CN111699200B - 针对pd-1的单域抗体和其变体 - Google Patents
针对pd-1的单域抗体和其变体 Download PDFInfo
- Publication number
- CN111699200B CN111699200B CN201980012465.XA CN201980012465A CN111699200B CN 111699200 B CN111699200 B CN 111699200B CN 201980012465 A CN201980012465 A CN 201980012465A CN 111699200 B CN111699200 B CN 111699200B
- Authority
- CN
- China
- Prior art keywords
- amino acid
- seq
- acid sequence
- sdab
- construct
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images































































































































Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2803—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily
- C07K16/2818—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily against CD28 or CD152
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/505—Medicinal preparations containing antigens or antibodies comprising antibodies
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/20—Immunoglobulins specific features characterized by taxonomic origin
- C07K2317/22—Immunoglobulins specific features characterized by taxonomic origin from camelids, e.g. camel, llama or dromedary
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/20—Immunoglobulins specific features characterized by taxonomic origin
- C07K2317/24—Immunoglobulins specific features characterized by taxonomic origin containing regions, domains or residues from different species, e.g. chimeric, humanized or veneered
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/30—Immunoglobulins specific features characterized by aspects of specificity or valency
- C07K2317/31—Immunoglobulins specific features characterized by aspects of specificity or valency multispecific
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/56—Immunoglobulins specific features characterized by immunoglobulin fragments variable (Fv) region, i.e. VH and/or VL
- C07K2317/565—Complementarity determining region [CDR]
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/56—Immunoglobulins specific features characterized by immunoglobulin fragments variable (Fv) region, i.e. VH and/or VL
- C07K2317/567—Framework region [FR]
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/56—Immunoglobulins specific features characterized by immunoglobulin fragments variable (Fv) region, i.e. VH and/or VL
- C07K2317/569—Single domain, e.g. dAb, sdAb, VHH, VNAR or nanobody®
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/76—Antagonist effect on antigen, e.g. neutralization or inhibition of binding
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/90—Immunoglobulins specific features characterized by (pharmaco)kinetic aspects or by stability of the immunoglobulin
- C07K2317/92—Affinity (KD), association rate (Ka), dissociation rate (Kd) or EC50 value
Abstract
提供了包含特异性识别PD‑1的单域抗体(sdAb)部分的构建体。也提供了制备和使用这些构建体的方法。
Description
相关申请的交叉引用
本申请要求于2018年1月15日提交的国际专利申请第PCT/CN2018/072589号的优先权权益,所述专利申请的内容通过引用整体并入本文中。
呈ASCII文本文件形式的序列表的提交
呈ASCII文本文件形式的以下提交内容通过引用整体并入本文中:序列表的计算机可读形式(CRF)(文件名:761422000840SEQLIS T.txt,记录日期:2018年1月14日,大小:271KB)。
技术领域
本发明涉及包含特异性识别PD-1的单域抗体(sdAb)部分的构建体以及其制备和使用方法。
发明背景
主要表达于活化T细胞和B细胞上的免疫抑制性受体,程序性细胞死亡受体1(PD-1;也称为程序性死亡受体1、程序性细胞死亡蛋白1、CD279)是与CD28和细胞毒性T淋巴细胞相关蛋白-4(CTLA-4、CD152)有关的免疫球蛋白超家族成员。PD-1(和相似的家族成员)是I型跨膜糖蛋白,其含有结合其配体的细胞外Ig可变型(V型)域和结合传导分子的胞质尾。PD-1的胞质尾含有两种基于酪氨酸的信号传导基序:ITIM(基于免疫受体酪氨酸的抑制基序)和ITSM(基于免疫受体酪氨酸的转换基序)。
当通过程序性细胞死亡配体1(也称为程序性死亡配体1(PD-L1、CD274、B7-H1))和/或程序性细胞死亡配体2(也称为程序性死亡配体2(PD-L2、CD273、B7-DC))结合时,PD-1减弱T细胞反应。这些配体中的任一者与PD-1的结合转导抑制T细胞增殖、细胞因子产生和细胞溶解功能的信号。阻断PD-L1与PD-1的结合增强了肿瘤特异性CD8+T细胞免疫性,这有助于免疫系统对肿瘤细胞的清除。
抗体介导的PD-1/PD-L1相互作用的阻断已进入治疗难治性实体肿瘤的临床试验中,所述难治性实体肿瘤包括黑色素瘤、肾细胞癌、结肠直肠癌、非小细胞肺癌和血液恶性肿瘤。然而,仍然需要用于治疗、稳定、预防各种癌症和/或延迟其发展的最佳疗法,尤其是鉴于PD-1/PD-L1阻断后的抗性或复发。
本文所提及的所有出版物、专利、专利申请和公开专利申请的公开内容都特此通过引用整体并入本文中。
发明内容
本发明涉及抗PD-1构建体以及其制备和使用方法,所述抗PD-1构建体包含特异性识别PD-1的sdAb部分(下文称为“抗PD-1 sdAb”),例如抗PD-1 sdAb;抗PD-1 HCAb,例如包含融合至人类免疫球蛋白G(IgG)的结晶片段(Fc)片段的抗PD-1 sdAb的抗PD-1 sdAb-Fc融合蛋白;和多特异性(例如双特异性)抗原结合蛋白,其包含融合至例如其它sdAb、全长四链抗体或其抗原结合片段(例如,Fab或scFv)的抗PD-1 sdAb。
本申请的一个方面提供一种分离的抗PD-1构建体,其包含特异性识别PD-1的sdAb部分,其中所述sdAb部分包含:包含SEQ ID NO:37-72中的任一者的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:109-144中的任一者的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:181-216中的任一者的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,分离的抗PD-1构建体包含特异性识别PD-1的sdAb部分,其中所述sdAb部分包含:包含SEQ ID NO:37-72中的任一者的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:109-144中的任一者的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:181-216中的任一者的氨基酸序列的CDR3。在一些实施方案中,特异性识别PD-1的sdAb部分包含:包含SEQ ID NO:37-72中的任一者的氨基酸序列的CDR1;包含SEQ ID NO:109-144中的任一者的氨基酸序列的CDR2;和包含SEQ ID NO:181-216中的任一者的氨基酸序列的CDR3;或所述CDR的在CDR区中包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,氨基酸取代在CDR1和/或CDR2中,其中CDR3包含SEQID NO:181-216中的任一者的氨基酸序列。在一些实施方案中,特异性识别PD-1的sdAb部分包含:包含SEQ ID NO:37-72中的任一者的氨基酸序列的CDR1;包含SEQ ID NO:109-144中的任一者的氨基酸序列的CDR2;和包含SEQ ID NO:181-216中的任一者的氨基酸序列的CDR3。
在根据上述任一种分离的抗PD-1构建体的一些实施方案中,特异性识别PD-1的sdAb部分包括以下中的任一者:
(1)包含SEQ ID NO:37的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:109的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:181的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;
(2)包含SEQ ID NO:38的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:110的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:182的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;
(3)包含SEQ ID NO:39的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:111的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:183的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;
(4)包含SEQ ID NO:40的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:112的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:184的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;
(5)包含SEQ ID NO:41的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:113的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:185的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;
(6)包含SEQ ID NO:42的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:114的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:186的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;
(7)包含SEQ ID NO:43的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:115的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:187的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;
(8)包含SEQ ID NO:44的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:116的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:188的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;
(9)包含SEQ ID NO:45的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:117的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:189的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;
(10)包含SEQ ID NO:46的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:118的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:190的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;
(11)包含SEQ ID NO:47的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:119的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:191的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;
(12)包含SEQ ID NO:48的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:120的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:192的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;
(13)包含SEQ ID NO:49的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:121的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:193的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;
(14)包含SEQ ID NO:50的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:122的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:194的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;
(15)包含SEQ ID NO:51的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:123的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:195的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;
(16)包含SEQ ID NO:52的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:124的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:196的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;
(17)包含SEQ ID NO:53的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:125的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:197的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;
(18)包含SEQ ID NO:54的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:126的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:198的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;
(19)包含SEQ ID NO:55的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:127的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:199的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;
(20)包含SEQ ID NO:56的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:128的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:200的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;
(21)包含SEQ ID NO:57的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:129的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:201的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;
(22)包含SEQ ID NO:58的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:130的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:202的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;
(23)包含SEQ ID NO:59的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:131的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:203的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;
(24)包含SEQ ID NO:60的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:132的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:204的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;
(25)包含SEQ ID NO:61的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:133的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:205的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;
(26)包含SEQ ID NO:62的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:134的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:206的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;
(27)包含SEQ ID NO:63的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:135的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:207的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;
(28)包含SEQ ID NO:64的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:136的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:208的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;
(29)包含SEQ ID NO:65的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:137的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:209的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;
(30)包含SEQ ID NO:66的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:138的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:210的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;
(31)包含SEQ ID NO:67的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:139的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:211的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;
(32)包含SEQ ID NO:68的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:140的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:212的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;
(33)包含SEQ ID NO:69的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:141的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:213的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;
(34)包含SEQ ID NO:70的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:142的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:214的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;
(35)包含SEQ ID NO:71的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:143的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:215的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;或
(35)包含SEQ ID NO:72的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:144的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:216的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。
在根据上述任一种分离的抗PD-1构建体的一些实施方案中,特异性识别PD-1的sdAb部分包括以下中的任一者:
(1)包含SEQ ID NO:37的氨基酸序列的CDR1;包含SEQ ID NO:109的氨基酸序列的CDR2;和包含SEQ ID NO:181的氨基酸序列的CDR3;或所述CDR的在CDR区中包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;
(2)包含SEQ ID NO:38的氨基酸序列的CDR1;包含SEQ ID NO:110的氨基酸序列的CDR2;和包含SEQ ID NO:182的氨基酸序列的CDR3;或所述CDR的在CDR区中包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;
(3)包含SEQ ID NO:39的氨基酸序列的CDR1;包含SEQ ID NO:111的氨基酸序列的CDR2;和包含SEQ ID NO:183的氨基酸序列的CDR3;或所述CDR的在CDR区中包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;
(4)包含SEQ ID NO:40的氨基酸序列的CDR1;包含SEQ ID NO:112的氨基酸序列的CDR2;和包含SEQ ID NO:184的氨基酸序列的CDR3;或所述CDR的在CDR区中包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;
(5)包含SEQ ID NO:41的氨基酸序列的CDR1;包含SEQ ID NO:113的氨基酸序列的CDR2;和包含SEQ ID NO:185的氨基酸序列的CDR3;或所述CDR的在CDR区中包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;
(6)包含SEQ ID NO:42的氨基酸序列的CDR1;包含SEQ ID NO:114的氨基酸序列的CDR2;和包含SEQ ID NO:186的氨基酸序列的CDR3;或所述CDR的在CDR区中包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;
(7)包含SEQ ID NO:43的氨基酸序列的CDR1;包含SEQ ID NO:115的氨基酸序列的CDR2;和包含SEQ ID NO:187的氨基酸序列的CDR3;或所述CDR的在CDR区中包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;
(8)包含SEQ ID NO:44的氨基酸序列的CDR1;包含SEQ ID NO:116的氨基酸序列的CDR2;和包含SEQ ID NO:188的氨基酸序列的CDR3;或所述CDR的在CDR区中包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;
(9)包含SEQ ID NO:45的氨基酸序列的CDR1;包含SEQ ID NO:117的氨基酸序列的CDR2;和包含SEQ ID NO:189的氨基酸序列的CDR3;或所述CDR的在CDR区中包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;
(10)包含SEQ ID NO:46的氨基酸序列的CDR1;包含SEQ ID NO:118的氨基酸序列的CDR2;和包含SEQ ID NO:190的氨基酸序列的CDR3;或所述CDR的在CDR区中包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;
(11)包含SEQ ID NO:47的氨基酸序列的CDR1;包含SEQ ID NO:119的氨基酸序列的CDR2;和包含SEQ ID NO:191的氨基酸序列的CDR3;或所述CDR的在CDR区中包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;
(12)包含SEQ ID NO:48的氨基酸序列的CDR1;包含SEQ ID NO:120的氨基酸序列的CDR2;和包含SEQ ID NO:192的氨基酸序列的CDR3;或所述CDR的在CDR区中包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;
(13)包含SEQ ID NO:49的氨基酸序列的CDR1;包含SEQ ID NO:121的氨基酸序列的CDR2;和包含SEQ ID NO:193的氨基酸序列的CDR3;或所述CDR的在CDR区中包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;
(14)包含SEQ ID NO:50的氨基酸序列的CDR1;包含SEQ ID NO:122的氨基酸序列的CDR2;和包含SEQ ID NO:194的氨基酸序列的CDR3;或所述CDR的在CDR区中包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;
(15)包含SEQ ID NO:51的氨基酸序列的CDR1;包含SEQ ID NO:123的氨基酸序列的CDR2;和包含SEQ ID NO:195的氨基酸序列的CDR3;或所述CDR的在CDR区中包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;
(16)包含SEQ ID NO:52的氨基酸序列的CDR1;包含SEQ ID NO:124的氨基酸序列的CDR2;和包含SEQ ID NO:196的氨基酸序列的CDR3;或所述CDR的在CDR区中包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;
(17)包含SEQ ID NO:53的氨基酸序列的CDR1;包含SEQ ID NO:125的氨基酸序列的CDR2;和包含SEQ ID NO:197的氨基酸序列的CDR3;或所述CDR的在CDR区中包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;
(18)包含SEQ ID NO:54的氨基酸序列的CDR1;包含SEQ ID NO:126的氨基酸序列的CDR2;和包含SEQ ID NO:198的氨基酸序列的CDR3;或所述CDR的在CDR区中包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;
(19)包含SEQ ID NO:55的氨基酸序列的CDR1;包含SEQ ID NO:127的氨基酸序列的CDR2;和包含SEQ ID NO:199的氨基酸序列的CDR3;或所述CDR的在CDR区中包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;
(20)包含SEQ ID NO:56的氨基酸序列的CDR1;包含SEQ ID NO:128的氨基酸序列的CDR2;和包含SEQ ID NO:200的氨基酸序列的CDR3;或所述CDR的在CDR区中包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;
(21)包含SEQ ID NO:57的氨基酸序列的CDR1;包含SEQ ID NO:129的氨基酸序列的CDR2;和包含SEQ ID NO:201的氨基酸序列的CDR3;或所述CDR的在CDR区中包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;
(22)包含SEQ ID NO:58的氨基酸序列的CDR1;包含SEQ ID NO:130的氨基酸序列的CDR2;和包含SEQ ID NO:202的氨基酸序列的CDR3;或所述CDR的在CDR区中包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;
(23)包含SEQ ID NO:59的氨基酸序列的CDR1;包含SEQ ID NO:131的氨基酸序列的CDR2;和包含SEQ ID NO:203的氨基酸序列的CDR3;或所述CDR的在CDR区中包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;
(24)包含SEQ ID NO:60的氨基酸序列的CDR1;包含SEQ ID NO:132的氨基酸序列的CDR2;和包含SEQ ID NO:204的氨基酸序列的CDR3;或所述CDR的在CDR区中包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;
(25)包含SEQ ID NO:61的氨基酸序列的CDR1;包含SEQ ID NO:133的氨基酸序列的CDR2;和包含SEQ ID NO:205的氨基酸序列的CDR3;或所述CDR的在CDR区中包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;
(26)包含SEQ ID NO:62的氨基酸序列的CDR1;包含SEQ ID NO:134的氨基酸序列的CDR2;和包含SEQ ID NO:206的氨基酸序列的CDR3;或所述CDR的在CDR区中包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;
(27)包含SEQ ID NO:63的氨基酸序列的CDR1;包含SEQ ID NO:135的氨基酸序列的CDR2;和包含SEQ ID NO:207的氨基酸序列的CDR3;或所述CDR的在CDR区中包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;
(28)包含SEQ ID NO:64的氨基酸序列的CDR1;包含SEQ ID NO:136的氨基酸序列的CDR2;和包含SEQ ID NO:208的氨基酸序列的CDR3;或所述CDR的在CDR区中包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;
(29)包含SEQ ID NO:65的氨基酸序列的CDR1;包含SEQ ID NO:137的氨基酸序列的CDR2;和包含SEQ ID NO:209的氨基酸序列的CDR3;或所述CDR的在CDR区中包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;
(30)包含SEQ ID NO:66的氨基酸序列的CDR1;包含SEQ ID NO:138的氨基酸序列的CDR2;和包含SEQ ID NO:210的氨基酸序列的CDR3;或所述CDR的在CDR区中包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;
(31)包含SEQ ID NO:67的氨基酸序列的CDR1;包含SEQ ID NO:139的氨基酸序列的CDR2;和包含SEQ ID NO:211的氨基酸序列的CDR3;或所述CDR的在CDR区中包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;
(32)包含SEQ ID NO:68的氨基酸序列的CDR1;包含SEQ ID NO:140的氨基酸序列的CDR2;和包含SEQ ID NO:212的氨基酸序列的CDR3;或所述CDR的在CDR区中包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;
(33)包含SEQ ID NO:69的氨基酸序列的CDR1;包含SEQ ID NO:141的氨基酸序列的CDR2;和包含SEQ ID NO:213的氨基酸序列的CDR3;或所述CDR的在CDR区中包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;
(34)包含SEQ ID NO:70的氨基酸序列的CDR1;包含SEQ ID NO:142的氨基酸序列的CDR2;和包含SEQ ID NO:214的氨基酸序列的CDR3;或所述CDR的在CDR区中包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;
(35)包含SEQ ID NO:71的氨基酸序列的CDR1;包含SEQ ID NO:143的氨基酸序列的CDR2;和包含SEQ ID NO:215的氨基酸序列的CDR3;或所述CDR的在CDR区中包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;或
(36)包含SEQ ID NO:72的氨基酸序列的CDR1;包含SEQ ID NO:144的氨基酸序列的CDR2;和包含SEQ ID NO:216的氨基酸序列的CDR3;或所述CDR的在CDR区中包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。
在根据上述任一种分离的抗PD-1构建体的一些实施方案中,特异性识别PD-1的sdAb部分包含VHH域,所述VHH域包含以下中的任一者的氨基酸序列:a-1)在位置37处的氨基酸残基选自由以下组成的组:F、Y、L、I和V(例如F、Y或V,或例如F);a-2)在位置44处的氨基酸残基选自由以下组成的组:A、G、E、D、G、Q、R、S和L(例如E、Q或G,或例如E);a-3)在位置45处的氨基酸残基选自由以下组成的组:L、R和C(例如L或R);a-4)在位置103处的氨基酸残基选自由以下组成的组:W、R、G和S(例如W、G或R,或例如W);并且a-5)在位置108处的氨基酸残基是Q;或b-1)在位置37处的氨基酸残基选自由以下组成的组:F、Y、L、I和V(例如F、V或Y,或例如F);b-2)在位置44处的氨基酸残基选自由以下组成的组:E、Q和G;b-3)在位置45处的氨基酸残基是R;b-4)在位置103处的氨基酸残基选自由以下组成的组:W、R和S(例如W);并且b-5)在位置108处的氨基酸残基选自由以下组成的组:Q和L(例如Q);其中所述氨基酸位置是根据Kabat编号,并且其中当位置108是Q时,位置108可任选地被人源化为L。
在根据上述任一种分离的抗PD-1构建体的一些实施方案中,特异性识别PD-1的sdAb部分包含VHH域,所述VHH域包含SEQ ID NO:289-324中的任一者的氨基酸序列,或其与SEQ ID NO:289-324中的任一者具有至少约80%(例如至少约80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%中的任一者)序列同一性的变体。在一些实施方案中,特异性识别PD-1的sdAb部分包含VHH域,所述VHH域包含SEQ ID NO:289-324中的任一者的氨基酸序列,或其在VHH域中包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,氨基酸取代在CDR中,例如SEQ ID NO:289-324中的任一者的CDR1和/或CDR2和/或CDR3。在一些实施方案中,氨基酸取代在FR中,例如SEQ ID NO:289-324中的任一者的FR1和/或FR2和/或FR3和/或FR4。在一些实施方案中,氨基酸取代在CDR和FR两者中。在一些实施方案中,特异性识别PD-1的sdAb部分包含VHH域,所述VHH域包含SEQID NO:289-324中的任一者的氨基酸序列。
在根据上述任一种分离的抗PD-1构建体的一些实施方案中,特异性识别PD-1的sdAb部分与PD-1之间的结合的Kd是约10-5M至约10-12M(例如约10-5M至约10-12M、约10-7M至约10-12M、或约10-8M至约10-12M)。
在根据上述任一种分离的抗PD-1构建体的一些实施方案中,特异性识别PD-1的sdAb部分是骆驼科的、嵌合的、人类的、部分人源化的或完全人源化的sdAb部分。
在根据上述任一种分离的抗PD-1构建体的一些实施方案中,分离的抗PD-1构建体是仅重链抗体(HCAb),其包含经由任选的接头融合至Fc片段的特异性识别PD-1的sdAb部分。在一些实施方案中,HCAb是单体HCAb。在一些实施方案中,HCAb是二聚HCAb。在一些实施方案中,Fc片段是人类IgG1(hIgG1)Fc、无效应子(惰性)hIgG1 Fc、hIgG4 Fc或hIgG4 Fc(S228P)。在一些实施方案中,Fc片段包含SEQ ID NO:363-365中的任一者的氨基酸序列。在一些实施方案中,Fc片段是hIgG4 Fc(S228P)。在一些实施方案中,任选的接头包含SEQ IDNO:367-376中的任一者的氨基酸序列。在一些实施方案中,HCAb包含SEQ ID NO:325-360中的任一者的氨基酸序列。
在根据上述任一种分离的抗PD-1构建体的一些实施方案中,分离的抗PD-1构建体还包含特异性识别第二表位的第二抗体部分。在一些实施方案中,第二抗体部分是全长抗体、Fab、Fab'、(Fab')2、Fv、单链Fv(scFv)、scFv-scFv、微型抗体、双功能抗体或sdAb。在一些实施方案中,抗PD-1构建体具有单特异性。在一些实施方案中,抗PD-1构建体具有多特异性(例如双特异性)。在一些实施方案中,第二表位不来自PD-1。在一些实施方案中,第二表位来自PD-1但不同于与抗PD-1 sdAb部分特异性识别者。在一些实施方案中,第二表位与抗PD-1 sdAb部分特异性识别者相同。在一些实施方案中,特异性识别PD-1的sdAb部分和第二抗体部分任选地通过肽接头连接,例如包含SEQ ID NO:367-376中的任一者的氨基酸序列的肽接头。在一些实施方案中,第二抗体部分是sdAb,例如特异性识别PD-1或CTLA-4的sdAb。在一些实施方案中,第二抗体部分是Fab。在一些实施方案中,第二抗体部分是scFv。在一些实施方案中,第二抗体部分是由两条重链和两条轻链组成的全长抗体。在一些实施方案中,重链的Fc片段是IgG1 Fc、无效应子IgG1 Fc、IgG2 Fc、IgG4 Fc或IgG4 Fc(S228P),例如SEQ ID NO:363-365中的任一者。在一些实施方案中,特异性识别PD-1的sdAb部分的N末端融合至全长抗体的重链的至少一者的C末端。在一些实施方案中,特异性识别PD-1的sdAb部分的C末端融合至全长抗体的重链的至少一者的N末端。在一些实施方案中,特异性识别PD-1的sdAb部分的N末端融合至全长抗体的轻链的至少一者的C末端。在一些实施方案中,特异性识别PD-1的sdAb部分的C末端融合至全长抗体的轻链的至少一者的N末端。在一些实施方案中,分离的抗PD-1构建体包含四个相同的如上文所述的特异性识别PD-1的sdAb部分,每个抗PD-1 sdAb部分的C末端经由任选的肽接头融合至全长抗体的每条链的N末端。在一些实施方案中,分离的抗PD-1构建体包含四个相同的如上文所述的特异性识别PD-1的sdAb部分,两个抗PD-1 sdAb部分经由任选的肽接头彼此融合,其它两个抗PD-1 sdAb部分经由任选的肽接头彼此融合,并且每个抗PD-1 sdAb部分融合多肽的C末端经由任选的肽接头融合至全长抗体的每条重链的N末端。在一些实施方案中,分离的抗PD-1构建体由四条多肽链组成,其结构从N末端至C末端如下:(1)VL-CL;(2)抗PD-1 sdAb-VH-CH1-CH2-CH3;(3)抗PD-1 sdAb-VH-CH1-CH2-CH3;和(4)VL-CL,其中多肽链(1)和(2)的VH和VL形成特异性结合第二表位(例如,TIGIT、LAG-3、TIM-3、CTLA-4、PD-1(例如与本文所述的抗PD-1 sdAb部分识别者不同的第二PD-1表位))的第一拷贝的抗原结合位点,多肽链(3)和(4)的VH和VL形成特异性结合第二表位(例如,TIGIT、LAG-3、TIM-3、CTLA-4、PD-1(例如与本文所述的抗PD-1 sdAb部分识别者不同的第二PD-1表位))的第二拷贝的抗原结合位点,并且每个抗PD-1 sdAb特异性结合PD-1的拷贝。在一些实施方案中,分离的抗PD-1构建体由四条多肽链组成,其结构从N末端至C末端如下:(1)VL-CL;(2)VH-CH1-CH2-CH3-抗PD-1 sdAb;(3)VH-CH1-CH2-CH3-抗PD-1sdAb;和(4)VL-CL,其中多肽链(1)和(2)的VH和VL形成特异性结合第二表位(例如,TIGIT、LAG-3、TIM-3、CTLA-4、PD-1(例如与本文所述的抗PD-1 sdAb部分识别者不同的第二PD-1表位))的第一拷贝的抗原结合位点,多肽链(3)和(4)的VH和VL形成特异性结合第二表位(例如,TIGIT、LAG-3、TIM-3、CTLA-4、PD-1(例如与本文所述的抗PD-1 sdAb部分识别者不同的第二PD-1表位))的第二拷贝的抗原结合位点,并且每个抗PD-1 sdAb特异性结合PD-1的拷贝。在一些实施方案中,分离的抗PD-1构建体由四条多肽链组成,其结构从N末端至C末端如下:(1)抗PD-1 sdAb-VL-CL;(2)VH-CH1-CH2-CH3;(3)VH-CH1-CH2-CH3;和(4)抗PD-1 sdAb-VL-CL,其中多肽链(1)和(2)的VH和VL形成特异性结合第二表位(例如,TIGIT、LAG-3、TIM-3、CTLA-4、PD-1(例如与本文所述的抗PD-1 sdAb部分识别者不同的第二PD-1表位))的第一拷贝的抗原结合位点,多肽链(3)和(4)的VH和VL形成特异性结合第二表位(例如,TIGIT、LAG-3、TIM-3、CTLA-4、PD-1(例如与本文所述的抗PD-1 sdAb部分识别者不同的第二PD-1表位))的第二拷贝的抗原结合位点,并且每个抗PD-1 sdAb特异性结合PD-1的拷贝。在一些实施方案中,分离的抗PD-1构建体由四条多肽链组成,其结构从N末端至C末端如下:(1)VL-CL-抗PD-1 sdAb;(2)VH-CH1-CH2-CH3;(3)VH-CH1-CH2-CH3;和(4)VL-CL-抗PD-1 sdAb,其中多肽链(1)和(2)的VH和VL形成特异性结合第二表位(例如,TIGIT、LAG-3、TIM-3、CTLA-4、PD-1(例如与本文所述的抗PD-1 sdAb部分识别者不同的第二PD-1表位))的第一拷贝的抗原结合位点,多肽链(3)和(4)的VH和VL形成特异性结合第二表位(例如,TIGIT、LAG-3、TIM-3、CTLA-4、PD-1(例如与本文所述的抗PD-1 sdAb部分识别者不同的第二PD-1表位))的第二拷贝的抗原结合位点,并且每个抗PD-1 sdAb特异性结合PD-1的拷贝。在一些实施方案中,分离的抗PD-1构建体由四条多肽链组成,其结构从N末端至C末端如下:(1)抗PD-1 sdAb-VL-CL;(2)抗PD-1 sdAb-VH-CH1-CH2-CH3;(3)抗PD-1 sdAb-VH-CH1-CH2-CH3;和(4)抗PD-1 sdAb-VL-CL,其中多肽链(1)和(2)的VH和VL形成特异性结合第二表位(例如,TIGIT、LAG-3、TIM-3、CTLA-4、PD-1(例如与本文所述的抗PD-1 sdAb部分识别者不同的第二PD-1表位))的第一拷贝的抗原结合位点,多肽链(3)和(4)的VH和VL形成特异性结合第二表位(例如,TIGIT、LAG-3、TIM-3、CTLA-4、PD-1(例如与本文所述的抗PD-1 sdAb部分识别者不同的第二PD-1表位))的第二拷贝的抗原结合位点,并且每个抗PD-1 sdAb特异性结合PD-1的拷贝。在一些实施方案中,分离的抗PD-1构建体由四条多肽链组成,其结构从N末端至C末端如下:(1)VL-CL;(2)抗PD-1sdAb-抗PD-1 sdAb-VH-CH1-CH2-CH3;(3)抗PD-1 sdAb-抗PD-1 sdAb-VH-CH1-CH2-CH3;和(4)VL-CL,其中多肽链(1)和(2)的VH和VL形成特异性结合第二表位(例如,TIGIT、LAG-3、TIM-3、CTLA-4、PD-1(例如与本文所述的抗PD-1 sdAb部分识别者不同的第二PD-1表位))的第一拷贝的抗原结合位点,多肽链(3)和(4)的VH和VL形成特异性结合第二表位(例如,TIGIT、LAG-3、TIM-3、CTLA-4、PD-1(例如与本文所述的抗PD-1 sdAb部分识别者不同的第二PD-1表位))的第二拷贝的抗原结合位点,并且每个抗PD-1 sdAb特异性结合PD-1的拷贝。在一些实施方案中,分离的抗PD-1构建体由四条多肽链组成,其结构从N末端至C末端如下:(1)VL-CL;(2)VH-CH1-抗PD-1 sdAb-CH2-CH3;(3)VH-CH1-抗PD-1 sdAb-CH2-CH3;和(4)VL-CL,其中多肽链(1)和(2)的VH和VL形成特异性结合第二表位(例如,TIGIT、LAG-3、TIM-3、CTLA-4、PD-1(例如与本文所述的抗PD-1 sdAb部分识别者不同的第二PD-1表位))的第一拷贝的抗原结合位点,多肽链(3)和(4)的VH和VL形成特异性结合第二表位(例如,TIGIT、LAG-3、TIM-3、CTLA-4、PD-1(例如与本文所述的抗PD-1 sdAb部分识别者不同的第二PD-1表位))的第二拷贝的抗原结合位点,并且每个抗PD-1 sdAb特异性结合PD-1的拷贝。在一些实施方案中,分离的抗PD-1构建体由两条多肽链组成,其各自结构从N末端至C末端如下:VL-VH-抗PD-1 sdAb-CH2-CH3,其中每条多肽链的VH和VL形成特异性结合第二表位(例如,TIGIT、LAG-3、TIM-3、CTLA-4、PD-1(例如与本文所述的抗PD-1sdAb部分识别者不同的第二PD-1表位))的拷贝的scFv域,并且每个抗PD-1 sdAb特异性结合PD-1的拷贝。在一些实施方案中,分离的抗PD-1构建体由四条多肽链组成,其结构从N末端至C末端如下:(1)VL-CL-抗PD-1 sdAb-CL;(2)VH-CH1-抗PD-1 sdAb-CH1-CH2-CH3;(3)VH-CH1-抗PD-1 sdAb-CH1-CH2-CH3;和(4)VL-CL-抗PD-1sdAb-CL,其中多肽链(1)和(2)的VH和VL形成特异性结合第二表位(例如,TIGIT、LAG-3、TIM-3、CTLA-4、PD-1(例如与本文所述的抗PD-1 sdAb部分识别者不同的第二PD-1表位))的第一拷贝的抗原结合位点,多肽链(3)和(4)的VH和VL形成特异性结合第二表位(例如,TIGIT、LAG-3、TIM-3、CTLA-4、PD-1(例如与本文所述的抗PD-1 sdAb部分识别者不同的第二PD-1表位))的第二拷贝的抗原结合位点,并且每个抗PD-1 sdAb特异性结合PD-1的拷贝。在一些实施方案中,分离的抗PD-1构建体由四条多肽链组成,其结构从N末端至C末端如下:(1)抗PD-1 sdAb-CL;(2)VL-VH-抗PD-1 sdAb-CH1-CH2-CH3;(3)VL-VH-抗PD-1 sdAb-CH1-CH2-CH3;和(4)抗PD-1 sdAb-CL,其中多肽链(2)和(3)的VH和VL各自形成特异性结合第二表位(例如,TIGIT、LAG-3、TIM-3、CTLA-4、PD-1(例如与本文所述的抗PD-1 sdAb部分识别者不同的第二PD-1表位))的拷贝的scFv,并且每个抗PD-1 sdAb特异性结合PD-1的拷贝。在一些实施方案中,全长抗体(或包含VH和VL的抗原结合部分)特异性识别TIGIT。在一些实施方案中,抗TIGIT全长抗体(或包含VH和VL的抗原结合部分)包含:VH,所述VH包括包含SEQ ID NO:377的氨基酸序列的重链的HC-CDR1、HC-CDR2和HC-CDR3;和VL,所述VL包括包含SEQ ID NO:378的氨基酸序列的轻链的LC-CDR1、LC-CDR2和LC-CDR3。在一些实施方案中,抗TIGIT全长抗体包括包含SEQ ID NO:377的氨基酸序列的重链和包含SEQ ID NO:378的氨基酸序列的轻链。在一些实施方案中,特异性识别TIGIT的全长抗体(或包含VH和VL的抗原结合部分)衍生自替拉古单抗(tiragolumab)。在一些实施方案中,全长抗体(或包含VH和VL的抗原结合部分)特异性识别LAG-3。在一些实施方案中,抗LAG-3全长抗体(或包含VH和VL的抗原结合部分)包含:VH,所述VH包括包含SEQ ID NO:379的氨基酸序列的重链的HC-CDR1、HC-CDR2和HC-CDR3;和VL,所述VL包括包含SEQ ID NO:380的氨基酸序列的轻链的LC-CDR1、LC-CDR2和LC-CDR3。在一些实施方案中,抗LAG-3全长抗体包括包含SEQ ID NO:379的氨基酸序列的重链和包含SEQ ID NO:380的氨基酸序列的轻链。在一些实施方案中,特异性识别LAG-3的全长抗体(或包含VH和VL的抗原结合部分)衍生自瑞拉里单抗(relatlimab)。在一些实施方案中,全长抗体(或包含VH和VL的抗原结合部分)特异性识别TIM-3。在一些实施方案中,抗TIM-3全长抗体(或包含VH和VL的抗原结合部分)包含:VH,所述VH包括包含SEQ ID NO:381的氨基酸序列的重链的HC-CDR1、HC-CDR2和HC-CDR3;和VL,所述VL包括包含SEQ ID NO:382的氨基酸序列的轻链的LC-CDR1、LC-CDR2和LC-CDR3。在一些实施方案中,抗TIM-3全长抗体包括包含SEQ IDNO:381的氨基酸序列的重链和包含SEQ ID NO:382的氨基酸序列的轻链。在一些实施方案中,特异性识别TIM-3的全长抗体(或包含VH和VL的抗原结合部分)衍生自MBG453。在一些实施方案中,全长抗体(或包含VH和VL的抗原结合部分)特异性识别CTLA-4。在一些实施方案中,抗CTLA-4全长抗体(或包含VH和VL的抗原结合部分)包含:VH,所述VH包括包含SEQ IDNO:383的氨基酸序列的重链的HC-CDR1、HC-CDR2和HC-CDR3;和VL,所述VL包括包含SEQ IDNO:384的氨基酸序列的轻链的LC-CDR1、LC-CDR2和LC-CDR3。在一些实施方案中,抗CTLA-4全长抗体包括包含SEQ ID NO:383的氨基酸序列的重链和包含SEQ ID NO:384的氨基酸序列的轻链。在一些实施方案中,特异性识别CTLA-4的全长抗体(或包含VH和VL的抗原结合部分)衍生自伊匹单抗(Ipilimumab)(例如, )。在一些实施方案中,全长抗体(或包含VH和VL的抗原结合部分)特异性识别PD-1(例如与本文所述的抗PD-1 sdAb部分识别者不同的第二PD-1表位)。在一些实施方案中,抗PD-1全长抗体(或包含VH和VL的抗原结合部分)包含:VH,所述VH包括包含SEQ ID NO:385的氨基酸序列的重链的HC-CDR1、HC-CDR2和HC-CDR3;和VL,所述VL包括包含SEQ ID NO:386的氨基酸序列的轻链的LC-CDR1、LC-CDR2和LC-CDR3。在一些实施方案中,抗PD-1全长抗体包括包含SEQ ID NO:385的氨基酸序列的重链和包含SEQ ID NO:386的氨基酸序列的轻链。在一些实施方案中,特异性识别PD-1的全长抗体(或包含VH和VL的抗原结合部分)衍生自派姆单抗(Pembrolizumab)(例如,/>
)。在一些实施方案中,全长抗体(或包含VH和VL的抗原结合部分)特异性识别PD-1(例如与本文所述的抗PD-1 sdAb部分识别者不同的第二PD-1表位)。在一些实施方案中,抗PD-1全长抗体(或包含VH和VL的抗原结合部分)包含:VH,所述VH包括包含SEQ ID NO:385的氨基酸序列的重链的HC-CDR1、HC-CDR2和HC-CDR3;和VL,所述VL包括包含SEQ ID NO:386的氨基酸序列的轻链的LC-CDR1、LC-CDR2和LC-CDR3。在一些实施方案中,抗PD-1全长抗体包括包含SEQ ID NO:385的氨基酸序列的重链和包含SEQ ID NO:386的氨基酸序列的轻链。在一些实施方案中,特异性识别PD-1的全长抗体(或包含VH和VL的抗原结合部分)衍生自派姆单抗(Pembrolizumab)(例如,/> )或纳武单抗(nivolumab)(例如,/>
)或纳武单抗(nivolumab)(例如,/> )。/>
)。/>
在根据上述任一种分离的抗PD-1构建体的一些实施方案中,分离的抗PD-1构建体还包含生物活性蛋白或其片段。
还提供了一种分离的抗PD-1构建体,所述分离的抗PD-1构建体包含特异性识别PD-1的sdAb部分,其中所述sdAb部分包含SEQ ID NO:289-324中的任一者的CDR1、CDR2和CDR3。
还提供了一种分离的抗PD-1构建体(例如,抗PD-1 sdAb、抗PD-1 HCAb(例如,抗PD-1 sdAb-Fc融合物)、PD-1×TIGIT BABP、PD-1×LAG-3 BABP、PD-1×TIM-3 BABP、PD-1×CTLA-4 BABP或PD-1×PD-1 BABP),所述分离的抗PD-1构建体与上述分离的抗PD-1构建体竞争性地特异性结合PD-1。
还提供了一种药物组合物,所述药物组合物包含上述任一种分离的抗PD-1构建体和任选地药学上可接受的载体。
本申请的另一方面提供一种治疗具有PD-1相关疾病(例如癌症或免疫相关疾病)的个体的方法,所述方法包括向所述个体施用有效量的上述任一种药物组合物。在一些实施方案中,所述PD-1相关疾病是癌症。在一些实施方案中,所述癌症是实体肿瘤,例如结肠癌。在一些实施方案中,所述PD-1相关疾病是免疫相关疾病。在一些实施方案中,所述免疫相关疾病与T细胞功能障碍病症相关。在一些实施方案中,所述T细胞功能障碍病症的特征在于T细胞无反应(anergy)或分泌细胞因子、增殖或执行细胞溶解活性的能力降低。在一些实施方案中,所述T细胞功能障碍病症的特征在于T细胞耗竭(exhaustion)。在一些实施方案中,所述免疫相关疾病选自由以下组成的组:未解决的急性感染、慢性感染和肿瘤免疫性。在一些实施方案中,所述PD-1相关疾病是病原性感染。在一些实施方案中,所述方法还包括向所述个体施用另外的疗法(例如,癌症疗法),例如手术、放射、化学疗法、免疫疗法、激素疗法或其组合。在一些实施方案中,所述另外的疗法是免疫疗法。在一些实施方案中,所述免疫疗法包括向所述个体施用有效量的第二药物组合物,所述药物组合物包含免疫调节剂,例如免疫检查点抑制剂(例如,特异性识别TIGIT、LAG-3、TIM-3、CTLA-4、PD-1或PD-L1的抗体)。在一些实施方案中,全身(例如静脉内(i.v.)或腹膜内(i.p.))施用所述药物组合物。在一些实施方案中,局部(例如肿瘤内)施用所述药物组合物。在一些实施方案中,所述个体是人类。
还提供了一种分离的核酸,所述分离的核酸编码上述任一种分离的抗PD-1构建体。在一些实施方案中,所述分离的核酸包含SEQ ID NO:253-288中的任一者的核酸序列。
还提供了一种载体,所述载体包含上述任一种分离的核酸。
还提供了一种分离的宿主细胞,所述分离的宿主细胞包含上述任一种分离的核酸或载体。
还提供了一种试剂盒,所述试剂盒包含上述任一种分离的抗PD-1构建体、分离的核酸、载体或分离的宿主细胞。
本申请的另一方面提供了一种产生上述任一种分离的抗PD-1构建体的方法,所述方法包括在有效表达所编码的抗PD-1构建体的条件下培养包含上述任一种分离的核酸或载体的宿主细胞,或培养上述任一种分离的宿主细胞;以及从所述宿主细胞获得所表达的抗PD-1构建体。在一些实施方案中,所述方法还包括产生包含上述任一种分离的核酸或载体的宿主细胞。
附图说明
图1A-1B描绘在PD-1免疫之后第一骆驼的反应评估。图1A描绘免疫前血清和第6次免疫之后第一骆驼的免疫血清的免疫反应评估。图1B描绘第6次免疫之后重链抗体(IgG2和IgG3)的免疫反应评估(末梢采血)。将从免疫前血清分级的重链抗体用作阴性对照。
图2A-2B描绘在PD-1免疫之后第二骆驼的反应评估。图2A描绘免疫前血清和第6次免疫之后第二骆驼的免疫血清的免疫反应评估。图2B描绘第6次免疫之后重链抗体(IgG2和IgG3)的免疫反应评估(末梢采血)。将从免疫前血清分级的重链抗体用作阴性对照。
图3A-3F描绘通过表面等离子体共振测量的所选六种骆驼科sdAb的亲和力。kon、koff和KD值概述于图3G中。
图4A-4B描绘所生成sdAb与人类PD-1表达细胞的结合亲和力。图4A描绘通过流式细胞术的AS06962 sdAb、AS07424 sdAb和A31543 sdAb与人类PD-1表达细胞的结合。EC50数据概述于图4B中。
图5A-5B描绘通过流式细胞术测量的所生成sdAb的配体竞争活性评估。图5A描绘使用PD-L1 Fc配体和PD-1表达细胞系,通过流式细胞术测量的AS06962 sdAb和A31543sdAb的配体竞争活性评估。将 用作阳性抗PD-1对照抗体。IC50概述于图5B中。
用作阳性抗PD-1对照抗体。IC50概述于图5B中。
图6B-6L描绘通过表面等离子体共振测量的所生成骆驼科HCAb的亲和力。将 用作阳性抗PD-1对照抗体(图6K)。kon、koff和KD参数概述于图6A中。
用作阳性抗PD-1对照抗体(图6K)。kon、koff和KD参数概述于图6A中。
图7A-7X描绘通过流式细胞术的所生成骆驼科HCAb与人类PD-1表达细胞的结合能力。图7A-7V描绘所生成骆驼科HCAb与人类PD-1表达细胞的基于FACS的结合。将 用作阳性抗PD-1对照抗体(图7W)。EC50概述于图7X中。
用作阳性抗PD-1对照抗体(图7W)。EC50概述于图7X中。
图8A-8X描绘通过流式细胞术测量的所生成骆驼科HCAb的配体竞争活性评估。图8A-8V描绘使用PD-L1 Fc配体和PD-1表达细胞系的所生成骆驼科HCAb的基于FACS的配体竞争测定。将 用作阳性抗PD-1对照抗体(图8W)。IC50概述于图8X中。
用作阳性抗PD-1对照抗体(图8W)。IC50概述于图8X中。
图9A-9H描绘通过NFAT诱导荧光素酶报告基因活性测量的所生成骆驼科HCAb的生物活性评估。图9A-9F描绘在PD-1效应细胞和PD-L1细胞温育期间,在所生成骆驼科HCAb存在下,从IL-2启动子通过NFAT反应元件的RLU诱导。将 用作阳性抗PD-1对照抗体(图9G)。EC50概述于图9H中。
用作阳性抗PD-1对照抗体(图9G)。EC50概述于图9H中。
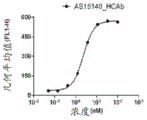
图10A-10C描绘通过混合淋巴细胞反应(MLR)测定的骆驼科HCAb AS15140_HCAb、AS15156_HCAb和AS15193_HCAb的功能活性评估。将 用作阳性抗PD-1对照抗体(图10D)。EC50概述于图10E中。
用作阳性抗PD-1对照抗体(图10D)。EC50概述于图10E中。
图11描绘亲本AS15193 sdAb、其对应的四种人源化变型和人类受体的序列比对。
图12A-12E描绘通过表面等离子体共振的四种人源化HCAb(图12B-12E)和亲本HCAb(AS15193_HCAb,图12A)的亲和力。kon、koff和KD值概述于图12F中。
图13A-13E描绘四种人源化HCAb(图13B-13E)和亲本HCAb(AS15193_HCAb,图13A)与人类PD-1表达细胞的结合亲和力。EC50概述于图13F中。
图14A-14F描绘通过流式细胞术测量的四种人源化HCAb的配体竞争活性评估。图14B-14E描绘使用PD-L1-Fc配体和PD-1表达细胞系的人源化HCAb的基于FACS的配体竞争测定。将亲本HCAb AS15193_HCAb用作阳性抗PD-1对照抗体(图14A)。IC50概述于图14F中。
图15A-15F描绘通过NFAT诱导荧光素酶报告基因活性所测量的四种人源化HCAb和其亲本HCAb的生物活性评估。图15B-15E描绘在PD-1效应细胞和PD-L1细胞温育期间,在人源化HCAb存在下,从IL-2启动子通过NFAT反应元件的RLU诱导。将亲本HCAb AS15193_HCAb用作阳性抗PD-1对照抗体(图15A)。EC50概述于图15F中。
图16描绘示例性BABP的示意性结构,所述示例性BABP包含具有两条相同重链和两条相同轻链的单特异性全长抗体和两个相同抗PD-1 sdAb,其中每个抗PD-1 sdAb的C末端经由任选的肽接头融合至一条重链的N末端。两个抗PD-1 sdAb特异性结合第一表位(PD-1)。全长抗体具有两个特异性结合第二表位的抗原结合位点。例如,BABP可由四条多肽链组成,其结构从N末端至C末端如下:(1)VL-CL;(2)VHH-VH-CH1-CH2-CH3;(3)VHH-VH-CH1-CH2-CH3;和(4)VL-CL,其中多肽链(1)和(2)的VH和VL形成特异性结合第二表位的第一拷贝的抗原结合位点,多肽链(3)和(4)的VH和VL形成特异性结合第二表位的第二拷贝的抗原结合位点,并且每个VHH特异性结合第一表位(PD-1)的拷贝。在替代形式中,每个抗PD-1 sdAb可省略,或被彼此融合的两个相同或不同的抗PD-1 sdAb代替。单特异性全长抗体可被双特异性全长抗体代替以进一步扩大结合特异性。
图17描绘示例性BABP的示意性结构,所述示例性BABP包含具有两条相同重链和两条相同轻链的单特异性全长抗体和两个相同抗PD-1 sdAb,其中每个抗PD-1 sdAb的N末端经由任选的肽接头融合至一条重链的C末端。两个抗PD-1 sdAb特异性结合第一表位(PD-1)。全长抗体具有两个特异性结合第二表位的抗原结合位点。例如,BABP可由四条多肽链组成,其结构从N末端至C末端如下:(1)VL-CL;(2)VH-CH1-CH2-CH3-VHH;(3)VH-CH1-CH2-CH3-VHH;和(4)VL-CL,其中多肽链(1)和(2)的VH和VL形成特异性结合第二表位的第一拷贝的抗原结合位点,多肽链(3)和(4)的VH和VL形成特异性结合第二表位的第二拷贝的抗原结合位点,并且每个VHH特异性结合第一表位(PD-1)的拷贝。在替代形式中,每个抗PD-1 sdAb可省略,或被彼此融合的两个相同或不同的抗PD-1 sdAb代替。单特异性全长抗体可被双特异性全长抗体代替以进一步扩大结合特异性。
图18描绘示例性BABP的示意性结构,所述示例性BABP包含具有两条相同重链和两条相同轻链的单特异性全长抗体和两个相同抗PD-1 sdAb,其中每个抗PD-1 sdAb的C末端经由任选的肽接头融合至一条轻链的N末端。两个抗PD-1 sdAb特异性结合第一表位(PD-1)。全长抗体具有两个特异性结合第二表位的抗原结合位点。例如,BABP可由四条多肽链组成,其结构从N末端至C末端如下:(1)VHH-VL-CL;(2)VH-CH1-CH2-CH3;(3)VH-CH1-CH2-CH3;和(4)VHH-VL-CL,其中多肽链(1)和(2)的VH和VL形成特异性结合第二表位的第一拷贝的抗原结合位点,多肽链(3)和(4)的VH和VL形成特异性结合第二表位的第二拷贝的抗原结合位点,并且每个VHH特异性结合第一表位(PD-1)的拷贝。在替代形式中,每个抗PD-1 sdAb可省略,或被彼此融合的两个相同或不同的抗PD-1 sdAb代替。单特异性全长抗体可被双特异性全长抗体代替以进一步扩大结合特异性。
图19描绘示例性BABP的示意性结构,所述示例性BABP包含具有两条相同重链和两条相同轻链的单特异性全长抗体和两个相同抗PD-1 sdAb,其中每个抗PD-1 sdAb的N末端经由任选的肽接头融合至一条轻链的C末端。两个抗PD-1 sdAb特异性结合第一表位。全长抗体具有两个特异性结合第二表位的抗原结合位点。例如,BABP可由四条多肽链组成,其结构从N末端至C末端如下:(1)VL-CL-VHH;(2)VH-CH1-CH2-CH3;(3)VH-CH1-CH2-CH3;和(4)VL-CL-VHH,其中多肽链(1)和(2)的VH和VL形成特异性结合第二表位的第一拷贝的抗原结合位点,多肽链(3)和(4)的VH和VL形成特异性结合第二表位的第二拷贝的抗原结合位点,并且每个VHH特异性结合第一表位(PD-1)的拷贝。在替代形式中,每个抗PD-1 sdAb可省略,或被彼此融合的两个相同或不同的抗PD-1 sdAb代替。单特异性全长抗体可被双特异性全长抗体代替以进一步扩大结合特异性。
图20描绘示例性BABP的示意性结构,所述示例性BABP包含具有两条相同重链和两条相同轻链的单特异性全长抗体和四个相同抗PD-1 sdAb,其中每个抗PD-1 sdAb的C末端经由任选的肽接头融合至单特异性全长抗体的重链或轻链的N末端。每个抗PD-1 sdAb特异性结合第一表位(PD-1)。全长抗体具有两个各自特异性结合第二表位的抗原结合位点。例如,BABP可由四条多肽链组成,其结构从N末端至C末端如下:(1)VHH-VL-CL;(2)VHH-VH-CH1-CH2-CH3;(3)VHH-VH-CH1-CH2-CH3;和(4)VHH-VL-CL,其中多肽链(1)和(2)的VH和VL形成特异性结合第二表位的第一拷贝的抗原结合位点,多肽链(3)和(4)的VH和VL形成特异性结合第二表位的第二拷贝的抗原结合位点,并且每个VHH特异性结合第一表位(PD-1)的拷贝。在替代形式中,每个抗PD-1 sdAb可省略,或被彼此融合的两个相同或不同的抗PD-1 sdAb代替。单特异性全长抗体可被双特异性全长抗体代替以进一步扩大结合特异性。
图21描绘示例性BABP的示意性结构,所述示例性BABP包含具有两条相同重链和两条相同轻链的单特异性全长抗体和四个相同抗PD-1 sdAb,其中两个相同抗PD-1 sdAb融合至每条重链的N末端,两个抗PD-1 sdAb经由任选的肽接头彼此融合,并且两个抗PD-1 sdAb经由任选的肽接头融合至每条重链的N末端。每个抗PD-1 sdAb特异性结合第一表位(PD-1)。全长抗体具有两个各自特异性结合第二表位的抗原结合位点。例如,BABP可由四条多肽链组成,其结构从N末端至C末端如下:(1)VL-CL;(2)VHH-VHH-VH-CH1-CH2-CH3;(3)VHH-VHH-VH-CH1-CH2-CH3;和(4)VL-CL,其中多肽链(1)和(2)的VH和VL形成特异性结合第二表位的第一拷贝的抗原结合位点,多肽链(3)和(4)的VH和VL形成特异性结合第二表位的第二拷贝的抗原结合位点,并且每个VHH特异性结合第一表位(PD-1)的拷贝。在替代形式中,每个抗PD-1sdAb可省略,或被彼此融合的两个相同或不同的抗PD-1 sdAb代替。单特异性全长抗体可被双特异性全长抗体代替以进一步扩大结合特异性。
图22描绘示例性BABP的示意性结构,所述示例性BABP包含两个相同的抗原结合(Fab)片段、两个相同的抗PD-1 sdAb和Fc区,其中每个抗PD-1 sdAb的N末端经由任选的肽接头融合至Fab片段的CH1区的C末端,并且每个抗PD-1 sdAb的C末端融合至Fc区的CH2区的N末端。每个抗PD-1 sdAb特异性结合第一表位(PD-1)。每个Fab片段特异性结合第二表位。例如,BABP可由四条多肽链组成,其结构从N末端至C末端如下:(1)VL-CL;(2)VH-CH1-VHH-CH2-CH3;(3)VH-CH1-VHH-CH2-CH3;和(4)VL-CL,其中多肽链(1)和(2)的VH和VL形成特异性结合第二表位的第一拷贝的抗原结合位点,多肽链(3)和(4)的VH和VL形成特异性结合第二表位的第二拷贝的抗原结合位点,并且每个VHH特异性结合第一表位(PD-1)的拷贝。在替代形式中,每个抗PD-1 sdAb可省略,或被彼此融合的两个相同或不同的抗PD-1 sdAb代替。在替代形式中,为了扩大特异性,两个Fab片段可特异性结合不同表位,和/或VHH片段可特异性结合不同表位。
图23描绘示例性BABP的示意性结构,所述示例性BABP包含两个相同的单链可变片段(scFv)、两个相同的抗PD-1 sdAb和Fc区,其中每个抗PD-1 sdAb的N末端经由任选的肽接头融合至scFv的C末端,并且每个抗PD-1 sdAb的C末端融合至Fc区的N末端。每个抗PD-1sdAb特异性结合第一表位(PD-1)。每个scFv特异性结合第二表位。例如,BABP可由两条多肽链组成,其各自结构从N末端至C末端如下:VL-VH-VHH-CH2-CH3,其中每个多肽链的VH和VL形成特异性结合第二表位的拷贝的scFv域,并且每个VHH特异性结合第一表位(PD-1)的拷贝。在替代形式中,scFv域可从N末端至C末端包含:VH-VL。在替代形式中,每个抗PD-1 sdAb可省略,或被彼此融合的两个相同或不同的抗PD-1 sdAb代替。另外,为了扩大特异性,两个scFv可特异性结合不同表位,和/或VHH片段可特异性结合不同表位。
图24描绘示例性BABP的示意性结构,所述示例性BABP包含两个相同的Fab片段、各自包含两个VHH片段的两个相同的Fab样片段和Fc区。在每个Fab样片段中,VH和VL区各自被抗PD-1 sdAb代替。每个Fab样片段特异性结合第一表位(PD-1)。每个Fab片段特异性结合第二表位。例如,BABP可由四条多肽链组成,其结构从N末端至C末端如下:(1)VL-CL-VHH-CL;(2)VH-CH1-VHH-CH1-CH2-CH3;(3)VH-CH1-VHH-CH1-CH2-CH3;和(4)VL-CL-VHH-CL,其中多肽链(1)和(2)的VH和VL形成特异性结合第二表位的第一拷贝的抗原结合位点,多肽链(3)和(4)的VH和VL形成特异性结合第二表位的第二拷贝的抗原结合位点,并且每个VHH特异性结合第一表位(PD-1)的拷贝。在替代形式中,为了扩大特异性,两个Fab片段可特异性结合不同表位,和/或Fab样片段可特异性结合不同表位(例如,与PD-1不同的表位)。
图25描绘示例性BABP的示意性结构,所述示例性BABP包含两个相同的scFv、各自包含两个VHH片段的两个相同的Fab样片段和Fc区。在每个Fab样片段中,VH和VL区各自被抗PD-1 sdAb代替。每个Fab样片段特异性结合第一表位(PD-1)。每个scFv特异性结合第二表位。例如,BABP可由四条多肽链组成,其结构从N末端至C末端如下:(1)VHH-CL;(2)VL-VH-VHH-CH1-CH2-CH3;(3)VL-VH-VHH-CH1-CH2-CH3;和(4)VHH-CL,其中多肽链(2)和(3)的VH和VL各自形成特异性结合第二表位的拷贝的scFv,并且每个VHH特异性结合第一表位(PD-1)的拷贝。在替代形式中,scFv的C末端可融合至包含VHH-CL的Fab样片段中的链的N末端;和/或scFv域可从N末端至C末端包含:VH-VL。另外,为了扩大特异性,两个scFv可特异性结合不同表位,和/或VHH片段可特异性结合不同表位(例如,与PD-1不同的表位)。
图26A-26B描绘示例性抗PD-1 HCAb的示意性结构。图26A描绘示例性单特异性二价抗PD-1 HCAb的示意性结构。图26B描绘示例性双特异性二价抗PD-1 HCAb的示意性结构。
图27描绘两种人源化HCAb AS15193VH8M1_HCAb和AS15193VH18M1_HCAb的体内功效研究。
图28描绘所选sdAb的纯化概要。
图29描绘所选HCAb的纯化概要。
具体实施方式
本发明提供新颖的特异性识别PD-1的sdAb(下文也称为“抗PD-1 sdAb”)和其抗体变体(例如,包含抗PD-1 sdAb的较大蛋白质或多肽,例如抗PD-1 sdAb-Fc融合蛋白(例如,抗PD-1 HCAb),融合至全长抗体、Fab或scFv的抗PD-1 sdAb,或包含抗PD-1 sdAb的多特异性抗原结合蛋白(MABP,例如双特异性抗原结合蛋白(BABP)),其用于治疗PD-1相关疾病(例如癌症)的用途和其制备方法。
sdAb因具有单个单体抗体可变域(例如重链可变域(VHH))而与常规4链抗体不同,其可不借助于轻链而展现出与抗原的高亲和力。已知骆驼科VHH是最小的功能性抗原结合片段,分子量为大约15kDa。
因此,本申请的一个方面提供一种分离的抗PD-1构建体,其包含特异性识别PD-1的sdAb部分。分离的抗PD-1构建体可以是例如抗PD-1 sdAb(例如天然、人源化或人类抗PD-1 sdAb),包含融合在一起的多种本文所述的抗PD-1 sdAb的多肽,包含融合至Fc片段(例如,人类IgG1 Fc、无效应子(惰性)hIgG1 Fc、hIgG4 Fc或hIgG4 Fc(S228P))的本文所述的抗PD-1 sdAb的抗PD-1 sdAb-Fc融合蛋白(例如,抗PD-1 HCAb),或包含融合至全长抗体(例如,特异性识别TIGIT、LAG-3、TIM-3、CTLA-4或PD-1(例如,与本文所述的抗PD-1 sdAb部分识别者不同的第二PD-1表位)的抗体)或其包含重链可变域(VH)和轻链可变域(VL)的抗原结合片段的本文所述的抗PD-1 sdAb的MABP。抗PD-1构建体可以是单特异性或多特异性(例如双特异性),单价或多价(例如二价)。
还提供了包含本文所述的抗PD-1构建体的组合物(例如药物组合物)、试剂盒和制品,其制备方法,和使用本文所述的抗PD-1构建体治疗PD-1相关疾病(例如癌症)的方法。
I.定义
术语“表位”意指能够特异性结合抗体的蛋白决定子。表位通常由分子的化学活性表面分组组成,例如氨基酸或糖侧链,并且通常具有特定三维结构特征以及特定电荷特征。构象和非构象表位的区别在于,在变性溶剂存在下,丧失与前者的结合而未丧失与后者的结合。
如本文所用,“治疗(treatment)”或“治疗(treating)”是用于获得有利或期望结果(包括临床结果)的方法。出于本发明的目的,有利或期望的临床结果包括但不限于以下的一种或多种:减轻由疾病引起的一种或多种症状;削弱疾病的程度;稳定疾病(例如,预防或延迟疾病的恶化);预防或延迟疾病的蔓延(例如,转移);预防或延迟疾病的复发;延迟或减缓疾病的进展;改善疾病状态;提供疾病的缓解(部分或全部);减少治疗疾病所需的一种或多种其它药物的剂量;延迟疾病的进展;提高生活质量;和/或延长存活。“治疗”还涵盖减少癌症的病理学后果。本发明的方法考虑这些治疗方面中的任一者或多者。
术语“预防(prevent)”和其类似词语例如“预防(prevented)”、“预防(preventing)”等指示用于预防、抑制疾病或疾患(例如癌症)或减少其复发可能性的方法。其还涉及延迟疾病或疾患复发或延迟疾病或疾患的症状复发。如本文所用,“预防(prevention)”和类似词语还包括在疾病或病状复发之前减少疾病或疾患的强度、效果、症状和/或负荷。
如本文所用,“延迟”癌症的发展意指推迟、阻碍、减缓、减慢、稳定和/或延后疾病的发展。这种延迟可以是不同时间长度,其取决于病史和/或正治疗的个体。“延迟”癌症发展的方法是与不使用所述方法相比较,在给定时段内减少疾病发展的机率和/或在给定时段内降低疾病程度的方法。这样的比较通常是基于临床研究,使用统计学显著数量的个体。癌症发展可使用标准方法检测,包括但不限于计算机轴向断层扫描(CAT扫描)、磁共振成像(MRI)、腹部超声波、凝血测试、动脉摄影术或活检。发展还可指最初不可检测的癌症进展并且包括发生、复发和发作。
本文所用的术语“有效量”是指足以治疗指定病症、疾患或疾病例如改善、缓和、减轻和/或延迟其症状中的一种或多种的药剂或药剂组合的量。关于癌症,有效量包含足以引起肿瘤缩小和/或降低肿瘤生长速率(例如抑制肿瘤生长)或预防或延迟其它不需要的细胞增殖的量。在一些实施方案中,有效量是足以延迟发展的量。在一些实施方案中,有效量是足以预防或延迟复发的量。有效量可以一次或多次施用的形式施用。有效量的药物或组合物可:(i)减少癌细胞数量;(ii)减小肿瘤大小;(iii)在一定程度上抑制、减慢、减缓并优选阻止癌细胞浸润至外周器官中;(iv)抑制(即,在一定程度上减缓并优选阻止)肿瘤转移;(v)抑制肿瘤生长;(vi)预防或延迟肿瘤发生和/或复发;和/或(vii)在一定程度上缓解与癌症相关的一种或多种症状。
如本文所用,“个体”或“受试者”是指哺乳动物,包括但不限于人类、牛、马、猫、犬、啮齿动物或灵长类动物。在一些实施方案中,个体是人类。
术语“抗体”、“抗原结合部分”或“抗体部分”以其最广泛意义使用并且涵盖各种抗体结构,包括但不限于单克隆抗体、多克隆抗体、多特异性抗体(例如,双特异性抗体)、全长抗体和其抗原结合片段,只要其展现出期望的抗原结合活性即可。
基本的4链抗体单元是由两条相同轻(L)链和两条相同重(H)链组成的异四聚糖蛋白。IgM抗体由5个基本的异四聚体单元连同称为J链的额外多肽组成,并且含有10个抗原结合位点,而IgA抗体包含2-5个基本的4链单元,所述单元可聚合以与J链组合的形式形成多价装配物。在IgG的情况下,4链单元通常是约150,000道尔顿。每个L链通过一个共价二硫键与H链连接,而两条H链通过一个或多个二硫键(其取决于H链同型)彼此连接。每个H链和L链还具有规则隔开的链内二硫桥。每个H链在N末端具有可变域(VH),接着对于α和γ链中的每一个来说是三个恒定域(CH),并且对于μ和ε同型来说是四个CH域。每个L链在N末端具有可变域(VL),接着在其另一端是恒定域。VL与VH对齐,并且CL与重链的第一恒定域(CH1)对齐。据认为特定氨基酸残基形成轻链可变域与重链可变域之间的界面。将VH和VL配对在一起形成单一抗原结合位点。关于不同类别抗体的结构和性质,参见例如Basic and ClinicalImmunology,第8版,Daniel P.Sties,Abba I.Terr和Tristram G.Parsolw(编),Appleton&Lange,Norwalk,Conn.,1994,第71页和第6章。来自任何脊椎动物物种的L链可基于其恒定域的氨基酸序列归为两种截然不同的类型(称为κ和λ)之一。取决于其重链恒定域(CH)的氨基酸序列,免疫球蛋白可归于不同类别或同型。存在五类免疫球蛋白:IgA、IgD、IgE、IgG和IgM,其分别具有称为α、δ、ε、γ和μ的重链。基于CH序列和功能的相对较小的差异,γ和α类别被进一步分成子类,例如,人类表达以下子类:IgG1、IgG2A、IgG2B、IgG3、IgG4、IgA1和IgA2。
术语“仅重链抗体”或“HCAb”是指包含重链但缺少通常存在于在4-链抗体中的轻链的功能性抗体。已知骆驼科动物(例如骆驼、美洲驼或羊驼)产生HCAb。
术语“单域抗体”或“sdAb”是指具有三个互补决定区(CDR)的单一抗原结合多肽。单独sdAb能够在不与对应的含CDR的多肽配对的情况下结合抗原。在一些情况下,单域抗体由骆驼科HCAb工程改造,并且其重链可变域在本文中称为“VHH”(重链抗体的重链的可变域)。骆驼科sdAb是已知最小的抗原结合抗体片段之一(参见例如Hamers-Casterman等,Nature 363:446-8(1993);Greenberg等,Nature 374:168-73(1995);Hassanzadeh-Ghassabeh等,Nanomedicine(Lond),8:1013-26(2013))。基本的VHH从N末端至C末端具有以下结构:FR1-CDR1-FR2-CDR2-FR3-CDR3-FR4,其中FR1至FR4分别是指框架区1至4,并且其中CDR1至CDR3是指互补决定区1至3。
“分离的”抗体(或构建体)是已鉴定、从其产生环境(例如,天然或重组)的组分分离和/或回收者。优选地,分离的多肽不与来自其产生环境的所有其它组分缔合。其产生环境的污染物组分(例如得自重组转染细胞的组分)是通常干扰抗体的研究、诊断或治疗用途的物质,并且可包括酶、激素和其它蛋白质或非蛋白质溶质。在优选实施方案中,多肽将被纯化至:(1)如通过例如劳里法(Lowry method)所确定的大于95重量%抗体,并且在一些实施方案中大于99重量%;(2)足以通过使用转杯式测序仪(spinning cup sequenator)获得N末端或内部氨基酸序列的至少15个残基的程度;或(3)通过使用考马斯蓝(CoomassieBlue)或优选银染色,在非还原或还原条件下进行的SDS-PAGE至均质。分离的抗体(或构建体)包括原位处于重组细胞内的抗体,因为将不存在抗体的天然环境中的至少一种组分。然而通常,分离的多肽、抗体或构建体通过至少一个纯化步骤制备。
抗体的“可变区”或“可变域”是指抗体的重链或轻链的氨基末端域。重链和轻链的可变域可分别称为“VH”和“VL”。这些域通常是抗体的最易变部分(相对于相同类别的其它抗体)并且含有抗原结合位点。来自骆驼科物种的仅重链抗体具有单一重链可变区,其被称为“VHH”。因此VHH是一种特殊类型的VH。
术语“可变”是指可变域的某些区段的序列在抗体之间广泛不同。V域介导抗原结合并且界定特定抗体对其特定抗原的特异性。然而,可变性未在可变域的整个跨度内均匀地分布。而是,其集中于重链和轻链可变域中称为互补决定区(CDR)或超变区(HVR)的三个区段中。可变域的更高保守部分称为框架区(FR)。天然重链和轻链的可变域各自包含四个FR区,其主要采用β-折叠构型,由三个CDR连接,所述CDR形成连接β-折叠结构的环并且在一些情况下形成β-折叠结构的一部分。每个链中的CDR通过FR区紧密地保持在一起,并且与来自另一链的CDR一起有助于抗体的抗原结合位点的形成(参见Kabat等,Sequences ofImmunological Interest,第五版,National Institute of Health,Bethesda,Md.(1991))。恒定域不直接参与抗体与抗原的结合,但展现出各种效应功能,例如抗体参与抗体依赖性细胞毒性。
如本文所用的术语“单克隆抗体”是指从实质上均质的抗体群体获得的抗体,即,构成所述群体的个别抗体除了可以微量的形式存在的可能天然存在的突变和/或翻译后修饰(例如,异构化、酰胺化)之外是相同的。单克隆抗体具有高特异性,其针对单一抗原位点。与通常包括针对不同决定子(表位)的不同抗体的多克隆抗体制剂形成对比,每个单克隆抗体针对抗原上的单一决定子。除了特异性,单克隆抗体的优势在于,它们通过杂交瘤培养来合成,不受其它免疫球蛋白污染。修饰语“单克隆”指示抗体的特性是获自实质上均质的抗体群体,并且不应理解为需要通过任何特定方法来产生抗体。例如,有待根据本发明使用的单克隆抗体可通过多种技术制成,包括例如杂交瘤方法(例如,Kohler和Milstein.,Nature,256:495-97(1975);Hongo等,Hybridoma,14(3):253-260(1995);Harlow等,Antibodies:A Laboratory Manual,(Cold Spring Harbor Laboratory Press,第2版,1988);Hammerling等,Monoclonal Antibodies and T-Cell Hybridomas 563-681(Elsevier,N.Y.,1981));重组DNA方法(参见例如美国专利第4,816,567号);噬菌体展示技术(参见例如Clackson等,Nature,352:624-628(1991);Marks等,J.Mol.Biol.222:581-597(1992);Sidhu等,J.Mol.Biol.338(2):299-310(2004);Lee等,J.Mol.Biol.340(5):1073-1093(2004);Fellouse,Proc.Natl.Acad.Sci.USA 101(34):12467-12472(2004);和Lee等,J.Immunol.Methods 284(1-2):119-132(2004));和用于在具有编码人类免疫球蛋白序列的部分或全部人类免疫球蛋白基因座或基因的动物中产生人类或人类样抗体的技术(参见例如WO 1998/24893;WO 1996/34096;WO 1996/33735;WO 1991/10741;Jakobovits等,Proc.Natl.Acad.Sci.USA 90:2551(1993);Jakobovits等,Nature 362:255-258(1993);Bruggemann等,Year in Immunol.7:33(1993);美国专利第5,545,807号、第5,545,806号、第5,569,825号、第5,625,126号、第5,633,425号和第5,661,016号;Marks等,Bio/Technology 10:779-783(1992);Lonberg等,Nature 368:856-859(1994);Morrison,Nature 368:812-813(1994);Fishwild等,Nature Biotechnol.14:845-851(1996);Neuberger,Nature Biotechnol.14:826(1996);和Lonberg和Huszar,Intern.Rev.Immunol.13:65-93(1995))。
术语“全长抗体”、“完整抗体”或“全抗体”可互换地用于指代以实质上完整形式的抗体,与抗体片段不同。具体来说,全长4链抗体包括具有重链和轻链(包括Fc区)的抗体。全长仅重链抗体包括重链可变域(例如VHH)和Fc区。恒定域可以是天然序列恒定域(例如,人类天然序列恒定域)或其氨基酸序列变体。在一些情况下,完整抗体可具有一种或多种效应功能。
“抗体片段”或“抗原结合片段”包含完整抗体的一部分,优选地完整抗体的抗原结合区和/或可变区。抗体片段的实例包括但不限于Fab、Fab'、F(ab')2和Fv片段;双功能抗体;线性抗体(参见美国专利第5,641,870号,实例2;Zapata等,Protein Eng.8(10):1057-1062(1995));单链抗体(scFv)分子;单域抗体(例如VHH);和由抗体片段形成的多特异性抗体。抗体的木瓜蛋白酶消化产生两个相同的抗原结合片段(称为“Fab”片段)和残余“Fc”片段(名称反映易于结晶的能力)。Fab片段由整条L链连同H链的可变域(VH)和一条重链的第一恒定结构域(CH1)组成。每个Fab片段关于抗原结合是单价的,即,其具有单一抗原结合位点。抗体的木瓜蛋白酶处理产生单一大型F(ab')2片段,所述片段大体上对应于两个具有不同抗原结合活性的二硫化物连接Fab片段并且仍能够交联抗原。Fab'片段因在CH1域的羧基末端处具有少量额外残基(包括来自抗体铰链区的一个或多个半胱氨酸)而与Fab片段不同。Fab'-SH是本文中恒定域的半胱氨酸残基携带自由硫醇基的Fab'的名称。F(ab')2抗体片段最初以其之间具有铰链半胱氨酸的Fab'片段对的形式产生。抗体片段的其它化学偶联也是已知的。
术语“恒定域”是指免疫球蛋白分子的以下部分,其相对于所述免疫球蛋白的含有抗原结合位点的其它部分(可变域)具有较保守的氨基酸序列。恒定域含有重链的CH1、CH2和CH3域(统称为CH)和轻链的CHL(或CL)域。
任何哺乳动物物种的抗体(免疫球蛋白)的“轻链”均可基于其恒定域的氨基酸序列而归为两种明显不同的类型(称为卡帕(“κ”)和拉姆达(“λ”))之一。
“Fv”是含有完全抗原识别和结合位点的最小抗体片段。这种片段由以紧密、非共价缔合形式的一个重链可变区结构域和一个轻链可变区结构域的二聚体组成。这两个域的折叠产生六个高变环(从H链和L链各自产生3个环),所述高变环有助于氨基酸残基的抗原结合并且赋予抗体以抗原结合特异性。然而,即使单一可变域(或仅包含三个特异于抗原的CDR的Fv的一半)具有识别并结合抗原的能力,但是与整个结合位点相比,亲和力较低。
“单链Fv”(也缩写为“sFv”或“scFv”)是包含连接至单一多肽链中的VH和VL抗体域的抗体片段。优选地,scFv多肽还包含VH与VL域之间的多肽接头,所述多肽接头能够使scFv形成用于抗原结合的期望结构。关于scFv的评述,参见Pluckthun,The Pharmacology ofMonoclonal Antibodies,第113卷,Rosenburg和Moore编,Springer-Verlag,New York,第269-315页(1994)。
术语“双功能抗体”是指以下小型抗体片段,其通过在VH与VL域之间以短接头(约5-10个残基)构建sFv片段(参见前一段落)来制备,使得达成V域的链内而非链间配对,从而得到二价片段,即具有两个抗原结合位点的片段。双特异性抗体是两个“交叉”sFv片段的异二聚体,其中两种抗体的VH和VL域存在于不同多肽链上。双功能抗体更详细地描述于例如EP404,097;WO 93/11161;Hollinger等,Proc.Natl.Acad.Sci.USA 90:6444-6448(1993)。
具体来说,本文中的单克隆抗体包括“嵌合”抗体(免疫球蛋白),其中重链和/或轻链的一部分与源自特定物种或属于特定抗体类别或子类的抗体中对应的序列相同或同源,而所述链的其余部分与源自另一物种或属于另一抗体类别或子类的抗体中对应的序列相同或同源,以及所述抗体的片段,只要其展现出期望的生物活性即可(美国专利第4,816,567号;Morrison等,Proc.Natl.Acad.Sci.USA,81:6851-6855(1984))。“人源化抗体”用作“嵌合抗体”的子集。
非人类(例如,美洲驼或骆驼)抗体的“人源化”形式是含有源自非人类免疫球蛋白的最小序列的嵌合抗体。在一些实施方案中,人源化抗体是以下人类免疫球蛋白(受者抗体),其中来自受者CDR(下文定义)的残基被具有所需特异性、亲和力和/或能力的来自例如小鼠、大鼠、兔、骆驼、美洲驼、羊驼或非人类灵长类动物的非人类物种(供者抗体)CDR的残基代替。在一些情况下,人类免疫球蛋白的框架区(“FR”)残基被对应的非人类残基代替。此外,人源化抗体可包含不存在于受者抗体或供者抗体中的残基。可进行这些修饰以进一步完善抗体性能,例如结合亲和力。通常,人源化抗体将包含至少一个并且通常两个可变域的实质上全部,其中全部或实质上全部高变环对应于非人类免疫球蛋白序列的高变环,并且全部或实质上全部FR区是人类免疫球蛋白序列的FR区,但是FR区可包括一个或多个的个别FR残基取代,其改善抗体性能,例如结合亲和力、异构化、免疫原性等。FR中这些氨基酸取代的数目通常在H链中不多于6个,并且在L链中不多于3个。人源化抗体任选地还将包含免疫球蛋白恒定区(Fc)的至少一部分,通常是人类免疫球蛋白的恒定区。关于进一步细节,参见例如Jones等,Nature 321:522-525(1986);Riechmann等,Nature 332:323-329(1988);和Presta,Curr.Op.Struct.Biol.2:593-596(1992)。还参见例如Vaswani和Hamilton,Ann.Allergy,Asthma&Immunol.1:105-115(1998);Harris,Biochem.Soc.Transactions23:1035-1038(1995);Hurle和Gross,Curr.Op.Biotech.5:428-433(1994);和美国专利第6,982,321号和第7,087,409号。
“人类抗体”是具有对应于人类所产生的抗体的氨基酸序列的氨基酸序列和/或已使用如本文所公开的制备人类抗体的任一技术制成的抗体。这种人类抗体定义特定地排除包含非人类抗原结合残基的人源化抗体。人类抗体可使用本领域中已知的各种技术产生,包括噬菌体展示文库。Hoogenboom和Winter,J.Mol.Biol.,227:381(1991);Marks等,J.Mol.Biol.,222:581(1991)。在Cole等,Monoclonal Antibodies and Cancer Therapy,Alan R.Liss,第77页(1985);Boerner等,J.Immunol.,147(1):86-95(1991)中所述的方法也可用于制备人类单克隆抗体。还参见van Dijk和van de Winkel,Curr.Opin.Pharmacol.,5:368-74(2001)。人类抗体可通过向转基因动物施用抗原来制备,所述转基因动物已经被修饰以响应于抗原攻击而产生此类抗体,但其内源基因座已失能,例如经免疫转基因鼠(xenomice)(关于XENOMOUSETM技术,参见例如美国专利第6,075,181号和第6,150,584号)。关于经由人类B细胞杂交瘤技术生成的人类抗体,还参见例如Li等,Proc.Natl.Acad.Sci.USA,103:3557-3562(2006)。
本文所用的术语“高变区”、“HVR”或“HV”是指抗体可变域的在序列方面高度可变和/或形成结构确定环的各区。通常,单域抗体包含三个HVR(或CDR):HVR1(或CDR1)、HVR2(或CDR2)和HVR3(或CDR3)。在三个HVR中,HVR3(或CDR3)显示最大多样性,并且据认为其在赋予抗体以良好特异性方面发挥独特作用。参见例如Hamers-Casterman等,Nature 363:446-448(1993);Sheriff等,Nature Struct.Biol.3:733-736(1996)。
术语“互补决定区”或“CDR”用于指代如通过Kabat系统所定义的高变区。参见Kabat等,Sequences of Proteins of Immunological Interest,第5版,Public HealthService,National Institutes of Health,Bethesda,Md.(1991)。
多个HVR描述在使用中并且涵盖在本文中。Kabat互补决定区(CDR)是基于序列可变性并且最常用(Kabat等,Sequences of Proteins of Immunological Interest,第5版,Public Health Service,National Institutes of Health,Bethesda,Md.(1991))。Chothia替代地指结构环的位置(Chothia和Lesk,J.Mol.Biol.196:901-917(1987))。AbMHVR表示Kabat HVR与Chothia结构环之间的折衷,并且是通过Oxford Molecular的AbM抗体建模软件来使用。“接触”HVR是基于可用复合物晶体结构的分析。来自这些HVR中的每一者的残基在以下表1中指出。
表1.HVR描述。


