendung der folgenden
Formel:
worin
[RNA]
[P]/2 die Gesamt-RNA-Konzentration
ist, die die Hälfte
des Proteins bindet, und F 0 / i = [RNA
i]/[RNA] ist.
-
Mit
dieser Schätzung
der Konzentration von Protein in Komplexen kann eine anfängliche
Annäherung für die Konzentration
von jedem Protein-RNA-Spezies-i-Komplex unter Verwendung der folgenden
Formel durchgeführt
werden:
Lösungen für die Werte
von [P:RNA
i], die Gleichung (4) erfüllen, können durch
wiederholte Anwendung des Newton-Verfahrens unter Verwendung von
Gleichung (7) auf ein hohes Niveau der Exaktheit verfeinert werden.
Bei dieser Ausführung
erzielen die Erfinder Lösungen
mit mehr als zwölf
signifikanten Stellen in weniger als vier oder fünf Wiederholungen des Newton-Verfahrens.
Diese rasche Annäherung
an eine exakte Lösung ist
auf die anfänglichen
Annäherungen
in Gleichung (10) zurückzuführen, die
typischerweise eine oder mehrere signifikante Stellen zu Beginn
ergeben – je
nach dem Bereich der Gleichgewichts-Dissoziationskonstanten und
der Häufigkeit
von jeder RNA-Spezies. Ein Grund für dieses Niveau der Exaktheit
ist, dass Fehler in [P:RNA] dazu neigen, sich in Gleichung (10)
aufzuheben, sobald [P] – [P:RNA]
größer als
Kd
i ist, beispielsweise wenn [RNA] weniger
als Kd
i ist oder wenn Kd
i weniger
als <Kd> ist. Interessanterweise
bedeutet dies, dass Exaktheit für
jeglichen Protein-RNA-Spezies-i-Komplex
mit besserer Bindung als der Haupt-RNA-Pool höher ist. Repräsentative
Beispiele für
die anfängliche
Exaktheit von Anreicherungsberechnungen – definiert als die Steigerung
des Anteils des Gesamt-RNA-Pools, der sich aus den am besten bindenden
RNA-Spezies aus jedem Durchgang zusammensetzt, und angenähert durch
Einsetzen von Gleichung (10) in Gleichung (20) –. Die gezeigte Gesamtexaktheit
spiegelt die Exaktheit der Gleichgewichtskonzentrationen wider,
die für
jeden Protein-RNA-Spezies-i-Komplex unter Verwendung von Gleichung
(10) berechnet wurden. Im folgenden Abschnitt profitieren die Erfinder
von dieser Exaktheit, um die optimalen RNA- und Proteinkonzentrationen
für maximale Anreicherung
zu berechnen.
-
Abtrennen.
-
Jegliches
Verfahren zur Abtrennung verschiedener Spezies von Nucleinsäuresequenzen – einschließlich Filterbindung
(Tuerk & Gold,
1990), Gelmobilil tätsverschiebungen
(Blackwell & Weintraub,
1990), Affinitätschromatographie
(Ellington & Szostak,
1990); Green et al., 1990; Oliphant & Struhl, 1987; Oliphant & Struhl, 1988),
Antikörperfällung, Phasentrennungen
oder Schutz vor nukleolytischer Spaltung (Robertson & Joyce, 1990) – könnte zu
seinem Vorteil mit SELEX verwendet werden. Bei Filterbindung beispielsweise
haften die meisten Protein-RNA-Komplexe an einem Nitrocellulosefilter,
während
die meisten freien RNA-Moleküle durchgewaschen
werden (Uhlenbeck et al., 1983; Yarus, 1976; Yarus & Berg, 1967; Yarus & Berg, 1970).
Die tatsächliche
Fraktion von Protein-RNA-Komplex, die anhaftet und dann vom Filter
entfernt werden kann, wird im nächsten
Abschnitt behandelt.
