KR20150105635A - 서열 조작을 위한 crispr-cas 성분 시스템, 방법 및 조성물 - Google Patents
서열 조작을 위한 crispr-cas 성분 시스템, 방법 및 조성물 Download PDFInfo
- Publication number
- KR20150105635A KR20150105635A KR1020157018662A KR20157018662A KR20150105635A KR 20150105635 A KR20150105635 A KR 20150105635A KR 1020157018662 A KR1020157018662 A KR 1020157018662A KR 20157018662 A KR20157018662 A KR 20157018662A KR 20150105635 A KR20150105635 A KR 20150105635A
- Authority
- KR
- South Korea
- Prior art keywords
- sequence
- crispr
- target
- enzyme
- tracr
- Prior art date
Links
Images


























































































Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/14—Hydrolases (3)
- C12N9/16—Hydrolases (3) acting on ester bonds (3.1)
- C12N9/22—Ribonucleases RNAses, DNAses
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
- C12N15/113—Non-coding nucleic acids modulating the expression of genes, e.g. antisense oligonucleotides; Antisense DNA or RNA; Triplex- forming oligonucleotides; Catalytic nucleic acids, e.g. ribozymes; Nucleic acids used in co-suppression or gene silencing
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/74—Vectors or expression systems specially adapted for prokaryotic hosts other than E. coli, e.g. Lactobacillus, Micromonospora
- C12N15/746—Vectors or expression systems specially adapted for prokaryotic hosts other than E. coli, e.g. Lactobacillus, Micromonospora for lactic acid bacteria (Streptococcus; Lactococcus; Lactobacillus; Pediococcus; Enterococcus; Leuconostoc; Propionibacterium; Bifidobacterium; Sporolactobacillus)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/10—Processes for the isolation, preparation or purification of DNA or RNA
- C12N15/102—Mutagenizing nucleic acids
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/70—Vectors or expression systems specially adapted for E. coli
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/74—Vectors or expression systems specially adapted for prokaryotic hosts other than E. coli, e.g. Lactobacillus, Micromonospora
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/79—Vectors or expression systems specially adapted for eukaryotic hosts
- C12N15/82—Vectors or expression systems specially adapted for eukaryotic hosts for plant cells, e.g. plant artificial chromosomes (PACs)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/79—Vectors or expression systems specially adapted for eukaryotic hosts
- C12N15/85—Vectors or expression systems specially adapted for eukaryotic hosts for animal cells
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/79—Vectors or expression systems specially adapted for eukaryotic hosts
- C12N15/85—Vectors or expression systems specially adapted for eukaryotic hosts for animal cells
- C12N15/8509—Vectors or expression systems specially adapted for eukaryotic hosts for animal cells for producing genetically modified animals, e.g. transgenic
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/87—Introduction of foreign genetic material using processes not otherwise provided for, e.g. co-transformation
- C12N15/90—Stable introduction of foreign DNA into chromosome
- C12N15/902—Stable introduction of foreign DNA into chromosome using homologous recombination
- C12N15/907—Stable introduction of foreign DNA into chromosome using homologous recombination in mammalian cells
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B20/00—ICT specially adapted for functional genomics or proteomics, e.g. genotype-phenotype associations
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B20/00—ICT specially adapted for functional genomics or proteomics, e.g. genotype-phenotype associations
- G16B20/20—Allele or variant detection, e.g. single nucleotide polymorphism [SNP] detection
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B20/00—ICT specially adapted for functional genomics or proteomics, e.g. genotype-phenotype associations
- G16B20/30—Detection of binding sites or motifs
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B20/00—ICT specially adapted for functional genomics or proteomics, e.g. genotype-phenotype associations
- G16B20/50—Mutagenesis
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B30/00—ICT specially adapted for sequence analysis involving nucleotides or amino acids
- G16B30/10—Sequence alignment; Homology search
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/10—Processes for the isolation, preparation or purification of DNA or RNA
- C12N15/1034—Isolating an individual clone by screening libraries
- C12N15/1082—Preparation or screening gene libraries by chromosomal integration of polynucleotide sequences, HR-, site-specific-recombination, transposons, viral vectors
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/79—Vectors or expression systems specially adapted for eukaryotic hosts
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/10—Type of nucleic acid
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/10—Type of nucleic acid
- C12N2310/12—Type of nucleic acid catalytic nucleic acids, e.g. ribozymes
- C12N2310/122—Hairpin
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/10—Type of nucleic acid
- C12N2310/20—Type of nucleic acid involving clustered regularly interspaced short palindromic repeats [CRISPRs]
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/30—Chemical structure
- C12N2310/35—Nature of the modification
- C12N2310/351—Conjugate
- C12N2310/3519—Fusion with another nucleic acid
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/50—Physical structure
- C12N2310/53—Physical structure partially self-complementary or closed
- C12N2310/531—Stem-loop; Hairpin
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2320/00—Applications; Uses
- C12N2320/10—Applications; Uses in screening processes
- C12N2320/11—Applications; Uses in screening processes for the determination of target sites, i.e. of active nucleic acids
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2320/00—Applications; Uses
- C12N2320/30—Special therapeutic applications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2750/00—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA ssDNA viruses
- C12N2750/00011—Details
- C12N2750/14011—Parvoviridae
- C12N2750/14111—Dependovirus, e.g. adenoassociated viruses
- C12N2750/14141—Use of virus, viral particle or viral elements as a vector
- C12N2750/14143—Use of virus, viral particle or viral elements as a vector viral genome or elements thereof as genetic vector
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2800/00—Nucleic acids vectors
- C12N2800/10—Plasmid DNA
- C12N2800/101—Plasmid DNA for bacteria
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B30/00—ICT specially adapted for sequence analysis involving nucleotides or amino acids
Landscapes
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Genetics & Genomics (AREA)
- Engineering & Computer Science (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Chemical & Material Sciences (AREA)
- Biotechnology (AREA)
- Wood Science & Technology (AREA)
- Zoology (AREA)
- Organic Chemistry (AREA)
- Biomedical Technology (AREA)
- General Engineering & Computer Science (AREA)
- Molecular Biology (AREA)
- Physics & Mathematics (AREA)
- General Health & Medical Sciences (AREA)
- Biophysics (AREA)
- Biochemistry (AREA)
- Microbiology (AREA)
- Plant Pathology (AREA)
- Bioinformatics & Computational Biology (AREA)
- Medical Informatics (AREA)
- Evolutionary Biology (AREA)
- Theoretical Computer Science (AREA)
- Analytical Chemistry (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Spectroscopy & Molecular Physics (AREA)
- Cell Biology (AREA)
- Medicinal Chemistry (AREA)
- Mycology (AREA)
- Veterinary Medicine (AREA)
- Crystallography & Structural Chemistry (AREA)
- Micro-Organisms Or Cultivation Processes Thereof (AREA)
- Enzymes And Modification Thereof (AREA)
- Peptides Or Proteins (AREA)
- Medicines That Contain Protein Lipid Enzymes And Other Medicines (AREA)
- Breeding Of Plants And Reproduction By Means Of Culturing (AREA)
- Virology (AREA)
- Measuring Or Testing Involving Enzymes Or Micro-Organisms (AREA)
Abstract
본 발명은 표적 서열의 서열 및/또는 활성의 조작을 위한 시스템, 방법 및 조성물을 제공한다. 일부가 CRISPR 복합체의 하나 이상의 성분을 인코딩하는 벡터 및 벡터 시스템, 및 이러한 벡터의 설계 및 사용 방법이 제공된다. 또한, 진핵 세포에서 CRISPR 복합체 형성의 유도 방법 및 CRISPR/Cas 시스템을 사용하여 정밀한 돌연변이를 도입함에 의한 특정 세포의 선택 방법이 제공된다.
Description
관련 출원 및 참조에 의한 포함
본 출원은 각각 2012년 12월 12일, 2013년 1월 2일, 2013년 2월 25일, 2013년 3월 15일 및 2013년 6월 17일에 출원되고, 모두 명칭이 "SYSTEMS METHODS AND COMPOSITIONS FOR SEQUENCE MANIPULATION"이며, 각각 브로드(Broad) 참조번호 BI-2011/008/WSGR 사건 번호 44063-701.101, BI-2011/008/WSGR 사건 번호 44063-701.102, 브로드 참조번호 BI-2011/008/VP 사건 번호 44790.01.2003, BI-2011/008/VP 사건 번호 44790.02.2003 및 BI-2011/008/VP 사건 번호 44790.03.2003을 갖는 미국 가출원 제61/736,527호, 제61/748,427호, 제61/768,959호, 제61/791,409호 및 제61/835,931호에 대한 우선권을 주장한다.
각각 2013년 1월 30일; 2013년 2월 25일; 2013년 3월 15일; 2013년 3월 28일; 2013년 4월 20일; 2013년 5월 6일; 및 2013년 5월 28일에 출원되고, 각각 명칭이 "ENGINEERING AND OPTIMIZATION OF SYSTEMS, METHODS AND COMPOSITIONS FOR SEQUENCE MANIPULATION"인 미국 가출원 제61/758,468호; 제61/769,046호; 제61/802,174호; 제61/806,375호; 제61/814,263호; 제61/819,803호 및 제61/828,130호를 참조한다. 또한, 각각이 2013년 6월 17일에 출원된 미국 가출원 제61/835,936호, 제61/836,127호, 제61/836,101호, 제61/836,080호, 제61/836,123호 및 제61/835,973호를 참조한다. 또한, 각각 2013년 7월 2일 및 2013년 10월 15일에 출원되고, 명칭이 "CRISPR-CAS SYSTEMS AND METHODS FOR ALTERING EXPRESSION OF GENE PRODUCTS"이며, 각각이 브로드 참조번호 BI-2011/008A를 갖는 미국 가출원 제61/842,322호 및 미국 특허 출원 제14/054,414호를 참조한다.
전술한 출원, 및 상기 출원에 또는 상기 출원의 절차 중에 인용된 모든 문헌("출원 인용 문헌") 및 상기 출원 인용 문헌에 인용되거나 참고된 모든 문헌, 및 본원에서 인용되거나 참고된 모든 문헌("본원 인용 문헌") 및 본원 인용 문헌에 인용되거나 참고된 모든 문헌은, 본원에 언급되거나 본원에 참고로 포함된 임의의 문헌에 언급된 임의의 제품에 대한 임의의 제조사의 지침서, 설명서, 제품 명세서 및 제품 시트(sheet)와 함께, 본원에 참고로 포함되어 있으며, 그리고 본 발명의 실시에 사용될 수 있다. 더욱 구체적으로, 모든 참조된 문헌은 마치 각각의 개별 문헌을 참고로 포함하는 것으로 특정적으로 그리고 개별적으로 나타내는 것과 동일한 정도로 참고로 포함된다.
기술 분야
본 발명은 일반적으로 클러스터링되고 규칙적으로 산재된 짧은 팔린드로믹 반복부(Clustered Regularly Interspaced Short Palindromic Repeats; CRISPR) 및 그의 성분과 관련된 벡터 시스템을 사용할 수 있는 게놈 변동(genomic perturbation) 또는 유전자-교정(gene-editing)과 같이 서열 표적화를 수반하는 유전자 발현의 제어를 위해 사용되는 시스템, 방법 및 조성물에 관한 것이다.
연방 정부가 후원하는 연구에 대한 성명
본 발명은 미국 국립 보건원(National Institutes of Health)에 의해 지급된 NIH 파이오니어 어워드(Pioneer Award) DP1MH100706 하의 정부 지원으로 수행되었다. 정부는 본 발명에 소정의 권리를 갖는다.
게놈 시퀀싱(sequencing) 기술 및 분석 방법의 최근의 진전에 의해, 다양한 생물학적 기능 및 질병(disease)과 관련된 유전적 요인을 분류하고 발견하는 능력이 상당히 가속화되었다. 개별 유전 요소의 선택적 변동을 가능하게 함으로써 원인이 되는 유전 변이의 체계적인 역의 조작을 가능하게 할 뿐 아니라, 합성 생물학, 생명공학 및 의학 응용을 진전시키기 위하여, 정밀한 게놈 표적화 기술이 필요하다. 게놈-교정 기술, 예를 들어, 디자이너 징크 핑거, 전사 활성화제-유사 이펙터(effector)(TALE) 또는 귀소 메가뉴클레아제(homing meganuclease)가 표적화된 게놈 변동을 생성하는데 이용가능하지만, 가격이 알맞고, 설립하기 용이하며, 확대가능하고, 진핵 게놈 내의 다수의 위치를 표적화하는데 부합되는 새로운 게놈 조작 기술이 필요하다.
다수의 응용에서 대안의 강력한 서열 표적화 시스템 및 기술이 긴급하게 필요하다. 본 발명은 이러한 요구를 다루며, 관련 이점을 제공한다. CRISPR/Cas 또는 CRISPR-Cas 시스템(두 용어 모두는 본 출원에서 상호교환가능하게 사용된다)은 특정 서열을 표적화하기 위해 맞춤형 단백질의 생성을 필요로 하지 않고, 오히려, 단일의 Cas 효소가 짧은 RNA 분자에 의해 프로그램화되어, 특정 DNA 표적을 인식할 수 있으며, 다시 말하면, Cas 효소는 상기 짧은 RNA 분자를 사용하여 특정 DNA 표적에 동원될 수 있다. 게놈 시퀀싱(sequencing) 기술 및 분석 방법의 레퍼토리에 CRISPR-Cas 시스템을 부가하면, 방법을 상당히 단순화시킬 수 있으며, 다양한 생물학적 기능 및 질병과 관련된 유전적 요인을 분류하고 발견하는 능력을 가속화시킬 수 있다. 유해 영향 없이 게놈 교정을 위해 효율적으로 CRISPR-Cas 시스템을 사용하기 위하여, 조작의 양태, 및 청구된 발명의 양태인 이들 게놈 조작 도구의 최적화를 이해하는 것이 중요하다.
일 양태에서, 본 발명은 하나 이상의 벡터를 포함하는 벡터 시스템을 제공한다. 일부 구현예에서, 시스템은 (a) tracr 메이트(mate) 서열, 및 tracr 메이트 서열의 상류에 하나 이상의 가이드 서열을 삽입하기 위한 하나 이상의 삽입 부위에 작동가능하게 연결된 제1 조절 요소로서, 상기 가이드 서열은 발현되는 경우, 진핵 세포 내의 표적 서열로의 CRISPR 복합체의 서열-특이적 결합을 유도하고, 상기 CRISPR 복합체는 (1) 상기 표적 서열에 혼성화되는 가이드 서열, 및 (2) 상기 tracr 서열에 혼성화되는 tracr 메이트 서열과 복합체화된 CRISPR 효소를 포함하는 제1 조절 요소; 및 (b) 핵 국소화 서열을 포함하는 상기 CRISPR 효소를 인코딩하는 효소-코딩 서열에 작동가능하게 연결된 제2 조절 요소를 포함하며; 성분 (a) 및 (b)는 상기 시스템의 동일한 또는 상이한 벡터에 위치한다. 일부 구현예에서, 성분 (a)는 제1 조절 요소의 제어 하에 tracr 메이트 서열의 하류의 tracr 서열을 더 포함한다. 일부 구현예에서, 성분 (a)는 제1 조절 요소에 작동가능하게 연결된 2개 이상의 가이드 서열을 더 포함하며, 2개 이상의 가이드 서열의 각각은 발현되는 경우, 진핵 세포 내의 상이한 표적 서열로의 CRISPR 복합체의 서열 특이적 결합을 지시한다. 일부 구현예에서, 상기 시스템은 제3 조절 요소, 예를 들어, 중합효소 III 프로모터의 제어 하에 tracr 서열을 포함한다. 일부 구현예에서, tracr 서열은 최적으로 정렬되는 경우, tracr 메이트 서열의 길이를 따라 적어도 50%, 60%, 70%, 80%, 90%, 95% 또는 99%의 서열 상보성을 나타낸다. 최적의 정렬의 결정은 당업자의 이해 범위 내에 있다. 예를 들어, 공개적이며 상업적으로 이용가능한 정렬 알고리즘 및 프로그램, 예를 들어, 비제한적으로 ClustalW, matlab의 Smith-Waterman, Bowtie, Geneious, Biopython 및 SeqMan이 존재한다. 일부 구현예에서, CRISPR 복합체는 진핵 세포의 핵에서 검출가능한 양으로 상기 CRISPR 복합체의 축적을 유도하기에 충분한 세기의 하나 이상의 핵 국소화 서열을 포함한다. 이론에 구속되지 않으면서, 핵 국소화 서열은 진핵생물에서 CRISPR 복합체 활성에 필요하지 않지만, 이러한 서열을 포함하여, 시스템의 활성을 증진시켜, 특히 핵 내의 핵산 분자를 표적화하는 것으로 여겨진다. 일부 구현예에서, CRISPR 효소는 II형 CRISPR 시스템 효소이다. 일부 구현예에서, CRISPR 효소는 Cas9 효소이다. 일부 구현예에서, Cas9 효소는 스트렙토코커스 뉴모니애(S. pneumoniae), 스트렙토코커스 피오게네스(S. pyogenes) 또는 스트렙토코커스 써모필러스(S. thermophilus) Cas9이며, 이들 유기체로부터 유래된 돌연변이된 Cas9를 포함할 수 있다. 효소는 Cas9 상동체 또는 오솔로그(ortholog)일 수 있다. 일부 구현예에서, CRISPR 효소는 진핵 세포에서의 발현을 위해 코돈-최적화된다. 일부 구현예에서, CRISPR 효소는 표적 서열의 위치에서 1개 또는 2개 가닥의 절단을 유도한다. 일부 구현예에서, CRISPR 효소에는 DNA 가닥 절단 활성이 결여된다. 일부 구현예에서, 제1 조절 요소는 중합효소 III 프로모터이다. 일부 구현예에서, 제2 조절 요소는 중합효소 II 프로모터이다. 일부 구현예에서, 가이드 서열은 적어도 15, 16, 17, 18, 19, 20, 25개 뉴클레오티드 또는 10 내지 30개 또는 15 내지 25개 또는 15 내지 20개 뉴클레오티드 길이이다. 일반적으로, 그리고 본원에서, 용어 "벡터"는 그것이 연결된 다른 핵산을 수송할 수 있는 핵산 분자를 지칭한다. 벡터는 단일-가닥, 이중-가닥 또는 부분 이중-가닥인 핵산 분자; 하나 이상의 자유 말단을 포함하거나, 자유 말단을 포함하지 않는(예를 들어, 환형) 핵산 분자; DNA, RNA 또는 둘 모두를 포함하는 핵산 분자; 및 당업계에 공지되어 있는 다른 종류의 폴리뉴클레오티드를 포함하나 이들에 한정되지 않는다. 하나의 유형의 벡터는 "플라스미드"이며, 이는 추가의 DNA 세그먼트가 예를 들어, 표준 분자 클로닝 기술에 의해 삽입될 수 있는 환형 이중 가닥 DNA 루프를 지칭한다. 다른 유형의 벡터는 바이러스 벡터이며, 여기서, 바이러스-유래 DNA 또는 RNA 서열은 바이러스(예를 들어, 레트로바이러스, 복제 결함 레트로바이러스, 아데노바이러스, 복제 결함 아데노바이러스 및 아데노-관련 바이러스)로의 패키징을 위한 벡터에 존재한다. 또한, 바이러스 벡터는 숙주 세포로의 트랜스펙션(transfection)을 위해 바이러스가 지니는 폴리뉴클레오티드도 포함한다. 특정 벡터(예를 들어, 박테리아 복제 원점을 갖는 박테리아 벡터 및 에피솜 포유동물 벡터)는 그들이 도입되는 숙주 세포에서 자가 복제할 수 있다. 기타 벡터(예를 들어, 비-에피솜 포유동물 벡터)는 숙주 세포로의 도입시에 숙주 세포의 게놈으로 통합되며, 이에 의해, 숙주 게놈과 함께 복제된다. 게다가, 특정 벡터는 그들이 작동가능하게 연결된 유전자의 발현을 유도할 수 있다. 이러한 벡터는 본원에서 "발현 벡터"로 지칭된다. 재조합 DNA 기술에 유용한 통상적인 발현 벡터는 종종 플라스미드의 형태로 존재한다.
재조합 발현 벡터는 숙주 세포에서의 핵산의 발현에 적절한 형태의 본 발명의 핵산을 포함할 수 있으며, 이는 재조합 발현 벡터가, 발현을 위해 사용될 숙주 세포에 기초하여 선택될 수 있는, 발현될 핵산 서열에 작동가능하게 연결된 하나 이상의 조절 요소를 포함하는 것을 의미한다. 재조합 발현 벡터 내에서, "작동가능하게 연결된"은 대상 뉴클레오티드 서열이 (예를 들어, 시험관내 전사/번역 시스템 내에서, 또는 벡터가 숙주 세포 내로 도입되는 경우 숙주 세포 내에서) 뉴클레오티드 서열의 발현을 가능하게 하는 방식으로 조절 요소(들)에 연결된 것을 의미하는 의도이다.
용어 "조절 요소"는 프로모터, 인핸서, 내부 리보솜 진입 부위(internal ribosomal entry site; IRES) 및 기타 발현 제어 요소(예를 들어, 전사 종결 신호, 예를 들어, 폴리아데닐화 신호 및 폴리-U 서열)를 포함하는 의도이다. 이러한 조절 요소는 예를 들어, 문헌[Goeddel, GENE EXPRESSION TECHNOLOGY: METHODS IN ENZYMOLOGY 185, Academic Press, San Diego, Calif. (1990)]에 기술되어 있다. 조절 요소는 많은 유형의 숙주 세포에서 뉴클레오티드 서열의 구성적 발현을 유도하는 조절 요소 및 특정 숙주 세포에서만 뉴클레오티드 서열의 발현을 유도하는 조절 요소(예를 들어, 조직-특이적 조절 서열)를 포함한다. 조직-특이적 프로모터는 요망되는 대상 조직, 예를 들어, 근육, 뉴런, 뼈, 피부, 혈액, 특정 기관(예를 들어, 간, 췌장) 또는 특정 세포 유형(예를 들어, 림프구)에서 주로 발현을 유도할 수 있다. 또한, 조절 요소는 시간-의존적 방식으로, 예를 들어, 세포-주기 의존적 또는 발생 단계-의존적 방식으로 발현을 유도할 수 있으며, 이는 조직 또는 세포-유형에 특이적이거나 그렇지 않을 수 있다. 일부 구현예에서, 벡터는 하나 이상의 pol III 프로모터(예를 들어, 1, 2, 3, 4, 5개 또는 그 이상의 pol III 프로모터), 하나 이상의 pol II 프로모터(예를 들어, 1, 2, 3, 4, 5개 또는 그 이상의 pol II 프로모터), 하나 이상의 pol I 프로모터(예를 들어, 1, 2, 3, 4, 5개 또는 그 이상의 pol I 프로모터) 또는 그들의 조합을 포함한다. pol III 프로모터의 예에는 U6 및 H1 프로모터가 포함되나 이들에 한정되지 않는다. pol II 프로모터의 예에는 레트로바이러스 라우스 육종 바이러스(RSV) LTR 프로모터(선택적으로 RSV 인핸서가 존재), 사이토메갈로바이러스(CMV) 프로모터(선택적으로 CMV 인핸서가 존재)[예를 들어, 문헌(Boshart et al, Cell, 41:521-530 (1985)) 참조], SV40 프로모터, 디하이드로폴레이트 환원효소 프로모터, β-액틴 프로모터, 포스포글리세롤 키나제(PGK) 프로모터 및 EF1α 프로모터가 포함되나 이들에 한정되지 않는다. 또한, 용어 "조절 요소"에는 인핸서 요소, 예를 들어, WPRE; CMV 인핸서; HTLV-I의 LTR 내의 R-U5' 세그먼트(문헌[Mol. Cell. Biol., Vol. 8(1), p. 466-472, 1988]); SV40 인핸서; 및 토끼 β-글로빈의 엑손 2와 3 사이의 인트론 서열(문헌[Proc. Natl. Acad. Sci. USA., Vol. 78(3), p. 1527-31, 1981])이 포함된다. 발현 벡터의 설계가 형질전환될 숙주 세포의 선택, 요망되는 발현 수준 등과 같은 인자에 따라 달라질 수 있음이 당업자에 의해 인식될 것이다. 벡터를 숙주 세포로 도입하여, 전사물, 본원에 기술된 바와 같은 핵산에 의해 인코딩된 융합 단백질 또는 펩티드를 포함하는 단백질 또는 펩티드(예를 들어, 클러스터링되고 규칙적으로 산재된 짧은 팔린드로믹 반복부(CRISPR) 전사물, 단백질, 효소, 그의 돌연변이체 형태, 그의 융합 단백질 등)를 생성할 수 있다.
유리한 벡터는 렌티바이러스 및 아데노-관련 바이러스를 포함하며, 또한, 이러한 벡터의 유형은 특정 세포 유형을 표적화하기 위해 선택될 수 있다.
일 양태에서, 본 발명은 하나 이상의 핵 국소화 서열을 포함하는, CRISPR 효소를 인코딩하는 효소-코딩 서열에 작동가능하게 연결된 조절 요소를 포함하는 벡터를 제공한다. 일부 구현예에서, 상기 조절 요소는 상기 CRISPR 효소가 진핵 세포의 핵에서 검출가능한 양으로 축적되도록 진핵 세포에서 CRISPR 효소의 전사를 유도한다. 일부 구현예에서, 조절 요소는 중합효소 II 프로모터이다. 일부 구현예에서, CRISPR 효소는 II형 CRISPR 시스템 효소이다. 일부 구현예에서, CRISPR 효소는 Cas9 효소이다. 일부 구현예에서, Cas9 효소는 스트렙토코커스 뉴모니애, 스트렙토코커스 피오게네스 또는 스트렙토코커스 써모필러스 Cas9이며, 이들 유기체로부터 유래된 돌연변이된 Cas9를 포함할 수 있다. 일부 구현예에서, CRISPR 효소는 진핵 세포에서의 발현을 위해 코돈-최적화된다. 일부 구현예에서, CRISPR 효소는 표적 서열의 위치에서 1개 또는 2개의 가닥의 절단을 유도한다. 일부 구현예에서, CRISPR 효소는 DNA 가닥 절단 활성이 결여된다.
일 양태에서, 본 발명은 진핵 세포의 핵에서 검출가능한 양의 CRISPR 효소의 축적을 유도하기에 충분한 세기의 하나 이상의 핵 국소화 서열을 포함하는 상기 CRISPR 효소를 제공한다. 일부 구현예에서, CRISPR 효소는 II형 CRISPR 시스템 효소이다. 일부 구현예에서, CRISPR 효소는 Cas9 효소이다. 일부 구현예에서, Cas9 효소는 스트렙토코커스 뉴모니애, 스트렙토코커스 피오게네스 또는 스트렙토코커스 써모필러스 Cas9이며, 이들 유기체로부터 유래된 돌연변이된 Cas9를 포함할 수 있다. 효소는 Cas9 상동체 또는 오솔로그일 수 있다. 일부 구현예에서, CRISPR 효소는 그것이 결합하는 표적 서열의 1개 이상의 가닥을 절단하는 능력이 결여된다.
일 양태에서, 본 발명은 (a) tracr 메이트 서열, 및 tracr 메이트 서열의 상류에 하나 이상의 가이드 서열을 삽입하기 위한 하나 이상의 삽입 부위에 작동가능하게 연결된 제1 조절 요소로서, 상기 가이드 서열은 발현되는 경우, 진핵 세포 내의 표적 서열로의 CRISPR 복합체의 서열-특이적 결합을 유도하고, 상기 CRISPR 복합체는 (1) 상기 표적 서열에 혼성화되는 가이드 서열, 및 (2) 상기 tracr 서열에 혼성화되는 tracr 메이트 서열과 복합체화된 CRISPR 효소를 포함하는 제1 조절 요소; 및/또는 (b) 핵 국소화 서열을 포함하는 상기 CRISPR 효소를 인코딩하는 효소-코딩 서열에 작동가능하게 연결된 제2 조절 요소를 포함하는 진핵 숙주 세포를 제공한다. 일부 구현예에서, 숙주 세포는 성분 (a) 및 (b)를 포함한다. 일부 구현예에서, 성분 (a), 성분 (b) 또는 성분 (a) 및 (b)는 숙주 진핵 세포의 게놈 내로 안정적으로 통합된다. 일부 구현예에서, 성분 (a)는 제1 조절 요소의 제어 하에 tracr 메이트 서열의 하류의 tracr 서열을 더 포함한다. 일부 구현예에서, 성분 (a)는 제1 조절 요소에 작동가능하게 연결된 2개 이상의 가이드 서열을 더 포함하며, 2개 이상의 가이드 서열의 각각은 발현되는 경우, 진핵 세포 내의 상이한 표적 서열로의 CRISPR 복합체의 서열 특이적 결합을 유도한다. 일부 구현예에서, 진핵 숙주 세포는 상기 tracr 서열에 작동가능하게 연결된 제3 조절 요소, 예를 들어, 중합효소 III 프로모터를 더 포함한다. 일부 구현예에서, tracr 서열은 최적으로 정렬되는 경우 tracr 메이트 서열의 길이를 따라 적어도 50%, 60%, 70%, 80%, 90%, 95% 또는 99%의 서열 상보성을 나타낸다. 일부 구현예에서, CRISPR 효소는 진핵 세포의 핵에서 검출가능한 양의 상기 CRISPR 효소의 축적을 유도하기에 충분한 세기의 하나 이상의 핵 국소화 서열을 포함한다. 일부 구현예에서, CRISPR 효소는 II형 CRISPR 시스템 효소이다. 일부 구현예에서, CRISPR 효소는 Cas9 효소이다. 일부 구현예에서, Cas9 효소는 스트렙토코커스 뉴모니애, 스트렙토코커스 피오게네스 또는 스트렙토코커스 써모필러스 Cas9이며, 이들 유기체로부터 유래된 돌연변이된 Cas9를 포함할 수 있다. 효소는 Cas9 상동체 또는 오솔로그일 수 있다. 일부 구현예에서, CRISPR 효소는 진핵 세포에서의 발현을 위해 코돈-최적화된다. 일부 구현예에서, CRISPR 효소는 표적 서열의 위치에서 1개 또는 2개의 가닥의 절단을 유도한다. 일부 구현예에서, CRISPR 효소는 DNA 가닥 절단 활성이 결여된다. 일부 구현예에서, 제1 조절 요소는 중합효소 III 프로모터이다. 일부 구현예에서, 제2 조절 요소는 중합효소 II 프로모터이다. 일부 구현예에서, 가이드 서열은 적어도 15, 16, 17, 18, 19, 20, 25개 뉴클레오티드 또는 10 내지 30개 또는 15 내지 25개 또는 15 내지 20개 뉴클레오티드 길이이다. 일 양태에서, 본 발명은 기술된 구현예 중 임의의 것에 따른 진핵 숙주 세포를 포함하는 비-인간 진핵 유기체; 바람직하게는 다세포 진핵 유기체를 제공한다. 다른 양태에서, 본 발명은 기술된 구현예 중 임의의 것에 따른 진핵 숙주 세포를 포함하는 진핵 유기체; 바람직하게는 다세포 진핵 유기체를 제공한다. 이들 양태의 일부 구현예에서 유기체는 동물; 예를 들어, 포유동물일 수 있다. 또한, 유기체는 절지동물, 예를 들어, 곤충일 수 있다. 또한, 유기체는 식물일 수도 있다. 추가로, 유기체는 진균일 수 있다.
일 양태에서, 본 발명은 본원에 기술된 성분 중 하나 이상을 포함하는 키트를 제공한다. 일부 구현예에서, 키트는 벡터 시스템 및 키트 사용 지침서를 포함한다. 일부 구현예에서, 벡터 시스템은 (a) tracr 메이트 서열, 및 tracr 메이트 서열의 상류에 하나 이상의 가이드 서열을 삽입하기 위한 하나 이상의 삽입 부위에 작동가능하게 연결된 제1 조절 요소로서, 상기 가이드 서열은 발현되는 경우, 진핵 세포 내의 표적 서열로의 CRISPR 복합체의 서열-특이적 결합을 유도하고, 상기 CRISPR 복합체는 (1) 상기 표적 서열에 혼성화되는 가이드 서열, 및 (2) 상기 tracr 서열에 혼성화되는 tracr 메이트 서열과 복합체화된 CRISPR 효소를 포함하는 제1 조절 요소; 및/또는 (b) 핵 국소화 서열을 포함하는 상기 CRISPR 효소를 인코딩하는 효소-코딩 서열에 작동가능하게 연결된 제2 조절 요소를 포함한다. 일부 구현예에서, 키트는 시스템의 동일한 또는 상이한 벡터에 위치한 성분 (a) 및 (b)를 포함한다. 일부 구현예에서, 성분 (a)는 제1 조절 요소의 제어 하에 tracr 메이트 서열의 하류의 tracr 서열을 더 포함한다. 일부 구현예에서, 성분 (a)는 제1 조절 요소에 작동가능하게 연결된 2개 이상의 가이드 서열을 더 포함하며, 2개 이상의 가이드 서열의 각각은 발현되는 경우, 진핵 세포 내의 상이한 표적 서열로의 CRISPR 복합체의 서열 특이적 결합을 유도한다. 일부 구현예에서, 시스템은 상기 tracr 서열에 작동가능하게 연결된 제3 조절 요소, 예를 들어, 중합효소 III 프로모터를 더 포함한다. 일부 구현예에서, tracr 서열은 최적으로 정렬되는 경우 tracr 메이트 서열의 길이를 따라 적어도 50%, 60%, 70%, 80%, 90%, 95% 또는 99%의 서열 상보성을 나타낸다. 일부 구현예에서, CRISPR 효소는 진핵 세포의 핵에서 검출가능한 양의 상기 CRISPR 효소의 축적을 유도하기에 충분한 세기의 하나 이상의 핵 국소화 서열을 포함한다. 일부 구현예에서, CRISPR 효소는 II형 CRISPR 시스템 효소이다. 일부 구현예에서, CRISPR 효소는 Cas9 효소이다. 일부 구현예에서, Cas9 효소는 스트렙토코커스 뉴모니애, 스트렙토코커스 피오게네스 또는 스트렙토코커스 써모필러스 Cas9이며, 이들 유기체로부터 유래된 돌연변이된 Cas9를 포함할 수 있다. 효소는 Cas9 상동체 또는 오솔로그일 수 있다. 일부 구현예에서, CRISPR 효소는 진핵 세포에서의 발현을 위해 코돈-최적화된다. 일부 구현예에서, CRISPR 효소는 표적 서열의 위치에서 1개 또는 2개의 가닥의 절단을 유도한다. 일부 구현예에서, CRISPR 효소는 DNA 가닥 절단 활성이 결여된다. 일부 구현예에서, 제1 조절 요소는 중합효소 III 프로모터이다. 일부 구현예에서, 제2 조절 요소는 중합효소 II 프로모터이다. 일부 구현예에서, 가이드 서열은 적어도 15, 16, 17, 18, 19, 20, 25개 뉴클레오티드 또는 10 내지 30개 또는 15 내지 25개 또는 15 내지 20개 뉴클레오티드 길이이다.
일 양태에서, 본 발명은 진핵 세포에서의 표적 폴리뉴클레오티드의 변경 방법을 제공한다. 일부 구현예에서, 상기 방법은 CRISPR 복합체가 표적 폴리뉴클레오티드에 결합하게 하여, 상기 표적 폴리뉴클레오티드의 절단을 초래하여, 표적 폴리뉴클레오티드를 변경시키는 단계를 포함하며, 여기서, CRISPR 복합체는 상기 표적 폴리뉴클레오티드 내의 표적 서열에 혼성화되는 가이드 서열과 복합체화된 CRISPR 효소를 포함하며, 상기 가이드 서열은 tracr 메이트 서열에 연결되며, tracr 메이트 서열은 차례로 tracr 서열에 혼성화된다. 일부 구현예에서, 상기 절단은 상기 CRISPR 효소에 의한, 표적 서열의 위치에서의 1개 또는 2개의 가닥의 절단을 포함한다. 일부 구현예에서, 상기 절단은 감소된 표적 유전자의 전사를 야기한다. 일부 구현예에서, 상기 방법은 외인성 주형 폴리뉴클레오티드와의 상동성 재조합에 의해 상기 절단된 표적 폴리뉴클레오티드를 수복하는 단계를 더 포함하며, 상기 수복은 상기 표적 폴리뉴클레오티드의 하나 이상의 뉴클레오티드의 삽입, 결실 또는 치환을 포함하는 돌연변이를 야기한다. 일부 구현예에서, 상기 돌연변이는 표적 서열을 포함하는 유전자로부터 발현되는 단백질의 하나 이상의 아미노산 변화를 야기한다. 일부 구현예에서, 상기 방법은 하나 이상의 벡터를 상기 진핵 세포로 전달하는 단계를 더 포함하며, 하나 이상의 벡터는 CRISPR 효소, tracr 메이트 서열에 연결된 가이드 서열 및 tracr 서열 중 하나 이상의 발현을 유도한다. 일부 구현예에서, 상기 벡터는 대상체 내의 진핵 세포로 전달된다. 일부 구현예에서, 상기 변경은 세포 배양물 중의 상기 진핵 세포에서 발생한다. 일부 구현예에서, 상기 방법은 상기 변경 전에 상기 진핵 세포를 대상체로부터 분리하는 단계를 더 포함한다. 일부 구현예에서, 상기 방법은 상기 진핵 세포 및/또는 그로부터 유래된 세포를 상기 대상체로 복귀시키는 단계를 더 포함한다.
일 양태에서, 본 발명은 진핵 세포에서의 폴리뉴클레오티드의 발현의 변경 방법을 제공한다. 일부 구현예에서, 상기 방법은 CRISPR 복합체가 폴리뉴클레오티드에 결합하게 하여, 상기 결합이 상기 폴리뉴클레오티드의 증가되거나 감소된 발현을 야기하도록 하는 단계를 포함하며; 여기서, CRISPR 복합체는 상기 폴리뉴클레오티드 내의 표적 서열에 혼성화되는 가이드 서열과 복합체화된 CRISPR 효소를 포함하고, 상기 가이드 서열은 tracr 메이트 서열에 연결되고, tracr 메이트 서열은 차례로 tracr 서열로 혼성화된다. 일부 구현예에서, 상기 방법은 하나 이상의 벡터를 상기 진핵 세포로 전달하는 단계를 더 포함하며, 여기서, 하나 이상의 벡터는 CRISPR 효소, tracr 메이트 서열에 연결된 가이드 서열 및 tracr 서열 중 하나 이상의 발현을 유도한다.
일 양태에서, 본 발명은 돌연변이된 질병 유전자를 포함하는 모델 진핵 세포의 생성 방법을 제공한다. 일부 구현예에서, 질병 유전자는 질병을 갖거나 질병이 발생할 위험의 증가와 관련된 임의의 유전자이다. 일부 구현예에서, 상기 방법은 (a) 하나 이상의 벡터를 진핵 세포로 도입하는 단계로서, 하나 이상의 벡터는 CRISPR 효소, tracr 메이트 서열에 연결된 가이드 서열 및 tracr 서열 중 하나 이상의 발현을 유도하는 단계; 및 (b) CRISPR 복합체가 표적 폴리뉴클레오티드에 결합하게 하여, 상기 질병 유전자 내의 표적 폴리뉴클레오티드의 절단을 야기하여, 돌연변이된 질병 유전자를 포함하는 모델 진핵 세포를 생성하는 단계로서, CRISPR 복합체가 (1) 표적 폴리뉴클레오티드 내의 표적 서열에 혼성화되는 가이드 서열, 및 (2) tracr 서열에 혼성화되는 tracr 메이트 서열과 복합체화되는 CRISPR 효소를 포함하는 단계를 포함한다. 일부 구현예에서, 상기 절단은 상기 CRISPR 효소에 의한, 표적 서열의 위치에서의 1개 또는 2개의 가닥의 절단을 포함한다. 일부 구현예에서, 상기 절단은 표적 유전자의 감소된 전사를 야기한다. 일부 구현예에서, 상기 방법은 외인성 주형 폴리뉴클레오티드와의 상동성 재조합에 의해 상기 절단된 표적 폴리뉴클레오티드를 수복하는 단계를 더 포함하며, 상기 수복은 상기 표적 폴리뉴클레오티드의 하나 이상의 뉴클레오티드의 삽입, 결실 또는 치환을 포함하는 돌연변이를 야기한다. 일부 구현예에서, 상기 돌연변이는 표적 서열을 포함하는 유전자로부터의 단백질 발현의 하나 이상의 아미노산 변화를 야기한다.
일 양태에서, 본 발명은 질병 유전자와 관련된 세포 신호전달 사건을 조절하는 생물학적 활성 작용제의 개발 방법을 제공한다. 일부 구현예에서, 질병 유전자는 질병을 갖거나 질병이 발생할 위험의 증가와 관련된 임의의 유전자이다. 일부 구현예에서, 상기 방법은 (a) 시험 화합물을 기술된 구현예 중 임의의 것의 모델 세포와 접촉시키는 단계; 및 (b) 상기 질병 유전자의 상기 돌연변이와 관련된 세포 신호전달 사건의 감소 또는 증가를 나타내는 판독치의 변화를 검출하여, 상기 질병 유전자와 관련된 상기 세포 신호전달 사건을 조절하는 상기 생물학적 활성 작용제를 개발하는 단계를 포함한다.
일 양태에서, 본 발명은 tracr 메이트 서열의 상류에 가이드 서열을 포함하는 재조합 폴리뉴클레오티드를 제공하며, 가이드 서열은 발현되는 경우, 진핵 세포에 존재하는 상응하는 표적 서열로의 CRISPR 복합체의 서열-특이적 결합을 유도한다. 일부 구현예에서, 표적 서열은 진핵 세포에 존재하는 바이러스 서열이다. 일부 구현예에서, 표적 서열은 원암유전자(proto-oncogene) 또는 암유전자이다.
일 양태에서, 본 발명은 하나 이상의 돌연변이를 하나 이상의 원핵 세포(들) 내의 유전자에 도입함에 의한 하나 이상의 원핵 세포(들)의 선택 방법을 제공하며, 상기 방법은 하나 이상의 벡터를 원핵 세포(들)로 도입하는 단계로서, 하나 이상의 벡터가 CRISPR 효소, tracr 메이트 서열에 연결된 가이드 서열, tracr 서열 및 교정 주형 중 하나 이상의 발현을 유도하고; 교정 주형이 CRISPR 효소 절단을 없애는 하나 이상의 돌연변이를 포함하는 단계; 선택될 세포(들)에서 교정 주형과 표적 폴리뉴클레오티드의 상동성 재조합을 가능하게 하는 단계; CRISPR 복합체가 표적 폴리뉴클레오티드에 결합되게 하여, 상기 유전자 내의 표적 폴리뉴클레오티드의 절단을 초래하는 단계로서, CRISPR 복합체는 (1) 표적 폴리뉴클레오티드 내의 표적 서열에 혼성화되는 가이드 서열 및 (2) tracr 서열에 혼성화되는 tracr 메이트 서열과 복합체화되는 CRISPR 효소를 포함하고, 표적 폴리뉴클레오티드로의 CRISPR 복합체의 결합이 세포사를 유도하여, 하나 이상의 돌연변이가 도입된 하나 이상의 원핵 세포(들)가 선택되게 하는 단계를 포함한다. 바람직한 구현예에서, CRISPR 효소는 Cas9이다. 본 발명의 다른 양태에서, 선택될 세포는 진핵 세포일 수 있다. 본 발명의 양태는 선택 마커 또는 반대-선택 시스템을 포함할 수 있는 2-단계 과정을 필요로 하지 않고 특정 세포의 선택을 가능하게 한다.
따라서, 본 발명의 목적은 발명 내에 해당 출원인이 권리를 보유하고 있는 임의의 선행기술에서 공지된 제품, 그 제품의 제조 절차 또는 그 제품의 사용 방법을 포함하지 않으며, 이로써 임의의 선행기술에서 공지된 제품, 절차 및 방법에 대해서는 권리포기를 개시한다. 또한, 본 발명은 본 발명의 범위 내에 USPTO(35 U.S.C. § 112, 제1 단락) 또는 EPO(EPC의 제83조)의 기재된 사항 및 구현 요건을 충족하지 않는 임의의 제품, 절차 또는 그 제품의 제조 또는 그 제품의 사용 방법을 포함하지 않는 것을 의도로 하며, 이로써 해당 출원인이 권리를 유지하고 있는 임의의 선행기술에서 기재된 제품, 그 제품의 제조 절차 또는 그 제품의 사용 방법에 대한 권리 포기를 개시하는 것을 추가로 언급한다.
본 개시내용 및 특히 청구범위 및/또는 단락에서, "함유한다", "함유된", "함유하는" 등과 같은 용어가 미국 특허법에 귀속되는 의미를 가질 수 있고; 예를 들어, "포함한다", "포함된", "포함하는" 등을 의미할 수 있으며; "본질적으로 이루어지는" 및 "본질적으로 이루어진다"와 같은 용어가 미국 특허법에 귀속되는 의미를 갖고, 예를 들어, 명백하게 열거되지 않는 구성요소를 허용하지만, 선행 기술에서 발견되거나 본 발명의 기본적인 또는 새로운 특징에 영향을 미치는 구성요소를 배제함이 주목된다. 상기 및 기타 구현예는 하기 상세한 설명으로부터 개시되거나, 그로부터 명백하고 그에 의해 포함된다.
본 발명의 신규의 특징은 특히 첨부된 청구범위에 개시되어 있다. 본 발명의 원리가 이용된 예시적인 구현예에 기재되어 있는 하기의 상세한 설명을 참조함으로써 본 발명의 특징 및 장점을 더욱 잘 이해할 것이며, 첨부된 도면은 다음과 같다:
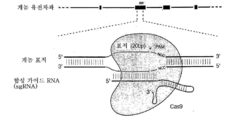
도 1은 CRISPR 시스템의 개략적 모델을 보여준다. 스트렙토코커스 피오게네스 유래의 Cas9 뉴클레아제(황색)는 20-nt 가이드 서열(청색) 및 스캐폴드(적색)로 이루어진 합성 가이드 RNA(sgRNA)에 의해 게놈 DNA에 표적화된다. 가이드 서열은 필수 5'-NGG 프로토스페이서 인접 모티프(protospacer adjacent motif, PAM; 진홍색)의 인접 상류의 DNA 표적(청색)과 염기쌍을 형성하며, Cas9는 PAM의 약 3 bp 상류(적색 삼각형)에서 이중 가닥 파단(DSB)을 매개한다.
도 2a 내지 도 2f는 예시적인 CRISPR 시스템, 가능한 작용 메카니즘, 진핵 세포에서의 발현을 위한 예시적인 적합화, 및 핵 국소화 및 CRISPR 활성을 평가하는 시험의 결과를 보여준다.
도 3은 진핵 세포에서의 CRISPR 시스템 요소의 발현을 위한 예시적인 발현 카세트, 예시적인 가이드 서열의 예측된 구조, 및 진핵 및 원핵 세포에서 측정시 CRISPR 시스템 활성을 보여준다.
도 4a 내지 도 4d는 예시적인 표적에 대한 SpCas9 특이성의 평가의 결과를 보여준다.
도 5a 내지 도 5g는 예시적인 벡터 시스템 및 진핵 세포에서 상동성 재조합의 유도에서의 그의 사용에 대한 결과를 보여준다.
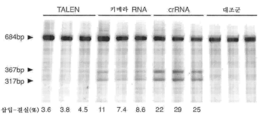
도 6은 프로토스페이서 서열의 표를 제공하며, 인간 및 마우스 게놈 내의 유전자좌(loci)에 대한 상응하는 PAM이 있는 예시적인 스트렙토코커스 피오게네스 및 스트렙토코커스 써모필러스 CRISPR 시스템에 기초하여 설계된 프로토스페이서 표적에 대한 변형 효율 결과를 요약한 것이다. 세포를 Cas9 및 pre-crRNA/tracrRNA 또는 키메라 RNA 중 어느 하나로 트랜스펙션시키고, 트랜스펙션 후 72시간에 분석하였다. 삽입-결실(indel) 백분율은 표기된 세포주로부터의 서베이어(Surveyor) 검정 결과에 기초하여 계산된다(모든 프로토스페이서 표적에 대하여 N=3, 오차는 S.E.M.이고, N.D.는 서베이어 검정을 사용하여 검출가능하지 않음을 나타내며, N.T.는 이러한 연구에서 시험하지 않음을 나타낸다).
도 7a 내지 도 7c는 Cas9-매개의 유전자 표적화를 위한 상이한 tracrRNA 전사물의 비교를 보여준다.
도 8은 이중 가닥 파단-유도 마이크로-삽입 및 -결실의 검출을 위한 서베이어 뉴클레아제 검정의 개략도를 보여준다.
도 9A 및 도 9B는 진핵 세포에서 CRISPR 시스템 요소의 발현을 위한 예시적인 비시스트로닉(bicistronic) 발현 벡터를 보여준다.
도 10은 박테리아 플라스미드 형질전환 간섭 검정, 거기에 사용된 발현 카세트 및 플라스미드, 및 거기에 사용된 세포의 형질전환 효율을 보여준다.
도 11A 내지 도 11C는 인간 게놈에서 인접 스트렙토코커스 피오게네스 SF370 유전자좌 1 PAM(NGG)(도 10A) 간의 거리 및 스트렙토코커스 써모필러스 LMD9 유전자좌 2 PAM(NNAGAAW)(도 10B) 간의 거리; 및 염색체(Chr)에 의한 각 PAM에 대한 거리(도 10C)의 히스토그램을 보여준다.
도 12A 내지 도 12C는 예시적인 CRISPR 시스템, 진핵 세포에서의 발현을 위한 예시적인 적합화 및 CRISPR 활성을 평가하는 시험의 결과를 보여준다.
도 13A 내지 도 13C는 포유동물 세포에서 게놈 유전자좌의 표적화를 위한 CRISPR 시스템의 예시적인 조작을 보여준다.
도 14A 및 도 14B는 포유동물 세포에서 crRNA 가공의 노던 블롯(Northern blot) 분석의 결과를 보여준다.
도 15는 인간 PVALB 및 마우스 Th 유전자좌에서 프로토스페이서의 예시적인 선택을 보여준다.
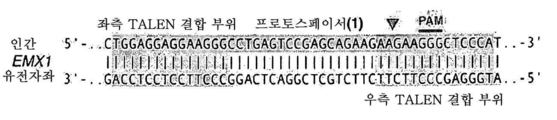
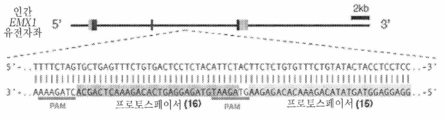
도 16은 인간 EMX1 유전자좌에서 스트렙토코커스 써모필러스 CRISPR 시스템의 예시적인 프로토스페이서 및 상응하는 PAM 서열 표적을 보여준다.
도 17은 서베이어, RFLP, 게놈 시퀀싱 및 노던 블롯 검정을 위해 사용되는 프라이머 및 프로브에 대한 서열의 표를 제공한다.
도 18a 내지 도 18c는 키메라 RNA를 사용한 CRISPR 시스템의 예시적인 조작 및 진핵 세포에서 시스템 활성에 대한 서베이어 검정의 결과를 보여준다.
도 19a 및 도 19b는 진핵 세포에서 CRISPR 시스템 활성에 대한 서베이어 검정의 결과의 그래프 표현을 보여준다.
도 20은 UCSC 게놈 브라우저(browser)를 사용한 인간 게놈 내의 일부 스트렙토코커스 피오게네스 Cas9 표적 부위의 예시적인 가시화를 보여준다.
도 21은 가이드 서열, tracr 메이트 서열 및 tracr 서열을 포함하는 예시적인 키메라 RNA에 대한 예측된 2차 구조를 보여준다.
도 22는 진핵 세포에서 CRISPR 시스템 요소의 발현을 위한 예시적인 비시스트로닉 발현 벡터를 보여준다.
도 23은 내인성 표적에 대한 Cas9 뉴클레아제 활성이 게놈 교정을 위해 이용될 수 있음을 보여준다. (a) CRISPR 시스템을 사용한 게놈 교정의 개념. CRISPR 표적화 작제물(construct)은 염색체 유전자좌의 절단을 유도하며, 이를 표적과 재조합되어 절단을 방지하는 교정 주형과 동시-형질전환시켰다. CRISPR 공격을 견뎌내는 카나마이신-내성 형질전환체는 교정 주형에 의해 도입된 변형을 포함하였다. tracr, 트랜스-활성화(trans-activating) CRISPR RNA; aphA-3, 카나마이신 내성 유전자. (b) 교정 주형 없이, 또는 R6 야생형 srtA 또는 R6370.1 교정 주형과 함께 R68232.5 세포에서의 crR6M DNA의 형질전환. R6 srtA 또는 R6370. 1 중 어느 하나의 재조합에 의해, Cas9에 의한 절단이 방지된다. 형질전환 효율을 crR6M DNA ㎍당 콜로니 형성 단위(cfu)로 계산하였고; 적어도 3개의 독립적인 실험으로부터의 평균값이 표준편차와 함께 나타나 있다. PCR 분석을 각 형질전환에서 8개의 클론에서 수행하였다. "Un."은 균주 R68232.5의 교정되지 않은 srtA 유전자좌를 나타내고; "Ed."는 교정 주형을 보여준다. R68232.5 및 R6370.1 표적은 EaeI을 사용한 제한에 의해 구별된다.
도 24는 Cas9 절단을 없애는 PAM 및 씨드(seed) 서열의 분석을 보여준다. (a) 무작위화된 PAM 서열 또는 무작위화된 씨드 서열이 있는 PCR 산물을 crR6 세포에서 형질전환시켰다. 이들 세포는 R6 게놈에 존재하지 않는 R68232.5 세포의 염색체 영역(분홍색으로 강조표시)을 표적화하는 crRNA가 로딩된 Cas9를 발현하였다. 비활성 PAM 또는 씨드 서열을 지니는 2×105개 초과의 클로람페니콜-내성 형질전환체를 표적 영역의 증폭 및 딥 시퀀싱(deep sequencing)을 위해 조합하였다. (b) crR6 세포에서 무작위 PAM 작제물의 형질전환 후의 판독치의 수의 상대적 비율(R6 형질전환체의 판독치의 수와 비교). 각 3-뉴클레오티드 PAM 서열에 대한 상대적 존재비가 나타나 있다. 심하게 부족한 서열(severely underrepresented sequence; NGG)은 적색으로; 불완전하게 부족한 것은 주황색으로 나타나 있다(NAG). (c) crR6 세포에서 무작위 씨드 서열 작제물의 형질전환 후의 판독치의 수의 상대적 비율(R6 형질전환체의 판독치의 수와 비교). 프로토스페이서 서열의 처음 20개 뉴클레오티드의 각 위치에 대한 각 뉴클레오티드의 상대적 존재비가 나타나 있다. 높은 존재비는 Cas9에 의한 절단의 결여, 즉, CRISPR 불활성화 돌연변이를 나타낸다. 회색 선은 야생형 서열의 수준을 나타낸다. 점선은 돌연변이가 절단을 유의미하게 방해하는 수준을 초과하는 수준을 나타낸다(실시예 5에서 섹션 "딥 시퀀싱 데이터의 분석" 참조).
도 25는 스트렙토코커스 뉴모니애에서 CRISPR 시스템을 사용한 단일 및 다중 돌연변이의 도입을 보여준다. (a) 야생형 및 교정된(녹색 뉴클레오티드; 밑줄이 있는 아미노산 잔기) bgaA의 뉴클레오티드 및 아미노산 서열. 프로토스페이서, PAM 및 제한 부위가 나타나 있다. (b) 교정 주형 또는 대조군의 존재 하에 표적화 작제물이 형질전환된 세포의 형질전환 효율. (c) 각 교정 실험 후에 BtgZI(R→A) 및 TseI(NE→AA)을 사용하여 분해된 8개의 형질전환체에 대한 PCR 분석. bgaA의 결실은 보다 작은 PCR 산물로서 드러났다. (d) 야생형 및 교정된 균주의 β-갈락토시다제 활성을 측정하기 위한 밀러(Miller) 검정. (e) 단일-단계, 이중 결실을 위하여, 표적화 작제물은 2개의 스페이서(이러한 경우에, srtA 및 bgaA와 매치)를 함유하였으며, 2개의 상이한 교정 주형으로 동시-형질전환시켰다. (f) srtA 및 bgaA 유전자좌에서 결실을 검출하기 위한 8개의 형질전환체에 대한 PCR 분석. 8개 중 6개의 형질전환체가 둘 모두의 유전자의 결실을 함유하였다.
도 26은 CRISPR 시스템을 사용한 교정의 기본적인 메카니즘을 제공한다. (a) 종결 코돈을 에리트로마이신 내성 유전자 ermAM에 도입하여, 균주 JEN53을 생성하였다. 교정 주형으로서 ermAM 야생형 서열을 사용하여 종결 코돈을 표적화하고, CRISPR::ermAM(종결) 작제물을 사용함으로써 야생형 서열을 복구시킬 수 있다. (b) 돌연변이 및 야생형 ermAM 서열. (c) 총 cfu 또는 카나마이신-내성(kanR) cfu로부터 계산된 에리트로마이신-내성(ermR) cfu의 분율. (d) CRISPR 작제물 및 교정 주형 둘 모두를 획득한 총 세포의 분율. CRISPR 표적화 작제물의 동시-형질전환에 의해, 더 많은 형질전환체가 생성되었다(t-검정, p=0.011). 모든 경우에서, 값은 3개의 독립적인 실험에 대한 평균 ± 표준 편차를 보여준다.
도 27은 에스케리키아 콜라이(E. coli)에서 CRISPR 시스템을 사용한 게놈 교정을 예시한 것이다. (a) 교정하기 위한 유전자를 표적으로 하는 CRISPR 어레이를 지니는 카나마이신-내성 플라스미드(pCRISPR)를 돌연변이를 지정하는 올리고뉴클레오티드와 함께, cas9 및 tracr를 갖는 클로람페니콜-내성 플라스미드(pCas9)를 함유하는 HME63 재조합 균주에 형질전환시킬 수 있다. (b) 스트렙토마이신 내성을 부여하는 K42T 돌연변이를 rpsL 유전자에 도입시켰다. (c) 총 cfu 또는 카나마이신-내성(kanR) cfu로부터 계산된 스트렙토마이신-내성 (strepR) cfu의 분율. (d) pCRISPR 플라스미드 및 교정 올리고뉴클레오티드 둘 모두를 획득한 총 세포의 분율. pCRISPR 표적화 플라스미드의 동시-형질전환에 의해 더 많은 형질전환체가 생성되었다(t-검정, p=0.004). 모든 경우에, 값은 3개의 독립적인 실험에 대한 평균 ± 표준편차를 보여주었다.
도 28은 crR6 게놈 DNA의 형질전환이 표적화된 유전자좌의 교정을 야기하는 것을 예시한다. (a) 스트렙토코커스 뉴모니애 R6의 IS1167 요소를 스트렙토코커스 피오게네스 SF370의 CRISPR01 유전자좌로 대체하여, crR6 균주를 생성하였다. 이러한 유전자좌는 Cas9 뉴클레아제, 6개의 스페이서가 있는 CRISPR 어레이, crRNA 생물발생에 필요한 tracrRNA, 및 Cas1, Cas2 및 Csn2, 표적화에 필요하지 않은 단백질을 인코딩한다. 균주 crR6M은 cas1, cas2 및 csn2가 없는 최소 기능성 CRISPR 시스템을 함유한다. aphA-3 유전자는 카나마이신 내성을 인코딩한다. 스트렙토코커스 박테리오파지 φ8232.5 및 φ370.1 유래의 프로토스페이서를 클로람페니콜 내성 유전자(cat)에 융합시키고, 균주 R6의 srtA 유전자에 통합시켜, 균주 R68232.5 및 R6370.1을 생성하였다. (b) 좌측 패널: R68232.5 및 R6370.1 내의 crR6 및 crR6M 게놈 DNA의 형질전환. 세포 컴피턴스(competence)의 대조군으로서, 스트렙토마이신 내성 유전자도 또한 형질전환시켰다. 우측 패널: crR6 게놈 DNA를 사용한 8개 R68232.5 형질전환체의 PCR 분석. srtA 유전자좌를 증폭시키는 프라이머를 PCR을 위해 사용하였다. 유전자형 분석된 콜로니 8개 중 7개에서, crR6 게놈 DNA로부터의 야생형 유전자좌에 의하여 R68232.5 srtA 유전자좌가 대체되었다.
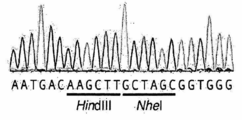
도 29는 이러한 연구에서 수득되는 교정된 세포의 DNA 서열의 크로마토그램을 제공한다. 모든 경우에, 야생형 및 돌연변이체 프로토스페이서 및 PAM 서열(또는 그들의 역 상보물)이 표기되어 있다. 적절한 경우, 프로토스페이서에 의해 인코딩된 아미노산 서열이 제공되어 있다. 각각의 교정 실험을 위하여, PCR 및 제한 분석으로 요망되는 변형의 도입을 입증하는 모든 균주를 시퀀싱하였다. 대표적인 크로마토그램이 나타나 있다. (a) R68232.5 표적으로의 PAM 돌연변이의 도입에 대한 크로마토그램(도 23d). (b) β-갈락토시다제(bgaA)로의 R>A 및 NE>AA 돌연변이의 도입에 대한 크로마토그램(도 25c). (c) bgaA ORF 내의 6664 bp 결실의 도입에 대한 크로마토그램(도 25c 및 도 25f). 점선은 결실 한계를 나타낸다. (d) srtA ORF 내의 729 bp 결실의 도입에 대한 크로마토그램(도 25f). 점선은 결실 한계를 나타낸다. (e) ermAM 내의 조기 종결 코돈의 생성에 대한 크로마토그램(도 33). (f) 에스케리키아 콜라이에서의 rpsL 교정(도 27).
도 30은 상이한 PAM을 함유하는 무작위 스트렙토코커스 뉴모니애 표적에 대한 CRISPR 면역성을 예시한다. (a) 스트렙토코커스 뉴모니애 R6 게놈에 대한 10개의 무작위 표적의 위치. 선택된 표적은 상이한 PAM을 가지며, 둘 모두의 가닥 상에 존재한다. (b) 표적에 상응하는 스페이서를 플라스미드 pLZ12 상의 최소 CRISPR 어레이에 클로닝하고, 트랜스로 가공 및 표적화 기구를 제공하는 균주 crR6Rc로 형질전환시켰다. (c) 균주 R6 및 crR6Rc에서의 상이한 플라스미드의 형질전환 효율. crR6Rc에서 pDB99-108(T1-T10)의 형질전환에 대하여 콜로니가 회수되지 않았다. 파선은 검정의 검출 한계를 나타낸다.
도 31은 표적화된 게놈 교정을 위한 일반적 계획을 제공한다. 표적화된 게놈 교정을 용이하게 하기 위하여, crR6M을 tracrRNA, Cas9 및 CRISPR 어레이의 오직 하나의 반복부 뒤에 카나마이신 내성 마커(aphA-3)를 함유하도록 더 조작하여, 균주 crR6Rk를 생성하였다. 이러한 균주 유래의 DNA를 신규 스페이서(N으로 표기된 녹색 박스)를 도입하기 위해 설계된 프라이머를 사용한 PCR을 위한 주형으로 사용한다. 좌측 및 우측 PCR을 깁슨(Gibson) 방법을 사용하여 조립하여, 표적화 작제물을 생성하였다. 그 다음, 표적화 및 교정 작제물 둘 모두를 균주 crR6Rc로 형질전환시키며, 이는 crR6Rk와 동등하나, 카나마이신 내성 마커가 클로람페니콜 내성 마커(cat)에 의해 대체된 균주이다. 약 90%의 카나마이신-내성 형질전환체가 요망되는 돌연변이를 함유한다.
도 32는 PAM 간의 거리의 분포를 예시한다. NGG 및 CCN은 유효한 PAM인 것으로 여겨진다. 데이터는 스트렙토코커스 뉴모니애 R6 게놈에 대하여, 그리고 동일한 GC-함량(39.7 %)이 있는 동일한 길이의 무작위 서열에 대하여 나타나 있다. 점선은 R6 게놈에서 PAM 간의 평균 거리(12)를 나타낸다.
도 33은 표적화 작제물로서 게놈 DNA를 사용한 ermAM 유전자좌의 CRISPR-매개의 교정을 예시한다. 게놈 DNA를 표적화 작제물로서 사용하기 위하여, CRISPR 자가면역성을 피하는 것이 필요하며, 이에 따라 염색체에 존재하지 않는 서열에 대한 스페이서를 사용해야 한다(이러한 경우, ermAM 에리트로마이신 내성 유전자). (a) 야생형 및 돌연변이(적색 문자) ermAM 유전자의 뉴클레오티드 및 아미노산 서열. 프로토스페이서 및 PAM 서열이 나타나 있다. (b) 게놈 DNA를 사용한 ermAM 유전자좌의 CRISPR-매개의 교정에 대한 개략도. ermAM-표적화 스페이서(청색 네모)를 지니는 작제물을 PCR 및 깁슨 조립에 의해 제조하고, 균주 crR6Rc로 형질전환시켜, 균주 JEN37을 생성한다. 그 다음, JEN37의 게놈 DNA를 표적화 작제물로 사용하고, 교정 주형과 함께 JEN38로 동시-형질전환시키고, 이 균주에서, srtA 유전자는 ermAM의 야생형 카피로 대체되었다. 카나마이신-내성 형질전환체는 교정된 유전자형(JEN43)을 함유한다. (c) 표적화 및 교정 또는 대조군 주형의 동시-형질전환 후에 수득되는 카나마이신-내성 세포의 수. 대조군 주형의 존재 하에, 5.4×103 cfu/㎖을 수득하고, 교정 주형을 사용하는 경우 4.3×105 cfu/㎖을 수득하였다. 이러한 차이는 약 99%[(4.3×105-5.4×103)/4.3×105]의 교정 효율을 나타낸다. (d) 교정된 세포의 존재에 대하여 점검하기 위하여, 7개의 카나마이신-내성 클론 및 JEN38을 에리트로마이신이 있거나(erm+), 에리트로마이신이 없는(erm-) 아가 플레이트에 스트리킹하였다. 오직 양의 대조군만이 에리트로마이신에 대한 내성을 나타내었다. 또한, 이들 형질전환체 중 하나의 ermAM mut 유전자형을 DNA 시퀀싱에 의해 확인하였다(도 29e).
도 34는 CRISPR-매개의 게놈 교정에 의한 돌연변이의 순차적 도입을 예시한다. (a) CRISPR-매개의 게놈 교정에 의한 돌연변이의 순차적 도입에 대한 개략도. 먼저, R6을 crR6Rk를 생성하도록 조작한다. crR6Rk를 ΔsrtA 프레임내 결실을 위한 교정 작제물과 함께, 교정된 세포의 클로람페니콜 선택을 위해 cat에 융합된 srtA-표적화 작제물로 동시-형질전환시킨다. 균주 crR6 ΔsrtA를 클로람페니콜에서의 선택에 의해 생성한다. 이후에, ΔsrtA 균주를 교정된 세포의 카나마이신 선택을 위해 aphA-3에 융합된 bgaA-표적화 작제물 및 ΔbgaA 프레임내 결실을 함유하는 교정 작제물로 동시-형질전환시킨다. 마지막으로, 조작된 CRISPR 유전자좌를, 먼저 야생형 IS1167 유전자좌를 함유하는 R6 DNA 및 bgaA 프로토스페이서를 지니는 플라스미드(pDB97)로 동시 형질전환시키고, 스펙티노마이신에서 선택함으로써 염색체로부터 제거할 수 있다. (b) srtA 유전자좌에서 결실을 검출하기 위한 8개의 클로람페니콜(Cam)-내성 형질전환체에 대한 PCR 분석. (c) 밀러(Miller) 검정에 의해 측정시 β-갈락토시다제 활성. 스트렙토코커스 뉴모니애에서, 이러한 효소는 소타제(sortase) A에 의해 세포벽에 부착된다. srtA 유전자의 결실에 의해 상청액으로의 β-갈락토시다제의 방출이 야기된다. ΔbgaA 돌연변이체는 활성을 보이지 않는다. (d) 야생형 IS1167에 의한 CRISPR 유전자좌의 대체를 검출하기 위한 8개의 스펙티노마이신(Spec)-내성 형질전환체에 대한 PCR 분석.
도 35는 스트렙토코커스 뉴모니애에서의 CRISPR의 백그라운드 돌연변이 빈도를 예시한다. (a) JEN53에서 ermAM 교정 주형과 함께, 또는 이것 없이 CRISPR::Ø 또는 CRISPR::erm(종결) 표적화 작제물의 형질전환. CRISPR::Ø와 CRISPR::erm(종결) 간의 kanR CFU의 차이는 Cas9 절단이 비-교정된 세포를 사멸시키는 것을 나타낸다. 교정 주형의 부재 하에 CRISPR 간섭을 피하는 돌연변이체는 3×10-3의 빈도로 관찰된다. (b) 도피물의 CRISPR 유전자좌의 PCR 분석은 8개 중 7개가 스페이서 결실을 가짐을 보여준다. (c) 도피물 #2는 cas9 내의 점 돌연변이를 지닌다.
도 36은 스트렙토코커스 피오게네스 CRISPR 유전자좌 1의 필수 요소가 pCas9를 사용하여 에스케리키아 콜라이에서 재구성되는 것을 예시한다. 플라스미드는 tracrRNA, Cas9, 및 crRNA 어레이를 유도하는 리더 서열을 함유한다. pCRISPR 플라스미드는 오직 리더 및 어레이만을 함유하였다. 스페이서는 어닐링된 올리고뉴클레오티드를 사용하여 BsaI 부위 사이의 crRNA 어레이에 삽입될 수 있다. 올리고뉴클레오티드 설계는 하측에 나타나 있다. pCas9는 클로람페니콜 내성(CmR)을 지니며, 저-카피 pACYC184 플라스미드 백본에 기초한다. pCRISPR은 고-카피수 pZE21 플라스미드에 기초한다. 2개의 플라스미드가 필요하였는데, 이는 Cas9가 또한 존재한다면 클로닝 숙주로서 이러한 유기체를 사용하여 에스케리키아 콜라이 염색체를 표적화하는 스페이서를 함유하는 pCRISPR 플라스미드가 작제될 수 없기 때문이다(그것은 숙주를 사멸시킬 것이다).
도 37은 에스케리키아 콜라이 MG1655에서의 CRISPR-유도 교정을 예시한다. 스트렙토마이신 내성을 부여하고 CRISPR 면역성을 없애는 점 돌연변이를 지니는 올리고뉴클레오티드(W542)를 rpsL을 표적화하는 플라스미드(pCRISPR::rpsL) 또는 대조군 플라스미드(pCRISPR::Ø)와 함께 pCas9를 함유하는 야생형 에스케리키아 콜라이 균주 MG1655로 동시 형질전환시켰다. 형질전환체를 스트렙토마이신 또는 카나마이신 중 어느 하나를 함유하는 배지에서 선택하였다. 파선은 형질전환 검정의 검출 한계를 나타낸다.
도 38은 에스케리키아 콜라이 HME63에서의 CRISPR의 백그라운드 돌연변이 빈도를 예시한다. (a) HME63 컴피턴트 세포로의 pCRISPR::Ø 또는 pCRISPR::rpsL 플라스미드의 형질전환. CRISPR 간섭을 피하는 돌연변이체가 2.6×10-4의 빈도로 관찰되었다. (b) 도피물의 CRISPR 어레이의 증폭에 의해, 8개 중 8개에서 스페이서가 결실됨이 나타났다.
도 39a 내지 도 39d는 3개 그룹의 큰 Cas9(약 1400개 아미노산) 및 2개 그룹의 작은 Cas9(약 1100개 아미노산)를 포함하는 5개 과의 Cas9를 보여주는 계통 분석의 원형 표기를 보여준다.
도 40a 내지 도 40f는 3개 그룹의 큰 Cas9(약 1400개 아미노산) 및 2개 그룹의 작은 Cas9(약 1100개 아미노산)를 포함하는 5개 과의 Cas9를 보여주는 계통 분석의 선형 표기를 보여준다.
도 41a 내지 도 41m은 돌연변이 점이 SpCas9 유전자 내에 위치하는 서열을 보여준다.
도 42는 전사 활성화 도메인(VP64)이 촉매 도메인 내에 2개의 돌연변이(D10 및 H840)가 있는 Cas9에 융합된 개략적 작제물을 보여준다.
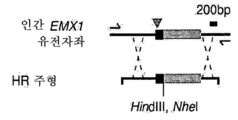
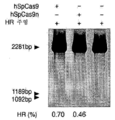
도 43a 내지 도 43d는 상동성 재조합을 통한 게놈 교정을 보여준다. (a) RuvC I 촉매 도메인 내에 D10A 돌연변이가 있는 SpCas9 닉카아제(nickase)의 개략도. (b) 수복 주형으로서 센스 또는 안티센스 단일 가닥 올리고뉴클레오티드를 사용하는 인간 EMX1 유전자좌에서의 상동성 재조합(HR)을 나타내는 개략도. 위의 적색 화살표는 sgRNA 절단 부위를 나타내며; 유전자형분석을 위한 PCR 프라이머(표 J 및 K)는 우측 패널에 화살표로 표시되어 있다. (c) HR에 의해 변형된 영역의 서열. d, 야생형(wt) 및 EMX1 표적 1 유전자좌에서의 닉카아제(D10A) SpCas9-매개의 삽입-결실에 대한 서베이어 검정(n=3). 화살표는 예상되는 단편 크기의 위치를 나타낸다.
도 44a 및 도 44b는 SpCas9에 대한 단일 벡터 설계를 보여준다.
도 45는 NLS-Csn1 작제물 NLS-Csn1, Csn1, Csn1-NLS, NLS-Csn1-NLS, NLS-Csn1-GFP-NLS 및 UnTFN의 절단의 정량화를 보여준다.
도 46은 NLS-Cas9, Cas9, Cas9-NLS 및 NLS-Cas9-NLS의 인덱스 빈도를 보여준다.
도 47은 닉카아제 돌연변이(개별적으로)가 있는 SpCas9가 이중 가닥 파단을 유도하지 않음을 입증하는 겔을 보여준다.
도 48은 이러한 실험에서 상동성 재조합(HR) 주형으로 사용되는 올리고 DNA의 설계 및 Cas9 단백질 및 HR 주형의 상이한 조합에 의해 유도되는 HR 효율의 비교를 보여준다.
도 49a는 조건성 Cas9, Rosa26 표적화 벡터 맵을 보여준다.
도 49b는 구성성 Cas9, Rosa26 표적화 벡터 맵을 보여준다.
도 50a 내지 도 50h는 도 49a 및 도 49b의 벡터 맵에 존재하는 각 요소의 서열을 보여준다.
도 51은 구성성 및 조건성 Cas9 작제물에서의 중요한 요소의 개략도를 보여준다.
도 52는 구성성 및 조건성 Cas9 작제물의 발현의 기능 확인을 보여준다.
도 53은 서베이어에 의한 Cas9 뉴클레아제 활성의 확인을 보여준다.
도 54는 Cas9 뉴클레아제 활성의 정량화를 보여준다.
도 55는 작제물 설계 및 상동성 재조합(HR) 전략을 보여준다.
도 56은 두 가지 상이한 겔 노출 시간(상측 줄은 3분 동안, 그리고 하측 줄은 1분 동안)에서의 구성성(우측) 및 조건성(좌측) 작제물에 대한 게놈 PCR 유전자형분석 결과를 보여준다.
도 57은 mESC에서의 Cas9 활성화를 보여준다.
도 58은 2개의 가이드 RNA와 함께 Cas9의 닉카아제 버전을 사용하여 NHEJ를 통해 유전자 녹아웃을 매개하는데 사용되는 전략의 개략도를 보여준다.
도 59는 DNA 이중 가닥 파단(DSB) 수복이 유전자 교정을 촉진하는 방법을 보여준다. 오류-유발(error-prone) 비상동성 말단 연결(NHEJ) 경로에서, DSB의 말단을 내인성 DNA 수복 기구에 의해 가공하고, 함께 재연결하는데, 이는 연접 부위에서 무작위 삽입-결실(indel) 돌연변이를 야기할 수 있다. 유전자의 코딩 영역 내에서 발생한 삽입-결실 돌연변이는 해독틀 이동 및 조기 종결 코돈을 야기하여, 유전자 녹아웃을 유발할 수 있다. 대안적으로, 플라스미드 또는 단일-가닥 올리고데옥시뉴클레오티드(ssODN)의 형태의 수복 주형을 공급하여, 상동성-유도 수복(HDR) 경로를 활용할 수 있으며, 이는 높은 충실도와 정밀한 교정을 가능하게 한다.
도 60은 실험의 일정표 및 개요를 보여준다. 시약 설계, 작제, 입증 및 세포주 증식을 위한 단계. 각 표적에 대한 맞춤형 sgRNA(담청색 막대) 및 유전자형분석 프라이머를 본 발명자들의 온라인 설계 툴(웹사이트 genome-engineering.org/tools에서 이용가능)을 통해 인 실리코(in silico)로 설계한다. 그 다음, sgRNA 발현 벡터를 Cas9를 함유하는 플라스미드(PX330)로 클로닝하고, DNA 시퀀싱을 통해 입증한다. 그 다음, 완성된 플라스미드(pCRISPR) 및 상동성 유도 수복을 촉진하기 위한 선택적 수복 주형을 세포로 트랜스펙션시키고, 표적화된 절단을 매개하는 능력에 대하여 검정한다. 마지막으로, 트랜스펙션된 세포를 클론으로 증식시켜, 한정된 돌연변이를 갖는 동질 유전자형 세포주를 유도할 수 있다.
도 61a 내지 도 61c는 표적 선택 및 시약 제조를 보여준다. (a) 스트렙토코커스 피오게네스 Cas9에 대하여, 20-bp 표적(청색으로 강조표시) 뒤에 5'-NGG가 있어야 하며, 이는 게놈 DNA 상의 어느 하나의 가닥에 존재할 수 있다. 본 발명자들은 표적 선택을 보조하는데에서 이러한 프로토콜에 기술된 온라인 툴(www.genome-engineering.org/tools)을 사용하는 것을 권고한다. (b) Cas9 발현 플라스미드(PX165) 및 PCR-증폭 U6-유도 sgRNA 발현 카세트의 동시-트랜스펙션에 대한 개략도. U6 프로모터-함유 PCR 주형 및 고정된 정방향 프라이머(U6 Fwd)를 사용하여, sgRNA-인코딩 DNA를 U6 역방향 프라이머(U6 Rev)에 부착시키고, 연장된 DNA 올리고(IDT로부터의 울트라머(Ultramer) 올리고)로서 합성할 수 있다. U6 Rev에서 가이드 서열(청색 N)이 5'-NGG 측부 배치(flanking) 표적 서열의 역 상보물임을 주목한다. (c) Cas9 및 sgRNA 스캐폴드(scaffold)를 함유하는 플라스미드(PX330)로의 가이드 서열 올리고의 무흔적(scarless) 클로닝에 대한 개략도. 가이드 올리고(청색 N)는 PS330 상의 BbsI 부위의 쌍으로의 라이게이션을 위한 오버행을 함유하며, 상측 및 하측 가닥 배향은 게놈 표적의 것과 일치한다(즉, 상측 올리고는 게놈 DNA 내의 5'-NGG 앞의 20-bp 서열임). BbsI을 사용한 PX330의 분해에 의해, 어닐링된 올리고의 직접 삽입으로의 II형 제한 부위(청색 윤곽선)의 대체가 가능하게 된다. 가이드 서열의 제1 염기 전에 추가의 G가 배치되는 것을 주목할 가치가 있다. 본 발명자들은 가이드 서열의 앞의 추가의 G가 표적화 효율에 불리하게 영향을 미치지 않는 것을 발견하였다. 선택된 20-nt 가이드 서열이 구아닌으로 시작하지 않는 경우에, 추가의 구아닌은 sgRNA가 전사물의 제1 염기에서 구아닌을 선호하는 U6 프로모터에 의해 효율적으로 전사되게 보장할 것이다.
도 62a 내지 도 62d는 다중 NHEJ에 대한 예상되는 결과를 보여준다. (a) 삽입-결실 백분율을 결정하기 위해 사용되는 서베이어 검정의 개략도. 먼저, Cas9-표적화 세포의 이종 집단 유래의 게놈 DNA를 PCR에 의해 증폭시킨다. 그 다음, 앰플리콘을 천천히 다시 어닐링시켜, 헤테로듀플렉스를 생성한다. 다시 어닐링된 헤테로듀플렉스를 서베이어 뉴클레아제에 의해 절단하는 한편, 호모듀플렉스를 손상되지 않게 둔다. Cas9-매개의 절단 효율(삽입-결실%)을 겔 밴드의 통합 세기에 의해 결정시, 절단된 DNA의 분율에 기초하여 계산한다. (b) 인간 GRIN2B 및 DYRK1A 유전자좌를 표적화하도록 2개의 sgRNA(주황색 및 청색 막대)를 설계한다. 서베이어 겔은 트랜스펙션된 세포 내의 둘 모두의 유전자좌에서의 변형을 보여준다. 유색 화살표는 각 유전자좌에 대한 예상된 단편 크기를 나타낸다. (c) 인간 EMX1 유전자좌에서 엑손(진청색)을 절개하도록 sgRNA의 쌍(담청색 및 녹색 막대)을 설계한다. 표적 서열 및 PAM(적색)은 각각의 색상으로 나타나 있으며, 절단 부위는 적색 삼각형으로 표기된다. 예측된 연접은 하기에 나타나 있다. sgRNA 3, 4 또는 둘 모두가 트랜스펙션된 세포 집단으로부터 분리된 개별 클론을 약 270-bp의 결실을 반영하는 PCR(OUT 정방향, OUT 역방향)에 의해 검정한다. 변형이 없고(12/23), 1-대립형질(10/23) 및 2-대립형질(1/23) 변형이 있는 대표적인 클론이 나타나 있다. IN 정방향 및 IN 역방향 프라이머를 사용하여 역위 사건에 대하여 스크리닝한다(도 6d). (d) EMX1 엑손 결실이 있는 클론 세포주의 정량화. 2개 쌍의 sgRNA(3.1, 3.2 좌측-측부 배치 sgRNA; 4.1, 4.2, 우측 측부 배치 sgRNA)를 사용하여 하나의 EMX1 엑손 주위의 가변적 크기의 결실을 매개한다. 트랜스펙션된 세포를 클론으로 분리하고, 결실 및 역위 사건에 대한 유전자형 분석을 위해 증식시킨다. 105개 클론 중에, 각각 이종 및 동종 결실을 지니는 51(49%) 및 11(10%)개가 스크리닝된다. 연접이 가변적일 수 있기 때문에, 대략적 결실 크기가 제공된다.
도 63a 내지 도 63c는 HEK293FT 및 HUES9 세포에서 Cas9의 야생형 및 닉카아제 돌연변이체 둘 모두를 사용하여 1.0 내지 27% 범위의 효율로 HR을 매개하기 위한 ssODN 및 표적화 벡터의 응용을 보여준다.
도 64는 포유동물 세포에서의 신속하고 효율적인 CRISPR 표적화를 위한 PCR 기반의 방법의 개략도를 보여준다. 인간 RNA 중합효소 III 프로모터 U6을 함유하는 플라스미드를 U6-특이적 정방향 프라이머 및 U6 프로모터의 부분, 가이드 서열이 있는 sgRNA(+85) 스캐폴드 및 전사 종결을 위한 7개의 T 뉴클레오티드의 역 상보물을 지니는 역방향 프라이머를 사용하여 PCR 증폭시켰다. 생성된 PCR 산물을 정제하고, CBh 프로모터에 의해 유도되는 Cas9를 지니는 플라스미드와 동시-전달한다.
도 65는 각각의 gRNA 및 각각의 대조군에 대한 트랜스게노믹스(Transgenomics)로부터의 서베이어 돌연변이 검출 키트 결과를 보여준다. 양의 서베이어 결과는 게놈 PCR에 상응하는 하나의 큰 밴드, 및 돌연변이 부위에서 이중-가닥 파단을 만드는 서베이어 뉴클레아제의 산물인 2개의 더 작은 밴드이다. 각각의 gRNA를 hSpCas9로의 일시적 리포솜 동시-트랜스펙션에 의해 마우스 세포주, Neuro-N2a에서 입증하였다. 트랜스펙션 후 72시간에, 게놈 DNA를 에피센트레(Epicentre)로부터의 퀵익스트랙트(QuickExtract) DNA를 사용하여 정제하였다. PCR을 수행하여, 대상 유전자좌를 증폭시켰다.
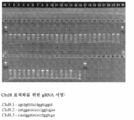
도 66은 38마리의 살아있는 새끼(레인(lane) 1~38), 1마리의 죽은 새끼(레인 39) 및 1마리의 비교용 야생형 새끼(레인 40)에 대한 서베이어 결과를 보여준다. 새끼 1 내지 19에 gRNA Chd8.2를 주사하고, 새끼 20~38에 gRNA Chd8.3을 주사하였다. 38마리의 살아 있는 새끼 중에 13마리는 돌연변이에 대하여 양성이었다. 또한, 1마리의 죽은 새끼는 돌연변이를 가졌다. 야생형 샘플에서 돌연변이가 검출되지 않았다. 게놈 PCR 시퀀싱은 서베이어 검정 관찰과 일치하였다.
도 67은 상이한 Cas9 NLS 작제물의 설계를 보여준다. 모든 Cas9는 Sp Cas9의 인간-코돈-최적화 버전이었다. NLS 서열은 N-말단 또는 C-말단 중 어느 하나에서 cas9 유전자에 연결된다. 상이한 NLS 설계를 갖는 모든 Cas9 변이체를 EF1a 프로모터를 함유하여, EF1a 프로모터에 의해 유도되는 백본 벡터로 클로닝하였다. 동일한 벡터에서, U6 프로모터에 의해 유도되는 인간 EMX1 유전자좌를 표적화하는 키메라 RNA가 존재하여, 함께 2-성분 시스템을 형성한다.
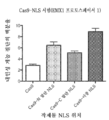
도 68은 상이한 NLS 설계를 갖는 Cas9 변이체에 의해 유도되는 게놈 절단의 효율을 보여준다. 백분율은 각 작제물에 의해 절단된 인간 EMX1 게놈 DNA의 부분을 나타낸다. 모든 실험은 3개의 생물학적 반복 검증으로부터의 것이다. n = 3, 오차는 S.E.M을 나타낸다.
도 69a는 전사 활성화 활성을 갖는 CRISPR-TF(전사 인자)의 설계를 보여준다. 키메라 RNA는 U6 프로모터에 의해 발현되는 한편, 3중 NLS 및 VP64 기능적 도메인에 작동가능하게 연결된, 인간-코돈-최적화, 이중-돌연변이 버전의 Cas9 단백질(hSpCas9m)은 EF1a 프로모터에 의해 발현된다. 이중 돌연변이, D10A 및 H840A는 cas9 단백질이 임의의 절단을 도입할 수 없지만, 키메라 RNA에 의해 유도되는 경우 표적 DNA로의 그의 결합 능력을 유지하게 한다.
도 69b는 CRISPR-TF 시스템(키메라 RNA 및 Cas9-NLS-VP64 융합 단백질)을 사용한 인간 SOX2 유전자의 전사 활성화를 보여준다. 293FT 세포를 2개의 성분을 지니는 플라스미드로 트랜스펙션시켰다: (1) 인간 SOX2 게놈 유전자좌 내의 또는 그 근처의 20-bp 서열을 표적화하는 U6-유도된 상이한 키메라 RNA, 및 (2) EF1a-유도 hSpCas9m(이중 돌연변이)-NLS-VP64 융합 단백질. 트랜스펙션 96시간 후에, 293FT 세포를 수집하고, 활성화 수준을 qRT-PCR 검정을 사용하여 mRNA 발현의 유도에 의해 측정한다. 모든 발현 수준을 대조군(회색 막대)에 대하여 정규화시키고, 이는 키메라 RNA가 없는 CRISPR-TF 백본 플라스미드가 트랜스펙션된 세포로부터의 결과를 나타낸다. SOX2 mRNA를 검출하기 위해 사용되는 qRT-PCR 프로브는 택맨 휴먼 진 익스프레션 어세이(Taqman Human Gene Expression Assay)(라이프 테크놀로지즈(Life Technologies))이다. 모든 실험은 3개의 생물학적 반복 검증으로부터의 데이터를 나타낸다. n = 3, 오차 바는 s.e.m을 나타낸다.
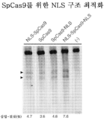
도 70은 SpCas9에 대한 NLS 구조 최적화를 도시한다.
도 71은 NGGNN 서열에 대한 QQ 플롯을 보여준다.
도 72는 핏팅된 정규 분포(흑색 선) 및 .99 분위수(점선)를 사용한 데이터 밀도의 히스토그램을 보여준다.
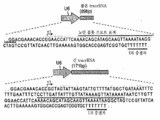
도 73a 내지 도 73c는 dgRNA::cas9**에 의한 bgaA 발현의 RNA-유도 억제를 보여준다. a. Cas9 단백질은 tracrRNA에, 그리고 전구체 CRISPR RNA에 결합하며, 이는 RNAseIII에 의해 가공되어 crRNA를 형성한다. crRNA는 bgaA 프로모터로의 Cas9의 결합을 유도하며, 전사를 억제한다. b. Cas9**를 bgaA 프로모터로 지향시키는데 사용되는 표적이 표시되어 있다. 추정의 -35, -10, 및 bgaA 시작 코돈이 볼드체로 나타나 있다. c. 표적화의 부재 하에서, 그리고 4개의 상이한 표적에 대하여 밀러 검정에 의해 측정시 베타갈락토시다제 활성.
도 74a 내지 도 74e는 Cas9** 매개의 억제의 특성화를 보여준다. a. gfpmut2 유전자 및 -35 및 -10 신호를 포함하는 그의 프로모터는 연구에 사용되는 상이한 표적 부위의 위치와 함께 표현된다. b. 코딩 가닥의 표적화 시의 상대적 형광. c. 비-코딩 가닥의 표적화 시의 상대적 형광. d. T5, T10, B10 또는 표적이 없는 대조군 균주로부터 추출된 RNA에서의 프로브 B477 및 B478을 사용한 노던 블롯. e. B1, T5 및 B10의 crRNA의 5' 말단에서의 증가된 수의 돌연변이의 영향.
본원에서 도면은 오직 예시의 목적을 위한 것이며, 반드시 척도에 따라 도시된 것은 아니다.
도 1은 CRISPR 시스템의 개략적 모델을 보여준다. 스트렙토코커스 피오게네스 유래의 Cas9 뉴클레아제(황색)는 20-nt 가이드 서열(청색) 및 스캐폴드(적색)로 이루어진 합성 가이드 RNA(sgRNA)에 의해 게놈 DNA에 표적화된다. 가이드 서열은 필수 5'-NGG 프로토스페이서 인접 모티프(protospacer adjacent motif, PAM; 진홍색)의 인접 상류의 DNA 표적(청색)과 염기쌍을 형성하며, Cas9는 PAM의 약 3 bp 상류(적색 삼각형)에서 이중 가닥 파단(DSB)을 매개한다.
도 2a 내지 도 2f는 예시적인 CRISPR 시스템, 가능한 작용 메카니즘, 진핵 세포에서의 발현을 위한 예시적인 적합화, 및 핵 국소화 및 CRISPR 활성을 평가하는 시험의 결과를 보여준다.
도 3은 진핵 세포에서의 CRISPR 시스템 요소의 발현을 위한 예시적인 발현 카세트, 예시적인 가이드 서열의 예측된 구조, 및 진핵 및 원핵 세포에서 측정시 CRISPR 시스템 활성을 보여준다.
도 4a 내지 도 4d는 예시적인 표적에 대한 SpCas9 특이성의 평가의 결과를 보여준다.
도 5a 내지 도 5g는 예시적인 벡터 시스템 및 진핵 세포에서 상동성 재조합의 유도에서의 그의 사용에 대한 결과를 보여준다.
도 6은 프로토스페이서 서열의 표를 제공하며, 인간 및 마우스 게놈 내의 유전자좌(loci)에 대한 상응하는 PAM이 있는 예시적인 스트렙토코커스 피오게네스 및 스트렙토코커스 써모필러스 CRISPR 시스템에 기초하여 설계된 프로토스페이서 표적에 대한 변형 효율 결과를 요약한 것이다. 세포를 Cas9 및 pre-crRNA/tracrRNA 또는 키메라 RNA 중 어느 하나로 트랜스펙션시키고, 트랜스펙션 후 72시간에 분석하였다. 삽입-결실(indel) 백분율은 표기된 세포주로부터의 서베이어(Surveyor) 검정 결과에 기초하여 계산된다(모든 프로토스페이서 표적에 대하여 N=3, 오차는 S.E.M.이고, N.D.는 서베이어 검정을 사용하여 검출가능하지 않음을 나타내며, N.T.는 이러한 연구에서 시험하지 않음을 나타낸다).
도 7a 내지 도 7c는 Cas9-매개의 유전자 표적화를 위한 상이한 tracrRNA 전사물의 비교를 보여준다.
도 8은 이중 가닥 파단-유도 마이크로-삽입 및 -결실의 검출을 위한 서베이어 뉴클레아제 검정의 개략도를 보여준다.
도 9A 및 도 9B는 진핵 세포에서 CRISPR 시스템 요소의 발현을 위한 예시적인 비시스트로닉(bicistronic) 발현 벡터를 보여준다.
도 10은 박테리아 플라스미드 형질전환 간섭 검정, 거기에 사용된 발현 카세트 및 플라스미드, 및 거기에 사용된 세포의 형질전환 효율을 보여준다.
도 11A 내지 도 11C는 인간 게놈에서 인접 스트렙토코커스 피오게네스 SF370 유전자좌 1 PAM(NGG)(도 10A) 간의 거리 및 스트렙토코커스 써모필러스 LMD9 유전자좌 2 PAM(NNAGAAW)(도 10B) 간의 거리; 및 염색체(Chr)에 의한 각 PAM에 대한 거리(도 10C)의 히스토그램을 보여준다.
도 12A 내지 도 12C는 예시적인 CRISPR 시스템, 진핵 세포에서의 발현을 위한 예시적인 적합화 및 CRISPR 활성을 평가하는 시험의 결과를 보여준다.
도 13A 내지 도 13C는 포유동물 세포에서 게놈 유전자좌의 표적화를 위한 CRISPR 시스템의 예시적인 조작을 보여준다.
도 14A 및 도 14B는 포유동물 세포에서 crRNA 가공의 노던 블롯(Northern blot) 분석의 결과를 보여준다.
도 15는 인간 PVALB 및 마우스 Th 유전자좌에서 프로토스페이서의 예시적인 선택을 보여준다.
도 16은 인간 EMX1 유전자좌에서 스트렙토코커스 써모필러스 CRISPR 시스템의 예시적인 프로토스페이서 및 상응하는 PAM 서열 표적을 보여준다.
도 17은 서베이어, RFLP, 게놈 시퀀싱 및 노던 블롯 검정을 위해 사용되는 프라이머 및 프로브에 대한 서열의 표를 제공한다.
도 18a 내지 도 18c는 키메라 RNA를 사용한 CRISPR 시스템의 예시적인 조작 및 진핵 세포에서 시스템 활성에 대한 서베이어 검정의 결과를 보여준다.
도 19a 및 도 19b는 진핵 세포에서 CRISPR 시스템 활성에 대한 서베이어 검정의 결과의 그래프 표현을 보여준다.
도 20은 UCSC 게놈 브라우저(browser)를 사용한 인간 게놈 내의 일부 스트렙토코커스 피오게네스 Cas9 표적 부위의 예시적인 가시화를 보여준다.
도 21은 가이드 서열, tracr 메이트 서열 및 tracr 서열을 포함하는 예시적인 키메라 RNA에 대한 예측된 2차 구조를 보여준다.
도 22는 진핵 세포에서 CRISPR 시스템 요소의 발현을 위한 예시적인 비시스트로닉 발현 벡터를 보여준다.
도 23은 내인성 표적에 대한 Cas9 뉴클레아제 활성이 게놈 교정을 위해 이용될 수 있음을 보여준다. (a) CRISPR 시스템을 사용한 게놈 교정의 개념. CRISPR 표적화 작제물(construct)은 염색체 유전자좌의 절단을 유도하며, 이를 표적과 재조합되어 절단을 방지하는 교정 주형과 동시-형질전환시켰다. CRISPR 공격을 견뎌내는 카나마이신-내성 형질전환체는 교정 주형에 의해 도입된 변형을 포함하였다. tracr, 트랜스-활성화(trans-activating) CRISPR RNA; aphA-3, 카나마이신 내성 유전자. (b) 교정 주형 없이, 또는 R6 야생형 srtA 또는 R6370.1 교정 주형과 함께 R68232.5 세포에서의 crR6M DNA의 형질전환. R6 srtA 또는 R6370. 1 중 어느 하나의 재조합에 의해, Cas9에 의한 절단이 방지된다. 형질전환 효율을 crR6M DNA ㎍당 콜로니 형성 단위(cfu)로 계산하였고; 적어도 3개의 독립적인 실험으로부터의 평균값이 표준편차와 함께 나타나 있다. PCR 분석을 각 형질전환에서 8개의 클론에서 수행하였다. "Un."은 균주 R68232.5의 교정되지 않은 srtA 유전자좌를 나타내고; "Ed."는 교정 주형을 보여준다. R68232.5 및 R6370.1 표적은 EaeI을 사용한 제한에 의해 구별된다.
도 24는 Cas9 절단을 없애는 PAM 및 씨드(seed) 서열의 분석을 보여준다. (a) 무작위화된 PAM 서열 또는 무작위화된 씨드 서열이 있는 PCR 산물을 crR6 세포에서 형질전환시켰다. 이들 세포는 R6 게놈에 존재하지 않는 R68232.5 세포의 염색체 영역(분홍색으로 강조표시)을 표적화하는 crRNA가 로딩된 Cas9를 발현하였다. 비활성 PAM 또는 씨드 서열을 지니는 2×105개 초과의 클로람페니콜-내성 형질전환체를 표적 영역의 증폭 및 딥 시퀀싱(deep sequencing)을 위해 조합하였다. (b) crR6 세포에서 무작위 PAM 작제물의 형질전환 후의 판독치의 수의 상대적 비율(R6 형질전환체의 판독치의 수와 비교). 각 3-뉴클레오티드 PAM 서열에 대한 상대적 존재비가 나타나 있다. 심하게 부족한 서열(severely underrepresented sequence; NGG)은 적색으로; 불완전하게 부족한 것은 주황색으로 나타나 있다(NAG). (c) crR6 세포에서 무작위 씨드 서열 작제물의 형질전환 후의 판독치의 수의 상대적 비율(R6 형질전환체의 판독치의 수와 비교). 프로토스페이서 서열의 처음 20개 뉴클레오티드의 각 위치에 대한 각 뉴클레오티드의 상대적 존재비가 나타나 있다. 높은 존재비는 Cas9에 의한 절단의 결여, 즉, CRISPR 불활성화 돌연변이를 나타낸다. 회색 선은 야생형 서열의 수준을 나타낸다. 점선은 돌연변이가 절단을 유의미하게 방해하는 수준을 초과하는 수준을 나타낸다(실시예 5에서 섹션 "딥 시퀀싱 데이터의 분석" 참조).
도 25는 스트렙토코커스 뉴모니애에서 CRISPR 시스템을 사용한 단일 및 다중 돌연변이의 도입을 보여준다. (a) 야생형 및 교정된(녹색 뉴클레오티드; 밑줄이 있는 아미노산 잔기) bgaA의 뉴클레오티드 및 아미노산 서열. 프로토스페이서, PAM 및 제한 부위가 나타나 있다. (b) 교정 주형 또는 대조군의 존재 하에 표적화 작제물이 형질전환된 세포의 형질전환 효율. (c) 각 교정 실험 후에 BtgZI(R→A) 및 TseI(NE→AA)을 사용하여 분해된 8개의 형질전환체에 대한 PCR 분석. bgaA의 결실은 보다 작은 PCR 산물로서 드러났다. (d) 야생형 및 교정된 균주의 β-갈락토시다제 활성을 측정하기 위한 밀러(Miller) 검정. (e) 단일-단계, 이중 결실을 위하여, 표적화 작제물은 2개의 스페이서(이러한 경우에, srtA 및 bgaA와 매치)를 함유하였으며, 2개의 상이한 교정 주형으로 동시-형질전환시켰다. (f) srtA 및 bgaA 유전자좌에서 결실을 검출하기 위한 8개의 형질전환체에 대한 PCR 분석. 8개 중 6개의 형질전환체가 둘 모두의 유전자의 결실을 함유하였다.
도 26은 CRISPR 시스템을 사용한 교정의 기본적인 메카니즘을 제공한다. (a) 종결 코돈을 에리트로마이신 내성 유전자 ermAM에 도입하여, 균주 JEN53을 생성하였다. 교정 주형으로서 ermAM 야생형 서열을 사용하여 종결 코돈을 표적화하고, CRISPR::ermAM(종결) 작제물을 사용함으로써 야생형 서열을 복구시킬 수 있다. (b) 돌연변이 및 야생형 ermAM 서열. (c) 총 cfu 또는 카나마이신-내성(kanR) cfu로부터 계산된 에리트로마이신-내성(ermR) cfu의 분율. (d) CRISPR 작제물 및 교정 주형 둘 모두를 획득한 총 세포의 분율. CRISPR 표적화 작제물의 동시-형질전환에 의해, 더 많은 형질전환체가 생성되었다(t-검정, p=0.011). 모든 경우에서, 값은 3개의 독립적인 실험에 대한 평균 ± 표준 편차를 보여준다.
도 27은 에스케리키아 콜라이(E. coli)에서 CRISPR 시스템을 사용한 게놈 교정을 예시한 것이다. (a) 교정하기 위한 유전자를 표적으로 하는 CRISPR 어레이를 지니는 카나마이신-내성 플라스미드(pCRISPR)를 돌연변이를 지정하는 올리고뉴클레오티드와 함께, cas9 및 tracr를 갖는 클로람페니콜-내성 플라스미드(pCas9)를 함유하는 HME63 재조합 균주에 형질전환시킬 수 있다. (b) 스트렙토마이신 내성을 부여하는 K42T 돌연변이를 rpsL 유전자에 도입시켰다. (c) 총 cfu 또는 카나마이신-내성(kanR) cfu로부터 계산된 스트렙토마이신-내성 (strepR) cfu의 분율. (d) pCRISPR 플라스미드 및 교정 올리고뉴클레오티드 둘 모두를 획득한 총 세포의 분율. pCRISPR 표적화 플라스미드의 동시-형질전환에 의해 더 많은 형질전환체가 생성되었다(t-검정, p=0.004). 모든 경우에, 값은 3개의 독립적인 실험에 대한 평균 ± 표준편차를 보여주었다.
도 28은 crR6 게놈 DNA의 형질전환이 표적화된 유전자좌의 교정을 야기하는 것을 예시한다. (a) 스트렙토코커스 뉴모니애 R6의 IS1167 요소를 스트렙토코커스 피오게네스 SF370의 CRISPR01 유전자좌로 대체하여, crR6 균주를 생성하였다. 이러한 유전자좌는 Cas9 뉴클레아제, 6개의 스페이서가 있는 CRISPR 어레이, crRNA 생물발생에 필요한 tracrRNA, 및 Cas1, Cas2 및 Csn2, 표적화에 필요하지 않은 단백질을 인코딩한다. 균주 crR6M은 cas1, cas2 및 csn2가 없는 최소 기능성 CRISPR 시스템을 함유한다. aphA-3 유전자는 카나마이신 내성을 인코딩한다. 스트렙토코커스 박테리오파지 φ8232.5 및 φ370.1 유래의 프로토스페이서를 클로람페니콜 내성 유전자(cat)에 융합시키고, 균주 R6의 srtA 유전자에 통합시켜, 균주 R68232.5 및 R6370.1을 생성하였다. (b) 좌측 패널: R68232.5 및 R6370.1 내의 crR6 및 crR6M 게놈 DNA의 형질전환. 세포 컴피턴스(competence)의 대조군으로서, 스트렙토마이신 내성 유전자도 또한 형질전환시켰다. 우측 패널: crR6 게놈 DNA를 사용한 8개 R68232.5 형질전환체의 PCR 분석. srtA 유전자좌를 증폭시키는 프라이머를 PCR을 위해 사용하였다. 유전자형 분석된 콜로니 8개 중 7개에서, crR6 게놈 DNA로부터의 야생형 유전자좌에 의하여 R68232.5 srtA 유전자좌가 대체되었다.
도 29는 이러한 연구에서 수득되는 교정된 세포의 DNA 서열의 크로마토그램을 제공한다. 모든 경우에, 야생형 및 돌연변이체 프로토스페이서 및 PAM 서열(또는 그들의 역 상보물)이 표기되어 있다. 적절한 경우, 프로토스페이서에 의해 인코딩된 아미노산 서열이 제공되어 있다. 각각의 교정 실험을 위하여, PCR 및 제한 분석으로 요망되는 변형의 도입을 입증하는 모든 균주를 시퀀싱하였다. 대표적인 크로마토그램이 나타나 있다. (a) R68232.5 표적으로의 PAM 돌연변이의 도입에 대한 크로마토그램(도 23d). (b) β-갈락토시다제(bgaA)로의 R>A 및 NE>AA 돌연변이의 도입에 대한 크로마토그램(도 25c). (c) bgaA ORF 내의 6664 bp 결실의 도입에 대한 크로마토그램(도 25c 및 도 25f). 점선은 결실 한계를 나타낸다. (d) srtA ORF 내의 729 bp 결실의 도입에 대한 크로마토그램(도 25f). 점선은 결실 한계를 나타낸다. (e) ermAM 내의 조기 종결 코돈의 생성에 대한 크로마토그램(도 33). (f) 에스케리키아 콜라이에서의 rpsL 교정(도 27).
도 30은 상이한 PAM을 함유하는 무작위 스트렙토코커스 뉴모니애 표적에 대한 CRISPR 면역성을 예시한다. (a) 스트렙토코커스 뉴모니애 R6 게놈에 대한 10개의 무작위 표적의 위치. 선택된 표적은 상이한 PAM을 가지며, 둘 모두의 가닥 상에 존재한다. (b) 표적에 상응하는 스페이서를 플라스미드 pLZ12 상의 최소 CRISPR 어레이에 클로닝하고, 트랜스로 가공 및 표적화 기구를 제공하는 균주 crR6Rc로 형질전환시켰다. (c) 균주 R6 및 crR6Rc에서의 상이한 플라스미드의 형질전환 효율. crR6Rc에서 pDB99-108(T1-T10)의 형질전환에 대하여 콜로니가 회수되지 않았다. 파선은 검정의 검출 한계를 나타낸다.
도 31은 표적화된 게놈 교정을 위한 일반적 계획을 제공한다. 표적화된 게놈 교정을 용이하게 하기 위하여, crR6M을 tracrRNA, Cas9 및 CRISPR 어레이의 오직 하나의 반복부 뒤에 카나마이신 내성 마커(aphA-3)를 함유하도록 더 조작하여, 균주 crR6Rk를 생성하였다. 이러한 균주 유래의 DNA를 신규 스페이서(N으로 표기된 녹색 박스)를 도입하기 위해 설계된 프라이머를 사용한 PCR을 위한 주형으로 사용한다. 좌측 및 우측 PCR을 깁슨(Gibson) 방법을 사용하여 조립하여, 표적화 작제물을 생성하였다. 그 다음, 표적화 및 교정 작제물 둘 모두를 균주 crR6Rc로 형질전환시키며, 이는 crR6Rk와 동등하나, 카나마이신 내성 마커가 클로람페니콜 내성 마커(cat)에 의해 대체된 균주이다. 약 90%의 카나마이신-내성 형질전환체가 요망되는 돌연변이를 함유한다.
도 32는 PAM 간의 거리의 분포를 예시한다. NGG 및 CCN은 유효한 PAM인 것으로 여겨진다. 데이터는 스트렙토코커스 뉴모니애 R6 게놈에 대하여, 그리고 동일한 GC-함량(39.7 %)이 있는 동일한 길이의 무작위 서열에 대하여 나타나 있다. 점선은 R6 게놈에서 PAM 간의 평균 거리(12)를 나타낸다.
도 33은 표적화 작제물로서 게놈 DNA를 사용한 ermAM 유전자좌의 CRISPR-매개의 교정을 예시한다. 게놈 DNA를 표적화 작제물로서 사용하기 위하여, CRISPR 자가면역성을 피하는 것이 필요하며, 이에 따라 염색체에 존재하지 않는 서열에 대한 스페이서를 사용해야 한다(이러한 경우, ermAM 에리트로마이신 내성 유전자). (a) 야생형 및 돌연변이(적색 문자) ermAM 유전자의 뉴클레오티드 및 아미노산 서열. 프로토스페이서 및 PAM 서열이 나타나 있다. (b) 게놈 DNA를 사용한 ermAM 유전자좌의 CRISPR-매개의 교정에 대한 개략도. ermAM-표적화 스페이서(청색 네모)를 지니는 작제물을 PCR 및 깁슨 조립에 의해 제조하고, 균주 crR6Rc로 형질전환시켜, 균주 JEN37을 생성한다. 그 다음, JEN37의 게놈 DNA를 표적화 작제물로 사용하고, 교정 주형과 함께 JEN38로 동시-형질전환시키고, 이 균주에서, srtA 유전자는 ermAM의 야생형 카피로 대체되었다. 카나마이신-내성 형질전환체는 교정된 유전자형(JEN43)을 함유한다. (c) 표적화 및 교정 또는 대조군 주형의 동시-형질전환 후에 수득되는 카나마이신-내성 세포의 수. 대조군 주형의 존재 하에, 5.4×103 cfu/㎖을 수득하고, 교정 주형을 사용하는 경우 4.3×105 cfu/㎖을 수득하였다. 이러한 차이는 약 99%[(4.3×105-5.4×103)/4.3×105]의 교정 효율을 나타낸다. (d) 교정된 세포의 존재에 대하여 점검하기 위하여, 7개의 카나마이신-내성 클론 및 JEN38을 에리트로마이신이 있거나(erm+), 에리트로마이신이 없는(erm-) 아가 플레이트에 스트리킹하였다. 오직 양의 대조군만이 에리트로마이신에 대한 내성을 나타내었다. 또한, 이들 형질전환체 중 하나의 ermAM mut 유전자형을 DNA 시퀀싱에 의해 확인하였다(도 29e).
도 34는 CRISPR-매개의 게놈 교정에 의한 돌연변이의 순차적 도입을 예시한다. (a) CRISPR-매개의 게놈 교정에 의한 돌연변이의 순차적 도입에 대한 개략도. 먼저, R6을 crR6Rk를 생성하도록 조작한다. crR6Rk를 ΔsrtA 프레임내 결실을 위한 교정 작제물과 함께, 교정된 세포의 클로람페니콜 선택을 위해 cat에 융합된 srtA-표적화 작제물로 동시-형질전환시킨다. 균주 crR6 ΔsrtA를 클로람페니콜에서의 선택에 의해 생성한다. 이후에, ΔsrtA 균주를 교정된 세포의 카나마이신 선택을 위해 aphA-3에 융합된 bgaA-표적화 작제물 및 ΔbgaA 프레임내 결실을 함유하는 교정 작제물로 동시-형질전환시킨다. 마지막으로, 조작된 CRISPR 유전자좌를, 먼저 야생형 IS1167 유전자좌를 함유하는 R6 DNA 및 bgaA 프로토스페이서를 지니는 플라스미드(pDB97)로 동시 형질전환시키고, 스펙티노마이신에서 선택함으로써 염색체로부터 제거할 수 있다. (b) srtA 유전자좌에서 결실을 검출하기 위한 8개의 클로람페니콜(Cam)-내성 형질전환체에 대한 PCR 분석. (c) 밀러(Miller) 검정에 의해 측정시 β-갈락토시다제 활성. 스트렙토코커스 뉴모니애에서, 이러한 효소는 소타제(sortase) A에 의해 세포벽에 부착된다. srtA 유전자의 결실에 의해 상청액으로의 β-갈락토시다제의 방출이 야기된다. ΔbgaA 돌연변이체는 활성을 보이지 않는다. (d) 야생형 IS1167에 의한 CRISPR 유전자좌의 대체를 검출하기 위한 8개의 스펙티노마이신(Spec)-내성 형질전환체에 대한 PCR 분석.
도 35는 스트렙토코커스 뉴모니애에서의 CRISPR의 백그라운드 돌연변이 빈도를 예시한다. (a) JEN53에서 ermAM 교정 주형과 함께, 또는 이것 없이 CRISPR::Ø 또는 CRISPR::erm(종결) 표적화 작제물의 형질전환. CRISPR::Ø와 CRISPR::erm(종결) 간의 kanR CFU의 차이는 Cas9 절단이 비-교정된 세포를 사멸시키는 것을 나타낸다. 교정 주형의 부재 하에 CRISPR 간섭을 피하는 돌연변이체는 3×10-3의 빈도로 관찰된다. (b) 도피물의 CRISPR 유전자좌의 PCR 분석은 8개 중 7개가 스페이서 결실을 가짐을 보여준다. (c) 도피물 #2는 cas9 내의 점 돌연변이를 지닌다.
도 36은 스트렙토코커스 피오게네스 CRISPR 유전자좌 1의 필수 요소가 pCas9를 사용하여 에스케리키아 콜라이에서 재구성되는 것을 예시한다. 플라스미드는 tracrRNA, Cas9, 및 crRNA 어레이를 유도하는 리더 서열을 함유한다. pCRISPR 플라스미드는 오직 리더 및 어레이만을 함유하였다. 스페이서는 어닐링된 올리고뉴클레오티드를 사용하여 BsaI 부위 사이의 crRNA 어레이에 삽입될 수 있다. 올리고뉴클레오티드 설계는 하측에 나타나 있다. pCas9는 클로람페니콜 내성(CmR)을 지니며, 저-카피 pACYC184 플라스미드 백본에 기초한다. pCRISPR은 고-카피수 pZE21 플라스미드에 기초한다. 2개의 플라스미드가 필요하였는데, 이는 Cas9가 또한 존재한다면 클로닝 숙주로서 이러한 유기체를 사용하여 에스케리키아 콜라이 염색체를 표적화하는 스페이서를 함유하는 pCRISPR 플라스미드가 작제될 수 없기 때문이다(그것은 숙주를 사멸시킬 것이다).
도 37은 에스케리키아 콜라이 MG1655에서의 CRISPR-유도 교정을 예시한다. 스트렙토마이신 내성을 부여하고 CRISPR 면역성을 없애는 점 돌연변이를 지니는 올리고뉴클레오티드(W542)를 rpsL을 표적화하는 플라스미드(pCRISPR::rpsL) 또는 대조군 플라스미드(pCRISPR::Ø)와 함께 pCas9를 함유하는 야생형 에스케리키아 콜라이 균주 MG1655로 동시 형질전환시켰다. 형질전환체를 스트렙토마이신 또는 카나마이신 중 어느 하나를 함유하는 배지에서 선택하였다. 파선은 형질전환 검정의 검출 한계를 나타낸다.
도 38은 에스케리키아 콜라이 HME63에서의 CRISPR의 백그라운드 돌연변이 빈도를 예시한다. (a) HME63 컴피턴트 세포로의 pCRISPR::Ø 또는 pCRISPR::rpsL 플라스미드의 형질전환. CRISPR 간섭을 피하는 돌연변이체가 2.6×10-4의 빈도로 관찰되었다. (b) 도피물의 CRISPR 어레이의 증폭에 의해, 8개 중 8개에서 스페이서가 결실됨이 나타났다.
도 39a 내지 도 39d는 3개 그룹의 큰 Cas9(약 1400개 아미노산) 및 2개 그룹의 작은 Cas9(약 1100개 아미노산)를 포함하는 5개 과의 Cas9를 보여주는 계통 분석의 원형 표기를 보여준다.
도 40a 내지 도 40f는 3개 그룹의 큰 Cas9(약 1400개 아미노산) 및 2개 그룹의 작은 Cas9(약 1100개 아미노산)를 포함하는 5개 과의 Cas9를 보여주는 계통 분석의 선형 표기를 보여준다.
도 41a 내지 도 41m은 돌연변이 점이 SpCas9 유전자 내에 위치하는 서열을 보여준다.
도 42는 전사 활성화 도메인(VP64)이 촉매 도메인 내에 2개의 돌연변이(D10 및 H840)가 있는 Cas9에 융합된 개략적 작제물을 보여준다.
도 43a 내지 도 43d는 상동성 재조합을 통한 게놈 교정을 보여준다. (a) RuvC I 촉매 도메인 내에 D10A 돌연변이가 있는 SpCas9 닉카아제(nickase)의 개략도. (b) 수복 주형으로서 센스 또는 안티센스 단일 가닥 올리고뉴클레오티드를 사용하는 인간 EMX1 유전자좌에서의 상동성 재조합(HR)을 나타내는 개략도. 위의 적색 화살표는 sgRNA 절단 부위를 나타내며; 유전자형분석을 위한 PCR 프라이머(표 J 및 K)는 우측 패널에 화살표로 표시되어 있다. (c) HR에 의해 변형된 영역의 서열. d, 야생형(wt) 및 EMX1 표적 1 유전자좌에서의 닉카아제(D10A) SpCas9-매개의 삽입-결실에 대한 서베이어 검정(n=3). 화살표는 예상되는 단편 크기의 위치를 나타낸다.
도 44a 및 도 44b는 SpCas9에 대한 단일 벡터 설계를 보여준다.
도 45는 NLS-Csn1 작제물 NLS-Csn1, Csn1, Csn1-NLS, NLS-Csn1-NLS, NLS-Csn1-GFP-NLS 및 UnTFN의 절단의 정량화를 보여준다.
도 46은 NLS-Cas9, Cas9, Cas9-NLS 및 NLS-Cas9-NLS의 인덱스 빈도를 보여준다.
도 47은 닉카아제 돌연변이(개별적으로)가 있는 SpCas9가 이중 가닥 파단을 유도하지 않음을 입증하는 겔을 보여준다.
도 48은 이러한 실험에서 상동성 재조합(HR) 주형으로 사용되는 올리고 DNA의 설계 및 Cas9 단백질 및 HR 주형의 상이한 조합에 의해 유도되는 HR 효율의 비교를 보여준다.
도 49a는 조건성 Cas9, Rosa26 표적화 벡터 맵을 보여준다.
도 49b는 구성성 Cas9, Rosa26 표적화 벡터 맵을 보여준다.
도 50a 내지 도 50h는 도 49a 및 도 49b의 벡터 맵에 존재하는 각 요소의 서열을 보여준다.
도 51은 구성성 및 조건성 Cas9 작제물에서의 중요한 요소의 개략도를 보여준다.
도 52는 구성성 및 조건성 Cas9 작제물의 발현의 기능 확인을 보여준다.
도 53은 서베이어에 의한 Cas9 뉴클레아제 활성의 확인을 보여준다.
도 54는 Cas9 뉴클레아제 활성의 정량화를 보여준다.
도 55는 작제물 설계 및 상동성 재조합(HR) 전략을 보여준다.
도 56은 두 가지 상이한 겔 노출 시간(상측 줄은 3분 동안, 그리고 하측 줄은 1분 동안)에서의 구성성(우측) 및 조건성(좌측) 작제물에 대한 게놈 PCR 유전자형분석 결과를 보여준다.
도 57은 mESC에서의 Cas9 활성화를 보여준다.
도 58은 2개의 가이드 RNA와 함께 Cas9의 닉카아제 버전을 사용하여 NHEJ를 통해 유전자 녹아웃을 매개하는데 사용되는 전략의 개략도를 보여준다.
도 59는 DNA 이중 가닥 파단(DSB) 수복이 유전자 교정을 촉진하는 방법을 보여준다. 오류-유발(error-prone) 비상동성 말단 연결(NHEJ) 경로에서, DSB의 말단을 내인성 DNA 수복 기구에 의해 가공하고, 함께 재연결하는데, 이는 연접 부위에서 무작위 삽입-결실(indel) 돌연변이를 야기할 수 있다. 유전자의 코딩 영역 내에서 발생한 삽입-결실 돌연변이는 해독틀 이동 및 조기 종결 코돈을 야기하여, 유전자 녹아웃을 유발할 수 있다. 대안적으로, 플라스미드 또는 단일-가닥 올리고데옥시뉴클레오티드(ssODN)의 형태의 수복 주형을 공급하여, 상동성-유도 수복(HDR) 경로를 활용할 수 있으며, 이는 높은 충실도와 정밀한 교정을 가능하게 한다.
도 60은 실험의 일정표 및 개요를 보여준다. 시약 설계, 작제, 입증 및 세포주 증식을 위한 단계. 각 표적에 대한 맞춤형 sgRNA(담청색 막대) 및 유전자형분석 프라이머를 본 발명자들의 온라인 설계 툴(웹사이트 genome-engineering.org/tools에서 이용가능)을 통해 인 실리코(in silico)로 설계한다. 그 다음, sgRNA 발현 벡터를 Cas9를 함유하는 플라스미드(PX330)로 클로닝하고, DNA 시퀀싱을 통해 입증한다. 그 다음, 완성된 플라스미드(pCRISPR) 및 상동성 유도 수복을 촉진하기 위한 선택적 수복 주형을 세포로 트랜스펙션시키고, 표적화된 절단을 매개하는 능력에 대하여 검정한다. 마지막으로, 트랜스펙션된 세포를 클론으로 증식시켜, 한정된 돌연변이를 갖는 동질 유전자형 세포주를 유도할 수 있다.
도 61a 내지 도 61c는 표적 선택 및 시약 제조를 보여준다. (a) 스트렙토코커스 피오게네스 Cas9에 대하여, 20-bp 표적(청색으로 강조표시) 뒤에 5'-NGG가 있어야 하며, 이는 게놈 DNA 상의 어느 하나의 가닥에 존재할 수 있다. 본 발명자들은 표적 선택을 보조하는데에서 이러한 프로토콜에 기술된 온라인 툴(www.genome-engineering.org/tools)을 사용하는 것을 권고한다. (b) Cas9 발현 플라스미드(PX165) 및 PCR-증폭 U6-유도 sgRNA 발현 카세트의 동시-트랜스펙션에 대한 개략도. U6 프로모터-함유 PCR 주형 및 고정된 정방향 프라이머(U6 Fwd)를 사용하여, sgRNA-인코딩 DNA를 U6 역방향 프라이머(U6 Rev)에 부착시키고, 연장된 DNA 올리고(IDT로부터의 울트라머(Ultramer) 올리고)로서 합성할 수 있다. U6 Rev에서 가이드 서열(청색 N)이 5'-NGG 측부 배치(flanking) 표적 서열의 역 상보물임을 주목한다. (c) Cas9 및 sgRNA 스캐폴드(scaffold)를 함유하는 플라스미드(PX330)로의 가이드 서열 올리고의 무흔적(scarless) 클로닝에 대한 개략도. 가이드 올리고(청색 N)는 PS330 상의 BbsI 부위의 쌍으로의 라이게이션을 위한 오버행을 함유하며, 상측 및 하측 가닥 배향은 게놈 표적의 것과 일치한다(즉, 상측 올리고는 게놈 DNA 내의 5'-NGG 앞의 20-bp 서열임). BbsI을 사용한 PX330의 분해에 의해, 어닐링된 올리고의 직접 삽입으로의 II형 제한 부위(청색 윤곽선)의 대체가 가능하게 된다. 가이드 서열의 제1 염기 전에 추가의 G가 배치되는 것을 주목할 가치가 있다. 본 발명자들은 가이드 서열의 앞의 추가의 G가 표적화 효율에 불리하게 영향을 미치지 않는 것을 발견하였다. 선택된 20-nt 가이드 서열이 구아닌으로 시작하지 않는 경우에, 추가의 구아닌은 sgRNA가 전사물의 제1 염기에서 구아닌을 선호하는 U6 프로모터에 의해 효율적으로 전사되게 보장할 것이다.
도 62a 내지 도 62d는 다중 NHEJ에 대한 예상되는 결과를 보여준다. (a) 삽입-결실 백분율을 결정하기 위해 사용되는 서베이어 검정의 개략도. 먼저, Cas9-표적화 세포의 이종 집단 유래의 게놈 DNA를 PCR에 의해 증폭시킨다. 그 다음, 앰플리콘을 천천히 다시 어닐링시켜, 헤테로듀플렉스를 생성한다. 다시 어닐링된 헤테로듀플렉스를 서베이어 뉴클레아제에 의해 절단하는 한편, 호모듀플렉스를 손상되지 않게 둔다. Cas9-매개의 절단 효율(삽입-결실%)을 겔 밴드의 통합 세기에 의해 결정시, 절단된 DNA의 분율에 기초하여 계산한다. (b) 인간 GRIN2B 및 DYRK1A 유전자좌를 표적화하도록 2개의 sgRNA(주황색 및 청색 막대)를 설계한다. 서베이어 겔은 트랜스펙션된 세포 내의 둘 모두의 유전자좌에서의 변형을 보여준다. 유색 화살표는 각 유전자좌에 대한 예상된 단편 크기를 나타낸다. (c) 인간 EMX1 유전자좌에서 엑손(진청색)을 절개하도록 sgRNA의 쌍(담청색 및 녹색 막대)을 설계한다. 표적 서열 및 PAM(적색)은 각각의 색상으로 나타나 있으며, 절단 부위는 적색 삼각형으로 표기된다. 예측된 연접은 하기에 나타나 있다. sgRNA 3, 4 또는 둘 모두가 트랜스펙션된 세포 집단으로부터 분리된 개별 클론을 약 270-bp의 결실을 반영하는 PCR(OUT 정방향, OUT 역방향)에 의해 검정한다. 변형이 없고(12/23), 1-대립형질(10/23) 및 2-대립형질(1/23) 변형이 있는 대표적인 클론이 나타나 있다. IN 정방향 및 IN 역방향 프라이머를 사용하여 역위 사건에 대하여 스크리닝한다(도 6d). (d) EMX1 엑손 결실이 있는 클론 세포주의 정량화. 2개 쌍의 sgRNA(3.1, 3.2 좌측-측부 배치 sgRNA; 4.1, 4.2, 우측 측부 배치 sgRNA)를 사용하여 하나의 EMX1 엑손 주위의 가변적 크기의 결실을 매개한다. 트랜스펙션된 세포를 클론으로 분리하고, 결실 및 역위 사건에 대한 유전자형 분석을 위해 증식시킨다. 105개 클론 중에, 각각 이종 및 동종 결실을 지니는 51(49%) 및 11(10%)개가 스크리닝된다. 연접이 가변적일 수 있기 때문에, 대략적 결실 크기가 제공된다.
도 63a 내지 도 63c는 HEK293FT 및 HUES9 세포에서 Cas9의 야생형 및 닉카아제 돌연변이체 둘 모두를 사용하여 1.0 내지 27% 범위의 효율로 HR을 매개하기 위한 ssODN 및 표적화 벡터의 응용을 보여준다.
도 64는 포유동물 세포에서의 신속하고 효율적인 CRISPR 표적화를 위한 PCR 기반의 방법의 개략도를 보여준다. 인간 RNA 중합효소 III 프로모터 U6을 함유하는 플라스미드를 U6-특이적 정방향 프라이머 및 U6 프로모터의 부분, 가이드 서열이 있는 sgRNA(+85) 스캐폴드 및 전사 종결을 위한 7개의 T 뉴클레오티드의 역 상보물을 지니는 역방향 프라이머를 사용하여 PCR 증폭시켰다. 생성된 PCR 산물을 정제하고, CBh 프로모터에 의해 유도되는 Cas9를 지니는 플라스미드와 동시-전달한다.
도 65는 각각의 gRNA 및 각각의 대조군에 대한 트랜스게노믹스(Transgenomics)로부터의 서베이어 돌연변이 검출 키트 결과를 보여준다. 양의 서베이어 결과는 게놈 PCR에 상응하는 하나의 큰 밴드, 및 돌연변이 부위에서 이중-가닥 파단을 만드는 서베이어 뉴클레아제의 산물인 2개의 더 작은 밴드이다. 각각의 gRNA를 hSpCas9로의 일시적 리포솜 동시-트랜스펙션에 의해 마우스 세포주, Neuro-N2a에서 입증하였다. 트랜스펙션 후 72시간에, 게놈 DNA를 에피센트레(Epicentre)로부터의 퀵익스트랙트(QuickExtract) DNA를 사용하여 정제하였다. PCR을 수행하여, 대상 유전자좌를 증폭시켰다.
도 66은 38마리의 살아있는 새끼(레인(lane) 1~38), 1마리의 죽은 새끼(레인 39) 및 1마리의 비교용 야생형 새끼(레인 40)에 대한 서베이어 결과를 보여준다. 새끼 1 내지 19에 gRNA Chd8.2를 주사하고, 새끼 20~38에 gRNA Chd8.3을 주사하였다. 38마리의 살아 있는 새끼 중에 13마리는 돌연변이에 대하여 양성이었다. 또한, 1마리의 죽은 새끼는 돌연변이를 가졌다. 야생형 샘플에서 돌연변이가 검출되지 않았다. 게놈 PCR 시퀀싱은 서베이어 검정 관찰과 일치하였다.
도 67은 상이한 Cas9 NLS 작제물의 설계를 보여준다. 모든 Cas9는 Sp Cas9의 인간-코돈-최적화 버전이었다. NLS 서열은 N-말단 또는 C-말단 중 어느 하나에서 cas9 유전자에 연결된다. 상이한 NLS 설계를 갖는 모든 Cas9 변이체를 EF1a 프로모터를 함유하여, EF1a 프로모터에 의해 유도되는 백본 벡터로 클로닝하였다. 동일한 벡터에서, U6 프로모터에 의해 유도되는 인간 EMX1 유전자좌를 표적화하는 키메라 RNA가 존재하여, 함께 2-성분 시스템을 형성한다.
도 68은 상이한 NLS 설계를 갖는 Cas9 변이체에 의해 유도되는 게놈 절단의 효율을 보여준다. 백분율은 각 작제물에 의해 절단된 인간 EMX1 게놈 DNA의 부분을 나타낸다. 모든 실험은 3개의 생물학적 반복 검증으로부터의 것이다. n = 3, 오차는 S.E.M을 나타낸다.
도 69a는 전사 활성화 활성을 갖는 CRISPR-TF(전사 인자)의 설계를 보여준다. 키메라 RNA는 U6 프로모터에 의해 발현되는 한편, 3중 NLS 및 VP64 기능적 도메인에 작동가능하게 연결된, 인간-코돈-최적화, 이중-돌연변이 버전의 Cas9 단백질(hSpCas9m)은 EF1a 프로모터에 의해 발현된다. 이중 돌연변이, D10A 및 H840A는 cas9 단백질이 임의의 절단을 도입할 수 없지만, 키메라 RNA에 의해 유도되는 경우 표적 DNA로의 그의 결합 능력을 유지하게 한다.
도 69b는 CRISPR-TF 시스템(키메라 RNA 및 Cas9-NLS-VP64 융합 단백질)을 사용한 인간 SOX2 유전자의 전사 활성화를 보여준다. 293FT 세포를 2개의 성분을 지니는 플라스미드로 트랜스펙션시켰다: (1) 인간 SOX2 게놈 유전자좌 내의 또는 그 근처의 20-bp 서열을 표적화하는 U6-유도된 상이한 키메라 RNA, 및 (2) EF1a-유도 hSpCas9m(이중 돌연변이)-NLS-VP64 융합 단백질. 트랜스펙션 96시간 후에, 293FT 세포를 수집하고, 활성화 수준을 qRT-PCR 검정을 사용하여 mRNA 발현의 유도에 의해 측정한다. 모든 발현 수준을 대조군(회색 막대)에 대하여 정규화시키고, 이는 키메라 RNA가 없는 CRISPR-TF 백본 플라스미드가 트랜스펙션된 세포로부터의 결과를 나타낸다. SOX2 mRNA를 검출하기 위해 사용되는 qRT-PCR 프로브는 택맨 휴먼 진 익스프레션 어세이(Taqman Human Gene Expression Assay)(라이프 테크놀로지즈(Life Technologies))이다. 모든 실험은 3개의 생물학적 반복 검증으로부터의 데이터를 나타낸다. n = 3, 오차 바는 s.e.m을 나타낸다.
도 70은 SpCas9에 대한 NLS 구조 최적화를 도시한다.
도 71은 NGGNN 서열에 대한 QQ 플롯을 보여준다.
도 72는 핏팅된 정규 분포(흑색 선) 및 .99 분위수(점선)를 사용한 데이터 밀도의 히스토그램을 보여준다.
도 73a 내지 도 73c는 dgRNA::cas9**에 의한 bgaA 발현의 RNA-유도 억제를 보여준다. a. Cas9 단백질은 tracrRNA에, 그리고 전구체 CRISPR RNA에 결합하며, 이는 RNAseIII에 의해 가공되어 crRNA를 형성한다. crRNA는 bgaA 프로모터로의 Cas9의 결합을 유도하며, 전사를 억제한다. b. Cas9**를 bgaA 프로모터로 지향시키는데 사용되는 표적이 표시되어 있다. 추정의 -35, -10, 및 bgaA 시작 코돈이 볼드체로 나타나 있다. c. 표적화의 부재 하에서, 그리고 4개의 상이한 표적에 대하여 밀러 검정에 의해 측정시 베타갈락토시다제 활성.
도 74a 내지 도 74e는 Cas9** 매개의 억제의 특성화를 보여준다. a. gfpmut2 유전자 및 -35 및 -10 신호를 포함하는 그의 프로모터는 연구에 사용되는 상이한 표적 부위의 위치와 함께 표현된다. b. 코딩 가닥의 표적화 시의 상대적 형광. c. 비-코딩 가닥의 표적화 시의 상대적 형광. d. T5, T10, B10 또는 표적이 없는 대조군 균주로부터 추출된 RNA에서의 프로브 B477 및 B478을 사용한 노던 블롯. e. B1, T5 및 B10의 crRNA의 5' 말단에서의 증가된 수의 돌연변이의 영향.
본원에서 도면은 오직 예시의 목적을 위한 것이며, 반드시 척도에 따라 도시된 것은 아니다.
용어 "폴리뉴클레오티드", "뉴클레오티드", "뉴클레오티드 서열", "핵산" 및 "올리고뉴클레오티드"는 상호교환가능하게 사용된다. 그것들은 임의의 길이의 뉴클레오티드, 데옥시리보뉴클레오티드 또는 리보뉴클레오티드 중 어느 하나, 또는 그의 유사체의 중합체 형태를 말한다. 폴리뉴클레오티드는 임의의 3차원 구조를 가질 수 있으며, 기지의 또는 미지의 임의의 기능을 수행할 수 있다. 다음은 폴리뉴클레오티드의 비제한적인 예이다: 유전자 또는 유전자 단편의 코딩 또는 비-코딩 영역, 연관 분석으로부터 정의된 유전자좌들(유전자좌), 엑손, 인트론, 전령 RNA(mRNA), 운반 RNA, 리보솜 RNA, 짧은 간섭 RNA(siRNA), 짧은 헤어핀 RNA(shRNA), 마이크로-RNA(miRNA), 리보자임, cDNA, 재조합 폴리뉴클레오티드, 분지형 폴리뉴클레오티드, 플라스미드, 벡터, 임의의 서열의 분리된 DNA, 임의의 서열의 분리된 RNA, 핵산 프로브 및 프라이머. 폴리뉴클레오티드는 하나 이상의 변형된 뉴클레오티드, 예를 들어, 메틸화 뉴클레오티드 및 뉴클레오티드 유사체를 포함할 수 있다. 뉴클레오티드 구조에 대한 변형이 존재한다면, 중합체의 조립 전에 또는 후에 부여될 수 있다. 뉴클레오티드의 서열은 비-뉴클레오티드 성분에 의해 단속될 수 있다. 폴리뉴클레오티드는 중합화 후에, 예를 들어, 표지화 성분과의 컨쥬게이션에 의해 추가로 변형될 수 있다.
본 발명의 양태에서, 용어 "키메라 RNA", "키메라 가이드 RNA", "가이드 RNA", "단일의 가이드 RNA" 및 "합성 가이드 RNA"는 상호교환가능하게 사용되며, 가이드 서열, tracr 서열 및 tracr 메이트 서열을 포함하는 폴리뉴클레오티드 서열을 지칭한다. 용어 "가이드 서열"은 표적 부위를 지정하는 가이드 RNA 내의 약 20bp 서열을 지칭하며, 용어 "가이드" 또는 "스페이서"와 상호교환가능하게 사용될 수 있다. 또한, 용어 "tracr 메이트 서열"은 용어 "직접 반복부(들)"와 상호교환가능하게 사용될 수 있다.
본원에 사용되는 바와 같이, 용어 "야생형"은 당업자에 의해 이해되는 해당 분야의 용어이며, 그것이 돌연변이체 또는 변이체 형태로부터 구별되는 정도로 천연에서 발생하는 것과 같은 전형적인 형태의 유기체, 균주, 유전자 또는 특징을 의미한다.
본원에 사용되는 바와 같이, 용어 "변이체"는 천연에서 발생하는 것에서 벗어난 패턴을 갖는 특성의 표현을 의미하는 것으로 이해해야 한다.
용어 "비-천연 발생" 또는 "조작된"은 상호교환가능하게 사용되며, 인간의 손의 개입을 나타낸다. 상기 용어는 핵산 분자 또는 폴리펩티드에 대하여 언급되는 경우, 핵산 분자 또는 폴리펩티드에 천연에서 천연적으로 관련되어 있고, 천연에서 관찰되는 적어도 하나의 다른 성분이 적어도 실질적으로 없음을 의미한다.
"상보성"은 통상의 왓슨-크릭(Watson-Crick) 염기 쌍형성 또는 기타 비-통상적 유형에 의해 다른 핵산 서열과 수소 결합(들)을 형성하는 핵산의 능력을 지칭한다. 상보성 백분율은 제2 핵산 서열과 수소 결합(예를 들어, 왓슨-크릭 염기 쌍형성)을 형성할 수 있는 핵산 분자 내의 잔기의 백분율을 나타낸다(예를 들어, 10개 중 5, 6, 7, 8, 9, 10개는 50%, 60%, 70%, 80%, 90% 및 100% 상보성임). "완전한 상보성"은 핵산 서열의 모든 연속 잔기가 동일한 수의 제2 핵산 서열 내의 연속 잔기와 수소 결합할 것임을 의미한다. 본원에 사용되는 바와 같이, "실질적인 상보성"은 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 30, 35, 40, 45, 50개 이상의 뉴클레오티드의 영역에 걸쳐 적어도 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%, 97%, 98%, 99% 또는 100%인 상보성 정도를 지칭하거나, 엄격한 조건 하에서 혼성화하는 2개의 핵산을 지칭한다.
본원에 사용되는 바와 같이, 혼성화를 위한 "엄격한 조건"은 표적 서열에 대하여 상보성을 갖는 핵산 서열이 대개 표적 서열과 혼성화하며, 비-표적 서열에는 실질적으로 혼성화하지 않는 조건을 지칭한다. 엄격한 조건은 일반적으로 서열-의존적이며, 다수의 요인에 따라 달라진다. 일반적으로, 서열이 길수록, 서열이 그의 표적 서열에 특이적으로 혼성화하는 온도가 더 높아진다. 엄격한 조건의 비제한적인 예는 문헌[Tijssen (1993), Laboratory Techniques In Biochemistry And Molecular Biology-Hybridization With Nucleic Acid Probes Part I, Second Chapter "Overview of principles of hybridization and the strategy of nucleic acid probe assay", Elsevier, N.Y.]에 상세히 기재되어 있다.
"혼성화"는 하나 이상의 폴리뉴클레오티드가 반응하여, 복합체를 형성하고, 이 복합체는 뉴클레오티드 잔기의 염기 사이의 수소 결합을 통해 안정화되는 반응을 지칭한다. 수소 결합은 왓슨 크릭 염기 쌍형성, 후그스타인(Hoogstein) 결합 또는 임의의 다른 서열 특이적 방식으로 발생할 수 있다. 복합체는 듀플렉스 구조를 형성하는 2개의 가닥, 다중 가닥 복합체를 형성하는 3개 이상의 가닥, 단일의 자가 혼성화 가닥 또는 이들의 임의의 조합을 포함할 수 있다. 혼성화 반응은 PCR의 개시 또는 효소에 의한 폴리뉴클레오티드의 절단과 같은 보다 광범위한 과정에서 하나의 단계를 이룰 수 있다. 주어진 서열과 혼성화할 수 있는 서열은 주어진 서열의 "상보물"로 지칭된다.
본원에 사용되는 바와 같이, "발현"은 폴리뉴클레오티드가 DNA 주형으로부터 (예를 들어, mRNA 또는 기타 RNA 전사물로) 전사되는 과정 및/또는 이후에 전사된 mRNA가 펩티드, 폴리펩티드 또는 단백질로 번역되는 과정을 지칭한다. 전사물 및 인코딩된 폴리펩티드는 집합적으로 "유전자 산물"로 지칭될 수 있다. 폴리뉴클레오티드가 게놈 DNA로부터 유래된다면, 발현은 진핵 세포에서의 mRNA의 스플라이싱을 포함할 수 있다.
용어 "폴리펩티드", "펩티드" 및 "단백질"은 본원에서 임의의 길이의 아미노산의 중합체를 지칭하기 위해 상호교환가능하게 사용된다. 중합체는 선형 또는 분지형일 수 있으며, 그것은 변형된 아미노산을 포함할 수 있고, 그것은 비-아미노산에 의해 단속될 수 있다. 또한, 상기 용어는 변형된 아미노산 중합체, 예를 들어, 이황화 결합 형성, 글리코실화, 지질화(lipidation), 아세틸화, 인산화 또는 임의의 기타 조작, 예를 들어, 표지화 성분과의 컨쥬게이션을 포함한다. 본원에 사용되는 바와 같이, 용어 "아미노산"은 글리신 및 D 또는 L 광학 이성질체 및 아미노산 유사체 및 펩티도미메틱을 포함하는 천연 및/또는 비천연 또는 합성 아미노산을 포함한다.
용어 "대상체", "개체" 및 "환자"는 척추동물, 바람직하게는 포유동물, 더욱 바람직하게는 인간을 지칭하기 위해 본원에서 상호교환가능하게 사용된다. 포유동물은 쥣과, 원숭이, 인간, 농장 동물, 스포츠 동물 및 애완동물을 포함하나 이들에 한정되지 않는다. 생체내에서 수득되거나 시험관내에서 배양된 생물학적 엔티티(entity)의 조직, 세포 및 그들의 자손도 또한 포함된다.
용어 "치료제", "치료가능한 작용제" 또는 "치료 작용제"는 상호교환가능하게 사용되며, 대상체로의 투여 시에 몇몇 유리한 효과를 부여하는 분자 또는 화합물을 지칭한다. 유리한 효과는 진단적 결정을 가능하게 하는 것; 질병, 증상, 장애 또는 병태의 개선; 질병, 증상, 장애 또는 질환의 발병의 감소 또는 예방; 및 일반적으로 질병, 증상, 장애 또는 병태의 대응을 포함한다.
본원에 사용되는 바와 같이, "치료" 또는 "치료하는" 또는 "완화하는" 또는 "개선하는"은 상호교환가능하게 사용된다. 이들 용어는 치료 이익 및/또는 예방 이익을 포함하나 이들에 한정되지 않는 유리한 또는 요망되는 결과를 수득하는 방법을 지칭한다. 치료 이익은 치료 하의 하나 이상의 질병, 질환 또는 증상의 임의의 치료적으로 유의미한 개선 또는 그에 대한 효과를 의미한다. 예방 이익에 있어서, 조성물은 특정 질병, 질환 또는 증상이 발생할 위험이 있는 대상체에게 또는 질병, 질환 또는 증상이 아직 나타나지 않을지라도, 질병의 하나 이상의 생리학적 증상을 보고하는 대상체에게 투여될 수 있다.
용어 "유효량" 또는 "치료적 유효량"은 유리한 또는 요망되는 결과를 야기하기에 충분한 작용제의 양을 지칭한다. 치료적 유효량은 치료되는 대상체 및 병태, 대상체의 체중 및 연령, 병태의 중증도, 투여 방식 등 중 하나 이상에 따라 달라질 수 있으며, 이는 당업자에 의해 용이하게 결정될 수 있다. 또한, 상기 용어는 본원에 기술된 영상화 방법 중 임의의 것에 의한 검출을 위한 이미지를 제공할 용량에 적용된다. 특정 용량은 선택된 특정 작용제, 뒤따르는 투여 요법, 그것이 다른 화합물과 병용하여 투여되는지 여부, 투여 시기, 영상화되는 조직 및 그것을 운반하는 신체 전달 시스템 중 하나 이상에 따라 달라질 수 있다.
본 발명의 실시는 달리 나타내지 않는 한, 당업계의 기술 내에 있는 면역학, 생화학, 화학, 분자 생물학, 미생물학, 세포 생물학, 유전체학 및 재조합 DNA의 통상의 기술을 사용한다. 문헌[Sambrook, Fritsch and Maniatis, MOLECULAR CLONING: A LABORATORY MANUAL, 2nd edition (1989)]; 문헌[CURRENT PROTOCOLS IN MOLECULAR BIOLOGY (F. M. Ausubel, et al. eds., (1987))]; 시리즈 문헌[METHODS IN ENZYMOLOGY (Academic Press, Inc.): PCR 2: A PRACTICAL APPROACH (M.J. MacPherson, B.D. Hames and G.R. Taylor eds. (1995)), Harlow and Lane, eds. (1988) ANTIBODIES, A LABORATORY MANUAL, and ANIMAL CELL CULTURE (R.I. Freshney, ed. (1987))]을 참조한다.
본 발명의 몇몇 양태는 하나 이상의 벡터를 포함하는 벡터 시스템 또는 그와 같은 벡터에 관한 것이다. 벡터는 원핵 또는 진핵 세포에서 CRISPR 전사물(예를 들어, 핵산 전사물, 단백질 또는 효소)의 발현을 위해 설계될 수 있다. 예를 들어, CRISPR 전사물은 박테리아 세포, 예를 들어, 에스케리키아 콜라이, 곤충 세포(배큘로바이러스 발현 벡터 사용), 효모 세포 또는 포유동물 세포에서 발현될 수 있다. 적절한 숙주 세포는 문헌[Goeddel, GENE EXPRESSION TECHNOLOGY: METHODS IN ENZYMOLOGY 185, Academic Press, San Diego, Calif. (1990)]에 추가로 논의되어 있다. 대안적으로, 재조합 발현 벡터는 예를 들어, T7 프로모터 조절 서열 및 T7 중합효소를 사용하여 시험관내에서 전사되고 번역될 수 있다.
벡터는 원핵생물에 도입되고, 그에서 증식될 수 있다. 일부 구현예에서, 원핵생물은 진핵 세포로 도입되거나 또는 진핵 세포로 도입되는 벡터의 생성에서 중간체 벡터(예를 들어, 바이러스 벡터 패키징 시스템의 일부로서 플라스미드 증폭)로서 벡터의 카피를 증폭시키기 위해서 사용된다. 일부 구현예에서, 원핵생물은 벡터의 카피를 증폭시키고, 하나 이상의 핵산을 발현하기 위해, 예를 들어, 숙주 세포 또는 숙주 유기체로의 전달을 위한 하나 이상의 단백질의 공급원을 제공하기 위해 사용된다. 원핵생물에서의 단백질의 발현은 자주 융합 또는 비-융합 단백질 중 어느 하나의 발현을 유도하는 구성성 또는 유도성 프로모터를 함유하는 벡터를 사용하여 에스케리키아 콜라이에서 수행된다. 융합 벡터는 거기에 인코딩된 단백질로, 예를 들어, 재조합 단백질의 아미노 말단으로 수많은 아미노산을 부가한다. 이러한 융합 벡터는 다음과 같은 하나 이상의 목적을 제공할 수 있다: (i) 재조합 단백질의 발현의 증가; (ii) 재조합 단백질의 용해도의 증가; 및 (iii) 친화성 정제에서 리간드로 작용함으로써 재조합 단백질의 정제의 보조. 종종, 융합 발현 벡터에서, 단백질분해 절단 부위는 융합 모이어티와 재조합 단백질의 연접부에 도입되어, 융합 단백질의 정제 이후에 융합 모이어티로부터 재조합 단백질의 분리를 가능하게 한다. 이러한 효소 및 그들의 동족 인식 서열은 인자 Xa, 트롬빈 및 엔테로키나아제를 포함한다. 예시적인 융합 발현 벡터는 pGEX(파마시아 바이오테크 인코포레이티드(Pharmacia Biotech Inc); 문헌[Smith and Johnson, 1988. Gene 67: 31-40]), pMAL(미국 매사추세츠주 비벌리 소재의 뉴 잉글랜드 바이오랩스(New England Biolabs)) 및 pRIT5(미국 뉴저지주 피스카타웨이 소재의 파마시아(Pharmacia))를 포함하며, 이는 각각 글루타티온 S-트랜스퍼라제(GST), 말토스 E 결합 단백질 또는 단백질 A를 표적 재조합 단백질에 융합시킨다.
적절한 유도성 비-융합 에스케리키아 콜라이 발현 벡터의 예는 pTrc(문헌[Amrann et al., (1988) Gene 69:301-315]) 및 pET 11d(문헌[Studier et al., GENE EXPRESSION TECHNOLOGY: METHODS IN ENZYMOLOGY 185, Academic Press, San Diego, Calif. (1990) 60-89])를 포함한다.
일부 구현예에서, 벡터는 효모 발현 벡터이다. 효모 사카로마이세스 세레비지애에서의 발현을 위한 벡터의 예에는 pYepSec1(문헌[Baldari, et al., 1987. EMBO J. 6: 229-234]), pMFa(문헌[Kuijan and Herskowitz, 1982. Cell 30: 933-943]), pJRY88(문헌[Schultz et al., 1987. Gene 54: 113-123]), pYES2(미국 캘리포니아주 샌 디에고 소재의 인비트로겐 코포레이션) 및 picZ(미국 캘리포니아주 샌 디에고 소재의 인비트로겐 코포레이션)가 포함된다.
일부 구현예에서, 벡터는 배큘로바이러스 발현 벡터를 사용하여 곤충 세포에서 단백질 발현을 유도한다. 배양된 곤충 세포(예를 들어, SF9 세포)에서 단백질의 발현에 이용가능한 배큘로바이러스 벡터는 pAc 시리즈(문헌[Smith, et al., 1983. Mol. Cell. Biol. 3: 2156-2165]) 및 pVL 시리즈(문헌[Lucklow and Summers, 1989. Virology 170: 31-39])를 포함한다.
일부 구현예에서, 벡터는 포유동물 발현 벡터를 사용하여 포유동물 세포에서 하나 이상의 서열의 발현을 유도할 수 있다. 포유동물 발현 벡터의 예는 pCDM8(문헌[Seed, 1987. Nature 329: 840]) 및 pMT2PC(문헌[Kaufman, et al., 1987. EMBO J. 6: 187-195])를 포함한다. 포유동물 세포에서 사용되는 경우, 발현 벡터의 조절 기능은 전형적으로 하나 이상의 조절 요소에 의해 제공된다. 예를 들어, 통상적으로 사용되는 프로모터는 폴리오마, 아데노바이러스 2, 사이토메갈로바이러스, 유인원 바이러스 40 및 본원에 개시되고 당업계에 공지되어 있는 기타의 것으로부터 유래된다. 원핵 및 진핵 세포 둘 모두를 위한 다른 적절한 발현 시스템에 대하여, 예를 들어, 문헌[Sambrook, et al., MOLECULAR CLONING: A LABORATORY MANUAL. 2nd ed., Cold Spring Harbor Laboratory, Cold Spring Harbor Laboratory Press, Cold Spring Harbor, N.Y., 1989]의 16 및 17장을 참조한다.
일부 구현예에서, 재조합 포유동물 발현 벡터는 특정 세포 유형에서 우선적으로 핵산의 발현을 유도할 수 있다(예를 들어, 핵산을 발현하기 위하여 조직-특이적 조절 요소가 사용됨). 조직-특이적 조절 요소가 해당 분야에 공지되어 있다. 적절한 조직-특이적 프로모터의 비제한적인 예에는 알부민 프로모터(간-특이적; 문헌[Pinkert, et al., 1987. Genes Dev. 1: 268-277]), 림프-특이적 프로모터(문헌[Calame and Eaton, 1988. Adv. Immunol. 43: 235-275]), 특히, T 세포 수용체의 프로모터(문헌[Winoto and Baltimore, 1989. EMBO J. 8: 729-733]) 및 면역글로불린의 프로모터(문헌[Baneiji, et al., 1983. Cell 33: 729-740]; 문헌[Queen and Baltimore, 1983. Cell 33: 741-748]), 뉴런-특이적 프로모터(예를 들어, 신경섬유 프로모터; 문헌[Byrne and Ruddle, 1989. Proc. Natl. Acad. Sci. USA 86: 5473-5477]), 췌장-특이적 프로모터(문헌[Edlund, et al., 1985. Science 230: 912-916]) 및 유선-특이적 프로모터(예를 들어, 유장(milk whey) 프로모터; 미국 특허 제4,873,316호 및 유럽 출원 공개 제264,166호)가 포함된다. 발생-조절 프로모터, 예를 들어, 쥣과 hox 프로모터(문헌[Kessel and Gruss, 1990. Science 249: 374-379]) 및 α-태아단백질 프로모터(문헌[Campes and Tilghman, 1989. Genes Dev. 3: 537-546])도 또한 포함된다.
일부 구현예에서, 조절 요소는 CRISPR 시스템의 하나 이상의 요소에 작동가능하게 연결되어 CRISPR 시스템의 하나 이상의 요소의 발현을 유도한다. 일반적으로, SPIDR(스페이서 산재 직접 반복부)로도 공지되어 있는 CRISPR(클러스터링되고 규칙적으로 산재된 짧은 팔린드로믹 반복부)은 통상 특정 박테리아 종에 특이적인 DNA 유전자좌의 과를 구성한다. CRISPR 유전자좌는 에스케리키아 콜라이에서 인식되는 별개의 부류의 산재된 짧은 서열 반복부(SSR) 및 관련 유전자를 포함한다(문헌[Ishino et al., J. Bacteriol., 169:5429-5433 [1987]]; 및 문헌[Nakata et al., J. Bacteriol., 171:3553-3556 [1989]]). 유사한 산재된 SSR이 할로페락스 메디테라네이(Haloferax mediterranei), 스트렙토코커스 피오게네스, 아나바에나(Anabaena) 및 마이코박테리움 튜베르큘로시스(Mycobacterium tuberculosis)에서 확인되었다(문헌[Groenen et al., Mol. Microbiol., 10:1057-1065 [1993]]; 문헌[Hoe et al., Emerg. Infect. Dis., 5:254-263 [1999]]; 문헌[Masepohl et al., Biochim. Biophys. Acta 1307:26-30 [1996]]; 및 문헌[Mojica et al., Mol. Microbiol., 17:85-93 [1995]] 참조). CRISPR 유전자좌는 전형적으로 SRSR(규칙적으로 산재된 짧은 반복부(short regularly spaced repeats))로 명명된 반복부의 구조가 다른 SSR과 상이하다(문헌[Janssen et al., OMICS J. Integ. Biol., 6:23-33 [2002]]; 및 문헌[Mojica et al., Mol. Microbiol., 36:244-246 [2000]]). 일반적으로, 반복부는 실질적으로 고정된 길이를 갖는 독특한 개재 서열에 의해 규칙적으로 산재된 클러스터에 존재하는 짧은 요소이다(상기 문헌[Mojica et al., [2000]]). 반복 서열이 균주들 간에 고도로 보존되어 있지만, 산재된 반복부의 수와 스페이서 영역의 서열은 전형적으로 균주마다 상이하다(문헌[van Embden et al., J. Bacteriol., 182:2393-2401 [2000]]). CRISPR 유전자좌는 아에로피룸(Aeropyrum), 피로바쿨룸(Pyrobaculum), 술폴로부스(Sulfolobus), 아캐오글로부스(Archaeoglobus), 할로카르쿨라(Halocarcula), 메타노박테리움(Methanobacterium), 메타노코커스(Methanococcus), 메타노사르시나(Methanosarcina), 메타노피러스(Methanopyrus), 피로코커스(Pyrococcus), 피크로필러스(Picrophilus), 써모플라스마(Thermoplasma), 코리네박테리움(Corynebacterium), 마이코박테리움(Mycobacterium), 스트렙토마이세스(Streptomyces), 아퀴펙스(Aquifex), 포르피로모나스(Porphyromonas), 클로로비움(Chlorobium), 써머스(Thermus), 바실러스(Bacillus), 리스테리아(Listeria), 스타필로코커스(Staphylococcus), 클로스트리디움(Clostridium), 써모아나에로박터(Thermoanaerobacter), 마이코플라스마(Mycoplasma), 푸소박테리움(Fusobacterium), 아자쿠스(Azarcus), 크로모박테리움(Chromobacterium), 네이세리아(Neisseria), 니트로소모나스(Nitrosomonas), 데설포비브리오(Desulfovibrio), 게오박터(Geobacter), 믹소코커스(Myxococcus), 캄필로박터(Campylobacter), 볼리넬라(Wolinella), 아시네토박터(Acinetobacter), 에르위니아(Erwinia), 에스케리키아, 레지오넬라(Legionella), 메틸로코커스(Methylococcus), 파스퇴렐라(Pasteurella), 포토박테리움(Photobacterium), 살모넬라(Salmonella), 잔토모나스(Xanthomonas), 예르시니아(Yersinia), 트레포네마(Treponema) 및 써모토가(Thermotoga)를 포함하나 이들에 한정되지 않는 40개 초과의 원핵생물에서 확인되었다(예를 들어, 문헌[Jansen et al., Mol. Microbiol., 43:1565-1575 [2002]]; 및 문헌[Mojica et al., [2005]] 참조).
일반적으로, "CRISPR 시스템"은 집합적으로 Cas 유전자를 인코딩하는 서열, tracr(트랜스-활성화 CRISPR) 서열(예를 들어, tracrRNA 또는 활성 부분 tracrRNA), tracr-메이트 서열(내인성 CRISPR 시스템의 맥락에서 "직접 반복부" 및 tracrRNA-가공 부분 직접 반복부 포함), 가이드 서열(내인성 CRISPR 시스템의 맥락에서 "스페이서"로도 지칭) 또는 CRISPR 유전자좌로부터의 기타 서열 및 전사물을 포함하는 CRISPR-관련("Cas") 유전자의 발현에 수반되거나, 그의 활성을 유도하는 전사물 및 다른 요소를 지칭한다. 일부 구현예에서, CRISPR 시스템의 하나 이상의 요소는 I형, II형 또는 III형 CRISPR 시스템으로부터 유래된다. 일부 구현예에서, CRISPR 시스템의 하나 이상의 요소는 내인성 CRISPR 시스템을 포함하는 특정 유기체, 예를 들어, 스트렙토코커스 피오게네스로부터 유래된다. 일반적으로, CRISPR 시스템은 표적 서열의 부위에서 CRISPR 복합체의 형성을 증진시키는 요소(내인성 CRISPR 시스템의 맥락에서 프로토스페이서로도 지칭)를 특징으로 한다. CRISPR 복합체의 형성의 맥락에서, "표적 서열"은 가이드 서열이 상보성을 갖도록 설계된 서열을 지칭하며, 여기서, 표적 서열과 가이드 서열 간의 혼성화는 CRISPR 복합체의 형성을 증진시킨다. 본질적으로 완전한 상보성이 필요하지 않지만, 혼성화를 야기하고, CRISPR 복합체의 형성을 증진시키는 충분한 상보성이 존재한다. 표적 서열은 임의의 폴리뉴클레오티드, 예를 들어, DNA 또는 RNA 폴리뉴클레오티드를 포함할 수 있다. 일부 구현예에서, 표적 서열은 세포의 핵 또는 세포질 내에 위치한다. 일부 구현예에서, 표적 서열은 진핵 세포의 세포기관, 예를 들어, 미토콘드리아 또는 엽록체 내에 존재할 수 있다. 표적 서열을 포함하는 표적화된 유전자좌로의 재조합을 위해 사용될 수 있는 서열 또는 주형은 "교정 주형" 또는 "교정 폴리뉴클레오티드" 또는 "교정 서열"로 지칭된다. 본 발명의 양태에서, 외인성 주형 폴리뉴클레오티드는 교정 주형으로 지칭될 수 있다. 본 발명의 일 양태에서, 재조합은 상동성 재조합이다.
전형적으로, 내인성 CRISPR 시스템의 맥락에서, CRISPR 복합체(표적 서열에 혼성화되고, 하나 이상의 Cas 단백질과 복합체화되는 가이드 서열을 포함)의 형성은 표적 서열 내의 또는 그 근처의(예를 들어, 그로부터 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 20, 50개 이상의 염기쌍 내의) 하나의 또는 둘 모두의 가닥의 절단을 야기한다. 이론에 구속되지 않으면서, 야생형 tracr 서열의 전부 또는 그의 일부(예를 들어, 야생형 tracr 서열의 약 20, 26, 32, 45, 48, 54, 63, 67, 85개 이상의 뉴클레오티드)를 포함하거나 그로 이루어질 수 있는 tracr 서열은 또한, 가이드 서열에 작동가능하게 연결된 tracr 메이트 서열의 전부 또는 일부로의 tracr 서열의 적어도 일부분에 따른 혼성화에 의해서와 같이 CRISPR 복합체의 일부를 형성할 수 있다. 일부 구현예에서, tracr 서열은 혼성화하고, CRISPR 복합체의 형성에 참여하기에 충분한, tracr 메이트 서열에 대한 상보성을 갖는다. 표적 서열과 마찬가지로, 완전한 상보성이 필요하지 않지만, 작용성이기에 충분한 상보성이 존재하는 것으로 여겨진다. 일부 구현예에서, tracr 서열은 최적으로 정렬되는 경우 tracr 메이트 서열의 길이를 따라 적어도 50%, 60%, 70%, 80%, 90%, 95% 또는 99%의 서열 상보성을 갖는다. 일부 구현예에서, CRISPR 시스템의 하나 이상의 요소의 발현을 유도하는 하나 이상의 벡터는 CRISPR 시스템의 요소의 발현이 하나 이상의 표적 부위에서 CRISPR 복합체의 형성을 유도하도록 숙주 세포 내로 도입된다. 예를 들어, Cas 효소, tracr-메이트 서열에 연결된 가이드 서열 및 tracr 서열은 각각 개별 벡터 상의 개별 조절 요소에 작동가능하게 연결될 수 있다. 대안적으로, 동일하거나 상이한 조절 요소로부터 발현되는 요소 중 둘 이상은 단일의 벡터에서 조합될 수 있으며, 하나 이상의 추가의 벡터는 제1 벡터에 포함되지 않은 CRISPR 시스템의 임의의 성분을 제공한다. 단일의 벡터에서 조합되는 CRISPR 시스템 요소는 임의의 적절한 배향으로 배열될 수 있으며, 예를 들어, 하나의 요소는 제2 요소에 대하여 5'에(그의 "상류"에) 위치하거나 그에 대하여 3'에(그의 "하류"에) 위치한다. 하나의 요소의 코딩 서열은 제2 요소의 코딩 서열의 동일한 가닥 또는 반대 가닥에 위치할 수 있으며, 동일하거나 반대 방향으로 배향될 수 있다. 일부 구현예에서, 단일의 프로모터는 CRISPR 효소를 인코딩하는 전사물 및 하나 이상의 인트론 서열 내에(예를 들어, 각각이 상이한 인트론 내에, 2개 이상이 적어도 하나의 인트론 내에 또는 전부가 단일의 인트론 내에) 매립된 가이드 서열, tracr 메이트 서열(선택적으로 가이드 서열에 작동가능하게 연결), 및 tracr 서열 중 하나 이상의 발현을 유도한다. 일부 구현예에서, CRISPR 효소, 가이드 서열, tracr 메이트 서열 및 tracr 서열이 동일한 프로모터에 작동가능하게 연결되고, 그로부터 발현된다.
일부 구현예에서, 벡터는 하나 이상의 삽입 부위, 예를 들어, 제한 엔도뉴클레아제 인식 서열("클로닝 부위"로도 지칭)을 포함한다. 일부 구현예에서, 하나 이상의 삽입 부위(예를 들어, 약 1, 2, 3, 4, 5, 6, 7, 8, 9, 10개 이상의 삽입 부위)는 하나 이상의 벡터의 하나 이상의 서열 요소의 상류 및/또는 하류에 위치한다. 일부 구현예에서, 벡터는 tracr 메이트 서열의 상류에 있고, 선택적으로 tracr 메이트 서열에 작동가능하게 연결된 조절 요소의 하류에 있는 삽입 부위를 포함하여, 삽입 부위로의 가이드 서열의 삽입 후에, 그리고 발현 시에, 가이드 서열이 진핵 세포 내의 표적 서열로의 CRISPR 복합체의 서열-특이적 결합을 유도하게 한다. 일부 구현예에서, 벡터는 2개 이상의 삽입 부위를 포함하며, 각각의 삽입 부위는 2개의 tracr 메이트 서열 사이에 위치하여, 각 부위에서 가이드 서열의 삽입을 가능하게 한다. 이러한 배열에서, 2개 이상의 가이드 서열은 단일의 가이드 서열의 2개 이상의 카피, 2개 이상의 상이한 가이드 서열 또는 이들의 조합을 포함할 수 있다. 다수의 상이한 가이드 서열이 사용되는 경우, 단일의 발현 작제물을 사용하여 세포 내의 다수의 상이한 상응하는 표적 서열에 CRISPR 활성을 표적화할 수 있다. 예를 들어, 단일의 벡터는 약 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 15, 20개 이상의 가이드 서열을 포함할 수 있다. 일부 구현예에서, 약 1, 2, 3, 4, 5, 6, 7, 8, 9, 10개 이상의 이러한 가이드-서열-함유 벡터가 제공될 수 있으며, 선택적으로 세포로 전달될 수 있다.
일부 구현예에서, 벡터는 CRISPR 효소, 예를 들어, Cas 단백질을 인코딩하는 효소-코딩 서열에 작동가능하게 연결된 조절 요소를 포함한다. Cas 단백질의 비제한적인 예는 Cas1, Cas1B, Cas2, Cas3, Cas4, Cas5, Cas6, Cas7, Cas8, Cas9(Csn1 및 Csx12로도 알려짐), Cas10, Csy1, Csy2, Csy3, Cse1, Cse2, Csc1, Csc2, Csa5, Csn2, Csm2, Csm3, Csm4, Csm5, Csm6, Cmr1, Cmr3, Cmr4, Cmr5, Cmr6, Csb1, Csb2, Csb3, Csx17, Csx14, Csx10, Csx16, CsaX, Csx3, Csx1, Csx15, Csf1, Csf2, Csf3, Csf4, 그의 상동체 또는 그의 변형된 버전을 포함한다. 이들 효소가 알려져 있으며; 예를 들어, 스트렙토코커스 피오게네스 Cas9 단백질의 아미노산 서열은 수탁 번호 Q99ZW2 하에 스위스프로트(SwissProt) 데이터베이스에서 관찰될 수 있다. 일부 구현예에서, 비변형 CRISPR 효소, 예를 들어, Cas9는 DNA 절단 활성을 갖는다. 일부 구현예에서, CRISPR 효소는 Cas9이며, 스트렙토코커스 피오게네스 또는 스트렙토코커스 뉴모니애로부터의 Cas9일 수 있다. 일부 구현예에서, CRISPR 효소는 표적 서열 내 및/또는 표적 서열의 상보물 내에서와 같은 표적 서열의 위치에서 1개 또는 2개의 가닥의 절단을 유도한다. 일부 구현예에서, CRISPR 효소는 표적 서열의 처음 또는 마지막 뉴클레오티드로부터 약 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 15, 20, 25, 50, 100, 200, 500개 이상의 염기쌍에서 1개 또는 2개의 가닥의 절단을 유도한다. 일부 구현예에서, 벡터는 상응하는 야생형 효소에 대하여 돌연변이되어, 돌연변이된 CRISPR 효소에 표적 서열을 함유하는 표적 폴리뉴클레오티드의 1개 또는 2개 모두의 가닥의 절단 능력이 결여되게 한 CRISPR 효소를 인코딩한다. 예를 들어, 스트렙토코커스 피오게네스로부터의 Cas9의 RuvC I 촉매 도메인 내에서의 아스파르트산에서 알라닌으로의 치환(D10A)은 Cas9를 둘 모두의 가닥을 절단하는 뉴클레아제에서 닉카아제(단일 가닥 절단)로 전환시킨다. Cas9가 닉카아제가 되게 하는 돌연변이의 다른 예는 제한 없이, H840A, N854A 및 N863A를 포함한다. 일부 구현예에서, Cas9 닉카아제는 가이드 서열(들), 예를 들어, 각각 DNA 표적의 센스 및 안티센스 가닥을 표적화하는 2개의 가이드 서열과 병용하여 사용될 수 있다. 이러한 조합은 둘 모두의 가닥에 닉(nick)이 생기게 하고, NHEJ를 유도하는데 사용되게 한다. 본 발명자들은 돌연변이유발 NHEJ의 유도에서 2개의 닉카아제 표적(즉, DNA의 동일한 위치에, 그러나, 상이한 가닥에 표적화된 sgRNA)의 효능을 입증하였다(데이터 미도시). 단일의 닉카아제(단일의 sgRNA가 있는 Cas9-D10A)는 NHEJ를 유도하고, 삽입-결실을 생성할 수 없지만, 본 발명자들은 이중 닉카아제(Cas9-D10A 및 동일한 위치에서 상이한 가닥에 표적화된 2개의 sgRNA)가 인간 배아 줄기 세포(hESC)에서 그럴 수 있음을 보였다. 효율은 hESC에서 뉴클레아제(즉, D10 돌연변이가 없는 보통의 Cas9)의 약 50%이다.
추가의 예로서, Cas9의 2개 이상의 촉매 도메인(RuvC I, RuvC II 및 RuvC III)을 돌연변이시켜, 모든 DNA 절단 활성이 실질적으로 결여된 돌연변이된 Cas9를 생성할 수 있다. 일부 구현예에서, D10A 돌연변이를 H840A, N854A 또는 N863A 돌연변이 중 하나 이상과 조합하여, 모든 DNA 절단 활성이 실질적으로 결여된 Cas9 효소를 생성한다. 일부 구현예에서, CRISPR 효소는 돌연변이된 효소의 DNA 절단 활성이 비-돌연변이 형태에 대하여 약 25%, 10%, 5%, 1%, 0.1%, 0.01% 이하인 경우 모든 DNA 절단 활성이 실질적으로 결여된 것으로 여겨진다. 다른 돌연변이가 유용할 수 있으며; 여기서, Cas9 또는 다른 CRISPR 효소는 스트렙토코커스 피오게네스 이외의 종으로부터의 것이며, 유사한 효과를 달성하기 위하여 상응하는 아미노산의 돌연변이가 이루어질 수 있다.
일부 구현예에서, CRISPR 효소를 인코딩하는 효소 코딩 서열은 특정 세포, 예를 들어, 진핵 세포에서의 발현을 위해 코돈 최적화된다. 진핵 세포는 인간, 마우스, 랫트, 토끼, 개 또는 비인간 영장류를 포함하나 이들에 한정되지 않는 특정 유기체, 예를 들어, 포유동물의 것이거나 그로부터 유래될 수 있다. 일반적으로, 코돈 최적화는 고유 서열의 적어도 하나의 코돈(예를 들어, 약 1, 2, 3, 4, 5, 10, 15, 20, 25, 50개 이상의 코돈)을 숙주 세포의 유전자에 더욱 빈번하게 또는 가장 빈번하게 사용되는 코돈으로 대체하면서, 고유 아미노산 서열을 유지함으로써 대상 숙주 세포에서의 발현의 증진을 위해 핵산 서열을 변형시키는 과정을 지칭한다. 다양한 종은 특정 아미노산의 특정 코돈에 대한 특정 편향을 나타낸다. 코돈 편향(유기체 간의 코돈 사용의 차이)은 종종 전령 RNA(mRNA)의 번역의 효율과 상호관련되며, 이는 차례로, 특히, 번역되는 코돈의 특성 및 특정 운반 RNA(tRNA) 분자의 이용가능성에 좌우되는 것으로 여겨진다. 세포에서의 선택된 tRNA의 우세는 일반적으로 펩티드 합성에 가장 빈번하게 사용되는 코돈을 반영하는 것이다. 따라서, 유전자는 코돈 최적화에 기초하여 주어진 유기체에서의 최적의 유전자 발현을 위해 맞춤화될 수 있다. 코돈 사용 표는 예를 들어, "코돈 사용 데이터베이스"에서 용이하게 이용가능하며, 이들 표는 다수의 방식으로 적합하게 될 수 있다. 문헌[Nakamura, Y., et al. "Codon usage tabulated from the international DNA sequence databases: status for the year 2000" Nucl. Acids Res. 28:292 (2000)]을 참조한다. 특정 숙주 세포에서의 발현을 위해 특정 서열을 코돈 최적화시키는 컴퓨터 알고리즘도 또한 이용가능하며, 예를 들어, 진 포르지(Gene Forge)(압타젠(Aptagen); 미국 펜실베니아주 야코부스)도 또한 이용가능하다. 일부 구현예에서, CRISPR 효소를 인코딩하는 서열 내의 하나 이상의 코돈(예를 들어, 1, 2, 3, 4, 5, 10, 15, 20, 25, 50개 이상 또는 모든 코돈)은 특정 아미노산에 대하여 가장 빈번하게 사용되는 코돈에 상응한다.
일부 구현예에서, 벡터는 하나 이상의 핵 국소화 서열(NLS), 예를 들어, 약 1, 2, 3, 4, 5, 6, 7, 8, 9, 10개 이상의 NLS를 포함하는 CRISPR 효소를 인코딩한다. 일부 구현예에서, CRISPR 효소는 아미노-말단에 또는 그 근처에 약 1, 2, 3, 4, 5, 6, 7, 8, 9, 10개 이상의 NLS, 카르복시-말단에 또는 그 근처에 약 1, 2, 3, 4, 5, 6, 7, 8, 9, 10개 이상의 NLS, 또는 이들의 조합(예를 들어, 아미노 말단에 하나 이상의 NLS 및 카르복시 말단에 하나 이상의 NLS)을 포함한다. 1개 초과의 NLS가 존재하는 경우, 각각은 단일의 NLS가 1개 초과의 카피로 존재하고/거나 1개 이상의 카피로 존재하는 하나 이상의 다른 NLS와 함께 존재할 수 있도록 다른 것들로부터 독립적으로 선택될 수 있다. 본 발명의 바람직한 구현예에서, CRISPR 효소는 최대 6개의 NLS를 포함한다. 일부 구현예에서, NLS는 NLS의 가장 가까운 아미노산이 N- 또는 C-말단으로부터 폴리펩티드 쇄를 따라 약 1, 2, 3, 4, 5, 10, 15, 20, 25, 30, 40, 50개 이상의 아미노산 내에 존재하는 경우 N- 또는 C-말단 근처에 있는 것으로 여겨진다. 전형적으로, NLS는 단백질 표면에 노출된 양으로 하전된 라이신 또는 아르기닌이 있는 하나 이상의 짧은 서열로 이루어지나, 다른 유형의 NLS이 알려져 있다. NLS의 비제한적인 예는 하기로부터 유래된 NLS 서열을 포함한다: 아미노산 서열 PKKKRKV를 갖는 SV40 바이러스 대형 T-항원의 NLS; 뉴클레오플라스민(nucleoplasmin)으로부터의 NLS(예를 들어, 서열 KRPAATKKAGQAKKKK를 갖는 뉴클레오플라스민 이분(bipartite) NLS); 아미노산 서열 PAAKRVKLD 또는 RQRRNELKRSP를 갖는 c-myc NLS; 서열 NQSSNFGPMKGGNFGGRSSGPYGGGGQYFAKPRNQGGY를 갖는 hRNPA1 M9 NLS; 임포틴-알파로부터의 IBB 도메인의 서열 RMRIZFKNKGKDTAELRRRRVEVSVELRKAKKDEQILKRRNV; 마이오마(myoma) T 단백질의 서열 VSRKRPRP 및 PPKKARED; 인간 p53의 서열 POPKKKPL; 마우스 c-abl IV의 서열 SALIKKKKKMAP; 인플루엔자 바이러스 NS1의 서열 DRLRR 및 PKQKKRK; 간염 바이러스 델타 항원의 서열 RKLKKKIKKL; 마우스 Mx1 단백질의 서열 REKKKFLKRR; 인간 폴리(ADP-리보스) 중합효소의 서열 KRKGDEVDGVDEVAKKKSKK; 및 스테로이드 호르몬 수용체(인간) 글루코코르티코이드의 서열 RKCLQAGMNLEARKTKK.
일반적으로, 하나 이상의 NLS는 진핵 세포의 핵에서 검출가능한 양의 CRISPR 효소의 축적을 유도하기에 충분한 세기의 것이다. 일반적으로, 핵 국소화 활성의 세기는 CRISPR 효소 내의 NLS의 수, 사용되는 특정 NLS(들) 또는 이들 인자의 조합으로부터 유래할 수 있다. 핵에서의 축적의 검출은 임의의 적절한 기술에 의해 수행될 수 있다. 예를 들어, 검출가능한 마커는 예를 들어, 핵의 위치를 검출하기 위한 수단(예를 들어, 핵에 특이적인 염색제, 예를 들어, DAPI)과 함께 세포 내의 위치가 가시화될 수 있도록 CRISPR 효소에 융합될 수 있다. 검출가능한 마커의 예는 형광 단백질(예를 들어, 녹색 형광 단백질 또는 GFP; RFP; CFP) 및 에피토프 태그(HA 태그, flag 태그, SNAP 태그)를 포함한다. 또한, 세포 핵을 세포로부터 분리할 수 있으며, 그 다음, 그의 내용물을 단백질을 검출하기 위한 임의의 적절한 과정, 예를 들어, 면역조직화학, 웨스턴 블롯 또는 효소 활성 검정에 의해 분석할 수 있다. 또한, 핵에서의 축적은 예를 들어, CRISPR 효소 또는 복합체에 노출되지 않거나, 하나 이상의 NLS가 결여된 CRISPR 효소에 노출된 대조군과 비교하여, 간접적으로, 예를 들어, CRISPR 복합체 형성의 영향에 대한 검정(예를 들어, 표적 서열에서의 DNA 절단 또는 돌연변이에 대한 검정, 또는 CRISPR 복합체 형성 및/또는 CRISPR 효소 활성에 의해 영향을 받는 변경된 유전자 발현 활성에 대한 검정)에 의해 결정될 수 있다.
일반적으로, 가이드 서열은 표적 서열과 혼성화하고, 표적 서열로의 CRISPR 복합체의 서열-특이적 결합을 유도하기에 충분한, 표적 폴리뉴클레오티드 서열과의 상보성을 갖는 임의의 폴리뉴클레오티드 서열이다. 일부 구현예에서, 가이드 서열과 그의 상응하는 표적 서열 간의 상보성의 정도는 적절한 정렬 알고리즘을 사용하여 최적으로 정렬되는 경우, 약 50%, 60%, 75%, 80%, 85%, 90%, 95%, 97.5%, 99% 이상이다. 최적의 정렬은 서열을 정렬하기에 적절한 임의의 알고리즘의 사용으로 결정될 수 있으며, 그의 비제한적인 예는 스미스-워터만(Smith-Waterman) 알고리즘, 니들만-분쉬(Needleman-Wunsch) 알고리즘, 버로우즈-휠러 트랜스폼(Burrows-Wheeler Transform)에 기초한 알고리즘(예를 들어, 버로우즈 휠러 얼라이너(Burrows Wheeler Aligner)), ClustalW, Clustal X, BLAT, 노보얼라인(Novoalign)(노보크라프트 테크놀로지즈(Novocraft Technologies), ELAND(일루미나(Illumina), 미국 캘리포니아주 샌 디에고), SOAP(soap.genomics.org.cn에서 이용가능) 및 Maq(maq.sourceforge.net에서 이용가능)를 포함한다. 일부 구현예에서, 가이드 서열은 약 5, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 35, 40, 45, 50, 75개 이상의 뉴클레오티드 길이이다. 일부 구현예에서, 가이드 서열은 약 75, 50, 45, 40, 35, 30, 25, 20, 15, 12개 이하의 뉴클레오티드 길이이다. 표적 서열로의 CRISPR 복합체의 서열-특이적 결합을 유도하는 가이드 서열의 능력은 임의의 적절한 검정에 의해 평가될 수 있다. 예를 들어, 시험되는 가이드 서열을 포함하는 CRISPR 복합체를 형성하기에 충분한 CRISPR 시스템의 성분은 예를 들어, CRISPR 서열의 성분을 인코딩하는 벡터로의 트랜스펙션 후에, 예를 들어, 본원에 기술된 바와 같은 서베이어 검정에 의한 표적 서열 내의 우선적인 절단의 평가에 의해서, 상응하는 표적 서열을 갖는 숙주 세포로 제공될 수 있다. 유사하게, 표적 폴리뉴클레오티드 서열의 절단은 표적 서열, 시험되는 가이드 서열 및 시험 가이드 서열과 상이한 대조군 가이드 서열을 포함하는 CRISPR 복합체의 성분을 제공하고, 표적 서열에서 시험 및 대조군 가이드 서열 반응 간의 결합 또는 절단 비율을 비교함으로써 시험관에서 평가될 수 있다. 다른 검정이 가능하며, 당업자에게 떠오를 것이다.
가이드 서열은 임의의 표적 서열을 표적화하도록 선택될 수 있다. 일부 구현예에서, 표적 서열은 세포의 게놈 내의 서열이다. 예시적인 표적 서열은 표적 게놈에서 독특한 것들을 포함한다. 예를 들어, 스트렙토코커스 피오게네스 Cas9에 대하여, 게놈 내의 독특한 표적 서열은 형태 MMMMMMMMNNNNNNNNNNNNXGG의 Cas9 표적 부위를 포함할 수 있으며, 여기서, NNNNNNNNNNNNXGG(N은 A, G, T 또는 C이며; X는 임의의 것일 수 있음)는 게놈 내에 단일의 존재를 갖는다. 게놈 내의 독특한 표적 서열은 형태 MMMMMMMMMNNNNNNNNNNNXGG의 스트렙토코커스 피오게네스 Cas9 표적 부위를 포함할 수 있으며, 여기서, NNNNNNNNNNNXGG(N은 A, G, T 또는 C이며; X는 임의의 것일 수 있음)는 게놈 내에 단일의 존재를 갖는다. 스트렙토코커스 써모필러스 CRISPR1 Cas9에 대하여, 게놈 내의 독특한 표적 서열은 형태 MMMMMMMMNNNNNNNNNNNNXXAGAAW의 Cas9 표적 부위를 포함할 수 있으며, 여기서, NNNNNNNNNNNNXXAGAAW(N은 A, G, T 또는 C이고; X는 임의의 것일 수 있으며; W는 A 또는 T임)는 게놈 내에 단일의 존재를 갖는다. 게놈 내의 독특한 표적 서열은 형태 MMMMMMMMMNNNNNNNNNNNXXAGAAW의 스트렙토코커스 써모필러스 CRISPR1 Cas9 표적 부위를 포함할 수 있으며, 여기서, NNNNNNNNNNNXXAGAAW(N은 A, G, T 또는 C이고; X는 임의의 것일 수 있으며; W는 A 또는 T임)는 게놈 내에 단일의 존재를 갖는다. 스트렙토코커스 피오게네스 Cas9에 대하여, 게놈 내의 독특한 표적 서열은 형태 MMMMMMMMNNNNNNNNNNNNXGGXG의 Cas9 표적 부위를 포함할 수 있으며, 여기서, NNNNNNNNNNNNXGGXG(N은 A, G, T 또는 C이고; X는 임의의 것일 수 있음)는 게놈 내에 단일의 존재를 갖는다. 게놈 내의 독특한 표적 서열은 형태 MMMMMMMMMNNNNNNNNNNNXGGXG의 스트렙토코커스 피오게네스 Cas9 표적 부위를 포함할 수 있으며, 여기서, NNNNNNNNNNNXGGXG(N은 A, G, T 또는 C이고; X는 임의의 것일 수 있음)는 게놈 내에 단일의 존재를 갖는다. 이들 서열 각각에서, "M"은 A, G, T 또는 C일 수 있으며, 서열을 독특한 것으로 확인하는데 고려될 필요는 없다.
일부 구현예에서, 가이드 서열은 가이드 서열 내의 2차 구조의 정도를 감소시키기 위해 선택된다. 2차 구조는 임의의 적절한 폴리뉴클레오티드 폴딩 알고리즘에 의해 결정될 수 있다. 일부 프로그램은 최소 깁스(Gibbs) 자유 에너지의 계산에 기초한다. 이러한 알고리즘의 일 예는 문헌[Zuker and Stiegler (Nucleic Acids Res. 9 (1981), 133-148)]에 기술된 바와 같은 mFold이다. 다른 예시적인 폴딩 알고리즘은 센트로이드 구조 예측 알고리즘(예를 들어, 문헌[A.R. Gruber et al., 2008, Cell 106(1): 23-24]; 및 문헌[PA Carr and GM Church, 2009, Nature Biotechnology 27(12): 1151-62] 참조)을 사용하는 비엔나 대학의 이론 화학 기관에서 개발된 온라인 웹서버 RNAfold이다. 추가의 알고리즘은 본원에 참조로 포함되는 미국 출원 번호 TBA(대리인 사건 번호 44790.11.2022; 브로드 참조번호 BI-2013/004A)에서 찾을 수 있다.
일반적으로, tracr 메이트 서열은 다음 중 하나 이상을 증진시키기에 충분한, tracr 서열과의 상보성을 갖는 임의의 서열을 포함한다: (1) 상응하는 tracr 서열을 함유하는 세포에서 tracr 메이트 서열이 측부 배치된 가이드 서열의 절제; 및 (2) 표적 서열에서의 CRISPR 복합체의 형성으로서, CRISPR 복합체가 tracr 서열에 혼성화되는 tracr 메이트 서열을 포함하는 표적 서열에서의 CRISPR 복합체의 형성. 일반적으로, 상보성의 정도는 2개의 서열 중 더 짧은 서열의 길이에 따른 tracr 메이트 서열과 tracr 서열의 최적의 정렬을 참조한다. 최적의 정렬은 임의의 적절한 정렬 알고리즘에 의해 결정될 수 있으며, tracr 서열 또는 tracr 메이트 서열 중 어느 하나에서의 자가-상보성과 같이 2차 구조를 추가로 설명할 수 있다. 일부 구현예에서, 2개 중 보다 짧은 것의 길이를 따른 tracr 서열과 tracr 메이트 서열 간의 상보성의 정도는 최적으로 정렬되는 경우, 약 25%, 30%, 40%, 50%, 60%, 70%, 80%, 90%, 95%, 97.5%, 99% 이상이다. tracr 서열과 tracr 메이트 서열 간의 최적의 정렬의 예시는 도 12B 및 도 13B에 제공되어 있다. 일부 구현예에서, tracr 서열은 약 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 25, 30, 40, 50개 이상의 뉴클레오티드 길이이다. 일부 구현예에서, tracr 서열 및 tracr 메이트 서열은 2개 간의 혼성화가 헤어핀과 같은 2차 구조를 갖는 전사물을 생성하도록 단일의 전사물 내에 함유된다. 헤어핀 구조에 사용하기에 바람직한 루프 형성 서열은 4개 뉴클레오티드 길이이며, 가장 바람직하게는 서열 GAAA를 갖는다. 그러나, 대안적인 서열과 같이 더 길거나 더 짧은 루프 서열이 사용될 수 있다. 서열은 바람직하게는 뉴클레오티드 트리플렛(예를 들어, AAA) 및 추가의 뉴클레오티드(예를 들어, C 또는 G)를 포함한다. 루프 형성 서열의 예는 CAAA 및 AAAG를 포함한다. 본 발명의 일 구현예에서, 전사물 또는 전사된 폴리뉴클레오티드 서열은 적어도 2개 이상의 헤어핀을 갖는다. 바람직한 구현예에서, 전사물은 2, 3, 4 또는 5개의 헤어핀을 갖는다. 본 발명의 추가의 구현예에서, 전사물은 최대 5개의 헤어핀을 갖는다. 일부 구현예에서, 단일의 전사물은 전사 종결 서열을 더 포함하며; 바람직하게는 이것은 폴리T 서열, 예를 들어, 6개의 T 뉴클레오티드이다. 이러한 헤어핀 구조의 예는 도 13B의 하부에 제공되며, 여기서, 루프의 상류 및 마지막 "N"의 5' 서열의 부분은 tracr 메이트 서열에 상응하며, 루프의 3' 서열의 부분은 tracr 서열에 상응한다. 가이드 서열, tracr 메이트 서열 및 tracr 서열을 포함하는 단일의 폴리뉴클레오티드의 추가의 비제한적인 예는 하기와 같으며(5'에서 3'으로 표기), 여기서, "N"은 가이드 서열의 염기를 나타내고, 소문자의 제1 블록은 tracr 메이트 서열을 나타내며, 소문자의 제2 블록은 tracr 서열을 나타내고, 마지막 폴리-T 서열은 전사 종결자를 나타낸다:

일부 구현예에서, 서열 (1) 내지 (3)은 스트렙토코커스 써모필러스 CRISPR1 유래의 Cas9와 함께 사용된다. 일부 구현예에서, 서열 (4) 내지 (6)은 스트렙토코커스 피오게네스 유래의 Cas9와 함께 사용된다. 일부 구현예에서, tracr 서열은 tracr 메이트 서열을 포함하는 전사물과 별개의 전사물이다(예를 들어, 도 13B의 상부에 예시).
일부 구현예에서, 재조합 주형도 또한 제공된다. 재조합 주형은 개별 벡터에 포함되거나, 개별 폴리뉴클레오티드로서 제공되는 본원에 기술된 바와 같은 다른 벡터의 성분일 수 있다. 일부 구현예에서, 재조합 주형은 상동성 재조합에서, 예를 들어, CRISPR 복합체의 일부로서 CRISPR 효소에 의해 닉이 생기거나 절단되는 표적 서열 내 또는 그 근처에서 주형으로 소용되도록 설계된다. 주형 폴리뉴클레오티드는 임의의 적절한 길이, 예를 들어, 약 10, 15, 20, 25, 50, 75, 100, 150, 200, 500, 1000개 이상의 뉴클레오티드 길이의 것일 수 있다. 일부 구현예에서, 주형 폴리뉴클레오티드는 표적 서열을 포함하는 폴리뉴클레오티드의 부분에 상보적이다. 최적으로 정렬되는 경우, 주형 폴리뉴클레오티드는 표적 서열의 하나 이상의 뉴클레오티드(예를 들어, 약 1, 5, 10, 15, 20, 25, 30, 35, 40, 45, 50, 60, 70, 80, 90, 100개 이상의 뉴클레오티드)와 중첩할 수 있다. 일부 구현예에서, 주형 서열 및 표적 서열을 포함하는 폴리뉴클레오티드가 최적으로 정렬되는 경우, 주형 폴리뉴클레오티드의 가장 가까운 뉴클레오티드는 표적 서열로부터 약 1, 5, 10, 15, 20, 25, 50, 75, 100, 200, 300, 400, 500, 1000, 5000, 10000개 이상의 뉴클레오티드 이내이다.
일부 구현예에서, CRISPR 효소는 하나 이상의 이종 단백질 도메인(예를 들어, CRISPR 효소에 더하여 약 1, 2, 3, 4, 5, 6, 7, 8, 9, 10개 이상의 도메인)을 포함하는 융합 단백질의 부분이다. CRISPR 효소 융합 단백질은 임의의 추가의 단백질 서열 및 선택적으로 임의의 2개 도메인 사이의 링커 서열을 포함할 수 있다. CRISPR 효소에 융합될 수 있는 단백질 도메인의 예는 비제한적으로 에피토프 태그, 리포터 유전자 서열 및 하기의 활성 중 하나 이상을 갖는 단백질 도메인을 포함한다: 메틸라제 활성, 데메틸라제 활성, 전사 활성화 활성, 전사 억제 활성, 전사 방출 인자(transcription release factor) 활성, 히스톤 변형 활성, RNA 절단 활성 및 핵산 결합 활성. 에피토프 태그의 비제한적인 예는 히스티딘(His) 태그, V5 태그, FLAG 태그, 인플루엔자 헤마글루티닌(HA) 태그, Myc 태그, VSV-G 태그 및 티오레독신(Trx) 태그를 포함한다. 리포터 유전자의 예는 글루타티온-S-트랜스퍼라제(GST), 호스라디시(horseradish) 과산화효소(HRP), 클로람페니콜 아세틸트랜스퍼라제(CAT) 베타-갈락토시다제, 베타-글루쿠로니다제, 루시퍼라제, 녹색 형광 단백질(GFP), HcRed, DsRed, 청록색 형광 단백질(CFP), 황색 형광 단백질(YFP) 및 청색 형광 단백질(BFP)을 포함하는 자가형광 단백질을 포함하나 이들에 한정되지 않는다. CRISPR 효소는 DNA 분자에 결합하거나, 말토스 결합 단백질(MBP), S-태그, Lex A DNA 결합 도메인(DBD) 융합체, GAL4 DNA 결합 도메인 융합체 및 단순 포진 바이러스(HSV) BP16 단백질 융합체를 포함하나 이들에 한정되지 않는 다른 세포 분자에 결합하는 단백질 또는 단백질의 단편을 인코딩하는 유전자 서열에 융합될 수 있다. CRISPR 효소를 포함하는 융합 단백질의 부분을 형성할 수 있는 추가의 도메인은 본원에 참조로 포함되는 US20110059502호에 기술되어 있다. 일부 구현예에서, 태그가 부착된 CRISPR 효소를 사용하여 표적 서열의 위치를 확인한다.
일부 양태에서, 본 발명은 하나 이상의 폴리뉴클레오티드, 예를 들어, 본원에 기술된 바와 같은 하나 이상의 벡터, 그의 하나 이상의 전사물 및/또는 그로부터 전사된 하나의 단백질 또는 단백질들을 숙주 세포에 전달하는 단계를 포함한다. 일부 양태에서, 본 발명은 이러한 방법에 의해 생성된 세포, 및 이러한 세포를 포함하거나 이로부터 생성된 유기체(예를 들어, 동물, 식물 또는 진균)를 추가로 제공한다. 일부 구현예에서, 가이드 서열과 조합된(선택적으로 복합체화된) CRISPR 효소는 세포로 전달된다. 통상의 바이러스 및 비-바이러스 기반의 유전자 운반 방법을 사용하여 핵산을 포유동물 세포 또는 표적 조직에 도입할 수 있다. 이러한 방법을 사용하여 CRISPR 시스템의 성분을 인코딩하는 핵산을 배양물 중의 또는 숙주 유기체 내의 세포로 투여할 수 있다. 비-바이러스 벡터 전달 시스템은 DNA 플라스미드, RNA(예를 들어, 본원에 기술된 벡터의 전사물), 네이키드(naked) 핵산 및 전달 비히클, 예를 들어, 리포솜과 복합체화된 핵산을 포함한다. 바이러스 벡터 전달 시스템은 DNA 및 RNA 바이러스를 포함하며, 이는 세포로의 전달 후에 에피솜 또는 통합된 게놈을 갖는다. 유전자 치료법 절차의 개요에 대해서는 문헌[Anderson, Science 256:808-813 (1992)]; 문헌[Nabel & Felgner, TIBTECH 11:211-217 (1993)]; 문헌[Mitani & Caskey, TIBTECH 11:162-166 (1993)]; 문헌[Dillon, TIBTECH 11:167-175 (1993)]; 문헌[Miller, Nature 357:455-460 (1992)]; 문헌[Van Brunt, Biotechnology 6(10):1149-1154 (1988)]; 문헌[Vigne, Restorative Neurology and Neuroscience 8:35-36 (1995)]; 문헌[Kremer & Perricaudet, British Medical Bulletin 51(1):31-44 (1995)]; 문헌[Haddada et al., in Current Topics in Microbiology and Immunology, Doerfler and Boehm (eds) (1995)]; 및 문헌[Yu et al., Gene Therapy 1:13-26 (1994)]을 참조한다.
핵산의 비-바이러스 전달 방법은 리포펙션(lipofection), 뉴클레오펙션(nucleofection), 미세주입, 비올리스틱스(biolistics), 비로좀(virosome), 리포솜, 면역리포솜, 다가양이온 또는 지질:핵산 컨쥬게이트, 네이키드 DNA, 인공 비리온 및 작용제-증진된 DNA의 흡수를 포함한다. 리포펙션은 예를 들어, 미국 특허 제5,049,386호, 제4,946,787호; 및 제4,897,355호에 기술되어 있으며, 리포펙션 시약은 상업적으로 시판된다(예를 들어, 트랜스펙탐(Transfectam)™ 및 리포펙틴(Lipofectin)™). 폴리뉴클레오티드의 효율적인 수용체-인식 리포펙션에 적절한 양이온 및 중성 지질은 펠그너(Felgner)의 WO 91/17424호; WO 91/16024호의 것들을 포함한다. 전달은 세포로(예를 들어, 시험관내 또는 생체외 투여) 또는 표적 조직으로(예를 들어, 생체내 투여) 이루어질 수 있다.
표적화된 리포솜, 예를 들어, 면역지질 복합체를 포함하는 지질:핵산 복합체의 제제는 당업자에게 널리 공지되어 있다(예를 들어, 문헌[Crystal, Science 270:404-410 (1995)]; 문헌[Blaese et al., Cancer Gene Ther. 2:291-297 (1995)]; 문헌[Behr et al., Bioconjugate Chem. 5:382-389 (1994)]; 문헌[Remy et al., Bioconjugate Chem. 5:647-654 (1994)]; 문헌[Gao et al., Gene Therapy 2:710-722 (1995)]; 문헌[Ahmad et al., Cancer Res. 52:4817-4820 (1992)]; 미국 특허 제4,186,183호, 제4,217,344호, 제4,235,871호, 제4,261,975호, 제4,485,054호, 제4,501,728호, 제4,774,085호, 제4,837,028호 및 제4,946,787호 참조).
핵산의 전달을 위한 RNA 또는 DNA 바이러스 기반의 시스템의 사용은 바이러스를 체내의 특정 세포에 표적화하고, 바이러스 페이로드(payload)를 핵에 수송하기 위한 고도로 발달된 과정을 이용한다. 바이러스 벡터를 환자에게 직접 투여하거나(생체내), 그들을 사용하여 시험관내에서 세포를 처리할 수 있으며, 변형된 세포가 선택적으로 환자에게 투여될 수 있다(생체외). 통상의 바이러스 기반의 시스템에는 유전자 운반을 위한 레트로바이러스, 렌티바이러스, 아데노바이러스, 아데노-관련 및 단순 포진 바이러스 벡터가 포함될 수 있다. 레트로바이러스, 렌티바이러스 및 아데노-관련 바이러스 유전자 운반 방법을 사용하여 숙주 게놈으로의 통합이 가능하며, 종종 삽입된 트랜스유전자의 장기간 발현을 야기한다. 또한, 높은 형질도입 효율이 많은 상이한 세포 유형 및 표적 조직에서 관찰되었다.
레트로바이러스의 편향성은 외래 외피 단백질을 혼입시키고, 잠재적 표적 집단의 표적 세포를 증식시킴으로써 변경될 수 있다. 렌티바이러스 벡터는 비-분열 세포에 형질도입할 수 있거나, 그를 감염시킬 수 있으며, 전형적으로 높은 바이러스 역가를 생성하는 레트로바이러스 벡터이다. 따라서, 레트로바이러스 유전자 운반 시스템의 선택은 표적 조직에 따라 달라질 것이다. 레트로바이러스 벡터는 최대 6 내지 10kb의 외래 서열에 대하여 패키징 능력을 갖는 시스-작용성 긴 말단 반복부로 이루어진다. 최소 시스-작용성 LTR은 벡터의 복제 및 패키징에 충분하며, 이는 이어서, 치료적 유전자를 표적 세포로 통합시켜, 영구적인 트랜스유전자 발현을 제공하는데 사용된다. 널리 사용되는 레트로바이러스 벡터는 쥣과 백혈병 바이러스(MuLV), 긴팔원숭이 유인원 백혈병 바이러스(GaLV), 원숭이 면역 결핍 바이러스(SIV), 인간 면역 결핍 바이러스(HIV) 및 그들의 조합에 기초한 것들을 포함한다(예를 들어, 문헌[Buchscher et al., J. Virol. 66:2731-2739 (1992)]; 문헌[Johann et al., J. Virol. 66:1635-1640 (1992)]; 문헌[Sommnerfelt et al., Virol. 176:58-59 (1990)]; 문헌[Wilson et al., J. Virol. 63:2374-2378 (1989)]; 문헌[Miller et al., J. Virol. 65:2220-2224 (1991)]; PCT/US94/05700호 참조). 일시적 발현이 바람직한 출원에서, 아데노바이러스 기반의 시스템이 사용될 수 있다. 아데노바이러스 기반의 벡터는 많은 세포 유형에서 매우 높은 형질도입 효율을 가질 수 있으며, 세포 분열을 필요로 하지 않는다. 이러한 벡터를 사용하여, 높은 역가 및 발현 수준이 수득된다. 이러한 벡터는 비교적 간단한 시스템에서 대량 생성될 수 있다. 예를 들어, 핵산 및 펩티드의 시험관내 생성에서, 그리고 생체내 및 생체외 유전자 치료법 절차를 위하여, 아데노-관련 바이러스("AAV") 벡터를 사용하여, 표적 핵산으로 세포를 형질도입시킬 수도 있다(예를 들어, 문헌[West et al., Virology 160:38-47 (1987)]; 미국 특허 제4,797,368호; WO 93/24641호; 문헌[Kotin, Human Gene Therapy 5:793-801 (1994)]; 문헌[Muzyczka, J. Clin. Invest. 94:1351 (1994)] 참조). 재조합 AAV 벡터의 작제는 미국 특허 제5,173,414호; 문헌[Tratschin et al., Mol. Cell. Biol. 5:3251-3260 (1985)]; 문헌[Tratschin, et al., Mol. Cell. Biol. 4:2072-2081 (1984)]; 문헌[Hermonat & Muzyczka, PNAS 81:6466-6470 (1984)]; 및 문헌[Samulski et al., J. Virol. 63:03822-3828 (1989)]을 포함하는 수많은 간행물에 기술되어 있다.
패키징 세포는 전형적으로 숙주 세포를 감염시킬 수 있는 바이러스 입자를 형성하기 위해 사용된다. 이러한 세포는 아데노바이러스를 패키징하는 293 세포, 레트로바이러스를 패키징하는 ψ2 세포 또는 PA317 세포를 포함한다. 유전자 치료법에 사용되는 바이러스 벡터는 통상적으로 핵산 벡터를 바이러스 입자로 패키징하는 세포주를 생성함으로써 생성된다. 벡터는 전형적으로 패키징 및 이후의 숙주로의 통합에 필요한 최소 바이러스 서열을 함유하며, 다른 바이러스 서열은 발현될 폴리뉴클레오티드(들)에 대한 발현 카세트로 대체된다. 소실 바이러스 기능은 전형적으로 패키징 세포주에 의해 트랜스로 공급된다. 예를 들어, 유전자 치료법에 사용되는 AAV 벡터는 전형적으로 패키징 및 숙주 게놈으로의 통합에 필요한 AAV 게놈 유래의 ITR 서열만을 갖는다. 바이러스 DNA는 다른 AAV 유전자, 즉, rep 및 cap을 인코딩하나 ITR 서열이 결여된 헬퍼 플라스미드를 함유하는 세포주에서 패키징된다. 또한, 세포주는 헬퍼로서 아데노바이러스로 감염될 수 있다. 헬퍼 바이러스는 AAV 벡터의 복제 및 헬퍼 플라스미드로부터 AAV 유전자의 발현을 촉진시킨다. 헬퍼 플라스미드는 ITR 서열의 결여로 인해 충분한 양으로 패키징되지 않는다. 아데노바이러스로의 오염은 예를 들어, 아데노바이러스가 AAV보다 더 민감한 열 처리에 의해 감소될 수 있다. 세포로의 핵산의 전달을 위한 추가의 방법은 당업자에게 공지되어 있다. 예를 들어, 본원에 참조로 포함되는 US20030087817호를 참조한다.
일부 구현예에서, 숙주 세포는 본원에 기술된 하나 이상의 벡터로 일시적으로 또는 비-일시적으로 트랜스펙션된다. 일부 구현예에서, 세포는 그것이 대상체에서 천연적으로 발생한 대로 트랜스펙션된다. 일부 구현예에서, 트랜스펙션되는 세포는 대상체로부터 취해진다. 일부 구현예에서, 세포는 세포주와 같이 대상체로부터 취해진 세포로부터 유래된다. 조직 배양을 위한 매우 다양한 세포주가 당업계에 공지되어 있다. 세포주의 예는 C8161, CCRF-CEM, MOLT, mIMCD-3, NHDF, HeLa-S3, Huh1, Huh4, Huh7, HUVEC, HASMC, HEKn, HEKa, MiaPaCell, Panc1, PC-3, TF1, CTLL-2, C1R, Rat6, CV1, RPTE, A10, T24, J82, A375, ARH-77, Calu1, SW480, SW620, SKOV3, SK-UT, CaCo2, P388D1, SEM-K2, WEHI-231, HB56, TIB55, Jurkat, J45.01, LRMB, Bcl-1, BC-3, IC21, DLD2, Raw264.7, NRK, NRK-52E, MRC5, MEF, Hep G2, HeLa B, HeLa T4, COS, COS-1, COS-6, COS-M6A, BS-C-1 원숭이 신장 상피, BALB/3T3 마우스 배아 섬유아세포, 3T3 Swiss, 3T3-L1, 132-d5 인간 태아 섬유아세포; 10.1 마우스 섬유아세포, 293-T, 3T3, 721, 9L, A2780, A2780ADR, A2780cis, A172, A20, A253, A431, A-549, ALC, B16, B35, BCP-1 세포, BEAS-2B, bEnd.3, BHK-21, BR 293, BxPC3, C3H-10T1/2, C6/36, Cal-27, CHO, CHO-7, CHO-IR, CHO-K1, CHO-K2, CHO-T, CHO Dhfr -/-, COR-L23, COR-L23/CPR, COR-L23/5010, COR-L23/R23, COS-7, COV-434, CML T1, CMT, CT26, D17, DH82, DU145, DuCaP, EL4, EM2, EM3, EMT6/AR1, EMT6/AR10.0, FM3, H1299, H69, HB54, HB55, HCA2, HEK-293, HeLa, Hepa1c1c7, HL-60, HMEC, HT-29, Jurkat, JY 세포, K562 세포, Ku812, KCL22, KG1, KYO1, LNCap, Ma-Mel 1-48, MC-38, MCF-7, MCF-10A, MDA-MB-231, MDA-MB-468, MDA-MB-435, MDCK II, MDCK II, MOR/0.2R, MONO-MAC 6, MTD-1A, MyEnd, NCI-H69/CPR, NCI-H69/LX10, NCI-H69/LX20, NCI-H69/LX4, NIH-3T3, NALM-1, NW-145, OPCN / OPCT 세포주, Peer, PNT-1A / PNT 2, RenCa, RIN-5F, RMA/RMAS, Saos-2 세포, Sf-9, SkBr3, T2, T-47D, T84, THP1 세포주, U373, U87, U937, VCaP, Vero 세포, WM39, WT-49, X63, YAC-1, YAR 및 그의 트랜스제닉 변이형을 포함하나 이들에 한정되지 않는다. 세포주는 당업자에게 공지되어 있는 다양한 공급원으로부터 입수가능하다(예를 들어, 아메리칸 타입 컬쳐 콜렉션(American Type Culture Collection; ATCC)(미국 버지니아주 머내서스 소재) 참조). 일부 구현예에서, 본원에 기술된 하나 이상의 벡터로 트랜스펙션된 세포를 사용하여 하나 이상의 벡터-유래 서열을 포함하는 신규 세포주를 확립한다. 일부 구현예에서, 본원에 기술된 바와 같은 CRISPR 시스템의 성분이 일시적으로 트랜스펙션되고(예를 들어, 하나 이상의 벡터의 일시적 트랜스펙션 또는 RNA로의 트랜스펙션에 의해), CRISPR 복합체의 활성을 통해 변형된 세포를 사용하여, 변형을 포함하나 임의의 다른 외인성 서열이 결여된 세포를 포함하는 신규 세포주를 확립한다. 일부 구현예에서, 일시적으로 또는 비-일시적으로 본원에 기술된 하나 이상의 벡터로 트랜스펙션된 세포 또는 이러한 세포로부터 유래된 세포주가 하나 이상의 시험 화합물의 평가에서 사용된다.
일부 구현예에서, 본원에 기술된 하나 이상의 벡터를 사용하여 비-인간 트랜스제닉 동물 또는 트랜스제닉 식물을 생성한다. 일부 구현예에서, 트랜스제닉 동물은 포유동물, 예를 들어, 마우스, 랫트 또는 토끼이다. 특정 구현예에서, 유기체 또는 대상체는 식물이다. 특정 구현예에서, 유기체 또는 대상체 또는 식물은 조류이다. 트랜스제닉 식물 및 동물의 생성 방법은 당업계에 공지되어 있으며, 일반적으로 본원에 기술된 바와 같은 세포 트랜스펙션 방법으로 시작한다.
일 양태에서, 본 발명은 진핵 세포에서의 표적 폴리뉴클레오티드의 변형 방법을 제공한다. 일부 구현예에서, 상기 방법은 CRISPR 복합체가 표적 폴리뉴클레오티드에 결합하게 하여, 상기 표적 폴리뉴클레오티드의 절단을 초래하여, 표적 폴리뉴클레오티드를 변형시키는 단계를 포함하며, 여기서, CRISPR 복합체는 상기 표적 폴리뉴클레오티드 내의 표적 서열에 혼성화된 가이드 서열과 복합체화된 CRISPR 효소를 포함하고, 상기 가이드 서열은 tracr 메이트 서열에 연결되며, tracr 메이트 서열은 차례로 tracr 서열에 혼성화된다.
일 양태에서, 본 발명은 진핵 세포에서의 표적 폴리뉴클레오티드의 발현의 변경 방법을 제공한다. 일부 구현예에서, 상기 방법은 CRISPR 복합체가 폴리뉴클레오티드에 결합하여, 상기 결합이 상기 폴리뉴클레오티드의 발현 증가 또는 감소를 야기하도록 하는 단계를 포함하며; 여기서, CRISPR 복합체는 상기 폴리뉴클레오티드 내의 표적 서열에 혼성화되는 가이드 서열과 복합체화된 CRISPR 효소를 포함하며, 상기 가이드 서열은 tracr 메이트 서열에 연결되며, tracr 메이트 서열은 차례로 tracr 서열에 혼성화된다.
작물 유전체학의 최근의 진전으로, 효율적이며 비용 효율이 높은 유전자 교정 및 조작을 수행하기 위한 CRISPR-Cas 시스템의 사용 능력은 단일 및 다중 유전자 조작의 신속한 선택과 비교를 가능하게 하여, 향상된 생성 및 증진된 특성을 위해 이러한 게놈을 형질전환시킬 것이다. 이와 관련하여, 다음의 미국 특허 및 간행물을 참조한다: 각각의 모든 내용 및 개시내용이 본원에 참조로 포함되는 미국 특허 제6,603,061호(Agrobacterium-Mediated Plant Transformation Method); 미국 특허 제7,868,149호(Plant Genome Sequences and Uses Thereof) 및 US 2009/0100536호(Transgenic Plants with Enhanced Agronomic Traits). 본 발명의 실시에 있어서, 문헌[Morrell et al "Crop genomics:advances and applications" Nat Rev Genet. 2011 Dec 29;13(2):85-96]의 내용 및 개시내용도 또한 그들 전문이 본원에 참조로 포함된다. 본 발명의 유리한 구현예에서, CRISPR/Cas9 시스템을 사용하여, 미세조류를 조작한다(실시예 15). 따라서, 본원에서 동물 세포에 대한 참고내용은 다르게 명백하지 않은 한, 필요한 부분만 약간 수정하여 식물 세포에도 적용할 수 있다.
일 양태에서, 본 발명은 생체내, 생체외 또는 시험관내에서 이루어질 수 있는 진핵 세포에서의 표적 폴리뉴클레오티드의 변형 방법을 제공한다. 일부 구현예에서, 상기 방법은 인간 또는 비-인간 동물 또는 식물(미세조류 포함)로부터 세포 또는 세포 집단을 샘플링하는 단계 및 세포 또는 세포들을 변형시키는 단계를 포함한다. 배양은 생체외에서 임의의 단계에서 일어날 수 있다. 세포 또는 세포들은 심지어 비-인간 동물 또는 식물(미세조류 포함)로 재도입될 수 있다.
식물에서, 병원체는 종종 숙주-특이적이다. 예를 들어, 푸사리움 옥시스포룸(Fusarium oxysporum) f. sp. 리코페르시시(lycopersici)는 토마토 시듦을 야기하나 오직 토마토만을 공격하고, 푸사리움 옥시스포룸 f. 디안티이 푸키니아 그라미니스(dianthii Puccinia graminis) f. sp. 트리티시(tritici)는 오직 밀만을 공격한다. 식물은 대부분의 병원체에 저항하는 기존의 방어 및 유도된 방어를 갖는다. 식물 세대에 걸친 돌연변이 및 재조합 사건은 유전적 변이를 야기하며, 이는 특히 병원체가 식물보다 더 많은 빈도로 재생되기 때문에, 감수성이 생기게 한다. 식물에서는 비-숙주 저항성이 존재할 수 있는데, 예를 들어 숙주 및 병원체는 양립불가능하다. 또한, 수평 저항성, 예를 들어, 통상적으로 많은 유전자에 의해 제어되는 모든 종류의 병원체에 대한 불완전한 저항성, 및 수직 저항성, 예를 들어, 통상 소수의 유전자에 의해 제어되는 일부 종류의 병원체에 대해서는 완전하지만 다른 종류에 대해서는 그렇지 않은 저항성이 존재할 수 있다. 유전자 대 유전자(Gene-for-Gene) 수준에 있어서, 식물 및 병원체는 함께 진화하며, 하나의 균형의 유전적 변화는 다른 것을 변화시킨다. 따라서, 천연 가변성을 사용하여, 육종자는 수율, 품질, 균일성, 내한성, 저항성에 대해 가장 유용한 유전자를 조합한다. 저항성 유전자의 공급원은 고유 또는 외래 품종, 토종(Heirloom) 품종, 야생 식물 동류 및 유도된 돌연변이, 예를 들어 돌연변이유발 작용제로 식물 물질을 처리하는 것을 포함한다. 본 발명을 사용하여, 식물 육종자에게 돌연변이를 유도하는 신규 도구가 제공된다. 따라서, 당업자는 저항성 유전자 공급원의 게놈을 분석할 수 있으며, 요망되는 특징 또는 특성을 갖는 품종에서 본 발명을 이용하여 이전의 돌연변이유발 작용제보다 더 큰 정밀도로 저항성 유전자의 발생을 유도하여, 이에 따라 식물 육종 프로그램을 가속화시키고 향상시킨다.
일 양태에서, 본 발명은 상기 방법 및 조성물에 개시된 임의의 하나 이상의 요소를 함유하는 키트를 제공한다. 일부 구현예에서, 키트는 벡터 시스템 및 키트의 사용을 위한 지침서를 포함한다. 일부 구현예에서, 벡터 시스템은 (a) tracr 메이트 서열, 및 tracr 메이트 서열의 상류에 가이드 서열을 삽입하기 위한 하나 이상의 삽입 부위에 작동가능하게 연결된 제1 조절 요소로서, 가이드 서열은 발현되는 경우, 진핵 세포 내의 표적 서열로의 CRISPR 복합체의 서열-특이적 결합을 유도하고, CRISPR 복합체는 (1) 표적 서열에 혼성화되는 가이드 서열, 및 (2) tracr 서열에 혼성화되는 tracr 메이트 서열과 복합체화된 CRISPR 효소를 포함하는 제1 조절 요소; 및/또는 (b) 핵 국소화 서열을 포함하는 상기 CRISPR 효소를 인코딩하는 효소-코딩 서열에 작동가능하게 연결된 제2 조절 요소를 포함한다. 요소는 개별적으로 또는 조합하여 제공될 수 있으며, 임의의 적절한 용기, 예를 들어, 바이얼, 병 또는 튜브에 제공될 수 있다. 일부 구현예에서, 키트는 1가지 이상의 언어, 예를 들어, 1가지 초과의 언어의 지침서를 포함한다.
일부 구현예에서, 키트는 본원에 기술된 요소 중 하나 이상을 사용하는 과정에 사용하기 위한 하나 이상의 시약을 포함한다. 시약은 임의의 적절한 용기에 제공될 수 있다. 예를 들어, 키트는 하나 이상의 반응 또는 저장 완충제를 제공할 수 있다. 시약은 특정 검정에 사용가능한 형태 또는 사용 전에 하나 이상의 다른 성분의 첨가를 필요로 하는 형태(예를 들어, 농축물 또는 동결건조 형태)로 제공될 수 있다. 완충제는 탄산나트륨 완충제, 중탄산나트륨 완충제, 붕산염 완충제, 트리스(Tris) 완충제, MOPS 완충제, HEPES 완충제 및 그들의 조합을 포함하나 이들에 한정되지 않는 임의의 완충제일 수 있다. 일부 구현예에서, 완충제는 알칼리성이다. 일부 구현예에서, 완충제는 약 7 내지 약 10의 pH를 갖는다. 일부 구현예에서, 키트는 가이드 서열과 조절 요소를 작동가능하게 연결하도록, 벡터에 삽입하기 위한 가이드 서열에 상응하는 하나 이상의 올리고뉴클레오티드를 포함한다. 일부 구현예에서, 키트는 상동성 재조합 주형 폴리뉴클레오티드를 포함한다.
일 양태에서, 본 발명은 CRISPR 시스템의 하나 이상의 요소의 사용 방법을 제공한다. 본 발명의 CRISPR 복합체는 효율적인 표적 폴리뉴클레오티드의 변형 수단을 제공한다. 본 발명의 CRISPR 복합체는 다수의 세포 유형에서 표적 폴리뉴클레오티드를 변형시키는(예를 들어, 결실시키는, 삽입하는, 전위시키는, 불활성화시키는, 활성화시키는) 것을 포함하는 매우 다양한 유용성을 갖는다. 이와 같이, 본 발명의 CRISPR 복합체는 예를 들어, 유전자 치료법, 약물 스크리닝, 질병 진단 및 예후에서 넓은 스펙트럼의 응용을 갖는다. 예시적인 CRISPR 복합체는 표적 폴리뉴클레오티드 내의 표적 서열에 혼성화되는 가이드 서열과 복합체화되는 CRISPR 효소를 포함한다. 가이드 서열은 tracr 메이트 서열에 연결되며, tracr 메이트 서열은 차례로 tracr 서열에 혼성화된다.
CRISPR 복합체의 표적 폴리뉴클레오티드는 진핵 세포에 대해 내인성이거나 외인성인 임의의 폴리뉴클레오티드일 수 있다. 예를 들어, 표적 폴리뉴클레오티드는 진핵 세포의 핵에 존재하는 폴리뉴클레오티드일 수 있다. 표적 폴리뉴클레오티드는 유전자 산물(예를 들어, 단백질)을 코딩하는 서열 또는 비-코딩 서열(예를 들어, 조절 폴리뉴클레오티드 또는 정크(junk) DNA)일 수 있다. 이론에 구속되지 않으면서, 표적 서열이 PAM(프로토스페이서 인접 모티프); 즉, CRISPR 복합체에 의해 인식되는 짧은 서열과 회합되어야 하는 것으로 여겨진다. PAM에 대한 정밀한 서열 및 길이 요건은 사용되는 CRISPR 효소에 따라 달라지지만, PAM은 전형적으로 프로토스페이서(즉, 표적 서열)에 인접한 2 내지 5개 염기쌍 서열이다. PAM 서열의 예는 하기 실시예 섹션에 제공되어 있으며, 당업자는 주어진 CRISPR 효소와 함께 사용하기 위한 추가의 PAM 서열을 확인할 수 있을 것이다.
CRISPR 복합체의 표적 폴리뉴클레오티드는 모두의 내용이 본원에 참조로 포함되는, 각각 브로드 참조번호 BI-2011/008/WSGR 사건 번호 44063-701.101 및 BI-2011/008/WSGR 사건 번호 44063-701.102를 갖고, 둘 모두 명칭이 SYSTEMS METHODS AND COMPOSITIONS FOR SEQUENCE MANIPULATION이고, 각각 2012년 12월 12일 및 2013년 1월 2일에 출원된 미국 가출원 제61/736,527호 및 제61/748,427호에 열거된 바와 같은 다수의 질병-관련 유전자 및 폴리뉴클레오티드, 및 신호전달 생화학 경로-관련 유전자 및 폴리뉴클레오티드를 포함할 수 있다.
표적 폴리뉴클레오티드의 예는 신호전달 생화학 경로와 관련된 서열, 예를 들어, 신호전달 생화학적 경로-관련 유전자 또는 폴리뉴클레오티드를 포함한다. 표적 폴리뉴클레오티드의 예는 질병 관련 유전자 또는 폴리뉴클레오티드를 포함한다. "질병-관련" 유전자 또는 폴리뉴클레오티드는 질병이 없는 대조군의 조직 또는 세포와 비교하여, 질병-발생 조직으로부터 유래된 세포에서 비정상적인 수준 또는 비정상적인 형태로 전사 또는 번역 산물을 생성하는 임의의 유전자 또는 폴리뉴클레오티드를 지칭한다. 그것은 비정상적으로 높은 수준으로 발현되는 유전자일 수 있으며; 그것은 비정상적으로 낮은 수준으로 발현되는 유전자일 수 있고, 여기서, 변경된 발현은 질병의 발생 및/또는 진행과 관련이 있다. 또한, 질병-관련 유전자는 질병의 병인에 직접적인 원인이 있거나, 그에 원인이 있는 유전자(들)와 연관 불균형이 있는 돌연변이(들) 또는 유전적 변이를 갖는 유전자를 지칭한다. 전사 또는 번역된 산물은 공지된 것이거나 미공지된 것일 수 있으며, 정상 또는 비정상 수준으로 존재할 수 있다.
질병-관련 유전자 및 폴리뉴클레오티드의 예는 맥쿠식-네이선스 유전의학연구소(McKusick-Nathans Institute of Genetic Medicine), 존스 홉킨스 대학(Johns Hopkins University)(미국 메릴랜드주 볼티모어) 및 미국 국립생물공학정보센터(National Center for Biotechnology Information), 국립 의학 도서관(미국 메릴랜드주 베데스다)로부터 이용가능하며, 월드 와이드 웹에서 이용가능하다.
질병-관련 유전자 및 폴리뉴클레오티드의 예는 표 A 및 B에 열거되어 있다. 질병 특이적 정보는 맥쿠식-네이선스 유전의학연구소, 존스 홉킨스 대학(미국 메릴랜드주 볼티모어) 및 미국 국립생물공학정보센터, 국립 의학 도서관(미국 메릴랜드주 베데스다)로부터 이용가능하며, 월드 와이드 웹에서 이용가능하다. 신호전달 생화학 경로-관련 유전자 및 폴리뉴클레오티드의 예는 표 C에 열거되어 있다.
이들 유전자 및 경로의 돌연변이는 기능에 영향을 미치는 부적절한 단백질 또는 부적절한 양의 단백질의 생성을 야기할 수 있다. 유전자, 질병 및 단백질의 추가의 예는 2012년 12월 12일에 출원된 미국 가출원 제61/736,527호 및 2013년 2월 2일에 출원된 제61/748,427호로부터 본원에 참고로 포함된다. 이러한 유전자, 단백질 및 경로는 CRISPR 복합체의 표적 폴리뉴클레오티드일 수 있다.
표 A