HVR可包含如下“延长HVR”:在VL中,24-36或24-34(L1)、46-56或50-56(L2)和89-97或89-96(L3),以及在VH中,26-35(H1)、50-65或49-65(H2)和93-102、94-102或95-102(H3)。这些定义中的每一者的可变域残基是根据Kabat等(出处同上)进行编号。
单域抗体(例如VHH)的氨基酸残基是根据Kabat等给出的VH域的一般编号进行编号(“Sequence of proteins of immunological interest”,US Public Health Services,NIH Bethesda,Md.,公开号91),如Riechmann和Muyldermans,J.Immunol.Methods,2000年6月,23;240(1-2):185-195的文章中对来自骆驼科动物的VHH域所应用。根据这种编号,VHH的FR1包含在位置1-30处的氨基酸残基,VHH的CDR1包含在位置31-35处的氨基酸残基,VHH的FR2包含在位置36-49处的氨基酸,VHH的CDR2包含在位置50-65处的氨基酸残基,VHH的FR3包含在位置66-94处的氨基酸残基,VHH的CDR3包含在位置95-102处的氨基酸残基,并且VHH的FR4包含在位置103-113处的氨基酸残基。在这方面中应该注意,如针对VH域和VHH域的技术所熟知,每个CDR中氨基酸残基的总数可能有所不同,并且可能不对应于Kabat编号所指示的氨基酸残基的总数(也就是说,在实际序列中根据Kabat编号的一个或多个位置可不被占据,或者实际序列可含有比Kabat编号所允许的数目多的氨基酸残基)。
表述“如Kabat中的可变域残基编号”或“如Kabat中的氨基酸位置编号”和其变型是指用于Kabat等(出处同上)中的抗体编译的重链可变域或轻链可变域的编号系统。使用这种编号系统,实际线性氨基酸序列可含有较少或额外氨基酸,所述氨基酸对应于可变域的FR或HVR的缩短或对其进行的插入。例如,重链可变域可包括H2的残基52之后的单一氨基酸插入(根据Kabat的残基52a)和重链FR残基82之后的插入残基(例如根据Kabat的残基82a、82b和82c等)。可通过将抗体序列中具有同源性的区与“标准”Kabat编号序列比对来确定给定抗体中残基的Kabat编号。
除非本文另外指示,否则免疫球蛋白重链中残基的编号是如Kabat等(出处同上)的EU索引的编号。“如Kabat中的EU索引”是指人类IgG1 EU抗体的残基编号。
“框架”或“FR”残基是除了如本文所定义的HVR残基以外的那些可变域残基。
“人类共同框架”或“受体人类框架”是表示人类免疫球蛋白VL或VH框架序列的选择中最常出现的氨基酸残基的框架。通常,人类免疫球蛋白VL或VH序列选自可变域序列的亚群。通常,序列的亚群是如Kabat等,Sequences of Proteins of ImmunologicalInterest,第5版,Public Health Service,National Institutes of Health,Bethesda,Md.(1991)中的亚群。实例包括对于VL,亚群可以是如Kabat等(出处同上)中的亚群κI、κII、κIII或κIV。此外,对于VH,亚群可以是如Kabat等中的亚群I、亚群II或亚群III。或者,人类共同框架可来源于上述者,其中特定残基,例如当人类框架残基是基于其与供者框架的同源性通过将供者框架序列与各种人类框架序列的集合进行比对来选择时。“来源于”人类免疫球蛋白框架或人类共同框架的受体人类框架可包含其相同的氨基酸序列,或者其可含有预先存在的氨基酸序列变化。在一些实施方案中,预先存在的氨基酸变化的数目是10个以下、9个以下、8个以下、7个以下、6个以下、5个以下、4个以下、3个以下或2个以下。
“亲和力成熟”抗体是在其一个或多个CDR中具有一个或多个改变而导致抗体对抗原的亲和力相较于不具有那些改变的亲本抗体有所改善的抗体。在一些实施方案中,亲和力成熟抗体对靶抗原具有纳摩尔或甚至皮摩尔亲和力。亲和力成熟抗体是通过本领域中已知的程序产生。例如,Marks等,Bio/Technology 10:779-783(1992)描述通过VH域和VL域改组的亲和力成熟。CDR和/或框架残基的随机诱变描述于例如:Barbas等,ProcNat.Acad.Sci.USA 91:3809-3813(1994);Schier等,Gene 169:147-155(1995);Yelton等,J.Immunol.155:1994-2004(1995);Jackson等,J.Immunol.154(7):3310-9(1995);和Hawkins等,J.Mol.Biol.226:889-896(1992)。
如本文所用,术语“特异性结合”、“特异性识别”或“特异于”是指可测量且可再现的相互作用,例如靶标与抗原结合蛋白(例如sdAb)之间的结合,所述结合在存在包括生物分子的分子异质群体的情况下确定靶标存在。例如,特异性结合靶标(其可以是表位)的抗原结合蛋白(例如sdAb)是与其结合其它靶标相比,以较大亲和力、亲合力、更容易和/或以较长持续时间结合所述靶标的抗原结合蛋白(例如sdAb)。在一些实施方案中,抗原结合蛋白(例如sdAb)与不相关靶标的结合程度是抗原结合蛋白(例如sdAb)与靶标的结合的小于约10%,例如通过放射免疫分析(RIA)所测量。在一些实施方案中,特异性结合靶标的抗原结合蛋白(例如sdAb)具有≤10-5M、≤10-6M、≤10-7M、≤10-8M、≤10-9M、≤10-10M、≤10-11M或≤10-12M的解离常数(Kd)。在一些实施方案中,抗原结合蛋白特异性结合在来自不同物种的蛋白中保守的蛋白上的表位。在一些实施方案中,特异性结合可包括但不需要专一性结合。抗体或抗原结合域的结合特异性可通过本领域中已知的方法以实验方式确定。这样的方法包括但不限于蛋白质印迹法、ELISA测试、RIA测试、ECL测试、IRMA测试、EIA测试、BIAcore测试和肽扫描。
术语“特异性”是指抗原结合蛋白(例如sdAb)对抗原的特定表位的选择性识别。例如,天然抗体具有单特异性。如本文所用的术语“多特异性”表示抗原结合蛋白具有多表位特异性(即,能够特异性结合一种生物分子上的两种、三种或三种以上不同表位或能够特异性结合两种、三种或三种以上不同生物分子上的表位)。如本文所用的“双特异性”表示抗原结合蛋白具有两种不同的抗原结合特异性。除非另外指示,否则所列出的双特异性抗体所结合的抗原的顺序是任意的。也就是说,例如,术语“抗TIGIT/PD-1”、“抗PD-1/TIGIT”、“TIGIT×PD-1”、“PD-1×TIGIT”、“PD-1/TIGIT”、“TIGIT/PD-1”、“PD-1-TIGIT”和“TIGIT-PD-1”可互换地用于指代特异性结合TIGIT和PD-1的双特异性抗体。如本文所用的术语“单特异性”表示具有一个或多个结合位点的抗原结合蛋白(例如sdAb),每个结合位点结合相同抗原的相同表位。
如本文所用的术语“价”表示抗原结合蛋白中指定数目的结合位点的存在。例如天然抗体或全长抗体具有两个结合位点并且是二价的。因此,术语“三价”、“四价”、“五价”和“六价”分别表示抗原结合蛋白中两个结合位点、三个结合位点、四个结合位点、五个结合位点和六个结合位点的存在。
“抗体效应功能”是指可归因于抗体的Fc区(天然序列Fc区或氨基酸序列变体Fc区)的那些生物活性,并且随抗体同型而有所不同。抗体效应功能的实例包括:C1q结合和补体依赖性细胞毒性;Fc受体结合;抗体依赖性细胞介导的细胞毒性(ADCC);吞噬作用;细胞表面受体(例如B细胞受体)的下调;和B细胞活化。“减少或最小化的”抗体效应功能意指其从野生型或未经修饰的抗体减少至少50%(或者60%、65%、70%、75%、80%、85%、90%、95%、96%、97%、98%、99%)。本领域的普通技术人员可易于确定和测量抗体效应功能的确定。在一个优选实施方案中,补体结合、补体依赖性细胞毒性和抗体依赖性细胞毒性的抗体效应功能受到影响。在一些实施方案中,效应功能通过恒定区中消除糖基化的突变(例如“无效应子突变”)而消除。在一个方面,无效应子突变是CH2区中的N297A或DANA突变(D265A+N297A)。Shields等,J.Biol.Chem.276(9):6591-6604(2001)。或者,导致减少或消除效应功能的额外突变包括:K322A和L234A/L235A(LALA)。或者,效应功能可通过生产技术来减少或消除,例如在未糖基化的宿主细胞(例如,大肠杆菌(E.coli.))中的表达或以导致糖基化模式改变成在促进效应功能时无效或不太有效的方式(例如Shinkawa等,J.Biol.Chem.278(5):3466-3473(2003))。
“抗体依赖性细胞介导的细胞毒性”或ADCC是指一种细胞毒性形式,其中结合至某些细胞毒性细胞(例如,自然杀伤(NK)细胞、嗜中性粒细胞和巨噬细胞)上存在的Fc受体(FcR)上的分泌Ig使得这些细胞毒性效应细胞能够与携带抗原的靶细胞特异性结合并随后以细胞毒素杀伤靶细胞。抗体“武装”细胞毒性细胞并且是通过这种机制杀伤靶细胞所需的。用于介导ADCC的初级细胞(NK细胞)仅表达FcγRIII,而单核细胞表达FcγRI、FcγRII和FcγRIII。造血细胞上的Fc表达概述于Ravetch和Kinet,Annu.Rev.Immunol.9:457-92(1991)的第464页的表2中。为了评估所关注的分子的ADCC活性,可执行体外ADCC测定,例如美国专利第5,500,362号或第5,821,337号中所述。用于此类测定的有用效应细胞包括外周血单核细胞(PBMC)和自然杀伤(NK)细胞。或者或另外,可例如在动物模型(例如Clynes等,PNAS USA 95:652-656(1998)中所公开的动物模型)中体内评估所关注的分子的ADCC活性。
本文中的术语“Fc区”或“片段可结晶区”用于定义免疫球蛋白重链的C末端区,包括天然序列Fc区和变体Fc区。尽管免疫球蛋白重链的Fc区的边界可能有所不同,但人类IgG重链Fc区通常定义为从在位置Cys226处的氨基酸残基或从Pro230伸长至其羧基末端。Fc区的C末端赖氨酸(根据EU编号系统的残基447)可例如在抗体的产生或纯化期间,或通过重组工程改造编码抗体的重链的核酸来除去。因此,完整抗体的组合物可包含所有K447均去除的抗体群体、无K447残基去除的抗体群体、和具有存在和不存在K447残基的抗体的混合物的抗体群体。用于本文所述的抗体中的合适的天然序列Fc区包括人类IgG1、IgG2(IgG2A、IgG2B)、IgG3和IgG4。
“Fc受体”或“FcR”描述结合抗体Fc区的受体。优选FcR是天然序列人类FcR。此外,优选FcR是结合IgG抗体(γ受体)并包括FcγRI、FcγRII和FcγRIII子类的受体(包括这些受体的等位基因变体和替代剪接形式)的FcR,FcγRII受体包括FcγRIIA(“活化受体”)和FcγRIIB(“抑制受体”),其具有主要在其细胞质域中不同的类似氨基酸序列。活化受体FcγRIIA在其细胞质域中含有基于免疫受体酪氨酸的活化基序(ITAM)。抑制受体FcγRIIB在其细胞质域中含有基于免疫受体酪氨酸的抑制基序(ITIM)。(参见M. Annu.Rev.Immunol.15:203-234(1997))。FcR评述于Ravetch和Kinet,Annu.Rev.Immunol.9:457-92(1991);Capel等,Immunomethods 4:25-34(1994);和de Haas等,J.Lab.Clin.Med.126:330-41(1995)中。其它FcR(包括将来待鉴定的FcR)在本文中由术语“FcR”涵盖。
Annu.Rev.Immunol.15:203-234(1997))。FcR评述于Ravetch和Kinet,Annu.Rev.Immunol.9:457-92(1991);Capel等,Immunomethods 4:25-34(1994);和de Haas等,J.Lab.Clin.Med.126:330-41(1995)中。其它FcR(包括将来待鉴定的FcR)在本文中由术语“FcR”涵盖。
术语“Fc受体”或“FcR”还包括新生儿受体FcRn,其负责将母体IgG转移至胎儿。Guyer等,J.Immunol.117:587(1976)和Kim等,J.Immunol.24:249(1994)。测量与FcRn结合的方法是已知的(参见例如Ghetie和Ward,Immunol.Today 18:(12):592-8(1997);Ghetie等,Nature Biotechnology 15(7):637-40(1997);Hinton等,J.Biol.Chem.279(8):6213-6(2004);WO 2004/92219(Hinton等))。可以例如在表达人类FcRn的转基因小鼠或转染人类细胞系中或者在施用具有变体Fc区的多肽的灵长类动物中测定体内与FcRn的结合和人类FcRn高亲和力结合多肽的血清半衰期。WO 2004/42072(Presta)描述了改进或减弱与FcR的结合的抗体变体。还参见例如Shields等,J.Biol.Chem.9(2):6591-6604(2001)。
“补体依赖性细胞毒性”或“CDC”是指靶细胞在补体存在下的溶解。经典补体路径的活化是通过补体系统的第一组分(C1q)与结合其同源抗原的(适当子类的)抗体的结合来起始。为了评估补体活化,可执行CDC测定,例如,如Gazzano-Santoro等,J.Immunol.Methods 202:163(1996)中所述。Fc区氨基酸序列改变和C1q结合能力增加或减小的抗体变体描述于美国专利第6,194,551B1号和WO99/51642中。所述专利公开的内容以引用的方式明确地并入本文中。还参见Idusogie等,J.Immunol.164:4178-4184(2000)。
“结合亲和力”通常是指分子(例如抗体)的单一结合位点与其结合搭配物(例如抗原)之间的非共价相互作用的总强度。除非另外指示,否则如本文所用,“结合亲和力”是指反映结合对成员之间的1:1相互作用的固有结合亲和力。结合亲和力可通过Kd、Koff、Kon或Ka指示。如本文所用,术语“Koff”意欲指代抗体(或抗原结合域)从抗体/抗原复合物中解离的解离速率常数,如从动力学选择设置所确定,以s-1为单位表示。如本文所用,术语“Kon”意欲指代抗体(或抗原结合域)与抗原缔合以形成抗体/抗原复合物的缔合速率常数,以M-1s-1为单位表示。如本文所用,术语平衡解离常数“KD”或“Kd”是指特定抗体-抗原相互作用的解离常数,并且描述在平衡时占据存在于抗体分子溶液中的所有抗体结合域的一半所需的抗原浓度,并且等于Koff/Kon,以M为单位表示。Kd的测量预先假定所有结合剂都在溶液中。在抗体系留于细胞壁的情况下,例如在酵母表达系统中,相应的平衡速率常数表示为EC50,这给出Kd的良好近似值。亲和力常数Ka是解离常数Kd的倒数,以M-1为单位表示。解离常数(KD或Kd)用作显示抗体与抗原的亲和力的指标。例如,通过使用标记有多种标记物试剂的抗体的Scatchard方法,以及通过使用BiacoreX(Amersham Biosciences制造)(其是直接出售的测量试剂盒)或类似试剂盒根据试剂盒附带的用户手册和实验操作方法,有可能进行简单的分析。可以使用这些方法导出的KD值以M(摩尔)为单位表示。特异性结合靶标的抗体或其抗原结合片段可具有例如≤10-5M、≤10-6M、≤10-7M、≤10-8M、≤10-9M、≤10-10M、≤10-11M或≤10-12M的解离常数(Kd)。
半数最大抑制浓度(IC50)是物质(例如抗体)抑制特定生物或生物化学功能的有效性的量度。其指示抑制给定生物过程(例如,PD-1与PD-L1/PD-L2,或过程的组分即酶、细胞、细胞受体或微生物之间的结合)达一半需要多少特定药物或其它物质(抑制剂,例如抗体)。所述值通常表示为摩尔浓度。对于激动剂药物或其它物质(例如抗体)的IC50与“EC50”相当。EC50还表示在体内获得最大作用的50%所需的血浆浓度。如本文所用,“IC50”用于指示在体外中和50%抗原生物活性(例如PD-1生物活性)所需的抗体(例如抗PD-1 sdAb)的有效浓度。IC50或EC50可通过生物测定进行测量,例如通过FACS的配体结合抑制分析(竞争结合测定)、基于细胞的细胞因子释放测定或放大发光邻近均相测定(AlphaLISA)。
关于肽、多肽或抗体序列的“氨基酸序列同一性百分比(%)”和“同源性”定义为,在比对序列并引入空位(如果需要)以达到最大序列同一性百分比之后,候选序列中与特定肽或多肽序列中氨基酸残基相同的氨基酸残基的百分比,并且不将任何保守取代视为序列同一性的一部分。出于确定氨基酸序列同一性百分比的目的所进行的比对可以本领域技术范围内的各种方式实现,例如使用公众可用的计算机软件,例如BLAST、BLAST-2、ALIGN或MEGALIGNTM(DNASTAR)软件。本领域技术人员可确定测量比对的适当参数,包括在所比较的序列的全长范围内达到最大比对所需的任何算法。
编码本文所述的构建体、抗体或其抗原结合片段的“分离的”核酸分子是经过鉴定并且与至少一种在其产生环境中普遍与之缔合的污染物核酸分子分离的核酸分子。优选地,分离的核酸分子不与所有与产生环境相关的组分缔合。编码本文所述的多肽和抗体的分离的核酸分子是除了其在自然界中存在的形式或情况以外的形式。因此分离的核酸分子区别于天然存在于细胞中编码本文所述的多肽和抗体的核酸。分离的核酸包括普遍含有核酸分子的细胞中所含有的核酸分子,但所述核酸分子存在于染色体外或存在于与其天然染色体位置不同的染色体位置处。
术语“控制序列”是指在特定宿主有机体中表达可操作地连接的编码序列所必需的DNA序列。适于原核生物的控制序列例如包括启动子、任选地操纵子序列和核糖体结合位点。已知真核细胞利用启动子、聚腺苷酸化信号和增强子。
当核酸与另一核酸序列处于某一功能关系时,其是“可操作地连接”。例如,如果用于前序列或分泌前导序列的DNA被表达为参与多肽的分泌的前蛋白,则其可操作性连接至用于多肽的DNA;如果启动子或增强子影响编码序列的转录,则其可操作性连接至所述序列;或如果核糖体结合位点被定位成促进翻译,则其可操作性连接至编码序列。通常,“可操作地连接”意指连接的DNA序列是邻近的,并且在分泌前导序列的情况下,是邻近的并处于阅读相中。然而,增强子不必是邻近的。连接通过在适宜限制位点处的接合实现。如果此类位点不存在,则根据常规实践使用合成寡核苷酸衔接子(adaptor)或接头。
如本文所用,术语“载体”是指能够增殖与之连接的另一核酸的核酸分子。所述术语包括呈自我复制核酸结构的载体以及并入其所引入的宿主细胞的基因组中的载体。某些载体能够引导与其可操作地连接的核酸的表达。这类载体在本文中称为“表达载体”。
如本文所用的术语“转染”或“转化”或“转导”是指将外源性核酸转移或引入至宿主细胞中的过程。“转染”或“转化”或“转导”细胞是已经转染、转化或转导有外源性核酸的细胞。细胞包括原代受试者细胞和其后代。
术语“宿主细胞”、“宿主细胞系”和“宿主细胞培养物”可互换使用并且指代已引入外源性核酸的细胞,包括这类细胞的后代。宿主细胞包括“转化体”和“转化细胞”,其包括原代转化细胞和源于其的后代而不考虑继代数目。后代可能在核酸含量方面不与亲本细胞完全一致,但可含有突变。本文中包括如在原始转化细胞中所筛选或选择具有相同功能或生物活性的突变型后代。
“辅助环境”是指个体已具有癌症病史并且通常(但不必要)对疗法有反应的临床环境,所述疗法包括但不限于手术(例如,手术切除)、放射疗法和化学疗法。然而,这些个体因其癌症病史而被视为处于发展疾病的风险。“辅助环境”中的治疗或施用是指随后的治疗模式。风险程度(例如,当辅助环境中的个体被视为“高风险”或“低风险”时)取决于若干因素,最通常是首次治疗时的疾病程度。
“新辅助环境”是指在初步/确定性疗法之前进行方法的临床环境。
术语“药物组合物”的“药物制剂”是指以下制剂,其以允许活性成分的生物活性有效的形式,并且不含有对施用制剂的受试者有不可接受毒性的额外组分。这样的制剂是无菌的。“无菌”制剂是灭菌的或不含所有活的微生物和其孢子。
应理解,本文所述的本发明的实施方案包括“由实施方案组成”和/或“基本上由实施方案组成”。
本文中对“约”某值或参数的提及包括(并描述)关于所述值或参数本身的变化。例如,提及“约X”的描述包括“X”的描述。
如本文所用,对“非”某值或参数的提及通常是指并描述“除”某值或参数之外。例如,所述方法不用于治疗X型癌症意指所述方法用于治疗除X之外类型的癌症。
除非上下文另外明确规定,否则如本文和所附权利要求书中所用,单数形式“一”、“或”和“所述”包括复数个所指物。
II.抗PD-1构建体
(I)抗PD-1单域抗体部分
本文所述的分离的抗PD-1构建体包含特异性识别PD-1(或“抗PD-1 sdAb”)的单域抗体(sdAb)部分。在一些实施方案中,分离的抗PD-1构建体是抗PD-1 sdAb。
在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:37-72中的任一者的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:109-144中的任一者的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:181-216中的任一者的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,抗PD-1 sdAb部分与PD-1之间的结合的Kd是约10-5M至约10-12M(例如约10-7M至约10-12M、或约10-8M至约10-12M)。在一些实施方案中,抗PD-1 sdAb部分是骆驼科的、嵌合的、人类的、部分人源化的或完全人源化的抗PD-1 sdAb部分。
在一些实施方案中,抗PD-1 sdAb部分包含CDR3,所述CDR3包含SEQ ID NO:181-216中的任一者的氨基酸序列,并且氨基酸取代在CDR1和/或CDR2中。因此,在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:37-72中的任一者的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:109-144中的任一者的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:181-216中的任一者的氨基酸序列的CDR3。在一些实施方案中,抗PD-1 sdAb部分与PD-1之间的结合的Kd是约10-5M至约10-12M(例如约10-7M至约10-12M、或约10-8M至约10-12M)。在一些实施方案中,抗PD-1 sdAb部分是骆驼科的、嵌合的、人类的、部分人源化的或完全人源化的抗PD-1 sdAb部分。
在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:37-72中的任一者的氨基酸序列的CDR1;包含SEQ ID NO:109-144中的任一者的氨基酸序列的CDR2;和包含SEQ ID NO:181-216中的任一者的氨基酸序列的CDR3;或所述CDR的在CDR区中包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,氨基酸取代在CDR1和/或CDR2中。在一些实施方案中,提供一种抗PD-1sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:37-72中的任一者的氨基酸序列的CDR1;包含SEQ ID NO:109-144中的任一者的氨基酸序列的CDR2;和包含SEQ ID NO:181-216中的任一者的氨基酸序列的CDR3;或所述CDR的在CDR区中包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体,其中氨基酸取代在CDR1和/或CDR2中。在一些实施方案中,抗PD-1 sdAb部分与PD-1之间的结合的Kd是约10-5M至约10-12M(例如约10-7M至约10-12M、或约10-8M至约10-12M)。在一些实施方案中,抗PD-1 sdAb部分是骆驼科的、嵌合的、人类的、部分人源化的或完全人源化的抗PD-1 sdAb部分。
在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:37-72中的任一者的氨基酸序列的CDR1;包含SEQ ID NO:109-144中的任一者的氨基酸序列的CDR2;和包含SEQ ID NO:181-216中的任一者的氨基酸序列的CDR3。在一些实施方案中,抗PD-1 sdAb部分与PD-1之间的结合的Kd是约10-5M至约10-12M(例如约10-7M至约10-12M、或约10-8M至约10-12M)。在一些实施方案中,抗PD-1 sdAb部分是骆驼科的、嵌合的、人类的、部分人源化的或完全人源化的抗PD-1 sdAb部分。
本文所说明的CDR的序列提供于表3中。所述CDR可以各种成对组合的形式组合以生成许多抗PD-1 sdAb部分。
例如,在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:37的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:109的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:181的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:37的氨基酸序列的CDR1;包含SEQ ID NO:109的氨基酸序列的CDR2;和包含SEQ ID NO:181的氨基酸序列的CDR3;或所述CDR的在CDR区中包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,氨基酸取代在CDR1和/或CDR2中。在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:37的氨基酸序列的CDR1;包含SEQ ID NO:109的氨基酸序列的CDR2;和包含SEQ ID NO:181的氨基酸序列的CDR3。在一些实施方案中,抗PD-1 sdAb部分与PD-1之间的结合的Kd是约10-5M至约10-12M(例如约10-7M至约10-12M、或约10-8M至约10-12M)。在一些实施方案中,抗PD-1 sdAb部分是骆驼科的、嵌合的、人类的、部分人源化的或完全人源化的抗PD-1 sdAb部分。
在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:38的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:110的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:182的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:38的氨基酸序列的CDR1;包含SEQ ID NO:110的氨基酸序列的CDR2;和包含SEQ ID NO:182的氨基酸序列的CDR3;或所述CDR的在CDR区中包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,氨基酸取代在CDR1和/或CDR2中。在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:38的氨基酸序列的CDR1;包含SEQ ID NO:110的氨基酸序列的CDR2;和包含SEQ ID NO:182的氨基酸序列的CDR3。在一些实施方案中,抗PD-1 sdAb部分与PD-1之间的结合的Kd是约10-5M至约10-12M(例如约10-7M至约10-12M、或约10-8M至约10-12M)。在一些实施方案中,抗PD-1 sdAb部分是骆驼科的、嵌合的、人类的、部分人源化的或完全人源化的抗PD-1 sdAb部分。
在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:39的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:111的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:183的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:39的氨基酸序列的CDR1;包含SEQ ID NO:111的氨基酸序列的CDR2;和包含SEQ ID NO:183的氨基酸序列的CDR3;或所述CDR的在CDR区中包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,氨基酸取代在CDR1和/或CDR2中。在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:39的氨基酸序列的CDR1;包含SEQ ID NO:111的氨基酸序列的CDR2;和包含SEQ ID NO:183的氨基酸序列的CDR3。在一些实施方案中,抗PD-1 sdAb部分与PD-1之间的结合的Kd是约10-5M至约10-12M(例如约10-7M至约10-12M、或约10-8M至约10-12M)。在一些实施方案中,抗PD-1 sdAb部分是骆驼科的、嵌合的、人类的、部分人源化的或完全人源化的抗PD-1 sdAb部分。
在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:40的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:112的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:184的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:40的氨基酸序列的CDR1;包含SEQ ID NO:112的氨基酸序列的CDR2;和包含SEQ ID NO:184的氨基酸序列的CDR3;或所述CDR的在CDR区中包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,氨基酸取代在CDR1和/或CDR2中。在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:40的氨基酸序列的CDR1;包含SEQ ID NO:112的氨基酸序列的CDR2;和包含SEQ ID NO:184的氨基酸序列的CDR3。在一些实施方案中,抗PD-1 sdAb部分与PD-1之间的结合的Kd是约10-5M至约10-12M(例如约10-7M至约10-12M、或约10-8M至约10-12M)。在一些实施方案中,抗PD-1 sdAb部分是骆驼科的、嵌合的、人类的、部分人源化的或完全人源化的抗PD-1 sdAb部分。
在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:41的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:113的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:185的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:41的氨基酸序列的CDR1;包含SEQ ID NO:113的氨基酸序列的CDR2;和包含SEQ ID NO:185的氨基酸序列的CDR3;或所述CDR的在CDR区中包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,氨基酸取代在CDR1和/或CDR2中。在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:41的氨基酸序列的CDR1;包含SEQ ID NO:113的氨基酸序列的CDR2;和包含SEQ ID NO:185的氨基酸序列的CDR3。在一些实施方案中,抗PD-1 sdAb部分与PD-1之间的结合的Kd是约10-5M至约10-12M(例如约10-7M至约10-12M、或约10-8M至约10-12M)。在一些实施方案中,抗PD-1 sdAb部分是骆驼科的、嵌合的、人类的、部分人源化的或完全人源化的抗PD-1 sdAb部分。
在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:42的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:114的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:186的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:42的氨基酸序列的CDR1;包含SEQ ID NO:114的氨基酸序列的CDR2;和包含SEQ ID NO:186的氨基酸序列的CDR3;或所述CDR的在CDR区中包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,氨基酸取代在CDR1和/或CDR2中。在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:42的氨基酸序列的CDR1;包含SEQ ID NO:114的氨基酸序列的CDR2;和包含SEQ ID NO:186的氨基酸序列的CDR3。在一些实施方案中,抗PD-1 sdAb部分与PD-1之间的结合的Kd是约10-5M至约10-12M(例如约10-7M至约10-12M、或约10-8M至约10-12M)。在一些实施方案中,抗PD-1 sdAb部分是骆驼科的、嵌合的、人类的、部分人源化的或完全人源化的抗PD-1 sdAb部分。
在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:43的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:115的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:187的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:43的氨基酸序列的CDR1;包含SEQ ID NO:115的氨基酸序列的CDR2;和包含SEQ ID NO:187的氨基酸序列的CDR3;或所述CDR的在CDR区中包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,氨基酸取代在CDR1和/或CDR2中。在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:43的氨基酸序列的CDR1;包含SEQ ID NO:115的氨基酸序列的CDR2;和包含SEQ ID NO:187的氨基酸序列的CDR3。在一些实施方案中,抗PD-1 sdAb部分与PD-1之间的结合的Kd是约10-5M至约10-12M(例如约10-7M至约10-12M、或约10-8M至约10-12M)。在一些实施方案中,抗PD-1 sdAb部分是骆驼科的、嵌合的、人类的、部分人源化的或完全人源化的抗PD-1 sdAb部分。
在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:44的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:116的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:188的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:44的氨基酸序列的CDR1;包含SEQ ID NO:116的氨基酸序列的CDR2;和包含SEQ ID NO:188的氨基酸序列的CDR3;或所述CDR的在CDR区中包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,氨基酸取代在CDR1和/或CDR2中。在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:44的氨基酸序列的CDR1;包含SEQ ID NO:116的氨基酸序列的CDR2;和包含SEQ ID NO:188的氨基酸序列的CDR3。在一些实施方案中,抗PD-1 sdAb部分与PD-1之间的结合的Kd是约10-5M至约10-12M(例如约10-7M至约10-12M、或约10-8M至约10-12M)。在一些实施方案中,抗PD-1 sdAb部分是骆驼科的、嵌合的、人类的、部分人源化的或完全人源化的抗PD-1 sdAb部分。
在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:45的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:117的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:189的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:45的氨基酸序列的CDR1;包含SEQ ID NO:117的氨基酸序列的CDR2;和包含SEQ ID NO:189的氨基酸序列的CDR3;或所述CDR的在CDR区中包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,氨基酸取代在CDR1和/或CDR2中。在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:45的氨基酸序列的CDR1;包含SEQ ID NO:117的氨基酸序列的CDR2;和包含SEQ ID NO:189的氨基酸序列的CDR3。在一些实施方案中,抗PD-1 sdAb部分与PD-1之间的结合的Kd是约10-5M至约10-12M(例如约10-7M至约10-12M、或约10-8M至约10-12M)。在一些实施方案中,抗PD-1 sdAb部分是骆驼科的、嵌合的、人类的、部分人源化的或完全人源化的抗PD-1 sdAb部分。
在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:46的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:118的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:190的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:46的氨基酸序列的CDR1;包含SEQ ID NO:118的氨基酸序列的CDR2;和包含SEQ ID NO:190的氨基酸序列的CDR3;或所述CDR的在CDR区中包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,氨基酸取代在CDR1和/或CDR2中。在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:46的氨基酸序列的CDR1;包含SEQ ID NO:118的氨基酸序列的CDR2;和包含SEQ ID NO:190的氨基酸序列的CDR3。在一些实施方案中,抗PD-1 sdAb部分与PD-1之间的结合的Kd是约10-5M至约10-12M(例如约10-7M至约10-12M、或约10-8M至约10-12M)。在一些实施方案中,抗PD-1 sdAb部分是骆驼科的、嵌合的、人类的、部分人源化的或完全人源化的抗PD-1 sdAb部分。
在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:47的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:119的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:191的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:47的氨基酸序列的CDR1;包含SEQ ID NO:119的氨基酸序列的CDR2;和包含SEQ ID NO:191的氨基酸序列的CDR3;或所述CDR的在CDR区中包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,氨基酸取代在CDR1和/或CDR2中。在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:47的氨基酸序列的CDR1;包含SEQ ID NO:119的氨基酸序列的CDR2;和包含SEQ ID NO:191的氨基酸序列的CDR3。在一些实施方案中,抗PD-1 sdAb部分与PD-1之间的结合的Kd是约10-5M至约10-12M(例如约10-7M至约10-12M、或约10-8M至约10-12M)。在一些实施方案中,抗PD-1 sdAb部分是骆驼科的、嵌合的、人类的、部分人源化的或完全人源化的抗PD-1 sdAb部分。
在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:48的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:120的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:192的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:48的氨基酸序列的CDR1;包含SEQ ID NO:120的氨基酸序列的CDR2;和包含SEQ ID NO:192的氨基酸序列的CDR3;或所述CDR的在CDR区中包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,氨基酸取代在CDR1和/或CDR2中。在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:48的氨基酸序列的CDR1;包含SEQ ID NO:120的氨基酸序列的CDR2;和包含SEQ ID NO:192的氨基酸序列的CDR3。在一些实施方案中,抗PD-1 sdAb部分与PD-1之间的结合的Kd是约10-5M至约10-12M(例如约10-7M至约10-12M、或约10-8M至约10-12M)。在一些实施方案中,抗PD-1 sdAb部分是骆驼科的、嵌合的、人类的、部分人源化的或完全人源化的抗PD-1 sdAb部分。
在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:49的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:121的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:193的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:49的氨基酸序列的CDR1;包含SEQ ID NO:121的氨基酸序列的CDR2;和包含SEQ ID NO:193的氨基酸序列的CDR3;或所述CDR的在CDR区中包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,氨基酸取代在CDR1和/或CDR2中。在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:49的氨基酸序列的CDR1;包含SEQ ID NO:121的氨基酸序列的CDR2;和包含SEQ ID NO:193的氨基酸序列的CDR3。在一些实施方案中,抗PD-1 sdAb部分与PD-1之间的结合的Kd是约10-5M至约10-12M(例如约10-7M至约10-12M、或约10-8M至约10-12M)。在一些实施方案中,抗PD-1 sdAb部分是骆驼科的、嵌合的、人类的、部分人源化的或完全人源化的抗PD-1 sdAb部分。
在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:50的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:122的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:194的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:50的氨基酸序列的CDR1;包含SEQ ID NO:122的氨基酸序列的CDR2;和包含SEQ ID NO:194的氨基酸序列的CDR3;或所述CDR的在CDR区中包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,氨基酸取代在CDR1和/或CDR2中。在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:50的氨基酸序列的CDR1;包含SEQ ID NO:122的氨基酸序列的CDR2;和包含SEQ ID NO:194的氨基酸序列的CDR3。在一些实施方案中,抗PD-1 sdAb部分与PD-1之间的结合的Kd是约10-5M至约10-12M(例如约10-7M至约10-12M、或约10-8M至约10-12M)。在一些实施方案中,抗PD-1 sdAb部分是骆驼科的、嵌合的、人类的、部分人源化的或完全人源化的抗PD-1 sdAb部分。
在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:51的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:123的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:195的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:51的氨基酸序列的CDR1;包含SEQ ID NO:123的氨基酸序列的CDR2;和包含SEQ ID NO:195的氨基酸序列的CDR3;或所述CDR的在CDR区中包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,氨基酸取代在CDR1和/或CDR2中。在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:51的氨基酸序列的CDR1;包含SEQ ID NO:123的氨基酸序列的CDR2;和包含SEQ ID NO:195的氨基酸序列的CDR3。在一些实施方案中,抗PD-1 sdAb部分与PD-1之间的结合的Kd是约10-5M至约10-12M(例如约10-7M至约10-12M、或约10-8M至约10-12M)。在一些实施方案中,抗PD-1 sdAb部分是骆驼科的、嵌合的、人类的、部分人源化的或完全人源化的抗PD-1 sdAb部分。
在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:52的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:124的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:196的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:52的氨基酸序列的CDR1;包含SEQ ID NO:124的氨基酸序列的CDR2;和包含SEQ ID NO:196的氨基酸序列的CDR3;或所述CDR的在CDR区中包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,氨基酸取代在CDR1和/或CDR2中。在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:52的氨基酸序列的CDR1;包含SEQ ID NO:124的氨基酸序列的CDR2;和包含SEQ ID NO:196的氨基酸序列的CDR3。在一些实施方案中,抗PD-1 sdAb部分与PD-1之间的结合的Kd是约10-5M至约10-12M(例如约10-7M至约10-12M、或约10-8M至约10-12M)。在一些实施方案中,抗PD-1 sdAb部分是骆驼科的、嵌合的、人类的、部分人源化的或完全人源化的抗PD-1 sdAb部分。
在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:53的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:125的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:197的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:53的氨基酸序列的CDR1;包含SEQ ID NO:125的氨基酸序列的CDR2;和包含SEQ ID NO:197的氨基酸序列的CDR3;或所述CDR的在CDR区中包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,氨基酸取代在CDR1和/或CDR2中。在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:53的氨基酸序列的CDR1;包含SEQ ID NO:125的氨基酸序列的CDR2;和包含SEQ ID NO:197的氨基酸序列的CDR3。在一些实施方案中,抗PD-1 sdAb部分与PD-1之间的结合的Kd是约10-5M至约10-12M(例如约10-7M至约10-12M、或约10-8M至约10-12M)。在一些实施方案中,抗PD-1 sdAb部分是骆驼科的、嵌合的、人类的、部分人源化的或完全人源化的抗PD-1 sdAb部分。
在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:54的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:126的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:198的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:54的氨基酸序列的CDR1;包含SEQ ID NO:126的氨基酸序列的CDR2;和包含SEQ ID NO:198的氨基酸序列的CDR3;或所述CDR的在CDR区中包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,氨基酸取代在CDR1和/或CDR2中。在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:54的氨基酸序列的CDR1;包含SEQ ID NO:126的氨基酸序列的CDR2;和包含SEQ ID NO:198的氨基酸序列的CDR3。在一些实施方案中,抗PD-1 sdAb部分与PD-1之间的结合的Kd是约10-5M至约10-12M(例如约10-7M至约10-12M、或约10-8M至约10-12M)。在一些实施方案中,抗PD-1 sdAb部分是骆驼科的、嵌合的、人类的、部分人源化的或完全人源化的抗PD-1 sdAb部分。
在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:55的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:127的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:199的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:55的氨基酸序列的CDR1;包含SEQ ID NO:127的氨基酸序列的CDR2;和包含SEQ ID NO:199的氨基酸序列的CDR3;或所述CDR的在CDR区中包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,氨基酸取代在CDR1和/或CDR2中。在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:55的氨基酸序列的CDR1;包含SEQ ID NO:127的氨基酸序列的CDR2;和包含SEQ ID NO:199的氨基酸序列的CDR3。在一些实施方案中,抗PD-1 sdAb部分与PD-1之间的结合的Kd是约10-5M至约10-12M(例如约10-7M至约10-12M、或约10-8M至约10-12M)。在一些实施方案中,抗PD-1 sdAb部分是骆驼科的、嵌合的、人类的、部分人源化的或完全人源化的抗PD-1 sdAb部分。
在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:56的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:128的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:200的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:56的氨基酸序列的CDR1;包含SEQ ID NO:128的氨基酸序列的CDR2;和包含SEQ ID NO:200的氨基酸序列的CDR3;或所述CDR的在CDR区中包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,氨基酸取代在CDR1和/或CDR2中。在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:56的氨基酸序列的CDR1;包含SEQ ID NO:128的氨基酸序列的CDR2;和包含SEQ ID NO:200的氨基酸序列的CDR3。在一些实施方案中,抗PD-1 sdAb部分与PD-1之间的结合的Kd是约10-5M至约10-12M(例如约10-7M至约10-12M、或约10-8M至约10-12M)。在一些实施方案中,抗PD-1 sdAb部分是骆驼科的、嵌合的、人类的、部分人源化的或完全人源化的抗PD-1 sdAb部分。
在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:57的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:129的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:201的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:57的氨基酸序列的CDR1;包含SEQ ID NO:129的氨基酸序列的CDR2;和包含SEQ ID NO:201的氨基酸序列的CDR3;或所述CDR的在CDR区中包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,氨基酸取代在CDR1和/或CDR2中。在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:57的氨基酸序列的CDR1;包含SEQ ID NO:129的氨基酸序列的CDR2;和包含SEQ ID NO:201的氨基酸序列的CDR3。在一些实施方案中,抗PD-1 sdAb部分与PD-1之间的结合的Kd是约10-5M至约10-12M(例如约10-7M至约10-12M、或约10-8M至约10-12M)。在一些实施方案中,抗PD-1 sdAb部分是骆驼科的、嵌合的、人类的、部分人源化的或完全人源化的抗PD-1 sdAb部分。
在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:58的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:130的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:202的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:58的氨基酸序列的CDR1;包含SEQ ID NO:130的氨基酸序列的CDR2;和包含SEQ ID NO:202的氨基酸序列的CDR3;或所述CDR的在CDR区中包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,氨基酸取代在CDR1和/或CDR2中。在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:58的氨基酸序列的CDR1;包含SEQ ID NO:130的氨基酸序列的CDR2;和包含SEQ ID NO:202的氨基酸序列的CDR3。在一些实施方案中,抗PD-1 sdAb部分与PD-1之间的结合的Kd是约10-5M至约10-12M(例如约10-7M至约10-12M、或约10-8M至约10-12M)。在一些实施方案中,抗PD-1 sdAb部分是骆驼科的、嵌合的、人类的、部分人源化的或完全人源化的抗PD-1 sdAb部分。
在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:59的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:131的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:203的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:59的氨基酸序列的CDR1;包含SEQ ID NO:131的氨基酸序列的CDR2;和包含SEQ ID NO:203的氨基酸序列的CDR3;或所述CDR的在CDR区中包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,氨基酸取代在CDR1和/或CDR2中。在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:59的氨基酸序列的CDR1;包含SEQ ID NO:131的氨基酸序列的CDR2;和包含SEQ ID NO:203的氨基酸序列的CDR3。在一些实施方案中,抗PD-1 sdAb部分与PD-1之间的结合的Kd是约10-5M至约10-12M(例如约10-7M至约10-12M、或约10-8M至约10-12M)。在一些实施方案中,抗PD-1 sdAb部分是骆驼科的、嵌合的、人类的、部分人源化的或完全人源化的抗PD-1 sdAb部分。
在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:60的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:132的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:204的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:60的氨基酸序列的CDR1;包含SEQ ID NO:132的氨基酸序列的CDR2;和包含SEQ ID NO:204的氨基酸序列的CDR3;或所述CDR的在CDR区中包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,氨基酸取代在CDR1和/或CDR2中。在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:60的氨基酸序列的CDR1;包含SEQ ID NO:132的氨基酸序列的CDR2;和包含SEQ ID NO:204的氨基酸序列的CDR3。在一些实施方案中,抗PD-1 sdAb部分与PD-1之间的结合的Kd是约10-5M至约10-12M(例如约10-7M至约10-12M、或约10-8M至约10-12M)。在一些实施方案中,抗PD-1 sdAb部分是骆驼科的、嵌合的、人类的、部分人源化的或完全人源化的抗PD-1 sdAb部分。
在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:61的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:133的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:205的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:61的氨基酸序列的CDR1;包含SEQ ID NO:133的氨基酸序列的CDR2;和包含SEQ ID NO:205的氨基酸序列的CDR3;或所述CDR的在CDR区中包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,氨基酸取代在CDR1和/或CDR2中。在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:61的氨基酸序列的CDR1;包含SEQ ID NO:133的氨基酸序列的CDR2;和包含SEQ ID NO:205的氨基酸序列的CDR3。在一些实施方案中,抗PD-1 sdAb部分与PD-1之间的结合的Kd是约10-5M至约10-12M(例如约10-7M至约10-12M、或约10-8M至约10-12M)。在一些实施方案中,抗PD-1 sdAb部分是骆驼科的、嵌合的、人类的、部分人源化的或完全人源化的抗PD-1 sdAb部分。
在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:62的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:134的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:206的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:62的氨基酸序列的CDR1;包含SEQ ID NO:134的氨基酸序列的CDR2;和包含SEQ ID NO:206的氨基酸序列的CDR3;或所述CDR的在CDR区中包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,氨基酸取代在CDR1和/或CDR2中。在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:62的氨基酸序列的CDR1;包含SEQ ID NO:134的氨基酸序列的CDR2;和包含SEQ ID NO:206的氨基酸序列的CDR3。在一些实施方案中,抗PD-1 sdAb部分与PD-1之间的结合的Kd是约10-5M至约10-12M(例如约10-7M至约10-12M、或约10-8M至约10-12M)。在一些实施方案中,抗PD-1 sdAb部分是骆驼科的、嵌合的、人类的、部分人源化的或完全人源化的抗PD-1 sdAb部分。
在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:63的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:135的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:207的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:63的氨基酸序列的CDR1;包含SEQ ID NO:135的氨基酸序列的CDR2;和包含SEQ ID NO:207的氨基酸序列的CDR3;或所述CDR的在CDR区中包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,氨基酸取代在CDR1和/或CDR2中。在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:63的氨基酸序列的CDR1;包含SEQ ID NO:135的氨基酸序列的CDR2;和包含SEQ ID NO:207的氨基酸序列的CDR3。在一些实施方案中,抗PD-1 sdAb部分与PD-1之间的结合的Kd是约10-5M至约10-12M(例如约10-7M至约10-12M、或约10-8M至约10-12M)。在一些实施方案中,抗PD-1 sdAb部分是骆驼科的、嵌合的、人类的、部分人源化的或完全人源化的抗PD-1 sdAb部分。
在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:64的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:136的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:208的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:64的氨基酸序列的CDR1;包含SEQ ID NO:136的氨基酸序列的CDR2;和包含SEQ ID NO:208的氨基酸序列的CDR3;或所述CDR的在CDR区中包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,氨基酸取代在CDR1和/或CDR2中。在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:64的氨基酸序列的CDR1;包含SEQ ID NO:136的氨基酸序列的CDR2;和包含SEQ ID NO:208的氨基酸序列的CDR3。在一些实施方案中,抗PD-1 sdAb部分与PD-1之间的结合的Kd是约10-5M至约10-12M(例如约10-7M至约10-12M、或约10-8M至约10-12M)。在一些实施方案中,抗PD-1 sdAb部分是骆驼科的、嵌合的、人类的、部分人源化的或完全人源化的抗PD-1 sdAb部分。
在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:65的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:137的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:209的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:65的氨基酸序列的CDR1;包含SEQ ID NO:137的氨基酸序列的CDR2;和包含SEQ ID NO:209的氨基酸序列的CDR3;或所述CDR的在CDR区中包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,氨基酸取代在CDR1和/或CDR2中。在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:65的氨基酸序列的CDR1;包含SEQ ID NO:137的氨基酸序列的CDR2;和包含SEQ ID NO:209的氨基酸序列的CDR3。在一些实施方案中,抗PD-1 sdAb部分与PD-1之间的结合的Kd是约10-5M至约10-12M(例如约10-7M至约10-12M、或约10-8M至约10-12M)。在一些实施方案中,抗PD-1 sdAb部分是骆驼科的、嵌合的、人类的、部分人源化的或完全人源化的抗PD-1 sdAb部分。
在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:66的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:138的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:210的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:66的氨基酸序列的CDR1;包含SEQ ID NO:138的氨基酸序列的CDR2;和包含SEQ ID NO:210的氨基酸序列的CDR3;或所述CDR的在CDR区中包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,氨基酸取代在CDR1和/或CDR2中。在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:66的氨基酸序列的CDR1;包含SEQ ID NO:138的氨基酸序列的CDR2;和包含SEQ ID NO:210的氨基酸序列的CDR3。在一些实施方案中,抗PD-1 sdAb部分与PD-1之间的结合的Kd是约10-5M至约10-12M(例如约10-7M至约10-12M、或约10-8M至约10-12M)。在一些实施方案中,抗PD-1 sdAb部分是骆驼科的、嵌合的、人类的、部分人源化的或完全人源化的抗PD-1 sdAb部分。
在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:67的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:139的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:211的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:67的氨基酸序列的CDR1;包含SEQ ID NO:139的氨基酸序列的CDR2;和包含SEQ ID NO:211的氨基酸序列的CDR3;或所述CDR的在CDR区中包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,氨基酸取代在CDR1和/或CDR2中。在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:67的氨基酸序列的CDR1;包含SEQ ID NO:139的氨基酸序列的CDR2;和包含SEQ ID NO:211的氨基酸序列的CDR3。在一些实施方案中,抗PD-1 sdAb部分与PD-1之间的结合的Kd是约10-5M至约10-12M(例如约10-7M至约10-12M、或约10-8M至约10-12M)。在一些实施方案中,抗PD-1 sdAb部分是骆驼科的、嵌合的、人类的、部分人源化的或完全人源化的抗PD-1 sdAb部分。
在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:68的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:140的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:212的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:68的氨基酸序列的CDR1;包含SEQ ID NO:140的氨基酸序列的CDR2;和包含SEQ ID NO:212的氨基酸序列的CDR3;或所述CDR的在CDR区中包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,氨基酸取代在CDR1和/或CDR2中。在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:68的氨基酸序列的CDR1;包含SEQ ID NO:140的氨基酸序列的CDR2;和包含SEQ ID NO:212的氨基酸序列的CDR3。在一些实施方案中,抗PD-1 sdAb部分与PD-1之间的结合的Kd是约10-5M至约10-12M(例如约10-7M至约10-12M、或约10-8M至约10-12M)。在一些实施方案中,抗PD-1 sdAb部分是骆驼科的、嵌合的、人类的、部分人源化的或完全人源化的抗PD-1 sdAb部分。
在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:69的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:141的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:213的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:69的氨基酸序列的CDR1;包含SEQ ID NO:141的氨基酸序列的CDR2;和包含SEQ ID NO:213的氨基酸序列的CDR3;或所述CDR的在CDR区中包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,氨基酸取代在CDR1和/或CDR2中。在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:69的氨基酸序列的CDR1;包含SEQ ID NO:141的氨基酸序列的CDR2;和包含SEQ ID NO:213的氨基酸序列的CDR3。在一些实施方案中,抗PD-1 sdAb部分与PD-1之间的结合的Kd是约10-5M至约10-12M(例如约10-7M至约10-12M、或约10-8M至约10-12M)。在一些实施方案中,抗PD-1 sdAb部分是骆驼科的、嵌合的、人类的、部分人源化的或完全人源化的抗PD-1 sdAb部分。
在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:70的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:142的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:214的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:70的氨基酸序列的CDR1;包含SEQ ID NO:142的氨基酸序列的CDR2;和包含SEQ ID NO:214的氨基酸序列的CDR3;或所述CDR的在CDR区中包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,氨基酸取代在CDR1和/或CDR2中。在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:70的氨基酸序列的CDR1;包含SEQ ID NO:142的氨基酸序列的CDR2;和包含SEQ ID NO:214的氨基酸序列的CDR3。在一些实施方案中,抗PD-1 sdAb部分与PD-1之间的结合的Kd是约10-5M至约10-12M(例如约10-7M至约10-12M、或约10-8M至约10-12M)。在一些实施方案中,抗PD-1 sdAb部分是骆驼科的、嵌合的、人类的、部分人源化的或完全人源化的抗PD-1 sdAb部分。
在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:71的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:143的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:215的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:71的氨基酸序列的CDR1;包含SEQ ID NO:143的氨基酸序列的CDR2;和包含SEQ ID NO:215的氨基酸序列的CDR3;或所述CDR的在CDR区中包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,氨基酸取代在CDR1和/或CDR2中。在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:71的氨基酸序列的CDR1;包含SEQ ID NO:143的氨基酸序列的CDR2;和包含SEQ ID NO:215的氨基酸序列的CDR3。在一些实施方案中,抗PD-1 sdAb部分与PD-1之间的结合的Kd是约10-5M至约10-12M(例如约10-7M至约10-12M、或约10-8M至约10-12M)。在一些实施方案中,抗PD-1 sdAb部分是骆驼科的、嵌合的、人类的、部分人源化的或完全人源化的抗PD-1 sdAb部分。
在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:72的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:144的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:216的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:72的氨基酸序列的CDR1;包含SEQ ID NO:144的氨基酸序列的CDR2;和包含SEQ ID NO:216的氨基酸序列的CDR3;或所述CDR的在CDR区中包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,氨基酸取代在CDR1和/或CDR2中。在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:72的氨基酸序列的CDR1;包含SEQ ID NO:144的氨基酸序列的CDR2;和包含SEQ ID NO:216的氨基酸序列的CDR3。在一些实施方案中,抗PD-1 sdAb部分与PD-1之间的结合的Kd是约10-5M至约10-12M(例如约10-7M至约10-12M、或约10-8M至约10-12M)。在一些实施方案中,抗PD-1 sdAb部分是骆驼科的、嵌合的、人类的、部分人源化的或完全人源化的抗PD-1 sdAb部分。
抗PD-1 sdAb部分可在一个或多个FR序列中包含一个或多个“标志残基(hallmarkresidue)”。在一些实施方案中,抗PD-1 sdAb部分包含VHH域,所述VHH域包含以下中的任一者的氨基酸序列:a-1)在位置37处的氨基酸残基选自由以下组成的组:F、Y、L、I和V(例如F、Y或V,或例如F);a-2)在位置44处的氨基酸残基选自由以下组成的组:A、G、E、D、G、Q、R、S和L(例如E、Q或G,或例如E);a-3)在位置45处的氨基酸残基选自由以下组成的组:L、R和C(例如L或R);a-4)在位置103处的氨基酸残基选自由以下组成的组:W、R、G和S(例如W、G或R,或例如W);并且a-5)在位置108处的氨基酸残基是Q;或b-1)在位置37处的氨基酸残基选自由以下组成的组:F、Y、L、I和V(例如F、V或Y,或例如F);b-2)在位置44处的氨基酸残基选自由以下组成的组:E、Q和G;b-3)在位置45处的氨基酸残基是R;b-4)在位置103处的氨基酸残基选自由以下组成的组:W、R和S(例如W);并且b-5)在位置108处的氨基酸残基选自由以下组成的组:Q和L(例如Q);其中氨基酸位置是根据Kabat编号。应注意,在根据Kabat编号的氨基酸位置37、44、45、103和108处的这些“标志残基”应用于天然VHH序列的抗PD-1 sdAb部分,并且可在人源化期间被取代。例如,在根据Kabat编号的氨基酸位置108处的Q可任选地被人源化为L。其它人源化取代将是本领域技术人员显而易见的。例如,可通过将天然存在的VHH的FR序列与一个或多个密切相关的人类VH的对应FR序列相比较,然后使用本领域已知(也如本文所述)的方法将一个或多个这些潜在有用的人源化取代引入至所述VHH中来确定潜在有用的人源化取代。可测试所得人源化VHH序列的PD-1结合亲和力、稳定性、表达的容易性和水平和/或其它期望性质。可能的残基取代还可来自抗体VH域,其中VH/VL界面包含一个或多个高电荷氨基酸残基。本文所述的抗PD-1 sdAb部分可被部分或完全人源化。优选地,所得人源化抗PD-1 sdAb以如本文所述的Kd、Kon和Koff结合至PD-1。
在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含VHH域,所述VHH域包含SEQ ID NO:289-324中的任一者的氨基酸序列,或其与SEQ ID NO:289-324中的任一者具有至少约80%(例如至少约80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%中的任一者)序列同一性的变体。在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含VHH域,所述VHH域包含SEQ ID NO:289-324中的任一者的氨基酸序列,或其在VHH域中包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,包括包含SEQ ID NO:289-324中的任一者的氨基酸序列的VHH或其变体的抗PD-1 sdAb部分在CDR中包含氨基酸取代,例如SEQ ID NO:289-324中的任一者的CDR1和/或CDR2和/或CDR3。在一些实施方案中,包括包含SEQ ID NO:289-324中的任一者的氨基酸序列的VHH域或其变体的抗PD-1 sdAb部分包含SEQ ID NO:289-324中的任一者的CDR1、CDR2和CDR3,并且氨基酸取代在FR中,例如SEQ ID NO:289-324中的任一者的FR1和/或FR2和/或FR3和/或FR4。在一些实施方案中,包括包含SEQ ID NO:289-324中的任一者的氨基酸序列的VHH域或其变体的抗PD-1 sdAb部分在CDR和FR两者中包含氨基酸取代。在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含VHH域,所述VHH域包含SEQ ID NO:289-324中的任一者的氨基酸序列。在一些实施方案中,提供一种抗PD-1 sdAb部分,所述抗PD-1 sdAb部分包含SEQ ID NO:289-324中的任一者的CDR1、CDR2和CDR3。在一些实施方案中,抗PD-1 sdAb部分与PD-1之间的结合的Kd是约10-5M至约10-12M(例如约10-7M至约10-12M、或约10-8M至约10-12M)。在一些实施方案中,抗PD-1sdAb部分是骆驼科的、嵌合的、人类的、部分人源化的或完全人源化的抗PD-1 sdAb部分。
在一些实施方案中,提供一种抗PD-1 sdAb部分(下文称为“竞争性抗PD-1 sdAb部分”或“竞争性抗PD-1 sdAb”)或包含抗PD-1 sdAb部分的抗PD-1构建体(下文称为“竞争性抗PD-1构建体”),其与本文所述的任一种抗PD-1 sdAb部分竞争性地特异性结合PD-1。在一些实施方案中,可使用ELISA测定来确定竞争性结合。在一些实施方案中,提供一种抗PD-1sdAb部分(或包含抗PD-1 sdAb部分的抗PD-1构建体),其与包含SEQ ID NO:289-324中的任一者的氨基酸序列的抗PD-1 sdAb部分竞争性地特异性结合PD-1。在一些实施方案中,提供一种抗PD-1 sdAb部分(或包含抗PD-1 sdAb部分的抗PD-1构建体),其与包含以下的抗PD-1sdAb部分竞争性地特异性结合PD-1:包含SEQ ID NO:37-72中的任一者的氨基酸序列的CDR1;包含SEQ ID NO:109-144中的任一者的氨基酸序列的CDR2;和包含SEQ ID NO:181-216中的任一者的氨基酸序列的CDR3。在一些实施方案中,竞争性抗PD-1 sdAb部分与PD-1之间的结合的Kd是约10-5M至约10-12M(例如约10-7M至约10-12M、或约10-8M至约10-12M)。在一些实施方案中,竞争性抗PD-1 sdAb部分是骆驼科的、嵌合的、人类的、部分人源化的或完全人源化的抗PD-1 sdAb部分。
单域抗体
示例性sdAb包括但不限于:仅重链抗体的重链可变域(例如,骆驼科(Camelidae)的VHH(重链抗体的重链可变域)或软骨鱼的VNAR(鲨鱼新抗原受体的可变域));天然不含轻链的结合分子;来源于常规4链抗体的单域(例如VH或VL);人源化仅重链抗体;由表达人类重链区段的转基因小鼠或大鼠所产生的人类单域抗体;和除来源于抗体者之外的经工程改造的域和单域支架。sdAb可来源于任何物种,包括但不限于小鼠、大鼠、人类、骆驼、美洲驼、八目鳗、鱼、鲨鱼、山羊、兔和牛。本文所涵盖的sdAb还包括来自除骆驼科和鲨鱼之外的物种的天然存在的sdAb分子。
在一些实施方案中,sdAb来源于已知为不含轻链的重链抗体(本文也称为“仅重链抗体”或“HCAb”)的天然存在的单域抗原结合分子。这类单域分子公开于例如WO 94/04678和Hamers-Casterman,C.等,(1993)Nature 363:446-448。为清晰起见,来源于天然不含轻链的重链分子的可变域在本文称为VHH,以与四链免疫球蛋白的常规VH区分。这种VHH分子可来源于骆驼科物种中所产生的抗体,例如骆驼、美洲驼、骆马、单峰骆驼、驼羊和原驼。除骆驼科之外的其它物种可产生天然不含轻链的重链分子,并且这类VHH在本申请的范围内。
在一些实施方案中,sdAb来源于软骨鱼中存在的免疫球蛋白的可变区。例如,sdAb可来源于鲨鱼血清中存在的免疫球蛋白同型,称为新抗原受体(NAR)。产生来源于NAR可变区的单域分子(“IgNAR”)的方法描述于WO 03/014161和Streltsov(2005)Protein Sci.14:2901-2909。
在一些实施方案中,sdAb是重组、CDR接枝、人源化、骆驼源化、去免疫和/或体外生成(例如,通过噬菌体展示选择)sdAb。在一些实施方案中,框架区的氨基酸序列可通过框架区中特定氨基酸残基的“骆驼源化”来改变。骆驼源化是指常规4链抗体的(天然存在的)VH域的氨基酸序列中的一个或多个氨基酸残基被重链抗体的VHH域中对应位置处存在的一个或多个氨基酸残基代替或取代。这可例如基于本文进一步描述,以本身已知的方式执行,这是本领域技术人员显而易见的。这类“骆驼源化”取代优选插入在形成和/或存在于VH-VL的氨基酸位置和/或所谓的骆驼科标志残基处,如本文所定义(参见例如WO 94/04678;Davies和Riechmann FEBS Letters 339:285-290,1994;Davies和Riechmann ProteinEngineering 9(6):531-537,1996;Riechmann J.Mol.Biol.259:957-969,1996;和Riechmann和Muyldermans J.Immunol.Meth.231:25-38,1999)。
在一些实施方案中,sdAb是由表达人类重链区段的转基因小鼠或大鼠所产生的人类sdAb。参见例如US20090307787A1、美国专利第8,754,287号、US20150289489A1、US20100122358A1和WO2004049794。在一些实施方案中,sdAb是亲和力成熟的。
在一些实施方案中,针对特定抗原或靶标的天然存在的VHH域可获自骆驼科VHH序列的(原生或免疫)文库。这类方法可涉及或可不涉及使用所述抗原或靶标或其至少一部分、片段、抗原决定子或表位,使用一种或多种本身已知的筛选技术来筛选这种文库。这样的文库和技术例如描述于WO 99/37681、WO 01/90190、WO 03/025020和WO 03/035694。或者,可使用来源于(原生或免疫)VHH文库的改进合成或半合成文库,例如通过例如随机诱变和/或CDR改组的技术获自(原生或免疫)VHH文库的VHH文库,如例如WO 00/43507中所述。
在一些实施方案中,sdAb是从常规4链抗体生成。参见例如EP 0 368 684;Ward等,(Nature 1989年10月,12;341(6242):544-6;Holt等,Trends Biotechnol.,2003,21(11):484-490;WO 06/030220;和WO 06/003388。
因为sdAb的独特性质,将VHH域用作单抗原结合蛋白或抗原结合域(即,较大蛋白质或多肽的一部分)提供许多优于常规VH和VL、scFv和常规抗体片段(例如Fab或(Fab')2)的显著优势:1)以高亲和力结合抗原仅需要单个域,所以不必具有第二域,也不必确保这两个域以正确的空间构象和构型存在(例如,不必在折叠期间将重链和轻链配对,不必使用专门设计的接头,例如就scFv而言);2)可从单个基因表达VHH域和其它sdAb并且不需要翻译后折叠或修饰;3)可容易地将VHH域和其它sdAb工程改造成多价和/或多特异性形式(例如本申请中所述的那些);4)VHH域和其它sdAb可溶性高并且不具有聚集倾向(如Ward等,Nature.1989年10月,12;341(6242):544-6所述的小鼠来源“dAb”的情况下);5)VHH域和其它sdAb对热、pH、蛋白酶和其它变性剂或条件稳定性高;6)VHH域和其它sdAb可以简单且相对便宜的方式制备(即使在大生产规模下),例如使用微生物发酵,不必使用哺乳动物表达系统(例如常规抗体片段的生产所需);7)与常规4链抗体和其抗原结合片段相比,VHH域和其它sdAb相对较小(大约15kDa,或比常规IgG小10倍),因此具有(较)高组织渗透能力,例如对于实体肿瘤和其它致密组织;并且8)VHH域和其它sdAb可展现出所谓的“凹槽(cavity)结合性质”(由于其CDR3环比常规VH域的CDR3环长)并且可因此触及常规4链抗体和其抗原结合片段不可及的靶标和表位,例如,已显示VHH域和其它sdAb可抑制酶(参见例如WO1997049805;Transue等,Proteins.1998Sep 1;32(4):515-22;Lauwereys等,EMBOJ.1998年7月,1;17(13):3512-20)。
PD-1
术语“程序性细胞死亡蛋白1”、“PD-1”、“PD-1抗原”、“PD-1表位”和“程序性死亡1”可互换使用,并且包括人类PD-1的变体、同功异型物、物种同源物以及与PD-1具有至少一个共同表位的类似物。
人类PD-1的氨基酸序列公开于Genbank登录号NP_005009。氨基酸1-20的区是前导肽;氨基酸21-170的区是细胞外域;氨基酸171-191的区是跨膜域;并且氨基酸192-288的区是胞质域。
特定人类PD-1序列的氨基酸序列与Genbank登录号NP_005009的人类PD-1具有至少90%同一性,并且与其它物种(例如,鼠类)的PD-1氨基酸序列相比,含有将氨基酸序列鉴定为人类的氨基酸残基。在一些实施方案中,人类PD-1的氨基酸序列可与Genbank登录号NP_005009的人类PD-1具有至少约95%、96%、97%、98%或99%同一性。在一些实施方案中,人类PD-1序列将显示与Genbank登录号NP_005009的人类PD-1相比不多于10个氨基酸差异。在一些实施方案中,人类PD-1可显示与Genbank登录号NP_005009的人类PD-1相比不多于5、4、3、2或1个氨基酸差异。可如本文所述确定同一性百分比。在一些实施方案中,人类PD-1序列可因例如具有保守突变或在非保守区中具有突变而与Genbank登录号NP_005009的人类PD-1不同,并且PD-1具有与Genbank登录号NP_005009的人类PD-1实质上相同的生物学功能。例如,人类PD-1的生物学功能是在PD-1的细胞外域中具有表位,其被本公开的抗PD-1构建体特异性结合,或人类PD-1的生物学功能是调节T细胞活性。在一些实施方案中,本文所述的抗PD-1 sdAb部分特异性识别与Genbank登录号NP_005009的人类PD-1具有100%氨基酸序列同一性的PD-1多肽。在一些实施方案中,本文所述的抗PD-1 sdAb部分特异性识别包含SEQ ID NO:361或362的氨基酸序列的PD-1多肽。
在一些实施方案中,抗PD-1 sdAb部分可与来自除人类之外的物种的PD-1或结构上与人类PD-1相关的其它蛋白质(例如,人类PD-1同源物)交叉反应。在一些实施方案中,抗PD-1 sdAb部分完全特异于人类PD-1,并且不展现出物种或其它类型的交叉反应性。在一些实施方案中,抗PD-1 sdAb部分特异性识别人类PD-1的可溶性同功异型物。在一些实施方案中,抗PD-1 sdAb部分特异性识别人类PD-1的膜结合同功异型物(例如,SEQ ID NO:361)。
在一些实施方案中,本文所述的抗PD-1 sdAb部分特异性识别PD-1的细胞外域(ECD)。在一些实施方案中,抗PD-1 sdAb部分特异性识别PD-1 ECD的N末端部分。在一些实施方案中,抗PD-1 sdAb部分特异性识别PD-1 ECD的C末端部分。在一些实施方案中,抗PD-1sdAb部分特异性识别PD-1 ECD的中间部分。在一些实施方案中,抗PD-1 sdAb部分所特异性识别的PD-1的ECD的氨基酸序列与Genbank登录号NP_005009的人类PD-1的ECD具有至少约95%、96%、97%、98%或99%同一性。在一些实施方案中,抗PD-1 sdAb部分所特异性识别的PD-1的ECD的氨基酸序列与Genbank登录号NP_005009的人类PD-1的ECD具有100%同一性。在一些实施方案中,抗PD-1 sdAb部分特异性识别包含SEQ ID NO:362的氨基酸序列的PD-1多肽。
抗体亲和力
抗体或抗原结合域的结合特异性可通过本领域中已知的方法以实验方式确定。这类方法包含但不限于蛋白质印迹法、ELISA测试、RIA测试、ECL测试、IRMA测试、EIA测试、BIAcore测试和肽扫描。
在一些实施方案中,抗PD-1 sdAb部分与PD-1之间的结合的Kd是约10-5M至约10-6M、约10-6M至约10-7M、约10-7M至约10-8M、约10-8M至约10-9M、约10-9M至约10-10M、约10-10M至约10-11M、约10-11M至约10-12M、约10-5M至约10-12M、约10-6M至约10-12M、约10-7M至约10-12M、约10-8M至约10-12M、约10-9M至约10-12M、约10-10M至约10-12M、约10-5M至约10-11M、约10-7M至约10-11M、约10-8M至约10-11M、约10-9M至约10-11M、约10-5M至约10-10M、约10-7M至约10-10M、约10-8M至约10-10M、约10-5M至约10-9M、约10-7M至约10-9M、约10-5M至约10-8M、或约10-6M至约10-8M。
在一些实施方案中,抗PD-1 sdAb部分与PD-1之间的结合的Kon是约102M-1s-1至约104M-1s-1、约104M-1s-1至约106M-1s-1、约106M-1s-1至约107M-1s-1、约102M-1s-1至约107M-1s-1、约103M-1s-1至约107M-1s-1、约104M-1s-1至约107M-1s-1、约105M-1s-1至约107M-1s-1、约103M-1s-1至约106M-1s-1或约104M-1s-1至约106M-1s-1。
在一些实施方案中,抗PD-1 sdAb部分与PD-1之间的结合的Koff是约1s-1至约10-2s-1、约10-2s-1至约10-4s-1、约10-4s-1至约10-5s-1、约10-5s-1至约10-6s-1、约1s-1至约10-6s-1、约10-2s-1至约10-6s-1、约10-3s-1至约10-6s-1、约10-4s-1至约10-6s-1、约10-2s-1至约10-5s-1或约10-3s-1至约10-5s-1。
在一些实施方案中,在放大发光邻近均相测定(AlphaLISA)中,抗PD-1 sdAb部分的EC50小于10nM。在一些实施方案中,在通过FACS的配体结合抑制分析(竞争结合测定)或基于细胞的细胞因子释放测定中,抗PD-1 sdAb部分的EC50小于500nM。在一些实施方案中,抗PD-1 sdAb部分的EC50小于1nM(例如约0.001nM至约0.01nM、约0.01nM至约0.1nM、约0.1nM至约1nM等)、约1nM至约10nM、约10nM至约50nM、约50nM至约100nM、约100nM至约200nM、约200nM至约300nM、约300nM至约400nM、或约400nM至约500nM。
在一些实施方案中,在AlphaLISA中,抗PD-1 sdAb部分的IC50小于10nM。在一些实施方案中,在通过FACS的配体结合抑制分析(竞争结合测定)或基于细胞的细胞因子释放测定中,抗PD-1 sdAb部分的IC50小于500nM。在一些实施方案中,抗PD-1 sdAb部分的IC50小于1nM(例如约0.001nM至约0.01nM、约0.01nM至约0.1nM、约0.1nM至约1nM等)、约1nM至约10nM、约10nM至约50nM、约50nM至约100nM、约100nM至约200nM、约200nM至约300nM、约300nM至约400nM、或约400nM至约500nM。
嵌合或人源化抗体
在一些实施方案中,本文所提供的抗PD-1 sdAb部分是嵌合抗体。某些嵌合抗体描述于例如美国专利第4,816,567号;和Morrison等,Proc.Natl.Acad.Sci.USA,81:6851-6855(1984)中。在一个实施例中,嵌合抗体包含非人类可变区(例如,来源于骆驼科物种例如美洲驼的可变区)和人类恒定区。在另一个实施例中,嵌合抗体是“类别转换”抗体,其中类别或子类已从亲本抗体的类别或子类改变。嵌合抗体包括其抗原结合片段。
在一些实施方案中,嵌合抗体是人源化抗体。通常,非人类抗体被人源化以降低对人类的免疫原性,同时保留亲本非人类抗体的特异性和亲和力。通常,人源化抗体包含一个或多个可变域,其中HVR例如CDR(或其部分)来源于非人类抗体,并且FR(或其部分)来源于人类抗体序列。人源化抗体任选地还将包含人类恒定区的至少一部分。在一些实施方案中,人源化抗体中的一些FR残基被来自非人类抗体(例如,HVR残基所来源的抗体)的对应残基取代以例如恢复或改善抗体特异性或亲和力。
人源化抗体和其制备方法例如评述于Almagro和Fransson,Front.Biosci.13:1619-1633(2008)中,并且进一步描述于例如Riechmann等,Nature 332:323-329(1988);Queen等,Proc.Nat'l Acad.Sci.USA 86:10029-10033(1989);美国专利第5,821,337号、第7,527,791号、第6,982,321号和第7,087,409号;Kashmiri等,Methods 36:25-34(2005)(描述SDR(a-CDR)接枝);Padlan,Mol.Immunol.28:489-498(1991)(描述“表面重塑”);Dall'Acqua等,Methods 36:43-60(2005)(描述“FR改组”);和Osbourn等,Methods 36:61-68(2005)和Klimka等,Br.J.Cancer,83:252-260(2000)(描述FR改组的“引导选择”方法)中。
可用于人源化的人类框架区包括但不限于:使用“最佳拟合”方法选择的框架区(参见例如Sims等,J.Immunol.151:2296(1993));来源于轻链或重链可变区的特定亚群的人类抗体的共有序列的框架区(参见例如Carter等,Proc.Natl.Acad.Sci.USA,89:4285(1992);和Presta等,J.Immunol.,151:2623(1993));人类成熟(体细胞突变)框架区或人类种系框架区(参见例如Almagro和Fransson,Front.Biosci.13:1619-1633(2008));和来源于筛选FR文库的框架区(参见例如Baca等,J.Biol.Chem.272:10678-10684(1997)和Rosok等,J.Biol.Chem.271:22611-22618(1996))。
在一些实施方案中,抗PD-1 sdAb被修饰,例如被人源化,而不降低所述域对抗原的天然亲和力,并且同时降低其对异源物种的免疫原性。例如,可确定美洲驼抗体的抗体可变域(VHH)的氨基酸残基,并且将例如框架区中的一个或多个骆驼科氨基酸被其在人类共有序列中存在的人类对应物代替,所述多肽不失去其典型特征,即人源化不显著影响所得多肽的抗原结合能力。骆驼科单域抗体的人源化需要在单一多肽链中引入并诱变有限量的氨基酸。这与scFv、Fab'、(Fab')2和IgG的人源化相反,其需要在两条链(轻链和重链)中引入氨基酸变化并且保留两条链的组装。
