WO2016159213A1 - ポリペプチド異種多量体の製造方法 - Google Patents
ポリペプチド異種多量体の製造方法 Download PDFInfo
- Publication number
- WO2016159213A1 WO2016159213A1 PCT/JP2016/060616 JP2016060616W WO2016159213A1 WO 2016159213 A1 WO2016159213 A1 WO 2016159213A1 JP 2016060616 W JP2016060616 W JP 2016060616W WO 2016159213 A1 WO2016159213 A1 WO 2016159213A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- amino acid
- cys
- polypeptide
- numbering
- acid residues
- Prior art date
Links
Images

















Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/46—Hybrid immunoglobulins
- C07K16/461—Igs containing Ig-regions, -domains or -residues form different species
- C07K16/464—Igs containing CDR-residues from one specie grafted between FR-residues from another
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N33/00—Investigating or analysing materials by specific methods not covered by groups G01N1/00 - G01N31/00
- G01N33/48—Biological material, e.g. blood, urine; Haemocytometers
- G01N33/50—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2866—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against receptors for cytokines, lymphokines, interferons
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/46—Hybrid immunoglobulins
- C07K16/468—Immunoglobulins having two or more different antigen binding sites, e.g. multifunctional antibodies
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N33/00—Investigating or analysing materials by specific methods not covered by groups G01N1/00 - G01N31/00
- G01N33/15—Medicinal preparations ; Physical properties thereof, e.g. dissolubility
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N33/00—Investigating or analysing materials by specific methods not covered by groups G01N1/00 - G01N31/00
- G01N33/48—Biological material, e.g. blood, urine; Haemocytometers
- G01N33/50—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing
- G01N33/53—Immunoassay; Biospecific binding assay; Materials therefor
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/30—Immunoglobulins specific features characterized by aspects of specificity or valency
- C07K2317/31—Immunoglobulins specific features characterized by aspects of specificity or valency multispecific
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/52—Constant or Fc region; Isotype
- C07K2317/526—CH3 domain
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/52—Constant or Fc region; Isotype
- C07K2317/53—Hinge
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/55—Fab or Fab'
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/56—Immunoglobulins specific features characterized by immunoglobulin fragments variable (Fv) region, i.e. VH and/or VL
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/56—Immunoglobulins specific features characterized by immunoglobulin fragments variable (Fv) region, i.e. VH and/or VL
- C07K2317/565—Complementarity determining region [CDR]
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/60—Immunoglobulins specific features characterized by non-natural combinations of immunoglobulin fragments
- C07K2317/62—Immunoglobulins specific features characterized by non-natural combinations of immunoglobulin fragments comprising only variable region components
- C07K2317/624—Disulfide-stabilized antibody (dsFv)
Definitions
- the present invention relates to a method for producing a polypeptide heteromultimer, a polypeptide heteromultimer in which amino acids in a heavy chain constant region are modified so that heterogeneity of the polypeptide is promoted, and the like.
- Non-patent Documents 1 and 2 there are bispecific antibodies capable of simultaneously recognizing two kinds of antigens or epitopes, and these are expected to have high target specificity and a function of simultaneously inhibiting a plurality of pathways.
- Catamaxomab already on the market is a bispecific antibody that binds to the epithelial cell adhesion factor EpCAM and CD3 expressed on T cells, and is used as a therapeutic agent for malignant ascites.
- Non-patent document 3 For example, when introducing a total of four genes, H chain and L chain genes that constitute IgG with two variable regions, into a cell and secreting it by co-expression, two types of H chain covalent bonds and H chains Since the non-covalent bond between the L chain and the L chain occurs randomly, the ratio of the target bispecific antibody is extremely small, and the production efficiency is significantly reduced.
- Patent Document 2 A method for introducing different charges into the CH3 region of each IgG ⁇ H chain has also been reported (Patent Document 2). Specifically, by substituting an amino acid present in the CH3 region of one H chain with an amino acid having a positive charge, and substituting an amino acid present in the CH3 region of the other H chain with an amino acid having a negative charge, It is a method that causes the promotion of heterogeneous H chain formation and the inhibition of homologous H chain formation. On the other hand, a technique for controlling the combination of H chain and L chain has also been reported (Non-patent Document 6). This technique is a technique that efficiently induces the desired combination of H chain and L chain by using one Fab of the antibody with the light chain constant region (CL) and H chain CH1 region replaced.
- Non-patent Document 6 This technique is a technique that efficiently induces the desired combination of H chain and L chain by using one Fab of the antibody with the light chain constant region (CL) and H chain CH1 region replaced.
- bispecific antibodies can be formed with high efficiency by combining heterogeneous H chain formation technology and H chain L chain combination control technology. However, it is difficult to completely control the combination of H chain and L chain, resulting in a complicated molecular design. There is also a problem that it is difficult to maintain high affinity for two types of antigens with a common L chain.
- Fab-Arm-Exchange has been reported as a method for producing bispecific antibodies using monoclonal antibodies prepared separately in advance, instead of the genetic recombination method as described above.
- This is a technology developed based on the knowledge that non-patent document 7 that IgG4 is exchanged with endogenous IgG4 in vivo to produce Bispecific antibody.
- By mixing two kinds of IgG4 in vitro It has been reported that bispecific antibodies are produced (Patent Document 3), and that the reaction occurs more efficiently under reducing conditions (Non-Patent Document 8).
- the amino acid residues important for this reaction were identified at the 228th position of the hinge region characteristic of IgG4 and the 409th position of the CH3 region.
- Patent Document 4 Fab Arm Exchange is highly versatile because the desired bispecific antibody can be obtained simply by mixing monoclonal antibodies prepared by a general method in vitro. However, since the half-molecule exchange reaction occurs randomly, the bispecific antibody obtained by mixing two kinds of antibodies theoretically represents 50% of the total antibody amount present in the system. Therefore, a method to improve the bispecific antibody production rate was examined, and asymmetric amino acid modifications were introduced into the two types of antibodies, that is, K409R modification was introduced into one H chain, and F405L was introduced into the other H chain. It has been reported that the reaction efficiency is greatly improved (Patent Document 5, Non-Patent Documents 9 and 10).
- the present invention has been made in view of such a situation, and its object is to promote heterogeneity of a polypeptide under reducing conditions for the efficient and stable production of heterologous multimers and to produce a desired heterologous. It is to provide an excellent technique with higher reaction efficiency for obtaining multimers.
- the present inventors selected a polypeptide having a heavy chain constant region as a polypeptide to be subjected to a heteromultimer, and conducted earnest research on a method for controlling dissociation and association between the heavy chain constant regions.
- a specific amino acid present in the heavy chain constant region By substituting a specific amino acid present in the heavy chain constant region, the dissociation of the heavy chain constant region can be promoted and the association can be controlled under the reduction condition, which is more efficient than the conventional technique.
- a heteromolecule of the inventors discovered a method of forming a stable heteromolecule by eliminating disulfide bonds in the core hinge region formed by general antibodies and forming disulfide bonds between L chains or CH3 regions.
- the present invention is based on such knowledge, and specifically provides the following [1] to [32].
- [1] a) providing a homozygous first polypeptide having a first antigen-binding activity and comprising a heavy chain constant region; b) providing a homologue of a second polypeptide having a second antigen binding activity different from the first antigen binding activity and comprising a heavy chain constant region; c) incubating the homologue of the first polypeptide and the homologue of the second polypeptide together under reducing conditions that allow cysteines outside the core hinge region to undergo disulfide bond isomerization; And d) obtaining a heteromultimer comprising the first and second polypeptides, Amino acid residues in the core hinge region do not form disulfide bonds, A method for producing heterogeneous multimers.
- the cysteine residues at positions 131 and / or 220 by EU numbering are modified to other amino acid residues.
- the set of cysteines in the CH3 regions contained in the heavy chain constant regions of the first and second polypeptides is any one of the following (1) to (5): [7] Manufacturing method described in: (1) Amino acid residues at positions 349 and 356 by EU numbering (2) Amino acid residues at positions 394 and 394 by EU numbering (3) Amino acid residues at positions 351 and 351 by EU numbering (4) EU numbering 407 and 407 amino acid residues by (5) EU amino acid numbering 349 and 354 amino acid residues.
- the set of amino acid residues in the CH3 region of the second polypeptide has an opposite charge to the set of amino acid residues in the CH3 region of the first polypeptide; [1] The production method according to any one of [12]. [14] The production method according to [13], wherein the amino acid residue having the same type of charge is selected from one or more amino acid residues included in the following group (A) or (B): : (A) glutamic acid (E), aspartic acid (D); (B) Lysine (K), arginine (R), histidine (H).
- a set of amino acid residues having the same kind of charge in each of the first and second polypeptides is a set of any one of the following (1) to (4): ] Or the production method according to [14]: (1) Amino acid residues at positions 356 and 439 by EU numbering (2) Amino acid residues at positions 357 and 370 by EU numbering (3) Amino acid residues at positions 399 and 409 by EU numbering (4) (i ) Amino acid residues at positions 399 and 409 by EU numbering, and (ii) amino acid residues at positions 356 and 439 by EU numbering.
- [20] a) providing a homozygous first polypeptide having a first antigen-binding activity and comprising a heavy chain constant region; b) providing a homologue of a second polypeptide having a second antigen binding activity different from the first antigen binding activity and comprising a heavy chain constant region; c) obtaining a heteromultimer comprising the first and second polypeptides, A method for producing a heterogeneous multimer, The production method, wherein the heavy chain constant regions of the first and second polypeptides are modified as described in any of the following (1) to (5): (1) The first polypeptide has an amino acid residue other than Cys (C) at position 226 by EU numbering, an amino acid residue other than Cys (C) at position 229, and Cys (C) at position 349.
- EU polypeptide amino acid residue other than Cys (C) at position 226 by EU numbering, amino acid residue other than Cys (C) at position 229, and Cys (C) at position 356;
- the EU numbering position 226 is an amino acid residue other than Cys (C)
- position 229 is an amino acid residue other than Cys (C)
- position 394 is Cys (C).
- EU numbering 226 is an amino acid residue other than Cys (C)
- 229 is an amino acid residue other than Cys (C)
- 351 Cys (C).
- the EU numbering position 226 is an amino acid residue other than Cys (C)
- position 229 is an amino acid residue other than Cys (C)
- position 407 is Cys (C).
- the first polypeptide has EU numbering at position 226, an amino acid residue other than Cys (C), position 229, an amino acid residue other than Cys (C), and position 349, Cys (C).
- This polypeptide has an EU numbering of amino acid residue other than Cys (C) at position 226, amino acid residue other than Cys (C) at position 229, and Cys (C) at position 354.
- [21] a) providing a homozygous first polypeptide having a first antigen-binding activity and comprising a heavy chain constant region; b) providing a homologue of a second polypeptide having a second antigen binding activity different from the first antigen binding activity and comprising a heavy chain constant region; c) obtaining a heteromultimer comprising the first and second polypeptides, A method for producing a heterogeneous multimer, Providing in step a) an antibody light chain that is a third polypeptide that forms a multimer with the first polypeptide, and forming a multimer with the second polypeptide in step b) Providing an antibody light chain that is a fourth polypeptide; The production method, wherein the heavy chain constant regions of the first and second polypeptides are modified as described in any of the following (1) to (6): (1) The first and second polypeptides are amino acid residues other than Cys (C) at position 131 by EU numbering, amino acid residues other than Cys (C) at position
- the first and second polypeptides are deleted by amino acid residue other than Cys (C) at positions 131 and positions 219 to 229 by EU numbering; (5) The first and second polypeptides are deleted at positions 219-229 by EU numbering; (6) The first and second polypeptides are amino acid residues other than Cys (C) at position 226 by EU numbering, amino acid residues other than Cys (C) at position 229, and Tyr (Y ) -Gly (G) -Pro (P) -Pro (P).
- step c) according to [1], [20] and [21] comprises contact with a reducing agent.
- step c) comprises the addition of an agent selected from the group consisting of glutathione, L-cysteine, dithiothreitol, ⁇ -mercapto-ethanol, TCEP and 2-MEA Method.
- step c) comprises the addition of an agent selected from the group consisting of glutathione, L-cysteine, dithiothreitol, ⁇ -mercapto-ethanol, TCEP and 2-MEA Method.
- step c) comprises the addition of an agent selected from the group consisting of glutathione, L-cysteine, dithiothreitol, ⁇ -mercapto-ethanol, TCEP and 2-MEA Method.
- step c) comprises the addition of an agent selected from the group consisting of glutathione, L-cysteine, dithiothreitol, ⁇ -mercapto-ethanol, TCEP and 2-MEA Method.
- step c) comprises the addition of an agent selected from the group consisting of glutathione,
- a dimer is formed by a first polypeptide that is an antibody heavy chain and a third polypeptide that is an antibody light chain, and a second polypeptide that is an antibody heavy chain and a fourth polypeptide that is an antibody light chain.
- a bispecific antibody comprising a first, second, third and fourth polypeptide as a component, which forms a dimer with the polypeptide of: In each of the CH3 regions contained in the heavy chain constant region of the first and / or second polypeptide, selected from the amino acid residues at positions 349, 351, 354, 356, 394 and 407 by EU numbering Wherein at least one amino acid residue is cysteine, Bispecific antibody.
- a dimer is formed by a first polypeptide that is an antibody heavy chain and a third polypeptide that is an antibody light chain, and a second polypeptide that is an antibody heavy chain and a fourth polypeptide that is an antibody light chain.
- a bispecific antibody comprising a first, second, third and fourth polypeptide as a component, which forms a dimer with the polypeptide of:
- Each of the first and second polypeptides has an amino acid residue represented by any one of the following (1) to (6): Bispecific antibodies: (1) The first and second polypeptides are amino acid residues other than Cys (C) at position 131 by EU numbering, amino acid residues other than Cys (C) at position 226, and positions other than Cys (C) at position 229 An amino acid residue; (2) The first and second polypeptides are amino acid residues other than Cys (C) at position 131 by EU numbering, amino acid residues other than Cys (C) at position 226, Pro (P) at position 228, 229 The position is an amino acid
- the first and second polypeptides are deleted by amino acid residue other than Cys (C) at positions 131 and positions 219 to 229 by EU numbering; (5) The first and second polypeptides are deleted at positions 219-229 by EU numbering; (6) The first and second polypeptides are amino acid residues other than Cys (C) at position 226 by EU numbering, amino acid residues other than Cys (C) at position 229, and Tyr (Y ) -Gly (G) -Pro (P) -Pro (P).
- a composition comprising the heteromultimer or bispecific antibody according to any one of [26] to [28] and a pharmaceutically acceptable carrier.
- [30] A method for producing the bispecific antibody according to [27] or [28].
- [31] A method for screening heteromultimers, wherein the following steps are further performed after step d) according to [1]: e) measuring the activity of the heteromultimer, f) selecting a heteromultimer having the desired activity.
- [32] A method for producing a heteromultimer, wherein the following step is further performed after step f) according to [31]: g) obtaining the CDR or variable region of the first polypeptide, the second polypeptide, the third polypeptide and the fourth polypeptide of the heteromultimer selected in step f) according to [31] , h) Transplanting the obtained CDR or variable region into another heterologous multimer.
- the dissociation of the heavy chain constant region can be promoted and the association can be controlled under the reduction condition, which is more efficient than the conventional technique.
- a manufacturing method was provided in which the desired heteromolecule was formed.
- the method for producing a heteromultimer according to the present invention is characterized by modifying amino acid residues in the heavy chain constant region. By introducing the modification of the amino acid residue of the present invention into these regions, dissociation and association between polypeptides are promoted, and a desired heteromultimer can be obtained more efficiently than in the prior art.
- BiAb is a purified Bispecific antibody (bispecific antibody)
- H54 homo is a monoclonal antibody having a variable region of H54 / L28
- MRA homo has a variable region of MRAH / MRAL.
- Monoclonal antibodies are shown.
- the numerical value shown as a percentage in the figure indicates the Bispecific antibody production rate, and is calculated by dividing the peak area corresponding to the Bispecific antibody by the area of all antibodies present in the system and multiplying by 100.
- FIG. 5 is a diagram showing a continuation of FIG. 5-1. It is a figure which shows the result of having analyzed the Fab * Arm * Exchange reaction product and the original homozygote in Example 3 by non-reducing polyacrylamide gel electrophoresis (SDS-PAGE).
- FIG. 7 is a diagram showing a continuation of FIG. It is a figure which shows the result of having analyzed the Fab * Arm * Exchange reaction product in Example 4 by non-reducing polyacrylamide gel electrophoresis (SDS-PAGE). It is a figure which shows the analysis result of the Fab * Arm * Exchange reaction product by the ion exchange chromatography in Example 5.
- SDS-PAGE non-reducing polyacrylamide gel electrophoresis
- FIG. 12 is a diagram showing a continuation of FIG. 12-1. It is a figure which shows the result of having analyzed the Fab * Arm * Exchange reaction product in Example 7 by non-reducing polyacrylamide gel electrophoresis (SDS-PAGE). It is a figure which shows the result of having analyzed the homozygous which becomes the origin of Fab * Arm * Exchange reaction product in Example 7 by non-reducing polyacrylamide gel electrophoresis (SDS-PAGE).
- the present invention promotes dissociation of each homozygote of a polypeptide having a first antigen-binding activity and a polypeptide having a second antigen-binding activity different from the first antigen-binding activity under reducing conditions
- the present invention relates to a method for producing a desired heteromultimer by modifying amino acid residues of a heavy chain constant region in order to control heteromerization. Furthermore, the present invention relates to a method for selecting a desired heterologous multimer.
- Polypeptide in the present invention refers to a polypeptide (heavy chain constant region-containing polypeptide) and a protein (heavy chain constant region-containing protein) containing a heavy chain constant region in the amino acid sequence.
- polypeptide which consists of a sequence designed artificially may be sufficient.
- any of natural polypeptide, synthetic polypeptide, recombinant polypeptide, etc. may be sufficient.
- fragments of the above polypeptides are also included in the polypeptides of the present invention.
- the polypeptide of the present invention may be a monomer or a multimer.
- polypeptide multimer when “polypeptide multimer” is not specified, the description of “polypeptide” is a monomer or (homologous). (Alternatively, it may exist in either a hetero) multimeric state. In the present application, the “polypeptide” or “polypeptide multimer” may be an antibody.
- antibody refers to an immunoglobulin that is naturally occurring or that has been partially or completely synthesized.
- the antibody can be isolated from natural resources such as plasma and serum in which it naturally exists, or from the culture supernatant of hybridoma cells producing the antibody, or partially or completely by using techniques such as genetic recombination Can be synthesized.
- Preferred examples of antibodies include immunoglobulin isotypes and subclasses of those isotypes.
- human immunoglobulins nine classes (isotypes) of IgG1, IgG2, IgG3, IgG4, IgA1, IgA2, IgD, IgE, and IgM are known.
- the antibody of the present invention may include IgG1, IgG2, IgG3, and IgG4 as human immunoglobulins, and IgG1, IgG2a, IgG2b, and IgG3 as mouse immunoglobulins.
- IgG1 is preferable.
- human IgG1 human IgG2, human IgG3, and human IgG4 constant regions
- sequences of proteins of immunological interest NIH Publication No.91-3242
- amino acid sequence at positions 356 to 358 represented by EU numbering may be DEL or EEM.
- the “second antigen-binding activity different from the first antigen-binding activity” is not limited to the case where the first antigen and the second antigen are different, and the first antigen and the second antigen are It is the same, but includes cases where the binding sites and epitopes are different.
- Fc region is used to define the C-terminal region of an immunoglobulin heavy chain, including the native sequence Fc region and the variant Fc region. Although the border of the Fc region of an immunoglobulin heavy chain may vary, it refers to a region consisting of the hinge region or a part thereof, CH2, and CH3 domains in an antibody molecule. Usually, a human IgG heavy chain Fc region is defined as extending from the amino acid residue at position Cys226 to the carboxyl terminus of the Fc region, but is not limited thereto.
- the Fc region of an immunoglobulin contains two constant regions, CH2 and CH3.
- the “CH2” domain of the human IgG Fc region usually extends from amino acid 231 to amino acid 340.
- the “CH3” domain extends from the carboxyl terminus in the Fc region to the CH2 region. That is, it extends from amino acid 341 of IgG to about amino acid 447.
- the Fc region can be suitably obtained by partially eluting an IgG monoclonal antibody or the like with a proteolytic enzyme such as pepsin and then re-eluting the fraction adsorbed on the protein A or protein G column.
- proteolytic enzymes are not particularly limited as long as they can digest full-length antibodies so that Fab and F (ab ') 2 can be produced in a limited manner by appropriately setting the reaction conditions of the enzyme such as pH.
- pepsin, papain, etc. can be illustrated.
- association of polypeptides can be said to refer to a state in which two or more polypeptide regions interact, for example.
- controlling the association means controlling so as to achieve a desired association state, and more specifically, an undesirable association between polypeptides (preferably, polypeptides having the same amino acid sequence). It means to control to make it difficult to form an association between peptides.
- the “interface” usually refers to an association surface at the time of association (interaction), and the amino acid residues forming the interface are usually included in the polypeptide region subjected to the association.
- One or more amino acid residues more preferably amino acid residues that are approached during the association and involved in the interaction.
- the interaction includes a case where amino acid residues approaching at the time of association form a hydrogen bond, an electrostatic interaction, a salt bridge, and the like.
- the term “homo” of a polypeptide refers to a polypeptide multimer in which polypeptides having the same amino acid sequence are associated with each other.
- the “heteroform” of the polypeptide is an association between the first polypeptide and a second polypeptide that differs in amino acid sequence from the first polypeptide by at least one amino acid residue.
- a polypeptide multimer is
- dissociation of a polypeptide refers to a state where two or more polypeptides are separated from each other into a single polypeptide in a homozygous polypeptide.
- heteromultimer cocoon refers to a polypeptide multimer composed of a plurality of types of polypeptides, which can associate with each other. More particularly, a “heterologous multimer” has at least a first polypeptide and a second polypeptide, wherein the second polypeptide is at least one amino acid sequence from the first polypeptide. Molecules with different amino acid residues.
- the heteromultimer has an antigen-binding activity for at least two different ligands, antigens, receptors, substrates, etc., but is not limited thereto, and the same ligand, antigen , A receptor, or a substrate, etc., and those having binding activity at different epitopes.
- the heterologous multimer may contain another type of polypeptide. That is, the “heterologous multimer” of the present invention is not limited to a heterodimer, and includes, for example, a heterotrimer, a heterotetramer, and the like.
- each of the first polypeptide and the second polypeptide is a third
- a multimer (dimer) can be formed with the polypeptide.
- the formed dimers can form multimers (tetramers).
- the two third polypeptides may have completely the same amino acid sequence (may have binding activity against the same antigen). Alternatively, it may have two or more activities while having the same amino acid sequence (for example, it may have binding activity to two or more different antigens).
- the third polypeptide forms a dimer with either the first polypeptide or the second polypeptide, and forms a polypeptide multimer. I can do it.
- the first polypeptide and the second polypeptide preferably have binding activity to different antigens.
- the present invention is not limited to this, and it is not limited to this. It may have a binding activity.
- the third polypeptide may be a polypeptide having a binding activity to the same antigen as either or both of the first polypeptide and the second polypeptide. Alternatively, it may be a polypeptide having a binding activity for an antigen different from the first polypeptide or the second polypeptide.
- the polypeptide multimer of the present invention can be a polypeptide multimer comprising the first polypeptide, the second polypeptide, the third polypeptide, and the fourth polypeptide.
- the first polypeptide and the second polypeptide can form a multimer (dimer) with the third polypeptide and the fourth polypeptide, respectively.
- a dimer can be formed by forming a disulfide bond between the first polypeptide and the third polypeptide, and the second polypeptide and the fourth polypeptide.
- the third polypeptide and the fourth polypeptide may be the same.
- the first polypeptide and the second polypeptide have binding activity to different antigens, but the invention is not particularly limited to this, and different sites / epitopes of the same antigen. May have binding activity.
- the third polypeptide may be a polypeptide having a binding activity to the same antigen as either or both of the first polypeptide and the second polypeptide. Alternatively, it may be a polypeptide having a binding activity for an antigen different from the first polypeptide or the second polypeptide.
- the fourth polypeptide may be a polypeptide having a binding activity to the same antigen as either the first polypeptide or the second polypeptide. Alternatively, it may be a polypeptide having a binding activity for an antigen different from the first polypeptide or the second polypeptide.
- the third polypeptide and the fourth polypeptide may be the same.
- the “heterologous multimer” in the present invention is a bispecific antibody
- the first polypeptide and the second polypeptide each contain an antibody heavy chain amino acid sequence against antigen A, against antigen B.
- the third polypeptide is a polypeptide comprising the antibody light chain amino acid sequence for antigen A
- the fourth polypeptide is the antibody light chain amino acid sequence for antigen B. It can be a polypeptide comprising. Note that the third polypeptide and the fourth polypeptide may be the same.
- the “polypeptide having an antigen-binding activity” refers to a protein or peptide such as an antigen or a ligand, such as a variable region of an antibody heavy chain or light chain, a receptor, a fusion peptide of a receptor and an Fc region, Scaffold, or a fragment thereof.
- any polypeptide can be used as long as it is a conformationally stable polypeptide capable of binding to at least one antigen.
- polypeptides include antibody variable region fragments, fibronectin, protein A domain, LDL receptor A domain, lipocalin, etc., as well as Nygren et al. (Current Opinion in Structural Biology, 7: 463-469 (1997), Journal of Immunol Methods, 290: 3-28 (2004)), Binz et al. (Nature Biotech 23: 1257-1266 (2005)), Hosse et al. (Protein Science 15: 14-27 (2006)). However, it is not limited to these.
- Antibody variable regions, receptors, fusion peptides of receptors and Fc regions, Scaffold and methods for obtaining these fragments are well known to those skilled in the art.
- a polypeptide comprising the amino acid sequence of the heavy chain constant region and the amino acid sequence of the light chain constant region can also be used.
- reducing conditions refers to a cysteine residue that forms an inter-heavy chain disulfide bond in the heavy chain hinge region, a cysteine residue that forms an inter-light chain disulfide bond, or a disulfide bond between CH3. This refers to conditions or environments where cysteine residues introduced for this purpose are more likely to be reduced than are oxidized, and preferably these cysteine residues undergo disulfide bond isomerization.
- cysteine residues do not cause significant isomerization of disulfide bonds, but form cysteine residues in the heavy chain hinge region or inter-light chain disulfide bonds
- Cysteine introduced for the purpose of forming a disulfide bond between cysteine residues or CH3 Residues refers to conditions or environment makes it possible to cause isomerization of disulfide bonds.
- the time for incubating a homologue of a first polypeptide containing a heavy chain constant region and a homologue of a second polypeptide containing a heavy chain constant region together under reducing conditions is determined by those skilled in the art. Can be set as appropriate.
- the “reducing agent” in the present invention refers to a compound that reduces a molecule in its environment, that is, a compound that changes a molecule to a more reduced state and a more reducing state in that environment.
- the reducing agent acts by donating electrons, so that it itself becomes oxidized after reduction of the substrate. Therefore, a reducing agent is an agent that donates electrons.
- Examples of reducing agents include dithiothreitol (DTT), mercaptoethanol, cysteine, thioglycolic acid, cysteamine (2-mercaptoethylamine: 2-MEA), glutathione (GSH), TCEP (tris (2-carboxyethyl) phosphine ) And sodium borohydride.
- “isomerization of disulfide bonds” refers to exchange of disulfide bonds between cysteines contained in different polypeptides, that is, rearrangement of disulfide bonds.
- “isomerization of disulfide bonds” in a heavy chain refers to the exchange of disulfide bonds between cysteines contained in different heavy chains, ie, rearrangement of disulfide bonds.
- “disulfide bond isomerization” in a light chain refers to the exchange of disulfide bonds between cysteines contained in different light chains, ie, rearrangement of disulfide bonds.
- “Disulfide bond formation” refers to the process of forming a covalent bond between two cysteines present in one or two polypeptides, and this bond is schematized as “-S--S-”.
- Reduction of disulfide bond refers to a process in which two thiol groups (—SH groups) are generated by cleavage of a disulfide bond.
- Fc ⁇ R or “FcgR” in the present invention is an Fc ⁇ receptor, which means a receptor capable of binding to the Fc region of IgG1, IgG2, IgG3, and IgG4 monoclonal antibodies, and is substantially encoded by the Fc ⁇ receptor gene.
- Fc ⁇ receptor means a receptor capable of binding to the Fc region of IgG1, IgG2, IgG3, and IgG4 monoclonal antibodies, and is substantially encoded by the Fc ⁇ receptor gene.
- this family includes, for example, Fc ⁇ RI (CD64) including isoforms Fc ⁇ RIa, Fc ⁇ RIb and Fc ⁇ RIc; including isoforms Fc ⁇ RIIa (including allotypes H131 (H) and R131 (R)), Fc ⁇ RIIb (Fc ⁇ RIIb-1 and Fc ⁇ RIIb (including Fc ⁇ RIIb-2) and Fc ⁇ RIIc including Fc ⁇ RIIc (CD32); and isoforms Fc ⁇ RIIIa (including allotypes V158 and F158) and Fc ⁇ RIIIb (including allotypes Fc ⁇ RIIIb-NA1 and Fc ⁇ RIIIb-NA2), and any Undiscovered human Fc ⁇ Rs or Fc ⁇ R isoforms or allotypes are also included.
- Fc ⁇ RI CD64
- isoforms Fc ⁇ RIIa including allotypes H131 (H) and R131 (R)
- Fc ⁇ RIIb Fc ⁇ RIIb-1 and Fc
- Fc ⁇ R includes, but is not limited to, those derived from human, mouse, rat, rabbit and monkey, and may be derived from any organism.
- Mouse Fc ⁇ Rs include, for example, Fc ⁇ RI (CD64), Fc ⁇ RII (CD32), Fc ⁇ RIII (CD16) and Fc ⁇ RIII-2 (CD16-2), Fc ⁇ RIV, and any undiscovered mouse Fc ⁇ Rs or Fc ⁇ R isoforms or allotypes .
- substitution may mean “modification” or “substitution” even when the amino acids before and after modification or before and after substitution are the same. “Modification” may also include “substitution”.
- the method comprises the step of amino acid residues of antibody heavy chain constant region . It is a method characterized by introducing a mutation. The method may optionally further include a step of introducing an amino acid modification related to interface control using the following charge repulsion or the like, and a step of introducing an amino acid modification that makes the stability of the heavy chain CH3 region unstable. . In one embodiment, the method is a method for producing a heteromultimer comprising the following steps.
- hinge region or “hinge region” means a region composed of amino acids from the 216th to the 230th EU numbering in the antibody heavy chain.
- core hinge region is a region sandwiched by at least two cysteine residues forming an inter-heavy chain disulfide bond in the hinge region.
- EU numbering 226 to 229 in the antibody heavy chain for example, EU numbering 226 to 229 in the antibody heavy chain.
- a region composed of the second amino acid is mentioned.
- the core hinge region in human IgG1 refers to a region consisting of EU heavy number 226th Cys, 227th Pro, 228th Pro, 229th Cys in the antibody heavy chain.
- outside the hinge region means a region or part other than the hinge region, such as a heavy chain variable region, a CH1 region, a CH2 region, a CH3 region, a light chain variable region, a light chain constant region, and the like.
- outside of the core hinge region means a region obtained by adding a region other than the core hinge region in the hinge region to the region expressed as the outside of the hinge region.
- cysteine residue at positions 226 and / or 229 by EU numbering has been altered or deleted to another amino acid residue, or the core hinge region has been deleted.
- the cysteine residues at positions 226 and 229 by EU numbering may be altered or deleted to other amino acid residues, or the core hinge region may be deleted.
- the other amino acid is not particularly limited as long as it is other than a cysteine residue, and may be any amino acid residue that does not form a disulfide bond.
- positions 220 to 225 by EU numbering may be replaced with Tyr (Y) -Gly (G) -Pro (P) -Pro (P), or positions 219 to 229 by EU numbering may be missing. .
- the present invention provides a heteromultimer utilizing isomerization of a cysteine disulfide bond in CH3 of a polypeptide containing an antibody heavy chain constant region (disulfide bond between CH3 regions). It is a method. Cysteine used in this method is not particularly limited as long as it is a cysteine present in CH3, but preferably at least one of positions 349, 351, 354, 356, 394 and 407 by EU numbering is cysteine. It can be used after being modified.
- a polypeptide containing CH3 in which one or more positions at positions 349, 351, 354, 356, 394, and 407 by EU numbering is cysteine may be used.
- the heavy chain constant region is IgG1
- one or more of positions 355, 356, 409, 419 and 445 by EU numbering may be further modified, for example, position 355 is changed to Gln (Q).
- Position 356 may be modified with Glu (E), position 409 with Arg (R), position 419 with Glu (E), or position 445 with Leu (L).
- each of the CH3 regions contained in the heavy chain constant region of the first and / or second polypeptide at positions 349, 351, 354, 356, 394, and 407 by EU numbering
- a method for producing a heterologous multimer comprising first and second polypeptides, wherein at least one amino acid residue selected from amino acid residues is cysteine.
- the first and second polypeptides each of which is a cysteine, is any one of the following (1) to (5), including the first and second polypeptides.
- a method of producing a multimer is provided. (1) Amino acid residues at positions 349 and 356 by EU numbering (2) Amino acid residues at positions 394 and 394 by EU numbering (3) Amino acid residues at positions 351 and 351 by EU numbering (4) EU numbering 407 and 407 amino acid residues by (5) EU numbering 349 and 354 amino acid residues
- the core hinge region preferably does not contain cysteine.
- cysteine at position 226 and / or 229 by EU numbering is modified with other amino acids, and amino acid residues at positions 226 to 229 by EU numbering are SPPS. SPSS may be used, but is not limited to these. Further, the cysteine at position 226 and / or 229 by EU numbering may be deleted.
- the other amino acid residues contained in the hinge region may be modified or deleted, and other amino acids may be inserted.
- EU numbering position 220 may be substituted with serine, or EU numbering positions 220 to 225 may be substituted with IgG4 sequences, but it is not particularly limited thereto.
- EU numbering positions 219 to 229 may be deleted, but the invention is not limited thereto.
- a part or all of the hinge region may be missing.
- EU numbering 216 to 230 may be deleted in IgG1 or IgG4.
- the heavy chain constant regions of the first and second polypeptides are amino acid residues represented by any one of the following (1) to (5), respectively.
- the first polypeptide has an amino acid residue other than Cys (C) at position 226 by EU numbering, an amino acid residue other than Cys (C) at position 229, and Cys (C) at position 349.
- amino acid residue other than Cys (C) is at position 226 by EU numbering
- amino acid residue other than Cys (C) is at position 229
- Cys (C) is at position 356.
- the EU numbering position 226 is an amino acid residue other than Cys (C)
- position 229 is an amino acid residue other than Cys (C)
- position 394 is Cys (C).
- EU numbering 226 is an amino acid residue other than Cys (C)
- 229 is an amino acid residue other than Cys (C)
- 351 is Cys (C).
- the EU numbering position 226 is an amino acid residue other than Cys (C)
- position 229 is an amino acid residue other than Cys (C)
- position 407 is Cys (C).
- the first polypeptide has EU numbering at position 226, an amino acid residue other than Cys (C), position 229, an amino acid residue other than Cys (C), and position 349, Cys (C).
- This polypeptide has an amino acid residue other than Cys (C) at position 226 by EU numbering, an amino acid residue other than Cys (C) at position 229, and Cys (C) at position 354.
- the heavy chain constant region of each of the first and second polypeptides is an amino acid residue represented by any one of the following (1) to (5), and the first and second polypeptides contain the first and second polypeptides.
- a method of manufacturing a body is provided.
- the first polypeptide is Ser (S) at position 226 by EU numbering, Ser (S) at position 229 and Cys (C) at position 349, and the second polypeptide is position 226 by EU numbering.
- Ser (S), position 229 is Ser (S) and position 356 is Cys (C).
- the first and second polypeptides are Ser (S) at position 226 by EU numbering, Ser (S) at position 229, and Cys (C) at position 394.
- the first and second polypeptides are Ser (S) at position 226 by EU numbering, Ser (S) at position 229 and Cys (C) at position 351.
- the first and second polypeptides are Ser (S) at position 226 by EU numbering, Ser (S) at position 229 and Cys (C) at position 407.
- the first polypeptide has Ser (S) at position 226 by EU numbering, Ser (S) at position 229 and Cys (C) at position 349, and the second polypeptide has position 226 by EU numbering.
- Ser (S), 229 is Ser (S)
- 354 is Cys (C).
- the heavy chain constant region of each of the first and second polypeptides is an amino acid residue represented by any one of the following (1) to (5), and the first and second polypeptides contain the first and second polypeptides.
- a method of manufacturing a body is provided.
- the first polypeptide has amino acid residues other than Cys (C) at position 226 by EU numbering, amino acid residues other than Pro (P) at position 228, amino acids other than Cys (C) at position 229, and Cys at position 349.
- the second polypeptide has amino acid residues other than Cys (C) at position 226 by EU numbering, amino acid residues other than Cy (C) at position 228, amino acids other than Cys (C) at position 229 The position is Cys (C).
- the first and second polypeptides are amino acid residues other than Cys (C) at position 226 by EU numbering, amino acid residues other than Cy (C) at position 228, and amino acids 394 at position 229.
- the position is Cys (C).
- the first and second polypeptides are amino acid residues other than Cys (C) at position 226 by EU numbering, amino acid residues other than Cy (C) at position 228, and amino acid residues other than Cys (C) at position 229.
- the position is Cys (C).
- the first and second polypeptides are amino acid residues other than Cys (C) at position 226 by EU numbering, amino acid residues other than Cy (C) at position 228, and amino acids 407 at position 229.
- the position is Cys (C).
- the first polypeptide has EU numbering at position 226, which is an amino acid residue other than Cys (C), position 228 is at Pro (P), position 229 is other than Cys (C), and position 349 is Cys.
- the second polypeptide is amino acid residue other than Cys (C) at position 226 by EU numbering, amino acid residue other than Cy (C) at position 228, amino acid residue other than Cys (C) at position 354 The position is Cys (C).
- the heavy chain constant region of each of the first and second polypeptides is an amino acid residue represented by any one of the following (1) to (5), and the first and second polypeptides contain the first and second polypeptides.
- a method of manufacturing a body is provided.
- the first polypeptide is Ser (S) at position 226 by EU numbering, Pro (P) at position 228, Ser (S) at position 229, and Cys (C) at position 349.
- the peptide is Ser (S) at position 226 by EU numbering, Pro (P) at position 228, Ser (S) at position 229, and Cys (C) at position 356.
- the first and second polypeptides are Ser (S) at position 226 by EU numbering, Pro (P) at position 228, Ser (S) at position 229, and Cys (C) at position 394.
- the first and second polypeptides are Ser (S) at position 226 by EU numbering, Pro (P) at position 228, Ser (S) at position 229, and Cys (C) at position 351.
- the first and second polypeptides are Ser (S) at position 226 by EU numbering, Pro (P) at position 228, Ser (S) at position 229, and Cys (C) at position 407.
- the first polypeptide is Ser (S) at position 226 by EU numbering, Pro (P) at position 228, Ser (S) at position 229, and Cys (C) at position 349.
- Peptides are Ser (S) at position 226 by EU numbering, Pro (P) at position 228, Ser (S) at position 229, and Cys (C) at position 354.
- the heavy chain constant regions of the first and second polypeptides are amino acid residues represented by any of the following (1) to (6), respectively, Provided are methods for producing heterologous multimers comprising peptides.
- the first polypeptide is an amino acid residue other than Cys (C) at position 226 by EU numbering, an amino acid residue other than Cys (C) at position 229, and Cys (C) at position 349;
- Position 356 is one of Lys (K), Arg (R), and His (H)
- the second polypeptide is an amino acid residue other than Cys (C) at position 226 by EU numbering, and position 229 is Cys ( Amino acid residues other than C) and 356 are Cys (C), and 439 is Glu (E) or Asp (D).
- the first polypeptide has EU numbering at position 226 for amino acid residues other than Cys (C), position 229 for amino acid residues other than Cys (C), position 349 for Cys (C) and position 397 for Tyr (Y) and position 356 is one of Lys (K), Arg (R) and His (H), and the second polypeptide is an amino acid other than Cys (C) at position 226 by EU numbering.
- position 229 is an amino acid residue other than Cys (C)
- position 356 is Cys (C) and position 397 is Tyr (Y)
- position 439 is Glu (E) or Asp (D) .
- the first and second polypeptides have EU numbering at position 226, which is an amino acid residue other than Cys (C), position 229 is an amino acid residue other than Cys (C), and position 394 is Cys (C).
- Position 356 by EU numbering is one of Lys (K), Arg (R) and His (H), and the other polypeptide is position 439 by EU numbering at Glu (E) or Asp ( D).
- the first polypeptide has EU numbering at position 226, an amino acid residue other than Cys (C), position 229, an amino acid residue other than Cys (C), position 349, Cys (C), Polypeptide of EU numbering is amino acid residue other than Cys (C) at position 226, amino acid residue other than Cys (C) at position 229, and Cys (C) at position 354, while one polypeptide is EU numbering
- the position 356 by is any one of Lys (K), Arg (R) and His (H), and the other polypeptide is position 439 by EU numbering is Glu (E) or Asp (D).
- the first and second polypeptides have EU numbering at position 226, which is an amino acid residue other than Cys (C), position 229 is an amino acid residue other than Cys (C), and position 351 is Cys (C).
- Position 356 by EU numbering is one of Lys (K), Arg (R) and His (H), and the other polypeptide is position 439 by EU numbering at Glu (E) or Asp ( D).
- the first and second polypeptides have EU numbering at position 226, an amino acid residue other than Cys (C), position 229, an amino acid residue other than Cys (C), and position 407, Cys (C).
- Position 356 by EU numbering is one of Lys (K), Arg (R) and His (H), and the other polypeptide is position 439 by EU numbering at Glu (E) or Asp ( D).
- the heavy chain constant regions of the first and second polypeptides are the amino acid residues shown in any of the following (1) to (6), respectively, Provided are methods for producing heterologous multimers comprising peptides.
- position 226 by EU numbering is Ser (S)
- position 229 is Ser (S)
- position 349 is Cys (C)
- position 356 is Lys (K)
- the second polypeptide has Ser (S) at position 226, Ser (S) at position 229 and Cys (C) at position 356 by EU numbering, and 439
- the position is Glu (E) or Asp (D).
- the first polypeptide is Ser (S) at position 226 by EU numbering, Ser (S) at position 229, Cys (C) at position 349 and Tyr (Y) at position 397, and position 356. Is one of Lys (K), Arg (R), and His (H), and the second polypeptide is Ser (S) at position 226 by EU numbering, Ser (S) at position 229, and Cys at position 356.
- C) and 397 are Tyr (Y), and 439 is Glu (E) or Asp (D).
- the first and second polypeptides are Ser (S) at position 226 by EU numbering, Ser (S) at position 229 and Cys (C) at position 394, and one polypeptide is 356 by EU numbering.
- the position is one of Lys (K), Arg (R) and His (H), and the other polypeptide is Glu (E) or Asp (D) at position 439 by EU numbering.
- the first polypeptide is Ser (S) at position 226 by EU numbering, Ser (S) at position 229, Cys (C) at position 349, and the second polypeptide is position 226 by EU numbering.
- Ser (S), position 229 is Ser (S)
- position 354 is Cys (C)
- one of the polypeptides is EU numbering at position 356, which is either Lys (K), Arg (R) or His (H)
- position 439 by EU numbering is Glu (E) or Asp (D).
- the first and second polypeptides are Ser (S) at position 226 by EU numbering, Ser (S) at position 229, Cys (C) at position 351, and one polypeptide is 356 by EU numbering.
- the position is one of Lys (K), Arg (R) and His (H), and the other polypeptide is Glu (E) or Asp (D) at position 439 by EU numbering.
- the first and second polypeptides are Ser (S) at position 226 by EU numbering, Ser (S) at position 229 and Cys (C) at position 407, and one polypeptide is 356 by EU numbering.
- the position is one of Lys (K), Arg (R) and His (H), and the other polypeptide is Glu (E) or Asp (D) at position 439 by EU numbering.
- the heavy chain constant regions of the first and second polypeptides are the amino acid residues shown in any of the following (1) to (6), respectively, and the heterologous mass containing the first and second polypeptides
- a method of manufacturing a body is provided.
- the first polypeptide has amino acid residues other than Cys (C) at position 226 by EU numbering, amino acid residues other than Pro (P) at position 228, amino acids other than Cys (C) at position 229, and Cys at position 349.
- C) and position 356 is one of Lys (K), Arg (R) and His (H), and the second polypeptide is an amino acid other than Cys (C) at position 226 by EU numbering.
- position 228 is Pro (P)
- position 229 is an amino acid residue other than Cys (C)
- position 356 is Cys (C)
- position 439 is Glu (E) or Asp (D).
- the first polypeptide is amino acid residue other than Cys (C) at position 226 by EU numbering
- position 349 at Cys (C) and 397 are Tyr (Y) and 356 is any of Lys (K), Arg (R) and His (H)
- the second polypeptide is position 226 by EU numbering.
- the first and second polypeptides are amino acid residues other than Cys (C) at position 226 by EU numbering, amino acid residues other than Cy (C) at position 228, and amino acid residues other than Cys (C) at position 229.
- the position is Cys (C), one of the polypeptides is at position 356 by EU numbering, one of Lys (K), Arg (R) and His (H), and the other polypeptide is at position 439 by EU numbering Is Glu (E) or Asp (D).
- the first polypeptide is amino acid residue other than Cys (C) at position 226 according to EU numbering, amino acid residue other than Cy (C) at position 228, amino acid residue other than Cys (C) at position 229, and Cys at position 349 (C)
- the second polypeptide is amino acid residue other than Cys (C) at position 226 by EU numbering, amino acid residue other than Cys (C) at position 228, amino acid residue other than Cys (C) at position 354,
- the position is Cys (C), one of the polypeptides is at position 356 by EU numbering, one of Lys (K), Arg (R) and His (H), and the other polypeptide is at position 439 by EU numbering Is Glu (E) or Asp (D).
- the first and second polypeptides are amino acid residues other than Cys (C) at position 226 by EU numbering, amino acid residues other than Cy (C) at position 228, amino acids at positions 229 other than Cys (C), 351
- the position is Cys (C)
- one of the polypeptides is at position 356 by EU numbering, one of Lys (K), Arg (R) and His (H)
- the other polypeptide is at position 439 by EU numbering Is Glu (E) or Asp (D).
- the first and second polypeptides are amino acid residues other than Cys (C) at position 226 by EU numbering, amino acid residues other than Cy (C) at position 228, and amino acids 407 at position 229.
- the position is Cys (C), one of the polypeptides is at position 356 by EU numbering, one of Lys (K), Arg (R) and His (H), and the other polypeptide is at position 439 by EU numbering Is Glu (E) or Asp (D).
- the heavy chain constant regions of the first and second polypeptides are the amino acid residues shown in any of the following (1) to (6), respectively, and the heterologous mass containing the first and second polypeptides
- a method of manufacturing a body is provided.
- the first polypeptide is Ser (S) at position 226 by EU numbering, Pro (P) at position 228, Ser (S) at position 229, Cys (C) at position 349, and position 356.
- the second polypeptide is Ser (S) at position 226 by EU numbering, Pro (P) at position 228, and Ser at position 229.
- the first polypeptide is Ser (S) at position 226 by EU numbering, Pro (P) at position 228, Ser (S) at position 229, Cys (C) at position 349 and Tyr (Y at position 397 ), And position 356 is one of Lys (K), Arg (R), and His (H), and the second polypeptide is EU (numbered) at position 226, Ser (S), and position 228 is Pro. (P), Ser (S) at position 229, Cys (C) at position 356, Tyr (Y) at position 397, and Glu (E) or Asp (D) at position 439.
- the first and second polypeptides are Ser (S) at position 226 by EU numbering, Pro (P) at position 228, Ser (S) at position 229 and Cys (C) at position 394, Polypeptide of 356 by EU numbering is one of Lys (K), Arg (R) and His (H), and the other polypeptide is 439 by EU numbering at Glu (E) or Asp (D) It is.
- the first polypeptide is Ser (S) at position 226 by EU numbering, Pro (P) at position 228, Ser (S) at position 229, Cys (C) at position 349,
- the peptide is Ser (S) at position 226 by EU numbering, Pro (P) at position 228, Ser (S) at position 229, Cys (C) at position 354, while one polypeptide is at position 356 by EU numbering.
- One of Lys (K), Arg (R) and His (H), and the other polypeptide is Glu (E) or Asp (D) at position 439 by EU numbering.
- the first and second polypeptides are Ser (S) at position 226 by EU numbering, Pro (P) at position 228, Ser (S) at position 229, Cys (C) at position 351, Polypeptide of 356 by EU numbering is one of Lys (K), Arg (R) and His (H), and the other polypeptide is 439 by EU numbering at Glu (E) or Asp (D) It is.
- the first and second polypeptides are Ser (S) at position 226 by EU numbering, Pro (P) at position 228, Ser (S) at position 229 and Cys (C) at position 407, Polypeptide of 356 by EU numbering is one of Lys (K), Arg (R) and His (H), and the other polypeptide is 439 by EU numbering at Glu (E) or Asp (D) It is.
- the heavy chain constant regions of the first and second polypeptides are amino acid residues represented by any of the following (1) to (6), respectively.
- the first polypeptide has EU numbering at position 226 for amino acid residues other than Cys (C), position 229 for amino acid residues other than Cys (C), position 349 for Cys (C) and position 356 for Lys (K), and the second polypeptide is amino acid residue other than Cys (C) at position 226 by EU numbering, amino acid residue other than Cys (C) at position 229, Cys (C) and 439 at position 356
- the place is Glu (E).
- the first polypeptide has EU numbering at position 226 for amino acid residues other than Cys (C), position 229 for amino acid residues other than Cys (C), position 349 for Cys (C), position 356 for Lys (K) and 397 are Tyr (Y), and the second polypeptide has an EU numbering of position 226, an amino acid residue other than Cys (C), position 229, an amino acid residue other than Cys (C), 356
- the position is Cys (C)
- the position 397 is Tyr (Y)
- the position 439 is Glu (E).
- the first polypeptide has EU numbering at position 226 for amino acid residues other than Cys (C), position 229 for amino acid residues other than Cys (C), position 394 for Cys (C) and position 356 for Lys (K), and the second polypeptide is amino acid residue other than Cys (C) at position 226 by EU numbering, amino acid residue other than Cys (C) at position 229, Cys (C) and 439 at position 394
- the place is Glu (E).
- the first polypeptide has EU numbering at position 226 for amino acid residues other than Cys (C), position 229 for amino acid residues other than Cys (C), position 349 for Cys (C) and position 356 for Lys (K), and the second polypeptide is an amino acid residue other than Cys (C) at position 226 by EU numbering, an amino acid residue other than Cys (C) at position 229, and Cys (C) and 439 at position 354.
- the place is Glu (E).
- the first polypeptide has EU numbering at position 226 for amino acid residues other than Cys (C), position 229 for amino acid residues other than Cys (C), position 351 for Cys (C) and position 356 for Lys (K), and the second polypeptide is amino acid residue other than Cys (C) at position 226 by EU numbering, amino acid residue other than Cys (C) at position 229, Cys (C) and 439 at position 351
- the place is Glu (E).
- the first polypeptide has EU numbering at position 226 for amino acid residues other than Cys (C), position 229 for amino acid residues other than Cys (C), position 407 for Cys (C) and position 356 for Lys (K), the second polypeptide is amino acid residue other than Cys (C) at position 226 by EU numbering, amino acid residue other than Cys (C) at position 229, Cys (C) and 439 at position 407
- the place is Glu (E).