표 B:



표 C:













또한, 본 발명의 구현예는 유전자의 녹아웃, 유전자의 증폭 및 DNA 반복부 불안정성 및 신경계 장애와 관련된 특정 돌연변이의 수복에 관한 방법 및 조성물에 관한 것이다(문헌[Robert D. Wells, Tetsuo Ashizawa, Genetic Instabilities and Neurological Diseases, Second Edition, Academic Press, Oct 13, 2011 - Medical]). 연쇄 반복(tandem repeat) 서열의 특정 양태는 20개 초과의 인간 질병의 원인이 되는 것으로 관찰되었다(반복부 불안정성의 새로운 이해: RNA·DNA 하이브리드의 역할. 문헌[McIvor EI, Polak U, Napierala M. RNA Biol. 2010 Sep-Oct;7(5):551-8]). CRISPR-Cas 시스템은 이들 게놈 불안정성의 결함을 교정하도록 이용될 수 있다.
본 발명의 추가의 양태는 라포라 질병(Lafora disease)과 관련이 있는 것으로 확인된 EMP2A 및 EMP2B 유전자의 결함을 교정하기 위하여 CRISPR-Cas 시스템을 사용하는 것에 관한 것이다. 라포라 질병은 청소년기에 간질성 발작으로 시작할 수 있는 진행성 간대성근경련 간질을 특징으로 하는 상염색체 열성 질환이다. 소수의 경우의 질병이 아직 확인되지 않은 유전자의 돌연변이에 의해 유발될 수 있다. 질병은 발작, 근육연축, 보행곤란, 치매 및 결국에는 사망을 야기한다. 질병 진행에 대하여 효율적인 것으로 입증된 치료법이 현재 존재하지 않는다. 또한, 간질과 관련된 다른 유전자 이상은 CRISPR-Cas 시스템에 의해 표적화될 수 있으며, 근본이 되는 유전학은 문헌[Genetics of Epilepsy and Genetic Epilepsies, edited by Giuliano Avanzini, Jeffrey L. Noebels, Mariani Foundation Paediatric Neurology:20; 2009]에 추가로 기술되어 있다.
본 발명의 또 다른 양태에서, CRISPR-Cas 시스템을 사용하여 문헌[Genetic Diseases of the Eye, Second Edition, edited by Elias I. Traboulsi, Oxford University Press, 2012]에 추가로 기술된 몇몇 유전자 돌연변이로부터 야기되는 안구 결함을 교정할 수 있다.
본 발명의 몇몇 추가의 양태는 토픽 세부항목 유전 장애하에 국립보건원의 웹사이트(health.nih.gov/topic/GeneticDisorders의 웹사이트)에 추가로 기술된 매우 다양한 유전 질병과 관련된 결함을 교정하는 것에 관한 것이다. 유전적 뇌 질병은 부신백질이영양증, 뇌들보 무발생, 에카르디 증후군, 알퍼스병, 알츠하이머병, 바르트 증후군, 배튼병, CADASIL, 소뇌변성, 파브리병, 게르스트만 슈투로이슬러 샤잉커 병, 헌팅톤병 및 기타 3중 반복 장애, 라이병, 레슈-니한 증후군, 멘케스 질병, 사립체성 근병증 및 NINDS 거대후두각을 포함할 수 있으나 이들에 한정되지 않는다. 이들 질병은 세부항목 유전 뇌 장애하에 국립보건원의 웹사이트에 추가로 기술되어 있다.
일부 구현예에서, 질환은 신생물일 수 있다. 일부 구현예에서, 질환이 신생물인 경우, 표적화될 유전자는 표 A에 열거된 것들 중 임의의 것이다(이러한 경우에, PTEN 등). 일부 구현예에서, 질환은 연령-관련 황반 변성일 수 있다. 일부 구현예에서, 질환은 정신분열 장애일 수 있다. 일부 구현예에서, 질환은 트리뉴클레오티드 반복 장애일 수 있다. 일부 구현예에서, 질환은 유약 X 증후군일 수 있다. 일부 구현예에서, 질환은 세크레타제 관련 장애일 수 있다. 일부 구현예에서, 질환은 프리온-관련 장애일 수 있다. 일부 구현예에서, 질환은 ALS일 수 있다. 일부 구현예에서, 질환은 약물 중독일 수 있다. 일부 구현예에서, 질환은 자폐증일 수 있다. 일부 구현예에서, 질환은 알츠하이머병일 수 있다. 일부 구현예에서, 질환은 염증일 수 있다. 일부 구현예에서, 질환은 파킨슨병일 수 있다.
파킨슨병과 관련된 단백질의 예는 α-시누클레인, DJ-1, LRRK2, PINK1, Parkin, UCHL1, 신필린(Synphilin)-1 및 NURR1을 포함하나 이들에 한정되지 않는다.
중독 관련 단백질의 예는 예를 들어, ABAT를 포함할 수 있다.
염증-관련 단백질의 예는 예를 들어, Ccr2 유전자에 의해 인코딩된 단핵구 화학주성 단백질-1(MCP1), Ccr5 유전자에 의해 인코딩된 C-C 케모카인 수용체 5형(CCR5), Fcgr2b 유전자에 의해 인코딩된 IgG 수용체 IIB(FCGR2b, CD32로도 명명) 또는 Fcer1g 유전자에 의해 인코딩된 Fc 엡실론(epsilon) R1g(FCER1g) 단백질을 포함할 수 있다.
심혈관 질병 관련 단백질의 예는 예를 들어, IL1B(인터류킨 1, 베타), XDH(잔틴 데하이드로게나제), TP53(종양 단백질 p53), PTGIS(프로스타글란딘 I2(프로스타사이클린(prostacyclin)) 신타제), MB(미오글로빈), IL4(인터류킨 4), ANGPT1(안지오포이에틴 1), ABCG8(ATP-결합 카세트, 하위-과 G(WHITE), 구성원 8) 또는 CTSK(카텝신 K)를 포함할 수 있다.
알츠하이머병 관련 단백질의 예는 예를 들어, VLDLR 유전자에 의해 인코딩되는 극저밀도 리포단백질 수용체 단백질(VLDLR), UBA1 유전자에 의해 인코딩되는 유비퀴틴-유사 변형 활성화 효소(UBA1) 또는 UBA3 유전자에 의해 인코딩되는 NEDD8-활성화 효소 E1 촉매 서브유닛 단백질(UBE1C)을 포함할 수 있다.
자폐 스펙트럼 장애와 관련된 단백질의 예는 예를 들어, BZRAP1 유전자에 의해 인코딩되는 벤조디아자핀 수용체(주변) 관련 단백질 1(BZRAP1), AFF2 유전자(MFR2로도 명명)에 의해 인코딩되는 AF4/FMR2 과 구성원 2 단백질(AFF2), FXR1 유전자에 의해 인코딩되는 유약 X 정신 지체 상염색체 상동체 1 단백질(FXR1) 또는 FXR2 유전자에 의해 인코딩되는 유약 X 정신 지체 상염색체 상동체 2 단백질(FXR2)을 포함할 수 있다.
황반 변성과 관련된 단백질의 예는 예를 들어, ABCR 유전자에 의해 인코딩되는 ATP-결합 카세트, 하위과 A(ABC1) 구성원 4 단백질(ABCA4), APOE 유전자에 의해 인코딩되는 아포리포단백질 E 단백질(APOE) 또는 CCL2 유전자에 의해 인코딩되는 케모카인(C-C 모티프) 리간드 2 단백질(CCL2)을 포함할 수 있다.
정신분열증 관련 단백질의 예는 NRG1, ErbB4, CPLX1, TPH1, TPH2, NRXN1, GSK3A, BDNF, DISC1, GSK3B 및 그들의 조합을 포함할 수 있다.
종양 저해에 수반되는 단백질의 예는 예를 들어, ATM(돌연변이된 혈관확장성 운동실조증), ATR(혈관확장성 운동실조증 및 Rad3 관련), EGFR(상피 성장 인자 수용체), ERBB2(v-erb-b2 적혈모구성 백혈병 바이러스 암유전자 상동체 2), ERBB3(v-erb-b2 적혈모구성 백혈병 바이러스 암유전자 상동체 3), ERBB4(v-erb-b2 적혈모구성 백혈병 바이러스 암유전자 상동체 4), Notch 1, Notch2, Notch 3 또는 Notch 4를 포함할 수 있다.
세크레타제 장애와 관련된 단백질의 예는 예를 들어, PSENEN(프레세닐린 인핸서 2 상동체(C. 엘레간스(C. elegans)), CTSB(카텝신 B), PSEN1(프레세닐린 1), APP(아밀로이드 베타(A4) 전구체 단백질), APH1B(앞인두 결함 1 상동체 B(C. 엘레간스)), PSEN2(프레세닐린 2(알츠하이머병 4)) 또는 BACE1(베타-부위 APP-절단 효소 1)을 포함할 수 있다.
근위축성 측삭 경화증과 관련된 단백질의 예는 SOD1(슈퍼옥시드 디스뮤타제(dismutase) 1), ALS2(근위축성 측삭 경화증 2), FUS(육종에서 융합), TARDBP(TAR DNA 결합 단백질), VAGFA(혈관 내피 성장 인자 A), VAGFB(혈관 내피 성장 인자 B) 및 VAGFC(혈관 내피 성장 인자 C) 및 그들의 임의의 조합을 포함할 수 있다.
프리온 질병과 관련된 단백질의 예는 SOD1(슈퍼옥시드 디스뮤타제 1), ALS2(근위축성 측삭 경화증 2), FUS(육종에서 융합), TARDBP(TAR DNA 결합 단백질), VAGFA(혈관 내피 성장 인자 A), VAGFB(혈관 내피 성장 인자 B) 및 VAGFC(혈관 내피 성장 인자 C) 및 그들의 임의의 조합을 포함할 수 있다.
프리온 장애에서의 신경변성 질환과 관련된 단백질의 예는 예를 들어, A2M(알파-2-마크로글로불린), AATF(아폽토시스 길항작용 전사 인자), ACPP(전립선 산 포스파타제), ACTA2(액틴 알파 2 평활근 대동맥), ADAM22(ADAM 메탈로펩티다제 도메인), ADORA3(아데노신 A3 수용체) 또는 ADRA1D(알파-1D 아드레노수용체에 대한 알파-1D 아드레날린 작용성 수용체)를 포함할 수 있다.
면역결핍과 관련된 단백질의 예는 예를 들어, A2M[알파-2-마크로글로불린]; AANAT[아릴알킬아민 N-아세틸트랜스퍼라제]; ABCA1[ATP-결합 카세트, 하위과 A(ABC1), 구성원 1]; ABCA2[ATP-결합 카세트, 하위과 A(ABC1), 구성원 2]; 또는 ABCA3[ATP-결합 카세트, 하위과 A(ABC1), 구성원 3];을 포함할 수 있다.
트리뉴클레오티드 반복 장애와 관련된 단백질의 예는 예를 들어, AR(안드로겐 수용체), FMR1(유약 X 정신 지체 1), HTT(헌팅틴) 또는 DMPK(근긴장성 이영양증-단백질 키나제), FXN(프라탁신(frataxin)), ATXN2(아탁신(ataxin) 2)를 포함한다.
신경전달 장애와 관련된 단백질의 예는 예를 들어, SST(소마토스타틴), NOS1(산화질소 신타제 1(뉴런)), ADRA2A(아드레날린 작용성, 알파-2A-, 수용체), ADRA2C(아드레날린 작용성, 알파-2C-, 수용체), TACR1(타키키닌 수용체 1) 또는 HTR2c(5-하이드록시트립타민(세로토닌) 수용체 2C)를 포함한다.
신경발달-관련 서열의 예는 예를 들어, A2BP1[아탁신 2-결합 단백질 1], AADAT[아미노아디페이트 아미노트랜스퍼라제], AANAT[아릴알킬아민 N-아세틸트랜스퍼라제], ABAT[4-아미노부티레이트 아미노트랜스퍼라제], ABCA1[ATP-결합 카세트, 하위과 A(ABC1), 구성원 1] 또는 ABCA13[ATP-결합 카세트, 하위과 A(ABC1), 구성원 13]을 포함한다.
본 발명의 시스템으로 치료가능한 바람직한 질환의 추가의 예는 에카르디 고우티에레스(Aicardi-Goutieres) 증후군; 알렉산더병; 알란-헌든-두들리(Allan-Herndon-Dudley) 증후군; POLG-관련 장애; 알파-만노시도시스(Alpha-Mannosidosis)(II 및 III형); 알스트스트롬(Alstrom) 증후군; 안젤만(Angelman); 증후군; 혈관확장성 운동실조증; 신경 세로이드 리포푸신증; 베타-지중해빈혈; 양쪽성 시신경위축 및 (영아) 1형 시신경위축; 망막모세포종(양쪽성); 캐너번병; 뇌-눈-얼굴-골격 증후군 1[COFS1]; 뇌힘줄황색종증; 코넬리아디란지 증후군; MAPT-관련 장애; 유전적 프리온 질병; 드라벳 증후군; 조기-발병 가족성 알츠하이머병; 프리드리히 운동실조[FRDA]; 프린스 증후군; 푸코시드 축적증; 후쿠야마형 선천성 근이영양증; 갈락토시알리도시스; 고셰병; 유기 산혈증; 혈구탐식성 림프조직구증; 허친슨-길포오드 조로증 증후군; II형 뮤코리피드증; 유아 유리 시알산 축적병; PLA2G6-관련 신경변성; 제벨 랑쥐-닐슨 증후군; 연접부 수포성 표피박리증; 헌팅톤병; 크라베병(유아); 미토콘드리아 DNA-관련 레이 증후군 및 NARP; 레슈-니한 증후군; LIS1-관련 뇌회결손; 로우 증후군; 단풍시럽뇨병; MECP2 중복 증후군; ATP7A-관련 구리 수송 장애; LAMA2-관련 근이영양증; 아릴설파타제 A 결핍; I, II 또는 III형 점액다당류증; 퍼옥시좀 생물발생 장애; 젤웨거 증후군 스펙트럼; 뇌 철 축적 장애가 있는 신경변성; 산 스핑고미엘리나제 결핍; C형 니만 픽병; 글리신 뇌병증; ARX-관련 장애; 요소 사이클 장애; COL1A1/2-관련 불완전골형성; 미토콘드리아 DNA 결실 증후군; PLP1-관련 장애; 페리(Perry) 증후군; 펠란-맥더미드 증후군; II형 글리코겐 축적병(폼페병)(유아); MAPT-관련 장애; MECP2-관련 장애; 1형 어깨엉덩관절 점상 연골형성이상; 로버츠 증후군; 샌드호프병; 쉰들러병 - 1형; 아데노신 탈아미노효소 결핍; 스미스-렘리-오피츠 증후군; 척수성 근위축; 유아-발병 척수소뇌성 실조증; 헥소사미니다제 A 결핍; 1형 치사성 이형성증; VI형 콜라겐-관련 장애; I형 어셔 증후군; 선천성 근이영양증; 울프-허쉬호른 증후군; 리소좀산 리파제 결핍; 및 색소성 건피증으로부터 선택될 수 있다.
명백한 바와 같이, 본 발명의 시스템이 임의의 대상 폴리뉴클레오티드 서열을 표적화하기 위해 사용될 수 있음이 예상된다. 본 발명의 시스템을 사용하여 유용하게 치료될 수 있는 질환 또는 질병의 일부 예는 상기 표에 포함되어 있으며, 그들 질환과 현재 관련되어 있는 유전자의 예도 또한 거기에 제공된다. 그러나, 예시된 유전자는 배타적인 것은 아니다.
실시예
하기의 실시예는 본 발명의 다양한 구현예를 예시할 목적으로 제공되며, 어떠한 방식으로든 본 발명을 제한하고자 하지 않는다. 본원에 기술된 방법과 함께 본 발명의 실시예는 본원에서 바람직한 구현예를 대표하는 것이며, 예시적이고, 본 발명의 범주에 대한 제한으로 의도되지 않는다. 거기에서의 변화 및 다른 용도는 청구범위의 범주에 의해 정의되는 바와 같은 본 발명의 목적에 포함되며, 당업자에게 수행될 것이다.
실시예
1: 진핵
세포의 핵에서의
CRISPR
복합체 활성
예시적인 II형 CRISPR 시스템은 스트렙토코커스 피오게네스 SF370 유래의 II형 CRISPR 유전자좌이며, 이는 4개 유전자, Cas9, Casl, Cas2 및 Csn1의 클러스터 뿐 아니라 2개의 비-코딩 RNA 요소, tracrRNA, 및 비-반복 서열의 짧은 스트레치(스페이서, 각각 30bp)에 의해 산재된 반복 서열의 특징적 어레이(직접 반복부)를 포함한다. 이러한 시스템에서, 표적화된 DNA 이중-가닥 파단(DSB)은 4개의 순차적 단계로 생성된다(도 2a). 먼저, 2개의 비-코딩 RNA, pre-crRNA 어레이 및 tracrRNA를 CRISPR 유전자좌로부터 전사시킨다. 두번째로, tracrRNA를 pre-crRNA 의 직접 반복부에 혼성화시키고, 이어서 개별 스페이서 서열을 함유하는 성숙 crRNA로 가공한다. 세 번째로, 성숙 crRNA:tracrRNA 복합체는 crRNA의 스페이서 영역과 프로토스페이서 DNA 사이의 헤테로듀플렉스 형성을 통해 Cas9를 프로토스페이서 및 상응하는 PAM으로 구성된 DNA 표적으로 유도한다. 마지막으로, Cas9는 PAM의 상류의 표적 DNA의 절단을 매개하여 프로토스페이서 내에 DSB를 생성한다(도 2a). 이러한 실시예는 진핵 세포의 핵에서 CRISPR 복합체 활성을 유도하기 위해 이러한 RNA-프로그램화가능 뉴클레아제 시스템을 조정하는 예시적인 과정을 기술한다.
세포 배양 및
트랜스펙션
인간 배아 신장(HEK) 세포주 HEK 293FT(라이프 테크놀로지즈(Life Technologies))를 10% 우태아혈청(하이클론(HyClone)), 2mM GlutaMAX(라이프 테크놀로지즈), 100U/㎖ 페니실린 및 100㎍/㎖ 스트렙토마이신이 보충된 둘베코 개질 이글스 배지(DMEM)에서 37℃에서 5% C02 인큐베이션과 함께 유지시켰다. 마우스 neuro2A(N2A) 세포주(ATCC)를 37℃에서 5% C02와 함께, 5% 우태아혈청(하이클론), 2mM GlutaMAX(라이프 테크놀로지즈), 100U/㎖ 페니실린 및 100㎍/㎖ 스트렙토마이신이 보충된 DMEM으로 유지시켰다.
트랜스펙션 1일 전, 웰당 200,000개 세포의 밀도로 HEK 293FT 또는 N2A 세포를 24-웰 플레이트(코닝(Corning))에 씨딩하였다. 세포를 제조사의 권고 프로토콜에 따라 리포펙타민(Lipofectamine) 2000(라이프 테크놀로지즈)을 사용하여 트랜스펙션시켰다. 24-웰 플레이트의 각 웰에 대해 총 800 ng의 플라스미드를 사용하였다.
게놈 변형에 대한 서베이어 검정 및 시퀀싱 분석
HEK 293FT 또는 N2A 세포를 상기 기술한 바와 같이 플라스미드 DNA로 트랜스펙션시켰다. 트랜스펙션 후에, 게놈 DNA 추출 전 72시간 동안 37℃에서 세포를 인큐베이션시켰다. 게놈 DNA를 제조사의 프로토콜에 따라 퀵익스트랙트(QuickExtract) DNA 추출 키트(에피센트레(Epicentre))를 사용하여 추출하였다. 간략하게, 세포를 퀵익스트랙트 용액에 재현탁시키고, 65℃에서 15분 동안, 그리고 98℃에서 10분 동안 인큐베이션시켰다. 추출된 게놈 DNA를 바로 처리하거나 20℃에서 보관하였다.
각 유전자에 대한 CRISPR 표적 부위의 주변의 게놈 영역을 PCR 증폭시키고, 산물을 제조사의 프로토콜에 따라 퀴아퀵 스핀 컬럼(QiaQuick Spin Column)(퀴아젠(Qiagen))을 사용하여 정제하였다. 총 400ng의 정제된 PCR 산물을 2㎕ 10X Taq 중합효소 PCR 완충제(엔자이머틱스(Enzymatics)) 및 초순수와 총 20㎕ 부피로 혼합하고, 재어닐링 과정을 거치게 하여 헤테로듀플렉스가 형성되게 하였다: 95℃에서 10 분, 95℃에서 85℃(-2℃/초로 램핑(ramping)), 85℃에서 25℃(-0.25℃/초), 및 25℃에서 1분 유지. 재어닐링 후, 산물을 제조사의 권고 프로토콜에 따라 서베이어 뉴클레아제 및 서베이어 인핸서 S(트랜스게노믹스(Transgenomics))로 처리하고, 4-20% 노벡스(Novex) TBE 폴리-아크릴아미드 겔(라이프 테크놀로지즈)에서 분석하였다. 겔을 SYBR 골드(Gold) DNA 염색제(라이프 테크놀로지즈)로 30분 동안 염색하고, Gel Doc 겔 영상화 시스템(바이오-라드(Bio-rad))으로 영상화하였다. 정량화는 절단된 DNA의 분율의 척도로서 상대적 밴드 세기를 기반으로 하였다. 도 8은 이러한 서베이어 검정의 개략적 예시를 제공한다.
상동성 재조합의 검출을 위한 제한 단편 길이 다형성 검정
HEK 293FT 및 N2A 세포를 플라스미드 DNA로 트랜스펙션시키고, 37℃에서 72시간 동안 인큐베이션시킨 후 상기 기재한 바와 같이 게놈 DNA를 추출하였다. 표적 게놈 영역을 상동성 재조합(HR) 주형의 상동성 암(arm) 외측의 프라이머를 사용하여 PCR 증폭시켰다. PCR 산물을 1% 아가로오스 겔 상에서 분리하고 MinElute GelExtraction 키트(퀴아젠)를 사용하여 추출하였다. 정제된 산물을 HindIII(퍼멘터스(Fermentas))로 분해시키고 6% 노벡스 TBE 폴리-아크릴아미드 겔(라이프 테크놀로지즈)에서 분석하였다.
RNA 2차 구조 예측 및 분석
센트로이드 구조 예측 알고리즘을 사용하는 비엔나 대학의 이론 화학 기관에서 개발된 온라인 웹서버 RNAfold를 사용하여 RNA 2차 구조 예측을 수행하였다(예를 들어, 문헌[A.R. Gruber et al., 2008, Cell 106(1): 23-24]; 및 문헌[PA Carr and GM Church, 2009, Nature Biotechnology 27(12): 1151-62] 참조).
박테리아 플라스미드 형질전환 간섭 검정
CRISPR 활성에 충분한 스트렙토코커스 피오게네스 CRISPR 유전자좌 1의 요소를 pCRISPR 플라스미드를 사용하여 에스케리키아 콜라이에서 재구성하였다(도 10A에 개략적으로 예시). pCRISPR은 tracrRNA, SpCas9, 및 crRNA 어레이를 유도하는 리더 서열을 함유하였다. 스페이서("가이드 서열"로도 지칭)를 예시된 바와 같이 어닐링된 올리고뉴클레오티드를 사용하여 BsaI 부위 사이에 crRNA 어레이 내로 삽입하였다. 인접 CRISPR 모티프 서열(PAM)과 함께 프로토스페이서("표적 서열"로도 지칭) 서열을 pUC19 내로 삽입시킴으로써 간섭 검정에 사용되는 챌린지(challenge) 플라스미드를 작제하였다(도 10B 참조). 챌린지 플라스미드는 앰피실린 내성을 함유하였다. 도 10C는 간섭 검정의 개략적 표현을 제공한다. pCRISPR 및 적절한 스페이서를 이미 지니고 있는 화학적으로 컴피턴트인 에스케리키아 콜라이 균주를 상응하는 프로토스페이서-PAM 서열을 함유하는 챌린지 플라스미드로 형질전환시켰다. pUC19를 사용하여, 각각의 pCRISPR을 지니는 컴피턴트 균주의 형질전환 효율을 평가하였다. CRISPR 활성은 프로토스페이서를 지니는 pPSP 플라스미드의 절단을 야기하여, 다르게는 프로토스페이서가 결여된 pUC19에 의해 부여되는 앰피실린 내성을 불가능하게 하였다. 도 10D는 도 4c에 예시된 검정에 사용되는 각각의 pCRISPR을 지니는 에스케리키아 콜라이 균주의 컴피턴스를 예시한다.
RNA 정제
HEK 293FT 세포를 상기 언급한 바와 같이 유지시키고 트랜스펙션시켰다. 세포를 트립신처리에 의해 수집한 후 인산 완충 염수(PBS)로 세척하였다. 전체 세포 RNA를 제조사의 프로토콜에 따라 TRI 시약(시그마(Sigma))으로 추출하였다. 추출한 전체 RNA를 나노드롭(Naonodrop)(써모 사이언티픽(Thermo Scientific))을 사용하여 정량화하고 동일 농도로 정규화하였다.
포유류 세포 내의
crRNA
및
tracrRNA
발현의 노던
블롯
분석
RNA를 동일 부피의 2X 로딩 완충제(앰비온(Ambion))와 혼합하고, 5분 동안 95℃로 가열하고, 1분 동안 얼음 상에서 냉각시킨 후, 적어도 30분 동안 겔을 사전-전개시킨 후 8% 변성 폴리아크릴아미드 겔(SequaGel, 내셔널 디아그노스틱스(National Diagnostics)) 상에 로딩하였다. 샘플을 40W 한도에서 1.5시간 동안 전기영동하였다. 그 후, RNA를 실온에서 1.5시간 동안 반-건조 운반 장치(바이오-라드) 내에서 300 mA에서 하이본드(Hybond) N+ 멤브레인(지이 헬쓰케어(GE Healthcare)) 에 옮겼다. RNA를 스트라타진(Stratagene) UV 가교제 스트라타링커(Stratalinker)(스트라타진) 상의 자동가교 버튼을 사용하여 멤브레인에 가교시켰다. 멤브레인을 ULTRAhyb-Oligo 혼성화 완충제(앰비온) 중에서 30분 동안, 42℃에서 회전시키면서 사전-혼성화한 후, 프로브를 첨가하고 밤새 혼성화하였다. 프로브를 IDT에서 주문하고 T4 폴리뉴클레오티드 키나제(뉴 잉글랜드 바이오랩스(New England Biolabs))와 함께 [감마-32P] ATP(퍼킨 엘머(Perkin Elmer))로 표지하였다. 멤브레인을 사전가온된(42℃) 2xSSC, 0.5% SDS로 1분 동안 1회 세척한 후 42℃ 에서 2회 30분 세척하였다. 멤브레인을 1시간 동안 또는 밤새 실온에서 인광체 스크린에 노출시킨 후 포스포르이미저(phosphorimager)(타이푼(Typhoon))로 스캔하였다.
박테리아
CRISPR
시스템
작제
및 평가
tracrRNA, Cas9 및 리더를 포함하는 CRISPR 유전자좌 요소를 깁슨 조립을 위한 측부 배치 상동성 암과 함께, 스트렙토코커스 피오게네스 SF370 게놈 DNA로부터 PCR 증폭시켰다. 2개의 BsaI IIS형 부위를 2개의 직접 반복부 사이에 도입하여, 용이한 스페이서의 삽입을 가능하게 하였다(도 9). PCR 산물을 깁슨 조립 마스터 믹스(NEB)를 사용하여 tet 프로모터의 하류에 EcoRV-분해 pACYC184 내로 클로닝하였다. Csn2의 마지막 50bp를 제외하고 다른 내인성 CRISPR 시스템 요소를 생략하였다. 상보성 오버행을 지니는 스페이서를 인코딩하는 올리고(인테그레이티드 디엔에이 테크놀로지(Integrated DNA Technology))를 BsaI-분해 벡터 pDC000(NEB) 내로 클로닝한 다음, T7 리가제(엔자이머틱스)를 사용하여 라이게이션시켜, pCRISPR 플라스미드를 생성하였다. 양립가능한 오버행(인테그레이티드 디엔에이 테크놀로지)을 지니는 혼성화된 올리고를 BamHI-분해 pUC19 내로 라이게이션시킴으로써 PAM 서열(본원에서 "CRISPR 모티프 서열"로도 지칭)이 있는 스페이서를 함유하는 챌린지 플라스미드를 생성하였다. 모든 작제물에 대한 클로닝을 에스케리키아 콜라이 균주 JM109(자이모 리서치)에서 수행하였다.
pCRISPR을 지니는 세포를 제조사의 지침에 따라 Z-컴피턴트 에스케리키아 콜라이 형질전환 키트 및 완충제 세트(자이모 리서치, T3001)를 사용하여 컴피턴트로 만들었다. 형질전환 검정에서, pCRISPR을 지니는 컴피턴트 세포의 50 ㎕ 분취액을 얼음 위에서 해동시킨 다음, 얼음에서 30분 동안 1 ng의 스페이서 플라스미드 또는 pUC19로 형질전환시킨 다음, 42℃에서 45초 열 충격을 가하고, 2분간 얼음에 두었다. 이후에, 250 ㎕의 SOC(인비트로겐)를 첨가한 다음, 37℃에서 1시간 동안 진탕 인큐베이션을 수행하고, SOC 후 결과물 100 ㎕를 이중 선택 플레이트(12.5 ㎍/㎖ 클로람페니콜, 100 ㎍/㎖ 앰피실린)에 플레이팅하였다. DNA의 cfu/ng을 수득하기 위하여, 총 콜로니 개수에 3을 곱하였다.
포유동물 세포에서의 CRISPR 성분의 발현을 향상시키기 위하여, 스트렙토코커스 피오게네스(S. 피오게네스)의 SF370 유전자좌 1 유래의 2개의 유전자, Cas9(SpCas9) 및 RNase III(SpRNase III)를 코돈-최적화시켰다. 핵 국소화를 용이하게 하기 위하여, 핵 국소화 신호(NLS)를 SpCas9 및 SpRNase III 둘 모두의 아미노(N)- 또는 카르복실(C)-말단에 포함시켰다(도 2b). 또한, 단백질 발현의 가시화를 용이하게 하기 위하여, 형광 단백질 마커도 또한 단백질 둘 모두의 N- 또는 C-말단에 포함시켰다(도 2b). NLS가 N- 및 C-말단 둘 모두에 부착된 SpCas9의 버전(2xNLS-SpCas9)도 또한 생성하였다. NLS-융합 SpCas9 및 SpRNase III를 함유하는 작제물을 293FT 인간 배아 신장(HEK) 세포 내로 트랜스펙션시키고, SpCas9 및 SpRNase III에 대한 NLS의 상대적 위치지정이 그들의 핵 국소화 효율에 영향을 미치는 것으로 관찰되었다. C-말단 NLS는 SpRNase III를 핵에 표적화시키는데 충분하였지만, 단일의 카피의 이들 특정 NLS를 SpCas9의 N- 또는 C-말단 중 어느 하나로 부착하면, 이러한 시스템에서 적당한 핵 국소화를 달성할 수 없었다. 이러한 실시예에서, C-말단 NLS는 뉴클레오플라스민의 것이었으며(KRPAATKKAGQAKKKK), C-말단 NLS는 SV40 대형 T-항원의 것이었다(PKKKRKV). 시험한 SpCas9의 버전 중에, 오직 2xNLS-SpCas9만이 핵 국소화를 나타내었다(도 2b).
스트렙토코커스 피오게네스 SF370의 CRISPR 유전자좌로부터의 tracrRNA은 2개의 전사 시작 부위를 가져, 89-뉴클레오티드(nt) 및 171 nt의 2개의 전사물을 야기하며, 이는 이후에 동일한 75 nt 성숙 tracrRNA로 가공된다. 보다 짧은 89 nt tracrRNA를 포유동물 세포에서의 발현을 위해 선택하였다(도 7b에 나타낸 서베이어 검정의 결과에 의해 결정시 작용성이 있는 도 7a에 예시된 발현 작제물). 전사 시작 부위는 +1로 표시되며, 전사 종결자 및 노던 블롯에 의해 프로빙되는 서열도 또한 표시되어 있다. 가공된 tracrRNA의 발현도 또한 노던 블롯에 의해 확인하였다. 도 7c는 긴 또는 짧은 tracrRNA, 및 SpCas9 및 DR-EMX1(1)-DR을 지니는 U6 발현 작제물이 트랜스펙션된 293FT 세포로부터 추출된 전체 RNA의 노던 블롯 분석의 결과를 보여준다. 좌측 및 우측 패널은 각각 SpRNase III의 부재 또는 존재 하에 트랜스펙션된 293FT 세포로부터의 것이다. U6은 인간 U6 snRNA를 표적화하는 프로브로 블롯팅된 로딩 대조군을 나타낸다. 짧은 tracrRNA 발현 작제물의 트랜스펙션은 풍부한 수준의 tracrRNA의 가공된 형태를 야기한다(약 75 bp). 매우 소량의 긴 tracrRNA가 노던 블롯에서 검출된다.
정밀한 전사 개시를 촉진시키기 위하여 RNA 중합효소 III 기반의 U6 프로모터를 선택하여, tracrRNA의 발현을 유도하였다(도 2c). 유사하게, U6 프로모터 기반의 작제물을 2개의 직접 반복부(DR, 또한 용어 "tracr-메이트 서열"에 포함; 도 2c)가 측부 배치된 단일의 스페이서로 구성된 pre-crRNA 어레이를 발현하도록 발생시켰다. 초기 스페이서를 대뇌 피질의 발생의 주요 유전자인 인간 EMX1 유전자좌 내의 33-염기-쌍(bp) 표적 부위(30-bp 프로토스페이서 + Cas9의 NGG 인식 모티프를 만족시키는 3-bp CRISPR 모티프(PAM) 서열)를 표적화하도록 설계하였다(도 2c).
포유동물 세포에서 CRISPR 시스템(SpCas9, SpRNase III, tracrRNA 및 pre-crRNA)의 이종 발현이 포유동물 염색체의 표적화된 절단을 달성할 수 있는지를 시험하기 위하여, HEK 293FT 세포를 CRISPR 성분의 조합으로 트랜스펙션시켰다. 포유동물 핵에서 DSB가 삽입-결실의 형성을 야기하는 비-상동 말단 연결(NHEJ) 경로에 의해 부분적으로 수복되기 때문에, 서베이어 검정을 사용하여, 표적 EMX1 유전자좌에서 잠재적인 절단 활성을 검출하였다(도 8)(예를 들어, 문헌[Guschin et al., 2010, Methods Mol Biol 649: 247] 참조). 모든 4개의 CRISPR 성분의 동시-트랜스펙션은 프로토스페이서에서 최대 5.0% 절단을 유도할 수 있었다(도 2d 참조). 또한, SpRNase III을 제한 모든 CRISPR 성분의 동시-트랜스펙션에 의해, 프로토스페이서에서 최대 4.7% 삽입-결실이 유도되었으며, 이는 crRNA 성숙을 보조할 수 있는 내인성 포유동물 RNase, 예를 들어, 관련 Dicer 및 Drosha 효소가 존재할 수 있음을 시사한다. 남아 있는 3개 성분 중 임의의 것의 제거에 의해, CRISPR 시스템의 게놈 절단 활성이 없어졌다(도 2d). 표적 유전자좌를 함유하는 앰플리콘(amplicon)의 생거(Sanger) 시퀀싱에 의해, 절단 활성이 입증되었으며: 43개의 시퀀싱된 클론 중에, 5개의 돌연변이된 대립형질(11.6%)이 관찰되었다. 다양한 가이드 서열을 사용하는 유사한 실험에 의해, 29%만큼 높은 삽입-결실 백분율을 생성하였다(도 4 내지 7, 12 및 13 참조). 이들 결과는 포유동물 세포에서의 효율적인 CRISPR-매개의 게놈 변형을 위한 3-성분 시스템을 정의한다. 절단 효율을 최적화시키기 위하여, 본 발명자들은 또한 상이한 아이소형의 tracrRNA가 절단 효율에 영향을 미치는지를 시험하였으며, 이러한 예시적인 시스템에서, 오직 짧은(89-bp) 전사물 형태만이 인간 EMX1 게놈 유전자좌의 절단을 매개할 수 있는 것이 관찰되었다(도 7b).
도 14는 포유동물 세포에서의 crRNA 가공의 추가의 노던 블롯 분석을 제공한다. 도 14A는 2개의 직접 반복부가 측부 배치된 단일의 스페이서(DR-EMX1(1)-DR)에 대한 발현 벡터를 보여주는 개략도를 예시한다. 인간 EMX1 유전자좌 프로토스페이서 1을 표적화하는 30 bp 스페이서(도 6 참조) 및 직접 반복부 서열은 도 14A 아래의 서열에 나타나 있다. 선은 역-상보 서열을 사용하여 EMX1(1) crRNA 검출을 위한 노던 블롯 프로브를 생성한 영역을 나타낸다. 도 14B는 DR-EMX1(1)-DR을 지니는 U6 발현 작제물로 트랜스펙션된 293FT 세포로부터 추출된 전체 RNA의 노던 블롯 분석을 보여준다. 좌측 및 우측 패널은 각각 SpRNase III의 부재 또는 존재 하에 트랜스펙션된 293FT 세포로부터의 것이다. DR-EMX1(1)-DR은 SpCas9 및 짧은 tracrRNA의 존재 하에서만 성숙 crRNA로 처리되었고, SpRNase III의 존재에 따라 달라지지 않았다. 트랜스펙션된 293FT 전체 RNA로부터 검출된 성숙 crRNA는 약 33 bp이며, 스트렙토코커스 피오게네스로부터의 39 내지 42 bp 성숙 crRNA보다 더 짧다. 이들 결과는 CRISPR 시스템이 진핵 세포로 이식될 수 있으며, 내인성 포유동물 표적 폴리뉴클레오티드의 절단을 용이하게 하도록 재프로그램화될 수 있음을 보여준다.
도 2는 이러한 실시예에 기술된 박테리아 CRISPR 시스템을 예시한다. 도 2a는 스트렙토코커스 피오게네스 SF370으로부터의 CRISPR 유전자좌 1 및 이러한 시스템에 의한 제안된 CRISPR-매개의 DNA 절단의 메카니즘을 보여주는 개략도를 예시한다. 직접 반복부-스페이서 어레이로부터 가공된 성숙 crRNA는 Cas9를 상보성 프로토스페이서 및 프로토스페이서-인접 모티프(PAM)로 구성된 게놈 표적에 지향시킨다. 표적-스페이서 염기 쌍형성 시에, Cas9는 표적 DNA에서 이중 가닥 파단을 매개한다. 도 2b는 포유동물 핵으로의 유입을 가능하게 하는 핵 국소화 신호(NLS)가 있는 스트렙토코커스 피오게네스 Cas9(SpCas9) 및 RNase III(SpRNase III)의 조작을 예시한다. 도 2c는 정밀한 전사 개시 및 종결을 촉진하기 위한 구성성 EF1a 프로모터에 의해 유도되는 SpCas9 및 SpRNase III 및 RNA Pol3 프로모터 U6에 의해 유도되는 tracrRNA 및 pre-crRNA 어레이(DR-스페이서-DR)의 포유동물 발현을 예시한다. 만족스러운 PAM 서열이 있는 인간 EMX1 유전자좌로부터의 프로토스페이서는 pre-crRNA 검정에서 스페이서로 사용된다. 도 2d는 SpCas9-매개의 최소 삽입 및 결실을 위한 서베이어 뉴클레아제 검정을 예시한다. SpRNase III, tracrRNA 및 EMX1-표적 스페이서를 지니는 pre-crRNA 어레이의 존재 및 부재 하에 SpCas9를 발현시켰다. 도 2e는 표적 유전자좌와 EMX1-표적화 crRNA 사이의 염기 쌍형성의 개략적 표현, 및 SpCas9 절단 부위에 인접한 마이크로 결실을 보이는 예시적인 크로마토그램을 예시한다. 도 2f는 다양한 마이크로 삽입 및 결실을 보이는 43개의 클론 앰플리콘의 시퀀싱 분석으로부터 확인된 돌연변이된 대립형질을 예시한다. 줄표는 결실된 염기를 나타내며, 비-정렬 또는 미스매치된 염기는 삽입 또는 돌연변이를 나타낸다. 스케일 바(scale bar) = 10 ㎛.
3-성분 시스템을 더욱 단순화시키기 위하여, 키메라 crRNA-tracrRNA 하이브리드 설계를 조정하였으며, 여기서, 성숙 crRNA(가이드 서열 포함)는 스템-루프를 통해 부분 tracrRNA에 융합되어, 천연 crRNA:tracrRNA 듀플렉스를 모방한다(도 3a). 동시-전달 효율을 증가시키기 위하여, 비시스트로닉 발현 벡터를 생성하여, 트랜스펙션된 세포에서 키메라 RNA 및 SpCas9의 동시-발현을 유도하였다(도 3a 및 도 8). 병행하여, 비시스트로닉 벡터를 사용하여 SpCas9와 함께 pre-crRNA(DR-가이드 서열-DR)를 발현하여, 따로 발현되는 tracrRNA와 함께 crRNA로 가공되도록 유도하였다(도 13B 상부 및 하부 비교). 도 9는 hSpCas9가 있는 pre-crRNA 어레이(도 9A) 또는 키메라 crRNA(도 9B에서 가이드 서열 삽입 부위의 하류 및 EF1α 프로모터의 상류에 짧은 선으로 표현)에 대한 비시스트로닉 발현 벡터의 개략적 표현을 제공하며, 다양한 요소의 위치 및 가이드 서열 삽입 점을 보여준다. 도 9B에서 가이드 서열 삽입 부위의 위치 주위의 확대된 서열은 또한 부분 DR 서열(GTTTAGAGCTA) 및 부분 tracrRNA 서열(TAGCAAGTTAAAATAAGGCTAGTCCGTTTTT)을 보여준다. 가이드 서열은 어닐링된 올리고뉴클레오티드를 사용하여 BbsI 부위 사이에 삽입될 수 있다. 올리고뉴클레오티드에 대한 서열 설계는 도 9에서 개략적 표현 밑에 나타나 있으며, 적절한 라이게이션 어댑터가 표기되어 있다. WPRE는 우드척(Woodchuck) 간염 바이러스 전사후 조절 요소를 나타낸다. 키메라 RNA-매개의 절단의 효율을 상기 기술된 동일한 EMX1 유전자좌를 표적화함으로써 시험하였다. 앰플리콘의 서베이어 검정 및 생거 시퀀싱 둘 모두를 사용하여, 본 발명자들은 키메라 RNA 설계가 대략 4.7% 변형률로, 인간 EMX1 유전자좌의 절단을 용이하게 하는 것을 확인하였다(도 4).
인간 EMX1 및 PVALB, 및 마우스 Th 유전자좌 내의 다수의 영역을 표적화하는 키메라 RNA를 설계하여 인간 및 마우스 세포 둘 모두에서 추가의 게놈 유전자좌를 표적화함으로써 진핵 세포에서 CRISPR-매개의 절단의 일반화가능성을 시험하였다. 도 15는 인간 PVALB(도 15a) 및 마우스 Th(도 15b) 유전자좌에서의 일부 추가의 표적화된 프로토스페이서의 선택을 예시한 것이다. 유전자좌의 개략도 및 각각의 마지막 엑손 내의 3개의 프로토스페이서의 위치가 제공된다. 밑줄이 있는 서열은 30 bp의 프로토스페이서 서열 및 3' 말단에서 PAM 서열에 상응하는 3 bp를 포함한다. 센스 및 안티-센스 가닥 상의 프로토스페이서는 각각 DNA 서열 상측 및 하측에 표기되어 있다. 인간 PVALB 및 마우스 Th 유전자좌 각각에 대하여 6.3% 및 0.75%의 변형률이 달성되었으며, 이는 다수의 유기체에 걸쳐 상이한 유전자좌의 변형에서의 CRISPR 시스템의 넓은 응용가능성을 입증한다(도 3b 및 도 6). 키메라 작제물을 사용하여 각 유전자좌에 대하여 3개의 스페이서 중 1개에서만 절단이 검출되었지만, 동시-발현되는 pre-crRNA 배열을 사용하는 경우 27%에 미치는 삽입-결실 생성 효율로, 모든 표적 서열이 절단되었다(도 6).
도 13은 SpCas9가 포유동물 세포에서 다수의 게놈 유전자좌를 표적화하도록 재프로그램화될 수 있다는 추가의 예시를 제공한다. 도 13A는 5개의 프로토스페이서의 위치를 밑줄이 있는 서열로 나타내어 보여주는 인간 EMX1 유전자좌의 개략도를 제공한다. 도 13B는 pre-crRNA의 직접 반복부 영역과 tracrRNA 간의 혼성화를 보여주는 pre-crRNA/trcrRNA 복합체의 개략도(상측) 및 20 bp 가이드 서열, 및 헤어핀 구조로 혼성화되는 부분 직접 반복부 및 tracrRNA 서열로 구성된 tracr 메이트 서열 및 tracr 서열을 포함하는 키메라 RNA 설계의 개략도(하측)를 제공한다. 인간 EMX1 유전자좌 내의 5개의 프로토스페이서에서의 Cas9-매개의 절단의 효능을 비교하는 서베이어 검정의 결과는 도 13C에 예시되어 있다. 각각의 프로토스페이서는 가공된 pre-crRNA/tracrRNA 복합체(crRNA) 또는 키메라 RNA(chiRNA)를 사용하여 표적화된다.
RNA의 2차 구조가 분자간 상호작용에 결정적일 수 있기 때문에, 최소 자유 에너지 및 볼쯔만(Boltzmann)-가중 구조 앙상블에 기초한 구조 예측 알고리즘을 사용하여 본 발명자들의 게놈 표적화 실험에 사용되는 모든 가이드 서열의 추정상 2차 구조를 비교하였다(도 3b)(예를 들어, 문헌[Gruber et al., 2008, Nucleic Acids Research, 36: W70] 참조). 분석에 의해, 대부분의 경우에, 키메라 crRNA 맥락에서 효율적인 가이드 서열에 2차 구조 모티프가 실질적으로 없지만, 비효율적인 가이드 서열은 표적 프로토스페이서 DNA와의 염기 쌍형성을 막을 수 있는 내부 2차 구조를 형성할 가능성이 더 큰 것으로 드러났다. 따라서, 키메라 crRNA를 사용하는 경우, 스페이서 2차 구조의 가변성이 CRISPR-매개 간섭의 효율에 영향을 미칠 수 있다.
도 3은 예시적인 발현 벡터를 예시한다. 도 3a는 합성 crRNA-tracrRNA 키메라(키메라 RNA), 및 SpCas9의 발현을 유도하기 위한 비-시스트로닉 벡터의 개략도를 제공한다. 키메라 가이드 RNA는 게놈 표적 부위 내의 프로토스페이서에 상응하는 20-bp 가이드 서열을 함유한다. 도 3b는 인간 EMX1, PVALB, 및 마우스 Th 유전자좌를 표적화하는 가이드 서열, 및 그들의 예측된 2차 구조를 보여주는 개략도를 제공한다. 각 표적 부위에서의 변형 효율은 RNA 2차 구조 도면 아래에 표기되어 있다(EMX1, n = 216개 앰플리콘 시퀀싱 판독치; PVALB, n = 224개 판독치; Th, n = 265개 판독치). 폴딩 알고리즘에 의해, 레인보우 스케일로 표기시 각 염기가 예측되는 2차 구조의 그의 추정 확률에 따라 채색된 결과가 생성되었으며, 이는 도 3b에 그레이 스케일로 재현된다. SpCas9에 대한 추가의 벡터 설계는 도 44에 나타나 있으며, 이는 가이드 올리고에 대한 삽입 부위에 연결된 U6 프로모터 및 SpCas9 코딩 서열에 연결된 Cbh 프로모터를 혼입한 단일의 발현 벡터를 예시한다. 도 44b에 나타낸 벡터는 H1 프로모터에 연결된 tracrRNA 코딩 서열을 포함한다.
천연적으로 CRISPR이 작동되는 원핵 세포에서 2차 구조를 함유하는 스페이서가 기능할 수 있는지를 시험하기 위하여, 프로토스페이서를 지니는 플라스미드의 형질전환 간섭을, 스트렙토코커스 피오게네스 SF370 CRISPR 유전자좌 1을 이종 발현하는 에스케리키아 콜라이 균주에서 시험하였다(도 10). CRISPR 유전자좌를 저-카피 에스케리키아 콜라이 발현 벡터로 클로닝하고, crRNA 어레이를 DR의 쌍이 측부 배치된 단일의 스페이서로 대체하였다(pCRISPR). 상이한 pCRISPR 플라스미드를 지니는 에스케리키아 콜라이 균주를, 상응하는 프로토스페이서 및 PAM 서열을 함유하는 챌린지 플라스미드로 형질전환시켰다(도 10C). 박테리아 검정에서, 모든 스페이서는 효율적인 CRISPR 간섭을 촉진시켰다(도 4c). 이들 결과는 포유동물 세포에서 CRISPR 활성의 효율에 영향을 미치는 추가의 인자가 존재함을 시사한다.
CRISPR-매개의 절단의 특이성을 조사하기 위하여, 포유동물 게놈에서 프로토스페이서 절단에 대한 가이드 서열 내의 단일-뉴클레오티드 돌연변이의 영향을, 단일의 점 돌연변이가 있는 일련의 EMX1-표적화 키메라 crRNA를 사용하여 분석하였다(도 4a). 도 4b는 상이한 돌연변이 키메라 RNA와 쌍을 형성하는 경우, Cas9의 절단 효율을 비교하는 서베이어 뉴클레아제 검정의 결과를 예시한다. PAM의 최대 12-bp 5'의 단일-염기 미스매치는 SpCas9에 의한 게놈 절단을 실질적으로 없애는 한편, 더 먼 상류 위치에 돌연변이가 있는 스페이서는 원래의 프로토스페이서 표적에 대한 활성을 보유하였다(도 4b). PAM에 더하여, SpCas9는 마지막 12-bp의 스페이서 내에 단일-염기 특이성을 갖는다. 또한, CRISPR은 동일한 EMX1 프로토스페이서를 표적화하는 TALE 뉴클레아제(TALEN)의 쌍만큼 효율적으로 게놈 절단을 매개할 수 있다. 도 4c는 EMX1을 표적화하는 TALEN의 설계를 보여주는 개략도를 제공하며, 도 4d는 TALEN 및 Cas9의 효율을 비교하는 서베이어 겔을 보여준다(n=3).
오류-유발 NHEJ 메카니즘을 통해 포유동물 세포에서 CRISPR-매개의 유전자 교정을 달성하기 위한 성분의 세트를 확립하면, 상동성 재조합(HR), 게놈에서 정밀한 교정을 이루기 위한 고충실도 유전자 수복 경로를 자극하는 CRISPR의 능력을 시험하였다. 야생형 SpCas9는 부위-특이적 DSB를 매개할 수 있는데, 이는 NHEJ 및 HR 둘 모두를 통해 수복될 수 있다. 또한, SpCas9의 RuvC I 촉매 도메인에서의 아스파르트산염에서 알라닌으로의 치환(D10A)을 조작하여 뉴클레아제를 닉카아제로 전환시켜(SpCas9n; 도 5a에 예시)(예를 들어, 문헌[Sapranauskas et al., 2011, Nucleic Acids Research, 39: 9275]; 문헌[Gasiunas et al., 2012, Proc. Natl. Acad. Sci. USA, 109:E2579] 참조), 닉이 있는 게놈 DNA가 고-충실도 상동성-유도 수복(HDR)을 겪게 하였다. 서베이어 검정에 의해, SpCas9n이 EMX1 프로토스페이서 표적에서 삽입-결실을 생성하지 않음이 확인되었다. 도 5b에 예시된 바와 같이, EMX1-표적화 키메라 crRNA와 SpCas9의 동시-발현에 의해, 표적 부위에서 삽입-결실이 생성되는 한편, SpCas9n과의 동시-발현은 그렇지 않았다(n=3). 또한, 327개 앰플리콘의 시퀀싱에 의해, SpCas9n에 의해 유도되는 임의의 삽입-결실이 검출되지 않았다. 동일한 유전자좌를 선택하여, HEK 293FT 세포를 EMX1, hSpCas9 또는 hSpCas9n을 표적화하는 키메라 RNA, 및 프로토스페이서 근처에 제한 부위(HindIII 및 NheI)의 쌍을 도입하기 위한 HR 주형으로 동시-트랜스펙션시킴으로써 CRISPR-매개의 HR을 시험하였다. 도 5c는 재조합 지점 및 프라이머 어닐링 서열(화살표)의 상대적 위치와 함께, HR 전략의 개략적 예시를 제공한다. SpCas9 및 SpCas9n은 실제로 HR 주형이 EMX1 유전자좌로 통합되는 것을 촉매작용시킨다. 표적 영역의 PCR 증폭 후에, HindIII를 사용한 제한 분해에 의해, 예상되는 단편 크기(도 5d에 나타낸 제한 단편 길이 다형성 겔 분석에서 화살표)에 상응하는 절단 산물이 나타났으며, SpCas9 및 SpCas9n은 유사한 수준의 HR 효율을 매개한다. 본 발명자들은 게놈 앰플리콘의 생거 시퀀싱을 사용하여 HR을 추가로 입증하였다(도 5e). 이들 결과는 포유동물 게놈 내로의 표적화된 유전자 삽입을 촉진시키기 위한 CRISPR의 유용성을 입증한다. 야생형 SpCas9의 14-bp(스페이서로부터 12-bp 및 PAM으로부터 2-bp) 표적 특이성을 고려하여, 단일 가닥 파단이 오류-유발 NHEJ 경로에 대한 기질이 아니기 때문에, 닉카아제의 이용가능성은 표적외 변형 가능성을 상당히 감소시킬 수 있다.
배열된 스페이서가 있는 CRISPR 유전자좌의 천연 구조를 모방하는 발현 작제물(도 2a)을 작제하여, 다중 서열 표적화의 가능성을 시험하였다. EMX1- 및 PVALB-표적화 스페이서의 쌍을 인코딩하는 단일의 CRISPR 어레이를 사용하여, 둘 모두의 유전자좌에서의 효율적인 절단이 검출되었다(도 4f, crRNA 어레이의 개략적 설계 및 효율적인 절단의 매개를 보여주는 서베이어 블롯을 보여줌). 119 bp 만큼 이격된 EMX1 내의 2개의 표적에 대한 스페이서를 사용하여 동시 발생 DSB을 통한 보다 큰 게놈 영역의 표적화된 결실도 또한 시험하고, 1.6% 결실 효능(182개 앰플리콘 중 3개; 도 4g)을 검출하였다. 이는 CRISPR 시스템이 단일의 게놈 내에서 다중화 교정을 매개할 수 있음을 나타낸다.
실시예
2:
CRISPR
시스템 변형 및 대안
서열-특이적 DNA 절단을 프로그램화시키기 위하여 RNA를 사용하는 능력은 다양한 연구 및 산업 응용을 위한 신규한 부류의 게놈 조작 도구를 정한다. CRISPR 시스템의 몇몇 양태를 추가로 향상시켜, CRISPR 표적화의 효율 및 다능성을 증가시킬 수 있다. 최적의 Cas9 활성은 포유동물 핵에 존재하는 것보다 더 높은 수준의 유리 Mg2 +의 이용가능성에 따라 달라질 수 있으며(예를 들어, 문헌[Jinek et al., 2012, Science, 337:816] 참조), 프로토스페이서의 인접 하류 NGG 모티프에 대한 선호는 인간 게놈에서 평균하여 12-bp 마다를 표적화하는 능력을 제한한다(도 11, 인간 염색체 서열의 + 및 - 가닥 둘 모두를 평가). 이들 제약 중 일부는 미생물 메타게놈에 걸친 CRISPR 유전자좌의 다양성을 연구함으로써 극복될 수 있다(예를 들어, 문헌[Makarova et al., 2011, Nat Rev Microbiol, 9:467] 참조). 다른 CRISPR 유전자좌는 실시예 1에 기술된 것과 유사한 과정에 의해 포유동물 세포 환경으로 이식될 수 있다. 예를 들어, 도 12는 CRISPR-매개의 게놈 교정을 달성하기 위한, 포유동물 세포에서의 이종 발현을 위한 스트렙토코커스 써모필러스 LMD-9의 CRISPR 1으로부터의 II형 CRISPR 시스템의 조정을 예시한다. 도 12A는 스트렙토코커스 써모필러스 LMD-9 유래의 CRISPR 1의 개략적 표현을 제공한다. 도 12B는 스트렙토코커스 써모필러스 CRISPR 시스템에 대한 발현 시스템의 설계를 예시한다. 인간 코돈-최적화 hStCas9는 구성성 EF1α 프로모터를 사용하여 발현된다. 성숙 버전의 tracrRNA 및 crRNA는 U6 프로모터를 사용하여 발현되어, 정밀한 전사 개시를 조장한다. 성숙 crRNA 및 tracrRNA로부터의 서열이 예시되어 있다. crRNA 서열에서 소문자 "a"로 표기된 단일의 염기를 사용하여 RNA polIII 전사 종결자로 제공되는 polyU 서열을 제거한다. 도 12C는 인간 EMX1 유전자좌를 표적화하는 가이드 서열 및 그들의 예측된 2차 구조를 보여주는 개략도를 제공한다. 각 표적 부위에서의 변형 효율은 RNA 2차 구조 아래에 표기되어 있다. 구조를 생성하는 알고리즘은 예측되는 2차 구조의 그의 추정 확률에 따라 각 염기를 채색하며, 이는 도 12C에 그레이 스케일로 재현되는 레인보우 스케일로 표기된다. 도 12d는 서베이어 검정을 사용한 표적 유전자좌에서의 hStCas9-매개의 절단의 결과를 보여준다. RNA 가이드 스페이서 1 및 2는 각각 14% 및 6.4%를 유도하였다. 이들 2개의 프로토스페이서 부위에서의 생물학적 반복 검증에 걸친 절단 활성의 통계적 분석도 또한 도 6에 제공된다. 도 16은 인간 EMX1 유전자좌에서의 스트렙토코커스 써모필러스 CRISPR 시스템의 추가의 프로토스페이서 및 상응하는 PAM 서열 표적의 개략도를 제공한다. 2개의 프로토스페이서 서열이 강조표시되어 있으며, NNAGAAW 모티프를 만족시키는 그들의 상응하는 PAM 서열은 상응하는 강조표시된 서열에 대하여 3'에 밑줄을 침으로써 표기된다. 둘 모두의 프로토스페이서는 안티-센스 가닥을 표적화한다.
실시예
3: 샘플 표적 서열 선택 알고리즘
소프트웨어 프로그램을 설계하여, 특정 CRISPR 효소에 대하여 요망되는 가이드 서열 길이 및 CRISPR 모티프 서열(PAM)에 기초하여 투입 DNA 서열의 둘 모두의 가닥에서 후보 CRISPR 표적 서열을 확인한다. 예를 들어, PAM 서열 NGG가 있는 스트렙토코커스 피오게네스 유래의 Cas9에 대한 표적 부위는 투입 서열, 및 투입 서열의 역-상보물 둘 모두에서 5'-Nx-NGG-3'을 검색함으로써 확인될 수 있다. 마찬가지로, PAM 서열 NNAGAAW가 있는 스트렙토코커스 써모필러스 CRISPR1의 Cas9에 대한 표적 부위는 투입 서열, 및 투입 서열의 역-상보물 둘 모두에서 5'-Nx-NNAGAAW-3'을 검색함으로써 확인될 수 있다. 마찬가지로, PAM 서열 NGGNG가 있는 스트렙토코커스 써모필러스 CRISPR3의 Cas9에 대한 표적 부위는 투입 서열, 및 투입 서열의 역-상보물 둘 모두에서 5'-Nx-NGGNG-3'을 검색함으로써 확인될 수 있다. Nx에서 값 "x"는 프로그램에 의해 고정되거나, 사용자에 의해 지정될 수 있으며, 예를 들어, 20일 수 있다.
게놈에서의 DNA 표적 부위의 다수의 존재가 비특이적인 게놈 교정을 야기할 수 있기 때문에, 모든 가능한 부위를 확인한 후에, 프로그램은 그들이 관련 참조 게놈에 나타나는 횟수에 기초하여 서열을 필터링한다. 서열 특이성이 '씨드(seed)' 서열, 예를 들어, PAM 서열 그 자체를 포함하여 PAM 서열로부터 5'의 11 내지 12 bp에 의해 결정되는 CRISPR 효소에 있어서, 필터링 단계는 씨드 서열에 기초하여 이루어질 수 있다. 따라서, 추가의 게놈 유전자좌에서 교정을 피하기 위하여, 결과는 관련 게놈에서의 씨드:PAM 서열의 발생 수에 기초하여 필터링된다. 사용자가 씨드 서열의 길이를 선택하게 할 수 있다. 또한, 필터를 통과시키기 위하여, 사용자가 게놈 내의 씨드:PAM 서열의 발생 수를 지정하게 할 수 있다. 디폴트는 독특한 서열에 대하여 스크리닝하는 것이다. 여과 수준은 씨드 서열의 길이와 게놈에서의 서열의 발생 수 둘 모두를 변화시킴으로써 변경된다. 프로그램은 추가로 또는 대안적으로, 확인된 표적 서열(들)의 역 상보물을 제공함으로써 보고된 표적 서열(들)에 상보적인 가이드 서열의 서열을 제공할 수 있다.
서열 선택을 최적화시키기 위한 방법 및 알고리즘의 추가의 상세사항은 본원에 참조로 포함되는 미국 출원 제61/836,080호(대리인 사건 번호 44790.11.2022)에서 찾을 수 있다.
실시예
4: 다중
키메라
crRNA
-
tracrRNA
하이브리드의
평가
본 실시예는 상이한 길이의 야생형 tracrRNA 서열이 혼입된 tracr 서열을 갖는 키메라 RNA(chiRNA; 단일의 전사물에 가이드 서열, tracr 메이트 서열 및 tracr 서열을 포함)에 대해 수득된 결과를 기술한다. 도 18a는 키메라 RNA 및 Cas9에 대한 비시스트로닉 발현 벡터의 개략도를 예시한다. Cas9는 CBh 프로모터에 의해 유도되며, 키메라 RNA는 U6 프로모터에 의해 유도된다. 키메라 가이드 RNA는 표기된 바와 같은 다양한 위치에서 절단되는 tracr 서열(하부 가닥의 처음 "U"에서 전사물의 마지막까지 계속)에 연결된 20 bp 가이드 서열(N)로 구성된다. 가이드 및 tracr 서열은 tracr-메이트 서열 GUUUUAGAGCUA에 이어서 루프 서열 GAAA에 의해 분리된다. 인간 EMX1 및 PVALB 유전자좌에서의 Cas9-매개의 삽입-결실에 대한 서베이어 검정의 결과는 각각 도 18b 및 도 18c에 예시되어 있다. 화살표는 예상된 서베이어 단편을 나타낸다. chiRNA는 그들의 "+n" 표기로 표시되며, crRNA는 가이드 및 tracr 서열이 개별 전사물로서 발현되는 하이브리드 RNA를 지칭한다. 3벌로 수행되는 이들 결과의 정량화는 각각 도 18b 및 도 18c에 상응하는 도 19a 및 도 19b의 히스토그램에 의해 예시되어 있다("N.D."는 삽입-결실이 검출되지 않음을 나타낸다). 프로토스페이서 ID 및 그들의 상응하는 게놈 표적, 프로토스페이서 서열, PAM 서열 및 가닥 위치는 표 D에 제공되어 있다. 하이브리드 시스템에서 개별 전사물의 경우에는 전체 프로토스페이서 서열에 상보적이거나, 키메라 RNA의 경우에는 밑줄이 있는 부분에만 상보성이도록 가이드 서열을 설계하였다.

세포 배양 및
트랜스펙션
.
인간 배아 신장(HEK) 세포주 293FT(라이프 테크놀로지즈)를 10% 우태아혈청(하이클론), 2mM GlutaMAX(라이프 테크놀로지즈), 100U/㎖ 페니실린 및 100㎍/㎖ 스트렙토마이신이 보충된 둘베코 개질 이글스 배지(DMEM)에서 37℃에서 5% C02 인큐베이션시키면서 유지시켰다. 293FT 세포를 웰마다 150,000개 세포의 밀도로 트랜스펙션 24시간 전에 24-웰 플레이트(코닝)에 씨딩하였다. 세포를 제조사의 권고된 프로토콜에 따라 리포펙타민 2000(라이프 테크놀로지즈)을 사용하여 트랜스펙션시켰다. 24-웰 플레이트의 각 웰에 대하여 총 500 ng의 플라스미드를 사용하였다.
게놈 변형에 대한 서베이어 검정
293FT 세포를 상기 기재한 바와 같이 플라스미드 DNA로 트랜스펙션하였다. 게놈 DNA 추출 전에, 트랜스펙션 후 72시간 동안 37℃에서 세포를 인큐베이션하였다. 게놈 DNA를 제조사의 프로토콜에 따라 퀵익스트랙트 DNA 추출 용액(에피센트레)을 사용하여 추출하였다. 간략하게, 펠렛화된 세포를 퀵익스트랙트 용액에 재현탁화시키고, 65℃에서 15분 동안 및 98℃에서 10분 동안 인큐베이션하였다. 각 유전자에 대한 CRISPR 표적 부위의 측부에 배치된 게놈 부위를 PCR 증폭시키고(표 E에 열거된 프라이머), 산물을 제조사의 프로토콜에 따라 퀴아퀵 스핀 컬럼(퀴아젠)을 사용하여 정제하였다. 총 400 ng의 정제된 PCR 산물을 2㎕ 10X Taq DNA 중합효소 PCR 완충제(엔자이머틱스) 및 초순수와 총 20 ㎕ 부피로 혼합하고, 재어닐링 과정을 거치게 하여 헤테로듀플렉스가 형성되게 하였다: 95℃에서 10분, 95℃에서 85℃(-2℃/초로 램핑), 85℃에서 25℃(-0.25℃/초), 및 25℃에서 1분 유지. 재어닐링 후, 산물을 제조사의 권고 프로토콜에 따라 서베이어 뉴클레아제 및 서베이어 인핸서 S(트랜스게노믹스)로 처리하고, 4 내지 20% 노벡스 TBE 폴리-아크릴아미드 겔(라이프 테크놀로지즈)에서 분석하였다. 겔을 SYBR 골드 DNA 염색제(라이프 테크놀로지즈)로 30분 동안 염색하고, Gel Doc 겔 영상화 시스템(바이오-라드)으로 영상화하였다. 정량화는 상대적 밴드 세기를 기반으로 하였다.

독특한
CRISPR
표적 부위의 컴퓨터에 의한 확인
인간, 마우스, 랫트, 제브라피시, 초파리 및 C. 엘레간스 게놈에서 스트렙토코커스 피오게네스 SF370 Cas9(SpCas9) 효소에 대한 독특한 표적 부위를 확인하기 위하여, 본 발명자들은 DNA 서열의 둘 모두의 가닥을 스캐닝하고, 모든 가능한 SpCas9 표적 부위를 확인하기 위한 소프트웨어 패키지를 개발하였다. 이러한 실시예에 있어서, 각각의 SpCas9 표적 부위는 작용에 있어서 NGG 프로토스페이서 인접 모티프(PAM) 서열이 뒤에 오는 20 bp 서열로서 정의되며, 본 발명자들은 모든 염색체에서 이러한 5'-N20-NGG-3' 정의를 만족시키는 모든 서열을 확인하였다. 비-특이적인 게놈 교정을 방지하기 위하여, 모든 잠재적인 부위를 확인한 후에, 모든 표적 부위를 그들이 관련 참조 게놈에 나타나는 횟수에 기초하여 필터링하였다. 예를 들어, PAM 서열로부터 5'의 대략 11 내지 12 bp 서열일 수 있는 '씨드' 서열에 의해 부여되는 Cas9 활성의 서열 특이성을 이용하기 위하여, 5'-NNNNNNNNNN-NGG-3' 서열이 관련 게놈에서 독특한 것으로 선택되었다. 모든 게놈 서열을 UCSC 게놈 브라우저(Genome Browser)(인간 게놈 hg19, 마우스 게놈 mm9, 랫트 게놈 rn5, 제브라피시 게놈 danRer7, 드로소필라 멜라노개스터(D. melanogaster) 게놈 dm4 및 C. 엘레간스 게놈 ce10)로부터 다운로드하였다. UCSC 게놈 브라우저 정보를 사용하여 브라우징하기 위하여 전체 검색 결과가 이용가능하다. 인간 게놈 내의 몇몇 표적 부위의 예시적인 가시화가 도 21에 제공되어 있다.
먼저, 인간 HEK 293FT 세포에서 EMX1 유전자좌 내의 3개의 부위를 표적화시켰다. 각 chiRNA의 게놈 변형 효율을 서베이어 뉴클레아제 검정을 사용하여 평가하였으며, 이 검정은 DNA 이중-가닥 파단(DSB) 및 비-상동성 말단 연결(NHEJ) DNA 손상 수복 경로에 의한 그들의 이후의 수복으로부터 야기되는 돌연변이를 검출한다. chiRNA(+n)로 표기된 작제물은 야생형 tracrRNA의 최대 +n 뉴클레오티드가 키메라 RNA 작제물에 포함되는 것을 나타내며, 48, 54, 67 및 85의 값이 n에 대해 사용된다. 보다 긴 야생형 tracrRNA의 단편을 함유하는 키메라 RNA(chiRNA(+67) 및 chiRNA(+85))는 모든 3개의 EMX1 표적 부위에서 DNA 절단을 매개하며, chiRNA(+85)는 특히 개별 전사물에서 가이드 및 tracr 서열을 발현하는 상응하는 crRNA/tracrRNA 하이브리드보다 상당히 더 높은 수준의 DNA 절단을 나타낸다(도 18b 및 도 19a). 또한, 하이브리드 시스템(개별 전사물로 발현되는 가이드 서열 및 tracr 서열)을 사용하여 검출가능한 절단을 제공하지 않는 PVALB 유전자좌 내의 2개의 부위를 chiRNA를 사용하여 표적화하였다. chiRNA(+67) 및 chiRNA(+85)는 2개의 PVALB 프로토스페이서에서 상당한 절단을 매개할 수 있었다(도 18c 및 도 19b).
EMX1 및 PVALB 유전자좌 내의 모든 5개의 표적에 있어서, tracr 서열 길이의 증가와 일치하는 게놈 변형 효율의 증가가 관찰되었다. 임의의 이론에 구속되지 않고, tracrRNA의 3' 말단에 의해 형성되는 2차 구조는 CRISPR 복합체 형성 비율을 향상시키는데 역할을 수행할 수 있다. 본 실시예에 사용되는 키메라 RNA의 각각에 대하여 예측된 2차 구조의 예시는 도 21에 제공되어 있다. 2차 구조를 최소 자유 에너지 및 분배 함수 알고리즘을 사용하는 RNAfold(http://rna.tbi.univie.ac.at/cgi-bin/RNAfold.cgi)를 사용하여 예측하였다. 각 염기에 대한 의사 색채(pseudocolor)(그레이 스케일로 재현)는 쌍형성 가능성을 나타낸다. 보다 긴 tracr 서열을 갖는 chiRNA가 고유 CRISPR crRNA/tracrRNA 하이브리드에 의해 절단될 수 없었던 표적을 절단할 수 있기 때문에, 키메라 RNA가 그의 고유 하이브리드 대응물보다 더욱 효율적으로 Cas9에 로딩될 수 있다. 진핵 세포 및 유기체에서 부위-특이적 게놈 교정을 위한 Cas9의 응용을 용이하게 하기 위하여, 스트렙토코커스 피오게네스 Cas9에 대한 모든 예측된 독특한 표적 부위를 인간, 마우스, 랫트, 지브라피시, C. 엘레간스 및 드로소필라 멜라노개스터 게놈에서 컴퓨터로 확인하였다. 키메라 RNA를 다른 미생물 유래의 Cas9 효소를 위해 설계하여, CRISPR RNA-프로그램화가능한 뉴클레아제의 표적 공간을 확대할 수 있다.
도 22는 야생형 tracr RNA 서열의 최대 +85 뉴클레오티드 및 핵 국소화 서열이 있는 SpCas9를 포함하는 키메라 RNA의 발현을 위한 예시적인 비시스트로닉 발현 벡터를 예시한다. SpCas9는 CBh 프로모터로부터 발현되며, bGH 폴리A 신호(bGH pA)로 종결된다. 개략도 바로 아래에 예시되어 있는 확대된 서열은 가이드 서열 삽입 부위 주위의 영역에 상응하며, 5'에서 3'으로, U6 프로모터의 3'-부분(제1 음영 영역), BbsI 절단 부위(화살표), 부분 직접 반복부(tracr 메이트 서열 GTTTTAGAGCTA, 밑줄), 루프 서열 GAAA, 및 +85 tracr 서열(루프 서열 뒤의 밑줄이 있는 서열)을 포함한다. 예시적인 가이드 서열 삽입물은 가이드 서열 삽입 부위 아래에 예시되어 있으며, 선택된 표적에 대한 가이드 서열의 뉴클레오티드는 "N"으로 표시된다.
상기 실시예에 기술된 서열은 하기와 같다(폴리뉴클레오티드 서열은 5'에서 3'이다):
U6-짧은 tracrRNA(스트렙토코커스 피오게네스 SF370):

U6-긴 tracrRNA(스트렙토코커스 피오게네스 SF370):


U6-DR-BbsI 백본-DR(스트렙토코커스 피오게네스 SF370):

U6-키메라 RNA-BbsI 백본(스트렙토코커스 피오게네스 SF370)

NLS-SpCas9-EGFP:


SpCas9-EGFP-NLS:


NLS-SpCas9-EGFP-NLS:


NLS-SpCas9-NLS:


NLS-mCherry-SpRNase3:

SpRNase3-mCherry-NLS:

NLS-SpCas9n-NLS(D10A 닉카아제 돌연변이는 소문자임):

hEMX1-HR 주형-HindII-NheI:


NLS-StCsn1-NLS:

U6-St_tracrRNA(7-97):

U6-DR-스페이서-DR(스트렙토코커스 피오게네스 SF370)

+48 tracr RNA를 함유하는 키메라 RNA(스트렙토코커스 피오게네스 SF370)

+54 tracr RNA를 함유하는 키메라 RNA(스트렙토코커스 피오게네스 SF370)

+67 tracr RNA를 함유하는 키메라 RNA(스트렙토코커스 피오게네스 SF370)

+85 tracr RNA를 함유하는 키메라 RNA(스트렙토코커스 피오게네스 SF370)

CBh-NLS-SpCas9-NLS



스트렙토코커스 써모필러스 LMD-9 CRISPR1 Cas9에 대한 예시적인 키메라 RNA(NNAGAAW의 PAM 존재)

스트렙토코커스 써모필러스 LMD-9 CRISPR1 Cas9에 대한 예시적인 키메라 RNA(NNAGAAW의 PAM 존재)

스트렙토코커스 써모필러스 LMD-9 CRISPR1 Cas9에 대한 예시적인 키메라 RNA(NNAGAAW의 PAM 존재)

스트렙토코커스 써모필러스 LMD-9 CRISPR1 Cas9에 대한 예시적인 키메라 RNA(NNAGAAW의 PAM 존재)

스트렙토코커스 써모필러스 LMD-9 CRISPR1 Cas9에 대한 예시적인 키메라 RNA(NNAGAAW의 PAM 존재)

스트렙토코커스 써모필러스 LMD-9 CRISPR1 Cas9에 대한 예시적인 키메라 RNA(NNAGAAW의 PAM 존재)

스트렙토코커스 써모필러스 LMD-9 CRISPR1 Cas9에 대한 예시적인 키메라 RNA(NNAGAAW의 PAM 존재)

스트렙토코커스 써모필러스 LMD-9 CRISPR1 Cas9에 대한 예시적인 키메라 RNA(NNAGAAW의 PAM 존재)

스트렙토코커스 써모필러스 LMD-9 CRISPR1 Cas9에 대한 예시적인 키메라 RNA(NNAGAAW의 PAM 존재)

스트렙토코커스 써모필러스 LMD-9 CRISPR3 Cas9에 대한 예시적인 키메라 RNA(NGGNG의 PAM 존재)

스트렙토코커스 써모필러스 LMD-9 CRISPR3 유전자좌 유래의 Cas9의 코돈-최적화 버전(5' 및 3' 말단 둘 모두에 NLS 존재)




실시예
5:
CRISPR
-
Cas
시스템을 사용한 박테리아 게놈의 RNA-유도 교정
본 발명자들은 스트렙토코커스 뉴모니애 및 에스케리키아 콜라이의 게놈에 정밀한 돌연변이를 도입하기 위해 CRISPR-관련 엔도뉴클레아제 Cas9를 사용하였다. 상기 방법은 표적화된 부위에서의 Cas9-유도 절단에 의존하여, 비돌연변이 세포를 사멸시키며, 선택가능한 마커 또는 반대-선택 시스템을 필요로 하지 않는다. 짧은 CRISPR RNA(crRNA)의 서열을 변화시켜, 교정 주형에서 단일- 및 다중-뉴클레오티드를 변화시킴으로써 Cas9 특이성을 재프로그램화시켰다. 2개의 crRNA의 동시의 사용은 다중 돌연변이유발을 가능하게 하였다. 스트렙토코커스 뉴모니애에서, Cas9 절단을 견뎌내는 거의 100%의 세포가 요망되는 돌연변이를 포함하였으며, 에스케리키아 콜라이에서 리컴비니어링(recombineering)과 병용되는 경우에는 65%가 그러하였다. 본 발명자들은 표적화가능한 서열의 범위를 정하기 위하여 Cas9 표적 요건을 철저히 분석하였으며, 이들 요건을 만족시키지 않는 교정 부위에 대한 전략을 제시하여, 박테리아 게놈 조작을 위한 이러한 기술의 다능성을 뒷받침한다.
유전자 기능의 이해는 세포 내의 DNA 서열을 제어된 방식으로 변경할 가능성에 좌우된다. 진핵생물에서의 부위-특이적 돌연변이유발은 대상 돌연변이를 함유하는 주형 DNA의 상동성 재조합을 촉진시키는 서열-특이적 뉴클레아제의 사용에 의해 달성된다. 아연 핑거 뉴클레아제(ZFN), 전사 활성화제-유사 이펙터 뉴클레아제(TALEN) 및 귀소 메가뉴클레아제를 프로그램화하여, 특정 위치에서 게놈을 절단할 수 있으나, 이들 방법은 각각의 표적 서열을 위하여 신규 효소의 조작을 필요로 한다. 원핵 유기체에서, 돌연변이유발 방법은 교정된 유전자좌에 선택 마커를 도입하거나, 반대-선택 시스템을 포함하는 2-단계 과정을 필요로 한다. 더욱 최근에, 파지 재조합 단백질이 선형 DNA 또는 올리고뉴클레오티드의 상동성 재조합을 촉진시키는 기술인 리컴비니어링을 위해 사용되었다. 그러나, 돌연변이의 선택이 존재하지 않기 때문에, 리컴비니어링 효율은 비교적 낮아서(점 돌연변이에 대한 0.1 내지 10%는 보다 큰 변형에 대해서 10-5 내지 10- 6로 감소됨), 많은 경우에 다수의 콜로니의 스크리닝을 필요로 할 수 있다. 따라서, 진핵 및 원핵 유기체 둘 모두의 유전자 조작을 위한, 입수가능하고, 사용하기 용이하고, 효율적인 신규 기술이 여전히 필요하다.
원핵생물의 CRISPR(클러스터링되고 규칙적으로 산재된 짧은 팔린드로믹 반복부) 적응 면역계에서의 최근의 연구에 의해, 서열 특이성이 작은 RNA에 의해 프로그램화되는 뉴클레아제의 확인이 야기되었다. CRISPR 유전자좌는 박테리오파지의 게놈 및 다른 이동 유전 요소와 매치되는 '스페이서' 서열에 의해 분리된 일련의 반복부로 구성된다. 반복부-스페이서 어레이는 긴 전구체로 전사되고, 반복 서열 내에서 가공되어, CRISPR 시스템에 의해 절단되는 표적 서열(프로토스페이서로도 공지됨)을 특정하는 작은 crRNA를 생성한다. 프로토스페이서-인접 모티프(PAM)로 공지되어 있는 표적 영역의 인접 하류의 서열 모티프의 존재가 절단에 필수적이다. CRISPR-관련(cas) 유전자는 통상 반복부-스페이서 어레이의 측부에 배치되며, crRNA 생합성 및 표적화를 담당하는 효소 기구를 인코딩한다. Cas9는 crRNA 가이드를 사용하여 절단 부위를 특정하는 dsDNA 엔도뉴클레아제이다. Cas9로의 crRNA 가이드의 로딩은 crRNA 전구체의 가공 동안 발생하며, 전구체에 대한 작은 RNA 안티센스, tracrRNA 및 RNAse III를 필요로 한다. ZFN 또는 TALEN을 사용한 게놈 교정과 대조적으로, Cas9 표적 특이성의 변화는 단백질 조작을 필요로 하지 않고, 짧은 crRNA 가이드의 설계만을 필요로 한다.
본 발명자들은 최근에 스트렙토코커스 뉴모니애에서, 염색체 유전자좌를 표적화하는 CRISPR 시스템의 도입이 형질전환된 세포의 사멸을 야기함을 보여주었다. 간헐적인 생존 세포가 표적 영역 내에 돌연변이를 함유하는 것으로 관찰되었으며, 이는 내인성 표적에 대한 Cas9 dsDNA 엔도뉴클레아제 활성이 게놈 교정을 위해 사용될 수 있음을 시사한다. 본 발명자들은 마커-결여(marker-less) 돌연변이가 주형 DNA 단편의 형질전환을 통해 도입될 수 있음을 보여주며, 주형 DNA 단편은 게놈에서 재조합될 것이며, Cas9 표적 인식을 제거한다. 몇몇 상이한 crRNA를 사용한 Cas9의 특이성의 유도는 동시에 다중 돌연변이의 도입을 가능하게 한다. 또한, 본 발명자들은 Cas9 표적화를 위한 서열 요건을 상세히 특징짓고, 상기 방법이 에스케리키아 콜라이에서 게놈 교정을 위해 리컴비니어링과 조합될 수 있음을 보여준다.
결과: 염색체 표적의 Cas9 절단에 의한 게놈 교정
스트렙토코커스 뉴모니애 균주 crR6은 박테리오파지 φ8232.5에 존재하는 표적 서열을 절단하는 Cas9-기반의 CRISPR 시스템을 함유한다. 이러한 표적을 제2 균주 R68232.5의 srtA 염색체 유전자좌로 통합시켰다. PAM 영역 내에 돌연변이를 함유하는 변경된 표적 서열을 제3 균주 R6370.1의 srtA 유전자좌로 통합시켜, 이러한 균주에서 CRISPR 절단이 '면제'되게 하였다(도 28a). 본 발명자들은 R68232.5 및 R6370.1 세포를 crR6 세포 유래의 게놈 DNA로 형질전환시켰으며, R68232.5 세포의 성공적인 형질전환이 표적 유전자좌의 절단 및 세포사를 야기할 것으로 예상된다. 이러한 예상과 대조적으로, 본 발명자들은 R6370.1 형질전환체보다 대략 10배 더 낮은 효율임에도 불구하고, R68232.5 형질전환체를 분리하였다(도 28b). 8개의 R68232.5 형질전환체의 유전자 분석(도 28)에 의해, 대다수가 φ8232.5 표적을 Cas9 인식에 필요한 프로토스페이서를 함유하지 않는 crR6 게놈의 야생형 srtA 유전자좌로 대체함으로써 Cas9 표적화의 독성을 제거하는 이중 재조합 사건의 산물임이 드러났다. 이들 결과는 표적화된 유전자좌로의 재조합을 위한 주형(교정 주형)과, 게놈 유전자좌를 표적화하는 CRISPR 시스템(표적화 작제물)의 동시의 도입이 표적화된 게놈 교정을 야기한다는 증거였다(도 23a).
게놈 교정을 위한 단순화된 시스템을 생성하기 위하여, 본 발명자들은 cas1, cas2 및 csn2, CRISPR 표적화에 불필요한 것으로 보이는 유전자를 결실시킴으로써 균주 crR6에서 CRISPR 유전자좌를 변형시켜, 균주 crR6M을 제공하였다(도 28a). 이러한 균주는 crR6의 동일한 특성을 보유하였다(도 28b). Cas9-기반의 교정의 효율을 증가시키고, 선택된 주형 DNA가 도입된 돌연변이를 제어하는데 사용될 수 있음을 입증하기 위하여, 본 발명자들은 R68232.5 세포를 야생형 srtA 유전자 또는 돌연변이 R6370.1 표적의 PCR 산물로 동시-형질전환시켰으며, 이 중 어느 하나는 Cas9에 의한 절단에 저항성이 있어야 한다. 이는 단독의 게놈 crR6 DNA와 비교하여 5배 내지 10배의 형질전환 빈도 증가를 야기하였다(도 23b). 또한, 교정의 효율을 실질적으로 증가시켰으며, 시험되는 형질전환체 8개 중 8개는 야생형 srtA 카피를 함유하며, 8개 중 7개는 R6370.1 표적에 존재하는 PAM 돌연변이를 함유한다(도 23b 및 도 29a). 이들 결과는 함께, Cas9에 의해 보조되는 게놈 교정의 가능성을 보여준다.
Cas9 표적 요건의 분석: 게놈에 특정 변화를 도입하기 위하여, Cas9-매개의 절단을 없애는 돌연변이를 지니는 교정 주형을 사용하여, 이에 의해 세포사를 방지해야 한다. 이것은 표적의 결실 또는 다른 서열에 의한 그의 대체(유전자 삽입)가 추구되는 경우에 달성하기 용이하다. 목적이 유전자 융합을 생성하는 것이거나, 단일-뉴클레오티드 돌연변이를 생성하는 것인 경우, Cas9 뉴클레아제 활성의 폐지는 PAM 또는 프로토스페이서 서열 중 어느 하나를 변경하는 교정 주형에 돌연변이를 도입함으로써만 가능하게 될 것이다. CRISPR-매개의 교정의 제약을 결정하기 위하여, 본 발명자들은 CRISPR 표적화를 폐지하는 PAM 및 프로토스페이서 돌연변이의 철저한 분석을 수행하였다.
이전의 연구에 의해, 스트렙토코커스 피오게네스 Cas9가 프로토스페이서의 인접 하류에 NGG PAM을 필요로 하는 것으로 제안되었다. 그러나, 오직 매우 제한된 수의 PAM-불활성화 돌연변이만이 지금까지 기술되어 있기 때문에, 본 발명자들은 CRISPR 절단을 없애는 프로토스페이서 뒤의 모든 5-뉴클레오티드 서열을 찾기 위하여 체계적 분석을 행하였다. 본 발명자들은 무작위 올리고뉴클레오티드를 사용하여, 이종 PCR 산물에서 모든 가능한 1,024개 PAM 서열을 생성하고, 이를 crR6 또는 R6 세포로 형질전환시켰다. 기능적 PAM을 지니는 작제물은 crR6에서 Cas9에 의해 인식되고 Cas9에 의해 파괴될 것으로 예상되나 R6 세포에서는 그렇지 않았다(도 24a). 2×105개 초과의 콜로니를 함께 풀링하여, 모든 표적의 동시-증폭을 위한 주형으로 사용하기 위해 DNA를 추출하였다. PCR 산물을 딥 시퀀싱하고, 모든 1,024개 서열을 함유하는 것을 관찰하였으며, 커버리지 범위는 5 내지 42,472개 판독치였다(섹션 "딥 시퀀싱 데이터의 분석" 참조). R6 샘플에 비한 crR6 샘플에서의 그의 판독치의 상대적 비율에 의해, 각 PAM의 기능성을 추산하였다. PAM의 처음 3개 염기의 분석에 의해, 2개의 마지막 염기에 걸쳐 평균을 내어, NGG 패턴이 crR6 형질전환체에서 과소표현되는(under-represented) 것이 명백하게 나타났다(도 24b). 더욱이, 다음의 2개의 염기는 NGG PAM에 검출가능한 영향을 갖지 않았으며(섹션 "딥 시퀀싱 데이터의 분석" 참조), 이는 NGGNN 서열이 Cas9 활성을 가능하게 하기에 충분하였음을 보여준다. NAG PAM 서열에 대하여 부분적 표적화가 관찰되었다(도 24b). 또한, NNGGN 패턴은 CRISPR 표적화를 부분적으로 불활성화시켰으며(표 G), 이는 NGG 모티프가 1 bp 이동되는 경우에도 여전히 Cas9에 의해 감소된 효율로 인식될 수 있음을 나타낸다. 이들 데이터는 Cas9 표적 인식의 분자 메카니즘을 설명하며, 그들에 의해, NGG(또는 상보적 가닥에서 CCN) 서열이 Cas9 표적화에 충분하며, 교정 주형 내의 NGG에서 NAG 또는 NNGGN로의 돌연변이를 피해야 하는 것이 드러났다. 이들 3-뉴클레오티드 서열의 높은 빈도(8 bp마다 1회) 때문에, 이는 게놈의 대부분 위치가 교정될 수 있음을 의미한다. 실제로, 본 발명자들은 다양한 PAM을 지니는 10개의 무작위 선택 표적을 시험하고, 모두가 작용성인 것으로 관찰되었다(도 30).
Cas9-매개의 절단을 방해하는 다른 방법은 교정 주형의 프로토스페이서 영역에 돌연변이를 도입하는 것이다. '씨드 서열'(PAM에 바로 인접한 8 내지 10개 프로토스페이서 뉴클레오티드) 내의 점 돌연변이가 CRISPR 뉴클레아제에 의한 절단을 없앨 수 있는 것이 알려져 있다. 그러나, 이러한 영역의 정확한 길이는 알려져 있지 않으며, 씨드 내의 임의의 뉴클레오티드에 대한 돌연변이가 Cas9 표적 인식을 방해할 수 있는지 여부는 명백하지 않다. 본 발명자들은 상기 기술된 동일한 딥 시퀀싱 방법을 행하여, crRNA와의 염기쌍 접촉에 수반되는 전체 프로토스페이서 서열을 무작위화시키고, 표적화를 방해하는 모든 서열을 결정하였다. R68232.5 세포에 존재하는 spc1 표적 내의 20개의 매칭 뉴클레오티드(14)의 각 위치(도 23a)를 무작위화시키고, crR6 및 R6 세포로 형질전환시켰다(도 24a). 씨드 서열의 존재와 일치하게, PAM의 인접 상류 12개 뉴클레오티드 내의 돌연변이만이 Cas9에 의한 절단을 없앴다(도 24c). 그러나, 상이한 돌연변이는 현저하게 상이한 영향을 나타내었다. 씨드의 원위(PAM으로부터)(12 내지 7)는 대부분의 돌연변이를 허용하였으며, 오직 하나의 특정 염기 치환만이 표적화를 없앴다. 대조적으로, 근위(3을 제외하고 6 내지 1) 내의 임의의 뉴클레오티드에 대한 돌연변이는 각 특정 치환에 대하여 상이한 수준이지만 Cas9 활성을 제거하였다. 위치 3에서, 오직 2개의 치환만이 CRISPR 활성에 상이한 세기로 영향을 미쳤다. 본 발명자들은 씨드 서열 돌연변이가 CRISPR 표적화를 방지할 수 있지만, 씨드의 각 위치에서 이루어질 수 있는 뉴클레오티드 변화에 관한 제약이 존재하는 것으로 결론지었다. 더욱이, 이들 제약은 상이한 스페이서 서열에 대하여 달라질 가능성이 크다. 따라서, 본 발명자들은 PAM 서열 내의 돌연변이가 가능하다면, 바람직한 교정 전략인 것으로 여긴다. 대안적으로, 씨드 서열 내의 다중 돌연변이를 도입하여, Cas9 뉴클레아제 활성을 방지할 수 있다.
스트렙토코커스 뉴모니아에서의 Cas9 -매개의 게놈 교정: 표적화된 게놈 교정을 위한 신속하고 효율적인 방법을 개발하기 위하여, 본 발명자들은 스페이서가 PCR에 의해 용이하게 도입될 수 있는 균주인 균주 crR6Rk를 조작하였다(도 33). 본 발명자들은 활성이 용이하게 측정될 수 있는 스트렙토코커스 뉴모니애의 β-갈락토시다제(bgaA) 유전자를 교정하기로 하였다. 본 발명자들은 이러한 효소의 활성 부위에 아미노산의 알라닌 치환을 도입하였다: R481A(R→A) 및 N563A,E564A(NE→AA) 돌연변이. 상이한 교정 전략을 예시하기 위하여, 본 발명자들은 PAM 서열 및 프로토스페이서 씨드 둘 모두의 돌연변이를 설계하였다. 둘 모두의 경우에, TGG PAM 서열(상보적인 가닥에서 CCA, 도 26)에 인접한 β-갈락토시다제 유전자의 영역에 상보적인 crRNA가 있는 동일한 표적화 작제물을 사용하였다. R→A 교정 주형에 의해, 프로토스페이서 씨드 서열 상에 3-뉴클레오티드 미스매치를 생성하였다(CGT에서 GCA, BtgZI 제한 부위도 도입). NE→AA 교정 주형에서, 본 발명자들은 프로토스페이서 영역의 218 nt 하류 돌연변이(AAT GAA에서 GCT GCA, TseI 제한 부위도 생성)와, 비활성 PAM을 생성하는 동의 돌연변이(TGG에서 TTG)를 동시에 도입하였다. 이러한 마지막 교정 전략에 의해, 적절한 표적을 선택하기 어려울 수 있는 곳에 돌연변이를 만들기 위한 원위 PAM의 사용 가능성이 입증된다. 예를 들어, 39.7% GC 함량을 갖는 스트렙토코커스 뉴모니애 R6 게놈이 평균 12 bp마다 하나의 PAM 모티프를 함유하지만, 일부 PAM 모티프는 최대 194 bp에 의해 분리된다(도 33). 또한, 본 발명자들은 6,664 bp의 ΔbgaA 프레임내 결실을 설계하였다. 모든 3가지 경우에, 표적화 및 교정 주형의 동시-형질전환에 의해, 야생형 bgaA 서열을 함유하는 대조군 교정 주형과의 동시-형질전환보다 10배 더 많은 카나마이신-내성 세포가 생성되었다(도 25b). 본 발명자들은 24개 형질전환체(각 교정 실험을 위하여 8개)를 유전자형 분석하였으며, 하나를 제외한 모두에 요망되는 변화가 혼입된 것이 관찰되었다(도 25c). 또한, DNA 시퀀싱에 의해, 표적 영역에서 도입된 돌연변이의 존재뿐 아니라, 2차 돌연변이의 부재를 확인하였다(도 29b 및 도 29c). 마지막으로, 본 발명자들은 β-갈락토시다제 활성을 측정하여, 모든 교정된 세포가 예상되는 표현형을 나타내는 것을 확인하였다(도 25d).
또한, Cas9-매개의 교정을 사용하여 생물학적 경로의 연구를 위해 다중 돌연변이를 생성하였다. 본 발명자들은 표면 단백질을 그람(Gram)-양성 박테리아의 외피에 부착시키는 소타제-의존성 경로에 대해 이를 예시하기로 하였다. 본 발명자들은 클로람페니콜-내성 표적화 작제물 및 ΔsrtA 교정 주형의 동시-형질전환에 의한 소타제 결실(도 33a 및 도 33b)에 이어서, 이전의 것을 대체하는 카나마이신-내성 표적화 작제물을 사용한 ΔbgaA 결실을 도입하였다. 스트렙토코커스 뉴모니애에서, β-갈락토시다제는 소타제에 의해 세포벽에 공유 결합된다. 따라서, srtA의 결실은 상청액으로의 표면 단백질의 방출을 야기하는 한편, 이중 결실은 검출가능한 β-갈락토시다제 활성을 갖지 않는다(도 34c). 이러한 순차적 선택은 다중 돌연변이를 생성하는데 필요한 것만큼 많이 반복될 수 있다.
또한, 이들 2개의 돌연변이는 동시에 도입될 수 있다. 본 발명자들은 하나는 srtA와 매치되고, 다른 것은 bgaA와 매치되는 2개의 스페이서를 함유하는 표적화 작제물을 설계하였으며, 그것을 동시에 교정 주형 둘 모두와 동시-형질전환시켰다(도 25e). 형질전환체의 유전자 분석에 의해, 교정이 8개 중 6개 경우에서 발생하는 것으로 나타났다(도 25f). 특히, 나머지 2개의 클론은 각각 ΔsrtA 또는 ΔbgaA 결실 중 어느 하나를 함유하였으며, 이는 Cas9를 사용하여 조합 돌연변이유발을 수행할 가능성을 뒷받침한다. 마지막으로, CRISPR 서열을 제거하기 위하여, 본 발명자들은 야생형 균주 R6 유래의 게놈 DNA와 함께 bgaA 표적 및 스펙티노마이신 내성 유전자를 함유하는 플라스미드를 도입하였다. 플라스미드를 보유하는 스펙티노마이신-내성 형질전환체에는 CRISPR 서열이 제거되었다(도 34a 및 도 34d).
교정의 메카니즘 및 효율: Cas9를 사용한 게놈 교정의 근본 메카니즘을 이해하기 위하여, 본 발명자들은 교정 효율을 Cas9 절단과 독립적으로 측정하는 실험을 설계하였다. 본 발명자들은 ermAM 에리트로마이신 내성 유전자를 srtA 유전자좌에 통합시키고, Cas9-매개의 교정을 사용하여 조기 종결 코돈을 도입하였다(도 33). 얻어진 균주(JEN53)는 ermAM(종결) 대립형질을 함유하며, 에리트로마이신에 감수성이다. 이러한 균주를 사용하여, Cas9 절단의 사용과 함께 또는 이것 없이 항생제 내성을 수복하는 세포의 분율을 측정함으로써 ermAM 유전자가 수복되는 효율을 평가할 수 있다. JEN53을 ermAM(종결) 대립형질을 표적화하는 카나마이신-내성 CRISPR 작제물(CRISPR::ermAM(종결)) 또는 스페이서가 없는 대조군 작제물(CRISPR::Ø) 중 어느 하나와 함께 야생형 대립형질을 수복하는 교정 주형으로 형질전환시켰다(도 26a 및 도 26b). 카나마이신 선택의 부재 하에, 교정된 콜로니의 분율은 대략 10-2이었으며(에리트로마이신-내성 cfu/총 cfu)(도 26c), 이는 교정되지 않은 세포에 대한 Cas9-매개의 선택 부재의 재조합의 기준선 빈도를 나타낸다. 그러나, 카나마이신 선택을 적용하고, 대조군 CRISPR 작제물을 동시-형질전환시키면, 교정된 콜로니의 분율이 약 10-1로 증가되었다(카나마이신- 및 에리트로마이신-내성 cfu/카나마이신-내성 cfu)(도 26c). 이러한 결과는 ermAM 유전자좌에서의 재조합에 대하여 동시-선택되는 CRISPR 유전자좌의 재조합에 대한 선택이, 게놈의 Cas9 절단과 독립적인 것을 보여주며, 이는 세포의 하위집단이 형질전환 및/또는 재조합 경향이 더 큰 것을 시사한다. CRISPR::ermAM(종결) 작제물의 형질전환에 이어서 카나마이신 선택은 에리트로마이신-내성, 교정된 세포의 분율의 99%까지의 증가를 야기하였다(도 26c). 이러한 증가가 교정되지 않은 세포의 사멸에 의해 야기되는지 결정하기 위하여, 본 발명자들은 CRISPR::ermAM(종결) 또는 CRISPR::Ø 작제물로의 JEN53 세포의 동시-형질전환 후에 수득되는 카나마이신-내성 콜로니 형성 단위(cfu)를 비교하였다.
본 발명자들은 ermAM(종결) 작제물의 형질전환 후에 5.3배 더 적은 카나마이신-내성 콜로니를 계수하였으며(2.5×104/4.7×103, 도 35a), 이 결과는 실제로 Cas9에 의한 염색체 유전자좌의 표적화가 교정되지 않은 세포의 사멸을 야기하는 것을 시사한다. 마지막으로, 박테리아 염색체 내의 dsDNA 파단의 도입은 손상된 DNA의 재조합 비율을 증가시키는 수복 메카니즘을 촉발시키는 것으로 알려져 있기 때문에, 본 발명자들은 Cas9에 의한 절단이 교정 주형의 재조합을 유도하는지를 조사하였다. 본 발명자들은 CRISPR::Ø 작제물과의 동시-형질전환보다 CRISPR::erm(종결) 작제물과의 동시-형질전환 후에 2.2배 더 많은 콜로니를 계수하였으며(도 26d), 이는 온건한 재조합의 유도가 존재함을 나타낸다. 이들 결과는 함께, 형질전환가능한 세포의 동시-선택, Cas9-매개의 절단에 의한 재조합의 유도 및 교정되지 않은 세포에 대한 선택, 각각이 스트렙토코커스 뉴모니애에서 높은 효율의 게놈 교정에 기여하는 것을 보여준다.
Cas9에 의한 게놈의 절단이 교정되지 않은 세포를 사멸시킬 것이기 때문에, 카나마이신 내성-함유 Cas9 카세트를 제공받고, 교정 주형을 제공받지 않은 임의의 세포를 회수할 것으로 예상되지 않을 것이다. 그러나, 교정 주형의 부재 하에, 본 발명자들은 CRISPR::ermAM(종결) 작제물의 형질전환 후에 많은 카나마이신-내성 콜로니를 회수하였다(도 35a). CRISPR-유도 사멸을 '도피하는' 이들 세포는 방법의 한계를 결정하는 백그라운드를 보여주었다. 이러한 백그라운드 빈도는 이러한 실험에서 CRISPR::ermAM(종결)/CRISPR::Ø cfu의 비, 2.6×10- 3(7.1×101/2.7×104)로서 계산될 수 있어서, 교정 주형의 재조합 빈도가 이러한 값 미만이면, CRISPR 선택은 백그라운드보다 요망되는 돌연변이체를 효율적으로 회수할 수 없음을 의미한다. 이들 세포의 기원을 이해하기 위하여, 본 발명자들은 8개의 백그라운드 콜로니를 유전자형 분석하고, 7개가 표적화 스페이서의 결실을 함유하고(도 35b), 하나가 아마도 Cas9에 불활성화 돌연변이를 갖는 것을 발견하였다(도 35c).
에스케리키아 콜라이에서 Cas9를 사용한 게놈 교정: CRISPR-Cas 시스템의 염색체 통합을 통한 Cas9 표적화의 활성화는 고도의 재조합유발(recombinogenic) 유기체에서만 가능하다. 다른 미생물에 적용가능한 더욱 일반적인 방법을 개발하기 위하여, 본 발명자들은 플라스미드 기반의 CRISPR-Cas 시스템을 사용하여 에스케리키아 콜라이에서 게놈 교정을 수행하기로 하였다. 2개의 플라스미드를 작제하였다: tracrRNA, Cas9 및 클로람페니콜 내성 카세트를 지니는 pCas9 플라스미드(도 36) 및 CRISPR 스페이서의 어레이를 지니는 pCRISPR 카나마이신-내성 플라스미드. CRISPR 선택과 독립적으로 교정의 효율을 측정하기 위하여, 본 발명자들은 스트렙토마이신 내성을 부여하는 rpsL 유전자에서 A에서 C로의 전환의 도입을 추구하였다. 본 발명자들은 야생형의 Cas9 절단을 유도할 스페이서를 지니지만 돌연변이 rpsL 대립형질을 지니지 않는 pCRISPR::rpsL 플라스미드를 작제하였다(도 27b). 먼저, pCas9 플라스미드를 에스케리키아 콜라이 MG1655로 도입하고, 얻어진 균주를 pCRISPR::rpsL 플라스미드와, W542, A에서 C로의 돌연변이를 함유하는 교정 올리고뉴클레오티드를 동시-형질전환시켰다. pCRISPR::rpsL 플라스미드의 형질전환 후에 스트렙토마이신-내성 콜로니만을 회수하였으며, 이는 Cas9 절단이 올리고뉴클레오티드의 재조합을 유도하는 것을 시사한다(도 37). 그러나, 스트렙토마이신-내성 콜로니의 개수는 아마도 Cas9에 의한 절단을 피하는 세포인 카나마이신-내성 콜로니의 개수보다 100배 더 적었다. 따라서, 이들 조건에서, Cas9에 의한 절단은 돌연변이의 도입을 용이하게 하지만, 효율은 '도피물'의 백그라운드보다 많이 돌연변이 세포를 선택하기에 충분하지 않았다.
에스케리키아 콜라이에서 게놈 교정의 효율을 향상시키기 위하여, 본 발명자들은 Cas9-유도 세포사를 사용하여, 리컴비니어링과 함께 본 발명자들의 CRISPR 시스템을 적용하여, 요망되는 돌연변이를 선택하였다. pCas9 플라스미드를 리컴비니어링 균주 HME63(31)으로 도입하였으며, 이는 □-레드(red) 파지의 Gam, Exo 및 Beta 기능을 함유한다. 얻어진 균주를 pCRISPR::rpsL 플라스미드(또는 pCRISPR::Ø 대조군) 및 W542 올리고뉴클레오티드와 동시-형질전환시켰다(도 27a). 리컴비니어링 효율은 5.3×10-5이었으며, 대조군 플라스미드를 사용하는 경우 스트렙토마이신-내성이 되는 전체 세포의 분율로서 계산하였다(도 27c). 대조적으로, pCRISPR::rpsL 플라스미드로의 형질전환은 돌연변이 세포의 백분율을 65 ± 14%로 증가시켰다(도 27c 및 도 29f). 본 발명자들은 pCRISPR::rpsL 플라스미드의 형질전환 후에 cfu의 수가 대조군 플라스미드보다 약 1000배 감소하는 것을 관찰하였으며(4.8×105/5.3×102, 도 38a), 이는 선택이 교정되지 않은 세포의 CRISPR-유도 사멸로부터 야기됨을 시사한다. 본 발명자들의 방법의 중요한 매개변수인 Cas9 절단이 불활성화되는 비율을 측정하기 위하여, 본 발명자들은 W542 교정 올리고뉴클레오티드 없이, pCRISPR::rpsL 또는 대조군 플라스미드 중 어느 하나로 세포를 형질전환시켰다(도 38a). pCRISPR::rpsL/pCRISPR::Ø cfu의 비로 측정되는 CRISPR '도피물'의 백그라운드는 2.5×10-4(1.2×102/4.8×105)이었다. 이들 도피물 중 8개의 유전자형 분석에 의해, 모든 경우에, 표적화 스페이서의 결실이 존재하였음이 드러났다(도 38b). 이러한 백그라운드는 rpsL 돌연변이의 리컴비니어링 효율, 5.3×10-5보다 더 높았으며, 이는 65%의 교정된 세포를 얻기 위하여, Cas9 절단이 올리고뉴클레오티드 재조합을 유도해야 하는 것을 시사한다. 이를 확인하기 위하여, 본 발명자들은 pCRISPR::rpsL 또는 pCRISPR::Ø의 형질전환 후에 카나마이신- 및 스트렙토마이신-내성 cfu의 수를 비교하였다(도 27d). 스트렙토코커스 뉴모니애에서와 같이, 본 발명자들은 온건한 재조합의 유도, 약 6.7배(2.0×10-4/3.0×10-5)를 관찰하였다. 이들 결과는 함께, CRISPR 시스템이 리컴비니어링에 의해 도입되는 돌연변이의 선택 방법을 제공함을 나타낸다.
본 발명자들은 CRISPR-Cas 시스템이 야생형 세포를 사멸시키는 표적화 작제물과, CRISPR 절단을 제거하고, 요망되는 돌연변이를 도입하는 교정 주형의 동시-도입에 의해 박테리아에서 표적화된 게놈 교정을 위해 사용될 수 있음을 보여주었다. 상이한 유형의 돌연변이(삽입, 결실 또는 무흔적 단일-뉴클레오티드 치환)가 생성될 수 있다. 다중 돌연변이가 동시에 도입될 수 있다. CRISPR 시스템을 사용한 교정의 특이성 및 다능성은 Cas9 엔도뉴클레아제의 몇몇 독특한 특성에 좌우된다: (i) 그의 표적 특이성은 효소를 조작할 필요 없이, 작은 RNA로 프로그램화될 수 있고, (ii) 20 bp RNA-DNA 상호작용에 의해 결정되는 표적 특이성이 매우 높고, 비-표적 인식의 가능성이 낮았으며, (iii) 대부분의 서열이 표적화될 수 있고, 유일한 요건은 인접 NGG 서열의 존재이며, (iv) NGG 서열 내의 대부분의 돌연변이 및 프로토스페이서의 씨드 서열 내의 돌연변이가 표적화를 없앤다.
본 발명자들은 CRISPR 시스템을 사용한 게놈 조작이 고도의 재조합유발 박테리아, 예를 들어, 스트렙토코커스 뉴모니애에서뿐 아니라 에스케리키아 콜라이에서도 작동되었음을 보여주었다. 에스케리키아 콜라이에서의 결과는 상기 방법이 플라스미드가 도입될 수 있는 다른 미생물에 적용가능할 수 있음을 시사한다. 에스케리키아 콜라이에서, 상기 방법은 돌연변이유발 올리고뉴클레오티드의 리컴비니어링을 보완한다. 리컴비니어링이 가능하지 않은 미생물에서 이러한 방법을 사용하기 위하여, 플라스미드 상의 교정 주형을 제공함으로써 숙주 상동성 재조합 기구가 사용될 수 있다. 또한, 축적된 증거는 CRISPR-매개의 염색체의 절단이 많은 박테리아 및 고세균에서 세포사를 야기하는 것을 나타내기 때문에, 교정의 목적으로 내인성 CRISPR-Cas 시스템을 사용하는 것을 계획할 수 있다.
스트렙토코커스 뉴모니애 및 에스케리키아 콜라이 둘 모두에서, 본 발명자들은 Cas9 절단에 의한 표적 부위에서의 작은 재조합의 유도 및 형질전환가능한 세포의 동시-선택에 의해 교정이 용이하게 되지만, 교정에 가장 기여하는 메카니즘은 비-교정 세포에 대한 선택이었음을 관찰하였다. 따라서, 상기 방법의 주요 제약은 CRISPR-유도 세포사를 피하고, 요망되는 돌연변이가 결여된 세포의 백그라운드의 존재였다. 본 발명자들은 이들 '도피물'이 아마도 표적화 스페이서의 측부에 배치된 반복 서열의 재조합 후에, 주로 표적화 스페이서의 결실을 통해 발생함을 보여주었다. 추가의 개선은 기능성 crRNA의 생물발생을 지지할 수 있으나, 서로 충분히 상이하여, 재조합을 없애는 플랭킹 서열의 조작에 집중할 수 있다. 대안적으로, 키메라 crRNA의 직접적인 형질전환이 연구될 수 있다. 특정 경우의 에스케리키아 콜라이에서, 이러한 유기체가 클로닝 숙주로도 사용되었다면, CRISPR-Cas 시스템의 작제는 가능하지 않았다. 본 발명자들은 Cas9 및 tracrRNA를 CRISPR 어레이와 상이한 플라스미드에 배치함으로써 이러한 문제를 해결하였다. 또한, 유도가능한 시스템의 조작으로 이러한 제약을 피할 수 있다.
신규한 DNA 합성 기술이 높은 처리율로, 비용 효율적으로 임의의 서열을 생성하는 능력을 제공하지만, 생 세포에 합성 DNA를 통합시켜, 기능성 게놈을 생성하려는 도전과제가 남아 있다. 최근에, 동시-선택 MAGE 전략은 주어진 유전자좌에서 또는 그 근처에서 재조합을 달성할 가능성이 증가된 세포의 하위집단을 선택함으로써, 리컴비니어링의 돌연변이 효율을 향상시키는 것으로 나타났다. 이러한 방법에서, 선택가능한 돌연변이의 도입을 사용하여 인근의 선택 불가능한 돌연변이의 생성 기회를 증가시킨다. 이러한 전략에 의해 제공되는 간접적 선택에 반대로, CRISPR 시스템의 사용은 요망되는 돌연변이를 직접적으로 선택하고, 그를 높은 효율로 회수할 수 있게 한다. 이들 기술을 유전자 조작의 툴박스(toolbox)에 부가하고, DNA 합성과 함께, 그들은 실질적으로 생물공학 목적을 위해 유기체를 조작하는 능력 및 유전자 기능을 해독하는 능력 둘 모두를 진전시킬 수 있다. 또한, 2개의 다른 연구는 포유동물 게놈의 CRISPR-보조 조작에 관한 것이다. 이들 crRNA-유도 게놈 교정 기술이 기초 과학 및 의학에 광범위하게 유용할 수 있는 것으로 예상된다.
균주 및 배양 조건. 스트렙토코커스 뉴모니애 균주 R6은 알렉산더 토마즈(Alexander Tomasz) 박사에 의해 제공되었다. 균주 crR6을 이전의 연구에서 생성하였다. 스트렙토코커스 뉴모니애의 액체 배양물을 THYE 배지(30g/ℓ 토드-헤위트(Todd-Hewitt) 아가, 5 g/ℓ 효모 추출물)에서 성장시켰다. 세포를 5% 피브린 제거 양 혈액이 보충된 TSA(tryptic soy agar)에 플레이팅하였다. 적절한 경우, 하기와 같은 항생제를 첨가하였다: 카나마이신(400 ㎍/㎖), 클로람페니콜(5 ㎍/㎖), 에리트로마이신(1 ㎍/㎖), 스트렙토마이신(100 ㎍/㎖) 또는 스펙티노마이신(100 ㎍/㎖). β-갈락토시다제 활성의 측정은 이전에 기술된 바와 같은 밀러 검정을 사용하여 이루어졌다.
에스케리키아 콜라이 균주 MG1655 및 HME63(MG1655로부터 유래, Δ(argF-lac) U169 λ cI857 Δcro-bioA galK tyr 145 UAG mutS<>amp)(31)은 각각 제프 로버츠(Jeff Roberts) 및 도날드 코트(Donald Court)에 의해 제공받았다. 에스케리키아 콜라이의 액체 배양물을 LB 배지(디프코)에서 성장시켰다. 적절한 경우, 다음과 같은 항생제를 첨가하였다: 클로람페니콜(25 ㎍/㎖), 카나마이신(25 ㎍/㎖) 및 스트렙토마이신(50 ㎍/㎖).
스트렙토코커스 뉴모니애 형질전환. 컴피턴트 세포를 이전에 기술된 바와 같이 제조하였다(23). 모든 게놈 교정 형질전환을 위하여, 세포를 얼음 위에서 온건하게 해동시키고, 100 ng/㎖의 컴피턴스-자극 펩티드 CSP1가 보충된 10배 부피의 M2 배지에 재현탁화시킨 다음(40), 교정 작제물을 첨가하였다(교정 작제물을 0.7 ng/㎕ 내지 2.5 ㎍/㎕의 최종 농도로 세포에 첨가하였다). 세포를 2 ㎕의 표적화 작제물의 첨가 전에 37℃에서 20분 인큐베이션시킨 다음, 37℃에서 40분 인큐베이션시켰다. 세포의 단계 희석액을 적절한 배지에 플레이팅하여, 콜로니 형성 단위(cfu) 계수를 결정하였다.
에스케리키아 콜라이 람다 - 레드 리컴비니어링. 균주 HME63을 모든 리컴비니어링 실험을 위해 사용하였다. 이전에 공개된 프로토콜(6)에 따라 리컴비니어링 세포를 제조하고, 취급하였다. 약술하면, 플레이트로부터 수득된 단일의 콜로니로부터 접종된 2 ㎖의 밤샘 배양물(LB 배지)을 30℃에서 성장시켰다. 밤샘 배양물을 100배 희석하고, OD600이 0.4 내지 0.5가 될 때까지(대략 3시간), 진탕시키면서(200rpm) 30℃에서 성장시켰다. 람다-레드 유도를 위하여, 배양물을 42℃ 수조로 옮겨, 200rpm에서 15분 동안 진탕시켰다. 유도 직후에, 배양물을 얼음-물 슬러리에서 와류시키고, 얼음에서 5 내지 10분 동안 냉각시켰다. 그 다음, 세포를 프로토콜에 따라 세척하고 분취하였다. 전기-형질전환을 위하여, 50 ㎕의 세포를 1 mM의 무염 올리고(IDT) 또는 100 내지 150 ng의 플라스미드 DNA(퀴아프렙 스핀 미니프렙 키트(퀴아젠)로 제조)와 혼합하였다. 세포를 1.8kV에서 1 ㎜ 진 펄서 큐벳(Gene Pulser cuvette)(바이오-래드)을 사용하여 전기천공시키고, 1 ㎖의 실온 LB 배지에 바로 재현탁화시켰다. 세포를 30℃에서 1 내지 2시간 동안 회수한 후에, 적절한 항생제 내성이 있는 LB 아가에 플레이팅하고, 32℃에서 하룻밤 인큐베이션시켰다.
스트렙토코커스 뉴모니애 게놈 DNA의 제조. 형질전환 목적을 위하여, 스트렙토코커스 뉴모니애 게놈 DNA를 제조사(프로메가)에 의해 제공되는 지침서에 따라, 위자드(Wizard) 게놈 DNA 정제 키트를 사용하여 추출하였다. 유전자형 분석 목적을 위하여, 700 ㎕의 하룻밤 스트렙토코커스 뉴모니애 배양물을 펠렛화시키고, 60 ㎕의 라이소자임 용액(2 ㎎/㎖)에 재현탁화시키고, 37℃에서 30분 인큐베이션시켰다. 게놈 DNA를 퀴아프렙 스핀 미니프렙 키트(퀴아젠)를 사용하여 추출하였다.
균주 작제. 이러한 연구에 사용되는 모든 프라이머는 표 G에 제공되어 있다. 스트렙토코커스 뉴모니애 crR6M을 생성하기 위하여, 중간체 균주, LAM226을 제조하였다. 이러한 균주에서, 스트렙토코커스 뉴모니애 crR6 균주의 CRISPR 어레이에 인접한 aphA-3 유전자(카나마이신 내성 제공)를 cat 유전자(클로람페니콜 내성 제공)로 대체시켰다. 약술하면, crR6 게놈 DNA를 각각 프라이머 L448/L444 및 L447/L481을 사용하여 증폭시켰다. cat 유전자를 프라이머 L445/L446을 사용하여 플라스미드 pC194로부터 증폭시켰다. 각 PCR 산물을 겔-정제하고, 3개 모두를 프라이머 L448/L481을 사용하여 SOEing PCR에 의해 융합시켰다. 얻어진 PCR 산물을 컴피턴트 스트렙토코커스 뉴모니애 crR6 세포로 형질전환시키고, 클로람페니콜-내성 형질전환체를 선택하였다. 스트렙토코커스 뉴모니애 crR6M을 생성하기 위하여, 스트렙토코커스 뉴모니애 crR6 게놈 DNA를 각각 프라이머 L409/L488 및 L448/L481을 사용하여 PCR에 의해 증폭시켰다. 각 PCR 산물을 겔-정제하고, 그들을 프라이머 L409/L481을 사용하여 SOEing PCR에 의해 융합시켰다. 얻어진 PCR 산물을 컴피턴트 스트렙토코커스 뉴모니애 LAM226 세포로 형질전환시키고, 카나마이신-내성 형질전환체를 선택하였다.
스트렙토코커스 뉴모니애 crR6Rc를 생성하기 위하여, 스트렙토코커스 뉴모니애 crR6M 게놈 DNA를 프라이머 L430/W286을 사용하여 PCR에 의해 증폭시키고, 스트렙토코커스 뉴모니애 LAM226 게놈 DNA를 프라이머 W288/L481을 사용하여 PCR에 의해 증폭시켰다. 각각의 PCR 산물을 겔-정제하고, 그들을 프라이머 L430/L481을 사용하여 SOEing PCR에 의해 융합시켰다. 얻어진 PCR 산물을 컴피턴트 스트렙토코커스 뉴모니애 crR6M 세포로 형질전환시키고, 클로람페니콜-내성 형질전환체를 선택하였다.
스트렙토코커스 뉴모니애 crR6Rk를 생성하기 위하여, 스트렙토코커스 뉴모니애 crR6M 게놈 DNA를 각각 프라이머 L430/W286 및 W287/L481을 사용하여 PCR에 의해 증폭시켰다. 각 PCR 산물을 겔-정제하고, 그들을 프라이머 L430/L481을 사용하여 SOEing PCR에 의해 융합시켰다. 얻어진 PCR 산물을 컴피턴트 스트렙토코커스 뉴모니애 crR6Rc 세포로 형질전환시키고, 카나마이신-내성 형질전환체를 선택하였다.
JEN37을 생성하기 위하여, 스트렙토코커스 뉴모니애 crR6Rk 게놈 DNA를 각각 프라이머 L430/W356 및 W357/L481을 사용하여 PCR에 의해 증폭시켰다. 각각의 PCR 산물을 겔-정제하고, 그들을 프라이머 L430/L481을 사용하여 SOEing PCR에 의해 융합시켰다. 얻어진 PCR 산물을 컴피턴트 스트렙토코커스 뉴모니애 crR6Rc 세포로 형질전환시키고, 카나마이신-내성 형질전환체를 선택하였다.
JEN38을 생성하기 위하여, R6 게놈 DNA를 각각 프라이머 L422/L461 및 L459/L426을 사용하여 증폭시켰다. ermAM 유전자(에리트로마이신 내성 지정)를 프라이머 L457/L458을 사용하여 플라스미드 pFW15 43으로부터 증폭시켰다. 각각의 PCR 산물을 겔-정제하고, 3개 모두를 프라이머 L422/L426을 사용하여 SOEing PCR에 의해 융합시켰다. 얻어진 PCR 산물을 컴피턴트 스트렙토코커스 뉴모니애 crR6Rc 세포로 형질전환시키고, 에리트로마이신-내성 형질전환체를 선택하였다.
스트렙토코커스 뉴모니애 JEN53을 2 단계로 생성하였다. 먼저, JEN43을 도 33에 예시된 바와 같이 작제하였다. JEN25의 게놈 DNA를 컴피턴트 JEN43 세포로 형질전환시키고, 클로람페니콜 및 에리트로마이신 둘 모두에서 선택함으로써 JEN53을 생성하였다.
스트렙토코커스 뉴모니애 JEN62를 생성하기 위하여, 스트렙토코커스 뉴모니애 crR6Rk 게놈 DNA를 각각 프라이머 W256/W365 및 W366/L403을 사용하여 PCR에 의해 증폭시켰다. 각각의 PCR 산물을 정제하고, 깁슨 조립에 의해 라이게이션시켰다. 조립 산물을 컴피턴트 스트렙토코커스 뉴모니애 crR6Rc 세포로 형질전환시키고, 카나마이신-내성 형질전환체를 선택하였다.
플라스미드 작제. pDB97을 인산화 및 올리고뉴클레오티드 B296/B297의 어닐링에 이어서 EcoRI/BamHI에 의해 분해된 pLZ12spec에서의 라이게이션을 통해 작제하였다. 본 발명자들은 pLZ12spec를 완전히 시퀀싱하고, 유전자은행(genebank)에 그 서열을 기탁하였다(수탁 번호: KC112384).
CRISPR 리더 서열을 반복부-스페이서-반복부 단위와 함께 pLZ12spec로 클로닝한 후에 pDB98을 수득하였다. 이는 프라이머 B298/B320 및 B299/B321을 사용한 crR6Rc DNA의 증폭에 이어서, 둘 모두의 산물의 SOEing PCR 및 제한 부위 BamHI/EcoRI을 사용한 pLZ12spec에서의 클로닝을 통해 달성되었다. 이러한 방식으로, pDB98 내의 스페이서 서열이 서로 반대 방향으로 2개의 BsaI 제한 부위를 함유하여 신규한 스페이서의 무흔적 클로닝을 가능하게 하도록 조작하였다.
올리고뉴클레오티드 B300/B301(pDB99), B302/B303(pDB100), B304/B305(pDB101), B306/B307(pDB102), B308/B309(pDB103), B310/B311(pDB104), B312/B313(pDB105), B314/B315(pDB106), B315/B317(pDB107), B318/B319(pDB108)의 어닐링에 이어서, BsaI에 의한 pDB98 절단부에서의 라이게이션에 의해, pDB99 내지 pDB108을 작제하였다.
pCas9 플라스미드를 하기와 같이 작제하였다. 필수 CRISPR 요소를 깁슨 조립을 위한 측부에 배치된 상동성 암과 함께 스트렙토코커스 피오게네스 SF370 게놈 DNA로부터 증폭시켰다. tracrRNA 및 Cas9를 올리고 HC008 및 HC010으로 증폭시켰다. 리더 및 CRISPR 서열을 HC011/HC014 및 HC015/HC009로 증폭시켜, 2개의 BsaI IIS형 부위를 2개의 직접 반복부 사이에 도입하여, 스페이서의 용이한 삽입을 가능하게 하였다.
올리고 B298+B299를 사용한 증폭, 및 EcoRI 및 BamHI으로의 제한 분해를 통해 pCas9 CRISPR 어레이를 pZE21-MCS1에 서브클로닝함으로써 pCRISPR을 작제하였다. 올리고 B352+B353의 어닐링 및 BsaI 절단 pCRISPR로의 클로닝에 의해 rpsL 표적화 스페이서를 클로닝하여, pCRISPR::rpsL을 제공하였다.
표적화 및 교정 작제물의 생성. 게놈 교정에 사용되는 표적화 작제물을 좌측(Left) PCR 및 우측(Right) PCR의 깁슨 조립에 의해 제조하였다(표 G). 교정 작제물을 적용가능한 경우 PCR 산물 A(PCR A), PCR 산물 B(PCR B) 및 PCR 산물 C(PCR C)를 융합시키는 SOEing PCR에 의해 제조하였다(표 G). CRISPR::Ø 및 CRISPR::ermAM(종결) 표적화 작제물을 올리고 L409 및 L481을 사용하여, 각각 JEN62 및 crR6 게놈 DNA의 PCR 증폭에 의해 생성하였다.
무작위 PAM 또는 프로토스페이서 서열이 있는 표적의 생성. 스페이서 1 표적 뒤의 5개 뉴클레오티드를 프라이머 W377/ L426을 사용한 R68232.5 게놈 DNA의 증폭을 통해 무작위화시켰다. 그 다음, 이러한 PCR 산물을 프라이머 L422/W376을 사용하여 동일한 주형으로부터 증폭되는 cat 유전자 및 srtA 상류 영역과 조립하였다. 80 ng의 조립된 DNA를 사용하여 균주 R6 및 crR6을 형질전환시켰다. 무작위 표적에 대한 샘플을 하기의 프라이머를 사용하여 제조하였다: 표적의 염기 1 내지 10을 무작위화시키기 위한 B280-B290/L426 및 염기 10 내지 20을 무작위화시키기 위한 B269-B278/L426. 프라이머 L422/B268 및 L422/B279를 사용하여, cat 유전자 및 srtA 상류 영역을 증폭시켜, 각각 처음 및 마지막 10개 PCR 산물과 조립하였다. 조립된 작제물을 함께 풀링하고, 30 ng을 R6 및 crR6에 형질전환시켰다. 형질전환 후에, 세포를 클로람페니콜 선택 하에 플레이팅하였다. 각 샘플에 대하여 2×105개 초과의 세포를 1 ㎖의 THYE에서 함께 풀링하고, 게놈 DNA를 프로메가 위자드 키트로 추출하였다. 프라이머 B250/B251을 사용하여 표적 영역을 증폭시켰다. PCR 산물에 태그를 붙이고, 300 사이클을 사용하여 하나의 일루미나 MiSeq 쌍형성 말단 레인에서 전개시켰다.
딥 시퀀싱 데이터의 분석.
무작위화된 PAM: 무작위화된 PAM 실험을 위하여, 3,429,406개의 판독치를 crR6에 대하여 수득하고, 3,253,998개를 R6에 대하여 수득하였다. 그들 중 오직 절반만이 PAM-표적에 상응할 것으로 예상되고, 나머지 반은 PCR 산물의 다른 말단에 배열될 것으로 예상될 것이다. crR6 판독치 중 1,623,008개 및 R6 판독치 중 1,537,131개가 오류가 없는 표적 서열을 지닌다. 이들 판독치 중에, 각각의 가능한 PAM의 발생은 보충 파일에 나타나 있다. PAM의 기능성을 추정하기 위하여, R6 샘플에 비한 crR6 샘플에서의 그의 상대적 비율을 계산하고, rijklm으로 표기하고, 여기서, I,j,k,l,m은 4개의 가능한 염기 중 하나이다. 하기의 통계 모델을 구축하였다:
상기 식에서, ε은 잔차 오차이고, b2는 PAM의 제2 염기의 영향이고, b3은 제3 염기의 영향이며, b4는 제4 염기의 영향이고, b2b3은 제2 염기와 제3 염기 간의 상호작용이며, b3b4는 제3 염기와 제4 염기 간의 상호작용이다. 분산의 분석을 수행하였다:

이러한 모델에 부가되는 경우, b1 또는 b5는 유의미한 것으로 보이지 않으며, 포함되는 것 이외의 상호작용도 또한 폐기될 수 있다. 모델 선택은 R의 분산분석 방법을 사용하여 거의 완전한 모델의 연속적 비교를 통해 이루어졌다. 터키스 아니스트 유의성 검정(Tukey’s honest significance test)을 사용하여 영향들 간의 쌍별 차이가 유의미한지를 결정하였다.
NGGNN 패턴은 모든 다른 패턴과 유의미하게 상이하고 가장 강력한 영향을 지닌다(하기 표 참조).
위치 1, 4 또는 5가 NGGNN 패턴에 영향을 미치지 않는 것을 보여주기 위하여, 본 발명자들은 오직 이들 서열만을 검토하였다. 그들의 영향은 정규 분포되는 것으로 나타나며(도 71의 QQ 플롯 참조), R의 분산분석 방법을 사용하는 모델 비교는 널(null) 모델이 최적의 것임을 보여주며, 다시 말하면, b1, b4 및 b5의 유의미한 영향이 존재하지 않는다.

NAGNN 및 NNGGN 패턴의 부분 간섭
NAGNN 패턴은 모든 다른 패턴과 유의미하게 상이하나 NGGNN보다 훨씬 더 적은 영향을 지닌다(하기 터키스 아니스트 유의성 검정 참조).
마지막으로, NTGGN 및 NCGGN 패턴은 유사하며, 본페로니 조정 쌍별 스튜던트-검정(student-test)에 의해 나타내는 바와 같이, NTGHN 및 NCGHN 패턴(여기서, H는 A, T 또는 C임)보다 유의미하게 더 많은 CRISPR 간섭을 보인다.

이들 결과는 함께, 일반적으로 NNGGN 패턴이 NGGGN의 경우에 완전한 간섭 또는 NAGGN, NTGGN 또는 NCGGN의 경우에 부분적 간섭을 생성한다는 결론에 이르게 한다.

무작위화된
표적
무작위화 표적 실험을 위하여, 540,726개 판독치를 crR6에 대하여 수득하고, 753,570개를 R6에 대하여 수득하였다. 전술한 바와 같이, 판독치의 오직 절반만이 PCR 산물의 대상 말단에 배열되는 것으로 예상된다. 오류가 없거나 단일의 점 돌연변이가 있는 표적을 지니는 판독치에 대한 필터링 후에, 217,656개 및 353,141개의 판독치가 각각 crR6 및 R6에 대하여 유지되었다. R6 샘플에 비한 crR6 샘플에서의 각 돌연변이체의 상대 비율을 계산하였다(도 24c). 씨드 서열 외측의 모든 돌연변이(PAM으로부터 13 내지 20개 염기가 떨어져 있음)는 완전한 간섭을 보인다. 그들 서열을 참조물질로 사용하여, 씨드 서열 내측의 다른 돌연변이가 간섭을 상당히 방해하는 것이라 할 수 있는지를 결정하였다. 정규 분포를 MASS R 패키지의 fitdistr 함수를 사용하여 이들 서열에 핏팅시켰다. 핏팅된 분포의 0.99 분위수는 도 24c에 점선으로 나타나 있다. 도 72는 핏팅된 정규 분포(흑색 선) 및 .99 분위수(점선)와 함께 데이터 밀도의 히스토그램을 보여준다.





실시예
6.
스트렙토코커스
피오게네스
Cas9(SpCas9로 지칭)에
대한 가이드 RNA의 최적화
본 발명자들은 세포에서 RNA를 증가시키기 위하여 tracrRNA 및 직접 반복부 서열을 돌연변이시키거나 키메라 가이드 RNA를 돌연변이시켰다.
최적화는 tracrRNA 및 가이드 RNA 내에 티민(T)의 스트레치가 존재한다는 관찰을 기초로 한 것이며, 이는 pol 3 프로모터에 의한 조기 전사 종결을 야기할 수 있다. 따라서, 본 발명자들은 하기의 최적화된 서열을 생성하였다. 최적화된 tracrRNA 및 상응하는 최적화된 직접 반복부가 쌍으로 제시되어 있다.
최적화된 tracrRNA 1(돌연변이는 밑줄):

최적화된 직접 반복부 1(돌연변이는 밑줄):
최적화된 tracrRNA 2(돌연변이는 밑줄):

최적화된 직접 반복부 2(돌연변이는 밑줄):
또한, 본 발명자들은 진핵 세포에서의 최적의 활성을 위해 키메라 가이드 RNA를 최적화시켰다.
원래 가이드 RNA:

최적화된 키메라 가이드 RNA 서열 1:

최적화된 키메라 가이드 RNA 서열 2:

최적화된 키메라 가이드 RNA 서열 3:

본 발명자들은 최적화된 키메라 가이드 RNA가 도 3에 나타낸 바와 같이 더 잘 작동하는 것을 보여주었다. 293FT 세포를 Cas9 및 U6-가이드 RNA DNA 카세트로 동시-트랜스펙션시켜, 상기 나타낸 4개의 RNA 형태 중 하나를 발현함으로써 실험을 행하였다. 가이드 RNA의 표적은 인간 Emx1 유전자좌 내의 동일한 표적 부위이다: "GTCACCTCCAATGACTAGGG".
실시예
7:
스트렙토코커스
써모필러스
LMD
-9
CRISPR1
Cas9(St1Cas9로 지칭)의
최적화
본 발명자들은 도 4에 나타낸 바와 같이 가이드 키메라 RNA를 설계하였다.
St1Cas9 가이드 RNA는 폴리 티민(T)의 스트레치를 파단시킴으로써, SpCas9 가이드 RNA에 대해서와 동일한 유형의 최적화를 겪을 수 있다.
실시예
8:
Cas9
다양성 및 돌연변이
CRISPR-Cas 시스템은 박테리아 및 고세균에 걸쳐 다양한 종에 의해 사용되는 침투하는 외인성 DNA에 대한 적응 면역 메카니즘이다. II형 CRISPR-Cas9 시스템은 CRISPR 유전자좌로의 외래 DNA의 "획득"을 담당하는 단백질을 암호화하는 유전자의 세트 및 DNA 절단 메카니즘의 "실행"을 암호화하는 유전자의 세트로 구성되며; 이들은 DNA 뉴클레아제(Cas9), 비-코딩 트랜스활성화 cr-RNA(tracrRNA), 및 직접 반복부가 측부에 배치된 외래 DNA-유래 스페이서의 어레이(crRNAs)를 포함한다. Cas9에 의한 성숙 시에, tracRNA 및 crRNA 듀플렉스는 Cas9 뉴클레아제를 스페이서 가이드 서열에 의해 특정되는 표적 DNA 서열로 안내하며, 절단에 필요하며 각각의 CRISPR-Cas 시스템에 특이적인 표적 DNA 내의 짧은 서열 모티프 근처의 DNA에서 이중 가닥 파단을 매개한다. II형 CRISPR-Cas 시스템이 박테리아 계에서 관찰되며, Cas9 단백질 서열 및 크기, tracrRNA 및 crRNA 직접 반복부 서열, 이들 요소의 게놈 구성 및 표적 절단을 위한 모티프 요건이 매우 다양하다. 하나의 종이 다중의 별개의 CRISPR-Cas 시스템을 가질 수 있다.
본 발명자들은 공지된 Cas9에 대한 서열 상동성 및 공지된 하위도메인에 이종상동성인 구조에 기초하여 확인된 박테리아 종으로부터, HNH 엔도뉴클레아제 도메인 및 RuvC 엔도뉴클레아제 도메인을 포함하는 207개의 추정의 Cas9를 평가하였다[유진 쿠닌(Eugene Koonin) 및 키라 마카로바(Kira Makarova)로부터의 정보]. 이러한 세트의 단백질 서열 보존에 기초한 계통발생 분석에 의해, 3개 그룹의 큰 Cas9(약 1400개 아미노산) 및 2개의 작은 Cas9(약 1100개 아미노산)를 포함하는 5개 과의 Cas9가 드러났다(도 39 및 도 40a 내지 도 40f).
이러한 실시예에서, 본 발명자들은 하기의 돌연변이가 SpCas9를 닉킹 효소로 전환시킬 수 있음을 보여준다: D10A, E762A, H840A, N854A, N863A, D986A.
본 발명자들은 돌연변이 점이 SpCas9 유전자 내에 위치하는 곳을 보여주는 서열을 제공한다(도 41). 또한, 본 발명자들은 닉카아제가 여전히 상동성 재조합을 매개할 수 있음을 보여준다(도 2에 표기된 검정). 추가로, 본 발명자들은 이들 돌연변이가 있는 SpCas9(개별적으로)가 이중 가닥 파단을 유도하지 않음을 보여준다(도 47).
실시예
9: RNA-유도
Cas9
뉴클레아제의 DNA
표적화
특이성에 대한 추가 사항
세포 배양 및 트랜스펙션
인간 배아 신장(HEK) 세포주 293FT(라이프 테크놀로지즈)를 5% CO2 인큐베이션과 함께 37℃에서 10% 우태아혈청(하이클론), 2mM GlutaMAX(라이프 테크놀로지즈), 100U/㎖ 페니실린 및 100 ㎍/㎖ 스트렙토마이신이 보충된 둘베코 변형 이글스 배지(DMEM)에서 유지시켰다.
293FT 세포를 트랜스펙션 24시간 전에, 6-웰 플레이트, 24-웰 플레이트 또는 96-웰 플레이트(코닝) 중 어느 하나에 씨딩하였다. 세포를 리포펙타민 2000(라이프 테크놀로지즈)을 사용하여 제조사의 권고 프로토콜에 따라 80 내지 90% 컨플루언스로 트랜스펙션시켰다. 6-웰 플레이트의 각 웰에 대하여, 총 1 ㎍의 Cas9+sgRNA 플라스미드를 사용하였다. 다르게 표시되지 않는 한, 24-웰 플레이트의 각 웰에 대하여, 총 500 ng의 Cas9+sgRNA 플라스미드를 사용하였다. 96-웰 플레이트의 각 웰에 대하여, 65 ng의 Cas9 플라스미드를 U6-sgRNA PCR 산물에 대하여 1:1 몰비로 사용하였다.
인간 배아 줄기 세포주 HUES9(하버드 줄기 세포 기관 코어(Harvard Stem Cell Institute core))를 100 ㎍/㎖ 노르모신(Normocin)(인비보겐(InvivoGen))이 보충된 mTesR 배지(스템셀 테크놀로지즈(Stemcell Technologies))에서 겔트렉스(GelTrex)(라이프 테크놀로지즈) 상에서 피더-부재(feeder-free) 조건으로 유지시켰다. HUES9 세포를 제조사의 프로토콜에 따라 아막사(Amaxa) P3 프라이머리 셀(Primary Cell) 4-D 뉴클레오펙터(Nucleofector) 키트(론자(Lonza))로 트랜스펙션시켰다.
게놈 변형에 대한 서베이어 뉴클레아제 검정
293FT 세포를 상기 기술된 바와 같이 플라스미드 DNA로 트랜스펙션시켰다. 세포를 게놈 DNA 추출 전에 트랜스펙션 후 72시간 동안 37℃에서 인큐베이션시켰다. 게놈 DNA를 제조사의 프로토콜에 따라 퀵익스트랙트 DNA 익스트랙션 용액(에피센트레)을 사용하여 추출하였다. 약술하면, 펠렛화된 세포를 퀵익스트랙트 용액에 재현탁화시키고, 65℃에서 15분 동안 및 98℃에서 10분 동안 인큐베이션하였다.
각 유전자에 대한 CRISPR 표적 부위의 측부에 배치된 게놈 영역을 PCR 증폭시키고(표 J 및 K에 열거된 프라이머), 산물을 제조사의 프로토콜에 따라 퀴아퀵 스핀 컬럼(퀴아젠)을 사용하여 정제하였다. 총 400ng의 정제된 PCR 산물을 2㎕ 10X Taq DNA 중합효소 PCR 완충제(엔자이머틱스) 및 초순수와 최종 부피 20㎕로 혼합하고, 재어닐링 과정을 거치게 하여 헤테로듀플렉스가 형성되게 하였다: 95℃에서 10 분, 95℃에서 85℃(-2℃/초로 램핑), 85℃에서 25℃(-0.25℃/초), 및 25℃에서 1분 유지. 재어닐링 후, 산물을 제조사의 권고 프로토콜에 따라 서베이어 뉴클레아제 및 서베이어 인핸서 S(트랜스게노믹스)로 처리하고, 4-20% 노벡스 TBE 폴리-아크릴아미드 겔(라이프 테크놀로지즈)에서 분석하였다. 겔을 SYBR 골드 DNA 염색제(라이프 테크놀로지즈)로 30분 동안 염색하고, Gel Doc 겔 영상화 시스템(바이오-라드)으로 영상화하였다. 정량화는 상대적 밴드 세기를 기반으로 하였다.
인간 세포 내의 tracrRNA 발현의 노던 블롯 분석
노던 블롯을 이전에 기술된 바와 같이 수행하였다. 약술하면, RNA를 8% 변성 폴리아크릴아미드 겔(SequaGel, 내셔널 디아그노스틱스)에 로딩하기 전에 5분 동안 95℃로 가열하였다. 그 후, RNA를 사전-혼성화 하이본드 N+ 멤브레인(지이 헬쓰케어)으로 옮기고, 스트라타진 UV 가교제(스트라타진)와 가교시켰다. 프로브를 T4 폴리뉴클레오티드 키나제(뉴 잉글랜드 바이오랩스)를 사용하여 [감마-32P] ATP(퍼킨 엘머)로 표지하였다. 세척 후에, 멤브레인을 1시간 동안 인광체 스크린에 노출시키고, 포스포르이미저(타이푼)로 스캔하였다.
DNA 메틸화 상태를 평가하기 위한 비설피트(bisulfite) 시퀀싱
HEK 293FT 세포를 상기 기술된 바와 같이 Cas9로 트랜스펙션시켰다. 게놈 DNA를 DNeasy 혈액 및 조직 키트(퀴아젠)를 사용하여 분리하고, EZ DNA 메틸레이션-라이트닝(Methylation-Lightning) 키트(자이모 리서치)를 사용하여 비설피트 전환시켰다. 비설피트 PCR을 비설피트 프라이머 시커(Bisulfite Primer Seeker)(자이모 리서치, 표 J 및 K)를 사용하여 설계된 프라이머와 함께 KAPA2G 로버스트 핫스타트(Robust HotStart) DNA 중합효소(카파 바이오시스템즈(KAPA Biosystems))를 사용하여 행하였다. 초래된 PCR 앰플리콘을 겔-정제하고, EcoRI 및 HindIII로 분해하고, pUC19 백본으로 라이게이션시킨 다음, 형질전환시켰다. 그 다음, 개별 클론을 생거 시퀀싱하여, DNA 메틸화 상태를 평가하였다.
시험관내 전사 및 절단 검정
HEK 293FT 세포를 상기 기술된 바와 같이 Cas9로 트랜스펙션시켰다. 그 다음, 전체 세포 용해물을 프로테아제 억제제 칵테일(Protease Inhibitor Cocktail)(로슈(Roche))이 보충된 용해 완충제(20 mM HEPES, 100 mM KCl, 5 mM MgCl2, 1 mM DTT, 5% 글리세롤, 0.1% 트리톤(Triton) X-100)로 제조하였다. T7-유도 sgRNA를 제조사의 권고된 프로토콜에 따라 맞춤형 올리고(실시예 10) 및 HiScribe T7 시험관내 전사 키트(NEB)를 사용하여 시험관내 전사시켰다. 메틸화 표적 부위를 만들기 위하여, pUC19 플라스미드를 M.SssI에 의해 메틸화시킨 다음, NheI에 의해 선형화시켰다. 시험관내 절단 검정을 하기와 같이 수행하였다: 20 ㎕ 절단 반응에 대하여, 10 ㎕의 세포 용해물을 2 ㎕의 절단 완충제(100 mM HEPES, 500 mM KCl, 25 mM MgCl2, 5 mM DTT, 25% 글리세롤), 시험관내 전사된 RNA 및 300 ng의 pUC19 플라스미드 DNA와 인큐베이션시킨다.
표적화 특이성을 평가하기 위한 딥 시퀀싱
96-웰 플레이트에 플레이팅된 HEK 293FT 세포를 게놈 DNA를 추출하기 72시간 전에, Cas9 플라스미드 DNA 및 단일의 가이드 RNA(sgRNA) PCR 카세트로 트랜스펙션시켰다(도 72). 각 유전자에 대한 CRISPR 표적 부위의 측부에 배치된 게놈 영역을 융합 PCR 방법에 의해 증폭시켜(도 74, 도 80)(실시예 10), 일루미나 P5 어댑터 및 독특한 샘플-특이적 바코드를 표적 앰플리콘에 부착시켰다(도 73에 기술된 개략도). PCR 산물을 제조사의 권고된 프로토콜에 따라 에코노스핀(EconoSpin) 96-웰 필터 플레이트(에포크 라이프 사이언스즈(Epoch Life Sciences))를 사용하여 정제하였다.
바코드가 부착되고 정제된 DNA 샘플을 Quant-iT 피코그린(PicoGreen) dsDNA 어세이 키트 또는 Qubit 2.0 플루오로미터(Fluorometer)(라이프 테크놀로지즈)에 의해 정량화하고, 등몰비로 풀링하였다. 그 다음, 시퀀싱 라이브러리를 일루미나 MiSeq 퍼스널 시퀀서(Personal Sequencer)(라이프 테크놀로지즈)를 사용하여 딥 시퀀싱하였다.
시퀀싱 데이터 분석 및 삽입-결실 검출
MiSeq 판독치를 적어도 23의 평균 프레드(Phred) 품질(Q 점수), 및 바코드 및 앰플리콘 정방향 프라이머에 대한 완벽한 서열 매치를 요구함으로써 필터링하였다. 온- 및 오프-표적 유전자좌로부터의 판독치를 먼저, 표적 부위의 상류 및 하류 50개 뉴클레오티드를 포함하는 앰플리콘 서열(총 120bp)에 대하여 스미스-워터만 정렬을 수행함으로써 분석하였다. 한편, 표적 부위의 5개 뉴클레오티드 상류에서 5개 뉴클레오티드 하류까지(총 30 bp) 삽입-결실에 대하여 정렬을 분석하였다. 그들의 정렬의 부분이 MiSeq 판독치 그 자체의 범위 밖에 있거나, 매치된 염기-쌍이 그들의 전체 길이의 85% 미만으로 포함되면, 분석된 표적 영역을 폐기하였다.
각 샘플에 대한 음성 대조군은 추정의 절단 사건으로서 삽입-결실의 포함 또는 배제에 대한 기준을 제공하였다. 각 샘플에 있어서, 그의 품질 점수가 μ-σ를 초과하는 경우에만 삽입-결실을 계수하였으며, 여기서, μ는 그 샘플에 상응하는 음성 대조군의 평균 품질-점수였고, σ는 그의 표준 편차였다. 이는 음성 대조군 및 그들의 상응하는 샘플 둘 모두에 대한 전체 표적-영역 삽입-결실 비율을 제공하였다. 음성 대조군의 표적-영역-마다-판독마다의 오류율, q, 샘플의 관찰된 삽입-결실 계수 n 및 그의 판독-계수 R을 사용하여, 실제 삽입-결실이 있는 표적-영역을 갖는 판독의 분율에 대한 최대-우도 추정치, p를 하기와 같이 이항 오차 모델을 적용함으로써 유도하였다.
적어도 1개의 삽입-결실을 갖는 것으로 부정확하게 계수된 표적 영역을 갖는 샘플에서 판독치의 (미공지의) 수를 E로 하여, 본 발명자들은 다음을 작성할 수 있다(실제 삽입-결실의 개수에 대하여 어떠한 추정도 하지 않음):

R(1-p)는 실제 삽입-결실이 없는 표적-영역을 갖는 판독치의 수이다. 반면, 삽입-결실을 갖는 것으로 관찰된 판독치의 수가 n이기 때문에, n=E+Rp이고, 다시 말하면, 오차가 있으나 실제 삽입-결실이 없는 표적-영역을 갖는 판독치의 수 + 표적-영역이 정확하게 삽입-결실을 갖는 판독치의 수이다. 이어서, 본 발명자들은 상기 식을 다시 작성할 수 있다:

실제-삽입-결실이 있는 표적-영역의 빈도의 모든 값, P가 동일한 선험적 가능성이 있는 것으로 이해하며,  이다. 따라서, 실제-삽입-결실이 있는 표적 영역의 빈도에 대한 최대-우도 추정치(MLE)를
이다. 따라서, 실제-삽입-결실이 있는 표적 영역의 빈도에 대한 최대-우도 추정치(MLE)를  를 최대화시키는 p의 값으로 설정하였다. 이를 수치적으로 평가하였다.
를 최대화시키는 p의 값으로 설정하였다. 이를 수치적으로 평가하였다.
시퀀싱 라이브러리 그들 자체에서 실제-삽입-결실 판독치 빈도에 오차 범위를 정하기 위하여, 실제-삽입-결실 표적-영역에 대한 MLE-추정치, Rp, 및 판독치 수, R을 고려하여, 윌슨 점수 간격(2)을 각 샘플에 대하여 계산하였다. 명시적으로, 하한, l 및 상한, u를 다음과 같이 계산하였다.


여기서, z, 1의 분산 정규 분포에 필요한 신뢰도에 대한 표준 점수를 1.96로 설정하였으며, 이는 95%의 신뢰도를 의미한다. 각각의 생물학적 반복 검증에 대한 최대 상한 및 최소 하한은 도 80 내지 도 83에 열거되어 있다.
상대적 Cas9 및 sgRNA 발현의 qRT-PCR 분석
24-웰 플레이트에 플레이팅된 293FT 세포를 상기 기술된 바와 같이 트랜스펙션시켰다. 트랜스펙션 72시간 후에, miRNeasy 마이크로(Micro) 키트(퀴아젠)를 사용하여 전체 RNA를 수집하였다. sgRNA에 대한 역방향-가닥 합성을 qScript 플렉스(Flex) cDNA 키트(VWR) 및 맞춤형 제1 가닥 합성 프라이머(표 J 및 K)를 사용하여 수행하였다. 내인성 대조군으로서 GAPDH를 사용하여 패스트(Fast) SYBR 그린 마스터 믹스(라이프 테크놀로지즈) 및 맞춤형 프라이머(표 J 및 K)와 함께 qPCR 분석을 수행하였다. 상대적 정량화를 ΔΔCT 방법에 의해 계산하였다.







실시예
10: 추가 서열
모든 서열은 5'→3' 방향으로 존재한다. U6 전사를 위하여, 밑줄이 있는 T의 스트링(string)은 전사 종결자로 소용된다.
> U6-짧은 tracrRNA(스트렙토코커스 피오게네스 SF370)

(tracrRNA 서열은 볼드체)
>U6-DR-가이드 서열-DR(스트렙토코커스 피오게네스 SF370)

(직접 반복부 서열은 회색으로 강조표시되어 있으며, 가이드 서열은 볼드체 N임)
>+48 tracrRNA를 함유하는 sgRNA(스트렙토코커스 피오게네스 SF370)

(가이드 서열은 볼드체 N이며, tracrRNA 단편은 볼드체임)
> +54 tracrRNA를 함유하는 sgRNA(스트렙토코커스 피오게네스 SF370)

(가이드 서열은 볼드체 N이며, tracrRNA 단편은 볼드체임)
> +67 tracrRNA를 함유하는 sgRNA(스트렙토코커스 피오게네스 SF370)

(가이드 서열은 볼드체 N이며, tracrRNA 단편은 볼드체임)
> +85 tracrRNA를 함유하는 sgRNA(스트렙토코커스 피오게네스 SF370)

(가이드 서열은 볼드체 N이며, tracrRNA 단편은 볼드체임)
> CBh-NLS-SpCas9-NLS




(NLS-hSpCas9-NLS은 볼드체로 강조표시되어 있음)
> EMX1 가이드 1.1, 1.14, 1.17에 대한 시퀀싱 앰플리콘

> EMX1 가이드 1.2, 1.16에 대한 시퀀싱 앰플리콘

> EMX1 가이드 1.3, 1.13, 1.15에 대한 시퀀싱 앰플리콘

> EMX1 가이드 1.6에 대한 시퀀싱 앰플리콘

> EMX1 가이드 1.10에 대한 시퀀싱 앰플리콘

> EMX1 가이드 1.11, 1.12에 대한 시퀀싱 앰플리콘

> EMX1 가이드 1.18, 1.19에 대한 시퀀싱 앰플리콘

> EMX1 가이드 1.20에 대한 시퀀싱 앰플리콘

> 표적 가닥과의 어닐링을 위한 T7 프로모터 F 프라이머
> 메틸화를 위한 pUC19 표적 부위 1을 함유하는 올리고(T7 역방향)

> 메틸화를 위한 pUC19 표적 부위 2를 함유하는 올리고(T7 역방향)

실시예
11: 올리고-매개의
Cas9
-유도
상동성
재조합
올리고 상동성 재조합 시험은 상이한 Cas9 변이체 및 상이한 HR 주형에 걸친 효율의 비교이다(올리고 대 플라스미드).
293FT 세포를 사용하였다. SpCas9 = 야생형 Cas9 및 SpCas9n = 닉카아제 Cas9(D10A). 키메라 RNA 표적은 실시예 5, 9 및 10에서와 동일한 EMX1 프로토스페이서 표적 1 및 PAGE 정제를 사용하여 IDT에 의해 합성된 올리고이다.
도 44는 이러한 실험에서 상동성 재조합(HR) 주형으로 사용되는 올리고 DNA의 설계를 도시한 것이다. 긴 올리고는 EMX1 유전자좌와 100 bp 상동성 및 HindIII 제한 부위를 함유한다. 293FT 세포를 먼저, 인간 EMX1 유전자좌 및 야생형 cas9 단백질을 표적화하는 키메라 RNA를 함유하는 플라스미드, 및 두번째로, HR 주형으로서 올리고 DNA로 동시-트랜스펙션시켰다. 샘플은 리포펙타민 2000을 사용한 트랜스펙션 96시간 후에 수집된 293FT 세포로부터의 것이다. 모든 산물을 EMX1 HR 프라이머를 사용하여 증폭시키고, 겔을 정제한 다음, HindIII로 분해하여, 인간 게놈으로의 HR 주형의 통합의 효율을 검출하였다.
도 45 및 도 46은 Cas9 단백질 및 HR 주형의 상이한 조합에 의해 유도되는 HR 효율의 비교를 도시한다. 사용된 Cas9 작제물은 야생형 Cas9 또는 Cas9의 닉카아제 버전(Cas9n) 중 어느 하나였다. 사용된 HR 주형은 안티센스 올리고 DNA(상기 도면에서 안티센스-올리고) 또는 센스 올리고 DNA(상기 도면에서 센스-올리고), 또는 플라스미드 HR 주형(상기 도면에서 HR 주형)이었다. 센스/안티-센스 정의에서, 전사된 mRNA에 상응하는 서열을 지니는 활동적으로 전사되는 가닥이 게놈의 센스 가닥으로 정의된다. HR 효율은 모든 게놈 PCR 증폭된 산물에 대한 HindIII 분해 밴드의 백분율로 나타나 있다(하측 숫자).
실시예
12: 자폐증 마우스
최근의 대규모 시퀀싱 계획에 의해 질병과 관련된 다수의 유전자를 생성하였다. 유전자의 발견은 유전자가 초래하는 것 및 유전자가 질병 표현형을 야기하는 방법의 이해의 시작일 뿐이다. 후보 유전자를 연구하기 위한 현재의 기술 및 방법은 느리고 수고롭다. 골드 스탠다드, 유전자 표적화 및 유전자 녹아웃은 상당한 시간과, 재정 및 연구 인원의 면에서 자원의 투자를 필요로 한다. 본 발명자들은 hSpCas9 뉴클레아제를 사용하여 많은 유전자를 표적화하기 시작하고, 임의의 다른 기술에 비하여 더 높은 효율과 더 낮은 턴어라운드(turnaround)로 표적화한다. hSpCas9의 높은 효율 때문에, 본 발명자들은 마우스 접합체로의 RNA 주입을 행하고, mESC에서 임의의 사전의 유전자 표적화를 행할 필요 없이 즉시 게놈-변형 동물을 얻을 수 있다.
크로모도메인 헬리카제 DNA 결합 단백질 8(CHD8)은 초기 척추동물 발생 및 형태형성에 수반되는 중심이 되는 유전자이다. CHD8이 결여된 마우스는 배아 발생 동안 사망한다. CHD8 유전자의 돌연변이는 인간의 자폐 스펙트럼 장애와 관련이 있다. 이러한 관련은 네이쳐(Nature)에 동시에 공개된 3개의 상이한 논문에서 이루어졌다. 동일한 3개의 연구에 의해, 자폐 스펙트럼 장애와 관련된 유전자의 과다가 확인되었다. 본 발명자들의 목적은 모든 논문에서 관찰되었던 4개의 유전자, Chd8, Katnal2, Kctd13 및 Scn2a에 대한 녹아웃 마우스를 생성하는 것이었다. 또한, 본 발명자들은 자폐 스펙트럼 장애, 정신분열증 및 ADHD와 관련된 2개의 다른 유전자, GIT1, CACNA1C 및 CACNB2를 선택하였다. 그리고 마지막으로, 본 발명자들은 양성 대조군으로서, MeCP2를 표적화하기로 결정하였다.
각 유전자에 대하여, 본 발명자들은 유전자를 녹아웃시킬 것 같은 3개의 gRNA를 설계하였다. 녹아웃은 hSpCas9 뉴클레아제가 이중 가닥 파단을 만든 후에 발생할 것이며, 오류 유발 DNA 수복 경로, 비상동성 말단 연결이 파단을 교정하여, 돌연변이를 생성할 것이다. 아마도 결과는 유전자를 녹아웃시킬 프레임쉬프트(frameshift) 돌연변이일 것이다. 표적화 전략은 유전자의 엑손에서 PAM 서열, NGG를 가지며, 게놈에서 독특한 프로토-스페이서를 찾는 것을 수반한다. 제1 엑손 내의 프로토-스페이서가 선호되며, 이는 유전자에 가장 유해할 것이다.
각각의 gRNA를 hSpCas9와의 리포솜의 일시적 동시-트랜스펙션에 의해 마우스 세포주, Neuro-N2a에서 입증하였다. 트랜스펙션하고 72시간 후에, 에피센트레로부터의 퀵익스트랙트 DNA를 사용하여 게놈 DNA를 정제하였다. PCR을 수행하여, 대상 유전자좌를 증폭시켰다. 이후에, 트랜스게노믹스로부터의 서베이어 돌연변이 검출 키트를 수행하였다. 각 gRNA 및 각각의 대조군에 대한 서베이어 결과는 도 A1에 나타나 있다. 양의 서베이어 결과는 게놈 PCR에 상응하는 하나의 큰 밴드 및 돌연변이 부위에 이중-가닥 파단을 만드는 서베이어 뉴클레아제의 산물인 더 작은 2개의 밴드이다. 또한, 각 gRNA의 평균 절단 효율을 각 gRNA에 대하여 결정하였다. 주입을 위해 선택한 gRNA는 게놈 내에서 가장 독특한, 가장 높은 효율의 gRNA였다.
RNA(hSpCas9+gRNA RNA)를 접합체의 전핵에 주입하고, 이후에 수양모(foster mother)에 이식하였다. 수양모가 만삭이 되게 하고, 출산 10일 후에 꼬리 자르기(tail snip)에 의해 새끼를 샘플링하였다. DNA를 추출하고, PCR을 위한 주형으로 사용하고, 이를 이어서 서베이어에 의해 처리하였다. 또한, PCR 산물을 시퀀싱을 위해 보냈다. 서베이어 검정 또는 PCR 시퀀싱 중 어느 하나에서 양성으로 검출된 동물에서, 그들의 게놈 PCR 산물을 pUC19 벡터로 클로닝하고, 시퀀싱하여, 각 대립형질로부터 추정의 돌연변이를 결정하였다.
지금까지, Chd8 표적화 실험으로부터의 마우스 새끼를 대립형질 시퀀싱 시점까지 완전히 처리하였다. 38마리의 살아 있는 새끼(레인 1 내지 38) 및 1마리의 죽은 새끼(레인 39) 및 비교를 위한 1마리 야생형 새끼(레인 40)에 대한 서베이어 결과는 도 A2에 나타나 있다. 새끼 1 내지 19에 gRNA Chd8.2를 주입하고, 새끼 20 내지 38에 gRNA Chd8.3을 주입하였다. 38마리의 살아 있는 새끼 중에, 13마리가 돌연변이에 대하여 양성이었다. 1마리의 죽은 새끼도 또한 돌연변이를 가졌다. 야생형 샘플에서 검출되는 돌연변이가 존재하지 않았다. 게놈 PCR 시퀀싱은 서베이어 검정 관찰과 일치하였다.
실시예
13:
CRISPR
/
Cas
-매개의 전사 조절
도 67은 전사 활성화 활성이 있는 CRISPR-TF(전사 인자)의 설계를 도시한 것이다. 키메라 RNA는 U6 프로모터에 의해 발현되는 한편, 3중 NLS 및 VP64 기능성 도메인에 작동가능하게 연결된 인간-코돈-최적화, 이중-돌연변이 버전의 Cas9 단백질(hSpCas9m)은 EF1a 프로모터에 의해 발현된다. 이중 돌연변이, D10A 및 H840A는 cas9 단백질이 임의의 절단을 도입할 수 없게 하고, 키메라 RNA에 의해 유도되는 경우 표적 DNA에 결합하는 그의 능력을 유지한다.
도 68은 CRISPR-TF 시스템(키메라 RNA 및 Cas9-NLS-VP64 융합 단백질)을 사용한 인간 SOX2 유전자의 전사 활성화를 도시한 것이다. 293FT 세포를 2개의 성분을 갖는 플라스미드로 트랜스펙션시켰다: (1) 인간 SOX2 게놈 유전자좌 내의 또는 그 주위의 20-bp 서열을 표적화하는 U6-유도의 상이한 키메라 RNA, 및 (2) EF1a-유도 hSpCas9m(이중 돌연변이체)-NLS-VP64 융합 단백질. 트랜스펙션하고 96시간 후에, 293FT 세포를 수집하고, qRT-PCR 검정을 사용하여 mRNA 발현의 유도에 의해 활성화 수준을 측정한다. 모든 발현 수준을 대조군(회색 막대)에 대하여 정규화시키며, 대조군은 키메라 RNA 없이 CRISPR-TF 백본 플라스미드가 트랜스펙션된 세포로부터의 결과를 나타낸다. SOX2 mRNA의 검출에 사용되는 qRT-PCR 프로브는 택맨(Taqman) 인간 유전자 발현 검정(라이프 테크놀로지즈)이다. 모든 실험은 3개의 생물학적 반복 검증으로부터의 데이터를 나타내며, n=3이고, 오차 막대는 s.e.m.을 나타낸다.
실시예
14:
NLS
:
Cas9
NLS
293FT 세포를 2개의 성분을 함유하는 플라스미드로 트랜스펙션시켰다: (1) 상이한 NLS 설계가 있는 Cas9(야생형 인간-코돈-최적화 Sp Cas9)의 발현을 유도하는 EF1a 프로모터, (2) 인간 EMX1 유전자좌를 표적화하는 동일한 키메라 RNA를 유도하는 U6 프로모터.
세포를 트랜스팩션 후 72시간에 수집한 다음, 제조사의 프로토콜에 따라 50 ㎕의 퀵익스트랙트 게놈 DNA 추출 용액으로 추출하였다. 표적 EMX1 게놈 DNA를 PCR 증폭시킨 다음, 1% 아가로스 겔을 사용하여 겔 정제하였다. 게놈 PCR 산물을 다시 어닐링시키고, 제조사의 프로토콜에 따라 서베이어 검정으로 처리하였다. 상이한 작제물의 게놈 절단 효율을 4-12% TBE-PAGE 겔(라이프 테크놀로지즈)에서 SDS-PAGE를 사용하여 측정하고, 분석하고, 이미지랩(ImageLab)(바이오-라드) 소프트웨어로 정량화시켰으며, 모두 제조사의 프로토콜을 따랐다.
도 69는 상이한 Cas9 NLS 작제물의 설계를 도시한 것이다. 모든 Cas9는 인간-코돈-최적화 버전의 Sp Cas9였다. NLS 서열은 N-말단 또는 C-말단에서 cas9 유전자에 연결된다. 상이한 NLS 설계가 있는 모든 Cas9 변이체를 EF1a 프로모터를 함유하여, EF1a 프로모터에 의해 유도되는 백본 벡터로 클로닝하였다. 동일한 벡터에, U6 프로모터에 의해 유도되는 인간 EMX1 유전자좌를 표적화하는 키메라 RNA가 존재하여, 함께 2-성분 시스템을 형성한다.

도 70은 상이한 NLS 설계를 지니는 Cas9 변이체에 의해 유도되는 게놈 절단의 효율을 도시한 것이다. 상기 백분율은 각 작제물에 의해 절단되었던 인간 EMX1 게놈 DNA의 부분을 나타낸다. 모든 실험은 3개의 생물학적 반복검증으로부터의 것이다. n = 3이고, 오차는 S.E.M을 나타낸다.
실시예
15:
Cas9를
사용한 미세조류의 조작
Cas9의
전달 방법
방법 1: 본 발명자들은 구성성 프로모터, 예를 들어, Hsp70A-Rbc S2 또는 베타2-투불린의 제어 하에 Cas9를 발현하는 벡터를 사용하여 Cas9 및 가이드 RNA를 전달한다.
방법 2: 본 발명자들은 구성성 프로모터, 예를 들어, Hsp70A-Rbc S2 또는 베타2-투불린의 제어 하에 Cas9 및 T7 중합효소를 발현하는 벡터를 사용하여 Cas9 및 T7 중합효소를 전달한다. 가이드 RNA는 가이드 RNA를 유도하는 T7 프로모터를 함유하는 벡터를 사용하여 전달될 것이다.
방법 3: 본 발명자들은 Cas9 mRNA 및 시험관내 전사된 가이드 RNA를 조류 세포로 전달한다. RNA는 시험관내 전사될 수 있다. Cas9 mRNA는 Cas9에 대한 코딩 영역, 및 Cop1으로부터의 3'UTR로 구성되어, Cas9 mRNA의 안정화를 보장할 것이다.
상동성 재조합을 위하여, 본 발명자들은 추가의 상동성 유도 수복 주형을 제공한다.
베타-2 투불린 프로모터에 이어서 Cop1의 3' UTR의 제어 하에 Cas9의 발현을 유도하는 카세트에 대한 서열.




베타-2 투불린 프로모터에 이어서 Cop1의 3' UTR의 제어 하에 T7 중합효소의 발현을 유도하는 카세트에 대한 서열:


T7 프로모터에 의해 유도되는 가이드 RNA의 서열(T7 프로모터, N은 표적화 서열을 나타낸다):
유전자 전달:
클라미도모나스(Chlamydomonas) 자원 센터로부터의 클라미도모나스 라인하르티이(Chlamydomonas reinhardtii) 균주 CC-124 및 CC-125는 전기천공법을 위해 사용될 것이다. 전기천공법 프로토콜은 진아트(GeneArt) 클라미도모나스 조작 키트로부터의 표준 권고 프로토콜을 따른다.
또한, 본 발명자들은 Cas9를 구성적으로 발현하는 클라미도모나스 라인하르티이의 세포주를 생성한다. 이는 pChlamy1(PvuI을 사용하여 선형화)을 사용하고, 하이그로마이신 내성 콜로니를 선택하여 행해질 수 있다. Cas9를 함유하는 pChlamy1에 대한 서열은 하기에 나타나 있다. 이러한 방식으로 유전자 녹아웃을 달성하기 위하여, 간단하게 가이드 RNA를 위해 RNA를 전달할 필요가 있다. 상동성 재조합을 위하여, 본 발명자들은 가이드 RNA 및 선형화된 상동성 재조합 주형을 전달한다.
pChlamy1-Cas9:






모든 변형된 클라미도모나스 라인하르티이 세포에 있어서, 본 발명자들은 PCR, 서베이어 뉴클레아제 검정 및 DNA 시퀀싱을 사용하여, 성공적인 변형을 확인하였다.
실시예
16:
박테리아에서의
전사 억제제로서의
Cas9의
용도
전사를 인공적으로 제어하는 능력은 유전자 기능의 연구 및 요망되는 특성을 갖는 합성 유전자 네트워크의 구축 둘 모두에 필수적이다. 본 발명자들은 프로그램화가능한 전사 억제제로서의 RNA-유도 Cas9 단백질의 용도를 본원에서 기술한다.
본 발명자들은 이전에 스트렙토코커스 피오게네스 SF370의 Cas9 단백질을 사용하여 스트렙토코커스 뉴모니애에서 게놈 교정을 유도할 수 있는 방법을 입증하였다. 이러한 연구에서, 본 발명자들은 cas9, tracrRNA 및 반복부로 구성된 최소 CRISPR 시스템을 함유하는 crR6Rk 균주를 조작하였다. D10A-H840 돌연변이를 이러한 균주에서 cas9로 도입하여, 균주 crR6Rk**를 제공하였다. bgaA β-갈락토시다제 유전자 프로모터의 상이한 위치를 표적화하는 4개의 스페이서를 이전에 기술된 pDB98 플라스미드가 지니는 CRISPR 어레이에 클로닝하였다. 본 발명자들은 표적화된 위치에 따라 β-갈락토시다제 활성의 X 내지 Y배 감소를 관찰하였으며, 이는 프로그램화가능한 억제제로서의 Cas9의 능력을 보여준다(도 73).
에스케리키아 콜라이에서 Cas9** 억제를 달성하기 위하여, 녹색 형광 단백질(GFP) 리포터 플라스미드(pDB127)를 작제하여, 구성성 프로모터로부터 gfpmut2 유전자를 발현시켰다. 둘 모두의 가닥에 몇몇 NPP PAM을 지니도록 프로모터를 설계하여, 다양한 위치에서 Cas9** 결합의 영향을 측정하였다. 본 발명자들은 D10A-H840 돌연변이를 pCas9로 도입하였으며, 기술된 플라스미드는 tracrRNA, cas9, 및 신규한 스페이서의 용이한 클로닝을 위해 설계된 최소 CRISPR 어레이를 지닌다. 22개의 상이한 스페이서를 설계하여, gfpmut2 프로모터 및 오픈 리딩 프레임의 상이한 영역을 표적화하였다. -35 및 -10 프로모터 요소 및 사인-달가르노(Shine-Dalgarno) 서열과 중첩되거나 그에 인접한 영역의 표적화 시에 대략 20배의 형광의 감소가 관찰되었다. 둘 모두의 가닥 상의 표적은 유사한 억제 수준을 보였다. 이들 결과는 임의의 위치의 프로모터 영역으로의 Cas9**의 결합이 아마도 RNAP 결합의 입체적 억제를 통해 전사 개시를 방지할 것임을 뒷받침한다.
Cas9**가 전사 연장을 방지할 수 있는지 결정하기 위하여, 본 발명자들은 그를 gpfmut2의 리딩 프레임으로 지향시켰다. 코딩 및 비-코딩 가닥이 표적화되는 경우 둘 모두에 형광의 감소가 관찰되었으며, 이는 Cas9 결합이 실제로 진행 중인 RNAP에 대한 장애물을 나타내기에 충분히 강력한 것을 시사한다. 그러나, 코딩 가닥이 표적인 경우 발현의 40% 감소가 관찰되었지만, 비-코딩 가닥에 대하여 20배 감소가 관찰되었다(도 21b, T9, T10 및 T11을 B9, B10 및 B11과 비교). 전사에 대한 Cas9** 결합의 영향을 직접 결정하기 위하여, 본 발명자들은 T5, T10, B10 또는 pDB127을 표적화하지 않는 대조군 작제물을 지니는 균주로부터 RNA를 추출하고, 그것을 B10 및 T10 표적 부위 전에 결합하는 프로브(B477) 또는 그 후에 결합하는 프로브(B510)를 사용하는 노던 블롯 분석으로 처리하였다. 본 발명자들의 형광 방법과 일치하게, Cas9**가 프로모터 영역(T5 표적)에 지향되는 경우에 gfpmut2 전사는 검출되지 않았으며, T10 영역의 표적화 후에 전사가 관찰되었다. 흥미롭게도, B477 프로브를 사용하여 보다 작은 전사물이 관찰되었다. 이러한 밴드는 Cas9**에 의해 단속되는 전사물의 예상되는 크기에 상응하며, 코딩 가닥으로의 dgRNA::Cas9** 결합에 의해 전사 종결이 야기되는 것을 직접적으로 나타낸다. 놀랍게도, 본 발명자들은 비-코딩 가닥이 표적화되는 경우(B10) 전사물을 검출하지 않았다. B10 영역으로의 Cas9** 결합이 전사 개시를 간섭할 확률이 낮기 때문에, 이러한 결과는 mRNA이 분해되었음을 시사한다. dgRNA::Cas9는 시험관 내에서 ssRNA에 결합하는 것으로 보인다. 본 발명자들은 결합이 숙주 뉴클레아제에 의한 mRNA의 분해를 촉발할 수 있는 것으로 추측하였다. 실제로, 리보솜 스톨링(stalling)이 에스케리키아 콜라이에서 번역된 mRNA에 대한 절단을 유도할 수 있다.
일부 응용은 그의 완전한 억제보다는 유전자 발현의 정밀한 조정을 필요로 한다. 본 발명자들은 crRNA/표적 상호작용을 약화시킬 미스매치의 도입을 통해 중간의 억제 수준을 달성하고자 하였다. 본 발명자들은 crRNA의 5' 말단에서의 돌연변이 수의 증가와 함께 B1, T5 및 B10 작제물에 기초하여 일련의 스페이서를 생성하였다. B1 및 T5에서의 최대 8개의 돌연변이는 억제 수준에 영향을 미치지 않았으며, 추가의 돌연변이에 대하여 형광의 점진적인 증가가 관찰되었다.
crRNA와 그의 표적 간의 오직 8nt의 매치에서 관찰된 억제에 의해, 전사 조절제로서 Cas9**의 이용의 오프-표적화 효과의 의문이 제기된다. 또한, 우수한 PAM(NGG)이 Cas9 결합에 필요하기 때문에, 일부 수준의 호흡을 수득하기 위하여 매치되는 뉴클레오티드의 수는 10개이다. 10nt 매치는 약 1Mbp마다 1번 무작위로 발생하며, 이에 따라, 이러한 부위는 작은 박테리아 게놈에서도 관찰될 가능성이 있다. 그러나, 전사를 효율적으로 억제하기 위하여, 이러한 부위가 유전자의 프로모터 영역에 존재할 필요가 있으며, 이는 오프-표적화가 훨씬 더 적은 확률이 되게 한다. 또한, 본 발명자들은 유전자의 비-코딩 가닥이 표적화된다면, 유전자 발현이 영향을 받을 수 있음을 보여주었다. 이것이 발생하기 위하여, 무작위 표적은 우측 배향으로 존재해야 할 것이나, 이러한 사건은 상대적으로 더 많이 발생할 것 같다. 사실상, 본 연구의 과정 동안, 본 발명자들은 pCas9**에서 설계된 스페이서 중 하나를 작제할 수 없었다. 본 발명자들은 이후에 이러한 스페이서가 필수 murC 유전자에서 우수한 PAM 다음에 12bp 매치를 보이는 것을 관찰하였다. 이러한 오프-표적화를 설계된 스페이서의 계통적 제거에 의해 용이하게 피할 수 있었다.
본 발명의 양태는 하기의 번호를 매긴 단락에 추가로 기술된다:
1. 하나 이상의 벡터를 포함하는 벡터 시스템으로서, 상기 시스템이
a. traer 메이트 서열 및 traer 메이트 서열의 상류에 가이드 서열을 삽입하기 위한 하나 이상의 삽입 부위에 작동가능하게 연결된 제1 조절 요소로서, 상기 가이드 서열은 발현되는 경우, 진핵 세포 내의 표적 서열로의 CRISPR 복합체의 서열-특이적 결합을 유도하고, 상기 CRISPR 복합체는 (1) 상기 표적 서열에 혼성화되는 가이드 서열, 및 (2) traer 서열에 혼성화되는 traer 메이트 서열과 복합체화된 CRISPR 효소를 포함하는 제1 조절 요소; 및
b. 핵 국소화 서열을 포함하는 상기 CRISPR 효소를 인코딩하는 효소-코딩 서열에 작동가능하게 연결된 제2 조절 요소를 포함하며,
성분 (a) 및 (b)가 상기 시스템의 동일한 또는 상이한 벡터에 위치한 벡터 시스템.
2. 단락 1에 있어서, 성분 (a)가 상기 제1 조절 요소의 제어 하에 상기 traer 메이트 서열의 하류의 traer 서열을 더 포함하는 벡터 시스템.
3. 단락 1에 있어서, 성분 (a)가 상기 제1 조절 요소에 작동가능하게 연결된 2개 이상의 가이드 서열을 더 포함하며, 상기 2개 이상의 가이드 서열의 각각은 발현되는 경우, 진핵 세포 내의 상이한 표적 서열로의 상기 CRISPR 복합체의 서열 특이적인 결합을 유도하는 벡터 시스템.
4. 단락 1에 있어서, 상기 시스템이 제3 조절 요소의 제어 하에 상기 traer 서열을 포함하는 벡터 시스템.
5. 단락 1에 있어서, 상기 traer 서열이 최적으로 정렬되는 경우 상기 traer 메이트 서열의 길이를 따라 적어도 50%의 서열 상보성을 나타내는 벡터 시스템.
6. 단락 1에 있어서, 상기 CRISPR 효소가 진핵 세포의 핵에 검출가능한 양의 상기 CRISPR 효소의 축적을 유도하기에 충분한 세기의 하나 이상의 핵 국소화 서열을 포함하는 벡터 시스템.
7. 단락 1에 있어서, 상기 CRISPR 효소가 II형 CRISPR 시스템 효소인 벡터 시스템.
8. 단락 1에 있어서, 상기 CRISPR 효소가 Cas9 효소인 벡터 시스템.
9. 단락 1에 있어서, 상기 CRISPR 효소가 진핵 세포에서의 발현을 위해 코돈-최적화된 벡터 시스템.
10. 단락 1에 있어서, 상기 CRISPR 효소가 상기 표적 서열의 위치에서 1개 또는 2개의 가닥의 절단을 유도하는 벡터 시스템.
11. 단락 1에 있어서, 상기 CRISPR 효소는 DNA 가닥 절단 활성이 결여된 벡터 시스템.
12. 단락 1에 있어서, 상기 제1 조절 요소가 중합효소 III 프로모터인 벡터 시스템.
13. 단락 1에 있어서, 상기 제2 조절 요소가 중합효소 II 프로모터인 벡터 시스템.
14. 단락 4에 있어서, 상기 제3 조절 요소가 중합효소 III 프로모터인 벡터 시스템.
15. 단락 1에 있어서, 상기 가이드 서열이 적어도 15개 뉴클레오티드 길이인 벡터 시스템.
16. 단락 1에 있어서, 최적으로 폴딩되는 경우 상기 가이드 서열의 50% 미만의 뉴클레오티드가 자가-상보적 염기-쌍형성에 참여하는 벡터 시스템.
17. 하나 이상의 핵 국소화 서열을 포함하는 CRISPR 효소를 인코딩하는 효소-코딩 서열에 작동가능하게 연결된 조절 요소를 포함하는 벡터로서, 상기 조절 요소가 진핵 세포에서 CRISPR 효소의 전사를 유도하여, 상기 CRISPR 효소가 진핵 세포의 핵에서 검출가능한 양으로 축적되게 하는 벡터.
18. 단락 17에 있어서, 상기 조절 요소가 중합효소 II 프로모터인 벡터.
19. 단락 17에 있어서, 상기 CRISPR 효소가 II형 CRISPR 시스템 효소인 벡터.
20. 단락 17에 있어서, 상기 CRISPR 효소가 Cas9 효소인 벡터.
21. 단락 17에 있어서, 상기 CRISPR 효소는 그것이 결합하는 표적 서열의 하나 이상의 가닥을 절단하는 능력이 결여된 벡터.
22. 진핵 세포의 핵에 검출가능한 양의 상기 CRISPR 효소의 축적을 유도하기에 충분한 세기의 하나 이상의 핵 국소화 서열을 포함하는 CRISPR 효소.
23. 단락 22에 있어서, 상기 CRISPR 효소가 II형 CRISPR 시스템 효소인 CRISPR 효소.
24. 단락 22에 있어서, 상기 CRISPR 효소가 Cas9 효소인 CRISPR 효소.
25. 단락 22에 있어서, 상기 CRISPR 효소는 그것이 결합하는 표적 서열의 하나 이상의 가닥을 절단하는 능력이 결여된 CRISPR 효소.
26. a. traer 메이트 서열 및 traer 메이트 서열의 상류에 가이드 서열을 삽입하기 위한 하나 이상의 삽입 부위에 작동가능하게 연결된 제1 조절 요소로서, 상기 가이드 서열은 발현되는 경우, 진핵 세포 내의 표적 서열로의 CRISPR 복합체의 서열-특이적 결합을 유도하고, 상기 CRISPR 복합체는 (1) 상기 표적 서열에 혼성화되는 가이드 서열, 및 (2) traer 서열에 혼성화되는 traer 메이트 서열과 복합체화된 CRISPR 효소를 포함하는 제1 조절 요소; 및/또는
b. 핵 국소화 서열을 포함하는 상기 CRISPR 효소를 인코딩하는 효소-코딩 서열에 작동가능하게 연결된 제2 조절 요소를 포함하는 진핵 숙주 세포.
27. 단락 26에 있어서, 상기 숙주 세포가 성분 (a) 및 (b)를 포함하는 진핵 숙주 세포.
28. 단락 26에 있어서, 성분 (a), 성분 (b), 또는 성분 (a) 및 (b)가 상기 숙주 진핵 세포의 게놈 내로 안정적으로 통합되는 진핵 숙주 세포.
29. 단락 26에 있어서, 성분 (a)가 상기 제1 조절 요소의 제어 하에 traer 메이트 서열의 하류의 traer 서열을 더 포함하는 진핵 숙주 세포.
30. 단락 26에 있어서, 성분 (a)가 상기 제1 조절 요소에 작동가능하게 연결된 2개 이상의 가이드 서열을 더 포함하며, 상기 2개 이상의 가이드 서열의 각각은 발현되는 경우, 진핵 세포에서 상이한 표적 서열로의 CRISPR 복합체의 서열 특이적 결합을 유도하는 진핵 숙주 세포.
31. 단락 26에 있어서, 상기 traer 서열에 작동가능하게 연결된 제3 조절 요소를 더 포함하는 진핵 숙주 세포.
32. 단락 26에 있어서, 상기 traer 서열이 최적으로 정렬되는 경우 traer 메이트 서열의 길이를 따라 적어도 50%의 서열 상보성을 나타내는 진핵 숙주 세포.
33. 단락 26에 있어서, 상기 CRISPR 효소가 진핵 세포의 핵에 검출가능한 양의 상기 CRISPR 효소의 축적을 유도하기에 충분한 세기의 하나 이상의 핵 국소화 서열을 포함하는 진핵 숙주 세포.
34. 단락 26에 있어서, 상기 CRISPR 효소가 II형 CRISPR 시스템 효소인 진핵 숙주 세포.
35. 단락 26에 있어서, 상기 CRISPR 효소가 Cas9 효소인 진핵 숙주 세포.
36. 단락 26에 있어서, 상기 CRISPR 효소가 진핵 세포에서의 발현을 위해 코돈-최적화된 진핵 숙주 세포.
37. 단락 26에 있어서, 상기 CRISPR 효소가 상기 표적 서열의 위치에서 1개 또는 2개 가닥의 절단을 유도하는 진핵 숙주 세포.
38. 단락 26에 있어서, 상기 CRISPR 효소는 DNA 가닥 절단 활성이 결여된 진핵 숙주 세포.
39. 단락 26에 있어서, 상기 제1 조절 요소가 중합효소 III 프로모터인 진핵 숙주 세포.
40. 단락 26에 있어서, 상기 제2 조절 요소가 중합효소 II 프로모터인 진핵 숙주 세포.
41. 단락 31에 있어서, 상기 제3 조절 요소가 중합효소 III 프로모터인 진핵 숙주 세포.
42. 단락 26에 있어서, 상기 가이드 서열이 적어도 15개 뉴클레오티드 길이인 진핵 숙주 세포.
43. 단락 26에 있어서, 최적으로 폴딩되는 경우 가이드 서열의 50% 미만의 뉴클레오티드가 자가-상보적 염기-쌍형성에 참여하는 진핵 숙주 세포.
44. 단락 26 내지 단락 43 중 어느 하나 단락의 진핵 숙주 세포를 포함하는 비인간 동물.
45. 벡터 시스템 및 키트를 사용하기 위한 지침서를 포함하는 키트로서, 상기 벡터 시스템이
a. traer 메이트 서열 및 traer 메이트 서열의 상류에 가이드 서열을 삽입하기 위한 하나 이상의 삽입 부위에 작동가능하게 연결된 제1 조절 요소로서, 상기 가이드 서열은 발현되는 경우, 진핵 세포 내의 표적 서열로의 CRISPR 복합체의 서열-특이적 결합을 유도하고, 상기 CRISPR 복합체는 (1) 상기 표적 서열에 혼성화되는 가이드 서열, 및 (2) traer 서열에 혼성화되는 traer 메이트 서열과 복합체화된 CRISPR 효소를 포함하는 제1 조절 요소; 및/또는
b. 핵 국소화 서열을 포함하는 상기 CRISPR 효소를 인코딩하는 효소-코딩 서열에 작동가능하게 연결된 제2 조절 요소를 포함하는 키트.
46. 단락 45에 있어서, 상기 키트가 상기 시스템의 동일한 또는 상이한 벡터에 위치한 성분 (a) 및 (b)를 포함하는 키트.
47. 단락 45에 있어서, 성분 (a)가 상기 제1 조절 요소의 제어 하에 traer 메이트 서열의 하류의 traer 서열을 더 포함하는 키트.
48. 단락 45에 있어서, 성분 (a)가 제1 조절 요소에 작동가능하게 연결된 2개 이상의 가이드 서열을 더 포함하며, 상기 2개 이상의 가이드 서열의 각각은 발현되는 경우, 진핵 세포 내의 상이한 표적 서열로의 CRISPR 복합체의 서열 특이적인 결합을 유도하는 키트.
49. 단락 45에 있어서, 상기 시스템이 제3 조절 요소의 제어 하에 상기 traer 서열을 포함하는 키트.
50. 단락 45에 있어서, 상기 traer 서열이 최적으로 정렬되는 경우 traer 메이트 서열의 길이를 따라 적어도 50%의 서열 상보성을 나타내는 키트.
51. 단락 45에 있어서, 상기 CRISPR 효소가 진핵 세포의 핵에 검출가능한 양의 상기 CRISPR 효소의 축적을 유도하기에 충분한 세기의 하나 이상의 핵 국소화 서열을 포함하는 키트.
52. 단락 45에 있어서, 상기 CRISPR 효소가 II형 CRISPR 시스템 효소인 키트.
53. 단락 45에 있어서, 상기 CRISPR 효소가 Cas9 효소인 키트.
54. 단락 45에 있어서, 상기 CRISPR 효소가 진핵 세포에서의 발현을 위해 코돈-최적화된 키트.
55. 단락 45에 있어서, 상기 CRISPR 효소가 상기 표적 서열의 위치에서 1개 또는 2개의 가닥의 절단을 유도하는 키트.
56. 단락 45에 있어서, 상기 CRISPR 효소는 DNA 가닥 절단 활성이 결여된 키트.
57. 단락 45에 있어서, 상기 제1 조절 요소가 중합효소 III 프로모터인 키트.
58. 단락 45에 있어서, 상기 제2 조절 요소가 중합효소 II 프로모터인 키트.
59. 단락 49에 있어서, 상기 제3 조절 요소가 중합효소 III 프로모터인 키트.
60. 단락 45에 있어서, 상기 가이드 서열이 적어도 15개 뉴클레오티드 길이인 키트.
61. 단락 45에 있어서, 최적으로 폴딩되는 경우 상기 가이드 서열의 50% 미만의 뉴클레오티드가 자가-상보적 염기-쌍형성에 참여하는 키트.
62. CRISPR 복합체에 의한 표적화를 위해 진핵 세포에서 핵산 서열 내의 후보 표적 서열을 선택하기 위한 컴퓨터 시스템으로서,
a. 상기 핵산 서열을 수신하고/거나 저장하도록 구성된 메모리 유닛(memory unit); 및
b. 단독으로 또는 조합되어, (i) 상기 핵산 서열 내에 CRISPR 모티프 서열을 배치하고, (ii) 상기 배치된 CRISPR 모티프 서열에 인접한 서열을 CRISPR 복합체가 결합하는 후보 표적 서열로서 선택하도록 프로그램화된 하나 이상의 프로세서를 포함하는 컴퓨터 시스템.
63. 단락 62에 있어서, 상기 배치 단계가 상기 표적 서열로부터 약 500개 뉴클레오티드 미만으로 떨어져 배치된 CRISPR 모티프 서열을 확인하는 것을 포함하는 컴퓨터 시스템.
64. 단락 62에 있어서, 상기 후보 표적 서열이 적어도 10개 뉴클레오티드 길이인 컴퓨터 시스템.
65. 단락 62에 있어서, 상기 후보 표적 서열의 3' 말단의 뉴클레오티드가 상기 CRISPR 모티프 서열의 상류의 약 10개 이하의 뉴클레오티드에 배치되는 컴퓨터 시스템.
66. 단락 62에 있어서, 상기 진핵 세포에서의 핵산 서열이 진핵 게놈에 내인성인 컴퓨터 시스템.
67. 제62항에 있어서, 상기 진핵 세포에서의 핵산 서열이 진핵 게놈에 외인성인 컴퓨터 시스템.
68. 하나 이상의 프로세서에 의한 실행 시에 CRISPR 복합체에 의한 표적화를 위해 진핵 세포에서 핵산 서열 내의 후보 표적 서열을 선택하는 방법을 구현하는 코드를 포함하는 컴퓨터-판독가능 매체로서, 상기 방법이 (a) CRISPR 모티프 서열을 상기 핵산 서열 내에 배치하는 단계, 및 (b) 상기 배치된 CRISPR 모티프 서열에 인접한 서열을 CRISPR 복합체가 결합하는 후보 표적 서열로서 선택하는 단계를 포함하는 컴퓨터-판독가능 매체.
69. 단락 68에 있어서, 상기 배치하는 단계가 상기 표적 서열로부터 약 500개 뉴클레오티드 미만으로 떨어지게 CRISPR 모티프 서열을 배치하는 것을 포함하는 컴퓨터-판독가능 매체.
70. 단락 68에 있어서, 상기 후보 표적 서열이 적어도 10개 뉴클레오티드 길이인 컴퓨터-판독가능.
71. 단락 68에 있어서, 후보 표적 서열의 3' 말단에서 뉴클레오티드가 CRISPR 모티프 서열의 상류의 약 10개 이하의 뉴클레오티드에 배치되는 컴퓨터-판독가능.
72. 단락 68에 있어서, 상기 진핵 세포에서 핵산 서열이 진핵 게놈에 대해 내인성인 컴퓨터-판독가능.
73. 단락 68에 있어서, 상기 진핵 세포에서 상기 핵산 서열이 진핵 게놈에 대해 외인성인 컴퓨터-판독가능.
74. 진핵 세포에서의 표적 폴리뉴클레오티드의 변형 방법으로서, 상기 방법은 CRISPR 복합체가 상기 표적 폴리뉴클레오티드에 결합하게 하여, 상기 표적 폴리뉴클레오티드의 절단을 초래하여, 상기 표적 폴리뉴클레오티드를 변형시키는 단계를 포함하며, 상기 CRISPR 복합체는 상기 표적 폴리뉴클레오티드 내의 표적 서열에 혼성화되는 가이드 서열과 복합체화되는 CRISPR 효소를 포함하고, 상기 가이드 서열은 traer 메이트 서열에 연결되며, 상기 traer 메이트 서열은 차례로 traer 서열에 혼성화되는 방법.
75. 단락 74에 있어서, 상기 절단이 상기 CRISPR 효소에 의한 표적 서열의 위치에서의 1개 또는 2개의 가닥의 절단을 포함하는 방법.
76. 단락 74에 있어서, 상기 절단이 표적 유전자의 전사의 감소를 야기하는 방법.
77. 단락 74에 있어서, 외인성 주형 폴리뉴클레오티드와의 상동성 재조합에 의해 상기 절단된 표적 폴리뉴클레오티드를 수복하는 단계를 더 포함하며, 상기 수복이 상기 표적 폴리뉴클레오티드의 하나 이상의 뉴클레오티드의 삽입, 결실 또는 치환을 포함하는 돌연변이를 야기하는 방법.
78. 단락 77에 있어서, 상기 돌연변이가 표적 서열을 포함하는 유전자로부터 발현되는 단백질의 하나 이상의 아미노산 변화를 야기하는 방법.
79. 단락 74에 있어서, 하나 이상의 벡터를 상기 진핵 세포로 전달하는 단계를 더 포함하며, 상기 하나 이상의 벡터가 CRISPR 효소, traer 메이트 서열에 연결된 가이드 서열 및 traer 서열 중 하나 이상의 발현을 유도하는 방법.
80. 단락 79에 있어서, 상기 벡터가 대상체 내의 진핵 세포로 전달되는 방법.
81. 단락 74에 있어서, 상기 변형이 세포 배양물 중의 상기 진핵 세포에서 일어나는 방법.
82. 단락 74에 있어서, 상기 변형 전에 대상체로부터 상기 진핵 세포를 분리하는 단계를 더 포함하는 방법.
83. 단락 82에 있어서, 상기 진핵 세포 및/또는 그로부터 유래된 세포를 상기 대상체에게 복귀시키는 단계를 더 포함하는 방법.
84. 진핵 세포에서의 폴리뉴클레오티드의 발현의 변경 방법으로서, 상기 방법은 CRISPR 복합체가 폴리뉴클레오티드에 결합하게 하여, 상기 결합이 상기 폴리뉴클레오티드의 발현의 증가 또는 감소를 야기하게 하는 단계를 포함하며; 상기 CRISPR 복합체가 상기 폴리뉴클레오티드 내의 표적 서열에 혼성화되는 가이드 서열과 복합체화된 CRISPR 효소를 포함하며, 상기 가이드 서열이 traer 메이트 서열에 연결되고, 상기 traer 메이트 서열이 차례로 traer 서열에 혼성화되는 방법.
85. 단락 74에 있어서, 하나 이상의 벡터를 상기 진핵 세포로 전달하는 단계를 더 포함하며, 상기 하나 이상의 벡터가 CRISPR 효소, traer 메이트 서열에 연결된 가이드 서열 및 traer 서열 중 하나 이상의 발현을 유도하는 방법.
86. 돌연변이된 질병 유전자를 포함하는 모델 진핵 세포의 생성 방법으로서, 상기 방법이
a. 하나 이상의 벡터를 진핵 세포로 도입하는 단계로서, 상기 하나 이상의 벡터가 CRISPR 효소, traer 메이트 서열에 연결된 가이드 서열 및 traer 서열 중 하나 이상의 발현을 유도하는 단계; 및
b. CRISPR 복합체가 표적 폴리뉴클레오티드에 결합하게 하여, 상기 질병 유전자 내의 표적 폴리뉴클레오티드의 절단을 초래하여, 돌연변이된 질병 유전자를 포함하는 모델 진핵 세포를 생성하는 단계로서, 상기 CRISPR 복합체가 (1) 표적 폴리뉴클레오티드 내의 표적 서열에 혼성화되는 가이드 서열, 및 (2) traer 서열에 혼성화되는 traer 메이트 서열과 복합체화되는 CRISPR 효소를 포함하는 단계를 포함하는 방법.
87. 단락 86에 있어서, 상기 절단이 표적 서열의 위치에서 상기 CRISPR 효소에 의한 1개 또는 2개의 가닥의 절단을 포함하는 방법.
88. 단락 86에 있어서, 상기 절단이 표적 유전자의 전사의 감소를 야기하는 방법.
89. 단락 86에 있어서, 외인성 주형 폴리뉴클레오티드와의 상동성 재조합에 의해 상기 절단된 표적 폴리뉴클레오티드를 수복하는 단계를 더 포함하며, 상기 수복이 상기 표적 폴리뉴클레오티드의 하나 이상의 뉴클레오티드의 삽입, 결실 또는 치환을 포함하는 돌연변이를 야기하는 방법.
90. 단락 89에 있어서, 상기 돌연변이가 표적 서열을 포함하는 유전자로부터 발현되는 단백질의 하나 이상의 아미노산 변화를 야기하는 방법.
91. a. 시험 화합물을 단락 86 내지 90 중 어느 하나 단락의 모델 세포와 접촉시키는 단계; 및
b. 상기 질병 유전자의 상기 돌연변이와 관련된 세포 신호전달 사건의 감소 또는 증가를 나타내는 판독치의 변화를 검출하여, 상기 질병 유전자와 관련된 상기 세포 신호전달 사건을 조절하는 상기 생물학적 활성 작용제를 개발하는 단계를 포함하는 질병 유전자와 관련된 세포 신호전달 사건을 조절하는 생물학적 활성 작용제의 개발 방법.
92. traer 메이트 서열의 상류에 가이드 서열을 포함하는 재조합 폴리뉴클레오티드로서, 상기 가이드 서열이 발현되는 경우 진핵 세포에 존재하는 상응하는 표적 서열로의 CRISPR 복합체의 서열-특이적 결합을 유도하는 재조합 폴리뉴클레오티드.
93. 단락 89에 있어서, 상기 표적 서열이 진핵 세포에 존재하는 바이러스 서열인 재조합 폴리뉴클레오티드.
94. 단락 89에 있어서, 상기 표적 서열이 원암유전자 또는 암유전자인 재조합 폴리뉴클레오티드.
본 발명의 바람직한 구현예가 본원에 나타나고 기술되어 있지만, 이러한 구현예가 오직 예시로만 제공되는 것이 당업자에게 명백할 것이다. 수많은 변이, 변화 및 치환이 이제 본 발명으로부터 벗어남 없이, 당업자에게 일어날 것이다. 본원에 기술된 본 발명의 구현예에 대한 다양한 대안이 본 발명을 실시하는데 사용될 수 있음을 이해해야 한다. 하기의 청구범위가 본 발명의 범주를 한정하며, 이들 청구범위의 범주 내의 방법 및 구조, 및 그들의 등가물이 그에 의해 커버되는 것으로 의도된다.