包含VHH域的sdAb可被人源化以具有人类样序列。在一些实施方案中,本文所用的VHH域的FR区与人类VH框架区包含至少约50%、60%、70%、80%、90%、95%或95%以上中的任一者的氨基酸序列同源性。一类示例性人源化VHH域的特征在于,VHH在根据Kabat编号的位置45处(例如L45)携带由甘氨酸、丙氨酸、缬氨酸、亮氨酸、异亮氨酸、脯氨酸、苯丙氨酸、酪氨酸、色氨酸、甲硫氨酸、丝氨酸、苏氨酸、天冬酰胺或谷氨酸组成的组的氨基酸并且在位置103处携带色氨酸。因此,属于这类的多肽显示与人类VH框架区具有高氨基酸序列同源性,并且所述多肽可直接向人类施用而不期望自其发生非所要的免疫反应,并且没有进一步人源化的负担。
另一类示例性人源化骆驼科单域抗体已描述于WO 03/035694中并且含有通常存在于人类来源或其它物种的常规抗体中的疏水性FR2残基,但通过在位置103上的带电精氨酸残基来补偿这种亲水性损失,所述带电精氨酸残基取代双链抗体的VH中存在的保守色氨酸。因此,属于这两类的多肽显示与人类VH框架区具有高氨基酸序列同源性,并且所述肽可直接向人类施用而不期望自其发生非所要的免疫反应,并且没有进一步人源化的负担。
人类抗体
在一些实施方案中,本文所提供的抗PD-1 sdAb部分是人类抗体(称为人类域抗体或人类DAb)。可使用本领域中已知的各种技术来产生人类抗体。人类抗体通常描述于vanDijk和van de Winkel,Curr.Opin.Pharmacol.5:368-74(2001);Lonberg,Curr.Opin.Immunol.20:450-459(2008);和Chen,Mol.Immunol.47(4):912-21(2010)。能够产生完全人类单域抗体(或DAb)的转基因小鼠或大鼠是本领域已知的。参见例如US20090307787A1、美国专利第8,754,287号、US20150289489A1、US20100122358A1和WO2004049794。
人类抗体(例如,人类DAb)可通过向已经修改以响应于抗原攻击而产生完整人类抗体或具有人类可变区的完整抗体的转基因动物施用免疫原来制备。这样的动物通常含有人类免疫球蛋白基因座的全部或一部分,其代替内源性免疫球蛋白基因座,或存在于染色体外或随机整合至动物染色体中。在这类转基因小鼠中,内源性免疫球蛋白基因座一般已失活。从转基因动物获得人类抗体的方法的评述参见Lonberg,Nat.Biotech.23:1117-1125(2005)。还参见例如描述XENOMOUSETM技术的美国专利第6,075,181号和第6,150,584号;描述 技术的美国专利第5,770,429号;描述/>
技术的美国专利第5,770,429号;描述/> 技术的美国专利第7,041,870号;和描述/>
技术的美国专利第7,041,870号;和描述/> 技术的美国专利申请公开第US 2007/0061900号。由这类动物生成的完整抗体的人类可变区可进一步被修饰,例如通过与不同的人类恒定区组合。
技术的美国专利申请公开第US 2007/0061900号。由这类动物生成的完整抗体的人类可变区可进一步被修饰,例如通过与不同的人类恒定区组合。
人类抗体(例如,人类DAb)还可通过基于杂交瘤的方法制成。用于产生人类单克隆抗体的人类骨髓瘤和小鼠-人类异源骨髓瘤细胞系已有描述(参见例如KozborJ.Immunol.,133:3001(1984);Brodeur等,Monoclonal Antibody Production Techniquesand Applications,第51-63页(Marcel Dekker,Inc.,New York,1987);和Boerner等,J.Immunol.,147:86(1991))。经由人类B细胞杂交瘤技术生成的人类抗体还描述于Li等,Proc.Natl.Acad.Sci.USA,103:3557-3562(2006)中。额外方法包括例如美国专利第7,189,826号(描述从杂交瘤细胞系产生单克隆人类IgM抗体)和Ni,Xiandai Mianyixue,26(4):265-268(2006)(描述人类-人类杂交瘤)中所描述的那些方法。人类杂交瘤技术(三源杂交瘤技术(Trioma technology))也描述于Vollmers和Brandlein,Histology andHistopathology,20(3):927-937(2005),以及Vollmers和Brandlein,Methods andFindings in Experimental and Clinical Pharmacology,27(3):185-91(2005)。
人类抗体(例如,人类DAb)还可通过分离选自人类来源噬菌体展示文库的Fv克隆可变域序列生成。这类可变域序列然后可与期望的人类恒定域组合。下文描述用于从抗体文库选择人类抗体的技术。
一种用于获得针对特定抗原或靶标的VHH序列的技术涉及:合适地免疫能够表达重链抗体的转基因哺乳动物(即,以便产生免疫反应和/或针对所述抗原或靶标的重链抗体);从所述转基因哺乳动物获得合适的含有所述VHH序列(编码所述VHH序列的核酸序列)的生物样本(例如血液样本、血清样本或B细胞样本);然后从所述样本开始,使用本身已知的任何合适的技术(例如本文所述的任何方法或杂交瘤技术),生成针对所述抗原或靶标的VHH序列。例如,出于此目的,可使用重链抗体表达小鼠以及另外的方法和技术,其描述于WO02/085945、WO 04/049794和WO 06/008548和Janssens等,Proc.Natl.Acad.Sci.USA.2006年10月,10;103(41):15130-5。例如,这类重链抗体表达小鼠可表达具有任何合适(单)可变域的重链抗体,例如天然来源的(单)可变域(例如,人类(单)可变域、骆驼科(单)可变域或鲨鱼(单)可变域),以及例如合成或半合成(单)可变域。
文库来源的抗体
本申请的抗体可通过筛选组合文库中具有一种或多种期望活性的抗体来分离。例如,本领域中已知多种用于生成噬菌体展示文库和筛选这类文库中具有期望结合特征的抗体的方法。这类方法评述于例如Hoogenboom等,Methods in Molecular Biology 178:1-37(O'Brien等编,Human Press,Totowa,NJ,2001),并且进一步描述于例如McCafferty等,Nature 348:552-554;Clackson等,Nature 352:624-628(1991);Marks等,J.Mol.Biol.222:581-597(1992);Marks和Bradbury,Methods in Molecular Biology248:161-175(Lo编,Human Press,Totowa,NJ,2003);Sidhu等,J.Mol.Biol.338(2):299-310(2004);Lee等,J.Mol.Biol.340(5):1073-1093(2004);Fellouse,Proc.Natl.Acad.Sci.USA 101(34):12467-12472(2004);和Lee等,J.Immunol.Methods284(1-2):119-132(2004)。已描述用于构建单域抗体文库的方法,例如参见美国专利第7371849号。
在某些噬菌体展示方法中,通过聚合酶链反应(PCR)分开克隆VH和VL基因的全库并且随机重组于噬菌体文库中,然后可筛选所述文库中的抗原结合噬菌体,如Winter等,Ann.Rev.Immunol.,12:433-455,1994中所述。VHH基因的全库可通过PCR以类似方式克隆,随机重组于噬菌体文库中,并且筛选抗原结合噬菌体。噬菌体通常展示呈scFv片段或呈Fab片段形式的抗体片段。来自经免疫来源的文库提供对免疫原具有高亲和力的抗体而无需构建杂交瘤。或者,可克隆天然全库(例如来自人类)以提供针对广泛范围的非自体抗原以及自体抗原的单抗体来源而无需任何免疫,如Griffiths等,EMBO J,12:725-734(1993)所描述。最终,天然文库还可以合成方式通过从干细胞克隆未经重排的V基因区段,并且使用含有随机序列以编码高度可变CDR3区和实现体外重排的PCR引物来制得,如由Hoogenboom和Winter,J.Mol.Biol.,227:381-388(1992)所描述。描述人类抗体噬菌体文库的专利公开包括例如:美国专利第5,750,373号,以及美国专利公开第2005/0079574号、第2005/0119455号、第2005/0266000号、第2007/0117126号、第2007/0160598号、第2007/0237764号、第2007/0292936号和第2009/0002360号。
从人类抗体文库分离的抗体或抗体片段在本文中视为人类抗体或人类抗体片段。
生物活性
本文所述的抗PD-1 sdAb部分的生物活性可通过测量其半数最大有效浓度(EC50)或半数最大抑制浓度(IC50)来确定,所述半数最大有效浓度是抗体结合其靶标的有效性的量度,所述半数最大抑制浓度是抗体抑制特定生物或生化功能(例如抑制PD-1与PD-L1/PD-L2之间的结合)的有效性的量度。例如,此处EC50可用于指示在细胞表面上结合50%PD-1所需的抗PD-1 sdAb的有效浓度,IC50可用于指示体外中和50%PD-1生物活性所需的抗-PD-1sdAb的有效浓度。EC50还表示在体内获得最大作用的50%所需的血浆浓度。EC50或IC50可通过本领域中已知的测定进行测量,例如生物测定,例如通过FACS的配体结合抑制分析(竞争结合测定)、基于细胞的细胞因子释放测定或放大发光邻近均相测定(AlphaLISA)。
例如,可以使用流式细胞术研究配体结合的阻断(也参见实施例1)。表达人类PD-1的CHO细胞可从贴壁式培养瓶解离,并与用于测试的不同浓度的抗PD-1 sdAb和恒定浓度的被标记的PD-L1蛋白或被标记的PD-L2蛋白(例如被生物素标记的人类PD-L1-Fc蛋白或被生物素标记的人类PD-L2-Fc蛋白)混合。可采用抗PD-1抗体阳性对照,例如 将混合物在室温下平衡30分钟,用FACS缓冲液(含有1%BSA的PBS)洗涤三次。然后,添加恒定浓度的特异性识别被标记的PD-L1或PD-L2蛋白的抗体(例如PE/Cy5抗生蛋白链菌素二级抗体)并在室温下温育15分钟。用FACS缓冲液洗涤细胞并通过流式细胞术分析。可使用Prism(GraphPad软件,San Diego,CA),使用非线性回归分析数据以计算IC50。竞争测定的结果可说明抗PD-1 sdAb抑制被标记的PD-L1/PD-L2与PD-1之间的相互作用的能力。
将混合物在室温下平衡30分钟,用FACS缓冲液(含有1%BSA的PBS)洗涤三次。然后,添加恒定浓度的特异性识别被标记的PD-L1或PD-L2蛋白的抗体(例如PE/Cy5抗生蛋白链菌素二级抗体)并在室温下温育15分钟。用FACS缓冲液洗涤细胞并通过流式细胞术分析。可使用Prism(GraphPad软件,San Diego,CA),使用非线性回归分析数据以计算IC50。竞争测定的结果可说明抗PD-1 sdAb抑制被标记的PD-L1/PD-L2与PD-1之间的相互作用的能力。
还可通过基于PD-1的细胞因子释放的阻断测定来测试抗PD-1 sdAb部分的生物活性(也参见实施例1)。与对细胞增殖相比,PD-1信号传导通常对细胞因子产生具有较大影响,其中对IFN-γ、TNF-α和IL-2产生的影响显著。因此,通过抗PD-1抗体的PD-1路径的阻断可使用多种监测T细胞增殖、IFN-γ释放或IL-2分泌的生物测定进行研究。PD-1介导的抑制性信号传导还取决于TCR信号传导的强度,其中在低水平TCR刺激下传递较大抑制。这种减少可通过经由CD28的共刺激(Freeman等,J.Exp.Med.192:1027-34(2000))或IL-2的存在(Carter等,Eur.J.Immunol.32:634-43(2002))来克服。PD-L1和PD-L2已显示在结合至PD-1时(Freeman等,J.Exp.Med.192:1027-34(2000))或在IL-2存在时(Carter等,Eur.J.Immunol.32:634-43(2002))下调T细胞活化。
例如,将PD-1效应细胞(以人类PD-1蛋白和NFAT荧光素酶稳定转染的Jurkat细胞)和CHO-K1/人类CD274(稳定表达人类PD-L1的CHO-K1)混合于孔中。在不同的浓度下将抗PD-1 sdAb添加至各孔中。没有抗体可用作背景对照。可采用阴性对照(例如人类IgG4)和阳性对照(例如 )。在37℃/5%CO2温育箱中温育24小时后,从每个测试孔取出培养基以供IL-2分泌测量(Cisbio)。测量每个测试抗体的EC50值,所述值将反映测试抗PD-1sdAb阻断Jurkat细胞上PD-1与PD-L1之间的相互作用的能力(PD-1/PD-L1相互作用抑制T细胞IL-2产生)。
)。在37℃/5%CO2温育箱中温育24小时后,从每个测试孔取出培养基以供IL-2分泌测量(Cisbio)。测量每个测试抗体的EC50值,所述值将反映测试抗PD-1sdAb阻断Jurkat细胞上PD-1与PD-L1之间的相互作用的能力(PD-1/PD-L1相互作用抑制T细胞IL-2产生)。
还可通过基于PD-1的荧光素酶报告基因活性的阻断测定来测试抗PD-1 sdAb部分的生物活性(也参见实施例1)。效应细胞含有荧光素酶构建体,其在破坏PD-1/PD-L1受体-配体相互作用时被诱导。例如,可将PD-1效应细胞(用人类PD-1蛋白和NFAT荧光素酶稳定转染的Jurkat细胞)铺板过夜,然后与连续稀释的包含抗PD-1 sdAb的抗PD-1构建体一起温育,接着以合适的E:T比率添加PD-L1表达细胞(CHO-K1/人类CD274)。在37℃、5%CO2下诱导6小时后,可添加Bio-GloTM荧光素酶测定试剂并可确定发光。结果可说明抗PD-1 sdAb抑制PD-L1与PD-1之间的相互作用的能力。
在一些实施方案中,抗PD-1 sdAb部分阻断或拮抗由PD-1受体转导的信号。在一些实施方案中,抗PD-1 sdAb部分可结合PD-1上的表位,以便抑制PD-1与PD-L1/PD-L2相互作用。在一些实施方案中,在抗体组合位点与PD-1配体结合位点的比率大于1:1并且抗体浓度大于10-8M的条件下,抗PD-1 sdAb部分可将PD-1与PD-L1/PD-L2的结合降低至少约5%、10%、20%、25%、30%、40%、50%、60%、70%、75%、80%、90%、95%、99%或99.9%中的任一者。
(II)包含抗PD-1 sdAb部分的构建体
包含抗PD-1 sdAb部分的抗PD-1构建体可具有任何可能的形式。
在一些实施方案中,包含抗PD-1 sdAb部分的抗PD-1构建体还可包含额外多肽序列,例如一个或多个抗体部分(或抗原结合部分)或者免疫球蛋白的Fc片段。这些额外多肽序列可改变或可不改变或以其它方式影响抗PD-1 sdAb的(生物学)性质,并且可以为本文所述的抗PD-1 sdAb增加或不增加另外的功能。在一些实施方案中,额外多肽序列赋予本发明的抗PD-1 sdAb以一种或多种期望性质或功能。
在一些实施方案中,额外多肽序列可包含特异性识别第二表位的第二抗体部分或第二抗原结合部分(例如sdAb、scFv、Fab、全长抗体等)。在一些实施方案中,第二表位来自PD-1。在一些实施方案中,第二表位不来自PD-1。在一些实施方案中,第二抗体部分(或第二抗原结合部分)特异性识别PD-1上与本文所述的抗PD-1 sdAb相同的表位。在一些实施方案中,第二抗体部分(或第二抗原结合部分)特异性识别PD-1上与本文所述的抗PD-1 sdAb不同的表位。在一些实施方案中,抗PD-1构建体包含两个或两个以上的经由任选的接头(例如肽接头,例如,下文“肽接头”节中所公开的任一者)连接在一起的抗PD-1-sdAb部分。连接在一起的两个或两个以上的抗PD-1-sdAb部分可以相同或不同。在一些实施方案中,任选的肽接头包含SEQ ID NO:367-376中的任一者的氨基酸序列。
在一些实施方案中,额外多肽序列可包含特异性识别CTLA-4的第二抗体部分或第二抗原结合部分(例如sdAb、scFv、Fab、全长抗体等)。在一些实施方案中,抗PD-1构建体包含经由任选的接头(例如肽接头,例如,下文“肽接头”节中所公开的任一者)连接在一起的一个或多个本文所述的抗PD-1-sdAb部分和一个或多个抗CTLA-4 sdAb。连接在一起的一个或多个抗PD-1-sdAb部分可以相同或不同,连接在一起的一个或多个抗CTLA-4-sdAb可以相同或不同。抗CTLA-4 sdAb可具有任何序列,例如PCT/CN2017/105506和PCT/CN2016/101777中所公开的任一者,所述文献通过引用整体并入本文中。在一些实施方案中,抗CTLA-4sdAb包含A34311VH11、AS07014VH11或AS07189TKDVH11的氨基酸序列。包含本文所述的抗PD-1 sdAb部分和抗CTLA-4 sdAb的抗PD-1构建体可具有任何形式,例如从N末端至C末端:(抗CTLA-4 sdAb1)-L1-(抗CTLA-4 sdAb2)-L2-(抗PD-1 sdAb)、(抗CTLA-4 sdAb1)-L1-(抗PD-1 sdAb)-L2-(抗CTLA-4 sdAb2)、(抗PD-1 sdAb)-L1-(抗CTLA-4 sdAb1)-L2-(抗CTLA-4sdAb2)、(抗PD-1 sdAb1)-L1-(抗PD-1 sdAb2)-L2-(抗CTLA-4 sdAb)、(抗PD-1 sdAb1)-L1-(抗CTLA-4 sdAb)-L2-(抗PD-1 sdAb2)、(抗CTLA-4 sdAb)-L1-(抗PD-1 sdAb1)-L2-(抗PD-1sdAb2)等。(L1和L2可以是相同或不同的任选接头,例如任选的肽接头)。在一些实施方案中,任选的肽接头包含SEQ ID NO:367-376中的任一者的氨基酸序列。
在一些实施方案中,与本文所述的抗PD-1 sdAb本身相比,额外多肽序列可增加抗体构建体半衰期、溶解性或吸收,降低免疫原性或毒性,消除或减弱不期望的副作用,和/或赋予本发明的抗PD-1构建体以其它有利性质和/或降低其不希望的性质。这类额外多肽序列的一些非限制性实例是血清蛋白,例如人类血清白蛋白(HSA;参见例如WO 00/27435)或半抗原分子(例如,由循环抗体识别的半抗原,参见例如WO 98/22141)。已显示,将免疫球蛋白的片段(例如VH域)连接至血清白蛋白或其片段可增加抗体半衰期(参见例如WO 00/27435和WO 01/077137)。因此,在一些实施方案中,本发明的抗PD-1构建体可包含任选地经由合适的接头(例如肽接头)连接的血清白蛋白(或其合适的片段)的本文所述的抗PD-1sdAb部分。在一些实施方案中,本文所述的抗PD-1 sdAb部分可连接至血清白蛋白的至少包含血清白蛋白III域的片段(参见PCT/EP2007/002817)。抗PD-1 sdAb-HSA融合蛋白可具有任何形式,例如(sdAb)n-HSA(n是至少1的整数)、sdAb-HSA-sdAb等。在一些实施方案中,任选的肽接头包含SEQ ID NO:367-376中的任一者的氨基酸序列。
抗PD-1仅重链抗体(HCAb)
在一些实施方案中,分离的抗PD-1构建体是包含本文所述的抗PD-1 sdAb部分的仅重链抗体(HCAb)。在一些实施方案中,本文所述的抗PD-1 sdAb部分可任选地经由接头序列连接至一个或多个(优选人类)CH2和/或CH3域,例如Fc片段,以增加其体内半衰期。
因此在一些实施方案中,分离的抗PD-1构建体是包含融合至免疫球蛋白(例如IgA、IgD、IgE、IgG和IgM)的Fc片段的本文所述的抗PD-1 sdAb部分的抗PD-1 HCAb。在一些实施方案中,抗PD-1 HCAb包含IgG的Fc片段,例如IgG1、IgG2、IgG3或IgG4中的任一者。在一些实施方案中,Fc片段是人类Fc,例如人类IgG1(hIgG1)Fc、hIgG2 Fc或hIgG4 Fc。在一些实施方案中,Fc片段无效应子,具有减少、最小化或消除的抗体效应功能例如ADCC、CDC和/或ADCP(抗体依赖性T细胞吞噬)。例如,在一些实施方案中,无效应子Fc在CH2区中包含N297A或DANA突变(D265A+N297A)。在一些实施方案中,无效应子Fc包含K322A和L234A/L235A(LALA)突变。在一些实施方案中,Fc片段是无效应子(惰性)IgG1 Fc,例如无效应子hIgG1Fc。在一些实施方案中,Fc片段是人类IgG4 Fc(S228P)。在一些实施方案中,Fc片段包含SEQID NO:363-365中的任一者的氨基酸序列。在一些实施方案中,抗PD-1 HCAb是单体抗PD-1HCAb。在一些实施方案中,抗PD-1 HCAb是二聚抗PD-1 HCAb。在一些实施方案中,抗PD-1HCAb是多特异性且多价的(例如双特异性且二价的),例如,包含两个或两个以上的本文所述的抗PD-1 sdAb部分(如图26B所示例)。在一些实施方案中,抗PD-1 HCAb是单特异性且多价的(例如,二价的;如图26A所示例)。
在一些实施方案中,抗PD-1 sdAb部分和Fc片段任选地由肽接头连接。在一些实施方案中,肽接头是人类IgG1铰链(SEQ ID NO:369)。在一些实施方案中,肽接头是突变的人类IgG1铰链(SEQ ID NO:368)。在一些实施方案中,肽接头是人类IgG4铰链(SEQ ID NO:367)。在一些实施方案中,肽接头是hIgG2铰链。在一些实施方案中,肽接头包含SEQ ID NO:367-376中的任一者的氨基酸序列,例如SEQ ID NO:371、375或376。
因此在一些实施方案中,提供一种分离的抗PD-1 HCAb,其包含特异性识别PD-1的sdAb部分,其中所述抗PD-1 sdAb部分包含:包含SEQ ID NO:37-72中的任一者的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:109-144中的任一者的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:181-216中的任一者的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体,并且其中所述抗PD-1 sdAb经由任选的接头融合至免疫球蛋白的Fc片段。在一些实施方案中,提供一种分离的抗PD-1 HCAb,其包含特异性识别PD-1的sdAb部分,其中所述sdAb部分包含:包含SEQ ID NO:37-72中的任一者的氨基酸序列的CDR1;包含SEQ ID NO:109-144中的任一者的氨基酸序列的CDR2;和包含SEQ ID NO:181-216中的任一者的氨基酸序列的CDR3;或所述CDR的在CDR区中包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体,并且其中所述抗PD-1 sdAb部分经由任选的接头融合至免疫球蛋白的Fc片段。在一些实施方案中,氨基酸取代在CDR1和/或CDR2中。在一些实施方案中,提供一种抗PD-1 HCAb,其包含特异性识别PD-1的sdAb部分,其中所述sdAb部分包含:包含SEQ ID NO:37-72中的任一者的氨基酸序列的CDR1;包含SEQ ID NO:109-144中的任一者的氨基酸序列的CDR2;和包含SEQ ID NO:181-216中的任一者的氨基酸序列的CDR3,并且其中所述抗PD-1 sdAb部分经由任选的接头融合至免疫球蛋白的Fc片段。在一些实施方案中,提供一种分离的抗PD-1HCAb,其包含特异性识别PD-1的sdAb部分,其中所述sdAb部分包含VHH域,所述VHH域包含SEQID NO:289-324中的任一者的氨基酸序列,或其与SEQ ID NO:289-324中的任一者具有至少约80%(例如至少约80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%中的任一者)序列同一性的变体,并且其中所述抗PD-1 sdAb部分经由任选的接头融合至免疫球蛋白的Fc片段。在一些实施方案中,提供一种分离的抗PD-1 HCAb,其包含特异性识别PD-1的sdAb部分,其中所述sdAb部分包括包含SEQ ID NO:289-324中的任一者的氨基酸序列的VHH域,或其在VHH域中包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体,并且其中所述抗PD-1 sdAb部分经由任选的接头融合至免疫球蛋白的Fc片段。在一些实施方案中,VHH域中的氨基酸取代在CDR中,例如SEQ ID NO:289-324中的任一者的CDR1和/或CDR2和/或CDR3。在一些实施方案中,VHH域中的氨基酸取代在FR中,例如SEQ ID NO:289-324中的任一者的FR1和/或FR2和/或FR3和/或FR4。在一些实施方案中,氨基酸取代在SEQ ID NO:289-324中的任一者的CDR和FR两者中。在一些实施方案中,提供一种分离的抗PD-1 HCAb,其包含特异性识别PD-1的sdAb部分,其中所述sdAb部分包括包含SEQ ID NO:289-324中的任一者的氨基酸序列的VHH域,并且其中所述抗PD-1 sdAb部分经由任选的接头融合至免疫球蛋白的Fc片段。在一些实施方案中,提供一种分离的抗PD-1 HCAb,其包含特异性识别PD-1的sdAb部分,其中所述sdAb部分包含SEQ ID NO:289-324中的任一者的CDR1、CDR2和CDR3,并且其中所述抗PD-1 sdAb部分经由任选的接头融合至免疫球蛋白的Fc片段。在一些实施方案中,提供一种分离的抗PD-1 HCAb,其包含两个特异性识别PD-1的sdAb部分,其中每个抗PD-1 sdAb部分包含:包含SEQ ID NO:37-72中的任一者的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:109-144中的任一者的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:181-216中的任一者的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体,并且其中每个抗PD-1 sdAb的C末端经由任选的接头融合至免疫球蛋白的Fc片段的N末端。在一些实施方案中,所述两个抗PD-1 sdAb部分相同(如图26A所示例)。在一些实施方案中,所述两个抗PD-1 sdAb部分不同(如图26B所示例)。在一些实施方案中,Fc片段是人类IgG1 Fc、无效应子人类IgG1 Fc、hIgG2 Fc、人类IgG4 Fc或hIgG4 Fc(S228P)。在一些实施方案中,Fc片段包含SEQ ID NO:363-365中的任一者的氨基酸序列。在一些实施方案中,抗PD-1 HCAb是单体抗PD-1 HCAb。在一些实施方案中,抗PD-1 HCAb是二聚抗PD-1 HCAb。在一些实施方案中,抗PD-1sdAb部分和Fc片段任选地由肽接头连接。在一些实施方案中,肽接头包含SEQID NO:367-376中的任一者的氨基酸序列。在一些实施方案中,抗PD-1 sdAb部分与PD-1之间的结合的Kd是约10-5M至约10-12M(例如约10-7M至约10-12M、或约10-8M至约10-12M)。在一些实施方案中,抗PD-1 sdAb部分是骆驼科的、嵌合的、人类的、部分人源化的或完全人源化的抗PD-1 sdAb部分。
在一些实施方案中,提供一种分离的抗PD-1 HCAb,其包含SEQ ID NO:325-360中的任一者的氨基酸序列。
在一些实施方案中,还提供一种分离的抗PD-1 HCAb(下文称为“竞争性抗PD-1HCAb”),其与本文所述的分离的抗PD-1 HCAb、抗PD-1 sdAb或包含抗PD-1 sdAb的抗PD-1构建体中的任一者竞争性地特异性结合PD-1。可使用ELISA测定来确定竞争性结合。例如,在一些实施方案中,提供一种分离的抗PD-1 HCAb,其与包含SEQ ID NO:325-360中的任一者的氨基酸序列的抗PD-1 HCAb竞争性地特异性结合PD-1。在一些实施方案中,提供一种分离的抗PD-1 HCAb,其与包括包含以下的抗PD-1 sdAb部分的抗PD-1 HCAb竞争性地特异性结合PD-1:包含SEQ ID NO:37-72中的任一者的氨基酸序列的CDR1;包含SEQ ID NO:109-144中的任一者的氨基酸序列的CDR2;和包含SEQ ID NO:181-216中的任一者的氨基酸序列的CDR3。在一些实施方案中,提供一种分离的抗PD-1 HCAb,其与包含以下的抗PD-1 sdAb部分(或包含抗PD-1 sdAb部分的抗PD-1构建体)竞争性地特异性结合PD-1:包含SEQ ID NO:37-72中的任一者的氨基酸序列的CDR1;包含SEQ ID NO:109-144中的任一者的氨基酸序列的CDR2;和包含SEQ ID NO:181-216中的任一者的氨基酸序列的CDR3。在一些实施方案中,竞争性抗PD-1 HCAb的Fc片段包含SEQ ID NO:363-365中的任一者的氨基酸序列。在一些实施方案中,竞争性抗PD-1 HCAb与PD-1之间的结合的Kd是约10-5M至约10-12M(例如约10-7M至约10-12M、或约10-8M至约10-12M)。在一些实施方案中,竞争性抗PD-1 HCAb部分是骆驼科的、嵌合的、人类的、部分人源化的或完全人源化的抗PD-1 HCAb部分。
多价和/或多特异性抗体
在一些实施方案中,分离的抗PD-1构建体包含融合至一个或多个其它抗体部分或抗原结合部分(例如特异性识别另一表位的抗体部分)的本文所述的抗PD-1 sdAb部分。所述一个或多个其它抗体部分可具有任何抗体或抗体片段形式,例如全长抗体、Fab、Fab'、(Fab')2、Fv、scFv、scFv-scFv、微型抗体、双功能抗体或sdAb。在一些实施方案中,所述一个或多个抗体部分(或抗原结合部分)包含重链可变域(VH)和轻链可变域(VL)。关于某些抗体片段的评述,参见Hudson等,Nat.Med.9:129-134(2003)。关于scFv片段的评述,参见例如Pluckthün,The Pharmacology of Monoclonal Antibodies,第113卷,Rosenburg和Moore,(Springer-Verlag,New York),第269-315页(1994);还参见WO 93/16185;以及美国专利第5,571,894号和第5,587,458号。关于包含救助受体结合表位残基并且具有增加的体内半衰期的Fab和F(ab')2片段的讨论,参见美国专利第5,869,046号。关于多特异性抗体的评述,参见Weidle等,Cancer Genomics Proteomics,10(1):1-18,2013;Geering和Fussenegger,Trends Biotechnol.,33(2):65-79,2015;Stamova等,Antibodies,1(2):172-198,2012。双功能抗体是可为二价或双特异性的具有两个抗原结合位点的抗体片段。参见例如EP 404,097;WO 1993/01161;Hudson等,Nat.Med.9:129-134(2003);和Hollinger等,Proc.Natl.Acad.Sci.USA 90:6444-6448(1993)。三功能抗体和四功能抗体也描述于Hudson等,Nat.Med.9:129-134(2003)中。抗体片段可通过各种技术制成,包括但不限于蛋白水解消化完整抗体以及通过重组宿主细胞(例如大肠杆菌或噬菌体)产生,如本文所述。
用于制造多特异性抗体的技术包括但不限于具有不同特异性的两个免疫球蛋白重链-轻链对的重组共表达(参见Milstein和Cuello,Nature 305:537(1983),WO 93/08829,和Traunecker等,EMBO J.10:3655(1991)),和“孔中结(knob-in-hole)”工程改造(参见例如美国专利第5,731,168号)。多特异性抗体还可通过以下制得:工程改造针对制造抗体Fc-异二聚分子的静电转向效应(WO 2009/089004A1);使两种或两种以上的抗体或片段交联(参见例如美国专利第4,676,980号,和Brennan等,Science,229:81(1985));使用亮氨酸拉链来产生双特异性抗体(参见例如Kostelny等,J.Immunol.,148(5):1547-1553(1992));使用用于制造双特异性抗体片段的“双抗体”技术(参见例如Hollinger等,Proc.Natl.Acad.Sci.USA,90:6444-6448(1993));和使用单链Fv(sFv)二聚体(参见例如Gruber等,J.Immunol.,152:5368(1994));和如例如Tutt等,J.Immunol.147:60(1991)中所述制备三特异性抗体;以及产生包含串联单域抗体的多肽(参见例如美国专利申请第20110028695号;和Conrath等,J.Biol.Chem.,2001;276(10):7346-50)。本文还包括具有三个或三个以上的功能性抗原结合位点的工程化抗体,包括“章鱼抗体(Octopus antibody)”(参见例如US 2006/0025576A1)。
肽接头
在一些实施方案中,抗PD-1构建体内的抗PD-1 sdAb和其它一个或多个抗体部分(例如全长抗体、sdAb或包含VH和VL的抗原结合部分)可任选地通过肽接头连接。抗PD-1构建体中使用的肽接头的长度、柔性程度和/或其它性质可能对性质具有一些影响,所述性质包括但不限于对于一种或多种特定抗原或表位的亲和力、特异性或亲合力。例如,可以选择较长的肽接头以确保两个相邻域在空间上不相互干扰。在一些实施方案中,肽接头包含柔性残基(例如甘氨酸和丝氨酸),使得相邻域相对于彼此自由移动。例如,甘氨酸-丝氨酸双联体可以是合适的肽接头。
肽接头可具有任何合适的长度。在一些实施方案中,肽接头的长度为至少约1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、25、30、35、40、50、75、100个或100个以上的氨基酸中的任一者。在一些实施方案中,肽接头的长度为不多于约100、75、50、40、35、30、25、20、19、18、17、16、15、14、13、12、11、10、9、8、7、6、5个或5个以下的氨基酸中的任一者。在一些实施方案中,肽接头的长度为约1个氨基酸至约10个氨基酸、约1个氨基酸至约20个氨基酸、约1个氨基酸至约30个氨基酸、约5个氨基酸至约15个氨基酸、约10个氨基酸至约25个氨基酸、约5个氨基酸至约30个氨基酸、约10个氨基酸至约30个氨基酸长、约30个氨基酸至约50个氨基酸、约50个氨基酸至约100个氨基酸、或约1个氨基酸至约100个氨基酸中的任一者。
肽接头可具有天然存在的序列或非天然存在的序列。例如,来源于仅重链抗体的铰链区的序列可用作接头。参见例如WO1996/34103。在一些实施方案中,肽接头是人类IgG1铰链(SEQ ID NO:369)。在一些实施方案中,肽接头是突变的人类IgG1铰链(SEQ ID NO:368)。在一些实施方案中,肽接头是人类IgG4铰链(SEQ ID NO:367)。在一些实施方案中,肽接头是hIgG2铰链。在一些实施方案中,肽接头是柔性接头。示例性柔性接头包括甘氨酸聚合物(G)n(SEQ ID NO:372)、甘氨酸-丝氨酸聚合物(包括例如(GS)n(SEQ ID NO:373)、(GSGGS)n(SEQ ID NO:374)、(GGGS)n(SEQ ID NO:375)和(GGGGS)n(SEQ ID NO:376),其中n是至少1的整数)、甘氨酸-丙氨酸聚合物、丙氨酸-丝氨酸聚合物和本领域中已知的其它柔性接头。在一些实施方案中,肽接头包含SEQ ID NO:370(GGGGSGGGS)或371(GGGGSGGGGSGGGGS)的氨基酸序列。
在一些实施方案中,包含本文所述的抗PD-1 sdAb部分和一个或多个其它抗体部分(例如全长抗体、sdAb或包含VH和VL的抗原结合部分)的抗PD-1构建体具有单特异性。在一些实施方案中,包含本文所述的抗PD-1 sdAb部分和一个或多个其它抗体部分(例如全长抗体、sdAb或包含VH和VL的抗原结合部分)的抗PD-1构建体具有多特异性(例如双特异性)。多特异性分子是对至少两种不同表位具有结合特异性的分子(例如对两种表位具有结合特异性的双特异性抗体)。还考虑到具有多于两种价态和/或两种特异性的多特异性分子。例如,可制备三特异性抗体。Tutt等,J.Immunol.147:60(1991)。应理解,本领域技术人员可选择本文所述的个别多特异性分子的适当特征以彼此组合来形成本发明的多特异性抗PD-1构建体。
在一些实施方案中,抗PD-1构建体是多价但单特异性的,即,抗PD-1构建体包含本文所述的抗PD-1 sdAb部分和至少第二抗体部分(例如全长抗体、sdAb或包含VH和VL的抗原结合部分),所述第二抗体部分特异性识别与本文所述的抗PD-1 sdAb部分相同的PD-1表位。在一些实施方案中,所述一个或多个特异性识别与本文所述的抗PD-1 sdAb部分相同的PD-1表位的抗体部分可包含与抗PD-1 sdAb部分相同的CDR和/或相同的VHH氨基酸序列。例如,抗PD-1构建体可包含两个或两个以上的本文所述的抗PD-1 sdAb部分,其中所述两个或两个以上的抗PD-1 sdAb部分相同并且任选地通过肽接头连接。在一些实施方案中,肽接头包含SEQ ID NO:367-376中的任一者的氨基酸序列。
在一些实施方案中,抗PD-1构建体是多价且多特异性的(例如,双特异性的),即,抗PD-1构建体包含本文所述的抗PD-1 sdAb部分和至少第二抗体部分(例如全长抗体、sdAb或包含VH和VL的抗原结合部分),所述第二抗体部分特异性识别除PD-1之外的第二抗原,或本文所述的抗PD-1 sdAb部分所识别的不同PD-1表位。在一些实施方案中,第二抗体部分是sdAb,例如抗PD-1 sdAb或抗CTLA-4 sdAb(例如PCT/CN2017/105506和PCT/CN2016/101777中所公开的任一者,所述文献通过引用整体并入本文中)。在一些实施方案中,第二抗体部分特异性识别人类血清白蛋白(HSA)。在一些实施方案中,本文所述的抗PD-1 sdAb部分融合至第二抗体部分的N末端和/或C末端。在一些实施方案中,抗PD-1构建体是三价且双特异性的。在一些实施方案中,抗PD-1构建体包含两个本文所述的抗PD-1 sdAb部分和第二抗体部分(例如抗HSA sdAb、抗CTLA-4 sdAb),其中第二抗体部分在所述两个抗PD-1 sdAb部分之间。在一些实施方案中,抗体部分任选地通过肽接头连接。在一些实施方案中,肽接头包含SEQ ID NO:367-376中的任一者的氨基酸序列。
包含两个或两个以上的抗PD-1 sdAb部分的单特异性或多特异性抗PD-1构建体可相较于本文所述的单抗PD-1 sdAb部分具有增加的亲合力。
包含融合至全长抗体的抗PD-1 sdAb部分的双特异性抗体
在一些实施方案中,抗PD-1构建体包含融合至第二抗体部分的本文所述的抗PD-1sdAb部分,其中所述第二抗体部分是由两条重链和两条轻链组成的全长抗体(例如特异性识别TIGIT、LAG-3、TIM-3、CTLA-4或PD-1(例如,与本文所述的抗PD-1 sdAb部分所识别不同的第二PD-1表位)的全长抗体)。在一些实施方案中,抗PD-1 sdAb部分和全长抗体经由任选的接头(例如肽接头)连接。
因此在一些实施方案中,提供一种分离的抗PD-1构建体,其包含特异性识别PD-1的sdAb部分和全长抗体(例如特异性识别TIGIT、LAG-3、TIM-3、CTLA-4或PD-1(例如,与本文所述的抗PD-1 sdAb部分所识别不同的第二PD-1表位)的全长抗体),其中所述抗PD-1 sdAb部分包含:包含SEQ ID NO:37-72中的任一者的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:109-144中的任一者的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:181-216中的任一者的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,提供一种分离的抗PD-1构建体,其包含特异性识别PD-1的sdAb部分和全长抗体(例如特异性识别TIGIT、LAG-3、TIM-3、CTLA-4或PD-1(例如,与本文所述的抗PD-1 sdAb部分所识别不同的第二PD-1表位)的全长抗体),其中所述抗PD-1 sdAb部分包含:包含SEQ ID NO:37-72中的任一者的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:109-144中的任一者的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:181-216中的任一者的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;并且其中所述抗PD-1 sdAb部分的N末端融合至全长抗体的至少一条重链的C末端(如图17所示例)。在一些实施方案中,提供一种分离的抗PD-1构建体,其包含特异性识别PD-1的sdAb部分和全长抗体(例如特异性识别TIGIT、LAG-3、TIM-3、CTLA-4或PD-1(例如,与本文所述的抗PD-1 sdAb部分所识别不同的第二PD-1表位)的全长抗体),其中所述抗PD-1 sdAb部分包含:包含SEQ ID NO:37-72中的任一者的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:109-144中的任一者的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:181-216中的任一者的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;并且其中所述抗PD-1 sdAb部分的C末端融合至全长抗体的至少一条重链的N末端(如图16所示例)。在一些实施方案中,提供一种分离的抗PD-1构建体,其包含特异性识别PD-1的sdAb部分和全长抗体(例如特异性识别TIGIT、LAG-3、TIM-3、CTLA-4或PD-1(例如,与本文所述的抗PD-1 sdAb部分所识别不同的第二PD-1表位)的全长抗体),其中所述抗PD-1 sdAb部分包含:包含SEQ ID NO:37-72中的任一者的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:109-144中的任一者的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:181-216中的任一者的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;并且其中所述抗PD-1 sdAb部分的N末端融合至全长抗体的至少一条轻链的C末端(如图19所示例)。在一些实施方案中,提供一种分离的抗PD-1构建体,其包含特异性识别PD-1的sdAb部分和全长抗体(例如特异性识别TIGIT、LAG-3、TIM-3、CTLA-4或PD-1(例如,与本文所述的抗PD-1 sdAb部分所识别不同的第二PD-1表位)的全长抗体),其中所述抗PD-1 sdAb部分包含:包含SEQ ID NO:37-72中的任一者的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:109-144中的任一者的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:181-216中的任一者的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;并且其中所述抗PD-1 sdAb部分的C末端融合至全长抗体的至少一条轻链的N末端(如图18所示例)。在一些实施方案中,提供一种分离的抗PD-1构建体,其包含四个特异性识别PD-1的sdAb部分和全长抗体(例如特异性识别TIGIT、LAG-3、TIM-3、CTLA-4或PD-1(例如,与本文所述的抗PD-1 sdAb部分所识别不同的第二PD-1表位)的全长抗体),其中每个抗PD-1 sdAb部分包含:包含SEQ ID NO:37-72中的任一者的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:109-144中的任一者的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:181-216中的任一者的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;并且其中抗PD-1 sdAb部分的C末端融合至全长抗体的重链和轻链两者的N末端(如图20所示例)。在一些实施方案中,提供一种分离的抗PD-1构建体,其包含四个特异性识别PD-1的sdAb部分和全长抗体(例如特异性识别TIGIT、LAG-3、TIM-3、CTLA-4或PD-1(例如,与本文所述的抗PD-1 sdAb部分所识别不同的第二PD-1表位)的全长抗体),其中每个抗PD-1 sdAb部分包含:包含SEQ ID NO:37-72中的任一者的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQID NO:109-144中的任一者的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:181-216中的任一者的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;其中两个抗PD-1 sdAb部分经由第一任选的接头融合在一起,并且其它两个抗PD-1 sdAb部分经由第二任选的接头融合在一起,并且其中两个抗PD-1 sdAb融合物的每个组的C末端经由第三和第四任选的接头融合至全长抗体的每条重链的N末端(如图21所示例)。在一些实施方案中,四个抗PD-1 sdAb部分相同。在一些实施方案中,四个抗PD-1 sdAb部分不同。在一些实施方案中,抗PD-1 sdAb部分包含:包含SEQ ID NO:37-72中的任一者的氨基酸序列的CDR1;包含SEQ ID NO:109-144中的任一者的氨基酸序列的CDR2;和包含SEQ ID NO:181-216中的任一者的氨基酸序列的CDR3。在一些实施方案中,抗PD-1 sdAb部分包含VHH域,所述VHH域包含SEQ ID NO:289-324中的任一者的氨基酸序列。在一些实施方案中,抗PD-1 sdAb部分包含SEQ ID NO:289-324中的任一者的CDR1、CDR2和CDR3。在一些实施方案中,全长抗体的Fc片段是hIgG1 Fc、无效应子hIgG1 Fc、hIgG2 Fc、hIgG4 Fc或hIgG4 Fc(S228P)。在一些实施方案中,全长抗体的Fc片段包含SEQ ID NO:363-365中的任一者的氨基酸序列。在一些实施方案中,全长抗体是刺激性免疫检查点分子的活化剂。在一些实施方案中,全长抗体是免疫检查点抑制剂,例如TIGIT、LAG-3、TIM-3、CTLA-4或PD-1的抑制剂(例如,特异性识别与本文所述的抗PD-1 sdAb部分所识别不同的第二PD-1表位的抗体)。在一些实施方案中,全长抗体是抗TIGIT抗体。在一些实施方案中,抗TIGIT抗体包含:包含SEQ ID NO:377的氨基酸序列的HC-CDR1、HC-CDR2和HC-CDR3的VH;以及包含SEQ ID NO:378的氨基酸序列的LC-CDR1、LC-CDR2和LC-CDR3的VL。在一些实施方案中,抗TIGIT抗体包括包含SEQ ID NO:377的氨基酸序列的重链和包含SEQ ID NO:378的氨基酸序列的轻链。在一些实施方案中,抗TIGIT抗体是替拉古单抗。在一些实施方案中,全长抗体是抗LAG-3抗体。在一些实施方案中,抗LAG-3抗体包含:包含SEQ ID NO:379的氨基酸序列的HC-CDR1、HC-CDR2和HC-CDR3的VH;以及包含SEQ ID NO:380的氨基酸序列的LC-CDR1、LC-CDR2和LC-CDR3的VL。在一些实施方案中,抗LAG-3抗体包括包含SEQ ID NO:379的氨基酸序列的重链和包含SEQ ID NO:380的氨基酸序列的轻链。在一些实施方案中,抗LAG-3抗体是瑞拉里单抗。在一些实施方案中,全长抗体是抗TIM-3抗体。在一些实施方案中,抗TIM-3抗体包含:包含SEQ ID NO:381的氨基酸序列的HC-CDR1、HC-CDR2和HC-CDR3的VH;以及包含SEQ ID NO:382的氨基酸序列的LC-CDR1、LC-CDR2和LC-CDR3的VL。在一些实施方案中,抗TIM-3抗体包括包含SEQ ID NO:381的氨基酸序列的重链和包含SEQ ID NO:382的氨基酸序列的轻链。在一些实施方案中,抗TIM-3抗体是MBG453。在一些实施方案中,全长抗体是抗CTLA-4抗体。在一些实施方案中,抗CTLA-4抗体包含:包含SEQ ID NO:383的氨基酸序列的HC-CDR1、HC-CDR2和HC-CDR3的VH;以及包含SEQID NO:384的氨基酸序列的LC-CDR1、LC-CDR2和LC-CDR3的VL。在一些实施方案中,抗CTLA-4抗体包括包含SEQ ID NO:383的氨基酸序列的重链和包含SEQ ID NO:384的氨基酸序列的轻链。在一些实施方案中,抗CTLA-4抗体是伊匹单抗(例如, )。在一些实施方案中,全长抗体是抗PD-1抗体(例如,特异性识别与本文所述的抗PD-1 sdAb部分所识别不同的第二PD-1表位)。在一些实施方案中,抗PD-1全长抗体包含:包含SEQ ID NO:385的氨基酸序列的HC-CDR1、HC-CDR2和HC-CDR3的VH;以及包含SEQ ID NO:386的氨基酸序列的LC-CDR1、LC-CDR2和LC-CDR3的VL。在一些实施方案中,抗PD-1全长抗体包括包含SEQ ID NO:385的氨基酸序列的重链和包含SEQ ID NO:386的氨基酸序列的轻链。在一些实施方案中,抗PD-1全长抗体是派姆单抗(例如,/>
)。在一些实施方案中,全长抗体是抗PD-1抗体(例如,特异性识别与本文所述的抗PD-1 sdAb部分所识别不同的第二PD-1表位)。在一些实施方案中,抗PD-1全长抗体包含:包含SEQ ID NO:385的氨基酸序列的HC-CDR1、HC-CDR2和HC-CDR3的VH;以及包含SEQ ID NO:386的氨基酸序列的LC-CDR1、LC-CDR2和LC-CDR3的VL。在一些实施方案中,抗PD-1全长抗体包括包含SEQ ID NO:385的氨基酸序列的重链和包含SEQ ID NO:386的氨基酸序列的轻链。在一些实施方案中,抗PD-1全长抗体是派姆单抗(例如,/> )或纳武单抗(例如,/>
)或纳武单抗(例如,/> )。在一些实施方案中,抗PD-1 sdAb部分和全长抗体任选地由肽接头连接。在一些实施方案中,肽接头包含SEQ ID NO:367-376中的任一者的氨基酸序列。在一些实施方案中,抗PD-1 sdAb部分与PD-1之间的结合的Kd是约10-5M至约10-12M(例如约10-7M至约10-12M、或约10-8M至约10- 12M)。在一些实施方案中,抗PD-1 sdAb部分是骆驼科的、嵌合的、人类的、部分人源化的或完全人源化的抗PD-1 sdAb部分。
)。在一些实施方案中,抗PD-1 sdAb部分和全长抗体任选地由肽接头连接。在一些实施方案中,肽接头包含SEQ ID NO:367-376中的任一者的氨基酸序列。在一些实施方案中,抗PD-1 sdAb部分与PD-1之间的结合的Kd是约10-5M至约10-12M(例如约10-7M至约10-12M、或约10-8M至约10- 12M)。在一些实施方案中,抗PD-1 sdAb部分是骆驼科的、嵌合的、人类的、部分人源化的或完全人源化的抗PD-1 sdAb部分。
TIGIT
具有Ig和ITIM域的T细胞免疫受体(TIGIT,也称为Vstm3或WUCAM)是属于CD28家族的免疫受体。TIGIT经由若干机制发挥其抑制性免疫检查点功能。第一,在结合其主要配体CD155(PVR)后,其ITIM域中TIGIT的随后磷酸化转导抑制性信号以经由NF-κB路径下调T细胞和NK细胞中的IFN-γ表达。第二,由于TIGIT在高于CD226的亲和力下与PVR相互作用,因此其与CD226竞争并减弱由CD226转导的刺激性信号。第三,PVR在树突细胞上结合TIGIT可导致IL-10表达的上调和IL-12表达的下调,因此损害树突细胞的抗肿瘤免疫反应。最后,最近的研究指示,TIGIT可直接顺式结合CD226以抑制CD226二聚化,这是T细胞活化所必需的。因此,TIGIT在感染和癌症的免疫反应中充当重要的负调控因子,并且已提出阻断TIGIT信号传导是增强T细胞和NK细胞免疫性以供癌症治疗的方法。可应用于本申请的示例性抗TIGIT抗体包括但不限于替拉古单抗。
包含针对TIGIT和PD-1的双特异性的构建体在下文中称为“抗TIGIT/PD-1抗体”、“抗TIGIT/PD-1构建体”、“PD-1×TIGIT抗体”或“PD-1×TIGIT BABP”。
LAG-3
LAG-3(淋巴细胞活化基因-3,CD223)通过对Treg的作用以及对CD8+T细胞的直接作用起到抑制免疫反应的作用(Huang等,2004,Immunity.21(4):503-13;Grosso等,2007,JClin Invest.117(11):3383-92)。可应用于本申请的示例性抗LAG-3抗体包括但不限于瑞拉里单抗(BMS-986016)。
包含针对LAG-3和PD-1的双特异性的构建体在下文中称为“抗LAG-3/PD-1抗体”、“抗LAG-3/PD-1构建体”、“PD-1×LAG-3抗体”或“PD-1×LAG-3 BABP”。
TIM-3
含有T细胞免疫球蛋白和粘蛋白域-3(TIM-3)也称为A型肝炎病毒细胞受体2(HAVCR2)。它是免疫检查点分子,其与淋巴细胞活性的抑制相关,并且在一些情况下诱导淋巴细胞无反应(Pardoll D.,Nature Reviews,2012年4月,第12卷:252)。TIM-3是半乳糖凝集素9(GAL9)的受体,其在各种类型的癌症(包括乳腺癌)中被上调。TIM-3被鉴定为由耗竭CD8+T细胞表达的另一重要抑制性受体。在小鼠癌症模型中,已显示大多数功能不良肿瘤浸润CD8+T细胞实际上共表达PD-1和TIM-3。可应用于本申请的示例性抗TIM-3抗体包括但不限于MBG453。
包含针对TIM-3和PD-1的双特异性的构建体在下文中称为“抗TIM-3/PD-1抗体”、“抗TIM-3/PD-1构建体”、“PD-1×TIM-3抗体”或“PD-1×TIM-3 BABP”。
CTLA-4
细胞毒性T淋巴细胞相关蛋白4(CTLA-4或CD152)是CD28的同源物,并且已知为活化T细胞上被上调的抑制性免疫检查点分子。CTLA-4也结合至B7-1和B7-2,但亲和力大于CD28。B7与CTLA-4之间的相互作用阻抑T细胞活化,其组成肿瘤免疫逃逸的重要机制。抗CTLA-4抗体疗法已在许多癌症中显示出前景,例如黑色素瘤。可应用于本申请的示例性抗CTLA-4抗体包括但不限于伊匹单抗(例如, )。
)。
包含针对CTLA-4和PD-1的双特异性的构建体在下文中称为“抗CTLA-4/PD-1抗体”、“抗CTLA-4/PD-1构建体”、“PD-1×CTLA-4抗体”或“PD-1×CTLA-4 BABP”。
PD-1
在一些实施方案中,第二抗体部分是由两条重链和两条轻链组成的全长抗体,其特异性识别PD-1的另一表位,与本文所述的抗PD-1 sdAb部分所识别的PD-1表位不同。在一些实施方案中,将本文所述的抗PD-1 sdAb部分与特异性识别不同PD-1表位的抗PD-1全长抗体融合将增加抗体效力。可应用于本申请的示例性抗PD-1抗体包括但不限于派姆单抗(例如, )和纳武单抗(例如,/>
)和纳武单抗(例如,/> )。
)。
包含针对PD-1的双特异性的构建体在下文中称为“抗PD-1/PD-1抗体”、“抗PD-1/PD-1构建体”、“PD-1/PD-1抗体”或“PD-1×PD-1 BABP”。
在一些实施方案中,还提供一种抗PD-1构建体,其包含特异性识别PD-1的sdAb部分(下文称为“竞争性抗PD-1构建体”),其与以下中的任一者竞争性地特异性结合PD-1:本文所述的抗PD-1构建体(例如抗PD-1 sdAb部分、抗PD-1 sdAb-Fc融合蛋白(例如,抗PD-1HCAb)、包含本文所述的抗PD-1 sdAb部分的多特异性或单特异性抗PD-1构建体(例如,本文所述的PD-1×TIGIT BABP、PD-1×LAG-3 BABP、PD-1×TIM-3 BABP、PD-1×CTLA-4 BABP或PD-1×PD-1 BABP)。
抗PD-1多特异性抗原结合蛋白(MABP)
在一些实施方案中,提供一种分离的抗PD-1构建体,其包含融合至包含VH和VL的全长抗体或抗原结合片段的本文所述的抗PD-1 sdAb部分,其中所述抗PD-1构建体具有多特异性(下文称为“多特异性抗PD-1构建体”或“抗PD-1多特异性抗原结合蛋白(MABP)”)。在一些实施方案中,抗PD-1 MABP具有双特异性(下文称为“双特异性抗PD-1构建体”或“抗PD-1双特异性抗原结合蛋白(BABP)”)。抗PD-1 sdAb部分特异性结合与包含VH和VL的全长抗体或抗原结合片段所识别的靶标不同的PD-1,从而赋予广泛的靶向能力。由于sdAb较小,因此在一些实施方案中,与全长抗体或抗原结合片段组分相比,本文所述的抗PD-1 MABP(例如,抗PD-1 BABP)可具有类似的分子量和药代动力学性质。例如,可通过将一个或多个抗PD-1sdAb部分与具有经证实的临床功效和安全性的单克隆抗体融合来设计抗PD-1 MABP,以提供增加的临床益处和期望的药代动力学性质,而不妨碍多特异性构建体的表达性。在一些实施方案中,将一个或多个本文所述的抗PD-1 sdAb部分通过任选的肽接头融合至全长抗体或抗原结合片段。本文所述的抗PD-1 MABP(例如,抗PD-1 BABP)可用于靶向除PD-1之外的多种疾病相关表位或抗原组合,例如与免疫检查点分子、细胞表面抗原(例如肿瘤抗原)或促炎性分子组合的PD-1,从而提供可用于治疗多种疾病和疾患(例如癌症、炎症和自身免疫疾病)的药剂。抗PD-1 MABP(例如,抗PD-1 BABP)可具有任何形式,例如PCT/CN2017/093644中所公开者,所述文献通过引用整体并入本文中。
示例性抗PD-1 MABP和BABP
在一些实施方案中,抗PD-1 MABP(例如,BABP)包含:(a)第一抗原结合部分,其包含本文所述的特异性识别PD-1的sdAb部分;和(b)第二抗原结合部分,其包含VH和VL,其中所述VH和VL一起形成特异性结合TIGIT的抗原结合位点,其中第一抗原结合部分和第二抗原结合部分彼此融合(下文称为“PD-1×TIGIT MABP”或“PD-1×TIGIT BABP”)。在一些实施方案中,抗PD-1 MABP(例如,BABP)包含:(a)第一抗原结合部分,其包含本文所述的特异性识别PD-1的sdAb部分;和(b)第二抗原结合部分,其包含VH和VL,其中所述VH和VL一起形成特异性结合LAG-3的抗原结合位点,其中第一抗原结合部分和第二抗原结合部分彼此融合(下文称为“PD-1×LAG-3 MABP”或“PD-1×LAG-3 BABP”)。在一些实施方案中,抗PD-1 MABP(例如,BABP)包含:(a)第一抗原结合部分,其包含本文所述的特异性识别PD-1的sdAb部分;和(b)第二抗原结合部分,其包含VH和VL,其中所述VH和VL一起形成特异性结合TIM-3的抗原结合位点,其中第一抗原结合部分和第二抗原结合部分彼此融合(下文称为“PD-1×TIM-3MABP”或“PD-1×TIM-3 BABP”)。在一些实施方案中,抗PD-1 MABP(例如,BABP)包含:(a)第一抗原结合部分,其包含本文所述的特异性识别PD-1的sdAb部分;和(b)第二抗原结合部分,其包含VH和VL,其中所述VH和VL一起形成特异性结合CTLA-4的抗原结合位点,其中第一抗原结合部分和第二抗原结合部分彼此融合(下文称为“PD-1×CTLA-4 MABP”或“PD-1×CTLA-4 BABP”)。在一些实施方案中,抗PD-1 MABP(例如,BABP)包含:(a)第一抗原结合部分,其包含本文所述的特异性识别PD-1的sdAb部分;和(b)第二抗原结合部分,其包含VH和VL,其中所述VH和VL一起形成特异性结合与本文所述的抗PD-1 sdAb部分所识别不同的第二PD-1表位,其中第一抗原结合部分和第二抗原结合部分彼此融合(下文称为“PD-1×PD-1MABP”或“PD-1×PD-1 BABP”)。
在一些实施方案中,提供一种抗PD-1 BABP,所述抗PD-1 BABP包含:(a)第一多肽,其从N末端至C末端包含:VH-CH1-CH2-CH3-抗PD-1 sdAb部分;和(b)第二多肽,其从N末端至C末端包含:VL-CL,其中VH和VL形成特异性结合第二表位(例如,TIGIT、LAG-3、TIM-3、CTLA-4、PD-1(例如与本文所述的抗PD-1 sdAb部分所识别不同的第二PD-1表位))的抗原结合位点,并且其中抗PD-1 sdAb部分包含:包含SEQ ID NO:37-72中的任一者的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ IDNO:109-144中的任一者的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:181-216中的任一者的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,抗PD-1 sdAb包含:包含SEQ ID NO:37-72中的任一者的氨基酸序列的CDR1;包含SEQ ID NO:109-144中的任一者的氨基酸序列的CDR2;和包含SEQ ID NO:181-216中的任一者的氨基酸序列的CDR3。在一些实施方案中,抗PD-1 sdAb部分包含VHH域,所述VHH域包含SEQ ID NO:289-324中的任一者的氨基酸序列。在一些实施方案中,VH和VL形成特异性结合TIGIT的抗原结合位点。在一些实施方案中,VH和VL域来源于替拉古单抗。在一些实施方案中,VH包含SEQ ID NO:377的氨基酸序列的HC-CDR1、HC-CDR2和HC-CDR3,并且VL包含SEQ IDNO:378的氨基酸序列的LC-CDR1、LC-CDR2和LC-CDR3。在一些实施方案中,VH和VL形成特异性结合LAG-3的抗原结合位点。在一些实施方案中,VH和VL域来源于瑞拉里单抗。在一些实施方案中,VH包含SEQ ID NO:379的氨基酸序列的HC-CDR1、HC-CDR2和HC-CDR3,并且VL包含SEQID NO:380的氨基酸序列的LC-CDR1、LC-CDR2和LC-CDR3。在一些实施方案中,VH和VL形成特异性结合TIM-3的抗原结合位点。在一些实施方案中,VH和VL域来源于MBG453。在一些实施方案中,VH包含SEQ ID NO:381的氨基酸序列的HC-CDR1、HC-CDR2和HC-CDR3,并且VL包含SEQID NO:382的氨基酸序列的LC-CDR1、LC-CDR2和LC-CDR3。在一些实施方案中,VH和VL形成特异性结合CTLA-4的抗原结合位点。在一些实施方案中,VH和VL域来源于伊匹单抗(例如, )。在一些实施方案中,VH包含SEQ ID NO:383的氨基酸序列的HC-CDR1、HC-CDR2和HC-CDR3,并且VL包含SEQ ID NO:384的氨基酸序列的LC-CDR1、LC-CDR2和LC-CDR3。在一些实施方案中,VH和VL形成特异性结合PD-1(例如与本文所述的抗PD-1 sdAb部分识别不同的第二PD-1表位)的抗原结合位点。在一些实施方案中,VH和VL域来源于派姆单抗(例如,
)。在一些实施方案中,VH包含SEQ ID NO:383的氨基酸序列的HC-CDR1、HC-CDR2和HC-CDR3,并且VL包含SEQ ID NO:384的氨基酸序列的LC-CDR1、LC-CDR2和LC-CDR3。在一些实施方案中,VH和VL形成特异性结合PD-1(例如与本文所述的抗PD-1 sdAb部分识别不同的第二PD-1表位)的抗原结合位点。在一些实施方案中,VH和VL域来源于派姆单抗(例如, )或纳武单抗(例如,/>
)或纳武单抗(例如,/> )。在一些实施方案中,VH包含SEQ ID NO:385的氨基酸序列的HC-CDR1、HC-CDR2和HC-CDR3,并且VL包含SEQ ID NO:386的氨基酸序列的LC-CDR1、LC-CDR2和LC-CDR3。在一些实施方案中,CH3和抗PD-1 sdAb部分任选地经由肽接头彼此融合,例如包含SEQ ID NO:367-376中的任一者的氨基酸序列的肽接头。在一些实施方案中,CH2和CH3域来源于IgG1 Fc、无效应子IgG1 Fc、IgG2 Fc、IgG4 Fc或IgG4 Fc(S228P),例如SEQ ID NO:363-365中的任一者。在一些实施方案中,抗PD-1 BABP包含第一多肽的两个相同拷贝和第二多肽的两个相同拷贝。在一些实施方案中,抗PD-1 sdAb部分与PD-1之间的结合的Kd是约10-5M至约10-12M(例如约10-7M至约10-12M、或约10-8M至约10-12M)。在一些实施方案中,抗PD-1 sdAb部分是骆驼科的、嵌合的、人类的、部分人源化的或完全人源化的抗PD-1 sdAb部分。在一些实施方案中,PD-1 BABP具有如图17中所示的结构。
)。在一些实施方案中,VH包含SEQ ID NO:385的氨基酸序列的HC-CDR1、HC-CDR2和HC-CDR3,并且VL包含SEQ ID NO:386的氨基酸序列的LC-CDR1、LC-CDR2和LC-CDR3。在一些实施方案中,CH3和抗PD-1 sdAb部分任选地经由肽接头彼此融合,例如包含SEQ ID NO:367-376中的任一者的氨基酸序列的肽接头。在一些实施方案中,CH2和CH3域来源于IgG1 Fc、无效应子IgG1 Fc、IgG2 Fc、IgG4 Fc或IgG4 Fc(S228P),例如SEQ ID NO:363-365中的任一者。在一些实施方案中,抗PD-1 BABP包含第一多肽的两个相同拷贝和第二多肽的两个相同拷贝。在一些实施方案中,抗PD-1 sdAb部分与PD-1之间的结合的Kd是约10-5M至约10-12M(例如约10-7M至约10-12M、或约10-8M至约10-12M)。在一些实施方案中,抗PD-1 sdAb部分是骆驼科的、嵌合的、人类的、部分人源化的或完全人源化的抗PD-1 sdAb部分。在一些实施方案中,PD-1 BABP具有如图17中所示的结构。
在一些实施方案中,提供一种抗PD-1 BABP,所述抗PD-1 BABP包含:(a)第一多肽,其从N末端至C末端包含:抗PD-1 sdAb部分-VH-CH1-CH2-CH3;和(b)第二多肽,其从N末端至C末端包含:VL-CL,其中VH和VL形成特异性结合第二表位(例如,TIGIT、LAG-3、TIM-3、CTLA-4、PD-1(例如与本文所述的抗PD-1 sdAb部分所识别不同的第二PD-1表位))的抗原结合位点,并且其中抗PD-1 sdAb部分包含:包含SEQ ID NO:37-72中的任一者的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ IDNO:109-144中的任一者的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:181-216中的任一者的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,抗PD-1 sdAb部分包含:包含SEQ ID NO:37-72中的任一者的氨基酸序列的CDR1;包含SEQ ID NO:109-144中的任一者的氨基酸序列的CDR2;和包含SEQ ID NO:181-216中的任一者的氨基酸序列的CDR3。在一些实施方案中,抗PD-1 sdAb部分包含VHH域,所述VHH域包含SEQ ID NO:289-324中的任一者的氨基酸序列。在一些实施方案中,VH和VL形成特异性结合TIGIT的抗原结合位点。在一些实施方案中,VH和VL域来源于替拉古单抗。在一些实施方案中,VH包含SEQ ID NO:377的氨基酸序列的HC-CDR1、HC-CDR2和HC-CDR3,并且VL包含SEQ IDNO:378的氨基酸序列的LC-CDR1、LC-CDR2和LC-CDR3。在一些实施方案中,VH和VL形成特异性结合LAG-3的抗原结合位点。在一些实施方案中,VH和VL域来源于瑞拉里单抗。在一些实施方案中,VH包含SEQ ID NO:379的氨基酸序列的HC-CDR1、HC-CDR2和HC-CDR3,并且VL包含SEQID NO:380的氨基酸序列的LC-CDR1、LC-CDR2和LC-CDR3。在一些实施方案中,VH和VL形成特异性结合TIM-3的抗原结合位点。在一些实施方案中,VH和VL域来源于MBG453。在一些实施方案中,VH包含SEQ ID NO:381的氨基酸序列的HC-CDR1、HC-CDR2和HC-CDR3,并且VL包含SEQID NO:382的氨基酸序列的LC-CDR1、LC-CDR2和LC-CDR3。在一些实施方案中,VH和VL形成特异性结合CTLA-4的抗原结合位点。在一些实施方案中,VH和VL域来源于伊匹单抗(例如, )。在一些实施方案中,VH包含SEQ ID NO:383的氨基酸序列的HC-CDR1、HC-CDR2和HC-CDR3,并且VL包含SEQ ID NO:384的氨基酸序列的LC-CDR1、LC-CDR2和LC-CDR3。在一些实施方案中,VH和VL形成特异性结合PD-1(例如与本文所述的抗PD-1 sdAb部分识别不同的第二PD-1表位)的抗原结合位点。在一些实施方案中,VH和VL域来源于派姆单抗(例如,
)。在一些实施方案中,VH包含SEQ ID NO:383的氨基酸序列的HC-CDR1、HC-CDR2和HC-CDR3,并且VL包含SEQ ID NO:384的氨基酸序列的LC-CDR1、LC-CDR2和LC-CDR3。在一些实施方案中,VH和VL形成特异性结合PD-1(例如与本文所述的抗PD-1 sdAb部分识别不同的第二PD-1表位)的抗原结合位点。在一些实施方案中,VH和VL域来源于派姆单抗(例如, )或纳武单抗(例如,/>
)或纳武单抗(例如,/> )。在一些实施方案中,VH包含SEQ ID NO:385的氨基酸序列的HC-CDR1、HC-CDR2和HC-CDR3,并且VL包含SEQ ID NO:386的氨基酸序列的LC-CDR1、LC-CDR2和LC-CDR3。在一些实施方案中,VH和抗PD-1 sdAb部分任选地经由肽接头彼此融合,例如包含SEQ ID NO:367-376中的任一者的氨基酸序列的肽接头。在一些实施方案中,CH2和CH3域来源于IgG1 Fc、无效应子IgG1 Fc、IgG2 Fc、IgG4 Fc或IgG4 Fc(S228P),例如SEQ ID NO:363-365中的任一者。在一些实施方案中,抗PD-1 BABP包含第一多肽的两个相同拷贝和第二多肽的两个相同拷贝。在一些实施方案中,抗PD-1 sdAb部分与PD-1之间的结合的Kd是约10-5M至约10-12M(例如约10-7M至约10-12M、或约10-8M至约10-12M)。在一些实施方案中,抗PD-1 sdAb部分是骆驼科的、嵌合的、人类的、部分人源化的或完全人源化的抗PD-1 sdAb部分。在一些实施方案中,PD-1 BABP具有如图16中所示的结构。
)。在一些实施方案中,VH包含SEQ ID NO:385的氨基酸序列的HC-CDR1、HC-CDR2和HC-CDR3,并且VL包含SEQ ID NO:386的氨基酸序列的LC-CDR1、LC-CDR2和LC-CDR3。在一些实施方案中,VH和抗PD-1 sdAb部分任选地经由肽接头彼此融合,例如包含SEQ ID NO:367-376中的任一者的氨基酸序列的肽接头。在一些实施方案中,CH2和CH3域来源于IgG1 Fc、无效应子IgG1 Fc、IgG2 Fc、IgG4 Fc或IgG4 Fc(S228P),例如SEQ ID NO:363-365中的任一者。在一些实施方案中,抗PD-1 BABP包含第一多肽的两个相同拷贝和第二多肽的两个相同拷贝。在一些实施方案中,抗PD-1 sdAb部分与PD-1之间的结合的Kd是约10-5M至约10-12M(例如约10-7M至约10-12M、或约10-8M至约10-12M)。在一些实施方案中,抗PD-1 sdAb部分是骆驼科的、嵌合的、人类的、部分人源化的或完全人源化的抗PD-1 sdAb部分。在一些实施方案中,PD-1 BABP具有如图16中所示的结构。
在一些实施方案中,提供一种抗PD-1 BABP,其包含:(a)第一多肽,其从N末端至C末端包含:VH-CH1-CH2-CH3;和(b)第二多肽,其从N末端至C末端包含:VL-CL-抗PD-1 sdAb部分,其中VH和VL形成特异性结合第二表位(例如,TIGIT、LAG-3、TIM-3、CTLA-4、PD-1(例如与本文所述的抗PD-1 sdAb部分所识别不同的第二PD-1表位))的抗原结合位点,并且其中抗PD-1 sdAb部分包含:包含SEQ ID NO:37-72中的任一者的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:109-144中的任一者的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:181-216中的任一者的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,抗PD-1sdAb部分包含:包含SEQ ID NO:37-72中的任一者的氨基酸序列的CDR1;包含SEQ ID NO:109-144中的任一者的氨基酸序列的CDR2;和包含SEQ ID NO:181-216中的任一者的氨基酸序列的CDR3。在一些实施方案中,抗PD-1 sdAb部分包含VHH域,所述VHH域包含SEQ ID NO:289-324中的任一者的氨基酸序列。在一些实施方案中,VH和VL形成特异性结合TIGIT的抗原结合位点。在一些实施方案中,VH和VL域来源于替拉古单抗。在一些实施方案中,VH包含SEQID NO:377的氨基酸序列的HC-CDR1、HC-CDR2和HC-CDR3,并且VL包含SEQ ID NO:378的氨基酸序列的LC-CDR1、LC-CDR2和LC-CDR3。在一些实施方案中,VH和VL形成特异性结合LAG-3的抗原结合位点。在一些实施方案中,VH和VL域来源于瑞拉里单抗。在一些实施方案中,VH包含SEQ ID NO:379的氨基酸序列的HC-CDR1、HC-CDR2和HC-CDR3,并且VL包含SEQ ID NO:380的氨基酸序列的LC-CDR1、LC-CDR2和LC-CDR3。在一些实施方案中,VH和VL形成特异性结合TIM-3的抗原结合位点。在一些实施方案中,VH和VL域来源于MBG453。在一些实施方案中,VH包含SEQ ID NO:381的氨基酸序列的HC-CDR1、HC-CDR2和HC-CDR3,并且VL包含SEQ ID NO:382的氨基酸序列的LC-CDR1、LC-CDR2和LC-CDR3。在一些实施方案中,VH和VL形成特异性结合CTLA-4的抗原结合位点。在一些实施方案中,VH和VL域来源于伊匹单抗(例如, )。在一些实施方案中,VH包含SEQ ID NO:383的氨基酸序列的HC-CDR1、HC-CDR2和HC-CDR3,并且VL包含SEQ ID NO:384的氨基酸序列的LC-CDR1、LC-CDR2和LC-CDR3。在一些实施方案中,VH和VL形成特异性结合PD-1(例如与本文所述的抗PD-1 sdAb部分识别不同的第二PD-1表位)的抗原结合位点。在一些实施方案中,VH和VL域来源于派姆单抗(例如,/>
)。在一些实施方案中,VH包含SEQ ID NO:383的氨基酸序列的HC-CDR1、HC-CDR2和HC-CDR3,并且VL包含SEQ ID NO:384的氨基酸序列的LC-CDR1、LC-CDR2和LC-CDR3。在一些实施方案中,VH和VL形成特异性结合PD-1(例如与本文所述的抗PD-1 sdAb部分识别不同的第二PD-1表位)的抗原结合位点。在一些实施方案中,VH和VL域来源于派姆单抗(例如,/> )或纳武单抗(例如,/>
)或纳武单抗(例如,/> )。在一些实施方案中,VH包含SEQ ID NO:385的氨基酸序列的HC-CDR1、HC-CDR2和HC-CDR3,并且VL包含SEQ ID NO:386的氨基酸序列的LC-CDR1、LC-CDR2和LC-CDR3。在一些实施方案中,CL和抗PD-1 sdAb部分任选地经由肽接头彼此融合,例如包含SEQ ID NO:367-376中的任一者的氨基酸序列的肽接头。在一些实施方案中,CH2和CH3域来源于IgG1 Fc、无效应子IgG1 Fc、IgG2 Fc、IgG4 Fc或IgG4 Fc(S228P),例如SEQ ID NO:363-365中的任一者。在一些实施方案中,抗PD-1 BABP包含第一多肽的两个相同拷贝和第二多肽的两个相同拷贝。在一些实施方案中,抗PD-1 sdAb部分与PD-1之间的结合的Kd是约10-5M至约10-12M(例如约10-7M至约10-12M、或约10-8M至约10-12M)。在一些实施方案中,抗PD-1sdAb部分是骆驼科的、嵌合的、人类的、部分人源化的或完全人源化的抗PD-1 sdAb部分。在一些实施方案中,PD-1 BABP具有如图19中所示的结构。
)。在一些实施方案中,VH包含SEQ ID NO:385的氨基酸序列的HC-CDR1、HC-CDR2和HC-CDR3,并且VL包含SEQ ID NO:386的氨基酸序列的LC-CDR1、LC-CDR2和LC-CDR3。在一些实施方案中,CL和抗PD-1 sdAb部分任选地经由肽接头彼此融合,例如包含SEQ ID NO:367-376中的任一者的氨基酸序列的肽接头。在一些实施方案中,CH2和CH3域来源于IgG1 Fc、无效应子IgG1 Fc、IgG2 Fc、IgG4 Fc或IgG4 Fc(S228P),例如SEQ ID NO:363-365中的任一者。在一些实施方案中,抗PD-1 BABP包含第一多肽的两个相同拷贝和第二多肽的两个相同拷贝。在一些实施方案中,抗PD-1 sdAb部分与PD-1之间的结合的Kd是约10-5M至约10-12M(例如约10-7M至约10-12M、或约10-8M至约10-12M)。在一些实施方案中,抗PD-1sdAb部分是骆驼科的、嵌合的、人类的、部分人源化的或完全人源化的抗PD-1 sdAb部分。在一些实施方案中,PD-1 BABP具有如图19中所示的结构。
在一些实施方案中,提供一种抗PD-1 BABP,其包含:(a)第一多肽,其从N末端至C末端包含:VH-CH1-CH2-CH3;和(b)第二多肽,其从N末端至C末端包含:抗PD-1 sdAb部分-VL-CL,其中VH和VL形成特异性结合第二表位(例如,TIGIT、LAG-3、TIM-3、CTLA-4、PD-1(例如与本文所述的抗PD-1 sdAb部分所识别不同的第二PD-1表位))的抗原结合位点,并且其中抗PD-1 sdAb部分包含:包含SEQ ID NO:37-72中的任一者的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:109-144中的任一者的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:181-216中的任一者的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,抗PD-1sdAb部分包含:包含SEQ ID NO:37-72中的任一者的氨基酸序列的CDR1;包含SEQ ID NO:109-144中的任一者的氨基酸序列的CDR2;和包含SEQ ID NO:181-216中的任一者的氨基酸序列的CDR3。在一些实施方案中,抗PD-1 sdAb部分包含VHH域,所述VHH域包含SEQ ID NO:289-324中的任一者的氨基酸序列。在一些实施方案中,VH和VL形成特异性结合TIGIT的抗原结合位点。在一些实施方案中,VH和VL域来源于替拉古单抗。在一些实施方案中,VH包含SEQID NO:377的氨基酸序列的HC-CDR1、HC-CDR2和HC-CDR3,并且VL包含SEQ ID NO:378的氨基酸序列的LC-CDR1、LC-CDR2和LC-CDR3。在一些实施方案中,VH和VL形成特异性结合LAG-3的抗原结合位点。在一些实施方案中,VH和VL域来源于瑞拉里单抗。在一些实施方案中,VH包含SEQ ID NO:379的氨基酸序列的HC-CDR1、HC-CDR2和HC-CDR3,并且VL包含SEQ ID NO:380的氨基酸序列的LC-CDR1、LC-CDR2和LC-CDR3。在一些实施方案中,VH和VL形成特异性结合TIM-3的抗原结合位点。在一些实施方案中,VH和VL域来源于MBG453。在一些实施方案中,VH包含SEQ ID NO:381的氨基酸序列的HC-CDR1、HC-CDR2和HC-CDR3,并且VL包含SEQ ID NO:382的氨基酸序列的LC-CDR1、LC-CDR2和LC-CDR3。在一些实施方案中,VH和VL形成特异性结合CTLA-4的抗原结合位点。在一些实施方案中,VH和VL域来源于伊匹单抗(例如, )。在一些实施方案中,VH包含SEQ ID NO:383的氨基酸序列的HC-CDR1、HC-CDR2和HC-CDR3,并且VL包含SEQ ID NO:384的氨基酸序列的LC-CDR1、LC-CDR2和LC-CDR3。在一些实施方案中,VH和VL形成特异性结合PD-1(例如与本文所述的抗PD-1 sdAb部分识别不同的第二PD-1表位)的抗原结合位点。在一些实施方案中,VH和VL域来源于派姆单抗(例如,/>
)。在一些实施方案中,VH包含SEQ ID NO:383的氨基酸序列的HC-CDR1、HC-CDR2和HC-CDR3,并且VL包含SEQ ID NO:384的氨基酸序列的LC-CDR1、LC-CDR2和LC-CDR3。在一些实施方案中,VH和VL形成特异性结合PD-1(例如与本文所述的抗PD-1 sdAb部分识别不同的第二PD-1表位)的抗原结合位点。在一些实施方案中,VH和VL域来源于派姆单抗(例如,/> )或纳武单抗(例如,/>
)或纳武单抗(例如,/> )。在一些实施方案中,VH包含SEQ ID NO:385的氨基酸序列的HC-CDR1、HC-CDR2和HC-CDR3,并且VL包含SEQ ID NO:386的氨基酸序列的LC-CDR1、LC-CDR2和LC-CDR3。在一些实施方案中,VL和抗PD-1 sdAb部分任选地经由肽接头彼此融合,例如包含SEQ ID NO:367-376中的任一者的氨基酸序列的肽接头。在一些实施方案中,CH2和CH3域来源于IgG1 Fc、无效应子IgG1 Fc、IgG2 Fc、IgG4 Fc或IgG4 Fc(S228P),例如SEQ ID NO:363-365中的任一者。在一些实施方案中,抗PD-1 BABP包含第一多肽的两个相同拷贝和第二多肽的两个相同拷贝。在一些实施方案中,抗PD-1 sdAb部分与PD-1之间的结合的Kd是约10-5M至约10-12M(例如约10-7M至约10-12M、或约10-8M至约10-12M)。在一些实施方案中,抗PD-1sdAb部分是骆驼科的、嵌合的、人类的、部分人源化的或完全人源化的抗PD-1 sdAb部分。在一些实施方案中,PD-1 BABP具有如图18中所示的结构。
)。在一些实施方案中,VH包含SEQ ID NO:385的氨基酸序列的HC-CDR1、HC-CDR2和HC-CDR3,并且VL包含SEQ ID NO:386的氨基酸序列的LC-CDR1、LC-CDR2和LC-CDR3。在一些实施方案中,VL和抗PD-1 sdAb部分任选地经由肽接头彼此融合,例如包含SEQ ID NO:367-376中的任一者的氨基酸序列的肽接头。在一些实施方案中,CH2和CH3域来源于IgG1 Fc、无效应子IgG1 Fc、IgG2 Fc、IgG4 Fc或IgG4 Fc(S228P),例如SEQ ID NO:363-365中的任一者。在一些实施方案中,抗PD-1 BABP包含第一多肽的两个相同拷贝和第二多肽的两个相同拷贝。在一些实施方案中,抗PD-1 sdAb部分与PD-1之间的结合的Kd是约10-5M至约10-12M(例如约10-7M至约10-12M、或约10-8M至约10-12M)。在一些实施方案中,抗PD-1sdAb部分是骆驼科的、嵌合的、人类的、部分人源化的或完全人源化的抗PD-1 sdAb部分。在一些实施方案中,PD-1 BABP具有如图18中所示的结构。
在一些实施方案中,提供一种抗PD-1 MABP(例如,BABP),其包含:(a)第一多肽,其从N末端至C末端包含:抗PD-1 sdAb1部分-VH-CH1-CH2-CH3;和(b)第二多肽,其从N末端至C末端包含:抗PD-1 sdAb2部分-VL-CL,其中VH和VL形成特异性结合第二表位(例如,TIGIT、LAG-3、TIM-3、CTLA-4、PD-1(例如与本文所述的抗PD-1 sdAb部分所识别不同的第二PD-1表位))的抗原结合位点,并且其中抗PD-1 sdAb1部分和抗PD-1 sdAb2部分各自包含:包含SEQID NO:37-72中的任一者的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:109-144中的任一者的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:181-216中的任一者的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,抗PD-1 sdAb1部分和抗PD-1sdAb2部分各自包含:包含SEQ ID NO:37-72中的任一者的氨基酸序列的CDR1;包含SEQ IDNO:109-144中的任一者的氨基酸序列的CDR2;和包含SEQ ID NO:181-216中的任一者的氨基酸序列的CDR3。在一些实施方案中,抗PD-1 sdAb1部分和抗PD-1 sdAb2部分各自包含VHH域,所述VHH域包含SEQ ID NO:289-324中的任一者的氨基酸序列。在一些实施方案中,抗PD-1 sdAb1部分和抗PD-1 sdAb2部分相同。在一些实施方案中,抗PD-1 sdAb1部分和抗PD-1 sdAb2部分不同。在一些实施方案中,VH和VL形成特异性结合TIGIT的抗原结合位点。在一些实施方案中,VH和VL域来源于替拉古单抗。在一些实施方案中,VH包含SEQ ID NO:377的氨基酸序列的HC-CDR1、HC-CDR2和HC-CDR3,并且VL包含SEQ ID NO:378的氨基酸序列的LC-CDR1、LC-CDR2和LC-CDR3。在一些实施方案中,VH和VL形成特异性结合LAG-3的抗原结合位点。在一些实施方案中,VH和VL域来源于瑞拉里单抗。在一些实施方案中,VH包含SEQ ID NO:379的氨基酸序列的HC-CDR1、HC-CDR2和HC-CDR3,并且VL包含SEQ ID NO:380的氨基酸序列的LC-CDR1、LC-CDR2和LC-CDR3。在一些实施方案中,VH和VL形成特异性结合TIM-3的抗原结合位点。在一些实施方案中,VH和VL域来源于MBG453。在一些实施方案中,VH包含SEQ ID NO:381的氨基酸序列的HC-CDR1、HC-CDR2和HC-CDR3,并且VL包含SEQ ID NO:382的氨基酸序列的LC-CDR1、LC-CDR2和LC-CDR3。在一些实施方案中,VH和VL形成特异性结合CTLA-4的抗原结合位点。在一些实施方案中,VH和VL域来源于伊匹单抗(例如, )。在一些实施方案中,VH包含SEQ ID NO:383的氨基酸序列的HC-CDR1、HC-CDR2和HC-CDR3,并且VL包含SEQ IDNO:384的氨基酸序列的LC-CDR1、LC-CDR2和LC-CDR3。在一些实施方案中,VH和VL形成特异性结合PD-1(例如与本文所述的抗PD-1 sdAb部分识别不同的第二PD-1表位)的抗原结合位点。在一些实施方案中,VH和VL域来源于派姆单抗(例如,/>
)。在一些实施方案中,VH包含SEQ ID NO:383的氨基酸序列的HC-CDR1、HC-CDR2和HC-CDR3,并且VL包含SEQ IDNO:384的氨基酸序列的LC-CDR1、LC-CDR2和LC-CDR3。在一些实施方案中,VH和VL形成特异性结合PD-1(例如与本文所述的抗PD-1 sdAb部分识别不同的第二PD-1表位)的抗原结合位点。在一些实施方案中,VH和VL域来源于派姆单抗(例如,/> )或纳武单抗(例如,
)或纳武单抗(例如, )。在一些实施方案中,VH包含SEQ ID NO:385的氨基酸序列的HC-CDR1、HC-CDR2和HC-CDR3,并且VL包含SEQ ID NO:386的氨基酸序列的LC-CDR1、LC-CDR2和LC-CDR3。在一些实施方案中,VL和抗PD-1 sdAb2部分任选地经由肽接头彼此融合,例如包含SEQ ID NO:367-376中的任一者的氨基酸序列的肽接头。在一些实施方案中,VH和抗PD-1 sdAb1部分任选地经由肽接头彼此融合,例如包含SEQ ID NO:367-376中的任一者的氨基酸序列的肽接头。在一些实施方案中,CH2和CH3域来源于IgG1 Fc、无效应子IgG1 Fc、IgG2 Fc、IgG4 Fc或IgG4 Fc(S228P),例如SEQ ID NO:363-365中的任一者。在一些实施方案中,抗PD-1 MABP(例如,BABP)包含第一多肽的两个相同拷贝和第二多肽的两个相同拷贝。在一些实施方案中,抗PD-1 sdAb部分与PD-1之间的结合的Kd是约10-5M至约10-12M(例如约10-7M至约10-12M、或约10-8M至约10-12M)。在一些实施方案中,抗PD-1 sdAb部分是骆驼科的、嵌合的、人类的、部分人源化的或完全人源化的抗PD-1 sdAb部分。在一些实施方案中,PD-1 MABP(例如,BABP)具有如图20中所示的结构。
)。在一些实施方案中,VH包含SEQ ID NO:385的氨基酸序列的HC-CDR1、HC-CDR2和HC-CDR3,并且VL包含SEQ ID NO:386的氨基酸序列的LC-CDR1、LC-CDR2和LC-CDR3。在一些实施方案中,VL和抗PD-1 sdAb2部分任选地经由肽接头彼此融合,例如包含SEQ ID NO:367-376中的任一者的氨基酸序列的肽接头。在一些实施方案中,VH和抗PD-1 sdAb1部分任选地经由肽接头彼此融合,例如包含SEQ ID NO:367-376中的任一者的氨基酸序列的肽接头。在一些实施方案中,CH2和CH3域来源于IgG1 Fc、无效应子IgG1 Fc、IgG2 Fc、IgG4 Fc或IgG4 Fc(S228P),例如SEQ ID NO:363-365中的任一者。在一些实施方案中,抗PD-1 MABP(例如,BABP)包含第一多肽的两个相同拷贝和第二多肽的两个相同拷贝。在一些实施方案中,抗PD-1 sdAb部分与PD-1之间的结合的Kd是约10-5M至约10-12M(例如约10-7M至约10-12M、或约10-8M至约10-12M)。在一些实施方案中,抗PD-1 sdAb部分是骆驼科的、嵌合的、人类的、部分人源化的或完全人源化的抗PD-1 sdAb部分。在一些实施方案中,PD-1 MABP(例如,BABP)具有如图20中所示的结构。
在一些实施方案中,提供一种抗PD-1 MABP(例如,BABP),其包含:(a)第一多肽,其从N末端至C末端包含:抗PD-1 sdAb1部分-抗PD-1 sdAb2部分-VH-CH1-CH2-CH3;和(b)第二多肽,其从N末端至C末端包含:VL-CL,其中VH和VL形成特异性结合第二表位(例如,TIGIT、LAG-3、TIM-3、CTLA-4、PD-1(例如与本文所述的抗PD-1 sdAb部分所识别不同的第二PD-1表位))的抗原结合位点,并且其中抗PD-1 sdAb1部分和抗PD-1 sdAb2部分各自包含:包含SEQID NO:37-72中的任一者的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:109-144中的任一者的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:181-216中的任一者的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,抗PD-1 sdAb1部分和抗PD-1sdAb2部分各自包含:包含SEQ ID NO:37-72中的任一者的氨基酸序列的CDR1;包含SEQ IDNO:109-144中的任一者的氨基酸序列的CDR2;和包含SEQ ID NO:181-216中的任一者的氨基酸序列的CDR3。在一些实施方案中,抗PD-1 sdAb1部分和抗PD-1 sdAb2部分各自包含VHH域,所述VHH域包含SEQ ID NO:289-324中的任一者的氨基酸序列。在一些实施方案中,抗PD-1 sdAb1部分和抗PD-1 sdAb2部分相同。在一些实施方案中,抗PD-1 sdAb1部分和抗PD-1 sdAb2部分不同。在一些实施方案中,VH和VL形成特异性结合TIGIT的抗原结合位点。在一些实施方案中,VH和VL域来源于替拉古单抗。在一些实施方案中,VH包含SEQ ID NO:377的氨基酸序列的HC-CDR1、HC-CDR2和HC-CDR3,并且VL包含SEQ ID NO:378的氨基酸序列的LC-CDR1、LC-CDR2和LC-CDR3。在一些实施方案中,VH和VL形成特异性结合LAG-3的抗原结合位点。在一些实施方案中,VH和VL域来源于瑞拉里单抗。在一些实施方案中,VH包含SEQ ID NO:379的氨基酸序列的HC-CDR1、HC-CDR2和HC-CDR3,并且VL包含SEQ ID NO:380的氨基酸序列的LC-CDR1、LC-CDR2和LC-CDR3。在一些实施方案中,VH和VL形成特异性结合TIM-3的抗原结合位点。在一些实施方案中,VH和VL域来源于MBG453。在一些实施方案中,VH包含SEQ ID NO:381的氨基酸序列的HC-CDR1、HC-CDR2和HC-CDR3,并且VL包含SEQ ID NO:382的氨基酸序列的LC-CDR1、LC-CDR2和LC-CDR3。在一些实施方案中,VH和VL形成特异性结合CTLA-4的抗原结合位点。在一些实施方案中,VH和VL域来源于伊匹单抗(例如, )。在一些实施方案中,VH包含SEQ ID NO:383的氨基酸序列的HC-CDR1、HC-CDR2和HC-CDR3,并且VL包含SEQ IDNO:384的氨基酸序列的LC-CDR1、LC-CDR2和LC-CDR3。在一些实施方案中,VH和VL形成特异性结合PD-1(例如与本文所述的抗PD-1 sdAb部分识别不同的第二PD-1表位)的抗原结合位点。在一些实施方案中,VH和VL域来源于派姆单抗(例如,/>
)。在一些实施方案中,VH包含SEQ ID NO:383的氨基酸序列的HC-CDR1、HC-CDR2和HC-CDR3,并且VL包含SEQ IDNO:384的氨基酸序列的LC-CDR1、LC-CDR2和LC-CDR3。在一些实施方案中,VH和VL形成特异性结合PD-1(例如与本文所述的抗PD-1 sdAb部分识别不同的第二PD-1表位)的抗原结合位点。在一些实施方案中,VH和VL域来源于派姆单抗(例如,/> )或纳武单抗(例如,
)或纳武单抗(例如, )。在一些实施方案中,VH包含SEQ ID NO:385的氨基酸序列的HC-CDR1、HC-CDR2和HC-CDR3,并且VL包含SEQ ID NO:386的氨基酸序列的LC-CDR1、LC-CDR2和LC-CDR3。在一些实施方案中,抗PD-1 sdAb1部分和抗PD-1 sdAb2部分和/或VH和抗PD-1 sdAb2部分任选地经由肽接头彼此融合,例如包含SEQ ID NO:367-376中的任一者的氨基酸序列的肽接头。在一些实施方案中,CH2和CH3域来源于IgG1 Fc、无效应子IgG1 Fc、IgG2 Fc、IgG4 Fc或IgG4Fc(S228P),例如SEQ ID NO:363-365中的任一者。在一些实施方案中,抗PD-1 MABP(例如,BABP)包含第一多肽的两个相同拷贝和第二多肽的两个相同拷贝。在一些实施方案中,抗PD-1 sdAb部分与PD-1之间的结合的Kd是约10-5M至约10-12M(例如约10-7M至约10-12M、或约10-8M至约10-12M)。在一些实施方案中,抗PD-1 sdAb部分是骆驼科的、嵌合的、人类的、部分人源化的或完全人源化的抗PD-1 sdAb部分。在一些实施方案中,PD-1 MABP(例如,BABP)具有如图21中所示的结构。
)。在一些实施方案中,VH包含SEQ ID NO:385的氨基酸序列的HC-CDR1、HC-CDR2和HC-CDR3,并且VL包含SEQ ID NO:386的氨基酸序列的LC-CDR1、LC-CDR2和LC-CDR3。在一些实施方案中,抗PD-1 sdAb1部分和抗PD-1 sdAb2部分和/或VH和抗PD-1 sdAb2部分任选地经由肽接头彼此融合,例如包含SEQ ID NO:367-376中的任一者的氨基酸序列的肽接头。在一些实施方案中,CH2和CH3域来源于IgG1 Fc、无效应子IgG1 Fc、IgG2 Fc、IgG4 Fc或IgG4Fc(S228P),例如SEQ ID NO:363-365中的任一者。在一些实施方案中,抗PD-1 MABP(例如,BABP)包含第一多肽的两个相同拷贝和第二多肽的两个相同拷贝。在一些实施方案中,抗PD-1 sdAb部分与PD-1之间的结合的Kd是约10-5M至约10-12M(例如约10-7M至约10-12M、或约10-8M至约10-12M)。在一些实施方案中,抗PD-1 sdAb部分是骆驼科的、嵌合的、人类的、部分人源化的或完全人源化的抗PD-1 sdAb部分。在一些实施方案中,PD-1 MABP(例如,BABP)具有如图21中所示的结构。
在一些实施方案中,提供一种抗PD-1 BABP,所述抗PD-1 BABP包含:(a)第一多肽,其从N末端至C末端包含:VH-CH1-抗PD-1 sdAb部分-CH2-CH3;和(b)第二多肽,其从N末端至C末端包含:VL-CL,其中VH和VL形成特异性结合第二表位(例如,TIGIT、LAG-3、TIM-3、CTLA-4、PD-1(例如与本文所述的抗PD-1 sdAb部分所识别不同的第二PD-1表位))的抗原结合位点,并且其中抗PD-1 sdAb部分包含:包含SEQ ID NO:37-72中的任一者的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ IDNO:109-144中的任一者的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:181-216中的任一者的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,抗PD-1 sdAb部分包含:包含SEQ ID NO:37-72中的任一者的氨基酸序列的CDR1;包含SEQ ID NO:109-144中的任一者的氨基酸序列的CDR2;和包含SEQ ID NO:181-216中的任一者的氨基酸序列的CDR3。在一些实施方案中,抗PD-1 sdAb部分包含VHH域,所述VHH域包含SEQ ID NO:289-324中的任一者的氨基酸序列。在一些实施方案中,VH和VL形成特异性结合TIGIT的抗原结合位点。在一些实施方案中,VH和VL域来源于替拉古单抗。在一些实施方案中,VH包含SEQ ID NO:377的氨基酸序列的HC-CDR1、HC-CDR2和HC-CDR3,并且VL包含SEQ IDNO:378的氨基酸序列的LC-CDR1、LC-CDR2和LC-CDR3。在一些实施方案中,VH和VL形成特异性结合LAG-3的抗原结合位点。在一些实施方案中,VH和VL域来源于瑞拉里单抗。在一些实施方案中,VH包含SEQ ID NO:379的氨基酸序列的HC-CDR1、HC-CDR2和HC-CDR3,并且VL包含SEQID NO:380的氨基酸序列的LC-CDR1、LC-CDR2和LC-CDR3。在一些实施方案中,VH和VL形成特异性结合TIM-3的抗原结合位点。在一些实施方案中,VH和VL域来源于MBG453。在一些实施方案中,VH包含SEQ ID NO:381的氨基酸序列的HC-CDR1、HC-CDR2和HC-CDR3,并且VL包含SEQID NO:382的氨基酸序列的LC-CDR1、LC-CDR2和LC-CDR3。在一些实施方案中,VH和VL形成特异性结合CTLA-4的抗原结合位点。在一些实施方案中,VH和VL域来源于伊匹单抗(例如, )。在一些实施方案中,VH包含SEQ ID NO:383的氨基酸序列的HC-CDR1、HC-CDR2和HC-CDR3,并且VL包含SEQ ID NO:384的氨基酸序列的LC-CDR1、LC-CDR2和LC-CDR3。在一些实施方案中,VH和VL形成特异性结合PD-1(例如与本文所述的抗PD-1 sdAb部分识别不同的第二PD-1表位)的抗原结合位点。在一些实施方案中,VH和VL域来源于派姆单抗(例如,
)。在一些实施方案中,VH包含SEQ ID NO:383的氨基酸序列的HC-CDR1、HC-CDR2和HC-CDR3,并且VL包含SEQ ID NO:384的氨基酸序列的LC-CDR1、LC-CDR2和LC-CDR3。在一些实施方案中,VH和VL形成特异性结合PD-1(例如与本文所述的抗PD-1 sdAb部分识别不同的第二PD-1表位)的抗原结合位点。在一些实施方案中,VH和VL域来源于派姆单抗(例如, )或纳武单抗(例如,/>
