CN105732816B - 经修饰的级联核糖核蛋白及其用途 - Google Patents
经修饰的级联核糖核蛋白及其用途 Download PDFInfo
- Publication number
- CN105732816B CN105732816B CN201610081216.4A CN201610081216A CN105732816B CN 105732816 B CN105732816 B CN 105732816B CN 201610081216 A CN201610081216 A CN 201610081216A CN 105732816 B CN105732816 B CN 105732816B
- Authority
- CN
- China
- Prior art keywords
- leu
- ala
- gly
- val
- arg
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 102000004389 Ribonucleoproteins Human genes 0.000 title claims abstract description 39
- 108010081734 Ribonucleoproteins Proteins 0.000 title claims abstract description 39
- 108090000623 proteins and genes Proteins 0.000 claims abstract description 108
- 150000007523 nucleic acids Chemical class 0.000 claims abstract description 102
- 102000039446 nucleic acids Human genes 0.000 claims abstract description 88
- 108020004707 nucleic acids Proteins 0.000 claims abstract description 88
- 102000004169 proteins and genes Human genes 0.000 claims abstract description 82
- 230000000051 modifying effect Effects 0.000 claims abstract description 33
- 238000013518 transcription Methods 0.000 claims abstract description 27
- 230000035897 transcription Effects 0.000 claims abstract description 27
- 230000003213 activating effect Effects 0.000 claims abstract description 24
- 102000002067 Protein Subunits Human genes 0.000 claims abstract description 16
- 230000002401 inhibitory effect Effects 0.000 claims abstract description 11
- 108020004414 DNA Proteins 0.000 claims description 128
- 238000000034 method Methods 0.000 claims description 56
- 108020001507 fusion proteins Proteins 0.000 claims description 31
- 102000037865 fusion proteins Human genes 0.000 claims description 31
- 102000053602 DNA Human genes 0.000 claims description 26
- 230000027455 binding Effects 0.000 claims description 26
- 238000000338 in vitro Methods 0.000 claims description 25
- 108010001267 Protein Subunits Proteins 0.000 claims description 13
- 108010077850 Nuclear Localization Signals Proteins 0.000 claims description 11
- 239000013604 expression vector Substances 0.000 claims description 11
- 230000004048 modification Effects 0.000 claims description 9
- 238000012986 modification Methods 0.000 claims description 9
- 108091079001 CRISPR RNA Proteins 0.000 claims description 7
- 108010042407 Endonucleases Proteins 0.000 claims description 6
- 102000004533 Endonucleases Human genes 0.000 claims description 6
- 210000003527 eukaryotic cell Anatomy 0.000 claims description 4
- 108091032973 (ribonucleotides)n+m Proteins 0.000 abstract description 72
- 238000003776 cleavage reaction Methods 0.000 abstract description 59
- 230000007017 scission Effects 0.000 abstract description 58
- 125000003275 alpha amino acid group Chemical group 0.000 abstract description 46
- 108010077544 Chromatin Proteins 0.000 abstract description 19
- 210000003483 chromatin Anatomy 0.000 abstract description 19
- 238000012800 visualization Methods 0.000 abstract description 6
- 238000010353 genetic engineering Methods 0.000 abstract description 4
- 230000035772 mutation Effects 0.000 abstract description 4
- 108010040467 CRISPR-Associated Proteins Proteins 0.000 abstract description 3
- 239000000539 dimer Substances 0.000 abstract description 3
- 238000012239 gene modification Methods 0.000 abstract description 3
- 238000002744 homologous recombination Methods 0.000 abstract description 3
- 230000006801 homologous recombination Effects 0.000 abstract description 3
- 230000006780 non-homologous end joining Effects 0.000 abstract description 3
- 108091028664 Ribonucleotide Proteins 0.000 abstract description 2
- 230000005860 defense response to virus Effects 0.000 abstract description 2
- 230000005017 genetic modification Effects 0.000 abstract description 2
- 235000013617 genetically modified food Nutrition 0.000 abstract description 2
- 230000029279 positive regulation of transcription, DNA-dependent Effects 0.000 abstract description 2
- 230000008439 repair process Effects 0.000 abstract description 2
- 239000002336 ribonucleotide Substances 0.000 abstract description 2
- 125000002652 ribonucleotide group Chemical group 0.000 abstract description 2
- 230000003044 adaptive effect Effects 0.000 abstract 1
- 230000002730 additional effect Effects 0.000 abstract 1
- 230000010354 integration Effects 0.000 abstract 1
- 230000037426 transcriptional repression Effects 0.000 abstract 1
- 239000013612 plasmid Substances 0.000 description 81
- 210000004027 cell Anatomy 0.000 description 71
- 230000000694 effects Effects 0.000 description 41
- 101710163270 Nuclease Proteins 0.000 description 30
- 108091028043 Nucleic acid sequence Proteins 0.000 description 28
- 241000588724 Escherichia coli Species 0.000 description 26
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 26
- 239000000872 buffer Substances 0.000 description 25
- 108010050848 glycylleucine Proteins 0.000 description 25
- 239000002773 nucleotide Substances 0.000 description 23
- 230000000295 complement effect Effects 0.000 description 22
- 230000004927 fusion Effects 0.000 description 22
- 230000014509 gene expression Effects 0.000 description 22
- YBAFDPFAUTYYRW-UHFFFAOYSA-N N-L-alpha-glutamyl-L-leucine Natural products CC(C)CC(C(O)=O)NC(=O)C(N)CCC(O)=O YBAFDPFAUTYYRW-UHFFFAOYSA-N 0.000 description 20
- 125000003729 nucleotide group Chemical group 0.000 description 19
- 125000006850 spacer group Chemical group 0.000 description 18
- 230000002103 transcriptional effect Effects 0.000 description 18
- 238000004458 analytical method Methods 0.000 description 16
- 230000008685 targeting Effects 0.000 description 15
- 241000894006 Bacteria Species 0.000 description 14
- 238000003556 assay Methods 0.000 description 14
- VPZXBVLAVMBEQI-UHFFFAOYSA-N glycyl-DL-alpha-alanine Natural products OC(=O)C(C)NC(=O)CN VPZXBVLAVMBEQI-UHFFFAOYSA-N 0.000 description 14
- 241000701959 Escherichia virus Lambda Species 0.000 description 13
- 239000000499 gel Substances 0.000 description 13
- 230000000754 repressing effect Effects 0.000 description 13
- 239000011780 sodium chloride Substances 0.000 description 13
- 241000880493 Leptailurus serval Species 0.000 description 12
- 108010087924 alanylproline Proteins 0.000 description 12
- 108010049041 glutamylalanine Proteins 0.000 description 12
- XBGGUPMXALFZOT-UHFFFAOYSA-N glycyl-L-tyrosine hemihydrate Natural products NCC(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 XBGGUPMXALFZOT-UHFFFAOYSA-N 0.000 description 12
- 238000001727 in vivo Methods 0.000 description 12
- 108010064235 lysylglycine Proteins 0.000 description 12
- 108090000765 processed proteins & peptides Proteins 0.000 description 12
- 108010061238 threonyl-glycine Proteins 0.000 description 12
- 108091033409 CRISPR Proteins 0.000 description 11
- JBCLFWXMTIKCCB-UHFFFAOYSA-N H-Gly-Phe-OH Natural products NCC(=O)NC(C(O)=O)CC1=CC=CC=C1 JBCLFWXMTIKCCB-UHFFFAOYSA-N 0.000 description 11
- 108010047495 alanylglycine Proteins 0.000 description 11
- KOSRFJWDECSPRO-UHFFFAOYSA-N alpha-L-glutamyl-L-glutamic acid Natural products OC(=O)CCC(N)C(=O)NC(CCC(O)=O)C(O)=O KOSRFJWDECSPRO-UHFFFAOYSA-N 0.000 description 11
- 150000001413 amino acids Chemical class 0.000 description 11
- 108010093581 aspartyl-proline Proteins 0.000 description 11
- 229920001184 polypeptide Polymers 0.000 description 11
- 102000004196 processed proteins & peptides Human genes 0.000 description 11
- COYSIHFOCOMGCF-UHFFFAOYSA-N Val-Arg-Gly Natural products CC(C)C(N)C(=O)NC(C(=O)NCC(O)=O)CCCN=C(N)N COYSIHFOCOMGCF-UHFFFAOYSA-N 0.000 description 10
- 108010038633 aspartylglutamate Proteins 0.000 description 10
- 108010078144 glutaminyl-glycine Proteins 0.000 description 10
- 238000009396 hybridization Methods 0.000 description 10
- 108010057821 leucylproline Proteins 0.000 description 10
- UCSJYZPVAKXKNQ-HZYVHMACSA-N streptomycin Chemical compound CN[C@H]1[C@H](O)[C@@H](O)[C@H](CO)O[C@H]1O[C@@H]1[C@](C=O)(O)[C@H](C)O[C@H]1O[C@@H]1[C@@H](NC(N)=N)[C@H](O)[C@@H](NC(N)=N)[C@H](O)[C@H]1O UCSJYZPVAKXKNQ-HZYVHMACSA-N 0.000 description 10
- 108010080629 tryptophan-leucine Proteins 0.000 description 10
- PEDCQBHIVMGVHV-UHFFFAOYSA-N Glycerine Chemical compound OCC(O)CO PEDCQBHIVMGVHV-UHFFFAOYSA-N 0.000 description 9
- 108060004795 Methyltransferase Proteins 0.000 description 9
- 108010063718 gamma-glutamylaspartic acid Proteins 0.000 description 9
- 208000015181 infectious disease Diseases 0.000 description 9
- YMHOBZXQZVXHBM-UHFFFAOYSA-N 2,5-dimethoxy-4-bromophenethylamine Chemical compound COC1=CC(CCN)=C(OC)C=C1Br YMHOBZXQZVXHBM-UHFFFAOYSA-N 0.000 description 8
- BIZNDKMFQHDOIE-KKUMJFAQSA-N Leu-Phe-Asn Chemical compound CC(C)C[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CC(N)=O)C(O)=O)CC1=CC=CC=C1 BIZNDKMFQHDOIE-KKUMJFAQSA-N 0.000 description 8
- CVUDMNSZAIZFAE-UHFFFAOYSA-N Val-Arg-Pro Natural products NC(N)=NCCCC(NC(=O)C(N)C(C)C)C(=O)N1CCCC1C(O)=O CVUDMNSZAIZFAE-UHFFFAOYSA-N 0.000 description 8
- 241000545067 Venus Species 0.000 description 8
- 108010069020 alanyl-prolyl-glycine Proteins 0.000 description 8
- 108010087823 glycyltyrosine Proteins 0.000 description 8
- 210000005260 human cell Anatomy 0.000 description 8
- 108010038320 lysylphenylalanine Proteins 0.000 description 8
- 239000000047 product Substances 0.000 description 8
- 239000000523 sample Substances 0.000 description 8
- CWFMWBHMIMNZLN-NAKRPEOUSA-N (2s)-1-[(2s)-2-[[(2s,3s)-2-amino-3-methylpentanoyl]amino]propanoyl]pyrrolidine-2-carboxylic acid Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](C)C(=O)N1CCC[C@H]1C(O)=O CWFMWBHMIMNZLN-NAKRPEOUSA-N 0.000 description 7
- JKMHFZQWWAIEOD-UHFFFAOYSA-N 2-[4-(2-hydroxyethyl)piperazin-1-yl]ethanesulfonic acid Chemical compound OCC[NH+]1CCN(CCS([O-])(=O)=O)CC1 JKMHFZQWWAIEOD-UHFFFAOYSA-N 0.000 description 7
- LGYZYFFDELZWRS-DCAQKATOSA-N Glu-Glu-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CCC(O)=O LGYZYFFDELZWRS-DCAQKATOSA-N 0.000 description 7
- 239000007995 HEPES buffer Substances 0.000 description 7
- SITLTJHOQZFJGG-UHFFFAOYSA-N N-L-alpha-glutamyl-L-valine Natural products CC(C)C(C(O)=O)NC(=O)C(N)CCC(O)=O SITLTJHOQZFJGG-UHFFFAOYSA-N 0.000 description 7
- XMBSYZWANAQXEV-UHFFFAOYSA-N N-alpha-L-glutamyl-L-phenylalanine Natural products OC(=O)CCC(N)C(=O)NC(C(O)=O)CC1=CC=CC=C1 XMBSYZWANAQXEV-UHFFFAOYSA-N 0.000 description 7
- AJHCSUXXECOXOY-UHFFFAOYSA-N N-glycyl-L-tryptophan Natural products C1=CC=C2C(CC(NC(=O)CN)C(O)=O)=CNC2=C1 AJHCSUXXECOXOY-UHFFFAOYSA-N 0.000 description 7
- 108010002311 N-glycylglutamic acid Proteins 0.000 description 7
- 108010005233 alanylglutamic acid Proteins 0.000 description 7
- 108010070944 alanylhistidine Proteins 0.000 description 7
- 230000000840 anti-viral effect Effects 0.000 description 7
- 108010060035 arginylproline Proteins 0.000 description 7
- 238000010378 bimolecular fluorescence complementation Methods 0.000 description 7
- 238000006073 displacement reaction Methods 0.000 description 7
- 108010055341 glutamyl-glutamic acid Proteins 0.000 description 7
- 108010027668 glycyl-alanyl-valine Proteins 0.000 description 7
- XKUKSGPZAADMRA-UHFFFAOYSA-N glycyl-glycyl-glycine Natural products NCC(=O)NCC(=O)NCC(O)=O XKUKSGPZAADMRA-UHFFFAOYSA-N 0.000 description 7
- 108010066198 glycyl-leucyl-phenylalanine Proteins 0.000 description 7
- 238000011534 incubation Methods 0.000 description 7
- 230000003993 interaction Effects 0.000 description 7
- 108010034529 leucyl-lysine Proteins 0.000 description 7
- 239000003550 marker Substances 0.000 description 7
- 230000009870 specific binding Effects 0.000 description 7
- 238000005406 washing Methods 0.000 description 7
- WEVYAHXRMPXWCK-UHFFFAOYSA-N Acetonitrile Chemical compound CC#N WEVYAHXRMPXWCK-UHFFFAOYSA-N 0.000 description 6
- 108010076441 Ala-His-His Proteins 0.000 description 6
- UGVQELHRNUDMAA-BYPYZUCNSA-N Gly-Ala-Gly Chemical compound [NH3+]CC(=O)N[C@@H](C)C(=O)NCC([O-])=O UGVQELHRNUDMAA-BYPYZUCNSA-N 0.000 description 6
- OQQKUTVULYLCDG-ONGXEEELSA-N Gly-Lys-Val Chemical compound CC(C)[C@H](NC(=O)[C@H](CCCCN)NC(=O)CN)C(O)=O OQQKUTVULYLCDG-ONGXEEELSA-N 0.000 description 6
- GLYJPWIRLBAIJH-UHFFFAOYSA-N Ile-Lys-Pro Natural products CCC(C)C(N)C(=O)NC(CCCCN)C(=O)N1CCCC1C(O)=O GLYJPWIRLBAIJH-UHFFFAOYSA-N 0.000 description 6
- SENJXOPIZNYLHU-UHFFFAOYSA-N L-leucyl-L-arginine Natural products CC(C)CC(N)C(=O)NC(C(O)=O)CCCN=C(N)N SENJXOPIZNYLHU-UHFFFAOYSA-N 0.000 description 6
- WNGVUZWBXZKQES-YUMQZZPRSA-N Leu-Ala-Gly Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)NCC(O)=O WNGVUZWBXZKQES-YUMQZZPRSA-N 0.000 description 6
- QESXLSQLQHHTIX-RHYQMDGZSA-N Leu-Val-Thr Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O QESXLSQLQHHTIX-RHYQMDGZSA-N 0.000 description 6
- 239000006137 Luria-Bertani broth Substances 0.000 description 6
- BQVUABVGYYSDCJ-UHFFFAOYSA-N Nalpha-L-Leucyl-L-tryptophan Natural products C1=CC=C2C(CC(NC(=O)C(N)CC(C)C)C(O)=O)=CNC2=C1 BQVUABVGYYSDCJ-UHFFFAOYSA-N 0.000 description 6
- MRNRMSDVVSKPGM-AVGNSLFASA-N Phe-Asn-Gln Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O MRNRMSDVVSKPGM-AVGNSLFASA-N 0.000 description 6
- RIYZXJVARWJLKS-KKUMJFAQSA-N Phe-Asp-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CC1=CC=CC=C1 RIYZXJVARWJLKS-KKUMJFAQSA-N 0.000 description 6
- ISWSIDIOOBJBQZ-UHFFFAOYSA-N Phenol Chemical compound OC1=CC=CC=C1 ISWSIDIOOBJBQZ-UHFFFAOYSA-N 0.000 description 6
- NCXVJIQMWSGRHY-KXNHARMFSA-N Thr-Leu-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N1CCC[C@@H]1C(=O)O)N)O NCXVJIQMWSGRHY-KXNHARMFSA-N 0.000 description 6
- ZMANZCXQSJIPKH-UHFFFAOYSA-N Triethylamine Chemical compound CCN(CC)CC ZMANZCXQSJIPKH-UHFFFAOYSA-N 0.000 description 6
- ZLFHAAGHGQBQQN-GUBZILKMSA-N Val-Ala-Pro Natural products CC(C)[C@H](N)C(=O)N[C@@H](C)C(=O)N1CCC[C@H]1C(O)=O ZLFHAAGHGQBQQN-GUBZILKMSA-N 0.000 description 6
- COYSIHFOCOMGCF-WPRPVWTQSA-N Val-Arg-Gly Chemical compound CC(C)[C@H](N)C(=O)N[C@H](C(=O)NCC(O)=O)CCCN=C(N)N COYSIHFOCOMGCF-WPRPVWTQSA-N 0.000 description 6
- 108010041407 alanylaspartic acid Proteins 0.000 description 6
- 108010044940 alanylglutamine Proteins 0.000 description 6
- 108010047857 aspartylglycine Proteins 0.000 description 6
- 108010016616 cysteinylglycine Proteins 0.000 description 6
- 238000013461 design Methods 0.000 description 6
- 238000001514 detection method Methods 0.000 description 6
- 108091006047 fluorescent proteins Proteins 0.000 description 6
- 102000034287 fluorescent proteins Human genes 0.000 description 6
- 230000002068 genetic effect Effects 0.000 description 6
- 108010089804 glycyl-threonine Proteins 0.000 description 6
- 108010015792 glycyllysine Proteins 0.000 description 6
- 108010037850 glycylvaline Proteins 0.000 description 6
- 108010040030 histidinoalanine Proteins 0.000 description 6
- 108010085325 histidylproline Proteins 0.000 description 6
- 108010000761 leucylarginine Proteins 0.000 description 6
- 238000002360 preparation method Methods 0.000 description 6
- 108010029020 prolylglycine Proteins 0.000 description 6
- 108010053725 prolylvaline Proteins 0.000 description 6
- 230000009466 transformation Effects 0.000 description 6
- 108010073969 valyllysine Proteins 0.000 description 6
- ZIWWTZWAKYBUOB-CIUDSAMLSA-N Ala-Asp-Leu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O ZIWWTZWAKYBUOB-CIUDSAMLSA-N 0.000 description 5
- SQKPKIJVWHAWNF-DCAQKATOSA-N Arg-Asp-Lys Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCCN)C(O)=O SQKPKIJVWHAWNF-DCAQKATOSA-N 0.000 description 5
- PAPSMOYMQDWIOR-AVGNSLFASA-N Arg-Lys-Val Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(O)=O PAPSMOYMQDWIOR-AVGNSLFASA-N 0.000 description 5
- IZSMEUDYADKZTJ-KJEVXHAQSA-N Arg-Tyr-Thr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O IZSMEUDYADKZTJ-KJEVXHAQSA-N 0.000 description 5
- FUHFYEKSGWOWGZ-XHNCKOQMSA-N Asn-Gln-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CC(=O)N)N)C(=O)O FUHFYEKSGWOWGZ-XHNCKOQMSA-N 0.000 description 5
- YDJVIBMKAMQPPP-LAEOZQHASA-N Asp-Glu-Val Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O YDJVIBMKAMQPPP-LAEOZQHASA-N 0.000 description 5
- GIKOVDMXBAFXDF-NHCYSSNCSA-N Asp-Val-Leu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O GIKOVDMXBAFXDF-NHCYSSNCSA-N 0.000 description 5
- 238000010446 CRISPR interference Methods 0.000 description 5
- 238000010453 CRISPR/Cas method Methods 0.000 description 5
- 230000007018 DNA scission Effects 0.000 description 5
- 230000004568 DNA-binding Effects 0.000 description 5
- 102000004190 Enzymes Human genes 0.000 description 5
- 108090000790 Enzymes Proteins 0.000 description 5
- 101100007788 Escherichia coli (strain K12) casA gene Proteins 0.000 description 5
- REJJNXODKSHOKA-ACZMJKKPSA-N Gln-Ala-Asp Chemical compound C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CCC(=O)N)N REJJNXODKSHOKA-ACZMJKKPSA-N 0.000 description 5
- WOMUDRVDJMHTCV-DCAQKATOSA-N Glu-Arg-Arg Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O WOMUDRVDJMHTCV-DCAQKATOSA-N 0.000 description 5
- VGBSZQSKQRMLHD-MNXVOIDGSA-N Glu-Leu-Ile Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O VGBSZQSKQRMLHD-MNXVOIDGSA-N 0.000 description 5
- MWMJCGBSIORNCD-AVGNSLFASA-N Glu-Leu-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O MWMJCGBSIORNCD-AVGNSLFASA-N 0.000 description 5
- JSNNHGHYGYMVCK-XVKPBYJWSA-N Gly-Glu-Val Chemical compound [H]NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O JSNNHGHYGYMVCK-XVKPBYJWSA-N 0.000 description 5
- CLNSYANKYVMZNM-UWVGGRQHSA-N Gly-Lys-Arg Chemical compound NCCCC[C@H](NC(=O)CN)C(=O)N[C@H](C(O)=O)CCCN=C(N)N CLNSYANKYVMZNM-UWVGGRQHSA-N 0.000 description 5
- LPXHYGGZJOCAFR-MNXVOIDGSA-N Ile-Glu-Leu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CC(C)C)C(=O)O)N LPXHYGGZJOCAFR-MNXVOIDGSA-N 0.000 description 5
- IITVUURPOYGCTD-NAKRPEOUSA-N Ile-Pro-Ala Chemical compound CC[C@H](C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O IITVUURPOYGCTD-NAKRPEOUSA-N 0.000 description 5
- PMGDADKJMCOXHX-UHFFFAOYSA-N L-Arginyl-L-glutamin-acetat Natural products NC(=N)NCCCC(N)C(=O)NC(CCC(N)=O)C(O)=O PMGDADKJMCOXHX-UHFFFAOYSA-N 0.000 description 5
- HASRFYOMVPJRPU-SRVKXCTJSA-N Leu-Arg-Glu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCC(O)=O)C(O)=O HASRFYOMVPJRPU-SRVKXCTJSA-N 0.000 description 5
- KCXUCYYZNZFGLL-SRVKXCTJSA-N Lys-Ala-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O KCXUCYYZNZFGLL-SRVKXCTJSA-N 0.000 description 5
- 108010085220 Multiprotein Complexes Proteins 0.000 description 5
- 102000007474 Multiprotein Complexes Human genes 0.000 description 5
- 108010079364 N-glycylalanine Proteins 0.000 description 5
- CYZBFPYMSJGBRL-DRZSPHRISA-N Phe-Ala-Glu Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(O)=O CYZBFPYMSJGBRL-DRZSPHRISA-N 0.000 description 5
- AUJWXNGCAQWLEI-KBPBESRZSA-N Phe-Lys-Gly Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCCCN)C(=O)NCC(O)=O AUJWXNGCAQWLEI-KBPBESRZSA-N 0.000 description 5
- UQFYNFTYDHUIMI-WHFBIAKZSA-N Ser-Gly-Ala Chemical compound OC(=O)[C@H](C)NC(=O)CNC(=O)[C@@H](N)CO UQFYNFTYDHUIMI-WHFBIAKZSA-N 0.000 description 5
- 241000187392 Streptomyces griseus Species 0.000 description 5
- FWTFAZKJORVTIR-VZFHVOOUSA-N Thr-Ser-Ala Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O FWTFAZKJORVTIR-VZFHVOOUSA-N 0.000 description 5
- AKHDFZHUPGVFEJ-YEPSODPASA-N Thr-Val-Gly Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)NCC(O)=O AKHDFZHUPGVFEJ-YEPSODPASA-N 0.000 description 5
- HLDFBNPSURDYEN-VHWLVUOQSA-N Trp-Ile-Asp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N HLDFBNPSURDYEN-VHWLVUOQSA-N 0.000 description 5
- AZSHAZJLOZQYAY-FXQIFTODSA-N Val-Ala-Ser Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O AZSHAZJLOZQYAY-FXQIFTODSA-N 0.000 description 5
- SYSWVVCYSXBVJG-RHYQMDGZSA-N Val-Leu-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](C(C)C)N)O SYSWVVCYSXBVJG-RHYQMDGZSA-N 0.000 description 5
- RWOGENDAOGMHLX-DCAQKATOSA-N Val-Lys-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](C(C)C)N RWOGENDAOGMHLX-DCAQKATOSA-N 0.000 description 5
- NZYNRRGJJVSSTJ-GUBZILKMSA-N Val-Ser-Val Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O NZYNRRGJJVSSTJ-GUBZILKMSA-N 0.000 description 5
- DFQZDQPLWBSFEJ-LSJOCFKGSA-N Val-Val-Asn Chemical compound CC(C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(=O)N)C(=O)O)N DFQZDQPLWBSFEJ-LSJOCFKGSA-N 0.000 description 5
- 108010045023 alanyl-prolyl-tyrosine Proteins 0.000 description 5
- 229960000723 ampicillin Drugs 0.000 description 5
- AVKUERGKIZMTKX-NJBDSQKTSA-N ampicillin Chemical compound C1([C@@H](N)C(=O)N[C@H]2[C@H]3SC([C@@H](N3C2=O)C(O)=O)(C)C)=CC=CC=C1 AVKUERGKIZMTKX-NJBDSQKTSA-N 0.000 description 5
- 108010013835 arginine glutamate Proteins 0.000 description 5
- 108010009111 arginyl-glycyl-glutamic acid Proteins 0.000 description 5
- 108010068380 arginylarginine Proteins 0.000 description 5
- 108010077245 asparaginyl-proline Proteins 0.000 description 5
- 108010040443 aspartyl-aspartic acid Proteins 0.000 description 5
- 108010069205 aspartyl-phenylalanine Proteins 0.000 description 5
- 230000001580 bacterial effect Effects 0.000 description 5
- 229960005091 chloramphenicol Drugs 0.000 description 5
- WIIZWVCIJKGZOK-RKDXNWHRSA-N chloramphenicol Chemical compound ClC(Cl)C(=O)N[C@H](CO)[C@H](O)C1=CC=C([N+]([O-])=O)C=C1 WIIZWVCIJKGZOK-RKDXNWHRSA-N 0.000 description 5
- 230000001419 dependent effect Effects 0.000 description 5
- 238000010494 dissociation reaction Methods 0.000 description 5
- 230000005593 dissociations Effects 0.000 description 5
- 230000006870 function Effects 0.000 description 5
- 230000005714 functional activity Effects 0.000 description 5
- 108010026364 glycyl-glycyl-leucine Proteins 0.000 description 5
- 108010059898 glycyl-tyrosyl-lysine Proteins 0.000 description 5
- 108010081551 glycylphenylalanine Proteins 0.000 description 5
- 229930027917 kanamycin Natural products 0.000 description 5
- 229960000318 kanamycin Drugs 0.000 description 5
- SBUJHOSQTJFQJX-NOAMYHISSA-N kanamycin Chemical compound O[C@@H]1[C@@H](O)[C@H](O)[C@@H](CN)O[C@@H]1O[C@H]1[C@H](O)[C@@H](O[C@@H]2[C@@H]([C@@H](N)[C@H](O)[C@@H](CO)O2)O)[C@H](N)C[C@@H]1N SBUJHOSQTJFQJX-NOAMYHISSA-N 0.000 description 5
- 229930182823 kanamycin A Natural products 0.000 description 5
- 108010009932 leucyl-alanyl-glycyl-valine Proteins 0.000 description 5
- 108010054155 lysyllysine Proteins 0.000 description 5
- 108020004999 messenger RNA Proteins 0.000 description 5
- 238000000746 purification Methods 0.000 description 5
- 229960005322 streptomycin Drugs 0.000 description 5
- 108091005957 yellow fluorescent proteins Proteins 0.000 description 5
- VWWKKDNCCLAGRM-GVXVVHGQSA-N (2s)-2-[[2-[[(2s)-2-[[(2s)-2-amino-4-methylpentanoyl]amino]propanoyl]amino]acetyl]amino]-3-methylbutanoic acid Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O VWWKKDNCCLAGRM-GVXVVHGQSA-N 0.000 description 4
- XCVRVWZTXPCYJT-BIIVOSGPSA-N Ala-Asn-Pro Chemical compound C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N1CCC[C@@H]1C(=O)O)N XCVRVWZTXPCYJT-BIIVOSGPSA-N 0.000 description 4
- BLGHHPHXVJWCNK-GUBZILKMSA-N Ala-Gln-Leu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O BLGHHPHXVJWCNK-GUBZILKMSA-N 0.000 description 4
- NWVVKQZOVSTDBQ-CIUDSAMLSA-N Ala-Glu-Arg Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O NWVVKQZOVSTDBQ-CIUDSAMLSA-N 0.000 description 4
- HXNNRBHASOSVPG-GUBZILKMSA-N Ala-Glu-Leu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O HXNNRBHASOSVPG-GUBZILKMSA-N 0.000 description 4
- SMCGQGDVTPFXKB-XPUUQOCRSA-N Ala-Gly-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@H](C)N SMCGQGDVTPFXKB-XPUUQOCRSA-N 0.000 description 4
- ATAKEVCGTRZKLI-UWJYBYFXSA-N Ala-His-His Chemical compound C([C@H](NC(=O)[C@@H](N)C)C(=O)N[C@@H](CC=1NC=NC=1)C(O)=O)C1=CN=CN1 ATAKEVCGTRZKLI-UWJYBYFXSA-N 0.000 description 4
- OYJCVIGKMXUVKB-GARJFASQSA-N Ala-Leu-Pro Chemical compound C[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N1CCC[C@@H]1C(=O)O)N OYJCVIGKMXUVKB-GARJFASQSA-N 0.000 description 4
- CYBJZLQSUJEMAS-LFSVMHDDSA-N Ala-Phe-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)NC(=O)[C@H](C)N)O CYBJZLQSUJEMAS-LFSVMHDDSA-N 0.000 description 4
- REWSWYIDQIELBE-FXQIFTODSA-N Ala-Val-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O REWSWYIDQIELBE-FXQIFTODSA-N 0.000 description 4
- CYXCAHZVPFREJD-LURJTMIESA-N Arg-Gly-Gly Chemical compound NC(=N)NCCC[C@H](N)C(=O)NCC(=O)NCC(O)=O CYXCAHZVPFREJD-LURJTMIESA-N 0.000 description 4
- OQCWXQJLCDPRHV-UWVGGRQHSA-N Arg-Gly-Leu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)NCC(=O)N[C@@H](CC(C)C)C(O)=O OQCWXQJLCDPRHV-UWVGGRQHSA-N 0.000 description 4
- GSUFZRURORXYTM-STQMWFEESA-N Arg-Phe-Gly Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@H](C(=O)NCC(O)=O)CC1=CC=CC=C1 GSUFZRURORXYTM-STQMWFEESA-N 0.000 description 4
- YNDLOUMBVDVALC-ZLUOBGJFSA-N Asn-Ala-Ala Chemical compound C[C@@H](C(=O)N[C@@H](C)C(=O)O)NC(=O)[C@H](CC(=O)N)N YNDLOUMBVDVALC-ZLUOBGJFSA-N 0.000 description 4
- FAEFJTCTNZTPHX-ACZMJKKPSA-N Asn-Gln-Ala Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(O)=O FAEFJTCTNZTPHX-ACZMJKKPSA-N 0.000 description 4
- UBKOVSLDWIHYSY-ACZMJKKPSA-N Asn-Glu-Ser Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O UBKOVSLDWIHYSY-ACZMJKKPSA-N 0.000 description 4
- HFPXZWPUVFVNLL-GUBZILKMSA-N Asn-Leu-Gln Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O HFPXZWPUVFVNLL-GUBZILKMSA-N 0.000 description 4
- YXVAESUIQFDBHN-SRVKXCTJSA-N Asn-Phe-Ser Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(O)=O YXVAESUIQFDBHN-SRVKXCTJSA-N 0.000 description 4
- TZOZNVLBTAFJRW-UGYAYLCHSA-N Asp-Ile-Asp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CC(=O)O)N TZOZNVLBTAFJRW-UGYAYLCHSA-N 0.000 description 4
- 102000014914 Carrier Proteins Human genes 0.000 description 4
- HEDRZPFGACZZDS-UHFFFAOYSA-N Chloroform Chemical compound ClC(Cl)Cl HEDRZPFGACZZDS-UHFFFAOYSA-N 0.000 description 4
- SDXQKJAWASHMIZ-CIUDSAMLSA-N Cys-Glu-Met Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCSC)C(O)=O SDXQKJAWASHMIZ-CIUDSAMLSA-N 0.000 description 4
- 101100382541 Escherichia coli (strain K12) casD gene Proteins 0.000 description 4
- KVXVVDFOZNYYKZ-DCAQKATOSA-N Gln-Gln-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O KVXVVDFOZNYYKZ-DCAQKATOSA-N 0.000 description 4
- RGAOLBZBLOJUTP-GRLWGSQLSA-N Gln-Ile-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)O)NC(=O)[C@H](CCC(=O)N)N RGAOLBZBLOJUTP-GRLWGSQLSA-N 0.000 description 4
- LGIKBBLQVSWUGK-DCAQKATOSA-N Gln-Leu-Gln Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O LGIKBBLQVSWUGK-DCAQKATOSA-N 0.000 description 4
- LPIKVBWNNVFHCQ-GUBZILKMSA-N Gln-Ser-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O LPIKVBWNNVFHCQ-GUBZILKMSA-N 0.000 description 4
- ITYRYNUZHPNCIK-GUBZILKMSA-N Glu-Ala-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O ITYRYNUZHPNCIK-GUBZILKMSA-N 0.000 description 4
- NCWOMXABNYEPLY-NRPADANISA-N Glu-Ala-Val Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](C(C)C)C(O)=O NCWOMXABNYEPLY-NRPADANISA-N 0.000 description 4
- VXKCPBPQEKKERH-IUCAKERBSA-N Gly-Arg-Pro Chemical compound NC(N)=NCCC[C@H](NC(=O)CN)C(=O)N1CCC[C@H]1C(O)=O VXKCPBPQEKKERH-IUCAKERBSA-N 0.000 description 4
- KKBWDNZXYLGJEY-UHFFFAOYSA-N Gly-Arg-Pro Natural products NCC(=O)NC(CCNC(=N)N)C(=O)N1CCCC1C(=O)O KKBWDNZXYLGJEY-UHFFFAOYSA-N 0.000 description 4
- XTQFHTHIAKKCTM-YFKPBYRVSA-N Gly-Glu-Gly Chemical compound NCC(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O XTQFHTHIAKKCTM-YFKPBYRVSA-N 0.000 description 4
- BUEFQXUHTUZXHR-LURJTMIESA-N Gly-Gly-Pro zwitterion Chemical compound NCC(=O)NCC(=O)N1CCC[C@H]1C(O)=O BUEFQXUHTUZXHR-LURJTMIESA-N 0.000 description 4
- NSTUFLGQJCOCDL-UWVGGRQHSA-N Gly-Leu-Arg Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N NSTUFLGQJCOCDL-UWVGGRQHSA-N 0.000 description 4
- JPVGHHQGKPQYIL-KBPBESRZSA-N Gly-Phe-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CC1=CC=CC=C1 JPVGHHQGKPQYIL-KBPBESRZSA-N 0.000 description 4
- YLEIWGJJBFBFHC-KBPBESRZSA-N Gly-Phe-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CC1=CC=CC=C1 YLEIWGJJBFBFHC-KBPBESRZSA-N 0.000 description 4
- JFFAPRNXXLRINI-NHCYSSNCSA-N His-Asp-Val Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O JFFAPRNXXLRINI-NHCYSSNCSA-N 0.000 description 4
- PQKCQZHAGILVIM-NKIYYHGXSA-N His-Glu-Thr Chemical compound C[C@@H](O)[C@H](NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)Cc1cnc[nH]1)C(O)=O PQKCQZHAGILVIM-NKIYYHGXSA-N 0.000 description 4
- VAXBXNPRXPHGHG-BJDJZHNGSA-N Ile-Ala-Leu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)O)N VAXBXNPRXPHGHG-BJDJZHNGSA-N 0.000 description 4
- FADYJNXDPBKVCA-UHFFFAOYSA-N L-Phenylalanyl-L-lysin Natural products NCCCCC(C(O)=O)NC(=O)C(N)CC1=CC=CC=C1 FADYJNXDPBKVCA-UHFFFAOYSA-N 0.000 description 4
- SITWEMZOJNKJCH-UHFFFAOYSA-N L-alanine-L-arginine Natural products CC(N)C(=O)NC(C(O)=O)CCCNC(N)=N SITWEMZOJNKJCH-UHFFFAOYSA-N 0.000 description 4
- UGTHTQWIQKEDEH-BQBZGAKWSA-N L-alanyl-L-prolylglycine zwitterion Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O UGTHTQWIQKEDEH-BQBZGAKWSA-N 0.000 description 4
- BQSLGJHIAGOZCD-CIUDSAMLSA-N Leu-Ala-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O BQSLGJHIAGOZCD-CIUDSAMLSA-N 0.000 description 4
- VIWUBXKCYJGNCL-SRVKXCTJSA-N Leu-Asn-His Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@H](C(O)=O)CC1=CN=CN1 VIWUBXKCYJGNCL-SRVKXCTJSA-N 0.000 description 4
- BKTXKJMNTSMJDQ-AVGNSLFASA-N Leu-His-Gln Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N BKTXKJMNTSMJDQ-AVGNSLFASA-N 0.000 description 4
- IAJFFZORSWOZPQ-SRVKXCTJSA-N Leu-Leu-Asn Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O IAJFFZORSWOZPQ-SRVKXCTJSA-N 0.000 description 4
- JNDYEOUZBLOVOF-AVGNSLFASA-N Leu-Leu-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O JNDYEOUZBLOVOF-AVGNSLFASA-N 0.000 description 4
- RTIRBWJPYJYTLO-MELADBBJSA-N Leu-Lys-Pro Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N1CCC[C@@H]1C(=O)O)N RTIRBWJPYJYTLO-MELADBBJSA-N 0.000 description 4
- MJTOYIHCKVQICL-ULQDDVLXSA-N Leu-Met-Phe Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)N MJTOYIHCKVQICL-ULQDDVLXSA-N 0.000 description 4
- LFSQWRSVPNKJGP-WDCWCFNPSA-N Leu-Thr-Glu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CCC(O)=O LFSQWRSVPNKJGP-WDCWCFNPSA-N 0.000 description 4
- GZRABTMNWJXFMH-UVOCVTCTSA-N Leu-Thr-Thr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O GZRABTMNWJXFMH-UVOCVTCTSA-N 0.000 description 4
- BGGTYDNTOYRTTR-MEYUZBJRSA-N Leu-Tyr-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@H](CC(C)C)N)O BGGTYDNTOYRTTR-MEYUZBJRSA-N 0.000 description 4
- IMAKMJCBYCSMHM-AVGNSLFASA-N Lys-Glu-Lys Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@H](C(O)=O)CCCCN IMAKMJCBYCSMHM-AVGNSLFASA-N 0.000 description 4
- AIRZWUMAHCDDHR-KKUMJFAQSA-N Lys-Leu-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O AIRZWUMAHCDDHR-KKUMJFAQSA-N 0.000 description 4
- WBSCNDJQPKSPII-KKUMJFAQSA-N Lys-Lys-Lys Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(O)=O WBSCNDJQPKSPII-KKUMJFAQSA-N 0.000 description 4
- JMNRXRPBHFGXQX-GUBZILKMSA-N Lys-Ser-Glu Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCC(O)=O JMNRXRPBHFGXQX-GUBZILKMSA-N 0.000 description 4
- PLOUVAYOMTYJRG-JXUBOQSCSA-N Lys-Thr-Ala Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O PLOUVAYOMTYJRG-JXUBOQSCSA-N 0.000 description 4
- 101100387131 Myxococcus xanthus (strain DK1622) devS gene Proteins 0.000 description 4
- WUGMRIBZSVSJNP-UHFFFAOYSA-N N-L-alanyl-L-tryptophan Natural products C1=CC=C2C(CC(NC(=O)C(N)C)C(O)=O)=CNC2=C1 WUGMRIBZSVSJNP-UHFFFAOYSA-N 0.000 description 4
- BPIMVBKDLSBKIJ-FCLVOEFKSA-N Phe-Thr-Phe Chemical compound C([C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=CC=C1 BPIMVBKDLSBKIJ-FCLVOEFKSA-N 0.000 description 4
- SGCZFWSQERRKBD-BQBZGAKWSA-N Pro-Asp-Gly Chemical compound OC(=O)CNC(=O)[C@H](CC(O)=O)NC(=O)[C@@H]1CCCN1 SGCZFWSQERRKBD-BQBZGAKWSA-N 0.000 description 4
- XSXABUHLKPUVLX-JYJNAYRXSA-N Pro-Ser-Trp Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC2=CNC3=CC=CC=C32)C(=O)O XSXABUHLKPUVLX-JYJNAYRXSA-N 0.000 description 4
- YIPFBJGBRCJJJD-FHWLQOOXSA-N Pro-Trp-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@@H]3CCCN3 YIPFBJGBRCJJJD-FHWLQOOXSA-N 0.000 description 4
- WWXNZNWZNZPDIF-SRVKXCTJSA-N Pro-Val-Arg Chemical compound NC(N)=NCCC[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H]1CCCN1 WWXNZNWZNZPDIF-SRVKXCTJSA-N 0.000 description 4
- BRKHVZNDAOMAHX-BIIVOSGPSA-N Ser-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CO)N BRKHVZNDAOMAHX-BIIVOSGPSA-N 0.000 description 4
- QEDMOZUJTGEIBF-FXQIFTODSA-N Ser-Arg-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(O)=O QEDMOZUJTGEIBF-FXQIFTODSA-N 0.000 description 4
- HBOABDXGTMMDSE-GUBZILKMSA-N Ser-Arg-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C(C)C)C(O)=O HBOABDXGTMMDSE-GUBZILKMSA-N 0.000 description 4
- VAUMZJHYZQXZBQ-WHFBIAKZSA-N Ser-Asn-Gly Chemical compound OC[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O VAUMZJHYZQXZBQ-WHFBIAKZSA-N 0.000 description 4
- LALNXSXEYFUUDD-GUBZILKMSA-N Ser-Glu-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O LALNXSXEYFUUDD-GUBZILKMSA-N 0.000 description 4
- WSTIOCFMWXNOCX-YUMQZZPRSA-N Ser-Gly-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CO)N WSTIOCFMWXNOCX-YUMQZZPRSA-N 0.000 description 4
- RIAKPZVSNBBNRE-BJDJZHNGSA-N Ser-Ile-Leu Chemical compound OC[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(C)C)C(O)=O RIAKPZVSNBBNRE-BJDJZHNGSA-N 0.000 description 4
- GARULAKWZGFIKC-RWRJDSDZSA-N Thr-Gln-Ile Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O GARULAKWZGFIKC-RWRJDSDZSA-N 0.000 description 4
- YGCDFAJJCRVQKU-RCWTZXSCSA-N Thr-Pro-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)[C@@H](C)O YGCDFAJJCRVQKU-RCWTZXSCSA-N 0.000 description 4
- QJIODPFLAASXJC-JHYOHUSXSA-N Thr-Thr-Phe Chemical compound C[C@H]([C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)N)O QJIODPFLAASXJC-JHYOHUSXSA-N 0.000 description 4
- AKFLVKKWVZMFOT-IHRRRGAJSA-N Tyr-Arg-Asn Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(N)=O)C(O)=O AKFLVKKWVZMFOT-IHRRRGAJSA-N 0.000 description 4
- ASQFIHTXXMFENG-XPUUQOCRSA-N Val-Ala-Gly Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C)C(=O)NCC(O)=O ASQFIHTXXMFENG-XPUUQOCRSA-N 0.000 description 4
- BMGOFDMKDVVGJG-NHCYSSNCSA-N Val-Asp-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CCCCN)C(=O)O)N BMGOFDMKDVVGJG-NHCYSSNCSA-N 0.000 description 4
- SZTTYWIUCGSURQ-AUTRQRHGSA-N Val-Glu-Glu Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O SZTTYWIUCGSURQ-AUTRQRHGSA-N 0.000 description 4
- HCHKCACWOHOZIP-UHFFFAOYSA-N Zinc Chemical compound [Zn] HCHKCACWOHOZIP-UHFFFAOYSA-N 0.000 description 4
- 108010076324 alanyl-glycyl-glycine Proteins 0.000 description 4
- 108010086434 alanyl-seryl-glycine Proteins 0.000 description 4
- 108010092854 aspartyllysine Proteins 0.000 description 4
- 238000005452 bending Methods 0.000 description 4
- SRBFZHDQGSBBOR-UHFFFAOYSA-N beta-D-Pyranose-Lyxose Natural products OC1COC(O)C(O)C1O SRBFZHDQGSBBOR-UHFFFAOYSA-N 0.000 description 4
- 108091008324 binding proteins Proteins 0.000 description 4
- 101150049463 cas5 gene Proteins 0.000 description 4
- 108010004073 cysteinylcysteine Proteins 0.000 description 4
- 238000002474 experimental method Methods 0.000 description 4
- 238000011049 filling Methods 0.000 description 4
- 239000012634 fragment Substances 0.000 description 4
- 108010013768 glutamyl-aspartyl-proline Proteins 0.000 description 4
- HPAIKDPJURGQLN-UHFFFAOYSA-N glycyl-L-histidyl-L-phenylalanine Natural products C=1C=CC=CC=1CC(C(O)=O)NC(=O)C(NC(=O)CN)CC1=CN=CN1 HPAIKDPJURGQLN-UHFFFAOYSA-N 0.000 description 4
- 108010010096 glycyl-glycyl-tyrosine Proteins 0.000 description 4
- 108010084389 glycyltryptophan Proteins 0.000 description 4
- 108010036413 histidylglycine Proteins 0.000 description 4
- 108010025306 histidylleucine Proteins 0.000 description 4
- 230000001976 improved effect Effects 0.000 description 4
- 230000001965 increasing effect Effects 0.000 description 4
- BPHPUYQFMNQIOC-NXRLNHOXSA-N isopropyl beta-D-thiogalactopyranoside Chemical compound CC(C)S[C@@H]1O[C@H](CO)[C@H](O)[C@H](O)[C@H]1O BPHPUYQFMNQIOC-NXRLNHOXSA-N 0.000 description 4
- 238000002372 labelling Methods 0.000 description 4
- 108010090333 leucyl-lysyl-proline Proteins 0.000 description 4
- 108010030617 leucyl-phenylalanyl-valine Proteins 0.000 description 4
- 108010003700 lysyl aspartic acid Proteins 0.000 description 4
- 239000011777 magnesium Substances 0.000 description 4
- TWRXJAOTZQYOKJ-UHFFFAOYSA-L magnesium chloride Substances [Mg+2].[Cl-].[Cl-] TWRXJAOTZQYOKJ-UHFFFAOYSA-L 0.000 description 4
- 229910001629 magnesium chloride Inorganic materials 0.000 description 4
- 230000007246 mechanism Effects 0.000 description 4
- 108010056582 methionylglutamic acid Proteins 0.000 description 4
- 210000004940 nucleus Anatomy 0.000 description 4
- 230000009438 off-target cleavage Effects 0.000 description 4
- 230000037361 pathway Effects 0.000 description 4
- 108010070409 phenylalanyl-glycyl-glycine Proteins 0.000 description 4
- 108010024607 phenylalanylalanine Proteins 0.000 description 4
- 108010051242 phenylalanylserine Proteins 0.000 description 4
- 102000040430 polynucleotide Human genes 0.000 description 4
- 108091033319 polynucleotide Proteins 0.000 description 4
- 239000002157 polynucleotide Substances 0.000 description 4
- SCVFZCLFOSHCOH-UHFFFAOYSA-M potassium acetate Chemical compound [K+].CC([O-])=O SCVFZCLFOSHCOH-UHFFFAOYSA-M 0.000 description 4
- 108010031719 prolyl-serine Proteins 0.000 description 4
- 108010090894 prolylleucine Proteins 0.000 description 4
- 238000012552 review Methods 0.000 description 4
- 108010026333 seryl-proline Proteins 0.000 description 4
- 108091006107 transcriptional repressors Proteins 0.000 description 4
- 238000001890 transfection Methods 0.000 description 4
- 238000011144 upstream manufacturing Methods 0.000 description 4
- 239000013598 vector Substances 0.000 description 4
- 229910052725 zinc Inorganic materials 0.000 description 4
- 239000011701 zinc Substances 0.000 description 4
- AUTOLBMXDDTRRT-JGVFFNPUSA-N (4R,5S)-dethiobiotin Chemical compound C[C@@H]1NC(=O)N[C@@H]1CCCCCC(O)=O AUTOLBMXDDTRRT-JGVFFNPUSA-N 0.000 description 3
- 102000040650 (ribonucleotides)n+m Human genes 0.000 description 3
- QKNYBSVHEMOAJP-UHFFFAOYSA-N 2-amino-2-(hydroxymethyl)propane-1,3-diol;hydron;chloride Chemical compound Cl.OCC(N)(CO)CO QKNYBSVHEMOAJP-UHFFFAOYSA-N 0.000 description 3
- VKIGAWAEXPTIOL-UHFFFAOYSA-N 2-hydroxyhexanenitrile Chemical compound CCCCC(O)C#N VKIGAWAEXPTIOL-UHFFFAOYSA-N 0.000 description 3
- FWMNVWWHGCHHJJ-SKKKGAJSSA-N 4-amino-1-[(2r)-6-amino-2-[[(2r)-2-[[(2r)-2-[[(2r)-2-amino-3-phenylpropanoyl]amino]-3-phenylpropanoyl]amino]-4-methylpentanoyl]amino]hexanoyl]piperidine-4-carboxylic acid Chemical compound C([C@H](C(=O)N[C@H](CC(C)C)C(=O)N[C@H](CCCCN)C(=O)N1CCC(N)(CC1)C(O)=O)NC(=O)[C@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 FWMNVWWHGCHHJJ-SKKKGAJSSA-N 0.000 description 3
- HHGYNJRJIINWAK-FXQIFTODSA-N Ala-Ala-Arg Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N HHGYNJRJIINWAK-FXQIFTODSA-N 0.000 description 3
- BUANFPRKJKJSRR-ACZMJKKPSA-N Ala-Ala-Gln Chemical compound C[C@H]([NH3+])C(=O)N[C@@H](C)C(=O)N[C@H](C([O-])=O)CCC(N)=O BUANFPRKJKJSRR-ACZMJKKPSA-N 0.000 description 3
- KQFRUSHJPKXBMB-BHDSKKPTSA-N Ala-Ala-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](C)NC(=O)[C@@H](N)C)C(O)=O)=CNC2=C1 KQFRUSHJPKXBMB-BHDSKKPTSA-N 0.000 description 3
- ZEXDYVGDZJBRMO-ACZMJKKPSA-N Ala-Asn-Gln Chemical compound C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N ZEXDYVGDZJBRMO-ACZMJKKPSA-N 0.000 description 3
- ZIBWKCRKNFYTPT-ZKWXMUAHSA-N Ala-Asn-Val Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](C(C)C)C(O)=O ZIBWKCRKNFYTPT-ZKWXMUAHSA-N 0.000 description 3
- NHCPCLJZRSIDHS-ZLUOBGJFSA-N Ala-Asp-Ala Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(O)=O NHCPCLJZRSIDHS-ZLUOBGJFSA-N 0.000 description 3
- LGFCAXJBAZESCF-ACZMJKKPSA-N Ala-Gln-Ala Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(O)=O LGFCAXJBAZESCF-ACZMJKKPSA-N 0.000 description 3
- FUSPCLTUKXQREV-ACZMJKKPSA-N Ala-Glu-Ala Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O FUSPCLTUKXQREV-ACZMJKKPSA-N 0.000 description 3
- PAIHPOGPJVUFJY-WDSKDSINSA-N Ala-Glu-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O PAIHPOGPJVUFJY-WDSKDSINSA-N 0.000 description 3
- BVSGPHDECMJBDE-HGNGGELXSA-N Ala-Glu-His Chemical compound C[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N BVSGPHDECMJBDE-HGNGGELXSA-N 0.000 description 3
- PCIFXPRIFWKWLK-YUMQZZPRSA-N Ala-Gly-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)CNC(=O)[C@H](C)N PCIFXPRIFWKWLK-YUMQZZPRSA-N 0.000 description 3
- NOGFDULFCFXBHB-CIUDSAMLSA-N Ala-Leu-Cys Chemical compound C[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CS)C(=O)O)N NOGFDULFCFXBHB-CIUDSAMLSA-N 0.000 description 3
- SUHLZMHFRALVSY-YUMQZZPRSA-N Ala-Lys-Gly Chemical compound NCCCC[C@H](NC(=O)[C@@H](N)C)C(=O)NCC(O)=O SUHLZMHFRALVSY-YUMQZZPRSA-N 0.000 description 3
- NINQYGGNRIBFSC-CIUDSAMLSA-N Ala-Lys-Ser Chemical compound NCCCC[C@H](NC(=O)[C@@H](N)C)C(=O)N[C@@H](CO)C(O)=O NINQYGGNRIBFSC-CIUDSAMLSA-N 0.000 description 3
- IHMCQESUJVZTKW-UBHSHLNASA-N Ala-Phe-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@H](C)N)CC1=CC=CC=C1 IHMCQESUJVZTKW-UBHSHLNASA-N 0.000 description 3
- IPZQNYYAYVRKKK-FXQIFTODSA-N Ala-Pro-Ala Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O IPZQNYYAYVRKKK-FXQIFTODSA-N 0.000 description 3
- BHTBAVZSZCQZPT-GUBZILKMSA-N Ala-Pro-Met Chemical compound CSCC[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H](C)N BHTBAVZSZCQZPT-GUBZILKMSA-N 0.000 description 3
- FFZJHQODAYHGPO-KZVJFYERSA-N Ala-Pro-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H](C)N FFZJHQODAYHGPO-KZVJFYERSA-N 0.000 description 3
- CQJHFKKGZXKZBC-BPNCWPANSA-N Ala-Pro-Tyr Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 CQJHFKKGZXKZBC-BPNCWPANSA-N 0.000 description 3
- IOFVWPYSRSCWHI-JXUBOQSCSA-N Ala-Thr-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@H](C)N IOFVWPYSRSCWHI-JXUBOQSCSA-N 0.000 description 3
- QOIGKCBMXUCDQU-KDXUFGMBSA-N Ala-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](C)N)O QOIGKCBMXUCDQU-KDXUFGMBSA-N 0.000 description 3
- AETQNIIFKCMVHP-UVBJJODRSA-N Ala-Trp-Arg Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O AETQNIIFKCMVHP-UVBJJODRSA-N 0.000 description 3
- PGNNQOJOEGFAOR-KWQFWETISA-N Ala-Tyr-Gly Chemical compound OC(=O)CNC(=O)[C@@H](NC(=O)[C@@H](N)C)CC1=CC=C(O)C=C1 PGNNQOJOEGFAOR-KWQFWETISA-N 0.000 description 3
- 108091093088 Amplicon Proteins 0.000 description 3
- VBFJESQBIWCWRL-DCAQKATOSA-N Arg-Ala-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCNC(N)=N VBFJESQBIWCWRL-DCAQKATOSA-N 0.000 description 3
- NTAZNGWBXRVEDJ-FXQIFTODSA-N Arg-Asp-Asp Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O NTAZNGWBXRVEDJ-FXQIFTODSA-N 0.000 description 3
- DXQIQUIQYAGRCC-CIUDSAMLSA-N Arg-Asp-Gln Chemical compound C(C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N)CN=C(N)N DXQIQUIQYAGRCC-CIUDSAMLSA-N 0.000 description 3
- GMFAGHNRXPSSJS-SRVKXCTJSA-N Arg-Leu-Gln Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O GMFAGHNRXPSSJS-SRVKXCTJSA-N 0.000 description 3
- NMRHDSAOIURTNT-RWMBFGLXSA-N Arg-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N NMRHDSAOIURTNT-RWMBFGLXSA-N 0.000 description 3
- ASQKVGRCKOFKIU-KZVJFYERSA-N Arg-Thr-Ala Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](C)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N)O ASQKVGRCKOFKIU-KZVJFYERSA-N 0.000 description 3
- XRNXPIGJPQHCPC-RCWTZXSCSA-N Arg-Thr-Val Chemical compound CC(C)[C@H](NC(=O)[C@@H](NC(=O)[C@@H](N)CCCNC(N)=N)[C@@H](C)O)C(O)=O XRNXPIGJPQHCPC-RCWTZXSCSA-N 0.000 description 3
- IYVSIZAXNLOKFQ-BYULHYEWSA-N Asn-Asp-Val Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O IYVSIZAXNLOKFQ-BYULHYEWSA-N 0.000 description 3
- VJTWLBMESLDOMK-WDSKDSINSA-N Asn-Gln-Gly Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O VJTWLBMESLDOMK-WDSKDSINSA-N 0.000 description 3
- MSBDSTRUMZFSEU-PEFMBERDSA-N Asn-Glu-Ile Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O MSBDSTRUMZFSEU-PEFMBERDSA-N 0.000 description 3
- CTQIOCMSIJATNX-WHFBIAKZSA-N Asn-Gly-Ala Chemical compound [H]N[C@@H](CC(N)=O)C(=O)NCC(=O)N[C@@H](C)C(O)=O CTQIOCMSIJATNX-WHFBIAKZSA-N 0.000 description 3
- JNCRAQVYJZGIOW-QSFUFRPTSA-N Asn-Val-Ile Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O JNCRAQVYJZGIOW-QSFUFRPTSA-N 0.000 description 3
- PZXPWHFYZXTFBI-YUMQZZPRSA-N Asp-Gly-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CC(O)=O PZXPWHFYZXTFBI-YUMQZZPRSA-N 0.000 description 3
- UJGRZQYSNYTCAX-SRVKXCTJSA-N Asp-Leu-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC(O)=O UJGRZQYSNYTCAX-SRVKXCTJSA-N 0.000 description 3
- WMLFFCRUSPNENW-ZLUOBGJFSA-N Asp-Ser-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O WMLFFCRUSPNENW-ZLUOBGJFSA-N 0.000 description 3
- QOJJMJKTMKNFEF-ZKWXMUAHSA-N Asp-Val-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CC(O)=O QOJJMJKTMKNFEF-ZKWXMUAHSA-N 0.000 description 3
- BIVLWXQGXJLGKG-BIIVOSGPSA-N Cys-Asp-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)O)NC(=O)[C@H](CS)N)C(=O)O BIVLWXQGXJLGKG-BIIVOSGPSA-N 0.000 description 3
- VCIIDXDOPGHMDQ-WDSKDSINSA-N Cys-Gly-Gln Chemical compound [H]N[C@@H](CS)C(=O)NCC(=O)N[C@@H](CCC(N)=O)C(O)=O VCIIDXDOPGHMDQ-WDSKDSINSA-N 0.000 description 3
- BCWIFCLVCRAIQK-ZLUOBGJFSA-N Cys-Ser-Cys Chemical compound C([C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CS)N)O BCWIFCLVCRAIQK-ZLUOBGJFSA-N 0.000 description 3
- NRVQLLDIJJEIIZ-VZFHVOOUSA-N Cys-Thr-Ala Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](C)C(=O)O)NC(=O)[C@H](CS)N)O NRVQLLDIJJEIIZ-VZFHVOOUSA-N 0.000 description 3
- 108090000626 DNA-directed RNA polymerases Proteins 0.000 description 3
- 102000004163 DNA-directed RNA polymerases Human genes 0.000 description 3
- 108010008532 Deoxyribonuclease I Proteins 0.000 description 3
- 102000007260 Deoxyribonuclease I Human genes 0.000 description 3
- KCXVZYZYPLLWCC-UHFFFAOYSA-N EDTA Chemical compound OC(=O)CN(CC(O)=O)CCN(CC(O)=O)CC(O)=O KCXVZYZYPLLWCC-UHFFFAOYSA-N 0.000 description 3
- WUAYFMZULZDSLB-ACZMJKKPSA-N Gln-Ala-Asn Chemical compound NC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCC(N)=O WUAYFMZULZDSLB-ACZMJKKPSA-N 0.000 description 3
- OYTPNWYZORARHL-XHNCKOQMSA-N Gln-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCC(=O)N)N OYTPNWYZORARHL-XHNCKOQMSA-N 0.000 description 3
- NVEASDQHBRZPSU-BQBZGAKWSA-N Gln-Gln-Gly Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O NVEASDQHBRZPSU-BQBZGAKWSA-N 0.000 description 3
- FGYPOQPQTUNESW-IUCAKERBSA-N Gln-Gly-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CCC(=O)N)N FGYPOQPQTUNESW-IUCAKERBSA-N 0.000 description 3
- XFAUJGNLHIGXET-AVGNSLFASA-N Gln-Leu-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O XFAUJGNLHIGXET-AVGNSLFASA-N 0.000 description 3
- FNAJNWPDTIXYJN-CIUDSAMLSA-N Gln-Pro-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CCC(N)=O FNAJNWPDTIXYJN-CIUDSAMLSA-N 0.000 description 3
- RWQCWSGOOOEGPB-FXQIFTODSA-N Gln-Ser-Glu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(O)=O RWQCWSGOOOEGPB-FXQIFTODSA-N 0.000 description 3
- OTQSTOXRUBVWAP-NRPADANISA-N Gln-Ser-Val Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O OTQSTOXRUBVWAP-NRPADANISA-N 0.000 description 3
- NSEKYCAADBNQFE-XIRDDKMYSA-N Gln-Trp-Arg Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CCC(N)=O)N)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O)=CNC2=C1 NSEKYCAADBNQFE-XIRDDKMYSA-N 0.000 description 3
- SGVGIVDZLSHSEN-RYUDHWBXSA-N Gln-Tyr-Gly Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)NCC(O)=O SGVGIVDZLSHSEN-RYUDHWBXSA-N 0.000 description 3
- LTUVYLVIZHJCOQ-KKUMJFAQSA-N Glu-Arg-Phe Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O LTUVYLVIZHJCOQ-KKUMJFAQSA-N 0.000 description 3
- XXCDTYBVGMPIOA-FXQIFTODSA-N Glu-Asp-Glu Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O XXCDTYBVGMPIOA-FXQIFTODSA-N 0.000 description 3
- IESFZVCAVACGPH-PEFMBERDSA-N Glu-Asp-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CCC(O)=O IESFZVCAVACGPH-PEFMBERDSA-N 0.000 description 3
- CKOFNWCLWRYUHK-XHNCKOQMSA-N Glu-Asp-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)O)NC(=O)[C@H](CCC(=O)O)N)C(=O)O CKOFNWCLWRYUHK-XHNCKOQMSA-N 0.000 description 3
- WPLGNDORMXTMQS-FXQIFTODSA-N Glu-Gln-Ser Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O WPLGNDORMXTMQS-FXQIFTODSA-N 0.000 description 3
- DVLZZEPUNFEUBW-AVGNSLFASA-N Glu-His-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC1=CN=CN1)NC(=O)[C@H](CCC(=O)O)N DVLZZEPUNFEUBW-AVGNSLFASA-N 0.000 description 3
- VGOFRWOTSXVPAU-SDDRHHMPSA-N Glu-His-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CN=CN2)NC(=O)[C@H](CCC(=O)O)N)C(=O)O VGOFRWOTSXVPAU-SDDRHHMPSA-N 0.000 description 3
- VSRCAOIHMGCIJK-SRVKXCTJSA-N Glu-Leu-Arg Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O VSRCAOIHMGCIJK-SRVKXCTJSA-N 0.000 description 3
- SJJHXJDSNQJMMW-SRVKXCTJSA-N Glu-Lys-Arg Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O SJJHXJDSNQJMMW-SRVKXCTJSA-N 0.000 description 3
- ZAPFAWQHBOHWLL-GUBZILKMSA-N Glu-Ser-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CCC(=O)O)N ZAPFAWQHBOHWLL-GUBZILKMSA-N 0.000 description 3
- FGGKGJHCVMYGCD-UKJIMTQDSA-N Glu-Val-Ile Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O FGGKGJHCVMYGCD-UKJIMTQDSA-N 0.000 description 3
- JRDYDYXZKFNNRQ-XPUUQOCRSA-N Gly-Ala-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)CN JRDYDYXZKFNNRQ-XPUUQOCRSA-N 0.000 description 3
- WKJKBELXHCTHIJ-WPRPVWTQSA-N Gly-Arg-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CCCN=C(N)N WKJKBELXHCTHIJ-WPRPVWTQSA-N 0.000 description 3
- JVWPPCWUDRJGAE-YUMQZZPRSA-N Gly-Asn-Leu Chemical compound [H]NCC(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O JVWPPCWUDRJGAE-YUMQZZPRSA-N 0.000 description 3
- LXXLEUBUOMCAMR-NKWVEPMBSA-N Gly-Asp-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)O)NC(=O)CN)C(=O)O LXXLEUBUOMCAMR-NKWVEPMBSA-N 0.000 description 3
- BYYNJRSNDARRBX-YFKPBYRVSA-N Gly-Gln-Gly Chemical compound NCC(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O BYYNJRSNDARRBX-YFKPBYRVSA-N 0.000 description 3
- IDOGEHIWMJMAHT-BYPYZUCNSA-N Gly-Gly-Cys Chemical compound NCC(=O)NCC(=O)N[C@@H](CS)C(O)=O IDOGEHIWMJMAHT-BYPYZUCNSA-N 0.000 description 3
- XPJBQTCXPJNIFE-ZETCQYMHSA-N Gly-Gly-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)CNC(=O)CN XPJBQTCXPJNIFE-ZETCQYMHSA-N 0.000 description 3
- ULZCYBYDTUMHNF-IUCAKERBSA-N Gly-Leu-Glu Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O ULZCYBYDTUMHNF-IUCAKERBSA-N 0.000 description 3
- UHPAZODVFFYEEL-QWRGUYRKSA-N Gly-Leu-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)CN UHPAZODVFFYEEL-QWRGUYRKSA-N 0.000 description 3
- JPAACTMBBBGAAR-HOTGVXAUSA-N Gly-Leu-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@@H](NC(=O)CN)CC(C)C)C(O)=O)=CNC2=C1 JPAACTMBBBGAAR-HOTGVXAUSA-N 0.000 description 3
- VLIJYPMATZSOLL-YUMQZZPRSA-N Gly-Lys-Cys Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)CN VLIJYPMATZSOLL-YUMQZZPRSA-N 0.000 description 3
- IGOYNRWLWHWAQO-JTQLQIEISA-N Gly-Phe-Gly Chemical compound OC(=O)CNC(=O)[C@@H](NC(=O)CN)CC1=CC=CC=C1 IGOYNRWLWHWAQO-JTQLQIEISA-N 0.000 description 3
- VDCRBJACQKOSMS-JSGCOSHPSA-N Gly-Phe-Val Chemical compound [H]NCC(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](C(C)C)C(O)=O VDCRBJACQKOSMS-JSGCOSHPSA-N 0.000 description 3
- HAOUOFNNJJLVNS-BQBZGAKWSA-N Gly-Pro-Ser Chemical compound NCC(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O HAOUOFNNJJLVNS-BQBZGAKWSA-N 0.000 description 3
- ABPRMMYHROQBLY-NKWVEPMBSA-N Gly-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)CN)C(=O)O ABPRMMYHROQBLY-NKWVEPMBSA-N 0.000 description 3
- RYAOJUMWLWUGNW-QMMMGPOBSA-N Gly-Val-Gly Chemical compound NCC(=O)N[C@@H](C(C)C)C(=O)NCC(O)=O RYAOJUMWLWUGNW-QMMMGPOBSA-N 0.000 description 3
- ZVXMEWXHFBYJPI-LSJOCFKGSA-N Gly-Val-Ile Chemical compound [H]NCC(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O ZVXMEWXHFBYJPI-LSJOCFKGSA-N 0.000 description 3
- 108010043121 Green Fluorescent Proteins Proteins 0.000 description 3
- 102000004144 Green Fluorescent Proteins Human genes 0.000 description 3
- 108020005004 Guide RNA Proteins 0.000 description 3
- AFPFGFUGETYOSY-HGNGGELXSA-N His-Ala-Glu Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(O)=O AFPFGFUGETYOSY-HGNGGELXSA-N 0.000 description 3
- IWXMHXYOACDSIA-PYJNHQTQSA-N His-Ile-Val Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C(C)C)C(O)=O IWXMHXYOACDSIA-PYJNHQTQSA-N 0.000 description 3
- WHKLDLQHSYAVGU-ACRUOGEOSA-N His-Phe-Tyr Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O WHKLDLQHSYAVGU-ACRUOGEOSA-N 0.000 description 3
- PYNPBMCLAKTHJL-SRVKXCTJSA-N His-Pro-Glu Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O PYNPBMCLAKTHJL-SRVKXCTJSA-N 0.000 description 3
- 101000615488 Homo sapiens Methyl-CpG-binding domain protein 2 Proteins 0.000 description 3
- VSZALHITQINTGC-GHCJXIJMSA-N Ile-Ala-Asp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C)C(=O)N[C@@H](CC(=O)O)C(=O)O)N VSZALHITQINTGC-GHCJXIJMSA-N 0.000 description 3
- SCHZQZPYHBWYEQ-PEFMBERDSA-N Ile-Asn-Glu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N SCHZQZPYHBWYEQ-PEFMBERDSA-N 0.000 description 3
- IGJWJGIHUFQANP-LAEOZQHASA-N Ile-Gly-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)NCC(=O)N[C@@H](CCC(=O)N)C(=O)O)N IGJWJGIHUFQANP-LAEOZQHASA-N 0.000 description 3
- MQFGXJNSUJTXDT-QSFUFRPTSA-N Ile-Gly-Ile Chemical compound N[C@@H]([C@@H](C)CC)C(=O)NCC(=O)N[C@@H]([C@@H](C)CC)C(=O)O MQFGXJNSUJTXDT-QSFUFRPTSA-N 0.000 description 3
- PDTMWFVVNZYWTR-NHCYSSNCSA-N Ile-Gly-Lys Chemical compound CC[C@H](C)[C@H](N)C(=O)NCC(=O)N[C@@H](CCCCN)C(O)=O PDTMWFVVNZYWTR-NHCYSSNCSA-N 0.000 description 3
- WIZPFZKOFZXDQG-HTFCKZLJSA-N Ile-Ile-Ala Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C)C(O)=O WIZPFZKOFZXDQG-HTFCKZLJSA-N 0.000 description 3
- AKOYRLRUFBZOSP-BJDJZHNGSA-N Ile-Lys-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)O)N AKOYRLRUFBZOSP-BJDJZHNGSA-N 0.000 description 3
- FJWALBCCVIHZBS-QXEWZRGKSA-N Ile-Met-Gly Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCSC)C(=O)NCC(=O)O)N FJWALBCCVIHZBS-QXEWZRGKSA-N 0.000 description 3
- OWSWUWDMSNXTNE-GMOBBJLQSA-N Ile-Pro-Asp Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(=O)O)C(=O)O)N OWSWUWDMSNXTNE-GMOBBJLQSA-N 0.000 description 3
- KFZMGEQAYNKOFK-UHFFFAOYSA-N Isopropanol Chemical compound CC(C)O KFZMGEQAYNKOFK-UHFFFAOYSA-N 0.000 description 3
- IBMVEYRWAWIOTN-UHFFFAOYSA-N L-Leucyl-L-Arginyl-L-Proline Natural products CC(C)CC(N)C(=O)NC(CCCN=C(N)N)C(=O)N1CCCC1C(O)=O IBMVEYRWAWIOTN-UHFFFAOYSA-N 0.000 description 3
- SRBFZHDQGSBBOR-HWQSCIPKSA-N L-arabinopyranose Chemical compound O[C@H]1COC(O)[C@H](O)[C@H]1O SRBFZHDQGSBBOR-HWQSCIPKSA-N 0.000 description 3
- RCFDOSNHHZGBOY-UHFFFAOYSA-N L-isoleucyl-L-alanine Natural products CCC(C)C(N)C(=O)NC(C)C(O)=O RCFDOSNHHZGBOY-UHFFFAOYSA-N 0.000 description 3
- LHSGPCFBGJHPCY-UHFFFAOYSA-N L-leucine-L-tyrosine Natural products CC(C)CC(N)C(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 LHSGPCFBGJHPCY-UHFFFAOYSA-N 0.000 description 3
- LZDNBBYBDGBADK-UHFFFAOYSA-N L-valyl-L-tryptophan Natural products C1=CC=C2C(CC(NC(=O)C(N)C(C)C)C(O)=O)=CNC2=C1 LZDNBBYBDGBADK-UHFFFAOYSA-N 0.000 description 3
- CZCSUZMIRKFFFA-CIUDSAMLSA-N Leu-Ala-Asn Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(O)=O CZCSUZMIRKFFFA-CIUDSAMLSA-N 0.000 description 3
- PBCHMHROGNUXMK-DLOVCJGASA-N Leu-Ala-His Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CN=CN1 PBCHMHROGNUXMK-DLOVCJGASA-N 0.000 description 3
- REPPKAMYTOJTFC-DCAQKATOSA-N Leu-Arg-Asp Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(O)=O REPPKAMYTOJTFC-DCAQKATOSA-N 0.000 description 3
- YOZCKMXHBYKOMQ-IHRRRGAJSA-N Leu-Arg-Lys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCCCN)C(=O)O)N YOZCKMXHBYKOMQ-IHRRRGAJSA-N 0.000 description 3
- IGUOAYLTQJLPPD-DCAQKATOSA-N Leu-Asn-Arg Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@H](C(O)=O)CCCN=C(N)N IGUOAYLTQJLPPD-DCAQKATOSA-N 0.000 description 3
- WGNOPSQMIQERPK-UHFFFAOYSA-N Leu-Asn-Pro Natural products CC(C)CC(N)C(=O)NC(CC(=O)N)C(=O)N1CCCC1C(=O)O WGNOPSQMIQERPK-UHFFFAOYSA-N 0.000 description 3
- BPANDPNDMJHFEV-CIUDSAMLSA-N Leu-Asp-Ala Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(O)=O BPANDPNDMJHFEV-CIUDSAMLSA-N 0.000 description 3
- ZURHXHNAEJJRNU-CIUDSAMLSA-N Leu-Asp-Asn Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O ZURHXHNAEJJRNU-CIUDSAMLSA-N 0.000 description 3
- ILJREDZFPHTUIE-GUBZILKMSA-N Leu-Asp-Glu Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O ILJREDZFPHTUIE-GUBZILKMSA-N 0.000 description 3
- QVFGXCVIXXBFHO-AVGNSLFASA-N Leu-Glu-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O QVFGXCVIXXBFHO-AVGNSLFASA-N 0.000 description 3
- UCDHVOALNXENLC-KBPBESRZSA-N Leu-Gly-Tyr Chemical compound CC(C)C[C@H]([NH3+])C(=O)NCC(=O)N[C@H](C([O-])=O)CC1=CC=C(O)C=C1 UCDHVOALNXENLC-KBPBESRZSA-N 0.000 description 3
- KOSWSHVQIVTVQF-ZPFDUUQYSA-N Leu-Ile-Asp Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(O)=O)C(O)=O KOSWSHVQIVTVQF-ZPFDUUQYSA-N 0.000 description 3
- QJXHMYMRGDOHRU-NHCYSSNCSA-N Leu-Ile-Gly Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)NCC(O)=O QJXHMYMRGDOHRU-NHCYSSNCSA-N 0.000 description 3
- OMHLATXVNQSALM-FQUUOJAGSA-N Leu-Ile-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC(C)C)N OMHLATXVNQSALM-FQUUOJAGSA-N 0.000 description 3
- HRTRLSRYZZKPCO-BJDJZHNGSA-N Leu-Ile-Ser Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O HRTRLSRYZZKPCO-BJDJZHNGSA-N 0.000 description 3
- DSFYPIUSAMSERP-IHRRRGAJSA-N Leu-Leu-Arg Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N DSFYPIUSAMSERP-IHRRRGAJSA-N 0.000 description 3
- FAELBUXXFQLUAX-AJNGGQMLSA-N Leu-Leu-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC(C)C FAELBUXXFQLUAX-AJNGGQMLSA-N 0.000 description 3
- UHNQRAFSEBGZFZ-YESZJQIVSA-N Leu-Phe-Pro Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N2CCC[C@@H]2C(=O)O)N UHNQRAFSEBGZFZ-YESZJQIVSA-N 0.000 description 3
- MAXILRZVORNXBE-PMVMPFDFSA-N Leu-Phe-Trp Chemical compound C([C@H](NC(=O)[C@@H](N)CC(C)C)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(O)=O)C1=CC=CC=C1 MAXILRZVORNXBE-PMVMPFDFSA-N 0.000 description 3
- QMKFDEUJGYNFMC-AVGNSLFASA-N Leu-Pro-Arg Chemical compound CC(C)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCN=C(N)N)C(O)=O QMKFDEUJGYNFMC-AVGNSLFASA-N 0.000 description 3
- SBANPBVRHYIMRR-UHFFFAOYSA-N Leu-Ser-Pro Natural products CC(C)CC(N)C(=O)NC(CO)C(=O)N1CCCC1C(O)=O SBANPBVRHYIMRR-UHFFFAOYSA-N 0.000 description 3
- MPOHDJKRBLVGCT-CIUDSAMLSA-N Lys-Ala-Asn Chemical compound C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CCCCN)N MPOHDJKRBLVGCT-CIUDSAMLSA-N 0.000 description 3
- IRNSXVOWSXSULE-DCAQKATOSA-N Lys-Ala-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCCN IRNSXVOWSXSULE-DCAQKATOSA-N 0.000 description 3
- PGBPWPTUOSCNLE-JYJNAYRXSA-N Lys-Gln-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCCCN)N PGBPWPTUOSCNLE-JYJNAYRXSA-N 0.000 description 3
- QZONCCHVHCOBSK-YUMQZZPRSA-N Lys-Gly-Asn Chemical compound [H]N[C@@H](CCCCN)C(=O)NCC(=O)N[C@@H](CC(N)=O)C(O)=O QZONCCHVHCOBSK-YUMQZZPRSA-N 0.000 description 3
- HAUUXTXKJNVIFY-ONGXEEELSA-N Lys-Gly-Val Chemical compound [H]N[C@@H](CCCCN)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O HAUUXTXKJNVIFY-ONGXEEELSA-N 0.000 description 3
- YDDDRTIPNTWGIG-SRVKXCTJSA-N Lys-Lys-Ser Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O YDDDRTIPNTWGIG-SRVKXCTJSA-N 0.000 description 3
- LNMKRJJLEFASGA-BZSNNMDCSA-N Lys-Phe-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(C)C)C(O)=O LNMKRJJLEFASGA-BZSNNMDCSA-N 0.000 description 3
- SBQDRNOLGSYHQA-YUMQZZPRSA-N Lys-Ser-Gly Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)NCC(O)=O SBQDRNOLGSYHQA-YUMQZZPRSA-N 0.000 description 3
- 102100025169 Max-binding protein MNT Human genes 0.000 description 3
- IHITVQKJXQQGLJ-LPEHRKFASA-N Met-Asn-Pro Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N1CCC[C@@H]1C(=O)O)N IHITVQKJXQQGLJ-LPEHRKFASA-N 0.000 description 3
- UZWMJZSOXGOVIN-LURJTMIESA-N Met-Gly-Gly Chemical compound CSCC[C@H](N)C(=O)NCC(=O)NCC(O)=O UZWMJZSOXGOVIN-LURJTMIESA-N 0.000 description 3
- GRKPXCKLOOUDFG-UFYCRDLUSA-N Met-Phe-Tyr Chemical compound C([C@H](NC(=O)[C@@H](N)CCSC)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=CC=C1 GRKPXCKLOOUDFG-UFYCRDLUSA-N 0.000 description 3
- OKKJLVBELUTLKV-UHFFFAOYSA-N Methanol Chemical compound OC OKKJLVBELUTLKV-UHFFFAOYSA-N 0.000 description 3
- 102100021299 Methyl-CpG-binding domain protein 2 Human genes 0.000 description 3
- 101100387128 Myxococcus xanthus (strain DK1622) devR gene Proteins 0.000 description 3
- KZNQNBZMBZJQJO-UHFFFAOYSA-N N-glycyl-L-proline Natural products NCC(=O)N1CCCC1C(O)=O KZNQNBZMBZJQJO-UHFFFAOYSA-N 0.000 description 3
- 108010066427 N-valyltryptophan Proteins 0.000 description 3
- 108091034117 Oligonucleotide Proteins 0.000 description 3
- MSSXKZBDKZAHCX-UNQGMJICSA-N Phe-Thr-Val Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O MSSXKZBDKZAHCX-UNQGMJICSA-N 0.000 description 3
- CGBYDGAJHSOGFQ-LPEHRKFASA-N Pro-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@@H]2CCCN2 CGBYDGAJHSOGFQ-LPEHRKFASA-N 0.000 description 3
- OCSACVPBMIYNJE-GUBZILKMSA-N Pro-Arg-Asn Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(N)=O)C(O)=O OCSACVPBMIYNJE-GUBZILKMSA-N 0.000 description 3
- VCYJKOLZYPYGJV-AVGNSLFASA-N Pro-Arg-Leu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(O)=O VCYJKOLZYPYGJV-AVGNSLFASA-N 0.000 description 3
- OBVCYFIHIIYIQF-CIUDSAMLSA-N Pro-Asn-Glu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O OBVCYFIHIIYIQF-CIUDSAMLSA-N 0.000 description 3
- HAAQQNHQZBOWFO-LURJTMIESA-N Pro-Gly-Gly Chemical compound OC(=O)CNC(=O)CNC(=O)[C@@H]1CCCN1 HAAQQNHQZBOWFO-LURJTMIESA-N 0.000 description 3
- YTWNSIDWAFSEEI-RWMBFGLXSA-N Pro-His-Pro Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CC2=CN=CN2)C(=O)N3CCC[C@@H]3C(=O)O YTWNSIDWAFSEEI-RWMBFGLXSA-N 0.000 description 3
- XYHMFGGWNOFUOU-QXEWZRGKSA-N Pro-Ile-Gly Chemical compound OC(=O)CNC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H]1CCCN1 XYHMFGGWNOFUOU-QXEWZRGKSA-N 0.000 description 3
- VTFXTWDFPTWNJY-RHYQMDGZSA-N Pro-Leu-Thr Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O VTFXTWDFPTWNJY-RHYQMDGZSA-N 0.000 description 3
- WVXQQUWOKUZIEG-VEVYYDQMSA-N Pro-Thr-Asn Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(O)=O WVXQQUWOKUZIEG-VEVYYDQMSA-N 0.000 description 3
- JXVXYRZQIUPYSA-NHCYSSNCSA-N Pro-Val-Gln Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O JXVXYRZQIUPYSA-NHCYSSNCSA-N 0.000 description 3
- MMGJPDWSIOAGTH-ACZMJKKPSA-N Ser-Ala-Gln Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(N)=O)C(O)=O MMGJPDWSIOAGTH-ACZMJKKPSA-N 0.000 description 3
- SNNSYBWPPVAXQW-ZLUOBGJFSA-N Ser-Cys-Cys Chemical compound C([C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CS)C(=O)O)N)O SNNSYBWPPVAXQW-ZLUOBGJFSA-N 0.000 description 3
- GZFAWAQTEYDKII-YUMQZZPRSA-N Ser-Gly-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CO GZFAWAQTEYDKII-YUMQZZPRSA-N 0.000 description 3
- JEHPKECJCALLRW-CUJWVEQBSA-N Ser-His-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O JEHPKECJCALLRW-CUJWVEQBSA-N 0.000 description 3
- KCGIREHVWRXNDH-GARJFASQSA-N Ser-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CO)N KCGIREHVWRXNDH-GARJFASQSA-N 0.000 description 3
- JWOBLHJRDADHLN-KKUMJFAQSA-N Ser-Leu-Tyr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O JWOBLHJRDADHLN-KKUMJFAQSA-N 0.000 description 3
- XQAPEISNMXNKGE-FXQIFTODSA-N Ser-Pro-Cys Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CO)N)C(=O)N[C@@H](CS)C(=O)O XQAPEISNMXNKGE-FXQIFTODSA-N 0.000 description 3