SEQUENCE LISTING
<110> THE BROAD INSTITUTE, INC.
<120> CRISPR-CAS COMPONENT SYSTEMS, METHODS AND COMPOSITIONS FOR
SEQUENCE MANIPULATION
<130> 44790.99.2003
<140> PCT/US2013/074611
<141> 2013-12-12
<150> 61/835,931
<151> 2013-06-17
<150> 61/791,409
<151> 2013-03-15
<150> 61/768,959
<151> 2013-02-25
<150> 61/748,427
<151> 2013-01-02
<150> 61/736,527
<151> 2012-12-12
<160> 529
<170> PatentIn version 3.5
<210> 1
<211> 7
<212> PRT
<213> Simian virus 40
<400> 1
Pro Lys Lys Lys Arg Lys Val
1 5
<210> 2
<211> 16
<212> PRT
<213> Unknown
<220>
<221> source
<223> /note="Description of Unknown:
Nucleoplasmin bipartite NLS sequence"
<400> 2
Lys Arg Pro Ala Ala Thr Lys Lys Ala Gly Gln Ala Lys Lys Lys Lys
1 5 10 15
<210> 3
<211> 9
<212> PRT
<213> Unknown
<220>
<221> source
<223> /note="Description of Unknown:
C-myc NLS sequence"
<400> 3
Pro Ala Ala Lys Arg Val Lys Leu Asp
1 5
<210> 4
<211> 11
<212> PRT
<213> Unknown
<220>
<221> source
<223> /note="Description of Unknown:
C-myc NLS sequence"
<400> 4
Arg Gln Arg Arg Asn Glu Leu Lys Arg Ser Pro
1 5 10
<210> 5
<211> 38
<212> PRT
<213> Homo sapiens
<400> 5
Asn Gln Ser Ser Asn Phe Gly Pro Met Lys Gly Gly Asn Phe Gly Gly
1 5 10 15
Arg Ser Ser Gly Pro Tyr Gly Gly Gly Gly Gln Tyr Phe Ala Lys Pro
20 25 30
Arg Asn Gln Gly Gly Tyr
35
<210> 6
<211> 42
<212> PRT
<213> Unknown
<220>
<221> source
<223> /note="Description of Unknown:
IBB domain from importin-alpha sequence"
<400> 6
Arg Met Arg Ile Glx Phe Lys Asn Lys Gly Lys Asp Thr Ala Glu Leu
1 5 10 15
Arg Arg Arg Arg Val Glu Val Ser Val Glu Leu Arg Lys Ala Lys Lys
20 25 30
Asp Glu Gln Ile Leu Lys Arg Arg Asn Val
35 40
<210> 7
<211> 8
<212> PRT
<213> Unknown
<220>
<221> source
<223> /note="Description of Unknown:
Myoma T protein sequence"
<400> 7
Val Ser Arg Lys Arg Pro Arg Pro
1 5
<210> 8
<211> 8
<212> PRT
<213> Unknown
<220>
<221> source
<223> /note="Description of Unknown:
Myoma T protein sequence"
<400> 8
Pro Pro Lys Lys Ala Arg Glu Asp
1 5
<210> 9
<211> 8
<212> PRT
<213> Homo sapiens
<400> 9
Pro Gln Pro Lys Lys Lys Pro Leu
1 5
<210> 10
<211> 12
<212> PRT
<213> Mus musculus
<400> 10
Ser Ala Leu Ile Lys Lys Lys Lys Lys Met Ala Pro
1 5 10
<210> 11
<211> 5
<212> PRT
<213> Influenza virus
<400> 11
Asp Arg Leu Arg Arg
1 5
<210> 12
<211> 7
<212> PRT
<213> Influenza virus
<400> 12
Pro Lys Gln Lys Lys Arg Lys
1 5
<210> 13
<211> 10
<212> PRT
<213> Hepatitus delta virus
<400> 13
Arg Lys Leu Lys Lys Lys Ile Lys Lys Leu
1 5 10
<210> 14
<211> 10
<212> PRT
<213> Mus musculus
<400> 14
Arg Glu Lys Lys Lys Phe Leu Lys Arg Arg
1 5 10
<210> 15
<211> 20
<212> PRT
<213> Homo sapiens
<400> 15
Lys Arg Lys Gly Asp Glu Val Asp Gly Val Asp Glu Val Ala Lys Lys
1 5 10 15
Lys Ser Lys Lys
20
<210> 16
<211> 17
<212> PRT
<213> Homo sapiens
<400> 16
Arg Lys Cys Leu Gln Ala Gly Met Asn Leu Glu Ala Arg Lys Thr Lys
1 5 10 15
Lys
<210> 17
<211> 27
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<220>
<221> modified_base
<222> (1)..(20)
<223> a, c, t or g
<220>
<221> modified_base
<222> (21)..(22)
<223> a, c, t, g, unknown or other
<400> 17
nnnnnnnnnn nnnnnnnnnn nnagaaw 27
<210> 18
<211> 19
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<220>
<221> modified_base
<222> (1)..(12)
<223> a, c, t or g
<220>
<221> modified_base
<222> (13)..(14)
<223> a, c, t, g, unknown or other
<400> 18
nnnnnnnnnn nnnnagaaw 19
<210> 19
<211> 27
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<220>
<221> modified_base
<222> (1)..(20)
<223> a, c, t or g
<220>
<221> modified_base
<222> (21)..(22)
<223> a, c, t, g, unknown or other
<400> 19
nnnnnnnnnn nnnnnnnnnn nnagaaw 27
<210> 20
<211> 18
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<220>
<221> modified_base
<222> (1)..(11)
<223> a, c, t or g
<220>
<221> modified_base
<222> (12)..(13)
<223> a, c, t, g, unknown or other
<400> 20
nnnnnnnnnn nnnagaaw 18
<210> 21
<211> 137
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<220>
<221> modified_base
<222> (1)..(20)
<223> a, c, t, g, unknown or other
<400> 21
nnnnnnnnnn nnnnnnnnnn gtttttgtac tctcaagatt tagaaataaa tcttgcagaa 60
gctacaaaga taaggcttca tgccgaaatc aacaccctgt cattttatgg cagggtgttt 120
tcgttattta atttttt 137
<210> 22
<211> 123
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<220>
<221> modified_base
<222> (1)..(20)
<223> a, c, t, g, unknown or other
<400> 22
nnnnnnnnnn nnnnnnnnnn gtttttgtac tctcagaaat gcagaagcta caaagataag 60
gcttcatgcc gaaatcaaca ccctgtcatt ttatggcagg gtgttttcgt tatttaattt 120
ttt 123
<210> 23
<211> 110
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<220>
<221> modified_base
<222> (1)..(20)
<223> a, c, t, g, unknown or other
<400> 23
nnnnnnnnnn nnnnnnnnnn gtttttgtac tctcagaaat gcagaagcta caaagataag 60
gcttcatgcc gaaatcaaca ccctgtcatt ttatggcagg gtgttttttt 110
<210> 24
<211> 102
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<220>
<221> modified_base
<222> (1)..(20)
<223> a, c, t, g, unknown or other
<400> 24
nnnnnnnnnn nnnnnnnnnn gttttagagc tagaaatagc aagttaaaat aaggctagtc 60
cgttatcaac ttgaaaaagt ggcaccgagt cggtgctttt tt 102
<210> 25
<211> 88
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<220>
<221> modified_base
<222> (1)..(20)
<223> a, c, t, g, unknown or other
<400> 25
nnnnnnnnnn nnnnnnnnnn gttttagagc tagaaatagc aagttaaaat aaggctagtc 60
cgttatcaac ttgaaaaagt gttttttt 88
<210> 26
<211> 76
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<220>
<221> modified_base
<222> (1)..(20)
<223> a, c, t, g, unknown or other
<400> 26
nnnnnnnnnn nnnnnnnnnn gttttagagc tagaaatagc aagttaaaat aaggctagtc 60
cgttatcatt tttttt 76
<210> 27
<211> 12
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 27
gttttagagc ta 12
<210> 28
<211> 31
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 28
tagcaagtta aaataaggct agtccgtttt t 31
<210> 29
<211> 27
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<220>
<221> modified_base
<222> (1)..(22)
<223> a, c, t, g, unknown or other
<400> 29
nnnnnnnnnn nnnnnnnnnn nnagaaw 27
<210> 30
<211> 12
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 30
guuuuagagc ua 12
<210> 31
<211> 33
<212> DNA
<213> Homo sapiens
<400> 31
ggacatcgat gtcacctcca atgactaggg tgg 33
<210> 32
<211> 33
<212> DNA
<213> Homo sapiens
<400> 32
cattggaggt gacatcgatg tcctccccat tgg 33
<210> 33
<211> 33
<212> DNA
<213> Homo sapiens
<400> 33
ggaagggcct gagtccgagc agaagaagaa ggg 33
<210> 34
<211> 33
<212> DNA
<213> Homo sapiens
<400> 34
ggtggcgaga ggggccgaga ttgggtgttc agg 33
<210> 35
<211> 33
<212> DNA
<213> Homo sapiens
<400> 35
atgcaggagg gtggcgagag gggccgagat tgg 33
<210> 36
<211> 21
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 36
aaaaccaccc ttctctctgg c 21
<210> 37
<211> 21
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 37
ggagattgga gacacggaga g 21
<210> 38
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 38
ctggaaagcc aatgcctgac 20
<210> 39
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 39
ggcagcaaac tccttgtcct 20
<210> 40
<211> 335
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 40
gagggcctat ttcccatgat tccttcatat ttgcatatac gatacaaggc tgttagagag 60
ataattggaa ttaatttgac tgtaaacaca aagatattag tacaaaatac gtgacgtaga 120
aagtaataat ttcttgggta gtttgcagtt ttaaaattat gttttaaaat ggactatcat 180
atgcttaccg taacttgaaa gtatttcgat ttcttggctt tatatatctt gtggaaagga 240
cgaaacaccg gaaccattca aaacagcata gcaagttaaa ataaggctag tccgttatca 300
acttgaaaaa gtggcaccga gtcggtgctt ttttt 335
<210> 41
<211> 423
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 41
gagggcctat ttcccatgat tccttcatat ttgcatatac gatacaaggc tgttagagag 60
ataattggaa ttaatttgac tgtaaacaca aagatattag tacaaaatac gtgacgtaga 120
aagtaataat ttcttgggta gtttgcagtt ttaaaattat gttttaaaat ggactatcat 180
atgcttaccg taacttgaaa gtatttcgat ttcttggctt tatatatctt gtggaaagga 240
cgaaacaccg gtagtattaa gtattgtttt atggctgata aatttctttg aatttctcct 300
tgattatttg ttataaaagt tataaaataa tcttgttgga accattcaaa acagcatagc 360
aagttaaaat aaggctagtc cgttatcaac ttgaaaaagt ggcaccgagt cggtgctttt 420
ttt 423
<210> 42
<211> 339
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 42
gagggcctat ttcccatgat tccttcatat ttgcatatac gatacaaggc tgttagagag 60
ataattggaa ttaatttgac tgtaaacaca aagatattag tacaaaatac gtgacgtaga 120
aagtaataat ttcttgggta gtttgcagtt ttaaaattat gttttaaaat ggactatcat 180
atgcttaccg taacttgaaa gtatttcgat ttcttggctt tatatatctt gtggaaagga 240
cgaaacaccg ggttttagag ctatgctgtt ttgaatggtc ccaaaacggg tcttcgagaa 300
gacgttttag agctatgctg ttttgaatgg tcccaaaac 339
<210> 43
<211> 309
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 43
gagggcctat ttcccatgat tccttcatat ttgcatatac gatacaaggc tgttagagag 60
ataattggaa ttaatttgac tgtaaacaca aagatattag tacaaaatac gtgacgtaga 120
aagtaataat ttcttgggta gtttgcagtt ttaaaattat gttttaaaat ggactatcat 180
atgcttaccg taacttgaaa gtatttcgat ttcttggctt tatatatctt gtggaaagga 240
cgaaacaccg ggtcttcgag aagacctgtt ttagagctag aaatagcaag ttaaaataag 300
gctagtccg 309
<210> 44
<211> 1648
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 44
Met Asp Tyr Lys Asp His Asp Gly Asp Tyr Lys Asp His Asp Ile Asp
1 5 10 15
Tyr Lys Asp Asp Asp Asp Lys Met Ala Pro Lys Lys Lys Arg Lys Val
20 25 30
Gly Ile His Gly Val Pro Ala Ala Asp Lys Lys Tyr Ser Ile Gly Leu
35 40 45
Asp Ile Gly Thr Asn Ser Val Gly Trp Ala Val Ile Thr Asp Glu Tyr
50 55 60
Lys Val Pro Ser Lys Lys Phe Lys Val Leu Gly Asn Thr Asp Arg His
65 70 75 80
Ser Ile Lys Lys Asn Leu Ile Gly Ala Leu Leu Phe Asp Ser Gly Glu
85 90 95
Thr Ala Glu Ala Thr Arg Leu Lys Arg Thr Ala Arg Arg Arg Tyr Thr
100 105 110
Arg Arg Lys Asn Arg Ile Cys Tyr Leu Gln Glu Ile Phe Ser Asn Glu
115 120 125
Met Ala Lys Val Asp Asp Ser Phe Phe His Arg Leu Glu Glu Ser Phe
130 135 140
Leu Val Glu Glu Asp Lys Lys His Glu Arg His Pro Ile Phe Gly Asn
145 150 155 160
Ile Val Asp Glu Val Ala Tyr His Glu Lys Tyr Pro Thr Ile Tyr His
165 170 175
Leu Arg Lys Lys Leu Val Asp Ser Thr Asp Lys Ala Asp Leu Arg Leu
180 185 190
Ile Tyr Leu Ala Leu Ala His Met Ile Lys Phe Arg Gly His Phe Leu
195 200 205
Ile Glu Gly Asp Leu Asn Pro Asp Asn Ser Asp Val Asp Lys Leu Phe
210 215 220
Ile Gln Leu Val Gln Thr Tyr Asn Gln Leu Phe Glu Glu Asn Pro Ile
225 230 235 240
Asn Ala Ser Gly Val Asp Ala Lys Ala Ile Leu Ser Ala Arg Leu Ser
245 250 255
Lys Ser Arg Arg Leu Glu Asn Leu Ile Ala Gln Leu Pro Gly Glu Lys
260 265 270
Lys Asn Gly Leu Phe Gly Asn Leu Ile Ala Leu Ser Leu Gly Leu Thr
275 280 285
Pro Asn Phe Lys Ser Asn Phe Asp Leu Ala Glu Asp Ala Lys Leu Gln
290 295 300
Leu Ser Lys Asp Thr Tyr Asp Asp Asp Leu Asp Asn Leu Leu Ala Gln
305 310 315 320
Ile Gly Asp Gln Tyr Ala Asp Leu Phe Leu Ala Ala Lys Asn Leu Ser
325 330 335
Asp Ala Ile Leu Leu Ser Asp Ile Leu Arg Val Asn Thr Glu Ile Thr
340 345 350
Lys Ala Pro Leu Ser Ala Ser Met Ile Lys Arg Tyr Asp Glu His His
355 360 365
Gln Asp Leu Thr Leu Leu Lys Ala Leu Val Arg Gln Gln Leu Pro Glu
370 375 380
Lys Tyr Lys Glu Ile Phe Phe Asp Gln Ser Lys Asn Gly Tyr Ala Gly
385 390 395 400
Tyr Ile Asp Gly Gly Ala Ser Gln Glu Glu Phe Tyr Lys Phe Ile Lys
405 410 415
Pro Ile Leu Glu Lys Met Asp Gly Thr Glu Glu Leu Leu Val Lys Leu
420 425 430
Asn Arg Glu Asp Leu Leu Arg Lys Gln Arg Thr Phe Asp Asn Gly Ser
435 440 445
Ile Pro His Gln Ile His Leu Gly Glu Leu His Ala Ile Leu Arg Arg
450 455 460
Gln Glu Asp Phe Tyr Pro Phe Leu Lys Asp Asn Arg Glu Lys Ile Glu
465 470 475 480
Lys Ile Leu Thr Phe Arg Ile Pro Tyr Tyr Val Gly Pro Leu Ala Arg
485 490 495
Gly Asn Ser Arg Phe Ala Trp Met Thr Arg Lys Ser Glu Glu Thr Ile
500 505 510
Thr Pro Trp Asn Phe Glu Glu Val Val Asp Lys Gly Ala Ser Ala Gln
515 520 525
Ser Phe Ile Glu Arg Met Thr Asn Phe Asp Lys Asn Leu Pro Asn Glu
530 535 540
Lys Val Leu Pro Lys His Ser Leu Leu Tyr Glu Tyr Phe Thr Val Tyr
545 550 555 560
Asn Glu Leu Thr Lys Val Lys Tyr Val Thr Glu Gly Met Arg Lys Pro
565 570 575
Ala Phe Leu Ser Gly Glu Gln Lys Lys Ala Ile Val Asp Leu Leu Phe
580 585 590
Lys Thr Asn Arg Lys Val Thr Val Lys Gln Leu Lys Glu Asp Tyr Phe
595 600 605
Lys Lys Ile Glu Cys Phe Asp Ser Val Glu Ile Ser Gly Val Glu Asp
610 615 620
Arg Phe Asn Ala Ser Leu Gly Thr Tyr His Asp Leu Leu Lys Ile Ile
625 630 635 640
Lys Asp Lys Asp Phe Leu Asp Asn Glu Glu Asn Glu Asp Ile Leu Glu
645 650 655
Asp Ile Val Leu Thr Leu Thr Leu Phe Glu Asp Arg Glu Met Ile Glu
660 665 670
Glu Arg Leu Lys Thr Tyr Ala His Leu Phe Asp Asp Lys Val Met Lys
675 680 685
Gln Leu Lys Arg Arg Arg Tyr Thr Gly Trp Gly Arg Leu Ser Arg Lys
690 695 700
Leu Ile Asn Gly Ile Arg Asp Lys Gln Ser Gly Lys Thr Ile Leu Asp
705 710 715 720
Phe Leu Lys Ser Asp Gly Phe Ala Asn Arg Asn Phe Met Gln Leu Ile
725 730 735
His Asp Asp Ser Leu Thr Phe Lys Glu Asp Ile Gln Lys Ala Gln Val
740 745 750
Ser Gly Gln Gly Asp Ser Leu His Glu His Ile Ala Asn Leu Ala Gly
755 760 765
Ser Pro Ala Ile Lys Lys Gly Ile Leu Gln Thr Val Lys Val Val Asp
770 775 780
Glu Leu Val Lys Val Met Gly Arg His Lys Pro Glu Asn Ile Val Ile
785 790 795 800
Glu Met Ala Arg Glu Asn Gln Thr Thr Gln Lys Gly Gln Lys Asn Ser
805 810 815
Arg Glu Arg Met Lys Arg Ile Glu Glu Gly Ile Lys Glu Leu Gly Ser
820 825 830
Gln Ile Leu Lys Glu His Pro Val Glu Asn Thr Gln Leu Gln Asn Glu
835 840 845
Lys Leu Tyr Leu Tyr Tyr Leu Gln Asn Gly Arg Asp Met Tyr Val Asp
850 855 860
Gln Glu Leu Asp Ile Asn Arg Leu Ser Asp Tyr Asp Val Asp His Ile
865 870 875 880
Val Pro Gln Ser Phe Leu Lys Asp Asp Ser Ile Asp Asn Lys Val Leu
885 890 895
Thr Arg Ser Asp Lys Asn Arg Gly Lys Ser Asp Asn Val Pro Ser Glu
900 905 910
Glu Val Val Lys Lys Met Lys Asn Tyr Trp Arg Gln Leu Leu Asn Ala
915 920 925
Lys Leu Ile Thr Gln Arg Lys Phe Asp Asn Leu Thr Lys Ala Glu Arg
930 935 940
Gly Gly Leu Ser Glu Leu Asp Lys Ala Gly Phe Ile Lys Arg Gln Leu
945 950 955 960
Val Glu Thr Arg Gln Ile Thr Lys His Val Ala Gln Ile Leu Asp Ser
965 970 975
Arg Met Asn Thr Lys Tyr Asp Glu Asn Asp Lys Leu Ile Arg Glu Val
980 985 990
Lys Val Ile Thr Leu Lys Ser Lys Leu Val Ser Asp Phe Arg Lys Asp
995 1000 1005
Phe Gln Phe Tyr Lys Val Arg Glu Ile Asn Asn Tyr His His Ala
1010 1015 1020
His Asp Ala Tyr Leu Asn Ala Val Val Gly Thr Ala Leu Ile Lys
1025 1030 1035
Lys Tyr Pro Lys Leu Glu Ser Glu Phe Val Tyr Gly Asp Tyr Lys
1040 1045 1050
Val Tyr Asp Val Arg Lys Met Ile Ala Lys Ser Glu Gln Glu Ile
1055 1060 1065
Gly Lys Ala Thr Ala Lys Tyr Phe Phe Tyr Ser Asn Ile Met Asn
1070 1075 1080
Phe Phe Lys Thr Glu Ile Thr Leu Ala Asn Gly Glu Ile Arg Lys
1085 1090 1095
Arg Pro Leu Ile Glu Thr Asn Gly Glu Thr Gly Glu Ile Val Trp
1100 1105 1110
Asp Lys Gly Arg Asp Phe Ala Thr Val Arg Lys Val Leu Ser Met
1115 1120 1125
Pro Gln Val Asn Ile Val Lys Lys Thr Glu Val Gln Thr Gly Gly
1130 1135 1140
Phe Ser Lys Glu Ser Ile Leu Pro Lys Arg Asn Ser Asp Lys Leu
1145 1150 1155
Ile Ala Arg Lys Lys Asp Trp Asp Pro Lys Lys Tyr Gly Gly Phe
1160 1165 1170
Asp Ser Pro Thr Val Ala Tyr Ser Val Leu Val Val Ala Lys Val
1175 1180 1185
Glu Lys Gly Lys Ser Lys Lys Leu Lys Ser Val Lys Glu Leu Leu
1190 1195 1200
Gly Ile Thr Ile Met Glu Arg Ser Ser Phe Glu Lys Asn Pro Ile
1205 1210 1215
Asp Phe Leu Glu Ala Lys Gly Tyr Lys Glu Val Lys Lys Asp Leu
1220 1225 1230
Ile Ile Lys Leu Pro Lys Tyr Ser Leu Phe Glu Leu Glu Asn Gly
1235 1240 1245
Arg Lys Arg Met Leu Ala Ser Ala Gly Glu Leu Gln Lys Gly Asn
1250 1255 1260
Glu Leu Ala Leu Pro Ser Lys Tyr Val Asn Phe Leu Tyr Leu Ala
1265 1270 1275
Ser His Tyr Glu Lys Leu Lys Gly Ser Pro Glu Asp Asn Glu Gln
1280 1285 1290
Lys Gln Leu Phe Val Glu Gln His Lys His Tyr Leu Asp Glu Ile
1295 1300 1305
Ile Glu Gln Ile Ser Glu Phe Ser Lys Arg Val Ile Leu Ala Asp
1310 1315 1320
Ala Asn Leu Asp Lys Val Leu Ser Ala Tyr Asn Lys His Arg Asp
1325 1330 1335
Lys Pro Ile Arg Glu Gln Ala Glu Asn Ile Ile His Leu Phe Thr
1340 1345 1350
Leu Thr Asn Leu Gly Ala Pro Ala Ala Phe Lys Tyr Phe Asp Thr
1355 1360 1365
Thr Ile Asp Arg Lys Arg Tyr Thr Ser Thr Lys Glu Val Leu Asp
1370 1375 1380
Ala Thr Leu Ile His Gln Ser Ile Thr Gly Leu Tyr Glu Thr Arg
1385 1390 1395
Ile Asp Leu Ser Gln Leu Gly Gly Asp Ala Ala Ala Val Ser Lys
1400 1405 1410
Gly Glu Glu Leu Phe Thr Gly Val Val Pro Ile Leu Val Glu Leu
1415 1420 1425
Asp Gly Asp Val Asn Gly His Lys Phe Ser Val Ser Gly Glu Gly
1430 1435 1440
Glu Gly Asp Ala Thr Tyr Gly Lys Leu Thr Leu Lys Phe Ile Cys
1445 1450 1455
Thr Thr Gly Lys Leu Pro Val Pro Trp Pro Thr Leu Val Thr Thr
1460 1465 1470
Leu Thr Tyr Gly Val Gln Cys Phe Ser Arg Tyr Pro Asp His Met
1475 1480 1485
Lys Gln His Asp Phe Phe Lys Ser Ala Met Pro Glu Gly Tyr Val
1490 1495 1500
Gln Glu Arg Thr Ile Phe Phe Lys Asp Asp Gly Asn Tyr Lys Thr
1505 1510 1515
Arg Ala Glu Val Lys Phe Glu Gly Asp Thr Leu Val Asn Arg Ile
1520 1525 1530
Glu Leu Lys Gly Ile Asp Phe Lys Glu Asp Gly Asn Ile Leu Gly
1535 1540 1545
His Lys Leu Glu Tyr Asn Tyr Asn Ser His Asn Val Tyr Ile Met
1550 1555 1560
Ala Asp Lys Gln Lys Asn Gly Ile Lys Val Asn Phe Lys Ile Arg
1565 1570 1575
His Asn Ile Glu Asp Gly Ser Val Gln Leu Ala Asp His Tyr Gln
1580 1585 1590
Gln Asn Thr Pro Ile Gly Asp Gly Pro Val Leu Leu Pro Asp Asn
1595 1600 1605
His Tyr Leu Ser Thr Gln Ser Ala Leu Ser Lys Asp Pro Asn Glu
1610 1615 1620
Lys Arg Asp His Met Val Leu Leu Glu Phe Val Thr Ala Ala Gly
1625 1630 1635
Ile Thr Leu Gly Met Asp Glu Leu Tyr Lys
1640 1645
<210> 45
<211> 1625
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 45
Met Asp Lys Lys Tyr Ser Ile Gly Leu Asp Ile Gly Thr Asn Ser Val
1 5 10 15
Gly Trp Ala Val Ile Thr Asp Glu Tyr Lys Val Pro Ser Lys Lys Phe
20 25 30
Lys Val Leu Gly Asn Thr Asp Arg His Ser Ile Lys Lys Asn Leu Ile
35 40 45
Gly Ala Leu Leu Phe Asp Ser Gly Glu Thr Ala Glu Ala Thr Arg Leu
50 55 60
Lys Arg Thr Ala Arg Arg Arg Tyr Thr Arg Arg Lys Asn Arg Ile Cys
65 70 75 80
Tyr Leu Gln Glu Ile Phe Ser Asn Glu Met Ala Lys Val Asp Asp Ser
85 90 95
Phe Phe His Arg Leu Glu Glu Ser Phe Leu Val Glu Glu Asp Lys Lys
100 105 110
His Glu Arg His Pro Ile Phe Gly Asn Ile Val Asp Glu Val Ala Tyr
115 120 125
His Glu Lys Tyr Pro Thr Ile Tyr His Leu Arg Lys Lys Leu Val Asp
130 135 140
Ser Thr Asp Lys Ala Asp Leu Arg Leu Ile Tyr Leu Ala Leu Ala His
145 150 155 160
Met Ile Lys Phe Arg Gly His Phe Leu Ile Glu Gly Asp Leu Asn Pro
165 170 175
Asp Asn Ser Asp Val Asp Lys Leu Phe Ile Gln Leu Val Gln Thr Tyr
180 185 190
Asn Gln Leu Phe Glu Glu Asn Pro Ile Asn Ala Ser Gly Val Asp Ala
195 200 205
Lys Ala Ile Leu Ser Ala Arg Leu Ser Lys Ser Arg Arg Leu Glu Asn
210 215 220
Leu Ile Ala Gln Leu Pro Gly Glu Lys Lys Asn Gly Leu Phe Gly Asn
225 230 235 240
Leu Ile Ala Leu Ser Leu Gly Leu Thr Pro Asn Phe Lys Ser Asn Phe
245 250 255
Asp Leu Ala Glu Asp Ala Lys Leu Gln Leu Ser Lys Asp Thr Tyr Asp
260 265 270
Asp Asp Leu Asp Asn Leu Leu Ala Gln Ile Gly Asp Gln Tyr Ala Asp
275 280 285
Leu Phe Leu Ala Ala Lys Asn Leu Ser Asp Ala Ile Leu Leu Ser Asp
290 295 300
Ile Leu Arg Val Asn Thr Glu Ile Thr Lys Ala Pro Leu Ser Ala Ser
305 310 315 320
Met Ile Lys Arg Tyr Asp Glu His His Gln Asp Leu Thr Leu Leu Lys
325 330 335
Ala Leu Val Arg Gln Gln Leu Pro Glu Lys Tyr Lys Glu Ile Phe Phe
340 345 350
Asp Gln Ser Lys Asn Gly Tyr Ala Gly Tyr Ile Asp Gly Gly Ala Ser
355 360 365
Gln Glu Glu Phe Tyr Lys Phe Ile Lys Pro Ile Leu Glu Lys Met Asp
370 375 380
Gly Thr Glu Glu Leu Leu Val Lys Leu Asn Arg Glu Asp Leu Leu Arg
385 390 395 400
Lys Gln Arg Thr Phe Asp Asn Gly Ser Ile Pro His Gln Ile His Leu
405 410 415
Gly Glu Leu His Ala Ile Leu Arg Arg Gln Glu Asp Phe Tyr Pro Phe
420 425 430
Leu Lys Asp Asn Arg Glu Lys Ile Glu Lys Ile Leu Thr Phe Arg Ile
435 440 445
Pro Tyr Tyr Val Gly Pro Leu Ala Arg Gly Asn Ser Arg Phe Ala Trp
450 455 460
Met Thr Arg Lys Ser Glu Glu Thr Ile Thr Pro Trp Asn Phe Glu Glu
465 470 475 480
Val Val Asp Lys Gly Ala Ser Ala Gln Ser Phe Ile Glu Arg Met Thr
485 490 495
Asn Phe Asp Lys Asn Leu Pro Asn Glu Lys Val Leu Pro Lys His Ser
500 505 510
Leu Leu Tyr Glu Tyr Phe Thr Val Tyr Asn Glu Leu Thr Lys Val Lys
515 520 525
Tyr Val Thr Glu Gly Met Arg Lys Pro Ala Phe Leu Ser Gly Glu Gln
530 535 540
Lys Lys Ala Ile Val Asp Leu Leu Phe Lys Thr Asn Arg Lys Val Thr
545 550 555 560
Val Lys Gln Leu Lys Glu Asp Tyr Phe Lys Lys Ile Glu Cys Phe Asp
565 570 575
Ser Val Glu Ile Ser Gly Val Glu Asp Arg Phe Asn Ala Ser Leu Gly
580 585 590
Thr Tyr His Asp Leu Leu Lys Ile Ile Lys Asp Lys Asp Phe Leu Asp
595 600 605
Asn Glu Glu Asn Glu Asp Ile Leu Glu Asp Ile Val Leu Thr Leu Thr
610 615 620
Leu Phe Glu Asp Arg Glu Met Ile Glu Glu Arg Leu Lys Thr Tyr Ala
625 630 635 640
His Leu Phe Asp Asp Lys Val Met Lys Gln Leu Lys Arg Arg Arg Tyr
645 650 655
Thr Gly Trp Gly Arg Leu Ser Arg Lys Leu Ile Asn Gly Ile Arg Asp
660 665 670
Lys Gln Ser Gly Lys Thr Ile Leu Asp Phe Leu Lys Ser Asp Gly Phe
675 680 685
Ala Asn Arg Asn Phe Met Gln Leu Ile His Asp Asp Ser Leu Thr Phe
690 695 700
Lys Glu Asp Ile Gln Lys Ala Gln Val Ser Gly Gln Gly Asp Ser Leu
705 710 715 720
His Glu His Ile Ala Asn Leu Ala Gly Ser Pro Ala Ile Lys Lys Gly
725 730 735
Ile Leu Gln Thr Val Lys Val Val Asp Glu Leu Val Lys Val Met Gly
740 745 750
Arg His Lys Pro Glu Asn Ile Val Ile Glu Met Ala Arg Glu Asn Gln
755 760 765
Thr Thr Gln Lys Gly Gln Lys Asn Ser Arg Glu Arg Met Lys Arg Ile
770 775 780
Glu Glu Gly Ile Lys Glu Leu Gly Ser Gln Ile Leu Lys Glu His Pro
785 790 795 800
Val Glu Asn Thr Gln Leu Gln Asn Glu Lys Leu Tyr Leu Tyr Tyr Leu
805 810 815
Gln Asn Gly Arg Asp Met Tyr Val Asp Gln Glu Leu Asp Ile Asn Arg
820 825 830
Leu Ser Asp Tyr Asp Val Asp His Ile Val Pro Gln Ser Phe Leu Lys
835 840 845
Asp Asp Ser Ile Asp Asn Lys Val Leu Thr Arg Ser Asp Lys Asn Arg
850 855 860
Gly Lys Ser Asp Asn Val Pro Ser Glu Glu Val Val Lys Lys Met Lys
865 870 875 880
Asn Tyr Trp Arg Gln Leu Leu Asn Ala Lys Leu Ile Thr Gln Arg Lys
885 890 895
Phe Asp Asn Leu Thr Lys Ala Glu Arg Gly Gly Leu Ser Glu Leu Asp
900 905 910
Lys Ala Gly Phe Ile Lys Arg Gln Leu Val Glu Thr Arg Gln Ile Thr
915 920 925
Lys His Val Ala Gln Ile Leu Asp Ser Arg Met Asn Thr Lys Tyr Asp
930 935 940
Glu Asn Asp Lys Leu Ile Arg Glu Val Lys Val Ile Thr Leu Lys Ser
945 950 955 960
Lys Leu Val Ser Asp Phe Arg Lys Asp Phe Gln Phe Tyr Lys Val Arg
965 970 975
Glu Ile Asn Asn Tyr His His Ala His Asp Ala Tyr Leu Asn Ala Val
980 985 990
Val Gly Thr Ala Leu Ile Lys Lys Tyr Pro Lys Leu Glu Ser Glu Phe
995 1000 1005
Val Tyr Gly Asp Tyr Lys Val Tyr Asp Val Arg Lys Met Ile Ala
1010 1015 1020
Lys Ser Glu Gln Glu Ile Gly Lys Ala Thr Ala Lys Tyr Phe Phe
1025 1030 1035
Tyr Ser Asn Ile Met Asn Phe Phe Lys Thr Glu Ile Thr Leu Ala
1040 1045 1050
Asn Gly Glu Ile Arg Lys Arg Pro Leu Ile Glu Thr Asn Gly Glu
1055 1060 1065
Thr Gly Glu Ile Val Trp Asp Lys Gly Arg Asp Phe Ala Thr Val
1070 1075 1080
Arg Lys Val Leu Ser Met Pro Gln Val Asn Ile Val Lys Lys Thr
1085 1090 1095
Glu Val Gln Thr Gly Gly Phe Ser Lys Glu Ser Ile Leu Pro Lys
1100 1105 1110
Arg Asn Ser Asp Lys Leu Ile Ala Arg Lys Lys Asp Trp Asp Pro
1115 1120 1125
Lys Lys Tyr Gly Gly Phe Asp Ser Pro Thr Val Ala Tyr Ser Val
1130 1135 1140
Leu Val Val Ala Lys Val Glu Lys Gly Lys Ser Lys Lys Leu Lys
1145 1150 1155
Ser Val Lys Glu Leu Leu Gly Ile Thr Ile Met Glu Arg Ser Ser
1160 1165 1170
Phe Glu Lys Asn Pro Ile Asp Phe Leu Glu Ala Lys Gly Tyr Lys
1175 1180 1185
Glu Val Lys Lys Asp Leu Ile Ile Lys Leu Pro Lys Tyr Ser Leu
1190 1195 1200
Phe Glu Leu Glu Asn Gly Arg Lys Arg Met Leu Ala Ser Ala Gly
1205 1210 1215
Glu Leu Gln Lys Gly Asn Glu Leu Ala Leu Pro Ser Lys Tyr Val
1220 1225 1230
Asn Phe Leu Tyr Leu Ala Ser His Tyr Glu Lys Leu Lys Gly Ser
1235 1240 1245
Pro Glu Asp Asn Glu Gln Lys Gln Leu Phe Val Glu Gln His Lys
1250 1255 1260
His Tyr Leu Asp Glu Ile Ile Glu Gln Ile Ser Glu Phe Ser Lys
1265 1270 1275
Arg Val Ile Leu Ala Asp Ala Asn Leu Asp Lys Val Leu Ser Ala
1280 1285 1290
Tyr Asn Lys His Arg Asp Lys Pro Ile Arg Glu Gln Ala Glu Asn
1295 1300 1305
Ile Ile His Leu Phe Thr Leu Thr Asn Leu Gly Ala Pro Ala Ala
1310 1315 1320
Phe Lys Tyr Phe Asp Thr Thr Ile Asp Arg Lys Arg Tyr Thr Ser
1325 1330 1335
Thr Lys Glu Val Leu Asp Ala Thr Leu Ile His Gln Ser Ile Thr
1340 1345 1350
Gly Leu Tyr Glu Thr Arg Ile Asp Leu Ser Gln Leu Gly Gly Asp
1355 1360 1365
Ala Ala Ala Val Ser Lys Gly Glu Glu Leu Phe Thr Gly Val Val
1370 1375 1380
Pro Ile Leu Val Glu Leu Asp Gly Asp Val Asn Gly His Lys Phe
1385 1390 1395
Ser Val Ser Gly Glu Gly Glu Gly Asp Ala Thr Tyr Gly Lys Leu
1400 1405 1410
Thr Leu Lys Phe Ile Cys Thr Thr Gly Lys Leu Pro Val Pro Trp
1415 1420 1425
Pro Thr Leu Val Thr Thr Leu Thr Tyr Gly Val Gln Cys Phe Ser
1430 1435 1440
Arg Tyr Pro Asp His Met Lys Gln His Asp Phe Phe Lys Ser Ala
1445 1450 1455
Met Pro Glu Gly Tyr Val Gln Glu Arg Thr Ile Phe Phe Lys Asp
1460 1465 1470
Asp Gly Asn Tyr Lys Thr Arg Ala Glu Val Lys Phe Glu Gly Asp
1475 1480 1485
Thr Leu Val Asn Arg Ile Glu Leu Lys Gly Ile Asp Phe Lys Glu
1490 1495 1500
Asp Gly Asn Ile Leu Gly His Lys Leu Glu Tyr Asn Tyr Asn Ser
1505 1510 1515
His Asn Val Tyr Ile Met Ala Asp Lys Gln Lys Asn Gly Ile Lys
1520 1525 1530
Val Asn Phe Lys Ile Arg His Asn Ile Glu Asp Gly Ser Val Gln
1535 1540 1545
Leu Ala Asp His Tyr Gln Gln Asn Thr Pro Ile Gly Asp Gly Pro
1550 1555 1560
Val Leu Leu Pro Asp Asn His Tyr Leu Ser Thr Gln Ser Ala Leu
1565 1570 1575
Ser Lys Asp Pro Asn Glu Lys Arg Asp His Met Val Leu Leu Glu
1580 1585 1590
Phe Val Thr Ala Ala Gly Ile Thr Leu Gly Met Asp Glu Leu Tyr
1595 1600 1605
Lys Lys Arg Pro Ala Ala Thr Lys Lys Ala Gly Gln Ala Lys Lys
1610 1615 1620
Lys Lys
1625
<210> 46
<211> 1664
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 46
Met Asp Tyr Lys Asp His Asp Gly Asp Tyr Lys Asp His Asp Ile Asp
1 5 10 15
Tyr Lys Asp Asp Asp Asp Lys Met Ala Pro Lys Lys Lys Arg Lys Val
20 25 30
Gly Ile His Gly Val Pro Ala Ala Asp Lys Lys Tyr Ser Ile Gly Leu
35 40 45
Asp Ile Gly Thr Asn Ser Val Gly Trp Ala Val Ile Thr Asp Glu Tyr
50 55 60
Lys Val Pro Ser Lys Lys Phe Lys Val Leu Gly Asn Thr Asp Arg His
65 70 75 80
Ser Ile Lys Lys Asn Leu Ile Gly Ala Leu Leu Phe Asp Ser Gly Glu
85 90 95
Thr Ala Glu Ala Thr Arg Leu Lys Arg Thr Ala Arg Arg Arg Tyr Thr
100 105 110
Arg Arg Lys Asn Arg Ile Cys Tyr Leu Gln Glu Ile Phe Ser Asn Glu
115 120 125
Met Ala Lys Val Asp Asp Ser Phe Phe His Arg Leu Glu Glu Ser Phe
130 135 140
Leu Val Glu Glu Asp Lys Lys His Glu Arg His Pro Ile Phe Gly Asn
145 150 155 160
Ile Val Asp Glu Val Ala Tyr His Glu Lys Tyr Pro Thr Ile Tyr His
165 170 175
Leu Arg Lys Lys Leu Val Asp Ser Thr Asp Lys Ala Asp Leu Arg Leu
180 185 190
Ile Tyr Leu Ala Leu Ala His Met Ile Lys Phe Arg Gly His Phe Leu
195 200 205
Ile Glu Gly Asp Leu Asn Pro Asp Asn Ser Asp Val Asp Lys Leu Phe
210 215 220
Ile Gln Leu Val Gln Thr Tyr Asn Gln Leu Phe Glu Glu Asn Pro Ile
225 230 235 240
Asn Ala Ser Gly Val Asp Ala Lys Ala Ile Leu Ser Ala Arg Leu Ser
245 250 255
Lys Ser Arg Arg Leu Glu Asn Leu Ile Ala Gln Leu Pro Gly Glu Lys
260 265 270
Lys Asn Gly Leu Phe Gly Asn Leu Ile Ala Leu Ser Leu Gly Leu Thr
275 280 285
Pro Asn Phe Lys Ser Asn Phe Asp Leu Ala Glu Asp Ala Lys Leu Gln
290 295 300
Leu Ser Lys Asp Thr Tyr Asp Asp Asp Leu Asp Asn Leu Leu Ala Gln
305 310 315 320
Ile Gly Asp Gln Tyr Ala Asp Leu Phe Leu Ala Ala Lys Asn Leu Ser
325 330 335
Asp Ala Ile Leu Leu Ser Asp Ile Leu Arg Val Asn Thr Glu Ile Thr
340 345 350
Lys Ala Pro Leu Ser Ala Ser Met Ile Lys Arg Tyr Asp Glu His His
355 360 365
Gln Asp Leu Thr Leu Leu Lys Ala Leu Val Arg Gln Gln Leu Pro Glu
370 375 380
Lys Tyr Lys Glu Ile Phe Phe Asp Gln Ser Lys Asn Gly Tyr Ala Gly
385 390 395 400
Tyr Ile Asp Gly Gly Ala Ser Gln Glu Glu Phe Tyr Lys Phe Ile Lys
405 410 415
Pro Ile Leu Glu Lys Met Asp Gly Thr Glu Glu Leu Leu Val Lys Leu
420 425 430
Asn Arg Glu Asp Leu Leu Arg Lys Gln Arg Thr Phe Asp Asn Gly Ser
435 440 445
Ile Pro His Gln Ile His Leu Gly Glu Leu His Ala Ile Leu Arg Arg
450 455 460
Gln Glu Asp Phe Tyr Pro Phe Leu Lys Asp Asn Arg Glu Lys Ile Glu
465 470 475 480
Lys Ile Leu Thr Phe Arg Ile Pro Tyr Tyr Val Gly Pro Leu Ala Arg
485 490 495
Gly Asn Ser Arg Phe Ala Trp Met Thr Arg Lys Ser Glu Glu Thr Ile
500 505 510
Thr Pro Trp Asn Phe Glu Glu Val Val Asp Lys Gly Ala Ser Ala Gln
515 520 525
Ser Phe Ile Glu Arg Met Thr Asn Phe Asp Lys Asn Leu Pro Asn Glu
530 535 540
Lys Val Leu Pro Lys His Ser Leu Leu Tyr Glu Tyr Phe Thr Val Tyr
545 550 555 560
Asn Glu Leu Thr Lys Val Lys Tyr Val Thr Glu Gly Met Arg Lys Pro
565 570 575
Ala Phe Leu Ser Gly Glu Gln Lys Lys Ala Ile Val Asp Leu Leu Phe
580 585 590
Lys Thr Asn Arg Lys Val Thr Val Lys Gln Leu Lys Glu Asp Tyr Phe
595 600 605
Lys Lys Ile Glu Cys Phe Asp Ser Val Glu Ile Ser Gly Val Glu Asp
610 615 620
Arg Phe Asn Ala Ser Leu Gly Thr Tyr His Asp Leu Leu Lys Ile Ile
625 630 635 640
Lys Asp Lys Asp Phe Leu Asp Asn Glu Glu Asn Glu Asp Ile Leu Glu
645 650 655
Asp Ile Val Leu Thr Leu Thr Leu Phe Glu Asp Arg Glu Met Ile Glu
660 665 670
Glu Arg Leu Lys Thr Tyr Ala His Leu Phe Asp Asp Lys Val Met Lys
675 680 685
Gln Leu Lys Arg Arg Arg Tyr Thr Gly Trp Gly Arg Leu Ser Arg Lys
690 695 700
Leu Ile Asn Gly Ile Arg Asp Lys Gln Ser Gly Lys Thr Ile Leu Asp
705 710 715 720
Phe Leu Lys Ser Asp Gly Phe Ala Asn Arg Asn Phe Met Gln Leu Ile
725 730 735
His Asp Asp Ser Leu Thr Phe Lys Glu Asp Ile Gln Lys Ala Gln Val
740 745 750
Ser Gly Gln Gly Asp Ser Leu His Glu His Ile Ala Asn Leu Ala Gly
755 760 765
Ser Pro Ala Ile Lys Lys Gly Ile Leu Gln Thr Val Lys Val Val Asp
770 775 780
Glu Leu Val Lys Val Met Gly Arg His Lys Pro Glu Asn Ile Val Ile
785 790 795 800
Glu Met Ala Arg Glu Asn Gln Thr Thr Gln Lys Gly Gln Lys Asn Ser
805 810 815
Arg Glu Arg Met Lys Arg Ile Glu Glu Gly Ile Lys Glu Leu Gly Ser
820 825 830
Gln Ile Leu Lys Glu His Pro Val Glu Asn Thr Gln Leu Gln Asn Glu
835 840 845
Lys Leu Tyr Leu Tyr Tyr Leu Gln Asn Gly Arg Asp Met Tyr Val Asp
850 855 860
Gln Glu Leu Asp Ile Asn Arg Leu Ser Asp Tyr Asp Val Asp His Ile
865 870 875 880
Val Pro Gln Ser Phe Leu Lys Asp Asp Ser Ile Asp Asn Lys Val Leu
885 890 895
Thr Arg Ser Asp Lys Asn Arg Gly Lys Ser Asp Asn Val Pro Ser Glu
900 905 910
Glu Val Val Lys Lys Met Lys Asn Tyr Trp Arg Gln Leu Leu Asn Ala
915 920 925
Lys Leu Ile Thr Gln Arg Lys Phe Asp Asn Leu Thr Lys Ala Glu Arg
930 935 940
Gly Gly Leu Ser Glu Leu Asp Lys Ala Gly Phe Ile Lys Arg Gln Leu
945 950 955 960
Val Glu Thr Arg Gln Ile Thr Lys His Val Ala Gln Ile Leu Asp Ser
965 970 975
Arg Met Asn Thr Lys Tyr Asp Glu Asn Asp Lys Leu Ile Arg Glu Val
980 985 990
Lys Val Ile Thr Leu Lys Ser Lys Leu Val Ser Asp Phe Arg Lys Asp
995 1000 1005
Phe Gln Phe Tyr Lys Val Arg Glu Ile Asn Asn Tyr His His Ala
1010 1015 1020
His Asp Ala Tyr Leu Asn Ala Val Val Gly Thr Ala Leu Ile Lys
1025 1030 1035
Lys Tyr Pro Lys Leu Glu Ser Glu Phe Val Tyr Gly Asp Tyr Lys
1040 1045 1050
Val Tyr Asp Val Arg Lys Met Ile Ala Lys Ser Glu Gln Glu Ile
1055 1060 1065
Gly Lys Ala Thr Ala Lys Tyr Phe Phe Tyr Ser Asn Ile Met Asn
1070 1075 1080
Phe Phe Lys Thr Glu Ile Thr Leu Ala Asn Gly Glu Ile Arg Lys
1085 1090 1095
Arg Pro Leu Ile Glu Thr Asn Gly Glu Thr Gly Glu Ile Val Trp
1100 1105 1110
Asp Lys Gly Arg Asp Phe Ala Thr Val Arg Lys Val Leu Ser Met
1115 1120 1125
Pro Gln Val Asn Ile Val Lys Lys Thr Glu Val Gln Thr Gly Gly
1130 1135 1140
Phe Ser Lys Glu Ser Ile Leu Pro Lys Arg Asn Ser Asp Lys Leu
1145 1150 1155
Ile Ala Arg Lys Lys Asp Trp Asp Pro Lys Lys Tyr Gly Gly Phe
1160 1165 1170
Asp Ser Pro Thr Val Ala Tyr Ser Val Leu Val Val Ala Lys Val
1175 1180 1185
Glu Lys Gly Lys Ser Lys Lys Leu Lys Ser Val Lys Glu Leu Leu
1190 1195 1200
Gly Ile Thr Ile Met Glu Arg Ser Ser Phe Glu Lys Asn Pro Ile
1205 1210 1215
Asp Phe Leu Glu Ala Lys Gly Tyr Lys Glu Val Lys Lys Asp Leu
1220 1225 1230
Ile Ile Lys Leu Pro Lys Tyr Ser Leu Phe Glu Leu Glu Asn Gly
1235 1240 1245
Arg Lys Arg Met Leu Ala Ser Ala Gly Glu Leu Gln Lys Gly Asn
1250 1255 1260
Glu Leu Ala Leu Pro Ser Lys Tyr Val Asn Phe Leu Tyr Leu Ala
1265 1270 1275
Ser His Tyr Glu Lys Leu Lys Gly Ser Pro Glu Asp Asn Glu Gln
1280 1285 1290
Lys Gln Leu Phe Val Glu Gln His Lys His Tyr Leu Asp Glu Ile
1295 1300 1305
Ile Glu Gln Ile Ser Glu Phe Ser Lys Arg Val Ile Leu Ala Asp
1310 1315 1320
Ala Asn Leu Asp Lys Val Leu Ser Ala Tyr Asn Lys His Arg Asp
1325 1330 1335
Lys Pro Ile Arg Glu Gln Ala Glu Asn Ile Ile His Leu Phe Thr
1340 1345 1350
Leu Thr Asn Leu Gly Ala Pro Ala Ala Phe Lys Tyr Phe Asp Thr
1355 1360 1365
Thr Ile Asp Arg Lys Arg Tyr Thr Ser Thr Lys Glu Val Leu Asp
1370 1375 1380
Ala Thr Leu Ile His Gln Ser Ile Thr Gly Leu Tyr Glu Thr Arg
1385 1390 1395
Ile Asp Leu Ser Gln Leu Gly Gly Asp Ala Ala Ala Val Ser Lys
1400 1405 1410
Gly Glu Glu Leu Phe Thr Gly Val Val Pro Ile Leu Val Glu Leu
1415 1420 1425
Asp Gly Asp Val Asn Gly His Lys Phe Ser Val Ser Gly Glu Gly
1430 1435 1440
Glu Gly Asp Ala Thr Tyr Gly Lys Leu Thr Leu Lys Phe Ile Cys
1445 1450 1455
Thr Thr Gly Lys Leu Pro Val Pro Trp Pro Thr Leu Val Thr Thr
1460 1465 1470
Leu Thr Tyr Gly Val Gln Cys Phe Ser Arg Tyr Pro Asp His Met
1475 1480 1485
Lys Gln His Asp Phe Phe Lys Ser Ala Met Pro Glu Gly Tyr Val
1490 1495 1500
Gln Glu Arg Thr Ile Phe Phe Lys Asp Asp Gly Asn Tyr Lys Thr
1505 1510 1515
Arg Ala Glu Val Lys Phe Glu Gly Asp Thr Leu Val Asn Arg Ile
1520 1525 1530
Glu Leu Lys Gly Ile Asp Phe Lys Glu Asp Gly Asn Ile Leu Gly
1535 1540 1545
His Lys Leu Glu Tyr Asn Tyr Asn Ser His Asn Val Tyr Ile Met
1550 1555 1560
Ala Asp Lys Gln Lys Asn Gly Ile Lys Val Asn Phe Lys Ile Arg
1565 1570 1575
His Asn Ile Glu Asp Gly Ser Val Gln Leu Ala Asp His Tyr Gln
1580 1585 1590
Gln Asn Thr Pro Ile Gly Asp Gly Pro Val Leu Leu Pro Asp Asn
1595 1600 1605
His Tyr Leu Ser Thr Gln Ser Ala Leu Ser Lys Asp Pro Asn Glu
1610 1615 1620
Lys Arg Asp His Met Val Leu Leu Glu Phe Val Thr Ala Ala Gly
1625 1630 1635
Ile Thr Leu Gly Met Asp Glu Leu Tyr Lys Lys Arg Pro Ala Ala
1640 1645 1650
Thr Lys Lys Ala Gly Gln Ala Lys Lys Lys Lys
1655 1660
<210> 47
<211> 1423
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 47
Met Asp Tyr Lys Asp His Asp Gly Asp Tyr Lys Asp His Asp Ile Asp
1 5 10 15
Tyr Lys Asp Asp Asp Asp Lys Met Ala Pro Lys Lys Lys Arg Lys Val
20 25 30
Gly Ile His Gly Val Pro Ala Ala Asp Lys Lys Tyr Ser Ile Gly Leu
35 40 45
Asp Ile Gly Thr Asn Ser Val Gly Trp Ala Val Ile Thr Asp Glu Tyr
50 55 60
Lys Val Pro Ser Lys Lys Phe Lys Val Leu Gly Asn Thr Asp Arg His
65 70 75 80
Ser Ile Lys Lys Asn Leu Ile Gly Ala Leu Leu Phe Asp Ser Gly Glu
85 90 95
Thr Ala Glu Ala Thr Arg Leu Lys Arg Thr Ala Arg Arg Arg Tyr Thr
100 105 110
Arg Arg Lys Asn Arg Ile Cys Tyr Leu Gln Glu Ile Phe Ser Asn Glu
115 120 125
Met Ala Lys Val Asp Asp Ser Phe Phe His Arg Leu Glu Glu Ser Phe
130 135 140
Leu Val Glu Glu Asp Lys Lys His Glu Arg His Pro Ile Phe Gly Asn
145 150 155 160
Ile Val Asp Glu Val Ala Tyr His Glu Lys Tyr Pro Thr Ile Tyr His
165 170 175
Leu Arg Lys Lys Leu Val Asp Ser Thr Asp Lys Ala Asp Leu Arg Leu
180 185 190
Ile Tyr Leu Ala Leu Ala His Met Ile Lys Phe Arg Gly His Phe Leu
195 200 205
Ile Glu Gly Asp Leu Asn Pro Asp Asn Ser Asp Val Asp Lys Leu Phe
210 215 220
Ile Gln Leu Val Gln Thr Tyr Asn Gln Leu Phe Glu Glu Asn Pro Ile
225 230 235 240
Asn Ala Ser Gly Val Asp Ala Lys Ala Ile Leu Ser Ala Arg Leu Ser
245 250 255
Lys Ser Arg Arg Leu Glu Asn Leu Ile Ala Gln Leu Pro Gly Glu Lys
260 265 270
Lys Asn Gly Leu Phe Gly Asn Leu Ile Ala Leu Ser Leu Gly Leu Thr
275 280 285
Pro Asn Phe Lys Ser Asn Phe Asp Leu Ala Glu Asp Ala Lys Leu Gln
290 295 300
Leu Ser Lys Asp Thr Tyr Asp Asp Asp Leu Asp Asn Leu Leu Ala Gln
305 310 315 320
Ile Gly Asp Gln Tyr Ala Asp Leu Phe Leu Ala Ala Lys Asn Leu Ser
325 330 335
Asp Ala Ile Leu Leu Ser Asp Ile Leu Arg Val Asn Thr Glu Ile Thr
340 345 350
Lys Ala Pro Leu Ser Ala Ser Met Ile Lys Arg Tyr Asp Glu His His
355 360 365
Gln Asp Leu Thr Leu Leu Lys Ala Leu Val Arg Gln Gln Leu Pro Glu
370 375 380
Lys Tyr Lys Glu Ile Phe Phe Asp Gln Ser Lys Asn Gly Tyr Ala Gly
385 390 395 400
Tyr Ile Asp Gly Gly Ala Ser Gln Glu Glu Phe Tyr Lys Phe Ile Lys
405 410 415
Pro Ile Leu Glu Lys Met Asp Gly Thr Glu Glu Leu Leu Val Lys Leu
420 425 430
Asn Arg Glu Asp Leu Leu Arg Lys Gln Arg Thr Phe Asp Asn Gly Ser
435 440 445
Ile Pro His Gln Ile His Leu Gly Glu Leu His Ala Ile Leu Arg Arg
450 455 460
Gln Glu Asp Phe Tyr Pro Phe Leu Lys Asp Asn Arg Glu Lys Ile Glu
465 470 475 480
Lys Ile Leu Thr Phe Arg Ile Pro Tyr Tyr Val Gly Pro Leu Ala Arg
485 490 495
Gly Asn Ser Arg Phe Ala Trp Met Thr Arg Lys Ser Glu Glu Thr Ile
500 505 510
Thr Pro Trp Asn Phe Glu Glu Val Val Asp Lys Gly Ala Ser Ala Gln
515 520 525
Ser Phe Ile Glu Arg Met Thr Asn Phe Asp Lys Asn Leu Pro Asn Glu
530 535 540
Lys Val Leu Pro Lys His Ser Leu Leu Tyr Glu Tyr Phe Thr Val Tyr
545 550 555 560
Asn Glu Leu Thr Lys Val Lys Tyr Val Thr Glu Gly Met Arg Lys Pro
565 570 575
Ala Phe Leu Ser Gly Glu Gln Lys Lys Ala Ile Val Asp Leu Leu Phe
580 585 590
Lys Thr Asn Arg Lys Val Thr Val Lys Gln Leu Lys Glu Asp Tyr Phe
595 600 605
Lys Lys Ile Glu Cys Phe Asp Ser Val Glu Ile Ser Gly Val Glu Asp
610 615 620
Arg Phe Asn Ala Ser Leu Gly Thr Tyr His Asp Leu Leu Lys Ile Ile
625 630 635 640
Lys Asp Lys Asp Phe Leu Asp Asn Glu Glu Asn Glu Asp Ile Leu Glu
645 650 655
Asp Ile Val Leu Thr Leu Thr Leu Phe Glu Asp Arg Glu Met Ile Glu
660 665 670
Glu Arg Leu Lys Thr Tyr Ala His Leu Phe Asp Asp Lys Val Met Lys
675 680 685
Gln Leu Lys Arg Arg Arg Tyr Thr Gly Trp Gly Arg Leu Ser Arg Lys
690 695 700
Leu Ile Asn Gly Ile Arg Asp Lys Gln Ser Gly Lys Thr Ile Leu Asp
705 710 715 720
Phe Leu Lys Ser Asp Gly Phe Ala Asn Arg Asn Phe Met Gln Leu Ile
725 730 735
His Asp Asp Ser Leu Thr Phe Lys Glu Asp Ile Gln Lys Ala Gln Val
740 745 750
Ser Gly Gln Gly Asp Ser Leu His Glu His Ile Ala Asn Leu Ala Gly
755 760 765
Ser Pro Ala Ile Lys Lys Gly Ile Leu Gln Thr Val Lys Val Val Asp
770 775 780
Glu Leu Val Lys Val Met Gly Arg His Lys Pro Glu Asn Ile Val Ile
785 790 795 800
Glu Met Ala Arg Glu Asn Gln Thr Thr Gln Lys Gly Gln Lys Asn Ser
805 810 815
Arg Glu Arg Met Lys Arg Ile Glu Glu Gly Ile Lys Glu Leu Gly Ser
820 825 830
Gln Ile Leu Lys Glu His Pro Val Glu Asn Thr Gln Leu Gln Asn Glu
835 840 845
Lys Leu Tyr Leu Tyr Tyr Leu Gln Asn Gly Arg Asp Met Tyr Val Asp
850 855 860
Gln Glu Leu Asp Ile Asn Arg Leu Ser Asp Tyr Asp Val Asp His Ile
865 870 875 880
Val Pro Gln Ser Phe Leu Lys Asp Asp Ser Ile Asp Asn Lys Val Leu
885 890 895
Thr Arg Ser Asp Lys Asn Arg Gly Lys Ser Asp Asn Val Pro Ser Glu
900 905 910
Glu Val Val Lys Lys Met Lys Asn Tyr Trp Arg Gln Leu Leu Asn Ala
915 920 925
Lys Leu Ile Thr Gln Arg Lys Phe Asp Asn Leu Thr Lys Ala Glu Arg
930 935 940
Gly Gly Leu Ser Glu Leu Asp Lys Ala Gly Phe Ile Lys Arg Gln Leu
945 950 955 960
Val Glu Thr Arg Gln Ile Thr Lys His Val Ala Gln Ile Leu Asp Ser
965 970 975
Arg Met Asn Thr Lys Tyr Asp Glu Asn Asp Lys Leu Ile Arg Glu Val
980 985 990
Lys Val Ile Thr Leu Lys Ser Lys Leu Val Ser Asp Phe Arg Lys Asp
995 1000 1005
Phe Gln Phe Tyr Lys Val Arg Glu Ile Asn Asn Tyr His His Ala
1010 1015 1020
His Asp Ala Tyr Leu Asn Ala Val Val Gly Thr Ala Leu Ile Lys
1025 1030 1035
Lys Tyr Pro Lys Leu Glu Ser Glu Phe Val Tyr Gly Asp Tyr Lys
1040 1045 1050
Val Tyr Asp Val Arg Lys Met Ile Ala Lys Ser Glu Gln Glu Ile
1055 1060 1065
Gly Lys Ala Thr Ala Lys Tyr Phe Phe Tyr Ser Asn Ile Met Asn
1070 1075 1080
Phe Phe Lys Thr Glu Ile Thr Leu Ala Asn Gly Glu Ile Arg Lys
1085 1090 1095
Arg Pro Leu Ile Glu Thr Asn Gly Glu Thr Gly Glu Ile Val Trp
1100 1105 1110
Asp Lys Gly Arg Asp Phe Ala Thr Val Arg Lys Val Leu Ser Met
1115 1120 1125
Pro Gln Val Asn Ile Val Lys Lys Thr Glu Val Gln Thr Gly Gly
1130 1135 1140
Phe Ser Lys Glu Ser Ile Leu Pro Lys Arg Asn Ser Asp Lys Leu
1145 1150 1155
Ile Ala Arg Lys Lys Asp Trp Asp Pro Lys Lys Tyr Gly Gly Phe
1160 1165 1170
Asp Ser Pro Thr Val Ala Tyr Ser Val Leu Val Val Ala Lys Val
1175 1180 1185
Glu Lys Gly Lys Ser Lys Lys Leu Lys Ser Val Lys Glu Leu Leu
1190 1195 1200
Gly Ile Thr Ile Met Glu Arg Ser Ser Phe Glu Lys Asn Pro Ile
1205 1210 1215
Asp Phe Leu Glu Ala Lys Gly Tyr Lys Glu Val Lys Lys Asp Leu
1220 1225 1230
Ile Ile Lys Leu Pro Lys Tyr Ser Leu Phe Glu Leu Glu Asn Gly
1235 1240 1245
Arg Lys Arg Met Leu Ala Ser Ala Gly Glu Leu Gln Lys Gly Asn
1250 1255 1260
Glu Leu Ala Leu Pro Ser Lys Tyr Val Asn Phe Leu Tyr Leu Ala
1265 1270 1275
Ser His Tyr Glu Lys Leu Lys Gly Ser Pro Glu Asp Asn Glu Gln
1280 1285 1290
Lys Gln Leu Phe Val Glu Gln His Lys His Tyr Leu Asp Glu Ile
1295 1300 1305
Ile Glu Gln Ile Ser Glu Phe Ser Lys Arg Val Ile Leu Ala Asp
1310 1315 1320
Ala Asn Leu Asp Lys Val Leu Ser Ala Tyr Asn Lys His Arg Asp
1325 1330 1335
Lys Pro Ile Arg Glu Gln Ala Glu Asn Ile Ile His Leu Phe Thr
1340 1345 1350
Leu Thr Asn Leu Gly Ala Pro Ala Ala Phe Lys Tyr Phe Asp Thr
1355 1360 1365
Thr Ile Asp Arg Lys Arg Tyr Thr Ser Thr Lys Glu Val Leu Asp
1370 1375 1380
Ala Thr Leu Ile His Gln Ser Ile Thr Gly Leu Tyr Glu Thr Arg
1385 1390 1395
Ile Asp Leu Ser Gln Leu Gly Gly Asp Lys Arg Pro Ala Ala Thr
1400 1405 1410
Lys Lys Ala Gly Gln Ala Lys Lys Lys Lys
1415 1420
<210> 48
<211> 483
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 48
Met Phe Leu Phe Leu Ser Leu Thr Ser Phe Leu Ser Ser Ser Arg Thr
1 5 10 15
Leu Val Ser Lys Gly Glu Glu Asp Asn Met Ala Ile Ile Lys Glu Phe
20 25 30
Met Arg Phe Lys Val His Met Glu Gly Ser Val Asn Gly His Glu Phe
35 40 45
Glu Ile Glu Gly Glu Gly Glu Gly Arg Pro Tyr Glu Gly Thr Gln Thr
50 55 60
Ala Lys Leu Lys Val Thr Lys Gly Gly Pro Leu Pro Phe Ala Trp Asp
65 70 75 80
Ile Leu Ser Pro Gln Phe Met Tyr Gly Ser Lys Ala Tyr Val Lys His
85 90 95
Pro Ala Asp Ile Pro Asp Tyr Leu Lys Leu Ser Phe Pro Glu Gly Phe
100 105 110
Lys Trp Glu Arg Val Met Asn Phe Glu Asp Gly Gly Val Val Thr Val
115 120 125
Thr Gln Asp Ser Ser Leu Gln Asp Gly Glu Phe Ile Tyr Lys Val Lys
130 135 140
Leu Arg Gly Thr Asn Phe Pro Ser Asp Gly Pro Val Met Gln Lys Lys
145 150 155 160
Thr Met Gly Trp Glu Ala Ser Ser Glu Arg Met Tyr Pro Glu Asp Gly
165 170 175
Ala Leu Lys Gly Glu Ile Lys Gln Arg Leu Lys Leu Lys Asp Gly Gly
180 185 190
His Tyr Asp Ala Glu Val Lys Thr Thr Tyr Lys Ala Lys Lys Pro Val
195 200 205
Gln Leu Pro Gly Ala Tyr Asn Val Asn Ile Lys Leu Asp Ile Thr Ser
210 215 220
His Asn Glu Asp Tyr Thr Ile Val Glu Gln Tyr Glu Arg Ala Glu Gly
225 230 235 240
Arg His Ser Thr Gly Gly Met Asp Glu Leu Tyr Lys Gly Ser Lys Gln
245 250 255
Leu Glu Glu Leu Leu Ser Thr Ser Phe Asp Ile Gln Phe Asn Asp Leu
260 265 270
Thr Leu Leu Glu Thr Ala Phe Thr His Thr Ser Tyr Ala Asn Glu His
275 280 285
Arg Leu Leu Asn Val Ser His Asn Glu Arg Leu Glu Phe Leu Gly Asp
290 295 300
Ala Val Leu Gln Leu Ile Ile Ser Glu Tyr Leu Phe Ala Lys Tyr Pro
305 310 315 320
Lys Lys Thr Glu Gly Asp Met Ser Lys Leu Arg Ser Met Ile Val Arg
325 330 335
Glu Glu Ser Leu Ala Gly Phe Ser Arg Phe Cys Ser Phe Asp Ala Tyr
340 345 350
Ile Lys Leu Gly Lys Gly Glu Glu Lys Ser Gly Gly Arg Arg Arg Asp
355 360 365
Thr Ile Leu Gly Asp Leu Phe Glu Ala Phe Leu Gly Ala Leu Leu Leu
370 375 380
Asp Lys Gly Ile Asp Ala Val Arg Arg Phe Leu Lys Gln Val Met Ile
385 390 395 400
Pro Gln Val Glu Lys Gly Asn Phe Glu Arg Val Lys Asp Tyr Lys Thr
405 410 415
Cys Leu Gln Glu Phe Leu Gln Thr Lys Gly Asp Val Ala Ile Asp Tyr
420 425 430
Gln Val Ile Ser Glu Lys Gly Pro Ala His Ala Lys Gln Phe Glu Val
435 440 445
Ser Ile Val Val Asn Gly Ala Val Leu Ser Lys Gly Leu Gly Lys Ser
450 455 460
Lys Lys Leu Ala Glu Gln Asp Ala Ala Lys Asn Ala Leu Ala Gln Leu
465 470 475 480
Ser Glu Val
<210> 49
<211> 483
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 49
Met Lys Gln Leu Glu Glu Leu Leu Ser Thr Ser Phe Asp Ile Gln Phe
1 5 10 15
Asn Asp Leu Thr Leu Leu Glu Thr Ala Phe Thr His Thr Ser Tyr Ala
20 25 30
Asn Glu His Arg Leu Leu Asn Val Ser His Asn Glu Arg Leu Glu Phe
35 40 45
Leu Gly Asp Ala Val Leu Gln Leu Ile Ile Ser Glu Tyr Leu Phe Ala
50 55 60
Lys Tyr Pro Lys Lys Thr Glu Gly Asp Met Ser Lys Leu Arg Ser Met
65 70 75 80
Ile Val Arg Glu Glu Ser Leu Ala Gly Phe Ser Arg Phe Cys Ser Phe
85 90 95
Asp Ala Tyr Ile Lys Leu Gly Lys Gly Glu Glu Lys Ser Gly Gly Arg
100 105 110
Arg Arg Asp Thr Ile Leu Gly Asp Leu Phe Glu Ala Phe Leu Gly Ala
115 120 125
Leu Leu Leu Asp Lys Gly Ile Asp Ala Val Arg Arg Phe Leu Lys Gln
130 135 140
Val Met Ile Pro Gln Val Glu Lys Gly Asn Phe Glu Arg Val Lys Asp
145 150 155 160
Tyr Lys Thr Cys Leu Gln Glu Phe Leu Gln Thr Lys Gly Asp Val Ala
165 170 175
Ile Asp Tyr Gln Val Ile Ser Glu Lys Gly Pro Ala His Ala Lys Gln
180 185 190
Phe Glu Val Ser Ile Val Val Asn Gly Ala Val Leu Ser Lys Gly Leu
195 200 205
Gly Lys Ser Lys Lys Leu Ala Glu Gln Asp Ala Ala Lys Asn Ala Leu
210 215 220
Ala Gln Leu Ser Glu Val Gly Ser Val Ser Lys Gly Glu Glu Asp Asn
225 230 235 240
Met Ala Ile Ile Lys Glu Phe Met Arg Phe Lys Val His Met Glu Gly
245 250 255
Ser Val Asn Gly His Glu Phe Glu Ile Glu Gly Glu Gly Glu Gly Arg
260 265 270
Pro Tyr Glu Gly Thr Gln Thr Ala Lys Leu Lys Val Thr Lys Gly Gly
275 280 285
Pro Leu Pro Phe Ala Trp Asp Ile Leu Ser Pro Gln Phe Met Tyr Gly
290 295 300
Ser Lys Ala Tyr Val Lys His Pro Ala Asp Ile Pro Asp Tyr Leu Lys
305 310 315 320
Leu Ser Phe Pro Glu Gly Phe Lys Trp Glu Arg Val Met Asn Phe Glu
325 330 335
Asp Gly Gly Val Val Thr Val Thr Gln Asp Ser Ser Leu Gln Asp Gly
340 345 350
Glu Phe Ile Tyr Lys Val Lys Leu Arg Gly Thr Asn Phe Pro Ser Asp
355 360 365
Gly Pro Val Met Gln Lys Lys Thr Met Gly Trp Glu Ala Ser Ser Glu
370 375 380
Arg Met Tyr Pro Glu Asp Gly Ala Leu Lys Gly Glu Ile Lys Gln Arg
385 390 395 400
Leu Lys Leu Lys Asp Gly Gly His Tyr Asp Ala Glu Val Lys Thr Thr
405 410 415
Tyr Lys Ala Lys Lys Pro Val Gln Leu Pro Gly Ala Tyr Asn Val Asn
420 425 430
Ile Lys Leu Asp Ile Thr Ser His Asn Glu Asp Tyr Thr Ile Val Glu
435 440 445
Gln Tyr Glu Arg Ala Glu Gly Arg His Ser Thr Gly Gly Met Asp Glu
450 455 460
Leu Tyr Lys Lys Arg Pro Ala Ala Thr Lys Lys Ala Gly Gln Ala Lys
465 470 475 480
Lys Lys Lys
<210> 50
<211> 1423
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 50
Met Asp Tyr Lys Asp His Asp Gly Asp Tyr Lys Asp His Asp Ile Asp
1 5 10 15
Tyr Lys Asp Asp Asp Asp Lys Met Ala Pro Lys Lys Lys Arg Lys Val
20 25 30
Gly Ile His Gly Val Pro Ala Ala Asp Lys Lys Tyr Ser Ile Gly Leu
35 40 45
Ala Ile Gly Thr Asn Ser Val Gly Trp Ala Val Ile Thr Asp Glu Tyr
50 55 60
Lys Val Pro Ser Lys Lys Phe Lys Val Leu Gly Asn Thr Asp Arg His
65 70 75 80
Ser Ile Lys Lys Asn Leu Ile Gly Ala Leu Leu Phe Asp Ser Gly Glu
85 90 95
Thr Ala Glu Ala Thr Arg Leu Lys Arg Thr Ala Arg Arg Arg Tyr Thr
100 105 110
Arg Arg Lys Asn Arg Ile Cys Tyr Leu Gln Glu Ile Phe Ser Asn Glu
115 120 125
Met Ala Lys Val Asp Asp Ser Phe Phe His Arg Leu Glu Glu Ser Phe
130 135 140
Leu Val Glu Glu Asp Lys Lys His Glu Arg His Pro Ile Phe Gly Asn
145 150 155 160
Ile Val Asp Glu Val Ala Tyr His Glu Lys Tyr Pro Thr Ile Tyr His
165 170 175
Leu Arg Lys Lys Leu Val Asp Ser Thr Asp Lys Ala Asp Leu Arg Leu
180 185 190
Ile Tyr Leu Ala Leu Ala His Met Ile Lys Phe Arg Gly His Phe Leu
195 200 205
Ile Glu Gly Asp Leu Asn Pro Asp Asn Ser Asp Val Asp Lys Leu Phe
210 215 220
Ile Gln Leu Val Gln Thr Tyr Asn Gln Leu Phe Glu Glu Asn Pro Ile
225 230 235 240
Asn Ala Ser Gly Val Asp Ala Lys Ala Ile Leu Ser Ala Arg Leu Ser
245 250 255
Lys Ser Arg Arg Leu Glu Asn Leu Ile Ala Gln Leu Pro Gly Glu Lys
260 265 270
Lys Asn Gly Leu Phe Gly Asn Leu Ile Ala Leu Ser Leu Gly Leu Thr
275 280 285
Pro Asn Phe Lys Ser Asn Phe Asp Leu Ala Glu Asp Ala Lys Leu Gln
290 295 300
Leu Ser Lys Asp Thr Tyr Asp Asp Asp Leu Asp Asn Leu Leu Ala Gln
305 310 315 320
Ile Gly Asp Gln Tyr Ala Asp Leu Phe Leu Ala Ala Lys Asn Leu Ser
325 330 335
Asp Ala Ile Leu Leu Ser Asp Ile Leu Arg Val Asn Thr Glu Ile Thr
340 345 350
Lys Ala Pro Leu Ser Ala Ser Met Ile Lys Arg Tyr Asp Glu His His
355 360 365
Gln Asp Leu Thr Leu Leu Lys Ala Leu Val Arg Gln Gln Leu Pro Glu
370 375 380
Lys Tyr Lys Glu Ile Phe Phe Asp Gln Ser Lys Asn Gly Tyr Ala Gly
385 390 395 400
Tyr Ile Asp Gly Gly Ala Ser Gln Glu Glu Phe Tyr Lys Phe Ile Lys
405 410 415
Pro Ile Leu Glu Lys Met Asp Gly Thr Glu Glu Leu Leu Val Lys Leu
420 425 430
Asn Arg Glu Asp Leu Leu Arg Lys Gln Arg Thr Phe Asp Asn Gly Ser
435 440 445
Ile Pro His Gln Ile His Leu Gly Glu Leu His Ala Ile Leu Arg Arg
450 455 460
Gln Glu Asp Phe Tyr Pro Phe Leu Lys Asp Asn Arg Glu Lys Ile Glu
465 470 475 480
Lys Ile Leu Thr Phe Arg Ile Pro Tyr Tyr Val Gly Pro Leu Ala Arg
485 490 495
Gly Asn Ser Arg Phe Ala Trp Met Thr Arg Lys Ser Glu Glu Thr Ile
500 505 510
Thr Pro Trp Asn Phe Glu Glu Val Val Asp Lys Gly Ala Ser Ala Gln
515 520 525
Ser Phe Ile Glu Arg Met Thr Asn Phe Asp Lys Asn Leu Pro Asn Glu
530 535 540
Lys Val Leu Pro Lys His Ser Leu Leu Tyr Glu Tyr Phe Thr Val Tyr
545 550 555 560
Asn Glu Leu Thr Lys Val Lys Tyr Val Thr Glu Gly Met Arg Lys Pro
565 570 575
Ala Phe Leu Ser Gly Glu Gln Lys Lys Ala Ile Val Asp Leu Leu Phe
580 585 590
Lys Thr Asn Arg Lys Val Thr Val Lys Gln Leu Lys Glu Asp Tyr Phe
595 600 605
Lys Lys Ile Glu Cys Phe Asp Ser Val Glu Ile Ser Gly Val Glu Asp
610 615 620
Arg Phe Asn Ala Ser Leu Gly Thr Tyr His Asp Leu Leu Lys Ile Ile
625 630 635 640
Lys Asp Lys Asp Phe Leu Asp Asn Glu Glu Asn Glu Asp Ile Leu Glu
645 650 655
Asp Ile Val Leu Thr Leu Thr Leu Phe Glu Asp Arg Glu Met Ile Glu
660 665 670
Glu Arg Leu Lys Thr Tyr Ala His Leu Phe Asp Asp Lys Val Met Lys
675 680 685
Gln Leu Lys Arg Arg Arg Tyr Thr Gly Trp Gly Arg Leu Ser Arg Lys
690 695 700
Leu Ile Asn Gly Ile Arg Asp Lys Gln Ser Gly Lys Thr Ile Leu Asp
705 710 715 720
Phe Leu Lys Ser Asp Gly Phe Ala Asn Arg Asn Phe Met Gln Leu Ile
725 730 735
His Asp Asp Ser Leu Thr Phe Lys Glu Asp Ile Gln Lys Ala Gln Val
740 745 750
Ser Gly Gln Gly Asp Ser Leu His Glu His Ile Ala Asn Leu Ala Gly
755 760 765
Ser Pro Ala Ile Lys Lys Gly Ile Leu Gln Thr Val Lys Val Val Asp
770 775 780
Glu Leu Val Lys Val Met Gly Arg His Lys Pro Glu Asn Ile Val Ile
785 790 795 800
Glu Met Ala Arg Glu Asn Gln Thr Thr Gln Lys Gly Gln Lys Asn Ser
805 810 815
Arg Glu Arg Met Lys Arg Ile Glu Glu Gly Ile Lys Glu Leu Gly Ser
820 825 830
Gln Ile Leu Lys Glu His Pro Val Glu Asn Thr Gln Leu Gln Asn Glu
835 840 845
Lys Leu Tyr Leu Tyr Tyr Leu Gln Asn Gly Arg Asp Met Tyr Val Asp
850 855 860
Gln Glu Leu Asp Ile Asn Arg Leu Ser Asp Tyr Asp Val Asp His Ile
865 870 875 880
Val Pro Gln Ser Phe Leu Lys Asp Asp Ser Ile Asp Asn Lys Val Leu
885 890 895
Thr Arg Ser Asp Lys Asn Arg Gly Lys Ser Asp Asn Val Pro Ser Glu
900 905 910
Glu Val Val Lys Lys Met Lys Asn Tyr Trp Arg Gln Leu Leu Asn Ala
915 920 925
Lys Leu Ile Thr Gln Arg Lys Phe Asp Asn Leu Thr Lys Ala Glu Arg
930 935 940
Gly Gly Leu Ser Glu Leu Asp Lys Ala Gly Phe Ile Lys Arg Gln Leu
945 950 955 960
Val Glu Thr Arg Gln Ile Thr Lys His Val Ala Gln Ile Leu Asp Ser
965 970 975
Arg Met Asn Thr Lys Tyr Asp Glu Asn Asp Lys Leu Ile Arg Glu Val
980 985 990
Lys Val Ile Thr Leu Lys Ser Lys Leu Val Ser Asp Phe Arg Lys Asp
995 1000 1005
Phe Gln Phe Tyr Lys Val Arg Glu Ile Asn Asn Tyr His His Ala
1010 1015 1020
His Asp Ala Tyr Leu Asn Ala Val Val Gly Thr Ala Leu Ile Lys
1025 1030 1035
Lys Tyr Pro Lys Leu Glu Ser Glu Phe Val Tyr Gly Asp Tyr Lys
1040 1045 1050
Val Tyr Asp Val Arg Lys Met Ile Ala Lys Ser Glu Gln Glu Ile
1055 1060 1065
Gly Lys Ala Thr Ala Lys Tyr Phe Phe Tyr Ser Asn Ile Met Asn
1070 1075 1080
Phe Phe Lys Thr Glu Ile Thr Leu Ala Asn Gly Glu Ile Arg Lys
1085 1090 1095
Arg Pro Leu Ile Glu Thr Asn Gly Glu Thr Gly Glu Ile Val Trp
1100 1105 1110
Asp Lys Gly Arg Asp Phe Ala Thr Val Arg Lys Val Leu Ser Met
1115 1120 1125
Pro Gln Val Asn Ile Val Lys Lys Thr Glu Val Gln Thr Gly Gly
1130 1135 1140
Phe Ser Lys Glu Ser Ile Leu Pro Lys Arg Asn Ser Asp Lys Leu
1145 1150 1155
Ile Ala Arg Lys Lys Asp Trp Asp Pro Lys Lys Tyr Gly Gly Phe
1160 1165 1170
Asp Ser Pro Thr Val Ala Tyr Ser Val Leu Val Val Ala Lys Val
1175 1180 1185
Glu Lys Gly Lys Ser Lys Lys Leu Lys Ser Val Lys Glu Leu Leu
1190 1195 1200
Gly Ile Thr Ile Met Glu Arg Ser Ser Phe Glu Lys Asn Pro Ile
1205 1210 1215
Asp Phe Leu Glu Ala Lys Gly Tyr Lys Glu Val Lys Lys Asp Leu
1220 1225 1230
Ile Ile Lys Leu Pro Lys Tyr Ser Leu Phe Glu Leu Glu Asn Gly
1235 1240 1245
Arg Lys Arg Met Leu Ala Ser Ala Gly Glu Leu Gln Lys Gly Asn
1250 1255 1260
Glu Leu Ala Leu Pro Ser Lys Tyr Val Asn Phe Leu Tyr Leu Ala
1265 1270 1275
Ser His Tyr Glu Lys Leu Lys Gly Ser Pro Glu Asp Asn Glu Gln
1280 1285 1290
Lys Gln Leu Phe Val Glu Gln His Lys His Tyr Leu Asp Glu Ile
1295 1300 1305
Ile Glu Gln Ile Ser Glu Phe Ser Lys Arg Val Ile Leu Ala Asp
1310 1315 1320
Ala Asn Leu Asp Lys Val Leu Ser Ala Tyr Asn Lys His Arg Asp
1325 1330 1335
Lys Pro Ile Arg Glu Gln Ala Glu Asn Ile Ile His Leu Phe Thr
1340 1345 1350
Leu Thr Asn Leu Gly Ala Pro Ala Ala Phe Lys Tyr Phe Asp Thr
1355 1360 1365
Thr Ile Asp Arg Lys Arg Tyr Thr Ser Thr Lys Glu Val Leu Asp
1370 1375 1380
Ala Thr Leu Ile His Gln Ser Ile Thr Gly Leu Tyr Glu Thr Arg
1385 1390 1395
Ile Asp Leu Ser Gln Leu Gly Gly Asp Lys Arg Pro Ala Ala Thr
1400 1405 1410
Lys Lys Ala Gly Gln Ala Lys Lys Lys Lys
1415 1420
<210> 51
<211> 2012
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 51
gaatgctgcc ctcagacccg cttcctccct gtccttgtct gtccaaggag aatgaggtct 60
cactggtgga tttcggacta ccctgaggag ctggcacctg agggacaagg ccccccacct 120
gcccagctcc agcctctgat gaggggtggg agagagctac atgaggttgc taagaaagcc 180
tcccctgaag gagaccacac agtgtgtgag gttggagtct ctagcagcgg gttctgtgcc 240
cccagggata gtctggctgt ccaggcactg ctcttgatat aaacaccacc tcctagttat 300
gaaaccatgc ccattctgcc tctctgtatg gaaaagagca tggggctggc ccgtggggtg 360
gtgtccactt taggccctgt gggagatcat gggaacccac gcagtgggtc ataggctctc 420
tcatttacta ctcacatcca ctctgtgaag aagcgattat gatctctcct ctagaaactc 480
gtagagtccc atgtctgccg gcttccagag cctgcactcc tccaccttgg cttggctttg 540
ctggggctag aggagctagg atgcacagca gctctgtgac cctttgtttg agaggaacag 600
gaaaaccacc cttctctctg gcccactgtg tcctcttcct gccctgccat ccccttctgt 660
gaatgttaga cccatgggag cagctggtca gaggggaccc cggcctgggg cccctaaccc 720
tatgtagcct cagtcttccc atcaggctct cagctcagcc tgagtgttga ggccccagtg 780
gctgctctgg gggcctcctg agtttctcat ctgtgcccct ccctccctgg cccaggtgaa 840
ggtgtggttc cagaaccgga ggacaaagta caaacggcag aagctggagg aggaagggcc 900
tgagtccgag cagaagaaga agggctccca tcacatcaac cggtggcgca ttgccacgaa 960
gcaggccaat ggggaggaca tcgatgtcac ctccaatgac aagcttgcta gcggtgggca 1020
accacaaacc cacgagggca gagtgctgct tgctgctggc caggcccctg cgtgggccca 1080
agctggactc tggccactcc ctggccaggc tttggggagg cctggagtca tggccccaca 1140
gggcttgaag cccggggccg ccattgacag agggacaagc aatgggctgg ctgaggcctg 1200
ggaccacttg gccttctcct cggagagcct gcctgcctgg gcgggcccgc ccgccaccgc 1260
agcctcccag ctgctctccg tgtctccaat ctcccttttg ttttgatgca tttctgtttt 1320
aatttatttt ccaggcacca ctgtagttta gtgatcccca gtgtccccct tccctatggg 1380
aataataaaa gtctctctct taatgacacg ggcatccagc tccagcccca gagcctgggg 1440
tggtagattc cggctctgag ggccagtggg ggctggtaga gcaaacgcgt tcagggcctg 1500
ggagcctggg gtggggtact ggtggagggg gtcaagggta attcattaac tcctctcttt 1560
tgttggggga ccctggtctc tacctccagc tccacagcag gagaaacagg ctagacatag 1620
ggaagggcca tcctgtatct tgagggagga caggcccagg tctttcttaa cgtattgaga 1680
ggtgggaatc aggcccaggt agttcaatgg gagagggaga gtgcttccct ctgcctagag 1740
actctggtgg cttctccagt tgaggagaaa ccagaggaaa ggggaggatt ggggtctggg 1800
ggagggaaca ccattcacaa aggctgacgg ttccagtccg aagtcgtggg cccaccagga 1860
tgctcacctg tccttggaga accgctgggc aggttgagac tgcagagaca gggcttaagg 1920
ctgagcctgc aaccagtccc cagtgactca gggcctcctc agcccaagaa agagcaacgt 1980
gccagggccc gctgagctct tgtgttcacc tg 2012
<210> 52
<211> 1153
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 52
Met Lys Arg Pro Ala Ala Thr Lys Lys Ala Gly Gln Ala Lys Lys Lys
1 5 10 15
Lys Ser Asp Leu Val Leu Gly Leu Asp Ile Gly Ile Gly Ser Val Gly
20 25 30
Val Gly Ile Leu Asn Lys Val Thr Gly Glu Ile Ile His Lys Asn Ser
35 40 45
Arg Ile Phe Pro Ala Ala Gln Ala Glu Asn Asn Leu Val Arg Arg Thr
50 55 60
Asn Arg Gln Gly Arg Arg Leu Ala Arg Arg Lys Lys His Arg Arg Val
65 70 75 80
Arg Leu Asn Arg Leu Phe Glu Glu Ser Gly Leu Ile Thr Asp Phe Thr
85 90 95
Lys Ile Ser Ile Asn Leu Asn Pro Tyr Gln Leu Arg Val Lys Gly Leu
100 105 110
Thr Asp Glu Leu Ser Asn Glu Glu Leu Phe Ile Ala Leu Lys Asn Met
115 120 125
Val Lys His Arg Gly Ile Ser Tyr Leu Asp Asp Ala Ser Asp Asp Gly
130 135 140
Asn Ser Ser Val Gly Asp Tyr Ala Gln Ile Val Lys Glu Asn Ser Lys
145 150 155 160
Gln Leu Glu Thr Lys Thr Pro Gly Gln Ile Gln Leu Glu Arg Tyr Gln
165 170 175
Thr Tyr Gly Gln Leu Arg Gly Asp Phe Thr Val Glu Lys Asp Gly Lys
180 185 190
Lys His Arg Leu Ile Asn Val Phe Pro Thr Ser Ala Tyr Arg Ser Glu
195 200 205
Ala Leu Arg Ile Leu Gln Thr Gln Gln Glu Phe Asn Pro Gln Ile Thr
210 215 220
Asp Glu Phe Ile Asn Arg Tyr Leu Glu Ile Leu Thr Gly Lys Arg Lys
225 230 235 240
Tyr Tyr His Gly Pro Gly Asn Glu Lys Ser Arg Thr Asp Tyr Gly Arg
245 250 255
Tyr Arg Thr Ser Gly Glu Thr Leu Asp Asn Ile Phe Gly Ile Leu Ile
260 265 270
Gly Lys Cys Thr Phe Tyr Pro Asp Glu Phe Arg Ala Ala Lys Ala Ser
275 280 285
Tyr Thr Ala Gln Glu Phe Asn Leu Leu Asn Asp Leu Asn Asn Leu Thr
290 295 300
Val Pro Thr Glu Thr Lys Lys Leu Ser Lys Glu Gln Lys Asn Gln Ile
305 310 315 320
Ile Asn Tyr Val Lys Asn Glu Lys Ala Met Gly Pro Ala Lys Leu Phe
325 330 335
Lys Tyr Ile Ala Lys Leu Leu Ser Cys Asp Val Ala Asp Ile Lys Gly
340 345 350
Tyr Arg Ile Asp Lys Ser Gly Lys Ala Glu Ile His Thr Phe Glu Ala
355 360 365
Tyr Arg Lys Met Lys Thr Leu Glu Thr Leu Asp Ile Glu Gln Met Asp
370 375 380
Arg Glu Thr Leu Asp Lys Leu Ala Tyr Val Leu Thr Leu Asn Thr Glu
385 390 395 400
Arg Glu Gly Ile Gln Glu Ala Leu Glu His Glu Phe Ala Asp Gly Ser
405 410 415
Phe Ser Gln Lys Gln Val Asp Glu Leu Val Gln Phe Arg Lys Ala Asn
420 425 430
Ser Ser Ile Phe Gly Lys Gly Trp His Asn Phe Ser Val Lys Leu Met
435 440 445
Met Glu Leu Ile Pro Glu Leu Tyr Glu Thr Ser Glu Glu Gln Met Thr
450 455 460
Ile Leu Thr Arg Leu Gly Lys Gln Lys Thr Thr Ser Ser Ser Asn Lys
465 470 475 480
Thr Lys Tyr Ile Asp Glu Lys Leu Leu Thr Glu Glu Ile Tyr Asn Pro
485 490 495
Val Val Ala Lys Ser Val Arg Gln Ala Ile Lys Ile Val Asn Ala Ala
500 505 510
Ile Lys Glu Tyr Gly Asp Phe Asp Asn Ile Val Ile Glu Met Ala Arg
515 520 525
Glu Thr Asn Glu Asp Asp Glu Lys Lys Ala Ile Gln Lys Ile Gln Lys
530 535 540
Ala Asn Lys Asp Glu Lys Asp Ala Ala Met Leu Lys Ala Ala Asn Gln
545 550 555 560
Tyr Asn Gly Lys Ala Glu Leu Pro His Ser Val Phe His Gly His Lys
565 570 575
Gln Leu Ala Thr Lys Ile Arg Leu Trp His Gln Gln Gly Glu Arg Cys
580 585 590
Leu Tyr Thr Gly Lys Thr Ile Ser Ile His Asp Leu Ile Asn Asn Ser
595 600 605
Asn Gln Phe Glu Val Asp His Ile Leu Pro Leu Ser Ile Thr Phe Asp
610 615 620
Asp Ser Leu Ala Asn Lys Val Leu Val Tyr Ala Thr Ala Asn Gln Glu
625 630 635 640
Lys Gly Gln Arg Thr Pro Tyr Gln Ala Leu Asp Ser Met Asp Asp Ala
645 650 655
Trp Ser Phe Arg Glu Leu Lys Ala Phe Val Arg Glu Ser Lys Thr Leu
660 665 670
Ser Asn Lys Lys Lys Glu Tyr Leu Leu Thr Glu Glu Asp Ile Ser Lys
675 680 685
Phe Asp Val Arg Lys Lys Phe Ile Glu Arg Asn Leu Val Asp Thr Arg
690 695 700
Tyr Ala Ser Arg Val Val Leu Asn Ala Leu Gln Glu His Phe Arg Ala
705 710 715 720
His Lys Ile Asp Thr Lys Val Ser Val Val Arg Gly Gln Phe Thr Ser
725 730 735
Gln Leu Arg Arg His Trp Gly Ile Glu Lys Thr Arg Asp Thr Tyr His
740 745 750
His His Ala Val Asp Ala Leu Ile Ile Ala Ala Ser Ser Gln Leu Asn
755 760 765
Leu Trp Lys Lys Gln Lys Asn Thr Leu Val Ser Tyr Ser Glu Asp Gln
770 775 780
Leu Leu Asp Ile Glu Thr Gly Glu Leu Ile Ser Asp Asp Glu Tyr Lys
785 790 795 800
Glu Ser Val Phe Lys Ala Pro Tyr Gln His Phe Val Asp Thr Leu Lys
805 810 815
Ser Lys Glu Phe Glu Asp Ser Ile Leu Phe Ser Tyr Gln Val Asp Ser
820 825 830
Lys Phe Asn Arg Lys Ile Ser Asp Ala Thr Ile Tyr Ala Thr Arg Gln
835 840 845
Ala Lys Val Gly Lys Asp Lys Ala Asp Glu Thr Tyr Val Leu Gly Lys
850 855 860
Ile Lys Asp Ile Tyr Thr Gln Asp Gly Tyr Asp Ala Phe Met Lys Ile
865 870 875 880
Tyr Lys Lys Asp Lys Ser Lys Phe Leu Met Tyr Arg His Asp Pro Gln
885 890 895
Thr Phe Glu Lys Val Ile Glu Pro Ile Leu Glu Asn Tyr Pro Asn Lys
900 905 910
Gln Ile Asn Glu Lys Gly Lys Glu Val Pro Cys Asn Pro Phe Leu Lys
915 920 925
Tyr Lys Glu Glu His Gly Tyr Ile Arg Lys Tyr Ser Lys Lys Gly Asn
930 935 940
Gly Pro Glu Ile Lys Ser Leu Lys Tyr Tyr Asp Ser Lys Leu Gly Asn
945 950 955 960
His Ile Asp Ile Thr Pro Lys Asp Ser Asn Asn Lys Val Val Leu Gln
965 970 975
Ser Val Ser Pro Trp Arg Ala Asp Val Tyr Phe Asn Lys Thr Thr Gly
980 985 990
Lys Tyr Glu Ile Leu Gly Leu Lys Tyr Ala Asp Leu Gln Phe Glu Lys
995 1000 1005
Gly Thr Gly Thr Tyr Lys Ile Ser Gln Glu Lys Tyr Asn Asp Ile
1010 1015 1020
Lys Lys Lys Glu Gly Val Asp Ser Asp Ser Glu Phe Lys Phe Thr
1025 1030 1035
Leu Tyr Lys Asn Asp Leu Leu Leu Val Lys Asp Thr Glu Thr Lys
1040 1045 1050
Glu Gln Gln Leu Phe Arg Phe Leu Ser Arg Thr Met Pro Lys Gln
1055 1060 1065
Lys His Tyr Val Glu Leu Lys Pro Tyr Asp Lys Gln Lys Phe Glu
1070 1075 1080
Gly Gly Glu Ala Leu Ile Lys Val Leu Gly Asn Val Ala Asn Ser
1085 1090 1095
Gly Gln Cys Lys Lys Gly Leu Gly Lys Ser Asn Ile Ser Ile Tyr
1100 1105 1110
Lys Val Arg Thr Asp Val Leu Gly Asn Gln His Ile Ile Lys Asn
1115 1120 1125
Glu Gly Asp Lys Pro Lys Leu Asp Phe Lys Arg Pro Ala Ala Thr
1130 1135 1140
Lys Lys Ala Gly Gln Ala Lys Lys Lys Lys
1145 1150
<210> 53
<211> 340
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 53
gagggcctat ttcccatgat tccttcatat ttgcatatac gatacaaggc tgttagagag 60
ataattggaa ttaatttgac tgtaaacaca aagatattag tacaaaatac gtgacgtaga 120
aagtaataat ttcttgggta gtttgcagtt ttaaaattat gttttaaaat ggactatcat 180
atgcttaccg taacttgaaa gtatttcgat ttcttggctt tatatatctt gtggaaagga 240
cgaaacaccg ttacttaaat cttgcagaag ctacaaagat aaggcttcat gccgaaatca 300
acaccctgtc attttatggc agggtgtttt cgttatttaa 340
<210> 54
<211> 360
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<220>
<221> modified_base
<222> (288)..(317)
<223> a, c, t, g, unknown or other
<400> 54
gagggcctat ttcccatgat tccttcatat ttgcatatac gatacaaggc tgttagagag 60
ataattggaa ttaatttgac tgtaaacaca aagatattag tacaaaatac gtgacgtaga 120
aagtaataat ttcttgggta gtttgcagtt ttaaaattat gttttaaaat ggactatcat 180
atgcttaccg taacttgaaa gtatttcgat ttcttggctt tatatatctt gtggaaagga 240
cgaaacaccg ggttttagag ctatgctgtt ttgaatggtc ccaaaacnnn nnnnnnnnnn 300
nnnnnnnnnn nnnnnnngtt ttagagctat gctgttttga atggtcccaa aacttttttt 360
<210> 55
<211> 318
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<220>
<221> modified_base
<222> (250)..(269)
<223> a, c, t, g, unknown or other
<400> 55
gagggcctat ttcccatgat tccttcatat ttgcatatac gatacaaggc tgttagagag 60
ataattggaa ttaatttgac tgtaaacaca aagatattag tacaaaatac gtgacgtaga 120
aagtaataat ttcttgggta gtttgcagtt ttaaaattat gttttaaaat ggactatcat 180
atgcttaccg taacttgaaa gtatttcgat ttcttggctt tatatatctt gtggaaagga 240
cgaaacaccn nnnnnnnnnn nnnnnnnnng ttttagagct agaaatagca agttaaaata 300
aggctagtcc gttttttt 318
<210> 56
<211> 325
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<220>
<221> modified_base
<222> (250)..(269)
<223> a, c, t, g, unknown or other
<400> 56
gagggcctat ttcccatgat tccttcatat ttgcatatac gatacaaggc tgttagagag 60
ataattggaa ttaatttgac tgtaaacaca aagatattag tacaaaatac gtgacgtaga 120
aagtaataat ttcttgggta gtttgcagtt ttaaaattat gttttaaaat ggactatcat 180
atgcttaccg taacttgaaa gtatttcgat ttcttggctt tatatatctt gtggaaagga 240
cgaaacaccn nnnnnnnnnn nnnnnnnnng ttttagagct agaaatagca agttaaaata 300
aggctagtcc gttatcattt ttttt 325
<210> 57
<211> 337
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<220>
<221> modified_base
<222> (250)..(269)
<223> a, c, t, g, unknown or other
<400> 57
gagggcctat ttcccatgat tccttcatat ttgcatatac gatacaaggc tgttagagag 60
ataattggaa ttaatttgac tgtaaacaca aagatattag tacaaaatac gtgacgtaga 120
aagtaataat ttcttgggta gtttgcagtt ttaaaattat gttttaaaat ggactatcat 180
atgcttaccg taacttgaaa gtatttcgat ttcttggctt tatatatctt gtggaaagga 240
cgaaacaccn nnnnnnnnnn nnnnnnnnng ttttagagct agaaatagca agttaaaata 300
aggctagtcc gttatcaact tgaaaaagtg ttttttt 337
<210> 58
<211> 352
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<220>
<221> modified_base
<222> (250)..(269)
<223> a, c, t, g, unknown or other
<400> 58
gagggcctat ttcccatgat tccttcatat ttgcatatac gatacaaggc tgttagagag 60
ataattggaa ttaatttgac tgtaaacaca aagatattag tacaaaatac gtgacgtaga 120
aagtaataat ttcttgggta gtttgcagtt ttaaaattat gttttaaaat ggactatcat 180
atgcttaccg taacttgaaa gtatttcgat ttcttggctt tatatatctt gtggaaagga 240
cgaaacaccn nnnnnnnnnn nnnnnnnnng ttttagagct agaaatagca agttaaaata 300
aggctagtcc gttatcaact tgaaaaagtg gcaccgagtc ggtgcttttt tt 352
<210> 59
<211> 5101
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 59
cgttacataa cttacggtaa atggcccgcc tggctgaccg cccaacgacc cccgcccatt 60
gacgtcaata atgacgtatg ttcccatagt aacgccaata gggactttcc attgacgtca 120
atgggtggag tatttacggt aaactgccca cttggcagta catcaagtgt atcatatgcc 180
aagtacgccc cctattgacg tcaatgacgg taaatggccc gcctggcatt atgcccagta 240
catgacctta tgggactttc ctacttggca gtacatctac gtattagtca tcgctattac 300
catggtcgag gtgagcccca cgttctgctt cactctcccc atctcccccc cctccccacc 360
cccaattttg tatttattta ttttttaatt attttgtgca gcgatggggg cggggggggg 420
gggggggcgc gcgccaggcg gggcggggcg gggcgagggg cggggcgggg cgaggcggag 480
aggtgcggcg gcagccaatc agagcggcgc gctccgaaag tttcctttta tggcgaggcg 540
gcggcggcgg cggccctata aaaagcgaag cgcgcggcgg gcgggagtcg ctgcgacgct 600
gccttcgccc cgtgccccgc tccgccgccg cctcgcgccg cccgccccgg ctctgactga 660
ccgcgttact cccacaggtg agcgggcggg acggcccttc tcctccgggc tgtaattagc 720
tgagcaagag gtaagggttt aagggatggt tggttggtgg ggtattaatg tttaattacc 780
tggagcacct gcctgaaatc actttttttc aggttggacc ggtgccacca tggactataa 840
ggaccacgac ggagactaca aggatcatga tattgattac aaagacgatg acgataagat 900
ggccccaaag aagaagcgga aggtcggtat ccacggagtc ccagcagccg acaagaagta 960
cagcatcggc ctggacatcg gcaccaactc tgtgggctgg gccgtgatca ccgacgagta 1020
caaggtgccc agcaagaaat tcaaggtgct gggcaacacc gaccggcaca gcatcaagaa 1080
gaacctgatc ggagccctgc tgttcgacag cggcgaaaca gccgaggcca cccggctgaa 1140
gagaaccgcc agaagaagat acaccagacg gaagaaccgg atctgctatc tgcaagagat 1200
cttcagcaac gagatggcca aggtggacga cagcttcttc cacagactgg aagagtcctt 1260
cctggtggaa gaggataaga agcacgagcg gcaccccatc ttcggcaaca tcgtggacga 1320
ggtggcctac cacgagaagt accccaccat ctaccacctg agaaagaaac tggtggacag 1380
caccgacaag gccgacctgc ggctgatcta tctggccctg gcccacatga tcaagttccg 1440
gggccacttc ctgatcgagg gcgacctgaa ccccgacaac agcgacgtgg acaagctgtt 1500
catccagctg gtgcagacct acaaccagct gttcgaggaa aaccccatca acgccagcgg 1560
cgtggacgcc aaggccatcc tgtctgccag actgagcaag agcagacggc tggaaaatct 1620
gatcgcccag ctgcccggcg agaagaagaa tggcctgttc ggcaacctga ttgccctgag 1680
cctgggcctg acccccaact tcaagagcaa cttcgacctg gccgaggatg ccaaactgca 1740
gctgagcaag gacacctacg acgacgacct ggacaacctg ctggcccaga tcggcgacca 1800
gtacgccgac ctgtttctgg ccgccaagaa cctgtccgac gccatcctgc tgagcgacat 1860
cctgagagtg aacaccgaga tcaccaaggc ccccctgagc gcctctatga tcaagagata 1920
cgacgagcac caccaggacc tgaccctgct gaaagctctc gtgcggcagc agctgcctga 1980
gaagtacaaa gagattttct tcgaccagag caagaacggc tacgccggct acattgacgg 2040
cggagccagc caggaagagt tctacaagtt catcaagccc atcctggaaa agatggacgg 2100
caccgaggaa ctgctcgtga agctgaacag agaggacctg ctgcggaagc agcggacctt 2160
cgacaacggc agcatccccc accagatcca cctgggagag ctgcacgcca ttctgcggcg 2220
gcaggaagat ttttacccat tcctgaagga caaccgggaa aagatcgaga agatcctgac 2280
cttccgcatc ccctactacg tgggccctct ggccagggga aacagcagat tcgcctggat 2340
gaccagaaag agcgaggaaa ccatcacccc ctggaacttc gaggaagtgg tggacaaggg 2400
cgcttccgcc cagagcttca tcgagcggat gaccaacttc gataagaacc tgcccaacga 2460
gaaggtgctg cccaagcaca gcctgctgta cgagtacttc accgtgtata acgagctgac 2520
caaagtgaaa tacgtgaccg agggaatgag aaagcccgcc ttcctgagcg gcgagcagaa 2580
aaaggccatc gtggacctgc tgttcaagac caaccggaaa gtgaccgtga agcagctgaa 2640
agaggactac ttcaagaaaa tcgagtgctt cgactccgtg gaaatctccg gcgtggaaga 2700
tcggttcaac gcctccctgg gcacatacca cgatctgctg aaaattatca aggacaagga 2760
cttcctggac aatgaggaaa acgaggacat tctggaagat atcgtgctga ccctgacact 2820
gtttgaggac agagagatga tcgaggaacg gctgaaaacc tatgcccacc tgttcgacga 2880
caaagtgatg aagcagctga agcggcggag atacaccggc tggggcaggc tgagccggaa 2940
gctgatcaac ggcatccggg acaagcagtc cggcaagaca atcctggatt tcctgaagtc 3000
cgacggcttc gccaacagaa acttcatgca gctgatccac gacgacagcc tgacctttaa 3060
agaggacatc cagaaagccc aggtgtccgg ccagggcgat agcctgcacg agcacattgc 3120
caatctggcc ggcagccccg ccattaagaa gggcatcctg cagacagtga aggtggtgga 3180
cgagctcgtg aaagtgatgg gccggcacaa gcccgagaac atcgtgatcg aaatggccag 3240
agagaaccag accacccaga agggacagaa gaacagccgc gagagaatga agcggatcga 3300
agagggcatc aaagagctgg gcagccagat cctgaaagaa caccccgtgg aaaacaccca 3360
gctgcagaac gagaagctgt acctgtacta cctgcagaat gggcgggata tgtacgtgga 3420
ccaggaactg gacatcaacc ggctgtccga ctacgatgtg gaccatatcg tgcctcagag 3480
ctttctgaag gacgactcca tcgacaacaa ggtgctgacc agaagcgaca agaaccgggg 3540
caagagcgac aacgtgccct ccgaagaggt cgtgaagaag atgaagaact actggcggca 3600
gctgctgaac gccaagctga ttacccagag aaagttcgac aatctgacca aggccgagag 3660
aggcggcctg agcgaactgg ataaggccgg cttcatcaag agacagctgg tggaaacccg 3720
gcagatcaca aagcacgtgg cacagatcct ggactcccgg atgaacacta agtacgacga 3780
gaatgacaag ctgatccggg aagtgaaagt gatcaccctg aagtccaagc tggtgtccga 3840
tttccggaag gatttccagt tttacaaagt gcgcgagatc aacaactacc accacgccca 3900
cgacgcctac ctgaacgccg tcgtgggaac cgccctgatc aaaaagtacc ctaagctgga 3960
aagcgagttc gtgtacggcg actacaaggt gtacgacgtg cggaagatga tcgccaagag 4020
cgagcaggaa atcggcaagg ctaccgccaa gtacttcttc tacagcaaca tcatgaactt 4080
tttcaagacc gagattaccc tggccaacgg cgagatccgg aagcggcctc tgatcgagac 4140
aaacggcgaa accggggaga tcgtgtggga taagggccgg gattttgcca ccgtgcggaa 4200
agtgctgagc atgccccaag tgaatatcgt gaaaaagacc gaggtgcaga caggcggctt 4260
cagcaaagag tctatcctgc ccaagaggaa cagcgataag ctgatcgcca gaaagaagga 4320
ctgggaccct aagaagtacg gcggcttcga cagccccacc gtggcctatt ctgtgctggt 4380
ggtggccaaa gtggaaaagg gcaagtccaa gaaactgaag agtgtgaaag agctgctggg 4440
gatcaccatc atggaaagaa gcagcttcga gaagaatccc atcgactttc tggaagccaa 4500
gggctacaaa gaagtgaaaa aggacctgat catcaagctg cctaagtact ccctgttcga 4560
gctggaaaac ggccggaaga gaatgctggc ctctgccggc gaactgcaga agggaaacga 4620
actggccctg ccctccaaat atgtgaactt cctgtacctg gccagccact atgagaagct 4680
gaagggctcc cccgaggata atgagcagaa acagctgttt gtggaacagc acaagcacta 4740
cctggacgag atcatcgagc agatcagcga gttctccaag agagtgatcc tggccgacgc 4800
taatctggac aaagtgctgt ccgcctacaa caagcaccgg gataagccca tcagagagca 4860
ggccgagaat atcatccacc tgtttaccct gaccaatctg ggagcccctg ccgccttcaa 4920
gtactttgac accaccatcg accggaagag gtacaccagc accaaagagg tgctggacgc 4980
caccctgatc caccagagca tcaccggcct gtacgagaca cggatcgacc tgtctcagct 5040
gggaggcgac tttctttttc ttagcttgac cagctttctt agtagcagca ggacgcttta 5100
a 5101
<210> 60
<211> 137
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<220>
<221> modified_base
<222> (1)..(20)
<223> a, c, t, g, unknown or other
<400> 60
nnnnnnnnnn nnnnnnnnnn gttattgtac tctcaagatt tagaaataaa tcttgcagaa 60
gctacaaaga taaggcttca tgccgaaatc aacaccctgt cattttatgg cagggtgttt 120
tcgttattta atttttt 137
<210> 61
<211> 123
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<220>
<221> modified_base
<222> (1)..(20)
<223> a, c, t, g, unknown or other
<400> 61
nnnnnnnnnn nnnnnnnnnn gttattgtac tctcagaaat gcagaagcta caaagataag 60
gcttcatgcc gaaatcaaca ccctgtcatt ttatggcagg gtgttttcgt tatttaattt 120
ttt 123
<210> 62
<211> 110
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<220>
<221> modified_base
<222> (1)..(20)
<223> a, c, t, g, unknown or other
<400> 62
nnnnnnnnnn nnnnnnnnnn gttattgtac tctcagaaat gcagaagcta caaagataag 60
gcttcatgcc gaaatcaaca ccctgtcatt ttatggcagg gtgttttttt 110
<210> 63
<211> 137
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<220>
<221> modified_base
<222> (1)..(20)
<223> a, c, t, g, unknown or other
<400> 63
nnnnnnnnnn nnnnnnnnnn gttattgtac tctcaagatt tagaaataaa tcttgcagaa 60
gctacaatga taaggcttca tgccgaaatc aacaccctgt cattttatgg cagggtgttt 120
tcgttattta atttttt 137
<210> 64
<211> 123
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<220>
<221> modified_base
<222> (1)..(20)
<223> a, c, t, g, unknown or other
<400> 64
nnnnnnnnnn nnnnnnnnnn gttattgtac tctcagaaat gcagaagcta caatgataag 60
gcttcatgcc gaaatcaaca ccctgtcatt ttatggcagg gtgttttcgt tatttaattt 120
ttt 123
<210> 65
<211> 110
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<220>
<221> modified_base
<222> (1)..(20)
<223> a, c, t, g, unknown or other
<400> 65
nnnnnnnnnn nnnnnnnnnn gttattgtac tctcagaaat gcagaagcta caatgataag 60
gcttcatgcc gaaatcaaca ccctgtcatt ttatggcagg gtgttttttt 110
<210> 66
<211> 107
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<220>
<221> modified_base
<222> (1)..(20)
<223> a, c, t, g, unknown or other
<400> 66
nnnnnnnnnn nnnnnnnnnn gttttagagc tgtggaaaca cagcgagtta aaataaggct 60
tagtccgtac tcaacttgaa aaggtggcac cgattcggtg ttttttt 107
<210> 67
<211> 4263
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 67
atgaaaaggc cggcggccac gaaaaaggcc ggccaggcaa aaaagaaaaa gaccaagccc 60
tacagcatcg gcctggacat cggcaccaat agcgtgggct gggccgtgac caccgacaac 120
tacaaggtgc ccagcaagaa aatgaaggtg ctgggcaaca cctccaagaa gtacatcaag 180
aaaaacctgc tgggcgtgct gctgttcgac agcggcatta cagccgaggg cagacggctg 240
aagagaaccg ccagacggcg gtacacccgg cggagaaaca gaatcctgta tctgcaagag 300
atcttcagca ccgagatggc taccctggac gacgccttct tccagcggct ggacgacagc 360
ttcctggtgc ccgacgacaa gcgggacagc aagtacccca tcttcggcaa cctggtggaa 420
gagaaggcct accacgacga gttccccacc atctaccacc tgagaaagta cctggccgac 480
agcaccaaga aggccgacct gagactggtg tatctggccc tggcccacat gatcaagtac 540
cggggccact tcctgatcga gggcgagttc aacagcaaga acaacgacat ccagaagaac 600
ttccaggact tcctggacac ctacaacgcc atcttcgaga gcgacctgtc cctggaaaac 660
agcaagcagc tggaagagat cgtgaaggac aagatcagca agctggaaaa gaaggaccgc 720
atcctgaagc tgttccccgg cgagaagaac agcggaatct tcagcgagtt tctgaagctg 780
atcgtgggca accaggccga cttcagaaag tgcttcaacc tggacgagaa agccagcctg 840
cacttcagca aagagagcta cgacgaggac ctggaaaccc tgctgggata tatcggcgac 900
gactacagcg acgtgttcct gaaggccaag aagctgtacg acgctatcct gctgagcggc 960
ttcctgaccg tgaccgacaa cgagacagag gccccactga gcagcgccat gattaagcgg 1020
tacaacgagc acaaagagga tctggctctg ctgaaagagt acatccggaa catcagcctg 1080
aaaacctaca atgaggtgtt caaggacgac accaagaacg gctacgccgg ctacatcgac 1140
ggcaagacca accaggaaga tttctatgtg tacctgaaga agctgctggc cgagttcgag 1200
ggggccgact actttctgga aaaaatcgac cgcgaggatt tcctgcggaa gcagcggacc 1260
ttcgacaacg gcagcatccc ctaccagatc catctgcagg aaatgcgggc catcctggac 1320
aagcaggcca agttctaccc attcctggcc aagaacaaag agcggatcga gaagatcctg 1380
accttccgca tcccttacta cgtgggcccc ctggccagag gcaacagcga ttttgcctgg 1440
tccatccgga agcgcaatga gaagatcacc ccctggaact tcgaggacgt gatcgacaaa 1500
gagtccagcg ccgaggcctt catcaaccgg atgaccagct tcgacctgta cctgcccgag 1560
gaaaaggtgc tgcccaagca cagcctgctg tacgagacat tcaatgtgta taacgagctg 1620
accaaagtgc ggtttatcgc cgagtctatg cgggactacc agttcctgga ctccaagcag 1680
aaaaaggaca tcgtgcggct gtacttcaag gacaagcgga aagtgaccga taaggacatc 1740
atcgagtacc tgcacgccat ctacggctac gatggcatcg agctgaaggg catcgagaag 1800
cagttcaact ccagcctgag cacataccac gacctgctga acattatcaa cgacaaagaa 1860
tttctggacg actccagcaa cgaggccatc atcgaagaga tcatccacac cctgaccatc 1920
tttgaggacc gcgagatgat caagcagcgg ctgagcaagt tcgagaacat cttcgacaag 1980
agcgtgctga aaaagctgag cagacggcac tacaccggct ggggcaagct gagcgccaag 2040
ctgatcaacg gcatccggga cgagaagtcc ggcaacacaa tcctggacta cctgatcgac 2100
gacggcatca gcaaccggaa cttcatgcag ctgatccacg acgacgccct gagcttcaag 2160
aagaagatcc agaaggccca gatcatcggg gacgaggaca agggcaacat caaagaagtc 2220
gtgaagtccc tgcccggcag ccccgccatc aagaagggaa tcctgcagag catcaagatc 2280
gtggacgagc tcgtgaaagt gatgggcggc agaaagcccg agagcatcgt ggtggaaatg 2340
gctagagaga accagtacac caatcagggc aagagcaaca gccagcagag actgaagaga 2400
ctggaaaagt ccctgaaaga gctgggcagc aagattctga aagagaatat ccctgccaag 2460
ctgtccaaga tcgacaacaa cgccctgcag aacgaccggc tgtacctgta ctacctgcag 2520
aatggcaagg acatgtatac aggcgacgac ctggatatcg accgcctgag caactacgac 2580
atcgaccata ttatccccca ggccttcctg aaagacaaca gcattgacaa caaagtgctg 2640
gtgtcctccg ccagcaaccg cggcaagtcc gatgatgtgc ccagcctgga agtcgtgaaa 2700
aagagaaaga ccttctggta tcagctgctg aaaagcaagc tgattagcca gaggaagttc 2760
gacaacctga ccaaggccga gagaggcggc ctgagccctg aagataaggc cggcttcatc 2820
cagagacagc tggtggaaac ccggcagatc accaagcacg tggccagact gctggatgag 2880
aagtttaaca acaagaagga cgagaacaac cgggccgtgc ggaccgtgaa gatcatcacc 2940
ctgaagtcca ccctggtgtc ccagttccgg aaggacttcg agctgtataa agtgcgcgag 3000
atcaatgact ttcaccacgc ccacgacgcc tacctgaatg ccgtggtggc ttccgccctg 3060
ctgaagaagt accctaagct ggaacccgag ttcgtgtacg gcgactaccc caagtacaac 3120
tccttcagag agcggaagtc cgccaccgag aaggtgtact tctactccaa catcatgaat 3180
atctttaaga agtccatctc cctggccgat ggcagagtga tcgagcggcc cctgatcgaa 3240
gtgaacgaag agacaggcga gagcgtgtgg aacaaagaaa gcgacctggc caccgtgcgg 3300
cgggtgctga gttatcctca agtgaatgtc gtgaagaagg tggaagaaca gaaccacggc 3360
ctggatcggg gcaagcccaa gggcctgttc aacgccaacc tgtccagcaa gcctaagccc 3420
aactccaacg agaatctcgt gggggccaaa gagtacctgg accctaagaa gtacggcgga 3480
tacgccggca tctccaatag cttcaccgtg ctcgtgaagg gcacaatcga gaagggcgct 3540
aagaaaaaga tcacaaacgt gctggaattt caggggatct ctatcctgga ccggatcaac 3600
taccggaagg ataagctgaa ctttctgctg gaaaaaggct acaaggacat tgagctgatt 3660
atcgagctgc ctaagtactc cctgttcgaa ctgagcgacg gctccagacg gatgctggcc 3720
tccatcctgt ccaccaacaa caagcggggc gagatccaca agggaaacca gatcttcctg 3780
agccagaaat ttgtgaaact gctgtaccac gccaagcgga tctccaacac catcaatgag 3840
aaccaccgga aatacgtgga aaaccacaag aaagagtttg aggaactgtt ctactacatc 3900
ctggagttca acgagaacta tgtgggagcc aagaagaacg gcaaactgct gaactccgcc 3960
ttccagagct ggcagaacca cagcatcgac gagctgtgca gctccttcat cggccctacc 4020
ggcagcgagc ggaagggact gtttgagctg acctccagag gctctgccgc cgactttgag 4080
ttcctgggag tgaagatccc ccggtacaga gactacaccc cctctagtct gctgaaggac 4140
gccaccctga tccaccagag cgtgaccggc ctgtacgaaa cccggatcga cctggctaag 4200
ctgggcgagg gaaagcgtcc tgctgctact aagaaagctg gtcaagctaa gaaaaagaaa 4260
taa 4263
<210> 68
<211> 53
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 68
tcctagcagg atttctgata ttactgtcac gttttagagc tatgctgttt tga 53
<210> 69
<211> 53
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 69
gtgacagtaa tatcagaaat cctgctagga gttttgggac cattcaaaac agc 53
<210> 70
<211> 25
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 70
gggtttcaag tctttgtagc aagag 25
<210> 71
<211> 24
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 71
gccaatgaac gggaaccctt ggtc 24
<210> 72
<211> 25
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<220>
<221> modified_base
<222> (1)..(4)
<223> a, c, t, g, unknown or other
<400> 72
nnnngacgag gcaatggctg aaatc 25
<210> 73
<211> 25
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<220>
<221> modified_base
<222> (1)..(4)
<223> a, c, t, g, unknown or other
<400> 73
nnnnttattt ggctcatatt tgctg 25
<210> 74
<211> 25
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 74
ctttacacca atcgctgcaa cagac 25
<210> 75
<211> 45
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 75
caaaatttct agtcttcttt gcctttcccc ataaaaccct cctta 45
<210> 76
<211> 45
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 76
agggttttat ggggaaaggc aaagaagact agaaattttg atacc 45
<210> 77
<211> 25
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 77
cttacggtgc ataaagtcaa tttcc 25
<210> 78
<211> 21
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 78
tggctcgatt tcagccattg c 21
<210> 79
<211> 43
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<220>
<221> modified_base
<222> (33)..(33)
<223> a, c, t, g, unknown or other
<400> 79
ctttgacgag gcaatggctg aaatcgagcc aanaaagcgc aag 43
<210> 80
<211> 43
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<220>
<221> modified_base
<222> (34)..(34)
<223> a, c, t, g, unknown or other
<400> 80
ctttgacgag gcaatggctg aaatcgagcc aaanaagcgc aag 43
<210> 81
<211> 43
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<220>
<221> modified_base
<222> (35)..(35)
<223> a, c, t, g, unknown or other
<400> 81
ctttgacgag gcaatggctg aaatcgagcc aaaanagcgc aag 43
<210> 82
<211> 43
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<220>
<221> modified_base
<222> (36)..(36)
<223> a, c, t, g, unknown or other
<400> 82
ctttgacgag gcaatggctg aaatcgagcc aaaaangcgc aag 43
<210> 83
<211> 43
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<220>
<221> modified_base
<222> (37)..(37)
<223> a, c, t, g, unknown or other
<400> 83
ctttgacgag gcaatggctg aaatcgagcc aaaaaancgc aag 43
<210> 84
<211> 43
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<220>
<221> modified_base
<222> (38)..(38)
<223> a, c, t, g, unknown or other
<400> 84
ctttgacgag gcaatggctg aaatcgagcc aaaaaagngc aag 43
<210> 85
<211> 46
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<220>
<221> modified_base
<222> (39)..(39)
<223> a, c, t, g, unknown or other
<400> 85
ctttgacgag gcaatggctg aaatcgagcc aaaaaagcnc aagaag 46
<210> 86
<211> 46
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<220>
<221> modified_base
<222> (40)..(40)
<223> a, c, t, g, unknown or other
<400> 86
ctttgacgag gcaatggctg aaatcgagcc aaaaaagcgn aagaag 46
<210> 87
<211> 46
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<220>
<221> modified_base
<222> (41)..(41)
<223> a, c, t, g, unknown or other
<400> 87
ctttgacgag gcaatggctg aaatcgagcc aaaaaagcgc nagaag 46
<210> 88
<211> 23
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 88
gcgctttttt ggctcgattt cag 23
<210> 89
<211> 40
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<220>
<221> modified_base
<222> (31)..(31)
<223> a, c, t, g, unknown or other
<400> 89
caatggctga aatcgagcca aaaaagcgca ngaagaaatc 40
<210> 90
<211> 40
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<220>
<221> modified_base
<222> (32)..(32)
<223> a, c, t, g, unknown or other
<400> 90
caatggctga aatcgagcca aaaaagcgca anaagaaatc 40
<210> 91
<211> 40
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<220>
<221> modified_base
<222> (33)..(33)
<223> a, c, t, g, unknown or other
<400> 91
caatggctga aatcgagcca aaaaagcgca agnagaaatc 40
<210> 92
<211> 40
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<220>
<221> modified_base
<222> (34)..(34)
<223> a, c, t, g, unknown or other
<400> 92
caatggctga aatcgagcca aaaaagcgca agangaaatc 40
<210> 93
<211> 40
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<220>
<221> modified_base
<222> (35)..(35)
<223> a, c, t, g, unknown or other
<400> 93
caatggctga aatcgagcca aaaaagcgca agaanaaatc 40
<210> 94
<211> 44
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<220>
<221> modified_base
<222> (36)..(36)
<223> a, c, t, g, unknown or other
<400> 94
caatggctga aatcgagcca aaaaagcgca agaagnaatc aacc 44
<210> 95
<211> 44
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<220>
<221> modified_base
<222> (37)..(37)
<223> a, c, t, g, unknown or other
<400> 95
caatggctga aatcgagcca aaaaagcgca agaaganatc aacc 44
<210> 96
<211> 44
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<220>
<221> modified_base
<222> (38)..(38)