)或纳武单抗(例如,/> )。在一些实施方案中,VH包含SEQ ID NO:385的氨基酸序列的HC-CDR1、HC-CDR2和HC-CDR3,并且VL包含SEQ ID NO:386的氨基酸序列的LC-CDR1、LC-CDR2和LC-CDR3。在一些实施方案中,CH1和抗PD-1 sdAb部分任选地经由肽接头彼此融合,例如包含SEQ ID NO:367-376中的任一者的氨基酸序列的肽接头。在一些实施方案中,CH2和CH3域来源于IgG1 Fc、无效应子IgG1 Fc、IgG2 Fc、IgG4 Fc或IgG4 Fc(S228P),例如SEQ ID NO:363-365中的任一者。在一些实施方案中,抗PD-1 BABP包含第一多肽的两个相同拷贝和第二多肽的两个相同拷贝。在一些实施方案中,抗PD-1 sdAb部分与PD-1之间的结合的Kd是约10-5M至约10-12M(例如约10-7M至约10-12M、或约10-8M至约10-12M)。在一些实施方案中,抗PD-1 sdAb部分是骆驼科的、嵌合的、人类的、部分人源化的或完全人源化的抗PD-1 sdAb部分。在一些实施方案中,PD-1 BABP具有如图22中所示的结构。
)。在一些实施方案中,VH包含SEQ ID NO:385的氨基酸序列的HC-CDR1、HC-CDR2和HC-CDR3,并且VL包含SEQ ID NO:386的氨基酸序列的LC-CDR1、LC-CDR2和LC-CDR3。在一些实施方案中,CH1和抗PD-1 sdAb部分任选地经由肽接头彼此融合,例如包含SEQ ID NO:367-376中的任一者的氨基酸序列的肽接头。在一些实施方案中,CH2和CH3域来源于IgG1 Fc、无效应子IgG1 Fc、IgG2 Fc、IgG4 Fc或IgG4 Fc(S228P),例如SEQ ID NO:363-365中的任一者。在一些实施方案中,抗PD-1 BABP包含第一多肽的两个相同拷贝和第二多肽的两个相同拷贝。在一些实施方案中,抗PD-1 sdAb部分与PD-1之间的结合的Kd是约10-5M至约10-12M(例如约10-7M至约10-12M、或约10-8M至约10-12M)。在一些实施方案中,抗PD-1 sdAb部分是骆驼科的、嵌合的、人类的、部分人源化的或完全人源化的抗PD-1 sdAb部分。在一些实施方案中,PD-1 BABP具有如图22中所示的结构。
在一些实施方案中,提供一种抗PD-1 BABP,所述抗PD-1 BABP包含从N末端至C末端包含VL-VH-抗PD-1 sdAb部分-CH2-CH3的多肽,其中VL和VH在一起形成特异性结合第二表位(例如,TIGIT、LAG-3、TIM-3、CTLA-4、PD-1(例如与本文所述的抗PD-1 sdAb部分所识别不同的第二PD-1表位))的scFv,并且其中抗PD-1 sdAb部分包含:包含SEQ ID NO:37-72中的任一者的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:109-144中的任一者的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:181-216中的任一者的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,提供一种抗PD-1 BABP,所述抗PD-1 BABP包含从N末端至C末端包含VH-VL-抗PD-1 sdAb部分-CH2-CH3的多肽,其中VL和VH在一起形成特异性结合第二表位(例如,TIGIT、LAG-3、TIM-3、CTLA-4、PD-1(例如与本文所述的抗PD-1 sdAb部分所识别不同的第二PD-1表位))的scFv,并且其中抗PD-1 sdAb部分包含:包含SEQ ID NO:37-72中的任一者的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:109-144中的任一者的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:181-216中的任一者的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,抗PD-1 sdAb部分包含:包含SEQ ID NO:37-72中的任一者的氨基酸序列的CDR1;包含SEQ ID NO:109-144中的任一者的氨基酸序列的CDR2;和包含SEQ ID NO:181-216中的任一者的氨基酸序列的CDR3。在一些实施方案中,抗PD-1sdAb部分包含VHH域,所述VHH域包含SEQ ID NO:289-324中的任一者的氨基酸序列。在一些实施方案中,scFv(或形成scFv的VL和VH)特异性结合TIGIT。在一些实施方案中,scFv(或形成scFv的VL和VH)来源于替拉古单抗。在一些实施方案中,VH包含SEQ ID NO:377的氨基酸序列的HC-CDR1、HC-CDR2和HC-CDR3,并且VL包含SEQ ID NO:378的氨基酸序列的LC-CDR1、LC-CDR2和LC-CDR3。在一些实施方案中,scFv(或形成scFv的VL和VH)特异性结合LAG-3。在一些实施方案中,scFv(或形成scFv的VL和VH)来源于瑞拉里单抗。在一些实施方案中,VH包含SEQID NO:379的氨基酸序列的HC-CDR1、HC-CDR2和HC-CDR3,并且VL包含SEQ ID NO:380的氨基酸序列的LC-CDR1、LC-CDR2和LC-CDR3。在一些实施方案中,scFv(或形成scFv的VL和VH)特异性结合TIM-3。在一些实施方案中,scFv(或形成scFv的VL和VH)来源于MBG453。在一些实施方案中,VH包含SEQ ID NO:381的氨基酸序列的HC-CDR1、HC-CDR2和HC-CDR3,并且VL包含SEQID NO:382的氨基酸序列的LC-CDR1、LC-CDR2和LC-CDR3。在一些实施方案中,scFv(或形成scFv的VL和VH)特异性结合CTLA-4。在一些实施方案中,scFv(或形成scFv的VL和VH)来源于伊匹单抗(例如, )。在一些实施方案中,VH包含SEQ ID NO:383的氨基酸序列的HC-CDR1、HC-CDR2和HC-CDR3,并且VL包含SEQ ID NO:384的氨基酸序列的LC-CDR1、LC-CDR2和LC-CDR3。在一些实施方案中,scFv(或形成scFv的VL和VH)特异性结合PD-1(例如与本文所述的抗PD-1 sdAb部分识别不同的第二PD-1表位)。在一些实施方案中,scFv(或形成scFv的VL和VH)来源于派姆单抗(例如,/>
)。在一些实施方案中,VH包含SEQ ID NO:383的氨基酸序列的HC-CDR1、HC-CDR2和HC-CDR3,并且VL包含SEQ ID NO:384的氨基酸序列的LC-CDR1、LC-CDR2和LC-CDR3。在一些实施方案中,scFv(或形成scFv的VL和VH)特异性结合PD-1(例如与本文所述的抗PD-1 sdAb部分识别不同的第二PD-1表位)。在一些实施方案中,scFv(或形成scFv的VL和VH)来源于派姆单抗(例如,/> )或纳武单抗(例如,/>
)或纳武单抗(例如,/> )。在一些实施方案中,VH包含SEQ ID NO:385的氨基酸序列的HC-CDR1、HC-CDR2和HC-CDR3,并且VL包含SEQID NO:386的氨基酸序列的LC-CDR1、LC-CDR2和LC-CDR3。在一些实施方案中,形成scFv的VH和VL和/或scFv和抗PD-1 sdAb部分任选地经由肽接头彼此融合,例如包含SEQ ID NO:367-376中的任一者的氨基酸序列的肽接头。在一些实施方案中,CH2和CH3域来源于IgG1 Fc、无效应子IgG1 Fc、IgG2 Fc、IgG4 Fc或IgG4 Fc(S228P),例如SEQ ID NO:363-365中的任一者。在一些实施方案中,抗PD-1 BABP包含多肽的两个相同拷贝。在一些实施方案中,抗PD-1sdAb部分与PD-1之间的结合的Kd是约10-5M至约10-12M(例如约10-7M至约10-12M、或约10-8M至约10-12M)。在一些实施方案中,抗PD-1 sdAb部分是骆驼科的、嵌合的、人类的、部分人源化的或完全人源化的抗PD-1 sdAb部分。在一些实施方案中,PD-1 BABP具有如图23中所示的结构。
)。在一些实施方案中,VH包含SEQ ID NO:385的氨基酸序列的HC-CDR1、HC-CDR2和HC-CDR3,并且VL包含SEQID NO:386的氨基酸序列的LC-CDR1、LC-CDR2和LC-CDR3。在一些实施方案中,形成scFv的VH和VL和/或scFv和抗PD-1 sdAb部分任选地经由肽接头彼此融合,例如包含SEQ ID NO:367-376中的任一者的氨基酸序列的肽接头。在一些实施方案中,CH2和CH3域来源于IgG1 Fc、无效应子IgG1 Fc、IgG2 Fc、IgG4 Fc或IgG4 Fc(S228P),例如SEQ ID NO:363-365中的任一者。在一些实施方案中,抗PD-1 BABP包含多肽的两个相同拷贝。在一些实施方案中,抗PD-1sdAb部分与PD-1之间的结合的Kd是约10-5M至约10-12M(例如约10-7M至约10-12M、或约10-8M至约10-12M)。在一些实施方案中,抗PD-1 sdAb部分是骆驼科的、嵌合的、人类的、部分人源化的或完全人源化的抗PD-1 sdAb部分。在一些实施方案中,PD-1 BABP具有如图23中所示的结构。
在一些实施方案中,提供一种抗PD-1 MABP(例如,BABP),其包含:(a)第一多肽,其从N末端至C末端包含:VH-CH1-抗PD-1 sdAb1部分-CH1-CH2-CH3;和(b)第二多肽,其从N末端至C末端包含:VL-CL-抗PD-1 sdAb2部分-CL,其中VH和VL形成特异性结合第二表位(例如,TIGIT、LAG-3、TIM-3、CTLA-4、PD-1(例如与本文所述的抗PD-1 sdAb部分所识别不同的第二PD-1表位))的抗原结合位点,并且其中抗PD-1 sdAb1部分和抗PD-1 sdAb2部分各自包含:包含SEQ ID NO:37-72中的任一者的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:109-144中的任一者的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:181-216中的任一者的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,抗PD-1 sdAb1部分和抗PD-1sdAb2部分各自包含:包含SEQ ID NO:37-72中的任一者的氨基酸序列的CDR1;包含SEQ IDNO:109-144中的任一者的氨基酸序列的CDR2;和包含SEQ ID NO:181-216中的任一者的氨基酸序列的CDR3。在一些实施方案中,抗PD-1 sdAb1部分和抗PD-1 sdAb2部分各自包含VHH域,所述VHH域包含SEQ ID NO:289-324中的任一者的氨基酸序列。在一些实施方案中,抗PD-1 sdAb1部分和抗PD-1 sdAb2部分相同。在一些实施方案中,抗PD-1 sdAb1部分和抗PD-1 sdAb2部分不同。在一些实施方案中,VH和VL形成特异性结合TIGIT的抗原结合位点。在一些实施方案中,VH和VL域来源于替拉古单抗。在一些实施方案中,VH包含SEQ ID NO:377的氨基酸序列的HC-CDR1、HC-CDR2和HC-CDR3,并且VL包含SEQ ID NO:378的氨基酸序列的LC-CDR1、LC-CDR2和LC-CDR3。在一些实施方案中,VH和VL形成特异性结合LAG-3的抗原结合位点。在一些实施方案中,VH和VL域来源于瑞拉里单抗。在一些实施方案中,VH包含SEQ ID NO:379的氨基酸序列的HC-CDR1、HC-CDR2和HC-CDR3,并且VL包含SEQ ID NO:380的氨基酸序列的LC-CDR1、LC-CDR2和LC-CDR3。在一些实施方案中,VH和VL形成特异性结合TIM-3的抗原结合位点。在一些实施方案中,VH和VL域来源于MBG453。在一些实施方案中,VH包含SEQ ID NO:381的氨基酸序列的HC-CDR1、HC-CDR2和HC-CDR3,并且VL包含SEQ ID NO:382的氨基酸序列的LC-CDR1、LC-CDR2和LC-CDR3。在一些实施方案中,VH和VL形成特异性结合CTLA-4的抗原结合位点。在一些实施方案中,VH和VL域来源于伊匹单抗(例如, )。在一些实施方案中,VH包含SEQ ID NO:383的氨基酸序列的HC-CDR1、HC-CDR2和HC-CDR3,并且VL包含SEQ IDNO:384的氨基酸序列的LC-CDR1、LC-CDR2和LC-CDR3。在一些实施方案中,VH和VL形成特异性结合PD-1(例如与本文所述的抗PD-1 sdAb部分识别不同的第二PD-1表位)的抗原结合位点。在一些实施方案中,VH和VL域来源于派姆单抗(例如,/>
)。在一些实施方案中,VH包含SEQ ID NO:383的氨基酸序列的HC-CDR1、HC-CDR2和HC-CDR3,并且VL包含SEQ IDNO:384的氨基酸序列的LC-CDR1、LC-CDR2和LC-CDR3。在一些实施方案中,VH和VL形成特异性结合PD-1(例如与本文所述的抗PD-1 sdAb部分识别不同的第二PD-1表位)的抗原结合位点。在一些实施方案中,VH和VL域来源于派姆单抗(例如,/> )或纳武单抗(例如,
)或纳武单抗(例如, )。在一些实施方案中,VH包含SEQ ID NO:385的氨基酸序列的HC-CDR1、HC-CDR2和HC-CDR3,并且VL包含SEQ ID NO:386的氨基酸序列的LC-CDR1、LC-CDR2和LC-CDR3。在一些实施方案中,CH1和抗PD-1 sdAb1部分和/或CL和抗PD-1 sdAb2部分任选地经由肽接头彼此融合,例如包含SEQ ID NO:367-376中的任一者的氨基酸序列的肽接头。在一些实施方案中,CH2和CH3域来源于IgG1 Fc、无效应子IgG1 Fc、IgG2 Fc、IgG4 Fc或IgG4 Fc(S228P),例如SEQ ID NO:363-365中的任一者。在一些实施方案中,抗PD-1 MABP(例如,BABP)包含第一多肽的两个相同拷贝和第二多肽的两个相同拷贝。在一些实施方案中,抗PD-1 sdAb部分与PD-1之间的结合的Kd是约10-5M至约10-12M(例如约10-7M至约10-12M、或约10-8M至约10-12M)。在一些实施方案中,抗PD-1 sdAb部分是骆驼科的、嵌合的、人类的、部分人源化的或完全人源化的抗PD-1 sdAb部分。在一些实施方案中,PD-1 MABP(例如,BABP)具有如图24中所示的结构。
)。在一些实施方案中,VH包含SEQ ID NO:385的氨基酸序列的HC-CDR1、HC-CDR2和HC-CDR3,并且VL包含SEQ ID NO:386的氨基酸序列的LC-CDR1、LC-CDR2和LC-CDR3。在一些实施方案中,CH1和抗PD-1 sdAb1部分和/或CL和抗PD-1 sdAb2部分任选地经由肽接头彼此融合,例如包含SEQ ID NO:367-376中的任一者的氨基酸序列的肽接头。在一些实施方案中,CH2和CH3域来源于IgG1 Fc、无效应子IgG1 Fc、IgG2 Fc、IgG4 Fc或IgG4 Fc(S228P),例如SEQ ID NO:363-365中的任一者。在一些实施方案中,抗PD-1 MABP(例如,BABP)包含第一多肽的两个相同拷贝和第二多肽的两个相同拷贝。在一些实施方案中,抗PD-1 sdAb部分与PD-1之间的结合的Kd是约10-5M至约10-12M(例如约10-7M至约10-12M、或约10-8M至约10-12M)。在一些实施方案中,抗PD-1 sdAb部分是骆驼科的、嵌合的、人类的、部分人源化的或完全人源化的抗PD-1 sdAb部分。在一些实施方案中,PD-1 MABP(例如,BABP)具有如图24中所示的结构。
在一些实施方案中,提供一种抗PD-1 MABP(例如,BABP),所述抗PD-1 MABP包含:(a)第一多肽,其从N末端至C末端包含:VL-VH-抗PD-1 sdAb1部分-CH2-CH3;和(b)第二多肽,其从N末端至C末端包含:抗PD-1 sdAb2部分-CL,其中VL和VH形成特异性结合第二表位(例如,TIGIT、LAG-3、TIM-3、CTLA-4、PD-1(例如与本文所述的抗PD-1 sdAb部分所识别不同的第二PD-1表位))的scFv,并且其中抗PD-1 sdAb1部分和抗PD-1 sdAb2部分各自包含:包含SEQ ID NO:37-72中的任一者的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:109-144中的任一者的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:181-216中的任一者的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,提供一种抗PD-1 MABP(例如,BABP),其包含:(a)第一多肽,其从N末端至C末端包含:VH-VL-抗PD-1 sdAb1部分-CH2-CH3;和(b)第二多肽,其从N末端至C末端包含:抗PD-1 sdAb2部分-CL,其中VL和VH形成特异性结合第二表位(例如,TIGIT、LAG-3、TIM-3、CTLA-4、PD-1(例如与本文所述的抗PD-1 sdAb部分所识别不同的第二PD-1表位))的scFv,并且其中抗PD-1 sdAb1部分和抗PD-1 sdAb2部分各自包含:包含SEQ ID NO:37-72中的任一者的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:109-144中的任一者的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:181-216中的任一者的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,抗PD-1 sdAb1部分和抗PD-1 sdAb2部分各自包含:包含SEQ ID NO:37-72中的任一者的氨基酸序列的CDR1;包含SEQ ID NO:109-144中的任一者的氨基酸序列的CDR2;和包含SEQ ID NO:181-216中的任一者的氨基酸序列的CDR3。在一些实施方案中,抗PD-1 sdAb1部分和抗PD-1 sdAb2部分各自包含VHH域,所述VHH域包含SEQ ID NO:289-324中的任一者的氨基酸序列。在一些实施方案中,抗PD-1 sdAb1部分和抗PD-1 sdAb2部分相同。在一些实施方案中,抗PD-1 sdAb1部分和抗PD-1 sdAb2部分不同。在一些实施方案中,scFv(或形成scFv的VL和VH)特异性结合TIGIT。在一些实施方案中,scFv(或形成scFv的VL和VH)来源于替拉古单抗。在一些实施方案中,VH包含SEQ ID NO:377的氨基酸序列的HC-CDR1、HC-CDR2和HC-CDR3,并且VL包含SEQ ID NO:378的氨基酸序列的LC-CDR1、LC-CDR2和LC-CDR3。在一些实施方案中,scFv(或形成scFv的VL和VH)特异性结合LAG-3。在一些实施方案中,scFv(或形成scFv的VL和VH)来源于瑞拉里单抗。在一些实施方案中,VH包含SEQ ID NO:379的氨基酸序列的HC-CDR1、HC-CDR2和HC-CDR3,并且VL包含SEQ ID NO:380的氨基酸序列的LC-CDR1、LC-CDR2和LC-CDR3。在一些实施方案中,scFv(或形成scFv的VL和VH)特异性结合TIM-3。在一些实施方案中,scFv(或形成scFv的VL和VH)来源于MBG453。在一些实施方案中,VH包含SEQ ID NO:381的氨基酸序列的HC-CDR1、HC-CDR2和HC-CDR3,并且VL包含SEQ ID NO:382的氨基酸序列的LC-CDR1、LC-CDR2和LC-CDR3。在一些实施方案中,scFv(或形成scFv的VL和VH)特异性结合CTLA-4。在一些实施方案中,scFv(或形成scFv的VL和VH)来源于伊匹单抗(例如, )。在一些实施方案中,VH包含SEQ ID NO:383的氨基酸序列的HC-CDR1、HC-CDR2和HC-CDR3,并且VL包含SEQ IDNO:384的氨基酸序列的LC-CDR1、LC-CDR2和LC-CDR3。在一些实施方案中,scFv(或形成scFv的VL和VH)特异性结合PD-1(例如与本文所述的抗PD-1 sdAb部分识别不同的第二PD-1表位)。在一些实施方案中,scFv(或形成scFv的VL和VH)来源于派姆单抗(例如,/>
)。在一些实施方案中,VH包含SEQ ID NO:383的氨基酸序列的HC-CDR1、HC-CDR2和HC-CDR3,并且VL包含SEQ IDNO:384的氨基酸序列的LC-CDR1、LC-CDR2和LC-CDR3。在一些实施方案中,scFv(或形成scFv的VL和VH)特异性结合PD-1(例如与本文所述的抗PD-1 sdAb部分识别不同的第二PD-1表位)。在一些实施方案中,scFv(或形成scFv的VL和VH)来源于派姆单抗(例如,/> )或纳武单抗(例如,/>
)或纳武单抗(例如,/> )。在一些实施方案中,VH包含SEQ ID NO:385的氨基酸序列的HC-CDR1、HC-CDR2和HC-CDR3,并且VL包含SEQ ID NO:386的氨基酸序列的LC-CDR1、LC-CDR2和LC-CDR3。在一些实施方案中,形成scFv的VH和VL和/或scFv和抗PD-1 sdAb1部分任选地经由肽接头彼此融合,例如包含SEQ ID NO:367-376中的任一者的氨基酸序列的肽接头。在一些实施方案中,CH2和CH3域来源于IgG1 Fc、无效应子IgG1 Fc、IgG2 Fc、IgG4 Fc或IgG4 Fc(S228P),例如SEQ ID NO:363-365中的任一者。在一些实施方案中,抗PD-1 MABP(例如,BABP)包含第一多肽的两个相同拷贝和第二多肽的两个相同拷贝。在一些实施方案中,抗PD-1 sdAb部分与PD-1之间的结合的Kd是约10-5M至约10-12M(例如约10-7M至约10-12M、或约10-8M至约10-12M)。在一些实施方案中,抗PD-1 sdAb部分是骆驼科的、嵌合的、人类的、部分人源化的或完全人源化的抗PD-1 sdAb部分。在一些实施方案中,PD-1 MABP(例如,BABP)具有如图25中所示的结构。
)。在一些实施方案中,VH包含SEQ ID NO:385的氨基酸序列的HC-CDR1、HC-CDR2和HC-CDR3,并且VL包含SEQ ID NO:386的氨基酸序列的LC-CDR1、LC-CDR2和LC-CDR3。在一些实施方案中,形成scFv的VH和VL和/或scFv和抗PD-1 sdAb1部分任选地经由肽接头彼此融合,例如包含SEQ ID NO:367-376中的任一者的氨基酸序列的肽接头。在一些实施方案中,CH2和CH3域来源于IgG1 Fc、无效应子IgG1 Fc、IgG2 Fc、IgG4 Fc或IgG4 Fc(S228P),例如SEQ ID NO:363-365中的任一者。在一些实施方案中,抗PD-1 MABP(例如,BABP)包含第一多肽的两个相同拷贝和第二多肽的两个相同拷贝。在一些实施方案中,抗PD-1 sdAb部分与PD-1之间的结合的Kd是约10-5M至约10-12M(例如约10-7M至约10-12M、或约10-8M至约10-12M)。在一些实施方案中,抗PD-1 sdAb部分是骆驼科的、嵌合的、人类的、部分人源化的或完全人源化的抗PD-1 sdAb部分。在一些实施方案中,PD-1 MABP(例如,BABP)具有如图25中所示的结构。
在一些实施方案中,还提供一种抗PD-1 MABP(例如,BABP),其包含特异性识别PD-1的sdAb部分(下文称为“竞争性抗PD-1构建体”、“竞争性抗PD-1 MABP”或“竞争性抗PD-1BABP”),其与以下中的任一者竞争性地特异性结合PD-1:本文所述的抗PD-1构建体(例如抗PD-1 sdAb部分、抗PD-1 sdAb-Fc融合蛋白(例如,HCAb)、包含本文所述的抗PD-1 sdAb部分的多特异性(例如,双特异性)或单特异性抗PD-1构建体(例如,本文所述的抗PD-1/TIGIT、抗PD-1/LAG-3、抗PD-1/TIM-3、抗PD-1/CTLA-4或抗PD-1/PD-1构建体(例如,MABP或BABP))。
(III)抗PD-1构建体抗体变体
在一些实施方案中,考虑到本文所提供的抗PD-1构建体(例如,抗PD-1 sdAb部分、抗PD-1 sdAb-Fc融合蛋白(例如,HCAb)、抗PD-1 MABP/BABP)的氨基酸序列变体。例如,可能需要改善抗体的结合亲和力和/或其它生物特性。抗体的氨基酸序列变体可通过将适当修饰引入编码抗体的核酸序列中或通过肽合成来制备。这样的修饰包括例如抗体的氨基酸序列内残基的缺失和/或插入和/或取代。可进行缺失、插入和取代的任何组合以获得最终构建体,条件是最终构建体具有期望特征,例如抗原结合。
a)取代、插入、缺失和变体
在一些实施方案中,提供具有一个或多个氨基酸取代的抗体变体。用于取代诱变的所关注位点包括HVR(或CDR)和FR。保守取代显示于表2中的标题“优选取代”下。更实质性变化提供于表2中的标题“示例性取代”下,并且如下文参考氨基酸侧链类别进一步描述。氨基酸取代可引入至所关注抗体中,并且针对如下所需活性筛选产物:例如保留/改善的抗原结合、降低的免疫原性、或改善的ADCC或CDC。
表2.氨基酸取代
| 原始残基 | 示例性取代 | 优选取代 |
| Ala(A) | Val;Leu;Ile | Val |
| Arg(R) | Lys;Gln;Asn | Lys |
| Asn(N) | Gln;His;Asp、Lys;Arg | Gln |
| Asp(D) | Glu;Asn | Glu |
| Cys(C) | Ser;Ala | Ser |
| Gln(Q) | Asn;Glu | Asn |
| Glu(E) | Asp;Gln | Asp |
| Gly(G) | Ala | Ala |
| His(H) | Asn;Gln;Lys;Arg | Arg |
| Ile(I) | Leu;Val;Met;Ala;Phe;正亮氨酸 | Leu |
| Leu(L) | 正亮氨酸;Ile;Val;Met;Ala;Phe | Ile |
| Lys(K) | Arg;Gln;Asn | Arg |
| Met(M) | Leu;Phe;Ile | Leu |
| Phe(F) | Trp;Leu;Val;Ile;Ala;Tyr | Tyr |
| Pro(P) | Ala | Ala |
| Ser(S) | Thr | Thr |
| Thr(T) | Val;Ser | Ser |
| Trp(W) | Tyr;Phe | Tyr |
| Tyr(Y) | Trp;Phe;Thr;Ser | Phe |
| Val(V) | Ile;Leu;Met;Phe;Ala;正亮氨酸 | Leu |
氨基酸可根据常见侧链性质进行分组:(1)疏水性:正亮氨酸、Met、Ala、Val、Leu、Ile;(2)中性亲水性:Cys、Ser、Thr、Asn、Gln;(3)酸性:Asp、Glu;(4)碱性:His、Lys、Arg;(5)影响链取向的残基:Gly、Pro;和(6)芳香性:Trp、Tyr、Phe。
非保守性取代将必然伴有将这些类别中的一个类别的成员换成另一个类别。
一种类型的取代型变体涉及取代亲本抗体(例如人源化抗体或人类抗体)的一个或多个高变区残基。通常,所产生的被选择用于进一步研究的变体将相对于亲本抗体具有某些生物特性的修饰(例如,改善)(例如,增加的亲和力、降低的免疫原性)和/或将具有实质上保持的亲本抗体的某些生物特性。一种示例性取代变体是亲和力成熟抗体,其可例如使用基于噬菌体展示的亲和力成熟技术(例如本文所述的那些)适宜地产生。简言之,一个或多个HVR残基发生突变并且所述变体抗体在噬菌体上展示并针对特定生物活性(例如,结合亲和力)进行筛选。
可在HVR中产生改变(例如,取代),例如以改善抗体亲和力。可在HVR“热点”(即由在体细胞成熟过程期间以高频率经受突变的密码子编码的残基)(参见例如Chowdhury,Methods Mol.Biol.207:179-196(2008))和/或SDR(a-CDR)中进行这些改变,并且测试所得变异型VH或VL的结合亲和力。通过构建并从二级文库重新选择的亲和力成熟已描述于例如Hoogenboom等.Methods in Molecular Biology 178:1-37(O’Brien等编,Human Press,Totowa,NJ,(2001))中。在亲和力成熟的一些实施方案中,通过多种方法(例如易错PCR、链改组或寡核苷酸引导的诱变)中的任一者将多样性引入至所选用于成熟的可变基因中。然后产生二级文库。然后筛选文库以鉴定具有所需亲和力的任何抗体变体。引入多样性的另一方法涉及HVR定向方法,其中使若干HVR残基(例如一次4-6个残基)随机化。牵涉于抗原结合中的HVR残基可例如使用丙氨酸扫描诱变或模型化特定地加以鉴定。通常尤其靶向CDR-H3和CDR-L3。
在一些实施方案中,取代、插入或缺失可出现于一个或多个HVR内,只要所述改变不会实质上降低所述抗体结合抗原的能力。例如,可在HVR中产生不会实质上降低结合亲和力的保守改变(例如,如本文所提供的保守取代)。这些改变可在HVR“热点”或CDR以外。在上文所提供的变体VHH序列的一些实施方案中,各HVR未改变,或含有仅一种、两种或三种氨基酸取代。
适用于鉴定抗体中可被靶向用于诱变的残基或区域的方法被称为“丙氨酸扫描诱变”,如由Cunningham和Wells(1989)Science,244:1081-1085所述。在这种方法中,鉴定某一残基或一组目标残基(例如带电残基,例如Arg、Asp、His、Lys和Glu)并用中性或带负电氨基酸(例如,丙氨酸或聚丙氨酸)代替以确定所述抗体与抗原的相互作用是否受到影响。进一步取代可在氨基酸位置处引入,证明对初始取代的功能敏感性。或者或另外,抗原-抗体复合物的晶体结构用来鉴定抗体与抗原之间的接触点。所述接触残基和相邻残基可作为取代候选物被靶向或消除。可筛选变体以确定其是否含有所需特性。
氨基酸序列插入包括长度为一个残基至含有一百个或更多个残基的多肽范围内的氨基末端和/或羧基末端融合体,以及单个或多个氨基酸残基的序列内插入。末端插入的实例包括具有N末端甲硫氨酰基残基的抗体。所述抗体分子的其它插入变体包括所述抗体的N末端或C末端融合至酶(例如,针对ADEPT)或增加所述抗体的血清半衰期的多肽。
b)糖基化变体
在一些实施方案中,改变本文所提供的分离的抗PD-1抗体以增加或降低构建体糖基化的程度。向抗体中添加糖基化位点或使抗体缺失糖基化位点可通过改变氨基酸序列以便产生或去除一个或多个糖基化位点来便利地实现。
在抗PD-1构建体包含Fc区(例如,抗PD-1 sdAb-Fc融合蛋白(例如,HCAb)、PD-1×TIGIT MABP、PD-1×LAG-3 MABP、PD-1×TIM-3 MABP、PD-1×CTLA-4 MABP或PD-1×PD-1MABP)的情况下,与之连接的碳水化合物可改变。由哺乳动物细胞产生的原生抗体通常包含分支链双触角寡糖,其通常通过N键连接至Fc区的CH2域的Asn297上。参见例如Wright等.TIBTECH 15:26-32(1997)。寡糖可包括各种碳水化合物,例如甘露糖、N-乙酰基葡糖胺(GlcNAc)、半乳糖和唾液酸,以及连接于双触角寡糖结构的“主干”中的GlcNAc上的岩藻糖。在一些实施方案中,可对本申请的抗PD-1构建体中的寡糖进行修饰以产生具有某些改善特性的抗体变体。
在一些实施方案中,提供具有缺乏(直接或间接)连接至Fc区上的岩藻糖的碳水化合物结构的抗PD-1构建体抗体变体。例如,这种抗体中岩藻糖的量可以是1%至80%、1%至65%、5%至65%或20%至40%。通过如通过MALDI-TOF质谱法所测量,相对于连接至Asn297的所有糖结构(例如,复合、杂合和高甘露糖结构)的总和,计算糖链内的Asn297处的岩藻糖的平均量来测定岩藻糖的量,如例如WO2008/077546中所述。Asn297是指位于Fc区中的大致位置297处的天冬酰胺残基(Fc区残基的EU编号);然而,Asn297还可由于抗体中的微小序列变化而位于位置297上游或下游约±3个氨基酸处,即在位置294与300之间。这样的岩藻糖基化变体可具有改善的ADCC功能。参见例如美国专利公开第US2003/0157108号(Presta,L.);第US 2004/0093621号(Kyowa Hakko Kogyo Co.,Ltd)。关于“脱岩藻糖基化”或“缺乏岩藻糖”抗体变体的公开的实例包括:US 2003/0157108;WO 2000/61739;WO 2001/29246;US 2003/0115614;US 2002/0164328;US 2004/0093621;US 2004/0132140;US 2004/0110704;US 2004/0110282;US 2004/0109865;WO 2003/085119;WO 2003/084570;WO2005/035586;WO 2005/035778;WO2005/053742;WO 2002/031140;Okazaki等,J.Mol.Biol.336:1239-1249(2004);Yamane-Ohnuki等,Biotech.Bioeng.87:614(2004)。能够产生脱岩藻糖基化抗体的细胞系的实例包括缺乏蛋白质岩藻糖基化作用的Lec13 CHO细胞(Ripka等,Arch.Biochem.Biophys.249:533-545(1986);美国专利申请第US 2003/0157108 A1号,Presta,L;和WO 2004/056312 A1,Adams等,尤其在实施例11中)和基因敲除细胞系,例如α-1,6-岩藻糖基转移酶基因FUT8基因敲除CHO细胞(参见例如Yama ne-Ohnuki等,Biotech.Bioeng.87:614(2004);Kanda,Y.等,Biotec hnol.Bioeng.,94(4):680-688(2006);和WO2003/085107)。
抗PD-1构建体变体进一步具有平分寡糖,例如其中连接于抗体的Fc区上的双触角寡糖通过GlcNAc平分。所述抗体变体可具有降低的岩藻糖基化和/或改善的ADCC功能。这类抗体变体的实例描述于例如WO 2003/011878(Jean-Mairet等);美国专利第6,602,684号(Umana等);和US 2005/0123546(Umana等)。还提供在连接至Fc区的寡糖中具有至少一个半乳糖残基的抗体变体。所述抗体变体可具有改善的CDC功能。这类抗体变体描述于例如WO1997/30087(Patel等);WO 1998/58964(Raju,S.);和WO 1999/22764(Raju,S.)中。
c)Fc区变体
在一些实施方案中,可将一种或多种氨基酸修饰引入至本文所提供的抗PD-1构建体(例如,抗PD-1 sdAb-Fc融合蛋白(例如,HCAb)、PD-1×TIGIT MABP、PD-1×LAG-3 MABP、PD-1×TIM-3 MABP、PD-1×CTLA-4 MABP或PD-1×PD-1 MABP)的Fc区中,从而生成Fc区变体。Fc区变体可包含人类Fc区序列(例如人类IgG1、IgG2、IgG3或IgG4 Fc区),其在一个或多个氨基酸位置处包含氨基酸修饰(例如取代)。
在一些实施方案中,本申请涵盖一种抗PD-1构建体(例如,抗PD-1 sdAb-Fc融合蛋白(例如,HCAb)、PD-1×TIGIT MABP、PD-1×LAG-3 MABP、PD-1×TIM-3 MABP、PD-1×CTLA-4MABP或PD-1×PD-1 MABP)变体,其具有一些但非所有效应功能,所述效应功能使其成为抗PD-1构建体的体内半衰期重要但某些效应功能(例如补体和ADCC)不必要或有害的应用的理想候选物。可进行体外和/或体内细胞毒性测定以确认CDC和/或ADCC活性的降低/减少。例如,可以进行Fc受体(FcR)结合测定以确保抗体缺乏FcγR结合(因此有可能缺乏ADCC活性),但保留FcRn结合能力。用于介导ADCC的初级细胞(NK细胞)仅表达FcγRIII,而单核细胞表达FcγRI、FcγRII和FcγRIII。造血细胞上的FcR表达概述于Ravetch和Kinet,Annu.Rev.Immunol.9:457-492(1991)第464页中的表2中。用于评估所关注分子的ADCC活性的体外测定的非限制性实例描述于美国专利第5,500,362号(参见例如Hellstrom,I.等,Proc.Nat'l Acad.Sci.USA 83:7059-7063(1986))和Hellstrom,I等,Proc.Nat'lAcad.Sci.USA 82:1499-1502(1985);第5,821,337号(参见Bruggemann,M.等,J.Exp.Med.166:1351-1361(1987))。或者,可采用非放射性测定方法(参见例如流式细胞术的ACTITM非放射性细胞毒性测定(CellTechnology,Inc.Mountain View,CA);和CytoTox 非放射性细胞毒性测定(Promega,Madison,WI))。用于这类测定的有用效应细胞包括外周血单核细胞(PBMC)和自然杀伤(NK)细胞。或者或另外,所关注的分子的ADCC活性可例如在动物模型中进行体内评估,例如Clynes等,Proc.Nat'l Acad.Sci.USA 95:652-656(1998)中公开的动物模型。还可进行C1q结合测定以确认抗体不能结合C1q并且因此缺乏CDC活性。参见例如WO 2006/029879和WO 2005/100402中的C1q和C3c结合ELISA。为评估补体活化,可进行CDC测定(参见例如Gazzano-Santoro等,J.Immunol.Methods 202:163(1996);Cragg,M.S.等,Blood 101:1045-1052(2003);和Cragg,M.S.和M.J.Glennie,Blood103:2738-2743(2004))。还可使用本领域中已知的方法进行FcRn结合和体内清除率/半衰期确定(参见例如Petkova,S.B.等,Int'l.Immunol.18(12):1759-1769(2006))。
非放射性细胞毒性测定(Promega,Madison,WI))。用于这类测定的有用效应细胞包括外周血单核细胞(PBMC)和自然杀伤(NK)细胞。或者或另外,所关注的分子的ADCC活性可例如在动物模型中进行体内评估,例如Clynes等,Proc.Nat'l Acad.Sci.USA 95:652-656(1998)中公开的动物模型。还可进行C1q结合测定以确认抗体不能结合C1q并且因此缺乏CDC活性。参见例如WO 2006/029879和WO 2005/100402中的C1q和C3c结合ELISA。为评估补体活化,可进行CDC测定(参见例如Gazzano-Santoro等,J.Immunol.Methods 202:163(1996);Cragg,M.S.等,Blood 101:1045-1052(2003);和Cragg,M.S.和M.J.Glennie,Blood103:2738-2743(2004))。还可使用本领域中已知的方法进行FcRn结合和体内清除率/半衰期确定(参见例如Petkova,S.B.等,Int'l.Immunol.18(12):1759-1769(2006))。
具有降低的效应功能的抗体包括具有Fc区残基238、265、269、270、297、327和329中的一个或多个的取代的那些(美国专利第6,737,056号)。这样的Fc突变体包括在氨基酸位置265、269、270、297和327中的两处或更多处具有取代的Fc突变体,包括残基265和297取代成丙氨酸的所谓的“DANA”Fc突变体(美国专利第7,332,581号)。
与FcR的结合改善或削弱的某些抗体变体已有描述。(参见例如美国专利第6,737,056号;WO 2004/056312和Shields等,J.Biol.Chem.9(2):6591-6604(2001))。
在一些实施方案中,抗PD-1构建体变体包含具有一个或多个改善ADCC的氨基酸取代(例如在Fc区的位置298、333和/或334(EU残基编号)处的取代)的Fc区。
涵盖包含本文所述的任何Fc变体的抗PD-1构建体(例如本文所述的抗PD-1 sdAb-Fc融合蛋白(例如,HCAb)、融合至全长抗体的抗PD-1 sdAb或抗PD-1 MABP/BABP)或其组合。
d)半胱氨酸工程化抗体变体
在一些实施方案中,可能需要产生半胱氨酸工程化抗PD-1构建体,例如“thioMAb”,其中抗体的一个或多个残基被半胱氨酸残基取代。在特定实施方案中,被取代残基存在于抗体的可及位点处。通过用半胱氨酸取代那些残基,反应性硫醇基由此被定位于抗体的可及位点处并且可用于使抗体缀合于其它部分(例如药物部分或接头-药物部分)以产生免疫缀合物,如本文中进一步描述。在一些实施方案中,以下残基中的任一者或多者可被半胱氨酸取代:重链的A118(EU编号);和重链Fc区的S400(EU编号)。可如例如美国专利第7,521,541号中所述来生成半胱氨酸工程改造抗PD-1构建体。
III.药物组合物
本申请还提供了药物组合物,所述药物组合物包含如本文所述的包含特异性识别PD-1的sdAb的任一种抗PD-1构建体(例如抗PD-1 sdAb、抗PD-1 sdAb-Fc融合蛋白(例如,HCAb)、抗PD-1/TIGIT双特异性抗体(例如,PD-1×TIGIT BABP)、抗PD-1/LAG-3双特异性抗体(例如,PD-1×LAG-3 BABP)、抗PD-1/TIM-3双特异性抗体(例如,PD-1×TIM-3 BABP)、抗PD-1/CTLA-4双特异性抗体(例如,PD-1×CTLA-4 BABP)或抗PD-1/PD-1双特异性抗体(例如,PD-1×PD-1 BABP))和任选地药学上可接受的载体。药物组合物可通过将本文所述的具有期望纯度的抗PD-1构建体与任选的药学上可接受的载体、赋形剂或稳定剂混合来制备(Remington's Pharmaceutical Sciences第16版,Osol,A.编(1980)),其为冻干制剂或水溶液形式。
药物组合物优选是稳定的,其中包含本文所述的抗PD-1 sdAb部分的抗PD-1构建体在储存时基本上保持其物理和化学稳定性以及完整性。用于测量蛋白稳定性的各种分析技术是本领域中可用的并且评述于Peptide and Protein Drug Delivery,247-301,Vincent Lee编,Marcel Dekker,Inc.,New York,N.Y.,Pubs.(1991)以及Jones,A.Adv.Drug Delivery Rev.10:29-90(1993)。
为了使药物组合物用于体内施用,它们必须是无菌的。可通过经由无菌过滤膜过滤来使药物组合物无菌。通常将本文中的药物组合物放置于具有无菌进入端口的容器中,例如具有皮下注射针可刺穿的塞子的静脉内溶液袋或小瓶。
施用途径是根据已知且公认的方法,例如通过单次或多次推注或者以合适方式长时间输注,例如通过皮下、静脉内、腹膜内、肌肉内、动脉内、病灶内或关节内途径进行注射或输注,局部施用,吸入,或通过持续释放或延长释放方式。在一些实施方案中,局部(例如肿瘤内)施用药物组合物。
本文中的药物组合物还可含有所治疗的特定适应症所需的一种以上的活性化合物,优选是具有互补活性并且不会对彼此有不利影响的化合物。或者或另外,组合物可包含细胞毒性剂、化学治疗剂、细胞因子、免疫抑制剂或生长抑制剂。这些分子适宜以对预期目的有效的量以组合形式存在。
IV.治疗PD-1相关疾病的方法
如本文所述的包含特异性识别PD-1的sdAb部分的抗PD-1构建体(例如抗PD-1sdAb、抗PD-1 sdAb-Fc融合蛋白(例如,HCAb)、抗PD-1/TIGIT双特异性抗体(例如,PD-1×TIGIT BABP)、抗PD-1/LAG-3双特异性抗体(例如,PD-1×LAG-3 BABP)、抗PD-1/TIM-3双特异性抗体(例如,PD-1×TIM-3 BABP)、抗PD-1/CTLA-4双特异性抗体(例如,PD-1×CTLA-4BABP)或抗PD-1/PD-1双特异性抗体(例如,PD-1×PD-1 BABP))以及其组合物(例如药物组合物)可用于多种应用,例如诊断、分子测定和疗法。
本发明的一个方面提供一种治疗有需要的个体中的PD-1相关疾病或疾患的方法,所述方法包括向所述个体施用有效量的包含本文所述的抗PD-1构建体的药物组合物。在一些实施方案中,PD-1相关疾病是癌症,例如实体肿瘤(例如,结肠癌)。在一些实施方案中,PD-1相关疾病是病原性感染,例如病毒感染。在一些实施方案中,PD-1相关疾病是免疫相关疾病。在一些实施方案中,免疫相关疾病与T细胞功能障碍病症相关。在一些实施方案中,T细胞功能障碍病症的特征在于T细胞无反应或分泌细胞因子、增殖或执行细胞溶解活性的能力降低。在一些实施方案中,T细胞功能障碍病症的特征在于T细胞耗竭。在一些实施方案中,T细胞是CD4+和CD8+T细胞。在一些实施方案中,免疫相关疾病选自由以下组成的组:未解决的急性感染、慢性感染和肿瘤免疫性。在一些实施方案中,本文所述的抗PD-1构建体可用于增加、增强或刺激有需要的受试者的免疫反应或功能。在一些实施方案中,PD-1相关疾病(例如,癌症、免疫相关疾病)部分耐免疫检查点分子单阻断(例如,部分耐抗TIGIT、LAG-3、TIM-3、CTLA-4、PD-1抗体单一疗法治疗)。
本发明在某种程度上涵盖抗PD-1蛋白构建体(例如抗PD-1 sdAb、抗PD-1 sdAb-Fc融合蛋白(例如,HCAb)、抗PD-1/TIGIT双特异性抗体(例如,PD-1×TIGIT BABP)、抗PD-1/LAG-3双特异性抗体(例如,PD-1×LAG-3 BABP)、抗PD-1/TIM-3双特异性抗体(例如,PD-1×TIM-3 BABP)、抗PD-1/CTLA-4双特异性抗体(例如,PD-1×CTLA-4 BABP)或抗PD-1/PD-1双特异性抗体(例如,PD-1×PD-1 BABP))、编码其的核酸分子或载体、包含编码其的核酸分子或载体的宿主细胞,其可单独地或以与另一疗法组合的形式,并且在至少一些方面,连同药学上可接受的载体或赋形剂一起施用。在一些实施方案中,在施用抗PD-1构建体之前,它们可与本领域熟知的合适的药物载体和赋形剂组合。根据本公开所制备的组合物可用于治疗癌症或延迟癌症恶化,或增加、增强或刺激有需要的受试者的免疫反应或功能。
在一些实施方案中,提供一种治疗PD-1相关疾病(例如,癌症、免疫相关疾病例如与T细胞功能障碍病症相关的疾病)的方法,所述方法包含向个体施用有效量的药物组合物,所述药物组合物包含分离的抗PD-1构建体的和任选地药学上可接受的载体,所述分离的抗PD-1构建体包含特异性识别PD-1的sdAb部分(例如抗PD-1 sdAb、抗PD-1 sdAb-Fc融合蛋白(例如,HCAb)、抗PD-1/TIGIT双特异性抗体(例如,PD-1×TIGIT BABP)、抗PD-1/LAG-3双特异性抗体(例如,PD-1×LAG-3 BABP)、抗PD-1/TIM-3双特异性抗体(例如,PD-1×TIM-3BABP)、抗PD-1/CTLA-4双特异性抗体(例如,PD-1×CTLA-4 BABP)或抗PD-1/PD-1双特异性抗体(例如,PD-1×PD-1 BABP)),其中所述抗PD-1 sdAb部分包含:包含SEQ ID NO:37-72中的任一者的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:109-144中的任一者的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:181-216中的任一者的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,抗PD-1 sdAb部分与PD-1之间的结合的Kd是约10-5M至约10-12M(例如约10-7M至约10-12M、或约10-8M至约10-12M)。在一些实施方案中,抗PD-1 sdAb部分是骆驼科的、嵌合的、人类的、部分人源化的或完全人源化的抗PD-1 sdAb部分。在一些实施方案中,抗PD-1 sdAb部分包含VHH域,所述VHH域包含SEQ ID NO:289-324中的任一者的氨基酸序列。在一些实施方案中,PD-1相关疾病是癌症。在一些实施方案中,癌症是实体肿瘤(例如结肠癌)。在一些实施方案中,PD-1相关疾病是免疫相关疾病。在一些实施方案中,免疫相关疾病与T细胞功能障碍病症相关。在一些实施方案中,T细胞功能障碍病症的特征在于T细胞无反应或分泌细胞因子、增殖或执行细胞溶解活性的能力降低。在一些实施方案中,T细胞功能障碍病症的特征在于T细胞耗竭。在一些实施方案中,免疫相关疾病选自由以下组成的组:未解决的急性感染、慢性感染和肿瘤免疫性。在一些实施方案中,PD-1相关疾病(例如,癌症、免疫相关疾病)部分耐免疫检查点抑制剂单一疗法(例如,部分耐抗TIGIT、LAG-3、TIM-3、CTLA-4、PD-1抗体单一疗法治疗)。在一些实施方案中,所述方法还包括向所述个体施用额外疗法(例如癌症疗法,例如手术、放射、化学疗法、免疫疗法、激素疗法或其组合)。在一些实施方案中,额外疗法是免疫疗法,例如,通过向个体施用有效量的包含免疫调节剂的第二药物组合物。在一些实施方案中,免疫调节剂是免疫检查点抑制剂,例如,抗TIGIT、抗LAG-3、抗TIM-3、抗CTLA-4、抗PD-1或抗PD-L1抗体。在一些实施方案中,全身(例如静脉内或腹膜内)施用药物组合物。在一些实施方案中,局部(例如肿瘤内)施用药物组合物。在一些实施方案中,个体是人类。在一些实施方案中,所述治疗癌症的方法具有以下生物活性中的一种或多种:(1)杀伤癌细胞(包括旁观者杀伤);(2)抑制癌细胞的增殖;(3)在肿瘤中诱导免疫应答;(4)减小肿瘤大小;(5)缓解患有癌症的个体的一种或多种症状;(6)抑制肿瘤转移;(7)延长生存期;(8)延长癌症进展时间;以及(9)预防、抑制癌症复发或降低癌症复发的可能性。在一些实施方案中,通过本文所述的药物组合物介导的杀伤癌细胞的方法可实现至少约40%、50%、60%、70%、80%、90%、95%或95%以上中的任一者的肿瘤细胞死亡率。在一些实施方案中,通过本文所述的药物组合物介导的杀伤癌细胞的方法可实现至少约10%、20%、30%、40%、50%、60%、70%、80%、90%、95%或95%以上中的任一者的旁观肿瘤细胞(例如未受编码抗PD-1构建体的溶瘤VV感染)死亡率。在一些实施方案中,通过本文所述的药物组合物介导的减小肿瘤大小的方法可使肿瘤大小减小至少约10%(包括例如至少约20%、30%、40%、60%、70%、80%、90%或100%中的任一者)。在一些实施方案中,通过本文所述的药物组合物介导的抑制肿瘤转移的方法可抑制至少约10%(包括例如至少约20%、30%、40%、60%、70%、80%、90%或100%中的任一者)转移。在一些实施方案中,通过本文所述的药物组合物介导的延长个体(例如人类)生存期的方法可将个体的生存期延长至少1、2、3、4、5、6、7、8、9、10、11、12、18或24个月中的任一者。在一些实施方案中,通过本文所述的药物组合物介导的延长癌症进展时间的方法可将癌症进展时间延长至少1、2、3、4、5、6、7、8、9、10、11或12周中的任一者。在一些实施方案中,所述治疗免疫相关疾病的方法可增加、增强或刺激受试者的免疫反应或功能。在一些实施方案中,免疫反应或功能是通过活化效应细胞(例如,T细胞,例如CD8+和/或CD4+T细胞)、扩增(增加)效应细胞群体和/或杀伤受试者的靶细胞(例如,靶肿瘤细胞)来增加、增强和/或刺激。
在一些实施方案中,所述方法适用于治疗具有异常PD-1或PD-L1/PD-L2表达、活性和/或信号传导的癌症,作为非限制性实例,所述癌症包括血液癌症和/或实体肿瘤。可使用本发明的抗体抑制其生长的一些癌症包括通常对免疫疗法有反应的癌症。用于治疗的癌症的非限制性实例包括黑色素瘤(例如,转移性恶性黑色素瘤)、肾癌(例如透明细胞癌)、前列腺癌(例如激素难治性前列腺腺癌)、乳腺癌、结肠癌和肺癌(例如非小细胞肺癌)、胃癌、卵巢癌和胶质母细胞瘤。另外,本发明包括可使用本发明的抗体抑制生长的难治性或复发性恶性肿瘤。可以使用本发明的抗体治疗的其它癌症的实例包括骨癌、胰腺癌、皮肤癌、头颈癌、皮肤或眼内恶性黑色素瘤、子宫癌、卵巢癌、直肠癌、肛门区域癌、胃癌、睾丸癌、子宫癌、输卵管癌、子宫内膜癌、宫颈癌、阴道癌、外阴癌、霍奇金病(Hodgkin's Disease)、非霍奇金淋巴瘤(non-Hodgkin's lymphoma)、食道癌、小肠癌、内分泌系统癌、甲状腺癌、甲状旁腺癌、肾上腺癌、软组织肉瘤、尿道癌、阴茎癌、慢性或急性白血病包括急性骨髓性白血病、慢性骨髓性白血病、急性成淋巴细胞性白血病、慢性淋巴细胞性白血病、儿童实体瘤、淋巴细胞性淋巴瘤、膀胱癌、肾或输尿管癌、肾盂癌、中枢神经系统(CNS)赘瘤、原发性CNS淋巴瘤、肿瘤血管生成、脊髓轴肿瘤、脑干胶质瘤、垂体腺瘤、卡波西肉瘤(Kaposi's sarcoma)、表皮样癌、鳞状细胞癌、T细胞淋巴瘤、环境诱发的癌症包括由石棉诱发的癌症,以及所述癌症的组合。本发明还可用于治疗转移性癌症,尤其是表达PD-1或PD-L1/PD-L2的转移性癌症。在一些实施方案中,PD-1或PD-L1/PD-L2表达、活性和/或信号传导异常的癌症部分耐PD-1单阻断(例如,部分耐抗PD-1抗体单一疗法治疗)或部分耐免疫检查点抑制剂单一疗法(例如,抗TIGIT、LAG-3、TIM-3、CTLA-4抗体单一疗法治疗)。在这种情况下,可使用本文所述的抗PD-1 MABP(例如,BABP),例如PD-1×TIGIT、PD-1×LAG-3、PD-1×TIM-3、PD-1×CTLA-4或PD-1×PD-1 MABP(例如,BABP)。
本文描述的方法适用于治疗多种癌症,包括实体癌症和液体癌症。所述方法适用于所有阶段的癌症,包括早期癌症、非转移性癌症、原发性癌症、晚期癌症、局部晚期癌症、转移性癌症或缓解期癌症。本文描述的方法可以用作第一疗法、第二疗法、第三疗法或与本领域已知的其它类型的癌症疗法的组合疗法,例如化学疗法、手术、激素疗法、放射、基因疗法、免疫疗法(例如T细胞疗法或施用免疫调节剂)、骨髓移植、干细胞移植、靶向疗法、冷冻疗法、超声疗法、光动力疗法、射频消融等,在辅助环境或新辅助环境中(即,所述方法可以在初步/确定性治疗之前进行)。在一些实施方案中,所述方法用于治疗先前已经治疗的个体。在一些实施方案中,癌症对于先前疗法是难以治愈的。在一些实施方案中,所述方法用于治疗先前未接受过治疗的个体。在一些实施方案中,癌症部分耐免疫检查点抑制剂单一疗法(例如,部分耐抗TIGIT、LAG-3、TIM-3、CTLA-4、PD-1抗体单一疗法治疗)。
因此在一些实施方案中,提供一种治疗癌症(例如癌或腺癌,例如PD-1表达、活性和/或信号传导异常的癌症,和/或TIGIT/LAG-3/TIM-3/CTLA-4表达、活性和/或信号传导异常的癌症)的方法,所述方法包含向个体施用有效量的药物组合物,所述药物组合物包含抗PD-1构建体(例如,PD-1×TIGIT、PD-1×LAG-3、PD-1×TIM-3、PD-1×CTLA-4、PD-1×PD-1MABP或BABP,其对应于TIGIT/LAG-3/TIM-3/CTLA-4/PD-1表达、活性和/或信号传导异常)和任选地药学上可接受的载体,所述抗PD-1构建体包含:(a)包含抗PD-1 sdAb部分的第一抗原结合部分,所述抗PD-1 sdAb部分包含:包含SEQ ID NO:37-72中的任一者的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:109-144中的任一者的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:181-216中的任一者的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和(b)包含VH和VL的第二抗原结合部分,其中VH和VL在一起形成特异性结合第二免疫检查点分子(例如,TIGIT、LAG-3、TIM-3、CTLA-4、PD-1(例如与本文所述的抗PD-1 sdAb部分所识别不同的第二PD-1表位))的抗原结合位点,其中第一抗原结合部分融合至第二抗原结合部分。在一些实施方案中,第二抗原结合部分包括包含VH的重链和包含VL的轻链。在一些实施方案中,第一抗原结合部分在重链的N末端、轻链的N末端、Fc区的N末端、重链的C末端或轻链的C末端处融合至第二抗原结合部分。在一些实施方案中,第二抗原结合部分包含全长4链抗体或其抗原结合部分(例如,Fab或scFv)。在一些实施方案中,第一抗原结合部分融合至包含Fab或scFv的第二抗原部分的C末端。在一些实施方案中,第一抗原结合部分和第二抗原结合部分经由肽接头(例如包含SEQ ID NO:367-376中的任一者的氨基酸序列的肽接头)融合。在一些实施方案中,第二抗原结合部分包含Fc片段(例如,来源于IgG4、IgG2或IgG1)。在一些实施方案中,Fc片段包含SEQ ID NO:363-365中的任一者的氨基酸序列。在一些实施方案中,提供一种治疗癌症(例如癌或腺癌,例如PD-1表达、活性和/或信号传导异常的癌症,和/或TIGIT/LAG-3/TIM-3/CTLA-4表达、活性和/或信号传导异常的癌症)的方法,所述方法包含向个体施用有效量的药物组合物,所述药物组合物包含分离的抗PD-1构建体和任选地药学上可接受的载体,所述抗PD-1构建体包含特异性识别PD-1、融合至全长抗体(例如,特异性识别TIGIT、LAG-3、TIM-3、CTLA-4或PD-1(例如与本文所述的抗PD-1 sdAb部分所识别不同的第二PD-1表位)的抗体,其对应于TIGIT/LAG-3/TIM-3/CTLA-4/PD-1表达异常)的sdAb部分,其中所述抗PD-1 sdAb部分包含:包含SEQ ID NO:37-72中的任一者的氨基酸序列的CDR1,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;包含SEQ ID NO:109-144中的任一者的氨基酸序列的CDR2,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体;和包含SEQ ID NO:181-216中的任一者的氨基酸序列的CDR3,或其包含至多约3个(例如约1个、2个或3个中的任一者)氨基酸取代的变体。在一些实施方案中,VH和VL域来源于替拉古单抗。在一些实施方案中,VH包含SEQ ID NO:377的氨基酸序列的HC-CDR1、HC-CDR2和HC-CDR3,并且VL包含SEQ ID NO:378的氨基酸序列的LC-CDR1、LC-CDR2和LC-CDR3。在一些实施方案中,全长抗体是抗TIGIT抗体,其包括包含SEQ IDNO:377的氨基酸序列的重链和包含SEQ ID NO:378的氨基酸序列的轻链。在一些实施方案中,VH和VL域来源于瑞拉里单抗。在一些实施方案中,VH包含SEQ ID NO:379的氨基酸序列的HC-CDR1、HC-CDR2和HC-CDR3,并且VL包含SEQ ID NO:380的氨基酸序列的LC-CDR1、LC-CDR2和LC-CDR3。在一些实施方案中,全长抗体是抗LAG-3抗体,其包括包含SEQ ID NO:379的氨基酸序列的重链和包含SEQ ID NO:380的氨基酸序列的轻链。在一些实施方案中,VH和VL域来源于MBG453。在一些实施方案中,VH包含SEQ ID NO:381的氨基酸序列的HC-CDR1、HC-CDR2和HC-CDR3,并且VL包含SEQ ID NO:382的氨基酸序列的LC-CDR1、LC-CDR2和LC-CDR3。在一些实施方案中,全长抗体是抗TIM-3抗体,其包括包含SEQ ID NO:381的氨基酸序列的重链和包含SEQ ID NO:382的氨基酸序列的轻链。在一些实施方案中,VH和VL域来源于伊匹单抗(例如, )。在一些实施方案中,VH包含SEQ ID NO:383的氨基酸序列的HC-CDR1、HC-CDR2和HC-CDR3,并且VL包含SEQ ID NO:384的氨基酸序列的LC-CDR1、LC-CDR2和LC-CDR3。在一些实施方案中,全长抗体是抗CTLA-4抗体,其包括包含SEQ ID NO:383的氨基酸序列的重链和包含SEQ ID NO:384的氨基酸序列的轻链。在一些实施方案中,VH和VL域来源于派姆单抗(例如,/>
)。在一些实施方案中,VH包含SEQ ID NO:383的氨基酸序列的HC-CDR1、HC-CDR2和HC-CDR3,并且VL包含SEQ ID NO:384的氨基酸序列的LC-CDR1、LC-CDR2和LC-CDR3。在一些实施方案中,全长抗体是抗CTLA-4抗体,其包括包含SEQ ID NO:383的氨基酸序列的重链和包含SEQ ID NO:384的氨基酸序列的轻链。在一些实施方案中,VH和VL域来源于派姆单抗(例如,/> )或纳武单抗(例如,/>
)或纳武单抗(例如,/> )。在一些实施方案中,VH包含SEQ ID NO:385的氨基酸序列的HC-CDR1、HC-CDR2和HC-CDR3,并且VL包含SEQ ID NO:386的氨基酸序列的LC-CDR1、LC-CDR2和LC-CDR3。在一些实施方案中,全长抗体是抗PD-1抗体,其包括包含SEQ ID NO:385的氨基酸序列的重链和包含SEQ ID NO:386的氨基酸序列的轻链。在一些实施方案中,抗PD-1 sdAb部分与PD-1之间的结合的Kd是约10-5M至约10-12M(例如约10-7M至约10-12M、或约10-8M至约10-12M)。在一些实施方案中,抗PD-1 sdAb部分是骆驼科的、嵌合的、人类的、部分人源化的或完全人源化的抗PD-1 sdAb部分。在一些实施方案中,抗PD-1 sdAb部分的N末端融合至全长抗体的重链的至少一者的C末端。在一些实施方案中,抗PD-1 sdAb部分的C末端融合至全长抗体的重链的至少一者的N末端。在一些实施方案中,抗PD-1 sdAb部分的N末端融合至全长抗体的轻链的至少一者的C末端。在一些实施方案中,抗PD-1 sdAb部分的C末端融合至全长抗体的轻链的至少一者的N末端。在一些实施方案中,抗PD-1构建体包含四个抗PD-1 sdAb部分,其中每个抗PD-1 sdAb部分的C末端融合至全长抗体各链的N末端。在一些实施方案中,抗PD-1构建体包含四个抗PD-1 sdAb部分,其中两个抗PD-1 sdAb部分融合在一起,其进一步融合至全长抗体的各重链的N末端。在一些实施方案中,抗PD-1 sdAb部分包含VHH域,所述VHH域包含SEQ ID NO:289-324中的任一者的氨基酸序列。在一些实施方案中,抗PD-1 sdAb部分和全长抗体任选地通过肽接头(例如包含SEQID NO:367-376中的任一者的氨基酸序列的肽接头)连接。在一些实施方案中,癌症是实体肿瘤(例如结肠癌)。在一些实施方案中,全身(例如静脉内或腹膜内)施用药物组合物。在一些实施方案中,局部(例如肿瘤内)施用药物组合物。在一些实施方案中,所述方法还包括向个体施用另外的癌症疗法(例如手术、放射、化学疗法、免疫疗法、激素疗法或其组合)。在一些实施方案中,个体是人类。在一些实施方案中,癌症部分耐免疫检查点分子单阻断(例如,部分耐抗PD-1抗体、抗TIGIT抗体、抗LAG-3抗体、抗TIM-3抗体或抗CTLA-4抗体单一疗法治疗)。
)。在一些实施方案中,VH包含SEQ ID NO:385的氨基酸序列的HC-CDR1、HC-CDR2和HC-CDR3,并且VL包含SEQ ID NO:386的氨基酸序列的LC-CDR1、LC-CDR2和LC-CDR3。在一些实施方案中,全长抗体是抗PD-1抗体,其包括包含SEQ ID NO:385的氨基酸序列的重链和包含SEQ ID NO:386的氨基酸序列的轻链。在一些实施方案中,抗PD-1 sdAb部分与PD-1之间的结合的Kd是约10-5M至约10-12M(例如约10-7M至约10-12M、或约10-8M至约10-12M)。在一些实施方案中,抗PD-1 sdAb部分是骆驼科的、嵌合的、人类的、部分人源化的或完全人源化的抗PD-1 sdAb部分。在一些实施方案中,抗PD-1 sdAb部分的N末端融合至全长抗体的重链的至少一者的C末端。在一些实施方案中,抗PD-1 sdAb部分的C末端融合至全长抗体的重链的至少一者的N末端。在一些实施方案中,抗PD-1 sdAb部分的N末端融合至全长抗体的轻链的至少一者的C末端。在一些实施方案中,抗PD-1 sdAb部分的C末端融合至全长抗体的轻链的至少一者的N末端。在一些实施方案中,抗PD-1构建体包含四个抗PD-1 sdAb部分,其中每个抗PD-1 sdAb部分的C末端融合至全长抗体各链的N末端。在一些实施方案中,抗PD-1构建体包含四个抗PD-1 sdAb部分,其中两个抗PD-1 sdAb部分融合在一起,其进一步融合至全长抗体的各重链的N末端。在一些实施方案中,抗PD-1 sdAb部分包含VHH域,所述VHH域包含SEQ ID NO:289-324中的任一者的氨基酸序列。在一些实施方案中,抗PD-1 sdAb部分和全长抗体任选地通过肽接头(例如包含SEQID NO:367-376中的任一者的氨基酸序列的肽接头)连接。在一些实施方案中,癌症是实体肿瘤(例如结肠癌)。在一些实施方案中,全身(例如静脉内或腹膜内)施用药物组合物。在一些实施方案中,局部(例如肿瘤内)施用药物组合物。在一些实施方案中,所述方法还包括向个体施用另外的癌症疗法(例如手术、放射、化学疗法、免疫疗法、激素疗法或其组合)。在一些实施方案中,个体是人类。在一些实施方案中,癌症部分耐免疫检查点分子单阻断(例如,部分耐抗PD-1抗体、抗TIGIT抗体、抗LAG-3抗体、抗TIM-3抗体或抗CTLA-4抗体单一疗法治疗)。
本申请的药物组合物的剂量和所需药物浓度可根据设想的特定用途而变化。确定适当剂量或施用途径完全在普通技术者的技术范围内。动物实验为人类疗法的有效剂量的确定提供可靠的指导。有效剂量的物种间类推可以遵循Mordenti,J.和Chappell,W.“TheUse of Interspecies Scaling in Toxicokinetics,”Toxicokinetics and New DrugDevelopment,Yacobi等编,Pergamon Press,New York 1989,第42-46页来进行。
根据已知方法将本申请的药物组合物(包括但不限于重构和液体制剂)施用于需要用本文所述的抗PD-1构建体(例如抗PD-1 sdAb、抗PD-1 sdAb-Fc融合蛋白(例如,HCAb)、抗PD-1/TIGIT双特异性抗体(例如,PD-1×TIGIT BABP)、抗PD-1/LAG-3双特异性抗体(例如,PD-1×LAG-3 BABP)、抗PD-1/TIM-3双特异性抗体(例如,PD-1×TIM-3 BABP)、抗PD-1/CTLA-4双特异性抗体(例如,PD-1×CTLA-4BABP)或抗PD-1/PD-1双特异性抗体(例如,PD-1×PD-1 BABP))进行治疗的个体(优选人类),所述方法例如呈推注形式或经一段时间连续输注来静脉内施用,通过肌肉内、腹膜内、脑脊髓内、皮下、静脉内(i.v.)、关节内、滑膜内、鞘内、口服、局部或吸入途径。重构制剂可通过将冻干的本文所述的抗PD-1构建体溶解在稀释剂中使得蛋白质分散于各处来制备。适用于本申请的示例性药学上可接受的(对人类施用安全且无毒)稀释剂包括但不限于无菌水、抑菌性注射用水(BWFI)、pH缓冲溶液(例如磷酸盐缓冲盐水)、无菌盐水溶液、林格氏溶液或右旋糖溶液、或盐和/或缓冲剂的水溶液。
在一些实施方案中,药物组合物是通过皮下(即在皮肤下)施用来向个体施用。出于这类目的,可使用注射器来注射药物组合物。然而,可使用其它用于施用药物组合物的装置,例如注射装置、注射笔、自动注射器装置、无针装置和皮下贴片递送系统。在一些实施方案中,药物组合物经静脉内施用于个体。在一些实施方案中,药物组合物通过输注(例如静脉内输注)施用于个体。免疫疗法的输注技术是本领域已知的(参见例如Rosenberg等,NewEng.J.of Med.319:1676(1988))。
V.制备方法
本文所述的抗PD-1构建体(例如抗PD-1 sdAb、抗PD-1 sdAb-Fc融合蛋白(例如,HCAb)、抗PD-1/TIGIT双特异性抗体(例如,PD-1×TIGIT BABP)、抗PD-1/LAG-3双特异性抗体(例如,PD-1×LAG-3 BABP)、抗PD-1/TIM-3双特异性抗体(例如,PD-1×TIM-3 BABP)、抗PD-1/CTLA-4双特异性抗体(例如,PD-1×CTLA-4 BABP)或抗PD-1/PD-1双特异性抗体(例如,PD-1×PD-1 BABP)可使用本领域中已知或如本文所述的任何方法制备。还参见实施例1-3。在一些实施方案中,提供一种产生抗PD-1构建体的方法,所述方法包括:(a)在有效表达所编码的抗PD-1构建体的条件下培养包含编码本文所述的抗PD-1构建体的分离的核酸或载体的宿主细胞;以及(b)从所述宿主细胞获得所表达的抗PD-1构建体。在一些实施方案中,步骤(a)的方法还包括产生包含编码本文所述的抗PD-1构建体的分离的核酸或载体的宿主细胞。
制备sdAb的方法已有所描述。参见例如Els Pardon等,Nature Protocol,2014;9(3):674。sdAb(例如VHH)可使用本领域中已知的方法获得,例如通过将骆驼科物种(例如骆驼或美洲驼)免疫并从其获得杂交瘤,或通过使用本领域中已知的分子生物技术克隆单域抗体文库并随后通过利用未选择文库的个别克隆进行的ELISA或通过使用噬菌体展示进行选择。
对于sdAb的重组产生,将编码单域抗体的核酸分离并插入至可复制载体中以供进一步克隆(DNA的扩增)或以供表达。编码单域抗体的DNA易于分离并使用常规程序(例如,通过使用能够特异性结合编码抗体重链和轻链的基因的寡核苷酸探针)来测序。许多载体可供使用。载体的选择部分取决于待使用的宿主细胞。通常,优选的宿主细胞来源于原核或真核(通常是哺乳动物)。在一些实施方案中,编码本文所述的抗PD-1构建体的分离的核酸包含SEQ ID NO:253-288中的任一者的核酸序列。
1.真核细胞中的重组产生
对于真核表达,载体组分通常包括但不限于以下中的一者或多者:信号序列、复制起点、一个或多个标志基因,以及增强子元件、启动子和转录终止序列。
a)信号序列组分
用于真核宿主的载体还可以是编码信号序列或在成熟蛋白质或多肽的N末端处具有特异性裂解位点的其它多肽的插入物。优选地选择的异源信号序列是由宿主细胞识别和加工(即,通过信号肽酶裂解)的信号序列。在哺乳动物细胞表达中,可获得哺乳动物信号序列以及病毒性分泌前导序列,例如单纯疱疹gD信号。
这种前体区的DNA在阅读框中连接至编码本申请的抗体的DNA。
b)复制起点
通常,复制起点组分不是哺乳动物表达载体所需(通常可仅使用SV40起点,因为其含有早期启动子)。
c)选择基因组分
表达和克隆载体可含有选择基因,所述选择基因也称为可选择标志物。典型的选择基因编码的蛋白质(a)赋予对抗生素或其它毒素(例如氨苄青霉素、新霉素、氨甲蝶呤或四环素)的抗性,(b)补充营养缺陷型缺陷,或(c)供应无法从复合培养基获得的关键营养物,例如,就杆菌而言,编码D-丙氨酸外消旋酶的基因。
选择方案的一个实例利用药物来阻止宿主细胞的生长。用异源基因成功地转化的那些细胞产生赋予抗药性的蛋白质,因此在所述选择方案中存活。所述显性选择的实例使用药物新霉素、霉酚酸和潮霉素。
适用于哺乳动物细胞的可选择标志物的另一个实例是能够鉴定有能力吸收编码本申请的抗体的核酸的细胞的那些可选择标志物,例如DHFR、胸苷激酶、金属硫蛋白-I和-II(优选地灵长类动物金属硫蛋白基因)、腺苷脱氨酶、鸟氨酸脱羧酶等。
例如,首先通过在含有DHFR的竞争性拮抗剂氨甲蝶呤(Mtx)的培养基中培养所有转化体来鉴定用DHFR选择基因转化的细胞。当使用野生型DHFR时,适当的宿主细胞是缺乏DHFR活性的中国仓鼠卵巢(CHO)细胞系(例如ATCC CRL-9096)。
或者,用编码多肽的DNA序列、野生型DHFR蛋白和例如氨基糖苷3'-磷酸转移酶(APH)的另一种可选择标志物转化或共转化的宿主细胞(特别是含有内源DHFR的野生型宿主)可通过在含有用于可选择标志物的选择剂的培养基中进行细胞生长来选择,所述选择剂例如氨基糖苷抗生素,例如卡那霉素、新霉素或G418。参见美国专利第4,965,199号。
d)启动子组分
表达和克隆载体通常含有由宿主有机体识别并且可操作地连接至编码所需多肽序列的核酸的启动子。几乎所有的真核基因均具有位于起始转录的位点上游大约25至30个碱基处的富AT区。在许多基因的转录开始的上游70至80个碱基处发现的另一个序列是CNCAAT区,其中N可以是任何核苷酸。在大多数真核基因的3'端处是AATAAA序列,其可以是用于添加聚腺苷酸尾至编码序列的3'端中的信号。所有这些序列均可插入至真核表达载体中。
适用于原核宿主的其它启动子包括PhoA启动子、-内酰胺酶和乳糖启动子系统、碱性磷酸酶启动子、色氨酸(trp)启动子系统和杂合启动子如tac启动子。然而,其它已知的细菌启动子也是合适的。用于细菌系统的启动子还含有可操作地连接至编码抗体的DNA的夏因-达尔加诺(Shine-Dalgarno;S.D.)序列。
来自哺乳动物宿主细胞中的载体的多肽转录例如通过以下各者来控制:从例如多瘤病毒、禽痘病毒、腺病毒(例如腺病毒2)、牛乳头瘤病毒、禽肉瘤病毒、巨细胞病毒、逆转录病毒、乙型肝炎病毒且最优选猿猴病毒40(SV40)的病毒的基因组获得的启动子,异源哺乳动物启动子(例如肌动蛋白启动子或免疫球蛋白启动子),热休克启动子,条件是这些启动子与宿主细胞系统相容。
SV40病毒的早期和晚期启动子便利地以还含有SV40病毒复制起点的SV40限制性片段形式获得。人类巨细胞病毒的立即早期启动子便利地以HindIII E限制性片段形式获得。使用牛乳头瘤病毒作为载体在哺乳动物宿主中表达DNA的系统公开于美国专利第4,419,446号中。这种系统的改进描述于美国专利第4,601,978号中。关于在来自单纯疱疹病毒的胸苷激酶启动子控制下人类干扰素cDNA在小鼠细胞中的表达,也参见Reyes等,Nature297:598-601(1982)。或者,劳斯肉瘤病毒长末端重复序列可用作启动子。
e)增强子元件组分
通过将增强子序列插入载体中,通常可以提高高等真核生物对编码本申请抗体的DNA的转录。现在已知许多来自哺乳动物基因(球蛋白、弹性蛋白酶、白蛋白、甲胎蛋白和胰岛素)的增强子序列。然而,通常,人们将使用来自真核细胞病毒的增强子。实例包括在复制起点(100-270bp)的后侧上的SV40增强子、巨细胞病毒早期启动子增强子、在复制起点的后侧上的多瘤病毒增强子、和腺病毒增强子。关于用于真核启动子的活化的增强元件,还参见Yaniv,Nature 297:17-18(1982)。增强子可剪接至载体中编码多肽序列的5'或3'位置,但优选位于启动子的5'位点。
f)转录终止组分
用于真核宿主细胞(酵母、真菌、昆虫、植物、动物、人类或来自其它多细胞有机体的有核细胞)中的表达载体还含有终止转录和稳定mRNA所必需的序列。这些序列通常可从真核或病毒DNA或cDNA的5'和偶尔3'未翻译区获得。这些区含有转录为编码多肽的mRNA的非翻译部分中的聚腺苷酸化片段的核苷酸区段。一种可用的转录终止组分是牛生长激素聚腺苷酸化区。参见WO94/11026和其中所公开的表达载体。
g)宿主细胞的选择和转化
用于在本文中的载体中克隆或表达DNA的合适宿主细胞包括本文所述的高等真核细胞,包括脊椎动物宿主细胞。培养物(组织培养物)中脊椎动物细胞的增殖已成为常规程序。适用的哺乳动物宿主细胞系的实例是由SV40转化的猴肾CV1细胞系(COS-7,ATCC CRL1651);人类胚胎肾细胞系(293细胞或被亚克隆用于悬浮培养物中生长的293细胞,Graham等,J.Gen Virol.36:59(1977));幼仓鼠肾细胞(BHK,ATCC CCL 10);中国仓鼠卵巢细胞/-DHFR(CHO,Urlaub等,Proc.Natl.Acad.Sci.USA 77:4216(1980));小鼠足细胞(TM4,Mather,Biol.Reprod.23:243-251(1980));猴肾细胞(CV1 ATCC CCL 70);非洲绿猴肾细胞(VERO-76,ATCC CRL-1587);人类宫颈癌细胞(HELA,ATCC CCL 2);犬肾细胞(MDCK,ATCCCCL 34);布法罗大鼠(buffalo rat)肝细胞(BRL 3A,ATCC CRL 1442);人类肺细胞(W138,ATCC CCL 75);人类肝细胞(Hep G2,HB 8065);小鼠乳房肿瘤(MMT 060562,ATCC CCL51);TR1细胞(Mather等,Annals N.Y.Acad.Sci.383:44-68(1982));MRC 5细胞;FS4细胞;和人类肝细胞瘤细胞系(Hep G2)。
宿主细胞被上述表达或克隆载体转化以供抗体产生并且在常规营养培养基中培养,所述营养培养基适当时被改进用于诱导启动子、选择转化体或扩增编码所需序列的基因。
h)培养宿主细胞
用于产生本申请的抗体的宿主细胞可在多种培养基中培养。例如Ham氏F10(Sigma)、最低必需培养基((MEM),Sigma)、RPMI-1640(Sigma)和杜氏改良伊格尔氏培养基((DMEM),Sigma)的市售培养基适用于培养宿主细胞。另外,Ham等,Meth.Enz.58:44(1979);Barnes等,Anal.Biochem.102:255(1980);美国专利第4,767,704号;第4,657,866号;第4,927,762号;第4,560,655号;或第5,122,469号;WO 90/03430;WO 87/00195;或美国专利再审30,985中所述的任何培养基均可用作所述宿主细胞的培养基。任何这些培养基均可在必要时补充激素和/或其它生长因子(例如胰岛素、转铁蛋白或表皮生长因子)、盐(例如氯化钠、钙、镁和磷酸盐)、缓冲液(例如HEPES)、核苷酸(例如腺苷和胸苷)、抗生素(例如GENTAMYCINTM药物)、痕量元素(定义为通常以微摩尔浓度范围内的最终浓度存在的无机化合物)和葡萄糖或等效能源。还可包括在本领域技术人员将已知的适当浓度的任何其它必要补充物。例如温度、pH等的培养条件是先前用于针对表达所选择的宿主细胞的那些条件,并且将是普通技术人员显而易知的。
i)蛋白纯化
当使用重组技术时,抗体可以在细胞内、周质空间中产生或直接分泌至培养基中。如果抗体在细胞内产生,则作为第一步骤,例如通过离心或超滤去除宿主细胞或裂解片段的微粒碎片。Carter等,Bio/Technology 10:163-167(1992)描述了用于分离出分泌至大肠杆菌的周质空间的抗体的程序。简言之,在约30分钟内在乙酸钠(pH 3.5)、EDTA和苯甲基磺酰氟(PMSF)存在下解冻细胞糊状物。通过离心去除细胞碎片。当抗体分泌至培养基中时,通常首先使用市售的蛋白质浓缩滤器(例如Amicon或Millipore Pellicon超滤单元)来浓缩这类表达系统的上清液。蛋白酶抑制剂(例如PMSF)可包括在任何前述步骤中以抑制蛋白水解,并且可包括抗生素以防止外来污染物生长。
由细胞制备的蛋白组合物可使用例如羟磷灰石色谱法、凝胶电泳、透析和亲和色谱法来纯化,其中亲和色谱法是优选的纯化技术。蛋白A作为亲和配体的适合性取决于抗体中存在的任何免疫球蛋白Fc域的种类和同型。蛋白A可用于纯化基于含有1、2或4条重链的人类免疫球蛋白的抗体(Lindmark等,J.Immunol.Meth.62:1-13(1983))。蛋白G被推荐用于所有小鼠同型和人类3(Guss等,EMBO J.5:15671575(1986))。亲和配体所连接的基质最常是琼脂糖,但也可使用其它基质。机械稳定的基质(例如可控孔径玻璃或聚(苯乙烯-二乙烯基)苯)与琼脂糖相比可实现较快流速和较短加工时间。当抗体包含CH3域时,BakerbondABXTMresin(J.T.Baker,Phillipsburg,N.J.)可用于纯化。还可使用其它用于蛋白质纯化的技术,例如离子交换柱分馏、乙醇沉淀、反相HPLC、硅胶色谱法、肝素SEPHAROSETM色谱法、阴离子或阳离子交换树脂(例如聚天冬氨酸柱)色谱法、聚焦色谱法、SDS-PAGE和硫酸铵沉淀,这取决于待回收的抗体。
在任何初步纯化步骤之后,可使用pH在约2.5-4.5之间的洗脱缓冲液对包含所关注的抗体和污染物的混合物进行低pH疏水性作用色谱分析,优选在低盐浓度(例如,约0-0.25M盐)下进行。
2.多克隆抗体
多克隆抗体通常通过多次皮下(s.c.)或腹膜内(i.p.)注射相关抗原和佐剂而在动物中产生。可能有用的是,使用双功能或衍生剂(例如,顺丁烯二酰亚胺苯甲酰基磺基琥珀酰亚胺酯(通过半胱氨酸残基缀合)、N-羟基琥珀酰亚胺(通过赖氨酸残基)、戊二醛、琥珀酸酐、SOCl2或R1N═C═NR,其中R和R1独立地是低级烷基),将相关抗原与在待免疫的物种中具有免疫原性的蛋白质缀合,所述蛋白质例如匙孔血蓝蛋白(keyhole limpethemocyanin;KLH)、血清白蛋白、牛甲状腺球蛋白或大豆胰蛋白酶抑制剂。可采用的佐剂的实例包括弗氏完全佐剂(Freund's adjuvant)和MPL-TDM佐剂(单磷酰基脂质A、合成海藻糖双棒状霉菌酸酯)。本领域技术人员可选择免疫方案而无需过多的实验。
通过将例如100μg或5μg的蛋白质或缀合物(分别针对兔或小鼠)与3体积的弗氏完全佐剂组合并将溶液在多个部位处进行皮内注射来使动物对抗原、免疫原性缀合物或衍生物免疫。一个月后,通过在多个部位进行皮下注射,用1/5至1/10原始量的含肽或缀合物的弗氏完全佐剂对动物加强免疫。7至14天后,将动物放血并测定血清的抗体滴度。对动物进行加强免疫,直至滴度平稳。缀合物还可呈蛋白融合物在重组细胞培养物中制成。此外,例如明矾的聚集剂适于增强免疫反应。关于骆驼中的免疫,也参见实施例1。
VI.制品和试剂盒
还提供了试剂盒和制品,所述试剂盒和制品包括本文所述的以下中的任一者:分离的抗PD-1构建体(例如抗PD-1 sdAb、抗PD-1 sdAb-Fc融合蛋白(例如,HCAb)、抗PD-1/TIGIT双特异性抗体(例如,PD-1×TIGIT BABP)、抗PD-1/LAG-3双特异性抗体(例如,PD-1×LAG-3 BABP)、抗PD-1/TIM-3双特异性抗体(例如,PD-1×TIM-3BABP)、抗PD-1/CTLA-4双特异性抗体(例如,PD-1×CTLA-4 BABP)或抗PD-1/PD-1双特异性抗体(例如,PD-1×PD-1BABP))、编码其的分离的核酸或载体、或包含编码抗PD-1构建体的分离的核酸或载体的分离的宿主细胞。在一些实施方案中,提供一种试剂盒,所述试剂盒包括本文所述的任一种药物组合物并且优选提供其使用说明。
本申请的试剂盒处于合适的包装中。合适的包装包括但不限于小瓶、瓶子、广口瓶、柔性包装(例如,密封Mylar或塑料袋)等。试剂盒可任选地提供额外组分,例如缓冲液和解释信息。本申请因此还提供制品,其包括小瓶(例如密封小瓶)、瓶子、广口瓶、柔性包装等。
试剂盒可包括多个单位剂量的药物组合物和使用说明书,其包装量足以在药房(例如,医院药房和复配药房)中储存和使用。
实施例
以下实施例仅意图例示本发明,并且因此不应视为以任何方式限制本发明。提供以下实施例和详细描述是用于说明而非用于限制。
实施例1:抗PD-1 sdAb和抗PD-1 HCAb的生成
免疫接种
根据所有当前动物福利法规,用重组PD-1细胞外域(ECD)蛋白(登录号NP_005009.2,SEQ ID NO:362)对两头骆驼进行免疫接种。对于免疫接种,将抗原与CFA(初级免疫)或IFA(加强免疫)一起配制成乳液。在颈部通过肌肉内双点注射来施用抗原。每只动物在每周一次的间隔下接受两次含有100μg PD-1 ECD的乳液注射和随后4次含有50μg抗原的注射。在免疫接种期间的不同时间点,从动物收集10ml血液样本并制备血清。在用固定化PD-1 ECD蛋白的基于ELISA的实验中使用血清样本验证抗原特异性体液免疫反应的诱导(图1A-1B和图2A-2B)。最后一次免疫之后五天,收集200ml血液样本。使用Ficoll-Paque梯度(Amersham Biosciences)从200ml血液样本中分离出外周血淋巴细胞(PBL),其作为骆驼科重链免疫球蛋白(HCAb)的基因来源,得到5×108个PBL。预期抗体的最大多样性等于所取样的B淋巴细胞数,其是PBL数的约20%(1×108)。骆驼的重链抗体分数为B淋巴细胞数的至多20%。因此,将200ml血液样本中HCAb的最大多样性计算为2×107种不同分子。
文库构建和结合物选择
将提取自PBL和淋巴结的RNA用作扩增sdAb编码基因片段的RT-PCR的起始材料。将这些片段克隆到内部噬菌粒载体中。载体编码与sdAb编码序列同框的C末端His6标签。文库大小多于1×109。根据标准方案制备文库噬菌体并在过滤灭菌之后在4℃下储存以供进一步使用。
使用固相淘选(panning)以及基于细胞的淘选,用上述文库进行选择。挑选出克隆并在96深孔板(1ml体积)中生长,并且通过添加IPTG和0.1%Triton诱导上清液中sdAb表达。分析上清液中其结合PD-1 ECD蛋白(通过ELISA)和PD-1稳定细胞系(通过FACS)的能力。对阳性结合物进行测序,并且选择独特的克隆以供进一步表征(表3)。
sdAb产生
通过 从周质提取物中纯化出所选的His6标记sdAb。根据制造商的说明书加工NTA树脂。在RT下于旋转器上将所制备的周质提取物与所述树脂一起温育30分钟。用PBS洗涤树脂并转移至柱。用15mM咪唑洗涤填充树脂。使用150mM咪唑从柱洗脱出sdAb。通过在Hybond膜上点样来分析洗脱级分并用丽春红(Ponceau)显现。将含有蛋白的级分汇集并针对PBS透析。将透析蛋白收集,过滤灭菌,确定浓度并在-20℃下储存。
从周质提取物中纯化出所选的His6标记sdAb。根据制造商的说明书加工NTA树脂。在RT下于旋转器上将所制备的周质提取物与所述树脂一起温育30分钟。用PBS洗涤树脂并转移至柱。用15mM咪唑洗涤填充树脂。使用150mM咪唑从柱洗脱出sdAb。通过在Hybond膜上点样来分析洗脱级分并用丽春红(Ponceau)显现。将含有蛋白的级分汇集并针对PBS透析。将透析蛋白收集,过滤灭菌,确定浓度并在-20℃下储存。
为了确定纯度,在12%SDS-PAGE凝胶上分析蛋白质样本。将10μl Laemmli样本缓冲液添加至10μl(2μg)纯化蛋白中,然后将样本在95℃下加热10分钟,冷却并加载至12%SDS-PAGE凝胶上。根据一般程序加工凝胶并用考马斯亮蓝(Coomassie Brilliant Blue,CBB)染色。纯化数据概述于图28中。
通过表面等离子体共振(SPR)的sdAb的亲和力测量
在BIAcore T200仪器(GE Healthcare)上通过SPR确定sdAb的结合动力学。简言之,在约50RU的密度下将PD-1 ECD胺偶联至CM5传感器芯片。将5种浓度的以3倍连续稀释(从2nM开始至162nM)的sdAb注射在涂布传感器芯片上。所有实验中流速为30μl/min。缔合期为5分钟,并且解离期为5、10或15分钟。使用甘氨酸/HCl pH 1.5使芯片再生。将在不同浓度sdAb下的结合曲线拟合至1:1朗缪尔(Langmuir)结合模型以计算动力学参数kon、koff和KD(关于sdAb亲和力数据,参见图3A-3F)。用Biacore T200评估软件(GE Healthcare)执行感测图加工和数据分析。亲和力参数概述于图3G中。
通过FACS分析的与在细胞上表达的PD-1的结合
使用基于荧光活性细胞分选(FACS)测定来确定sdAb与CHO细胞上表达的PD-1的结合。将表达人类PD-1的CHO细胞从贴壁式培养瓶解离并与不同浓度的抗体混合(都在96孔板中)。将混合物在室温下平衡30分钟,用FACS缓冲液(含有1%BSA的PBS)洗涤三次。然后添加二级抗体荧光素异硫氰酸盐(FITC)缀合的抗人类κ抗体(Jackson ImmunoResearch)并在室温下温育15分钟。再次用FACS缓冲液洗涤细胞并通过流式细胞术分析。使用Prism(GraphPad软件,San Diego,CA)使用非线性回归分析数据,并计算EC50值。从图4A-4B可见,FACS结合测定说明A31543、AS06962和AS07424 sdAb可在低浓度(1-10μg/ml)下结合PD-1。
通过FACS分析的配体结合的抑制
使用流式细胞术研究配体结合的阻断。对于抗PD-1 sdAb评估,将表达人类PD-1的CHO细胞从贴壁式培养瓶解离并与不同浓度的抗体和恒定浓度的生物素标记的人类PD-L1/Fc或人类PD-L2/Fc蛋白混合(都在96孔板中)。将 用作抗PD-1抗体阳性对照。将混合物在室温下平衡30分钟,用FACS缓冲液(含有1%BSA的PBS)洗涤三次。然后添加PE/Cy5抗生蛋白链菌素二级抗体并在室温下温育15分钟。再次用FACS缓冲液洗涤细胞并通过流式细胞术分析(图5A)。使用Prism(GraphPad软件,San Diego,CA)使用非线性回归分析数据,并计算IC50值(图5B)。
用作抗PD-1抗体阳性对照。将混合物在室温下平衡30分钟,用FACS缓冲液(含有1%BSA的PBS)洗涤三次。然后添加PE/Cy5抗生蛋白链菌素二级抗体并在室温下温育15分钟。再次用FACS缓冲液洗涤细胞并通过流式细胞术分析(图5A)。使用Prism(GraphPad软件,San Diego,CA)使用非线性回归分析数据,并计算IC50值(图5B)。
HCAb构建、产生和表征
从上文研究选择具有功能活性和慢解离速率的sdAb用于HCAb构建和生产。将所选sdAb的DNA序列与人类IgG4 Fc(S228P)的DNA序列融合以制备HCAb构建体。将HCAb构建体转染至CHO细胞中以供HCAb表达。通过蛋白A柱纯化条件培养基中分泌的HCAb。纯化数据概述于图29中。
通过表面等离子体共振(SPR)的HCAb的亲和力测量
使用SPR生物传感器Biacore T200(GE Healthcare)确定抗PD-1骆驼科HCAb的结合动力学。通过Fc捕获方法在约50 RU的密度下将抗体固定在传感器芯片上。将5种浓度的以3倍连续稀释(从3nM开始至243nM)的人类PD-1-His抗原注射在涂布传感器芯片上。所有实验中的流速为30μl/min。使用甘氨酸/HCl pH 1.5使芯片再生。将在不同浓度PD-1-His抗原下的结合曲线拟合至1:1朗缪尔结合模型以计算动力学参数kon、koff和KD(关于HCAb亲和力数据,参见图6B-6K)。将 用作实验对照(图6L)。用Biacore T200评估软件(GEHealthcare)执行感测图加工和数据分析。亲和力参数概述于图6A中。
用作实验对照(图6L)。用Biacore T200评估软件(GEHealthcare)执行感测图加工和数据分析。亲和力参数概述于图6A中。
如图6A-6L中可见,所选HCAb(AS15140_HCAb、AS15152_HCAb、AS15156_HCAb、AS15193_HCAb、AS06962_HCAb、AS15881_HCAb、AS15883_HCAb、AS15892_HCAb、AS15899_HCAb和AS25170_HCAb)显示与 相当的结合亲和力。
相当的结合亲和力。
通过FACS分析的HCAb与在细胞上表达的PD-1的结合
如上所述,测试22种经纯化抗PD-1 HCAb对CHO细胞上表达的PD-1的结合能力(图7A-7V)。将 用作实验对照(图7W)。EC50概述于图7X中。如图7A-7X可见,FACS结合测定说明所有22种HCAb都展现出与细胞表面上PD-1的良好结合。
用作实验对照(图7W)。EC50概述于图7X中。如图7A-7X可见,FACS结合测定说明所有22种HCAb都展现出与细胞表面上PD-1的良好结合。
通过FACS分析的配体结合的抑制
类似地如上所述,通过FACS分析测试22种经纯化抗PD-1 HCAb抑制PD-1和PD-L1结合的能力(图8A-8V)。将 用作实验对照(图8W)。IC50概述于图8X中。如图8A-8X可见,竞争测定说明抗PD-1 HCAb在低浓度(1-10μg/ml)下有效抑制PD-1/PD-L1相互作用的能力。并且根据FACS数据的IC50,所有22种HCAb都显示出良好的配体竞争活性。
用作实验对照(图8W)。IC50概述于图8X中。如图8A-8X可见,竞争测定说明抗PD-1 HCAb在低浓度(1-10μg/ml)下有效抑制PD-1/PD-L1相互作用的能力。并且根据FACS数据的IC50,所有22种HCAb都显示出良好的配体竞争活性。
基于PD-1的功能阻断测定
使用稳定表达PD-L1和Jurkat效应细胞的CHO-K1细胞评估抗PD-1 HCAb评估的PD-1阻断。效应细胞含有荧光素酶构建体,其在破坏PD-1/PD-L1受体-配体相互作用时被诱导,例如当表达PD-L1的细胞与表达PD-1的效应细胞混合时。因此,可通过测量荧光素酶报告基因活性来评估抗PD-1 HCAb抑制CHO-K1稳定细胞上PD-L1与效应细胞上PD-1的相互作用的功效。如下进行测定。
第一天,将表达PD-L1的CHO-K1细胞在37℃水浴中解冻,直至细胞刚好解冻(约3-4分钟),并将0.5mL解冻的细胞转移至14.5mL细胞回收培养基(10%FBS/F-12)中。通过轻轻颠倒管1-2次将细胞悬浮液充分混合。然后将细胞悬浮液转移至无菌试剂储集器,并以每孔25μL细胞悬浮液分配至测定板中。添加每孔100μL测定培养基作为空白对照。对作为空白对照的各孔添加每孔100μL细胞回收培养基。然后将板盖上盖子并在CO2温育箱中在37℃下温育过夜。
接着,将PD-1Jurkat效应细胞在37℃水浴中解冻,直至细胞刚好解冻(约3-4分钟)。通过上下吸取将小瓶中的细胞悬浮液轻轻混合,并且将0.5mL细胞添加至5.9mL测定缓冲液中。通过轻轻颠倒管1-2次将细胞悬浮液充分混合。使细胞快速离心,然后转移至无菌试剂储集器中的200μL测定缓冲液中,并且将40μL具有细胞的缓冲液分配至含有各种浓度的抗PD-1 HCAb或对照抗体的各孔中(从1μM开始,以3倍稀释,总计8种浓度)。然后向各孔中添加160μL PD-L1 CHO-K1细胞。将板盖上盖子并在CO2温育箱中在37℃下温育六小时。
通过将一瓶缓冲液转移至含有底物的瓶中来重构荧光素酶测定系统。将系统在室温下储存并避光保存以供某天使用。6小时温育之后,将测定板从CO2温育箱中移出并在周围温度下平衡5-10分钟。向各孔中添加80μL试剂。将板在周围温度下温育5-10分钟。在 发现系统(Promega,Madison,WI)或具有辉光型(glow-type)发光读取能力的读板器中测量发光。
发现系统(Promega,Madison,WI)或具有辉光型(glow-type)发光读取能力的读板器中测量发光。
发光表示为相对光单位(RLU)。将具有稀释HCAb或 对照的孔的RLU值标准化至无抗体的RLU以得到荧光素酶诱导倍数。将数据绘制为RLU诱导倍数对HCAb抗体(或
对照的孔的RLU值标准化至无抗体的RLU以得到荧光素酶诱导倍数。将数据绘制为RLU诱导倍数对HCAb抗体(或 对照)的Log10浓度。将数据拟合至曲线并使用例如GraphPad Prism的曲线拟合软件确定各HCAb和对照抗PD-1抗体/>
对照)的Log10浓度。将数据拟合至曲线并使用例如GraphPad Prism的曲线拟合软件确定各HCAb和对照抗PD-1抗体/> 的EC50(图9A-9G)。EC50数据概述于图9H中。
的EC50(图9A-9G)。EC50数据概述于图9H中。
还可通过确定包含表达PD-1的靶细胞和活化T细胞的混合淋巴细胞反应(MLR)中的IL-2分泌水平来研究抗体的PD-1抑制,其中抗PD-1 HCAb是以各种浓度提供。
使用分离试剂盒(Miltenyl Biotec)从PBMC纯化人类CD4+T细胞和同种异体单核细胞。将单核细胞诱导至树突细胞中。各孔含有105个CD4+T细胞和104个同种异体树突细胞,最终工作体积为200μl。在不同的浓度下将抗PD-1 HCAb添加至各孔中。将无抗体用作背景对照。将人类IgG4用作阴性对照(未示出),并且将 用作阳性抗PD-1抗体对照。在37℃/5%CO2温育箱中温育72小时之后,从各测试孔取出100μl培养基以供IL-2分泌测量(Cisbio)。使用MLR中IL-2的抗体浓度依赖性分泌来得出抗PD-1抗体的抗PD-1活性的EC50(图10A-10C),并与全长PD-1抗体/>
用作阳性抗PD-1抗体对照。在37℃/5%CO2温育箱中温育72小时之后,从各测试孔取出100μl培养基以供IL-2分泌测量(Cisbio)。使用MLR中IL-2的抗体浓度依赖性分泌来得出抗PD-1抗体的抗PD-1活性的EC50(图10A-10C),并与全长PD-1抗体/> 的EC50值相比较(图10D)。MLR测定的EC50概述于图10E中。与基于FACS的配体竞争测定结果一致(图8A-8X),通过MLR,三种所选HCAb在靶向PD-1中的功能活性与单克隆抗体/>
的EC50值相比较(图10D)。MLR测定的EC50概述于图10E中。与基于FACS的配体竞争测定结果一致(图8A-8X),通过MLR,三种所选HCAb在靶向PD-1中的功能活性与单克隆抗体/> 相当。
相当。
实施例2:抗PD-1 sdAb人源化和表征
抗PD-1 sdAb的人源化
将AS15193 sdAb的蛋白质序列与具有最高同源程度的3个最接近的人类种系序列比对。选择最佳人类种系序列作为人类受体。建立同源性模型。根据模型分析数据,对抗原结合或抗体支架形成可能关键的残基保持不变,而选择其余残基以供转化为人类对应物。基于结合、稳定性和功能活性数据生成并选择三组序列优化变体。基于结合和解离速率排序数据选择四种变体(AS15193VH8、AS15193VH8M1、AS15193VH18和AS15193VH18M1)。将骆驼科亲本sdAb、人源化变体和人类受体序列在图11中进行比对。人源化sdAb在其名称中以“VH”指示。
实施例3:人源化HCAb构建、产生和表征
从在实施例2中使用BIAcore T200的上文解离排序研究(数据未示出)选择具有功能活性和慢解离速率的4种sdAb(AS15193VH8、AS15193VH8M1、AS15193VH18和AS15193VH18M1)以供HCAb构建和生产。将所选sdAb的DNA序列与人类IgG4 Fc(S228P)的DNA序列融合以制备人源化HCAb构建体。将HCAb构建体转染至CHO细胞中以供HCAb表达。通过蛋白A柱纯化条件培养基中分泌的HCAb。
通过表面等离子体共振(SPR)的人源化HCAb的亲和力测量
使用SPR生物传感器Biacore T200(GE Healthcare)确定抗PD-1人源化HCAb的结合动力学。通过Fc捕获方法将抗体固定在传感器芯片上,如实施例1中所提及。将抗原PD-1-His蛋白用作分析物(4种浓度的以3倍连续稀释的人类PD-1-His抗原(从1nM开始至27nM))。使用Biacore T200评估软件获得解离(kd)和缔合(ka)速率常数(图12A-12E)。根据kd与ka之比计算表观解离常数(KD)。数据概述于图12F中。根据数据,人源化HCAb(AS15193VH8_HCAb、AS15193VH8M1_HCAb、AS15193VH18_HCAb和AS15193VH18M1_HCAb)的结合亲和力接近其亲本HCAb(AS15193_HCAb),表明抗体亲和力在人源化后得以保持。
通过FACS分析的人源化HCAb与在细胞上表达的PD-1的结合
测试经纯化人源化抗PD-1 HCAb对CHO细胞上表达的PD-1的结合能力,如实施例1中所述。如图13A-13E可见,FACS结合测定说明各种人源化HCAb展现出与亲本AS15193_HCAb相当的结合能力。FACS结合EC50数据概述于图13F中。与上文结合亲和力结果一致,人源化HCAb(AS15193VH8_HCAb、AS15193VH8M1_HCAb、AS15193VH18_HCAb和AS15193VH18M1_HCAb)也显示出与其亲本AS15193_HCAb相当的结合能力。
通过FACS分析的配体结合的抑制
通过FACS分析测试经纯化人源化抗PD-1 HCAb抑制PD-1/PD-L1结合的能力,如实施例1中所述。如图14A-14E可见,竞争测定说明人源化抗PD-1 HCAb在低浓度(1-10μg/ml)下有效抑制PD-1/PD-L1相互作用的能力。并且根据FACS数据的IC50(图14F),4种人源化HCAb显示出与其亲本AS15193_HCAb相当的配体阻断活性。
基于PD-1的功能阻断测定
通过基于IL-2的荧光素酶报告基因测定研究4种人源化HCAb的PD-1抑制,如实施例1中所述。使用IL-2报告基因的抗体浓度依赖性活化来得出人源化抗PD-1 HCAb的抗PD-1活性的EC50值,并且与亲本AS15193_HCAb的EC50值相比较(图15A-15E)。与基于FACS的配体竞争测定结果一致,4种人源化HCAb的功能活性与其亲本AS15193_HCAb相当。数据概述于图15F中。
人源化HCAb的体内活性
在这里呈现的研究中,研究了PD-1人源化HCAb阻断对鼠科肿瘤模型的功效。提出抑制PD-1/PD-L1相互作用通过恢复抗肿瘤CD8+T细胞反应来发挥治疗作用,因此在同源鼠科肿瘤模型中进行临床前功效研究,其中宿主的免疫系统是完全完整的。使用人类PD-1转基因小鼠。
在该研究中,小鼠在右腰窝皮下接种1×106个人类PD-L1过表达MC38结肠癌细胞。当肿瘤达到约100mm3的平均体积时,将小鼠分成治疗组(n=5)(定义为研究第0天)。该研究中测试2种人源化抗PD-1 HCAb:AS15193VH8M1_HCAb和AS15193VH18M1_HCAb。各组每周两次静脉内施用基准抗体Keytruda(1mg/kg)或人源化HCAb(0.53mg/kg)达2周。2个对照组用1ml/kg PBS或1mg/kg人类IgG4同型对照处理。在研究持续时期内每周两次测量肿瘤。当与对照组相比较时,所有处理组都显示出显著的功效(P<0.050)(图27)。这些观测结果支持抗PD-1疗法作为驱动抗肿瘤CD8+T细胞反应的有效策略。
序列表
表3.抗PD-1 sdAb SEQ ID NO