-
Da
eine Fraktion freier RNA-Moleküle
auch am Filter als nichtspezifischer Hintergrund anhaftet, wird die
Gesamtmenge von jeder RNA-Spezies i, die am Filter abgenommen wird,
unter Verwendung der folgenden Formel berechnet, die sowohl das
erwünschte
Signal aus den am besten bindenden RNA-Molekülen in Protein-RNA-Komplexen als auch
das Rauschen von freien RNA-Molekülen, die als nichtspezifischer
Hintergrund abgenommen werden, plus konkurrierender RNA-Moleküle in Protein-RNA-Komplexen
berücksichtigt: RNAfilti = Vol·([P:RNAi]
+ BG·([RNAi] – (P:RNAi]))·6,02·1023, i = l, ... n, (11)worin RNA filt / i die
Anzahl an Molekülen
von abgenommener RNA-Spezies i, Vol das Volumen des Reaktionsgemisches,
das durch den Filter geführt
wird, [P:RNAi] die Gleichgewichtskonzentration
von Protein-RNA-Spezies-i-Komplex, berechnet wie im vorangehenden
Abschnitt beschrieben, BG die Fraktion von freier RNA, abgenommen
als nichtspezifischer Hintergrund, und [RNAi]
die Gesamt-RNA-Spezies-i-Konzentration
ist. Jegliches Verfahren zur Abtrennung ergibt typischerweise weniger
als perfekte Abtrennung von gebundenen und ungebundenen Liganden
und erfordert folglich ein Maß für die Fraktion
freier Liganden, die als Hintergrund mit gebundenen Liganden in
jedem Durchgang abgenommen wurden.
-
Wie
bereits erwähnt
können
nicht alle Protein-RNA-Komplexe in Lösung am Filter abgenommen werden.
Darüber
hinaus kann RNA in fest gebundenen Komplexen besser am Filter zurückgehalten
werden als RNA in schwach gebundenen Komplexen. Sobald dies eintritt,
würde Anreicherung
an RNA-Molekülen,
die sich fest binden, in jedem Durchgang von SELEX weiter gesteigert
werden. Andererseits würde
ihre Anreicherung, wenn manche Moleküle nicht vom Filter eluiert
werden könnten,
auch reduziert werden.
-
Amplifikation und neuerliche
Normalisierung.
-
Die
Menge von jeder RNA-Spezies i, die aus dem Filter gewonnen wird,
wird unter Verwendung der folgenden Formel berechnet: RNApcri = FR·RNAfilti , i = l, ... n, (12)worin FR
die Fraktion von RNA ist, die vom Filter gewonnen werden kann, und
RNA filt / i die Anzahl an Molekülen von
RNA-Spezies i ist, die an den Filtern abgenommenen wurden, berechnet
mit Gleichung (11). In dieser Behandlung wird der Wert von FR als
konstant angenommen und wird sowohl durch die Fraktion von Protein-RNA-Komplex, die am Filter
anhaftet, als auch durch die Fraktion von RNA in diesen Komplexen,
die durch reverse Transkriptase gewonnen und kopiert werden kann,
um cDNA für
PCR herzustellen, bestimmt. Die Annahme, dass FR für alle Spezies
konstant ist, ist ein vernünftiger
Ausgangspunkt, da unter Gewährung
einer ausreichenden Dauer, wenn alle Moleküle dieselben Primerstellen
für PCR
aufweisen und ein Überschuss
von Primermolekülen
verwendet wird, jede Spezies – unabhängig davon,
ob selten oder häufig
vorhanden – praktisch
dieselbe Wahrscheinlichkeit aufweist, mit einem Primermolekül zu anellieren.
Auch gibt es keine unterschiedliche Amplifikationsgeschwindigkeit
auf Grundlage der Größe, da jedes
RNA-Molekül
dieselbe Länge aufweist.
Natürlich
wird, wenn irgendeine RNA-Spezies eine Sekundärstruktur aufweist, die Primeranellierung für cDNA-Synthese
stört,
oder wenn die Primär-
oder Sekundärstruktur
der entsprechenden cDNA die Geschwindigkeit von DNA-Polymerase während PCR-Amplifikation
herabsetzt, Anreicherung dieser Spezies reduziert. Die Erfinder
nehmen diese Wirkungen nicht in die Erfindung auf, da es keine guten
Regeln gibt, nach denen vorhergesagt werden kann, welche Strukturen
tatsächlich
einen Unterschied ausmachen. Wird mehr über diese Strukturen in Erfah rung
gebracht, so können
jegliche signifikante Wirkungen zur mathematischen Beschreibung
von SELEX zugesetzt werden.