<223> a, c, t, g, unknown or other
<400> 96
caatggctga aatcgagcca aaaaagcgca agaagaantc aacc 44
<210> 97
<211> 44
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<220>
<221> modified_base
<222> (39)..(39)
<223> a, c, t, g, unknown or other
<400> 97
caatggctga aatcgagcca aaaaagcgca agaagaaanc aacc 44
<210> 98
<211> 47
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<220>
<221> modified_base
<222> (40)..(40)
<223> a, c, t, g, unknown or other
<400> 98
caatggctga aatcgagcca aaaaagcgca agaagaaatn aaccagc 47
<210> 99
<211> 47
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<220>
<221> modified_base
<222> (41)..(41)
<223> a, c, t, g, unknown or other
<400> 99
caatggctga aatcgagcca aaaaagcgca agaagaaatc naccagc 47
<210> 100
<211> 31
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 100
gatcctccat ccgtacaacc cacaaccctg g 31
<210> 101
<211> 31
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 101
aattccaggg ttgtgggttg tacggatgga g 31
<210> 102
<211> 34
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 102
catggatcct atttcttaat aactaaaaat atgg 34
<210> 103
<211> 33
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 103
catgaattca actcaacaag tctcagtgtg ctg 33
<210> 104
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 104
aaacattttt tctccattta ggaaaaagga tgctg 35
<210> 105
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 105
aaaacagcat cctttttcct aaatggagaa aaaat 35
<210> 106
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 106
aaaccttaaa tcagtcacaa atagcagcaa aattg 35
<210> 107
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 107
aaaacaattt tgctgctatt tgtgactgat ttaag 35
<210> 108
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 108
aaacttttca tcatacgacc aatctgcttt atttg 35
<210> 109
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 109
aaaacaaata aagcagattg gtcgtatgat gaaaa 35
<210> 110
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 110
aaactcgtcc agaagttatc gtaaaagaaa tcgag 35
<210> 111
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 111
aaaactcgat ttcttttacg ataacttctg gacga 35
<210> 112
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 112
aaacaatctc tccaaggttt ccttaaaaat ctctg 35
<210> 113
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 113
aaaacagaga tttttaagga aaccttggag agatt 35
<210> 114
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 114
aaacgccatc gtcaggaaga agctatgctt gagtg 35
<210> 115
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 115
aaaacactca agcatagctt cttcctgacg atggc 35
<210> 116
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 116
aaacatctct atacttattg aaatttcttt gtatg 35
<210> 117
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 117
aaaacataca aagaaatttc aataagtata gagat 35
<210> 118
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 118
aaactagctg tgatagtccg caaaaccagc cttcg 35
<210> 119
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 119
aaaacgaagg ctggttttgc ggactatcac agcta 35
<210> 120
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 120
aaacatcgga aggtcgagca agtaattatc ttttg 35
<210> 121
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 121
aaaacaaaag ataattactt gctcgacctt ccgat 35
<210> 122
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 122
aaacaagatg gtatcgcaaa gtaagtgaca ataag 35
<210> 123
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 123
aaaacttatt gtcacttact ttgcgatacc atctt 35
<210> 124
<211> 52
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 124
gagacctttg agcttccgag actggtctca gttttgggac cattcaaaac ag 52
<210> 125
<211> 52
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 125
tgagaccagt ctcggaagct caaaggtctc gttttagagc tatgctgttt tg 52
<210> 126
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 126
aaactacttt acgcagcgcg gagttcggtt ttttg 35
<210> 127
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 127
aaaacaaaaa accgaactcc gcgctgcgta aagta 35
<210> 128
<211> 45
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 128
atgccggtac tgccgggcct cttgcgggat tacgaaatca tcctg 45
<210> 129
<211> 45
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 129
gtgactggcg atgctgtcgg aatggacgat cacactactc ttctt 45
<210> 130
<211> 50
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 130
ttaagaaata atcttcatct aaaatatact tcagtcacct cctagctgac 50
<210> 131
<211> 48
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 131
attgatttga gtcagctagg aggtgactga agtatatttt agatgaag 48
<210> 132
<211> 85
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 132
gagacctttg agcttccgag actggtctca gttttgggac cattcaaaac agcatagctc 60
taaaacctcg tagactattt ttgtc 85
<210> 133
<211> 84
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 133
gagaccagtc tcggaagctc aaaggtctcg ttttagagct atgctgtttt gaatggtccc 60
aaaacttcag cacactgaga cttg 84
<210> 134
<211> 21
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 134
agtcatccca gcaacaaatg g 21
<210> 135
<211> 31
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 135
cgtggtaaat cggataacgt tccaagtgaa g 31
<210> 136
<211> 22
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 136
tgctcttctt cacaaacaag gg 22
<210> 137
<211> 21
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 137
aagccaaagt ttggcaccac c 21
<210> 138
<211> 22
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 138
gtagcttatt cagtcctagt gg 22
<210> 139
<211> 45
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 139
cgtttgttga actaatgggt gcaaattacg aatcttctcc tgacg 45
<210> 140
<211> 45
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 140
cgtcaggaga agattcgtaa tttgcaccca ttagttcaac aaacg 45
<210> 141
<211> 48
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 141
gatattatgg agcctatttt tgtgggtttt taggcataaa actatatg 48
<210> 142
<211> 48
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 142
catatagttt tatgcctaaa aacccacaaa aataggctcc ataatatc 48
<210> 143
<211> 27
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 143
attatttctt aataactaaa aatatgg 27
<210> 144
<211> 24
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 144
cgtgtacaat tgctagcgta cggc 24
<210> 145
<211> 24
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 145
gcaccggtga tcactagtcc tagg 24
<210> 146
<211> 47
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 146
cctaggacta gtgatcaccg gtgcaaatat gagccaaata aatatat 47
<210> 147
<211> 44
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 147
gccgtacgct agcaattgta cacgtttgtt gaactaatgg gtgc 44
<210> 148
<211> 25
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 148
ttcaaatttt cccatttgat tctcc 25
<210> 149
<211> 47
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 149
ccatattttt agttattaag aaataatacc agccatcagt cacctcc 47
<210> 150
<211> 23
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 150
agacgattca atagacaata agg 23
<210> 151
<211> 45
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 151
gttttgggac cattcaaaac agcatagctc taaaacctcg tagac 45
<210> 152
<211> 50
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 152
gctatgctgt tttgaatggt cccaaaacca ttattttaac acacgaggtg 50
<210> 153
<211> 50
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 153
gctatgctgt tttgaatggt cccaaaacgc acccattagt tcaacaaacg 50
<210> 154
<211> 23
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 154
aattcttttc ttcatcatcg gtc 23
<210> 155
<211> 24
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 155
aagaaagaat gaagattgtt catg 24
<210> 156
<211> 25
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 156
ggtactaatc aaaatagtga ggagg 25
<210> 157
<211> 23
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 157
gtttttcaaa atctgcggtt gcg 23
<210> 158
<211> 26
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 158
aaaaattgaa aaaatggtgg aaacac 26
<210> 159
<211> 53
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 159
atttcgtaaa cggtatcggt ttcttttaaa gttttgggac cattcaaaac agc 53
<210> 160
<211> 53
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 160
tttaaaagaa accgataccg tttacgaaat gttttagagc tatgctgttt tga 53
<210> 161
<211> 53
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 161
aaacggtatc ggtttctttt aaattcaatt gttttgggac cattcaaaac agc 53
<210> 162
<211> 53
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 162
aattgaattt aaaagaaacc gataccgttt gttttagagc tatgctgttt tga 53
<210> 163
<211> 39
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 163
gttccttaaa ccaaaacggt atcggtttct tttaaattc 39
<210> 164
<211> 47
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 164
gaaaccgata ccgttttggt ttaaggaaca ggtaaagggc atttaac 47
<210> 165
<211> 22
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 165
cgatttcagc cattgcctcg tc 22
<210> 166
<211> 56
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<220>
<221> modified_base
<222> (29)..(33)
<223> a, c, t, g, unknown or other
<400> 166
gcctttgacg aggcaatggc tgaaatcgnn nnnaaaaagc gcaagaagaa atcaac 56
<210> 167
<211> 53
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 167
tccgtacaac ccacaaccct gctagtgagc gttttgggac cattcaaaac agc 53
<210> 168
<211> 53
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 168
gctcactagc agggttgtgg gttgtacgga gttttagagc tatgctgttt tga 53
<210> 169
<211> 23
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 169
ttgttgccac tcttccttct ttc 23
<210> 170
<211> 41
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 170
cagggttgtg ggttgttgcg atggagttaa ctcccatctc c 41
<210> 171
<211> 41
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 171
gggagttaac tccatcgcaa caacccacaa ccctgctagt g 41
<210> 172
<211> 22
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 172
gtggtatcta tcgtgatgtg ac 22
<210> 173
<211> 23
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 173
ttaccgaaac ggaatttatc tgc 23
<210> 174
<211> 22
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 174
aaagctagag ttccgcaatt gg 22
<210> 175
<211> 37
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 175
gtgggttgta cggattgagt taactcccat ctccttc 37
<210> 176
<211> 38
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 176
gatgggagtt aactcaatcc gtacaaccca caaccctg 38
<210> 177
<211> 40
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 177
gcttcaccta ttgcagcacc aattgaccac atgaagatag 40
<210> 178
<211> 41
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 178
gtggtcaatt ggtgctgcaa taggtgaagc taatggtgat g 41
<210> 179
<211> 39
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 179
ctgatttgta ttaattttga gacattatgc ttcaccttc 39
<210> 180
<211> 40
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 180
gcataatgtc tcaaaattaa tacaaatcag tgaaatcatg 40
<210> 181
<211> 52
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 181
gttttgggac cattcaaaac agcatagctc taaaacgtga cagtaatatc ag 52
<210> 182
<211> 53
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 182
gttttagagc tatgctgttt tgaatggtcc caaaacgctc actagcaggg ttg 53
<210> 183
<211> 59
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 183
atactttacg cagcgcggag ttcggttttg taggagtggt agtatataca cgagtacat 59
<210> 184
<211> 33
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 184
gctcactagc agggttgtgg gttgtacgga tgg 33
<210> 185
<211> 33
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 185
tcctagcagg atttctgata ttactgtcac tgg 33
<210> 186
<211> 33
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 186
tttaaaagaa accgataccg tttacgaaat tgg 33
<210> 187
<211> 84
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 187
ggaaccattc ataacagcat agcaagttat aataaggcta gtccgttatc aacttgaaaa 60
agtggcaccg agtcggtgct tttt 84
<210> 188
<211> 36
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 188
gttatagagc tatgctgtta tgaatggtcc caaaac 36
<210> 189
<211> 84
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 189
ggaaccattc aatacagcat agcaagttaa tataaggcta gtccgttatc aacttgaaaa 60
agtggcaccg agtcggtgct tttt 84
<210> 190
<211> 36
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 190
gtattagagc tatgctgtat tgaatggtcc caaaac 36
<210> 191
<211> 103
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<220>
<221> modified_base
<222> (1)..(20)
<223> a, c, t, g, unknown or other
<400> 191
nnnnnnnnnn nnnnnnnnnn gttttagagc tagaaatagc aagttaaaat aaggctagtc 60
cgttatcaac ttgaaaaagt ggcaccgagt cggtgctttt ttt 103
<210> 192
<211> 103
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<220>
<221> modified_base
<222> (1)..(20)
<223> a, c, t, g, unknown or other
<400> 192
nnnnnnnnnn nnnnnnnnnn gtattagagc tagaaatagc aagttaatat aaggctagtc 60
cgttatcaac ttgaaaaagt ggcaccgagt cggtgctttt ttt 103
<210> 193
<211> 123
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<220>
<221> modified_base
<222> (1)..(20)
<223> a, c, t, g, unknown or other
<400> 193
nnnnnnnnnn nnnnnnnnnn gttttagagc tatgctgttt tggaaacaaa acagcatagc 60
aagttaaaat aaggctagtc cgttatcaac ttgaaaaagt ggcaccgagt cggtgctttt 120
ttt 123
<210> 194
<211> 123
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<220>
<221> modified_base
<222> (1)..(20)
<223> a, c, t, g, unknown or other
<400> 194
nnnnnnnnnn nnnnnnnnnn gtattagagc tatgctgtat tggaaacaat acagcatagc 60
aagttaatat aaggctagtc cgttatcaac ttgaaaaagt ggcaccgagt cggtgctttt 120
ttt 123
<210> 195
<211> 20
<212> DNA
<213> Homo sapiens
<400> 195
gtcacctcca atgactaggg 20
<210> 196
<211> 23
<212> DNA
<213> Homo sapiens
<400> 196
gacatcgatg tcctccccat tgg 23
<210> 197
<211> 23
<212> DNA
<213> Homo sapiens
<400> 197
gagtccgagc agaagaagaa ggg 23
<210> 198
<211> 23
<212> DNA
<213> Homo sapiens
<400> 198
gcgccaccgg ttgatgtgat ggg 23
<210> 199
<211> 23
<212> DNA
<213> Homo sapiens
<400> 199
ggggcacaga tgagaaactc agg 23
<210> 200
<211> 23
<212> DNA
<213> Homo sapiens
<400> 200
gtacaaacgg cagaagctgg agg 23
<210> 201
<211> 23
<212> DNA
<213> Homo sapiens
<400> 201
ggcagaagct ggaggaggaa ggg 23
<210> 202
<211> 23
<212> DNA
<213> Homo sapiens
<400> 202
ggagcccttc ttcttctgct cgg 23
<210> 203
<211> 23
<212> DNA
<213> Homo sapiens
<400> 203
gggcaaccac aaacccacga ggg 23
<210> 204
<211> 23
<212> DNA
<213> Homo sapiens
<400> 204
gctcccatca catcaaccgg tgg 23
<210> 205
<211> 23
<212> DNA
<213> Homo sapiens
<400> 205
gtggcgcatt gccacgaagc agg 23
<210> 206
<211> 23
<212> DNA
<213> Homo sapiens
<400> 206
ggcagagtgc tgcttgctgc tgg 23
<210> 207
<211> 23
<212> DNA
<213> Homo sapiens
<400> 207
gcccctgcgt gggcccaagc tgg 23
<210> 208
<211> 23
<212> DNA
<213> Homo sapiens
<400> 208
gagtggccag agtccagctt ggg 23
<210> 209
<211> 23
<212> DNA
<213> Homo sapiens
<400> 209
ggcctcccca aagcctggcc agg 23
<210> 210
<211> 23
<212> DNA
<213> Homo sapiens
<400> 210
ggggccgaga ttgggtgttc agg 23
<210> 211
<211> 23
<212> DNA
<213> Homo sapiens
<400> 211
gtggcgagag gggccgagat tgg 23
<210> 212
<211> 23
<212> DNA
<213> Homo sapiens
<400> 212
gagtgccgcc gaggcggggc ggg 23
<210> 213
<211> 23
<212> DNA
<213> Homo sapiens
<400> 213
ggagtgccgc cgaggcgggg cgg 23
<210> 214
<211> 23
<212> DNA
<213> Homo sapiens
<400> 214
ggagaggagt gccgccgagg cgg 23
<210> 215
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 215
ccatcccctt ctgtgaatgt 20
<210> 216
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 216
ggagattgga gacacggaga 20
<210> 217
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 217
aagcaccgac tcggtgccac 20
<210> 218
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 218
tcacctccaa tgactagggg 20
<210> 219
<211> 22
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 219
caagttgata acggactagc ct 22
<210> 220
<211> 23
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 220
agtccgagca gaagaagaag ttt 23
<210> 221
<211> 25
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 221
tttcaagttg ataacggact agcct 25
<210> 222
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 222
aaacagcaga ttcgcctgga 20
<210> 223
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 223
tcatccgctc gatgaagctc 20
<210> 224
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 224
tccaaaatca agtggggcga 20
<210> 225
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 225
tgatgaccct tttggctccc 20
<210> 226
<211> 45
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 226
gaggaattct ttttttgtty gaatatgttg gaggtttttt ggaag 45
<210> 227
<211> 42
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 227
gagaagctta aataaaaaac racaatactc aacccaacaa cc 42
<210> 228
<211> 17
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 228
caggaaacag ctatgac 17
<210> 229
<211> 39
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 229
gcctctagag gtacctgagg gcctatttcc catgattcc 39
<210> 230
<211> 133
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<220>
<221> modified_base
<222> (92)..(111)
<223> a, c, t, g, unknown or other
<400> 230
acctctagaa aaaaagcacc gactcggtgc cactttttca agttgataac ggactagcct 60
tattttaact tgctatttct agctctaaaa cnnnnnnnnn nnnnnnnnnn nggtgtttcg 120
tcctttccac aag 133
<210> 231
<211> 133
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<220>
<221> modified_base
<222> (92)..(111)
<223> a, c, t, g, unknown or other
<400> 231
acctctagaa aaaaagcacc gactcggtgc cactttttca agttgataac ggactagcct 60
tatattaact tgctatttct agctctaata cnnnnnnnnn nnnnnnnnnn nggtgtttcg 120
tcctttccac aag 133
<210> 232
<211> 153
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<220>
<221> modified_base
<222> (112)..(131)
<223> a, c, t, g, unknown or other
<400> 232
acctctagaa aaaaagcacc gactcggtgc cactttttca agttgataac ggactagcct 60
tattttaact tgctatgctg ttttgtttcc aaaacagcat agctctaaaa cnnnnnnnnn 120
nnnnnnnnnn nggtgtttcg tcctttccac aag 153
<210> 233
<211> 153
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<220>
<221> modified_base
<222> (112)..(131)
<223> a, c, t, g, unknown or other
<400> 233
acctctagaa aaaaagcacc gactcggtgc cactttttca agttgataac ggactagcct 60
tatattaact tgctatgctg tattgtttcc aatacagcat agctctaata cnnnnnnnnn 120
nnnnnnnnnn nggtgtttcg tcctttccac aag 153
<210> 234
<211> 22
<212> DNA
<213> Homo sapiens
<220>
<221> modified_base
<222> (20)..(20)
<223> a, c, t, g, unknown or other
<400> 234
aggccccagt ggctgctctn aa 22
<210> 235
<211> 22
<212> DNA
<213> Homo sapiens
<220>
<221> modified_base
<222> (20)..(20)
<223> a, c, t, g, unknown or other
<400> 235
acatcaaccg gtggcgcatn at 22
<210> 236
<211> 22
<212> DNA
<213> Homo sapiens
<220>
<221> modified_base
<222> (20)..(20)
<223> a, c, t, g, unknown or other
<400> 236
aaggtgtggt tccagaaccn ac 22
<210> 237
<211> 22
<212> DNA
<213> Homo sapiens
<220>
<221> modified_base
<222> (20)..(20)
<223> a, c, t, g, unknown or other
<400> 237
ccatcacatc aaccggtggn ag 22
<210> 238
<211> 22
<212> DNA
<213> Homo sapiens
<220>
<221> modified_base
<222> (20)..(20)
<223> a, c, t, g, unknown or other
<400> 238
aaacggcaga agctggaggn ta 22
<210> 239
<211> 22
<212> DNA
<213> Homo sapiens
<220>
<221> modified_base
<222> (20)..(20)
<223> a, c, t, g, unknown or other
<400> 239
ggcagaagct ggaggaggan tt 22
<210> 240
<211> 22
<212> DNA
<213> Homo sapiens
<220>
<221> modified_base
<222> (20)..(20)
<223> a, c, t, g, unknown or other
<400> 240
ggtgtggttc cagaaccggn tc 22
<210> 241
<211> 22
<212> DNA
<213> Homo sapiens
<220>
<221> modified_base
<222> (20)..(20)
<223> a, c, t, g, unknown or other
<400> 241
aaccggagga caaagtacan tg 22
<210> 242
<211> 22
<212> DNA
<213> Homo sapiens
<220>
<221> modified_base
<222> (20)..(20)
<223> a, c, t, g, unknown or other
<400> 242
ttccagaacc ggaggacaan ca 22
<210> 243
<211> 22
<212> DNA
<213> Homo sapiens
<220>
<221> modified_base
<222> (20)..(20)
<223> a, c, t, g, unknown or other
<400> 243
gtgtggttcc agaaccggan ct 22
<210> 244
<211> 22
<212> DNA
<213> Homo sapiens
<220>
<221> modified_base
<222> (20)..(20)
<223> a, c, t, g, unknown or other
<400> 244
tccagaaccg gaggacaaan cc 22
<210> 245
<211> 22
<212> DNA
<213> Homo sapiens
<220>
<221> modified_base
<222> (20)..(20)
<223> a, c, t, g, unknown or other
<400> 245
cagaagctgg aggaggaagn cg 22
<210> 246
<211> 22
<212> DNA
<213> Homo sapiens
<220>
<221> modified_base
<222> (20)..(20)
<223> a, c, t, g, unknown or other
<400> 246
catcaaccgg tggcgcattn ga 22
<210> 247
<211> 22
<212> DNA
<213> Homo sapiens
<220>
<221> modified_base
<222> (20)..(20)
<223> a, c, t, g, unknown or other
<400> 247
gcagaagctg gaggaggaan gt 22
<210> 248
<211> 22
<212> DNA
<213> Homo sapiens
<220>
<221> modified_base
<222> (20)..(20)
<223> a, c, t, g, unknown or other
<400> 248
cctccctccc tggcccaggn gc 22
<210> 249
<211> 22
<212> DNA
<213> Homo sapiens
<220>
<221> modified_base
<222> (20)..(20)
<223> a, c, t, g, unknown or other
<400> 249
tcatctgtgc ccctccctcn aa 22
<210> 250
<211> 22
<212> DNA
<213> Homo sapiens
<220>
<221> modified_base
<222> (20)..(20)
<223> a, c, t, g, unknown or other
<400> 250
gggaggacat cgatgtcacn at 22
<210> 251
<211> 22
<212> DNA
<213> Homo sapiens
<220>
<221> modified_base
<222> (20)..(20)
<223> a, c, t, g, unknown or other
<400> 251
caaacggcag aagctggagn ac 22
<210> 252
<211> 22
<212> DNA
<213> Homo sapiens
<220>
<221> modified_base
<222> (20)..(20)
<223> a, c, t, g, unknown or other
<400> 252
gggtgggcaa ccacaaaccn ag 22
<210> 253
<211> 22
<212> DNA
<213> Homo sapiens
<220>
<221> modified_base
<222> (20)..(20)
<223> a, c, t, g, unknown or other
<400> 253
ggtgggcaac cacaaacccn ta 22
<210> 254
<211> 22
<212> DNA
<213> Homo sapiens
<220>
<221> modified_base
<222> (20)..(20)
<223> a, c, t, g, unknown or other
<400> 254
ggctcccatc acatcaaccn tt 22
<210> 255
<211> 22
<212> DNA
<213> Homo sapiens
<220>
<221> modified_base
<222> (20)..(20)
<223> a, c, t, g, unknown or other
<400> 255
gaagggcctg agtccgagcn tc 22
<210> 256
<211> 22
<212> DNA
<213> Homo sapiens
<220>
<221> modified_base
<222> (20)..(20)
<223> a, c, t, g, unknown or other
<400> 256
caaccggtgg cgcattgccn tg 22
<210> 257
<211> 22
<212> DNA
<213> Homo sapiens
<220>
<221> modified_base
<222> (20)..(20)
<223> a, c, t, g, unknown or other
<400> 257
aggaggaagg gcctgagtcn ca 22
<210> 258
<211> 22
<212> DNA
<213> Homo sapiens
<220>
<221> modified_base
<222> (20)..(20)
<223> a, c, t, g, unknown or other
<400> 258
agctggagga ggaagggccn ct 22
<210> 259
<211> 22
<212> DNA
<213> Homo sapiens
<220>
<221> modified_base
<222> (20)..(20)
<223> a, c, t, g, unknown or other
<400> 259
gcattgccac gaagcaggcn cc 22
<210> 260
<211> 22
<212> DNA
<213> Homo sapiens
<220>
<221> modified_base
<222> (20)..(20)
<223> a, c, t, g, unknown or other
<400> 260
attgccacga agcaggccan cg 22
<210> 261
<211> 22
<212> DNA
<213> Homo sapiens
<220>
<221> modified_base
<222> (20)..(20)
<223> a, c, t, g, unknown or other
<400> 261
agaaccggag gacaaagtan ga 22
<210> 262
<211> 22
<212> DNA
<213> Homo sapiens
<220>
<221> modified_base
<222> (20)..(20)
<223> a, c, t, g, unknown or other
<400> 262
tcaaccggtg gcgcattgcn gt 22
<210> 263
<211> 22
<212> DNA
<213> Homo sapiens
<220>
<221> modified_base
<222> (20)..(20)
<223> a, c, t, g, unknown or other
<400> 263
gaagctggag gaggaagggn gc 22
<210> 264
<211> 123
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 264
ccaatgggga ggacatcgat gtcacctcca atgactaggg tgggcaacca caaacccacg 60
agggcagagt gctgcttgct gctggccagg cccctgcgtg ggcccaagct ggactctggc 120
cac 123
<210> 265
<211> 121
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 265
cgagcagaag aagaagggct cccatcacat caaccggtgg cgcattgcca cgaagcaggc 60
caatggggag gacatcgatg tcacctccaa tgactagggt gggcaaccac aaacccacga 120
g 121
<210> 266
<211> 128
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 266
ggaggacaaa gtacaaacgg cagaagctgg aggaggaagg gcctgagtcc gagcagaaga 60
agaagggctc ccatcacatc aaccggtggc gcattgccac gaagcaggcc aatggggagg 120
acatcgat 128
<210> 267
<211> 130
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 267
agaagctgga ggaggaaggg cctgagtccg agcagaagaa gaagggctcc catcacatca 60
accggtggcg cattgccacg aagcaggcca atggggagga catcgatgtc acctccaatg 120
actagggtgg 130
<210> 268
<211> 125
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 268
cctcagtctt cccatcaggc tctcagctca gcctgagtgt tgaggcccca gtggctgctc 60
tgggggcctc ctgagtttct catctgtgcc cctccctccc tggcccaggt gaaggtgtgg 120
ttcca 125
<210> 269
<211> 129
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 269
tcatctgtgc ccctccctcc ctggcccagg tgaaggtgtg gttccagaac cggaggacaa 60
agtacaaacg gcagaagctg gaggaggaag ggcctgagtc cgagcagaag aagaagggct 120
cccatcaca 129
<210> 270
<211> 129
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 270
ctccaatgac tagggtgggc aaccacaaac ccacgagggc agagtgctgc ttgctgctgg 60
ccaggcccct gcgtgggccc aagctggact ctggccactc cctggccagg ctttggggag 120
gcctggagt 129
<210> 271
<211> 127
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 271
ctgcttgctg ctggccaggc ccctgcgtgg gcccaagctg gactctggcc actccctggc 60
caggctttgg ggaggcctgg agtcatggcc ccacagggct tgaagcccgg ggccgccatt 120
gacagag 127
<210> 272
<211> 25
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 272
gaaattaata cgactcacta taggg 25
<210> 273
<211> 126
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 273
aaaaaagcac cgactcggtg ccactttttc aagttgataa cggactagcc ttattttaac 60
ttgctatttc tagctctaaa acaacgacga gcgtgacacc accctatagt gagtcgtatt 120
aatttc 126
<210> 274
<211> 126
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 274
aaaaaagcac cgactcggtg ccactttttc aagttgataa cggactagcc ttattttaac 60
ttgctatttc tagctctaaa acgcaacaat taatagactg gacctatagt gagtcgtatt 120
aatttc 126
<210> 275
<211> 4677
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 275
tctttcttgc gctatgacac ttccagcaaa aggtagggcg ggctgcgaga cggcttcccg 60
gcgctgcatg caacaccgat gatgcttcga ccccccgaag ctccttcggg gctgcatggg 120
cgctccgatg ccgctccagg gcgagcgctg tttaaatagc caggcccccg attgcaaaga 180
cattatagcg agctaccaaa gccatattca aacacctaga tcactaccac ttctacacag 240
gccactcgag cttgtgatcg cactccgcta agggggcgcc tcttcctctt cgtttcagtc 300
acaacccgca aacatgtacc catacgatgt tccagattac gcttcgccga agaaaaagcg 360
caaggtcgaa gcgtccgaca agaagtacag catcggcctg gacatcggca ccaactctgt 420
gggctgggcc gtgatcaccg acgagtacaa ggtgcccagc aagaaattca aggtgctggg 480
caacaccgac cggcacagca tcaagaagaa cctgatcgga gccctgctgt tcgacagcgg 540
cgaaacagcc gaggccaccc ggctgaagag aaccgccaga agaagataca ccagacggaa 600
gaaccggatc tgctatctgc aagagatctt cagcaacgag atggccaagg tggacgacag 660
cttcttccac agactggaag agtccttcct ggtggaagag gataagaagc acgagcggca 720
ccccatcttc ggcaacatcg tggacgaggt ggcctaccac gagaagtacc ccaccatcta 780
ccacctgaga aagaaactgg tggacagcac cgacaaggcc gacctgcggc tgatctatct 840
ggccctggcc cacatgatca agttccgggg ccacttcctg atcgagggcg acctgaaccc 900
cgacaacagc gacgtggaca agctgttcat ccagctggtg cagacctaca accagctgtt 960
cgaggaaaac cccatcaacg ccagcggcgt ggacgccaag gccatcctgt ctgccagact 1020
gagcaagagc agacggctgg aaaatctgat cgcccagctg cccggcgaga agaagaatgg 1080
cctgttcggc aacctgattg ccctgagcct gggcctgacc cccaacttca agagcaactt 1140
cgacctggcc gaggatgcca aactgcagct gagcaaggac acctacgacg acgacctgga 1200
caacctgctg gcccagatcg gcgaccagta cgccgacctg tttctggccg ccaagaacct 1260
gtccgacgcc atcctgctga gcgacatcct gagagtgaac accgagatca ccaaggcccc 1320
cctgagcgcc tctatgatca agagatacga cgagcaccac caggacctga ccctgctgaa 1380
agctctcgtg cggcagcagc tgcctgagaa gtacaaagag attttcttcg accagagcaa 1440
gaacggctac gccggctaca ttgacggcgg agccagccag gaagagttct acaagttcat 1500
caagcccatc ctggaaaaga tggacggcac cgaggaactg ctcgtgaagc tgaacagaga 1560
ggacctgctg cggaagcagc ggaccttcga caacggcagc atcccccacc agatccacct 1620
gggagagctg cacgccattc tgcggcggca ggaagatttt tacccattcc tgaaggacaa 1680
ccgggaaaag atcgagaaga tcctgacctt ccgcatcccc tactacgtgg gccctctggc 1740
caggggaaac agcagattcg cctggatgac cagaaagagc gaggaaacca tcaccccctg 1800
gaacttcgag gaagtggtgg acaagggcgc ttccgcccag agcttcatcg agcggatgac 1860
caacttcgat aagaacctgc ccaacgagaa ggtgctgccc aagcacagcc tgctgtacga 1920
gtacttcacc gtgtataacg agctgaccaa agtgaaatac gtgaccgagg gaatgagaaa 1980
gcccgccttc ctgagcggcg agcagaaaaa ggccatcgtg gacctgctgt tcaagaccaa 2040
ccggaaagtg accgtgaagc agctgaaaga ggactacttc aagaaaatcg agtgcttcga 2100
ctccgtggaa atctccggcg tggaagatcg gttcaacgcc tccctgggca cataccacga 2160
tctgctgaaa attatcaagg acaaggactt cctggacaat gaggaaaacg aggacattct 2220
ggaagatatc gtgctgaccc tgacactgtt tgaggacaga gagatgatcg aggaacggct 2280
gaaaacctat gcccacctgt tcgacgacaa agtgatgaag cagctgaagc ggcggagata 2340
caccggctgg ggcaggctga gccggaagct gatcaacggc atccgggaca agcagtccgg 2400
caagacaatc ctggatttcc tgaagtccga cggcttcgcc aacagaaact tcatgcagct 2460
gatccacgac gacagcctga cctttaaaga ggacatccag aaagcccagg tgtccggcca 2520
gggcgatagc ctgcacgagc acattgccaa tctggccggc agccccgcca ttaagaaggg 2580
catcctgcag acagtgaagg tggtggacga gctcgtgaaa gtgatgggcc ggcacaagcc 2640
cgagaacatc gtgatcgaaa tggccagaga gaaccagacc acccagaagg gacagaagaa 2700
cagccgcgag agaatgaagc ggatcgaaga gggcatcaaa gagctgggca gccagatcct 2760
gaaagaacac cccgtggaaa acacccagct gcagaacgag aagctgtacc tgtactacct 2820
gcagaatggg cgggatatgt acgtggacca ggaactggac atcaaccggc tgtccgacta 2880
cgatgtggac catatcgtgc ctcagagctt tctgaaggac gactccatcg acaacaaggt 2940
gctgaccaga agcgacaaga accggggcaa gagcgacaac gtgccctccg aagaggtcgt 3000
gaagaagatg aagaactact ggcggcagct gctgaacgcc aagctgatta cccagagaaa 3060
gttcgacaat ctgaccaagg ccgagagagg cggcctgagc gaactggata aggccggctt 3120
catcaagaga cagctggtgg aaacccggca gatcacaaag cacgtggcac agatcctgga 3180
ctcccggatg aacactaagt acgacgagaa tgacaagctg atccgggaag tgaaagtgat 3240
caccctgaag tccaagctgg tgtccgattt ccggaaggat ttccagtttt acaaagtgcg 3300
cgagatcaac aactaccacc acgcccacga cgcctacctg aacgccgtcg tgggaaccgc 3360
cctgatcaaa aagtacccta agctggaaag cgagttcgtg tacggcgact acaaggtgta 3420
cgacgtgcgg aagatgatcg ccaagagcga gcaggaaatc ggcaaggcta ccgccaagta 3480
cttcttctac agcaacatca tgaacttttt caagaccgag attaccctgg ccaacggcga 3540
gatccggaag cggcctctga tcgagacaaa cggcgaaacc ggggagatcg tgtgggataa 3600
gggccgggat tttgccaccg tgcggaaagt gctgagcatg ccccaagtga atatcgtgaa 3660
aaagaccgag gtgcagacag gcggcttcag caaagagtct atcctgccca agaggaacag 3720
cgataagctg atcgccagaa agaaggactg ggaccctaag aagtacggcg gcttcgacag 3780
ccccaccgtg gcctattctg tgctggtggt ggccaaagtg gaaaagggca agtccaagaa 3840
actgaagagt gtgaaagagc tgctggggat caccatcatg gaaagaagca gcttcgagaa 3900
gaatcccatc gactttctgg aagccaaggg ctacaaagaa gtgaaaaagg acctgatcat 3960
caagctgcct aagtactccc tgttcgagct ggaaaacggc cggaagagaa tgctggcctc 4020
tgccggcgaa ctgcagaagg gaaacgaact ggccctgccc tccaaatatg tgaacttcct 4080
gtacctggcc agccactatg agaagctgaa gggctccccc gaggataatg agcagaaaca 4140
gctgtttgtg gaacagcaca agcactacct ggacgagatc atcgagcaga tcagcgagtt 4200
ctccaagaga gtgatcctgg ccgacgctaa tctggacaaa gtgctgtccg cctacaacaa 4260
gcaccgggat aagcccatca gagagcaggc cgagaatatc atccacctgt ttaccctgac 4320
caatctggga gcccctgccg ccttcaagta ctttgacacc accatcgacc ggaagaggta 4380
caccagcacc aaagaggtgc tggacgccac cctgatccac cagagcatca ccggcctgta 4440
cgagacacgg atcgacctgt ctcagctggg aggcgacagc cccaagaaga agagaaaggt 4500
ggaggccagc taaggatccg gcaagactgg ccccgcttgg caacgcaaca gtgagcccct 4560
ccctagtgtg tttggggatg tgactatgta ttcgtgtgtt ggccaacggg tcaacccgaa 4620
cagattgata cccgccttgg catttcctgt cagaatgtaa cgtcagttga tggtact 4677
<210> 276
<211> 3150
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 276
tctttcttgc gctatgacac ttccagcaaa aggtagggcg ggctgcgaga cggcttcccg 60
gcgctgcatg caacaccgat gatgcttcga ccccccgaag ctccttcggg gctgcatggg 120
cgctccgatg ccgctccagg gcgagcgctg tttaaatagc caggcccccg attgcaaaga 180
cattatagcg agctaccaaa gccatattca aacacctaga tcactaccac ttctacacag 240
gccactcgag cttgtgatcg cactccgcta agggggcgcc tcttcctctt cgtttcagtc 300
acaacccgca aacatgccta agaagaagag gaaggttaac acgattaaca tcgctaagaa 360
cgacttctct gacatcgaac tggctgctat cccgttcaac actctggctg accattacgg 420
tgagcgttta gctcgcgaac agttggccct tgagcatgag tcttacgaga tgggtgaagc 480
acgcttccgc aagatgtttg agcgtcaact taaagctggt gaggttgcgg ataacgctgc 540
cgccaagcct ctcatcacta ccctactccc taagatgatt gcacgcatca acgactggtt 600
tgaggaagtg aaagctaagc gcggcaagcg cccgacagcc ttccagttcc tgcaagaaat 660
caagccggaa gccgtagcgt acatcaccat taagaccact ctggcttgcc taaccagtgc 720
tgacaataca accgttcagg ctgtagcaag cgcaatcggt cgggccattg aggacgaggc 780
tcgcttcggt cgtatccgtg accttgaagc taagcacttc aagaaaaacg ttgaggaaca 840
actcaacaag cgcgtagggc acgtctacaa gaaagcattt atgcaagttg tcgaggctga 900
catgctctct aagggtctac tcggtggcga ggcgtggtct tcgtggcata aggaagactc 960
tattcatgta ggagtacgct gcatcgagat gctcattgag tcaaccggaa tggttagctt 1020
acaccgccaa aatgctggcg tagtaggtca agactctgag actatcgaac tcgcacctga 1080
atacgctgag gctatcgcaa cccgtgcagg tgcgctggct ggcatctctc cgatgttcca 1140
accttgcgta gttcctccta agccgtggac tggcattact ggtggtggct attgggctaa 1200
cggtcgtcgt cctctggcgc tggtgcgtac tcacagtaag aaagcactga tgcgctacga 1260
agacgtttac atgcctgagg tgtacaaagc gattaacatt gcgcaaaaca ccgcatggaa 1320
aatcaacaag aaagtcctag cggtcgccaa cgtaatcacc aagtggaagc attgtccggt 1380
cgaggacatc cctgcgattg agcgtgaaga actcccgatg aaaccggaag acatcgacat 1440
gaatcctgag gctctcaccg cgtggaaacg tgctgccgct gctgtgtacc gcaaggacaa 1500
ggctcgcaag tctcgccgta tcagccttga gttcatgctt gagcaagcca ataagtttgc 1560
taaccataag gccatctggt tcccttacaa catggactgg cgcggtcgtg tttacgctgt 1620
gtcaatgttc aacccgcaag gtaacgatat gaccaaagga ctgcttacgc tggcgaaagg 1680
taaaccaatc ggtaaggaag gttactactg gctgaaaatc cacggtgcaa actgtgcggg 1740
tgtcgacaag gttccgttcc ctgagcgcat caagttcatt gaggaaaacc acgagaacat 1800
catggcttgc gctaagtctc cactggagaa cacttggtgg gctgagcaag attctccgtt 1860
ctgcttcctt gcgttctgct ttgagtacgc tggggtacag caccacggcc tgagctataa 1920
ctgctccctt ccgctggcgt ttgacgggtc ttgctctggc atccagcact tctccgcgat 1980
gctccgagat gaggtaggtg gtcgcgcggt taacttgctt cctagtgaaa ccgttcagga 2040
catctacggg attgttgcta agaaagtcaa cgagattcta caagcagacg caatcaatgg 2100
gaccgataac gaagtagtta ccgtgaccga tgagaacact ggtgaaatct ctgagaaagt 2160
caagctgggc actaaggcac tggctggtca atggctggct tacggtgtta ctcgcagtgt 2220
gactaagcgt tcagtcatga cgctggctta cgggtccaaa gagttcggct tccgtcaaca 2280
agtgctggaa gataccattc agccagctat tgattccggc aagggtctga tgttcactca 2340
gccgaatcag gctgctggat acatggctaa gctgatttgg gaatctgtga gcgtgacggt 2400
ggtagctgcg gttgaagcaa tgaactggct taagtctgct gctaagctgc tggctgctga 2460
ggtcaaagat aagaagactg gagagattct tcgcaagcgt tgcgctgtgc attgggtaac 2520
tcctgatggt ttccctgtgt ggcaggaata caagaagcct attcagacgc gcttgaacct 2580
gatgttcctc ggtcagttcc gcttacagcc taccattaac accaacaaag atagcgagat 2640
tgatgcacac aaacaggagt ctggtatcgc tcctaacttt gtacacagcc aagacggtag 2700
ccaccttcgt aagactgtag tgtgggcaca cgagaagtac ggaatcgaat cttttgcact 2760
gattcacgac tccttcggta cgattccggc tgacgctgcg aacctgttca aagcagtgcg 2820
cgaaactatg gttgacacat atgagtcttg tgatgtactg gctgatttct acgaccagtt 2880
cgctgaccag ttgcacgagt ctcaattgga caaaatgcca gcacttccgg ctaaaggtaa 2940
cttgaacctc cgtgacatct tagagtcgga cttcgcgttc gcgtaaggat ccggcaagac 3000
tggccccgct tggcaacgca acagtgagcc cctccctagt gtgtttgggg atgtgactat 3060
gtattcgtgt gttggccaac gggtcaaccc gaacagattg atacccgcct tggcatttcc 3120
tgtcagaatg taacgtcagt tgatggtact 3150
<210> 277
<211> 125
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<220>
<221> modified_base
<222> (23)..(42)
<223> a, c, t, g, unknown or other
<400> 277
gaaattaata cgactcacta tannnnnnnn nnnnnnnnnn nngttttaga gctagaaata 60
gcaagttaaa ataaggctag tccgttatca acttgaaaaa gtggcaccga gtcggtgctt 120
ttttt 125
<210> 278
<211> 8452
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 278
tgcggtattt cacaccgcat caggtggcac ttttcgggga aatgtgcgcg gaacccctat 60
ttgtttattt ttctaaatac attcaaatat gtatccgctc atgagattat caaaaaggat 120
cttcacctag atccttttaa attaaaaatg aagttttaaa tcaatctaaa gtatatatga 180
gtaaacttgg tctgacagtt accaatgctt aatcagtgag gcacctatct cagcgatctg 240
tctatttcgt tcatccatag ttgcctgact ccccgtcgtg tagataacta cgatacggga 300
gggcttacca tctggcccca gtgctgcaat gataccgcga gacccacgct caccggctcc 360
agatttatca gcaataaacc agccagccgg aagggccgag cgcagaagtg gtcctgcaac 420
tttatccgcc tccatccagt ctattaattg ttgccgggaa gctagagtaa gtagttcgcc 480
agttaatagt ttgcgcaacg ttgttgccat tgctacaggc atcgtggtgt cacgctcgtc 540
gtttggtatg gcttcattca gctccggttc ccaacgatca aggcgagtta catgatcccc 600
catgttgtgc aaaaaagcgg ttagctcctt cggtcctccg atcgttgtca gaagtaagtt 660
ggccgcagtg ttatcactca tggttatggc agcactgcat aattctctta ctgtcatgcc 720
atccgtaaga tgcttttctg tgactggtga gtactcaacc aagtcattct gagaatagtg 780
tatgcggcga ccgagttgct cttgcccggc gtcaatacgg gataataccg cgccacatag 840
cagaacttta aaagtgctca tcattggaaa acgttcttcg gggcgaaaac tctcaaggat 900
cttaccgctg ttgagatcca gttcgatgta acccactcgt gcacccaact gatcttcagc 960
atcttttact ttcaccagcg tttctgggtg agcaaaaaca ggaaggcaaa atgccgcaaa 1020
aaagggaata agggcgacac ggaaatgttg aatactcata ctcttccttt ttcaatatta 1080
ttgaagcatt tatcagggtt attgtctcat gaccaaaatc ccttaacgtg agttttcgtt 1140
ccactgagcg tcagaccccg tagaaaagat caaaggatct tcttgagatc ctttttttct 1200
gcgcgtaatc tgctgcttgc aaacaaaaaa accaccgcta ccagcggtgg tttgtttgcc 1260
ggatcaagag ctaccaactc tttttccgaa ggtaactggc ttcagcagag cgcagatacc 1320
aaatactgtt cttctagtgt agccgtagtt aggccaccac ttcaagaact ctgtagcacc 1380
gcctacatac ctcgctctgc taatcctgtt accagtggct gttgccagtg gcgataagtc 1440
gtgtcttacc gggttggact caagacgata gttaccggat aaggcgcagc ggtcgggctg 1500
aacggggggt tcgtgcacac agcccagctt ggagcgaacg acctacaccg aactgagata 1560
cctacagcgt gagctatgag aaagcgccac gcttcccgaa gggagaaagg cggacaggta 1620
tccggtaagc ggcagggtcg gaacaggaga gcgcacgagg gagcttccag ggggaaacgc 1680
ctggtatctt tatagtcctg tcgggtttcg ccacctctga cttgagcgtc gatttttgtg 1740
atgctcgtca ggggggcgga gcctatggaa aaacgccagc aacgcggcct ttttacggtt 1800
cctggccttt tgctggcctt ttgctcacat gttctttcct gcgttatccc ctgattctgt 1860
ggataaccgt attaccgcct ttgagtgagc tgataccgct cgccgcagcc gaacgaccga 1920
gcgcagcgag tcagtgagcg aggaagcggt cgctgaggct tgacatgatt ggtgcgtatg 1980
tttgtatgaa gctacaggac tgatttggcg ggctatgagg gcgggggaag ctctggaagg 2040
gccgcgatgg ggcgcgcggc gtccagaagg cgccatacgg cccgctggcg gcacccatcc 2100
ggtataaaag cccgcgaccc cgaacggtga cctccacttt cagcgacaaa cgagcactta 2160
tacatacgcg actattctgc cgctatacat aaccactcag ctagcttaag atcccatcaa 2220
gcttgcatgc cgggcgcgcc agaaggagcg cagccaaacc aggatgatgt ttgatggggt 2280
atttgagcac ttgcaaccct tatccggaag ccccctggcc cacaaaggct aggcgccaat 2340
gcaagcagtt cgcatgcagc ccctggagcg gtgccctcct gataaaccgg ccagggggcc 2400
tatgttcttt acttttttac aagagaagtc actcaacatc ttaaaatggc caggtgagtc 2460
gacgagcaag cccggcggat caggcagcgt gcttgcagat ttgacttgca acgcccgcat 2520
tgtgtcgacg aaggcttttg gctcctctgt cgctgtctca agcagcatct aaccctgcgt 2580
cgccgtttcc atttgcagga gattcgaggt accatgtacc catacgatgt tccagattac 2640
gcttcgccga agaaaaagcg caaggtcgaa gcgtccgaca agaagtacag catcggcctg 2700
gacatcggca ccaactctgt gggctgggcc gtgatcaccg acgagtacaa ggtgcccagc 2760
aagaaattca aggtgctggg caacaccgac cggcacagca tcaagaagaa cctgatcgga 2820
gccctgctgt tcgacagcgg cgaaacagcc gaggccaccc ggctgaagag aaccgccaga 2880
agaagataca ccagacggaa gaaccggatc tgctatctgc aagagatctt cagcaacgag 2940
atggccaagg tggacgacag cttcttccac agactggaag agtccttcct ggtggaagag 3000
gataagaagc acgagcggca ccccatcttc ggcaacatcg tggacgaggt ggcctaccac 3060
gagaagtacc ccaccatcta ccacctgaga aagaaactgg tggacagcac cgacaaggcc 3120
gacctgcggc tgatctatct ggccctggcc cacatgatca agttccgggg ccacttcctg 3180
atcgagggcg acctgaaccc cgacaacagc gacgtggaca agctgttcat ccagctggtg 3240
cagacctaca accagctgtt cgaggaaaac cccatcaacg ccagcggcgt ggacgccaag 3300
gccatcctgt ctgccagact gagcaagagc agacggctgg aaaatctgat cgcccagctg 3360
cccggcgaga agaagaatgg cctgttcggc aacctgattg ccctgagcct gggcctgacc 3420
cccaacttca agagcaactt cgacctggcc gaggatgcca aactgcagct gagcaaggac 3480
acctacgacg acgacctgga caacctgctg gcccagatcg gcgaccagta cgccgacctg 3540
tttctggccg ccaagaacct gtccgacgcc atcctgctga gcgacatcct gagagtgaac 3600
accgagatca ccaaggcccc cctgagcgcc tctatgatca agagatacga cgagcaccac 3660
caggacctga ccctgctgaa agctctcgtg cggcagcagc tgcctgagaa gtacaaagag 3720
attttcttcg accagagcaa gaacggctac gccggctaca ttgacggcgg agccagccag 3780
gaagagttct acaagttcat caagcccatc ctggaaaaga tggacggcac cgaggaactg 3840
ctcgtgaagc tgaacagaga ggacctgctg cggaagcagc ggaccttcga caacggcagc 3900
atcccccacc agatccacct gggagagctg cacgccattc tgcggcggca ggaagatttt 3960
tacccattcc tgaaggacaa ccgggaaaag atcgagaaga tcctgacctt ccgcatcccc 4020
tactacgtgg gccctctggc caggggaaac agcagattcg cctggatgac cagaaagagc 4080
gaggaaacca tcaccccctg gaacttcgag gaagtggtgg acaagggcgc ttccgcccag 4140
agcttcatcg agcggatgac caacttcgat aagaacctgc ccaacgagaa ggtgctgccc 4200
aagcacagcc tgctgtacga gtacttcacc gtgtataacg agctgaccaa agtgaaatac 4260
gtgaccgagg gaatgagaaa gcccgccttc ctgagcggcg agcagaaaaa ggccatcgtg 4320
gacctgctgt tcaagaccaa ccggaaagtg accgtgaagc agctgaaaga ggactacttc 4380
aagaaaatcg agtgcttcga ctccgtggaa atctccggcg tggaagatcg gttcaacgcc 4440
tccctgggca cataccacga tctgctgaaa attatcaagg acaaggactt cctggacaat 4500
gaggaaaacg aggacattct ggaagatatc gtgctgaccc tgacactgtt tgaggacaga 4560
gagatgatcg aggaacggct gaaaacctat gcccacctgt tcgacgacaa agtgatgaag 4620
cagctgaagc ggcggagata caccggctgg ggcaggctga gccggaagct gatcaacggc 4680
atccgggaca agcagtccgg caagacaatc ctggatttcc tgaagtccga cggcttcgcc 4740
aacagaaact tcatgcagct gatccacgac gacagcctga cctttaaaga ggacatccag 4800
aaagcccagg tgtccggcca gggcgatagc ctgcacgagc acattgccaa tctggccggc 4860
agccccgcca ttaagaaggg catcctgcag acagtgaagg tggtggacga gctcgtgaaa 4920
gtgatgggcc ggcacaagcc cgagaacatc gtgatcgaaa tggccagaga gaaccagacc 4980
acccagaagg gacagaagaa cagccgcgag agaatgaagc ggatcgaaga gggcatcaaa 5040
gagctgggca gccagatcct gaaagaacac cccgtggaaa acacccagct gcagaacgag 5100
aagctgtacc tgtactacct gcagaatggg cgggatatgt acgtggacca ggaactggac 5160
atcaaccggc tgtccgacta cgatgtggac catatcgtgc ctcagagctt tctgaaggac 5220
gactccatcg acaacaaggt gctgaccaga agcgacaaga accggggcaa gagcgacaac 5280
gtgccctccg aagaggtcgt gaagaagatg aagaactact ggcggcagct gctgaacgcc 5340
aagctgatta cccagagaaa gttcgacaat ctgaccaagg ccgagagagg cggcctgagc 5400
gaactggata aggccggctt catcaagaga cagctggtgg aaacccggca gatcacaaag 5460
cacgtggcac agatcctgga ctcccggatg aacactaagt acgacgagaa tgacaagctg 5520
atccgggaag tgaaagtgat caccctgaag tccaagctgg tgtccgattt ccggaaggat 5580
ttccagtttt acaaagtgcg cgagatcaac aactaccacc acgcccacga cgcctacctg 5640
aacgccgtcg tgggaaccgc cctgatcaaa aagtacccta agctggaaag cgagttcgtg 5700
tacggcgact acaaggtgta cgacgtgcgg aagatgatcg ccaagagcga gcaggaaatc 5760
ggcaaggcta ccgccaagta cttcttctac agcaacatca tgaacttttt caagaccgag 5820
attaccctgg ccaacggcga gatccggaag cggcctctga tcgagacaaa cggcgaaacc 5880
ggggagatcg tgtgggataa gggccgggat tttgccaccg tgcggaaagt gctgagcatg 5940
ccccaagtga atatcgtgaa aaagaccgag gtgcagacag gcggcttcag caaagagtct 6000
atcctgccca agaggaacag cgataagctg atcgccagaa agaaggactg ggaccctaag 6060
aagtacggcg gcttcgacag ccccaccgtg gcctattctg tgctggtggt ggccaaagtg 6120
gaaaagggca agtccaagaa actgaagagt gtgaaagagc tgctggggat caccatcatg 6180
gaaagaagca gcttcgagaa gaatcccatc gactttctgg aagccaaggg ctacaaagaa 6240
gtgaaaaagg acctgatcat caagctgcct aagtactccc tgttcgagct ggaaaacggc 6300
cggaagagaa tgctggcctc tgccggcgaa ctgcagaagg gaaacgaact ggccctgccc 6360
tccaaatatg tgaacttcct gtacctggcc agccactatg agaagctgaa gggctccccc 6420
gaggataatg agcagaaaca gctgtttgtg gaacagcaca agcactacct ggacgagatc 6480
atcgagcaga tcagcgagtt ctccaagaga gtgatcctgg ccgacgctaa tctggacaaa 6540
gtgctgtccg cctacaacaa gcaccgggat aagcccatca gagagcaggc cgagaatatc 6600
atccacctgt ttaccctgac caatctggga gcccctgccg ccttcaagta ctttgacacc 6660
accatcgacc ggaagaggta caccagcacc aaagaggtgc tggacgccac cctgatccac 6720
cagagcatca ccggcctgta cgagacacgg atcgacctgt ctcagctggg aggcgacagc 6780
cccaagaaga agagaaaggt ggaggccagc taacatatga ttcgaatgtc tttcttgcgc 6840
tatgacactt ccagcaaaag gtagggcggg ctgcgagacg gcttcccggc gctgcatgca 6900
acaccgatga tgcttcgacc ccccgaagct ccttcggggc tgcatgggcg ctccgatgcc 6960
gctccagggc gagcgctgtt taaatagcca ggcccccgat tgcaaagaca ttatagcgag 7020
ctaccaaagc catattcaaa cacctagatc actaccactt ctacacaggc cactcgagct 7080
tgtgatcgca ctccgctaag ggggcgcctc ttcctcttcg tttcagtcac aacccgcaaa 7140
catgacacaa gaatccctgt tacttctcga ccgtattgat tcggatgatt cctacgcgag 7200
cctgcggaac gaccaggaat tctgggaggt gagtcgacga gcaagcccgg cggatcaggc 7260
agcgtgcttg cagatttgac ttgcaacgcc cgcattgtgt cgacgaaggc ttttggctcc 7320
tctgtcgctg tctcaagcag catctaaccc tgcgtcgccg tttccatttg cagccgctgg 7380
cccgccgagc cctggaggag ctcgggctgc cggtgccgcc ggtgctgcgg gtgcccggcg 7440
agagcaccaa ccccgtactg gtcggcgagc ccggcccggt gatcaagctg ttcggcgagc 7500
actggtgcgg tccggagagc ctcgcgtcgg agtcggaggc gtacgcggtc ctggcggacg 7560
ccccggtgcc ggtgccccgc ctcctcggcc gcggcgagct gcggcccggc accggagcct 7620
ggccgtggcc ctacctggtg atgagccgga tgaccggcac cacctggcgg tccgcgatgg 7680
acggcacgac cgaccggaac gcgctgctcg ccctggcccg cgaactcggc cgggtgctcg 7740
gccggctgca cagggtgccg ctgaccggga acaccgtgct caccccccat tccgaggtct 7800
tcccggaact gctgcgggaa cgccgcgcgg cgaccgtcga ggaccaccgc gggtggggct 7860
acctctcgcc ccggctgctg gaccgcctgg aggactggct gccggacgtg gacacgctgc 7920
tggccggccg cgaaccccgg ttcgtccacg gcgacctgca cgggaccaac atcttcgtgg 7980
acctggccgc gaccgaggtc accgggatcg tcgacttcac cgacgtctat gcgggagact 8040
cccgctacag cctggtgcaa ctgcatctca acgccttccg gggcgaccgc gagatcctgg 8100
ccgcgctgct cgacggggcg cagtggaagc ggaccgagga cttcgcccgc gaactgctcg 8160
ccttcacctt cctgcacgac ttcgaggtgt tcgaggagac cccgctggat ctctccggct 8220
tcaccgatcc ggaggaactg gcgcagttcc tctgggggcc gccggacacc gcccccggcg 8280
cctgataagg atccggcaag actggccccg cttggcaacg caacagtgag cccctcccta 8340
gtgtgtttgg ggatgtgact atgtattcgt gtgttggcca acgggtcaac ccgaacagat 8400
tgatacccgc cttggcattt cctgtcagaa tgtaacgtca gttgatggta ct 8452
<210> 279
<211> 102
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 279
gttttagagc tatgctgttt tgaatggtcc caaaacggaa gggcctgagt ccgagcagaa 60
gaagaagttt tagagctatg ctgttttgaa tggtcccaaa ac 102
<210> 280
<211> 100
<212> DNA
<213> Homo sapiens
<400> 280
cggaggacaa agtacaaacg gcagaagctg gaggaggaag ggcctgagtc cgagcagaag 60
aagaagggct cccatcacat caaccggtgg cgcattgcca 100
<210> 281
<211> 50
<212> DNA
<213> Homo sapiens
<400> 281
agctggagga ggaagggcct gagtccgagc agaagaagaa gggctcccac 50
<210> 282
<211> 30
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 282
gaguccgagc agaagaagaa guuuuagagc 30
<210> 283
<211> 49
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 283
agctggagga ggaagggcct gagtccgagc agaagagaag ggctcccat 49
<210> 284
<211> 53
<212> DNA
<213> Homo sapiens
<400> 284
ctggaggagg aagggcctga gtccgagcag aagaagaagg gctcccatca cat 53
<210> 285
<211> 52
<212> DNA
<213> Homo sapiens
<400> 285
ctggaggagg aagggcctga gtccgagcag aagagaaggg ctcccatcac at 52
<210> 286
<211> 54
<212> DNA
<213> Homo sapiens
<400> 286
ctggaggagg aagggcctga gtccgagcag aagaaagaag ggctcccatc acat 54
<210> 287
<211> 50
<212> DNA
<213> Homo sapiens
<400> 287
ctggaggagg aagggcctga gtccgagcag aagaagggct cccatcacat 50
<210> 288
<211> 47
<212> DNA
<213> Homo sapiens
<400> 288
ctggaggagg aagggcctga gcccgagcag aagggctccc atcacat 47
<210> 289
<211> 66
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<220>
<221> source
<223> /note="Description of Combined DNA/RNA Molecule: Synthetic
oligonucleotide"
<220>
<221> modified_base
<222> (1)..(20)
<223> a, c, t, g, unknown or other
<400> 289
nnnnnnnnnn nnnnnnnnnn guuuuagagc uagaaauagc aaguuaaaau aaggctagtc 60
cguuuu 66
<210> 290
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 290
gaguccgagc agaagaagaa 20
<210> 291
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 291
gacaucgaug uccuccccau 20
<210> 292
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 292
gucaccucca augacuaggg 20
<210> 293
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 293
auuggguguu cagggcagag 20
<210> 294
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 294
guggcgagag gggccgagau 20
<210> 295
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 295
ggggccgaga uuggguguuc 20
<210> 296
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 296
gugccauuag cuaaaugcau 20
<210> 297
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 297
guaccaccca caggugccag 20
<210> 298
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 298
gaaagccucu gggccaggaa 20
<210> 299
<211> 48
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 299
ctggaggagg aagggcctga gtccgagcag aagaagaagg gctcccat 48
<210> 300
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 300
gaguccgagc agaagaagau 20
<210> 301
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 301
gaguccgagc agaagaagua 20
<210> 302
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 302
gaguccgagc agaagaacaa 20
<210> 303
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 303
gaguccgagc agaagaugaa 20
<210> 304
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 304
gaguccgagc agaaguagaa 20
<210> 305
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 305
gaguccgagc agaugaagaa 20
<210> 306
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 306
gaguccgagc acaagaagaa 20
<210> 307
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 307
gaguccgagg agaagaagaa 20
<210> 308
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 308
gaguccgugc agaagaagaa 20
<210> 309
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 309
gagucggagc agaagaagaa 20
<210> 310
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 310
gagaccgagc agaagaagaa 20
<210> 311
<211> 24
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 311
aatgacaagc ttgctagcgg tggg 24
<210> 312
<211> 39
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 312
aaaacggaag ggcctgagtc cgagcagaag aagaagttt 39
<210> 313
<211> 39
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 313
aaacaggggc cgagattggg tgttcagggc agaggtttt 39
<210> 314
<211> 38
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 314
aaaacggaag ggcctgagtc cgagcagaag aagaagtt 38
<210> 315
<211> 40
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 315
aacggaggga ggggcacaga tgagaaactc agggttttag 40
<210> 316
<211> 38
<212> DNA
<213> Homo sapiens
<400> 316
agcccttctt cttctgctcg gactcaggcc cttcctcc 38
<210> 317
<211> 40
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 317
cagggaggga ggggcacaga tgagaaactc aggaggcccc 40
<210> 318
<211> 80
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 318
ggcaatgcgc caccggttga tgtgatggga gcccttctag gaggccccca gagcagccac 60
tggggcctca acactcaggc 80
<210> 319
<211> 23
<212> DNA
<213> Homo sapiens
<400> 319
gtcacctcca atgactaggg tgg 23
<210> 320
<211> 25
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<220>
<221> modified_base
<222> (6)..(25)
<223> a, c, t, g, unknown or other
<400> 320
caccgnnnnn nnnnnnnnnn nnnnn 25
<210> 321
<211> 25
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<220>
<221> modified_base
<222> (5)..(24)
<223> a, c, t, g, unknown or other
<400> 321
aaacnnnnnn nnnnnnnnnn nnnnc 25
<210> 322
<211> 33
<212> DNA
<213> Homo sapiens
<400> 322
catcgatgtc ctccccattg gcctgcttcg tgg 33
<210> 323
<211> 33
<212> DNA
<213> Homo sapiens
<400> 323
ttcgtggcaa tgcgccaccg gttgatgtga tgg 33
<210> 324
<211> 33
<212> DNA
<213> Homo sapiens
<400> 324
tcgtggcaat gcgccaccgg ttgatgtgat ggg 33
<210> 325
<211> 33
<212> DNA
<213> Homo sapiens
<400> 325
tccagcttct gccgtttgta ctttgtcctc cgg 33
<210> 326
<211> 33
<212> DNA
<213> Homo sapiens
<400> 326
ggagggaggg gcacagatga gaaactcagg agg 33
<210> 327
<211> 33
<212> DNA
<213> Homo sapiens
<400> 327
aggggccgag attgggtgtt cagggcagag agg 33
<210> 328
<211> 54
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 328
aacaccgggt cttcgagaag acctgtttta gagctagaaa tagcaagtta aaat 54
<210> 329
<211> 54
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 329
caaaacgggt cttcgagaag acgttttaga gctatgctgt tttgaatggt ccca 54
<210> 330
<211> 33
<212> DNA
<213> Mus musculus
<400> 330
caagcactga gtgccattag ctaaatgcat agg 33
<210> 331
<211> 33
<212> DNA
<213> Mus musculus
<400> 331
aatgcatagg gtaccaccca caggtgccag ggg 33
<210> 332
<211> 33
<212> DNA
<213> Mus musculus
<400> 332
acacacatgg gaaagcctct gggccaggaa agg 33
<210> 333
<211> 37
<212> DNA
<213> Homo sapiens
<400> 333
ggaggaggta gtatacagaa acacagagaa gtagaat 37
<210> 334
<211> 37
<212> DNA
<213> Homo sapiens
<400> 334
agaatgtaga ggagtcacag aaactcagca ctagaaa 37
<210> 335
<211> 98
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 335
ggacgaaaca ccggaaccat tcaaaacagc atagcaagtt aaaataaggc tagtccgtta 60
tcaacttgaa aaagtggcac cgagtcggtg cttttttt 98
<210> 336
<211> 186
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 336
ggacgaaaca ccggtagtat taagtattgt tttatggctg ataaatttct ttgaatttct 60
ccttgattat ttgttataaa agttataaaa taatcttgtt ggaaccattc aaaacagcat 120
agcaagttaa aataaggcta gtccgttatc aacttgaaaa agtggcaccg agtcggtgct 180
tttttt 186
<210> 337
<211> 95
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 337
gggttttaga gctatgctgt tttgaatggt cccaaaacgg gtcttcgaga agacgtttta 60
gagctatgct gttttgaatg gtcccaaaac ttttt 95
<210> 338
<211> 36
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<220>
<221> modified_base
<222> (5)..(34)
<223> a, c, t, g, unknown or other
<400> 338
aaacnnnnnn nnnnnnnnnn nnnnnnnnnn nnnngt 36
<210> 339
<211> 36
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<220>
<221> modified_base
<222> (7)..(36)
<223> a, c, t, g, unknown or other
<400> 339
taaaacnnnn nnnnnnnnnn nnnnnnnnnn nnnnnn 36
<210> 340
<211> 84
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 340
gtggaaagga cgaaacaccg ggtcttcgag aagacctgtt ttagagctag aaatagcaag 60
ttaaaataag gctagtccgt tttt 84
<210> 341
<211> 24
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<220>
<221> modified_base
<222> (6)..(24)
<223> a, c, t, g, unknown or other
<400> 341
caccgnnnnn nnnnnnnnnn nnnn 24
<210> 342
<211> 24
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<220>
<221> modified_base
<222> (5)..(23)
<223> a, c, t, g, unknown or other
<400> 342
aaacnnnnnn nnnnnnnnnn nnnc 24
<210> 343
<211> 88
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 343
gttttagagc tatgctgttt tgaatggtcc caaaactgag accaaaggtc tcgttttaga 60
gctatgctgt tttgaatggt cccaaaac 88
<210> 344
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 344
aaacggaagg gcctgagtcc gagcagaaga agaag 35
<210> 345
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 345
aaaacttctt cttctgctcg gactcaggcc cttcc 35
<210> 346
<211> 46
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<220>
<221> modified_base
<222> (1)..(19)
<223> a, c, u, g, unknown or other
<400> 346
nnnnnnnnnn nnnnnnnnng uuauuguacu cucaagauuu auuuuu 46
<210> 347
<211> 91
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 347
guuacuuaaa ucuugcagaa gcuacaaaga uaaggcuuca ugccgaaauc aacacccugu 60
cauuuuaugg caggguguuu ucguuauuua a 91
<210> 348
<211> 70
<212> DNA
<213> Homo sapiens
<400> 348
ttttctagtg ctgagtttct gtgactcctc tacattctac ttctctgtgt ttctgtatac 60
tacctcctcc 70
<210> 349
<211> 122
<212> DNA
<213> Homo sapiens
<400> 349
ggaggaaggg cctgagtccg agcagaagaa gaagggctcc catcacatca accggtggcg 60
cattgccacg aagcaggcca atggggagga catcgatgtc acctccaatg actagggtgg 120
gc 122
<210> 350
<211> 48
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<220>
<221> modified_base
<222> (3)..(32)
<223> a, c, u, g, unknown or other
<400> 350
acnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnguuuuaga gcuaugcu 48
<210> 351
<211> 67
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<220>
<221> source
<223> /note="Description of Combined DNA/RNA Molecule: Synthetic
oligonucleotide"
<400> 351
agcauagcaa guuaaaauaa ggctaguccg uuaucaacuu gaaaaagugg caccgagucg 60
gugcuuu 67
<210> 352
<211> 62
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<220>
<221> modified_base
<222> (1)..(20)
<223> a, c, u, g, unknown or other
<400> 352
nnnnnnnnnn nnnnnnnnnn guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc 60
cg 62
<210> 353
<211> 73
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 353
tgaatggtcc caaaacggaa gggcctgagt ccgagcagaa gaagaagttt tagagctatg 60
ctgttttgaa tgg 73
<210> 354
<211> 69
<212> DNA
<213> Homo sapiens
<400> 354
ctggtcttcc acctctctgc cctgaacacc caatctcggc ccctctcgcc accctcctgc 60
atttctgtt 69
<210> 355
<211> 138
<212> DNA
<213> Mus musculus
<400> 355
acccaagcac tgagtgccat tagctaaatg catagggtac cacccacagg tgccaggggc 60
ctttcccaaa gttcccagcc ccttctccaa cctttcctgg cccagaggct ttcccatgtg 120
tgtggctgga ccctttga 138
<210> 356
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 356
gtgctttgca gaggcctacc 20
<210> 357
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 357
cctggagcgc atgcagtagt 20
<210> 358
<211> 22
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 358
accttctgtg tttccaccat tc 22
<210> 359
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 359
ttggggagtg cacagacttc 20
<210> 360
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 360
ggctccctgg gttcaaagta 20
<210> 361
<211> 21
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 361
agaggggtct ggatgtcgta a 21
<210> 362
<211> 30
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
probe"
<400> 362
tagctctaaa acttcttctt ctgctcggac 30
<210> 363
<211> 30
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
probe"
<400> 363
ctagccttat tttaacttgc tatgctgttt 30
<210> 364
<211> 99
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<220>
<221> modified_base
<222> (1)..(20)
<223> a, c, u, g, unknown or other
<400> 364
nnnnnnnnnn nnnnnnnnnn guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc 60
cguuaucaac uugaaaaagu ggcaccgagu cggugcuuu 99
<210> 365
<211> 12
<212> DNA
<213> Homo sapiens
<400> 365
tagcgggtaa gc 12
<210> 366
<211> 12
<212> DNA
<213> Homo sapiens
<400> 366
tcggtgacat gt 12
<210> 367
<211> 12
<212> DNA
<213> Homo sapiens
<400> 367
actccccgta gg 12
<210> 368
<211> 12
<212> DNA
<213> Homo sapiens
<400> 368
actgcgtgtt aa 12
<210> 369
<211> 12
<212> DNA
<213> Homo sapiens
<400> 369
acgtcgcctg at 12
<210> 370
<211> 12
<212> DNA
<213> Homo sapiens
<400> 370
taggtcgacc ag 12
<210> 371
<211> 12
<212> DNA
<213> Homo sapiens
<400> 371
ggcgttaatg at 12
<210> 372
<211> 12
<212> DNA
<213> Homo sapiens
<400> 372
tgtcgcatgt ta 12
<210> 373
<211> 12
<212> DNA
<213> Homo sapiens
<400> 373
atggaaacgc at 12
<210> 374
<211> 12
<212> DNA
<213> Homo sapiens
<400> 374
gccgaattcc tc 12
<210> 375
<211> 12
<212> DNA
<213> Homo sapiens
<400> 375
gcatggtacg ga 12
<210> 376
<211> 12
<212> DNA
<213> Homo sapiens
<400> 376
cggtactctt ac 12
<210> 377
<211> 12
<212> DNA
<213> Homo sapiens
<400> 377
gcctgtgccg ta 12
<210> 378
<211> 12
<212> DNA
<213> Homo sapiens
<400> 378
tacggtaagt cg 12
<210> 379
<211> 12
<212> DNA
<213> Homo sapiens
<400> 379
cacgaaatta cc 12
<210> 380
<211> 12
<212> DNA
<213> Homo sapiens
<400> 380
aaccaagata cg 12
<210> 381
<211> 12
<212> DNA
<213> Homo sapiens
<400> 381
gagtcgatac gc 12
<210> 382
<211> 12
<212> DNA
<213> Homo sapiens
<400> 382
gtctcacgat cg 12
<210> 383
<211> 12
<212> DNA
<213> Homo sapiens
<400> 383
tcgtcgggtg ca 12
<210> 384
<211> 12
<212> DNA
<213> Homo sapiens
<400> 384
actccgtagt ga 12
<210> 385
<211> 12
<212> DNA
<213> Homo sapiens
<400> 385
caggacgtcc gt 12
<210> 386
<211> 12
<212> DNA
<213> Homo sapiens
<400> 386
tcgtatccct ac 12
<210> 387
<211> 12
<212> DNA
<213> Homo sapiens
<400> 387
tttcaaggcc gg 12
<210> 388
<211> 12
<212> DNA
<213> Homo sapiens
<400> 388
cgccggtgga at 12
<210> 389
<211> 12
<212> DNA
<213> Homo sapiens
<400> 389
gaacccgtcc ta 12
<210> 390
<211> 12
<212> DNA
<213> Homo sapiens
<400> 390
gattcatcag cg 12
<210> 391
<211> 12
<212> DNA
<213> Homo sapiens
<400> 391
acaccggtct tc 12
<210> 392
<211> 12
<212> DNA
<213> Homo sapiens
<400> 392
atcgtgccct aa 12
<210> 393
<211> 12
<212> DNA
<213> Homo sapiens
<400> 393
gcgtcaatgt tc 12
<210> 394
<211> 12
<212> DNA
<213> Homo sapiens
<400> 394
ctccgtatct cg 12
<210> 395
<211> 12
<212> DNA
<213> Homo sapiens
<400> 395
ccgattcctt cg 12
<210> 396
<211> 12
<212> DNA
<213> Homo sapiens
<400> 396
tgcgcctcca gt 12
<210> 397
<211> 12
<212> DNA
<213> Homo sapiens
<400> 397
taacgtcgga gc 12
<210> 398
<211> 12
<212> DNA
<213> Homo sapiens
<400> 398
aaggtcgccc at 12
<210> 399
<211> 12
<212> DNA
<213> Homo sapiens
<400> 399
gtcggggact at 12
<210> 400
<211> 12
<212> DNA
<213> Homo sapiens
<400> 400
ttcgagcgat tt 12
<210> 401
<211> 12
<212> DNA
<213> Homo sapiens
<400> 401
tgagtcgtcg ag 12
<210> 402
<211> 12
<212> DNA
<213> Homo sapiens
<400> 402
tttacgcaga gg 12
<210> 403
<211> 12
<212> DNA
<213> Homo sapiens
<400> 403
aggaagtatc gc 12
<210> 404
<211> 12
<212> DNA
<213> Homo sapiens
<400> 404
actcgatacc at 12
<210> 405
<211> 12
<212> DNA
<213> Homo sapiens
<400> 405
cgctacatag ca 12
<210> 406
<211> 12
<212> DNA
<213> Homo sapiens
<400> 406
ttcataaccg gc 12
<210> 407
<211> 12
<212> DNA
<213> Homo sapiens
<400> 407
ccaaacggtt aa 12
<210> 408
<211> 12
<212> DNA
<213> Homo sapiens
<400> 408
cgattccttc gt 12
<210> 409
<211> 12
<212> DNA
<213> Homo sapiens
<400> 409
cgtcatgaat aa 12
<210> 410
<211> 12
<212> DNA
<213> Homo sapiens
<400> 410
agtggcgatg ac 12
<210> 411
<211> 12
<212> DNA
<213> Homo sapiens
<400> 411
cccctacggc ac 12
<210> 412
<211> 12
<212> DNA
<213> Homo sapiens
<400> 412
gccaacccgc ac 12
<210> 413
<211> 12
<212> DNA
<213> Homo sapiens
<400> 413
tgggacaccg gt 12
<210> 414
<211> 12
<212> DNA
<213> Homo sapiens
<400> 414
ttgactgcgg cg 12
<210> 415
<211> 12
<212> DNA
<213> Homo sapiens
<400> 415
actatgcgta gg 12
<210> 416
<211> 12
<212> DNA
<213> Homo sapiens
<400> 416
tcacccaaag cg 12
<210> 417
<211> 12
<212> DNA
<213> Homo sapiens
<400> 417
gcaggacgtc cg 12
<210> 418
<211> 12
<212> DNA
<213> Homo sapiens
<400> 418
acaccgaaaa cg 12
<210> 419
<211> 12
<212> DNA
<213> Homo sapiens
<400> 419
cggtgtattg ag 12
<210> 420
<211> 12
<212> DNA
<213> Homo sapiens
<400> 420
cacgaggtat gc 12
<210> 421
<211> 12
<212> DNA
<213> Homo sapiens
<400> 421
taaagcgacc cg 12
<210> 422
<211> 12
<212> DNA
<213> Homo sapiens
<400> 422
cttagtcggc ca 12
<210> 423
<211> 12
<212> DNA
<213> Homo sapiens
<400> 423
cgaaaacgtg gc 12
<210> 424
<211> 12
<212> DNA
<213> Homo sapiens
<400> 424
cgtgccctga ac 12
<210> 425
<211> 12
<212> DNA
<213> Homo sapiens
<400> 425
tttaccatcg aa 12
<210> 426
<211> 12
<212> DNA
<213> Homo sapiens
<400> 426
cgtagccatg tt 12
<210> 427
<211> 12
<212> DNA
<213> Homo sapiens
<400> 427
cccaaacggt ta 12
<210> 428
<211> 12
<212> DNA
<213> Homo sapiens
<400> 428
gcgttatcag aa 12
<210> 429
<211> 12
<212> DNA
<213> Homo sapiens
<400> 429
tcgatggtaa ac 12
<210> 430
<211> 12
<212> DNA
<213> Homo sapiens
<400> 430
cgactttttg ca 12
<210> 431
<211> 12
<212> DNA
<213> Homo sapiens
<400> 431
tcgacgactc ac 12
<210> 432
<211> 12
<212> DNA
<213> Homo sapiens
<400> 432
acgcgtcaga ta 12
<210> 433
<211> 12
<212> DNA
<213> Homo sapiens
<400> 433
cgtacggcac ag 12
<210> 434
<211> 12
<212> DNA
<213> Homo sapiens
<400> 434
ctatgccgtg ca 12
<210> 435
<211> 12
<212> DNA
<213> Homo sapiens
<400> 435
cgcgtcagat at 12
<210> 436
<211> 12
<212> DNA
<213> Homo sapiens
<400> 436
aagatcggta gc 12
<210> 437
<211> 12
<212> DNA
<213> Homo sapiens
<400> 437
cttcgcaagg ag 12
<210> 438
<211> 12
<212> DNA
<213> Homo sapiens
<400> 438
gtcgtggact ac 12
<210> 439
<211> 12
<212> DNA
<213> Homo sapiens
<400> 439
ggtcgtcatc aa 12
<210> 440
<211> 12
<212> DNA
<213> Homo sapiens
<400> 440
gttaacagcg tg 12
<210> 441
<211> 12
<212> DNA
<213> Homo sapiens
<400> 441
tagctaaccg tt 12
<210> 442
<211> 12
<212> DNA
<213> Homo sapiens
<400> 442
agtaaaggcg ct 12
<210> 443
<211> 12
<212> DNA
<213> Homo sapiens
<400> 443
ggtaatttcg tg 12
<210> 444
<211> 69
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 444
gucaccucca augacuaggg guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc 60
cguuuuuuu 69
<210> 445
<211> 69
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 445
gacaucgaug uccuccccau guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc 60
cguuuuuuu 69
<210> 446
<211> 69
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 446
gaguccgagc agaagaagaa guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc 60
cguuuuuuu 69
<210> 447
<211> 69
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 447
ggggccgaga uuggguguuc guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc 60
cguuuuuuu 69
<210> 448
<211> 69
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 448
guggcgagag gggccgagau guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc 60
cguuuuuuu 69
<210> 449
<211> 76
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 449
gucaccucca augacuaggg guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc 60
cguuaucauu uuuuuu 76
<210> 450
<211> 76
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 450
gacaucgaug uccuccccau guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc 60
cguuaucauu uuuuuu 76
<210> 451
<211> 76
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 451
gaguccgagc agaagaagaa guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc 60
cguuaucauu uuuuuu 76
<210> 452
<211> 76
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 452
ggggccgaga uuggguguuc guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc 60
cguuaucauu uuuuuu 76
<210> 453
<211> 76
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 453
guggcgagag gggccgagau guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc 60
cguuaucauu uuuuuu 76
<210> 454
<211> 88
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 454
gucaccucca augacuaggg guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc 60
cguuaucaac uugaaaaagu guuuuuuu 88
<210> 455
<211> 88
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 455
gacaucgaug uccuccccau guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc 60
cguuaucaac uugaaaaagu guuuuuuu 88
<210> 456
<211> 88
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 456
gaguccgagc agaagaagaa guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc 60
cguuaucaac uugaaaaagu guuuuuuu 88
<210> 457
<211> 88
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 457
ggggccgaga uuggguguuc guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc 60
cguuaucaac uugaaaaagu guuuuuuu 88
<210> 458
<211> 88
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 458
guggcgagag gggccgagau guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc 60
cguuaucaac uugaaaaagu guuuuuuu 88
<210> 459
<211> 103
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 459
gucaccucca augacuaggg guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc 60
cguuaucaac uugaaaaagu ggcaccgagu cggugcuuuu uuu 103
<210> 460
<211> 103
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 460
gacaucgaug uccuccccau guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc 60
cguuaucaac uugaaaaagu ggcaccgagu cggugcuuuu uuu 103
<210> 461
<211> 103
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 461
gaguccgagc agaagaagaa guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc 60
cguuaucaac uugaaaaagu ggcaccgagu cggugcuuuu uuu 103
<210> 462
<211> 103
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 462
ggggccgaga uuggguguuc guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc 60
cguuaucaac uugaaaaagu ggcaccgagu cggugcuuuu uuu 103
<210> 463
<211> 103
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 463
guggcgagag gggccgagau guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc 60
cguuaucaac uugaaaaagu ggcaccgagu cggugcuuuu uuu 103
<210> 464
<211> 120
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 464
gtggaaagga cgaaacaccg ggtcttcgag aagacctgtt ttagagctag aaatagcaag 60
ttaaaataag gctagtccgt tatcaacttg aaaaagtggc accgagtcgg tgcttttttt 120
<210> 465
<211> 40
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 465
tcggtgcgct ggttgatttc ttcttgcgct tttttggctt 40
<210> 466
<211> 26
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 466
gauuucuucu ugcgcuuuuu guuuua 26
<210> 467
<211> 26
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<220>
<221> modified_base
<222> (22)..(26)
<223> a, c, t, g, unknown or other
<400> 467
tgatttcttc ttgcgctttt tnnnnn 26
<210> 468
<211> 26
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<220>
<221> modified_base
<222> (21)..(21)
<223> a, c, t, g, unknown or other
<400> 468
tgatttcttc ttgcgctttt ntggct 26
<210> 469
<211> 26
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<220>
<221> modified_base
<222> (2)..(2)
<223> a, c, t, g, unknown or other
<400> 469
tnatttcttc ttgcgctttt ttggct 26
<210> 470
<211> 23
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 470
gatttcttct tgcgcttttt tgg 23
<210> 471
<211> 34
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<220>
<221> CDS
<222> (1)..(33)
<400> 471
tcc atc cgt aca acc cac aac cct gct agt gag c 34
Ser Ile Arg Thr Thr His Asn Pro Ala Ser Glu
1 5 10
<210> 472
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 472
Ser Ile Arg Thr Thr His Asn Pro Ala Ser Glu
1 5 10
<210> 473
<211> 34
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<220>
<221> CDS
<222> (1)..(33)
<400> 473
tcc atc gca aca acc cac aac cct gct agt gag c 34
Ser Ile Ala Thr Thr His Asn Pro Ala Ser Glu
1 5 10
<210> 474
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 474
Ser Ile Ala Thr Thr His Asn Pro Ala Ser Glu
1 5 10
<210> 475
<211> 34
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<220>
<221> CDS
<222> (1)..(33)
<400> 475
tca atc cgt aca acc cac aac cct gct agt gag c 34
Ser Ile Arg Thr Thr His Asn Pro Ala Ser Glu
1 5 10
<210> 476
<211> 42
<212> DNA
<213> Homo sapiens
<220>
<221> CDS
<222> (1)..(36)
<400> 476
caa ttg aat tta aaa gaa acc gat acc gtt ttg gtt taagga 42
Gln Leu Asn Leu Lys Glu Thr Asp Thr Val Leu Val
1 5 10
<210> 477
<211> 12
<212> PRT
<213> Homo sapiens
<400> 477
Gln Leu Asn Leu Lys Glu Thr Asp Thr Val Leu Val
1 5 10
<210> 478
<211> 42
<212> DNA
<213> Homo sapiens
<220>
<221> CDS
<222> (1)..(42)
<400> 478
caa ttg aat tta aaa gaa acc gat acc gtt tac gaa att gga 42
Gln Leu Asn Leu Lys Glu Thr Asp Thr Val Tyr Glu Ile Gly
1 5 10
<210> 479
<211> 14
<212> PRT
<213> Homo sapiens
<400> 479
Gln Leu Asn Leu Lys Glu Thr Asp Thr Val Tyr Glu Ile Gly
1 5 10
<210> 480
<211> 34
<212> DNA
<213> Homo sapiens
<220>
<221> CDS
<222> (2)..(34)
<400> 480
t cct aaa aaa ccg aac tcc gcg ctg cgt aaa gta 34
Pro Lys Lys Pro Asn Ser Ala Leu Arg Lys Val
1 5 10
<210> 481
<211> 11
<212> PRT
<213> Homo sapiens
<400> 481
Pro Lys Lys Pro Asn Ser Ala Leu Arg Lys Val
1 5 10
<210> 482
<211> 34
<212> DNA
<213> Homo sapiens
<220>
<221> CDS
<222> (2)..(34)
<400> 482
t cct aca aaa ccg aac tcc gcg ctg cgt aaa gta 34
Pro Thr Lys Pro Asn Ser Ala Leu Arg Lys Val
1 5 10
<210> 483
<211> 11
<212> PRT
<213> Homo sapiens
<400> 483
Pro Thr Lys Pro Asn Ser Ala Leu Arg Lys Val
1 5 10
<210> 484
<211> 33
<212> DNA
<213> Homo sapiens
<400> 484
tgcgctggtt gatttcttct tgcgcttttt tgg 33
<210> 485
<211> 33
<212> DNA
<213> Homo sapiens
<400> 485
tacgctggtt gatttcttct tgcgcttttt ttg 33
<210> 486
<211> 27
<212> DNA
<213> Homo sapiens
<400> 486
ggagggtttt atggggaaag gccattg 27
<210> 487
<211> 29
<212> DNA
<213> Homo sapiens
<400> 487
gtaaaaaaga agactagaaa ttttgatac 29
<210> 488
<211> 46
<212> DNA
<213> Homo sapiens
<400> 488
ggagggtttt atggggaaag gcaaagaaga ctagaaattt tgatac 46
<210> 489
<211> 27
<212> DNA
<213> Homo sapiens
<400> 489
aggtgaagca taatgtctca aaaaata 27
<210> 490
<211> 29
<212> DNA
<213> Homo sapiens
<400> 490
attttattaa tacaaatcag tgaaatcat 29
<210> 491
<211> 46
<212> DNA
<213> Homo sapiens
<400> 491
aggtgaagca taatgtctca aaattaatac aaatcagtga aatcat 46
<210> 492
<211> 36
<212> DNA
<213> Homo sapiens
<220>
<221> CDS
<222> (1)..(36)
<400> 492
aat tta aaa gaa acc gat acc gtt tac gaa att gga 36
Asn Leu Lys Glu Thr Asp Thr Val Tyr Glu Ile Gly
1 5 10
<210> 493
<211> 12
<212> PRT
<213> Homo sapiens
<400> 493
Asn Leu Lys Glu Thr Asp Thr Val Tyr Glu Ile Gly
1 5 10
<210> 494
<211> 36
<212> DNA
<213> Homo sapiens
<220>
<221> CDS
<222> (1)..(30)
<400> 494
aat tta aaa gaa acc gat acc gtt ttg gtt taagga 36
Asn Leu Lys Glu Thr Asp Thr Val Leu Val
1 5 10
<210> 495
<211> 10
<212> PRT
<213> Homo sapiens
<400> 495
Asn Leu Lys Glu Thr Asp Thr Val Leu Val
1 5 10
<210> 496
<211> 36
<212> DNA
<213> Homo sapiens
<220>
<221> CDS
<222> (1)..(36)
<400> 496
tgg gat cca aaa aaa tat ggt ggt ttt gat agt cca 36
Trp Asp Pro Lys Lys Tyr Gly Gly Phe Asp Ser Pro
1 5 10
<210> 497
<211> 12
<212> PRT
<213> Homo sapiens
<400> 497
Trp Asp Pro Lys Lys Tyr Gly Gly Phe Asp Ser Pro
1 5 10
<210> 498
<211> 36
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<220>
<221> CDS
<222> (1)..(36)
<400> 498
tgg gat cca aaa aaa tat tgt ggt ttt gat agt cca 36
Trp Asp Pro Lys Lys Tyr Cys Gly Phe Asp Ser Pro
1 5 10
<210> 499
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 499
Trp Asp Pro Lys Lys Tyr Cys Gly Phe Asp Ser Pro
1 5 10
<210> 500
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 500
aaactacttt acgcagcgcg gagttcggtt ttttg 35
<210> 501
<211> 4104
<212> DNA
<213> Homo sapiens
<220>
<221> CDS
<222> (1)..(4104)
<400> 501
atg gac aag aag tac agc atc ggc ctg gac atc ggc acc aac tct gtg 48
Met Asp Lys Lys Tyr Ser Ile Gly Leu Asp Ile Gly Thr Asn Ser Val
1 5 10 15
ggc tgg gcc gtg atc acc gac gag tac aag gtg ccc agc aag aaa ttc 96
Gly Trp Ala Val Ile Thr Asp Glu Tyr Lys Val Pro Ser Lys Lys Phe
20 25 30
aag gtg ctg ggc aac acc gac cgg cac agc atc aag aag aac ctg atc 144
Lys Val Leu Gly Asn Thr Asp Arg His Ser Ile Lys Lys Asn Leu Ile
35 40 45
gga gcc ctg ctg ttc gac agc ggc gaa aca gcc gag gcc acc cgg ctg 192
Gly Ala Leu Leu Phe Asp Ser Gly Glu Thr Ala Glu Ala Thr Arg Leu
50 55 60
aag aga acc gcc aga aga aga tac acc aga cgg aag aac cgg atc tgc 240
Lys Arg Thr Ala Arg Arg Arg Tyr Thr Arg Arg Lys Asn Arg Ile Cys
65 70 75 80
tat ctg caa gag atc ttc agc aac gag atg gcc aag gtg gac gac agc 288
Tyr Leu Gln Glu Ile Phe Ser Asn Glu Met Ala Lys Val Asp Asp Ser
85 90 95
ttc ttc cac aga ctg gaa gag tcc ttc ctg gtg gaa gag gat aag aag 336
Phe Phe His Arg Leu Glu Glu Ser Phe Leu Val Glu Glu Asp Lys Lys
100 105 110
cac gag cgg cac ccc atc ttc ggc aac atc gtg gac gag gtg gcc tac 384
His Glu Arg His Pro Ile Phe Gly Asn Ile Val Asp Glu Val Ala Tyr
115 120 125
cac gag aag tac ccc acc atc tac cac ctg aga aag aaa ctg gtg gac 432
His Glu Lys Tyr Pro Thr Ile Tyr His Leu Arg Lys Lys Leu Val Asp
130 135 140
agc acc gac aag gcc gac ctg cgg ctg atc tat ctg gcc ctg gcc cac 480
Ser Thr Asp Lys Ala Asp Leu Arg Leu Ile Tyr Leu Ala Leu Ala His
145 150 155 160
atg atc aag ttc cgg ggc cac ttc ctg atc gag ggc gac ctg aac ccc 528
Met Ile Lys Phe Arg Gly His Phe Leu Ile Glu Gly Asp Leu Asn Pro
165 170 175
gac aac agc gac gtg gac aag ctg ttc atc cag ctg gtg cag acc tac 576
Asp Asn Ser Asp Val Asp Lys Leu Phe Ile Gln Leu Val Gln Thr Tyr
180 185 190
aac cag ctg ttc gag gaa aac ccc atc aac gcc agc ggc gtg gac gcc 624
Asn Gln Leu Phe Glu Glu Asn Pro Ile Asn Ala Ser Gly Val Asp Ala
195 200 205
aag gcc atc ctg tct gcc aga ctg agc aag agc aga cgg ctg gaa aat 672
Lys Ala Ile Leu Ser Ala Arg Leu Ser Lys Ser Arg Arg Leu Glu Asn
210 215 220
ctg atc gcc cag ctg ccc ggc gag aag aag aat ggc ctg ttc ggc aac 720
Leu Ile Ala Gln Leu Pro Gly Glu Lys Lys Asn Gly Leu Phe Gly Asn
225 230 235 240
ctg att gcc ctg agc ctg ggc ctg acc ccc aac ttc aag agc aac ttc 768
Leu Ile Ala Leu Ser Leu Gly Leu Thr Pro Asn Phe Lys Ser Asn Phe
245 250 255
gac ctg gcc gag gat gcc aaa ctg cag ctg agc aag gac acc tac gac 816
Asp Leu Ala Glu Asp Ala Lys Leu Gln Leu Ser Lys Asp Thr Tyr Asp
260 265 270
gac gac ctg gac aac ctg ctg gcc cag atc ggc gac cag tac gcc gac 864
Asp Asp Leu Asp Asn Leu Leu Ala Gln Ile Gly Asp Gln Tyr Ala Asp
275 280 285
ctg ttt ctg gcc gcc aag aac ctg tcc gac gcc atc ctg ctg agc gac 912
Leu Phe Leu Ala Ala Lys Asn Leu Ser Asp Ala Ile Leu Leu Ser Asp
290 295 300
atc ctg aga gtg aac acc gag atc acc aag gcc ccc ctg agc gcc tct 960
Ile Leu Arg Val Asn Thr Glu Ile Thr Lys Ala Pro Leu Ser Ala Ser
305 310 315 320
atg atc aag aga tac gac gag cac cac cag gac ctg acc ctg ctg aaa 1008
Met Ile Lys Arg Tyr Asp Glu His His Gln Asp Leu Thr Leu Leu Lys
325 330 335
gct ctc gtg cgg cag cag ctg cct gag aag tac aaa gag att ttc ttc 1056
Ala Leu Val Arg Gln Gln Leu Pro Glu Lys Tyr Lys Glu Ile Phe Phe
340 345 350
gac cag agc aag aac ggc tac gcc ggc tac att gac ggc gga gcc agc 1104
Asp Gln Ser Lys Asn Gly Tyr Ala Gly Tyr Ile Asp Gly Gly Ala Ser
355 360 365
cag gaa gag ttc tac aag ttc atc aag ccc atc ctg gaa aag atg gac 1152
Gln Glu Glu Phe Tyr Lys Phe Ile Lys Pro Ile Leu Glu Lys Met Asp
370 375 380
ggc acc gag gaa ctg ctc gtg aag ctg aac aga gag gac ctg ctg cgg 1200
Gly Thr Glu Glu Leu Leu Val Lys Leu Asn Arg Glu Asp Leu Leu Arg
385 390 395 400
aag cag cgg acc ttc gac aac ggc agc atc ccc cac cag atc cac ctg 1248
Lys Gln Arg Thr Phe Asp Asn Gly Ser Ile Pro His Gln Ile His Leu
405 410 415
gga gag ctg cac gcc att ctg cgg cgg cag gaa gat ttt tac cca ttc 1296
Gly Glu Leu His Ala Ile Leu Arg Arg Gln Glu Asp Phe Tyr Pro Phe
420 425 430
ctg aag gac aac cgg gaa aag atc gag aag atc ctg acc ttc cgc atc 1344
Leu Lys Asp Asn Arg Glu Lys Ile Glu Lys Ile Leu Thr Phe Arg Ile
435 440 445
ccc tac tac gtg ggc cct ctg gcc agg gga aac agc aga ttc gcc tgg 1392
Pro Tyr Tyr Val Gly Pro Leu Ala Arg Gly Asn Ser Arg Phe Ala Trp
450 455 460
atg acc aga aag agc gag gaa acc atc acc ccc tgg aac ttc gag gaa 1440
Met Thr Arg Lys Ser Glu Glu Thr Ile Thr Pro Trp Asn Phe Glu Glu
465 470 475 480
gtg gtg gac aag ggc gct tcc gcc cag agc ttc atc gag cgg atg acc 1488
Val Val Asp Lys Gly Ala Ser Ala Gln Ser Phe Ile Glu Arg Met Thr
485 490 495
aac ttc gat aag aac ctg ccc aac gag aag gtg ctg ccc aag cac agc 1536
Asn Phe Asp Lys Asn Leu Pro Asn Glu Lys Val Leu Pro Lys His Ser
500 505 510
ctg ctg tac gag tac ttc acc gtg tat aac gag ctg acc aaa gtg aaa 1584
Leu Leu Tyr Glu Tyr Phe Thr Val Tyr Asn Glu Leu Thr Lys Val Lys
515 520 525
tac gtg acc gag gga atg aga aag ccc gcc ttc ctg agc ggc gag cag 1632
Tyr Val Thr Glu Gly Met Arg Lys Pro Ala Phe Leu Ser Gly Glu Gln
530 535 540
aaa aag gcc atc gtg gac ctg ctg ttc aag acc aac cgg aaa gtg acc 1680
Lys Lys Ala Ile Val Asp Leu Leu Phe Lys Thr Asn Arg Lys Val Thr
545 550 555 560
gtg aag cag ctg aaa gag gac tac ttc aag aaa atc gag tgc ttc gac 1728
Val Lys Gln Leu Lys Glu Asp Tyr Phe Lys Lys Ile Glu Cys Phe Asp
565 570 575
tcc gtg gaa atc tcc ggc gtg gaa gat cgg ttc aac gcc tcc ctg ggc 1776
Ser Val Glu Ile Ser Gly Val Glu Asp Arg Phe Asn Ala Ser Leu Gly
580 585 590
aca tac cac gat ctg ctg aaa att atc aag gac aag gac ttc ctg gac 1824
Thr Tyr His Asp Leu Leu Lys Ile Ile Lys Asp Lys Asp Phe Leu Asp
595 600 605
aat gag gaa aac gag gac att ctg gaa gat atc gtg ctg acc ctg aca 1872
Asn Glu Glu Asn Glu Asp Ile Leu Glu Asp Ile Val Leu Thr Leu Thr
610 615 620
ctg ttt gag gac aga gag atg atc gag gaa cgg ctg aaa acc tat gcc 1920
Leu Phe Glu Asp Arg Glu Met Ile Glu Glu Arg Leu Lys Thr Tyr Ala
625 630 635 640
cac ctg ttc gac gac aaa gtg atg aag cag ctg aag cgg cgg aga tac 1968
His Leu Phe Asp Asp Lys Val Met Lys Gln Leu Lys Arg Arg Arg Tyr
645 650 655
acc ggc tgg ggc agg ctg agc cgg aag ctg atc aac ggc atc cgg gac 2016
Thr Gly Trp Gly Arg Leu Ser Arg Lys Leu Ile Asn Gly Ile Arg Asp
660 665 670
aag cag tcc ggc aag aca atc ctg gat ttc ctg aag tcc gac ggc ttc 2064
Lys Gln Ser Gly Lys Thr Ile Leu Asp Phe Leu Lys Ser Asp Gly Phe
675 680 685
gcc aac aga aac ttc atg cag ctg atc cac gac gac agc ctg acc ttt 2112
Ala Asn Arg Asn Phe Met Gln Leu Ile His Asp Asp Ser Leu Thr Phe
690 695 700
aaa gag gac atc cag aaa gcc cag gtg tcc ggc cag ggc gat agc ctg 2160
Lys Glu Asp Ile Gln Lys Ala Gln Val Ser Gly Gln Gly Asp Ser Leu
705 710 715 720
cac gag cac att gcc aat ctg gcc ggc agc ccc gcc att aag aag ggc 2208
His Glu His Ile Ala Asn Leu Ala Gly Ser Pro Ala Ile Lys Lys Gly
725 730 735
atc ctg cag aca gtg aag gtg gtg gac gag ctc gtg aaa gtg atg ggc 2256
Ile Leu Gln Thr Val Lys Val Val Asp Glu Leu Val Lys Val Met Gly
740 745 750
cgg cac aag ccc gag aac atc gtg atc gcc atg gcc aga gag aac cag 2304
Arg His Lys Pro Glu Asn Ile Val Ile Ala Met Ala Arg Glu Asn Gln
755 760 765
acc acc cag aag gga cag aag aac agc cgc gag aga atg aag cgg atc 2352
Thr Thr Gln Lys Gly Gln Lys Asn Ser Arg Glu Arg Met Lys Arg Ile
770 775 780
gaa gag ggc atc aaa gag ctg ggc agc cag atc ctg aaa gaa cac ccc 2400
Glu Glu Gly Ile Lys Glu Leu Gly Ser Gln Ile Leu Lys Glu His Pro
785 790 795 800
gtg gaa aac acc cag ctg cag aac gag aag ctg tac ctg tac tac ctg 2448
Val Glu Asn Thr Gln Leu Gln Asn Glu Lys Leu Tyr Leu Tyr Tyr Leu
805 810 815
cag aat ggg cgg gat atg tac gtg gac cag gaa ctg gac atc aac cgg 2496
Gln Asn Gly Arg Asp Met Tyr Val Asp Gln Glu Leu Asp Ile Asn Arg
820 825 830
ctg tcc gac tac gat gtg gac gcc atc gtg cct cag agc ttt ctg aag 2544
Leu Ser Asp Tyr Asp Val Asp Ala Ile Val Pro Gln Ser Phe Leu Lys
835 840 845
gac gac tcc atc gac gcc aag gtg ctg acc aga agc gac aag gcc cgg 2592
Asp Asp Ser Ile Asp Ala Lys Val Leu Thr Arg Ser Asp Lys Ala Arg
850 855 860
ggc aag agc gac aac gtg ccc tcc gaa gag gtc gtg aag aag atg aag 2640
Gly Lys Ser Asp Asn Val Pro Ser Glu Glu Val Val Lys Lys Met Lys
865 870 875 880
aac tac tgg cgg cag ctg ctg aac gcc aag ctg att acc cag aga aag 2688
Asn Tyr Trp Arg Gln Leu Leu Asn Ala Lys Leu Ile Thr Gln Arg Lys
885 890 895
ttc gac aat ctg acc aag gcc gag aga ggc ggc ctg agc gaa ctg gat 2736
Phe Asp Asn Leu Thr Lys Ala Glu Arg Gly Gly Leu Ser Glu Leu Asp
900 905 910
aag gcc ggc ttc atc aag aga cag ctg gtg gaa acc cgg cag atc aca 2784
Lys Ala Gly Phe Ile Lys Arg Gln Leu Val Glu Thr Arg Gln Ile Thr
915 920 925
aag cac gtg gca cag atc ctg gac tcc cgg atg aac act aag tac gac 2832
Lys His Val Ala Gln Ile Leu Asp Ser Arg Met Asn Thr Lys Tyr Asp
930 935 940
gag aat gac aag ctg atc cgg gaa gtg aaa gtg atc acc ctg aag tcc 2880
Glu Asn Asp Lys Leu Ile Arg Glu Val Lys Val Ile Thr Leu Lys Ser
945 950 955 960
aag ctg gtg tcc gat ttc cgg aag gat ttc cag ttt tac aaa gtg cgc 2928
Lys Leu Val Ser Asp Phe Arg Lys Asp Phe Gln Phe Tyr Lys Val Arg
965 970 975
gag atc aac aac tac cac cac gcc cac gcc gcc tac ctg aac gcc gtc 2976
Glu Ile Asn Asn Tyr His His Ala His Ala Ala Tyr Leu Asn Ala Val
980 985 990
gtg gga acc gcc ctg atc aaa aag tac cct aag ctg gaa agc gag ttc 3024
Val Gly Thr Ala Leu Ile Lys Lys Tyr Pro Lys Leu Glu Ser Glu Phe
995 1000 1005
gtg tac ggc gac tac aag gtg tac gac gtg cgg aag atg atc gcc 3069
Val Tyr Gly Asp Tyr Lys Val Tyr Asp Val Arg Lys Met Ile Ala
1010 1015 1020
aag agc gag cag gaa atc ggc aag gct acc gcc aag tac ttc ttc 3114
Lys Ser Glu Gln Glu Ile Gly Lys Ala Thr Ala Lys Tyr Phe Phe
1025 1030 1035
tac agc aac atc atg aac ttt ttc aag acc gag att acc ctg gcc 3159
Tyr Ser Asn Ile Met Asn Phe Phe Lys Thr Glu Ile Thr Leu Ala
1040 1045 1050
aac ggc gag atc cgg aag cgg cct ctg atc gag aca aac ggc gaa 3204
Asn Gly Glu Ile Arg Lys Arg Pro Leu Ile Glu Thr Asn Gly Glu
1055 1060 1065
acc ggg gag atc gtg tgg gat aag ggc cgg gat ttt gcc acc gtg 3249
Thr Gly Glu Ile Val Trp Asp Lys Gly Arg Asp Phe Ala Thr Val
1070 1075 1080
cgg aaa gtg ctg agc atg ccc caa gtg aat atc gtg aaa aag acc 3294
Arg Lys Val Leu Ser Met Pro Gln Val Asn Ile Val Lys Lys Thr
1085 1090 1095
gag gtg cag aca ggc ggc ttc agc aaa gag tct atc ctg ccc aag 3339
Glu Val Gln Thr Gly Gly Phe Ser Lys Glu Ser Ile Leu Pro Lys
1100 1105 1110
agg aac agc gat aag ctg atc gcc aga aag aag gac tgg gac cct 3384
Arg Asn Ser Asp Lys Leu Ile Ala Arg Lys Lys Asp Trp Asp Pro
1115 1120 1125
aag aag tac ggc ggc ttc gac agc ccc acc gtg gcc tat tct gtg 3429
Lys Lys Tyr Gly Gly Phe Asp Ser Pro Thr Val Ala Tyr Ser Val
1130 1135 1140
ctg gtg gtg gcc aaa gtg gaa aag ggc aag tcc aag aaa ctg aag 3474
Leu Val Val Ala Lys Val Glu Lys Gly Lys Ser Lys Lys Leu Lys
1145 1150 1155
agt gtg aaa gag ctg ctg ggg atc acc atc atg gaa aga agc agc 3519
Ser Val Lys Glu Leu Leu Gly Ile Thr Ile Met Glu Arg Ser Ser
1160 1165 1170
ttc gag aag aat ccc atc gac ttt ctg gaa gcc aag ggc tac aaa 3564
Phe Glu Lys Asn Pro Ile Asp Phe Leu Glu Ala Lys Gly Tyr Lys
1175 1180 1185
gaa gtg aaa aag gac ctg atc atc aag ctg cct aag tac tcc ctg 3609
Glu Val Lys Lys Asp Leu Ile Ile Lys Leu Pro Lys Tyr Ser Leu
1190 1195 1200
ttc gag ctg gaa aac ggc cgg aag aga atg ctg gcc tct gcc ggc 3654
Phe Glu Leu Glu Asn Gly Arg Lys Arg Met Leu Ala Ser Ala Gly
1205 1210 1215
gaa ctg cag aag gga aac gaa ctg gcc ctg ccc tcc aaa tat gtg 3699
Glu Leu Gln Lys Gly Asn Glu Leu Ala Leu Pro Ser Lys Tyr Val
1220 1225 1230
aac ttc ctg tac ctg gcc agc cac tat gag aag ctg aag ggc tcc 3744
Asn Phe Leu Tyr Leu Ala Ser His Tyr Glu Lys Leu Lys Gly Ser
1235 1240 1245
ccc gag gat aat gag cag aaa cag ctg ttt gtg gaa cag cac aag 3789
Pro Glu Asp Asn Glu Gln Lys Gln Leu Phe Val Glu Gln His Lys
1250 1255 1260
cac tac ctg gac gag atc atc gag cag atc agc gag ttc tcc aag 3834
His Tyr Leu Asp Glu Ile Ile Glu Gln Ile Ser Glu Phe Ser Lys
1265 1270 1275
aga gtg atc ctg gcc gac gct aat ctg gac aaa gtg ctg tcc gcc 3879
Arg Val Ile Leu Ala Asp Ala Asn Leu Asp Lys Val Leu Ser Ala
1280 1285 1290
tac aac aag cac cgg gat aag ccc atc aga gag cag gcc gag aat 3924
Tyr Asn Lys His Arg Asp Lys Pro Ile Arg Glu Gln Ala Glu Asn
1295 1300 1305
atc atc cac ctg ttt acc ctg acc aat ctg gga gcc cct gcc gcc 3969
Ile Ile His Leu Phe Thr Leu Thr Asn Leu Gly Ala Pro Ala Ala
1310 1315 1320
ttc aag tac ttt gac acc acc atc gac cgg aag agg tac acc agc 4014
Phe Lys Tyr Phe Asp Thr Thr Ile Asp Arg Lys Arg Tyr Thr Ser
1325 1330 1335
acc aaa gag gtg ctg gac gcc acc ctg atc cac cag agc atc acc 4059
Thr Lys Glu Val Leu Asp Ala Thr Leu Ile His Gln Ser Ile Thr
1340 1345 1350
ggc ctg tac gag aca cgg atc gac ctg tct cag ctg gga ggc gac 4104
Gly Leu Tyr Glu Thr Arg Ile Asp Leu Ser Gln Leu Gly Gly Asp
1355 1360 1365
<210> 502
<211> 1368
<212> PRT
<213> Homo sapiens
<400> 502
Met Asp Lys Lys Tyr Ser Ile Gly Leu Asp Ile Gly Thr Asn Ser Val
1 5 10 15
Gly Trp Ala Val Ile Thr Asp Glu Tyr Lys Val Pro Ser Lys Lys Phe
20 25 30
Lys Val Leu Gly Asn Thr Asp Arg His Ser Ile Lys Lys Asn Leu Ile
35 40 45
Gly Ala Leu Leu Phe Asp Ser Gly Glu Thr Ala Glu Ala Thr Arg Leu
50 55 60
Lys Arg Thr Ala Arg Arg Arg Tyr Thr Arg Arg Lys Asn Arg Ile Cys
65 70 75 80
Tyr Leu Gln Glu Ile Phe Ser Asn Glu Met Ala Lys Val Asp Asp Ser
85 90 95
Phe Phe His Arg Leu Glu Glu Ser Phe Leu Val Glu Glu Asp Lys Lys
100 105 110
His Glu Arg His Pro Ile Phe Gly Asn Ile Val Asp Glu Val Ala Tyr
115 120 125
His Glu Lys Tyr Pro Thr Ile Tyr His Leu Arg Lys Lys Leu Val Asp
130 135 140
Ser Thr Asp Lys Ala Asp Leu Arg Leu Ile Tyr Leu Ala Leu Ala His
145 150 155 160
Met Ile Lys Phe Arg Gly His Phe Leu Ile Glu Gly Asp Leu Asn Pro
165 170 175
Asp Asn Ser Asp Val Asp Lys Leu Phe Ile Gln Leu Val Gln Thr Tyr
180 185 190
Asn Gln Leu Phe Glu Glu Asn Pro Ile Asn Ala Ser Gly Val Asp Ala
195 200 205
Lys Ala Ile Leu Ser Ala Arg Leu Ser Lys Ser Arg Arg Leu Glu Asn
210 215 220
Leu Ile Ala Gln Leu Pro Gly Glu Lys Lys Asn Gly Leu Phe Gly Asn
225 230 235 240
Leu Ile Ala Leu Ser Leu Gly Leu Thr Pro Asn Phe Lys Ser Asn Phe
245 250 255
Asp Leu Ala Glu Asp Ala Lys Leu Gln Leu Ser Lys Asp Thr Tyr Asp
260 265 270
Asp Asp Leu Asp Asn Leu Leu Ala Gln Ile Gly Asp Gln Tyr Ala Asp
275 280 285
Leu Phe Leu Ala Ala Lys Asn Leu Ser Asp Ala Ile Leu Leu Ser Asp
290 295 300
Ile Leu Arg Val Asn Thr Glu Ile Thr Lys Ala Pro Leu Ser Ala Ser
305 310 315 320
Met Ile Lys Arg Tyr Asp Glu His His Gln Asp Leu Thr Leu Leu Lys
325 330 335
Ala Leu Val Arg Gln Gln Leu Pro Glu Lys Tyr Lys Glu Ile Phe Phe
340 345 350
Asp Gln Ser Lys Asn Gly Tyr Ala Gly Tyr Ile Asp Gly Gly Ala Ser
355 360 365
Gln Glu Glu Phe Tyr Lys Phe Ile Lys Pro Ile Leu Glu Lys Met Asp
370 375 380
Gly Thr Glu Glu Leu Leu Val Lys Leu Asn Arg Glu Asp Leu Leu Arg
385 390 395 400
Lys Gln Arg Thr Phe Asp Asn Gly Ser Ile Pro His Gln Ile His Leu
405 410 415
Gly Glu Leu His Ala Ile Leu Arg Arg Gln Glu Asp Phe Tyr Pro Phe
420 425 430
Leu Lys Asp Asn Arg Glu Lys Ile Glu Lys Ile Leu Thr Phe Arg Ile
435 440 445
Pro Tyr Tyr Val Gly Pro Leu Ala Arg Gly Asn Ser Arg Phe Ala Trp
450 455 460
Met Thr Arg Lys Ser Glu Glu Thr Ile Thr Pro Trp Asn Phe Glu Glu
465 470 475 480
Val Val Asp Lys Gly Ala Ser Ala Gln Ser Phe Ile Glu Arg Met Thr
485 490 495
Asn Phe Asp Lys Asn Leu Pro Asn Glu Lys Val Leu Pro Lys His Ser
500 505 510
Leu Leu Tyr Glu Tyr Phe Thr Val Tyr Asn Glu Leu Thr Lys Val Lys
515 520 525
Tyr Val Thr Glu Gly Met Arg Lys Pro Ala Phe Leu Ser Gly Glu Gln
530 535 540
Lys Lys Ala Ile Val Asp Leu Leu Phe Lys Thr Asn Arg Lys Val Thr
545 550 555 560
Val Lys Gln Leu Lys Glu Asp Tyr Phe Lys Lys Ile Glu Cys Phe Asp
565 570 575
Ser Val Glu Ile Ser Gly Val Glu Asp Arg Phe Asn Ala Ser Leu Gly
580 585 590
Thr Tyr His Asp Leu Leu Lys Ile Ile Lys Asp Lys Asp Phe Leu Asp
595 600 605
Asn Glu Glu Asn Glu Asp Ile Leu Glu Asp Ile Val Leu Thr Leu Thr
610 615 620
Leu Phe Glu Asp Arg Glu Met Ile Glu Glu Arg Leu Lys Thr Tyr Ala
625 630 635 640
His Leu Phe Asp Asp Lys Val Met Lys Gln Leu Lys Arg Arg Arg Tyr
645 650 655
Thr Gly Trp Gly Arg Leu Ser Arg Lys Leu Ile Asn Gly Ile Arg Asp
660 665 670
Lys Gln Ser Gly Lys Thr Ile Leu Asp Phe Leu Lys Ser Asp Gly Phe
675 680 685
Ala Asn Arg Asn Phe Met Gln Leu Ile His Asp Asp Ser Leu Thr Phe
690 695 700
Lys Glu Asp Ile Gln Lys Ala Gln Val Ser Gly Gln Gly Asp Ser Leu
705 710 715 720
His Glu His Ile Ala Asn Leu Ala Gly Ser Pro Ala Ile Lys Lys Gly
725 730 735
Ile Leu Gln Thr Val Lys Val Val Asp Glu Leu Val Lys Val Met Gly
740 745 750
Arg His Lys Pro Glu Asn Ile Val Ile Ala Met Ala Arg Glu Asn Gln
755 760 765
Thr Thr Gln Lys Gly Gln Lys Asn Ser Arg Glu Arg Met Lys Arg Ile
770 775 780
Glu Glu Gly Ile Lys Glu Leu Gly Ser Gln Ile Leu Lys Glu His Pro
785 790 795 800
Val Glu Asn Thr Gln Leu Gln Asn Glu Lys Leu Tyr Leu Tyr Tyr Leu
805 810 815
Gln Asn Gly Arg Asp Met Tyr Val Asp Gln Glu Leu Asp Ile Asn Arg
820 825 830
Leu Ser Asp Tyr Asp Val Asp Ala Ile Val Pro Gln Ser Phe Leu Lys
835 840 845
Asp Asp Ser Ile Asp Ala Lys Val Leu Thr Arg Ser Asp Lys Ala Arg
850 855 860
Gly Lys Ser Asp Asn Val Pro Ser Glu Glu Val Val Lys Lys Met Lys
865 870 875 880
Asn Tyr Trp Arg Gln Leu Leu Asn Ala Lys Leu Ile Thr Gln Arg Lys
885 890 895
Phe Asp Asn Leu Thr Lys Ala Glu Arg Gly Gly Leu Ser Glu Leu Asp
900 905 910
Lys Ala Gly Phe Ile Lys Arg Gln Leu Val Glu Thr Arg Gln Ile Thr
915 920 925
Lys His Val Ala Gln Ile Leu Asp Ser Arg Met Asn Thr Lys Tyr Asp
930 935 940
Glu Asn Asp Lys Leu Ile Arg Glu Val Lys Val Ile Thr Leu Lys Ser
945 950 955 960
Lys Leu Val Ser Asp Phe Arg Lys Asp Phe Gln Phe Tyr Lys Val Arg
965 970 975
Glu Ile Asn Asn Tyr His His Ala His Ala Ala Tyr Leu Asn Ala Val
980 985 990
Val Gly Thr Ala Leu Ile Lys Lys Tyr Pro Lys Leu Glu Ser Glu Phe
995 1000 1005
Val Tyr Gly Asp Tyr Lys Val Tyr Asp Val Arg Lys Met Ile Ala
1010 1015 1020
Lys Ser Glu Gln Glu Ile Gly Lys Ala Thr Ala Lys Tyr Phe Phe
1025 1030 1035
Tyr Ser Asn Ile Met Asn Phe Phe Lys Thr Glu Ile Thr Leu Ala
1040 1045 1050
Asn Gly Glu Ile Arg Lys Arg Pro Leu Ile Glu Thr Asn Gly Glu
1055 1060 1065
Thr Gly Glu Ile Val Trp Asp Lys Gly Arg Asp Phe Ala Thr Val
1070 1075 1080
Arg Lys Val Leu Ser Met Pro Gln Val Asn Ile Val Lys Lys Thr
1085 1090 1095
Glu Val Gln Thr Gly Gly Phe Ser Lys Glu Ser Ile Leu Pro Lys
1100 1105 1110
Arg Asn Ser Asp Lys Leu Ile Ala Arg Lys Lys Asp Trp Asp Pro
1115 1120 1125
Lys Lys Tyr Gly Gly Phe Asp Ser Pro Thr Val Ala Tyr Ser Val
1130 1135 1140
Leu Val Val Ala Lys Val Glu Lys Gly Lys Ser Lys Lys Leu Lys
1145 1150 1155
Ser Val Lys Glu Leu Leu Gly Ile Thr Ile Met Glu Arg Ser Ser
1160 1165 1170
Phe Glu Lys Asn Pro Ile Asp Phe Leu Glu Ala Lys Gly Tyr Lys
1175 1180 1185
Glu Val Lys Lys Asp Leu Ile Ile Lys Leu Pro Lys Tyr Ser Leu
1190 1195 1200
Phe Glu Leu Glu Asn Gly Arg Lys Arg Met Leu Ala Ser Ala Gly
1205 1210 1215
Glu Leu Gln Lys Gly Asn Glu Leu Ala Leu Pro Ser Lys Tyr Val
1220 1225 1230
Asn Phe Leu Tyr Leu Ala Ser His Tyr Glu Lys Leu Lys Gly Ser
1235 1240 1245
Pro Glu Asp Asn Glu Gln Lys Gln Leu Phe Val Glu Gln His Lys
1250 1255 1260
His Tyr Leu Asp Glu Ile Ile Glu Gln Ile Ser Glu Phe Ser Lys
1265 1270 1275
Arg Val Ile Leu Ala Asp Ala Asn Leu Asp Lys Val Leu Ser Ala
1280 1285 1290
Tyr Asn Lys His Arg Asp Lys Pro Ile Arg Glu Gln Ala Glu Asn
1295 1300 1305
Ile Ile His Leu Phe Thr Leu Thr Asn Leu Gly Ala Pro Ala Ala
1310 1315 1320
Phe Lys Tyr Phe Asp Thr Thr Ile Asp Arg Lys Arg Tyr Thr Ser
1325 1330 1335
Thr Lys Glu Val Leu Asp Ala Thr Leu Ile His Gln Ser Ile Thr
1340 1345 1350
Gly Leu Tyr Glu Thr Arg Ile Asp Leu Ser Gln Leu Gly Gly Asp
1355 1360 1365
<210> 503
<211> 15
<212> DNA
<213> Homo sapiens
<400> 503
cagaagaaga agggc 15
<210> 504
<211> 51
<212> DNA
<213> Homo sapiens
<400> 504
ccaatgggga ggacatcgat gtcacctcca atgactaggg tggtgggcaa c 51
<210> 505
<211> 15
<212> DNA
<213> Homo sapiens
<400> 505
ctctggccac tccct 15
<210> 506
<211> 52
<212> DNA
<213> Homo sapiens
<400> 506
acatcgatgt cacctccaat gacaagcttg ctagcggtgg gcaaccacaa ac 52
<210> 507
<211> 1733
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 507
ccgtttaaac aattctgcag gaatctagtt attaatagta atcaattacg gggtcattag 60
ttcatagccc atatatggag ttccgcgtta cataacttac ggtaaatggc ccgcctggct 120
gaccgcccaa cgacccccgc ccattgacgt caataatgac gtatgttccc atagtaacgc 180
caatagggac tttccattga cgtcaatggg tggagtattt acggtaaact gcccacttgg 240
cagtacatca agtgtatcat atgccaagta cgccccctat tgacgtcaat gacggtaaat 300
ggcccgcctg gcattatgcc cagtacatga ccttatggga ctttcctact tggcagtaca 360
tctacgtatt agtcatcgct attaccatgg tcgaggtgag ccccacgttc tgcttcactc 420
tccccatctc ccccccctcc ccacccccaa ttttgtattt atttattttt taattatttt 480
gtgcagcgat gggggcgggg gggggggggg ggcgcgcgcc aggcggggcg gggcggggcg 540
aggggcgggg cggggcgagg cggagaggtg cggcggcagc caatcagagc ggcgcgctcc 600
gaaagtttcc ttttatggcg aggcggcggc ggcggcggcc ctataaaaag cgaagcgcgc 660
ggcgggcgga agtcgctgcg cgctgccttc gccccgtgcc ccgctccgcc gccgcctcgc 720
gccgcccgcc ccggctctga ctgaccgcgt tactcccaca ggtgagcggg cgggacggcc 780
cttctcctcc gggctgtaat tagcgcttgg tttaatgacg gcttgtttct tttctgtggc 840
tgcgtgaaag ccttgagggg ctccgggagg gccctttgtg cggggggagc ggctcggggg 900
gtgcgtgcgt gtgtgtgtgc gtggggagcg ccgcgtgcgg ctccgcgctg cccggcggct 960
gtgagcgctg cgggcgcggc gcggggcttt gtgcgctccg cagtgtgcgc gaggggagcg 1020
cggccggggg cggtgccccg cggtgcgggg ggggctgcga ggggaacaaa ggctgcgtgc 1080
ggggtgtgtg cgtggggggg tgagcagggg gtgtgggcgc gtcggtcggg ctgcaacccc 1140
ccctgcaccc ccctccccga gttgctgagc acggcccggc ttcgggtgcg gggctccgta 1200
cggggcgtgg cgcggggctc gccgtgccgg gcggggggtg gcggcaggtg ggggtgccgg 1260
gcggggcggg gccgcctcgg gccggggagg gctcggggga ggggcgcggc ggcccccgga 1320
gcgccggcgg ctgtcgaggc gcggcgagcc gcagccattg ccttttatgg taatcgtgcg 1380
agagggcgca gggacttcct ttgtcccaaa tctgtgcgga gccgaaatct gggaggcgcc 1440
gccgcacccc ctctagcggg cgcggggcga agcggtgcgg cgccggcagg aaggaaatgg 1500
gcggggaggg ccttcgtgcg tcgccgcgcc gccgtcccct tctccctctc cagcctcggg 1560
gctgtccgcg gggggacggc tgccttcggg ggggacgggg cagggcgggg ttcggcttct 1620
ggcgtgtgac cggcggctct agagcctctg ctaaccatgt tcatgccttc ttctttttcc 1680
tacagctcct gggcaacgtg ctggttattg tgctgtctca tcattttggc aaa 1733
<210> 508
<211> 4269
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 508
atggactata aggaccacga cggagactac aaggatcatg atattgatta caaagacgat 60
gacgataaga tggccccaaa gaagaagcgg aaggtcggta tccacggagt cccagcagcc 120
gacaagaagt acagcatcgg cctggacatc ggcaccaact ctgtgggctg ggccgtgatc 180
accgacgagt acaaggtgcc cagcaagaaa ttcaaggtgc tgggcaacac cgaccggcac 240
agcatcaaga agaacctgat cggagccctg ctgttcgaca gcggcgaaac agccgaggcc 300
acccggctga agagaaccgc cagaagaaga tacaccagac ggaagaaccg gatctgctat 360
ctgcaagaga tcttcagcaa cgagatggcc aaggtggacg acagcttctt ccacagactg 420
gaagagtcct tcctggtgga agaggataag aagcacgagc ggcaccccat cttcggcaac 480
atcgtggacg aggtggccta ccacgagaag taccccacca tctaccacct gagaaagaaa 540
ctggtggaca gcaccgacaa ggccgacctg cggctgatct atctggccct ggcccacatg 600
atcaagttcc ggggccactt cctgatcgag ggcgacctga accccgacaa cagcgacgtg 660
gacaagctgt tcatccagct ggtgcagacc tacaaccagc tgttcgagga aaaccccatc 720
aacgccagcg gcgtggacgc caaggccatc ctgtctgcca gactgagcaa gagcagacgg 780
ctggaaaatc tgatcgccca gctgcccggc gagaagaaga atggcctgtt cggaaacctg 840
attgccctga gcctgggcct gacccccaac ttcaagagca acttcgacct ggccgaggat 900
gccaaactgc agctgagcaa ggacacctac gacgacgacc tggacaacct gctggcccag 960
atcggcgacc agtacgccga cctgtttctg gccgccaaga acctgtccga cgccatcctg 1020
ctgagcgaca tcctgagagt gaacaccgag atcaccaagg cccccctgag cgcctctatg 1080
atcaagagat acgacgagca ccaccaggac ctgaccctgc tgaaagctct cgtgcggcag 1140
cagctgcctg agaagtacaa agagattttc ttcgaccaga gcaagaacgg ctacgccggc 1200
tacattgacg gcggagccag ccaggaagag ttctacaagt tcatcaagcc catcctggaa 1260
aagatggacg gcaccgagga actgctcgtg aagctgaaca gagaggacct gctgcggaag 1320
cagcggacct tcgacaacgg cagcatcccc caccagatcc acctgggaga gctgcacgcc 1380
attctgcggc ggcaggaaga tttttaccca ttcctgaagg acaaccggga aaagatcgag 1440
aagatcctga ccttccgcat cccctactac gtgggccctc tggccagggg aaacagcaga 1500
ttcgcctgga tgaccagaaa gagcgaggaa accatcaccc cctggaactt cgaggaagtg 1560
gtggacaagg gcgcttccgc ccagagcttc atcgagcgga tgaccaactt cgataagaac 1620
ctgcccaacg agaaggtgct gcccaagcac agcctgctgt acgagtactt caccgtgtat 1680
aacgagctga ccaaagtgaa atacgtgacc gagggaatga gaaagcccgc cttcctgagc 1740
ggcgagcaga aaaaggccat cgtggacctg ctgttcaaga ccaaccggaa agtgaccgtg 1800
aagcagctga aagaggacta cttcaagaaa atcgagtgct tcgactccgt ggaaatctcc 1860
ggcgtggaag atcggttcaa cgcctccctg ggcacatacc acgatctgct gaaaattatc 1920
aaggacaagg acttcctgga caatgaggaa aacgaggaca ttctggaaga tatcgtgctg 1980
accctgacac tgtttgagga cagagagatg atcgaggaac ggctgaaaac ctatgcccac 2040
ctgttcgacg acaaagtgat gaagcagctg aagcggcgga gatacaccgg ctggggcagg 2100
ctgagccgga agctgatcaa cggcatccgg gacaagcagt ccggcaagac aatcctggat 2160
ttcctgaagt ccgacggctt cgccaacaga aacttcatgc agctgatcca cgacgacagc 2220
ctgaccttta aagaggacat ccagaaagcc caggtgtccg gccagggcga tagcctgcac 2280
gagcacattg ccaatctggc cggcagcccc gccattaaga agggcatcct gcagacagtg 2340
aaggtggtgg acgagctcgt gaaagtgatg ggccggcaca agcccgagaa catcgtgatc 2400
gaaatggcca gagagaacca gaccacccag aagggacaga agaacagccg cgagagaatg 2460
aagcggatcg aagagggcat caaagagctg ggcagccaga tcctgaaaga acaccccgtg 2520
gaaaacaccc agctgcagaa cgagaagctg tacctgtact acctgcagaa tgggcgggat 2580
atgtacgtgg accaggaact ggacatcaac cggctgtccg actacgatgt ggaccatatc 2640
gtgcctcaga gctttctgaa ggacgactcc atcgacaaca aggtgctgac cagaagcgac 2700
aagaaccggg gcaagagcga caacgtgccc tccgaagagg tcgtgaagaa gatgaagaac 2760
tactggcggc agctgctgaa cgccaagctg attacccaga gaaagttcga caatctgacc 2820
aaggccgaga gaggcggcct gagcgaactg gataaggccg gcttcatcaa gagacagctg 2880
gtggaaaccc ggcagatcac aaagcacgtg gcacagatcc tggactcccg gatgaacact 2940
aagtacgacg agaatgacaa gctgatccgg gaagtgaaag tgatcaccct gaagtccaag 3000
ctggtgtccg atttccggaa ggatttccag ttttacaaag tgcgcgagat caacaactac 3060
caccacgccc acgacgccta cctgaacgcc gtcgtgggaa ccgccctgat caaaaagtac 3120
cctaagctgg aaagcgagtt cgtgtacggc gactacaagg tgtacgacgt gcggaagatg 3180
atcgccaaga gcgagcagga aatcggcaag gctaccgcca agtacttctt ctacagcaac 3240
atcatgaact ttttcaagac cgagattacc ctggccaacg gcgagatccg gaagcggcct 3300
ctgatcgaga caaacggcga aaccggggag atcgtgtggg ataagggccg ggattttgcc 3360
accgtgcgga aagtgctgag catgccccaa gtgaatatcg tgaaaaagac cgaggtgcag 3420
acaggcggct tcagcaaaga gtctatcctg cccaagagga acagcgataa gctgatcgcc 3480
agaaagaagg actgggaccc taagaagtac ggcggcttcg acagccccac cgtggcctat 3540
tctgtgctgg tggtggccaa agtggaaaag ggcaagtcca agaaactgaa gagtgtgaaa 3600
gagctgctgg ggatcaccat catggaaaga agcagcttcg agaagaatcc catcgacttt 3660
ctggaagcca agggctacaa agaagtgaaa aaggacctga tcatcaagct gcctaagtac 3720
tccctgttcg agctggaaaa cggccggaag agaatgctgg cctctgccgg cgaactgcag 3780
aagggaaacg aactggccct gccctccaaa tatgtgaact tcctgtacct ggccagccac 3840
tatgagaagc tgaagggctc ccccgaggat aatgagcaga aacagctgtt tgtggaacag 3900
cacaagcact acctggacga gatcatcgag cagatcagcg agttctccaa gagagtgatc 3960
ctggccgacg ctaatctgga caaagtgctg tccgcctaca acaagcaccg ggataagccc 4020
atcagagagc aggccgagaa tatcatccac ctgtttaccc tgaccaatct gggagcccct 4080
gccgccttca agtactttga caccaccatc gaccggaaga ggtacaccag caccaaagag 4140
gtgctggacg ccaccctgat ccaccagagc atcaccggcc tgtacgagac acggatcgac 4200
ctgtctcagc tgggaggcga caaaaggccg gcggccacga aaaaggccgg ccaggcaaaa 4260
aagaaaaag 4269
<210> 509
<211> 780
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 509
ggaagcggag ccactaactt ctccctgttg aaacaagcag gggatgtcga agagaatccc 60
gggccagtga gcaagggcga ggagctgttc accggggtgg tgcccatcct ggtcgagctg 120
gacggcgacg taaacggcca caagttcagc gtgtccggcg agggcgaggg cgatgccacc 180
tacggcaagc tgaccctgaa gttcatctgc accaccggca agctgcccgt gccctggccc 240
accctcgtga ccaccctgac ctacggcgtg cagtgcttca gccgctaccc cgaccacatg 300
aagcagcacg acttcttcaa gtccgccatg cccgaaggct acgtccagga gcgcaccatc 360
ttcttcaagg acgacggcaa ctacaagacc cgcgccgagg tgaagttcga gggcgacacc 420
ctggtgaacc gcatcgagct gaagggcatc gacttcaagg aggacggcaa catcctgggg 480
cacaagctgg agtacaacta caacagccac aacgtctata tcatggccga caagcagaag 540
aacggcatca aggtgaactt caagatccgc cacaacatcg aggacggcag cgtgcagctc 600
gccgaccact accagcagaa cacccccatc ggcgacggcc ccgtgctgct gcccgacaac 660
cactacctga gcacccagtc cgccctgagc aaagacccca acgagaagcg cgatcacatg 720
gtcctgctgg agttcgtgac cgccgccggg atcactctcg gcatggacga gctgtacaag 780
<210> 510
<211> 597
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 510
cgataatcaa cctctggatt acaaaatttg tgaaagattg actggtattc ttaactatgt 60
tgctcctttt acgctatgtg gatacgctgc tttaatgcct ttgtatcatg ctattgcttc 120
ccgtatggct ttcattttct cctccttgta taaatcctgg ttgctgtctc tttatgagga 180
gttgtggccc gttgtcaggc aacgtggcgt ggtgtgcact gtgtttgctg acgcaacccc 240
cactggttgg ggcattgcca ccacctgtca gctcctttcc gggactttcg ctttccccct 300
ccctattgcc acggcggaac tcatcgccgc ctgccttgcc cgctgctgga caggggctcg 360
gctgttgggc actgacaatt ccgtggtgtt gtcggggaaa tcatcgtcct ttccttggct 420
gctcgcctgt gttgccacct ggattctgcg cgggacgtcc ttctgctacg tcccttcggc 480
cctcaatcca gcggaccttc cttcccgcgg cctgctgccg gctctgcggc ctcttccgcg 540
tcttcgcctt cgccctcaga cgagtcggat ctccctttgg gccgcctccc cgcatcg 597
<210> 511
<211> 210
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 511
cgacctcgac tgtgccttct agttgccagc catctgttgt ttgcccctcc cccgtgcctt 60
ccttgaccct ggaaggtgcc actcccactg tcctttccta ataaaatgag gaaattgcat 120
cgcattgtct gagtaggtgt cattctattc tggggggtgg ggtggggcag gacagcaagg 180
gggaggattg ggaagacaat ggcaggcatg 210
<210> 512
<211> 906
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<220>
<221> modified_base
<222> (109)..(109)
<223> a, c, t, g, unknown or other
<220>
<221> modified_base
<222> (135)..(135)
<223> a, c, t, g, unknown or other
<400> 512
ataacttcgt ataatgtatg ctatacgaag ttattcgcga tgaataaatg aaagcttgca 60
gatctgcgac tctagaggat ctgcgactct agaggatcat aatcagccnt accacatttt 120
gtagaggttt tactngcttt aaaaaacctc ccacacctcc ccctgaacct gaaacataaa 180
atgaatgcaa ttgttgttgt taacttgttt attgcagctt ataatggtta caaataaagc 240
aatagcatca caaatttcac aaataaagca tttttttcac tgcattctag ttgtggtttg 300
tccaaactca tcaatgtatc ttatcatgtc tggatctgcg actctagagg atcataatca 360
gccataccac atttgtagag gttttacttg ctttaaaaaa cctcccacac ctccccctga 420
acctgaaaca taaaatgaat gcaattgttg ttgttaactt gtttattgca gcttataatg 480
gttacaaata aagcaatagc atcacaaatt tcacaaataa agcatttttt tcactgcatt 540
ctagttgtgg tttgtccaaa ctcatcaatg tatcttatca tgtctggatc tgcgactcta 600
gaggatcata atcagccata ccacatttgt agaggtttta cttgctttaa aaaacctccc 660
acacctcccc ctgaacctga aacataaaat gaatgcaatt gttgttgtta acttgtttat 720
tgcagcttat aatggttaca aataaagcaa tagcatcaca aatttcacaa ataaagcatt 780
tttttcactg cattctagtt gtggtttgtc caaactcatc aatgtatctt atcatgtctg 840
gatccccatc aagctgatcc ggaaccctta atataacttc gtataatgta tgctatacga 900
agttat 906
<210> 513
<211> 1079
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 513
caggccctcc gagcgtggtg gagccgttct gtgagacagc cgggtacgag tcgtgacgct 60
ggaaggggca agcgggtggt gggcaggaat gcggtccgcc ctgcagcaac cggaggggga 120
gggagaaggg agcggaaaag tctccaccgg acgcggccat ggctcggggg ggggggggca 180
gcggaggagc gcttccggcc gacgtctcgt cgctgattgg cttcttttcc tcccgccgtg 240
tgtgaaaaca caaatggcgt gttttggttg gcgtaaggcg cctgtcagtt aacggcagcc 300
ggagtgcgca gccgccggca gcctcgctct gcccactggg tggggcggga ggtaggtggg 360
gtgaggcgag ctggacgtgc gggcgcggtc ggcctctggc ggggcggggg aggggaggga 420
gggtcagcga aagtagctcg cgcgcgagcg gccgcccacc ctccccttcc tctgggggag 480
tcgttttacc cgccgccggc cgggcctcgt cgtctgattg gctctcgggg cccagaaaac 540
tggcccttgc cattggctcg tgttcgtgca agttgagtcc atccgccggc cagcgggggc 600
ggcgaggagg cgctcccagg ttccggccct cccctcggcc ccgcgccgca gagtctggcc 660
gcgcgcccct gcgcaacgtg gcaggaagcg cgcgctgggg gcggggacgg gcagtagggc 720
tgagcggctg cggggcgggt gcaagcacgt ttccgacttg agttgcctca agaggggcgt 780
gctgagccag acctccatcg cgcactccgg ggagtggagg gaaggagcga gggctcagtt 840
gggctgtttt ggaggcagga agcacttgct ctcccaaagt cgctctgagt tgttatcagt 900
aagggagctg cagtggagta ggcggggaga aggccgcacc cttctccgga ggggggaggg 960
gagtgttgca atacctttct gggagttctc tgctgcctcc tggcttctga ggaccgccct 1020
gggcctggga gaatcccttc cccctcttcc ctcgtgatct gcaactccag tctttctag 1079
<210> 514
<211> 4336
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 514
agatgggcgg gagtcttctg ggcaggctta aaggctaacc tggtgtgtgg gcgttgtcct 60
gcaggggaat tgaacaggtg taaaattgga gggacaagac ttcccacaga ttttcggttt 120
tgtcgggaag ttttttaata ggggcaaata aggaaaatgg gaggataggt agtcatctgg 180
ggttttatgc agcaaaacta caggttatta ttgcttgtga tccgcctcgg agtattttcc 240
atcgaggtag attaaagaca tgctcacccg agttttatac tctcctgctt gagatcctta 300
ctacagtatg aaattacagt gtcgcgagtt agactatgta agcagaattt taatcatttt 360
taaagagccc agtacttcat atccatttct cccgctcctt ctgcagcctt atcaaaaggt 420
attttagaac actcatttta gccccatttt catttattat actggcttat ccaaccccta 480
gacagagcat tggcattttc cctttcctga tcttagaagt ctgatgactc atgaaaccag 540
acagattagt tacatacacc acaaatcgag gctgtagctg gggcctcaac actgcagttc 600
ttttataact ccttagtaca ctttttgttg atcctttgcc ttgatcctta attttcagtg 660
tctatcacct ctcccgtcag gtggtgttcc acatttgggc ctattctcag tccagggagt 720
tttacaacaa tagatgtatt gagaatccaa cctaaagctt aactttccac tcccatgaat 780
gcctctctcc tttttctcca tttataaact gagctattaa ccattaatgg tttccaggtg 840
gatgtctcct cccccaatat tacctgatgt atcttacata ttgccaggct gatattttaa 900
gacattaaaa ggtatatttc attattgagc cacatggtat tgattactgc ttactaaaat 960
tttgtcattg tacacatctg taaaaggtgg ttccttttgg aatgcaaagt tcaggtgttt 1020
gttgtctttc ctgacctaag gtcttgtgag cttgtatttt ttctatttaa gcagtgcttt 1080
ctcttggact ggcttgactc atggcattct acacgttatt gctggtctaa atgtgatttt 1140
gccaagcttc ttcaggacct ataattttgc ttgacttgta gccaaacaca agtaaaatga 1200
ttaagcaaca aatgtatttg tgaagcttgg tttttaggtt gttgtgttgt gtgtgcttgt 1260
gctctataat aatactatcc aggggctgga gaggtggctc ggagttcaag agcacagact 1320
gctcttccag aagtcctgag ttcaattccc agcaaccaca tggtggctca caaccatctg 1380
taatgggatc tgatgccctc ttctggtgtg tctgaagacc acaagtgtat tcacattaaa 1440
taaataaatc ctccttcttc ttcttttttt tttttttaaa gagaatactg tctccagtag 1500
aatttactga agtaatgaaa tactttgtgt ttgttccaat atggtagcca ataatcaaat 1560
tactctttaa gcactggaaa tgttaccaag gaactaattt ttatttgaag tgtaactgtg 1620
gacagaggag ccataactgc agacttgtgg gatacagaag accaatgcag actttaatgt 1680
cttttctctt acactaagca ataaagaaat aaaaattgaa cttctagtat cctatttgtt 1740
taaactgcta gctttactta acttttgtgc ttcatctata caaagctgaa agctaagtct 1800
gcagccatta ctaaacatga aagcaagtaa tgataatttt ggatttcaaa aatgtagggc 1860
cagagtttag ccagccagtg gtggtgcttg cctttatgcc tttaatccca gcactctgga 1920
ggcagagaca ggcagatctc tgagtttgag cccagcctgg tctacacatc aagttctatc 1980
taggatagcc aggaatacac acagaaaccc tgttggggag gggggctctg agatttcata 2040
aaattataat tgaagcattc cctaatgagc cactatggat gtggctaaat ccgtctacct 2100
ttctgatgag atttgggtat tattttttct gtctctgctg ttggttgggt cttttgacac 2160
tgtgggcttt ctttaaagcc tccttcctgc catgtggtct cttgtttgct actaacttcc 2220
catggcttaa atggcatggc tttttgcctt ctaagggcag ctgctgagat ttgcagcctg 2280
atttccaggg tggggttggg aaatctttca aacactaaaa ttgtccttta attttttttt 2340
taaaaaatgg gttatataat aaacctcata aaatagttat gaggagtgag gtggactaat 2400
attaaatgag tccctcccct ataaaagagc tattaaggct ttttgtctta tacttaactt 2460
tttttttaaa tgtggtatct ttagaaccaa gggtcttaga gttttagtat acagaaactg 2520
ttgcatcgct taatcagatt ttctagtttc aaatccagag aatccaaatt cttcacagcc 2580
aaagtcaaat taagaatttc tgacttttaa tgttaatttg cttactgtga atataaaaat 2640
gatagctttt cctgaggcag ggtctcacta tgtatctctg cctgatctgc aacaagatat 2700
gtagactaaa gttctgcctg cttttgtctc ctgaatacta aggttaaaat gtagtaatac 2760
ttttggaact tgcaggtcag attcttttat aggggacaca ctaagggagc ttgggtgata 2820
gttggtaaat gtgtttaagt gatgaaaact tgaattatta tcaccgcaac ctacttttta 2880
aaaaaaaaag ccaggcctgt tagagcatgc ttaagggatc cctaggactt gctgagcaca 2940
caagagtagt tacttggcag gctcctggtg agagcatatt tcaaaaaaca aggcagacaa 3000
ccaagaaact acagttaagg ttacctgtct ttaaaccatc tgcatataca cagggatatt 3060
aaaatattcc aaataatatt tcattcaagt tttcccccat caaattggga catggatttc 3120
tccggtgaat aggcagagtt ggaaactaaa caaatgttgg ttttgtgatt tgtgaaattg 3180
ttttcaagtg atagttaaag cccatgagat acagaacaaa gctgctattt cgaggtctct 3240
tggtttatac tcagaagcac ttctttgggt ttccctgcac tatcctgatc atgtgctagg 3300
cctaccttag gctgattgtt gttcaaataa acttaagttt cctgtcaggt gatgtcatat 3360
gatttcatat atcaaggcaa aacatgttat atatgttaaa catttgtact taatgtgaaa 3420
gttaggtctt tgtgggtttg atttttaatt ttcaaaacct gagctaaata agtcattttt 3480
acatgtctta catttggtgg aattgtataa ttgtggtttg caggcaagac tctctgacct 3540
agtaacccta cctatagagc actttgctgg gtcacaagtc taggagtcaa gcatttcacc 3600
ttgaagttga gacgttttgt tagtgtatac tagtttatat gttggaggac atgtttatcc 3660
agaagatatt caggactatt tttgactggg ctaaggaatt gattctgatt agcactgtta 3720
gtgagcattg agtggccttt aggcttgaat tggagtcact tgtatatctc aaataatgct 3780
ggcctttttt aaaagccctt gttctttatc accctgtttt ctacataatt tttgttcaaa 3840
gaaatacttg tttggatctc cttttgacaa caatagcatg ttttcaagcc atattttttt 3900
tccttttttt tttttttttt ggtttttcga gacagggttt ctctgtatag ccctggctgt 3960
cctggaactc actttgtaga ccaggctggc ctcgaactca gaaatccgcc tgcctctgcc 4020
tcctgagtgc cgggattaaa ggcgtgcacc accacgcctg gctaagttgg atattttgtt 4080
atataactat aaccaatact aactccactg ggtggatttt taattcagtc agtagtctta 4140
agtggtcttt attggccctt cattaaaatc tactgttcac tctaacagag gctgttggta 4200
ctagtggcac ttaagcaact tcctacggat atactagcag attaagggtc agggatagaa 4260
actagtctag cgttttgtat acctaccagc tttatactac cttgttctga tagaaatatt 4320
tcaggacatc tagctt 4336
<210> 515
<211> 1846
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 515
aattctaccg ggtaggggag gcgcttttcc caaggcagtc tggagcatgc gctttagcag 60
ccccgctggg cacttggcgc tacacaagtg gcctctggcc tcgcacacat tccacatcca 120
ccggtaggcg ccaaccggct ccgttctttg gtggcccctt cgcgccacct tctactcctc 180
ccctagtcag gaagttcccc cccgccccgc agctcgcgtc gtgcaggacg tgacaaatgg 240
aagtagcacg tctcactagt ctcgtgcaga tggacagcac cgctgagcaa tggaagcggg 300
taggcctttg gggcagcggc caatagcagc tttgctcctt cgctttctgg gctcagaggc 360
tgggaagggg tgggtccggg ggcgggctca ggggcgggct caggggcggg gcgggcgccc 420
gaaggtcctc cggaggcccg gcattctgca cgcttcaaaa gcgcacgtct gccgcgctgt 480
tctcctcttc ctcatctccg ggcctttcga cctgcaatcg ccgctagcga agttcctatt 540
ctctagaaag tataggaact tcgccaccat gggatcggcc attgaacaag atggattgca 600
cgcaggttct ccggccgctt gggtggagag gctattcggc tatgactggg cacaacagac 660
aatcggctgc tctgatgccg ccgtgttccg gctgtcagcg caggggcgcc cggttctttt 720
tgtcaagacc gacctgtccg gtgccctgaa tgaactgcag gacgaggcag cgcggctatc 780
gtggctggcc acgacgggcg ttccttgcgc agctgtgctc gacgttgtca ctgaagcggg 840
aagggactgg ctgctattgg gcgaagtgcc ggggcaggat ctcctgtcat ctcaccttgc 900
tcctgccgag aaagtatcca tcatggctga tgcaatgcgg cggctgcata cgcttgatcc 960
ggctacctgc ccattcgacc accaagcgaa acatcgcatc gagcgagcac gtactcggat 1020
ggaagccggt cttgtcgatc aggatgatct ggacgaagag catcaggggc tcgcgccagc 1080
cgaactgttc gccaggctca aggcgcgcat gcccgacggc gatgatctcg tcgtgaccca 1140
tggcgatgcc tgcttgccga atatcatggt ggaaaatggc cgcttttctg gattcatcga 1200
ctgtggccgg ctgggtgtgg cggaccgcta tcaggacata gcgttggcta cccgtgatat 1260
tgctgaagag cttggcggcg aatgggctga ccgcttcctc gtgctttacg gtatcgccgc 1320
tcccgattcg cagcgcatcg ccttctatcg ccttcttgac gagttcttct gaggggatcc 1380
gctgtaagtc tgcagaaatt gatgatctat taaacaataa agatgtccac taaaatggaa 1440
gtttttcctg tcatactttg ttaagaaggg tgagaacaga gtacctacat tttgaatgga 1500
aggattggag ctacgggggt gggggtgggg tgggattaga taaatgcctg ctctttactg 1560
aaggctcttt actattgctt tatgataatg tttcatagtt ggatatcata atttaaacaa 1620
gcaaaaccaa attaagggcc agctcattcc tcccactcat gatctataga tctatagatc 1680
tctcgtggga tcattgtttt tctcttgatt cccactttgt ggttctaagt actgtggttt 1740
ccaaatgtgt cagtttcata gcctgaagaa cgagatcagc agcctctgtt ccacatacac 1800
ttcattctca gtattgtttt gccaagttct aattccatca gaaagc 1846
<210> 516
<211> 1519
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 516
taccgggtag gggaggcgct tttcccaagg cagtctggag catgcgcttt agcagccccg 60
ctgggcactt ggcgctacac aagtggcctc tggcctcgca cacattccac atccaccggt 120
aggcgccaac cggctccgtt ctttggtggc cccttcgcgc caccttctac tcctccccta 180
gtcaggaagt tcccccccgc cccgcagctc gcgtcgtgca ggacgtgaca aatggaagta 240
gcacgtctca ctagtctcgt gcagatggac agcaccgctg agcaatggaa gcgggtaggc 300
ctttggggca gcggccaata gcagctttgc tccttcgctt tctgggctca gaggctggga 360
aggggtgggt ccgggggcgg gctcaggggc gggctcaggg gcggggcggg cgcccgaagg 420
tcctccggag gcccggcatt ctgcacgctt caaaagcgca cgtctgccgc gctgttctcc 480
tcttcctcat ctccgggcct ttcgacctgc aggtcctcgc catggatcct gatgatgttg 540
ttgattcttc taaatctttt gtgatggaaa acttttcttc gtaccacggg actaaacctg 600
gttatgtaga ttccattcaa aaaggtatac aaaagccaaa atctggtaca caaggaaatt 660
atgacgatga ttggaaaggg ttttatagta ccgacaataa atacgacgct gcgggatact 720
ctgtagataa tgaaaacccg ctctctggaa aagctggagg cgtggtcaaa gtgacgtatc 780
caggactgac gaaggttctc gcactaaaag tggataatgc cgaaactatt aagaaagagt 840
taggtttaag tctcactgaa ccgttgatgg agcaagtcgg aacggaagag tttatcaaaa 900
ggttcggtga tggtgcttcg cgtgtagtgc tcagccttcc cttcgctgag gggagttcta 960
gcgttgaata tattaataac tgggaacagg cgaaagcgtt aagcgtagaa cttgagatta 1020
attttgaaac ccgtggaaaa cgtggccaag atgcgatgta tgagtatatg gctcaagcct 1080
gtgcaggaaa tcgtgtcagg cgatctcttt gtgaaggaac cttacttctg tggtgtgaca 1140
taattggaca aactacctac agagatttaa agctctaagg taaatataaa atttttaagt 1200
gtataatgtg ttaaactact gattctaatt gtttgtgtat tttagattcc aacctatgga 1260
actgatgaat gggagcagtg gtggaatgca gatcctagag ctcgctgatc agcctcgact 1320
gtgccttcta gttgccagcc atctgttgtt tgcccctccc ccgtgccttc cttgaccctg 1380
gaaggtgcca ctcccactgt cctttcctaa taaaatgagg aaattgcatc gcattgtctg 1440
agtaggtgtc attctattct ggggggtggg gtggggcagg acagcaaggg ggaggattgg 1500
gaagacaata gcaggcatg 1519
<210> 517
<211> 23
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 517
gagggcctat ttcccatgat tcc 23
<210> 518
<211> 22
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 518
cttgtggaaa ggacgaaaca cc 22
<210> 519
<211> 45
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<220>
<221> modified_base
<222> (4)..(23)
<223> a, c, t, g, unknown or other
<400> 519
aacnnnnnnn nnnnnnnnnn nnnggtgttt cgtcctttcc acaag 45
<210> 520
<211> 28
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 520
cctgagtgtt gaggccccag tggctgct 28
<210> 521
<211> 37
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 521
acgagggcag agtgctgctt gctgctggcc aggcccc 37
<210> 522
<211> 68
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 522
catcaggctc tcagctcagc ctgagtgttg aggccctgct ggccaggccc ctgcgtgggc 60
ccaagctg 68
<210> 523
<211> 27
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 523
gagggcctat ttcccatgat tccttca 27
<210> 524
<211> 125
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<220>
<221> modified_base
<222> (84)..(103)
<223> a, c, t, g, unknown or other
<400> 524
aaaaaaagca ccgactcggt gccacttttt caagttgata acggactagc cttattttaa 60
cttgctattt ctagctctaa aacnnnnnnn nnnnnnnnnn nnnggtgttt cgtcctttcc 120
acaag 125
<210> 525
<211> 111
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<220>
<221> modified_base
<222> (9)..(28)
<223> a, c, t, g, unknown or other
<400> 525
gaaacaccnn nnnnnnnnnn nnnnnnnngt tttagagcta gaaatagcaa gttaaaataa 60
ggctagtccg ttatcaactt gaaaaagtgg caccgagtcg gtgctttttt t 111
<210> 526
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 526
agctgtttta ctggtcggct 20
<210> 527
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 527
aatggataca cctggtcgaa 20
<210> 528
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 528
caatggatac acctggtcga 20
<210> 529
<211> 68
<212> DNA
<213> Homo sapiens
<400> 529
accatgtata ccacttgggc tttggcagta gctaactgca ctaaatataa tataaggagg 60
gttttatg 68
Claims (34)
- I. CRISPR-Cas 시스템 키메라 RNA(chiRNA) 폴리뉴클레오티드 서열에 작동가능하게 연결된 제1 조절 요소로서, 상기 폴리뉴클레오티드 서열이
(a) 진핵 세포 내의 표적 서열에 혼성화할 수 있는 가이드 서열,
(b) tracr 메이트(mate) 서열, 및
(c) tracr 서열을 포함하는 제1 조절 요소, 및
II. CRISPR 효소의 말단 부근에 적어도 하나 이상의 핵 국소화 서열(NLS)을 포함하는 CRISPR 효소를 인코딩하는 효소-코딩 서열에 작동가능하게 연결된 제2 조절 요소를 포함하는 하나 이상의 벡터를 포함하는 벡터 시스템을 포함하는 비-천연 발생 또는 조작된(engineered) 조성물로서,
(a), (b) 및 (c)가 5'에서 3' 배향으로 배열되고,
성분 I 및 II가 상기 시스템의 동일한 또는 상이한 벡터에 배치되며,
전사되는 경우, 상기 tracr 메이트 서열이 상기 tracr 서열에 혼성화되고, 상기 가이드 서열이 상기 표적 서열로의 CRISPR 복합체의 서열-특이적 결합을 유도하며,
상기 CRISPR 복합체가 (1) 상기 표적 서열에 혼성화되는 가이드 서열, 및 (2) 상기 tracr 서열에 혼성화되는 tracr 메이트 서열과 복합체화되는 CRISPR 효소를 포함하고,
상기 키메라 RNA 폴리뉴클레오티드 서열이 2개 이상의 헤어핀(hairpin)을 포함하는 조성물. - 제1항에 있어서, 다중의 chiRNA 폴리뉴클레오티드 서열을 사용하여 다중화 시스템을 제공하는 조성물.
- 다중화 CRISPR 효소 시스템으로서, 상기 시스템이
I. CRISPR-Cas 시스템 키메라 RNA(chiRNA) 폴리뉴클레오티드 서열에 작동가능하게 연결된 제1 조절 요소로서, 상기 폴리뉴클레오티드 서열이
(a) 진핵 세포 내의 표적 서열에 혼성화할 수 있는 가이드 서열,
(b) tracr 메이트(mate) 서열, 및
(c) tracr 서열을 포함하는 제1 조절 요소, 및
II. CRISPR 효소의 말단 부근에 적어도 하나 이상의 핵 국소화 서열(NLS)을 포함하는 CRISPR 효소를 인코딩하는 효소-코딩 서열에 작동가능하게 연결된 제2 조절 요소를 포함하는 하나 이상의 벡터를 포함하는 벡터 시스템을 포함하고,
(a), (b) 및 (c)가 5'에서 3' 배향으로 배열되고,
성분 I 및 II가 상기 시스템의 동일한 또는 상이한 벡터에 배치되며,
전사되는 경우, 상기 tracr 메이트 서열이 상기 tracr 서열에 혼성화되고, 상기 가이드 서열이 상기 표적 서열로의 CRISPR 복합체의 서열-특이적 결합을 유도하며,
상기 CRISPR 복합체가 (1) 상기 표적 서열에 혼성화되는 가이드 서열, 및 (2) 상기 tracr 서열에 혼성화되는 tracr 메이트 서열과 복합체화되는 CRISPR 효소를 포함하고,
chiRNA 폴리뉴클레오티드 서열이 2개 이상의 헤어핀을 포함하며,
상기 다중화 시스템에서, 다중의 chiRNA 폴리뉴클레오티드 서열이 사용되는 다중화 CRISPR 효소 시스템. - 제1항, 제2항 또는 제3항에 있어서, 상기 제1 조절 요소가 중합효소 III 프로모터인 조성물 또는 시스템.
- 제1항 내지 제4항 중 어느 한 항에 있어서, 상기 제2 조절 요소가 중합효소 II 프로모터인 조성물 또는 시스템.
- 제1항 내지 제5항 중 어느 한 항에 있어서, 상기 CRISPR 효소가 진핵 세포의 핵에 검출가능한 양의 상기 CRISPR 효소의 축적을 유도하기에 충분한 세기의 하나 이상의 NLS를 포함하는 조성물 또는 시스템.
- 제1항 내지 제6항 중 어느 한 항에 있어서, 상기 tracr 서열이 최적으로 정렬되는 경우 상기 tracr 메이트 서열의 길이를 따라 적어도 50%의 서열 상보성을 나타내는 조성물 또는 시스템.
- 제1항 내지 제7항 중 어느 한 항에 있어서, 상기 CRISPR 효소가 II형 CRISPR 시스템 효소인 조성물 또는 시스템.
- 제1항 내지 제8항 중 어느 한 항에 있어서, 상기 CRISPR 효소가 Cas9 효소인 조성물 또는 시스템.
- 제1항 내지 제9항 중 어느 한 항에 있어서, 상기 CRISPR 효소가 진핵 세포에서의 발현을 위해 코돈-최적화된 조성물 또는 시스템.
- 제1항 내지 제10항 중 어느 한 항에 있어서, 상기 가이드 서열이 적어도 15개 뉴클레오티드 길이인 조성물 또는 시스템.
- 제1항 내지 제11항 중 어느 한 항에 있어서, 상기 키메라 RNA 폴리뉴클레오티드 서열이 2, 3, 4 또는 5개의 헤어핀을 포함하는 조성물 또는 시스템.
- I. (a) 진핵 세포 내의 표적 서열에 혼성화할 수 있는 가이드 서열, 및
(b) tracr 메이트 서열에 작동가능하게 연결된 제1 조절 요소,
II. CRISPR 효소의 말단의 부근에 적어도 하나 이상의 핵 국소화 서열(NLS)을 포함하는 CRISPR 효소를 인코딩하는 효소-코딩 서열에 작동가능하게 연결된 제2 조절 요소, 및
III. tracr 서열에 작동가능하게 연결된 제3 조절 요소를 포함하는 하나 이상의 벡터를 포함하는 벡터 시스템을 포함하는 비-천연 발생 또는 조작된 조성물로서,
성분 I, II 및 III이 상기 시스템의 동일한 또는 상이한 벡터에 배치되고,
전사되는 경우, 상기 tracr 메이트 서열이 상기 tracr 서열에 혼성화되며, 상기 가이드 서열이 상기 표적 서열로의 CRISPR 복합체의 서열-특이적 결합을 유도하고,
상기 CRISPR 복합체가 (1) 상기 표적 서열에 혼성화되는 가이드 서열, 및 (2) 상기 tracr 서열에 혼성화되는 tracr 메이트 서열과 복합체화된 CRISPR 효소를 포함하는 비-천연 발생 또는 조작된 조성물. - 제13항에 있어서, 다중의 가이드 서열 및 단일의 tracr 서열을 사용하여 다중화 시스템을 제공하는 조성물.
- 다중화 CRISPR 효소 시스템으로서, 상기 시스템이
I. (a) 진핵 세포 내의 표적 서열에 혼성화할 수 있는 가이드 서열, 및
(b) tracr 메이트 서열에 작동가능하게 연결된 제1 조절 요소,
II. CRISPR 효소의 말단의 부근에 적어도 하나 이상의 핵 국소화 서열(NLS)을 포함하는 CRISPR 효소를 인코딩하는 효소-코딩 서열에 작동가능하게 연결된 제2 조절 요소, 및
III. tracr 서열에 작동가능하게 연결된 제3 조절 요소를 포함하는 하나 이상의 벡터를 포함하는 벡터 시스템을 포함하며,
성분 I, II 및 III이 상기 시스템의 동일한 또는 상이한 벡터에 배치되고,
전사되는 경우, 상기 tracr 메이트 서열이 상기 tracr 서열에 혼성화되며, 상기 가이드 서열이 상기 표적 서열로의 CRISPR 복합체의 서열-특이적 결합을 유도하고,
상기 CRISPR 복합체가 (1) 상기 표적 서열에 혼성화되는 가이드 서열, 및 (2) 상기 tracr 서열에 혼성화되는 tracr 메이트 서열과 복합체화된 CRISPR 효소를 포함하며,
상기 다중화 시스템에서, 다중의 가이드 서열 및 단일의 tracr 서열이 사용되는 다중화 CRISPR 효소 시스템. - 제13항 내지 제15항 중 어느 한 항에 있어서, 상기 제1 조절 요소가 중합효소 III 프로모터인 조성물 또는 시스템.
- 제13항 내지 제16항 중 어느 한 항에 있어서, 상기 제2 조절 요소가 중합효소 II 프로모터인 조성물 또는 시스템.
- 제13항 내지 제17항 중 어느 한 항에 있어서, 상기 제3 조절 요소가 중합효소 III 프로모터인 조성물 또는 시스템.
- 제13항 내지 제18항 중 어느 한 항에 있어서, 상기 CRISPR 효소가 진핵 세포의 핵에서 검출가능한 양의 상기 CRISPR 효소의 축적을 유도하기에 충분한 세기의 하나 이상의 NLS를 포함하는 조성물 또는 시스템.
- 제13항 내지 제19항 중 어느 한 항에 있어서, 상기 tracr 서열이 최적으로 정렬되는 경우 상기 tracr 메이트 서열의 길이를 따라 적어도 50%의 서열 상보성을 나타내는 조성물 또는 시스템.
- 제13항 내지 제20항 중 어느 한 항에 있어서, 상기 CRISPR 효소가 II형 CRISPR 시스템 효소인 조성물 또는 시스템.
- 제13항 내지 제21항 중 어느 한 항에 있어서, 상기 CRISPR 효소가 Cas9 효소인 조성물 또는 시스템.
- 제13항 내지 제22항 중 어느 한 항에 있어서, 상기 CRISPR 효소가 진핵 세포에서의 발현을 위해 코돈-최적화된 조성물 또는 시스템.
- 제13항 내지 제23항 중 어느 한 항에 있어서, 상기 가이드 서열이 적어도 15개 뉴클레오티드 길이인 조성물 또는 시스템.
- 제1항 내지 제24항 중 어느 한 항의 조성물 또는 시스템을 포함하는 진핵 숙주 세포.
- 제25항의 진핵 숙주 세포를 포함하는 유기체.
- 제25항의 진핵 숙주 세포를 포함하는 비-인간 유기체.
- 제1항 내지 제24항 중 어느 한 항의 조성물 및 키트의 사용에 대한 지침서(instruction)를 포함하는 키트.
- 게놈 유전자좌를 제1항 내지 제24항 중 어느 한 항의 조성물과 접촉시키는 단계, 및
상기 게놈 유전자좌의 발현이 변경되는지를 결정하는 단계를 포함하는 진핵 세포에서의 대상 게놈 유전자좌의 발현의 변경 방법. - 제29항에 있어서, 상기 가이드 서열이 CRISPR 모티프 서열의 존재에 기초하여 상기 표적 서열로의 상기 CRISPR 복합체의 서열-특이적 결합을 유도하는 방법.
- 제30항에 있어서, 상기 CRISPR 모티프 서열이 NAG인 방법.
- 하나 이상의 원핵 세포(들) 내의 유전자에 하나 이상의 돌연변이를 도입함에 의한 하나 이상의 원핵 세포(들)의 선택 방법으로서, 상기 방법이
하나 이상의 벡터를 상기 원핵 세포(들)에 도입하는 단계로서, 상기 하나 이상의 벡터가 CRISPR 효소, tracr 메이트 서열에 연결된 가이드 서열, tracr 서열 및 교정 주형 중 하나 이상의 발현을 유도하며,
상기 교정 주형이 CRISPR 효소 절단을 없애는 하나 이상의 돌연변이를 포함하는 단계;
선택될 세포(들) 내의 표적 폴리뉴클레오티드와 상기 교정 주형의 상동성 재조합을 가능하게 하는 단계;
CRISPR 복합체가 표적 폴리뉴클레오티드에 결합하게 하여, 상기 유전자 내의 표적 폴리뉴클레오티드의 절단을 초래하여, 하나 이상의 돌연변이가 도입된 하나 이상의 원핵 세포(들)가 선택되게 하는 단계로서, 상기 CRISPR 복합체가 (1) 상기 표적 폴리뉴클레오티드 내의 표적 서열에 혼성화되는 가이드 서열, 및 (2) 상기 tracr 서열에 혼성화되는 tracr 메이트 서열과 복합체화되는 CRISPR 효소를 포함하고,
상기 표적 폴리뉴클레오티드로의 상기 CRISPR 복합체의 결합이 세포사를 유도하는 단계를 포함하는 방법. - 제32항에 있어서, 상기 CRISPR 효소가 II형 CRISPR 시스템 효소인 방법.
- 제33항에 있어서, 상기 CRISPR 효소가 Cas9인 방법.
Applications Claiming Priority (11)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201261736527P | 2012-12-12 | 2012-12-12 | |
| US61/736,527 | 2012-12-12 | ||
| US201361748427P | 2013-01-02 | 2013-01-02 | |
| US61/748,427 | 2013-01-02 | ||
| US201361768959P | 2013-02-25 | 2013-02-25 | |
| US61/768,959 | 2013-02-25 | ||
| US201361791409P | 2013-03-15 | 2013-03-15 | |
| US61/791,409 | 2013-03-15 | ||
| US201361835931P | 2013-06-17 | 2013-06-17 | |
| US61/835,931 | 2013-06-17 | ||
| PCT/US2013/074611 WO2014093595A1 (en) | 2012-12-12 | 2013-12-12 | Crispr-cas component systems, methods and compositions for sequence manipulation |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20150105635A true KR20150105635A (ko) | 2015-09-17 |
Family
ID=49881125
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020157018662A KR20150105635A (ko) | 2012-12-12 | 2013-12-12 | 서열 조작을 위한 crispr-cas 성분 시스템, 방법 및 조성물 |
Country Status (11)
| Country | Link |
|---|---|
| US (24) | US20140189896A1 (ko) |
| EP (8) | EP4286402A3 (ko) |
| JP (4) | JP2016505256A (ko) |
| KR (1) | KR20150105635A (ko) |
| CN (3) | CN114634950A (ko) |
| AU (3) | AU2013359262C1 (ko) |
| BR (2) | BR112015013786B1 (ko) |
| CA (1) | CA2894668A1 (ko) |
| DK (1) | DK3252160T3 (ko) |
| HK (2) | HK1206388A1 (ko) |
| WO (1) | WO2014093595A1 (ko) |
Cited By (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2018030874A1 (ko) * | 2016-08-12 | 2018-02-15 | 주식회사 툴젠 | 조작된 면역조절요소 및 이에 의해 변형된 면역 활성 |
| CN109844118A (zh) * | 2016-08-12 | 2019-06-04 | 株式会社图尔金 | 经操纵的免疫调节因子以及由此改变的免疫力 |
| KR20190093171A (ko) * | 2018-01-31 | 2019-08-08 | 서울대학교산학협력단 | CRISPR/Cas9 시스템을 통한 닭 백혈병 바이러스(Avian Leukosis Virus, ALV) 저항성 조류의 제조방법 |
| KR20220039034A (ko) * | 2020-09-21 | 2022-03-29 | 한국과학기술원 | 파브알부민 유전자 발현 억제용 CRISPR/Cas9 시스템 및 이의 용도 |
Families Citing this family (754)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US9314005B2 (en) | 2009-07-01 | 2016-04-19 | Transposagen Biopharmaceuticals, Inc. | Genetically modified rat models for severe combined immunodeficiency (SCID) |
| US9528124B2 (en) | 2013-08-27 | 2016-12-27 | Recombinetics, Inc. | Efficient non-meiotic allele introgression |
| US10920242B2 (en) | 2011-02-25 | 2021-02-16 | Recombinetics, Inc. | Non-meiotic allele introgression |
| CA2853829C (en) | 2011-07-22 | 2023-09-26 | President And Fellows Of Harvard College | Evaluation and improvement of nuclease cleavage specificity |
| US11021737B2 (en) | 2011-12-22 | 2021-06-01 | President And Fellows Of Harvard College | Compositions and methods for analyte detection |
| GB201122458D0 (en) | 2011-12-30 | 2012-02-08 | Univ Wageningen | Modified cascade ribonucleoproteins and uses thereof |
| US9737480B2 (en) | 2012-02-06 | 2017-08-22 | President And Fellows Of Harvard College | ARRDC1-mediated microvesicles (ARMMs) and uses thereof |
| US9637739B2 (en) | 2012-03-20 | 2017-05-02 | Vilnius University | RNA-directed DNA cleavage by the Cas9-crRNA complex |
| ES2683071T3 (es) | 2012-04-25 | 2018-09-24 | Regeneron Pharmaceuticals, Inc. | Direccionamiento mediado por nucleasas con grandes vectores de direccionamiento |
| WO2013163628A2 (en) | 2012-04-27 | 2013-10-31 | Duke University | Genetic correction of mutated genes |
| DK2800811T3 (en) | 2012-05-25 | 2017-07-17 | Univ Vienna | METHODS AND COMPOSITIONS FOR RNA DIRECTIVE TARGET DNA MODIFICATION AND FOR RNA DIRECTIVE MODULATION OF TRANSCRIPTION |
| BR112014031891A2 (pt) | 2012-06-19 | 2017-08-01 | Univ Minnesota | direcionamento genético nas plantas utilizando vírus de dna |
| US10648001B2 (en) | 2012-07-11 | 2020-05-12 | Sangamo Therapeutics, Inc. | Method of treating mucopolysaccharidosis type I or II |
| EP3196301B1 (en) | 2012-07-11 | 2018-10-17 | Sangamo Therapeutics, Inc. | Methods and compositions for the treatment of monogenic diseases |
| JP2015527889A (ja) * | 2012-07-25 | 2015-09-24 | ザ ブロード インスティテュート, インコーポレイテッド | 誘導可能なdna結合タンパク質およびゲノム撹乱ツール、ならびにそれらの適用 |
| SG11201503059XA (en) | 2012-10-23 | 2015-06-29 | Toolgen Inc | Composition for cleaving a target dna comprising a guide rna specific for the target dna and cas protein-encoding nucleic acid or cas protein, and use thereof |
| WO2014071182A1 (en) | 2012-11-01 | 2014-05-08 | Massachusetts Institute Of Technology | Directed evolution of synthetic gene cluster |
| KR102243092B1 (ko) | 2012-12-06 | 2021-04-22 | 시그마-알드리치 컴퍼니., 엘엘씨 | Crispr-기초된 유전체 변형과 조절 |
| WO2014093709A1 (en) | 2012-12-12 | 2014-06-19 | The Broad Institute, Inc. | Methods, models, systems, and apparatus for identifying target sequences for cas enzymes or crispr-cas systems for target sequences and conveying results thereof |
| EP4286402A3 (en) | 2012-12-12 | 2024-02-14 | The Broad Institute, Inc. | Crispr-cas component systems, methods and compositions for sequence manipulation |
| WO2014093655A2 (en) | 2012-12-12 | 2014-06-19 | The Broad Institute, Inc. | Engineering and optimization of systems, methods and compositions for sequence manipulation with functional domains |
| DK3064585T3 (da) | 2012-12-12 | 2020-04-27 | Broad Inst Inc | Konstruering og optimering af forbedrede systemer, fremgangsmåder og enzymsammensætninger til sekvensmanipulation |
| SG11201504523UA (en) | 2012-12-12 | 2015-07-30 | Broad Inst Inc | Delivery, engineering and optimization of systems, methods and compositions for sequence manipulation and therapeutic applications |
| US8697359B1 (en) | 2012-12-12 | 2014-04-15 | The Broad Institute, Inc. | CRISPR-Cas systems and methods for altering expression of gene products |
| EP3031921A1 (en) | 2012-12-12 | 2016-06-15 | The Broad Institute, Inc. | Delivery, engineering and optimization of systems, methods and compositions for sequence manipulation and therapeutic applications |
| CN105121641A (zh) * | 2012-12-17 | 2015-12-02 | 哈佛大学校长及研究员协会 | Rna-引导的人类基因组工程化 |
| CA2898184A1 (en) | 2013-01-16 | 2014-07-24 | Emory University | Cas9-nucleic acid complexes and uses related thereto |
| US11135273B2 (en) | 2013-02-07 | 2021-10-05 | The Rockefeller University | Sequence specific antimicrobials |
| US10660943B2 (en) | 2013-02-07 | 2020-05-26 | The Rockefeller University | Sequence specific antimicrobials |
| EP2971184B1 (en) | 2013-03-12 | 2019-04-17 | President and Fellows of Harvard College | Method of generating a three-dimensional nucleic acid containing matrix |
| EP2971167B1 (en) | 2013-03-14 | 2019-07-31 | Caribou Biosciences, Inc. | Compositions and methods of nucleic acid-targeting nucleic acids |
| US10760064B2 (en) | 2013-03-15 | 2020-09-01 | The General Hospital Corporation | RNA-guided targeting of genetic and epigenomic regulatory proteins to specific genomic loci |
| US9234213B2 (en) | 2013-03-15 | 2016-01-12 | System Biosciences, Llc | Compositions and methods directed to CRISPR/Cas genomic engineering systems |
| US20140364333A1 (en) * | 2013-03-15 | 2014-12-11 | President And Fellows Of Harvard College | Methods for Live Imaging of Cells |
| IL289396B2 (en) | 2013-03-15 | 2023-12-01 | The General Hospital Coporation | Using tru-grnas to increase the specificity of RNA-guided genome editing |
| WO2014165825A2 (en) | 2013-04-04 | 2014-10-09 | President And Fellows Of Harvard College | Therapeutic uses of genome editing with crispr/cas systems |
| RS62263B1 (sr) | 2013-04-16 | 2021-09-30 | Regeneron Pharma | Ciljana modifikacija genoma pacova |
| US9873907B2 (en) | 2013-05-29 | 2018-01-23 | Agilent Technologies, Inc. | Method for fragmenting genomic DNA using CAS9 |
| CA2913865C (en) * | 2013-05-29 | 2022-07-19 | Cellectis | A method for producing precise dna cleavage using cas9 nickase activity |
| US20140356956A1 (en) | 2013-06-04 | 2014-12-04 | President And Fellows Of Harvard College | RNA-Guided Transcriptional Regulation |
| EP3603679B1 (en) * | 2013-06-04 | 2022-08-10 | President and Fellows of Harvard College | Rna-guided transcriptional regulation |
| EP3004370B1 (en) * | 2013-06-05 | 2024-08-21 | Duke University | Rna-guided gene editing and gene regulation |
| WO2014201015A2 (en) | 2013-06-11 | 2014-12-18 | The Regents Of The University Of California | Methods and compositions for target dna modification |
| CA2915842C (en) | 2013-06-17 | 2022-11-29 | The Broad Institute, Inc. | Delivery and use of the crispr-cas systems, vectors and compositions for hepatic targeting and therapy |
| CN106062197A (zh) | 2013-06-17 | 2016-10-26 | 布罗德研究所有限公司 | 用于序列操纵的串联指导系统、方法和组合物的递送、工程化和优化 |
| WO2014204727A1 (en) | 2013-06-17 | 2014-12-24 | The Broad Institute Inc. | Functional genomics using crispr-cas systems, compositions methods, screens and applications thereof |
| KR20160056869A (ko) * | 2013-06-17 | 2016-05-20 | 더 브로드 인스티튜트, 인코퍼레이티드 | 바이러스 구성성분을 사용하여 장애 및 질환을 표적화하기 위한 crispr-cas 시스템 및 조성물의 전달, 용도 및 치료 적용 |
| EP4245853A3 (en) | 2013-06-17 | 2023-10-18 | The Broad Institute, Inc. | Optimized crispr-cas double nickase systems, methods and compositions for sequence manipulation |
| US10011850B2 (en) | 2013-06-21 | 2018-07-03 | The General Hospital Corporation | Using RNA-guided FokI Nucleases (RFNs) to increase specificity for RNA-Guided Genome Editing |
| EP3019595A4 (en) | 2013-07-09 | 2016-11-30 | THERAPEUTIC USES OF A GENERIC CHANGE WITH CRISPR / CAS SYSTEMS | |
| US20150044192A1 (en) | 2013-08-09 | 2015-02-12 | President And Fellows Of Harvard College | Methods for identifying a target site of a cas9 nuclease |
| MX2016002306A (es) | 2013-08-22 | 2016-07-08 | Du Pont | Promotor u6 de polimerasa iii de soja y metodos de uso. |
| US9359599B2 (en) | 2013-08-22 | 2016-06-07 | President And Fellows Of Harvard College | Engineered transcription activator-like effector (TALE) domains and uses thereof |
| EP4074330A1 (en) * | 2013-09-05 | 2022-10-19 | Massachusetts Institute of Technology | Tuning microbial populations with programmable nucleases |
| US9228207B2 (en) | 2013-09-06 | 2016-01-05 | President And Fellows Of Harvard College | Switchable gRNAs comprising aptamers |
| US9388430B2 (en) | 2013-09-06 | 2016-07-12 | President And Fellows Of Harvard College | Cas9-recombinase fusion proteins and uses thereof |
| US9737604B2 (en) | 2013-09-06 | 2017-08-22 | President And Fellows Of Harvard College | Use of cationic lipids to deliver CAS9 |
| DE202014010413U1 (de) * | 2013-09-18 | 2015-12-08 | Kymab Limited | Zellen und Organismen |
| WO2015054507A1 (en) | 2013-10-10 | 2015-04-16 | Pronutria, Inc. | Nutritive polypeptide production systems, and methods of manufacture and use thereof |
| WO2015065964A1 (en) | 2013-10-28 | 2015-05-07 | The Broad Institute Inc. | Functional genomics using crispr-cas systems, compositions, methods, screens and applications thereof |
| CA2930015A1 (en) | 2013-11-07 | 2015-05-14 | Editas Medicine, Inc. | Crispr-related methods and compositions with governing grnas |
| US11326209B2 (en) | 2013-11-07 | 2022-05-10 | Massachusetts Institute Of Technology | Cell-based genomic recorded accumulative memory |
| RU2725520C2 (ru) | 2013-12-11 | 2020-07-02 | Регенерон Фармасьютикалс, Инк. | Способы и композиции для направленной модификации генома |
| WO2015089364A1 (en) | 2013-12-12 | 2015-06-18 | The Broad Institute Inc. | Crystal structure of a crispr-cas system, and uses thereof |
| CA2932472A1 (en) | 2013-12-12 | 2015-06-18 | Massachusetts Institute Of Technology | Compositions and methods of use of crispr-cas systems in nucleotide repeat disorders |
| JP6793547B2 (ja) | 2013-12-12 | 2020-12-02 | ザ・ブロード・インスティテュート・インコーポレイテッド | 最適化機能CRISPR−Cas系による配列操作のための系、方法および組成物 |
| EP4219699A1 (en) | 2013-12-12 | 2023-08-02 | The Broad Institute, Inc. | Engineering of systems, methods and optimized guide compositions with new architectures for sequence manipulation |
| CN106536729A (zh) | 2013-12-12 | 2017-03-22 | 布罗德研究所有限公司 | 使用粒子递送组分靶向障碍和疾病的crispr‑cas系统和组合物的递送、用途和治疗应用 |
| US11053481B2 (en) | 2013-12-12 | 2021-07-06 | President And Fellows Of Harvard College | Fusions of Cas9 domains and nucleic acid-editing domains |
| WO2015089462A1 (en) | 2013-12-12 | 2015-06-18 | The Broad Institute Inc. | Delivery, use and therapeutic applications of the crispr-cas systems and compositions for genome editing |
| AU2014361784A1 (en) | 2013-12-12 | 2016-06-23 | Massachusetts Institute Of Technology | Delivery, use and therapeutic applications of the CRISPR-Cas systems and compositions for HBV and viral diseases and disorders |
| WO2015089277A1 (en) * | 2013-12-12 | 2015-06-18 | The Regents Of The University Of California | Methods and compositions for modifying a single stranded target nucleic acid |
| CN116478927A (zh) | 2013-12-19 | 2023-07-25 | 诺华股份有限公司 | 人间皮素嵌合抗原受体及其用途 |
| US9963689B2 (en) | 2013-12-31 | 2018-05-08 | The Regents Of The University Of California | Cas9 crystals and methods of use thereof |
| EP4063503A1 (en) | 2014-02-11 | 2022-09-28 | The Regents of the University of Colorado, a body corporate | Crispr enabled multiplexed genome engineering |
| BR112016019068A2 (pt) | 2014-02-18 | 2017-10-10 | Univ Duke | construto, vetor recombinante, composição farmacêutica, método de inibição de replicação viral ou expressão de uma sequência alvo em uma célula infectada com um vírus, polipeptídeo de sau cas9 recombinante, construto de sau cas9 recombinante, construto recombinante para expressão de um rna guia individual e kit |
| CA2940653A1 (en) | 2014-02-27 | 2015-09-03 | Vijay Kuchroo | T cell balance gene expression, compositions of matters and methods of use thereof |
| US11186843B2 (en) | 2014-02-27 | 2021-11-30 | Monsanto Technology Llc | Compositions and methods for site directed genomic modification |
| CN111471675A (zh) | 2014-03-05 | 2020-07-31 | 国立大学法人神户大学 | 特异性转变靶向dna序列的核酸碱基的基因组序列的修饰方法、及其使用的分子复合体 |
| EP3114227B1 (en) | 2014-03-05 | 2021-07-21 | Editas Medicine, Inc. | Crispr/cas-related methods and compositions for treating usher syndrome and retinitis pigmentosa |
| US11339437B2 (en) | 2014-03-10 | 2022-05-24 | Editas Medicine, Inc. | Compositions and methods for treating CEP290-associated disease |
| US11141493B2 (en) | 2014-03-10 | 2021-10-12 | Editas Medicine, Inc. | Compositions and methods for treating CEP290-associated disease |
| WO2015138510A1 (en) | 2014-03-10 | 2015-09-17 | Editas Medicine., Inc. | Crispr/cas-related methods and compositions for treating leber's congenital amaurosis 10 (lca10) |
| EP3593812A3 (en) | 2014-03-15 | 2020-05-27 | Novartis AG | Treatment of cancer using chimeric antigen receptor |
| EP3981876A1 (en) | 2014-03-26 | 2022-04-13 | Editas Medicine, Inc. | Crispr/cas-related methods and compositions for treating sickle cell disease |
| EP3122877B1 (en) | 2014-03-26 | 2023-03-22 | University of Maryland, College Park | Targeted genome editing in zygotes of domestic large animals |
| EP3540061A1 (en) * | 2014-04-02 | 2019-09-18 | Editas Medicine, Inc. | Crispr/cas-related methods and compositions for treating primary open angle glaucoma |
| SG10202109752XA (en) | 2014-04-07 | 2021-10-28 | Novartis Ag | Treatment of cancer using anti-cd19 chimeric antigen receptor |
| CN106536739B (zh) * | 2014-04-14 | 2021-08-03 | 内梅西斯生物有限公司 | 治疗剂 |
| GB201406968D0 (en) | 2014-04-17 | 2014-06-04 | Green Biologics Ltd | Deletion mutants |
| GB201406970D0 (en) | 2014-04-17 | 2014-06-04 | Green Biologics Ltd | Targeted mutations |
| CN111647627A (zh) | 2014-04-28 | 2020-09-11 | 重组股份有限公司 | 多重基因编辑 |
| US10280419B2 (en) | 2014-05-09 | 2019-05-07 | UNIVERSITé LAVAL | Reduction of amyloid beta peptide production via modification of the APP gene using the CRISPR/Cas system |
| PL3145934T3 (pl) | 2014-05-19 | 2021-08-16 | Pfizer Inc. | Podstawione związki 6,8-dioksabicyklo[3.2.1]oktano-2,3-diolu jako środki kierujące do ASGPR |
| CN106536056B (zh) | 2014-06-13 | 2021-07-16 | 儿童医学中心公司 | 分离线粒体的产品和方法 |
| CA2953362A1 (en) | 2014-06-23 | 2015-12-30 | The General Hospital Corporation | Genomewide unbiased identification of dsbs evaluated by sequencing (guide-seq) |
| BR112017000621B1 (pt) * | 2014-07-11 | 2024-03-12 | Pioneer Hi-Bred International, Inc | Método para melhorar um traço agronômico de uma planta de milho ou de soja |
| AU2015288157A1 (en) | 2014-07-11 | 2017-01-19 | E. I. Du Pont De Nemours And Company | Compositions and methods for producing plants resistant to glyphosate herbicide |
| WO2016011203A1 (en) | 2014-07-15 | 2016-01-21 | Life Technologies Corporation | Compositions with lipid aggregates and methods for efficient delivery of molecules to cells |
| WO2016014576A1 (en) | 2014-07-21 | 2016-01-28 | Novartis Ag | Treatment of cancer using a cd33 chimeric antigen receptor |
| EP3193915A1 (en) | 2014-07-21 | 2017-07-26 | Novartis AG | Combinations of low, immune enhancing. doses of mtor inhibitors and cars |
| MY181834A (en) | 2014-07-21 | 2021-01-08 | Novartis Ag | Treatment of cancer using humanized anti-bcma chimeric antigen receptor |
| US11542488B2 (en) | 2014-07-21 | 2023-01-03 | Novartis Ag | Sortase synthesized chimeric antigen receptors |
| US10077453B2 (en) | 2014-07-30 | 2018-09-18 | President And Fellows Of Harvard College | CAS9 proteins including ligand-dependent inteins |
| EP4205749A1 (en) | 2014-07-31 | 2023-07-05 | Novartis AG | Subset-optimized chimeric antigen receptor-containing cells |
| US10513711B2 (en) | 2014-08-13 | 2019-12-24 | Dupont Us Holding, Llc | Genetic targeting in non-conventional yeast using an RNA-guided endonuclease |
| JP6919118B2 (ja) | 2014-08-14 | 2021-08-18 | ノバルティス アーゲー | GFRα−4キメラ抗原受容体を用いる癌の治療 |
| EP3180426B1 (en) | 2014-08-17 | 2019-12-25 | The Broad Institute, Inc. | Genome editing using cas9 nickases |
| RU2724999C2 (ru) | 2014-08-19 | 2020-06-29 | Новартис Аг | Химерный антигенный рецептор (car) против cd123 для использования в лечении злокачественных опухолей |
| ES2730378T3 (es) * | 2014-08-27 | 2019-11-11 | Caribou Biosciences Inc | Procedimientos para incrementar la eficiencia de la modificación mediada por Cas9 |
| US10450584B2 (en) | 2014-08-28 | 2019-10-22 | North Carolina State University | Cas9 proteins and guiding features for DNA targeting and genome editing |
| EP3188763B1 (en) * | 2014-09-02 | 2020-05-13 | The Regents of The University of California | Methods and compositions for rna-directed target dna modification |
| MX2017002930A (es) | 2014-09-12 | 2017-06-06 | Du Pont | Generacion de sitios de integracion especifica de sitio para loci de rasgos complejos en maiz y soja, y metodos de uso. |
| WO2016044605A1 (en) | 2014-09-17 | 2016-03-24 | Beatty, Gregory | Targeting cytotoxic cells with chimeric receptors for adoptive immunotherapy |
| US9616114B1 (en) | 2014-09-18 | 2017-04-11 | David Gordon Bermudes | Modified bacteria having improved pharmacokinetics and tumor colonization enhancing antitumor activity |
| WO2016049182A1 (en) | 2014-09-23 | 2016-03-31 | Aggentics, Inc. | Materials and methods for producing animals with short hair |
| WO2016049251A1 (en) | 2014-09-24 | 2016-03-31 | The Broad Institute Inc. | Delivery, use and therapeutic applications of the crispr-cas systems and compositions for modeling mutations in leukocytes |
| WO2016049024A2 (en) | 2014-09-24 | 2016-03-31 | The Broad Institute Inc. | Delivery, use and therapeutic applications of the crispr-cas systems and compositions for modeling competition of multiple cancer mutations in vivo |
| WO2016049163A2 (en) | 2014-09-24 | 2016-03-31 | The Broad Institute Inc. | Use and production of chd8+/- transgenic animals with behavioral phenotypes characteristic of autism spectrum disorder |
| US10040048B1 (en) | 2014-09-25 | 2018-08-07 | Synthego Corporation | Automated modular system and method for production of biopolymers |
| WO2016049258A2 (en) | 2014-09-25 | 2016-03-31 | The Broad Institute Inc. | Functional screening with optimized functional crispr-cas systems |
| WO2016061073A1 (en) * | 2014-10-14 | 2016-04-21 | Memorial Sloan-Kettering Cancer Center | Composition and method for in vivo engineering of chromosomal rearrangements |
| CN105602935B (zh) * | 2014-10-20 | 2020-11-13 | 聂凌云 | 一种新型线粒体基因组编辑工具 |
| US20170247762A1 (en) | 2014-10-27 | 2017-08-31 | The Board Institute Inc. | Compositions, methods and use of synthetic lethal screening |
| US9816080B2 (en) | 2014-10-31 | 2017-11-14 | President And Fellows Of Harvard College | Delivery of CAS9 via ARRDC1-mediated microvesicles (ARMMs) |
| US10208298B2 (en) | 2014-11-06 | 2019-02-19 | E.I. Du Pont De Nemours And Company | Peptide-mediated delivery of RNA-guided endonuclease into cells |
| CA2963820A1 (en) | 2014-11-07 | 2016-05-12 | Editas Medicine, Inc. | Methods for improving crispr/cas-mediated genome-editing |
| SI3221457T1 (sl) | 2014-11-21 | 2019-08-30 | Regeneron Pharmaceuticals, Inc. | Postopki in sestavki za ciljno genetsko modifikacijo z uporabo vodilnih RNK v parih |
| EP3224381B1 (en) | 2014-11-25 | 2019-09-04 | The Brigham and Women's Hospital, Inc. | Method of identifying a person having a predisposition to or afflicted with a cardiometabolic disease |
| US20180057839A1 (en) | 2014-11-26 | 2018-03-01 | The Regents Of The University Of California | Therapeutic compositions comprising transcription factors and methods of making and using the same |
| GB201421096D0 (en) | 2014-11-27 | 2015-01-14 | Imp Innovations Ltd | Genome editing methods |
| WO2016082135A1 (zh) * | 2014-11-27 | 2016-06-02 | 中国农业科学院北京畜牧兽医研究所 | 一种利用定点切割系统对猪h11位点定点插入的方法 |
| AU2015355546B2 (en) | 2014-12-03 | 2021-10-14 | Agilent Technologies, Inc. | Guide RNA with chemical modifications |
| EP3229586A4 (en) | 2014-12-10 | 2018-10-24 | Regents of the University of Minnesota | Genetically modified cells, tissues, and organs for treating disease |
| EP3230452A1 (en) | 2014-12-12 | 2017-10-18 | The Broad Institute Inc. | Dead guides for crispr transcription factors |
| WO2016094874A1 (en) | 2014-12-12 | 2016-06-16 | The Broad Institute Inc. | Escorted and functionalized guides for crispr-cas systems |
| WO2016094880A1 (en) | 2014-12-12 | 2016-06-16 | The Broad Institute Inc. | Delivery, use and therapeutic applications of crispr systems and compositions for genome editing as to hematopoietic stem cells (hscs) |
| WO2016094867A1 (en) | 2014-12-12 | 2016-06-16 | The Broad Institute Inc. | Protected guide rnas (pgrnas) |
| WO2016100333A1 (en) | 2014-12-15 | 2016-06-23 | Syngenta Participations Ag | Pesticidal microrna carriers and use thereof |
| AU2015362784B2 (en) * | 2014-12-16 | 2021-05-13 | Danisco Us Inc | Fungal genome modification systems and methods of use |
| MX2017007907A (es) * | 2014-12-17 | 2017-09-18 | Du Pont | Composiciones y métodos para la edición genética eficaz en e. coli usando sistemas de ácido desoxirribonucleico (arn) guía/endonucleasa de sistema asociado a repeticiones palindrómicas cortas agrupadas regularmente espaciadas (cas) en combinación con moldes de modificación de polinucleótido circular. |
| US20190054117A1 (en) | 2014-12-19 | 2019-02-21 | Novartis Ag | Dimerization switches and uses thereof |
| WO2016100974A1 (en) | 2014-12-19 | 2016-06-23 | The Broad Institute Inc. | Unbiased identification of double-strand breaks and genomic rearrangement by genome-wide insert capture sequencing |
| US10190106B2 (en) | 2014-12-22 | 2019-01-29 | Univesity Of Massachusetts | Cas9-DNA targeting unit chimeras |
| WO2016106236A1 (en) | 2014-12-23 | 2016-06-30 | The Broad Institute Inc. | Rna-targeting system |
| ES2785329T3 (es) | 2014-12-23 | 2020-10-06 | Syngenta Participations Ag | Métodos y composiciones para identificar y enriquecer células que comprenden modificaciones genómicas específicas para el sitio |
| CA2970370A1 (en) | 2014-12-24 | 2016-06-30 | Massachusetts Institute Of Technology | Crispr having or associated with destabilization domains |
| WO2016108926A1 (en) | 2014-12-30 | 2016-07-07 | The Broad Institute Inc. | Crispr mediated in vivo modeling and genetic screening of tumor growth and metastasis |
| CA2972454A1 (en) | 2014-12-31 | 2016-07-07 | Synthetic Genomics, Inc. | Compositions and methods for high efficiency in vivo genome editing |
| US11208638B2 (en) | 2015-01-12 | 2021-12-28 | The Regents Of The University Of California | Heterodimeric Cas9 and methods of use thereof |
| EP3250689B1 (en) | 2015-01-28 | 2020-11-04 | The Regents of The University of California | Methods and compositions for labeling a single-stranded target nucleic acid |
| CN111518811A (zh) | 2015-01-28 | 2020-08-11 | 先锋国际良种公司 | Crispr杂合dna/rna多核苷酸及使用方法 |
| JP6929791B2 (ja) | 2015-02-09 | 2021-09-01 | デューク ユニバーシティ | エピゲノム編集のための組成物および方法 |
| WO2016138488A2 (en) | 2015-02-26 | 2016-09-01 | The Broad Institute Inc. | T cell balance gene expression, compositions of matters and methods of use thereof |
| US11261466B2 (en) | 2015-03-02 | 2022-03-01 | Sinai Health System | Homologous recombination factors |
| WO2016141224A1 (en) | 2015-03-03 | 2016-09-09 | The General Hospital Corporation | Engineered crispr-cas9 nucleases with altered pam specificity |
| CN104673816A (zh) * | 2015-03-05 | 2015-06-03 | 广东医学院 | 一种pCr-NHEJ载体及其构建方法及其用于细菌基因定点敲除的应用 |
| BR112017017260A2 (pt) | 2015-03-27 | 2018-04-17 | Du Pont | construções de dna, vetor, célula, plantas, semente, método de expressão de rna e método de modificação de local alvo |
| EP3280803B1 (en) | 2015-04-06 | 2021-05-26 | The Board of Trustees of the Leland Stanford Junior University | Chemically modified guide rnas for crispr/cas-mediated gene regulation |
| WO2016168594A1 (en) * | 2015-04-16 | 2016-10-20 | President And Fellows Of Harvard College | Sensor systems for target ligands and uses thereof |
| GB201506509D0 (en) | 2015-04-16 | 2015-06-03 | Univ Wageningen | Nuclease-mediated genome editing |
| US20180298068A1 (en) | 2015-04-23 | 2018-10-18 | Novartis Ag | Treatment of cancer using chimeric antigen receptor and protein kinase a blocker |
| JP2018522249A (ja) | 2015-04-24 | 2018-08-09 | エディタス・メディシン、インコーポレイテッド | Cas9分子/ガイドrna分子複合体の評価 |
| WO2016176617A2 (en) | 2015-04-29 | 2016-11-03 | New York University | Method for treating high-grade gliomas |
| CN106191040B (zh) * | 2015-04-30 | 2021-09-14 | 杭州菁因康生物科技有限公司 | 基因打靶方法 |
| SG11201708706YA (en) | 2015-05-06 | 2017-11-29 | Snipr Tech Ltd | Altering microbial populations & modifying microbiota |
| WO2016182893A1 (en) | 2015-05-08 | 2016-11-17 | Teh Broad Institute Inc. | Functional genomics using crispr-cas systems for saturating mutagenesis of non-coding elements, compositions, methods, libraries and applications thereof |
| AU2016261600B2 (en) | 2015-05-08 | 2021-09-23 | President And Fellows Of Harvard College | Universal donor stem cells and related methods |
| EP3294896A1 (en) | 2015-05-11 | 2018-03-21 | Editas Medicine, Inc. | Optimized crispr/cas9 systems and methods for gene editing in stem cells |
| WO2016183438A1 (en) * | 2015-05-14 | 2016-11-17 | Massachusetts Institute Of Technology | Self-targeting genome editing system |
| MX2017014561A (es) | 2015-05-15 | 2018-03-02 | Pioneer Hi Bred Int | Nuevos sistemas de arn guia/endonucleasa cas. |
| WO2016187904A1 (zh) * | 2015-05-22 | 2016-12-01 | 深圳市第二人民医院 | CRISPR-Cas9特异性敲除猪CMAH基因的方法及用于特异性靶向CMAH基因的sgRNA |
| US20180148711A1 (en) * | 2015-05-28 | 2018-05-31 | Coda Biotherapeutics, Inc. | Genome editing vectors |
| EP4039816A1 (en) * | 2015-05-29 | 2022-08-10 | North Carolina State University | Methods for screening bacteria, archaea, algae, and yeast using crispr nucleic acids |
| WO2016196655A1 (en) | 2015-06-03 | 2016-12-08 | The Regents Of The University Of California | Cas9 variants and methods of use thereof |
| WO2016196887A1 (en) | 2015-06-03 | 2016-12-08 | Board Of Regents Of The University Of Nebraska | Dna editing using single-stranded dna |
| EP3302525A2 (en) | 2015-06-05 | 2018-04-11 | Novartis AG | Methods and compositions for diagnosing, treating, and monitoring treatment of shank3 deficiency associated disorders |
| JP7396783B2 (ja) | 2015-06-09 | 2023-12-12 | エディタス・メディシン、インコーポレイテッド | 移植を改善するためのcrispr/cas関連方法および組成物 |
| WO2016198500A1 (en) * | 2015-06-10 | 2016-12-15 | INSERM (Institut National de la Santé et de la Recherche Médicale) | Methods and compositions for rna-guided treatment of human cytomegalovirus (hcmv) infection |
| EP3307890A1 (en) | 2015-06-10 | 2018-04-18 | Board of Regents, The University of Texas System | Use of exosomes for the treatment of disease |
| WO2016200263A1 (en) * | 2015-06-12 | 2016-12-15 | Erasmus University Medical Center Rotterdam | New crispr assays |
| WO2016205728A1 (en) | 2015-06-17 | 2016-12-22 | Massachusetts Institute Of Technology | Crispr mediated recording of cellular events |
| EP3310932B1 (en) | 2015-06-17 | 2023-08-30 | The UAB Research Foundation | Crispr/cas9 complex for genomic editing |
| CN108026545A (zh) | 2015-06-17 | 2018-05-11 | Uab研究基金会 | 用于将功能性多肽引入到血细胞谱系细胞中的crispr/cas9复合物 |
| CA3012631A1 (en) | 2015-06-18 | 2016-12-22 | The Broad Institute Inc. | Novel crispr enzymes and systems |
| US10648020B2 (en) | 2015-06-18 | 2020-05-12 | The Broad Institute, Inc. | CRISPR enzymes and systems |
| WO2016205759A1 (en) | 2015-06-18 | 2016-12-22 | The Broad Institute Inc. | Engineering and optimization of systems, methods, enzymes and guide scaffolds of cas9 orthologs and variants for sequence manipulation |
| CN109536474A (zh) * | 2015-06-18 | 2019-03-29 | 布罗德研究所有限公司 | 降低脱靶效应的crispr酶突变 |
| US9790490B2 (en) * | 2015-06-18 | 2017-10-17 | The Broad Institute Inc. | CRISPR enzymes and systems |
| WO2016205745A2 (en) | 2015-06-18 | 2016-12-22 | The Broad Institute Inc. | Cell sorting |
| WO2016205749A1 (en) | 2015-06-18 | 2016-12-22 | The Broad Institute Inc. | Novel crispr enzymes and systems |
| CA2990699A1 (en) | 2015-06-29 | 2017-01-05 | Ionis Pharmaceuticals, Inc. | Modified crispr rna and modified single crispr rna and uses thereof |
| EP3322679A4 (en) | 2015-07-13 | 2019-07-10 | Pivot Bio, Inc. | METHODS AND COMPOSITIONS FOR IMPROVING THE CHARACTERISTICS OF A PLANT |
| CN108291218B (zh) | 2015-07-15 | 2022-08-19 | 新泽西鲁特格斯州立大学 | 核酸酶非依赖性靶向基因编辑平台及其用途 |
| EP3325018A4 (en) | 2015-07-22 | 2019-04-24 | Duke University | HIGH EFFICIENCY SCREENING OF REGULATORY ELEMENT FUNCTION USING EPIGENOUS EDITING TECHNOLOGIES |
| EP3328399B1 (en) | 2015-07-31 | 2023-12-27 | Regents of the University of Minnesota | Modified cells and methods of therapy |
| US9580727B1 (en) | 2015-08-07 | 2017-02-28 | Caribou Biosciences, Inc. | Compositions and methods of engineered CRISPR-Cas9 systems using split-nexus Cas9-associated polynucleotides |
| WO2017027392A1 (en) | 2015-08-07 | 2017-02-16 | Novartis Ag | Treatment of cancer using chimeric cd3 receptor proteins |
| EP3334746B1 (en) | 2015-08-14 | 2021-11-24 | The University Of Sydney | Connexin 45 inhibition for therapy |
| WO2017031370A1 (en) | 2015-08-18 | 2017-02-23 | The Broad Institute, Inc. | Methods and compositions for altering function and structure of chromatin loops and/or domains |
| EP3341727B1 (en) * | 2015-08-25 | 2022-08-10 | Duke University | Compositions and methods of improving specificity in genomic engineering using rna-guided endonucleases |
| US9512446B1 (en) | 2015-08-28 | 2016-12-06 | The General Hospital Corporation | Engineered CRISPR-Cas9 nucleases |
| US9926546B2 (en) | 2015-08-28 | 2018-03-27 | The General Hospital Corporation | Engineered CRISPR-Cas9 nucleases |
| CA2996888A1 (en) | 2015-08-28 | 2017-03-09 | The General Hospital Corporation | Engineered crispr-cas9 nucleases |
| JP6664693B2 (ja) | 2015-09-09 | 2020-03-13 | 国立大学法人神戸大学 | 標的化したdna配列の核酸塩基を特異的に変換する、グラム陽性菌のゲノム配列の変換方法、及びそれに用いる分子複合体 |
| IL241462A0 (en) | 2015-09-10 | 2015-11-30 | Yeda Res & Dev | Heterologous engineering of betalain pigments in plants |
| WO2017044843A1 (en) | 2015-09-11 | 2017-03-16 | The General Hospital Corporation | Full interrogation of nuclease dsbs and sequencing (find-seq) |
| US11667911B2 (en) | 2015-09-24 | 2023-06-06 | Editas Medicine, Inc. | Use of exonucleases to improve CRISPR/CAS-mediated genome editing |
| CA3000762A1 (en) | 2015-09-30 | 2017-04-06 | The General Hospital Corporation | Comprehensive in vitro reporting of cleavage events by sequencing (circle-seq) |
| EP3359664A4 (en) | 2015-10-05 | 2019-03-20 | Massachusetts Institute Of Technology | NITROGEN FIXATION WITH REINFORCED NIF CLUSTERS |
| US20190255107A1 (en) | 2015-10-09 | 2019-08-22 | The Brigham And Women's Hospital, Inc. | Modulation of novel immune checkpoint targets |
| JP7011590B2 (ja) | 2015-10-12 | 2022-02-10 | イー・アイ・デュポン・ドウ・ヌムール・アンド・カンパニー | 細胞内での遺伝子組換えおよび相同組換えの増加のための保護dna鋳型および使用方法 |
| WO2017066497A2 (en) | 2015-10-13 | 2017-04-20 | Duke University | Genome engineering with type i crispr systems in eukaryotic cells |
| EP3362561A2 (en) * | 2015-10-16 | 2018-08-22 | Astrazeneca AB | Inducible modification of a cell genome |
| AU2016341041A1 (en) | 2015-10-20 | 2018-03-15 | Pioneer Hi-Bred International, Inc. | Methods and compositions for marker-free genome modification |
| US10968253B2 (en) | 2015-10-20 | 2021-04-06 | Institut National De La Sante Et De La Recherche Medicale (Inserm) | Methods and products for genetic engineering |
| WO2017070605A1 (en) | 2015-10-22 | 2017-04-27 | The Broad Institute Inc. | Type vi-b crispr enzymes and systems |
| EP3350327B1 (en) | 2015-10-23 | 2018-09-26 | Caribou Biosciences, Inc. | Engineered crispr class 2 cross-type nucleic-acid targeting nucleic acids |
| IL294014B2 (en) | 2015-10-23 | 2024-07-01 | Harvard College | Nucleobase editors and their uses |
| US11492670B2 (en) | 2015-10-27 | 2022-11-08 | The Broad Institute Inc. | Compositions and methods for targeting cancer-specific sequence variations |
| US11092607B2 (en) | 2015-10-28 | 2021-08-17 | The Board Institute, Inc. | Multiplex analysis of single cell constituents |
| WO2017075465A1 (en) | 2015-10-28 | 2017-05-04 | The Broad Institute Inc. | Compositions and methods for evaluating and modulating immune responses by detecting and targeting gata3 |
| EP3368689B1 (en) | 2015-10-28 | 2020-06-17 | The Broad Institute, Inc. | Composition for modulating immune responses by use of immune cell gene signature |
| WO2017075294A1 (en) | 2015-10-28 | 2017-05-04 | The Board Institute Inc. | Assays for massively combinatorial perturbation profiling and cellular circuit reconstruction |
| WO2017075451A1 (en) | 2015-10-28 | 2017-05-04 | The Broad Institute Inc. | Compositions and methods for evaluating and modulating immune responses by detecting and targeting pou2af1 |
| WO2017079406A1 (en) | 2015-11-03 | 2017-05-11 | President And Fellows Of Harvard College | Method and apparatus for volumetric imaging of a three-dimensional nucleic acid containing matrix |
| EP3370513A1 (en) * | 2015-11-06 | 2018-09-12 | The Jackson Laboratory | Large genomic dna knock-in and uses thereof |
| CA2947904A1 (en) * | 2015-11-12 | 2017-05-12 | Pfizer Inc. | Tissue-specific genome engineering using crispr-cas9 |
| JP6929865B2 (ja) | 2015-11-13 | 2021-09-01 | タラ ムーア | 角膜ジストロフィーの治療方法 |
| WO2017083766A1 (en) * | 2015-11-13 | 2017-05-18 | Massachusetts Institute Of Technology | High-throughput crispr-based library screening |
| CA3005633C (en) | 2015-11-16 | 2023-11-21 | Research Institute Of Nationwide Children's Hospital | Materials and methods for treatment of titin-based myopathies and other titinopathies |
| CA3005878A1 (en) | 2015-11-19 | 2017-05-26 | The Brigham And Women's Hospital, Inc. | Lymphocyte antigen cd5-like (cd5l)-interleukin 12b (p40) heterodimers in immunity |
| DK3382019T3 (da) * | 2015-11-27 | 2022-05-30 | Univ Kobe Nat Univ Corp | Fremgangsmåde til omdannelse af enkimet plantegenomsekvens, hvori nukleinsyrebase i målrettet DNA-sekvens specifikt omdannes, og molekylært kompleks anvendt deri |
| US20170151287A1 (en) | 2015-11-30 | 2017-06-01 | Flagship Ventures Management, Inc. | Methods and compositions of chondrisomes |
| CN105296518A (zh) * | 2015-12-01 | 2016-02-03 | 中国农业大学 | 一种用于CRISPR/Cas9技术的同源臂载体构建方法 |
| ES2735773T3 (es) | 2015-12-04 | 2019-12-20 | Caribou Biosciences Inc | Acidos nucleicos manipulados dirigidos a ácidos nucleicos |
| CA3007635A1 (en) | 2015-12-07 | 2017-06-15 | Zymergen Inc. | Promoters from corynebacterium glutamicum |
| US11208649B2 (en) | 2015-12-07 | 2021-12-28 | Zymergen Inc. | HTP genomic engineering platform |
| US9988624B2 (en) | 2015-12-07 | 2018-06-05 | Zymergen Inc. | Microbial strain improvement by a HTP genomic engineering platform |
| US20180362961A1 (en) | 2015-12-11 | 2018-12-20 | Danisco Us Inc. | Methods and compositions for enhanced nuclease-mediated genome modification and reduced off-target site effects |
| DK3390631T3 (da) | 2015-12-18 | 2020-07-13 | Danisco Us Inc | Fremgangsmåder og sammensætninger til t-rna-baseret guide-rna-ekspression |
| US12110490B2 (en) | 2015-12-18 | 2024-10-08 | The Broad Institute, Inc. | CRISPR enzymes and systems |
| WO2017112620A1 (en) | 2015-12-22 | 2017-06-29 | North Carolina State University | Methods and compositions for delivery of crispr based antimicrobials |
| WO2017114497A1 (en) | 2015-12-30 | 2017-07-06 | Novartis Ag | Immune effector cell therapies with enhanced efficacy |
| KR20180095719A (ko) | 2016-01-11 | 2018-08-27 | 더 보드 어브 트러스티스 어브 더 리랜드 스탠포드 주니어 유니버시티 | 키메라 단백질 및 면역요법 방법 |
| IL260532B2 (en) | 2016-01-11 | 2023-12-01 | Univ Leland Stanford Junior | Systems containing chaperone proteins and their uses for controlling gene expression |
| WO2017132239A1 (en) | 2016-01-26 | 2017-08-03 | Pioneer Hi-Bred International, Inc. | Waxy corn |
| US10876129B2 (en) | 2016-02-12 | 2020-12-29 | Ceres, Inc. | Methods and materials for high throughput testing of mutagenized allele combinations |
| US10973930B2 (en) | 2016-02-18 | 2021-04-13 | The Penn State Research Foundation | Generating GABAergic neurons in brains |
| US20190249172A1 (en) | 2016-02-18 | 2019-08-15 | The Regents Of The University Of California | Methods and compositions for gene editing in stem cells |
| EP3420102B1 (en) | 2016-02-22 | 2024-04-03 | Massachusetts Institute of Technology | Methods for identifying and modulating immune phenotypes |
| WO2017151444A1 (en) | 2016-02-29 | 2017-09-08 | Agilent Technologies, Inc. | Methods and compositions for blocking off-target nucleic acids from cleavage by crispr proteins |
| JP2019507610A (ja) | 2016-03-04 | 2019-03-22 | インドア バイオテクノロジーズ インコーポレイテッド | CRISPR−Casゲノム編集に基づく、Fel d1ノックアウト並びに関連組成物及び方法 |
| WO2017155714A1 (en) | 2016-03-11 | 2017-09-14 | Pioneer Hi-Bred International, Inc. | Novel cas9 systems and methods of use |
| WO2017155715A1 (en) | 2016-03-11 | 2017-09-14 | Pioneer Hi-Bred International, Inc. | Novel cas9 systems and methods of use |
| EP3699280A3 (en) | 2016-03-11 | 2020-11-18 | Pioneer Hi-Bred International, Inc. | Novel cas9 systems and methods of use |
| EP3429567B1 (en) | 2016-03-16 | 2024-01-10 | The J. David Gladstone Institutes | Methods and compositions for treating obesity and/or diabetes and for identifying candidate treatment agents |
| EP3219799A1 (en) | 2016-03-17 | 2017-09-20 | IMBA-Institut für Molekulare Biotechnologie GmbH | Conditional crispr sgrna expression |
| WO2017161325A1 (en) | 2016-03-17 | 2017-09-21 | Massachusetts Institute Of Technology | Methods for identifying and modulating co-occurant cellular phenotypes |
| EP3433362B1 (en) * | 2016-03-23 | 2021-05-05 | Dana-Farber Cancer Institute, Inc. | Methods for enhancing the efficiency of gene editing |
| EP3433364A1 (en) | 2016-03-25 | 2019-01-30 | Editas Medicine, Inc. | Systems and methods for treating alpha 1-antitrypsin (a1at) deficiency |
| US11597924B2 (en) | 2016-03-25 | 2023-03-07 | Editas Medicine, Inc. | Genome editing systems comprising repair-modulating enzyme molecules and methods of their use |
| EP4047092A1 (en) | 2016-04-13 | 2022-08-24 | Editas Medicine, Inc. | Cas9 fusion molecules, gene editing systems, and methods of use thereof |
| EP4219721A3 (en) | 2016-04-15 | 2023-09-06 | Novartis AG | Compositions and methods for selective protein expression |
| WO2017184786A1 (en) | 2016-04-19 | 2017-10-26 | The Broad Institute Inc. | Cpf1 complexes with reduced indel activity |
| CN105861485B (zh) * | 2016-04-20 | 2021-08-17 | 上海伊丽萨生物科技有限公司 | 一种提高基因置换效率的方法 |
| PT3445406T (pt) * | 2016-04-20 | 2021-08-30 | Fundacion Instituto De Investig Sanitaria Fundacion Jimenez Diaz | Composições e métodos para potenciar a expressão de gene de pklr |
| CN116200465A (zh) | 2016-04-25 | 2023-06-02 | 哈佛学院董事及会员团体 | 用于原位分子检测的杂交链反应方法 |
| WO2017201425A1 (en) * | 2016-05-20 | 2017-11-23 | The Trustees Columbia University In The City Of New York | Anabolic enhancers for ameliorating neurodegeneration |
| US11098033B2 (en) | 2016-05-24 | 2021-08-24 | Indiana University Research And Technology Corporation | Ku inhibitors and their use |
| GB201609811D0 (en) | 2016-06-05 | 2016-07-20 | Snipr Technologies Ltd | Methods, cells, systems, arrays, RNA and kits |
| US10767175B2 (en) | 2016-06-08 | 2020-09-08 | Agilent Technologies, Inc. | High specificity genome editing using chemically modified guide RNAs |
| WO2017219027A1 (en) | 2016-06-17 | 2017-12-21 | The Broad Institute Inc. | Type vi crispr orthologs and systems |
| WO2017223128A1 (en) | 2016-06-21 | 2017-12-28 | The Curators Of The University Of Missouri | Modified dystrophin proteins |
| JP2019518478A (ja) | 2016-06-24 | 2019-07-04 | ザ リージェンツ オブ ザ ユニバーシティ オブ コロラド,ア ボディー コーポレイトTHE REGENTS OF THE UNIVERSITY OF COLORADO,a body corporate | バーコードを付けたコンビナトリアルライブラリーを生成する方法 |
| US11471462B2 (en) | 2016-06-27 | 2022-10-18 | The Broad Institute, Inc. | Compositions and methods for detecting and treating diabetes |
| KR102345898B1 (ko) | 2016-06-30 | 2022-01-03 | 지머젠 인코포레이티드 | 글루코오스 투과 효소 라이브러리를 생성하는 방법 및 이의 용도 |
| WO2018005655A2 (en) | 2016-06-30 | 2018-01-04 | Zymergen Inc. | Methods for generating a bacterial hemoglobin library and uses thereof |
| WO2018005117A1 (en) | 2016-07-01 | 2018-01-04 | Microsoft Technology Licensing, Llc | Storage through iterative dna editing |
| US11359234B2 (en) | 2016-07-01 | 2022-06-14 | Microsoft Technology Licensing, Llc | Barcoding sequences for identification of gene expression |
| US20180004537A1 (en) | 2016-07-01 | 2018-01-04 | Microsoft Technology Licensing, Llc | Molecular State Machines |
| US11124805B2 (en) | 2016-07-13 | 2021-09-21 | Vertex Pharmaceuticals Incorporated | Methods, compositions and kits for increasing genome editing efficiency |
| AU2017295886C1 (en) | 2016-07-15 | 2024-05-16 | Novartis Ag | Treatment and prevention of cytokine release syndrome using a chimeric antigen receptor in combination with a kinase inhibitor |
| BR112019001887A2 (pt) | 2016-08-02 | 2019-07-09 | Editas Medicine Inc | composições e métodos para o tratamento de doença associada a cep290 |
| US11078481B1 (en) | 2016-08-03 | 2021-08-03 | KSQ Therapeutics, Inc. | Methods for screening for cancer targets |
| IL308426A (en) | 2016-08-03 | 2024-01-01 | Harvard College | Adenosine nuclear base editors and their uses |
| US11661590B2 (en) | 2016-08-09 | 2023-05-30 | President And Fellows Of Harvard College | Programmable CAS9-recombinase fusion proteins and uses thereof |
| CN110114461A (zh) | 2016-08-17 | 2019-08-09 | 博德研究所 | 新型crispr酶和系统 |
| WO2018035364A1 (en) | 2016-08-17 | 2018-02-22 | The Broad Institute Inc. | Product and methods useful for modulating and evaluating immune responses |
| WO2018035250A1 (en) | 2016-08-17 | 2018-02-22 | The Broad Institute, Inc. | Methods for identifying class 2 crispr-cas systems |
| JP2019524149A (ja) | 2016-08-20 | 2019-09-05 | アベリノ ラボ ユーエスエー インコーポレイテッドAvellino Lab USA, Inc. | 一本鎖ガイドRNA、CRISPR/Cas9システム、及びそれらの使用方法 |
| WO2020225754A1 (en) | 2019-05-06 | 2020-11-12 | Mcmullen Tara | Crispr gene editing for autosomal dominant diseases |
| US11542509B2 (en) | 2016-08-24 | 2023-01-03 | President And Fellows Of Harvard College | Incorporation of unnatural amino acids into proteins using base editing |
| US11078483B1 (en) | 2016-09-02 | 2021-08-03 | KSQ Therapeutics, Inc. | Methods for measuring and improving CRISPR reagent function |
| US10960085B2 (en) | 2016-09-07 | 2021-03-30 | Sangamo Therapeutics, Inc. | Modulation of liver genes |
| WO2018049025A2 (en) | 2016-09-07 | 2018-03-15 | The Broad Institute Inc. | Compositions and methods for evaluating and modulating immune responses |
| IL247752A0 (en) | 2016-09-11 | 2016-11-30 | Yeda Res & Dev | Compositions and methods for modulating gene expression for site-directed mutagenesis |
| US20190225974A1 (en) | 2016-09-23 | 2019-07-25 | BASF Agricultural Solutions Seed US LLC | Targeted genome optimization in plants |
| JP2019532672A (ja) | 2016-09-28 | 2019-11-14 | ノバルティス アーゲー | 多孔質膜系巨大分子送達システム |
| JP2019532644A (ja) | 2016-09-30 | 2019-11-14 | ザ リージェンツ オブ ザ ユニバーシティ オブ カリフォルニア | Rna誘導型核酸修飾酵素及びその使用方法 |
| EP3518981A4 (en) | 2016-10-03 | 2020-06-10 | President and Fellows of Harvard College | DELIVERING THERAPEUTIC RNAS VIA ARRDC1-MEDIATED MICROVESICLES |
| US10669539B2 (en) | 2016-10-06 | 2020-06-02 | Pioneer Biolabs, Llc | Methods and compositions for generating CRISPR guide RNA libraries |
| WO2018067991A1 (en) | 2016-10-07 | 2018-04-12 | The Brigham And Women's Hospital, Inc. | Modulation of novel immune checkpoint targets |
| CA3037560A1 (en) | 2016-10-13 | 2018-04-19 | Pioneer Hi-Bred International, Inc. | Generating northern leaf blight resistant maize |
| SG11201903089RA (en) | 2016-10-14 | 2019-05-30 | Harvard College | Aav delivery of nucleobase editors |
| GB201617559D0 (en) | 2016-10-17 | 2016-11-30 | University Court Of The University Of Edinburgh The | Swine comprising modified cd163 and associated methods |
| US10738338B2 (en) | 2016-10-18 | 2020-08-11 | The Research Foundation for the State University | Method and composition for biocatalytic protein-oligonucleotide conjugation and protein-oligonucleotide conjugate |
| GB2604416B (en) | 2016-10-18 | 2023-03-15 | Univ Minnesota | Tumor infiltating lymphocytes and methods of therapy |
| WO2018081531A2 (en) | 2016-10-28 | 2018-05-03 | Ariad Pharmaceuticals, Inc. | Methods for human t-cell activation |
| CN110234762A (zh) * | 2016-10-28 | 2019-09-13 | 吉尼松公司 | 用于治疗肌强直性营养不良的组合物和方法 |
| WO2018076335A1 (en) | 2016-10-31 | 2018-05-03 | Institute Of Genetics And Developmental Biology, Chinese Academy Of Sciences | Compositions and methods for enhancing abiotic stress tolerance |
| WO2018083606A1 (en) | 2016-11-01 | 2018-05-11 | Novartis Ag | Methods and compositions for enhancing gene editing |
| CA3042259A1 (en) | 2016-11-04 | 2018-05-11 | Flagship Pioneering Innovations V. Inc. | Novel plant cells, plants, and seeds |
| EP3541955A1 (en) | 2016-11-15 | 2019-09-25 | Genomic Vision | Method for the monitoring of modified nucleases induced-gene editing events by molecular combing |
| WO2018100431A1 (en) | 2016-11-29 | 2018-06-07 | Genomic Vision | Method for designing a set of polynucleotide sequences for analysis of specific events in a genetic region of interest |
| US9816093B1 (en) | 2016-12-06 | 2017-11-14 | Caribou Biosciences, Inc. | Engineered nucleic acid-targeting nucleic acids |
| US11180535B1 (en) | 2016-12-07 | 2021-11-23 | David Gordon Bermudes | Saccharide binding, tumor penetration, and cytotoxic antitumor chimeric peptides from therapeutic bacteria |
| US11129906B1 (en) | 2016-12-07 | 2021-09-28 | David Gordon Bermudes | Chimeric protein toxins for expression by therapeutic bacteria |
| WO2018112282A1 (en) | 2016-12-14 | 2018-06-21 | Ligandal, Inc. | Compositions and methods for nucleic acid and/or protein payload delivery |
| WO2018119359A1 (en) | 2016-12-23 | 2018-06-28 | President And Fellows Of Harvard College | Editing of ccr5 receptor gene to protect against hiv infection |
| US12065666B2 (en) | 2017-01-05 | 2024-08-20 | Rutgers, The State University Of New Jersey | Targeted gene editing platform independent of DNA double strand break and uses thereof |
| WO2018127585A1 (en) | 2017-01-06 | 2018-07-12 | Txcell | Monospecific regulatory t cell population with cytotoxicity for b cells |
| EP4095263A1 (en) | 2017-01-06 | 2022-11-30 | Editas Medicine, Inc. | Methods of assessing nuclease cleavage |
| EP3346001A1 (en) | 2017-01-06 | 2018-07-11 | TXCell | Monospecific regulatory t cell population with cytotoxicity for b cells |
| US11519009B2 (en) | 2017-01-09 | 2022-12-06 | University Of Massachusetts | Complexes for gene deletion and editing |
| CN110799474B (zh) | 2017-01-12 | 2022-07-26 | 皮沃特生物公司 | 用于改良植物性状的方法及组合物 |
| ES2912408T3 (es) | 2017-01-26 | 2022-05-25 | Novartis Ag | Composiciones de CD28 y métodos para terapia con receptores quiméricos para antígenos |
| US11624071B2 (en) | 2017-01-28 | 2023-04-11 | Inari Agriculture Technology, Inc. | Method of creating a plurality of targeted insertions in a plant cell |
| CN110582509A (zh) | 2017-01-31 | 2019-12-17 | 诺华股份有限公司 | 使用具有多特异性的嵌合t细胞受体蛋白治疗癌症 |
| TW201839136A (zh) | 2017-02-06 | 2018-11-01 | 瑞士商諾華公司 | 治療血色素異常症之組合物及方法 |
| KR20190116282A (ko) | 2017-02-10 | 2019-10-14 | 지머젠 인코포레이티드 | 복수의 숙주를 위한 다중 dna 구조체의 조립 및 편집을 위한 모듈식 범용 플라스미드 디자인 전략 |
| AU2018225180B2 (en) * | 2017-02-22 | 2024-09-12 | Io Biosciences, Inc. | Nucleic acid constructs comprising gene editing multi-sites and uses thereof |
| US10828330B2 (en) | 2017-02-22 | 2020-11-10 | IO Bioscience, Inc. | Nucleic acid constructs comprising gene editing multi-sites and uses thereof |
| EP3589647A1 (en) | 2017-02-28 | 2020-01-08 | Novartis AG | Shp inhibitor compositions and uses for chimeric antigen receptor therapy |
| US11898179B2 (en) | 2017-03-09 | 2024-02-13 | President And Fellows Of Harvard College | Suppression of pain by gene editing |
| EP3592777A1 (en) | 2017-03-10 | 2020-01-15 | President and Fellows of Harvard College | Cytosine to guanine base editor |
| EP3596217A1 (en) | 2017-03-14 | 2020-01-22 | Editas Medicine, Inc. | Systems and methods for the treatment of hemoglobinopathies |
| JP2020511141A (ja) | 2017-03-15 | 2020-04-16 | ザ・ブロード・インスティテュート・インコーポレイテッド | 新規Cas13bオルソログCRISPR酵素及び系 |
| WO2018170436A1 (en) | 2017-03-16 | 2018-09-20 | Jacobs Farm Del Cabo | Basil with high tolerance to downy mildew |
| WO2018170515A1 (en) | 2017-03-17 | 2018-09-20 | The Broad Institute, Inc. | Methods for identifying and modulating co-occurant cellular phenotypes |
| JP7191388B2 (ja) | 2017-03-23 | 2022-12-19 | プレジデント アンド フェローズ オブ ハーバード カレッジ | 核酸によってプログラム可能なdna結合蛋白質を含む核酸塩基編集因子 |
| EP3601579B1 (en) | 2017-03-31 | 2023-10-04 | Pioneer Hi-Bred International, Inc. | Expression modulating elements and use thereof |
| WO2018183908A1 (en) | 2017-03-31 | 2018-10-04 | Dana-Farber Cancer Institute, Inc. | Compositions and methods for treating ovarian tumors |
| EP3606518A4 (en) | 2017-04-01 | 2021-04-07 | The Broad Institute, Inc. | METHODS AND COMPOSITIONS FOR DETECTION AND MODULATION OF IMMUNOTHERAPY RESISTANCE GENE SIGNATURE IN CANCER |
| BR112019021378A2 (pt) | 2017-04-12 | 2020-05-05 | Massachusetts Inst Technology | ortólogos de crispr tipo vi inovadores e sistemas |
| US20210115407A1 (en) | 2017-04-12 | 2021-04-22 | The Broad Institute, Inc. | Respiratory and sweat gland ionocytes |
| US20200071773A1 (en) | 2017-04-12 | 2020-03-05 | Massachusetts Eye And Ear Infirmary | Tumor signature for metastasis, compositions of matter methods of use thereof |
| US20200405639A1 (en) | 2017-04-14 | 2020-12-31 | The Broad Institute, Inc. | Novel delivery of large payloads |
| WO2018195019A1 (en) | 2017-04-18 | 2018-10-25 | The Broad Institute Inc. | Compositions for detecting secretion and methods of use |
| US11834670B2 (en) | 2017-04-19 | 2023-12-05 | Global Life Sciences Solutions Usa Llc | Site-specific DNA modification using a donor DNA repair template having tandem repeat sequences |
| US12058986B2 (en) | 2017-04-20 | 2024-08-13 | Egenesis, Inc. | Method for generating a genetically modified pig with inactivated porcine endogenous retrovirus (PERV) elements |
| WO2018195545A2 (en) | 2017-04-21 | 2018-10-25 | The General Hospital Corporation | Variants of cpf1 (cas12a) with altered pam specificity |
| EP3612232A1 (en) | 2017-04-21 | 2020-02-26 | The Broad Institute, Inc. | Targeted delivery to beta cells |
| WO2018201086A1 (en) | 2017-04-28 | 2018-11-01 | Editas Medicine, Inc. | Methods and systems for analyzing guide rna molecules |
| EP3615055A1 (en) | 2017-04-28 | 2020-03-04 | Novartis AG | Cells expressing a bcma-targeting chimeric antigen receptor, and combination therapy with a gamma secretase inhibitor |
| EP3615068A1 (en) | 2017-04-28 | 2020-03-04 | Novartis AG | Bcma-targeting agent, and combination therapy with a gamma secretase inhibitor |
| WO2018204777A2 (en) | 2017-05-05 | 2018-11-08 | The Broad Institute, Inc. | Methods for identification and modification of lncrna associated with target genotypes and phenotypes |
| EP3622070A2 (en) | 2017-05-10 | 2020-03-18 | Editas Medicine, Inc. | Crispr/rna-guided nuclease systems and methods |
| US11560566B2 (en) | 2017-05-12 | 2023-01-24 | President And Fellows Of Harvard College | Aptazyme-embedded guide RNAs for use with CRISPR-Cas9 in genome editing and transcriptional activation |
| KR102678809B1 (ko) | 2017-05-18 | 2024-06-26 | 더 브로드 인스티튜트, 인코퍼레이티드 | 표적화된 핵산 편집을 위한 시스템, 방법 및 조성물 |
| AU2018273968A1 (en) | 2017-05-25 | 2019-11-28 | The General Hospital Corporation | Using split deaminases to limit unwanted off-target base editor deamination |
| EP3409104A1 (en) | 2017-05-31 | 2018-12-05 | Vilmorin et Cie | Tomato plant resistant to tomato yellow leaf curl virus, powdery mildew, and nematodes |
| EP3409106A1 (en) | 2017-06-01 | 2018-12-05 | Vilmorin et Cie | Tolerance in plants of solanum lycopersicum to the tobamovirus tomato brown rugose fruit virus (tbrfv) |
| WO2020249996A1 (en) | 2019-06-14 | 2020-12-17 | Vilmorin & Cie | Resistance in plants of solanum lycopersicum to the tobamovirus tomato brown rugose fruit virus |
| CA3065946A1 (en) | 2017-06-05 | 2018-12-13 | Research Institute At Nationwide Children's Hospital | Enhanced modified viral capsid proteins |
| EP3635113A4 (en) | 2017-06-05 | 2021-03-17 | Fred Hutchinson Cancer Research Center | GENOMIC SAFE HARBORS FOR GENETIC THERAPIES IN HUMAN STEM CELLS AND MANIPULATED NANOPARTICLES TO DELIVER TARGETED GENETIC THERAPIES |
| WO2018226900A2 (en) | 2017-06-06 | 2018-12-13 | Zymergen Inc. | A htp genomic engineering platform for improving fungal strains |
| WO2018226880A1 (en) | 2017-06-06 | 2018-12-13 | Zymergen Inc. | A htp genomic engineering platform for improving escherichia coli |
| US11807869B2 (en) * | 2017-06-08 | 2023-11-07 | Osaka University | Method for producing DNA-edited eukaryotic cell, and kit used in the same |
| WO2018227114A1 (en) | 2017-06-09 | 2018-12-13 | Editas Medicine, Inc. | Engineered cas9 nucleases |
| WO2018226972A2 (en) | 2017-06-09 | 2018-12-13 | Vilmorin & Cie | Compositions and methods for genome editing |
| BR112019026226A2 (pt) | 2017-06-13 | 2020-06-30 | Flagship Pioneering Innovations V, Inc. | composições compreendendo curóns e usos dos mesmos |
| WO2018232195A1 (en) | 2017-06-14 | 2018-12-20 | The Broad Institute, Inc. | Compositions and methods targeting complement component 3 for inhibiting tumor growth |
| MX2019015188A (es) | 2017-06-15 | 2020-08-03 | Univ California | Inserciones de adn no virales orientadas. |
| US9982279B1 (en) | 2017-06-23 | 2018-05-29 | Inscripta, Inc. | Nucleic acid-guided nucleases |
| US10011849B1 (en) | 2017-06-23 | 2018-07-03 | Inscripta, Inc. | Nucleic acid-guided nucleases |
| CA3064601A1 (en) | 2017-06-26 | 2019-01-03 | The Broad Institute, Inc. | Crispr/cas-adenine deaminase based compositions, systems, and methods for targeted nucleic acid editing |
| WO2019003193A1 (en) | 2017-06-30 | 2019-01-03 | Novartis Ag | METHODS FOR TREATING DISEASES USING GENE EDITING SYSTEMS |
| EP3645021A4 (en) | 2017-06-30 | 2021-04-21 | Intima Bioscience, Inc. | ADENO-ASSOCIATED VIRAL VECTORS FOR GENE THERAPY |
| US10392616B2 (en) | 2017-06-30 | 2019-08-27 | Arbor Biotechnologies, Inc. | CRISPR RNA targeting enzymes and systems and uses thereof |
| WO2019014581A1 (en) | 2017-07-14 | 2019-01-17 | The Broad Institute, Inc. | METHODS AND COMPOSITIONS FOR MODULATING THE ACTIVITY OF A CYTOTOXIC LYMPHOCYTE |
| US11866726B2 (en) | 2017-07-14 | 2024-01-09 | Editas Medicine, Inc. | Systems and methods for targeted integration and genome editing and detection thereof using integrated priming sites |
| US12105089B2 (en) | 2017-07-17 | 2024-10-01 | The Broad Institute, Inc. | Cell atlas of the healthy and ulcerative colitis human colon |
| US10510743B2 (en) * | 2017-07-18 | 2019-12-17 | Hong Kong Applied Science and Technology Research Institute Company, Limited | Step fin field-effect-transistor (FinFET) with slim top of fin and thick bottom of fin for electro-static-discharge (ESD) or electrical over-stress (EOS) protection |
| CN111315883B (zh) * | 2017-07-18 | 2024-06-18 | 杰诺维有限公司 | 用于全长t细胞受体可读框的快速装配和多样化的两组分载体文库系统 |
| WO2019023291A2 (en) | 2017-07-25 | 2019-01-31 | Dana-Farber Cancer Institute, Inc. | COMPOSITIONS AND METHODS FOR PRODUCTION AND DECODING OF GUIDE RNA LIBRARIES AND USES THEREOF |
| CN111801345A (zh) | 2017-07-28 | 2020-10-20 | 哈佛大学的校长及成员们 | 使用噬菌体辅助连续进化(pace)的进化碱基编辑器的方法和组合物 |
| EP3950957A1 (en) | 2017-08-08 | 2022-02-09 | Depixus | In vitro isolation and enrichment of nucleic acids using site-specific nucleases |
| US11970720B2 (en) | 2017-08-22 | 2024-04-30 | Salk Institute For Biological Studies | RNA targeting methods and compositions |
| US10476825B2 (en) | 2017-08-22 | 2019-11-12 | Salk Institue for Biological Studies | RNA targeting methods and compositions |
| BR112020003596A2 (pt) | 2017-08-23 | 2020-09-01 | The General Hospital Corporation | nucleases de crispr-cas9 engenheiradas com especificidade de pam alterada |
| SG11202001008RA (en) * | 2017-08-25 | 2020-03-30 | Codiak Biosciences Inc | Preparation of therapeutic exosomes using membrane proteins |
| US11319532B2 (en) | 2017-08-30 | 2022-05-03 | President And Fellows Of Harvard College | High efficiency base editors comprising Gam |
| WO2019055838A1 (en) | 2017-09-15 | 2019-03-21 | Covercress Inc. | LOW-FIBER-BASED ECO-BASED FOOD AND METHODS OF PREPARATION |
| EP3684821A4 (en) | 2017-09-19 | 2021-06-16 | The University Of British Columbia | ANTI-HLA-A2 ANTIBODIES AND METHOD OF USING THEREOF |
| CN109517820B (zh) | 2017-09-20 | 2021-09-24 | 北京宇繁生物科技有限公司 | 一种靶向HPK1的gRNA以及HPK1基因编辑方法 |
| SG11202002532XA (en) | 2017-09-20 | 2020-04-29 | Univ British Columbia | Novel anti-hla-a2 antibodies and uses thereof |
| EP3684397A4 (en) | 2017-09-21 | 2021-08-18 | The Broad Institute, Inc. | SYSTEMS, METHODS AND COMPOSITIONS FOR TARGETED EDITION OF NUCLEIC ACIDS |
| WO2019060759A1 (en) | 2017-09-21 | 2019-03-28 | Dana-Farber Cancer Institute, Inc. | ISOLATION, PRESERVATION, COMPOSITIONS AND USES OF PLANT EXTRACTS JUSTICIA |
| US11252928B2 (en) | 2017-09-21 | 2022-02-22 | The Condard-Pyle Company | Miniature rose plant named ‘Meibenbino’ |
| US11917978B2 (en) | 2017-09-21 | 2024-03-05 | The Conard Pyle Company | Miniature rose plant named ‘meibenbino’ |
| WO2019070755A1 (en) | 2017-10-02 | 2019-04-11 | The Broad Institute, Inc. | METHODS AND COMPOSITIONS FOR DETECTING AND MODULATING A GENETIC SIGNATURE OF IMMUNOTHERAPY RESISTANCE IN CANCER |
| WO2019071054A1 (en) | 2017-10-04 | 2019-04-11 | The Broad Institute, Inc. | METHODS AND COMPOSITIONS FOR MODIFYING THE FUNCTION AND STRUCTURE OF BUCKLES AND / OR CHROMATIN DOMAINS |
| EP3694993A4 (en) | 2017-10-11 | 2021-10-13 | The General Hospital Corporation | METHOD OF DETECTING A SITE-SPECIFIC AND UNDESIRED GENOMIC DESAMINATION INDUCED BY BASE EDITING TECHNOLOGIES |
| CN111757937A (zh) | 2017-10-16 | 2020-10-09 | 布罗德研究所股份有限公司 | 腺苷碱基编辑器的用途 |
| WO2019079362A1 (en) | 2017-10-16 | 2019-04-25 | Massachusetts Institute Of Technology | HOST-PATHOGENIC INTERACTION OF MYCOBACTERIUM TUBERCULOSIS |
| JP7403461B2 (ja) | 2017-10-16 | 2023-12-22 | セントロ デ インベスティガシオンス エネルジェチカス メディオアンビエンタゥス イェ テクノロジカス オー.エイ. エム.ピー. | ピルビン酸キナーゼ欠損症を治療するためのpklr送達用レンチウイルスベクター |
| WO2019079772A1 (en) | 2017-10-20 | 2019-04-25 | Fred Hutchinson Cancer Research Center | SYSTEMS AND METHODS FOR GENETICALLY MODIFIED B-LYMPHOCYTES FOR EXPRESSING SELECTED ANTIBODIES |
| CN111587287A (zh) | 2017-10-25 | 2020-08-25 | 皮沃特生物股份有限公司 | 用于改良固氮的工程微生物的方法和组合物 |
| IL274179B2 (en) | 2017-10-27 | 2024-02-01 | Univ California | Targeted replacement of endogenous T cell receptors |
| US11547614B2 (en) | 2017-10-31 | 2023-01-10 | The Broad Institute, Inc. | Methods and compositions for studying cell evolution |
| WO2019089798A1 (en) | 2017-10-31 | 2019-05-09 | Novartis Ag | Anti-car compositions and methods |
| JP2021503278A (ja) | 2017-11-01 | 2021-02-12 | ザ リージェンツ オブ ザ ユニバーシティ オブ カリフォルニア | CasZ組成物及び使用方法 |
| EP3704245A1 (en) | 2017-11-01 | 2020-09-09 | Novartis AG | Synthetic rnas and methods of use |
| WO2019090173A1 (en) | 2017-11-02 | 2019-05-09 | Arbor Biotechnologies, Inc. | Novel crispr-associated transposon systems and components |
| EP3710039A4 (en) | 2017-11-13 | 2021-08-04 | The Broad Institute, Inc. | METHODS AND COMPOSITIONS FOR CANCER TREATMENT BY TARGETING THE CLEC2D-KLRB1 PATH |
| CR20200251A (es) | 2017-11-17 | 2020-07-17 | Iovance Biotherapeutics Inc | Expansión de til de aspirados con aguja fina y biopsias por punción |
| JP2021503885A (ja) | 2017-11-22 | 2021-02-15 | アイオバンス バイオセラピューティクス,インコーポレイテッド | 末梢血からの末梢血リンパ球(pbl)の拡大培養 |
| US11098328B2 (en) | 2017-12-05 | 2021-08-24 | Synthetic Genomics, Inc. | Algal lipid productivity via genetic modification of a signaling protein |
| WO2019113506A1 (en) | 2017-12-07 | 2019-06-13 | The Broad Institute, Inc. | Methods and compositions for multiplexing single cell and single nuclei sequencing |
| EP3720869A4 (en) | 2017-12-08 | 2021-11-24 | Synthetic Genomics, Inc. | IMPROVEMENT OF ALGAE LIPID PRODUCTIVITY BY GENETIC MODIFICATION OF A PROTEIN CONTAINING A TPR DOMAIN |
| WO2019118893A1 (en) | 2017-12-15 | 2019-06-20 | Dana-Farber Cancer Institute, Inc. | Stabilized peptide-mediated targeted protein degradation |
| AU2018386002B2 (en) | 2017-12-15 | 2024-07-25 | Danisco Us Inc | CAS9 variants and methods of use |
| BR112020013131A2 (pt) | 2017-12-28 | 2020-12-08 | Codiak Biosciences, Inc. | Exossomos para imuno-oncologia e terapia anti-inflamatória |
| WO2019133881A1 (en) | 2017-12-29 | 2019-07-04 | Rubius Therapeutics, Inc. | Gene editing and targeted transcriptional modulation for enginerering erythroid cells |
| US11994512B2 (en) | 2018-01-04 | 2024-05-28 | Massachusetts Institute Of Technology | Single-cell genomic methods to generate ex vivo cell systems that recapitulate in vivo biology with improved fidelity |
| CN111566121A (zh) | 2018-01-12 | 2020-08-21 | 巴斯夫欧洲公司 | 小麦7a染色体上决定每穗小穗数QTL的基因 |
| CA3088791A1 (en) | 2018-01-17 | 2019-07-25 | Vertex Pharmaceuticals Incorporated | Quinoxalinone compounds, compositions, methods, and kits for increasing genome editing efficiency |
| MA51619A (fr) | 2018-01-17 | 2021-04-14 | Vertex Pharma | Inhibiteurs de la protéine kinase dépendante de l'adn |
| CN111741955B (zh) | 2018-01-17 | 2024-02-23 | 沃泰克斯药物股份有限公司 | Dna-pk抑制剂 |
| US20210084936A1 (en) | 2018-01-19 | 2021-03-25 | Covercress Inc. | Low glucosinolate pennycress meal and methods of making |
| WO2019147743A1 (en) | 2018-01-26 | 2019-08-01 | Massachusetts Institute Of Technology | Structure-guided chemical modification of guide rna and its applications |
| US11926835B1 (en) | 2018-01-29 | 2024-03-12 | Inari Agriculture Technology, Inc. | Methods for efficient tomato genome editing |
| KR20200119239A (ko) | 2018-02-08 | 2020-10-19 | 지머젠 인코포레이티드 | 코리네박테리움에서 crispr을 사용하는 게놈 편집 |
| KR102465067B1 (ko) * | 2018-02-15 | 2022-11-10 | 시그마-알드리치 컴퍼니., 엘엘씨 | 진핵 게놈 변형을 위한 조작된 cas9 시스템 |
| WO2019165168A1 (en) | 2018-02-23 | 2019-08-29 | Pioneer Hi-Bred International, Inc. | Novel cas9 orthologs |
| WO2019173125A1 (en) | 2018-03-09 | 2019-09-12 | Pioneer Hi-Bred International, Inc. | Compositions and methods for modification of fatty acids in soybean |
| SG11202008956XA (en) | 2018-03-14 | 2020-10-29 | Editas Medicine Inc | Systems and methods for the treatment of hemoglobinopathies |
| DE202019005567U1 (de) | 2018-03-14 | 2021-02-16 | Arbor Biotechnologies, Inc. | Neue CRISPR-DNA-Targeting-Enzyme und -Systeme |
| WO2019178428A1 (en) | 2018-03-14 | 2019-09-19 | Arbor Biotechnologies, Inc. | Novel crispr dna and rna targeting enzymes and systems |
| US10760075B2 (en) | 2018-04-30 | 2020-09-01 | Snipr Biome Aps | Treating and preventing microbial infections |
| KR20200141470A (ko) | 2018-04-06 | 2020-12-18 | 칠드런'즈 메디컬 센터 코포레이션 | 체세포 재프로그래밍 및 각인의 조정을 위한 조성물 및 방법 |
| AU2019250692A1 (en) | 2018-04-13 | 2020-11-05 | Sangamo Therapeutics France | Chimeric antigen receptor specific for Interleukin-23 receptor |
| WO2019204378A1 (en) | 2018-04-17 | 2019-10-24 | The General Hospital Corporation | Sensitive in vitro assays for substrate preferences and sites of nucleic acid binding, modifying, and cleaving agents |
| JP7555822B2 (ja) | 2018-04-19 | 2024-09-25 | ザ・リージエンツ・オブ・ザ・ユニバーシテイー・オブ・カリフオルニア | ゲノム編集のための組成物および方法 |
| WO2019204585A1 (en) | 2018-04-19 | 2019-10-24 | Massachusetts Institute Of Technology | Single-stranded break detection in double-stranded dna |
| SI3560330T1 (sl) | 2018-04-24 | 2022-08-31 | KWS SAAT SE & Co. KGaA | Rastline z izboljšano prebavljivostjo in markerskimi haplotipi |
| US11957695B2 (en) | 2018-04-26 | 2024-04-16 | The Broad Institute, Inc. | Methods and compositions targeting glucocorticoid signaling for modulating immune responses |
| WO2019210153A1 (en) | 2018-04-27 | 2019-10-31 | Novartis Ag | Car t cell therapies with enhanced efficacy |
| US20210147831A1 (en) | 2018-04-27 | 2021-05-20 | The Broad Institute, Inc. | Sequencing-based proteomics |
| AU2019261647A1 (en) | 2018-04-27 | 2020-11-26 | Genedit Inc. | Cationic polymer and use for biomolecule delivery |
| SG11202010319RA (en) | 2018-04-27 | 2020-11-27 | Iovance Biotherapeutics Inc | Closed process for expansion and gene editing of tumor infiltrating lymphocytes and uses of same in immunotherapy |
| WO2019213660A2 (en) | 2018-05-04 | 2019-11-07 | The Broad Institute, Inc. | Compositions and methods for modulating cgrp signaling to regulate innate lymphoid cell inflammatory responses |
| US20210198664A1 (en) | 2018-05-16 | 2021-07-01 | Arbor Biotechnologies, Inc. | Novel crispr-associated systems and components |
| KR20210045360A (ko) | 2018-05-16 | 2021-04-26 | 신테고 코포레이션 | 가이드 rna 설계 및 사용을 위한 방법 및 시스템 |
| EP3802887A2 (en) | 2018-05-25 | 2021-04-14 | Pioneer Hi-Bred International, Inc. | Systems and methods for improved breeding by modulating recombination rates |
| CN108707628B (zh) * | 2018-05-28 | 2021-11-23 | 上海海洋大学 | 斑马鱼notch2基因突变体的制备方法 |
| US20210371932A1 (en) | 2018-06-01 | 2021-12-02 | Massachusetts Institute Of Technology | Methods and compositions for detecting and modulating microenvironment gene signatures from the csf of metastasis patients |
| US11866719B1 (en) | 2018-06-04 | 2024-01-09 | Inari Agriculture Technology, Inc. | Heterologous integration of regulatory elements to alter gene expression in wheat cells and wheat plants |
| EP3578658A1 (en) * | 2018-06-08 | 2019-12-11 | Johann Wolfgang Goethe-Universität Frankfurt | Method for generating a gene editing vector with fixed guide rna pairs |
| US20220403001A1 (en) | 2018-06-12 | 2022-12-22 | Obsidian Therapeutics, Inc. | Pde5 derived regulatory constructs and methods of use in immunotherapy |
| TW202016139A (zh) | 2018-06-13 | 2020-05-01 | 瑞士商諾華公司 | Bcma 嵌合抗原受體及其用途 |
| US12036240B2 (en) | 2018-06-14 | 2024-07-16 | The Broad Institute, Inc. | Compositions and methods targeting complement component 3 for inhibiting tumor growth |
| EP3813949B1 (en) * | 2018-06-19 | 2024-05-29 | Lunella Biotech, Inc. | Energetic" cancer stem cells (e-cscs): a new hyper-metabolic and proliferative tumor cell phenotype, driven by mitochondrial energy |
| WO2020006049A1 (en) | 2018-06-26 | 2020-01-02 | The Broad Institute, Inc. | Crispr/cas and transposase based amplification compositions, systems and methods |
| US20210269866A1 (en) | 2018-06-26 | 2021-09-02 | The Broad Institute, Inc. | Crispr effector system based amplification methods, systems, and diagnostics |
| CN112739668A (zh) | 2018-06-27 | 2021-04-30 | 皮沃特生物股份有限公司 | 包括重构固氮微生物的农业组合物 |
| EP3814369A1 (en) | 2018-06-29 | 2021-05-05 | Stichting Het Nederlands Kanker Instituut- Antoni van Leeuwenhoek Ziekenhuis | Tweak-receptor agonists for use in combination with immunotherapy of a cancer |
| EP3821012A4 (en) | 2018-07-13 | 2022-04-20 | The Regents of The University of California | RETROTRANSPOSON-BASED DELIVERY VEHICLE AND METHOD OF USE THEREOF |
| WO2020018142A1 (en) | 2018-07-16 | 2020-01-23 | Arbor Biotechnologies, Inc. | Novel crispr dna targeting enzymes and systems |
| CN113348245A (zh) | 2018-07-31 | 2021-09-03 | 博德研究所 | 新型crispr酶和系统 |
| EP4442836A2 (en) | 2018-08-01 | 2024-10-09 | Mammoth Biosciences, Inc. | Programmable nuclease compositions and methods of use thereof |
| EP3833761A1 (en) | 2018-08-07 | 2021-06-16 | The Broad Institute, Inc. | Novel cas12b enzymes and systems |
| MX2021001592A (es) | 2018-08-10 | 2021-09-21 | Sangamo Therapeutics France | Nuevas construcciones de car que comprenden dominios de tnfr2. |
| EP3607819A1 (en) | 2018-08-10 | 2020-02-12 | Vilmorin et Cie | Resistance to xanthomonas campestris pv. campestris (xcc) in cauliflower |
| EP3821020A4 (en) | 2018-08-15 | 2022-05-04 | Zymergen Inc. | APPLICATIONS OF CRISPRI IN HIGH-THROUGHPUT METABOLIC ENGINEERING |
| US20210324357A1 (en) | 2018-08-20 | 2021-10-21 | The Brigham And Women's Hospital, Inc. | Degradation domain modifications for spatio-temporal control of rna-guided nucleases |
| US20210317429A1 (en) | 2018-08-20 | 2021-10-14 | The Broad Institute, Inc. | Methods and compositions for optochemical control of crispr-cas9 |
| AU2019326408A1 (en) | 2018-08-23 | 2021-03-11 | Sangamo Therapeutics, Inc. | Engineered target specific base editors |
| US11459551B1 (en) | 2018-08-31 | 2022-10-04 | Inari Agriculture Technology, Inc. | Compositions, systems, and methods for genome editing |
| WO2020051507A1 (en) | 2018-09-06 | 2020-03-12 | The Broad Institute, Inc. | Nucleic acid assemblies for use in targeted delivery |
| EP3849565A4 (en) | 2018-09-12 | 2022-12-28 | Fred Hutchinson Cancer Research Center | REDUCING CD33 EXPRESSION FOR SELECTIVE PROTECTION OF THERAPEUTIC CELLS |
| CA3113095A1 (en) | 2018-09-18 | 2020-03-26 | Vnv Newco Inc. | Arc-based capsids and uses thereof |
| CN109265562B (zh) * | 2018-09-26 | 2021-03-30 | 北京市农林科学院 | 一种切刻酶及其在基因组碱基替换中的应用 |
| GB201815820D0 (en) | 2018-09-28 | 2018-11-14 | Univ Wageningen | Off-target activity inhibitors for guided endonucleases |
| EP3861120A4 (en) | 2018-10-01 | 2023-08-16 | North Carolina State University | RECOMBINANT TYPE I CRISPR-CAS SYSTEM |
| WO2020076976A1 (en) | 2018-10-10 | 2020-04-16 | Readcoor, Inc. | Three-dimensional spatial molecular indexing |
| WO2020077236A1 (en) | 2018-10-12 | 2020-04-16 | The Broad Institute, Inc. | Method for extracting nuclei or whole cells from formalin-fixed paraffin-embedded tissues |
| US11851663B2 (en) | 2018-10-14 | 2023-12-26 | Snipr Biome Aps | Single-vector type I vectors |
| WO2020081730A2 (en) | 2018-10-16 | 2020-04-23 | Massachusetts Institute Of Technology | Methods and compositions for modulating microenvironment |
| WO2020086742A1 (en) | 2018-10-24 | 2020-04-30 | Obsidian Therapeutics, Inc. | Er tunable protein regulation |
| EP3870628B1 (en) | 2018-10-24 | 2024-04-03 | Genedit Inc. | Cationic polymer with alkyl side chains and use for biomolecule delivery |
| US11407995B1 (en) | 2018-10-26 | 2022-08-09 | Inari Agriculture Technology, Inc. | RNA-guided nucleases and DNA binding proteins |
| SG11202104347UA (en) * | 2018-10-29 | 2021-05-28 | Univ China Agricultural | Novel crispr/cas12f enzyme and system |
| CA3117805A1 (en) | 2018-10-31 | 2020-05-07 | Zymergen Inc. | Multiplexed deterministic assembly of dna libraries |
| KR20210084557A (ko) | 2018-10-31 | 2021-07-07 | 파이어니어 하이 부렛드 인터내쇼날 인코포레이팃드 | 오크로박트럼-매개 유전자 편집을 위한 조성물 및 방법 |
| US11970733B2 (en) | 2018-11-01 | 2024-04-30 | Synthego Corporation | Methods for analyzing nucleic acid sequences |
| US11434477B1 (en) | 2018-11-02 | 2022-09-06 | Inari Agriculture Technology, Inc. | RNA-guided nucleases and DNA binding proteins |
| TW202039829A (zh) | 2018-11-05 | 2020-11-01 | 美商艾歐凡斯生物治療公司 | 改善之腫瘤反應性t細胞的選擇 |
| MX2021005216A (es) | 2018-11-05 | 2021-06-18 | Iovance Biotherapeutics Inc | Procesos para la produccion de linfocitos infiltrantes de tumor y usos de los mismos en inmunoterapia. |
| CA3118493A1 (en) | 2018-11-05 | 2020-05-14 | Iovance Biotherapeutics, Inc. | Expansion of tils utilizing akt pathway inhibitors |
| JP2022512899A (ja) | 2018-11-05 | 2022-02-07 | アイオバンス バイオセラピューティクス,インコーポレイテッド | 抗pd-1抗体に対して不応性のnsclc患者の治療 |
| WO2020102659A1 (en) | 2018-11-15 | 2020-05-22 | The Broad Institute, Inc. | G-to-t base editors and uses thereof |
| US11166996B2 (en) | 2018-12-12 | 2021-11-09 | Flagship Pioneering Innovations V, Inc. | Anellovirus compositions and methods of use |
| CN113166744A (zh) | 2018-12-14 | 2021-07-23 | 先锋国际良种公司 | 用于基因组编辑的新颖crispr-cas系统 |
| CA3124110A1 (en) | 2018-12-17 | 2020-06-25 | The Broad Institute, Inc. | Crispr-associated transposase systems and methods of use thereof |
| WO2020131586A2 (en) | 2018-12-17 | 2020-06-25 | The Broad Institute, Inc. | Methods for identifying neoantigens |
| BR112021011629A2 (pt) | 2018-12-18 | 2021-09-08 | Braskem S.A. | Via de coprodução de derivados de 3-hp e acetil-coa a partir de malonato semialdeído |
| EP3898949A1 (en) | 2018-12-19 | 2021-10-27 | Iovance Biotherapeutics, Inc. | Methods of expanding tumor infiltrating lymphocytes using engineered cytokine receptor pairs and uses thereof |
| US20220017911A1 (en) | 2018-12-21 | 2022-01-20 | Pivot Bio, Inc. | Methods, compositions, and media for improving plant traits |
| BR112021012231A2 (pt) | 2018-12-28 | 2021-09-28 | Braskem S.A. | Modulação do fluxo de carbono através das vias de meg e c3 para a produção melhorada de monoetileno glicol e compostos c3 |
| US20220073626A1 (en) | 2019-01-03 | 2022-03-10 | Institut National De La Santé Et De La Recheche Médicale (Inserm) | Methods and pharmaceutical compositions for enhancing cd8+ t cell-dependent immune responses in subjects suffering from cancer |
| EP3931313A2 (en) | 2019-01-04 | 2022-01-05 | Mammoth Biosciences, Inc. | Programmable nuclease improvements and compositions and methods for nucleic acid amplification and detection |
| US11739156B2 (en) | 2019-01-06 | 2023-08-29 | The Broad Institute, Inc. Massachusetts Institute of Technology | Methods and compositions for overcoming immunosuppression |
| EP3911746A1 (en) | 2019-01-14 | 2021-11-24 | Institut National de la Santé et de la Recherche Médicale (INSERM) | Methods and kits for generating and selecting a variant of a binding protein with increased binding affinity and/or specificity |
| EP3921417A4 (en) | 2019-02-04 | 2022-11-09 | The General Hospital Corporation | ADENINE DNA BASE EDITOR VARIANTS WITH REDUCED OFF-TARGET RNA EDITING |
| EP3921416A1 (en) | 2019-02-06 | 2021-12-15 | Fred Hutchinson Cancer Research Center | Minicircle producing bacteria engineered to differentially methylate nucleic acid molecules therein |
| US20220145330A1 (en) | 2019-02-10 | 2022-05-12 | The J. David Gladstone Institutes, a testamentary trust established under the Will of J. David Glads | Modified mitochondrion and methods of use thereof |
| KR20210136044A (ko) | 2019-03-01 | 2021-11-16 | 브라스켐 에세.아. | 4-하이드록시메틸푸르푸랄 및 그 유도체의 생체 내 합성 방법 |
| CN110177061B (zh) * | 2019-03-01 | 2023-04-07 | 致讯科技(天津)有限公司 | 一种异构网络中信号干扰的协调方法 |
| US20220133795A1 (en) | 2019-03-01 | 2022-05-05 | Iovance Biotherapeutics, Inc. | Expansion of Tumor Infiltrating Lymphocytes From Liquid Tumors and Therapeutic Uses Thereof |
| WO2020181195A1 (en) | 2019-03-06 | 2020-09-10 | The Broad Institute, Inc. | T:a to a:t base editing through adenine excision |
| WO2020181180A1 (en) | 2019-03-06 | 2020-09-10 | The Broad Institute, Inc. | A:t to c:g base editors and uses thereof |
| WO2020181178A1 (en) | 2019-03-06 | 2020-09-10 | The Broad Institute, Inc. | T:a to a:t base editing through thymine alkylation |
| WO2020181202A1 (en) | 2019-03-06 | 2020-09-10 | The Broad Institute, Inc. | A:t to t:a base editing through adenine deamination and oxidation |
| US20220170013A1 (en) | 2019-03-06 | 2022-06-02 | The Broad Institute, Inc. | T:a to a:t base editing through adenosine methylation |
| CA3130789A1 (en) | 2019-03-07 | 2020-09-10 | The Regents Of The University Of California | Crispr-cas effector polypeptides and methods of use thereof |
| US11053515B2 (en) | 2019-03-08 | 2021-07-06 | Zymergen Inc. | Pooled genome editing in microbes |
| EP3935159A1 (en) | 2019-03-08 | 2022-01-12 | Obsidian Therapeutics, Inc. | Human carbonic anhydrase 2 compositions and methods for tunable regulation |
| CN113728106A (zh) | 2019-03-08 | 2021-11-30 | 齐默尔根公司 | 微生物中的迭代基因组编辑 |
| IL286357B2 (en) | 2019-03-18 | 2024-10-01 | Regeneron Pharmaceuticals Inc | A CRISPR/CAS screening platform to identify genetic modifiers of tau seeding or aggregation |
| WO2020190927A1 (en) | 2019-03-18 | 2020-09-24 | Regeneron Pharmaceuticals, Inc. | Crispr/cas dropout screening platform to reveal genetic vulnerabilities associated with tau aggregation |
| WO2020191243A1 (en) | 2019-03-19 | 2020-09-24 | The Broad Institute, Inc. | Methods and compositions for editing nucleotide sequences |
| US20220162649A1 (en) | 2019-04-01 | 2022-05-26 | The Broad Institute, Inc. | Novel nucleic acid modifiers |
| RU2710731C1 (ru) * | 2019-04-02 | 2020-01-10 | Общество с ограниченной ответственностью "Зеленые линии" | Система редактирования генома дрожжей debaryomyces hansenii на основе crispr/cas9 |
| US11746361B2 (en) | 2019-04-04 | 2023-09-05 | Braskem S.A. | Metabolic engineering for simultaneous consumption of Xylose and glucose for production of chemicals from second generation sugars |
| WO2020214842A1 (en) | 2019-04-17 | 2020-10-22 | The Broad Institute, Inc. | Adenine base editors with reduced off-target effects |
| US20220340711A1 (en) | 2019-04-23 | 2022-10-27 | GenEdit, Inc. | Cationic polymer with alkyl side chains |
| CA3137739A1 (en) | 2019-04-24 | 2020-10-29 | Pivot Bio, Inc. | Gene targets for nitrogen fixation targeting for improving plant traits |
| WO2020219742A1 (en) | 2019-04-24 | 2020-10-29 | Novartis Ag | Compositions and methods for selective protein degradation |
| US20220220495A1 (en) | 2019-05-10 | 2022-07-14 | Basf Se | Regulatory nucleic acid molecules for enhancing gene expression in plants |
| US20220249559A1 (en) | 2019-05-13 | 2022-08-11 | Iovance Biotherapeutics, Inc. | Methods and compositions for selecting tumor infiltrating lymphocytes and uses of the same in immunotherapy |
| EP3969607A1 (en) | 2019-05-13 | 2022-03-23 | KWS SAAT SE & Co. KGaA | Drought tolerance in corn |
| US20220220469A1 (en) | 2019-05-20 | 2022-07-14 | The Broad Institute, Inc. | Non-class i multi-component nucleic acid targeting systems |
| WO2020236967A1 (en) | 2019-05-20 | 2020-11-26 | The Broad Institute, Inc. | Random crispr-cas deletion mutant |
| WO2020236982A1 (en) | 2019-05-20 | 2020-11-26 | The Broad Institute, Inc. | Aav delivery of nucleobase editors |
| AR118995A1 (es) | 2019-05-25 | 2021-11-17 | Kws Saat Se & Co Kgaa | Mejorador de la inducción de haploides |
| WO2020243370A1 (en) | 2019-05-28 | 2020-12-03 | Genedit Inc. | Polymer comprising multiple functionalized sidechains for biomolecule delivery |
| WO2020243661A1 (en) | 2019-05-31 | 2020-12-03 | The Broad Institute, Inc. | Methods for treating metabolic disorders by targeting adcy5 |
| WO2020247321A1 (en) * | 2019-06-01 | 2020-12-10 | Sivec Biotechnologies, Llc | A bacterial platform for delivery of gene-editing systems to eukaryotic cells |
| WO2020244759A1 (en) | 2019-06-05 | 2020-12-10 | Klemm & Sohn Gmbh & Co. Kg | New plants having a white foliage phenotype |
| WO2020252340A1 (en) | 2019-06-14 | 2020-12-17 | Regeneron Pharmaceuticals, Inc. | Models of tauopathy |
| WO2020254850A1 (en) | 2019-06-21 | 2020-12-24 | Vilmorin & Cie | Improvement of quality and permanence of green color of peppers at maturity and over-maturity |
| JP2022539343A (ja) | 2019-06-24 | 2022-09-08 | プロメガ コーポレイション | 細胞中に生体分子を送達するための修飾ポリアミンポリマー |
| JP2022539338A (ja) | 2019-06-25 | 2022-09-08 | イナリ アグリカルチャー テクノロジー, インコーポレイテッド | 改良された相同性依存性修復ゲノム編集 |
| MX2021015433A (es) | 2019-07-02 | 2022-06-08 | Hutchinson Fred Cancer Res | Vectores ad35 recombinantes y mejoras de la terapia génica relacionadas. |
| GB201909597D0 (en) | 2019-07-03 | 2019-08-14 | Univ Wageningen | Crispr type v-u1 system from mycobacterium mucogenicum and uses thereof |
| CN114401986A (zh) | 2019-07-08 | 2022-04-26 | 国家儿童医院研究所 | 破坏生物膜的抗体组合物 |
| CN110452966A (zh) * | 2019-07-17 | 2019-11-15 | 浙江善测禾骑士生物科技有限公司 | 一种利用raa-crispr蛋白酶系统快速检测方法 |
| CN110387405A (zh) * | 2019-07-17 | 2019-10-29 | 浙江善测禾骑士生物科技有限公司 | 一种快速检测核酸的(rt)raa-crispr系统 |
| WO2021009299A1 (en) | 2019-07-17 | 2021-01-21 | INSERM (Institut National de la Santé et de la Recherche Médicale) | Bcl-xl:fkbp12 fusion proteins suitable for screening agents capable of slowing down the aging process |
| WO2021019272A1 (en) | 2019-07-31 | 2021-02-04 | Vilmorin & Cie | Tolerance to tolcndv in cucumber |
| EP3772542A1 (en) | 2019-08-07 | 2021-02-10 | KWS SAAT SE & Co. KGaA | Modifying genetic variation in crops by modulating the pachytene checkpoint protein 2 |
| WO2021028359A1 (en) | 2019-08-09 | 2021-02-18 | Sangamo Therapeutics France | Controlled expression of chimeric antigen receptors in t cells |
| WO2021030666A1 (en) | 2019-08-15 | 2021-02-18 | The Broad Institute, Inc. | Base editing by transglycosylation |
| US20220282284A1 (en) * | 2019-08-15 | 2022-09-08 | The Rockefeller University | Crispr genome editing with cell surface display to produce homozygously edited eukaryotic cells |
| US20220298501A1 (en) | 2019-08-30 | 2022-09-22 | The Broad Institute, Inc. | Crispr-associated mu transposase systems |
| US20220348937A1 (en) | 2019-09-06 | 2022-11-03 | Obsidian Therapeutics, Inc. | Compositions and methods for dhfr tunable protein regulation |
| US20230203515A1 (en) | 2019-09-12 | 2023-06-29 | Basf Se | Regulatory Nucleic Acid Molecules for Enhancing Gene Expression in Plants |
| CN110541001A (zh) * | 2019-09-20 | 2019-12-06 | 福建上源生物科学技术有限公司 | 精确大片段基因删除结合终止密码子插入的基因敲除法 |
| CA3151563A1 (en) | 2019-09-20 | 2021-03-25 | Feng Zhang | Novel type vi crispr enzymes and systems |
| CN114391040A (zh) | 2019-09-23 | 2022-04-22 | 欧米茄治疗公司 | 用于调节载脂蛋白b(apob)基因表达的组合物和方法 |
| US11987791B2 (en) | 2019-09-23 | 2024-05-21 | Omega Therapeutics, Inc. | Compositions and methods for modulating hepatocyte nuclear factor 4-alpha (HNF4α) gene expression |
| US11981922B2 (en) | 2019-10-03 | 2024-05-14 | Dana-Farber Cancer Institute, Inc. | Methods and compositions for the modulation of cell interactions and signaling in the tumor microenvironment |
| WO2021069387A1 (en) | 2019-10-07 | 2021-04-15 | Basf Se | Regulatory nucleic acid molecules for enhancing gene expression in plants |
| EP3808766A1 (en) | 2019-10-15 | 2021-04-21 | Sangamo Therapeutics France | Chimeric antigen receptor specific for interleukin-23 receptor |
| CN114846022A (zh) | 2019-10-17 | 2022-08-02 | 科沃施种子欧洲股份两合公司 | 通过阻抑基因的下调增强作物的疾病抗性 |
| CA3155727A1 (en) | 2019-10-25 | 2021-04-29 | Cecile Chartier-Courtaud | Gene editing of tumor infiltrating lymphocytes and uses of same in immunotherapy |
| WO2021094805A1 (en) | 2019-11-14 | 2021-05-20 | Vilmorin & Cie | Resistance to acidovorax valerianellae in corn salad |
| JP2023503899A (ja) | 2019-11-22 | 2023-02-01 | プレジデント・アンド・フェロウズ・オブ・ハーバード・カレッジ | 薬物送達のためのイオン液体 |
| US20230086199A1 (en) | 2019-11-26 | 2023-03-23 | The Broad Institute, Inc. | Systems and methods for evaluating cas9-independent off-target editing of nucleic acids |
| EP4064830A1 (en) | 2019-11-29 | 2022-10-05 | Basf Se | Increasing resistance against fungal infections in plants |
| EP4073262A4 (en) * | 2019-12-02 | 2023-12-27 | Council of Scientific & Industrial Research | METHOD AND KIT FOR DETECTING POLYNUCLEOTIDE |
| EP4069852A1 (en) | 2019-12-03 | 2022-10-12 | Basf Se | Regulatory nucleic acid molecules for enhancing gene expression in plants |
| WO2021118990A1 (en) | 2019-12-11 | 2021-06-17 | Iovance Biotherapeutics, Inc. | Processes for the production of tumor infiltrating lymphocytes (tils) and methods of using the same |
| WO2021117874A1 (ja) | 2019-12-13 | 2021-06-17 | 中外製薬株式会社 | 細胞外プリン受容体リガンドを検出するシステムおよび当該システムを導入した非ヒト動物 |
| JP2023506284A (ja) | 2019-12-19 | 2023-02-15 | ビーエーエスエフ ソシエタス・ヨーロピア | ファインケミカルを生成する際の空時収率、炭素変換効率、及び炭素基質適応性の増加 |
| US20230041211A1 (en) | 2019-12-20 | 2023-02-09 | Basf Se | Decreasing toxicity of terpenes and increasing the production potential in micro-organisms |
| WO2021221690A1 (en) | 2020-05-01 | 2021-11-04 | Pivot Bio, Inc. | Modified bacterial strains for improved fixation of nitrogen |
| CN116234906A (zh) | 2020-01-13 | 2023-06-06 | 萨那生物技术股份有限公司 | 血型抗原的修饰 |
| KR20220130158A (ko) | 2020-01-23 | 2022-09-26 | 더 칠드런스 메디칼 센터 코포레이션 | 인간 만능 줄기 세포로부터의 무-간질 t 세포 분화 |
| EP4100519A2 (en) | 2020-02-05 | 2022-12-14 | The Broad Institute, Inc. | Adenine base editors and uses thereof |
| US12116580B2 (en) | 2020-02-21 | 2024-10-15 | The Board Of Trustees Of The University Of Illinois | Genetic toolbox for metabolic engineering of non-conventional yeast |
| EP3872190A1 (en) | 2020-02-26 | 2021-09-01 | Antibodies-Online GmbH | A method of using cut&run or cut&tag to validate crispr-cas targeting |
| CN116096886A (zh) | 2020-03-11 | 2023-05-09 | 欧米茄治疗公司 | 用于调节叉头框p3(foxp3)基因表达的组合物和方法 |
| JP2023518538A (ja) | 2020-03-20 | 2023-05-02 | インセルム(インスティチュート ナショナル デ ラ サンテ エ デ ラ リシェルシェ メディカル) | ヒトcd45rcに特異的なキメラ抗原受容体およびその使用 |
| WO2021202938A1 (en) | 2020-04-03 | 2021-10-07 | Creyon Bio, Inc. | Oligonucleotide-based machine learning |
| WO2021216622A1 (en) | 2020-04-21 | 2021-10-28 | Aspen Neuroscience, Inc. | Gene editing of gba1 in stem cells and method of use of cells differentiated therefrom |
| US20230165909A1 (en) | 2020-04-21 | 2023-06-01 | Aspen Neuroscience, Inc. | Gene editing of lrrk2 in stem cells and method of use of cells differentiated therefrom |
| CA3172637A1 (en) | 2020-05-01 | 2021-11-04 | Pivot Bio, Inc. | Measurement of nitrogen fixation and incorporation |
| WO2021222567A2 (en) | 2020-05-01 | 2021-11-04 | Pivot Bio, Inc. | Modified bacterial strains for improved fixation of nitrogen |
| EP4146794A1 (en) | 2020-05-04 | 2023-03-15 | Iovance Biotherapeutics, Inc. | Processes for production of tumor infiltrating lymphocytes and uses of the same in immunotherapy |
| US20230193212A1 (en) | 2020-05-06 | 2023-06-22 | Orchard Therapeutics (Europe) Limited | Treatment for neurodegenerative diseases |
| DE112021002672T5 (de) | 2020-05-08 | 2023-04-13 | President And Fellows Of Harvard College | Vefahren und zusammensetzungen zum gleichzeitigen editieren beider stränge einer doppelsträngigen nukleotid-zielsequenz |
| CA3172323A1 (en) | 2020-05-13 | 2021-11-18 | Pivot Bio, Inc. | De-repression of nitrogen fixation in gram-positive microorganisms |
| GB202007943D0 (en) | 2020-05-27 | 2020-07-08 | Snipr Biome Aps | Products & methods |
| UY39237A (es) | 2020-05-29 | 2021-12-31 | Kws Saat Se & Co Kgaa | Inducción de haploides en plantas |
| WO2021245435A1 (en) | 2020-06-03 | 2021-12-09 | Vilmorin & Cie | Melon plants resistant to scab disease, aphids and powdery mildew |
| JP2023530234A (ja) | 2020-06-05 | 2023-07-14 | ザ・ブロード・インスティテュート・インコーポレイテッド | 新生物を治療するための組成物および方法 |
| AU2021285274A1 (en) | 2020-06-05 | 2023-02-02 | Vilmorin & Cie | Resistance in plants of solanum lycopersicum to the TOBRFV |
| AU2021288224A1 (en) | 2020-06-11 | 2023-01-05 | Novartis Ag | ZBTB32 inhibitors and uses thereof |
| US20230235315A1 (en) | 2020-07-10 | 2023-07-27 | Horizon Discovery Limited | Method for producing genetically modified cells |
| WO2022029080A1 (en) | 2020-08-03 | 2022-02-10 | INSERM (Institut National de la Santé et de la Recherche Médicale) | Population of treg cells functionally committed to exert a regulatory activity and their use for adoptive therapy |
| WO2022034474A1 (en) | 2020-08-10 | 2022-02-17 | Novartis Ag | Treatments for retinal degenerative diseases |
| EP4200425A1 (en) | 2020-08-18 | 2023-06-28 | Pioneer Hi-Bred International, Inc. | Multiple disease resistance genes and genomic stacks thereof |
| HRP20240903T1 (hr) | 2020-08-20 | 2024-10-11 | A2 Biotherapeutics, Inc. | Pripravci i metode za liječenje egfr pozitivnih karcinoma |
| AU2021329375A1 (en) | 2020-08-20 | 2023-04-20 | A2 Biotherapeutics, Inc. | Compositions and methods for treating ceacam positive cancers |
| EP4100028A4 (en) | 2020-08-20 | 2023-07-26 | A2 Biotherapeutics, Inc. | COMPOSITIONS AND METHODS FOR THE TREATMENT OF MESOTHELIN-POSITIVE CANCERS |
| CN112080587A (zh) * | 2020-08-31 | 2020-12-15 | 上海海关动植物与食品检验检疫技术中心 | 用于高效检测新型冠状病毒的raa-crispr扩增引物组、试剂盒及方法 |
| US11944063B2 (en) | 2020-09-30 | 2024-04-02 | Spring Meadow Nursery, Inc. | Hydrangea ‘SMNHPH’ |
| WO2022188039A1 (en) | 2021-03-09 | 2022-09-15 | Huigene Therapeutics Co., Ltd. | Engineered crispr/cas13 system and uses thereof |
| WO2022068912A1 (en) | 2020-09-30 | 2022-04-07 | Huigene Therapeutics Co., Ltd. | Engineered crispr/cas13 system and uses thereof |
| EP4221492A1 (en) | 2020-10-02 | 2023-08-09 | Vilmorin & Cie | Melon with extended shelf life |
| WO2022076606A1 (en) | 2020-10-06 | 2022-04-14 | Iovance Biotherapeutics, Inc. | Treatment of nsclc patients with tumor infiltrating lymphocyte therapies |
| US20230372397A1 (en) | 2020-10-06 | 2023-11-23 | Iovance Biotherapeutics, Inc. | Treatment of nsclc patients with tumor infiltrating lymphocyte therapies |
| EP3984355B1 (en) | 2020-10-16 | 2024-05-15 | Klemm & Sohn GmbH & Co. KG | Double-flowering dwarf calibrachoa |
| US11155884B1 (en) | 2020-10-16 | 2021-10-26 | Klemm & Sohn Gmbh & Co. Kg | Double-flowering dwarf Calibrachoa |
| US20230147779A1 (en) | 2020-10-28 | 2023-05-11 | GeneEdit, Inc. | Polymer with cationic and hydrophobic side chains |
| WO2022093977A1 (en) | 2020-10-30 | 2022-05-05 | Fortiphyte, Inc. | Pathogen resistance in plants |
| WO2022104061A1 (en) | 2020-11-13 | 2022-05-19 | Novartis Ag | Combination therapies with chimeric antigen receptor (car)-expressing cells |
| EP4001429A1 (en) | 2020-11-16 | 2022-05-25 | Antibodies-Online GmbH | Analysis of crispr-cas binding and cleavage sites followed by high-throughput sequencing (abc-seq) |
| WO2022117884A1 (en) | 2020-12-03 | 2022-06-09 | Vilmorin & Cie | Tomato plants resistant to tobrfv, tmv, tomv and tommv and corresponding resistance genes |
| JP2023554395A (ja) | 2020-12-17 | 2023-12-27 | アイオバンス バイオセラピューティクス,インコーポレイテッド | Ctla-4及びpd-1阻害剤と併用した腫瘍浸潤リンパ球療法による治療 |
| JP2024500403A (ja) | 2020-12-17 | 2024-01-09 | アイオバンス バイオセラピューティクス,インコーポレイテッド | 腫瘍浸潤リンパ球によるがんの治療 |
| BR112023012460A2 (pt) | 2020-12-23 | 2023-11-07 | Flagship Pioneering Innovations V Inc | Conjunto in vitro de capsídeos de anellovirus que envolvem rna |
| JP2024501757A (ja) | 2021-01-05 | 2024-01-15 | ホライズン・ディスカバリー・リミテッド | 遺伝子組換え細胞の製造方法 |
| WO2022150776A1 (en) * | 2021-01-11 | 2022-07-14 | Vedere Bio Ii, Inc. | OPTOGENETIC COMPOSITIONS COMPRISING A CBh PROMOTER SEQUENCE AND METHODS FOR USE |
| AU2022207981A1 (en) | 2021-01-12 | 2023-07-27 | March Therapeutics, Inc. | Context-dependent, double-stranded dna-specific deaminases and uses thereof |
| TW202241508A (zh) | 2021-01-29 | 2022-11-01 | 美商艾歐凡斯生物治療公司 | 細胞介素相關之腫瘤浸潤性淋巴球組合物及方法 |
| WO2022177979A1 (en) | 2021-02-16 | 2022-08-25 | A2 Biotherapeutics, Inc. | Compositions and methods for treating her2 positive cancers |
| WO2022188797A1 (en) | 2021-03-09 | 2022-09-15 | Huigene Therapeutics Co., Ltd. | Engineered crispr/cas13 system and uses thereof |
| WO2022198141A1 (en) | 2021-03-19 | 2022-09-22 | Iovance Biotherapeutics, Inc. | Methods for tumor infiltrating lymphocyte (til) expansion related to cd39/cd69 selection and gene knockout in tils |
| JP2024519601A (ja) | 2021-03-31 | 2024-05-20 | エントラーダ セラピューティクス,インコーポレイティド | 環状細胞透過性ペプチド |
| WO2022241408A1 (en) | 2021-05-10 | 2022-11-17 | Entrada Therapeutics, Inc. | Compositions and methods for modulating tissue distribution of intracellular therapeutics |
| WO2022208489A1 (en) | 2021-04-02 | 2022-10-06 | Vilmorin & Cie | Semi-determinate or determinate growth habit trait in cucurbita |
| EP4323501A1 (en) | 2021-04-16 | 2024-02-21 | Beam Therapeutics Inc. | Genetic modification of hepatocytes |
| EP4326287A2 (en) | 2021-04-19 | 2024-02-28 | Iovance Biotherapeutics, Inc. | Chimeric costimulatory receptors, chemokine receptors, and the use of same in cellular immunotherapies |
| WO2022235929A1 (en) | 2021-05-05 | 2022-11-10 | Radius Pharmaceuticals, Inc. | Animal model having homologous recombination of mouse pth1 receptor |
| JP2024518476A (ja) | 2021-05-10 | 2024-05-01 | エントラーダ セラピューティクス,インコーポレイティド | mRNAスプライシングを調節するための組成物及び方法 |
| EP4337263A1 (en) | 2021-05-10 | 2024-03-20 | Entrada Therapeutics, Inc. | Compositions and methods for modulating interferon regulatory factor-5 (irf-5) activity |
| WO2022240824A1 (en) | 2021-05-13 | 2022-11-17 | The United States Of America, As Represented By The Secretary, Department Of Health And Human Services | Compositions and methods for treating sickle cell diseases |
| JP2024519029A (ja) | 2021-05-17 | 2024-05-08 | アイオバンス バイオセラピューティクス,インコーポレイテッド | Pd-1遺伝子編集された腫瘍浸潤リンパ球及び免疫療法におけるその使用 |
| JP2024520528A (ja) | 2021-06-01 | 2024-05-24 | アーバー バイオテクノロジーズ, インコーポレイテッド | Crisprヌクレアーゼを含む遺伝子編集システム及びそれらの使用 |
| US20240287487A1 (en) | 2021-06-11 | 2024-08-29 | The Broad Institute, Inc. | Improved cytosine to guanine base editors |
| JP2024525141A (ja) | 2021-06-11 | 2024-07-10 | ジーンエディット インコーポレイテッド | ポリアミン基およびポリアルキレンオキシド基を有する側鎖を含む生分解性ポリマー |
| US20240271212A1 (en) * | 2021-06-14 | 2024-08-15 | The University Of Chicago | Characterization and treatment of asthma |
| WO2022271818A1 (en) | 2021-06-23 | 2022-12-29 | Entrada Therapeutics, Inc. | Antisense compounds and methods for targeting cug repeats |
| MX2024000026A (es) | 2021-07-02 | 2024-02-20 | Pivot Bio Inc | Cepas bacterianas dise?adas por ingenieria genetica para fijacion de nitrogeno mejorada. |
| EP4367242A2 (en) | 2021-07-07 | 2024-05-15 | Omega Therapeutics, Inc. | Compositions and methods for modulating secreted frizzled receptor protein 1 (sfrp1) gene expression |
| WO2023004074A2 (en) | 2021-07-22 | 2023-01-26 | Iovance Biotherapeutics, Inc. | Method for cryopreservation of solid tumor fragments |
| TW202327631A (zh) | 2021-07-28 | 2023-07-16 | 美商艾歐凡斯生物治療公司 | 利用腫瘤浸潤性淋巴球療法與kras抑制劑組合治療癌症患者 |
| CA3187918A1 (en) | 2021-07-30 | 2023-01-30 | Helaina, Inc. | Methods and compositions for protein synthesis and secretion |
| CN118368974A (zh) | 2021-07-30 | 2024-07-19 | 科沃施种子欧洲股份两合公司 | 具有提高的消化率和标记单倍型的植物 |
| IL310564A (en) | 2021-08-06 | 2024-03-01 | Vilmorin & Cie | Resistance to Leveillula Taurica in pepper plant |
| WO2023031885A1 (en) | 2021-09-02 | 2023-03-09 | SESVanderHave NV | Methods and compositions for ppo herbicide tolerance |
| JP2024534945A (ja) | 2021-09-10 | 2024-09-26 | アジレント・テクノロジーズ・インク | 化学修飾を有するプライム編集のためのガイドrna |
| JP2024536223A (ja) | 2021-09-30 | 2024-10-04 | ザ ボード オブ リージェンツ オブ ザ ユニバーシティー オブ テキサス システム | Slc13a5遺伝子療法ベクターおよびその使用 |
| WO2023059846A1 (en) | 2021-10-08 | 2023-04-13 | President And Fellows Of Harvard College | Ionic liquids for drug delivery |
| AU2022366987A1 (en) | 2021-10-14 | 2024-05-16 | Arsenal Biosciences, Inc. | Immune cells having co-expressed shrnas and logic gate systems |
| AR127482A1 (es) | 2021-10-27 | 2024-01-31 | Iovance Biotherapeutics Inc | Sistemas y métodos para coordinar la fabricación de células para inmunoterapia específica de paciente |
| CA3237300A1 (en) | 2021-11-01 | 2023-05-04 | Tome Biosciences, Inc. | Single construct platform for simultaneous delivery of gene editing machinery and nucleic acid cargo |
| CA3236802A1 (en) * | 2021-11-03 | 2023-05-11 | The University Of California | Serine recombinases |
| CA3237482A1 (en) | 2021-11-03 | 2023-05-11 | The J. David Gladstone Institutes, A Testamentary Trust Established Under The Will Of J. David Gladstone | Precise genome editing using retrons |
| AU2022388729A1 (en) | 2021-11-10 | 2024-05-16 | Iovance Biotherapeutics, Inc. | Methods of expansion treatment utilizing cd8 tumor infiltrating lymphocytes |
| WO2023092153A2 (en) * | 2021-11-22 | 2023-05-25 | The Texas A&M University System | Methods and compositions targeting nucleus accumbens-associated protein-1 for treatment of autoimmune disorders and cancers |
| WO2023096996A2 (en) | 2021-11-24 | 2023-06-01 | Research Institute At Nationwide Children's Hospital | Chimeric hsv expressing hil21 to boost anti-tumor immune activity |
| EP4437092A1 (en) | 2021-11-26 | 2024-10-02 | Epigenic Therapeutics Inc. | Method of modulating pcsk9 and uses thereof |
| WO2023102406A1 (en) | 2021-12-01 | 2023-06-08 | The Board Of Regents Of The Univesity Of Texas System | Vector genome design to express optimized cln7 transgene |
| WO2023102518A1 (en) | 2021-12-03 | 2023-06-08 | The Board Of Regents Of The University Of Texas System | Gnao1 gene therapy vectors and uses thereof |
| GB202118058D0 (en) | 2021-12-14 | 2022-01-26 | Univ Warwick | Methods to increase yields in crops |
| US20230279442A1 (en) | 2021-12-15 | 2023-09-07 | Versitech Limited | Engineered cas9-nucleases and method of use thereof |
| WO2023115041A1 (en) | 2021-12-17 | 2023-06-22 | Sana Biotechnology, Inc. | Modified paramyxoviridae attachment glycoproteins |
| EP4448549A2 (en) | 2021-12-17 | 2024-10-23 | Sana Biotechnology, Inc. | Modified paramyxoviridae fusion glycoproteins |
| WO2023122805A1 (en) | 2021-12-20 | 2023-06-29 | Vestaron Corporation | Sorbitol driven selection pressure method |
| IL313765A (en) | 2021-12-22 | 2024-08-01 | Tome Biosciences Inc | Joint provision of a gene editor structure and a donor template |
| WO2023122800A1 (en) | 2021-12-23 | 2023-06-29 | University Of Massachusetts | Therapeutic treatment for fragile x-associated disorder |
| WO2023133595A2 (en) | 2022-01-10 | 2023-07-13 | Sana Biotechnology, Inc. | Methods of ex vivo dosing and administration of lipid particles or viral vectors and related systems and uses |
| WO2023141602A2 (en) | 2022-01-21 | 2023-07-27 | Renagade Therapeutics Management Inc. | Engineered retrons and methods of use |
| WO2023147476A1 (en) | 2022-01-28 | 2023-08-03 | The Board Of Regents Of The University Of Texas System | Transgene casette designed to express the human codon-optimized gene fmr1 |
| WO2023147488A1 (en) | 2022-01-28 | 2023-08-03 | Iovance Biotherapeutics, Inc. | Cytokine associated tumor infiltrating lymphocytes compositions and methods |
| WO2023150518A1 (en) | 2022-02-01 | 2023-08-10 | Sana Biotechnology, Inc. | Cd3-targeted lentiviral vectors and uses thereof |
| WO2023150647A1 (en) | 2022-02-02 | 2023-08-10 | Sana Biotechnology, Inc. | Methods of repeat dosing and administration of lipid particles or viral vectors and related systems and uses |
| WO2023156587A1 (en) | 2022-02-18 | 2023-08-24 | INSERM (Institut National de la Santé et de la Recherche Médicale) | Use of tcr-deficient car-tregs in combination with anti-tcr complex monoclonal antibodies for inducing durable tolerance |
| AU2023248451A1 (en) | 2022-04-04 | 2024-10-17 | President And Fellows Of Harvard College | Cas9 variants having non-canonical pam specificities and uses thereof |
| WO2023196877A1 (en) | 2022-04-06 | 2023-10-12 | Iovance Biotherapeutics, Inc. | Treatment of nsclc patients with tumor infiltrating lymphocyte therapies |
| EP4256950A1 (en) | 2022-04-06 | 2023-10-11 | Vilmorin et Cie | Tolerance to cgmmv in cucumber |
| WO2023201369A1 (en) | 2022-04-15 | 2023-10-19 | Iovance Biotherapeutics, Inc. | Til expansion processes using specific cytokine combinations and/or akti treatment |
| WO2023205744A1 (en) | 2022-04-20 | 2023-10-26 | Tome Biosciences, Inc. | Programmable gene insertion compositions |
| WO2023212715A1 (en) | 2022-04-28 | 2023-11-02 | The Broad Institute, Inc. | Aav vectors encoding base editors and uses thereof |
| WO2023215831A1 (en) | 2022-05-04 | 2023-11-09 | Tome Biosciences, Inc. | Guide rna compositions for programmable gene insertion |
| WO2023220040A1 (en) | 2022-05-09 | 2023-11-16 | Synteny Therapeutics, Inc. | Erythroparvovirus with a modified capsid for gene therapy |
| WO2023220035A1 (en) | 2022-05-09 | 2023-11-16 | Synteny Therapeutics, Inc. | Erythroparvovirus compositions and methods for gene therapy |
| WO2023219933A1 (en) | 2022-05-09 | 2023-11-16 | Entrada Therapeutics, Inc. | Compositions and methods for delivery of nucleic acid therapeutics |
| WO2023220043A1 (en) | 2022-05-09 | 2023-11-16 | Synteny Therapeutics, Inc. | Erythroparvovirus with a modified genome for gene therapy |
| WO2023220608A1 (en) | 2022-05-10 | 2023-11-16 | Iovance Biotherapeutics, Inc. | Treatment of cancer patients with tumor infiltrating lymphocyte therapies in combination with an il-15r agonist |
| WO2023225670A2 (en) | 2022-05-20 | 2023-11-23 | Tome Biosciences, Inc. | Ex vivo programmable gene insertion |
| WO2023230566A2 (en) | 2022-05-25 | 2023-11-30 | Flagship Pioneering Innovations Vii, Llc | Compositions and methods for modulating cytokines |
| WO2023230578A2 (en) | 2022-05-25 | 2023-11-30 | Flagship Pioneering Innovations Vii, Llc | Compositions and methods for modulating circulating factors |
| WO2023230549A2 (en) | 2022-05-25 | 2023-11-30 | Flagship Pioneering Innovations Vii, Llc | Compositions and methods for modulation of tumor suppressors and oncogenes |
| WO2023230573A2 (en) | 2022-05-25 | 2023-11-30 | Flagship Pioneering Innovations Vii, Llc | Compositions and methods for modulation of immune responses |
| WO2023230570A2 (en) | 2022-05-25 | 2023-11-30 | Flagship Pioneering Innovations Vii, Llc | Compositions and methods for modulating genetic drivers |
| WO2023250511A2 (en) | 2022-06-24 | 2023-12-28 | Tune Therapeutics, Inc. | Compositions, systems, and methods for reducing low-density lipoprotein through targeted gene repression |
| GB202209518D0 (en) | 2022-06-29 | 2022-08-10 | Snipr Biome Aps | Treating & preventing E coli infections |
| WO2024005863A1 (en) | 2022-06-30 | 2024-01-04 | Inari Agriculture Technology, Inc. | Compositions, systems, and methods for genome editing |
| WO2024006802A1 (en) | 2022-06-30 | 2024-01-04 | Pioneer Hi-Bred International, Inc. | Artificial intelligence-mediated methods and systems for genome editing |
| WO2024005864A1 (en) | 2022-06-30 | 2024-01-04 | Inari Agriculture Technology, Inc. | Compositions, systems, and methods for genome editing |
| EP4299733A1 (en) | 2022-06-30 | 2024-01-03 | Inari Agriculture Technology, Inc. | Compositions, systems, and methods for genome editing |
| EP4299739A1 (en) | 2022-06-30 | 2024-01-03 | Inari Agriculture Technology, Inc. | Compositions, systems, and methods for genome editing |
| GB2621813A (en) | 2022-06-30 | 2024-02-28 | Univ Newcastle | Preventing disease recurrence in Mitochondrial replacement therapy |
| WO2024020346A2 (en) | 2022-07-18 | 2024-01-25 | Renagade Therapeutics Management Inc. | Gene editing components, systems, and methods of use |
| WO2024020587A2 (en) | 2022-07-22 | 2024-01-25 | Tome Biosciences, Inc. | Pleiopluripotent stem cell programmable gene insertion |
| WO2024023578A1 (en) | 2022-07-28 | 2024-02-01 | Institut Pasteur | Hsc70-4 in host-induced and spray-induced gene silencing |
| WO2024026406A2 (en) | 2022-07-29 | 2024-02-01 | Vestaron Corporation | Next Generation ACTX Peptides |
| WO2024036190A2 (en) | 2022-08-09 | 2024-02-15 | Pioneer Hi-Bred International, Inc. | Guide polynucleotide multiplexing |
| WO2024040083A1 (en) | 2022-08-16 | 2024-02-22 | The Broad Institute, Inc. | Evolved cytosine deaminases and methods of editing dna using same |
| WO2024040222A1 (en) | 2022-08-19 | 2024-02-22 | Generation Bio Co. | Cleavable closed-ended dna (cedna) and methods of use thereof |
| WO2024044655A1 (en) | 2022-08-24 | 2024-02-29 | Sana Biotechnology, Inc. | Delivery of heterologous proteins |
| WO2024044723A1 (en) | 2022-08-25 | 2024-02-29 | Renagade Therapeutics Management Inc. | Engineered retrons and methods of use |
| WO2024042199A1 (en) | 2022-08-26 | 2024-02-29 | KWS SAAT SE & Co. KGaA | Use of paired genes in hybrid breeding |
| WO2024047605A1 (en) | 2022-09-01 | 2024-03-07 | SESVanderHave NV | Methods and compositions for ppo herbicide tolerance |
| WO2024050544A2 (en) | 2022-09-01 | 2024-03-07 | J.R. Simplot Company | Enhanced targeted knock-in frequency in host genomes through crispr exonuclease processing |
| WO2024052318A1 (en) | 2022-09-06 | 2024-03-14 | Institut National de la Santé et de la Recherche Médicale | Novel dual split car-t cells for the treatment of cd38-positive hematological malignancies |
| WO2024064824A2 (en) | 2022-09-21 | 2024-03-28 | Yale University | Compositions and methods for identification of membrane targets for enhancement of nk cell therapy |
| WO2024064838A1 (en) | 2022-09-21 | 2024-03-28 | Sana Biotechnology, Inc. | Lipid particles comprising variant paramyxovirus attachment glycoproteins and uses thereof |
| WO2024081820A1 (en) | 2022-10-13 | 2024-04-18 | Sana Biotechnology, Inc. | Viral particles targeting hematopoietic stem cells |
| WO2024083579A1 (en) | 2022-10-20 | 2024-04-25 | Basf Se | Regulatory nucleic acid molecules for enhancing gene expression in plants |
| WO2024098024A1 (en) | 2022-11-04 | 2024-05-10 | Iovance Biotherapeutics, Inc. | Expansion of tumor infiltrating lymphocytes from liquid tumors and therapeutic uses thereof |
| WO2024098027A1 (en) | 2022-11-04 | 2024-05-10 | Iovance Biotherapeutics, Inc. | Methods for tumor infiltrating lymphocyte (til) expansion related to cd39/cd103 selection |
| WO2024102434A1 (en) | 2022-11-10 | 2024-05-16 | Senda Biosciences, Inc. | Rna compositions comprising lipid nanoparticles or lipid reconstructed natural messenger packs |
| WO2024112571A2 (en) | 2022-11-21 | 2024-05-30 | Iovance Biotherapeutics, Inc. | Two-dimensional processes for the expansion of tumor infiltrating lymphocytes and therapies therefrom |
| WO2024118836A1 (en) | 2022-11-30 | 2024-06-06 | Iovance Biotherapeutics, Inc. | Processes for production of tumor infiltrating lymphocytes with shortened rep step |
| WO2024119157A1 (en) | 2022-12-02 | 2024-06-06 | Sana Biotechnology, Inc. | Lipid particles with cofusogens and methods of producing and using the same |
| WO2024123786A1 (en) | 2022-12-06 | 2024-06-13 | Pioneer Hi-Bred International, Inc. | Methods and compositions for co-delivery of t-dnas expressing multiple guide polynucleotides into plants |
| WO2024138194A1 (en) | 2022-12-22 | 2024-06-27 | Tome Biosciences, Inc. | Platforms, compositions, and methods for in vivo programmable gene insertion |
| WO2024137259A1 (en) | 2022-12-23 | 2024-06-27 | Pivot Bio, Inc. | Combination of various nitrogen fixing bacteria with various biological products to achieve synergistic effects |
| WO2024141599A1 (en) | 2022-12-29 | 2024-07-04 | Vilmorin & Cie | Tomato plants resistant to resistance-breaking tswv strains and corresponding resistance genes |
| WO2024155745A1 (en) | 2023-01-18 | 2024-07-25 | The Broad Institute, Inc. | Base editing-mediated readthrough of premature termination codons (bert) |
| WO2024161358A1 (en) | 2023-02-01 | 2024-08-08 | Dlf Seeds A/S | Beet yellows virus resistance |
| WO2024168265A1 (en) | 2023-02-10 | 2024-08-15 | Possible Medicines Llc | Aav delivery of rna guided recombination system |
| WO2024168253A1 (en) | 2023-02-10 | 2024-08-15 | Possible Medicines Llc | Delivery of an rna guided recombination system |
| WO2024173645A1 (en) | 2023-02-15 | 2024-08-22 | Arbor Biotechnologies, Inc. | Gene editing method for inhibiting aberrant splicing in stathmin 2 (stmn2) transcript |
| WO2024196921A1 (en) | 2023-03-20 | 2024-09-26 | Pioneer Hi-Bred International, Inc. | Cas polypeptides with altered pam recognition |
| WO2024206911A2 (en) | 2023-03-30 | 2024-10-03 | Children's Hospital Medical Center | Clinical-grade organoids |
| WO2024211287A1 (en) | 2023-04-03 | 2024-10-10 | Seagen Inc. | Production cell lines with targeted integration sites |
Family Cites Families (81)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US2011A (en) | 1841-03-18 | Appabatxts for piling saws | ||
| US44790A (en) | 1864-10-25 | Improvement in force-pumps | ||
| US2011008A (en) | 1929-04-15 | 1935-08-13 | Rca Corp | Electric discharge tube |
| US4217344A (en) | 1976-06-23 | 1980-08-12 | L'oreal | Compositions containing aqueous dispersions of lipid spheres |
| US4235871A (en) | 1978-02-24 | 1980-11-25 | Papahadjopoulos Demetrios P | Method of encapsulating biologically active materials in lipid vesicles |
| US4186183A (en) | 1978-03-29 | 1980-01-29 | The United States Of America As Represented By The Secretary Of The Army | Liposome carriers in chemotherapy of leishmaniasis |
| US4261975A (en) | 1979-09-19 | 1981-04-14 | Merck & Co., Inc. | Viral liposome particle |
| US4485054A (en) | 1982-10-04 | 1984-11-27 | Lipoderm Pharmaceuticals Limited | Method of encapsulating biologically active materials in multilamellar lipid vesicles (MLV) |
| US4501728A (en) | 1983-01-06 | 1985-02-26 | Technology Unlimited, Inc. | Masking of liposomes from RES recognition |
| US4946787A (en) | 1985-01-07 | 1990-08-07 | Syntex (U.S.A.) Inc. | N-(ω,(ω-1)-dialkyloxy)- and N-(ω,(ω-1)-dialkenyloxy)-alk-1-yl-N,N,N-tetrasubstituted ammonium lipids and uses therefor |
| US4897355A (en) | 1985-01-07 | 1990-01-30 | Syntex (U.S.A.) Inc. | N[ω,(ω-1)-dialkyloxy]- and N-[ω,(ω-1)-dialkenyloxy]-alk-1-yl-N,N,N-tetrasubstituted ammonium lipids and uses therefor |
| US5049386A (en) | 1985-01-07 | 1991-09-17 | Syntex (U.S.A.) Inc. | N-ω,(ω-1)-dialkyloxy)- and N-(ω,(ω-1)-dialkenyloxy)Alk-1-YL-N,N,N-tetrasubstituted ammonium lipids and uses therefor |
| US4797368A (en) | 1985-03-15 | 1989-01-10 | The United States Of America As Represented By The Department Of Health And Human Services | Adeno-associated virus as eukaryotic expression vector |
| US4774085A (en) | 1985-07-09 | 1988-09-27 | 501 Board of Regents, Univ. of Texas | Pharmaceutical administration systems containing a mixture of immunomodulators |
| DE122007000007I2 (de) | 1986-04-09 | 2010-12-30 | Genzyme Corp | Genetisch transformierte Tiere, die ein gewünschtes Protein in Milch absondern |
| US4837028A (en) | 1986-12-24 | 1989-06-06 | Liposome Technology, Inc. | Liposomes with enhanced circulation time |
| US4873316A (en) | 1987-06-23 | 1989-10-10 | Biogen, Inc. | Isolation of exogenous recombinant proteins from the milk of transgenic mammals |
| US5264618A (en) | 1990-04-19 | 1993-11-23 | Vical, Inc. | Cationic lipids for intracellular delivery of biologically active molecules |
| WO1991017424A1 (en) | 1990-05-03 | 1991-11-14 | Vical, Inc. | Intracellular delivery of biologically active substances by means of self-assembling lipid complexes |
| US5173414A (en) | 1990-10-30 | 1992-12-22 | Applied Immune Sciences, Inc. | Production of recombinant adeno-associated virus vectors |
| US7150982B2 (en) | 1991-09-09 | 2006-12-19 | Third Wave Technologies, Inc. | RNA detection assays |
| US5587308A (en) | 1992-06-02 | 1996-12-24 | The United States Of America As Represented By The Department Of Health & Human Services | Modified adeno-associated virus vector capable of expression from a novel promoter |
| US6534261B1 (en) | 1999-01-12 | 2003-03-18 | Sangamo Biosciences, Inc. | Regulation of endogenous gene expression in cells using zinc finger proteins |
| US7868149B2 (en) | 1999-07-20 | 2011-01-11 | Monsanto Technology Llc | Plant genome sequence and uses thereof |
| US6603061B1 (en) | 1999-07-29 | 2003-08-05 | Monsanto Company | Agrobacterium-mediated plant transformation method |
| US20090100536A1 (en) | 2001-12-04 | 2009-04-16 | Monsanto Company | Transgenic plants with enhanced agronomic traits |
| WO2003087993A2 (en) | 2002-04-09 | 2003-10-23 | Beattie Kenneth L | Oligonucleotide probes for genosensor chips |
| US20070134796A1 (en) * | 2005-07-26 | 2007-06-14 | Sangamo Biosciences, Inc. | Targeted integration and expression of exogenous nucleic acid sequences |
| WO2005070948A1 (en) | 2004-01-23 | 2005-08-04 | Intronn, Inc. | Correction of alpha-1-antitrypsin genetic defects using spliceosome mediated rna trans splicing |
| US20050220796A1 (en) | 2004-03-31 | 2005-10-06 | Dynan William S | Compositions and methods for modulating DNA repair |
| WO2006116756A1 (en) | 2005-04-28 | 2006-11-02 | Benitec, Limited. | Multiple-rnai expression cassettes for simultaneous delivery of rnai agents related to heterozygotic expression patterns |
| US7892224B2 (en) | 2005-06-01 | 2011-02-22 | Brainlab Ag | Inverse catheter planning |
| EP1994182B1 (en) | 2006-03-15 | 2019-05-29 | Siemens Healthcare Diagnostics Inc. | Degenerate nucleobase analogs |
| WO2008093152A1 (en) * | 2007-02-01 | 2008-08-07 | Cellectis | Obligate heterodimer meganucleases and uses thereof |
| TR201905633T4 (tr) | 2007-03-02 | 2019-05-21 | Dupont Nutrition Biosci Aps | İyileştirilmiş faj direnci olan kültürler. |
| US8546553B2 (en) | 2008-07-25 | 2013-10-01 | University Of Georgia Research Foundation, Inc. | Prokaryotic RNAi-like system and methods of use |
| US20100076057A1 (en) * | 2008-09-23 | 2010-03-25 | Northwestern University | TARGET DNA INTERFERENCE WITH crRNA |
| WO2010054108A2 (en) | 2008-11-06 | 2010-05-14 | University Of Georgia Research Foundation, Inc. | Cas6 polypeptides and methods of use |
| CN102625655B (zh) * | 2008-12-04 | 2016-07-06 | 桑格摩生物科学股份有限公司 | 使用锌指核酸酶在大鼠中进行基因组编辑 |
| US20110016540A1 (en) | 2008-12-04 | 2011-01-20 | Sigma-Aldrich Co. | Genome editing of genes associated with trinucleotide repeat expansion disorders in animals |
| WO2010075424A2 (en) * | 2008-12-22 | 2010-07-01 | The Regents Of University Of California | Compositions and methods for downregulating prokaryotic genes |
| US20110239315A1 (en) | 2009-01-12 | 2011-09-29 | Ulla Bonas | Modular dna-binding domains and methods of use |
| US8889394B2 (en) | 2009-09-07 | 2014-11-18 | Empire Technology Development Llc | Multiple domain proteins |
| US9404099B2 (en) * | 2009-11-27 | 2016-08-02 | Basf Plant Science Company Gmbh | Optimized endonucleases and uses thereof |
| US10087431B2 (en) | 2010-03-10 | 2018-10-02 | The Regents Of The University Of California | Methods of generating nucleic acid fragments |
| BR112012028805A2 (pt) | 2010-05-10 | 2019-09-24 | The Regents Of The Univ Of California E Nereus Pharmaceuticals Inc | composições de endorribonuclease e métodos de uso das mesmas. |
| EP3156062A1 (en) | 2010-05-17 | 2017-04-19 | Sangamo BioSciences, Inc. | Novel dna-binding proteins and uses thereof |
| JP5711234B2 (ja) * | 2010-07-29 | 2015-04-30 | タカラバイオ株式会社 | 標的塩基検出用rna含有プローブの製造方法 |
| DK2601611T3 (da) | 2010-08-02 | 2021-02-01 | Integrated Dna Tech Inc | Fremgangsmåder til forudsigelse af stabilitet og smeltetemperaturer for nukleinsyreduplekser |
| US9405700B2 (en) | 2010-11-04 | 2016-08-02 | Sonics, Inc. | Methods and apparatus for virtualization in an integrated circuit |
| WO2012149470A1 (en) * | 2011-04-27 | 2012-11-01 | Amyris, Inc. | Methods for genomic modification |
| US20140113376A1 (en) | 2011-06-01 | 2014-04-24 | Rotem Sorek | Compositions and methods for downregulating prokaryotic genes |
| US8555733B2 (en) | 2011-09-23 | 2013-10-15 | Airgas, Inc. | System and method for analyzing a refrigerant sample |
| US20130122096A1 (en) | 2011-11-14 | 2013-05-16 | Silenseed Ltd. | Compositions for drug delivery and methods of manufacturing and using same |
| US8450107B1 (en) | 2011-11-30 | 2013-05-28 | The Broad Institute Inc. | Nucleotide-specific recognition sequences for designer TAL effectors |
| GB201122458D0 (en) | 2011-12-30 | 2012-02-08 | Univ Wageningen | Modified cascade ribonucleoproteins and uses thereof |
| AU2013225950B2 (en) | 2012-02-29 | 2018-02-15 | Sangamo Therapeutics, Inc. | Methods and compositions for treating huntington's disease |
| WO2013141680A1 (en) * | 2012-03-20 | 2013-09-26 | Vilnius University | RNA-DIRECTED DNA CLEAVAGE BY THE Cas9-crRNA COMPLEX |
| US9637739B2 (en) * | 2012-03-20 | 2017-05-02 | Vilnius University | RNA-directed DNA cleavage by the Cas9-crRNA complex |
| DK2800811T3 (en) * | 2012-05-25 | 2017-07-17 | Univ Vienna | METHODS AND COMPOSITIONS FOR RNA DIRECTIVE TARGET DNA MODIFICATION AND FOR RNA DIRECTIVE MODULATION OF TRANSCRIPTION |
| SG11201503059XA (en) * | 2012-10-23 | 2015-06-29 | Toolgen Inc | Composition for cleaving a target dna comprising a guide rna specific for the target dna and cas protein-encoding nucleic acid or cas protein, and use thereof |
| KR102243092B1 (ko) | 2012-12-06 | 2021-04-22 | 시그마-알드리치 컴퍼니., 엘엘씨 | Crispr-기초된 유전체 변형과 조절 |
| WO2014093479A1 (en) | 2012-12-11 | 2014-06-19 | Montana State University | Crispr (clustered regularly interspaced short palindromic repeats) rna-guided control of gene regulation |
| WO2014093709A1 (en) | 2012-12-12 | 2014-06-19 | The Broad Institute, Inc. | Methods, models, systems, and apparatus for identifying target sequences for cas enzymes or crispr-cas systems for target sequences and conveying results thereof |
| DK3064585T3 (da) | 2012-12-12 | 2020-04-27 | Broad Inst Inc | Konstruering og optimering af forbedrede systemer, fremgangsmåder og enzymsammensætninger til sekvensmanipulation |
| EP4286402A3 (en) | 2012-12-12 | 2024-02-14 | The Broad Institute, Inc. | Crispr-cas component systems, methods and compositions for sequence manipulation |
| US20140310830A1 (en) | 2012-12-12 | 2014-10-16 | Feng Zhang | CRISPR-Cas Nickase Systems, Methods And Compositions For Sequence Manipulation in Eukaryotes |
| EP2931899A1 (en) | 2012-12-12 | 2015-10-21 | The Broad Institute, Inc. | Functional genomics using crispr-cas systems, compositions, methods, knock out libraries and applications thereof |
| EP3031921A1 (en) | 2012-12-12 | 2016-06-15 | The Broad Institute, Inc. | Delivery, engineering and optimization of systems, methods and compositions for sequence manipulation and therapeutic applications |
| KR20150105633A (ko) | 2012-12-12 | 2015-09-17 | 더 브로드 인스티튜트, 인코퍼레이티드 | 서열 조작을 위한 시스템, 방법 및 최적화된 가이드 조성물의 조작 |
| WO2014093655A2 (en) | 2012-12-12 | 2014-06-19 | The Broad Institute, Inc. | Engineering and optimization of systems, methods and compositions for sequence manipulation with functional domains |
| US8697359B1 (en) | 2012-12-12 | 2014-04-15 | The Broad Institute, Inc. | CRISPR-Cas systems and methods for altering expression of gene products |
| SG11201504523UA (en) | 2012-12-12 | 2015-07-30 | Broad Inst Inc | Delivery, engineering and optimization of systems, methods and compositions for sequence manipulation and therapeutic applications |
| CN105121641A (zh) | 2012-12-17 | 2015-12-02 | 哈佛大学校长及研究员协会 | Rna-引导的人类基因组工程化 |
| US10660943B2 (en) * | 2013-02-07 | 2020-05-26 | The Rockefeller University | Sequence specific antimicrobials |
| WO2014165825A2 (en) * | 2013-04-04 | 2014-10-09 | President And Fellows Of Harvard College | Therapeutic uses of genome editing with crispr/cas systems |
| KR20160056869A (ko) | 2013-06-17 | 2016-05-20 | 더 브로드 인스티튜트, 인코퍼레이티드 | 바이러스 구성성분을 사용하여 장애 및 질환을 표적화하기 위한 crispr-cas 시스템 및 조성물의 전달, 용도 및 치료 적용 |
| CN106062197A (zh) | 2013-06-17 | 2016-10-26 | 布罗德研究所有限公司 | 用于序列操纵的串联指导系统、方法和组合物的递送、工程化和优化 |
| EP4245853A3 (en) * | 2013-06-17 | 2023-10-18 | The Broad Institute, Inc. | Optimized crispr-cas double nickase systems, methods and compositions for sequence manipulation |
| CN106536729A (zh) | 2013-12-12 | 2017-03-22 | 布罗德研究所有限公司 | 使用粒子递送组分靶向障碍和疾病的crispr‑cas系统和组合物的递送、用途和治疗应用 |
| WO2016073955A2 (en) * | 2014-11-06 | 2016-05-12 | President And Fellows Of Harvard College | Cells lacking b2m surface expression and methods for allogeneic administration of such cells |
-
2013
- 2013-12-12 EP EP23192260.0A patent/EP4286402A3/en active Pending
- 2013-12-12 EP EP23192951.4A patent/EP4286404A3/en active Pending
- 2013-12-12 CN CN202111233527.5A patent/CN114634950A/zh active Pending
- 2013-12-12 BR BR112015013786-5A patent/BR112015013786B1/pt active IP Right Grant
- 2013-12-12 DK DK17162030.5T patent/DK3252160T3/da active
- 2013-12-12 BR BR122021008308-8A patent/BR122021008308B1/pt active IP Right Grant
- 2013-12-12 KR KR1020157018662A patent/KR20150105635A/ko unknown
- 2013-12-12 EP EP13812430.0A patent/EP2825654B1/en active Active
- 2013-12-12 CN CN201910829026.XA patent/CN110982844B/zh active Active
- 2013-12-12 EP EP23192949.8A patent/EP4286403A3/en active Pending
- 2013-12-12 EP EP23161559.2A patent/EP4234696A3/en active Pending
- 2013-12-12 EP EP14188820.6A patent/EP2840140B2/en active Active
- 2013-12-12 EP EP17162030.5A patent/EP3252160B1/en active Active
- 2013-12-12 JP JP2015547530A patent/JP2016505256A/ja active Pending
- 2013-12-12 EP EP20198492.9A patent/EP3825401A1/en active Pending
- 2013-12-12 AU AU2013359262A patent/AU2013359262C1/en active Active
- 2013-12-12 CN CN201380072868.6A patent/CN105658796B/zh active Active
- 2013-12-12 WO PCT/US2013/074611 patent/WO2014093595A1/en active Application Filing
- 2013-12-12 CA CA2894668A patent/CA2894668A1/en active Pending
- 2013-12-12 US US14/105,035 patent/US20140189896A1/en not_active Abandoned
-
2014
- 2014-02-18 US US14/183,486 patent/US8795965B2/en active Active
- 2014-04-23 US US14/259,420 patent/US8871445B2/en active Active
- 2014-09-26 US US14/497,627 patent/US20150031134A1/en not_active Abandoned
- 2014-10-24 US US14/523,799 patent/US9840713B2/en active Active
-
2015
- 2015-07-21 HK HK15106920.5A patent/HK1206388A1/xx unknown
- 2015-09-08 HK HK15108722.1A patent/HK1208056A1/xx unknown
-
2016
- 2016-01-07 US US14/990,444 patent/US9822372B2/en active Active
- 2016-01-08 US US14/991,083 patent/US20160115489A1/en not_active Abandoned
- 2016-08-05 US US15/230,161 patent/US20180327756A1/en active Pending
-
2017
- 2017-12-11 US US15/838,064 patent/US20180305704A1/en not_active Abandoned
-
2018
- 2018-02-02 US US15/887,377 patent/US20180179547A1/en not_active Abandoned
- 2018-04-30 US US15/967,510 patent/US20190040399A1/en not_active Abandoned
- 2018-04-30 US US15/967,495 patent/US20190017058A1/en active Pending
- 2018-11-01 US US16/178,551 patent/US20190292550A1/en not_active Abandoned
-
2019
- 2019-04-22 JP JP2019080952A patent/JP6896786B2/ja active Active
- 2019-06-18 US US16/445,150 patent/US20200032277A1/en not_active Abandoned
- 2019-06-18 US US16/445,156 patent/US20200032278A1/en not_active Abandoned
- 2019-08-05 US US16/532,442 patent/US20200063147A1/en active Pending
- 2019-08-07 US US16/535,043 patent/US20200080094A1/en active Pending
- 2019-12-16 AU AU2019280394A patent/AU2019280394B2/en active Active
-
2020
- 2020-06-19 US US16/906,580 patent/US20200318123A1/en active Pending
- 2020-09-28 US US17/034,754 patent/US20210079407A1/en active Pending
-
2021
- 2021-06-09 JP JP2021096264A patent/JP7269990B2/ja active Active
- 2021-10-18 US US17/503,928 patent/US20220135985A1/en active Pending
-
2022
- 2022-06-01 AU AU2022203763A patent/AU2022203763A1/en active Pending
-
2023
- 2023-02-14 US US18/109,550 patent/US20240182913A1/en active Pending
- 2023-03-29 US US18/128,122 patent/US20230340505A1/en active Pending
- 2023-04-13 US US18/134,317 patent/US20230374527A1/en active Pending
- 2023-04-24 JP JP2023070572A patent/JP7542681B2/ja active Active
- 2023-08-23 US US18/454,343 patent/US20240117365A1/en active Pending
Cited By (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2018030874A1 (ko) * | 2016-08-12 | 2018-02-15 | 주식회사 툴젠 | 조작된 면역조절요소 및 이에 의해 변형된 면역 활성 |
| CN109844118A (zh) * | 2016-08-12 | 2019-06-04 | 株式会社图尔金 | 经操纵的免疫调节因子以及由此改变的免疫力 |
| KR20190075019A (ko) * | 2016-08-12 | 2019-06-28 | 주식회사 툴젠 | 조작된 면역조절요소 및 이에 의해 변형된 면역 활성 |
| US12012598B2 (en) | 2016-08-12 | 2024-06-18 | Toolgen Incorporated | Manipulated immunoregulatory element and immunity altered thereby |
| KR20190093171A (ko) * | 2018-01-31 | 2019-08-08 | 서울대학교산학협력단 | CRISPR/Cas9 시스템을 통한 닭 백혈병 바이러스(Avian Leukosis Virus, ALV) 저항성 조류의 제조방법 |
| KR20220039034A (ko) * | 2020-09-21 | 2022-03-29 | 한국과학기술원 | 파브알부민 유전자 발현 억제용 CRISPR/Cas9 시스템 및 이의 용도 |
Also Published As
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| AU2019280394B2 (en) | CRISPR-Cas component systems, methods and compositions for sequence manipulation | |
| JP7198328B2 (ja) | 配列操作のための系、方法および最適化ガイド組成物のエンジニアリング | |
| JP2024023239A (ja) | 配列操作のための最適化されたCRISPR-Cas二重ニッカーゼ系、方法および組成物 | |
| JP7090775B2 (ja) | 遺伝子産物の発現を変更するためのCRISPR-Cas系および方法 | |
| DK2784162T3 (en) | Design of systems, methods and optimized control manipulations for sequence manipulation | |
| RU2701662C2 (ru) | Компоненты системы crispr-cas, способы и композиции для манипуляции с последовательностями | |
| KR20150105634A (ko) | 서열 조작을 위한 개선된 시스템, 방법 및 효소 조성물의 유전자 조작 및 최적화 | |
| JP2020511931A (ja) | 改良された遺伝子編集 | |
| RU2796549C2 (ru) | Компоненты системы crispr-cas, способы и композиции для манипуляции с последовательностями |