SEQ ID NO:253(A31543 sdAb核酸序列)
CAGGTACAGCTGGTGGAGTCTGGGGGAGGCAAGGTGCAGCCTGGGGGGTCTCTGAGACTCTCCTGTGCAGCCTCTGGAGGCACTTTGGATTATTATGCCATAGGCTGGTTCCGCCAGGCCCCAGGGAAGGAGCGCGAGGCCGTGTCATGTATTAGTAGTAGCGATGGTAGCACATACTATGCAGACTCCGTGAAGGGCCGATTCACCATCTCCAGAGACAATGCCAAGAACACGGTGTATCTTCAAATGAACAGCCTGAAACCTGGGGACACGGCCGTTTATCACTGTGCGACAGATCGGGCGTGCGGTAGTAGCTGGTTAGGGGCCGAATCATGGGCCCAGGGGACCCAGGTCACCGTCTCCTCA
SEQ ID NO:254(AS06962 sdAb核酸序列)
CAGGTGCACCTGGTGGATTCTGGGGGAGGCTTGGTGCAGCCTGGGGGGTCTCTGAGACTCTCCTGTGCAGCCTCTGGAAGCATCACCAGTAGAAATACCATGGGCTGGTACCGGCAGGTTCCAGGGAAGCAGCGCGAATTGGTCGCGCTAATTGCGACTTTTGTCACACATTATGCGGACTCCGTGAAGGGCCGATTCACCATCTCCAGAGATAACGCCAGGAAGATGGTGTTTCTAGAGATGAACAGCCTGCAACCTGAGGACACGGGCGCGTATTATTGTTATGTCGATGTCTCGCCCTATTGGGGCCGGGGGACCCAGGTCACCGTCTCCTCA
SEQ ID NO:255(AS15090 sdAb核酸序列)
CAGGTGCAACTGGTGGAGTCTGGGGGAGGCTCGGTGCAGGCTGGAGGGTCTCTGAGACTCTCCTGTGCAGCCTCTGGATACACCTATATTCCCAACTGCATGGCCTGGTTCCGCCAGGCTCCAGGGAAGGAGCGCGAGGGGGTCACACTTATTTTTACTGGTGATGGTACCTCAACCTATGTCGACTCCGTGAAGGGCCGATTCACCATCTCCCAAGACAACGCCAAGAACACGGTGTATCTGCAAATGAACAGCCTGAAACCCGAGGACACTGCCTTGTACTACTGTGCGGCAGCCGAACGTTGTAGTGGTTCAAACGACAGAATATCCTTTTGGGGAATTAGCTACTGGGGCCAGGGGACCCAGGTCACCGTCTCCTCA
SEQ ID NO:256(AS15140 sdAb核酸序列)
CAGGTGCAACTGGTGGAGTCTGGGGGAGGCTCGGTGCAGGCTGGGGGGTCTTTGAGACTCTCCTGTACAGCCTCTGCATACACCTACAGTAACATCTGTTTGGGCTGGCTCCGCCAGGCTCCAGGGGGGGGGCTCGAGGCTGTCGCAACGATTTATATTGCGGATCAGACATCATACTATGCCGACTCCGTGAAGGGCCGATTCCGCATCTCTAAAGACGCCGCCAAGAACGCGGTGTATCTGCAAATGAGCAGCCTGAGACCTGAGGACACTGCCATGTACTACTGTGCGTCCCGGTACGGTAGTACCTGCGGCGAATATTTAGCTGACTATACCTCCCGGGCCCAGGGGACCCAGGTCACCGTCTCCTCA
SEQ ID NO:257(AS15152 sdAb核酸序列)
CAGATGCAGCTGGTGGAGTCTGGGGGAGGCTCGGTGCAGGCTGGAGGGTCTCTGAGACTCTCTTGTGCAGTCTCTGGATACATCTACAATCGCAACTTCATGGGCTGGTTCCGCCAGGCTCCCGGGAAGGAGCGCGAGGGGGTCGCGGCTATTTATACTGGTGGCCCATACACATACTATACCGACTCCGTGCAGGGCCGATTCACCATCTCCCAAGACAACACCAAGAACACGGTGTATCTGCAAATGAACAGCCTGAAACCTGAGGACACTGCCATGTATTACTGTGTGTCAGATCTTTCGGACGGTACTTGGGACCAGGGCCGATGGAACTACTGGGGCCAGGGGACCCAGGTCACCGTCTCCTCA
SEQ ID NO:258(AS15156 sdAb核酸序列)
CAGGTGCAACTGGTGGAGTCTGGGGGAGGCTCGGCGCAGGCTGGAGGGTCTCTGAGACTCTCCTGTGCAGTCTCTGGATACATTTACAATCGTAACTTCATGGGCTGGTTCCGCCAGGTTCCAGGAAAGGTGCGCGAGGGGGTCGCAGCAATTTATACTGGTACTGAACGCACGTACTATGCCGACTCCGTGAAGGGCCGATTCACCATCTCCCAAGACAACGCCAAGAACACGGTGTATCTGCAGATGAATAGTCTGAAACCTGAGGACACTGCCATGTACTACTGTGTGGCGGATTTGCGGGATGGTACTTGGGATACGGGCGTATGGAACACCTGGGGCCAGGGGACCCAGGTCACCGTCTCCTCA
SEQ ID NO:259(AS15193 sdAb核酸序列)
CAGATTCAGCTGGTGGAGTCTGGGGGAGGCTCGGCGCAGGCTGGAGGGTCTCTGAGACTCTCCTGTGTAGTCTCTGGAAACATCTACAATCGTAACTTCATGGGCTGGTTCCGCCAGGCTCCAGGGAAGGTGCGCGAGGGGGTCGCAGCAATTTATACTGGTACTAGTCGCACGTACTATGCCGACTCCGTGAAGGGCCGATTCACCATCTCCCAAGACAACGCCAAGAATACGGTGTATCTGCAAATGAATAGTCTGAAACCTGAGGACACTGCCATGTACTACTGTGCGGCGGATTTGCGGGATGGTTTCTGGGATACGGGCGTATGGAACACCTGGGGCCAGGGGACCCAGGTCACCGTCTCCTCA
SEQ ID NO:260(AS15872 sdAb核酸序列)
CAGGTGCAACTGGTGGAGTCTGGGGGAGGCTTGGTGCAGCCTGGGGGGTCTCTGACACTCTCCTGTGCAGCCTCTGGATTCACGTTCAGTACCGCCGCCATGAGCTGGGTCCGCCAGGTTCCAGAGGAGGGACTCGAGTGGGTCGCATCTATTGATAGTAGTGGTAGTCGCACATACTATGCGGGCTCCGTGAAGGGCCGATTCACCATCTCCAGAGACAACGCCAAGAACACGCTGTATTTGCAATTGAACAGCCTGAAAGCTGAGGACACGGCCATGTATTACTGTGCAAAAGATCACATGAGCTGGTTGCCGCGGGGCCAGGGGACCCAGGTCACCGTCTCCTCA
SEQ ID NO:261(AS15881 sdAb核酸序列)
CAGGTGCAACTGGTGGAGTCTGGGGGAGGATCGGTGCAGGCTGGAGGGTCTCTGAGACTCTCCTGTGCAGCCTCTGGATTCACCGACAGTTCGTACTGCGGGGCCTGGTTTCGCCAGGTTCCAGGGAAGGAGCGCGAGGGGGTCGCGATTATCGATAGATATGGTGGGACAATGTACAAAGACTCCGTGAAGGGCCGATTCACCATCTCCAAAGACACTGCCAAGAATATTCTGTATCTGCAAATGAACAGCCTGAAACTTGAGGACACTGCCATGTACTACTGTGCGGCAGCCGAATATCGAGGCTCTTCGTGTGACGCGGAGAGTGGCTACTGGGGCCAGGGGACCCAGGTCACCGTCTCCTCA
SEQ ID NO:262(AS15883 sdAb核酸序列)
CAGGTGCACCTGATGGAGTCTGGGGGAGGTTCGGTGCAGGCTGGAGGGTCCCTGACTCTCTCCTGTGCAGCCTCTGTATTCACCGACAGTAACTACTGCATGGCCTGGTTCCGCCAGGTTCCAGGGAAGGAGCGCGAGGGGGTCGCAATTATCGATAGATATGGTGGTACGATGTACAAAGACTCCGTGAAGGGCCGATTCACCATCTCCAAAGACACTGCCAAGAATATTCTGTATCTGCAAATGAACAGCCTGAAACTTGAGGACACTGCCATGTACTACTGTGCGGCAGCCGGGTATCGAGGCTCTTCGTGTGACGCGGATAGTGGCTACTGGGGCCAGGGGACCCAGGTCACCGTCTCCTCA
SEQ ID NO:263(AS15892 sdAb核酸序列)
CAGATTCAGCTGGTGGAGTCTGGGGGAGGATCGGTGCAGGCTGGAGGGTCTCTGAGACTCTCCTGTGCAGCCTCTGGATTCACCGACAGTTCGTACTGCGGGGCCTGGTTTCGCCAGGTTCCAGGGAAGGAGCGCGAGGGGGTCGCGATTATCGATAGATATGGTGGGACAATGTACAAAGACTCCGTGAAGGGCCGATTCACCATCTCCAAAGACACTGCCAAGAATATTCTGTATCTGCAAATGAACAGCCTGAAACTTGAGGACACTGCCATGTACTACTGTGCGGCAGCCGAATATCGAGGCTCTTCGTGTGACGCGGAGAGTGGCTACTGGGGCCAGGGGACCCAGGTCACCGTCTCCTCA
SEQ ID NO:264(AS15899 sdAb核酸序列)
CAGGTGCAACTGGTGGAGTCTGGGGGAGGCTCGGTGCAGGCTGGAGGGTCTCTGAGACTCTCCTGTGCAGCCTCTGGATACACCGCCGGTAGCCTCTGCATGGGCTGGTTCCGCCAGGCTCCAGGGAAGGAGCGCGAGGGGGTCGCAGCTATTTATACTGGTGGTGGTAGCACATACTATGCCGACTCCGTGAAGGGCCGATTCACCATCTCCCAAGACAACGCCAAGAACACGGTGTATCTGCAAATGAACAGCCTGAAACCTGAGGACACTGCCCAGTACTACTGCGGGGCGGGTAGTAGGGAAGACTACTGCGACAGGGGTTACATCTATGATCACTGGGGCCAGGGGACCCAGGTCACCGTCTCCTCA
SEQ ID NO:265(AS17049 sdAb核酸序列)
CAGGTGAAGTTAGTGGAGTCTGGGGGAGGCTCGGTGCAGGCTGGAGGGTACCTGAGACTCTCCTGTGCAGCCTCTGGAGACACCAACAACTTGAACTTCAGGGGCTGGTTCCGCCAGGCTCCAGGGAAGGAGCGCGAGGGGGTCGCAGTTATCACTCACTCTGGTAGCACATACTATGCCGAATCCGTGAAGGGCCGATTCACCATCTCCCAAGACCTCGCCAAGAACACGATGTATCTGCAAATGAACAGTCTGAAACCTGAGGACACTGCTATGTACTACTGTGCGGCAGCAGATGTGTGGCGTATTAGCTGGTCCTTTGTTCCGGAACTCTTTAGTTACTGGGGCCAGGGGACCCAGGTCACCGTCTCCTCA
SEQ ID NO:266(AS17118 sdAb核酸序列)
CAGGTGCAGCTGGTGGAGTCTGGGGGAGGCTCGGTGCAGGCTGGAGGGTCTCTGAGACTCTCTTGTGCAGGCTCTGGATTTACCTTCAATAACTACGCCATGGGCTGGTTCCGCCAGGCTCCAGGGAAGGAGCGCGAGGGAATCGCGGGAATTTGGACTGGTGGTGGTAGTACATACTATGCCGACTCCGTGAAGGGCCGATTCACCATCTCCGAAGACGTCGCCAAGAACACGGTGTATCTGCAAATGGACAGCCTGAAACCTGAGGACACTGCCATGTACTACTGTGCGGCCGAGCGCTGGGACTATAGCGACTGGCGACGCCTAAAGAGGGGGGACTATAACTACTGGGGCCAGGGGACCCAGGTCACCGTCTCCTCA
SEQ ID NO:267(AS24984 sdAb核酸序列)
CAGGTGCACCTGATGGAGTCTGGGGGAGGGTCGGTGCCGTCTGGAGGGTCTCTGAGACTCTCCTGTGCAGTCTCTGGATCTGGATACAGCTATAGTCGCGGCTGCTTCGCATGGTTCCAGCAGCGTCCAGGGAAGGAGCGCGAGGGGGTCGCAATTATTAATATGGATGGGCACACAAGATACTCAGACTCCGTGCAGGGCCGATTCATCATCTCCCAAGACAAGGCCAAGAACACACTACATCTGCAAATGAACACCCTGAGACCTGACGACACGGCCATGTATTACTGTGCGTACGATCGCAGTCAGTGTTACGTGCTAAGCGACCGCTTACGCCTCCCAGGTACCTTTAGTGACTGGGGCCAGGGGACCCAGGTCACCGTCTCCTCA
SEQ ID NO:268(AS25037 sdAb核酸序列)
GAGGTGCAACTGGCGGAGTCTGGGGGAGGCTCGGTGCAGGCTGGAGGGTCTCTGAAACTCTCCTGTTTAGCCTCGCAATGGATCAGTAGTGATTGCGGAATGGCCTGGTACCGCCAGGCTCCAGGGAAGGAGCGCGAATTGGTCTCACGCATTAGTAGTGATGATACCACAACCTATGCAGACTCCGTGAAGGGCCGATTCACCATCTCCCAAGACAGTGCCAAGAACACGCTGTATCTGCAAATGAACAAGCTGAAAACTGAAGACACGGGCGTGTATTATTGTGCGGCAGAAGCCAAGAGCACTATAACGAGCCTGTGCTACCCCTTGAACTACTGGGGCCAGGGGACCCAGGTCACCGTCTCCTCA
SEQ ID NO:269(AS25064 sdAb核酸序列)
CAGGTGCAGCTGGTGGAGTCTGGGGGAGGCTCCGTGCAGGCTGGAGGGTCTCTGAGACTCACCTGTGCAGCCACTGGATACTCTTGGAGACCCGACTGCATGGGCTGGTACCGCCAGGCTGCAGAGAAGGAGCGCGAGGGGGTCGCAGTTATTGATGCTGATGGTATCACAAGCTACGCAGACGCCGCGAAGGGCCGATTCACCATCTCCCGAGACAACAACAAGATCACTCTATATCTGCAAATGCTGAAACCTGACGACACTGGCATGTACGTCTGTGTGGTAGGATGGAGAGTAAGCAGTGGTGGTAACTGCCAATTCAATGACTACTGGGGTCAGGGGACCCAGGTCACCGTCTCCTCA
SEQ ID NO:270(AS25067 sdAb核酸序列)
CAGGTGCACCTGATGGAGTCTGGGGGAGGCGCGGTGCAGACCGGAGGGTCTCTGAGGCTCTCCTGTGCAGTATCGGGAATCTCCATCAGTCCAGACTGCATGGGCTGGTTCCGCCAGGCTCCAGGGAAGAAGCGCGAGGCGGTCACGACAATTTTTGCTAATACTGGTAGCGCGCGCTATGGCGACTCCGTGAAGGGCCGATTCACCAGCTCCCAAGGCAACGCCAAGAATACGCTGTATCTGCAAATGGACAGCGTGAAACTTGATGACACTGGCACGTACTACTGTGCGGCACGGTTTACGGGGGGTGACTGCTTTGATCATCAGCCATTGGCGTGGCGCTTCTGGGGCCAGGGGACCCAGGTCACCGTCTCCTCA
SEQ ID NO:271(AS25071 sdAb核酸序列)
GAGGTGCAACTGGCGGAGTCTGGGGGAGGGTCGGTGCAGTCTGGAGGGTCTCTGAGACTCTCCTGTGCAGTCTCTGGATCTGGATACAGCTATAGTCGCGGCTGCTTCGCGTGGTTCCAGCAGCGTCCAGGAAAGGAGCGCGAGGGGGTCGCAATTATTAATAGTGATGGGCACACAGCATACTCAGACTCCGTGCAGGGCCGATTCATCATCTCCCAAGACAAGGCCAAGAACACACTATATCTGCAAATGAACAGCCTGAAACCTGACGACACGGCCATGTATTACTGTGCGTACGATCGCAGTCAGTGTTACGTGCTTCGCGACCGCTTACGCCTCCCAGATACCTTTACTGACTGGGGCCAGGGGACCCAGGTCACCGTCTCCTCA
SEQ ID NO:272(AS25115 sdAb核酸序列)
CAGGTGCACCTGGTGGAGTCTGGGGGAGCCTCGGTGCAGGCTGGAGGGTCTCTGAGACTCTCCTGTGCAGCCACTGCGTACACCGCCAGTAATTATTGCATGGGCTGGTTCCGCCAGTCTCCAGGGAAGGAGCGCGAGGCAGTCGCAAGTATTAATGATGACGGCGTCACAAGCTACGCAGACTCCGTGAAGGGCCGATTCACCATCTCCCAAGACAGCGCCAAGAAGACTCTGTATCTCCAAATGAACCGCCTGAAACCTGAGGACACTGCCATGTACTACTGTGCGGCCACCCCGGATGGTTACTGCTACGCCGAGAGACTTTCCCGGTGGAGATATGAGTTCTGGGGCCAGGGGACCCAGGTCACCGTCTCCTCA
SEQ ID NO:273(AS25117 sdAb核酸序列)
GAGGTGCAGCTGGCGGAGTCTGGGGGAGGCTCGGTGCAGGCTGGAGGGTCTCTGAGGCTCTCCTGTGTAATATCAGGAACCTCCATCAGTCCAGACTGCATGGGCTGGTTCCGCCAGGCTCCAGGGAAGAAGCGCGAGGCAGTCATGAGTATTTTTACAAATACTGGTAGCACGCGCTATGGCGACTCCGTGAAGGGCCGATTCACCAGCTCCCAAGGCAACGCCAAGAATACGCTGTATCTGCAAATGGACAGCTTGAAACTTGATGACACTGCCACGTACTACTGTGCGGCCCGGTATACGGGGGGTGACTGCTTTAATCTTGAACCATTGGCGTGGCGCTTCTGGGGCCAGGGGACCCAGGTCACCGTCTCCTCA
SEQ ID NO:274(AS25119 sdAb核酸序列)
CAGGTTCAGCTGGTGGAGTCTGGGGGAGGCTCCGTGCAGGCTGGAGGGCCTCTGAGACTCACCTGTGCAGCCACTGGATACTCTTGGAGACCCGACTGCATGGGCTGGTACCGCCAGGCTGCAGAGAAGGAGCGCGAGGGGGTCGCAGTTATTGATGCTGATGGTATCACAAGTTACGCAGACGCCGCGAAGGGCCGATTCACCATCTCCCGAGACAACAACAACATCACTCTATATCTGCAAATGCTGAAACCTGACGACACTGGCATGTACGTCTGTGTGATAGGATGGAGAGTAAGCAGTGGTGGTAACTGCCAATTCAATGACTACTGGGGTCAGGGGACCCAGGTCACCGTCTCCTCA
SEQ ID NO:275(AS25149 sdAb核酸序列)
CAGGTTCAGCTGGTGGAGTCTGGGGGAGGGTCGGTGCAGTCTGGAGGGTCTCTGAAACTCTCCTGTGCAGTCTCTGGATCTGGATACAGCTATAGTCGCGGCTGCTTCGCATGGTTCCAACAGCGTCCAGGGAAGGAGCGCGAGGGGGTCGCAATTATTAATAGCGATGGACACACAAGATACTCAGACTCCGTGCAGGGCCGATTCATCATCTCCCAAGACAAGGCCAAGAACACACTATATCTCCAAATGAACAGCCTGAAACCTGACGACGCGGCCATGTATTACTGTGCGTACGATCGCAATCAGTGTTACGTTCTTCTCGACCGCTTACGCCTCCCAGGTACCTTTAGTGACTGGGGCCAGGGGACCCAGGTCACCGTCTCCTCA
SEQ ID NO:276(AS25164 sdAb核酸序列)
GAGGTGCAGCTGGTGGAGTCTGGGGGAGGGTCGGTGCAGTCTGGAGGGTCTCTGAGACTCTCCTGTGCAGTCTCTGGATCTGGATACAGCTATAATCGCGGCTGCTTCGCGTGGTTCCAGCAGCGTCCAGGGAAGGAGCGCGAGGGGGTCGCAATTATTAATAGCGATGGGCACACAACGTACGGAGACTCCGTGCAGGGCCGATTCATCATCTCCCAAGACAAGGCCAAGAACACACTAGATCTGCAAATGAACAGCCTGAAACCTGACGACACGGCCATGTATTACTGTGCGTACGATCGCAATCAGTGTTACGTGCTTCGCGACCGCTTACGCCTCCCAGATACCTTTACTGACTGGGGCCAGGGGACCCAGGTCACCGTCTCCTCA
SEQ ID NO:277(AS25170 sdAb核酸序列)
CAGGTGAAGTTGGTGGAGTCTGGGGGAGGGTTGGTGCAGTCTGGAGGGTCTCTGAGACTCTCCTGTGCAGTCTCTGGATCTGGATACAGCTATAGTCGCGGCTGCTTCGCATGGTTCCAGCAGCGTCCAGGGAAGGAGCGCGAGGGGGTCGCAATTATTAATATGGATGGGCACACAATGTACTCAGACTTGGCGCAGGGCCGATTCATCATCTCCCAAGACAAGGCCAAGAACACACTATATCTGCAAATGAACAGCCTGAAACCTGACGACACGGCCATGTATTACTGTGCGTACGATCGCGATCAGTGTTACGTACTTCGGGACCGCTTACGCCTCCCAGATACCTTTAATGACTGGGGCCAGGGGACCCAGGTCACCGTCTCCTCA
SEQ ID NO:278(AS25222 sdAb核酸序列)
CAGATTCAGCTGGTGGAGTCTGGGGGAGGCTCGGTGCAGGCTGGAGGGTCTCTGAGGCTCTCCTGTGCAGTGACAGGAATCTCCATCAGTCCAGACTGCATGGGCTGGTTCCGCCAGGCTCCAGGGAAGAAGCGCGAGGCAGTCGCGACTATTTTTACTAATACTGCGAGCACGCGCTATGGCGACTCCGTGAAGGGCCGATTCACCAGCTCCCAAGGGAACGGCAAGAATACGCTGTATCTGCAAATGGACAGCTTGAACGTTGATGACACTGCCACGTACTACTGTGCGGCCCGCTATACGGGGGGTAACTGCTTTAATCTTGAGCCATTGGCGTGGCACTTCTGGGGCCAGGGGACCCAGGTCACCGTCTCCTCA
SEQ ID NO:279(AS25396 sdAb核酸序列)
CAGGTGCACCTGATGGAGTCTGGGGGAGGCTCGGTGCAGGCTGGAGGGTCTCTGAGGCTCTCCTGTGTAGTATCAGGAATCTCCATCAGTCCAGACTGTATGGGGTGGTTCCGCCAGGCTCCAGGGAAGAAGCGCGAGGCAGTCGCGACTATTTTTACTAATACTCGTAGGACGCGCTATGGCGACTCCGTGAAGGGCCGAGTCACCAGCTCCCAAGGCAACGCCAAGAATACGCTGTATCTAAAAATGGACAACTTGAGGCACGATGACACTGCCACGTACTACTGTGCGGCCCGGTATACGGGGGGTGACTGCTTTAATCTTGACCCATTGTCCTGGCGCTTCTGGGGCCAGGGGACCCAGGTCACCGTCTCCTCA
SEQ ID NO:280(AS25457 sdAb核酸序列)
CAGGTGCAGCTGGTGGAGTCTGGGGGAGGCTCGGTGCAGGCTGGAGGGTCTCTGAGGCTCTCCTGTGCAGTATCAGGAATCTCCATCAGTCCAGACTGCATGGGCTGGTTCCGCCAGGCTCCAGGGAAGAAGCGCGAGGCAGTCGCGACTATTTTTACTAATACTCGTAGCACGCGCTATGGCGACTCCGTGAAGGGCCGATTCACCAGCTCCCAAGGCAACGCCAAGAATACGCTGTATCTGCAAATGGACAGCTTGAAACTTGATGACACTGCCACGTACTACTGTGCGGCCCGGTATACGGGGGGTGACTGCTTTAATCTTGAGCCTGTGGCGTGGCGCTTCTGGGGCCAGGGGACCCAGGTCACCGTCTCCTCA
SEQ ID NO:281(AS25487 sdAb核酸序列)
GAGGTGCAGCTGGTGGAGTCTGGGGGAGGCTTGGTGCAGCCTGGGGGGTCTCTGAGACTCTCCTGTGCAGCCTCTGGCTTCACCTTCAGTGTTTGGTCGATGTCCTGGGTCCGCCAGGCTCCAGGGGAGGGACTCGAGTGGGTCTCAACTATCACTGGGAGTGGCGCACAAACATATTATGCAAGCTCAGTGAGGGGCCGATTCACCACCTCCAGAGACAACGCCAAGAACACGGTATATCTGCAAATGAACAGCCTGAAATCTGACGACACGGCCGTGTATTATTGTGAGAGAGGAAATGGTCAGACTGCTATGGAGGCTCTCATTAACCCGCCCGAGCGTCCGGGGACCCAGGTCACCGTCTCCTCA
SEQ ID NO:282(AS25095 sdAb核酸序列)
CAGGTGCAGCTGGTGGAGTCTGGGGGAGGCTTGATGCAGCCTGGGGGGTCTTTGAGACTCTCCTGTGCAGCCTCTGGATTCACCTTCAGTAGTTACTGGATGTACTGGGTCCGCCAGGCTCCAGGGAAGGGGCTTGAGTGGGTCTCGGTTATTAATAGAGCTGGTGATTCCGCCTGGTATGCAGACTCAGTGACGGGCCGATTCACCATCTCCAGAGACAACGCCAAGAACACGGTGTATCTGCAAATGGACAGCCTGAAACCTGAGGACACGGCCATGTACTACTGTGCGGCAGACTCGAGGGGGTACGGTGGTGACTGGTACAAGCTCCTCTCAGACTTTAATTATTGCGGCCAGGGGACCCAGGTCACCGTCTCCTCA
SEQ ID NO:283(AS25435 sdAb核酸序列)
CAGGTGCAGCTGGTGGAGTCTGGGGGAGGCTCGGTGCAGGCTGGAGGGTCTCTGAGACTCTCCTGTGCAGCCACTGCGTACACCGCCAGTTTCTACTGCATGGGCTGGTTCCGCCAGGCTCCAGGGAAGGAGCGCGAGGCGGTCGCAAGTATTAATGATGACGGCGTCACAATGTACGCAGACTCCGTGAAGGGCCAATTCACCATCTCCCAAGACAGCGCCACGAAGACTCTGTATCTGCAAATGAACCGCCTGAAACCTGAGGACACCGCCATGTACTACTGTGCGGCCACCCCGGAAGGTTACTGCTACGCCGAGAGACTTTCCACGTGGAGATATACGTTCTGGGGCCAGGGGACCCAGGTCACCGTCTCCTCA
SEQ ID NO:284(AS25156 sdAb核酸序列)
GAGGTGCAGCTGGTGGAGTCTGGGGGAGGGTCGGTGCAGTCTGGAGGGTCTCTGAGACTCTCCTGTGCAGTCTCTGGATCTGGATACAGCTATAGTCGCGGCTGCTTCGCGTGGTTCCAGCAGCGTCCAGGAAAGGAGCGCGAGGGGGTCGCAATTATTAATAGCGATGGGCACACAAGATACTCAGACTCCGTGCAGGGCCGATTCATCATCTCCCAAGACAAGGCCAAGAACACACTATATCTGCAAATGAACAGCCTGAAACCTGACGACACGGCCATGTATTACTGTGCGTACGATTGCAGTCAGTGTTACGTGCTTCGCGACCGCTTACGCCTCCCAGATACCTTTACTGACTGGGGCCAGGGGACCCAGGTCACCGTCTCCTCA
SEQ ID NO:285(AS15193VH8 sdAb核酸序列)
GAGGTGCAGCTGGTGGAGAGCGGAGGAGGACTGGTGCAGCCAGGAGGCTCTCTGAGACTGTCCTGCGCCGTGAGCGGCAACATCTACAACAGAAATTTCATGGGATGGTTTAGGCAGGCTCCTGGCAAGGGACTGGAGGGCGTGTCCGCCATCTATACCGGCACATCTCGCACCTACTATGCTGACTCCGTGAAGGGCAGGTTCACCATCTCTCGGGATAACTCCAAGAATACAGTGTACCTGCAGATGAACTCTCTGAGGGCCGAGGACACAGCCGTGTACTATTGTGCCGCTGACCTGCGGGATGGCTTTTGGGATACCGGCGTGTGGAATACATGGGGCCAGGGCACCCTGGTGACAGTGTCCAGC
SEQ ID NO:286(AS15193VH8M1 sdAb核酸序列)
GAGGTGCAGCTGGTGGAGAGCGGAGGAGGACTGGTGCAGCCAGGAGGCTCTCTGAGACTGTCCTGCGCCGTGAGCGGCAACATCTACAACAGAAATTTCATGGGATGGTTTAGGCAGGCTCCTGGCAAGGGACTGGAGGGCGTGTCCGCCATCTATACCGGCACATCTCGCACCTACTATGCTGACTCCGTGAAGGGCAGGTTCACCATCTCTCGGGATAACTCCAAGAATACAGTGTACCTGCAGATGAACTCTCTGAGGGCCGAGGACACAGCCGTGTACTATTGTGCCGCTGACCTGCGGGAGGGCTTTTGGGATACCGGCGTGTGGAATACATGGGGCCAGGGCACCCTGGTGACAGTGTCCAGC
SEQ ID NO:287(AS15193VH18 sdAb核酸序列)
GAGGTGCAGCTGGTGGAGTCCGGAGGAGGACTGGTGCAGCCAGGAGGCTCTCTGAGGCTGTCCTGCGCCGTGAGCGGAAACATCTACAACAGAAATTTCATGGGATGGTTTAGGCAGGCTCCTGGCAAGGGAAGGGAGGGCGTGTCTGCTATCTATACCGGCACATCCAGGACCTACTATGCCGACAGCGTGAAGGGCAGGTTCACCATCTCTCGGGATAACGCTAAGAATACAGTGTACCTGCAGATGAACTCCCTGCGGCCAGAGGACACAGCCGTGTACTATTGTGCCGCTGACCTGAGAGATGGCTTTTGGGATACCGGCGTGTGGAATACATGGGGCCAGGGCACCCTGGTGACAGTGTCCAGC
SEQ ID NO:288(AS15193VH18M1 sdAb核酸序列)
GAGGTGCAGCTGGTGGAGTCCGGAGGAGGACTGGTGCAGCCAGGAGGCTCTCTGAGGCTGTCCTGCGCCGTGAGCGGAAACATCTACAACAGAAATTTCATGGGATGGTTTAGGCAGGCTCCTGGCAAGGGAAGGGAGGGCGTGTCTGCTATCTATACCGGCACATCCAGGACCTACTATGCCGACAGCGTGAAGGGCAGGTTCACCATCTCTCGGGATAACGCTAAGAATACAGTGTACCTGCAGATGAACTCCCTGCGGCCAGAGGACACAGCCGTGTACTATTGTGCCGCTGACCTGAGAGAGGGCTTTTGGGATACCGGCGTGTGGAATACATGGGGCCAGGGCACCCTGGTGACAGTGTCCAGC
SEQ ID NO:289(A31543 sdAb氨基酸序列;CDR加下划线)
QVQLVESGGGKVQPGGSLRLSCAASGGTLDYYAIGWFRQAPGKEREAVSCISSSDGSTYYADSVKGRFTISRDNAKNTVYLQMNSLKPGDTAVYHCATDRACGSSWLGAESWAQGTQVTVSS
SEQ ID NO:290(AS06962 sdAb氨基酸序列;CDR加下划线)
QVHLVDSGGGLVQPGGSLRLSCAASGSITSRNTMGWYRQVPGKQRELVALIATFVTHYADSVKGRFTISRDNARKMVFLEMNSLQPEDTGAYYCYVDVSPYWGRGTQVTVSS
SEQ ID NO:291(AS15090 sdAb氨基酸序列;CDR加下划线)
QVQLVESGGGSVQAGGSLRLSCAASGYTYIPNCMAWFRQAPGKEREGVTLIFTGDGTSTYVDSVKGRFTISQDNAKNTVYLQMNSLKPEDTALYYCAAAERCSGSNDRISFWGISYWGQGTQVTVSS
SEQ ID NO:292(AS15140 sdAb氨基酸序列;CDR加下划线)
QVQLVESGGGSVQAGGSLRLSCTASAYTYSNICLGWLRQAPGGGLEAVATIYIADQTSYYADSVKGRFRISKDAAKNAVYLQMSSLRPEDTAMYYCASRYGSTCGEYLADYTSRAQGTQVTVSS
SEQ ID NO:293(AS15152 sdAb氨基酸序列;CDR加下划线)
QMQLVESGGGSVQAGGSLRLSCAVSGYIYNRNFMGWFRQAPGKEREGVAAIYTGGPYTYYTDSVQGRFTISQDNTKNTVYLQMNSLKPEDTAMYYCVSDLSDGTWDQGRWNYWGQGTQVTVSS
SEQ ID NO:294(AS15156 sdAb氨基酸序列;CDR加下划线)
QVQLVESGGGSAQAGGSLRLSCAVSGYIYNRNFMGWFRQVPGKVREGVAAIYTGTERTYYADSVKGRFTISQDNAKNTVYLQMNSLKPEDTAMYYCVADLRDGTWDTGVWNTWGQGTQVTVSS
SEQ ID NO:295(AS15193 sdAb氨基酸序列;CDR加下划线)
QIQLVESGGGSAQAGGSLRLSCVVSGNIYNRNFMGWFRQAPGKVREGVAAIYTGTSRTYYADSVKGRFTISQDNAKNTVYLQMNSLKPEDTAMYYCAADLRDGFWDTGVWNTWGQGTQVTVSS
SEQ ID NO:296(AS15872 sdAb氨基酸序列;CDR加下划线)
QVQLVESGGGLVQPGGSLTLSCAASGFTFSTAAMSWVRQVPEEGLEWVASIDSSGSRTYYAGSVKGRFTISRDNAKNTLYLQLNSLKAEDTAMYYCAKDHMSWLPRGQGTQVTVSS
SEQ ID NO:297(AS15881 sdAb氨基酸序列;CDR加下划线)
QVQLVESGGGSVQAGGSLRLSCAASGFTDSSYCGAWFRQVPGKEREGVAIIDRYGGTMYKDSVKGRFTISKDTAKNILYLQMNSLKLEDTAMYYCAAAEYRGSSCDAESGYWGQGTQVTVSS
SEQ ID NO:298(AS15883 sdAb氨基酸序列;CDR加下划线)
QVHLMESGGGSVQAGGSLTLSCAASVFTDSNYCMAWFRQVPGKEREGVAIIDRYGGTMYKDSVKGRFTISKDTAKNILYLQMNSLKLEDTAMYYCAAAGYRGSSCDADSGYWGQGTQVTVSS
SEQ ID NO:299(AS15892 sdAb氨基酸序列;CDR加下划线)
QIQLVESGGGSVQAGGSLRLSCAASGFTDSSYCGAWFRQVPGKEREGVAIIDRYGGTMYKDSVKGRFTISKDTAKNILYLQMNSLKLEDTAMYYCAAAEYRGSSCDAESGYWGQGTQVTVSS
SEQ ID NO:300(AS15899 sdAb氨基酸序列;CDR加下划线)
QVQLVESGGGSVQAGGSLRLSCAASGYTAGSLCMGWFRQAPGKEREGVAAIYTGGGSTYYADSVKGRFTISQDNAKNTVYLQMNSLKPEDTAQYYCGAGSREDYCDRGYIYDHWGQGTQVTVSS
SEQ ID NO:301(AS17049 sdAb氨基酸序列;CDR加下划线)
QVKLVESGGGSVQAGGYLRLSCAASGDTNNLNFRGWFRQAPGKEREGVAVITHSGSTYYAESVKGRFTISQDLAKNTMYLQMNSLKPEDTAMYYCAAADVWRISWSFVPELFSYWGQGTQVTVSS
SEQ ID NO:302(AS17118 sdAb氨基酸序列;CDR加下划线)
QVQLVESGGGSVQAGGSLRLSCAGSGFTFNNYAMGWFRQAPGKEREGIAGIWTGGGSTYYADSVKGRFTISEDVAKNTVYLQMDSLKPEDTAMYYCAAERWDYSDWRRLKRGDYNYWGQGTQVTVSS
SEQ ID NO:303(AS24984 sdAb氨基酸序列;CDR加下划线)
QVHLMESGGGSVPSGGSLRLSCAVSGSGYSYSRGCFAWFQQRPGKEREGVAIINMDGHTRYSDSVQGRFIISQDKAKNTLHLQMNTLRPDDTAMYYCAYDRSQCYVLSDRLRLPGTFSDWGQGTQVTVSS
SEQ ID NO:304(AS25037 sdAb氨基酸序列;CDR加下划线)
EVQLAESGGGSVQAGGSLKLSCLASQWISSDCGMAWYRQAPGKERELVSRISSDDTTTYADSVKGRFTISQDSAKNTLYLQMNKLKTEDTGVYYCAAEAKSTITSLCYPLNYWGQGTQVTVSS
SEQ ID NO:305(AS25064 sdAb氨基酸序列;CDR加下划线)
QVQLVESGGGSVQAGGSLRLTCAATGYSWRPDCMGWYRQAAEKEREGVAVIDADGITSYADAAKGRFTISRDNNKITLYLQMLKPDDTGMYVCVVGWRVSSGGNCQFNDYWGQGTQVTVSS
SEQ ID NO:306(AS25067 sdAb氨基酸序列;CDR加下划线)
QVHLMESGGGAVQTGGSLRLSCAVSGISISPDCMGWFRQAPGKKREAVTTIFANTGSARYGDSVKGRFTSSQGNAKNTLYLQMDSVKLDDTGTYYCAARFTGGDCFDHQPLAWRFWGQGTQVTVSS
SEQ ID NO:307(AS25071 sdAb氨基酸序列;CDR加下划线)
EVQLAESGGGSVQSGGSLRLSCAVSGSGYSYSRGCFAWFQQRPGKEREGVAIINSDGHTAYSDSVQGRFIISQDKAKNTLYLQMNSLKPDDTAMYYCAYDRSQCYVLRDRLRLPDTFTDWGQGTQVTVSS
SEQ ID NO:308(AS25115 sdAb氨基酸序列;CDR加下划线)
QVHLVESGGASVQAGGSLRLSCAATAYTASNYCMGWFRQSPGKEREAVASINDDGVTSYADSVKGRFTISQDSAKKTLYLQMNRLKPEDTAMYYCAATPDGYCYAERLSRWRYEFWGQGTQVTVSS
SEQ ID NO:309(AS25117 sdAb氨基酸序列;CDR加下划线)
EVQLAESGGGSVQAGGSLRLSCVISGTSISPDCMGWFRQAPGKKREAVMSIFTNTGSTRYGDSVKGRFTSSQGNAKNTLYLQMDSLKLDDTATYYCAARYTGGDCFNLEPLAWRFWGQGTQVTVSS
SEQ ID NO:310(AS25119 sdAb氨基酸序列;CDR加下划线)
QVQLVESGGGSVQAGGPLRLTCAATGYSWRPDCMGWYRQAAEKEREGVAVIDADGITSYADAAKGRFTISRDNNNITLYLQMLKPDDTGMYVCVIGWRVSSGGNCQFNDYWGQGTQVTVSS
SEQ ID NO:311(AS25149 sdAb氨基酸序列;CDR加下划线)
QVQLVESGGGSVQSGGSLKLSCAVSGSGYSYSRGCFAWFQQRPGKEREGVAIINSDGHTRYSDSVQGRFIISQDKAKNTLYLQMNSLKPDDAAMYYCAYDRNQCYVLLDRLRLPGTFSDWGQGTQVTVSS
SEQ ID NO:312(AS25156 sdAb氨基酸序列;CDR加下划线)
EVQLVESGGGSVQSGGSLRLSCAVSGSGYSYSRGCFAWFQQRPGKEREGVAIINSDGHTRYSDSVQGRFIISQDKAKNTLYLQMNSLKPDDTAMYYCAYDCSQCYVLRDRLRLPDTFTDWGQGTQVTVSS
SEQ ID NO:313(AS25164 sdAb氨基酸序列;CDR加下划线)
EVQLVESGGGSVQSGGSLRLSCAVSGSGYSYNRGCFAWFQQRPGKEREGVAIINSDGHTTYGDSVQGRFIISQDKAKNTLDLQMNSLKPDDTAMYYCAYDRNQCYVLRDRLRLPDTFTDWGQGTQVTVSS
SEQ ID NO:314(AS25170 sdAb氨基酸序列;CDR加下划线)
QVKLVESGGGLVQSGGSLRLSCAVSGSGYSYSRGCFAWFQQRPGKEREGVAIINMDGHTMYSDLAQGRFIISQDKAKNTLYLQMNSLKPDDTAMYYCAYDRDQCYVLRDRLRLPDTFNDWGQGTQVTVSS
SEQ ID NO:315(AS25222 sdAb氨基酸序列;CDR加下划线)
QIQLVESGGGSVQAGGSLRLSCAVTGISISPDCMGWFRQAPGKKREAVATIFTNTASTRYGDSVKGRFTSSQGNGKNTLYLQMDSLNVDDTATYYCAARYTGGNCFNLEPLAWHFWGQGTQVTVSS
SEQ ID NO:316(AS25396 sdAb氨基酸序列;CDR加下划线)
QVHLMESGGGSVQAGGSLRLSCVVSGISISPDCMGWFRQAPGKKREAVATIFTNTRRTRYGDSVKGRVTSSQGNAKNTLYLKMDNLRHDDTATYYCAARYTGGDCFNLDPLSWRFWGQGTQVTVSS
SEQ ID NO:317(AS25457 sdAb氨基酸序列;CDR加下划线)
QVQLVESGGGSVQAGGSLRLSCAVSGISISPDCMGWFRQAPGKKREAVATIFTNTRSTRYGDSVKGRFTSSQGNAKNTLYLQMDSLKLDDTATYYCAARYTGGDCFNLEPVAWRFWGQGTQVTVSS
SEQ ID NO:318(AS25487 sdAb氨基酸序列;CDR加下划线)
EVQLVESGGGLVQPGGSLRLSCAASGFTFSVWSMSWVRQAPGEGLEWVSTITGSGAQTYYASSVRGRFTTSRDNAKNTVYLQMNSLKSDDTAVYYCERGNGQTAMEALINPPERPGTQVTVSS
SEQ ID NO:319(AS25095 sdAb氨基酸序列;CDR加下划线)
QVQLVESGGGLMQPGGSLRLSCAASGFTFSSYWMYWVRQAPGKGLEWVSVINRAGDSAWYADSVTGRFTISRDNAKNTVYLQMDSLKPEDTAMYYCAADSRGYGGDWYKLLSDFNYCGQGTQVTVSS
SEQ ID NO:320(AS25435 sdAb氨基酸序列;CDR加下划线)
QVQLVESGGGSVQAGGSLRLSCAATAYTASFYCMGWFRQAPGKEREAVASINDDGVTMYADSVKGQFTISQDSATKTLYLQMNRLKPEDTAMYYCAATPEGYCYAERLSTWRYTFWGQGTQVTVSS
SEQ ID NO:321(AS15193VH8 sdAb氨基酸序列;CDR加下划线)
EVQLVESGGGLVQPGGSLRLSCAVSGNIYNRNFMGWFRQAPGKGLEGVSAIYTGTSRTYYADSVKGRFTISRDNSKNTVYLQMNSLRAEDTAVYYCAADLRDGFWDTGVWNTWGQGTLVTVSS
SEQ ID NO:322(AS15193VH8M1 sdAb氨基酸序列;CDR加下划线)
EVQLVESGGGLVQPGGSLRLSCAVSGNIYNRNFMGWFRQAPGKGLEGVSAIYTGTSRTYYADSVKGRFTISRDNSKNTVYLQMNSLRAEDTAVYYCAADLREGFWDTGVWNTWGQGTLVTVSS
SEQ ID NO:323(AS15193VH18 sdAb氨基酸序列;CDR加下划线)
EVQLVESGGGLVQPGGSLRLSCAVSGNIYNRNFMGWFRQAPGKGREGVSAIYTGTSRTYYADSVKGRFTISRDNAKNTVYLQMNSLRPEDTAVYYCAADLRDGFWDTGVWNTWGQGTLVTVSS
SEQ ID NO:324(AS15193VH18M1 sdAb氨基酸序列;CDR加下划线)
EVQLVESGGGLVQPGGSLRLSCAVSGNIYNRNFMGWFRQAPGKGREGVSAIYTGTSRTYYADSVKGRFTISRDNAKNTVYLQMNSLRPEDTAVYYCAADLREGFWDTGVWNTWGQGTLVTVSS
SEQ ID NO:325(A31543 HCAb氨基酸序列;CDR加下划线,接头以粗体表示)