- the heavy chain constant regions of the first and second polypeptides are the amino acid residues shown in any of the following (1) to (6), respectively.
- the first polypeptide is Ser (S) at position 226 by EU numbering, Ser (S) at position 229, Cys (C) at position 349, and Lys (K) at position 356.
- the peptide is Ser (S) at position 226 by EU numbering, Ser (S) at position 229, Cys (C) at position 356, and Glu (E) at position 439.
- the first polypeptide is Ser (S) at position 226 by EU numbering, Ser (S) at position 229, Cys (C) at position 349, Lys (K) at position 356, and Tyr (Y at position 397 ),
- the second polypeptide is Ser (S) at position 226 by EU numbering, Ser (S) at position 229, Cys (C) at position 356, Tyr (Y) at position 397 and Glu ( E).
- the first polypeptide is Ser (S) at position 226 by EU numbering, Ser (S) at position 229, Cys (C) at position 394, and Lys (K) at position 356.
- the peptide is Ser (S) at position 226 by EU numbering, Ser (S) at position 229, Cys (C) at position 394, and Glu (E) at position 439.
- the first polypeptide is Ser (S) at position 226 by EU numbering, Ser (S) at position 229, Cys (C) at position 349 and Lys (K) at position 356.
- the peptide is Ser (S) at position 226, Ser (S) at position 229, Cys (C) at position 354, and Glu (E) at position 439.
- the first polypeptide is Ser (S) at position 226 by EU numbering, Ser (S) at position 229, Cys (C) at position 351, and Lys (K) at position 356. According to EU numbering, the peptide is Ser (S) at position 226, Ser (S) at position 229, Cys (C) at position 351, and Glu (E) at position 439.
- the first polypeptide is Ser (S) at position 226 by EU numbering, Ser (S) at position 229, Cys (C) at position 407, and Lys (K) at position 356. According to EU numbering, the peptide is Ser (S) at position 226, Ser (S) at position 229, Cys (C) at position 407, and Glu (E) at position 439.
- the heavy chain constant regions of the first and second polypeptides are the amino acid residues shown in any of the following (1) to (6), respectively, and the heterologous mass containing the first and second polypeptides
- a method of manufacturing a body is provided.
- the first polypeptide is amino acid residue other than Cys (C) at position 226 by EU numbering
- amino acid residue other than Cy (C) at position 228, amino acid residue other than Cys (C) at position 229, and Cys at position 349 (C) and 356 are Lys (K)
- the second polypeptide is an amino acid residue other than Cys (C) by EU numbering
- 228 is Pro
- 229 is Cys (C ) Amino acid residues other than)
- position 356 is Cys (C) and position 439 is Glu (E).
- the first polypeptide is amino acid residue other than Cys (C) at position 226 by EU numbering, position 228 at position Pro (P), position 229 at position other than Cys (C), position 349 at Cys (C), Lys (K) at position 356 and Tyr (Y) at position 397
- the second polypeptide is amino acid residue other than Cys (C) at position 226 by EU numbering, and Pro (P ), Amino acid residue other than Cys (C), position 356 is Cys (C), position 397 is Tyr (Y), and position 439 is Glu (E).
- the first polypeptide is amino acid residue other than Cys (C) at position 226 by EU numbering, amino acid residue other than Cy (C) at position 228, amino acid residue other than Cys (C) at position 229, and Cys at position 394.
- C) and 356 are Lys (K)
- the second polypeptide is an amino acid residue other than Cys (C) by EU numbering
- 228 is Pro
- 229 is Cys (C ) Amino acid residues other than)
- position 394 is Cys (C) and position 439 is Glu (E).
- the first polypeptide is amino acid residue other than Cys (C) at position 226 according to EU numbering
- amino acid residue other than Cy (C) at position 228, amino acid residue other than Cys (C) at position 229, and Cys at position 349 (C) and 356 are Lys (K)
- the second polypeptide is an amino acid residue other than Cys (C) by EU numbering
- 228 is Pro (P)
- 229 is Cys (C ) Amino acid residues other than)
- Cys (C) at position 354 and Glu (E) at position 439 is amino acid residue other than Cys (C) at position 226 according to EU numbering
- the second polypeptide is an amino acid residue other than Cys (C) by EU numbering
- 228 is Pro
- 229 is Cys (C
- the first polypeptide has EU numbering at position 226, which is an amino acid residue other than Cys (C), position 228 is Pro (P), position 229 is an amino acid residue other than Cys (C), and position 351 is Cys. (C) and 356 are Lys (K), the second polypeptide is an amino acid residue other than Cys (C) by EU numbering, 228 is Pro (P), 229 is Cys (C ) Amino acid residues other than), Cys (C) at position 351 and Glu (E) at position 439.
- the first polypeptide is amino acid residue other than Cys (C) at position 226 by EU numbering, position 228 at position Pro (P), position 229 at position other than Cys (C), position 407 at Cys (C) and 356 are Lys (K), the second polypeptide is an amino acid residue other than Cys (C) by EU numbering, 228 is Pro (P), 229 is Cys (C ) Amino acid residues other than), position 407 is Cys (C) and position 439 is Glu (E).
- the heavy chain constant regions of the first and second polypeptides are the amino acid residues shown in any of the following (1) to (6), respectively, and the heterologous mass containing the first and second polypeptides
- a method of manufacturing a body is provided.
- the first polypeptide is Ser (S) at position 226 by EU numbering, Pro (P) at position 228, Ser (S) at position 229, Cys (C) at position 349 and Lys (K at position 356.
- the second polypeptide is Ser (S) at position 226 by EU numbering, Pro (P) at position 228, Ser (S) at position 229, Cys (C) at position 356, and Glu ( E).
- the first polypeptide is Ser (S) at position 226 by EU numbering, Pro (P) at position 228, Ser (S) at position 229, Cys (C) at position 349, Lys (K at position 356 ) And 397 are Tyr (Y), and the second polypeptide is EU (numbered 226: Ser (S), 228: Pro (P), 229: Ser (S), 356: Cys ( C), 397 is Tyr (Y) and 439 is Glu (E).
- the first polypeptide is Ser (S) at position 226 by EU numbering, Pro (P) at position 228, Ser (S) at position 229, Cys (C) at position 394 and Lys (K at position 356.
- the second polypeptide is Ser (S) at position 226 by EU numbering, Pro (P) at position 228, Ser (S) at position 229, Cys (C) at position 394 and Glu (position at position 439).
- the first polypeptide is Ser (S) at position 226 by EU numbering, Pro (P) at position 228, Ser (S) at position 229, Cys (C) at position 349 and Lys (K at position 356. )
- the second polypeptide is Ser (S) at position 226 by EU numbering, Pro (P) at position 228, Ser (S) at position 229, Cys (C) at position 354 and Glu ( E).
- the first polypeptide is Ser (S) at position 226 by EU numbering, Pro (P) at position 228, Ser (S) at position 229, Cys (C) at position 351 and Lys (K at position 356. )
- the second polypeptide is Ser (S) at position 226 by EU numbering, Pro (P) at position 228, Ser (S) at position 229, Cys (C) at position 351 and Glu ( E).
- the first polypeptide is Ser (S) at position 226 by EU numbering, Pro (P) at position 228, Ser (S) at position 229, Cys (C) at position 407, and Lys (K at position 356. )
- the second polypeptide is Ser (S) at position 226 by EU numbering, Pro (P) at position 228, Ser (S) at position 229, Cys (C) at position 407 and Glu ( E).
- a first polypeptide that is an antibody heavy chain and a third polypeptide that is an antibody light chain form a dimer
- the second polypeptide that is an antibody heavy chain and an antibody A bispecific antibody comprising a first, second, third and fourth polypeptide as a component, which forms a dimer with a fourth polypeptide that is a light chain, comprising:
- a bispecific antibody is provided in which the amino acid residue at a predetermined position in the CH3 region contained in the heavy chain constant region of the second polypeptide is cysteine.
- a bispecific antibody in which the set of cysteines in the first and second polypeptides is any one of the following (1) to (5).
- Amino acid residues at positions 351 and 351 by EU numbering (4) EU numbering 407 and 407 amino acid residues by (5) EU numbering 349 and 354 amino acid residues
- the first polypeptide has an amino acid residue other than Cys (C) at position 226 by EU numbering, an amino acid residue other than Cys (C) at position 229, and Cys (C) at position 349.
- amino acid residue other than Cys (C) is at position 226 by EU numbering
- amino acid residue other than Cys (C) is at position 229
- Cys (C) is at position 356.
- the EU numbering position 226 is an amino acid residue other than Cys (C)
- position 229 is an amino acid residue other than Cys (C)
- position 394 is Cys (C).
- EU numbering 226 is an amino acid residue other than Cys (C)
- 229 is an amino acid residue other than Cys (C)
- 351 is Cys (C).
- the EU numbering position 226 is an amino acid residue other than Cys (C)
- position 229 is an amino acid residue other than Cys (C)
- position 407 is Cys (C).
- the first polypeptide has EU numbering at position 226, an amino acid residue other than Cys (C), position 229, an amino acid residue other than Cys (C), and position 349, Cys (C).
- This polypeptide has an amino acid residue other than Cys (C) at position 226 by EU numbering, an amino acid residue other than Cys (C) at position 229, and Cys (C) at position 354.
- the first polypeptide is Ser (S) at position 226 by EU numbering, Ser (S) at position 229 and Cys (C) at position 349, and the second polypeptide is position 226 by EU numbering.
- Ser (S), position 229 is Ser (S) and position 356 is Cys (C).
- the first and second polypeptides are Ser (S) at position 226 by EU numbering, Ser (S) at position 229, and Cys (C) at position 394.
- the first and second polypeptides are Ser (S) at position 226 by EU numbering, Ser (S) at position 229 and Cys (C) at position 351.
- the first and second polypeptides are Ser (S) at position 226 by EU numbering, Ser (S) at position 229 and Cys (C) at position 407.
- the first polypeptide has Ser (S) at position 226 by EU numbering, Ser (S) at position 229 and Cys (C) at position 349, and the second polypeptide has position 226 by EU numbering.
- Ser (S), 229 is Ser (S)
- 354 is Cys (C).
- the first polypeptide has amino acid residues other than Cys (C) at position 226 by EU numbering, amino acid residues other than Pro (P) at position 228, amino acids other than Cys (C) at position 229, and Cys at position 349.
- the second polypeptide has amino acid residues other than Cys (C) at position 226 by EU numbering, amino acid residues other than Cy (C) at position 228, amino acids other than Cys (C) at position 229 The position is Cys (C).
- the first and second polypeptides are amino acid residues other than Cys (C) at position 226 by EU numbering, amino acid residues other than Cy (C) at position 228, and amino acids 394 at position 229.
- the position is Cys (C).
- the first and second polypeptides are amino acid residues other than Cys (C) at position 226 by EU numbering, amino acid residues other than Cy (C) at position 228, and amino acid residues other than Cys (C) at position 229.
- the position is Cys (C).
- the first and second polypeptides are amino acid residues other than Cys (C) at position 226 by EU numbering, amino acid residues other than Cy (C) at position 228, and amino acids 407 at position 229.
- the position is Cys (C).
- the first polypeptide has EU numbering at position 226, which is an amino acid residue other than Cys (C), position 228 is at Pro (P), position 229 is other than Cys (C), and position 349 is Cys.
- the second polypeptide is amino acid residue other than Cys (C) at position 226 by EU numbering, amino acid residue other than Cy (C) at position 228, amino acid residue other than Cys (C) at position 354 The position is Cys (C).
- the first polypeptide is Ser (S) at position 226 by EU numbering, Pro (P) at position 228, Ser (S) at position 229, and Cys (C) at position 349.
- the peptide is Ser (S) at position 226 by EU numbering, Pro (P) at position 228, Ser (S) at position 229, and Cys (C) at position 356.
- the first and second polypeptides are Ser (S) at position 226 by EU numbering, Pro (P) at position 228, Ser (S) at position 229, and Cys (C) at position 394.
- the first and second polypeptides are Ser (S) at position 226 by EU numbering, Pro (P) at position 228, Ser (S) at position 229, and Cys (C) at position 351.
- the first and second polypeptides are Ser (S) at position 226 by EU numbering, Pro (P) at position 228, Ser (S) at position 229, and Cys (C) at position 407.
- the first polypeptide is Ser (S) at position 226 by EU numbering, Pro (P) at position 228, Ser (S) at position 229, and Cys (C) at position 349.
- Peptides are Ser (S) at position 226 by EU numbering, Pro (P) at position 228, Ser (S) at position 229, and Cys (C) at position 354.
- the first polypeptide is an amino acid residue other than Cys (C) at position 226 by EU numbering, an amino acid residue other than Cys (C) at position 229, and Cys (C) at position 349;
- Position 356 is one of Lys (K), Arg (R), and His (H), and the second polypeptide is an amino acid residue other than Cys (C) at position 226 by EU numbering, and position 229 is Cys ( Amino acid residues other than C) and 356 are Cys (C), and 439 is Glu (E) or Asp (D).
- the first polypeptide has EU numbering at position 226 for amino acid residues other than Cys (C), position 229 for amino acid residues other than Cys (C), position 349 for Cys (C) and position 397 for Tyr (Y) and position 356 is one of Lys (K), Arg (R) and His (H), and the second polypeptide is an amino acid other than Cys (C) at position 226 by EU numbering.
- position 229 is an amino acid residue other than Cys (C)
- position 356 is Cys (C) and position 397 is Tyr (Y)
- position 439 is Glu (E) or Asp (D) .
- the first and second polypeptides have EU numbering at position 226, which is an amino acid residue other than Cys (C), position 229 is an amino acid residue other than Cys (C), and position 394 is Cys (C).
- Position 356 by EU numbering is one of Lys (K), Arg (R) and His (H), and the other polypeptide is position 439 by EU numbering at Glu (E) or Asp ( D).
- the first polypeptide has EU numbering at position 226, an amino acid residue other than Cys (C), position 229, an amino acid residue other than Cys (C), position 349, Cys (C), Polypeptide of EU numbering is amino acid residue other than Cys (C) at position 226, amino acid residue other than Cys (C) at position 229, and Cys (C) at position 354, while one polypeptide is EU numbering
- the position 356 by is any one of Lys (K), Arg (R) and His (H), and the other polypeptide is position 439 by EU numbering is Glu (E) or Asp (D).
- the first and second polypeptides have EU numbering at position 226, which is an amino acid residue other than Cys (C), position 229 is an amino acid residue other than Cys (C), and position 351 is Cys (C).
- Position 356 by EU numbering is one of Lys (K), Arg (R) and His (H), and the other polypeptide is position 439 by EU numbering at Glu (E) or Asp ( D).
- the first and second polypeptides have EU numbering at position 226, an amino acid residue other than Cys (C), position 229, an amino acid residue other than Cys (C), and position 407, Cys (C).
- Position 356 by EU numbering is one of Lys (K), Arg (R) and His (H), and the other polypeptide is position 439 by EU numbering at Glu (E) or Asp ( D).
- the present invention provides a bispecific antibody in which the heavy chain constant regions of the first and second polypeptides are amino acid residues shown in any of the following (1) to (6), respectively. .
- position 226 by EU numbering is Ser (S)
- position 229 is Ser (S)
- position 349 is Cys (C)
- position 356 is Lys (K)
- the second polypeptide has Ser (S) at position 226, Ser (S) at position 229 and Cys (C) at position 356 by EU numbering, and 439
- the position is Glu (E) or Asp (D).
- the first polypeptide is Ser (S) at position 226 by EU numbering, Ser (S) at position 229, Cys (C) at position 349 and Tyr (Y) at position 397, and position 356. Is one of Lys (K), Arg (R), and His (H), and the second polypeptide is Ser (S) at position 226 by EU numbering, Ser (S) at position 229, and Cys at position 356.
- C) and 397 are Tyr (Y), and 439 is Glu (E) or Asp (D).
- the first and second polypeptides are Ser (S) at position 226 by EU numbering, Ser (S) at position 229 and Cys (C) at position 394, and one polypeptide is 356 by EU numbering.
- the position is one of Lys (K), Arg (R) and His (H), and the other polypeptide is Glu (E) or Asp (D) at position 439 by EU numbering.
- the first polypeptide is Ser (S) at position 226 by EU numbering, Ser (S) at position 229, Cys (C) at position 349, and the second polypeptide is position 226 by EU numbering.
- Ser (S), position 229 is Ser (S)
- position 354 is Cys (C)
- one of the polypeptides is EU numbering at position 356, which is either Lys (K), Arg (R) or His (H)
- position 439 by EU numbering is Glu (E) or Asp (D).
- the first and second polypeptides are Ser (S) at position 226 by EU numbering, Ser (S) at position 229, Cys (C) at position 351, and one polypeptide is 356 by EU numbering.
- the position is one of Lys (K), Arg (R) and His (H), and the other polypeptide is Glu (E) or Asp (D) at position 439 by EU numbering.
- the first and second polypeptides are Ser (S) at position 226 by EU numbering, Ser (S) at position 229 and Cys (C) at position 407, and one polypeptide is 356 by EU numbering.
- the position is one of Lys (K), Arg (R) and His (H), and the other polypeptide is Glu (E) or Asp (D) at position 439 by EU numbering.
- the first polypeptide has amino acid residues other than Cys (C) at position 226 by EU numbering, amino acid residues other than Pro (P) at position 228, amino acids other than Cys (C) at position 229, and Cys at position 349.
- C) and position 356 is one of Lys (K), Arg (R) and His (H), and the second polypeptide is an amino acid other than Cys (C) at position 226 by EU numbering.
- position 228 is Pro (P)
- position 229 is an amino acid residue other than Cys (C)
- position 356 is Cys (C)
- position 439 is Glu (E) or Asp (D).
- the first polypeptide is amino acid residue other than Cys (C) at position 226 by EU numbering
- position 349 at Cys (C) and 397 are Tyr (Y) and 356 is any of Lys (K), Arg (R) and His (H)
- the second polypeptide is position 226 by EU numbering.
- the first and second polypeptides are amino acid residues other than Cys (C) at position 226 by EU numbering, amino acid residues other than Cy (C) at position 228, and amino acid residues other than Cys (C) at position 229.
- the position is Cys (C), one of the polypeptides is at position 356 by EU numbering, one of Lys (K), Arg (R) and His (H), and the other polypeptide is at position 439 by EU numbering Is Glu (E) or Asp (D).
- the first polypeptide is amino acid residue other than Cys (C) at position 226 according to EU numbering, amino acid residue other than Cy (C) at position 228, amino acid residue other than Cys (C) at position 229, and Cys at position 349 (C)
- the second polypeptide is amino acid residue other than Cys (C) at position 226 by EU numbering, amino acid residue other than Cys (C) at position 228, amino acid residue other than Cys (C) at position 354,
- the position is Cys (C), one of the polypeptides is at position 356 by EU numbering, one of Lys (K), Arg (R) and His (H), and the other polypeptide is at position 439 by EU numbering Is Glu (E) or Asp (D).
- the first and second polypeptides are amino acid residues other than Cys (C) at position 226 by EU numbering, amino acid residues other than Cy (C) at position 228, amino acids at positions 229 other than Cys (C), 351
- the position is Cys (C)
- one of the polypeptides is at position 356 by EU numbering, one of Lys (K), Arg (R) and His (H)
- the other polypeptide is at position 439 by EU numbering Is Glu (E) or Asp (D).
- the first and second polypeptides are amino acid residues other than Cys (C) at position 226 by EU numbering, amino acid residues other than Cy (C) at position 228, and amino acids 407 at position 229.
- the position is Cys (C), one of the polypeptides is at position 356 by EU numbering, one of Lys (K), Arg (R) and His (H), and the other polypeptide is at position 439 by EU numbering Is Glu (E) or Asp (D).
- the first polypeptide is Ser (S) at position 226 by EU numbering, Pro (P) at position 228, Ser (S) at position 229, Cys (C) at position 349, and position 356.
- the second polypeptide is Ser (S) at position 226 by EU numbering, Pro (P) at position 228, and Ser at position 229.
- (S) and 356 are Cys (C), and 439 is Glu (E) or Asp (D).
- the first polypeptide is Ser (S) at position 226 by EU numbering, Pro (P) at position 228, Ser (S) at position 229, Cys (C) at position 349 and Tyr (Y at position 397 ), And position 356 is one of Lys (K), Arg (R), and His (H), and the second polypeptide is EU (numbered) at position 226, Ser (S), and position 228 is Pro. (P), Ser (S) at position 229, Cys (C) at position 356, Tyr (Y) at position 397, and Glu (E) or Asp (D) at position 439.
- the first and second polypeptides are Ser (S) at position 226 by EU numbering, Pro (P) at position 228, Ser (S) at position 229 and Cys (C) at position 394, Polypeptide of 356 by EU numbering is one of Lys (K), Arg (R) and His (H), and the other polypeptide is 439 by EU numbering at Glu (E) or Asp (D) It is.
- the first polypeptide is Ser (S) at position 226 by EU numbering, Pro (P) at position 228, Ser (S) at position 229, Cys (C) at position 349,
- the peptide is Ser (S) at position 226 by EU numbering, Pro (P) at position 228, Ser (S) at position 229, Cys (C) at position 354, while one polypeptide is at position 356 by EU numbering.
- One of Lys (K), Arg (R) and His (H), and the other polypeptide is Glu (E) or Asp (D) at position 439 by EU numbering.
- the first and second polypeptides are Ser (S) at position 226 by EU numbering, Pro (P) at position 228, Ser (S) at position 229, Cys (C) at position 351, Polypeptide of 356 by EU numbering is one of Lys (K), Arg (R) and His (H), and the other polypeptide is 439 by EU numbering at Glu (E) or Asp (D) It is.
- the first and second polypeptides are Ser (S) at position 226 by EU numbering, Pro (P) at position 228, Ser (S) at position 229 and Cys (C) at position 407, Polypeptide of 356 by EU numbering is one of Lys (K), Arg (R) and His (H), and the other polypeptide is 439 by EU numbering at Glu (E) or Asp (D) It is.
- a bispecific antibody in which the heavy chain constant regions of the first and second polypeptides are each amino acid residues shown in any of (1) to (6) below is provided.
- the first polypeptide has EU numbering at position 226 for amino acid residues other than Cys (C), position 229 for amino acid residues other than Cys (C), position 349 for Cys (C) and position 356 for Lys (K), and the second polypeptide is amino acid residue other than Cys (C) at position 226 by EU numbering, amino acid residue other than Cys (C) at position 229, Cys (C) and 439 at position 356
- the place is Glu (E).
- the first polypeptide has EU numbering at position 226 for amino acid residues other than Cys (C), position 229 for amino acid residues other than Cys (C), position 349 for Cys (C), position 356 for Lys (K) and 397 are Tyr (Y), and the second polypeptide has an EU numbering of position 226, an amino acid residue other than Cys (C), position 229, an amino acid residue other than Cys (C), 356
- the position is Cys (C)
- the position 397 is Tyr (Y)
- the position 439 is Glu (E).
- the first polypeptide has EU numbering at position 226 for amino acid residues other than Cys (C), position 229 for amino acid residues other than Cys (C), position 394 for Cys (C) and position 356 for Lys (K), and the second polypeptide is amino acid residue other than Cys (C) at position 226 by EU numbering, amino acid residue other than Cys (C) at position 229, Cys (C) and 439 at position 394
- the place is Glu (E).
- the first polypeptide has EU numbering at position 226 for amino acid residues other than Cys (C), position 229 for amino acid residues other than Cys (C), position 349 for Cys (C) and position 356 for Lys (K), and the second polypeptide is an amino acid residue other than Cys (C) at position 226 by EU numbering, an amino acid residue other than Cys (C) at position 229, and Cys (C) and 439 at position 354.
- the place is Glu (E).
- the first polypeptide has EU numbering at position 226 for amino acid residues other than Cys (C), position 229 for amino acid residues other than Cys (C), position 351 for Cys (C) and position 356 for Lys (K), and the second polypeptide is amino acid residue other than Cys (C) at position 226 by EU numbering, amino acid residue other than Cys (C) at position 229, Cys (C) and 439 at position 351
- the place is Glu (E).
- the first polypeptide has EU numbering at position 226 for amino acid residues other than Cys (C), position 229 for amino acid residues other than Cys (C), position 407 for Cys (C) and position 356 for Lys (K), the second polypeptide is amino acid residue other than Cys (C) at position 226 by EU numbering, amino acid residue other than Cys (C) at position 229, Cys (C) and 439 at position 407
- the place is Glu (E).
- the present invention provides a bispecific antibody in which the heavy chain constant regions of the first and second polypeptides are amino acid residues shown in any of the following (1) to (6), respectively. .
- the first polypeptide is Ser (S) at position 226 by EU numbering, Ser (S) at position 229, Cys (C) at position 349, and Lys (K) at position 356.
- the peptide is Ser (S) at position 226 by EU numbering, Ser (S) at position 229, Cys (C) at position 356, and Glu (E) at position 439.
- the first polypeptide is Ser (S) at position 226 by EU numbering, Ser (S) at position 229, Cys (C) at position 349, Lys (K) at position 356, and Tyr (Y at position 397 ),
- the second polypeptide is Ser (S) at position 226 by EU numbering, Ser (S) at position 229, Cys (C) at position 356, Tyr (Y) at position 397 and Glu ( E).
- the first polypeptide is Ser (S) at position 226 by EU numbering, Ser (S) at position 229, Cys (C) at position 394, and Lys (K) at position 356.
- the peptide is Ser (S) at position 226 by EU numbering, Ser (S) at position 229, Cys (C) at position 394, and Glu (E) at position 439.
- the first polypeptide is Ser (S) at position 226 by EU numbering, Ser (S) at position 229, Cys (C) at position 349 and Lys (K) at position 356.
- the peptide is Ser (S) at position 226, Ser (S) at position 229, Cys (C) at position 354, and Glu (E) at position 439.
- the first polypeptide is Ser (S) at position 226 by EU numbering, Ser (S) at position 229, Cys (C) at position 351, and Lys (K) at position 356. According to EU numbering, the peptide is Ser (S) at position 226, Ser (S) at position 229, Cys (C) at position 351, and Glu (E) at position 439.
- the first polypeptide is Ser (S) at position 226 by EU numbering, Ser (S) at position 229, Cys (C) at position 407, and Lys (K) at position 356. According to EU numbering, the peptide is Ser (S) at position 226, Ser (S) at position 229, Cys (C) at position 407, and Glu (E) at position 439.
- the first polypeptide is amino acid residue other than Cys (C) at position 226 by EU numbering
- the second polypeptide is an amino acid residue other than Cys (C) by EU numbering
- 228 is Pro
- 229 is Cys (C ) Amino acid residues other than)
- position 356 is Cys (C) and position 439 is Glu (E).
- the first polypeptide is amino acid residue other than Cys (C) at position 226 by EU numbering, position 228 at position Pro (P), position 229 at position other than Cys (C), position 349 at Cys (C), Lys (K) at position 356 and Tyr (Y) at position 397
- the second polypeptide is amino acid residue other than Cys (C) at position 226 by EU numbering, and Pro (P ), Amino acid residue other than Cys (C), position 356 is Cys (C), position 397 is Tyr (Y), and position 439 is Glu (E).
- the first polypeptide is amino acid residue other than Cys (C) at position 226 by EU numbering, amino acid residue other than Cy (C) at position 228, amino acid residue other than Cys (C) at position 229, and Cys at position 394.
- C) and 356 are Lys (K)
- the second polypeptide is an amino acid residue other than Cys (C) by EU numbering
- 228 is Pro
- 229 is Cys (C ) Amino acid residues other than)
- position 394 is Cys (C) and position 439 is Glu (E).
- the first polypeptide is amino acid residue other than Cys (C) at position 226 according to EU numbering
- amino acid residue other than Cy (C) at position 228, amino acid residue other than Cys (C) at position 229, and Cys at position 349 (C) and 356 are Lys (K)
- the second polypeptide is an amino acid residue other than Cys (C) by EU numbering
- 228 is Pro (P)
- 229 is Cys (C ) Amino acid residues other than)
- Cys (C) at position 354 and Glu (E) at position 439 is amino acid residue other than Cys (C) at position 226 according to EU numbering
- the second polypeptide is an amino acid residue other than Cys (C) by EU numbering
- 228 is Pro
- 229 is Cys (C
- the first polypeptide has EU numbering at position 226, which is an amino acid residue other than Cys (C), position 228 is Pro (P), position 229 is an amino acid residue other than Cys (C), and position 351 is Cys. (C) and 356 are Lys (K), the second polypeptide is an amino acid residue other than Cys (C) by EU numbering, 228 is Pro (P), 229 is Cys (C ) Amino acid residues other than), Cys (C) at position 351 and Glu (E) at position 439.
- the first polypeptide is amino acid residue other than Cys (C) at position 226 by EU numbering, position 228 at position Pro (P), position 229 at position other than Cys (C), position 407 at Cys (C) and 356 are Lys (K), the second polypeptide is an amino acid residue other than Cys (C) by EU numbering, 228 is Pro (P), 229 is Cys (C ) Amino acid residues other than), position 407 is Cys (C) and position 439 is Glu (E).
- the first polypeptide is Ser (S) at position 226 by EU numbering, Pro (P) at position 228, Ser (S) at position 229, Cys (C) at position 349 and Lys (K at position 356. )
- the second polypeptide is Ser (S) at position 226 by EU numbering, Pro (P) at position 228, Ser (S) at position 229, Cys (C) at position 356, and Glu ( E).
- the first polypeptide is Ser (S) at position 226 by EU numbering, Pro (P) at position 228, Ser (S) at position 229, Cys (C) at position 349, Lys (K at position 356 ) And 397 are Tyr (Y), and the second polypeptide is EU (numbered 226: Ser (S), 228: Pro (P), 229: Ser (S), 356: Cys ( C), 397 is Tyr (Y) and 439 is Glu (E).
- the first polypeptide is Ser (S) at position 226 by EU numbering, Pro (P) at position 228, Ser (S) at position 229, Cys (C) at position 394 and Lys (K at position 356.
- the second polypeptide is Ser (S) at position 226 by EU numbering, Pro (P) at position 228, Ser (S) at position 229, Cys (C) at position 394 and Glu (position at position 439).
- the first polypeptide is Ser (S) at position 226 by EU numbering, Pro (P) at position 228, Ser (S) at position 229, Cys (C) at position 349 and Lys (K at position 356. )
- the second polypeptide is Ser (S) at position 226 by EU numbering, Pro (P) at position 228, Ser (S) at position 229, Cys (C) at position 354 and Glu ( E).
- the first polypeptide is Ser (S) at position 226 by EU numbering, Pro (P) at position 228, Ser (S) at position 229, Cys (C) at position 351 and Lys (K at position 356. )
- the second polypeptide is Ser (S) at position 226 by EU numbering, Pro (P) at position 228, Ser (S) at position 229, Cys (C) at position 351 and Glu ( E).
- the first polypeptide is Ser (S) at position 226 by EU numbering, Pro (P) at position 228, Ser (S) at position 229, Cys (C) at position 407, and Lys (K at position 356. )
- the second polypeptide is Ser (S) at position 226 by EU numbering, Pro (P) at position 228, Ser (S) at position 229, Cys (C) at position 407 and Glu ( E).
- the present invention is a method for producing a heteromultimer utilizing isomerization of a disulfide bond of cysteine (disulfide bond between L chains) in an antibody light chain constant region.
- the cysteine used in the present method is not particularly limited as long as it is a cysteine present in the antibody light chain constant region, and includes, for example, cysteine at the L chain C-terminus (position 214).
- cysteine at position 131 by EU numbering of antibody heavy chain constant region is changed to other amino acid, for example Ser (S).
- Ser (S) amino acid
- cysteine at position 220 by EU numbering of the antibody heavy chain constant region is modified to another amino acid, such as Ser (S), but is not particularly limited to this modification.
- polypeptide containing an IgG4 antibody heavy chain constant region whose amino acid position is other than cysteine at position 131 by EU numbering or a polypeptide containing an IgG1 antibody heavy chain constant region whose amino acid position is other than cysteine at position 220 by EU numbering is used. May be.
- the core hinge region preferably does not contain cysteine.
- cysteine at position 226 and / or 229 by EU numbering is modified with other amino acids, and amino acid residues at positions 226 to 229 by EU numbering are SPPS. SPSS may be used, but is not limited to these. Further, the cysteine at position 226 and / or 229 by EU numbering may be deleted.
- amino acid residues contained in the hinge region may be modified and / or deleted, and other amino acids may be inserted.
- EU numbering position 220 may be substituted with serine, or EU numbering positions 220 to 225 may be substituted with IgG4 sequences, but it is not particularly limited thereto.
- EU numbering positions 219 to 229 may be deleted, but the invention is not limited thereto.
- IgG1 or IgG4 may lack positions 216 to 230 due to EU numbering.
- a method for producing a heterogeneous multimer is provided.
- the first and second polypeptides are amino acid residues other than Cys (C) at position 131 by EU numbering.
- position 220 by EU numbering is an amino acid residue other than Cys (C).
- (1) is IgG4 and (2) is IgG1.
- the heavy chain constant regions of the first and second polypeptides each have an amino acid residue shown in any of (1) to (2) below, and the first and second polypeptides contain a large amount of heterogeneous
- a method of manufacturing a body is provided.
- the first and second polypeptides are Ser (S) at position 131 by EU numbering.
- position 220 by EU numbering is Ser (S) or Tyr (Y).
- (1) is IgG4 and (2) is IgG1.
- a method for producing a heterogeneous multimer comprising (1) The first and second polypeptides are amino acid residues other than Cys (C) at position 131 by EU numbering, amino acid residues other than Cys (C) at position 226, and positions other than Cys (C) at position 229 An amino acid residue.
- the first and second polypeptides are amino acid residues other than Cys (C) at position 131 by EU numbering, amino acid residues other than Cys (C) at position 226, Pro (P) at position 228, 229 The position is an amino acid residue other than Cys (C).
- the first and second polypeptides are amino acid residues other than Cys (C) at position 220 by EU numbering, amino acid residues other than Cys (C) at position 226, and positions other than Cys (C) at position 229. An amino acid residue.
- the first and second polypeptides are deleted by amino acid residues other than Cys (C) at positions 131 and positions 219 to 229 by EU numbering.
- the first and second polypeptides are deleted at positions 219 to 229 due to EU numbering.
- the first and second polypeptides are amino acid residues other than Cys (C) at position 226 by EU numbering, amino acid residues other than Cys (C) at position 229, and Tyr (Y ) -Gly (G) -Pro (P) -Pro (P).
- Preferably (1), (2) and (4) are IgG4 and (3), (5) and (6) are IgG1.
- the heavy chain constant regions of the first and second polypeptides each have an amino acid residue shown in any of (1) to (6) below, and the first and second polypeptides contain a large amount of heterogeneous
- a method of manufacturing a body is provided.
- the first and second polypeptides are Ser (S) at position 131, Ser (S) at position 226, and Ser (S) at position 229 by EU numbering.
- the first and second polypeptides are Ser (S) at position 131, Ser (S) at position 226, Pro (P) at position 228, and Ser (S) at position 229 by EU numbering.
- the first and second polypeptides are Ser (S) or Tyr (Y) at position 220 by EU numbering, Ser (S) at position 226, and Ser (S) at position 229.
- the first and second polypeptides lack Ser (S) at position 131 and positions 219 to 229 by EU numbering.
- the first and second polypeptides are deleted at positions 219 to 229 due to EU numbering.
- the first and second polypeptides are Ser (S) at position 226 by EU numbering, Ser (S) at position 229, and Tyr (Y) -Gly (G) -Pro (P at positions 220-225. ) -Pro (P).
- (1), (2) and (4) are IgG4 and (3)
- (5) and (6) are IgG1.
- a method for producing a heterogeneous multimer comprising (1) The first and second polypeptides are amino acid residues other than Cys (C) at position 131 by EU numbering, amino acid residues other than Cys (C) at position 226, and positions other than Cys (C) at position 229 An amino acid residue.
- the first and second polypeptides are amino acid residues other than Cys (C) at position 131 by EU numbering, amino acid residues other than Cys (C) at position 226, Pro (P) at position 228, 229 The position is an amino acid residue other than Cys (C).
- the first and second polypeptides are amino acid residues other than Cys (C) at position 220 by EU numbering, amino acid residues other than Cys (C) at position 226, and positions other than Cys (C) at position 229.
- the amino acid residue and position 409 is Arg (R).
- the first and second polypeptides are deleted by amino acid residues other than Cys (C) at positions 131 and positions 219 to 229 by EU numbering.
- the first and second polypeptides are deleted at positions 219 to 229 by EU numbering, and position 409 is Arg (R).
- the first and second polypeptides are amino acid residues other than Cys (C) at position 226 by EU numbering, amino acid residues other than Cys (C) at position 229, and Tyr (Y ) -Gly (G) -Pro (P) -Pro (P), position 409 is Arg (R).
- Preferably (1), (2) and (4) are IgG4 and (3), (5) and (6) are IgG1.
- the heavy chain constant regions of the first and second polypeptides each have an amino acid residue shown in any of (1) to (6) below, and the first and second polypeptides contain a large amount of heterogeneous
- a method of manufacturing a body is provided.
- the first and second polypeptides are Ser (S) at position 131, Ser (S) at position 226, and Ser (S) at position 229 by EU numbering.
- the first and second polypeptides are Ser (S) at position 131, Ser (S) at position 226, Pro (P) at position 228, and Ser (S) at position 229 by EU numbering.
- the first and second polypeptides are Ser (S) or Tyr (Y) at position 220 by EU numbering, Ser (S) at position 226, Ser (S) at position 229, and Arg (R at position 409. ).
- the first and second polypeptides lack Ser (S) at position 131 and positions 219 to 229 by EU numbering.
- the first and second polypeptides are deleted at positions 219 to 229 by EU numbering, and position 409 is Arg (R).
- the first and second polypeptides are Ser (S) at position 226 by EU numbering, Ser (S) at position 229, and Tyr (Y) -Gly (G) -Pro (P at positions 220-225. ) -Pro (P), position 409 is Arg (R).
- (1), (2) and (4) are IgG4 and (3)
- (5) and (6) are IgG1.
- a method for producing a heterogeneous multimer comprising (1) The first polypeptide has an amino acid residue other than Cys (C) at position 131 by EU numbering, an amino acid residue other than Cys (C) at position 226, and an amino acid residue other than Cys (C) at position 229 And position 356 is any one of Lys (K), Arg (R) and His (H), and the second polypeptide has an amino acid residue other than Cys (C) at position 131 by EU numbering, Position 226 is an amino acid residue other than Cys (C), position 229 is an amino acid residue other than Cys (C), and position 439 is Glu (E) or Asp (D).
- amino acid residue other than Cys (C) at position 131 by EU numbering amino acid residue other than Cys (C) at position 226, Pro (P) at position 228 and Cys at position 229 (C) is an amino acid residue, and position 356 is one of Lys (K), Arg (R) and His (H), and the second polypeptide has position 131 by EU numbering at Cys ( Amino acid residues other than C), position 226 is an amino acid residue other than Cys (C), position 228 is an amino acid residue other than Pro (P) and position 229 is other than Cys (C), and position 439 is Glu.
- the first polypeptide which is (E) or Asp (D), is amino acid residue other than Cys (C) at position 220 by EU numbering
- amino acid residue other than Cys (C) at position 226, and position 229 Is an amino acid residue other than Cys (C)
- position 356 is any of Lys (K), Arg (R) and His (H)
- the second polypeptide has position 220 by EU numbering.
- position 226 is an amino acid other than Cys (C)
- Acid residue and position 229 is an amino acid residue except Cys (C)
- 439 of is Glu (E) or Asp (D).
- the first polypeptide has an amino acid residue other than Cys (C) at position 131 by EU numbering, positions 219-229 deleted, and position 356 at Lys (K), Arg (R ) And His (H), and the second polypeptide has an amino acid residue other than Cys (C) at position 131 by EU numbering, positions 219 to 229 are deleted, and position 439 Is Glu (E) or Asp (D).
- the first polypeptide is deleted at positions 219 to 229 by EU numbering, and position 356 is one of Lys (K), Arg (R), and His (H).
- the polypeptide lacks positions 219 to 229 by EU numbering, and position 439 is Glu (E) or Asp (D).
- the first polypeptide has EU numbering at position 226 for amino acid residues other than Cys (C), position 229 for amino acid residues other than Cys (C), and positions 220 to 225 for Tyr (Y) -Gly (G) -Pro (P) -Pro (P) and position 356 is any of Lys (K), Arg (R) and His (H), and the second polypeptide is obtained by EU numbering.
- Position 226 is an amino acid residue other than Cys (C)
- position 229 is an amino acid residue other than Cys (C)
- positions 220 to 225 are Tyr (Y) -Gly (G) -Pro (P) -Pro (P )
- position 439 is Glu (E) or Asp (D).
- (1), (2) and (4) are IgG4 and (3)
- (5) and (6) are IgG1.
- a method for producing a heterogeneous multimer comprising (1) The first polypeptide has an amino acid residue other than Cys (C) at position 131 by EU numbering, an amino acid residue other than Cys (C) at position 226, and an amino acid residue other than Cys (C) at position 229 And position 356 is any one of Lys (K), Arg (R) and His (H), and the second polypeptide has an amino acid residue other than Cys (C) at position 131 by EU numbering, Position 226 is an amino acid residue other than Cys (C), position 229 is an amino acid residue other than Cys (C), and position 439 is Glu (E) or Asp (D).
- amino acid residue other than Cys (C) at position 131 by EU numbering amino acid residue other than Cys (C) at position 226, Pro (P) at position 228 and Cys at position 229 (C) is an amino acid residue, and position 356 is one of Lys (K), Arg (R) and His (H), and the second polypeptide has position 131 by EU numbering at Cys ( Amino acid residues other than C), position 226 is an amino acid residue other than Cys (C), position 228 is an amino acid residue other than Pro (P) and position 229 is other than Cys (C), and position 439 is Glu.
- the first polypeptide is (E) or Asp (D).
- position 220 is an amino acid residue other than Cys (C)
- position 226 is an amino acid residue other than Cys (C)
- position 229 Is an amino acid residue other than Cys (C) and position 409 is Arg (R)
- position 356 is any of Lys (K), Arg (R) and His (H)
- the second poly Peptides are amino acid residues other than Cys (C) at position 220 by EU numbering, and positions 226 at Cys (C Amino acid residue other than C), amino acid residue other than Cys (C) at position 229 and Arg (R) at position 409, and Glu (E) or Asp (D) at position 439.
- the first polypeptide has an amino acid residue other than Cys (C) at position 131 by EU numbering, positions 219-229 deleted, and position 356 at Lys (K), Arg (R ) And His (H), and the second polypeptide has an amino acid residue other than Cys (C) at position 131 by EU numbering, positions 219 to 229 are deleted, and position 439 Is Glu (E) or Asp (D).
- positions 219 to 229 are deleted by EU numbering, position 409 is Arg (R), and position 356 is Lys (K), Arg (R) and His (H ),
- the second polypeptide is deleted at positions 219 to 229 by EU numbering, position 409 is Arg (R), and position 439 is Glu (E) or Asp (D) It is.
- the first polypeptide has EU numbering at position 226 for amino acid residues other than Cys (C), position 229 for amino acid residues other than Cys (C), and positions 220 to 225 for Tyr (Y) -Gly (G) -Pro (P) -Pro (P), position 409 is Arg (R), position 356 is one of Lys (K), Arg (R) and His (H), In the polypeptide of No.
- EU numbering 226 is an amino acid residue other than Cys (C)
- 229 is an amino acid residue other than Cys (C)
- 220 to 225 are Tyr (Y) -Gly (G)- Pro (P) -Pro (P)
- position 409 is Arg (R)
- position 439 is Glu (E) or Asp (D).
- (1), (2) and (4) are IgG4 and (3), (5) and (6) are IgG1.
- the heavy chain constant regions of the first and second polypeptides each have an amino acid residue shown in any of (1) to (6) below, and the first and second polypeptides contain a large amount of heterogeneous
- a method of manufacturing a body is provided.
- the first polypeptide has Ser (S) at position 131 by EU numbering, Ser (S) at position 226 and Ser (S) at position 229, and Lys (K), Arg (position 356). R) and His (H), and the second polypeptide is Ser (S) at position 131, Ser (S) at position 226 and Ser (S) at position 229 by EU numbering, and Position 439 is Glu (E) or Asp (D).
- the 1st polypeptide is Ser (S) at position 131 by EU numbering, Ser (S) at position 226, Pro (P) at position 228, Ser (S) at position 229, and position 356 Is one of Lys (K), Arg (R) and His (H), and the second polypeptide has EU numbering at position 131, Ser (S), position 226, Ser (S), position 228, Pro. (P) and position 229 are Ser (S) and position 439 is Glu (E) or Asp (D).
- the first polypeptide has position 220 by EU numbering Ser (S) or Tyr (Y), position 226 is Ser (S) and position 229 is Ser (S), position 356 is either Lys (K), Arg (R), or His (H), According to the EU numbering, position 220 is Ser (S) or Tyr (Y), position 226 is Ser (S) and position 229 is Ser (S), and position 439 is Glu (E) or Asp ( D).
- the first polypeptide is EU (numbered) at position 226, Ser (S), position 229, Ser (S), position 220-225, Tyr (Y) -Gly (G) -Pro (P) -Pro (P) and position 356 is one of Lys (K), Arg (R) and His (H), and the second polypeptide is position 226 by EU numbering at position Ser (S) and position 229.
- Is Ser (S), positions 220 to 225 are Tyr (Y) -Gly (G) -Pro (P) -Pro (P), and position 439 is Glu (E) or Asp (D) .
- (1), (2) and (4) are IgG4 and (3)
- (5) and (6) are IgG1.
- the heavy chain constant regions of the first and second polypeptides each have an amino acid residue shown in any of (1) to (6) below, and the first and second polypeptides contain a large amount of heterogeneous
- a method of manufacturing a body is provided.
- the first polypeptide has Ser (S) at position 131 by EU numbering, Ser (S) at position 226 and Ser (S) at position 229, and Lys (K), Arg (position 356). R) and His (H), and the second polypeptide is Ser (S) at position 131, Ser (S) at position 226 and Ser (S) at position 229 by EU numbering, and Position 439 is Glu (E) or Asp (D).
- the 1st polypeptide is Ser (S) at position 131 by EU numbering, Ser (S) at position 226, Pro (P) at position 228, Ser (S) at position 229, and position 356 Is one of Lys (K), Arg (R) and His (H), and the second polypeptide has EU numbering at position 131, Ser (S), position 226, Ser (S), position 228, Pro. (P) and position 229 are Ser (S) and position 439 is Glu (E) or Asp (D).
- the first polypeptide has position 220 by EU numbering Ser (S) or Tyr (Y), position 226 is Ser (S), position 229 is Ser (S), position 409 is Arg (R), position 356 is Lys (K), Arg (R) and His (H)
- the second polypeptide is Ser (S) or Tyr (Y) at position 220 by EU numbering, Ser (S) at position 226, Ser (S) at position 229, and Arg (R at position 409. ) And position 439 is Glu (E) or Asp (D).
- positions 219 to 229 are deleted by EU numbering, position 409 is Arg (R), and position 356 is Lys (K), Arg (R) and His (H ),
- the second polypeptide is deleted at positions 219 to 229 by EU numbering, position 409 is Arg (R), and position 439 is Glu (E) or Asp (D) It is.
- the first polypeptide is EU (numbered) at position 226, Ser (S), position 229, Ser (S), position 220-225, Tyr (Y) -Gly (G) -Pro (P) -Pro (P), position 409 is Arg (R), position 356 is any of Lys (K), Arg (R) and His (H), and the second polypeptide is position 226 by EU numbering.
- Is Ser (S), 229 is Ser (S), 220-225 is Tyr (Y) -Gly (G) -Pro (P) -Pro (P), 409 is Arg (R), And position 439 is Glu (E) or Asp (D).
- (1), (2) and (4) are IgG4 and (3)
- (5) and (6) are IgG1.
- a method for producing a heterogeneous multimer comprising (1) The first polypeptide is amino acid residue other than Cys (C) at position 131 by EU numbering, amino acid residue other than Cys (C) at position 226, and amino acid residue other than Cys (C) at position 229 And the 356th position is Lys (K), the second polypeptide is amino acid residue other than Cys (C) at position 131 by EU numbering, position 226 is an amino acid residue other than Cys (C), position 229 is Cys Amino acid residues other than (C) and position 439 are Glu (E).
- amino acid residue other than Cys (C) at position 220 by EU numbering amino acid residue other than Cys (C) at position 226, and amino acid residue other than Cys (C) at position 229 And 356 is Lys (K)
- amino acid residue other than Cys (C) at position 220 by EU numbering or Tyr (Y) amino acid residue other than Cys (C) is at position 226
- Position 229 is an amino acid residue other than Cys (C) and position 439 is Glu (E).
- the first polypeptide is amino acid residue other than Cys (C) at position 131 by EU numbering, positions 219 to 229 are deleted, position 356 is Lys (K), and the second polypeptide In EU numbering, amino acid residues other than Cys (C) are deleted at position 131, positions 219 to 229 are deleted, and position 439 is Glu (E).
- the first polypeptide is deleted at positions 219 to 229 by EU numbering, 356 is Lys (K), and the second polypeptide is deleted at positions 219 to 229 by EU numbering. , 439th place is Glu (E).
- the first polypeptide has EU numbering at position 226 for amino acid residues other than Cys (C), position 229 for amino acid residues other than Cys (C), and positions 220 to 225 for Tyr (Y) -Gly (G) -Pro (P) -Pro (P), position 356 is Lys (K), the second polypeptide is 226 by EU numbering, amino acid residue other than Cys (C), position 229 is Ser (S), positions 220 to 225 are Tyr (Y) -Gly (G) -Pro (P) -Pro (P), and position 439 is Glu (E).
- (1), (2) and (4) are IgG4 and (3), (5) and (6) are IgG1.
- a method for producing a heterogeneous multimer comprising (1) The first polypeptide is amino acid residue other than Cys (C) at position 131 by EU numbering, amino acid residue other than Cys (C) at position 226, and amino acid residue other than Cys (C) at position 229 And the 356th position is Lys (K), the second polypeptide is amino acid residue other than Cys (C) at position 131 by EU numbering, position 226 is an amino acid residue other than Cys (C), position 229 is Cys Amino acid residues other than (C) and position 439 are Glu (E).
- amino acid residue other than Cys (C) at position 220 by EU numbering amino acid residue other than Cys (C) at position 226, and amino acid residue other than Cys (C) at position 229 409 position is Arg (R) and 356 position is Lys (K)
- the second polypeptide is the amino acid residue other than Cys (C) at position 220 by EU numbering or Tyr (Y)
- position 226 is Cys.
- Amino acid residues other than (C) amino acid residue other than Cys (C) at position 229, Arg (R) at position 409, and Glu (E) at position 439.
- the first polypeptide is amino acid residue other than Cys (C) at position 131 by EU numbering, positions 219 to 229 are deleted, position 356 is Lys (K), and the second polypeptide In EU numbering, amino acid residues other than Cys (C) are deleted at position 131, positions 219 to 229 are deleted, and position 439 is Glu (E).
- the first polypeptide is deleted at positions 219 to 229 by EU numbering, Arg (R) at position 409 and Lys (K) at position 356, and the second polypeptide is 219 by EU numbering. Positions 229 to 229 are deleted, position 409 is Arg (R) and position 439 is Glu (E).
- the first polypeptide has EU numbering at position 226 for amino acid residues other than Cys (C), position 229 for amino acid residues other than Cys (C), and positions 220 to 225 for Tyr (Y) -Gly (G) -Pro (P) -Pro (P), position 409 is Arg (R) and position 356 is Lys (K), and the second polypeptide is position 226 by EU numbering other than Cys (C).