-
Die
Gesamtmenge von RNA, die aus dem Filter gewonnen wird, wird durch
Summieren der Anzahl an Molekülen
von jeder Spezies, die abgenommen wurde, um cDNA-Kopien für PCR-Amplifikation herzustellen, berechnet:
-
Jegliche „Träger"- oder „nichtspezifische
Konkurrenz"-Moleküle sollten
aus der Summe in Gleichung (13) ausgeschlossen werden, da ohne PCR-Primerstellen
diese Moleküle
nicht amplifizieren. Arbeitsvorschriften zu Affinitätsmessungen
umfassen häufig
diese nichtspezifischen Konkurrenz-RNA-Moleküle, und werden solche Moleküle auch
in SELEX verwendet, so sollten sie eindeutig nicht-amplifizierbar
sein. Interessanterweise ist, sobald nichtspezifische Konkurrenzmoleküle mit dem
Protein an derselben Stelle wie das am besten bindende Ligandenmolekül wechselwirken,
die hauptsächliche
Konsequenz aus dem Zusatz von Konkurrenzmolekülen eine Reduktion der Anzahl
spezifischer Stellen, die für
Selektion verfügbar
sind. Somit müssen,
um die Proteinkonzentration zu bestimmen, die die erwünschte Menge
von amplifizierbaren Ligandenmolekülen mit einer hohen Konzentration
von vorhandenen nicht-spezifischen
Konkurrenzmolekülen
bindet, korrekte Bindungskurven durch Einbinden der geeigneten Konzentration
von diesen Molekülen
in jede Titrierung erstellt werden. Die Vorteile der Verwendung
einer hohen Konzentration von nichtspezifischen, nicht-amplifizierbaren Konkurrenzmolekülen in jedem
SELEX-Durchgang können
eine Reduktion der Adsorption von amplifizierbaren Ligandenmolekülen an jeglichen
nichtspezifischen Stellen an Laborgeräten, eine Reduktion der Bindung von
amplifizierbaren Ligandenmolekülen
an jeder nichtspezifischen Stelle am Targetprotein oder eine Reduktion
der Fraktion von freien amplifizierbaren Molekülen, abgenommen als nichtspezifischer
Hintergrund, an „falsch
abtrennenden" Stellen
umfassen, jedoch nur, wenn solche Stellen in einer signifikanten
Anzahl vorhanden sind und durch die Menge an verwendeten nichtspezifischen
Konkurrenzmolekülen
wirksam gesättigt werden.
Werden diese Bedingungen nicht erfüllt, so ist die Wirkung des
Zusetzens von nichtspezifischen Konkurrenzmolekülen im Wesentlichen dieselbe
wie jene einer Reduktion der Menge von verwendetem Protein.
-
Die
Menge von jeder amplifizierbaren RNA-Spezies i, die nach einem Durchgang
gewonnen wird, in Bezug auf die Summe aus Gleichung (13), wird wie
folgt berechnet:
-
Nach
PCR-Amplifikation von cDNA-Kopien und neuerlicher Normalisierung
des RNA-Pools zurück zu seiner
ursprünglichen
Konzentration durch In-vitro-Transkription (aus identischen Promotorstellen
an allen cDNA-Molekülen)
beträgt
die Konzentration von jeder RNA-Spezies nach einem SELEX-Durchgang: [RNAi]
= F1i ·[RNA],
i = l, ... n, (15)worin
[RNA] die Gesamtkonzentration des RNA-Pools ist. Für jeden
zusätzlichen
Durchgang von SELEX kann die Konzentration von jeder RNA-Spezies
durch Iteration der Gleichungen (7)–(15) berechnet werden, worin F 1 / i für jede RNA-Spezies
aus einem Durchgang die Ausgangsfraktion F 0 / i im nächsten Durchgang ist [siehe
Gleichung (9)].