SEQ ID NO:326(AS06962 HCAb氨基酸序列;CDR加下划线,接头以粗体表示)

SEQ ID NO:327(AS15090 HCAb氨基酸序列;CDR加下划线,接头以粗体表示)

SEQ ID NO:328(AS15140 HCAb氨基酸序列;CDR加下划线,接头以粗体表示)


SEQ ID NO:329(AS15152 HCAb氨基酸序列;CDR加下划线,接头以粗体表示)

SEQ ID NO:330(AS15156 HCAb氨基酸序列;CDR加下划线,接头以粗体表示)

SEQ ID NO:331(AS15193 HCAb氨基酸序列;CDR加下划线,接头以粗体表示)


SEQ ID NO:332(AS15872 HCAb氨基酸序列;CDR加下划线,接头以粗体表示)

SEQ ID NO:333(AS15881 HCAb氨基酸序列;CDR加下划线,接头以粗体表示)

SEQ ID NO:334(AS15883 HCAb氨基酸序列;CDR加下划线,接头以粗体表示)

SEQ ID NO:335(AS15892 HCAb氨基酸序列;CDR加下划线,接头以粗体表示)

SEQ ID NO:336(AS15899 HCAb氨基酸序列;CDR加下划线,接头以粗体表示)


SEQ ID NO:337(AS17049 HCAb氨基酸序列;CDR加下划线,接头以粗体表示)

SEQ ID NO:338(AS17118 HCAb氨基酸序列;CDR加下划线,接头以粗体表示)

SEQ ID NO:339(AS24984 HCAb氨基酸序列;CDR加下划线,接头以粗体表示)

SEQ ID NO:340(AS25037 HCAb氨基酸序列;CDR加下划线,接头以粗体表示)

SEQ ID NO:341(AS25064 HCAb氨基酸序列;CDR加下划线,接头以粗体表示)


SEQ ID NO:342(AS25067 HCAb氨基酸序列;CDR加下划线,接头以粗体表示)

SEQ ID NO:343(AS25071 HCAb氨基酸序列;CDR加下划线,接头以粗体表示)

SEQ ID NO:344(AS25115 HCAb氨基酸序列;CDR加下划线,接头以粗体表示)

SEQ ID NO:345(AS25117 HCAb氨基酸序列;CDR加下划线,接头以粗体表示)

SEQ ID NO:346(AS25119 HCAb氨基酸序列;CDR加下划线,接头以粗体表示)


SEQ ID NO:347(AS25149 HCAb氨基酸序列;CDR加下划线,接头以粗体表示)

SEQ ID NO:348(AS25156 HCAb氨基酸序列;CDR加下划线,接头以粗体表示)

SEQ ID NO:349(AS25164 HCAb氨基酸序列;CDR加下划线,接头以粗体表示)

SEQ ID NO:350(AS25170 HCAb氨基酸序列;CDR加下划线,接头以粗体表示)

SEQ ID NO:351(AS25222 HCAb氨基酸序列;CDR加下划线,接头以粗体表示)


SEQ ID NO:352(AS25396 HCAb氨基酸序列;CDR加下划线,接头以粗体表示)

SEQ ID NO:353(AS25457 HCAb氨基酸序列;CDR加下划线,接头以粗体表示)

SEQ ID NO:354(AS25487 HCAb氨基酸序列;CDR加下划线,接头以粗体表示)

SEQ ID NO:355(AS25095 HCAb氨基酸序列;CDR加下划线,接头以粗体表示)

SEQ ID NO:356(AS25435 HCAb氨基酸序列;CDR加下划线,接头以粗体表示)


SEQ ID NO:357(AS15193VH8 HCAb氨基酸序列;CDR加下划线,接头以粗体表示)

SEQ ID NO:358(AS15193VH8M1 HCAb氨基酸序列;CDR加下划线,接头以粗体表示)

SEQ ID NO:359(AS15193VH18 HCAb氨基酸序列;CDR加下划线,接头以粗体表示)


SEQ ID NO:360(AS15193VH18M1 HCAb氨基酸序列;CDR加下划线,接头以粗体表示)