- Amino acid residue, position 229 is Ser (S), position 220-225 is Tyr (Y) -Gly (G) -Pro (P) -Pro (P), position 409 is Arg (R) and position 439 is Glu (E).
- (1), (2) and (4) are IgG4 and (3), (5) and (6) are IgG1.
- the heavy chain constant regions of the first and second polypeptides each have an amino acid residue shown in any of (1) to (6) below, and the first and second polypeptides contain a large amount of heterogeneous
- a method of manufacturing a body is provided.
- the first polypeptide is Ser (S) at position 131 by EU numbering, Ser (S) at position 226, Ser (S) at position 229 and Lys (K) at position 356.
- Peptide according to EU numbering is Ser (S) at position 131, Ser (S) at position 226, Ser (S) at position 229, and Glu (E) at position 439.
- the first polypeptide is Ser (S) at position 131 by EU numbering, Ser (S) at position 226, Pro (P) at position 228, Ser (S) at position 229 and Lys (K at position 356.
- the second polypeptide is Ser (S) at position 131 by EU numbering, Ser (S) at position 226, Pro (P) at position 228, Ser (S) at position 229, and Glu (position at position 439).
- the first polypeptide is Ser (S) or Tyr (Y) at position 220 by EU numbering, Ser (S) at position 226, Ser (S) at position 229, and Lys (K) at position 356.
- the second polypeptide is Ser (S) or Tyr (Y) at position 220 by EU numbering, Ser (S) at position 226, Ser (S) at position 229, and Glu (E) at position 439.
- the first polypeptide has Ser (S) at position 131 by EU numbering, deletions at positions 219 to 229 and Lys (K) at position 356, and the second polypeptide has 131 by EU numbering.
- the position is Ser (S), positions 219 to 229 are deleted, and position 439 is Glu (E).
- the first polypeptide is deleted at positions 219 to 229 by EU numbering, 356 is Lys (K), and the second polypeptide is deleted at positions 219 to 229 by EU numbering.
- the first polypeptide is EU (numbered) at position 226, Ser (S), position 229, Ser (S), position 220-225, Tyr (Y) -Gly (G) -Pro (P) -Pro (P), position 356 is Lys (K), and the second polypeptide is Ser (S) at position 226 by EU numbering, Ser (S) at position 229, and Tyr (Y)-at positions 220-225.
- position 439 is Glu (E).
- (1), (2) and (4) are IgG4 and (3)
- (5) and (6) are IgG1.
- the heavy chain constant regions of the first and second polypeptides each have an amino acid residue shown in any of (1) to (6) below, and the first and second polypeptides contain a large amount of heterogeneous
- a method of manufacturing a body is provided.
- the first polypeptide is Ser (S) at position 131 by EU numbering, Ser (S) at position 226, Ser (S) at position 229 and Lys (K) at position 356.
- Peptide according to EU numbering is Ser (S) at position 131, Ser (S) at position 226, Ser (S) at position 229, and Glu (E) at position 439.
- the first polypeptide is Ser (S) at position 131 by EU numbering, Ser (S) at position 226, Pro (P) at position 228, Ser (S) at position 229 and Lys (K at position 356.
- the second polypeptide is Ser (S) at position 131 by EU numbering, Ser (S) at position 226, Pro (P) at position 228, Ser (S) at position 229, and Glu (position at position 439).
- position 220 by EU numbering is Ser (S) or Tyr (Y)
- position 226 is Ser (S)
- position 229 is Ser (S)
- position 409 is Arg (R) and 356.
- the second polypeptide is Ser (S) or Tyr (Y) by EU numbering
- position 226 is Ser (S)
- position 229 is Ser (S)
- position 409 is the second polypeptide.
- Arg (R) and 439 are Glu (E).
- the first polypeptide has Ser (S) at position 131 by EU numbering, deletions at positions 219 to 229 and Lys (K) at position 356, and the second polypeptide has 131 by EU numbering.
- the position is Ser (S), positions 219 to 229 are deleted, and position 439 is Glu (E).
- the first polypeptide is deleted at positions 219 to 229 by EU numbering, Arg (R) at position 409 and Lys (K) at position 356, and the second polypeptide is 219 by EU numbering.
- Positions 229 to 229 are deleted, position 409 is Arg (R) and position 439 is Glu (E).
- the first polypeptide is EU (numbered) at position 226, Ser (S), position 229, Ser (S), position 220-225, Tyr (Y) -Gly (G) -Pro (P) -Pro (P), position 409 is Arg (R), position 356 is Lys (K), and the second polypeptide is EU (numbered 226 position Ser (S), position 229 position Ser (S), position 220- Position 225 is Tyr (Y) -Gly (G) -Pro (P) -Pro (P), position 409 is Arg (R), and position 439 is Glu (E).
- (1), (2) and (4) are IgG4 and (3)
- (5) and (6) are IgG1.
- a first polypeptide that is an antibody heavy chain and a third polypeptide that is an antibody light chain form a dimer
- a second polypeptide that is an antibody heavy chain and A bispecific antibody comprising a first polypeptide, a second polypeptide, a third polypeptide, and a fourth polypeptide as a component, which forms a dimer with a fourth polypeptide that is an antibody light chain, comprising: And / or a bispecific antibody comprising the first and second polypeptides, wherein the second polypeptide has the amino acid residues shown below:
- first and second polypeptides in which the heavy chain constant regions of the first and second polypeptides each have an amino acid residue shown in any of (1) to (2) below: Bispecific antibodies comprising are provided.
- the first and second polypeptides are amino acid residues other than Cys (C) at position 131 by EU numbering.
- position 220 by EU numbering is an amino acid residue other than Cys (C).
- (1) is IgG4 and (2) is IgG1.
- the first and second polypeptides are Ser (S) at position 131 by EU numbering.
- position 220 by EU numbering is Ser (S) or Tyr (Y).
- (1) is IgG4 and (2) is IgG1.
- first and second polypeptides in which the heavy chain constant regions of the first and second polypeptides each have an amino acid residue shown in any of (1) to (6) below: Bispecific antibodies comprising are provided.
- the first and second polypeptides are amino acid residues other than Cys (C) at position 131 by EU numbering, amino acid residues other than Cys (C) at position 226, and positions other than Cys (C) at position 229 An amino acid residue.
- the first and second polypeptides are amino acid residues other than Cys (C) at position 131 by EU numbering, amino acid residues other than Cys (C) at position 226, Pro (P) at position 228, 229 The position is an amino acid residue other than Cys (C).
- the first and second polypeptides are amino acid residues other than Cys (C) at position 220 by EU numbering, amino acid residues other than Cys (C) at position 226, and positions other than Cys (C) at position 229. An amino acid residue.
- the first and second polypeptides are deleted by amino acid residues other than Cys (C) at positions 131 and positions 219 to 229 by EU numbering.
- the first and second polypeptides are deleted at positions 219 to 229 due to EU numbering.
- the first and second polypeptides are amino acid residues other than Cys (C) at position 226 by EU numbering, amino acid residues other than Cys (C) at position 229, and Tyr (Y ) -Gly (G) -Pro (P) -Pro (P).
- Preferably (1), (2) and (4) are IgG4 and (3), (5) and (6) are IgG1.
- the first and second polypeptides are Ser (S) at position 131, Ser (S) at position 226, and Ser (S) at position 229 by EU numbering.
- the first and second polypeptides are Ser (S) at position 131, Ser (S) at position 226, Pro (P) at position 228, and Ser (S) at position 229 by EU numbering.
- the first and second polypeptides are Ser (S) or Tyr (Y) at position 220 by EU numbering, Ser (S) at position 226, and Ser (S) at position 229.
- the first and second polypeptides lack Ser (S) at position 131 and positions 219 to 229 by EU numbering. (5) The first and second polypeptides are deleted at positions 219 to 229 due to EU numbering. (6) The first and second polypeptides are Ser (S) at position 226 by EU numbering, Ser (S) at position 229, and Tyr (Y) -Gly (G) -Pro (P at positions 220-225. ) -Pro (P).
- (1), (2) and (4) are IgG4 and (3), (5) and (6) are IgG1.
- first and second polypeptides in which the heavy chain constant regions of the first and second polypeptides each have an amino acid residue shown in any of (1) to (6) below: Bispecific antibodies comprising are provided.
- the first and second polypeptides are amino acid residues other than Cys (C) at position 131 by EU numbering, amino acid residues other than Cys (C) at position 226, and positions other than Cys (C) at position 229 An amino acid residue.
- the first and second polypeptides are amino acid residues other than Cys (C) at position 131 by EU numbering, amino acid residues other than Cys (C) at position 226, Pro (P) at position 228, 229 The position is an amino acid residue other than Cys (C).
- the first and second polypeptides are amino acid residues other than Cys (C) at position 220 by EU numbering, amino acid residues other than Cys (C) at position 226, and positions other than Cys (C) at position 229.
- the amino acid residue and position 409 is Arg (R).
- the first and second polypeptides are deleted by amino acid residues other than Cys (C) at positions 131 and positions 219 to 229 by EU numbering.
- the first and second polypeptides are deleted at positions 219 to 229 by EU numbering, and position 409 is Arg (R).
- the first and second polypeptides are amino acid residues other than Cys (C) at position 226 by EU numbering, amino acid residues other than Cys (C) at position 229, and Tyr (Y ) -Gly (G) -Pro (P) -Pro (P), position 409 is Arg (R).
- Preferably (1), (2) and (4) are IgG4 and (3), (5) and (6) are IgG1.
- the first and second polypeptides are Ser (S) at position 131, Ser (S) at position 226, and Ser (S) at position 229 by EU numbering.
- the first and second polypeptides are Ser (S) at position 131, Ser (S) at position 226, Pro (P) at position 228, and Ser (S) at position 229 by EU numbering.
- the first and second polypeptides are Ser (S) or Tyr (Y) at position 220 by EU numbering, Ser (S) at position 226, Ser (S) at position 229, and Arg (R at position 409. ).
- the first and second polypeptides lack Ser (S) at position 131 and positions 219 to 229 by EU numbering.
- the first and second polypeptides are deleted at positions 219 to 229 by EU numbering, and position 409 is Arg (R).
- the first and second polypeptides are Ser (S) at position 226 by EU numbering, Ser (S) at position 229, and Tyr (Y) -Gly (G) -Pro (P at positions 220-225. ) -Pro (P), position 409 is Arg (R).
- (1), (2) and (4) are IgG4 and (3)
- (5) and (6) are IgG1.
- first and second polypeptides in which the heavy chain constant regions of the first and second polypeptides each have an amino acid residue shown in any of (1) to (6) below: Bispecific antibodies comprising are provided.
- the first polypeptide has an amino acid residue other than Cys (C) at position 131 by EU numbering, an amino acid residue other than Cys (C) at position 226, and an amino acid residue other than Cys (C) at position 229
- And position 356 is any one of Lys (K), Arg (R) and His (H)
- the second polypeptide has an amino acid residue other than Cys (C) at position 131 by EU numbering
- Position 226 is an amino acid residue other than Cys (C)
- position 229 is an amino acid residue other than Cys (C)
- position 439 is Glu (E) or Asp (D).
- amino acid residue other than Cys (C) at position 131 by EU numbering amino acid residue other than Cys (C) at position 226, Pro (P) at position 228 and Cys at position 229 (C) is an amino acid residue, and position 356 is one of Lys (K), Arg (R) and His (H), and the second polypeptide has position 131 by EU numbering at Cys ( Amino acid residues other than C), position 226 is an amino acid residue other than Cys (C), position 228 is an amino acid residue other than Pro (P) and position 229 is other than Cys (C), and position 439 is Glu.
- the first polypeptide which is (E) or Asp (D), is amino acid residue other than Cys (C) at position 220 by EU numbering
- amino acid residue other than Cys (C) at position 226, and position 229 Is an amino acid residue other than Cys (C)
- position 356 is any of Lys (K), Arg (R) and His (H)
- the second polypeptide has position 220 by EU numbering.
- position 226 is an amino acid other than Cys (C)
- Acid residue and position 229 is an amino acid residue except Cys (C)
- 439 of is Glu (E) or Asp (D).
- the first polypeptide has an amino acid residue other than Cys (C) at position 131 by EU numbering, positions 219-229 deleted, and position 356 at Lys (K), Arg (R ) And His (H), and the second polypeptide has an amino acid residue other than Cys (C) at position 131 by EU numbering, positions 219 to 229 are deleted, and position 439 Is Glu (E) or Asp (D).
- the first polypeptide is deleted at positions 219 to 229 by EU numbering, and position 356 is one of Lys (K), Arg (R), and His (H).
- the polypeptide lacks positions 219 to 229 by EU numbering, and position 439 is Glu (E) or Asp (D).
- the first polypeptide has EU numbering at position 226 for amino acid residues other than Cys (C), position 229 for amino acid residues other than Cys (C), and positions 220 to 225 for Tyr (Y) -Gly (G) -Pro (P) -Pro (P) and position 356 is any of Lys (K), Arg (R) and His (H), and the second polypeptide is obtained by EU numbering.
- Position 226 is an amino acid residue other than Cys (C)
- position 229 is an amino acid residue other than Cys (C)
- positions 220 to 225 are Tyr (Y) -Gly (G) -Pro (P) -Pro (P )
- position 439 is Glu (E) or Asp (D).
- (1), (2) and (4) are IgG4 and (3)
- (5) and (6) are IgG1.
- first and second polypeptides in which the heavy chain constant regions of the first and second polypeptides each have an amino acid residue shown in any of (1) to (6) below: Bispecific antibodies comprising are provided.
- the first polypeptide has an amino acid residue other than Cys (C) at position 131 by EU numbering, an amino acid residue other than Cys (C) at position 226, and an amino acid residue other than Cys (C) at position 229
- And position 356 is any one of Lys (K), Arg (R) and His (H)
- the second polypeptide has an amino acid residue other than Cys (C) at position 131 by EU numbering
- Position 226 is an amino acid residue other than Cys (C)
- position 229 is an amino acid residue other than Cys (C)
- position 439 is Glu (E) or Asp (D).
- amino acid residue other than Cys (C) at position 131 by EU numbering amino acid residue other than Cys (C) at position 226, Pro (P) at position 228 and Cys at position 229 (C) is an amino acid residue, and position 356 is one of Lys (K), Arg (R) and His (H), and the second polypeptide has position 131 by EU numbering at Cys ( Amino acid residues other than C), position 226 is an amino acid residue other than Cys (C), position 228 is an amino acid residue other than Pro (P) and position 229 is other than Cys (C), and position 439 is Glu.
- the first polypeptide is (E) or Asp (D).
- position 220 is an amino acid residue other than Cys (C)
- position 226 is an amino acid residue other than Cys (C)
- position 229 Is an amino acid residue other than Cys (C) and position 409 is Arg (R)
- position 356 is any of Lys (K), Arg (R) and His (H)
- the second poly Peptides are amino acid residues other than Cys (C) at position 220 by EU numbering, and positions 226 at Cys (C Amino acid residue other than C), amino acid residue other than Cys (C) at position 229 and Arg (R) at position 409, and Glu (E) or Asp (D) at position 439.
- the first polypeptide has an amino acid residue other than Cys (C) at position 131 by EU numbering, positions 219-229 deleted, and position 356 at Lys (K), Arg (R ) And His (H), and the second polypeptide has an amino acid residue other than Cys (C) at position 131 by EU numbering, positions 219 to 229 are deleted, and position 439 Is Glu (E) or Asp (D).
- positions 219 to 229 are deleted by EU numbering, position 409 is Arg (R), and position 356 is Lys (K), Arg (R) and His (H ),
- the second polypeptide is deleted at positions 219 to 229 by EU numbering, position 409 is Arg (R), and position 439 is Glu (E) or Asp (D) It is.
- the first polypeptide has EU numbering at position 226 for amino acid residues other than Cys (C), position 229 for amino acid residues other than Cys (C), and positions 220 to 225 for Tyr (Y) -Gly (G) -Pro (P) -Pro (P), position 409 is Arg (R), position 356 is one of Lys (K), Arg (R) and His (H), In the polypeptide of No.
- EU numbering 226 is an amino acid residue other than Cys (C)
- 229 is an amino acid residue other than Cys (C)
- 220 to 225 are Tyr (Y) -Gly (G)- Pro (P) -Pro (P)
- position 409 is Arg (R)
- position 439 is Glu (E) or Asp (D).
- (1), (2) and (4) are IgG4 and (3), (5) and (6) are IgG1.
- the first polypeptide has Ser (S) at position 131 by EU numbering, Ser (S) at position 226 and Ser (S) at position 229, and Lys (K), Arg (position 356). R) and His (H), and the second polypeptide is Ser (S) at position 131, Ser (S) at position 226 and Ser (S) at position 229 by EU numbering, and Position 439 is Glu (E) or Asp (D).
- the 1st polypeptide is Ser (S) at position 131 by EU numbering, Ser (S) at position 226, Pro (P) at position 228, Ser (S) at position 229, and position 356 Is one of Lys (K), Arg (R) and His (H), and the second polypeptide has EU numbering at position 131, Ser (S), position 226, Ser (S), position 228, Pro. (P) and position 229 are Ser (S) and position 439 is Glu (E) or Asp (D).
- the first polypeptide has position 220 by EU numbering Ser (S) or Tyr (Y), position 226 is Ser (S) and position 229 is Ser (S), position 356 is either Lys (K), Arg (R), or His (H), According to the EU numbering, position 220 is Ser (S) or Tyr (Y), position 226 is Ser (S) and position 229 is Ser (S), and position 439 is Glu (E) or Asp ( D).
- the first polypeptide is EU (numbered) at position 226, Ser (S), position 229, Ser (S), position 220-225, Tyr (Y) -Gly (G) -Pro (P) -Pro (P) and position 356 is one of Lys (K), Arg (R) and His (H), and the second polypeptide is position 226 by EU numbering at position Ser (S) and position 229.
- Is Ser (S), positions 220 to 225 are Tyr (Y) -Gly (G) -Pro (P) -Pro (P), and position 439 is Glu (E) or Asp (D) .
- (1), (2) and (4) are IgG4 and (3)
- (5) and (6) are IgG1.
- the first polypeptide has Ser (S) at position 131 by EU numbering, Ser (S) at position 226 and Ser (S) at position 229, and Lys (K), Arg (position 356). R) and His (H), and the second polypeptide is Ser (S) at position 131, Ser (S) at position 226 and Ser (S) at position 229 by EU numbering, and Position 439 is Glu (E) or Asp (D).
- the 1st polypeptide is Ser (S) at position 131 by EU numbering, Ser (S) at position 226, Pro (P) at position 228, Ser (S) at position 229, and position 356 Is one of Lys (K), Arg (R) and His (H), and the second polypeptide has EU numbering at position 131, Ser (S), position 226, Ser (S), position 228, Pro. (P) and position 229 are Ser (S) and position 439 is Glu (E) or Asp (D).
- the first polypeptide has position 220 by EU numbering Ser (S) or Tyr (Y), position 226 is Ser (S), position 229 is Ser (S), position 409 is Arg (R), position 356 is Lys (K), Arg (R) and His (H)
- the second polypeptide is Ser (S) or Tyr (Y) at position 220 by EU numbering, Ser (S) at position 226, Ser (S) at position 229, and Arg (R at position 409. ) And position 439 is Glu (E) or Asp (D).
- positions 219 to 229 are deleted by EU numbering, position 409 is Arg (R), and position 356 is Lys (K), Arg (R) and His (H ),
- the second polypeptide is deleted at positions 219 to 229 by EU numbering, position 409 is Arg (R), and position 439 is Glu (E) or Asp (D) It is.
- the first polypeptide is EU (numbered) at position 226, Ser (S), position 229, Ser (S), position 220-225, Tyr (Y) -Gly (G) -Pro (P) -Pro (P), position 409 is Arg (R), position 356 is any of Lys (K), Arg (R) and His (H), and the second polypeptide is position 226 by EU numbering.
- Is Ser (S), 229 is Ser (S), 220-225 is Tyr (Y) -Gly (G) -Pro (P) -Pro (P), 409 is Arg (R), And position 439 is Glu (E) or Asp (D).
- (1), (2) and (4) are IgG4 and (3)
- (5) and (6) are IgG1.
- first and second polypeptides in which the heavy chain constant regions of the first and second polypeptides each have an amino acid residue shown in any of (1) to (6) below: Bispecific antibodies comprising are provided.
- the first polypeptide is amino acid residue other than Cys (C) at position 131 by EU numbering, amino acid residue other than Cys (C) at position 226, and amino acid residue other than Cys (C) at position 229 And the 356th position is Lys (K)
- the second polypeptide is amino acid residue other than Cys (C) at position 131 by EU numbering
- position 226 is an amino acid residue other than Cys (C)
- position 229 is Cys Amino acid residues other than (C) and position 439 are Glu (E).
- amino acid residue other than Cys (C) at position 220 by EU numbering amino acid residue other than Cys (C) at position 226, and amino acid residue other than Cys (C) at position 229 And 356 is Lys (K)
- amino acid residue other than Cys (C) at position 220 by EU numbering or Tyr (Y) amino acid residue other than Cys (C) is at position 226
- Position 229 is an amino acid residue other than Cys (C) and position 439 is Glu (E).
- the first polypeptide is amino acid residue other than Cys (C) at position 131 by EU numbering, positions 219 to 229 are deleted, position 356 is Lys (K), and the second polypeptide In EU numbering, amino acid residues other than Cys (C) are deleted at position 131, positions 219 to 229 are deleted, and position 439 is Glu (E).
- the first polypeptide is deleted at positions 219 to 229 by EU numbering, 356 is Lys (K), and the second polypeptide is deleted at positions 219 to 229 by EU numbering. , 439th place is Glu (E).
- the first polypeptide has EU numbering at position 226 for amino acid residues other than Cys (C), position 229 for amino acid residues other than Cys (C), and positions 220 to 225 for Tyr (Y) -Gly (G) -Pro (P) -Pro (P), position 356 is Lys (K), the second polypeptide is 226 by EU numbering, amino acid residue other than Cys (C), position 229 is Ser (S), positions 220 to 225 are Tyr (Y) -Gly (G) -Pro (P) -Pro (P), and position 439 is Glu (E).
- (1), (2) and (4) are IgG4 and (3), (5) and (6) are IgG1.
- first and second polypeptides in which the heavy chain constant regions of the first and second polypeptides each have an amino acid residue shown in any of (1) to (6) below: Bispecific antibodies comprising are provided.
- the first polypeptide is amino acid residue other than Cys (C) at position 131 by EU numbering, amino acid residue other than Cys (C) at position 226, and amino acid residue other than Cys (C) at position 229 And the 356th position is Lys (K)
- the second polypeptide is amino acid residue other than Cys (C) at position 131 by EU numbering
- position 226 is an amino acid residue other than Cys (C)
- position 229 is Cys Amino acid residues other than (C) and position 439 are Glu (E).
- amino acid residue other than Cys (C) at position 220 by EU numbering amino acid residue other than Cys (C) at position 226, and amino acid residue other than Cys (C) at position 229 409 position is Arg (R) and 356 position is Lys (K)
- the second polypeptide is the amino acid residue other than Cys (C) at position 220 by EU numbering or Tyr (Y)
- position 226 is Cys.
- Amino acid residues other than (C) amino acid residue other than Cys (C) at position 229, Arg (R) at position 409, and Glu (E) at position 439.
- the first polypeptide is amino acid residue other than Cys (C) at position 131 by EU numbering, positions 219 to 229 are deleted, position 356 is Lys (K), and the second polypeptide In EU numbering, amino acid residues other than Cys (C) are deleted at position 131, positions 219 to 229 are deleted, and position 439 is Glu (E).
- the first polypeptide is deleted at positions 219 to 229 by EU numbering, Arg (R) at position 409 and Lys (K) at position 356, and the second polypeptide is 219 by EU numbering. Positions 229 to 229 are deleted, position 409 is Arg (R) and position 439 is Glu (E).
- the first polypeptide has EU numbering at position 226 for amino acid residues other than Cys (C), position 229 for amino acid residues other than Cys (C), and positions 220 to 225 for Tyr (Y) -Gly (G) -Pro (P) -Pro (P), position 409 is Arg (R) and position 356 is Lys (K), and the second polypeptide is position 226 by EU numbering other than Cys (C).
- Amino acid residue, position 229 is Ser (S), position 220-225 is Tyr (Y) -Gly (G) -Pro (P) -Pro (P), position 409 is Arg (R) and position 439 is Glu (E).
- (1), (2) and (4) are IgG4 and (3), (5) and (6) are IgG1.
- the first polypeptide is Ser (S) at position 131 by EU numbering, Ser (S) at position 226, Ser (S) at position 229 and Lys (K) at position 356.
- Peptide according to EU numbering is Ser (S) at position 131, Ser (S) at position 226, Ser (S) at position 229, and Glu (E) at position 439.
- the first polypeptide is Ser (S) at position 131 by EU numbering, Ser (S) at position 226, Pro (P) at position 228, Ser (S) at position 229 and Lys (K at position 356.
- the second polypeptide is Ser (S) at position 131 by EU numbering, Ser (S) at position 226, Pro (P) at position 228, Ser (S) at position 229, and Glu (position at position 439).
- the first polypeptide is Ser (S) or Tyr (Y) at position 220 by EU numbering, Ser (S) at position 226, Ser (S) at position 229, and Lys (K) at position 356.
- the second polypeptide is Ser (S) or Tyr (Y) at position 220 by EU numbering, Ser (S) at position 226, Ser (S) at position 229, and Glu (E) at position 439.
- the first polypeptide has Ser (S) at position 131 by EU numbering, deletions at positions 219 to 229 and Lys (K) at position 356, and the second polypeptide has 131 by EU numbering.
- the position is Ser (S), positions 219 to 229 are deleted, and position 439 is Glu (E).
- the first polypeptide is deleted at positions 219 to 229 by EU numbering, 356 is Lys (K), and the second polypeptide is deleted at positions 219 to 229 by EU numbering.
- the first polypeptide is EU (numbered) at position 226, Ser (S), position 229, Ser (S), position 220-225, Tyr (Y) -Gly (G) -Pro (P) -Pro (P), position 356 is Lys (K), and the second polypeptide is Ser (S) at position 226 by EU numbering, Ser (S) at position 229, and Tyr (Y)-at positions 220-225.
- position 439 is Glu (E).
- (1), (2) and (4) are IgG4 and (3)
- (5) and (6) are IgG1.
- the first polypeptide is Ser (S) at position 131 by EU numbering, Ser (S) at position 226, Ser (S) at position 229 and Lys (K) at position 356.
- Peptide according to EU numbering is Ser (S) at position 131, Ser (S) at position 226, Ser (S) at position 229, and Glu (E) at position 439.
- the first polypeptide is Ser (S) at position 131 by EU numbering, Ser (S) at position 226, Pro (P) at position 228, Ser (S) at position 229 and Lys (K at position 356.
- the second polypeptide is Ser (S) at position 131 by EU numbering, Ser (S) at position 226, Pro (P) at position 228, Ser (S) at position 229, and Glu (position at position 439).
- position 220 by EU numbering is Ser (S) or Tyr (Y)
- position 226 is Ser (S)
- position 229 is Ser (S)
- position 409 is Arg (R) and 356.
- the second polypeptide is Ser (S) or Tyr (Y) by EU numbering
- position 226 is Ser (S)
- position 229 is Ser (S)
- position 409 is the second polypeptide.
- Arg (R) and 439 are Glu (E).
- the first polypeptide has Ser (S) at position 131 by EU numbering, deletions at positions 219 to 229 and Lys (K) at position 356, and the second polypeptide has 131 by EU numbering.
- the position is Ser (S), positions 219 to 229 are deleted, and position 439 is Glu (E).
- the first polypeptide is deleted at positions 219 to 229 by EU numbering, Arg (R) at position 409 and Lys (K) at position 356, and the second polypeptide is 219 by EU numbering.
- Positions 229 to 229 are deleted, position 409 is Arg (R) and position 439 is Glu (E).
- the first polypeptide is EU (numbered) at position 226, Ser (S), position 229, Ser (S), position 220-225, Tyr (Y) -Gly (G) -Pro (P) -Pro (P), position 409 is Arg (R), position 356 is Lys (K), and the second polypeptide is EU (numbered 226 position Ser (S), position 229 position Ser (S), position 220- Position 225 is Tyr (Y) -Gly (G) -Pro (P) -Pro (P), position 409 is Arg (R), and position 439 is Glu (E).
- (1), (2) and (4) are IgG4 and (3)
- (5) and (6) are IgG1.
- Modification using the repulsion of amino acid residues In the production method of the present invention, the dissociation of homozygotes of the first and second polypeptides is promoted, and the association between the polypeptides forming one or more multimers is controlled. In order to achieve this, a step of modifying amino acid residues forming an interface between polypeptides may be further added.
- polypeptide having the first antigen-binding activity and the polypeptide having the second antigen-binding activity of the present invention can include the amino acid sequence of the antibody heavy chain constant region or the amino acid sequence of the antibody Fc region.
- the amino acid sequence of the antibody Fc region or antibody heavy chain constant region includes, but is not limited to, the amino acid sequence of a human IgG type constant region or Fc region.
- the IgG type constant region or Fc region may be any of natural IgG1, IgG2, IgG3, and IgG4 isotypes. Alternatively, these variants may be used.
- the Fc region EU numbering 447 lysine and EU numbering 446 glycine may be removed by recombinant engineering of the nucleic acid encoding them.
- the polypeptide having the third antigen-binding activity and the polypeptide having the fourth antigen-binding activity of the present invention can include the amino acid sequence of the antibody light chain constant region.
- the amino acid sequence of the antibody light chain constant region include, but are not limited to, the amino acid sequences of human kappa and human lambda type constant regions. Alternatively, these variants may be used.
- the polypeptide having the antigen-binding activity of the present invention can contain the amino acid sequence of the antibody variable region (for example, the amino acid sequence of CDR1, CDR2, CDR3, FR1, FR2, FR3, FR4).
- the step includes a step of introducing a charge repulsion at the interface of the constant region of the heavy chain in order to suppress association between the heavy chains.
- Examples of combinations of amino acid residues that contact at the interface of the heavy chain constant region include regions opposite to positions 356 and 439, positions 357 and 370, positions 399 and 409 in the CH3 region.
- the heavy chain constant region was indicated by EU numbering.
- the present invention relates to an antibody containing two or more heavy chain variable regions and an Fc region-containing protein (eg, IgG type antibody, minibody (Alt M et al. FEBS Letters 199 9; 454: 90-94 ), Immunoadhesin (Non-patent Document 2), etc., and one to three pairs selected from the following amino acid residue groups shown in (1) to (3) in the first heavy chain constant region: A polypeptide having amino acid residues of the same type of charge is provided. (1) EU amino acid numbering residues 356 and 439 (2) Amino acid residues at positions 357 and 370 by EU numbering (3) EU numbering amino acid residues at positions 399 and 409
- the present invention provides 1 to 3 sets of amino acid residues selected from the set of amino acid residues shown in the above (1) to (3) in a second heavy chain constant region different from the first heavy chain constant region.
- An amino acid residue at the same position as the group having the same kind of charge among the amino acid residue groups shown in (1) to (3) in the first heavy chain constant region A polypeptide having a charge opposite to an amino acid residue in one heavy chain constant region is provided.
- the “charged amino acid residue” is preferably selected from, for example, amino acid residues included in any of the following groups (a) or (b): (a) glutamic acid (E), aspartic acid (D); (b) Lysine (K), arginine (R), histidine (H).
- ⁇ having the same kind of charge '' means, for example, that two or more amino acid residues are amino acid residues included in any one group of (a) or (b) above. It means having.
- ⁇ Having opposite charges '' means, for example, an amino acid residue in which at least one amino acid residue of two or more amino acid residues is included in any one group of the above (a) or (b) When it has, it means that the remaining amino acid residues have amino acid residues included in different groups.
- the first heavy chain CH3 region and the second heavy chain CH3 region may be cross-linked by a disulfide bond.
- association interface control modification examples include the following modifications: (1) Modification of Asp (D) at position 356 by EU numbering in the first heavy chain constant region to Lys (K), Arg (R) or His (H), and in the second heavy chain constant region Modification of Lys (K) at position 439 to Glu (E) or Asp (D) by EU numbering; (2) Modification of Glu (E) at position 357 by EU numbering in the first heavy chain constant region to Lys (K), Arg (R) or His (H), and in the second heavy chain constant region Modification of Lys (K) at position 370 to Glu (E) or Asp (D) by EU numbering; (3) Modification of Asp (D) at position 399 to Lys (K), Arg (R) or His (H) by EU numbering in the first heavy chain constant region, and in the second heavy chain constant region Modification of Lys (K) at position 409 to Glu (E) or Asp (D) by EU numbering.
- the method for producing a mouse heterologous multimer in the method for producing a mouse heterologous multimer, dissociation of homozygotes of the first and second polypeptides is promoted, and the association between the polypeptides forming one or more multimers is achieved.
- a step of modifying amino acid residues forming an interface between polypeptides may be further added. Examples of combinations of amino acid residues that contact at the interface of the heavy chain constant region include regions opposite to positions 356 and 439, positions 360 and 371, positions 399 and 409 in the CH3 region.
- the heavy chain constant region was indicated by EU numbering.
- the present invention relates to an antibody containing two or more heavy chain constant regions and an Fc region-containing protein (for example, IgG type antibody, minibody (Alt M et al.
- Non-patent Document 2 Immunoadhesin (Non-patent Document 2), etc., and one to three pairs selected from the following amino acid residue groups shown in (1) to (3) in the first heavy chain constant region: A polypeptide having amino acid residues of the same type of charge is provided.
- EU amino acid numbering residues 356 and 439 (2) EU amino acid residues at positions 360 and 371 (3) EU numbering amino acid residues at positions 399 and 409
- the present invention provides 1 to 3 sets of amino acid residues selected from the set of amino acid residues shown in the above (1) to (3) in a second heavy chain constant region different from the first heavy chain constant region.
- An amino acid residue at the same position as the group having the same kind of charge among the amino acid residue groups shown in (1) to (3) in the first heavy chain constant region A polypeptide having a charge opposite to an amino acid residue in one heavy chain constant region is provided.
- the “charged amino acid residue” is preferably selected from, for example, amino acid residues included in any of the following groups (a) or (b): (a) glutamic acid (E), aspartic acid (D); (b) Lysine (K), arginine (R), histidine (H).
- ⁇ having the same kind of charge '' means, for example, that two or more amino acid residues are amino acid residues included in any one group of (a) or (b) above. It means having.
- ⁇ Having opposite charges '' means, for example, an amino acid residue in which at least one amino acid residue of two or more amino acid residues is included in any one group of the above (a) or (b) When it has, it means that the remaining amino acid residues have amino acid residues included in different groups.
- the first heavy chain CH3 region and the second heavy chain CH3 region may be cross-linked by a disulfide bond.
- association interface control modification examples include the following modifications: (1) Modification of Asp (D) at position 356 by EU numbering in the first heavy chain constant region to Lys (K), Arg (R) or His (H), and in the second heavy chain constant region Modification of Lys (K) at position 439 to Glu (E) or Asp (D) by EU numbering; (2) Modification of Glu (E) at position 360 to Lys (K), Arg (R) or His (H) by EU numbering in the first heavy chain constant region, and in the second heavy chain constant region Modification of Lys (K) at position 371 to Glu (E) or Asp (D) by EU numbering; (3) Modification of Asp (D) at position 399 to Lys (K), Arg (R) or His (H) by EU numbering in the first heavy chain constant region, and in the second heavy chain constant region Modification of Lys (K) at position 409 to Glu (E) or Asp (D) by EU numbering
- amino acid residues subjected to “modification” are not limited to amino acid residues in the constant region of the polypeptide.
- a person skilled in the art can find amino acid residues that form an interface for polypeptide variants or heterologous multimers by homology modeling using commercially available software, etc. Amino acid residues can be subjected to modification.
- the “modification” of an amino acid residue in the method of the present invention specifically refers to substitution of an original amino acid residue with another amino acid residue, deletion of the original amino acid residue, new amino acid residue Although it refers to adding a residue, etc., it preferably refers to substituting the original amino acid residue with another amino acid residue.
- a step of introducing amino acid residue mutations may be further added.
- CH3 region stability is unstable means that a homozygote of a polypeptide in which at least one or more modifications have been made to the amino acid residues in the Fc region, compared to a homozygote of an unmodified polypeptide, This refers to a state where each polypeptide is easily separated into simple substances.
- the stability of the CH3 region is unstable preferably means that the heat denaturation intermediate temperature (Tm) of the heavy chain CH3 region at pH 7.4 is 72.5 ° C. or lower, 72.0 ° C. or lower, 71.5 ° C. or lower, 71.0 ° C. or lower.
- Tm heat denaturation intermediate temperature
- the amino acid residue of the CH3 region has been modified so as to be 70.5 ° C. or less, and more preferably 70.4 ° C. or less, 70.3 ° C. or less, 70.2 ° C. or less, 70.1 ° C. or less, 70.0 ° C. or less, 69.9 ° C.
- the following is a state in which the amino acid residues in the CH3 region are modified to be 69.8 ° C or lower, 69.7 ° C or lower, 69.6 ° C or lower, 69.5 ° C or lower, 69.0 ° C or lower, 68.5 ° C or lower, 68.0 ° C or lower, 67.5 ° C or lower.
- Tm of the heavy chain CH3 region can be measured by the method described in Reference Example 6 of the present specification, and a buffer solution used for the measurement can be appropriately selected.
- the step of introducing amino acid residue mutations in the heavy chain constant region so that the stability of the heavy chain CH3 region becomes unstable means that the amino acid residues at the EU numbering positions 397 and / or 392 in the heavy chain CH3 region It is a stage characterized by introducing a mutation of The step may optionally be combined with a step of introducing an amino acid modification related to interface control using the charge repulsion or the like.
- EU numbering of the heavy chain CH3 region is also performed in the step of introducing amino acid residue mutations into the heavy chain constant region so that the stability of the mouse-derived heavy chain CH3 region becomes unstable.
- An amino acid residue mutation can be introduced at positions 397 and / or 392.
- the step may optionally be combined with a step of introducing an amino acid modification related to interface control using the charge repulsion or the like.
- the amino acid residue that introduces a mutation at position 397 is preferably modified to an amino acid having a bulky side chain or a branched side chain amino acid.
- the amino acid residue for introducing a mutation at position 392 is preferably modified to a negatively charged amino acid, an amino acid with a bulky side chain, or a side chain branched amino acid.
- amino acids with bulky side chains are Met (M), Phe (F), Tyr (Y), Val (V), Leu (L), Ile (I), Trp (W), Arg ( R), His (H), Glu (E), Lys (K), Gln (Q), Asp (D), Asn (N), Cys (C), Thr (T), etc., preferably Met (M), Phe (F), Thr (T) and Tyr (Y).
- side-chain branched amino acids include Val (V), Ile (I), Leu (L), and preferably include Val (V) and Ile (I).
- Asp (D) and Glu (E) can be mentioned.
- EU numbering In another embodiment, in the step of introducing amino acid residue mutations in the heavy chain constant region so that the stability of the heavy chain CH3 region becomes unstable, for example, when the antibody heavy chain constant region is of IgG1 type, EU numbering
- 355, 356, 409, 419, and 445 may be modified, for example, 355 is Gln (Q), 356 is Glu (E), and 409 is Arg ( R), position 419 may be modified with Glu (E), position 445 may be modified with Leu (L).
- heterologous multimer in the present invention include multispecific antibodies and heterofusion proteins.
- One non-limiting aspect of the present invention is to provide amino acid modification of a heteromultimer that enhances binding to Fc ⁇ R.
- Preferable amino acid modification sites include, but are not limited to, modification of the amino acid at position 397 of EU numbering.
- the amino acid residue that introduces a mutation at position 397 is preferably modified to an amino acid with a bulky side chain or a branched side chain amino acid.
- more preferably multispecific antibodies IgG type, scFv-IgG, Tandem scFv-Fc, DVD-Ig, Diabody-Fc, Single chain Diabody-Fc, IgG-scFv, sVD-IgG, Tandemab, scFv Examples include light chain C-terminal fusion, tri-specific C-terminal fusion, tri-specific N-terminal fusion, IgG-Fab, and the like (Bispecific Antibodies, Roland E. Kontermann, 2011, WO2010034441, and WO2010145792).
- the term “antibody” is used in the broadest sense. As long as the desired biological activity is exhibited, monoclonal antibodies, polyclonal antibodies, antibody variants (chimeric antibodies, humanized antibodies, low molecular weight antibodies (antibodies) Fragments), multispecific antibodies, and the like.
- “antibody” may be either a polypeptide or a heteromultimer. Preferred antibodies are low molecular weight antibodies such as monoclonal antibodies, chimeric antibodies, humanized antibodies, and antibody fragments.
- the method for controlling dissociation and / or association of the present invention can be preferably used when obtaining (creating) these antibodies.
- Preferred polypeptides or heterologous multimers used in the method of the present invention include, for example, polypeptides or heteromultimers having antibody heavy chain variable regions and light chain variable regions. More preferably, in a preferred embodiment of the present invention, the polypeptide or heterologous multimer of the present invention contains two or more heavy chain variable regions and two or more light chain variable regions. Examples include a method for controlling dissociation and / or association of multimers.
- the polypeptide having the antigen-binding activity of the present invention can contain an amino acid sequence of an antibody heavy chain or an amino acid sequence of an antibody light chain. More specifically, the polypeptide having the first antigen-binding activity and the polypeptide having the second antigen-binding activity can contain the amino acid sequence of the antibody heavy chain, and have a third antigen-binding activity.
- the peptide and polypeptide having fourth antigen binding activity can comprise the amino acid sequence of an antibody light chain.
- the target polypeptide multimer forms a dimer with the first polypeptide and the third polypeptide, forms a dimer with the second polypeptide and the fourth polypeptide
- a polypeptide having the first and second antigen-binding activities is an antibody heavy chain.
- a polypeptide multimer which is a polypeptide comprising an amino acid sequence and wherein the polypeptide having the third and fourth antigen-binding activities is a polypeptide comprising the amino acid sequence of an antibody light chain.
- bispecific antibodies can be mentioned as multispecific antibodies.
- the present invention includes, for example, two types of heavy chains (the first polypeptide and the second polypeptide of the polypeptide multimer in the present invention) and two types of light chains (
- the present invention relates to a method for controlling dissociation and / or association of a bispecific antibody composed of a third polypeptide and a fourth polypeptide of a polypeptide multimer in the present invention.
- the “bispecific antibody” of the preferred embodiment of the present invention will be described in more detail.
- the “first polypeptide and second polypeptide” are the two heavy chains (H chains) forming the antibody.
- the “third polypeptide and the fourth polypeptide” mean one L chain (first L chain) of two light chains (L chains) forming a bispecific antibody, And the other L chain that is different from the L chain (second L chain), one of the two L chains is arbitrarily set as the first L chain, and the other is the second L chain. It can be.
- the first L chain and the first H chain are derived from the same antibody that recognizes a certain antigen (or epitope), and the second L chain and the second H chain are also a certain antigen (or epitope). Derived from the same antibody that recognizes.
- the L chain-H chain pair formed by the first H chain / L chain is referred to as the first pair (or the first HL molecule)
- the heavy chain pair is referred to as the second pair (or second HL molecule).
- the antigens recognized by the first and second pairs may be the same, but preferably recognize different epitopes.
- the H chain and the L chain of the first pair and the second pair have different amino acid sequences.
- the first pair and the second pair may recognize completely different antigens, or different sites (different epitopes) on the same antigen.
- the antigen is a heteroreceptor
- the multispecific antibody recognizes different domains that make up the heteroreceptor, or if the antigen is a monomer, the multispecific antibody Recognizes multiple sites of monomeric antigens).
- such a molecule binds to two antigens, but may have specificity for more (eg, three types) antigens.
- an antigen such as a protein, peptide, gene or sugar
- the other may recognize a radioactive substance, a chemotherapeutic agent, a cytotoxic substance such as a cell-derived toxin, or the like.
- the specific H chain and L chain are arbitrarily designated as a first pair and a second pair. Can be determined.
- Fusion protein in the present invention describes a protein in which two or more identical or substantially similar protein molecules are joined via an Ig hinge region amino acid sequence linker.
- the prefix “hetero” is used.
- a “heterofusion protein” contains two or more proteins joined together by one or more proteins that are different from one or more remaining proteins.
- the “antibody” in the present invention includes those in which the amino acid sequence is further modified by amino acid substitution, deletion, addition and / or insertion, chimerization, humanization, or the like. Amino acid substitutions, deletions, additions and / or insertions, and amino acid sequence modifications such as humanization and chimerization can be performed by methods known to those skilled in the art. Similarly, the variable region and constant region of an antibody used when the antibody of the present invention is produced as a recombinant antibody is also replaced by amino acid substitution, deletion, addition and / or insertion, chimerization, humanization, etc. The sequence may be altered.
- the antibody in the present invention may be an antibody derived from any animal such as a mouse antibody, a human antibody, a rat antibody, a rabbit antibody, a goat antibody, or a camel antibody.
- a modified antibody having a substituted amino acid sequence such as a chimeric antibody, particularly a humanized antibody may be used.
- any antibody such as a modified antibody, an antibody fragment, or a low molecular weight antibody to which various molecules are bound may be used.
- a “chimeric antibody” is an antibody produced by combining sequences derived from different animals.
- an antibody comprising a heavy chain and light chain variable (V) region of a mouse antibody and a human antibody heavy chain and light chain constant (C) region can be exemplified.
- V heavy chain and light chain variable
- C human antibody heavy chain and light chain constant
- the production of a chimeric antibody is known.
- a chimeric antibody can be produced by ligating DNA encoding an antibody V region with DNA encoding a human antibody C region, introducing the DNA into an expression vector and introducing it into a host. Obtainable.
- Humanized antibody refers to an antibody derived from a mammal other than a human, also referred to as a reshaped human antibody, such as a complementarity determination region (CDR) of a mouse antibody to the CDR of a human antibody. It is transplanted.
- CDR complementarity determination region
- Methods for identifying CDRs are known (Kabat et al., Sequence of Proteins of Immunological Interest (1987), National Institute of Health, Bethesda, Md .; Chothia et al., Nature (1989) 342: 877) .
- general gene recombination techniques are also known (see European Patent Application Publication No. EP-125023 and WO96 / 02576).
- the CDR of a mouse antibody is determined by a known method, and a DNA encoding an antibody in which the CDR is linked to a framework region (FR) of a human antibody is obtained.
- FR framework region
- Such DNA can be synthesized by PCR using several oligonucleotides prepared as primers with overlapping portions in both CDR and FR terminal regions (described in WO98 / 13388). (See how).
- the FR of the human antibody linked via CDR is selected such that the CDR forms a good antigen binding site.
- the FR amino acid in the variable region of the antibody may be modified so that the CDR of the reshaped human antibody forms an appropriate antigen-binding site (Sato et al., Cancer Res. (1993) 53: 851-6).
- the amino acid residues in FR that can be modified include those that bind directly to the antigen by non-covalent bonds (Amit et al., Science (1986) 233: 747-53), and those that affect or act on the CDR structure (Chothia et al., J. Mol. Biol. 1987 (1987) 196: 901-17) and parts related to the VH-VL interaction (EP239400 patent publication).
- the antibodies in the present invention are chimeric antibodies or humanized antibodies
- those derived from human antibodies are preferably used for the C region of these antibodies.
- C ⁇ 1, C ⁇ 2, C ⁇ 3, and C ⁇ 4 can be used for the H chain
- C ⁇ and C ⁇ can be used for the L chain.
- the human antibody C region may be modified as necessary.
- the chimeric antibody in the present invention preferably comprises a variable region of a non-human mammal-derived antibody and a constant region derived from a human antibody.
- humanized antibodies are preferably composed of CDRs of antibodies derived from mammals other than humans, and FR and C regions derived from human antibodies.
- the constant region derived from a human antibody has a unique amino acid sequence for each isotype such as IgG (IgG1, IgG2, IgG3, IgG4), IgM, IgA, IgD, and IgE.
- the constant region used for the humanized antibody in the present invention may be a constant region of an antibody belonging to any isotype.
- the constant region of human IgG is used, but is not limited thereto.
- the FR derived from a human antibody used for a humanized antibody is not particularly limited, and may be an antibody belonging to any isotype.
- variable region and constant region of the chimeric antibody and humanized antibody in the present invention may be modified by deletion, substitution, insertion and / or addition as long as they show the binding specificity of the original antibody.
- Chimeric antibodies and humanized antibodies using human-derived sequences are considered useful when administered to humans for therapeutic purposes, because their antigenicity in the human body is reduced.
- an amino acid mutation that modifies the isoelectric point (pI value) of a polypeptide is introduced into the polypeptide of the present invention, thereby achieving the first target. It is possible to purify or produce a polypeptide multimer having the fourth polypeptide with higher purity and efficiency (WO2007114325, US20130171095). Amino acid mutations introduced to promote polypeptide association include Protein Eng. 1996 Jul; 9 (7): 617-21., Protein Eng Des Sel. 2010 Apr; 23 (4): 195-202. , J Biol Chem. 2010 Jun 18; 285 (25): 19637-46., WO2009080254, US20130195849, etc. It is also possible to use a heteroassociation method and a method for promoting association of a specific combination of a heavy chain and a light chain described in WO2009080251, WO2009080252, WO2009080253 and the like.
- Non-limiting embodiments of the present invention include antibody technology (WO2013 / 180200) that dissociates and binds to antigens depending on the concentration of molecules existing specifically in the target tissue. The combination of is mentioned.
- Non-limiting embodiments of the present invention include combinations with constant region modification techniques (WO2013047752) aimed at enhancing binding to Fc ⁇ R.
- any complement component can be used as long as it is a polypeptide that forms a complement cascade, but preferred complements include C1q, C1r, or C1s complement components involved in opsonin binding. It is mentioned in.
- An Fc region whose binding activity to the complement of the Fc region is higher than the binding activity of the natural Fc region to the complement can be produced by altering the amino acid of the natural Fc region.
- the natural type Fc region here refers to an Fc region represented by human IgG1, IgG2, IgG3, or IgG4.
- binding activity to the complement of the Fc region is higher than the binding activity to the complement of the natural Fc region can be appropriately determined using known immunological methods such as FACS and ELISA.
- “Amino acid modification” or “amino acid modification” of the Fc region includes modification to an amino acid sequence different from the amino acid sequence of the starting Fc region. Any Fc region can be used as the starting domain so long as the modified variant of the starting Fc region can bind complement in the neutral pH range.
- an Fc region that has been further modified with an Fc region that has already been modified as a starting Fc region can also be suitably used as the Fc region of the present invention.
- the starting Fc region can mean the polypeptide itself, a composition comprising the starting Fc region, or the amino acid sequence encoding the starting Fc region.
- the starting Fc region can include the Fc regions of known IgG antibodies produced recombinantly as outlined in the antibody section.
- the origin of the starting Fc region can be obtained from any organism or person, including but not limited to a non-human animal.
- any organism suitably includes an organism selected from mice, rats, guinea pigs, hamsters, gerbils, cats, rabbits, dogs, goats, sheep, cows, horses, camels, and non-human primates. .
- the starting Fc region can also be obtained from a cynomolgus monkey, marmoset, rhesus monkey, chimpanzee, or human.
- the starting Fc region can be obtained from human IgG1, but is not limited to a particular class of IgG. This means that the Fc region of human IgG1, IgG2, IgG3, or IgG4 can be appropriately used as the starting Fc region.
- the Fc region of any class or subclass of IgG from any of the aforementioned organisms can preferably be used as the starting Fc region. Examples of naturally occurring IgG variants or engineered forms are described in the known literature (Curr. Opin.
- the amino acid can be modified at any position as long as it has a binding activity to complement or can enhance the binding activity to complement binding.
- the antigen-binding molecule contains the Fc region of human IgG1 as the human Fc region, it is preferable that the antigen-binding molecule contains a modification that has an effect of enhancing the binding to complement than the binding activity of the starting Fc region of human IgG1.