- FKYWFUYPVKLJLP-DCAQKATOSA-N Ser-Pro-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CO FKYWFUYPVKLJLP-DCAQKATOSA-N 0.000 description 3
- JCLAFVNDBJMLBC-JBDRJPRFSA-N Ser-Ser-Ile Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O JCLAFVNDBJMLBC-JBDRJPRFSA-N 0.000 description 3
- BMKNXTJLHFIAAH-CIUDSAMLSA-N Ser-Ser-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O BMKNXTJLHFIAAH-CIUDSAMLSA-N 0.000 description 3
- PMTWIUBUQRGCSB-FXQIFTODSA-N Ser-Val-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C)C(O)=O PMTWIUBUQRGCSB-FXQIFTODSA-N 0.000 description 3
- SIEBDTCABMZCLF-XGEHTFHBSA-N Ser-Val-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O SIEBDTCABMZCLF-XGEHTFHBSA-N 0.000 description 3
- 241000194020 Streptococcus thermophilus Species 0.000 description 3
- 241000187747 Streptomyces Species 0.000 description 3
- IRKWVRSEQFTGGV-VEVYYDQMSA-N Thr-Asn-Arg Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O IRKWVRSEQFTGGV-VEVYYDQMSA-N 0.000 description 3
- VASYSJHSMSBTDU-LKXGYXEUSA-N Thr-Asn-Cys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CS)C(=O)O)N)O VASYSJHSMSBTDU-LKXGYXEUSA-N 0.000 description 3
- WLDUCKSCDRIVLJ-NUMRIWBASA-N Thr-Gln-Asp Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC(=O)O)C(=O)O)N)O WLDUCKSCDRIVLJ-NUMRIWBASA-N 0.000 description 3
- CQNFRKAKGDSJFR-NUMRIWBASA-N Thr-Glu-Asn Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CC(=O)N)C(=O)O)N)O CQNFRKAKGDSJFR-NUMRIWBASA-N 0.000 description 3
- VTVVYQOXJCZVEB-WDCWCFNPSA-N Thr-Leu-Glu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O VTVVYQOXJCZVEB-WDCWCFNPSA-N 0.000 description 3
- BDENGIGFTNYZSJ-RCWTZXSCSA-N Thr-Pro-Met Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCSC)C(O)=O BDENGIGFTNYZSJ-RCWTZXSCSA-N 0.000 description 3
- BKIOKSLLAAZYTC-KKHAAJSZSA-N Thr-Val-Asn Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O BKIOKSLLAAZYTC-KKHAAJSZSA-N 0.000 description 3
- PWONLXBUSVIZPH-RHYQMDGZSA-N Thr-Val-Lys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCCN)C(=O)O)N)O PWONLXBUSVIZPH-RHYQMDGZSA-N 0.000 description 3
- SCQBNMKLZVCXNX-ZFWWWQNUSA-N Trp-Arg-Gly Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)NCC(=O)O)N SCQBNMKLZVCXNX-ZFWWWQNUSA-N 0.000 description 3
- DQDXHYIEITXNJY-BPUTZDHNSA-N Trp-Gln-Gln Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N DQDXHYIEITXNJY-BPUTZDHNSA-N 0.000 description 3
- RRXPAFGTFQIEMD-IVJVFBROSA-N Trp-Ile-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC2=CNC3=CC=CC=C32)N RRXPAFGTFQIEMD-IVJVFBROSA-N 0.000 description 3
- OGZRZMJASKKMJZ-XIRDDKMYSA-N Trp-Leu-Asp Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N OGZRZMJASKKMJZ-XIRDDKMYSA-N 0.000 description 3
- VPRHDRKAPYZMHL-SZMVWBNQSA-N Trp-Leu-Glu Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O)=CNC2=C1 VPRHDRKAPYZMHL-SZMVWBNQSA-N 0.000 description 3
- 108010028230 Trp-Ser- His-Pro-Gln-Phe-Glu-Lys Proteins 0.000 description 3
- HKIUVWMZYFBIHG-KKUMJFAQSA-N Tyr-Arg-Gln Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N)O HKIUVWMZYFBIHG-KKUMJFAQSA-N 0.000 description 3
- GAYLGYUVTDMLKC-UWJYBYFXSA-N Tyr-Asp-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 GAYLGYUVTDMLKC-UWJYBYFXSA-N 0.000 description 3
- CDHQEOXPWBDFPL-QWRGUYRKSA-N Tyr-Gly-Asn Chemical compound NC(=O)C[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CC1=CC=C(O)C=C1 CDHQEOXPWBDFPL-QWRGUYRKSA-N 0.000 description 3
- AKLNEFNQWLHIGY-QWRGUYRKSA-N Tyr-Gly-Asp Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)NCC(=O)N[C@@H](CC(=O)O)C(=O)O)N)O AKLNEFNQWLHIGY-QWRGUYRKSA-N 0.000 description 3
- LDKDSFQSEUOCOO-RPTUDFQQSA-N Tyr-Thr-Phe Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O LDKDSFQSEUOCOO-RPTUDFQQSA-N 0.000 description 3
- OBKOPLHSRDATFO-XHSDSOJGSA-N Tyr-Val-Pro Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC2=CC=C(C=C2)O)N OBKOPLHSRDATFO-XHSDSOJGSA-N 0.000 description 3
- YFOCMOVJBQDBCE-NRPADANISA-N Val-Ala-Glu Chemical compound C[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@H](C(C)C)N YFOCMOVJBQDBCE-NRPADANISA-N 0.000 description 3
- SLLKXDSRVAOREO-KZVJFYERSA-N Val-Ala-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](C)NC(=O)[C@H](C(C)C)N)O SLLKXDSRVAOREO-KZVJFYERSA-N 0.000 description 3
- CVUDMNSZAIZFAE-TUAOUCFPSA-N Val-Arg-Pro Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N1CCC[C@@H]1C(=O)O)N CVUDMNSZAIZFAE-TUAOUCFPSA-N 0.000 description 3
- VLOYGOZDPGYWFO-LAEOZQHASA-N Val-Asp-Glu Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O VLOYGOZDPGYWFO-LAEOZQHASA-N 0.000 description 3
- FOADDSDHGRFUOC-DZKIICNBSA-N Val-Glu-Phe Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)N FOADDSDHGRFUOC-DZKIICNBSA-N 0.000 description 3
- SDUBQHUJJWQTEU-XUXIUFHCSA-N Val-Ile-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](C(C)C)N SDUBQHUJJWQTEU-XUXIUFHCSA-N 0.000 description 3
- GUIYPEKUEMQBIK-JSGCOSHPSA-N Val-Tyr-Gly Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](Cc1ccc(O)cc1)C(=O)NCC(O)=O GUIYPEKUEMQBIK-JSGCOSHPSA-N 0.000 description 3
- RTJPAGFXOWEBAI-SRVKXCTJSA-N Val-Val-Arg Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N RTJPAGFXOWEBAI-SRVKXCTJSA-N 0.000 description 3
- NLNCNKIVJPEFBC-DLOVCJGASA-N Val-Val-Glu Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CCC(O)=O NLNCNKIVJPEFBC-DLOVCJGASA-N 0.000 description 3
- 241000700605 Viruses Species 0.000 description 3
- 108010017070 Zinc Finger Nucleases Proteins 0.000 description 3
- 230000004913 activation Effects 0.000 description 3
- 239000011543 agarose gel Substances 0.000 description 3
- 108010024078 alanyl-glycyl-serine Proteins 0.000 description 3
- 108010070783 alanyltyrosine Proteins 0.000 description 3
- 125000000539 amino acid group Chemical group 0.000 description 3
- 108010008355 arginyl-glutamine Proteins 0.000 description 3
- 108010001271 arginyl-glutamyl-arginine Proteins 0.000 description 3
- 108010043240 arginyl-leucyl-glycine Proteins 0.000 description 3
- 108010062796 arginyllysine Proteins 0.000 description 3
- 238000003491 array Methods 0.000 description 3
- 238000004630 atomic force microscopy Methods 0.000 description 3
- 230000004071 biological effect Effects 0.000 description 3
- 210000004899 c-terminal region Anatomy 0.000 description 3
- 101150044165 cas7 gene Proteins 0.000 description 3
- 230000015556 catabolic process Effects 0.000 description 3
- 230000008859 change Effects 0.000 description 3
- 238000006243 chemical reaction Methods 0.000 description 3
- 210000000805 cytoplasm Anatomy 0.000 description 3
- 235000013365 dairy product Nutrition 0.000 description 3
- 238000006731 degradation reaction Methods 0.000 description 3
- 108010054813 diprotin B Proteins 0.000 description 3
- 238000000605 extraction Methods 0.000 description 3
- 108010079547 glutamylmethionine Proteins 0.000 description 3
- 108010078326 glycyl-glycyl-valine Proteins 0.000 description 3
- 108010010147 glycylglutamine Proteins 0.000 description 3
- 239000005090 green fluorescent protein Substances 0.000 description 3
- 108010028295 histidylhistidine Proteins 0.000 description 3
- 108010012058 leucyltyrosine Proteins 0.000 description 3
- 108010009298 lysylglutamic acid Proteins 0.000 description 3
- 108010017391 lysylvaline Proteins 0.000 description 3
- 229910052749 magnesium Inorganic materials 0.000 description 3
- 238000004519 manufacturing process Methods 0.000 description 3
- 238000004949 mass spectrometry Methods 0.000 description 3
- 108010005942 methionylglycine Proteins 0.000 description 3
- 238000000520 microinjection Methods 0.000 description 3
- 239000000203 mixture Substances 0.000 description 3
- 230000009871 nonspecific binding Effects 0.000 description 3
- -1 nuclease-helicase Proteins 0.000 description 3
- 210000000056 organ Anatomy 0.000 description 3
- 108010084572 phenylalanyl-valine Proteins 0.000 description 3
- 108010020755 prolyl-glycyl-glycine Proteins 0.000 description 3
- 108010004914 prolylarginine Proteins 0.000 description 3
- 108010070643 prolylglutamic acid Proteins 0.000 description 3
- WPPDXAHGCGPUPK-UHFFFAOYSA-N red 2 Chemical compound C1=CC=CC=C1C(C1=CC=CC=C11)=C(C=2C=3C4=CC=C5C6=CC=C7C8=C(C=9C=CC=CC=9)C9=CC=CC=C9C(C=9C=CC=CC=9)=C8C8=CC=C(C6=C87)C(C=35)=CC=2)C4=C1C1=CC=CC=C1 WPPDXAHGCGPUPK-UHFFFAOYSA-N 0.000 description 3
- 108091008146 restriction endonucleases Proteins 0.000 description 3
- 238000012216 screening Methods 0.000 description 3
- 238000012163 sequencing technique Methods 0.000 description 3
- 108010071207 serylmethionine Proteins 0.000 description 3
- 239000000243 solution Substances 0.000 description 3
- 210000000130 stem cell Anatomy 0.000 description 3
- 239000000758 substrate Substances 0.000 description 3
- 238000003786 synthesis reaction Methods 0.000 description 3
- 210000001519 tissue Anatomy 0.000 description 3
- 238000010361 transduction Methods 0.000 description 3
- 230000026683 transduction Effects 0.000 description 3
- 230000001131 transforming effect Effects 0.000 description 3
- 108700004896 tripeptide FEG Proteins 0.000 description 3
- 108010084932 tryptophyl-proline Proteins 0.000 description 3
- 108010020532 tyrosyl-proline Proteins 0.000 description 3
- 241001515965 unidentified phage Species 0.000 description 3
- 230000003612 virological effect Effects 0.000 description 3
- 108010013043 Acetylesterase Proteins 0.000 description 2
- 241000589158 Agrobacterium Species 0.000 description 2
- ODWSTKXGQGYHSH-FXQIFTODSA-N Ala-Arg-Ala Chemical compound C[C@H](N)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(O)=O ODWSTKXGQGYHSH-FXQIFTODSA-N 0.000 description 2
- DVWVZSJAYIJZFI-FXQIFTODSA-N Ala-Arg-Asn Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(N)=O)C(O)=O DVWVZSJAYIJZFI-FXQIFTODSA-N 0.000 description 2
- SSSROGPPPVTHLX-FXQIFTODSA-N Ala-Arg-Asp Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(O)=O SSSROGPPPVTHLX-FXQIFTODSA-N 0.000 description 2
- TTXMOJWKNRJWQJ-FXQIFTODSA-N Ala-Arg-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)C)CCCN=C(N)N TTXMOJWKNRJWQJ-FXQIFTODSA-N 0.000 description 2
- DWINFPQUSSHSFS-UVBJJODRSA-N Ala-Arg-Trp Chemical compound N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CNC2=CC=CC=C12)C(=O)O DWINFPQUSSHSFS-UVBJJODRSA-N 0.000 description 2
- KIUYPHAMDKDICO-WHFBIAKZSA-N Ala-Asp-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O KIUYPHAMDKDICO-WHFBIAKZSA-N 0.000 description 2
- YSMPVONNIWLJML-FXQIFTODSA-N Ala-Asp-Pro Chemical compound C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N1CCC[C@H]1C(O)=O YSMPVONNIWLJML-FXQIFTODSA-N 0.000 description 2
- NFDVJAKFMXHJEQ-HERUPUMHSA-N Ala-Asp-Trp Chemical compound C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)N NFDVJAKFMXHJEQ-HERUPUMHSA-N 0.000 description 2
- ZODMADSIQZZBSQ-FXQIFTODSA-N Ala-Gln-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O ZODMADSIQZZBSQ-FXQIFTODSA-N 0.000 description 2
- JPGBXANAQYHTLA-DRZSPHRISA-N Ala-Gln-Phe Chemical compound C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 JPGBXANAQYHTLA-DRZSPHRISA-N 0.000 description 2
- YIGLXQRFQVWFEY-NRPADANISA-N Ala-Gln-Val Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(O)=O YIGLXQRFQVWFEY-NRPADANISA-N 0.000 description 2
- MQIGTEQXYCRLGK-BQBZGAKWSA-N Ala-Gly-Pro Chemical compound C[C@H](N)C(=O)NCC(=O)N1CCC[C@H]1C(O)=O MQIGTEQXYCRLGK-BQBZGAKWSA-N 0.000 description 2
- JEPNLGMEZMCFEX-QSFUFRPTSA-N Ala-His-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CN=CN1)NC(=O)[C@H](C)N JEPNLGMEZMCFEX-QSFUFRPTSA-N 0.000 description 2
- PNALXAODQKTNLV-JBDRJPRFSA-N Ala-Ile-Ala Chemical compound C[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C)C(O)=O PNALXAODQKTNLV-JBDRJPRFSA-N 0.000 description 2
- QQACQIHVWCVBBR-GVARAGBVSA-N Ala-Ile-Tyr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O QQACQIHVWCVBBR-GVARAGBVSA-N 0.000 description 2
- YHKANGMVQWRMAP-DCAQKATOSA-N Ala-Leu-Arg Chemical compound C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N YHKANGMVQWRMAP-DCAQKATOSA-N 0.000 description 2
- SOBIAADAMRHGKH-CIUDSAMLSA-N Ala-Leu-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O SOBIAADAMRHGKH-CIUDSAMLSA-N 0.000 description 2
- SDZRIBWEVVRDQI-CIUDSAMLSA-N Ala-Lys-Asp Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(O)=O SDZRIBWEVVRDQI-CIUDSAMLSA-N 0.000 description 2
- DGLQWAFPIXDKRL-UBHSHLNASA-N Ala-Met-Phe Chemical compound C[C@@H](C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)N DGLQWAFPIXDKRL-UBHSHLNASA-N 0.000 description 2
- 108010011667 Ala-Phe-Ala Proteins 0.000 description 2
- XRUJOVRWNMBAAA-NHCYSSNCSA-N Ala-Phe-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H](NC(=O)[C@@H](N)C)CC1=CC=CC=C1 XRUJOVRWNMBAAA-NHCYSSNCSA-N 0.000 description 2
- FEGOCLZUJUFCHP-CIUDSAMLSA-N Ala-Pro-Gln Chemical compound [H]N[C@@H](C)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(O)=O FEGOCLZUJUFCHP-CIUDSAMLSA-N 0.000 description 2
- OMCKWYSDUQBYCN-FXQIFTODSA-N Ala-Ser-Met Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCSC)C(O)=O OMCKWYSDUQBYCN-FXQIFTODSA-N 0.000 description 2
- NCQMBSJGJMYKCK-ZLUOBGJFSA-N Ala-Ser-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O NCQMBSJGJMYKCK-ZLUOBGJFSA-N 0.000 description 2
- KTXKIYXZQFWJKB-VZFHVOOUSA-N Ala-Thr-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O KTXKIYXZQFWJKB-VZFHVOOUSA-N 0.000 description 2
- IEAUDUOCWNPZBR-LKTVYLICSA-N Ala-Trp-Gln Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N IEAUDUOCWNPZBR-LKTVYLICSA-N 0.000 description 2
- YXXPVUOMPSZURS-ZLIFDBKOSA-N Ala-Trp-Leu Chemical compound C1=CC=C2C(C[C@@H](C(=O)N[C@@H](CC(C)C)C(O)=O)NC(=O)[C@H](C)N)=CNC2=C1 YXXPVUOMPSZURS-ZLIFDBKOSA-N 0.000 description 2
- QRIYOHQJRDHFKF-UWJYBYFXSA-N Ala-Tyr-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)C)CC1=CC=C(O)C=C1 QRIYOHQJRDHFKF-UWJYBYFXSA-N 0.000 description 2
- BVLPIIBTWIYOML-ZKWXMUAHSA-N Ala-Val-Asp Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O BVLPIIBTWIYOML-ZKWXMUAHSA-N 0.000 description 2
- 241000223600 Alternaria Species 0.000 description 2
- KWKQGHSSNHPGOW-BQBZGAKWSA-N Arg-Ala-Gly Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(=O)NCC(O)=O KWKQGHSSNHPGOW-BQBZGAKWSA-N 0.000 description 2
- OLDOLPWZEMHNIA-PJODQICGSA-N Arg-Ala-Trp Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O OLDOLPWZEMHNIA-PJODQICGSA-N 0.000 description 2
- UXJCMQFPDWCHKX-DCAQKATOSA-N Arg-Arg-Glu Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCC(O)=O)C(O)=O UXJCMQFPDWCHKX-DCAQKATOSA-N 0.000 description 2
- JGDGLDNAQJJGJI-AVGNSLFASA-N Arg-Arg-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CCCN=C(N)N)N JGDGLDNAQJJGJI-AVGNSLFASA-N 0.000 description 2
- HJVGMOYJDDXLMI-AVGNSLFASA-N Arg-Arg-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@@H](N)CCCNC(N)=N HJVGMOYJDDXLMI-AVGNSLFASA-N 0.000 description 2
- USNSOPDIZILSJP-FXQIFTODSA-N Arg-Asn-Asn Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O USNSOPDIZILSJP-FXQIFTODSA-N 0.000 description 2
- QPOARHANPULOTM-GMOBBJLQSA-N Arg-Asn-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CCCN=C(N)N)N QPOARHANPULOTM-GMOBBJLQSA-N 0.000 description 2
- ZTKHZAXGTFXUDD-VEVYYDQMSA-N Arg-Asn-Thr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O ZTKHZAXGTFXUDD-VEVYYDQMSA-N 0.000 description 2
- IGULQRCJLQQPSM-DCAQKATOSA-N Arg-Cys-Leu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(C)C)C(O)=O IGULQRCJLQQPSM-DCAQKATOSA-N 0.000 description 2
- KBBKCNHWCDJPGN-GUBZILKMSA-N Arg-Gln-Gln Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O KBBKCNHWCDJPGN-GUBZILKMSA-N 0.000 description 2
- HPKSHFSEXICTLI-CIUDSAMLSA-N Arg-Glu-Ala Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O HPKSHFSEXICTLI-CIUDSAMLSA-N 0.000 description 2
- QAODJPUKWNNNRP-DCAQKATOSA-N Arg-Glu-Arg Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O QAODJPUKWNNNRP-DCAQKATOSA-N 0.000 description 2
- HQIZDMIGUJOSNI-IUCAKERBSA-N Arg-Gly-Arg Chemical compound N[C@@H](CCCNC(N)=N)C(=O)NCC(=O)N[C@@H](CCCNC(N)=N)C(O)=O HQIZDMIGUJOSNI-IUCAKERBSA-N 0.000 description 2
- AUFHLLPVPSMEOG-YUMQZZPRSA-N Arg-Gly-Glu Chemical compound NC(N)=NCCC[C@H](N)C(=O)NCC(=O)N[C@@H](CCC(O)=O)C(O)=O AUFHLLPVPSMEOG-YUMQZZPRSA-N 0.000 description 2
- YBIAYFFIVAZXPK-AVGNSLFASA-N Arg-His-Arg Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O YBIAYFFIVAZXPK-AVGNSLFASA-N 0.000 description 2
- NVCIXQYNWYTLDO-IHRRRGAJSA-N Arg-His-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC1=CN=CN1)NC(=O)[C@H](CCCN=C(N)N)N NVCIXQYNWYTLDO-IHRRRGAJSA-N 0.000 description 2
- RKQRHMKFNBYOTN-IHRRRGAJSA-N Arg-His-Lys Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N RKQRHMKFNBYOTN-IHRRRGAJSA-N 0.000 description 2
- IRRMIGDCPOPZJW-ULQDDVLXSA-N Arg-His-Phe Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O IRRMIGDCPOPZJW-ULQDDVLXSA-N 0.000 description 2
- OOIMKQRCPJBGPD-XUXIUFHCSA-N Arg-Ile-Leu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(C)C)C(O)=O OOIMKQRCPJBGPD-XUXIUFHCSA-N 0.000 description 2
- OKKMBOSPBDASEP-CYDGBPFRSA-N Arg-Ile-Met Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCSC)C(O)=O OKKMBOSPBDASEP-CYDGBPFRSA-N 0.000 description 2
- LVMUGODRNHFGRA-AVGNSLFASA-N Arg-Leu-Arg Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O LVMUGODRNHFGRA-AVGNSLFASA-N 0.000 description 2
- UHFUZWSZQKMDSX-DCAQKATOSA-N Arg-Leu-Asn Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N UHFUZWSZQKMDSX-DCAQKATOSA-N 0.000 description 2
- XUGATJVGQUGQKY-ULQDDVLXSA-N Arg-Lys-Phe Chemical compound NC(=N)NCCC[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 XUGATJVGQUGQKY-ULQDDVLXSA-N 0.000 description 2
- GRRXPUAICOGISM-RWMBFGLXSA-N Arg-Lys-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCCN)NC(=O)[C@H](CCCN=C(N)N)N)C(=O)O GRRXPUAICOGISM-RWMBFGLXSA-N 0.000 description 2
- VVJTWSRNMJNDPN-IUCAKERBSA-N Arg-Met-Gly Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCSC)C(=O)NCC(O)=O VVJTWSRNMJNDPN-IUCAKERBSA-N 0.000 description 2
- OISWSORSLQOGFV-AVGNSLFASA-N Arg-Met-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CCSC)NC(=O)[C@@H](N)CCCN=C(N)N OISWSORSLQOGFV-AVGNSLFASA-N 0.000 description 2
- BSYKSCBTTQKOJG-GUBZILKMSA-N Arg-Pro-Ala Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O BSYKSCBTTQKOJG-GUBZILKMSA-N 0.000 description 2
- DNBMCNQKNOKOSD-DCAQKATOSA-N Arg-Pro-Gln Chemical compound NC(N)=NCCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(O)=O DNBMCNQKNOKOSD-DCAQKATOSA-N 0.000 description 2
- VUGWHBXPMAHEGZ-SRVKXCTJSA-N Arg-Pro-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CCCN=C(N)N VUGWHBXPMAHEGZ-SRVKXCTJSA-N 0.000 description 2
- DNLQVHBBMPZUGJ-BQBZGAKWSA-N Arg-Ser-Gly Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O DNLQVHBBMPZUGJ-BQBZGAKWSA-N 0.000 description 2
- KMFPQTITXUKJOV-DCAQKATOSA-N Arg-Ser-Leu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O KMFPQTITXUKJOV-DCAQKATOSA-N 0.000 description 2
- LRPZJPMQGKGHSG-XGEHTFHBSA-N Arg-Ser-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CCCN=C(N)N)N)O LRPZJPMQGKGHSG-XGEHTFHBSA-N 0.000 description 2
- OQPAZKMGCWPERI-GUBZILKMSA-N Arg-Ser-Val Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O OQPAZKMGCWPERI-GUBZILKMSA-N 0.000 description 2
- LYJXHXGPWDTLKW-HJGDQZAQSA-N Arg-Thr-Gln Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N)O LYJXHXGPWDTLKW-HJGDQZAQSA-N 0.000 description 2
- XMZZGVGKGXRIGJ-JYJNAYRXSA-N Arg-Tyr-Val Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C(C)C)C(O)=O XMZZGVGKGXRIGJ-JYJNAYRXSA-N 0.000 description 2
- ISVACHFCVRKIDG-SRVKXCTJSA-N Arg-Val-Arg Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O ISVACHFCVRKIDG-SRVKXCTJSA-N 0.000 description 2
- ULBHWNVWSCJLCO-NHCYSSNCSA-N Arg-Val-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CCCN=C(N)N ULBHWNVWSCJLCO-NHCYSSNCSA-N 0.000 description 2
- SUMJNGAMIQSNGX-TUAOUCFPSA-N Arg-Val-Pro Chemical compound CC(C)[C@H](NC(=O)[C@@H](N)CCCNC(N)=N)C(=O)N1CCC[C@@H]1C(O)=O SUMJNGAMIQSNGX-TUAOUCFPSA-N 0.000 description 2
- XKRFYHLGVUSROY-UHFFFAOYSA-N Argon Chemical compound [Ar] XKRFYHLGVUSROY-UHFFFAOYSA-N 0.000 description 2
- JJGRJMKUOYXZRA-LPEHRKFASA-N Asn-Arg-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CC(=O)N)N)C(=O)O JJGRJMKUOYXZRA-LPEHRKFASA-N 0.000 description 2
- JEPNYDRDYNSFIU-QXEWZRGKSA-N Asn-Arg-Val Chemical compound CC(C)[C@H](NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@@H](N)CC(N)=O)C(O)=O JEPNYDRDYNSFIU-QXEWZRGKSA-N 0.000 description 2
- KXEGPPNPXOKKHK-ZLUOBGJFSA-N Asn-Asp-Ala Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(O)=O KXEGPPNPXOKKHK-ZLUOBGJFSA-N 0.000 description 2
- HLTLEIXYIJDFOY-ZLUOBGJFSA-N Asn-Cys-Asn Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(N)=O)C(O)=O HLTLEIXYIJDFOY-ZLUOBGJFSA-N 0.000 description 2
- KUYKVGODHGHFDI-ACZMJKKPSA-N Asn-Gln-Ser Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O KUYKVGODHGHFDI-ACZMJKKPSA-N 0.000 description 2
- OKZOABJQOMAYEC-NUMRIWBASA-N Asn-Gln-Thr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O OKZOABJQOMAYEC-NUMRIWBASA-N 0.000 description 2
- GYOHQKJEQQJBOY-QEJZJMRPSA-N Asn-Glu-Trp Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CC(=O)N)N GYOHQKJEQQJBOY-QEJZJMRPSA-N 0.000 description 2
- KLKHFFMNGWULBN-VKHMYHEASA-N Asn-Gly Chemical compound NC(=O)C[C@H](N)C(=O)NCC(O)=O KLKHFFMNGWULBN-VKHMYHEASA-N 0.000 description 2
- OPEPUCYIGFEGSW-WDSKDSINSA-N Asn-Gly-Glu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)NCC(=O)N[C@@H](CCC(O)=O)C(O)=O OPEPUCYIGFEGSW-WDSKDSINSA-N 0.000 description 2
- HYQYLOSCICEYTR-YUMQZZPRSA-N Asn-Gly-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)NCC(=O)N[C@@H](CC(C)C)C(O)=O HYQYLOSCICEYTR-YUMQZZPRSA-N 0.000 description 2
- UDSVWSUXKYXSTR-QWRGUYRKSA-N Asn-Gly-Tyr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)NCC(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O UDSVWSUXKYXSTR-QWRGUYRKSA-N 0.000 description 2
- NKLRWRRVYGQNIH-GHCJXIJMSA-N Asn-Ile-Ala Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C)C(O)=O NKLRWRRVYGQNIH-GHCJXIJMSA-N 0.000 description 2
- NLRJGXZWTKXRHP-DCAQKATOSA-N Asn-Leu-Arg Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O NLRJGXZWTKXRHP-DCAQKATOSA-N 0.000 description 2
- GLWFAWNYGWBMOC-SRVKXCTJSA-N Asn-Leu-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O GLWFAWNYGWBMOC-SRVKXCTJSA-N 0.000 description 2
- JLNFZLNDHONLND-GARJFASQSA-N Asn-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC(=O)N)N JLNFZLNDHONLND-GARJFASQSA-N 0.000 description 2
- FTSAJSADJCMDHH-CIUDSAMLSA-N Asn-Lys-Asp Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CC(=O)N)N FTSAJSADJCMDHH-CIUDSAMLSA-N 0.000 description 2
- JTXVXGXTRXMOFJ-FXQIFTODSA-N Asn-Pro-Asn Chemical compound NC(=O)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(N)=O)C(O)=O JTXVXGXTRXMOFJ-FXQIFTODSA-N 0.000 description 2
- WUQXMTITJLFXAU-JIOCBJNQSA-N Asn-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC(=O)N)N)O WUQXMTITJLFXAU-JIOCBJNQSA-N 0.000 description 2
- QNNBHTFDFFFHGC-KKUMJFAQSA-N Asn-Tyr-Lys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC(=O)N)N)O QNNBHTFDFFFHGC-KKUMJFAQSA-N 0.000 description 2
- XEDQMTWEYFBOIK-ACZMJKKPSA-N Asp-Ala-Glu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(O)=O XEDQMTWEYFBOIK-ACZMJKKPSA-N 0.000 description 2
- NJIKKGUVGUBICV-ZLUOBGJFSA-N Asp-Ala-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC(O)=O NJIKKGUVGUBICV-ZLUOBGJFSA-N 0.000 description 2
- IXIWEFWRKIUMQX-DCAQKATOSA-N Asp-Arg-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@@H](N)CC(O)=O IXIWEFWRKIUMQX-DCAQKATOSA-N 0.000 description 2
- DBWYWXNMZZYIRY-LPEHRKFASA-N Asp-Arg-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CC(=O)O)N)C(=O)O DBWYWXNMZZYIRY-LPEHRKFASA-N 0.000 description 2
- NYLBGYLHBDFRHL-VEVYYDQMSA-N Asp-Arg-Thr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(O)=O NYLBGYLHBDFRHL-VEVYYDQMSA-N 0.000 description 2
- XYBJLTKSGFBLCS-QXEWZRGKSA-N Asp-Arg-Val Chemical compound NC(N)=NCCC[C@@H](C(=O)N[C@@H](C(C)C)C(O)=O)NC(=O)[C@@H](N)CC(O)=O XYBJLTKSGFBLCS-QXEWZRGKSA-N 0.000 description 2
- UGKZHCBLMLSANF-CIUDSAMLSA-N Asp-Asn-Leu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O UGKZHCBLMLSANF-CIUDSAMLSA-N 0.000 description 2
- ICTXFVKYAGQURS-UBHSHLNASA-N Asp-Asn-Trp Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O ICTXFVKYAGQURS-UBHSHLNASA-N 0.000 description 2
- PXLNPFOJZQMXAT-BYULHYEWSA-N Asp-Asp-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CC(O)=O PXLNPFOJZQMXAT-BYULHYEWSA-N 0.000 description 2
- PDECQIHABNQRHN-GUBZILKMSA-N Asp-Glu-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC(O)=O PDECQIHABNQRHN-GUBZILKMSA-N 0.000 description 2
- LTXGDRFJRZSZAV-CIUDSAMLSA-N Asp-Glu-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CC(=O)O)N LTXGDRFJRZSZAV-CIUDSAMLSA-N 0.000 description 2
- WSGVTKZFVJSJOG-RCOVLWMOSA-N Asp-Gly-Val Chemical compound [H]N[C@@H](CC(O)=O)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O WSGVTKZFVJSJOG-RCOVLWMOSA-N 0.000 description 2
- SPKCGKRUYKMDHP-GUDRVLHUSA-N Asp-Ile-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC(=O)O)N SPKCGKRUYKMDHP-GUDRVLHUSA-N 0.000 description 2
- SCQIQCWLOMOEFP-DCAQKATOSA-N Asp-Leu-Arg Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O SCQIQCWLOMOEFP-DCAQKATOSA-N 0.000 description 2
- IVPNEDNYYYFAGI-GARJFASQSA-N Asp-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC(=O)O)N IVPNEDNYYYFAGI-GARJFASQSA-N 0.000 description 2
- MYOHQBFRJQFIDZ-KKUMJFAQSA-N Asp-Leu-Tyr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O MYOHQBFRJQFIDZ-KKUMJFAQSA-N 0.000 description 2
- QNMKWNONJGKJJC-NHCYSSNCSA-N Asp-Leu-Val Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O QNMKWNONJGKJJC-NHCYSSNCSA-N 0.000 description 2
- GKWFMNNNYZHJHV-SRVKXCTJSA-N Asp-Lys-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CC(O)=O GKWFMNNNYZHJHV-SRVKXCTJSA-N 0.000 description 2
- SJLDOGLMVPHPLZ-IHRRRGAJSA-N Asp-Met-Phe Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CCSC)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 SJLDOGLMVPHPLZ-IHRRRGAJSA-N 0.000 description 2
- LTCKTLYKRMCFOC-KKUMJFAQSA-N Asp-Phe-Leu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(C)C)C(O)=O LTCKTLYKRMCFOC-KKUMJFAQSA-N 0.000 description 2
- JUWISGAGWSDGDH-KKUMJFAQSA-N Asp-Phe-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)CC(O)=O)CC1=CC=CC=C1 JUWISGAGWSDGDH-KKUMJFAQSA-N 0.000 description 2
- AHWRSSLYSGLBGD-CIUDSAMLSA-N Asp-Pro-Glu Chemical compound OC(=O)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O AHWRSSLYSGLBGD-CIUDSAMLSA-N 0.000 description 2
- MVRGBQGZSDJBSM-GMOBBJLQSA-N Asp-Pro-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@@H]1CCCN1C(=O)[C@H](CC(=O)O)N MVRGBQGZSDJBSM-GMOBBJLQSA-N 0.000 description 2
- QSFHZPQUAAQHAQ-CIUDSAMLSA-N Asp-Ser-Leu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O QSFHZPQUAAQHAQ-CIUDSAMLSA-N 0.000 description 2
- NAAAPCLFJPURAM-HJGDQZAQSA-N Asp-Thr-Lys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC(=O)O)N)O NAAAPCLFJPURAM-HJGDQZAQSA-N 0.000 description 2
- JDDYEZGPYBBPBN-JRQIVUDYSA-N Asp-Thr-Tyr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O JDDYEZGPYBBPBN-JRQIVUDYSA-N 0.000 description 2
- YUELDQUPTAYEGM-XIRDDKMYSA-N Asp-Trp-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H](CC(=O)O)N YUELDQUPTAYEGM-XIRDDKMYSA-N 0.000 description 2
- XMKXONRMGJXCJV-LAEOZQHASA-N Asp-Val-Glu Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O XMKXONRMGJXCJV-LAEOZQHASA-N 0.000 description 2
- XQFLFQWOBXPMHW-NHCYSSNCSA-N Asp-Val-His Chemical compound N[C@@H](CC(=O)O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CNC=N1)C(=O)O XQFLFQWOBXPMHW-NHCYSSNCSA-N 0.000 description 2
- 241000186000 Bifidobacterium Species 0.000 description 2
- 101150017501 CCR5 gene Proteins 0.000 description 2
- 241000282693 Cercopithecidae Species 0.000 description 2
- ZOLXQKZHYOHHMD-DLOVCJGASA-N Cys-Ala-Phe Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)NC(=O)[C@H](CS)N ZOLXQKZHYOHHMD-DLOVCJGASA-N 0.000 description 2
- 102000052510 DNA-Binding Proteins Human genes 0.000 description 2
- 101710096438 DNA-binding protein Proteins 0.000 description 2
- 101100007792 Escherichia coli (strain K12) casB gene Proteins 0.000 description 2
- 101100005249 Escherichia coli (strain K12) ygcB gene Proteins 0.000 description 2
- 108060002716 Exonuclease Proteins 0.000 description 2
- 241000589565 Flavobacterium Species 0.000 description 2
- SHERTACNJPYHAR-ACZMJKKPSA-N Gln-Ala-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCC(N)=O SHERTACNJPYHAR-ACZMJKKPSA-N 0.000 description 2
- ZNZPKVQURDQFFS-FXQIFTODSA-N Gln-Glu-Ser Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O ZNZPKVQURDQFFS-FXQIFTODSA-N 0.000 description 2
- CLPQUWHBWXFJOX-BQBZGAKWSA-N Gln-Gly-Gln Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)NCC(=O)N[C@@H](CCC(N)=O)C(O)=O CLPQUWHBWXFJOX-BQBZGAKWSA-N 0.000 description 2
- MFJAPSYJQJCQDN-BQBZGAKWSA-N Gln-Gly-Glu Chemical compound NC(=O)CC[C@H](N)C(=O)NCC(=O)N[C@@H](CCC(O)=O)C(O)=O MFJAPSYJQJCQDN-BQBZGAKWSA-N 0.000 description 2
- LTXLIIZACMCQTO-GUBZILKMSA-N Gln-His-Asp Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CCC(=O)N)N LTXLIIZACMCQTO-GUBZILKMSA-N 0.000 description 2
- KQOPMGBHNQBCEL-HVTMNAMFSA-N Gln-His-Ile Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O KQOPMGBHNQBCEL-HVTMNAMFSA-N 0.000 description 2
- HDUDGCZEOZEFOA-KBIXCLLPSA-N Gln-Ile-Ala Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C)C(=O)O)NC(=O)[C@H](CCC(=O)N)N HDUDGCZEOZEFOA-KBIXCLLPSA-N 0.000 description 2
- ITZWDGBYBPUZRG-KBIXCLLPSA-N Gln-Ile-Ser Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O ITZWDGBYBPUZRG-KBIXCLLPSA-N 0.000 description 2
- MLSKFHLRFVGNLL-WDCWCFNPSA-N Gln-Leu-Thr Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O MLSKFHLRFVGNLL-WDCWCFNPSA-N 0.000 description 2
- GURIQZQSTBBHRV-SRVKXCTJSA-N Gln-Lys-Arg Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O GURIQZQSTBBHRV-SRVKXCTJSA-N 0.000 description 2
- UWKPRVKWEKEMSY-DCAQKATOSA-N Gln-Lys-Gln Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(N)=O)C(O)=O UWKPRVKWEKEMSY-DCAQKATOSA-N 0.000 description 2
- SFAFZYYMAWOCIC-KKUMJFAQSA-N Gln-Phe-Arg Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)NC(=O)[C@H](CCC(=O)N)N SFAFZYYMAWOCIC-KKUMJFAQSA-N 0.000 description 2
- OZEQPCDLCDRCGY-SOUVJXGZSA-N Gln-Phe-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=CC=C2)NC(=O)[C@H](CCC(=O)N)N)C(=O)O OZEQPCDLCDRCGY-SOUVJXGZSA-N 0.000 description 2
- UWMDGPFFTKDUIY-HJGDQZAQSA-N Gln-Pro-Thr Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(O)=O UWMDGPFFTKDUIY-HJGDQZAQSA-N 0.000 description 2
- OUBUHIODTNUUTC-WDCWCFNPSA-N Gln-Thr-Lys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCC(=O)N)N)O OUBUHIODTNUUTC-WDCWCFNPSA-N 0.000 description 2
- ZZLDMBMFKZFQMU-NRPADANISA-N Gln-Val-Ala Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C)C(O)=O ZZLDMBMFKZFQMU-NRPADANISA-N 0.000 description 2
- VEYGCDYMOXHJLS-GVXVVHGQSA-N Gln-Val-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O VEYGCDYMOXHJLS-GVXVVHGQSA-N 0.000 description 2
- LKDIBBOKUAASNP-FXQIFTODSA-N Glu-Ala-Glu Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(O)=O LKDIBBOKUAASNP-FXQIFTODSA-N 0.000 description 2
- PBEQPAZRHDVJQI-SRVKXCTJSA-N Glu-Arg-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CCC(=O)O)N PBEQPAZRHDVJQI-SRVKXCTJSA-N 0.000 description 2
- CKRUHITYRFNUKW-WDSKDSINSA-N Glu-Asn-Gly Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O CKRUHITYRFNUKW-WDSKDSINSA-N 0.000 description 2
- ZOXBSICWUDAOHX-GUBZILKMSA-N Glu-Asn-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CCC(O)=O ZOXBSICWUDAOHX-GUBZILKMSA-N 0.000 description 2
- PBFGQTGPSKWHJA-QEJZJMRPSA-N Glu-Asp-Trp Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O PBFGQTGPSKWHJA-QEJZJMRPSA-N 0.000 description 2
- CGOHAEBMDSEKFB-FXQIFTODSA-N Glu-Glu-Ala Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O CGOHAEBMDSEKFB-FXQIFTODSA-N 0.000 description 2
- MUSGDMDGNGXULI-DCAQKATOSA-N Glu-Glu-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CCC(O)=O MUSGDMDGNGXULI-DCAQKATOSA-N 0.000 description 2
- QJCKNLPMTPXXEM-AUTRQRHGSA-N Glu-Glu-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CCC(O)=O QJCKNLPMTPXXEM-AUTRQRHGSA-N 0.000 description 2
- PXXGVUVQWQGGIG-YUMQZZPRSA-N Glu-Gly-Arg Chemical compound OC(=O)CC[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCCN=C(N)N PXXGVUVQWQGGIG-YUMQZZPRSA-N 0.000 description 2
- HILMIYALTUQTRC-XVKPBYJWSA-N Glu-Gly-Val Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O HILMIYALTUQTRC-XVKPBYJWSA-N 0.000 description 2
- LZMQSTPFYJLVJB-GUBZILKMSA-N Glu-Leu-Cys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CCC(=O)O)N LZMQSTPFYJLVJB-GUBZILKMSA-N 0.000 description 2
- WNRZUESNGGDCJX-JYJNAYRXSA-N Glu-Leu-Phe Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O WNRZUESNGGDCJX-JYJNAYRXSA-N 0.000 description 2
- ILWHFUZZCFYSKT-AVGNSLFASA-N Glu-Lys-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(O)=O ILWHFUZZCFYSKT-AVGNSLFASA-N 0.000 description 2
- MFNUFCFRAZPJFW-JYJNAYRXSA-N Glu-Lys-Phe Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 MFNUFCFRAZPJFW-JYJNAYRXSA-N 0.000 description 2
- LKOAAMXDJGEYMS-ZPFDUUQYSA-N Glu-Met-Ile Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCSC)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O LKOAAMXDJGEYMS-ZPFDUUQYSA-N 0.000 description 2
- SOEPMWQCTJITPZ-SRVKXCTJSA-N Glu-Met-Lys Chemical compound CSCC[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCC(=O)O)N SOEPMWQCTJITPZ-SRVKXCTJSA-N 0.000 description 2
- KJBGAZSLZAQDPV-KKUMJFAQSA-N Glu-Phe-Arg Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)NC(=O)[C@H](CCC(=O)O)N KJBGAZSLZAQDPV-KKUMJFAQSA-N 0.000 description 2
- WZAYJXZPSJOXCP-QAETUUGQSA-N Glu-Phe-Gln-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](NC(=O)[C@H](CCC(O)=O)N)CC1=CC=CC=C1 WZAYJXZPSJOXCP-QAETUUGQSA-N 0.000 description 2
- YTRBQAQSUDSIQE-FHWLQOOXSA-N Glu-Phe-Phe Chemical compound C([C@H](NC(=O)[C@H](CCC(O)=O)N)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=CC=C1 YTRBQAQSUDSIQE-FHWLQOOXSA-N 0.000 description 2
- SYWCGQOIIARSIX-SRVKXCTJSA-N Glu-Pro-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(O)=O SYWCGQOIIARSIX-SRVKXCTJSA-N 0.000 description 2
- ALMBZBOCGSVSAI-ACZMJKKPSA-N Glu-Ser-Asn Chemical compound C(CC(=O)O)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(=O)N)C(=O)O)N ALMBZBOCGSVSAI-ACZMJKKPSA-N 0.000 description 2
- SYAYROHMAIHWFB-KBIXCLLPSA-N Glu-Ser-Ile Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O SYAYROHMAIHWFB-KBIXCLLPSA-N 0.000 description 2
- XAXJIUAWAFVADB-VJBMBRPKSA-N Glu-Trp-Trp Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC3=CNC4=CC=CC=C43)C(=O)O)NC(=O)[C@H](CCC(=O)O)N XAXJIUAWAFVADB-VJBMBRPKSA-N 0.000 description 2
- HJTSRYLPAYGEEC-SIUGBPQLSA-N Glu-Tyr-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@H](CCC(=O)O)N HJTSRYLPAYGEEC-SIUGBPQLSA-N 0.000 description 2
- MLILEEIVMRUYBX-NHCYSSNCSA-N Glu-Val-Arg Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O MLILEEIVMRUYBX-NHCYSSNCSA-N 0.000 description 2
- PYTZFYUXZZHOAD-WHFBIAKZSA-N Gly-Ala-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)CN PYTZFYUXZZHOAD-WHFBIAKZSA-N 0.000 description 2
- YMUFWNJHVPQNQD-ZKWXMUAHSA-N Gly-Ala-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)CN YMUFWNJHVPQNQD-ZKWXMUAHSA-N 0.000 description 2
- QXPRJQPCFXMCIY-NKWVEPMBSA-N Gly-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)CN QXPRJQPCFXMCIY-NKWVEPMBSA-N 0.000 description 2
- LJPIRKICOISLKN-WHFBIAKZSA-N Gly-Ala-Ser Chemical compound NCC(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O LJPIRKICOISLKN-WHFBIAKZSA-N 0.000 description 2
- QSDKBRMVXSWAQE-BFHQHQDPSA-N Gly-Ala-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)CN QSDKBRMVXSWAQE-BFHQHQDPSA-N 0.000 description 2
- RJIVPOXLQFJRTG-LURJTMIESA-N Gly-Arg-Gly Chemical compound OC(=O)CNC(=O)[C@@H](NC(=O)CN)CCCN=C(N)N RJIVPOXLQFJRTG-LURJTMIESA-N 0.000 description 2
- KFMBRBPXHVMDFN-UWVGGRQHSA-N Gly-Arg-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CCCNC(N)=N KFMBRBPXHVMDFN-UWVGGRQHSA-N 0.000 description 2
- MXXXVOYFNVJHMA-IUCAKERBSA-N Gly-Arg-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)CN MXXXVOYFNVJHMA-IUCAKERBSA-N 0.000 description 2
- GWCRIHNSVMOBEQ-BQBZGAKWSA-N Gly-Arg-Ser Chemical compound [H]NCC(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(O)=O GWCRIHNSVMOBEQ-BQBZGAKWSA-N 0.000 description 2
- LURCIJSJAKFCRO-QWRGUYRKSA-N Gly-Asn-Tyr Chemical compound [H]NCC(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O LURCIJSJAKFCRO-QWRGUYRKSA-N 0.000 description 2
- KQDMENMTYNBWMR-WHFBIAKZSA-N Gly-Asp-Ala Chemical compound [H]NCC(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(O)=O KQDMENMTYNBWMR-WHFBIAKZSA-N 0.000 description 2
- YYQGVXNKAXUTJU-YUMQZZPRSA-N Gly-Cys-His Chemical compound NCC(=O)N[C@@H](CS)C(=O)N[C@@H](Cc1cnc[nH]1)C(O)=O YYQGVXNKAXUTJU-YUMQZZPRSA-N 0.000 description 2
- MOJKRXIRAZPZLW-WDSKDSINSA-N Gly-Glu-Ala Chemical compound [H]NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O MOJKRXIRAZPZLW-WDSKDSINSA-N 0.000 description 2
- STVHDEHTKFXBJQ-LAEOZQHASA-N Gly-Glu-Ile Chemical compound [H]NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O STVHDEHTKFXBJQ-LAEOZQHASA-N 0.000 description 2
- YYPFZVIXAVDHIK-IUCAKERBSA-N Gly-Glu-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)CN YYPFZVIXAVDHIK-IUCAKERBSA-N 0.000 description 2
- NTOWAXLMQFKJPT-YUMQZZPRSA-N Gly-Glu-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)CN NTOWAXLMQFKJPT-YUMQZZPRSA-N 0.000 description 2
- BEQGFMIBZFNROK-JGVFFNPUSA-N Gly-Glu-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)O)NC(=O)CN)C(=O)O BEQGFMIBZFNROK-JGVFFNPUSA-N 0.000 description 2
- QITBQGJOXQYMOA-ZETCQYMHSA-N Gly-Gly-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)CNC(=O)CN QITBQGJOXQYMOA-ZETCQYMHSA-N 0.000 description 2
- KAJAOGBVWCYGHZ-JTQLQIEISA-N Gly-Gly-Phe Chemical compound [NH3+]CC(=O)NCC(=O)N[C@H](C([O-])=O)CC1=CC=CC=C1 KAJAOGBVWCYGHZ-JTQLQIEISA-N 0.000 description 2
- YWAQATDNEKZFFK-BYPYZUCNSA-N Gly-Gly-Ser Chemical compound NCC(=O)NCC(=O)N[C@@H](CO)C(O)=O YWAQATDNEKZFFK-BYPYZUCNSA-N 0.000 description 2
- UQJNXZSSGQIPIQ-FBCQKBJTSA-N Gly-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)CN UQJNXZSSGQIPIQ-FBCQKBJTSA-N 0.000 description 2
- INLIXXRWNUKVCF-JTQLQIEISA-N Gly-Gly-Tyr Chemical compound NCC(=O)NCC(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 INLIXXRWNUKVCF-JTQLQIEISA-N 0.000 description 2
- CQIIXEHDSZUSAG-QWRGUYRKSA-N Gly-His-His Chemical compound C([C@H](NC(=O)CN)C(=O)N[C@@H](CC=1NC=NC=1)C(O)=O)C1=CN=CN1 CQIIXEHDSZUSAG-QWRGUYRKSA-N 0.000 description 2
- HPAIKDPJURGQLN-KBPBESRZSA-N Gly-His-Phe Chemical compound C([C@H](NC(=O)CN)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CNC=N1 HPAIKDPJURGQLN-KBPBESRZSA-N 0.000 description 2
- VIIBEIQMLJEUJG-LAEOZQHASA-N Gly-Ile-Gln Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(N)=O)C(O)=O VIIBEIQMLJEUJG-LAEOZQHASA-N 0.000 description 2
- HMHRTKOWRUPPNU-RCOVLWMOSA-N Gly-Ile-Gly Chemical compound NCC(=O)N[C@@H]([C@@H](C)CC)C(=O)NCC(O)=O HMHRTKOWRUPPNU-RCOVLWMOSA-N 0.000 description 2
- YTSVAIMKVLZUDU-YUMQZZPRSA-N Gly-Leu-Asp Chemical compound [H]NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O YTSVAIMKVLZUDU-YUMQZZPRSA-N 0.000 description 2
- VBOBNHSVQKKTOT-YUMQZZPRSA-N Gly-Lys-Ala Chemical compound [H]NCC(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(O)=O VBOBNHSVQKKTOT-YUMQZZPRSA-N 0.000 description 2
- OJNZVYSGVYLQIN-BQBZGAKWSA-N Gly-Met-Asp Chemical compound [H]NCC(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(O)=O)C(O)=O OJNZVYSGVYLQIN-BQBZGAKWSA-N 0.000 description 2
- NSVOVKWEKGEOQB-LURJTMIESA-N Gly-Pro-Gly Chemical compound NCC(=O)N1CCC[C@H]1C(=O)NCC(O)=O NSVOVKWEKGEOQB-LURJTMIESA-N 0.000 description 2
- IRJWAYCXIYUHQE-WHFBIAKZSA-N Gly-Ser-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CO)NC(=O)CN IRJWAYCXIYUHQE-WHFBIAKZSA-N 0.000 description 2
- YXTFLTJYLIAZQG-FJXKBIBVSA-N Gly-Thr-Arg Chemical compound NCC(=O)N[C@@H]([C@H](O)C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N YXTFLTJYLIAZQG-FJXKBIBVSA-N 0.000 description 2
- ZZWUYQXMIFTIIY-WEDXCCLWSA-N Gly-Thr-Leu Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O ZZWUYQXMIFTIIY-WEDXCCLWSA-N 0.000 description 2
- FXTUGWXZTFMTIV-GJZGRUSLSA-N Gly-Trp-Arg Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)NC(=O)CN FXTUGWXZTFMTIV-GJZGRUSLSA-N 0.000 description 2
- PYFHPYDQHCEVIT-KBPBESRZSA-N Gly-Trp-Gln Chemical compound [H]NCC(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CCC(N)=O)C(O)=O PYFHPYDQHCEVIT-KBPBESRZSA-N 0.000 description 2
- YJDALMUYJIENAG-QWRGUYRKSA-N Gly-Tyr-Asn Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)CN)O YJDALMUYJIENAG-QWRGUYRKSA-N 0.000 description 2
- PNUFMLXHOLFRLD-KBPBESRZSA-N Gly-Tyr-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CC1=CC=C(O)C=C1 PNUFMLXHOLFRLD-KBPBESRZSA-N 0.000 description 2
- SYOJVRNQCXYEOV-XVKPBYJWSA-N Gly-Val-Glu Chemical compound [H]NCC(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O SYOJVRNQCXYEOV-XVKPBYJWSA-N 0.000 description 2
- BAYQNCWLXIDLHX-ONGXEEELSA-N Gly-Val-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)CN BAYQNCWLXIDLHX-ONGXEEELSA-N 0.000 description 2
- YGHSQRJSHKYUJY-SCZZXKLOSA-N Gly-Val-Pro Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)CN YGHSQRJSHKYUJY-SCZZXKLOSA-N 0.000 description 2
- ZNPRMNDAFQKATM-LKTVYLICSA-N His-Ala-Tyr Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O ZNPRMNDAFQKATM-LKTVYLICSA-N 0.000 description 2
- JBJNKUOMNZGQIM-PYJNHQTQSA-N His-Arg-Ile Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O JBJNKUOMNZGQIM-PYJNHQTQSA-N 0.000 description 2
- ZJSMFRTVYSLKQU-DJFWLOJKSA-N His-Asp-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CC1=CN=CN1)N ZJSMFRTVYSLKQU-DJFWLOJKSA-N 0.000 description 2
- HVCRQRQPIIRNLY-IUCAKERBSA-N His-Gln-Gly Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)NCC(=O)O)N HVCRQRQPIIRNLY-IUCAKERBSA-N 0.000 description 2
- VHHYJBSXXMPQGZ-AVGNSLFASA-N His-Gln-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CC1=CN=CN1)N VHHYJBSXXMPQGZ-AVGNSLFASA-N 0.000 description 2
- WGHJXSONOOTTCZ-JYJNAYRXSA-N His-Glu-Tyr Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O WGHJXSONOOTTCZ-JYJNAYRXSA-N 0.000 description 2
- JBSLJUPMTYLLFH-MELADBBJSA-N His-His-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CN=CN2)NC(=O)[C@H](CC3=CN=CN3)N)C(=O)O JBSLJUPMTYLLFH-MELADBBJSA-N 0.000 description 2
- AIPUZFXMXAHZKY-QWRGUYRKSA-N His-Leu-Gly Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O AIPUZFXMXAHZKY-QWRGUYRKSA-N 0.000 description 2
- UXSATKFPUVZVDK-KKUMJFAQSA-N His-Lys-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CC1=CN=CN1)N UXSATKFPUVZVDK-KKUMJFAQSA-N 0.000 description 2
- SOYCWSKCUVDLMC-AVGNSLFASA-N His-Pro-Arg Chemical compound N[C@@H](Cc1cnc[nH]1)C(=O)N2CCC[C@H]2C(=O)N[C@@H](CCCNC(=N)N)C(=O)O SOYCWSKCUVDLMC-AVGNSLFASA-N 0.000 description 2
- PGXZHYYGOPKYKM-IHRRRGAJSA-N His-Pro-Lys Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CC2=CN=CN2)N)C(=O)N[C@@H](CCCCN)C(=O)O PGXZHYYGOPKYKM-IHRRRGAJSA-N 0.000 description 2
- PBVQWNDMFFCPIZ-ULQDDVLXSA-N His-Pro-Phe Chemical compound C([C@H](N)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CN=CN1 PBVQWNDMFFCPIZ-ULQDDVLXSA-N 0.000 description 2
- GIRSNERMXCMDBO-GARJFASQSA-N His-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CC2=CN=CN2)N)C(=O)O GIRSNERMXCMDBO-GARJFASQSA-N 0.000 description 2
- PFOUFRJYHWZJKW-NKIYYHGXSA-N His-Thr-Gln Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CC1=CN=CN1)N)O PFOUFRJYHWZJKW-NKIYYHGXSA-N 0.000 description 2
- 102000008157 Histone Demethylases Human genes 0.000 description 2
- 108010074870 Histone Demethylases Proteins 0.000 description 2
- 102000011787 Histone Methyltransferases Human genes 0.000 description 2
- 108010036115 Histone Methyltransferases Proteins 0.000 description 2
- 101000946926 Homo sapiens C-C chemokine receptor type 5 Proteins 0.000 description 2
- 101100438883 Homo sapiens CCR5 gene Proteins 0.000 description 2
- 241000725303 Human immunodeficiency virus Species 0.000 description 2
- XENGULNPUDGALZ-ZPFDUUQYSA-N Ile-Asn-Leu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC(C)C)C(=O)O)N XENGULNPUDGALZ-ZPFDUUQYSA-N 0.000 description 2
- ZZHGKECPZXPXJF-PCBIJLKTSA-N Ile-Asn-Phe Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 ZZHGKECPZXPXJF-PCBIJLKTSA-N 0.000 description 2
- NBJAAWYRLGCJOF-UGYAYLCHSA-N Ile-Asp-Asn Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC(=O)N)C(=O)O)N NBJAAWYRLGCJOF-UGYAYLCHSA-N 0.000 description 2
- RGSOCXHDOPQREB-ZPFDUUQYSA-N Ile-Asp-Leu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC(C)C)C(=O)O)N RGSOCXHDOPQREB-ZPFDUUQYSA-N 0.000 description 2
- AQTWDZDISVGCAC-CFMVVWHZSA-N Ile-Asp-Tyr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)O)N AQTWDZDISVGCAC-CFMVVWHZSA-N 0.000 description 2
- KMBPQYKVZBMRMH-PEFMBERDSA-N Ile-Gln-Asn Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O KMBPQYKVZBMRMH-PEFMBERDSA-N 0.000 description 2
- JRYQSFOFUFXPTB-RWRJDSDZSA-N Ile-Gln-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H]([C@@H](C)O)C(=O)O)N JRYQSFOFUFXPTB-RWRJDSDZSA-N 0.000 description 2
- UBHUJPVCJHPSEU-GRLWGSQLSA-N Ile-Glu-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)O)N UBHUJPVCJHPSEU-GRLWGSQLSA-N 0.000 description 2
- CDGLBYSAZFIIJO-RCOVLWMOSA-N Ile-Gly-Gly Chemical compound CC[C@H](C)[C@H]([NH3+])C(=O)NCC(=O)NCC([O-])=O CDGLBYSAZFIIJO-RCOVLWMOSA-N 0.000 description 2
- ODPKZZLRDNXTJZ-WHOFXGATSA-N Ile-Gly-Phe Chemical compound CC[C@H](C)[C@@H](C(=O)NCC(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)N ODPKZZLRDNXTJZ-WHOFXGATSA-N 0.000 description 2
- GQKSJYINYYWPMR-NGZCFLSTSA-N Ile-Gly-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)NCC(=O)N1CCC[C@@H]1C(=O)O)N GQKSJYINYYWPMR-NGZCFLSTSA-N 0.000 description 2
- RIVKTKFVWXRNSJ-GRLWGSQLSA-N Ile-Ile-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N RIVKTKFVWXRNSJ-GRLWGSQLSA-N 0.000 description 2
- HUORUFRRJHELPD-MNXVOIDGSA-N Ile-Leu-Glu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N HUORUFRRJHELPD-MNXVOIDGSA-N 0.000 description 2
- UIEZQYNXCYHMQS-BJDJZHNGSA-N Ile-Lys-Ala Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(=O)O)N UIEZQYNXCYHMQS-BJDJZHNGSA-N 0.000 description 2
- NZGTYCMLUGYMCV-XUXIUFHCSA-N Ile-Lys-Arg Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N NZGTYCMLUGYMCV-XUXIUFHCSA-N 0.000 description 2
- GLYJPWIRLBAIJH-FQUUOJAGSA-N Ile-Lys-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N1CCC[C@@H]1C(=O)O)N GLYJPWIRLBAIJH-FQUUOJAGSA-N 0.000 description 2
- CKRFDMPBSWYOBT-PPCPHDFISA-N Ile-Lys-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(=O)O)N CKRFDMPBSWYOBT-PPCPHDFISA-N 0.000 description 2
- BCISUQVFDGYZBO-QSFUFRPTSA-N Ile-Val-Asp Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC(O)=O BCISUQVFDGYZBO-QSFUFRPTSA-N 0.000 description 2
- JZBVBOKASHNXAD-NAKRPEOUSA-N Ile-Val-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(=O)O)N JZBVBOKASHNXAD-NAKRPEOUSA-N 0.000 description 2
- APQYGMBHIVXFML-OSUNSFLBSA-N Ile-Val-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)O)N APQYGMBHIVXFML-OSUNSFLBSA-N 0.000 description 2
- 108010065920 Insulin Lispro Proteins 0.000 description 2
- 241000186660 Lactobacillus Species 0.000 description 2
- 101710128836 Large T antigen Proteins 0.000 description 2
- 241000272168 Laridae Species 0.000 description 2
- LJHGALIOHLRRQN-DCAQKATOSA-N Leu-Ala-Arg Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N LJHGALIOHLRRQN-DCAQKATOSA-N 0.000 description 2
- GRZSCTXVCDUIPO-SRVKXCTJSA-N Leu-Arg-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(O)=O GRZSCTXVCDUIPO-SRVKXCTJSA-N 0.000 description 2
- KSZCCRIGNVSHFH-UWVGGRQHSA-N Leu-Arg-Gly Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)NCC(O)=O KSZCCRIGNVSHFH-UWVGGRQHSA-N 0.000 description 2
- STAVRDQLZOTNKJ-RHYQMDGZSA-N Leu-Arg-Thr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(O)=O STAVRDQLZOTNKJ-RHYQMDGZSA-N 0.000 description 2
- YKNBJXOJTURHCU-DCAQKATOSA-N Leu-Asp-Arg Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CCCN=C(N)N YKNBJXOJTURHCU-DCAQKATOSA-N 0.000 description 2
- KWURTLAFFDOTEQ-GUBZILKMSA-N Leu-Cys-Glu Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N KWURTLAFFDOTEQ-GUBZILKMSA-N 0.000 description 2
- IASQBRJGRVXNJI-YUMQZZPRSA-N Leu-Cys-Gly Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CS)C(=O)NCC(O)=O IASQBRJGRVXNJI-YUMQZZPRSA-N 0.000 description 2
- FQZPTCNSNPWHLJ-AVGNSLFASA-N Leu-Gln-Lys Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCCN)C(O)=O FQZPTCNSNPWHLJ-AVGNSLFASA-N 0.000 description 2
- CIVKXGPFXDIQBV-WDCWCFNPSA-N Leu-Gln-Thr Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O CIVKXGPFXDIQBV-WDCWCFNPSA-N 0.000 description 2
- WIDZHJTYKYBLSR-DCAQKATOSA-N Leu-Glu-Glu Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O WIDZHJTYKYBLSR-DCAQKATOSA-N 0.000 description 2
- BABSVXFGKFLIGW-UWVGGRQHSA-N Leu-Gly-Arg Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCCNC(N)=N BABSVXFGKFLIGW-UWVGGRQHSA-N 0.000 description 2
- VZBIUJURDLFFOE-IHRRRGAJSA-N Leu-His-Arg Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O VZBIUJURDLFFOE-IHRRRGAJSA-N 0.000 description 2
- DBSLVQBXKVKDKJ-BJDJZHNGSA-N Leu-Ile-Ala Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C)C(O)=O DBSLVQBXKVKDKJ-BJDJZHNGSA-N 0.000 description 2
- SEMUSFOBZGKBGW-YTFOTSKYSA-N Leu-Ile-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O SEMUSFOBZGKBGW-YTFOTSKYSA-N 0.000 description 2
- HNDWYLYAYNBWMP-AJNGGQMLSA-N Leu-Ile-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC(C)C)N HNDWYLYAYNBWMP-AJNGGQMLSA-N 0.000 description 2
- YOKVEHGYYQEQOP-QWRGUYRKSA-N Leu-Leu-Gly Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O YOKVEHGYYQEQOP-QWRGUYRKSA-N 0.000 description 2
- RXGLHDWAZQECBI-SRVKXCTJSA-N Leu-Leu-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O RXGLHDWAZQECBI-SRVKXCTJSA-N 0.000 description 2
- VCHVSKNMTXWIIP-SRVKXCTJSA-N Leu-Lys-Ser Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O VCHVSKNMTXWIIP-SRVKXCTJSA-N 0.000 description 2
- ONPJGOIVICHWBW-BZSNNMDCSA-N Leu-Lys-Tyr Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 ONPJGOIVICHWBW-BZSNNMDCSA-N 0.000 description 2
- MJWVXZABPOKJJF-ACRUOGEOSA-N Leu-Phe-Phe Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O MJWVXZABPOKJJF-ACRUOGEOSA-N 0.000 description 2
- FYPWFNKQVVEELI-ULQDDVLXSA-N Leu-Phe-Val Chemical compound CC(C)C[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](C(C)C)C(O)=O)CC1=CC=CC=C1 FYPWFNKQVVEELI-ULQDDVLXSA-N 0.000 description 2
- WMIOEVKKYIMVKI-DCAQKATOSA-N Leu-Pro-Ala Chemical compound [H]N[C@@H](CC(C)C)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O WMIOEVKKYIMVKI-DCAQKATOSA-N 0.000 description 2
- XOWMDXHFSBCAKQ-SRVKXCTJSA-N Leu-Ser-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC(C)C XOWMDXHFSBCAKQ-SRVKXCTJSA-N 0.000 description 2
- ZJZNLRVCZWUONM-JXUBOQSCSA-N Leu-Thr-Ala Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O ZJZNLRVCZWUONM-JXUBOQSCSA-N 0.000 description 2
- ZDJQVSIPFLMNOX-RHYQMDGZSA-N Leu-Thr-Arg Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CCCN=C(N)N ZDJQVSIPFLMNOX-RHYQMDGZSA-N 0.000 description 2
- LJBVRCDPWOJOEK-PPCPHDFISA-N Leu-Thr-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O LJBVRCDPWOJOEK-PPCPHDFISA-N 0.000 description 2
- QWWPYKKLXWOITQ-VOAKCMCISA-N Leu-Thr-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CC(C)C QWWPYKKLXWOITQ-VOAKCMCISA-N 0.000 description 2
- KLSUAWUZBMAZCL-RHYQMDGZSA-N Leu-Thr-Pro Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N1CCC[C@H]1C(O)=O KLSUAWUZBMAZCL-RHYQMDGZSA-N 0.000 description 2
- URJUVJDTPXCQFL-IHPCNDPISA-N Leu-Trp-His Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)N[C@@H](CC3=CN=CN3)C(=O)O)N URJUVJDTPXCQFL-IHPCNDPISA-N 0.000 description 2
- RDFIVFHPOSOXMW-ACRUOGEOSA-N Leu-Tyr-Phe Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O RDFIVFHPOSOXMW-ACRUOGEOSA-N 0.000 description 2
- MVJRBCJCRYGCKV-GVXVVHGQSA-N Leu-Val-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O MVJRBCJCRYGCKV-GVXVVHGQSA-N 0.000 description 2
- AIMGJYMCTAABEN-GVXVVHGQSA-N Leu-Val-Glu Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O AIMGJYMCTAABEN-GVXVVHGQSA-N 0.000 description 2
- LMDVGHQPPPLYAR-IHRRRGAJSA-N Leu-Val-His Chemical compound N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CNC=N1)C(=O)O LMDVGHQPPPLYAR-IHRRRGAJSA-N 0.000 description 2
- YQFZRHYZLARWDY-IHRRRGAJSA-N Leu-Val-Lys Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CCCCN YQFZRHYZLARWDY-IHRRRGAJSA-N 0.000 description 2
- 239000006142 Luria-Bertani Agar Substances 0.000 description 2
- JCFYLFOCALSNLQ-GUBZILKMSA-N Lys-Ala-Gln Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(N)=O)C(O)=O JCFYLFOCALSNLQ-GUBZILKMSA-N 0.000 description 2
- XFIHDSBIPWEYJJ-YUMQZZPRSA-N Lys-Ala-Gly Chemical compound OC(=O)CNC(=O)[C@H](C)NC(=O)[C@@H](N)CCCCN XFIHDSBIPWEYJJ-YUMQZZPRSA-N 0.000 description 2
- ZQCVMVCVPFYXHZ-SRVKXCTJSA-N Lys-Asn-Lys Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@H](C(O)=O)CCCCN ZQCVMVCVPFYXHZ-SRVKXCTJSA-N 0.000 description 2
- SSJBMGCZZXCGJJ-DCAQKATOSA-N Lys-Asp-Met Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCSC)C(O)=O SSJBMGCZZXCGJJ-DCAQKATOSA-N 0.000 description 2
- QIJVAFLRMVBHMU-KKUMJFAQSA-N Lys-Asp-Phe Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O QIJVAFLRMVBHMU-KKUMJFAQSA-N 0.000 description 2
- ZXEUFAVXODIPHC-GUBZILKMSA-N Lys-Glu-Asn Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O ZXEUFAVXODIPHC-GUBZILKMSA-N 0.000 description 2
- GQFDWEDHOQRNLC-QWRGUYRKSA-N Lys-Gly-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CCCCN GQFDWEDHOQRNLC-QWRGUYRKSA-N 0.000 description 2
- WAIHHELKYSFIQN-XUXIUFHCSA-N Lys-Ile-Val Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C(C)C)C(O)=O WAIHHELKYSFIQN-XUXIUFHCSA-N 0.000 description 2
- VMTYLUGCXIEDMV-QWRGUYRKSA-N Lys-Leu-Gly Chemical compound OC(=O)CNC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CCCCN VMTYLUGCXIEDMV-QWRGUYRKSA-N 0.000 description 2
- HVAUKHLDSDDROB-KKUMJFAQSA-N Lys-Lys-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(O)=O HVAUKHLDSDDROB-KKUMJFAQSA-N 0.000 description 2
- QBHGXFQJFPWJIH-XUXIUFHCSA-N Lys-Pro-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CCCCN QBHGXFQJFPWJIH-XUXIUFHCSA-N 0.000 description 2
- GHKXHCMRAUYLBS-CIUDSAMLSA-N Lys-Ser-Asn Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O GHKXHCMRAUYLBS-CIUDSAMLSA-N 0.000 description 2
- QVTDVTONTRSQMF-WDCWCFNPSA-N Lys-Thr-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H]([C@H](O)C)NC(=O)[C@@H](N)CCCCN QVTDVTONTRSQMF-WDCWCFNPSA-N 0.000 description 2
- HMZPYMSEAALNAE-ULQDDVLXSA-N Lys-Val-Tyr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O HMZPYMSEAALNAE-ULQDDVLXSA-N 0.000 description 2
- FYYHWMGAXLPEAU-UHFFFAOYSA-N Magnesium Chemical compound [Mg] FYYHWMGAXLPEAU-UHFFFAOYSA-N 0.000 description 2
- KUQWVNFMZLHAPA-CIUDSAMLSA-N Met-Ala-Gln Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(N)=O)C(O)=O KUQWVNFMZLHAPA-CIUDSAMLSA-N 0.000 description 2
- YNOVBMBQSQTLFM-DCAQKATOSA-N Met-Asn-Leu Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O YNOVBMBQSQTLFM-DCAQKATOSA-N 0.000 description 2
- HHCOOFPGNXKFGR-HJGDQZAQSA-N Met-Gln-Thr Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O HHCOOFPGNXKFGR-HJGDQZAQSA-N 0.000 description 2
- SJDQOYTYNGZZJX-SRVKXCTJSA-N Met-Glu-Leu Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O SJDQOYTYNGZZJX-SRVKXCTJSA-N 0.000 description 2
- VZBXCMCHIHEPBL-SRVKXCTJSA-N Met-Glu-Lys Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@H](C(O)=O)CCCCN VZBXCMCHIHEPBL-SRVKXCTJSA-N 0.000 description 2
- STLBOMUOQNIALW-BQBZGAKWSA-N Met-Gly-Cys Chemical compound CSCC[C@H](N)C(=O)NCC(=O)N[C@@H](CS)C(O)=O STLBOMUOQNIALW-BQBZGAKWSA-N 0.000 description 2
- RXWPLVRJQNWXRQ-IHRRRGAJSA-N Met-His-His Chemical compound C([C@H](NC(=O)[C@@H](N)CCSC)C(=O)N[C@@H](CC=1N=CNC=1)C(O)=O)C1=CNC=N1 RXWPLVRJQNWXRQ-IHRRRGAJSA-N 0.000 description 2
- CHDYFPCQVUOJEB-ULQDDVLXSA-N Met-Leu-Phe Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 CHDYFPCQVUOJEB-ULQDDVLXSA-N 0.000 description 2
- WTHGNAAQXISJHP-AVGNSLFASA-N Met-Lys-Val Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(O)=O WTHGNAAQXISJHP-AVGNSLFASA-N 0.000 description 2
- BJPQKNHZHUCQNQ-SRVKXCTJSA-N Met-Pro-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@@H]1CCCN1C(=O)[C@H](CCSC)N BJPQKNHZHUCQNQ-SRVKXCTJSA-N 0.000 description 2
- PCTFVQATEGYHJU-FXQIFTODSA-N Met-Ser-Asn Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O PCTFVQATEGYHJU-FXQIFTODSA-N 0.000 description 2
- FZDOBWIKRQORAC-ULQDDVLXSA-N Met-Tyr-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@H](CCSC)N FZDOBWIKRQORAC-ULQDDVLXSA-N 0.000 description 2
- 102000016397 Methyltransferase Human genes 0.000 description 2
- 102000007999 Nuclear Proteins Human genes 0.000 description 2
- 108010089610 Nuclear Proteins Proteins 0.000 description 2
- LSXGADJXBDFXQU-DLOVCJGASA-N Phe-Ala-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC1=CC=CC=C1 LSXGADJXBDFXQU-DLOVCJGASA-N 0.000 description 2
- BBDSZDHUCPSYAC-QEJZJMRPSA-N Phe-Ala-Leu Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O BBDSZDHUCPSYAC-QEJZJMRPSA-N 0.000 description 2
- SEPNOAFMZLLCEW-UBHSHLNASA-N Phe-Ala-Val Chemical compound N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](C)C(=O)N[C@@H](C(C)C)C(=O)O SEPNOAFMZLLCEW-UBHSHLNASA-N 0.000 description 2
- MQWISMJKHOUEMW-ULQDDVLXSA-N Phe-Arg-His Chemical compound C([C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC=1NC=NC=1)C(O)=O)C1=CC=CC=C1 MQWISMJKHOUEMW-ULQDDVLXSA-N 0.000 description 2
- HTTYNOXBBOWZTB-SRVKXCTJSA-N Phe-Asn-Asn Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC(=O)N)C(=O)O)N HTTYNOXBBOWZTB-SRVKXCTJSA-N 0.000 description 2
- SPXWRYVHOZVYBU-ULQDDVLXSA-N Phe-His-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CN=CN1)NC(=O)[C@H](CC2=CC=CC=C2)N SPXWRYVHOZVYBU-ULQDDVLXSA-N 0.000 description 2
- KXUZHWXENMYOHC-QEJZJMRPSA-N Phe-Leu-Ala Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(O)=O KXUZHWXENMYOHC-QEJZJMRPSA-N 0.000 description 2
- LRBSWBVUCLLRLU-BZSNNMDCSA-N Phe-Leu-Lys Chemical compound CC(C)C[C@H](NC(=O)[C@@H](N)Cc1ccccc1)C(=O)N[C@@H](CCCCN)C(O)=O LRBSWBVUCLLRLU-BZSNNMDCSA-N 0.000 description 2
- RMKGXGPQIPLTFC-KKUMJFAQSA-N Phe-Lys-Asn Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(O)=O RMKGXGPQIPLTFC-KKUMJFAQSA-N 0.000 description 2
- KLXQWABNAWDRAY-ACRUOGEOSA-N Phe-Lys-Phe Chemical compound C([C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=CC=C1 KLXQWABNAWDRAY-ACRUOGEOSA-N 0.000 description 2
- SCKXGHWQPPURGT-KKUMJFAQSA-N Phe-Lys-Ser Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O SCKXGHWQPPURGT-KKUMJFAQSA-N 0.000 description 2
- PTLMYJOMJLTMCB-KKUMJFAQSA-N Phe-Met-Gln Chemical compound CSCC[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)N PTLMYJOMJLTMCB-KKUMJFAQSA-N 0.000 description 2
- DEZCWWXTRAKZKJ-UFYCRDLUSA-N Phe-Phe-Met Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCSC)C(O)=O DEZCWWXTRAKZKJ-UFYCRDLUSA-N 0.000 description 2
- YFXXRYFWJFQAFW-JHYOHUSXSA-N Phe-Thr-Thr Chemical compound C[C@H]([C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)N)O YFXXRYFWJFQAFW-JHYOHUSXSA-N 0.000 description 2
- IEIFEYBAYFSRBQ-IHRRRGAJSA-N Phe-Val-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)N IEIFEYBAYFSRBQ-IHRRRGAJSA-N 0.000 description 2
- 102000045595 Phosphoprotein Phosphatases Human genes 0.000 description 2
- 108700019535 Phosphoprotein Phosphatases Proteins 0.000 description 2
- IFMDQWDAJUMMJC-DCAQKATOSA-N Pro-Ala-Leu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O IFMDQWDAJUMMJC-DCAQKATOSA-N 0.000 description 2
- XQLBWXHVZVBNJM-FXQIFTODSA-N Pro-Ala-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1 XQLBWXHVZVBNJM-FXQIFTODSA-N 0.000 description 2
- NGNNPLJHUFCOMZ-FXQIFTODSA-N Pro-Asp-Cys Chemical compound SC[C@@H](C(O)=O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@@H]1CCCN1 NGNNPLJHUFCOMZ-FXQIFTODSA-N 0.000 description 2
- KPDRZQUWJKTMBP-DCAQKATOSA-N Pro-Asp-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@@H]1CCCN1 KPDRZQUWJKTMBP-DCAQKATOSA-N 0.000 description 2
- NOXSEHJOXCWRHK-DCAQKATOSA-N Pro-Cys-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@@H]1CCCN1 NOXSEHJOXCWRHK-DCAQKATOSA-N 0.000 description 2
- ZPPVJIJMIKTERM-YUMQZZPRSA-N Pro-Gln-Gly Chemical compound OC(=O)CNC(=O)[C@H](CCC(=O)N)NC(=O)[C@@H]1CCCN1 ZPPVJIJMIKTERM-YUMQZZPRSA-N 0.000 description 2
- DIFXZGPHVCIVSQ-CIUDSAMLSA-N Pro-Gln-Ser Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O DIFXZGPHVCIVSQ-CIUDSAMLSA-N 0.000 description 2
- ZTVCLZLGHZXLOT-ULQDDVLXSA-N Pro-Glu-Trp Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CC2=CNC3=CC=CC=C32)C(=O)O ZTVCLZLGHZXLOT-ULQDDVLXSA-N 0.000 description 2
- JMVQDLDPDBXAAX-YUMQZZPRSA-N Pro-Gly-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H]1CCCN1 JMVQDLDPDBXAAX-YUMQZZPRSA-N 0.000 description 2
- FKLSMYYLJHYPHH-UWVGGRQHSA-N Pro-Gly-Leu Chemical compound [H]N1CCC[C@H]1C(=O)NCC(=O)N[C@@H](CC(C)C)C(O)=O FKLSMYYLJHYPHH-UWVGGRQHSA-N 0.000 description 2
- FEVDNIBDCRKMER-IUCAKERBSA-N Pro-Gly-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)CNC(=O)[C@@H]1CCCN1 FEVDNIBDCRKMER-IUCAKERBSA-N 0.000 description 2
- AQSMZTIEJMZQEC-DCAQKATOSA-N Pro-His-Ser Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CC2=CN=CN2)C(=O)N[C@@H](CO)C(=O)O AQSMZTIEJMZQEC-DCAQKATOSA-N 0.000 description 2
- LXLFEIHKWGHJJB-XUXIUFHCSA-N Pro-Ile-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@@H]1CCCN1 LXLFEIHKWGHJJB-XUXIUFHCSA-N 0.000 description 2
- UREQLMJCKFLLHM-NAKRPEOUSA-N Pro-Ile-Ser Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O UREQLMJCKFLLHM-NAKRPEOUSA-N 0.000 description 2
- HFNPOYOKIPGAEI-SRVKXCTJSA-N Pro-Leu-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H]1CCCN1 HFNPOYOKIPGAEI-SRVKXCTJSA-N 0.000 description 2
- SUENWIFTSTWUKD-AVGNSLFASA-N Pro-Leu-Val Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O SUENWIFTSTWUKD-AVGNSLFASA-N 0.000 description 2
- XZBYTHCRAVAXQQ-DCAQKATOSA-N Pro-Met-Glu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCC(O)=O)C(O)=O XZBYTHCRAVAXQQ-DCAQKATOSA-N 0.000 description 2
- QGLFRQCECIWXFA-RCWTZXSCSA-N Pro-Met-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CCSC)NC(=O)[C@@H]1CCCN1)O QGLFRQCECIWXFA-RCWTZXSCSA-N 0.000 description 2
- DSGSTPRKNYHGCL-JYJNAYRXSA-N Pro-Phe-Met Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCSC)C(O)=O DSGSTPRKNYHGCL-JYJNAYRXSA-N 0.000 description 2
- DCHQYSOGURGJST-FJXKBIBVSA-N Pro-Thr-Gly Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O DCHQYSOGURGJST-FJXKBIBVSA-N 0.000 description 2
- CNUIHOAISPKQPY-HSHDSVGOSA-N Pro-Thr-Trp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O CNUIHOAISPKQPY-HSHDSVGOSA-N 0.000 description 2
- VVEQUISRWJDGMX-VKOGCVSHSA-N Pro-Trp-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@@H]3CCCN3 VVEQUISRWJDGMX-VKOGCVSHSA-N 0.000 description 2
- HOJUNFDJDAPVBI-BZSNNMDCSA-N Pro-Trp-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@@H]3CCCN3 HOJUNFDJDAPVBI-BZSNNMDCSA-N 0.000 description 2
- KHRLUIPIMIQFGT-AVGNSLFASA-N Pro-Val-Leu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O KHRLUIPIMIQFGT-AVGNSLFASA-N 0.000 description 2
- YDTUEBLEAVANFH-RCWTZXSCSA-N Pro-Val-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H]1CCCN1 YDTUEBLEAVANFH-RCWTZXSCSA-N 0.000 description 2
- 102000001253 Protein Kinase Human genes 0.000 description 2
- 108010076504 Protein Sorting Signals Proteins 0.000 description 2
- 241000205156 Pyrococcus furiosus Species 0.000 description 2
- 108010003201 RGH 0205 Proteins 0.000 description 2
- 241000607142 Salmonella Species 0.000 description 2
- BTKUIVBNGBFTTP-WHFBIAKZSA-N Ser-Ala-Gly Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)NCC(O)=O BTKUIVBNGBFTTP-WHFBIAKZSA-N 0.000 description 2
- GXXTUIUYTWGPMV-FXQIFTODSA-N Ser-Arg-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(O)=O GXXTUIUYTWGPMV-FXQIFTODSA-N 0.000 description 2
- WDXYVIIVDIDOSX-DCAQKATOSA-N Ser-Arg-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)CO)CCCN=C(N)N WDXYVIIVDIDOSX-DCAQKATOSA-N 0.000 description 2
- QFBNNYNWKYKVJO-DCAQKATOSA-N Ser-Arg-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)CO)CCCN=C(N)N QFBNNYNWKYKVJO-DCAQKATOSA-N 0.000 description 2
- FIDMVVBUOCMMJG-CIUDSAMLSA-N Ser-Asn-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CO FIDMVVBUOCMMJG-CIUDSAMLSA-N 0.000 description 2
- MESDJCNHLZBMEP-ZLUOBGJFSA-N Ser-Asp-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O MESDJCNHLZBMEP-ZLUOBGJFSA-N 0.000 description 2
- CRZRTKAVUUGKEQ-ACZMJKKPSA-N Ser-Gln-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(O)=O CRZRTKAVUUGKEQ-ACZMJKKPSA-N 0.000 description 2
- AEGUWTFAQQWVLC-BQBZGAKWSA-N Ser-Gly-Arg Chemical compound [H]N[C@@H](CO)C(=O)NCC(=O)N[C@@H](CCCNC(N)=N)C(O)=O AEGUWTFAQQWVLC-BQBZGAKWSA-N 0.000 description 2
- IXCHOHLPHNGFTJ-YUMQZZPRSA-N Ser-Gly-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CO)N IXCHOHLPHNGFTJ-YUMQZZPRSA-N 0.000 description 2
- IOVHBRCQOGWAQH-ZKWXMUAHSA-N Ser-Gly-Ile Chemical compound [H]N[C@@H](CO)C(=O)NCC(=O)N[C@@H]([C@@H](C)CC)C(O)=O IOVHBRCQOGWAQH-ZKWXMUAHSA-N 0.000 description 2
- UIGMAMGZOJVTDN-WHFBIAKZSA-N Ser-Gly-Ser Chemical compound OC[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O UIGMAMGZOJVTDN-WHFBIAKZSA-N 0.000 description 2
- HEUVHBXOVZONPU-BJDJZHNGSA-N Ser-Leu-Ile Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O HEUVHBXOVZONPU-BJDJZHNGSA-N 0.000 description 2
- YUJLIIRMIAGMCQ-CIUDSAMLSA-N Ser-Leu-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O YUJLIIRMIAGMCQ-CIUDSAMLSA-N 0.000 description 2
- PMCMLDNPAZUYGI-DCAQKATOSA-N Ser-Lys-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(O)=O PMCMLDNPAZUYGI-DCAQKATOSA-N 0.000 description 2
- AMRRYKHCILPAKD-FXQIFTODSA-N Ser-Met-Asn Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CO)N AMRRYKHCILPAKD-FXQIFTODSA-N 0.000 description 2
- UGTZYIPOBYXWRW-SRVKXCTJSA-N Ser-Phe-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(O)=O)C(O)=O UGTZYIPOBYXWRW-SRVKXCTJSA-N 0.000 description 2
- GZGFSPWOMUKKCV-NAKRPEOUSA-N Ser-Pro-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CO GZGFSPWOMUKKCV-NAKRPEOUSA-N 0.000 description 2
- QUGRFWPMPVIAPW-IHRRRGAJSA-N Ser-Pro-Phe Chemical compound OC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 QUGRFWPMPVIAPW-IHRRRGAJSA-N 0.000 description 2
- KQNDIKOYWZTZIX-FXQIFTODSA-N Ser-Ser-Arg Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCCNC(N)=N KQNDIKOYWZTZIX-FXQIFTODSA-N 0.000 description 2
- VGQVAVQWKJLIRM-FXQIFTODSA-N Ser-Ser-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O VGQVAVQWKJLIRM-FXQIFTODSA-N 0.000 description 2
- XJDMUQCLVSCRSJ-VZFHVOOUSA-N Ser-Thr-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O XJDMUQCLVSCRSJ-VZFHVOOUSA-N 0.000 description 2
- NERYDXBVARJIQS-JYBASQMISA-N Ser-Trp-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H](CO)N)O NERYDXBVARJIQS-JYBASQMISA-N 0.000 description 2
- BEBVVQPDSHHWQL-NRPADANISA-N Ser-Val-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O BEBVVQPDSHHWQL-NRPADANISA-N 0.000 description 2
- YEDSOSIKVUMIJE-DCAQKATOSA-N Ser-Val-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O YEDSOSIKVUMIJE-DCAQKATOSA-N 0.000 description 2
- 241000194017 Streptococcus Species 0.000 description 2
- 101000933157 Streptococcus thermophilus CRISPR-associated endoribonuclease Cas6 Proteins 0.000 description 2
- FQPQPTHMHZKGFM-XQXXSGGOSA-N Thr-Ala-Glu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(O)=O FQPQPTHMHZKGFM-XQXXSGGOSA-N 0.000 description 2
- PXQUBKWZENPDGE-CIQUZCHMSA-N Thr-Ala-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](C)NC(=O)[C@H]([C@@H](C)O)N PXQUBKWZENPDGE-CIQUZCHMSA-N 0.000 description 2
- BSNZTJXVDOINSR-JXUBOQSCSA-N Thr-Ala-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O BSNZTJXVDOINSR-JXUBOQSCSA-N 0.000 description 2
- TWLMXDWFVNEFFK-FJXKBIBVSA-N Thr-Arg-Gly Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)NCC(O)=O TWLMXDWFVNEFFK-FJXKBIBVSA-N 0.000 description 2
- VFEHSAJCWWHDBH-RHYQMDGZSA-N Thr-Arg-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(O)=O VFEHSAJCWWHDBH-RHYQMDGZSA-N 0.000 description 2
- CEXFELBFVHLYDZ-XGEHTFHBSA-N Thr-Arg-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(O)=O CEXFELBFVHLYDZ-XGEHTFHBSA-N 0.000 description 2
- OYTNZCBFDXGQGE-XQXXSGGOSA-N Thr-Gln-Ala Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](C)C(=O)O)N)O OYTNZCBFDXGQGE-XQXXSGGOSA-N 0.000 description 2
- OQCXTUQTKQFDCX-HTUGSXCWSA-N Thr-Glu-Phe Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)N)O OQCXTUQTKQFDCX-HTUGSXCWSA-N 0.000 description 2
- JKGGPMOUIAAJAA-YEPSODPASA-N Thr-Gly-Val Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O JKGGPMOUIAAJAA-YEPSODPASA-N 0.000 description 2
- IGGFFPOIFHZYKC-PBCZWWQYSA-N Thr-His-Asp Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CC(=O)O)C(=O)O)N)O IGGFFPOIFHZYKC-PBCZWWQYSA-N 0.000 description 2
- YUOCMLNTUZAGNF-KLHWPWHYSA-N Thr-His-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N2CCC[C@@H]2C(=O)O)N)O YUOCMLNTUZAGNF-KLHWPWHYSA-N 0.000 description 2
- CRZNCABIJLRFKZ-IUKAMOBKSA-N Thr-Ile-Asp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H]([C@@H](C)O)N CRZNCABIJLRFKZ-IUKAMOBKSA-N 0.000 description 2
- KRDSCBLRHORMRK-JXUBOQSCSA-N Thr-Lys-Ala Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(O)=O KRDSCBLRHORMRK-JXUBOQSCSA-N 0.000 description 2
- CJXURNZYNHCYFD-WDCWCFNPSA-N Thr-Lys-Gln Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N)O CJXURNZYNHCYFD-WDCWCFNPSA-N 0.000 description 2
- UJQVSMNQMQHVRY-KZVJFYERSA-N Thr-Met-Ala Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](C)C(O)=O UJQVSMNQMQHVRY-KZVJFYERSA-N 0.000 description 2
- MXDOAJQRJBMGMO-FJXKBIBVSA-N Thr-Pro-Gly Chemical compound C[C@@H](O)[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O MXDOAJQRJBMGMO-FJXKBIBVSA-N 0.000 description 2
- STUAPCLEDMKXKL-LKXGYXEUSA-N Thr-Ser-Asn Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O STUAPCLEDMKXKL-LKXGYXEUSA-N 0.000 description 2
- SGAOHNPSEPVAFP-ZDLURKLDSA-N Thr-Ser-Gly Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)NCC(O)=O SGAOHNPSEPVAFP-ZDLURKLDSA-N 0.000 description 2
- GJOBRAHDRIDAPT-NGTWOADLSA-N Thr-Trp-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H]([C@@H](C)O)N GJOBRAHDRIDAPT-NGTWOADLSA-N 0.000 description 2
- CXUFDWZBHKUGKK-CABZTGNLSA-N Trp-Ala-Gly Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](C)C(=O)NCC(O)=O)=CNC2=C1 CXUFDWZBHKUGKK-CABZTGNLSA-N 0.000 description 2
- PXYJUECTGMGIDT-WDSOQIARSA-N Trp-Arg-Leu Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC(C)C)C(O)=O)=CNC2=C1 PXYJUECTGMGIDT-WDSOQIARSA-N 0.000 description 2
- DXHHCIYKHRKBOC-BHYGNILZSA-N Trp-Gln-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CC2=CNC3=CC=CC=C32)N)C(=O)O DXHHCIYKHRKBOC-BHYGNILZSA-N 0.000 description 2
- ILDJYIDXESUBOE-HSCHXYMDSA-N Trp-Ile-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N ILDJYIDXESUBOE-HSCHXYMDSA-N 0.000 description 2
- AIISTODACBDQLW-WDSOQIARSA-N Trp-Leu-Arg Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O)=CNC2=C1 AIISTODACBDQLW-WDSOQIARSA-N 0.000 description 2
- YVXIAOOYAKBAAI-SZMVWBNQSA-N Trp-Leu-Gln Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O)=CNC2=C1 YVXIAOOYAKBAAI-SZMVWBNQSA-N 0.000 description 2
- GWBWCGITOYODER-YTQUADARSA-N Trp-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC2=CNC3=CC=CC=C32)N GWBWCGITOYODER-YTQUADARSA-N 0.000 description 2
- NLWCSMOXNKBRLC-WDSOQIARSA-N Trp-Lys-Val Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(O)=O NLWCSMOXNKBRLC-WDSOQIARSA-N 0.000 description 2
- LWHUUHCERHMOAB-WDSOQIARSA-N Trp-Pro-His Chemical compound N[C@@H](Cc1c[nH]c2ccccc12)C(=O)N1CCC[C@H]1C(=O)N[C@@H](Cc1cnc[nH]1)C(O)=O LWHUUHCERHMOAB-WDSOQIARSA-N 0.000 description 2
- SDNVRAKIJVKAGS-LKTVYLICSA-N Tyr-Ala-His Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CC2=CC=C(C=C2)O)N SDNVRAKIJVKAGS-LKTVYLICSA-N 0.000 description 2
- AKXBNSZMYAOGLS-STQMWFEESA-N Tyr-Arg-Gly Chemical compound NC(N)=NCCC[C@@H](C(=O)NCC(O)=O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 AKXBNSZMYAOGLS-STQMWFEESA-N 0.000 description 2
- CRWOSTCODDFEKZ-HRCADAONSA-N Tyr-Arg-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CC2=CC=C(C=C2)O)N)C(=O)O CRWOSTCODDFEKZ-HRCADAONSA-N 0.000 description 2
- TWAVEIJGFCBWCG-JYJNAYRXSA-N Tyr-Gln-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CC1=CC=C(C=C1)O)N TWAVEIJGFCBWCG-JYJNAYRXSA-N 0.000 description 2
- NMKJPMCEKQHRPD-IRXDYDNUSA-N Tyr-Gly-Tyr Chemical compound C([C@H](N)C(=O)NCC(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=C(O)C=C1 NMKJPMCEKQHRPD-IRXDYDNUSA-N 0.000 description 2
- CTDPLKMBVALCGN-JSGCOSHPSA-N Tyr-Gly-Val Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O CTDPLKMBVALCGN-JSGCOSHPSA-N 0.000 description 2
- MVFQLSPDMMFCMW-KKUMJFAQSA-N Tyr-Leu-Asn Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O MVFQLSPDMMFCMW-KKUMJFAQSA-N 0.000 description 2
- BSCBBPKDVOZICB-KKUMJFAQSA-N Tyr-Leu-Asp Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O BSCBBPKDVOZICB-KKUMJFAQSA-N 0.000 description 2
- NVZVJIUDICCMHZ-BZSNNMDCSA-N Tyr-Phe-Ser Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(O)=O NVZVJIUDICCMHZ-BZSNNMDCSA-N 0.000 description 2
- ARMNWLJYHCOSHE-KKUMJFAQSA-N Tyr-Pro-Gln Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(O)=O ARMNWLJYHCOSHE-KKUMJFAQSA-N 0.000 description 2
- YYLHVUCSTXXKBS-IHRRRGAJSA-N Tyr-Pro-Ser Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O YYLHVUCSTXXKBS-IHRRRGAJSA-N 0.000 description 2
- ZPFLBLFITJCBTP-QWRGUYRKSA-N Tyr-Ser-Gly Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CO)C(=O)NCC(O)=O ZPFLBLFITJCBTP-QWRGUYRKSA-N 0.000 description 2
- ZZDYJFVIKVSUFA-WLTAIBSBSA-N Tyr-Thr-Gly Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O ZZDYJFVIKVSUFA-WLTAIBSBSA-N 0.000 description 2
- JHDZONWZTCKTJR-KJEVXHAQSA-N Tyr-Thr-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 JHDZONWZTCKTJR-KJEVXHAQSA-N 0.000 description 2
- FZSPNKUFROZBSG-ZKWXMUAHSA-N Val-Ala-Asp Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC(O)=O FZSPNKUFROZBSG-ZKWXMUAHSA-N 0.000 description 2
- ZLFHAAGHGQBQQN-AEJSXWLSSA-N Val-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](C(C)C)N ZLFHAAGHGQBQQN-AEJSXWLSSA-N 0.000 description 2
- GXAZTLJYINLMJL-LAEOZQHASA-N Val-Asn-Gln Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N GXAZTLJYINLMJL-LAEOZQHASA-N 0.000 description 2
- UDNYEPLJTRDMEJ-RCOVLWMOSA-N Val-Asn-Gly Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)NCC(=O)O)N UDNYEPLJTRDMEJ-RCOVLWMOSA-N 0.000 description 2
- QGFPYRPIUXBYGR-YDHLFZDLSA-N Val-Asn-Phe Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)N QGFPYRPIUXBYGR-YDHLFZDLSA-N 0.000 description 2
- SCBITHMBEJNRHC-LSJOCFKGSA-N Val-Asp-Val Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](C(C)C)C(=O)O)N SCBITHMBEJNRHC-LSJOCFKGSA-N 0.000 description 2
- SRWWRLKBEJZFPW-IHRRRGAJSA-N Val-Cys-Phe Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)N SRWWRLKBEJZFPW-IHRRRGAJSA-N 0.000 description 2
- CPTQYHDSVGVGDZ-UKJIMTQDSA-N Val-Gln-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](C(C)C)N CPTQYHDSVGVGDZ-UKJIMTQDSA-N 0.000 description 2
- JXGWQYWDUOWQHA-DZKIICNBSA-N Val-Gln-Phe Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)N JXGWQYWDUOWQHA-DZKIICNBSA-N 0.000 description 2
- JTWIMNMUYLQNPI-WPRPVWTQSA-N Val-Gly-Arg Chemical compound CC(C)[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCCNC(N)=N JTWIMNMUYLQNPI-WPRPVWTQSA-N 0.000 description 2
- PIFJAFRUVWZRKR-QMMMGPOBSA-N Val-Gly-Gly Chemical compound CC(C)[C@H]([NH3+])C(=O)NCC(=O)NCC([O-])=O PIFJAFRUVWZRKR-QMMMGPOBSA-N 0.000 description 2
- URIRWLJVWHYLET-ONGXEEELSA-N Val-Gly-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)C(C)C URIRWLJVWHYLET-ONGXEEELSA-N 0.000 description 2
- FEFZWCSXEMVSPO-LSJOCFKGSA-N Val-His-Ala Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](Cc1cnc[nH]1)C(=O)N[C@@H](C)C(O)=O FEFZWCSXEMVSPO-LSJOCFKGSA-N 0.000 description 2
- RHYOAUJXSRWVJT-GVXVVHGQSA-N Val-His-Glu Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N RHYOAUJXSRWVJT-GVXVVHGQSA-N 0.000 description 2
- OVBMCNDKCWAXMZ-NAKRPEOUSA-N Val-Ile-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](C(C)C)N OVBMCNDKCWAXMZ-NAKRPEOUSA-N 0.000 description 2
- UMPVMAYCLYMYGA-ONGXEEELSA-N Val-Leu-Gly Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O UMPVMAYCLYMYGA-ONGXEEELSA-N 0.000 description 2
- BTWMICVCQLKKNR-DCAQKATOSA-N Val-Leu-Ser Chemical compound CC(C)[C@H]([NH3+])C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C([O-])=O BTWMICVCQLKKNR-DCAQKATOSA-N 0.000 description 2
- YMTOEGGOCHVGEH-IHRRRGAJSA-N Val-Lys-Lys Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(O)=O YMTOEGGOCHVGEH-IHRRRGAJSA-N 0.000 description 2
- VENKIVFKIPGEJN-NHCYSSNCSA-N Val-Met-Glu Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N VENKIVFKIPGEJN-NHCYSSNCSA-N 0.000 description 2
- LJSZPMSUYKKKCP-UBHSHLNASA-N Val-Phe-Ala Chemical compound CC(C)[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](C)C(O)=O)CC1=CC=CC=C1 LJSZPMSUYKKKCP-UBHSHLNASA-N 0.000 description 2
- VNGKMNPAENRGDC-JYJNAYRXSA-N Val-Phe-Arg Chemical compound NC(N)=NCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)C(C)C)CC1=CC=CC=C1 VNGKMNPAENRGDC-JYJNAYRXSA-N 0.000 description 2
- XBJKAZATRJBDCU-GUBZILKMSA-N Val-Pro-Ala Chemical compound CC(C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O XBJKAZATRJBDCU-GUBZILKMSA-N 0.000 description 2
- VSCIANXXVZOYOC-AVGNSLFASA-N Val-Pro-His Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC2=CN=CN2)C(=O)O)N VSCIANXXVZOYOC-AVGNSLFASA-N 0.000 description 2
- AJNUKMZFHXUBMK-GUBZILKMSA-N Val-Ser-Arg Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N AJNUKMZFHXUBMK-GUBZILKMSA-N 0.000 description 2
- DVLWZWNAQUBZBC-ZNSHCXBVSA-N Val-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](C(C)C)N)O DVLWZWNAQUBZBC-ZNSHCXBVSA-N 0.000 description 2
- WBPFYNYTYASCQP-CYDGBPFRSA-N Val-Val-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](C(C)C)NC(=O)[C@H](C(C)C)N WBPFYNYTYASCQP-CYDGBPFRSA-N 0.000 description 2
- JSOXWWFKRJKTMT-WOPDTQHZSA-N Val-Val-Pro Chemical compound CC(C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N1CCC[C@@H]1C(=O)O)N JSOXWWFKRJKTMT-WOPDTQHZSA-N 0.000 description 2
- JLCPHMBAVCMARE-UHFFFAOYSA-N [3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-hydroxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methyl [5-(6-aminopurin-9-yl)-2-(hydroxymethyl)oxolan-3-yl] hydrogen phosphate Polymers Cc1cn(C2CC(OP(O)(=O)OCC3OC(CC3OP(O)(=O)OCC3OC(CC3O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c3nc(N)[nH]c4=O)C(COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3CO)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cc(C)c(=O)[nH]c3=O)n3cc(C)c(=O)[nH]c3=O)n3ccc(N)nc3=O)n3cc(C)c(=O)[nH]c3=O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)O2)c(=O)[nH]c1=O JLCPHMBAVCMARE-UHFFFAOYSA-N 0.000 description 2
- 239000012190 activator Substances 0.000 description 2
- 230000004721 adaptive immunity Effects 0.000 description 2
- 238000001261 affinity purification Methods 0.000 description 2
- 108010078114 alanyl-tryptophyl-alanine Proteins 0.000 description 2
- 108010045350 alanyl-tyrosyl-alanine Proteins 0.000 description 2
- 230000003321 amplification Effects 0.000 description 2
- 238000000137 annealing Methods 0.000 description 2
- 108010069926 arginyl-glycyl-serine Proteins 0.000 description 2
- 108010066119 arginyl-leucyl-aspartyl-serine Proteins 0.000 description 2
- 108010010430 asparagine-proline-alanine Proteins 0.000 description 2
- 230000015572 biosynthetic process Effects 0.000 description 2
- 229910052791 calcium Inorganic materials 0.000 description 2
- 239000011575 calcium Substances 0.000 description 2
- 239000001110 calcium chloride Substances 0.000 description 2
- 229910001628 calcium chloride Inorganic materials 0.000 description 2
- 101150055191 cas3 gene Proteins 0.000 description 2
- 238000005119 centrifugation Methods 0.000 description 2
- 125000001309 chloro group Chemical group Cl* 0.000 description 2
- 238000004587 chromatography analysis Methods 0.000 description 2
- 210000000349 chromosome Anatomy 0.000 description 2
- 230000001332 colony forming effect Effects 0.000 description 2
- 230000007123 defense Effects 0.000 description 2
- 238000010586 diagram Methods 0.000 description 2
- FSXRLASFHBWESK-UHFFFAOYSA-N dipeptide phenylalanyl-tyrosine Natural products C=1C=C(O)C=CC=1CC(C(O)=O)NC(=O)C(N)CC1=CC=CC=C1 FSXRLASFHBWESK-UHFFFAOYSA-N 0.000 description 2
- VHJLVAABSRFDPM-QWWZWVQMSA-N dithiothreitol Chemical compound SC[C@@H](O)[C@H](O)CS VHJLVAABSRFDPM-QWWZWVQMSA-N 0.000 description 2
- 230000003828 downregulation Effects 0.000 description 2
- 238000001962 electrophoresis Methods 0.000 description 2
- 238000002330 electrospray ionisation mass spectrometry Methods 0.000 description 2
- 210000001671 embryonic stem cell Anatomy 0.000 description 2
- 230000002616 endonucleolytic effect Effects 0.000 description 2
- 230000007613 environmental effect Effects 0.000 description 2
- 102000013165 exonuclease Human genes 0.000 description 2
- 238000000799 fluorescence microscopy Methods 0.000 description 2
- 239000007789 gas Substances 0.000 description 2
- 238000010362 genome editing Methods 0.000 description 2
- 108010085059 glutamyl-arginyl-proline Proteins 0.000 description 2
- 108010042598 glutamyl-aspartyl-glycine Proteins 0.000 description 2
- 108010073628 glutamyl-valyl-phenylalanine Proteins 0.000 description 2
- 108010090037 glycyl-alanyl-isoleucine Proteins 0.000 description 2
- 108010072405 glycyl-aspartyl-glycine Proteins 0.000 description 2
- 108010062266 glycyl-glycyl-argininal Proteins 0.000 description 2
- 108010067216 glycyl-glycyl-glycine Proteins 0.000 description 2
- 108010051307 glycyl-glycyl-proline Proteins 0.000 description 2
- 108010045126 glycyl-tyrosyl-glycine Proteins 0.000 description 2
- 229910001385 heavy metal Inorganic materials 0.000 description 2
- 239000000833 heterodimer Substances 0.000 description 2
- 238000004128 high performance liquid chromatography Methods 0.000 description 2
- 102000048160 human CCR5 Human genes 0.000 description 2
- 238000003384 imaging method Methods 0.000 description 2
- 238000011065 in-situ storage Methods 0.000 description 2
- 230000005764 inhibitory process Effects 0.000 description 2
- 150000002500 ions Chemical class 0.000 description 2
- PHTQWCKDNZKARW-UHFFFAOYSA-N isoamylol Chemical compound CC(C)CCO PHTQWCKDNZKARW-UHFFFAOYSA-N 0.000 description 2
- 229940039696 lactobacillus Drugs 0.000 description 2
- 108010077158 leucinyl-arginyl-tryptophan Proteins 0.000 description 2
- 108010083708 leucyl-aspartyl-valine Proteins 0.000 description 2
- 108010047926 leucyl-lysyl-tyrosine Proteins 0.000 description 2
- 108010073472 leucyl-prolyl-proline Proteins 0.000 description 2
- 239000003446 ligand Substances 0.000 description 2
- 230000004807 localization Effects 0.000 description 2
- 210000004962 mammalian cell Anatomy 0.000 description 2
- 239000000463 material Substances 0.000 description 2
- 238000005259 measurement Methods 0.000 description 2
- 239000002609 medium Substances 0.000 description 2
- 229910021645 metal ion Inorganic materials 0.000 description 2
- BDAGIHXWWSANSR-UHFFFAOYSA-N methanoic acid Natural products OC=O BDAGIHXWWSANSR-UHFFFAOYSA-N 0.000 description 2
- 108010063431 methionyl-aspartyl-glycine Proteins 0.000 description 2
- 230000011987 methylation Effects 0.000 description 2
- 238000007069 methylation reaction Methods 0.000 description 2
- 244000005700 microbiome Species 0.000 description 2
- 238000001000 micrograph Methods 0.000 description 2
- 238000012544 monitoring process Methods 0.000 description 2
- 239000013642 negative control Substances 0.000 description 2
- 238000003199 nucleic acid amplification method Methods 0.000 description 2
- 230000030648 nucleus localization Effects 0.000 description 2
- 239000002245 particle Substances 0.000 description 2
- 239000008194 pharmaceutical composition Substances 0.000 description 2
- 108010018625 phenylalanylarginine Proteins 0.000 description 2
- 108010012581 phenylalanylglutamate Proteins 0.000 description 2
- 108010073025 phenylalanylphenylalanine Proteins 0.000 description 2
- 230000004962 physiological condition Effects 0.000 description 2
- 235000011056 potassium acetate Nutrition 0.000 description 2
- 239000002243 precursor Substances 0.000 description 2
- 230000008569 process Effects 0.000 description 2
- 108010077112 prolyl-proline Proteins 0.000 description 2
- 108010079317 prolyl-tyrosine Proteins 0.000 description 2
- 108060006633 protein kinase Proteins 0.000 description 2
- 230000004850 protein–protein interaction Effects 0.000 description 2
- 230000003252 repetitive effect Effects 0.000 description 2
- 238000011160 research Methods 0.000 description 2
- 230000002441 reversible effect Effects 0.000 description 2
- FGDZQCVHDSGLHJ-UHFFFAOYSA-M rubidium chloride Chemical compound [Cl-].[Rb+] FGDZQCVHDSGLHJ-UHFFFAOYSA-M 0.000 description 2
- 150000003839 salts Chemical class 0.000 description 2
- 238000000926 separation method Methods 0.000 description 2
- 230000035939 shock Effects 0.000 description 2
- 238000002415 sodium dodecyl sulfate polyacrylamide gel electrophoresis Methods 0.000 description 2
- 239000007790 solid phase Substances 0.000 description 2
- 241000894007 species Species 0.000 description 2
- 239000007858 starting material Substances 0.000 description 2
- 230000004960 subcellular localization Effects 0.000 description 2
- 238000012360 testing method Methods 0.000 description 2
- 108091006106 transcriptional activators Proteins 0.000 description 2
- 230000032258 transport Effects 0.000 description 2
- 108010051110 tyrosyl-lysine Proteins 0.000 description 2
- 108010035579 valyl-tyrosyl-leucyl-prolyl-arginine Proteins 0.000 description 2
- PFTAWBLQPZVEMU-DZGCQCFKSA-N (+)-catechin Chemical compound C1([C@H]2OC3=CC(O)=CC(O)=C3C[C@@H]2O)=CC=C(O)C(O)=C1 PFTAWBLQPZVEMU-DZGCQCFKSA-N 0.000 description 1
- BRPMXFSTKXXNHF-IUCAKERBSA-N (2s)-1-[2-[[(2s)-pyrrolidine-2-carbonyl]amino]acetyl]pyrrolidine-2-carboxylic acid Chemical compound OC(=O)[C@@H]1CCCN1C(=O)CNC(=O)[C@H]1NCCC1 BRPMXFSTKXXNHF-IUCAKERBSA-N 0.000 description 1
- SUQWGICKJIJKNO-IHRRRGAJSA-N (2s)-2-[[2-[[(2s)-6-amino-2-[[(2s)-2,6-diaminohexanoyl]amino]hexanoyl]amino]acetyl]amino]pentanedioic acid Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)NCC(=O)N[C@@H](CCC(O)=O)C(O)=O SUQWGICKJIJKNO-IHRRRGAJSA-N 0.000 description 1
- HNSDLXPSAYFUHK-UHFFFAOYSA-N 1,4-bis(2-ethylhexyl) sulfosuccinate Chemical compound CCCCC(CC)COC(=O)CC(S(O)(=O)=O)C(=O)OCC(CC)CCCC HNSDLXPSAYFUHK-UHFFFAOYSA-N 0.000 description 1
- PPINMSZPTPRQQB-NHCYSSNCSA-N 2-[[(2s)-1-[(2s)-2-[[(2s)-2-amino-3-methylbutanoyl]amino]propanoyl]pyrrolidine-2-carbonyl]amino]acetic acid Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O PPINMSZPTPRQQB-NHCYSSNCSA-N 0.000 description 1
- OTEWWRBKGONZBW-UHFFFAOYSA-N 2-[[2-[[2-[(2-azaniumylacetyl)amino]-4-methylpentanoyl]amino]acetyl]amino]acetate Chemical compound NCC(=O)NC(CC(C)C)C(=O)NCC(=O)NCC(O)=O OTEWWRBKGONZBW-UHFFFAOYSA-N 0.000 description 1
- OSWFIVFLDKOXQC-UHFFFAOYSA-N 4-(3-methoxyphenyl)aniline Chemical compound COC1=CC=CC(C=2C=CC(N)=CC=2)=C1 OSWFIVFLDKOXQC-UHFFFAOYSA-N 0.000 description 1
- QFVHZQCOUORWEI-UHFFFAOYSA-N 4-[(4-anilino-5-sulfonaphthalen-1-yl)diazenyl]-5-hydroxynaphthalene-2,7-disulfonic acid Chemical compound C=12C(O)=CC(S(O)(=O)=O)=CC2=CC(S(O)(=O)=O)=CC=1N=NC(C1=CC=CC(=C11)S(O)(=O)=O)=CC=C1NC1=CC=CC=C1 QFVHZQCOUORWEI-UHFFFAOYSA-N 0.000 description 1
- 108020005029 5' Flanking Region Proteins 0.000 description 1
- 244000235603 Acacia catechu Species 0.000 description 1
- RLMISHABBKUNFO-WHFBIAKZSA-N Ala-Ala-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)NCC(O)=O RLMISHABBKUNFO-WHFBIAKZSA-N 0.000 description 1
- CXRCVCURMBFFOL-FXQIFTODSA-N Ala-Ala-Pro Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)N1CCC[C@H]1C(O)=O CXRCVCURMBFFOL-FXQIFTODSA-N 0.000 description 1
- ZFXQNADNEBRERM-BJDJZHNGSA-N Ala-Ala-Pro-Pro Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 ZFXQNADNEBRERM-BJDJZHNGSA-N 0.000 description 1
- YYSWCHMLFJLLBJ-ZLUOBGJFSA-N Ala-Ala-Ser Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O YYSWCHMLFJLLBJ-ZLUOBGJFSA-N 0.000 description 1
- UGLPMYSCWHTZQU-AUTRQRHGSA-N Ala-Ala-Tyr Chemical compound C[C@H]([NH3+])C(=O)N[C@@H](C)C(=O)N[C@H](C([O-])=O)CC1=CC=C(O)C=C1 UGLPMYSCWHTZQU-AUTRQRHGSA-N 0.000 description 1
- WRDANSJTFOHBPI-FXQIFTODSA-N Ala-Arg-Cys Chemical compound C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CS)C(=O)O)N WRDANSJTFOHBPI-FXQIFTODSA-N 0.000 description 1
- YWWATNIVMOCSAV-UBHSHLNASA-N Ala-Arg-Phe Chemical compound NC(=N)NCCC[C@H](NC(=O)[C@@H](N)C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 YWWATNIVMOCSAV-UBHSHLNASA-N 0.000 description 1
- UCIYCBSJBQGDGM-LPEHRKFASA-N Ala-Arg-Pro Chemical compound C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N1CCC[C@@H]1C(=O)O)N UCIYCBSJBQGDGM-LPEHRKFASA-N 0.000 description 1
- YAXNATKKPOWVCP-ZLUOBGJFSA-N Ala-Asn-Ala Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](C)C(O)=O YAXNATKKPOWVCP-ZLUOBGJFSA-N 0.000 description 1
- STACJSVFHSEZJV-GHCJXIJMSA-N Ala-Asn-Ile Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O STACJSVFHSEZJV-GHCJXIJMSA-N 0.000 description 1
- PBAMJJXWDQXOJA-FXQIFTODSA-N Ala-Asp-Arg Chemical compound C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CCCN=C(N)N PBAMJJXWDQXOJA-FXQIFTODSA-N 0.000 description 1
- WXERCAHAIKMTKX-ZLUOBGJFSA-N Ala-Asp-Asp Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O WXERCAHAIKMTKX-ZLUOBGJFSA-N 0.000 description 1
- MCKSLROAGSDNFC-ACZMJKKPSA-N Ala-Asp-Gln Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O MCKSLROAGSDNFC-ACZMJKKPSA-N 0.000 description 1
- WDIYWDJLXOCGRW-ACZMJKKPSA-N Ala-Asp-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O WDIYWDJLXOCGRW-ACZMJKKPSA-N 0.000 description 1
- GWFSQQNGMPGBEF-GHCJXIJMSA-N Ala-Asp-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](C)N GWFSQQNGMPGBEF-GHCJXIJMSA-N 0.000 description 1
- FOWHQTWRLFTELJ-FXQIFTODSA-N Ala-Asp-Met Chemical compound C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CCSC)C(=O)O)N FOWHQTWRLFTELJ-FXQIFTODSA-N 0.000 description 1
- BUDNAJYVCUHLSV-ZLUOBGJFSA-N Ala-Asp-Ser Chemical compound C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O BUDNAJYVCUHLSV-ZLUOBGJFSA-N 0.000 description 1
- IKKVASZHTMKJIR-ZKWXMUAHSA-N Ala-Asp-Val Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O IKKVASZHTMKJIR-ZKWXMUAHSA-N 0.000 description 1
- DECCMEWNXSNSDO-ZLUOBGJFSA-N Ala-Cys-Ala Chemical compound C[C@H](N)C(=O)N[C@@H](CS)C(=O)N[C@@H](C)C(O)=O DECCMEWNXSNSDO-ZLUOBGJFSA-N 0.000 description 1
- CXZFXHGJJPVUJE-CIUDSAMLSA-N Ala-Cys-Leu Chemical compound C[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(C)C)C(=O)O)N CXZFXHGJJPVUJE-CIUDSAMLSA-N 0.000 description 1
- MIPWEZAIMPYQST-FXQIFTODSA-N Ala-Cys-Val Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CS)C(=O)N[C@@H](C(C)C)C(O)=O MIPWEZAIMPYQST-FXQIFTODSA-N 0.000 description 1
- CXQODNIBUNQWAS-CIUDSAMLSA-N Ala-Gln-Arg Chemical compound C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@H](C(O)=O)CCCN=C(N)N CXQODNIBUNQWAS-CIUDSAMLSA-N 0.000 description 1
- CSAHOYQKNHGDHX-ACZMJKKPSA-N Ala-Gln-Asn Chemical compound C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O CSAHOYQKNHGDHX-ACZMJKKPSA-N 0.000 description 1
- NKJBKNVQHBZUIX-ACZMJKKPSA-N Ala-Gln-Asp Chemical compound C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O NKJBKNVQHBZUIX-ACZMJKKPSA-N 0.000 description 1
- RXTBLQVXNIECFP-FXQIFTODSA-N Ala-Gln-Gln Chemical compound C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O RXTBLQVXNIECFP-FXQIFTODSA-N 0.000 description 1
- FVSOUJZKYWEFOB-KBIXCLLPSA-N Ala-Gln-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](C)N FVSOUJZKYWEFOB-KBIXCLLPSA-N 0.000 description 1
- IXTPACPAXIOCRG-ACZMJKKPSA-N Ala-Glu-Cys Chemical compound C[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CS)C(=O)O)N IXTPACPAXIOCRG-ACZMJKKPSA-N 0.000 description 1
- HMRWQTHUDVXMGH-GUBZILKMSA-N Ala-Glu-Lys Chemical compound C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@H](C(O)=O)CCCCN HMRWQTHUDVXMGH-GUBZILKMSA-N 0.000 description 1
- FBHOPGDGELNWRH-DRZSPHRISA-N Ala-Glu-Phe Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O FBHOPGDGELNWRH-DRZSPHRISA-N 0.000 description 1
- VBRDBGCROKWTPV-XHNCKOQMSA-N Ala-Glu-Pro Chemical compound C[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N1CCC[C@@H]1C(=O)O)N VBRDBGCROKWTPV-XHNCKOQMSA-N 0.000 description 1
- OMMDTNGURYRDAC-NRPADANISA-N Ala-Glu-Val Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O OMMDTNGURYRDAC-NRPADANISA-N 0.000 description 1
- WGDNWOMKBUXFHR-BQBZGAKWSA-N Ala-Gly-Arg Chemical compound C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCCN=C(N)N WGDNWOMKBUXFHR-BQBZGAKWSA-N 0.000 description 1
- MPLOSMWGDNJSEV-WHFBIAKZSA-N Ala-Gly-Asp Chemical compound [H]N[C@@H](C)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(O)=O MPLOSMWGDNJSEV-WHFBIAKZSA-N 0.000 description 1
- WMYJZJRILUVVRG-WDSKDSINSA-N Ala-Gly-Gln Chemical compound C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCC(N)=O WMYJZJRILUVVRG-WDSKDSINSA-N 0.000 description 1
- BEMGNWZECGIJOI-WDSKDSINSA-N Ala-Gly-Glu Chemical compound [H]N[C@@H](C)C(=O)NCC(=O)N[C@@H](CCC(O)=O)C(O)=O BEMGNWZECGIJOI-WDSKDSINSA-N 0.000 description 1
- VGPWRRFOPXVGOH-BYPYZUCNSA-N Ala-Gly-Gly Chemical compound C[C@H](N)C(=O)NCC(=O)NCC(O)=O VGPWRRFOPXVGOH-BYPYZUCNSA-N 0.000 description 1
- BLIMFWGRQKRCGT-YUMQZZPRSA-N Ala-Gly-Lys Chemical compound C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCCCN BLIMFWGRQKRCGT-YUMQZZPRSA-N 0.000 description 1
- QHASENCZLDHBGX-ONGXEEELSA-N Ala-Gly-Phe Chemical compound C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 QHASENCZLDHBGX-ONGXEEELSA-N 0.000 description 1
- LTSBJNNXPBBNDT-HGNGGELXSA-N Ala-His-Gln Chemical compound N[C@@H](C)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCC(N)=O)C(=O)O LTSBJNNXPBBNDT-HGNGGELXSA-N 0.000 description 1
- KMGOBAQSCKTBGD-DLOVCJGASA-N Ala-His-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@H](C)N)CC1=CN=CN1 KMGOBAQSCKTBGD-DLOVCJGASA-N 0.000 description 1
- FAJIYNONGXEXAI-CQDKDKBSSA-N Ala-His-Phe Chemical compound C([C@H](NC(=O)[C@@H](N)C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CNC=N1 FAJIYNONGXEXAI-CQDKDKBSSA-N 0.000 description 1
- HUUOZYZWNCXTFK-INTQDDNPSA-N Ala-His-Pro Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N2CCC[C@@H]2C(=O)O)N HUUOZYZWNCXTFK-INTQDDNPSA-N 0.000 description 1
- GRIFPSOFWFIICX-GOPGUHFVSA-N Ala-His-Trp Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O GRIFPSOFWFIICX-GOPGUHFVSA-N 0.000 description 1
- NYDBKUNVSALYPX-NAKRPEOUSA-N Ala-Ile-Arg Chemical compound C[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@H](C(O)=O)CCCN=C(N)N NYDBKUNVSALYPX-NAKRPEOUSA-N 0.000 description 1
- TZDNWXDLYFIFPT-BJDJZHNGSA-N Ala-Ile-Leu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(C)C)C(O)=O TZDNWXDLYFIFPT-BJDJZHNGSA-N 0.000 description 1
- QCTFKEJEIMPOLW-JURCDPSOSA-N Ala-Ile-Phe Chemical compound C[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 QCTFKEJEIMPOLW-JURCDPSOSA-N 0.000 description 1
- LNNSWWRRYJLGNI-NAKRPEOUSA-N Ala-Ile-Val Chemical compound C[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C(C)C)C(O)=O LNNSWWRRYJLGNI-NAKRPEOUSA-N 0.000 description 1
- HHRAXZAYZFFRAM-CIUDSAMLSA-N Ala-Leu-Asn Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O HHRAXZAYZFFRAM-CIUDSAMLSA-N 0.000 description 1
- GHBSKQGCIYSCNS-NAKRPEOUSA-N Ala-Leu-Asp-Asp Chemical compound C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O GHBSKQGCIYSCNS-NAKRPEOUSA-N 0.000 description 1
- SUMYEVXWCAYLLJ-GUBZILKMSA-N Ala-Leu-Gln Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O SUMYEVXWCAYLLJ-GUBZILKMSA-N 0.000 description 1
- CCDFBRZVTDDJNM-GUBZILKMSA-N Ala-Leu-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O CCDFBRZVTDDJNM-GUBZILKMSA-N 0.000 description 1
- MNZHHDPWDWQJCQ-YUMQZZPRSA-N Ala-Leu-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O MNZHHDPWDWQJCQ-YUMQZZPRSA-N 0.000 description 1
- DPNZTBKGAUAZQU-DLOVCJGASA-N Ala-Leu-His Chemical compound C[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N DPNZTBKGAUAZQU-DLOVCJGASA-N 0.000 description 1
- ZKEHTYWGPMMGBC-XUXIUFHCSA-N Ala-Leu-Leu-Ser Chemical compound C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O ZKEHTYWGPMMGBC-XUXIUFHCSA-N 0.000 description 1
- UWIQWPWWZUHBAO-ZLIFDBKOSA-N Ala-Leu-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@@H](NC(=O)[C@H](C)N)CC(C)C)C(O)=O)=CNC2=C1 UWIQWPWWZUHBAO-ZLIFDBKOSA-N 0.000 description 1
- CHFFHQUVXHEGBY-GARJFASQSA-N Ala-Lys-Pro Chemical compound C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N1CCC[C@@H]1C(=O)O)N CHFFHQUVXHEGBY-GARJFASQSA-N 0.000 description 1
- XUCHENWTTBFODJ-FXQIFTODSA-N Ala-Met-Ala Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](C)C(O)=O XUCHENWTTBFODJ-FXQIFTODSA-N 0.000 description 1
- VHEVVUZDDUCAKU-FXQIFTODSA-N Ala-Met-Asp Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(O)=O)C(O)=O VHEVVUZDDUCAKU-FXQIFTODSA-N 0.000 description 1
- CJQAEJMHBAOQHA-DLOVCJGASA-N Ala-Phe-Asn Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(=O)N)C(=O)O)N CJQAEJMHBAOQHA-DLOVCJGASA-N 0.000 description 1
- BFMIRJBURUXDRG-DLOVCJGASA-N Ala-Phe-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)C)CC1=CC=CC=C1 BFMIRJBURUXDRG-DLOVCJGASA-N 0.000 description 1
- OSRZOHXQCUFIQG-FPMFFAJLSA-N Ala-Phe-Pro Chemical compound C([C@H](NC(=O)[C@@H]([NH3+])C)C(=O)N1[C@H](CCC1)C([O-])=O)C1=CC=CC=C1 OSRZOHXQCUFIQG-FPMFFAJLSA-N 0.000 description 1
- DXTYEWAQOXYRHZ-KKXDTOCCSA-N Ala-Phe-Tyr Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)O)N DXTYEWAQOXYRHZ-KKXDTOCCSA-N 0.000 description 1
- FQNILRVJOJBFFC-FXQIFTODSA-N Ala-Pro-Asp Chemical compound C[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(=O)O)C(=O)O)N FQNILRVJOJBFFC-FXQIFTODSA-N 0.000 description 1
- XAXHGSOBFPIRFG-LSJOCFKGSA-N Ala-Pro-His Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](Cc1cnc[nH]1)C(O)=O XAXHGSOBFPIRFG-LSJOCFKGSA-N 0.000 description 1
- DCVYRWFAMZFSDA-ZLUOBGJFSA-N Ala-Ser-Ala Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O DCVYRWFAMZFSDA-ZLUOBGJFSA-N 0.000 description 1
- VJVQKGYHIZPSNS-FXQIFTODSA-N Ala-Ser-Arg Chemical compound C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCCN=C(N)N VJVQKGYHIZPSNS-FXQIFTODSA-N 0.000 description 1
- KLALXKYLOMZDQT-ZLUOBGJFSA-N Ala-Ser-Asn Chemical compound C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC(N)=O KLALXKYLOMZDQT-ZLUOBGJFSA-N 0.000 description 1
- RMAWDDRDTRSZIR-ZLUOBGJFSA-N Ala-Ser-Asp Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O RMAWDDRDTRSZIR-ZLUOBGJFSA-N 0.000 description 1
- YYAVDNKUWLAFCV-ACZMJKKPSA-N Ala-Ser-Gln Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(O)=O YYAVDNKUWLAFCV-ACZMJKKPSA-N 0.000 description 1
- RTZCUEHYUQZIDE-WHFBIAKZSA-N Ala-Ser-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O RTZCUEHYUQZIDE-WHFBIAKZSA-N 0.000 description 1
- NHWYNIZWLJYZAG-XVYDVKMFSA-N Ala-Ser-His Chemical compound C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N NHWYNIZWLJYZAG-XVYDVKMFSA-N 0.000 description 1
- HOVPGJUNRLMIOZ-CIUDSAMLSA-N Ala-Ser-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@H](C)N HOVPGJUNRLMIOZ-CIUDSAMLSA-N 0.000 description 1
- OEVCHROQUIVQFZ-YTLHQDLWSA-N Ala-Thr-Ala Chemical compound C[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@@H](C)C(O)=O OEVCHROQUIVQFZ-YTLHQDLWSA-N 0.000 description 1
- HCBKAOZYACJUEF-XQXXSGGOSA-N Ala-Thr-Gln Chemical compound N[C@@H](C)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@@H](CCC(N)=O)C(=O)O HCBKAOZYACJUEF-XQXXSGGOSA-N 0.000 description 1
- WNHNMKOFKCHKKD-BFHQHQDPSA-N Ala-Thr-Gly Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O WNHNMKOFKCHKKD-BFHQHQDPSA-N 0.000 description 1
- IETUUAHKCHOQHP-KZVJFYERSA-N Ala-Thr-Val Chemical compound CC(C)[C@H](NC(=O)[C@@H](NC(=O)[C@H](C)N)[C@@H](C)O)C(O)=O IETUUAHKCHOQHP-KZVJFYERSA-N 0.000 description 1
- ZVWXMTTZJKBJCI-BHDSKKPTSA-N Ala-Trp-Ala Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@@H](N)C)C(=O)N[C@@H](C)C(O)=O)=CNC2=C1 ZVWXMTTZJKBJCI-BHDSKKPTSA-N 0.000 description 1
- PXAFZDXYEIIUTF-LKTVYLICSA-N Ala-Trp-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CCC(O)=O)C(O)=O PXAFZDXYEIIUTF-LKTVYLICSA-N 0.000 description 1
- PHQXWZGXKAFWAZ-ZLIFDBKOSA-N Ala-Trp-Lys Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@@H](N)C)C(=O)N[C@@H](CCCCN)C(O)=O)=CNC2=C1 PHQXWZGXKAFWAZ-ZLIFDBKOSA-N 0.000 description 1
- ZJLORAAXDAJLDC-CQDKDKBSSA-N Ala-Tyr-Leu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(C)C)C(O)=O ZJLORAAXDAJLDC-CQDKDKBSSA-N 0.000 description 1
- ZCUFMRIQCPNOHZ-NRPADANISA-N Ala-Val-Gln Chemical compound C[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N ZCUFMRIQCPNOHZ-NRPADANISA-N 0.000 description 1
- VHAQSYHSDKERBS-XPUUQOCRSA-N Ala-Val-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)NCC(O)=O VHAQSYHSDKERBS-XPUUQOCRSA-N 0.000 description 1
- NLYYHIKRBRMAJV-AEJSXWLSSA-N Ala-Val-Pro Chemical compound C[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N1CCC[C@@H]1C(=O)O)N NLYYHIKRBRMAJV-AEJSXWLSSA-N 0.000 description 1
- OMSKGWFGWCQFBD-KZVJFYERSA-N Ala-Val-Thr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O OMSKGWFGWCQFBD-KZVJFYERSA-N 0.000 description 1
- SSQHYGLFYWZWDV-UVBJJODRSA-N Ala-Val-Trp Chemical compound CC(C)[C@H](NC(=O)[C@H](C)N)C(=O)N[C@@H](Cc1c[nH]c2ccccc12)C(O)=O SSQHYGLFYWZWDV-UVBJJODRSA-N 0.000 description 1
- 108700028369 Alleles Proteins 0.000 description 1
- USFZMSVCRYTOJT-UHFFFAOYSA-N Ammonium acetate Chemical compound N.CC(O)=O USFZMSVCRYTOJT-UHFFFAOYSA-N 0.000 description 1
- 239000005695 Ammonium acetate Substances 0.000 description 1
- 241000203069 Archaea Species 0.000 description 1
- 235000006226 Areca catechu Nutrition 0.000 description 1
- SGYSTDWPNPKJPP-GUBZILKMSA-N Arg-Ala-Arg Chemical compound NC(=N)NCCC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O SGYSTDWPNPKJPP-GUBZILKMSA-N 0.000 description 1
- MCYJBCKCAPERSE-FXQIFTODSA-N Arg-Ala-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCN=C(N)N MCYJBCKCAPERSE-FXQIFTODSA-N 0.000 description 1
- GXCSUJQOECMKPV-CIUDSAMLSA-N Arg-Ala-Gln Chemical compound C[C@H](NC(=O)[C@@H](N)CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(O)=O GXCSUJQOECMKPV-CIUDSAMLSA-N 0.000 description 1
- PEFFAAKJGBZBKL-NAKRPEOUSA-N Arg-Ala-Ile Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O PEFFAAKJGBZBKL-NAKRPEOUSA-N 0.000 description 1
- GIVATXIGCXFQQA-FXQIFTODSA-N Arg-Ala-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCN=C(N)N GIVATXIGCXFQQA-FXQIFTODSA-N 0.000 description 1
- QEKBCDODJBBWHV-GUBZILKMSA-N Arg-Arg-Ala Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(O)=O QEKBCDODJBBWHV-GUBZILKMSA-N 0.000 description 1
- MUXONAMCEUBVGA-DCAQKATOSA-N Arg-Arg-Gln Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCC(N)=O)C(O)=O MUXONAMCEUBVGA-DCAQKATOSA-N 0.000 description 1
- BHSYMWWMVRPCPA-CYDGBPFRSA-N Arg-Arg-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@@H](N)CCCN=C(N)N BHSYMWWMVRPCPA-CYDGBPFRSA-N 0.000 description 1
- HJWQFFYRVFEWRM-SRVKXCTJSA-N Arg-Arg-Met Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCSC)C(O)=O HJWQFFYRVFEWRM-SRVKXCTJSA-N 0.000 description 1
- OVVUNXXROOFSIM-SDDRHHMPSA-N Arg-Arg-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CCCN=C(N)N)N)C(=O)O OVVUNXXROOFSIM-SDDRHHMPSA-N 0.000 description 1
- UISQLSIBJKEJSS-GUBZILKMSA-N Arg-Arg-Ser Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CO)C(O)=O UISQLSIBJKEJSS-GUBZILKMSA-N 0.000 description 1
- JTKLCCFLSLCCST-SZMVWBNQSA-N Arg-Arg-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CCCN=C(N)N)N)C(O)=O)=CNC2=C1 JTKLCCFLSLCCST-SZMVWBNQSA-N 0.000 description 1
- DCGLNNVKIZXQOJ-FXQIFTODSA-N Arg-Asn-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CCCN=C(N)N)N DCGLNNVKIZXQOJ-FXQIFTODSA-N 0.000 description 1
- NONSEUUPKITYQT-BQBZGAKWSA-N Arg-Asn-Gly Chemical compound C(C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)NCC(=O)O)N)CN=C(N)N NONSEUUPKITYQT-BQBZGAKWSA-N 0.000 description 1
- MAISCYVJLBBRNU-DCAQKATOSA-N Arg-Asn-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CCCN=C(N)N)N MAISCYVJLBBRNU-DCAQKATOSA-N 0.000 description 1
- OZNSCVPYWZRQPY-CIUDSAMLSA-N Arg-Asp-Glu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O OZNSCVPYWZRQPY-CIUDSAMLSA-N 0.000 description 1
- JSHVMZANPXCDTL-GMOBBJLQSA-N Arg-Asp-Ile Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O JSHVMZANPXCDTL-GMOBBJLQSA-N 0.000 description 1
- HKRXJBBCQBAGIM-FXQIFTODSA-N Arg-Asp-Ser Chemical compound C(C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CO)C(=O)O)N)CN=C(N)N HKRXJBBCQBAGIM-FXQIFTODSA-N 0.000 description 1
- YSUVMPICYVWRBX-VEVYYDQMSA-N Arg-Asp-Thr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O YSUVMPICYVWRBX-VEVYYDQMSA-N 0.000 description 1
- LLZXKVAAEWBUPB-KKUMJFAQSA-N Arg-Gln-Phe Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O LLZXKVAAEWBUPB-KKUMJFAQSA-N 0.000 description 1
- BEXGZLUHRXTZCC-CIUDSAMLSA-N Arg-Gln-Ser Chemical compound C(C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CO)C(=O)O)N)CN=C(N)N BEXGZLUHRXTZCC-CIUDSAMLSA-N 0.000 description 1
- YHQGEARSFILVHL-HJGDQZAQSA-N Arg-Gln-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCCN=C(N)N)N)O YHQGEARSFILVHL-HJGDQZAQSA-N 0.000 description 1
- NYZGVTGOMPHSJW-CIUDSAMLSA-N Arg-Glu-Cys Chemical compound C(C[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CS)C(=O)O)N)CN=C(N)N NYZGVTGOMPHSJW-CIUDSAMLSA-N 0.000 description 1
- MZRBYBIQTIKERR-GUBZILKMSA-N Arg-Glu-Gln Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O MZRBYBIQTIKERR-GUBZILKMSA-N 0.000 description 1
- PNQWAUXQDBIJDY-GUBZILKMSA-N Arg-Glu-Glu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O PNQWAUXQDBIJDY-GUBZILKMSA-N 0.000 description 1
- PBSOQGZLPFVXPU-YUMQZZPRSA-N Arg-Glu-Gly Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O PBSOQGZLPFVXPU-YUMQZZPRSA-N 0.000 description 1
- NKBQZKVMKJJDLX-SRVKXCTJSA-N Arg-Glu-Leu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O NKBQZKVMKJJDLX-SRVKXCTJSA-N 0.000 description 1
- SKTGPBFTMNLIHQ-KKUMJFAQSA-N Arg-Glu-Phe Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O SKTGPBFTMNLIHQ-KKUMJFAQSA-N 0.000 description 1
- RFXXUWGNVRJTNQ-QXEWZRGKSA-N Arg-Gly-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CCCN=C(N)N)N RFXXUWGNVRJTNQ-QXEWZRGKSA-N 0.000 description 1
- WVNFNPGXYADPPO-BQBZGAKWSA-N Arg-Gly-Ser Chemical compound NC(N)=NCCC[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O WVNFNPGXYADPPO-BQBZGAKWSA-N 0.000 description 1
- KRQSPVKUISQQFS-FJXKBIBVSA-N Arg-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CCCN=C(N)N KRQSPVKUISQQFS-FJXKBIBVSA-N 0.000 description 1
- JTZUZBADHGISJD-SRVKXCTJSA-N Arg-His-Glu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCC(O)=O)C(O)=O JTZUZBADHGISJD-SRVKXCTJSA-N 0.000 description 1
- MMGCRPZQZWTZTA-IHRRRGAJSA-N Arg-His-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CC2=CN=CN2)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N MMGCRPZQZWTZTA-IHRRRGAJSA-N 0.000 description 1
- UBCPNBUIQNMDNH-NAKRPEOUSA-N Arg-Ile-Ala Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C)C(O)=O UBCPNBUIQNMDNH-NAKRPEOUSA-N 0.000 description 1
- UZGFHWIJWPUPOH-IHRRRGAJSA-N Arg-Leu-Lys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N UZGFHWIJWPUPOH-IHRRRGAJSA-N 0.000 description 1
- JEOCWTUOMKEEMF-RHYQMDGZSA-N Arg-Leu-Thr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O JEOCWTUOMKEEMF-RHYQMDGZSA-N 0.000 description 1
- OGSQONVYSTZIJB-WDSOQIARSA-N Arg-Leu-Trp Chemical compound CC(C)C[C@H](NC(=O)[C@@H](N)CCCN=C(N)N)C(=O)N[C@@H](Cc1c[nH]c2ccccc12)C(O)=O OGSQONVYSTZIJB-WDSOQIARSA-N 0.000 description 1
- MJINRRBEMOLJAK-DCAQKATOSA-N Arg-Lys-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CCCN=C(N)N MJINRRBEMOLJAK-DCAQKATOSA-N 0.000 description 1
- BNYNOWJESJJIOI-XUXIUFHCSA-N Arg-Lys-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CCCN=C(N)N)N BNYNOWJESJJIOI-XUXIUFHCSA-N 0.000 description 1
- NPAVRDPEFVKELR-DCAQKATOSA-N Arg-Lys-Ser Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O NPAVRDPEFVKELR-DCAQKATOSA-N 0.000 description 1
- RIQBRKVTFBWEDY-RHYQMDGZSA-N Arg-Lys-Thr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(O)=O RIQBRKVTFBWEDY-RHYQMDGZSA-N 0.000 description 1
- VIINVRPKMUZYOI-DCAQKATOSA-N Arg-Met-Glu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCC(O)=O)C(O)=O VIINVRPKMUZYOI-DCAQKATOSA-N 0.000 description 1
- LCBSSOCDWUTQQV-SDDRHHMPSA-N Arg-Met-Pro Chemical compound CSCC[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N LCBSSOCDWUTQQV-SDDRHHMPSA-N 0.000 description 1
- INXWADWANGLMPJ-JYJNAYRXSA-N Arg-Phe-Arg Chemical compound NC(=N)NCCC[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CCCNC(N)=N)C(O)=O)CC1=CC=CC=C1 INXWADWANGLMPJ-JYJNAYRXSA-N 0.000 description 1
- YTMKMRSYXHBGER-IHRRRGAJSA-N Arg-Phe-Asn Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N YTMKMRSYXHBGER-IHRRRGAJSA-N 0.000 description 1
- LXMKTIZAGIBQRX-HRCADAONSA-N Arg-Phe-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=CC=C2)NC(=O)[C@H](CCCN=C(N)N)N)C(=O)O LXMKTIZAGIBQRX-HRCADAONSA-N 0.000 description 1
- PRLPSDIHSRITSF-UNQGMJICSA-N Arg-Phe-Thr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O PRLPSDIHSRITSF-UNQGMJICSA-N 0.000 description 1
- HGKHPCFTRQDHCU-IUCAKERBSA-N Arg-Pro-Gly Chemical compound NC(N)=NCCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O HGKHPCFTRQDHCU-IUCAKERBSA-N 0.000 description 1
- YFHATWYGAAXQCF-JYJNAYRXSA-N Arg-Pro-Phe Chemical compound NC(N)=NCCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 YFHATWYGAAXQCF-JYJNAYRXSA-N 0.000 description 1
- JOTRDIXZHNQYGP-DCAQKATOSA-N Arg-Ser-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CCCN=C(N)N)N JOTRDIXZHNQYGP-DCAQKATOSA-N 0.000 description 1
- JPAWCMXVNZPJLO-IHRRRGAJSA-N Arg-Ser-Phe Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O JPAWCMXVNZPJLO-IHRRRGAJSA-N 0.000 description 1
- ICRHGPYYXMWHIE-LPEHRKFASA-N Arg-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CCCN=C(N)N)N)C(=O)O ICRHGPYYXMWHIE-LPEHRKFASA-N 0.000 description 1
- UZSQXCMNUPKLCC-FJXKBIBVSA-N Arg-Thr-Gly Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O UZSQXCMNUPKLCC-FJXKBIBVSA-N 0.000 description 1
- YNSUUAOAFCVINY-OSUNSFLBSA-N Arg-Thr-Ile Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O YNSUUAOAFCVINY-OSUNSFLBSA-N 0.000 description 1
- INOIAEUXVVNJKA-XGEHTFHBSA-N Arg-Thr-Ser Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O INOIAEUXVVNJKA-XGEHTFHBSA-N 0.000 description 1
- ZPWMEWYQBWSGAO-ZJDVBMNYSA-N Arg-Thr-Thr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O ZPWMEWYQBWSGAO-ZJDVBMNYSA-N 0.000 description 1
- XOZYYXMHMIEJET-XIRDDKMYSA-N Arg-Trp-Glu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CCC(O)=O)C(O)=O XOZYYXMHMIEJET-XIRDDKMYSA-N 0.000 description 1
- QMQZYILAWUOLPV-JYJNAYRXSA-N Arg-Tyr-Arg Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CCCN=C(N)N)C(O)=O)CC1=CC=C(O)C=C1 QMQZYILAWUOLPV-JYJNAYRXSA-N 0.000 description 1
- QCTOLCVIGRLMQS-HRCADAONSA-N Arg-Tyr-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=C(C=C2)O)NC(=O)[C@H](CCCN=C(N)N)N)C(=O)O QCTOLCVIGRLMQS-HRCADAONSA-N 0.000 description 1
- KEZVOBAKAXHMOF-GUBZILKMSA-N Arg-Val-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CCCN=C(N)N KEZVOBAKAXHMOF-GUBZILKMSA-N 0.000 description 1
- PSUXEQYPYZLNER-QXEWZRGKSA-N Arg-Val-Asn Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O PSUXEQYPYZLNER-QXEWZRGKSA-N 0.000 description 1
- VYZBPPBKFCHCIS-WPRPVWTQSA-N Arg-Val-Gly Chemical compound OC(=O)CNC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CCCN=C(N)N VYZBPPBKFCHCIS-WPRPVWTQSA-N 0.000 description 1
- XEOXPCNONWHHSW-AVGNSLFASA-N Arg-Val-His Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N XEOXPCNONWHHSW-AVGNSLFASA-N 0.000 description 1
- WTUZDHWWGUQEKN-SRVKXCTJSA-N Arg-Val-Met Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCSC)C(O)=O WTUZDHWWGUQEKN-SRVKXCTJSA-N 0.000 description 1
- CPTXATAOUQJQRO-GUBZILKMSA-N Arg-Val-Ser Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O CPTXATAOUQJQRO-GUBZILKMSA-N 0.000 description 1
- ANAHQDPQQBDOBM-UHFFFAOYSA-N Arg-Val-Tyr Natural products CC(C)C(NC(=O)C(N)CCNC(=N)N)C(=O)NC(Cc1ccc(O)cc1)C(=O)O ANAHQDPQQBDOBM-UHFFFAOYSA-N 0.000 description 1
- QQEWINYJRFBLNN-DLOVCJGASA-N Asn-Ala-Phe Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 QQEWINYJRFBLNN-DLOVCJGASA-N 0.000 description 1
- VDCIPFYVCICPEC-FXQIFTODSA-N Asn-Arg-Ala Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(O)=O VDCIPFYVCICPEC-FXQIFTODSA-N 0.000 description 1
- LXTGAOAXPSJWOU-DCAQKATOSA-N Asn-Arg-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CC(=O)N)N LXTGAOAXPSJWOU-DCAQKATOSA-N 0.000 description 1
- PCKRJVZAQZWNKM-WHFBIAKZSA-N Asn-Asn-Gly Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O PCKRJVZAQZWNKM-WHFBIAKZSA-N 0.000 description 1
- XXAOXVBAWLMTDR-ZLUOBGJFSA-N Asn-Cys-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CC(=O)N)N XXAOXVBAWLMTDR-ZLUOBGJFSA-N 0.000 description 1
- XVAPVJNJGLWGCS-ACZMJKKPSA-N Asn-Glu-Asn Chemical compound C(CC(=O)O)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CC(=O)N)N XVAPVJNJGLWGCS-ACZMJKKPSA-N 0.000 description 1
- ASCGFDYEKSRNPL-CIUDSAMLSA-N Asn-Glu-Met Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCSC)C(O)=O ASCGFDYEKSRNPL-CIUDSAMLSA-N 0.000 description 1
- OLVIPTLKNSAYRJ-YUMQZZPRSA-N Asn-Gly-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CC(=O)N)N OLVIPTLKNSAYRJ-YUMQZZPRSA-N 0.000 description 1
- RAKKBBHMTJSXOY-XVYDVKMFSA-N Asn-His-Ala Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](C)C(O)=O RAKKBBHMTJSXOY-XVYDVKMFSA-N 0.000 description 1
- VXLBDJWTONZHJN-YUMQZZPRSA-N Asn-His-Gly Chemical compound C1=C(NC=N1)C[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CC(=O)N)N VXLBDJWTONZHJN-YUMQZZPRSA-N 0.000 description 1
- ACKNRKFVYUVWAC-ZPFDUUQYSA-N Asn-Ile-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC(=O)N)N ACKNRKFVYUVWAC-ZPFDUUQYSA-N 0.000 description 1
- PNHQRQTVBRDIEF-CIUDSAMLSA-N Asn-Leu-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC(=O)N)N PNHQRQTVBRDIEF-CIUDSAMLSA-N 0.000 description 1
- BXUHCIXDSWRSBS-CIUDSAMLSA-N Asn-Leu-Asp Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O BXUHCIXDSWRSBS-CIUDSAMLSA-N 0.000 description 1
- WIDVAWAQBRAKTI-YUMQZZPRSA-N Asn-Leu-Gly Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O WIDVAWAQBRAKTI-YUMQZZPRSA-N 0.000 description 1
- BZWRLDPIWKOVKB-ZPFDUUQYSA-N Asn-Leu-Ile Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O BZWRLDPIWKOVKB-ZPFDUUQYSA-N 0.000 description 1
- ALHMNHZJBYBYHS-DCAQKATOSA-N Asn-Lys-Arg Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O ALHMNHZJBYBYHS-DCAQKATOSA-N 0.000 description 1
- KHCNTVRVAYCPQE-CIUDSAMLSA-N Asn-Lys-Asn Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(O)=O KHCNTVRVAYCPQE-CIUDSAMLSA-N 0.000 description 1
- RZNAMKZJPBQWDJ-SRVKXCTJSA-N Asn-Lys-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CC(=O)N)N RZNAMKZJPBQWDJ-SRVKXCTJSA-N 0.000 description 1
- PPCORQFLAZWUNO-QWRGUYRKSA-N Asn-Phe-Gly Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CC(=O)N)N PPCORQFLAZWUNO-QWRGUYRKSA-N 0.000 description 1
- HPASIOLTWSNMFB-OLHMAJIHSA-N Asn-Thr-Asp Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(O)=O HPASIOLTWSNMFB-OLHMAJIHSA-N 0.000 description 1
- ZUFPUBYQYWCMDB-NUMRIWBASA-N Asn-Thr-Glu Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O ZUFPUBYQYWCMDB-NUMRIWBASA-N 0.000 description 1
- UPAGTDJAORYMEC-VHWLVUOQSA-N Asn-Trp-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H](CC(=O)N)N UPAGTDJAORYMEC-VHWLVUOQSA-N 0.000 description 1
- KRXIWXCXOARFNT-ZLUOBGJFSA-N Asp-Ala-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC(O)=O KRXIWXCXOARFNT-ZLUOBGJFSA-N 0.000 description 1
- UWMIZBCTVWVMFI-FXQIFTODSA-N Asp-Ala-Arg Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O UWMIZBCTVWVMFI-FXQIFTODSA-N 0.000 description 1
- PBVLJOIPOGUQQP-CIUDSAMLSA-N Asp-Ala-Leu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O PBVLJOIPOGUQQP-CIUDSAMLSA-N 0.000 description 1
- ZVTDYGWRRPMFCL-WFBYXXMGSA-N Asp-Ala-Trp Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)NC(=O)[C@H](CC(=O)O)N ZVTDYGWRRPMFCL-WFBYXXMGSA-N 0.000 description 1
- BLQBMRNMBAYREH-UWJYBYFXSA-N Asp-Ala-Tyr Chemical compound N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)O BLQBMRNMBAYREH-UWJYBYFXSA-N 0.000 description 1
- RGKKALNPOYURGE-ZKWXMUAHSA-N Asp-Ala-Val Chemical compound N[C@@H](CC(=O)O)C(=O)N[C@@H](C)C(=O)N[C@@H](C(C)C)C(=O)O RGKKALNPOYURGE-ZKWXMUAHSA-N 0.000 description 1
- GVPSCJQLUGIKAM-GUBZILKMSA-N Asp-Arg-Arg Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O GVPSCJQLUGIKAM-GUBZILKMSA-N 0.000 description 1
- SOYOSFXLXYZNRG-CIUDSAMLSA-N Asp-Arg-Gln Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(O)=O SOYOSFXLXYZNRG-CIUDSAMLSA-N 0.000 description 1
- MRQQMVZUHXUPEV-IHRRRGAJSA-N Asp-Arg-Phe Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O MRQQMVZUHXUPEV-IHRRRGAJSA-N 0.000 description 1
- FAEIQWHBRBWUBN-FXQIFTODSA-N Asp-Arg-Ser Chemical compound C(C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CC(=O)O)N)CN=C(N)N FAEIQWHBRBWUBN-FXQIFTODSA-N 0.000 description 1
- HTOZUYZQPICRAP-BPUTZDHNSA-N Asp-Arg-Trp Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CC(=O)O)N HTOZUYZQPICRAP-BPUTZDHNSA-N 0.000 description 1
- QRULNKJGYQQZMW-ZLUOBGJFSA-N Asp-Asn-Asp Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O QRULNKJGYQQZMW-ZLUOBGJFSA-N 0.000 description 1
- FANQWNCPNFEPGZ-WHFBIAKZSA-N Asp-Asp-Gly Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O FANQWNCPNFEPGZ-WHFBIAKZSA-N 0.000 description 1
- CELPEWWLSXMVPH-CIUDSAMLSA-N Asp-Asp-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CC(O)=O CELPEWWLSXMVPH-CIUDSAMLSA-N 0.000 description 1
- LKIYSIYBKYLKPU-BIIVOSGPSA-N Asp-Asp-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)O)NC(=O)[C@H](CC(=O)O)N)C(=O)O LKIYSIYBKYLKPU-BIIVOSGPSA-N 0.000 description 1
- QXHVOUSPVAWEMX-ZLUOBGJFSA-N Asp-Asp-Ser Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O QXHVOUSPVAWEMX-ZLUOBGJFSA-N 0.000 description 1
- BFOYULZBKYOKAN-OLHMAJIHSA-N Asp-Asp-Thr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O BFOYULZBKYOKAN-OLHMAJIHSA-N 0.000 description 1
- APYNREQHZOGYHV-ACZMJKKPSA-N Asp-Cys-Gln Chemical compound C(CC(=O)N)[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CC(=O)O)N APYNREQHZOGYHV-ACZMJKKPSA-N 0.000 description 1
- NYQHSUGFEWDWPD-ACZMJKKPSA-N Asp-Gln-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CC(=O)O)N NYQHSUGFEWDWPD-ACZMJKKPSA-N 0.000 description 1
- SNAWMGHSCHKSDK-GUBZILKMSA-N Asp-Gln-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CC(=O)O)N SNAWMGHSCHKSDK-GUBZILKMSA-N 0.000 description 1
- JRBVWZLHBGYZNY-QEJZJMRPSA-N Asp-Gln-Trp Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O JRBVWZLHBGYZNY-QEJZJMRPSA-N 0.000 description 1
- IJHUZMGJRGNXIW-CIUDSAMLSA-N Asp-Glu-Arg Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O IJHUZMGJRGNXIW-CIUDSAMLSA-N 0.000 description 1
- OVPHVTCDVYYTHN-AVGNSLFASA-N Asp-Glu-Phe Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 OVPHVTCDVYYTHN-AVGNSLFASA-N 0.000 description 1
- DTNUIAJCPRMNBT-WHFBIAKZSA-N Asp-Gly-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)NCC(=O)N[C@@H](C)C(O)=O DTNUIAJCPRMNBT-WHFBIAKZSA-N 0.000 description 1
- WBDWQKRLTVCDSY-WHFBIAKZSA-N Asp-Gly-Asp Chemical compound OC(=O)C[C@H](N)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(O)=O WBDWQKRLTVCDSY-WHFBIAKZSA-N 0.000 description 1
- HAFCJCDJGIOYPW-WDSKDSINSA-N Asp-Gly-Gln Chemical compound OC(=O)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCC(N)=O HAFCJCDJGIOYPW-WDSKDSINSA-N 0.000 description 1
- VIRHEUMYXXLCBF-WDSKDSINSA-N Asp-Gly-Glu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)NCC(=O)N[C@@H](CCC(O)=O)C(O)=O VIRHEUMYXXLCBF-WDSKDSINSA-N 0.000 description 1
- SNDBKTFJWVEVPO-WHFBIAKZSA-N Asp-Gly-Ser Chemical compound [H]N[C@@H](CC(O)=O)C(=O)NCC(=O)N[C@@H](CO)C(O)=O SNDBKTFJWVEVPO-WHFBIAKZSA-N 0.000 description 1
- CRNKLABLTICXDV-GUBZILKMSA-N Asp-His-Glu Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@H](CC(=O)O)N CRNKLABLTICXDV-GUBZILKMSA-N 0.000 description 1
- OOXKFYNWRVGYFM-XIRDDKMYSA-N Asp-His-Trp Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)O)NC(=O)[C@H](CC3=CN=CN3)NC(=O)[C@H](CC(=O)O)N OOXKFYNWRVGYFM-XIRDDKMYSA-N 0.000 description 1
- MFTVXYMXSAQZNL-DJFWLOJKSA-N Asp-Ile-His Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CC(=O)O)N MFTVXYMXSAQZNL-DJFWLOJKSA-N 0.000 description 1
- RTXQQDVBACBSCW-CFMVVWHZSA-N Asp-Ile-Tyr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O RTXQQDVBACBSCW-CFMVVWHZSA-N 0.000 description 1
- JNNVNVRBYUJYGS-CIUDSAMLSA-N Asp-Leu-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(O)=O JNNVNVRBYUJYGS-CIUDSAMLSA-N 0.000 description 1
- XLILXFRAKOYEJX-GUBZILKMSA-N Asp-Leu-Gln Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O XLILXFRAKOYEJX-GUBZILKMSA-N 0.000 description 1
- AYFVRYXNDHBECD-YUMQZZPRSA-N Asp-Leu-Gly Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O AYFVRYXNDHBECD-YUMQZZPRSA-N 0.000 description 1
- RQHLMGCXCZUOGT-ZPFDUUQYSA-N Asp-Leu-Ile Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O RQHLMGCXCZUOGT-ZPFDUUQYSA-N 0.000 description 1
- LBOVBQONZJRWPV-YUMQZZPRSA-N Asp-Lys-Gly Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)NCC(O)=O LBOVBQONZJRWPV-YUMQZZPRSA-N 0.000 description 1
- DPNWSMBUYCLEDG-CIUDSAMLSA-N Asp-Lys-Ser Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O DPNWSMBUYCLEDG-CIUDSAMLSA-N 0.000 description 1
- JXGJJQJHXHXJQF-CIUDSAMLSA-N Asp-Met-Glu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCC(O)=O)C(O)=O JXGJJQJHXHXJQF-CIUDSAMLSA-N 0.000 description 1
- RRUWMFBLFLUZSI-LPEHRKFASA-N Asp-Met-Pro Chemical compound CSCC[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC(=O)O)N RRUWMFBLFLUZSI-LPEHRKFASA-N 0.000 description 1
- DJCAHYVLMSRBFR-QXEWZRGKSA-N Asp-Met-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](CCSC)NC(=O)[C@@H](N)CC(O)=O DJCAHYVLMSRBFR-QXEWZRGKSA-N 0.000 description 1
- GPPIDDWYKJPRES-YDHLFZDLSA-N Asp-Phe-Val Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](C(C)C)C(O)=O GPPIDDWYKJPRES-YDHLFZDLSA-N 0.000 description 1
- ZKAOJVJQGVUIIU-GUBZILKMSA-N Asp-Pro-Arg Chemical compound OC(=O)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(O)=O ZKAOJVJQGVUIIU-GUBZILKMSA-N 0.000 description 1
- HICVMZCGVFKTPM-BQBZGAKWSA-N Asp-Pro-Gly Chemical compound OC(=O)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O HICVMZCGVFKTPM-BQBZGAKWSA-N 0.000 description 1
- XUVTWGPERWIERB-IHRRRGAJSA-N Asp-Pro-Phe Chemical compound N[C@@H](CC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](Cc1ccccc1)C(O)=O XUVTWGPERWIERB-IHRRRGAJSA-N 0.000 description 1
- DINOVZWPTMGSRF-QXEWZRGKSA-N Asp-Pro-Val Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(O)=O DINOVZWPTMGSRF-QXEWZRGKSA-N 0.000 description 1
- ZBYLEBZCVKLPCY-FXQIFTODSA-N Asp-Ser-Arg Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O ZBYLEBZCVKLPCY-FXQIFTODSA-N 0.000 description 1
- KGHLGJAXYSVNJP-WHFBIAKZSA-N Asp-Ser-Gly Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O KGHLGJAXYSVNJP-WHFBIAKZSA-N 0.000 description 1
- NBKLEMWHDLAUEM-CIUDSAMLSA-N Asp-Ser-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CC(=O)O)N NBKLEMWHDLAUEM-CIUDSAMLSA-N 0.000 description 1
- HRVQDZOWMLFAOD-BIIVOSGPSA-N Asp-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CC(=O)O)N)C(=O)O HRVQDZOWMLFAOD-BIIVOSGPSA-N 0.000 description 1
- MNQMTYSEKZHIDF-GCJQMDKQSA-N Asp-Thr-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O MNQMTYSEKZHIDF-GCJQMDKQSA-N 0.000 description 1
- IWLZBRTUIVXZJD-OLHMAJIHSA-N Asp-Thr-Asp Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(O)=O IWLZBRTUIVXZJD-OLHMAJIHSA-N 0.000 description 1
- JJQGZGOEDSSHTE-FOHZUACHSA-N Asp-Thr-Gly Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O JJQGZGOEDSSHTE-FOHZUACHSA-N 0.000 description 1
- PDIYGFYAMZZFCW-JIOCBJNQSA-N Asp-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC(=O)O)N)O PDIYGFYAMZZFCW-JIOCBJNQSA-N 0.000 description 1
- RSMZEHCMIOKNMW-GSSVUCPTSA-N Asp-Thr-Thr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O RSMZEHCMIOKNMW-GSSVUCPTSA-N 0.000 description 1
- KCOPOPKJRHVGPE-AQZXSJQPSA-N Asp-Thr-Trp Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O KCOPOPKJRHVGPE-AQZXSJQPSA-N 0.000 description 1
- XOASPVGNFAMYBD-WFBYXXMGSA-N Asp-Trp-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](C)C(O)=O XOASPVGNFAMYBD-WFBYXXMGSA-N 0.000 description 1
- KACWACLNYLSVCA-VHWLVUOQSA-N Asp-Trp-Ile Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O KACWACLNYLSVCA-VHWLVUOQSA-N 0.000 description 1
- ZVYYMCXVPZEAPU-CWRNSKLLSA-N Asp-Trp-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CNC3=CC=CC=C32)NC(=O)[C@H](CC(=O)O)N)C(=O)O ZVYYMCXVPZEAPU-CWRNSKLLSA-N 0.000 description 1
- WAEDSQFVZJUHLI-BYULHYEWSA-N Asp-Val-Asp Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O WAEDSQFVZJUHLI-BYULHYEWSA-N 0.000 description 1
- XWKPSMRPIKKDDU-RCOVLWMOSA-N Asp-Val-Gly Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)NCC(O)=O XWKPSMRPIKKDDU-RCOVLWMOSA-N 0.000 description 1
- RKXVTTIQNKPCHU-KKHAAJSZSA-N Asp-Val-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CC(O)=O RKXVTTIQNKPCHU-KKHAAJSZSA-N 0.000 description 1
- 241000972773 Aulopiformes Species 0.000 description 1
- 101000583080 Bunodosoma granuliferum Delta-actitoxin-Bgr2a Proteins 0.000 description 1
- 101710149870 C-C chemokine receptor type 5 Proteins 0.000 description 1
- 102100035875 C-C chemokine receptor type 5 Human genes 0.000 description 1
- 101100098985 Caenorhabditis elegans cct-3 gene Proteins 0.000 description 1
- OYPRJOBELJOOCE-UHFFFAOYSA-N Calcium Chemical compound [Ca] OYPRJOBELJOOCE-UHFFFAOYSA-N 0.000 description 1
- 108010051109 Cell-Penetrating Peptides Proteins 0.000 description 1
- 102000020313 Cell-Penetrating Peptides Human genes 0.000 description 1
- 108091026890 Coding region Proteins 0.000 description 1
- 108020004394 Complementary RNA Proteins 0.000 description 1
- NOCCABSVTRONIN-CIUDSAMLSA-N Cys-Ala-Leu Chemical compound C[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)O)NC(=O)[C@H](CS)N NOCCABSVTRONIN-CIUDSAMLSA-N 0.000 description 1
- NLCZGISONIGRQP-DCAQKATOSA-N Cys-Arg-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CS)N NLCZGISONIGRQP-DCAQKATOSA-N 0.000 description 1
- YRKJQKATZOTUEN-ACZMJKKPSA-N Cys-Gln-Cys Chemical compound C(CC(=O)N)[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CS)N YRKJQKATZOTUEN-ACZMJKKPSA-N 0.000 description 1
- AVFGSUXQKHIQJS-QEJZJMRPSA-N Cys-Gln-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](CS)N)C(O)=O)=CNC2=C1 AVFGSUXQKHIQJS-QEJZJMRPSA-N 0.000 description 1
- DZLQXIFVQFTFJY-BYPYZUCNSA-N Cys-Gly-Gly Chemical compound SC[C@H](N)C(=O)NCC(=O)NCC(O)=O DZLQXIFVQFTFJY-BYPYZUCNSA-N 0.000 description 1
- SSNJZBGOMNLSLA-CIUDSAMLSA-N Cys-Leu-Asn Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O SSNJZBGOMNLSLA-CIUDSAMLSA-N 0.000 description 1
- OHLLDUNVMPPUMD-DCAQKATOSA-N Cys-Leu-Val Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](C(C)C)C(=O)O)NC(=O)[C@H](CS)N OHLLDUNVMPPUMD-DCAQKATOSA-N 0.000 description 1
- DQUWSUWXPWGTQT-DCAQKATOSA-N Cys-Pro-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CS DQUWSUWXPWGTQT-DCAQKATOSA-N 0.000 description 1
- BCFXQBXXDSEHRS-FXQIFTODSA-N Cys-Ser-Arg Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O BCFXQBXXDSEHRS-FXQIFTODSA-N 0.000 description 1
- GGRDJANMZPGMNS-CIUDSAMLSA-N Cys-Ser-Leu Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O GGRDJANMZPGMNS-CIUDSAMLSA-N 0.000 description 1
- IRDBEBCCTCNXGZ-AVGNSLFASA-N Cys-Tyr-Gln Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CS)N)O IRDBEBCCTCNXGZ-AVGNSLFASA-N 0.000 description 1
- OEDPLIBVQGRKGZ-AVGNSLFASA-N Cys-Tyr-Glu Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(O)=O)C(O)=O OEDPLIBVQGRKGZ-AVGNSLFASA-N 0.000 description 1
- 102000004594 DNA Polymerase I Human genes 0.000 description 1
- 108010017826 DNA Polymerase I Proteins 0.000 description 1
- 230000033616 DNA repair Effects 0.000 description 1
- 230000006820 DNA synthesis Effects 0.000 description 1
- 206010013457 Dissociation Diseases 0.000 description 1
- 241000196324 Embryophyta Species 0.000 description 1
- 108010067770 Endopeptidase K Proteins 0.000 description 1
- 102100030011 Endoribonuclease Human genes 0.000 description 1
- 108010093099 Endoribonucleases Proteins 0.000 description 1
- 101100273257 Escherichia coli (strain K12) casE gene Proteins 0.000 description 1
- 101100326871 Escherichia coli (strain K12) ygbF gene Proteins 0.000 description 1
- 101100438439 Escherichia coli (strain K12) ygbT gene Proteins 0.000 description 1
- 101000763865 Escherichia phage lambda Tip attachment protein J Proteins 0.000 description 1
- 241000206602 Eukaryota Species 0.000 description 1
- 108010007577 Exodeoxyribonuclease I Proteins 0.000 description 1
- 102100029075 Exonuclease 1 Human genes 0.000 description 1
- INKFLNZBTSNFON-CIUDSAMLSA-N Gln-Ala-Arg Chemical compound NC(=O)CC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O INKFLNZBTSNFON-CIUDSAMLSA-N 0.000 description 1
- KVYVOGYEMPEXBT-GUBZILKMSA-N Gln-Ala-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCC(N)=O KVYVOGYEMPEXBT-GUBZILKMSA-N 0.000 description 1
- MLZRSFQRBDNJON-GUBZILKMSA-N Gln-Ala-Lys Chemical compound C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCC(=O)N)N MLZRSFQRBDNJON-GUBZILKMSA-N 0.000 description 1
- JSYULGSPLTZDHM-NRPADANISA-N Gln-Ala-Val Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](C(C)C)C(O)=O JSYULGSPLTZDHM-NRPADANISA-N 0.000 description 1
- XOKGKOQWADCLFQ-GARJFASQSA-N Gln-Arg-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CCC(=O)N)N)C(=O)O XOKGKOQWADCLFQ-GARJFASQSA-N 0.000 description 1
- MQANCSUBSBJNLU-KKUMJFAQSA-N Gln-Arg-Tyr Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O MQANCSUBSBJNLU-KKUMJFAQSA-N 0.000 description 1
- LJEPDHWNQXPXMM-NHCYSSNCSA-N Gln-Arg-Val Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C(C)C)C(O)=O LJEPDHWNQXPXMM-NHCYSSNCSA-N 0.000 description 1
- GMGKDVVBSVVKCT-NUMRIWBASA-N Gln-Asn-Thr Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O GMGKDVVBSVVKCT-NUMRIWBASA-N 0.000 description 1
- CYTSBCIIEHUPDU-ACZMJKKPSA-N Gln-Asp-Ala Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(O)=O CYTSBCIIEHUPDU-ACZMJKKPSA-N 0.000 description 1
- RKAQZCDMSUQTSS-FXQIFTODSA-N Gln-Asp-Gln Chemical compound C(CC(=O)N)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N RKAQZCDMSUQTSS-FXQIFTODSA-N 0.000 description 1
- IKDOHQHEFPPGJG-FXQIFTODSA-N Gln-Asp-Glu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O IKDOHQHEFPPGJG-FXQIFTODSA-N 0.000 description 1
- KZEUVLLVULIPNX-GUBZILKMSA-N Gln-Asp-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CCC(=O)N)N KZEUVLLVULIPNX-GUBZILKMSA-N 0.000 description 1
- UZMWDBOHAOSCCH-ACZMJKKPSA-N Gln-Cys-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CS)NC(=O)[C@@H](N)CCC(N)=O UZMWDBOHAOSCCH-ACZMJKKPSA-N 0.000 description 1
- LPYPANUXJGFMGV-FXQIFTODSA-N Gln-Gln-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCC(=O)N)N LPYPANUXJGFMGV-FXQIFTODSA-N 0.000 description 1
- AJDMYLOISOCHHC-YVNDNENWSA-N Gln-Gln-Ile Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O AJDMYLOISOCHHC-YVNDNENWSA-N 0.000 description 1
- GHYJGDCPHMSFEJ-GUBZILKMSA-N Gln-Gln-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCC(=O)N)N GHYJGDCPHMSFEJ-GUBZILKMSA-N 0.000 description 1
- RBWKVOSARCFSQQ-FXQIFTODSA-N Gln-Gln-Ser Chemical compound NC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O RBWKVOSARCFSQQ-FXQIFTODSA-N 0.000 description 1
- BLOXULLYFRGYKZ-GUBZILKMSA-N Gln-Glu-Arg Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O BLOXULLYFRGYKZ-GUBZILKMSA-N 0.000 description 1
- MAGNEQBFSBREJL-DCAQKATOSA-N Gln-Glu-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CCC(=O)N)N MAGNEQBFSBREJL-DCAQKATOSA-N 0.000 description 1
- VSXBYIJUAXPAAL-WDSKDSINSA-N Gln-Gly-Ala Chemical compound OC(=O)[C@H](C)NC(=O)CNC(=O)[C@@H](N)CCC(N)=O VSXBYIJUAXPAAL-WDSKDSINSA-N 0.000 description 1
- XKBASPWPBXNVLQ-WDSKDSINSA-N Gln-Gly-Asn Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)NCC(=O)N[C@@H](CC(N)=O)C(O)=O XKBASPWPBXNVLQ-WDSKDSINSA-N 0.000 description 1
- SMLDOQHTOAAFJQ-WDSKDSINSA-N Gln-Gly-Ser Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)NCC(=O)N[C@@H](CO)C(O)=O SMLDOQHTOAAFJQ-WDSKDSINSA-N 0.000 description 1
- NXPXQIZKDOXIHH-JSGCOSHPSA-N Gln-Gly-Trp Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CCC(=O)N)N NXPXQIZKDOXIHH-JSGCOSHPSA-N 0.000 description 1
- ORYMMTRPKVTGSJ-XVKPBYJWSA-N Gln-Gly-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CCC(N)=O ORYMMTRPKVTGSJ-XVKPBYJWSA-N 0.000 description 1
- VZRAXPGTUNDIDK-GUBZILKMSA-N Gln-Leu-Asn Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CCC(=O)N)N VZRAXPGTUNDIDK-GUBZILKMSA-N 0.000 description 1
- YPMDZWPZFOZYFG-GUBZILKMSA-N Gln-Leu-Ser Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O YPMDZWPZFOZYFG-GUBZILKMSA-N 0.000 description 1
- TWIAMTNJOMRDAK-GUBZILKMSA-N Gln-Lys-Asp Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(O)=O TWIAMTNJOMRDAK-GUBZILKMSA-N 0.000 description 1
- FKXCBKCOSVIGCT-AVGNSLFASA-N Gln-Lys-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(O)=O FKXCBKCOSVIGCT-AVGNSLFASA-N 0.000 description 1
- LVRKAFPPFJRIOF-GARJFASQSA-N Gln-Met-Pro Chemical compound CSCC[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCC(=O)N)N LVRKAFPPFJRIOF-GARJFASQSA-N 0.000 description 1
- JNVGVECJCOZHCN-DRZSPHRISA-N Gln-Phe-Ala Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](C)C(O)=O JNVGVECJCOZHCN-DRZSPHRISA-N 0.000 description 1
- QBEWLBKBGXVVPD-RYUDHWBXSA-N Gln-Phe-Gly Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CCC(=O)N)N QBEWLBKBGXVVPD-RYUDHWBXSA-N 0.000 description 1
- XUMFMAVDHQDATI-DCAQKATOSA-N Gln-Pro-Arg Chemical compound NC(=O)CC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCN=C(N)N)C(O)=O XUMFMAVDHQDATI-DCAQKATOSA-N 0.000 description 1
- HMIXCETWRYDVMO-GUBZILKMSA-N Gln-Pro-Glu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O HMIXCETWRYDVMO-GUBZILKMSA-N 0.000 description 1
- FQCILXROGNOZON-YUMQZZPRSA-N Gln-Pro-Gly Chemical compound NC(=O)CC[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O FQCILXROGNOZON-YUMQZZPRSA-N 0.000 description 1
- DCWNCMRZIZSZBL-KKUMJFAQSA-N Gln-Pro-Tyr Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CCC(=O)N)N)C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)O DCWNCMRZIZSZBL-KKUMJFAQSA-N 0.000 description 1
- LGWNISYVKDNJRP-FXQIFTODSA-N Gln-Ser-Gln Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(O)=O LGWNISYVKDNJRP-FXQIFTODSA-N 0.000 description 1
- SYZZMPFLOLSMHL-XHNCKOQMSA-N Gln-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CCC(=O)N)N)C(=O)O SYZZMPFLOLSMHL-XHNCKOQMSA-N 0.000 description 1
- NHMRJKKAVMENKJ-WDCWCFNPSA-N Gln-Thr-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O NHMRJKKAVMENKJ-WDCWCFNPSA-N 0.000 description 1
- ARYKRXHBIPLULY-XKBZYTNZSA-N Gln-Thr-Ser Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O ARYKRXHBIPLULY-XKBZYTNZSA-N 0.000 description 1
- STHSGOZLFLFGSS-SUSMZKCASA-N Gln-Thr-Thr Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O STHSGOZLFLFGSS-SUSMZKCASA-N 0.000 description 1
- HLRLXVPRJJITSK-IFFSRLJSSA-N Gln-Thr-Val Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O HLRLXVPRJJITSK-IFFSRLJSSA-N 0.000 description 1
- RBSKVTZUFMIWFU-XEGUGMAKSA-N Gln-Trp-Ala Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](C)C(O)=O RBSKVTZUFMIWFU-XEGUGMAKSA-N 0.000 description 1
- IIMZHVKZBGSEKZ-SZMVWBNQSA-N Gln-Trp-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CC(C)C)C(O)=O IIMZHVKZBGSEKZ-SZMVWBNQSA-N 0.000 description 1
- VCUNGPMMPNJSGS-JYJNAYRXSA-N Gln-Tyr-Lys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCC(=O)N)N)O VCUNGPMMPNJSGS-JYJNAYRXSA-N 0.000 description 1
- HGBHRZBXOOHRDH-JBACZVJFSA-N Gln-Tyr-Trp Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O HGBHRZBXOOHRDH-JBACZVJFSA-N 0.000 description 1
- OACPJRQRAHMQEQ-NHCYSSNCSA-N Gln-Val-Arg Chemical compound NC(=O)CC[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O OACPJRQRAHMQEQ-NHCYSSNCSA-N 0.000 description 1
- BBFCMGBMYIAGRS-AUTRQRHGSA-N Gln-Val-Glu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O BBFCMGBMYIAGRS-AUTRQRHGSA-N 0.000 description 1
- MKRDNSWGJWTBKZ-GVXVVHGQSA-N Gln-Val-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCC(=O)N)N MKRDNSWGJWTBKZ-GVXVVHGQSA-N 0.000 description 1
- VYOILACOFPPNQH-UMNHJUIQSA-N Gln-Val-Pro Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCC(=O)N)N VYOILACOFPPNQH-UMNHJUIQSA-N 0.000 description 1
- RUFHOVYUYSNDNY-ACZMJKKPSA-N Glu-Ala-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCC(O)=O RUFHOVYUYSNDNY-ACZMJKKPSA-N 0.000 description 1
- WZZSKAJIHTUUSG-ACZMJKKPSA-N Glu-Ala-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCC(O)=O WZZSKAJIHTUUSG-ACZMJKKPSA-N 0.000 description 1
- UTKUTMJSWKKHEM-WDSKDSINSA-N Glu-Ala-Gly Chemical compound OC(=O)CNC(=O)[C@H](C)NC(=O)[C@@H](N)CCC(O)=O UTKUTMJSWKKHEM-WDSKDSINSA-N 0.000 description 1
- BPDVTFBJZNBHEU-HGNGGELXSA-N Glu-Ala-His Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CN=CN1 BPDVTFBJZNBHEU-HGNGGELXSA-N 0.000 description 1
- RSUVOPBMWMTVDI-XEGUGMAKSA-N Glu-Ala-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@@H](NC(=O)[C@@H](N)CCC(O)=O)C)C(O)=O)=CNC2=C1 RSUVOPBMWMTVDI-XEGUGMAKSA-N 0.000 description 1
- KKCUFHUTMKQQCF-SRVKXCTJSA-N Glu-Arg-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(O)=O KKCUFHUTMKQQCF-SRVKXCTJSA-N 0.000 description 1
- VPKBCVUDBNINAH-GARJFASQSA-N Glu-Arg-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CCC(=O)O)N)C(=O)O VPKBCVUDBNINAH-GARJFASQSA-N 0.000 description 1
- SYDJILXOZNEEDK-XIRDDKMYSA-N Glu-Arg-Trp Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O SYDJILXOZNEEDK-XIRDDKMYSA-N 0.000 description 1
- GCYFUZJHAXJKKE-KKUMJFAQSA-N Glu-Arg-Tyr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O GCYFUZJHAXJKKE-KKUMJFAQSA-N 0.000 description 1
- GLWXKFRTOHKGIT-ACZMJKKPSA-N Glu-Asn-Asn Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O GLWXKFRTOHKGIT-ACZMJKKPSA-N 0.000 description 1
- MLCPTRRNICEKIS-FXQIFTODSA-N Glu-Asn-Gln Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O MLCPTRRNICEKIS-FXQIFTODSA-N 0.000 description 1
- RDPOETHPAQEGDP-ACZMJKKPSA-N Glu-Asp-Ala Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(O)=O RDPOETHPAQEGDP-ACZMJKKPSA-N 0.000 description 1
- JVSBYEDSSRZQGV-GUBZILKMSA-N Glu-Asp-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CCC(O)=O JVSBYEDSSRZQGV-GUBZILKMSA-N 0.000 description 1
- CYHBMLHCQXXCCT-AVGNSLFASA-N Glu-Asp-Tyr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O CYHBMLHCQXXCCT-AVGNSLFASA-N 0.000 description 1
- OXEMJGCAJFFREE-FXQIFTODSA-N Glu-Gln-Ala Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(O)=O OXEMJGCAJFFREE-FXQIFTODSA-N 0.000 description 1
- YSPJWDABFLRKDK-QAETUUGQSA-N Glu-Gln-Gln-Tyr Chemical compound N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](Cc1ccc(O)cc1)C(O)=O YSPJWDABFLRKDK-QAETUUGQSA-N 0.000 description 1
- PVBBEKPHARMPHX-DCAQKATOSA-N Glu-Gln-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](N)CCC(O)=O PVBBEKPHARMPHX-DCAQKATOSA-N 0.000 description 1
- MIQCYAJSDGNCNK-BPUTZDHNSA-N Glu-Gln-Trp Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O MIQCYAJSDGNCNK-BPUTZDHNSA-N 0.000 description 1
- QQLBPVKLJBAXBS-FXQIFTODSA-N Glu-Glu-Asn Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O QQLBPVKLJBAXBS-FXQIFTODSA-N 0.000 description 1
- NKLRYVLERDYDBI-FXQIFTODSA-N Glu-Glu-Asp Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O NKLRYVLERDYDBI-FXQIFTODSA-N 0.000 description 1
- PHONAZGUEGIOEM-GLLZPBPUSA-N Glu-Glu-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O PHONAZGUEGIOEM-GLLZPBPUSA-N 0.000 description 1
- BUAKRRKDHSSIKK-IHRRRGAJSA-N Glu-Glu-Tyr Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 BUAKRRKDHSSIKK-IHRRRGAJSA-N 0.000 description 1
- LRPXYSGPOBVBEH-IUCAKERBSA-N Glu-Gly-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)NCC(=O)N[C@@H](CC(C)C)C(O)=O LRPXYSGPOBVBEH-IUCAKERBSA-N 0.000 description 1
- VOORMNJKNBGYGK-YUMQZZPRSA-N Glu-Gly-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CCC(=O)O)N VOORMNJKNBGYGK-YUMQZZPRSA-N 0.000 description 1
- ZWQVYZXPYSYPJD-RYUDHWBXSA-N Glu-Gly-Phe Chemical compound OC(=O)CC[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 ZWQVYZXPYSYPJD-RYUDHWBXSA-N 0.000 description 1
- RAUDKMVXNOWDLS-WDSKDSINSA-N Glu-Gly-Ser Chemical compound OC(=O)CC[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O RAUDKMVXNOWDLS-WDSKDSINSA-N 0.000 description 1
- BRKUZSLQMPNVFN-SRVKXCTJSA-N Glu-His-Arg Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O BRKUZSLQMPNVFN-SRVKXCTJSA-N 0.000 description 1
- GXMXPCXXKVWOSM-KQXIARHKSA-N Glu-Ile-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCC(=O)O)N GXMXPCXXKVWOSM-KQXIARHKSA-N 0.000 description 1
- INGJLBQKTRJLFO-UKJIMTQDSA-N Glu-Ile-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H](N)CCC(O)=O INGJLBQKTRJLFO-UKJIMTQDSA-N 0.000 description 1
- VMKCPNBBPGGQBJ-GUBZILKMSA-N Glu-Leu-Asn Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CCC(=O)O)N VMKCPNBBPGGQBJ-GUBZILKMSA-N 0.000 description 1
- IRXNJYPKBVERCW-DCAQKATOSA-N Glu-Leu-Glu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O IRXNJYPKBVERCW-DCAQKATOSA-N 0.000 description 1
- UGSVSNXPJJDJKL-SDDRHHMPSA-N Glu-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCC(=O)O)N UGSVSNXPJJDJKL-SDDRHHMPSA-N 0.000 description 1
- JJSVALISDCNFCU-SZMVWBNQSA-N Glu-Leu-Trp Chemical compound CC(C)C[C@H](NC(=O)[C@@H](N)CCC(O)=O)C(=O)N[C@@H](Cc1c[nH]c2ccccc12)C(O)=O JJSVALISDCNFCU-SZMVWBNQSA-N 0.000 description 1
- OQXDUSZKISQQSS-GUBZILKMSA-N Glu-Lys-Ala Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(O)=O OQXDUSZKISQQSS-GUBZILKMSA-N 0.000 description 1
- BCYGDJXHAGZNPQ-DCAQKATOSA-N Glu-Lys-Glu Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(O)=O BCYGDJXHAGZNPQ-DCAQKATOSA-N 0.000 description 1
- XNOWYPDMSLSRKP-GUBZILKMSA-N Glu-Met-Gln Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCC(N)=O)C(O)=O XNOWYPDMSLSRKP-GUBZILKMSA-N 0.000 description 1
- JHSRJMUJOGLIHK-GUBZILKMSA-N Glu-Met-Glu Chemical compound CSCC[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@H](CCC(=O)O)N JHSRJMUJOGLIHK-GUBZILKMSA-N 0.000 description 1
- FGSGPLRPQCZBSQ-AVGNSLFASA-N Glu-Phe-Ser Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(O)=O FGSGPLRPQCZBSQ-AVGNSLFASA-N 0.000 description 1
- QJVZSVUYZFYLFQ-CIUDSAMLSA-N Glu-Pro-Ala Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O QJVZSVUYZFYLFQ-CIUDSAMLSA-N 0.000 description 1
- TWYFJOHWGCCRIR-DCAQKATOSA-N Glu-Pro-Arg Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(O)=O TWYFJOHWGCCRIR-DCAQKATOSA-N 0.000 description 1
- UDEPRBFQTWGLCW-CIUDSAMLSA-N Glu-Pro-Asp Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(O)=O UDEPRBFQTWGLCW-CIUDSAMLSA-N 0.000 description 1
- DXVOKNVIKORTHQ-GUBZILKMSA-N Glu-Pro-Glu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O DXVOKNVIKORTHQ-GUBZILKMSA-N 0.000 description 1
- CQAHWYDHKUWYIX-YUMQZZPRSA-N Glu-Pro-Gly Chemical compound OC(=O)CC[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O CQAHWYDHKUWYIX-YUMQZZPRSA-N 0.000 description 1
- PAZQYODKOZHXGA-SRVKXCTJSA-N Glu-Pro-His Chemical compound N[C@@H](CCC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](Cc1cnc[nH]1)C(O)=O PAZQYODKOZHXGA-SRVKXCTJSA-N 0.000 description 1
- BFEZQZKEPRKKHV-SRVKXCTJSA-N Glu-Pro-Lys Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CCC(=O)O)N)C(=O)N[C@@H](CCCCN)C(=O)O BFEZQZKEPRKKHV-SRVKXCTJSA-N 0.000 description 1
- BIYNPVYAZOUVFQ-CIUDSAMLSA-N Glu-Pro-Ser Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O BIYNPVYAZOUVFQ-CIUDSAMLSA-N 0.000 description 1
- NNQDRRUXFJYCCJ-NHCYSSNCSA-N Glu-Pro-Val Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(O)=O NNQDRRUXFJYCCJ-NHCYSSNCSA-N 0.000 description 1
- IDEODOAVGCMUQV-GUBZILKMSA-N Glu-Ser-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O IDEODOAVGCMUQV-GUBZILKMSA-N 0.000 description 1
- HZISRJBYZAODRV-XQXXSGGOSA-N Glu-Thr-Ala Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O HZISRJBYZAODRV-XQXXSGGOSA-N 0.000 description 1
- GPSHCSTUYOQPAI-JHEQGTHGSA-N Glu-Thr-Gly Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O GPSHCSTUYOQPAI-JHEQGTHGSA-N 0.000 description 1
- RGJKYNUINKGPJN-RWRJDSDZSA-N Glu-Thr-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@H](CCC(=O)O)N RGJKYNUINKGPJN-RWRJDSDZSA-N 0.000 description 1
- JVZLZVJTIXVIHK-SXNHZJKMSA-N Glu-Trp-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H](CCC(=O)O)N JVZLZVJTIXVIHK-SXNHZJKMSA-N 0.000 description 1
- HGJREIGJLUQBTJ-SZMVWBNQSA-N Glu-Trp-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CC(C)C)C(O)=O HGJREIGJLUQBTJ-SZMVWBNQSA-N 0.000 description 1
- CGWHAXBNGYQBBK-JBACZVJFSA-N Glu-Trp-Tyr Chemical compound C([C@H](NC(=O)[C@H](CC=1C2=CC=CC=C2NC=1)NC(=O)[C@H](CCC(O)=O)N)C(O)=O)C1=CC=C(O)C=C1 CGWHAXBNGYQBBK-JBACZVJFSA-N 0.000 description 1
- XOEKMEAOMXMURD-JYJNAYRXSA-N Glu-Tyr-His Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CC2=CN=CN2)C(=O)O)NC(=O)[C@H](CCC(=O)O)N)O XOEKMEAOMXMURD-JYJNAYRXSA-N 0.000 description 1
- UUTGYDAKPISJAO-JYJNAYRXSA-N Glu-Tyr-Leu Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CC(C)C)C(O)=O)CC1=CC=C(O)C=C1 UUTGYDAKPISJAO-JYJNAYRXSA-N 0.000 description 1
- HQTDNEZTGZUWSY-XVKPBYJWSA-N Glu-Val-Gly Chemical compound CC(C)[C@H](NC(=O)[C@@H](N)CCC(O)=O)C(=O)NCC(O)=O HQTDNEZTGZUWSY-XVKPBYJWSA-N 0.000 description 1
- ZALGPUWUVHOGAE-GVXVVHGQSA-N Glu-Val-His Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CCC(=O)O)N ZALGPUWUVHOGAE-GVXVVHGQSA-N 0.000 description 1
- VIPDPMHGICREIS-GVXVVHGQSA-N Glu-Val-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O VIPDPMHGICREIS-GVXVVHGQSA-N 0.000 description 1
- FVGOGEGGQLNZGH-DZKIICNBSA-N Glu-Val-Phe Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 FVGOGEGGQLNZGH-DZKIICNBSA-N 0.000 description 1
- SOYWRINXUSUWEQ-DLOVCJGASA-N Glu-Val-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CCC(O)=O SOYWRINXUSUWEQ-DLOVCJGASA-N 0.000 description 1
- WQZGKKKJIJFFOK-GASJEMHNSA-N Glucose Natural products OC[C@H]1OC(O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-GASJEMHNSA-N 0.000 description 1
- PUUYVMYCMIWHFE-BQBZGAKWSA-N Gly-Ala-Arg Chemical compound NCC(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N PUUYVMYCMIWHFE-BQBZGAKWSA-N 0.000 description 1
- RLFSBAPJTYKSLG-WHFBIAKZSA-N Gly-Ala-Asp Chemical compound NCC(=O)N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(O)=O RLFSBAPJTYKSLG-WHFBIAKZSA-N 0.000 description 1
- GZUKEVBTYNNUQF-WDSKDSINSA-N Gly-Ala-Gln Chemical compound NCC(=O)N[C@@H](C)C(=O)N[C@@H](CCC(N)=O)C(O)=O GZUKEVBTYNNUQF-WDSKDSINSA-N 0.000 description 1
- MFVQGXGQRIXBPK-WDSKDSINSA-N Gly-Ala-Glu Chemical compound NCC(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(O)=O MFVQGXGQRIXBPK-WDSKDSINSA-N 0.000 description 1
- JXYMPBCYRKWJEE-BQBZGAKWSA-N Gly-Arg-Ala Chemical compound [H]NCC(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(O)=O JXYMPBCYRKWJEE-BQBZGAKWSA-N 0.000 description 1
- UPOJUWHGMDJUQZ-IUCAKERBSA-N Gly-Arg-Arg Chemical compound NC(=N)NCCC[C@H](NC(=O)CN)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O UPOJUWHGMDJUQZ-IUCAKERBSA-N 0.000 description 1
- CLODWIOAKCSBAN-BQBZGAKWSA-N Gly-Arg-Asp Chemical compound NC(N)=NCCC[C@H](NC(=O)CN)C(=O)N[C@@H](CC(O)=O)C(O)=O CLODWIOAKCSBAN-BQBZGAKWSA-N 0.000 description 1
- DTPOVRRYXPJJAZ-FJXKBIBVSA-N Gly-Arg-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CCCN=C(N)N DTPOVRRYXPJJAZ-FJXKBIBVSA-N 0.000 description 1
- UXJHNZODTMHWRD-WHFBIAKZSA-N Gly-Asn-Ala Chemical compound [H]NCC(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](C)C(O)=O UXJHNZODTMHWRD-WHFBIAKZSA-N 0.000 description 1
- DWUKOTKSTDWGAE-BQBZGAKWSA-N Gly-Asn-Arg Chemical compound NCC(=O)N[C@@H](CC(N)=O)C(=O)N[C@H](C(O)=O)CCCN=C(N)N DWUKOTKSTDWGAE-BQBZGAKWSA-N 0.000 description 1
- XCLCVBYNGXEVDU-WHFBIAKZSA-N Gly-Asn-Ser Chemical compound NCC(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O XCLCVBYNGXEVDU-WHFBIAKZSA-N 0.000 description 1
- XBWMTPAIUQIWKA-BYULHYEWSA-N Gly-Asp-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)CN XBWMTPAIUQIWKA-BYULHYEWSA-N 0.000 description 1
- MHHUEAIBJZWDBH-YUMQZZPRSA-N Gly-Asp-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)CN MHHUEAIBJZWDBH-YUMQZZPRSA-N 0.000 description 1
- ZRZILYKEJBMFHY-BQBZGAKWSA-N Gly-Asp-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)CN ZRZILYKEJBMFHY-BQBZGAKWSA-N 0.000 description 1
- PMNHJLASAAWELO-FOHZUACHSA-N Gly-Asp-Thr Chemical compound [H]NCC(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O PMNHJLASAAWELO-FOHZUACHSA-N 0.000 description 1
- GVVKYKCOFMMTKZ-WHFBIAKZSA-N Gly-Cys-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CS)NC(=O)CN GVVKYKCOFMMTKZ-WHFBIAKZSA-N 0.000 description 1
- GYAUWXXORNTCHU-QWRGUYRKSA-N Gly-Cys-Tyr Chemical compound NCC(=O)N[C@@H](CS)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 GYAUWXXORNTCHU-QWRGUYRKSA-N 0.000 description 1
- KTSZUNRRYXPZTK-BQBZGAKWSA-N Gly-Gln-Glu Chemical compound NCC(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O KTSZUNRRYXPZTK-BQBZGAKWSA-N 0.000 description 1
- BPQYBFAXRGMGGY-LAEOZQHASA-N Gly-Gln-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)CN BPQYBFAXRGMGGY-LAEOZQHASA-N 0.000 description 1
- PABFFPWEJMEVEC-JGVFFNPUSA-N Gly-Gln-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)N)NC(=O)CN)C(=O)O PABFFPWEJMEVEC-JGVFFNPUSA-N 0.000 description 1
- QPDUVFSVVAOUHE-XVKPBYJWSA-N Gly-Gln-Val Chemical compound CC(C)[C@H](NC(=O)[C@H](CCC(N)=O)NC(=O)CN)C(O)=O QPDUVFSVVAOUHE-XVKPBYJWSA-N 0.000 description 1
- DHDOADIPGZTAHT-YUMQZZPRSA-N Gly-Glu-Arg Chemical compound NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@H](C(O)=O)CCCN=C(N)N DHDOADIPGZTAHT-YUMQZZPRSA-N 0.000 description 1
- FIQQRCFQXGLOSZ-WDSKDSINSA-N Gly-Glu-Asp Chemical compound [H]NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O FIQQRCFQXGLOSZ-WDSKDSINSA-N 0.000 description 1
- QSVCIFZPGLOZGH-WDSKDSINSA-N Gly-Glu-Ser Chemical compound NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O QSVCIFZPGLOZGH-WDSKDSINSA-N 0.000 description 1
- HQRHFUYMGCHHJS-LURJTMIESA-N Gly-Gly-Arg Chemical compound NCC(=O)NCC(=O)N[C@H](C(O)=O)CCCN=C(N)N HQRHFUYMGCHHJS-LURJTMIESA-N 0.000 description 1
- QPCVIQJVRGXUSA-LURJTMIESA-N Gly-Gly-Met Chemical compound CSCC[C@@H](C(O)=O)NC(=O)CNC(=O)CN QPCVIQJVRGXUSA-LURJTMIESA-N 0.000 description 1
- OLPPXYMMIARYAL-QMMMGPOBSA-N Gly-Gly-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)CNC(=O)CN OLPPXYMMIARYAL-QMMMGPOBSA-N 0.000 description 1
- YFGONBOFGGWKKY-VHSXEESVSA-N Gly-His-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CN=CN2)NC(=O)CN)C(=O)O YFGONBOFGGWKKY-VHSXEESVSA-N 0.000 description 1
- UESJMAMHDLEHGM-NHCYSSNCSA-N Gly-Ile-Leu Chemical compound NCC(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(C)C)C(O)=O UESJMAMHDLEHGM-NHCYSSNCSA-N 0.000 description 1
- BHPQOIPBLYJNAW-NGZCFLSTSA-N Gly-Ile-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)CN BHPQOIPBLYJNAW-NGZCFLSTSA-N 0.000 description 1
- HAXARWKYFIIHKD-ZKWXMUAHSA-N Gly-Ile-Ser Chemical compound NCC(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O HAXARWKYFIIHKD-ZKWXMUAHSA-N 0.000 description 1
- SCWYHUQOOFRVHP-MBLNEYKQSA-N Gly-Ile-Thr Chemical compound NCC(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(O)=O SCWYHUQOOFRVHP-MBLNEYKQSA-N 0.000 description 1
- IUZGUFAJDBHQQV-YUMQZZPRSA-N Gly-Leu-Asn Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O IUZGUFAJDBHQQV-YUMQZZPRSA-N 0.000 description 1
- CCBIBMKQNXHNIN-ZETCQYMHSA-N Gly-Leu-Gly Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O CCBIBMKQNXHNIN-ZETCQYMHSA-N 0.000 description 1
- LRQXRHGQEVWGPV-NHCYSSNCSA-N Gly-Leu-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)CN LRQXRHGQEVWGPV-NHCYSSNCSA-N 0.000 description 1
- LLZXNUUIBOALNY-QWRGUYRKSA-N Gly-Leu-Lys Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CCCCN LLZXNUUIBOALNY-QWRGUYRKSA-N 0.000 description 1
- TVUWMSBGMVAHSJ-KBPBESRZSA-N Gly-Leu-Phe Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 TVUWMSBGMVAHSJ-KBPBESRZSA-N 0.000 description 1
- NNCSJUBVFBDDLC-YUMQZZPRSA-N Gly-Leu-Ser Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O NNCSJUBVFBDDLC-YUMQZZPRSA-N 0.000 description 1
- MIIVFRCYJABHTQ-ONGXEEELSA-N Gly-Leu-Val Chemical compound [H]NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O MIIVFRCYJABHTQ-ONGXEEELSA-N 0.000 description 1
- BXICSAQLIHFDDL-YUMQZZPRSA-N Gly-Lys-Asn Chemical compound [H]NCC(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(O)=O BXICSAQLIHFDDL-YUMQZZPRSA-N 0.000 description 1
- FHQRLHFYVZAQHU-IUCAKERBSA-N Gly-Lys-Gln Chemical compound [H]NCC(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(N)=O)C(O)=O FHQRLHFYVZAQHU-IUCAKERBSA-N 0.000 description 1
- PDUHNKAFQXQNLH-ZETCQYMHSA-N Gly-Lys-Gly Chemical compound NCCCC[C@H](NC(=O)CN)C(=O)NCC(O)=O PDUHNKAFQXQNLH-ZETCQYMHSA-N 0.000 description 1
- IUKIDFVOUHZRAK-QWRGUYRKSA-N Gly-Lys-His Chemical compound NCCCC[C@H](NC(=O)CN)C(=O)N[C@H](C(O)=O)CC1=CN=CN1 IUKIDFVOUHZRAK-QWRGUYRKSA-N 0.000 description 1
- MHZXESQPPXOING-KBPBESRZSA-N Gly-Lys-Phe Chemical compound [H]NCC(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O MHZXESQPPXOING-KBPBESRZSA-N 0.000 description 1
- NTBOEZICHOSJEE-YUMQZZPRSA-N Gly-Lys-Ser Chemical compound [H]NCC(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O NTBOEZICHOSJEE-YUMQZZPRSA-N 0.000 description 1
- IFHJOBKVXBESRE-YUMQZZPRSA-N Gly-Met-Gln Chemical compound CSCC[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)CN IFHJOBKVXBESRE-YUMQZZPRSA-N 0.000 description 1
- RUDRIZRGOLQSMX-IUCAKERBSA-N Gly-Met-Met Chemical compound [H]NCC(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCSC)C(O)=O RUDRIZRGOLQSMX-IUCAKERBSA-N 0.000 description 1
- IBYOLNARKHMLBG-WHOFXGATSA-N Gly-Phe-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CC1=CC=CC=C1 IBYOLNARKHMLBG-WHOFXGATSA-N 0.000 description 1
- GGLIDLCEPDHEJO-BQBZGAKWSA-N Gly-Pro-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1C(=O)CN GGLIDLCEPDHEJO-BQBZGAKWSA-N 0.000 description 1
- JYPCXBJRLBHWME-IUCAKERBSA-N Gly-Pro-Arg Chemical compound NCC(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(O)=O JYPCXBJRLBHWME-IUCAKERBSA-N 0.000 description 1
- WDXLKVQATNEAJQ-BQBZGAKWSA-N Gly-Pro-Asp Chemical compound NCC(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(O)=O WDXLKVQATNEAJQ-BQBZGAKWSA-N 0.000 description 1
- JJGBXTYGTKWGAT-YUMQZZPRSA-N Gly-Pro-Glu Chemical compound NCC(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O JJGBXTYGTKWGAT-YUMQZZPRSA-N 0.000 description 1
- OOCFXNOVSLSHAB-IUCAKERBSA-N Gly-Pro-Pro Chemical compound NCC(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 OOCFXNOVSLSHAB-IUCAKERBSA-N 0.000 description 1
- ISSDODCYBOWWIP-GJZGRUSLSA-N Gly-Pro-Trp Chemical compound [H]NCC(=O)N1CCC[C@H]1C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O ISSDODCYBOWWIP-GJZGRUSLSA-N 0.000 description 1
- LBDXVCBAJJNJNN-WHFBIAKZSA-N Gly-Ser-Cys Chemical compound NCC(=O)N[C@@H](CO)C(=O)N[C@@H](CS)C(O)=O LBDXVCBAJJNJNN-WHFBIAKZSA-N 0.000 description 1
- FGPLUIQCSKGLTI-WDSKDSINSA-N Gly-Ser-Glu Chemical compound NCC(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCC(O)=O FGPLUIQCSKGLTI-WDSKDSINSA-N 0.000 description 1
- ZLCLYFGMKFCDCN-XPUUQOCRSA-N Gly-Ser-Val Chemical compound CC(C)[C@H](NC(=O)[C@H](CO)NC(=O)CN)C(O)=O ZLCLYFGMKFCDCN-XPUUQOCRSA-N 0.000 description 1
- CQMFNTVQVLQRLT-JHEQGTHGSA-N Gly-Thr-Gln Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(N)=O)C(O)=O CQMFNTVQVLQRLT-JHEQGTHGSA-N 0.000 description 1
- DBUNZBWUWCIELX-JHEQGTHGSA-N Gly-Thr-Glu Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(O)=O DBUNZBWUWCIELX-JHEQGTHGSA-N 0.000 description 1
- JQFILXICXLDTRR-FBCQKBJTSA-N Gly-Thr-Gly Chemical compound NCC(=O)N[C@@H]([C@H](O)C)C(=O)NCC(O)=O JQFILXICXLDTRR-FBCQKBJTSA-N 0.000 description 1
- HUFUVTYGPOUCBN-MBLNEYKQSA-N Gly-Thr-Ile Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O HUFUVTYGPOUCBN-MBLNEYKQSA-N 0.000 description 1
- MYXNLWDWWOTERK-BHNWBGBOSA-N Gly-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)CN)O MYXNLWDWWOTERK-BHNWBGBOSA-N 0.000 description 1
- FFALDIDGPLUDKV-ZDLURKLDSA-N Gly-Thr-Ser Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O FFALDIDGPLUDKV-ZDLURKLDSA-N 0.000 description 1
- ONSARSFSJHTMFJ-STQMWFEESA-N Gly-Trp-Ser Chemical compound [H]NCC(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CO)C(O)=O ONSARSFSJHTMFJ-STQMWFEESA-N 0.000 description 1
- MREVELMMFOLESM-HOCLYGCPSA-N Gly-Trp-Val Chemical compound [H]NCC(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](C(C)C)C(O)=O MREVELMMFOLESM-HOCLYGCPSA-N 0.000 description 1
- HQSKKSLNLSTONK-JTQLQIEISA-N Gly-Tyr-Gly Chemical compound OC(=O)CNC(=O)[C@@H](NC(=O)CN)CC1=CC=C(O)C=C1 HQSKKSLNLSTONK-JTQLQIEISA-N 0.000 description 1
- NGBGZCUWFVVJKC-IRXDYDNUSA-N Gly-Tyr-Tyr Chemical compound C([C@H](NC(=O)CN)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=C(O)C=C1 NGBGZCUWFVVJKC-IRXDYDNUSA-N 0.000 description 1
- GWCJMBNBFYBQCV-XPUUQOCRSA-N Gly-Val-Ala Chemical compound NCC(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C)C(O)=O GWCJMBNBFYBQCV-XPUUQOCRSA-N 0.000 description 1
- GJHWILMUOANXTG-WPRPVWTQSA-N Gly-Val-Arg Chemical compound [H]NCC(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O GJHWILMUOANXTG-WPRPVWTQSA-N 0.000 description 1
- DKJWUIYLMLUBDX-XPUUQOCRSA-N Gly-Val-Cys Chemical compound NCC(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CS)C(=O)O DKJWUIYLMLUBDX-XPUUQOCRSA-N 0.000 description 1
- FULZDMOZUZKGQU-ONGXEEELSA-N Gly-Val-His Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)CN FULZDMOZUZKGQU-ONGXEEELSA-N 0.000 description 1
- BNMRSWQOHIQTFL-JSGCOSHPSA-N Gly-Val-Phe Chemical compound NCC(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 BNMRSWQOHIQTFL-JSGCOSHPSA-N 0.000 description 1
- SBVMXEZQJVUARN-XPUUQOCRSA-N Gly-Val-Ser Chemical compound NCC(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O SBVMXEZQJVUARN-XPUUQOCRSA-N 0.000 description 1
- KSOBNUBCYHGUKH-UWVGGRQHSA-N Gly-Val-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)CN KSOBNUBCYHGUKH-UWVGGRQHSA-N 0.000 description 1
- 102000010437 HD domains Human genes 0.000 description 1
- 108050001906 HD domains Proteins 0.000 description 1
- 241000238631 Hexapoda Species 0.000 description 1
- BIAKMWKJMQLZOJ-ZKWXMUAHSA-N His-Ala-Ala Chemical compound C[C@H](NC(=O)[C@H](C)NC(=O)[C@@H](N)Cc1cnc[nH]1)C(O)=O BIAKMWKJMQLZOJ-ZKWXMUAHSA-N 0.000 description 1
- DCRODRAURLJOFY-XPUUQOCRSA-N His-Ala-Gly Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](C)C(=O)NCC(O)=O DCRODRAURLJOFY-XPUUQOCRSA-N 0.000 description 1
- IPIVXQQRZXEUGW-UWJYBYFXSA-N His-Ala-His Chemical compound C([C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CC=1NC=NC=1)C(O)=O)C1=CN=CN1 IPIVXQQRZXEUGW-UWJYBYFXSA-N 0.000 description 1
- AWASVTXPTOLPPP-MBLNEYKQSA-N His-Ala-Thr Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O AWASVTXPTOLPPP-MBLNEYKQSA-N 0.000 description 1
- HXKZJLWGSWQKEA-LSJOCFKGSA-N His-Ala-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC1=CN=CN1 HXKZJLWGSWQKEA-LSJOCFKGSA-N 0.000 description 1
- PDSUIXMZYNURGI-AVGNSLFASA-N His-Arg-Arg Chemical compound NC(N)=NCCC[C@@H](C(O)=O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@@H](N)CC1=CN=CN1 PDSUIXMZYNURGI-AVGNSLFASA-N 0.000 description 1
- CJGDTAHEMXLRMB-ULQDDVLXSA-N His-Arg-Phe Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O CJGDTAHEMXLRMB-ULQDDVLXSA-N 0.000 description 1
- LYSMQLXUCAKELQ-DCAQKATOSA-N His-Asp-Arg Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N LYSMQLXUCAKELQ-DCAQKATOSA-N 0.000 description 1
- LMMPTUVWHCFTOT-GARJFASQSA-N His-Asp-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)O)NC(=O)[C@H](CC2=CN=CN2)N)C(=O)O LMMPTUVWHCFTOT-GARJFASQSA-N 0.000 description 1
- WYWBYSPRCFADBM-GARJFASQSA-N His-Cys-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CS)NC(=O)[C@H](CC2=CN=CN2)N)C(=O)O WYWBYSPRCFADBM-GARJFASQSA-N 0.000 description 1
- FYVHHKMHFPMBBG-GUBZILKMSA-N His-Gln-Asp Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC(=O)O)C(=O)O)N FYVHHKMHFPMBBG-GUBZILKMSA-N 0.000 description 1
- FIMNVXRZGUAGBI-AVGNSLFASA-N His-Glu-Leu Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O FIMNVXRZGUAGBI-AVGNSLFASA-N 0.000 description 1
- OSZUPUINVNPCOE-SDDRHHMPSA-N His-Glu-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CC2=CN=CN2)N)C(=O)O OSZUPUINVNPCOE-SDDRHHMPSA-N 0.000 description 1
- RGPWUJOMKFYFSR-QWRGUYRKSA-N His-Gly-Leu Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)NCC(=O)N[C@@H](CC(C)C)C(O)=O RGPWUJOMKFYFSR-QWRGUYRKSA-N 0.000 description 1
- NTXIJPDAHXSHNL-ONGXEEELSA-N His-Gly-Val Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O NTXIJPDAHXSHNL-ONGXEEELSA-N 0.000 description 1
- CSTNMMIHMYJGFR-IHRRRGAJSA-N His-His-Arg Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1NC=NC=1)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O)C1=CN=CN1 CSTNMMIHMYJGFR-IHRRRGAJSA-N 0.000 description 1
- JIUYRPFQJJRSJB-QWRGUYRKSA-N His-His-Gly Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1NC=NC=1)C(=O)NCC(O)=O)C1=CN=CN1 JIUYRPFQJJRSJB-QWRGUYRKSA-N 0.000 description 1
- LBQAHBIVXQSBIR-HVTMNAMFSA-N His-Ile-Glu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@H](CC1=CN=CN1)N LBQAHBIVXQSBIR-HVTMNAMFSA-N 0.000 description 1
- ZRSJXIKQXUGKRB-TUBUOCAGSA-N His-Ile-Thr Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(O)=O ZRSJXIKQXUGKRB-TUBUOCAGSA-N 0.000 description 1
- WTJBVCUCLWFGAH-JUKXBJQTSA-N His-Ile-Tyr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)O)NC(=O)[C@H](CC2=CN=CN2)N WTJBVCUCLWFGAH-JUKXBJQTSA-N 0.000 description 1
- VYUXYMRNGALHEA-DLOVCJGASA-N His-Leu-Ala Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(O)=O VYUXYMRNGALHEA-DLOVCJGASA-N 0.000 description 1
- YAALVYQFVJNXIV-KKUMJFAQSA-N His-Leu-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC1=CN=CN1 YAALVYQFVJNXIV-KKUMJFAQSA-N 0.000 description 1
- ZSKJIISDJXJQPV-BZSNNMDCSA-N His-Leu-Phe Chemical compound C([C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CN=CN1 ZSKJIISDJXJQPV-BZSNNMDCSA-N 0.000 description 1
- NKRWVZQTPXPNRZ-SRVKXCTJSA-N His-Met-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CCSC)NC(=O)[C@@H](N)CC1=CN=CN1 NKRWVZQTPXPNRZ-SRVKXCTJSA-N 0.000 description 1
- WSEITRHJRVDTRX-QTKMDUPCSA-N His-Met-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CCSC)NC(=O)[C@H](CC1=CN=CN1)N)O WSEITRHJRVDTRX-QTKMDUPCSA-N 0.000 description 1
- JSQIXEHORHLQEE-MEYUZBJRSA-N His-Phe-Thr Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O JSQIXEHORHLQEE-MEYUZBJRSA-N 0.000 description 1
- XIGFLVCAVQQGNS-IHRRRGAJSA-N His-Pro-His Chemical compound C([C@H](N)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CC=1NC=NC=1)C(O)=O)C1=CN=CN1 XIGFLVCAVQQGNS-IHRRRGAJSA-N 0.000 description 1
- FLXCRBXJRJSDHX-AVGNSLFASA-N His-Pro-Val Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(O)=O FLXCRBXJRJSDHX-AVGNSLFASA-N 0.000 description 1
- FHKZHRMERJUXRJ-DCAQKATOSA-N His-Ser-Arg Chemical compound NC(N)=NCCC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CN=CN1 FHKZHRMERJUXRJ-DCAQKATOSA-N 0.000 description 1
- CSRRMQFXMBPSIL-SIXJUCDHSA-N His-Trp-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H](CC3=CN=CN3)N CSRRMQFXMBPSIL-SIXJUCDHSA-N 0.000 description 1
- PUFNQIPSRXVLQJ-IHRRRGAJSA-N His-Val-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC1=CN=CN1)N PUFNQIPSRXVLQJ-IHRRRGAJSA-N 0.000 description 1
- DRKZDEFADVYTLU-AVGNSLFASA-N His-Val-Val Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C(C)C)C(O)=O DRKZDEFADVYTLU-AVGNSLFASA-N 0.000 description 1
- NKVZTQVGUNLLQW-JBDRJPRFSA-N Ile-Ala-Ala Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C)C(=O)N[C@@H](C)C(=O)O)N NKVZTQVGUNLLQW-JBDRJPRFSA-N 0.000 description 1
- AQCUAZTZSPQJFF-ZKWXMUAHSA-N Ile-Ala-Gly Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](C)C(=O)NCC(O)=O AQCUAZTZSPQJFF-ZKWXMUAHSA-N 0.000 description 1
- HDOYNXLPTRQLAD-JBDRJPRFSA-N Ile-Ala-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(=O)O)N HDOYNXLPTRQLAD-JBDRJPRFSA-N 0.000 description 1
- CYHYBSGMHMHKOA-CIQUZCHMSA-N Ile-Ala-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(=O)O)N CYHYBSGMHMHKOA-CIQUZCHMSA-N 0.000 description 1
- WZPIKDWQVRTATP-SYWGBEHUSA-N Ile-Ala-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](C)NC(=O)[C@@H](N)[C@@H](C)CC)C(O)=O)=CNC2=C1 WZPIKDWQVRTATP-SYWGBEHUSA-N 0.000 description 1
- MKWSZEHGHSLNPF-NAKRPEOUSA-N Ile-Ala-Val Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C)C(=O)N[C@@H](C(C)C)C(=O)O)N MKWSZEHGHSLNPF-NAKRPEOUSA-N 0.000 description 1
- TZCGZYWNIDZZMR-NAKRPEOUSA-N Ile-Arg-Ala Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](C)C(=O)O)N TZCGZYWNIDZZMR-NAKRPEOUSA-N 0.000 description 1
- TZCGZYWNIDZZMR-UHFFFAOYSA-N Ile-Arg-Ala Natural products CCC(C)C(N)C(=O)NC(C(=O)NC(C)C(O)=O)CCCN=C(N)N TZCGZYWNIDZZMR-UHFFFAOYSA-N 0.000 description 1
- QLRMMMQNCWBNPQ-QXEWZRGKSA-N Ile-Arg-Gly Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)NCC(=O)O)N QLRMMMQNCWBNPQ-QXEWZRGKSA-N 0.000 description 1
- VZIFYHYNQDIPLI-HJWJTTGWSA-N Ile-Arg-Phe Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)N VZIFYHYNQDIPLI-HJWJTTGWSA-N 0.000 description 1
- QADCTXFNLZBZAB-GHCJXIJMSA-N Ile-Asn-Ala Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](C)C(=O)O)N QADCTXFNLZBZAB-GHCJXIJMSA-N 0.000 description 1
- UKTUOMWSJPXODT-GUDRVLHUSA-N Ile-Asn-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N1CCC[C@@H]1C(=O)O)N UKTUOMWSJPXODT-GUDRVLHUSA-N 0.000 description 1
- IDAHFEPYTJJZFD-PEFMBERDSA-N Ile-Asp-Glu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N IDAHFEPYTJJZFD-PEFMBERDSA-N 0.000 description 1
- NKRJALPCDNXULF-BYULHYEWSA-N Ile-Asp-Gly Chemical compound [H]N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O NKRJALPCDNXULF-BYULHYEWSA-N 0.000 description 1
- CCHSQWLCOOZREA-GMOBBJLQSA-N Ile-Asp-Met Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CCSC)C(=O)O)N CCHSQWLCOOZREA-GMOBBJLQSA-N 0.000 description 1
- NPROWIBAWYMPAZ-GUDRVLHUSA-N Ile-Asp-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N1CCC[C@@H]1C(=O)O)N NPROWIBAWYMPAZ-GUDRVLHUSA-N 0.000 description 1
- FADXGVVLSPPEQY-GHCJXIJMSA-N Ile-Cys-Asn Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(=O)N)C(=O)O)N FADXGVVLSPPEQY-GHCJXIJMSA-N 0.000 description 1
- LLHYWBGDMBGNHA-VGDYDELISA-N Ile-Cys-His Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N LLHYWBGDMBGNHA-VGDYDELISA-N 0.000 description 1
- OVPYIUNCVSOVNF-ZPFDUUQYSA-N Ile-Gln-Pro Natural products CC[C@H](C)[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N1CCC[C@H]1C(O)=O OVPYIUNCVSOVNF-ZPFDUUQYSA-N 0.000 description 1
- WZDCVAWMBUNDDY-KBIXCLLPSA-N Ile-Glu-Ala Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](C)C(=O)O)N WZDCVAWMBUNDDY-KBIXCLLPSA-N 0.000 description 1
- LPFBXFILACZHIB-LAEOZQHASA-N Ile-Gly-Glu Chemical compound CC[C@H](C)[C@@H](C(=O)NCC(=O)N[C@@H](CCC(=O)O)C(=O)O)N LPFBXFILACZHIB-LAEOZQHASA-N 0.000 description 1
- RWYCOSAAAJBJQL-KCTSRDHCSA-N Ile-Gly-Trp Chemical compound CC[C@H](C)[C@@H](C(=O)NCC(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)N RWYCOSAAAJBJQL-KCTSRDHCSA-N 0.000 description 1
- APDIECQNNDGFPD-PYJNHQTQSA-N Ile-His-Val Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](C(C)C)C(=O)O)N APDIECQNNDGFPD-PYJNHQTQSA-N 0.000 description 1
- PWDSHAAAFXISLE-SXTJYALSSA-N Ile-Ile-Asp Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(O)=O)C(O)=O PWDSHAAAFXISLE-SXTJYALSSA-N 0.000 description 1
- SJLVSMMIFYTSGY-GRLWGSQLSA-N Ile-Ile-Glu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N SJLVSMMIFYTSGY-GRLWGSQLSA-N 0.000 description 1
- OUUCIIJSBIBCHB-ZPFDUUQYSA-N Ile-Leu-Asp Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O OUUCIIJSBIBCHB-ZPFDUUQYSA-N 0.000 description 1
- HPCFRQWLTRDGHT-AJNGGQMLSA-N Ile-Leu-Leu Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O HPCFRQWLTRDGHT-AJNGGQMLSA-N 0.000 description 1
- DSDPLOODKXISDT-XUXIUFHCSA-N Ile-Leu-Val Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O DSDPLOODKXISDT-XUXIUFHCSA-N 0.000 description 1
- RVNOXPZHMUWCLW-GMOBBJLQSA-N Ile-Met-Asn Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(=O)N)C(=O)O)N RVNOXPZHMUWCLW-GMOBBJLQSA-N 0.000 description 1
- YKZAMJXNJUWFIK-JBDRJPRFSA-N Ile-Ser-Ala Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(=O)O)N YKZAMJXNJUWFIK-JBDRJPRFSA-N 0.000 description 1
- JNLSTRPWUXOORL-MMWGEVLESA-N Ile-Ser-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N1CCC[C@@H]1C(=O)O)N JNLSTRPWUXOORL-MMWGEVLESA-N 0.000 description 1
- PXKACEXYLPBMAD-JBDRJPRFSA-N Ile-Ser-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)O)N PXKACEXYLPBMAD-JBDRJPRFSA-N 0.000 description 1
- RQJUKVXWAKJDBW-SVSWQMSJSA-N Ile-Ser-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)O)N RQJUKVXWAKJDBW-SVSWQMSJSA-N 0.000 description 1
- HXIDVIFHRYRXLZ-NAKRPEOUSA-N Ile-Ser-Val Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)O)N HXIDVIFHRYRXLZ-NAKRPEOUSA-N 0.000 description 1
- CNMOKANDJMLAIF-CIQUZCHMSA-N Ile-Thr-Ala Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O CNMOKANDJMLAIF-CIQUZCHMSA-N 0.000 description 1
- SAEWJTCJQVZQNZ-IUKAMOBKSA-N Ile-Thr-Asn Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(=O)N)C(=O)O)N SAEWJTCJQVZQNZ-IUKAMOBKSA-N 0.000 description 1
- NAFIFZNBSPWYOO-RWRJDSDZSA-N Ile-Thr-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N NAFIFZNBSPWYOO-RWRJDSDZSA-N 0.000 description 1
- COWHUQXTSYTKQC-RWRJDSDZSA-N Ile-Thr-Glu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N COWHUQXTSYTKQC-RWRJDSDZSA-N 0.000 description 1
- DGTOKVBDZXJHNZ-WZLNRYEVSA-N Ile-Thr-Tyr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)O)N DGTOKVBDZXJHNZ-WZLNRYEVSA-N 0.000 description 1
- VBGCPJBKUXRYDA-DSYPUSFNSA-N Ile-Trp-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)N[C@@H](CCCCN)C(=O)O)N VBGCPJBKUXRYDA-DSYPUSFNSA-N 0.000 description 1
- HGCNKOLVKRAVHD-UHFFFAOYSA-N L-Met-L-Phe Natural products CSCCC(N)C(=O)NC(C(O)=O)CC1=CC=CC=C1 HGCNKOLVKRAVHD-UHFFFAOYSA-N 0.000 description 1
- KFKWRHQBZQICHA-STQMWFEESA-N L-leucyl-L-phenylalanine Natural products CC(C)C[C@H](N)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 KFKWRHQBZQICHA-STQMWFEESA-N 0.000 description 1
- MJOZZTKJZQFKDK-GUBZILKMSA-N Leu-Ala-Gln Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CCC(N)=O MJOZZTKJZQFKDK-GUBZILKMSA-N 0.000 description 1
- CQQGCWPXDHTTNF-GUBZILKMSA-N Leu-Ala-Glu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CCC(O)=O CQQGCWPXDHTTNF-GUBZILKMSA-N 0.000 description 1
- DQPQTXMIRBUWKO-DCAQKATOSA-N Leu-Ala-Met Chemical compound C[C@@H](C(=O)N[C@@H](CCSC)C(=O)O)NC(=O)[C@H](CC(C)C)N DQPQTXMIRBUWKO-DCAQKATOSA-N 0.000 description 1
- HXWALXSAVBLTPK-NUTKFTJISA-N Leu-Ala-Trp Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)NC(=O)[C@H](CC(C)C)N HXWALXSAVBLTPK-NUTKFTJISA-N 0.000 description 1
- SUPVSFFZWVOEOI-CQDKDKBSSA-N Leu-Ala-Tyr Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 SUPVSFFZWVOEOI-CQDKDKBSSA-N 0.000 description 1
- SUPVSFFZWVOEOI-UHFFFAOYSA-N Leu-Ala-Tyr Natural products CC(C)CC(N)C(=O)NC(C)C(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 SUPVSFFZWVOEOI-UHFFFAOYSA-N 0.000 description 1
- IBMVEYRWAWIOTN-RWMBFGLXSA-N Leu-Arg-Pro Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N1CCC[C@@H]1C(O)=O IBMVEYRWAWIOTN-RWMBFGLXSA-N 0.000 description 1
- XYUBOFCTGPZFSA-WDSOQIARSA-N Leu-Arg-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@@H](N)CC(C)C)C(O)=O)=CNC2=C1 XYUBOFCTGPZFSA-WDSOQIARSA-N 0.000 description 1
- VCSBGUACOYUIGD-CIUDSAMLSA-N Leu-Asn-Asp Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O VCSBGUACOYUIGD-CIUDSAMLSA-N 0.000 description 1
- JKGHDYGZRDWHGA-SRVKXCTJSA-N Leu-Asn-Leu Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O JKGHDYGZRDWHGA-SRVKXCTJSA-N 0.000 description 1
- WGNOPSQMIQERPK-GARJFASQSA-N Leu-Asn-Pro Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N1CCC[C@@H]1C(=O)O)N WGNOPSQMIQERPK-GARJFASQSA-N 0.000 description 1
- ULXYQAJWJGLCNR-YUMQZZPRSA-N Leu-Asp-Gly Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O ULXYQAJWJGLCNR-YUMQZZPRSA-N 0.000 description 1
- PVMPDMIKUVNOBD-CIUDSAMLSA-N Leu-Asp-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O PVMPDMIKUVNOBD-CIUDSAMLSA-N 0.000 description 1
- RRSLQOLASISYTB-CIUDSAMLSA-N Leu-Cys-Asp Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(O)=O)C(O)=O RRSLQOLASISYTB-CIUDSAMLSA-N 0.000 description 1
- HUEBCHPSXSQUGN-GARJFASQSA-N Leu-Cys-Pro Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CS)C(=O)N1CCC[C@@H]1C(=O)O)N HUEBCHPSXSQUGN-GARJFASQSA-N 0.000 description 1
- FOEHRHOBWFQSNW-KATARQTJSA-N Leu-Cys-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CC(C)C)N)O FOEHRHOBWFQSNW-KATARQTJSA-N 0.000 description 1
- WCTCIIAGNMFYAO-DCAQKATOSA-N Leu-Cys-Val Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CS)C(=O)N[C@@H](C(C)C)C(O)=O WCTCIIAGNMFYAO-DCAQKATOSA-N 0.000 description 1
- KAFOIVJDVSZUMD-UHFFFAOYSA-N Leu-Gln-Gln Natural products CC(C)CC(N)C(=O)NC(CCC(N)=O)C(=O)NC(CCC(N)=O)C(O)=O KAFOIVJDVSZUMD-UHFFFAOYSA-N 0.000 description 1
- ZTLGVASZOIKNIX-DCAQKATOSA-N Leu-Gln-Glu Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N ZTLGVASZOIKNIX-DCAQKATOSA-N 0.000 description 1
- DPWGZWUMUUJQDT-IUCAKERBSA-N Leu-Gln-Gly Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O DPWGZWUMUUJQDT-IUCAKERBSA-N 0.000 description 1
- CQGSYZCULZMEDE-SRVKXCTJSA-N Leu-Gln-Pro Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N1CCC[C@H]1C(O)=O CQGSYZCULZMEDE-SRVKXCTJSA-N 0.000 description 1
- CQGSYZCULZMEDE-UHFFFAOYSA-N Leu-Gln-Pro Natural products CC(C)CC(N)C(=O)NC(CCC(N)=O)C(=O)N1CCCC1C(O)=O CQGSYZCULZMEDE-UHFFFAOYSA-N 0.000 description 1
- GPICTNQYKHHHTH-GUBZILKMSA-N Leu-Gln-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O GPICTNQYKHHHTH-GUBZILKMSA-N 0.000 description 1
- DZQMXBALGUHGJT-GUBZILKMSA-N Leu-Glu-Ala Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O DZQMXBALGUHGJT-GUBZILKMSA-N 0.000 description 1
- RVVBWTWPNFDYBE-SRVKXCTJSA-N Leu-Glu-Arg Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O RVVBWTWPNFDYBE-SRVKXCTJSA-N 0.000 description 1
- NEEOBPIXKWSBRF-IUCAKERBSA-N Leu-Glu-Gly Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O NEEOBPIXKWSBRF-IUCAKERBSA-N 0.000 description 1
- PRZVBIAOPFGAQF-SRVKXCTJSA-N Leu-Glu-Met Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCSC)C(O)=O PRZVBIAOPFGAQF-SRVKXCTJSA-N 0.000 description 1
- FMEICTQWUKNAGC-YUMQZZPRSA-N Leu-Gly-Asn Chemical compound [H]N[C@@H](CC(C)C)C(=O)NCC(=O)N[C@@H](CC(N)=O)C(O)=O FMEICTQWUKNAGC-YUMQZZPRSA-N 0.000 description 1
- LAPSXOAUPNOINL-YUMQZZPRSA-N Leu-Gly-Asp Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC(O)=O LAPSXOAUPNOINL-YUMQZZPRSA-N 0.000 description 1
- CCQLQKZTXZBXTN-NHCYSSNCSA-N Leu-Gly-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)NCC(=O)N[C@@H]([C@@H](C)CC)C(O)=O CCQLQKZTXZBXTN-NHCYSSNCSA-N 0.000 description 1
- HYIFFZAQXPUEAU-QWRGUYRKSA-N Leu-Gly-Leu Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC(C)C HYIFFZAQXPUEAU-QWRGUYRKSA-N 0.000 description 1
- APFJUBGRZGMQFF-QWRGUYRKSA-N Leu-Gly-Lys Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCCCN APFJUBGRZGMQFF-QWRGUYRKSA-N 0.000 description 1
- KEVYYIMVELOXCT-KBPBESRZSA-N Leu-Gly-Phe Chemical compound CC(C)C[C@H]([NH3+])C(=O)NCC(=O)N[C@H](C([O-])=O)CC1=CC=CC=C1 KEVYYIMVELOXCT-KBPBESRZSA-N 0.000 description 1
- YFBBUHJJUXXZOF-UWVGGRQHSA-N Leu-Gly-Pro Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N1CCC[C@H]1C(O)=O YFBBUHJJUXXZOF-UWVGGRQHSA-N 0.000 description 1
- VGPCJSXPPOQPBK-YUMQZZPRSA-N Leu-Gly-Ser Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O VGPCJSXPPOQPBK-YUMQZZPRSA-N 0.000 description 1
- BTNXKBVLWJBTNR-SRVKXCTJSA-N Leu-His-Asn Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(N)=O)C(O)=O BTNXKBVLWJBTNR-SRVKXCTJSA-N 0.000 description 1
- YWYQSLOTVIRCFE-SRVKXCTJSA-N Leu-His-Asp Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(O)=O)C(O)=O YWYQSLOTVIRCFE-SRVKXCTJSA-N 0.000 description 1
- KXODZBLFVFSLAI-AVGNSLFASA-N Leu-His-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)CC(C)C)CC1=CN=CN1 KXODZBLFVFSLAI-AVGNSLFASA-N 0.000 description 1
- WRLPVDVHNWSSCL-MELADBBJSA-N Leu-His-Pro Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N2CCC[C@@H]2C(=O)O)N WRLPVDVHNWSSCL-MELADBBJSA-N 0.000 description 1
- OYQUOLRTJHWVSQ-SRVKXCTJSA-N Leu-His-Ser Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CO)C(O)=O OYQUOLRTJHWVSQ-SRVKXCTJSA-N 0.000 description 1
- OHZIZVWQXJPBJS-IXOXFDKPSA-N Leu-His-Thr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O OHZIZVWQXJPBJS-IXOXFDKPSA-N 0.000 description 1
- USLNHQZCDQJBOV-ZPFDUUQYSA-N Leu-Ile-Asn Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(N)=O)C(O)=O USLNHQZCDQJBOV-ZPFDUUQYSA-N 0.000 description 1
- KUIDCYNIEJBZBU-AJNGGQMLSA-N Leu-Ile-Leu Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(C)C)C(O)=O KUIDCYNIEJBZBU-AJNGGQMLSA-N 0.000 description 1
- JKSIBWITFMQTOA-XUXIUFHCSA-N Leu-Ile-Val Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C(C)C)C(O)=O JKSIBWITFMQTOA-XUXIUFHCSA-N 0.000 description 1
- PDQDCFBVYXEFSD-SRVKXCTJSA-N Leu-Leu-Asp Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O PDQDCFBVYXEFSD-SRVKXCTJSA-N 0.000 description 1
- QNBVTHNJGCOVFA-AVGNSLFASA-N Leu-Leu-Glu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CCC(O)=O QNBVTHNJGCOVFA-AVGNSLFASA-N 0.000 description 1
- XVZCXCTYGHPNEM-UHFFFAOYSA-N Leu-Leu-Pro Natural products CC(C)CC(N)C(=O)NC(CC(C)C)C(=O)N1CCCC1C(O)=O XVZCXCTYGHPNEM-UHFFFAOYSA-N 0.000 description 1
- IEWBEPKLKUXQBU-VOAKCMCISA-N Leu-Leu-Thr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O IEWBEPKLKUXQBU-VOAKCMCISA-N 0.000 description 1
- FOBUGKUBUJOWAD-IHPCNDPISA-N Leu-Leu-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC(C)C)C(O)=O)=CNC2=C1 FOBUGKUBUJOWAD-IHPCNDPISA-N 0.000 description 1
- UCNNZELZXFXXJQ-BZSNNMDCSA-N Leu-Leu-Tyr Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 UCNNZELZXFXXJQ-BZSNNMDCSA-N 0.000 description 1
- RZXLZBIUTDQHJQ-SRVKXCTJSA-N Leu-Lys-Asp Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(O)=O RZXLZBIUTDQHJQ-SRVKXCTJSA-N 0.000 description 1
- CPONGMJGVIAWEH-DCAQKATOSA-N Leu-Met-Ala Chemical compound CSCC[C@H](NC(=O)[C@@H](N)CC(C)C)C(=O)N[C@@H](C)C(O)=O CPONGMJGVIAWEH-DCAQKATOSA-N 0.000 description 1
- WXZOHBVPVKABQN-DCAQKATOSA-N Leu-Met-Asp Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(=O)O)C(=O)O)N WXZOHBVPVKABQN-DCAQKATOSA-N 0.000 description 1
- INCJJHQRZGQLFC-KBPBESRZSA-N Leu-Phe-Gly Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)NCC(O)=O INCJJHQRZGQLFC-KBPBESRZSA-N 0.000 description 1
- KTOIECMYZZGVSI-BZSNNMDCSA-N Leu-Phe-His Chemical compound C([C@H](NC(=O)[C@@H](N)CC(C)C)C(=O)N[C@@H](CC=1NC=NC=1)C(O)=O)C1=CC=CC=C1 KTOIECMYZZGVSI-BZSNNMDCSA-N 0.000 description 1
- DRWMRVFCKKXHCH-BZSNNMDCSA-N Leu-Phe-Leu Chemical compound CC(C)C[C@H]([NH3+])C(=O)N[C@H](C(=O)N[C@@H](CC(C)C)C([O-])=O)CC1=CC=CC=C1 DRWMRVFCKKXHCH-BZSNNMDCSA-N 0.000 description 1
- BMVFXOQHDQZAQU-DCAQKATOSA-N Leu-Pro-Asp Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(=O)O)C(=O)O)N BMVFXOQHDQZAQU-DCAQKATOSA-N 0.000 description 1
- VULJUQZPSOASBZ-SRVKXCTJSA-N Leu-Pro-Glu Chemical compound [H]N[C@@H](CC(C)C)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O VULJUQZPSOASBZ-SRVKXCTJSA-N 0.000 description 1
- KWLWZYMNUZJKMZ-IHRRRGAJSA-N Leu-Pro-Leu Chemical compound CC(C)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(O)=O KWLWZYMNUZJKMZ-IHRRRGAJSA-N 0.000 description 1
- UCXQIIIFOOGYEM-ULQDDVLXSA-N Leu-Pro-Tyr Chemical compound CC(C)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 UCXQIIIFOOGYEM-ULQDDVLXSA-N 0.000 description 1
- IRMLZWSRWSGTOP-CIUDSAMLSA-N Leu-Ser-Ala Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O IRMLZWSRWSGTOP-CIUDSAMLSA-N 0.000 description 1
- AKVBOOKXVAMKSS-GUBZILKMSA-N Leu-Ser-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(O)=O AKVBOOKXVAMKSS-GUBZILKMSA-N 0.000 description 1
- RGUXWMDNCPMQFB-YUMQZZPRSA-N Leu-Ser-Gly Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O RGUXWMDNCPMQFB-YUMQZZPRSA-N 0.000 description 1
- ADJWHHZETYAAAX-SRVKXCTJSA-N Leu-Ser-His Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N ADJWHHZETYAAAX-SRVKXCTJSA-N 0.000 description 1
- AMSSKPUHBUQBOQ-SRVKXCTJSA-N Leu-Ser-Lys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)O)N AMSSKPUHBUQBOQ-SRVKXCTJSA-N 0.000 description 1
- SBANPBVRHYIMRR-GARJFASQSA-N Leu-Ser-Pro Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CO)C(=O)N1CCC[C@@H]1C(=O)O)N SBANPBVRHYIMRR-GARJFASQSA-N 0.000 description 1
- VDIARPPNADFEAV-WEDXCCLWSA-N Leu-Thr-Gly Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O VDIARPPNADFEAV-WEDXCCLWSA-N 0.000 description 1
- URHJPNHRQMQGOZ-RHYQMDGZSA-N Leu-Thr-Met Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCSC)C(O)=O URHJPNHRQMQGOZ-RHYQMDGZSA-N 0.000 description 1
- ILDSIMPXNFWKLH-KATARQTJSA-N Leu-Thr-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O ILDSIMPXNFWKLH-KATARQTJSA-N 0.000 description 1
- AIQWYVFNBNNOLU-RHYQMDGZSA-N Leu-Thr-Val Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O AIQWYVFNBNNOLU-RHYQMDGZSA-N 0.000 description 1
- IDGRADDMTTWOQC-WDSOQIARSA-N Leu-Trp-Arg Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O IDGRADDMTTWOQC-WDSOQIARSA-N 0.000 description 1
- ONHCDMBHPQIPAI-YTQUADARSA-N Leu-Trp-Pro Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)N3CCC[C@@H]3C(=O)O)N ONHCDMBHPQIPAI-YTQUADARSA-N 0.000 description 1
- SUYRAPCRSCCPAK-VFAJRCTISA-N Leu-Trp-Thr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H]([C@@H](C)O)C(O)=O SUYRAPCRSCCPAK-VFAJRCTISA-N 0.000 description 1
- SXOFUVGLPHCPRQ-KKUMJFAQSA-N Leu-Tyr-Cys Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CS)C(O)=O SXOFUVGLPHCPRQ-KKUMJFAQSA-N 0.000 description 1
- SEOXPEFQEOYURL-PMVMPFDFSA-N Leu-Tyr-Trp Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O SEOXPEFQEOYURL-PMVMPFDFSA-N 0.000 description 1
- CGHXMODRYJISSK-NHCYSSNCSA-N Leu-Val-Asp Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC(O)=O CGHXMODRYJISSK-NHCYSSNCSA-N 0.000 description 1
- TUIOUEWKFFVNLH-DCAQKATOSA-N Leu-Val-Cys Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CS)C(O)=O TUIOUEWKFFVNLH-DCAQKATOSA-N 0.000 description 1
- AAKRWBIIGKPOKQ-ONGXEEELSA-N Leu-Val-Gly Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)NCC(O)=O AAKRWBIIGKPOKQ-ONGXEEELSA-N 0.000 description 1
- VKVDRTGWLVZJOM-DCAQKATOSA-N Leu-Val-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O VKVDRTGWLVZJOM-DCAQKATOSA-N 0.000 description 1
- MSFITIBEMPWCBD-ULQDDVLXSA-N Leu-Val-Tyr Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 MSFITIBEMPWCBD-ULQDDVLXSA-N 0.000 description 1
- FZIJIFCXUCZHOL-CIUDSAMLSA-N Lys-Ala-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCCN FZIJIFCXUCZHOL-CIUDSAMLSA-N 0.000 description 1
- PNPYKQFJGRFYJE-GUBZILKMSA-N Lys-Ala-Glu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(O)=O PNPYKQFJGRFYJE-GUBZILKMSA-N 0.000 description 1
- WXJKFRMKJORORD-DCAQKATOSA-N Lys-Arg-Ala Chemical compound NC(=N)NCCC[C@@H](C(=O)N[C@@H](C)C(O)=O)NC(=O)[C@@H](N)CCCCN WXJKFRMKJORORD-DCAQKATOSA-N 0.000 description 1
- ALSRJRIWBNENFY-DCAQKATOSA-N Lys-Arg-Asn Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(N)=O)C(O)=O ALSRJRIWBNENFY-DCAQKATOSA-N 0.000 description 1
- NTEVEUCLFMWSND-SRVKXCTJSA-N Lys-Arg-Gln Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(O)=O NTEVEUCLFMWSND-SRVKXCTJSA-N 0.000 description 1
- JGAMUXDWYSXYLM-SRVKXCTJSA-N Lys-Arg-Glu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(O)=O JGAMUXDWYSXYLM-SRVKXCTJSA-N 0.000 description 1
- QYOXSYXPHUHOJR-GUBZILKMSA-N Lys-Asn-Glu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O QYOXSYXPHUHOJR-GUBZILKMSA-N 0.000 description 1
- HQVDJTYKCMIWJP-YUMQZZPRSA-N Lys-Asn-Gly Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O HQVDJTYKCMIWJP-YUMQZZPRSA-N 0.000 description 1
- AAORVPFVUIHEAB-YUMQZZPRSA-N Lys-Asp-Gly Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O AAORVPFVUIHEAB-YUMQZZPRSA-N 0.000 description 1
- NRQRKMYZONPCTM-CIUDSAMLSA-N Lys-Asp-Ser Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O NRQRKMYZONPCTM-CIUDSAMLSA-N 0.000 description 1
- WTZUSCUIVPVCRH-SRVKXCTJSA-N Lys-Gln-Arg Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@H](C(O)=O)CCCN=C(N)N WTZUSCUIVPVCRH-SRVKXCTJSA-N 0.000 description 1
- HWMZUBUEOYAQSC-DCAQKATOSA-N Lys-Gln-Glu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O HWMZUBUEOYAQSC-DCAQKATOSA-N 0.000 description 1
- RZHLIPMZXOEJTL-AVGNSLFASA-N Lys-Gln-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCCCN)N RZHLIPMZXOEJTL-AVGNSLFASA-N 0.000 description 1
- GJJQCBVRWDGLMQ-GUBZILKMSA-N Lys-Glu-Ala Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O GJJQCBVRWDGLMQ-GUBZILKMSA-N 0.000 description 1
- GCMWRRQAKQXDED-IUCAKERBSA-N Lys-Glu-Gly Chemical compound [NH3+]CCCC[C@H]([NH3+])C(=O)N[C@@H](CCC([O-])=O)C(=O)NCC([O-])=O GCMWRRQAKQXDED-IUCAKERBSA-N 0.000 description 1
- GPJGFSFYBJGYRX-YUMQZZPRSA-N Lys-Gly-Asp Chemical compound NCCCC[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC(O)=O GPJGFSFYBJGYRX-YUMQZZPRSA-N 0.000 description 1
- KKFVKBWCXXLKIK-AVGNSLFASA-N Lys-His-Glu Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@H](CCCCN)N KKFVKBWCXXLKIK-AVGNSLFASA-N 0.000 description 1
- WOEDRPCHKPSFDT-MXAVVETBSA-N Lys-His-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CN=CN1)NC(=O)[C@H](CCCCN)N WOEDRPCHKPSFDT-MXAVVETBSA-N 0.000 description 1
- OWRUUFUVXFREBD-KKUMJFAQSA-N Lys-His-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(C)C)C(O)=O OWRUUFUVXFREBD-KKUMJFAQSA-N 0.000 description 1
- NJNRBRKHOWSGMN-SRVKXCTJSA-N Lys-Leu-Asn Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O NJNRBRKHOWSGMN-SRVKXCTJSA-N 0.000 description 1
- YPLVCBKEPJPBDQ-MELADBBJSA-N Lys-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCCCN)N YPLVCBKEPJPBDQ-MELADBBJSA-N 0.000 description 1
- UDXSLGLHFUBRRM-OEAJRASXSA-N Lys-Phe-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)NC(=O)[C@H](CCCCN)N)O UDXSLGLHFUBRRM-OEAJRASXSA-N 0.000 description 1
- SVSQSPICRKBMSZ-SRVKXCTJSA-N Lys-Pro-Gln Chemical compound [H]N[C@@H](CCCCN)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(O)=O SVSQSPICRKBMSZ-SRVKXCTJSA-N 0.000 description 1
- YTJFXEDRUOQGSP-DCAQKATOSA-N Lys-Pro-Ser Chemical compound [H]N[C@@H](CCCCN)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O YTJFXEDRUOQGSP-DCAQKATOSA-N 0.000 description 1
- LOGFVTREOLYCPF-RHYQMDGZSA-N Lys-Pro-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CCCCN LOGFVTREOLYCPF-RHYQMDGZSA-N 0.000 description 1
- DIBZLYZXTSVGLN-CIUDSAMLSA-N Lys-Ser-Ser Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O DIBZLYZXTSVGLN-CIUDSAMLSA-N 0.000 description 1
- CUHGAUZONORRIC-HJGDQZAQSA-N Lys-Thr-Asn Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CCCCN)N)O CUHGAUZONORRIC-HJGDQZAQSA-N 0.000 description 1
- JHNOXVASMSXSNB-WEDXCCLWSA-N Lys-Thr-Gly Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O JHNOXVASMSXSNB-WEDXCCLWSA-N 0.000 description 1
- RPWTZTBIFGENIA-VOAKCMCISA-N Lys-Thr-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O RPWTZTBIFGENIA-VOAKCMCISA-N 0.000 description 1
- MIMXMVDLMDMOJD-BZSNNMDCSA-N Lys-Tyr-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(C)C)C(O)=O MIMXMVDLMDMOJD-BZSNNMDCSA-N 0.000 description 1
- DRRXXZBXDMLGFC-IHRRRGAJSA-N Lys-Val-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CCCCN DRRXXZBXDMLGFC-IHRRRGAJSA-N 0.000 description 1
- TXTZMVNJIRZABH-ULQDDVLXSA-N Lys-Val-Phe Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 TXTZMVNJIRZABH-ULQDDVLXSA-N 0.000 description 1
- 239000007993 MOPS buffer Substances 0.000 description 1
- 229910021380 Manganese Chloride Inorganic materials 0.000 description 1
- VHGIWFGJIHTASW-FXQIFTODSA-N Met-Ala-Asp Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC(O)=O VHGIWFGJIHTASW-FXQIFTODSA-N 0.000 description 1
- GAELMDJMQDUDLJ-BQBZGAKWSA-N Met-Ala-Gly Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C)C(=O)NCC(O)=O GAELMDJMQDUDLJ-BQBZGAKWSA-N 0.000 description 1
- MUYQDMBLDFEVRJ-LSJOCFKGSA-N Met-Ala-His Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CNC=N1 MUYQDMBLDFEVRJ-LSJOCFKGSA-N 0.000 description 1
- ULNXMMYXQKGNPG-LPEHRKFASA-N Met-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCSC)N ULNXMMYXQKGNPG-LPEHRKFASA-N 0.000 description 1
- DLAFCQWUMFMZSN-GUBZILKMSA-N Met-Arg-Ala Chemical compound CSCC[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](C)C(O)=O)CCCN=C(N)N DLAFCQWUMFMZSN-GUBZILKMSA-N 0.000 description 1
- DCHHUGLTVLJYKA-FXQIFTODSA-N Met-Asn-Ala Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](C)C(O)=O DCHHUGLTVLJYKA-FXQIFTODSA-N 0.000 description 1
- ACYHZNZHIZWLQF-BQBZGAKWSA-N Met-Asn-Gly Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O ACYHZNZHIZWLQF-BQBZGAKWSA-N 0.000 description 1
- DBOMZJOESVYERT-GUBZILKMSA-N Met-Asn-Met Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CCSC)C(=O)O)N DBOMZJOESVYERT-GUBZILKMSA-N 0.000 description 1
- TUSOIZOVPJCMFC-FXQIFTODSA-N Met-Asp-Asp Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O TUSOIZOVPJCMFC-FXQIFTODSA-N 0.000 description 1
- GODBLDDYHFTUAH-CIUDSAMLSA-N Met-Asp-Glu Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CCC(O)=O GODBLDDYHFTUAH-CIUDSAMLSA-N 0.000 description 1
- FJVJLMZUIGMFFU-BQBZGAKWSA-N Met-Asp-Gly Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O FJVJLMZUIGMFFU-BQBZGAKWSA-N 0.000 description 1
- KQBJYJXPZBNEIK-DCAQKATOSA-N Met-Glu-Arg Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@H](C(O)=O)CCCNC(N)=N KQBJYJXPZBNEIK-DCAQKATOSA-N 0.000 description 1
- YORIKIDJCPKBON-YUMQZZPRSA-N Met-Glu-Gly Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O YORIKIDJCPKBON-YUMQZZPRSA-N 0.000 description 1
- OGAZPKJHHZPYFK-GARJFASQSA-N Met-Glu-Pro Chemical compound CSCC[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N1CCC[C@@H]1C(=O)O)N OGAZPKJHHZPYFK-GARJFASQSA-N 0.000 description 1
- AFFKUNVPPLQUGA-DCAQKATOSA-N Met-Leu-Ala Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(O)=O AFFKUNVPPLQUGA-DCAQKATOSA-N 0.000 description 1
- SODXFJOPSCXOHE-IHRRRGAJSA-N Met-Leu-Leu Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O SODXFJOPSCXOHE-IHRRRGAJSA-N 0.000 description 1
- XDGFFEZAZHRZFR-RHYQMDGZSA-N Met-Leu-Thr Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O XDGFFEZAZHRZFR-RHYQMDGZSA-N 0.000 description 1
- CNAGWYQWQDMUGC-IHRRRGAJSA-N Met-Phe-Asn Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(=O)N)C(=O)O)N CNAGWYQWQDMUGC-IHRRRGAJSA-N 0.000 description 1
- NTYQUVLERIHPMU-HRCADAONSA-N Met-Phe-Pro Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N2CCC[C@@H]2C(=O)O)N NTYQUVLERIHPMU-HRCADAONSA-N 0.000 description 1
- WYDFQSJOARJAMM-GUBZILKMSA-N Met-Pro-Asp Chemical compound CSCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(O)=O WYDFQSJOARJAMM-GUBZILKMSA-N 0.000 description 1
- QEDGNYFHLXXIDC-DCAQKATOSA-N Met-Pro-Gln Chemical compound CSCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(O)=O QEDGNYFHLXXIDC-DCAQKATOSA-N 0.000 description 1
- LUYURUYVNYGKGM-RCWTZXSCSA-N Met-Pro-Thr Chemical compound CSCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(O)=O LUYURUYVNYGKGM-RCWTZXSCSA-N 0.000 description 1
- IHRFZLQEQVHXFA-RHYQMDGZSA-N Met-Thr-Lys Chemical compound CSCC[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CCCCN IHRFZLQEQVHXFA-RHYQMDGZSA-N 0.000 description 1
- GWADARYJIJDYRC-XGEHTFHBSA-N Met-Thr-Ser Chemical compound CSCC[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O GWADARYJIJDYRC-XGEHTFHBSA-N 0.000 description 1
- JACMWNXOOUYXCD-JYJNAYRXSA-N Met-Val-Phe Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 JACMWNXOOUYXCD-JYJNAYRXSA-N 0.000 description 1
- 101100219625 Mus musculus Casd1 gene Proteins 0.000 description 1
- WYBVBIHNJWOLCJ-UHFFFAOYSA-N N-L-arginyl-L-leucine Natural products CC(C)CC(C(O)=O)NC(=O)C(N)CCCN=C(N)N WYBVBIHNJWOLCJ-UHFFFAOYSA-N 0.000 description 1
- 108010047562 NGR peptide Proteins 0.000 description 1
- 108020004711 Nucleic Acid Probes Proteins 0.000 description 1
- 229910019142 PO4 Inorganic materials 0.000 description 1
- 108020002230 Pancreatic Ribonuclease Proteins 0.000 description 1
- 102000005891 Pancreatic ribonuclease Human genes 0.000 description 1
- 206010034133 Pathogen resistance Diseases 0.000 description 1
- WGXOKDLDIWSOCV-MELADBBJSA-N Phe-Asn-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)N)NC(=O)[C@H](CC2=CC=CC=C2)N)C(=O)O WGXOKDLDIWSOCV-MELADBBJSA-N 0.000 description 1
- PDUVELWDJZOUEI-IHRRRGAJSA-N Phe-Cys-Arg Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O PDUVELWDJZOUEI-IHRRRGAJSA-N 0.000 description 1
- KKYHKZCMETTXEO-AVGNSLFASA-N Phe-Cys-Glu Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N KKYHKZCMETTXEO-AVGNSLFASA-N 0.000 description 1
- LXUJDHOKVUYHRC-KKUMJFAQSA-N Phe-Cys-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CC1=CC=CC=C1)N LXUJDHOKVUYHRC-KKUMJFAQSA-N 0.000 description 1
- KOUUGTKGEQZRHV-KKUMJFAQSA-N Phe-Gln-Arg Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O KOUUGTKGEQZRHV-KKUMJFAQSA-N 0.000 description 1
- SXJGROGVINAYSH-AVGNSLFASA-N Phe-Gln-Asp Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC(=O)O)C(=O)O)N SXJGROGVINAYSH-AVGNSLFASA-N 0.000 description 1
- KAGCQPSEVAETCA-JYJNAYRXSA-N Phe-Gln-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CC1=CC=CC=C1)N KAGCQPSEVAETCA-JYJNAYRXSA-N 0.000 description 1
- NKLDZIPTGKBDBB-HTUGSXCWSA-N Phe-Gln-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CC1=CC=CC=C1)N)O NKLDZIPTGKBDBB-HTUGSXCWSA-N 0.000 description 1
- MFQXSDWKUXTOPZ-DZKIICNBSA-N Phe-Gln-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CC1=CC=CC=C1)N MFQXSDWKUXTOPZ-DZKIICNBSA-N 0.000 description 1
- JWQWPTLEOFNCGX-AVGNSLFASA-N Phe-Glu-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC1=CC=CC=C1 JWQWPTLEOFNCGX-AVGNSLFASA-N 0.000 description 1
- JEBWZLWTRPZQRX-QWRGUYRKSA-N Phe-Gly-Asp Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(O)=O JEBWZLWTRPZQRX-QWRGUYRKSA-N 0.000 description 1
- NAXPHWZXEXNDIW-JTQLQIEISA-N Phe-Gly-Gly Chemical compound OC(=O)CNC(=O)CNC(=O)[C@@H](N)CC1=CC=CC=C1 NAXPHWZXEXNDIW-JTQLQIEISA-N 0.000 description 1
- XEXSSIBQYNKFBX-KBPBESRZSA-N Phe-Gly-His Chemical compound C([C@H](N)C(=O)NCC(=O)N[C@@H](CC=1N=CNC=1)C(O)=O)C1=CC=CC=C1 XEXSSIBQYNKFBX-KBPBESRZSA-N 0.000 description 1
- OVJMCXAPGFDGMG-HKUYNNGSSA-N Phe-Gly-Trp Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)NCC(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O OVJMCXAPGFDGMG-HKUYNNGSSA-N 0.000 description 1
- WKTSCAXSYITIJJ-PCBIJLKTSA-N Phe-Ile-Asn Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(N)=O)C(O)=O WKTSCAXSYITIJJ-PCBIJLKTSA-N 0.000 description 1
- GYEPCBNTTRORKW-PCBIJLKTSA-N Phe-Ile-Asp Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(O)=O)C(O)=O GYEPCBNTTRORKW-PCBIJLKTSA-N 0.000 description 1
- CMHTUJQZQXFNTQ-OEAJRASXSA-N Phe-Leu-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC1=CC=CC=C1)N)O CMHTUJQZQXFNTQ-OEAJRASXSA-N 0.000 description 1
- DNAXXTQSTKOHFO-QEJZJMRPSA-N Phe-Lys-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CC1=CC=CC=C1 DNAXXTQSTKOHFO-QEJZJMRPSA-N 0.000 description 1
- BSHMIVKDJQGLNT-ACRUOGEOSA-N Phe-Lys-Tyr Chemical compound C([C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=CC=C1 BSHMIVKDJQGLNT-ACRUOGEOSA-N 0.000 description 1
- KAJLHCWRWDSROH-BZSNNMDCSA-N Phe-Phe-Asp Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](CC(O)=O)C(O)=O)C1=CC=CC=C1 KAJLHCWRWDSROH-BZSNNMDCSA-N 0.000 description 1
- GPLWGAYGROGDEN-BZSNNMDCSA-N Phe-Phe-Ser Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(O)=O GPLWGAYGROGDEN-BZSNNMDCSA-N 0.000 description 1
- RVEVENLSADZUMS-IHRRRGAJSA-N Phe-Pro-Asn Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(N)=O)C(O)=O RVEVENLSADZUMS-IHRRRGAJSA-N 0.000 description 1
- QARPMYDMYVLFMW-KKUMJFAQSA-N Phe-Pro-Glu Chemical compound C([C@H](N)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CCC(O)=O)C(O)=O)C1=CC=CC=C1 QARPMYDMYVLFMW-KKUMJFAQSA-N 0.000 description 1
- ODGNUUUDJONJSC-UFYCRDLUSA-N Phe-Pro-Tyr Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CC2=CC=CC=C2)N)C(=O)N[C@@H](CC3=CC=C(C=C3)O)C(=O)O ODGNUUUDJONJSC-UFYCRDLUSA-N 0.000 description 1
- JXQVYPWVGUOIDV-MXAVVETBSA-N Phe-Ser-Ile Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O JXQVYPWVGUOIDV-MXAVVETBSA-N 0.000 description 1
- MCIXMYKSPQUMJG-SRVKXCTJSA-N Phe-Ser-Ser Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O MCIXMYKSPQUMJG-SRVKXCTJSA-N 0.000 description 1
- UMIHVJQSXFWWMW-JBACZVJFSA-N Phe-Trp-Gln Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC2=CNC3=CC=CC=C32)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N UMIHVJQSXFWWMW-JBACZVJFSA-N 0.000 description 1
- VFDRDMOMHBJGKD-UFYCRDLUSA-N Phe-Tyr-Arg Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N VFDRDMOMHBJGKD-UFYCRDLUSA-N 0.000 description 1
- QUUCAHIYARMNBL-FHWLQOOXSA-N Phe-Tyr-Gln Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N QUUCAHIYARMNBL-FHWLQOOXSA-N 0.000 description 1
- ZYNBEWGJFXTBDU-ACRUOGEOSA-N Phe-Tyr-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@H](CC2=CC=CC=C2)N ZYNBEWGJFXTBDU-ACRUOGEOSA-N 0.000 description 1
- GOUWCZRDTWTODO-YDHLFZDLSA-N Phe-Val-Asn Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O GOUWCZRDTWTODO-YDHLFZDLSA-N 0.000 description 1
- 108010010677 Phosphodiesterase I Proteins 0.000 description 1
- 108091000080 Phosphotransferase Proteins 0.000 description 1
- 101000686495 Platymeris rhadamanthus Venom redulysin 2 Proteins 0.000 description 1
- 229920001213 Polysorbate 20 Polymers 0.000 description 1
- DZZCICYRSZASNF-FXQIFTODSA-N Pro-Ala-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1 DZZCICYRSZASNF-FXQIFTODSA-N 0.000 description 1
- VXCHGLYSIOOZIS-GUBZILKMSA-N Pro-Ala-Arg Chemical compound NC(N)=NCCC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1 VXCHGLYSIOOZIS-GUBZILKMSA-N 0.000 description 1
- DBALDZKOTNSBFM-FXQIFTODSA-N Pro-Ala-Asn Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(O)=O DBALDZKOTNSBFM-FXQIFTODSA-N 0.000 description 1
- APKRGYLBSCWJJP-FXQIFTODSA-N Pro-Ala-Asp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(O)=O APKRGYLBSCWJJP-FXQIFTODSA-N 0.000 description 1
- IWNOFCGBMSFTBC-CIUDSAMLSA-N Pro-Ala-Glu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(O)=O IWNOFCGBMSFTBC-CIUDSAMLSA-N 0.000 description 1
- KIZQGKLMXKGDIV-BQBZGAKWSA-N Pro-Ala-Gly Chemical compound OC(=O)CNC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1 KIZQGKLMXKGDIV-BQBZGAKWSA-N 0.000 description 1
- FCCBQBZXIAZNIG-LSJOCFKGSA-N Pro-Ala-His Chemical compound C[C@H](NC(=O)[C@@H]1CCCN1)C(=O)N[C@@H](Cc1cnc[nH]1)C(O)=O FCCBQBZXIAZNIG-LSJOCFKGSA-N 0.000 description 1
- FYQSMXKJYTZYRP-DCAQKATOSA-N Pro-Ala-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1 FYQSMXKJYTZYRP-DCAQKATOSA-N 0.000 description 1
- HFZNNDWPHBRNPV-KZVJFYERSA-N Pro-Ala-Thr Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O HFZNNDWPHBRNPV-KZVJFYERSA-N 0.000 description 1
- NHDVNAKDACFHPX-GUBZILKMSA-N Pro-Arg-Ala Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(O)=O NHDVNAKDACFHPX-GUBZILKMSA-N 0.000 description 1
- LNLNHXIQPGKRJQ-SRVKXCTJSA-N Pro-Arg-Arg Chemical compound NC(N)=NCCC[C@@H](C(O)=O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@@H]1CCCN1 LNLNHXIQPGKRJQ-SRVKXCTJSA-N 0.000 description 1
- SSSFPISOZOLQNP-GUBZILKMSA-N Pro-Arg-Asp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(O)=O SSSFPISOZOLQNP-GUBZILKMSA-N 0.000 description 1
- IHCXPSYCHXFXKT-DCAQKATOSA-N Pro-Arg-Glu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(O)=O IHCXPSYCHXFXKT-DCAQKATOSA-N 0.000 description 1
- QBFONMUYNSNKIX-AVGNSLFASA-N Pro-Arg-His Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC2=CN=CN2)C(=O)O QBFONMUYNSNKIX-AVGNSLFASA-N 0.000 description 1
- QSKCKTUQPICLSO-AVGNSLFASA-N Pro-Arg-Lys Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCCCN)C(=O)O QSKCKTUQPICLSO-AVGNSLFASA-N 0.000 description 1
- UTAUEDINXUMHLG-FXQIFTODSA-N Pro-Asp-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@@H]1CCCN1 UTAUEDINXUMHLG-FXQIFTODSA-N 0.000 description 1
- ILMLVTGTUJPQFP-FXQIFTODSA-N Pro-Asp-Asp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O ILMLVTGTUJPQFP-FXQIFTODSA-N 0.000 description 1
- KIGGUSRFHJCIEJ-DCAQKATOSA-N Pro-Asp-His Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC2=CN=CN2)C(=O)O KIGGUSRFHJCIEJ-DCAQKATOSA-N 0.000 description 1
- ZCXQTRXYZOSGJR-FXQIFTODSA-N Pro-Asp-Ser Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O ZCXQTRXYZOSGJR-FXQIFTODSA-N 0.000 description 1
- TUYWCHPXKQTISF-LPEHRKFASA-N Pro-Cys-Pro Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CS)C(=O)N2CCC[C@@H]2C(=O)O TUYWCHPXKQTISF-LPEHRKFASA-N 0.000 description 1
- UPJGUQPLYWTISV-GUBZILKMSA-N Pro-Gln-Glu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O UPJGUQPLYWTISV-GUBZILKMSA-N 0.000 description 1
- LANQLYHLMYDWJP-SRVKXCTJSA-N Pro-Gln-Lys Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CCCCN)C(=O)O LANQLYHLMYDWJP-SRVKXCTJSA-N 0.000 description 1
- SKICPQLTOXGWGO-GARJFASQSA-N Pro-Gln-Pro Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CCC(=O)N)C(=O)N2CCC[C@@H]2C(=O)O SKICPQLTOXGWGO-GARJFASQSA-N 0.000 description 1
- PULPZRAHVFBVTO-DCAQKATOSA-N Pro-Glu-Arg Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O PULPZRAHVFBVTO-DCAQKATOSA-N 0.000 description 1
- NMELOOXSGDRBRU-YUMQZZPRSA-N Pro-Glu-Gly Chemical compound OC(=O)CNC(=O)[C@H](CCC(=O)O)NC(=O)[C@@H]1CCCN1 NMELOOXSGDRBRU-YUMQZZPRSA-N 0.000 description 1
- NXEYSLRNNPWCRN-SRVKXCTJSA-N Pro-Glu-Leu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O NXEYSLRNNPWCRN-SRVKXCTJSA-N 0.000 description 1
- CLNJSLSHKJECME-BQBZGAKWSA-N Pro-Gly-Ala Chemical compound OC(=O)[C@H](C)NC(=O)CNC(=O)[C@@H]1CCCN1 CLNJSLSHKJECME-BQBZGAKWSA-N 0.000 description 1
- WSRWHZRUOCACLJ-UWVGGRQHSA-N Pro-Gly-His Chemical compound C([C@@H](C(=O)O)NC(=O)CNC(=O)[C@H]1NCCC1)C1=CN=CN1 WSRWHZRUOCACLJ-UWVGGRQHSA-N 0.000 description 1
- HAEGAELAYWSUNC-WPRPVWTQSA-N Pro-Gly-Val Chemical compound [H]N1CCC[C@H]1C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O HAEGAELAYWSUNC-WPRPVWTQSA-N 0.000 description 1
- STASJMBVVHNWCG-IHRRRGAJSA-N Pro-His-Leu Chemical compound C([C@@H](C(=O)N[C@@H](CC(C)C)C([O-])=O)NC(=O)[C@H]1[NH2+]CCC1)C1=CN=CN1 STASJMBVVHNWCG-IHRRRGAJSA-N 0.000 description 1
- AQGUSRZKDZYGGV-GMOBBJLQSA-N Pro-Ile-Asp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(O)=O)C(O)=O AQGUSRZKDZYGGV-GMOBBJLQSA-N 0.000 description 1
- RUDOLGWDSKQQFF-DCAQKATOSA-N Pro-Leu-Asn Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O RUDOLGWDSKQQFF-DCAQKATOSA-N 0.000 description 1
- FXGIMYRVJJEIIM-UWVGGRQHSA-N Pro-Leu-Gly Chemical compound OC(=O)CNC(=O)[C@H](CC(C)C)NC(=O)[C@@H]1CCCN1 FXGIMYRVJJEIIM-UWVGGRQHSA-N 0.000 description 1
- FKYKZHOKDOPHSA-DCAQKATOSA-N Pro-Leu-Ser Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O FKYKZHOKDOPHSA-DCAQKATOSA-N 0.000 description 1
- RMODQFBNDDENCP-IHRRRGAJSA-N Pro-Lys-Leu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(O)=O RMODQFBNDDENCP-IHRRRGAJSA-N 0.000 description 1
- WOIFYRZPIORBRY-AVGNSLFASA-N Pro-Lys-Val Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(O)=O WOIFYRZPIORBRY-AVGNSLFASA-N 0.000 description 1
- ZJXXCGZFYQQETF-CYDGBPFRSA-N Pro-Met-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CCSC)NC(=O)[C@@H]1CCCN1 ZJXXCGZFYQQETF-CYDGBPFRSA-N 0.000 description 1
- QCMYJBKTMIWZAP-AVGNSLFASA-N Pro-Met-Lys Chemical compound CSCC[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@@H]1CCCN1 QCMYJBKTMIWZAP-AVGNSLFASA-N 0.000 description 1
- ZUZINZIJHJFJRN-UBHSHLNASA-N Pro-Phe-Ala Chemical compound C([C@@H](C(=O)N[C@@H](C)C(O)=O)NC(=O)[C@H]1NCCC1)C1=CC=CC=C1 ZUZINZIJHJFJRN-UBHSHLNASA-N 0.000 description 1
- AJBQTGZIZQXBLT-STQMWFEESA-N Pro-Phe-Gly Chemical compound C([C@@H](C(=O)NCC(=O)O)NC(=O)[C@H]1NCCC1)C1=CC=CC=C1 AJBQTGZIZQXBLT-STQMWFEESA-N 0.000 description 1
- JLMZKEQFMVORMA-SRVKXCTJSA-N Pro-Pro-Arg Chemical compound NC(N)=NCCC[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H]1NCCC1 JLMZKEQFMVORMA-SRVKXCTJSA-N 0.000 description 1
- FHZJRBVMLGOHBX-GUBZILKMSA-N Pro-Pro-Asp Chemical compound OC(=O)C[C@H](NC(=O)[C@@H]1CCCN1C(=O)[C@@H]1CCCN1)C(O)=O FHZJRBVMLGOHBX-GUBZILKMSA-N 0.000 description 1
- RFWXYTJSVDUBBZ-DCAQKATOSA-N Pro-Pro-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H]1NCCC1 RFWXYTJSVDUBBZ-DCAQKATOSA-N 0.000 description 1
- LEIKGVHQTKHOLM-IUCAKERBSA-N Pro-Pro-Gly Chemical compound OC(=O)CNC(=O)[C@@H]1CCCN1C(=O)[C@H]1NCCC1 LEIKGVHQTKHOLM-IUCAKERBSA-N 0.000 description 1
- FDMKYQQYJKYCLV-GUBZILKMSA-N Pro-Pro-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H]1NCCC1 FDMKYQQYJKYCLV-GUBZILKMSA-N 0.000 description 1
- GOMUXSCOIWIJFP-GUBZILKMSA-N Pro-Ser-Arg Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O GOMUXSCOIWIJFP-GUBZILKMSA-N 0.000 description 1
- GMJDSFYVTAMIBF-FXQIFTODSA-N Pro-Ser-Asp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O GMJDSFYVTAMIBF-FXQIFTODSA-N 0.000 description 1
- LNICFEXCAHIJOR-DCAQKATOSA-N Pro-Ser-Leu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O LNICFEXCAHIJOR-DCAQKATOSA-N 0.000 description 1
- QKDIHFHGHBYTKB-IHRRRGAJSA-N Pro-Ser-Phe Chemical compound N([C@@H](CO)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C(=O)[C@@H]1CCCN1 QKDIHFHGHBYTKB-IHRRRGAJSA-N 0.000 description 1
- PKHDJFHFMGQMPS-RCWTZXSCSA-N Pro-Thr-Arg Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O PKHDJFHFMGQMPS-RCWTZXSCSA-N 0.000 description 1
- CWZUFLWPEFHWEI-IHRRRGAJSA-N Pro-Tyr-Asp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(O)=O)C(O)=O CWZUFLWPEFHWEI-IHRRRGAJSA-N 0.000 description 1
- FZXSYIPVAFVYBH-KKUMJFAQSA-N Pro-Tyr-Glu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(O)=O)C(O)=O FZXSYIPVAFVYBH-KKUMJFAQSA-N 0.000 description 1
- LZHHZYDPMZEMRX-STQMWFEESA-N Pro-Tyr-Gly Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)NCC(O)=O LZHHZYDPMZEMRX-STQMWFEESA-N 0.000 description 1
- OOZJHTXCLJUODH-QXEWZRGKSA-N Pro-Val-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H]1CCCN1 OOZJHTXCLJUODH-QXEWZRGKSA-N 0.000 description 1
- UCTIUWKCVNGEFH-OBJOEFQTSA-N Pro-Val-Gly-Pro Chemical compound N([C@@H](C(C)C)C(=O)NCC(=O)N1[C@@H](CCC1)C(O)=O)C(=O)[C@@H]1CCCN1 UCTIUWKCVNGEFH-OBJOEFQTSA-N 0.000 description 1
- IIRBTQHFVNGPMQ-AVGNSLFASA-N Pro-Val-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@@H]1CCCN1 IIRBTQHFVNGPMQ-AVGNSLFASA-N 0.000 description 1
- MTMJNKFZDQEVSY-BZSNNMDCSA-N Pro-Val-Trp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O MTMJNKFZDQEVSY-BZSNNMDCSA-N 0.000 description 1
- FHJQROWZEJFZPO-SRVKXCTJSA-N Pro-Val-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H]1CCCN1 FHJQROWZEJFZPO-SRVKXCTJSA-N 0.000 description 1
- 102000055027 Protein Methyltransferases Human genes 0.000 description 1
- 108700040121 Protein Methyltransferases Proteins 0.000 description 1
- 108010079005 RDV peptide Proteins 0.000 description 1
- 238000002123 RNA extraction Methods 0.000 description 1
- 230000004570 RNA-binding Effects 0.000 description 1
- 108010046983 Ribonuclease T1 Proteins 0.000 description 1
- 108010083644 Ribonucleases Proteins 0.000 description 1
- 102000006382 Ribonucleases Human genes 0.000 description 1
- 238000012300 Sequence Analysis Methods 0.000 description 1
- ZUGXSSFMTXKHJS-ZLUOBGJFSA-N Ser-Ala-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H](C)C(O)=O ZUGXSSFMTXKHJS-ZLUOBGJFSA-N 0.000 description 1
- SRTCFKGBYBZRHA-ACZMJKKPSA-N Ser-Ala-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(O)=O SRTCFKGBYBZRHA-ACZMJKKPSA-N 0.000 description 1
- HRNQLKCLPVKZNE-CIUDSAMLSA-N Ser-Ala-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O HRNQLKCLPVKZNE-CIUDSAMLSA-N 0.000 description 1
- JPIDMRXXNMIVKY-VZFHVOOUSA-N Ser-Ala-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O JPIDMRXXNMIVKY-VZFHVOOUSA-N 0.000 description 1
- PZZJMBYSYAKYPK-UWJYBYFXSA-N Ser-Ala-Tyr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O PZZJMBYSYAKYPK-UWJYBYFXSA-N 0.000 description 1
- QGMLKFGTGXWAHF-IHRRRGAJSA-N Ser-Arg-Phe Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O QGMLKFGTGXWAHF-IHRRRGAJSA-N 0.000 description 1
- VGNYHOBZJKWRGI-CIUDSAMLSA-N Ser-Asn-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CO VGNYHOBZJKWRGI-CIUDSAMLSA-N 0.000 description 1
- TYYBJUYSTWJHGO-ZKWXMUAHSA-N Ser-Asn-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](C(C)C)C(O)=O TYYBJUYSTWJHGO-ZKWXMUAHSA-N 0.000 description 1
- BNFVPSRLHHPQKS-WHFBIAKZSA-N Ser-Asp-Gly Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O BNFVPSRLHHPQKS-WHFBIAKZSA-N 0.000 description 1
- SFZKGGOGCNQPJY-CIUDSAMLSA-N Ser-Asp-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CO)N SFZKGGOGCNQPJY-CIUDSAMLSA-N 0.000 description 1
- BGOWRLSWJCVYAQ-CIUDSAMLSA-N Ser-Asp-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O BGOWRLSWJCVYAQ-CIUDSAMLSA-N 0.000 description 1
- GHPQVUYZQQGEDA-BIIVOSGPSA-N Ser-Asp-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)O)NC(=O)[C@H](CO)N)C(=O)O GHPQVUYZQQGEDA-BIIVOSGPSA-N 0.000 description 1
- KJMOINFQVCCSDX-XKBZYTNZSA-N Ser-Gln-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O KJMOINFQVCCSDX-XKBZYTNZSA-N 0.000 description 1
- SMIDBHKWSYUBRZ-ACZMJKKPSA-N Ser-Glu-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O SMIDBHKWSYUBRZ-ACZMJKKPSA-N 0.000 description 1
- PVDTYLHUWAEYGY-CIUDSAMLSA-N Ser-Glu-Arg Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O PVDTYLHUWAEYGY-CIUDSAMLSA-N 0.000 description 1
- UOLGINIHBRIECN-FXQIFTODSA-N Ser-Glu-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O UOLGINIHBRIECN-FXQIFTODSA-N 0.000 description 1
- YRBGKVIWMNEVCZ-WDSKDSINSA-N Ser-Glu-Gly Chemical compound OC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O YRBGKVIWMNEVCZ-WDSKDSINSA-N 0.000 description 1
- UFKPDBLKLOBMRH-XHNCKOQMSA-N Ser-Glu-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CO)N)C(=O)O UFKPDBLKLOBMRH-XHNCKOQMSA-N 0.000 description 1
- VQBCMLMPEWPUTB-ACZMJKKPSA-N Ser-Glu-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O VQBCMLMPEWPUTB-ACZMJKKPSA-N 0.000 description 1
- OHKFXGKHSJKKAL-NRPADANISA-N Ser-Glu-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O OHKFXGKHSJKKAL-NRPADANISA-N 0.000 description 1
- KDGARKCAKHBEDB-NKWVEPMBSA-N Ser-Gly-Pro Chemical compound C1C[C@@H](N(C1)C(=O)CNC(=O)[C@H](CO)N)C(=O)O KDGARKCAKHBEDB-NKWVEPMBSA-N 0.000 description 1
- XXXAXOWMBOKTRN-XPUUQOCRSA-N Ser-Gly-Val Chemical compound [H]N[C@@H](CO)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O XXXAXOWMBOKTRN-XPUUQOCRSA-N 0.000 description 1
- HMRAQFJFTOLDKW-GUBZILKMSA-N Ser-His-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCC(O)=O)C(O)=O HMRAQFJFTOLDKW-GUBZILKMSA-N 0.000 description 1
- CICQXRWZNVXFCU-SRVKXCTJSA-N Ser-His-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(C)C)C(O)=O CICQXRWZNVXFCU-SRVKXCTJSA-N 0.000 description 1
- LQESNKGTTNHZPZ-GHCJXIJMSA-N Ser-Ile-Asn Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(N)=O)C(O)=O LQESNKGTTNHZPZ-GHCJXIJMSA-N 0.000 description 1
- CJINPXGSKSZQNE-KBIXCLLPSA-N Ser-Ile-Gln Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(N)=O)C(O)=O CJINPXGSKSZQNE-KBIXCLLPSA-N 0.000 description 1
- IFPBAGJBHSNYPR-ZKWXMUAHSA-N Ser-Ile-Gly Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(=O)NCC(O)=O IFPBAGJBHSNYPR-ZKWXMUAHSA-N 0.000 description 1
- JIPVNVNKXJLFJF-BJDJZHNGSA-N Ser-Ile-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CO)N JIPVNVNKXJLFJF-BJDJZHNGSA-N 0.000 description 1
- MQQBBLVOUUJKLH-HJPIBITLSA-N Ser-Ile-Tyr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O MQQBBLVOUUJKLH-HJPIBITLSA-N 0.000 description 1
- DOSZISJPMCYEHT-NAKRPEOUSA-N Ser-Ile-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C(C)C)C(O)=O DOSZISJPMCYEHT-NAKRPEOUSA-N 0.000 description 1
- FUMGHWDRRFCKEP-CIUDSAMLSA-N Ser-Leu-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(O)=O FUMGHWDRRFCKEP-CIUDSAMLSA-N 0.000 description 1
- KCNSGAMPBPYUAI-CIUDSAMLSA-N Ser-Leu-Asn Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O KCNSGAMPBPYUAI-CIUDSAMLSA-N 0.000 description 1
- NLOAIFSWUUFQFR-CIUDSAMLSA-N Ser-Leu-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O NLOAIFSWUUFQFR-CIUDSAMLSA-N 0.000 description 1
- GJFYFGOEWLDQGW-GUBZILKMSA-N Ser-Leu-Gln Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CO)N GJFYFGOEWLDQGW-GUBZILKMSA-N 0.000 description 1
- MUJQWSAWLLRJCE-KATARQTJSA-N Ser-Leu-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O MUJQWSAWLLRJCE-KATARQTJSA-N 0.000 description 1
- UGGWCAFQPKANMW-FXQIFTODSA-N Ser-Met-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](C)C(O)=O UGGWCAFQPKANMW-FXQIFTODSA-N 0.000 description 1
- ZSLFCBHEINFXRS-LPEHRKFASA-N Ser-Met-Pro Chemical compound CSCC[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CO)N ZSLFCBHEINFXRS-LPEHRKFASA-N 0.000 description 1
- QMCDMHWAKMUGJE-IHRRRGAJSA-N Ser-Phe-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](C(C)C)C(O)=O QMCDMHWAKMUGJE-IHRRRGAJSA-N 0.000 description 1
- ADJDNJCSPNFFPI-FXQIFTODSA-N Ser-Pro-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CO ADJDNJCSPNFFPI-FXQIFTODSA-N 0.000 description 1
- NUEHQDHDLDXCRU-GUBZILKMSA-N Ser-Pro-Arg Chemical compound OC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCN=C(N)N)C(O)=O NUEHQDHDLDXCRU-GUBZILKMSA-N 0.000 description 1
- FLONGDPORFIVQW-XGEHTFHBSA-N Ser-Pro-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CO FLONGDPORFIVQW-XGEHTFHBSA-N 0.000 description 1
- CKDXFSPMIDSMGV-GUBZILKMSA-N Ser-Pro-Val Chemical compound [H]N[C@@H](CO)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(O)=O CKDXFSPMIDSMGV-GUBZILKMSA-N 0.000 description 1
- FZXOPYUEQGDGMS-ACZMJKKPSA-N Ser-Ser-Gln Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(O)=O FZXOPYUEQGDGMS-ACZMJKKPSA-N 0.000 description 1
- CUXJENOFJXOSOZ-BIIVOSGPSA-N Ser-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CO)N)C(=O)O CUXJENOFJXOSOZ-BIIVOSGPSA-N 0.000 description 1
- XQJCEKXQUJQNNK-ZLUOBGJFSA-N Ser-Ser-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O XQJCEKXQUJQNNK-ZLUOBGJFSA-N 0.000 description 1
- DKGRNFUXVTYRAS-UBHSHLNASA-N Ser-Ser-Trp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O DKGRNFUXVTYRAS-UBHSHLNASA-N 0.000 description 1
- WUXCHQZLUHBSDJ-LKXGYXEUSA-N Ser-Thr-Asp Chemical compound OC[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@@H](CC(O)=O)C(O)=O WUXCHQZLUHBSDJ-LKXGYXEUSA-N 0.000 description 1
- FVFUOQIYDPAIJR-XIRDDKMYSA-N Ser-Trp-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H](CO)N FVFUOQIYDPAIJR-XIRDDKMYSA-N 0.000 description 1
- VAIWUNAAPZZGRI-IHPCNDPISA-N Ser-Trp-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)[C@H](CC2=CNC3=CC=CC=C32)NC(=O)[C@H](CO)N VAIWUNAAPZZGRI-IHPCNDPISA-N 0.000 description 1
- PQEQXWRVHQAAKS-SRVKXCTJSA-N Ser-Tyr-Asn Chemical compound NC(=O)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@H](CO)N)CC1=CC=C(O)C=C1 PQEQXWRVHQAAKS-SRVKXCTJSA-N 0.000 description 1
- VVKVHAOOUGNDPJ-SRVKXCTJSA-N Ser-Tyr-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CO)C(O)=O VVKVHAOOUGNDPJ-SRVKXCTJSA-N 0.000 description 1
- IAOHCSQDQDWRQU-GUBZILKMSA-N Ser-Val-Arg Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O IAOHCSQDQDWRQU-GUBZILKMSA-N 0.000 description 1
- JZRYFUGREMECBH-XPUUQOCRSA-N Ser-Val-Gly Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)NCC(O)=O JZRYFUGREMECBH-XPUUQOCRSA-N 0.000 description 1
- SYCFMSYTIFXWAJ-DCAQKATOSA-N Ser-Val-His Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CO)N SYCFMSYTIFXWAJ-DCAQKATOSA-N 0.000 description 1
- 241000187180 Streptomyces sp. Species 0.000 description 1
- 239000012505 Superdex™ Substances 0.000 description 1
- 101100329497 Thermoproteus tenax (strain ATCC 35583 / DSM 2078 / JCM 9277 / NBRC 100435 / Kra 1) cas2 gene Proteins 0.000 description 1
- 101100273269 Thermus thermophilus (strain ATCC 27634 / DSM 579 / HB8) cse3 gene Proteins 0.000 description 1
- IGROJMCBGRFRGI-YTLHQDLWSA-N Thr-Ala-Ala Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](C)C(O)=O IGROJMCBGRFRGI-YTLHQDLWSA-N 0.000 description 1
- DFTCYYILCSQGIZ-GCJQMDKQSA-N Thr-Ala-Asn Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(O)=O DFTCYYILCSQGIZ-GCJQMDKQSA-N 0.000 description 1
- STGXWWBXWXZOER-MBLNEYKQSA-N Thr-Ala-His Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CN=CN1 STGXWWBXWXZOER-MBLNEYKQSA-N 0.000 description 1
- NFMPFBCXABPALN-OWLDWWDNSA-N Thr-Ala-Trp Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](C)C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)N)O NFMPFBCXABPALN-OWLDWWDNSA-N 0.000 description 1
- XSLXHSYIVPGEER-KZVJFYERSA-N Thr-Ala-Val Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(=O)N[C@@H](C(C)C)C(O)=O XSLXHSYIVPGEER-KZVJFYERSA-N 0.000 description 1
- CAGTXGDOIFXLPC-KZVJFYERSA-N Thr-Arg-Ala Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](C)C(O)=O)CCCN=C(N)N CAGTXGDOIFXLPC-KZVJFYERSA-N 0.000 description 1
- JMZKMSTYXHFYAK-VEVYYDQMSA-N Thr-Arg-Asn Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC(=O)N)C(=O)O)N)O JMZKMSTYXHFYAK-VEVYYDQMSA-N 0.000 description 1
- GLQFKOVWXPPFTP-VEVYYDQMSA-N Thr-Arg-Asp Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(O)=O GLQFKOVWXPPFTP-VEVYYDQMSA-N 0.000 description 1
- JMQUAZXYFAEOIH-XGEHTFHBSA-N Thr-Arg-Cys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CS)C(=O)O)N)O JMQUAZXYFAEOIH-XGEHTFHBSA-N 0.000 description 1
- GZYNMZQXFRWDFH-YTWAJWBKSA-N Thr-Arg-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N1CCC[C@@H]1C(=O)O)N)O GZYNMZQXFRWDFH-YTWAJWBKSA-N 0.000 description 1
- TZKPNGDGUVREEB-FOHZUACHSA-N Thr-Asn-Gly Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O TZKPNGDGUVREEB-FOHZUACHSA-N 0.000 description 1
- PQLXHSACXPGWPD-GSSVUCPTSA-N Thr-Asn-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O PQLXHSACXPGWPD-GSSVUCPTSA-N 0.000 description 1
- JXKMXEBNZCKSDY-JIOCBJNQSA-N Thr-Asp-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N1CCC[C@@H]1C(=O)O)N)O JXKMXEBNZCKSDY-JIOCBJNQSA-N 0.000 description 1
- UTCFSBBXPWKLTG-XKBZYTNZSA-N Thr-Cys-Gln Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N)O UTCFSBBXPWKLTG-XKBZYTNZSA-N 0.000 description 1
- ZQUKYJOKQBRBCS-GLLZPBPUSA-N Thr-Gln-Gln Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N)O ZQUKYJOKQBRBCS-GLLZPBPUSA-N 0.000 description 1
- MQUZMZBFKCHVOB-HJGDQZAQSA-N Thr-Gln-Met Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCSC)C(O)=O MQUZMZBFKCHVOB-HJGDQZAQSA-N 0.000 description 1
- DKDHTRVDOUZZTP-IFFSRLJSSA-N Thr-Gln-Val Chemical compound CC(C)[C@H](NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](N)[C@@H](C)O)C(O)=O DKDHTRVDOUZZTP-IFFSRLJSSA-N 0.000 description 1
- LHEZGZQRLDBSRR-WDCWCFNPSA-N Thr-Glu-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O LHEZGZQRLDBSRR-WDCWCFNPSA-N 0.000 description 1
- XOTBWOCSLMBGMF-SUSMZKCASA-N Thr-Glu-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O XOTBWOCSLMBGMF-SUSMZKCASA-N 0.000 description 1
- BNGDYRRHRGOPHX-IFFSRLJSSA-N Thr-Glu-Val Chemical compound CC(C)[C@H](NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)[C@@H](C)O)C(O)=O BNGDYRRHRGOPHX-IFFSRLJSSA-N 0.000 description 1
- NIEWSKWFURSECR-FOHZUACHSA-N Thr-Gly-Asp Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(O)=O NIEWSKWFURSECR-FOHZUACHSA-N 0.000 description 1
- YZUWGFXVVZQJEI-PMVVWTBXSA-N Thr-Gly-His Chemical compound C[C@H]([C@@H](C(=O)NCC(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N)O YZUWGFXVVZQJEI-PMVVWTBXSA-N 0.000 description 1
- MPUMPERGHHJGRP-WEDXCCLWSA-N Thr-Gly-Lys Chemical compound C[C@H]([C@@H](C(=O)NCC(=O)N[C@@H](CCCCN)C(=O)O)N)O MPUMPERGHHJGRP-WEDXCCLWSA-N 0.000 description 1
- SIMKLINEDYOTKL-MBLNEYKQSA-N Thr-His-Ala Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](C)C(=O)O)N)O SIMKLINEDYOTKL-MBLNEYKQSA-N 0.000 description 1
- CYVQBKQYQGEELV-NKIYYHGXSA-N Thr-His-Gln Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N)O CYVQBKQYQGEELV-NKIYYHGXSA-N 0.000 description 1
- ZBKDBZUTTXINIX-RWRJDSDZSA-N Thr-Ile-Gln Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(N)=O)C(O)=O ZBKDBZUTTXINIX-RWRJDSDZSA-N 0.000 description 1
- XTCNBOBTROGWMW-RWRJDSDZSA-N Thr-Ile-Glu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@H]([C@@H](C)O)N XTCNBOBTROGWMW-RWRJDSDZSA-N 0.000 description 1
- JRAUIKJSEAKTGD-TUBUOCAGSA-N Thr-Ile-His Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H]([C@@H](C)O)N JRAUIKJSEAKTGD-TUBUOCAGSA-N 0.000 description 1
- MEJHFIOYJHTWMK-VOAKCMCISA-N Thr-Leu-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)[C@@H](C)O MEJHFIOYJHTWMK-VOAKCMCISA-N 0.000 description 1
- JLNMFGCJODTXDH-WEDXCCLWSA-N Thr-Lys-Gly Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(=O)NCC(O)=O JLNMFGCJODTXDH-WEDXCCLWSA-N 0.000 description 1
- NZRUWPIYECBYRK-HTUGSXCWSA-N Thr-Phe-Glu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(O)=O)C(O)=O NZRUWPIYECBYRK-HTUGSXCWSA-N 0.000 description 1
- MROIJTGJGIDEEJ-RCWTZXSCSA-N Thr-Pro-Pro Chemical compound C[C@@H](O)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 MROIJTGJGIDEEJ-RCWTZXSCSA-N 0.000 description 1
- GVMXJJAJLIEASL-ZJDVBMNYSA-N Thr-Pro-Thr Chemical compound C[C@@H](O)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(O)=O GVMXJJAJLIEASL-ZJDVBMNYSA-N 0.000 description 1
- PRTHQBSMXILLPC-XGEHTFHBSA-N Thr-Ser-Arg Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O PRTHQBSMXILLPC-XGEHTFHBSA-N 0.000 description 1
- UQCNIMDPYICBTR-KYNKHSRBSA-N Thr-Thr-Gly Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O UQCNIMDPYICBTR-KYNKHSRBSA-N 0.000 description 1
- ZOCJFNXUVSGBQI-HSHDSVGOSA-N Thr-Trp-Arg Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N)O ZOCJFNXUVSGBQI-HSHDSVGOSA-N 0.000 description 1
- SOUPNXUJAJENFU-SWRJLBSHSA-N Thr-Trp-Gln Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N)O SOUPNXUJAJENFU-SWRJLBSHSA-N 0.000 description 1
- MYNYCUXMIIWUNW-IEGACIPQSA-N Thr-Trp-Lys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)N[C@@H](CCCCN)C(=O)O)N)O MYNYCUXMIIWUNW-IEGACIPQSA-N 0.000 description 1
- BGHVVGPELPHRCI-HZTRNQAASA-N Thr-Trp-Trp Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)N[C@@H](CC3=CNC4=CC=CC=C43)C(=O)O)N)O BGHVVGPELPHRCI-HZTRNQAASA-N 0.000 description 1
- LXXCHJKHJYRMIY-FQPOAREZSA-N Thr-Tyr-Ala Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C)C(O)=O LXXCHJKHJYRMIY-FQPOAREZSA-N 0.000 description 1
- PELIQFPESHBTMA-WLTAIBSBSA-N Thr-Tyr-Gly Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@H](C(=O)NCC(O)=O)CC1=CC=C(O)C=C1 PELIQFPESHBTMA-WLTAIBSBSA-N 0.000 description 1
- OGOYMQWIWHGTGH-KZVJFYERSA-N Thr-Val-Ala Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C)C(O)=O OGOYMQWIWHGTGH-KZVJFYERSA-N 0.000 description 1
- FYBFTPLPAXZBOY-KKHAAJSZSA-N Thr-Val-Asp Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O FYBFTPLPAXZBOY-KKHAAJSZSA-N 0.000 description 1
- ILUOMMDDGREELW-OSUNSFLBSA-N Thr-Val-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)[C@@H](C)O ILUOMMDDGREELW-OSUNSFLBSA-N 0.000 description 1
- BPGDJSUFQKWUBK-KJEVXHAQSA-N Thr-Val-Tyr Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 BPGDJSUFQKWUBK-KJEVXHAQSA-N 0.000 description 1
- HYVLNORXQGKONN-NUTKFTJISA-N Trp-Ala-Lys Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCCN)C(O)=O)=CNC2=C1 HYVLNORXQGKONN-NUTKFTJISA-N 0.000 description 1
- VZBWRZGNEPBRDE-HZUKXOBISA-N Trp-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC2=CNC3=CC=CC=C32)N VZBWRZGNEPBRDE-HZUKXOBISA-N 0.000 description 1
- QNMIVTOQXUSGLN-SZMVWBNQSA-N Trp-Arg-Arg Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O)=CNC2=C1 QNMIVTOQXUSGLN-SZMVWBNQSA-N 0.000 description 1
- KZIQDVNORJKTMO-WDSOQIARSA-N Trp-Arg-His Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC3=CN=CN3)C(=O)O)N KZIQDVNORJKTMO-WDSOQIARSA-N 0.000 description 1
- VKMOGXREKGVZAF-QEJZJMRPSA-N Trp-Asp-Gln Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N VKMOGXREKGVZAF-QEJZJMRPSA-N 0.000 description 1
- FKAPNDWDLDWZNF-QEJZJMRPSA-N Trp-Asp-Glu Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N FKAPNDWDLDWZNF-QEJZJMRPSA-N 0.000 description 1
- NKUIXQOJUAEIET-AQZXSJQPSA-N Trp-Asp-Thr Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@H](O)C)C(O)=O)=CNC2=C1 NKUIXQOJUAEIET-AQZXSJQPSA-N 0.000 description 1
- AWYXDHQQFPZJNE-QEJZJMRPSA-N Trp-Gln-Ser Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CO)C(=O)O)N AWYXDHQQFPZJNE-QEJZJMRPSA-N 0.000 description 1
- OENGVSDBQHHGBU-QEJZJMRPSA-N Trp-Glu-Asn Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O OENGVSDBQHHGBU-QEJZJMRPSA-N 0.000 description 1
- DVIIYMVCSUQOJG-QEJZJMRPSA-N Trp-Glu-Asp Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O DVIIYMVCSUQOJG-QEJZJMRPSA-N 0.000 description 1
- BEWOXKJJMBKRQL-AAEUAGOBSA-N Trp-Gly-Asp Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)NCC(=O)N[C@@H](CC(=O)O)C(=O)O)N BEWOXKJJMBKRQL-AAEUAGOBSA-N 0.000 description 1
- DZIKVMCFXIIETR-JSGCOSHPSA-N Trp-Gly-Glu Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)NCC(=O)N[C@@H](CCC(O)=O)C(O)=O DZIKVMCFXIIETR-JSGCOSHPSA-N 0.000 description 1
- YYXIWHBHTARPOG-HJXMPXNTSA-N Trp-Ile-Ala Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C)C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N YYXIWHBHTARPOG-HJXMPXNTSA-N 0.000 description 1
- XGFGVFMXDXALEV-XIRDDKMYSA-N Trp-Leu-Asn Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N XGFGVFMXDXALEV-XIRDDKMYSA-N 0.000 description 1
- YLGQHMHKAASRGJ-WDSOQIARSA-N Trp-Leu-Met Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCSC)C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N YLGQHMHKAASRGJ-WDSOQIARSA-N 0.000 description 1
- WMBFONUKQXGLMU-WDSOQIARSA-N Trp-Leu-Val Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](C(C)C)C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N WMBFONUKQXGLMU-WDSOQIARSA-N 0.000 description 1
- DDJHCLVUUBEIIA-BVSLBCMMSA-N Trp-Met-Phe Chemical compound C([C@H](NC(=O)[C@@H](NC(=O)[C@@H](N)CC=1C2=CC=CC=C2NC=1)CCSC)C(O)=O)C1=CC=CC=C1 DDJHCLVUUBEIIA-BVSLBCMMSA-N 0.000 description 1
- UEFHVUQBYNRNQC-SFJXLCSZSA-N Trp-Phe-Thr Chemical compound C([C@@H](C(=O)N[C@@H]([C@H](O)C)C(O)=O)NC(=O)[C@@H](N)CC=1C2=CC=CC=C2NC=1)C1=CC=CC=C1 UEFHVUQBYNRNQC-SFJXLCSZSA-N 0.000 description 1
- MPYZGXUYLNPSNF-NAZCDGGXSA-N Trp-Thr-His Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CC2=CNC3=CC=CC=C32)N)O MPYZGXUYLNPSNF-NAZCDGGXSA-N 0.000 description 1
- UPUNWAXSLPBMRK-XTWBLICNSA-N Trp-Thr-Thr Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O UPUNWAXSLPBMRK-XTWBLICNSA-N 0.000 description 1
- MBLJBGZWLHTJBH-SZMVWBNQSA-N Trp-Val-Arg Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O)=CNC2=C1 MBLJBGZWLHTJBH-SZMVWBNQSA-N 0.000 description 1
- XQMGDVVKFRLQKH-BBRMVZONSA-N Trp-Val-Gly Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)NCC(O)=O)=CNC2=C1 XQMGDVVKFRLQKH-BBRMVZONSA-N 0.000 description 1
- 108010064978 Type II Site-Specific Deoxyribonucleases Proteins 0.000 description 1
- VCXWRWYFJLXITF-AUTRQRHGSA-N Tyr-Ala-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 VCXWRWYFJLXITF-AUTRQRHGSA-N 0.000 description 1
- NIHNMOSRSAYZIT-BPNCWPANSA-N Tyr-Ala-Arg Chemical compound NC(=N)NCCC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 NIHNMOSRSAYZIT-BPNCWPANSA-N 0.000 description 1
- BURPTJBFWIOHEY-UWJYBYFXSA-N Tyr-Ala-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 BURPTJBFWIOHEY-UWJYBYFXSA-N 0.000 description 1
- XLMDWQNAOKLKCP-XDTLVQLUSA-N Tyr-Ala-Gln Chemical compound C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N XLMDWQNAOKLKCP-XDTLVQLUSA-N 0.000 description 1
- LGEYOIQBBIPHQN-UWJYBYFXSA-N Tyr-Ala-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 LGEYOIQBBIPHQN-UWJYBYFXSA-N 0.000 description 1
- DYEGCOJHFNJBKB-UFYCRDLUSA-N Tyr-Arg-Tyr Chemical compound C([C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=C(O)C=C1 DYEGCOJHFNJBKB-UFYCRDLUSA-N 0.000 description 1
- YGKVNUAKYPGORG-AVGNSLFASA-N Tyr-Asp-Glu Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O YGKVNUAKYPGORG-AVGNSLFASA-N 0.000 description 1
- NLMXVDDEQFKQQU-CFMVVWHZSA-N Tyr-Asp-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 NLMXVDDEQFKQQU-CFMVVWHZSA-N 0.000 description 1
- MNMYOSZWCKYEDI-JRQIVUDYSA-N Tyr-Asp-Thr Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O MNMYOSZWCKYEDI-JRQIVUDYSA-N 0.000 description 1
- HKYTWJOWZTWBQB-AVGNSLFASA-N Tyr-Glu-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 HKYTWJOWZTWBQB-AVGNSLFASA-N 0.000 description 1
- NZFCWALTLNFHHC-JYJNAYRXSA-N Tyr-Glu-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 NZFCWALTLNFHHC-JYJNAYRXSA-N 0.000 description 1
- LHTGRUZSZOIAKM-SOUVJXGZSA-N Tyr-Glu-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CC2=CC=C(C=C2)O)N)C(=O)O LHTGRUZSZOIAKM-SOUVJXGZSA-N 0.000 description 1
- CNLKDWSAORJEMW-KWQFWETISA-N Tyr-Gly-Ala Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)NCC(=O)N[C@@H](C)C(O)=O CNLKDWSAORJEMW-KWQFWETISA-N 0.000 description 1
- QAYSODICXVZUIA-WLTAIBSBSA-N Tyr-Gly-Thr Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(O)=O QAYSODICXVZUIA-WLTAIBSBSA-N 0.000 description 1
- OHNXAUCZVWGTLL-KKUMJFAQSA-N Tyr-His-Cys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CC2=CN=CN2)C(=O)N[C@@H](CS)C(=O)O)N)O OHNXAUCZVWGTLL-KKUMJFAQSA-N 0.000 description 1
- DWAMXBFJNZIHMC-KBPBESRZSA-N Tyr-Leu-Gly Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O DWAMXBFJNZIHMC-KBPBESRZSA-N 0.000 description 1
- PRONOHBTMLNXCZ-BZSNNMDCSA-N Tyr-Leu-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 PRONOHBTMLNXCZ-BZSNNMDCSA-N 0.000 description 1
- MXFPBNFKVBHIRW-BZSNNMDCSA-N Tyr-Lys-His Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC2=CN=CN2)C(=O)O)N)O MXFPBNFKVBHIRW-BZSNNMDCSA-N 0.000 description 1
- SINRIKQYQJRGDQ-MEYUZBJRSA-N Tyr-Lys-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 SINRIKQYQJRGDQ-MEYUZBJRSA-N 0.000 description 1
- CDBXVDXSLPLFMD-BPNCWPANSA-N Tyr-Pro-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CC1=CC=C(O)C=C1 CDBXVDXSLPLFMD-BPNCWPANSA-N 0.000 description 1
- QKXAEWMHAAVVGS-KKUMJFAQSA-N Tyr-Pro-Glu Chemical compound N[C@@H](Cc1ccc(O)cc1)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O QKXAEWMHAAVVGS-KKUMJFAQSA-N 0.000 description 1
- BIWVVOHTKDLRMP-ULQDDVLXSA-N Tyr-Pro-Leu Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(O)=O BIWVVOHTKDLRMP-ULQDDVLXSA-N 0.000 description 1
- RGYCVIZZTUBSSG-JYJNAYRXSA-N Tyr-Pro-Val Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(O)=O RGYCVIZZTUBSSG-JYJNAYRXSA-N 0.000 description 1
- LUMQYLVYUIRHHU-YJRXYDGGSA-N Tyr-Ser-Thr Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O LUMQYLVYUIRHHU-YJRXYDGGSA-N 0.000 description 1
- NUQZCPSZHGIYTA-HKUYNNGSSA-N Tyr-Trp-Gly Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CC3=CC=C(C=C3)O)N NUQZCPSZHGIYTA-HKUYNNGSSA-N 0.000 description 1
- REJBPZVUHYNMEN-LSJOCFKGSA-N Val-Ala-His Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](C(C)C)N REJBPZVUHYNMEN-LSJOCFKGSA-N 0.000 description 1
- JOQSQZFKFYJKKJ-GUBZILKMSA-N Val-Arg-Cys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CS)C(=O)O)N JOQSQZFKFYJKKJ-GUBZILKMSA-N 0.000 description 1
- PAPWZOJOLKZEFR-AVGNSLFASA-N Val-Arg-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCCCN)C(=O)O)N PAPWZOJOLKZEFR-AVGNSLFASA-N 0.000 description 1
- UBTBGUDNDFZLGP-SRVKXCTJSA-N Val-Arg-Val Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](C(C)C)C(=O)O)N UBTBGUDNDFZLGP-SRVKXCTJSA-N 0.000 description 1
- LNYOXPDEIZJDEI-NHCYSSNCSA-N Val-Asn-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](C(C)C)N LNYOXPDEIZJDEI-NHCYSSNCSA-N 0.000 description 1
- QHDXUYOYTPWCSK-RCOVLWMOSA-N Val-Asp-Gly Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)NCC(=O)O)N QHDXUYOYTPWCSK-RCOVLWMOSA-N 0.000 description 1
- XLDYBRXERHITNH-QSFUFRPTSA-N Val-Asp-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)C(C)C XLDYBRXERHITNH-QSFUFRPTSA-N 0.000 description 1
- TZVUSFMQWPWHON-NHCYSSNCSA-N Val-Asp-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](C(C)C)N TZVUSFMQWPWHON-NHCYSSNCSA-N 0.000 description 1
- HHSILIQTHXABKM-YDHLFZDLSA-N Val-Asp-Phe Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](Cc1ccccc1)C(O)=O HHSILIQTHXABKM-YDHLFZDLSA-N 0.000 description 1
- DDNIHOWRDOXXPF-NGZCFLSTSA-N Val-Asp-Pro Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N1CCC[C@@H]1C(=O)O)N DDNIHOWRDOXXPF-NGZCFLSTSA-N 0.000 description 1
- YODDULVCGFQRFZ-ZKWXMUAHSA-N Val-Asp-Ser Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O YODDULVCGFQRFZ-ZKWXMUAHSA-N 0.000 description 1
- LHADRQBREKTRLR-DCAQKATOSA-N Val-Cys-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](C(C)C)N LHADRQBREKTRLR-DCAQKATOSA-N 0.000 description 1
- LMSBRIVOCYOKMU-NRPADANISA-N Val-Gln-Cys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CS)C(=O)O)N LMSBRIVOCYOKMU-NRPADANISA-N 0.000 description 1
- HURRXSNHCCSJHA-AUTRQRHGSA-N Val-Gln-Gln Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N HURRXSNHCCSJHA-AUTRQRHGSA-N 0.000 description 1
- OXVPMZVGCAPFIG-BQFCYCMXSA-N Val-Gln-Trp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)N OXVPMZVGCAPFIG-BQFCYCMXSA-N 0.000 description 1
- UZDHNIJRRTUKKC-DLOVCJGASA-N Val-Gln-Val Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](C(C)C)C(=O)O)N UZDHNIJRRTUKKC-DLOVCJGASA-N 0.000 description 1
- ROLGIBMFNMZANA-GVXVVHGQSA-N Val-Glu-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](C(C)C)N ROLGIBMFNMZANA-GVXVVHGQSA-N 0.000 description 1
- OQWNEUXPKHIEJO-NRPADANISA-N Val-Glu-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CO)C(=O)O)N OQWNEUXPKHIEJO-NRPADANISA-N 0.000 description 1
- NXRAUQGGHPCJIB-RCOVLWMOSA-N Val-Gly-Asn Chemical compound CC(C)[C@H](N)C(=O)NCC(=O)N[C@@H](CC(N)=O)C(O)=O NXRAUQGGHPCJIB-RCOVLWMOSA-N 0.000 description 1
- BEGDZYNDCNEGJZ-XVKPBYJWSA-N Val-Gly-Gln Chemical compound CC(C)[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCC(N)=O BEGDZYNDCNEGJZ-XVKPBYJWSA-N 0.000 description 1
- WFENBJPLZMPVAX-XVKPBYJWSA-N Val-Gly-Glu Chemical compound CC(C)[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCC(O)=O WFENBJPLZMPVAX-XVKPBYJWSA-N 0.000 description 1
- LAYSXAOGWHKNED-XPUUQOCRSA-N Val-Gly-Ser Chemical compound CC(C)[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O LAYSXAOGWHKNED-XPUUQOCRSA-N 0.000 description 1
- OPGWZDIYEYJVRX-AVGNSLFASA-N Val-His-Arg Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N OPGWZDIYEYJVRX-AVGNSLFASA-N 0.000 description 1
- KDKLLPMFFGYQJD-CYDGBPFRSA-N Val-Ile-Arg Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)NC(=O)[C@H](C(C)C)N KDKLLPMFFGYQJD-CYDGBPFRSA-N 0.000 description 1
- BZMIYHIJVVJPCK-QSFUFRPTSA-N Val-Ile-Asn Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](C(C)C)N BZMIYHIJVVJPCK-QSFUFRPTSA-N 0.000 description 1
- LKUDRJSNRWVGMS-QSFUFRPTSA-N Val-Ile-Asp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](C(C)C)N LKUDRJSNRWVGMS-QSFUFRPTSA-N 0.000 description 1
- VXDSPJJQUQDCKH-UKJIMTQDSA-N Val-Ile-Glu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@H](C(C)C)N VXDSPJJQUQDCKH-UKJIMTQDSA-N 0.000 description 1
- APEBUJBRGCMMHP-HJWJTTGWSA-N Val-Ile-Phe Chemical compound CC(C)[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 APEBUJBRGCMMHP-HJWJTTGWSA-N 0.000 description 1
- JZWZACGUZVCQPS-RNJOBUHISA-N Val-Ile-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](C(C)C)N JZWZACGUZVCQPS-RNJOBUHISA-N 0.000 description 1
- OTJMMKPMLUNTQT-AVGNSLFASA-N Val-Leu-Arg Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)NC(=O)[C@H](C(C)C)N OTJMMKPMLUNTQT-AVGNSLFASA-N 0.000 description 1
- HGJRMXOWUWVUOA-GVXVVHGQSA-N Val-Leu-Gln Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](C(C)C)N HGJRMXOWUWVUOA-GVXVVHGQSA-N 0.000 description 1
- LYERIXUFCYVFFX-GVXVVHGQSA-N Val-Leu-Glu Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@H](C(C)C)N LYERIXUFCYVFFX-GVXVVHGQSA-N 0.000 description 1
- AEMPCGRFEZTWIF-IHRRRGAJSA-N Val-Leu-Lys Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(O)=O AEMPCGRFEZTWIF-IHRRRGAJSA-N 0.000 description 1
- IJGPOONOTBNTFS-GVXVVHGQSA-N Val-Lys-Glu Chemical compound [H]N[C@@H](C(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(O)=O IJGPOONOTBNTFS-GVXVVHGQSA-N 0.000 description 1
- DIOSYUIWOQCXNR-ONGXEEELSA-N Val-Lys-Gly Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)NCC(O)=O DIOSYUIWOQCXNR-ONGXEEELSA-N 0.000 description 1
- XPKCFQZDQGVJCX-RHYQMDGZSA-N Val-Lys-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](C(C)C)N)O XPKCFQZDQGVJCX-RHYQMDGZSA-N 0.000 description 1
- RQOMPQGUGBILAG-AVGNSLFASA-N Val-Met-Leu Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(C)C)C(O)=O RQOMPQGUGBILAG-AVGNSLFASA-N 0.000 description 1
- WSUWDIVCPOJFCX-TUAOUCFPSA-N Val-Met-Pro Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCSC)C(=O)N1CCC[C@@H]1C(=O)O)N WSUWDIVCPOJFCX-TUAOUCFPSA-N 0.000 description 1
- QPPZEDOTPZOSEC-RCWTZXSCSA-N Val-Met-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CCSC)NC(=O)[C@H](C(C)C)N)O QPPZEDOTPZOSEC-RCWTZXSCSA-N 0.000 description 1
- PWCJARIQERIIGF-BZSNNMDCSA-N Val-Met-Trp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)N PWCJARIQERIIGF-BZSNNMDCSA-N 0.000 description 1
- MJFSRZZJQWZHFQ-SRVKXCTJSA-N Val-Met-Val Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCSC)C(=O)N[C@@H](C(C)C)C(=O)O)N MJFSRZZJQWZHFQ-SRVKXCTJSA-N 0.000 description 1
- HJSLDXZAZGFPDK-ULQDDVLXSA-N Val-Phe-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)NC(=O)[C@H](C(C)C)N HJSLDXZAZGFPDK-ULQDDVLXSA-N 0.000 description 1
- KISFXYYRKKNLOP-IHRRRGAJSA-N Val-Phe-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)O)N KISFXYYRKKNLOP-IHRRRGAJSA-N 0.000 description 1
- LGXUZJIQCGXKGZ-QXEWZRGKSA-N Val-Pro-Asn Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(=O)N)C(=O)O)N LGXUZJIQCGXKGZ-QXEWZRGKSA-N 0.000 description 1
- ZXYPHBKIZLAQTL-QXEWZRGKSA-N Val-Pro-Asp Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(=O)O)C(=O)O)N ZXYPHBKIZLAQTL-QXEWZRGKSA-N 0.000 description 1
- SJRUJQFQVLMZFW-WPRPVWTQSA-N Val-Pro-Gly Chemical compound CC(C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O SJRUJQFQVLMZFW-WPRPVWTQSA-N 0.000 description 1
- QIVPZSWBBHRNBA-JYJNAYRXSA-N Val-Pro-Phe Chemical compound CC(C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](Cc1ccccc1)C(O)=O QIVPZSWBBHRNBA-JYJNAYRXSA-N 0.000 description 1
- DOFAQXCYFQKSHT-SRVKXCTJSA-N Val-Pro-Pro Chemical compound CC(C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 DOFAQXCYFQKSHT-SRVKXCTJSA-N 0.000 description 1
- QSPOLEBZTMESFY-SRVKXCTJSA-N Val-Pro-Val Chemical compound CC(C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(O)=O QSPOLEBZTMESFY-SRVKXCTJSA-N 0.000 description 1
- LTTQCQRTSHJPPL-ZKWXMUAHSA-N Val-Ser-Asp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(=O)O)C(=O)O)N LTTQCQRTSHJPPL-ZKWXMUAHSA-N 0.000 description 1
- SDHZOOIGIUEPDY-JYJNAYRXSA-N Val-Ser-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CO)NC(=O)[C@@H](N)C(C)C)C(O)=O)=CNC2=C1 SDHZOOIGIUEPDY-JYJNAYRXSA-N 0.000 description 1
- CEKSLIVSNNGOKH-KZVJFYERSA-N Val-Thr-Ala Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](C)C(=O)O)NC(=O)[C@H](C(C)C)N)O CEKSLIVSNNGOKH-KZVJFYERSA-N 0.000 description 1
- YQYFYUSYEDNLSD-YEPSODPASA-N Val-Thr-Gly Chemical compound CC(C)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O YQYFYUSYEDNLSD-YEPSODPASA-N 0.000 description 1
- WUFHZIRMAZZWRS-OSUNSFLBSA-N Val-Thr-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@H](C(C)C)N WUFHZIRMAZZWRS-OSUNSFLBSA-N 0.000 description 1
- OFTXTCGQJXTNQS-XGEHTFHBSA-N Val-Thr-Ser Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](C(C)C)N)O OFTXTCGQJXTNQS-XGEHTFHBSA-N 0.000 description 1
- HTONZBWRYUKUKC-RCWTZXSCSA-N Val-Thr-Val Chemical compound CC(C)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O HTONZBWRYUKUKC-RCWTZXSCSA-N 0.000 description 1
- NGXQOQNXSGOYOI-BQFCYCMXSA-N Val-Trp-Gln Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@@H](N)C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O)=CNC2=C1 NGXQOQNXSGOYOI-BQFCYCMXSA-N 0.000 description 1
- PFMSJVIPEZMKSC-DZKIICNBSA-N Val-Tyr-Glu Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N PFMSJVIPEZMKSC-DZKIICNBSA-N 0.000 description 1
- VVIZITNVZUAEMI-DLOVCJGASA-N Val-Val-Gln Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CCC(N)=O VVIZITNVZUAEMI-DLOVCJGASA-N 0.000 description 1
- AEFJNECXZCODJM-UWVGGRQHSA-N Val-Val-Gly Chemical compound CC(C)[C@H]([NH3+])C(=O)N[C@@H](C(C)C)C(=O)NCC([O-])=O AEFJNECXZCODJM-UWVGGRQHSA-N 0.000 description 1
- LLJLBRRXKZTTRD-GUBZILKMSA-N Val-Val-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(=O)O)N LLJLBRRXKZTTRD-GUBZILKMSA-N 0.000 description 1
- 108020005202 Viral DNA Proteins 0.000 description 1
- 108010081404 acein-2 Proteins 0.000 description 1
- 230000009471 action Effects 0.000 description 1
- 108010008685 alanyl-glutamyl-aspartic acid Proteins 0.000 description 1
- 108010050025 alpha-glutamyltryptophan Proteins 0.000 description 1
- 230000004075 alteration Effects 0.000 description 1
- 235000019257 ammonium acetate Nutrition 0.000 description 1
- 229940043376 ammonium acetate Drugs 0.000 description 1
- 239000003242 anti bacterial agent Substances 0.000 description 1
- 229940088710 antibiotic agent Drugs 0.000 description 1
- 229940121357 antivirals Drugs 0.000 description 1
- 238000013459 approach Methods 0.000 description 1
- PYMYPHUHKUWMLA-WDCZJNDASA-N arabinose Chemical compound OC[C@@H](O)[C@@H](O)[C@H](O)C=O PYMYPHUHKUWMLA-WDCZJNDASA-N 0.000 description 1
- PYMYPHUHKUWMLA-UHFFFAOYSA-N arabinose Natural products OCC(O)C(O)C(O)C=O PYMYPHUHKUWMLA-UHFFFAOYSA-N 0.000 description 1
- 108010052670 arginyl-glutamyl-glutamic acid Proteins 0.000 description 1
- 108010018691 arginyl-threonyl-arginine Proteins 0.000 description 1
- 229910052786 argon Inorganic materials 0.000 description 1
- 108010066988 asparaginyl-alanyl-glycyl-alanine Proteins 0.000 description 1
- 238000005842 biochemical reaction Methods 0.000 description 1
- 239000012681 biocontrol agent Substances 0.000 description 1
- 239000002551 biofuel Substances 0.000 description 1
- 230000008436 biogenesis Effects 0.000 description 1
- 239000005388 borosilicate glass Substances 0.000 description 1
- 238000004364 calculation method Methods 0.000 description 1
- 238000003981 capillary liquid chromatography Methods 0.000 description 1
- 101150000705 cas1 gene Proteins 0.000 description 1
- 101150117416 cas2 gene Proteins 0.000 description 1
- 101150106467 cas6 gene Proteins 0.000 description 1
- 101150055766 cat gene Proteins 0.000 description 1
- 239000003054 catalyst Substances 0.000 description 1
- 230000003197 catalytic effect Effects 0.000 description 1
- 229920006317 cationic polymer Polymers 0.000 description 1
- 210000000170 cell membrane Anatomy 0.000 description 1
- 210000003855 cell nucleus Anatomy 0.000 description 1
- 239000003153 chemical reaction reagent Substances 0.000 description 1
- 239000003795 chemical substances by application Substances 0.000 description 1
- 238000010367 cloning Methods 0.000 description 1
- 238000000975 co-precipitation Methods 0.000 description 1
- 229910017052 cobalt Inorganic materials 0.000 description 1
- 239000010941 cobalt Substances 0.000 description 1
- GUTLYIVDDKVIGB-UHFFFAOYSA-N cobalt atom Chemical compound [Co] GUTLYIVDDKVIGB-UHFFFAOYSA-N 0.000 description 1
- 239000003184 complementary RNA Substances 0.000 description 1
- 230000008878 coupling Effects 0.000 description 1
- 238000010168 coupling process Methods 0.000 description 1
- 238000005859 coupling reaction Methods 0.000 description 1
- 239000013078 crystal Substances 0.000 description 1
- 238000005520 cutting process Methods 0.000 description 1
- 125000004122 cyclic group Chemical group 0.000 description 1
- 230000008260 defense mechanism Effects 0.000 description 1
- 238000012217 deletion Methods 0.000 description 1
- 230000037430 deletion Effects 0.000 description 1
- 238000002716 delivery method Methods 0.000 description 1
- 238000003936 denaturing gel electrophoresis Methods 0.000 description 1
- 230000008021 deposition Effects 0.000 description 1
- 235000015872 dietary supplement Nutrition 0.000 description 1
- 230000029087 digestion Effects 0.000 description 1
- 238000010790 dilution Methods 0.000 description 1
- 239000012895 dilution Substances 0.000 description 1
- 208000018459 dissociative disease Diseases 0.000 description 1
- 239000012154 double-distilled water Substances 0.000 description 1
- 230000005782 double-strand break Effects 0.000 description 1
- 230000011559 double-strand break repair via nonhomologous end joining Effects 0.000 description 1
- 239000003814 drug Substances 0.000 description 1
- 230000009977 dual effect Effects 0.000 description 1
- 239000000975 dye Substances 0.000 description 1
- 238000001493 electron microscopy Methods 0.000 description 1
- 238000002337 electrophoretic mobility shift assay Methods 0.000 description 1
- 238000004520 electroporation Methods 0.000 description 1
- 230000009881 electrostatic interaction Effects 0.000 description 1
- 238000010828 elution Methods 0.000 description 1
- 239000012149 elution buffer Substances 0.000 description 1
- 238000005516 engineering process Methods 0.000 description 1
- 238000011156 evaluation Methods 0.000 description 1
- 230000005284 excitation Effects 0.000 description 1
- 230000007717 exclusion Effects 0.000 description 1
- 230000001747 exhibiting effect Effects 0.000 description 1
- 239000013613 expression plasmid Substances 0.000 description 1
- 230000002349 favourable effect Effects 0.000 description 1
- 239000007850 fluorescent dye Substances 0.000 description 1
- 235000013305 food Nutrition 0.000 description 1
- 235000019253 formic acid Nutrition 0.000 description 1
- 238000002825 functional assay Methods 0.000 description 1
- 230000002538 fungal effect Effects 0.000 description 1
- 238000003144 genetic modification method Methods 0.000 description 1
- 238000011331 genomic analysis Methods 0.000 description 1
- 239000008103 glucose Substances 0.000 description 1
- 108010080575 glutamyl-aspartyl-alanine Proteins 0.000 description 1
- 108010057083 glutamyl-aspartyl-leucine Proteins 0.000 description 1
- 108010008237 glutamyl-valyl-glycine Proteins 0.000 description 1
- JYPCXBJRLBHWME-UHFFFAOYSA-N glycyl-L-prolyl-L-arginine Natural products NCC(=O)N1CCCC1C(=O)NC(CCCN=C(N)N)C(O)=O JYPCXBJRLBHWME-UHFFFAOYSA-N 0.000 description 1
- 108010019832 glycyl-asparaginyl-glycine Proteins 0.000 description 1
- 108010084264 glycyl-glycyl-cysteine Proteins 0.000 description 1
- 108010079413 glycyl-prolyl-glutamic acid Proteins 0.000 description 1
- 108010082286 glycyl-seryl-alanine Proteins 0.000 description 1
- 108010020688 glycylhistidine Proteins 0.000 description 1
- 108010077515 glycylproline Proteins 0.000 description 1
- 230000012010 growth Effects 0.000 description 1
- 238000005734 heterodimerization reaction Methods 0.000 description 1
- 108010050343 histidyl-alanyl-glutamine Proteins 0.000 description 1
- 108010092114 histidylphenylalanine Proteins 0.000 description 1
- 108010018006 histidylserine Proteins 0.000 description 1
- 239000000710 homodimer Substances 0.000 description 1
- 239000001257 hydrogen Substances 0.000 description 1
- 229910052739 hydrogen Inorganic materials 0.000 description 1
- 230000007062 hydrolysis Effects 0.000 description 1
- 238000006460 hydrolysis reaction Methods 0.000 description 1
- 238000007654 immersion Methods 0.000 description 1
- 210000000987 immune system Anatomy 0.000 description 1
- 230000036039 immunity Effects 0.000 description 1
- 230000003053 immunization Effects 0.000 description 1
- 238000002649 immunization Methods 0.000 description 1
- 230000000415 inactivating effect Effects 0.000 description 1
- 210000003000 inclusion body Anatomy 0.000 description 1
- 230000006698 induction Effects 0.000 description 1
- 230000001939 inductive effect Effects 0.000 description 1
- 239000002054 inoculum Substances 0.000 description 1
- 238000003780 insertion Methods 0.000 description 1
- 230000037431 insertion Effects 0.000 description 1
- 230000002452 interceptive effect Effects 0.000 description 1
- 108010031424 isoleucyl-prolyl-proline Proteins 0.000 description 1
- 108010044374 isoleucyl-tyrosine Proteins 0.000 description 1
- 108010078274 isoleucylvaline Proteins 0.000 description 1
- 238000000111 isothermal titration calorimetry Methods 0.000 description 1
- 108010053037 kyotorphin Proteins 0.000 description 1
- 238000011005 laboratory method Methods 0.000 description 1
- 108010044311 leucyl-glycyl-glycine Proteins 0.000 description 1
- 108010051673 leucyl-glycyl-phenylalanine Proteins 0.000 description 1
- 108010044056 leucyl-phenylalanine Proteins 0.000 description 1
- 108010091871 leucylmethionine Proteins 0.000 description 1
- 210000000265 leukocyte Anatomy 0.000 description 1
- 230000000670 limiting effect Effects 0.000 description 1
- 150000002632 lipids Chemical class 0.000 description 1
- 238000004895 liquid chromatography mass spectrometry Methods 0.000 description 1
- 108010053062 lysyl-arginyl-phenylalanyl-lysine Proteins 0.000 description 1
- 108010059573 lysyl-lysyl-glycyl-glutamic acid Proteins 0.000 description 1
- UEGPKNKPLBYCNK-UHFFFAOYSA-L magnesium acetate Chemical compound [Mg+2].CC([O-])=O.CC([O-])=O UEGPKNKPLBYCNK-UHFFFAOYSA-L 0.000 description 1
- 239000011654 magnesium acetate Substances 0.000 description 1
- 235000011285 magnesium acetate Nutrition 0.000 description 1
- 229940069446 magnesium acetate Drugs 0.000 description 1
- 230000014759 maintenance of location Effects 0.000 description 1
- 229910052748 manganese Inorganic materials 0.000 description 1
- 239000011572 manganese Substances 0.000 description 1
- 239000011565 manganese chloride Substances 0.000 description 1
- 239000011159 matrix material Substances 0.000 description 1
- 230000001404 mediated effect Effects 0.000 description 1
- 238000002844 melting Methods 0.000 description 1
- 230000008018 melting Effects 0.000 description 1
- 229910052751 metal Inorganic materials 0.000 description 1
- 239000002184 metal Substances 0.000 description 1
- 108010068488 methionylphenylalanine Proteins 0.000 description 1
- 239000008267 milk Substances 0.000 description 1
- 235000013336 milk Nutrition 0.000 description 1
- 210000004080 milk Anatomy 0.000 description 1
- 230000003278 mimic effect Effects 0.000 description 1
- 238000002156 mixing Methods 0.000 description 1
- 238000010369 molecular cloning Methods 0.000 description 1
- 238000002887 multiple sequence alignment Methods 0.000 description 1
- 210000004897 n-terminal region Anatomy 0.000 description 1
- 238000006386 neutralization reaction Methods 0.000 description 1
- 210000004492 nuclear pore Anatomy 0.000 description 1
- 239000002853 nucleic acid probe Substances 0.000 description 1
- 238000005457 optimization Methods 0.000 description 1
- 230000036961 partial effect Effects 0.000 description 1
- 230000000149 penetrating effect Effects 0.000 description 1
- 239000012071 phase Substances 0.000 description 1
- 108010073101 phenylalanylleucine Proteins 0.000 description 1
- NBIIXXVUZAFLBC-UHFFFAOYSA-K phosphate Chemical compound [O-]P([O-])([O-])=O NBIIXXVUZAFLBC-UHFFFAOYSA-K 0.000 description 1
- 239000010452 phosphate Substances 0.000 description 1
- 102000020233 phosphotransferase Human genes 0.000 description 1
- 238000000053 physical method Methods 0.000 description 1
- 239000002504 physiological saline solution Substances 0.000 description 1
- 108010025488 pinealon Proteins 0.000 description 1
- 230000007505 plaque formation Effects 0.000 description 1
- 238000002264 polyacrylamide gel electrophoresis Methods 0.000 description 1
- 239000000256 polyoxyethylene sorbitan monolaurate Substances 0.000 description 1
- 235000010486 polyoxyethylene sorbitan monolaurate Nutrition 0.000 description 1
- 229920003053 polystyrene-divinylbenzene Polymers 0.000 description 1
- 239000013641 positive control Substances 0.000 description 1
- 230000004481 post-translational protein modification Effects 0.000 description 1
- 239000006041 probiotic Substances 0.000 description 1
- 230000000529 probiotic effect Effects 0.000 description 1
- 235000018291 probiotics Nutrition 0.000 description 1
- 238000012545 processing Methods 0.000 description 1
- 210000001236 prokaryotic cell Anatomy 0.000 description 1
- 108010014614 prolyl-glycyl-proline Proteins 0.000 description 1
- 108700042769 prolyl-leucyl-glycine Proteins 0.000 description 1
- 108010093296 prolyl-prolyl-alanine Proteins 0.000 description 1
- 108010087846 prolyl-prolyl-glycine Proteins 0.000 description 1
- 230000017854 proteolysis Effects 0.000 description 1
- 230000002285 radioactive effect Effects 0.000 description 1
- 238000002708 random mutagenesis Methods 0.000 description 1
- 239000011535 reaction buffer Substances 0.000 description 1
- 239000011541 reaction mixture Substances 0.000 description 1
- 102000005962 receptors Human genes 0.000 description 1
- 108020003175 receptors Proteins 0.000 description 1
- 230000007115 recruitment Effects 0.000 description 1
- 239000011347 resin Substances 0.000 description 1
- 229920005989 resin Polymers 0.000 description 1
- 238000004007 reversed phase HPLC Methods 0.000 description 1
- 235000019515 salmon Nutrition 0.000 description 1
- 238000002864 sequence alignment Methods 0.000 description 1
- 108010048818 seryl-histidine Proteins 0.000 description 1
- 238000002741 site-directed mutagenesis Methods 0.000 description 1
- 238000001542 size-exclusion chromatography Methods 0.000 description 1
- 150000003384 small molecules Chemical class 0.000 description 1
- 230000007928 solubilization Effects 0.000 description 1
- 238000005063 solubilization Methods 0.000 description 1
- 108010089087 soymetide-4 Proteins 0.000 description 1
- 108010068698 spleen exonuclease Proteins 0.000 description 1
- 230000002269 spontaneous effect Effects 0.000 description 1
- 238000003860 storage Methods 0.000 description 1
- 239000000126 substance Substances 0.000 description 1
- 239000013589 supplement Substances 0.000 description 1
- 238000002198 surface plasmon resonance spectroscopy Methods 0.000 description 1
- 108010031491 threonyl-lysyl-glutamic acid Proteins 0.000 description 1
- 108010072986 threonyl-seryl-lysine Proteins 0.000 description 1
- 238000004448 titration Methods 0.000 description 1
- 231100000331 toxic Toxicity 0.000 description 1
- 230000002588 toxic effect Effects 0.000 description 1
- 230000002463 transducing effect Effects 0.000 description 1
- 238000003151 transfection method Methods 0.000 description 1
- 239000012096 transfection reagent Substances 0.000 description 1
- 230000005945 translocation Effects 0.000 description 1
- PIEPQKCYPFFYMG-UHFFFAOYSA-N tris acetate Chemical compound CC(O)=O.OCC(N)(CO)CO PIEPQKCYPFFYMG-UHFFFAOYSA-N 0.000 description 1
- 108010029384 tryptophyl-histidine Proteins 0.000 description 1
- 108010015666 tryptophyl-leucyl-glutamic acid Proteins 0.000 description 1
- 108010038745 tryptophylglycine Proteins 0.000 description 1
- 108010017949 tyrosyl-glycyl-glycine Proteins 0.000 description 1
- 230000003827 upregulation Effects 0.000 description 1
- IBIDRSSEHFLGSD-UHFFFAOYSA-N valinyl-arginine Natural products CC(C)C(N)C(=O)NC(C(O)=O)CCCN=C(N)N IBIDRSSEHFLGSD-UHFFFAOYSA-N 0.000 description 1
- 108010072644 valyl-alanyl-prolyl-glycine Proteins 0.000 description 1
- 108010015385 valyl-prolyl-proline Proteins 0.000 description 1
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Chemical compound O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 1
- 239000003643 water by type Substances 0.000 description 1
- 229910052724 xenon Inorganic materials 0.000 description 1
- FHNFHKCVQCLJFQ-UHFFFAOYSA-N xenon atom Chemical compound [Xe] FHNFHKCVQCLJFQ-UHFFFAOYSA-N 0.000 description 1
- 210000005253 yeast cell Anatomy 0.000 description 1
Images













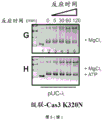











Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/195—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from bacteria
- C07K14/24—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from bacteria from Enterobacteriaceae (F), e.g. Citrobacter, Serratia, Proteus, Providencia, Morganella, Yersinia
- C07K14/245—Escherichia (G)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/14—Hydrolases (3)
- C12N9/16—Hydrolases (3) acting on ester bonds (3.1)
- C12N9/22—Ribonucleases RNAses, DNAses
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K48/00—Medicinal preparations containing genetic material which is inserted into cells of the living body to treat genetic diseases; Gene therapy
- A61K48/005—Medicinal preparations containing genetic material which is inserted into cells of the living body to treat genetic diseases; Gene therapy characterised by an aspect of the 'active' part of the composition delivered, i.e. the nucleic acid delivered
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P31/00—Antiinfectives, i.e. antibiotics, antiseptics, chemotherapeutics
- A61P31/12—Antivirals
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/195—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from bacteria
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/46—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans from vertebrates
- C07K14/47—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans from vertebrates from mammals
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K19/00—Hybrid peptides, i.e. peptides covalently bound to nucleic acids, or non-covalently bound protein-protein complexes
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
- C12N15/62—DNA sequences coding for fusion proteins
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/66—General methods for inserting a gene into a vector to form a recombinant vector using cleavage and ligation; Use of non-functional linkers or adaptors, e.g. linkers containing the sequence for a restriction endonuclease
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/70—Vectors or expression systems specially adapted for E. coli
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/74—Vectors or expression systems specially adapted for prokaryotic hosts other than E. coli, e.g. Lactobacillus, Micromonospora
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/79—Vectors or expression systems specially adapted for eukaryotic hosts
- C12N15/80—Vectors or expression systems specially adapted for eukaryotic hosts for fungi
- C12N15/81—Vectors or expression systems specially adapted for eukaryotic hosts for fungi for yeasts
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/79—Vectors or expression systems specially adapted for eukaryotic hosts
- C12N15/82—Vectors or expression systems specially adapted for eukaryotic hosts for plant cells, e.g. plant artificial chromosomes (PACs)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/79—Vectors or expression systems specially adapted for eukaryotic hosts
- C12N15/85—Vectors or expression systems specially adapted for eukaryotic hosts for animal cells
- C12N15/86—Viral vectors
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/87—Introduction of foreign genetic material using processes not otherwise provided for, e.g. co-transformation
- C12N15/90—Stable introduction of foreign DNA into chromosome
- C12N15/902—Stable introduction of foreign DNA into chromosome using homologous recombination
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/87—Introduction of foreign genetic material using processes not otherwise provided for, e.g. co-transformation
- C12N15/90—Stable introduction of foreign DNA into chromosome
- C12N15/902—Stable introduction of foreign DNA into chromosome using homologous recombination
- C12N15/907—Stable introduction of foreign DNA into chromosome using homologous recombination in mammalian cells
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/14—Hydrolases (3)
- C12N9/16—Hydrolases (3) acting on ester bonds (3.1)
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K38/00—Medicinal preparations containing peptides
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/01—Fusion polypeptide containing a localisation/targetting motif
- C07K2319/09—Fusion polypeptide containing a localisation/targetting motif containing a nuclear localisation signal
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/20—Fusion polypeptide containing a tag with affinity for a non-protein ligand
- C07K2319/22—Fusion polypeptide containing a tag with affinity for a non-protein ligand containing a Strep-tag
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/60—Fusion polypeptide containing spectroscopic/fluorescent detection, e.g. green fluorescent protein [GFP]
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/70—Fusion polypeptide containing domain for protein-protein interaction
- C07K2319/71—Fusion polypeptide containing domain for protein-protein interaction containing domain for transcriptional activaation, e.g. VP16
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/80—Fusion polypeptide containing a DNA binding domain, e.g. Lacl or Tet-repressor
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/85—Fusion polypeptide containing an RNA binding domain
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/10—Type of nucleic acid
- C12N2310/20—Type of nucleic acid involving clustered regularly interspaced short palindromic repeats [CRISPRs]
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Y—ENZYMES
- C12Y301/00—Hydrolases acting on ester bonds (3.1)
- C12Y301/21—Endodeoxyribonucleases producing 5'-phosphomonoesters (3.1.21)
- C12Y301/21004—Type II site-specific deoxyribonuclease (3.1.21.4)
Landscapes
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Genetics & Genomics (AREA)
- Chemical & Material Sciences (AREA)
- Engineering & Computer Science (AREA)
- Organic Chemistry (AREA)
- Zoology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Wood Science & Technology (AREA)
- Biomedical Technology (AREA)
- Molecular Biology (AREA)
- Biotechnology (AREA)
- General Engineering & Computer Science (AREA)
- General Health & Medical Sciences (AREA)
- Biochemistry (AREA)
- Biophysics (AREA)
- Microbiology (AREA)
- Physics & Mathematics (AREA)
- Plant Pathology (AREA)
- Medicinal Chemistry (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Mycology (AREA)
- Gastroenterology & Hepatology (AREA)
- Cell Biology (AREA)
- Pharmacology & Pharmacy (AREA)
- Public Health (AREA)
- Animal Behavior & Ethology (AREA)
- Virology (AREA)
- Veterinary Medicine (AREA)
- Epidemiology (AREA)
- Toxicology (AREA)
- Chemical Kinetics & Catalysis (AREA)
- Communicable Diseases (AREA)
- Oncology (AREA)
- General Chemical & Material Sciences (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- Peptides Or Proteins (AREA)
- Enzymes And Modification Thereof (AREA)
- Medicines That Contain Protein Lipid Enzymes And Other Medicines (AREA)
- Pharmaceuticals Containing Other Organic And Inorganic Compounds (AREA)
Abstract
一种用于适应性抗病毒防御的成簇规律间隔短回文重复序列(CRISPR)相关复合物(级联);所述级联蛋白质复合物至少包含CRISPR相关蛋白质亚基Cas7、Cas5和Cas6,其包括至少一个具有额外的氨基酸序列的亚基,该额外的氨基酸序列具有核酸或染色质修饰、可视化、转录激活或转录抑制活性。所述具有额外的活性的级联复合物与RNA分子组合,以产生核糖核蛋白复合物。该RNA分子被选择为与靶序列具有实质互补性。靶向的核糖核蛋白可用作遗传工程工具,在同源重组、非同源末端连接、基因修饰、基因整合、突变修复中用于核酸的精确切割,或用于它们的可视化、转录激活或抑制。与FokI二聚体融合的一对核糖核苷酸可用于在DNA中产生双链断裂,从而以序列特异性的方式促进这些应用。
Description
本申请是国际申请日为2012年12月21日、国家申请号为 201280071058.4(国际申请号为PCT/EP2012/076674)、发明名称为“经修饰的级联核糖核蛋白及其用途”的申请的分案申请。
本发明涉及遗传工程领域,更具体地涉及生物体(包括原核生物和真核生物)的基因和/或基因组修饰领域。本发明还涉及制作在基因组分析和遗传修饰方法中使用(无论体内还是体外)的位点特异性工具的方法。本发明更具体地涉及以序列特异性方式识别并关联于核酸序列的核糖核蛋白的领域。
细菌和古细菌具有多种多样的针对侵入性DNA的防御机制。所谓的CRISPR/Cas防御系统通过将质粒和病毒DNA片段整合到宿主染色体上的成簇规律间隔短回文重复序列(CRISPR)的基因座中来提供适应性免疫。病毒或质粒来源的序列,被称为间隔区,由重复的宿主来源的序列彼此隔开。这些重复元件是该免疫系统的遗传记忆,并且每个CRISPR基因座都含有在先前遇到外来遗传元件期间获得的独特“间隔区”序列的多样的所有组成成分(repertoire)。
外来DNA的获得是免疫的第一步,但是保护则需要将CRISPR 转录,并且需要将这些长的转录物加工成短的CRISPR来源的RNA (crRNA),这些CRISPR来源的RNA各自含有与外来核酸攻击物 (challenger)互补的独特间隔区序列。
除了crRNA,在若干生物体中的遗传实验已表明,获得免疫力的步骤、crRNA生物发生和靶向干扰还需要一组独特的CRISPR相关 (Cas)蛋白质。另外,来自在系统发生上不同的CRISPR系统的Cas蛋白亚组已被证明装配成包括crRNA的大复合物。
最近对CRISPR/Cas系统的多样性的重新评估导致分类为三种不同的类型(Makarova K.等人(2011)Nature Reviews Microbiology-AOP, 2011年5月9日;doi:10.1038/nrmicro2577),这些类型在cas基因含量上有所不同,并在整个CRISPR防御途径中显现出很大的差异。(本说明书中对CRISPR相关基因采用了Makarova分类和命名法。)CRISPR 基因座的RNA转录物(前crRNA)在I型和III型系统中被CRISPR相关(Cas)内切核糖核酸酶或在II型系统中被RNAase III在重复序列上特异性切割;生成的crRNA被Cas蛋白复合物所利用,作为引导RNA 来检测入侵DNA或RNA的互补序列。靶核酸的切割已在体外针对以尺子锚定机制(ruler-anchored mechanism)切割RNA的强烈火球菌(Pyrococcusfuriosus)III-B型系统得到证实,并且最近在体内针对在互补靶序列(原间隔区(protospacer))上切割DNA的嗜热链球菌 (Streptococcus thermophiles)II型系统得到证实。相比之下,对I型系统而言,CRISPR干扰的机制仍然在很大程度上是未知的。
模式生物体大肠杆菌(Escherichia coli)菌株K12拥有CRISPR/Cas I-E型(之前被称为CRISPR E亚型(Cse))。它含有八个cas基因(cas1、 cas2、cas3和cse1、cse2、cas7、cas5、cas6e)和下游CRISPR(2型重复)。在大肠杆菌K12中,这八个cas基因编码在CRISPR基因座的上游。Cas1 和Cas2似乎不是靶向干扰所需要的,而很有可能参与新靶序列的获得。相比之下,六种Cas蛋白:Cse1、Cse2、Cas3、Cas7、Cas5和Cas6e(之前也分别被称为CasA、CasB、Cas3、CasC/Cse4、CasD和CasE/Cse3) 对于针对λ噬菌体攻击的保护而言是必需的。这些蛋白质中的五种: Cse1、Cse2、Cas7、Cas5和Cas6e(之前分别被称为CasA、CasB、 CasC/Cse4、CasD和CasE/Cse3)与crRNA一起装配以形成被称为级联 (Cascade)的多亚基核糖核蛋白(RNP)。
在大肠杆菌中,级联(Cascade)是一种405kDa的核糖核蛋白复合物,其由化学计量不等的五种功能上必需的Cas蛋白 Cse11Cse22Cas76Cas51Cas6e1(即,按以前的命名法为CasA1B2C6D1E1) 以及61-nt CRISPR来源的RNA所组成。级联是专性RNP,其依赖于 crRNA以供复合物装配和稳定性以及入侵核酸序列的鉴别。级联是一种监视复合物,其发现并结合与crRNA的间隔区序列互补的外来核酸。
标题为“Structural basis for CRISPR RNA-guided DNA recognition byCascade”的Jore等人(2011),Nature Structural&Molecular Biology 18:529-537描述了前crRNA转录物如何被级联的Cas6e亚基所切割,从而导致成熟的61 nt crRNA被CRISPR复合物所保留。crRNA作为引导RNA,用于通过crRNA间隔区与互补的原间隔区之间的碱基配对,级联与双链(ds)DNA分子的序列特异性结合,从而形成所谓的 R-环。已知这是一个ATP非依赖性的过程。
标题为“Small CRISPR RNAs guide antiviral defense in prokaryotes”的Brouns S.J.J.等人(2008),Science 321:960-964教导了载有crRNA的级联需要Cas3来形成体内噬菌体抗性。
标题为“CRISPR interference:RNA-directed adaptive immunity in bacteriaand archaea”的Marraffini L和Sontheimer E.(2010),Nature Reviews Genetics 11:181-190是一篇综述文章,其总结了本领域现有技术的知识状态。针对基于CRISPR的应用和技术提出了一些建议,但这主要是在产生用于乳制品行业的驯化细菌的噬菌体抗性株的领域。提出强烈火球菌中crRNP复合物对RNA分子的体外特异性切割还有待于进一步开发。还提出对CRISPR系统的操作是一种可能的在医院中减少抗生素抗性菌株传播的方式。作者强调,将需要进一步的研究工作来探索该技术在这些领域的潜在效用。
名称为“Genetic cluster of strains of Streptococcus thermophilushaving unique rheological properties for dairy fermentation”的 US2011236530A1(Manoury等人)公开了能发酵牛奶从而使其具有高度粘性和弱拉丝性(weakly ropy)的某些嗜热链球菌(S.thermophilus)菌株。公开了限定序列的特定CRISPR基因座。
名称为“Cas6 polypeptides and methods of use”的US2011217739 A1(Terns等人)公开了具有Cas6内切核糖核酸酶活性的多肽。该多肽切割具有Cas6识别域和切割位点的靶RNA多核苷酸。切割可在体外或体内进行。对诸如大肠杆菌或沃氏富盐菌(Haloferaxvolcanii)的微生物进行遗传修饰以使其表达Cas6内切核糖核酸酶活性。
名称为“Bifidobacteria CRISPR sequences”的WO2010054154 (Danisco)公开了在双歧杆菌中发现的各种CRISPR序列,以及它们在制备细菌的遗传改变的菌株中的用途,其中该遗传改变的菌株在其噬菌体抗性特征方面进行了改变。
名称为“Prokaryotic RNAi-like system and methods of use”的US2011189776 A1(Terns等人)描述了在体外或在原核微生物体内灭活靶多核苷酸的方法。该方法使用具有5-10个核苷酸的5′区的 psiRNA,该核苷酸选自来自紧临间隔区上游的CRISPR基因座的重复序列。3′区与靶多核苷酸的一部分实质互补。还描述了在psiRNA和靶多核苷酸的存在下具有内切核酸酶活性的多肽。
名称为“Use of CRISPR associated genes(CAS)”的EP2341149 A1 (Danisco)描述了一个或多个Cas基因如何能用于调节细菌细胞对噬菌体的抗性;特别是在乳制品中提供起子培养物或益生菌培养物的细菌。
名称为“Compositions and methods for downregulating prokaryotic genes”的WO2010075424(The Regents of the University of California) 公开了包含CRISPR阵列的分离的多核苷酸。CRISPR的至少一个间隔区与原核生物的基因互补,从而能够下调该基因的表达;特别是当该基因与生物燃料生产相关时。
名称为“Cultures with improved phage resistance”的WO2008108989(Danisco)公开了选择细菌的噬菌体抗性菌株,以及选择具有与噬菌体RNA的区域有100%同一性的额外的间隔区的菌株。描述了用于乳制品行业的改良的菌株组合以及起子培养物轮换。描述了用作生物防治剂的某些噬菌体。
名称为“Molecular typing and subtyping of Salmonella by identificationof the variable nucleotide sequences of the CRISPR loci”的 WO2009115861(Institut Pasteur)公开了检测和鉴定沙门氏菌属 (Salmonella)细菌的方法,该方法利用了它们包含在CRISPR基因座中的可变核苷酸序列。
名称为“Detection and typing of bacterial strains”的WO2006073445(Danisco)描述了食物产品、膳食补充剂和环境样品中的细菌菌株的检测和分型。通过特定CRISPR核苷酸序列来鉴定乳杆菌属 (Lactobacillus)的菌株。
标题为“Genome editing with engineered zinc finger nucleases”的 UrnovF等人(2010),Nature 11:636-646是一篇关于锌指核酸酶及其如何已经在一系列模式生物中的反向遗传学领域中发挥作用的综述文章。已经开发了锌指核酸酶,从而使得精确靶向基因组切割成为可能,其后是在随后的修复过程中的基因修饰。然而,锌指核酸酶是通过将一些锌指DNA结合域与DNA切割域融合而产生的。DNA序列特异性是通过串联地偶联若干锌指而实现的,其中每个锌指均识别三核苷酸基序。该技术的显著缺点在于需要为每一个需要进行切割的新 DNA基因座开发新的锌指。这需要蛋白质工程和广泛的筛选,以确保DNA结合的特异性。
在遗传工程和基因组研究领域中,持续需要用于序列/位点特异性核酸检测和/或切割的改进试剂。
本发明人惊奇地发现,某些表达具有解旋酶-核酸酶活性的Cas3 的细菌将Cas3表达为与Cse1的融合体。本发明人还出乎意料地已经能够生产Cse1与其他核酸酶的人工融合体。
本发明人还发现,级联进行的Cas3非依赖性靶DNA识别标记出 DNA以供Cas3切割,并且发现该级联DNA结合受该靶DNA的拓扑学要求支配。
本发明人进一步发现,级联无法结合松弛的靶质粒,但令人惊讶的是级联对具有负超螺旋(nSC)拓扑结构的靶标显现出高亲和性。
因此,在第一方面,本发明提供了一种用于抗病毒防御的成簇规律间隔短回文重复序列(CRISPR)相关复合物(级联),该级联蛋白复合物或其部分至少包含如下CRISPR相关蛋白质亚基:
-Cas7(或COG 1857),其具有SEQ ID NO:3的氨基酸序列或与之有至少18%同一性的序列,
-Cas5(或COG1688),其具有SEQ ID NO:4的氨基酸序列或与之有至少17%同一性的序列,和
-Cas6(或COG 1583),其具有SEQ ID NO:5的氨基酸序列或与之有至少16%同一性的序列;
并且其中至少一个亚基包括提供核酸或染色质修饰、可视化、转录激活或转录抑制活性的额外的氨基酸序列。
包括具有核酸或染色质修饰、可视化、转录激活或转录抑制活性的额外的氨基酸序列的亚基是可被称为“连接到至少一个功能性部分上的亚基”的一个实例;功能性部分是由所述额外的氨基酸序列组成的多肽或蛋白质。转录激活活性可以是导致期望基因的激活或上调的活性;转录抑制活性导致期望基因的抑制或下调。如下文所进一步描述的,基因的选择是由于具有RNA分子的本发明级联复合物的靶向。
具有核酸或染色质修饰、可视化、转录激活或转录抑制活性的额外的氨基酸序列优选由连续的氨基酸残基形成。这些额外的氨基酸可被视为多肽或蛋白质,其为连续的,并形成所关注的Cas或Cse亚基的一部分。这样的多肽或蛋白质序列优选地通常不是任何Cas或Cse 亚基氨基酸序列的部分。换言之,具有核酸或染色质修饰、可视化、转录激活或转录抑制活性的额外的氯基酸序列可能不同于Cas或Cse 亚基氨基酸序列或其部分,即可能不同于Cas3亚基氨基酸序列或其部分。
根据需要,具有核酸或染色质修饰、可视化、转录激活或转录抑制活性的额外的氨基酸序列可获自或来源于相同的生物体,例如大肠杆菌,作为Cas或Cse亚基。
除以上内容以外和/或可替代地,具有核酸或染色质修饰、可视化、转录激活或转录抑制活性的额外的氨基酸序列可能是与Cas或Cse亚基的氨基酸序列“异源”的。因此,所述额外的氨基酸序列可获自或来源于与Cas和/或Cse亚基所来源或起源的生物体不同的生物体。
本文中,序列同一性可通过在国家生物技术信息中心(National Center forBiotechnology Information)网络服务器上的BLAST和随后的Cobalt多序列比对来确定,在该网络服务器上将所讨论的序列与参考序列(例如,SEQ ID NO:3、4或5)进行比较。可以依据基于 BLOSUM62矩阵的序列相似性百分比,或与给定的参考序列(例如, SEQ ID NO:3、4或5)的同一性百分比来定义氨基酸序列。序列的相似性或同一性涉及在计算与参考序列的保守百分比之前进行最优排列的初始步骤,并反映序列的进化关系的度量。
Cas7可具有与SEQ ID NO:3至少31%的序列相似性;Cas5可具有与SEQ ID NO:4至少26%的序列相似性。Cas6可具有与SEQ ID NO:5至少27%的序列相似性。
对于Cse1/CasA(502个氨基酸):
>gi|16130667|ref|NP_417240.1|含有CRISP RNA(crRNA)的级联抗病毒复合蛋白[大肠杆菌菌株K-12亚株MG1655]
MNLLIDNWIPVRPRNGGKVQIINLQSLYCSRDQWRLSLPRDDMEL AALALLVCIGQIIAPAKDDVEFRHRIMNPLTEDEFQQLIAPWIDMFY LNHAEHPFMQTKGVKANDVTPMEKLLAGVSGATNCAFVNQPGQ GEALCGGCTAIALFNQANQAPGFGGGFKSGLRGGTPVTTFVRGIDL RSTVLLNVLTLPRLQKQFPNESHTENQPTWIKPIKSNESIPASSIGFV RGLFWQPAHIELCDPIGIGKCSCCGQESNLRYTGFLKEKFTFTVNG LWPHPHSPCLVTVKKGEVEEKFLAFTTSAPSWTQISRVVVDKIIQN ENGNRVAAVVNQFRNIAPQSPLELIMGGYRNNQASILERRHDVLMFNQGWQQYGNVINEIVTVGLGYKTALRKALYTFAEGFKNKDFKG AGVSVHETAERHFYRQSELLIPDVLANVNFSQADEVIADLRDKLH QLCEMLFNQSVAPYAHHPKLISTLALARATLYKHLRELKPQGGPS NG[SEQ ID NO:1]
对于Cse2/CasB(160个氨基酸):
>gi|16130666|ref|NP_417239.1|含有CRISP RNA(crRNA)的级联抗病毒复合蛋白[大肠杆菌菌株K-12亚株MG1655]
MADEIDAMALYRAWQQLDNGSCAQIRRVSEPDELRDIPAFYRLVQ PFGWENPRHQQALLRMVFCLSAGKNVIRHQDKKSEQTTGISLGRA LANSGRINERRIFQLIRADRTADMVQLRRLLTHAEPVLDWPLMARMLTWWGKRERQQLLEDFVLTTNKNA[SEQ ID NO:2]
对于Cas7/CasC/Cse4(363个氨基酸):
>gi|16130665|ref|NP_417238.1|含有CRISP RNA(crRNA)的级联抗病毒复合蛋白[大肠杆菌菌株K-12亚株MG1655]
MSNFINIHVLISHSPSCLNRDDMNMQKDAIFGGKRRVRISSQSLKR AMRKSGYYAQNIGESSLRTIHLAQLRDVLRQKLGERFDQKIIDKTL ALLSGKSVDEAEKISADAVTPWVVGEIAWFCEQVAKAEADNLDD KKLLKVLKEDIAAIRVNLQQGVDIALSGRMATSGMMTELGKVDG AMSIAHAITTHQVDSDIDWFTAVDDLQEQGSAHLGTQEFSSGVFY RYANINLAQLQENLGGASREQALEIATHVVHMLATEVPGAKQRTY AAFNPADMVMVNFSDMPLSMANAFEKAVKAKDGFLQPSIQAFNQ YWDRVANGYGLNGAAAQFSLSDVDPITAQVKQMPTLEQLKSWVR NNGEA[SEQ ID NO:3]
对于Cas5/CasD(224个氨基酸):
>gi|90111483|ref|NP_417237.2|含有CRISP RNA(crRNA)的级联抗病毒复合蛋白[大肠杆菌菌株K-12亚株MG1655]
MRSYLILRLAGPMQAWGQPTFEGTRPTGRFPTRSGLLGLLGACLGI QRDDTSSLQALSESVQFAVRCDELILDDRRVSVTGLRDYHTVLGA REDYRGLKSHETIQTWREYLCDASFTVALWLTPHATMVISELEKA VLKPRYTPYLGRRSCPLTHPLFLGTCQASDPQKALLNYEPVGGDIY SEESVTGHHLKFTARDEPMITLPRQFASREWYVIKGGMDVSQ [SEQ ID NO:4]
对于Cas6e/CasE(199AA):
>gi|16130663|ref|NP_417236.1|CRISPR RNA前体切割酶;含有 CRISP RNA(crRNA)的级联抗病毒复合蛋白[大肠杆菌菌株K-12亚株 MG1655]
MYLSKVIIARAWSRDLYQLHQGLWHLFPNRPDAARDFLFHVEKR NTPEGCHVLLQSAQMPVSTAVATVIKTKQVEFQLQVGVPLYFRLR ANPIKTILDNQKRLDSKGNIKRCRVPLIKEAEQIAWLQRKLGNAAR VEDVHPISERPQYFSGDGKSGKIQTVCFEGVLTINDAPALIDLVQQG IGPAKSMGCGLLSLAPL[SEQ ID NO:5]
在定义落入本发明范围内的序列变体的范围时,为避免疑问,以下为分别对变异程度的可选限制,将应用于SEQ ID NO:1、2、3、4 或5中的每一个,起始于如依据上述各个同一性百分比所规定的变体的相应最宽范围。因此,变体的范围可包括:至少16%、或至少17%、或至少18%、或至少19%、或至少20%、或至少21%、或至少22%、或至少23%、或至少24%、或至少25%、或至少26%、或至少27%、或至少28%、或至少29%、或至少30%、或至少31%、或至少32%、或至少33%、或至少34%、或至少35%、或至少36%、或至少37%、或至少38%、或至少39%、或至少40%、或至少41%、或至少42%、或至少43%,至少44%、或至少45%、或至少46%、或至少47%、或至少48%、或至少49%、或至少50%、或至少51%、或至少52%、或至少53%、或至少54%、或至少55%、或至少56%、或至少57%、或至少58%、或至少59%、或至少60%、或至少61%、或至少62%、或至少63%、或至少64%、或至少65%、或至少66%、或至少67%、或至少68%、或至少69%、或至少70%、或至少71%,至少72%、或至少73%、或至少74%、或至少75%、或至少76%、或至少77%、或至少78%、或至少79%、或至少80%、或至少81%、或至少82%、或至少83%、或至少84%、或至少85%、或至少86%、或至少87%、或至少88%、或至少89%、或至少90%、或至少91%、或至少92%、或至少93%、或至少94%、或至少95%、或至少96%、或至少97%、或至少98%、或至少99%或100%的氨基酸序列同一性。
本文中,在Cas蛋白亚基的定义中一直使用Makarova等人(2011) 的命名法。Makarova等人的文章在第5页的表2中列出了Cas基因以及它们所属的家族和超家族的名称。本文中,对Cas蛋白或Cse蛋白亚基的引用包括对其一部分由这些亚基构成的家族或超家族的交叉引用。
本文中,本发明的Cas和Cse亚基的参考序列可被定义为编码氨基酸序列的核苷酸序列。例如,针对Cas7的SEQ ID NO:3的氨基酸序列还包括编码该氨基酸序列的所有核酸序列。因此,包含在本发明范围内的Cas7变体包括与参考核酸序列至少具有所限定的氨基酸同一性或相似性百分比的核苷酸序列;以及具有介于该下限与100%之间的所有可能的同一性或相似性百分比的核苷酸序列。
本发明的级联复合物可由从超过一种不同的细菌或古细菌原核生物衍生或修饰得到的亚基组成。并且,来自不同Cas亚型的亚基可以混合。
在一个优选的方面,Cas6亚基为以下SEQ ID NO:17的Cas6e亚基,或为与SEQ IDNO:17有至少16%同一性的序列。
优选的Cas6e亚基的序列为>gi|16130663|ref|NP_417236.1| CRISPR RNA前体切割酶;含有CRISP RNA(crRNA)的级联抗病毒复合蛋白[大肠杆菌菌株K-12亚株MG1655]:
MYLSKVIIARAWSRDLYQLHQGLWHLFPNRPDAARDFLFHVEKR NTPEGCHVLLQSAQMPVSTAVATVIKTKQVEFQLQVGVPLYFRLR ANPIKTILDNQKRLDSKGNIKRCRVPLIKEAEQIAWLQRKLGNAAR VEDVHPISERPQYFSGDGKSGKIQTVCFEGVLTINDAPALIDLVQQG IGPAKSMGCGLLSLAPL[SEQ ID NO:17]
本发明的级联复合物或其部分-其包含至少一个包括具有核酸或染色质修饰、可视化、转录激活或转录抑制活性的额外的氨基酸序列的亚基-可进一步包含具有SEQ IDNO:2的氨基酸序列或与之有至少20%同一性的序列的Cse2(或YgcK样)亚基或其部分。或者,Cse 亚基被限定为与SEQ ID NO:2有至少38%的相似性。任选地,在本发明的蛋白质复合物中,是Cse2亚基包括具有核酸或染色质修饰活性的额外的氨基酸序列。
此外或可替代地,本发明的级联复合物可进一步包含具有SEQ ID NO:1的氨基酸序列或与之有至少9%同一性的序列的Cse1(或YgcL 样)亚基或其部分。任选地,在本发明的蛋白质复合物中,是Cse1亚基包括具有核酸或染色质修饰、可视化、转录激活或转录抑制活性的额外的氨基酸序列。
在优选的实施方案中,本发明的级联复合物为I型CRISPR-Cas 系统蛋白质复合物;更优选为I-E亚型CRISPR-Cas蛋白质复合物,或其可基于I-A型或I-B型复合物。I-C、D或F型复合物是可能的。
在基于大肠杆菌系统的特别优选的实施方案中,亚基可具有以下化学计量:Cse11Cse22Cas76Cas51Cas61或Cse11Cse22Cas76Cas51Cas6e1。
具有核酸或染色质修饰、可视化、转录激活或转录抑制活性的额外的氨基酸序列可通过在天然或人工蛋白质表达系统中表达而翻译性地融合,或者通过化学合成步骤共价连接到至少一个亚基上;优选地,至少一个功能性部分至少融合或连接到Cse1、Cse2、Cas7、Cas5、 Cas6或Cas6e亚基中至少之一的N末端区域和/或C末端区域上。在特别优选的实施方案中,具有核酸或染色质修饰活性的额外的氨基酸序列融合或连接到Cse1、Cse2或Cas5亚基的N末端或C末端上;更优选地,该连接位于Cse1亚基的N末端、Cse2亚基的N末端或 Cas7亚基的N末端的区域。
具有核酸或染色质修饰、激活、抑制或可视化活性的额外的氨基酸序列可为蛋白质;任选地选自解旋酶、核酸酶、核酸酶-解旋酶、 DNA甲基转移酶(例如,Dam)或DNA脱甲基酶、组蛋白甲基转移酶、组蛋白脱甲基酶、乙酰化酶、脱乙酰酶、磷酸酶、激酶、转录(辅)激活物、RNA聚合酶亚基、转录阻抑物、DNA结合蛋白、DNA结构化蛋白、标志物蛋白、报告蛋白、荧光蛋白、配体结合蛋白(例如,mCherry 或重金属结合蛋白)、信号肽(例如,Tat-信号序列)、亚细胞定位序列(例如,核定位序列)或抗体表位。
所关注的蛋白质可为来自除级联蛋白亚基具有其序列起源的细菌物种以外的物种的异源蛋白质。
当蛋白质为核酸酶时,它可为选自诸如FokI的II型限制性内切核酸酶或其突变体或活性部分中的核酸酶。其他可使用的II型限制性内切核酸酶包括EcoR1、EcoRV、BgII、BamHI、BsgI和BspMI。优选地,本发明的一种蛋白质复合物可与FokI的N末端结构域融合,而本发明的另一种蛋白质复合物可与FokI的C末端结构域融合。随后这两种蛋白质复合物可一起使用,以实现核酸中有利的基因座特异性双链切割,借此,如RNA组分(下文将定义和描述)所指导的,并且由于靶核酸链(下文也将更详细地描述)中所谓的“原间隔区邻近基序”(PAM)序列的存在,遗传物质中切割的位置由使用者来设计和选择。
在一个优选的实施方案中,本发明的蛋白质复合物具有为经修饰的限制性内切核酸酶如FokI的额外的氨基酸序列。该修饰优选地位于催化域中。在优选的实施方案中,经修饰的FokI为与蛋白质复合物的Cse1蛋白融合的KKR Sharkey或ELD Sharkey。在本发明的这些复合物的优选应用中,这些复合物中的两种(KKR Sharkey和ELD Sharkey)可以组合在一起。采用经不同修饰的FokI的蛋白质复合物的异二聚体对在核酸的靶向双链切割中具有特别的优势。若使用同型二聚体,则由于非特异性活性,有可能在非靶位点处具有更多的切割。异二聚体方法有利地提高了材料样品中切割的保真度。
以上所限定和描述的含有具有核酸或染色质修饰、可视化、转录激活或转录抑制活性的额外的氨基酸序列的级联复合物是本发明总体系统的组成部分,其有利地允许使用者采用本文所限定的核酸或染色质修饰、可视化、转录激活或转录抑制实体中的任一个,以预先确定的方式选择需要进行切割、标记或以某种方式进行其他改变(例如,甲基化)的精确遗传基因座。该系统的其他组成部分是RNA分子,其充当将本发明的级联复合物引导至打算进行修饰、切割或标记的DNA 或RNA上的正确基因座的引导物。
优选地,本发明的级联复合物还包含RNA分子,该RNA分子包含与期望的靶核酸序列有至少50%同一性的核糖核苷酸序列,并且其中该蛋白质复合物与RNA分子形成核糖核蛋白复合物。优选地,当 RNA分子与其预期靶核酸序列杂交时,形成核糖核蛋白复合物。当级联-功能性部分组合的必需组分、RNA分子和核酸(DNA或RNA) 在合适的生理条件下(无论是在体内还是在体外)一起存在时,形成核糖核蛋白复合物。不希望受到任何特定理论的束缚,本发明人认为,在dsDNA尤其是负超螺旋DNA的情况下,与dsDNA关联的级联复合物会导致双链的局部解旋,这随后使RNA与一条链关联;然后整个核糖核蛋白复合物沿着DNA链移动,直至到达与该RNA序列的至少一部分实质互补的靶序列,在此位点处在RNA和DNA链之间发生稳定的相互作用,并且功能性部分的功能发挥作用,无论是通过在该基因座处DNA的修饰、核酸酶切割还是标记。
在优选的实施方案中,RNA分子的一部分具有与靶核酸序列至少50%的同一性;更优选与靶序列至少95%的同一性。在更优选的实施方案中,RNA分子的该部分沿其长度与靶DNA序列实质互补;即,只有一个、两个、三个、四个或五个可能连续或不连续的错配。RNA 分子(或其部分)可具有与靶序列至少51%、或至少52%、或至少53%、或至少54%、或至少55%、或至少56%、或至少57%、或至少58%、或至少59%、或至少60%、或至少61%、或至少62%、或至少63%、或至少64%、或至少65%、或至少66%、或至少67%、或至少68%、或至少69%、或至少70%、或至少71%、或至少72%、或至少73%、或至少74%、或至少75%、或至少76%、或至少77%、或至少78%、或至少79%、或至少80%、或至少81%、或至少82%、或至少83%、或至少84%、或至少85%、或至少86%、或至少87%、或至少88%、或至少89%、或至少90%、或至少91%、或至少92%、或至少93%、或至少94%、或至少95%、或至少96%、或至少97%、或至少98%、或至少99%或100%的同一性。
靶核酸可为DNA(ss或ds)或RNA。
在其他优选的实施方案中,RNA分子或其部分具有与靶核酸至少70%的同一性。在这样的同一性水平下,靶核酸优选为dsDNA。
RNA分子将优选地需要对靶核酸序列的高特异性和亲和性。如优选地通过非变性凝胶电泳或者等温滴定量热法、表面等离子体共振或基于荧光的滴定法所确定的,在1pM至1μM、优选1-100nM范围内的解离常数(Kd)是理想的。可使用电泳迁移率变动分析(EMSA),也称为凝胶阻滞分析(参见Semenova E等人(2011)Proc.Natl.Acad. Sci.USA 108:10098-10103)来确定亲和力。
RNA分子优选地模仿来自大自然的原核生物中被称为CRISPR RNA(crRNA)分子的那些分子。crRNA分子的结构已经确立并在Jore 等人(2011)Nature Structural&Molecular Biology 18:529-537中更详细地解释。简而言之,I-E型成熟crRNA通常为61个核苷酸长,并由8个核苷酸的5’“柄”区、32个核苷酸的“间隔区”序列和形成具有四核苷酸环的发夹的21个核苷酸的3’序列组成。然而,本发明中使用的RNA不是必须要严格设计成天然存在的crRNA的设计,无论是在长度、区域或特异性RNA序列方面。很明显地,本发明中使用的RNA 分子可基于公共数据库中的或新发现的基因序列信息来设计,然后人工制成,例如,全部或部分通过化学合成。本发明的RNA分子还可通过在遗传修饰的细胞或无细胞表达系统中表达的方式来设计和产生,这种选择可包括部分或全部RNA序列的合成。
crRNA的结构和要求也已在Semenova E等人(2011)Proc.Natl. Acad.Sci.USA108:10098-10103中描述。存在所谓的“SEED(种子)”部分,其形成间隔区序列的5’端,并且其5’侧翼为8个核苷酸的5’柄区。Semenova等人(2011)已经发现,SEED序列的所有残基应与靶序列互补,尽管对于第6位的残基而言,错配是可被容忍的。类似地,在设计和制备针对靶基因座的本发明核糖核蛋白复合物的RNA组分 (即序列)时,可应用针对SEED序列的必要的匹配和错配规则。
因此,本发明包括检测和/或定位靶核酸分子中的单碱基改变的方法,其包括:使核酸样品与如上文所述的本发明的核糖核蛋白复合物接触,或与如上文所述的本发明的级联复合物和单独的RNA组分接触,并且其中RNA组分(包括当在核糖核蛋白复合物中时)的序列使得它借助8个核苷酸残基的连续序列中的6位上的单碱基改变来区别正常的等位基因和突变的等位基因。
在本发明的实施方案中,RNA分子可具有在35-75个残基范围内的长度。在优选的实施方案中,与需要的核酸序列互补并用于靶向该核酸序列的RNA部分为32或33个残基的长度。(在天然存在的 crRNA的情况下,其将对应于间隔区部分;如Semenova等人(2011) 的图1所示)。
本发明的核糖核蛋白复合物可另外具有RNA组分,该RNA组分包含位于与核酸靶序列至少有基本互补实质互补性的RNA序列的5’侧的8个残基。(与核酸靶序列至少有基本互补实质互补性的RNA序列将被理解为对应于在crRNA的情况下对应于作为间隔区序列。RNA的5’侧翼序列将被认为与crRNA的5’柄区相对应。这在Semenova 等人(2011)的图1中示出)。
本发明的核糖核蛋白复合物可具有位于RNA序列的3’侧的发夹和四核苷酸环形成序列,该RNA序列与DNA靶序列至少有实质互补性。(在crRNA的情况下,这将对应于如Semenova等人(2011)的图1 中所示的间隔区序列侧翼的3’柄)。
在一些实施方案中,该RNA可为CRISPR RNA(crRNA)。
本发明的级联蛋白和复合物在体外可针对其与RNA引导组分相结合从而在靶核酸(其可为DNA或RNA)的存在下形成核糖核蛋白复合物的活性进行表征。电泳迁移率变动分析(EMSA)可用作针对本发明的复合物与其核酸靶标之间的相互作用的功能分析。基本地,将本发明的级联-功能性部分复合物与核酸靶标混合,通过EMSA或通过功能性部分的特定读取来监测该级联-功能性部分复合物的稳定的相互作用,例如靶DNA在期望的位点处的内切核苷酸切割。这可通过采用具有已知特异性并在靶DNA分子中具有切割位点的市售酶的进一步的限制性片段长度分析来确定。
可使用扫描/原子力显微镜(SFM/AFM)成像来实现在引导RNA的存在下本发明的级联蛋白或复合物与DNA或RNA的结合的可视化,并且这可提供一种针对本发明的功能性复合物的存在的试验。
本发明还提供了一种编码至少一种成簇规律间隔短回文重复序列(CRISPR)相关蛋白质亚基的核酸分子,该蛋白质亚基选自:
a.Cse1亚基,其具有SEQ ID NO:1的氨基酸序列或与之有至少9%同一性的序列;
b.Cse2亚基,其具有SEQ ID NO:2的氨基酸序列或与之有至少 20%同一性的序列;
c.Cas7亚基,其具有SEQ ID NO:3的氨基酸序列或与之有至少 18%同一性的序列;
d.Cas5亚基,其具有SEQ ID NO:4的氨基酸序列或与之有至少 17%同一性的序列;
e.Cas6亚基,其具有SEQ ID NO:5的氨基酸序列或与之有至少 16%同一性的序列;并且
其中至少a、b、c、d或e包括具有核酸或染色质修饰、可视化、转录激活或转录抑制活性的额外的氨基酸序列。
具有核酸或染色质修饰、可视化、转录激活或转录抑制活性的额外的氨基酸序列优选地与CRISPR相关蛋白质亚基融合。
在上文限定的本发明的核酸中,核苷酸序列可以是分别编码SEQ ID NO:1、SEQ IDNO:2、SEQ ID NO:3、SEQ ID NO:4或SEQ ID NO:5 的核苷酸序列,或者在定义其变异序列的范围时,其可以是优选在严格条件下,更优选在极高严格性的条件下,可与该核苷酸序列杂交的序列。各种严格的杂交条件将是本领域熟练的读者所熟悉的。当两个互补核酸分子经历一定量的彼此氢键键合(称为Watson-Crick碱基配对)时,发生核酸分子的杂交。杂交的严格性可根据核酸周围的环境(即化学/物理/生物)条件、温度、杂交方法的性质以及所使用的核酸分子的组成和长度而不同。关于达到特定严格性程度所需的杂交条件的计算在Sambrook等人,Molecular Cloning:A Laboratory Manual(Cold Spring HarborLaboratory Press,Cold Spring Harbor,NY,2001);以及 Tijssen,LaboratoryTechniques in Biochemistry and Molecular Biology-Hybridization with NucleicAcid Probes,第一部分第二章 (Elsevier,纽约,1993)中描述。Tm是核酸分子的50%的给定链与其互补链杂交时的温度。以下是一组示例性的杂交条件,而非限定性的:
极高严格性(允许享有至少90%同一性的序列杂交)
杂交: 5x SSC,于65℃,16小时
洗涤两次: 2x SSC,于室温(RT),每次15分钟
洗涤两次: 0.5x SSC,于65℃,每次20分钟
高严格性(允许享有至少80%同一性的序列杂交)
杂交: 5x-6x SSC,于65℃-70℃,16-20小时
洗涤两次: 2x SSC,于RT,每次5-20分钟
洗涤两次: 1x SSC,于55℃-70℃,每次30分钟
低严格性(允许享有至少50%同一性的序列杂交)
杂交: 6x SSC,于RT至55℃,16-20小时
洗涤至少两次: 2x-3x SSC,于RT至55℃,每次20-30分钟。
核酸分子可为分离的核酸分子,并且可为RNA或DNA分子。
所述额外的氨基酸序列可选自解旋酶、核酸酶、核酸酶-解旋酶(例如,Cas3)、DNA甲基转移酶(例如,Dam)、DNA脱甲基酶、组蛋白甲基转移酶、组蛋白脱甲基酶、乙酰化酶、脱乙酰酶、磷酸酶、激酶、转录(辅)激活物、RNA聚合酶亚基、转录阻抑物、DNA结合蛋白、 DNA结构化蛋白、标志物蛋白、报告蛋白、荧光蛋白、配体结合蛋白(例如,mCherry或重金属结合蛋白)、信号肽(例如,Tat-信号序列)、亚细胞定位序列(例如,核定位序列)或抗体表位。所述额外的氨基酸序列可以是或来自从中衍生出相关级联蛋白质亚基的生物体的不同蛋白质。
本发明包括一种包含如上文所限定的核酸分子的表达载体。一种表达载体可含有编码单一级联蛋白质亚基的核苷酸序列,并且还可含有编码额外的氨基酸序列的核苷酸序列,从而在表达时该亚基和额外的序列融合。其他表达载体可包含仅编码不与任何额外的氨基酸序列融合的一种或多种级联蛋白质亚基的核苷酸序列。
具有核酸或染色质修饰活性的额外的氨基酸序列可通过接头多肽与任何级联亚基融合。接头可为多达约60个或多达约100个氨基酸残基的任何长度。优选地,接头具有在10个至60个、更优选10-20 个的范围内的氨基酸数目。氨基酸优选地为极性的和/或小的和/或带电荷的氨基酸(例如,Gln、Ser、Thr、Pro、Ala、Glu、Asp、Lys、Arg、 His、Asn、Cys、Tyr)。接头肽优选地设计成获得融合的功能性部分与级联亚基的正确间隔及定位,其中该部分与该级联亚基融合以允许与靶核苷酸的适当的相互作用。
本发明的表达载体(含有或不含有编码在表达时将与级联蛋白质亚基融合的氨基酸残基的核苷酸序列)可进一步包含编码如上文所限定的RNA分子的序列。因此,这样的表达载体可在合适的宿主中使用,以产生可靶向期望的核苷酸序列的本发明的核糖核蛋白。
相应地,本发明还提供了一种修饰、可视化靶核酸,或激活或抑制靶核酸的转录的方法,该方法包括使核酸与如上文所限定的核糖核蛋白复合物接触。该修饰可通过切割核酸或与之结合来进行。
本发明还包括一种修饰、可视化靶核酸,或激活或抑制靶核酸的转录的方法,该方法包括使核酸接触如上文所限定的级联蛋白质复合物,加上如上文所限定的RNA分子。
按照上述方法,靶核酸的修饰、可视化或其转录的激活或抑制因此可在体外和在无细胞环境中进行;即,该方法作为生化反应进行,不论是游离在溶液中还是是否涉及固相。例如,靶核酸可结合到固相上。
在无细胞环境中,加入靶核酸、级联蛋白质复合物和RNA分子中的每一种的顺序由普通技术人员来选择。这三种组分可同时加入,以任意期望的顺序依次加入,或在不同的时间并以期望的顺序单独加入。因此,将靶核酸和RNA同时加入到反应混合物中,然后将本发明的级联蛋白质复合物随后以具体方法步骤的次序单独地加入是可能的。
靶核酸的修饰、可视化或其转录的激活或抑制可在细胞中原位进行,不论是分离的细胞还是作为多细胞组织、器官或生物体的一部分。因此,在完整组织和器官的情况下以及在生物体的情况下,该方法可在体内进行,或者其可通过将细胞从完整组织、器官或生物体中分离,然后使经核糖核蛋白复合物处理过的细胞返回至其之前的位置或不同的位置来进行,不论是在相同的还是不同的生物体内。因此,该方法将包括同种异体移植、自体移植、同种移植和异种移植。
在这些实施方案中,本发明的核糖核蛋白复合物或级联蛋白质复合物需要适当的向细胞内的递送形式,其将是本领域技术人员所熟知的,包括显微注射,不论是注射到细胞质内还是注射到细胞核内。
并且,在单独存在时,RNA分子需要适当的向细胞内的递送形式,不论是与级联蛋白质复合物同时、分别还是依次地。这样的将 RNA引入细胞的形式是本领域技术人员所熟知的,并且可包括经由常规转染方法的体外或离体递送。可分别使用诸如显微注射和电穿孔等物理方法,以及钙共沉淀和市售的阳离子聚合物和脂质,以及细胞穿透肽、细胞穿透颗粒(基因枪)。例如,病毒可用作递送载体,不论是递送至细胞质和/或细胞核——例如,通过本发明的级联蛋白质复合物或本发明的核糖核蛋白复合物与病毒颗粒的(可逆)融合。可使用病毒递送(例如,腺病毒递送)或土壤杆菌(Agrobacterium)介导的递送。
本发明还包括一种在细胞中修饰、可视化靶核酸、或激活或抑制靶核酸的转录的方法,该方法包括用如上文所述的任何表达载体转染、转化或转导该细胞。转染、转化或转导的方法是本领域技术人员所熟知的类型。在存在一种用于产生本发明的级联复合物的表达的表达载体且当RNA直接加入到细胞的情况下,可使用相同或不同的转染、转化或转导的方法。类似地,当存在一种正用于产生本发明的级联-功能性融合复合物的表达的表达载体且当另一种表达载体正用于通过表达而原位产生RNA时,可使用相同或不同的转染、转化或转导的方法。
在其他实施方案中,将编码本发明的级联复合物的mRNA引入细胞内,以使该级联复合物在细胞中表达。将级联蛋白复合物引导至期望的靶序列的RNA也被引入至该细胞中,不论是与该mRNA同时、分别还是依次地引入,从而在细胞中形成必需的核糖核蛋白复合物。
在上述修饰或可视化靶核酸的方法中,所述额外的氨基酸序列可以是标志物,并且该标志物与靶核酸相关联;优选地,其中该标志物为蛋白质;任选地为荧光蛋白,例如,绿色荧光蛋白(GFP)或黄色荧光蛋白(YFP)或mCherry。不论在体外、离体还是体外,本发明的方法可用于直接可视化核酸分子中的靶基因座,该核酸分子优选为更高阶结构的形式,诸如超螺旋质粒或染色体或诸如mRNA的单链靶核酸。靶基因座的直接可视化可使用电子显微镜检查或荧光显微镜检查。
可以使用其他种类的标签来标记靶核酸,包括有机染料分子、放射性标签和可为小分子的自旋标签。
在上述的本发明方法中,靶核酸为DNA;优选为dsDNA,尽管靶标可为RNA;优选为mRNA。
在用于修饰、可视化靶核酸、激活靶核酸的转录或抑制靶核酸的转录(其中靶核酸为dsDNA)的本发明的方法中,具有核酸或染色质修饰活性的额外的氨基酸序列可为核酸酶或解旋酶-核酸酶,并且该修饰优选为期望的基因座处的单链或双链断裂。采用这种方式,可通过使用级联-功能性部分复合物来使DNA的独特序列特异性切割工程化。最终核糖核蛋白复合物的RNA组分的所选序列为额外的氨基酸序列的作用提供了所需的序列特异性。
因此,本发明还提供了一种使细胞中的dsDNA分子在期望的基因座处进行非同源末端连接,从而从该dsDNA分子中除去至少一部分核苷酸序列,任选地敲除一个基因或多个基因的功能的方法,其中该方法包括采用如上文所述的任何修饰靶核酸的方法来制造双链断裂。
本发明进一步提供了一种将核酸同源重组到细胞中期望的基因座处的dsDNA分子内以修饰存在的核苷酸序列或插入期望的核苷酸序列的方法,其中该方法包括采用如上文所述的任何修饰靶核酸的方法在期望的基因座处产生双链或单链断裂。
本发明因此还提供了一种修饰、激活或抑制生物体中的基因表达的方法,该方法包括根据上文所述的任何方法来修饰靶核酸序列、激活靶核酸序列的转录或抑制靶核酸序列的转录,其中该核酸为 dsDNA,并且该功能性部分选自DNA修饰酶(例如,脱甲基酶或脱乙酰酶)、转录激活物或转录阻抑物。
本发明另外提供了一种修饰、激活或抑制生物体中的基因表达的方法,该方法包括根据上文所述的任何方法来修饰靶核酸序列、激活靶核酸序列的转录或抑制靶核酸序列的转录,其中该核酸为mRNA,并且该功能性部分为核糖核酸酶;任选地选自内切核酸酶、3’外切核酸酶或5’外切核酸酶。
在如上所述的本发明的任何方法中,经受该方法的细胞可以是原核细胞。类似地,该细胞可为以是真核细胞,例如,植物细胞、昆虫细胞、酵母细胞、真菌细胞、哺乳动物细胞或人细胞。当细胞是哺乳动物或人的细胞时,它可以是干细胞(但可能不是任何的人胚胎干细胞)。本发明中使用的这类干细胞优选为分离的干细胞。任选地,按照本发明的任何方法对细胞进行体外转染。
优选地,在本发明的任何方法中,靶核酸具有特定的三级结构,任选地为超螺旋的,更优选地其中该靶核酸为负超螺旋的。有利的是,本发明的核糖核蛋白复合物,不论是在体外产生的,或在细胞内形成的,还是通过细胞的表达机器在细胞内形成的,均可用于靶向以其他方式难以接近的基因座,以便应用期望的组分的功能活性,不论是特异性序列的标注或标记、核酸结构的修饰、基因表达的开启或关闭,还是涉及单链或双链切割、随后插入一个或多个核苷酸残基或盒的靶序列本身的修饰。
本发明还包括一种药物组合物,其包含如上文所述的本发明的级联蛋白质复合物或核糖核蛋白复合物。
本发明进一步包括一种药物组合物,其包含如上文所述的本发明的分离的核酸或表达载体。
还提供了一种试剂盒,其包含如上文所述的本发明的级联蛋白质复合物,以及如上文所述的本发明的RNA分子。
本发明包括一种用作药物的如上文所述的级联蛋白质复合物或核糖核蛋白复合物或核酸或载体。
本发明允许在指定的基因组基因座处物理地改变原核或真核宿主的DNA,或者改变给定基因座处基因的表达模式的多种可能性。可通过分别与合适的级联-亚基融合的功能域如核酸酶、甲基化酶、荧光蛋白、转录激活物或阻抑物,来对宿主基因组DNA进行切割、或甲基化修饰、荧光可视化、转录激活或抑制。此外,级联的RNA 引导的RNA结合能力允许用荧光级联融合蛋白监控活细胞中的RNA 运输,并提供了隔离或破坏宿主mRNA从而对宿主细胞的基因表达水平造成干扰的方法。
在本发明的任何方法中,可通过至少一种以下核苷酸三联体的存在来限定靶核酸,如果是dsDNA则优选如此:5’-CTT-3’、5’-CAT-3’、 5’-CCT-3’或5’-CTC-3’(或者如果靶标为RNA,则为5’-CUU-3’、 5’-CAU-3’、5’-CCU-3’或5’-CTC-3’)。三联体的位置是在与本发明的核糖核蛋白的RNA分子组分杂交的序列相邻的靶链上。三联体标记靶链序列中的位点,在该位点处,与核糖核蛋白的RNA分子组分的在靶标的5’至3’(下游)方向上不发生碱基配对(然而,碱基配对在该位点的靶序列的上游发生,其具有本发明核糖核蛋白的RNA分子组分的RNA序列的优选长度)。在天然I型CRISPR系统的情况下,三联体与被称为“PAM”(原间隔区邻近基序)的序列相对应。对于ssDNA 或ssRNA靶标,三联体之一的存在并非如此必要。
现将参考具体实施例和附图对本发明进行详细的描述,附图中:
图1显示了凝胶移位分析的结果,其中级联结合负超螺旋(nSC) 质粒DNA而不结合松弛的DNA。A)具有J3-级联(含有靶向(J3)crRNA) 的nSC质粒DNA的凝胶移位。将pUC-λ与2倍渐增量的J3-级联混合,pUC-λ:级联摩尔比从1∶0.5直至1∶256摩尔比。第一泳道和最后泳道仅含有pUC-λ。B)具有R44-级联(含有非靶向(R44)cRNA)的如(A) 中所述的凝胶移位。C)具有Nt.BspQI切刻的pUC-λ的如(A)中所述的凝胶移位。D)具有PdmI线性化的pUC-λ的如(A)中所述的凝胶移位。 E)针对游离J3-级联的浓度绘制的与J3-级联结合的pUC-λ分数的拟合给出了特异性结合的解离常数(Kd)。F)针对游离R44-级联的浓度绘制的与R44-级联结合的pUC-λ分数的拟合给出了非特异性结合的解离常数(Kd)。G)使用原间隔区序列中独特的BsmI限制位点,通过限制性分析监测的级联与原间隔区的特异性结合。泳道1和5仅含pUC-λ。泳道2和6含有与级联混合的pUC-λ。泳道3和7含有与级联混合的 pUC-λ,并且随后加入BsmI。泳道4和8含有与BsmI混合的pUC-λ。 H)与级联结合并且随后对质粒的一条链进行Nt.BspQI切割的pUC-λ的凝胶移位。泳道1和6仅含pUC-λ。泳道2和7含有与级联混合的 pUC-λ。泳道3和8含有与级联混合并且随后进行Nt.BspQI切刻的 pUC-λ。泳道4和9含有与级联混合的pUC-λ,接着加入与R-环中的替代链互补的ssDNA探针,随后用Nt.BspQI进行切刻。泳道5和10 含有用Nt.BspQI切刻的pUC-λ。H)与级联结合并且随后对质粒进行 Nt.BspQI切刻的pUC-λ的凝胶移位。泳道1和6仅含pUC-λ。泳道2 和7含有与级联混合的pUC-λ。泳道3和8含有与级联混合并且随后进行Nt.BspQI切割的pUC-λ。泳道4和9含有与级联混合的pUC-λ,接着加入与R-环中的替代链互补的ssDNA探针,随后用Nt.BspQI进行切割。泳道5和10含有用Nt.BspQI切割的pUC-λ。I)与级联结合并且随后对质粒的两条链都进行EcoRI切割的pUC-λ的凝胶移位。泳道1和6仅含pUC-λ。泳道2和7含有与级联混合的pUC-λ。泳道3 和8含有与级联混合并随后进行EcoRI切割的pUC-λ。泳道4和9含有与级联混合的pUC-λ,接着加入与R-环中的替代链互补的ssDNA 探针,并随后用EcoRI进行切割。泳道5和10含有用EcoRI切割的pUC-λ。
图2示出了扫描力显微照片,证明级联如何诱导靶DNA在原间隔区结合时的弯曲。A-P)具有包含靶向(J3)crRNA的J3-级联的nSC 质粒DNA的扫描力显微镜图像。pUC-λ与J3-级联以1∶7的pUC-λ:级联比例混合。每张图像示出了500x 500nm的表面区域。白点对应于级联。
图3示出了BiFC分析如何揭示级联和Cas3在靶标识别后相互作用。A)表达级联ΔCse1和CRISPR 7Tm(其靶向λ噬菌体基因组上的 7个原间隔区)以及Cse1-N155Venus和Cas3-C85Venus融合蛋白的细胞的Venus荧光。B)(A)中的细胞的亮视野图像。C)(A)与(B)的重叠。 D)λ噬菌体感染的细胞的Venus荧光,该细胞表达级联ΔCse1和 CRISPR 7Tm,以及Cse1-N155Venus和Cas3-C85Venus融合蛋白。 E)(G)中的细胞的亮视野图像。F)(G)与(H)的重叠。G)λ噬菌体感染的细胞的Venus荧光,该细胞表达级联ACse1和非靶向CRISPR R44,以及N155Venus和C85Venus蛋白。H)(J)中的细胞的亮视野图像。 I)(J)与(K)的重叠。J)每个菌株的4-7个个体细胞的荧光强度平均值,如使用LSM指示器(Car1 Zeiss)的图谱工具(profile tool)所确定的。
图4示出了CRISPR-干扰期间Cas3核酸酶和解旋酶的活性。A) 用pUC-λ转化表达级联、Cas3突变体和CRISPR J3的感受态BL21-AI 细胞。对每个表达Cas3突变体的菌株描述每微克pUC-λ的菌落形成单位(cfu/μg DNA)。表达野生型(wt)Cas3和crisprj3或crisprr44的细胞分别作为阳性对照和阴性对照。B)携带级联、Cas3突变体和 CRISPR编码质粒以及pUC-λ的BL21-AI细胞在抑制cas基因和 CRISPR表达的条件下生长。当t=0时,表达被诱导。示出了丢失pUC-λ的细胞随时间推移的百分数,如通过氨苄青霉素敏感细胞与氨苄青霉素抗性细胞的比例所确定的。
图5示出了级联-Cas3融合复合物如何提供体内抗性并具有体外核酸酶活性。A)纯化的级联和级联-Cas3融合复合物的考马斯蓝染色的SDS-PAGE。B)λ噬菌体对表达级联-Cas3融合复合物和靶向(J3) 或非靶向(R44)CRISPR的细胞的成斑率,以及对单独表达级联和Cas3 以及靶向(J3)CRISPR的细胞的成斑率。C)具有J3-级联-Cas3融合复合物的nSC靶质粒的凝胶移位(在不存在二价金属离子的情况下)。 pUC-λ与2倍渐增量的J3-级联-Cas3混合,pUC-λ∶J3-级联-Cas3摩尔比从1∶0.5至高达1∶128摩尔比。第一泳道和最后的泳道仅含有 pUC-λ。D)具有J3-级联-Cas3融合复合物的nSC非靶质粒的凝胶移位电泳(在不存在二价金属离子的情况下)。pUC-p7与2倍渐增量的J3- 级联-Cas3混合,pUC-p7∶J3-级联-Cas3摩尔比从1∶0.5至高达1∶128 摩尔比。第一泳道和最后的泳道仅含有pUC-p7。E)在10mM MgCl2的存在下,nSC靶质粒(pUC-λ,左)或nSC非靶质粒(pUC-p7,右)与 J3-级联-Cas3的温育。泳道1和7仅含有质粒。F)在2mM ATP的存在下进行的如(E)中所述的试验。G)用突变的J3-级联-Cas3K320N 复合物进行的如(E)中所述的试验。H)在2mM ATP的存在下进行的如(G)中所述的试验。
图6为显示大肠杆菌中CRISPR-干扰I型途径的模型的示意图。
图7为显示本发明的级联-FokI融合实施方案如何被用来创建 FokI二聚体的示意图,该FokI二聚体切割dsDNA以产生平末端作为非同源末端连接或同源重组过程的部分。
图8示出了BiFC分析如何揭示级联和Cas3在靶标识别时相互作用。表达不含Cse1的级联、Cse1-N155Venus和Cas3-C85Venus以及 CRISPR 7Tm(其靶向λ噬菌体基因组上的7个原间隔区)或非靶向 CRISPR R44的细胞的亮视野图像和Venus荧光的重叠。表达CRISPR7Tm的细胞仅在被λ噬菌体感染时是荧光的,而表达CRISPR R44的细胞为非荧光的。高强度的荧光点(细胞外)是由于反光的盐晶体。白色线条对应于10微米。
图9显示了编码CRISPR J3、级联和Cas3(野生型或S483AT485A) 的4个克隆的pUC-λ序列[SEQ ID NO:39-42],表明它们是携带原间隔区(部分)缺失或携带种子区中的单点突变的逃逸突变体,这解释了为什么不能恢复这些质粒。
图10示出了来自含有I-E型CRISPR/Cas系统的生物体的cas3 基因的序列比对。来自链霉菌(Streptomyces sp.)SPB78(第一序列,登录号:ZP_07272643.1)[SEQ ID NO:43]、灰色链霉菌(Streptomyces griseus)(第二序列,登录号:YP_001825054)[SEQ ID NO:44]和嗜酸细链孢菌(Catenulispora acidiphila)DSM 44928(第三序列,登录号: YP_003114638)[SEQ ID NO:45]中的cas3-cse1基因以及包括来自灰色链霉菌的多肽接头序列的人工大肠杆菌Cas3-Cse1融合蛋白[SEQ ID NO:46]的比对。
图11示出了级联KKR/ELD核酸酶对的设计,其中对FokI核酸酶结构域进行突变,以致只有由KKR和ELD核酸酶结构域组成的异二聚体和相对的结合位点之间的距离可发生变化,以确定级联核酸酶对之间的最佳距离。
图12是示出了级联-FokI核酸酶对的基因组靶向的示意图。
图13示出了级联-核酸酶复合物的SDS-PAGE凝胶。
图14示出了级联KKR/ELD对质粒DNA的体外切割试验的电泳凝胶。
图15示出了级联KKR/ELD的切割模式和频率[SEQ ID NO:47]。
实施例——所用的材料与方法
菌株、基因克隆、质粒和载体
全部使用大肠杆菌BL21-AI和大肠杆菌BL21(DE3)菌株。表1 列出了本研究中使用的所有质粒。之前所述的pWUR408、pWUR480、 pWUR404和pWUR547用来产生Strep-标记IIR44-级联,而 pWUR408、pWUR514和pWUR630用来产生Strep-标记II J3-级联 (Jore等人,(2011)Nature Structural&Molecular Biology 18,529-536; Semenova等人,(2011)Proceedings of the National Academy of Sciences of the United States ofAmerica 108,10098-10103)。pUC-λ (pWUR610)和pUC-p7(pWUR613)已经在别处(Jore等人,2011; Semenova等人,2011)有所描述。C85Venus蛋白由pWUR647编码, pWUR647对应于含有在BamHI和NotI位点之间克隆的合成 GA1070943构建体(表2)(Geneart)的pET52b(Novagen)。N155Venus 蛋白由pWUR648编码,pWUR648对应于含有在NotI和XhoI位点之间克隆的合成GA1070941构建体(表2)(Geneart)的pRSF1b (Novagen)。Cas3-C85Venus融合蛋白由pWUR649编码,pWUR649 对应于含有使用引物BG3186和BG3213(表3)在NcoI和BamHI位点之间扩增的Cas3扩增产物的pWUR647。CasA-N155Venus融合蛋白由pWUR650编码,pWUR650对应于含有使用引物BG3303和BG3212 (表3)在NcoI和BamHI位点之间扩增的CasA扩增产物的pWUR648。 CRISPR 7Tm由pWUR651编码,pWUR651对应于含有在NcoI和KpnI 位点之间克隆的合成GA1068859构建体(表2)(Geneart)的 pACYCDuet-1(Novagen)。编码级联的pWUR400、编码级联ΔCse1的 WUR401和编码Cas3的pWUR397在之前已有描述(Jore等人,2011)。编码Cas3H74A的pWUR652是使用引物BG3093、BG3094(表3)对 pWUR397进行定点诱变而构建的。
表1——所用的质粒


上表中的来源1是Brouns等人(2008)Science 321,960-964。
上表中的来源2是Jore等人(2011)Nature Structural&Molecular Biology 18:529-537。
表2——合成的构建体
GA1070943
ACTGGAAAGCGGGCAGTGAAAGGAAGGCCCATGAGGCCAGTTAATTAAGCGGA TCCTGGCGGCGGCAGCGGCGGCGGCAGCGACAAGCAGAAGAACGGCATCAAGG CGAACTTCAAGATCCGCCACAACATCGAGGACGGCGGCGTGCAGCTCGCCGACC ACTACCAGCAGAACACCCCCATCGGCGACGGCCCCGTGCTGCTGCCCGACAACC ACTACCTGAGCTACCAGTCCGCCCTGAGCAAAGACCCCAACGAGAAGCGCGATC ACATGGTCCTGCTGGAGTTCGTGACCGCCGCCGGGATCACTCTCGGCATGGACGA GCTGTACAAGTAAGCGGCCGCGGCGCGCCTAGGCCTTGACGGCCTTCCTTCAATT CGCCCTATAGTGAG[SEQ ID NO:6]
GA1070941
CACTATAGGGCGAATTGGCGGAAGGCCGTCAAGGCCGCATTTAATTAAGCGGCC GCAGGCGGCGGCAGCGGCGGCGGCAGCATGGTGAGCAAGGGCGAGGAGCTGTT CACCGGGGTGGTGCCCATCCTGGTCGAGCTGGACGGCGACGTAAACGGCCACAA GTTCAGCGTGTCCGGCGAGGGCGAGGGCGATGCCACCTACGGCAAGCTGACCCT GAAGCTCATCTGCACCACCGGCAAGCTGCCCGTGCCCTGGCCCACCCTCGTGACC ACCCTCGGCTACGGCCTGCAGTGCTTCGCCCGCTACCCCGACCACATGAAGCAGC ACGACTTCTTCAAGTCCGCCATGCCCGAAGGCTACGTCCAGGAGCGCACCATCTT CTTCAAGGACGACGGCAACTACAAGACCCGCGCCGAGGTGAAGTTCGAGGGCGA CACCCTGGTGAACCGCATCGAGCTGAAGGGCATCGACTTCAAGGAGGACGGCAA CATCCTGGGGCACAAGCTGGAGTACAACTACAACAGCCACAACGTCTATATCAC GGCCTAACTCGAGGGCGCGCCCTGGGCCTCATGGGCCTTCCGCTCACTGCCCGCT TTCCAG[SEQ ID NO:7]
GA1068859
CACTATAGGGCGAATTGGCGGAAGGCCGTCAAGGCCGCATGAGCTCCATGGAAA CAAAGAATTAGCTGATCTTTAATAATAAGGAAATGTTACATTAAGGTTGGTGGGT TGTTTTTATGGGAAAAAATGCTTTAAGAACAAATGTATACTTTTAGAGAGTTCCC 34CGCGCCAGCGGGGATAAACCGGGCCGATTGAAGGTCCGGTGGATGGCTTAAAAG AGTTCCCCGCGCCAGCGGGGATAAACCGCCGCAGGTACAGCAGGTAGCGCAGAT CATCAAGAGTTCCCCGCGCCAGCGGGGATAAACCGACTTCTCTCCGAAAAGTCA GGACGCTGTGGCAGAGTTCCCCGCGCCAGCGGGGATAAACCGCCTACGCGCTGA ACGCCAGCGGTGTGGTGAATGAGTTCCCCGCGCCAGCGGGGATAAACCGGTGTG GCCATGCACGCCTTTAACGGTGAACTGGAGTTCCCCGCGCCAGCGGGGATAAAC CGCACGAACTCAGCCAGAACGACAAACAAAAGGCGAGTTCCCCGCGCCAGCGG GGATAAACCGGCACCAGTACGCGCCCCACGCTGACGGTTTCTGAGTTCCCCGCGC CAGCGGGGATAAACCGCAGCTCCCATTTTCAAACCCAGGTACCCTGGGCCTCATGGGCCTTCCGCTCACTGCCCGCTTTCCAG[SEQ ID NO:8]
GA1047360
GAGCTCCCGGGCTGACGGTAATAGAGGCACCTACAGGCTCCGGTAAAACGGAAA CAGCGCTGGCCTATGCTTGGAAACTTATTGATCAACAAATTGCGGATAGTGTTAT TTTTGCCCTCCCAACACAAGCTACCGCGAATGCTATGCTTACGAGAATGGAAGCG AGCGCGAGCCACTTATTTTCATCCCCAAATCTTATTCTTGCTCATGGCAATTCACG GTTTAACCACCTCTTTCAATCAATAAAATCACGCGCGATTACTGAACAGGGGCAA GAAGAAGCGTGGGTTCAGTGTTGTCAGTGGTTGTCACAAAGCAATAAGAAAGTG TTTCTTGGGCAAATCGGCGTTTGCACGATTGATCAGGTGTTGATTTCGGTATTGCC AGTTAAACACCGCTTTATCCGTGGTTTGGGAATTGGTAGATCTGTTTTAATTGTTAATGAAGTTCATGCTTACGACACCTATATGAACGGCTTGCTCGAGGCAGTGCTCAA GGCTCAGGCTGATGTGGGAGGGAGTGTTATTCTTCTTTCCGCAACCCTACCAATG AAACAAAAACAGAAGCTTCTGGATACTTATGGTCTGCATACAGATCCAGTGGAA AATAACTCCGCATATCCACTCATTAACTGGCGAGGTGTGAATGGTGCGCAACGTTTTGATCTGCTAGCGGATCCGGTACC[SEQ ID NO:9]
表3——引物


蛋白质的生产和纯化
级联如(Jore等人,2011)所述进行表达和纯化。在整个纯化过程中,含有20mMHEPES pH 7.5、75mM NaCl、1mM DTT、2mM EDTA 的缓冲液用于重悬浮和洗涤。蛋白质的洗脱在含有4mM脱硫生物素的相同缓冲液中进行。级联-Cas3融合复合物以同样的方式表达和纯化,用20mM HEPES pH 7.5、200mM NaCl和1mM DTT进行洗涤步骤,并且在含有4mM脱硫生物素的20mM HEPES pH 7.5、75mM NaCl、1mM DTT中洗脱。
电泳迁移率变动分析
将纯化的级联或级联亚复合物与pUC-λ在含有20mM HEPES pH 7.5、75mM NaCl、1mM DTT、2mM EDTA的缓冲液中混合,并于 37℃温育15分钟。样品在0.8%TAE琼脂糖凝胶上电泳过夜,并用在TAE中1∶10000稀释的SybR safe(Invitrogen)进行后染色30分钟。在补充有5mM MgCl2的HEPES反应缓冲液中进行BsmI(Fermentas) 或Nt.BspQI(New EnglandBiolabs)切割。
扫描力显微镜检查
将纯化的级联与pUC-λ(以7∶1的比例,250nM级联,35nM DNA) 在含有20mM HEPESpH 7.5、75mM NaCl、0.2mM DTT、0.3mM EDTA的缓冲液中混合,并于37℃温育15分钟。随后,为了制备 AFM样品,将温育的混合物在重蒸馏水中稀释10倍,加入MgCl2至终浓度为1.2mM。蛋白质-DNA复合物的沉积和成像如前所述(Dame 等人,(2000)Nucleic Acids Res.28:3504-3510)进行。
荧光显微镜检查
携带CRISPR和cas基因编码质粒的BL21-AI细胞,在含有氨苄青霉素(100μg/ml)、卡那霉素(50μg/ml)、链霉素(50μg/ml)和氯霉素 (34μg/ml)的Luria-Bertani液体培养基(LB)中于37℃生长过夜。过夜培养物在新鲜的含有抗生素的LB中1∶100稀释,并于37℃生长1 小时。通过加入L-阿拉伯糖至终浓度为0.2%和加入IPTG至终浓度为 1mM来诱导cas基因和CRISPR的表达1小时。为了感染,将细胞与λ噬菌体以等于4的感染复数(MOI)混合。将细胞涂于聚-L-赖氨酸覆盖的显微镜载玻片上,并使用基于Axiovert倒置显微镜的ZeissLSM510共聚焦激光扫描显微镜进行分析,其中使用40x油浸物镜(1.3 的数值孔径(N.A.)),使用氩激光器作为激发源(514nm),并于530-600 nm检测。对于所有的测量都将针孔设定为203μm。
pUC-λ转化研究
含有卡那霉素(50μg/ml)、链霉素(50μg/ml)和氯霉素(34μg/ml) 的LB从过夜预接种物接种,并生长至OD600为0.3。用0.2%L-阿拉伯糖和1mM IPTG诱导cas基因和CRISPR的表达45分钟。通过4℃离心收集细胞,并通过在含有100mM RbCl2、50mM MnCl2、30mM 醋酸钾、10mM CaCl2和15%甘油的冰冷缓冲液(pH 5.8)中重悬浮使其成为感受态细胞。温育3小时后,收集细胞,并重悬浮于含有10mM MOPS、10mM RbCl、75mM CaCl2、15%甘油的pH 6.8缓冲液中。通过加入80ng pUC-λ,接着于42℃热激1分钟,并在冰上冷激5 分钟来进行转化。接下来,细胞在LB中于37℃生长45分钟,然后涂布到含有0.2%L-阿拉伯糖、1mM IPTG、氨苄青霉素(100μg/ml)、卡那霉素(50μg/ml)、链霉素(50μg/ml)和氯霉素(34μg/ml)的LB-琼脂平板上。
通过用pUC-λ转化含有cas基因和CRISPR编码质粒的BL21-AI 细胞来分析质粒消除(plasmid curing),同时细胞在0.2%葡萄糖的存在下生长以抑制T7-聚合酶基因的表达。通过收集细胞并重悬浮于含有 0.2%阿拉伯糖和1mM IPTG的LB中来诱导cas基因和CRISPR的表达。将细胞涂布到或者含有链霉素、卡那霉素和氯霉素(对pUC-λ是非选择性的)或者含有氨苄青霉素、链霉素、卡那霉素和氯霉素(对 pUC-λ是选择性的)的LB-琼脂上。生长过夜后,可从选择性和非选择性平板上的菌落形成单位的比例来计算质粒丢失的百分比。
λ噬菌体感染研究
如(Brouns等人(2008)Science 321,960-964)中所述,使用毒性λ噬菌体(λ病毒)来检测宿主对噬菌体感染的敏感性。如Brouns等人(2008) 所述,宿主对感染的敏感性以成斑率(含有抗-λCRISPR的菌株与含有非靶向R44CRISPR的菌株的噬菌斑计数比)计算。
实施例1——级联排他性地结合负超螺旋靶DNA
命名为pUC-λ的3kb的pUC19-衍生质粒含有与λ噬菌体J基因的一部分相对应的350bp的DNA片段,该DNA片段被J3-级联(与包含J3间隔区的crRNA相关联的级联)所靶向(Westra等人(2010) Molecular Microbiology 77,1380-1393)。电泳迁移率变动分析显示级联仅对负超螺旋(nSC)靶质粒具有高亲和性。在J3-级联与pUC-λ的摩尔比为6∶1时,所有nSC质粒被级联结合(参见图1A),而携带非靶向 crRNA R44的级联(R44-级联)在128∶1的摩尔比下显现出非特异性结合(参见图1B)。nSC pUC-λ对于J3-级联的解离常数(Kd)测定为13± 1.4nM(参见图1E),对于R44-级联的解离常数(Kd)测定为429±152 nM(参见图1F)。
J3-级联无法以可测量的亲和力结合松弛的靶DNA,诸如有切口的(参见图1C)或线性的pUC-λ(参见图1D),显示级联对具有nSC拓扑结构的较长的DNA底物具有高亲和力。
为将非特异性结合与特异性结合区分开,使用了位于原间隔区内的BsmI限制位点。在R44-级联的存在下将BsmI酶加入pUC-λ产生了线性产物(参见图1G,泳道4),而在J3-级联的存在下pUC-λ被保护免于BsmI切割(参见图1G,泳道7),这指示与原间隔区的特异性结合。这表明,级联与nSC质粒中的原间隔区序列的体外序列特异性结合并不需要Cas3。
级联与nSC pUC-λ结合后,用Nt.BspQI产生切口,形成OC拓扑结构。在链产生切口后,级联从质粒中释放出来,这可从不存在迁移率变动看出(参见图1H,比较泳道8与泳道10)。相反,当在DNA 被Nt.BspQI切割之前向该反应中加入与替代链互补的ssDNA探针时,级联仍与其DNA靶标结合(参见图1H,泳道9)。该探针人工地将级联R-环稳定在松弛的靶DNA上。当pUC-λ的两条DNA链在级联结合后都被切割时,获得相似的观察结果(参见图11,泳道8和泳道9)。
实施例2——级联诱导被结合的靶DNA的弯曲
对纯化的级联和pUC-λ之间形成的复合物进行可视化。形成含有单个结合的J3-级联复合物的特异性复合物,而在该试验中在相同的条件下,非特异性R44-级联不产生DNA结合的复合物。发现在所观察的81个DNA分子中有76%结合有J3-级联(参见图2A至图2P)。在这些复合物中,大多数情况下级联在环的顶端被发现(86%),而仅有小部分在非顶端位置被发现(14%)。这些数据显示,级联结合引起了DNA的弯曲和可能的缠绕,这或许有助于DNA双链体的局部解链。
实施例3——Cas3和Cse1的自然发生的融合:Cas3与级联在原间隔区识别后相互
作用
图S3表明,对来自包含I-E型CRISPR/Cas系统的生物体的cas3 基因的序列分析揭示了Cas3和Cse1在链霉菌(Streptomyces sp.) SPB78(登录号:ZP_07272643.1)、灰色链霉菌(登录号:YP_001825054) 和嗜酸细链孢菌DSM 44928(登录号:YP_003114638)中以融合蛋白出现。
实施例4——双分子荧光互补实验(BiFC)显示了级联的Cse1融合蛋白形成部分如
何继续与Cas3相互作用。
采用BiFC实验监测在λ噬菌体感染之前和之后体内Cas3与级联之间的相互作用。BiFC实验依赖于诸如黄色荧光蛋白(YFP)的荧光蛋白的非荧光半部在两个半部非常靠近时重新折叠并形成荧光分子的能力。这样,它提供了一种揭示蛋白质-蛋白质相互作用的工具,因为若局部浓度较高,例如,当荧光蛋白的两个半部与相互作用配偶体相融合时,重折叠效率大大增强。Cse1在C-端与Venus的N-端155 个氨基酸融合(Cse1-N155 Venus),Venus为YFP的改良形式(Nagai 等人(2002)Nature Biotechnology 20,87-90)。Cas3在C-端与Venus 的C-端85个氨基酸融合(Cas3-C85Venus)。
BiFC分析揭示了在不存在侵入DNA时级联不与Cas3相互作用 (图3ABC、图3 (续)和图8)。然而,一旦用λ噬菌体感染,表达级联ΔCsel、 Csel-N155Venus和Cas3-C85Venus的细胞如果共表达抗-λCRISPR 7Tm,则是荧光的(图3DEF、图3 (续)和图8)。当它们共表达非靶向 CRISPR R44时(图3GHI、图3 (续)和图8),细胞仍然为非荧光的。这表明,在感染期间一旦发生原间隔区识别,则级联和Cas3特异性相互作用,并且在级联-Cas3二元效应复合物中,Cse1和Cas3彼此非常靠近。
这些结果也非常清楚地表明,Cse1与异源蛋白质的融合并不会中断级联和crRNA的核糖核蛋白形成,也不会中断级联和Cas3与靶噬菌体DNA的相互作用,即便当Cas3本身也是融合蛋白时。
实施例5——制备经设计的Cas3-Cse1融合体产生了具有体内功能活性的蛋白质
提供Cas3 DNA切割活性的体外证据需要纯化的活性Cas3。尽管有各种溶解策略,在大肠杆菌BL21中过量产生的Cas3(Howard等人 (2011)Biochem.J.439,85-95)主要存在于无活性聚集体和包涵体中。 Cas3因此作为Cas-Cse1融合蛋白产生,其含有与灰色链霉菌中的Cas3-Cse1融合蛋白的接头相同的接头(参见图10)。当与级联ΔCse1 和CRISPR J3共表达时,融合-复合物是可溶的,并以高纯度获得,具有与级联相同的表观化学计量学性质(图5A)。当检测此复合物提供针对λ噬菌体感染的抗性的功能性时,表达融合-复合物J3-级联-Cas3 的细胞的成斑率(eop)与表达单独蛋白质的细胞的成斑率相同(图5B)。
由于J3-级联-Cas3融合-复合物在体内具有功能,因此使用此复合物进行体外DNA切割试验。当J3-级联-Cas3与pUC-λ在不存在二价金属的情况下温育时,在与针对级联观察到的摩尔比相似的摩尔比时观察到质粒结合(图5C),而与非靶质粒(pUC-p7,一种与pUC-λ大小相同但缺少原间隔区的pUC19衍生质粒)的特异性结合仅在高摩尔比时发生(图5D),这表明该复合物的特异性DNA结合也类似于单独的级联的特异性DNA结合。
有趣的是,J3-级联-Cas3融合复合物展示出对nSC靶质粒的镁依赖性内切核酸酶活性。在10mM Mg2+的存在下,J3-级联-Cas3使nSC pUC-λ产生切口(图5E,泳道3-7),但是对于不含靶序列(图5E,泳道 9-13)或具有松弛拓扑结构的底物却未观察到切割。未观察到所得OC 条带的移位,这与之前的如下观察结果一致:级联在切割后自发解离,而不需要ATP-依赖性Cas3解旋酶活性。相反,Cas3的解旋酶活性似乎参与了核酸外切质粒降解。当将镁和ATP都加入到反应中时,发生完全质粒降解(图5H)。
本发明人已发现,单独的级联无法结合松弛DNA上的原间隔区。与此相反,本发明人已发现,级联有效地定位负超螺旋DNA中的靶标,随后通过Cse1亚基募集Cas3。由Cas3HD-核酸酶结构域进行的核酸内切切割导致级联通过超螺旋的丧失而自发地从DNA中释放,从而再动员级联以定位新的靶标。然后进行性地对该靶标进行解旋,并通过Cas3的联合ATP依赖性解旋酶活性和HD-核酸酶活性进行切割,从而导致完全靶DNA降解和侵入物的中和。
参照图6,并且不希望受到任何具体理论的束缚,大肠杆菌中的 CRISPR干扰I型途径的运行机制可能包括:(1)首先,携带crRNA的级联利用邻近的PAM扫描nSC质粒DNA的原间隔区。在此期间是否发生链分离是未知的。(2)通过crRNA和DNA互补链之间的碱基配对实现序列特异性原间隔区结合,从而形成R-环。一旦结合,级联就诱发DNA弯曲。(3)一旦DNA结合,级联的Cse1亚基就募集Cas3。这可通过核酸结合时发生的级联构象变化而实现。(4)Cas3的HD-结构域(较暗的部分)催化R-环的替代链的Mg2+依赖性切口产生,从而使靶质粒的拓扑结构从nSC改变为松弛OC。(5a和5b)质粒松弛导致级联的自发解离。同时,Cas3展现出对靶质粒的ATP-依赖性外切核酸酶活性,靶dsDNA解旋需要解旋酶结构域,而连续切割活性需要HD- 核酸酶结构域。(6)Cas3在持续地向前移动、解旋和切割靶dsDNA时以ATP依赖性的方式降解整个质粒。
实施例6——人工Cas-strep标记融合蛋白的制备和级联复合物的装配
使用Jore等人(2011)Nature Structural&Molecular Biology 18: 529-537的补充表3中所列的表达质粒,如Brouns等人(2008)Science 321:960-4(2008)所述生产和纯化级联复合物。常规地用与CasB(或在CasCDE中为CasC)融合的N-端Strep-标记II对级联进行纯化。使用20mM Tris-HCl(pH 8.0)、0.1M NaCl、1mM二硫苏糖醇进行大小排阻色谱分析(Superdex 200HR 10/30(GE))。在大小排阻分析之前,将级联制剂(约0.3mg)与DNase I(Invitrogen)在2.5mM MgCl2的存在下于37℃温育15分钟。用等体积的苯酚∶氯仿∶异戊醇(25∶24∶1)pH8.0 (Fluka)通过抽提来分离共纯化的核苷酸,然后将其与补充有2.5mMMgCl2的DNase I(InVitrogen)或者与RNase A(Fermentas)一起于37℃温育10分钟。产生与Strep-标记的氨基酸序列融合的Cas亚基蛋白质。
使用λ噬菌体进行了能表明Strep-标记级联亚基的生物活性的噬菌斑试验,并且如Brouns等人(2008)所述计算成斑率(EOP)。
为了纯化crRNA,使用DNAsep柱50mm×4.6mm内径(I.D.) (Transgenomic,SanJose,CA),在具有UV260nm检测器的Agilent 1100 HPLC(Agilent)上通过离子对反相HPLC对样品进行分析。色谱分析通过使用以下缓冲液条件进行:A)0.1M三乙基乙酸胺(TEAA)(pH7.0)(Fluka);B)含有25%LC MS级乙腈(v/v)的缓冲液A(Fisher)。通过在75℃下注入纯化的完整级联,以1.0ml/min的流速使用从15%缓冲液B开始并在12.5分钟内增至60%缓冲液B的线性梯度,随后在2分钟内线性增至100%缓冲液B,从而获得crRNA。通过将HPLC 纯化的crRNA在终浓度为0.1M的HCl中于4℃温育1小时进行环状磷酸末端的水解。在ESI-MS分析之前,在真空浓缩器(Eppendorf)中将样品浓缩至5-10μl。
使用与在线毛细管液相色谱系统(Ultimate 3000,Dionex,UK)耦联的UHR-TOF质谱仪(maXis)或HCT Ultra PTM Discovery仪器(均来自Bruker Daltonics),在负模式下进行crRNA的电喷雾电离质谱分析。使用整体式(PS-DVB)毛细管柱进行RNA分离。使用以下缓冲液条件进行色谱分析:C)用三乙胺(TEA)调整至pH 7.0的0.4M 1,1,1,3,3,3,- 六氟-2-丙醇(HFIP,Sigma-Aldrich)和0.1mM TEAA,以及D)含有50%甲醇(v/v)的缓冲液C(Fisher)。以2μl/min的流速,使用20%的缓冲液D,在5分钟内增至40%的缓冲液D,随后在8分钟内线性增至60%的缓冲液D,于50℃下进行RNA分析。
通过非变性(native)质谱法,在5μM的蛋白质浓度下,在0.15M 乙酸铵(pH8.0)中对级联蛋白进行分析。使用截留值为10kDa的离心过滤器(Millipore),在4℃下通过五个连续浓缩和稀释步骤获得蛋白质制剂。蛋白质从硼硅玻璃毛细管中喷出,并用LCT电喷射飞行时间仪器或改良的四极飞行时间仪器(均来自Waters,UK)进行分析,该仪器均为了在高质量探测中具有最优性能而进行过调整(参见 Tahallah N等人(2001)Rapid Commun MassSpectrom 15:596-601 (2001)和van den Heuvel,R.H.等人Anal Chem 78:7473-83(2006))。单个Cas蛋白的准确质量测量在变性条件下(50%乙腈,50%MQ,0.1%甲酸)获得。通过向喷射溶液中加入2-丙醇至5%(v/v)的终浓度,产生在溶液中的亚复合物。仪器设置如下:针电压~1.2kV,锥电压~175V,源压力9mbar。使用氙气作为在1.5x 10-2mbar的压力下串联质谱分析的碰撞气。碰撞电压在10-200V之间变化。
使用电泳迁移率变动分析(EMSA)证明级联复合物对靶核酸的功能活性。通过将级联、CasBCDE或CasCDE与1nM标记的核酸在50 mM Tris-Cl pH 7.5、100mM NaCl中温育来进行EMSA。鲑精DNA (Invitrogen)用作竞争剂。在5%聚丙烯酰胺凝胶电泳之前,EMSA反应于37℃温育20-30分钟。将凝胶干燥,使用磷光存储屏和PMI磷光成像仪(Bio-Rad)进行分析。在1-10mM Ca、Mg或Mn离子的存在下检测级联的靶DNA结合活性和切割活性。
DNA靶标是凝胶纯化的长寡核苷酸(Isogen Life Sciences或 Biolegio),列于Jore等人(2011)的补充表3中。使用γ32P-ATP (PerkinElmer)和T4激酶(Fermentas)对该寡核苷酸进行末端标记。通过使互补寡核苷酸退火,并使用外切核酸酶I(Fermentas)消化剩余的 ssDNA来制备双链DNA靶标。使用含有α32P-CTP(PerkinElmer)的T7 Maxiscript或T7Mega Shortscript试剂盒(Ambion)来体外转录标记的RNA靶标,并通过DNase I(Fermentas)消化去除模板。通过使互补 RNA退火,并用RNase T1(Fermentas)消化剩余的ssRNA,随后进行苯酚抽提来制备双链RNA靶标。
使用含有R44原间隔区的质粒pWUR613来进行质粒迁移率变动分析。使用引物BG3297和BG 3298(参见Jore等人(2011)的补充表 3),从P7噬菌体基因组DNA中PCR扩增含有原间隔区的片段。将质粒(0.4μg)和级联以1∶10的摩尔比在含有5mM Tris-HCl(pH 7.5)和20mM NaCl的缓冲液中混合,并于37℃温育30分钟。然后通过蛋白酶K(Fluka)处理(0.15U,15min,37℃),随后苯酚/氯仿抽提,来移除级联蛋白。然后用RNaseH(Promega)(2U,1h,37℃)处理 RNA-DNA复合物。
与RNA组分(等同于crRNA)形成级联蛋白复合物或活性亚复合物的Strep-标记-Cas蛋白亚基融合体具有预期的扫描和特异性附着及切割核酸靶标的生物学和功能活性。Cas亚基与荧光染料的氨基酸链的融合体也与RNA组分(等同于crRNA)形成级联复合物和亚复合物,该RNA组分保留了生物学和功能活性,并允许靶核酸序列在例如ds DNA中的位置的可视化。
实施例7——级联-核酸酶对以及体外核酸酶活性的检测
已经通过随机诱变和筛选引入了六个名为“Sharkey”的突变,以改善来自海床黄杆菌(Flavobacterium okeanokoites)限制性内切酶FokI的非特异性核酸酶结构域的核酸酶活性和稳定性(参见Guo,J.等人(2010) J.Mol.Biol.400:96-107)。已经引入了其他降低脱靶切割活性的突变。这通过对ZFN对的FokI二聚体界面处的静电相互作用进行工程化,以产生一个具有带正电荷界面的FokI变体(KKR,E490K,I538K, H537R)和另一个具有带负电荷界面的FokI变体(ELD,Q486E,I499L, N496D)而实现(参见Doyon,Y.等人(2011)NatureMethods 8:74-9)。这些变体中的每一个作为同型二聚体都是催化上无活性的,从而降低了脱靶切割的频率。
级联-核酸酶设计
我们将改良的FokI核酸酶与Cse1的N-末端进行翻译融合,以生成分别为FokIKKR-Cse1和FokIELD-Cse1的Cse1变体。这两个变体与级联亚基(Cse2、Cas7、Cas5和Cas6e)共表达,并且两个不同CRISPR 质粒中的一个具有均一的间隔区。这使级联KKR复合物装载均一的P7-crRNA,而级联ELD复合物装载均一的M13 G8-crRNA。如Jore,M.M. 等人(2011)Nat.Struct.Mol.Biol.18(5):529-536.J所述,使用N-末端 StrepII-标记的Cse2纯化这些复合物。此外,可使用N-末端His-标记的FokI进行额外的纯化步骤,以确保全长且完整的级联-核酸酶融合复合物得到纯化。
本实施例中所用的融合蛋白的核苷酸和氨基酸序列如下:
>FokI-(Sharkey-ELD)-Cse1的核苷酸序列
ATGGCTCAACTGGTTAAAAGCGAACTGGAAGAGAAAAAAAGTGAACTGCGCCAC AAACTGAAATATGTGCCGCATGAATATATCGAGCTGATTGAAATTGCACGTAATC CGACCCAGGATCGTATTCTGGAAATGAAAGTGATGGAATTTTTTATGAAAGTGTA CGGCTATCGCGGTGAACATCTGGGTGGTAGCCGTAAACCGGATGGTGCAATTTAT ACCGTTGGTAGCCCGATTGATTATGGTGTTATTGTTGATACCAAAGCCTATAGCG GTGGTTATAATCTGCCGATTGGTCAGGCAGATGAAATGGAACGTTATGTGGAAG AAAATCAGACCCGTGATAAACATCTGAATCCGAATGAATGGTGGAAAGTTTATC CGAGCAGCGTTACCGAGTTTAAATTCCTGTTTGTTAGCGGTCACTTCAAAGGCAA CTATAAAGCACAGCTGACCCGTCTGAATCATATTACCAATTGTAATGGTGCAGTT CTGAGCGTTGAAGAACTGCTGATTGGTGGTGAAATGATTAAAGCAGGCACCCTG ACCCTGGAAGAAGTTCGTCGCAAATTTAACAATGGCGAAATCAACTTTGCGGAT CCCACCAACCGCGCGAAAGGCCTGGAAGCGGTGAGCGTGGCGAGCatgaatttgct tattgataactggattcctgtacgcccgcgaaacggggggaaagtccaaatcataaatctgcaatcgctatactgcagtagagatcagt ggcgattaagtttgccccgtgacgatatggaactggccgctttagcactgctggtttgcattgggcaaattatcgccccggcaaaagatg acgttgaatttcgacatcgcataatgaatccgctcactgaagatgagtttcaacaactcatcgcgccgtggatagatatgttctaccttaat cacgcagaacatccctttatgcagaccaaaggtgtcaaagcaaatgatgtgactccaatggaaaaactgttggctggggtaagcggcg cgacgaattgtgcatttgtcaatcaaccggggcagggtgaagcattatgtggtggatgcactgcgattgcgttattcaaccaggcgaat caggcaccaggttttggtggtggttttaaaagcggtttacgtggaggaacacctgtaacaacgttcgtacgtgggatcgatcttcgttcaa cggtgttactcaatgtcctcacattacctcgtcttcaaaaacaatttcctaatgaatcacatacggaaaaccaacctacctggattaaacct atcaagtccaatgagtctatacctgcttcgtcaattgggtttgtccgtggtctattctggcaaccagcgcatattgaattatgcgatcccatt gggattggtaaatgttcttgctgtggacaggaaagcaatttgcgttataccggttttcttaaggaaaaatttacctttacagttaatgggctat ggccccatccgcattccccttgtctggtaacagtcaagaaaggggaggttgaggaaaaatttcttgctttcaccacctccgcaccatcat ggacacaaatcagccgagttgtggtagataagattattcaaaatgaaaatggaaatcgcgtggcggcggttgtgaatcaattcagaaat attgcgccgcaaagtcctcttgaattgattatggggggatatcgtaataatcaagcatctattcttgaacggcgtcatgatgtgttgatgttt aatcaggggtggcaacaatacggcaatgtgataaacgaaatagtgactgttggtttgggatataaaacagccttacgcaaggcgttata tacctttgcagaagggtttaaaaataaagacttcaaaggggccggagtctctgttcatgagactgcagaaaggcatttctatcgacagag tgaattattaattcccgatgtactggcgaatgttaatttttcccaggctgatgaggtaatagctgatttacgagacaaacttcatcaattgtgtgaaatgctatttaatcaatctgtagctccctatgcacatcatcctaaattaataagcacattagcgcttgcccgcgccacgctatacaaaca tttacgggagttaaaaccgcaaggagggccatcaaatggctga[SEQ ID NO:18]
>FokI-(Sharkey-ELD)-Cse1的蛋白质序列
MAQLVKSELEEKKSELRHKLKYVPHEYIELIEIARNPTQDRILEMKVMEFFMKVYGY RGEHLGGSRKPDGAIYTVGSPIDYGVIVDTKAYSGGYNLPIGQADEMERYVEENQTR DKHLNPNEWWKVYPSSVTEFKFLFVSGHFKGNYKAQLTRLNHITNCNGAVLSVEEL LIGGEMIKAGTLTLEEVRRKFNNGEINFADPTNRAKGLEAVSVASMNLLIDNWIPVRP RNGGKVQIINLQSLYCSRDQWRLSLPRDDMELAALALLVCIGQIIAPAKDDVEFRHRI MNPLTEDEFQQLIAPWIDMFYLNHAEHPFMQTKGVKANDVTPMEKLLAGVSGATN CAFVNQPGQGEALCGGCTAIALFNQANQAPGFGGGFKSGLRGGTPVTTFVRGIDLRS TVLLNVLTLPRLQKQFPNESHTENQPTWIKPIKSNESIPASSIGFVRGLFWQPAHIELC DPIGIGKCSCCGQESNLRYTGFLKEKFTFTVNGLWPHPHSPCLVTVKKGEVEEKFLAFTTSAPSWTQISRVVVDKIIQNENGNRVAAVVNQFRNIAPQSPLELIMGGYRNNQASIL ERRHDVLMFNQGWQQYGNVINEIVTVGLGYKTALRKALYTFAEGFKNKDFKGAGV SVHETAERHFYRQSELLIPDVLANVNFSQADEVIADLRDKLHQLCEMLFNQSVAPYA HHPKLISTLALARATLYKHLRELKPQGGPSNG*[SEQ ID NO:19]
>FokI-(Sharkey-KKR)-Cse1的核苷酸序列
ATGGCTCAACTGGTTAAAAGCGAACTGGAAGAGAAAAAAAGTGAACTGCGCCAC AAACTGAAATATGTGCCGCATGAATATATCGAGCTGATTGAAATTGCACGTAATC CGACCCAGGATCGTATTCTGGAAATGAAAGTGATGGAATTTTTTATGAAAGTGTA CGGCTATCGCGGTGAACATCTGGGTGGTAGCCGTAAACCGGATGGTGCAATTTAT ACCGTTGGTAGCCCGATTGATTATGGTGTTATTGTTGATACCAAAGCCTATAGCG GTGGTTATAATCTGCCGATTGGTCAGGCAGATGAAATGCAGCGTTATGTGAAAG AAAATCAGACCCGCAACAAACATATTAACCCGAATGAATGGTGGAAAGTTTATC CGAGCAGCGTTACCGAGTTTAAATTCCTGTTTGTTAGCGGTCACTTCAAAGGCAA CTATAAAGCACAGCTGACCCGTCTGAATCGTAAAACCAATTGTAATGGTGCAGTT CTGAGCGTTGAAGAACTGCTGATTGGTGGTGAAATGATTAAAGCAGGCACCCTG ACCCTGGAAGAAGTTCGTCGCAAATTTAACAATGGCGAAATCAACTTTGCGGAT CCCACCAACCGCGCGAAAGGCCTGGAAGCGGTGAGCGTGGCGAGCatgaatttgct tattgataactggattcctgtacgcccgcgaaacggggggaaagtccaaatcataaatctgcaatcgctatactgcagtagagatcagt ggcgattaagtttgccccgtgacgatatggaactggccgctttagcactgctggtttgcattgggcaaattatcgccccggcaaaagatg acgttgaatttcgacatcgcataatgaatccgctcactgaagatgagtttcaacaactcatcgcgccgtggatagatatgttctaccttaat cacgcagaacatccctttatgcagaccaaaggtgtcaaagcaaatgatgtgactccaatggaaaaactgttggctggggtaagcggcg cgacgaattgtgcatttgtcaatcaaccggggcagggtgaagcattatgtggtggatgcactgcgattgcgttattcaaccaggcgaat caggcaccaggttttggtggtggttttaaaagcggtttacgtggaggaacacctgtaacaacgttcgtacgtgggatcgatcttcgttcaa cggtgttactcaatgtcctcacattacctcgtcttcaaaaacaatttcctaatgaatcacatacggaaaaccaacctacctggattaaacct atcaagtccaatgagtctatacctgcttcgtcaattgggtttgtccgtggtctattctggcaaccagcgcatattgaattatgcgatcccatt gggattggtaaatgttcttgctgtggacaggaaagcaatttgcgttataccggttttcttaaggaaaaatttacctttacagttaatgggctat ggccccatccgcattccccttgtctggtaacagtcaagaaaggggaggttgaggaaaaatttcttgctttcaccacctccgcaccatcat ggacacaaatcagccgagttgtggtagataagattattcaaaatgaaaatggaaatcgcgtggcggcggttgtgaatcaattcagaaat attgcgccgcaaagtcctcttgaattgattatggggggatatcgtaataatcaagcatctattcttgaacggcgtcatgatgtgttgatgttt aatcaggggtggcaacaatacggcaatgtgataaacgaaatagtgactgttggtttgggatataaaacagccttacgcaaggcgttata tacctttgcagaagggtttaaaaataaagacttcaaaggggccggagtctctgttcatgagactgcagaaaggcatttctatcgacagag tgaattattaattcccgatgtactggcgaatgttaatttttcccaggctgatgaggtaatagctgatttacgagacaaacttcatcaattgtgtgaaatgctatttaatcaatctgtagctccctatgcacatcatcctaaattaataagcacattagcgcttgcccgcgccacgctatacaaaca tttacgggagttaaaaccgcaaggagggccatcaaatggctga[SEQ ID NO:20]
>FokI-(Sharkey-KKR)-Cse1的蛋白质序列
MAQLVKSELEEKKSELRHKLKYVPHEYIELIEIARNPTQDRILEMKVMEFFMKVYGY RGEHLGGSRKPDGAIYTVGSPIDYGVIVDTKAYSGGYNLPIGQADEMQRYVKENQT RNKHINPNEWWKVYPSSVTEFKFLFVSGHFKGNYKAQLTRLNRKTNCNGAVLSVEE LLIGGEMIKAGTLTLEEVRRKFNNGEINFADPTNRAKGLEAVSVASMNLLIDNWIPV RPRNGGKVQIINLQSLYCSRDQWRLSLPRDDMELAALALLVCIGQIIAPAKDDVEFR HRIMNPLTEDEFQQLIAPWIDMFYLNHAEHPFMQTKGVKANDVTPMEKLLAGVSGA TNCAFVNQPGQGEALCGGCTAIALFNQANQAPGFGGGFKSGLRGGTPVTTFVRGIDL RSTVLLNVLTLPRLQKQFPNESHTENQPTWIKPIKSNESIPASSIGFVRGLFWQPAHIEL CDPIGIGKCSCCGQESNLRYTGFLKEKFTFTVNGLWPHPHSPCLVTVKKGEVEEKFL AFTTSAPSWTQISRVVVDKIIQNENGNRVAAVVNQFRNIAPQSPLELIMGGYRNNQA SILERRHDVLMFNQGWQQYGNVINEIVTVGLGYKTALRKALYTFAEGFKNKDFKGA GVSVHETAERHFYRQSELLIPDVLANVNFSQADEVIADLRDKLHQLCEMLFNQSVAP YAHHPKLISTLALARATLYKHLRELKPQGGPSNG*[SEQ ID NO:21]
>His6-双-单份NLS SV40-FokI-(Sharkey-KKR)-Cse1的核苷酸序列
ATGcatcaccatcatcaccacCCGAAAAAAAAGCGCAAAGTGGATCCGAAGAAAAAACGTAAAG TTGAAGATCCGAAAGACATGGCTCAACTGGTTAAAAGCGAACTGGAAGAGAAAA AAAGTGAACTGCGCCACAAACTGAAATATGTGCCGCATGAATATATCGAGCTGA TTGAAATTGCACGTAATCCGACCCAGGATCGTATTCTGGAAATGAAAGTGATGG AATTTTTTATGAAAGTGTACGGCTATCGCGGTGAACATCTGGGTGGTAGCCGTAA ACCGGATGGTGCAATTTATACCGTTGGTAGCCCGATTGATTATGGTGTTATTGTT GATACCAAAGCCTATAGCGGTGGTTATAATCTGCCGATTGGTCAGGCAGATGAA ATGCAGCGTTATGTGAAAGAAAATCAGACCCGCAACAAACATATTAACCCGAAT GAATGGTGGAAAGTTTATCCGAGCAGCGTTACCGAGTTTAAATTCCTGTTTGTTA GCGGTCACTTCAAAGGCAACTATAAAGCACAGCTGACCCGTCTGAATCGTAAAA CCAATTGTAATGGTGCAGTTCTGAGCGTTGAAGAACTGCTGATTGGTGGTGAAAT GATTAAAGCAGGCACCCTGACCCTGGAAGAAGTTCGTCGCAAATTTAACAATGG CGAAATCAACTTTGCGGATCCCACCAACCGCGCGAAAGGCCTGGAAGCGGTG AGCGTGGCGAGCatgaatttgcttattgataactggattcctgtacgcccgcgaaacggggggaaagtccaaatcataaat ctgcaatcgctatactgcagtagagatcagtggcgattaagtttgccccgtgacgatatggaactggccgctttagcactgctggtttgc attgggcaaattatcgccccggcaaaagatgacgttgaatttcgacatcgcataatgaatccgctcactgaagatgagtttcaacaactc atcgcgccgtggatagatatgttctaccttaatcacgcagaacatccctttatgcagaccaaaggtgtcaaagcaaatgatgtgactcca atggaaaaactgttggctggggtaagcggcgcgacgaattgtgcatttgtcaatcaaccggggcagggtgaagcattatgtggtggat gcactgcgattgcgttattcaaccaggcgaatcaggcaccaggttttggtggtggttttaaaagcggtttacgtggaggaacacctgtaa caacgttcgtacgtgggatcgatcttcgttcaacggtgttactcaatgtcctcacattacctcgtcttcaaaaacaatttcctaatgaatcac atacggaaaaccaacctacctggattaaacctatcaagtccaatgagtctatacctgcttcgtcaattgggtttgtccgtggtctattctgg caaccagcgcatattgaattatgcgatcccattgggattggtaaatgttcttgctgtggacaggaaagcaatttgcgttataccggttttctt aaggaaaaatttacctttacagttaatgggctatggccccatccgcattccccttgtctggtaacagtcaagaaaggggaggttgaggaa aaatttcttgctttcaccacctccgcaccatcatggacacaaatcagccgagttgtggtagataagattattcaaaatgaaaatggaaatc gcgtggcggcggttgtgaatcaattcagaaatattgcgccgcaaagtcctcttgaattgattatggggggatatcgtaataatcaagcatctattcttgaacggcgtcatgatgtgttgatgtttaatcaggggtggcaacaatacggcaatgtgataaacgaaatagtgactgttggtttg ggatataaaacagccttacgcaaggcgttatatacctttgcagaagggtttaaaaataaagacttcaaaggggccggagtctctgttcat gagactgcagaaaggcatttctatcgacagagtgaattattaattcccgatgtactggcgaatgttaatttttcccaggctgatgaggtaat agctgatttacgagacaaacttcatcaattgtgtgaaatgctatttaatcaatctgtagctccctatgcacatcatcctaaattaataagcaca ttagcgcttgcccgcgccacgctatacaaacatttacgggagttaaaaccgcaaggagggccatcaaatggctga[SEQ IDNO:22]
>His6-双-单份NLS SV40-FokI-(Sharkey-KKR)-Cse1的蛋白质序列
MHHHHHHPKKKRKVDPKKKRKVEDPKDMAQLVKSELEEKKSELRHKLKYVPHEYI ELIEIARNPTQDRILEMKVMEFFMKVYGYRGEHLGGSRKPDGAIYTVGSPIDYGVIVD TKAYSGGYNLPIGQADEMQRYVKENQTRNKHINPNEWWKVYPSSVTEFKFLFVSGH FKGNYKAQLTRLNRKTNCNGAVLSVEELLIGGEMIKAGTLTLEEVRRKFNNGEINFA DPTNRAKGLEAVSVASMNLLIDNWIPVRPRNGGKVQIINLQSLYCSRDQWRLSLPRD DMELAALALLVCIGQIIAPAKDDVEFRHRIMNPLTEDEFQQLIAPWIDMFYLNHAEHP FMQTKGVKANDVTPMEKLLAGVSGATNCAFVNQPGQGEALCGGCTAIALFNQANQ APGFGGGFKSGLRGGTPVTTFVRGIDLRSTVLLNVLTLPRLQKQFPNESHTENQPTWI KPIKSNESIPASSIGFVRGLFWQPAHIELCDPIGIGKCSCCGQESNLRYTGFLKEKFTFT VNGLWPHPHSPCLVTVKKGEVEEKFLAFTTSAPSWTQISRVVVDKIIQNENGNRVAA VVNQFRNIAPQSPLELIMGGYRNNQASILERRHDVLMFNQGWQQYGNVINEIVTVGL GYKTALRKALYTFAEGFKNKDFKGAGVSVHETAERHFYRQSELLIPDVLANVNFSQ ADEVIADLRDKLHQLCEMLFNQSVAPYAHHPKLISTLALARATLYKHLRELKPQGGPSNG*[SEQ ID NO:23]
>His6-双-单份NLS SV40-FokI(Sharkey-ELD)-Cse1的核苷酸序列
ATGcatcaccatcatcaccacCCGAAAAAAAAGCGCAAAGTGGATCCGAAGAAAAAACGTAAAG TTGAAGATCCGAAAGACATGGCTCAACTGGTTAAAAGCGAACTGGAAGAGAAAAA AAGTGAACTGCGCCACAAACTGAAATATGTGCCGCATGAATATATCGAGCTGAT TGAAATTGCACGTAATCCGACCCAGGATCGTATTCTGGAAATGAAAGTGATGGA ATTTTTTATGAAAGTGTACGGCTATCGCGGTGAACATCTGGGTGGTAGCCGTAAA CCGGATGGTGCAATTTATACCGTTGGTAGCCCGATTGATTATGGTGTTATTGTTG ATACCAAAGCCTATAGCGGTGGTTATAATCTGCCGATTGGTCAGGCAGATGAAA TGGAACGTTATGTGGAAGAAAATCAGACCCGTGATAAACATCTGAATCCGAATG AATGGTGGAAAGTTTATCCGAGCAGCGTTACCGAGTTTAAATTCCTGTTTGTTAG CGGTCACTTCAAAGGCAACTATAAAGCACAGCTGACCCGTCTGAATCATATTACC AATTGTAATGGTGCAGTTCTGAGCGTTGAAGAACTGCTGATTGGTGGTGAAATGA TTAAAGCAGGCACCCTGACCCTGGAAGAAGTTCGTCGCAAATTTAACAATGGCGAAATCAACTTTGCGGATCCCACCAACCGCGCGAAAGGCCTGGAAGCGGTGAG CGTGGCGAGCatgaatttgcttattgataactggattcctgtacgcccgcgaaacggggggaaagtccaaatcataaatctg caatcgctatactgcagtagagatcagtggcgattaagtttgccccgtgacgatatggaactggccgctttagcactgctggtttgcattgggcaaattatcgccccggcaaaagatgacgttgaatttcgacatcgcataatgaatccgctcactgaagatgagtttcaacaactcatcg cgccgtggatagatatgttctaccttaatcacgcagaacatccctttatgcagaccaaaggtgtcaaagcaaatgatgtgactccaatgg aaaaactgttggctggggtaagcggcgcgacgaattgtgcatttgtcaatcaaccggggcagggtgaagcattatgtggtggatgcac tgcgattgcgttattcaaccaggcgaatcaggcaccaggttttggtggtggttttaaaagcggtttacgtggaggaacacctgtaacaac gttcgtacgtgggatcgatcttcgttcaacggtgttactcaatgtcctcacattacctcgtcttcaaaaacaatttcctaatgaatcacatacggaaaaccaacctacctggattaaacctatcaagtccaatgagtctatacctgcttcgtcaattgggtttgtccgtggtctattctggcaacc agcgcatattgaattatgcgatcccattgggattggtaaatgttcttgctgtggacaggaaagcaatttgcgttataccggttttcttaagga aaaatttacctttacagttaatgggctatggccccatccgcattccccttgtctggtaacagtcaagaaaggggaggttgaggaaaaattt cttgctttcaccacctccgcaccatcatggacacaaatcagccgagttgtggtagataagattattcaaaatgaaaatggaaatcgcgtg gcggcggttgtgaatcaattcagaaatattgcgccgcaaagtcctcttgaattgattatggggggatatcgtaataatcaagcatctattct tgaacggcgtcatgatgtgttgatgtttaatcaggggtggcaacaatacggcaatgtgataaacgaaatagtgactgttggtttgggatat aaaacagccttacgcaaggcgttatatacctttgcagaagggtttaaaaataaagacttcaaaggggccggagtctctgttcatgagact gcagaaaggcatttctatcgacagagtgaattattaattcccgatgtactggcgaatgttaatttttcccaggctgatgaggtaatagctga tttacgagacaaacttcatcaattgtgtgaaatgctatttaatcaatctgtagctccctatgcacatcatcctaaattaataagcacattagcg cttgcccgcgccacgctatacaaacatttacgggagttaaaaccgcaaggagggccatcaaatggctga[SEQ IDNO:24]
>His6-双-单份NLS SV40-FokI-(Sharkey-ELD)-Cse1的蛋白质序列
MHHHHHHPKKKRKVDPKKKRKVEDPKDMAQLVKSELEEKKSELRHKLKYVPHEYI ELIEIARNPTQDRILEMKVMEFFMKVYGYRGEHLGGSRKPDGAIYTVGSPIDYGVIVD TKAYSGGYNLPIGQADEMERYVEENQTRDKHLNPNEWWKVYPSSVTEFKFLFVSGH FKGNYKAQLTRLNHITNCNGAVLSVEELLIGGEMIKAGTLTLEEVRRKFNNGEINFA DPTNRAKGLEAVSVASMNLLIDNWIPVRPRNGGKVQIINLQSLYCSRDQWRLSLPRD DMELAALALLVCIGQIIAPAKDDVEFRHRIMNPLTEDEFQQLIAPWIDMFYLNHAEHP FMQTKGVKANDVTPMEKLLAGVSGATNCAFVNQPGQGEALCGGCTAIALFNQANQ APGFGGGFKSGLRGGTPVTTFVRGIDLRSTVLLNVLTLPRLQKQFPNESHTENQPTWI KPIKSNESIPASSIGFVRGLFWQPAHIELCDPIGIGKCSCCGQESNLRYTGFLKEKFTFT VNGLWPHPHSPCLVTVKKGEVEEKFLAFTTSAPSWTQISRVVVDKIIQNENGNRVAA VVNQFRNIAPQSPLELIMGGYRNNQASILERRHDVLMFNQGWQQYGNVINEIVTVGL GYKTALRKALYTFAEGFKNKDFKGAGVSVHETAERHFYRQSELLIPDVLANVNFSQ ADEVIADLRDKLHQLCEMLFNQSVAPYAHHPKLISTLALARATLYKHLRELKPQGGPSNG*[SEQ ID NO:25]
DNA切割试验
使用人工构建的靶质粒作为底物检测复合物的特异性和活性。该质粒在相对链上含有M13和P7的结合位点,使得两个FokI结构域彼此面对(参见图11)。级联结合位点之间的距离在25至50个碱基对之间以5bp的增量变化。由于级联的结合位点需要其侧翼为四种已知 PAM序列(5′-原间隔区-CTT/CAT/CTC/CCT-3′)中的任意一种,所以此距离范围为几乎任何给定序列提供了足够的设计这样的配对的灵活性。
所使用的靶质粒的序列如下。数字指示M13和P7靶位点之间的距离。原间隔区以粗体示出,PAM以下划线示出:
靶质粒的序列。数字指示M13和P7靶位点之间的距离。(原间隔区为粗体,PAM以下划线标出)
>50bp
gaattcACAACGGTGAGCAAGTCA
 CTTGCTTTCGAGCGCTAGCTCTAGAACTAGTCCTCAGCCTAGGCCTCGTTCCGAAG
CTTGCTTTCGAGCGCTAGCTCTAGAACTAGTCCTCAGCCTAGGCCTCGTTCCGAAG  CATAGGCGGCCTTTAACTCg gatcc[SEQID NO:26]
CATAGGCGGCCTTTAACTCg gatcc[SEQID NO:26]
>45bp
gaattcACAACGGTGAGCAAGTCA
 CTTTTCGAGCGCTAGCTCTAGAACTAGTCCTCAGCCTAGGCCTCGTTCAAG
CTTTTCGAGCGCTAGCTCTAGAACTAGTCCTCAGCCTAGGCCTCGTTCAAG 
 ATAGGCGGCCTTTAACTCggatcc [SEQ IDNO:27]
ATAGGCGGCCTTTAACTCggatcc [SEQ IDNO:27]
>40bp
gaattcACAACGGTGAGCAAGTCA
 CTTCGAGCGCTAGCTCTAGAACTAGTCCTCAGCCTAGGCCTCGAAG
CTTCGAGCGCTAGCTCTAGAACTAGTCCTCAGCCTAGGCCTCGAAG 
 ATAGGCGGCCTTTAACTCggatcc[SEQ ID NO:28]
ATAGGCGGCCTTTAACTCggatcc[SEQ ID NO:28]
>35bp
gaattcACAACGGTGAGCAAGTCA
 CTTGCGCTAGCTCTAGAACTAGTCCTCAGCCTAGGCCTAAG
CTTGCGCTAGCTCTAGAACTAGTCCTCAGCCTAGGCCTAAG 
 ATAGGCGGCCTTTAACTCggatcc[SEQ ID NO:29]
ATAGGCGGCCTTTAACTCggatcc[SEQ ID NO:29]
>30bp
gaattcACAACGGTGAGCAAGTCA
 CTTGCTAGCTCTAGAACTAGTCCTCAGCCTAGGAAG
CTTGCTAGCTCTAGAACTAGTCCTCAGCCTAGGAAG 
 ATAGGCGGCCTTTAACTCggatcc[SEQ ID NO:30]
ATAGGCGGCCTTTAACTCggatcc[SEQ ID NO:30]
>25bp
gaattcACAACGGTGAGCAAGTCA
 CTTCTCTAGAACTAGTCCTCAGCCTAGGAAG
CTTCTCTAGAACTAGTCCTCAGCCTAGGAAG 
 ATAGGCGGCCTTTAACTCggatcc[SEQ ID NO:31]
ATAGGCGGCCTTTAACTCggatcc[SEQ ID NO:31]
靶质粒的切割在琼脂糖凝胶上进行分析,其中负超螺旋(nSC)质粒可以与线性或切口质粒区别开来。通过从琼脂糖凝胶中分离线性切割产物,并用大肠杆菌DNA聚合酶Klenow片段补平FokI切割所留下的凹进3′末端以产生平端,从而确定级联KKR/ELD对在靶载体中的切割位点。对线性载体进行自身连接、转化、扩增、分离和测序。凹进 3′末端的补平和再连接将导致序列中的代表由FokI切割所留下的突出端的额外核苷酸。通过将序列读取结果与原序列进行比对,可在克隆水平上发现切割位点并对其作图。以下,在补平FokI切割留下的凹进3′末端后掺入到序列内的额外的碱基以下划线标出:
FokI切割
5’CTTGCGCTAGCTCTAGAA CTAGTCCTCAGCCTAGGCCTAAG 3’
CTAGTCCTCAGCCTAGGCCTAAG 3’
3’GAACGCGATCGAGATCTTGATC AGGAGTCGGATCCGGATTC 5’
3’补平,连接
5’CTTGCGCTAGCTCTAGAACTAG-CTAGTCCTCAGCCTAGGCCTAAG 3’
3’GAACGCGATCGAGATCTTGATC-GATCAGGAGTCGGATCCGGATTC 5’
从上向下读取,以上的5′-3′序列分别为SEQ ID NO:32-35。
人细胞中靶基因座的切割
人CCR5基因编码C-C趋化因子受体5型蛋白质,其作为白细胞表面上人免疫缺陷病毒(HIV)的受体。除了人工GFP基因座之外,利用一对级联KKR/ELD核酸酶靶向CCR5基因。在CCR5的编码区上选择合适的结合位点对。采用DNA合成(Geneart)来构建两个含有靶向每个结合位点的均一间隔区的单独CRISPR阵列。
所用的人CCR5靶基因的选择和CRISPR设计如下:
>基因组人CCR5序列的一部分,含有整个ORF(位置347-1446)。GGTGGAACAAGATGGATTATCAAGTGTCAAGTCCAATCTATGACATCAATTATTA TACATCGGAGCCCTGCCAAAAAATCAATGTGAAGCAAATCGCAGCCCGCCTCCT GCCTCCGCTCTACTCACTGGTGTTCATCTTTGGTTTTGTGGGCAACATGCTGGTCATCCTCATCCTGATAAACTGCAAAAGGCTGAAGAGCATGACTGACATCTACCTGCT CAACCTGGCCATCTCTGACCTGTTTTTCCTTCTTACTGTCCCCTTCTGGGCTCACT ATGCTGCCGCCCAGTGGGACTTTGGAAATACAATGTGTCAACTCTTGACAGGGCT CTATTTTATAGGCTTCTTCTCTGGAATCTTCTTCATCATCCTCCTGACAATCGATAGGT ACCTGGCTGTCGTCCATGCTGTGTTTGCTTTAAAAGCCAGGACGGTCACCTT TGGGGTGGTGACAAGTGTGATCA CTTGGGTGGTGGCTGTGTTTGCGTCTCTCCCA GGAATCATCTTTACCAGATCTCAAAAAGAAGGTCTTCATTACACCTGCAGCTCTC ATTTTCCATACAGTCAGTATCAATTCTGGAAGAATTTCCAGACATTAAAGATAGT CATCTTGGGGCTGGTCCTGCCGCTGCTTGTCATGGTCATCTGCTACTCGGGAATC CTAAAAACTCTGCTTCGGTGTCGAAATGAGAAGAAGAGGCACAGGGCTGTGAGG CTTATCTTCACCATCATGATTGTTTATTTTCTCTTCTGGGCTCCCTACAACATTGTC CTTCTCCTGAACACCTTCCAGGAATTCTTTGGCCTGAATAATTGCAGTAGCTCTA ACAGGTTGGACCAAGCTATGCAGGTGACAGAGACTCTTGGGATGACGCACTGCT GCATCAACCCCATCATCTATGCCTTTGTCGGGGAGAAGTTCAGAAACTACCTCTT AGTCTTCTTCCAAAAGCACATTGCCAAACGCTTCTGCAAATGCTGTTCTATTTTCC AGCAAGAGGCTCCCGAGCGAGCAAGCTCAGTTTACACCCGATCCACTGGGGAGC AGGAAATATCTGTGGGCTTGTGACACGGACTCAAGTGGGCTGGTGACCCAGTC [SEQ ID NO:36]
Red1/2:所选的靶位点(距离:34bp,PAM 5’-CTT-3’)。“Red 1是上面第一次出现的以下划线标出的序列。Red2是第二个以下划线标出的序列。
>CRISPR阵列red1(斜体=间隔区,加粗=重复序列)
ccatggTAATACGACTCACTATAGGGAGAATTAGCTGATCTTTAATAATAAGGAAAT GTTACATTAAGGTTGGTGGGTTGTTTTTATGGGAAAAAATGCTTTAAGAACAAAT GTATACTTTTA



 AAAACAAAAGGCTCAGTCGGAAGACTGGGCCTTTTGTTTTAACC CCTTGGGGCCTCTAAACGGGTCTTGAGGGGTTTTTTGggtacc[SEQ ID NO:37]
AAAACAAAAGGCTCAGTCGGAAGACTGGGCCTTTTGTTTTAACC CCTTGGGGCCTCTAAACGGGTCTTGAGGGGTTTTTTGggtacc[SEQ ID NO:37]
>CRISPR阵列red2(斜体:间隔区,加粗:重复序列)
ccatggTAATACGACTCACTATAGGGAGAATTAGCTGATCTTTAATAATAAGGAAAT GTTACATTAAGGTTGGTGGGTTGTTTTTATGGGAAAAAATGCTTTAAGAACAAAT GTATACTTTTA



 AAAACAAAAGGCTCAGTCGGAAGACTGGGCCTTTTGTTTTAACCCC TTGGGGCCTCTAAACGGGTCTTGAGGGGTTTTTTGggtacc[SEQ ID NO:38]
AAAACAAAAGGCTCAGTCGGAAGACTGGGCCTTTTGTTTTAACCCC TTGGGGCCTCTAAACGGGTCTTGAGGGGTTTTTTGggtacc[SEQ ID NO:38]
级联KKR/ELD向人细胞的细胞核内的递送
级联作为多亚基蛋白质-RNA复合物是非常稳定的,并且容易在大肠杆菌中以毫克的量产生。复合物以其从大肠杆菌中纯化得到的完整形式的转染或显微注射用作递送方法(参见图12)。如图12中所示,级联-FokI核酸酶从大肠杆菌中纯化,并包封在蛋白质转染小泡中。然后它们与在细胞质中释放核酸酶的人HepG2细胞的细胞膜融合(步骤2)。然后由促进核孔通道的输入蛋白识别NLS序列(步骤3)。接着,级联KKR(空心矩形)和级联ELD(实心矩形)将找到并切割其靶位点(步骤4),诱导将改变靶位点从而导致所需的变化的DNA修复途径。级联KKR/ELD核酸酶仅需发挥作用一次,而不需要永久存在于细胞中编码在DNA上。
为将级联递送到人细胞内,使用来自各种来源(包括Pierce、NEB、 Fermentas和Clontech)的蛋白质转染试剂。这些试剂最近已被开发用于抗体的递送,并且在转染广泛的人类细胞系中是有用的,效率最高达90%。转染人HepG2细胞。此外,也转染其他细胞系,包括CHO-K1、 COS-7、HeLa和非胚胎干细胞。
为将级联KKR/ELD核酸酶对输入细胞核内,将来自猿猴病毒40 (SV40)的大T抗原的串联单份核定位信号(NLS)与FokI的N-末端融合。这确保只有完整的级联ELD/KKR输入细胞核内。(核孔复合物转位 RNA聚合酶(550kDa)及其他大蛋白质复合物)。作为转化之前的核查,用纯化的复合物和CCR5PCR扩增子在体外检查级联KKR/ELD核酸酶对的核酸酶活性,以排除转染性的、非生产性的级联KKR/ELD核酸酶对。
检验师分析(Surveyor assay)
将转染的细胞培养并传代数天。然后通过采用Guschin,D.Y.等人 (2010)MethodsMol.Biol.,649:247-256的检验师分析来评估体内靶 DNA切割的效率。简单来说,靶DNA基因座的PCR扩增子将与未处理细胞的PCR扩增子以1∶1混合。将其加热并使之退火,从而产生已被NHEJ错误地修复的靶位点处的错配。然后用错配核酸酶仅切割错配的DNA分子,当级联KKR/ELD对靶DNA的切割完成时,产生最多50%的切割。此程序后对经治疗的细胞的靶DNA扩增子进行测序。该试验允许对递送程序的快速评估和优化。
级联-核酸酶对的产生
如上文所述构建级联-核酸酶复合物。使用StrepII-标记的Cse2 亚基从大肠杆菌中亲和纯化产生当与天然级联相比时具有预期化学计量的复合物。参见图13,该图示出了只使用Streptactin纯化24小时后,天然级联(1)、具有P7CrRNA的级联KKR和具有M13 CrRNA的级联ELD的化学计量。天然级联(1)中的条带从上到下为:Cse1、Cas7、 Cas5、Cas6e、Cse2。级联KKR/ELD示出了FokI-Cse1融合带和代表由蛋白水解降解产生的、具有FokI的一小部分的Cse1的另一条带。
除了完整的FokI-Cse1融合蛋白,我们观察到,FokI-Cse1-融合蛋白的部分被蛋白水解切割,生成仅含有接头以及与之连接的一小部分 FokI的Cse1蛋白(如通过质谱法确认的,数据未示出)。在大多数蛋白质分离中,降解的融合蛋白的分数约为40%。分离的蛋白质于-20℃稳定地储存在含有额外的0.1%吐温20和50%甘油的洗脱缓冲液(20 mM HEPES pH7.5,75mM NaCl,1mM DTT,4mM脱硫生物素)中。
在这些储存条件下,已发现该复合物的完整性和活性稳定至少3 周(数据未示出)。
His6-标记和NLS向级联-核酸酶的引入
修饰级联核酸酶融合设计,以加入核仁定位信号(NLS),从而使得向真核细胞的细胞核中的转运称为可能。为此,将来自猿猴病毒 SV40的大T-抗原的串联单份NLS(序列:PKKKRKVDPKKKRKV) 与在N-末端前直接为His6-标记的FokI-Cse1融合蛋白的N-末端翻译性融合。该His6-标记(序列:MHHHHHH)允许在StrepII纯化之后的额外的Ni2+-树脂亲和纯化步骤。这个额外的步骤确保只分离全长级联 -核酸酶,而通过消除不完整的级联复合物与靶位点结合形成非生产性核酸酶对而提高切割效率。
体外切割试验
如上所述,在体外测定级联KKR/ELD的活性和特异性。图14A示出了原间隔区之间的距离为25-50bp(增量5bp,泳道1-6)的、与级联KKR/ELD在37℃下温育30分钟的质粒。泳道10包含以其三种可能的拓扑结构存在的靶质粒:最下面的条带表示质粒的最初的、负超螺旋(nSC)形式,中间的条带表示线性化的形式(被XbaI切割),而上面的条带表示开环(OC)形式(用Nt.BbrCI产生切口后)。泳道7示出了两个结合位点均已去除的质粒的温育(阴性对照)。因此,图14A示出了使用各种靶质粒的典型切割试验,该靶质粒中的结合位点间隔25至50个碱基对(以5bp的增量)(泳道1至6)。这些具有25-50bp距离的质粒与分别携带抗P7和M13crRNA的级联KKR/ELD一起温育。不含结合位点的质粒作为对照(泳道7)。原始质粒以负超螺旋形式存在(nSC,对照,泳道8),且带切口的或线性化的产物清晰可辨。经温育,在结合位点间隔30、35和40个碱基对时形成线性切割产物(泳道2、3、 4)。在25、45和50个碱基对的距离(泳道1、5、6)时,该靶质粒似乎被不完全切割,从而产生带切口的形式(OC)。这些结果表明在具有30 至40bp距离的质粒中具有最佳切割,从而对于任何给定的基因座在设计crRNA对时提供了足够的灵活性。更短和更长的距离均导致切口产生活性增加,同时产生更少的DSB。在两个原间隔区已被去除的质粒中存在极低的活性,从而表明靶特异性(泳道7)。
切割条件
为了评估用于切割试验的最佳缓冲液条件,并且为了估计复合物在生理条件下的活性是否是预期的,选择以下两种缓冲液:(1)NEB4 (New England Biolabs,50mM醋酸钾,20mM Tris-醋酸盐,10mM醋酸镁,1mM二硫苏糖醇,pH 7.9),以及(2)缓冲液O(Fermentas,50mM Tris-HCl,10mM MgCl2,100mM NaCl,0.1mg/mL BSA,pH 7.5)。在这两种中,推荐NEB4来实现完整的商品FokI酶的最佳活性。由快速筛选选择缓冲液O,以得到良好的活性和特异性(数据未示出)。图14B示出了与不同缓冲液经不同温育时间的温育。泳道1-4已与Fermentas缓冲液O温育(泳道1、2温育15分钟,泳道3、4温育30 分钟),泳道5、6已与NEB4温育(30分钟)。泳道1、3、5使用具有 35bp间隔的靶质粒,泳道2、4、6使用非靶质粒(无结合位点)。泳道 7、8分别只与级联KKR或级联ELD温育(缓冲液O)。泳道9是如(A)中的拓扑结构标志物。泳道10和11示出了在不添加级联时温育的靶质粒和非靶质粒。因此,在图14B中,检测对具有35个碱基对的距离的靶质粒的活性(泳道1、3、5),以及对非靶对照质粒的活性(泳道2、4、6)。NEB4(泳道5、6)中存在大量的非特异性切口产生和较少的切割,而缓冲液O只在具有大量特异性切割和极少切口产生的靶质粒中显示活性(泳道1-4)。此差异可能是由缓冲液O中的NaCl浓度引起的,较高的离子强度减弱蛋白质-蛋白质相互作用,从而导致较少的非特异性活性。15分钟或30分钟的温育在靶质粒和非靶质粒(分别为泳道 1、2或3、4)中均显示极少的差异。如预期的,只加入一种类型的级联(P7KKR或M13ELD)不会导致切割活性(泳道7、8)。本实验表明,由设计的对引起的特异性级联核酸酶活性在NaCl浓度至少为100mM 时出现,该浓度接近于细胞内部的生理盐水浓度(137mM NaCl)。预计级联核酸酶对在体内具有完全活性(在真核细胞中),虽然显现出可忽略不计的脱靶切割活性。
切割位点
确定具有35bp间隔的靶质粒(pTarget35)中的切割位点。图15显示了测序如何揭示在具有35个碱基对的间隔的靶质粒中的级联KKR/ELD的上游和下游切割位点。注释有潜在切割位点的pTarget35内的靶区域在图15A)中示出。原间隔区的部分显示为红色和蓝色。B)条图示出了四种不同的切割模式及其在测序克隆内的相对丰度。蓝色条表示所生成的突出端,而各条的左右边界代表左右切割位点(注释参见B)。
图15A示出了pTarget35的原始序列,切割位点从-7到+7编号,其中0位于两个原间隔区(以红色和蓝色表示)的中间。对17个克隆进行测序,它们均显示出在位点0周围切割,从而创建出介于3至5bp 之间的不同的突出端(参见图15B)。4bp的突出端最为丰富(累计88%),而3bp和5bp的突出端只出现一次(各6%)。切割如预期地精确发生,而没有克隆显现出脱靶切割。
在人细胞中切割靶基因座。
成功地修饰级联KKR/ELD核酸酶,以使之包含N-末端His6-标记,随后是双重单份核仁定位信号。这些修饰的级联核酸酶融合蛋白与两种合成构建的CRISPR阵列中的任一种共表达,每一种靶向人CCR5 基因中的结合位点。首先,通过检测对含有CCR5基因的此区域的质粒的活性,在体外验证此新核酸酶对的活性。将该核酸酶对转染到人类细胞系,例如,HeLa细胞系中。采用如上所述的检验师分析来评估靶标切割的效率。
序列表
<110> 瓦赫宁根大学
<120> 经修饰的级联核糖核蛋白及其用途
<130> P200547WO
<140> US 14/240,735
<141> 2014-02-24
<150> GB1122458.1
<151> 2011-12-30
<160> 47
<170> PatentIn version 3.5
<210> 1
<211> 502
<212> PRT
<213> 大肠杆菌
<400> 1
Met Asn Leu Leu Ile Asp Asn Trp Ile Pro Val Arg Pro Arg Asn Gly
1 5 10 15
Gly Lys Val Gln Ile Ile Asn Leu Gln Ser Leu Tyr Cys Ser Arg Asp
20 25 30
Gln Trp Arg Leu Ser Leu Pro Arg Asp Asp Met Glu Leu Ala Ala Leu
35 40 45
Ala Leu Leu Val Cys Ile Gly Gln Ile Ile Ala Pro Ala Lys Asp Asp
50 55 60
Val Glu Phe Arg His Arg Ile Met Asn Pro Leu Thr Glu Asp Glu Phe
65 70 75 80
Gln Gln Leu Ile Ala Pro Trp Ile Asp Met Phe Tyr Leu Asn His Ala
85 90 95
Glu His Pro Phe Met Gln Thr Lys Gly Val Lys Ala Asn Asp Val Thr
100 105 110
Pro Met Glu Lys Leu Leu Ala Gly Val Ser Gly Ala Thr Asn Cys Ala
115 120 125
Phe Val Asn Gln Pro Gly Gln Gly Glu Ala Leu Cys Gly Gly Cys Thr
130 135 140
Ala Ile Ala Leu Phe Asn Gln Ala Asn Gln Ala Pro Gly Phe Gly Gly
145 150 155 160
Gly Phe Lys Ser Gly Leu Arg Gly Gly Thr Pro Val Thr Thr Phe Val
165 170 175
Arg Gly Ile Asp Leu Arg Ser Thr Val Leu Leu Asn Val Leu Thr Leu
180 185 190
Pro Arg Leu Gln Lys Gln Phe Pro Asn Glu Ser His Thr Glu Asn Gln
195 200 205
Pro Thr Trp Ile Lys Pro Ile Lys Ser Asn Glu Ser Ile Pro Ala Ser
210 215 220
Ser Ile Gly Phe Val Arg Gly Leu Phe Trp Gln Pro Ala His Ile Glu
225 230 235 240
Leu Cys Asp Pro Ile Gly Ile Gly Lys Cys Ser Cys Cys Gly Gln Glu
245 250 255
Ser Asn Leu Arg Tyr Thr Gly Phe Leu Lys Glu Lys Phe Thr Phe Thr
260 265 270
Val Asn Gly Leu Trp Pro His Pro His Ser Pro Cys Leu Val Thr Val
275 280 285
Lys Lys Gly Glu Val Glu Glu Lys Phe Leu Ala Phe Thr Thr Ser Ala
290 295 300
Pro Ser Trp Thr Gln Ile Ser Arg Val Val Val Asp Lys Ile Ile Gln
305 310 315 320
Asn Glu Asn Gly Asn Arg Val Ala Ala Val Val Asn Gln Phe Arg Asn
325 330 335
Ile Ala Pro Gln Ser Pro Leu Glu Leu Ile Met Gly Gly Tyr Arg Asn
340 345 350
Asn Gln Ala Ser Ile Leu Glu Arg Arg His Asp Val Leu Met Phe Asn
355 360 365
Gln Gly Trp Gln Gln Tyr Gly Asn Val Ile Asn Glu Ile Val Thr Val
370 375 380
Gly Leu Gly Tyr Lys Thr Ala Leu Arg Lys Ala Leu Tyr Thr Phe Ala
385 390 395 400
Glu Gly Phe Lys Asn Lys Asp Phe Lys Gly Ala Gly Val Ser Val His
405 410 415
Glu Thr Ala Glu Arg His Phe Tyr Arg Gln Ser Glu Leu Leu Ile Pro
420 425 430
Asp Val Leu Ala Asn Val Asn Phe Ser Gln Ala Asp Glu Val Ile Ala
435 440 445
Asp Leu Arg Asp Lys Leu His Gln Leu Cys Glu Met Leu Phe Asn Gln
450 455 460
Ser Val Ala Pro Tyr Ala His His Pro Lys Leu Ile Ser Thr Leu Ala
465 470 475 480
Leu Ala Arg Ala Thr Leu Tyr Lys His Leu Arg Glu Leu Lys Pro Gln
485 490 495
Gly Gly Pro Ser Asn Gly
500
<210> 2
<211> 160
<212> PRT
<213> 大肠杆菌
<400> 2
Met Ala Asp Glu Ile Asp Ala Met Ala Leu Tyr Arg Ala Trp Gln Gln
1 5 10 15
Leu Asp Asn Gly Ser Cys Ala Gln Ile Arg Arg Val Ser Glu Pro Asp
20 25 30
Glu Leu Arg Asp Ile Pro Ala Phe Tyr Arg Leu Val Gln Pro Phe Gly
35 40 45
Trp Glu Asn Pro Arg His Gln Gln Ala Leu Leu Arg Met Val Phe Cys
50 55 60
Leu Ser Ala Gly Lys Asn Val Ile Arg His Gln Asp Lys Lys Ser Glu
65 70 75 80
Gln Thr Thr Gly Ile Ser Leu Gly Arg Ala Leu Ala Asn Ser Gly Arg
85 90 95
Ile Asn Glu Arg Arg Ile Phe Gln Leu Ile Arg Ala Asp Arg Thr Ala
100 105 110
Asp Met Val Gln Leu Arg Arg Leu Leu Thr His Ala Glu Pro Val Leu
115 120 125
Asp Trp Pro Leu Met Ala Arg Met Leu Thr Trp Trp Gly Lys Arg Glu
130 135 140
Arg Gln Gln Leu Leu Glu Asp Phe Val Leu Thr Thr Asn Lys Asn Ala
145 150 155 160
<210> 3
<211> 363
<212> PRT
<213> 大肠杆菌
<400> 3
Met Ser Asn Phe Ile Asn Ile His Val Leu Ile Ser His Ser Pro Ser
1 5 10 15
Cys Leu Asn Arg Asp Asp Met Asn Met Gln Lys Asp Ala Ile Phe Gly
20 25 30
Gly Lys Arg Arg Val Arg Ile Ser Ser Gln Ser Leu Lys Arg Ala Met
35 40 45
Arg Lys Ser Gly Tyr Tyr Ala Gln Asn Ile Gly Glu Ser Ser Leu Arg
50 55 60
Thr Ile His Leu Ala Gln Leu Arg Asp Val Leu Arg Gln Lys Leu Gly
65 70 75 80
Glu Arg Phe Asp Gln Lys Ile Ile Asp Lys Thr Leu Ala Leu Leu Ser
85 90 95
Gly Lys Ser Val Asp Glu Ala Glu Lys Ile Ser Ala Asp Ala Val Thr
100 105 110
Pro Trp Val Val Gly Glu Ile Ala Trp Phe Cys Glu Gln Val Ala Lys
115 120 125
Ala Glu Ala Asp Asn Leu Asp Asp Lys Lys Leu Leu Lys Val Leu Lys
130 135 140
Glu Asp Ile Ala Ala Ile Arg Val Asn Leu Gln Gln Gly Val Asp Ile
145 150 155 160
Ala Leu Ser Gly Arg Met Ala Thr Ser Gly Met Met Thr Glu Leu Gly
165 170 175
Lys Val Asp Gly Ala Met Ser Ile Ala His Ala Ile Thr Thr His Gln
180 185 190
Val Asp Ser Asp Ile Asp Trp Phe Thr Ala Val Asp Asp Leu Gln Glu
195 200 205
Gln Gly Ser Ala His Leu Gly Thr Gln Glu Phe Ser Ser Gly Val Phe
210 215 220
Tyr Arg Tyr Ala Asn Ile Asn Leu Ala Gln Leu Gln Glu Asn Leu Gly
225 230 235 240
Gly Ala Ser Arg Glu Gln Ala Leu Glu Ile Ala Thr His Val Val His
245 250 255
Met Leu Ala Thr Glu Val Pro Gly Ala Lys Gln Arg Thr Tyr Ala Ala
260 265 270
Phe Asn Pro Ala Asp Met Val Met Val Asn Phe Ser Asp Met Pro Leu
275 280 285
Ser Met Ala Asn Ala Phe Glu Lys Ala Val Lys Ala Lys Asp Gly Phe
290 295 300
Leu Gln Pro Ser Ile Gln Ala Phe Asn Gln Tyr Trp Asp Arg Val Ala
305 310 315 320
Asn Gly Tyr Gly Leu Asn Gly Ala Ala Ala Gln Phe Ser Leu Ser Asp
325 330 335
Val Asp Pro Ile Thr Ala Gln Val Lys Gln Met Pro Thr Leu Glu Gln
340 345 350
Leu Lys Ser Trp Val Arg Asn Asn Gly Glu Ala
355 360
<210> 4
<211> 224
<212> PRT
<213> 大肠杆菌
<400> 4
Met Arg Ser Tyr Leu Ile Leu Arg Leu Ala Gly Pro Met Gln Ala Trp
1 5 10 15
Gly Gln Pro Thr Phe Glu Gly Thr Arg Pro Thr Gly Arg Phe Pro Thr
20 25 30
Arg Ser Gly Leu Leu Gly Leu Leu Gly Ala Cys Leu Gly Ile Gln Arg
35 40 45
Asp Asp Thr Ser Ser Leu Gln Ala Leu Ser Glu Ser Val Gln Phe Ala
50 55 60
Val Arg Cys Asp Glu Leu Ile Leu Asp Asp Arg Arg Val Ser Val Thr
65 70 75 80
Gly Leu Arg Asp Tyr His Thr Val Leu Gly Ala Arg Glu Asp Tyr Arg
85 90 95
Gly Leu Lys Ser His Glu Thr Ile Gln Thr Trp Arg Glu Tyr Leu Cys
100 105 110
Asp Ala Ser Phe Thr Val Ala Leu Trp Leu Thr Pro His Ala Thr Met
115 120 125
Val Ile Ser Glu Leu Glu Lys Ala Val Leu Lys Pro Arg Tyr Thr Pro
130 135 140
Tyr Leu Gly Arg Arg Ser Cys Pro Leu Thr His Pro Leu Phe Leu Gly
145 150 155 160
Thr Cys Gln Ala Ser Asp Pro Gln Lys Ala Leu Leu Asn Tyr Glu Pro
165 170 175
Val Gly Gly Asp Ile Tyr Ser Glu Glu Ser Val Thr Gly His His Leu
180 185 190
Lys Phe Thr Ala Arg Asp Glu Pro Met Ile Thr Leu Pro Arg Gln Phe
195 200 205
Ala Ser Arg Glu Trp Tyr Val Ile Lys Gly Gly Met Asp Val Ser Gln
210 215 220
<210> 5
<211> 199
<212> PRT
<213> 大肠杆菌
<400> 5
Met Tyr Leu Ser Lys Val Ile Ile Ala Arg Ala Trp Ser Arg Asp Leu
1 5 10 15
Tyr Gln Leu His Gln Gly Leu Trp His Leu Phe Pro Asn Arg Pro Asp
20 25 30
Ala Ala Arg Asp Phe Leu Phe His Val Glu Lys Arg Asn Thr Pro Glu
35 40 45
Gly Cys His Val Leu Leu Gln Ser Ala Gln Met Pro Val Ser Thr Ala
50 55 60
Val Ala Thr Val Ile Lys Thr Lys Gln Val Glu Phe Gln Leu Gln Val
65 70 75 80
Gly Val Pro Leu Tyr Phe Arg Leu Arg Ala Asn Pro Ile Lys Thr Ile
85 90 95
Leu Asp Asn Gln Lys Arg Leu Asp Ser Lys Gly Asn Ile Lys Arg Cys
100 105 110
Arg Val Pro Leu Ile Lys Glu Ala Glu Gln Ile Ala Trp Leu Gln Arg
115 120 125
Lys Leu Gly Asn Ala Ala Arg Val Glu Asp Val His Pro Ile Ser Glu
130 135 140
Arg Pro Gln Tyr Phe Ser Gly Asp Gly Lys Ser Gly Lys Ile Gln Thr
145 150 155 160
Val Cys Phe Glu Gly Val Leu Thr Ile Asn Asp Ala Pro Ala Leu Ile
165 170 175
Asp Leu Val Gln Gln Gly Ile Gly Pro Ala Lys Ser Met Gly Cys Gly
180 185 190
Leu Leu Ser Leu Ala Pro Leu
195
<210> 6
<211> 392
<212> DNA
<213> 人工序列
<220>
<223> GA1070943
<400> 6
actggaaagc gggcagtgaa aggaaggccc atgaggccag ttaattaagc ggatcctggc 60
ggcggcagcg gcggcggcag cgacaagcag aagaacggca tcaaggcgaa cttcaagatc 120
cgccacaaca tcgaggacgg cggcgtgcag ctcgccgacc actaccagca gaacaccccc 180
atcggcgacg gccccgtgct gctgcccgac aaccactacc tgagctacca gtccgccctg 240
agcaaagacc ccaacgagaa gcgcgatcac atggtcctgc tggagttcgt gaccgccgcc 300
gggatcactc tcggcatgga cgagctgtac aagtaagcgg ccgcggcgcg cctaggcctt 360
gacggccttc cttcaattcg ccctatagtg ag 392
<210> 7
<211> 603
<212> DNA
<213> 人工序列
<220>
<223> GA1070941
<400> 7
cactataggg cgaattggcg gaaggccgtc aaggccgcat ttaattaagc ggccgcaggc 60
ggcggcagcg gcggcggcag catggtgagc aagggcgagg agctgttcac cggggtggtg 120
cccatcctgg tcgagctgga cggcgacgta aacggccaca agttcagcgt gtccggcgag 180
ggcgagggcg atgccaccta cggcaagctg accctgaagc tcatctgcac caccggcaag 240
ctgcccgtgc cctggcccac cctcgtgacc accctcggct acggcctgca gtgcttcgcc 300
cgctaccccg accacatgaa gcagcacgac ttcttcaagt ccgccatgcc cgaaggctac 360
gtccaggagc gcaccatctt cttcaaggac gacggcaact acaagacccg cgccgaggtg 420
aagttcgagg gcgacaccct ggtgaaccgc atcgagctga agggcatcga cttcaaggag 480
gacggcaaca tcctggggca caagctggag tacaactaca acagccacaa cgtctatatc 540
acggcctaac tcgagggcgc gccctgggcc tcatgggcct tccgctcact gcccgctttc 600
cag 603
<210> 8
<211> 679
<212> DNA
<213> 人工序列
<220>
<223> GA1068859
<400> 8
cactataggg cgaattggcg gaaggccgtc aaggccgcat gagctccatg gaaacaaaga 60
attagctgat ctttaataat aaggaaatgt tacattaagg ttggtgggtt gtttttatgg 120
gaaaaaatgc tttaagaaca aatgtatact tttagagagt tccccgcgcc agcggggata 180
aaccgggccg attgaaggtc cggtggatgg cttaaaagag ttccccgcgc cagcggggat 240
aaaccgccgc aggtacagca ggtagcgcag atcatcaaga gttccccgcg ccagcgggga 300
taaaccgact tctctccgaa aagtcaggac gctgtggcag agttccccgc gccagcgggg 360
ataaaccgcc tacgcgctga acgccagcgg tgtggtgaat gagttccccg cgccagcggg 420
gataaaccgg tgtggccatg cacgccttta acggtgaact ggagttcccc gcgccagcgg 480
ggataaaccg cacgaactca gccagaacga caaacaaaag gcgagttccc cgcgccagcg 540
gggataaacc ggcaccagta cgcgccccac gctgacggtt tctgagttcc ccgcgccagc 600
ggggataaac cgcagctccc attttcaaac ccaggtaccc tgggcctcat gggccttccg 660
ctcactgccc gctttccag 679
<210> 9
<211> 685
<212> DNA
<213> 人工序列
<220>
<223> GA1047360
<400> 9
gagctcccgg gctgacggta atagaggcac ctacaggctc cggtaaaacg gaaacagcgc 60
tggcctatgc ttggaaactt attgatcaac aaattgcgga tagtgttatt tttgccctcc 120
caacacaagc taccgcgaat gctatgctta cgagaatgga agcgagcgcg agccacttat 180
tttcatcccc aaatcttatt cttgctcatg gcaattcacg gtttaaccac ctctttcaat 240
caataaaatc acgcgcgatt actgaacagg ggcaagaaga agcgtgggtt cagtgttgtc 300
agtggttgtc acaaagcaat aagaaagtgt ttcttgggca aatcggcgtt tgcacgattg 360
atcaggtgtt gatttcggta ttgccagtta aacaccgctt tatccgtggt ttgggaattg 420
gtagatctgt tttaattgtt aatgaagttc atgcttacga cacctatatg aacggcttgc 480
tcgaggcagt gctcaaggct caggctgatg tgggagggag tgttattctt ctttccgcaa 540
ccctaccaat gaaacaaaaa cagaagcttc tggatactta tggtctgcat acagatccag 600
tggaaaataa ctccgcatat ccactcatta actggcgagg tgtgaatggt gcgcaacgtt 660
ttgatctgct agcggatccg gtacc 685
<210> 10
<211> 37
<212> DNA
<213> 人工序列
<220>
<223> 引物 BG3186
<400> 10
atagcgccat ggaacctttt aaatatatat gccatta 37
<210> 11
<211> 41
<212> DNA
<213> 人工序列
<220>
<223> 引物 BG3213
<400> 11
acagtgggat ccgctttggg atttgcaggg atgactctgg t 41
<210> 12
<211> 43
<212> DNA
<213> 人工序列
<220>
<223> 引物 BG3303
<400> 12
atagcgtcat gaatttgctt attgataact ggattcctgt acg 43
<210> 13
<211> 44
<212> DNA
<213> 人工序列
<220>
<223> 引物 BG3212
<400> 13
acagtggcgg ccgcgccatt tgatggccct ccttgcggtt ttaa 44
<210> 14
<211> 45
<212> DNA
<213> 人工序列
<220>
<223> 引物 BG3076
<400> 14
cgtatatcaa actttccaat agcatgaaga gcaatgaaaa ataac 45
<210> 15
<211> 23
<212> DNA
<213> 人工序列
<220>
<223> 引物 BG3449
<400> 15
atgataccgc gagacccacg ctc 23
<210> 16
<211> 24
<212> DNA
<213> 人工序列
<220>
<223> 引物 BG3451
<400> 16
cggataaagt tgcaggacca cttc 24
<210> 17
<211> 199
<212> PRT
<213> 大肠杆菌
<400> 17
Met Tyr Leu Ser Lys Val Ile Ile Ala Arg Ala Trp Ser Arg Asp Leu
1 5 10 15
Tyr Gln Leu His Gln Gly Leu Trp His Leu Phe Pro Asn Arg Pro Asp
20 25 30
Ala Ala Arg Asp Phe Leu Phe His Val Glu Lys Arg Asn Thr Pro Glu
35 40 45
Gly Cys His Val Leu Leu Gln Ser Ala Gln Met Pro Val Ser Thr Ala
50 55 60
Val Ala Thr Val Ile Lys Thr Lys Gln Val Glu Phe Gln Leu Gln Val
65 70 75 80
Gly Val Pro Leu Tyr Phe Arg Leu Arg Ala Asn Pro Ile Lys Thr Ile
85 90 95
Leu Asp Asn Gln Lys Arg Leu Asp Ser Lys Gly Asn Ile Lys Arg Cys
100 105 110
Arg Val Pro Leu Ile Lys Glu Ala Glu Gln Ile Ala Trp Leu Gln Arg
115 120 125
Lys Leu Gly Asn Ala Ala Arg Val Glu Asp Val His Pro Ile Ser Glu
130 135 140
Arg Pro Gln Tyr Phe Ser Gly Asp Gly Lys Ser Gly Lys Ile Gln Thr
145 150 155 160
Val Cys Phe Glu Gly Val Leu Thr Ile Asn Asp Ala Pro Ala Leu Ile
165 170 175
Asp Leu Val Gln Gln Gly Ile Gly Pro Ala Lys Ser Met Gly Cys Gly
180 185 190
Leu Leu Ser Leu Ala Pro Leu
195
<210> 18
<211> 2154
<212> DNA
<213> 人工序列
<220>
<223> 融合蛋白
<400> 18
atggctcaac tggttaaaag cgaactggaa gagaaaaaaa gtgaactgcg ccacaaactg 60
aaatatgtgc cgcatgaata tatcgagctg attgaaattg cacgtaatcc gacccaggat 120
cgtattctgg aaatgaaagt gatggaattt tttatgaaag tgtacggcta tcgcggtgaa 180
catctgggtg gtagccgtaa accggatggt gcaatttata ccgttggtag cccgattgat 240
tatggtgtta ttgttgatac caaagcctat agcggtggtt ataatctgcc gattggtcag 300
gcagatgaaa tggaacgtta tgtggaagaa aatcagaccc gtgataaaca tctgaatccg 360
aatgaatggt ggaaagttta tccgagcagc gttaccgagt ttaaattcct gtttgttagc 420
ggtcacttca aaggcaacta taaagcacag ctgacccgtc tgaatcatat taccaattgt 480
aatggtgcag ttctgagcgt tgaagaactg ctgattggtg gtgaaatgat taaagcaggc 540
accctgaccc tggaagaagt tcgtcgcaaa tttaacaatg gcgaaatcaa ctttgcggat 600
cccaccaacc gcgcgaaagg cctggaagcg gtgagcgtgg cgagcatgaa tttgcttatt 660
gataactgga ttcctgtacg cccgcgaaac ggggggaaag tccaaatcat aaatctgcaa 720
tcgctatact gcagtagaga tcagtggcga ttaagtttgc cccgtgacga tatggaactg 780
gccgctttag cactgctggt ttgcattggg caaattatcg ccccggcaaa agatgacgtt 840
gaatttcgac atcgcataat gaatccgctc actgaagatg agtttcaaca actcatcgcg 900
ccgtggatag atatgttcta ccttaatcac gcagaacatc cctttatgca gaccaaaggt 960
gtcaaagcaa atgatgtgac tccaatggaa aaactgttgg ctggggtaag cggcgcgacg 1020
aattgtgcat ttgtcaatca accggggcag ggtgaagcat tatgtggtgg atgcactgcg 1080
attgcgttat tcaaccaggc gaatcaggca ccaggttttg gtggtggttt taaaagcggt 1140
ttacgtggag gaacacctgt aacaacgttc gtacgtggga tcgatcttcg ttcaacggtg 1200
ttactcaatg tcctcacatt acctcgtctt caaaaacaat ttcctaatga atcacatacg 1260
gaaaaccaac ctacctggat taaacctatc aagtccaatg agtctatacc tgcttcgtca 1320
attgggtttg tccgtggtct attctggcaa ccagcgcata ttgaattatg cgatcccatt 1380
gggattggta aatgttcttg ctgtggacag gaaagcaatt tgcgttatac cggttttctt 1440
aaggaaaaat ttacctttac agttaatggg ctatggcccc atccgcattc cccttgtctg 1500
gtaacagtca agaaagggga ggttgaggaa aaatttcttg ctttcaccac ctccgcacca 1560
tcatggacac aaatcagccg agttgtggta gataagatta ttcaaaatga aaatggaaat 1620
cgcgtggcgg cggttgtgaa tcaattcaga aatattgcgc cgcaaagtcc tcttgaattg 1680
attatggggg gatatcgtaa taatcaagca tctattcttg aacggcgtca tgatgtgttg 1740
atgtttaatc aggggtggca acaatacggc aatgtgataa acgaaatagt gactgttggt 1800
ttgggatata aaacagcctt acgcaaggcg ttatatacct ttgcagaagg gtttaaaaat 1860
aaagacttca aaggggccgg agtctctgtt catgagactg cagaaaggca tttctatcga 1920
cagagtgaat tattaattcc cgatgtactg gcgaatgtta atttttccca ggctgatgag 1980
gtaatagctg atttacgaga caaacttcat caattgtgtg aaatgctatt taatcaatct 2040
gtagctccct atgcacatca tcctaaatta ataagcacat tagcgcttgc ccgcgccacg 2100
ctatacaaac atttacggga gttaaaaccg caaggagggc catcaaatgg ctga 2154
<210> 19
<211> 717
<212> PRT
<213> 人工序列
<220>
<223> 融合蛋白
<400> 19
Met Ala Gln Leu Val Lys Ser Glu Leu Glu Glu Lys Lys Ser Glu Leu
1 5 10 15
Arg His Lys Leu Lys Tyr Val Pro His Glu Tyr Ile Glu Leu Ile Glu
20 25 30
Ile Ala Arg Asn Pro Thr Gln Asp Arg Ile Leu Glu Met Lys Val Met
35 40 45
Glu Phe Phe Met Lys Val Tyr Gly Tyr Arg Gly Glu His Leu Gly Gly
50 55 60
Ser Arg Lys Pro Asp Gly Ala Ile Tyr Thr Val Gly Ser Pro Ile Asp
65 70 75 80
Tyr Gly Val Ile Val Asp Thr Lys Ala Tyr Ser Gly Gly Tyr Asn Leu
85 90 95
Pro Ile Gly Gln Ala Asp Glu Met Glu Arg Tyr Val Glu Glu Asn Gln
100 105 110
Thr Arg Asp Lys His Leu Asn Pro Asn Glu Trp Trp Lys Val Tyr Pro
115 120 125
Ser Ser Val Thr Glu Phe Lys Phe Leu Phe Val Ser Gly His Phe Lys
130 135 140
Gly Asn Tyr Lys Ala Gln Leu Thr Arg Leu Asn His Ile Thr Asn Cys
145 150 155 160
Asn Gly Ala Val Leu Ser Val Glu Glu Leu Leu Ile Gly Gly Glu Met
165 170 175
Ile Lys Ala Gly Thr Leu Thr Leu Glu Glu Val Arg Arg Lys Phe Asn
180 185 190
Asn Gly Glu Ile Asn Phe Ala Asp Pro Thr Asn Arg Ala Lys Gly Leu
195 200 205
Glu Ala Val Ser Val Ala Ser Met Asn Leu Leu Ile Asp Asn Trp Ile
210 215 220
Pro Val Arg Pro Arg Asn Gly Gly Lys Val Gln Ile Ile Asn Leu Gln
225 230 235 240
Ser Leu Tyr Cys Ser Arg Asp Gln Trp Arg Leu Ser Leu Pro Arg Asp
245 250 255
Asp Met Glu Leu Ala Ala Leu Ala Leu Leu Val Cys Ile Gly Gln Ile
260 265 270
Ile Ala Pro Ala Lys Asp Asp Val Glu Phe Arg His Arg Ile Met Asn
275 280 285
Pro Leu Thr Glu Asp Glu Phe Gln Gln Leu Ile Ala Pro Trp Ile Asp
290 295 300
Met Phe Tyr Leu Asn His Ala Glu His Pro Phe Met Gln Thr Lys Gly
305 310 315 320
Val Lys Ala Asn Asp Val Thr Pro Met Glu Lys Leu Leu Ala Gly Val
325 330 335
Ser Gly Ala Thr Asn Cys Ala Phe Val Asn Gln Pro Gly Gln Gly Glu
340 345 350
Ala Leu Cys Gly Gly Cys Thr Ala Ile Ala Leu Phe Asn Gln Ala Asn
355 360 365
Gln Ala Pro Gly Phe Gly Gly Gly Phe Lys Ser Gly Leu Arg Gly Gly
370 375 380
Thr Pro Val Thr Thr Phe Val Arg Gly Ile Asp Leu Arg Ser Thr Val
385 390 395 400
Leu Leu Asn Val Leu Thr Leu Pro Arg Leu Gln Lys Gln Phe Pro Asn
405 410 415
Glu Ser His Thr Glu Asn Gln Pro Thr Trp Ile Lys Pro Ile Lys Ser
420 425 430
Asn Glu Ser Ile Pro Ala Ser Ser Ile Gly Phe Val Arg Gly Leu Phe
435 440 445
Trp Gln Pro Ala His Ile Glu Leu Cys Asp Pro Ile Gly Ile Gly Lys
450 455 460
Cys Ser Cys Cys Gly Gln Glu Ser Asn Leu Arg Tyr Thr Gly Phe Leu
465 470 475 480
Lys Glu Lys Phe Thr Phe Thr Val Asn Gly Leu Trp Pro His Pro His
485 490 495
Ser Pro Cys Leu Val Thr Val Lys Lys Gly Glu Val Glu Glu Lys Phe
500 505 510
Leu Ala Phe Thr Thr Ser Ala Pro Ser Trp Thr Gln Ile Ser Arg Val
515 520 525
Val Val Asp Lys Ile Ile Gln Asn Glu Asn Gly Asn Arg Val Ala Ala
530 535 540
Val Val Asn Gln Phe Arg Asn Ile Ala Pro Gln Ser Pro Leu Glu Leu
545 550 555 560
Ile Met Gly Gly Tyr Arg Asn Asn Gln Ala Ser Ile Leu Glu Arg Arg
565 570 575
His Asp Val Leu Met Phe Asn Gln Gly Trp Gln Gln Tyr Gly Asn Val
580 585 590
Ile Asn Glu Ile Val Thr Val Gly Leu Gly Tyr Lys Thr Ala Leu Arg
595 600 605
Lys Ala Leu Tyr Thr Phe Ala Glu Gly Phe Lys Asn Lys Asp Phe Lys
610 615 620
Gly Ala Gly Val Ser Val His Glu Thr Ala Glu Arg His Phe Tyr Arg
625 630 635 640
Gln Ser Glu Leu Leu Ile Pro Asp Val Leu Ala Asn Val Asn Phe Ser
645 650 655
Gln Ala Asp Glu Val Ile Ala Asp Leu Arg Asp Lys Leu His Gln Leu
660 665 670
Cys Glu Met Leu Phe Asn Gln Ser Val Ala Pro Tyr Ala His His Pro
675 680 685
Lys Leu Ile Ser Thr Leu Ala Leu Ala Arg Ala Thr Leu Tyr Lys His
690 695 700
Leu Arg Glu Leu Lys Pro Gln Gly Gly Pro Ser Asn Gly
705 710 715
<210> 20
<211> 2154
<212> DNA
<213> 人工序列
<220>
<223> 融合蛋白
<400> 20
atggctcaac tggttaaaag cgaactggaa gagaaaaaaa gtgaactgcg ccacaaactg 60
aaatatgtgc cgcatgaata tatcgagctg attgaaattg cacgtaatcc gacccaggat 120
cgtattctgg aaatgaaagt gatggaattt tttatgaaag tgtacggcta tcgcggtgaa 180
catctgggtg gtagccgtaa accggatggt gcaatttata ccgttggtag cccgattgat 240
tatggtgtta ttgttgatac caaagcctat agcggtggtt ataatctgcc gattggtcag 300
gcagatgaaa tgcagcgtta tgtgaaagaa aatcagaccc gcaacaaaca tattaacccg 360
aatgaatggt ggaaagttta tccgagcagc gttaccgagt ttaaattcct gtttgttagc 420
ggtcacttca aaggcaacta taaagcacag ctgacccgtc tgaatcgtaa aaccaattgt 480
aatggtgcag ttctgagcgt tgaagaactg ctgattggtg gtgaaatgat taaagcaggc 540
accctgaccc tggaagaagt tcgtcgcaaa tttaacaatg gcgaaatcaa ctttgcggat 600
cccaccaacc gcgcgaaagg cctggaagcg gtgagcgtgg cgagcatgaa tttgcttatt 660
gataactgga ttcctgtacg cccgcgaaac ggggggaaag tccaaatcat aaatctgcaa 720
tcgctatact gcagtagaga tcagtggcga ttaagtttgc cccgtgacga tatggaactg 780
gccgctttag cactgctggt ttgcattggg caaattatcg ccccggcaaa agatgacgtt 840
gaatttcgac atcgcataat gaatccgctc actgaagatg agtttcaaca actcatcgcg 900
ccgtggatag atatgttcta ccttaatcac gcagaacatc cctttatgca gaccaaaggt 960
gtcaaagcaa atgatgtgac tccaatggaa aaactgttgg ctggggtaag cggcgcgacg 1020
aattgtgcat ttgtcaatca accggggcag ggtgaagcat tatgtggtgg atgcactgcg 1080
attgcgttat tcaaccaggc gaatcaggca ccaggttttg gtggtggttt taaaagcggt 1140
ttacgtggag gaacacctgt aacaacgttc gtacgtggga tcgatcttcg ttcaacggtg 1200
ttactcaatg tcctcacatt acctcgtctt caaaaacaat ttcctaatga atcacatacg 1260
gaaaaccaac ctacctggat taaacctatc aagtccaatg agtctatacc tgcttcgtca 1320
attgggtttg tccgtggtct attctggcaa ccagcgcata ttgaattatg cgatcccatt 1380
gggattggta aatgttcttg ctgtggacag gaaagcaatt tgcgttatac cggttttctt 1440
aaggaaaaat ttacctttac agttaatggg ctatggcccc atccgcattc cccttgtctg 1500
gtaacagtca agaaagggga ggttgaggaa aaatttcttg ctttcaccac ctccgcacca 1560
tcatggacac aaatcagccg agttgtggta gataagatta ttcaaaatga aaatggaaat 1620
cgcgtggcgg cggttgtgaa tcaattcaga aatattgcgc cgcaaagtcc tcttgaattg 1680
attatggggg gatatcgtaa taatcaagca tctattcttg aacggcgtca tgatgtgttg 1740
atgtttaatc aggggtggca acaatacggc aatgtgataa acgaaatagt gactgttggt 1800
ttgggatata aaacagcctt acgcaaggcg ttatatacct ttgcagaagg gtttaaaaat 1860
aaagacttca aaggggccgg agtctctgtt catgagactg cagaaaggca tttctatcga 1920
cagagtgaat tattaattcc cgatgtactg gcgaatgtta atttttccca ggctgatgag 1980
gtaatagctg atttacgaga caaacttcat caattgtgtg aaatgctatt taatcaatct 2040
gtagctccct atgcacatca tcctaaatta ataagcacat tagcgcttgc ccgcgccacg 2100
ctatacaaac atttacggga gttaaaaccg caaggagggc catcaaatgg ctga 2154
<210> 21
<211> 717
<212> PRT
<213> 人工序列
<220>
<223> 融合蛋白
<400> 21
Met Ala Gln Leu Val Lys Ser Glu Leu Glu Glu Lys Lys Ser Glu Leu
1 5 10 15
Arg His Lys Leu Lys Tyr Val Pro His Glu Tyr Ile Glu Leu Ile Glu
20 25 30
Ile Ala Arg Asn Pro Thr Gln Asp Arg Ile Leu Glu Met Lys Val Met
35 40 45
Glu Phe Phe Met Lys Val Tyr Gly Tyr Arg Gly Glu His Leu Gly Gly
50 55 60
Ser Arg Lys Pro Asp Gly Ala Ile Tyr Thr Val Gly Ser Pro Ile Asp
65 70 75 80
Tyr Gly Val Ile Val Asp Thr Lys Ala Tyr Ser Gly Gly Tyr Asn Leu
85 90 95
Pro Ile Gly Gln Ala Asp Glu Met Gln Arg Tyr Val Lys Glu Asn Gln
100 105 110
Thr Arg Asn Lys His Ile Asn Pro Asn Glu Trp Trp Lys Val Tyr Pro
115 120 125
Ser Ser Val Thr Glu Phe Lys Phe Leu Phe Val Ser Gly His Phe Lys
130 135 140
Gly Asn Tyr Lys Ala Gln Leu Thr Arg Leu Asn Arg Lys Thr Asn Cys
145 150 155 160
Asn Gly Ala Val Leu Ser Val Glu Glu Leu Leu Ile Gly Gly Glu Met
165 170 175
Ile Lys Ala Gly Thr Leu Thr Leu Glu Glu Val Arg Arg Lys Phe Asn
180 185 190
Asn Gly Glu Ile Asn Phe Ala Asp Pro Thr Asn Arg Ala Lys Gly Leu
195 200 205
Glu Ala Val Ser Val Ala Ser Met Asn Leu Leu Ile Asp Asn Trp Ile
210 215 220
Pro Val Arg Pro Arg Asn Gly Gly Lys Val Gln Ile Ile Asn Leu Gln
225 230 235 240
Ser Leu Tyr Cys Ser Arg Asp Gln Trp Arg Leu Ser Leu Pro Arg Asp
245 250 255
Asp Met Glu Leu Ala Ala Leu Ala Leu Leu Val Cys Ile Gly Gln Ile
260 265 270
Ile Ala Pro Ala Lys Asp Asp Val Glu Phe Arg His Arg Ile Met Asn
275 280 285
Pro Leu Thr Glu Asp Glu Phe Gln Gln Leu Ile Ala Pro Trp Ile Asp
290 295 300
Met Phe Tyr Leu Asn His Ala Glu His Pro Phe Met Gln Thr Lys Gly
305 310 315 320
Val Lys Ala Asn Asp Val Thr Pro Met Glu Lys Leu Leu Ala Gly Val
325 330 335
Ser Gly Ala Thr Asn Cys Ala Phe Val Asn Gln Pro Gly Gln Gly Glu
340 345 350
Ala Leu Cys Gly Gly Cys Thr Ala Ile Ala Leu Phe Asn Gln Ala Asn
355 360 365
Gln Ala Pro Gly Phe Gly Gly Gly Phe Lys Ser Gly Leu Arg Gly Gly
370 375 380
Thr Pro Val Thr Thr Phe Val Arg Gly Ile Asp Leu Arg Ser Thr Val
385 390 395 400
Leu Leu Asn Val Leu Thr Leu Pro Arg Leu Gln Lys Gln Phe Pro Asn
405 410 415
Glu Ser His Thr Glu Asn Gln Pro Thr Trp Ile Lys Pro Ile Lys Ser
420 425 430
Asn Glu Ser Ile Pro Ala Ser Ser Ile Gly Phe Val Arg Gly Leu Phe
435 440 445
Trp Gln Pro Ala His Ile Glu Leu Cys Asp Pro Ile Gly Ile Gly Lys
450 455 460
Cys Ser Cys Cys Gly Gln Glu Ser Asn Leu Arg Tyr Thr Gly Phe Leu
465 470 475 480
Lys Glu Lys Phe Thr Phe Thr Val Asn Gly Leu Trp Pro His Pro His
485 490 495
Ser Pro Cys Leu Val Thr Val Lys Lys Gly Glu Val Glu Glu Lys Phe
500 505 510
Leu Ala Phe Thr Thr Ser Ala Pro Ser Trp Thr Gln Ile Ser Arg Val
515 520 525
Val Val Asp Lys Ile Ile Gln Asn Glu Asn Gly Asn Arg Val Ala Ala
530 535 540
Val Val Asn Gln Phe Arg Asn Ile Ala Pro Gln Ser Pro Leu Glu Leu
545 550 555 560
Ile Met Gly Gly Tyr Arg Asn Asn Gln Ala Ser Ile Leu Glu Arg Arg
565 570 575
His Asp Val Leu Met Phe Asn Gln Gly Trp Gln Gln Tyr Gly Asn Val
580 585 590
Ile Asn Glu Ile Val Thr Val Gly Leu Gly Tyr Lys Thr Ala Leu Arg
595 600 605
Lys Ala Leu Tyr Thr Phe Ala Glu Gly Phe Lys Asn Lys Asp Phe Lys
610 615 620
Gly Ala Gly Val Ser Val His Glu Thr Ala Glu Arg His Phe Tyr Arg
625 630 635 640
Gln Ser Glu Leu Leu Ile Pro Asp Val Leu Ala Asn Val Asn Phe Ser
645 650 655
Gln Ala Asp Glu Val Ile Ala Asp Leu Arg Asp Lys Leu His Gln Leu
660 665 670
Cys Glu Met Leu Phe Asn Gln Ser Val Ala Pro Tyr Ala His His Pro
675 680 685
Lys Leu Ile Ser Thr Leu Ala Leu Ala Arg Ala Thr Leu Tyr Lys His
690 695 700
Leu Arg Glu Leu Lys Pro Gln Gly Gly Pro Ser Asn Gly
705 710 715
<210> 22
<211> 2235
<212> DNA
<213> 人工序列
<220>
<223> 融合蛋白
<400> 22
atgcatcacc atcatcacca cccgaaaaaa aagcgcaaag tggatccgaa gaaaaaacgt 60
aaagttgaag atccgaaaga catggctcaa ctggttaaaa gcgaactgga agagaaaaaa 120
agtgaactgc gccacaaact gaaatatgtg ccgcatgaat atatcgagct gattgaaatt 180
gcacgtaatc cgacccagga tcgtattctg gaaatgaaag tgatggaatt ttttatgaaa 240
gtgtacggct atcgcggtga acatctgggt ggtagccgta aaccggatgg tgcaatttat 300
accgttggta gcccgattga ttatggtgtt attgttgata ccaaagccta tagcggtggt 360
tataatctgc cgattggtca ggcagatgaa atgcagcgtt atgtgaaaga aaatcagacc 420
cgcaacaaac atattaaccc gaatgaatgg tggaaagttt atccgagcag cgttaccgag 480
tttaaattcc tgtttgttag cggtcacttc aaaggcaact ataaagcaca gctgacccgt 540
ctgaatcgta aaaccaattg taatggtgca gttctgagcg ttgaagaact gctgattggt 600
ggtgaaatga ttaaagcagg caccctgacc ctggaagaag ttcgtcgcaa atttaacaat 660
ggcgaaatca actttgcgga tcccaccaac cgcgcgaaag gcctggaagc ggtgagcgtg 720
gcgagcatga atttgcttat tgataactgg attcctgtac gcccgcgaaa cggggggaaa 780
gtccaaatca taaatctgca atcgctatac tgcagtagag atcagtggcg attaagtttg 840
ccccgtgacg atatggaact ggccgcttta gcactgctgg tttgcattgg gcaaattatc 900
gccccggcaa aagatgacgt tgaatttcga catcgcataa tgaatccgct cactgaagat 960
gagtttcaac aactcatcgc gccgtggata gatatgttct accttaatca cgcagaacat 1020
ccctttatgc agaccaaagg tgtcaaagca aatgatgtga ctccaatgga aaaactgttg 1080
gctggggtaa gcggcgcgac gaattgtgca tttgtcaatc aaccggggca gggtgaagca 1140
ttatgtggtg gatgcactgc gattgcgtta ttcaaccagg cgaatcaggc accaggtttt 1200
ggtggtggtt ttaaaagcgg tttacgtgga ggaacacctg taacaacgtt cgtacgtggg 1260
atcgatcttc gttcaacggt gttactcaat gtcctcacat tacctcgtct tcaaaaacaa 1320
tttcctaatg aatcacatac ggaaaaccaa cctacctgga ttaaacctat caagtccaat 1380
gagtctatac ctgcttcgtc aattgggttt gtccgtggtc tattctggca accagcgcat 1440
attgaattat gcgatcccat tgggattggt aaatgttctt gctgtggaca ggaaagcaat 1500
ttgcgttata ccggttttct taaggaaaaa tttaccttta cagttaatgg gctatggccc 1560
catccgcatt ccccttgtct ggtaacagtc aagaaagggg aggttgagga aaaatttctt 1620
gctttcacca cctccgcacc atcatggaca caaatcagcc gagttgtggt agataagatt 1680
attcaaaatg aaaatggaaa tcgcgtggcg gcggttgtga atcaattcag aaatattgcg 1740
ccgcaaagtc ctcttgaatt gattatgggg ggatatcgta ataatcaagc atctattctt 1800
gaacggcgtc atgatgtgtt gatgtttaat caggggtggc aacaatacgg caatgtgata 1860
aacgaaatag tgactgttgg tttgggatat aaaacagcct tacgcaaggc gttatatacc 1920
tttgcagaag ggtttaaaaa taaagacttc aaaggggccg gagtctctgt tcatgagact 1980
gcagaaaggc atttctatcg acagagtgaa ttattaattc ccgatgtact ggcgaatgtt 2040
aatttttccc aggctgatga ggtaatagct gatttacgag acaaacttca tcaattgtgt 2100
gaaatgctat ttaatcaatc tgtagctccc tatgcacatc atcctaaatt aataagcaca 2160
ttagcgcttg cccgcgccac gctatacaaa catttacggg agttaaaacc gcaaggaggg 2220
ccatcaaatg gctga 2235
<210> 23
<211> 744
<212> PRT
<213> 人工序列
<220>
<223> 融合蛋白
<400> 23
Met His His His His His His Pro Lys Lys Lys Arg Lys Val Asp Pro
1 5 10 15
Lys Lys Lys Arg Lys Val Glu Asp Pro Lys Asp Met Ala Gln Leu Val
20 25 30
Lys Ser Glu Leu Glu Glu Lys Lys Ser Glu Leu Arg His Lys Leu Lys
35 40 45
Tyr Val Pro His Glu Tyr Ile Glu Leu Ile Glu Ile Ala Arg Asn Pro
50 55 60
Thr Gln Asp Arg Ile Leu Glu Met Lys Val Met Glu Phe Phe Met Lys
65 70 75 80
Val Tyr Gly Tyr Arg Gly Glu His Leu Gly Gly Ser Arg Lys Pro Asp
85 90 95
Gly Ala Ile Tyr Thr Val Gly Ser Pro Ile Asp Tyr Gly Val Ile Val
100 105 110
Asp Thr Lys Ala Tyr Ser Gly Gly Tyr Asn Leu Pro Ile Gly Gln Ala
115 120 125
Asp Glu Met Gln Arg Tyr Val Lys Glu Asn Gln Thr Arg Asn Lys His
130 135 140
Ile Asn Pro Asn Glu Trp Trp Lys Val Tyr Pro Ser Ser Val Thr Glu
145 150 155 160
Phe Lys Phe Leu Phe Val Ser Gly His Phe Lys Gly Asn Tyr Lys Ala
165 170 175
Gln Leu Thr Arg Leu Asn Arg Lys Thr Asn Cys Asn Gly Ala Val Leu
180 185 190
Ser Val Glu Glu Leu Leu Ile Gly Gly Glu Met Ile Lys Ala Gly Thr
195 200 205
Leu Thr Leu Glu Glu Val Arg Arg Lys Phe Asn Asn Gly Glu Ile Asn
210 215 220
Phe Ala Asp Pro Thr Asn Arg Ala Lys Gly Leu Glu Ala Val Ser Val
225 230 235 240
Ala Ser Met Asn Leu Leu Ile Asp Asn Trp Ile Pro Val Arg Pro Arg
245 250 255
Asn Gly Gly Lys Val Gln Ile Ile Asn Leu Gln Ser Leu Tyr Cys Ser
260 265 270
Arg Asp Gln Trp Arg Leu Ser Leu Pro Arg Asp Asp Met Glu Leu Ala
275 280 285
Ala Leu Ala Leu Leu Val Cys Ile Gly Gln Ile Ile Ala Pro Ala Lys
290 295 300
Asp Asp Val Glu Phe Arg His Arg Ile Met Asn Pro Leu Thr Glu Asp
305 310 315 320
Glu Phe Gln Gln Leu Ile Ala Pro Trp Ile Asp Met Phe Tyr Leu Asn
325 330 335
His Ala Glu His Pro Phe Met Gln Thr Lys Gly Val Lys Ala Asn Asp
340 345 350
Val Thr Pro Met Glu Lys Leu Leu Ala Gly Val Ser Gly Ala Thr Asn
355 360 365
Cys Ala Phe Val Asn Gln Pro Gly Gln Gly Glu Ala Leu Cys Gly Gly
370 375 380
Cys Thr Ala Ile Ala Leu Phe Asn Gln Ala Asn Gln Ala Pro Gly Phe
385 390 395 400
Gly Gly Gly Phe Lys Ser Gly Leu Arg Gly Gly Thr Pro Val Thr Thr
405 410 415
Phe Val Arg Gly Ile Asp Leu Arg Ser Thr Val Leu Leu Asn Val Leu
420 425 430
Thr Leu Pro Arg Leu Gln Lys Gln Phe Pro Asn Glu Ser His Thr Glu
435 440 445
Asn Gln Pro Thr Trp Ile Lys Pro Ile Lys Ser Asn Glu Ser Ile Pro
450 455 460
Ala Ser Ser Ile Gly Phe Val Arg Gly Leu Phe Trp Gln Pro Ala His
465 470 475 480
Ile Glu Leu Cys Asp Pro Ile Gly Ile Gly Lys Cys Ser Cys Cys Gly
485 490 495
Gln Glu Ser Asn Leu Arg Tyr Thr Gly Phe Leu Lys Glu Lys Phe Thr
500 505 510
Phe Thr Val Asn Gly Leu Trp Pro His Pro His Ser Pro Cys Leu Val
515 520 525
Thr Val Lys Lys Gly Glu Val Glu Glu Lys Phe Leu Ala Phe Thr Thr
530 535 540
Ser Ala Pro Ser Trp Thr Gln Ile Ser Arg Val Val Val Asp Lys Ile
545 550 555 560
Ile Gln Asn Glu Asn Gly Asn Arg Val Ala Ala Val Val Asn Gln Phe
565 570 575
Arg Asn Ile Ala Pro Gln Ser Pro Leu Glu Leu Ile Met Gly Gly Tyr
580 585 590
Arg Asn Asn Gln Ala Ser Ile Leu Glu Arg Arg His Asp Val Leu Met
595 600 605
Phe Asn Gln Gly Trp Gln Gln Tyr Gly Asn Val Ile Asn Glu Ile Val
610 615 620
Thr Val Gly Leu Gly Tyr Lys Thr Ala Leu Arg Lys Ala Leu Tyr Thr
625 630 635 640
Phe Ala Glu Gly Phe Lys Asn Lys Asp Phe Lys Gly Ala Gly Val Ser
645 650 655
Val His Glu Thr Ala Glu Arg His Phe Tyr Arg Gln Ser Glu Leu Leu
660 665 670
Ile Pro Asp Val Leu Ala Asn Val Asn Phe Ser Gln Ala Asp Glu Val
675 680 685
Ile Ala Asp Leu Arg Asp Lys Leu His Gln Leu Cys Glu Met Leu Phe
690 695 700
Asn Gln Ser Val Ala Pro Tyr Ala His His Pro Lys Leu Ile Ser Thr
705 710 715 720
Leu Ala Leu Ala Arg Ala Thr Leu Tyr Lys His Leu Arg Glu Leu Lys
725 730 735
Pro Gln Gly Gly Pro Ser Asn Gly
740
<210> 24
<211> 2235
<212> DNA
<213> 人工序列
<220>
<223> 融合蛋白
<400> 24
atgcatcacc atcatcacca cccgaaaaaa aagcgcaaag tggatccgaa gaaaaaacgt 60
aaagttgaag atccgaaaga catggctcaa ctggttaaaa gcgaactgga agagaaaaaa 120
agtgaactgc gccacaaact gaaatatgtg ccgcatgaat atatcgagct gattgaaatt 180
gcacgtaatc cgacccagga tcgtattctg gaaatgaaag tgatggaatt ttttatgaaa 240
gtgtacggct atcgcggtga acatctgggt ggtagccgta aaccggatgg tgcaatttat 300
accgttggta gcccgattga ttatggtgtt attgttgata ccaaagccta tagcggtggt 360
tataatctgc cgattggtca ggcagatgaa atggaacgtt atgtggaaga aaatcagacc 420
cgtgataaac atctgaatcc gaatgaatgg tggaaagttt atccgagcag cgttaccgag 480
tttaaattcc tgtttgttag cggtcacttc aaaggcaact ataaagcaca gctgacccgt 540
ctgaatcata ttaccaattg taatggtgca gttctgagcg ttgaagaact gctgattggt 600
ggtgaaatga ttaaagcagg caccctgacc ctggaagaag ttcgtcgcaa atttaacaat 660
ggcgaaatca actttgcgga tcccaccaac cgcgcgaaag gcctggaagc ggtgagcgtg 720
gcgagcatga atttgcttat tgataactgg attcctgtac gcccgcgaaa cggggggaaa 780
gtccaaatca taaatctgca atcgctatac tgcagtagag atcagtggcg attaagtttg 840
ccccgtgacg atatggaact ggccgcttta gcactgctgg tttgcattgg gcaaattatc 900
gccccggcaa aagatgacgt tgaatttcga catcgcataa tgaatccgct cactgaagat 960
gagtttcaac aactcatcgc gccgtggata gatatgttct accttaatca cgcagaacat 1020
ccctttatgc agaccaaagg tgtcaaagca aatgatgtga ctccaatgga aaaactgttg 1080
gctggggtaa gcggcgcgac gaattgtgca tttgtcaatc aaccggggca gggtgaagca 1140
ttatgtggtg gatgcactgc gattgcgtta ttcaaccagg cgaatcaggc accaggtttt 1200
ggtggtggtt ttaaaagcgg tttacgtgga ggaacacctg taacaacgtt cgtacgtggg 1260
atcgatcttc gttcaacggt gttactcaat gtcctcacat tacctcgtct tcaaaaacaa 1320
tttcctaatg aatcacatac ggaaaaccaa cctacctgga ttaaacctat caagtccaat 1380
gagtctatac ctgcttcgtc aattgggttt gtccgtggtc tattctggca accagcgcat 1440
attgaattat gcgatcccat tgggattggt aaatgttctt gctgtggaca ggaaagcaat 1500
ttgcgttata ccggttttct taaggaaaaa tttaccttta cagttaatgg gctatggccc 1560
catccgcatt ccccttgtct ggtaacagtc aagaaagggg aggttgagga aaaatttctt 1620
gctttcacca cctccgcacc atcatggaca caaatcagcc gagttgtggt agataagatt 1680
attcaaaatg aaaatggaaa tcgcgtggcg gcggttgtga atcaattcag aaatattgcg 1740
ccgcaaagtc ctcttgaatt gattatgggg ggatatcgta ataatcaagc atctattctt 1800
gaacggcgtc atgatgtgtt gatgtttaat caggggtggc aacaatacgg caatgtgata 1860
aacgaaatag tgactgttgg tttgggatat aaaacagcct tacgcaaggc gttatatacc 1920
tttgcagaag ggtttaaaaa taaagacttc aaaggggccg gagtctctgt tcatgagact 1980
gcagaaaggc atttctatcg acagagtgaa ttattaattc ccgatgtact ggcgaatgtt 2040
aatttttccc aggctgatga ggtaatagct gatttacgag acaaacttca tcaattgtgt 2100
gaaatgctat ttaatcaatc tgtagctccc tatgcacatc atcctaaatt aataagcaca 2160
ttagcgcttg cccgcgccac gctatacaaa catttacggg agttaaaacc gcaaggaggg 2220
ccatcaaatg gctga 2235
<210> 25
<211> 744
<212> PRT
<213> 人工序列
<220>
<223> 融合蛋白
<400> 25
Met His His His His His His Pro Lys Lys Lys Arg Lys Val Asp Pro
1 5 10 15
Lys Lys Lys Arg Lys Val Glu Asp Pro Lys Asp Met Ala Gln Leu Val
20 25 30
Lys Ser Glu Leu Glu Glu Lys Lys Ser Glu Leu Arg His Lys Leu Lys
35 40 45
Tyr Val Pro His Glu Tyr Ile Glu Leu Ile Glu Ile Ala Arg Asn Pro
50 55 60
Thr Gln Asp Arg Ile Leu Glu Met Lys Val Met Glu Phe Phe Met Lys
65 70 75 80
Val Tyr Gly Tyr Arg Gly Glu His Leu Gly Gly Ser Arg Lys Pro Asp
85 90 95
Gly Ala Ile Tyr Thr Val Gly Ser Pro Ile Asp Tyr Gly Val Ile Val
100 105 110
Asp Thr Lys Ala Tyr Ser Gly Gly Tyr Asn Leu Pro Ile Gly Gln Ala
115 120 125
Asp Glu Met Glu Arg Tyr Val Glu Glu Asn Gln Thr Arg Asp Lys His
130 135 140
Leu Asn Pro Asn Glu Trp Trp Lys Val Tyr Pro Ser Ser Val Thr Glu
145 150 155 160
Phe Lys Phe Leu Phe Val Ser Gly His Phe Lys Gly Asn Tyr Lys Ala
165 170 175
Gln Leu Thr Arg Leu Asn His Ile Thr Asn Cys Asn Gly Ala Val Leu
180 185 190
Ser Val Glu Glu Leu Leu Ile Gly Gly Glu Met Ile Lys Ala Gly Thr
195 200 205
Leu Thr Leu Glu Glu Val Arg Arg Lys Phe Asn Asn Gly Glu Ile Asn
210 215 220
Phe Ala Asp Pro Thr Asn Arg Ala Lys Gly Leu Glu Ala Val Ser Val
225 230 235 240
Ala Ser Met Asn Leu Leu Ile Asp Asn Trp Ile Pro Val Arg Pro Arg
245 250 255
Asn Gly Gly Lys Val Gln Ile Ile Asn Leu Gln Ser Leu Tyr Cys Ser
260 265 270
Arg Asp Gln Trp Arg Leu Ser Leu Pro Arg Asp Asp Met Glu Leu Ala
275 280 285
Ala Leu Ala Leu Leu Val Cys Ile Gly Gln Ile Ile Ala Pro Ala Lys
290 295 300
Asp Asp Val Glu Phe Arg His Arg Ile Met Asn Pro Leu Thr Glu Asp
305 310 315 320
Glu Phe Gln Gln Leu Ile Ala Pro Trp Ile Asp Met Phe Tyr Leu Asn
325 330 335
His Ala Glu His Pro Phe Met Gln Thr Lys Gly Val Lys Ala Asn Asp
340 345 350
Val Thr Pro Met Glu Lys Leu Leu Ala Gly Val Ser Gly Ala Thr Asn
355 360 365
Cys Ala Phe Val Asn Gln Pro Gly Gln Gly Glu Ala Leu Cys Gly Gly
370 375 380
Cys Thr Ala Ile Ala Leu Phe Asn Gln Ala Asn Gln Ala Pro Gly Phe
385 390 395 400
Gly Gly Gly Phe Lys Ser Gly Leu Arg Gly Gly Thr Pro Val Thr Thr
405 410 415
Phe Val Arg Gly Ile Asp Leu Arg Ser Thr Val Leu Leu Asn Val Leu
420 425 430
Thr Leu Pro Arg Leu Gln Lys Gln Phe Pro Asn Glu Ser His Thr Glu
435 440 445
Asn Gln Pro Thr Trp Ile Lys Pro Ile Lys Ser Asn Glu Ser Ile Pro
450 455 460
Ala Ser Ser Ile Gly Phe Val Arg Gly Leu Phe Trp Gln Pro Ala His
465 470 475 480
Ile Glu Leu Cys Asp Pro Ile Gly Ile Gly Lys Cys Ser Cys Cys Gly
485 490 495
Gln Glu Ser Asn Leu Arg Tyr Thr Gly Phe Leu Lys Glu Lys Phe Thr
500 505 510
Phe Thr Val Asn Gly Leu Trp Pro His Pro His Ser Pro Cys Leu Val
515 520 525
Thr Val Lys Lys Gly Glu Val Glu Glu Lys Phe Leu Ala Phe Thr Thr
530 535 540
Ser Ala Pro Ser Trp Thr Gln Ile Ser Arg Val Val Val Asp Lys Ile
545 550 555 560
Ile Gln Asn Glu Asn Gly Asn Arg Val Ala Ala Val Val Asn Gln Phe
565 570 575
Arg Asn Ile Ala Pro Gln Ser Pro Leu Glu Leu Ile Met Gly Gly Tyr
580 585 590
Arg Asn Asn Gln Ala Ser Ile Leu Glu Arg Arg His Asp Val Leu Met
595 600 605
Phe Asn Gln Gly Trp Gln Gln Tyr Gly Asn Val Ile Asn Glu Ile Val
610 615 620
Thr Val Gly Leu Gly Tyr Lys Thr Ala Leu Arg Lys Ala Leu Tyr Thr
625 630 635 640
Phe Ala Glu Gly Phe Lys Asn Lys Asp Phe Lys Gly Ala Gly Val Ser
645 650 655
Val His Glu Thr Ala Glu Arg His Phe Tyr Arg Gln Ser Glu Leu Leu
660 665 670
Ile Pro Asp Val Leu Ala Asn Val Asn Phe Ser Gln Ala Asp Glu Val
675 680 685
Ile Ala Asp Leu Arg Asp Lys Leu His Gln Leu Cys Glu Met Leu Phe
690 695 700
Asn Gln Ser Val Ala Pro Tyr Ala His His Pro Lys Leu Ile Ser Thr
705 710 715 720
Leu Ala Leu Ala Arg Ala Thr Leu Tyr Lys His Leu Arg Glu Leu Lys
725 730 735
Pro Gln Gly Gly Pro Ser Asn Gly
740
<210> 26
<211> 168
<212> DNA
<213> 人工序列
<220>
<223> 靶质粒
<400> 26
gaattcacaa cggtgagcaa gtcactgttg gcaagccagg atctgaacaa taccgtcttg 60
ctttcgagcg ctagctctag aactagtcct cagcctaggc ctcgttccga agctgtcttt 120
cgctgctgag ggtgacgatc ccgcataggc ggcctttaac tcggatcc 168
<210> 27
<211> 163
<212> DNA
<213> 人工序列
<220>
<223> 靶质粒
<400> 27
gaattcacaa cggtgagcaa gtcactgttg gcaagccagg atctgaacaa taccgtcttt 60
tcgagcgcta gctctagaac tagtcctcag cctaggcctc gttcaagctg tctttcgctg 120
ctgagggtga cgatcccgca taggcggcct ttaactcgga tcc 163
<210> 28
<211> 158
<212> DNA
<213> 人工序列
<220>
<223> 靶质粒
<400> 28
gaattcacaa cggtgagcaa gtcactgttg gcaagccagg atctgaacaa taccgtcttc 60
gagcgctagc tctagaacta gtcctcagcc taggcctcga agctgtcttt cgctgctgag 120
ggtgacgatc ccgcataggc ggcctttaac tcggatcc 158
<210> 29
<211> 153
<212> DNA
<213> 人工序列
<220>
<223> 靶质粒
<400> 29
gaattcacaa cggtgagcaa gtcactgttg gcaagccagg atctgaacaa taccgtcttg 60
cgctagctct agaactagtc ctcagcctag gcctaagctg tctttcgctg ctgagggtga 120
cgatcccgca taggcggcct ttaactcgga tcc 153
<210> 30
<211> 148
<212> DNA
<213> 人工序列
<220>
<223> 靶质粒
<400> 30
gaattcacaa cggtgagcaa gtcactgttg gcaagccagg atctgaacaa taccgtcttg 60
ctagctctag aactagtcct cagcctagga agctgtcttt cgctgctgag ggtgacgatc 120
ccgcataggc ggcctttaac tcggatcc 148
<210> 31
<211> 143
<212> DNA
<213> 人工序列
<220>
<223> 靶质粒
<400> 31
gaattcacaa cggtgagcaa gtcactgttg gcaagccagg atctgaacaa taccgtcttc 60
tctagaacta gtcctcagcc taggaagctg tctttcgctg ctgagggtga cgatcccgca 120
taggcggcct ttaactcgga tcc 143
<210> 32
<211> 41
<212> DNA
<213> 人工序列
<220>
<223> 切割产物
<400> 32
cttgcgctag ctctagaact agtcctcagc ctaggcctaa g 41
<210> 33
<211> 41
<212> DNA
<213> 人工序列
<220>
<223> 切割产物
<400> 33
cttaggccta ggctgaggac tagttctaga gctagcgcaa g 41
<210> 34
<211> 45
<212> DNA
<213> 人工序列
<220>
<223> 补平连接
<400> 34
cttgcgctag ctctagaact agctagtcct cagcctaggc ctaag 45
<210> 35
<211> 45
<212> DNA
<213> 人工序列
<220>
<223> 补平连接
<400> 35
cttaggccta ggctgaggac tagctagttc tagagctagc gcaag 45
<210> 36
<211> 1100
<212> DNA
<213> 智人
<400> 36
ggtggaacaa gatggattat caagtgtcaa gtccaatcta tgacatcaat tattatacat 60
cggagccctg ccaaaaaatc aatgtgaagc aaatcgcagc ccgcctcctg cctccgctct 120
actcactggt gttcatcttt ggttttgtgg gcaacatgct ggtcatcctc atcctgataa 180
actgcaaaag gctgaagagc atgactgaca tctacctgct caacctggcc atctctgacc 240
tgtttttcct tcttactgtc cccttctggg ctcactatgc tgccgcccag tgggactttg 300
gaaatacaat gtgtcaactc ttgacagggc tctattttat aggcttcttc tctggaatct 360
tcttcatcat cctcctgaca atcgataggt acctggctgt cgtccatgct gtgtttgctt 420
taaaagccag gacggtcacc tttggggtgg tgacaagtgt gatcacttgg gtggtggctg 480
tgtttgcgtc tctcccagga atcatcttta ccagatctca aaaagaaggt cttcattaca 540
cctgcagctc tcattttcca tacagtcagt atcaattctg gaagaatttc cagacattaa 600
agatagtcat cttggggctg gtcctgccgc tgcttgtcat ggtcatctgc tactcgggaa 660
tcctaaaaac tctgcttcgg tgtcgaaatg agaagaagag gcacagggct gtgaggctta 720
tcttcaccat catgattgtt tattttctct tctgggctcc ctacaacatt gtccttctcc 780
tgaacacctt ccaggaattc tttggcctga ataattgcag tagctctaac aggttggacc 840
aagctatgca ggtgacagag actcttggga tgacgcactg ctgcatcaac cccatcatct 900
atgcctttgt cggggagaag ttcagaaact acctcttagt cttcttccaa aagcacattg 960
ccaaacgctt ctgcaaatgc tgttctattt tccagcaaga ggctcccgag cgagcaagct 1020
cagtttacac ccgatccact ggggagcagg aaatatctgt gggcttgtga cacggactca 1080
agtgggctgg tgacccagtc 1100
<210> 37
<211> 424
<212> DNA
<213> 人工序列
<220>
<223> CRISPR 阵列 red1
<400> 37
ccatggtaat acgactcact atagggagaa ttagctgatc tttaataata aggaaatgtt 60
acattaaggt tggtgggttg tttttatggg aaaaaatgct ttaagaacaa atgtatactt 120
ttagagagtt ccccgcgcca gcggggataa accgcaaaca cagcatggac gacagccagg 180
tacctagagt tccccgcgcc agcggggata aaccgcaaac acagcatgga cgacagccag 240
gtacctagag ttccccgcgc cagcggggat aaaccgcaaa cacagcatgg acgacagcca 300
ggtacctaga gttccccgcg ccagcgggga taaaccgaaa acaaaaggct cagtcggaag 360
actgggcctt ttgttttaac cccttggggc ctctaaacgg gtcttgaggg gttttttggg 420
tacc 424
<210> 38
<211> 424
<212> DNA
<213> 人工序列
<220>
<223> CRISPR 阵列 red2
<400> 38
ccatggtaat acgactcact atagggagaa ttagctgatc tttaataata aggaaatgtt 60
acattaaggt tggtgggttg tttttatggg aaaaaatgct ttaagaacaa atgtatactt 120
ttagagagtt ccccgcgcca gcggggataa accgtgtgat cacttgggtg gtggctgtgt 180
ttgcgtgagt tccccgcgcc agcggggata aaccgtgtga tcacttgggt ggtggctgtg 240
tttgcgtgag ttccccgcgc cagcggggat aaaccgtgtg atcacttggg tggtggctgt 300
gtttgcgtga gttccccgcg ccagcgggga taaaccgaaa acaaaaggct cagtcggaag 360
actgggcctt ttgttttaac cccttggggc ctctaaacgg gtcttgaggg gttttttggg 420
tacc 424
<210> 39
<211> 43
<212> DNA
<213> 人工序列
<220>
<223> 质粒
<400> 39
aaggatgcca gtgataagtg gaatgccatg tgggctgtca aaa 43
<210> 40
<211> 43
<212> DNA
<213> 人工序列
<220>
<223> 质粒变体 1
<400> 40
aaggatgcga gtgataagtg gaatgccatg tgggctgtca aaa 43
<210> 41
<211> 19
<212> DNA
<213> 人工序列
<220>
<223> 质粒变体 2
<400> 41
gccatgtggg ctgtcaaaa 19
<210> 42
<211> 23
<212> DNA
<213> 人工序列
<220>
<223> 质粒变体 3
<400> 42
gaatgccatg tgggctgtca aaa 23
<210> 43
<211> 1604
<212> PRT
<213> 链霉菌 SPB78
<400> 43
Met Pro Asp Gln Leu Asn Ala Pro Thr Pro Leu Gly Asp Arg Leu Thr
1 5 10 15
Gly Ala Val Arg Thr Val Trp Ala Lys His Asp Arg Asp Thr Gly Lys
20 25 30
Trp Leu Pro Leu Trp Arg His Met Thr Asp Ser Ala Ala Val Ala Gly
35 40 45
Leu Leu Trp Asp His Trp Leu Pro Arg Asn Ile Lys Asp Leu Ile Ala
50 55 60
Glu Pro Leu Pro Gly Gly Val Ala Asp Ala Arg Ser Leu Cys Val Trp
65 70 75 80
Leu Ala Gly Thr His Asp Ile Gly Lys Ala Thr Pro Ala Phe Ala Cys
85 90 95
Gln Val Asp Glu Leu Ala Gly Val Met Thr Ala Ala Gly Leu Asp Met
100 105 110
Arg Thr Ser Lys Gln Leu Gly Glu Asp Arg Arg Met Ala Pro His Gly
115 120 125
Leu Ala Gly Gln Val Leu Leu Gln Glu Trp Leu Glu Glu Arg Arg Gly
130 135 140
Trp Thr His Arg Ala Ser Ala Gln Phe Ala Val Val Ala Gly Gly His
145 150 155 160
His Gly Val Pro Pro Asp His Met Gln Leu His Asn Leu Asp Ala His
165 170 175
Pro Glu Leu Leu Arg Thr Gln Gly Leu Ala Glu Ala Gln Trp Arg Ala
180 185 190
Val Gln Asp Glu Leu Leu Asp Ala Cys Ala Leu Val Phe Gly Val Glu
195 200 205
Glu Arg Leu Asp Ala Trp Arg Thr Val Lys Leu Pro Gln Thr Val Gln
210 215 220
Val Leu Leu Thr Ala Thr Val Ile Val Ser Asp Trp Ile Ala Ser Asn
225 230 235 240
Pro Asp Leu Phe Pro Tyr Phe Pro Glu Glu His Pro Arg Glu Glu Ala
245 250 255
Glu Arg Val Ala Ala Ala Trp Gln Gly Leu Leu Leu Pro Ala Pro Trp
260 265 270
Glu Pro Glu Glu Pro Ser Ala Pro Ala Ala Glu Phe Tyr Ala Ser Arg
275 280 285
Phe Ala Leu Pro Pro Gly Ala Val Val Arg Pro Val Gln Glu Gln Ala
290 295 300
Leu Ala Met Ala Arg Asp Met Glu Arg Pro Gly Met Leu Ile Ile Glu
305 310 315 320
Ala Pro Met Gly Glu Gly Lys Thr Glu Ala Ala Leu Ala Val Ala Glu
325 330 335
Val Phe Ala Ala Arg Ser Gly Ala Gly Gly Cys Tyr Val Ala Leu Pro
340 345 350
Thr Met Ala Thr Ser Asn Ala Met Phe Pro Arg Leu Leu Arg Trp Leu
355 360 365
Asp Arg Leu Pro Arg Ala Asp Val Ser Gly Gly Arg Asp His Glu Gln
370 375 380
Arg Ser Val Leu Leu Ala His Ala Lys Ser Ala Leu Gln Glu Asp Tyr
385 390 395 400
Ala Thr Leu Met Arg Glu Ser His Arg Thr Ile Ala Ala Val Asp Ala
405 410 415
Tyr Gly Asp Asp Ser Arg Pro Arg Lys Gly Arg Pro Ala Ala Asp Gly
420 425 430
Val Arg Arg Lys Ala Pro Ala Glu Leu Val Ala His Gln Trp Leu Arg
435 440 445
Gly Arg Lys Lys Gly Leu Leu Ala Ser Phe Ala Val Gly Thr Ile Asp
450 455 460
Gln Leu Leu Met Ala Gly Leu Lys Ser Arg His Leu Ala Leu Arg His
465 470 475 480
Leu Ala Met Ala Gly Lys Val Val Val Ile Asp Glu Val His Ala Tyr
485 490 495
Asp Thr Tyr Met Asn Ala Tyr Leu Asp Arg Val Leu Ala Trp Leu Gly
500 505 510
Glu Tyr Arg Val Pro Val Val Val Leu Ser Ala Thr Leu Pro Ala Arg
515 520 525
Arg Arg Gly Glu Leu Ala Ala Ala Tyr Thr Gly Glu Asp Ala Gln Ala
530 535 540
Leu Thr Glu Ala Thr Gly Tyr Pro Leu Leu Thr Ala Val Val Pro Gly
545 550 555 560
Arg Glu Ala Val Gln Phe Val Ala Ala Ala Ser Gly Arg Gly Ser Asp
565 570 575
Val Leu Leu Glu Lys Leu Asp Asp Asp Asp Glu Ala Leu Ala Asp Arg
580 585 590
Leu Asp Thr Asp Leu Ala Asp Gly Gly Cys Ala Leu Val Val Arg Asn
595 600 605
Thr Val Asp Arg Val Met Asp Thr Ala Ser Val Leu Arg Glu Arg Phe
610 615 620
Gly Ala Asp His Val Thr Val Ala His Ala Arg Phe Val Asp Leu Asp
625 630 635 640
Arg Ala Arg Lys Asp Ser Glu Leu Leu Ala Arg Phe Gly Pro Pro Asp
645 650 655
Pro Asp Gly Gly Ser Pro Gln Arg Pro Arg Asn Ala His Ile Val Val
660 665 670
Ala Ser Gln Val Ala Glu Gln Ser Leu Asp Val Asp Phe Asp Leu Leu
675 680 685
Val Ser Asp Leu Cys Pro Val Asp Leu Leu Leu Gln Arg Met Gly Arg
690 695 700
Leu His Arg His Pro Arg Gly Arg Asp Gln Glu Arg Arg Pro Ala Arg
705 710 715 720
Leu Arg Gln Ala Arg Cys Leu Val Thr Gly Val Gly Trp Asp Thr Ser
725 730 735
Pro Ala Pro Glu Ala Asp Glu Gly Ser Arg Ala Ile Tyr Gly Ala Tyr
740 745 750
Ser Leu Leu Arg Ser Leu Ala Val Leu Ala Pro His Leu Gly Thr Ala
755 760 765
Gly Ala Ala Gly His Pro Leu Arg Leu Pro Glu Asp Ile Ser Pro Leu
770 775 780
Val Arg Arg Ala Tyr Gly Glu Glu Asp Pro Cys Pro Pro Glu Trp Glu
785 790 795 800
Pro Val Leu Ala Pro Ala Arg Asp Lys Tyr Arg Thr Ala Arg Glu Arg
805 810 815
Gln Ser Gln Lys Ala Glu Val Phe Arg Leu Asp Glu Val Arg Lys Ala
820 825 830
Gly Arg Pro Leu Ile Gly Trp Ile Asp Ala Gly Val Gly Asp Ala Asp
835 840 845
Asp Thr Pro Val Gly Arg Ala Gln Val Arg Asp Thr Lys Glu Gly Leu
850 855 860
Glu Val Leu Val Val Arg Arg Arg Ala Asp Gly Ser Leu Cys Thr Leu
865 870 875 880
Pro Trp Leu Asp Lys Gly Arg Gly Gly Leu Glu Leu Pro Val Asp Ala
885 890 895
Val Pro Ser Ala Leu Ala Ala Arg Ala Val Ala Ala Ser Gly Leu Arg
900 905 910
Leu Pro Tyr His Phe Thr Ser Ser Pro Gln Thr Leu Asp Arg Thr Leu
915 920 925
Ala Glu Leu Glu Glu Leu Tyr Val Pro Ala Trp Gln Glu Lys Glu Ser
930 935 940
His Trp Ile Ala Gly Glu Leu Ile Leu Ala Leu Asp Glu Glu Gly Arg
945 950 955 960
Ala Ala Leu Ala Gly Gln Gln Leu Val Tyr Asn Pro Glu Glu Gly Leu
965 970 975
Leu Val Ala Ser Ala Asp Ala Asn Thr Glu Ala Thr Ser Gly Arg Val
980 985 990
Met Asp Gly Lys Pro Ser Ser Ala Gly Asp Gly Lys Pro Gly His Ala
995 1000 1005
Ala Asp Gly Asn Arg Ala Arg Thr Thr Val Gly Gln Ser Pro Ala
1010 1015 1020
Asp Arg Gln Thr His Gln Pro Pro Glu Gly Glu Arg His Pro Val
1025 1030 1035
Pro Pro Ser Ala Ala Pro Pro Pro Ala Arg Pro Ser Phe Asp Leu
1040 1045 1050
Thr Ser Arg Pro Trp Leu Pro Val Leu Leu Lys Asp Gly Ser Glu
1055 1060 1065
Arg Glu Leu Ser Leu Pro Glu Val Phe Asp Gln Ala Arg Asp Ile
1070 1075 1080
Arg Arg Leu Val Gly Asp Leu Pro Thr Gln Asp Phe Ala Leu Thr
1085 1090 1095
Arg Met Leu Leu Ala Leu Leu Tyr Asp Ala Leu Ser Glu Pro Gly
1100 1105 1110
Gly Asp Met Ala Pro Ala Asp Thr Asp Ala Trp Glu Glu Leu Trp
1115 1120 1125
Leu Ser Gln Ser Ala Tyr Ala Ala Pro Val Ala Ala Tyr Leu His
1130 1135 1140
Arg Tyr Arg Glu Arg Phe Asp Leu Leu His Pro Glu Ser Pro Phe
1145 1150 1155
Phe Gln Thr Pro Gly Leu Arg Thr Ala Lys Asn Glu Val Phe Ser
1160 1165 1170
Leu Asn Arg Leu Val Ala Asp Val Pro Asn Gly Asp Pro Phe Phe
1175 1180 1185
Ser Met Arg Arg Pro Gly Val Asp Arg Leu Gly Phe Ala Glu Ala
1190 1195 1200
Ala Arg Trp Leu Val His Ala Gln Ala Tyr Asp Thr Ser Gly Ile
1205 1210 1215
Lys Thr Gly Ala Val Gly Asp Pro Arg Val Lys Ala Gly Lys Gly
1220 1225 1230
Tyr Pro Gln Gly Pro Ala Trp Ala Gly Asn Leu Gly Gly Val Leu
1235 1240 1245
Leu Glu Gly Asp Asn Leu His Glu Thr Leu Leu Leu Asn Leu Ile
1250 1255 1260
Ala Gly Asp Thr Pro Gly Val His Ala Ala Glu Val Asp Arg Pro
1265 1270 1275
Ala Trp Arg Ala Glu Pro Ser Gly Pro Ala Pro Ala Pro Asp Leu
1280 1285 1290
Gly Leu Arg Pro Tyr Gly Leu Arg Asp Leu Tyr Thr Trp Gln Ser
1295 1300 1305
Arg Arg Ile Arg Leu His His Asp Ala Asp Gly Val His Gly Val
1310 1315 1320
Val Leu Ala Tyr Gly Asp Ser Leu Glu Pro His Asn Arg His Gly
1325 1330 1335
His Glu Pro Met Thr Ser Trp Arg Arg Ser Pro Thr Gln Glu Lys
1340 1345 1350
Lys Arg Gln Glu Asn Leu Val Tyr Leu Pro Arg Glu His Asp Pro
1355 1360 1365
Ser Arg Leu Ala Trp Arg Gly Met Asp Gly Leu Leu Ala Gly Arg
1370 1375 1380
Glu Thr Gly Ser Ala Gln Gly Pro Asp Gly Ala Asp Arg Leu Ala
1385 1390 1395
Pro Lys Val Val Gln Trp Ala Ala Gln Leu Thr Thr Glu Gly Leu
1400 1405 1410
Leu Pro Arg Gly Tyr Leu Ile Arg Thr Arg Val Ile Gly Ala Arg
1415 1420 1425
Tyr Gly Thr Gln Gln Ser Val Ile Asp Glu Val Val Asp Asp Gly
1430 1435 1440
Val Leu Met Pro Ala Val Leu Leu His Glu Ala Asp Arg Arg Tyr
1445 1450 1455
Gly Asp Lys Ala Val Asp Ala Leu His Asp Ala Glu Lys Ala Val
1460 1465 1470
Gly Ala Leu Ala Gln Leu Ala Ala Asp Leu Ala Leu Ala Val Gly
1475 1480 1485
Thr Asp Pro Glu Pro Gly Arg Asn Thr Ala Arg Asp Leu Gly Phe
1490 1495 1500
Gly Thr Leu Asp Thr His Tyr Arg Arg Trp Leu Arg Glu Leu Gly
1505 1510 1515
Gly Thr Ser Asp Pro Glu Glu His Arg Asp Arg Trp Lys Gln Glu
1520 1525 1530
Val Arg Arg Leu Val Ala Glu Leu Gly Glu Arg Leu Leu Asp Gly
1535 1540 1545
Ala Gly Pro Ala Ala Trp Glu Gly Arg Leu Val Glu Thr Gly Lys
1550 1555 1560
Gly Thr Arg Trp Leu Asn Asp Ala Ala Ala Glu Leu Arg Phe Arg
1565 1570 1575
Thr Arg Leu Arg Glu Phe Leu Thr Thr Ala Pro Asp Thr Pro Thr
1580 1585 1590
Ser Pro Arg Pro Ala Pro Val Glu Ser Pro Ala
1595 1600
<210> 44
<211> 1559
<212> PRT
<213> 灰色链霉菌(Streptomyces griseus)
<400> 44
Met Ser Asn Thr Pro Met Ser Arg Asp His Pro Glu Ser Leu Ser Ala
1 5 10 15
Tyr Ala Arg Leu Ser Pro Val Ser Arg Thr Ala Trp Gly Lys His Asp
20 25 30
Arg Gln Thr Glu Gln Trp Leu Pro Leu Trp Arg His Met Ala Asp Ser
35 40 45
Ala Ala Val Ala Glu Arg Leu Trp Asp Gln Trp Val Pro Asp Asn Val
50 55 60
Lys Ala Leu Ile Ala Asp Ala Phe Pro Gln Gly Ala Gln Asp Ala Arg
65 70 75 80
Arg Val Ala Val Phe Leu Ala Cys Val His Asp Ile Gly Lys Ala Thr
85 90 95
Pro Ala Phe Ala Cys Gln Val Asp Gly Leu Ala Asp Arg Met Arg Ala
100 105 110
Ala Gly Leu Ser Met Pro Tyr Leu Lys Gln Phe Gly Leu Asp Arg Arg
115 120 125
Met Ala Pro His Gly Leu Ala Gly Gln Leu Leu Leu Gln Glu Trp Leu
130 135 140
Ala Glu Arg Phe Gly Trp Ser Glu Arg Ala Ser Gly Gln Phe Ala Val
145 150 155 160
Val Ala Gly Gly His His Gly Thr Pro Pro Asp His Gln His Ile His
165 170 175
Asp Leu Gly Leu Arg Pro His Leu Leu Arg Thr Ala Gly Glu Ser Gln
180 185 190
Asp Thr Trp Arg Ser Val Gln Asp Glu Leu Met Asp Ala Cys Ala Val
195 200 205
Arg Ala Gly Val Gly Gly Arg Phe Gly Ala Trp Arg Ser Val Arg Leu
210 215 220
Pro Gln Pro Val Gln Val Val Leu Thr Ala Ile Val Ile Val Ser Asp
225 230 235 240
Trp Ile Ala Ser Ser Ser Glu Leu Phe Pro Tyr Asp Pro Ala Ser Trp
245 250 255
Ser Pro Val Gly Pro Glu Gly Glu Gly Arg Arg Leu Thr Ala Ala Trp
260 265 270
Gly Gly Leu Asp Leu Pro Gly Pro Trp Arg Ala Asp Gln Pro Asp Cys
275 280 285
Thr Ala Ala Glu Leu Phe Gly Lys Arg Phe Asp Leu Pro Glu Gly Ala
290 295 300
Gly Val Arg Pro Val Gln Glu Glu Ala Val Arg Val Ala Gln Glu Leu
305 310 315 320
Pro Gly Pro Gly Leu Leu Ile Ile Glu Ala Pro Met Gly Glu Gly Lys
325 330 335
Thr Glu Ala Ala Phe Ala Ala Ala Glu Ile Leu Ala Ala Arg Thr Gly
340 345 350
Ala Gly Gly Cys Leu Val Ala Leu Pro Thr Arg Ala Thr Gly Asp Ala
355 360 365
Met Phe Pro Arg Leu Leu Arg Trp Leu Glu Arg Leu Pro Ser Asp Gly
370 375 380
Pro Arg Ser Val Val Leu Ala His Ala Lys Ala Ala Leu Asn Glu Val
385 390 395 400
Trp Ala Gly Met Thr Lys Ala Asp Arg Arg Lys Ile Thr Ala Val Asp
405 410 415
Leu Asp Ser Gln Val Glu Asp Val Ser Ser Ala Gly Gly Ala Arg Arg
420 425 430
Ala Asn Pro Ala Ser Leu His Ala His Gln Trp Leu Arg Gly Arg Lys
435 440 445
Lys Ala Leu Leu Ser Ser Phe Ala Val Gly Thr Val Asp Gln Val Leu
450 455 460
Phe Ala Gly Leu Lys Ser Arg His Leu Ala Leu Arg His Leu Ala Val
465 470 475 480
Ala Gly Lys Val Val Ile Val Asp Glu Val His Ala Tyr Asp Ala Tyr
485 490 495
Met Ser Ala Tyr Leu Asp Arg Val Leu Glu Trp Leu Ala Ala Tyr Arg
500 505 510
Val Pro Val Val Met Leu Ser Ala Thr Leu Pro Ala His Arg Arg Arg
515 520 525
Glu Leu Ala Ala Ala Tyr Ala Gly Glu Glu Thr Pro Glu Leu Ala Asp
530 535 540
Ala Leu Ala Leu Pro Asp Asp Ala Tyr Pro Leu Ile Thr Ala Val Ala
545 550 555 560
Pro Gly Gly Leu Val Leu Thr Ala Arg Pro Glu Pro Ala Ser Gly Arg
565 570 575
Arg Thr Glu Val Val Leu Glu Arg Leu Gly Asp Gly Pro Ala Leu Leu
580 585 590
Ala Ala Arg Leu Asp Glu Glu Leu Arg Asp Gly Gly Cys Ala Leu Val
595 600 605
Val Arg Asn Thr Val Asp Arg Val Leu Glu Ala Ala Glu His Leu Arg
610 615 620
Ala His Phe Gly Ala Glu Ala Val Thr Val Ala His Ser Arg Phe Val
625 630 635 640
Ala Ala Asp Arg Ala Arg Asn Asp Thr Val Leu Arg Glu Arg Phe Gly
645 650 655
Pro Gly Gly Asp Arg Pro Ala Gly Pro His Ile Val Val Ala Ser Gln
660 665 670
Val Val Glu Gln Ser Leu Asp Ile Asp Phe Asp Leu Leu Val Thr Asp
675 680 685
Leu Ala Pro Val Asp Leu Val Leu Gln Arg Met Gly Arg Leu His Arg
690 695 700
His Pro Arg Thr Arg Pro Pro Arg Leu Ser Arg Ala Arg Cys Leu Ile
705 710 715 720
Thr Gly Val Glu Asp Trp His Ala Glu Arg Pro Val Pro Val Arg Gly
725 730 735
Ser Leu Ala Val Tyr Gln Gly Pro His Thr Leu Leu Arg Ala Leu Ala
740 745 750
Val Leu Gly Pro His Leu Asp Gly Val Pro Leu Val Leu Pro Asp His
755 760 765
Ile Ser Pro Leu Val Gln Ala Ala Tyr Asp Glu Arg Pro Val Gly Pro
770 775 780
Ala His Trp Ala Pro Val Leu Asp Glu Ala Arg Arg Gln Tyr Leu Thr
785 790 795 800
Arg Leu Ala Glu Lys Arg Glu Arg Ala Asp Val Phe Arg Leu Gly Pro
805 810 815
Val Arg Arg Pro Gly Arg Pro Leu Phe Gly Trp Leu Asp Gly Asn Ala
820 825 830
Gly Asp Ala Asp Asp Ser Arg Thr Gly Arg Ala Gln Val Arg Asp Ser
835 840 845
Glu Glu Ser Leu Glu Val Leu Val Val Gln Arg Arg Ala Asp Gly Arg
850 855 860
Leu Thr Thr Val Ser Trp Leu Asp Gly Gly Arg Gly Gly Leu Asp Leu
865 870 875 880
Pro Glu His Ala Pro Pro Pro Pro Arg Ala Ala Glu Val Val Ala Ala
885 890 895
Cys Ala Leu Thr Leu Pro Arg Ser Leu Thr His Pro Gly Val Ile Asp
900 905 910
Arg Thr Ile Ala Glu Leu Glu Arg Phe Val Val Pro Ala Trp Gln Val
915 920 925
Lys Glu Cys Pro Trp Leu Ala Gly Glu Leu Leu Leu Val Leu Asp Glu
930 935 940
Asp Cys Gln Thr Arg Leu Ser Gly Leu Glu Val His Tyr Ser Thr Asp
945 950 955 960
Gln Gly Leu Arg Val Gly Ser Val Gly Thr Arg Ser Thr Asn Arg Ala
965 970 975
Lys Gly Leu Glu Ala Val Ser Val Ala Ser Phe Asp Leu Val Ser Arg
980 985 990
Pro Trp Leu Pro Val Gln Tyr Glu Asp Gly Ala Thr Gly Glu Leu Ser
995 1000 1005
Leu Arg Glu Val Phe Ala Arg Ala Gly Glu Val Arg Arg Leu Val
1010 1015 1020
Gly Asp Leu Pro Thr Gln Glu Leu Ala Leu Leu Arg Leu Leu Leu
1025 1030 1035
Ala Ile Leu Tyr Asp Ala Tyr Asp Glu Ala Pro Gly Arg Ser Gly
1040 1045 1050
Gly Ala Pro Ala Gln Leu Glu Asp Trp Glu Ala Leu Trp Asp Glu
1055 1060 1065
Pro Asp Ser Phe Ala Val Val Ala Gly Tyr Leu Asp Arg His Arg
1070 1075 1080
Asp Arg Phe Asp Leu Leu His Pro Glu Arg Pro Phe Phe Gln Val
1085 1090 1095
Ala Gly Leu His Thr Gln Lys His Glu Val Ala Ser Leu Asn Arg
1100 1105 1110
Ile Val Ala Asp Val Pro Asn Gly Glu Ala Phe Phe Ser Met Arg
1115 1120 1125
Arg Pro Gly Val His Arg Leu Gly Leu Ala Glu Ala Ala Arg Trp
1130 1135 1140
Leu Val His Thr His Ala Tyr Asp Ala Ser Gly Ile Lys Ser Gly
1145 1150 1155
Met Glu Gly Asp Ala Arg Val Lys Gly Gly Lys Val Tyr Pro Gln
1160 1165 1170
Gly Val Gly Trp Val Gly Gly Leu Gly Gly Val Phe Ala Glu Gly
1175 1180 1185
Ala Ser Leu Arg Glu Thr Leu Leu Leu Asn Leu Ile Pro Thr Asp
1190 1195 1200
Glu Asp Ile Leu Thr Ser Glu Pro Lys Ala Asp Leu Pro Val Trp
1205 1210 1215
Arg Arg Glu Thr Pro Pro Gly Pro Gly Val Val Glu Gly Asp Pro
1220 1225 1230
Ser Ala Pro Arg Pro Ala Gly Pro Arg Asp Leu Tyr Thr Trp Gln
1235 1240 1245
Ser Arg Arg Leu Leu Leu His Thr Glu Gly Ser Asp Ala Ile Gly
1250 1255 1260
Val Val Leu Gly Tyr Gly Asp Pro Leu Ser Pro Ala Asn Arg Gln
1265 1270 1275
Lys Thr Glu Pro Met Thr Gly Trp Arg Arg Ser Pro Ala Gln Glu
1280 1285 1290
Lys Lys Leu Gly Arg Pro Leu Val Tyr Leu Pro Arg Gln His Asp
1295 1300 1305
Pro Gly Arg Ala Ala Trp Arg Gly Leu Ala Ser Leu Leu Tyr Pro
1310 1315 1320
Gln Gly Glu Asp Gly Asp Thr Thr Gly Arg Gly Thr Asp Arg Ser
1325 1330 1335
Arg Pro Ala Gly Ile Val Arg Trp Leu Ala Leu Leu Ser Thr Glu
1340 1345 1350
Gly Val Leu Pro Lys Gly Ser Leu Ile Arg Thr Arg Leu Val Gly
1355 1360 1365
Ala Val Tyr Gly Thr Gln Gln Ser Val Val Asp Asp Val Val Asp
1370 1375 1380
Asp Ser Ile Ala Leu Pro Val Val Leu Leu His Gln Asp Arg Arg
1385 1390 1395
Leu His Gly Ala Val Ala Val Asp Ala Val Ala Asp Ala Glu Arg
1400 1405 1410
Ala Val Ser Ala Leu Gly His Leu Ala Gly Asn Leu Ala Arg Ala
1415 1420 1425
Ser Gly Ser Glu Ala Gly Pro Ala Thr Ala Thr Ala Arg Asp Gln
1430 1435 1440
Gly Phe Gly Ala Leu Asp Gly Pro Tyr Arg Arg Trp Leu Val Asp
1445 1450 1455
Leu Ala Glu Asp Thr Asp Leu Glu Arg Ala Arg Ala Ala Trp Arg
1460 1465 1470
Asp Thr Val Arg Leu Val Val Leu Gly Ile Gly Arg Glu Leu Leu
1475 1480 1485
Asp Ala Ala Gly Arg Ala Ala Ala Glu Gly Arg Val Ile Glu Leu
1490 1495 1500
Pro Gly Val Gly Lys Arg Trp Ile Asp Ser Ser Arg Ala Asp Leu
1505 1510 1515
Trp Phe Arg Thr Arg Ile Asn Arg Val Leu Pro Arg Pro Leu Pro
1520 1525 1530
Glu Ala His Ala Pro Thr Ala Asp Ile His Ala Gly His Ala Val
1535 1540 1545
Arg Ala Asp Glu Ala Leu Ser Glu Glu Thr Val
1550 1555
<210> 45
<211> 1540
<212> PRT
<213> 嗜酸细链孢菌(Catenulispora acidiphila)
<400> 45
Met Phe Asn Val Gly Ser Thr Arg Cys Trp Gly Asp Gly Gly Leu Arg
1 5 10 15
Asn Ala Ala Glu Asp Leu Ser Ala Ala Thr Arg Ser Ala Trp Ala Lys
20 25 30
Ser Asp Pro Asp Ser Gly Gln Ser Leu Ser Leu Ile Arg His Leu Ala
35 40 45
Asp Ser Ala Ala Ile Ala Glu His Leu Trp Asp Gln Trp Leu Pro Asp
50 55 60
His Val Lys Ser Leu Ile Ala Glu Gly Leu Pro Glu Gly Leu Val Asp
65 70 75 80
Gly Arg Thr Leu Ala Val Trp Leu Ala Gly Thr His Asp Ile Gly Lys
85 90 95
Leu Thr Pro Ala Phe Ala Cys Gln Cys Glu Pro Leu Ala Gln Ala Met
100 105 110
Arg Glu Cys Gly Leu Asp Met Pro Thr Arg Thr Gln Phe Gly Asp Asp
115 120 125
Arg Arg Val Ala Pro His Gly Leu Ala Gly Gln Val Leu Leu Arg Glu
130 135 140
Trp Leu Met Glu Arg His Gly Trp Ser Gly Arg Ser Ala Asp Ala Phe
145 150 155 160
Thr Val Ile Ala Gly Gly His His Gly Val Pro Pro Ser Tyr Ser Gln
165 170 175
Leu His Asp Leu Asp Ala Tyr Pro Glu Leu Leu Arg Thr Pro Gly Ala
180 185 190
Ser Glu Gly Ile Trp Lys Ser Ser Gln His Glu Leu Leu Asp Ala Cys
195 200 205
Ala Val Met Thr Gly Ala Ser Ser Arg Leu Ala His Trp Arg Gly Leu
210 215 220
Arg Leu Ser Gln Gln Ala Gln Val Leu Leu Thr Gly Leu Val Ile Val
225 230 235 240
Ala Asp Trp Ile Ala Ser Asn Thr Asp Leu Phe Pro Tyr Pro Ala Leu
245 250 255
Gly Thr Gly Glu Ala Ala Ile Asp Pro Gly Lys Arg Val Glu Leu Ala
260 265 270
Trp Arg Gly Leu Glu Leu Pro Ala Pro Trp Ala Pro Lys Tyr Leu Met
275 280 285
Pro Gly Met Gln Gly Leu Leu Ala Ser Arg Phe Gly Leu Pro Ala Asp
290 295 300
Ala Gln Leu Arg Pro Val Gln Gln Met Ala Val Gln Leu Ala Ser Ala
305 310 315 320
Asn Ala Ala Pro Gly Leu Leu Val Ile Glu Ala Pro Met Gly Glu Gly
325 330 335
Lys Thr Glu Ala Ala Leu Leu Ala Ala Glu Ile Leu Ala Ala Arg Ser
340 345 350
Gly Ala Gly Gly Val Phe Leu Ala Leu Pro Thr Gln Ala Thr Ser Asn
355 360 365
Ala Met Phe Ala Arg Val Val Asn Trp Leu Arg Gln Val Pro Arg Glu
370 375 380
Gly Val Ala Ser Val His Leu Ala His Gly Lys Ala Ala Leu Asp Asp
385 390 395 400
Ala Phe Ala Ser Phe Leu Arg Ala Ala Pro Arg Leu Thr Ser Ile Asp
405 410 415
Ala Asp Gly Tyr Ala Gly Glu Ala Asn Val Arg Arg Asp Arg Arg Ala
420 425 430
Gly Ser Ala Asp Met Val Ala His Gln Trp Leu Arg Gly Arg Lys Lys
435 440 445
Gly Ile Leu Ser Pro Phe Val Val Gly Thr Ile Asp Gln Leu Leu Phe
450 455 460
Thr Gly Leu Lys Ser Arg His Leu Ala Leu Arg His Leu Ala Val Ala
465 470 475 480
Gly Lys Val Val Val Ile Asp Glu Val His Ala Tyr Asp Ala Tyr Met
485 490 495
Ser Val Tyr Leu Glu Arg Val Leu Ser Trp Leu Gly Ala Tyr Arg Val
500 505 510
Pro Val Val Leu Leu Ser Ala Thr Leu Pro Ala Asp Arg Arg Gln Ala
515 520 525
Leu Val Glu Ala Tyr Gly Gly Ile Thr Ser Glu Ala Leu Arg Asp Ala
530 535 540
Arg Glu Ala Tyr Pro Val Leu Thr Ala Val Thr Ile Gly Ala Pro Ala
545 550 555 560
Gln Ala Val Gly Thr Glu Pro Ala Glu Gly Arg Arg Val Asp Val Asn
565 570 575
Val Glu Ala Phe Asp Asp Asp Leu Gly Arg Leu Ala Asp Arg Leu Glu
580 585 590
Ala Glu Leu Val Asp Gly Gly Cys Ala Leu Ile Ile Arg Asn Thr Val
595 600 605
Gly Arg Val Leu Gln Thr Ala Gln Gln Leu Arg Glu Arg Phe Gly Ala
610 615 620
Gly Gln Val Thr Val Ala His Ser Arg Phe Ile Asp Leu Asp Arg Ala
625 630 635 640
Arg Lys Asp Ala Asp Leu Leu Ala Arg Phe Gly His Asp Gly Ala Arg
645 650 655
Pro Arg Arg His Ile Val Val Ala Ser Gln Val Ala Glu Gln Ser Leu
660 665 670
Asp Ile Asp Phe Asp Leu Leu Val Thr Asp Leu Ala Pro Ile Asp Leu
675 680 685
Val Leu Gln Arg Met Gly Arg Val His Arg His His Arg Gly Gly Pro
690 695 700
Glu Gln Ser Glu Arg Pro Pro Ser Leu Arg Thr Ala Arg Cys Leu Val
705 710 715 720
Thr Gly Val Asp Trp Ala Gly Ile Pro Ser Ala Pro Ile Ala Gly Ser
725 730 735
Val Ala Val Tyr Gly Leu His Pro Leu Leu Arg Ser Leu Ala Val Leu
740 745 750
Gln Pro Tyr Leu Thr Gly Ser Ala Leu Thr Leu Pro Gly Asp Ile Asn
755 760 765
Pro Leu Val Gln Cys Ala Tyr Ala Gln Ser Phe Val Ala Pro Thr Gly
770 775 780
Trp Gly Glu Ala Met Asp Ala Ala Gln Ala Glu His Met Ala His Ile
785 790 795 800
Val Gln Gln Arg Glu Gly Ala Met Ala Phe Cys Leu Asp Glu Val Arg
805 810 815
Gly Pro Gly Arg Ser Leu Ile Gly Trp Ile Asp Gly Gly Val Gly Asp
820 825 830
Ala Asp Asp Thr Arg Ala Gly Arg Ala Gln Val Arg Asp Ser Pro Glu
835 840 845
Thr Ile Glu Val Leu Val Val Gln Arg Gly Ser Asp Gly Val Leu Arg
850 855 860
Thr Leu Pro Trp Leu Asp Arg Gly Arg Gly Gly Leu Glu Leu Pro Thr
865 870 875 880
Glu Ala Val Pro Pro Pro Arg Ala Ala Arg Ala Ala Ala Ala Ser Ala
885 890 895
Leu Arg Leu Pro Gly Leu Phe Ala Lys Pro Trp Met Phe Asp Arg Val
900 905 910
Leu Arg Glu Leu Glu Arg Glu Tyr His Glu Ala Trp Gln Ala Lys Glu
915 920 925
Ser Ser Trp Leu Gln Gly Glu Leu Leu Leu Val Leu Asp Glu Glu Cys
930 935 940
Arg Thr Val Leu Ala Gly Tyr Glu Leu Ser Tyr Asn Pro Asp Asp Gly
945 950 955 960
Leu Glu Met Val Met Pro Gly Glu Pro His Ala Ala Val Val Arg Asp
965 970 975
Lys Glu Ala Ser Asp Asp Lys Thr Ala Ser Phe Asp Leu Thr Ser Ala
980 985 990
Pro Trp Leu Pro Val Leu Tyr Ala Asp Gly Met Gln Gly Val Leu Ser
995 1000 1005
Leu Arg Asp Val Phe Ala Gln Ser Asn Leu Ile Arg Arg Leu Val
1010 1015 1020
Gly Asp Leu Pro Thr Gln Asp Phe Ala Leu Leu Arg Leu Leu Leu
1025 1030 1035
Ala Val Leu Tyr Asp Ala Val Asp Gly Pro Arg Asp Gly Gln Asp
1040 1045 1050
Trp Glu Asp Leu Trp Thr Ser Asp Asp Pro Phe Ala Ala Val Pro
1055 1060 1065
Ala Tyr Leu Asp Ser His Arg Glu Arg Phe Asp Leu Leu His Pro
1070 1075 1080
Ala Thr Pro Phe Tyr Gln Val Pro Gly Leu Gln Thr Ala Lys Gly
1085 1090 1095
Glu Val Gly Pro Leu Asn Lys Ile Val Ala Asp Val Pro Asp Gly
1100 1105 1110
Asp Pro Phe Leu Thr Met Arg Met Pro Gly Val Glu Gln Leu Ser
1115 1120 1125
Phe Ala Glu Ala Ala Arg Trp Leu Val His Thr Gln Ala Phe Asp
1130 1135 1140
Thr Ser Gly Ile Lys Ser Gly Val Val Gly Asp Pro Lys Ala Val
1145 1150 1155
Asn Gly Lys Arg Tyr Pro Gln Gly Val Ala Trp Leu Gly Asn Leu
1160 1165 1170
Gly Gly Val Phe Ala Glu Gly Asp Thr Leu Arg Gln Thr Leu Leu
1175 1180 1185
Leu Asn Leu Ile Pro Ala Asp Thr Thr Asn Leu Gln Val Thr Ser
1190 1195 1200
Ala Gln Asp Val Pro Ala Trp Arg Gly Thr Asn Gly Arg Ala Gly
1205 1210 1215
Ser Asp His Ala Asp Ala Glu Pro Arg Val Pro Ala Gly Leu Arg
1220 1225 1230
Asp Leu Tyr Thr Trp Gln Ser Arg Arg Ile Arg Leu Glu Tyr Asp
1235 1240 1245
Thr Arg Gly Val Thr Gly Ala Val Leu Thr Tyr Gly Asp Glu Leu
1250 1255 1260
Thr Ala His Asn Lys His Gly Val Glu Pro Met Thr Gly Trp Arg
1265 1270 1275
Arg Ser Lys Pro Gln Glu Lys Lys Leu Gly Leu Ser Thr Val Tyr
1280 1285 1290
Met Pro Gln Gln His Asp Pro Thr Arg Ala Ala Trp Arg Gly Ile
1295 1300 1305
Glu Ser Leu Leu Ala Gly Ser Ala Gly Ser Gly Ser Ser Gln Thr
1310 1315 1320
Gly Glu Pro Ala Ser His Tyr Arg Pro Lys Ile Val Asp Trp Leu
1325 1330 1335
Gly Glu Leu Ala His His Gly Asn Leu Pro Ser Arg Gly Leu Ile
1340 1345 1350
Arg Val Arg Thr Ser Gly Ala Val Tyr Gly Thr Gln Gln Ser Ile
1355 1360 1365
Ile Asp Glu Val Val Ser Asp Glu Leu Thr Met Ala Val Val Leu
1370 1375 1380
Leu His Glu Asp Asp Pro Arg Phe Gly Lys Ala Ala Val Thr Ala
1385 1390 1395
Val Lys Asp Ala Asp Ser Ala Val Ala Ala Leu Gly Asp Leu Ala
1400 1405 1410
Ser Asp Leu Ala Arg Ala Ala Gly Leu Asp Pro Glu Pro Glu Arg
1415 1420 1425
Val Thr Ala Arg Asp Arg Ala Phe Gly Ala Leu Asp Gly Pro Tyr
1430 1435 1440
Arg Arg Trp Leu Leu Asp Leu Gly Asn Ser Thr Asp Pro Ala Ala
1445 1450 1455
Met Arg Ala Val Trp Gln Gly Arg Val Tyr Asp Ile Ile Ala Val
1460 1465 1470
Gln Gly Gln Met Leu Leu Asp Ser Ala Gly Ser Ala Ala Ala Gln
1475 1480 1485
Gly Arg Met Val Lys Thr Thr Arg Gly Glu Arg Trp Met Asp Asp
1490 1495 1500
Ser Leu Ala Asp Leu Tyr Phe Lys Gly Arg Ile Ala Lys Ala Leu
1505 1510 1515
Ser Ser Arg Leu Gly Lys Lys Pro Thr Asp Pro Gly Glu Pro Val
1520 1525 1530
Gly Ile Gln Glu Asp Pro Ala
1535 1540
<210> 46
<211> 1407
<212> PRT
<213> 人工序列
<220>
<223> 融合 Cas3-Cse1
<400> 46
Met Glu Pro Phe Lys Tyr Ile Cys His Tyr Trp Gly Lys Ser Ser Lys
1 5 10 15
Ser Leu Thr Lys Gly Asn Asp Ile His Leu Leu Ile Tyr His Cys Leu
20 25 30
Asp Val Ala Ala Val Ala Asp Cys Trp Trp Asp Gln Ser Val Val Leu
35 40 45
Gln Asn Thr Phe Cys Arg Asn Glu Met Leu Ser Lys Gln Arg Val Lys
50 55 60
Ala Trp Leu Leu Phe Phe Ile Ala Leu His Asp Ile Gly Lys Phe Asp
65 70 75 80
Ile Arg Phe Gln Tyr Lys Ser Ala Glu Ser Trp Leu Lys Leu Asn Pro
85 90 95
Ala Thr Pro Ser Leu Asn Gly Pro Ser Thr Gln Met Cys Arg Lys Phe
100 105 110
Asn His Gly Ala Ala Gly Leu Tyr Trp Phe Asn Gln Asp Ser Leu Ser
115 120 125
Glu Gln Ser Leu Gly Asp Phe Phe Ser Phe Phe Asp Ala Ala Pro His
130 135 140
Pro Tyr Glu Ser Trp Phe Pro Trp Val Glu Ala Val Thr Gly His His
145 150 155 160
Gly Phe Ile Leu His Ser Gln Asp Gln Asp Lys Ser Arg Trp Glu Met
165 170 175
Pro Ala Ser Leu Ala Ser Tyr Ala Ala Gln Asp Lys Gln Ala Arg Glu
180 185 190
Glu Trp Ile Ser Val Leu Glu Ala Leu Phe Leu Thr Pro Ala Gly Leu
195 200 205
Ser Ile Asn Asp Ile Pro Pro Asp Cys Ser Ser Leu Leu Ala Gly Phe
210 215 220
Cys Ser Leu Ala Asp Trp Leu Gly Ser Trp Thr Thr Thr Asn Thr Phe
225 230 235 240
Leu Phe Asn Glu Asp Ala Pro Ser Asp Ile Asn Ala Leu Arg Thr Tyr
245 250 255
Phe Gln Asp Arg Gln Gln Asp Ala Ser Arg Val Leu Glu Leu Ser Gly
260 265 270
Leu Val Ser Asn Lys Arg Cys Tyr Glu Gly Val His Ala Leu Leu Asp
275 280 285
Asn Gly Tyr Gln Pro Arg Gln Leu Gln Val Leu Val Asp Ala Leu Pro
290 295 300
Val Ala Pro Gly Leu Thr Val Ile Glu Ala Pro Thr Gly Ser Gly Lys
305 310 315 320
Thr Glu Thr Ala Leu Ala Tyr Ala Trp Lys Leu Ile Asp Gln Gln Ile
325 330 335
Ala Asp Ser Val Ile Phe Ala Leu Pro Thr Gln Ala Thr Ala Asn Ala
340 345 350
Met Leu Thr Arg Met Glu Ala Ser Ala Ser His Leu Phe Ser Ser Pro
355 360 365
Asn Leu Ile Leu Ala His Gly Asn Ser Arg Phe Asn His Leu Phe Gln
370 375 380
Ser Ile Lys Ser Arg Ala Ile Thr Glu Gln Gly Gln Glu Glu Ala Trp
385 390 395 400
Val Gln Cys Cys Gln Trp Leu Ser Gln Ser Asn Lys Lys Val Phe Leu
405 410 415
Gly Gln Ile Gly Val Cys Thr Ile Asp Gln Val Leu Ile Ser Val Leu
420 425 430
Pro Val Lys His Arg Phe Ile Arg Gly Leu Gly Ile Gly Arg Ser Val
435 440 445
Leu Ile Val Asp Glu Val His Ala Tyr Asp Thr Tyr Met Asn Gly Leu
450 455 460
Leu Glu Ala Val Leu Lys Ala Gln Ala Asp Val Gly Gly Ser Val Ile
465 470 475 480
Leu Leu Ser Ala Thr Leu Pro Met Lys Gln Lys Gln Lys Leu Leu Asp
485 490 495
Thr Tyr Gly Leu His Thr Asp Pro Val Glu Asn Asn Ser Ala Tyr Pro
500 505 510
Leu Ile Asn Trp Arg Gly Val Asn Gly Ala Gln Arg Phe Asp Leu Leu
515 520 525
Ala His Pro Glu Gln Leu Pro Pro Arg Phe Ser Ile Gln Pro Glu Pro
530 535 540
Ile Cys Leu Ala Asp Met Leu Pro Asp Leu Thr Met Leu Glu Arg Met
545 550 555 560
Ile Ala Ala Ala Asn Ala Gly Ala Gln Val Cys Leu Ile Cys Asn Leu
565 570 575
Val Asp Val Ala Gln Val Cys Tyr Gln Arg Leu Lys Glu Leu Asn Asn
580 585 590
Thr Gln Val Asp Ile Asp Leu Phe His Ala Arg Phe Thr Leu Asn Asp
595 600 605
Arg Arg Glu Lys Glu Asn Arg Val Ile Ser Asn Phe Gly Lys Asn Gly
610 615 620
Lys Arg Asn Val Gly Arg Ile Leu Val Ala Thr Gln Val Val Glu Gln
625 630 635 640
Ser Leu Asp Val Asp Phe Asp Trp Leu Ile Thr Gln His Cys Pro Ala
645 650 655
Asp Leu Leu Phe Gln Arg Leu Gly Arg Leu His Arg His His Arg Lys
660 665 670
Tyr Arg Pro Ala Gly Phe Glu Ile Pro Val Ala Thr Ile Leu Leu Pro
675 680 685
Asp Gly Glu Gly Tyr Gly Arg His Glu His Ile Tyr Ser Asn Val Arg
690 695 700
Val Met Trp Arg Thr Gln Gln His Ile Glu Glu Leu Asn Gly Ala Ser
705 710 715 720
Leu Phe Phe Pro Asp Ala Tyr Arg Gln Trp Leu Asp Ser Ile Tyr Asp
725 730 735
Asp Ala Glu Met Asp Glu Pro Glu Trp Val Gly Asn Gly Met Asp Lys
740 745 750
Phe Glu Ser Ala Glu Cys Glu Lys Arg Phe Lys Ala Arg Lys Val Leu
755 760 765
Gln Trp Ala Glu Glu Tyr Ser Leu Gln Asp Asn Asp Glu Thr Ile Leu
770 775 780
Ala Val Thr Arg Asp Gly Glu Met Ser Leu Pro Leu Leu Pro Tyr Val
785 790 795 800
Gln Thr Ser Ser Gly Lys Gln Leu Leu Asp Gly Gln Val Tyr Glu Asp
805 810 815
Leu Ser His Glu Gln Gln Tyr Glu Ala Leu Ala Leu Asn Arg Val Asn
820 825 830
Val Pro Phe Thr Trp Lys Arg Ser Phe Ser Glu Val Val Asp Glu Asp
835 840 845
Gly Leu Leu Trp Leu Glu Gly Lys Gln Asn Leu Asp Gly Trp Val Trp
850 855 860
Gln Gly Asn Ser Ile Val Ile Thr Tyr Thr Gly Asp Glu Gly Met Thr
865 870 875 880
Arg Val Ile Pro Ala Asn Pro Lys Gly Asp Pro Thr Asn Arg Ala Lys
885 890 895
Gly Leu Glu Ala Val Ser Val Ala Ser Met Asn Leu Leu Ile Asp Asn
900 905 910
Trp Ile Pro Val Arg Pro Arg Asn Gly Gly Lys Val Gln Ile Ile Asn
915 920 925
Leu Gln Ser Leu Tyr Cys Ser Arg Asp Gln Trp Arg Leu Ser Leu Pro
930 935 940
Arg Asp Asp Met Glu Leu Ala Ala Leu Ala Leu Leu Val Cys Ile Gly
945 950 955 960
Gln Ile Ile Ala Pro Ala Lys Asp Asp Val Glu Phe Arg His Arg Ile
965 970 975
Met Asn Pro Leu Thr Glu Asp Glu Phe Gln Gln Leu Ile Ala Pro Trp
980 985 990
Ile Asp Met Phe Tyr Leu Asn His Ala Glu His Pro Phe Met Gln Thr
995 1000 1005
Lys Gly Val Lys Ala Asn Asp Val Thr Pro Met Glu Lys Leu Leu
1010 1015 1020
Ala Gly Val Ser Gly Ala Thr Asn Cys Ala Phe Val Asn Gln Pro
1025 1030 1035
Gly Gln Gly Glu Ala Leu Cys Gly Gly Cys Thr Ala Ile Ala Leu
1040 1045 1050
Phe Asn Gln Ala Asn Gln Ala Pro Gly Phe Gly Gly Gly Phe Lys
1055 1060 1065
Ser Gly Leu Arg Gly Gly Thr Pro Val Thr Thr Phe Val Arg Gly
1070 1075 1080
Ile Asp Leu Arg Ser Thr Val Leu Leu Asn Val Leu Thr Leu Pro
1085 1090 1095
Arg Leu Gln Lys Gln Phe Pro Asn Glu Ser His Thr Glu Asn Gln
1100 1105 1110
Pro Thr Trp Ile Lys Pro Ile Lys Ser Asn Glu Ser Ile Pro Ala
1115 1120 1125
Ser Ser Ile Gly Phe Val Arg Gly Leu Phe Trp Gln Pro Ala His
1130 1135 1140
Ile Glu Leu Cys Asp Pro Ile Gly Ile Gly Lys Cys Ser Cys Cys
1145 1150 1155
Gly Gln Glu Ser Asn Leu Arg Tyr Thr Gly Phe Leu Lys Glu Lys
1160 1165 1170
Phe Thr Phe Thr Val Asn Gly Leu Trp Pro His Pro His Ser Pro
1175 1180 1185
Cys Leu Val Thr Val Lys Lys Gly Glu Val Glu Glu Lys Phe Leu
1190 1195 1200
Ala Phe Thr Thr Ser Ala Pro Ser Trp Thr Gln Ile Ser Arg Val
1205 1210 1215
Val Val Asp Lys Ile Ile Gln Asn Glu Asn Gly Asn Arg Val Ala
1220 1225 1230
Ala Val Val Asn Gln Phe Arg Asn Ile Ala Pro Gln Ser Pro Leu
1235 1240 1245
Glu Leu Ile Met Gly Gly Tyr Arg Asn Asn Gln Ala Ser Ile Leu
1250 1255 1260
Glu Arg Arg His Asp Val Leu Met Phe Asn Gln Gly Trp Gln Gln
1265 1270 1275
Tyr Gly Asn Val Ile Asn Glu Ile Val Thr Val Gly Leu Gly Tyr
1280 1285 1290
Lys Thr Ala Leu Arg Lys Ala Leu Tyr Thr Phe Ala Glu Gly Phe
1295 1300 1305
Lys Asn Lys Asp Phe Lys Gly Ala Gly Val Ser Val His Glu Thr
1310 1315 1320
Ala Glu Arg His Phe Tyr Arg Gln Ser Glu Leu Leu Ile Pro Asp
1325 1330 1335
Val Leu Ala Asn Val Asn Phe Ser Gln Ala Asp Glu Val Ile Ala
1340 1345 1350
Asp Leu Arg Asp Lys Leu His Gln Leu Cys Glu Met Leu Phe Asn
1355 1360 1365
Gln Ser Val Ala Pro Tyr Ala His His Pro Lys Leu Ile Ser Thr
1370 1375 1380
Leu Ala Leu Ala Arg Ala Thr Leu Tyr Lys His Leu Arg Glu Leu
1385 1390 1395
Lys Pro Gln Gly Gly Pro Ser Asn Gly
1400 1405
<210> 47
<211> 49
<212> DNA
<213> 人工序列
<220>
<223> 级联序列切割
<400> 47
ccgtcttgcg ctagctctag aactagtcct cagcctaggc ctaagctgt 49
Claims (11)
1.I型成簇规律间隔短回文重复序列(CRISPR)相关Cse1蛋白质亚基和FokI核酸内切酶或经修饰的FokI核酸内切酶的人工融合蛋白,其中所述修饰的FokI核酸内切酶为KKRSharkey或ELD Sharkey。
2.如权利要求1所述的人工融合蛋白,其中所述人工融合蛋白还包含核定位信号。
3.一种核酸分子,其编码权利要求1或2所述的人工融合蛋白。
4.一种表达载体,其包含权利要求3所述的核酸分子。
5.一种级联蛋白质复合物,其包含权利要求1或2所述的人工融合蛋白。
6.一种核糖核蛋白复合物,其包含如权利要求1或2所述的人工融合蛋白和CRISPR RNA(crRNA)分子。
7.如权利要求6所述的核糖核蛋白复合物,其还包含Cas6蛋白质亚基、Cas5蛋白质亚基、Cse2蛋白质亚基和Cas7蛋白质亚基。
8.一种真核细胞,其包含权利要求6或7所述的核糖核蛋白复合物。
9.一种在体外修饰、可视化靶核酸,或激活或抑制靶核酸的转录的方法,其包含使所述的靶核酸与权利要求6或7所述的核糖核蛋白复合物接触。
10.如权利要求9所述的方法,其中所述的修饰的方法为结合和/或切割所述靶核酸。
11.如权利要求9或10所述的方法,其中所述靶核酸为双链DNA(dsDNA)。
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| GB1122458.1 | 2011-12-30 | ||
| GB201122458A GB201122458D0 (en) | 2011-12-30 | 2011-12-30 | Modified cascade ribonucleoproteins and uses thereof |
| CN201280071058.4A CN104321429A (zh) | 2011-12-30 | 2012-12-21 | 经修饰的级联核糖核蛋白及其用途 |
Related Parent Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201280071058.4A Division CN104321429A (zh) | 2011-12-30 | 2012-12-21 | 经修饰的级联核糖核蛋白及其用途 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN105732816A CN105732816A (zh) | 2016-07-06 |
| CN105732816B true CN105732816B (zh) | 2020-12-25 |
Family
ID=45695084
Family Applications (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201280071058.4A Pending CN104321429A (zh) | 2011-12-30 | 2012-12-21 | 经修饰的级联核糖核蛋白及其用途 |
| CN201610081216.4A Active CN105732816B (zh) | 2011-12-30 | 2012-12-21 | 经修饰的级联核糖核蛋白及其用途 |
Family Applications Before (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201280071058.4A Pending CN104321429A (zh) | 2011-12-30 | 2012-12-21 | 经修饰的级联核糖核蛋白及其用途 |
Country Status (26)
| Country | Link |
|---|---|
| US (9) | US20140294773A1 (zh) |
| EP (2) | EP3091072B1 (zh) |
| JP (1) | JP6408914B2 (zh) |
| KR (1) | KR101889589B1 (zh) |
| CN (2) | CN104321429A (zh) |
| AU (1) | AU2012360975B2 (zh) |
| BR (1) | BR112014016228B1 (zh) |
| CA (1) | CA2862018C (zh) |
| CY (1) | CY1120538T1 (zh) |
| DE (1) | DE212012000234U1 (zh) |
| DK (1) | DK3091072T3 (zh) |
| ES (1) | ES2689256T3 (zh) |
| GB (3) | GB201122458D0 (zh) |
| HR (1) | HRP20181150T1 (zh) |
| HU (1) | HUE039617T2 (zh) |
| IL (1) | IL233399A0 (zh) |
| IN (1) | IN2014DN05937A (zh) |
| LT (1) | LT3091072T (zh) |
| MX (1) | MX364830B (zh) |
| PL (1) | PL3091072T3 (zh) |
| PT (1) | PT3091072T (zh) |
| RS (1) | RS57604B1 (zh) |
| RU (1) | RU2014127702A (zh) |
| SG (1) | SG11201403713QA (zh) |
| SI (1) | SI3091072T1 (zh) |
| WO (1) | WO2013098244A1 (zh) |
Families Citing this family (206)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US7790756B2 (en) | 2006-10-11 | 2010-09-07 | Deciphera Pharmaceuticals, Llc | Kinase inhibitors useful for the treatment of myleoproliferative diseases and other proliferative diseases |
| KR101867359B1 (ko) | 2010-05-10 | 2018-07-23 | 더 리젠츠 오브 더 유니버시티 오브 캘리포니아 | 엔도리보뉴클레아제 조성물들 및 이들의 사용 방법들 |
| AU2012333134B2 (en) | 2011-07-22 | 2017-05-25 | John Paul Guilinger | Evaluation and improvement of nuclease cleavage specificity |
| EP2790708A4 (en) | 2011-12-16 | 2015-11-04 | Targetgene Biotechnologies Ltd | COMPOSITIONS AND METHODS FOR MODIFICATION OF A PREDETERMINED TARGET NUCLEIC ACID SEQUENCE |
| US11021737B2 (en) | 2011-12-22 | 2021-06-01 | President And Fellows Of Harvard College | Compositions and methods for analyte detection |
| GB201122458D0 (en) | 2011-12-30 | 2012-02-08 | Univ Wageningen | Modified cascade ribonucleoproteins and uses thereof |
| EP3597741A1 (en) | 2012-04-27 | 2020-01-22 | Duke University | Genetic correction of mutated genes |
| NZ728024A (en) | 2012-05-25 | 2019-05-31 | Univ California | Methods and compositions for rna-directed target dna modification and for rna-directed modulation of transcription |
| EP3346003B1 (en) | 2012-10-23 | 2021-06-09 | Toolgen Incorporated | Composition for cleaving a target dna comprising a guide rna specific for the target dna and cas protein-encoding nucleic acid or cas protein, and use thereof |
| WO2014089290A1 (en) | 2012-12-06 | 2014-06-12 | Sigma-Aldrich Co. Llc | Crispr-based genome modification and regulation |
| EP2840140B2 (en) | 2012-12-12 | 2023-02-22 | The Broad Institute, Inc. | Crispr-Cas based method for mutation of prokaryotic cells |
| PL2771468T3 (pl) | 2012-12-12 | 2015-07-31 | Broad Inst Inc | Inżynieria systemów, metod i zoptymalizowanych kompozycji kierujących dla manipulacji sekwencjami |
| IL293526A (en) | 2012-12-12 | 2022-08-01 | Harvard College | Providing, engineering and optimizing systems, methods and compositions for sequence manipulation and therapeutic applications |
| US8697359B1 (en) | 2012-12-12 | 2014-04-15 | The Broad Institute, Inc. | CRISPR-Cas systems and methods for altering expression of gene products |
| EP3434776A1 (en) | 2012-12-12 | 2019-01-30 | The Broad Institute, Inc. | Methods, models, systems, and apparatus for identifying target sequences for cas enzymes or crispr-cas systems for target sequences and conveying results thereof |
| DK2931898T3 (en) | 2012-12-12 | 2016-06-20 | Massachusetts Inst Technology | CONSTRUCTION AND OPTIMIZATION OF SYSTEMS, PROCEDURES AND COMPOSITIONS FOR SEQUENCE MANIPULATION WITH FUNCTIONAL DOMAINS |
| WO2014093694A1 (en) | 2012-12-12 | 2014-06-19 | The Broad Institute, Inc. | Crispr-cas nickase systems, methods and compositions for sequence manipulation in eukaryotes |
| DK2898075T3 (en) | 2012-12-12 | 2016-06-27 | Broad Inst Inc | CONSTRUCTION AND OPTIMIZATION OF IMPROVED SYSTEMS, PROCEDURES AND ENZYME COMPOSITIONS FOR SEQUENCE MANIPULATION |
| WO2014099750A2 (en) | 2012-12-17 | 2014-06-26 | President And Fellows Of Harvard College | Rna-guided human genome engineering |
| US10138509B2 (en) | 2013-03-12 | 2018-11-27 | President And Fellows Of Harvard College | Method for generating a three-dimensional nucleic acid containing matrix |
| KR20170108172A (ko) | 2013-03-14 | 2017-09-26 | 카리부 바이오사이언시스 인코포레이티드 | 핵산-표적화 핵산의 조성물 및 방법 |
| KR102405549B1 (ko) | 2013-03-15 | 2022-06-08 | 더 제너럴 하스피탈 코포레이션 | Rna-안내 게놈 편집을 위해 특이성을 증가시키기 위한 절단된 안내 rna(tru-grnas)의 이용 |
| US10760064B2 (en) | 2013-03-15 | 2020-09-01 | The General Hospital Corporation | RNA-guided targeting of genetic and epigenomic regulatory proteins to specific genomic loci |
| US9902973B2 (en) | 2013-04-11 | 2018-02-27 | Caribou Biosciences, Inc. | Methods of modifying a target nucleic acid with an argonaute |
| US9267135B2 (en) | 2013-06-04 | 2016-02-23 | President And Fellows Of Harvard College | RNA-guided transcriptional regulation |
| KR102282990B1 (ko) | 2013-06-04 | 2021-07-28 | 프레지던트 앤드 펠로우즈 오브 하바드 칼리지 | Rna-가이드된 전사 조절 |
| CN105492611A (zh) | 2013-06-17 | 2016-04-13 | 布罗德研究所有限公司 | 用于序列操纵的优化的crispr-cas双切口酶系统、方法以及组合物 |
| EP3011029B1 (en) | 2013-06-17 | 2019-12-11 | The Broad Institute, Inc. | Delivery, engineering and optimization of tandem guide systems, methods and compositions for sequence manipulation |
| AU2014281031B2 (en) | 2013-06-17 | 2020-05-21 | Massachusetts Institute Of Technology | Delivery, use and therapeutic applications of the CRISPR-Cas systems and compositions for targeting disorders and diseases using viral components |
| WO2014204727A1 (en) | 2013-06-17 | 2014-12-24 | The Broad Institute Inc. | Functional genomics using crispr-cas systems, compositions methods, screens and applications thereof |
| EP3011031B1 (en) | 2013-06-17 | 2020-09-30 | The Broad Institute Inc. | Delivery and use of the crispr-cas systems, vectors and compositions for hepatic targeting and therapy |
| US10011850B2 (en) | 2013-06-21 | 2018-07-03 | The General Hospital Corporation | Using RNA-guided FokI Nucleases (RFNs) to increase specificity for RNA-Guided Genome Editing |
| SG10201800213VA (en) * | 2013-07-10 | 2018-02-27 | Harvard College | Orthogonal cas9 proteins for rna-guided gene regulation and editing |
| US11060083B2 (en) | 2013-07-19 | 2021-07-13 | Larix Bioscience Llc | Methods and compositions for producing double allele knock outs |
| EP3022304B1 (en) * | 2013-07-19 | 2018-12-26 | Larix Biosciences LLC | Methods and compositions for producing double allele knock outs |
| CN103388006B (zh) * | 2013-07-26 | 2015-10-28 | 华东师范大学 | 一种基因定点突变的构建方法 |
| US10563225B2 (en) | 2013-07-26 | 2020-02-18 | President And Fellows Of Harvard College | Genome engineering |
| US20150044772A1 (en) * | 2013-08-09 | 2015-02-12 | Sage Labs, Inc. | Crispr/cas system-based novel fusion protein and its applications in genome editing |
| US20150044192A1 (en) | 2013-08-09 | 2015-02-12 | President And Fellows Of Harvard College | Methods for identifying a target site of a cas9 nuclease |
| AU2014308898B2 (en) | 2013-08-22 | 2020-05-14 | Pioneer Hi-Bred International, Inc. | Genome modification using guide polynucleotide/Cas endonuclease systems and methods of use |
| US9359599B2 (en) | 2013-08-22 | 2016-06-07 | President And Fellows Of Harvard College | Engineered transcription activator-like effector (TALE) domains and uses thereof |
| EP3038661B1 (en) | 2013-08-29 | 2023-12-27 | Temple University Of The Commonwealth System Of Higher Education | Methods and compositions for rna-guided treatment of hiv infection |
| US9526784B2 (en) | 2013-09-06 | 2016-12-27 | President And Fellows Of Harvard College | Delivery system for functional nucleases |
| US9340800B2 (en) | 2013-09-06 | 2016-05-17 | President And Fellows Of Harvard College | Extended DNA-sensing GRNAS |
| US9322037B2 (en) | 2013-09-06 | 2016-04-26 | President And Fellows Of Harvard College | Cas9-FokI fusion proteins and uses thereof |
| EP3842528A1 (en) | 2013-09-18 | 2021-06-30 | Kymab Limited | Methods, cells and organisms |
| WO2015065964A1 (en) | 2013-10-28 | 2015-05-07 | The Broad Institute Inc. | Functional genomics using crispr-cas systems, compositions, methods, screens and applications thereof |
| WO2015066119A1 (en) | 2013-10-30 | 2015-05-07 | North Carolina State University | Compositions and methods related to a type-ii crispr-cas system in lactobacillus buchneri |
| US9834791B2 (en) | 2013-11-07 | 2017-12-05 | Editas Medicine, Inc. | CRISPR-related methods and compositions with governing gRNAS |
| US9074199B1 (en) | 2013-11-19 | 2015-07-07 | President And Fellows Of Harvard College | Mutant Cas9 proteins |
| US10787684B2 (en) | 2013-11-19 | 2020-09-29 | President And Fellows Of Harvard College | Large gene excision and insertion |
| CA2932439A1 (en) | 2013-12-12 | 2015-06-18 | The Broad Institute, Inc. | Crispr-cas systems and methods for altering expression of gene products, structural information and inducible modular cas enzymes |
| US20150166984A1 (en) | 2013-12-12 | 2015-06-18 | President And Fellows Of Harvard College | Methods for correcting alpha-antitrypsin point mutations |
| WO2015089351A1 (en) | 2013-12-12 | 2015-06-18 | The Broad Institute Inc. | Compositions and methods of use of crispr-cas systems in nucleotide repeat disorders |
| WO2015089364A1 (en) | 2013-12-12 | 2015-06-18 | The Broad Institute Inc. | Crystal structure of a crispr-cas system, and uses thereof |
| EP3080271B1 (en) | 2013-12-12 | 2020-02-12 | The Broad Institute, Inc. | Systems, methods and compositions for sequence manipulation with optimized functional crispr-cas systems |
| EP3079725B1 (en) | 2013-12-12 | 2019-10-16 | The Broad Institute, Inc. | Delivery, use and therapeutic applications of the crispr-cas systems and compositions for genome editing |
| MX2016007797A (es) | 2013-12-19 | 2016-09-07 | Amyris Inc | Metodos para integracion genomica. |
| US10787654B2 (en) | 2014-01-24 | 2020-09-29 | North Carolina State University | Methods and compositions for sequence guiding Cas9 targeting |
| PL3115457T3 (pl) | 2014-03-05 | 2020-01-31 | National University Corporation Kobe University | Sposób modyfikacji sekwencji genomowej do specyficznego przekształcania zasad kwasu nukleinowego docelowej sekwencji dna oraz kompleks molekularny do zastosowania w nim |
| US11028388B2 (en) | 2014-03-05 | 2021-06-08 | Editas Medicine, Inc. | CRISPR/Cas-related methods and compositions for treating Usher syndrome and retinitis pigmentosa |
| WO2015138510A1 (en) | 2014-03-10 | 2015-09-17 | Editas Medicine., Inc. | Crispr/cas-related methods and compositions for treating leber's congenital amaurosis 10 (lca10) |
| US11339437B2 (en) | 2014-03-10 | 2022-05-24 | Editas Medicine, Inc. | Compositions and methods for treating CEP290-associated disease |
| US11141493B2 (en) | 2014-03-10 | 2021-10-12 | Editas Medicine, Inc. | Compositions and methods for treating CEP290-associated disease |
| WO2015148863A2 (en) | 2014-03-26 | 2015-10-01 | Editas Medicine, Inc. | Crispr/cas-related methods and compositions for treating sickle cell disease |
| US11318206B2 (en) | 2014-03-28 | 2022-05-03 | Aposense Ltd | Compounds and methods for trans-membrane delivery of molecules |
| EP3125946B1 (en) * | 2014-03-28 | 2022-12-07 | Aposense Ltd. | Compounds and methods for trans-membrane delivery of molecules |
| CA2944978C (en) * | 2014-04-08 | 2024-02-13 | North Carolina State University | Methods and compositions for rna-directed repression of transcription using crispr-associated genes |
| CA2953362A1 (en) | 2014-06-23 | 2015-12-30 | The General Hospital Corporation | Genomewide unbiased identification of dsbs evaluated by sequencing (guide-seq) |
| AU2015288157A1 (en) | 2014-07-11 | 2017-01-19 | E. I. Du Pont De Nemours And Company | Compositions and methods for producing plants resistant to glyphosate herbicide |
| AU2015298571B2 (en) | 2014-07-30 | 2020-09-03 | President And Fellows Of Harvard College | Cas9 proteins including ligand-dependent inteins |
| SG11201701245QA (en) | 2014-08-27 | 2017-03-30 | Caribou Biosciences Inc | Methods for increasing cas9-mediated engineering efficiency |
| US10450584B2 (en) | 2014-08-28 | 2019-10-22 | North Carolina State University | Cas9 proteins and guiding features for DNA targeting and genome editing |
| US11560568B2 (en) | 2014-09-12 | 2023-01-24 | E. I. Du Pont De Nemours And Company | Generation of site-specific-integration sites for complex trait loci in corn and soybean, and methods of use |
| WO2016073990A2 (en) | 2014-11-07 | 2016-05-12 | Editas Medicine, Inc. | Methods for improving crispr/cas-mediated genome-editing |
| CN107250148B (zh) | 2014-12-03 | 2021-04-16 | 安捷伦科技有限公司 | 具有化学修饰的指导rna |
| CA2969847A1 (en) | 2014-12-10 | 2016-06-16 | Regents Of The University Of Minnesota | Genetically modified cells, tissues, and organs for treating disease |
| EP3985115A1 (en) | 2014-12-12 | 2022-04-20 | The Broad Institute, Inc. | Protected guide rnas (pgrnas) |
| RU2713328C2 (ru) | 2015-01-28 | 2020-02-04 | Пайонир Хай-Бред Интернэшнл, Инк. | Гибридные днк/рнк-полинуклеотиды crispr и способы применения |
| US9944912B2 (en) | 2015-03-03 | 2018-04-17 | The General Hospital Corporation | Engineered CRISPR-Cas9 nucleases with altered PAM specificity |
| KR101675023B1 (ko) * | 2015-03-26 | 2016-11-10 | 한국생명공학연구원 | 표적 유전자 특이적 핵산 프로브 및 FokⅠ 제한효소 이량체를 이용하여 세포 내에서 표적 유전자를 특이적으로 편집하기 위한 조성물 및 이의 용도 |
| BR112017017260A2 (pt) | 2015-03-27 | 2018-04-17 | Du Pont | construções de dna, vetor, célula, plantas, semente, método de expressão de rna e método de modificação de local alvo |
| AU2016246450B2 (en) | 2015-04-06 | 2022-03-17 | Agilent Technologies, Inc. | Chemically modified guide RNAs for CRISPR/Cas-mediated gene regulation |
| KR102535217B1 (ko) | 2015-04-24 | 2023-05-19 | 에디타스 메디신, 인코포레이티드 | Cas9 분자/가이드 rna 분자 복합체의 평가 |
| WO2016182959A1 (en) | 2015-05-11 | 2016-11-17 | Editas Medicine, Inc. | Optimized crispr/cas9 systems and methods for gene editing in stem cells |
| JP2018516563A (ja) | 2015-05-29 | 2018-06-28 | ノース カロライナ ステート ユニバーシティNorth Carolina State University | Crispr核酸を用いて、細菌、古細菌、藻類、および、酵母をスクリーニングする方法 |
| WO2016196738A1 (en) | 2015-06-02 | 2016-12-08 | Monsanto Technology Llc | Compositions and methods for delivery of a polynucleotide into a plant |
| EP3303585A4 (en) | 2015-06-03 | 2018-10-31 | Board of Regents of the University of Nebraska | Dna editing using single-stranded dna |
| WO2016201047A1 (en) | 2015-06-09 | 2016-12-15 | Editas Medicine, Inc. | Crispr/cas-related methods and compositions for improving transplantation |
| CA2983874C (en) * | 2015-06-15 | 2022-06-21 | North Carolina State University | Methods and compositions for efficient delivery of nucleic acids and rna-based antimicrobials |
| WO2016205759A1 (en) | 2015-06-18 | 2016-12-22 | The Broad Institute Inc. | Engineering and optimization of systems, methods, enzymes and guide scaffolds of cas9 orthologs and variants for sequence manipulation |
| CN108290933A (zh) | 2015-06-18 | 2018-07-17 | 布罗德研究所有限公司 | 降低脱靶效应的crispr酶突变 |
| JP2018524992A (ja) * | 2015-07-23 | 2018-09-06 | メイヨ・ファウンデーション・フォー・メディカル・エデュケーション・アンド・リサーチ | ミトコンドリアdnaの編集 |
| JP7409773B2 (ja) | 2015-07-31 | 2024-01-09 | リージェンツ オブ ザ ユニバーシティ オブ ミネソタ | 改変された細胞および治療の方法 |
| US9580727B1 (en) | 2015-08-07 | 2017-02-28 | Caribou Biosciences, Inc. | Compositions and methods of engineered CRISPR-Cas9 systems using split-nexus Cas9-associated polynucleotides |
| US9926546B2 (en) | 2015-08-28 | 2018-03-27 | The General Hospital Corporation | Engineered CRISPR-Cas9 nucleases |
| WO2017040348A1 (en) | 2015-08-28 | 2017-03-09 | The General Hospital Corporation | Engineered crispr-cas9 nucleases |
| US9512446B1 (en) | 2015-08-28 | 2016-12-06 | The General Hospital Corporation | Engineered CRISPR-Cas9 nucleases |
| CN108271384B (zh) | 2015-09-09 | 2022-04-15 | 国立大学法人神户大学 | 用于特异性转变靶向dna序列的核酸碱基的革兰氏阳性菌的基因组序列的转变方法、及其使用的分子复合体 |
| DK3348636T3 (da) * | 2015-09-09 | 2022-02-28 | Univ Kobe Nat Univ Corp | Fremgangsmåde til modificering af en genomsekvens, der specifikt omdanner nukleobasen af en targetteret DNA-sekvens, og molekylær sekvens anvendt i fremgangsmåden |
| JP2018530536A (ja) | 2015-09-11 | 2018-10-18 | ザ ジェネラル ホスピタル コーポレイション | ヌクレアーゼDSBの完全照合およびシーケンシング(FIND−seq) |
| WO2017053879A1 (en) | 2015-09-24 | 2017-03-30 | Editas Medicine, Inc. | Use of exonucleases to improve crispr/cas-mediated genome editing |
| WO2017058751A1 (en) | 2015-09-28 | 2017-04-06 | North Carolina State University | Methods and compositions for sequence specific antimicrobials |
| CN105331627B (zh) * | 2015-09-30 | 2019-04-02 | 华中农业大学 | 一种利用内源CRISPR-Cas系统进行原核生物基因组编辑的方法 |
| WO2017059313A1 (en) | 2015-09-30 | 2017-04-06 | The General Hospital Corporation | Comprehensive in vitro reporting of cleavage events by sequencing (circle-seq) |
| EP4089175A1 (en) * | 2015-10-13 | 2022-11-16 | Duke University | Genome engineering with type i crispr systems in eukaryotic cells |
| EP3350327B1 (en) | 2015-10-23 | 2018-09-26 | Caribou Biosciences, Inc. | Engineered crispr class 2 cross-type nucleic-acid targeting nucleic acids |
| SG10202104041PA (en) | 2015-10-23 | 2021-06-29 | Harvard College | Nucleobase editors and uses thereof |
| CA3004285A1 (en) | 2015-11-03 | 2017-05-11 | President And Fellows Of Harvard College | Method and apparatus for volumetric imaging of a three-dimensional nucleic acid containing matrix |
| BR112018010681A8 (pt) | 2015-11-27 | 2019-02-26 | Univ Kobe Nat Univ Corp | método para modificar um sítio alvejado, complexo de enzima de modificação de ácido nucleico, e, ácido nucleico. |
| US11542466B2 (en) | 2015-12-22 | 2023-01-03 | North Carolina State University | Methods and compositions for delivery of CRISPR based antimicrobials |
| SG10202112024PA (en) | 2016-01-11 | 2021-12-30 | Univ Leland Stanford Junior | Chimeric proteins and methods of immunotherapy |
| EA201891619A1 (ru) | 2016-01-11 | 2019-02-28 | Те Борд Оф Трастиз Оф Те Лилэнд Стэнфорд Джуниор Юниверсити | Химерные белки и способы регулирования экспрессии генов |
| CN116904404A (zh) | 2016-01-27 | 2023-10-20 | 昂克诺斯公司 | 溶瘤病毒载体及其用途 |
| EP3433363A1 (en) | 2016-03-25 | 2019-01-30 | Editas Medicine, Inc. | Genome editing systems comprising repair-modulating enzyme molecules and methods of their use |
| WO2017165862A1 (en) | 2016-03-25 | 2017-09-28 | Editas Medicine, Inc. | Systems and methods for treating alpha 1-antitrypsin (a1at) deficiency |
| WO2017180694A1 (en) | 2016-04-13 | 2017-10-19 | Editas Medicine, Inc. | Cas9 fusion molecules gene editing systems, and methods of use thereof |
| CA3022290A1 (en) | 2016-04-25 | 2017-11-02 | President And Fellows Of Harvard College | Hybridization chain reaction methods for in situ molecular detection |
| JP7093310B2 (ja) | 2016-05-18 | 2022-06-29 | アミリス, インコーポレイテッド | 外因性ランディングパッドへの核酸のゲノム組込みのための組成物および方法 |
| IL295358B2 (en) | 2016-06-02 | 2023-09-01 | Sigma Aldrich Co Llc | Use of programmable DNA-binding proteins to enhance targeted genome modification |
| US10767175B2 (en) | 2016-06-08 | 2020-09-08 | Agilent Technologies, Inc. | High specificity genome editing using chemically modified guide RNAs |
| EP3472311A4 (en) * | 2016-06-17 | 2020-03-04 | Montana State University | BIDIRECTIONAL TARGETING FOR GENOMEDITATION |
| US11566263B2 (en) | 2016-08-02 | 2023-01-31 | Editas Medicine, Inc. | Compositions and methods for treating CEP290 associated disease |
| SG11201900907YA (en) | 2016-08-03 | 2019-02-27 | Harvard College | Adenosine nucleobase editors and uses thereof |
| US11078481B1 (en) | 2016-08-03 | 2021-08-03 | KSQ Therapeutics, Inc. | Methods for screening for cancer targets |
| WO2018031683A1 (en) | 2016-08-09 | 2018-02-15 | President And Fellows Of Harvard College | Programmable cas9-recombinase fusion proteins and uses thereof |
| US11542509B2 (en) | 2016-08-24 | 2023-01-03 | President And Fellows Of Harvard College | Incorporation of unnatural amino acids into proteins using base editing |
| US11078483B1 (en) | 2016-09-02 | 2021-08-03 | KSQ Therapeutics, Inc. | Methods for measuring and improving CRISPR reagent function |
| US20190225974A1 (en) | 2016-09-23 | 2019-07-25 | BASF Agricultural Solutions Seed US LLC | Targeted genome optimization in plants |
| KR20190067209A (ko) | 2016-10-14 | 2019-06-14 | 더 제너럴 하스피탈 코포레이션 | 후성적으로 조절되는 부위-특이적 뉴클레아제 |
| EP3526320A1 (en) | 2016-10-14 | 2019-08-21 | President and Fellows of Harvard College | Aav delivery of nucleobase editors |
| GB2605883B (en) | 2016-10-18 | 2023-03-15 | Univ Minnesota | Tumor infiltrating lymphocytes and methods of therapy |
| US9816093B1 (en) | 2016-12-06 | 2017-11-14 | Caribou Biosciences, Inc. | Engineered nucleic acid-targeting nucleic acids |
| US10745677B2 (en) | 2016-12-23 | 2020-08-18 | President And Fellows Of Harvard College | Editing of CCR5 receptor gene to protect against HIV infection |
| CA3049640A1 (en) | 2017-01-09 | 2018-07-12 | Aposense Ltd. | Compounds and methods for trans-membrane delivery of molecules |
| US11866699B2 (en) | 2017-02-10 | 2024-01-09 | University Of Washington | Genome editing reagents and their use |
| US11898179B2 (en) | 2017-03-09 | 2024-02-13 | President And Fellows Of Harvard College | Suppression of pain by gene editing |
| WO2018165629A1 (en) | 2017-03-10 | 2018-09-13 | President And Fellows Of Harvard College | Cytosine to guanine base editor |
| EP3596217A1 (en) | 2017-03-14 | 2020-01-22 | Editas Medicine, Inc. | Systems and methods for the treatment of hemoglobinopathies |
| WO2018170436A1 (en) | 2017-03-16 | 2018-09-20 | Jacobs Farm Del Cabo | Basil with high tolerance to downy mildew |
| KR20190130613A (ko) | 2017-03-23 | 2019-11-22 | 프레지던트 앤드 펠로우즈 오브 하바드 칼리지 | 핵산 프로그램가능한 dna 결합 단백질을 포함하는 핵염기 편집제 |
| US10876101B2 (en) | 2017-03-28 | 2020-12-29 | Locanabio, Inc. | CRISPR-associated (Cas) protein |
| WO2018195545A2 (en) | 2017-04-21 | 2018-10-25 | The General Hospital Corporation | Variants of cpf1 (cas12a) with altered pam specificity |
| EP3615672A1 (en) | 2017-04-28 | 2020-03-04 | Editas Medicine, Inc. | Methods and systems for analyzing guide rna molecules |
| WO2018209158A2 (en) | 2017-05-10 | 2018-11-15 | Editas Medicine, Inc. | Crispr/rna-guided nuclease systems and methods |
| US11560566B2 (en) | 2017-05-12 | 2023-01-24 | President And Fellows Of Harvard College | Aptazyme-embedded guide RNAs for use with CRISPR-Cas9 in genome editing and transcriptional activation |
| EP3630198A4 (en) | 2017-05-25 | 2021-04-21 | The General Hospital Corporation | USE OF CLIVED DESAMINASES TO LIMIT UNWANTED OUT-OF-TARGET DESAMINATION FROM BASE EDITING |
| MX2019014497A (es) | 2017-06-08 | 2020-10-12 | Univ Osaka | Metodo para producir celula eucariota de adn editado, y kit usado en el mismo. |
| CN110997908A (zh) | 2017-06-09 | 2020-04-10 | 爱迪塔斯医药公司 | 工程化的cas9核酸酶 |
| MX2019015188A (es) | 2017-06-15 | 2020-08-03 | Univ California | Inserciones de adn no virales orientadas. |
| KR20200018572A (ko) | 2017-06-20 | 2020-02-19 | 지앙수 헨그루이 메디슨 컴퍼니 리미티드 | 시험관 내에서 T 세포 내 표적 유전자를 녹아웃시키는 방법 및 그 방법에 이용되는 crRNA |
| WO2019006418A2 (en) | 2017-06-30 | 2019-01-03 | Intima Bioscience, Inc. | ADENO-ASSOCIATED VIRAL VECTORS FOR GENE THERAPY |
| WO2019014564A1 (en) | 2017-07-14 | 2019-01-17 | Editas Medicine, Inc. | SYSTEMS AND METHODS OF TARGETED INTEGRATION AND GENOME EDITING AND DETECTION THEREOF WITH INTEGRATED PRIMING SITES |
| JP7249323B2 (ja) | 2017-07-26 | 2023-03-30 | オンコラス, インコーポレイテッド | 腫瘍溶解性ウイルスベクター及びその使用 |
| JP2020534795A (ja) | 2017-07-28 | 2020-12-03 | プレジデント アンド フェローズ オブ ハーバード カレッジ | ファージによって支援される連続的進化(pace)を用いて塩基編集因子を進化させるための方法および組成物 |
| BR112020003439A2 (pt) | 2017-08-21 | 2020-08-25 | Tokushima University | tecnologia de alteração específica de sequência alvo usando o reconhecimento alvo nucleotídico |
| WO2019040650A1 (en) | 2017-08-23 | 2019-02-28 | The General Hospital Corporation | GENETICALLY MODIFIED CRISPR-CAS9 NUCLEASES HAVING MODIFIED PAM SPECIFICITY |
| WO2019139645A2 (en) | 2017-08-30 | 2019-07-18 | President And Fellows Of Harvard College | High efficiency base editors comprising gam |
| US11252928B2 (en) | 2017-09-21 | 2022-02-22 | The Condard-Pyle Company | Miniature rose plant named ‘Meibenbino’ |
| US11917978B2 (en) | 2017-09-21 | 2024-03-05 | The Conard Pyle Company | Miniature rose plant named ‘meibenbino’ |
| EP3694993A4 (en) | 2017-10-11 | 2021-10-13 | The General Hospital Corporation | METHOD OF DETECTING A SITE-SPECIFIC AND UNDESIRED GENOMIC DESAMINATION INDUCED BY BASE EDITING TECHNOLOGIES |
| EP3697906A1 (en) | 2017-10-16 | 2020-08-26 | The Broad Institute, Inc. | Uses of adenosine base editors |
| MX2020004325A (es) | 2017-10-27 | 2020-11-09 | Univ California | Reemplazo dirigido de receptores de células t endógenos. |
| MX2020007466A (es) | 2018-01-12 | 2020-11-12 | Basf Se | Gen subyacente al qtl de la cantidad de espiguillas por espiga en trigo en el cromosoma 7a. |
| US20210093679A1 (en) | 2018-02-05 | 2021-04-01 | Novome Biotechnologies, Inc. | Engineered gut microbes and uses thereof |
| TW202126325A (zh) * | 2018-03-27 | 2021-07-16 | 南韓商G+Flas生命科學有限公司 | 用於治療癌症之包含引導rna及內切酶的藥學組成物 |
| CA3104989A1 (en) | 2018-03-27 | 2019-10-03 | G+Flas Life Sciences | Sequence-specific in vivo cell targeting |
| JP7422128B2 (ja) * | 2018-04-03 | 2024-01-25 | ジーフラス ライフ サイエンシズ,インク. | 配列特異的なインビボ細胞標的化 |
| CA3097044A1 (en) | 2018-04-17 | 2019-10-24 | The General Hospital Corporation | Sensitive in vitro assays for substrate preferences and sites of nucleic acid binding, modifying, and cleaving agents |
| WO2019222545A1 (en) | 2018-05-16 | 2019-11-21 | Synthego Corporation | Methods and systems for guide rna design and use |
| FR3082208A1 (fr) * | 2018-06-11 | 2019-12-13 | Fondation Mediterranee Infection | Methode de modification d'une sequence cible d'acide nucleique d'une cellule hote |
| US20210102183A1 (en) * | 2018-06-13 | 2021-04-08 | Caribou Biosciences, Inc. | Engineered cascade components and cascade complexes |
| EP3601574A4 (en) * | 2018-06-13 | 2020-03-18 | Caribou Biosciences, Inc. | TECHNICAL CASCADE COMPONENTS AND CASCADE COMPLEXES |
| US10227576B1 (en) * | 2018-06-13 | 2019-03-12 | Caribou Biosciences, Inc. | Engineered cascade components and cascade complexes |
| US20220315920A1 (en) * | 2018-06-21 | 2022-10-06 | Cornell Universtiy | Type i crispr system as a tool for genome editing |
| EP3844273A1 (en) | 2018-08-29 | 2021-07-07 | Amyris, Inc. | Cells and methods for selection based assay |
| GB201815820D0 (en) | 2018-09-28 | 2018-11-14 | Univ Wageningen | Off-target activity inhibitors for guided endonucleases |
| US10711267B2 (en) | 2018-10-01 | 2020-07-14 | North Carolina State University | Recombinant type I CRISPR-Cas system |
| US20220177943A1 (en) * | 2018-10-01 | 2022-06-09 | Rodolphe Barrangou | Recombinant type i crispr-cas system and uses thereof for screening for variant cells |
| WO2020092725A1 (en) * | 2018-11-01 | 2020-05-07 | Montana State University | Gene modulation with crispr system type i |
| EP3877517A4 (en) * | 2018-11-09 | 2022-09-07 | Inari Agriculture, Inc. | RNA-DRIVEN NUCLEASES AND DNA-BINDING PROTEINS |
| CA3117228A1 (en) | 2018-12-14 | 2020-06-18 | Pioneer Hi-Bred International, Inc. | Novel crispr-cas systems for genome editing |
| WO2020163396A1 (en) | 2019-02-04 | 2020-08-13 | The General Hospital Corporation | Adenine dna base editor variants with reduced off-target rna editing |
| WO2020176389A1 (en) | 2019-02-25 | 2020-09-03 | Caribou Biosciences, Inc. | Plasmids for gene editing |
| EP3942042A1 (en) | 2019-03-19 | 2022-01-26 | The Broad Institute, Inc. | Methods and compositions for editing nucleotide sequences |
| JP7426120B2 (ja) | 2019-04-05 | 2024-02-01 | 国立大学法人大阪大学 | ノックイン細胞の作製方法 |
| CN110438142A (zh) * | 2019-05-13 | 2019-11-12 | 安徽大学 | 一种基于I-B-Svi型CRISPR-Cas系统中SviCas5-6-7的转录调控方法 |
| WO2021092210A1 (en) * | 2019-11-06 | 2021-05-14 | Locus Biosciences, Inc. | Phage compositions comprising crispr-cas systems and methods of use thereof |
| WO2021138288A1 (en) * | 2019-12-31 | 2021-07-08 | Inari Agriculture, Inc. | Delivery of biological molecules to plant cells |
| WO2021149829A1 (ja) * | 2020-01-24 | 2021-07-29 | C4U株式会社 | 試料中の特定のdnaを検出する方法 |
| KR20230019843A (ko) | 2020-05-08 | 2023-02-09 | 더 브로드 인스티튜트, 인코퍼레이티드 | 표적 이중 가닥 뉴클레오티드 서열의 두 가닥의 동시 편집을 위한 방법 및 조성물 |
| CN111849978B (zh) * | 2020-06-11 | 2022-04-15 | 中山大学 | 一种基于Type I-F CRISPR/Cas的染色质成像方法和染色质成像系统 |
| CN111979240B (zh) * | 2020-06-11 | 2022-04-15 | 中山大学 | 一种基于Type I-F CRISPR/Cas的基因表达调控方法和调控系统 |
| US10894812B1 (en) | 2020-09-30 | 2021-01-19 | Alpine Roads, Inc. | Recombinant milk proteins |
| AU2021353004A1 (en) | 2020-09-30 | 2023-04-13 | Nobell Foods, Inc. | Recombinant milk proteins and food compositions comprising the same |
| US10947552B1 (en) | 2020-09-30 | 2021-03-16 | Alpine Roads, Inc. | Recombinant fusion proteins for producing milk proteins in plants |
| US11944063B2 (en) | 2020-09-30 | 2024-04-02 | Spring Meadow Nursery, Inc. | Hydrangea ‘SMNHPH’ |
| US11155884B1 (en) | 2020-10-16 | 2021-10-26 | Klemm & Sohn Gmbh & Co. Kg | Double-flowering dwarf Calibrachoa |
| EP3984355B1 (en) | 2020-10-16 | 2024-05-15 | Klemm & Sohn GmbH & Co. KG | Double-flowering dwarf calibrachoa |
| WO2022093977A1 (en) | 2020-10-30 | 2022-05-05 | Fortiphyte, Inc. | Pathogen resistance in plants |
| JP2023548979A (ja) | 2020-11-10 | 2023-11-21 | インダストリアル マイクロブス, インコーポレイテッド | 供給原料からポリ(hiba)を産生可能な微生物 |
| US20240102007A1 (en) | 2021-06-01 | 2024-03-28 | Arbor Biotechnologies, Inc. | Gene editing systems comprising a crispr nuclease and uses thereof |
| CA3231249A1 (en) * | 2021-09-09 | 2023-03-16 | Hedia MAAMAR | Coronavirus rapid diagnostics |
| CA3230927A1 (en) | 2021-09-10 | 2023-03-16 | Agilent Technologies, Inc. | Guide rnas with chemical modification for prime editing |
| US20230279442A1 (en) | 2021-12-15 | 2023-09-07 | Versitech Limited | Engineered cas9-nucleases and method of use thereof |
| CN115851664B (zh) * | 2022-09-19 | 2023-08-25 | 中国药科大学 | 一种I-B型CRISPR-Cascade-Cas3基因编辑系统及应用 |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN101426931A (zh) * | 2004-04-07 | 2009-05-06 | 安克塞斯生物公司 | 核酸检测系统 |
| CN101802216A (zh) * | 2007-04-05 | 2010-08-11 | 强生研究有限公司 | 核酸酶和复合体及其使用方法 |
Family Cites Families (122)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5034506A (en) | 1985-03-15 | 1991-07-23 | Anti-Gene Development Group | Uncharged morpholino-based polymers having achiral intersubunit linkages |
| WO1988008450A1 (en) | 1987-05-01 | 1988-11-03 | Birdwell Finlayson | Gene therapy for metabolite disorders |
| US5350689A (en) | 1987-05-20 | 1994-09-27 | Ciba-Geigy Corporation | Zea mays plants and transgenic Zea mays plants regenerated from protoplasts or protoplast-derived cells |
| US5767367A (en) | 1990-06-23 | 1998-06-16 | Hoechst Aktiengesellschaft | Zea mays (L.) with capability of long term, highly efficient plant regeneration including fertile transgenic maize plants having a heterologous gene, and their preparation |
| US5489677A (en) | 1990-07-27 | 1996-02-06 | Isis Pharmaceuticals, Inc. | Oligonucleoside linkages containing adjacent oxygen and nitrogen atoms |
| US5602240A (en) | 1990-07-27 | 1997-02-11 | Ciba Geigy Ag. | Backbone modified oligonucleotide analogs |
| FR2688514A1 (fr) | 1992-03-16 | 1993-09-17 | Centre Nat Rech Scient | Adenovirus recombinants defectifs exprimant des cytokines et medicaments antitumoraux les contenant. |
| US5625048A (en) | 1994-11-10 | 1997-04-29 | The Regents Of The University Of California | Modified green fluorescent proteins |
| US5968738A (en) | 1995-12-06 | 1999-10-19 | The Board Of Trustees Of The Leland Stanford Junior University | Two-reporter FACS analysis of mammalian cells using green fluorescent proteins |
| US20020182673A1 (en) | 1998-05-15 | 2002-12-05 | Genentech, Inc. | IL-17 homologous polypedies and therapeutic uses thereof |
| US6306610B1 (en) | 1998-09-18 | 2001-10-23 | Massachusetts Institute Of Technology | Biological applications of quantum dots |
| WO2000046386A2 (en) | 1999-02-03 | 2000-08-10 | The Children's Medical Center Corporation | Gene repair involving the induction of double-stranded dna cleavage at a chromosomal target site |
| CA2396058C (en) | 1999-12-28 | 2009-09-15 | Ribonomics, Inc. | Methods for isolating and characterizing endogenous mrna-protein (mrnp) complexes |
| WO2002026967A2 (en) | 2000-09-25 | 2002-04-04 | Thomas Jefferson University | Targeted gene correction by single-stranded oligodeoxynucleotides |
| EP2277894A1 (en) | 2000-10-27 | 2011-01-26 | Novartis Vaccines and Diagnostics S.r.l. | Nucleic acids and proteins from streptococcus groups A & B |
| US20060253913A1 (en) | 2001-12-21 | 2006-11-09 | Yue-Jin Huang | Production of hSA-linked butyrylcholinesterases in transgenic mammals |
| JP4968498B2 (ja) | 2002-01-23 | 2012-07-04 | ユニバーシティ オブ ユタ リサーチ ファウンデーション | ジンクフィンガーヌクレアーゼを用いる、標的化された染色体変異誘発 |
| EP2368982A3 (en) | 2002-03-21 | 2011-10-12 | Sangamo BioSciences, Inc. | Methods and compositions for using zinc finger endonucleases to enhance homologous recombination |
| AU2003224897A1 (en) | 2002-04-09 | 2003-10-27 | Kenneth L. Beattie | Oligonucleotide probes for genosensor chips |
| JP2006502748A (ja) | 2002-09-05 | 2006-01-26 | カリフォルニア インスティテュート オブ テクノロジー | 遺伝子ターゲッティングを誘発するキメラヌクレアーゼの使用方法 |
| US20120196370A1 (en) | 2010-12-03 | 2012-08-02 | Fyodor Urnov | Methods and compositions for targeted genomic deletion |
| US7972854B2 (en) | 2004-02-05 | 2011-07-05 | Sangamo Biosciences, Inc. | Methods and compositions for targeted cleavage and recombination |
| US7919277B2 (en) | 2004-04-28 | 2011-04-05 | Danisco A/S | Detection and typing of bacterial strains |
| US7892224B2 (en) | 2005-06-01 | 2011-02-22 | Brainlab Ag | Inverse catheter planning |
| CA2615532C (en) | 2005-07-26 | 2016-06-28 | Sangamo Biosciences, Inc. | Targeted integration and expression of exogenous nucleic acid sequences |
| DK2325332T3 (da) | 2005-08-26 | 2013-01-28 | Dupont Nutrition Biosci Aps | Anvendelse af CRISPR-associerede gener (CAS) |
| ATE513053T1 (de) | 2006-05-10 | 2011-07-15 | Deinove Sa | Verfahren zur chromosomenmanipulation unter verwendung eines neuen dna-reparatursystems |
| PL2018441T3 (pl) | 2006-05-19 | 2012-03-30 | Dupont Nutrition Biosci Aps | Mikroorganizmy znakowane i sposoby znakowania |
| WO2007139982A2 (en) | 2006-05-25 | 2007-12-06 | Sangamo Biosciences, Inc. | Methods and compositions for gene inactivation |
| US20100034924A1 (en) | 2006-06-16 | 2010-02-11 | Christophe Fremaux | Bacterium |
| EP2518155B1 (en) | 2006-08-04 | 2014-07-23 | Georgia State University Research Foundation, Inc. | Enzyme sensors, methods for preparing and using such sensors, and methods of detecting protease activity |
| EP2489275B1 (en) | 2007-03-02 | 2016-09-21 | DuPont Nutrition Biosciences ApS | CRISPR escape phage mutants |
| FR2925918A1 (fr) | 2007-12-28 | 2009-07-03 | Pasteur Institut | Typage et sous-typage moleculaire de salmonella par identification des sequences nucleotidiques variables des loci crispr |
| US8546553B2 (en) | 2008-07-25 | 2013-10-01 | University Of Georgia Research Foundation, Inc. | Prokaryotic RNAi-like system and methods of use |
| EP2313515B1 (en) | 2008-08-22 | 2015-03-04 | Sangamo BioSciences, Inc. | Methods and compositions for targeted single-stranded cleavage and targeted integration |
| ES2738980T3 (es) | 2008-09-15 | 2020-01-28 | Childrens Medical Ct Corp | Modulación de BCL11A para el tratamiento de hemoglobinopatías |
| US20100076057A1 (en) * | 2008-09-23 | 2010-03-25 | Northwestern University | TARGET DNA INTERFERENCE WITH crRNA |
| US9404098B2 (en) | 2008-11-06 | 2016-08-02 | University Of Georgia Research Foundation, Inc. | Method for cleaving a target RNA using a Cas6 polypeptide |
| US10662227B2 (en) | 2008-11-07 | 2020-05-26 | Dupont Nutrition Biosciences Aps | Bifidobacteria CRISPR sequences |
| CN102264895B (zh) | 2008-12-12 | 2015-01-28 | 杜邦营养生物科学有限公司 | 用于乳品发酵的具有独特流变性质的嗜热链球菌菌株的遗传簇 |
| WO2010075424A2 (en) | 2008-12-22 | 2010-07-01 | The Regents Of University Of California | Compositions and methods for downregulating prokaryotic genes |
| EP2419511B1 (en) | 2009-04-09 | 2018-01-17 | Sangamo Therapeutics, Inc. | Targeted integration into stem cells |
| LT2424571T (lt) | 2009-04-30 | 2020-08-10 | Ospedale San Raffaele S.R.L. | Genų vektorius |
| KR20100133319A (ko) | 2009-06-11 | 2010-12-21 | 주식회사 툴젠 | 표적 특이적인 게놈의 재배열을 위한 표적 특이적 뉴클레아제 및 이의 용도 |
| US20120192298A1 (en) | 2009-07-24 | 2012-07-26 | Sigma Aldrich Co. Llc | Method for genome editing |
| KR20120097483A (ko) | 2009-07-24 | 2012-09-04 | 시그마-알드리치 컴퍼니., 엘엘씨 | 게놈 편집을 위한 방법 |
| AU2010281705B2 (en) | 2009-07-28 | 2015-02-05 | Sangamo Therapeutics, Inc. | Methods and compositions for treating trinucleotide repeat disorders |
| KR20120038020A (ko) | 2009-08-11 | 2012-04-20 | 상가모 바이오사이언스 인코포레이티드 | 표적화 변형에 대한 동형접합성 유기체 |
| DK2292731T3 (en) | 2009-08-13 | 2018-07-23 | Dupont Nutrition Biosci Aps | Process for producing complex cultures |
| US9371537B2 (en) | 2009-09-25 | 2016-06-21 | Basf Plant Science Company Gmbh | Plants having enhanced yield-related traits resulted from modulated expression of a SGT1 polypeptide and a method for making the same |
| GB2487341A (en) | 2009-11-02 | 2012-07-18 | Nugen Technologies Inc | Compositions and methods for targeted nucleic acid sequence selection and amplification |
| US20120324603A1 (en) | 2009-11-27 | 2012-12-20 | BASF Plant Sceience Company GmbH | Chimeric Endonucleases and Uses Thereof |
| US20110294114A1 (en) | 2009-12-04 | 2011-12-01 | Cincinnati Children's Hospital Medical Center | Optimization of determinants for successful genetic correction of diseases, mediated by hematopoietic stem cells |
| EP2510096B2 (en) | 2009-12-10 | 2018-02-07 | Regents of the University of Minnesota | Tal effector-mediated dna modification |
| US20110203012A1 (en) | 2010-01-21 | 2011-08-18 | Dotson Stanton B | Methods and compositions for use of directed recombination in plant breeding |
| EP2534173B1 (en) * | 2010-02-08 | 2019-09-11 | Sangamo Therapeutics, Inc. | Engineered cleavage half-domains |
| WO2011100058A1 (en) | 2010-02-09 | 2011-08-18 | Sangamo Biosciences, Inc. | Targeted genomic modification with partially single-stranded donor molecules |
| US10087431B2 (en) | 2010-03-10 | 2018-10-02 | The Regents Of The University Of California | Methods of generating nucleic acid fragments |
| CN102971421A (zh) | 2010-04-13 | 2013-03-13 | 西格马-奥尔德里奇有限责任公司 | 产生内源标记的蛋白的方法 |
| KR101867359B1 (ko) | 2010-05-10 | 2018-07-23 | 더 리젠츠 오브 더 유니버시티 오브 캘리포니아 | 엔도리보뉴클레아제 조성물들 및 이들의 사용 방법들 |
| CA2798988C (en) | 2010-05-17 | 2020-03-10 | Sangamo Biosciences, Inc. | Tal-effector (tale) dna-binding polypeptides and uses thereof |
| EP2392208B1 (en) * | 2010-06-07 | 2016-05-04 | Helmholtz Zentrum München Deutsches Forschungszentrum für Gesundheit und Umwelt (GmbH) | Fusion proteins comprising a DNA-binding domain of a Tal effector protein and a non-specific cleavage domain of a restriction nuclease and their use |
| US20140148361A1 (en) | 2010-06-07 | 2014-05-29 | Barry L. Stoddard | Generation and Expression of Engineered I-ONUI Endonuclease and Its Homologues and Uses Thereof |
| WO2012012738A1 (en) | 2010-07-23 | 2012-01-26 | Sigma-Aldrich Co., Llc | Genome editing using targeting endonucleases and single-stranded nucleic acids |
| US9081737B2 (en) | 2010-08-02 | 2015-07-14 | Integrated Dna Technologies, Inc. | Methods for predicting stability and melting temperatures of nucleic acid duplexes |
| DK2630156T3 (en) | 2010-10-20 | 2018-12-17 | Dupont Nutrition Biosci Aps | CRISPR-CAS SEQUENCES OF LACTOCOCCUS |
| KR20120096395A (ko) | 2011-02-22 | 2012-08-30 | 주식회사 툴젠 | 뉴클레아제에 의해 유전자 변형된 세포를 농축시키는 방법 |
| EP2702160B1 (en) | 2011-04-27 | 2020-05-27 | Amyris, Inc. | Methods for genomic modification |
| US20140113376A1 (en) | 2011-06-01 | 2014-04-24 | Rotem Sorek | Compositions and methods for downregulating prokaryotic genes |
| US8927218B2 (en) | 2011-06-27 | 2015-01-06 | Flir Systems, Inc. | Methods and compositions for segregating target nucleic acid from mixed nucleic acid samples |
| IL277027B (en) | 2011-09-21 | 2022-07-01 | Sangamo Therapeutics Inc | Methods and preparations for regulating transgene expression |
| US8450107B1 (en) | 2011-11-30 | 2013-05-28 | The Broad Institute Inc. | Nucleotide-specific recognition sequences for designer TAL effectors |
| EP2790708A4 (en) | 2011-12-16 | 2015-11-04 | Targetgene Biotechnologies Ltd | COMPOSITIONS AND METHODS FOR MODIFICATION OF A PREDETERMINED TARGET NUCLEIC ACID SEQUENCE |
| GB201122458D0 (en) | 2011-12-30 | 2012-02-08 | Univ Wageningen | Modified cascade ribonucleoproteins and uses thereof |
| IN2014DN07853A (zh) | 2012-02-24 | 2015-04-24 | Hutchinson Fred Cancer Res | |
| RU2639277C2 (ru) | 2012-02-29 | 2017-12-20 | Сангамо Байосайенсиз, Инк. | Способы и составы лечения болезни хантингтона |
| US9637739B2 (en) | 2012-03-20 | 2017-05-02 | Vilnius University | RNA-directed DNA cleavage by the Cas9-crRNA complex |
| WO2013141680A1 (en) | 2012-03-20 | 2013-09-26 | Vilnius University | RNA-DIRECTED DNA CLEAVAGE BY THE Cas9-crRNA COMPLEX |
| AU2013204327B2 (en) | 2012-04-20 | 2016-09-01 | Aviagen | Cell transfection method |
| BR112014026203A2 (pt) | 2012-04-23 | 2017-07-18 | Bayer Cropscience Nv | engenharia do genoma direcionado nas plantas |
| JP6352250B2 (ja) | 2012-05-02 | 2018-07-04 | ダウ アグロサイエンシィズ エルエルシー | リンゴ酸デヒドロゲナーゼの標的改変 |
| WO2013169802A1 (en) | 2012-05-07 | 2013-11-14 | Sangamo Biosciences, Inc. | Methods and compositions for nuclease-mediated targeted integration of transgenes |
| WO2013169398A2 (en) | 2012-05-09 | 2013-11-14 | Georgia Tech Research Corporation | Systems and methods for improving nuclease specificity and activity |
| NZ728024A (en) * | 2012-05-25 | 2019-05-31 | Univ California | Methods and compositions for rna-directed target dna modification and for rna-directed modulation of transcription |
| CA2876860A1 (en) | 2012-05-30 | 2013-12-05 | Baylor College Of Medicine | Supercoiled minivectors as a tool for dna repair, alteration and replacement |
| US9102936B2 (en) | 2012-06-11 | 2015-08-11 | Agilent Technologies, Inc. | Method of adaptor-dimer subtraction using a CRISPR CAS6 protein |
| MX2014015204A (es) | 2012-06-12 | 2015-08-07 | Genentech Inc | Metodos y composiciones para generar alelos con inactivacion condicional. |
| EP2674501A1 (en) | 2012-06-14 | 2013-12-18 | Agence nationale de sécurité sanitaire de l'alimentation,de l'environnement et du travail | Method for detecting and identifying enterohemorrhagic Escherichia coli |
| WO2013188638A2 (en) | 2012-06-15 | 2013-12-19 | The Regents Of The University Of California | Endoribonucleases and methods of use thereof |
| CA2877290A1 (en) | 2012-06-19 | 2013-12-27 | Daniel F. Voytas | Gene targeting in plants using dna viruses |
| DK3444342T3 (da) | 2012-07-11 | 2020-08-24 | Sangamo Therapeutics Inc | Fremgangsmåder og sammensætninger til behandlingen af lysosomale aflejringssygdomme |
| US10883119B2 (en) | 2012-07-11 | 2021-01-05 | Sangamo Therapeutics, Inc. | Methods and compositions for delivery of biologics |
| KR20230065381A (ko) | 2012-07-25 | 2023-05-11 | 더 브로드 인스티튜트, 인코퍼레이티드 | 유도 dna 결합 단백질 및 게놈 교란 도구 및 이의 적용 |
| EP2890780B8 (en) | 2012-08-29 | 2020-08-19 | Sangamo Therapeutics, Inc. | Methods and compositions for treatment of a genetic condition |
| UA119135C2 (uk) | 2012-09-07 | 2019-05-10 | ДАУ АГРОСАЙЄНСІЗ ЕлЕлСі | Спосіб отримання трансгенної рослини |
| UA118090C2 (uk) | 2012-09-07 | 2018-11-26 | ДАУ АГРОСАЙЄНСІЗ ЕлЕлСі | Спосіб інтегрування послідовності нуклеїнової кислоти, що представляє інтерес, у ген fad2 у клітині сої та специфічний для локусу fad2 білок, що зв'язується, здатний індукувати спрямований розрив |
| US9914930B2 (en) | 2012-09-07 | 2018-03-13 | Dow Agrosciences Llc | FAD3 performance loci and corresponding target site specific binding proteins capable of inducing targeted breaks |
| EP2906602B1 (en) | 2012-10-12 | 2019-01-16 | The General Hospital Corporation | Transcription activator-like effector (tale) - lysine-specific demethylase 1 (lsd1) fusion proteins |
| EP3346003B1 (en) | 2012-10-23 | 2021-06-09 | Toolgen Incorporated | Composition for cleaving a target dna comprising a guide rna specific for the target dna and cas protein-encoding nucleic acid or cas protein, and use thereof |
| KR20150100651A (ko) | 2012-10-30 | 2015-09-02 | 리컴비네틱스 인코포레이티드 | 동물의 성적 성숙 조절 |
| CA2890160A1 (en) | 2012-10-31 | 2014-05-08 | Cellectis | Coupling herbicide resistance with targeted insertion of transgenes in plants |
| US20140127752A1 (en) | 2012-11-07 | 2014-05-08 | Zhaohui Zhou | Method, composition, and reagent kit for targeted genomic enrichment |
| WO2014089290A1 (en) * | 2012-12-06 | 2014-06-12 | Sigma-Aldrich Co. Llc | Crispr-based genome modification and regulation |
| WO2014093694A1 (en) | 2012-12-12 | 2014-06-19 | The Broad Institute, Inc. | Crispr-cas nickase systems, methods and compositions for sequence manipulation in eukaryotes |
| PL2771468T3 (pl) | 2012-12-12 | 2015-07-31 | Broad Inst Inc | Inżynieria systemów, metod i zoptymalizowanych kompozycji kierujących dla manipulacji sekwencjami |
| DK2898075T3 (en) | 2012-12-12 | 2016-06-27 | Broad Inst Inc | CONSTRUCTION AND OPTIMIZATION OF IMPROVED SYSTEMS, PROCEDURES AND ENZYME COMPOSITIONS FOR SEQUENCE MANIPULATION |
| EP2940140B1 (en) | 2012-12-12 | 2019-03-27 | The Broad Institute, Inc. | Engineering of systems, methods and optimized guide compositions for sequence manipulation |
| EP2840140B2 (en) | 2012-12-12 | 2023-02-22 | The Broad Institute, Inc. | Crispr-Cas based method for mutation of prokaryotic cells |
| EP2931899A1 (en) | 2012-12-12 | 2015-10-21 | The Broad Institute, Inc. | Functional genomics using crispr-cas systems, compositions, methods, knock out libraries and applications thereof |
| DK2931898T3 (en) | 2012-12-12 | 2016-06-20 | Massachusetts Inst Technology | CONSTRUCTION AND OPTIMIZATION OF SYSTEMS, PROCEDURES AND COMPOSITIONS FOR SEQUENCE MANIPULATION WITH FUNCTIONAL DOMAINS |
| EP3434776A1 (en) | 2012-12-12 | 2019-01-30 | The Broad Institute, Inc. | Methods, models, systems, and apparatus for identifying target sequences for cas enzymes or crispr-cas systems for target sequences and conveying results thereof |
| US8697359B1 (en) | 2012-12-12 | 2014-04-15 | The Broad Institute, Inc. | CRISPR-Cas systems and methods for altering expression of gene products |
| IL293526A (en) | 2012-12-12 | 2022-08-01 | Harvard College | Providing, engineering and optimizing systems, methods and compositions for sequence manipulation and therapeutic applications |
| WO2014099750A2 (en) | 2012-12-17 | 2014-06-26 | President And Fellows Of Harvard College | Rna-guided human genome engineering |
| DK3491915T3 (da) | 2012-12-27 | 2023-08-28 | Keygene Nv | Fremgangsmåde til at inducere en målrettet translokation i en plante |
| CN104995302B (zh) | 2013-01-16 | 2021-08-31 | 爱默蕾大学 | Cas9-核酸复合物及其相关用途 |
| CN103233028B (zh) | 2013-01-25 | 2015-05-13 | 南京徇齐生物技术有限公司 | 一种无物种限制无生物安全性问题的真核生物基因打靶方法及螺旋结构dna序列 |
| KR102405549B1 (ko) * | 2013-03-15 | 2022-06-08 | 더 제너럴 하스피탈 코포레이션 | Rna-안내 게놈 편집을 위해 특이성을 증가시키기 위한 절단된 안내 rna(tru-grnas)의 이용 |
| CN103224947B (zh) | 2013-04-28 | 2015-06-10 | 陕西师范大学 | 一种基因打靶系统 |
| KR102551324B1 (ko) * | 2013-06-05 | 2023-07-05 | 듀크 유니버시티 | Rna-가이드 유전자 편집 및 유전자 조절 |
| CN103343120B (zh) | 2013-07-04 | 2015-03-04 | 中国科学院遗传与发育生物学研究所 | 一种小麦基因组定点改造方法 |
| US10227576B1 (en) * | 2018-06-13 | 2019-03-12 | Caribou Biosciences, Inc. | Engineered cascade components and cascade complexes |
-
2011
- 2011-12-30 GB GB201122458A patent/GB201122458D0/en not_active Ceased
-
2012
- 2012-12-21 CN CN201280071058.4A patent/CN104321429A/zh active Pending
- 2012-12-21 DK DK16169431.0T patent/DK3091072T3/en active
- 2012-12-21 AU AU2012360975A patent/AU2012360975B2/en active Active
- 2012-12-21 IN IN5937DEN2014 patent/IN2014DN05937A/en unknown
- 2012-12-21 EP EP16169431.0A patent/EP3091072B1/en active Active
- 2012-12-21 EP EP12812999.6A patent/EP2798060A1/en not_active Withdrawn
- 2012-12-21 ES ES16169431.0T patent/ES2689256T3/es active Active
- 2012-12-21 DE DE212012000234.0U patent/DE212012000234U1/de not_active Expired - Lifetime
- 2012-12-21 US US14/240,735 patent/US20140294773A1/en not_active Abandoned
- 2012-12-21 LT LTEP16169431.0T patent/LT3091072T/lt unknown
- 2012-12-21 WO PCT/EP2012/076674 patent/WO2013098244A1/en active Application Filing
- 2012-12-21 PL PL16169431T patent/PL3091072T3/pl unknown
- 2012-12-21 KR KR1020147021336A patent/KR101889589B1/ko active IP Right Grant
- 2012-12-21 CA CA2862018A patent/CA2862018C/en active Active
- 2012-12-21 CN CN201610081216.4A patent/CN105732816B/zh active Active
- 2012-12-21 JP JP2014549450A patent/JP6408914B2/ja active Active
- 2012-12-21 GB GB1411878.0A patent/GB2512246B/en active Active
- 2012-12-21 RS RS20180906A patent/RS57604B1/sr unknown
- 2012-12-21 SG SG11201403713QA patent/SG11201403713QA/en unknown
- 2012-12-21 BR BR112014016228-0A patent/BR112014016228B1/pt active IP Right Grant
- 2012-12-21 PT PT161694310T patent/PT3091072T/pt unknown
- 2012-12-21 HU HUE16169431A patent/HUE039617T2/hu unknown
- 2012-12-21 SI SI201231344T patent/SI3091072T1/sl unknown
- 2012-12-21 RU RU2014127702A patent/RU2014127702A/ru not_active Application Discontinuation
- 2012-12-21 GB GB1605069.2A patent/GB2534074A/en not_active Withdrawn
- 2012-12-21 MX MX2014007910A patent/MX364830B/es active IP Right Grant
-
2014
- 2014-06-26 IL IL233399A patent/IL233399A0/en active IP Right Grant
- 2014-07-08 US US14/326,099 patent/US20150024499A1/en not_active Abandoned
-
2016
- 2016-01-15 US US14/997,467 patent/US20160186152A1/en not_active Abandoned
- 2016-01-15 US US14/997,474 patent/US9885026B2/en active Active
-
2017
- 2017-11-02 US US15/802,413 patent/US10435678B2/en active Active
-
2018
- 2018-07-23 HR HRP20181150TT patent/HRP20181150T1/hr unknown
- 2018-08-01 CY CY20181100802T patent/CY1120538T1/el unknown
-
2019
- 2019-08-28 US US16/554,225 patent/US10711257B2/en active Active
-
2020
- 2020-06-26 US US16/914,203 patent/US10954498B2/en active Active
-
2021
- 2021-02-18 US US17/179,215 patent/US11939604B2/en active Active
-
2024
- 2024-01-25 US US18/422,843 patent/US20240174998A1/en active Pending
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN101426931A (zh) * | 2004-04-07 | 2009-05-06 | 安克塞斯生物公司 | 核酸检测系统 |
| CN101802216A (zh) * | 2007-04-05 | 2010-08-11 | 强生研究有限公司 | 核酸酶和复合体及其使用方法 |
Non-Patent Citations (3)
| Title |
|---|
| CRISPR-based adaptive and heritable immunity in prokaryotes;John van der Oost等;《Trends in Biochemical Sciences》;pubmed;20090730;第34卷(第8期);摘要,第402页右栏第3-4段图2b * |
| Enhancing zinc-finger-nuclease activity with improved obligate heterodimeric architectures;Yannick Doyon等;《Nature Methods》;pubmed;20101205;第8卷(第1期);摘要,表1 * |
| John van der Oost等.CRISPR-based adaptive and heritable immunity in prokaryotes.《Trends in Biochemical Sciences》.pubmed,2009,第34卷(第8期),摘要,第402页右栏第3-4段图2b. * |
Also Published As
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11939604B2 (en) | Modified cascade ribonucleoproteins and uses thereof | |
| US11427818B2 (en) | S. pyogenes CAS9 mutant genes and polypeptides encoded by same | |
| US11913014B2 (en) | S. pyogenes Cas9 mutant genes and polypeptides encoded by same | |
| KR102647766B1 (ko) | 클래스 ii, 타입 v crispr 시스템 | |
| KR20190104344A (ko) | 열안정성 cas9 뉴클레아제 | |
| CN114410625A (zh) | 通过Cas9-crRNA复合物的RNA指导的DNA裂解 | |
| KR20240055073A (ko) | 클래스 ii, v형 crispr 시스템 | |
| EP1539945B1 (en) | Recombinant type ii restriction endonucleases, mmei and related endonucleases and methods for producing the same | |
| CN114525293B (zh) | 新型CRISPR-Cas9抑制蛋白及其改造应用于化学可控的基因编辑的方法 | |
| KR20240049306A (ko) | Ruvc 도메인을 갖는 효소 | |
| WO2022013133A1 (en) | Methods for modulating cas-effector activity | |
| GB2617659A (en) | Enzymes with RUVC domains |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| C06 | Publication | ||
| PB01 | Publication | ||
| C10 | Entry into substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| REG | Reference to a national code |
Ref country code: HK Ref legal event code: DE Ref document number: 1226741 Country of ref document: HK |
|
| GR01 | Patent grant | ||
| GR01 | Patent grant |