 TABELLE 4
TABELLE 4 TABELLE 4 (Fortsetzung)
TABELLE 4 (Fortsetzung)

 TABELLE 6 (Fortsetzung)
TABELLE 6 (Fortsetzung) TABELLE 7
TABELLE 7 TABELLE 7 (Fortsetzung)
TABELLE 7 (Fortsetzung) TABELLE 7 (Fortsetzung)
TABELLE 7 (Fortsetzung) TABELLE 8
TABELLE 8 TABELLE 9
TABELLE 9 TABELLE 9 (Fortsetzung)
TABELLE 9 (Fortsetzung) TABELLE 10
TABELLE 10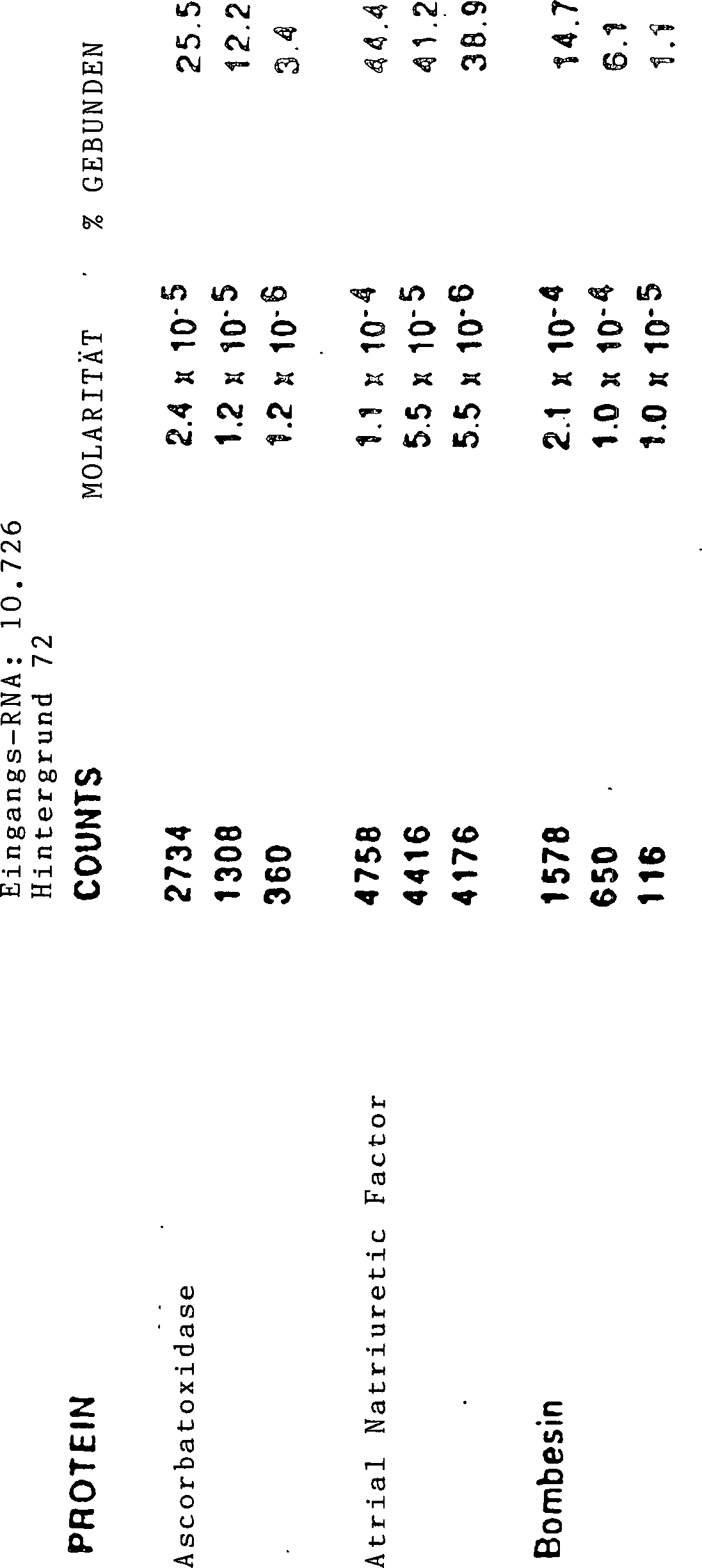 TABELLE 11 MOTIV 1
TABELLE 11 MOTIV 1 MOTIV II
MOTIV II TABELLE 11 (Fortsetzung) MOTIV III
TABELLE 11 (Fortsetzung) MOTIV III TABELLE 12
TABELLE 12 TABELLE 13
TABELLE 13








 worin [RNA][P]/2 die Gesamt-RNA-Konzentration ist, die die Hälfte des Proteins bindet, und F 0 / i = [RNAi]/[RNA] ist.
worin [RNA][P]/2 die Gesamt-RNA-Konzentration ist, die die Hälfte des Proteins bindet, und F 0 / i = [RNAi]/[RNA] ist.