- Examples of amino acids for modifying the binding activity to complement include Duncan et al. (Nature (1988) 332, 738-740), Tao et al. (J. Exp. Med. (1993) 178, 661-667), Brekke et al. (Eur. J. Immunol. (1994) 24, 2542-2547), Xu et al. (Immunol. The amino acids in the region are exemplified.
- amino acids that can be modified to enhance the binding activity to C1q include at least one amino acid selected from positions 231 to 238 and positions 318 to 337 represented by EU numbering.
- Non-limiting examples of such amino acids are selected from the group of positions 235, 237, 267, 268, 276, 318, 320, 322, 324, 327, 331, and 333
- Examples include at least one amino acid. These amino acid modifications enhance binding to the complement of the Fc region of IgG type immunoglobulins.
- Particularly preferred modifications are represented, for example, by EU numbering of the Fc region; 267th amino acid is Glu, 268 of the amino acid is either Phe or Tyr, Arg for the amino acid at position 276; 324 of the amino acid is Thr, Gly is the 327th amino acid 331 amino acid is Pro, or 333 of the amino acid is Ala, Asp, Gly, one of Ser or Val, Is mentioned.
- the number of amino acids to be modified is not particularly limited, and only one amino acid can be modified, or two or more amino acids in which these are arbitrarily combined can be modified.
- Examples of other combinations of the present invention and other constant region modification technologies include FcRn binding enhancement modified Fc technology at acidic pH (WO2002060919, WO2004035752, WO2000042072), FcRn binding enhancement modified Fc technology at neutral pH (WO2011122011, WO2012133782) ), Selective Fc ⁇ receptor selective binding enhancement technology (WO2012115241, WO2013125667), active Fc ⁇ receptor selective binding enhancement technology (ADCC activity enhancement technology) (WO2013002362), technology for reducing the binding activity to Rheumatoid factor (WO2013046704) ) And other antibody modification techniques.
- FcRn binding enhancement modified Fc technology at acidic pH WO2002060919, WO2004035752, WO2000042072
- FcRn binding enhancement modified Fc technology at neutral pH WO2011122011, WO2012133782
- Selective Fc ⁇ receptor selective binding enhancement technology WO2012115241, WO2013125667
- ADCC activity enhancement technology WO2013002362
- variable region modification techniques examples include combinations with modification techniques such as pH-dependent antibodies (WO2009125825) and calcium-dependent antibodies (WO2012073992).
- Antibody library, immunization and hybridoma production Known as a gene encoding the H chain or L chain of an antibody before mutation introduction in the method of the present invention (in the present specification, it may be simply referred to as “the antibody of the present invention”)
- the antibody of the present invention can also be used, and can also be obtained by methods known to those skilled in the art. For example, it can be obtained from an antibody library, or can be obtained by cloning a gene encoding an antibody from a hybridoma producing a monoclonal antibody.
- antibody libraries are already known as antibody libraries, and methods for producing antibody libraries are also known, those skilled in the art can appropriately obtain antibody libraries.
- antibody phage libraries Clackson et al., Nature 1991, 352: 624-8, Marks et al., J. Mol. Biol. 1991, 222: 581-97, Waterhouses et al., Nucleic Acids Res 1993, 21: 2265-6, Griffiths et al., EMBO J. 1994, 13: 3245-60, Vaughan et al., Nature Biotechnology 1996, ⁇ 14: 309-14, and Japanese National Publication No. 20-504970 Can be referred to.
- variable region of a human antibody is expressed as a single chain antibody (scFv) on the surface of the phage by the phage display method, and a phage that binds to the antigen can be selected.
- scFv single chain antibody
- a suitable expression vector can be prepared based on the sequence to obtain a human antibody.
- WO92 / 01047, WO92 / 20791, WO93 / 06213, WO93 / 11236, WO93 / 19172, WO95 / 01438, and WO95 / 15388 can be referred to.
- a method for obtaining a gene encoding an antibody from a hybridoma basically uses a known technique, and uses a desired antigen or a cell that expresses a desired antigen as a sensitizing antigen. Therefore, immunization is performed, the resulting immune cells are fused with known parental cells by ordinary cell fusion methods, monoclonal antibody-producing cells (hybridomas) are screened by ordinary screening methods, and reverse transcription is performed from the resulting hybridoma mRNA. It can be obtained by synthesizing cDNA of an antibody variable region (V region) using an enzyme and ligating it with DNA encoding a desired antibody constant region (C region).
- V region antibody variable region
- C region desired antibody constant region
- the sensitizing antigen for obtaining the antibody genes encoding the H chain and L chain described above includes a complete antigen having immunogenicity, an immunity It includes both incomplete antigens including haptens and the like that do not exhibit virulence.
- a full-length protein of the target protein or a partial peptide can be used.
- substances composed of polysaccharides, nucleic acids, lipids and the like can serve as antigens, and the antigen of the antibody of the present invention is not particularly limited.
- the antigen can be prepared by a method known to those skilled in the art, for example, according to a method using baculovirus (for example, WO98 / 46777).
- the hybridoma can be prepared, for example, according to the method of Milstein et al. (G. Kohler and C. Milstein, Methods Enzymol. 1981, 73: 3-46).
- immunization may be performed by binding to an immunogenic macromolecule such as albumin.
- it can also be made a soluble antigen by combining an antigen with another molecule as required.
- a transmembrane molecule such as a receptor
- the extracellular region of the receptor can be used as a fragment, or a cell expressing the transmembrane molecule on the cell surface can be used as an immunogen.
- Antibody-producing cells can be obtained by immunizing animals with the appropriate sensitizing antigen described above.
- antibody-producing cells can be obtained by immunizing lymphocytes capable of producing antibodies in vitro.
- Various mammals can be used as the animal to be immunized, and rodents, rabbits, and primates are generally used. Examples include rodents such as mice, rats and hamsters, rabbits such as rabbits, and primates such as monkeys such as cynomolgus monkeys, rhesus monkeys, baboons and chimpanzees.
- transgenic animals having a repertoire of human antibody genes are also known, and human antibodies can be obtained by using such animals (WO96 / 34096; Mendez et al., Nat.
- a desired human antibody having an antigen-binding activity can also be obtained (see Japanese Patent Publication No. 1-59878).
- a desired human antibody can be obtained by immunizing a transgenic animal having all repertoires of human antibody genes with a desired antigen (WO93 / 12227, WO92 / 03918, WO94 / 02602, WO96 / 34096, (See WO96 / 33735).
- the sensitizing antigen is appropriately diluted and suspended in Phosphate-Buffered Saline (PBS) or physiological saline, etc., mixed with an adjuvant as necessary, and emulsified, and then intraperitoneally or subcutaneously. This is done by injection. Thereafter, the sensitizing antigen mixed with Freund's incomplete adjuvant is preferably administered several times every 4 to 21 days. Confirmation of antibody production can be performed by measuring the desired antibody titer in the serum of animals by a conventional method.
- PBS Phosphate-Buffered Saline
- physiological saline physiological saline
- Hybridomas can be prepared by fusing antibody-producing cells obtained from animals or lymphocytes immunized with the desired antigen with myeloma cells using a conventional fusion agent (e.g., polyethylene glycol) (Goding , Monoclonal Antibodies: Principles and Practice, Academic Press, 1986, 59-103). If necessary, hybridoma cells are cultured and expanded, and the binding specificity of the antibody produced from the hybridoma is measured by a known analysis method such as immunoprecipitation, radioimmunoassay (RIA), enzyme-linked immunosorbent assay (ELISA), etc. . Thereafter, if necessary, the hybridoma producing the antibody whose target specificity, affinity or activity is measured can be subcloned by a technique such as limiting dilution.
- a conventional fusion agent e.g., polyethylene glycol
- a probe encoding a gene encoding the selected antibody from a hybridoma or an antibody-producing cell for example, an oligo complementary to a sequence encoding an antibody constant region.
- a probe for example, an oligo complementary to a sequence encoding an antibody constant region.
- nucleotides for example, nucleotides.
- Immunoglobulins are classified into five different classes: IgA, IgD, IgE, IgG and IgM. Furthermore, these classes are divided into several subclasses (isotypes) (eg, IgG-1, IgG-2, IgG-3, and IgG-4; IgA-1 and IgA-2, etc.).
- the H chain and L chain used for the production of the antibody in the present invention may be derived from antibodies belonging to any of these classes and subclasses, and are not particularly limited, but IgG is particularly preferred.
- a chimeric antibody is an antibody comprising a human antibody H chain, L chain variable region and a human antibody H chain, L chain constant region, and a DNA encoding the variable region of a mouse antibody. Can be obtained by linking to a DNA encoding the constant region of a human antibody, incorporating it into an expression vector, introducing it into a host, and producing it.
- a humanized antibody also called a reshaped human antibody, is a DNA sequence designed to link the complementarity-determining regions (CDRs) of non-human mammals such as mouse antibodies.
- CDRs complementarity-determining regions
- the obtained DNA is obtained by ligating with DNA encoding a human antibody constant region, then incorporating it into an expression vector, introducing it into a host and producing it (see EP239400; WO96 / 02576).
- the FR of the human antibody to be ligated via CDR one in which the complementarity determining region forms a favorable antigen binding site is selected.
- the amino acid in the framework region of the variable region of the antibody may be substituted so that the complementarity-determining region of the reshaped human antibody forms an appropriate antigen-binding site (K. Sato et al. . 1993, 53: 851-856).
- modifications may be made to improve the biological properties of the antibody, such as binding to an antigen.
- modification can be carried out by methods such as site-specific mutation (see, for example, Kunkel (1985) Proc. Natl. Acad. Sci. USA 82: 488), PCR mutation, cassette mutation, and the like.
- antibody variants with improved biological properties are 70% or more, more preferably 80% or more, and even more preferably 90% or more (eg, 95% or more, 97%, 98%, 99%, etc.) amino acids It has the amino acid sequence of the variable region of an antibody based on sequence homology and / or similarity.
- sequence homology and / or similarity is homologous to the original antibody residues after aligning the sequences and introducing gaps as necessary to maximize sequence homology. Defined as the percentage of amino acid residues that are (same residues) or similar (amino acid residues that are grouped in the same group based on the characteristics of the side chains of common amino acids).
- natural amino acid residues are based on the properties of their side chains (1) hydrophobicity: alanine, isoleucine, norleucine, valine, methionine and leucine; (2) neutral hydrophilicity: asparagine, glutamine, cysteine, threonine And (3) acidity: aspartic acid and glutamic acid; (4) basicity: arginine, histidine and lysine; (5) residues that affect chain orientation: glycine and proline; and (6) aromaticity: tyrosine. , Tryptophan and phenylalanine.
- variable regions of the H chain and L chain interact to form the antigen binding site of the antibody.
- CDRs complementarity determining regions
- the antibody gene encoding the H chain and L chain of the present invention is only required to maintain the binding property of the polypeptide encoded by the gene with the desired antigen. What is necessary is just to encode the fragment part containing a binding site.
- an active antibody or polypeptide By using the dissociation and / or association control method of the present invention, for example, an active antibody or polypeptide can be efficiently produced.
- the activity include binding activity, neutralizing activity, cytotoxic activity, agonist activity, antagonist activity, enzyme activity and the like.
- Agonist activity is an activity that induces some change in physiological activity, for example, when a signal is transmitted into a cell by binding an antibody to an antigen such as a receptor.
- physiological activities include proliferation activity, survival activity, differentiation activity, transcription activity, membrane transport activity, binding activity, proteolytic activity, phosphorylation / dephosphorylation activity, redox activity, transfer activity, nucleolytic activity, Examples include, but are not limited to, dehydration activity, cell death-inducing activity, and apoptosis-inducing activity.
- an antibody or polypeptide that recognizes a desired antigen or binds to a desired receptor can be efficiently produced.
- the antigen is not particularly limited, and any antigen may be used.
- an antigen for example, a ligand (cytokine, chemokine, etc.), a receptor, a cancer antigen, an MHC antigen, a differentiation antigen, an immunoglobulin and an immune complex partially containing an immunoglobulin are preferably exemplified.
- cytokines examples include interleukins 1-18, colony stimulating factors (G-CSF, M-CSF, GM-CSF, etc.), interferons (IFN- ⁇ , IFN- ⁇ , IFN- ⁇ , etc.), growth factors ( EGF, FGF, IGF, NGF, PDGF, TGF, HGF, etc.), tumor necrosis factor (TNF- ⁇ , TNF- ⁇ ), lymphotoxin, erythropoietin, leptin, SCF, TPO, MCAF, BMP.
- chemokines examples include CC chemokines such as CCL1 to CCL28, CXC chemokines such as CXCL1 to CXCL17, C chemokines such as XCL1 to XCL2, and CX3C chemokines such as CX3CL1.
- receptors include, for example, hematopoietic factor receptor family, cytokine receptor family, tyrosine kinase type receptor family, serine / threonine kinase type receptor family, TNF receptor family, G protein coupled receptor family, GPI Examples include receptors belonging to the receptor family such as anchor type receptor family, tyrosine phosphatase type receptor family, adhesion factor family, hormone receptor family and the like. Regarding the receptors belonging to these receptor families and their characteristics, a number of documents such as Cooke BA., King RJB., Van der Molen HJ. Ed. New Comprehesive Biochemistry Vol.
- Specific receptors belonging to the above receptor family include, for example, human or mouse erythropoietin (EPO) receptors (Blood (1990) 76 (1), 31-35, Cell (1989) 57 (2), 277- 285), human or mouse granulocyte colony stimulating factor (G-CSF) receptor (Proc. Natl. Acad. Sci. USA. (1990) 87 (22), 8702-8706, mG-CSFR, Cell (1990) 61 (2), 341-350), human or mouse thrombopoietin (TPO) receptor (Proc Natl Acad Sci U S A. (1992) 89 (12), 5640-5644, EMBO J.
- EPO erythropoietin
- human or mouse leptin receptor human or mouse growth hormone (GH) receptor, human or mouse Interleukin (IL) -10 receptor, human or mouse insulin-like growth factor (IGF) -I receptor, human or mouse leukemia inhibitory factor (LIF) receptor, human or mouse ciliary neurotrophic factor (CNTF) receptor A body etc. are illustrated suitably.
- GH growth hormone
- IL Interleukin
- IGF insulin-like growth factor
- LIF human or mouse leukemia inhibitory factor
- CNTF ciliary neurotrophic factor
- Cancer antigens are antigens that are expressed as cells become malignant and are also called tumor-specific antigens.
- abnormal sugar chains appearing on the cell surface and protein molecules when cells become cancerous are also cancer antigens and are also called cancer sugar chain antigens.
- cancer antigens include, for example, GPC3 (Int J Cancer. (2003) 103 (4) that belongs to the GPI-anchored receptor family as the above receptor but is expressed in several cancers including liver cancer. , 455-65), EpCAM expressed in multiple cancers including lung cancer (Proc Natl Acad Sci U S A. (1989) 86 (1), ⁇ ⁇ 27-31), CA19-9, CA15-3, serial SSEA -1 (SLX) and the like are preferable.
- GPC3 Int J Cancer. (2003) 103 (4) that belongs to the GPI-anchored receptor family as the above receptor but is expressed in several cancers including liver cancer. , 455-65
- EpCAM expressed in multiple cancers including lung cancer Proc Natl Acad Sci U S A. (19
- MHC antigens are mainly classified into MHC class I antigen and MHC class II antigen, which includes HLA-A, -B, -C, -E, -F, -G, -H.
- MHC class II antigens include HLA-DR, -DQ, and -DP.
- Differentiation antigens include CD1, CD2, CD4, CD5, CD6, CD7, CD8, CD10, CD11a, CD11b, CD11c, CD13, CD14, CD15s, CD16, CD18, CD19, CD20, CD21, CD23, CD25, CD28, CD29 , CD30, CD32, CD33, CD34, CD35, CD38, CD40, CD41a, CD41b, CD42a, CD42b, CD43, CD44, CD45, CD45RO, CD48, CD49a, CD49b, CD49c, CD49d, CD49e, CD49f, CD51, CD54, CD55 , CD56, CD57, CD58, CD61, CD62E, CD62L, CD62P, CD64, CD69, CD71, CD73, CD95, CD102, CD106, CD122, CD126, CDw130.
- Immunoglobulins include IgA, IgM, IgD, IgG, and IgE.
- the immune complex includes at least any component of immunoglobulin.
- Other antigens include the following molecules: 17-IA, 4-1BB, 4Dc, 6-keto-PGF1a, 8-iso-PGF2a, 8-oxo-dG, A1 adenosine receptor, A33, ACE, ACE- 2, Activin, Activin A, Activin AB, Activin B, Activin C, Activin RIA, Activin RIA ALK-2, Activin RIB ALK-4, Activin RIIA, Activin RIIB, ADAM10, ADAM12, ADAM15, ADAM17 / TACE, ADAM8 , ADAM9, ADAMTS, ADAMTS4, ADAMTS5, addressin, aFGF, ALCAM, ALK, ALK-1, ALK-7, alpha-1-antitry
- one specificity of the bispecific antibody targets a cancer antigen and the other specificity is an antigen expressed on CTL (Cytotoxic T T lymphocyte), such as CD3 or TNFRSF.
- CTL Cytotoxic T T lymphocyte
- TNFRSF Tumor Necrosis Factor Receptor Super Family
- TNFRSF9 CD137
- TNFRSF5 CD40
- TNFRSF4 OFX40
- the present invention also provides isomerization of disulfide bonds via cysteines outside the core hinge region so that dissociation and / or association between polypeptides is controlled.
- Modification of amino acid residues eg, modification at amino acid residues at positions 131, 220, 349, 356, 394, 351, 354, and 407 by EU numbering
- a method for producing a heteromultimer comprising: (a) an amino acid residue that enables isomerization of a disulfide bond via a cysteine outside the core hinge region so that dissociation and association between polypeptides are controlled.
- Modifying the nucleic acid encoding the group from the original nucleic acid (b) culturing a host cell having the nucleic acid so as to express the polypeptide, (c) a culture of the host cell Step recovering Luo the polypeptide, and (d) under reducing conditions, each polypeptide was incubated, comprising the step of recovering the heterodimer of the desired polypeptide, to provide a production method of a heterologous multimer.
- modifying a nucleic acid means modifying a nucleic acid so as to correspond to an amino acid residue introduced by “modification” in the present invention. More specifically, it means that a nucleic acid encoding an original (before modification) amino acid residue is modified to a nucleic acid encoding an amino acid residue introduced by the modification. Usually, it means that genetic manipulation or mutation treatment is performed such that at least one base is inserted, deleted or substituted into the original nucleic acid so as to be a codon encoding the target amino acid residue. That is, the codon encoding the original amino acid residue is replaced by the codon encoding the amino acid residue introduced by modification.
- nucleic acid modification can be appropriately performed by those skilled in the art using known techniques such as site-directed mutagenesis and PCR mutagenesis.
- the nucleic acid in the present invention is usually carried (inserted) in an appropriate vector and introduced into a host cell.
- the vector is not particularly limited as long as it stably holds the inserted nucleic acid.
- the cloning vector is preferably a pBluescript vector (Stratagene), but is commercially available.
- Various vectors can be used.
- An expression vector is particularly useful when a vector is used for the purpose of producing the polypeptide of the present invention.
- the expression vector is not particularly limited as long as it is a vector that expresses a polypeptide in vitro, in E. coli, in cultured cells, or in an individual organism.
- pBEST vector manufactured by Promega
- E. coli PET vector manufactured by Invitrogen
- pME18S-FL3 vector GeneBank Accession No. AB009864
- pME18S vector Mol Cell Biol. 8: 466-472 (1988)
- the DNA of the present invention can be inserted into a vector by a conventional method, for example, by a ligase reaction using a restriction enzyme site (Current ⁇ ⁇ ⁇ protocols in Molecular Biology edit. Ausubel et al. (1987) Publish. John Wiley & Sons, Section IV 11.4-11.11.
- the host cell is not particularly limited, and various host cells can be used depending on the purpose.
- Examples of cells for expressing the polypeptide include bacterial cells (eg, Streptococcus, Staphylococcus, E. coli, Streptomyces, Bacillus subtilis), fungal cells (eg, yeast, Aspergillus), insect cells (eg, Drosophila S2). Spodoptera SF9), animal cells (eg, CHO, COS, HeLa, C127, 3T3, BHK, HEK293, BowesB melanoma cells) and plant cells.
- Vector introduction into host cells can be performed by, for example, calcium phosphate precipitation method, electric pulse perforation method (Current protocols in Molecular Biology edit. Ausubel et al. (1987) Publish. John Wiley & Sons.Section 9.1-9.9), lipofectamine method (GIBCO -BRL) and a known method such as a microinjection method.
- an appropriate secretion signal can be incorporated into the polypeptide of interest.
- These signals may be endogenous to the polypeptide of interest or may be heterologous signals.
- the polypeptide is collected when the polypeptide of the present invention is secreted into the medium.
- the polypeptide of the present invention is produced intracellularly, the cell is first lysed, and then the polypeptide is recovered.
- ammonium sulfate or ethanol precipitation acid extraction, anion or cation exchange chromatography, phosphocellulose chromatography, hydrophobic interaction chromatography, affinity chromatography, Known methods including hydroxylapatite chromatography and lectin chromatography can be used.
- each cell line producing homozygotes of the first and second polypeptides is cultured, and the culture supernatant is purified and purified antibody is used to purify the FAE (Fab Arm Exchange).
- FAE Fab Arm Exchange
- Method of causing the reaction culturing each cell line that produces homozygotes of the first and second polypeptides, respectively, mixing the culture supernatant without purification, causing a FAE reaction in the mixed culture supernatant, A method for subsequent purification; a cell line producing a homologue of the first polypeptide and a cell line producing a homologue of the second polypeptide are mixed and cultured, and the culture supernatant is purified and purified antibody is used.
- FAE Fab Arm Exchange
- the present invention provides, as a non-limiting embodiment, the following steps a) to c): a) culturing cell lines that produce homozygotes of the first and second polypeptides respectively. b) The culture supernatant of each cell line is mixed and homologous to the first polypeptide so that cysteines that form disulfide bonds between heavy chains or light chains outside the core hinge region cause disulfide bond isomerization. Incubating the body and a homozygote of the second polypeptide together; and c) providing a method for producing a heteromultimer comprising the step of obtaining a heteromultimer comprising first and second polypeptides.
- the present invention provides, as a non-limiting embodiment, the following steps a) to c): a) culturing cell lines that produce homozygotes of the first and second polypeptides respectively. b) The culture supernatant of each cell line is mixed, and the homozygote of the first polypeptide and the homologue of the second polypeptide are both put together so that cysteine outside the core hinge region causes disulfide bond isomerization. Incubating, and c) providing a method for producing a heteromultimer comprising the step of obtaining a heteromultimer comprising first and second polypeptides.
- the present invention provides a method for selecting (screening) a desired heterologous multimer.
- the method is a method of selecting a heteromultimer having a desired property (activity) including the following steps: a) providing a first set of polypeptides and a second set of polypeptides, wherein each polypeptide comprising the first set is different from each polypeptide comprising the second set
- Each of the polypeptides having specificity and constituting the first and second sets has an isomerization of disulfide bonds caused by cysteines that form disulfide bonds between heavy chains or light chains outside the core hinge region.
- the present invention provides a method for producing a heteromultimer after the method for producing a heteromultimer of the present invention, comprising:-measuring the activity of the heteromultimer; and selecting a heteromultimer having a desired activity.
- a method of screening That is, the screening method includes the following steps.
- the desired property is not particularly limited, and examples thereof include binding activity, neutralization activity, cytotoxic activity, agonist activity, antagonist activity, enzyme activity and the like.
- Agonist activity is an activity that induces some change in physiological activity, for example, when a signal is transmitted into a cell by binding an antibody to an antigen such as a receptor.
- physiological activities include proliferation activity, survival activity, differentiation activity, transcription activity, membrane transport activity, binding activity, proteolytic activity, phosphorylation / dephosphorylation activity, redox activity, transfer activity, nucleolytic activity, Examples include, but are not limited to, dehydration activity, cell death-inducing activity, and apoptosis-inducing activity.
- the present invention further provides that after the screening method of the present invention-a desired region of the first polypeptide, the second polypeptide, the third polypeptide and the fourth polypeptide of the selected heteromultimer (eg, CDR, variable region, constant region, etc.) are obtained, and-a method for producing a heteromultimer is provided, wherein the obtained region is transplanted into another heteromultimer. That is, the manufacturing method includes the following steps.
- the pharmaceutical composition or the present invention also relates to a composition (drug) comprising the heteromultimer of the present invention and a pharmaceutically acceptable carrier.
- the pharmaceutical composition usually refers to a drug for treatment or prevention of a disease, or examination / diagnosis.
- the pharmaceutical composition of the present invention can be formulated by methods known to those skilled in the art. For example, it can be used parenterally in the form of a sterile solution with water or other pharmaceutically acceptable liquid, or an injection of suspension.
- a pharmacologically acceptable carrier or medium specifically, sterile water or physiological saline, vegetable oil, emulsifier, suspension, surfactant, stabilizer, flavoring agent, excipient, vehicle, preservative
- a pharmaceutical preparation by combining with a binder or the like as appropriate and mixing in a unit dosage form generally required for pharmaceutical practice. The amount of the active ingredient in these preparations is set so as to obtain an appropriate volume within the indicated range.
- a sterile composition for injection can be formulated in accordance with normal pharmaceutical practice using a vehicle such as distilled water for injection.
- aqueous solutions for injection examples include isotonic solutions containing, for example, physiological saline, glucose and other adjuvants (for example, D-sorbitol, D-mannose, D-mannitol, sodium chloride).
- a suitable solubilizing agent such as alcohol (ethanol etc.), polyalcohol (propylene glycol, polyethylene glycol etc.), nonionic surfactant (polysorbate 80 (TM), HCO-50 etc.) may be used in combination.
- oily liquid examples include sesame oil and soybean oil, and benzyl benzoate and / or benzyl alcohol may be used in combination as a solubilizing agent.
- blend with a buffering agent for example, phosphate buffer and sodium acetate buffer
- a soothing agent for example, procaine hydrochloride
- a stabilizer for example, benzyl alcohol and phenol
- antioxidant for example, benzyl alcohol and phenol
- composition of the present invention is preferably administered by parenteral administration.
- the composition can be an injection, nasal, pulmonary, or transdermal composition.
- it can be administered systemically or locally by intravenous injection, intramuscular injection, intraperitoneal injection, subcutaneous injection, or the like.
- the administration method can be appropriately selected depending on the age and symptoms of the patient.
- the dosage of the pharmaceutical composition containing the antibody or the polynucleotide encoding the antibody can be set, for example, in the range of 0.0001 mg to 1000 mg per kg body weight. Alternatively, for example, the dose may be 0.001 to 100,000 mg per patient, but the present invention is not necessarily limited to these values.
- the dose and administration method vary depending on the patient's weight, age, symptoms, etc., but those skilled in the art can set an appropriate dose and administration method in consideration of these conditions.
- the above-mentioned heteromultimer of the present invention is useful as an active ingredient of a therapeutic agent or preventive agent for cancer.
- Cancers include, but are not limited to: lung cancer (including small cell lung cancer, non-small cell lung cancer, lung adenocarcinoma and squamous cell carcinoma), colon cancer, rectal cancer, colon cancer, Breast cancer, liver cancer, stomach cancer, pancreatic cancer, renal cancer, prostate cancer, ovarian cancer, thyroid cancer, bile duct cancer, peritoneal cancer, mesothelioma, squamous cell carcinoma, cervical cancer, endometrial cancer, bladder cancer, esophageal cancer, head and neck Cancer, nasopharyngeal cancer, salivary gland tumor, thymoma, skin cancer, basal cell tumor, malignant melanoma, anal cancer, penile cancer, testicular cancer, Wilms tumor, acute myeloid leukemia (acute myelocytic leukemia, acute myelob
- polypeptide of the present invention or the heteromultimer can be formulated in combination with other pharmaceutical ingredients.
- the present invention also relates to diseases such as immune / inflammatory diseases (for example, cancer) comprising the step of administering the heterologous multimer of the present invention, the heteromultimer produced by the production method of the present invention, or the pharmaceutical composition of the present invention. ).
- the present invention also provides a kit for use in the therapeutic or prophylactic method of the present invention, comprising at least the heteromultimer of the present invention, the heteromultimer produced by the production method of the present invention, or the pharmaceutical composition of the present invention. provide.
- the kit may be packaged with a pharmaceutically acceptable carrier, a medium, instructions describing the method of use, and the like.
- the present invention also relates to the use of the heteromultimer of the present invention or the heteromultimer produced by the production method of the present invention in the manufacture of a medicament (for example, a therapeutic or prophylactic agent for immune / inflammatory diseases).
- the present invention also relates to a heteromultimer of the present invention or a heteromultimer produced by the production method of the present invention for use in the therapeutic or preventive method of the present invention.
- Example 1 Examination of Fab Arm Exchange Efficiency Improvement by Introducing Antibody Association Interface Control Modification In Fab Arm Exchange, two homo-antibodies were mixed in the presence of a reducing agent, and the resulting four antibody molecule arms (half) Bispecific antibodies (bispecific antibodies) are generated by the recombination of molecules consisting of a single heavy chain and a single light chain, referred to as a child or HL molecule. Since recombination of HL molecules occurs randomly, the target Bispecific antibody can theoretically obtain only 50% of the total amount of antibody present in the system. However, by introducing different charges into two types of homoantibodies in advance, heterodimerization occurs more preferentially than homodimerization when the resulting HL molecules recombine with each other.
- the antibody heavy chain variable region includes WT (H) (SEQ ID NO: 1 hereinafter referred to as MRAH) and H54 (SEQ ID NO: 2) which are heavy chain variable regions of antibodies against human interleukin 6 receptor disclosed in WO2009 / 125825. ) was used.
- WT H
- H54 SEQ ID NO: 2
- MRAH-G1d SEQ ID NO: 3
- H54-G1d SEQ ID NO: 3 having G1d from which the Cly terminal Gly and Lys of the heavy chain constant region of human IgG1 were removed as antibody heavy chain constant regions.
- MRAH-wtG4d SEQ ID NO: 5
- H54-wtG4d SEQ ID NO: 6
- MRAH-G1dsr SEQ ID NO: 7
- H54-G1dsr SEQ ID NO: 8
- MRAH-G1d and H54-G1d were modified with P228S and K409R so as to be an IgG4-type hinge sequence and CH3 domain sequence.
- MRAH-G1dsrP1 (SEQ ID NO: 9) in which D356K was introduced into MRAH-G1dsr
- H54-G1dsrN1 (SEQ ID NO: 10) in which K439E was introduced into H54-G1dsr
- MRAH into which E356K was introduced into MRAH-wtG4d MRAH-wtG4d
- -wtG4dP1 SEQ ID NO: 11
- H54-wtG4dN1 SEQ ID NO: 12
- MRAL-k0 SEQ ID NO: 13
- H54 H54
- L28-k0 SEQ ID NO: 14
- FIG. 1 shows the results of evaluation of reaction products by ion exchange chromatography.
- Example 2 Fab Arm Exchange in a homozygous form having a hinge sequence of human natural IgG1
- P228S modification was introduced into human IgG1 and Fab Arm Exchange was performed.
- natural IgG4 administered in vivo undergoes a half-molecule exchange with endogenous IgG4.
- the cause is Ser located at the 228th EU numbering in the hinge region, and it has been reported that the use of IgG1 type Pro improves stability and prevents exchange in vivo. (Labrijn AF et al. Nat. Biotechnol. 2009, 27, 767-771).
- the hinge sequence of the produced Bispecific antibody is preferably 226C-227P-228P-229C. Therefore, in this study, it was verified whether Fab Arm Exchange occurs efficiently even with the hinge sequence of natural human IgG1 by introducing an association interface control modification.
- MRAH-G1drP1 (SEQ ID NO: 15) in which K409R and D356K were introduced into MRAH-G1d
- H54-G1drN1 (SEQ ID NO: 16) in which K409R and K439E were introduced into H54-G1d were prepared.
- MRAL-k0 is used as the antibody L chain when H54 is used
- MRAH-G1drP1 / MRAL-k0 and H54-G1drN1 / L28-k0 are used according to the method of Reference Example 1 Expression and purification.
- the disulfide bond between the L chains is formed only at one location, it is considered that the disulfide bond is more easily reduced than the two disulfide bonds formed by the core hinge. If a disulfide bond between L chains can be cleaved by addition of a reducing agent and HL molecules can be efficiently generated, a Bispecific antibody may be produced with high efficiency as shown in FIG. Then, it verified whether Fab Arm Exchange reaction (Bispecific antibody production rate) could be performed with high efficiency by adding the modification which controls the association interface in CH3 area
- Fab Arm Exchange reaction Bispecific antibody production rate
- Fab-Arm-Exchange reaction (Bispecific antibody generation) can be performed with high efficiency by adding a modification that controls the association interface in the CH3 region to a variant having C220S modification. I verified.
- MRAH-G4d (SEQ ID NO: 17) and H54-G4d (SEQ ID NO: 18) having a G1-type hinge structure were prepared by introducing S228P into the hinge part of the heavy chain constant region of MRAH-wtG4d and H54-wtG4d.
- MRAH-G4dv1 (SEQ ID NO: 19) and H54-G4dv1 (SEQ ID NO: 20) into which C131S was introduced as a modification for removing the disulfide bond between the H chain and the L chain were compared with MRAH-G4d and H54-G4d.
- MRAH-G4dv1 and H54-G4dv1 are MRAH-G4dv2P1 (SEQ ID NO: 21), H54-, in which E356K or K439E is introduced as a modification of C226S, C229S and CH3 interface control, respectively, which are modifications for removing the disulfide bond at the hinge part.
- G4dv2N1 (SEQ ID NO: 22) was prepared.
- MRAH-wtG4d and H54-wtG4d are modified with C131S as a modification for removing the disulfide bond between the H chain and the L chain, C226S, C229S and the modifications for removing the disulfide bond at the hinge part.
- MRAH-wtG4dv2P1 (SEQ ID NO: 46) and H54-wtG4dv2N1 (SEQ ID NO: 47) into which E356K or K439E was introduced as CH3 interface control modifications were prepared.
- MRAH-G1dv1 SEQ ID NO: 23
- H54-G1dv1 SEQ ID NO: 23
- C220S was introduced as a modification for removing the disulfide bond between the H chain and the L chain relative to MRAH-G1d and H54-G1d SEQ ID NO: 24
- MRAH-G1dv1 and H54-G1dv1, C226S, C229S which are modifications for removing the disulfide bond in the hinge part
- MRAH-G1dv2rP1 SEQ ID NO: 25
- H54-G1dv2rN1 SEQ ID NO: 26
- natural human IgG1 has a longer hinge region than natural human IgG4.
- EU numbering 220 to 225 in the hinge region was replaced with YGPP, which is a human natural IgG4 sequence, for G1dv2rP1 and G1dv2rN1 MRAH-G1dv3rP1 (SEQ ID NO: 27) and H54-G1dv3rN1 (SEQ ID NO: 28) were prepared.
- the produced modified products are shown in Table 1 and Table 2 below.
- FIGS. 5-1 and 5-2 show the results of evaluation of reaction products by CE-IEF.
- G4dv2P1 Bispecification of G4dv2P1 // N1 in which MRAH-wtG4dP1 / MRAL-k0 and wtG4dP1 // N1 in which H54-wtG4dN1 / L28-k0 were reacted, or MRAH-G4dv2P1 / MRAL-k0 and H54-G4dv2N1 / L28-k0 were reacted in The antibody production rates were 94.3% and 96.2%, respectively.
- Bispecific antibody production rates of G1dv3rP1 // N1 obtained by reacting MRAH-G1dv3rP1 / MRAL-k0 and H54-G1dv3rN1 / L28-k0 were 94.4%, 87.7%, and 84.1%, respectively.
- FIG. 6 shows the results of evaluation of FAE reaction products and their homozygotes by non-reducing polyacrylamide gel electrophoresis (SDS-PAGE).
- MRAH-wtG4dP1 / MRAL-k0, H54-wtG4dN1 / L28-k0 and MRAH-G1drP1 / MRAL-k0, H54-G1drN1 / L28-k0 are HL molecules due to the presence of disulfide bonds between the H chain and L chain and at the hinge part. Electrophoresed as a homodimer.
- MRAH-G4dv2P1 / MRAL-k0, H54-G1dv2rP1 / MRAL-k0, H54-G1dv2rN1 / L28-k0, MRAH-G1dv3rP1 lacking the disulfide bond between the H and L chains
- an H chain, an L chain, and an L chain dimer (L2 in the figure) in which the L chain was associated by a disulfide bond were observed.
- wtG4dP1 // N1 and G1drP1 // N1 are observed as HL molecular dimers in which two H chains and two L chains are associated, and the disulfide bond at the hinge part cleaved by the reducing agent is the FAE reaction. It is suggested that they are recombined during heterodimerization associated with.
- G4dv2P1 // N1, G1dv2rP1 // N1, and G1dv3rP1 // N1 after the FAE reaction only the H chain and L chain monomers were observed, and the L chain dimer was not observed.
- the disulfide bond between the L chains is cleaved, and the produced HL molecules associate to purify the bispecific antibody.
- the disulfide bond between the L chains cannot be recombined with this heterodimerization.
- Example 3 it is thought that there is an influence of reducing conditions as one of the reasons why a disulfide bond was not formed between the L chains of G4dv2P1 // N1, G1dv2rP1 // N1, and G1dv3rP1 // N1, and 2-MEA
- the reduction conditions were examined using DTT and TCEP.
- FIGS. 7-1 and 7-2 The results of evaluation of reaction products by ion exchange chromatography are shown in FIGS. 7-1 and 7-2.
- the reaction efficiencies of G1drP1 // N1, G1dv2rP1 // N1, G1dv3rP1 // N1, and G4dv2P1 // N1 were 97.9%, 79.0%, 80.4%, and 91.40%, respectively.
- Example 5 Fab arm exchange with human native IgG4 lacking hinge region
- the distance between each L chain C-terminal is increased depending on the structure of the hinge part.
- Example 3 it was thought that it was due to this distance that no disulfide bond was formed between the L chains of G4dv2P1 // N1 after the FAE reaction. Therefore, it was verified whether a disulfide bond could be formed between the L chains after the FAE reaction by reducing the distance between the C-terminals of the L chains by deleting the hinge region.
- MRA- G4dv4 / MRAL-k0 (SEQ ID NO: 29), H54-G4dv4 / L28-k0 (SEQ ID NO: 30), MRAH-G4dv4P1 / MRAL-k0 (SEQ ID NO: 31) and H54-G4dv4N1 / L28-k0 (SEQ ID NO: 32) Produced.
- FIG. 9 shows the results of evaluation of reaction products by ion exchange chromatography.
- the reaction efficiency of G4dv4P1 // N1 obtained by mixing MRAH-G4dv4P1 / MRAL-k0 and H54-G4dv4N1 / L28-k0 was 95.4%.
- FIG. MRAH-G4dv4P1 / MRAL-k0 lacking the hinge region increased the amount of L chain dimer compared to MRAH-G4dv2P1 / MRAL-k0.
- Example 6 Fab arm exchange with human IgG4 lacking hinge region
- MRAH-G4dv4P1 / MRAL-k0 and H54-G4dv4N1 / L28-k0 lacking the hinge region were used to reduce the disulfide bond between the L chains by using DTT or TCEP, and then different HL molecules Were associated to re-form the disulfide bond between the L chains.
- WO2011131746 discloses that an FAE reaction can be efficiently caused by performing an FAE reaction using an antibody molecule having 405L on one of two types of antibody molecules and 409R on the other.
- this molecule Since this molecule has a normal native IgG1 hinge region, it is necessary to reduce two disulfide bonds in order to generate HL molecules in the FAE reaction process.
- the disulfide bond that needs to be reduced for HL molecule generation is one between the L chains, It was considered that the FAE reaction could proceed under milder reducing conditions.
- the antibody molecule disclosed in WO2011131746 was compared with MRAH-G4dv4P1 / MRAL-k0 and H54-G4dv4N1 / L28-k0 in terms of FAE reaction efficiency under milder reducing conditions.
- MRAH-G1d / MRAL-k0 sequence number 33
- H54-G1dl / MRAL-k0 sequence with F405L added to H54-G1d / L28-k0 No. 34
- MRAH-G1dr / MRAL-k0, H54-G1dl / L28-k0, MRAH-G4dv4P1 / MRAL-k0, H54-G4dv4N1 / L28-k0 were expressed and purified according to the method of Reference Example 1.
- FIG. 11 shows the results of evaluation of reaction products by ion exchange chromatography.
- the reaction efficiency of G1dr // dl obtained by mixing MRAH-G1dr / MRAL-k0 and H54-G1dl / L28-k0 at 5 mM or 0.5 mM mMSH was 8.5% and 0.4%.
- the reaction efficiencies of G4dv4P1 // N1 obtained by mixing MRAH-G4dv4P1 / MRAL-k0 and H54-G4dv4N1 / L28-k0 at 5 mmM or 0.5 mmMGSH were 94.5% and 65.6%. From the above results, it was shown that by using the FAE reaction performed by reducing the disulfide bond between the L chains, the reaction can proceed with high efficiency even under milder reducing conditions.
- Example 7 Fab arm exchange with natural human IgG4 in which disulfide bonds are formed between CH3 regions.
- the FAE reaction in which disulfide bonds between L chains are reduced to generate HL molecules is compared with the FAE reaction in which disulfide bonds in the native IgG1 hinge region are reduced to generate HL molecules.
- the reaction can proceed with high efficiency under milder reducing conditions. This is considered to be due to the fact that there is only one disulfide bond to be reduced and that there are fewer than in the case of reducing the normal hinge region.
- the site for forming this disulfide bond is not particularly limited to the hinge region, and any region of the antibody may be considered. Therefore, we next investigated the FAE reaction with a molecule in which one disulfide bond was formed between the CH3 regions.
- MRAH-G4d and H54-G4d / L28-k0 were added with C226S and C229S to eliminate the disulfide bond in the hinge region, and further with charge modification for CH3 interface control and modification for CH3 intersulfide disulfide bond formation, MRAH-G4dNX010P (SEQ ID NO: 35), MRAH-G4dNX010N (SEQ ID NO: 36), MRAH-G4dNX011P (SEQ ID NO: 37), MRAH-G4dNX011N (SEQ ID NO: 38), MRAH-G4dNX012P (SEQ ID NO: 39), MRAH-G4dNX012N (sequence) No.
- FIGS. 13-1 and 13-2 The results of evaluation of the reaction product and its homozygote by non-reducing SDS-PAGE are shown in FIGS. 13-1 and 13-2, respectively.
- G4dNX010P // 010N
- G4dNX011P // 011N
- G4dNX010P // 013N
- G4dNX014P // 014N where the FAE reaction has progressed
- the antibody molecule after the reaction forms an HL molecule dimer (H2L2 in the figure)
- CH3 It is thought that the disulfide bond between them was reformed.
- the antibody molecule forms HL molecular dimer (H2L2 in the figure) in MRAH-G4dNX014P / MRAL-k0 and H54-G4dNX014N / L28-k0, and disulfide between CH3 MRAH-G4dNX010P / MRAL-k0, H54-G4dNX010N / L28-k0, MRAH-G4dNX011P / MRAL-k0, H54-G4dNX011N / L28-k0 and H54-G4dNX013N / L28- In k0, HL molecules are the main component, and it is considered that disulfide bonds between CH3 are not formed.
- MRAH-G4dNX010P / MRAL-k0 and H54-G4dNX010N / L28-k0, MRAH-G4dNX011P / MRAL-k0 and H54-G4dNX011N / L28-k0 or MRAH-G4dNX010P did not form disulfide bonds between CH3 in the homozygote
- the distance between Y349C modifications added, the distance between E356C modifications, or the distance between Y349C and S354C is far from forming a disulfide bond, but the HL molecule
- the distance between Y349C and E356C or the distance between Y349C and S354C are considered to be able to form a disulfide bond.
- the prepared plasmid was transiently introduced into a human fetal kidney cancer cell-derived HEK293H strain (Invitrogen) or FreeStyle293 cells (Invitrogen) to express the antibody.
- the culture supernatant was obtained through a 0.22 ⁇ m filter MILLEX®-GV (Millipore) or a 0.45 ⁇ m filter MILLEX®-GV (Millipore).
- the antibody was purified by a method known to those skilled in the art using rProtein A Sepharose Fast Flow (GE Healthcare) or Protein G Sepharose 4 Fast Flow (GE Healthcare).
- the purified antibody concentration was measured by measuring the absorbance at 280 nm using a spectrophotometer, and the antibody concentration was calculated from the obtained value using an extinction coefficient calculated by a method such as PACE (Protein Science 1995; 4: 2411-2423).
- CE-IEF CE-IEF was measured by a method known to those skilled in the art using PA800 Plus (Beckman Coulter). Pharmalyte was analyzed with a pI range of 5 to 10.5 by mixing equal amounts of those with a broad range of 5 to 8 and 8 to 10.5. The analysis was performed using a 4 mg / mL antibody solution, and the results were analyzed using 32 karat software (Beckman Coulter). Bispecific antibody production rate (%) was obtained by dividing the area value of Bispecific antibody by the area value of all antibodies present in the system and multiplying by 100.
- Non-reducing SDS-PAGE Disulfide bonds were evaluated by SDS polyacrylamide gel electrophoresis using a Mini-PROTEAN Tetra system (BIO-RAD).
- Mini-PROTEAN TGX Gel (4-20%, BIO-RAD) for electrophoresis gel Tris-Glycine SDS Sample After diluting the antibody-containing solution with Buffer (2x, TEFCO), a sample that had been heat-treated at 95 ° C. for 2 min was electrophoresed.
- the gel after electrophoresis was stained using CBB Stain One (Nacalai Tesque). The stained gel was imaged using Typhoon FLA 9500 (GE Healthcare).
- Tm Measurement of Tm of CH3 domain was performed by a method known to those skilled in the art using Rotor-gene Q (QIAGEN).
- a sample mixed with an antibody concentration of 0.1 mg / mL and a SYPRO orange concentration of 10 ⁇ concentrate was heated from 30 ° C. to 99 ° C., and the fluorescence intensity (excitation wavelength: 470 nm, fluorescence wavelength: 555 nm) was measured every 0.4 ° C. Measurement was performed in PBS (Sigma, pH 7.4).
- the analysis was performed using Rotor-gene Q series software, and the inflection point obtained by the first derivative of the fluorescence intensity was defined as Tm.
- the Tm of the MR3 was calculated using the fact that Tm of MRAH was around 70 ° C for CH2, Fab was around 95 ° C, and Tm of H54 was around 70 ° C for CH2 and Fab was around 90 ° C.