SEQ ID NO:361(人类PD-1氨基酸序列,不包括前导肽)
PGWFLDSPDRPWNPPTFSPALLVVTEGDNATFTCSFSNTSESFVLNWYRMSPSNQTDKLAAFPEDRSQPGQDCRFRVTQLPNGRDFHMSVVRARRNDSGTYLCGAISLAPKAQIKESLRAELRVTERRAEVPTAHPSPSPRPAGQFQTLVVGVVGGLLGSLVLLVWVLAVICSRAARGTIGARRTGQPLKEDPSAVPVFSVDYGELDFQWREKTPEPPVPCVPEQTEYATIVFPSGMGTSSPARRGSADGPRSAQPLRPEDGHCSWPL
SEQ ID NO:362(人类PD-1氨基酸序列的细胞外域)
PGWFLDSPDRPWNPPTFSPALLVVTEGDNATFTCSFSNTSESFVLNWYRMSPSNQTDKLAAFPEDRSQPGQDCRFRVTQLPNGRDFHMSVVRARRNDSGTYLCGAISLAPKAQIKESLRAELRVTERRAEVPTAHPSPSPRPAGQFQTLV
SEQ ID NO:363(IgG4 Fc氨基酸序列)
APEFLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSQEDPEVQFNWYVDGVEVHNAKTKPREEQFNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKGLPSSIEKTISKAKGQPREPQVYTLPPSQEEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSRLTVDKSRWQEGNVFSCSVMHEALHNHYTQKSLSLSLGK
SEQ ID NO:364(IgG1惰性Fc氨基酸序列)
APELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYASTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK
SEQ ID NO:365(IgG1 Fc氨基酸序列)
APELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK
SEQ ID NO:366(人类受体氨基酸序列)
QVQLVESGGGVVQPGGSLRLSCAASGFTFSSYGMHWVRQAPGKGLEWVSVIYSGGSSTYYADSVKGRFTISRDNSKNTLYLQMNSLRAEDTAVYYCAK
SEQ ID NO:367(人类IgG4(hIgG4)铰链氨基酸序列)
ESKYGPPCPPCP
SEQ ID NO:368(经突变人类IgG1(hIgG1)铰链氨基酸序列)
EPKSSDKTHTSPPSP
SEQ ID NO:369(人类IgG1(hIgG1)铰链氨基酸序列)
EPKSCDKTHTCPPCP
SEQ ID NO:370(连接肽(9GS)氨基酸序列)
GGGGSGGGS
SEQ ID NO:371(连接肽氨基酸序列)
GGGGSGGGGSGGGGS
SEQ ID NO:372(连接肽氨基酸序列,n是至少1的整数)
(G)n
SEQ ID NO:373(连接肽氨基酸序列,n是至少1的整数)
(GS)n
SEQ ID NO:374(连接肽氨基酸序列,n是至少1的整数)
(GSGGS)n
SEQ ID NO:375(连接肽氨基酸序列,n是至少1的整数)
(GGGS)n
SEQ ID NO:376(连接肽氨基酸序列,n是至少1的整数)
(GGGGS)n
SEQ ID NO:377(抗TIGIT mAb替拉古单抗重链氨基酸序列)
EVQLQQSGPGLVKPSQTLSLTCAISGDSVSSNSAAWNWIRQSPSRGLEWLGKTYYRFKWYSDYAVSVKGRITINPDTSKNQFSLQLNSVTPEDTAVFYCTRESTTYDLLAGPFDYWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK
SEQ ID NO:378(抗TIGIT mAb替拉古单抗轻链氨基酸序列)
DIVMTQSPDSLAVSLGERATINCKSSQTVLYSSNNKKYLAWYQQKPGQPPNLLIYWASTRESGVPDRESGSGSGTDFTLTISSLQAEDVAVYYCQQYYSTPFTFGPGTKVEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC
SEQ ID NO:379(抗LAG-3mAb瑞拉里单抗重链氨基酸序列)
QVQLQQWGAGLLKPSETLSLTCAVYGGSFSDYYWNWIRQPPGKGLEWIGEINHRGSTNSNPSLKSRVTLSLDTSKNQFSLKLRSVTAADTAVYYCAFGYSDYEYNWFDPWGQGTLVTVSSASTKGPSVFPLAPCSRSTSESTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTKTYTCNVDHKPSNTKVDKRVESKYGPPCPPCPAPEFLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSQEDPEVQFNWYVDGVEVHNAKTKPREEQFNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKGLPSSIEKTISKAKGQPREPQVYTLPPSQEEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSRLTVDKSRWQEGNVFSCSVMHEALHNHYTQKSLSLSLG
SEQ ID NO:380(抗LAG-3mAb瑞拉里单抗轻链氨基酸序列)
EIVLTQSPATLSLSPGERATLSCRASQSISSYLAWYQQKPGQAPRLLIYDASNRATGIPARFSGSGSGTDFTLTISSLEPEDFAVYYCQQRSNWPLTFGQGTNLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC
SEQ ID NO:381(抗TIM-3mAb MBG453重链氨基酸序列)
QVQLVQSGAEVKKPGASVKVSCKASGYTFTSYNMHWVRQAPGQGLEWIGDIYPGQGDTSYNQKFKGRATMTADKSTSTVYMELSSLRSEDTAVYYCARVGGAFPMDYWGQGTLVTVSSASTKGPSVFPLAPCSRSTSESTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTKTYTCNVDHKPSNTKVDKRVESKYGPPCPPCPAPEFLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSQEDPEVQFNWYVDGVEVHNAKTKPREEQFNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKGLPSSIEKTISKAKGQPREPQVYTLPPSQEEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSRLTVDKSRWQEGNVFSCSVMHEALHNHYTQKSLSLSLGK
SEQ ID NO:382(抗TIM-3mAb MBG453轻链氨基酸序列)
DIVLTQSPDSLAVSLGERATINCRASESVEYYGTSLMQWYQQKPGQPPKLLIYAASNVESGVPDRFSGSGSGTDFTLTISSLQAEDVAVYYCQQSRKDPSTFGGGTKVEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC
SEQ ID NO:383(抗CTLA-4mAb伊匹单抗重链氨基酸序列)
QVQLVESGGGVVQPGRSLRLSCAASGFTFSSYTMHWVRQAPGKGLEWVTFISYDGNNKYYADSVKGRFTISRDNSKNTLYLQMNSLRAEDTAIYYCARTGWLGPFDYWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKRVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK
SEQ ID NO:384(抗CTLA-4mAb伊匹单抗轻链氨基酸序列)
EIVLTQSPGTLSLSPGERATLSCRASQSVGSSYLAWYQQKPGQAPRLLIYGAFSRATGIPDRFSGSGSGTDFTLTISRLEPEDFAVYYCQQYGSSPWTFGQGTKVEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC
SEQ ID NO:385(抗PD-1mAb派姆单抗(IgG4 S228P)重链氨基酸序列)
QVQLVQSGVEVKKPGASVKVSCKASGYTFTNYYMYWVRQAPGQGLEWMGGINPSNGGTNFNEKFKNRVTLTTDSSTTTAYMELKSLQFDDTAVYYCARRDYRFDMGFDYWGQGTTVTVSSASTKGPSVFPLAPCSRSTSESTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTKTYTCNVDHKPSNTKVDKRVESKYGPPCPPCPAPEFLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSQEDPEVQFNWYVDGVEVHNAKTKPREEQFNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKGLPSSIEKTISKAKGQPREPQVYTLPPSQEEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSRLTVDKSRWQEGNVFSCSVMHEALHNHYTQKSLSLSLGK
SEQ ID NO:386(抗PD-1mAb派姆单抗(IgG4 S228P)轻链氨基酸序列)
EIVLTQSPATLSLSPGERATLSCRASKGVSTSGYSYLHWYQQKPGQAPRLLIYLASYLESGVPARFSGSGSGTDFTLTISSLEPEDFAVYYCQHSRDLPLTFGGGTKVEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC
序列表
<110> 南京传奇生物科技有限公司(Nanjing Legend Biotech Co., Ltd.)
<120> 针对PD-1的单域抗体和其变体
<130> 761422000840
<140> 尚未分配
<141> 同时随同提交
<160> 386
<170> FastSEQ for Windows Version 4.0
<210> 1
<211> 25
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 1
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Lys Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser
20 25
<210> 2
<211> 25
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 2
Gln Val His Leu Val Asp Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser
20 25
<210> 3
<211> 25
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 3
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Ser Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser
20 25
<210> 4
<211> 25
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 4
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Ser Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Thr Ala Ser
20 25
<210> 5
<211> 25
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 5
Gln Met Gln Leu Val Glu Ser Gly Gly Gly Ser Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Val Ser
20 25
<210> 6
<211> 25
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 6
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Ser Ala Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Val Ser
20 25
<210> 7
<211> 25
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 7
Gln Ile Gln Leu Val Glu Ser Gly Gly Gly Ser Ala Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Val Val Ser
20 25
<210> 8
<211> 25
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 8
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Thr Leu Ser Cys Ala Ala Ser
20 25
<210> 9
<211> 25
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 9
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Ser Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser
20 25
<210> 10
<211> 25
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 10
Gln Val His Leu Met Glu Ser Gly Gly Gly Ser Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Thr Leu Ser Cys Ala Ala Ser
20 25
<210> 11
<211> 25
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 11
Gln Ile Gln Leu Val Glu Ser Gly Gly Gly Ser Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser
20 25
<210> 12
<211> 25
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 12
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Ser Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser
20 25
<210> 13
<211> 25
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 13
Gln Val Lys Leu Val Glu Ser Gly Gly Gly Ser Val Gln Ala Gly Gly
1 5 10 15
Tyr Leu Arg Leu Ser Cys Ala Ala Ser
20 25
<210> 14
<211> 25
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 14
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Ser Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Gly Ser
20 25
<210> 15
<211> 25
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 15
Gln Val His Leu Met Glu Ser Gly Gly Gly Ser Val Pro Ser Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Val Ser
20 25
<210> 16
<211> 25
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 16
Glu Val Gln Leu Ala Glu Ser Gly Gly Gly Ser Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Lys Leu Ser Cys Leu Ala Ser
20 25
<210> 17
<211> 25
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 17
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Ser Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Thr Cys Ala Ala Thr
20 25
<210> 18
<211> 25
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 18
Gln Val His Leu Met Glu Ser Gly Gly Gly Ala Val Gln Thr Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Val Ser
20 25
<210> 19
<211> 25
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 19
Glu Val Gln Leu Ala Glu Ser Gly Gly Gly Ser Val Gln Ser Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Val Ser
20 25
<210> 20
<211> 25
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 20
Gln Val His Leu Val Glu Ser Gly Gly Ala Ser Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Thr
20 25
<210> 21
<211> 25
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 21
Glu Val Gln Leu Ala Glu Ser Gly Gly Gly Ser Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Val Ile Ser
20 25
<210> 22
<211> 25
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 22
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Ser Val Gln Ala Gly Gly
1 5 10 15
Pro Leu Arg Leu Thr Cys Ala Ala Thr
20 25
<210> 23
<211> 25
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 23
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Ser Val Gln Ser Gly Gly
1 5 10 15
Ser Leu Lys Leu Ser Cys Ala Val Ser
20 25
<210> 24
<211> 25
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 24
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Ser Val Gln Ser Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Val Ser
20 25
<210> 25
<211> 25
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 25
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Ser Val Gln Ser Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Val Ser
20 25
<210> 26
<211> 25
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 26
Gln Val Lys Leu Val Glu Ser Gly Gly Gly Leu Val Gln Ser Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Val Ser
20 25
<210> 27
<211> 25
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 27
Gln Ile Gln Leu Val Glu Ser Gly Gly Gly Ser Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Val Thr
20 25
<210> 28
<211> 25
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 28
Gln Val His Leu Met Glu Ser Gly Gly Gly Ser Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Val Val Ser
20 25
<210> 29
<211> 25
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 29
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Ser Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Val Ser
20 25
<210> 30
<211> 25
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 30
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser
20 25
<210> 31
<211> 25
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 31
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Leu Met Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser
20 25
<210> 32
<211> 25
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 32
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Ser Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Thr
20 25
<210> 33
<211> 25
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 33
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Val Ser
20 25
<210> 34
<211> 25
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 34
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Val Ser
20 25
<210> 35
<211> 25
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 35
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Val Ser
20 25
<210> 36
<211> 25
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 36
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Val Ser
20 25
<210> 37
<211> 10
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 37
Gly Gly Thr Leu Asp Tyr Tyr Ala Ile Gly
1 5 10
<210> 38
<211> 10
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 38
Gly Ser Ile Thr Ser Arg Asn Thr Met Gly
1 5 10
<210> 39
<211> 10
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 39
Gly Tyr Thr Tyr Ile Pro Asn Cys Met Ala
1 5 10
<210> 40
<211> 10
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 40
Ala Tyr Thr Tyr Ser Asn Ile Cys Leu Gly
1 5 10
<210> 41
<211> 10
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 41
Gly Tyr Ile Tyr Asn Arg Asn Phe Met Gly
1 5 10
<210> 42
<211> 10
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 42
Gly Tyr Ile Tyr Asn Arg Asn Phe Met Gly
1 5 10
<210> 43
<211> 10
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 43
Gly Asn Ile Tyr Asn Arg Asn Phe Met Gly
1 5 10
<210> 44
<211> 10
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 44
Gly Phe Thr Phe Ser Thr Ala Ala Met Ser
1 5 10
<210> 45
<211> 10
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 45
Gly Phe Thr Asp Ser Ser Tyr Cys Gly Ala
1 5 10
<210> 46
<211> 10
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 46
Val Phe Thr Asp Ser Asn Tyr Cys Met Ala
1 5 10
<210> 47
<211> 10
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 47
Gly Phe Thr Asp Ser Ser Tyr Cys Gly Ala
1 5 10
<210> 48
<211> 10
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 48
Gly Tyr Thr Ala Gly Ser Leu Cys Met Gly
1 5 10
<210> 49
<211> 10
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 49
Gly Asp Thr Asn Asn Leu Asn Phe Arg Gly
1 5 10
<210> 50
<211> 10
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 50
Gly Phe Thr Phe Asn Asn Tyr Ala Met Gly
1 5 10
<210> 51
<211> 12
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 51
Gly Ser Gly Tyr Ser Tyr Ser Arg Gly Cys Phe Ala
1 5 10
<210> 52
<211> 10
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 52
Gln Trp Ile Ser Ser Asp Cys Gly Met Ala
1 5 10
<210> 53
<211> 10
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 53
Gly Tyr Ser Trp Arg Pro Asp Cys Met Gly
1 5 10
<210> 54
<211> 10
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 54
Gly Ile Ser Ile Ser Pro Asp Cys Met Gly
1 5 10
<210> 55
<211> 12
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 55
Gly Ser Gly Tyr Ser Tyr Ser Arg Gly Cys Phe Ala
1 5 10
<210> 56
<211> 10
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 56
Ala Tyr Thr Ala Ser Asn Tyr Cys Met Gly
1 5 10
<210> 57
<211> 10
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 57
Gly Thr Ser Ile Ser Pro Asp Cys Met Gly
1 5 10
<210> 58
<211> 10
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 58
Gly Tyr Ser Trp Arg Pro Asp Cys Met Gly
1 5 10
<210> 59
<211> 12
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 59
Gly Ser Gly Tyr Ser Tyr Ser Arg Gly Cys Phe Ala
1 5 10
<210> 60
<211> 12
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 60
Gly Ser Gly Tyr Ser Tyr Ser Arg Gly Cys Phe Ala
1 5 10
<210> 61
<211> 12
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 61
Gly Ser Gly Tyr Ser Tyr Asn Arg Gly Cys Phe Ala
1 5 10
<210> 62
<211> 12
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 62
Gly Ser Gly Tyr Ser Tyr Ser Arg Gly Cys Phe Ala
1 5 10
<210> 63
<211> 10
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 63
Gly Ile Ser Ile Ser Pro Asp Cys Met Gly
1 5 10
<210> 64
<211> 10
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 64
Gly Ile Ser Ile Ser Pro Asp Cys Met Gly
1 5 10
<210> 65
<211> 10
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 65
Gly Ile Ser Ile Ser Pro Asp Cys Met Gly
1 5 10
<210> 66
<211> 10
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 66
Gly Phe Thr Phe Ser Val Trp Ser Met Ser
1 5 10
<210> 67
<211> 10
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 67
Gly Phe Thr Phe Ser Ser Tyr Trp Met Tyr
1 5 10
<210> 68
<211> 10
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 68
Ala Tyr Thr Ala Ser Phe Tyr Cys Met Gly
1 5 10
<210> 69
<211> 10
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 69
Gly Asn Ile Tyr Asn Arg Asn Phe Met Gly
1 5 10
<210> 70
<211> 10
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 70
Gly Asn Ile Tyr Asn Arg Asn Phe Met Gly
1 5 10
<210> 71
<211> 10
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 71
Gly Asn Ile Tyr Asn Arg Asn Phe Met Gly
1 5 10
<210> 72
<211> 10
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 72
Gly Asn Ile Tyr Asn Arg Asn Phe Met Gly
1 5 10
<210> 73
<211> 14
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 73
Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Ala Val Ser
1 5 10
<210> 74
<211> 14
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 74
Trp Tyr Arg Gln Val Pro Gly Lys Gln Arg Glu Leu Val Ala
1 5 10
<210> 75
<211> 14
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 75
Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Gly Val Thr
1 5 10
<210> 76
<211> 14
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 76
Trp Leu Arg Gln Ala Pro Gly Gly Gly Leu Glu Ala Val Ala
1 5 10
<210> 77
<211> 14
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 77
Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Gly Val Ala
1 5 10
<210> 78
<211> 14
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 78
Trp Phe Arg Gln Val Pro Gly Lys Val Arg Glu Gly Val Ala
1 5 10
<210> 79
<211> 14
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 79
Trp Phe Arg Gln Ala Pro Gly Lys Val Arg Glu Gly Val Ala
1 5 10
<210> 80
<211> 14
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 80
Trp Val Arg Gln Val Pro Glu Glu Gly Leu Glu Trp Val Ala
1 5 10
<210> 81
<211> 14
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 81
Trp Phe Arg Gln Val Pro Gly Lys Glu Arg Glu Gly Val Ala
1 5 10
<210> 82
<211> 14
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 82
Trp Phe Arg Gln Val Pro Gly Lys Glu Arg Glu Gly Val Ala
1 5 10
<210> 83
<211> 14
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 83
Trp Phe Arg Gln Val Pro Gly Lys Glu Arg Glu Gly Val Ala
1 5 10
<210> 84
<211> 14
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 84
Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Gly Val Ala
1 5 10
<210> 85
<211> 14
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 85
Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Gly Val Ala
1 5 10
<210> 86
<211> 14
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 86
Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Gly Ile Ala
1 5 10
<210> 87
<211> 14
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 87
Trp Phe Gln Gln Arg Pro Gly Lys Glu Arg Glu Gly Val Ala
1 5 10
<210> 88
<211> 14
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 88
Trp Tyr Arg Gln Ala Pro Gly Lys Glu Arg Glu Leu Val Ser
1 5 10
<210> 89
<211> 14
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 89
Trp Tyr Arg Gln Ala Ala Glu Lys Glu Arg Glu Gly Val Ala
1 5 10
<210> 90
<211> 14
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 90
Trp Phe Arg Gln Ala Pro Gly Lys Lys Arg Glu Ala Val Thr
1 5 10
<210> 91
<211> 14
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 91
Trp Phe Gln Gln Arg Pro Gly Lys Glu Arg Glu Gly Val Ala
1 5 10
<210> 92
<211> 14
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 92
Trp Phe Arg Gln Ser Pro Gly Lys Glu Arg Glu Ala Val Ala
1 5 10
<210> 93
<211> 14
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 93
Trp Phe Arg Gln Ala Pro Gly Lys Lys Arg Glu Ala Val Met
1 5 10
<210> 94
<211> 14
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 94
Trp Tyr Arg Gln Ala Ala Glu Lys Glu Arg Glu Gly Val Ala
1 5 10
<210> 95
<211> 14
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 95
Trp Phe Gln Gln Arg Pro Gly Lys Glu Arg Glu Gly Val Ala
1 5 10
<210> 96
<211> 14
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 96
Trp Phe Gln Gln Arg Pro Gly Lys Glu Arg Glu Gly Val Ala
1 5 10
<210> 97
<211> 14
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 97
Trp Phe Gln Gln Arg Pro Gly Lys Glu Arg Glu Gly Val Ala
1 5 10
<210> 98
<211> 14
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 98
Trp Phe Gln Gln Arg Pro Gly Lys Glu Arg Glu Gly Val Ala
1 5 10
<210> 99
<211> 14
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 99
Trp Phe Arg Gln Ala Pro Gly Lys Lys Arg Glu Ala Val Ala
1 5 10
<210> 100
<211> 14
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 100
Trp Phe Arg Gln Ala Pro Gly Lys Lys Arg Glu Ala Val Ala
1 5 10
<210> 101
<211> 14
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 101
Trp Phe Arg Gln Ala Pro Gly Lys Lys Arg Glu Ala Val Ala
1 5 10
<210> 102
<211> 14
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 102
Trp Val Arg Gln Ala Pro Gly Glu Gly Leu Glu Trp Val Ser
1 5 10
<210> 103
<211> 14
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 103
Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val Ser
1 5 10
<210> 104
<211> 14
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 104
Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Ala Val Ala
1 5 10
<210> 105
<211> 14
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 105
Trp Phe Arg Gln Ala Pro Gly Lys Gly Leu Glu Gly Val Ser
1 5 10
<210> 106
<211> 14
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 106
Trp Phe Arg Gln Ala Pro Gly Lys Gly Leu Glu Gly Val Ser
1 5 10
<210> 107
<211> 14
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 107
Trp Phe Arg Gln Ala Pro Gly Lys Gly Arg Glu Gly Val Ser
1 5 10
<210> 108
<211> 14
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 108
Trp Phe Arg Gln Ala Pro Gly Lys Gly Arg Glu Gly Val Ser
1 5 10
<210> 109
<211> 17
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 109
Cys Ile Ser Ser Ser Asp Gly Ser Thr Tyr Tyr Ala Asp Ser Val Lys
1 5 10 15
Gly
<210> 110
<211> 15
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 110
Leu Ile Ala Thr Phe Val Thr His Tyr Ala Asp Ser Val Lys Gly
1 5 10 15
<210> 111
<211> 17
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 111
Leu Ile Phe Thr Gly Asp Gly Thr Ser Thr Tyr Val Asp Ser Val Lys
1 5 10 15
Gly
<210> 112
<211> 17
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 112
Thr Ile Tyr Ile Ala Asp Gln Thr Ser Tyr Tyr Ala Asp Ser Val Lys
1 5 10 15
Gly
<210> 113
<211> 17
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 113
Ala Ile Tyr Thr Gly Gly Pro Tyr Thr Tyr Tyr Thr Asp Ser Val Gln
1 5 10 15
Gly
<210> 114
<211> 17
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 114
Ala Ile Tyr Thr Gly Thr Glu Arg Thr Tyr Tyr Ala Asp Ser Val Lys
1 5 10 15
Gly
<210> 115
<211> 17
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 115
Ala Ile Tyr Thr Gly Thr Ser Arg Thr Tyr Tyr Ala Asp Ser Val Lys
1 5 10 15
Gly
<210> 116
<211> 17
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 116
Ser Ile Asp Ser Ser Gly Ser Arg Thr Tyr Tyr Ala Gly Ser Val Lys
1 5 10 15
Gly
<210> 117
<211> 16
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 117
Ile Ile Asp Arg Tyr Gly Gly Thr Met Tyr Lys Asp Ser Val Lys Gly
1 5 10 15
<210> 118
<211> 16
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 118
Ile Ile Asp Arg Tyr Gly Gly Thr Met Tyr Lys Asp Ser Val Lys Gly
1 5 10 15
<210> 119
<211> 16
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 119
Ile Ile Asp Arg Tyr Gly Gly Thr Met Tyr Lys Asp Ser Val Lys Gly
1 5 10 15
<210> 120
<211> 17
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 120
Ala Ile Tyr Thr Gly Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val Lys
1 5 10 15
Gly
<210> 121
<211> 16
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 121
Val Ile Thr His Ser Gly Ser Thr Tyr Tyr Ala Glu Ser Val Lys Gly
1 5 10 15
<210> 122
<211> 17
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 122
Gly Ile Trp Thr Gly Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val Lys
1 5 10 15
Gly
<210> 123
<211> 16
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 123
Ile Ile Asn Met Asp Gly His Thr Arg Tyr Ser Asp Ser Val Gln Gly
1 5 10 15
<210> 124
<211> 16
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 124
Arg Ile Ser Ser Asp Asp Thr Thr Thr Tyr Ala Asp Ser Val Lys Gly
1 5 10 15
<210> 125
<211> 16
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 125
Val Ile Asp Ala Asp Gly Ile Thr Ser Tyr Ala Asp Ala Ala Lys Gly
1 5 10 15
<210> 126
<211> 17
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 126
Thr Ile Phe Ala Asn Thr Gly Ser Ala Arg Tyr Gly Asp Ser Val Lys
1 5 10 15
Gly
<210> 127
<211> 16
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 127
Ile Ile Asn Ser Asp Gly His Thr Ala Tyr Ser Asp Ser Val Gln Gly
1 5 10 15
<210> 128
<211> 16
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 128
Ser Ile Asn Asp Asp Gly Val Thr Ser Tyr Ala Asp Ser Val Lys Gly
1 5 10 15
<210> 129
<211> 17
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 129
Ser Ile Phe Thr Asn Thr Gly Ser Thr Arg Tyr Gly Asp Ser Val Lys
1 5 10 15
Gly
<210> 130
<211> 16
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 130
Val Ile Asp Ala Asp Gly Ile Thr Ser Tyr Ala Asp Ala Ala Lys Gly
1 5 10 15
<210> 131
<211> 16
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 131
Ile Ile Asn Ser Asp Gly His Thr Arg Tyr Ser Asp Ser Val Gln Gly
1 5 10 15
<210> 132
<211> 16
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 132
Ile Ile Asn Ser Asp Gly His Thr Arg Tyr Ser Asp Ser Val Gln Gly
1 5 10 15
<210> 133
<211> 16
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 133
Ile Ile Asn Ser Asp Gly His Thr Thr Tyr Gly Asp Ser Val Gln Gly
1 5 10 15
<210> 134
<211> 16
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 134
Ile Ile Asn Met Asp Gly His Thr Met Tyr Ser Asp Leu Ala Gln Gly
1 5 10 15
<210> 135
<211> 17
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 135
Thr Ile Phe Thr Asn Thr Ala Ser Thr Arg Tyr Gly Asp Ser Val Lys
1 5 10 15
Gly
<210> 136
<211> 17
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 136
Thr Ile Phe Thr Asn Thr Arg Arg Thr Arg Tyr Gly Asp Ser Val Lys
1 5 10 15
Gly
<210> 137
<211> 17
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 137
Thr Ile Phe Thr Asn Thr Arg Ser Thr Arg Tyr Gly Asp Ser Val Lys
1 5 10 15
Gly
<210> 138
<211> 17
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 138
Thr Ile Thr Gly Ser Gly Ala Gln Thr Tyr Tyr Ala Ser Ser Val Arg
1 5 10 15
Gly
<210> 139
<211> 17
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 139
Val Ile Asn Arg Ala Gly Asp Ser Ala Trp Tyr Ala Asp Ser Val Thr
1 5 10 15
Gly
<210> 140
<211> 16
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 140
Ser Ile Asn Asp Asp Gly Val Thr Met Tyr Ala Asp Ser Val Lys Gly
1 5 10 15
<210> 141
<211> 17
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 141
Ala Ile Tyr Thr Gly Thr Ser Arg Thr Tyr Tyr Ala Asp Ser Val Lys
1 5 10 15
Gly
<210> 142
<211> 17
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 142
Ala Ile Tyr Thr Gly Thr Ser Arg Thr Tyr Tyr Ala Asp Ser Val Lys
1 5 10 15
Gly
<210> 143
<211> 17
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 143
Ala Ile Tyr Thr Gly Thr Ser Arg Thr Tyr Tyr Ala Asp Ser Val Lys
1 5 10 15
Gly
<210> 144
<211> 17
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 144
Ala Ile Tyr Thr Gly Thr Ser Arg Thr Tyr Tyr Ala Asp Ser Val Lys
1 5 10 15
Gly
<210> 145
<211> 32
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 145
Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr Leu Gln
1 5 10 15
Met Asn Ser Leu Lys Pro Gly Asp Thr Ala Val Tyr His Cys Ala Thr
20 25 30
<210> 146
<211> 32
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 146
Arg Phe Thr Ile Ser Arg Asp Asn Ala Arg Lys Met Val Phe Leu Glu
1 5 10 15
Met Asn Ser Leu Gln Pro Glu Asp Thr Gly Ala Tyr Tyr Cys Tyr Val
20 25 30
<210> 147
<211> 32
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 147
Arg Phe Thr Ile Ser Gln Asp Asn Ala Lys Asn Thr Val Tyr Leu Gln
1 5 10 15
Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Leu Tyr Tyr Cys Ala Ala
20 25 30
<210> 148
<211> 32
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 148
Arg Phe Arg Ile Ser Lys Asp Ala Ala Lys Asn Ala Val Tyr Leu Gln
1 5 10 15
Met Ser Ser Leu Arg Pro Glu Asp Thr Ala Met Tyr Tyr Cys Ala Ser
20 25 30
<210> 149
<211> 32
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 149
Arg Phe Thr Ile Ser Gln Asp Asn Thr Lys Asn Thr Val Tyr Leu Gln
1 5 10 15
Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Met Tyr Tyr Cys Val Ser
20 25 30
<210> 150
<211> 32
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 150
Arg Phe Thr Ile Ser Gln Asp Asn Ala Lys Asn Thr Val Tyr Leu Gln
1 5 10 15
Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Met Tyr Tyr Cys Val Ala
20 25 30
<210> 151
<211> 32
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 151
Arg Phe Thr Ile Ser Gln Asp Asn Ala Lys Asn Thr Val Tyr Leu Gln
1 5 10 15
Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Met Tyr Tyr Cys Ala Ala
20 25 30
<210> 152
<211> 32
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 152
Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Leu Tyr Leu Gln
1 5 10 15
Leu Asn Ser Leu Lys Ala Glu Asp Thr Ala Met Tyr Tyr Cys Ala Lys
20 25 30
<210> 153
<211> 32
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 153
Arg Phe Thr Ile Ser Lys Asp Thr Ala Lys Asn Ile Leu Tyr Leu Gln
1 5 10 15
Met Asn Ser Leu Lys Leu Glu Asp Thr Ala Met Tyr Tyr Cys Ala Ala
20 25 30
<210> 154
<211> 32
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 154
Arg Phe Thr Ile Ser Lys Asp Thr Ala Lys Asn Ile Leu Tyr Leu Gln
1 5 10 15
Met Asn Ser Leu Lys Leu Glu Asp Thr Ala Met Tyr Tyr Cys Ala Ala
20 25 30
<210> 155
<211> 32
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 155
Arg Phe Thr Ile Ser Lys Asp Thr Ala Lys Asn Ile Leu Tyr Leu Gln
1 5 10 15
Met Asn Ser Leu Lys Leu Glu Asp Thr Ala Met Tyr Tyr Cys Ala Ala
20 25 30
<210> 156
<211> 32
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 156
Arg Phe Thr Ile Ser Gln Asp Asn Ala Lys Asn Thr Val Tyr Leu Gln
1 5 10 15
Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Gln Tyr Tyr Cys Gly Ala
20 25 30
<210> 157
<211> 32
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 157
Arg Phe Thr Ile Ser Gln Asp Leu Ala Lys Asn Thr Met Tyr Leu Gln
1 5 10 15
Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Met Tyr Tyr Cys Ala Ala
20 25 30
<210> 158
<211> 32
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 158
Arg Phe Thr Ile Ser Glu Asp Val Ala Lys Asn Thr Val Tyr Leu Gln
1 5 10 15
Met Asp Ser Leu Lys Pro Glu Asp Thr Ala Met Tyr Tyr Cys Ala Ala
20 25 30
<210> 159
<211> 32
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 159
Arg Phe Ile Ile Ser Gln Asp Lys Ala Lys Asn Thr Leu His Leu Gln
1 5 10 15
Met Asn Thr Leu Arg Pro Asp Asp Thr Ala Met Tyr Tyr Cys Ala Tyr
20 25 30
<210> 160
<211> 32
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 160
Arg Phe Thr Ile Ser Gln Asp Ser Ala Lys Asn Thr Leu Tyr Leu Gln
1 5 10 15
Met Asn Lys Leu Lys Thr Glu Asp Thr Gly Val Tyr Tyr Cys Ala Ala
20 25 30
<210> 161
<211> 30
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 161
Arg Phe Thr Ile Ser Arg Asp Asn Asn Lys Ile Thr Leu Tyr Leu Gln
1 5 10 15
Met Leu Lys Pro Asp Asp Thr Gly Met Tyr Val Cys Val Val
20 25 30
<210> 162
<211> 32
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 162
Arg Phe Thr Ser Ser Gln Gly Asn Ala Lys Asn Thr Leu Tyr Leu Gln
1 5 10 15
Met Asp Ser Val Lys Leu Asp Asp Thr Gly Thr Tyr Tyr Cys Ala Ala
20 25 30
<210> 163
<211> 32
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 163
Arg Phe Ile Ile Ser Gln Asp Lys Ala Lys Asn Thr Leu Tyr Leu Gln
1 5 10 15
Met Asn Ser Leu Lys Pro Asp Asp Thr Ala Met Tyr Tyr Cys Ala Tyr
20 25 30
<210> 164
<211> 32
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 164
Arg Phe Thr Ile Ser Gln Asp Ser Ala Lys Lys Thr Leu Tyr Leu Gln
1 5 10 15
Met Asn Arg Leu Lys Pro Glu Asp Thr Ala Met Tyr Tyr Cys Ala Ala
20 25 30
<210> 165
<211> 32
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 165
Arg Phe Thr Ser Ser Gln Gly Asn Ala Lys Asn Thr Leu Tyr Leu Gln
1 5 10 15
Met Asp Ser Leu Lys Leu Asp Asp Thr Ala Thr Tyr Tyr Cys Ala Ala
20 25 30
<210> 166
<211> 30
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 166
Arg Phe Thr Ile Ser Arg Asp Asn Asn Asn Ile Thr Leu Tyr Leu Gln
1 5 10 15
Met Leu Lys Pro Asp Asp Thr Gly Met Tyr Val Cys Val Ile
20 25 30
<210> 167
<211> 32
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 167
Arg Phe Ile Ile Ser Gln Asp Lys Ala Lys Asn Thr Leu Tyr Leu Gln
1 5 10 15
Met Asn Ser Leu Lys Pro Asp Asp Ala Ala Met Tyr Tyr Cys Ala Tyr
20 25 30
<210> 168
<211> 32
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 168
Arg Phe Ile Ile Ser Gln Asp Lys Ala Lys Asn Thr Leu Tyr Leu Gln
1 5 10 15
Met Asn Ser Leu Lys Pro Asp Asp Thr Ala Met Tyr Tyr Cys Ala Tyr
20 25 30
<210> 169
<211> 32
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 169
Arg Phe Ile Ile Ser Gln Asp Lys Ala Lys Asn Thr Leu Asp Leu Gln
1 5 10 15
Met Asn Ser Leu Lys Pro Asp Asp Thr Ala Met Tyr Tyr Cys Ala Tyr
20 25 30
<210> 170
<211> 32
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 170
Arg Phe Ile Ile Ser Gln Asp Lys Ala Lys Asn Thr Leu Tyr Leu Gln
1 5 10 15
Met Asn Ser Leu Lys Pro Asp Asp Thr Ala Met Tyr Tyr Cys Ala Tyr
20 25 30
<210> 171
<211> 32
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 171
Arg Phe Thr Ser Ser Gln Gly Asn Gly Lys Asn Thr Leu Tyr Leu Gln
1 5 10 15
Met Asp Ser Leu Asn Val Asp Asp Thr Ala Thr Tyr Tyr Cys Ala Ala
20 25 30
<210> 172
<211> 32
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 172
Arg Val Thr Ser Ser Gln Gly Asn Ala Lys Asn Thr Leu Tyr Leu Lys
1 5 10 15
Met Asp Asn Leu Arg His Asp Asp Thr Ala Thr Tyr Tyr Cys Ala Ala
20 25 30
<210> 173
<211> 32
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 173
Arg Phe Thr Ser Ser Gln Gly Asn Ala Lys Asn Thr Leu Tyr Leu Gln
1 5 10 15
Met Asp Ser Leu Lys Leu Asp Asp Thr Ala Thr Tyr Tyr Cys Ala Ala
20 25 30
<210> 174
<211> 32
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 174
Arg Phe Thr Thr Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr Leu Gln
1 5 10 15
Met Asn Ser Leu Lys Ser Asp Asp Thr Ala Val Tyr Tyr Cys Glu Arg
20 25 30
<210> 175
<211> 32
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 175
Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr Leu Gln
1 5 10 15
Met Asp Ser Leu Lys Pro Glu Asp Thr Ala Met Tyr Tyr Cys Ala Ala
20 25 30
<210> 176
<211> 32
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 176
Gln Phe Thr Ile Ser Gln Asp Ser Ala Thr Lys Thr Leu Tyr Leu Gln
1 5 10 15
Met Asn Arg Leu Lys Pro Glu Asp Thr Ala Met Tyr Tyr Cys Ala Ala
20 25 30
<210> 177
<211> 32
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 177
Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr Leu Gln
1 5 10 15
Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala Ala
20 25 30
<210> 178
<211> 32
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 178
Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr Leu Gln
1 5 10 15
Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala Ala
20 25 30
<210> 179
<211> 32
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 179
Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr Leu Gln
1 5 10 15
Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys Ala Ala
20 25 30
<210> 180
<211> 32
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 180
Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr Leu Gln
1 5 10 15
Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys Ala Ala
20 25 30
<210> 181
<211> 13
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 181
Asp Arg Ala Cys Gly Ser Ser Trp Leu Gly Ala Glu Ser
1 5 10
<210> 182
<211> 5
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 182
Asp Val Ser Pro Tyr
1 5
<210> 183
<211> 18
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 183
Ala Glu Arg Cys Ser Gly Ser Asn Asp Arg Ile Ser Phe Trp Gly Ile
1 5 10 15
Ser Tyr
<210> 184
<211> 15
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 184
Arg Tyr Gly Ser Thr Cys Gly Glu Tyr Leu Ala Asp Tyr Thr Ser
1 5 10 15
<210> 185
<211> 14
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 185
Asp Leu Ser Asp Gly Thr Trp Asp Gln Gly Arg Trp Asn Tyr
1 5 10
<210> 186
<211> 14
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 186
Asp Leu Arg Asp Gly Thr Trp Asp Thr Gly Val Trp Asn Thr
1 5 10
<210> 187
<211> 14
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 187
Asp Leu Arg Asp Gly Phe Trp Asp Thr Gly Val Trp Asn Thr
1 5 10
<210> 188
<211> 7
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 188
Asp His Met Ser Trp Leu Pro
1 5
<210> 189
<211> 14
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 189
Ala Glu Tyr Arg Gly Ser Ser Cys Asp Ala Glu Ser Gly Tyr
1 5 10
<210> 190
<211> 14
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 190
Ala Gly Tyr Arg Gly Ser Ser Cys Asp Ala Asp Ser Gly Tyr
1 5 10
<210> 191
<211> 14
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 191
Ala Glu Tyr Arg Gly Ser Ser Cys Asp Ala Glu Ser Gly Tyr
1 5 10
<210> 192
<211> 15
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 192
Gly Ser Arg Glu Asp Tyr Cys Asp Arg Gly Tyr Ile Tyr Asp His
1 5 10 15
<210> 193
<211> 17
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 193
Ala Asp Val Trp Arg Ile Ser Trp Ser Phe Val Pro Glu Leu Phe Ser
1 5 10 15
Tyr
<210> 194
<211> 18
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 194
Glu Arg Trp Asp Tyr Ser Asp Trp Arg Arg Leu Lys Arg Gly Asp Tyr
1 5 10 15
Asn Tyr
<210> 195
<211> 20
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 195
Asp Arg Ser Gln Cys Tyr Val Leu Ser Asp Arg Leu Arg Leu Pro Gly
1 5 10 15
Thr Phe Ser Asp
20
<210> 196
<211> 15
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 196
Glu Ala Lys Ser Thr Ile Thr Ser Leu Cys Tyr Pro Leu Asn Tyr
1 5 10 15
<210> 197
<211> 15
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 197
Gly Trp Arg Val Ser Ser Gly Gly Asn Cys Gln Phe Asn Asp Tyr
1 5 10 15
<210> 198
<211> 14
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 198
Arg Phe Thr Gly Gly Asp Cys Phe Asp His Gln Pro Leu Ala
1 5 10
<210> 199
<211> 20
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 199
Asp Arg Ser Gln Cys Tyr Val Leu Arg Asp Arg Leu Arg Leu Pro Asp
1 5 10 15
Thr Phe Thr Asp
20
<210> 200
<211> 18
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 200
Thr Pro Asp Gly Tyr Cys Tyr Ala Glu Arg Leu Ser Arg Trp Arg Tyr
1 5 10 15
Glu Phe
<210> 201
<211> 17
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 201
Arg Tyr Thr Gly Gly Asp Cys Phe Asn Leu Glu Pro Leu Ala Trp Arg
1 5 10 15
Phe
<210> 202
<211> 15
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 202
Gly Trp Arg Val Ser Ser Gly Gly Asn Cys Gln Phe Asn Asp Tyr
1 5 10 15
<210> 203
<211> 20
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 203
Asp Arg Asn Gln Cys Tyr Val Leu Leu Asp Arg Leu Arg Leu Pro Gly
1 5 10 15
Thr Phe Ser Asp
20
<210> 204
<211> 20
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 204
Asp Cys Ser Gln Cys Tyr Val Leu Arg Asp Arg Leu Arg Leu Pro Asp
1 5 10 15
Thr Phe Thr Asp
20
<210> 205
<211> 20
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 205
Asp Arg Asn Gln Cys Tyr Val Leu Arg Asp Arg Leu Arg Leu Pro Asp
1 5 10 15
Thr Phe Thr Asp
20
<210> 206
<211> 20
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 206
Asp Arg Asp Gln Cys Tyr Val Leu Arg Asp Arg Leu Arg Leu Pro Asp
1 5 10 15
Thr Phe Asn Asp
20
<210> 207
<211> 17
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 207
Arg Tyr Thr Gly Gly Asn Cys Phe Asn Leu Glu Pro Leu Ala Trp His
1 5 10 15
Phe
<210> 208
<211> 17
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 208
Arg Tyr Thr Gly Gly Asp Cys Phe Asn Leu Asp Pro Leu Ser Trp Arg
1 5 10 15
Phe
<210> 209
<211> 17
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 209
Arg Tyr Thr Gly Gly Asp Cys Phe Asn Leu Glu Pro Val Ala Trp Arg
1 5 10 15
Phe
<210> 210
<211> 14
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 210
Gly Asn Gly Gln Thr Ala Met Glu Ala Leu Ile Asn Pro Pro
1 5 10
<210> 211
<211> 18
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 211
Asp Ser Arg Gly Tyr Gly Gly Asp Trp Tyr Lys Leu Leu Ser Asp Phe
1 5 10 15
Asn Tyr
<210> 212
<211> 18
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 212
Thr Pro Glu Gly Tyr Cys Tyr Ala Glu Arg Leu Ser Thr Trp Arg Tyr
1 5 10 15
Thr Phe
<210> 213
<211> 14
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 213
Asp Leu Arg Asp Gly Phe Trp Asp Thr Gly Val Trp Asn Thr
1 5 10
<210> 214
<211> 14
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 214
Asp Leu Arg Glu Gly Phe Trp Asp Thr Gly Val Trp Asn Thr
1 5 10
<210> 215
<211> 14
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 215
Asp Leu Arg Asp Gly Phe Trp Asp Thr Gly Val Trp Asn Thr
1 5 10
<210> 216
<211> 14
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 216
Asp Leu Arg Glu Gly Phe Trp Asp Thr Gly Val Trp Asn Thr
1 5 10
<210> 217
<211> 11
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 217
Trp Ala Gln Gly Thr Gln Val Thr Val Ser Ser
1 5 10
<210> 218
<211> 11
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 218
Trp Gly Arg Gly Thr Gln Val Thr Val Ser Ser
1 5 10
<210> 219
<211> 11
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 219
Trp Gly Gln Gly Thr Gln Val Thr Val Ser Ser
1 5 10
<210> 220
<211> 11
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 220
Arg Ala Gln Gly Thr Gln Val Thr Val Ser Ser
1 5 10
<210> 221
<211> 11
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 221
Trp Gly Gln Gly Thr Gln Val Thr Val Ser Ser
1 5 10
<210> 222
<211> 11
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 222
Trp Gly Gln Gly Thr Gln Val Thr Val Ser Ser
1 5 10
<210> 223
<211> 11
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 223
Trp Gly Gln Gly Thr Gln Val Thr Val Ser Ser
1 5 10
<210> 224
<211> 11
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 224
Arg Gly Gln Gly Thr Gln Val Thr Val Ser Ser
1 5 10
<210> 225
<211> 11
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 225
Trp Gly Gln Gly Thr Gln Val Thr Val Ser Ser
1 5 10
<210> 226
<211> 11
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 226
Trp Gly Gln Gly Thr Gln Val Thr Val Ser Ser
1 5 10
<210> 227
<211> 11
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 227
Trp Gly Gln Gly Thr Gln Val Thr Val Ser Ser
1 5 10
<210> 228
<211> 11
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 228
Trp Gly Gln Gly Thr Gln Val Thr Val Ser Ser
1 5 10
<210> 229
<211> 11
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 229
Trp Gly Gln Gly Thr Gln Val Thr Val Ser Ser
1 5 10
<210> 230
<211> 11
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 230
Trp Gly Gln Gly Thr Gln Val Thr Val Ser Ser
1 5 10
<210> 231
<211> 11
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 231
Trp Gly Gln Gly Thr Gln Val Thr Val Ser Ser
1 5 10
<210> 232
<211> 11
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 232
Trp Gly Gln Gly Thr Gln Val Thr Val Ser Ser
1 5 10
<210> 233
<211> 11
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 233
Trp Gly Gln Gly Thr Gln Val Thr Val Ser Ser
1 5 10
<210> 234
<211> 14
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 234
Trp Arg Phe Trp Gly Gln Gly Thr Gln Val Thr Val Ser Ser
1 5 10
<210> 235
<211> 11
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 235
Trp Gly Gln Gly Thr Gln Val Thr Val Ser Ser
1 5 10
<210> 236
<211> 11
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 236
Trp Gly Gln Gly Thr Gln Val Thr Val Ser Ser
1 5 10
<210> 237
<211> 11
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 237
Trp Gly Gln Gly Thr Gln Val Thr Val Ser Ser
1 5 10
<210> 238
<211> 11
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 238
Trp Gly Gln Gly Thr Gln Val Thr Val Ser Ser
1 5 10
<210> 239
<211> 11
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 239
Trp Gly Gln Gly Thr Gln Val Thr Val Ser Ser
1 5 10
<210> 240
<211> 11
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 240
Trp Gly Gln Gly Thr Gln Val Thr Val Ser Ser
1 5 10
<210> 241
<211> 11
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 241
Trp Gly Gln Gly Thr Gln Val Thr Val Ser Ser
1 5 10
<210> 242
<211> 11
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 242
Trp Gly Gln Gly Thr Gln Val Thr Val Ser Ser
1 5 10
<210> 243
<211> 11
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 243
Trp Gly Gln Gly Thr Gln Val Thr Val Ser Ser
1 5 10
<210> 244
<211> 11
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 244
Trp Gly Gln Gly Thr Gln Val Thr Val Ser Ser
1 5 10
<210> 245
<211> 11
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 245
Trp Gly Gln Gly Thr Gln Val Thr Val Ser Ser
1 5 10
<210> 246
<211> 11
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 246
Glu Arg Pro Gly Thr Gln Val Thr Val Ser Ser
1 5 10
<210> 247
<211> 11
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 247
Cys Gly Gln Gly Thr Gln Val Thr Val Ser Ser
1 5 10
<210> 248
<211> 11
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 248
Trp Gly Gln Gly Thr Gln Val Thr Val Ser Ser
1 5 10
<210> 249
<211> 11
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 249
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
1 5 10
<210> 250
<211> 11
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 250
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
1 5 10
<210> 251
<211> 11
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 251
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
1 5 10
<210> 252
<211> 11
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 252
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
1 5 10
<210> 253
<211> 366
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 253
caggtacagc tggtggagtc tgggggaggc aaggtgcagc ctggggggtc tctgagactc 60
tcctgtgcag cctctggagg cactttggat tattatgcca taggctggtt ccgccaggcc 120
ccagggaagg agcgcgaggc cgtgtcatgt attagtagta gcgatggtag cacatactat 180
gcagactccg tgaagggccg attcaccatc tccagagaca atgccaagaa cacggtgtat 240
cttcaaatga acagcctgaa acctggggac acggccgttt atcactgtgc gacagatcgg 300
gcgtgcggta gtagctggtt aggggccgaa tcatgggccc aggggaccca ggtcaccgtc 360
tcctca 366
<210> 254
<211> 336
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 254
caggtgcacc tggtggattc tgggggaggc ttggtgcagc ctggggggtc tctgagactc 60
tcctgtgcag cctctggaag catcaccagt agaaatacca tgggctggta ccggcaggtt 120
ccagggaagc agcgcgaatt ggtcgcgcta attgcgactt ttgtcacaca ttatgcggac 180
tccgtgaagg gccgattcac catctccaga gataacgcca ggaagatggt gtttctagag 240
atgaacagcc tgcaacctga ggacacgggc gcgtattatt gttatgtcga tgtctcgccc 300
tattggggcc gggggaccca ggtcaccgtc tcctca 336
<210> 255
<211> 381
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 255
caggtgcaac tggtggagtc tgggggaggc tcggtgcagg ctggagggtc tctgagactc 60
tcctgtgcag cctctggata cacctatatt cccaactgca tggcctggtt ccgccaggct 120
ccagggaagg agcgcgaggg ggtcacactt atttttactg gtgatggtac ctcaacctat 180
gtcgactccg tgaagggccg attcaccatc tcccaagaca acgccaagaa cacggtgtat 240
ctgcaaatga acagcctgaa acccgaggac actgccttgt actactgtgc ggcagccgaa 300
cgttgtagtg gttcaaacga cagaatatcc ttttggggaa ttagctactg gggccagggg 360
acccaggtca ccgtctcctc a 381
<210> 256
<211> 372
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 256
caggtgcaac tggtggagtc tgggggaggc tcggtgcagg ctggggggtc tttgagactc 60
tcctgtacag cctctgcata cacctacagt aacatctgtt tgggctggct ccgccaggct 120
ccaggggggg ggctcgaggc tgtcgcaacg atttatattg cggatcagac atcatactat 180
gccgactccg tgaagggccg attccgcatc tctaaagacg ccgccaagaa cgcggtgtat 240
ctgcaaatga gcagcctgag acctgaggac actgccatgt actactgtgc gtcccggtac 300
ggtagtacct gcggcgaata tttagctgac tatacctccc gggcccaggg gacccaggtc 360
accgtctcct ca 372
<210> 257
<211> 369
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 257
cagatgcagc tggtggagtc tgggggaggc tcggtgcagg ctggagggtc tctgagactc 60
tcttgtgcag tctctggata catctacaat cgcaacttca tgggctggtt ccgccaggct 120
cccgggaagg agcgcgaggg ggtcgcggct atttatactg gtggcccata cacatactat 180
accgactccg tgcagggccg attcaccatc tcccaagaca acaccaagaa cacggtgtat 240
ctgcaaatga acagcctgaa acctgaggac actgccatgt attactgtgt gtcagatctt 300
tcggacggta cttgggacca gggccgatgg aactactggg gccaggggac ccaggtcacc 360
gtctcctca 369
<210> 258
<211> 369
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 258
caggtgcaac tggtggagtc tgggggaggc tcggcgcagg ctggagggtc tctgagactc 60
tcctgtgcag tctctggata catttacaat cgtaacttca tgggctggtt ccgccaggtt 120
ccaggaaagg tgcgcgaggg ggtcgcagca atttatactg gtactgaacg cacgtactat 180
gccgactccg tgaagggccg attcaccatc tcccaagaca acgccaagaa cacggtgtat 240
ctgcagatga atagtctgaa acctgaggac actgccatgt actactgtgt ggcggatttg 300
cgggatggta cttgggatac gggcgtatgg aacacctggg gccaggggac ccaggtcacc 360
gtctcctca 369
<210> 259
<211> 369
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 259
cagattcagc tggtggagtc tgggggaggc tcggcgcagg ctggagggtc tctgagactc 60
tcctgtgtag tctctggaaa catctacaat cgtaacttca tgggctggtt ccgccaggct 120
ccagggaagg tgcgcgaggg ggtcgcagca atttatactg gtactagtcg cacgtactat 180
gccgactccg tgaagggccg attcaccatc tcccaagaca acgccaagaa tacggtgtat 240
ctgcaaatga atagtctgaa acctgaggac actgccatgt actactgtgc ggcggatttg 300
cgggatggtt tctgggatac gggcgtatgg aacacctggg gccaggggac ccaggtcacc 360
gtctcctca 369
<210> 260
<211> 348
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 260
caggtgcaac tggtggagtc tgggggaggc ttggtgcagc ctggggggtc tctgacactc 60
tcctgtgcag cctctggatt cacgttcagt accgccgcca tgagctgggt ccgccaggtt 120
ccagaggagg gactcgagtg ggtcgcatct attgatagta gtggtagtcg cacatactat 180
gcgggctccg tgaagggccg attcaccatc tccagagaca acgccaagaa cacgctgtat 240
ttgcaattga acagcctgaa agctgaggac acggccatgt attactgtgc aaaagatcac 300
atgagctggt tgccgcgggg ccaggggacc caggtcaccg tctcctca 348
<210> 261
<211> 366
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 261
caggtgcaac tggtggagtc tgggggagga tcggtgcagg ctggagggtc tctgagactc 60
tcctgtgcag cctctggatt caccgacagt tcgtactgcg gggcctggtt tcgccaggtt 120
ccagggaagg agcgcgaggg ggtcgcgatt atcgatagat atggtgggac aatgtacaaa 180
gactccgtga agggccgatt caccatctcc aaagacactg ccaagaatat tctgtatctg 240
caaatgaaca gcctgaaact tgaggacact gccatgtact actgtgcggc agccgaatat 300
cgaggctctt cgtgtgacgc ggagagtggc tactggggcc aggggaccca ggtcaccgtc 360
tcctca 366
<210> 262
<211> 366
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 262
caggtgcacc tgatggagtc tgggggaggt tcggtgcagg ctggagggtc cctgactctc 60
tcctgtgcag cctctgtatt caccgacagt aactactgca tggcctggtt ccgccaggtt 120
ccagggaagg agcgcgaggg ggtcgcaatt atcgatagat atggtggtac gatgtacaaa 180
gactccgtga agggccgatt caccatctcc aaagacactg ccaagaatat tctgtatctg 240
caaatgaaca gcctgaaact tgaggacact gccatgtact actgtgcggc agccgggtat 300
cgaggctctt cgtgtgacgc ggatagtggc tactggggcc aggggaccca ggtcaccgtc 360
tcctca 366
<210> 263
<211> 366
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 263
cagattcagc tggtggagtc tgggggagga tcggtgcagg ctggagggtc tctgagactc 60
tcctgtgcag cctctggatt caccgacagt tcgtactgcg gggcctggtt tcgccaggtt 120
ccagggaagg agcgcgaggg ggtcgcgatt atcgatagat atggtgggac aatgtacaaa 180
gactccgtga agggccgatt caccatctcc aaagacactg ccaagaatat tctgtatctg 240
caaatgaaca gcctgaaact tgaggacact gccatgtact actgtgcggc agccgaatat 300
cgaggctctt cgtgtgacgc ggagagtggc tactggggcc aggggaccca ggtcaccgtc 360
tcctca 366
<210> 264
<211> 372
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 264
caggtgcaac tggtggagtc tgggggaggc tcggtgcagg ctggagggtc tctgagactc 60
tcctgtgcag cctctggata caccgccggt agcctctgca tgggctggtt ccgccaggct 120
ccagggaagg agcgcgaggg ggtcgcagct atttatactg gtggtggtag cacatactat 180
gccgactccg tgaagggccg attcaccatc tcccaagaca acgccaagaa cacggtgtat 240
ctgcaaatga acagcctgaa acctgaggac actgcccagt actactgcgg ggcgggtagt 300
agggaagact actgcgacag gggttacatc tatgatcact ggggccaggg gacccaggtc 360
accgtctcct ca 372
<210> 265
<211> 375
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 265
caggtgaagt tagtggagtc tgggggaggc tcggtgcagg ctggagggta cctgagactc 60
tcctgtgcag cctctggaga caccaacaac ttgaacttca ggggctggtt ccgccaggct 120
ccagggaagg agcgcgaggg ggtcgcagtt atcactcact ctggtagcac atactatgcc 180
gaatccgtga agggccgatt caccatctcc caagacctcg ccaagaacac gatgtatctg 240
caaatgaaca gtctgaaacc tgaggacact gctatgtact actgtgcggc agcagatgtg 300
tggcgtatta gctggtcctt tgttccggaa ctctttagtt actggggcca ggggacccag 360
gtcaccgtct cctca 375
<210> 266
<211> 381
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 266
caggtgcagc tggtggagtc tgggggaggc tcggtgcagg ctggagggtc tctgagactc 60
tcttgtgcag gctctggatt taccttcaat aactacgcca tgggctggtt ccgccaggct 120
ccagggaagg agcgcgaggg aatcgcggga atttggactg gtggtggtag tacatactat 180
gccgactccg tgaagggccg attcaccatc tccgaagacg tcgccaagaa cacggtgtat 240
ctgcaaatgg acagcctgaa acctgaggac actgccatgt actactgtgc ggccgagcgc 300
tgggactata gcgactggcg acgcctaaag aggggggact ataactactg gggccagggg 360
acccaggtca ccgtctcctc a 381
<210> 267
<211> 390
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 267
caggtgcacc tgatggagtc tgggggaggg tcggtgccgt ctggagggtc tctgagactc 60
tcctgtgcag tctctggatc tggatacagc tatagtcgcg gctgcttcgc atggttccag 120
cagcgtccag ggaaggagcg cgagggggtc gcaattatta atatggatgg gcacacaaga 180
tactcagact ccgtgcaggg ccgattcatc atctcccaag acaaggccaa gaacacacta 240
catctgcaaa tgaacaccct gagacctgac gacacggcca tgtattactg tgcgtacgat 300
cgcagtcagt gttacgtgct aagcgaccgc ttacgcctcc caggtacctt tagtgactgg 360
ggccagggga cccaggtcac cgtctcctca 390
<210> 268
<211> 369
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 268
gaggtgcaac tggcggagtc tgggggaggc tcggtgcagg ctggagggtc tctgaaactc 60
tcctgtttag cctcgcaatg gatcagtagt gattgcggaa tggcctggta ccgccaggct 120
ccagggaagg agcgcgaatt ggtctcacgc attagtagtg atgataccac aacctatgca 180
gactccgtga agggccgatt caccatctcc caagacagtg ccaagaacac gctgtatctg 240
caaatgaaca agctgaaaac tgaagacacg ggcgtgtatt attgtgcggc agaagccaag 300
agcactataa cgagcctgtg ctaccccttg aactactggg gccaggggac ccaggtcacc 360
gtctcctca 369
<210> 269
<211> 363
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 269
caggtgcagc tggtggagtc tgggggaggc tccgtgcagg ctggagggtc tctgagactc 60
acctgtgcag ccactggata ctcttggaga cccgactgca tgggctggta ccgccaggct 120
gcagagaagg agcgcgaggg ggtcgcagtt attgatgctg atggtatcac aagctacgca 180
gacgccgcga agggccgatt caccatctcc cgagacaaca acaagatcac tctatatctg 240
caaatgctga aacctgacga cactggcatg tacgtctgtg tggtaggatg gagagtaagc 300
agtggtggta actgccaatt caatgactac tggggtcagg ggacccaggt caccgtctcc 360
tca 363
<210> 270
<211> 378
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 270
caggtgcacc tgatggagtc tgggggaggc gcggtgcaga ccggagggtc tctgaggctc 60
tcctgtgcag tatcgggaat ctccatcagt ccagactgca tgggctggtt ccgccaggct 120
ccagggaaga agcgcgaggc ggtcacgaca atttttgcta atactggtag cgcgcgctat 180
ggcgactccg tgaagggccg attcaccagc tcccaaggca acgccaagaa tacgctgtat 240
ctgcaaatgg acagcgtgaa acttgatgac actggcacgt actactgtgc ggcacggttt 300
acggggggtg actgctttga tcatcagcca ttggcgtggc gcttctgggg ccaggggacc 360
caggtcaccg tctcctca 378
<210> 271
<211> 390
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 271
gaggtgcaac tggcggagtc tgggggaggg tcggtgcagt ctggagggtc tctgagactc 60
tcctgtgcag tctctggatc tggatacagc tatagtcgcg gctgcttcgc gtggttccag 120
cagcgtccag gaaaggagcg cgagggggtc gcaattatta atagtgatgg gcacacagca 180
tactcagact ccgtgcaggg ccgattcatc atctcccaag acaaggccaa gaacacacta 240
tatctgcaaa tgaacagcct gaaacctgac gacacggcca tgtattactg tgcgtacgat 300
cgcagtcagt gttacgtgct tcgcgaccgc ttacgcctcc cagatacctt tactgactgg 360
ggccagggga cccaggtcac cgtctcctca 390
<210> 272
<211> 378
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 272
caggtgcacc tggtggagtc tgggggagcc tcggtgcagg ctggagggtc tctgagactc 60
tcctgtgcag ccactgcgta caccgccagt aattattgca tgggctggtt ccgccagtct 120
ccagggaagg agcgcgaggc agtcgcaagt attaatgatg acggcgtcac aagctacgca 180
gactccgtga agggccgatt caccatctcc caagacagcg ccaagaagac tctgtatctc 240
caaatgaacc gcctgaaacc tgaggacact gccatgtact actgtgcggc caccccggat 300
ggttactgct acgccgagag actttcccgg tggagatatg agttctgggg ccaggggacc 360
caggtcaccg tctcctca 378
<210> 273
<211> 378
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 273
gaggtgcagc tggcggagtc tgggggaggc tcggtgcagg ctggagggtc tctgaggctc 60
tcctgtgtaa tatcaggaac ctccatcagt ccagactgca tgggctggtt ccgccaggct 120
ccagggaaga agcgcgaggc agtcatgagt atttttacaa atactggtag cacgcgctat 180
ggcgactccg tgaagggccg attcaccagc tcccaaggca acgccaagaa tacgctgtat 240
ctgcaaatgg acagcttgaa acttgatgac actgccacgt actactgtgc ggcccggtat 300
acggggggtg actgctttaa tcttgaacca ttggcgtggc gcttctgggg ccaggggacc 360
caggtcaccg tctcctca 378
<210> 274
<211> 363
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 274
caggttcagc tggtggagtc tgggggaggc tccgtgcagg ctggagggcc tctgagactc 60
acctgtgcag ccactggata ctcttggaga cccgactgca tgggctggta ccgccaggct 120
gcagagaagg agcgcgaggg ggtcgcagtt attgatgctg atggtatcac aagttacgca 180
gacgccgcga agggccgatt caccatctcc cgagacaaca acaacatcac tctatatctg 240
caaatgctga aacctgacga cactggcatg tacgtctgtg tgataggatg gagagtaagc 300
agtggtggta actgccaatt caatgactac tggggtcagg ggacccaggt caccgtctcc 360
tca 363
<210> 275
<211> 390
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 275
caggttcagc tggtggagtc tgggggaggg tcggtgcagt ctggagggtc tctgaaactc 60
tcctgtgcag tctctggatc tggatacagc tatagtcgcg gctgcttcgc atggttccaa 120
cagcgtccag ggaaggagcg cgagggggtc gcaattatta atagcgatgg acacacaaga 180
tactcagact ccgtgcaggg ccgattcatc atctcccaag acaaggccaa gaacacacta 240
tatctccaaa tgaacagcct gaaacctgac gacgcggcca tgtattactg tgcgtacgat 300
cgcaatcagt gttacgttct tctcgaccgc ttacgcctcc caggtacctt tagtgactgg 360
ggccagggga cccaggtcac cgtctcctca 390
<210> 276
<211> 390
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 276
gaggtgcagc tggtggagtc tgggggaggg tcggtgcagt ctggagggtc tctgagactc 60
tcctgtgcag tctctggatc tggatacagc tataatcgcg gctgcttcgc gtggttccag 120
cagcgtccag ggaaggagcg cgagggggtc gcaattatta atagcgatgg gcacacaacg 180
tacggagact ccgtgcaggg ccgattcatc atctcccaag acaaggccaa gaacacacta 240
gatctgcaaa tgaacagcct gaaacctgac gacacggcca tgtattactg tgcgtacgat 300
cgcaatcagt gttacgtgct tcgcgaccgc ttacgcctcc cagatacctt tactgactgg 360
ggccagggga cccaggtcac cgtctcctca 390
<210> 277
<211> 390
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 277
caggtgaagt tggtggagtc tgggggaggg ttggtgcagt ctggagggtc tctgagactc 60
tcctgtgcag tctctggatc tggatacagc tatagtcgcg gctgcttcgc atggttccag 120
cagcgtccag ggaaggagcg cgagggggtc gcaattatta atatggatgg gcacacaatg 180
tactcagact tggcgcaggg ccgattcatc atctcccaag acaaggccaa gaacacacta 240
tatctgcaaa tgaacagcct gaaacctgac gacacggcca tgtattactg tgcgtacgat 300
cgcgatcagt gttacgtact tcgggaccgc ttacgcctcc cagatacctt taatgactgg 360
ggccagggga cccaggtcac cgtctcctca 390
<210> 278
<211> 378
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 278
cagattcagc tggtggagtc tgggggaggc tcggtgcagg ctggagggtc tctgaggctc 60
tcctgtgcag tgacaggaat ctccatcagt ccagactgca tgggctggtt ccgccaggct 120
ccagggaaga agcgcgaggc agtcgcgact atttttacta atactgcgag cacgcgctat 180
ggcgactccg tgaagggccg attcaccagc tcccaaggga acggcaagaa tacgctgtat 240
ctgcaaatgg acagcttgaa cgttgatgac actgccacgt actactgtgc ggcccgctat 300
acggggggta actgctttaa tcttgagcca ttggcgtggc acttctgggg ccaggggacc 360
caggtcaccg tctcctca 378
<210> 279
<211> 378
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 279
caggtgcacc tgatggagtc tgggggaggc tcggtgcagg ctggagggtc tctgaggctc 60
tcctgtgtag tatcaggaat ctccatcagt ccagactgta tggggtggtt ccgccaggct 120
ccagggaaga agcgcgaggc agtcgcgact atttttacta atactcgtag gacgcgctat 180
ggcgactccg tgaagggccg agtcaccagc tcccaaggca acgccaagaa tacgctgtat 240
ctaaaaatgg acaacttgag gcacgatgac actgccacgt actactgtgc ggcccggtat 300
acggggggtg actgctttaa tcttgaccca ttgtcctggc gcttctgggg ccaggggacc 360
caggtcaccg tctcctca 378
<210> 280
<211> 378
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 280
caggtgcagc tggtggagtc tgggggaggc tcggtgcagg ctggagggtc tctgaggctc 60
tcctgtgcag tatcaggaat ctccatcagt ccagactgca tgggctggtt ccgccaggct 120
ccagggaaga agcgcgaggc agtcgcgact atttttacta atactcgtag cacgcgctat 180
ggcgactccg tgaagggccg attcaccagc tcccaaggca acgccaagaa tacgctgtat 240
ctgcaaatgg acagcttgaa acttgatgac actgccacgt actactgtgc ggcccggtat 300
acggggggtg actgctttaa tcttgagcct gtggcgtggc gcttctgggg ccaggggacc 360
caggtcaccg tctcctca 378
<210> 281
<211> 369
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 281
gaggtgcagc tggtggagtc tgggggaggc ttggtgcagc ctggggggtc tctgagactc 60
tcctgtgcag cctctggctt caccttcagt gtttggtcga tgtcctgggt ccgccaggct 120
ccaggggagg gactcgagtg ggtctcaact atcactggga gtggcgcaca aacatattat 180
gcaagctcag tgaggggccg attcaccacc tccagagaca acgccaagaa cacggtatat 240
ctgcaaatga acagcctgaa atctgacgac acggccgtgt attattgtga gagaggaaat 300
ggtcagactg ctatggaggc tctcattaac ccgcccgagc gtccggggac ccaggtcacc 360
gtctcctca 369
<210> 282
<211> 381
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 282
caggtgcagc tggtggagtc tgggggaggc ttgatgcagc ctggggggtc tttgagactc 60
tcctgtgcag cctctggatt caccttcagt agttactgga tgtactgggt ccgccaggct 120
ccagggaagg ggcttgagtg ggtctcggtt attaatagag ctggtgattc cgcctggtat 180
gcagactcag tgacgggccg attcaccatc tccagagaca acgccaagaa cacggtgtat 240
ctgcaaatgg acagcctgaa acctgaggac acggccatgt actactgtgc ggcagactcg 300
agggggtacg gtggtgactg gtacaagctc ctctcagact ttaattattg cggccagggg 360
acccaggtca ccgtctcctc a 381
<210> 283
<211> 378
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 283
caggtgcagc tggtggagtc tgggggaggc tcggtgcagg ctggagggtc tctgagactc 60
tcctgtgcag ccactgcgta caccgccagt ttctactgca tgggctggtt ccgccaggct 120
ccagggaagg agcgcgaggc ggtcgcaagt attaatgatg acggcgtcac aatgtacgca 180
gactccgtga agggccaatt caccatctcc caagacagcg ccacgaagac tctgtatctg 240
caaatgaacc gcctgaaacc tgaggacacc gccatgtact actgtgcggc caccccggaa 300
ggttactgct acgccgagag actttccacg tggagatata cgttctgggg ccaggggacc 360
caggtcaccg tctcctca 378
<210> 284
<211> 390
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 284
gaggtgcagc tggtggagtc tgggggaggg tcggtgcagt ctggagggtc tctgagactc 60
tcctgtgcag tctctggatc tggatacagc tatagtcgcg gctgcttcgc gtggttccag 120
cagcgtccag gaaaggagcg cgagggggtc gcaattatta atagcgatgg gcacacaaga 180
tactcagact ccgtgcaggg ccgattcatc atctcccaag acaaggccaa gaacacacta 240
tatctgcaaa tgaacagcct gaaacctgac gacacggcca tgtattactg tgcgtacgat 300
tgcagtcagt gttacgtgct tcgcgaccgc ttacgcctcc cagatacctt tactgactgg 360
ggccagggga cccaggtcac cgtctcctca 390
<210> 285
<211> 369
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 285
gaggtgcagc tggtggagag cggaggagga ctggtgcagc caggaggctc tctgagactg 60
tcctgcgccg tgagcggcaa catctacaac agaaatttca tgggatggtt taggcaggct 120
cctggcaagg gactggaggg cgtgtccgcc atctataccg gcacatctcg cacctactat 180
gctgactccg tgaagggcag gttcaccatc tctcgggata actccaagaa tacagtgtac 240
ctgcagatga actctctgag ggccgaggac acagccgtgt actattgtgc cgctgacctg 300
cgggatggct tttgggatac cggcgtgtgg aatacatggg gccagggcac cctggtgaca 360
gtgtccagc 369
<210> 286
<211> 369
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 286
gaggtgcagc tggtggagag cggaggagga ctggtgcagc caggaggctc tctgagactg 60
tcctgcgccg tgagcggcaa catctacaac agaaatttca tgggatggtt taggcaggct 120
cctggcaagg gactggaggg cgtgtccgcc atctataccg gcacatctcg cacctactat 180
gctgactccg tgaagggcag gttcaccatc tctcgggata actccaagaa tacagtgtac 240
ctgcagatga actctctgag ggccgaggac acagccgtgt actattgtgc cgctgacctg 300
cgggagggct tttgggatac cggcgtgtgg aatacatggg gccagggcac cctggtgaca 360
gtgtccagc 369
<210> 287
<211> 369
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 287
gaggtgcagc tggtggagtc cggaggagga ctggtgcagc caggaggctc tctgaggctg 60
tcctgcgccg tgagcggaaa catctacaac agaaatttca tgggatggtt taggcaggct 120
cctggcaagg gaagggaggg cgtgtctgct atctataccg gcacatccag gacctactat 180
gccgacagcg tgaagggcag gttcaccatc tctcgggata acgctaagaa tacagtgtac 240
ctgcagatga actccctgcg gccagaggac acagccgtgt actattgtgc cgctgacctg 300
agagatggct tttgggatac cggcgtgtgg aatacatggg gccagggcac cctggtgaca 360
gtgtccagc 369
<210> 288
<211> 369
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 288
gaggtgcagc tggtggagtc cggaggagga ctggtgcagc caggaggctc tctgaggctg 60
tcctgcgccg tgagcggaaa catctacaac agaaatttca tgggatggtt taggcaggct 120
cctggcaagg gaagggaggg cgtgtctgct atctataccg gcacatccag gacctactat 180
gccgacagcg tgaagggcag gttcaccatc tctcgggata acgctaagaa tacagtgtac 240
ctgcagatga actccctgcg gccagaggac acagccgtgt actattgtgc cgctgacctg 300
agagagggct tttgggatac cggcgtgtgg aatacatggg gccagggcac cctggtgaca 360
gtgtccagc 369
<210> 289
<211> 122
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 289
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Lys Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr Leu Asp Tyr Tyr
20 25 30
Ala Ile Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Ala Val
35 40 45
Ser Cys Ile Ser Ser Ser Asp Gly Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Lys Pro Gly Asp Thr Ala Val Tyr His Cys
85 90 95
Ala Thr Asp Arg Ala Cys Gly Ser Ser Trp Leu Gly Ala Glu Ser Trp
100 105 110
Ala Gln Gly Thr Gln Val Thr Val Ser Ser
115 120
<210> 290
<211> 112
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 290
Gln Val His Leu Val Asp Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile Thr Ser Arg Asn
20 25 30
Thr Met Gly Trp Tyr Arg Gln Val Pro Gly Lys Gln Arg Glu Leu Val
35 40 45
Ala Leu Ile Ala Thr Phe Val Thr His Tyr Ala Asp Ser Val Lys Gly
50 55 60
Arg Phe Thr Ile Ser Arg Asp Asn Ala Arg Lys Met Val Phe Leu Glu
65 70 75 80
Met Asn Ser Leu Gln Pro Glu Asp Thr Gly Ala Tyr Tyr Cys Tyr Val
85 90 95
Asp Val Ser Pro Tyr Trp Gly Arg Gly Thr Gln Val Thr Val Ser Ser
100 105 110
<210> 291
<211> 127
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 291
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Ser Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Tyr Thr Tyr Ile Pro Asn
20 25 30
Cys Met Ala Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Gly Val
35 40 45
Thr Leu Ile Phe Thr Gly Asp Gly Thr Ser Thr Tyr Val Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Gln Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Ala Ala Glu Arg Cys Ser Gly Ser Asn Asp Arg Ile Ser Phe Trp
100 105 110
Gly Ile Ser Tyr Trp Gly Gln Gly Thr Gln Val Thr Val Ser Ser
115 120 125
<210> 292
<211> 124
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 292
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Ser Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Thr Ala Ser Ala Tyr Thr Tyr Ser Asn Ile
20 25 30
Cys Leu Gly Trp Leu Arg Gln Ala Pro Gly Gly Gly Leu Glu Ala Val
35 40 45
Ala Thr Ile Tyr Ile Ala Asp Gln Thr Ser Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Arg Ile Ser Lys Asp Ala Ala Lys Asn Ala Val Tyr
65 70 75 80
Leu Gln Met Ser Ser Leu Arg Pro Glu Asp Thr Ala Met Tyr Tyr Cys
85 90 95
Ala Ser Arg Tyr Gly Ser Thr Cys Gly Glu Tyr Leu Ala Asp Tyr Thr
100 105 110
Ser Arg Ala Gln Gly Thr Gln Val Thr Val Ser Ser
115 120
<210> 293
<211> 123
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 293
Gln Met Gln Leu Val Glu Ser Gly Gly Gly Ser Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Val Ser Gly Tyr Ile Tyr Asn Arg Asn
20 25 30
Phe Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Gly Val
35 40 45
Ala Ala Ile Tyr Thr Gly Gly Pro Tyr Thr Tyr Tyr Thr Asp Ser Val
50 55 60
Gln Gly Arg Phe Thr Ile Ser Gln Asp Asn Thr Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Met Tyr Tyr Cys
85 90 95
Val Ser Asp Leu Ser Asp Gly Thr Trp Asp Gln Gly Arg Trp Asn Tyr
100 105 110
Trp Gly Gln Gly Thr Gln Val Thr Val Ser Ser
115 120
<210> 294
<211> 123
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 294
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Ser Ala Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Val Ser Gly Tyr Ile Tyr Asn Arg Asn
20 25 30
Phe Met Gly Trp Phe Arg Gln Val Pro Gly Lys Val Arg Glu Gly Val
35 40 45
Ala Ala Ile Tyr Thr Gly Thr Glu Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Gln Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Met Tyr Tyr Cys
85 90 95
Val Ala Asp Leu Arg Asp Gly Thr Trp Asp Thr Gly Val Trp Asn Thr
100 105 110
Trp Gly Gln Gly Thr Gln Val Thr Val Ser Ser
115 120
<210> 295
<211> 123
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 295
Gln Ile Gln Leu Val Glu Ser Gly Gly Gly Ser Ala Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Val Val Ser Gly Asn Ile Tyr Asn Arg Asn
20 25 30
Phe Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Val Arg Glu Gly Val
35 40 45
Ala Ala Ile Tyr Thr Gly Thr Ser Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Gln Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Met Tyr Tyr Cys
85 90 95
Ala Ala Asp Leu Arg Asp Gly Phe Trp Asp Thr Gly Val Trp Asn Thr
100 105 110
Trp Gly Gln Gly Thr Gln Val Thr Val Ser Ser
115 120
<210> 296
<211> 116
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 296
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Thr Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Thr Ala
20 25 30
Ala Met Ser Trp Val Arg Gln Val Pro Glu Glu Gly Leu Glu Trp Val
35 40 45
Ala Ser Ile Asp Ser Ser Gly Ser Arg Thr Tyr Tyr Ala Gly Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Leu Asn Ser Leu Lys Ala Glu Asp Thr Ala Met Tyr Tyr Cys
85 90 95
Ala Lys Asp His Met Ser Trp Leu Pro Arg Gly Gln Gly Thr Gln Val
100 105 110
Thr Val Ser Ser
115
<210> 297
<211> 122
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 297
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Ser Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Asp Ser Ser Tyr
20 25 30
Cys Gly Ala Trp Phe Arg Gln Val Pro Gly Lys Glu Arg Glu Gly Val
35 40 45
Ala Ile Ile Asp Arg Tyr Gly Gly Thr Met Tyr Lys Asp Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Lys Asp Thr Ala Lys Asn Ile Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Leu Glu Asp Thr Ala Met Tyr Tyr Cys Ala
85 90 95
Ala Ala Glu Tyr Arg Gly Ser Ser Cys Asp Ala Glu Ser Gly Tyr Trp
100 105 110
Gly Gln Gly Thr Gln Val Thr Val Ser Ser
115 120
<210> 298
<211> 122
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 298
Gln Val His Leu Met Glu Ser Gly Gly Gly Ser Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Thr Leu Ser Cys Ala Ala Ser Val Phe Thr Asp Ser Asn Tyr
20 25 30
Cys Met Ala Trp Phe Arg Gln Val Pro Gly Lys Glu Arg Glu Gly Val
35 40 45
Ala Ile Ile Asp Arg Tyr Gly Gly Thr Met Tyr Lys Asp Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Lys Asp Thr Ala Lys Asn Ile Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Leu Glu Asp Thr Ala Met Tyr Tyr Cys Ala
85 90 95
Ala Ala Gly Tyr Arg Gly Ser Ser Cys Asp Ala Asp Ser Gly Tyr Trp
100 105 110
Gly Gln Gly Thr Gln Val Thr Val Ser Ser
115 120
<210> 299
<211> 122
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 299
Gln Ile Gln Leu Val Glu Ser Gly Gly Gly Ser Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Asp Ser Ser Tyr
20 25 30
Cys Gly Ala Trp Phe Arg Gln Val Pro Gly Lys Glu Arg Glu Gly Val
35 40 45
Ala Ile Ile Asp Arg Tyr Gly Gly Thr Met Tyr Lys Asp Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Lys Asp Thr Ala Lys Asn Ile Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Leu Glu Asp Thr Ala Met Tyr Tyr Cys Ala
85 90 95
Ala Ala Glu Tyr Arg Gly Ser Ser Cys Asp Ala Glu Ser Gly Tyr Trp
100 105 110
Gly Gln Gly Thr Gln Val Thr Val Ser Ser
115 120
<210> 300
<211> 124
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 300
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Ser Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Tyr Thr Ala Gly Ser Leu
20 25 30
Cys Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Gly Val
35 40 45
Ala Ala Ile Tyr Thr Gly Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Gln Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Gln Tyr Tyr Cys
85 90 95
Gly Ala Gly Ser Arg Glu Asp Tyr Cys Asp Arg Gly Tyr Ile Tyr Asp
100 105 110
His Trp Gly Gln Gly Thr Gln Val Thr Val Ser Ser
115 120
<210> 301
<211> 125
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 301
Gln Val Lys Leu Val Glu Ser Gly Gly Gly Ser Val Gln Ala Gly Gly
1 5 10 15
Tyr Leu Arg Leu Ser Cys Ala Ala Ser Gly Asp Thr Asn Asn Leu Asn
20 25 30
Phe Arg Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Gly Val
35 40 45
Ala Val Ile Thr His Ser Gly Ser Thr Tyr Tyr Ala Glu Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Gln Asp Leu Ala Lys Asn Thr Met Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Met Tyr Tyr Cys Ala
85 90 95
Ala Ala Asp Val Trp Arg Ile Ser Trp Ser Phe Val Pro Glu Leu Phe
100 105 110
Ser Tyr Trp Gly Gln Gly Thr Gln Val Thr Val Ser Ser
115 120 125
<210> 302
<211> 127
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 302
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Ser Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Gly Ser Gly Phe Thr Phe Asn Asn Tyr
20 25 30
Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Gly Ile
35 40 45
Ala Gly Ile Trp Thr Gly Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Glu Asp Val Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asp Ser Leu Lys Pro Glu Asp Thr Ala Met Tyr Tyr Cys
85 90 95
Ala Ala Glu Arg Trp Asp Tyr Ser Asp Trp Arg Arg Leu Lys Arg Gly
100 105 110
Asp Tyr Asn Tyr Trp Gly Gln Gly Thr Gln Val Thr Val Ser Ser
115 120 125
<210> 303
<211> 130
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 303
Gln Val His Leu Met Glu Ser Gly Gly Gly Ser Val Pro Ser Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Val Ser Gly Ser Gly Tyr Ser Tyr Ser
20 25 30
Arg Gly Cys Phe Ala Trp Phe Gln Gln Arg Pro Gly Lys Glu Arg Glu
35 40 45
Gly Val Ala Ile Ile Asn Met Asp Gly His Thr Arg Tyr Ser Asp Ser
50 55 60
Val Gln Gly Arg Phe Ile Ile Ser Gln Asp Lys Ala Lys Asn Thr Leu
65 70 75 80
His Leu Gln Met Asn Thr Leu Arg Pro Asp Asp Thr Ala Met Tyr Tyr
85 90 95
Cys Ala Tyr Asp Arg Ser Gln Cys Tyr Val Leu Ser Asp Arg Leu Arg
100 105 110
Leu Pro Gly Thr Phe Ser Asp Trp Gly Gln Gly Thr Gln Val Thr Val
115 120 125
Ser Ser
130
<210> 304
<211> 123
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 304
Glu Val Gln Leu Ala Glu Ser Gly Gly Gly Ser Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Lys Leu Ser Cys Leu Ala Ser Gln Trp Ile Ser Ser Asp Cys
20 25 30
Gly Met Ala Trp Tyr Arg Gln Ala Pro Gly Lys Glu Arg Glu Leu Val
35 40 45
Ser Arg Ile Ser Ser Asp Asp Thr Thr Thr Tyr Ala Asp Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Gln Asp Ser Ala Lys Asn Thr Leu Tyr Leu
65 70 75 80
Gln Met Asn Lys Leu Lys Thr Glu Asp Thr Gly Val Tyr Tyr Cys Ala
85 90 95
Ala Glu Ala Lys Ser Thr Ile Thr Ser Leu Cys Tyr Pro Leu Asn Tyr
100 105 110
Trp Gly Gln Gly Thr Gln Val Thr Val Ser Ser
115 120
<210> 305
<211> 121
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 305
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Ser Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Thr Cys Ala Ala Thr Gly Tyr Ser Trp Arg Pro Asp
20 25 30
Cys Met Gly Trp Tyr Arg Gln Ala Ala Glu Lys Glu Arg Glu Gly Val
35 40 45
Ala Val Ile Asp Ala Asp Gly Ile Thr Ser Tyr Ala Asp Ala Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Asn Lys Ile Thr Leu Tyr Leu
65 70 75 80
Gln Met Leu Lys Pro Asp Asp Thr Gly Met Tyr Val Cys Val Val Gly
85 90 95
Trp Arg Val Ser Ser Gly Gly Asn Cys Gln Phe Asn Asp Tyr Trp Gly
100 105 110
Gln Gly Thr Gln Val Thr Val Ser Ser
115 120
<210> 306
<211> 126
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 306
Gln Val His Leu Met Glu Ser Gly Gly Gly Ala Val Gln Thr Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Val Ser Gly Ile Ser Ile Ser Pro Asp
20 25 30
Cys Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Lys Arg Glu Ala Val
35 40 45
Thr Thr Ile Phe Ala Asn Thr Gly Ser Ala Arg Tyr Gly Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ser Ser Gln Gly Asn Ala Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asp Ser Val Lys Leu Asp Asp Thr Gly Thr Tyr Tyr Cys
85 90 95
Ala Ala Arg Phe Thr Gly Gly Asp Cys Phe Asp His Gln Pro Leu Ala
100 105 110
Trp Arg Phe Trp Gly Gln Gly Thr Gln Val Thr Val Ser Ser
115 120 125
<210> 307
<211> 130
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 307
Glu Val Gln Leu Ala Glu Ser Gly Gly Gly Ser Val Gln Ser Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Val Ser Gly Ser Gly Tyr Ser Tyr Ser
20 25 30
Arg Gly Cys Phe Ala Trp Phe Gln Gln Arg Pro Gly Lys Glu Arg Glu
35 40 45
Gly Val Ala Ile Ile Asn Ser Asp Gly His Thr Ala Tyr Ser Asp Ser
50 55 60
Val Gln Gly Arg Phe Ile Ile Ser Gln Asp Lys Ala Lys Asn Thr Leu
65 70 75 80
Tyr Leu Gln Met Asn Ser Leu Lys Pro Asp Asp Thr Ala Met Tyr Tyr
85 90 95
Cys Ala Tyr Asp Arg Ser Gln Cys Tyr Val Leu Arg Asp Arg Leu Arg
100 105 110
Leu Pro Asp Thr Phe Thr Asp Trp Gly Gln Gly Thr Gln Val Thr Val
115 120 125
Ser Ser
130
<210> 308
<211> 126
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 308
Gln Val His Leu Val Glu Ser Gly Gly Ala Ser Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Thr Ala Tyr Thr Ala Ser Asn Tyr
20 25 30
Cys Met Gly Trp Phe Arg Gln Ser Pro Gly Lys Glu Arg Glu Ala Val
35 40 45
Ala Ser Ile Asn Asp Asp Gly Val Thr Ser Tyr Ala Asp Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Gln Asp Ser Ala Lys Lys Thr Leu Tyr Leu
65 70 75 80
Gln Met Asn Arg Leu Lys Pro Glu Asp Thr Ala Met Tyr Tyr Cys Ala
85 90 95
Ala Thr Pro Asp Gly Tyr Cys Tyr Ala Glu Arg Leu Ser Arg Trp Arg
100 105 110
Tyr Glu Phe Trp Gly Gln Gly Thr Gln Val Thr Val Ser Ser
115 120 125
<210> 309
<211> 126
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 309
Glu Val Gln Leu Ala Glu Ser Gly Gly Gly Ser Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Val Ile Ser Gly Thr Ser Ile Ser Pro Asp
20 25 30
Cys Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Lys Arg Glu Ala Val
35 40 45
Met Ser Ile Phe Thr Asn Thr Gly Ser Thr Arg Tyr Gly Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ser Ser Gln Gly Asn Ala Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asp Ser Leu Lys Leu Asp Asp Thr Ala Thr Tyr Tyr Cys
85 90 95
Ala Ala Arg Tyr Thr Gly Gly Asp Cys Phe Asn Leu Glu Pro Leu Ala
100 105 110
Trp Arg Phe Trp Gly Gln Gly Thr Gln Val Thr Val Ser Ser
115 120 125
<210> 310
<211> 121
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 310
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Ser Val Gln Ala Gly Gly
1 5 10 15
Pro Leu Arg Leu Thr Cys Ala Ala Thr Gly Tyr Ser Trp Arg Pro Asp
20 25 30
Cys Met Gly Trp Tyr Arg Gln Ala Ala Glu Lys Glu Arg Glu Gly Val
35 40 45
Ala Val Ile Asp Ala Asp Gly Ile Thr Ser Tyr Ala Asp Ala Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Asn Asn Ile Thr Leu Tyr Leu
65 70 75 80
Gln Met Leu Lys Pro Asp Asp Thr Gly Met Tyr Val Cys Val Ile Gly
85 90 95
Trp Arg Val Ser Ser Gly Gly Asn Cys Gln Phe Asn Asp Tyr Trp Gly
100 105 110
Gln Gly Thr Gln Val Thr Val Ser Ser
115 120
<210> 311
<211> 130
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 311
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Ser Val Gln Ser Gly Gly
1 5 10 15
Ser Leu Lys Leu Ser Cys Ala Val Ser Gly Ser Gly Tyr Ser Tyr Ser
20 25 30
Arg Gly Cys Phe Ala Trp Phe Gln Gln Arg Pro Gly Lys Glu Arg Glu
35 40 45
Gly Val Ala Ile Ile Asn Ser Asp Gly His Thr Arg Tyr Ser Asp Ser
50 55 60
Val Gln Gly Arg Phe Ile Ile Ser Gln Asp Lys Ala Lys Asn Thr Leu
65 70 75 80
Tyr Leu Gln Met Asn Ser Leu Lys Pro Asp Asp Ala Ala Met Tyr Tyr
85 90 95
Cys Ala Tyr Asp Arg Asn Gln Cys Tyr Val Leu Leu Asp Arg Leu Arg
100 105 110
Leu Pro Gly Thr Phe Ser Asp Trp Gly Gln Gly Thr Gln Val Thr Val
115 120 125
Ser Ser
130
<210> 312
<211> 130
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 312
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Ser Val Gln Ser Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Val Ser Gly Ser Gly Tyr Ser Tyr Ser
20 25 30
Arg Gly Cys Phe Ala Trp Phe Gln Gln Arg Pro Gly Lys Glu Arg Glu
35 40 45
Gly Val Ala Ile Ile Asn Ser Asp Gly His Thr Arg Tyr Ser Asp Ser
50 55 60
Val Gln Gly Arg Phe Ile Ile Ser Gln Asp Lys Ala Lys Asn Thr Leu
65 70 75 80
Tyr Leu Gln Met Asn Ser Leu Lys Pro Asp Asp Thr Ala Met Tyr Tyr
85 90 95
Cys Ala Tyr Asp Cys Ser Gln Cys Tyr Val Leu Arg Asp Arg Leu Arg
100 105 110
Leu Pro Asp Thr Phe Thr Asp Trp Gly Gln Gly Thr Gln Val Thr Val
115 120 125
Ser Ser
130
<210> 313
<211> 130
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 313
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Ser Val Gln Ser Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Val Ser Gly Ser Gly Tyr Ser Tyr Asn
20 25 30
Arg Gly Cys Phe Ala Trp Phe Gln Gln Arg Pro Gly Lys Glu Arg Glu
35 40 45
Gly Val Ala Ile Ile Asn Ser Asp Gly His Thr Thr Tyr Gly Asp Ser
50 55 60
Val Gln Gly Arg Phe Ile Ile Ser Gln Asp Lys Ala Lys Asn Thr Leu
65 70 75 80
Asp Leu Gln Met Asn Ser Leu Lys Pro Asp Asp Thr Ala Met Tyr Tyr
85 90 95
Cys Ala Tyr Asp Arg Asn Gln Cys Tyr Val Leu Arg Asp Arg Leu Arg
100 105 110
Leu Pro Asp Thr Phe Thr Asp Trp Gly Gln Gly Thr Gln Val Thr Val
115 120 125
Ser Ser
130
<210> 314
<211> 130
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 314
Gln Val Lys Leu Val Glu Ser Gly Gly Gly Leu Val Gln Ser Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Val Ser Gly Ser Gly Tyr Ser Tyr Ser
20 25 30
Arg Gly Cys Phe Ala Trp Phe Gln Gln Arg Pro Gly Lys Glu Arg Glu
35 40 45
Gly Val Ala Ile Ile Asn Met Asp Gly His Thr Met Tyr Ser Asp Leu
50 55 60
Ala Gln Gly Arg Phe Ile Ile Ser Gln Asp Lys Ala Lys Asn Thr Leu
65 70 75 80
Tyr Leu Gln Met Asn Ser Leu Lys Pro Asp Asp Thr Ala Met Tyr Tyr
85 90 95
Cys Ala Tyr Asp Arg Asp Gln Cys Tyr Val Leu Arg Asp Arg Leu Arg
100 105 110
Leu Pro Asp Thr Phe Asn Asp Trp Gly Gln Gly Thr Gln Val Thr Val
115 120 125
Ser Ser
130
<210> 315
<211> 126
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 315
Gln Ile Gln Leu Val Glu Ser Gly Gly Gly Ser Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Val Thr Gly Ile Ser Ile Ser Pro Asp
20 25 30
Cys Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Lys Arg Glu Ala Val
35 40 45
Ala Thr Ile Phe Thr Asn Thr Ala Ser Thr Arg Tyr Gly Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ser Ser Gln Gly Asn Gly Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asp Ser Leu Asn Val Asp Asp Thr Ala Thr Tyr Tyr Cys
85 90 95
Ala Ala Arg Tyr Thr Gly Gly Asn Cys Phe Asn Leu Glu Pro Leu Ala
100 105 110
Trp His Phe Trp Gly Gln Gly Thr Gln Val Thr Val Ser Ser
115 120 125
<210> 316
<211> 126
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 316
Gln Val His Leu Met Glu Ser Gly Gly Gly Ser Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Val Val Ser Gly Ile Ser Ile Ser Pro Asp
20 25 30
Cys Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Lys Arg Glu Ala Val
35 40 45
Ala Thr Ile Phe Thr Asn Thr Arg Arg Thr Arg Tyr Gly Asp Ser Val
50 55 60
Lys Gly Arg Val Thr Ser Ser Gln Gly Asn Ala Lys Asn Thr Leu Tyr
65 70 75 80
Leu Lys Met Asp Asn Leu Arg His Asp Asp Thr Ala Thr Tyr Tyr Cys
85 90 95
Ala Ala Arg Tyr Thr Gly Gly Asp Cys Phe Asn Leu Asp Pro Leu Ser
100 105 110
Trp Arg Phe Trp Gly Gln Gly Thr Gln Val Thr Val Ser Ser
115 120 125
<210> 317
<211> 126
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 317
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Ser Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Val Ser Gly Ile Ser Ile Ser Pro Asp
20 25 30
Cys Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Lys Arg Glu Ala Val
35 40 45
Ala Thr Ile Phe Thr Asn Thr Arg Ser Thr Arg Tyr Gly Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ser Ser Gln Gly Asn Ala Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asp Ser Leu Lys Leu Asp Asp Thr Ala Thr Tyr Tyr Cys
85 90 95
Ala Ala Arg Tyr Thr Gly Gly Asp Cys Phe Asn Leu Glu Pro Val Ala
100 105 110
Trp Arg Phe Trp Gly Gln Gly Thr Gln Val Thr Val Ser Ser
115 120 125
<210> 318
<211> 123
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 318
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Val Trp
20 25 30
Ser Met Ser Trp Val Arg Gln Ala Pro Gly Glu Gly Leu Glu Trp Val
35 40 45
Ser Thr Ile Thr Gly Ser Gly Ala Gln Thr Tyr Tyr Ala Ser Ser Val
50 55 60
Arg Gly Arg Phe Thr Thr Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Lys Ser Asp Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Glu Arg Gly Asn Gly Gln Thr Ala Met Glu Ala Leu Ile Asn Pro Pro
100 105 110
Glu Arg Pro Gly Thr Gln Val Thr Val Ser Ser
115 120
<210> 319
<211> 127
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 319
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Leu Met Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Trp Met Tyr Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Val Ile Asn Arg Ala Gly Asp Ser Ala Trp Tyr Ala Asp Ser Val
50 55 60
Thr Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asp Ser Leu Lys Pro Glu Asp Thr Ala Met Tyr Tyr Cys
85 90 95
Ala Ala Asp Ser Arg Gly Tyr Gly Gly Asp Trp Tyr Lys Leu Leu Ser
100 105 110
Asp Phe Asn Tyr Cys Gly Gln Gly Thr Gln Val Thr Val Ser Ser
115 120 125
<210> 320
<211> 126
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 320
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Ser Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Thr Ala Tyr Thr Ala Ser Phe Tyr
20 25 30
Cys Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Ala Val
35 40 45
Ala Ser Ile Asn Asp Asp Gly Val Thr Met Tyr Ala Asp Ser Val Lys
50 55 60
Gly Gln Phe Thr Ile Ser Gln Asp Ser Ala Thr Lys Thr Leu Tyr Leu
65 70 75 80
Gln Met Asn Arg Leu Lys Pro Glu Asp Thr Ala Met Tyr Tyr Cys Ala
85 90 95
Ala Thr Pro Glu Gly Tyr Cys Tyr Ala Glu Arg Leu Ser Thr Trp Arg
100 105 110
Tyr Thr Phe Trp Gly Gln Gly Thr Gln Val Thr Val Ser Ser
115 120 125
<210> 321
<211> 123
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 321
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Val Ser Gly Asn Ile Tyr Asn Arg Asn
20 25 30
Phe Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Gly Leu Glu Gly Val
35 40 45
Ser Ala Ile Tyr Thr Gly Thr Ser Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ala Asp Leu Arg Asp Gly Phe Trp Asp Thr Gly Val Trp Asn Thr
100 105 110
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 322
<211> 123
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 322
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Val Ser Gly Asn Ile Tyr Asn Arg Asn
20 25 30
Phe Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Gly Leu Glu Gly Val
35 40 45
Ser Ala Ile Tyr Thr Gly Thr Ser Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ala Asp Leu Arg Glu Gly Phe Trp Asp Thr Gly Val Trp Asn Thr
100 105 110
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 323
<211> 123
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 323
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Val Ser Gly Asn Ile Tyr Asn Arg Asn
20 25 30
Phe Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Gly Arg Glu Gly Val
35 40 45
Ser Ala Ile Tyr Thr Gly Thr Ser Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ala Asp Leu Arg Asp Gly Phe Trp Asp Thr Gly Val Trp Asn Thr
100 105 110
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 324
<211> 123
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 324
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Val Ser Gly Asn Ile Tyr Asn Arg Asn
20 25 30
Phe Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Gly Arg Glu Gly Val
35 40 45
Ser Ala Ile Tyr Thr Gly Thr Ser Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ala Asp Leu Arg Glu Gly Phe Trp Asp Thr Gly Val Trp Asn Thr
100 105 110
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 325
<211> 351
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 325
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Lys Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr Leu Asp Tyr Tyr
20 25 30
Ala Ile Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Ala Val
35 40 45
Ser Cys Ile Ser Ser Ser Asp Gly Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Lys Pro Gly Asp Thr Ala Val Tyr His Cys
85 90 95
Ala Thr Asp Arg Ala Cys Gly Ser Ser Trp Leu Gly Ala Glu Ser Trp
100 105 110
Ala Gln Gly Thr Gln Val Thr Val Ser Ser Glu Ser Lys Tyr Gly Pro
115 120 125
Pro Cys Pro Pro Cys Pro Ala Pro Glu Phe Leu Gly Gly Pro Ser Val
130 135 140
Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr
145 150 155 160
Pro Glu Val Thr Cys Val Val Val Asp Val Ser Gln Glu Asp Pro Glu
165 170 175
Val Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys
180 185 190
Thr Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr Tyr Arg Val Val Ser
195 200 205
Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys
210 215 220
Cys Lys Val Ser Asn Lys Gly Leu Pro Ser Ser Ile Glu Lys Thr Ile
225 230 235 240
Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro
245 250 255
Pro Ser Gln Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu
260 265 270
Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn
275 280 285
Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser
290 295 300
Asp Gly Ser Phe Phe Leu Tyr Ser Arg Leu Thr Val Asp Lys Ser Arg
305 310 315 320
Trp Gln Glu Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu
325 330 335
His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Leu Gly Lys
340 345 350
<210> 326
<211> 341
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 326
Gln Val His Leu Val Asp Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile Thr Ser Arg Asn
20 25 30
Thr Met Gly Trp Tyr Arg Gln Val Pro Gly Lys Gln Arg Glu Leu Val
35 40 45
Ala Leu Ile Ala Thr Phe Val Thr His Tyr Ala Asp Ser Val Lys Gly
50 55 60
Arg Phe Thr Ile Ser Arg Asp Asn Ala Arg Lys Met Val Phe Leu Glu
65 70 75 80
Met Asn Ser Leu Gln Pro Glu Asp Thr Gly Ala Tyr Tyr Cys Tyr Val
85 90 95
Asp Val Ser Pro Tyr Trp Gly Arg Gly Thr Gln Val Thr Val Ser Ser
100 105 110
Glu Ser Lys Tyr Gly Pro Pro Cys Pro Pro Cys Pro Ala Pro Glu Phe
115 120 125
Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr
130 135 140
Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val
145 150 155 160
Ser Gln Glu Asp Pro Glu Val Gln Phe Asn Trp Tyr Val Asp Gly Val
165 170 175
Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Phe Asn Ser
180 185 190
Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu
195 200 205
Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Gly Leu Pro Ser
210 215 220
Ser Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro
225 230 235 240
Gln Val Tyr Thr Leu Pro Pro Ser Gln Glu Glu Met Thr Lys Asn Gln
245 250 255
Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala
260 265 270
Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr
275 280 285
Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Arg Leu
290 295 300
Thr Val Asp Lys Ser Arg Trp Gln Glu Gly Asn Val Phe Ser Cys Ser
305 310 315 320
Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser
325 330 335
Leu Ser Leu Gly Lys
340
<210> 327
<211> 356
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 327
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Ser Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Tyr Thr Tyr Ile Pro Asn
20 25 30
Cys Met Ala Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Gly Val
35 40 45
Thr Leu Ile Phe Thr Gly Asp Gly Thr Ser Thr Tyr Val Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Gln Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Ala Ala Glu Arg Cys Ser Gly Ser Asn Asp Arg Ile Ser Phe Trp
100 105 110
Gly Ile Ser Tyr Trp Gly Gln Gly Thr Gln Val Thr Val Ser Ser Glu
115 120 125
Ser Lys Tyr Gly Pro Pro Cys Pro Pro Cys Pro Ala Pro Glu Phe Leu
130 135 140
Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu
145 150 155 160
Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser
165 170 175
Gln Glu Asp Pro Glu Val Gln Phe Asn Trp Tyr Val Asp Gly Val Glu
180 185 190
Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr
195 200 205
Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn
210 215 220
Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Gly Leu Pro Ser Ser
225 230 235 240
Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln
245 250 255
Val Tyr Thr Leu Pro Pro Ser Gln Glu Glu Met Thr Lys Asn Gln Val
260 265 270
Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val
275 280 285
Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro
290 295 300
Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Arg Leu Thr
305 310 315 320
Val Asp Lys Ser Arg Trp Gln Glu Gly Asn Val Phe Ser Cys Ser Val
325 330 335
Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu
340 345 350
Ser Leu Gly Lys
355
<210> 328
<211> 353
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 328
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Ser Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Thr Ala Ser Ala Tyr Thr Tyr Ser Asn Ile
20 25 30
Cys Leu Gly Trp Leu Arg Gln Ala Pro Gly Gly Gly Leu Glu Ala Val
35 40 45
Ala Thr Ile Tyr Ile Ala Asp Gln Thr Ser Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Arg Ile Ser Lys Asp Ala Ala Lys Asn Ala Val Tyr
65 70 75 80
Leu Gln Met Ser Ser Leu Arg Pro Glu Asp Thr Ala Met Tyr Tyr Cys
85 90 95
Ala Ser Arg Tyr Gly Ser Thr Cys Gly Glu Tyr Leu Ala Asp Tyr Thr
100 105 110
Ser Arg Ala Gln Gly Thr Gln Val Thr Val Ser Ser Glu Ser Lys Tyr
115 120 125
Gly Pro Pro Cys Pro Pro Cys Pro Ala Pro Glu Phe Leu Gly Gly Pro
130 135 140
Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser
145 150 155 160
Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser Gln Glu Asp
165 170 175
Pro Glu Val Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn
180 185 190
Ala Lys Thr Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr Tyr Arg Val
195 200 205
Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu
210 215 220
Tyr Lys Cys Lys Val Ser Asn Lys Gly Leu Pro Ser Ser Ile Glu Lys
225 230 235 240
Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr
245 250 255
Leu Pro Pro Ser Gln Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr
260 265 270
Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu
275 280 285
Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu
290 295 300
Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Arg Leu Thr Val Asp Lys
305 310 315 320
Ser Arg Trp Gln Glu Gly Asn Val Phe Ser Cys Ser Val Met His Glu
325 330 335
Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Leu Gly
340 345 350
Lys
<210> 329
<211> 352
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 329
Gln Met Gln Leu Val Glu Ser Gly Gly Gly Ser Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Val Ser Gly Tyr Ile Tyr Asn Arg Asn
20 25 30
Phe Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Gly Val
35 40 45
Ala Ala Ile Tyr Thr Gly Gly Pro Tyr Thr Tyr Tyr Thr Asp Ser Val
50 55 60
Gln Gly Arg Phe Thr Ile Ser Gln Asp Asn Thr Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Met Tyr Tyr Cys
85 90 95
Val Ser Asp Leu Ser Asp Gly Thr Trp Asp Gln Gly Arg Trp Asn Tyr
100 105 110
Trp Gly Gln Gly Thr Gln Val Thr Val Ser Ser Glu Ser Lys Tyr Gly
115 120 125
Pro Pro Cys Pro Pro Cys Pro Ala Pro Glu Phe Leu Gly Gly Pro Ser
130 135 140
Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg
145 150 155 160
Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser Gln Glu Asp Pro
165 170 175
Glu Val Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala
180 185 190
Lys Thr Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr Tyr Arg Val Val
195 200 205
Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr
210 215 220
Lys Cys Lys Val Ser Asn Lys Gly Leu Pro Ser Ser Ile Glu Lys Thr
225 230 235 240
Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu
245 250 255
Pro Pro Ser Gln Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys
260 265 270
Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser
275 280 285
Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp
290 295 300
Ser Asp Gly Ser Phe Phe Leu Tyr Ser Arg Leu Thr Val Asp Lys Ser
305 310 315 320
Arg Trp Gln Glu Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala
325 330 335
Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Leu Gly Lys
340 345 350
<210> 330
<211> 352
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 330
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Ser Ala Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Val Ser Gly Tyr Ile Tyr Asn Arg Asn
20 25 30
Phe Met Gly Trp Phe Arg Gln Val Pro Gly Lys Val Arg Glu Gly Val
35 40 45
Ala Ala Ile Tyr Thr Gly Thr Glu Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Gln Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Met Tyr Tyr Cys
85 90 95
Val Ala Asp Leu Arg Asp Gly Thr Trp Asp Thr Gly Val Trp Asn Thr
100 105 110
Trp Gly Gln Gly Thr Gln Val Thr Val Ser Ser Glu Ser Lys Tyr Gly
115 120 125
Pro Pro Cys Pro Pro Cys Pro Ala Pro Glu Phe Leu Gly Gly Pro Ser
130 135 140
Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg
145 150 155 160
Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser Gln Glu Asp Pro
165 170 175
Glu Val Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala
180 185 190
Lys Thr Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr Tyr Arg Val Val
195 200 205
Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr
210 215 220
Lys Cys Lys Val Ser Asn Lys Gly Leu Pro Ser Ser Ile Glu Lys Thr
225 230 235 240
Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu
245 250 255
Pro Pro Ser Gln Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys
260 265 270
Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser
275 280 285
Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp
290 295 300
Ser Asp Gly Ser Phe Phe Leu Tyr Ser Arg Leu Thr Val Asp Lys Ser
305 310 315 320
Arg Trp Gln Glu Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala
325 330 335
Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Leu Gly Lys
340 345 350
<210> 331
<211> 352
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 331
Gln Ile Gln Leu Val Glu Ser Gly Gly Gly Ser Ala Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Val Val Ser Gly Asn Ile Tyr Asn Arg Asn
20 25 30
Phe Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Val Arg Glu Gly Val
35 40 45
Ala Ala Ile Tyr Thr Gly Thr Ser Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Gln Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Met Tyr Tyr Cys
85 90 95
Ala Ala Asp Leu Arg Asp Gly Phe Trp Asp Thr Gly Val Trp Asn Thr
100 105 110
Trp Gly Gln Gly Thr Gln Val Thr Val Ser Ser Glu Ser Lys Tyr Gly
115 120 125
Pro Pro Cys Pro Pro Cys Pro Ala Pro Glu Phe Leu Gly Gly Pro Ser
130 135 140
Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg
145 150 155 160
Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser Gln Glu Asp Pro
165 170 175
Glu Val Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala
180 185 190
Lys Thr Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr Tyr Arg Val Val
195 200 205
Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr
210 215 220
Lys Cys Lys Val Ser Asn Lys Gly Leu Pro Ser Ser Ile Glu Lys Thr
225 230 235 240
Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu
245 250 255
Pro Pro Ser Gln Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys
260 265 270
Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser
275 280 285
Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp
290 295 300
Ser Asp Gly Ser Phe Phe Leu Tyr Ser Arg Leu Thr Val Asp Lys Ser
305 310 315 320
Arg Trp Gln Glu Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala
325 330 335
Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Leu Gly Lys
340 345 350
<210> 332
<211> 345
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 332
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Thr Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Thr Ala
20 25 30
Ala Met Ser Trp Val Arg Gln Val Pro Glu Glu Gly Leu Glu Trp Val
35 40 45
Ala Ser Ile Asp Ser Ser Gly Ser Arg Thr Tyr Tyr Ala Gly Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Leu Asn Ser Leu Lys Ala Glu Asp Thr Ala Met Tyr Tyr Cys
85 90 95
Ala Lys Asp His Met Ser Trp Leu Pro Arg Gly Gln Gly Thr Gln Val
100 105 110
Thr Val Ser Ser Glu Ser Lys Tyr Gly Pro Pro Cys Pro Pro Cys Pro
115 120 125
Ala Pro Glu Phe Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys
130 135 140
Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val
145 150 155 160
Val Val Asp Val Ser Gln Glu Asp Pro Glu Val Gln Phe Asn Trp Tyr
165 170 175
Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu
180 185 190
Gln Phe Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His
195 200 205
Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys
210 215 220
Gly Leu Pro Ser Ser Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln
225 230 235 240
Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Gln Glu Glu Met
245 250 255
Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro
260 265 270
Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn
275 280 285
Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu
290 295 300
Tyr Ser Arg Leu Thr Val Asp Lys Ser Arg Trp Gln Glu Gly Asn Val
305 310 315 320
Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln
325 330 335
Lys Ser Leu Ser Leu Ser Leu Gly Lys
340 345
<210> 333
<211> 351
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 333
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Ser Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Asp Ser Ser Tyr
20 25 30
Cys Gly Ala Trp Phe Arg Gln Val Pro Gly Lys Glu Arg Glu Gly Val
35 40 45
Ala Ile Ile Asp Arg Tyr Gly Gly Thr Met Tyr Lys Asp Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Lys Asp Thr Ala Lys Asn Ile Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Leu Glu Asp Thr Ala Met Tyr Tyr Cys Ala
85 90 95
Ala Ala Glu Tyr Arg Gly Ser Ser Cys Asp Ala Glu Ser Gly Tyr Trp
100 105 110
Gly Gln Gly Thr Gln Val Thr Val Ser Ser Glu Ser Lys Tyr Gly Pro
115 120 125
Pro Cys Pro Pro Cys Pro Ala Pro Glu Phe Leu Gly Gly Pro Ser Val
130 135 140
Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr
145 150 155 160
Pro Glu Val Thr Cys Val Val Val Asp Val Ser Gln Glu Asp Pro Glu
165 170 175
Val Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys
180 185 190
Thr Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr Tyr Arg Val Val Ser
195 200 205
Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys
210 215 220
Cys Lys Val Ser Asn Lys Gly Leu Pro Ser Ser Ile Glu Lys Thr Ile
225 230 235 240
Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro
245 250 255
Pro Ser Gln Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu
260 265 270
Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn
275 280 285
Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser
290 295 300
Asp Gly Ser Phe Phe Leu Tyr Ser Arg Leu Thr Val Asp Lys Ser Arg
305 310 315 320
Trp Gln Glu Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu
325 330 335
His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Leu Gly Lys
340 345 350
<210> 334
<211> 351
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 334
Gln Val His Leu Met Glu Ser Gly Gly Gly Ser Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Thr Leu Ser Cys Ala Ala Ser Val Phe Thr Asp Ser Asn Tyr
20 25 30
Cys Met Ala Trp Phe Arg Gln Val Pro Gly Lys Glu Arg Glu Gly Val
35 40 45
Ala Ile Ile Asp Arg Tyr Gly Gly Thr Met Tyr Lys Asp Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Lys Asp Thr Ala Lys Asn Ile Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Leu Glu Asp Thr Ala Met Tyr Tyr Cys Ala
85 90 95
Ala Ala Gly Tyr Arg Gly Ser Ser Cys Asp Ala Asp Ser Gly Tyr Trp
100 105 110
Gly Gln Gly Thr Gln Val Thr Val Ser Ser Glu Ser Lys Tyr Gly Pro
115 120 125
Pro Cys Pro Pro Cys Pro Ala Pro Glu Phe Leu Gly Gly Pro Ser Val
130 135 140
Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr
145 150 155 160
Pro Glu Val Thr Cys Val Val Val Asp Val Ser Gln Glu Asp Pro Glu
165 170 175
Val Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys
180 185 190
Thr Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr Tyr Arg Val Val Ser
195 200 205
Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys
210 215 220
Cys Lys Val Ser Asn Lys Gly Leu Pro Ser Ser Ile Glu Lys Thr Ile
225 230 235 240
Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro
245 250 255
Pro Ser Gln Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu
260 265 270
Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn
275 280 285
Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser
290 295 300
Asp Gly Ser Phe Phe Leu Tyr Ser Arg Leu Thr Val Asp Lys Ser Arg
305 310 315 320
Trp Gln Glu Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu
325 330 335