Landscapes
- Health & Medical Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Immunology (AREA)
- Molecular Biology (AREA)
- Engineering & Computer Science (AREA)
- Organic Chemistry (AREA)
- Biochemistry (AREA)
- Medicinal Chemistry (AREA)
- General Health & Medical Sciences (AREA)
- Biophysics (AREA)
- Biomedical Technology (AREA)
- Urology & Nephrology (AREA)
- Hematology (AREA)
- Genetics & Genomics (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Analytical Chemistry (AREA)
- Physics & Mathematics (AREA)
- Food Science & Technology (AREA)
- General Physics & Mathematics (AREA)
- Pathology (AREA)
- Cell Biology (AREA)
- Microbiology (AREA)
- Biotechnology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Pharmacology & Pharmacy (AREA)
- Peptides Or Proteins (AREA)
- Preparation Of Compounds By Using Micro-Organisms (AREA)
Abstract
Description
〔1〕a) 第1の抗原結合活性を有し、重鎖定常領域を含む第1のポリペプチドのホモ体を提供する段階、
b) 該第1の抗原結合活性とは異なる第2の抗原結合活性を有し、重鎖定常領域を含む第2のポリペプチドのホモ体を提供する段階、
c) コアヒンジ領域外のシステインがジスルフィド結合の異性化を起こすことを可能にする還元条件下で、該第1のポリペプチドのホモ体および該第2のポリペプチドのホモ体を共にインキュベートする段階、ならびに
d) 第1及び第2のポリペプチドを含む異種多量体を得る段階
を含み、
コアヒンジ領域内のアミノ酸残基がジスルフィド結合を形成しない、
異種多量体を製造するための方法。
〔2〕〔1〕の段階a)において、第1のポリペプチドと多量体を形成する第3のポリペプチドを提供する段階を含み、かつ段階b)において、第2のポリペプチドと多量体を形成する第4のポリペプチドを提供する段階を含む、〔1〕に記載の製造方法。
〔3〕第3のポリペプチド及び第4のポリペプチドが抗体軽鎖である、〔2〕に記載の製造方法。
〔4〕コアヒンジ領域外が軽鎖定常領域である、〔1〕~〔3〕のいずれか一項に記載の製造方法。
〔5〕前記第1及び/又は第2のポリペプチドの重鎖定常領域において、EUナンバリングによる131位及び/又は220位のシステイン残基が他のアミノ酸残基に改変されている、〔4〕に記載の製造方法。
〔6〕コアヒンジ領域外が重鎖定常領域に含まれるCH3領域である、〔1〕~〔3〕のいずれか一項に記載の製造方法。
〔7〕前記第1及び第2のポリペプチドの重鎖定常領域に含まれるCH3領域のそれぞれにおいて、EUナンバリングによる349位、351位、354位、356位、394位及び407位のアミノ酸残基から選択される少なくとも一つのアミノ酸残基がシステインである、〔6〕に記載の製造方法。
〔8〕前記第1及び第2のポリペプチドの重鎖定常領域に含まれるCH3領域においてそれぞれシステインである組が、以下の(1)~(5)のいずれか1組である、〔7〕に記載の製造方法:
(1) EUナンバリングによる349位および356位のアミノ酸残基
(2) EUナンバリングによる394位および394位のアミノ酸残基
(3) EUナンバリングによる351位および351位のアミノ酸残基
(4) EUナンバリングによる407位および407位のアミノ酸残基
(5) EUナンバリングによる349位および354位のアミノ酸残基。
〔9〕EUナンバリングによる226位および/または229位のシステイン残基が他のアミノ酸残基に改変されている若しくは欠損している、又はコアヒンジ領域が欠損している、〔1〕~〔8〕のいずれか一項に記載の製造方法。
〔10〕さらにEUナンバリングによる220位から225位がTyr(Y)-Gly(G)-Pro(P)-Pro(P)に置換され、又はEUナンバリングによる219位から229位が欠損している、〔9〕に記載の製造方法。
〔11〕第1及び/又は第2のポリペプチドにおいて、第1及び/又は第2のポリペプチドのCH3領域の安定性が不安定になるようにアミノ酸が改変されている、〔1〕~〔10〕のいずれか一項に記載の製造方法。
〔12〕前記第1及び/又は第2のポリペプチドにおいて、EUナンバリングによる392位、397位及び409位のアミノ酸残基のうち少なくとも一つが改変されている、〔11〕に記載の製造方法。
〔13〕前記第1及び/又は第2のポリペプチドの重鎖定常領域に含まれるCH3領域において、
(1) EUナンバリングによる356位および439位のアミノ酸残基
(2) EUナンバリングによる357位および370位のアミノ酸残基
(3) EUナンバリングによる399位および409位のアミノ酸残基
に示すアミノ酸残基の組から選択される1組ないし3組のアミノ酸残基が同種の電荷を有し、
前記第1のポリペプチドのCH3領域及び前記第2のポリペプチドのCH3領域の両方において、前記(1)~(3)に示すアミノ酸残基の組のうち同じ組のアミノ酸残基がそれぞれ同種の電荷を有する場合、前記第2のポリペプチドのCH3領域における当該組のアミノ酸残基が、前記第1のポリペプチドのCH3領域における当該組のアミノ酸残基とは反対の電荷を有する、
〔1〕~〔12〕のいずれか一項に記載の製造方法。
〔14〕前記同種の電荷を有するアミノ酸残基が、以下の(A)または(B)いずれかの群に含まれる1つ以上のアミノ酸残基から選択される、〔13〕に記載の製造方法:
(A)グルタミン酸 (E)、アスパラギン酸 (D);
(B)リジン(K)、アルギニン(R)、ヒスチジン(H)。
〔15〕第1及び第2のポリペプチドにおいてそれぞれ同種の電荷を有するアミノ酸残基の組が、以下の(1)~(4)のいずれか1組のアミノ酸残基の組である、〔13〕または〔14〕に記載の製造方法:
(1) EUナンバリングによる356位および439位のアミノ酸残基
(2) EUナンバリングによる357位および370位のアミノ酸残基
(3) EUナンバリングによる399位および409位のアミノ酸残基
(4)(i) EUナンバリングによる399位および409位のアミノ酸残基、並びに
(ii) EUナンバリングによる356位および439位のアミノ酸残基。
〔16〕第1及び/又は第2のポリペプチドの重鎖定常領域がIgG1、IgG2、IgG3又はIgG4タイプである、〔1〕~〔15〕のいずれか一項に記載の製造方法。
〔17〕第1及び/又は第2のポリペプチドの重鎖定常領域がマウス由来の重鎖定常領域である、〔1〕~〔12〕のいずれか一項に記載の製造方法。
〔18〕前記第1及び/又は第2のポリペプチドの重鎖定常領域に含まれるCH3領域において、
(1) EUナンバリングによる356位および439位のアミノ酸残基
(2) EUナンバリングによる360位および371位のアミノ酸残基
(3) EUナンバリングによる399位および409位のアミノ酸残基
に示すアミノ酸残基の組から選択される1組ないし3組のアミノ酸残基が同種の電荷を有し、
前記第1のポリペプチドのCH3領域及び前記第2のポリペプチドのCH3領域の両方において、前記(1)~(3)に示すアミノ酸残基の組のうち同じ組のアミノ酸残基がそれぞれ同種の電荷を有する場合、前記第2のポリペプチドのCH3領域における当該組のアミノ酸残基が、前記第1のポリペプチドのCH3領域における当該組のアミノ酸残基とは反対の電荷を有する、
〔17〕に記載の異種多量体を製造するための方法。
〔19〕第1及び/又は第2のポリペプチドにおいて、
EUナンバリングによる397位がMet(M)、Phe(F)若しくはTyr(Y)に改変されており、かつ/又は
EUナンバリングによる392位がAsp(D)、Glu(E)、Thr(T)、Val(V)若しくはIle(I)に改変されており、かつ/又は
EUナンバリングによる409位がArg(R)に改変されている、
〔1〕~〔18〕のいずれか一項に記載の製造方法。
〔20〕a) 第1の抗原結合活性を有し、重鎖定常領域を含む第1のポリペプチドのホモ体を提供する段階、
b) 該第1の抗原結合活性とは異なる第2の抗原結合活性を有し、重鎖定常領域を含む第2のポリペプチドのホモ体を提供する段階、
c) 第1及び第2のポリペプチドを含む異種多量体を得る段階
を含む、
異種多量体を製造するための方法であって、
第1及び第2のポリペプチドの重鎖定常領域が、それぞれ以下の(1)~(5)のいずれかに記載のように改変されている、当該製造方法:
(1)第1のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基及び349位がCys(C)であり、第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基及び356位がCys(C)である;
(2)第1及び第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基及び394位がCys(C)である;
(3)第1及び第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基及び351位がCys(C)である;
(4)第1及び第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基及び407位がCys(C)である;
(5)第1のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基及び349位がCys(C)であり、第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基及び354位がCys(C)である。
〔21〕a) 第1の抗原結合活性を有し、重鎖定常領域を含む第1のポリペプチドのホモ体を提供する段階、
b) 該第1の抗原結合活性とは異なる第2の抗原結合活性を有し、重鎖定常領域を含む第2のポリペプチドのホモ体を提供する段階、
c) 第1及び第2のポリペプチドを含む異種多量体を得る段階
を含む、
異種多量体を製造するための方法であって、
段階a)において、第1のポリペプチドと多量体を形成する第3のポリペプチドである抗体軽鎖を提供する段階を含み、かつ段階b)において、第2のポリペプチドと多量体を形成する第4のポリペプチドである抗体軽鎖を提供する段階を含み、
第1及び第2のポリペプチドの重鎖定常領域が、それぞれ以下の(1)~(6)のいずれかに記載のように改変されている、当該製造方法:
(1)第1及び第2のポリペプチドはEUナンバリングによる131位がCys(C)以外のアミノ酸残基、226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基である;
(2)第1及び第2のポリペプチドはEUナンバリングによる131位がCys(C)以外のアミノ酸残基、226位がCys(C)以外のアミノ酸残基、228位がPro(P)、229位がCys(C)以外のアミノ酸残基である;
(3)第1及び第2のポリペプチドはEUナンバリングによる220位がCys(C)以外のアミノ酸残基、226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基である;
(4)第1及び第2のポリペプチドはEUナンバリングによる131位がCys(C)以外のアミノ酸残基、219位~229位が欠失している;
(5)第1及び第2のポリペプチドはEUナンバリングによる219位~229位が欠失している;
(6)第1及び第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基、220位~225位がTyr(Y)-Gly(G)-Pro(P)-Pro(P)である。
〔22〕〔1〕、〔20〕及び〔21〕に記載の段階c)が還元剤との接触を含む、〔1〕~〔21〕のいずれか一項に記載の製造方法。
〔23〕段階c)が、グルタチオン、L-システイン、ジチオスレイトール、β-メルカプト-エタノール、TCEPおよび2-MEAからなる群より選択される作用物質の添加を含む、〔22〕に記載の製造方法。
〔24〕前記異種多量体が多重特異性抗体又はヘテロFc融合タンパク質である、〔1〕~〔23〕のいずれか一項に記載の製造方法。
〔25〕前記異種多量体が二重特異性抗体である、〔1〕~〔24〕のいずれか一項に記載の製造方法。
〔26〕〔1〕~〔25〕のいずれか一項に記載の方法によって製造された異種多量体又は二重特異性抗体。
〔27〕抗体重鎖である第1のポリペプチドと抗体軽鎖である第3のポリペプチドで2量体を形成し、抗体重鎖である第2のポリペプチドと抗体軽鎖である第4のポリペプチドで2量体を形成している、第1、第2、第3および第4のポリペプチドを構成要素として含む二重特異性抗体であって、
第1及び/又は第2のポリペプチドの重鎖定常領域に含まれるCH3領域のそれぞれにおいて、EUナンバリングによる349位、351位、354位、356位、394位及び407位のアミノ酸残基から選択される少なくとも一つのアミノ酸残基がシステインである、
二重特異性抗体。
〔28〕抗体重鎖である第1のポリペプチドと抗体軽鎖である第3のポリペプチドで2量体を形成し、抗体重鎖である第2のポリペプチドと抗体軽鎖である第4のポリペプチドで2量体を形成している、第1、第2、第3および第4のポリペプチドを構成要素として含む二重特異性抗体であって、
第1及び第2のポリペプチドが、それぞれ以下の(1)~(6)のいずれかに示すアミノ酸残基を有する、
二重特異性抗体:
(1)第1及び第2のポリペプチドはEUナンバリングによる131位がCys(C)以外のアミノ酸残基、226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基である;
(2)第1及び第2のポリペプチドはEUナンバリングによる131位がCys(C)以外のアミノ酸残基、226位がCys(C)以外のアミノ酸残基、228位がPro(P)、229位がCys(C)以外のアミノ酸残基である;
(3)第1及び第2のポリペプチドはEUナンバリングによる220位がCys(C)以外のアミノ酸残基、226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基である;
(4)第1及び第2のポリペプチドはEUナンバリングによる131位がCys(C)以外のアミノ酸残基、219位~229位が欠失している;
(5)第1及び第2のポリペプチドはEUナンバリングによる219位~229位が欠失している;
(6)第1及び第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基、220位~225位がTyr(Y)-Gly(G)-Pro(P)-Pro(P)である。
〔29〕〔26〕~〔28〕のいずれか一項に記載の異種多量体又は二重特異性抗体、及び医薬的に許容される担体を含む組成物。
〔30〕〔27〕または〔28〕に記載の二重特異性抗体を製造する方法。
〔31〕〔1〕に記載の段階d)の後にさらに以下の段階を行う、異種多量体をスクリーニングする方法:
e) 異種多量体の活性を測定する段階、
f) 所望の活性を有する異種多量体を選択する段階。
〔32〕〔31〕に記載の段階f)の後にさらに以下の段階を行う、異種多量体を製造する方法:
g) 〔31〕に記載の段階f)で選択した異種多量体の第1のポリペプチド、第2のポリペプチド、第3のポリペプチド及び第4のポリペプチドのCDR又は可変領域を取得する段階、
h) 取得したCDR又は可変領域を別の異種多量体に移植する段階。
本発明における「ポリペプチド」とは、アミノ酸配列中に重鎖定常領域を含む、ポリペプチド(重鎖定常領域含有ポリペプチド)およびタンパク質(重鎖定常領域含有タンパク質)を指す。また、通常、生物由来のポリペプチドであるが、特に限定されず、例えば、人工的に設計された配列からなるポリペプチドであってもよい。また、天然ポリペプチド、あるいは合成ポリペプチド、組換えポリペプチド等のいずれであってもよい。さらに、上記のポリペプチドの断片もまた、本発明のポリペプチドに含まれる。また、本発明のポリペプチドは単量体であっても多量体であってもよく、特に「ポリペプチド多量体」と明記していない場合、「ポリペプチド」なる記載は単量体または(ホモもしくはヘテロ)多量体のいずれかの状態で存在し得る。尚、本願においては「ポリペプチド」または「ポリペプチド多量体」は抗体であってもよい。
Scaffoldとしては、少なくとも1つの抗原に結合することができる立体構造的に安定なポリペプチドであれば、どのようなポリペプチドであっても用いることができる。そのようなポリペプチドとしては、例えば、抗体可変領域断片、フィブロネクチン、Protein Aドメイン、LDL受容体Aドメイン、リポカリン等のほか、Nygrenら(Current Opinion in Structural Biology, 7:463-469(1997)、Journal of Immunol Methods, 290:3-28(2004))、Binzら(Nature Biotech 23:1257-1266(2005))、Hosseら(Protein Science 15:14-27(2006))に記載の分子が挙げられるがこれらに限定されない。
本発明のポリペプチド間の解離及び/又は会合制御方法の好ましい態様にあっては、当該方法は、抗体重鎖定常領域のアミノ酸残基の変異を導入することを特徴とする方法である。当該方法は、任意で、下記電荷反発等を利用した界面制御に係るアミノ酸改変を導入する段階、重鎖CH3領域の安定性が不安定になるようなアミノ酸改変を導入する段階をさらに含んでもよい。
一つの態様にあっては、当該方法は、以下の段階を含む、異種多量体を製造するための方法である。
a) 第1の抗原結合活性を有し、重鎖定常領域を含む第1のポリペプチドのホモ体を提供する段階、
b) 該第1の抗原結合活性とは異なる第2の抗原結合活性を有し、重鎖定常領域を含む第2のポリペプチドのホモ体を提供する段階、
c)コアヒンジ領域外のシステインがジスルフィド結合の異性化を起こすことを可能にする還元条件下で、該第1のポリペプチドのホモ体および該第2のポリペプチドのホモ体を共にインキュベートする段階、ならびに
d) 第1及び第2のポリペプチドを含む異種多量体を得る段階
を含み、
コアヒンジ領域内のアミノ酸残基がジスルフィド結合を形成しない。
一つの態様にあっては、本発明は、抗体重鎖定常領域を含むポリペプチドのCH3にあるシステインのジスルフィド結合(CH3領域間のジスルフィド結合)の異性化を利用した異種多量体を製造するための方法である。本方法に用いるシステインとしては、CH3に存在するシステインであれば特に限定されないが、好ましくはEUナンバリングによる349位、351位、354位、356位、394位及び407位の一カ所以上をシステインに改変して用いることができる。また、EUナンバリングによる349位、351位、354位、356位、394位及び407位の一カ所以上がシステインであるCH3を含むポリペプチドを用いてもよい。尚、重鎖定常領域がIgG1の場合、さらにEUナンバリングによる355位、356位、409位、419位及び445位の一つ以上が改変されていてもよく、例えば355位はGln(Q)に、356位はGlu(E)に、409位はArg(R)に、419位はGlu(E)に、又は445位はLeu(L)に改変されていてもよい。
(1) EUナンバリングによる349位および356位のアミノ酸残基
(2) EUナンバリングによる394位および394位のアミノ酸残基
(3) EUナンバリングによる351位および351位のアミノ酸残基
(4) EUナンバリングによる407位および407位のアミノ酸残基
(5) EUナンバリングによる349位および354位のアミノ酸残基
(1)第1のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基及び349位がCys(C)であり、第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基及び356位がCys(C)である。
(2)第1及び第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基及び394位がCys(C)である。
(3)第1及び第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基及び351位がCys(C)である。
(4)第1及び第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基及び407位がCys(C)である。
(5)第1のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基及び349位がCys(C)であり、第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基及び354位がCys(C)ある。
(1)第1のポリペプチドはEUナンバリングによる226位がSer(S)、229位がSer(S)及び349位がCys(C)であり、第2のポリペプチドはEUナンバリングによる226位がSer(S)、229位がSer(S)及び356位がCys(C)である。
(2)第1及び第2のポリペプチドはEUナンバリングによる226位がSer(S)、229位がSer(S)及び394位がCys(C)である。
(3)第1及び第2のポリペプチドはEUナンバリングによる226位がSer(S)、229位がSer(S)及び351位がCys(C)である。
(4)第1及び第2のポリペプチドはEUナンバリングによる226位がSer(S)、229位がSer(S)及び407位がCys(C)である。
(5)第1のポリペプチドはEUナンバリングによる226位がSer(S)、229位がSer(S)及び349位がCys(C)であり、第2のポリペプチドはEUナンバリングによる226位がSer(S)、229位がSer(S)及び354位がCys(C)ある。
(1)第1のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、228位がPro(P)、229位がCys(C)以外のアミノ酸残基及び349位がCys(C)であり、第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、228位がPro(P)、229位がCys(C)以外のアミノ酸残基及び356位がCys(C)である。
(2)第1及び第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、228位がPro(P)、229位がCys(C)以外のアミノ酸残基及び394位がCys(C)である。
(3)第1及び第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、228位がPro(P)、229位がCys(C)以外のアミノ酸残基及び351位がCys(C)である。
(4)第1及び第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、228位がPro(P)、229位がCys(C)以外のアミノ酸残基及び407位がCys(C)である。
(5)第1のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、228位がPro(P)、229位がCys(C)以外のアミノ酸残基及び349位がCys(C)であり、第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、228位がPro(P)、229位がCys(C)以外のアミノ酸残基及び354位がCys(C)ある。
(1)第1のポリペプチドはEUナンバリングによる226位がSer(S)、228位がPro(P)、229位がSer(S)及び349位がCys(C)であり、第2のポリペプチドはEUナンバリングによる226位がSer(S)、228位がPro(P)、229位がSer(S)及び356位がCys(C)である。
(2)第1及び第2のポリペプチドはEUナンバリングによる226位がSer(S)、228位がPro(P)、229位がSer(S)及び394位がCys(C)である。
(3)第1及び第2のポリペプチドはEUナンバリングによる226位がSer(S)、228位がPro(P)、229位がSer(S)及び351位がCys(C)である。
(4)第1及び第2のポリペプチドはEUナンバリングによる226位がSer(S)、228位がPro(P)、229位がSer(S)及び407位がCys(C)である。
(5)第1のポリペプチドはEUナンバリングによる226位がSer(S)、228位がPro(P)、229位がSer(S)及び349位がCys(C)であり、第2のポリペプチドはEUナンバリングによる226位がSer(S)、228位がPro(P)、229位がSer(S)及び354位がCys(C)ある。
(1)第1のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基及び349位がCys(C)であり、かつ、356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基及び356位がCys(C)あり、かつ、439位はGlu(E)又はAsp(D)である。
(2)第1のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基、349位がCys(C)及び397位がTyr(Y)であり、かつ、356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基、356位がCys(C)及び397位がTyr(Y)であり、かつ、439位はGlu(E)又はAsp(D)である。
(3)第1及び第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基及び394位がCys(C)であり、一方のポリペプチドはEUナンバリングによる356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、他方のポリペプチドはEUナンバリングによる439位がGlu(E)又はAsp(D)である。
(4)第1のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基、349位がCys(C)であり、第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基、354位がCys(C)であり、一方のポリペプチドはEUナンバリングによる356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、他方のポリペプチドはEUナンバリングによる439位がGlu(E)又はAsp(D)である。
(5)第1及び第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基、351位がCys(C)であり、一方のポリペプチドはEUナンバリングによる356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、他方のポリペプチドはEUナンバリングによる439位がGlu(E)又はAsp(D)である。
(6)第1及び第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基及び407位がCys(C)であり、一方のポリペプチドはEUナンバリングによる356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、他方のポリペプチドはEUナンバリングによる439位がGlu(E)又はAsp(D)である。
(1)第1のポリペプチドはEUナンバリングによる226位がSer(S)、229位がSer(S)及び349位がCys(C)であり、かつ、356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、第2のポリペプチドはEUナンバリングによる226位がSer(S)、229位がSer(S)及び356位がCys(C)あり、かつ、439位はGlu(E)又はAsp(D)である。
(2)第1のポリペプチドはEUナンバリングによる226位がSer(S)、229位がSer(S)、349位がCys(C)及び397位がTyr(Y)であり、かつ、356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、第2のポリペプチドはEUナンバリングによる226位がSer(S)、229位がSer(S)、356位がCys(C)及び397位がTyr(Y)であり、かつ、439位はGlu(E)又はAsp(D)である。
(3)第1及び第2のポリペプチドはEUナンバリングによる226位がSer(S)、229位がSer(S)及び394位がCys(C)であり、一方のポリペプチドはEUナンバリングによる356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、他方のポリペプチドはEUナンバリングによる439位がGlu(E)又はAsp(D)である。
(4)第1のポリペプチドはEUナンバリングによる226位がSer(S)、229位がSer(S)、349位がCys(C)であり、第2のポリペプチドはEUナンバリングによる226位がSer(S)、229位がSer(S)、354位がCys(C)であり、一方のポリペプチドはEUナンバリングによる356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、他方のポリペプチドはEUナンバリングによる439位がGlu(E)又はAsp(D)である。
(5)第1及び第2のポリペプチドはEUナンバリングによる226位がSer(S)、229位がSer(S)、351位がCys(C)であり、一方のポリペプチドはEUナンバリングによる356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、他方のポリペプチドはEUナンバリングによる439位がGlu(E)又はAsp(D)である。
(6)第1及び第2のポリペプチドはEUナンバリングによる226位がSer(S)、229位がSer(S)及び407位がCys(C)であり、一方のポリペプチドはEUナンバリングによる356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、他方のポリペプチドはEUナンバリングによる439位がGlu(E)又はAsp(D)である。
(1)第1のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、228位がPro(P)、229位がCys(C)以外のアミノ酸残基及び349位がCys(C)であり、かつ、356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、228位がPro(P)、229位がCys(C)以外のアミノ酸残基及び356位がCys(C)あり、かつ、439位はGlu(E)又はAsp(D)である。
(2)第1のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、228位がPro(P)、229位がCys(C)以外のアミノ酸残基、349位がCys(C)及び397位がTyr(Y)であり、かつ、356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、228位がPro(P)、229位がCys(C)以外のアミノ酸残基、356位がCys(C)及び397位がTyr(Y)であり、かつ、439位はGlu(E)又はAsp(D)である。
(3)第1及び第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、228位がPro(P)、229位がCys(C)以外のアミノ酸残基及び394位がCys(C)であり、一方のポリペプチドはEUナンバリングによる356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、他方のポリペプチドはEUナンバリングによる439位がGlu(E)又はAsp(D)である。
(4)第1のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、228位がPro(P)、229位がCys(C)以外のアミノ酸残基、349位がCys(C)であり、第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、228位がPro(P)、229位がCys(C)以外のアミノ酸残基、354位がCys(C)であり、一方のポリペプチドはEUナンバリングによる356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、他方のポリペプチドはEUナンバリングによる439位がGlu(E)又はAsp(D)である。
(5)第1及び第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、228位がPro(P)、229位がCys(C)以外のアミノ酸残基、351位がCys(C)であり、一方のポリペプチドはEUナンバリングによる356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、他方のポリペプチドはEUナンバリングによる439位がGlu(E)又はAsp(D)である。
(6)第1及び第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、228位がPro(P)、229位がCys(C)以外のアミノ酸残基及び407位がCys(C)であり、一方のポリペプチドはEUナンバリングによる356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、他方のポリペプチドはEUナンバリングによる439位がGlu(E)又はAsp(D)である。
(1)第1のポリペプチドはEUナンバリングによる226位がSer(S)、228位がPro(P)、229位がSer(S)及び349位がCys(C)であり、かつ、356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、第2のポリペプチドはEUナンバリングによる226位がSer(S)、228位がPro(P)、229位がSer(S)及び356位がCys(C)あり、かつ、439位はGlu(E)又はAsp(D)である。
(2)第1のポリペプチドはEUナンバリングによる226位がSer(S)、228位がPro(P)、229位がSer(S)、349位がCys(C)及び397位がTyr(Y)であり、かつ、356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、第2のポリペプチドはEUナンバリングによる226位がSer(S)、228位がPro(P)、229位がSer(S)、356位がCys(C)及び397位がTyr(Y)であり、かつ、439位はGlu(E)又はAsp(D)である。
(3)第1及び第2のポリペプチドはEUナンバリングによる226位がSer(S)、228位がPro(P)、229位がSer(S)及び394位がCys(C)であり、一方のポリペプチドはEUナンバリングによる356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、他方のポリペプチドはEUナンバリングによる439位がGlu(E)又はAsp(D)である。
(4)第1のポリペプチドはEUナンバリングによる226位がSer(S)、228位がPro(P)、229位がSer(S)、349位がCys(C)であり、第2のポリペプチドはEUナンバリングによる226位がSer(S)、228位がPro(P)、229位がSer(S)、354位がCys(C)であり、一方のポリペプチドはEUナンバリングによる356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、他方のポリペプチドはEUナンバリングによる439位がGlu(E)又はAsp(D)である。
(5)第1及び第2のポリペプチドはEUナンバリングによる226位がSer(S)、228位がPro(P)、229位がSer(S)、351位がCys(C)であり、一方のポリペプチドはEUナンバリングによる356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、他方のポリペプチドはEUナンバリングによる439位がGlu(E)又はAsp(D)である。
(6)第1及び第2のポリペプチドはEUナンバリングによる226位がSer(S)、228位がPro(P)、229位がSer(S)及び407位がCys(C)であり、一方のポリペプチドはEUナンバリングによる356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、他方のポリペプチドはEUナンバリングによる439位がGlu(E)又はAsp(D)である。
(1)第1のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基、349位がCys(C)及び356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基、356位がCys(C)及び439位はGlu(E)である。
(2)第1のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基、349位がCys(C)、356位がLys(K)及び397位がTyr(Y)であり、第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基、356位がCys(C)、397位がTyr(Y)及び439位はGlu(E)である。
(3)第1のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基、394位がCys(C)及び356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基、394位がCys(C)及び439位はGlu(E)である。
(4)第1のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基、349位がCys(C)及び356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基、354位がCys(C)及び439位はGlu(E)である。
(5)第1のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基、351位がCys(C)及び356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基、351位がCys(C)及び439位はGlu(E)である。
(6)第1のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基、407位がCys(C)及び356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基、407位がCys(C)及び439位はGlu(E)である。
(1)第1のポリペプチドはEUナンバリングによる226位がSer(S)、229位がSer(S)、349位がCys(C)及び356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる226位がSer(S)、229位がSer(S)、356位がCys(C)及び439位はGlu(E)である。
(2)第1のポリペプチドはEUナンバリングによる226位がSer(S)、229位がSer(S)、349位がCys(C)、356位がLys(K)及び397位がTyr(Y)であり、第2のポリペプチドはEUナンバリングによる226位がSer(S)、229位がSer(S)、356位がCys(C)、397位がTyr(Y)及び439位はGlu(E)である。
(3)第1のポリペプチドはEUナンバリングによる226位がSer(S)、229位がSer(S)、394位がCys(C)及び356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる226位がSer(S)、229位がSer(S)、394位がCys(C)及び439位はGlu(E)である。
(4)第1のポリペプチドはEUナンバリングによる226位がSer(S)、229位がSer(S)、349位がCys(C)及び356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる226位がSer(S)、229位がSer(S)、354位がCys(C)及び439位はGlu(E)である。
(5)第1のポリペプチドはEUナンバリングによる226位がSer(S)、229位がSer(S)、351位がCys(C)及び356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる226位がSer(S)、229位がSer(S)、351位がCys(C)及び439位はGlu(E)である。
(6)第1のポリペプチドはEUナンバリングによる226位がSer(S)、229位がSer(S)、407位がCys(C)及び356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる226位がSer(S)、229位がSer(S)、407位がCys(C)及び439位はGlu(E)である。
(1)第1のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、228位がPro(P)、229位がCys(C)以外のアミノ酸残基、349位がCys(C)及び356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、228位がPro(P)、229位がCys(C)以外のアミノ酸残基、356位がCys(C)及び439位はGlu(E)である。
(2)第1のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、228位がPro(P)、229位がCys(C)以外のアミノ酸残基、349位がCys(C)、356位がLys(K)及び397位がTyr(Y)であり、第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、228位がPro(P)、229位がCys(C)以外のアミノ酸残基、356位がCys(C)、397位がTyr(Y)及び439位はGlu(E)である。
(3)第1のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、228位がPro(P)、229位がCys(C)以外のアミノ酸残基、394位がCys(C)及び356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、228位がPro(P)、229位がCys(C)以外のアミノ酸残基、394位がCys(C)及び439位はGlu(E)である。
(4)第1のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、228位がPro(P)、229位がCys(C)以外のアミノ酸残基、349位がCys(C)及び356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、228位がPro(P)、229位がCys(C)以外のアミノ酸残基、354位がCys(C)及び439位はGlu(E)である。
(5)第1のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、228位がPro(P)、229位がCys(C)以外のアミノ酸残基、351位がCys(C)及び356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、228位がPro(P)、229位がCys(C)以外のアミノ酸残基、351位がCys(C)及び439位はGlu(E)である。
(6)第1のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、228位がPro(P)、229位がCys(C)以外のアミノ酸残基、407位がCys(C)及び356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、228位がPro(P)、229位がCys(C)以外のアミノ酸残基、407位がCys(C)及び439位はGlu(E)である。
(1)第1のポリペプチドはEUナンバリングによる226位がSer(S)、228位がPro(P)、229位がSer(S)、349位がCys(C)及び356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる226位がSer(S)、228位がPro(P)、229位がSer(S)、356位がCys(C)及び439位はGlu(E)である。
(2)第1のポリペプチドはEUナンバリングによる226位がSer(S)、228位がPro(P)、229位がSer(S)、349位がCys(C)、356位がLys(K)及び397位がTyr(Y)であり、第2のポリペプチドはEUナンバリングによる226位がSer(S)、228位がPro(P)、229位がSer(S)、356位がCys(C)、397位がTyr(Y)及び439位はGlu(E)である。
(3)第1のポリペプチドはEUナンバリングによる226位がSer(S)、228位がPro(P)、229位がSer(S)、394位がCys(C)及び356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる226位がSer(S)、228位がPro(P)、229位がSer(S)、394位がCys(C)及び439位はGlu(E)である。
(4)第1のポリペプチドはEUナンバリングによる226位がSer(S)、228位がPro(P)、229位がSer(S)、349位がCys(C)及び356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる226位がSer(S)、228位がPro(P)、229位がSer(S)、354位がCys(C)及び439位はGlu(E)である。
(5)第1のポリペプチドはEUナンバリングによる226位がSer(S)、228位がPro(P)、229位がSer(S)、351位がCys(C)及び356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる226位がSer(S)、228位がPro(P)、229位がSer(S)、351位がCys(C)及び439位はGlu(E)である。
(6)第1のポリペプチドはEUナンバリングによる226位がSer(S)、228位がPro(P)、229位がSer(S)、407位がCys(C)及び356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる226位がSer(S)、228位がPro(P)、229位がSer(S)、407位がCys(C)及び439位はGlu(E)である。
(1) EUナンバリングによる349位および356位のアミノ酸残基
(2) EUナンバリングによる394位および394位のアミノ酸残基
(3) EUナンバリングによる351位および351位のアミノ酸残基
(4) EUナンバリングによる407位および407位のアミノ酸残基
(5) EUナンバリングによる349位および354位のアミノ酸残基
(1)第1のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基及び349位がCys(C)であり、第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基及び356位がCys(C)である。
(2)第1及び第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基及び394位がCys(C)である。
(3)第1及び第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基及び351位がCys(C)である。
(4)第1及び第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基及び407位がCys(C)である。
(5)第1のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基及び349位がCys(C)であり、第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基及び354位がCys(C)ある。
(1)第1のポリペプチドはEUナンバリングによる226位がSer(S)、229位がSer(S)及び349位がCys(C)であり、第2のポリペプチドはEUナンバリングによる226位がSer(S)、229位がSer(S)及び356位がCys(C)である。
(2)第1及び第2のポリペプチドはEUナンバリングによる226位がSer(S)、229位がSer(S)及び394位がCys(C)である。
(3)第1及び第2のポリペプチドはEUナンバリングによる226位がSer(S)、229位がSer(S)及び351位がCys(C)である。
(4)第1及び第2のポリペプチドはEUナンバリングによる226位がSer(S)、229位がSer(S)及び407位がCys(C)である。
(5)第1のポリペプチドはEUナンバリングによる226位がSer(S)、229位がSer(S)及び349位がCys(C)であり、第2のポリペプチドはEUナンバリングによる226位がSer(S)、229位がSer(S)及び354位がCys(C)ある。
(1)第1のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、228位がPro(P)、229位がCys(C)以外のアミノ酸残基及び349位がCys(C)であり、第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、228位がPro(P)、229位がCys(C)以外のアミノ酸残基及び356位がCys(C)である。
(2)第1及び第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、228位がPro(P)、229位がCys(C)以外のアミノ酸残基及び394位がCys(C)である。
(3)第1及び第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、228位がPro(P)、229位がCys(C)以外のアミノ酸残基及び351位がCys(C)である。
(4)第1及び第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、228位がPro(P)、229位がCys(C)以外のアミノ酸残基及び407位がCys(C)である。
(5)第1のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、228位がPro(P)、229位がCys(C)以外のアミノ酸残基及び349位がCys(C)であり、第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、228位がPro(P)、229位がCys(C)以外のアミノ酸残基及び354位がCys(C)ある。
(1)第1のポリペプチドはEUナンバリングによる226位がSer(S)、228位がPro(P)、229位がSer(S)及び349位がCys(C)であり、第2のポリペプチドはEUナンバリングによる226位がSer(S)、228位がPro(P)、229位がSer(S)及び356位がCys(C)である。
(2)第1及び第2のポリペプチドはEUナンバリングによる226位がSer(S)、228位がPro(P)、229位がSer(S)及び394位がCys(C)である。
(3)第1及び第2のポリペプチドはEUナンバリングによる226位がSer(S)、228位がPro(P)、229位がSer(S)及び351位がCys(C)である。
(4)第1及び第2のポリペプチドはEUナンバリングによる226位がSer(S)、228位がPro(P)、229位がSer(S)及び407位がCys(C)である。
(5)第1のポリペプチドはEUナンバリングによる226位がSer(S)、228位がPro(P)、229位がSer(S)及び349位がCys(C)であり、第2のポリペプチドはEUナンバリングによる226位がSer(S)、228位がPro(P)、229位がSer(S)及び354位がCys(C)ある。
(1)第1のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基及び349位がCys(C)であり、かつ、356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基及び356位がCys(C)あり、かつ、439位はGlu(E)又はAsp(D)である。
(2)第1のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基、349位がCys(C)及び397位がTyr(Y)であり、かつ、356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基、356位がCys(C)及び397位がTyr(Y)であり、かつ、439位はGlu(E)又はAsp(D)である。
(3)第1及び第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基及び394位がCys(C)であり、一方のポリペプチドはEUナンバリングによる356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、他方のポリペプチドはEUナンバリングによる439位がGlu(E)又はAsp(D)である。
(4)第1のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基、349位がCys(C)であり、第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基、354位がCys(C)であり、一方のポリペプチドはEUナンバリングによる356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、他方のポリペプチドはEUナンバリングによる439位がGlu(E)又はAsp(D)である。
(5)第1及び第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基、351位がCys(C)であり、一方のポリペプチドはEUナンバリングによる356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、他方のポリペプチドはEUナンバリングによる439位がGlu(E)又はAsp(D)である。
(6)第1及び第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基及び407位がCys(C)であり、一方のポリペプチドはEUナンバリングによる356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、他方のポリペプチドはEUナンバリングによる439位がGlu(E)又はAsp(D)である。
(1)第1のポリペプチドはEUナンバリングによる226位がSer(S)、229位がSer(S)及び349位がCys(C)であり、かつ、356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、第2のポリペプチドはEUナンバリングによる226位がSer(S)、229位がSer(S)及び356位がCys(C)あり、かつ、439位はGlu(E)又はAsp(D)である。
(2)第1のポリペプチドはEUナンバリングによる226位がSer(S)、229位がSer(S)、349位がCys(C)及び397位がTyr(Y)であり、かつ、356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、第2のポリペプチドはEUナンバリングによる226位がSer(S)、229位がSer(S)、356位がCys(C)及び397位がTyr(Y)であり、かつ、439位はGlu(E)又はAsp(D)である。
(3)第1及び第2のポリペプチドはEUナンバリングによる226位がSer(S)、229位がSer(S)及び394位がCys(C)であり、一方のポリペプチドはEUナンバリングによる356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、他方のポリペプチドはEUナンバリングによる439位がGlu(E)又はAsp(D)である。
(4)第1のポリペプチドはEUナンバリングによる226位がSer(S)、229位がSer(S)、349位がCys(C)であり、第2のポリペプチドはEUナンバリングによる226位がSer(S)、229位がSer(S)、354位がCys(C)であり、一方のポリペプチドはEUナンバリングによる356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、他方のポリペプチドはEUナンバリングによる439位がGlu(E)又はAsp(D)である。
(5)第1及び第2のポリペプチドはEUナンバリングによる226位がSer(S)、229位がSer(S)、351位がCys(C)であり、一方のポリペプチドはEUナンバリングによる356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、他方のポリペプチドはEUナンバリングによる439位がGlu(E)又はAsp(D)である。
(6)第1及び第2のポリペプチドはEUナンバリングによる226位がSer(S)、229位がSer(S)及び407位がCys(C)であり、一方のポリペプチドはEUナンバリングによる356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、他方のポリペプチドはEUナンバリングによる439位がGlu(E)又はAsp(D)である。
(1)第1のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、228位がPro(P)、229位がCys(C)以外のアミノ酸残基及び349位がCys(C)であり、かつ、356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、228位がPro(P)、229位がCys(C)以外のアミノ酸残基及び356位がCys(C)あり、かつ、439位はGlu(E)又はAsp(D)である。
(2)第1のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、228位がPro(P)、229位がCys(C)以外のアミノ酸残基、349位がCys(C)及び397位がTyr(Y)であり、かつ、356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、228位がPro(P)、229位がCys(C)以外のアミノ酸残基、356位がCys(C)及び397位がTyr(Y)であり、かつ、439位はGlu(E)又はAsp(D)である。
(3)第1及び第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、228位がPro(P)、229位がCys(C)以外のアミノ酸残基及び394位がCys(C)であり、一方のポリペプチドはEUナンバリングによる356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、他方のポリペプチドはEUナンバリングによる439位がGlu(E)又はAsp(D)である。
(4)第1のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、228位がPro(P)、229位がCys(C)以外のアミノ酸残基、349位がCys(C)であり、第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、228位がPro(P)、229位がCys(C)以外のアミノ酸残基、354位がCys(C)であり、一方のポリペプチドはEUナンバリングによる356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、他方のポリペプチドはEUナンバリングによる439位がGlu(E)又はAsp(D)である。
(5)第1及び第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、228位がPro(P)、229位がCys(C)以外のアミノ酸残基、351位がCys(C)であり、一方のポリペプチドはEUナンバリングによる356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、他方のポリペプチドはEUナンバリングによる439位がGlu(E)又はAsp(D)である。
(6)第1及び第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、228位がPro(P)、229位がCys(C)以外のアミノ酸残基及び407位がCys(C)であり、一方のポリペプチドはEUナンバリングによる356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、他方のポリペプチドはEUナンバリングによる439位がGlu(E)又はAsp(D)である。
(1)第1のポリペプチドはEUナンバリングによる226位がSer(S)、228位がPro(P)、229位がSer(S)及び349位がCys(C)であり、かつ、356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、第2のポリペプチドはEUナンバリングによる226位がSer(S)、228位がPro(P)、229位がSer(S)及び356位がCys(C)あり、かつ、439位はGlu(E)又はAsp(D)である。
(2)第1のポリペプチドはEUナンバリングによる226位がSer(S)、228位がPro(P)、229位がSer(S)、349位がCys(C)及び397位がTyr(Y)であり、かつ、356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、第2のポリペプチドはEUナンバリングによる226位がSer(S)、228位がPro(P)、229位がSer(S)、356位がCys(C)及び397位がTyr(Y)であり、かつ、439位はGlu(E)又はAsp(D)である。
(3)第1及び第2のポリペプチドはEUナンバリングによる226位がSer(S)、228位がPro(P)、229位がSer(S)及び394位がCys(C)であり、一方のポリペプチドはEUナンバリングによる356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、他方のポリペプチドはEUナンバリングによる439位がGlu(E)又はAsp(D)である。
(4)第1のポリペプチドはEUナンバリングによる226位がSer(S)、228位がPro(P)、229位がSer(S)、349位がCys(C)であり、第2のポリペプチドはEUナンバリングによる226位がSer(S)、228位がPro(P)、229位がSer(S)、354位がCys(C)であり、一方のポリペプチドはEUナンバリングによる356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、他方のポリペプチドはEUナンバリングによる439位がGlu(E)又はAsp(D)である。
(5)第1及び第2のポリペプチドはEUナンバリングによる226位がSer(S)、228位がPro(P)、229位がSer(S)、351位がCys(C)であり、一方のポリペプチドはEUナンバリングによる356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、他方のポリペプチドはEUナンバリングによる439位がGlu(E)又はAsp(D)である。
(6)第1及び第2のポリペプチドはEUナンバリングによる226位がSer(S)、228位がPro(P)、229位がSer(S)及び407位がCys(C)であり、一方のポリペプチドはEUナンバリングによる356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、他方のポリペプチドはEUナンバリングによる439位がGlu(E)又はAsp(D)である。
(1)第1のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基、349位がCys(C)及び356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基、356位がCys(C)及び439位はGlu(E)である。
(2)第1のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基、349位がCys(C)、356位がLys(K)及び397位がTyr(Y)であり、第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基、356位がCys(C)、397位がTyr(Y)及び439位はGlu(E)である。
(3)第1のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基、394位がCys(C)及び356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基、394位がCys(C)及び439位はGlu(E)である。
(4)第1のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基、349位がCys(C)及び356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基、354位がCys(C)及び439位はGlu(E)である。
(5)第1のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基、351位がCys(C)及び356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基、351位がCys(C)及び439位はGlu(E)である。
(6)第1のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基、407位がCys(C)及び356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基、407位がCys(C)及び439位はGlu(E)である。
(1)第1のポリペプチドはEUナンバリングによる226位がSer(S)、229位がSer(S)、349位がCys(C)及び356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる226位がSer(S)、229位がSer(S)、356位がCys(C)及び439位はGlu(E)である。
(2)第1のポリペプチドはEUナンバリングによる226位がSer(S)、229位がSer(S)、349位がCys(C)、356位がLys(K)及び397位がTyr(Y)であり、第2のポリペプチドはEUナンバリングによる226位がSer(S)、229位がSer(S)、356位がCys(C)、397位がTyr(Y)及び439位はGlu(E)である。
(3)第1のポリペプチドはEUナンバリングによる226位がSer(S)、229位がSer(S)、394位がCys(C)及び356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる226位がSer(S)、229位がSer(S)、394位がCys(C)及び439位はGlu(E)である。
(4)第1のポリペプチドはEUナンバリングによる226位がSer(S)、229位がSer(S)、349位がCys(C)及び356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる226位がSer(S)、229位がSer(S)、354位がCys(C)及び439位はGlu(E)である。
(5)第1のポリペプチドはEUナンバリングによる226位がSer(S)、229位がSer(S)、351位がCys(C)及び356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる226位がSer(S)、229位がSer(S)、351位がCys(C)及び439位はGlu(E)である。
(6)第1のポリペプチドはEUナンバリングによる226位がSer(S)、229位がSer(S)、407位がCys(C)及び356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる226位がSer(S)、229位がSer(S)、407位がCys(C)及び439位はGlu(E)である。
(1)第1のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、228位がPro(P)、229位がCys(C)以外のアミノ酸残基、349位がCys(C)及び356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、228位がPro(P)、229位がCys(C)以外のアミノ酸残基、356位がCys(C)及び439位はGlu(E)である。
(2)第1のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、228位がPro(P)、229位がCys(C)以外のアミノ酸残基、349位がCys(C)、356位がLys(K)及び397位がTyr(Y)であり、第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、228位がPro(P)、229位がCys(C)以外のアミノ酸残基、356位がCys(C)、397位がTyr(Y)及び439位はGlu(E)である。
(3)第1のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、228位がPro(P)、229位がCys(C)以外のアミノ酸残基、394位がCys(C)及び356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、228位がPro(P)、229位がCys(C)以外のアミノ酸残基、394位がCys(C)及び439位はGlu(E)である。
(4)第1のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、228位がPro(P)、229位がCys(C)以外のアミノ酸残基、349位がCys(C)及び356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、228位がPro(P)、229位がCys(C)以外のアミノ酸残基、354位がCys(C)及び439位はGlu(E)である。
(5)第1のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、228位がPro(P)、229位がCys(C)以外のアミノ酸残基、351位がCys(C)及び356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、228位がPro(P)、229位がCys(C)以外のアミノ酸残基、351位がCys(C)及び439位はGlu(E)である。
(6)第1のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、228位がPro(P)、229位がCys(C)以外のアミノ酸残基、407位がCys(C)及び356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、228位がPro(P)、229位がCys(C)以外のアミノ酸残基、407位がCys(C)及び439位はGlu(E)である。
(1)第1のポリペプチドはEUナンバリングによる226位がSer(S)、228位がPro(P)、229位がSer(S)、349位がCys(C)及び356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる226位がSer(S)、228位がPro(P)、229位がSer(S)、356位がCys(C)及び439位はGlu(E)である。
(2)第1のポリペプチドはEUナンバリングによる226位がSer(S)、228位がPro(P)、229位がSer(S)、349位がCys(C)、356位がLys(K)及び397位がTyr(Y)であり、第2のポリペプチドはEUナンバリングによる226位がSer(S)、228位がPro(P)、229位がSer(S)、356位がCys(C)、397位がTyr(Y)及び439位はGlu(E)である。
(3)第1のポリペプチドはEUナンバリングによる226位がSer(S)、228位がPro(P)、229位がSer(S)、394位がCys(C)及び356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる226位がSer(S)、228位がPro(P)、229位がSer(S)、394位がCys(C)及び439位はGlu(E)である。
(4)第1のポリペプチドはEUナンバリングによる226位がSer(S)、228位がPro(P)、229位がSer(S)、349位がCys(C)及び356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる226位がSer(S)、228位がPro(P)、229位がSer(S)、354位がCys(C)及び439位はGlu(E)である。
(5)第1のポリペプチドはEUナンバリングによる226位がSer(S)、228位がPro(P)、229位がSer(S)、351位がCys(C)及び356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる226位がSer(S)、228位がPro(P)、229位がSer(S)、351位がCys(C)及び439位はGlu(E)である。
(6)第1のポリペプチドはEUナンバリングによる226位がSer(S)、228位がPro(P)、229位がSer(S)、407位がCys(C)及び356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる226位がSer(S)、228位がPro(P)、229位がSer(S)、407位がCys(C)及び439位はGlu(E)である。
別の一つの態様にあっては、本発明は、抗体軽鎖定常領域にあるシステインのジスルフィド結合(L鎖間のジスルフィド結合)の異性化を利用した異種多量体を製造するための方法である。本方法に用いるシステインとしては抗体軽鎖定常領域に存在するシステインであれば特に限定されないが、例えばL鎖C末端(214位)のシステインが挙げられる。抗体軽鎖定常領域にあるシステインのジスルフィド結合の異性化を利用するには、例えばIgG4抗体の場合、抗体重鎖定常領域のEUナンバリングによる131位のシステインを他のアミノ酸、例えばSer(S)に改変するが、特にこの改変に限定されるものではない。また、IgG1抗体の場合、抗体重鎖定常領域のEUナンバリングによる220位のシステインを他のアミノ酸、例えばSer(S)に改変するが、特にこの改変に限定されるものではない。また、EUナンバリングによる131位がシステイン以外のアミノ酸であるIgG4抗体重鎖定常領域を含むポリペプチドや、EUナンバリングによる220位がシステイン以外のアミノ酸であるIgG1抗体重鎖定常領域を含むポリペプチドを用いてもよい。
(1)第1及び第2のポリペプチドはEUナンバリングによる131位がCys(C)以外のアミノ酸残基である。
(2)第1及び第2のポリペプチドはEUナンバリングによる220位がCys(C)以外のアミノ酸残基である。
好ましくは(1)はIgG4であり、(2)はIgG1である。
(1)第1及び第2のポリペプチドはEUナンバリングによる131位がSer(S)である。
(2)第1及び第2のポリペプチドはEUナンバリングによる220位がSer(S)又はTyr(Y)である。
好ましくは(1)はIgG4であり、(2)はIgG1である。
(1)第1及び第2のポリペプチドはEUナンバリングによる131位がCys(C)以外のアミノ酸残基、226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基である。
(2)第1及び第2のポリペプチドはEUナンバリングによる131位がCys(C)以外のアミノ酸残基、226位がCys(C)以外のアミノ酸残基、228位がPro(P)、229位がCys(C)以外のアミノ酸残基である。
(3)第1及び第2のポリペプチドはEUナンバリングによる220位がCys(C)以外のアミノ酸残基、226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基である。
(4)第1及び第2のポリペプチドはEUナンバリングによる131位がCys(C)以外のアミノ酸残基、219位~229位が欠失している。
(5)第1及び第2のポリペプチドはEUナンバリングによる219位~229位が欠失している。
(6)第1及び第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基、220位~225位がTyr(Y)-Gly(G)-Pro(P)-Pro(P)である。
好ましくは(1)、(2)及び(4)はIgG4であり、(3)、(5)及び(6)はIgG1である。
(1)第1及び第2のポリペプチドはEUナンバリングによる131位がSer(S)、226位がSer(S)、229位がSer(S)である。
(2)第1及び第2のポリペプチドはEUナンバリングによる131位がSer(S)、226位がSer(S)、228位がPro(P)、229位がSer(S)である。
(3)第1及び第2のポリペプチドはEUナンバリングによる220位がSer(S)又はTyr(Y)、226位がSer(S)、229位がSer(S)である。
(4)第1及び第2のポリペプチドはEUナンバリングによる131位がSer(S)、219位~229位が欠失している。
(5)第1及び第2のポリペプチドはEUナンバリングによる219位~229位が欠失している。
(6)第1及び第2のポリペプチドはEUナンバリングによる226位がSer(S)、229位がSer(S)、220位~225位がTyr(Y)-Gly(G)-Pro(P)-Pro(P)である。
好ましくは(1)、(2)及び(4)はIgG4であり、(3)、(5)及び(6)はIgG1である。
(1)第1及び第2のポリペプチドはEUナンバリングによる131位がCys(C)以外のアミノ酸残基、226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基である。
(2)第1及び第2のポリペプチドはEUナンバリングによる131位がCys(C)以外のアミノ酸残基、226位がCys(C)以外のアミノ酸残基、228位がPro(P)、229位がCys(C)以外のアミノ酸残基である。
(3)第1及び第2のポリペプチドはEUナンバリングによる220位がCys(C)以外のアミノ酸残基、226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基及び409位がArg(R)である。
(4)第1及び第2のポリペプチドはEUナンバリングによる131位がCys(C)以外のアミノ酸残基、219位~229位が欠失している。
(5)第1及び第2のポリペプチドはEUナンバリングによる219位~229位が欠失し、409位がArg(R)である。
(6)第1及び第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基、220位~225位がTyr(Y)-Gly(G)-Pro(P)-Pro(P)、409位がArg(R)である。
好ましくは(1)、(2)及び(4)はIgG4であり、(3)、(5)及び(6)はIgG1である。
(1)第1及び第2のポリペプチドはEUナンバリングによる131位がSer(S)、226位がSer(S)、229位がSer(S)である。
(2)第1及び第2のポリペプチドはEUナンバリングによる131位がSer(S)、226位がSer(S)、228位がPro(P)、229位がSer(S)である。
(3)第1及び第2のポリペプチドはEUナンバリングによる220位がSer(S)又はTyr(Y)、226位がSer(S)、229位がSer(S)及び409位がArg(R)である。
(4)第1及び第2のポリペプチドはEUナンバリングによる131位がSer(S)、219位~229位が欠失している。
(5)第1及び第2のポリペプチドはEUナンバリングによる219位~229位が欠失し、409位がArg(R)である。
(6)第1及び第2のポリペプチドはEUナンバリングによる226位がSer(S)、229位がSer(S)、220位~225位がTyr(Y)-Gly(G)-Pro(P)-Pro(P)、409位がArg(R)である。
好ましくは(1)、(2)及び(4)はIgG4であり、(3)、(5)及び(6)はIgG1である。
(1)第1のポリペプチドはEUナンバリングによる131位がCys(C)以外のアミノ酸残基、226位がCys(C)以外のアミノ酸残基及び229位がCys(C)以外のアミノ酸残基であり、かつ、356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、第2のポリペプチドはEUナンバリングによる131位がCys(C)以外のアミノ酸残基、226位がCys(C)以外のアミノ酸残基及び229位がCys(C)以外のアミノ酸残基であり、かつ、439位はGlu(E)又はAsp(D)である。
(2)第1のポリペプチドはEUナンバリングによる131位がCys(C)以外のアミノ酸残基、226位がCys(C)以外のアミノ酸残基、228位がPro(P)及び229位がCys(C)以外のアミノ酸残基であり、かつ、356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、第2のポリペプチドはEUナンバリングによる131位がCys(C)以外のアミノ酸残基、226位がCys(C)以外のアミノ酸残基、228位がPro(P)及び229位がCys(C)以外のアミノ酸残基であり、かつ、439位はGlu(E)又はAsp(D)である
(3)第1のポリペプチドはEUナンバリングによる220位がCys(C)以外のアミノ酸残基、226位がCys(C)以外のアミノ酸残基及び229位がCys(C)以外のアミノ酸残基であり、かつ、356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、第2のポリペプチドはEUナンバリングによる220位がCys(C)以外のアミノ酸残基、226位がCys(C)以外のアミノ酸残基及び229位がCys(C)以外のアミノ酸残基であり、かつ、439位はGlu(E)又はAsp(D)である。
(4)第1のポリペプチドはEUナンバリングによる131位がCys(C)以外のアミノ酸残基、219位~229位が欠失しており、かつ、356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、第2のポリペプチドはEUナンバリングによる131位がCys(C)以外のアミノ酸残基、219位~229位が欠失しており、かつ、439位はGlu(E)又はAsp(D)である。
(5)第1のポリペプチドはEUナンバリングによる219位~229位が欠失し、かつ、356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、第2のポリペプチドはEUナンバリングによる219位~229位が欠失し、かつ、439位はGlu(E)又はAsp(D)である。
(6)第1のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基、220位~225位がTyr(Y)-Gly(G)-Pro(P)-Pro(P)であり、かつ、356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基、220位~225位がTyr(Y)-Gly(G)-Pro(P)-Pro(P)であり、かつ、439位はGlu(E)又はAsp(D)である。
好ましくは(1)、(2)及び(4)はIgG4であり、(3)、(5)及び(6)はIgG1である。
(1)第1のポリペプチドはEUナンバリングによる131位がCys(C)以外のアミノ酸残基、226位がCys(C)以外のアミノ酸残基及び229位がCys(C)以外のアミノ酸残基であり、かつ、356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、第2のポリペプチドはEUナンバリングによる131位がCys(C)以外のアミノ酸残基、226位がCys(C)以外のアミノ酸残基及び229位がCys(C)以外のアミノ酸残基であり、かつ、439位はGlu(E)又はAsp(D)である。
(2)第1のポリペプチドはEUナンバリングによる131位がCys(C)以外のアミノ酸残基、226位がCys(C)以外のアミノ酸残基、228位がPro(P)及び229位がCys(C)以外のアミノ酸残基であり、かつ、356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、第2のポリペプチドはEUナンバリングによる131位がCys(C)以外のアミノ酸残基、226位がCys(C)以外のアミノ酸残基、228位がPro(P)及び229位がCys(C)以外のアミノ酸残基であり、かつ、439位はGlu(E)又はAsp(D)である
(3)第1のポリペプチドはEUナンバリングによる220位がCys(C)以外のアミノ酸残基、226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基及び409位がArg(R)であり、かつ、356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、第2のポリペプチドはEUナンバリングによる220位がCys(C)以外のアミノ酸残基、226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基及び409位がArg(R)であり、かつ、439位はGlu(E)又はAsp(D)である。
(4)第1のポリペプチドはEUナンバリングによる131位がCys(C)以外のアミノ酸残基、219位~229位が欠失しており、かつ、356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、第2のポリペプチドはEUナンバリングによる131位がCys(C)以外のアミノ酸残基、219位~229位が欠失しており、かつ、439位はGlu(E)又はAsp(D)である。
(5)第1のポリペプチドはEUナンバリングによる219位~229位が欠失し、409位がArg(R)であり、かつ、356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、第2のポリペプチドはEUナンバリングによる219位~229位が欠失し、409位がArg(R)であり、かつ、439位はGlu(E)又はAsp(D)である。
(6)第1のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基、220位~225位がTyr(Y)-Gly(G)-Pro(P)-Pro(P)、409位がArg(R)であり、かつ、356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基、220位~225位がTyr(Y)-Gly(G)-Pro(P)-Pro(P)、409位がArg(R)であり、かつ、439位はGlu(E)又はAsp(D)である。
好ましくは(1)、(2)及び(4)はIgG4であり、(3)、(5)及び(6)はIgG1である。
(1)第1のポリペプチドはEUナンバリングによる131位がSer(S)、226位がSer(S)及び229位がSer(S)であり、かつ、356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、第2のポリペプチドはEUナンバリングによる131位がSer(S)、226位がSer(S)及び229位がSer(S)であり、かつ、439位はGlu(E)又はAsp(D)である。
(2)第1のポリペプチドはEUナンバリングによる131位がSer(S)、226位がSer(S)、228位がPro(P)及び229位がSer(S)であり、かつ、356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、第2のポリペプチドはEUナンバリングによる131位がSer(S)、226位がSer(S)、228位がPro(P)及び229位がSer(S)であり、かつ、439位はGlu(E)又はAsp(D)である
(3)第1のポリペプチドはEUナンバリングによる220位がSer(S)又はTyr(Y)、226位がSer(S)及び229位がSer(S)であり、かつ、356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、第2のポリペプチドはEUナンバリングによる220位がSer(S)又はTyr(Y)、226位がSer(S)及び229位がSer(S)であり、かつ、439位はGlu(E)又はAsp(D)である。
(4)第1のポリペプチドはEUナンバリングによる131位がSer(S)、219位~229位が欠失しており、かつ、356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、第2のポリペプチドはEUナンバリングによる131位がSer(S)、219位~229位が欠失しており、かつ、439位はGlu(E)又はAsp(D)である。
(5)第1のポリペプチドはEUナンバリングによる219位~229位が欠失し、かつ、356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、第2のポリペプチドはEUナンバリングによる219位~229位が欠失し、かつ、439位はGlu(E)又はAsp(D)である。
(6)第1のポリペプチドはEUナンバリングによる226位がSer(S)、229位がSer(S)、220位~225位がTyr(Y)-Gly(G)-Pro(P)-Pro(P)であり、かつ、356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、第2のポリペプチドはEUナンバリングによる226位がSer(S)、229位がSer(S)、220位~225位がTyr(Y)-Gly(G)-Pro(P)-Pro(P)であり、かつ、439位はGlu(E)又はAsp(D)である。
好ましくは(1)、(2)及び(4)はIgG4であり、(3)、(5)及び(6)はIgG1である。
(1)第1のポリペプチドはEUナンバリングによる131位がSer(S)、226位がSer(S)及び229位がSer(S)であり、かつ、356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、第2のポリペプチドはEUナンバリングによる131位がSer(S)、226位がSer(S)及び229位がSer(S)であり、かつ、439位はGlu(E)又はAsp(D)である。
(2)第1のポリペプチドはEUナンバリングによる131位がSer(S)、226位がSer(S)、228位がPro(P)及び229位がSer(S)であり、かつ、356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、第2のポリペプチドはEUナンバリングによる131位がSer(S)、226位がSer(S)、228位がPro(P)及び229位がSer(S)であり、かつ、439位はGlu(E)又はAsp(D)である
(3)第1のポリペプチドはEUナンバリングによる220位がSer(S)又はTyr(Y)、226位がSer(S)、229位がSer(S)及び409位がArg(R)であり、かつ、356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、第2のポリペプチドはEUナンバリングによる220位がSer(S)又はTyr(Y)、226位がSer(S)、229位がSer(S)及び409位がArg(R)であり、かつ、439位はGlu(E)又はAsp(D)である。
(4)第1のポリペプチドはEUナンバリングによる131位がSer(S)、219位~229位が欠失しており、かつ、356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、第2のポリペプチドはEUナンバリングによる131位がSer(S)、219位~229位が欠失しており、かつ、439位はGlu(E)又はAsp(D)である。
(5)第1のポリペプチドはEUナンバリングによる219位~229位が欠失し、409位がArg(R)であり、かつ、356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、第2のポリペプチドはEUナンバリングによる219位~229位が欠失し、409位がArg(R)であり、かつ、439位はGlu(E)又はAsp(D)である。
(6)第1のポリペプチドはEUナンバリングによる226位がSer(S)、229位がSer(S)、220位~225位がTyr(Y)-Gly(G)-Pro(P)-Pro(P)、409位がArg(R)であり、かつ、356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、第2のポリペプチドはEUナンバリングによる226位がSer(S)、229位がSer(S)、220位~225位がTyr(Y)-Gly(G)-Pro(P)-Pro(P)、409位がArg(R)であり、かつ、439位はGlu(E)又はAsp(D)である。
好ましくは(1)、(2)及び(4)はIgG4であり、(3)、(5)及び(6)はIgG1である。
(1)第1のポリペプチドはEUナンバリングによる131位がCys(C)以外のアミノ酸残基、226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基及び356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる131位がCys(C)以外のアミノ酸残基、226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基及び439位はGlu(E)である。
(2)第1のポリペプチドはEUナンバリングによる131位がCys(C)以外のアミノ酸残基、226位がCys(C)以外のアミノ酸残基、228位がPro(P)、229位がCys(C)以外のアミノ酸残基及び356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる131位がCys(C)以外のアミノ酸残基、226位がCys(C)以外のアミノ酸残基、228位がPro(P)、229位がCys(C)以外のアミノ酸残基及び439位はGlu(E)である。
(3)第1のポリペプチドはEUナンバリングによる220位がCys(C)以外のアミノ酸残基、226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基及び356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる220位がCys(C)以外のアミノ酸残基又はTyr(Y)、226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基及び439位はGlu(E)である。
(4)第1のポリペプチドはEUナンバリングによる131位がCys(C)以外のアミノ酸残基、219位~229位が欠失し、356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる131位がCys(C)以外のアミノ酸残基、219位~229位が欠失し、439位はGlu(E)である。
(5)第1のポリペプチドはEUナンバリングによる219位~229位が欠失し、356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる219位~229位が欠失し、439位はGlu(E)である。
(6)第1のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基、220位~225位がTyr(Y)-Gly(G)-Pro(P)-Pro(P)、356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がSer(S)、220位~225位がTyr(Y)-Gly(G)-Pro(P)-Pro(P)、439位はGlu(E)である。
好ましくは(1)、(2)及び(4)はIgG4であり、(3)、(5)及び(6)はIgG1である。
(1)第1のポリペプチドはEUナンバリングによる131位がCys(C)以外のアミノ酸残基、226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基及び356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる131位がCys(C)以外のアミノ酸残基、226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基及び439位はGlu(E)である。
(2)第1のポリペプチドはEUナンバリングによる131位がCys(C)以外のアミノ酸残基、226位がCys(C)以外のアミノ酸残基、228位がPro(P)、229位がCys(C)以外のアミノ酸残基及び356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる131位がCys(C)以外のアミノ酸残基、226位がCys(C)以外のアミノ酸残基、228位がPro(P)、229位がCys(C)以外のアミノ酸残基及び439位はGlu(E)である。
(3)第1のポリペプチドはEUナンバリングによる220位がCys(C)以外のアミノ酸残基、226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基、409位がArg(R)及び356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる220位がCys(C)以外のアミノ酸残基又はTyr(Y)、226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基、409位がArg(R)及び439位はGlu(E)である。
(4)第1のポリペプチドはEUナンバリングによる131位がCys(C)以外のアミノ酸残基、219位~229位が欠失し、356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる131位がCys(C)以外のアミノ酸残基、219位~229位が欠失し、439位はGlu(E)である。
(5)第1のポリペプチドはEUナンバリングによる219位~229位が欠失し、409位がArg(R)及び356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる219位~229位が欠失し、409位がArg(R)及び439位はGlu(E)である。
(6)第1のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基、220位~225位がTyr(Y)-Gly(G)-Pro(P)-Pro(P)、409位がArg(R)及び356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がSer(S)、220位~225位がTyr(Y)-Gly(G)-Pro(P)-Pro(P)、409位がArg(R)及び439位はGlu(E)である。
好ましくは(1)、(2)及び(4)はIgG4であり、(3)、(5)及び(6)はIgG1である。
(1)第1のポリペプチドはEUナンバリングによる131位がSer(S)、226位がSer(S)、229位がSer(S)及び356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる131位がSer(S)、226位がSer(S)、229位がSer(S)及び439位はGlu(E)である。
(2)第1のポリペプチドはEUナンバリングによる131位がSer(S)、226位がSer(S)、228位がPro(P)、229位がSer(S)及び356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる131位がSer(S)、226位がSer(S)、228位がPro(P)、229位がSer(S)及び439位はGlu(E)である。
(3)第1のポリペプチドはEUナンバリングによる220位がSer(S)又はTyr(Y)、226位がSer(S)、229位がSer(S)及び356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる220位がSer(S)又はTyr(Y)、226位がSer(S)、229位がSer(S)及び439位はGlu(E)である。
(4)第1のポリペプチドはEUナンバリングによる131位がSer(S)、219位~229位が欠失し、356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる131位がSer(S)、219位~229位が欠失し、439位はGlu(E)である。
(5)第1のポリペプチドはEUナンバリングによる219位~229位が欠失し、356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる219位~229位が欠失し、439位はGlu(E)である。
(6)第1のポリペプチドはEUナンバリングによる226位がSer(S)、229位がSer(S)、220位~225位がTyr(Y)-Gly(G)-Pro(P)-Pro(P)、356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる226位がSer(S)、229位がSer(S)、220位~225位がTyr(Y)-Gly(G)-Pro(P)-Pro(P)、439位はGlu(E)である。
好ましくは(1)、(2)及び(4)はIgG4であり、(3)、(5)及び(6)はIgG1である。
(1)第1のポリペプチドはEUナンバリングによる131位がSer(S)、226位がSer(S)、229位がSer(S)及び356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる131位がSer(S)、226位がSer(S)、229位がSer(S)及び439位はGlu(E)である。
(2)第1のポリペプチドはEUナンバリングによる131位がSer(S)、226位がSer(S)、228位がPro(P)、229位がSer(S)及び356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる131位がSer(S)、226位がSer(S)、228位がPro(P)、229位がSer(S)及び439位はGlu(E)である。
(3)第1のポリペプチドはEUナンバリングによる220位がSer(S)又はTyr(Y)、226位がSer(S)、229位がSer(S)、409位がArg(R)及び356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる220位がSer(S)又はTyr(Y)、226位がSer(S)、229位がSer(S)、409位がArg(R)及び439位はGlu(E)である。
(4)第1のポリペプチドはEUナンバリングによる131位がSer(S)、219位~229位が欠失し、356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる131位がSer(S)、219位~229位が欠失し、439位はGlu(E)である。
(5)第1のポリペプチドはEUナンバリングによる219位~229位が欠失し、409位がArg(R)及び356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる219位~229位が欠失し、409位がArg(R)及び439位はGlu(E)である。
(6)第1のポリペプチドはEUナンバリングによる226位がSer(S)、229位がSer(S)、220位~225位がTyr(Y)-Gly(G)-Pro(P)-Pro(P)、409位がArg(R)及び356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる226位がSer(S)、229位がSer(S)、220位~225位がTyr(Y)-Gly(G)-Pro(P)-Pro(P)、409位がArg(R)及び439位はGlu(E)である。
好ましくは(1)、(2)及び(4)はIgG4であり、(3)、(5)及び(6)はIgG1である。
(1)第1及び第2のポリペプチドはEUナンバリングによる131位がCys(C)以外のアミノ酸残基である。
(2)第1及び第2のポリペプチドはEUナンバリングによる220位がCys(C)以外のアミノ酸残基である。
好ましくは(1)はIgG4であり、(2)はIgG1である。
(1)第1及び第2のポリペプチドはEUナンバリングによる131位がSer(S)である。
(2)第1及び第2のポリペプチドはEUナンバリングによる220位がSer(S)又はTyr(Y)である。
好ましくは(1)はIgG4であり、(2)はIgG1である。
(1)第1及び第2のポリペプチドはEUナンバリングによる131位がCys(C)以外のアミノ酸残基、226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基である。
(2)第1及び第2のポリペプチドはEUナンバリングによる131位がCys(C)以外のアミノ酸残基、226位がCys(C)以外のアミノ酸残基、228位がPro(P)、229位がCys(C)以外のアミノ酸残基である。
(3)第1及び第2のポリペプチドはEUナンバリングによる220位がCys(C)以外のアミノ酸残基、226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基である。
(4)第1及び第2のポリペプチドはEUナンバリングによる131位がCys(C)以外のアミノ酸残基、219位~229位が欠失している。
(5)第1及び第2のポリペプチドはEUナンバリングによる219位~229位が欠失している。
(6)第1及び第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基、220位~225位がTyr(Y)-Gly(G)-Pro(P)-Pro(P)である。
好ましくは(1)、(2)及び(4)はIgG4であり、(3)、(5)及び(6)はIgG1である。
(1)第1及び第2のポリペプチドはEUナンバリングによる131位がSer(S)、226位がSer(S)、229位がSer(S)である。
(2)第1及び第2のポリペプチドはEUナンバリングによる131位がSer(S)、226位がSer(S)、228位がPro(P)、229位がSer(S)である。
(3)第1及び第2のポリペプチドはEUナンバリングによる220位がSer(S)又はTyr(Y)、226位がSer(S)、229位がSer(S)である。
(4)第1及び第2のポリペプチドはEUナンバリングによる131位がSer(S)、219位~229位が欠失している。
(5)第1及び第2のポリペプチドはEUナンバリングによる219位~229位が欠失している。
(6)第1及び第2のポリペプチドはEUナンバリングによる226位がSer(S)、229位がSer(S)、220位~225位がTyr(Y)-Gly(G)-Pro(P)-Pro(P)である。
好ましくは(1)、(2)及び(4)はIgG4であり、(3)、(5)及び(6)はIgG1である。
(1)第1及び第2のポリペプチドはEUナンバリングによる131位がCys(C)以外のアミノ酸残基、226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基である。
(2)第1及び第2のポリペプチドはEUナンバリングによる131位がCys(C)以外のアミノ酸残基、226位がCys(C)以外のアミノ酸残基、228位がPro(P)、229位がCys(C)以外のアミノ酸残基である。
(3)第1及び第2のポリペプチドはEUナンバリングによる220位がCys(C)以外のアミノ酸残基、226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基及び409位がArg(R)である。
(4)第1及び第2のポリペプチドはEUナンバリングによる131位がCys(C)以外のアミノ酸残基、219位~229位が欠失している。
(5)第1及び第2のポリペプチドはEUナンバリングによる219位~229位が欠失し、409位がArg(R)である。
(6)第1及び第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基、220位~225位がTyr(Y)-Gly(G)-Pro(P)-Pro(P)、409位がArg(R)である。
好ましくは(1)、(2)及び(4)はIgG4であり、(3)、(5)及び(6)はIgG1である。
(1)第1及び第2のポリペプチドはEUナンバリングによる131位がSer(S)、226位がSer(S)、229位がSer(S)である。
(2)第1及び第2のポリペプチドはEUナンバリングによる131位がSer(S)、226位がSer(S)、228位がPro(P)、229位がSer(S)である。
(3)第1及び第2のポリペプチドはEUナンバリングによる220位がSer(S)又はTyr(Y)、226位がSer(S)、229位がSer(S)及び409位がArg(R)である。
(4)第1及び第2のポリペプチドはEUナンバリングによる131位がSer(S)、219位~229位が欠失している。
(5)第1及び第2のポリペプチドはEUナンバリングによる219位~229位が欠失し、409位がArg(R)である。
(6)第1及び第2のポリペプチドはEUナンバリングによる226位がSer(S)、229位がSer(S)、220位~225位がTyr(Y)-Gly(G)-Pro(P)-Pro(P)、409位がArg(R)である。
好ましくは(1)、(2)及び(4)はIgG4であり、(3)、(5)及び(6)はIgG1である。
(1)第1のポリペプチドはEUナンバリングによる131位がCys(C)以外のアミノ酸残基、226位がCys(C)以外のアミノ酸残基及び229位がCys(C)以外のアミノ酸残基であり、かつ、356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、第2のポリペプチドはEUナンバリングによる131位がCys(C)以外のアミノ酸残基、226位がCys(C)以外のアミノ酸残基及び229位がCys(C)以外のアミノ酸残基であり、かつ、439位はGlu(E)又はAsp(D)である。
(2)第1のポリペプチドはEUナンバリングによる131位がCys(C)以外のアミノ酸残基、226位がCys(C)以外のアミノ酸残基、228位がPro(P)及び229位がCys(C)以外のアミノ酸残基であり、かつ、356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、第2のポリペプチドはEUナンバリングによる131位がCys(C)以外のアミノ酸残基、226位がCys(C)以外のアミノ酸残基、228位がPro(P)及び229位がCys(C)以外のアミノ酸残基であり、かつ、439位はGlu(E)又はAsp(D)である
(3)第1のポリペプチドはEUナンバリングによる220位がCys(C)以外のアミノ酸残基、226位がCys(C)以外のアミノ酸残基及び229位がCys(C)以外のアミノ酸残基であり、かつ、356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、第2のポリペプチドはEUナンバリングによる220位がCys(C)以外のアミノ酸残基、226位がCys(C)以外のアミノ酸残基及び229位がCys(C)以外のアミノ酸残基であり、かつ、439位はGlu(E)又はAsp(D)である。
(4)第1のポリペプチドはEUナンバリングによる131位がCys(C)以外のアミノ酸残基、219位~229位が欠失しており、かつ、356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、第2のポリペプチドはEUナンバリングによる131位がCys(C)以外のアミノ酸残基、219位~229位が欠失しており、かつ、439位はGlu(E)又はAsp(D)である。
(5)第1のポリペプチドはEUナンバリングによる219位~229位が欠失し、かつ、356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、第2のポリペプチドはEUナンバリングによる219位~229位が欠失し、かつ、439位はGlu(E)又はAsp(D)である。
(6)第1のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基、220位~225位がTyr(Y)-Gly(G)-Pro(P)-Pro(P)であり、かつ、356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基、220位~225位がTyr(Y)-Gly(G)-Pro(P)-Pro(P)であり、かつ、439位はGlu(E)又はAsp(D)である。
好ましくは(1)、(2)及び(4)はIgG4であり、(3)、(5)及び(6)はIgG1である。
(1)第1のポリペプチドはEUナンバリングによる131位がCys(C)以外のアミノ酸残基、226位がCys(C)以外のアミノ酸残基及び229位がCys(C)以外のアミノ酸残基であり、かつ、356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、第2のポリペプチドはEUナンバリングによる131位がCys(C)以外のアミノ酸残基、226位がCys(C)以外のアミノ酸残基及び229位がCys(C)以外のアミノ酸残基であり、かつ、439位はGlu(E)又はAsp(D)である。
(2)第1のポリペプチドはEUナンバリングによる131位がCys(C)以外のアミノ酸残基、226位がCys(C)以外のアミノ酸残基、228位がPro(P)及び229位がCys(C)以外のアミノ酸残基であり、かつ、356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、第2のポリペプチドはEUナンバリングによる131位がCys(C)以外のアミノ酸残基、226位がCys(C)以外のアミノ酸残基、228位がPro(P)及び229位がCys(C)以外のアミノ酸残基であり、かつ、439位はGlu(E)又はAsp(D)である
(3)第1のポリペプチドはEUナンバリングによる220位がCys(C)以外のアミノ酸残基、226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基及び409位がArg(R)であり、かつ、356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、第2のポリペプチドはEUナンバリングによる220位がCys(C)以外のアミノ酸残基、226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基及び409位がArg(R)であり、かつ、439位はGlu(E)又はAsp(D)である。
(4)第1のポリペプチドはEUナンバリングによる131位がCys(C)以外のアミノ酸残基、219位~229位が欠失しており、かつ、356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、第2のポリペプチドはEUナンバリングによる131位がCys(C)以外のアミノ酸残基、219位~229位が欠失しており、かつ、439位はGlu(E)又はAsp(D)である。
(5)第1のポリペプチドはEUナンバリングによる219位~229位が欠失し、409位がArg(R)であり、かつ、356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、第2のポリペプチドはEUナンバリングによる219位~229位が欠失し、409位がArg(R)であり、かつ、439位はGlu(E)又はAsp(D)である。
(6)第1のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基、220位~225位がTyr(Y)-Gly(G)-Pro(P)-Pro(P)、409位がArg(R)であり、かつ、356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基、220位~225位がTyr(Y)-Gly(G)-Pro(P)-Pro(P)、409位がArg(R)であり、かつ、439位はGlu(E)又はAsp(D)である。
好ましくは(1)、(2)及び(4)はIgG4であり、(3)、(5)及び(6)はIgG1である。
(1)第1のポリペプチドはEUナンバリングによる131位がSer(S)、226位がSer(S)及び229位がSer(S)であり、かつ、356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、第2のポリペプチドはEUナンバリングによる131位がSer(S)、226位がSer(S)及び229位がSer(S)であり、かつ、439位はGlu(E)又はAsp(D)である。
(2)第1のポリペプチドはEUナンバリングによる131位がSer(S)、226位がSer(S)、228位がPro(P)及び229位がSer(S)であり、かつ、356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、第2のポリペプチドはEUナンバリングによる131位がSer(S)、226位がSer(S)、228位がPro(P)及び229位がSer(S)であり、かつ、439位はGlu(E)又はAsp(D)である
(3)第1のポリペプチドはEUナンバリングによる220位がSer(S)又はTyr(Y)、226位がSer(S)及び229位がSer(S)であり、かつ、356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、第2のポリペプチドはEUナンバリングによる220位がSer(S)又はTyr(Y)、226位がSer(S)及び229位がSer(S)であり、かつ、439位はGlu(E)又はAsp(D)である。
(4)第1のポリペプチドはEUナンバリングによる131位がSer(S)、219位~229位が欠失しており、かつ、356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、第2のポリペプチドはEUナンバリングによる131位がSer(S)、219位~229位が欠失しており、かつ、439位はGlu(E)又はAsp(D)である。
(5)第1のポリペプチドはEUナンバリングによる219位~229位が欠失し、かつ、356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、第2のポリペプチドはEUナンバリングによる219位~229位が欠失し、かつ、439位はGlu(E)又はAsp(D)である。
(6)第1のポリペプチドはEUナンバリングによる226位がSer(S)、229位がSer(S)、220位~225位がTyr(Y)-Gly(G)-Pro(P)-Pro(P)であり、かつ、356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、第2のポリペプチドはEUナンバリングによる226位がSer(S)、229位がSer(S)、220位~225位がTyr(Y)-Gly(G)-Pro(P)-Pro(P)であり、かつ、439位はGlu(E)又はAsp(D)である。
好ましくは(1)、(2)及び(4)はIgG4であり、(3)、(5)及び(6)はIgG1である。
(1)第1のポリペプチドはEUナンバリングによる131位がSer(S)、226位がSer(S)及び229位がSer(S)であり、かつ、356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、第2のポリペプチドはEUナンバリングによる131位がSer(S)、226位がSer(S)及び229位がSer(S)であり、かつ、439位はGlu(E)又はAsp(D)である。
(2)第1のポリペプチドはEUナンバリングによる131位がSer(S)、226位がSer(S)、228位がPro(P)及び229位がSer(S)であり、かつ、356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、第2のポリペプチドはEUナンバリングによる131位がSer(S)、226位がSer(S)、228位がPro(P)及び229位がSer(S)であり、かつ、439位はGlu(E)又はAsp(D)である
(3)第1のポリペプチドはEUナンバリングによる220位がSer(S)又はTyr(Y)、226位がSer(S)、229位がSer(S)及び409位がArg(R)であり、かつ、356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、第2のポリペプチドはEUナンバリングによる220位がSer(S)又はTyr(Y)、226位がSer(S)、229位がSer(S)及び409位がArg(R)であり、かつ、439位はGlu(E)又はAsp(D)である。
(4)第1のポリペプチドはEUナンバリングによる131位がSer(S)、219位~229位が欠失しており、かつ、356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、第2のポリペプチドはEUナンバリングによる131位がSer(S)、219位~229位が欠失しており、かつ、439位はGlu(E)又はAsp(D)である。
(5)第1のポリペプチドはEUナンバリングによる219位~229位が欠失し、409位がArg(R)であり、かつ、356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、第2のポリペプチドはEUナンバリングによる219位~229位が欠失し、409位がArg(R)であり、かつ、439位はGlu(E)又はAsp(D)である。
(6)第1のポリペプチドはEUナンバリングによる226位がSer(S)、229位がSer(S)、220位~225位がTyr(Y)-Gly(G)-Pro(P)-Pro(P)、409位がArg(R)であり、かつ、356位がLys(K)、Arg(R)及びHis(H)のいずれかであり、第2のポリペプチドはEUナンバリングによる226位がSer(S)、229位がSer(S)、220位~225位がTyr(Y)-Gly(G)-Pro(P)-Pro(P)、409位がArg(R)であり、かつ、439位はGlu(E)又はAsp(D)である。
好ましくは(1)、(2)及び(4)はIgG4であり、(3)、(5)及び(6)はIgG1である。
(1)第1のポリペプチドはEUナンバリングによる131位がCys(C)以外のアミノ酸残基、226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基及び356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる131位がCys(C)以外のアミノ酸残基、226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基及び439位はGlu(E)である。
(2)第1のポリペプチドはEUナンバリングによる131位がCys(C)以外のアミノ酸残基、226位がCys(C)以外のアミノ酸残基、228位がPro(P)、229位がCys(C)以外のアミノ酸残基及び356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる131位がCys(C)以外のアミノ酸残基、226位がCys(C)以外のアミノ酸残基、228位がPro(P)、229位がCys(C)以外のアミノ酸残基及び439位はGlu(E)である。
(3)第1のポリペプチドはEUナンバリングによる220位がCys(C)以外のアミノ酸残基、226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基及び356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる220位がCys(C)以外のアミノ酸残基又はTyr(Y)、226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基及び439位はGlu(E)である。
(4)第1のポリペプチドはEUナンバリングによる131位がCys(C)以外のアミノ酸残基、219位~229位が欠失し、356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる131位がCys(C)以外のアミノ酸残基、219位~229位が欠失し、439位はGlu(E)である。
(5)第1のポリペプチドはEUナンバリングによる219位~229位が欠失し、356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる219位~229位が欠失し、439位はGlu(E)である。
(6)第1のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基、220位~225位がTyr(Y)-Gly(G)-Pro(P)-Pro(P)、356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がSer(S)、220位~225位がTyr(Y)-Gly(G)-Pro(P)-Pro(P)、439位はGlu(E)である。
好ましくは(1)、(2)及び(4)はIgG4であり、(3)、(5)及び(6)はIgG1である。
(1)第1のポリペプチドはEUナンバリングによる131位がCys(C)以外のアミノ酸残基、226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基及び356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる131位がCys(C)以外のアミノ酸残基、226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基及び439位はGlu(E)である。
(2)第1のポリペプチドはEUナンバリングによる131位がCys(C)以外のアミノ酸残基、226位がCys(C)以外のアミノ酸残基、228位がPro(P)、229位がCys(C)以外のアミノ酸残基及び356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる131位がCys(C)以外のアミノ酸残基、226位がCys(C)以外のアミノ酸残基、228位がPro(P)、229位がCys(C)以外のアミノ酸残基及び439位はGlu(E)である。
(3)第1のポリペプチドはEUナンバリングによる220位がCys(C)以外のアミノ酸残基、226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基、409位がArg(R)及び356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる220位がCys(C)以外のアミノ酸残基又はTyr(Y)、226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基、409位がArg(R)及び439位はGlu(E)である。
(4)第1のポリペプチドはEUナンバリングによる131位がCys(C)以外のアミノ酸残基、219位~229位が欠失し、356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる131位がCys(C)以外のアミノ酸残基、219位~229位が欠失し、439位はGlu(E)である。
(5)第1のポリペプチドはEUナンバリングによる219位~229位が欠失し、409位がArg(R)及び356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる219位~229位が欠失し、409位がArg(R)及び439位はGlu(E)である。
(6)第1のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基、220位~225位がTyr(Y)-Gly(G)-Pro(P)-Pro(P)、409位がArg(R)及び356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がSer(S)、220位~225位がTyr(Y)-Gly(G)-Pro(P)-Pro(P)、409位がArg(R)及び439位はGlu(E)である。
好ましくは(1)、(2)及び(4)はIgG4であり、(3)、(5)及び(6)はIgG1である。
(1)第1のポリペプチドはEUナンバリングによる131位がSer(S)、226位がSer(S)、229位がSer(S)及び356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる131位がSer(S)、226位がSer(S)、229位がSer(S)及び439位はGlu(E)である。
(2)第1のポリペプチドはEUナンバリングによる131位がSer(S)、226位がSer(S)、228位がPro(P)、229位がSer(S)及び356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる131位がSer(S)、226位がSer(S)、228位がPro(P)、229位がSer(S)及び439位はGlu(E)である。
(3)第1のポリペプチドはEUナンバリングによる220位がSer(S)又はTyr(Y)、226位がSer(S)、229位がSer(S)及び356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる220位がSer(S)又はTyr(Y)、226位がSer(S)、229位がSer(S)及び439位はGlu(E)である。
(4)第1のポリペプチドはEUナンバリングによる131位がSer(S)、219位~229位が欠失し、356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる131位がSer(S)、219位~229位が欠失し、439位はGlu(E)である。
(5)第1のポリペプチドはEUナンバリングによる219位~229位が欠失し、356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる219位~229位が欠失し、439位はGlu(E)である。
(6)第1のポリペプチドはEUナンバリングによる226位がSer(S)、229位がSer(S)、220位~225位がTyr(Y)-Gly(G)-Pro(P)-Pro(P)、356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる226位がSer(S)、229位がSer(S)、220位~225位がTyr(Y)-Gly(G)-Pro(P)-Pro(P)、439位はGlu(E)である。
好ましくは(1)、(2)及び(4)はIgG4であり、(3)、(5)及び(6)はIgG1である。
(1)第1のポリペプチドはEUナンバリングによる131位がSer(S)、226位がSer(S)、229位がSer(S)及び356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる131位がSer(S)、226位がSer(S)、229位がSer(S)及び439位はGlu(E)である。
(2)第1のポリペプチドはEUナンバリングによる131位がSer(S)、226位がSer(S)、228位がPro(P)、229位がSer(S)及び356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる131位がSer(S)、226位がSer(S)、228位がPro(P)、229位がSer(S)及び439位はGlu(E)である。
(3)第1のポリペプチドはEUナンバリングによる220位がSer(S)又はTyr(Y)、226位がSer(S)、229位がSer(S)、409位がArg(R)及び356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる220位がSer(S)又はTyr(Y)、226位がSer(S)、229位がSer(S)、409位がArg(R)及び439位はGlu(E)である。
(4)第1のポリペプチドはEUナンバリングによる131位がSer(S)、219位~229位が欠失し、356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる131位がSer(S)、219位~229位が欠失し、439位はGlu(E)である。
(5)第1のポリペプチドはEUナンバリングによる219位~229位が欠失し、409位がArg(R)及び356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる219位~229位が欠失し、409位がArg(R)及び439位はGlu(E)である。
(6)第1のポリペプチドはEUナンバリングによる226位がSer(S)、229位がSer(S)、220位~225位がTyr(Y)-Gly(G)-Pro(P)-Pro(P)、409位がArg(R)及び356位がLys(K)であり、第2のポリペプチドはEUナンバリングによる226位がSer(S)、229位がSer(S)、220位~225位がTyr(Y)-Gly(G)-Pro(P)-Pro(P)、409位がArg(R)及び439位はGlu(E)である。
好ましくは(1)、(2)及び(4)はIgG4であり、(3)、(5)及び(6)はIgG1である。
本発明の製造方法では、第1及び第2のポリペプチドのホモ体の解離を促進し、1種以上の多量体を形成するポリペプチド間の会合を制御するために、ポリペプチド間の界面を形成するアミノ酸残基を改変する段階をさらに加えてもよい。
また、本発明の第3の抗原結合活性を有するポリペプチド及び第4の抗原結合活性を有するポリペプチドは、抗体軽鎖定常領域のアミノ酸配列を含むことが出来る。抗体軽鎖定常領域のアミノ酸配列としては、ヒトkappa、ヒトlambdaタイプの定常領域のアミノ酸配列を挙げることが出来るが、これらに限定されない。あるいは、これらの改変体であってもよい。
また、本発明の抗原結合活性を有するポリペプチドは、抗体可変領域のアミノ酸配列(例えばCDR1、CDR2、CDR3、FR1、FR2、FR3、FR4のアミノ酸配列)を含むことが出来る。
(1) EUナンバリングによる356位および439位のアミノ酸残基
(2) EUナンバリングによる357位および370位のアミノ酸残基
(3) EUナンバリングによる399位および409位のアミノ酸残基
(a)グルタミン酸(E)、アスパラギン酸(D);
(b)リジン(K)、アルギニン(R)、ヒスチジン(H)。
好ましい態様において、上記ポリペプチドは、第1の重鎖CH3領域と第2の重鎖CH3領域がジスルフィド結合により架橋されていてもよい。
(1) 第1の重鎖定常領域におけるEUナンバリングによる356位のAsp(D)の、Lys(K)、Arg(R)又はHis(H)への改変、及び第2の重鎖定常領域におけるEUナンバリングによる439位のLys(K)の、Glu(E)又はAsp(D)への改変;
(2) 第1の重鎖定常領域におけるEUナンバリングによる357位のGlu(E)の、Lys(K)、Arg(R)又はHis(H)への改変、及び第2の重鎖定常領域におけるEUナンバリングによる370位のLys(K)の、Glu(E)又はAsp(D)への改変;
(3) 第1の重鎖定常領域におけるEUナンバリングによる399位のAsp(D)の、Lys(K)、Arg(R)又はHis(H)への改変、及び第2の重鎖定常領域におけるEUナンバリングによる409位のLys(K)の、Glu(E)又はAsp(D)への改変。
(1) EUナンバリングによる356位および439位のアミノ酸残基
(2) EUナンバリングによる360位および371位のアミノ酸残基
(3) EUナンバリングによる399位および409位のアミノ酸残基
(a)グルタミン酸(E)、アスパラギン酸(D);
(b)リジン(K)、アルギニン(R)、ヒスチジン(H)。
好ましい態様において、上記ポリペプチドは、第1の重鎖CH3領域と第2の重鎖CH3領域がジスルフィド結合により架橋されていてもよい。
(1) 第1の重鎖定常領域におけるEUナンバリングによる356位のAsp(D)の、Lys(K)、Arg(R)又はHis(H)への改変、及び第2の重鎖定常領域におけるEUナンバリングによる439位のLys(K)の、Glu(E)又はAsp(D)への改変;
(2) 第1の重鎖定常領域におけるEUナンバリングによる360位のGlu(E)の、Lys(K)、Arg(R)又はHis(H)への改変、及び第2の重鎖定常領域におけるEUナンバリングによる371位のLys(K)の、Glu(E)又はAsp(D)への改変;
(3) 第1の重鎖定常領域におけるEUナンバリングによる399位のAsp(D)の、Lys(K)、Arg(R)又はHis(H)への改変、及び第2の重鎖定常領域におけるEUナンバリングによる409位のLys(K)の、Glu(E)又はAsp(D)への改変
本発明の製造方法では、重鎖CH3領域の安定性が不安定になるように、重鎖定常領域にアミノ酸残基の変異を導入する段階をさらに加えてもよい。
また、目的のポリペプチド多量体が、第1のポリペプチドと第3のポリペプチドで2量体を形成し、第2のポリペプチドと第4のポリペプチドで2量体を形成し、さらにこれら2量体同士が多量体を形成するような4量体である場合には、本発明のポリペプチド多量体として、例えば、第1と第2の抗原結合活性を有するポリペプチドが抗体重鎖のアミノ酸配列を含むポリペプチドであって、第3と第4の抗原結合活性を有するポリペプチドが抗体軽鎖のアミノ酸配列を含むポリペプチドであるポリペプチド多量体を用いることもできる。
本発明のさらなる好ましい態様としては、ポリペプチドの等電点(pI値)を改変するアミノ酸変異を、本発明のポリペプチドに導入することによって、目的の第1~第4のポリペプチドを有するポリペプチド多量体をより高純度に且つ効率的に精製あるいは製造することが可能である(WO2007114325、US20130171095)。ポリペプチドの会合を促進するために導入されるアミノ酸変異としては、Protein Eng. 1996 Jul;9(7):617-21.、Protein Eng Des Sel. 2010 Apr;23(4):195-202.、J Biol Chem. 2010 Jun 18;285(25):19637-46.、WO2009080254、US20130195849等に記載された、重鎖定常領域のCH3ドメインの改変により2種類の重鎖定常領域を含むポリペプチドをヘテロ会合化する方法、および、WO2009080251、WO2009080252、WO2009080253等に記載された、重鎖と軽鎖の特定の組み合わせの会合化を促進する方法等を用いることも可能である。
本発明の非限定の実施態様としては、標的組織特異的に存在する分子の濃度依存的に抗原から解離・結合する抗体技術(WO2013/180200)との組み合わせが挙げられる。
本発明の非限定の実施態様としては、FcγRへの結合増強を目的とした定常領域改変技術(WO2013047752)との組み合わせが挙げられる。
267位のアミノ酸がGlu、
268位のアミノ酸がPheまたはTyrのいずれか、
276位のアミノ酸がArg、
324位のアミノ酸がThr、
327位のアミノ酸がGly、
331位のアミノ酸がPro、もしくは
333位のアミノ酸がAla、Asp、Gly、SerまたはValのいずれか、
が挙げられる。また、改変されるアミノ酸の数は特に限定されず、一箇所のみのアミノ酸が改変され得るし、これらが任意に組み合わせられた二箇所以上のアミノ酸が改変され得る
本発明の方法における変異導入前の抗体(本明細書においては、単に「本発明の抗体」と記載する場合あり)のH鎖又はL鎖をコードする遺伝子として既知の配列を用いることも可能であり、又、当業者に公知の方法で取得することもできる。例えば、抗体ライブラリーから取得することも可能であるし、モノクローナル抗体を産生するハイブリドーマから抗体をコードする遺伝子をクローニングして取得することも可能である。
本発明の解離及び/又は会合制御方法を利用することにより、例えば、活性を有する抗体もしくはポリペプチドを効率的に作製することができる。該活性としては、例えば、結合活性、中和活性、細胞傷害活性、アゴニスト活性、アンタゴニスト活性、酵素活性等を挙げることができる。アゴニスト活性とは、受容体などの抗原に抗体が結合することにより、細胞内にシグナルが伝達される等して、何らかの生理的活性の変化を誘導する活性である。生理的活性としては、例えば、増殖活性、生存活性、分化活性、転写活性、膜輸送活性、結合活性、タンパク質分解活性、リン酸化/脱リン酸化活性、酸化還元活性、転移活性、核酸分解活性、脱水活性、細胞死誘導活性、アポトーシス誘導活性等を挙げることができるが、これらに限定されない。
サイトカインの例としては、インターロイキン1~18、コロニー刺激因子(G-CSF、M-CSF、GM-CSFなど)、インターフェロン(IFN-α、IFN-β、IFN-γ、など)、成長因子(EGF、FGF、IGF、NGF、PDGF、TGF、HGFなど)、腫瘍壊死因子(TNF-α、TNF-β)、リンホトキシン、エリスロポエチン、レプチン、SCF、TPO、MCAF、BMPを挙げることができる。
ケモカインの例としては、CCL1~CCL28などのCCケモカイン、CXCL1~CXCL17などのCXCケモカイン、XCL1~XCL2などのCケモカイン、CX3CL1などのCX3Cケモカインを挙げることができる。
その他の抗原としては下記のような分子;17-IA、4-1BB、4Dc、6-ケト-PGF1a、8-イソ-PGF2a、8-オキソ-dG、A1 アデノシン受容体、A33、ACE、ACE-2、アクチビン、アクチビンA、アクチビンAB、アクチビンB、アクチビンC、アクチビンRIA、アクチビンRIA ALK-2、アクチビンRIB ALK-4、アクチビンRIIA、アクチビンRIIB、ADAM、ADAM10、ADAM12、ADAM15、ADAM17/TACE、ADAM8、ADAM9、ADAMTS、ADAMTS4、ADAMTS5、アドレシン、aFGF、ALCAM、ALK、ALK-1、ALK-7、アルファ-1-アンチトリプシン、アルファ-V/ベータ-1アンタゴニスト、ANG、Ang、APAF-1、APE、APJ、APP、APRIL、AR、ARC、ART、アルテミン、抗Id、ASPARTIC、心房性ナトリウム利尿因子、av/b3インテグリン、Axl、b2M、B7-1、B7-2、B7-H、B-リンパ球刺激因子(BlyS)、BACE、BACE-1、Bad、BAFF、BAFF-R、Bag-1、BAK、Bax、BCA-1、BCAM、Bcl、BCMA、BDNF、b-ECGF、bFGF、BID、Bik、BIM、BLC、BL-CAM、BLK、BMP、BMP-2 BMP-2a、BMP-3(オステオゲニン(Osteogenin))、BMP-4 BMP-2b、BMP-5、BMP-6 Vgr-1、BMP-7(OP-1)、BMP-8(BMP-8a、OP-2)、BMPR、BMPR-IA(ALK-3)、BMPR-IB(ALK-6)、BRK-2、RPK-1、BMPR-II(BRK-3)、BMP、b-NGF、BOK、ボンベシン、骨由来神経栄養因子、BPDE、BPDE-DNA、BTC、補体因子3(C3)、C3a、C4、C10、CA125、CAD-8、カルシトニン、cAMP、癌胎児性抗原(CEA)、癌関連抗原、カテプシンA、カテプシンB、カテプシンC/DPPI、カテプシンD、カテプシンE、カテプシンH、カテプシンL、カテプシンO、カテプシンS、カテプシンV、カテプシンX/Z/P、CBL、CCI、CCK2、CCL、CCL1、CCL11、CCL12、CCL13、CCL14、CCL15、CCL16、CCL17、CCL18、CCL19、CCL2、CCL20、CCL21、CCL22、CCL23、CCL24、CCL25、CCL26、CCL27、CCL28、CCL3、CCL4、CCL5、CCL6、CCL7、CCL8、CCL9/10、CCR、CCR1、CCR10、CCR10、CCR2、CCR3、CCR4、CCR5、CCR6、CCR7、CCR8、CCR9、CD1、CD2、CD3、CD3E、CD4、CD5、CD6、CD7、CD8、CD10、CD11a、CD11b、CD11c、CD13、CD14、CD15、CD16、CD18、CD19、CD20、CD21、CD22、CD23、CD25、CD27L、CD28、CD29、CD30、CD30L、CD32、CD33(p67タンパク質)、CD34、CD38、CD40、CD40L、CD44、CD45、CD46、CD49a、CD52、CD54、CD55、CD56、CD61、CD64、CD66e、CD74、CD80(B7-1)、CD89、CD95、CD123、CD137、CD138、CD140a、CD146、CD147、CD148、CD152、CD164、CEACAM5、CFTR、cGMP、CINC、ボツリヌス菌毒素、ウェルシュ菌毒素、CKb8-1、CLC、CMV、CMV UL、CNTF、CNTN-1、COX、C-Ret、CRG-2、CT-1、CTACK、CTGF、CTLA-4、CX3CL1、CX3CR1、CXCL、CXCL1、CXCL2、CXCL3、CXCL4、CXCL5、CXCL6、CXCL7、CXCL8、CXCL9、CXCL10、CXCL11、CXCL12、CXCL13、CXCL14、CXCL15、CXCL16、CXCR、CXCR1、CXCR2、CXCR3、CXCR4、CXCR5、CXCR6、サイトケラチン腫瘍関連抗原、DAN、DCC、DcR3、DC-SIGN、補体制御因子(Decay accelerating factor)、des(1-3)-IGF-I(脳IGF-1)、Dhh、ジゴキシン、DNAM-1、Dnase、Dpp、DPPIV/CD26、Dtk、ECAD、EDA、EDA-A1、EDA-A2、EDAR、EGF、EGFR(ErbB-1)、EMA、EMMPRIN、ENA、エンドセリン受容体、エンケファリナーゼ、eNOS、Eot、エオタキシン1、EpCAM、エフリンB2/EphB4、EPO、ERCC、E-セレクチン、ET-1、ファクターIIa、ファクターVII、ファクターVIIIc、ファクターIX、線維芽細胞活性化タンパク質(FAP)、Fas、FcR1、FEN-1、フェリチン、FGF、FGF-19、FGF-2、FGF3、FGF-8、FGFR、FGFR-3、フィブリン、FL、FLIP、Flt-3、Flt-4、卵胞刺激ホルモン、フラクタルカイン、FZD1、FZD2、FZD3、FZD4、FZD5、FZD6、FZD7、FZD8、FZD9、FZD10、G250、Gas6、GCP-2、GCSF、GD2、GD3、GDF、GDF-1、GDF-3(Vgr-2)、GDF-5(BMP-14、CDMP-1)、GDF-6(BMP-13、CDMP-2)、GDF-7(BMP-12、CDMP-3)、GDF-8(ミオスタチン)、GDF-9、GDF-15(MIC-1)、GDNF、GDNF、GFAP、GFRa-1、GFR-アルファ1、GFR-アルファ2、GFR-アルファ3、GITR、グルカゴン、Glut4、糖タンパク質IIb/IIIa(GPIIb/IIIa)、GM-CSF、gp130、gp72、GRO、成長ホルモン放出因子、ハプテン(NP-capまたはNIP-cap)、HB-EGF、HCC、HCMV gBエンベロープ糖タンパク質、HCMV gHエンベロープ糖タンパク質、HCMV UL、造血成長因子(HGF)、Hep B gp120、ヘパラナーゼ、Her2、Her2/neu(ErbB-2)、Her3(ErbB-3)、Her4(ErbB-4)、単純ヘルペスウイルス(HSV) gB糖タンパク質、HSV gD糖タンパク質、HGFA、高分子量黒色腫関連抗原(HMW-MAA)、HIV gp120、HIV IIIB gp 120 V3ループ、HLA、HLA-DR、HM1.24、HMFG PEM、HRG、Hrk、ヒト心臓ミオシン、ヒトサイトメガロウイルス(HCMV)、ヒト成長ホルモン(HGH)、HVEM、I-309、IAP、ICAM、ICAM-1、ICAM-3、ICE、ICOS、IFNg、Ig、IgA受容体、IgE、IGF、IGF結合タンパク質、IGF-1R、IGFBP、IGF-I、IGF-II、IL、IL-1、IL-1R、IL-2、IL-2R、IL-4、IL-4R、IL-5、IL-5R、IL-6、IL-6R、IL-8、IL-9、IL-10、IL-12、IL-13、IL-15、IL-18、IL-18R、IL-23、インターフェロン(INF)-アルファ、INF-ベータ、INF-ガンマ、インヒビン、iNOS、インスリンA鎖、インスリンB鎖、インスリン様増殖因子1、インテグリンアルファ2、インテグリンアルファ3、インテグリンアルファ4、インテグリンアルファ4/ベータ1、インテグリンアルファ4/ベータ7、インテグリンアルファ5(アルファV)、インテグリンアルファ5/ベータ1、インテグリンアルファ5/ベータ3、インテグリンアルファ6、インテグリンベータ1、インテグリンベータ2、インターフェロンガンマ、IP-10、I-TAC、JE、カリクレイン2、カリクレイン5、カリクレイン6、カリクレイン11、カリクレイン12、カリクレイン14、カリクレイン15、カリクレインL1、カリクレインL2、カリクレインL3、カリクレインL4、KC、KDR、ケラチノサイト増殖因子(KGF)、ラミニン5、LAMP、LAP、LAP(TGF-1)、潜在的TGF-1、潜在的TGF-1 bp1、LBP、LDGF、LECT2、レフティ、ルイス-Y抗原、ルイス-Y関連抗原、LFA-1、LFA-3、Lfo、LIF、LIGHT、リポタンパク質、LIX、LKN、Lptn、L-セレクチン、LT-a、LT-b、LTB4、LTBP-1、肺表面、黄体形成ホルモン、リンホトキシンベータ受容体、Mac-1、MAdCAM、MAG、MAP2、MARC、MCAM、MCAM、MCK-2、MCP、M-CSF、MDC、Mer、メタロプロテアーゼ、MGDF受容体、MGMT、MHC(HLA-DR)、MIF、MIG、MIP、MIP-1-アルファ、MK、MMAC1、MMP、MMP-1、MMP-10、MMP-11、MMP-12、MMP-13、MMP-14、MMP-15、MMP-2、MMP-24、MMP-3、MMP-7、MMP-8、MMP-9、MPIF、Mpo、MSK、MSP、ムチン(Muc1)、MUC18、ミュラー管抑制物質、Mug、MuSK、NAIP、NAP、NCAD、N-Cアドヘリン、NCA 90、NCAM、NCAM、ネプリライシン、ニューロトロフィン-3、-4、または-6、ニュールツリン、神経成長因子(NGF)、NGFR、NGF-ベータ、nNOS、NO、NOS、Npn、NRG-3、NT、NTN、OB、OGG1、OPG、OPN、OSM、OX40L、OX40R、p150、p95、PADPr、副甲状腺ホルモン、PARC、PARP、PBR、PBSF、PCAD、P-カドヘリン、PCNA、PDGF、PDGF、PDK-1、PECAM、PEM、PF4、PGE、PGF、PGI2、PGJ2、PIN、PLA2、胎盤性アルカリホスファターゼ(PLAP)、PlGF、PLP、PP14、プロインスリン、プロレラキシン、プロテインC、PS、PSA、PSCA、前立腺特異的膜抗原(PSMA)、PTEN、PTHrp、Ptk、PTN、R51、RANK、RANKL、RANTES、RANTES、レラキシンA鎖、レラキシンB鎖、レニン、呼吸器多核体ウイルス(RSV)F、RSV Fgp、Ret、リウマイド因子、RLIP76、RPA2、RSK、S100、SCF/KL、SDF-1、SERINE、血清アルブミン、sFRP-3、Shh、SIGIRR、SK-1、SLAM、SLPI、SMAC、SMDF、SMOH、SOD、SPARC、Stat、STEAP、STEAP-II、TACE、TACI、TAG-72(腫瘍関連糖タンパク質-72)、TARC、TCA-3、T細胞受容体(例えば、T細胞受容体アルファ/ベータ)、TdT、TECK、TEM1、TEM5、TEM7、TEM8、TERT、睾丸PLAP様アルカリホスファターゼ、TfR、TGF、TGF-アルファ、TGF-ベータ、TGF-ベータ Pan Specific、TGF-ベータRI(ALK-5)、TGF-ベータRII、TGF-ベータRIIb、TGF-ベータRIII、TGF-ベータ1、TGF-ベータ2、TGF-ベータ3、TGF-ベータ4、TGF-ベータ5、トロンビン、胸腺Ck-1、甲状腺刺激ホルモン、Tie、TIMP、TIQ、組織因子、TMEFF2、Tmpo、TMPRSS2、TNF、TNF-アルファ、TNF-アルファベータ、TNF-ベータ2、TNFc、TNF-RI、TNF-RII、TNFRSF10A(TRAIL R1 Apo-2、DR4)、TNFRSF10B(TRAIL R2 DR5、KILLER、TRICK-2A、TRICK-B)、TNFRSF10C(TRAIL R3 DcR1、LIT、TRID)、TNFRSF10D(TRAIL R4 DcR2、TRUNDD)、TNFRSF11A(RANK ODF R、TRANCE R)、TNFRSF11B(OPG OCIF、TR1)、TNFRSF12(TWEAK R FN14)、TNFRSF13B(TACI)、TNFRSF13C(BAFF R)、TNFRSF14(HVEM ATAR、HveA、LIGHT R、TR2)、TNFRSF16(NGFR p75NTR)、TNFRSF17(BCMA)、TNFRSF18(GITR AITR)、TNFRSF19(TROY TAJ、TRADE)、TNFRSF19L(RELT)、TNFRSF1A(TNF RI CD120a、p55-60)、TNFRSF1B(TNF RII CD120b、p75-80)、TNFRSF26(TNFRH3)、TNFRSF3(LTbR TNF RIII、TNFC R)、TNFRSF4(OX40 ACT35、TXGP1 R)、TNFRSF5(CD40 p50)、TNFRSF6(Fas Apo-1、APT1、CD95)、TNFRSF6B(DcR3 M68、TR6)、TNFRSF7(CD27)、TNFRSF8(CD30)、TNFRSF9(4-1BB CD137、ILA)、TNFRSF21(DR6)、TNFRSF22(DcTRAIL R2 TNFRH2)、TNFRST23(DcTRAIL R1 TNFRH1)、TNFRSF25(DR3 Apo-3、LARD、TR-3、TRAMP、WSL-1)、TNFSF10(TRAIL Apo-2リガンド、TL2)、TNFSF11(TRANCE/RANKリガンド ODF、OPGリガンド)、TNFSF12(TWEAK Apo-3リガンド、DR3リガンド)、TNFSF13(APRIL TALL2)、TNFSF13B(BAFF BLYS、TALL1、THANK、TNFSF20)、TNFSF14(LIGHT HVEMリガンド、LTg)、TNFSF15(TL1A/VEGI)、TNFSF18(GITRリガンド AITRリガンド、TL6)、TNFSF1A(TNF-a コネクチン(Conectin)、DIF、TNFSF2)、TNFSF1B(TNF-b LTa、TNFSF1)、TNFSF3(LTb TNFC、p33)、TNFSF4(OX40リガンド gp34、TXGP1)、TNFSF5(CD40リガンド CD154、gp39、HIGM1、IMD3、TRAP)、TNFSF6(Fasリガンド Apo-1リガンド、APT1リガンド)、TNFSF7(CD27リガンド CD70)、TNFSF8(CD30リガンド CD153)、TNFSF9(4-1BBリガンド CD137リガンド)、TP-1、t-PA、Tpo、TRAIL、TRAIL R、TRAIL-R1、TRAIL-R2、TRANCE、トランスフェリン受容体、TRF、Trk、TROP-2、TSG、TSLP、腫瘍関連抗原CA125、腫瘍関連抗原発現ルイスY関連炭水化物、TWEAK、TXB2、Ung、uPAR、uPAR-1、ウロキナーゼ、VCAM、VCAM-1、VECAD、VE-カドヘリン、VE-カドヘリン-2、VEFGR-1(flt-1)、VEGF、VEGFR、VEGFR-3(flt-4)、VEGI、VIM、ウイルス抗原、VLA、VLA-1、VLA-4、VNRインテグリン、フォン・ヴィレブランド因子、WIF-1、WNT1、WNT2、WNT2B/13、WNT3、WNT3A、WNT4、WNT5A、WNT5B、WNT6、WNT7A、WNT7B、WNT8A、WNT8B、WNT9A、WNT9A、WNT9B、WNT10A、WNT10B、WNT11、WNT16、XCL1、XCL2、XCR1、XCR1、XEDAR、XIAP、XPD、HMGB1、IgA、Aβ、CD81、CD97、CD98、DDR1、DKK1、EREG、Hsp90、IL-17/IL-17R、IL-20/IL-20R、酸化LDL、PCSK9、プレカリクレイン、RON、TMEM16F、SOD1、クロモグラニン A、クロモグラニン B、tau、VAP1、高分子キニノーゲン、IL-31、IL-31R、Nav1.1、Nav1.2、Nav1.3、Nav1.4、Nav1.5、Nav1.6、Nav1.7、Nav1.8、Nav1.9、EPCR、C1、C1q、C1r、C1s、C2、C2a、C2b、C3、C3a、C3b、C4、C4a、C4b、C5、C5a、C5b、C6、C7、C8、C9、ファクター B、ファクター D、ファクター H、プロペルジン、スクレロスチン、フィブリノゲン、フィブリン、プロトロンビン、トロンビン、組織因子、ファクター V、ファクター Va、ファクター VII、ファクター VIIa、ファクター VIII、ファクター VIIIa、ファクター IX、ファクター IXa、ファクター X、ファクター Xa、ファクター XI、ファクター XIa、ファクター XII、ファクター XIIa、ファクター XIII、ファクター XIIIa、TFPI、アンチトロンビン III、EPCR、トロンボモデュリン、TAPI、tPA、プラスミノゲン、プラスミン、PAI-1、PAI-2、GPC3、シンデカン-1、シンデカン-2、シンデカン-3、シンデカン-4、LPA、S1Pならびにホルモンおよび成長因子のための受容体が例示され得る。
また、本発明の製造方法の別の態様においては、本発明は、ポリペプチド間の解離及び/又は会合が制御されるように、コアヒンジ領域外のシステインを介してジスルフィド結合の異性化を起こすことを可能にするアミノ酸残基の改変(例えば、EUナンバリングによる131位、220位、349位、356位、394位、351位、354位、及び407位のアミノ酸残基における改変)を有する異種多量体の製造方法であって、(a)ポリペプチド間の解離及び会合が制御されるように、コアヒンジ領域外のシステインを介してジスルフィド結合の異性化を起こすことを可能にするアミノ酸残基をコードする核酸を元の核酸から改変する段階、(b)当該ポリペプチドを発現するように、当該核酸を有する宿主細胞を培養する段階、(c)当該宿主細胞の培養物から当該ポリペプチドを回収する段階、及び(d)還元条件下、各ポリペプチドをインキュベートし、所望のポリペプチドのヘテロ体を回収する段階を含む、異種多量体の製造方法を提供する。
a) それぞれ第一及び第二のポリペプチドのホモ体を産生する細胞株を培養する段階、
b) 各細胞株の培養上清を混合し、コアヒンジ領域外において重鎖間もしくは軽鎖間でジスルフィド結合を形成するシステインがジスルフィド結合の異性化を起こすように、該第1のポリペプチドのホモ体および該第2のポリペプチドのホモ体を共にインキュベートする段階、ならびに
c) 第1及び第2のポリペプチドを含む異種多量体を得る段階
を含む、異種多量体の製造方法を提供する。
a) それぞれ第一及び第二のポリペプチドのホモ体を産生する細胞株を培養する段階、
b) 各細胞株の培養上清を混合し、コアヒンジ領域外のシステインがジスルフィド結合の異性化を起こすように、該第1のポリペプチドのホモ体および該第2のポリペプチドのホモ体を共にインキュベートする段階、ならびに
c) 第1及び第2のポリペプチドを含む異種多量体を得る段階
を含む、異種多量体の製造方法を提供する。
さらに本発明は、所望の異種多量体を選択する(スクリーニングする)方法を提供する。好ましい態様としては、当該方法は、以下の段階を含む、所望の特性(活性)を有する異種多量体を選択する方法である:
a) 第1のポリペプチドの組及び第2のポリペプチドの組を提供する段階であって、第1の組を構成する各ポリペプチドが第2の組を構成する各ポリペプチドとは異なる標的特異性を有し、かつ第1及び第2の組を構成する各ポリペプチドが、コアヒンジ領域外において重鎖間もしくは軽鎖間でジスルフィド結合を形成するシステインがジスルフィド結合の異性化を起こすことを可能にするアミノ酸改変を含む、段階、
b) 還元条件下で、該第1の組を構成する各ポリペプチドを該第2の組を構成する各ポリペプチドと共にインキュベートし、それによって複数種の異種多量体の混合物を作製する段階、
c) 結果として得られた複数種の異種多量体の混合物を所与の所望の特性(活性)についてアッセイする段階、および
d) 所望の特性(活性)を有する異種多量体を選択する段階。
- 異種多量体の活性を測定する段階、および
- 所望の活性を有する異種多量体を選択する段階
を行う、異種多量体をスクリーニングする方法を提供する。
すなわち、当該スクリーニング方法は、以下の段階を含む。
a) 第1の抗原結合活性を有し、重鎖定常領域を含む第1のポリペプチドのホモ体を提供する段階、
b) 該第1の抗原結合活性とは異なる第2の抗原結合活性を有し、重鎖定常領域を含む第2のポリペプチドのホモ体を提供する段階、
c) コアヒンジ領域外のシステインがジスルフィド結合の異性化を起こすことを可能にする還元条件下で、該第1のポリペプチドのホモ体および該第2のポリペプチドのホモ体を共にインキュベートする段階、ならびに
d) 第1及び第2のポリペプチドを含む異種多量体を得る段階、
e) 段階d)で得た異種多量体の活性を測定する段階、
f) 所望の活性を有する異種多量体を選択する段階。
- 選択した異種多量体の第1のポリペプチド、第2のポリペプチド、第3のポリペプチド及び第4のポリペプチドの所望の領域(例えば、CDR、可変領域、定常領域等)を取得する段階、ならびに
- 取得した領域を別の異種多量体に移植する段階
を行う、異種多量体を製造する方法を提供する。
すなわち、当該製造方法は、以下の段階を含む。
a) 第1の抗原結合活性を有し、重鎖定常領域を含む第1のポリペプチドのホモ体を提供する段階、
b) 該第1の抗原結合活性とは異なる第2の抗原結合活性を有し、重鎖定常領域を含む第2のポリペプチドのホモ体を提供する段階、
c) コアヒンジ領域外のシステインがジスルフィド結合の異性化を起こすことを可能にする還元条件下で、該第1のポリペプチドのホモ体および該第2のポリペプチドのホモ体を共にインキュベートする段階、ならびに
d) 第1及び第2のポリペプチドを含む異種多量体を得る段階、
e) 段階d)で得た異種多量体の活性を測定する段階、
f) 所望の活性を有する異種多量体を選択する段階
g) 段階f)で選択した異種多量体の第1のポリペプチド、第2のポリペプチド、第3のポリペプチド及び第4のポリペプチドの所望の領域(例えば、CDR、可変領域、定常領域等)を取得する段階、
h) 取得した領域を別の異種多量体に移植する段階。
また本発明は、本発明の異種多量体、および医薬的に許容される担体を含む組成物(薬剤)に関する。
アラニン:Ala:A
アルギニン:Arg:R
アスパラギン:Asn:N
アスパラギン酸:Asp:D
システイン:Cys:C
グルタミン:Gln:Q
グルタミン酸:Glu:E
グリシン:Gly:G
ヒスチジン:His:H
イソロイシン:Ile:I
ロイシン:Leu:L
リジン:Lys:K
メチオニン:Met:M
フェニルアラニン:Phe:F
プロリン:Pro:P
セリン:Ser:S
スレオニン:Thr:T
トリプトファン:Trp:W
チロシン:Tyr:Y
バリン:Val:V
Fab Arm Exchangeでは、2種類のホモ抗体を還元剤存在下で混合し、生じた4本の抗体分子片腕(半分子またはHL分子と称する、一本の重鎖および一本の軽鎖からなる分子)が再結合することによって、Bispecific抗体(二重特異性抗体)が生じる。HL分子の再結合はランダムに起こるため、目的のBispecific抗体は理論上、系中に存在する全抗体量の50%しか得られない。しかしながら、2種類のホモ抗体にあらかじめ異なる電荷を導入しておくことで、生じたHL分子同士が再結合する際にホモ2量化よりもヘテロ2量化がより優先的に起こり、高効率にBispecific抗体を作製できる可能性がある。そこでWO2006/106905で報告されている抗体のCH3領域における会合界面を制御する改変(2種類のH鎖をCH3領域の電荷的相互作用および反発を利用してヘテロ会合化させる改変)を用いることで、Fab Arm Exchangeの反応効率(Bispecific抗体生成率)が向上するかどうかを検証した。
(1) MRAH-wtG4d/MRAL-k0とH54-wtG4d/L28-k0
(2) MRAH-wtG4dP1/MRAL-k0とH54-wtG4dN1/L28-k0
(3) MRAH-G1dsr/MRAL-k0とH54-G1dsr/L28-k0
(4) MRAH-G1dsrP1/MRAL-k0とH54-G1dsrN1/L28-k0
反応条件: PBS(Sigma, pH7.4)中、[各mAb] = 0.2 mg/ml、[GSH(Sigma)] = 0.5 mM、0.05% Tween 20 (Junsei)、37℃、24時間。
実施例1ではヒンジ領域の配列を天然型ヒトIgG4型にするため、ヒトIgG1に対してP228S改変を導入し、Fab Arm Exchangeを行った。しかしながら生体内に投与された天然型IgG4は、内因性IgG4との半分子交換が起こることが報告されている。またその原因はヒンジ領域のうち、EUナンバリング228番目に位置するSerであり、これをIgG1型のProとすることで安定性が向上し、生体内での交換が起こらなくなることが報告されている(Labrijn AF et al. Nat. Biotechnol. 2009, 27, 767-771)。従って生体内に投与することを考えた場合、作製したBispecific抗体のヒンジ配列は226C-227P-228P-229Cとなっていることが望ましい。そこで本検討では、会合界面制御改変が導入されていることにより、天然型ヒトIgG1のヒンジ配列であっても効率よくFab Arm Exchangeが起こるかどうかについて検証した。
反応条件: TBS(Takara, pH7.6)中、[各mAb] = 0.2 mg/ml、0.05% Tween 20 (Junsei)、37℃、24時間。還元剤は[GSH(Sigma)] = 0.5 mMもしくは5 mMまたは[2-MEA(Sigma)] = 25 mMの3条件で検討した。
前述のように、FAE反応では、還元剤によるヒンジ領域のジスルフィド結合の切断によって生じるHL分子が再結合する。したがってこのHL分子を効率的に生み出すことができれば、より穏やかな還元条件でFAE反応を進行させることができると考えられる。天然型ヒトIgG4はC131S改変を導入することによってH鎖-L鎖間に形成されていたジスルフィド結合がL鎖間で形成されることが報告されている(Schuurman J et al. Mol. Immunol. 2001, 38, 1-8)。このL鎖間のジスルフィド結合は1ヶ所でのみ形成されるため、コアヒンジで形成される2本のジスルフィド結合と比較して還元されやすいと考えられる。還元剤添加によりL鎖間のジスルフィド結合を開裂させ、効率的にHL分子を生み出すことができれば図3に示すようにBispecific抗体を高効率で作製できる可能性がある。そこでC131S改変を有する改変体にCH3領域における会合界面を制御する改変を加えることで、Fab Arm Exchange反応(Bispecific抗体生成率)を高効率で行うことができるか検証した。

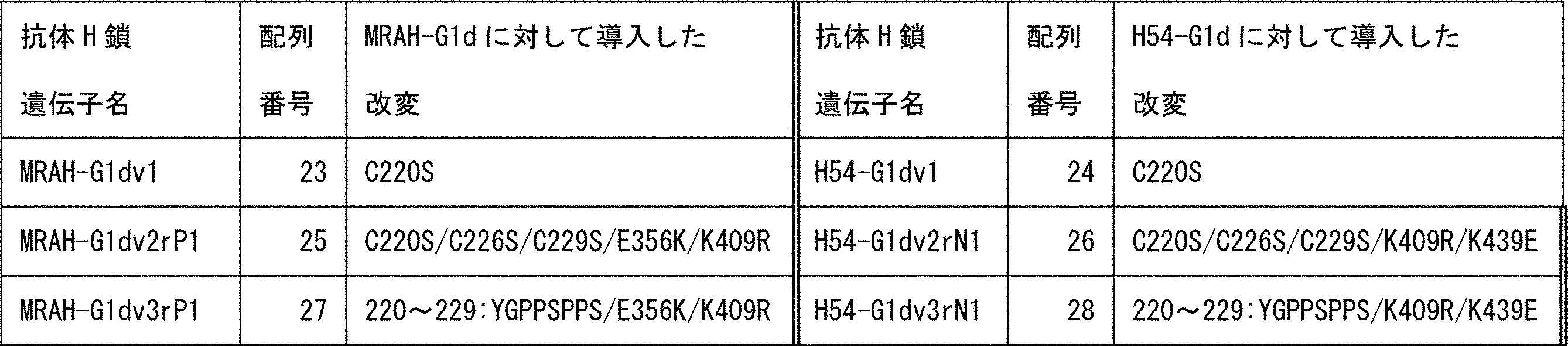
(1) MRAH-wtG4dP1/MRAL-k0とH54-wtG4dN1/L28-k0
(2) MRAH-wtG4dv2P1/MRAL-k0とH54-wtG4dv2N1/MRAL-k0
(3) MRAH-G4dv2P1/MRAL-k0とH54-G4dv2N1/L28-k0
(4) MRAH-G1drP1/MRAL-k0とH54-G1drN1/L28-k0
(5) MRAH-G1dv2rP1/MRAL-k0とH54-G1dv2rN1/L28-k0
(6) MRAH-G1dv3rP1/MRAL-k0とH54-G1dv3rN1/L28-k0
反応条件: TBS(TAKARA, pH7.4)中、[各mAb] = 2 mg/ml、[2-MEA(Sigma)] = 25 mM、37℃、90min
還元剤は種類によってその還元電位や反応様式が異なるが、2-MEAおよびDTTを用いた反応では、還元剤がジスルフィド結合を切断する際にタンパク質のチオール基に付加したのち、溶媒置換によって脱離すると考えられる。この脱離のしやすさは、還元剤の構造や濃度によって異なると考えられる。当然のことではあるが、還元剤が脱離していない状態ではジスルフィド結合を再形成することはできない。実施例3においてG4dv2P1//N1、G1dv2rP1//N1、G1dv3rP1//N1のL鎖間にジスルフィド結合が形成されなかった理由の一端として、還元条件による影響があるのではないかと考え、2-MEA,DTT,TCEPを用いて還元条件の検討を行った。
(1) MRAH-G1drP1/MRAL-k0とH54-G1drN1/L28-k0
(2) MRAH-G1dv2rP1/MRAL-k0とH54-G1dv2rN1/L28-k0
(3) MRAH-G1dv3rP1/MRAL-k0とH54-G1dv3rN1/L28-k0
(4) MRAH-G4dv2P1/MRAL-k0とH54-G4dv2N1/L28-k0
反応条件: TBS(TAKARA)中、[各mAb] = 0.45 mg/ml、[2-MEA] = 25 mM or [DTT] = 1 mM or [TCEP] = 1 mM、37℃、90min。
図4に示したヒトIgG1のヒンジ部の結晶構造を見ると、各L鎖C末端はヒンジ部の構造によって距離が遠くなっている。実施例3において、FAE反応後のG4dv2P1//N1のL鎖間にジスルフィド結合が形成されなかったのは、この距離によるのではないかと考えられた。そこで、ヒンジ領域を欠失することによってL鎖C末端の距離を近づけることにより、FAE反応後のL鎖間にジスルフィド結合を形成できるか検証した。
反応条件: TBS(Sigma, pH7.4)中、[各mAb] = 0.45 mg/ml、[2-MEA(Sigma)] = 25 mM、37℃、90min。
ここまでの実施例において、ヒンジ領域を欠失したMRAH-G4dv4P1/MRAL-k0およびH54-G4dv4N1/L28-k0をDTTやTCEPを用いることでL鎖間のジスルフィド結合を還元したのちに異なるHL分子が会合して、L鎖間のジスルフィド結合が再形成されることが示された。WO2011131746には、2種類の抗体分子の片方に405Lを、もう片方に409Rを持つ抗体分子を用いてFAE反応を行うことにより効率的にFAE反応を起こすことができると開示されている。この分子はヒンジ領域が通常の天然型IgG1であることから、FAE反応過程におけるHL分子の生成には2本のジスルフィド結合を還元する必要がある。一方、上記のMRAH-G4dv4P1/MRAL-k0およびH54-G4dv4N1/L28-k0を用いたFAE反応では、HL分子生成のために還元する必要のあるジスルフィド結合はL鎖間の1本となるため、より穏やかな還元条件でFAE反応を進行させることができる可能性があると考えられた。そこで次に、WO2011131746に開示されている抗体分子とMRAH-G4dv4P1/MRAL-k0およびH54-G4dv4N1/L28-k0とを、より穏やかな還元条件でのFAE反応効率について比較した。
(1) MRAH-G1dr/MRAL-k0とH54-G1dl/L28-k0
(2) MRAH-G4dv4P1/MRAL-k0とH54-G4dv4N1/L28-k0
反応条件: TBS(TAKARA)中、[各mAb] = 0.45 mg/ml、[GSH] = 5 mM or 0.5mM、37℃、90min。
実施例6で示された通り、L鎖間のジスルフィド結合を還元してHL分子を生成するFAE反応では、天然型IgG1のヒンジ領域のジスルフィド結合を還元してHL分子を生成するFAE反応に比べてより穏やかな還元条件で高効率に反応を進行させることができる。これは還元すべきジスルフィド結合が1本であり、通常のヒンジ領域を還元する場合と比較して少ないことが要因であると考えられる。このジスルフィド結合を形成する部位はヒンジ領域に特に限定されるわけではなく、抗体のどの領域であってもよいと考えられる。そこで次に、CH3領域間に1ヶ所ジスルフィド結合を形成させた分子でのFAE反応を検討した。

(1) MRAH-G4dNX010P/MRAL-k0とH54-G4dNX010N/L28-k0
(2) MRAH-G4dNX011P/MRAL-k0とH54-G4dNX011N/L28-k0
(3) MRAH-G4dNX012P/MRAL-k0とH54-G4dNX012N/L28-k0
(4) MRAH-G4dNX010P/MRAL-k0とH54-G4dNX013N/L28-k0
(5) MRAH-G4dNX014P/MRAL-k0とH54-G4dNX014N/L28-k0
(6) MRAH-G4dNX015P/MRAL-k0とH54-G4dNX015N/L28-k0
反応条件: TBS(Sigma, pH7.4)中、[各mAb] = 0.2 mg/ml又は0.225 mg/mL、[2-MEA(Sigma)] = 25 mM 37℃、90min。
抗体のH鎖およびL鎖の塩基配列をコードする全長の遺伝子の合成は、Assemble PCR等を用いて、当業者公知の方法で作製した。アミノ酸置換の導入はPCR等を用いて当業者公知の方法で行った。得られたプラスミド断片を動物細胞発現ベクターに挿入し、H鎖発現ベクターおよびL鎖発現ベクターを作製した。得られた発現ベクターの塩基配列は当業者公知の方法で決定した。作製したプラスミドをヒト胎児腎癌細胞由来HEK293H株(Invitrogen社)、またはFreeStyle293細胞(Invitrogen社)に、一過性に導入し、抗体の発現を行った。得られた培養上清を回収した後、0.22μmフィルターMILLEX(R)-GV(Millipore)、または0.45μmフィルターMILLEX(R)-GV(Millipore)を通して培養上清を得た。得られた培養上清から、rProtein A Sepharose Fast Flow(GEヘルスケア)またはProtein G Sepharose 4 Fast Flow(GEヘルスケア)を用いて当業者公知の方法で、抗体を精製した。精製抗体濃度は、分光光度計を用いて280 nmでの吸光度を測定し、得られた値からPACE等の方法により算出された吸光係数を用いて抗体濃度を算出した(Protein Science 1995 ; 4 : 2411-2423)。
CE-IEFの測定は、PA800 Plus(Beckman Coulter)を用いて当業者公知の方法で行った。Pharmalyteはbroad rangeが5~8と8~10.5のものを等量混合して、pI range 5~10.5で分析を行った。4 mg/mLの抗体溶液を用いて分析し、結果は32 karat software(Beckman Coulter)を用いて解析した。Bispecific抗体生成率(%)は、Bispecific抗体の面積値を系中に存在する全抗体の面積値で除し、100をかけた値を用いた。
Priminence UFLC(島津製作所)を用いたイオン交換クロマトグラフィー精製法において、各検体の分離が評価された。移動相には25 mM MES緩衝液、pH5.0ならびに500 mMの塩化ナトリウムを含む25 mM MES緩衝液、pH5.0を、カラムはProPac WCX-10 (Thermo Scientific)を用い、2液混合グラジエント法によりBispecific抗体が分離された。データの取得は215 nmの波長で実施し、Empower2(Waters)を用いて溶出結果が評価された。
Bispecific抗体生成率(%)は、Bispecific抗体の面積値を系中に存在する全抗体の面積値で除し、100をかけた値を用いた。片方のホモ体の回収率が悪い場合には、もう片方のホモ体の面積の2倍値をBispecific抗体の面積値と合わせた値を全抗体の面積値として計算した。
Mini-PROTEAN Tetra system(BIO-RAD)を用いたSDSポリアクリルアミドゲル電気泳動法により、ジスルフィド結合が評価された。Power SupplyにはPower Pac 3000 (BIO-RAD)またはPOWER SUPPLY KS-7510 (MARYSOL)を、泳動ゲルにはMini-PROTEAN TGX Gel(4-20%, BIO-RAD)を用い、Tris-Glycine SDS Sample Buffer(2x, TEFCO)で抗体含有液を希釈したのちに95℃で2min加熱処理したサンプルを電気泳動した。電気泳動後のゲルはCBB Stain One(ナカライテスク)を用いて染色した。染色後のゲルはTyphoon FLA 9500(GE Healthcare)を用いて画像化した。
Phastsystem(GE Healthcare)を用いた等電点電気泳動法により、FAE反応後の生成物を評価した。メーカーのプロトコールに従い、PhastGel Dry IEF(GE Healthcare)をPharmalyte 5-8(GE Healthcare)、Pharmalyte 8-10.5(GE Healthcare)を等量混合したアンフォライト溶液で膨潤させたのち、サンプルを電気泳動した。電気泳動後のゲルは、PlusOne Silver Staining Kit, Protein(GE Healthcare)を用いて銀染色した。染色後のゲルは乾燥後にスキャナを用いて画像化した。
CH3ドメインのTmの測定は、Rotor-gene Q (QIAGEN) を用いて当業者公知の方法で行った。抗体濃度0.1 mg/mL、SYPRO orange濃度10X concentrateで混合したサンプルを30℃から99℃まで昇温し、蛍光強度(励起波長470nm、蛍光波長555nm)を0.4℃毎に測定した。測定はPBS(Sigma, pH7.4)中で行った。解析はRotor-gene Q series software を用いて行い、蛍光強度の一次微分によって求めた変曲点をTmとした。MRAHのTmはCH2が70℃付近、Fabが95℃付近、H54のTmはCH2が70℃付近、Fabが90℃付近であることを利用してCH3ドメインのTmが算出された。
Claims (32)
- a) 第1の抗原結合活性を有し、重鎖定常領域を含む第1のポリペプチドのホモ体を提供する段階、
b) 該第1の抗原結合活性とは異なる第2の抗原結合活性を有し、重鎖定常領域を含む第2のポリペプチドのホモ体を提供する段階、
c) コアヒンジ領域外のシステインがジスルフィド結合の異性化を起こすことを可能にする還元条件下で、該第1のポリペプチドのホモ体および該第2のポリペプチドのホモ体を共にインキュベートする段階、ならびに
d) 第1及び第2のポリペプチドを含む異種多量体を得る段階
を含み、
コアヒンジ領域内のアミノ酸残基がジスルフィド結合を形成しない、
異種多量体を製造するための方法。 - 請求項1の段階a)において、第1のポリペプチドと多量体を形成する第3のポリペプチドを提供する段階を含み、かつ段階b)において、第2のポリペプチドと多量体を形成する第4のポリペプチドを提供する段階を含む、請求項1に記載の製造方法。
- 第3のポリペプチド及び第4のポリペプチドが抗体軽鎖である、請求項2に記載の製造方法。
- コアヒンジ領域外が軽鎖定常領域である、請求項1~3のいずれか一項に記載の製造方法。
- 前記第1及び/又は第2のポリペプチドの重鎖定常領域において、EUナンバリングによる131位及び/又は220位のシステイン残基が他のアミノ酸残基に改変されている、請求項4に記載の製造方法。
- コアヒンジ領域外が重鎖定常領域に含まれるCH3領域である、請求項1~3のいずれか一項に記載の製造方法。
- 前記第1及び第2のポリペプチドの重鎖定常領域に含まれるCH3領域のそれぞれにおいて、EUナンバリングによる349位、351位、354位、356位、394位及び407位のアミノ酸残基から選択される少なくとも一つのアミノ酸残基がシステインである、請求項6に記載の製造方法。
- 前記第1及び第2のポリペプチドの重鎖定常領域に含まれるCH3領域においてそれぞれシステインである組が、以下の(1)~(5)のいずれか1組である、請求項7に記載の製造方法:
(1) EUナンバリングによる349位および356位のアミノ酸残基
(2) EUナンバリングによる394位および394位のアミノ酸残基
(3) EUナンバリングによる351位および351位のアミノ酸残基
(4) EUナンバリングによる407位および407位のアミノ酸残基
(5) EUナンバリングによる349位および354位のアミノ酸残基。 - EUナンバリングによる226位および/または229位のシステイン残基が他のアミノ酸残基に改変されている若しくは欠損している、又はコアヒンジ領域が欠損している、請求項1~8のいずれか一項に記載の製造方法。
- さらにEUナンバリングによる220位から225位がTyr(Y)-Gly(G)-Pro(P)-Pro(P)に置換され、又はEUナンバリングによる219位から229位が欠損している、請求項9に記載の製造方法。
- 第1及び/又は第2のポリペプチドにおいて、第1及び/又は第2のポリペプチドのCH3領域の安定性が不安定になるようにアミノ酸が改変されている、請求項1~10のいずれか一項に記載の製造方法。
- 前記第1及び/又は第2のポリペプチドにおいて、EUナンバリングによる392位、397位及び409位のアミノ酸残基のうち少なくとも一つが改変されている、請求項11に記載の製造方法。
- 前記第1及び/又は第2のポリペプチドの重鎖定常領域に含まれるCH3領域において、
(1) EUナンバリングによる356位および439位のアミノ酸残基
(2) EUナンバリングによる357位および370位のアミノ酸残基
(3) EUナンバリングによる399位および409位のアミノ酸残基
に示すアミノ酸残基の組から選択される1組ないし3組のアミノ酸残基が同種の電荷を有し、
前記第1のポリペプチドのCH3領域及び前記第2のポリペプチドのCH3領域の両方において、前記(1)~(3)に示すアミノ酸残基の組のうち同じ組のアミノ酸残基がそれぞれ同種の電荷を有する場合、前記第2のポリペプチドのCH3領域における当該組のアミノ酸残基が、前記第1のポリペプチドのCH3領域における当該組のアミノ酸残基とは反対の電荷を有する、
請求項1~12のいずれか一項に記載の製造方法。 - 前記同種の電荷を有するアミノ酸残基が、以下の(A)または(B)いずれかの群に含まれる1つ以上のアミノ酸残基から選択される、請求項13に記載の製造方法:
(A)グルタミン酸 (E)、アスパラギン酸 (D);
(B)リジン(K)、アルギニン(R)、ヒスチジン(H)。 - 第1及び第2のポリペプチドにおいてそれぞれ同種の電荷を有するアミノ酸残基の組が、以下の(1)~(4)のいずれか1組のアミノ酸残基の組である、請求項13または14に記載の製造方法:
(1) EUナンバリングによる356位および439位のアミノ酸残基
(2) EUナンバリングによる357位および370位のアミノ酸残基
(3) EUナンバリングによる399位および409位のアミノ酸残基
(4)(i) EUナンバリングによる399位および409位のアミノ酸残基、並びに
(ii) EUナンバリングによる356位および439位のアミノ酸残基。 - 第1及び/又は第2のポリペプチドの重鎖定常領域がIgG1、IgG2、IgG3又はIgG4タイプである、請求項1~15のいずれか一項に記載の製造方法。
- 第1及び/又は第2のポリペプチドの重鎖定常領域がマウス由来の重鎖定常領域である、請求項1~12のいずれか一項に記載の製造方法。
- 前記第1及び/又は第2のポリペプチドの重鎖定常領域に含まれるCH3領域において、
(1) EUナンバリングによる356位および439位のアミノ酸残基
(2) EUナンバリングによる360位および371位のアミノ酸残基
(3) EUナンバリングによる399位および409位のアミノ酸残基
に示すアミノ酸残基の組から選択される1組ないし3組のアミノ酸残基が同種の電荷を有し、
前記第1のポリペプチドのCH3領域及び前記第2のポリペプチドのCH3領域の両方において、前記(1)~(3)に示すアミノ酸残基の組のうち同じ組のアミノ酸残基がそれぞれ同種の電荷を有する場合、前記第2のポリペプチドのCH3領域における当該組のアミノ酸残基が、前記第1のポリペプチドのCH3領域における当該組のアミノ酸残基とは反対の電荷を有する、
請求項17に記載の異種多量体を製造するための方法。 - 第1及び/又は第2のポリペプチドにおいて、
EUナンバリングによる397位がMet(M)、Phe(F)若しくはTyr(Y)に改変されており、かつ/又は
EUナンバリングによる392位がAsp(D)、Glu(E)、Thr(T)、Val(V)若しくはIle(I)に改変されており、かつ/又は
EUナンバリングによる409位がArg(R)に改変されている、
請求項1~18のいずれか一項に記載の製造方法。 - a) 第1の抗原結合活性を有し、重鎖定常領域を含む第1のポリペプチドのホモ体を提供する段階、
b) 該第1の抗原結合活性とは異なる第2の抗原結合活性を有し、重鎖定常領域を含む第2のポリペプチドのホモ体を提供する段階、
c) 第1及び第2のポリペプチドを含む異種多量体を得る段階
を含む、
異種多量体を製造するための方法であって、
第1及び第2のポリペプチドの重鎖定常領域が、それぞれ以下の(1)~(5)のいずれかに記載のように改変されている、当該製造方法:
(1)第1のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基及び349位がCys(C)であり、第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基及び356位がCys(C)である;
(2)第1及び第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基及び394位がCys(C)である;
(3)第1及び第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基及び351位がCys(C)である;
(4)第1及び第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基及び407位がCys(C)である;
(5)第1のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基及び349位がCys(C)であり、第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基及び354位がCys(C)である。 - a) 第1の抗原結合活性を有し、重鎖定常領域を含む第1のポリペプチドのホモ体を提供する段階、
b) 該第1の抗原結合活性とは異なる第2の抗原結合活性を有し、重鎖定常領域を含む第2のポリペプチドのホモ体を提供する段階、
c) 第1及び第2のポリペプチドを含む異種多量体を得る段階
を含む、
異種多量体を製造するための方法であって、
段階a)において、第1のポリペプチドと多量体を形成する第3のポリペプチドである抗体軽鎖を提供する段階を含み、かつ段階b)において、第2のポリペプチドと多量体を形成する第4のポリペプチドである抗体軽鎖を提供する段階を含み、
第1及び第2のポリペプチドの重鎖定常領域が、それぞれ以下の(1)~(6)のいずれかに記載のように改変されている、当該製造方法:
(1)第1及び第2のポリペプチドはEUナンバリングによる131位がCys(C)以外のアミノ酸残基、226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基である;
(2)第1及び第2のポリペプチドはEUナンバリングによる131位がCys(C)以外のアミノ酸残基、226位がCys(C)以外のアミノ酸残基、228位がPro(P)、229位がCys(C)以外のアミノ酸残基である;
(3)第1及び第2のポリペプチドはEUナンバリングによる220位がCys(C)以外のアミノ酸残基、226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基である;
(4)第1及び第2のポリペプチドはEUナンバリングによる131位がCys(C)以外のアミノ酸残基、219位~229位が欠失している;
(5)第1及び第2のポリペプチドはEUナンバリングによる219位~229位が欠失している;
(6)第1及び第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基、220位~225位がTyr(Y)-Gly(G)-Pro(P)-Pro(P)である。 - 請求項1、請求項20及び請求項21に記載の段階c)が還元剤との接触を含む、請求項1~21のいずれか一項に記載の製造方法。
- 段階c)が、グルタチオン、L-システイン、ジチオスレイトール、β-メルカプト-エタノール、TCEPおよび2-MEAからなる群より選択される作用物質の添加を含む、請求項22に記載の製造方法。
- 前記異種多量体が多重特異性抗体又はヘテロFc融合タンパク質である、請求項1~23のいずれか一項に記載の製造方法。
- 前記異種多量体が二重特異性抗体である、請求項1~24のいずれか一項に記載の製造方法。
- 請求項1~25のいずれか一項に記載の方法によって製造された異種多量体又は二重特異性抗体。
- 抗体重鎖である第1のポリペプチドと抗体軽鎖である第3のポリペプチドで2量体を形成し、抗体重鎖である第2のポリペプチドと抗体軽鎖である第4のポリペプチドで2量体を形成している、第1、第2、第3および第4のポリペプチドを構成要素として含む二重特異性抗体であって、
第1及び/又は第2のポリペプチドの重鎖定常領域に含まれるCH3領域のそれぞれにおいて、EUナンバリングによる349位、351位、354位、356位、394位及び407位のアミノ酸残基から選択される少なくとも一つのアミノ酸残基がシステインである、
二重特異性抗体。 - 抗体重鎖である第1のポリペプチドと抗体軽鎖である第3のポリペプチドで2量体を形成し、抗体重鎖である第2のポリペプチドと抗体軽鎖である第4のポリペプチドで2量体を形成している、第1、第2、第3および第4のポリペプチドを構成要素として含む二重特異性抗体であって、
第1及び第2のポリペプチドが、それぞれ以下の(1)~(6)のいずれかに示すアミノ酸残基を有する、
二重特異性抗体:
(1)第1及び第2のポリペプチドはEUナンバリングによる131位がCys(C)以外のアミノ酸残基、226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基である;
(2)第1及び第2のポリペプチドはEUナンバリングによる131位がCys(C)以外のアミノ酸残基、226位がCys(C)以外のアミノ酸残基、228位がPro(P)、229位がCys(C)以外のアミノ酸残基である;
(3)第1及び第2のポリペプチドはEUナンバリングによる220位がCys(C)以外のアミノ酸残基、226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基である;
(4)第1及び第2のポリペプチドはEUナンバリングによる131位がCys(C)以外のアミノ酸残基、219位~229位が欠失している;
(5)第1及び第2のポリペプチドはEUナンバリングによる219位~229位が欠失している;
(6)第1及び第2のポリペプチドはEUナンバリングによる226位がCys(C)以外のアミノ酸残基、229位がCys(C)以外のアミノ酸残基、220位~225位がTyr(Y)-Gly(G)-Pro(P)-Pro(P)である。 - 請求項26~28のいずれか一項に記載の異種多量体又は二重特異性抗体、及び医薬的に許容される担体を含む組成物。
- 請求項27または28に記載の二重特異性抗体を製造する方法。
- 請求項1に記載の段階d)の後にさらに以下の段階を行う、異種多量体をスクリーニングする方法:
e) 異種多量体の活性を測定する段階、
f) 所望の活性を有する異種多量体を選択する段階。 - 請求項31に記載の段階f)の後にさらに以下の段階を行う、異種多量体を製造する方法:
g) 請求項31に記載の段階f)で選択した異種多量体の第1のポリペプチド、第2のポリペプチド、第3のポリペプチド及び第4のポリペプチドのCDR又は可変領域を取得する段階、
h) 取得したCDR又は可変領域を別の異種多量体に移植する段階。
Priority Applications (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2017510171A JP7082484B2 (ja) | 2015-04-01 | 2016-03-31 | ポリペプチド異種多量体の製造方法 |
| EP16773093.6A EP3279216A4 (en) | 2015-04-01 | 2016-03-31 | PROCESS FOR PREPARING POLYPEPTIDE HETERO OLIGOMER |
| US15/562,186 US11142587B2 (en) | 2015-04-01 | 2016-03-31 | Method for producing polypeptide hetero-oligomer |
| US17/483,898 US20220010030A1 (en) | 2015-04-01 | 2021-09-24 | Method for producing polypeptide hetero-oligomer |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2015075448 | 2015-04-01 | ||
| JP2015-075448 | 2015-04-01 |
Related Child Applications (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US15/562,186 A-371-Of-International US11142587B2 (en) | 2015-04-01 | 2016-03-31 | Method for producing polypeptide hetero-oligomer |
| US17/483,898 Division US20220010030A1 (en) | 2015-04-01 | 2021-09-24 | Method for producing polypeptide hetero-oligomer |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2016159213A1 true WO2016159213A1 (ja) | 2016-10-06 |
Family
ID=57004697
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2016/060616 WO2016159213A1 (ja) | 2015-04-01 | 2016-03-31 | ポリペプチド異種多量体の製造方法 |
Country Status (4)
| Country | Link |
|---|---|
| US (2) | US11142587B2 (ja) |
| EP (1) | EP3279216A4 (ja) |
| JP (2) | JP7082484B2 (ja) |
| WO (1) | WO2016159213A1 (ja) |
Cited By (24)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US9975966B2 (en) | 2014-09-26 | 2018-05-22 | Chugai Seiyaku Kabushiki Kaisha | Cytotoxicity-inducing theraputic agent |
| US10011858B2 (en) | 2005-03-31 | 2018-07-03 | Chugai Seiyaku Kabushiki Kaisha | Methods for producing polypeptides by regulating polypeptide association |
| US10066018B2 (en) | 2009-03-19 | 2018-09-04 | Chugai Seiyaku Kabushiki Kaisha | Antibody constant region variant |
| US10150808B2 (en) | 2009-09-24 | 2018-12-11 | Chugai Seiyaku Kabushiki Kaisha | Modified antibody constant regions |
| US10253091B2 (en) | 2009-03-19 | 2019-04-09 | Chugai Seiyaku Kabushiki Kaisha | Antibody constant region variant |
| WO2019131988A1 (en) | 2017-12-28 | 2019-07-04 | Chugai Seiyaku Kabushiki Kaisha | Cytotoxicity-inducing therapeutic agent |
| US10435458B2 (en) | 2010-03-04 | 2019-10-08 | Chugai Seiyaku Kabushiki Kaisha | Antibody constant region variants with reduced Fcgammar binding |
| US10450381B2 (en) | 2010-11-17 | 2019-10-22 | Chugai Seiyaku Kabushiki Kaisha | Methods of treatment that include the administration of bispecific antibodies |
| WO2019244973A1 (ja) * | 2018-06-20 | 2019-12-26 | 中外製薬株式会社 | 標的細胞に対する免疫反応を活性化する方法およびその組成物 |
| WO2020067541A1 (ja) * | 2018-09-28 | 2020-04-02 | 協和キリン株式会社 | 抗体組成物 |
| EP3586872A4 (en) * | 2017-02-24 | 2020-12-30 | Chugai Seiyaku Kabushiki Kaisha | PHARMACEUTICAL COMPOSITION, ANTIG-BINDING MOLECULES, TREATMENT METHODS AND SCREENING METHODS |
| WO2021006328A1 (en) | 2019-07-10 | 2021-01-14 | Chugai Seiyaku Kabushiki Kaisha | Claudin-6 binding molecules and uses thereof |
| US10934344B2 (en) | 2006-03-31 | 2021-03-02 | Chugai Seiyaku Kabushiki Kaisha | Methods of modifying antibodies for purification of bispecific antibodies |
| US11046784B2 (en) | 2006-03-31 | 2021-06-29 | Chugai Seiyaku Kabushiki Kaisha | Methods for controlling blood pharmacokinetics of antibodies |
| US11072666B2 (en) | 2016-03-14 | 2021-07-27 | Chugai Seiyaku Kabushiki Kaisha | Cell injury inducing therapeutic drug for use in cancer therapy |
| US11124576B2 (en) | 2013-09-27 | 2021-09-21 | Chungai Seiyaku Kabushiki Kaisha | Method for producing polypeptide heteromultimer |
| WO2021201236A1 (ja) * | 2020-04-01 | 2021-10-07 | 協和キリン株式会社 | 抗体組成物 |
| US11142587B2 (en) | 2015-04-01 | 2021-10-12 | Chugai Seiyaku Kabushiki Kaisha | Method for producing polypeptide hetero-oligomer |
| US11248053B2 (en) | 2007-09-26 | 2022-02-15 | Chugai Seiyaku Kabushiki Kaisha | Method of modifying isoelectric point of antibody via amino acid substitution in CDR |
| US11332533B2 (en) | 2007-09-26 | 2022-05-17 | Chugai Seiyaku Kabushiki Kaisha | Modified antibody constant region |
| US11440949B2 (en) | 2016-10-05 | 2022-09-13 | Acceleron Pharma Inc. | TGF-beta superfamily type I and type II receptor heteromultimers and uses thereof |
| WO2023058705A1 (ja) | 2021-10-08 | 2023-04-13 | 中外製薬株式会社 | 抗hla-dq2.5抗体の製剤 |
| US11649262B2 (en) | 2015-12-28 | 2023-05-16 | Chugai Seiyaku Kabushiki Kaisha | Method for promoting efficiency of purification of Fc region-containing polypeptide |
| US11851476B2 (en) | 2011-10-31 | 2023-12-26 | Chugai Seiyaku Kabushiki Kaisha | Antigen-binding molecule having regulated conjugation between heavy-chain and light-chain |
Families Citing this family (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN110352074A (zh) | 2017-02-28 | 2019-10-18 | 西雅图遗传学公司 | 用于偶联的半胱氨酸突变抗体 |
| WO2022170619A1 (en) * | 2021-02-11 | 2022-08-18 | Adagene Pte. Ltd. | Anti-cd3 antibodies and methods of use thereof |
Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2006106905A1 (ja) * | 2005-03-31 | 2006-10-12 | Chugai Seiyaku Kabushiki Kaisha | 会合制御によるポリペプチド製造方法 |
| JP2010522701A (ja) * | 2007-03-29 | 2010-07-08 | ゲンマブ エー/エス | 二重特異性抗体およびその作製方法 |
| WO2010107109A1 (ja) * | 2009-03-19 | 2010-09-23 | 中外製薬株式会社 | 抗体定常領域改変体 |
| JP2012522527A (ja) * | 2009-04-07 | 2012-09-27 | ロシュ グリクアート アクチェンゲゼルシャフト | 三価の二重特異性抗体 |
| WO2014054804A1 (ja) * | 2012-10-05 | 2014-04-10 | 協和発酵キリン株式会社 | ヘテロダイマータンパク質組成物 |
| WO2015046467A1 (ja) * | 2013-09-27 | 2015-04-02 | 中外製薬株式会社 | ポリペプチド異種多量体の製造方法 |
Family Cites Families (265)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPS5144499B1 (ja) | 1970-08-29 | 1976-11-29 | ||
| JPS5334319B2 (ja) | 1971-12-28 | 1978-09-20 | ||
| JPS5717624B2 (ja) | 1974-04-17 | 1982-04-12 | ||
| US4208479A (en) | 1977-07-14 | 1980-06-17 | Syva Company | Label modified immunoassays |
| JPS5912436B2 (ja) | 1980-08-05 | 1984-03-23 | ファナック株式会社 | 工業用ロボットの安全機構 |
| US4474893A (en) | 1981-07-01 | 1984-10-02 | The University of Texas System Cancer Center | Recombinant monoclonal antibodies |
| US4444878A (en) | 1981-12-21 | 1984-04-24 | Boston Biomedical Research Institute, Inc. | Bispecific antibody determinants |
| JPH0234615Y2 (ja) | 1986-08-08 | 1990-09-18 | ||
| JPH06104071B2 (ja) | 1986-08-24 | 1994-12-21 | 財団法人化学及血清療法研究所 | 第▲ix▼因子コンホメ−シヨン特異性モノクロ−ナル抗体 |
| US5004697A (en) | 1987-08-17 | 1991-04-02 | Univ. Of Ca | Cationized antibodies for delivery through the blood-brain barrier |
| US5670373A (en) | 1988-01-22 | 1997-09-23 | Kishimoto; Tadamitsu | Antibody to human interleukin-6 receptor |
| US5322678A (en) | 1988-02-17 | 1994-06-21 | Neorx Corporation | Alteration of pharmacokinetics of proteins by charge modification |
| US6010902A (en) | 1988-04-04 | 2000-01-04 | Bristol-Meyers Squibb Company | Antibody heteroconjugates and bispecific antibodies for use in regulation of lymphocyte activity |
| US5126250A (en) | 1988-09-28 | 1992-06-30 | Eli Lilly And Company | Method for the reduction of heterogeneity of monoclonal antibodies |
| IL89491A0 (en) | 1988-11-17 | 1989-09-10 | Hybritech Inc | Bifunctional chimeric antibodies |
| DE3920358A1 (de) | 1989-06-22 | 1991-01-17 | Behringwerke Ag | Bispezifische und oligospezifische, mono- und oligovalente antikoerperkonstrukte, ihre herstellung und verwendung |
| GB8916400D0 (en) | 1989-07-18 | 1989-09-06 | Dynal As | Modified igg3 |
| WO1991008770A1 (en) | 1989-12-11 | 1991-06-27 | Immunomedics, Inc. | Method for antibody targeting of diagnostic or therapeutic agents |
| US5859205A (en) | 1989-12-21 | 1999-01-12 | Celltech Limited | Humanised antibodies |
| TW212184B (ja) | 1990-04-02 | 1993-09-01 | Takeda Pharm Industry Co Ltd | |
| JPH05184383A (ja) | 1990-06-19 | 1993-07-27 | Dainabotsuto Kk | 二重特異性抗体 |
| JPH05199894A (ja) | 1990-08-20 | 1993-08-10 | Takeda Chem Ind Ltd | 二重特異性抗体および抗体含有薬剤 |
| US5795965A (en) | 1991-04-25 | 1998-08-18 | Chugai Seiyaku Kabushiki Kaisha | Reshaped human to human interleukin-6 receptor |
| JPH05304992A (ja) | 1991-06-20 | 1993-11-19 | Takeda Chem Ind Ltd | ハイブリッド・モノクローナル抗体および抗体含有薬剤 |
| US6136310A (en) | 1991-07-25 | 2000-10-24 | Idec Pharmaceuticals Corporation | Recombinant anti-CD4 antibodies for human therapy |
| AU3178993A (en) | 1991-11-25 | 1993-06-28 | Enzon, Inc. | Multivalent antigen-binding proteins |
| US5667988A (en) | 1992-01-27 | 1997-09-16 | The Scripps Research Institute | Methods for producing antibody libraries using universal or randomized immunoglobulin light chains |
| JPH05203652A (ja) | 1992-01-28 | 1993-08-10 | Fuji Photo Film Co Ltd | 抗体酵素免疫分析法 |
| JPH05213775A (ja) | 1992-02-05 | 1993-08-24 | Otsuka Pharmaceut Co Ltd | Bfa抗体 |
| US6749853B1 (en) | 1992-03-05 | 2004-06-15 | Board Of Regents, The University Of Texas System | Combined methods and compositions for coagulation and tumor treatment |
| US6129914A (en) | 1992-03-27 | 2000-10-10 | Protein Design Labs, Inc. | Bispecific antibody effective to treat B-cell lymphoma and cell line |
| US5744446A (en) | 1992-04-07 | 1998-04-28 | Emory University | Hybrid human/animal factor VIII |
| US5639641A (en) | 1992-09-09 | 1997-06-17 | Immunogen Inc. | Resurfacing of rodent antibodies |
| ZA936260B (en) | 1992-09-09 | 1994-03-18 | Smithkline Beecham Corp | Novel antibodies for conferring passive immunity against infection by a pathogen in man |
| ATE199392T1 (de) | 1992-12-04 | 2001-03-15 | Medical Res Council | Multivalente und multispezifische bindungsproteine, deren herstellung und verwendung |
| WO1995001571A1 (en) | 1993-07-01 | 1995-01-12 | Baxter Diagnostics Inc. | Process for the preparation of factor x depleted plasma |
| UA40577C2 (uk) | 1993-08-02 | 2001-08-15 | Мерк Патент Гмбх | Біспецифічна молекула, що використовується для лізису пухлинних клітин, спосіб її одержання, моноклональне антитіло (варіанти), фармацевтичний препарат, фармацевтичний набір (варіанти), спосіб видалення пухлинних клітин |
| DE122009000068I2 (de) | 1994-06-03 | 2011-06-16 | Ascenion Gmbh | Verfahren zur Herstellung von heterologen bispezifischen Antikörpern |
| US5945311A (en) | 1994-06-03 | 1999-08-31 | GSF--Forschungszentrumfur Umweltund Gesundheit | Method for producing heterologous bi-specific antibodies |
| US8017121B2 (en) | 1994-06-30 | 2011-09-13 | Chugai Seiyaku Kabushika Kaisha | Chronic rheumatoid arthritis therapy containing IL-6 antagonist as effective component |
| ATE198712T1 (de) | 1994-07-11 | 2001-02-15 | Univ Texas | Verfahren und zusammensetzungen für die spezifische koagulation von tumorgefässen |
| US6309636B1 (en) | 1995-09-14 | 2001-10-30 | Cancer Research Institute Of Contra Costa | Recombinant peptides derived from the Mc3 anti-BA46 antibody, methods of use thereof, and methods of humanizing antibody peptides |
| CN101361972B (zh) | 1994-10-07 | 2011-05-25 | 中外制药株式会社 | 以il-6拮抗剂作为有效成分治疗慢性类风湿性关节炎 |
| RU2147442C1 (ru) | 1994-10-21 | 2000-04-20 | Кисимото Тадамицу | Фармацевтическая композиция для профилактики или лечения заболеваний, вызываемых образованием il-6 |
| WO1996016673A1 (en) | 1994-12-02 | 1996-06-06 | Chiron Corporation | Method of promoting an immune response with a bispecific antibody |
| US6485943B2 (en) | 1995-01-17 | 2002-11-26 | The University Of Chicago | Method for altering antibody light chain interactions |
| PT812136E (pt) | 1995-02-28 | 2001-04-30 | Procter & Gamble | Preparacao de bebidas nao gaseificadas com estabilidade microbiana superior |
| US5731168A (en) | 1995-03-01 | 1998-03-24 | Genentech, Inc. | Method for making heteromultimeric polypeptides |
| KR100259828B1 (ko) | 1995-09-11 | 2000-06-15 | 히라타 다다시 | 인체 인터루킨 5 수용체 알파-사슬에 대한 항체 |
| MA24512A1 (fr) | 1996-01-17 | 1998-12-31 | Univ Vermont And State Agrienl | Procede pour la preparation d'agents anticoagulants utiles dans le traitement de la thrombose |
| JP3032287U (ja) | 1996-06-10 | 1996-12-17 | 幸喜 高橋 | 人 形 |
| US20020147326A1 (en) | 1996-06-14 | 2002-10-10 | Smithkline Beecham Corporation | Hexameric fusion proteins and uses therefor |
| WO1998003546A1 (en) | 1996-07-19 | 1998-01-29 | Amgen Inc. | Analogs of cationic proteins |
| JPH10165184A (ja) | 1996-12-16 | 1998-06-23 | Tosoh Corp | 抗体、遺伝子及びキメラ抗体の製法 |
| US5990286A (en) | 1996-12-18 | 1999-11-23 | Techniclone, Inc. | Antibodies with reduced net positive charge |
| US6884879B1 (en) | 1997-04-07 | 2005-04-26 | Genentech, Inc. | Anti-VEGF antibodies |
| US20070059302A1 (en) | 1997-04-07 | 2007-03-15 | Genentech, Inc. | Anti-vegf antibodies |
| US20030207346A1 (en) | 1997-05-02 | 2003-11-06 | William R. Arathoon | Method for making multispecific antibodies having heteromultimeric and common components |
| US20020062010A1 (en) | 1997-05-02 | 2002-05-23 | Genentech, Inc. | Method for making multispecific antibodies having heteromultimeric and common components |
| IL132560A0 (en) | 1997-05-02 | 2001-03-19 | Genentech Inc | A method for making multispecific antibodies having heteromultimeric and common components |
| DE19725586C2 (de) | 1997-06-17 | 1999-06-24 | Gsf Forschungszentrum Umwelt | Verfahren zur Herstellung von Zellpräparaten zur Immunisierung mittels heterologer intakter bispezifischer und/oder trispezifischer Antikörper |
| US6207805B1 (en) | 1997-07-18 | 2001-03-27 | University Of Iowa Research Foundation | Prostate cell surface antigen-specific antibodies |
| US20020187150A1 (en) | 1997-08-15 | 2002-12-12 | Chugai Seiyaku Kabushiki Kaisha | Preventive and/or therapeutic agent for systemic lupus erythematosus comprising anti-IL-6 receptor antibody as an active ingredient |
| US6342220B1 (en) | 1997-08-25 | 2002-01-29 | Genentech, Inc. | Agonist antibodies |
| DE69838454T2 (de) | 1997-10-03 | 2008-02-07 | Chugai Seiyaku K.K. | Natürlicher menschlicher antikörper |
| DE69937994T2 (de) | 1998-03-17 | 2008-12-24 | Chugai Seiyaku K.K. | Prophylaktische oder therapeutische mittel gegen entzündliche erkrankungen des verdauungstraktes enthaltend antagonistische il-6 rezeptor antikörper |
| US6677436B1 (en) | 1998-04-03 | 2004-01-13 | Chugai Seiyaku Kabushiki Kaisha | Humanized antibody against human tissue factor (TF) and process of production of the humanized antibody |
| DE19819846B4 (de) | 1998-05-05 | 2016-11-24 | Deutsches Krebsforschungszentrum Stiftung des öffentlichen Rechts | Multivalente Antikörper-Konstrukte |
| GB9809951D0 (en) | 1998-05-08 | 1998-07-08 | Univ Cambridge Tech | Binding molecules |
| CA2341029A1 (en) | 1998-08-17 | 2000-02-24 | Abgenix, Inc. | Generation of modified molecules with increased serum half-lives |
| DE69942671D1 (de) | 1998-12-01 | 2010-09-23 | Facet Biotech Corp | Humanisierte antikoerper gegen gamma-interferon |
| US6737056B1 (en) | 1999-01-15 | 2004-05-18 | Genentech, Inc. | Polypeptide variants with altered effector function |
| US6972125B2 (en) | 1999-02-12 | 2005-12-06 | Genetics Institute, Llc | Humanized immunoglobulin reactive with B7-2 and methods of treatment therewith |
| SK782002A3 (en) | 1999-07-21 | 2003-08-05 | Lexigen Pharm Corp | FC fusion proteins for enhancing the immunogenicity of protein and peptide antigens |
| AT411997B (de) | 1999-09-14 | 2004-08-26 | Baxter Ag | Faktor ix/faktor ixa aktivierende antikörper und antikörper-derivate |
| SE9903895D0 (sv) | 1999-10-28 | 1999-10-28 | Active Biotech Ab | Novel compounds |
| WO2001075454A2 (en) | 2000-04-03 | 2001-10-11 | Oxford Glycosciences (Uk) Ltd. | Diagnosis and treatment of alzheimer's disease |
| WO2001082899A2 (en) | 2000-05-03 | 2001-11-08 | Mbt Munich Biotechnology Ag | Cationic diagnostic, imaging and therapeutic agents associated with activated vascular sites |
| US20020103345A1 (en) | 2000-05-24 | 2002-08-01 | Zhenping Zhu | Bispecific immunoglobulin-like antigen binding proteins and method of production |
| EP1304573A4 (en) | 2000-07-17 | 2006-06-07 | Chugai Pharmaceutical Co Ltd | METHOD FOR SCREENING A LIGAND WITH BIOLOGICAL ACTIVITY |
| ES2332402T5 (es) | 2000-10-12 | 2018-05-14 | Genentech, Inc. | Formulaciones de proteína concentradas de viscosidad reducida |
| EP1327680B1 (en) | 2000-10-20 | 2008-04-02 | Chugai Seiyaku Kabushiki Kaisha | Modified tpo agonist antibody |
| WO2002033073A1 (fr) | 2000-10-20 | 2002-04-25 | Chugai Seiyaku Kabushiki Kaisha | Anticorps agoniste degrade |
| AU2000279625A1 (en) | 2000-10-27 | 2002-05-15 | Chugai Seiyaku Kabushiki Kaisha | Blood mmp-3 level-lowering agent containing il-6 antgonist as the active ingredient |
| PT1355919E (pt) | 2000-12-12 | 2011-03-02 | Medimmune Llc | Moléculas com semivida longa, composições que as contêm e suas utilizações |
| DK1366067T3 (da) | 2001-03-07 | 2012-10-22 | Merck Patent Gmbh | Ekspressionsteknologi for proteiner indeholdende en hybrid isotype-antistof-enhed |
| UA80091C2 (en) | 2001-04-02 | 2007-08-27 | Chugai Pharmaceutical Co Ltd | Remedies for infant chronic arthritis-relating diseases and still's disease which contain an interleukin-6 (il-6) antagonist |
| AU2002258778C1 (en) | 2001-04-13 | 2008-12-04 | Biogen Ma Inc. | Antibodies to VLA-1 |
| US20040236080A1 (en) | 2001-06-22 | 2004-11-25 | Hiroyuki Aburatani | Cell proliferation inhibitors containing anti-glypican 3 antibody |
| US6833441B2 (en) | 2001-08-01 | 2004-12-21 | Abmaxis, Inc. | Compositions and methods for generating chimeric heteromultimers |
| US20030049203A1 (en) | 2001-08-31 | 2003-03-13 | Elmaleh David R. | Targeted nucleic acid constructs and uses related thereto |
| CN100423777C (zh) | 2001-10-25 | 2008-10-08 | 杰南技术公司 | 糖蛋白组合物 |
| US20030190705A1 (en) | 2001-10-29 | 2003-10-09 | Sunol Molecular Corporation | Method of humanizing immune system molecules |
| DE10156482A1 (de) | 2001-11-12 | 2003-05-28 | Gundram Jung | Bispezifisches Antikörper-Molekül |
| EP1573002A4 (en) | 2002-02-11 | 2008-07-16 | Genentech Inc | ANTIBODY VARIANTS WITH ACCELERATED ANTIGEN ASSOCIATED SPEEDS |
| US8188231B2 (en) | 2002-09-27 | 2012-05-29 | Xencor, Inc. | Optimized FC variants |
| AU2003217912A1 (en) * | 2002-03-01 | 2003-09-16 | Xencor | Antibody optimization |
| US7736652B2 (en) | 2002-03-21 | 2010-06-15 | The Regents Of The University Of California | Antibody fusion proteins: effective adjuvants of protein vaccination |
| WO2003087163A1 (fr) | 2002-04-15 | 2003-10-23 | Chugai Seiyaku Kabushiki Kaisha | Procede d'elaboration d'une banque scdb |
| DE60327199D1 (de) | 2002-04-26 | 2009-05-28 | Chugai Pharmaceutical Co Ltd | Verfahren zum screening auf agonistische antikörper |
| WO2005056606A2 (en) | 2003-12-03 | 2005-06-23 | Xencor, Inc | Optimized antibodies that target the epidermal growth factor receptor |
| EP1510943A4 (en) | 2002-05-31 | 2007-05-09 | Celestar Lexico Sciences Inc | INTERACTION PREDICTION DEVICE |
| JP2004086862A (ja) | 2002-05-31 | 2004-03-18 | Celestar Lexico-Sciences Inc | タンパク質相互作用情報処理装置、タンパク質相互作用情報処理方法、プログラム、および、記録媒体 |
| JP4836451B2 (ja) | 2002-07-18 | 2011-12-14 | メルス ベー ヴェー | 抗体混合物の組換え生産 |
| JP2005535341A (ja) | 2002-08-15 | 2005-11-24 | エピトミスク インコーポレーティッド | ヒト化ウサギ抗体 |
| JP2004086682A (ja) | 2002-08-28 | 2004-03-18 | Fujitsu Ltd | 機能ブロック設計方法および機能ブロック設計装置 |
| US7217797B2 (en) | 2002-10-15 | 2007-05-15 | Pdl Biopharma, Inc. | Alteration of FcRn binding affinities or serum half-lives of antibodies by mutagenesis |
| GB0224082D0 (en) | 2002-10-16 | 2002-11-27 | Celltech R&D Ltd | Biological products |
| CA2921578C (en) | 2002-12-24 | 2017-02-14 | Rinat Neuroscience Corp. | Anti-ngf antibodies and methods using same |
| AU2003303543A1 (en) | 2002-12-26 | 2004-07-29 | Chugai Seiyaku Kabushiki Kaisha | Agonist antibody against heteroreceptor |
| EP1605058B1 (en) | 2003-01-21 | 2009-05-13 | Chugai Seiyaku Kabushiki Kaisha | Method of screening light chain of antibody light chains |
| WO2004068931A2 (en) | 2003-02-07 | 2004-08-19 | Protein Design Labs Inc. | Amphiregulin antibodies and their use to treat cancer and psoriasis |
| GB2400851B (en) | 2003-04-25 | 2004-12-15 | Bioinvent Int Ab | Identifying binding of a polypeptide to a polypeptide target |
| JP2004321100A (ja) | 2003-04-25 | 2004-11-18 | Rikogaku Shinkokai | IgGのFc領域を含むタンパク質の変異体 |
| GB2401040A (en) | 2003-04-28 | 2004-11-03 | Chugai Pharmaceutical Co Ltd | Method for treating interleukin-6 related diseases |
| RS20150135A1 (en) | 2003-05-30 | 2015-08-31 | Genentech Inc. | TREATMENT WITH ANTI-VEGF ANTIBODIES |
| WO2004106375A1 (en) | 2003-05-30 | 2004-12-09 | Merus Biopharmaceuticals B.V. I.O. | Fab library for the preparation of anti vegf and anti rabies virus fabs |
| MXPA05013117A (es) | 2003-06-05 | 2006-03-17 | Genentech Inc | Terapia de combinacion para trastornos de celulas-b. |
| WO2004111233A1 (ja) | 2003-06-11 | 2004-12-23 | Chugai Seiyaku Kabushiki Kaisha | 抗体の製造方法 |
| EP1636264A2 (en) | 2003-06-24 | 2006-03-22 | MERCK PATENT GmbH | Tumour necrosis factor receptor molecules with reduced immunogenicity |
| US20050033029A1 (en) | 2003-06-30 | 2005-02-10 | Jin Lu | Engineered anti-target immunoglobulin derived proteins, compositions, methods and uses |
| US7297336B2 (en) | 2003-09-12 | 2007-11-20 | Baxter International Inc. | Factor IXa specific antibodies displaying factor VIIIa like activity |
| JP2005101105A (ja) | 2003-09-22 | 2005-04-14 | Canon Inc | 位置決め装置、露光装置、デバイス製造方法 |
| US20060134105A1 (en) | 2004-10-21 | 2006-06-22 | Xencor, Inc. | IgG immunoglobulin variants with optimized effector function |
| WO2005035753A1 (ja) | 2003-10-10 | 2005-04-21 | Chugai Seiyaku Kabushiki Kaisha | 機能蛋白質を代替する二重特異性抗体 |
| AU2003271186A1 (en) | 2003-10-14 | 2005-04-27 | Chugai Seiyaku Kabushiki Kaisha | Double specific antibodies substituting for functional protein |
| EP2385069A3 (en) | 2003-11-12 | 2012-05-30 | Biogen Idec MA Inc. | Neonatal Fc rReceptor (FcRn)- binding polypeptide variants, dimeric Fc binding proteins and methods related thereto |
| SI2418220T1 (sl) | 2003-12-10 | 2017-10-30 | E. R. Squibb & Sons, L.L.C. | Interferon alfa protitelesa in njihova uporaba |
| ES2537163T3 (es) | 2003-12-10 | 2015-06-03 | E. R. Squibb & Sons, L.L.C. | Anticuerpos de IP-10 y sus usos |
| AR048210A1 (es) | 2003-12-19 | 2006-04-12 | Chugai Pharmaceutical Co Ltd | Un agente preventivo para la vasculitis. |
| AU2004308439A1 (en) | 2003-12-22 | 2005-07-14 | Centocor, Inc. | Methods for generating multimeric molecules |
| KR101200188B1 (ko) | 2003-12-25 | 2012-11-13 | 교와 핫꼬 기린 가부시키가이샤 | 항 cd40 항체의 변이체 |
| BRPI0418286A (pt) | 2003-12-30 | 2007-05-02 | Merck Patent Gmbh | proteìnas de fusão de il-7 |
| US20050266425A1 (en) | 2003-12-31 | 2005-12-01 | Vaccinex, Inc. | Methods for producing and identifying multispecific antibodies |
| SI2177537T1 (sl) | 2004-01-09 | 2012-01-31 | Pfizer | Protitielesa proti MAdCAM |
| WO2005092925A2 (en) | 2004-03-24 | 2005-10-06 | Xencor, Inc. | Immunoglobulin variants outside the fc region |
| AR048335A1 (es) | 2004-03-24 | 2006-04-19 | Chugai Pharmaceutical Co Ltd | Agentes terapeuticos para trastornos del oido interno que contienen un antagonista de il- 6 como un ingrediente activo |
| WO2005112564A2 (en) | 2004-04-15 | 2005-12-01 | The Government Of The United States Of America As Represented By The Secretary Of The Department Of Health And Human Services | Germline and sequence variants of humanized antibodies and methods of making and using them |
| KR100620554B1 (ko) | 2004-06-05 | 2006-09-06 | 한국생명공학연구원 | Tag-72에 대한 인간화 항체 |
| AR049390A1 (es) | 2004-06-09 | 2006-07-26 | Wyeth Corp | Anticuerpos contra la interleuquina-13 humana y usos de los mismos |
| AU2005259992A1 (en) | 2004-06-25 | 2006-01-12 | Medimmune, Llc | Increasing the production of recombinant antibodies in mammalian cells by site-directed mutagenesis |
| EP2898897A3 (en) | 2004-07-09 | 2015-10-14 | Chugai Seiyaku Kabushiki Kaisha | Anti-glypican 3 antibody |
| WO2006019447A1 (en) | 2004-07-15 | 2006-02-23 | Xencor, Inc. | Optimized fc variants |
| MX2007002856A (es) * | 2004-09-02 | 2007-09-25 | Genentech Inc | Metodos para el uso de ligandos receptores de muerte y anticuerpos c20. |
| US7572456B2 (en) | 2004-09-13 | 2009-08-11 | Macrogenics, Inc. | Humanized antibodies against West Nile Virus and therapeutic and prophylactic uses thereof |
| US20060074225A1 (en) | 2004-09-14 | 2006-04-06 | Xencor, Inc. | Monomeric immunoglobulin Fc domains |
| US20080233131A1 (en) | 2004-09-14 | 2008-09-25 | Richard John Stebbings | Vaccine |
| US7563443B2 (en) | 2004-09-17 | 2009-07-21 | Domantis Limited | Monovalent anti-CD40L antibody polypeptides and compositions thereof |
| TWI380996B (zh) | 2004-09-17 | 2013-01-01 | Hoffmann La Roche | 抗ox40l抗體 |
| EP1810979B1 (en) | 2004-09-22 | 2012-06-20 | Kyowa Hakko Kirin Co., Ltd. | STABILIZED HUMAN IgG4 ANTIBODIES |
| WO2006047350A2 (en) | 2004-10-21 | 2006-05-04 | Xencor, Inc. | IgG IMMUNOGLOBULIN VARIANTS WITH OPTIMIZED EFFECTOR FUNCTION |
| SG156672A1 (en) | 2004-10-22 | 2009-11-26 | Amgen Inc | Methods for refolding of recombinant antibodies |
| US7462697B2 (en) | 2004-11-08 | 2008-12-09 | Epitomics, Inc. | Methods for antibody engineering |
| US7632497B2 (en) | 2004-11-10 | 2009-12-15 | Macrogenics, Inc. | Engineering Fc Antibody regions to confer effector function |
| AU2005317279C1 (en) | 2004-12-14 | 2014-07-17 | Cytiva Bioprocess R&D Ab | Purification of immunoglobulins |
| US8728828B2 (en) | 2004-12-22 | 2014-05-20 | Ge Healthcare Bio-Sciences Ab | Purification of immunoglobulins |
| JPWO2006067847A1 (ja) | 2004-12-22 | 2008-06-12 | 中外製薬株式会社 | フコーストランスポーターの機能が阻害された細胞を用いた抗体の作製方法 |
| CA2592015A1 (en) | 2004-12-27 | 2006-07-06 | Progenics Pharmaceuticals (Nevada), Inc. | Orally deliverable and anti-toxin antibodies and methods for making and using them |
| KR101564713B1 (ko) | 2004-12-28 | 2015-11-06 | 이나뜨 파르마 | Nkg2a에 대한 단클론 항체 |
| WO2006076594A2 (en) | 2005-01-12 | 2006-07-20 | Xencor, Inc. | Antibodies and fc fusion proteins with altered immunogenicity |
| WO2006075668A1 (ja) | 2005-01-12 | 2006-07-20 | Kirin Beer Kabushiki Kaisha | 安定化されたヒトIgG2およびIgG3抗体 |
| JP5057967B2 (ja) | 2005-03-31 | 2012-10-24 | 中外製薬株式会社 | sc(Fv)2構造異性体 |
| EP2824183B1 (en) | 2005-04-08 | 2020-07-29 | Chugai Seiyaku Kabushiki Kaisha | Methods for producing bispecific antibodies |
| CA2605037C (en) | 2005-04-15 | 2015-02-24 | Genentech, Inc. | Hgf beta chain variants |
| CA2606102C (en) | 2005-04-26 | 2014-09-30 | Medimmune, Inc. | Modulation of antibody effector function by hinge domain engineering |
| WO2006121852A2 (en) | 2005-05-05 | 2006-11-16 | Duke University | Anti-cd19 antibody therapy for autoimmune disease |
| US20090028854A1 (en) | 2005-06-10 | 2009-01-29 | Chugai Seiyaku Kabushiki Kaisha | sc(Fv)2 SITE-DIRECTED MUTANT |
| JP5085322B2 (ja) | 2005-06-10 | 2012-11-28 | 中外製薬株式会社 | sc(Fv)2を含有する医薬組成物 |
| KR20080025174A (ko) | 2005-06-23 | 2008-03-19 | 메디뮨 인코포레이티드 | 응집 및 단편화 프로파일이 최적화된 항체 제제 |
| MX2008000030A (es) | 2005-07-11 | 2008-04-02 | Macrogenics Inc | Metodos para el tratamiento de enfermedad autoinmune utilizando anticuerpos anti-cd16a humanizados. |
| SI1919503T1 (sl) | 2005-08-10 | 2015-02-27 | Macrogenics, Inc. | Identifikacija in inĺ˝eniring protiteles z variantnimi fc regijami in postopki za njih uporabo |
| CN101379086B (zh) | 2005-08-19 | 2013-07-17 | 惠氏公司 | 抗gdf-8的拮抗剂抗体以及在als和其他gdf-8-相关病症治疗中的用途 |
| AU2006297173A1 (en) | 2005-09-29 | 2007-04-12 | Viral Logic Systems Technology Corp. | Immunomodulatory compositions and uses therefor |
| EP1941907B1 (en) | 2005-10-14 | 2016-03-23 | Fukuoka University | Inhibitor of transplanted islet dysfunction in islet transplantation |
| KR101239051B1 (ko) | 2005-10-21 | 2013-03-04 | 추가이 세이야쿠 가부시키가이샤 | 심장질환 치료제 |
| WO2007060411A1 (en) | 2005-11-24 | 2007-05-31 | Ucb Pharma S.A. | Anti-tnf alpha antibodies which selectively inhibit tnf alpha signalling through the p55r |
| EP2006380A4 (en) | 2006-03-23 | 2010-08-11 | Kyowa Hakko Kirin Co Ltd | AGONIST ANTIBODY AGAINST THE HUMAN THROMBOPOIETINE RECEPTOR |
| PL1999154T3 (pl) | 2006-03-24 | 2013-03-29 | Merck Patent Gmbh | Skonstruowane metodami inżynierii heterodimeryczne domeny białkowe |
| EP3345616A1 (en) | 2006-03-31 | 2018-07-11 | Chugai Seiyaku Kabushiki Kaisha | Antibody modification method for purifying bispecific antibody |
| JP5624276B2 (ja) | 2006-03-31 | 2014-11-12 | 中外製薬株式会社 | 抗体の血中動態を制御する方法 |
| CA2648644C (en) | 2006-04-07 | 2016-01-05 | Osaka University | Muscle regeneration promoter |
| EP2035456A1 (en) | 2006-06-22 | 2009-03-18 | Novo Nordisk A/S | Production of bispecific antibodies |
| WO2008090960A1 (ja) | 2007-01-24 | 2008-07-31 | Kyowa Hakko Kirin Co., Ltd. | ガングリオシドgm2に特異的に結合する遺伝子組換え抗体組成物 |
| WO2008092117A2 (en) | 2007-01-25 | 2008-07-31 | Xencor, Inc. | Immunoglobulins with modifications in the fcr binding region |
| MX2009009912A (es) | 2007-03-27 | 2010-01-18 | Sea Lane Biotechnologies Llc | Constructos y colecciones que comprenden secuencias de cadena ligera sustitutas de anticuerpos. |
| US20100267934A1 (en) | 2007-05-31 | 2010-10-21 | Genmab A/S | Stable igg4 antibodies |
| WO2008145141A1 (en) | 2007-05-31 | 2008-12-04 | Genmab A/S | Method for extending the half-life of exogenous or endogenous soluble molecules |
| RS54624B1 (en) | 2007-07-17 | 2016-08-31 | E. R. Squibb & Sons, L.L.C. | MONOCLONIC ANTIBODIES AGAINST GLIPICAN-3 |
| EP2031064A1 (de) | 2007-08-29 | 2009-03-04 | Boehringer Ingelheim Pharma GmbH & Co. KG | Verfahren zur Steigerung von Proteintitern |
| MX2010002683A (es) | 2007-09-14 | 2010-03-26 | Amgen Inc | Poblaciones de anticuerpos homogeneos. |
| WO2009041734A1 (ja) | 2007-09-26 | 2009-04-02 | Kyowa Hakko Kirin Co., Ltd. | ヒトトロンボポエチン受容体に対するアゴニスト抗体 |
| KR102225009B1 (ko) | 2007-09-26 | 2021-03-08 | 추가이 세이야쿠 가부시키가이샤 | 항체 정상영역 개변체 |
| PE20140132A1 (es) | 2007-09-26 | 2014-02-14 | Chugai Pharmaceutical Co Ltd | Anticuerpo anti-receptor de il-6 |
| JP5334319B2 (ja) | 2007-09-26 | 2013-11-06 | 中外製薬株式会社 | Cdrのアミノ酸置換により抗体の等電点を改変する方法 |
| RU2010116756A (ru) | 2007-09-28 | 2011-11-10 | Чугаи Сейяку Кабусики Кайся (Jp) | Антитело против глипикана-3 с улучшенными кинетическими показателями в плазме |
| JO3076B1 (ar) | 2007-10-17 | 2017-03-15 | Janssen Alzheimer Immunotherap | نظم العلاج المناعي المعتمد على حالة apoe |
| AU2008314697B2 (en) | 2007-10-22 | 2013-08-29 | Merck Serono S.A. | Single IFN-beta fused to a mutated lgG Fc fragment |
| BRPI0821110B8 (pt) | 2007-12-05 | 2021-05-25 | Chugai Pharmaceutical Co Ltd | anticorpo de neutralização de anti-nr10/il31ra, composição farmacêutica compreendendo o referido anticorpo e uso do mesmo |
| ES2550757T3 (es) | 2007-12-18 | 2015-11-12 | Bioalliance C.V. | Anticuerpos que reconocen un epítopo que contiene carbohidratos en CD43 y ACE expresados en células cancerosas y métodos de uso de los mismos |
| PE20091174A1 (es) | 2007-12-27 | 2009-08-03 | Chugai Pharmaceutical Co Ltd | Formulacion liquida con contenido de alta concentracion de anticuerpo |
| PL2235064T3 (pl) | 2008-01-07 | 2016-06-30 | Amgen Inc | Sposób otrzymywania cząsteczek przeciwciał z heterodimerycznymi fc z zastosowaniem kierujących efektów elektrostatycznych |
| JP5608100B2 (ja) | 2008-02-08 | 2014-10-15 | メディミューン,エルエルシー | 低下したFcリガンド親和性を有する抗IFNAR1抗体 |
| KR20220162801A (ko) | 2008-04-11 | 2022-12-08 | 추가이 세이야쿠 가부시키가이샤 | 복수 분자의 항원에 반복 결합하는 항원 결합 분자 |
| CA2740098A1 (en) | 2008-10-10 | 2010-04-15 | Valerie Odegard | Tcr complex immunotherapeutics |
| AR074438A1 (es) | 2008-12-02 | 2011-01-19 | Pf Medicament | Proceso para la modulacion de la actividad antagonista de un anticuerpo monoclonal |
| WO2010064090A1 (en) | 2008-12-02 | 2010-06-10 | Pierre Fabre Medicament | Process for the modulation of the antagonistic activity of a monoclonal antibody |
| CN102272145B (zh) | 2009-01-12 | 2014-07-30 | 通用电气健康护理生物科学股份公司 | 亲和色谱基质 |
| EP2409991B1 (en) | 2009-03-19 | 2017-05-03 | Chugai Seiyaku Kabushiki Kaisha | Antibody constant region variant |
| EP2233500A1 (en) | 2009-03-20 | 2010-09-29 | LFB Biotechnologies | Optimized Fc variants |
| EP2424567B1 (en) | 2009-04-27 | 2018-11-21 | OncoMed Pharmaceuticals, Inc. | Method for making heteromultimeric molecules |
| MX2011014008A (es) | 2009-06-26 | 2012-06-01 | Regeneron Pharma | Anticuerpos biespecificos facilmente aislados con formato de inmunoglobulina original. |
| PE20121647A1 (es) | 2009-08-29 | 2012-12-31 | Abbvie Inc | Proteinas terapeuticas de union a dll4 |
| US10150808B2 (en) | 2009-09-24 | 2018-12-11 | Chugai Seiyaku Kabushiki Kaisha | Modified antibody constant regions |
| SI2522724T1 (sl) | 2009-12-25 | 2020-07-31 | Chuqai Seiyaku Kabushiki Kaisha | Postopek za spremembo polipeptida za čiščenje polipetidnih multimerov |
| EP3112382A1 (en) | 2009-12-29 | 2017-01-04 | Emergent Product Development Seattle, LLC | Heterodimer binding proteins and uses thereof |
| CA2787783A1 (en) | 2010-01-20 | 2011-07-28 | Tolerx, Inc. | Anti-ilt5 antibodies and ilt5-binding antibody fragments |
| JP5947727B2 (ja) | 2010-01-20 | 2016-07-06 | メルク・シャープ・アンド・ドーム・コーポレーションMerck Sharp & Dohme Corp. | 抗ilt5抗体およびilt5結合抗体断片による免疫調節 |
| TWI505838B (zh) | 2010-01-20 | 2015-11-01 | Chugai Pharmaceutical Co Ltd | Stabilized antibody solution containing |
| ES2602971T3 (es) | 2010-03-02 | 2017-02-23 | Kyowa Hakko Kirin Co., Ltd. | Composición de anticuerpo modificado |
| EP2543730B1 (en) | 2010-03-04 | 2018-10-31 | Chugai Seiyaku Kabushiki Kaisha | Antibody constant region variant |
| MX2012010481A (es) | 2010-03-11 | 2012-10-09 | Rinat Neuroscience Corp | Anticuerpos con union de antigenos dependiente del ph. |
| KR20130018256A (ko) | 2010-03-31 | 2013-02-20 | 제이에스알 가부시끼가이샤 | 친화성 크로마토그래피용 충전제 |
| BR112012026766B1 (pt) * | 2010-04-20 | 2021-11-03 | Genmab A/S | Métodos in vitro para gerar um anticorpo igg heterodimérico, para a seleção de um anticorpo biespecífico, vetor de expressão, anticorpo igg heterodimérico, composição farmacêutica, e, uso de um anticorpo igg heterodimérico |
| BR112012027001A2 (pt) | 2010-04-23 | 2016-07-19 | Genentech Inc | produção de proteínas heteromultiméricas |
| CA2797981C (en) | 2010-05-14 | 2019-04-23 | Rinat Neuroscience Corporation | Heterodimeric proteins and methods for producing and purifying them |
| AU2011283694B2 (en) | 2010-07-29 | 2017-04-13 | Xencor, Inc. | Antibodies with modified isoelectric points |
| US20130177555A1 (en) | 2010-08-13 | 2013-07-11 | Medimmune Limited | Monomeric Polypeptides Comprising Variant FC Regions And Methods Of Use |
| CN103429620B (zh) | 2010-11-05 | 2018-03-06 | 酵活有限公司 | 在Fc结构域中具有突变的稳定异源二聚的抗体设计 |
| TWI452136B (zh) | 2010-11-17 | 2014-09-11 | 中外製藥股份有限公司 | A multiple specific antigen-binding molecule that replaces the function of Factor VIII in blood coagulation |
| TWI638833B (zh) | 2010-11-30 | 2018-10-21 | 中外製藥股份有限公司 | 細胞傷害誘導治療劑 |
| CN108285488B (zh) | 2011-03-25 | 2023-01-24 | 伊克诺斯科学公司 | 异二聚体免疫球蛋白 |
| US20140112883A1 (en) | 2011-04-20 | 2014-04-24 | Liquidating Trust | Methods for reducing an adverse immune response to a foreign antigen in a human subject with anti-cd4 antibodies or cd4-binding fragments thereof or cd4-binding molecules |
| US10344050B2 (en) | 2011-10-27 | 2019-07-09 | Genmab A/S | Production of heterodimeric proteins |
| KR102398736B1 (ko) | 2011-10-31 | 2022-05-16 | 추가이 세이야쿠 가부시키가이샤 | 중쇄와 경쇄의 회합이 제어된 항원 결합 분자 |
| KR102052774B1 (ko) | 2011-11-04 | 2019-12-04 | 자임워크스 인코포레이티드 | Fc 도메인 내의 돌연변이를 갖는 안정한 이종이합체 항체 설계 |
| WO2014067011A1 (en) | 2012-11-02 | 2014-05-08 | Zymeworks Inc. | Crystal structures of heterodimeric fc domains |
| GB201203051D0 (en) | 2012-02-22 | 2012-04-04 | Ucb Pharma Sa | Biological products |
| SG11201404481RA (en) | 2012-03-08 | 2014-09-26 | Hoffmann La Roche | Abeta antibody formulation |
| WO2013136186A2 (en) | 2012-03-13 | 2013-09-19 | Novimmune S.A. | Readily isolated bispecific antibodies with native immunoglobulin format |
| EP2832856A4 (en) | 2012-03-29 | 2016-01-27 | Chugai Pharmaceutical Co Ltd | ANTI-LAMP5 ANTIBODIES AND USE THEREOF |
| PT2838917T (pt) | 2012-04-20 | 2019-09-12 | Merus Nv | Métodos e meios para a produção de moléculas similares a ig heterodiméricas |
| RU2673153C2 (ru) | 2012-04-20 | 2018-11-22 | АПТЕВО РИСЁРЧ ЭНД ДИВЕЛОПМЕНТ ЭлЭлСи | Полипептиды, связывающиеся с cd3 |
| US20140154270A1 (en) | 2012-05-21 | 2014-06-05 | Chen Wang | Purification of non-human antibodies using kosmotropic salt enhanced protein a affinity chromatography |
| SG11201407972RA (en) | 2012-06-01 | 2015-01-29 | Us Health | High-affinity monoclonal antibodies to glypican-3 and use thereof |
| AU2013302925B2 (en) | 2012-08-13 | 2018-07-05 | Regeneron Pharmaceuticals, Inc. | Anti-PCSK9 antibodies with pH-dependent binding characteristics |
| DK2900694T3 (en) | 2012-09-27 | 2018-11-19 | Merus Nv | BISPECIFIC IGG ANTIBODIES AS T-CELL ACTIVATORS |
| CN103833852A (zh) | 2012-11-23 | 2014-06-04 | 上海市肿瘤研究所 | 针对磷脂酰肌醇蛋白多糖-3和t细胞抗原的双特异性抗体 |
| CA2904528C (en) | 2013-03-15 | 2021-01-19 | Abbvie Biotherapeutics Inc. | Fc variants |
| CA2922950A1 (en) | 2013-09-30 | 2015-04-02 | Shinya Ishii | Method for producing antigen-binding molecule using modified helper phage |
| NZ720161A (en) | 2013-11-04 | 2022-07-29 | Ichnos Sciences SA | Production of t cell retargeting hetero-dimeric immunoglobulins |
| NZ724710A (en) | 2014-04-07 | 2024-02-23 | Chugai Pharmaceutical Co Ltd | Immunoactivating antigen-binding molecule |
| CN106459954A (zh) | 2014-05-13 | 2017-02-22 | 中外制药株式会社 | 用于具有免疫抑制功能的细胞的t细胞重定向的抗原结合分子 |
| TWI831106B (zh) | 2014-06-20 | 2024-02-01 | 日商中外製藥股份有限公司 | 用於因第viii凝血因子及/或活化的第viii凝血因子的活性降低或欠缺而發病及/或進展的疾病之預防及/或治療之醫藥組成物 |
| AR101262A1 (es) | 2014-07-26 | 2016-12-07 | Regeneron Pharma | Plataforma de purificación para anticuerpos biespecíficos |
| MA40764A (fr) | 2014-09-26 | 2017-08-01 | Chugai Pharmaceutical Co Ltd | Agent thérapeutique induisant une cytotoxicité |
| JP6630036B2 (ja) | 2014-09-30 | 2020-01-15 | Jsr株式会社 | 標的物の精製方法、及び、ミックスモード用担体 |
| JP7082484B2 (ja) | 2015-04-01 | 2022-06-08 | 中外製薬株式会社 | ポリペプチド異種多量体の製造方法 |
| BR112017016952A2 (pt) | 2015-04-17 | 2018-04-03 | F. Hoffmann-La Roche Ag | terapia de combinação com fatores de coagulação e anticorpos multiespecíficos |
| JP2018123055A (ja) | 2015-04-24 | 2018-08-09 | 公立大学法人奈良県立医科大学 | 血液凝固第viii因子(fviii)の機能を代替する多重特異性抗原結合分子を含有する、血液凝固第xi因子(fxi)異常症の予防および/または治療に用いられる医薬組成物 |
| BR112018009312A8 (pt) | 2015-12-28 | 2019-02-26 | Chugai Pharmaceutical Co Ltd | método para promover eficiência de purificação de polipeptídeo contendo região de fc |
| TWI797073B (zh) | 2016-01-25 | 2023-04-01 | 德商安美基研究(慕尼黑)公司 | 包含雙特異性抗體建構物之醫藥組合物 |
| MY196747A (en) | 2016-03-14 | 2023-05-03 | Chugai Pharmaceutical Co Ltd | Cell injury inducing therapeutic drug for use in cancer therapy |
| RU2746754C2 (ru) | 2016-03-14 | 2021-04-20 | Чугаи Сейяку Кабусики Кайся | Индуцирующее повреждение клеток терапевтическое лекарственное средство, предназначенное для противораковой терапии |
| RU2748046C2 (ru) | 2016-04-28 | 2021-05-19 | Чугаи Сейяку Кабусики Кайся | Препарат, содержащий антитело |
| KR20190133230A (ko) | 2017-03-31 | 2019-12-02 | 고리츠다이가쿠호징 나라켕리츠 이카다이가쿠 | 혈액 응고 제viii 인자의 기능을 대체하는 다중 특이성 항원 결합 분자를 함유하는, 혈액 응고 제ix 인자 이상증의 예방 및/또는 치료에 이용되는 의약 조성물 |
-
2016
- 2016-03-31 JP JP2017510171A patent/JP7082484B2/ja active Active
- 2016-03-31 US US15/562,186 patent/US11142587B2/en active Active
- 2016-03-31 EP EP16773093.6A patent/EP3279216A4/en active Pending
- 2016-03-31 WO PCT/JP2016/060616 patent/WO2016159213A1/ja active Application Filing
-
2021
- 2021-02-03 JP JP2021015499A patent/JP2021080260A/ja active Pending
- 2021-09-24 US US17/483,898 patent/US20220010030A1/en active Pending
Patent Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2006106905A1 (ja) * | 2005-03-31 | 2006-10-12 | Chugai Seiyaku Kabushiki Kaisha | 会合制御によるポリペプチド製造方法 |
| JP2010522701A (ja) * | 2007-03-29 | 2010-07-08 | ゲンマブ エー/エス | 二重特異性抗体およびその作製方法 |
| WO2010107109A1 (ja) * | 2009-03-19 | 2010-09-23 | 中外製薬株式会社 | 抗体定常領域改変体 |
| JP2012522527A (ja) * | 2009-04-07 | 2012-09-27 | ロシュ グリクアート アクチェンゲゼルシャフト | 三価の二重特異性抗体 |
| WO2014054804A1 (ja) * | 2012-10-05 | 2014-04-10 | 協和発酵キリン株式会社 | ヘテロダイマータンパク質組成物 |
| WO2015046467A1 (ja) * | 2013-09-27 | 2015-04-02 | 中外製薬株式会社 | ポリペプチド異種多量体の製造方法 |
Non-Patent Citations (6)
| Title |
|---|
| KUNIHIRO HATTORI: "ART-Ig no Gijutsu Shokai to Ketsuyubyo Chiryoyaku eno Oyo", CHUGAI SEIYAKU NI OKERU DOKUJI NO KAKUSHINTEKI KOTAI GIJUTSU, 18 December 2012 (2012-12-18), pages 42 - 57, XP009506602, Retrieved from the Internet <URL:www.chugai-pharm.co.jp/html/meetinq/pdf/121218jPresentation.pdf> [retrieved on 20160615] * |
| LABRIJN AF. ET AL.: "Efficient generation of stable bispecific IgG1 by controlled Fab-arm exchange", PROC NATL ACAD SCI USA, vol. 110, no. 13, 2013, pages 5145 - 5150, XP055201661 * |
| PETERS SJ. ET AL.: "Engineering an Improved IgG4 Molecule with Reduced Disulfide Bond Heterogeneity and Increased Fab Domain Thermal Stability", J BIOL CHEM., vol. 287, no. 29, 2012, pages 24525 - 24533, XP055069090 * |
| RISPENS T. ET AL.: "Dynamics of Inter-heavy Chain Interactions in Human Immunoglobulin G (IgG) Subclasses Studied by Kinetic Fab Arm Exchange", J. BIOL. CHEM., vol. 289, no. 9, 2014, pages 6098 - 6109, XP055125991 * |
| SCHUURMAN J. ET AL.: "The inter-heavy chain disulfide bonds of IgG4 are in equilibrium with intra-chain disulfide bonds", MOLECULAR IMMUNOLOGY, vol. 38, 2001, pages 1 - 8, XP002329378 * |
| See also references of EP3279216A4 * |
Cited By (28)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US11168344B2 (en) | 2005-03-31 | 2021-11-09 | Chugai Seiyaku Kabushiki Kaisha | Methods for producing polypeptides by regulating polypeptide association |
| US10011858B2 (en) | 2005-03-31 | 2018-07-03 | Chugai Seiyaku Kabushiki Kaisha | Methods for producing polypeptides by regulating polypeptide association |
| US11046784B2 (en) | 2006-03-31 | 2021-06-29 | Chugai Seiyaku Kabushiki Kaisha | Methods for controlling blood pharmacokinetics of antibodies |
| US10934344B2 (en) | 2006-03-31 | 2021-03-02 | Chugai Seiyaku Kabushiki Kaisha | Methods of modifying antibodies for purification of bispecific antibodies |
| US11332533B2 (en) | 2007-09-26 | 2022-05-17 | Chugai Seiyaku Kabushiki Kaisha | Modified antibody constant region |
| US11248053B2 (en) | 2007-09-26 | 2022-02-15 | Chugai Seiyaku Kabushiki Kaisha | Method of modifying isoelectric point of antibody via amino acid substitution in CDR |
| US10066018B2 (en) | 2009-03-19 | 2018-09-04 | Chugai Seiyaku Kabushiki Kaisha | Antibody constant region variant |
| US10253091B2 (en) | 2009-03-19 | 2019-04-09 | Chugai Seiyaku Kabushiki Kaisha | Antibody constant region variant |
| US10150808B2 (en) | 2009-09-24 | 2018-12-11 | Chugai Seiyaku Kabushiki Kaisha | Modified antibody constant regions |
| US10435458B2 (en) | 2010-03-04 | 2019-10-08 | Chugai Seiyaku Kabushiki Kaisha | Antibody constant region variants with reduced Fcgammar binding |
| US10450381B2 (en) | 2010-11-17 | 2019-10-22 | Chugai Seiyaku Kabushiki Kaisha | Methods of treatment that include the administration of bispecific antibodies |
| US11851476B2 (en) | 2011-10-31 | 2023-12-26 | Chugai Seiyaku Kabushiki Kaisha | Antigen-binding molecule having regulated conjugation between heavy-chain and light-chain |
| US11124576B2 (en) | 2013-09-27 | 2021-09-21 | Chungai Seiyaku Kabushiki Kaisha | Method for producing polypeptide heteromultimer |
| US9975966B2 (en) | 2014-09-26 | 2018-05-22 | Chugai Seiyaku Kabushiki Kaisha | Cytotoxicity-inducing theraputic agent |
| US11001643B2 (en) | 2014-09-26 | 2021-05-11 | Chugai Seiyaku Kabushiki Kaisha | Cytotoxicity-inducing therapeutic agent |
| US11142587B2 (en) | 2015-04-01 | 2021-10-12 | Chugai Seiyaku Kabushiki Kaisha | Method for producing polypeptide hetero-oligomer |
| US11649262B2 (en) | 2015-12-28 | 2023-05-16 | Chugai Seiyaku Kabushiki Kaisha | Method for promoting efficiency of purification of Fc region-containing polypeptide |
| US11072666B2 (en) | 2016-03-14 | 2021-07-27 | Chugai Seiyaku Kabushiki Kaisha | Cell injury inducing therapeutic drug for use in cancer therapy |
| US11440949B2 (en) | 2016-10-05 | 2022-09-13 | Acceleron Pharma Inc. | TGF-beta superfamily type I and type II receptor heteromultimers and uses thereof |
| EP3586872A4 (en) * | 2017-02-24 | 2020-12-30 | Chugai Seiyaku Kabushiki Kaisha | PHARMACEUTICAL COMPOSITION, ANTIG-BINDING MOLECULES, TREATMENT METHODS AND SCREENING METHODS |
| WO2019131988A1 (en) | 2017-12-28 | 2019-07-04 | Chugai Seiyaku Kabushiki Kaisha | Cytotoxicity-inducing therapeutic agent |
| JPWO2019244973A1 (ja) * | 2018-06-20 | 2021-07-08 | 中外製薬株式会社 | 標的細胞に対する免疫反応を活性化する方法およびその組成物 |
| WO2019244973A1 (ja) * | 2018-06-20 | 2019-12-26 | 中外製薬株式会社 | 標的細胞に対する免疫反応を活性化する方法およびその組成物 |
| JPWO2020067541A1 (ja) * | 2018-09-28 | 2021-08-30 | 協和キリン株式会社 | 抗体組成物 |
| WO2020067541A1 (ja) * | 2018-09-28 | 2020-04-02 | 協和キリン株式会社 | 抗体組成物 |
| WO2021006328A1 (en) | 2019-07-10 | 2021-01-14 | Chugai Seiyaku Kabushiki Kaisha | Claudin-6 binding molecules and uses thereof |
| WO2021201236A1 (ja) * | 2020-04-01 | 2021-10-07 | 協和キリン株式会社 | 抗体組成物 |
| WO2023058705A1 (ja) | 2021-10-08 | 2023-04-13 | 中外製薬株式会社 | 抗hla-dq2.5抗体の製剤 |
Also Published As
| Publication number | Publication date |
|---|---|
| EP3279216A4 (en) | 2019-06-19 |
| EP3279216A1 (en) | 2018-02-07 |
| US20220010030A1 (en) | 2022-01-13 |
| US11142587B2 (en) | 2021-10-12 |
| JP2021080260A (ja) | 2021-05-27 |
| JP7082484B2 (ja) | 2022-06-08 |
| JPWO2016159213A1 (ja) | 2018-02-15 |
| US20180057607A1 (en) | 2018-03-01 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US20220010030A1 (en) | Method for producing polypeptide hetero-oligomer | |
| JP6534615B2 (ja) | ポリペプチド異種多量体の製造方法 | |
| JP7360242B2 (ja) | マウスFcγRII特異的Fc抗体 | |
| JP6348936B2 (ja) | FcγRIIb特異的Fc抗体 | |
| US20200181258A1 (en) | Modified antibody constant region | |
| JP6501521B2 (ja) | FcγRIIb特異的Fc領域改変体 | |
| KR20140069332A (ko) | 항원 제거를 촉진하는 에프씨알엔 결합 도메인을 갖는 치료학적 항원 결합 분자 | |
| TW202323284A (zh) | 免疫靜默Fc變體 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 16773093 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2017510171 Country of ref document: JP Kind code of ref document: A |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 15562186 Country of ref document: US |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| REEP | Request for entry into the european phase |
Ref document number: 2016773093 Country of ref document: EP |