His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Leu Gly Lys
340 345 350
<210> 335
<211> 351
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 335
Gln Ile Gln Leu Val Glu Ser Gly Gly Gly Ser Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Asp Ser Ser Tyr
20 25 30
Cys Gly Ala Trp Phe Arg Gln Val Pro Gly Lys Glu Arg Glu Gly Val
35 40 45
Ala Ile Ile Asp Arg Tyr Gly Gly Thr Met Tyr Lys Asp Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Lys Asp Thr Ala Lys Asn Ile Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Leu Glu Asp Thr Ala Met Tyr Tyr Cys Ala
85 90 95
Ala Ala Glu Tyr Arg Gly Ser Ser Cys Asp Ala Glu Ser Gly Tyr Trp
100 105 110
Gly Gln Gly Thr Gln Val Thr Val Ser Ser Glu Ser Lys Tyr Gly Pro
115 120 125
Pro Cys Pro Pro Cys Pro Ala Pro Glu Phe Leu Gly Gly Pro Ser Val
130 135 140
Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr
145 150 155 160
Pro Glu Val Thr Cys Val Val Val Asp Val Ser Gln Glu Asp Pro Glu
165 170 175
Val Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys
180 185 190
Thr Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr Tyr Arg Val Val Ser
195 200 205
Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys
210 215 220
Cys Lys Val Ser Asn Lys Gly Leu Pro Ser Ser Ile Glu Lys Thr Ile
225 230 235 240
Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro
245 250 255
Pro Ser Gln Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu
260 265 270
Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn
275 280 285
Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser
290 295 300
Asp Gly Ser Phe Phe Leu Tyr Ser Arg Leu Thr Val Asp Lys Ser Arg
305 310 315 320
Trp Gln Glu Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu
325 330 335
His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Leu Gly Lys
340 345 350
<210> 336
<211> 353
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 336
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Ser Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Tyr Thr Ala Gly Ser Leu
20 25 30
Cys Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Gly Val
35 40 45
Ala Ala Ile Tyr Thr Gly Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Gln Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Gln Tyr Tyr Cys
85 90 95
Gly Ala Gly Ser Arg Glu Asp Tyr Cys Asp Arg Gly Tyr Ile Tyr Asp
100 105 110
His Trp Gly Gln Gly Thr Gln Val Thr Val Ser Ser Glu Ser Lys Tyr
115 120 125
Gly Pro Pro Cys Pro Pro Cys Pro Ala Pro Glu Phe Leu Gly Gly Pro
130 135 140
Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser
145 150 155 160
Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser Gln Glu Asp
165 170 175
Pro Glu Val Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn
180 185 190
Ala Lys Thr Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr Tyr Arg Val
195 200 205
Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu
210 215 220
Tyr Lys Cys Lys Val Ser Asn Lys Gly Leu Pro Ser Ser Ile Glu Lys
225 230 235 240
Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr
245 250 255
Leu Pro Pro Ser Gln Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr
260 265 270
Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu
275 280 285
Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu
290 295 300
Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Arg Leu Thr Val Asp Lys
305 310 315 320
Ser Arg Trp Gln Glu Gly Asn Val Phe Ser Cys Ser Val Met His Glu
325 330 335
Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Leu Gly
340 345 350
Lys
<210> 337
<211> 354
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 337
Gln Val Lys Leu Val Glu Ser Gly Gly Gly Ser Val Gln Ala Gly Gly
1 5 10 15
Tyr Leu Arg Leu Ser Cys Ala Ala Ser Gly Asp Thr Asn Asn Leu Asn
20 25 30
Phe Arg Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Gly Val
35 40 45
Ala Val Ile Thr His Ser Gly Ser Thr Tyr Tyr Ala Glu Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Gln Asp Leu Ala Lys Asn Thr Met Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Met Tyr Tyr Cys Ala
85 90 95
Ala Ala Asp Val Trp Arg Ile Ser Trp Ser Phe Val Pro Glu Leu Phe
100 105 110
Ser Tyr Trp Gly Gln Gly Thr Gln Val Thr Val Ser Ser Glu Ser Lys
115 120 125
Tyr Gly Pro Pro Cys Pro Pro Cys Pro Ala Pro Glu Phe Leu Gly Gly
130 135 140
Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile
145 150 155 160
Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser Gln Glu
165 170 175
Asp Pro Glu Val Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val His
180 185 190
Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr Tyr Arg
195 200 205
Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys
210 215 220
Glu Tyr Lys Cys Lys Val Ser Asn Lys Gly Leu Pro Ser Ser Ile Glu
225 230 235 240
Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr
245 250 255
Thr Leu Pro Pro Ser Gln Glu Glu Met Thr Lys Asn Gln Val Ser Leu
260 265 270
Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp
275 280 285
Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val
290 295 300
Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Arg Leu Thr Val Asp
305 310 315 320
Lys Ser Arg Trp Gln Glu Gly Asn Val Phe Ser Cys Ser Val Met His
325 330 335
Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Leu
340 345 350
Gly Lys
<210> 338
<211> 356
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 338
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Ser Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Gly Ser Gly Phe Thr Phe Asn Asn Tyr
20 25 30
Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Gly Ile
35 40 45
Ala Gly Ile Trp Thr Gly Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Glu Asp Val Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asp Ser Leu Lys Pro Glu Asp Thr Ala Met Tyr Tyr Cys
85 90 95
Ala Ala Glu Arg Trp Asp Tyr Ser Asp Trp Arg Arg Leu Lys Arg Gly
100 105 110
Asp Tyr Asn Tyr Trp Gly Gln Gly Thr Gln Val Thr Val Ser Ser Glu
115 120 125
Ser Lys Tyr Gly Pro Pro Cys Pro Pro Cys Pro Ala Pro Glu Phe Leu
130 135 140
Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu
145 150 155 160
Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser
165 170 175
Gln Glu Asp Pro Glu Val Gln Phe Asn Trp Tyr Val Asp Gly Val Glu
180 185 190
Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr
195 200 205
Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn
210 215 220
Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Gly Leu Pro Ser Ser
225 230 235 240
Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln
245 250 255
Val Tyr Thr Leu Pro Pro Ser Gln Glu Glu Met Thr Lys Asn Gln Val
260 265 270
Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val
275 280 285
Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro
290 295 300
Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Arg Leu Thr
305 310 315 320
Val Asp Lys Ser Arg Trp Gln Glu Gly Asn Val Phe Ser Cys Ser Val
325 330 335
Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu
340 345 350
Ser Leu Gly Lys
355
<210> 339
<211> 359
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 339
Gln Val His Leu Met Glu Ser Gly Gly Gly Ser Val Pro Ser Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Val Ser Gly Ser Gly Tyr Ser Tyr Ser
20 25 30
Arg Gly Cys Phe Ala Trp Phe Gln Gln Arg Pro Gly Lys Glu Arg Glu
35 40 45
Gly Val Ala Ile Ile Asn Met Asp Gly His Thr Arg Tyr Ser Asp Ser
50 55 60
Val Gln Gly Arg Phe Ile Ile Ser Gln Asp Lys Ala Lys Asn Thr Leu
65 70 75 80
His Leu Gln Met Asn Thr Leu Arg Pro Asp Asp Thr Ala Met Tyr Tyr
85 90 95
Cys Ala Tyr Asp Arg Ser Gln Cys Tyr Val Leu Ser Asp Arg Leu Arg
100 105 110
Leu Pro Gly Thr Phe Ser Asp Trp Gly Gln Gly Thr Gln Val Thr Val
115 120 125
Ser Ser Glu Ser Lys Tyr Gly Pro Pro Cys Pro Pro Cys Pro Ala Pro
130 135 140
Glu Phe Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys
145 150 155 160
Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val
165 170 175
Asp Val Ser Gln Glu Asp Pro Glu Val Gln Phe Asn Trp Tyr Val Asp
180 185 190
Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Phe
195 200 205
Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp
210 215 220
Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Gly Leu
225 230 235 240
Pro Ser Ser Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg
245 250 255
Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Gln Glu Glu Met Thr Lys
260 265 270
Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp
275 280 285
Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys
290 295 300
Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser
305 310 315 320
Arg Leu Thr Val Asp Lys Ser Arg Trp Gln Glu Gly Asn Val Phe Ser
325 330 335
Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser
340 345 350
Leu Ser Leu Ser Leu Gly Lys
355
<210> 340
<211> 352
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 340
Glu Val Gln Leu Ala Glu Ser Gly Gly Gly Ser Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Lys Leu Ser Cys Leu Ala Ser Gln Trp Ile Ser Ser Asp Cys
20 25 30
Gly Met Ala Trp Tyr Arg Gln Ala Pro Gly Lys Glu Arg Glu Leu Val
35 40 45
Ser Arg Ile Ser Ser Asp Asp Thr Thr Thr Tyr Ala Asp Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Gln Asp Ser Ala Lys Asn Thr Leu Tyr Leu
65 70 75 80
Gln Met Asn Lys Leu Lys Thr Glu Asp Thr Gly Val Tyr Tyr Cys Ala
85 90 95
Ala Glu Ala Lys Ser Thr Ile Thr Ser Leu Cys Tyr Pro Leu Asn Tyr
100 105 110
Trp Gly Gln Gly Thr Gln Val Thr Val Ser Ser Glu Ser Lys Tyr Gly
115 120 125
Pro Pro Cys Pro Pro Cys Pro Ala Pro Glu Phe Leu Gly Gly Pro Ser
130 135 140
Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg
145 150 155 160
Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser Gln Glu Asp Pro
165 170 175
Glu Val Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala
180 185 190
Lys Thr Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr Tyr Arg Val Val
195 200 205
Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr
210 215 220
Lys Cys Lys Val Ser Asn Lys Gly Leu Pro Ser Ser Ile Glu Lys Thr
225 230 235 240
Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu
245 250 255
Pro Pro Ser Gln Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys
260 265 270
Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser
275 280 285
Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp
290 295 300
Ser Asp Gly Ser Phe Phe Leu Tyr Ser Arg Leu Thr Val Asp Lys Ser
305 310 315 320
Arg Trp Gln Glu Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala
325 330 335
Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Leu Gly Lys
340 345 350
<210> 341
<211> 350
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 341
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Ser Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Thr Cys Ala Ala Thr Gly Tyr Ser Trp Arg Pro Asp
20 25 30
Cys Met Gly Trp Tyr Arg Gln Ala Ala Glu Lys Glu Arg Glu Gly Val
35 40 45
Ala Val Ile Asp Ala Asp Gly Ile Thr Ser Tyr Ala Asp Ala Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Asn Lys Ile Thr Leu Tyr Leu
65 70 75 80
Gln Met Leu Lys Pro Asp Asp Thr Gly Met Tyr Val Cys Val Val Gly
85 90 95
Trp Arg Val Ser Ser Gly Gly Asn Cys Gln Phe Asn Asp Tyr Trp Gly
100 105 110
Gln Gly Thr Gln Val Thr Val Ser Ser Glu Ser Lys Tyr Gly Pro Pro
115 120 125
Cys Pro Pro Cys Pro Ala Pro Glu Phe Leu Gly Gly Pro Ser Val Phe
130 135 140
Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro
145 150 155 160
Glu Val Thr Cys Val Val Val Asp Val Ser Gln Glu Asp Pro Glu Val
165 170 175
Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr
180 185 190
Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr Tyr Arg Val Val Ser Val
195 200 205
Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys
210 215 220
Lys Val Ser Asn Lys Gly Leu Pro Ser Ser Ile Glu Lys Thr Ile Ser
225 230 235 240
Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro
245 250 255
Ser Gln Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val
260 265 270
Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly
275 280 285
Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp
290 295 300
Gly Ser Phe Phe Leu Tyr Ser Arg Leu Thr Val Asp Lys Ser Arg Trp
305 310 315 320
Gln Glu Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His
325 330 335
Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Leu Gly Lys
340 345 350
<210> 342
<211> 355
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 342
Gln Val His Leu Met Glu Ser Gly Gly Gly Ala Val Gln Thr Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Val Ser Gly Ile Ser Ile Ser Pro Asp
20 25 30
Cys Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Lys Arg Glu Ala Val
35 40 45
Thr Thr Ile Phe Ala Asn Thr Gly Ser Ala Arg Tyr Gly Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ser Ser Gln Gly Asn Ala Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asp Ser Val Lys Leu Asp Asp Thr Gly Thr Tyr Tyr Cys
85 90 95
Ala Ala Arg Phe Thr Gly Gly Asp Cys Phe Asp His Gln Pro Leu Ala
100 105 110
Trp Arg Phe Trp Gly Gln Gly Thr Gln Val Thr Val Ser Ser Glu Ser
115 120 125
Lys Tyr Gly Pro Pro Cys Pro Pro Cys Pro Ala Pro Glu Phe Leu Gly
130 135 140
Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met
145 150 155 160
Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser Gln
165 170 175
Glu Asp Pro Glu Val Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val
180 185 190
His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr Tyr
195 200 205
Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly
210 215 220
Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Gly Leu Pro Ser Ser Ile
225 230 235 240
Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val
245 250 255
Tyr Thr Leu Pro Pro Ser Gln Glu Glu Met Thr Lys Asn Gln Val Ser
260 265 270
Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu
275 280 285
Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro
290 295 300
Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Arg Leu Thr Val
305 310 315 320
Asp Lys Ser Arg Trp Gln Glu Gly Asn Val Phe Ser Cys Ser Val Met
325 330 335
His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser
340 345 350
Leu Gly Lys
355
<210> 343
<211> 359
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 343
Glu Val Gln Leu Ala Glu Ser Gly Gly Gly Ser Val Gln Ser Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Val Ser Gly Ser Gly Tyr Ser Tyr Ser
20 25 30
Arg Gly Cys Phe Ala Trp Phe Gln Gln Arg Pro Gly Lys Glu Arg Glu
35 40 45
Gly Val Ala Ile Ile Asn Ser Asp Gly His Thr Ala Tyr Ser Asp Ser
50 55 60
Val Gln Gly Arg Phe Ile Ile Ser Gln Asp Lys Ala Lys Asn Thr Leu
65 70 75 80
Tyr Leu Gln Met Asn Ser Leu Lys Pro Asp Asp Thr Ala Met Tyr Tyr
85 90 95
Cys Ala Tyr Asp Arg Ser Gln Cys Tyr Val Leu Arg Asp Arg Leu Arg
100 105 110
Leu Pro Asp Thr Phe Thr Asp Trp Gly Gln Gly Thr Gln Val Thr Val
115 120 125
Ser Ser Glu Ser Lys Tyr Gly Pro Pro Cys Pro Pro Cys Pro Ala Pro
130 135 140
Glu Phe Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys
145 150 155 160
Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val
165 170 175
Asp Val Ser Gln Glu Asp Pro Glu Val Gln Phe Asn Trp Tyr Val Asp
180 185 190
Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Phe
195 200 205
Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp
210 215 220
Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Gly Leu
225 230 235 240
Pro Ser Ser Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg
245 250 255
Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Gln Glu Glu Met Thr Lys
260 265 270
Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp
275 280 285
Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys
290 295 300
Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser
305 310 315 320
Arg Leu Thr Val Asp Lys Ser Arg Trp Gln Glu Gly Asn Val Phe Ser
325 330 335
Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser
340 345 350
Leu Ser Leu Ser Leu Gly Lys
355
<210> 344
<211> 355
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 344
Gln Val His Leu Val Glu Ser Gly Gly Ala Ser Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Thr Ala Tyr Thr Ala Ser Asn Tyr
20 25 30
Cys Met Gly Trp Phe Arg Gln Ser Pro Gly Lys Glu Arg Glu Ala Val
35 40 45
Ala Ser Ile Asn Asp Asp Gly Val Thr Ser Tyr Ala Asp Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Gln Asp Ser Ala Lys Lys Thr Leu Tyr Leu
65 70 75 80
Gln Met Asn Arg Leu Lys Pro Glu Asp Thr Ala Met Tyr Tyr Cys Ala
85 90 95
Ala Thr Pro Asp Gly Tyr Cys Tyr Ala Glu Arg Leu Ser Arg Trp Arg
100 105 110
Tyr Glu Phe Trp Gly Gln Gly Thr Gln Val Thr Val Ser Ser Glu Ser
115 120 125
Lys Tyr Gly Pro Pro Cys Pro Pro Cys Pro Ala Pro Glu Phe Leu Gly
130 135 140
Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met
145 150 155 160
Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser Gln
165 170 175
Glu Asp Pro Glu Val Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val
180 185 190
His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr Tyr
195 200 205
Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly
210 215 220
Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Gly Leu Pro Ser Ser Ile
225 230 235 240
Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val
245 250 255
Tyr Thr Leu Pro Pro Ser Gln Glu Glu Met Thr Lys Asn Gln Val Ser
260 265 270
Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu
275 280 285
Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro
290 295 300
Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Arg Leu Thr Val
305 310 315 320
Asp Lys Ser Arg Trp Gln Glu Gly Asn Val Phe Ser Cys Ser Val Met
325 330 335
His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser
340 345 350
Leu Gly Lys
355
<210> 345
<211> 355
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 345
Glu Val Gln Leu Ala Glu Ser Gly Gly Gly Ser Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Val Ile Ser Gly Thr Ser Ile Ser Pro Asp
20 25 30
Cys Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Lys Arg Glu Ala Val
35 40 45
Met Ser Ile Phe Thr Asn Thr Gly Ser Thr Arg Tyr Gly Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ser Ser Gln Gly Asn Ala Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asp Ser Leu Lys Leu Asp Asp Thr Ala Thr Tyr Tyr Cys
85 90 95
Ala Ala Arg Tyr Thr Gly Gly Asp Cys Phe Asn Leu Glu Pro Leu Ala
100 105 110
Trp Arg Phe Trp Gly Gln Gly Thr Gln Val Thr Val Ser Ser Glu Ser
115 120 125
Lys Tyr Gly Pro Pro Cys Pro Pro Cys Pro Ala Pro Glu Phe Leu Gly
130 135 140
Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met
145 150 155 160
Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser Gln
165 170 175
Glu Asp Pro Glu Val Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val
180 185 190
His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr Tyr
195 200 205
Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly
210 215 220
Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Gly Leu Pro Ser Ser Ile
225 230 235 240
Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val
245 250 255
Tyr Thr Leu Pro Pro Ser Gln Glu Glu Met Thr Lys Asn Gln Val Ser
260 265 270
Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu
275 280 285
Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro
290 295 300
Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Arg Leu Thr Val
305 310 315 320
Asp Lys Ser Arg Trp Gln Glu Gly Asn Val Phe Ser Cys Ser Val Met
325 330 335
His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser
340 345 350
Leu Gly Lys
355
<210> 346
<211> 350
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 346
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Ser Val Gln Ala Gly Gly
1 5 10 15
Pro Leu Arg Leu Thr Cys Ala Ala Thr Gly Tyr Ser Trp Arg Pro Asp
20 25 30
Cys Met Gly Trp Tyr Arg Gln Ala Ala Glu Lys Glu Arg Glu Gly Val
35 40 45
Ala Val Ile Asp Ala Asp Gly Ile Thr Ser Tyr Ala Asp Ala Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Asn Asn Ile Thr Leu Tyr Leu
65 70 75 80
Gln Met Leu Lys Pro Asp Asp Thr Gly Met Tyr Val Cys Val Ile Gly
85 90 95
Trp Arg Val Ser Ser Gly Gly Asn Cys Gln Phe Asn Asp Tyr Trp Gly
100 105 110
Gln Gly Thr Gln Val Thr Val Ser Ser Glu Ser Lys Tyr Gly Pro Pro
115 120 125
Cys Pro Pro Cys Pro Ala Pro Glu Phe Leu Gly Gly Pro Ser Val Phe
130 135 140
Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro
145 150 155 160
Glu Val Thr Cys Val Val Val Asp Val Ser Gln Glu Asp Pro Glu Val
165 170 175
Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr
180 185 190
Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr Tyr Arg Val Val Ser Val
195 200 205
Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys
210 215 220
Lys Val Ser Asn Lys Gly Leu Pro Ser Ser Ile Glu Lys Thr Ile Ser
225 230 235 240
Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro
245 250 255
Ser Gln Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val
260 265 270
Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly
275 280 285
Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp
290 295 300
Gly Ser Phe Phe Leu Tyr Ser Arg Leu Thr Val Asp Lys Ser Arg Trp
305 310 315 320
Gln Glu Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His
325 330 335
Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Leu Gly Lys
340 345 350
<210> 347
<211> 359
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 347
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Ser Val Gln Ser Gly Gly
1 5 10 15
Ser Leu Lys Leu Ser Cys Ala Val Ser Gly Ser Gly Tyr Ser Tyr Ser
20 25 30
Arg Gly Cys Phe Ala Trp Phe Gln Gln Arg Pro Gly Lys Glu Arg Glu
35 40 45
Gly Val Ala Ile Ile Asn Ser Asp Gly His Thr Arg Tyr Ser Asp Ser
50 55 60
Val Gln Gly Arg Phe Ile Ile Ser Gln Asp Lys Ala Lys Asn Thr Leu
65 70 75 80
Tyr Leu Gln Met Asn Ser Leu Lys Pro Asp Asp Ala Ala Met Tyr Tyr
85 90 95
Cys Ala Tyr Asp Arg Asn Gln Cys Tyr Val Leu Leu Asp Arg Leu Arg
100 105 110
Leu Pro Gly Thr Phe Ser Asp Trp Gly Gln Gly Thr Gln Val Thr Val
115 120 125
Ser Ser Glu Ser Lys Tyr Gly Pro Pro Cys Pro Pro Cys Pro Ala Pro
130 135 140
Glu Phe Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys
145 150 155 160
Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val
165 170 175
Asp Val Ser Gln Glu Asp Pro Glu Val Gln Phe Asn Trp Tyr Val Asp
180 185 190
Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Phe
195 200 205
Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp
210 215 220
Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Gly Leu
225 230 235 240
Pro Ser Ser Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg
245 250 255
Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Gln Glu Glu Met Thr Lys
260 265 270
Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp
275 280 285
Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys
290 295 300
Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser
305 310 315 320
Arg Leu Thr Val Asp Lys Ser Arg Trp Gln Glu Gly Asn Val Phe Ser
325 330 335
Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser
340 345 350
Leu Ser Leu Ser Leu Gly Lys
355
<210> 348
<211> 359
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 348
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Ser Val Gln Ser Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Val Ser Gly Ser Gly Tyr Ser Tyr Ser
20 25 30
Arg Gly Cys Phe Ala Trp Phe Gln Gln Arg Pro Gly Lys Glu Arg Glu
35 40 45
Gly Val Ala Ile Ile Asn Ser Asp Gly His Thr Arg Tyr Ser Asp Ser
50 55 60
Val Gln Gly Arg Phe Ile Ile Ser Gln Asp Lys Ala Lys Asn Thr Leu
65 70 75 80
Tyr Leu Gln Met Asn Ser Leu Lys Pro Asp Asp Thr Ala Met Tyr Tyr
85 90 95
Cys Ala Tyr Asp Cys Ser Gln Cys Tyr Val Leu Arg Asp Arg Leu Arg
100 105 110
Leu Pro Asp Thr Phe Thr Asp Trp Gly Gln Gly Thr Gln Val Thr Val
115 120 125
Ser Ser Glu Ser Lys Tyr Gly Pro Pro Cys Pro Pro Cys Pro Ala Pro
130 135 140
Glu Phe Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys
145 150 155 160
Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val
165 170 175
Asp Val Ser Gln Glu Asp Pro Glu Val Gln Phe Asn Trp Tyr Val Asp
180 185 190
Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Phe
195 200 205
Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp
210 215 220
Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Gly Leu
225 230 235 240
Pro Ser Ser Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg
245 250 255
Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Gln Glu Glu Met Thr Lys
260 265 270
Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp
275 280 285
Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys
290 295 300
Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser
305 310 315 320
Arg Leu Thr Val Asp Lys Ser Arg Trp Gln Glu Gly Asn Val Phe Ser
325 330 335
Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser
340 345 350
Leu Ser Leu Ser Leu Gly Lys
355
<210> 349
<211> 359
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 349
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Ser Val Gln Ser Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Val Ser Gly Ser Gly Tyr Ser Tyr Asn
20 25 30
Arg Gly Cys Phe Ala Trp Phe Gln Gln Arg Pro Gly Lys Glu Arg Glu
35 40 45
Gly Val Ala Ile Ile Asn Ser Asp Gly His Thr Thr Tyr Gly Asp Ser
50 55 60
Val Gln Gly Arg Phe Ile Ile Ser Gln Asp Lys Ala Lys Asn Thr Leu
65 70 75 80
Asp Leu Gln Met Asn Ser Leu Lys Pro Asp Asp Thr Ala Met Tyr Tyr
85 90 95
Cys Ala Tyr Asp Arg Asn Gln Cys Tyr Val Leu Arg Asp Arg Leu Arg
100 105 110
Leu Pro Asp Thr Phe Thr Asp Trp Gly Gln Gly Thr Gln Val Thr Val
115 120 125
Ser Ser Glu Ser Lys Tyr Gly Pro Pro Cys Pro Pro Cys Pro Ala Pro
130 135 140
Glu Phe Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys
145 150 155 160
Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val
165 170 175
Asp Val Ser Gln Glu Asp Pro Glu Val Gln Phe Asn Trp Tyr Val Asp
180 185 190
Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Phe
195 200 205
Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp
210 215 220
Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Gly Leu
225 230 235 240
Pro Ser Ser Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg
245 250 255
Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Gln Glu Glu Met Thr Lys
260 265 270
Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp
275 280 285
Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys
290 295 300
Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser
305 310 315 320
Arg Leu Thr Val Asp Lys Ser Arg Trp Gln Glu Gly Asn Val Phe Ser
325 330 335
Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser
340 345 350
Leu Ser Leu Ser Leu Gly Lys
355
<210> 350
<211> 359
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 350
Gln Val Lys Leu Val Glu Ser Gly Gly Gly Leu Val Gln Ser Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Val Ser Gly Ser Gly Tyr Ser Tyr Ser
20 25 30
Arg Gly Cys Phe Ala Trp Phe Gln Gln Arg Pro Gly Lys Glu Arg Glu
35 40 45
Gly Val Ala Ile Ile Asn Met Asp Gly His Thr Met Tyr Ser Asp Leu
50 55 60
Ala Gln Gly Arg Phe Ile Ile Ser Gln Asp Lys Ala Lys Asn Thr Leu
65 70 75 80
Tyr Leu Gln Met Asn Ser Leu Lys Pro Asp Asp Thr Ala Met Tyr Tyr
85 90 95
Cys Ala Tyr Asp Arg Asp Gln Cys Tyr Val Leu Arg Asp Arg Leu Arg
100 105 110
Leu Pro Asp Thr Phe Asn Asp Trp Gly Gln Gly Thr Gln Val Thr Val
115 120 125
Ser Ser Glu Ser Lys Tyr Gly Pro Pro Cys Pro Pro Cys Pro Ala Pro
130 135 140
Glu Phe Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys
145 150 155 160
Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val
165 170 175
Asp Val Ser Gln Glu Asp Pro Glu Val Gln Phe Asn Trp Tyr Val Asp
180 185 190
Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Phe
195 200 205
Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp
210 215 220
Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Gly Leu
225 230 235 240
Pro Ser Ser Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg
245 250 255
Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Gln Glu Glu Met Thr Lys
260 265 270
Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp
275 280 285
Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys
290 295 300
Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser
305 310 315 320
Arg Leu Thr Val Asp Lys Ser Arg Trp Gln Glu Gly Asn Val Phe Ser
325 330 335
Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser
340 345 350
Leu Ser Leu Ser Leu Gly Lys
355
<210> 351
<211> 355
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 351
Gln Ile Gln Leu Val Glu Ser Gly Gly Gly Ser Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Val Thr Gly Ile Ser Ile Ser Pro Asp
20 25 30
Cys Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Lys Arg Glu Ala Val
35 40 45
Ala Thr Ile Phe Thr Asn Thr Ala Ser Thr Arg Tyr Gly Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ser Ser Gln Gly Asn Gly Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asp Ser Leu Asn Val Asp Asp Thr Ala Thr Tyr Tyr Cys
85 90 95
Ala Ala Arg Tyr Thr Gly Gly Asn Cys Phe Asn Leu Glu Pro Leu Ala
100 105 110
Trp His Phe Trp Gly Gln Gly Thr Gln Val Thr Val Ser Ser Glu Ser
115 120 125
Lys Tyr Gly Pro Pro Cys Pro Pro Cys Pro Ala Pro Glu Phe Leu Gly
130 135 140
Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met
145 150 155 160
Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser Gln
165 170 175
Glu Asp Pro Glu Val Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val
180 185 190
His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr Tyr
195 200 205
Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly
210 215 220
Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Gly Leu Pro Ser Ser Ile
225 230 235 240
Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val
245 250 255
Tyr Thr Leu Pro Pro Ser Gln Glu Glu Met Thr Lys Asn Gln Val Ser
260 265 270
Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu
275 280 285
Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro
290 295 300
Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Arg Leu Thr Val
305 310 315 320
Asp Lys Ser Arg Trp Gln Glu Gly Asn Val Phe Ser Cys Ser Val Met
325 330 335
His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser
340 345 350
Leu Gly Lys
355
<210> 352
<211> 355
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 352
Gln Val His Leu Met Glu Ser Gly Gly Gly Ser Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Val Val Ser Gly Ile Ser Ile Ser Pro Asp
20 25 30
Cys Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Lys Arg Glu Ala Val
35 40 45
Ala Thr Ile Phe Thr Asn Thr Arg Arg Thr Arg Tyr Gly Asp Ser Val
50 55 60
Lys Gly Arg Val Thr Ser Ser Gln Gly Asn Ala Lys Asn Thr Leu Tyr
65 70 75 80
Leu Lys Met Asp Asn Leu Arg His Asp Asp Thr Ala Thr Tyr Tyr Cys
85 90 95
Ala Ala Arg Tyr Thr Gly Gly Asp Cys Phe Asn Leu Asp Pro Leu Ser
100 105 110
Trp Arg Phe Trp Gly Gln Gly Thr Gln Val Thr Val Ser Ser Glu Ser
115 120 125
Lys Tyr Gly Pro Pro Cys Pro Pro Cys Pro Ala Pro Glu Phe Leu Gly
130 135 140
Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met
145 150 155 160
Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser Gln
165 170 175
Glu Asp Pro Glu Val Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val
180 185 190
His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr Tyr
195 200 205
Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly
210 215 220
Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Gly Leu Pro Ser Ser Ile
225 230 235 240
Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val
245 250 255
Tyr Thr Leu Pro Pro Ser Gln Glu Glu Met Thr Lys Asn Gln Val Ser
260 265 270
Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu
275 280 285
Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro
290 295 300
Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Arg Leu Thr Val
305 310 315 320
Asp Lys Ser Arg Trp Gln Glu Gly Asn Val Phe Ser Cys Ser Val Met
325 330 335
His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser
340 345 350
Leu Gly Lys
355
<210> 353
<211> 355
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 353
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Ser Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Val Ser Gly Ile Ser Ile Ser Pro Asp
20 25 30
Cys Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Lys Arg Glu Ala Val
35 40 45
Ala Thr Ile Phe Thr Asn Thr Arg Ser Thr Arg Tyr Gly Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ser Ser Gln Gly Asn Ala Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asp Ser Leu Lys Leu Asp Asp Thr Ala Thr Tyr Tyr Cys
85 90 95
Ala Ala Arg Tyr Thr Gly Gly Asp Cys Phe Asn Leu Glu Pro Val Ala
100 105 110
Trp Arg Phe Trp Gly Gln Gly Thr Gln Val Thr Val Ser Ser Glu Ser
115 120 125
Lys Tyr Gly Pro Pro Cys Pro Pro Cys Pro Ala Pro Glu Phe Leu Gly
130 135 140
Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met
145 150 155 160
Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser Gln
165 170 175
Glu Asp Pro Glu Val Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val
180 185 190
His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr Tyr
195 200 205
Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly
210 215 220
Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Gly Leu Pro Ser Ser Ile
225 230 235 240
Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val
245 250 255
Tyr Thr Leu Pro Pro Ser Gln Glu Glu Met Thr Lys Asn Gln Val Ser
260 265 270
Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu
275 280 285
Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro
290 295 300
Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Arg Leu Thr Val
305 310 315 320
Asp Lys Ser Arg Trp Gln Glu Gly Asn Val Phe Ser Cys Ser Val Met
325 330 335
His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser
340 345 350
Leu Gly Lys
355
<210> 354
<211> 352
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 354
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Val Trp
20 25 30
Ser Met Ser Trp Val Arg Gln Ala Pro Gly Glu Gly Leu Glu Trp Val
35 40 45
Ser Thr Ile Thr Gly Ser Gly Ala Gln Thr Tyr Tyr Ala Ser Ser Val
50 55 60
Arg Gly Arg Phe Thr Thr Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Lys Ser Asp Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Glu Arg Gly Asn Gly Gln Thr Ala Met Glu Ala Leu Ile Asn Pro Pro
100 105 110
Glu Arg Pro Gly Thr Gln Val Thr Val Ser Ser Glu Ser Lys Tyr Gly
115 120 125
Pro Pro Cys Pro Pro Cys Pro Ala Pro Glu Phe Leu Gly Gly Pro Ser
130 135 140
Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg
145 150 155 160
Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser Gln Glu Asp Pro
165 170 175
Glu Val Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala
180 185 190
Lys Thr Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr Tyr Arg Val Val
195 200 205
Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr
210 215 220
Lys Cys Lys Val Ser Asn Lys Gly Leu Pro Ser Ser Ile Glu Lys Thr
225 230 235 240
Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu
245 250 255
Pro Pro Ser Gln Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys
260 265 270
Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser
275 280 285
Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp
290 295 300
Ser Asp Gly Ser Phe Phe Leu Tyr Ser Arg Leu Thr Val Asp Lys Ser
305 310 315 320
Arg Trp Gln Glu Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala
325 330 335
Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Leu Gly Lys
340 345 350
<210> 355
<211> 356
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 355
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Leu Met Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Trp Met Tyr Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Val Ile Asn Arg Ala Gly Asp Ser Ala Trp Tyr Ala Asp Ser Val
50 55 60
Thr Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asp Ser Leu Lys Pro Glu Asp Thr Ala Met Tyr Tyr Cys
85 90 95
Ala Ala Asp Ser Arg Gly Tyr Gly Gly Asp Trp Tyr Lys Leu Leu Ser
100 105 110
Asp Phe Asn Tyr Cys Gly Gln Gly Thr Gln Val Thr Val Ser Ser Glu
115 120 125
Ser Lys Tyr Gly Pro Pro Cys Pro Pro Cys Pro Ala Pro Glu Phe Leu
130 135 140
Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu
145 150 155 160
Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser
165 170 175
Gln Glu Asp Pro Glu Val Gln Phe Asn Trp Tyr Val Asp Gly Val Glu
180 185 190
Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr
195 200 205
Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn
210 215 220
Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Gly Leu Pro Ser Ser
225 230 235 240
Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln
245 250 255
Val Tyr Thr Leu Pro Pro Ser Gln Glu Glu Met Thr Lys Asn Gln Val
260 265 270
Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val
275 280 285
Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro
290 295 300
Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Arg Leu Thr
305 310 315 320
Val Asp Lys Ser Arg Trp Gln Glu Gly Asn Val Phe Ser Cys Ser Val
325 330 335
Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu
340 345 350
Ser Leu Gly Lys
355
<210> 356
<211> 355
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 356
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Ser Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Thr Ala Tyr Thr Ala Ser Phe Tyr
20 25 30
Cys Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Ala Val
35 40 45
Ala Ser Ile Asn Asp Asp Gly Val Thr Met Tyr Ala Asp Ser Val Lys
50 55 60
Gly Gln Phe Thr Ile Ser Gln Asp Ser Ala Thr Lys Thr Leu Tyr Leu
65 70 75 80
Gln Met Asn Arg Leu Lys Pro Glu Asp Thr Ala Met Tyr Tyr Cys Ala
85 90 95
Ala Thr Pro Glu Gly Tyr Cys Tyr Ala Glu Arg Leu Ser Thr Trp Arg
100 105 110
Tyr Thr Phe Trp Gly Gln Gly Thr Gln Val Thr Val Ser Ser Glu Ser
115 120 125
Lys Tyr Gly Pro Pro Cys Pro Pro Cys Pro Ala Pro Glu Phe Leu Gly
130 135 140
Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met
145 150 155 160
Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser Gln
165 170 175
Glu Asp Pro Glu Val Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val
180 185 190
His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr Tyr
195 200 205
Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly
210 215 220
Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Gly Leu Pro Ser Ser Ile
225 230 235 240
Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val
245 250 255
Tyr Thr Leu Pro Pro Ser Gln Glu Glu Met Thr Lys Asn Gln Val Ser
260 265 270
Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu
275 280 285
Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro
290 295 300
Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Arg Leu Thr Val
305 310 315 320
Asp Lys Ser Arg Trp Gln Glu Gly Asn Val Phe Ser Cys Ser Val Met
325 330 335
His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser
340 345 350
Leu Gly Lys
355
<210> 357
<211> 352
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 357
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Val Ser Gly Asn Ile Tyr Asn Arg Asn
20 25 30
Phe Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Gly Leu Glu Gly Val
35 40 45
Ser Ala Ile Tyr Thr Gly Thr Ser Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ala Asp Leu Arg Asp Gly Phe Trp Asp Thr Gly Val Trp Asn Thr
100 105 110
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Glu Ser Lys Tyr Gly
115 120 125
Pro Pro Cys Pro Pro Cys Pro Ala Pro Glu Phe Leu Gly Gly Pro Ser
130 135 140
Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg
145 150 155 160
Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser Gln Glu Asp Pro
165 170 175
Glu Val Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala
180 185 190
Lys Thr Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr Tyr Arg Val Val
195 200 205
Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr
210 215 220
Lys Cys Lys Val Ser Asn Lys Gly Leu Pro Ser Ser Ile Glu Lys Thr
225 230 235 240
Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu
245 250 255
Pro Pro Ser Gln Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys
260 265 270
Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser
275 280 285
Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp
290 295 300
Ser Asp Gly Ser Phe Phe Leu Tyr Ser Arg Leu Thr Val Asp Lys Ser
305 310 315 320
Arg Trp Gln Glu Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala
325 330 335
Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Leu Gly Lys
340 345 350
<210> 358
<211> 352
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 358
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Val Ser Gly Asn Ile Tyr Asn Arg Asn
20 25 30
Phe Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Gly Leu Glu Gly Val
35 40 45
Ser Ala Ile Tyr Thr Gly Thr Ser Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ala Asp Leu Arg Glu Gly Phe Trp Asp Thr Gly Val Trp Asn Thr
100 105 110
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Glu Ser Lys Tyr Gly
115 120 125
Pro Pro Cys Pro Pro Cys Pro Ala Pro Glu Phe Leu Gly Gly Pro Ser
130 135 140
Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg
145 150 155 160
Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser Gln Glu Asp Pro
165 170 175
Glu Val Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala
180 185 190
Lys Thr Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr Tyr Arg Val Val
195 200 205
Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr
210 215 220
Lys Cys Lys Val Ser Asn Lys Gly Leu Pro Ser Ser Ile Glu Lys Thr
225 230 235 240
Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu
245 250 255
Pro Pro Ser Gln Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys
260 265 270
Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser
275 280 285
Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp
290 295 300
Ser Asp Gly Ser Phe Phe Leu Tyr Ser Arg Leu Thr Val Asp Lys Ser
305 310 315 320
Arg Trp Gln Glu Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala
325 330 335
Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Leu Gly Lys
340 345 350
<210> 359
<211> 352
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 359
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Val Ser Gly Asn Ile Tyr Asn Arg Asn
20 25 30
Phe Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Gly Arg Glu Gly Val
35 40 45
Ser Ala Ile Tyr Thr Gly Thr Ser Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ala Asp Leu Arg Asp Gly Phe Trp Asp Thr Gly Val Trp Asn Thr
100 105 110
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Glu Ser Lys Tyr Gly
115 120 125
Pro Pro Cys Pro Pro Cys Pro Ala Pro Glu Phe Leu Gly Gly Pro Ser
130 135 140
Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg
145 150 155 160
Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser Gln Glu Asp Pro
165 170 175
Glu Val Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala
180 185 190
Lys Thr Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr Tyr Arg Val Val
195 200 205
Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr
210 215 220
Lys Cys Lys Val Ser Asn Lys Gly Leu Pro Ser Ser Ile Glu Lys Thr
225 230 235 240
Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu
245 250 255
Pro Pro Ser Gln Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys
260 265 270
Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser
275 280 285
Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp
290 295 300
Ser Asp Gly Ser Phe Phe Leu Tyr Ser Arg Leu Thr Val Asp Lys Ser
305 310 315 320
Arg Trp Gln Glu Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala
325 330 335
Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Leu Gly Lys
340 345 350
<210> 360
<211> 352
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 360
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Val Ser Gly Asn Ile Tyr Asn Arg Asn
20 25 30
Phe Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Gly Arg Glu Gly Val
35 40 45
Ser Ala Ile Tyr Thr Gly Thr Ser Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ala Asp Leu Arg Glu Gly Phe Trp Asp Thr Gly Val Trp Asn Thr
100 105 110
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Glu Ser Lys Tyr Gly
115 120 125
Pro Pro Cys Pro Pro Cys Pro Ala Pro Glu Phe Leu Gly Gly Pro Ser
130 135 140
Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg
145 150 155 160
Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser Gln Glu Asp Pro
165 170 175
Glu Val Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala
180 185 190
Lys Thr Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr Tyr Arg Val Val
195 200 205
Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr
210 215 220
Lys Cys Lys Val Ser Asn Lys Gly Leu Pro Ser Ser Ile Glu Lys Thr
225 230 235 240
Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu
245 250 255
Pro Pro Ser Gln Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys
260 265 270
Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser
275 280 285
Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp
290 295 300
Ser Asp Gly Ser Phe Phe Leu Tyr Ser Arg Leu Thr Val Asp Lys Ser
305 310 315 320
Arg Trp Gln Glu Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala
325 330 335
Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Leu Gly Lys
340 345 350
<210> 361
<211> 268
<212> PRT
<213> 智人(Homo sapiens)
<400> 361
Pro Gly Trp Phe Leu Asp Ser Pro Asp Arg Pro Trp Asn Pro Pro Thr
1 5 10 15
Phe Ser Pro Ala Leu Leu Val Val Thr Glu Gly Asp Asn Ala Thr Phe
20 25 30
Thr Cys Ser Phe Ser Asn Thr Ser Glu Ser Phe Val Leu Asn Trp Tyr
35 40 45
Arg Met Ser Pro Ser Asn Gln Thr Asp Lys Leu Ala Ala Phe Pro Glu
50 55 60
Asp Arg Ser Gln Pro Gly Gln Asp Cys Arg Phe Arg Val Thr Gln Leu
65 70 75 80
Pro Asn Gly Arg Asp Phe His Met Ser Val Val Arg Ala Arg Arg Asn
85 90 95
Asp Ser Gly Thr Tyr Leu Cys Gly Ala Ile Ser Leu Ala Pro Lys Ala
100 105 110
Gln Ile Lys Glu Ser Leu Arg Ala Glu Leu Arg Val Thr Glu Arg Arg
115 120 125
Ala Glu Val Pro Thr Ala His Pro Ser Pro Ser Pro Arg Pro Ala Gly
130 135 140
Gln Phe Gln Thr Leu Val Val Gly Val Val Gly Gly Leu Leu Gly Ser
145 150 155 160
Leu Val Leu Leu Val Trp Val Leu Ala Val Ile Cys Ser Arg Ala Ala
165 170 175
Arg Gly Thr Ile Gly Ala Arg Arg Thr Gly Gln Pro Leu Lys Glu Asp
180 185 190
Pro Ser Ala Val Pro Val Phe Ser Val Asp Tyr Gly Glu Leu Asp Phe
195 200 205
Gln Trp Arg Glu Lys Thr Pro Glu Pro Pro Val Pro Cys Val Pro Glu
210 215 220
Gln Thr Glu Tyr Ala Thr Ile Val Phe Pro Ser Gly Met Gly Thr Ser
225 230 235 240
Ser Pro Ala Arg Arg Gly Ser Ala Asp Gly Pro Arg Ser Ala Gln Pro
245 250 255
Leu Arg Pro Glu Asp Gly His Cys Ser Trp Pro Leu
260 265
<210> 362
<211> 150
<212> PRT
<213> 智人(Homo sapiens)
<400> 362
Pro Gly Trp Phe Leu Asp Ser Pro Asp Arg Pro Trp Asn Pro Pro Thr
1 5 10 15
Phe Ser Pro Ala Leu Leu Val Val Thr Glu Gly Asp Asn Ala Thr Phe
20 25 30
Thr Cys Ser Phe Ser Asn Thr Ser Glu Ser Phe Val Leu Asn Trp Tyr
35 40 45
Arg Met Ser Pro Ser Asn Gln Thr Asp Lys Leu Ala Ala Phe Pro Glu
50 55 60
Asp Arg Ser Gln Pro Gly Gln Asp Cys Arg Phe Arg Val Thr Gln Leu
65 70 75 80
Pro Asn Gly Arg Asp Phe His Met Ser Val Val Arg Ala Arg Arg Asn
85 90 95
Asp Ser Gly Thr Tyr Leu Cys Gly Ala Ile Ser Leu Ala Pro Lys Ala
100 105 110
Gln Ile Lys Glu Ser Leu Arg Ala Glu Leu Arg Val Thr Glu Arg Arg
115 120 125
Ala Glu Val Pro Thr Ala His Pro Ser Pro Ser Pro Arg Pro Ala Gly
130 135 140
Gln Phe Gln Thr Leu Val
145 150
<210> 363
<211> 217
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 363
Ala Pro Glu Phe Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys
1 5 10 15
Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val
20 25 30
Val Val Asp Val Ser Gln Glu Asp Pro Glu Val Gln Phe Asn Trp Tyr
35 40 45
Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu
50 55 60
Gln Phe Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His
65 70 75 80
Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys
85 90 95
Gly Leu Pro Ser Ser Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln
100 105 110
Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Gln Glu Glu Met
115 120 125
Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro
130 135 140
Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn
145 150 155 160
Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu
165 170 175
Tyr Ser Arg Leu Thr Val Asp Lys Ser Arg Trp Gln Glu Gly Asn Val
180 185 190
Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln
195 200 205
Lys Ser Leu Ser Leu Ser Leu Gly Lys
210 215
<210> 364
<211> 217
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 364
Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys
1 5 10 15
Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val
20 25 30
Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr
35 40 45
Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu
50 55 60
Gln Tyr Ala Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His
65 70 75 80
Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys
85 90 95
Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln
100 105 110
Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Glu Glu Met
115 120 125
Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro
130 135 140
Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn
145 150 155 160
Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu
165 170 175
Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val
180 185 190
Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln
195 200 205
Lys Ser Leu Ser Leu Ser Pro Gly Lys
210 215
<210> 365
<211> 217
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 365
Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys
1 5 10 15
Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val
20 25 30
Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr
35 40 45
Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu
50 55 60
Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His
65 70 75 80
Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys
85 90 95
Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln
100 105 110
Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu Leu
115 120 125
Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro
130 135 140
Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn
145 150 155 160
Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu
165 170 175
Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val
180 185 190
Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln
195 200 205
Lys Ser Leu Ser Leu Ser Pro Gly Lys
210 215
<210> 366
<211> 98
<212> PRT
<213> 智人(Homo sapiens)
<400> 366
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Gly Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Val Ile Tyr Ser Gly Gly Ser Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys
<210> 367
<211> 12
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 367
Glu Ser Lys Tyr Gly Pro Pro Cys Pro Pro Cys Pro
1 5 10
<210> 368
<211> 15
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 368
Glu Pro Lys Ser Ser Asp Lys Thr His Thr Ser Pro Pro Ser Pro
1 5 10 15
<210> 369
<211> 15
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 369
Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro
1 5 10 15
<210> 370
<211> 9
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 370
Gly Gly Gly Gly Ser Gly Gly Gly Ser
1 5
<210> 371
<211> 15
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 371
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
1 5 10 15
<210> 372
<211> 1
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<220>
<221> 变体
<222> 1
<223> 可以至少一个重复序列存在
<400> 372
Gly
1
<210> 373
<211> 2
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<220>
<221> 变体
<222> (1)...(2)
<223> 可以至少一个重复序列存在
<400> 373
Gly Ser
1
<210> 374
<211> 5
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<220>
<221> 变体
<222> (1)...(5)
<223> 可以至少一个重复序列存在
<400> 374
Gly Ser Gly Gly Ser
1 5
<210> 375
<211> 4
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<220>
<221> 变体
<222> (1)...(4)
<223> 可以至少一个重复序列存在
<400> 375
Gly Gly Gly Ser
1
<210> 376
<211> 5
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<220>
<221> 变体
<222> (1)...(5)
<223> 可以至少一个重复序列存在
<400> 376
Gly Gly Gly Gly Ser
1 5
<210> 377
<211> 456
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 377
Glu Val Gln Leu Gln Gln Ser Gly Pro Gly Leu Val Lys Pro Ser Gln
1 5 10 15
Thr Leu Ser Leu Thr Cys Ala Ile Ser Gly Asp Ser Val Ser Ser Asn
20 25 30
Ser Ala Ala Trp Asn Trp Ile Arg Gln Ser Pro Ser Arg Gly Leu Glu
35 40 45
Trp Leu Gly Lys Thr Tyr Tyr Arg Phe Lys Trp Tyr Ser Asp Tyr Ala
50 55 60
Val Ser Val Lys Gly Arg Ile Thr Ile Asn Pro Asp Thr Ser Lys Asn
65 70 75 80
Gln Phe Ser Leu Gln Leu Asn Ser Val Thr Pro Glu Asp Thr Ala Val
85 90 95
Phe Tyr Cys Thr Arg Glu Ser Thr Thr Tyr Asp Leu Leu Ala Gly Pro
100 105 110
Phe Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ala Ser
115 120 125
Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr
130 135 140
Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro
145 150 155 160
Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val
165 170 175
His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser
180 185 190
Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile
195 200 205
Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val
210 215 220
Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala
225 230 235 240
Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro
245 250 255
Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val
260 265 270
Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val
275 280 285
Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln
290 295 300
Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln
305 310 315 320
Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala
325 330 335
Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro
340 345 350
Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Glu Glu Met Thr
355 360 365
Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser
370 375 380
Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr
385 390 395 400
Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr
405 410 415
Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe
420 425 430
Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys
435 440 445
Ser Leu Ser Leu Ser Pro Gly Lys
450 455
<210> 378
<211> 220
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 378
Asp Ile Val Met Thr Gln Ser Pro Asp Ser Leu Ala Val Ser Leu Gly
1 5 10 15
Glu Arg Ala Thr Ile Asn Cys Lys Ser Ser Gln Thr Val Leu Tyr Ser
20 25 30
Ser Asn Asn Lys Lys Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln
35 40 45
Pro Pro Asn Leu Leu Ile Tyr Trp Ala Ser Thr Arg Glu Ser Gly Val
50 55 60
Pro Asp Arg Glu Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr
65 70 75 80
Ile Ser Ser Leu Gln Ala Glu Asp Val Ala Val Tyr Tyr Cys Gln Gln
85 90 95
Tyr Tyr Ser Thr Pro Phe Thr Phe Gly Pro Gly Thr Lys Val Glu Ile
100 105 110
Lys Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp
115 120 125
Glu Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn
130 135 140
Phe Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu
145 150 155 160
Gln Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp
165 170 175
Ser Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr
180 185 190
Glu Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser
195 200 205
Ser Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
210 215 220
<210> 379
<211> 446
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 379
Gln Val Gln Leu Gln Gln Trp Gly Ala Gly Leu Leu Lys Pro Ser Glu
1 5 10 15
Thr Leu Ser Leu Thr Cys Ala Val Tyr Gly Gly Ser Phe Ser Asp Tyr
20 25 30
Tyr Trp Asn Trp Ile Arg Gln Pro Pro Gly Lys Gly Leu Glu Trp Ile
35 40 45
Gly Glu Ile Asn His Arg Gly Ser Thr Asn Ser Asn Pro Ser Leu Lys
50 55 60
Ser Arg Val Thr Leu Ser Leu Asp Thr Ser Lys Asn Gln Phe Ser Leu
65 70 75 80
Lys Leu Arg Ser Val Thr Ala Ala Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Phe Gly Tyr Ser Asp Tyr Glu Tyr Asn Trp Phe Asp Pro Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val
115 120 125
Phe Pro Leu Ala Pro Cys Ser Arg Ser Thr Ser Glu Ser Thr Ala Ala
130 135 140
Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser
145 150 155 160
Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val
165 170 175
Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro
180 185 190
Ser Ser Ser Leu Gly Thr Lys Thr Tyr Thr Cys Asn Val Asp His Lys
195 200 205
Pro Ser Asn Thr Lys Val Asp Lys Arg Val Glu Ser Lys Tyr Gly Pro
210 215 220
Pro Cys Pro Pro Cys Pro Ala Pro Glu Phe Leu Gly Gly Pro Ser Val
225 230 235 240
Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr
245 250 255
Pro Glu Val Thr Cys Val Val Val Asp Val Ser Gln Glu Asp Pro Glu
260 265 270
Val Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys
275 280 285
Thr Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr Tyr Arg Val Val Ser
290 295 300
Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys
305 310 315 320
Cys Lys Val Ser Asn Lys Gly Leu Pro Ser Ser Ile Glu Lys Thr Ile
325 330 335
Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro
340 345 350
Pro Ser Gln Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu
355 360 365
Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn
370 375 380
Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser
385 390 395 400
Asp Gly Ser Phe Phe Leu Tyr Ser Arg Leu Thr Val Asp Lys Ser Arg
405 410 415
Trp Gln Glu Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu
420 425 430
His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Leu Gly
435 440 445
<210> 380
<211> 214
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 380
Glu Ile Val Leu Thr Gln Ser Pro Ala Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser Ile Ser Ser Tyr
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu Ile
35 40 45
Tyr Asp Ala Ser Asn Arg Ala Thr Gly Ile Pro Ala Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Glu Pro
65 70 75 80
Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Arg Ser Asn Trp Pro Leu
85 90 95
Thr Phe Gly Gln Gly Thr Asn Leu Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 381
<211> 445
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 381
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr
20 25 30
Asn Met His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Ile
35 40 45
Gly Asp Ile Tyr Pro Gly Gln Gly Asp Thr Ser Tyr Asn Gln Lys Phe
50 55 60
Lys Gly Arg Ala Thr Met Thr Ala Asp Lys Ser Thr Ser Thr Val Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Val Gly Gly Ala Phe Pro Met Asp Tyr Trp Gly Gln Gly Thr
100 105 110
Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro
115 120 125
Leu Ala Pro Cys Ser Arg Ser Thr Ser Glu Ser Thr Ala Ala Leu Gly
130 135 140
Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn
145 150 155 160
Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln
165 170 175
Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser
180 185 190
Ser Leu Gly Thr Lys Thr Tyr Thr Cys Asn Val Asp His Lys Pro Ser
195 200 205
Asn Thr Lys Val Asp Lys Arg Val Glu Ser Lys Tyr Gly Pro Pro Cys
210 215 220
Pro Pro Cys Pro Ala Pro Glu Phe Leu Gly Gly Pro Ser Val Phe Leu
225 230 235 240
Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu
245 250 255
Val Thr Cys Val Val Val Asp Val Ser Gln Glu Asp Pro Glu Val Gln
260 265 270
Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys
275 280 285
Pro Arg Glu Glu Gln Phe Asn Ser Thr Tyr Arg Val Val Ser Val Leu
290 295 300
Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys
305 310 315 320
Val Ser Asn Lys Gly Leu Pro Ser Ser Ile Glu Lys Thr Ile Ser Lys
325 330 335
Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser
340 345 350
Gln Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys
355 360 365
Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln
370 375 380
Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly
385 390 395 400
Ser Phe Phe Leu Tyr Ser Arg Leu Thr Val Asp Lys Ser Arg Trp Gln
405 410 415
Glu Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn
420 425 430
His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Leu Gly Lys
435 440 445
<210> 382
<211> 218
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 382
Asp Ile Val Leu Thr Gln Ser Pro Asp Ser Leu Ala Val Ser Leu Gly
1 5 10 15
Glu Arg Ala Thr Ile Asn Cys Arg Ala Ser Glu Ser Val Glu Tyr Tyr
20 25 30
Gly Thr Ser Leu Met Gln Trp Tyr Gln Gln Lys Pro Gly Gln Pro Pro
35 40 45
Lys Leu Leu Ile Tyr Ala Ala Ser Asn Val Glu Ser Gly Val Pro Asp
50 55 60
Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser
65 70 75 80
Ser Leu Gln Ala Glu Asp Val Ala Val Tyr Tyr Cys Gln Gln Ser Arg
85 90 95
Lys Asp Pro Ser Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys Arg
100 105 110
Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln
115 120 125
Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr
130 135 140
Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser
145 150 155 160
Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr
165 170 175
Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys
180 185 190
His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro
195 200 205
Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
210 215
<210> 383
<211> 448
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 383
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Arg
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Thr Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Thr Phe Ile Ser Tyr Asp Gly Asn Asn Lys Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Ile Tyr Tyr Cys
85 90 95
Ala Arg Thr Gly Trp Leu Gly Pro Phe Asp Tyr Trp Gly Gln Gly Thr
100 105 110
Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro
115 120 125
Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly
130 135 140
Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn
145 150 155 160
Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln
165 170 175
Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser
180 185 190
Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser
195 200 205
Asn Thr Lys Val Asp Lys Arg Val Glu Pro Lys Ser Cys Asp Lys Thr
210 215 220
His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser
225 230 235 240
Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg
245 250 255
Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro
260 265 270
Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala
275 280 285
Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val
290 295 300
Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr
305 310 315 320
Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr
325 330 335
Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu
340 345 350
Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys
355 360 365
Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser
370 375 380
Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp
385 390 395 400
Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser
405 410 415
Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala
420 425 430
Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
435 440 445
<210> 384
<211> 215
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 384
Glu Ile Val Leu Thr Gln Ser Pro Gly Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser Val Gly Ser Ser
20 25 30
Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu
35 40 45
Ile Tyr Gly Ala Phe Ser Arg Ala Thr Gly Ile Pro Asp Arg Phe Ser
50 55 60
Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Arg Leu Glu
65 70 75 80
Pro Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Tyr Gly Ser Ser Pro
85 90 95
Trp Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Arg Thr Val Ala
100 105 110
Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser
115 120 125
Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu
130 135 140
Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser
145 150 155 160
Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu
165 170 175
Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val
180 185 190
Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys
195 200 205
Ser Phe Asn Arg Gly Glu Cys
210 215
<210> 385
<211> 447
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 385
Gln Val Gln Leu Val Gln Ser Gly Val Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asn Tyr
20 25 30
Tyr Met Tyr Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Gly Ile Asn Pro Ser Asn Gly Gly Thr Asn Phe Asn Glu Lys Phe
50 55 60
Lys Asn Arg Val Thr Leu Thr Thr Asp Ser Ser Thr Thr Thr Ala Tyr
65 70 75 80
Met Glu Leu Lys Ser Leu Gln Phe Asp Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Arg Asp Tyr Arg Phe Asp Met Gly Phe Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Thr Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val
115 120 125
Phe Pro Leu Ala Pro Cys Ser Arg Ser Thr Ser Glu Ser Thr Ala Ala
130 135 140
Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser
145 150 155 160
Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val
165 170 175
Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro
180 185 190
Ser Ser Ser Leu Gly Thr Lys Thr Tyr Thr Cys Asn Val Asp His Lys
195 200 205
Pro Ser Asn Thr Lys Val Asp Lys Arg Val Glu Ser Lys Tyr Gly Pro
210 215 220
Pro Cys Pro Pro Cys Pro Ala Pro Glu Phe Leu Gly Gly Pro Ser Val
225 230 235 240
Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr
245 250 255
Pro Glu Val Thr Cys Val Val Val Asp Val Ser Gln Glu Asp Pro Glu
260 265 270
Val Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys
275 280 285
Thr Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr Tyr Arg Val Val Ser
290 295 300
Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys
305 310 315 320
Cys Lys Val Ser Asn Lys Gly Leu Pro Ser Ser Ile Glu Lys Thr Ile
325 330 335
Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro
340 345 350
Pro Ser Gln Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu
355 360 365
Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn
370 375 380
Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser
385 390 395 400
Asp Gly Ser Phe Phe Leu Tyr Ser Arg Leu Thr Val Asp Lys Ser Arg
405 410 415
Trp Gln Glu Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu
420 425 430
His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Leu Gly Lys
435 440 445
<210> 386
<211> 218
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成构建体
<400> 386
Glu Ile Val Leu Thr Gln Ser Pro Ala Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Lys Gly Val Ser Thr Ser
20 25 30
Gly Tyr Ser Tyr Leu His Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro
35 40 45
Arg Leu Leu Ile Tyr Leu Ala Ser Tyr Leu Glu Ser Gly Val Pro Ala
50 55 60
Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser
65 70 75 80
Ser Leu Glu Pro Glu Asp Phe Ala Val Tyr Tyr Cys Gln His Ser Arg
85 90 95
Asp Leu Pro Leu Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys Arg
100 105 110
Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln
115 120 125
Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr
130 135 140
Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser
145 150 155 160
Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr
165 170 175
Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys
180 185 190
His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro
195 200 205
Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
210 215
Claims (40)
1.一种分离的抗PD-1构建体,所述分离的抗PD-1构建体包含特异性识别PD-1的单域抗体(sdAb)部分,其中所述sdAb部分包含:
如SEQ ID NO:43所示的氨基酸序列的CDR1;如SEQ ID NO:115所示的氨基酸序列的CDR2;和如SEQ ID NO:187或SEQ ID NO:214所示的氨基酸序列的CDR3。
2.如权利要求1所述的分离的抗PD-1构建体,其中所述sdAb部分与PD-1之间的结合的Kd是10-5M至10-12M。
3.如权利要求1所述的分离的抗PD-1构建体,其中所述sdAb部分与PD-1之间的结合的Kd是10-7M至10-12M。
4.如权利要求1所述的分离的抗PD-1构建体,其中所述sdAb部分是骆驼科的、嵌合的、部分人源化的或完全人源化的。
5.如权利要求1所述的分离的抗PD-1构建体,其中所述分离的抗PD-1构建体是仅重链抗体(HCAb),其包含经由任选的接头融合至Fc片段的所述抗PD-1的sdAb部分。
6.如权利要求5所述的分离的抗PD-1构建体,其中所述HCAb是单体或二聚HCAb。
7.如权利要求5所述的分离的抗PD-1构建体,其中所述Fc片段是人类IgG1Fc、无效应子hIgG1 Fc或hIgG4Fc。
8.如权利要求5所述的分离的抗PD-1构建体,其中所述任选的接头包含SEQ ID NOs:367-371中的任一者的氨基酸序列。
9.如权利要求5所述的分离的抗PD-1构建体,其中所述HCAb包含SEQ ID NOs:331,357,358,359或360中的任一者的氨基酸序列。
10.如权利要求1-9中任一项所述的分离的抗PD-1构建体,其中所述分离的抗PD-1构建体还包含特异性识别第二表位的第二抗体部分。
11.如权利要求10所述的分离的抗PD-1构建体,其中所述第二抗体部分是全长抗体、Fab、Fab'、(Fab')2、Fv、scFv-scFv、微型抗体或sdAb。
12.如权利要求10所述的分离的抗PD-1构建体,其中所述第二抗体部分是单链Fv(scFv)。
13.如权利要求10所述的分离的抗PD-1构建体,其中所述抗PD-1构建体具有多特异性。
14.如权利要求10所述的分离的抗PD-1构建体,其中所述抗PD-1的sdAb部分和所述第二抗体部分任选地通过肽接头连接。
15.如权利要求14所述的分离的抗PD-1构建体,其中所述肽接头包含SEQ ID NOs:367-371中的任一者的氨基酸序列。
16.如权利要求10所述的分离的抗PD-1构建体,其中所述第二抗体部分是特异性识别PD-1或CTLA-4的第二sdAb。
17.如权利要求10所述的分离的抗PD-1构建体,其中所述第二抗体部分是由两条重链和两条轻链组成的全长抗体。
18.如权利要求17所述的分离的抗PD-1构建体,其中所述重链的Fc片段是人类IgG1Fc、无效应子hIgG1 Fc或hIgG4 Fc。
19.如权利要求17所述的分离的抗PD-1构建体,包含如下任何一种结构:
(i)其中所述抗PD-1的sdAb部分的N末端融合至所述全长抗体的至少一条重链的C末端;
(ii)其中所述抗PD-1的sdAb部分的C末端融合至所述全长抗体的至少一条重链的N末端;
(iii)其中所述抗PD-1的sdAb部分的N末端融合至所述全长抗体的至少一条轻链的C末端;
(iv)其中所述抗PD-1的sdAb部分的C末端融合至所述全长抗体的至少一条轻链的N末端;
(v)所述的分离的抗PD-1构建体包含四个抗PD-1的sdAb部分,其中每个抗PD-1的sdAb部分的C末端与所述全长抗体的每一条链的N末端融合;或
(vi)所述的分离的抗PD-1构建体包含四个抗PD-1的sdAb部分,其中四个抗PD-1的sdAb部分中的每两个抗PD-1的sdAb部分融合在一起,并进一步与所述全长抗体的每一条重链的N末端融合。
20.如权利要求17所述的分离的抗PD-1构建体,其中所述全长抗体特异性识别TIGIT。
21.如权利要求20所述的分离的抗PD-1构建体,其中所述全长抗体包含:
(i)包含SEQ ID NO:377的氨基酸序列的重链的重链可变域(VH),以及包含SEQ ID NO:378的氨基酸序列的轻链的轻链可变域(VL);或
(ii)包含SEQ ID NO:377的氨基酸序列的重链,以及包含SEQ ID NO:378的氨基酸序列的轻链。
22.如权利要求17所述的分离的抗PD-1构建体,其中所述全长抗体特异性识别LAG-3。
23.如权利要求22所述的分离的抗PD-1构建体,其中所述全长抗体包含:
(i)包含SEQ ID NO:379的氨基酸序列的重链的重链可变域(VH),以及包含SEQ ID NO:380的氨基酸序列的轻链的轻链可变域(VL);或
(ii)包含SEQ ID NO:379的氨基酸序列的重链,以及包含SEQ ID NO:380的氨基酸序列的轻链。
24.如权利要求17所述的分离的抗PD-1构建体,其中所述全长抗体特异性识别TIM-3。
25.如权利要求24所述的分离的抗PD-1构建体,其中所述抗TIM-3全长抗体包含:
(i)包含SEQ ID NO:381的氨基酸序列的重链的重链可变域(VH),以及包含SEQ ID NO:382的氨基酸序列的轻链的轻链可变域(VL);或
(ii)包含SEQ ID NO:381的氨基酸序列的重链,以及包含SEQ ID NO:382的氨基酸序列的轻链。
26.如权利要求17所述的分离的抗PD-1构建体,其中所述全长抗体特异性识别CTLA-4。
27.如权利要求26所述的分离的抗PD-1构建体,其中所述抗CTLA-4全长抗体包含:
(i)包含SEQ ID NO:383的氨基酸序列的重链的重链可变域(VH),以及包含SEQ ID NO:384的氨基酸序列的轻链的轻链可变域(VL);或
(ii)包含SEQ ID NO:383的氨基酸序列的重链,以及包含SEQ ID NO:384的氨基酸序列的轻链。
28.如权利要求17所述的分离的抗PD-1构建体,其中所述全长抗体特异性识别PD-1。
29.如权利要求28所述的分离的抗PD-1构建体,其中所述抗PD-1全长抗体包含:
(i)包含SEQ ID NO:385的氨基酸序列的重链的重链可变域(VH),以及包含SEQ ID NO:386的氨基酸序列的轻链的轻链可变域(VL);或
(ii)包含SEQ ID NO:385的氨基酸序列的重链,以及包含SEQ ID NO:386的氨基酸序列的轻链。
30.如权利要求10-29任一项所述的分离的抗PD-1构建体,包含如下任何一种结构:
(a)所述的分离的抗PD-1构建体由四条多肽链组成,所述多肽链具有如下从N末端至C末端的结构:(i)VL-CL,(ii)VH-CH1-任选的肽接头-第一个抗PD-1的sdAb部分-CH2-CH3,(iii)VH-CH1-任选的肽接头-第二个抗PD-1的sdAb部分-CH2-CH3,和(iv)VL-CL;其中多肽链(i)的VL-CL和多肽链(ii)的VH-CH1形成特异性识别第二表位的第二抗体部分,并且多肽链(iv)的VL-CL和多肽链(iii)的VH-CH1形成特异性识别第三表位的第三抗体部分;
(b)所述的分离的抗PD-1构建体由二条多肽链组成,所述多肽链具有如下从N末端至C末端的结构:(i)第一个特异性识别第二表位的scFv-任选的肽接头-第一个抗PD-1的sdAb部分-CH2-CH3,and(ii)第二个特异性识别第三表位的scFv-任选的肽接头-第二个抗PD-1的sdAb部分-CH2-CH3;
(c)所述的分离的抗PD-1构建体由四条多肽链组成,所述多肽链具有如下从N末端至C末端的结构:(i)VL-CL-任选的肽接头-第一个抗PD-1的sdAb部分-CL,(ii)VH-CH1-任选的肽接头-第二个抗PD-1的sdAb部分-CH1-CH2-CH3,(iii)VH-CH1-任选的肽接头-第三个抗PD-1的sdAb部分-CH1-CH2-CH3,and(iv)VL-CL-任选的肽接头-第四个抗PD-1的sdAb部分-CL;其中多肽链(i)的VL-CL和多肽链(ii)的VH-CH1形成特异性识别第二表位的第二抗体部分,并且多肽链(iv)的VL-CL和多肽链(iii)的VH-CH1形成特异性识别第三表位的第三抗体部分;或
(d)所述的分离的抗PD-1构建体由四条多肽链组成,所述多肽链具有如下从N末端至C末端的结构:(i)第一个抗PD-1的sdAb部分-CL,(ii)第一个特异性识别第二表位的scFv-任选的肽接头-第二个抗PD-1的sdAb部分-CH1-CH2-CH3,(iii)第二个特异性识别第三表位的scFv-任选的肽接头-第三个抗PD-1的sdAb部分-CH1-CH2-CH3,和(iv)第四个抗PD-1的sdAb部分-CL。
31.一种药物组合物,所述药物组合物包含如权利要求1-30中任一项所述的分离的抗PD-1构建体和任选地药学上可接受的载体。
32.如权利要求1-30中任一项所述的分离的抗PD-1构建体或如权利要求31所述的药物组合物在制备用于治疗具有与PD-1相关的癌症或与PD-1相关的病原性感染的个体的药物中的应用。
33.如权利要求32所述的应用,其中所述癌症是结肠癌。
34.如权利要求32或33所述的应用,其中所述药物以有效量向所述个体施用。
35.一种分离的核酸,所述分离的核酸编码如权利要求1-30中任一项所述的分离的抗PD-1构建体。
36.一种载体,所述载体包含如权利要求35所述的分离的核酸。
37.一种分离的宿主细胞,所述分离的宿主细胞包含如权利要求35所述的分离的核酸或如权利要求36所述的载体。
38.一种试剂盒,所述试剂盒包含如权利要求1-30中任一项所述的分离的抗PD-1构建体、如权利要求35所述的分离的核酸、如权利要求36所述的载体、或如权利要求37所述的分离的宿主细胞。
39.一种产生抗PD-1构建体的方法,所述方法包括:(a)在有效表达所编码的抗PD-1构建体的条件下培养包含如权利要求35所述的分离的核酸或如权利要求36所述的载体的宿主细胞;以及(b)从所述宿主细胞获得所表达的抗PD-1构建体。
40.如权利要求39所述的方法,其中步骤(a)还包括产生包含如权利要求35所述的分离的核酸或如权利要求36所述的载体的宿主细胞。
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CNPCT/CN2018/072589 | 2018-01-15 | ||
| CN2018072589 | 2018-01-15 | ||
| PCT/CN2019/071691 WO2019137541A1 (en) | 2018-01-15 | 2019-01-15 | Single-domain antibodies and variants thereof against pd-1 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN111699200A CN111699200A (zh) | 2020-09-22 |
| CN111699200B true CN111699200B (zh) | 2023-05-26 |
Family
ID=67218527
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201980012465.XA Active CN111699200B (zh) | 2018-01-15 | 2019-01-15 | 针对pd-1的单域抗体和其变体 |
Country Status (11)
| Country | Link |
|---|---|
| US (1) | US11713353B2 (zh) |
| EP (1) | EP3740507A4 (zh) |
| JP (1) | JP7366908B2 (zh) |
| KR (1) | KR20200120641A (zh) |
| CN (1) | CN111699200B (zh) |
| AU (1) | AU2019207276A1 (zh) |
| CA (1) | CA3084518A1 (zh) |
| IL (1) | IL275740A (zh) |
| SG (1) | SG11202004233UA (zh) |
| TW (1) | TWI802633B (zh) |
| WO (1) | WO2019137541A1 (zh) |
Families Citing this family (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CA3084518A1 (en) | 2018-01-15 | 2019-07-18 | Nanjing Legend Biotech Co., Ltd. | Single-domain antibodies and variants thereof against pd-1 |
| WO2021043261A1 (zh) * | 2019-09-06 | 2021-03-11 | 北京拓界生物医药科技有限公司 | 抗pd-1单域抗体、其衍生蛋白及其医药用途 |
| CN112341538A (zh) * | 2020-10-27 | 2021-02-09 | 苏州复融生物技术有限公司 | 一种Fc单体多肽及其应用 |
| CN114685655B (zh) * | 2020-12-28 | 2024-04-12 | 浙江纳米抗体技术中心有限公司 | Pd-1结合分子及其应用 |
| CN114763384B (zh) * | 2021-01-14 | 2023-03-17 | 立凌生物制药(苏州)有限公司 | 靶向pd-1的单域抗体及其衍生物和用途 |
| CN114573704B (zh) * | 2021-03-10 | 2022-11-01 | 北京拓界生物医药科技有限公司 | Pd-1/ctla-4结合蛋白及其医药用途 |
| JP2024517558A (ja) | 2021-04-30 | 2024-04-23 | メディミューン,エルエルシー | 二重特異性pd-1及びtigit結合タンパク質並びにその使用 |
| CN115340605A (zh) * | 2021-05-14 | 2022-11-15 | 迈威(上海)生物科技股份有限公司 | 一种抗pd-l1单域抗体及其衍生蛋白 |
| WO2023100944A1 (ja) * | 2021-12-01 | 2023-06-08 | 株式会社Epsilon Molecular Engineering | ランダム領域搭載用フレームワーク配列を有するペプチド及びそのペプチドで構成されるペプチドライブラリ |
Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN106715469A (zh) * | 2014-08-27 | 2017-05-24 | 纪念斯隆-凯特琳癌症中心 | 抗体、组合物和用途 |
Family Cites Families (214)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US3773919A (en) | 1969-10-23 | 1973-11-20 | Du Pont | Polylactide-drug mixtures |
| USRE30985E (en) | 1978-01-01 | 1982-06-29 | Serum-free cell culture media | |
| US4419446A (en) | 1980-12-31 | 1983-12-06 | The United States Of America As Represented By The Department Of Health And Human Services | Recombinant DNA process utilizing a papilloma virus DNA as a vector |
| US4601978A (en) | 1982-11-24 | 1986-07-22 | The Regents Of The University Of California | Mammalian metallothionein promoter system |
| US4560655A (en) | 1982-12-16 | 1985-12-24 | Immunex Corporation | Serum-free cell culture medium and process for making same |
| US4657866A (en) | 1982-12-21 | 1987-04-14 | Sudhir Kumar | Serum-free, synthetic, completely chemically defined tissue culture media |
| US4816567A (en) | 1983-04-08 | 1989-03-28 | Genentech, Inc. | Recombinant immunoglobin preparations |
| US4767704A (en) | 1983-10-07 | 1988-08-30 | Columbia University In The City Of New York | Protein-free culture medium |
| US4965199A (en) | 1984-04-20 | 1990-10-23 | Genentech, Inc. | Preparation of functional human factor VIII in mammalian cells using methotrexate based selection |
| GB8516415D0 (en) | 1985-06-28 | 1985-07-31 | Celltech Ltd | Culture of animal cells |
| US4676980A (en) | 1985-09-23 | 1987-06-30 | The United States Of America As Represented By The Secretary Of The Department Of Health And Human Services | Target specific cross-linked heteroantibodies |
| US6548640B1 (en) | 1986-03-27 | 2003-04-15 | Btg International Limited | Altered antibodies |
| US4927762A (en) | 1986-04-01 | 1990-05-22 | Cell Enterprises, Inc. | Cell culture medium with antioxidant |
| US5567610A (en) | 1986-09-04 | 1996-10-22 | Bioinvent International Ab | Method of producing human monoclonal antibodies and kit therefor |
| IL85035A0 (en) | 1987-01-08 | 1988-06-30 | Int Genetic Eng | Polynucleotide molecule,a chimeric antibody with specificity for human b cell surface antigen,a process for the preparation and methods utilizing the same |
| DE3883899T3 (de) | 1987-03-18 | 1999-04-22 | Sb2 Inc | Geänderte antikörper. |
| EP0308936B1 (en) | 1987-09-23 | 1994-07-06 | Bristol-Myers Squibb Company | Antibody heteroconjugates for the killing of HIV-infected cells |
| ATE135397T1 (de) | 1988-09-23 | 1996-03-15 | Cetus Oncology Corp | Zellenzuchtmedium für erhöhtes zellenwachstum, zur erhöhung der langlebigkeit und expression der produkte |
| GB8823869D0 (en) | 1988-10-12 | 1988-11-16 | Medical Res Council | Production of antibodies |
| EP0368684B2 (en) | 1988-11-11 | 2004-09-29 | Medical Research Council | Cloning immunoglobulin variable domain sequences. |
| US5175384A (en) | 1988-12-05 | 1992-12-29 | Genpharm International | Transgenic mice depleted in mature t-cells and methods for making transgenic mice |
| DE3920358A1 (de) | 1989-06-22 | 1991-01-17 | Behringwerke Ag | Bispezifische und oligospezifische, mono- und oligovalente antikoerperkonstrukte, ihre herstellung und verwendung |
| EP0739904A1 (en) | 1989-06-29 | 1996-10-30 | Medarex, Inc. | Bispecific reagents for aids therapy |
| US6075181A (en) | 1990-01-12 | 2000-06-13 | Abgenix, Inc. | Human antibodies derived from immunized xenomice |
| US6150584A (en) | 1990-01-12 | 2000-11-21 | Abgenix, Inc. | Human antibodies derived from immunized xenomice |
| ATE356869T1 (de) | 1990-01-12 | 2007-04-15 | Amgen Fremont Inc | Bildung von xenogenen antikörpern |
| US5229275A (en) | 1990-04-26 | 1993-07-20 | Akzo N.V. | In-vitro method for producing antigen-specific human monoclonal antibodies |
| US5770429A (en) | 1990-08-29 | 1998-06-23 | Genpharm International, Inc. | Transgenic non-human animals capable of producing heterologous antibodies |
| ES2108048T3 (es) | 1990-08-29 | 1997-12-16 | Genpharm Int | Produccion y utilizacion de animales inferiores transgenicos capaces de producir anticuerpos heterologos. |
| US5661016A (en) | 1990-08-29 | 1997-08-26 | Genpharm International Inc. | Transgenic non-human animals capable of producing heterologous antibodies of various isotypes |
| US5633425A (en) | 1990-08-29 | 1997-05-27 | Genpharm International, Inc. | Transgenic non-human animals capable of producing heterologous antibodies |
| US5625126A (en) | 1990-08-29 | 1997-04-29 | Genpharm International, Inc. | Transgenic non-human animals for producing heterologous antibodies |
| US5545806A (en) | 1990-08-29 | 1996-08-13 | Genpharm International, Inc. | Ransgenic non-human animals for producing heterologous antibodies |
| US5122469A (en) | 1990-10-03 | 1992-06-16 | Genentech, Inc. | Method for culturing Chinese hamster ovary cells to improve production of recombinant proteins |
| US5508192A (en) | 1990-11-09 | 1996-04-16 | Board Of Regents, The University Of Texas System | Bacterial host strains for producing proteolytically sensitive polypeptides |
| US5264365A (en) | 1990-11-09 | 1993-11-23 | Board Of Regents, The University Of Texas System | Protease-deficient bacterial strains for production of proteolytically sensitive polypeptides |
| ES2113940T3 (es) | 1990-12-03 | 1998-05-16 | Genentech Inc | Metodo de enriquecimiento para variantes de proteinas con propiedades de union alteradas. |
| US5571894A (en) | 1991-02-05 | 1996-11-05 | Ciba-Geigy Corporation | Recombinant antibodies specific for a growth factor receptor |
| LU91067I2 (fr) | 1991-06-14 | 2004-04-02 | Genentech Inc | Trastuzumab et ses variantes et dérivés immuno chimiques y compris les immotoxines |
| GB9114948D0 (en) | 1991-07-11 | 1991-08-28 | Pfizer Ltd | Process for preparing sertraline intermediates |
| US7018809B1 (en) | 1991-09-19 | 2006-03-28 | Genentech, Inc. | Expression of functional antibody fragments |
| ES2136092T3 (es) | 1991-09-23 | 1999-11-16 | Medical Res Council | Procedimientos para la produccion de anticuerpos humanizados. |
| US5587458A (en) | 1991-10-07 | 1996-12-24 | Aronex Pharmaceuticals, Inc. | Anti-erbB-2 antibodies, combinations thereof, and therapeutic and diagnostic uses thereof |
| WO1993008829A1 (en) | 1991-11-04 | 1993-05-13 | The Regents Of The University Of California | Compositions that mediate killing of hiv-infected cells |
| ATE207080T1 (de) | 1991-11-25 | 2001-11-15 | Enzon Inc | Multivalente antigen-bindende proteine |
| DE69334255D1 (de) | 1992-02-06 | 2009-02-12 | Novartis Vaccines & Diagnostic | Marker für Krebs und biosynthetisches Bindeprotein dafür |
| US5573905A (en) | 1992-03-30 | 1996-11-12 | The Scripps Research Institute | Encoded combinatorial chemical libraries |
| WO1994004690A1 (en) | 1992-08-17 | 1994-03-03 | Genentech, Inc. | Bispecific immunoadhesins |
| ES2162823T5 (es) | 1992-08-21 | 2010-08-09 | Vrije Universiteit Brussel | Inmunoglobulinas desprovistas de cadenas ligeras. |
| EP1005870B1 (en) | 1992-11-13 | 2009-01-21 | Biogen Idec Inc. | Therapeutic application of chimeric antibodies to human B lymphocyte restricted differentiation antigen for treatment of B cell lymphoma |
| EP0714409A1 (en) | 1993-06-16 | 1996-06-05 | Celltech Therapeutics Limited | Antibodies |
| US5639635A (en) | 1994-11-03 | 1997-06-17 | Genentech, Inc. | Process for bacterial production of polypeptides |
| AU4289496A (en) | 1994-12-02 | 1996-06-19 | Chiron Corporation | Method of promoting an immune response with a bispecific antibody |
| US5840523A (en) | 1995-03-01 | 1998-11-24 | Genetech, Inc. | Methods and compositions for secretion of heterologous polypeptides |
| US5731168A (en) | 1995-03-01 | 1998-03-24 | Genentech, Inc. | Method for making heteromultimeric polypeptides |
| US5641870A (en) | 1995-04-20 | 1997-06-24 | Genentech, Inc. | Low pH hydrophobic interaction chromatography for antibody purification |
| US5869046A (en) | 1995-04-14 | 1999-02-09 | Genentech, Inc. | Altered polypeptides with increased half-life |
| US5739277A (en) | 1995-04-14 | 1998-04-14 | Genentech Inc. | Altered polypeptides with increased half-life |
| EP0739981A1 (en) | 1995-04-25 | 1996-10-30 | Vrije Universiteit Brussel | Variable fragments of immunoglobulins - use for therapeutic or veterinary purposes |
| AU5632296A (en) | 1995-04-27 | 1996-11-18 | Abgenix, Inc. | Human antibodies derived from immunized xenomice |
| WO1996034096A1 (en) | 1995-04-28 | 1996-10-31 | Abgenix, Inc. | Human antibodies derived from immunized xenomice |
| US5837234A (en) | 1995-06-07 | 1998-11-17 | Cytotherapeutics, Inc. | Bioartificial organ containing cells encapsulated in a permselective polyether suflfone membrane |
| DE19544393A1 (de) | 1995-11-15 | 1997-05-22 | Hoechst Schering Agrevo Gmbh | Synergistische herbizide Mischungen |
| GB9603256D0 (en) | 1996-02-16 | 1996-04-17 | Wellcome Found | Antibodies |
| WO1997038123A1 (en) | 1996-04-05 | 1997-10-16 | Board Of Regents, The University Of Texas System | Methods for producing soluble, biologically-active disulfide bond-containing eukaryotic proteins in bacterial cells |
| ATE374248T1 (de) | 1996-06-27 | 2007-10-15 | Vlaams Interuniv Inst Biotech | Antikörpermoleküle, die spezifisch mit dem aktiven zentrum oder dem aktiven spalt eines zielmoleküls interagieren |
| WO1998022141A2 (en) | 1996-11-19 | 1998-05-28 | Sangstat Medical Corporation | Enhanced effects for hapten conjugated therapeutics |
| WO1998024893A2 (en) | 1996-12-03 | 1998-06-11 | Abgenix, Inc. | TRANSGENIC MAMMALS HAVING HUMAN IG LOCI INCLUDING PLURAL VH AND Vλ REGIONS AND ANTIBODIES PRODUCED THEREFROM |
| EP0979281B1 (en) | 1997-05-02 | 2005-07-20 | Genentech, Inc. | A method for making multispecific antibodies having heteromultimeric and common components |
| US6083715A (en) | 1997-06-09 | 2000-07-04 | Board Of Regents, The University Of Texas System | Methods for producing heterologous disulfide bond-containing polypeptides in bacterial cells |
| PT994903E (pt) | 1997-06-24 | 2005-10-31 | Genentech Inc | Metodos e composicoes para glicoproteinas galactosiladas |
| AU759779B2 (en) | 1997-10-31 | 2003-05-01 | Genentech Inc. | Methods and compositions comprising glycoprotein glycoforms |
| US6610833B1 (en) | 1997-11-24 | 2003-08-26 | The Institute For Human Genetics And Biochemistry | Monoclonal human natural antibodies |
| BR9813365A (pt) | 1997-12-05 | 2004-06-15 | Scripps Research Inst | Método para produção e humanização de um anticorpo monoclonal de rato |
| AU3596599A (en) | 1998-01-26 | 1999-08-09 | Unilever Plc | Method for producing antibody fragments |
| US6194551B1 (en) | 1998-04-02 | 2001-02-27 | Genentech, Inc. | Polypeptide variants |
| JP2002510481A (ja) | 1998-04-02 | 2002-04-09 | ジェネンテック・インコーポレーテッド | 抗体変異体及びその断片 |
| ATE458007T1 (de) | 1998-04-20 | 2010-03-15 | Glycart Biotechnology Ag | Glykosylierungs-engineering von antikörpern zur verbesserung der antikörperabhängigen zellvermittelten zytotoxizität |
| GB9824632D0 (en) | 1998-11-10 | 1999-01-06 | Celltech Therapeutics Ltd | Biological compounds |
| US6737056B1 (en) | 1999-01-15 | 2004-05-18 | Genentech, Inc. | Polypeptide variants with altered effector function |
| PL209786B1 (pl) | 1999-01-15 | 2011-10-31 | Genentech Inc | Przeciwciało zawierające wariant regionu Fc ludzkiej IgG1, przeciwciało wiążące czynnik wzrostu śródbłonka naczyń oraz immunoadhezyna |
| ATE276359T1 (de) | 1999-01-19 | 2004-10-15 | Unilever Nv | Verfahren zur herstellung von antikörperfragmenten |
| EP2264166B1 (en) | 1999-04-09 | 2016-03-23 | Kyowa Hakko Kirin Co., Ltd. | Method for controlling the activity of immunologically functional molecule |
| CN1371416B (zh) | 1999-08-24 | 2012-10-10 | 梅达里克斯公司 | 人ctla-4抗体及其应用 |
| US7504256B1 (en) | 1999-10-19 | 2009-03-17 | Kyowa Hakko Kogyo Co., Ltd. | Process for producing polypeptide |
| US20030180714A1 (en) | 1999-12-15 | 2003-09-25 | Genentech, Inc. | Shotgun scanning |
| HUP0300369A2 (hu) | 2000-04-11 | 2003-06-28 | Genentech, Inc. | Többértékű antitestek és alkalmazásuk |
| WO2001079442A2 (en) | 2000-04-12 | 2001-10-25 | Human Genome Sciences, Inc. | Albumin fusion proteins |
| AU2001268855A1 (en) | 2000-05-26 | 2001-12-03 | National Research Council Of Canada | Single-domain antigen-binding antibody fragments derived from llama antibodies |
| DK2314686T4 (da) | 2000-10-06 | 2023-08-21 | Kyowa Kirin Co Ltd | Celler, der danner antistofsammensætninger |
| US6946292B2 (en) | 2000-10-06 | 2005-09-20 | Kyowa Hakko Kogyo Co., Ltd. | Cells producing antibody compositions with increased antibody dependent cytotoxic activity |
| US7064191B2 (en) | 2000-10-06 | 2006-06-20 | Kyowa Hakko Kogyo Co., Ltd. | Process for purifying antibody |
| US6596541B2 (en) | 2000-10-31 | 2003-07-22 | Regeneron Pharmaceuticals, Inc. | Methods of modifying eukaryotic cells |
| KR100857943B1 (ko) | 2000-11-30 | 2008-09-09 | 메다렉스, 인코포레이티드 | 인간 항체의 제조를 위한 형질전환 트랜스염색체 설치류 |
| GB0110029D0 (en) | 2001-04-24 | 2001-06-13 | Grosveld Frank | Transgenic animal |
| CN1195779C (zh) | 2001-05-24 | 2005-04-06 | 中国科学院遗传与发育生物学研究所 | 抗人卵巢癌抗人cd3双特异性抗体 |
| US20060073141A1 (en) | 2001-06-28 | 2006-04-06 | Domantis Limited | Compositions and methods for treating inflammatory disorders |
| WO2003011878A2 (en) | 2001-08-03 | 2003-02-13 | Glycart Biotechnology Ag | Antibody glycosylation variants having increased antibody-dependent cellular cytotoxicity |
| ES2337986T3 (es) | 2001-08-10 | 2010-05-03 | Aberdeen University | Dominios de union de antigenos de peces. |
| EP1433793A4 (en) | 2001-09-13 | 2006-01-25 | Inst Antibodies Co Ltd | METHOD FOR CREATING A CAMEL ANTIBODY LIBRARY |
| JP2005289809A (ja) | 2001-10-24 | 2005-10-20 | Vlaams Interuniversitair Inst Voor Biotechnologie Vzw (Vib Vzw) | 突然変異重鎖抗体 |
| WO2003035835A2 (en) | 2001-10-25 | 2003-05-01 | Genentech, Inc. | Glycoprotein compositions |
| US20040093621A1 (en) | 2001-12-25 | 2004-05-13 | Kyowa Hakko Kogyo Co., Ltd | Antibody composition which specifically binds to CD20 |
| AU2003236018A1 (en) | 2002-04-09 | 2003-10-20 | Kyowa Hakko Kirin Co., Ltd. | METHOD OF ENHANCING ACTIVITY OF ANTIBODY COMPOSITION OF BINDING TO FcGamma RECEPTOR IIIa |
| EP1502603A4 (en) | 2002-04-09 | 2006-12-13 | Kyowa Hakko Kogyo Kk | AN ANTIBODY COMPOSITION CONTAINING MEDICAMENT FOR PATIENTS WITH Fc gamma RIIIa POLYMORPHISM |
| US20040132140A1 (en) | 2002-04-09 | 2004-07-08 | Kyowa Hakko Kogyo Co., Ltd. | Production process for antibody composition |
| CA2481656A1 (en) | 2002-04-09 | 2003-10-16 | Kyowa Hakko Kogyo Co., Ltd. | Cells in which activity of the protein involved in transportation of gdp-fucose is reduced or lost |
| US7691568B2 (en) | 2002-04-09 | 2010-04-06 | Kyowa Hakko Kirin Co., Ltd | Antibody composition-containing medicament |
| US20040110704A1 (en) | 2002-04-09 | 2004-06-10 | Kyowa Hakko Kogyo Co., Ltd. | Cells of which genome is modified |
| WO2003102157A2 (en) | 2002-06-03 | 2003-12-11 | Genentech, Inc. | Synthetic antibody phage libraries |
| US7361740B2 (en) | 2002-10-15 | 2008-04-22 | Pdl Biopharma, Inc. | Alteration of FcRn binding affinities or serum half-lives of antibodies by mutagenesis |
| US7217797B2 (en) | 2002-10-15 | 2007-05-15 | Pdl Biopharma, Inc. | Alteration of FcRn binding affinities or serum half-lives of antibodies by mutagenesis |
| CA2502413A1 (en) | 2002-11-01 | 2004-05-21 | The Regents Of The University Of Colorado, A Body Corporate | Quantitative analysis of protein isoforms using matrix-assisted laser desorption/ionization time of flight mass spectrometry |
| GB0228210D0 (en) | 2002-12-03 | 2003-01-08 | Babraham Inst | Single chain antibodies |
| CN103833854B (zh) | 2002-12-16 | 2017-12-12 | 健泰科生物技术公司 | 免疫球蛋白变体及其用途 |
| WO2004065416A2 (en) | 2003-01-16 | 2004-08-05 | Genentech, Inc. | Synthetic antibody phage libraries |
| CA2542046A1 (en) | 2003-10-08 | 2005-04-21 | Kyowa Hakko Kogyo Co., Ltd. | Fused protein composition |
| CA2542125A1 (en) | 2003-10-09 | 2005-04-21 | Kyowa Hakko Kogyo Co., Ltd. | Process for producing antibody composition by using rna inhibiting the function of .alpha.1,6-fucosyltransferase |
| SI2380911T1 (en) | 2003-11-05 | 2018-07-31 | Roche Glycart Ag | ANTIGEN-RELATED PATIENTS WITH INCREASED ATTENTION ON THE RECEPTOR FC AND EFFECTORAL FUNCTION |
| WO2005053742A1 (ja) | 2003-12-04 | 2005-06-16 | Kyowa Hakko Kogyo Co., Ltd. | 抗体組成物を含有する医薬 |
| ES2527292T3 (es) | 2004-03-31 | 2015-01-22 | Genentech, Inc. | Anticuerpos anti-TGF-beta humanizados |
| US7785903B2 (en) | 2004-04-09 | 2010-08-31 | Genentech, Inc. | Variable domain library and uses |
| CA2885854C (en) | 2004-04-13 | 2017-02-21 | F. Hoffmann-La Roche Ag | Anti-p-selectin antibodies |
| BRPI0513577A (pt) | 2004-07-22 | 2008-05-06 | Univ Erasmus Medical Ct | moléculas ligantes |
| US7563443B2 (en) | 2004-09-17 | 2009-07-21 | Domantis Limited | Monovalent anti-CD40L antibody polypeptides and compositions thereof |
| TWI309240B (en) | 2004-09-17 | 2009-05-01 | Hoffmann La Roche | Anti-ox40l antibodies |
| SI1791565T1 (sl) | 2004-09-23 | 2016-08-31 | Genentech, Inc. | Cisteinsko konstruirana protitelesa in konjugati |
| FR2879605B1 (fr) | 2004-12-16 | 2008-10-17 | Centre Nat Rech Scient Cnrse | Production de formats d'anticorps et applications immunologiques de ces formats |
| CA2612355A1 (en) | 2005-06-16 | 2006-12-28 | Virxsys Corporation | Antibody complexes |
| US7612181B2 (en) | 2005-08-19 | 2009-11-03 | Abbott Laboratories | Dual variable domain immunoglobulin and uses thereof |
| MY169746A (en) | 2005-08-19 | 2019-05-14 | Abbvie Inc | Dual variable domain immunoglobulin and uses thereof |
| WO2007056441A2 (en) | 2005-11-07 | 2007-05-18 | Genentech, Inc. | Binding polypeptides with diversified and consensus vh/vl hypervariable sequences |
| WO2007064919A2 (en) | 2005-12-02 | 2007-06-07 | Genentech, Inc. | Binding polypeptides with restricted diversity sequences |
| BRPI0706750A2 (pt) | 2006-01-25 | 2011-04-05 | Univ Erasmus Medical Ct | geração de anticorpos de cadeia pesada em animais transgênicos |
| WO2007112940A2 (en) | 2006-03-31 | 2007-10-11 | Ablynx N.V. | Albumin-derived amino acid sequence, use thereof for increasing the half-life of therapeutic proteins and of other therapeutic compounds and entities, and constructs comprising the same |
| CA2651567A1 (en) | 2006-05-09 | 2007-11-22 | Genentech, Inc. | Binding polypeptides with optimized scaffolds |
| US20080226635A1 (en) | 2006-12-22 | 2008-09-18 | Hans Koll | Antibodies against insulin-like growth factor I receptor and uses thereof |
| CN101210048A (zh) | 2006-12-29 | 2008-07-02 | 中国医学科学院血液学研究所 | 用于靶向结合髓系白血病细胞的抗cd33的工程抗体及其表达载体和用途 |
| CN100592373C (zh) | 2007-05-25 | 2010-02-24 | 群康科技(深圳)有限公司 | 液晶显示面板驱动装置及其驱动方法 |
| CN104945508B (zh) | 2007-06-18 | 2019-02-22 | 默沙东有限责任公司 | 针对人程序性死亡受体pd-1的抗体 |
| EP2215125A1 (en) | 2007-11-27 | 2010-08-11 | Ablynx N.V. | Method for obtaining polypeptide constructs comprising two or more single domain antibodies |
| US20110008345A1 (en) | 2007-11-30 | 2011-01-13 | Claire Ashman | Antigen-binding constructs |
| MX350962B (es) | 2008-01-07 | 2017-09-27 | Amgen Inc | Metodo para fabricar moleculas heterodimericas de fragmentos cristalizables de anticuerpo, utilizando efectos electrostaticos de direccion. |
| US20100122358A1 (en) | 2008-06-06 | 2010-05-13 | Crescendo Biologics Limited | H-Chain-only antibodies |
| IT1394281B1 (it) | 2009-01-19 | 2012-06-06 | Zardi | Processo per la produzione di proteine di fusione polivalenti e polispecifiche utilizzando come struttura portante l'uteroglobina e prodotti cosi' ottenuti. |
| GB0903325D0 (en) | 2009-02-26 | 2009-04-08 | Univ Aberdeen | Antibody molecules |
| KR101431318B1 (ko) | 2009-04-02 | 2014-08-20 | 로슈 글리카트 아게 | 전장 항체 및 단일쇄 fab 단편을 포함하는 다중특이성 항체 |
| GB201005063D0 (en) | 2010-03-25 | 2010-05-12 | Ucb Pharma Sa | Biological products |
| KR101553244B1 (ko) | 2009-12-10 | 2015-09-15 | 리제너론 파마슈티칼스 인코포레이티드 | 중쇄 항체를 만드는 마우스 |
| TW201134488A (en) | 2010-03-11 | 2011-10-16 | Ucb Pharma Sa | PD-1 antibodies |
| EP2545078A1 (en) | 2010-03-11 | 2013-01-16 | UCB Pharma, S.A. | Pd-1 antibody |
| TWI586806B (zh) | 2010-04-23 | 2017-06-11 | 建南德克公司 | 異多聚體蛋白質之製造 |
| UA112062C2 (uk) | 2010-10-04 | 2016-07-25 | Бьорінгер Інгельхайм Інтернаціональ Гмбх | Cd33-зв'язувальний агент |
| PT2691112T (pt) | 2011-03-31 | 2018-07-10 | Merck Sharp & Dohme | Formulações estáveis de anticorpos para o recetor pd-1 humano de morte programada e tratamentos relacionados |
| KR101992502B1 (ko) | 2011-05-12 | 2019-06-24 | 제넨테크, 인크. | 프레임워크 시그너처 펩티드를 사용하여 동물 샘플에서 치료 항체를 검출하기 위한 다중 반응 모니터링 lc-ms/ms 방법 |
| CN107936121B (zh) | 2011-05-16 | 2022-01-14 | 埃泰美德(香港)有限公司 | 多特异性fab融合蛋白及其使用方法 |
| WO2013019906A1 (en) | 2011-08-01 | 2013-02-07 | Genentech, Inc. | Methods of treating cancer using pd-1 axis binding antagonists and mek inhibitors |
| TWI679212B (zh) | 2011-11-15 | 2019-12-11 | 美商安進股份有限公司 | 針對bcma之e3以及cd3的結合分子 |
| US20140370012A1 (en) | 2012-01-27 | 2014-12-18 | Gliknik Inc. | Fusion proteins comprising igg2 hinge domains |
| KR101911438B1 (ko) | 2012-10-31 | 2018-10-24 | 삼성전자주식회사 | 이중 특이 항원 결합 단백질 복합체 및 이중 특이 항체의 제조 방법 |
| US20160000842A1 (en) | 2013-03-05 | 2016-01-07 | Baylor College Of Medicine | Oncolytic virus |
| WO2014209804A1 (en) | 2013-06-24 | 2014-12-31 | Biomed Valley Discoveries, Inc. | Bispecific antibodies |
| CN104250302B (zh) * | 2013-06-26 | 2017-11-14 | 上海君实生物医药科技股份有限公司 | 抗pd‑1抗体及其应用 |
| CN112457403B (zh) * | 2013-09-13 | 2022-11-29 | 广州百济神州生物制药有限公司 | 抗pd1抗体及其作为治疗剂与诊断剂的用途 |
| US10350275B2 (en) | 2013-09-21 | 2019-07-16 | Advantagene, Inc. | Methods of cytotoxic gene therapy to treat tumors |
| KR20160093012A (ko) | 2013-11-05 | 2016-08-05 | 코그네이트 바이오서비시즈, 인코포레이티드 | 암 치료를 위한 체크포인트 억제제 및 치료제의 배합물 |
| JOP20200094A1 (ar) | 2014-01-24 | 2017-06-16 | Dana Farber Cancer Inst Inc | جزيئات جسم مضاد لـ pd-1 واستخداماتها |
| KR20160108568A (ko) | 2014-02-04 | 2016-09-19 | 인사이트 코포레이션 | 암을 치료하기 위한 pd-1 길항제 및 ido1 억제제의 조합 |
| JP6636498B2 (ja) | 2014-03-21 | 2020-01-29 | リジェネロン・ファーマシューティカルズ・インコーポレイテッドRegeneron Pharmaceuticals, Inc. | 単一ドメイン結合タンパク質を作る非ヒト動物 |
| TW201618775A (zh) | 2014-08-11 | 2016-06-01 | 艾森塔製藥公司 | Btk抑制劑、pi3k抑制劑、jak-2抑制劑、pd-1抑制劑及/或pd-l1抑制劑之治療組合物 |
| MA40579A (fr) | 2014-09-12 | 2016-03-17 | Genentech Inc | Anticorps anti-cll-1 et immunoconjugués |
| CA2964317C (en) | 2014-10-14 | 2021-10-05 | Halozyme, Inc. | Compositions of adenosine deaminase-2 (ada2), variants thereof and methods of using same |
| SG11201702401RA (en) | 2014-10-14 | 2017-04-27 | Novartis Ag | Antibody molecules to pd-l1 and uses thereof |
| EP3218409A2 (en) * | 2014-11-11 | 2017-09-20 | Sutro Biopharma, Inc. | Anti-pd-1 antibodies, compositions comprising anti-pd-1 antibodies and methods of using anti-pd-1 antibodies |
| BR112017010198A2 (pt) | 2014-11-17 | 2017-12-26 | Genentech Inc | terapia de combinação compreendendo agonistas de ligação a ox40 e antagonistas de ligação ao eixo de pd-1 |
| DK3286311T3 (da) | 2015-03-26 | 2021-05-17 | Oncosec Medical Inc | Fremgangsmåde til behandling af maligniteter |
| WO2016168769A1 (en) | 2015-04-15 | 2016-10-20 | The California Institute For Biomedical Research | Chimeric receptor t cell switches for her2 |
| WO2016187594A1 (en) | 2015-05-21 | 2016-11-24 | Harpoon Therapeutics, Inc. | Trispecific binding proteins and methods of use |
| TWI773646B (zh) | 2015-06-08 | 2022-08-11 | 美商宏觀基因股份有限公司 | 結合lag-3的分子和其使用方法 |
| WO2016201389A2 (en) | 2015-06-12 | 2016-12-15 | Alector Llc | Anti-cd33 antibodies and methods of use thereof |
| JP6996983B2 (ja) | 2015-06-16 | 2022-02-21 | ジェネンテック, インコーポレイテッド | 抗cll-1抗体及び使用方法 |
| WO2017024515A1 (en) | 2015-08-11 | 2017-02-16 | Wuxi Biologics (Cayman) Inc. | Novel anti-pd-1 antibodies |
| MA42626A (fr) | 2015-08-11 | 2018-06-20 | Open Monoclonal Tech Inc | Nouveaux anticorps anti-pd-1 |
| JP6861418B2 (ja) | 2015-09-02 | 2021-04-28 | イッサム リサーチ デベロップメント カンパニー オブ ザ ヘブリュー ユニバーシティー オブ エルサレム リミテッド | ヒトt細胞免疫グロブリン及びitimドメイン(tigit)に特異的な抗体 |
| TWI747841B (zh) | 2015-09-25 | 2021-12-01 | 美商建南德克公司 | 抗tigit抗體及使用方法 |
| EP3356401B1 (en) | 2015-09-30 | 2020-06-24 | IGM Biosciences, Inc. | Binding molecules with modified j-chain |
| TWI778943B (zh) | 2015-10-01 | 2022-10-01 | 美商潛能醫療有限公司 | 抗tigit抗原結合蛋白及其使用方法 |
| US10544222B2 (en) | 2015-11-18 | 2020-01-28 | Merck Sharp & Dohme Corp. | PD1/CTLA4 binders |
| MY189018A (en) * | 2015-11-18 | 2022-01-19 | Merck Sharp & Dohme | Pd1 and/or lag3 binders |
| EP3377533A2 (en) | 2015-11-19 | 2018-09-26 | Sutro Biopharma, Inc. | Anti-lag3 antibodies, compositions comprising anti-lag3 antibodies and methods of making and using anti-lag3 antibodies |
| WO2017125897A1 (en) | 2016-01-21 | 2017-07-27 | Novartis Ag | Multispecific molecules targeting cll-1 |
| EP3408671B1 (en) | 2016-01-25 | 2023-11-01 | F. Hoffmann-La Roche AG | Methods for assaying t-cell dependent bispecific antibodies |
| CN105754990A (zh) | 2016-01-29 | 2016-07-13 | 深圳精准医疗科技有限公司 | 一种pd-1/ctla-4双特异性抗体的制备方法及其应用 |
| JP2019510812A (ja) | 2016-02-26 | 2019-04-18 | イミュネクサス・ピーティーワイ・リミテッド | 多重特異性分子 |
| EP3432927A4 (en) | 2016-03-24 | 2019-11-20 | Gensun Biopharma Inc. | TRIPLE-SPECIFIC INHIBITORS FOR CANCER TREATMENT |
| WO2017196847A1 (en) | 2016-05-10 | 2017-11-16 | The United States Of America, As Represented By The Secretary, Department Of Health And Human Services | Variable new antigen receptor (vnar) antibodies and antibody conjugates targeting tumor and viral antigens |
| EP3243836A1 (en) | 2016-05-11 | 2017-11-15 | F. Hoffmann-La Roche AG | C-terminally fused tnf family ligand trimer-containing antigen binding molecules |
| IL262892B2 (en) | 2016-05-18 | 2024-04-01 | Boehringer Ingelheim Int | Anti-PD-1 and anti-LAG3 antibodies for cancer treatment |
| CN107400166A (zh) | 2016-05-19 | 2017-11-28 | 苏州康宁杰瑞生物科技有限公司 | 针对ctla4的单域抗体及其衍生蛋白 |
| WO2018014260A1 (en) | 2016-07-20 | 2018-01-25 | Nanjing Legend Biotech Co., Ltd. | Multispecific antigen binding proteins and methods of use thereof |
| CA2937157A1 (en) | 2016-07-25 | 2018-01-25 | Ucl Business Plc | Protein-based t-cell receptor knockdown |
| WO2018068201A1 (en) | 2016-10-11 | 2018-04-19 | Nanjing Legend Biotech Co., Ltd. | Single-domain antibodies and variants thereof against ctla-4 |
| CN106939050B (zh) | 2017-03-27 | 2019-05-10 | 顺昊细胞生物技术(天津)股份有限公司 | 抗pd1和cd19双特异性抗体及其应用 |
| EA039662B1 (ru) | 2017-10-03 | 2022-02-24 | Закрытое Акционерное Общество "Биокад" | Антитела, специфичные к cd47 и pd-l1 |
| CN109897111B (zh) | 2017-12-08 | 2021-02-23 | 杭州翰思生物医药有限公司 | 抗pd-1/cd47的双特异性抗体及其应用 |
| CN111527109A (zh) | 2017-12-26 | 2020-08-11 | 南京金斯瑞生物科技有限公司 | 以抗体Fc区为骨架的融合蛋白二聚体及其应用 |
| EP3732202A4 (en) | 2017-12-28 | 2022-06-15 | Nanjing Legend Biotech Co., Ltd. | SINGLE DOMAIN ANTIBODIES AND VARIANTS THEREOF AGAINST TIGIT |
| AU2019205406A1 (en) | 2018-01-08 | 2020-08-27 | Nanjing Legend Biotech Co., Ltd. | Multispecific antigen binding proteins and methods of use thereof |
| CA3084518A1 (en) | 2018-01-15 | 2019-07-18 | Nanjing Legend Biotech Co., Ltd. | Single-domain antibodies and variants thereof against pd-1 |
| CN108047333B (zh) | 2018-01-15 | 2021-05-25 | 浙江阿思科力生物科技有限公司 | 以cd33为靶点的特异性抗体、car-nk细胞及其制备和应用 |
| WO2019179434A1 (en) | 2018-03-20 | 2019-09-26 | Wuxi Biologics (Shanghai) Co., Ltd. | Novel bispecific pd-1/cd47 antibody molecules |
| KR20200138720A (ko) | 2018-03-30 | 2020-12-10 | 난징 레전드 바이오테크 씨오., 엘티디. | Lag-3에 대한 단일-도메인 항체 및 이의 용도 |
| US20210277126A1 (en) | 2018-09-10 | 2021-09-09 | Nanjing Legend Biotech Co., Ltd. | Single-domain antibodies against cll1 and constructs thereof |
| EP3998287A4 (en) | 2019-07-08 | 2023-08-09 | Nanjing GenScript Biotech Co., Ltd. | ANTI-CD47/ANTI-PD-1 BISPECIFIC ANTIBODY, METHOD FOR ITS PRODUCTION AND ITS USE |
-
2019
- 2019-01-15 CA CA3084518A patent/CA3084518A1/en active Pending
- 2019-01-15 US US16/962,023 patent/US11713353B2/en active Active
- 2019-01-15 TW TW108101554A patent/TWI802633B/zh active
- 2019-01-15 EP EP19738343.3A patent/EP3740507A4/en active Pending
- 2019-01-15 JP JP2020538951A patent/JP7366908B2/ja active Active
- 2019-01-15 WO PCT/CN2019/071691 patent/WO2019137541A1/en unknown
- 2019-01-15 SG SG11202004233UA patent/SG11202004233UA/en unknown
- 2019-01-15 KR KR1020207023545A patent/KR20200120641A/ko unknown
- 2019-01-15 AU AU2019207276A patent/AU2019207276A1/en active Pending
- 2019-01-15 CN CN201980012465.XA patent/CN111699200B/zh active Active
-
2020
- 2020-06-29 IL IL275740A patent/IL275740A/en unknown
Patent Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN106715469A (zh) * | 2014-08-27 | 2017-05-24 | 纪念斯隆-凯特琳癌症中心 | 抗体、组合物和用途 |
Also Published As
| Publication number | Publication date |
|---|---|
| TWI802633B (zh) | 2023-05-21 |
| IL275740A (en) | 2020-08-31 |
| AU2019207276A1 (en) | 2020-09-03 |
| US20200347135A1 (en) | 2020-11-05 |
| SG11202004233UA (en) | 2020-06-29 |
| EP3740507A4 (en) | 2022-08-24 |
| JP7366908B2 (ja) | 2023-10-23 |
| EP3740507A1 (en) | 2020-11-25 |
| WO2019137541A1 (en) | 2019-07-18 |
| CN111699200A (zh) | 2020-09-22 |
| JP2021510521A (ja) | 2021-04-30 |
| US11713353B2 (en) | 2023-08-01 |
| TW201932490A (zh) | 2019-08-16 |
| KR20200120641A (ko) | 2020-10-21 |
| CA3084518A1 (en) | 2019-07-18 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11613587B2 (en) | Combination therapy of T cell activating bispecific antigen binding molecules and PD-1 axis binding antagonists | |
| CN111699198B (zh) | 针对tigit的单域抗体和其变体 | |
| CN111699200B (zh) | 针对pd-1的单域抗体和其变体 | |
| CN109843923B (zh) | 针对ctla-4的单结构域抗体及其变体 | |
| CN111433224B (zh) | 抗pd-l1的单结构域抗体及其变体 | |
| CA3088332A1 (en) | Antibodies and variants thereof against tigit | |
| CN111886254B (zh) | 针对lag-3的单结构域抗体及其用途 | |
| WO2019129211A1 (en) | Antibodies and variants thereof against pd-l1 | |
| JP2022504826A (ja) | 4-1bb及び腫瘍関連抗原に結合する抗体構築物ならびにその使用 | |
| CN114008080A (zh) | 抗pd-l1/抗lag-3多抗原结合蛋白及其使用方法 | |
| KR20200118065A (ko) | 이중특이적 항원-결합 분자 및 이의 사용 방법 | |
| KR20220148228A (ko) | 항cd137 작제물, 다중 특이적 항체 및 그 용도 | |
| JP2024511424A (ja) | 抗igfbp7構築物およびその使用 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |