KR20220148228A - 항cd137 작제물, 다중 특이적 항체 및 그 용도 - Google Patents
항cd137 작제물, 다중 특이적 항체 및 그 용도 Download PDFInfo
- Publication number
- KR20220148228A KR20220148228A KR1020227033169A KR20227033169A KR20220148228A KR 20220148228 A KR20220148228 A KR 20220148228A KR 1020227033169 A KR1020227033169 A KR 1020227033169A KR 20227033169 A KR20227033169 A KR 20227033169A KR 20220148228 A KR20220148228 A KR 20220148228A
- Authority
- KR
- South Korea
- Prior art keywords
- seq
- amino acid
- acid sequence
- cdr1
- cdr2
- Prior art date
Links
Images

























Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2878—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the NGF-receptor/TNF-receptor superfamily, e.g. CD27, CD30, CD40, CD95
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/50—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates
- A61K47/51—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent
- A61K47/68—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment
- A61K47/6835—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment the modifying agent being an antibody or an immunoglobulin bearing at least one antigen-binding site
- A61K47/6849—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment the modifying agent being an antibody or an immunoglobulin bearing at least one antigen-binding site the antibody targeting a receptor, a cell surface antigen or a cell surface determinant
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2863—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against receptors for growth factors, growth regulators
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/505—Medicinal preparations containing antigens or antibodies comprising antibodies
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/20—Immunoglobulins specific features characterized by taxonomic origin
- C07K2317/21—Immunoglobulins specific features characterized by taxonomic origin from primates, e.g. man
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/20—Immunoglobulins specific features characterized by taxonomic origin
- C07K2317/24—Immunoglobulins specific features characterized by taxonomic origin containing regions, domains or residues from different species, e.g. chimeric, humanized or veneered
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/30—Immunoglobulins specific features characterized by aspects of specificity or valency
- C07K2317/31—Immunoglobulins specific features characterized by aspects of specificity or valency multispecific
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/30—Immunoglobulins specific features characterized by aspects of specificity or valency
- C07K2317/33—Crossreactivity, e.g. for species or epitope, or lack of said crossreactivity
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/52—Constant or Fc region; Isotype
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/56—Immunoglobulins specific features characterized by immunoglobulin fragments variable (Fv) region, i.e. VH and/or VL
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/56—Immunoglobulins specific features characterized by immunoglobulin fragments variable (Fv) region, i.e. VH and/or VL
- C07K2317/565—Complementarity determining region [CDR]
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/60—Immunoglobulins specific features characterized by non-natural combinations of immunoglobulin fragments
- C07K2317/62—Immunoglobulins specific features characterized by non-natural combinations of immunoglobulin fragments comprising only variable region components
- C07K2317/622—Single chain antibody (scFv)
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/71—Decreased effector function due to an Fc-modification
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/73—Inducing cell death, e.g. apoptosis, necrosis or inhibition of cell proliferation
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/75—Agonist effect on antigen
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/90—Immunoglobulins specific features characterized by (pharmaco)kinetic aspects or by stability of the immunoglobulin
- C07K2317/92—Affinity (KD), association rate (Ka), dissociation rate (Kd) or EC50 value
Landscapes
- Health & Medical Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Organic Chemistry (AREA)
- Immunology (AREA)
- Life Sciences & Earth Sciences (AREA)
- Medicinal Chemistry (AREA)
- General Health & Medical Sciences (AREA)
- Biochemistry (AREA)
- Genetics & Genomics (AREA)
- Molecular Biology (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Biophysics (AREA)
- Veterinary Medicine (AREA)
- Public Health (AREA)
- Animal Behavior & Ethology (AREA)
- Pharmacology & Pharmacy (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- General Chemical & Material Sciences (AREA)
- Chemical Kinetics & Catalysis (AREA)
- Cell Biology (AREA)
- Engineering & Computer Science (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Epidemiology (AREA)
- Peptides Or Proteins (AREA)
- Medicines Containing Antibodies Or Antigens For Use As Internal Diagnostic Agents (AREA)
- Preparation Of Compounds By Using Micro-Organisms (AREA)
- Micro-Organisms Or Cultivation Processes Thereof (AREA)
- Medicinal Preparation (AREA)
Abstract
본 발명은 CD137 및 하나 또는 여러가지 별도의 항원에 결합 특이성을 갖는 다중 특이적 항CD137 항체를 포함하는 CD137에 결합되는 항CD137 작제물, 및 이들을 이용하는 방법에 대해 개시한다. 몇몇 실시예에서, 하나 또는 여러가지 별도의 항원은 표피 성장 인자 수용체 (EGFR)를 포함한다.
Description
관련 출원의 교차 인용
본 출원은 2020년 2월 28일에 제출한 국제특허출원번호 PCT/CN 2020/077148에 대한 우선권을 주장하고, 그 전체 내용이 본문에 참조로서 포함되며, 이에 대한 우선권을 주장한다.
기술분야
본 출원은 CD137에 결합되는 항체(항CD137단일 특이성 항체 및 다중 특이적 항체 포함), 제조 방법 및 그 용도에 관한 것으로, 상기 용도는 질환 또는 병증 치료를 포함한다.
CD137(4-1BB 및 TNFRSF9라고도 함)은 종양 괴사 인자 수용체 슈퍼 패밀리(TNFRS)의 막횡단 단백질이다. 현재 CD137에 대한 이해에 따르면, 발현은 통상적으로 활성화 의존적이고 면역 세포의 광범위한 서브집단에 존재하고, 상기 면역 세포는 활성화된 NK 및 NKT세포, 조절 T 세포, 수지상 세포(DC), 자극된 비만 세포, 분화 중인 골수 세포, 단핵구, 호중구, 및 호산구를 포함한다(Wang, 2009, Immunological Reviews 229: 192-215). CD137의 발현은 종양 맥관 시스템(Broll, 2001, Amer. J. Clin. Pathol. 115(4): 543-549; Seaman, 2007, Cancer Cell 11: 539-554) 및 염증 또는 죽상동맥경화가 발생된 내피 세포 부위(Drenkard, 2007 FASEB J. 21: 456-463; Olofsson, 2008, Circulation 117: 1292-1301)에서도 입증되었다. CD137을 자극하는 리간드, 즉 CD137리간드(4-1BBL)는 활성화된 항원 제시 세포(APC), 골수양 선조 세포 및 조혈모세포에서 발현된다.
인간CD137는 255개의 아미노산의 단백질이다. 상기 수용체는 단량체 및 이량체 형태로 세포 표면에 발현되고, CD137리간드와 삼량체화되어 다운스트림 신호를 활성화할 수 있다. 마우스 및 인간 T세포에 관한 연구에 따르면, CD137은 증강된 세포 증식, 생존 및 사이토카인 생성을 촉진한다(Croft, 2009, Nat Rev Immunol 9: 271-285). 연구에 따르면, 일부 CD137작용제 mAb는 공동자극 분자의 발현을 증가시키고 세포용해성 T 림프구 반응을 현저하게 증강시켜, 다양한 모델에서 항 종양 효능을 나타낼 수 있다. CD137 작용제 mAb는 예방적 및 치료적 환경 효능을 갖고 있는 것으로 입증되었다. 이외에, CD137 단일 요법과 병용 요법의 종양 모델은 지속적인 항종양 보호적 T 세포 기억 반응을 확립하였다(Lynch, 2008, Immunol Rev. 22: 277-286). 본 분야에서 공인된 다양한 자가면역 모델(Vinay, 2006, J Mol Med 84: 726-736)에서, CD137 작용제는 또한 자가면역 반응을 억제하는 것으로 나타났다. CD137의 이러한 이중 활성은 잠재적인 항종양 활성을 제공하는 동시에 자가면역 부작용을 억제할 수 있고, 상기 부작용은 면역 관용을 파괴하는 면역 요법과 관련이 있을 수 있다.
본 출원에 인용된 모든 출판물, 특허, 특허출원 및 개시된 특허출원의 내용은 모두 그 전체 내용이 본문에 통합된다.
본 개시는 항CD137 작제물(예를 들어, 항CD137 모노클로날 항체 및 항CD137 다중 특이적 항체), 항CD137 작제물을 코딩하는 폴리뉴클레오티드, 키트, 세포 조성물을 조절하는 방법 및 상기 항CD137 작제물을 사용하여 대상체를 치료하는 방법을 제공한다. 본 발명에서 부분적으로 항CD137 단일 특이성 항체 및 다중 특이적 항체의 발견에 기반하여, 상기 항CD137 단일 특이성 항체 및 다중 특이적 항체는 임상 시험에서 발견된 기존 항CD137 항체에 비해 개선된 안전성 및 증강된 항 종양 효능을 나타낸다.
본 개시는 CD137 및 EGFR에 결합되는 다중 특이적 항체를 제공한다. 일부 실시예에서, 본문에 개시된 다중 특이적 항체는 CD137에 결합되는 제1 항체 부분 및 EGFR에 결합되는 제2 항체 부분을 포함한다. 일부 실시예에서, 상기 제1 항체 부분은 중쇄 가변 영역(VH) 및 경쇄 가변 영역(VL)을 포함하고, 여기서, a) 상기 VH는, i) GFX1X2X3DTYIX4(SEQ ID NO: 177)의 아미노산 서열을 포함하는 HC-CDR1(여기서 X1 = N 또는 C; X2 = I, P, L 또는 M; X3 = K, N, R, C 또는 Q; X4 = H 또는 Q), ii) X1IDPANGX2X3X4(SEQ ID NO: 178)의 아미노산 서열을 포함하는 HC-CDR2(여기서 X1 = K 또는 R; X2 = N, G, F, Y, A, D, L, M 또는 Q; X3 = S 또는 T; X4 = E 또는 M), 및 iii) GNLHYX1LMD(SEQ ID NO: 179ㅊ의 아미노산 서열을 포함하는 HC-CDR3(여기서 X1 = Y, A 또는 G); 또한, b) 상기 VL는, i) KASQX1X2X3TYX4S(SEQ ID NO: 180)의 아미노산 서열을 포함하는 LC-CDR1(여기서 X1 = A, P 또는 T; X2 = I, T 또는 P; X3 = N 또는 A; X4 = L, G 또는 H), ii) RX1NRX2X3X4(SEQ ID NO: 181)의 아미노산 서열을 포함하는 LC-CDR2(여기서 X1 = A, Y, V 또는 D; X2 = M, K, V 또는 A; X3 = V, P, Y 또는 G; X4 = D 또는 G), 및 iii) LQX1X2DFPYX3(SEQ ID NO: 182)의 아미노산 서열을 포함하는 LC-CDR3(여기서 X1 = Y, S 또는 F; X2 = D, V, L, R, E 또는 Q; X3 = T 또는 K)을 포함한다. 일부 실시예에서, HC-CDR1은 SEQ ID NO: 1, 11, 21, 31, 41, 51, 61, 71, 81, 91, 101, 111, 121, 131, 141, 261 및 271 중의 임의의 하나의 아미노산 서열을 포함하거나, 최대 약 3개의 아미노산에 의해 치환된 변이체를 포함하고; HC-CDR2는 SEQ ID NO: 2, 12, 22, 32, 42, 52, 62, 72, 82, 92, 102, 112, 122, 132, 142, 262 및 272 중의 임의의 하나의 아미노산 서열을 포함하거나, 최대 약 3개의 아미노산에 의해 치환된 변이체를 포함하며; HC-CDR3은 SEQ ID NO: 3, 13, 23, 33, 43, 53, 63, 73, 83, 93, 103, 113, 123, 133, 143, 263 및 273 중의 임의의 하나의 아미노산 서열을 포함하거나, 최대 약 3개의 아미노산에 의해 치환된 변이체를 포함하고; LC-CDR1은 SEQ ID NO: 4, 14, 24, 34, 44, 54, 64, 74, 84, 94, 104, 114, 124, 134, 144, 264 및 274 중의 임의의 하나의 아미노산 서열을 포함하거나 최대 약 3개의 아미노산에 의해 치환된 변이체를 포함하며; LC-CDR2는 SEQ ID NO: 5, 15, 25, 35, 45, 55, 65, 75, 85, 95, 105, 115, 125, 135, 145, 265 및 275 중의 임의의 하나의 아미노산 서열을 포함하거나, 최대 약 3개의 아미노산에 의해 치환된 변이체를 포함하고; LC-CDR3은 SEQ ID NO: 6, 16, 26, 36, 46, 56, 66, 76, 86, 96, 106, 116, 126, 136, 146, 266 및 276 중의 임의의 하나의 아미노산 서열을 포함하거나, 최대 약 3개의 아미노산에 의해 치환된 변이체를 포함한다.
일부 실시예에서, 상기 제1 항체 부분은 기준 항CD137 작제물과 교차 경쟁하여 CD137에 결합되고, 상기 기준 항CD137 작제물은 중쇄 가변 영역(VH)(상기 중쇄 가변 영역은 HC-CDR1, HC-CDR2 및 HC-CDR3 도메인을 포함) 및 경쇄 가변 영역(VL)(상기 경쇄 가변 영역은 LC-CDR1, LC-CDR2 및 LC-CDR3 도메인을 포함)을 포함하고,
a) SEQ ID NO: 1의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 2의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 3의 아미노산 서열을 포함하는 HC-CDR3을 포함하는 상기 VH, 및 SEQ ID NO: 4의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 5의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 6의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 상기 VL;
b) SEQ ID NO: 11의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 12의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 13의 아미노산 서열을 포함하는 HC-CDR3을 포함하는 상기 VH, 및 SEQ ID NO: 14의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 15의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 16의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 상기 VL;
c) SEQ ID NO: 21의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 22의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 23의 아미노산 서열을 포함하는 HC-CDR3을 포함하는 상기 VH, 및 SEQ ID NO: 24의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 25의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 26의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 상기 VL;
d) SEQ ID NO: 31의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 32의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 33의 아미노산 서열을 포함하는 HC-CDR3을 포함하는 상기 VH, 및 SEQ ID NO: 34의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 35의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 36의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 상기 VL;
e) SEQ ID NO: 41의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 42의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 43의 아미노산 서열을 포함하는 HC-CDR3을 포함하는 상기 VH, 및 SEQ ID NO: 44의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 45의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 46의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 상기 VL;
f) SEQ ID NO: 51의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 52의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 53의 아미노산 서열을 포함하는 HC-CDR3을 포함하는 상기 VH, 및 SEQ ID NO: 54의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 55의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 56의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 상기 VL;
g) SEQ ID NO: 61의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 62의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 63의 아미노산 서열을 포함하는 HC-CDR3을 포함하는 상기 VH, 및 SEQ ID NO: 64의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 65의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 66의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 상기 VL;
h) SEQ ID NO: 71의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 72의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 73의 아미노산 서열을 포함하는 HC-CDR3을 포함하는 상기 VH, 및 SEQ ID NO: 74의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 75의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 76의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 상기 VL;
i) SEQ ID NO: 81의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 82의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 83의 아미노산 서열을 포함하는 HC-CDR3을 포함하는 상기 VH, 및 SEQ ID NO: 84의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 85의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 86의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 상기 VL;
j) SEQ ID NO: 91의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 92의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 93의 아미노산 서열을 포함하는 HC-CDR3을 포함하는 상기 VH, 및 SEQ ID NO: 94의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 95의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 96의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 상기 VL;
k) SEQ ID NO: 101의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 102의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 103의 아미노산 서열을 포함하는 HC-CDR3을 포함하는 상기 VH, 및 SEQ ID NO: 104의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 105의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 106의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 상기 VL;
l) SEQ ID NO: 111의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 112의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 113의 아미노산 서열을 포함하는 HC-CDR3을 포함하는 상기 VH, 및 SEQ ID NO: 114의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 115의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 116의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 상기 VL;
m) SEQ ID NO: 121의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 122의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 123의 아미노산 서열을 포함하는 HC-CDR3을 포함하는 상기 VH, 및 SEQ ID NO: 124의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 125의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 126의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 상기 VL;
n) SEQ ID NO: 131의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 132의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 133의 아미노산 서열을 포함하는 HC-CDR3을 포함하는 상기 VH, 및 SEQ ID NO: 134의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 135의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 136의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 상기 VL;
o) SEQ ID NO: 261의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 262의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 263의 아미노산 서열을 포함하는 HC-CDR3을 포함하는 상기 VH, 및 SEQ ID NO: 264의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 265의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 266의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 상기 VL;
p) SEQ ID NO: 271의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 272의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 273의 아미노산 서열을 포함하는 HC-CDR3을 포함하는 상기 VH, 및 SEQ ID NO: 274의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 275의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 276의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 상기 VL로부터 선택된다.
일부 실시예에서, 상기 제1 항체 부분은 중쇄 가변 영역(VH)(상기 중쇄 가변 영역은 HC-CDR1, HC-CDR2 및 HC-CDR3 도메인을 포함); 및 경쇄 가변 영역(VL)(상기 경쇄 가변 영역은 LC-CDR1, LC-CDR2 및 LC-CDR3 도메인을 포함)을 포함하고, 여기서 상기 VH 및 상기 VL은,
a) SEQ ID NO: 1의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 2의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 3의 아미노산 서열을 포함하는 HC-CDR3을 포함하는 상기 VH, 및 SEQ ID NO: 4의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 5의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 6의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 VL;
b) SEQ ID NO: 11의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 12의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 13의 아미노산 서열을 포함하는 HC-CDR3을 포함하는 상기 VH, 및 SEQ ID NO: 14의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 15의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 16의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 상기 VL;
c) SEQ ID NO: 21의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 22의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 23의 아미노산 서열을 포함하는 HC-CDR3을 포함하는 상기 VH, 및 SEQ ID NO: 24의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 25의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 26의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 상기 VL;
d) SEQ ID NO: 31의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 32의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 33의 아미노산 서열을 포함하는 HC-CDR3을 포함하는 상기 VH, 및 SEQ ID NO: 34의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 35의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 36의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 상기 VL;
e) SEQ ID NO: 41의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 42의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 43의 아미노산 서열을 포함하는 HC-CDR3을 포함하는 상기 VH, 및 SEQ ID NO: 44의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 45의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 46의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 상기 VL;
f) SEQ ID NO: 51의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 52의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 53의 아미노산 서열을 포함하는 HC-CDR3을 포함하는 상기 VH, 및 SEQ ID NO: 54의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 55의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 56의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 상기 VL;
g) SEQ ID NO: 61의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 62의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 63의 아미노산 서열을 포함하는 HC-CDR3을 포함하는 상기 VH, 및 SEQ ID NO: 64의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 65의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 66의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 상기 VL;
h) SEQ ID NO: 71의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 72의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 73의 아미노산 서열을 포함하는 HC-CDR3을 포함하는 상기 VH, 및 SEQ ID NO: 74의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 75의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 76의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 상기 VL;
i) SEQ ID NO: 81의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 82의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 83의 아미노산 서열을 포함하는 HC-CDR3을 포함하는 상기 VH, 및 SEQ ID NO: 84의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 85의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 86의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 상기 VL;
j) SEQ ID NO: 91의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 92의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 93의 아미노산 서열을 포함하는 HC-CDR3을 포함하는 상기 VH, 및 SEQ ID NO: 94의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 95의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 96의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 상기 VL;
k) SEQ ID NO: 101의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 102의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 103의 아미노산 서열을 포함하는 HC-CDR3을 포함하는 상기 VH, 및 SEQ ID NO: 104의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 105의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 106의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 상기 VL;
l) SEQ ID NO: 111의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 112의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 113의 아미노산 서열을 포함하는 HC-CDR3을 포함하는 상기 VH, 및 SEQ ID NO: 114의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 115의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 116의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 상기 VL;
m) SEQ ID NO: 121의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 122의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 123의 아미노산 서열을 포함하는 HC-CDR3을 포함하는 상기 VH, 및 SEQ ID NO: 124의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 125의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 126의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 상기 VL;
n) SEQ ID NO: 131의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 132의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 133의 아미노산 서열을 포함하는 HC-CDR3을 포함하는 상기 VH, 및 SEQ ID NO: 134의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 135의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 136의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 상기 VL;
o) SEQ ID NO: 261의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 262의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 263의 아미노산 서열을 포함하는 HC-CDR3을 포함하는 상기 VH, 및 SEQ ID NO: 264의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 265의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 266의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 상기 VL;
p) SEQ ID NO: 271의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 272의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 273의 아미노산 서열을 포함하는 HC-CDR3을 포함하는 상기 VH, 및 SEQ ID NO: 274의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 275의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 276의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 상기 VL로부터 선택된다.
일부 실시형태에서, 상기 VH는 SEQ ID NO: 1의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 2의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 3의 아미노산 서열을 포함하는 HC-CDR3을 포함하고, 상기 VL는 SEQ ID NO: 4의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 5의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 6의 아미노산 서열을 포함하는 LC-CDR3을 포함한다. 일부 실시형태에서, 상기 VH는 SEQ ID NO: 11의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 12의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 13의 아미노산 서열을 포함하는 HC-CDR3을 포함하고, 상기 VL는 SEQ ID NO: 14의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 15의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 16의 아미노산 서열을 포함하는 LC-CDR3을 포함한다. 일부 실시형태에서, 상기 VH는 SEQ ID NO: 21의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 22의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 23의 아미노산 서열을 포함하는 HC-CDR3을 포함하고, 상기 VL는 SEQ ID NO: 24의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 25의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 26의 아미노산 서열을 포함하는 LC-CDR3을 포함한다. 일부 실시형태에서, 상기 VH는 SEQ ID NO: 31의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 32의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 33의 아미노산 서열을 포함하는 HC-CDR3을 포함하고, 상기 VL는 SEQ ID NO: 34의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 35의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 36의 아미노산 서열을 포함하는 LC-CDR3을 포함한다. 일부 실시형태에서, 상기 VH는 SEQ ID NO: 41의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 42의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 43의 아미노산 서열을 포함하는 HC-CDR3을 포함하고, 상기 VL는 SEQ ID NO: 44의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 45의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 46의 아미노산 서열을 포함하는 LC-CDR3을 포함한다. 일부 실시형태에서, 상기 VH는 SEQ ID NO: 51의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 52의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 53의 아미노산 서열을 포함하는 HC-CDR3을 포함하고, 상기 VL는 SEQ ID NO: 54의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 55의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 56의 아미노산 서열을 포함하는 LC-CDR3을 포함한다. 일부 실시형태에서, 상기 VH는 SEQ ID NO: 61의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 62의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 63의 아미노산 서열을 포함하는 HC-CDR3을 포함하고, 상기 VL는 SEQ ID NO: 64의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 65의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 66의 아미노산 서열을 포함하는 LC-CDR3을 포함한다. 일부 실시형태에서, 상기 VH는 SEQ ID NO: 71의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 72의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 73의 아미노산 서열을 포함하는 HC-CDR3을 포함하고, 상기 VL는 SEQ ID NO: 74의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 75의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 76의 아미노산 서열을 포함하는 LC-CDR3을 포함한다. 일부 실시형태에서, 상기 VH는 SEQ ID NO: 81의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 82의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 83의 아미노산 서열을 포함하는 HC-CDR3을 포함하고, 상기 VL는 SEQ ID NO: 84의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 85의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 86의 아미노산 서열을 포함하는 LC-CDR3을 포함한다. 일부 실시형태에서, 상기 VH는 SEQ ID NO: 91의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 92의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 93의 아미노산 서열을 포함하는 HC-CDR3을 포함하고, 상기 VL는 SEQ ID NO: 94의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 95의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 96의 아미노산 서열을 포함하는 LC-CDR3을 포함한다. 일부 실시형태에서, 상기 VH는 SEQ ID NO: 101의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 102의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 103의 아미노산 서열을 포함하는 HC-CDR3을 포함하고, 상기 VL는 SEQ ID NO: 104의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 105의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 106의 아미노산 서열을 포함하는 LC-CDR3을 포함한다. 일부 실시형태에서, 상기 VH는 SEQ ID NO: 111의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 112의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 113의 아미노산 서열을 포함하는 HC-CDR3을 포함하고, 상기 VL는 SEQ ID NO: 114의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 115의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 116의 아미노산 서열을 포함하는 LC-CDR3을 포함한다. 일부 실시형태에서, 상기 VH는 SEQ ID NO: 121의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 122의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 123의 아미노산 서열을 포함하는 HC-CDR3을 포함하고, 상기 VL는 SEQ ID NO: 124의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 125의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 126의 아미노산 서열을 포함하는 LC-CDR3을 포함한다. 일부 실시형태에서, 상기 VH는 SEQ ID NO: 131의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 132의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 133의 아미노산 서열을 포함하는 HC-CDR3을 포함하고, 상기 VL는 SEQ ID NO: 134의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 135의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 136의 아미노산 서열을 포함하는 LC-CDR3을 포함한다. 일부 실시형태에서, 상기 VH는 SEQ ID NO: 141의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 142의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 143의 아미노산 서열을 포함하는 HC-CDR3을 포함하고, 상기 VL는 SEQ ID NO: 144의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 145의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 146의 아미노산 서열을 포함하는 LC-CDR3을 포함한다. 일부 실시형태에서, 상기 VH는 SEQ ID NO: 261의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 262의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 263의 아미노산 서열을 포함하는 HC-CDR3을 포함하고, 상기 VL는 SEQ ID NO: 264의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 265의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 266의 아미노산 서열을 포함하는 LC-CDR3을 포함한다. 일부 실시형태에서, 상기 VH는 SEQ ID NO: 271의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 272의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 273의 아미노산 서열을 포함하는 HC-CDR3을 포함하고, 상기 VL는 SEQ ID NO: 274의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 275의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 276의 아미노산 서열을 포함하는 LC-CDR3을 포함한다.
일부 실시예에서, 상기 제1 항체 부분은,
a) SEQ ID NO: 7로 표시되는 서열을 갖는 VH쇄 영역 내의 CDR1, CDR2 및 CDR3의 아미노산 서열을 각각 포함하는 HC-CDR1, HC-CDR2 및 HC-CDR3; 및 SEQ ID NO: 8로 표시되는 서열을 갖는 VL쇄 영역 내의 CDR1, CDR2 및 CDR3의 아미노산 서열을 각각 포함하는 LC-CDR1, LC-CDR2 및 LC-CDR3;
b) SEQ ID NO: 17로 표시되는 서열을 갖는 VH쇄 영역 내의 CDR1, CDR2 및 CDR3의 아미노산 서열을 각각 포함하는 HC-CDR1, HC-CDR2 및 HC-CDR3; 및 SEQ ID NO: 18로 표시되는 서열을 갖는 VL쇄 영역 내의 CDR1, CDR2 및 CDR3의 아미노산 서열을 각각 포함하는 LC-CDR1, LC-CDR2 및 LC-CDR3;
c) SEQ ID NO: 27로 표시되는 서열을 갖는 VH쇄 영역 내의 CDR1, CDR2 및 CDR3의 아미노산 서열을 각각 포함하는 HC-CDR1, HC-CDR2 및 HC-CDR3; 및 SEQ ID NO: 28로 표시되는 서열을 갖는 VL쇄 영역 내의 CDR1, CDR2 및 CDR3의 아미노산 서열을 각각 포함하는 LC-CDR1, LC-CDR2 및 LC-CDR3;
d) SEQ ID NO: 37로 표시되는 서열을 갖는 VH쇄 영역 내의 CDR1, CDR2 및 CDR3의 아미노산 서열을 각각 포함하는 HC-CDR1, HC-CDR2 및 HC-CDR3; 및 SEQ ID NO: 38로 표시되는 서열을 갖는 VL쇄 영역 내의 CDR1, CDR2 및 CDR3의 아미노산 서열을 각각 포함하는 LC-CDR1, LC-CDR2 및 LC-CDR3;
e) SEQ ID NO: 47로 표시되는 서열을 갖는 VH쇄 영역 내의 CDR1, CDR2 및 CDR3의 아미노산 서열을 각각 포함하는 HC-CDR1, HC-CDR2 및 HC-CDR3; 및 SEQ ID NO: 48로 표시되는 서열을 갖는 VL쇄 영역 내의 CDR1, CDR2 및 CDR3의 아미노산 서열을 각각 포함하는 LC-CDR1, LC-CDR2 및 LC-CDR3;
f) SEQ ID NO: 57로 표시되는 서열을 갖는 VH쇄 영역 내의 CDR1, CDR2 및 CDR3의 아미노산 서열을 각각 포함하는 HC-CDR1, HC-CDR2 및 HC-CDR3; 및 SEQ ID NO: 58로 표시되는 서열을 갖는 VL쇄 영역 내의 CDR1, CDR2 및 CDR3의 아미노산 서열을 각각 포함하는 LC-CDR1, LC-CDR2 및 LC-CDR3;
g) SEQ ID NO: 67로 표시되는 서열을 갖는 VH쇄 영역 내의 CDR1, CDR2 및 CDR3의 아미노산 서열을 각각 포함하는 HC-CDR1, HC-CDR2 및 HC-CDR3; 및 SEQ ID NO: 68로 표시되는 서열을 갖는 VL쇄 영역 내의 CDR1, CDR2 및 CDR3의 아미노산 서열을 각각 포함하는 LC-CDR1, LC-CDR2 및 LC-CDR3;
h) SEQ ID NO: 77로 표시되는 서열을 갖는 VH쇄 영역 내의 CDR1, CDR2 및 CDR3의 아미노산 서열을 각각 포함하는 HC-CDR1, HC-CDR2 및 HC-CDR3; 및 SEQ ID NO: 78로 표시되는 서열을 갖는 VL쇄 영역 내의 CDR1, CDR2 및 CDR3의 아미노산 서열을 각각 포함하는 LC-CDR1, LC-CDR2 및 LC-CDR3;
i) SEQ ID NO: 87로 표시되는 서열을 갖는 VH쇄 영역 내의 CDR1, CDR2 및 CDR3의 아미노산 서열을 각각 포함하는 HC-CDR1, HC-CDR2 및 HC-CDR3; 및 SEQ ID NO: 88로 표시되는 서열을 갖는 VL쇄 영역 내의 CDR1, CDR2 및 CDR3의 아미노산 서열을 각각 포함하는 LC-CDR1, LC-CDR2 및 LC-CDR3;
j) SEQ ID NO: 97로 표시되는 서열을 갖는 VH쇄 영역 내의 CDR1, CDR2 및 CDR3의 아미노산 서열을 각각 포함하는 HC-CDR1, HC-CDR2 및 HC-CDR3; 및 SEQ ID NO: 98로 표시되는 서열을 갖는 VL쇄 영역 내의 CDR1, CDR2 및 CDR3의 아미노산 서열을 각각 포함하는 LC-CDR1, LC-CDR2 및 LC-CDR3;
k) SEQ ID NO: 107로 표시되는 서열을 갖는 VH쇄 영역 내의 CDR1, CDR2 및 CDR3의 아미노산 서열을 각각 포함하는 HC-CDR1, HC-CDR2 및 HC-CDR3; 및 SEQ ID NO: 108로 표시되는 서열을 갖는 VL쇄 영역 내의 CDR1, CDR2 및 CDR3의 아미노산 서열을 각각 포함하는 LC-CDR1, LC-CDR2 및 LC-CDR3;
l) SEQ ID NO: 117로 표시되는 서열을 갖는 VH쇄 영역 내의 CDR1, CDR2 및 CDR3의 아미노산 서열을 각각 포함하는 HC-CDR1, HC-CDR2 및 HC-CDR3; 및 SEQ ID NO: 118로 표시되는 서열을 갖는 VL쇄 영역 내의 CDR1, CDR2 및 CDR3의 아미노산 서열을 각각 포함하는 LC-CDR1, LC-CDR2 및 LC-CDR3;
m) SEQ ID NO: 127로 표시되는 서열을 갖는 VH쇄 영역 내의 CDR1, CDR2 및 CDR3의 아미노산 서열을 각각 포함하는 HC-CDR1, HC-CDR2 및 HC-CDR3; 및 SEQ ID NO: 128로 표시되는 서열을 갖는 VL쇄 영역 내의 CDR1, CDR2 및 CDR3의 아미노산 서열을 각각 포함하는 LC-CDR1, LC-CDR2 및 LC-CDR3; 또는
n) SEQ ID NO: 137로 표시되는 서열을 갖는 VH쇄 영역 내의 CDR1, CDR2 및 CDR3의 아미노산 서열을 각각 포함하는 HC-CDR1, HC-CDR2 및 HC-CDR3; 및 SEQ ID NO: 138로 표시되는 서열을 갖는 VL쇄 영역 내의 CDR1, CDR2 및 CDR3의 아미노산 서열을 각각 포함하는 LC-CDR1, LC-CDR2 및 LC-CDR3;
o) SEQ ID NO: 267로 표시되는 서열을 갖는 VH쇄 영역 내의 CDR1, CDR2 및 CDR3의 아미노산 서열을 각각 포함하는 HC-CDR1, HC-CDR2 및 HC-CDR3; 및 SEQ ID NO: 268로 표시되는 서열을 갖는 VL쇄 영역 내의 CDR1, CDR2 및 CDR3의 아미노산 서열을 각각 포함하는 LC-CDR1, LC-CDR2 및 LC-CDR3; 또는
p) SEQ ID NO: 277로 표시되는 서열을 갖는 VH쇄 영역 내의 CDR1, CDR2 및 CDR3의 아미노산 서열을 각각 포함하는 HC-CDR1, HC-CDR2 및 HC-CDR3; 및 SEQ ID NO: 278로 표시되는 서열을 갖는 VL쇄 영역 내의 CDR1, CDR2 및 CDR3의 아미노산 서열을 각각 포함하는 LC-CDR1, LC-CDR2 및 LC-CDR3을 포함한다.
일부 실시예에서, 상기 제1 항체 부분은,
(a) SEQ ID NO: 7로 표시되는 서열을 갖는 아미노산을 포함하는 중쇄 가변 영역; 및 SEQ ID NO: 8로 표시되는 서열을 갖는 아미노산을 포함하는 경쇄 가변 영역;
(b) SEQ ID NO: 17로 표시되는 서열을 갖는 아미노산을 포함하는 중쇄 가변 영역; 및 SEQ ID NO: 18로 표시되는 서열을 갖는 아미노산을 포함하는 경쇄 가변 영역;
(c) SEQ ID NO: 27로 표시되는 서열을 갖는 아미노산을 포함하는 중쇄 가변 영역; 및 SEQ ID NO: 28로 표시되는 서열을 갖는 아미노산을 포함하는 경쇄 가변 영역;
(d) SEQ ID NO: 37로 표시되는 서열을 갖는 아미노산을 포함하는 중쇄 가변 영역; 및 SEQ ID NO: 38로 표시되는 서열을 갖는 아미노산을 포함하는 경쇄 가변 영역;
(e) SEQ ID NO: 47로 표시되는 서열을 갖는 아미노산을 포함하는 중쇄 가변 영역; 및 SEQ ID NO: 48로 표시되는 서열을 갖는 아미노산을 포함하는 경쇄 가변 영역;
(f) SEQ ID NO: 57로 표시되는 서열을 갖는 아미노산을 포함하는 중쇄 가변 영역; 및 SEQ ID NO: 58로 표시되는 서열을 갖는 아미노산을 포함하는 경쇄 가변 영역;
(g) SEQ ID NO: 67로 표시되는 서열을 갖는 아미노산을 포함하는 중쇄 가변 영역; 및 SEQ ID NO: 68로 표시되는 서열을 갖는 아미노산을 포함하는 경쇄 가변 영역;
(h) SEQ ID NO: 77로 표시되는 서열을 갖는 아미노산을 포함하는 중쇄 가변 영역; 및 SEQ ID NO: 78로 표시되는 서열을 갖는 아미노산을 포함하는 경쇄 가변 영역;
(i) SEQ ID NO: 87로 표시되는 서열을 갖는 아미노산을 포함하는 중쇄 가변 영역; 및 SEQ ID NO: 88로 표시되는 서열을 갖는 아미노산을 포함하는 경쇄 가변 영역;
(j) SEQ ID NO: 97로 표시되는 서열을 갖는 아미노산을 포함하는 중쇄 가변 영역; 및 SEQ ID NO: 98로 표시되는 서열을 갖는 아미노산을 포함하는 경쇄 가변 영역;
(k) SEQ ID NO: 107로 표시되는 서열을 갖는 아미노산을 포함하는 중쇄 가변 영역; 및 SEQ ID NO: 108로 표시되는 서열을 갖는 아미노산을 포함하는 경쇄 가변 영역;
(l) SEQ ID NO: 117로 표시되는 서열을 갖는 아미노산을 포함하는 중쇄 가변 영역; 및 SEQ ID NO: 118로 표시되는 서열을 갖는 아미노산을 포함하는 경쇄 가변 영역;
(m) SEQ ID NO: 127로 표시되는 서열을 갖는 아미노산을 포함하는 중쇄 가변 영역; 및 SEQ ID NO: 128로 표시되는 서열을 갖는 아미노산을 포함하는 경쇄 가변 영역;
(n) SEQ ID NO: 137로 표시되는 서열을 갖는 아미노산을 포함하는 중쇄 가변 영역; 및 SEQ ID NO: 138로 표시되는 서열을 갖는 아미노산을 포함하는 경쇄 가변 영역;
(o) SEQ ID NO: 267로 표시되는 서열을 갖는 아미노산을 포함하는 중쇄 가변 영역; 및 SEQ ID NO: 268로 표시되는 서열을 갖는 아미노산을 포함하는 경쇄 가변 영역; 또는
(p) SEQ ID NO: 277로 표시되는 서열을 갖는 아미노산을 포함하는 중쇄 가변 영역; 및 SEQ ID NO: 278로 표시되는 서열을 갖는 아미노산을 포함하는 경쇄 가변 영역을 포함한다.
일부 실시예에서, 상기 제1 항체 부분은 중쇄 가변 영역(VH) 및 경쇄 가변 영역(VL)을 포함하고, 여기서, a) 상기 VH는 i) SEQ ID NO: 151-153 중의 임의의 하나의 아미노산 서열을 포함하거나 최대 약 3개의 아미노산에 의해 치환된 변이체를 포함하는 HC-CDR1; ii) SEQ ID NO: 154-156 중의 임의의 하나의 아미노산 서열을 포함하거나 최대 약 3개의 아미노산에 의해 치환된 변이체를 포함하는 HC-CDR2; iii) SEQ ID NO: 157-159 중의 임의의 하나의 아미노산 서열을 포함하거나 최대 약 3개의 아미노산에 의해 치환된 변이체를 포함하는 HC-CDR3을 포함하고; 및 b) 상기 VL는, i) SEQ ID NO: 160-163 중의 임의의 하나의 아미노산 서열을 포함하거나 최대 약 3개의 아미노산에 의해 치환된 변이체를 포함하는 LC-CDR1; ii) SEQ ID NO: 164-166 중의 임의의 하나의 아미노산 서열을 포함하거나 최대 약 3개의 아미노산에 의해 치환된 변이체를 포함하는 HC-CDR2; iii) SEQ ID NO: 167-169 중의 임의의 하나의 아미노산 서열을 포함하거나 최대 약 3개의 아미노산에 의해 치환된 변이체를 포함하는 HC-CDR3을 포함한다.
일부 실시예에서, 상기 제1 항체 부분은 중쇄 가변 영역(VH) 및 경쇄 가변 영역(VL)을 포함하고, 여기서,
a) 상기 VH는 SEQ ID NO: 151의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 154의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 157의 아미노산 서열을 포함하는 HC-CDR3을 포함하고, 상기 VL은 SEQ ID NO: 160의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 164의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 167의 아미노산 서열을 포함하는 LC-CDR3을 포함하고;
b) 상기 VH는 SEQ ID NO: 151의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 154의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 157의 아미노산 서열을 포함하는 HC-CDR3을 포함하며, 상기 VL은 SEQ ID NO: 162의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 166의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 169의 아미노산 서열을 포함하는 LC-CDR3을 포함하고;
c) 상기 VH는 SEQ ID NO: 152의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 155의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 158의 아미노산 서열을 포함하는 HC-CDR3을 포함하며, 상기 VL은 SEQ ID NO: 163의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 166의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 169의 아미노산 서열을 포함하는 LC-CDR3을 포함하고;
d) 상기 VH는 SEQ ID NO: 153의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 156의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 159의 아미노산 서열을 포함하는 HC-CDR3을 포함하며, 상기 VL은 SEQ ID NO: 160의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 164의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 167의 아미노산 서열을 포함하는 LC-CDR3을 포함하거나; 또는
e) 상기 VH는 SEQ ID NO: 153의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 156의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 159의 아미노산 서열을 포함하는 HC-CDR3을 포함하며, 상기 VL은 SEQ ID NO: 161의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 165의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 168의 아미노산 서열을 포함하는 LC-CDR3을 포함한다.
일부 실시예에서, 상기 제1 항체 부분은, 전장 항체, 다중 특이적 항체(예를 들어 이중 특이성 항체), 단일쇄Fv(scFv), Fab단편, Fab’단편, F(ab’)2, Fv단편, 이황화 결합이 안정적인 Fv단편(dsFv), (dsFv)2, VHH, Fv-Fc융합체, scFv-Fc융합체, scFv-Fv융합체, 디아바디, 트리바디, 및 테트라바디로 이루어진 군으로부터 선택되는 항체 또는 이의 항원 결합 단편을 포함한다. 일부 실시예에서, 상기 제1 항체 부분은 인간화된 항CD137전장 항체를 포함한다. 일부 실시예에서, 상기 제1 항체 부분은 인간화된 항CD137 단일쇄 Fv단편(scFv)을 포함한다. 일부 실시예에서, 상기 제1 항체 부분은 CD137 작용제 항체이다.
일부 실시예에서, 상기 제1 항체 부분은 항CD137 항체 부분을 포함하고, 상기 항CD137 항체 부분은 인간 면역 글로불린의 Fc영역을 포함한다. 일부 실시예에서, 상기 Fc영역은 IgG, IgA, IgD, IgE 및 IgM의 Fc영역으로 이루어진 군으로부터 선택된다. 일부 실시예에서, 상기 Fc영역은 IgG1, IgG2, IgG3 및 IgG4의 Fc영역으로 이루어진 군으로부터 선택된다.
일부 실시예에서, 상기 제1 항체 부분은 인간CD137 및 유인원CD137에 결합된다. 일부 실시예에서, 상기 제1 항체 부분은 마우스 CD137에 결합되지 않는다.
일부 실시예에서, 상기 제1 항체 부분은 중쇄 가변 영역(VH) 및 경쇄 가변 영역(V L)을 포함하는 항CD137 단일쇄 Fv단편을 함유하고, 상기 제2 항체 부분은 EGFR에 결합되고 두 가닥의 항체 중쇄 및 두 가닥의 항체 경쇄를 포함하는 전장 항체를 포함하며, 여기서 상기 중쇄는 각각 제2 중쇄 가변영역 (VH-2)을 포함하고, 상기 경쇄는 각각 제2 경쇄 가변영역 (VL-2)을 포함하며, 여기서 상기 항CD137 단일쇄 Fv단편은 전장 항체의 중쇄 또는 경쇄 중 적어도 한 가닥에 융합된다. 일부 실시예에서, 상기 항CD137 단일쇄 Fv단편은 전장 항체의 각 가닥의 중쇄의 C말단에 융합된다. 일부 실시예에서, 상기 항CD137 단일쇄 Fv단편은 전장 항체의 각 가닥의 중쇄의 N말단에 융합된다. 일부 실시예에서, 상기 항CD137 단일쇄 Fv단편은 전장 항체의 각 가닥의 경쇄의 C말단에 융합된다. 일부 실시예에서, 상기 항CD137 단일쇄 Fv단편은 전장 항체의 각 가닥의 경쇄의 N말단에 융합된다.
일부 실시예에서, 상기 항CD137 단일쇄 Fv단편의 VH 및 VL은 제1 펩티드 링커에 의해 융합된다. 일부 실시예에서, 상기 제1 펩티드 링커는 약 4개 내지 약 15개의 아미노산을 포함한다. 일부 실시예에서, 상기 제1 펩티드 링커는 링커를 포함하고, 상기 링커는 SEQ ID NO: 232-260 중의 임의의 서열을 포함한다. 일부 실시예에서, 상기 항 CD137 단일쇄 Fv 단편은 제2 펩티드 링커에 의해 전장 항체에 융합된다. 일부 실시예에서, 상기 제2 펩티드 링커는 약 4개 내지 약 15개의 아미노산을 포함한다. 일부 실시예에서, 상기 제2 펩티드 링커는 링커를 포함하고, 상기 링커는 SEQ ID NO: 232-260 중의 임의의 서열을 포함한다.
일부 실시예에서, 상기 제2 항체 부분은 IgG, IgA, IgD, IgE, IgM으로부터 유래된 Fc영역 및 이의 임의의 조합 및 이형 접합체로부터 선택되는 Fc영역을 포함한다. 일부 실시예에서, 상기 Fc영역은 인간 Fc영역을 포함한다. 일부 실시예에서, 상기 Fc영역은 IgG1, IgG2, IgG3, IgG4로부터 유래된 Fc영역 및 이의 임의의 조합 및 이형 접합체로부터 선택된다. 일부 실시예에서, 상기 Fc영역은 IgG1 Fc영역을 포함한다. 일부 실시예에서, 상기 IgG1 Fc영역은 L234A돌연변이 및 L235A돌연변이를 포함한다. 일부 실시예에서, 상기 Fc영역은 IgG4 Fc영역을 포함한다. 일부 실시예에서, 상기 IgG4 Fc영역은 F234A돌연변이 및 L235A돌연변이를 포함한다. 일부 실시예에서, 상기 IgG4 Fc영역은 S228P돌연변이를 포함한다.
일부 실시형태에서, 상기 EGFR은 인간 EGFR이다.
일부 실시형태에서, 상기 제2 항체 부분은 EGFR에 결합되고 제2 중쇄 가변영역 (VH-3) 및 제2 경쇄 가변영역 (VL-3)을 포함하는 항체 또는 항체 단편과 EGFR의 결합 에피토프를 경쟁하는 전장 항체를 포함하고, 여기서,
a) 상기 VH-3는 SEQ ID NO: 190의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 191의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 192의 아미노산 서열을 포함하는 HC-CDR3을 포함하며; b) 상기 VL-3는 SEQ ID NO: 193의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 194의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 195의 아미노산 서열을 포함하는 LC-CDR3을 포함하고;
b) 상기 V H-3은 SEQ ID NO: 198의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 199의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 200의 아미노산 서열을 포함하는 HC-CDR3을 포함하며; 및 b) 상기 V L-3은 SEQ ID NO: 201의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 202의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 203의 아미노산 서열을 포함하는 LC-CDR3을 포함하고;
c) 상기 V H-3는 SEQ ID NO: 206의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 207의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 208의 아미노산 서열을 포함하는 HC-CDR3을 포함하며; b) 상기 V L-3는 SEQ ID NO: 209의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 210의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 211의 아미노산 서열을 포함하는 LC-CDR3을 포함하고;
d) 상기 V H-3은 SEQ ID NO: 214의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 215의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 216의 아미노산 서열을 포함하는 HC-CDR3을 포함하며; b) 상기 V L-3은 SEQ ID NO: 217의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 218의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 219의 아미노산 서열을 포함하는 LC-CDR3을 포함하거나; 또는
e) 상기 V H-3은 SEQ ID NO: 222의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 223의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 224의 아미노산 서열을 포함하는 HC-CDR3을 포함하며; b) 상기 V L-3은 SEQ ID NO: 225의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 226의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 227의 아미노산 서열을 포함하는 LC-CDR3을 포함한다.
일부 실시형태에서, 상기 제2 항체 부분은 EGFR에 결합되고 제2 중쇄 가변영역 (VH-2) 및 제2 경쇄 가변영역 (V L-2)을 포함하는 전장 항체를 포함하고, 여기서,
a) 상기 V H-2는 SEQ ID NO: 190의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 191의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 192의 아미노산 서열을 포함하는 HC-CDR3을 포함하며; b) 상기 V L-2는 SEQ ID NO: 193의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 194의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 195의 아미노산 서열을 포함하는 LC-CDR3을 포함하고;
b) 상기 V H-2는 SEQ ID NO: 198의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 199의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 200의 아미노산 서열을 포함하는 HC-CDR3을 포함하며; b) 상기 V L-2는 SEQ ID NO: 201의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 202의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 203의 아미노산 서열을 포함하는 LC-CDR3을 포함하고;
c) 상기 V H-2는 SEQ ID NO: 206의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 207의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 208의 아미노산 서열을 포함하는 HC-CDR3을 포함하며; b) 상기 V L-2는 SEQ ID NO: 209의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 210의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 211의 아미노산 서열을 포함하는 LC-CDR3을 포함하고;
d) 상기 V H-2는 SEQ ID NO: 214의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 215의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 216의 아미노산 서열을 포함하는 HC-CDR3을 포함하며; b) 상기 V L-2는 SEQ ID NO: 217의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 218의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 219의 아미노산 서열을 포함하는 LC-CDR3을 포함하가나; 또는
e) 상기 V H-2는 SEQ ID NO: 222의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 223의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 224의 아미노산 서열을 포함하는 HC-CDR3을 포함하며; b) 상기 V L-2는 SEQ ID NO: 225의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 226의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 227의 아미노산 서열을 포함하는 LC-CDR3을 포함한다.
일부 실시형태에서, 상기 VH-2는 SEQ ID NO: 190의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 191의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 192의 아미노산 서열을 포함하는 HC-CDR3을 포함하고, 상기 V L-2 는 SEQ ID NO: 193의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 194의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 195의 아미노산 서열을 포함하는 LC-CDR3을 포함한다. 일부 실시형태에서, 상기 VH-2는 SEQ ID NO: 198의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 199의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 200의 아미노산 서열을 포함하는 HC-CDR3을 포함하고, 상기 V L-2 는 SEQ ID NO: 201의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 202의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 203의 아미노산 서열을 포함하는 LC-CDR3을 포함한다. 일부 실시형태에서, 상기 VH-2는 SEQ ID NO: 206의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 207의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 208의 아미노산 서열을 포함하는 HC-CDR3을 포함하고, 상기 V L-2 는 SEQ ID NO: 209의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 210의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 211의 아미노산 서열을 포함하는 LC-CDR3을 포함한다. 일부 실시형태에서, 상기 VH-2는 SEQ ID NO: 214의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 215의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 216의 아미노산 서열을 포함하는 HC-CDR3을 포함하고, 상기 V L-2 는 SEQ ID NO: 217의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 218의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 219의 아미노산 서열을 포함하는 LC-CDR3을 포함한다. 일부 실시형태에서, 상기 VH-2는 SEQ ID NO: 222의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 223의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 224의 아미노산 서열을 포함하는 HC-CDR3을 포함하고, 상기 V L-2 는 SEQ ID NO: 225의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 226의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 227의 아미노산 서열을 포함하는 LC-CDR3을 포함한다.
일부 실시형태에서, a) 상기 VH-2는 SEQ ID NO: 196과 적어도 약 90%의 서열 동일성을 갖는 아미노산 서열을 포함하고; 및/또는 상기 VL-2는 SEQ ID NO: 197과 적어도 약 90%의 서열 동일성을 갖는아미노산 서열을 포함하며; b) 상기 VH-2는 SEQ ID NO: 204와 적어도 약 90%의 서열 동일성을 갖는 아미노산 서열을 포함하고; 및/또는 상기 VL-2는 SEQ ID NO: 205와 적어도 약 90%의 서열 동일성을 갖는아미노산 서열을 포함하며; c) 상기 VH-2는 SEQ ID NO: 212와 적어도 약 90%의 서열 동일성을 갖는아미노산 서열을 포함하고; 및/또는 상기 VL-2는 SEQ ID NO: 213과 적어도 약 90%의 서열 동일성을 갖는 아미노산 서열을 포함하고; d) 상기 VH-2는 SEQ ID NO: 220과 적어도 약 90%의 서열 동일성을 갖는 아미노산 서열을 포함하며; 및/또는 상기 VL-2는 SEQ ID NO: 221과 적어도 약 90%의 서열 동일성을 갖는아미노산 서열을 포함하고; e) 상기 VH-2는 SEQ ID NO: 228과 적어도 약 90%의 서열 동일성을 갖는 아미노산 서열을 포함하며; 및/또는 상기 VL-2는 SEQ ID NO: 229와 적어도 약 90%의 서열 동일성을 갖는아미노산 서열을 포함한다. 일부 실시형태에서, a) 상기 VH-2는 SEQ ID NO: 196의 아미노산 서열을 포함하고; 상기 VL-2는 SEQ ID NO: 197의 아미노산 서열을 포함하며; b) 상기 VH-2는 SEQ ID NO: 204의 아미노산 서열을 포함하고; 상기 VL-2는 SEQ ID NO: 205의 아미노산 서열을 포함하며; c) 상기 VH-2는 SEQ ID NO: 212의 아미노산 서열을 포함하고; 상기 VL-2는 SEQ ID NO: 213의 아미노산 서열을 포함하며; d) 상기 VH-2는 SEQ ID NO: 220의 아미노산 서열을 포함하고; 상기 VL-2는 SEQ ID NO: 221의 아미노산 서열을 포함하거나; 또는 e) 상기 VH-2는 SEQ ID NO: 228의 아미노산 서열을 포함하며; 상기 VL-2는 SEQ ID NO: 229의 아미노산 서열을 포함한다.
일부 실시형태에서, 상기 다중 특이적 항체는 제1 항체 부분 및 제2 항체 부분을 포함하고, a) 상기 제1 항체 부분은 중쇄 가변 영역(VH) 및 경쇄 가변 영역(VL)을 포함하며, 여기서 상기 VH는 SEQ ID NO: 121의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 122의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 123의 아미노산 서열을 포함하는 HC-CDR3을 포함하고; 및 상기 VL은 SEQ ID NO: 124의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 125의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 126의 아미노산 서열을 포함하는 LC-CDR3을 포함하며; b) 상기 제2 항체 부분은 제2 중쇄 가변영역 (VH-2) 및 제2 경쇄 가변영역 (V L-2)을 포함하고, 여기서 상기 VH-2는 SEQ ID NO: 206의 아미노산 서열을 포함하는 제2 HC-CDR1, SEQ ID NO: 207의 아미노산 서열을 포함하는 제2 HC-CDR2 및 SEQ ID NO: 208의 아미노산 서열을 포함하는 제2 HC-CDR3을 포함하며; 상기 VL-2는 SEQ ID NO: 209의 아미노산 서열을 포함하는 제2 LC-CDR1, SEQ ID NO: 210의 아미노산 서열을 포함하는 제2 LC-CDR2 및 SEQ ID NO: 211의 아미노산 서열을 포함하는 제2 LC-CDR3을 포함한다.
일부 실시형태에서, 상기 다중 특이적 항체는 제1 항체 부분 및 제2 항체 부분을 포함하고, a) 상기 제1 항체 부분은 중쇄 가변 영역(VH) 및 경쇄 가변 영역(VL)을 포함하며, 여기서 상기 VH는 SEQ ID NO: 261의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 262의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 263의 아미노산 서열을 포함하는 HC-CDR3을 포함하고; 및 상기 VL은 SEQ ID NO: 264의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 265의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 266의 아미노산 서열을 포함하는 LC-CDR3을 포함하며; b) 상기 제2 항체 부분은 제2 중쇄 가변영역 (VH-2) 및 제2 경쇄 가변영역 (V L-2)을 포함하고, 여기서 상기 VH-2는 SEQ ID NO: 206의 아미노산 서열을 포함하는 제2 HC-CDR1, SEQ ID NO: 207의 아미노산 서열을 포함하는 제2 HC-CDR2 및 SEQ ID NO: 208의 아미노산 서열을 포함하는 제2 HC-CDR3을 포함하며; 상기 VL-2는 SEQ ID NO: 209의 아미노산 서열을 포함하는 제2 LC-CDR1, SEQ ID NO: 210의 아미노산 서열을 포함하는 제2 LC-CDR2 및 SEQ ID NO: 211의 아미노산 서열을 포함하는 제2 LC-CDR3을 포함한다.
일부 실시형태에서, 상기 다중 특이적 항체는 제1 항체 부분 및 제2 항체 부분을 포함하고, a) 상기 제1 항체 부분은 중쇄 가변 영역(VH) 및 경쇄 가변 영역(VL)을 포함하며, 여기서 상기 VH는 SEQ ID NO: 271의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 272의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 273의 아미노산 서열을 포함하는 HC-CDR3을 포함하고; 및 상기 VL은 SEQ ID NO: 274의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 275의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 276의 아미노산 서열을 포함하는 LC-CDR3을 포함하며; b) 상기 제2 항체 부분은 제2 중쇄 가변영역 (VH-2) 및 제2 경쇄 가변영역 (V L-2)을 포함하고, 여기서 상기 VH-2는 SEQ ID NO: 206의 아미노산 서열을 포함하는 제2 HC-CDR1, SEQ ID NO: 207의 아미노산 서열을 포함하는 제2 HC-CDR2 및 SEQ ID NO: 208의 아미노산 서열을 포함하는 제2 HC-CDR3을 포함하며; 상기 VL-2는 SEQ ID NO: 209의 아미노산 서열을 포함하는 제2 LC-CDR1, SEQ ID NO: 210의 아미노산 서열을 포함하는 제2 LC-CDR2 및 SEQ ID NO: 211의 아미노산 서열을 포함하는 제2 LC-CDR3을 포함한다.
일부 실시형태에서, 상기 항 CD137 단일쇄 Fv 단편은 항EGFR 전장 항체의 중쇄에 융합되고, 항CD137 단일쇄 Fv단편에 융합된 항EGFR 전장 항체의 중쇄는 SEQ ID NO: 183, 185, 188, 189, 230, 231, 259, 260, 281 또는 282 중의 임의의 하나의 아미노산 서열과 적어도 약 90%의 서열 동일성을 갖는 아미노산 서열을 포함한다. 일부 실시형태에서, 상기 항 CD137 단일쇄 Fv 단편은 항EGFR 전장 항체의 중쇄에 융합되고, 항CD137 단일쇄 Fv단편에 융합된 항EGFR 전장 항체의 중쇄는 SEQ ID NO: 183, 185, 188, 189, 230, 231, 259, 260, 281 또는 282 중의 임의의 하나의 아미노산 서열을 포함한다. 일부 실시형태에서, 상기 항 CD137 단일쇄 Fv 단편은 항EGFR 전장 항체의 중쇄에 융합되고, 항CD137 단일쇄 Fv단편에 융합된 항EGFR 전장 항체의 중쇄는 SEQ ID NO: 183의 아미노산 서열을 포함한다. 일부 실시형태에서, 상기 항 CD137 단일쇄 Fv 단편은 항EGFR 전장 항체의 중쇄에 융합되고, 항CD137 단일쇄 Fv단편에 융합된 항EGFR 전장 항체의 중쇄는 SEQ ID NO: 185의 아미노산 서열을 포함한다. 일부 실시형태에서, 상기 항 CD137 단일쇄 Fv 단편은 항EGFR 전장 항체의 중쇄에 융합되고, 항CD137 단일쇄 Fv단편에 융합된 항EGFR 전장 항체의 중쇄는 SEQ ID NO: 188의 아미노산 서열을 포함한다. 일부 실시형태에서, 상기 항 CD137 단일쇄 Fv 단편은 항EGFR 전장 항체의 중쇄에 융합되고, 항CD137 단일쇄 Fv단편에 융합된 항EGFR 전장 항체의 중쇄는 SEQ ID NO: 189의 아미노산 서열을 포함한다. 일부 실시형태에서, 상기 항 CD137 단일쇄 Fv 단편은 항EGFR 전장 항체의 중쇄에 융합되고, 항CD137 단일쇄 Fv단편에 융합된 항EGFR 전장 항체의 중쇄는 SEQ ID NO: 230의 아미노산 서열을 포함한다. 일부 실시형태에서, 상기 항 CD137 단일쇄 Fv 단편은 항EGFR 전장 항체의 중쇄에 융합되고, 항CD137 단일쇄 Fv단편에 융합된 항EGFR 전장 항체의 중쇄는 SEQ ID NO: 231의 아미노산 서열을 포함한다. 일부 실시형태에서, 상기 항 CD137 단일쇄 Fv 단편은 항EGFR 전장 항체의 중쇄에 융합되고, 항CD137 단일쇄 Fv단편에 융합된 항EGFR 전장 항체의 중쇄는 SEQ ID NO: 259의 아미노산 서열을 포함한다. 일부 실시형태에서, 상기 항 CD137 단일쇄 Fv 단편은 항EGFR 전장 항체의 중쇄에 융합되고, 항CD137 단일쇄 Fv단편에 융합된 항EGFR 전장 항체의 중쇄는 SEQ ID NO: 260의 아미노산 서열을 포함한다. 일부 실시형태에서, 상기 항 CD137 단일쇄 Fv 단편은 항EGFR 전장 항체의 중쇄에 융합되고, 항CD137 단일쇄 Fv단편에 융합된 항EGFR 전장 항체의 중쇄는 SEQ ID NO: 281의 아미노산 서열을 포함한다. 일부 실시형태에서, 상기 항 CD137 단일쇄 Fv 단편은 항EGFR 전장 항체의 중쇄에 융합되고, 항CD137 단일쇄 Fv단편에 융합된 항EGFR 전장 항체의 중쇄는 SEQ ID NO: 282의 아미노산 서열을 포함한다.
일부 실시형태에서, 포함된 항EGFR 전장 항체는 SEQ ID NO: 184, 186 또는 187의 아미노산 서열과 적어도 약 90%의 서열 동일성을 갖는 아미노산 서열을 포함하는 경쇄를 함유한다. 일부 실시형태에서, 상기 항EGFR전장 항체는 SEQ ID NO: 184의 아미노산 서열을 포함하는 경쇄를 함유한다. 일부 실시형태에서, 상기 항EGFR전장 항체는 SEQ ID NO: 186의 아미노산 서열을 포함하는 경쇄를 함유한다. 일부 실시형태에서, 상기 항EGFR전장 항체는 SEQ ID NO: 187의 아미노산 서열을 포함하는 경쇄를 함유한다.
본 개시는 치료제 또는 표지에 연결된 본문에 개시된 임의의 다중 특이적 항체를 포함하는 면역 접합체를 더 제공한다. 일부 실시예에서, 상기 표지는 방사성 동위원소, 형광 염료 및 효소로 이루어진 군으로부터 선택된다.
본 개시는 본문에 개시된 임의의 다중 특이적 항체 또는 임의의 면역 접합체 및 약학적으로 허용 가능한 담체를 포함하는 약물 조성물을 더 제공한다.
본 개시는 본문에 개시된 임의의 다중 특이적 항체를 코딩하는 단리된 핵산, 본문에 개시된 임의의 단리된 핵산을 포함하는 벡터, 및 본문에 개시된 임의의 단리된 핵산 또는 임의의 벡터를 포함하는 단리된 숙주 세포를 더 제공한다.
본 개시는 다중 특이적 항체를 생산하는 방법을 더 제공한다. 일부 실시예에서, 상기 방법은, a) 상기 다중 특이적 항체를 효과적으로 발현하는 조건 하에서, 본문에 개시된 임의의 숙주 세포를 배양하는 단계; 및 b) 상기 숙주 세포에서 발현된 다중 특이적 항체를 얻는 단계를 포함한다.
본 개시는 대상체 질환을 치료 또는 예방하는 방법을 더 제공한다. 일부 실시예에서, 상기 방법은 상기 대상체에 유효량의 본문에 개시된 임의의 다중 특이적 항체, 임의의 면역 접합체 또는 임의의 약물 조성물을 투여하는 단계를 포함한다. 일부 실시예에서, 상기 질환은 암 또는 종양이다. 일부 실시예에서, 상기 암은 유방암, 위암, 난소암, 폐암, 중피종, 자궁내막암, 자궁경부암, 식도암, 방광암, 침샘암, 고환암, 선암, 간암, 췌장암, 결장직장암, 피부암, 흉선암, 부신암, 두경부암, 뇌암, 갑상선 암, 육종, 골수종 및 백혈병로 이루어진 군으로부터 선택된다. 일부 실시형태에서, 상기 암 또는 종양은 EGFR 양성인 것이다. 일부 실시형태에서, 상기 암은 폐암, 결장직장암 또는 두경부암이다.
일부 실시예에서, 상기 다중 특이적 항체, 면역 접합체 또는약물 조성물은 상기 대상체에 비경구 투여된다. 일부 실시예에서, 상기 다중 특이적 항체, 면역 접합체 또는약물 조성물은 상기 대상체에 정맥내 투여된다. 일부 실시예에서, 상기 피험자는 인간이다.
본 개시는 약물로 사용되는 본문에 개시된 임의의 다중 특이적 항체를 제공한다. 본 개시는 암을 치료하기 위한 본문에 개시된 임의의 다중 특이적 항체를 더 제공한다. 일부 실시예에서, 상기 암은 유방암, 위암, 난소암, 폐암, 중피종, 자궁내막암, 자궁경부암, 식도암, 방광암, 침샘암, 고환암, 선암, 간암, 췌장암, 결장직장암, 피부암, 흉선암, 부신암, 두경부암, 뇌암, 갑상선 암, 육종, 골수종 및 백혈병으로 이루어진 군으로부터 선택된다.
본 개시는 본문에 개시된 임의의 다중 특이적 항체, 임의의 면역 접합체, 임의의 약물 조성물, 임의의 핵산, 임의의 벡터 또는 임의의 숙주 세포를 포함하는 키트를 더 제공한다. 일부 실시예에서, 상기 키트는 암 또는 종양을 치료 및/또는 예방하기 위한 서면 명세서를 더 포함한다.
도 1A-1F는 인간CD137 및 사이노몰구스 원숭이CD137에 대한 예시적 항CD137 항체 클론 2-9변이체의 결합 친화력을 나타낸다. 도 1A는 인간CD137에 대한 클론 2-9 IgG2 wt의 결합을 나타낸다. 도 1B는 사이노몰구스 원숭이CD137에 대한 클론 2-9 IgG2 wt의 결합을 나타낸다. 도 1C는 인간CD137에 대한 클론 2-9 IgG2 wt의 결합을 나타낸다. 도 1D는 인간CD137에 대한 클론 2-9-1 IgG1 SELF의 결합을 나타낸다. 도 1E는 인간CD137에 대한 클론 2-9-1 IgG1 SELF의 결합을 나타낸다. 도 1F는 인간CD137에 대한 클론 2-9-2 IgG4 wt의 결합을 나타낸다.
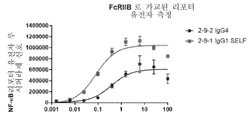
도 2A 및 2B는 FcγRIIB를 발현하는 293F세포가 존재하지 않는 경우(2A) 또는 FcγRIIB를 발현하는 293F세포가 존재하는 경우(2B), NF-κB 리포터 유전자 측정에서의 루시퍼라제 활성을 나타낸다. 기준 Ab 1 및 기준 항체Ab 2는 구현예 2에 따른 기준 항CD137 항체이다. αCD137 Ab 클론은 상이한 항CD137 모노클로날 항체를 나타낸다.
도 3A-3C는 FcγRIIB를 발현하는 293F세포가 존재하지 않는 경우(3A) 또는 FcγRIIB를 발현하는 293F세포가 존재하는 경우(3B 및 3C), NF-κB 리포터 유전자 측정에서의 루시퍼라제 활성을 나타낸다. 기준 Ab 1 및 기준 항체Ab 2는 구현예 2에 따른 기준 항CD137 항체이다. 2-9-1 IgG1 SELF는 IgG1 Fc 및 돌연변이 S267E/L328F를 포함한다. 2-9-1 IgG2 SELF는 IgG2 Fc 및 돌연변이S267E/L328F를 포함한다. 2-9 IgG2 wt는 야생형 인간IgG2 Fc를 포함한다. 2-9-2 IgG4는 야생형 인간IgG4 Fc를 포함한다.
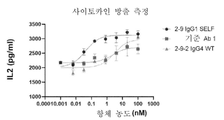
도 4A 및 4B는 상이한 농도의 상이한 항CD137 항체 존재 하에서, 공여체로부터 수득된 PBMC의 IFN-γ(4A) 및 IL2(4B) 산량을 나타낸다. 기준 Ab 1 및 기준 항체Ab 2는 구현예 2에 따른 기준 항CD137 항체이다. 2-9-1 IgG1 SELF는 IgG1 Fc 및 돌연변이 S267E/L328F를 포함한다. 2-9-1 IgG2 SELF는 IgG2 Fc 및 돌연변이 S267E/L328F를 포함한다. 2-9 IgG2 wt는 야생형 인간 IgG2 Fc를 포함한다. 2-9-2 IgG4는 야생형 인간 IgG4 Fc를 포함한다.
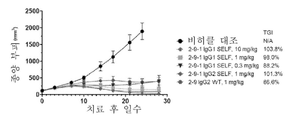
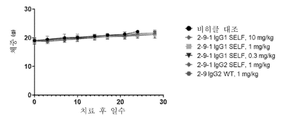
도 5A 및 5B는 MC38뮤린 결장직장암 모델에서 2-9변이체의 체내 연구 결과를 나타낸다. 도 5A는 벡터 대조군 및 치료군의 종양 성장 그래프를 나타낸다. 도 5B는 치료에서 마우스의 체중 변화를 나타낸다.
도 6A 및 6B는 MC38뮤린 결장직장암 모델에서 유토밀루맙 유사 약물의 체내 연구 결과를 나타낸다. 도 6A는 IgG 대조군 및 치료군의 종양 성장 그래프를 나타낸다. 도 6B는 치료에서 마우스의 체중 변화를 나타낸다.
도 7A 및 7B는 예시적 이중 특이성 항체의 설계를 나타내고, 여기서 항CD137 scFv는 일반적 결합 종양 관련 항원(7A) 및 특이적 결합 EGFR(7B)의 전장 항체에 융합된다. αTAA는 종양 관련 항원에 대한 항체를 대표한다. αCD137은 항CD137 scFv를 대표한다.
도 8은 CD137 및 EGFR에 대한 예시적 항CD137 x EGFR이중 특이성 항체의 결합 친화력을 나타낸다. 2-9scFv-αEGFR2-HC-C는 이중 특이성 항체를 대표하고, 여기서 클론 2-9로부터 유래된 항CD137 scFv는 전장 항EGFR항체의 중쇄의 C말단에 융합된다.
도 9A-9B는 CD137(9A) 및 EGFR(9B)에 대한 전체 세포 결합 측정법에 의해 측정된 예시적 항CD137 x EGFR 이중 특이성 항체 또는 항CD137 모노클로날 항체의 결합 친화력을 나타낸다. αEGFR은 EGFR에 결합되는 예시적 전장 항체를 대표한다. 실시예 4를 참조바란다. “aCD137-scFv-αEGFR-IgG1-링커7” 및 “aCD137-scFv-αEGFR-IgG1-링커10”은 이중 특이성 항체를 대표하고, 여기서 클론 2-9로부터 유래된 항CD137 scFv는 상이한 링커에 의해 전장 항EGFR항체의 중쇄의 C말단에 융합된다. Fc영역에서 LALA돌연변이를 갖는 상응하는 이중 특이성 항체도 테스트하였다.
도 10A-10B는 다양한 항CD137 x EGFR 이중 특이성 항체 또는 항CD137 모노클로날 항체가 존재하는 경우, EGFR이 높은 SKhep1세포(10A) 또는 EGFR이 낮은 SKBR3세포(10B)와 접촉한 후 293T세포에서의 CD137 활성화 수준을 나타낸다. “aCD137scFv-αEGFR-IgG1-링커7” 및 “aCD137-scFv-αEGFR-IgG1-링커10”은 이중 특이성 항체를 대표하고, 여기서 클론 2-9로부터 유래된 항CD137 scFv는 상이한 링커에 의해 전장 항EGFR항체의 중쇄의 C말단에 융합된다. Fc영역에서 LALA돌연변이를 갖는 상응하는 이중 특이성 항체도 테스트하였다.
도 11은 다양한 농도의 항CD137 x EGFR이중 특이성 항체가 존재하는 경우, EGFR이 높은 SKHep1세포 또는 EGFR이 낮은 SKBR3세포와 접촉한 후 공여체로부터 수득된 PBMC에 의한 IL-2 생성을 나타낸다. “aCD137scFv-αEGFR-IgG1-링커7” 및 “aCD137-scFv-αEGFR-IgG1-링커10”은 이중 특이성 항체를 대표하고, 여기서 클론 2-9로부터 유래된 항CD137 scFv는 상이한 링커에 의해 전장 항EGFR항체의 중쇄의 C말단에 융합된다. Fc영역에서 LALA돌연변이를 갖는 상응하는 이중 특이성 항체도 테스트하였다.
도 12는 다양한 항CD137 x EGFR 이중 특이성 항체 및 항CD137 모노클로날 항체 존재 하에서, 종양 세포가 없는 PBMC로부터의 IL-2 생성을 나타낸다. “aCD137scFv-αEGFR-IgG1-링커7” 및 “aCD137-scFv-αEGFR-IgG1-링커10”은 이중 특이성 항체를 대표하고, 여기서 클론 2-9로부터 유래된 항CD137 scFv는 상이한 링커에 의해 전장 항EGFR항체의 중쇄의 C말단에 융합된다. Fc영역에서 LALA돌연변이를 갖는 상응하는 이중 특이성 항체도 테스트하였다.
도 13A-13B는 항체 치료 후 LoVo/이종이식편을 지닌 hPBMC/인간화 ASID마우스의 종양 부피 변화를 나타낸다. 도 13A는 3개의 농도 수준의 항CD137 x EGFR이중 특이성 항체(aCD137scFv-αEGFR-IgG1-LALA)의 조제량 의존적 반응을 나타낸다. 도 13B는 a) 항CD137 x EGFR 이중 특이성 항체(aCD137scFv-αEGFR-IgG1-LALA (2 mg/kg), b) 모 항CD137 모노클로날 항체(2-9 mAb, 1.5 mg/kg) 및 모 항EGFR 모노클로날 항체(1.5 mg/kg)의 조제량 매칭 조합, c) 단지 모 항EGFR 모노클로날 항체(1.5 mg/kg) 및 d) 단지 모 항CD137 모노클로날 항체(2-9 mAb, 1.5 mg/kg)의 비교를 나타낸다. “aCD137scFv-αEGFR-IgG1-LALA”는 이중 특이성 항체를 대표하고, 여기서 클론 2-9로부터 유래된 항CD137 scFv는 GS링커(링커7)에 의해 Fc영역에서 LALA돌연변이를 갖는 전장 항EGFR항체의 중쇄의 C말단에 융합된다.
도 14A-14B는 항체 치료 후 A431/이종이식편을 지닌 hPBMC/인간화 ASID마우스의 종양 부피 변화를 나타낸다. 도 14A는 2개의 농도 수준의 항CD137 x EGFR이중 특이성 항체(aCD137scFv-αEGFR-IgG1-LALA)의 조제량 의존적 반응을 나타낸다. 도 14B는 a) 항CD137 x EGFR 이중 특이성 항체(aCD137scFv-αEGFR-IgG1-LALA (1.4 mg/kg), b) 모 항CD137 모노클로날 항체(2-9 mAb, 1 mg/kg) 및 모 항EGFR 모노클로날 항체(1 mg/kg)의 조제량 매칭 조합, c) 단지 모 항EGFR 모노클로날 항체(1 mg/kg) 및 d) 단지 모 항CD137 모노클로날 항체(2-9 mAb, 1 mg/kg)의 비교를 나타낸다. “aCD137scFv-αEGFR-IgG1-LALA”는 이중 특이성 항체를 대표하고, 여기서 클론 2-9로부터 유래된 항CD137 scFv는 GS링커에 의해 Fc영역에서 LALA돌연변이를 갖는 전장 항EGFR항체의 중쇄의 C말단에 융합된다.
도 2A 및 2B는 FcγRIIB를 발현하는 293F세포가 존재하지 않는 경우(2A) 또는 FcγRIIB를 발현하는 293F세포가 존재하는 경우(2B), NF-κB 리포터 유전자 측정에서의 루시퍼라제 활성을 나타낸다. 기준 Ab 1 및 기준 항체Ab 2는 구현예 2에 따른 기준 항CD137 항체이다. αCD137 Ab 클론은 상이한 항CD137 모노클로날 항체를 나타낸다.
도 3A-3C는 FcγRIIB를 발현하는 293F세포가 존재하지 않는 경우(3A) 또는 FcγRIIB를 발현하는 293F세포가 존재하는 경우(3B 및 3C), NF-κB 리포터 유전자 측정에서의 루시퍼라제 활성을 나타낸다. 기준 Ab 1 및 기준 항체Ab 2는 구현예 2에 따른 기준 항CD137 항체이다. 2-9-1 IgG1 SELF는 IgG1 Fc 및 돌연변이 S267E/L328F를 포함한다. 2-9-1 IgG2 SELF는 IgG2 Fc 및 돌연변이S267E/L328F를 포함한다. 2-9 IgG2 wt는 야생형 인간IgG2 Fc를 포함한다. 2-9-2 IgG4는 야생형 인간IgG4 Fc를 포함한다.
도 4A 및 4B는 상이한 농도의 상이한 항CD137 항체 존재 하에서, 공여체로부터 수득된 PBMC의 IFN-γ(4A) 및 IL2(4B) 산량을 나타낸다. 기준 Ab 1 및 기준 항체Ab 2는 구현예 2에 따른 기준 항CD137 항체이다. 2-9-1 IgG1 SELF는 IgG1 Fc 및 돌연변이 S267E/L328F를 포함한다. 2-9-1 IgG2 SELF는 IgG2 Fc 및 돌연변이 S267E/L328F를 포함한다. 2-9 IgG2 wt는 야생형 인간 IgG2 Fc를 포함한다. 2-9-2 IgG4는 야생형 인간 IgG4 Fc를 포함한다.
도 5A 및 5B는 MC38뮤린 결장직장암 모델에서 2-9변이체의 체내 연구 결과를 나타낸다. 도 5A는 벡터 대조군 및 치료군의 종양 성장 그래프를 나타낸다. 도 5B는 치료에서 마우스의 체중 변화를 나타낸다.
도 6A 및 6B는 MC38뮤린 결장직장암 모델에서 유토밀루맙 유사 약물의 체내 연구 결과를 나타낸다. 도 6A는 IgG 대조군 및 치료군의 종양 성장 그래프를 나타낸다. 도 6B는 치료에서 마우스의 체중 변화를 나타낸다.
도 7A 및 7B는 예시적 이중 특이성 항체의 설계를 나타내고, 여기서 항CD137 scFv는 일반적 결합 종양 관련 항원(7A) 및 특이적 결합 EGFR(7B)의 전장 항체에 융합된다. αTAA는 종양 관련 항원에 대한 항체를 대표한다. αCD137은 항CD137 scFv를 대표한다.
도 8은 CD137 및 EGFR에 대한 예시적 항CD137 x EGFR이중 특이성 항체의 결합 친화력을 나타낸다. 2-9scFv-αEGFR2-HC-C는 이중 특이성 항체를 대표하고, 여기서 클론 2-9로부터 유래된 항CD137 scFv는 전장 항EGFR항체의 중쇄의 C말단에 융합된다.
도 9A-9B는 CD137(9A) 및 EGFR(9B)에 대한 전체 세포 결합 측정법에 의해 측정된 예시적 항CD137 x EGFR 이중 특이성 항체 또는 항CD137 모노클로날 항체의 결합 친화력을 나타낸다. αEGFR은 EGFR에 결합되는 예시적 전장 항체를 대표한다. 실시예 4를 참조바란다. “aCD137-scFv-αEGFR-IgG1-링커7” 및 “aCD137-scFv-αEGFR-IgG1-링커10”은 이중 특이성 항체를 대표하고, 여기서 클론 2-9로부터 유래된 항CD137 scFv는 상이한 링커에 의해 전장 항EGFR항체의 중쇄의 C말단에 융합된다. Fc영역에서 LALA돌연변이를 갖는 상응하는 이중 특이성 항체도 테스트하였다.
도 10A-10B는 다양한 항CD137 x EGFR 이중 특이성 항체 또는 항CD137 모노클로날 항체가 존재하는 경우, EGFR이 높은 SKhep1세포(10A) 또는 EGFR이 낮은 SKBR3세포(10B)와 접촉한 후 293T세포에서의 CD137 활성화 수준을 나타낸다. “aCD137scFv-αEGFR-IgG1-링커7” 및 “aCD137-scFv-αEGFR-IgG1-링커10”은 이중 특이성 항체를 대표하고, 여기서 클론 2-9로부터 유래된 항CD137 scFv는 상이한 링커에 의해 전장 항EGFR항체의 중쇄의 C말단에 융합된다. Fc영역에서 LALA돌연변이를 갖는 상응하는 이중 특이성 항체도 테스트하였다.
도 11은 다양한 농도의 항CD137 x EGFR이중 특이성 항체가 존재하는 경우, EGFR이 높은 SKHep1세포 또는 EGFR이 낮은 SKBR3세포와 접촉한 후 공여체로부터 수득된 PBMC에 의한 IL-2 생성을 나타낸다. “aCD137scFv-αEGFR-IgG1-링커7” 및 “aCD137-scFv-αEGFR-IgG1-링커10”은 이중 특이성 항체를 대표하고, 여기서 클론 2-9로부터 유래된 항CD137 scFv는 상이한 링커에 의해 전장 항EGFR항체의 중쇄의 C말단에 융합된다. Fc영역에서 LALA돌연변이를 갖는 상응하는 이중 특이성 항체도 테스트하였다.
도 12는 다양한 항CD137 x EGFR 이중 특이성 항체 및 항CD137 모노클로날 항체 존재 하에서, 종양 세포가 없는 PBMC로부터의 IL-2 생성을 나타낸다. “aCD137scFv-αEGFR-IgG1-링커7” 및 “aCD137-scFv-αEGFR-IgG1-링커10”은 이중 특이성 항체를 대표하고, 여기서 클론 2-9로부터 유래된 항CD137 scFv는 상이한 링커에 의해 전장 항EGFR항체의 중쇄의 C말단에 융합된다. Fc영역에서 LALA돌연변이를 갖는 상응하는 이중 특이성 항체도 테스트하였다.
도 13A-13B는 항체 치료 후 LoVo/이종이식편을 지닌 hPBMC/인간화 ASID마우스의 종양 부피 변화를 나타낸다. 도 13A는 3개의 농도 수준의 항CD137 x EGFR이중 특이성 항체(aCD137scFv-αEGFR-IgG1-LALA)의 조제량 의존적 반응을 나타낸다. 도 13B는 a) 항CD137 x EGFR 이중 특이성 항체(aCD137scFv-αEGFR-IgG1-LALA (2 mg/kg), b) 모 항CD137 모노클로날 항체(2-9 mAb, 1.5 mg/kg) 및 모 항EGFR 모노클로날 항체(1.5 mg/kg)의 조제량 매칭 조합, c) 단지 모 항EGFR 모노클로날 항체(1.5 mg/kg) 및 d) 단지 모 항CD137 모노클로날 항체(2-9 mAb, 1.5 mg/kg)의 비교를 나타낸다. “aCD137scFv-αEGFR-IgG1-LALA”는 이중 특이성 항체를 대표하고, 여기서 클론 2-9로부터 유래된 항CD137 scFv는 GS링커(링커7)에 의해 Fc영역에서 LALA돌연변이를 갖는 전장 항EGFR항체의 중쇄의 C말단에 융합된다.
도 14A-14B는 항체 치료 후 A431/이종이식편을 지닌 hPBMC/인간화 ASID마우스의 종양 부피 변화를 나타낸다. 도 14A는 2개의 농도 수준의 항CD137 x EGFR이중 특이성 항체(aCD137scFv-αEGFR-IgG1-LALA)의 조제량 의존적 반응을 나타낸다. 도 14B는 a) 항CD137 x EGFR 이중 특이성 항체(aCD137scFv-αEGFR-IgG1-LALA (1.4 mg/kg), b) 모 항CD137 모노클로날 항체(2-9 mAb, 1 mg/kg) 및 모 항EGFR 모노클로날 항체(1 mg/kg)의 조제량 매칭 조합, c) 단지 모 항EGFR 모노클로날 항체(1 mg/kg) 및 d) 단지 모 항CD137 모노클로날 항체(2-9 mAb, 1 mg/kg)의 비교를 나타낸다. “aCD137scFv-αEGFR-IgG1-LALA”는 이중 특이성 항체를 대표하고, 여기서 클론 2-9로부터 유래된 항CD137 scFv는 GS링커에 의해 Fc영역에서 LALA돌연변이를 갖는 전장 항EGFR항체의 중쇄의 C말단에 융합된다.
본 출원은 CD137에 특이적으로 결합되는 신규한 항CD137 작제물(예를 들어, 종양 관련 항원(TAA)에 결합되는 항CD137 scFv, 모노클로날 항체 및 다중 특이적 항체), 상기 항CD137 작제물을 제조하는 방법, 상기 작제물을 사용하는 방법(예를 들어, 질환 또는 병증을 치료 하는 방법, 면역 반응을 조절하는 방법 또는 세포 조성물을 조절하는 방법)을 제공한다. 본 발명에서 부분적으로 항CD137 단일 특이성 항체 및 다중 특이적 항체의 발견에 기반하여, 상기 항CD137 단일 특이성 항체 및 다중 특이적 항체는 임상 시험에서 발견된 기존 항CD137 항체에 비해 개선된 안전성 및 증강된 항 종양 효능을 나타낸다.
I.
정의
용어 “항체”는 이의 가장 넓은 의미로 사용되고, 다양한 항체 구조를 포함하며, 이러한 항체 구조는 이들이 원하는 항원 결합 활성을 나타내는 한, 모노클로날 항체, 폴리클로날 항체, 다중 특이적 항체(예를 들어, 이중 특이성 항체), 전장 항체 및 이의 항체 단편을 포함하지만 이에 한정되지 않는다. 용어 “항체 부분”은 전장 항체 또는 이의 항원 결합 단편을 지칭한다.
전장 항체는 두 가닥의 중쇄 및 두 가닥의 경쇄를 포함한다. 경쇄 및 중쇄의 가변영역은 항원 결합을 담당한다. 중쇄 및 경쇄의 가변 도메인은 각각 “VH” 및 “VL”로 지칭될 수 있다. 두 가닥의 사슬의 가변영역은 통상적으로 3개의 초가변 루프를 포함하고, 상보적 결정 영역(CDR)(LC-CDR1, LC-CDR2 및 LC-CDR3을 포함하는 경쇄(LC)CDR, HC-CDR1, HC-CDR2 및 HC-CDR3을 포함하는 중쇄(HC)CDR)로 지칭된다. 본 개시의 항체 및 항원 결합 단편의 CDR 경계는, Kabat, Chothia 또는 Al-Lazikani (Al-Lazikani 1997; Chothia 1985; Chothia 1987; Chothia 1989; Kabat 1987; Kabat 1991)와 같은 범례를 통해 정의 또는 검증될 수 있다. 중쇄 또는 경쇄의 3개의 CDR은 프레임워크 영역(FR)으로 지칭되는 측면 세그먼트 사이에 삽입되고, 이들은 CDR보다 더 고도로 보존되고, 초가변 루프를 지원하는 스캐폴드를 형성하였다. 중쇄 및 경쇄의 불변영역은 항원 결합에 참여하지 않지만, 다양한 이펙트 기능을 나타낸다. 항체 중쇄 불변영역의 아미노산 서열에 따라 항체를 분류한다. 항체의 5가지 주요 클래스 또는 동종형은 IgA, IgD, IgE, IgG 및 IgM이고, α, δ, ε, γ 및 μ중쇄의 존재를 특징으로 한다. 여러가지 주요 항체 클래스는 lgG1(γ1중쇄), lgG2(γ2중쇄), lgG3(γ3중쇄), lgG4(γ4중쇄), lgA1(α1중쇄) 또는 lgA2(α2중쇄)와 같은 하위 클래스로 구분된다.
본문에 사용된 용어 “항원 결합 단편”은 항체 단편을 지칭하고, 예를 들어, 이중 특이성 항체, Fab, Fab’, F(ab’)2, Fv단편, 이황화 결합이 안정적인 Fv단편(dsFv), (dsFv)2, 이중 특이적 dsFv(dsFv-dsFv’), 이황화 결합이 안정적인 이중 특이성 항체(ds이중 특이성 항체), 단일쇄Fv(scFv), scFv이량체(2가 디아바디), 항체의 하나 또는 다수의 CDR을 포함하는 부분으로 형성된 다중 특이적 항체, 낙타화 단일 도메인 항체, 나노 항체, 도메인 항체, 2가 도메인 항체 또는 항원에 결합하지만 완전한 항체 구조를 포함하지 않는 임의의 기타 항체 단편을 포함한다. 항원 결합 단편은 모 항체 또는 모 항체 단편(예를 들어, 모 scFv)에 결합되는 동일한 항원에 결합될 수 있다. 일부 실시예에서, 항원 결합 단편은 특정 인간 항체로부터의 하나 또는 다수의 CDR을 포함할 수 있고, 상기 CDR은 하나 또는 다수의 상이한 인간 항체로부터의 프레임워크 영역에 접합된다.
“Fv”는 완전 항원 인식 부위와 항원 결합 부위를 함유하는 최소 항체 단편이다. 상기 단편은 긴밀한 비공유 결합에서 하나의 중쇄 가변영역 도메인 및 하나의 경쇄 가변영역 도메인의 이량체로 구성된다. 이 2개의 도메인의 접힘으로부터 항원 결합을 위한 아미노산 잔기에 기여하고 항체에 항원 결합 특이성을 부여하는 6개의 초가변 루프(각각 중쇄 및 경쇄로부터의 3개의 루프)가 나타난다. 그러나, 단일 가변 도메인(또는 3개의 항원 특이적 CDR만 포함하는 Fv의 절반)도 항원을 인식하고 결합할 수 있지만, 때로는 완전한 결합 부위보다 더 낮은 친화력으로 수행된다.
“단일쇄Fv”(또한 “sFv” 또는 “scFv”로 약칭)는 단일 폴리펩티드 사슬에 연결된 VH 및 VL항체 도메인을 포함하는 항체 단편이다. 일부 실시예에서, scFv폴리펩티드는 scFv가 항원 결합을 위해 원하는 구조를 형성하도록 하는VH 및 VL 도메인 사이의 폴리펩티드 링커를 추가로 포함한다. scFv에 대한 요약에 관하여, Pl ckthun의 The Pharmacology of Monoclonal Antibodies, 제113권, Rosenburg 및 Moore편집 Springer-Verlag, 뉴욕, 제269-315페이지 (1994)를 참조바란다.
ckthun의 The Pharmacology of Monoclonal Antibodies, 제113권, Rosenburg 및 Moore편집 Springer-Verlag, 뉴욕, 제269-315페이지 (1994)를 참조바란다.
본문에 사용된 바와 같이, 용어 “CDR” 또는 “상보적 결정 영역”은 중쇄 및 경쇄 폴리펩티드의 가변영역 내의 비욘속적인 항원 결합 부위를 지칭한다. 이러한 특정 영역은 이미 Kabat et al., J. Biol. Chem., 252: 6609-6616 (1977); Kabat et al., U.S. Dept. of Health and Human Services, “Sequences of proteins of immunological interest”(1991); Chothia et al., J. Mol. Biol. 196: 901-917 (1987); Al-Lazikani B. et al., J. Mol. Biol., 273: 927-948 (1997); MacCallum et al., J. Mol. Biol. 262: 732-745 (1996); Abhinandan 및 Martin, Mol. Immunol., 45: 3832-3839 (2008); Lefranc M.P. et al., Dev. Comp.Immunol., 27: 55-77 (2003); 및 Honegger 및 Pl ckthun, J. Mol. Biol., 309: 657-670 (2001)에 설명되었고, 여기서 정의는 서로 비교할 때 아미노산 잔기의 중복 또는 부분 집합을 포함한다. 그러나, 항체 또는 이식된 항체 또는 이의 변이체의 CDR을 지칭하기 위한 정의의 적용은 본문에서 정의되고 사용되는 용어의 범위 내에 속하는 것으로 의도된다. 상기 각각의 참고문헌에 정의된 CDR을 포함하는 아미노산 잔기는 하기 표 1에 비교로서 나열되었다. CDR 예측 알고리즘 및 인터페이스는 본 분야에서 공지된 것이고, 예를 들어, Abhinandan 및 Martin, Mol. Immunol., 45: 3832-3839 (2008); Ehrenmann F. et al., Nucleic Acids Res., 38: D301-D307 (2010); 및 Adolf-Bryfogle J. et al., Nucleic Acids Res., 43: D432-D438 (2015)을 포함한다. 본 단락에 인용된 참조문헌의 내용은 인용을 통해 그 전체가 본문에 통합되어, 본 출원에 사용되고 본문의 하나 이상의 청구범위에 포함될 수 있다.
ckthun, J. Mol. Biol., 309: 657-670 (2001)에 설명되었고, 여기서 정의는 서로 비교할 때 아미노산 잔기의 중복 또는 부분 집합을 포함한다. 그러나, 항체 또는 이식된 항체 또는 이의 변이체의 CDR을 지칭하기 위한 정의의 적용은 본문에서 정의되고 사용되는 용어의 범위 내에 속하는 것으로 의도된다. 상기 각각의 참고문헌에 정의된 CDR을 포함하는 아미노산 잔기는 하기 표 1에 비교로서 나열되었다. CDR 예측 알고리즘 및 인터페이스는 본 분야에서 공지된 것이고, 예를 들어, Abhinandan 및 Martin, Mol. Immunol., 45: 3832-3839 (2008); Ehrenmann F. et al., Nucleic Acids Res., 38: D301-D307 (2010); 및 Adolf-Bryfogle J. et al., Nucleic Acids Res., 43: D432-D438 (2015)을 포함한다. 본 단락에 인용된 참조문헌의 내용은 인용을 통해 그 전체가 본문에 통합되어, 본 출원에 사용되고 본문의 하나 이상의 청구범위에 포함될 수 있다.
표 1: CDR 정의

1잔기 넘버링은 Kabat et al., 의 명명법(위와 동일)을 따른다.
2잔기 넘버링은 Chothia et al., 의 명명법(위와 동일)을 따른다.
3잔기 넘버링은 MacCallum et al., 의 명명법(위와 동일)을 따른다.
4잔기 넘버링은 Lefranc et al., 의 명명법(위와 동일)을 따른다.
5잔기 넘버링은 Honegger 및 Pl ckthun, 의 명명법(위와 동일)을 따른다.
ckthun, 의 명명법(위와 동일)을 따른다.
“Kabat에서와 같은 가변 도메인 잔기의 넘버링” 또는 “Kabat에서와 같은 아미노산 위치 넘버링” 및 이의 변이체는 상술한 Kabat et al.,의 항체 편집에 사용된 중쇄 가변 도메인 또는 경쇄 가변 도메인의 넘버링 시스템을 지칭한다. 이 넘버링 시스템을 사용하여, 실제 직쇄 아미노산 서열은 가변 도메인의 FR 또는 초가변 영역(HVR)의 단축 또는 삽입에 대응되는 더 적거나 또는 별도의 아미노산을 포함할 수 있다. 예를 들어, 중쇄 가변 도메인은 H2의 잔기 52 이후의 단일 아미노산 삽입(Kabat에 따른 잔기 52a) 및 중쇄FR의 잔기 82 이후에 삽입된 잔기(예를 들어, Kabat에 따른 잔기 82a, 82b 및 82c 등)를 포함할 수 있다. 항체 서열에서 “표준” Kabat 넘버링 서열의 상동성 영역과 정렬함으로써 주어진 항체의 잔기의 Kabat넘버링을 결정할 수 있다.
본문에서 달리 설명되지 않는 한, 전장 항체(예를 들어, 본문에 개시된 항CD137 항체)의 CDR을 포함하는 아미노산 잔기는 상술한 Kabat et al., 의 Kabat 명명법에 따라 정의된 것이고, 공유 서열의 CDR을 포함하는 아미노산 잔기는 Kabat 명명법에 의해 정의된 것 외에, 면역글로블린 중쇄, 예를 들어 Fc영역에서 잔기 넘버링은 Kabat et al.,에 서술된 EU 인텍스의 넘버링이며, 여기서 변형은 실험 조건에 기반된 것이다. “Kabat에 서술된 EU 인텍스”는 인간IgG1 EU항체의 잔기의 넘버링을 지칭한다.
“프레임워크” 또는 “FR” 잔기는 본문에 정의된 CDR잔기 이외의 가변 도메인 잔기를 지칭한다.
“인간화”형태의 비인간(예를 들어 설치류 동물) 항체는 키메라 항체이고, 비인간 항체로부터 유래된 최소 서열을 포함한다. 대부분의 경우, 인간화 항체는 인간 면역 글로불린(수용체 항체)이고, 여기서, 수용체 초가변 영역(HVR)으로부터의 잔기는 비인간종(예를 들어 마우스, 래트, 토끼 또는 비인간 영장류)로부터의 원하는 항원 특이성, 친화력 및 용량을 갖는 초가변 영역(공여체 항체)의 잔기에 의해 대체된다. 일부 구현예에서, 인간 면역 글로불린의 프레임워크 영역(FR) 잔기는 대응되는 비인간 잔기에 의해 대체된다. 이외에, 인간화 항체는 수용체 항체 또는 공여체 항체에서 발견되지 않은 잔기를 포함할 수 있다. 이러한 변형의 수행은 항체 성능을 더욱 향상시킨다. 통상적으로, 인간화 항체는 적어도 하나, 전형적으로 두개의 가변 도메인에서의 기본적으로 전부를 포함할 것이고, 여기서 전부 또는 기본적으로 전부의 초가변 루프는 비인간 면역글로블린에 대응되며, 전부 또는 기본적으로 전부의 FR은 인간 면역글로블린 서열이다. 인간화 항체는 또한 선택적으로 면역글로불린 불변영역 (Fc)의 적어도 일부를 포함하고, 전형적으로 인간 면역 글로불린의 적어도 일부분을 포함한다. 자세한 내용은 Jones et al., Nature, 321: 522-525, (1986); Riechmann et al., Nature, 332: 323-329 (1988); 및 Presta, Curr. Op. Struct. Biol. 2:593-596 (1992)를 참조바란다.
“인간 항체”는 아미노산 서열을 갖는 항체이고, 상기 아미노산 서열은 인간에 의해 생성된 항체의 아미노산 서열에 대응되거나 및/또는 본문에 개시된 인간 항체를 제조하는 임의의 기술을 사용하여 제조된 항체이다. 인간 항체의 이러한 정의는 비인간 항원 결합 잔기를 포함하는 인간화 항체를 특별히 배제하였다. 본 분야에 공지된 다양한 기술(파지 디스플레이 라이브러리 포함)을 사용하여 인간 항체를 생성할 수 있다. Hoogenboom 및 Winter, J. Mol. Biol., 227: 381 (1991); Marks et al., J. Mol. Biol., 222: 581 (1991). 또한 인간 모노클로날 항체를 제조할 수 있는 것은 Cole et al., Monoclonal Antibodies and Cancer Therapy, Alan R. Liss, 제77페이지 (1985); Boerner et al., J. Immunol., 147(1): 86-95 (1991)에 설명된 방법이다. 또한 van Dijk 및 van de Winkel, Curr.Opin. Pharmacol., 5: 368-74 (2001)를 참조바란다. 인간 항체는 항원 공격에 반응하여 이러한 항체를 생성하도록 변형되었지만 내인성 유전자좌가 실효된 유전자 변형 동물(예를 들어 면역화된 xenomice)로 제조할 수 있다(예를 들어, XENOMOUSE™기술에 대한 미국 특허 번호 6,075,181 및 6,150,584 참조). 인간B세포 하이브리도마 기술에 의해 생성된 인간 항체에 대해서는, 예를 들어 Li et al., Proc. Natl. Acad. Sci. USA 103: 3557-3562 (2006)을 참조바란다.
“본문에서 검증된 폴리펩티드 및 항체 서열에 대한 아미노산 서열 동일성 백분율(%)” 또는 “상동성”은 서열(임의의 보존적 치환을 서열 동일성의 일부로 고려)을 정렬한 후, 후보 서열에서 비교된 폴리펩티드의 아미노산 잔기와 동일한 아미노산 잔기의 백분율로 정의된다. 아미노산 서열 동일성을 결정하기 위한 목적으로, 예를 들어 BLAST, BLAST-2, ALIGN, Megalign(DNASTAR) 또는 MUSCLE 소프트웨어와 같은 공개적으로 이용 가능한 컴퓨터 소프트웨어를 사용하여 본 분야의 기술의 다양한 방식으로 정렬을 달성할 수 있다. 당업자는 비교되는 서열의 전장에 걸쳐 최대 정렬을 달성하는데 필요한 임의의 알고리즘을 비롯한 정렬을 측정하기 위한 적절한 파라미터를 결정할 수 있다. 그러나, 본문의 목적에 따라, 서열 비교 컴퓨터 프로그램 MUSCLE을 사용하여 아미노산 서열 동일성%값(Edgar, R.C., Nucleic Acids Research 32(5): 1792-1797, 2004; Edgar, R.C., BMC Bioinformatics 5(1): 113, 2004)을 생성할 수 있다.
“상동성”은 2개의 폴리펩티드 사이 또는 2개의 핵산 분자 사이의 서열 유사성 또는 서열 동일성을 지칭한다. 2개의 비교된 서열 중 하나의 위치가 동일한 염기 또는 아미노산 단량체 서브 유닛에 의해 점유될 때, 예를 들어, 만약 2개의 DNA분자 중 각각에서 하나의 위치가 아데닌에 의해 점유되면, 상기 분자는 상기 위치에서 상동적이다. 2개의 서열 사이의 상동성 백분율은 2개의 서열이 공유하는 일치하거나 상동적인 위치의 수를 비교된 위치의 수로 나눈 값에 100을 곱한 함수이다. 예를 들어, 2개의 서열 중 10개의 위치 중의 6개가 일치하거나 상동적이면, 2개의 서열은 60% 상동적이다. 예를 들어, DNA서열 ATTGCC 및 TATGGC는 50%의 상동성을 갖는다. 통상적으로, 2개의 서열이 최대 상동성을 제공하도록 정렬될 때 비교가 이루어진다.
용어 “불변 도메인”은 항원 결합 부위를 포함하는 가변 도메인인 면역글로불린의 다른 일부에 비해, 더 보존된 아미노산 서열을 갖는 면역글로불린 분자의 부분을 지칭한다. 불변 도메인은 중쇄의 CH1, CH2 및 CH3 도메인(총체적으로 CH) 및 경쇄의 CHL(또는 CL) 도메인을 포함한다.
임의의 포유 동물 종의 항체(예를 들어 면역글로불린)의 “경쇄”는 모두 그 불변 도메인의 아미노산 서열에 따라 두 가지 유의하게 상이한 유형 중 하나로 지정될 수 있고, 각각 kappa(“κ”) 및 lambda(“λ”)로 지칭된다.
“CH1도메인”(“H1”도메인의 “C1”로도 지칭됨)은 통상적으로 약 아미노산 118 내지 약 아미노산 215(EU넘버링 시스템)이다.
“힌지 영역”은 일반적으로 인간 IgG1의 Glu216 내지 Pro230에 대응되는 IgG의 영역으로 정의된다(Burton, Molec. Immunol., 22: 161-206 (1985)). 다른 IgG 동종형의 힌지 영역은 중쇄 사이에 S-S결합을 형성하는 첫번째 및 마지막 시스테인 잔기를 동일한 위치에 배치함으로써 IgG1서열에 정렬될 수 있다.
인간IgG Fc영역(“C2”도메인으로도 지칭됨)의 “CH2도메인”은 약 아미노산 231 내지 약 아미노산 340이다. CH2도메인은 다른 도메인과 밀접하게 매칭되지 않는다는 점에서 독특하다. 오히려, 2개의 N에 연결된 분지형 탄수화물 사슬이 완전한 천연 IgG분자의 2개의 CH2도메인 사이에 삽입된다. 탄수화물은 도메인-도메인 매칭에 대한 대체물을 제공하고 CH2 도메인을 안정화하는데 도움이 될 수 있는 것으로 추측된다. Burton, Molec Immunol., 22: 161-206 (1985).
“CH3도메인”(“C2”도메인으로도 지칭됨)은 Fc영역에서 CH2도메인 Fc영역의 C말단에 가까운 잔기 영역(즉, 약 아미노산 잔기 341에서 항체 서열의 C말단까지(전형적으로 IgG의 아미노산 잔기 446 또는 447에 있음)을 포함한다.
분문의 용어 “Fc영역” 또는 “단편 결정화 가능한 영역”은 천연 서열 Fc 영역 및 변이체 Fc 영역을 포함하는 면역글로불린 중쇄의 C말단 영역을 정의하기 위한 것이다. 면역글로불린 중쇄의 Fc영역의 경계는 변화될 수 있지만, 통상적으로 인간IgG중쇄의 Fc영역을 Cys226위치의 아미노산 잔기 또는 Pro230에서 이의 카르복시 말단까지 연장되는 것으로 정의된다. 예를 들어 항체의 생산 또는 정제 동안 또는 항체 중쇄를 코딩하는 핵산의 재조합 조작에 의해 Fc영역의 C말단 라이신(EU넘버링 시스템에 따른 잔기 447)을 제거할 수 있다. 따라서, 완전한 항체의 조성물은 모든 K447잔기를 제거한 항체 집단, K447잔기를 제거하지 않은 항체 집단 및 K447잔기가 있거나 없는 항체 혼합물을 갖는 항체 집단을 포함할 수 있다. 본문에 기재된 항체에 적합한 천연 서열 Fc영역은 인간IgG1, IgG2(IgG2A, IgG2B), IgG3 및 IgG4를 포함한다.
“Fc수용체” 또는 “FcR”은 항체의 Fc영역에 결합하는 수용체를 설명한다. 바람직한 FcR은 천연 인간FcR이다. 이 외에, 바람직한 FcR은 IgG항체(γ수용체)에 결합하고 FcγRI, FcγRII 및 FcγRIII 서브 클래스의 수용체를 포함하는 FcR이며, 대립유전자 변이체 및 이러한 수용체의 스플라이스 형태를 포함하고, FcγRII수용체는 FcγRIIA(“활성화 수용체”) 및 FcγRIIB(“억제 수용체”)를 포함하며, 이들은 유사한 아미노산 서열을 갖고, 주요한 구별점은 세포질 도메인이다. 활성화 수용체FcγRIIA는 세포질 도메인에 면역 수용체 티로신 기반 활성화 모티프(ITAM)를 포함한다. 억제성 수용체FcγRIIB는 세포질 도메인에 면역 수용체 티로신 기반 억제 모티프(ITIM)를 포함한다. (M. Da ron, Annu.Rev. Immunol. 15:203-234 (1997)을 참조바란다. FcR은 Ravetch 및 Kinet, Annu.Rev. Immunol. 9: 457-92 (1991); Capel et al., Immunomethods 4: 25-34 (1994); 및 de Haas et al., J. Lab. Clin. Med. 126: 330-41 (1995)에 설명되어 있다. 본문의 용어 “FcR”은 미래에 검증될 FcR을 포함하는 다른 FcR을 포함한다.
ron, Annu.Rev. Immunol. 15:203-234 (1997)을 참조바란다. FcR은 Ravetch 및 Kinet, Annu.Rev. Immunol. 9: 457-92 (1991); Capel et al., Immunomethods 4: 25-34 (1994); 및 de Haas et al., J. Lab. Clin. Med. 126: 330-41 (1995)에 설명되어 있다. 본문의 용어 “FcR”은 미래에 검증될 FcR을 포함하는 다른 FcR을 포함한다.
본문에 사용된 바와 같이, 용어 “에피토프”는 항체 또는 항원 부분이 결합하는 항원에서의 특정 원자 또는 아미노산 라디칼을 지칭한다. 2개의 항체 또는 항원 부분이 항원에 경쟁적으로 결합하면, 이들은 항원 내의 동일한 에피토프에 결합할 수 있다.
본문에 사용된 바와 같이, 등몰 농도의 제1 항체 또는 이의 단편 존재 하에서, 제1 항체 또는 이의 단편은 제2 항체 또는 이의 단편의 타겟 항원 결합을 적어도 약 50%(예를 들어 적어도 약 55%, 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%, 98% 또는 99% 중의 임의의 하나)로 억제하는 경우, 상기 제1 항체 또는 이의 단편은 상기 제2 항체 또는 이의 단편과 상기 타겟 항원에 “경쟁적으로” 결합하거나, 또는 그 반대의 경우도 마찬가지이다. PCT 공개번호 WO 03/48731에서 항체의 교차 경쟁에 기반하여 이러한 항체 “비닝(binning)”하기 위한 고처리량 방법을 설명하였다.
본문에 사용된 바와 같이, 용어 “특이적 결합”, “특이적 인식” 및 “……에 대해 특이적”은 예를 들어 타겟과 항체 또는 항체 부분 사이의 결합과 같은 측정 가능하고 재현 가능한 상호작용을 지칭하고, 이질적인 분자(생체 분자 포함) 집단 존재 시 타겟의 존재를 결정한다. 예를 들어, 특이적 인식 타겟(에피토프일 수 있음)의 항체 또는 항체 부분은 상기 타겟에 결합하는 항체 또는 항체 부분이고, 친화력, 결합력, 준비성 및/또는 지속 시간은 다른 타겟과의 결합보다 길다. 일부 실시예에서, 항체와 관련되지 않는 타겟의 결합 정도는, 예를 들어 방사성 면역측정법(RIA)에 의해 측정된 항체와 타겟의 결합 정도의 약 10% 미만이다. 일부 실시예에서, 타겟에 특이적으로 결합하는 항체의 해리 상수 (KD) ≤ 10-5 M, ≤ 10-6 M, ≤ 10-7 M, ≤ 10-8 M, ≤ 10-9 M, ≤ 10-10 M, ≤ 10-11 M, 또는 ≤ 10-12 M이다. 일부 실시예에서, 항체는 상이한 종의 단백질로부터 보존된 단백질의 에피토프에 특이적으로 결합한다. 일부 실시예에서, 특이적 결합은 배타적 결합을 포함할 수 있지만 이를 필요로 하지는 않는다. 항체 또는 항원 결합 도메인의 결합 특이성은 본 분야에 공지된 방법에 의해 실험적으로 결정될 수 있다. 이러한 방법은 웨스턴 블롯, ELISA-, RIA-, ECL-, IRMA-, EIA-, BIACORETM-검정 및 펩티드 스캐닝을 포함하지만 이에 한정되지 않는다.
“단리된” 항체(또는 작제물)는 이의 생산 환경의 구성요소(예를 들어 천연 또는 재조합)로부터 검증, 단리 및/또는 회수된 항체이다. 바람직하게, 단리된 폴리펩티드는 이의 생산 환경의 다른 모든 성분과 결합되지 않는다.
본문에 기재된 작제물, 항체 또는 이의 항원 결합 단편을 코딩하는 “단리된” 핵산 분자는 이의 생산 환경에서 일반적으로 이와 관련된 적어도 하나의 오염물 핵산 분자로부터 검증 및 단리된 핵산 분자이다. 바람직하게, 단리된 핵산은 생산 환경과 관련된 다른 모든 성분과 결합되지 않는다. 본문에 기재된 폴리펩티드 및 항체를 코딩하는 단리된 핵산 분자의 형태는 천연적으로 존재하는 형태 또는 배경과 상이하다. 따라서, 단리된 핵산 분자는 세포에 천연적으로 존재하는 본문에 기재된 폴리펩티드 및 항체를 코딩하는 핵산과 상이하다. 단리된 핵산은 일반적으로 핵산 분자를 함유하는 세포에 함유된 핵산 분자를 포함하지만, 상기 핵산 분자는 염색체 외 또는 이의 천연 염색체 위치와 상이한 염색체 위치에 존재한다.
용어 “제어 서열”은 특정 숙주 생체에서 작동 가능하게 연결된 코딩 서열의 발현에 필요한 DNA서열을 지칭한다. 예를 들어, 원핵 생물에 사용하기에 적합한 제에 서열은 프로모터, 임의의 오퍼레이터 서열, 및 리보솜 결합 부위를 포함한다. 진핵 세포는 프로모터, 폴리아데닐화 신호 및 인핸서를 이용하는 것으로 알려져 있다.
핵산이 다른 핵산 서열과 기능적 관계에 있을 때, 상기 핵산은 “작동 가능하게 연결”된다. 예를 들어, 프리서열 또는 분비 리더 서열의 DNA가 폴리펩티드의 분비에 참여하는 프리프로테인으로 발현되면, 상기 프리서열 또는 분비 리더 서열의 DNA는 상기 폴리펩티드의 DNA에 작동 가능하게 연결되고; 프로모터 또는 인핸서가 코딩 서열의 전사에 영향을 미치면, 상기 프로모터 또는 인핸서는 상기 서열에 작동 가능하게 연결되거나; 또는 리보솜 결합 부위가 번역을 용이하게 하도록 위치하면, 상기 리포솜 결합측은 코딩 서열에 작동 가능하게 연결된다. 통상적으로, “작동 가능하게 연결된”은 연결되는 DNA서열이 연속적이고, 분비 리더 서열의 경우 연속적이며 리딩 프레임에 있음을 의미한다. 그러나, 인핸서는 연속적일 필요가 없다. 편리한 제한 부위에서 연결하여 연결을 달성한다. 이러한 부위가 존재하지 않으면, 일반적인 실천에 따라 합성된 올리고뉴클레오티드 어댑터 또는 코넥손을 사용한다.
본문에 사용된 바와 같이, 용어 “벡터”는 연결된 다른 핵산을 증식시킬 수 있는 핵산 분자를 지칭한다. 상기 용어는 자가 복제 핵산 구조인 벡터, 및 이들이 도입된 숙주 세포의 게놈에 통합된 벡터를 포함한다. 일부 벡터는 작동 가능하게 연결된 핵산의 발현을 지시할 수 있다. 이러한 벡터는 본문에서 “발현 벡터”로 지칭된다.
본문에 사용된 바와 같이, 용어 “형질감염된” 또는 “형질전환된” 또는 “형질도입된”은 외인성 핵산을 숙주 세포 내로 전달 또는 도입하는 과정을 지칭한다. “형질감염된” 또는 “형질전환된” 또는 “형질도입된” 세포는 외인성 핵산을 사용하여 형질감염, 형질전환 또는 형질도입된 세포이다. 상기 세포는 1차 타겟 세포 및 이의 자손을 포함한다.
용어 “숙주 세포”, “숙주 세포주” 및 “숙주 세포 배양물”은 상호 교환적으로 사용되고, 이러한 세포의 자손을 포함하는 외인성 핵산이 도입된 세포를 지칭한다. 숙주 세포는 계대 수에 관계없이 1차 형질전환된 세포 및 이로부터 유래된 자손을 포함하는 “형질전환체” 및 “형질 전환된 세포”를 포함한다. 자손의 핵산 함량은 모 세포와 완전히 동일하지 않을 수 있고, 돌연변이를 함유할 수 있다. 1차 형질전환된 세포에서 스크리닝되거나 선택된 것과 동일한 기능 또는 생물학적 활성을 갖는 돌연변이 자손은 본문에 포함된다.
본문에 사용된 바와 같이, “치료(treatment 또는 treating)”는 유익하거나 원하는 결과(임상 결과 포함)를 얻기 위한 방법이다. 본 출원의 목적에 따라, 유익하거나 바람직한 임상 결과는, 질환으로 인한 하나 또는 여러가지 증상 완화, 질환의 정도 감소, 질환의 안정화(예를 들어, 질환의 악화를 예방 또는 지연), 질환의 확산을 예방 또는 지연(예를 들어, 전이), 질환의 재발을 예방 또는 지연, 질환의 진행을 지연 또는 완화, 질환 상태 개선, 질환의 완화(부분적으로 또는 전체적으로) 제공, 질환 치료에 필요한 하나 또는 여러가지의 다른 약물의 조제량 감소, 질환의 진행 지연, 삶의 질 증가 또는 개선, 체중 증가 및/또는 생존 연장 중 하나 또는 다수를 포함하지만 이에 한정되지 않는다. “치료”는 또한 암의 병리학적 결과(예를 들어, 종양 부피)를 감소시키는 것을 포함한다. 본 출원의 방법은 이러한 치료 측면 중의 임의의 하나 또는 다수를 고려하였다.
암의 언어 환경에서, 용어 “치료”는 암세포의 성장 억제, 암세포 복제 억제, 전체 종양 부담 감소 및 질환과 관련된 하나 또는 여러가지의 증상 개선 중의 임의의 하나 또는 전부를 포함한다.
용어 “억제(“inhibition” 또는 “inhibit”)”는 임의의 표현형 특징의 감소 또는 중지를 의미하거나, 상기 특징의 발생율, 정도 또는 가능성의 감소 또는 중지를 의미한다. 기준과 비교하여, “감소” 또는 “억제”는 활성, 기능 및/또는 량을 감소, 저하 또는 방지를 의미한다. 몇몇 실시예에서, “저하” 또는 “억제”는 전체적으로 20% 또는 그 이상 감소시키는 능력을 의미한다. 다른 실시예에서, “저하” 또는 “억제”는 전체적으로 50% 또는 그 이상 감소시키는 능력을 의미한다. 또 다른 실시예에서, “저하” 또는 “억제”는 전체적으로 75%, 85%, 90%, 95% 또는 그 이상 감소시키는 능력을 의미한다.
본문에 사용된 바와 같이,“기준”은 비교 목적으로 사용되는 임의의 샘플, 표준 또는 수준을 의미한다. 기준은 건강 및/또는 질환이 없는 샘플로부터 수득될 수 있다. 몇몇 실시예에서, 기준은 한번도 치료되지 않은 샘플로부터 수득될 수 있다. 몇몇 실시예에서, 기준은 질환에 걸리지 않았거나 치료되지 않은 샘플로부터 수득된다. 일부 구현예에서, 기준은 상기 개인 또는 환자가 아닌 하나 또는 다수의 건강한 대상체로부터 수득된다.
본문에 사용된 바와 같이,“질환의 진행 지연”은 질환(예를 들어 암)의 진행을 연기, 저해, 완화, 느리게, 안정적, 억제 및/또는 지연시키는 것을 의미한다. 상기 지연은 상이한 시간의 길이를 가질 수 있고, 이는 질환의 병력 및/또는 치료될 대상체에 의해 결정될 수 있다. 상기 대상체가 상기 질환에 걸리지 않았기 때문에 충분하거나 현저한 지연은 실질적으로 예방을 포함할 수 있다는 것이 당업자에게 자명하다. 예를 들어, 말기 암(예를 들어 전이의 진행)을 지연시킬 수 있다.
본문에 사용된 바와 같이, “예방”은 질환에 걸리기 쉬울 수 있으나 상기 질환에 걸린 것으로 진단되지 않은 대상체에서 상기 질환의 발생 또는 재발에 대한 예방을 제공하는 것을 포함한다.
본문에 사용된 바와 같이, 기능 또는 활성을 “억제”하는 것은 관심의 조건 또는 파라미터 이외의 동일한 조건과 비교, 또는 대안적으로 다른 조건과 비교하여, 기능 또는 활성을 감소시키는 것이다. 예를 들어, 종양 성장을 억제하는 항체는 항체가 없을 때의 종양 성장 속도와 비교하여 종양 성장 속도를 감소시킨다.
용어 “피험자”, “대상체” 및 “환자”는 본문에서 상호 교환사용 가능하고, 인간, 소, 말, 고양이, 개, 설치류 또는 영장류 동물을 포함하나 이에 제한되지 않는 포유동물을 지칭한다. 일부 실시예에서, 대상체는 인간이다.
약제의 “유효량”은 필요한 조제량 및 기간 동안 치료 또는 예방 결과를 달성하기에 효과적인 양을 의미한다. 구체적인 조제량은, 선택된 특정 약제, 따라야 할 투여 방안, 다른 화합물과 조합되어 투여되는지 여부, 투여 시간, 영상화할 조직 및 이를 지닌 물리적 전달 시스템 중의 하나 이상의 변화에 의해 결정될 수 있다.
본 출원의 물질/분자, 작용제 또는 길항제의 “치료 유효량”은 예를 들어 질환 상태, 연령, 성별 및 대상체의 체중 및 상기 물질/분자, 작용제 또는 길항제에 의해 대상체에서 원하는 반응을 일으키는 능력 등 인소에 따라 변화될 수 있다. 치료 유효량은 상기 물질/분자, 작용제 또는 길항제의 임의의 독성 또는 유해 작용이 치료적으로 유익한 작용에 의해 상쇄되는 양일 수도 있다. 치료 유효량은 일회 또는 수회 투여되어 전달될 수 있다.
“예방 유효량”은 조제량에 의해 계량되고 원하는 예방적 결과를 달성하기 위해 필요한 기간 동안 유효한 양을 의미한다. 전형적으로, 그러나 반드시 그런 것은 아니지만, 예방적 조제량은 질환 이전 또는 초기에서 피험자 체내에 사용되기 때문에, 이러한 예방 유효량은 치료 유효량보다 적을 것이다.
용어 “약물 조제품” 및 “약물 조성물”은 하나 이상의 활성 성분의 생물학적 활성이 유효하도록 하는 형태로 되어 있고, 상기 조제품이 투여될 대상체에 허용되지 않는 독성의 기타 성분을 포함하지 않는 제제를 지칭한다. 이러한 조제품은 무균적인 것일 수 있다.
“약학적으로 허용 가능한 담체 ”는 치료제와 함께 사용하기 위한 당업계에서 통상적인 무독성 고체, 반고체 또는 액체 충전제, 희석제, 패킹 재료, 조제품 보조제 또는 담체 제제를 지칭하고, 이 둘은 공동으로 대상체에 투여하기 위한 “약물 조성물”을 구성한다 약학적으로 허용 가능한 담체는 사용된 조제량 및 농도에서 수용자에게 독성이 없고 조제품의 다른 성분과 양립할 수 있다. 약학적으로 허용 가능한 담체는 사용되는 조제폼에 적용된다.
“뮤균” 조제품은 무균적이거나 살아있는 미생물 및 포자를 기본적으로 함유하지 않는다.
하나 또는 여러가지 기타 치료제 “조합” 투여는 동시(병행) 및 연속적인 투여 또는 임의의 순서로 순차적으로 투여되는 것을 포함한다.
용어 “병행”은 두가지 또는 두가지 이상의 치료제의 투여를 지칭하기 위해 본문에서 사용되고, 여기서 투여?p 적어도 일부는 시간적으로 중첩되거나 하나의 치료제의 투여는 다른 하나의 치료제의 투여에 비해 짧은 기간 내에 속한다. 예를 들어, 두가지 또는 두가지 이상의 치료제는 약 60분을 초과하지 않는(예를 들어 약 30, 15, 10, 5 또는 1분 중의 임의의 하나를 초과하지 않음) 임의의 시간 간격으로 투여된다.
용어 “순차적으로”는 두가지 또는 두가지 이상의 치료제의 투여를 치칭하기 위해 본문에 사용되고, 여기서 중단은 하나 또는 여러가지 시약을 투여한 후 계속하여 하나 또는 여러가지 기타 약제를 투여하는 것이다. 예를 들어, 두가지 또는 두가지 이상의 치료제의 투여는 약 15분을 초과(예를 들어 약 20분, 30분, 40분, 50분, 또는 60분, 1일, 2일, 3일, 1주, 2주 또는 1개우러 또는 더욱 긴 시간 중의 임의의 하나)하는 시간 간격으로 투여된다.
본문에 사용된 바와 같이, “……와 결합”은 하나의 치료 방식 외의 다른 치료 방식의 투여를 의미한다. 마찬가지로, “……와 결합”은 대상체에 하나의 치료 방식을 투여하기 전, 투여 중 또는 투여 후, 다른 하나의 치료 방식을 투여하는 것을 의미한다.
용어 “패키지 삽입물”은 이러한 치료제의 사용에 대한 적응증, 사용법, 조제량, 투여, 조합 요법, 금기증 및/또는 경고에 대한 정보를 포함하는 치료 제품의 상업적 패키지에 일반적으로 포함된 설명서를 의미한다.
“제조 물품”은 적어도 하나의 시약의 임의의 제품(예를 들어, 패키지 또는 용기) 또는 키트를 포함하고, 상기 시약은 예를 들어 질환 또는 장애(예를 들어, 암)의 치료를 위한 약물 또는 본원에 기재된 바이오마커의 특이적 검출을 위한 프로브이다. 몇몇 실시예에서, 제품 또는 키트는 본원에 기재된 방법을 수행하기 위한 유닛으로서 보급, 유통 또는 판매된다.
본문에 서술된 출원의 실시예는 “……로 구성되는” 및/또는 “실질적으로 ……로 구성되는”을 포함하는 것으로 이해되어야 한다.
본문에서 “약” 값 또는 파라미터의 인용은 상기 값 또는 파라미터 자체에 대한 변형을 포함(설명)한다. 예를 들어, “약 X”에 관한 서술은 “X”의 서술을 포함한다.
본문에 사용된 바와 같이, “아닌” 값 또는 파라미터에 관한 언급은 통상적으로 “상이한” 값 또는 파라미터를 의미하고 설명한다. 예를 들어, X형 암을 치료하는데 사용되지 않는 방법은 X형과 상이한 암을 치료하는데 사용되는 방법을 의미한다.
본문에 사용된 용어 “약 X-Y”는 “약 X 내지 약 Y”과 동일한 의미를 갖는다.
본문 및 첨부된 청구범위에서 사용될 경우, 단수 형태 “하나/하나(a)”, “또는 (or)” 및 “이러한/상기(the)”는 문맥에서 명백하게 달리 지시하지 않는 한 복수 지시 대상을 포함한다.
II.
CD137 (4-1BB)
CD137 (4- 1BB)는 종양 괴사 수용체(TNF-R) 유전자 패밀리 구성원이고, 상기 패밀리는 세포의 증식, 분화 및 프로그램된 세포 사멸 조절에 관여하는 단백질을 포함한다. CD137은 30 kDa의 I형 막 당단백질이고, 55 kDa의 동종 이량체로 발현된다. 상기 수용체는 최초 마우스에서(B. Kwon et al., P.N.A.S. USA, 86: 1963-7 (1989)) 기술되었고, 이후 인간에서 검증되었다(M. Alderson et al., Eur.J. Immunol., 24: 2219-27 (1994); Z. Zhou et al., Immunol. Lett., 45: 67 (1995))(공개된 PCT출원 WO 95/07984 및 WO 96/29348, 및 미국특허번호 6,569,997은 참조로서 본문에 통합됨(SEQ ID NO: 2. 참조)). CD137의 인간 및 마우스 형태는 아미노산 수준에서 60%가 동일하다. 보존적 서열은 세포질 도메인 및 분자의 기타 5개의 영역에서 나타나고, 이는 이러한 잔기가 CD137 분자의 기능에 매우 중요할 수 있음을 시사한다(Z. Zhou et al., Immunol. Lett., 45: 67 (1995). CD137의 발현은 주로 림프구 계통의 세포(예를 들어 활성화된 T 세포, 활성화된 자연 살상(NK) 세포, NKT 세포, CD4+CD25+ 조절 T 세포) 뿐만 아니라, 활성화된 흉선 세포 및 림프구의 상피에서도 나타나는 것으로 나타났다. 이 외에, CD137은 수지상 세포, 단핵구, 호중구 및 호산구와 같은 골수 유래 세포에서도 발현되는 것으로 나타났다. CD137 발현은 면역/염증 세포로 크게 제한되지만, 염증 부위 및 종양의 소량의 조직과 관련된 내피 세포에서 CD137 발현을 설명하는 보고되었다.
T 세포에서 CD137의 기능적 활성은 잘 특성화되어 있다. 차선의 조제량의 항CD3 존재 하에 CD137을 통한 신호전달은 T-세포 증식 및 사이토카인 합성(주로 IFN-γ)을 유도하고 활성화된 세포 사멸을 억제할 수 있는 것으로 나타났다. 뮤린 및 인간 T세포 모두에서 이러한 작용을 관찰하였다(W. Shuford et al., J. Exp. Med., 186(l): 47-55 (1997); D. Vinay et al., Semin. Immunol, 10(6): 481-9 (1998); D. Laderach et al., Int. Immunol., 14(10): 1155-67 (2002)). 인간과 마우스에서, 공동자극은 항원 특이적 및 이펙터 CD8+ T 세포의 수를 증가시켜 IFN-γ 생산 및 세포독성과 같은 이펙터 기능을 향상시킨다. 항CD3 신호전달이 없는 경우, CD137에 의한 자극은 T 세포 기능을 변경하지 않고, 이는 CD137이 공동자극 분자인 것을 나타낸다.
마우스에서 작용성 항마우스 CD137 모노클로날 항체를 사용한 생체내 효능 연구는 암 치료에서 CD137 타겟 요법의 역할을 암시한다. Melero et al., 의 논문에서, 작용성 항마우스 CD137 항체는 P815 비만세포종 종양에서 치유가 생성되고, 면역저하 종양 모델 Ag l04에서 치유가 생성되었다(I. Melero et al., Nat. Med., 3(6): 682-5 (1997)). CD4+ 및 CD8+ T 세포 및 NK 세포는 각각의 서브집단의 선택적 생체 내 고갈이 항종양 효과의 감소 또는 완전한 손실을 초래하기 때문에 모두 항종양 효과에 필요하다. 또한 최소의 면역 반응 유도는 항CD137 요법이 효과적인 것에 필수 적이다. 몇몇 연구자들은 항CD137 항체를 사용하여 암 치료요법에서 이러한 방법의 가능성을 입증하였다(J. Kim et al., Cancer Res., 61(5): 2031-7 (2001); O. Martinet et al., Gene Ther., 9(12): 786-92 (2002); R. Miller et al., J. Immunol, 169(4): 1792-800 (2002); R. Wilcox et al., Cancer Res., 62(15): 4413-8 (2002)).
암에 대한 면역 발전에서의 작용 외에, 실험 데이터는 또한 자가면역 및 바이러스 질환의 치료를 위한 CD137 작용 창체의 사용을 지지한다(B. Kwon et al., Exp. Mol. Med., 35(1): 8-16 (2003); H. Salih et al., J. Immunol, 167(7): 4059-66 (2001); E. Kwon et al., P.N.A.S. USA, 96: 15074-79 (1999); J. Foell et al., N.Y. Acad. Sci., 987: 230-5 (2003); Y. Sun et al., Nat. Med., 8(12): 1405-13 (2002) S. K. Seo et al., Nat. Med. 10; 1099-94 (2004)).
III.
항CD137 작제물
일 양태에서, 본 발명은 CD137에 특이적으로 결합되는 항체 부분을 포함하는 새로운 CD137 특이적 작제물(예를 들어 단리된 항CD137 작제물)을 제공한다. 항CD137 작제물의 특이성은 CD137에 특이적으로 결합되는 전장 항체 또는 이의 항원-결합 단편과 같은 항CD137 항체 부분으로부터 유래된다. 일부 실시예에서, CD137에 특이적으로 결합되는 부분(예를 들어 항체 부분)에 대한 언급은 상기 부분이 적어도 약 10배(예를 들어 적어도 약 10, 102, 103, 104, 105, 106 또는 107배 중의 임의의 하나를 포함)로 비타겟에 대한 결합 친화력에 대한 친화력으로 CD137에 특이적으로 결합하는 것을 의미한다. 일부 실시예에서, 비타겟은 CD137이 아닌 항원이다. 결합 친화력은 ELISA, 형광 활성화 세포 분류(FACS) 분석, 또는 방사성 면역침전 분석(RIA)과 같은 당업계에 공지된 방법에 의해 결정될 수 있다. Kd는 예를 들어 Biacore 기기를 사용하는 표면 플라즈몬 공명(SPR) 측성 또는 예를 들어 Sapidyne 기기를 사용하는 동역학 배제 측정(KinExA)과 같은 당업계에 공지된 방법에 의해 결정될 수 있다.
예기되는 항CD137 작제물에는 항CD137 scFv, 항CD137 항체 부분 및 반감기 연장 도메인(예를 들어, Fc 영역, 알부민 결합 도메인)을 포함하는 융합 단백질, 항CD137 모노클로날 항체, 다중 특이적 항CD137분자(예를 들어 이중 특이성 항체)를 포함하지만 이에 한정되지 않는다. 상술된 예시적인 항CD137 작제물은 상호 확장 불가하며, 아래의 다양한 부분에서 추가로 논의된다.
일부 실시예에서, CD137(예를 들어, 인간 CD137)을 특이적으로 인식하는 항CD137 항체 부분을 포함하는 항CD137 작제물(예를 들어, 항CD137 scFv)이 제공되고, 여기서 상기 항CD137 항체 부분은 본문에 설명된 항CD137 항체 부분 중의 임의의 하나일 수 있다.
일부 실시예에서, 항CD137 작제물(예를 들어, 항CD137 scFv)을 제공하고, 이는 CD137에 결합되는 항CD137 항체 부분을 포함하며, 상기 항CD137 항체 부분은 중쇄 가변영역(VH) 및 경쇄 가변 영역(VL)을 포함하고, 여기서, a) 상기 VH는, i) GFX1X2X3DTYIX4(SEQ ID NO: 177)의 아미노산 서열을 포함하는 HC-CDR1(여기서 X1 = N 또는 C; X2 = I, P, L 또는 M; X3 = K, N, R, C 또는 Q; X4 = H 또는 Q), ii) 아미노산 서열X1IDPANGX2X3X4(SEQ ID NO: 178)을 포함하는 HC-CDR2(여기서 X1 = K 또는 R; X2 = N, G, F, Y, A, D, L, M 또는 Q; X3 = S 또는 T; X4 = E 또는 M), 및 iii) GNLHYX1LMD(SEQ ID NO: 179)의 아미노산 서열을 포함하는 HC-CDR3(여기서 X1 = Y, A 또는 G); b) 상기 VL는, i) KASQX1X2X3TYX4S(SEQ ID NO: 180)의 아미노산 서열을 포함하는 LC-CDR1(여기서 X1 = A, P 또는 T; X2 = I, T 또는 P; X3 = N 또는 A; X4 = L, G 또는 H), ii) RX1NRX2X3X4(SEQ ID NO: 181)의 아미노산 서열을 포함하는 LC-CDR2(여기서 X1 = A, Y, V 또는 D; X2 = M, K, V 또는 A; X3 = V, P, Y 또는 G; X4 = D 또는 G), 및 iii) LQX1X2DFPYX3(SEQ ID NO: 182)의 아미노산 서열을 포함하는 LC-CDR3(여기서 X1 = Y, S 또는 F; X2 = D, V, L, R, E 또는 Q; X3 = T 또는 K)을 포함한다.
일부 실시예에서, CD137에 결합되는 항CD137 항체 부분은, a) SEQ ID NO: 1, 11, 21, 31, 41, 51, 61, 71, 81, 91, 101, 111, 121, 131, 141, 261 및 271 중의 임의의 하나의 아미노산 서열을 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체를 포함하는 HC-CDR1; b) SEQ ID NO: 2, 12, 22, 32, 42, 52, 62, 72, 82, 92, 102, 112, 122, 132, 142, 262 및 272 중의 임의의 하나의 아미노산 서열을 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체를 포함하는 HC-CDR2; c) SEQ ID NO: 3, 13, 23, 33, 43, 53, 63, 73, 83, 93, 103, 113, 123, 133, 143, 263 및 273 중의 임의의 하나의 아미노산 서열을 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체를 포함하는 HC-CDR3; d) SEQ ID NO: 4, 14, 24, 34, 44, 54, 64, 74, 84, 94, 104, 114, 124, 134, 144, 264 및 274 중의 임의의 하나의 아미노산 서열을 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체를 포함하는 LC-CDR1; e) SEQ ID NO: 5, 15, 25, 35, 45, 55, 65, 75, 85, 95, 105, 115, 125, 135, 145, 265 및 275 중의 임의의 하나의 아미노산 서열을 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체를 포함하는 LC-CDR2; f) SEQ ID NO: 6, 16, 26, 36, 46, 56, 66, 76, 86, 96, 106, 116, 126, 136, 146, 266 및 276 중의 임의의 하나의 아미노산 서열을 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체를 포함하는 LC-CDR3을 포함한다. 일부 실시예에서, 아미노산 치환은 본 출원의 표 2에 나타낸 “예시적 치환”으로 제한된다. 일부 실시예에서, 아미노산 치환은 본 출원의 표 2에 나타낸 “바람직한 치환”으로 제한된다.
일부 실시예에서, 항CD137 항체 부분을 포함하는 항CD137 작제물을 제공하고, 상기 항CD137 항체 부분은 기준 항CD137 작제물과 교차 경쟁하여 CD137에 결합되며, 상기 항CD137 항체 부분은 중쇄 가변 영역(VH)(상기 중쇄 가변 영역은 HC-CDR1, HC-CDR2 및 HC-CDR3 도메인을 포함) 및 경쇄 가변 영역(VL)(상기 경쇄 가변 영역은 LC-CDR1, LC-CDR2 및 LC-CDR3 도메인을 포함)을 포함하고, a) SEQ ID NO: 1의 아미노산 서열을 포함하는 HC-CDR1을 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체, SEQ ID NO: 2의 아미노산 서열을 포함하는 HC-CDR2를 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체, 및 SEQ ID NO: 3의 아미노산 서열을 포함하는 HC-CDR3을 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체를 포함하는 VH, 및 SEQ ID NO: 4의 아미노산 서열을 포함하는 LC-CDR1을 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체, SEQ ID NO: 5의 아미노산 서열을 포함하는LC-CDR2를 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체, 및 SEQ ID NO: 6의 아미노산 서열을 포함하는 LC-CDR3을 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체를 포함하는 VL; b) SEQ ID NO: 11의 아미노산 서열을 포함하는 HC-CDR1을 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체, SEQ ID NO: 12의 아미노산 서열을 포함하는 HC-CDR2를 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체, 및 SEQ ID NO: 13의 아미노산 서열을 포함하는 HC-CDR3을 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체를 포함하는 VH, 및 SEQ ID NO: 14의 아미노산 서열을 포함하는 LC-CDR1을 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체, SEQ ID NO: 15의 아미노산 서열을 포함하는LC-CDR2를 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체, 및 SEQ ID NO: 16의 아미노산 서열을 포함하는 LC-CDR3을 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체를 포함하는 VL; c) SEQ ID NO: 21의 아미노산 서열을 포함하는 HC-CDR1을 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체, SEQ ID NO: 22의 아미노산 서열을 포함하는 HC-CDR2를 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체, 및 SEQ ID NO: 23의 아미노산 서열을 포함하는 HC-CDR3을 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체를 포함하는 VH, 및 SEQ ID NO: 24의 아미노산 서열을 포함하는 LC-CDR1을 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체, SEQ ID NO: 25의 아미노산 서열을 포함하는LC-CDR2를 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체, 및 SEQ ID NO: 26의 아미노산 서열을 포함하는 LC-CDR3을 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체를 포함하는 VL; d) SEQ ID NO: 31의 아미노산 서열을 포함하는 HC-CDR1을 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체, SEQ ID NO: 32의 아미노산 서열을 포함하는 HC-CDR2를 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체, 및 SEQ ID NO: 33의 아미노산 서열을 포함하는 HC-CDR3을 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체를 포함하는 VH, 및 SEQ ID NO: 34의 아미노산 서열을 포함하는 LC-CDR1을 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체, SEQ ID NO: 35의 아미노산 서열을 포함하는LC-CDR2를 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체, 및 SEQ ID NO: 36의 아미노산 서열을 포함하는 LC-CDR3을 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체를 포함하는 VL; e) SEQ ID NO: 41의 아미노산 서열을 포함하는 HC-CDR1을 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체, SEQ ID NO: 42의 아미노산 서열을 포함하는 HC-CDR2를 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체, 및 SEQ ID NO: 43의 아미노산 서열을 포함하는 HC-CDR3을 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체를 포함하는 VH, 및 SEQ ID NO: 44의 아미노산 서열을 포함하는 LC-CDR1을 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체, SEQ ID NO: 45의 아미노산 서열을 포함하는LC-CDR2를 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체, 및 SEQ ID NO: 46의 아미노산 서열을 포함하는 LC-CDR3을 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체를 포함하는 VL; f) SEQ ID NO: 51의 아미노산 서열을 포함하는 HC-CDR1을 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체, SEQ ID NO: 52의 아미노산 서열을 포함하는 HC-CDR2를 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체, 및 SEQ ID NO: 53의 아미노산 서열을 포함하는 HC-CDR3을 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체를 포함하는 VH, 및 SEQ ID NO: 54의 아미노산 서열을 포함하는 LC-CDR1을 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체, SEQ ID NO: 55의 아미노산 서열을 포함하는LC-CDR2를 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체, 및 SEQ ID NO: 56의 아미노산 서열을 포함하는 LC-CDR3을 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체를 포함하는 VL; g) SEQ ID NO: 61의 아미노산 서열을 포함하는 HC-CDR1을 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체, SEQ ID NO: 62의 아미노산 서열을 포함하는 HC-CDR2를 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체, 및 SEQ ID NO: 63의 아미노산 서열을 포함하는 HC-CDR3을 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체를 포함하는 VH, 및 SEQ ID NO: 64의 아미노산 서열을 포함하는 LC-CDR1을 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체, SEQ ID NO: 65의 아미노산 서열을 포함하는LC-CDR2를 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체, 및 SEQ ID NO: 66의 아미노산 서열을 포함하는 LC-CDR3을 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체를 포함하는 VL; h) SEQ ID NO: 71의 아미노산 서열을 포함하는 HC-CDR1을 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체, SEQ ID NO: 72의 아미노산 서열을 포함하는 HC-CDR2를 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체, 및 SEQ ID NO: 73의 아미노산 서열을 포함하는 HC-CDR3을 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체를 포함하는 VH, 및 SEQ ID NO: 74의 아미노산 서열을 포함하는 LC-CDR1을 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체, SEQ ID NO: 75의 아미노산 서열을 포함하는LC-CDR2를 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체, 및 SEQ ID NO: 76의 아미노산 서열을 포함하는 LC-CDR3을 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체를 포함하는 VL; i) SEQ ID NO: 81의 아미노산 서열을 포함하는 HC-CDR1을 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체, SEQ ID NO: 82의 아미노산 서열을 포함하는 HC-CDR2를 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체, 및 SEQ ID NO: 83의 아미노산 서열을 포함하는 HC-CDR3을 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체를 포함하는 VH, 및 SEQ ID NO: 84의 아미노산 서열을 포함하는 LC-CDR1을 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체, SEQ ID NO: 85의 아미노산 서열을 포함하는LC-CDR2를 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체, 및 SEQ ID NO: 86의 아미노산 서열을 포함하는 LC-CDR3을 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체를 포함하는 VL; j) SEQ ID NO: 91의 아미노산 서열을 포함하는 HC-CDR1을 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체, SEQ ID NO: 92의 아미노산 서열을 포함하는 HC-CDR2를 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체, 및 SEQ ID NO: 93의 아미노산 서열을 포함하는 HC-CDR3을 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체를 포함하는 VH, 및 SEQ ID NO: 94의 아미노산 서열을 포함하는 LC-CDR1을 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체, SEQ ID NO: 95의 아미노산 서열을 포함하는LC-CDR2를 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체, 및 SEQ ID NO: 96의 아미노산 서열을 포함하는 LC-CDR3을 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체를 포함하는 VL; k) SEQ ID NO: 101의 아미노산 서열을 포함하는 HC-CDR1을 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체, SEQ ID NO: 102의 아미노산 서열을 포함하는 HC-CDR2를 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체, 및 SEQ ID NO: 103의 아미노산 서열을 포함하는 HC-CDR3을 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체를 포함하는 VH, 및 SEQ ID NO: 104의 아미노산 서열을 포함하는 LC-CDR1을 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체, SEQ ID NO: 105의 아미노산 서열을 포함하는LC-CDR2를 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체, 및 SEQ ID NO: 106의 아미노산 서열을 포함하는 LC-CDR3을 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체를 포함하는 VL; l) SEQ ID NO: 111의 아미노산 서열을 포함하는 HC-CDR1을 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체, SEQ ID NO: 112의 아미노산 서열을 포함하는 HC-CDR2를 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체, 및 SEQ ID NO: 113의 아미노산 서열을 포함하는 HC-CDR3을 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체를 포함하는 VH, 및 SEQ ID NO: 114의 아미노산 서열을 포함하는 LC-CDR1을 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체, SEQ ID NO: 115의 아미노산 서열을 포함하는LC-CDR2를 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체, 및 SEQ ID NO: 116의 아미노산 서열을 포함하는 LC-CDR3을 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체를 포함하는 VL; m) SEQ ID NO: 121의 아미노산 서열을 포함하는 HC-CDR1을 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체, SEQ ID NO: 122의 아미노산 서열을 포함하는 HC-CDR2를 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체, 및 SEQ ID NO: 123의 아미노산 서열을 포함하는 HC-CDR3을 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체를 포함하는 VH, 및 SEQ ID NO: 124의 아미노산 서열을 포함하는 LC-CDR1을 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체, SEQ ID NO: 125의 아미노산 서열을 포함하는LC-CDR2를 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체, 및 SEQ ID NO: 126의 아미노산 서열을 포함하는 LC-CDR3을 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체를 포함하는 VL; n) SEQ ID NO: 131의 아미노산 서열을 포함하는 HC-CDR1을 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체, SEQ ID NO: 132의 아미노산 서열을 포함하는 HC-CDR2를 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체, 및 SEQ ID NO: 133의 아미노산 서열을 포함하는 HC-CDR3을 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체를 포함하는 VH, 및 SEQ ID NO: 134의 아미노산 서열을 포함하는 LC-CDR1을 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체, SEQ ID NO: 135의 아미노산 서열을 포함하는LC-CDR2를 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체, 및 SEQ ID NO: 136의 아미노산 서열을 포함하는 LC-CDR3을 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체를 포함하는 VL; o) SEQ ID NO: 261의 아미노산 서열을 포함하는 HC-CDR1을 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체, SEQ ID NO: 262의 아미노산 서열을 포함하는 HC-CDR2를 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체, 및 SEQ ID NO: 263의 아미노산 서열을 포함하는 HC-CDR3을 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체를 포함하는 VH, 및 SEQ ID NO: 264의 아미노산 서열을 포함하는 LC-CDR1을 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체, SEQ ID NO: 265의 아미노산 서열을 포함하는LC-CDR2를 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체, 및 SEQ ID NO: 266의 아미노산 서열을 포함하는 LC-CDR3을 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체를 포함하는 VL; p) SEQ ID NO: 271의 아미노산 서열을 포함하는 HC-CDR1을 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체, SEQ ID NO: 272의 아미노산 서열을 포함하는 HC-CDR2를 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체, 및 SEQ ID NO: 273의 아미노산 서열을 포함하는 HC-CDR3을 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체를 포함하는 VH, 및 SEQ ID NO: 274의 아미노산 서열을 포함하는 LC-CDR1을 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체, SEQ ID NO: 275의 아미노산 서열을 포함하는LC-CDR2를 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체, 및 SEQ ID NO: 276의 아미노산 서열을 포함하는 LC-CDR3을 포함하거나, 최대 약 3개(예를 들어 3개, 2개 또는 1개)의 아미노산에 의해 치환된 변이체를 포함하는 VL로이루어지 군으로부터 선택된다.
일부 실시예에서, 항CD137 작제물(예를 들어, 항CD137 scFv)을 제공하고, 이는 CD137에 결합되는 항CD137 항체 부분을 포함하며, 상기 항CD137 항체 부분은 중쇄 가변여역(VH) 및 경쇄 가변 영역(VL)을 포함하며, 여기서: a) 상기 VH는 i) DTYIH 또는 GFNIQDT의 아미노산 서열을 포함하는 HC-CDR1, ii) DPANGN의 아미노산 서열을 포함하는 HC-CDR2, 및 iii) GNLHYALMD의 아미노산 서열을 포함하는 HC-CDR3을 포함하고; b) 상기 VL은 i) NTYLS의 아미노산 서열을 포함하는 LC-CDR1, ii) RVNRKV의 아미노산 서열을 포함하는 LC-CDR2, 및 iii) LQYLDFPY의 아미노산 서열을 포함하는 LC-CDR3을 포함한다.
일부 실시예에서, 항CD137 작제물(예를 들어, 항CD137 scFv)을 제공하고, 이는 CD137에 결합되는 항CD137 항체 부분을 포함하며, 상기 항CD137 항체 부분은, a) SEQ ID No: 7, 17, 27, 37, 47, 57, 67, 77, 87, 97, 107, 117, 127, 137, 267 또는 277로 표시되는 서열의 VH쇄 영역 내의 CDR1, CDR2 및 CDR3을 갖는 아미노산 서열을 각각 포함하는 HC-CDR1, HC-CDR2 및 HC-CDR3; 및 b) SEQ ID No: 8, 18, 28, 38, 48, 58, 68, 78, 88, 98, 108, 118, 128, 138, 268 또는 278로 표시되는 서열을 갖는 VL쇄 영역 내의 CDR1, CDR2 및 CDR3의 아미노산 서열을 각각 포함하는 LC-CDR1, LC-CDR2 및 LC-CDR3을 포함한다.
일부 실시예에서, 항CD137 작제물(예를 들어, 항CD137 scFv)을 제공하고, CD137에 결합되는 항CD137 항체 부분을 포함하며, 상기 항CD137 항체 부분은, a) SEQ ID No: 7, 17, 27, 37, 47, 57, 67, 77, 87, 97, 107, 117, 127, 137, 267 또는 277로 표시되는 서열을 갖는 VH쇄 영역 또는 이의 변이체, 또는 SEQ ID NO: 7, 17, 27, 37, 47, 57, 67, 77, 87, 97, 107, 117, 127, 137, 267 또는 277과 적어도 약 80%(예를 들어 적어도 약 80%, 85%, 90%, 95%, 96%, 97%, 98% 또는 99% 중의 임의의 하나)의 서열 동일성을 갖는 변이체; 및 b) SEQ ID No: 8, 18, 28, 38, 48, 58, 68, 78, 88, 98, 108, 118, 128, 138, 268 또는 278로 표시되는 서열을 갖는 VL쇄 영역 또는 이의 변이체, 또는 SEQ ID NO: 8, 18, 28, 38, 48, 58, 68, 78, 88, 98, 108, 118, 128, 138, 268 또는 278과 적어도 약 80%(예를 들어 적어도 약 80%, 85%, 90%, 95%, 96%, 97%, 98% 또는 99% 중의 임의의 하나)의 서열 동일성을 갖는 변이체를 포함한다. 일부 실시예에서, VH쇄 영역 및 VL쇄 영역은 링커(예를 들어, 펩티드 링커)에 의해 연결된다.
일부 실시예에서, 항CD137 작제물(예를 들어, 항CD137 scFv)을 제공하고, 이는 CD137에 결합되는 항CD137 항체 부분을 포함하며, 상기 항CD137 항체 부분은 SEQ ID No: 7, 17, 27, 37, 47, 57, 67, 77, 87, 97, 107, 117, 127, 137, 267 또는 277로 표시되는 서열을 갖는 VH영역; 및 SEQ ID No: 8, 18, 28, 38, 48, 58, 68, 78, 88, 98, 108, 118, 128, 138, 268 또는 278로 표시되는 서열을 갖는 VL영역을 포함한다.
본문의 설명에 따른 항CD137 작제물 중의 임의의 하나의 일부 실시예에서, 항CD137 항체 부분은, (a) SEQ ID NO: 7로 표시되는 서열을 갖는 아미노산을 포함하는 중쇄 가변 영역; 및 SEQ ID NO: 8로 표시되는 서열을 갖는 아미노산을 포함하는 경쇄 가변 영역; (b) SEQ ID NO: 17로 표시되는 서열을 갖는 아미노산을 포함하는 중쇄 가변 영역; 및 SEQ ID NO: 18로 표시되는 서열을 갖는 아미노산을 포함하는 경쇄 가변 영역; (c) SEQ ID NO: 27로 표시되는 서열을 갖는 아미노산을 포함하는 중쇄 가변 영역; 및 SEQ ID NO: 28로 표시되는 서열을 갖는 아미노산을 포함하는 경쇄 가변 영역; (d) SEQ ID NO: 37로 표시되는 서열을 갖는 아미노산을 포함하는 중쇄 가변 영역; 및 SEQ ID NO: 38로 표시되는 서열을 갖는 아미노산을 포함하는 경쇄 가변 영역; (e) SEQ ID NO: 47로 표시되는 서열을 갖는 아미노산을 포함하는 중쇄 가변 영역; 및 SEQ ID NO: 48로 표시되는 서열을 갖는 아미노산을 포함하는 경쇄 가변 영역; (f) SEQ ID NO: 57로 표시되는 서열을 갖는 아미노산을 포함하는 중쇄 가변 영역; 및 SEQ ID NO: 58로 표시되는 서열을 갖는 아미노산을 포함하는 경쇄 가변 영역; (g) SEQ ID NO: 67로 표시되는 서열을 갖는 아미노산을 포함하는 중쇄 가변 영역; 및 SEQ ID NO: 68로 표시되는 서열을 갖는 아미노산을 포함하는 경쇄 가변 영역; (h) SEQ ID NO: 77로 표시되는 서열을 갖는 아미노산을 포함하는 중쇄 가변 영역; 및 SEQ ID NO: 78로 표시되는 서열을 갖는 아미노산을 포함하는 경쇄 가변 영역; (i) SEQ ID NO: 87로 표시되는 서열을 갖는 아미노산을 포함하는 중쇄 가변 영역; 및 SEQ ID NO: 88로 표시되는 서열을 갖는 아미노산을 포함하는 경쇄 가변 영역; (j) SEQ ID NO: 97로 표시되는 서열을 갖는 아미노산을 포함하는 중쇄 가변 영역; 및 SEQ ID NO: 98로 표시되는 서열을 갖는 아미노산을 포함하는 경쇄 가변 영역; (k) SEQ ID NO: 107로 표시되는 서열을 갖는 아미노산을 포함하는 중쇄 가변 영역; 및 SEQ ID NO: 108로 표시되는 서열을 갖는 아미노산을 포함하는 경쇄 가변 영역; (l) SEQ ID NO: 117로 표시되는 서열을 갖는 아미노산을 포함하는 중쇄 가변 영역; 및 SEQ ID NO: 118로 표시되는 서열을 갖는 아미노산을 포함하는 경쇄 가변 영역; (m) SEQ ID NO: 127로 표시되는 서열을 갖는 아미노산을 포함하는 중쇄 가변 영역; 및 SEQ ID NO: 128로 표시되는 서열을 갖는 아미노산을 포함하는 경쇄 가변 영역; (n) SEQ ID NO: 137로 표시되는 서열을 갖는 아미노산을 포함하는 중쇄 가변 영역; 및 SEQ ID NO: 138로 표시되는 서열을 갖는 아미노산을 포함하는 경쇄 가변 영역; (o) SEQ ID NO: 267로 표시되는 서열을 갖는 아미노산을 포함하는 중쇄 가변 영역; 및 SEQ ID NO: 268로 표시되는 서열을 갖는 아미노산을 포함하는 경쇄 가변 영역; 또는 (p) SEQ ID NO: 277로 표시되는 서열을 갖는 아미노산을 포함하는 중쇄 가변 영역; 및 SEQ ID NO: 278로 표시되는 서열을 갖는 아미노산을 포함하는 경쇄 가변 영역을 포함한다.
일부 실시예에서, 항CD137 작제물(예를 들어, 항CD137 scFv)을 제공하고, 이는 CD137에 결합되는 항CD137 항체 부분을 포함하며, 상기 항CD137 항체 부분은 SEQ ID No: 9, 19, 29, 39, 49, 59, 69, 79, 89, 99, 109, 119, 129, 139, 149, 269 또는 279로 표시되는 서열을 갖는 중쇄(HC); 및 SEQ ID No: 10, 20, 30, 40, 50, 60, 70, 80, 90, 100, 110, 120, 130, 140, 150, 270 또는 280으로 표시되는 서열을 갖는 경쇄 (LC)를 포함한다.
본문의 설명에 따른 항CD137 작제물 중의 임의의 하나의 일부 실시예에서, 항CD137 항체 부분은, SEQ ID NO: 9로 표시되는 서열을 갖는 아미노산을 포함하는 중쇄; 및 SEQ ID NO: 10으로 표시되는 서열을 갖는 아미노산을 포함하는 경쇄를 포함한다. 본문의 설명에 따른 항CD137 작제물 중의 임의의 하나의 일부 실시예에서, 항CD137 항체 부분은, SEQ ID NO: 19로 표시되는 서열을 갖는 아미노산을 포함하는 중쇄; 및 SEQ ID NO: 20으로 표시되는 서열을 갖는 아미노산을 포함하는 경쇄를 포함한다. 본문의 설명에 따른 항CD137 작제물 중의 임의의 하나의 일부 실시예에서, 항CD137 항체 부분은, SEQ ID NO: 29로 표시되는 서열을 갖는 아미노산을 포함하는 중쇄; 및 SEQ ID NO: 30으로 표시되는 서열을 갖는 아미노산을 포함하는 경쇄를 포함한다. 본문의 설명에 따른 항CD137 작제물 중의 임의의 하나의 일부 실시예에서, 항CD137 항체 부분은, SEQ ID NO: 39로 표시되는 서열을 갖는 아미노산을 포함하는 중쇄; 및 SEQ ID NO: 40으로 표시되는 서열을 갖는 아미노산을 포함하는 경쇄를 포함한다. 본문의 설명에 따른 항CD137 작제물 중의 임의의 하나의 일부 실시예에서, 항CD137 항체 부분은, SEQ ID NO: 49로 표시되는 서열을 갖는 아미노산을 포함하는 중쇄; 및 SEQ ID NO: 50으로 표시되는 서열을 갖는 아미노산을 포함하는 경쇄를 포함한다. 본문의 설명에 따른 항CD137 작제물 중의 임의의 하나의 일부 실시예에서, 항CD137 항체 부분은, SEQ ID NO: 59로 표시되는 서열을 갖는 아미노산을 포함하는 중쇄; 및 SEQ ID NO: 60으로 표시되는 서열을 갖는 아미노산을 포함하는 경쇄를 포함한다. 본문의 설명에 따른 항CD137 작제물 중의 임의의 하나의 일부 실시예에서, 항CD137 항체 부분은, SEQ ID NO: 69로 표시되는 서열을 갖는 아미노산을 포함하는 중쇄; 및 SEQ ID NO: 70으로 표시되는 서열을 갖는 아미노산을 포함하는 경쇄를 포함한다. 본문의 설명에 따른 항CD137 작제물 중의 임의의 하나의 일부 실시예에서, 항CD137 항체 부분은, SEQ ID NO: 79로 표시되는 서열을 갖는 아미노산을 포함하는 중쇄; 및 SEQ ID NO: 80으로 표시되는 서열을 갖는 아미노산을 포함하는 경쇄를 포함한다. 본문의 설명에 따른 항CD137 작제물 중의 임의의 하나의 일부 실시예에서, 항CD137 항체 부분은, SEQ ID NO: 89로 표시되는 서열을 갖는 아미노산을 포함하는 중쇄; 및 SEQ ID NO: 90으로 표시되는 서열을 갖는 아미노산을 포함하는 경쇄를 포함한다. 본문의 설명에 따른 항CD137 작제물 중의 임의의 하나의 일부 실시예에서, 항CD137 항체 부분은, SEQ ID NO: 99로 표시되는 서열을 갖는 아미노산을 포함하는 중쇄; 및 SEQ ID NO: 100으로 표시되는 서열을 갖는 아미노산을 포함하는 경쇄를 포함한다. 본문의 설명에 따른 항CD137 작제물 중의 임의의 하나의 일부 실시예에서, 항CD137 항체 부분은, SEQ ID NO: 109로 표시되는 서열을 갖는 아미노산을 포함하는 중쇄; 및 SEQ ID NO: 110으로 표시되는 서열을 갖는 아미노산을 포함하는 경쇄를 포함한다. 본문의 설명에 따른 항CD137 작제물 중의 임의의 하나의 일부 실시예에서, 항CD137 항체 부분은, SEQ ID NO: 119로 표시되는 서열을 갖는 아미노산을 포함하는 중쇄; 및 SEQ ID NO: 120으로 표시되는 서열을 갖는 아미노산을 포함하는 경쇄를 포함한다. 본문의 설명에 따른 항CD137 작제물 중의 임의의 하나의 일부 실시예에서, 항CD137 항체 부분은, SEQ ID NO: 129로 표시되는 서열을 갖는 아미노산을 포함하는 중쇄; 및 SEQ ID NO: 130으로 표시되는 서열을 갖는 아미노산을 포함하는 경쇄를 포함한다. 본문의 설명에 따른 항CD137 작제물 중의 임의의 하나의 일부 실시예에서, 항CD137 항체 부분은, SEQ ID NO: 139로 표시되는 서열을 갖는 아미노산을 포함하는 중쇄; 및 SEQ ID NO: 140으로 표시되는 서열을 갖는 아미노산을 포함하는 경쇄를 포함한다. 본문의 설명에 따른 항CD137 작제물 중의 임의의 하나의 일부 실시예에서, 항CD137 항체 부분은, SEQ ID NO: 149로 표시되는 서열을 갖는 아미노산을 포함하는 중쇄; 및 SEQ ID NO: 150으로 표시되는 서열을 갖는 아미노산을 포함하는 경쇄를 포함한다. 본문의 설명에 따른 항CD137 작제물 중의 임의의 하나의 일부 실시예에서, 항CD137 항체 부분은, SEQ ID NO: 269로 표시되는 서열을 갖는 아미노산을 포함하는 중쇄; 및 SEQ ID NO: 270으로 표시되는 서열을 갖는 아미노산을 포함하는 경쇄를 포함한다. 본문의 설명에 따른 항CD137 작제물 중의 임의의 하나의 일부 실시예에서, 항CD137 항체 부분은, SEQ ID NO: 279로 표시되는 서열을 갖는 아미노산을 포함하는 중쇄; 및 SEQ ID NO: 280으로 표시되는 서열을 갖는 아미노산을 포함하는 경쇄를 포함한다.
본 출원의 다른 양태에서 단리된 항CD137 작제물을 제공하고, 이는 CD137에 결합되는 항체 부분을 포함하며, 상기 항체 부분은 중쇄 가변영역(VH) 및 경쇄 가변 영역(VL)을 포함하고, 여기서, a) 상기 VH는, i) SEQ ID NO: 151-153 중의 임의의 하나의 아미노산 서열을 포함하거나, 최대 약 3개의 아미노산에 의해 치환된 변이체를 포함하는 HC-CDR1; ii) SEQ ID NO: 154-156 중의 임의의 하나의 아미노산 서열을 포함하거나, 최대 약 3개의 아미노산에 의해 치환된 변이체를 포함하는 HC-CDR2; iii) SEQ ID NO: 157-159 중의 임의의 하나의 아미노산 서열을 포함하거나, 최대 약 3개의 아미노산에 의해 치환된 변이체를 포함하는 HC-CDR3을 포함하고; b) 상기 VL는, i) SEQ ID NO: 160-163 중의 임의의 하나의 아미노산 서열을 포함하거나, 최대 약 3개의 아미노산에 의해 치환된 변이체를 포함하는 LC-CDR1; ii) SEQ ID NO: 164-166 중의 임의의 하나의 아미노산 서열을 포함하거나, 최대 약 3개의 아미노산에 의해 치환된 변이체를 포함하는 HC-CDR2; iii) SEQ ID NO: 167-169 중의 임의의 하나의 아미노산 서열을 포함하거나, 최대 약 3개의 아미노산에 의해 치환된 변이체를 포함하는 HC-CDR3을 포함한다.
일부 실시예에서, VH는 HC-CDR1, HC-CDR2 및 HC-CDR3을 포함하고, 상기 HC-CDR1은 아미노산 서열 SEQ ID NO: 151을 포함하며, 상기 HC-CDR2는 아미노산 서열 SEQ ID NO: 154를 포함하고, 상기 HC-CDR3은 아미노산 서열 SEQ ID NO: 157을 포함하며, VL은 LC-CDR1, LC-CDR2 및 LC-CDR3을 포함하고, 상기 LC-CDR1은 아미노산 서열 SEQ ID NO: 160을 포함하며, 상기 LC-CDR2는 아미노산 서열 SEQ ID NO: 164을 포함하고, 상기 LC-CDR3은 아미노산 서열 SEQ ID NO: 167을 포함한다.
일부 실시예에서, VH는 HC-CDR1, HC-CDR2 및 HC-CDR3을 포함하고, 상기 HC-CDR1은 아미노산 서열 SEQ ID NO: 151을 포함하며, 상기 HC-CDR2는 아미노산 서열 SEQ ID NO: 154를 포함하고, 상기 HC-CDR3은 아미노산 서열 SEQ ID NO: 157을 포함하며, VL은 LC-CDR1, LC-CDR2 및 LC-CDR3을 포함하고, 상기 LC-CDR1은 아미노산 서열 SEQ ID NO: 162를 포함하며, 상기 LC-CDR2는 아미노산 서열 SEQ ID NO: 166을 포함하고, 상기 LC-CDR3은 아미노산 서열 SEQ ID NO: 169를 포함한다.
일부 실시예에서, VH는 HC-CDR1, HC-CDR2 및 HC-CDR3을 포함하고, 상기 HC-CDR1은 아미노산 서열 SEQ ID NO: 152를 포함하며, 상기 HC-CDR2는 아미노산 서열 SEQ ID NO: 155를 포함하고, 상기 HC-CDR3은 아미노산 서열 SEQ ID NO: 158을 포함하며, VL은 LC-CDR1, LC-CDR2 및 LC-CDR3을 포함하고, 상기 LC-CDR1은 아미노산 서열 SEQ ID NO: 163을 포함하며, 상기 LC-CDR2는 아미노산 서열 SEQ ID NO: 166을 포함하고, 상기 LC-CDR3은 아미노산 서열 SEQ ID NO: 169를 포함한다.
일부 실시예에서, VH는 HC-CDR1, HC-CDR2 및 HC-CDR3을 포함하고, 상기 HC-CDR1은 아미노산 서열 SEQ ID NO: 153을 포함하며, 상기 HC-CDR2는 아미노산 서열 SEQ ID NO: 156을 포함하고, 상기 HC-CDR3은 아미노산 서열 SEQ ID NO: 159를 포함하며, VL은 LC-CDR1, LC-CDR2 및 LC-CDR3을 포함하고, 상기 LC-CDR1은 아미노산 서열 SEQ ID NO: 160을 포함하며, 상기 LC-CDR2는 아미노산 서열 SEQ ID NO: 164를 포함하고, 상기 LC-CDR3은 아미노산 서열 SEQ ID NO: 167을 포함한다.
일부 실시예에서, VH는 HC-CDR1, HC-CDR2 및 HC-CDR3을 포함하고, 상기 HC-CDR1은 아미노산 서열 SEQ ID NO: 153을 포함하며, 상기 HC-CDR2는 아미노산 서열 SEQ ID NO: 156을 포함하고, 상기 HC-CDR3은 아미노산 서열 SEQ ID NO: 159를 포함하며, VL은 LC-CDR1, LC-CDR2 및 LC-CDR3을 포함하고, 상기 LC-CDR1은 아미노산 서열 SEQ ID NO: 161을 포함하며, 상기 LC-CDR2는 아미노산 서열 SEQ ID NO: 165를 포함하고, 상기 LC-CDR3은 아미노산 서열 SEQ ID NO: 168을 포함한다.
본문의 설명에 따른 항CD137 작제물 중의 임의의 하나의 일부 실시예에서, 항CD137 항체 부분은, (a) SEQ ID NO: 170으로 표시되는 서열을 갖는 아미노산을 포함하는 중쇄 가변 영역; 및 SEQ ID NO: 173으로 표시되는 서열을 갖는 아미노산을 포함하는 경쇄 가변 영역; (b) SEQ ID NO: 170으로 표시되는 서열을 갖는 아미노산을 포함하는 중쇄 가변 영역; 및 SEQ ID NO: 176으로 표시되는 서열을 갖는 아미노산을 포함하는 경쇄 가변 영역; (c) SEQ ID NO: 171로 표시되는 서열을 갖는 아미노산을 포함하는 중쇄 가변 영역; 및 SEQ ID NO: 173으로 표시되는 서열을 갖는 아미노산을 포함하는 경쇄 가변 영역; (d) SEQ ID NO: 171로 표시되는 서열을 갖는 아미노산을 포함하는 중쇄 가변 영역; 및 SEQ ID NO: 174로 표시되는 서열을 갖는 아미노산을 포함하는 경쇄 가변 영역; 또는 (e) SEQ ID NO: 172로 표시되는 서열을 갖는 아미노산을 포함하는 중쇄 가변 영역; 및 SEQ ID NO: 175로 표시되는 서열을 갖는 아미노산을 포함하는 경쇄 가변 영역을 포함한다.
일부 실시예에서, 항CD137 작제물은, 전장 항체, 이중 특이성 항체, 단일쇄Fv(scFv), Fab단편, Fab’단편, F(ab’)2, Fv단편, 이황화 결합이 안정적인 Fv단편(dsFv), (dsFv)2, VHH, Fv-Fc융합체, scFv-Fc융합체, scFv-Fv융합체, 디아바디, 트리바디, 및 테트라바디로 이루어진 군으로부터 선택되는 항체 또는 이의 항원 결합 단편을 포함하거나 상기 군으로부터 선택되는 항체 또는 이의 항원 결합 단편이다. 일부 실시예에서, 항체 또는 항원 결합 단편은 키메라, 인간, 부분적으로 인간화, 완전 인간화 또는 반합성된 것이다. 일부 실시예에서, 항체 또는 이의 항원 결합 단편은 IgG, IgM, IgA, IgD 및 IgE로 이루어진 군으로부터 선택되는 면역글로블린 동종형이다. 일부 실시예에서, 항체 또는 이의 항원 결합 단편은 IgG1, IgG2, IgG3 또는 IgG4로 이루어진 군으로부터 선택되는 동종형을 갖는다.
일부 실시예에서, 작제물은 인간화된 항CD137전장 항체를 포함한다.
일부 실시예에서, 작제물은 인간화 항CD137 단일쇄 Fv단편을 포함한다.
일부 실시예에서, 상기 작제물은 인간CD137에 결합된다. 일부 실시예에서, 상기 작제물은 포유동물CD137(예를 들어 원숭이CD137)에 결합된다. 일부 실시예에서, 상기 작제물은 인간CD137 및 원숭이CD137 모두에 결합된다. 일부 실시예에서, 상기 작제물은 마우스 CD137에 결합되지 않는다.
상술된 바와 같이, 본문에 개시된 항CD137 작제물은 CD137에 결합되는 항CD137 항체 부분을 포함한다. 일부 실시예에서, 항CD137 항체 부분은 인간 및 유인원CD137에 결합된다.
일부 실시예에서, 본문에 개시된 항CD137 작제물에 포함된 항CD137 항체 부분은 CD137작용제이고, 여기서 상기 항체 부분과 CD137의 결합은 CD137에 의해 매개된 면역 신호 전달 경로를 증강시킬 수 있다. 일부 실시예에서, 상기 항체 부분과 CD137의 결합은 상기 항체 부분/CD137 복합물의 가교 및/또는 클러스터링 없이 CD137에 의해 매개된 면역 신호 전달 경로를 향상시키지 못한다. 일부 실시예에서, 상기 항체 부분과 CD137의 결합은 T세포 및/또는 NK세포와 같은 면역 세포를 활성화시킬 수 있다. 일부 실시예에서, 상기 항체 부분과 CD137의 결합은 상기 항체 부분/CD137 복합물의 가교 및/또는 클러스터링 없이 T세포및/또는NK세포와 같은 면역 세포를 활성화시킬 수 없다. 일부 실시예에서, 상기 항체 부분/CD137 복합물의 가교 및/또는 클러스터링은 본문에 개시된 항CD137 작제물의 제2 부분에 의해 매개될 수 있다. 일부 실시예에서, 상기 항체 부분/CD137 복합물의 가교 및/또는 클러스터링은 Fc 수용체와 항CD137 작제물의 Fc영역의 결합에 의해 매개될 수 있다. 일부 실시예에서, 상기 항체 부분/CD137 복합물의 가교 및/또는 클러스터링은 항CD137 작제물의 제2 항체 부분과 종양 관련 항원(TAA)의 결합에 의해 매개될 수 있다.
일부 실시예에서, 상기 항체 부분은 IgG, IgA, IgD, IgE, IgM으로부터 유래된 Fc영역 및 이의 임의의 조합 및 하이브리드로 이루어진 군으로부터 선택되는 Fc영역을 포함한다. 일부 실시예에서, Fc영역은 인간 IgG로부터 유래된다. 일부 실시예에서, Fc영역은 인간 IgG1, IgG2, IgG3, IgG4 또는 조합 또는 하이브리드IgG의 Fc영역을 포함한다. 몇몇 실시예에서, Fc영역은 IgG1 Fc영역이다. 일부 실시예에서, Fc영역은 IgG1의 CH2 및 CH3도메인을 포함한다. 몇몇 실시예에서, Fc영역은 IgG2 Fc영역이다. 일부 실시예에서, Fc영역은 IgG2의 CH2 및 CH3도메인을 포함한다. 몇몇 실시예에서, Fc영역은 IgG4 Fc영역이다. 일부 실시예에서, Fc영역은 IgG4의 CH2 및 CH3도메인을 포함한다. IgG4 Fc의 이펙터 활성이 IgG1 또는 IgG2 Fc 보다 낮은 것으로 알려져 있으므로, 일부 응용은 이상적일 수 있다. 일부 실시예에서, Fc영역은 마우스 면역글로블린으로부터 유래된다.
일부 실시예에서, 항체 부분은 Fc영역을 포함한다. 일부 실시예에서, 항체 부분은 Fc영역에 융합된 scFv이다. 일부 실시예에서, 항체 부분은 펩티드 링커에 의해 Fc영역에 융합된 scFv를 포함한다. 몇몇 실시예에서, Fc영역은 인간 IgG1 Fc영역이다. 일부 실시예에서, Fc영역은 제거율을 증가시키거나 반감기를 감소시키기 위한 하나 또는 다수의 돌연변이를 포함한다.
일부 실시예에서, Fc영역은 힌지 영역(Cys226에서 시작), IgG CH2도메인 및 CH3도메인을 포함하는 면역글로블린IgG 중쇄 불변 영역을 포함한다. 본문에 사용된 바와 같이, 용어 “힌지 영역” 또는 “힌지 서열”은 링커와 CH2도메인 사이에 위치된 아미노산 서열을 지칭한다. 일부 실시예에서, 융합 단백질은 Fc영역을 포함하고, 상기 Fc영역은 힌지 영역을 포함한다. 일부 실시예에서, 융합 단백질의 Fc영역은 힌지 영역에서 시작되어 IgG중쇄의 C말단으로 연장된다. 일부 실시예에서, 융합 단백질은 힌지 영역을 포함하지 않는 Fc영역을 포함한다.
일부 실시예에서, IgG CH2도메인은 Ala231에서 시작된다. 일부 실시예에서, CH3도메인은 Gly341에서 시작된다. 인간 IgG의 C말단 Lys잔기는 선택적으로 존재하지 않을 수 있는 것으로 이해될 수 있다. 또한 Fc의 원하는 구조 및/또는 안정성에 영향을 미치지 않으면서 Fc 영역에서 보존적 아미노산 치환이 본 발명의 범위 내에 있는 것으로 간주되는 것으로 이해되어야 한다.
일부 실시예에서, Fc영역의 각 사슬은 동일한 항체 부분에 융합된다. 일부 실시예에서, scFv-Fc는 각각 Fc 영역의 하나의 사슬에 융합된 본문에 기재된 2개의 동일한 scFv를 포함한다. 일부 실시예에서, scFv-Fc는 동종이량체이다.
일부 실시예에서, scFv-Fc는 각각 Fc 영역의 하나의 사슬에 융합된 본문에 기재된 2개의 동일한 scFv를 포함한다. 일부 실시예에서, scFv-Fc는 이종이량체이다. 본 분야에 공지된 방법에 의해 scFv-Fc에서 상이한 폴리펩티드의 이종이량체화를 촉진할 수 있고, 노브-인-홀 기술에 의한 이종이량체화를 포함하나 이에 제한되지 않는다. 노브-인-홀 기술의 구조 및 조립 방법은 예를 들어 US 5,821,333, US 7,642,228, US 2011/0287009 및 PCT/US 2012/059810에서 찾을 수 있고, 그 전체 내용은 여기에 참조로 통합된다. 이 기술은, 하나의 Fc의 CH3 도메인에서 작은 아미노산 잔기를 큰 아미노산 잔기로 대체하여 “노브”(또는 돌기)를 도입하고, 다른 하나의 Fc의 CH3 도메인에서 하나 이상의 큰 아미노산 잔기를 작은 아미노산 잔기로 대체하여 “홀”(또는 공동)를 도입함으로써 진행하였다. 일부 실시예에서, 융합 단백질에서 Fc영역의 한 가닥의 사슬은 노브를 포함하고, Fc영역의 제2 가닥의 사슬은 홀을 포함한다.
노브를 형성하기 위한 바람직한 잔기는 일반적으로 천연적으로 존재하는 아미노산 잔기이고, 바람직하게는 아르기닌(R), 페닐알라닌(F), 티로신(Y) 및 트립토판(W)으로부터 선택된다. 가장 바람직하게는 트립토판 및 티로신이다. 하나의 실시예에서, 노브를 형성하기 위한 원래 잔기는 알라닌, 아스파라긴, 아스파르트산, 글리신, 세린, 트레오닌 또는 발린과 같은 작은 측쇄 부피를 갖는다. 노브를 형성하기 위한 CH3 도메인에서의 예시적인 아미노산 치환은 T366W, T366Y 또는 F405W 치환을 포함하지만 이에 한정되지 않는다.
홀을 형성하기 위한 바람직한 잔기는 일반적으로 천연적으로 존재하는 아미노산 잔기이고, 바람직하게는 알라닌(A), 세린(S), 트레오닌(T) 및 발린(V)으로부터 선택된다. 하나의 실시예에서, 홀을 형성하기 위한 원시적 잔기는 티로신, 아르기닌, 페닐알라닌 또는 트립토판과 같은 큰 측쇄 부피를 갖는다. 홀을 형성하기 위한 CH3 도메인에서의 예시적인 아미노산 치환은 T366S, L368A, F405A, Y407A, Y407T 및 Y407V 치환을 포함하지만 이에 한정되지 않는다. 몇몇 실시예에서, 노브는 T366W치환을 포함하고, 홀은 T366S/L368A/Y407V치환을 포함한다. 이종이량체화에 도움이 되는 본 분야에 공지된 Fc 영역에 대한 다른 변형 또한 고려되고 본 출원에 포함된다는 것을 이해해야 한다.
본문에 설명된 변이체 중의 임의의 하나(예를 들어, Fc 변이체, 이펙터 기능 변이체, 글리코실화 변이체, 시스테인 조작된 변이체) 또는 이들의 조합을 포함하는 다른 scFv-Fc 변이체(단리된 항CD137 scFv-Fc의 변이체, 예를 들어 전장 항CD137 항체 변이체 포함)도 고려된다.
a) 항체 친화력
항체 부분의 결합 특이성은 본 분야에 공지된 방법에 의해 실험적으로 결정될 수 있다. 이러한 방법은 웨스턴 블롯, ELISA-, RIA-, ECL-, IRMA-, EIA-, BIACORETM-검정 및 펩티드 스캐닝을 포함하지만 이에 한정되지 않는다.
일부 실시예에서, 상기 항체 부분과 CD137 사이의 결합의 KD는 약 10-7 M 내지 약10-12 M, 약 10-7 M 내지 약10-8 M, 약 10-8 M 내지 약10-9 M, 약 10-9 M 내지 약10-10 M, 약 10-10 M 내지 약10-11 M, 약 10-11 M 내지 약10-12 M, 약 10-7 M 내지 약10-12 M, 약 10-8 M 내지 약10-12 M, 약 10-9 M 내지 약10-12 M, 약 10-10 M 내지 약10-12 M, 약 10-7 M 내지 약10-11 M, 약 10-8 M 내지 약10-11 M, 약 10-9 M 내지 약10-11 M, 약 10-7 M 내지 약10-10 M, 약 10-8 M 내지 약10-10 M 또는 약 10-7 M 내지 약10-9 M이다. 일부 실시예에서, 상기 항체 부분과 CD137 사이의 결합의 KD는 약 10-7 M, 10-8 M, 10-9 M, 10-10 M, 10-11 M 또는 10-12 M 중의 하나보다 더 강하다. 일부 실시예에서, CD137은 인간CD137이다.
일부 실시예에서, 상기 항체 부분과 CD137 사이의 결합의 Kon은 약 103 M-1s-1내지 약108 M-1s-1, 약 103 M-1s-1내지 약104 M-1s-1, 약 104 M-1s-1내지 약105 M-1s-1, 약 105 M-1s-1내지 약106 M-1s-1, 약 106 M-1s-1내지 약107 M-1s-1 또는 약 107 M-1s-1내지 약108 M-1s-1이다. 일부 실시예에서, 상기 항체 부분과 CD137 사이의 결합의 Kon은 약 103 M-1s-1내지 약105 M-1s-1, 약 104 M-1s-1내지 약106 M-1s-1, 약 105 M-1s-1내지 약107 M-1s-1, 약 106 M-1s-1내지 약108 M-1s-1, 약 104 M-1s-1내지 약107 M-1s-1 또는 약 105 M-1s-1내지 약108 M-1s-1이다. 일부 실시예에서, 상기 항체 부분과 CD137 사이의 결합의 Kon은 약 103 M-1s-1, 104 M-1s-1, 105 M-1s-1, 106 M-1s-1, 107 M-1s-1 또는 108 M-1s-1 중의 하나를 초과하지 않는다. 일부 실시예에서, CD137은 인간CD137 이다.
일부 실시예에서, 상기 항체 부분과 CD137 사이의 결합의 Koff는 약 1 s-1 내지 약 10-6 s-1, 약 1 s-1 내지 약 10-2 s-1, 약 10-2 s-1 내지 약 10-3 s-1, 약 10-3 s-1 내지 약10-4 s-1, 약 10-4 s-1 내지 약 10-5 s-1, 약 10-5 s-1 내지 약 10-6 s-1, 약 1 s-1 내지 약 10-5 s-1, 약 10-2 s-1 내지 약 10-6 s-1, 약 10-3 s-1 내지 약 10-6 s-1, 약 10-4 s-1 내지 약 10-6 s-1, 약 10-2 s-1내지 약 10-5 s-1 또는 약 10-3 s-1 내지 약 10-5 s-1이다. 일부 실시예에서, 상기 항체 부분과 CD137 사이의 결합의 Koff는 적어도 약 1 s-1, 10-2 s-1, 10-3 s-1, 10-4 s-1, 10-5 s-1 또는 10-6 s-1이다. 일부 실시예에서, CD137은 인간CD137 이다.
일부 실시예에서, 항CD137 항체 부분 또는 항CD137 작제물의 결합 친화력은 기존의 항CD137 항체(예를 들어, BMS-663513(유토밀루맙) 또는 PF-05082566(유토밀루맙)과 같은 항 인간CD137 항체)보다 더 높다(예를 들어, 더 작은 Kd값을 갖는다).
b) 키메라 항체 또는 인간화 항체
일부 실시예에서, 항체 부분은 키메라 항체이다. 일부 키메라 항체는, 예를 들어, 미국특허번호4,816,567; 및 Morrison et al., Proc. Natl. Acad. Sci. USA, 81: 6851-6855 (1984)에 설명되어 있다. 일부 실시예에서, 키메라 항체는 비인간 가변영역(예를 들어, 마우스의 가변영역) 및 인간 불변 영역을 포함한다. 일부 실시예에서, 키메라 항체는 클래스 또는 서브클래스가 모 항체의 클래스 또는 서브클래스에서 변경된 “클래스 전환” 항체이다. 키메라 항체는 이의 항원 결합 단편을 포함한다.
일부 실시예에서, 키메라 항체는 인간화 항체이고, 통상적으로, 비인간 항체를 인간화하여 인간에 대한 면역원성을 감소시키는 동시에, 모 비인간 항체의 특이성과 친화력을 유지한다. 통상적으로, 인간화 항체는 하나 또는 다수의 가변 도메인을 포함하고, 여기서, HVR, 예를 들어 CDR(또는 이의 일부)은 비인간 항체로부터 유래되며, FR(또는 이의 일부)은 인간 항체 서열로부터 유래된다. 인간화 항체는 인간 불변 영역의 적어도 일부를 선택적으로 포함할 수도 있다. 일부 실시예에서, 인간화 항체에서의 일부 FR 잔기는 비인간 항체(예를 들어, HVR 잔기로부터 유래된 항체)로부터의 상응하는 잔기에 의해 치환되어, 예를 들어 항체 특이성 또는 친화력을 회복하거나 개선한다.
인간화 항체 및 그 제조 방법은, 예를 들어 Almagro 및 Fransson, Front.Biosci. 13: 1619-1633 (2008)에 종합하여 서술되었고, 예를 들어, Riechmann et al., Nature 332: 323-329 (1988); Queen et al., Proc. Nat’l Acad. Sci. USA 86: 10029-10033 (1989); 미국특허번호5,821,337, 7,527,791, 6,982,321 및 7,087,409; Kashmiri et al., Methods 36: 25-34 (2005)(SDR (a-CDR) 이식 설명); Padlan, Mol. Immunol. 28: 489-498 (1991)(“재생표면” 설명); Dall’Acqua et al., Methods 36: 43-60 (2005)(“FR 셔플링” 설명); 및 Osbourn et al., Methods 36: 61-68 (2005) 및 Klimka et al., Br. J. Cancer, 83: 252-260 (2000)(FR셔플링에 대한 “지도 선택” 방법 설명)에 추가로 설명되어 있다.
인간화에 사용할 수 있는 인간 프레임워크 영역은, “최적의 피팅” 방법을 사용하여 선택한 프레임워크 영역(예를 들어, Sims et al., J. Immunol.151:2296 (1993) 참조); 경쇄 또는 중쇄 가변영역의 특정 하위 그룹의 인간 항체의 공통 서열로부터 유래된 프레임워크 영역(예를 들어, Carter et al.,Proc. Natl. Acad. Sci. USA, 89:4285 (1992); 및 Presta et al.,J. Immunol., 151:2623 (1993) 참조); 인간 성숙(체세포 돌연변이) 프레임워크 영역 또는 인간 생식계 프레임워크 영역(예를 들어Almagro 및 Fransson, Front.Biosci. 13:1619-1633 (2008) 참조); 및 FR 라이브러리를 스크리닝하여 얻은 프레임워크 영역(예를 들어 Baca et al., J. Biol. Chem. 272:10678-10684 (1997) 및 Rosok et al., J. Biol. Chem. 271: 22611-22618 (1996) 참조)을 포함하지만, 이에 한정되지 않는다.
c) 인간 항체
일부 실시예에서, 항체 부분은 인간 항체(인간 도메인 항체 또는 인 DAb로도 지칭됨)이다. 인간 항체는 본 분야에 공지된 다양한 기술을 사용하여 생성될 수 있다. 인간 항체는 일반적으로 van Dijk 및 van de Winkel, Curr. Opin. Pharmacol. 5: 368-74 (2001), Lonberg, Curr.Opin. Immunol. 20: 450-459 (2008), 및 Chen, Mol. Immunol. 47(4): 912-21 (2010)에 설명되어 있다. 완전한 인간 단일 도메인 항체(또는 DAb)를 생산할 수 있는 유전자 변형 마우스 또는 래트는 본 분야에 공지되어 있다. 예를 들어, US 20090307787 A1, 미국특허번호 8,754,287, US 20150289489 A1, US 20100122358 A1, 및 WO 2004049794를 참조바란다.
유전자 변형 동물에 면역원을 투여하여 인간 항체(예를 들어 인간DAb)를 제조할 수 있고, 상기 유전자 변형 동물은 항원 공격에 반응하여 완전한 인간 항체 또는 인간 가변영역을 갖는 완전한 항체를 생성하도록 변형된 것이다. 이러한 동물은 통상적으로 인간 면역글로불린 유전자좌의 전부 또는 일부를 포함하고, 이들은 내인성 면역글로불린 유전자좌를 치환하거나, 염색체 외에 존재하거나 동물의 염색체에 무작위로 통합된다. 이러한 유전자 변형 마우스에서, 내인성 면역글로불린 유전자좌는 통상적으로 불활성화되었다. 유전자 변형 동물에서 인간 항체를 얻는 방법에 대한 종합 서술은 Lonberg, Nat. Biotech. 23:1117-1125 (2005)를 참조바란다. 또한, 예를 들어 XENOMOUSETM 기술을 설명하는 미국특허번호 6,075,181 및 6,150,584; HuMab® 기술을 설명하는 미국특허번호 5,770,429; K-M MOUSE® 기술을 설명하는 미국특허번호 7041870,및 VelociMouse® 기술을 설명하는 미국특허출원 공개번호 US 2007/0061900을 참조바란다. 이러한 동물에 의해 생성된 완전한 항체로부터의 인간 가변영역(예를 들어, 상이한 인간 불변 영역에 결합)은 추가로 변형될 수 있다.
인간 항체(예를 들어, 인간 DAb)는 또한 하이브리도마 기반 방법에 의해 제조될 수 있다. 인간 모노클로날 항체를 생산하기 위한 인간 골수종 및 마우스인 간 이종 골수종 세포주에 대해 설명하였다(예를 들어, Kozbor J. Immunol., 133: 3001 (1984); Brodeur et al., Monoclonal Antibody Production Techniques and Applications, pp. 51-63 (Marcel Dekker, Inc., New York, 1987); 및 Boerner et al., J. Immunol., 147: 86 (1991) 참조). Li et al., Proc. Natl. Acad. Sci. USA, 103: 3557-3562 (2006)에는 인간B세포 하이브리도마 기술에 의해 생산된 인간 항체에 대해 추가로 설명되어 있다. 이 외의 방법은, 예를 들어, 미국 특허 번호 7,189,826(하이브리도마 세포주로부터 단일클론 인간IgM 항체의 생산 설명) 및 Ni, Xiandai Mianyixue, 26(4):265-268 (2006)(인간-인간 하이브리도마 설명)에 설명된 그러한 방법들을 포함한다. 인간 하이브리도마 기술(Trioma기술)은 또한 Vollmers 및 Brandlein, Histology and Histopathology, 20(3):927-937 (2005) 및 Vollmers 및 Brandlein, Methods and Findings in Experimental and Clinical Pharmacology, 27(3):185-91 (2005)에 설명되어 있다.
인간 항체(예를 들어 인간DAb)는 인간 파지 디스플레이 라이브러리로부터 선택된 Fv 클론 가변 도메인 서열을 단리함으로써 생성될 수도 있다. 이 후, 이러한 가변 도메인 서열은 원하는 인간 불변 도메인에 결합될 수 있다. 항체 라이브러리에서 인간 항체를 선택하는 기술은 아래에 설명되어 있다.
d) 라이브러리에서 유도된 항체
항체 부분은 조합 라이브러리에서 원하는 활성 또는 다양한 활성을 갖는 항체를 스크리닝함으로써 단리될 수 있다. 예를 들어, 파지 디스플레이 라이브러리를 생성하고 이러한 라이브러리에서 희망하는 결합 특징을 갖는 항체를 스크리닝하기 위한 다양한 방법은 본 분야에 공지되어 있다. 이러한 방법은 예를 들어 Hoogenboom et al., Methods in Molecular Biology 178: 1-37 (O’Brien et al.,편집, Human Press, Totowa, NJ, 2001)에 설명되어 있고, McCafferty et al., Nature 348: 552-554; Clackson et al., Nature 352: 624-628 (1991); Marks et al., J. Mol. Biol. 222: 581-597 (1992); Marks 및 Bradbury, Methods in Molecular Biology 248: 161-175 (Lo, 편집, Human Press, Totowa, NJ, 2003); Sidhu et al., J. Mol. Biol. 338(2): 299-310 (2004); Lee et al., J. Mol. Biol. 340(5): 1073-1093 (2004); Fellouse, Proc. Natl. Acad. Sci. USA 101(34): 12467-12472 (2004); 및 Lee et al., J. Immunol. Methods 284(1-2): 119-132(2004)과 같은 문헌에 추가로 설명되어 있다. 단일 도메인 항체 라이브러리를 구축하는 방법은 이미 설명하였고, 예를 들어, 미국 특허 번호 7371849를 참조바란다.
일부 파지 디스플레이 방법에서, 중합효소 연쇄 반응(PCR)을 통해 VH 및 VL 유전자 라이브러리를 각각 클론하고, 파지 라이브러리에서 무작위로 재조합한 후, Winter et al., Ann. Rev. Immunol., 12: 433-455 (1994)에 설명에 따라 항원 결합 파지를 스크리닝할 수 있다. 파지는 통상적으로 항체 단편을 scFv단편 또는 Fab단편으로 디스플레이한다. 면역원으로부터의 라이브러리는 하이브리도마를 구축할 필요 없이 면역원에 대한 높은 친화력의 항체를 제공할 수 있다. 대안적으로, Griffiths et al., EMBO J, 12: 725-734 (1993)에 설명된 바와 같이, 어떠한 면역도 필요없이, 천연 라이브러리(예를 들어, 인간에서 획득)를 클론하여 광범위한 비자가 및 자가 항원에 대한 항체의 단일 공급원을 제공할 수 있다. 마지막으로, Hoogenboom 및 Winter, J. Mol. Biol., 227: 381-388 (1992)에 설명된 바와 같이, 줄기 세포에서 재배열되지 않은 V유전자 단편을 클론하고, 무작위 서열을 포함하는 PCR프라이머를 사용하여 초가변 CDR3 영역을 코딩하여 체외에서 재배열을 완성함으로써, 천연 라이브러리를 합성할 수도 있다. 인간 항체 파지 라이브러리를 설명하는 특허 간행물은, 미국 특허 번호 5,750,373 및 미국 특허 공개 번호 2005/0079574, 2005/0119455, 2005/0266000, 2007/0117126, 2007/0160598, 2007/0237764, 2007/0292936 및 2009/0002360을 포함한다.
인간 항체 라이브러리에서 단리된 항체 또는 항체 단편은 본문에서 인간 항체 또는 인간 항체 단편으로 간주된다.
e) 치환, 삽입, 결실 및 변이
일부 실시예에서, 하나 또는 다수의 아미노산 치환을 갖는 항체 변이체를 제공하였다. 치환 돌연변이 유발을 위한 표적 부위는 HVR(또는 CDR) 및 FR을 포함한다. 보존적 치환은 “바람직한 치환”이라는 표제로 표 2에 나타내었다. 표 2에서 “예시적 치환” 이라는 표제로 더 실질적인 변경을 제공하였고, 하기에서와 같이 아미노산 측쇄 클래스를 참조하여 추가로 설명된다. 아미노산 치환을 목적 항체에 도입하고, 원하는 활성(예를 들어, 유지/개선된 항원 결합, 감소된 면역원성, 또는 개선된 ADCC 또는 CDC)에 대해 생성물을 스크리닝할 수 있다.
표 2. 아미노산 치환

아미노산은 일반적인 측쇄 특성에 따라, (1) 소수성: 노르루신, Met, Ala, Val, Leu, Ile; (2) 중성 친수성: Cys, Ser, Thr, Asn, Gln; (3) 산성: Asp, Glu; (4) 염기성: His, Lys, Arg; (5) 사슬 방향에 영향을 미치는 잔기: Gly, Pro; 및 (6) 방향족: Trp, Tyr, Phe 그룹으로 나뉠 수 있다.
비보존적 치환은 이러한 클래스 중 하나의 구성원을 다른 하나의 클래스로 교환하여야 한다.
한가지 유형의 치환 변이체는 모 항체(예를 들어, 인간화 또는 인간 항체)의 하나 또는 다수의 고도의 가변영역 잔기에 관련된다. 통상적으로, 추가 연구를 위해 선택되어 얻은 변이체는 모 항체에 비해 일부 생물학적 특성(예를 들어, 증가된 친화력, 감소된 면역원성)에서 변형(예를 들어, 개선)을 구비 및/또는 모 항체의 일부 생물학적 특성을 기본적으로 유지하였다. 예시적 치환 변이체는, 예를 들어 파지 디스플레이 기반 친화력 성숙 기술(예를 들어, 본문에 개시된 것)을 사용하여 편리하게 생성될 수 있는 친화력이 성숙된 항체이다. 간략하게, 하나 또는 다수의 HVR(또는 CDR) 잔기가 돌연변이되고, 변이체 항체가 파지에 디스플레이되며, 특정 생물학 활성 (예를 들어, 결합 친화력)에 대해 스크리닝된다.
예를 들어, 항체 친화력을 개선하기 위해 HVR(또는 CDR)에서 변경(예를 들어, 치환)이 이루어질 수 있다. 이러한 변경은 HVR(또는 CDR)“핫스팟”(즉, 체세포 성숙 과정 동안 높은 빈도로 돌연변이되는 코돈에 의해 코팅된 잔기)에서 이루어지고(예를 들어, Chowdhury, Methods Mol. Biol. 207: 179-196 (2008 및/또는 SDR(a-CDR)에서 이루어지며, 얻은 변이체 VH 또는 VL의 결합 친화력을 테스트할 수 있다. 구축 및 2차 라이브러리로부터의 재선택에 의한 친화력 성숙은, 예를 들어, Hoogenboom et al. Methods in Molecular Biology 178: 1-37(O’Brien et al., 편집, Human Press, Totowa, 뉴저지주(NJ), (2001))에 설명되어 있다. 친화력 성숙의 일부 실시예에서, 다양한 방법(예를 들어, 오류 빈발 PCR, 가닥 셔플링, 또는 올리고뉴클레오티드 지정 돌연변이 유발) 중 임의의 하나의 방법에 의해 성숙을 위한 가변 유전자에 다양성을 도입한다. 다음 2차 라이브러리를 생성한다. 다음 라이브러리를 스크리닝하여 희망하는 친화력을 갖는 임의의 항체 변이체를 감별한다. 다양성을 도입하는 또 다른 방법은 여러 HVR(또는 CDR) 잔기(예를 들어, 한 번에 4-6개 잔기)가 무작위화되는 HVR 지정 방법에 관한 것이다. 예를 들어, 알라닌 스캐닝 돌연변이 유발 또는 모델링을 사용하여 항원 결합에 관여하는 HVR(또는 CDR) 잔기를 특이적으로 감별할 수 있다. 특히, CDR-H3 및 CDR-L3은 종종 타겟으로 된다.
일부 실시예에서, 치환, 삽입 또는 결실은 이러한 변경이 실질적으로 항원에 결합하는 항체의 능력을 감소시키지 않는 한, 하나 또는 다수의 HVR(또는 CDR) 내에서 발생될 수 있다. 예를 들어, 기본적으로 결합 친화력을 감소시키지 않는 보존적 변경(예를 들어, 본문에 제공된 보존적 치환)은 HVR(또는 CDR)에서 이루어질 수 있다. 이러한 변경은 HVR “핫스팟” 또는 CDR 외에 있을 수 있다. 상기에 제공된 변이체VHH서열의 일부 실시예에서, 각각의 HVR(또는 CDR)은 변경되지 않거나, 1개, 2개, 또는 3개 이하의 아미노산 치환을 포함한다.
Cunningham 및 Wells (1989) Science, 244:1081-1085에 설명된 바와 같이, 돌연변이 유발을 타켓팅할 수 있는 항체의 잔기 또는 영역을 검증하기 위한 유용한 방법을 “알라닌 스캐닝 돌연변이 유발”이라고 한다. 이러한 방법에서, 표적 잔기의 잔기 또는 잔기 그룹(예를 들어, Arg, Asp, His, Lys 및 Glu와 같은 전하를 띈 잔기)을 감정하고, 중성 또는 음전하를 띈 아미노산(예를 들어, 알라닌 또는 폴리알라닌)으로 치환하여, 항체와 항원의 상호작용이 영향을 받는지 여부를 확인한다. 아미노산 위치에 별도의 치환을 도입하여, 초기 치환에 대한 기능적 민감성을 증명할 수 있다. 대안적으로 또는 별도로, 항원-항체 복합물의 결정 구조는 항체와 항원 사이의 접점 감정에 사용된다. 이러한 접촉 잔기 및 인접 잔기는 치환 후보로서 타겟팅되거나 제거될 수 있다. 변이체를 스크리닝하여 원하는 속성이 포함되어 있는지를 확인할 수 있다.
아미노산 서열 삽입은 1개 잔기 내지 100개 이상의 잔기를 함유하는 폴리펩티드의 길이 범위 내의 아미노기 말단 및/또는 카르복실기 말단 융합, 및 단일 또는 다중 아미노산 잔기의 서열 내 삽입을 포함한다. 말단 삽입의 구현예로 N-말단 메티오닐기 잔기를 갖는 항체를 포함한다. 항체 분자의 기타 삽입 변이체는 항체의 혈청 반감기를 증가시키는 효소(예를 들어, ADEPT의 경우) 또는 폴리펩티드에 대한 항체의 N- 또는 C-말단에 대한 융합을 포함한다.
f) 글리코실화 변이체
일부 실시예에서, 항체 부분을 변경하여 작제물의 클리코실화 정도를 증가 또는 감소시킨다. 항체에 대한 글리코실화 부위의 추가 또는 결실은 아미노산 서열을 변경하여 하나 또는 다수의 글리코실화 부위를 생성 또는 제거함으로써 편리하게 구현될 수 있다.
항체 부분이 Fc영역(예를 들어, scFv-Fc)을 포함할 경우, 이에 연결된 탄수화물은 변경될 수 있다. 포유 동물 세포에 의해 생산된 천연 항체는 일반적으로 N-결합에 의해 Fc영역CH2도메인의 Asn297에 연결된 분지형 바이안테너리 올리고당(biantennary oligosaccharide)을 포함한다. 예를 들어 Wright et al., TIBTECH 15: 26-32 (1997)를 참조바란다. 올리고당은 만노오스, N-아세틸글루코사민(GlcNAc), 갈락토오스 및 시알산과 같은 다양한 탄수화물뿐만 아니라 바이안테너리 올리고당 구조의 “줄기”에서 GlcNAc에 부착된 푸코스(fucose)를 포함할 수 있다. 일부 실시예에서, 항체 부분의 올리고당은 일부 개선된 특성을 갖는 항체 변이체를 생성하도록 변형될 수 있다.
일부 실시예에서, 항체 부분은 Fc영역에 (직접적으로 또는 간접적으로)부착된 푸코스가 결여된 탄수화물 구조를 갖는다. 예를 들어, 이러한 항체에서의 푸코스 함량은 1% 내지 80%, 1% 내지 65%, 5% 내지 65% 또는 20% 내지 40%일 수 있다. WO 2008/077546에 설명된 바와 같이, 푸코스의 량은 MALDI-TOF 질량 분석에 의해 측정된 Asn 297에 부착된 모든 당구조(예를 들어,복합, 이형 접합 및 높은 만노오스 구조)의 합과 비교하여, Asn297의 당 사슬 내 푸코스의 평균량을 계산하여 결정된다. Asn297은 Fc영역의 약 297번 위치에 위치한 아스파라긴 잔기(Fc영역 잔기의 EU 넘버링)를 지칭하고; 그러나,항체의 미세한 서열 변화로 인해, Asn297 또한 위치 297의 업스트림 또는 다운스트림 약 ± 3개의 아미노산, 즉 위치 294와 300 사이에 위치할 수 있다. 이러한 푸코실화된 변이체는 개선된 ADCC 기능을 가질 수 있다. 예를 들어, 미국 특허 공개 번호 US 2003/0157108 (Presta, L.); US 2004/0093621(Kyowa Hakko Kogyo Co., Ltd)을 참조바란다. “탈푸코실화 ” 또는 “푸코오스 결핍형” 항체 변이체와 관련된 출판물의 구현예는, US 2003/0157108; WO 2000/61739; WO 2001/29246; US 2003/0115614; US 2002/0164328; US 2004/0093621; US 2004/0132140; US 2004/0110704; US 2004/0110282; US 2004/0109865; WO 2003/085119; WO 2003/084570; WO 2005/035586; WO 2005/035778; WO 2005/053742; WO 2002/031140; Okazaki et al., J. Mol. Biol. 336: 1239-1249 (2004); Yamane-Ohnuki et al., Biotech. Bioeng. 87: 614 (2004)를 포함한다. 탈푸코실화된 항체를 생산할 수 있는 세포주의 구현예로, 단백질 푸코실화 작용 결핍형의 Lec13 CHO세포(Ripka et al., Arch. Biochem. Biophys. 249:533-545 (1986); 미국 특허 출원번호 US 2003/0157108 A1, Presta, L; 및 WO 2004/056312 A1, Adams et al.,특히 구현예 11), 및 α-1,6-푸코실트랜스퍼라제(α-1,6-fucosyltransferase gene) 유전자FUT8, 녹아웃 CHO세포와 같은 녹아웃 세포주(예를 들어, Yamane-Ohnuki et al., Biotech. Bioeng. 87: 614 (2004); Kanda, Y. et al., Biotechnol. Bioeng., 94(4):680-688 (2006); 및 WO 2003/085107 참조)를 포함한다.
일부 실시예에서, 항체 부분은 항체의 Fc영역에 부착된 바이안테너리 올리고당이 GlcNAc에 의해 이등분된, 이등분된 올리고당을 갖는다. 이러한 항체 변이체는 감소된 푸코실화 글리코실화 및/또는 개선된 ADCC 기능을 가질 수 있다. 이러한 항체 변이체의 구현예는, 예를 들어WO 2003/011878(Jean-Mairet et al.,); 미국 특허 번호 6,602,684(Umana et al.,); 및 US 2005/0123546(Umana et al.,)에 설명되어 있다. Fc영역에 연결된 올리고당 상에 적어도 하나의 갈락토스 잔기를 갖는 항체 변이체를 더 제공하였다. 이러한 항체 변이체는 개선된 CDC 기능을 갖는다. 이러한 항체 변이체는, 예를 들어WO 1997/30087 (Patel et al.,); WO 1998/58964 (Raju, S.); 및 WO 1999/22764 (Raju, S.)에 설명되어 있다.
g) Fc영역 변이체
일부 실시예에서, 하나 또는 다수의 아미노산 변형을 항체 부분의 Fc영역(예를 들어scFv-Fc) 내로 도입하여, Fc영역 변이체를 생성할 수 있다. Fc영역 변이체는 하나 또는 다수의 아미노산 위치에서의 아미노산 변형(예를 들어, 치환)을 포함하는 하나의 인간 Fc영역 서열(예를 들어, 인간IgG1, IgG2, IgG3 또는 IgG4 Fc영역)을 포함할 수 있다.
일부 실시예에서, 일부(그러나 전부가 아닌) 이펙터 기능이 있는 Fc 영역에서, 이러한 기능은 상기 단편을 생체 내 항체 부분의 반감기가 중요하지만 일부 이펙터 기능(예를 들어 보체 및 ADCC)이 불필요하거나 유해한 응용 분야에 이상적인 후보로 만든다. 체외 및/또는 체내 세포 독성 측정을 수행하여 CDC 및/또는 ADCC 활성의 감소/고갈을 확인할 수 있다. 예를 들어, Fc수용체(FcR) 결합 측정을 수행하여 항체가 FcγR결합 능력을 갖지 않도록 확보할 수 있지만(따라서 ADCC 활성이 결여될 수 있음), FcRn 결합 능력을 유지할 수 있다. ADCC 매개용 1차 세포 NK세포는 FcγRIII만을 발현하는 반면, 단핵구는 FcγRI, FcγRII 및 FcγRIII를 발현한다. 조혈 세포에서의 FcR발현은 Ravetch 및 Kinet에 요약되어 있고, Annu. Rev. Immunol. 9:457-492 (1991)의 제464페이지의 표 2에 있다. 미국 특허 번호 5,500,362에는, 관심 분자의 ADCC 활성을 평가하기 위한 체외 측정의 비제한적인 구현예(예를 들어, Hellstrom, I. et al., Proc. Nat’l Acad. Sci. USA, 83:7059-7063 (1986)) 및 Hellstrom, I et al., Proc. Nat'l Acad. Sci. USA, 82:1499-1502 (1985); 5,821,337 (Bruggemann, M. et al., J. Exp. Med., 166: 1351-1361 (1987) 참조)가 설명되어 있다. 대안적으로, 비방사성 측정 방법(예를 들어, 유속세포 분석용 ACTI™비방사성 세포 독성 측정(세포기술 회사(CellTechnology, Inc.)마운틴뷰(Mountain View),캘리포니아주); 및 CytoTox 96®비방사성 세포 독성 측정(프로메가회사(Promega), 매디슨, 위스콘신주) 참조)을 사용할 수 있다. 이러한 측정에 유용한 이펙터 세포는 말초 단핵구(PBMC) 및 자연 살해(NK)세포를 포함한다. 대안적으로 또는 별도로, 예를 들어 동물 모델에서, Clynes et al., Proc. Nat’l Acad. Sci. USA 95:652-656 (1998)에 개시된 것과 같이, 체내에서 목적 분자의 ADCC 활성을 평가할 수 있다. C1q 결합 측정을 수행하여 항체가 C1q에 결합할 수 없고, 또한 이로 인해 CDC 활성이 결여되어 있음을 확인할 수도 있다. 예를 들어, WO 2006/029879 및 WO 2005/100402에서의 C1q 및 C3c 결합 ELISA를 참조바란다. 보체 활성화를 평가하기 위해, CDC 측정을 수행할 수 있다(예를 들어, Gazzano-Santoro et al., J. Immunol. Methods 202:163 (1996); Cragg, M.S. et al., Blood 101:1045-1052 (2003); 및 Cragg, M.S. 및 M.J. Glennie, Blood 103:2738-2743 (2004) 참조). 본 분야에 공지된 방법을 사용하여 FcRn결합 및 체내 제거/반감기 측정을 수행할 수도 있다(예를 들어, Petkova, S.B. et al., Int’l. Immunol. 18(12):1759-1769 (2006) 참조).
감소된 이펙터 기능을 갖는 항체에는(미국 특허 번호 6,737,056), Fc영역 잔기 238, 265, 269, 270, 297, 327 및 329 중 하나 또는 다수를 갖는 치환된 항체가 포함된다. 이러한 Fc 돌연변이체에는 아미노산 265, 269, 270, 297 및 327번 중 2개 이상을 갖는 치환된 Fc돌연변이체가 포함되고, 잔기 265 및 297이 알라닌에 치환된 소위 “DANA”Fc돌연변이체(미국 특허 번호 7,332,581)가 포함된다.
본문에는 FcR에 대한 결합이 향상되거나 감소된 특정 항체 변이체가 설명되어 있다. (예를 들어 미국 특허 번호 6,737,056; WO 2004/056312, 및 Shields et al., J. Biol. Chem. 9(2):6591-6604 (2001) 참조).
몇몇 실시예에서, Fc영역은 IgG1 Fc영역 이다. 일부 실시예에서, IgG1 Fc영역은 L234A돌연변이 및/또는 L235A돌연변이를 포함한다. 일부 실시예에서, Fc영역은 IgG2 또는 IgG4 Fc영역이다. 일부 실시예에서, Fc영역은 S228P, F234A 및/또는 L235A돌연변이의 IgG4 Fc영역을 포함한다.
일부 실시예에서, 항체 부분은 하나 또는 다수의 아미노산 치환을 갖는 Fc영역을 포함하고, 이러한 치환(예를 들어, Fc영역 내의 298, 333 및/또는 334번의 치환(잔기의 EU넘버링))은 ADCC를 개선한다.
일부 실시예에서, Fc영역 내의 변경은 C1q결합 및/또는 보체 의존성 세포 독성(CDC) 변경을 초래하고(즉, 향상 또는 감소), 예를 들어, 미국 특허 번호 6,194,551, WO 99/51642 및 Idusogie et al., J. Immunol., 164: 4178-4184 (2000)에 설명되어 있다.
일부 실시예에서, 항체 부분(예를 들어, scFv-Fc) 변이체는 변이체Fc영역을 포함하고, 상기 변이체Fc영역은 반감기 변경 및/또는 신생아 Fc 수용체(FcRn)에 대한 결합을 변경하는 하나 또는 다수의 아미노산 치환을 포함한다. 연장된 반감기 및 신생아 Fc수용체(FcRn)와의 개선된 결합을 갖는 항체는 모IgG를 태아로 전달하는 역할을 한다(Guyer et al., J. Immunol.117:587 (1976) 및 Kim et al., J. Immunol. 24:249 (1994)), US 2005/0014934 A1에 설명된 바와 같다 (Hinton et al.,). 이러한 항체는 하나 또는 다수의 아미노산 치환을 갖는 Fc영역을 포함하고, 여기서, 이러한 치환은 Fc영역과 FcRn의 결합을 변경시켰다. 이러한 Fc 변이체는 하나 또는 다수의 Fc영역 잔기에서 치환(예를 들어 Fc영역 잔기434의 치환)을 갖는 변이체(미국 특허 번호 7,371,826)를 포함한다.
또한, Duncan 및 Winter, Nature 322:738-40 (1988); 미국 특허 번호 5,648,260; 미국 특허 번호 5,624,821; 및 Fc영역 변이체에 관한 기타 구현예의 WO 94/29351을 참조바란다.
h) 시스테인 조작된 항체 변이체
일부 실시예에서, 항체의 하나 또는 다수의 잔기가 시스테인 잔기로 치환된 “thioMAb”와 같은 시스테인 조작된 항체 부분을 생성하여야 할 수 있다. 구체적인 실시예에서, 치환된 잔기는 항체의 접근 가능한 부위에 나타난다. 본문에 추가로 설명된 바와 같이, 이러한 잔기를 시스테인으로 치환함으로써, 반응성 티올기는 항체의 접근 가능한 부위에 위치하고, 항체를 약물 부분 또는 링커-약물 부분과 같은 다른 부분에 결합하여 면역접합체 생성에 사용할 수 있다. 일부 실시예에서, 중쇄의 A118(EU넘버링); 및 중쇄Fc영역의 S400(EU넘버링) 중 어느 하나 또는 다수의 잔기는 시스테인으로 치환될 수 있다. 시스테인 조작된 항체 부분은 미국 특허 번호 7,521,541에 설명된 바와 같다.
i) 항체 유도체
일부 실시예에서, 본문에 따른 항체 부분은 본 분야에 공지되어 있고, 용이하게 획득 가능한 다른 비-단백질 부분을 포함하도록 추가로 변형될 수 있다. 항체 유도체화에 적합한 부분은 수용성 중합체가 포함되지만 이에 한정되지 않는다. 수용성 중합체의 비제한적인 구현예로, 폴리에틸렌 글리콜(PEG), 에틸렌 글리콜/프로필렌 글리콜, 카르복시메틸셀룰로오스(carboxymethylcellulose), 덱스트란(dextran), 폴리비닐 알코올(polyvinyl alcohol), 폴리비닐 피롤리돈(polyvinyl pyrrolidone), 폴리-1,3-디옥솔란(poly-1, 3-dioxolane), 폴리-1,3,6-트리옥산(poly-1,3,6-trioxane), 에틸렌/무수말레산 공중합체(ethylene/maleic anhydride copolymer), 폴리아미노산(polyaminoacids)(단독중합체(homopolymers) 또는 랜덤 공중합체(random copolymers)) 및 덱스트란(dextran) 또는 폴리(n-비닐 피롤리돈)폴리에틸렌 글리콜(poly(n-vinyl pyrrolidone)polyethylene glycol),프로프로필렌 글리콜 단독중합체(propropylene glycol homopolymers), 프롤리프로필렌 옥사이드/에틸렌 옥사이드 공중합체(prolypropylene oxide/ethylene oxide co-polymers), 폴리옥시에틸화 폴리올(polyoxyethylated polyols)(예를 들어, 글리세롤(glycerol)), 폴리비닐 알코올 및 이들의 혼합물을 포함하지만, 이에 한정되지 않는다. 폴리에틸렌 글리콜 프로피온알데히드(Polyethylene glycol propionaldehyde)는 물에 대한 안정성으로 인해 제조상 이점이 있을 수 있다. 중합체는 임의의 분자량일 수 있고, 분지쇄 또는 비분지쇄일 수 있다. 항체에 연결된 중합체의 수는 변경될 수 있고, 연결된 중합체가 하나를 초과하는 경우, 이들은 동일하거나 상이한 분자일 수 있다. 일반적으로, 유도체화에 사용되는 중합체 수 및/또는 유형은 하기 요소를 고려하여 결정될 수 있고, 이러한 요소로 개선될 항체의 특정 성질 또는 기능, 항체 유도체를 확정된 진단 조건 등에 대해 사용할지 여부 등을 포함하지만, 이에 한정되지 않는다.
일부 실시예에서,항체 부분은 하나 또는 다수의 생물학적 활성 단백질, 폴리펩티드 또는 이의 단편을 포함하도록 추가로 변형될 수 있다. 본문에서 상호 교환적으로 사용되는 “생물학적 활성의” 또는 “생물학적 활성을 갖는”은 체내에서 특정 기능을 수행하는 생물학적 활성을 나타내는 것을 의미한다. 예를 들어, 이는 특정 생체 분자(예를 들어, 단백질, DNA 등)에 결합한 후, 이러한 생체 분자의 활성을 촉진하거나 억제하는 것을 의미할 수 있다. 일부 실시예에서, 생물학적 활성 단백질 또는 이의 단편은, 활성 약물 물질로서 환자에게 투여되는 단백질 및 폴리펩티드; 질환 또는 병증 예방 또는 치료용, 및 진단 목적용 단백질 ?? 폴리펩티드(예를 들어, 진단 테스트 또는 체외 측정에 사용되는 효소); 및 질환 예방을 위해 환자에게 투여되는 단백질 및 폴리펩티드(예를 들어, 백신)를 포함하지만, 이에 한정되지 않는다.
j) 항CD137 scFv
일부 실시예에서의 항CD137 작제물은 본문에 기술된 항CD137 항체 부분의 scFv(이하 “항CD137 scFv”라고 함)를 포함한다. 항CD137-scFv는 본문에 기술된 항CD137 항체 부분(“항CD137 항체 부분” 부분을 참조) 중의 임의의 하나를 포함한다. 일부 실시예에서, 항CD137 scFv는 VL(CD137)-L-VH(CD137)의 배열(N-말단에서 C-말단)을 갖는다. 몇몇 실시예에서, 항CD137 scFv는 VH(CD137)-L-VL(CD137)의 배열(N-말단에서 C-말단)을 갖는다.
일부 실시예에서, 항CD137 scFv는 키메라, 인간, 부분적으로 인간화, 완전 인간화 또는 반합성된 것이다.
일부 실시예에서, scFv에서의 항CD137 VL 및 항CD137 VH는 링커(예를 들어, 펩티드 링커)에 의해 연결된다. 일부 실시예에서, 링커는 약 4개 내지 약 15개의 아미노산을 포함한다. 일부 실시예에서, 링커는 GS링커이다. 일부 실시예에서, 링커는 SEQ ID No: 232-260 중의 임의의 하나의 서열을 포함한다.
k) 항CD137융합 단백질
일부 실시예에서, 항CD137 작제물은 항CD137 항체 부분 및 반감기 연장 부분을 포함한다. 일부 실시예에서, 반감기 연장 부분은 Fc영역이다. 일부 실시예에서, 반감기 연장 부분은 알부민 결합 부분(예를 들어, 알부민 결합 항체 부분)이다.
일부 실시예에서, 반감기 연장 부분은 Fc영역(예를 들어 본문에 기술된 Fc영역 중의 임의의 하나 또는 이의 변이체)이다. 용어 “Fc영역”, “Fc도메인” 또는 “Fc”는 불변 영역의 적어도 일부를 포함하는 면역글로블린 중쇄의 C-말단 비항원 결합 영역을 지칭한다. 상기 용어는 천연 Fc영역 및 변이체Fc영역을 포함한다. 일부 실시예에서, 인간 IgG중쇄 Fc영역은 Cys226에서 중쇄의 카르복실기 말단으로 연장된다. 그러나, Fc 영역의 구조 또는 안정성에 영향을 미치지 않으면서, Fc 영역의 C-말단 라이신(Lys447)은 존재하거나 존재하지 않을 수 있다. 본문에서 달리 설명되지 않는 한, Kabat et al., Sequences of Proteins of Immunological Interest, 제5판, Public Health Service, National Institutes of Health, 베데스다, 메릴랜드주, 1991에 설명된 바와 같이, IgG 또는 Fc영역에서의 아미노산 잔기 넘버링은 항체에 대한 EU 넘버링 시스템(EU인텍스로도 지칭됨)에 따른다.
일부 실시예에서, Fc영역은 IgG, IgA, IgD, IgE, IgM의 Fc영역, 및 이의 임의의 조합 및 이형 접합체로 이루어진 군으로부터 선택된다. 일부 실시예에서, Fc영역은 IgG1, IgG2, IgG3, IgG4의 Fc영역, 및 이의 임의의 조합 및 이형 접합체로 이루어진 군으로부터 선택된다.
일부 실시예에서, 대응되는 야생형Fc영역과 비교하여, 상기 Fc영역은 감소된 이펙터 기능을 갖는다(예를 들어 항체 의존성 세포 독성(ADCC) 수준을 측정하여, 이펙터 기능이 적어도 약 30%, 40%, 50%, 60%, 70%, 80%, 85%, 90% 또는 95% 감소).
몇몇 실시예에서, Fc영역은 IgG1 Fc영역 이다. 일부 실시예에서, IgG1 Fc영역은 L234A 돌연변이 및/또는 L235A 돌연변이를 포함한다. 일부 실시예에서, Fc영역은 IgG2 또는 IgG4 Fc영역이다. 일부 실시예에서, Fc영역은 S228P, F234A 및/또는 L235A돌연변이의 IgG4 Fc영역을 포함한다.
일부 실시예에서, 항CD137 항체 부분 및 반감기 연장 부분은 링커(예를 들어“링커” 부분에 서술된 링커 중의 임의의 하나)에 의해 연결된다.
일부 실시예에서, 항CD137융합 단백질은 제2 항체를 추가로 포함한다. 일부 실시예에서, 상기 제2 항체는 종양 항원(예를 들어 본문에 서술된 종양 항원 중의 임의의 하나)에 결합된다.
l)다중 특이적 항체
또한 본문에서 CD137 및 제2 항원 모두에 결합되는 다중 특이적 항체(예를 들어, 이중 특이성 항체)를 제공하였다. 일부 실시예에서, 제2 항원은 또한 CD137이지만, 본문에 서술된 항CD137 항체 부분과 상이한 에피토프를 포함한다. 일부 실시예에서, 제2 항원은 CD137이 아니다. 일부 실시예에서, 제2 항원은 종양 관련 항원이다.
일부 실시예에서, 상기 다중 특이적 항체는, a) 본문에 서술된 임의의 항CD137 작제물을 포함하는 제1 항체 부분; 및 b) 비CD137인 제2 항원에 결합되는 제2 항체 부분을 포함한다. 일부 실시예에서, 상기 제2 항원은 종양 관련 항원을 포함한다.
일부 실시예에서, 상기 제1 항체 부분은 CD137에 결합되는 단일쇄Fv 단편을 포함한다. 일부 실시예에서, 상기 제2 항체 부분은 종양 관련 항원에 결합되고 두 가닥의 항체 중쇄 및 두 가닥의 항체 경쇄를 포함하는 전장 항체를 포함하고, 여기서, 상기 중쇄는 각각 제2 중쇄 가변영역 (VH-2)을 포함하며, 상기 경쇄는 각각 제2 경쇄 가변영역 (V L-2)을 포함하고, 여기서 상기 항CD137 단일쇄 Fv 단편은 전장 항체의 중쇄 또는 경쇄 중의 적어도 한가닥에 융합된다. 일부 실시예에서, 상기 항CD137 단일쇄 Fv단편은 전장 항체의 경쇄의 C말단에 융합된다. 일부 실시예에서, 상기 항CD137 단일쇄 Fv단편은 전장 항체의 경쇄의 N말단에 융합된다.
일부 실시예에서, 상기 다중 특이적 항체는, a) CD137에 결합되는 단일쇄Fv 단편을 포함하고, 여기서 상기 단일쇄Fv 단편은 제1 중쇄 가변 영역(VH-1) 및 제1 경쇄 가변 영역(V L-1)을 포함하는 제1 항체 부분, 및 b) 제2 항원(예를 들어, 종양 관련 항원)에 결합되고 두 가닥의 항체 중쇄 및 두 가닥의 항체 경쇄를 포함하는 전장 항체를 포함하며, 여기서 상기 중쇄는 각각 제2 중쇄 가변영역 (VH-2)을 포함하고, 상기 경쇄는 각각제2 경쇄 가변영역 (V L-2)을 포함하는 제2 항체 부분을 포함한다. 일부 실시예에서, 상기 항CD137 단일쇄 Fv단편은 전장 항체의 한 가닥 또는 두 가닥의 중쇄의 C말단에 융합된다. 일부 실시예에서, 상기 항CD137 단일쇄 Fv단편은 전장 항체의 한 가닥 또는 두 가닥의 중쇄의 N말단에 융합된다. 일부 실시예에서, 상기 항CD137 단일쇄 Fv단편은 전장 항체의 한 가닥 또는 두 가닥의 경쇄의 C말단에 융합된다. 일부 실시예에서, 상기 항CD137 단일쇄 Fv단편은 전장 항체의 한 가닥 또는 두 가닥의 경쇄의 N말단에 융합된다. 일부 실시예에서, 항CD137 단일쇄 Fv단편의 VH-1 및 VL-1은 제1 링커(예를 들어, 제1 펩티드 링커)에 의해 전장 항체에 융합된다. 일부 실시예에서, 상기 제1 링커는 약 1내지 약 30(약 4 내지 20, 약 3 내지 20, 약 6 내지 18 또는 약 10 내지 15)개의 아미노산을 포함한다. 일부 실시예에서, 상기 제1 링커는 GS링커이다. 일부 실시예에서, 상기 링커는 SEQ ID NO: 232-260중의 임의의 하나의 아미노산 서열을 갖는다. 일부 실시예에서, 전장 항체는 IgG, IgA, IgD, IgE, IgM으로부터 유래된 Fc영역 및 이의 임의의 조합 및 이형 접합체로부터 선택되는 Fc영역을 포함한다. 일부 실시예에서, 상기 Fc영역은 IgG1, IgG2, IgG3, IgG4로부터 유래된 Fc영역 및 이의 임의의 조합 및 이형 접합체로부터 선택된다. 일부 실시예에서, 상기 Fc영역은 IgGl Fc영역이다. 일부 실시예에서, 상기 IgG1 Fc영역은 L234A돌연변이 및/또는 L235A돌연변이를 포함한다. 일부 실시예에서, 상기 Fc영역은 IgG4 Fc영역이다. 일부 실시예에서, 상기 Fc영역은 IgG2 Fc영역이다. 일부 실시예에서, 상기 IgG4 Fc영역은 F234A돌연변이 및 L235A돌연변이를 포함한다. 일부 실시예에서, 상기 IgG4 Fc영역은 S228P돌연변이를 추가로 포함한다.
일부 실시예에서, 상기 다중 특이적 항체는, a) 본문에 따른 임의의 항CD137 작제물을 포함하는 전장 항체를 포함하는 제1 항체 부분, 및 b) 제2 항원(예를 들어, 종양 관련 항원)을 인식하는 단일쇄Fv단편을 포함하는 제2 항체 부분을 포함한다. 일부 실시예에서, 상기 단일쇄Fv단편은 항CD137전장 항체의 한 가닥 또는 두 가닥의 중쇄에 융합된다. 일부 실시예에서, 상기 단일쇄Fv단편은 항CD137전장 항체의 한 가닥 또는 두 가닥의 중쇄의 C말단에 융합된다. 일부 실시예에서, 상기 단일쇄Fv 단편은 항CD137전장 항체의 중쇄의 하나 또는 두개의 N말단에 융합된다. 일부 실시예에서, 상기 단일쇄Fv단편은 항CD137전장 항체의 한 가닥 또는 두 가닥의 경쇄에 융합된다. 일부 실시예에서, 상기 단일쇄Fv단편은 항CD137전장 항체의 한 가닥 또는 두 가닥의 경쇄의 C말단에 융합된다. 일부 실시예에서, 상기 단일쇄Fv단편은 전장 항체의 한 가닥 또는 두 가닥의항CD137경쇄의 N말단에 융합된다.
본문에 서술된 바와 같이, “종양 관련 항원”은 예를 들어 종양 세포(예를 들어 암세포)의 발현이 비종양 세포(예를 들어 비암세포)의 발현보다 현저하게 높은 (예를 들어 적어도 약 5%, 10%, 20%, 30%, 40%, 50%, 60% 또는 70% 높음) 임의의 항원을 지칭한다.
본문에 서술된 제2 항체 부분에 인식될 수 있는 예시적 종양 관련 항원은, α페토프로테인(AFP), CA15-3, CA27-29, CA19-9, CA-125, 칼레티닌(calretinin), 암배아 항원, CD34, CD99, CD117, 크로모그라닌(chromogranin), 사이토케라틴(cytokeratin), 데스민(desmin), 상피막 단백질(EMA), 인자VIII, CD31 FL1, 신경교섬유질산성단백질(GFAP), 수포성 질환 액체 단백질(GCDFP-15), HMB-45, 인간 융모생식샘자극호르몬(hCG), 인히빈(inhibin), 케라틴(keratin), CD45, 림프구 마커, MART-1(Melan-A), Myo Dl, 근육 특이적 액틴(MSA), 신경세사, 뉴런특이에놀라아제(NSE), 태반 알칼리 인산분해효소(PLAP), 전립선특이성항원, S100단백질, 평활근 액틴(SMA), 시냅토피신(synaptophysin), 티로글로불린(thyroglobulin), 갑상선 전사 인자-1, 종양M2-PK, 및 비멘틴(vimentin)을 포함하지만 이에 한정되지 않는다.
일부 실시예에서, 상기 종양 관련 항원은, HER-2, EGFR, PD-L1, c-Met, B세포성숙항원(BCMA), 탄산무수화효소IX(CA1X), 배아항원(CEA), CD5, CD7, CD10, CD19, CD20, CD22, CD30, CD33, CD34, CD38, CD41, CD44, CD49f, CD56, CD74, CD123, CD133, CD138, CD276(B7H3), 상피당단백질(EGP2), 영양막 세포 표면 항원 2(TROP-2), 상피당단백질-40(EGP-40), 상피 세포 부착 분자(EpCAM), 수용체티로신 단백질 키나제erb-B2, 3, 4, 엽산 결합 단백질(FBP), 태아 아세틸콜린 수용체(AChR), 엽산 수용체-a, 강글리오시드G2(GD2), 강글리오시드G3(GD3), 인간 텔로머라제 역전사효소(hTERT), 키나제 삽입 도메인 수용체(KDR), Lewis A(CA 1.9.9), Lewis Y(LeY), 글리피칸-3(GPC3), L1세포 부착 분자(L1CAM), 뮤신16(Muc-16), 뮤신1(Muc-1), NG2D리간드, 종양 태아 항원(h5T4), 전립선 줄기 세포 항원(PSCA), 전립선 특이적 막 항원(PSMA), 종양 관련 당단백질72(TAG-72), 클라우딘18.2(CLDN18.2), 혈관 내피 성장 인자R2(VEGF-R2), 윌름스 종양 단백질(WT-1), 1형 티로신-단백질 키나제 막횡단 수용체(ROR1) 및 이의 임의의 조합으로 이루어진 군으로부터 선택된다. 일부 실시예에서, 종양 관련 항원은 HER-2, EGFR, B7H3, c-Met 또는 PD-L1이다. 일부 실시예에서, 종양 관련 항원은 HER-2, EGFR, B7H3, c-Met 또는 PD-L1로 이루어진 군으로부터 선택된다.
m) 항CD137 x EGFR다중 특이적 항체
일부 실시형태에서, 본문에 개시된 다중 특이적 항체는, a) 단일쇄Fv단편인 본문에 개시된 임의의 항CD137 작제물을 구성하는 제1 항체 부분, 및 b) EGFR에 결합되고 두 가닥의 항체 중쇄 및 두 가닥의 항체 경쇄를 포함하는 전장 항체를 포함하고, 여기서 상기 중쇄는 각각 제2 중쇄 가변영역 (VH-2)을 포함하고, 상기 경쇄는 각각 제2 경쇄 가변영역 (V L-2)을 포함하며, 여기서 상기 항 CD137 단일쇄 Fv 단편이 전장 항체에 융합되는 제2 항체 부분을 포함한다. 일부 실시형태에서, 상기 항CD137 단일쇄 Fv단편은 전장 항체의 중쇄의 C말단에 융합된다. 일부 실시형태에서, 상기 항CD137 단일쇄 Fv단편은 전장 항체의 중쇄의 N말단에 융합된다. 일부 실시형태에서, 상기 항CD137 단일쇄 Fv단편은 전장 항체의 경쇄의 C말단에 융합된다. 일부 실시형태에서,
상기 항CD137 단일쇄 Fv단편은 전장 항체의 경쇄의 N말단에 융합된다. 일부 실시형태에서, 상기 EGFR은 인간 EGFR이다. 일부 실시형태에서, 상기 제2 항체 부분은 PCT/US 2015/033402(공개번호가 국제 공개 WO 2015184403)(그 전체 내용이 참조로서 본문에 통합됨)에 개시된 임의의 전장 항체일 수 있다. 일부 실시형태에서, EGFR에 결합된 전장 항체 또는 항EGFR항체 부분은 제3 중쇄 가변영역(VH-3) 및 제3 경쇄 가변영역(V L-3)을 포함하는 항체 또는 항체 단편과 EGFR의 결합 에피토프를 경쟁한다. 일부 실시형태에서, 상기 VH-3은 SEQ ID NO: 190의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 191의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 192의 아미노산 서열을 포함하는 HC-CDR3을 포함하고; 상기 VL-3은 SEQ ID NO: 193의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 194의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 195의 아미노산 서열을 포함하는 LC-CDR3을 포함한다. 일부 실시형태에서, 상기 VH-3은 SEQ ID NO: 198의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 199의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 200의 아미노산 서열을 포함하는 HC-CDR3을 포함하고; 상기 VL-3은 SEQ ID NO: 201의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 202의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 203의 아미노산 서열을 포함하는 LC-CDR3을 포함한다. 일부 실시형태에서, 상기 VH-3은 SEQ ID NO: 206의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 207의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 208의 아미노산 서열을 포함하는 HC-CDR3을 포함하고; 상기 VL-3은 SEQ ID NO: 209의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 210의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 211의 아미노산 서열을 포함하는 LC-CDR3을 포함한다. 일부 실시형태에서, 상기 VH-3은 SEQ ID NO: 214의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 215의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 216의 아미노산 서열을 포함하는 HC-CDR3을 포함하고; 상기 VL-3은 SEQ ID NO: 217의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 218의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 219의 아미노산 서열을 포함하는 LC-CDR3을 포함한다. 일부 실시형태에서, 상기 VH-3은 SEQ ID NO: 222의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 223의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 224의 아미노산 서열을 포함하는 HC-CDR3을 포함하고; 상기 VL-3은 SEQ ID NO: 225의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 226의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 227의 아미노산 서열을 포함하는 LC-CDR3을 포함한다.
일부 실시형태에서, 상기 VH-2는 SEQ ID NO: 190의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 191의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 192의 아미노산 서열을 포함하는 HC-CDR3을 포함하고, 상기 V L-2 는 SEQ ID NO: 193의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 194의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 195의 아미노산 서열을 포함하는 LC-CDR3을 포함한다. 일부 실시형태에서, 상기 VH-2는 SEQ ID NO: 198의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 199의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 200의 아미노산 서열을 포함하는 HC-CDR3을 포함하고, 상기 V L-2 는 SEQ ID NO: 201의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 202의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 203의 아미노산 서열을 포함하는 LC-CDR3을 포함한다. 일부 실시형태에서, 상기 VH-2는 SEQ ID NO: 206의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 207의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 208의 아미노산 서열을 포함하는 HC-CDR3을 포함하고, 상기 V L-2 는 SEQ ID NO: 209의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 210의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 211의 아미노산 서열을 포함하는 LC-CDR3을 포함한다. 일부 실시형태에서, 상기 VH-2는 SEQ ID NO: 214의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 215의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 216의 아미노산 서열을 포함하는 HC-CDR3을 포함하고, 상기 V L-2 는 SEQ ID NO: 217의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 218의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 219의 아미노산 서열을 포함하는 LC-CDR3을 포함한다. 일부 실시형태에서, 상기 VH-2는 SEQ ID NO: 222의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 223의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 224의 아미노산 서열을 포함하는 HC-CDR3을 포함하고, 상기 V L-2 는 SEQ ID NO: 225의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 226의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 227의 아미노산 서열을 포함하는 LC-CDR3을 포함한다.
일부 실시형태에서, 상기 VH-2는 SEQ ID NO: 196, 204, 212, 220 또는 228의 아미노산 서열 또는 SEQ ID NO: 196, 204, 212, 220 또는 228과 적어도 약 80%(예컨대 적어도 약 80%, 85%, 90%, 95%, 96%, 97%, 98% 또는 99% 중의 임의의 하나)의 서열 동일성을 갖는 변이체를 포함하고; 및/또는 상기 VL-2는 SEQ ID NO: 197, 205, 213, 221 또는 229의 아미노산 서열 또는 SEQ ID NO: 197, 205, 213, 221 또는 229와 적어도 약 80%(예컨대 적어도 약 80%, 85%, 90%, 95%, 96%, 97%, 98% 또는 99%중의 임의의 하나)의 서열 동일성을 갖는 변이체를 포함한다.
일부 실시형태에서, 상기 다중 특이적 항체는 제1 항체 부분 및 제2 항체 부분을 포함하고, a) 상기 제1 항체 부분은 중쇄 가변 영역(VH) 및 경쇄 가변 영역(VL)을 포함하며, 여기서 상기 VH는 SEQ ID NO: 121의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 122의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 123의 아미노산 서열을 포함하는 HC-CDR3을 포함하고; 및 상기 VL은 SEQ ID NO: 124의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 125의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 126의 아미노산 서열을 포함하는 LC-CDR3을 포함하며; b) 상기 제2 항체 부분은 제2 중쇄 가변영역 (VH-2) 및 제2 경쇄 가변영역 (V L-2)을 포함하고, 여기서 상기 VH-2는 SEQ ID NO: 206의 아미노산 서열을 포함하는 제2 HC-CDR1, SEQ ID NO: 207의 아미노산 서열을 포함하는 제2 HC-CDR2 및 SEQ ID NO: 208의 아미노산 서열을 포함하는 제2 HC-CDR3을 포함하며; 상기 VL-2는 SEQ ID NO: 209의 아미노산 서열을 포함하는 제2 LC-CDR1, SEQ ID NO: 210의 아미노산 서열을 포함하는 제2 LC-CDR2 및 SEQ ID NO: 211의 아미노산 서열을 포함하는 제2 LC-CDR3을 포함한다.
일부 실시형태에서, 상기 다중 특이적 항체는 제1 항체 부분 및 제2 항체 부분을 포함하고, a) 상기 제1 항체 부분은 중쇄 가변 영역(VH) 및 경쇄 가변 영역(VL)을 포함하며, 여기서 상기 VH는 SEQ ID NO: 261의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 262의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 263의 아미노산 서열을 포함하는 HC-CDR3을 포함하고; 및 상기 VL은 SEQ ID NO: 264의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 265의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 266의 아미노산 서열을 포함하는 LC-CDR3을 포함하며; b) 상기 제2 항체 부분은 제2 중쇄 가변영역 (VH-2) 및 제2 경쇄 가변영역 (V L-2)을 포함하고, 여기서 상기 VH-2는 SEQ ID NO: 206의 아미노산 서열을 포함하는 제2 HC-CDR1, SEQ ID NO: 207의 아미노산 서열을 포함하는 제2 HC-CDR2 및 SEQ ID NO: 208의 아미노산 서열을 포함하는 제2 HC-CDR3을 포함하며; 상기 VL-2는 SEQ ID NO: 209의 아미노산 서열을 포함하는 제2 LC-CDR1, SEQ ID NO: 210의 아미노산 서열을 포함하는 제2 LC-CDR2 및 SEQ ID NO: 211의 아미노산 서열을 포함하는 제2 LC-CDR3을 포함한다.
일부 실시형태에서, 상기 다중 특이적 항체는 제1 항체 부분 및 제2 항체 부분을 포함하고, a) 상기 제1 항체 부분은 중쇄 가변 영역(VH) 및 경쇄 가변 영역(VL)을 포함하며, 여기서 상기 VH는 SEQ ID NO: 271의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 272의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 273의 아미노산 서열을 포함하는 HC-CDR3을 포함하고; 및 상기 VL은 SEQ ID NO: 274의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 275의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 276의 아미노산 서열을 포함하는 LC-CDR3을 포함하며; b) 상기 제2 항체 부분은 제2 중쇄 가변영역 (VH-2) 및 제2 경쇄 가변영역 (V L-2)을 포함하고, 여기서 상기 VH-2는 SEQ ID NO: 206의 아미노산 서열을 포함하는 제2 HC-CDR1, SEQ ID NO: 207의 아미노산 서열을 포함하는 제2 HC-CDR2 및 SEQ ID NO: 208의 아미노산 서열을 포함하는 제2 HC-CDR3을 포함하며; 상기 VL-2는 SEQ ID NO: 209의 아미노산 서열을 포함하는 제2 LC-CDR1, SEQ ID NO: 210의 아미노산 서열을 포함하는 제2 LC-CDR2 및 SEQ ID NO: 211의 아미노산 서열을 포함하는 제2 LC-CDR3을 포함한다.
일부 실시형태에서, 상기 항 CD137 단일쇄 Fv 단편은 항EGFR전장 항체의 중쇄에 융합되고, 여기서 항CD137 단일쇄 Fv단편에 융합된 항EGFR전장 항체의 중쇄는 SEQ ID NO: 183, 185, 188, 189, 230, 231, 259, 260, 281 또는 282중의 임의의 하나의 아미노산 서열을 포함하거나, SEQ ID NO: 183, 185, 188, 189, 230, 231, 259, 260, 281 또는 282중의 임의의 하나의 아미노산 서열과 적어도 약 80%(예컨대 적어도 약 80%, 85%, 90%, 95%, 96%, 97%, 98% 또는 99% 중의 임의의 하나)의 서열 동일성을 갖는 아미노산 서열을 포함하는 변이체를 포함한다. 일부 실시형태에서, 상기 제2 항체 부분에 포함된 전장 항체는 경쇄를 포함하고, 상기 경쇄는 SEQ ID NO: 184, 186 또는 187중의 임의의 하나의 아미노산 서열을 포함하거나, SEQ ID NO: 184, 186 또는 187중의 임의의 하나의 아미노산 서열과 적어도 약 80%(예컨대 적어도 약 80%, 85%, 90%, 95%, 96%, 97%, 98% 또는 99% 중의 임의의 하나)의 서열 동일성을 갖는 아미노산 서열을 포함하는 변이체를 포함한다. 일부 실시형태에서, 상기 다중 특이적 항체는 SEQ ID NO: 183으로 표시되는 아미노산 서열을 포함하는 항CD137 scFv에 융합된 항EGFR중쇄 및 SEQ ID NO: 187로 표시되는 아미노산 서열을 포함하는 항EGFR경쇄를 포함한다. 일부 실시형태에서, 상기 다중 특이적 항체는 SEQ ID NO: 185로 표시되는 아미노산 서열을 포함하는 항CD137 scFv에 융합된 항EGFR중쇄 및 SEQ ID NO: 187로 표시되는 아미노산 서열을 포함하는 항EGFR경쇄를 포함한다. 일부 실시형태에서, 상기 다중 특이적 항체는 SEQ ID NO: 188로 표시되는 아미노산 서열을 포함하는 항CD137 scFv에 융합된 항EGFR중쇄 및 SEQ ID NO: 187로 표시되는 아미노산 서열을 포함하는 항EGFR경쇄를 포함한다. 일부 실시형태에서, 상기 다중 특이적 항체는 SEQ ID NO: 189로 표시되는 아미노산 서열을 포함하는 항CD137 scFv에 융합된 항EGFR중쇄 및 SEQ ID NO: 184로 표시되는 아미노산 서열을 포함하는 항EGFR경쇄를 포함한다. 일부 실시형태에서, 상기 다중 특이적 항체는 SEQ ID NO: 189로 표시되는 아미노산 서열을 포함하는 항CD137 scFv에 융합된 항EGFR중쇄 및 SEQ ID NO: 186으로 표시되는 아미노산 서열을 포함하는 항EGFR경쇄를 포함한다. 일부 실시형태에서, 상기 다중 특이적 항체는 SEQ ID NO: 230으로 표시되는 아미노산 서열을 포함하는 항CD137 scFv에 융합된 항EGFR중쇄 및 SEQ ID NO: 187로 표시되는 아미노산 서열을 포함하는 항EGFR경쇄를 포함한다. 일부 실시형태에서, 상기 다중 특이적 항체는 SEQ ID NO: 231로 표시되는 아미노산 서열을 포함하는 항CD137 scFv에 융합된 항EGFR중쇄 및 SEQ ID NO: 187로 표시되는 아미노산 서열을 포함하는 항EGFR경쇄를 포함한다. 일부 실시형태에서, 상기 다중 특이적 항체는 SEQ ID NO: 259로 표시되는 아미노산 서열을 포함하는 항CD137 scFv에 융합된 항EGFR중쇄 및 SEQ ID NO: 187로 표시되는 아미노산 서열을 포함하는 항EGFR경쇄를 포함한다. 일부 실시형태에서, 상기 다중 특이적 항체는 SEQ ID NO: 260으로 표시되는 아미노산 서열을 포함하는 항CD137 scFv에 융합된 항EGFR중쇄 및 SEQ ID NO: 187로 표시되는 아미노산 서열을 포함하는 항EGFR경쇄를 포함한다. 일부 실시형태에서, 상기 다중 특이적 항체는 SEQ ID NO: 281로 표시되는 아미노산 서열을 포함하는 항CD137 scFv에 융합된 항EGFR중쇄 및 SEQ ID NO: 187로 표시되는 아미노산 서열을 포함하는 항EGFR경쇄를 포함한다. 일부 실시형태에서, 상기 다중 특이적 항체는 SEQ ID NO: 282로 표시되는 아미노산 서열을 포함하는 항CD137 scFv에 융합된 항EGFR중쇄 및 SEQ ID NO: 187로 표시되는 아미노산 서열을 포함하는 항EGFR경쇄를 포함한다.
일부 실시형태에서, 다중 특이적 항체를 제공하였고, 본문에 개시된 CD137에 결합되는 항CD137 단일쇄 Fv단편 및 EGFR에 결합되고 두 가닥의 항체 중쇄 및 두 가닥의 항체 경쇄를 포함하는 전장 항체를 포함하고, a) 본문에 개시된 CD137에 결합되는 항CD137 단일쇄 Fv단편에서, 상기 단일쇄Fv단편은 제1 중쇄 가변 영역(VH-1) 및 제1 경쇄 가변 영역(V L-1)을 포함하고, 여기서 상기 VH-1은, i) SEQ ID NO: 141의 아미노산 서열을 포함하는 HC-CDR1, ii) SEQ ID NO: 142의 아미노산 서열을 포함하는HC-CDR2, 및 iii) SEQ ID NO: 143의 아미노산 서열을 포함하는 HC-CDR3을 포함하며, 상기 VL은, i) SEQ ID NO: 144의 아미노산 서열을 포함하는 LC-CDR1, ii) SEQ ID NO: 145의 아미노산 서열을 포함하는LC-CDR2, 및 iii) SEQ ID NO: 146의 아미노산 서열을 포함하는 LC-CDR3을 포함하며, b) EGFR에 결합되고 두 가닥의 항체 중쇄 및 두 가닥의 항체 경쇄를 포함하는 전장 항체에서, EGFR에 결합된 전장 항체는 제2 중쇄 가변영역 (VH-2) 및 제2 경쇄 가변영역 (V L-2)을 포함한다. 일부 실시형태에서, 상기 항CD137 단일쇄 Fv 단편은 전장 항체의 중쇄의 C말단에 융합된다. 일부 실시형태에서, 상기 항CD137 단일쇄 Fv단편은 전장 항체의 중쇄의 N말단에 융합된다.
일부 실시형태에서, 상기 VH-2는 SEQ ID NO: 190의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 191의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 192의 아미노산 서열을 포함하는 HC-CDR3을 포함하고, 상기 V L-2 는 SEQ ID NO: 193의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 194의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 195의 아미노산 서열을 포함하는 LC-CDR3을 포함한다. 일부 실시형태에서, 상기 VH-2는 SEQ ID NO: 198의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 199의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 200의 아미노산 서열을 포함하는 HC-CDR3을 포함하고, 상기 V L-2 는 SEQ ID NO: 201의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 202의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 203의 아미노산 서열을 포함하는 LC-CDR3을 포함한다. 일부 실시형태에서, 상기 VH-2는 SEQ ID NO: 206의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 207의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 208의 아미노산 서열을 포함하는 HC-CDR3을 포함하고, 상기 V L-2 는 SEQ ID NO: 209의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 210의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 211의 아미노산 서열을 포함하는 LC-CDR3을 포함한다. 일부 실시형태에서, 상기 VH-2는 SEQ ID NO: 214의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 215의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 216의 아미노산 서열을 포함하는 HC-CDR3을 포함하고, 상기 V L-2 는 SEQ ID NO: 217의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 218의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 219의 아미노산 서열을 포함하는 LC-CDR3을 포함한다. 일부 실시형태에서, 상기 VH-2는 SEQ ID NO: 222의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 223의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 224의 아미노산 서열을 포함하는 HC-CDR3을 포함하고, 상기 V L-2 는 SEQ ID NO: 225의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 226의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 227의 아미노산 서열을 포함하는 LC-CDR3을 포함한다.
일부 실시형태에서, 상기 VH-2는 SEQ ID NO: 196, 204, 212, 220 또는 228의 아미노산 서열 또는 SEQ ID NO: 196, 204, 212, 220 또는 228과 적어도 약 80%(예컨대 적어도 약 80%, 85%, 90%, 95%, 96%, 97%, 98% 또는 99% 중의 임의의 하나)의 서열 동일성을 갖는 변이체를 포함하고; 및/또는 상기 VL-2는 SEQ ID NO: 197, 205, 213, 221 또는 229의 아미노산 서열 또는 SEQ ID NO: 197, 205, 213, 221 또는 229와 적어도 약 80%(예컨대 적어도 약 80%, 85%, 90%, 95%, 96%, 97%, 98% 또는 99%중의 임의의 하나)의 서열 동일성을 갖는 변이체를 포함한다.
일부 실시형태에서, 상기 VH-1은 SEQ ID NO: 7, 17, 27, 37, 47, 57, 67, 77, 87, 97, 107, 117, 127, 137, 267 또는 277의 아미노산 서열 또는 SEQ ID NO: 7, 17, 27, 37, 47, 57, 67, 77, 87, 97, 107, 117, 127, 137, 267 또는 277과 적어도 약 80%(예컨대 적어도 약 80%, 85%, 90%, 95%, 96%, 97%, 98% 또는 99% 중의 임의의 하나)의 서열 동일성을 갖는 변이체를 포함하고; 및/또는 상기 VL-1은 SEQ ID NO: 8, 18, 28, 38, 48, 58, 68, 78, 88, 98, 108, 118, 128, 138, 268 또는 278의 아미노산 서열 또는 SEQ ID NO: 8, 18, 28, 38, 48, 58, 68, 78, 88, 98, 108, 118, 128, 138, 268 또는 278과 적어도 약 80%(예컨대 적어도 약 80%, 85%, 90%, 95%, 96%, 97%, 98% 또는 99% 중의 임의의 하나)의 서열 동일성을 갖는 변이체를 포함한다.
일부 실시형태에서, 상기 항 CD137 단일쇄 Fv 단편은 항EGFR전장 항체의 중쇄에 융합되고, 여기서 항CD137 단일쇄 Fv단편에 융합된 항EGFR전장 항체의 중쇄는 SEQ ID NO: 183, 185, 188, 189, 230, 231, 259, 260, 281 또는 282중의 임의의 하나의 아미노산 서열을 포함하거나, SEQ ID NO: 183, 185, 188, 189, 230, 231, 259, 260, 281 또는 282중의 임의의 하나의 아미노산 서열과 적어도 약 80%(예컨대 적어도 약 80%, 85%, 90%, 95%, 96%, 97%, 98% 또는 99% 중의 임의의 하나)의 서열 동일성을 갖는 아미노산 서열을 포함하는 변이체를 포함한다. 일부 실시형태에서, 상기 제2 항체 부분에 포함된 전장 항체는 경쇄를 포함하고, 상기 경쇄는 SEQ ID NO: 184, 186 또는 187중의 임의의 하나의 아미노산 서열을 포함하거나, SEQ ID NO: 184, 186 또는 187중의 임의의 하나의 아미노산 서열과 적어도 약 80%(예컨대 적어도 약 80%, 85%, 90%, 95%, 96%, 97%, 98% 또는 99% 중의 임의의 하나)의 서열 동일성을 갖는 아미노산 서열을 포함하는 변이체를 포함한다. 일부 실시형태에서, 상기 다중 특이적 항체는 SEQ ID NO: 183로 표시되는 아미노산 서열을 포함하는 항CD137 scFv에 융합된 항EGFR중쇄 및 SEQ ID NO: 187로 표시되는 아미노산 서열을 포함하는 항EGFR경쇄를 포함한다. 일부 실시형태에서, 상기 다중 특이적 항체는 SEQ ID NO: 185로 표시되는 아미노산 서열을 포함하는 항CD137 scFv에 융합된 항EGFR중쇄 및 SEQ ID NO: 187로 표시되는 아미노산 서열을 포함하는 항EGFR경쇄를 포함한다. 일부 실시형태에서, 상기 다중 특이적 항체는 SEQ ID NO: 188로 표시되는 아미노산 서열을 포함하는 항CD137 scFv에 융합된 항EGFR중쇄 및 SEQ ID NO: 187로 표시되는 아미노산 서열을 포함하는 항EGFR경쇄를 포함한다. 일부 실시형태에서, 상기 다중 특이적 항체는 SEQ ID NO: 189로 표시되는 아미노산 서열을 포함하는 항CD137 scFv에 융합된 항EGFR중쇄 및 SEQ ID NO: 184로 표시되는 아미노산 서열을 포함하는 항EGFR경쇄를 포함한다. 일부 실시형태에서, 상기 다중 특이적 항체는 SEQ ID NO: 189로 표시되는 아미노산 서열을 포함하는 항CD137 scFv에 융합된 항EGFR중쇄 및 SEQ ID NO: 186으로 표시되는 아미노산 서열을 포함하는 항EGFR경쇄를 포함한다. 일부 실시형태에서, 상기 다중 특이적 항체는 SEQ ID NO: 230으로 표시되는 아미노산 서열을 포함하는 항CD137 scFv에 융합된 항EGFR중쇄 및 SEQ ID NO: 187로 표시되는 아미노산 서열을 포함하는 항EGFR경쇄를 포함한다. 일부 실시형태에서, 상기 다중 특이적 항체는 SEQ ID NO: 231로 표시되는 아미노산 서열을 포함하는 항CD137 scFv에 융합된 항EGFR중쇄 및 SEQ ID NO: 187로 표시되는 아미노산 서열을 포함하는 항EGFR경쇄를 포함한다. 일부 실시형태에서, 상기 다중 특이적 항체는 SEQ ID NO: 259로 표시되는 아미노산 서열을 포함하는 항CD137 scFv에 융합된 항EGFR중쇄 및 SEQ ID NO: 187로 표시되는 아미노산 서열을 포함하는 항EGFR경쇄를 포함한다. 일부 실시형태에서, 상기 다중 특이적 항체는 SEQ ID NO: 260으로 표시되는 아미노산 서열을 포함하는 항CD137 scFv에 융합된 항EGFR중쇄 및 SEQ ID NO: 187로 표시되는 아미노산 서열을 포함하는 항EGFR경쇄를 포함한다. 일부 실시형태에서, 상기 다중 특이적 항체는 SEQ ID NO: 281로 표시되는 아미노산 서열을 포함하는 항CD137 scFv에 융합된 항EGFR중쇄 및 SEQ ID NO: 187로 표시되는 아미노산 서열을 포함하는 항EGFR경쇄를 포함한다. 일부 실시형태에서, 상기 다중 특이적 항체는 SEQ ID NO: 282로 표시되는 아미노산 서열을 포함하는 항CD137 scFv에 융합된 항EGFR중쇄 및 SEQ ID NO: 187로 표시되는 아미노산 서열을 포함하는 항EGFR경쇄를 포함한다.
일부 실시예에서, 항CD137 단일쇄 Fv단편의 VH-1 및 VL-1은 제1 링커(예를 들어, 제1 펩티드 링커)에 의해 전장 항체에 융합된다. 일부 실시예에서, 상기 제1 링커는 약 1내지 약 30(약 4 내지 20, 약 3 내지 20, 약 6 내지 18 또는 약 10 내지 15)개의 아미노산을 포함한다. 일부 실시예에서, 상기 제1 링커는 GS링커이다. 일부 실시예에서, 상기 링커는 SEQ ID NO: 232-260중의 임의의 하나의 아미노산 서열을 갖는다. 일부 실시예에서, 상기 항 CD137 단일쇄 Fv 단편은 제2 링커(예를 들어, 제2 펩티드 링커)에 의해 전장 항체에 융합된다. 일부 실시예에서, 상기 제2 펩티드 링커는 약 1내지 약30(예컨대 약 4 내지 20, 약 3 내지 20, 약 6 내지 18 또는 약 10 내지 15)개의 아미노산을 포함한다. 일부 실시예에서, 상기 제2 펩티드 링커는 SEQ ID NO: 232-258중의 임의의 하나의 서열을 포함하는 링커이다.
일부 실시예에서, 전장 항체는 IgG, IgA, IgD, IgE, IgM으로부터 유래된 Fc영역 및 이의 임의의 조합 및 이형 접합체로부터 선택되는 Fc영역을 갖는다. 일부 실시예에서, 상기 Fc영역은 IgG1, IgG2, IgG3, IgG4로부터 유래된 Fc영역 및 이의 임의의 조합 및 이형 접합체로부터 선택된다. 일부 실시예에서, 상기 Fc영역은 IgGl Fc영역이다. 일부 실시예에서, 상기 IgG1 Fc영역은 L234A돌연변이 및/또는 L235A돌연변이를 포함한다. 일부 실시예에서, 상기 Fc영역은 IgG4 Fc영역이다. 일부 실시예에서, 상기 Fc영역은 IgG2 Fc영역이다. 일부 실시예에서, 상기 IgG4 Fc영역은 S228P, F234A 및 L235A돌연변이를 포함한다.
o) 다중 특이적 항체 특성
일부 실시예에서, 본문에 따른 다중 특이적 항체는 CD137 및 제2 항원(예를 들어 HER2, EGFR, PD-L1)에 결합되는 기준 다중 특이적 항체에 비해 개선된 임상 특성을 갖는다. 일부 실시예에서, 상기 다중 특이적 항체는 기준 다중 특이적 항체의 ADCC 활성보다 개선된 ADCC 활성(예컨대 적어도 약 5%, 10%, 20%, 30%, 40%, 50%, 60% 또는 70% 높은 ADCC 의존성 세포 독성)을 나타낸다. 일부 실시예에서, 상기 다중 특이적 항체는 기준 다중 특이적 항체의 ADCC 활성보다 더 높은 항종양 작용(예컨대 종양 부하를 감소시키거나 생존율을 적어도 약 5%, 10%, 20%, 30%, 40%, 50%, 60% 또는 70% 이상 향상)을 나타낸다. 일부 실시예에서, 상기 다중 특이적 항체는 기준 다중 특이적 항체의 독성보다 더 적은 독성을 나타낸다.
일부 실시예에서, 상기 다중 특이적 항체는 CD137 및 종양 관련 항원 모두에 결합하고, 종양 관련 항원에 대해 양성이거나 높은 수준의 종양 관련 항원을 발현하는 종양 세포의 ADCC 활성은 기준 다중 특이적 항체의 ADCC 활성보다 향상된 것으로 (예컨대 비종양 세포에서의 TAA 발현이 적어도 약 25%, 50%, 75%, 100%, 150%, 200%, 250%, 300%, 400%, 500%, 600%, 700%, 800%, 900%, 10-배, 15-배, 20-배 높음) 나타났다. 일부 실시예에서, 세포 특이성에 관한 다중 특이적 항체의 EC50은 기준 다중 특이적 항체의 약 50%, 40%, 30%, 20%, 10%를 초과하지 않는다.
일부 실시예에서, 상기 다중 특이적 항체는 암 또는 종양이 없는 대상체에서 현저한 사이토카인(예컨대 IL-2, IFN-γ, TNF-α) 방출을 유도하지 않는다. 일부 실시예에서, 상기 다중 특이적 항체는 암 또는 종양이 있는 대상체에서의 비암성 조직에서 현저한 사이토카인(예컨대 IL-2, IFN-γ, TNF-α) 방출을 유도하지 않는다. 일부 실시예에서, 현저한 사이토카인 방출은 사이토카인의 방출 수준이 CD137 및 동일한 제2 항원에 결합하는 기준 다중 특이적 항체에 의해 유도된 수준의 적어도 약 70%, 60%, 50%, 40%, 30% 또는 20%인 것이다. 일부 실시예에서, 상기 다중 특이적 항체는 암 또는 종양이 없는 대상체에서 더 적은 사이토카인(예컨대 IL-2, IFN-γ, TNF-α) 방출(예를 들어 적어도 약 10%, 20%, 30%, 40%, 50%, 60%, 70%, 80% 또는 90% 적은 사이토카인 방출)을 유도한다. 일부 실시예에서, 상기 다중 특이적 항체는 암 또는 종양이 있는 대상체에서의 비암 조직에서 더 적은 사이토카인(예컨대 IL-2, IFN-γ, TNF-α) 방출(예컨대 적어도 약 10%, 20%, 30%, 40%, 50%, 60%, 70%, 80% 또는 90% 적은 사이토카인 방출)을 유도한다.
n) 직렬 scFv
일부 실시예에서의 다중 특이적 항CD137 분자는 직렬 scFv(본문에서도 “직렬 scFv다중 특이적 항CD137 항체”로 지칭됨)이고, 제1 scFv 및 제2 scFv를 포함하며, 상기 제1 scFv는 CD137을 특이적으로 인식하는 항CD137 항체 부분(본문에서 “항CD137 scFv”로 지칭됨)을 포함하며, 상기 제2 scFv는 제2 항원을 특이적으로 인식한다. 일부 실시예에서, 직렬 scFv 다중 특이적 항CD137 항체는 적어도 하나(예를 들어 적어도 약 2개, 3개, 4개, 5개 또는 그 이상 중의 임의의 하나)의 별도의 scFv를 추가로 포함한다.
일부 실시예에서, 직렬 scFv다중 특이적(예를 들어, 이중 특이적) 항CD137 항체를 제공하고, a) CD137을 특이적으로 인식하는 제1 scFv, 및 b) 제2 항원(예를 들어, 종양 관련 항원)을 특이적으로 인식하는 제2 scFv를 포함하며, 여기서 직렬scFv 다중 특이적 항CD137 항체는 직렬2-scFv 또는 직렬3-scFv이다. 일부 실시예에서, 직렬 scFv다중 특이적 항CD137 항체는 직렬 2-scFv이다. 일부 실시예에서, 직렬 scFv 다중 특이적 항CD137 항체는 이중 특이적 T세포 어댑터이다. 일부 실시예에서, 제2 scFv는 상이한 CD137에피토프에 결합된다. 일부 실시예에서, 제2 scFv는 비CD137의 제2 항원을 특이적으로 인식한다. 일부 실시예에서, 제2 scFv는 종양 관련 항원과 같은 제2 항원을 특이적으로 인식한다. 일부 실시예에서, 제1 CD137 scFv는 키메라, 인간, 부분적으로 인간화, 완전 인간화 또는 반합성된 것이다. 일부 실시예에서, 제2 scFv는 키메라, 인간, 부분적으로 인간화, 완전 인간화 또는 반합성된 것이다. 일부 실시예에서, 제1 및 제2 scFv는 모두 키메라, 인간, 부분적으로 인간화, 완전 인간화 또는 반합성된 것이다. 일부 실시예에서, 직렬 scFv 다중 특이적 항CD137 항체는 적어도 하나(예를 들어적어도 약 2개, 3개, 4개, 5개 또는 5개 이상 중의 임의의 하나)의 별도의 scFv를 추가로 포함한다. 일부 실시예에서, 제1 항CD137 scFv 및 제2 scFv는 링커(예를 들어, 펩티드 링커)에 의해 연결된다. 일부 실시예에서, 링커는 (GGGGS)n의 아미노산 서열을 포함하고, 여기서 n은 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 또는 그 이상이다. 일부 실시예에서, 링커는 TSGGGGS의 아미노산 서열을 포함한다. 일부 실시예에서, 제1 항CD137 scFv는 제2 scFv의 N-말단에 연결된다. 일부 실시예에서, 제1 항CD137 scFv는 제2 scFv의 C-말단에 연결된다. 일부 실시예에서, 직렬 scFv다중 특이적(예를 들어 이중 특이적) 항CD137 항체는 태그(예를 들어, 정제 목적의 펩티드 태그)를 추가로 포함한다. 일부 실시예에서, 태그는 직렬 scFv다중 특이적(예를 들어, 이중 특이적) 항CD137 항체의 N-말단에 연결된다. 일부 실시예에서, 태그는 직렬scFv다중 특이적(예를 들어, 이중 특이적) 항CD137 항체의 C-말단에 연결된다. 일부 실시예에서, 태그는 HHHHHH의 아미노산 서열을 포함한다.
일부 실시예에서, 직렬 scFv 다중 특이적 항CD137 항체는 2개의 scFv를 포함하는 직렬 2-scFv(본문에서 “직렬2-scFv이중 특이적 항CD137 항체”로 지칭됨)이다. 직렬 2-scFv 이중 특이적 항CD137 항체는 임의의 배열로 조립된 VH 및 VL을 가질 수 있고, 예를 들어 하기에 나열된 배열(N-말단에서 C-말단으로)을 가질 수 있으며, 여기서 X는 제2 scFv에 의해 결합된 제2 항원이고, L1, L2, 및 L3은 임의의 링커(예를 들어 펩티드 링커)이다. 적용 가능한 모든 링커에 관하여, “링커” 부분을 참조바란다. 일부 실시예에서, 링커(L1, L2 또는 L3)는 SRGGGGSGGGGSGGGGSLEMA의 아미노산 서열을 포함한다. 일부 실시예에서, 링커(L1, L2 또는 L3)는 (GGGGS)n서열 또는 (GGGGS)n서열을 포함하고, 여기서 n은 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 또는 그 이상이다. 일부 실시예에서, 링커(L1, L2 또는 L3)는 TSGGGGS의 아미노산 서열을 포함한다. 일부 실시예에서, 링커(L1, L2 또는 L3)는 GEGTSTGSGGSGGSGGAD의 아미노산 서열을 포함한다.
VL(CD137)-L1-VH(CD137)-L2-VL(X)-L3-VH(X);
VL(CD137)-L1-VH(CD137)-L2-VH(X)-L3-VL(X);
VH(CD137)-L1-VL(CD137)-L2-VL(X)-L3-VH(X);
VH(CD137)-L1-VL(CD137)-L2-VH(X)-L3-VL(X);
VL(X)-L1-VH(X)-L2-VL(CD137)-L3-VH(CD137);
VL(X)-L1-VH(X)-L2-VH(CD137)-L3-VL(CD137);
VH(X)-L1-VL(X)-L2-VL(CD137)-L3-VH(CD137);
VH(X)-L1-VL(X)-L2-VH(CD137)-L3-VL(CD137);
VL(CD137)-L1-VH(X)-L2-VL(X)-L3-VH(CD137);
VL(CD137)-L1-VL(X)-L2-VH(X)-L3-VH(CD137);
VH(CD137)-L1-VH(X)-L2-VL(X)-L3-VL(CD137);
VH(CD137)-L1-VL(X)-L2-VH(X)-L3-VL(CD137);
VL(X)-L1-VH(CD137)-L2-VL(CD137)-L3-VH(X);
VL(X)-L1-VL(CD137)-L2-VH(CD137)-L3-VH(X);
VH(X)-L1-VH(CD137)-L2-VL(CD137)-L3-VL(X); 또는
VH(X)-L1-VL(CD137)-L2-VH(CD137)-L3-VL(X).
o) 링커
일부 실시예에서, 본문에 서술된 항CD137 작제물은 2개의 부분(예를 들어, 본문에 서술된 이중 특이성 항체에서의 항CD137 항체 부분 및 반감기 연장 부분, 항CD137 scFv 및 전장 항체) 사이에 하나 또는 다수의 링커를 포함한다. 이중 특이성 항체에 사용된 하나 또는 다수의 링커의 길이, 유연성 및/또는 다른 특성은 특성에 일부 영향을 미칠 수 있고, 상기 특성은 하나 또는 여러가지 특정 항원 또는 에피토프에 대한 친화력, 특이성 또는 친화력을 포함하지만 이에 한정되지 않는다. 예를 들어, 2개의 인접한 도메인이 서로 공간 상에서 간섭하지 않도록 더 긴 링커를 선택할 수 있다. 몇몇 실시예에서, 링커(예를 들어펩티드 링커)는 인접한 도메인이 서로에 대해 자유롭게 이동하도록 가요성 잔기(예를 들어 글리신 및 세린)를 포함한다. 예를 들어, 글리신-세린 더를릿(doublet)은 적합한 펩티드 링커일 수 있다. 일부 실시예에서, 링커는 비펩티드 링커이다. 일부 실시예에서, 링커는 펩티드 링커이다. 일부 실시예에서, 링커는 분해 불가한 링커이다. 일부 실시예에서, 링커는 분해 가능한 링커이다.
다른 링커 고려 인소로 얻은 화합물의 물리적 또는 약동학적 특성의 영향을 포함하고, 예를 들어 용해도, 친유성, 친수성, 소수성, 안정성(더 안정적이거나 덜 안정적이고 계획된 분해), 강성, 유연성, 면역원성, 항체 결합의 조절, 미셀 또는 리포솜 도핑 능력 등을 포함한다.
2개 부분의 커플링은 하기 임의의 화학 반응에 의해 완성될 수 있다. 상기 화학 반응은 두 성분이 모두 각각의 활성을 유지하는 한, 2개의 분자를 이중 특이성 항체에 결합시키고, 예를 들어, 각각 CD137 및 제2 항원에 결합시킨다. 상기 커플링은 공유 결합, 친화력 결합, 삽입, 배위 결합 및 복합화와 같은 많은 화학적 메커니즘을 포함할 수 있다. 일부 실시예에서, 결합은 공유 결합이다. 공유 결합은 기존 측쇄의 직접 축합 또는 외부 가교 분자의 통합에 의해 구현될 수 있다. 이러한 경우, 많은 2가 또는 다가 링커제는 단백질 분자의 커플링에 사용될 수 있다. 예를 들어, 대표적인 커플링제로 티오에스테르, 카르보디이미드(carbodiimides), 숙신이미드 에스테르(succinimide esters), 디이소시아네이트(diisocyanates), 글루타르알데히드(glutaraldehyde), 디아조벤젠(diazobenzenes) 및 헥사메틸렌디아민(hexamethylene diamines)과 같은 유기 화합물을 포함할 수 있다. 상기 목록은 본 분야에 알려진 다양한 커플링제를 완전하게 하려는 것이 아니며, 보다 일반적인 커플링제의 예시이다(Killen 및 Lindstrom, Jour.Immun. 133: 1335-2549 (1984); Jansen et al., Immunological Reviews 62: 185-216 (1982); 및 Vitetta et al., Science 238: 1098 (1987) 참조).
본 출원에서 사용될 수 있는 링커는 문헌에 서술되어 있고(예를 들어, Ramakrishnan, S. et al., Cancer Res. 44: 201-208 (1984) 참조), MBS(M-말레이미도 벤조일-N-히드록시숙신이미드)의 용도에 대해 설명하였다. 일부 실시예에서, 본문에 사용된 비펩티드 링커는 (i) EDC(1-에틸-3-(3-디메틸아미노-프로필)카르보디이미드 염산염; (ii) SMPT(4-숙신이미딜옥시카르보닐-α-메틸-α-(2-피리딜-디티오)-톨루엔(Pierce Chem. Co., 카탈로그 번호(21558G); (iii) SPDP(숙신이미드 아미노-6[3-(2-피리딜디티오)프로피온이미도]헥사노에이트(Pierce Chem. Co, 카탈로그 번호#21651G); (iv) 설포-LC-SPDP(설포숙신이미드 6 [3-(2-피리딜디티오)프로피온아미드]헥사노에이트(Pierce Chem. Co, 카탈로그 번호#2165-G); 및 (v) EDC에 접합된 설포-NHS (N-히드록시설포-숙신이미드: Pierce Chem. Co, 카탈로그 번호#24510)를 포함한다.
본문에 서술된 링커는 상이한 속성을 갖는 성분을 포함하므로, 상이한 물리화학적 특성을 갖는 이중 특이성 항체를 생성할 수 있다. 예를 들어, 알킬 카르복실레이트의 설포-NHS 에스테르는 방향족 카르복실레이트의 설포-NHS 에스테르보다 더 안정적이다. NHS 에스테르를 포함하는 링커의 용해성은 설포-NHS 에스테르만 못하다. 이 외에, 링커SMPT는 공간 상에서 제한받는 이황화 결합을 포함하고, 안정성이 증강된 항체 융합 단백질을 형성할 수 있다. 이황화 결합은 체외에서 절단되어 사용 가능한 항체 융합 단백질이 적기 때문에, 통상적으로 다른 결합보다 안정적이 못하다. 특히, 설포-NHS는 카르보디이미드 커플링의 안정성을 향상시킬 수 있다. 설포-NHS와 함께 사용하는 경우 카르보디이미드 커플링(예를 들어 EDC)은 카르보디이미드 커플링 단독보다 가수분해에 더 강한 에스테르를 형성한다.
펩티드 링커는 천연적으로 존재하는 서열 또는 비천연적으로 존재하는 서열을 가질 수 있다. 예를 들어, 중쇄의 항체만을 갖는 힌지 영역으로부터 유래된 서열을 링커로 사용할 수 있다. 예를 들어, WO 1996/34103을 참조바란다.
펩티드 링커는 임의의 적합한 길이를 가질 수 있다. 일부 실시예에서, 펩티드 링커의 길이는 적어도 약 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 25, 30, 35, 40, 50, 75, 100개 또는 그 이상의 아미노산 중의 하나이다. 일부 실시예에서, 펩티드 링커의 길이는약 100, 75, 50, 40, 35, 30, 25, 20, 19, 18, 17, 16, 15, 14, 13, 12, 11, 10, 9, 8, 7, 6, 5개 또는 그 이하의 아미노산 중의 하나를 초과하지 않는다. 일부 실시예에서, 펩티드 링커의 길이는 약 1개의 아미노산 내지 약 10개의 아미노산, 약 1개의 아미노산 내지 약 20개의 아미노산, 약 1개의 아미노산 내지 약 30개의 아미노산, 약 5개의 아미노산 내지 약 15개의 아미노산, 약 10개의 아미노산 내지 약 25개의 아미노산, 약 5개의 아미노산 내지 약30개의 아미노산, 약 10개의 아미노산 내지 약30개의 아미노산 길이, 약 30개의 아미노산 내지 약50개의 아미노산, 약 50개의 아미노산 내지 약100개의 아미노산, 또는 약 1개의 아미노산 내지 약 100개의 아미노산 중의 임의의 하나이다.
이러한 펩티드 링커의 기본 기술 특징은 상기 펩티드 링커가 임의의 중합 활성을 포함하지 않는다는 것이다. 펩티드 링커의 특징(2차 구조 촉진 작용 결실을 포함)은 본 분야에 공지되어 있고, 예를 들어 Dall’Acqua et al. (Biochem. (1998) 37, 9266-9273), Cheadle et al. (Mol Immunol (1992) 29, 21-30) 및 Raag 및 Whitlow (FASEB (1995)9(1), 73-80)에 서술되어 있다. “펩티드 링커”의 경우, 특히 바람직한 아미노산은 Gly이다. 이 외에, 임의의 2차 구조를 촉진하지 않는 펩티드 링커도 바람직하다. 도메인 간의 연결은 예를 들어 유전자 공학에 의해 제공될 수 있다. 융합되고 작동 가능하게 연결된 이중 특이적 단일쇄 작제물을 제조하고 이를 포유동물 세포 또는 박테리아에서 발현시키는 방법은 본 분야에 공지되어 있다(예를 들어, WO 99/54440, Ausubel, Current Protocols in Molecular Biology, Green Publishing Associates and Wiley Interscience], 뉴욕 1989년 및 1994년 또는 Sambrook et al., Molecular Cloning: A Laboratory Manual, Cold Spring Harbor Laboratory Press, Cold Spring Harbor, 뉴욕, 2001년).
펩티드 링커는 안정적인 링커일 수 있고, 특히 매트릭스 메탈로프로티나제(MMP)와 같은 프로테아제에 의해 절단될 수 없는 안정한 링커일 수 있다.
상기 링커는 가요성 링커일 수 있다. 예시적 가요성 링커는 글리신 중합체(G)n, 글리신-세린 중합체(예를 들어, (GS)n, (GSGGS)n, (GGGGS)n 및 (GGGS)n를 포함하고, 여기서 n은 적어도 1인 정수임), 글리신-알라닌 중합체, 알라닌-세린 중합체 및 본 분야에 공지된 다른 가요성 링커를 포함한다. 글리신 및 글리신-세린 중합체는 상대적으로 구조화되지 않았으므로 구성 요소 사이의 중성 테더 역할을 할 수 있다. 글리신은 알라닌보다 훨씬 더 많은 phi-psi 공간에 들어가고 더 긴 측쇄를 갖는 잔기보다 받는 제한이 훨씬 적다(Scheraga, Rev. Computational Chem. 11 173-142 (1992) 참조). 통상의 기술자들은 항체 융합 단백질의 디자인이 전부 또는 부분적으로 유연한 링커를 포함할 수 있어, 링커가 유연성 링커 및 적은 유연성 구조를 부여하여 원하는 항체 융합 단백질 구조를 제공하는 하나 이상의 부분을 포함할 수 있다는 것을 인식할 것이다.
p) 면역 접합체
본문에 제공된 면역 접합체를 더 포함하고, 상기 면역 접합체는 치료제 또는 마커에 연결된 본문에 따른 임의의 항CD137 작제물(예를 들어 다중 특이적 항체)을 포함한다. 일부 실시예에서, 상기 마커는 방사성 동위원소, 형광 염료 및 효소로 이루어진 군으로부터 선택된다.
q) 핵산
또한 본문에 따른 항CD137 작제물 또는 항CD137 항체 부분을 코딩하는 핵산이 고려된다. 일부 실시예에서, 전장 항CD137 항체를 코딩하는 핵산(또는 한 세트 핵산)이 제공된다. 일부 실시예에서, 항CD137 scFv를 코딩하는 핵산(또는 한 세트 핵산)이 제공된다. 일부 실시예에서, 항CD137 Fc융합 단백질을 코딩하는 핵산(또는 한 세트 핵산)이 제공된다. 일부 실시예에서, 다중 특이적 항CD137 분자(예를 들어, 다중 특이적 항CD137 항체 또는 이중 특이적 항CD137 항체) 또는 이의 폴리펩티드 부분의 핵산(또는 한 세트 핵산)이 제공된다. 일부 실시예에서, 본문에 따른 항CD137 작제물을 코딩하는 핵산(또는 한 세트 핵산)은 펩티드 태그(예를 들어 단백질 정제 태그, 예를 들어, His태그, HA태그)를 코딩하는 핵산 서열을 추가로 포함할 수 있다.
항CD137 작제물을 포함하는 단리된 숙주 세포, 항CD137 작제물 폴리펩티드 성분을 코딩하는 단리된 핵산, 또는 본문에 따른 항CD137 작제물 폴리펩티드 성분을 코딩하는 핵산을 포함하는 벡터가 또한 본문에서 고려된다.
본 출원은 이러한 핵산 서열의 변이체를 포함한다. 예를 들어, 상기 변이체는 적어도 중등으로 엄격한 혼성화 조건에서 본 출원의 항CD137 작제물 또는 항CD137 항체 부분을 코딩하는 핵산 서열과 혼성화된 뉴클레오티드 서열을 포함한다.
본 발명은 또한 본 발명의 핵산이 삽입된 벡터를 더 제공한다.
표준 유전자 전달 방안을 사용하여, 본 발명의 핵산은 또한 핵산 면역 및 유전자 요법에 사용될 수 있다. 유전자 전달 방법은 본 분야에 공지되어 있다. 예를 들어, 미국특허번호 5,399,346, 5,580,859, 5,589,466의 전체 내용은 참조로서 본문에 포함된다. 일부 실시예에서, 본 발명에서 유전자 요법 벡터를 제공한다.
핵산을 여러 유형의 벡터에 클론할 수 있다. 예를 들어, 핵산을 벡터에 클론할 수 있고, 상기 벡터는 플라스미드, 파스미드, 파지 유도체, 동물 바이러스 및 코스미드를 포함하지만 이에 한정되지 않는다. 특히 관심 있는 벡터에 발현 벡터, 복제 벡터, 프로브 생성 벡터 및 시퀀싱 벡터를 포함한다.
이 외에, 발현 벡터를 바이러스 벡터의 형태로 세포에 제공할 수 있다. 바이러스 벡터 기술은 본 분야에 잘 알려져 있고, 예를 들어 Sambrook et al.(2001, Molecular Cloning: A Laboratory Manual, Cold Spring Harbor Laboratory, New York), 및 기타 바이러스학 및 분자 생물학 매뉴얼에 서술되어 있다. 벡터로 사용 가능한 바이러스는 레트로바이러스, 아데노바이러스, 아데노 관련 바이러스, 헤르페스바이러스 및 렌티바이러스를 포함하지만 이에 한정되지 않는다. 통상적으로, 적합한 벡터는 적어도 하나의 유기체에서 작용하는 복제 기점, 프로모터 서열, 편리한 제한 엔도뉴클레아제 부위, 및 하나 이상의 선택 가능한 표지를 함유한다(예를 들어, WO 01/96584; WO 01/29058; 및 미국특허번호 6, 326, 193참조).
III.
제조 방법
일부 실시예에서, CD137에 결합되는 항CD137 작제물 또는 항체 부분을 제조하는 방법, 및 폴리뉴클레오티드, 핵산 작제물, 벡터, 숙주 세포 또는 배지와 같은 상기 항CD137 작제물 또는 항체 부분을 제조하는 과정에서 생성된 조성물을 제공한다. 본문에 따른 항CD137 작제물 또는 항체 부분 또는 조성물은 일반적인 다양한 방법으로 제조될 수 있고, 구현예에서 더욱 구체적으로 서술된다.
항체 발현과 생성
본문에 따른 항체(항CD137 모노클로날 항체, 항CD137이중 특이성 항체 및 항CD137 항체 부분 포함)는 본 분야의 임의의 공지된 방법으로 제조될 수 있고, 하기 및 구현예에 따른 방법을 포함한다.
모노클로날 항체
모노클로날 항체는 기본적으로 균질한 항체 집단으로부터 수득되고, 즉 소량으로 존재하는 자연적으로 돌연변이 및/또는 번역 후 변형(예를 들어, 이성질화, 아미드화)될 수 있는 것을 제외하고, 상기 집단을 이루는 각각의 항체는 동일한 것이다. 따라서, 상기 수식어 “단일 클론”은 상기 항체의 특징이 분리된 항체가 아닌 혼합물을 나타낸다. 예를 들어, 상기 모노클로날 항체는 먼저 Kohler et al.(Nature, 256: 495 (1975))에 서술된 하이브리드도마 방법을 사용하여 제조할 수 있거나, 재조합 DNA방법으로 제조할 수 있다(미국특허번호 4,816,567). 상기 하이브리도마 방법에서, 마우스 또는 햄스터 또는 라마와 같은 다른 적합한 숙주 동물은 면역용 단백질에 특이적으로 결합될 항체를 생산하거나 생산할 수 있는 림프구를 유도하기 위해 전술한 바와 같이 면역화된다. 대안적으로, 림프구는 체외에서 면역될 수 있다. 다음, 적합한 융합제(예를 들어 폴리에틸렌 글리콜)를 사용하여 림프구와 골수종 세포를 융합하여 하이브리도마세포를 형성한다(Goding, Monoclonal Antibodies: Principles and Practice, 제59-103페이지 (Academic Press, 1986)). 또한 구현예 1에서의 낙타 면역을 참조바란다.
상기 면역제는 전형적으로 항원 단백질 또는 이의 융합 변이체를 포함한다. 통상적으로, 인간화 세포를 원하는 경우, 말초 혈액 림프구(“PBL”)를 사용하고, 또는 비인간 포유동물 래원을 원하는 경우, 비장세포 또는 림프절 세포를 사용한다. 다음, 적합한 융합제(예를 들어 폴리에틸렌 글리콜)를 사용하여 림프구와 불멸 세포주를 융합하여, 하이브리도마 세포를 형성한다. (Goding, Monoclonal Antibodies: Principles and Practice, (Academic Press, 1986), 제59-103페이지).
불멸화 세포주는 통상적으로 형질전환된 포유동물 세포이고, 특히, 설치류 동물, 소 및 인간화 골수종 세포이다. 통상적으로, 래트 또는 마우스 골수종 세포주를 사용한다. 이에 의해 제조된 하이브리도마 세포는 적합한 배지에 접종되어 성장되고, 바람직하게 상기 배지는 억제 융합되지 않은 모골수종 세포의 성장 또는 생존을 억제하는 하나 또는 여러가지 물질을 포함한다. 예를 들어, 모골수종 세포에서 하이포잔틴 구아닌 포스포리보실 트랜스퍼라제(HGPRT 또는 HPRT) 효소가 부족한 경우, 하이브리도마의 배지는 전형적으로 하이포잔틴, 아미노프테린 및 티미딘(HAT 배지)을 포함하며, 이들은 HGPRT 결핍형 세포의 성장을 억제하는 물질이다.
바람직한 불멸화 골수종 주세포는 효율적으로 융합하고, 선택된 항체 생산 세포에 의한 항체의 안정적인 고수준 생산을 지원하며, 배지(예를 들어 HAT 배지)에 민감한 것들이다. 여기서, 바람직한 뮤린의 골수종 주세포는, 미국 캘리포니아주 샌디에이고 Salk Institute Cell Distribution Center에서 수득된 MOPC-21 및 MPC-11마우스 종양, 및 미국 버지니아주 마나사스의 American Type Culture Collection에서 수득된 SP-2세포(및 이의 유도체, 예를 들어 X63-Ag8-653)로부터의 세포주이다. 인간골수종 및 마우스-인간 이종 골수종 주세포 또한 모노클로날 항체의 생성에 서술되어 있다(Kozbor, J. Immunol., 133: 3001 (1984); Brodeur et al., Monoclonal Antibody Production Techniques and Applications, pp. 51-63 (Marcel Dekker, Inc., New York, 1987)).
하이브리도마 세포가 성장하는 배지에서 항원에 대한 모노클로날 항체의 생산을 측정하였다. 바람직하게, 하이브리도마 세포에 의해 생성된 모노클로날 항체의 결합 특이성은 면역침전에 의하거나 방사성 면역 측정(RIA) 또는 효소결합면역흡착측정(ELISA)과 같은 체외 결합 측정에 의해 측정된다.
하이브리도마 세포를 배양하는 배지에서 원하는 항원에 대한 모노클로날 항체의 존재 여부를 측정할 수 있다. 바람직하게, 모노클로날 항체의 결합 친화력 및 특이성은 면역침전에 의하거나 방사성 면역 측정법(RIA) 또는 효소결합측정법(ELISA)과 같은 체외 결합 측정에 의해 측정할 수 있다. 이러한 기술 및 측정은 본 분야에 공지되어 있다. 예를 들어, 결합 친화력은 Munson et al., Anal. Biochem.], 107: 220 (1980)의 Scatchard 분석에 의해 확정될 수 있다.
원하는 특이성, 친화력 및/또는 활성의 항체를 생산할 수 있는 하이브리도마 세포를 검증한 후, 클론은 제한적인 희석 절차에 의해 서브클로닝되고, 표준 방법에 의해 배양한다(Goding, 상기와 같음). 상기 목적에 사용되는 적합한 배지는 예를 들어D-MEM 또는 RPMI-1640 배지를 포함한다. 이 외에, 하이브리도마 세포는 포유동물의 체내에서 종양으로서 성장될 수 있다.
통상적인 면역글로블린 정제 절차(예를 들어 단백질A-아가로스, 수산화인회석 크로마토그래피, 겔 전기영동, 투석 또는 친화성 크로마토그래피)를 통해, 서브클론에 의해 분비되는 모노클로날 항체는 배지, 복수액 또는 혈청으로부터 적절하게 단리된다.
모노클로날 항체는 미국특허번호 4,816,567에 서술되고 본문에 기재된 바와 같은 재조합 DNA방법에 의해 제조될 수 있다. 모노클로날 항체를 코딩하는 DNA는 통상적인 절차를 통해 (예를 들어, 뮤린 항체를 코딩하는 중쇄 및 경쇄의 유전자에 특이적으로 결합할 수 있는 올리고뉴클레오티드 프로브를 사용함으로써) 용이하게 단리되고 시퀀싱된다. 하이브리도마 세포는 이러한 DNA의 바람직한 래원으로 사용된다. 일단 단리되면, DNA는 발현 벡터에 배치될 수 있고, 다음 이러한 벡터를 면역글로블린을 별도로 생성하지 않는 숙주 세포(예를 들어 대장간균 세포, 유인원COS세포, 중국 햄스터 난소(CHO) 세포 또는 골수종 세포)로 형질감염시켜, 이러한 재조합 숙주 세포에서 모노클로날 항체를 합성한다. 박테리아에서 항체를 코딩하는 DNA의 재조합 발현에 관한 리뷰 문장으로 Skerra et al., Curr. Opinion in Immunol., 5: 256-262 (1993) 및 Pl ckthun, Immunol. Revs. 130:151-188 (1992)을 포함한다.
ckthun, Immunol. Revs. 130:151-188 (1992)을 포함한다.
다른 하나의 실시예에서, McCafferty et al., Nature, 348: 552-554 (1990)에 서술된 기술을 이용하여 생성된 항체 파지 라이브러리로부터 항체를 단리할 수 있다. Clackson et al., Nature, 352: 624-628 (1991) 및 Marks et al., J. Mol. Biol., 222: 581-597 (1991)은 각각 파지 라이브러리를 사용한 뮤린 및 인간 항체의 단리를 서술하였다. 후속 간행물은 사슬 셔플링을 통해(Marks et al., Bio/Technology, 10: 779-783 (1992), 조합 감염 및 체내 재조합을 초대형 파지 라이브러리를 구축하는 것을 전략으로(Waterhouse et al., Nucl. Acids Res., 21: 2265-2266 (1993)) 높은 친화력의 (nM 범위) 인간 항체를 생성하는 것을 서술하였다. 따라서, 이러한 기술은 모노클로날 항체를 단리하기 위한 기존의 모노클로날 항체 하이브리도마 기술에 대한 실행 가능한 대안이다.
DNA는 또한 예를 들어 상동 뮤린 서열을 인간 중쇄 및 경쇄 불변 도메인의 코딩 서열로 대체함으로써 변형될 수 있거나(미국특허번호 4,816,567; Morrison, et al., Proc. Natl Acad. Sci. USA, 81: 6851 (1984)), 또는 비-면역글로불린 폴리펩티드 코딩 서열의 전부 또는 일부를 면역글로불린 코딩 서열에 공유 결합함으로써 변형될 수 있다. 통상적으로, 이러한 비면역글로불린 폴리펩티드는 항체의 불변 도메인을 대체하거나 항체의 항원 결합 부위 중 하나의 가변 도메인을 대체하여, 키메라 2가 항체를 생성하고, 상기 키메라 2가 항체 항원에 대해 특이성이 있는 하나의 항원 결합 부위와 상이한 항원에 대해 특이성이 있는 다른 하나의 항원 결합 부위를 포함한다.
본문에 따른 모노클로날 항체는 1가일 수 있고, 이의 제조는 본 분야에 공지되어 있다. 예를 들어, 하나의 방법은 면역글로블린 경쇄 및 변형된 중쇄의 재조합 발현에 관한 것이다. 통상적으로 중쇄의 가교를 방지하기 위해 Fc영역에서의 임의의 포인트에서 중쇄가 절단된다. 대안적으로, 관련된 시스테인 잔기는 다른 하나의 아미노산 잔기에 의해 치환되거나 가교 방지를 위해 삭제될 수 있다. 체외 방법은 1가 항체의 제조에도 적합하다. 본 분야에 공지된 통상적인 기술을 이용하여 항체를 소화시켜 이의 단편(특히 Fab단편)을 생성할 수 있다.
키메라 또는 이형 접합 항체는 또한 합성 단백질 화학에서 공지된 방법(가교제에 관한 방법 포함)을 사용하여 체외에서 제조될 수 있다. 예를 들어, 면역독소는 이황화 결합 교환 반응을 사용하거나 티오에테르 결합의 형성에 의해 구성될 수 있다. 상기 목적에 사용되는 적합한 시약의 구현예로 이미노티올레이트(iminothiolate) 및 메틸-4-메르캅토부티르이미데이트(methyl-4-mercaptobutyrimidate)를 포함한다.
이 외에, 모노클로날 항체의 생산에 관하여 구현예를 참조바란다.
다중 특이적 항체
본문에서 또한 본문에 따른 다중 특이적 항체(예를 들어, 이중 특이성 항체)를 제조하는 방법을 제공한다. 본 분야에 공지되거나 본문에 기재된 임의의 방법(예를 들어 구현예 1 및 3)을 이용하여 다중 특이적 항체를 제조할 수 있다.
본 출원의 다중 특이적 항체를 제조하는 방법은 WO 2008119353 (Genmab 회사), WO 2011131746 (Genmab 회사) 및 van der Neut-Kolfschoten et al., (Science. 2007년 9월 14일; 317(5844): 1554-7)의 보도에 서술된 것들을 포함한다. 이중 특이성 항체를 제조하기 위한 다른 플랫폼의 실시예로 BiTE (Micromet 회사), DART (MacroGenics 회사), Fcab 및 Mab2 (F-star 회사), Fc조작된 IgGl(Xencor 회사) 또는 DuoBody를 포함하지만 이에 한정되지 않는다.
전통적인 방법, 예를 들어 상기 하이브리드 하이브리도마 및 화학적 접합 방법(Marvin 및 Zhu (2005) Acta Pharmacol Sin 26 : 649)을 사용할 수도 있다. 숙주 세포에서 2가지 성분의 공동 발현(예를 들어 항CD137 scFv에 융합된 항 종양 관련 항원 전장 항체의 중쇄 및 항종양 관련 항원 항체의 경쇄)은 원하는 이중특이성 항체 외에 항체 생성물의 혼합물이 존재할 수 있으며, 상기 다중 특이정 창체는 이어서 예를 들어 친화성 크로마토그래피 등에 의해 단리될 수 있다.
항체 부분을 코딩하는 핵산 분자
일부 실시예에서, 본문에 따른 항CD137 작제물 또는 항체 부분 중의 임의의 하나를 코딩하는 폴리뉴클레오티드를 제공하였다. 일부 실시예에서, 본문에 따른 임의의 하나의 방법으로 제조된 폴리뉴클레오티드를 제공하였다. 일부 실시예에서, 핵산 분자는 항체 부분(예를 들어, 항CD137 항체 부분)의 중쇄 또는 경쇄를 코딩하는 폴리뉴클레오티드를 포함한다. 일부 실시예에서, 핵산 분자는 항체 부분(예를 들어, 항CD137 항체 부분)의 중쇄 및 경쇄를 코딩하는 폴리뉴클레오티드를 포함한다. 일부 실시예에서, 제1 핵산 분자는 중쇄를 코딩하는 제1 폴리뉴클레오티드를 포함하고, 제2 핵산 분자는 경쇄를 코딩하는 제2 폴리뉴클레오티드를 포함한다. 일부 실시예에서, scFv(예를 들어, 항CD137 scFv)를 코딩하는 핵산 분자를 제공하였다.
일부 이러한 실시예에서, 상기 중쇄 및 경쇄는 하나의 핵산 분자 또는 2개의 단리된 핵산 분자로부터 2개의 단리된 폴리펩티드로 발현된다. 일부 실시예에서, 예를 들어, 항체가 scFv인 경우, 단일 폴리뉴클레오티드는 함께 연결된 중쇄 및 경쇄를 포함하는 단일 폴리펩티드를 코딩한다.
일부 실시예에서, 항체 부분(예를 들어, 항CD137 항체 부분)의 중쇄 또는 경쇄를 코딩하는 폴리뉴클레오티드는 리더 서열을 코딩하는 뉴클레오타이드 서열을 포함하고, 상기 리더 서열은 번역될 때 상기 중쇄 또는 경쇄의 N-말단에 위치한다. 상술된 바와 같이, 상기 리더 서열은 천연적인 중쇄 또는 경쇄 리더 서열일 수 있거나, 다른 이종 리더 서열일 수 있다.
일부 실시예에서, 상기 폴리뉴클레오티드는 DNA이다. 일부 실시예에서, 상기 폴리뉴클레오티드는 RNA이다. 일부 실시예에서, 상기 RNA는 mRNA이다.
핵산 분자는 본 분야에서 통상적인 재조합 DNA 기술을 사용하여 구축될 수 있다. 일부 실시예에서, 핵산 분자는 선택된 숙주 세포에서의 발현에 적합한 발현 벡터이다.
핵산 작제물
일부 실시예에서, 본문에 따른 임의의 폴리뉴클레오티드를 포함하는 핵산 작제물을 제공한다. 일부 실시예에서, 본문에 따른 임의의 방법으로 제조된 핵산 작제물을 제공한다.
일부 실시예에서, 상기 핵산 작제물은 폴리뉴클레오티드에 작동 가능하게 연결된 프로모터를 추가로 포함한다. 일부 실시예에서, 폴리뉴클레오티드는 유전자에 상응하고, 여기서 프로모터는 유전자의 야생형 프로모터이다.
벡터
일부 실시예에서, 본문에 따른 임의의 항체 부분(예를 들어, 항CD137 항체 부분)의 중쇄 및/또는 경쇄를 코딩하는 임의의 폴리뉴클레오티드 또는 본문에 따른 핵산 작제물을 포함하는 벡터를 제공한다. 일부 실시예에서, 본문에 따른 임의의 방법으로 제조된 벡터를 제공한다. 또한 임의의 항CD137 작제물(예를 들어, 항체, scFv, 융합 단백질, 또는 본문에 기재된 다른 형태의 작제물(예를 들어 항CD137 scFv))을 코딩하는 폴리뉴클레오티드를 포함하는 벡터를 제공한다. 이러한 벡터는 DNA 벡터, 파지 벡터, 바이러스 벡터, 레트로바이러스 벡터 등을 포함하지만 이에 제한되지 않는다. 일부 실시예에서, 벡터는 중쇄를 코딩하는 제1 폴리뉴클레오티드 서열 및 경쇄를 코딩하는 제2 폴리뉴클레오티드 서열을 포함한다. 일부 실시예에서, 상기 중쇄 및 경쇄는 벡터에서 2개의 단리된 폴리펩티드로 발현된다. 일부 실시예에서, 상기 중쇄 및 경쇄는 예를 들어 항체가 scFv인 경우와 같이 단일 폴리펩티드의 일부로서 발현된다.
일부 실시예에서, 제1 벡터는 중쇄를 코딩하는 폴리뉴클레오티드를 포함하고, 제2 벡터는 경쇄를 코딩하는 폴리뉴클레오티드를 포함한다. 일부 실시예에서, 제1 벡터 및 제2 벡터는 유사한 양(예를 들어, 유사한 몰량 또는 유사한 질량)으로 숙주 세포 내로 형질감염된다. 일부 실시예에서, 제1 벡터 및 제2 벡터는 5 : 1 내지 1 : 5의 몰비 또는 질량비로 숙주 세포에 형질감염된다. 일부 실시예에서, 중쇄를 코딩하는 벡터 및 경쇄를 코딩하는 벡터에 관하여, 1 : 1 내지 1 : 5 사이의 질량비를 사용한다. 일부 실시예에서, 중쇄를 코딩하는 벡터 및 경쇄를 코딩하는 벡터에 관하여, 1 : 2 사이의 질량비를 사용한다.
일부 실시예에서, CHO 또는 CHO 유래 세포 또는 NSO 세포에서 폴리펩티드 발현을 위해 최적화된 벡터가 선택된다. 예시적인 이러한 벡터는 예를 들어 Running Deer et al., Biotechnol. Prog. 20:880-889 (2004)에 서술되어 있다.
숙주 세포
일부 실시예에서, 본문에 따른 임의의 폴리펩티드, 핵산 작제물 및/또는 벡터를 포함하는 숙주 세포를 제공한다. 일부 실시예에서, 본문에 따른 임의의 방법으로 제조된 숙주 세포를 제공한다. 일부 실시예에서, 숙주 세포는 발효 조건 하에 본문에 기재된 임의의 항체 부분을 생산할 수 있다.
일부 실시예에서, 본문에 따른 항체 부분(예를 들어, 항CD137 항체 부분)은 원핵 세포(예를 들어, 박테리아 세포); 또는 진핵 세포(예를 들어, 진균 세포(예를 들어, 효모), 식물 세포, 곤충 세포 및 포유류 세포)에서 발현될 수 있다. 이러한 발현은 예를 들어 본 분야에 공지된 절차에 따라 수행될 수 있다. 폴리펩티드를 발현할 수 있는 예시적 진핵 세포는 COS세포(COS 7세포 포함); 293세포(293-6E세포 포함); CHO세포(CHO-S, DG44, Lec13 CHO세포 및 FUT8 CHO세포 포함); PER.C6®세포(Crucell); 및 NSO세포를 포함하지만 이에 한정되지 않는다. 일부 실시예에서, 본문에 따른 항체 부분(예를 들어, 항CD137 항체 부분)은 효모에서 발현될 수 있다. 예를 들어, 미국공개번호 US 2006/0270045 A1을 참조바란다. 일부 실시예에서, 특정 진핵 숙주 세포는 항체 부분의 중쇄 및/또는 경쇄에 대해 원하는 번역 후 변형되는 능력에 기반하여 선택된다. 예를 들어, 일부 실시예에서, CHO세포에 의해 생산된 폴리펩티드는 293 세포에서 생산된 동일한 폴리펩티드보다 더 높은 수준의 시알화 수준을 갖는다.
원하는 숙주 세포 내로 하나 이상의 핵산의 도입은 인산칼슘 형질감염, DEAE-덱스트란 매개 형질감염, 양이온성 지질 매개 형질감염, 전기천공, 형질도입, 감염 등을 포함하나 이에 제한되지 않는 임의의 방법에 의해 완성될 수 있다. 비제한적인 예시적인 방법은 예를 들어 Sambrook et al., Molecular Cloning, A Laboratory Manual, 제3판. Cold Spring Harbor Laboratory Press (2001)에 서술되었다. 핵산은 임의의 적합한 방법에 따라 원하는 숙주 세포에서 일시적으로 또는 안정적으로 형질감염될 수 있다.
본 발명은 또한 본문에 기재된 임의의 폴리뉴클레오티드 또는 벡터를 포함하는 숙주 세포를 제공한다. 일부 실시예에서, 본 발명은 항CD137 항체를 포함하는 숙주 세포를 제공한다. 이종 DNA를 과발현할 수 있는 임의의 숙주 세포는 목적 항체, 폴리펩티드 또는 단백질을 코딩하는 유전자를 단리할 목적으로 사용될 수 있다. 포유동물 숙주 세포의 비제한적인 실시예는 COS, HeLa 및 CHO 세포를 포함하지만 이에 한정되지는 않는다. 또한 PCT 공개 번호 WO 87/04462를 참조바란다. 적합한 비포유동물 숙주 세포는 원핵생물(예를 들어 대장간균 또는 고초균) 및 효모(예를 들어 출아형효모(S. cerevisae), 분열효모(S. pombe); 또는 크루이베로마이스 락티스(K. lactis))를 포함한다.
일부 실시예에서, 상기 항체 부분은 무세포 시스템에서 생산된다. 비제한적인 예시적인 무세포 시스템은 예를 들어 Sitaraman et al., Methods Mol. Biol. 498: 229-44 (2009); Spirin, Trends Biotechnol. 22: 538-45 (2004); Endo et al., Biotechnol. Adv. 21: 695-713 (2003)에 서술되었다.
배지
일부 실시예에서, 본문에 따른 임의의 항체 부분, 폴리뉴클레오티드, 핵산 작제물, 벡터및/또는숙주 세포를 포함하는 배지를 제공한다. 일부 실시예에서, 본문에 따른 임의의 방법으로 제조된 배지를 제공한다.
일부 실시예에서, 상기 배지는 하이포잔틴, 아미노프테린, 및/또는 티미딘(예를 들어, HAT 배지)을 포함한다. 일부 실시예에서, 상기 배지는 혈청을 포함하지 않는다. 일부 실시예에서, 상기 배지는 혈청을 포함한다. 일부 실시예에서, 상기 배지는 D-MEM 또는 RPMI-1640배지이다.
항체 부분의 정제
항CD137 작제물(예를 들어, 항CD137 모노클로날 항체 또는 이중 특이성 항체)은 임의의 적합한 방법에 의해 정제될 수 있다. 이러한 방법에는 친화성 매트릭스 또는 소수성 상호작용 크로마토그래피의 사용이 포함되지만 이에 한정되지 않는다. 적합한 친화성 리간드는 ROR1 ECD 및 항체 불변 영역에 결합하는 리간드를 포함한다. 예를 들어, 단백질 A, 단백질 G, 단백질 A/G 또는 항체 친화성 컬럼은 불변 영역에 결합하고 Fc 영역을 포함하는 항CD137 작제물을 정제에 사용될 수 있다. 부틸기 또는 페닐기 컬럼과 같은 소수성 상호작용 크로마토그래피는 항체와 같은 특정 폴리펩티드의 정제에도 적합할 수 있다. 이온 교환 크로마토그래피(예를 들어, 음이온 교환 크로마토그래피 및/또는 양이온 교환 크로마토그래피)는 항체와 같은 특정 폴리펩티드의 정제에 적합할 수도 있다. 혼합 모드 크로마토그래피(예를 들어, 역상/음이온 교환, 역상/양이온 교환, 친수성 상호작용/음이온 교환, 친수성 상호작용/양이온 교환 등)는 항체와 같은 특정 폴리펩티드의 정제에 적합할 수도 있다. 폴리펩티드를 정제하는 많은 방법은 본 분야에 공지되어 있다.
IV.
세포 조성물을 조절하는 방법
본문에 기재된 바와 같은 임의의 항CD137 작제물(임의의 다중 특이적 항체 포함)은 세포 조성물(예를 들어, T 세포 조성물)을 조절하는 방법에 사용될 수 있다. 상기 방법은 세포 조성물을 항CD137 작제물과 접촉시키는 것을 포함한다. 일부 실시예에서, 접촉 또는 적어도 일부 접촉은 생체 외에서 수행된다. 일부 실시예에서, 접촉 또는 적어도 일부 접촉은 체내에서 수행된다.
접촉
일부 실시예에서, 상기 접촉은 약제 존재 하에서 수행된다. 일부 실시예에서, 상기 약제는 CD3(예를 들어, 항CD3항체)에 결합된다. 일부 실시예에서, 상기 약제는 CD28(예를 들어, 항CD28항체)에 결합된다. 일부 실시예에서, 상기 약제는 CD3의 약제를 포함하고 CD28에 결합하는 약제를 포함한다. 일부 실시예에서, 상기 약제는 사이토카인(예를 들어, IL-2, IFNγ)이다. 일부 실시예에서, 상기 약제는, CD3에 결합되는 약제, CD28, IL-2, TNF-α 및 IFNγ에 결합되는 약제로 이루어진 군으로부터 선택된 하나 이상의 약제(예를 들어, 1, 2, 3, 4 또는 5개의 약제)를 포함한다. 일부 실시예에서, 상기 약제는 CD3에 결합되는 약제(예를 들어, 항CD3항체), IL-2 및 IFNγ를 포함한다.
일부 실시예에서, 상기 약제(예를 들어, 항CD3항체)의 농도는 적어도 약 0.01 μg/ml, 0.02 μg/ml, 0.03 μg/ml, 0.05 μg/ml, 0.075 μg/ml, 0.1 μg/ml, 0.125 μg/ml, 0.25 μg/ml, 0.5 μg/ml, 또는 1 μg/ml이다.
일부 실시예에서, 상기 접촉은 적어도 약 1시간, 2시간, 4시간, 8시간 또는 밤을 샌다. 일부 실시예에서, 상기 접촉은 적어도 약 1일, 2일 또는 3일 수행된다. 일부 실시예에서, 상기 접촉은 약 24시간, 12시간 또는 8시간 미만으로 수행된다. 일부 실시예에서, 상기 접촉은 약 14일, 10일, 7일, 5일 또는 3일 미만으로 수행된다. 일부 실시예에서, 상기 접촉은 약 0-48시간, 1-24시간, 2-20시간, 4-16시간 또는 8-12시간 수행된다.
일부 실시예에서, 상기 접촉은 약 0-20℃의 온도에서 수행된다. 일부 실시예에서, 상기 접촉은 약 2℃-8℃의 온도에서 수행된다.
세포 조성물
일부 실시예에서, 상기 세포 조성물은 면역 세포(예를 들어, 인간 면역 세포)를 포함한다. 일부 실시예에서, 상기 면역 세포는 T 세포(예를 들어, 농축된 T 세포, 예를 들어, 조성물 내의 세포는 적어도 50%, 60%, 70%, 80%, 90%, 또는 95%의 T 세포를 가짐)를 포함한다. 일부 실시예에서, 상기 T세포는 농축된 CD4+ T세포(예를 들어, 상기 조성물 내의 T세포는 적어도 50%, 60%, 70%, 80%, 90% 또는 95%의 CD4+ T세포를 가짐)이다. 일부 실시예에서, 상기 T세포는 농축된 CD8+ T세포(예를 들어, 상기 조성물 내의 T세포는 적어도 50%, 60%, 70%, 80%, 90% 또는 95%의 CD8+ T세포를 가짐)이다. 일부 실시예에서, 상기 T 세포는 조절 T 세포(Treg 세포)를 포함한다. 예를 들어, 상기 T 세포는 적어도 2.5%, 5%, 7.5%, 10%, 15% 또는 20%의 조절 T 세포를 포함한다. 일부 실시예에서, 상기 T세포는 재조합 수용체(예를 들어, 키메라 항원 수용체)를 포함하는조작된 T세포이다. 일부 실시예에서, 상기 면역 세포는 NK세포(예를 들어, 농축된 NK세포, 예를 들어, 조성물 내의 세포는 적어도 50%, 60%, 70%, 80%, 90%, 또는 95%의 NK세포를 가짐)를 포함한다. 일부 실시예에서, 상기 조성물 내의 세포는 사이토카인 유도 킬러(CIK) 세포를 포함한다. 일부 실시예에서, 상기 세포는 B 세포, 수지상 세포 또는 대식세포와 같은 임의의 하나 이상의 유형의 면역 세포를 포함한다.
일부 실시예에서, 상기 세포는 전처리되거나 약제로 동시에 처리된다. 일부 실시예에서, 상기 약제는 CD3(예를 들어, 항CD3항체)에 결합된다. 일부 실시예에서, 상기 약제는 CD28(예를 들어, 항CD28항체)에 결합된다. 일부 실시예에서, 상기 약제는 CD3의 약제를 포함하고 CD28에 결합하는 약제를 포함한다. 일부 실시예에서, 상기 약제는 사이토카인(예를 들어, IL-2, IFNγ)이다. 일부 실시예에서, 상기 약제는, CD3에 결합되는 약제, CD28, IL-2, TNF-α 및 IFNγ에 결합하는 약제로 이루어진 군으로부터 선택된 하나 이상(예를 들어, 1, 2, 3, 4 또는 5개의 약제) 약제를 포함한다.
일부 실시예에서, 상기 약제(예를 들어, 항CD3항체)의 농도는 적어도 약 0.01 μg/ml, 0.02 μg/ml, 0.03 μg/ml, 0.05 μg/ml, 0.075 μg/ml, 0.1 μg/ml, 0.125 μg/ml, 0.25 μg/ml, 0.5 μg/ml, 또는 1 μg/ml이다.
일부 실시예에서, 조성물 내의 세포는 상기 접촉 후에 대상체에 투여된다.
V.
대상체 면역 반응을 치료 또는 조절하는 방법
대상체 질환 또는 병증을 치료하거나 대상체 면역 반응을 조절하는 방법을 제공한다. 상기 방법은 본문에 따른 임의의 항CD137 작제물을 대상체(예를 들어, 포유동물, 예를 들어 인간)에 투여하는 단계를 포함한다.
일부 실시예에서, 상기 대상체에 유효량의 본문에 개시된 항CD137 작제물을 투여하는 단계를 포함하는 대상체의 질환 또는 병증을 치료하거나 면역 반응을 조절하는 방법을 제공한다. 일부 실시예에서, 상기 작제물은 본문에 따른 임의의 다중 특이적 항체이다.
일부 실시예에서, 상기 질환 또는 병증은 암이다. 일부 실시예에서, 상기 암은 흑색종, 교모세포종, 난소암, 폐암(예를 들어, NSCLC), 구강인두암, 결장직장암, 유방암, 두경부암, 또는 백혈병(예를 들어, AML)으로 이루어진 군으로부터 선택된다. 일부 실시예에서, 대상체는 인간이다. 일부 실시예에서, 상기 항체 부분은 키메라 또는 인간화된 것이다. 일부 실시예에서, 상기 항체 부분은 전장 항체이다. 일부 실시예에서, 상기 항체 부분은 IgG(예를 들어, IgG1, IgG2, IgG3, 또는 IgG4), IgM, IgA, IgD, 및 IgE로 이루어진 군으로부터 선택되는 동종형을 갖는다. 일부 실시예에서, 상기 항CD137 작제물의 유효량은 대상체의 총 체중의 약 0.005 μg/kg 내지 약 5 μg/kg이다. 일부 실시예에서, 상기 항체 약제는 정맥내, 복강내, 근육내, 피하 또는 경구로 투여된다.
일부 실시예에서, 상기 대상체는 포유동물(예를 들어, 인간, 비인간 영장류, 래트, 마우스, 소, 말, 돼지, 양, 염소, 개, 고양이 등)이다. 일부 실시예에서, 대상체는 인간이다. 일부 실시예에서, 상기 대상체는 임상 환자, 임상 시험 지원자, 실험 동물 등이다. 일부 실시예에서, 상기 대상체는 약 60세 미만(예를 들어, 약 50, 40, 30, 25, 20, 15 또는 10세 미만 중의 임의의 하나를 포함)이다. 일부 실시예에서, 상기 대상체 연령은 약 60를 초과한다(예를 들어 70, 80, 90 또는 100세 초과 중의 임의의 하나를 포함). 일부 실시예에서, 상기 대상체는 본문에 기재된 하나 또는 여러가지 질환 또는 장애(예를 들어, 암, 자가면역 질환, 또는 이식) 로 진단되거나 유전적 경향이 있는 것이다. 일부 실시예에서, 상기 대상체는 본문에 기재된 하나 이상의 질활 또는 장애와 관련된 하나 이상의 위험 인소를 갖는다.
면역 반응 조절
일부 실시예에서, 면역 반응의 조절은 개체에서 세포 집단의 조절을 포함한다. 일부 실시예에서, 상기 세포 집단은 T세포 집단이다. 일부 실시예에서, 상기 세포 집단은 수지상 세포이다. 일부 실시예에서, 상기 세포 집단은 대식 세포이다. 일부 실시예에서, 상기 세포 집단은 B세포이다. 일부 실시예에서, 상기 세포 집단은 NK세포이다. 일부 집단에서, 상기 세포 집단은 이펙터 T 세포 및/또는 기억 T 세포이다. 일부 실시예에서, 상기 세포 집단은 CD44가 높고 CD62L이 낮은 표현형에 의해 정의되는 이펙터/기억 T 세포이다.
일부 실시예에서, 상기 조절은 세포 집단의 증식을 촉진하는 것을 포함한다. 일부 실시예에서, 대조 작제물(예를 들어, 항CD137에 결합되지 않는 항체) 후의 기준 세포의 증식과 비교하여, 상기 항CD137 작제물 투여 후, 상기 세포 집단의 증식은 적어도 약20%, 30%, 40%, 50%, 60%, 70%, 80% 또는 90% 증가하였다. 일부 실시예에서, 대조 작제물(예를 들어, CD137에 결합되지 않는 항체) 후의 기준 세포의 증식과 비교하여, 상기 항CD137 작제물 투여 후, 상기 세포 집단의 증식은 적어도 약 1배, 1.2배, 1.5배, 1.7배, 2배, 2.5배, 3배, 3.5배, 4배, 4.5배, 5배, 5.5배 또는 6배 증가하였다.
항CD137다중 특이적 항체의 용도
일부 실시예에서, 대상체에 유효량의 본문에 개시된 다중 특이적 항체를 투여하는 단계를 포함하는 대상체의 질환 또는 병증(예를 들어 암)을 치료하는 방법을 제공한다.
일부 실시예에서, 대상체에 유효량의 본문에 개시된 다중 특이적 항체를 투여하는 단계를 포함하는 종양 또는 암을 치료하는 방법을 제공한다.
CD137 x EGFR 다중 특이적세포의 용도
일부 실시예에서, 대상체에 CD137 x EGFR 다중 특이적 항체(예컨대 본문에 따른 임의의 CD137 x EGFR이중 특이성 항체)를 투여하는 단계를 포함하는 대상체 중의 EGFR+암을 치료하는 방법을 제공한다.
일부 실시예에서, 상기 암은 EGFR 양성이다. 일부 실시예에서, 상기 암은 EGFR높음이다. 일부 실시예에서, 상기 EGFR 양성 암 또는 EGFR높음 암은 유방암, 폐암, 위암, 난소암, 흑색종, 두경부암, 유잉 육종, 골육종, 횡문근육종 및 자궁경부암으로부터 선택된다.
일부 실시예에서, 상기 EGFR 양성 암 또는 EGFR높음암은 유방암 또는 위암이다. 일부 실시예에서, 상기 EGFR높음 암은 SK-Hep1세포와 비슷하거나 더 높은 평균 EGFR 발현을 갖는다.
일부 실시예에서, 상기 EGFR높음 암은 SKBR3세포의 평균 EGFR 발현보다 적어도50%, 75%, 1-배, 2-배, 3-배, 4-배, 5-배, 6-배, 7-배, 8-배, 9-배, 10-배, 12-배, 15-배, 20-배, 25-배 또는 30-배 높은 평균 EGFR발현을 갖는다. 일부 실시예에서, 상기 암은 적어도 약 100, 200, 300, 400, 500, 600, 700, 800, 900, 1000, 1100, 1200, 1300, 1400, 1500, 1600, 1700, 1800, 1900, 2000, 2100, 2200, 2300, 2400 또는 2500의 평균 EGFR발현(MFI)을 갖는다. 일부 실시예에서, 상기 EGFR높음세포는 Sk-Hep1세포와 비슷한(예컨대 약 50% 내지 약 200%, 약 67% 내지 약 150%, 약 75% 내지 약 125%의 발현 수준 이내) EGFR발현 수준을 갖는다.
일부 실시형태에서, 상기 CD137 x EGFR이중 특이성 항체는 약 0.001 mg/kg 내지 약10 mg/kg(예컨대 약 0.001 mg/kg 내지 약0.01 mg/kg, 예컨대 약 0.01 mg/kg 내지 약0.1 mg/kg, 예컨대 약 0.1 mg/kg 내지 약1 mg/kg, 예컨대 약 1 mg/kg 내지 약10 mg/kg)의 조제량으로 대상체(예컨대 인간)에 투여된다. 일부 실시형태에서, 상기 CD137 x EGFR이중 특이성 항체은 약 0.01 mg/kg 내지 약 0.2 mg/kg의 조제량으로 대상체 (예컨대 인간)에 투여된다. 일부 실시형태에서, 상기 CD137 x EGFR이중 특이성 항체는 매주 약 1회 내지 3회(예컨대 매주 약 1회, 2회 또는 3회)의 빈도로 대상체에 투여된다. 일부 실시형태에서, 상기 CD137 x EGFR 이중 특이성 항체는 적어도 1주, 2주 또는 3주 기간 동안 투여된다.
질환 또는 병증
본문에 따른 항CD137 작제물은 임의의 질환 또는 병증 치료되 사용될 수 있다. 일부 실시예에서, 상기 질환 또는 병증은 감염 (예를 들어 박테리아 또는 바이러스 감염)이다. 일부 실시예에서, 상기 질환 또는 병증은 자가면역 장애이다. 일부 실시예에서, 상기 질환 또는 병증은 암이다. 일부 실시예에서, 상기 질환 또는 병증은 이식이다.
일부 실시예에서, 상기 항CD137 작제물은 암을 치료하는 방법에 사용된다. 본문에 기재된 임의의 방법을 사용하여 치료될 수 있는 암은 혈관화되지 않거나 충분히 혈관화되지 않은 종양 및 혈관화된 종양을 포함한다. 본 출원에 기재된 바와 같이, 항CD137 작제물로 치료되는 암 유형은 상피 암종, 모세포종, 육종, 양성 및 악성 종양, 및 악성 종양(예를 들어, 육종, 상피 암종 및 흑색종)을 포함하지만 이에 한정되지는 않는다. 성인 종양/암 및 소아 종양/암도 포함된다. 일부 실시예에서, 상기 암은 고형 종양이다.
각각의 실시예에서, 상기 암은 초기 암, 비전이성 암, 말기암, 국소 말기암, 전이성 암, 회복기 암, 재발성 암, 보조 요법 중인 암, 새로운 보조 치료 중인 암 또는 기본적으로 치료가 어려운 암이다.
본 출원의 방법에 의해 치료될 수 있는 암의 구현예는, 항문암, 성상세포종(예를 들어 소뇌 및 뇌), 기저 세포 암종, 방광암, 골암, (골육종 및 악성 섬유성 조직구종), 뇌종양(예를 들어 신경교종, 뇌간 신경교종) 종양, 소뇌 또는 대뇌 성상세포종(예를 들어 성상세포종, 악성 신경교종, 수모세포종 및 교모세포종)), 유방암, 중추신경계 림프종, 자궁경부암, 결장암, 결장직장암, 자궁내막암(자궁암), 식도암, 안구암(안구내 흑색종, 망막모세포종), 위(위 부위)암, 위장관기질종양(GIST), 두경부암, 간세포(간)암(예를 들어 상피 및 간세포암), 백혈병, 간암, 폐암(예를 들어 소세포폐암, 비소세포폐암, 폐선암, 폐편평세포암), 림프유사종(예를 들어 림프종), 수모세포종, 흑색종, 중피종, 골수이형성 증후군, 비인두암, 신경모세포종, 난소암, 췌장암, 부갑상선암, 복막암, 뇌하수체 종양, 림프종, 직장, 신장, 신우 및 요관암(이행 세포 암종), 횡문근육종, 피부암(예를 들어 비흑색종(예를 들어 편평상피세포암), 흑색종 및 메르켈세포암), 소장, 편평세포, 고환, 갑상선, 결절성 경화증 질환 및 이식 후 림프증식성 장애(PTLD)를 포함하지만 이에 한정되지 않는다.
일부 실시예에서, 상기 암은 흑색종, 교모세포종, 난소암, 폐암(예를 들어, NSCLC), 구강인두암, 결장직장암, 유방암, 두경부암, 또는 백혈병(예를 들어, AML)으로 이루어진 군으로부터 선택된다.
상기 항CD137 작제물을 투여하는 방법
대상체에 투여되는 본문에 따른 질환 또는 장애를 치료하기 위한 항CD137 작제물(예를 들어 항CD137모노클로날 또는 이중 특이성 항체)의 조제량은 특정 항CD137 작제물(예를 들어 항CD137모노클로날 또는 이중 특이성 항체), 투여 방법 및 치료 중인 질환 또는 장애의 유형에 따라 변한다. 일부 실시예에서, 상기 질환 또는 병증의 유형은 암이다. 일부 실시예에서, 상기 항CD137 작제물(예를 들어 항CD137 모노클로날 또는 이중 특이성 항체)의 유효량은 객관적 반응(예를 들어, 부분 반응 또는 완전 반응)을 야기하기에 효과적인 양이다. 일부 실시예에서, 상기 항CD137 작제물(예를 들어 항CD137 모노클로날 또는 이중 특이성 항체)의 유효량은 대상체에서 완전 반응을 야기하기에 충분한 양이다. 일부 실시예에서, 상기 항CD137 작제물(예를 들어 항CD137 모노클로날 또는 이중 특이성 항체)의 유효량은 대상체에서 부분 반응을 야기하기에 충분한 양이다. 일부 실시예에서, 상기 항CD137 작제물(예를 들어 항CD137 모노클로날 또는 이중 특이성 항체)의 유효량은 항CD137 작제물(예를 들어 항CD137 모노클로날 또는 이중 특이성 항체)를 사용하여 치료될 대상체 인간에서 약 20%, 25%, 30%, 35%, 40%, 45%, 50%, 55%, 60%, 64%, 65%, 70%, 75%, 80%, 85% 또는 90%를 초과하는 것 중의 임의의 하나의 총 반응율을 나타내기에 충분한 양이다. 예를 들어 RECIST 수준에 기반하여 본문에 기술된 방법을 사용한 치료에 대한 대상체의 반응을 결정할 수 있다.
일부 실시예에서, 상기 항CD137 작제물(예를 들어 항CD137 모노클로날 또는 이중 특이성 항체)의 유효량은 대상체가 진행되지 않고 생존을 연장하기에 충분한 양이다. 일부 실시예에서, 상기 항CD137 작제물(예를 들어 항CD137 모노클로날 또는 이중 특이성 항체)의 유효량은 대상체의 총 생존을 연장하기에 충분한 양이다. 일부 실시예에서, 상기 항CD137 작제물(예를 들어 항CD137 모노클로날 또는 이중 특이성 항체)의 유효량은 항CD137 작제물(예를 들어 항CD137 모노클로날 또는 이중 특이성 항체)를 사용하여 치료될 대상체 인간에서 약 50%, 60%, 70% 또는 77%를 초과하는 것 중의 임의의 하나에서 임상 효과를 나타내기에 충분한 양이다.
일부 실시예에서, 단독 또는 제2, 제3 및/또는 제4 약제와 조합되는 상기 항CD137 작제물(예를 들어 항CD137 모노클로날 또는 이중 특이성 항체)의 유효량은 치료 전과 동일한 피험자의 상응되는 종양 크기, 암세포 수량 또는 종양 성장 속도 대비, 또는 치료되지 않은 다른 피험자(예를 들어 플라세보 치료됨)의 상응되는 활성 대비, 종양 크기, 암세포 수량을 감소시키거나, 또는 종양 성장 속도를 적어도 약 10%, 20%, 30%, 40%, 50%, 60%, 70%, 80%, 90%, 95% 또는 100% 중의 임의의 하나로 저하시키기에 충분한 양이다. 효과의 정도는 정제된 효소를 사용한 체외 측정, 세포 기반 측정, 동물 모델 또는 인간 테스트와 같은 표준 방법을 사용하여 측정할 수 있다.
일부 실시예에서, 상기 항CD137 작제물의 유효량(예를 들어 항CD137 모노클로날 또는 이중 특이성 항체)은 독리학 효과(즉, 임상적으로 허용 가능한 독성 수준 이상의 효과)가 유도되는 수준 미만, 또는 조성물이 대상체에 투여될 때 잠재적인 부작용이 제어되거나 허용될 수 있는 수준의 양이다.
일부 실시예에서, 상기 항CD137 작제물(예를 들어 항CD137모노클로날 또는 이중 특이성 항체)의 유효량은 동일한 조제량 방안에 따른 조성물의 최대 내약 용량(MTD)에 근접하는 양이다. 일부 실시예에서, 상기 항CD137 작제물(예를 들어 항CD137 모노클로날 또는 이중 특이성 항체)의 유효량은 상기 MTD의 약 80%, 90%, 95% 또는 98% 중의 임의의 하나를 초과한다.
일부 실시예에서, 상기 항CD137 작제물(예를 들어 항CD137 모노클로날 또는 이중 특이성 항체)의 유효량은 치료되지 않은 대상체 대비, 상기 질환 또는 병증의 진행을 완화 또는 억제(예를 들어, 적어도 약5%, 10%, 15%, 20%, 30%, 40%, 50% 완화 또는 억제)하는 양이다. 일부 실시예에서, 상기 질환 또는 병증은 자가면역 질환이다. 일부 실시예에서, 상기 질환 또는 병증은 감염이다.
일부 실시예에서, 상기 항CD137 작제물(예를 들어 항CD137 모노클로날 또는 이중 특이성 항체)의 유효량은 치료되지 않은 대상체 대비, 병증(예를 들어 이식)의 부작용(자가 면역 반응)을 감소(예를 들어, 적어도 약 5%, 10%, 15%, 20%, 30%, 40% 또는 50% 감소)시키는 양이다.
임의의 일 양태의 일부 실시예에서, 상기 항CD137 작제물(예를 들어 항CD137 모노클로날 또는 이중 특이성 항체)의 유효량은 총 체적의 약 0.001 μg/kg 내지 약100 mg/kg의 범위 내에 있고, 예를 들어, 약 0.005 μg/kg 내지 약 50 mg/kg, 약 0.01 μg/kg 내지 약10 mg/kg 또는 약 0.01 μg/kg 내지 약 1 mg/kg이다.
일부 실시예에서, 상기 치료는 항CD137 작제물의 1회 초과 투여(예를 들어, 항CD137 작제물의 약 2회, 3회, 4회, 5회, 6회, 7회, 8회, 9회 또는 10회 투여)를 포함한다. 일부 실시예에서, 약 1주일 내에 2회의 투여가 수행된다. 일부 실시예에서, 2차 투여는 1차 투여 완료 후 적어도 약 1, 2, 3, 4, 5, 6, 또는 7일 후에 수행된다. 일부 실시예에서, 2차 투여는 1차 투여 완료 후 약1-14일, 1-10일, 1-7일, 2-6일 또는 3-5일에 수행된다. 일부 실시예에서, 상기 항CD137 작제물은 주당 약 1-3회(예를 들어, 주당 약 1회, 주당 약 2회, 또는 주당 약 3회) 투여된다.
상기 항CD137 작제물은 다양한 경로(예를 들어 정맥내, 동맥내, 복강내, 폐내, 경구, 흡입, 피막내, 근육내, 기관내, 피하, 안구내, 척추강내, 경점막 및 경피를 포함)에 의해 대상체(예를 들어 인간)에 투여될 수 있다. 일부 실시예에서, 항CD137 작제물은 대상체에 투여될 때 약물 조성물에 포함되어 있다. 일부 실시예에서, 조성물의 지속 방출 제제를 사용할 수 있다. 일부 실시예에서, 조성물은 정맥내 투여된다. 일부 실시예에서, 조성물은 복막내 투여된다. 일부 실시예에서, 조성물은 정맥내 투여된다. 일부 실시예에서, 조성물은 복막내 투여된다. 일부 실시예에서, 조성물은 근육내 투여된다. 일부 실시예에서, 조성물은 피하 투여된다. 일부 실시예에서, 조성물은 정맥내 투여된다. 일부 실시예에서, 조성물은 경구 투여된다.
조합 요법
본 출원은 또한 대상체에 항CD137 작제물을 투여하여 질환 또는 병증(예를 들어 암)을 치료하는 방법을 제공하고, 여기서 상기 방법은 제2 약제 또는 요법을 투여하는 단계를 추가로 포함한다. 일부 실시예에서, 제2 약제 또는 요법은 질환 또는 병증의 치료를 위한 표준 또는 통상적으로 사용되는 약제 또는 요법이다. 일부 실시예에서, 제2 약제 또는 요법은 화학 치료제이다. 일부 실시예에서, 제2 약제 또는 요법은 수술을 포함한다. 일부 실시예에서, 제2 약제 또는 요법은 방사성 요법을 포함한다. 일부 실시예에서, 제2 약제 또는 요법은 면역 요법을 포함한다. 일부 실시예에서, 제2 약제 또는 요법은 호르몬 요법을 포함한다. 일부 실시예에서, 제2 약제 또는 요법은 혈관신생 억제제를 포함한다. 일부 실시예에서, 제2 약제 또는 요법은 티로신 키나제 억제제를 포함한다. 일부 실시예에서, 제2 약제 또는 요법은 전염제를 포함한다.
일부 실시예에서, 항CD137 작제물은 제2 약제 또는 요법과 동시에 투여된다. 일부 실시예에서, 항CD137 작제물은 제2 약제 또는 요법과 병행 투여된다. 일부 실시예에서, 항CD137 작제물은 제2 약제 또는 요법과 순차적으로 투여된다. 일부 실시예에서, 항CD137 작제물은 제2 약제 또는 요법과 동일한 단위 제형으로 투여된다. 일부 실시예에서, 항CD137 작제물은 제2 약제 또는 요법과 상이한 단위 제형으로 투여된다.
일부 실시예에서, 제2 약제 또는 요법은 EGFR에 결합하는 작용제(예를 들어, 트라스투주맙 또는 트라스투주맙 엠탄신(trastuzumab emtansine))이다. 일부 실시예에서, 제2 약제 또는 요법은 EGFR에 결합된 약제이다. 일부 실시예에서, 제2 약제 또는 요법은 PD-L1 또는 PD-1(예를 들어, 항PD-1항체)을 타겟팅한다. 일부 실시예에서, 제2 약제는 CTLA-4를 타겟팅하는 약제(예를 들어, 항CTLA-4항체)이다. 일부 실시예에서, 제2 약제는 T세포(예를 들어, CAR T세포)를 포함한다. 일부 실시예에서, 제2 약제는 사이토카인을 포함한다. 일부 실시예에서, 제2 약제 또는 요법은 카르보플라틴, 파클리탁셀 및/또는 방사선 요법을 포함한다. 일부 실시예에서, 제2 약제 또는 요법은 HPV 백신과 같은 백신을 포함한다. 일부 실시예에서, 제2 약제 또는 요법은 EGFR 억제제(예를 들어, 세툭시맙)를 포함한다. 일부 실시예에서, 제2 약제 또는 요법은 항종양 효소 억제제(예를 들어, 이리노테칸)를 포함한다. 하기 표 3에서의 조합 요법을 참조바란다.
표 3. 예시적 조합 요법

VI.
조성물, 키트 및 제품
본문에서 또한 본문에 따른 항CD137 작제물 또는 항CD137 항체 부분 중의 임의의 하나를 포함하는 조성물(예를 들어 제제), 상기 항체 부분을 코딩하는 핵산, 상기 항체 부분을 코딩하는 핵산을 포함하는 벡터 또는 상기 핵산 또는 벡터를 포함하는 숙주 세포를 제공한다.
적합한 본문에 따른 항CD137 작제물 제제는 원하는 순도의 상기 항CD137 작제물 또는 항CD137 항체 부분을 임의의 약학적으로 허용 가능한 담체, 부형제 또는 안정제와 혼합하여, 동결건조된 제제 또는 수용액 형태로 얻을 수 있다(Remington's Pharmaceutical Sciences 제16판, Osol, A. Ed. (1980)). 허용 가능한 담체, 부형제 또는 안정제는 사용된 조제량 및 농도 하에서 수용체에 무독성이고, 완충액(예를 들어 인산염, 구연산염 및 기타 유기산; 아스코르브산(ascorbic acid) 및 메티오닌(methionine)을 포함한 항산화제); 방부제(예를 들어 옥타데실디메틸벤질암모늄 클로라이드(octadecyldimethylbenzyl ammonium chloride); 헥사메토늄 클로라이드(hexamethonium chloride); 벤잘코늄 클로라이드(benzalkonium chloride), 벤제토늄 클로라이드(benzethonium chloride); 페놀, 부탄올 또는 벤질 알코올; 메틸 파라벤(methylparaben) 또는 프로필파라벤(propylparaben)과 같은 알킬 파라벤(alkyl parabens); 카테콜(catechol); 레조르시놀(resorcinol); 시클로헥산올(cyclohexanol); 3-펜탄올(3-pentanol); 및 m-크레졸(m-cresol)); 저분자량(약 10개 미만의 잔기) 폴리펩타이드(polypeptides); 혈청 알부민(proteins), 젤라틴 또는 면역 글로불린과 같은 단백질; 폴리비닐피롤리돈과 같은 친수성 중합체; 글리신, 글루타민, 아스파라긴, 히스티딘, 아르기닌 또는 라이신과 같은 아미노산; 포도당, 만노오스 또는 덱스트린을 포함한 단당류, 이당류 및 기타 탄수화물; EDTA와 같은 킬레이트제; 수크로스, 만니톨, 트레할로스 또는 소르비톨과 같은 당; 나트륨과 같은 염 형성 반대 이온; 금속 착물(예를 들어 아연 단백질 착물) 및/또는 TWEEN™, PLURONICS™ 또는 폴리에틸렌 글리콜(PEG)과 같은 비이온성 계면활성제를 포함한다. 피하 투여에 적합한 동결건조 제형은 WO 97/04801에 기재되어 있다. 이러한 동결건조된 제형은 적절한 희석제를 사용하여 고단백질 농도로 재구성될 수 있고, 재구성된 제제는 영상화, 진단 또는 치료될 대상체에 피하 투여될 수 있다.
체내 투여용 조제품은 멸균 상태여야 한다. 예를 들어 무균 여과막을 통과한 여과에 의해 쉽게 구현될 수 있다.
또한 본문에 따른 항CD137 작제물 또는 항CD137 항체 부분 중의 임의의 하나를 포함하는 키트를 제공한다. 상기 키트는 본문에 따른 세포 조성물 또는 치료를 조절하는 임의의 방법에 사용할 수 있다.
일부 실시예에서, CD137에 결합되는 항CD137 작제물을 포함하는 키트를 제공한다.
일부 실시예에서, 상기 키트는 상기 항CD137 작제물을 대상체로 전달할 수 있는 장치를 추가로 포함한다. 비경구 전달과 같은 적용에 사용되는 장치 유형 중 하나는 조성물을 대상체에 주입하는데 사용되는 주사기이다. 흡입 장치는 일부 응용 분야에도 사용할 수 있다.
일부 실시예에서, 상기 키트는 질환 또는 병증(예를 들어, 암, 전염병, 자가면역 질환,또는 이식)의 치료를 위한 치료제를 추가로 포함한다.
본 출원의 키트는 적절한 패키지에 담겨 있다. 적합한 패키지는 바이알, 병, 항아리, 가요성 포장(예를 들어 밀봉된 폴리에스테르 필름 또는 비닐 봉지) 등이 포함되지만 이에 한정되지 않는다. 키트는 완충액 및 해석 정보와 같은 다른 구성 요소를 임의로 제공할 수 있다.
따라서, 본 출원은 또한 제조 제품을 제공한다. 상기 제품은 용기 및 상기 용기 상에 또는 용기와 관련된 표지 또는 포장 삽입물을 포함할 수 있다. 적합한 용기는 바이알(예를 들어, 밀봉된 바이알), 병, 항아리, 가요성 포장 등을 포함한다. 통상적으로, 상기 용기는 조성물을 수용하고, 무균 접근 포트를 가질 수 있다(예를 들어, 용기는 정맥내 용액백 또는 피하 주사바늘로 뚫을 수 있는 마개가 있는 바이알일 수 있음). 상기 표지 또는 패키지 삽입물은 상기 조성물이 대상체의 특정 병증을 영상화, 진단 또는 치료하는데 사용하기 위한 것임을 나타낸다. 상기 표지 또는 패키지 삽입물은 대상체에 상기 조성물을 적용하고 영상화하기 위한 설명을 추가로 포함한다. 상기 표지는 재조합 및/또는 사용 지침을 나타낼 수 있다. 상기 조성물을 수용하는 용기는 재구성된 제제의 반복 투여(예를 들어, 2-6회 투여)를 허용하는 여러 차례 사용되는 바이알일 수 있다. 패키지 삽입물은 통상적으로 진단 제품의 상업적 패키징에 포함된 설명서를 지칭하고, 이러한 설명서에는 해당 진단 제품의 사용에 대한 적응증, 사용법, 조제량, 투여, 금기증 및/또는 경고에 대한 정보가 포함되어 있디. 추가로, 제품은 제2 용기를 추가로 포함할 수 있고, 상기 용기는 약학적으로 허용 가능한 정균 주사용수(BWFI), 인산염 완충 식염수, 링거 용액 및 덱스트로스 용액과 같은 완충액을 포함한다. 다른 완충액, 희석제, 필터, 바늘 및 주사기를 비롯한 상업적 및 사용자 관점에서 원하는 다른 재료를 추가로 포함할 수 있다.
상기 키트 또는 제품은 약국(예를 들어 병원 약국 및 약물 조제 약국)에서 보관 및 사용하기에 충분한 양으로 패키징된, 조성물의 복수 단위 조제량 및 사용 설명서를 포함할 수 있다.
당업자는 본 발명의 범위 및 사상 내에서 다수의 실시예가 가능함을 인식할 것이다. 본 발명은 하기 비제한적인 구현예를 참조하여 더욱 상세하게 설명될 것이다. 하기 실시예는 본 발명을 추가로 설명하지만, 물론 어떤 방식으로도 그 범위를 제한하는 것으로 해석되어서는 아니 된다.
서열표





















구현예
하기 구현예는 단지 본 출원을 예시하는 것이고, 어떠한 방식으로 본 출원을 제한하는 것으로 해석되어서는 아니 된다. 하기 구현예 및 상세한 설명은 제한이 아니라 예시를 위해 제공된다.
구현예1: 항CD137 항체의 생성
A.
마우스 하이브리도마에서 항CD137 항체 생성
BALB/c마우스에서 인간CD137(4-1BB) 수용체에 대한 완전한 인간 모노클로날 항체를 생성하였다. RIBI 좌제(Ribi Immunochemical)에서, 인간CD137의 세포외 도메인은 면역 BALB/c마우스에 사용되었다. 동일한 양의 항원을 사용하여 융합 전에 마우스를 정맥내(i.v.) 부스팅하였다. 충분한 huCD137 항체 역가를 갖는 면역화된 마우스로부터의 림프절을 표준 절차에 따라 마우스 골수종 세포에 융합시켰다.
하이브리도마를 스크리닝하였다. ELISA를 통해 huCD137에 대한 결합을 측정하였다. 항 인간CD137 항체를 분비하는 하이브리도마를 검출하기 위해, ELISA 플레이트(Corning)를 4℃에서 밤새 PBS 중 1 μg/ml 인간 CD137-Fc 융합 단백질로 코팅하였다. 다음 플레이트를 0.5%의 Tween-20(PBS-T)을 포함하는 PBS로 3회 세척한 후, PBS-T + 5%의 우유로 실온에서 60분 동안 차단하였다. PBS에서 1:3으로 희석된 30 마이크로리터의 상등액을 플레이트에 첨가하고 환경 온도에서 1-2시간 동안 인큐베이션하였다. 다음, 플레이트를 전술한 바와 같이 세척하고, 양고추냉이 퍼옥시다제(HRP)에 접합된 염소 F(ab')2항 인간 IgG로 항체의 결합을 검출하였다. 플레이트를 TMB로 현상하고 450 nm에서 리딩하였다. 스크리닝에서 검증된 최적의 항CD137 하이브리도마 항체(클론 29.39, 44.21, 3.10, 30.19 및 6.62)의 아미노산 서열을 서열표(SEQ ID NO: 151-176) 및 표 4에 나타낸다.
표 4. 하이브리도마 항CD137 항체 서열표

B. 항CD137 항체의 인간화
하나의 대표적인 클론 29.39가 프레임워크의 인간화를 위해 선택되었다. 간단히 말해서, 클론된 서열은 Igblast를 수행하여 인간 생식계열 유전자 데이터베이스를 검색하는 것에 사용된다. 이상적인 생식계열 서열을 선택하고, 프레임워크 서열을 돌연변이시켜 마우스 서열에서 인간 서열로 프레임워크 서열을 변경시켰다. 중쇄에 관하여, 인간 생식계열 IGHV1-46*01을 사용하였고, 프레임워크에서 E1Q, K3Q, M5V, E6Q, L11V, 20V, T23K, K38R, R40A, E42G, I48M, D60A, L61Q, N62K, A67V, I69M, A71R, S75T, N76S, A78V, L80M, Q81E, T83R, S111V, L112S, 및 E113S 돌연변이시켰다. 경쇄에 관하여, 인간 생식계열 IGKV1-12*01을 사용하였고, 프레임워크에서 V3Q, M11V, Y12S, L15V, E17D, F36Y, S43A, T46L, Q69T, Y71F, S72T, D79Q, Y80P, M83F, G84A, 및 I85T 돌연변이시켰다. 작제물은 발현 벡터에 클론되고, SS320세포에 의해 항체 단백질이 생성되었다.
C. 친화력 성숙, 선택 및 변형
인간화 29.39클론에 대해 친화력 성숙을 수행하였다. 각각의 CDR 영역의 아미노산 단일 돌연변이에 사용되는 프라이머를 디자인하였다. 조립 PCR을 사용하여 돌연변이 라이브러리를 제조하고, 파스미드 벡터에 클론하였다. 형질전환된 TG1세포 및 클론된 DNA 시퀀싱에 의해 라이브러리 품질을 측정하였다. 헬퍼 파지를 사용하여 파지를 생산하고, 비오틴화된 인간CD137 ECD 또는 사이노몰구스 원숭이CD137 ECD로 코팅된 스트렙타비딘 커플링 면역자기 비드(Dynabeads)를 사용하여 파지 패닝(panning)하였다. 3라운드의 패닝 후, 용출된 패닝 생성물을 SS320세포 감염에 사용하고, 콜로니를 선택하여 IPTG가 포함된 2YT 배지에서 성장시켰다. ELISA 측정법으로 상등액에서 Fab의 결합 친화력을 검사하였다. 인간 및 사이노몰구스 원숭이CD137에 대한 양성 클론을 선택하였다. 최적의 14개의 결합물(클론 번호 3, 9, 23, 25, 33, 35, 5, 6, 17, 18, 19, 20, 2-9 및 2-11) 및 CDR(Kabat), VH, VL, 중쇄(HC) 및 경쇄(LC)는 서열표(SEQ ID NO: 1-140)에 나타내었다. 이러한 CDR(약간 변형된 Kabat), VH, VL, 중쇄(HC) 및 경쇄(LC)의 공유서열은 서열표(SEQ ID NO: 141-150)에 나타내었다. 이 외에, 상이한 IgG서브유닛을 포함하는 2-9의 서브클론을 합성하였다. 이들의 CDR영역(Kabat), VH, VL, 중쇄(HC) 및 경쇄(LC)는 서열표(SEQ ID NOS: 261-280)에 나열되었다.
구현예2: 예시적 항CD137 항체의 특성화
A. 친화력 평가
생물층 간섭 측정법을 사용하여 항CD137 항체 결합 동역학의 결합 및 해리 상수를 측정하였다. 30℃에서 FortieBio Octet Red 96에서 결합 동역학을 측정하고, FortieBio 데이터 분석(FortieBio Data Analysis) 9.0소프트웨어로 분석하였다. 항 인간 IgG Fc(AHC)센서를 사용하여 항CD137 항체 또는 대조군 항체를 포획하였다. 데이터 처리 동안, 동역학 완충액 웰만이 배경을 감한 기준 웰로 설정되었다. 각각의 항체-항원 결합에 대해, 데이터는 1 : 1 Langmuir모델을 사용하여 결합 및 해리에 대해 Rmax 연결된 전체 피팅으로 피팅하였다. 인간CD137-his는 인간CD137항원 C말단에 융합된 폴리히스티딘 태그가 있는 재조합 CD137항원(베이징 시노바이오 유한회사(Sino Biological), 10041-H08H)이다. 사이노몰구스 원숭이CD137-his는 사이노몰구스 원숭이CD137항원 C말단에 융합된 폴리히스티딘 태그가 있는 재조합 CD137항원(베이징 시노바이오 유한회사, 90847-K02H-100)이다.
도 1A-1B 및 표 5에서와 같이, 항CD137클론 2-9 IgG2는 인간CD137 및 사이노몰구스 원숭이CD137에 효과적으로 결합되고, KD는 각각 0.933 nM 및 2.76 nM이다. 마우스 CD137을 사용한 측정은 효과적인 결합을 나타내지 않았다(데이터는 표시되지 않음).
표 5. 예시적 항CD137 모노클로날 항체의 결합 친화력

도 1C-1D 및 표 6은 다른 라운드의 Octect 결합 시험에서 항CD137클론의 결합 결과를 나타내고, 여기서 2-9 IgG2 및 2-9-1 IgG1 SELF는 인간CD137에 효과적으로 결합되며, 이의 KD는 각각 5.50 nM 및 6.55 nM이다. 이 결과는 클론 2-9 IgG2 및 2-9-1 IgG1 SELF가 인간CD137에 유사한 결합 친화력을 갖는 것을 증명한다.
표 6. 예시적 항CD137 모노클로날 항체의 결합 친화력

Octect 결합 시험은 클론 2-9-1 IgG1 SELF 및 2-9-2 IgG4의 결합 친화력 비교에 사용된다. 도 1E-1F 및 표 7에 나타낸 바와 같이, 2-9-1 IgG1 SELF 및 2-9-2 IgG4는 인간CD137에 효과적으로 결합되고, 이의 KD는 각각 11.1 nM 및 12.9 nM이다. 이러한 결과는 클론 2-9-1 IgG1 SELF 및 2-9-2 IgG4가 인간CD137에 대해 유사한 결합 친화력을 갖는 것을 증명한다.
표 7. 예시적 항CD137 모노클로날 항체의 결합 친화력

B.
CD137 리포터 유전자 측정
현재, 여러 기존 항CD137 항체가 임상 중에 있다. 그러나, 이러한 항체는 안전성 위험이 있거나 효능이 부족하다. 예를 들어, II기 임상 시험에서 CD137에 대한 강력한 작용제 항체 유토밀루맙은 CD137 활성화 측면에서 매우 효과적이지만, 항체/항원 복합체의 가교 또는 응집 없이 CD137 신호 전달을 활성화 하는 능력이 낮은 조제량(≥ 1 mg/kg)에서 심각한 간독성을 유발한다. (Segal NH, et al., Clin Cancer Res. 2017년 4월 15일; 23(8): 1929-1936). 다른 하나의 기존의 항CD137 항체로서, 마찬가지로 II기 임상 시험에서 CD137에 대한 약한 작용제 항체 유토밀루맙은 (PF-05082566)은, 10 mg/kg에 달하는 높은 조제량에서 안전한 것으로 나타났지만, 임상 시험에서 제한적인 기능을 나타냈다. (Tolcher AW et al. Clin Cancer Res. 2017년 9월 15일; 23(18): 5349-5357.). 이러한 발견에 기반하여, 상기 차세대 항CD137 모노클로날 항체는 종양 부위에서만 특이적으로 높은 CD137 신호 활성화를 구현해야 한다. 낮은 독성과 높은 효능을 나타내는 항CD137 항체를 선택하기 위해, 두가지 기준 항체를 비교에 사용하였다. 기준 항체Ab 1는 미국특허번호 7,288,638에 개시된 유토밀루맙의 서열에 기반하여 내부에서 합성된 것이다. 기준 항체Ab 1은 국제공개번호 WO 2012/032433에 개시된 유토밀루맙의 서열에 기반하여 내부에서 합성된 것이다.
먼저, 리포터 유전자 측정에서 구현예 1에 서술된 항CD137단일 특이성 항체의 CD137작용제 활성에 대해 평가하였다. NF-κB리포터 유전자 세포주는 293T세포에서 CD137 및 NF-κB 루시퍼라제 리포터 유전자를 안정적으로 형질감염시켜 구축된 것이다. FcγRIIB 293F세포는 293F세포에서 FcγRIIB를 안정적으로 형질감염시켜 구축된 것이다. 상기 측정에서, FcγRIIB을 형질감염시킨 293F세포는 억제성 Fcγ 수용체인 높은 수준의 FcγRIIB를 발현하고 말초 조직보다는 종양 미세환경에 집중된 단핵구 및 대식세포 모의에 사용되었다. 상기 NF-κB리포터 유전자 및 CD137 이중 형질감염된 리포터 유전자 세포주293T는 표면에 CD137을 발현하고 다운스트림 신호 전달을 위해 NF-κB를 발현하는 T세포 모의에 사용되었다. 따라서, 상기 CD137/NF-κB 리포터 유전자 세포주와 상기 FcγRIIB 293F세포의 공동 배양은 종양 미세 환경에서의 T세포를 모의하는 반면, 단독으로 배양된 CD137/NF-κB리포터 유전자 세포주는 말초 조직에서의 T세포를 모의한다.
이러한 리포터 유전자 시스템에 사용된 두가지의 기준 항체에서, 기준 항체 1은 우렐루맙(Urelumab)을 대표하고, 강한 활성을 나타내지만 간독성도 있다. 기준 항체 2는 유토밀루맙을 대표하고, 약한 활성을 나타내지만, 간독성이 없다. 본문에서 상기 두가지 기준 항체를 사용하여 항CD137클론의 활성 및 잠재적인 안전성의 특징을 평가하였다.
배양 조건은 ATCC에서 권장하는 배지와 조건을 따랐다. FcγRIIB 293F세포를 96웰플레이트에 시딩하여 밤을 샌다. 60,000개의 세포/웰/100 ul의 배지를 시딩에 사용하였다. 일부 실험에서, 모의 293F 세포를 96웰 플레이트에 시딩하여 FcγRIIB 가교 없이 항체 효과를 관찰하였다. 2일째, 37℃에서 일련의 농도의 항체를 넣어 20분 동안 지속하였다. 다음, 120,000개의 FcγRIIB 293T 리포터 유전자 세포를 DMEM배지(HyClone, 카탈로그 번호16777-200)에서의 293T세포에 첨가하였다. 음성 대조군은 항체 처리 없이 및/또는 가교 또는 이펙터 세포 없이 샘플 형태로 제공된다. 5시간 후, 제조업체의 방안에 따라, Bright-Glo™루시퍼라제 측정 시스템(Promega, 카탈로그 번호E2610)을 사용하여 루시퍼라제 활성을 측정하였다.
결과적으로 항CD137 모노클로날 항체 존재 하에서, 루시퍼라제 활성은 조제량 의존적인 것으로 나타났다. 도 2A는 상기 항체로 처리된 단독적인 CD137/NF-κB 리포터 유전자 세포를 나타내고, 이는 말초 조직(여기서 억제 수용체FcγRIIB는 고도로 발현되지 않고 상기 항체에 결합하여 Fc영역에 가교/CD137 클러스터링을 촉진할 수 없음)에서의 CD137 활성화를 모의한다.
도 2B는 FcγRIIB 293F세포와 배양하고 상기 항체로 처리된 CD137/NF-κB리포터 유전자 세포를나태고, 종양 부위(여기서 억제 수용체FcγRIIB가 고도로 발현)의 CD137 활성화를 모의한다.
기준 Ab 1(강력한 CD137작용제)는, FcγRIIB에 의해 매개된 가교 /CD137클러스터링이 있거나 없이 NF-κB 활성화를 나타내고, 이는 상기 기준 항체가 말초 조직에서의 CD137 신호 전달을 활성화하고 말초 독성을 유발할 수 있는 것을 나타낸다. 기준 항체 2(약한 CD137작용제)는, FcγRIIB에 의해 매개된 가교/CD137클러스터링 하에서만 NF-κB활성화를 나타내고, 이는 임상 시험에서 상기 기준 항체가 더 우수한 안전성 특징상과 일치된다. 도 2A에서, 본문에 개시된 항CD137 mAb의 행위는 기준 항체 2와 유사하고, 이는 기준 항체 1 대비 상대적으로 안전한 임상 스펙트럼을 갖는 것을 나타낸다. 도 2B에서, 상기 항CD137 mAb는 기준 항체 Ab 2 대비 더욱 강력한 면역활성화를 나타내고, 이는 기준 항체 Ab 2 대비 더욱 우수한 치료 효능을 갖는 것을 나타낸다. 특히, 클론 2-9는 FCγRIIB에 의해 매개된 가교/CD137클러스터링 없이 거의 활성이 없는 반면, FcγRIIB에 의해 매개된 가교/CD137클러스터링에서 바람직한 활성을 나타낸다.
C.
Fc 변형된 항CD137 항체를 갖는 CD137 리포터 유전자 측정
최근의 개시에 따르면, 인간 IgG힌지 및 Fc는 치료성 항체 기능, 특히 각용성 항체에 형향을 미친다. 예를 들어, Fc돌연변이에 의해 증강된 FcγIIB결합능은 작용성 항체 기능을 증강시킬 수 있다. Fc 영역을 통한 체내 FcγRIIB 결합은 CD137 클러스터링을 매개하여, 타겟 세포에서 강력한 다운스트림 신호전달을 유도할 수 있는 듯하다. (White AL et al., Cancer Immunol Immunother. 2013년 5월; 62(5): 941-8). 문헌에서 IgG2 Fc힌지 영역의 배열 및 가요성이 면역 공동 자극 항체(예를 들어 항CD40항체 및 항CD137 항체)의 작용 활성에 영향을 미칠 수 있는 것을 강조하였다(White AL et al., Curr Top Microbiol Immunol. 2014; 382: 355-72). 이러한 발견에 기반하여, 다른 아이소타입(예를 들어 IgG2 야생형)과 비교하여, FcγRIIB 결합을 향상시키기 위한 Fc돌연변이를 갖는 항CD137 mAb IgG1 및 IgG2는 효능을 향상시킬 수 있다. 이 외에, 종양 부위에서 FcγRIIB의 더 높은 발현으로 인해, 상기 Fc 조작된 CD137 모노클로날 항체는 종양 부위에서 더 높은 효능을 유도하면서 더 낮은 말초 독성을 유지할 수 있다.
따라서, FcγRIIB 결합을 향상시키기 위한 Fc돌연변이(S267E/L328F)를 항CD137 모노클로날 항체의 CD137 작용제 활성(Chu SY et al. Mol Immunol. 2008년 9월; 45(15): 3926-33)은 리포터 유전자 측정에서 평가되고, 모IgG2 야생형 항체와 비교하였다.
이 외에, IgG4서브타입은 더 약한 이펙터 결합을 갖는 것으로 알려져 있고, 이는 말초 독성을 약화시키면서 종양 부의에서 항종양 효능을 유발할 수 있다. 따라서, 항CD137 모노클로날 항체는 또한 IgG4의 서브타입으로 테스트된다.
결과적으로 항CD137 모노클로날 항체 존재 하에서, 루시퍼라제 활성은 조제량 의존적인 것으로 나타났다. 도 3A에 도시된 바와 같디, FCγRIIB에 의해 매개된 가교/CD137클러스터링이 없는 경우, 모든 2-9로부터의 클론(Fc돌연변이가 있거나 없는)은 모두 활성이 없는 것으로 나타났고, 이는 안전한 임상 스펙트럼을 나타낸다. 도 3B는 FcγRIIB에 의해 매개된 가교/CD137클러스터링에서의 NF-κB리포터 유전자 신호를 나타내고, 종양 부위(여기서 억제성 수용체FcγRIIB 가 고도로 발현)의 CD137 활성화를 모의하였다. IgG2야생형모 항체 대비, 클론 2-9-1 IgG1 SELF 및 IgG2 SELF는 더욱 높은 CD137 활성화를 나타내고, 이는 증강된 FCγRIIB 결합이 CD137 활성화를 증강시키는 것을 나타낸다. 도 3C는 FcγRIIB에 의해 매개된 가교/CD137클러스터링의 경우, 2-9-1 IgG1 SELF 및 2-9-2 IgG4의 NF-κB리포터 유전자 신호의 비교를 나타낸다. 이 두개의 클론은 모두 높은 CD137 활성을 나타내고, 2-9-1 IgG1 SELF는 2-9-2 IgG4보다 더 높은 활성량을 나타낸다.
D.
사이토카인 방출 측정
다음, 사이토카인 방출에 대한 항CD137 단일 항체의 영향을 인간 말초 혈액 단핵 세포(PBMC)를 사용하여 테스트하였다. PBMC는 CD137양성 T세포 및 NK세포를 포함하고, 이들은 항CD137 모노클로날 항체의 타겟 세포이며, FcγRIIB를 발현하는 단핵구 및 대식 세포는 상기 PBMC에도 존재한다. T 세포가 항CD137 항체에 의해 활성화되면, 항종양 효능의 지표인 항종양 사이토카인(예를 들어 IFN-γ 또는 IL-2)이 분비된다. 항CD137 클론의 활성은 전술된 바와 같이 두가지의 기준 항체를 사용하여 이러한 리포터 유전자 시스템에서 평가되었다.
Ficoll-Paque® PLUS(카탈로그 번호17-1440-02, GE Healthcare)를 사용하여 인간 PBMC를 단리하였다. 1 ug/ml의 항CD3항체(OKT3) 및 항CD137 mAb 시리즈 희석액을 Gibco RPMI배지1640(카탈로그 번호A1049101, Thermo Fischer) 중의 PBMC에 첨가하였다. 48시간 후, 배지를 수집하고, ELISA방법(인간IFN-γ ELISA MAX™ Deluxe, 카탈로그 번호430106, BioLegend 회사; 인간IL2 ELISA MAX™ Deluxe, 카탈로그 번호421601, BioLegend 회사)을 이용하여 IFNγ 및 IL2 수준을 확정하였다.
도 4A에 도시된 바와 같이, 항CD137 항체 존재 하에서, IFNγ에 대한 이펙터 세포(즉 PBMC)의 조제량 의존성 분비를 관찰하였다. 예상대로, 강력한 작용제 기준 항체 1은 약한 작용제 참조 항체 2에 비해 더 높은 IFN-γ를 유도하였다. 이 외에, 상이한 Fc영역(예를 들어 2-9-1 IgG1 SELF, 2-9-1 IgG2 야생형 및 2-9-1 IgG2 SELF)의 클론 2-9는 상기 두가지 기준 항체보다 모두 더 높은 IFN-γ 최대 방출을 나타낸다. 상이한 공여체를 사용하여 3회 반복 실험하여, 유사한 결과를 관찰하였다.
도 4B에 도시된 바와 같이, 항CD137 항체 존재 하에서, IL2에 대한 이펙터 세포(즉 PBMC)의 조제량 의존성 분비를 관찰하였다. 예상대로, 강력한 작용제 기준 항체 1은 IL2 분비를 유도하였다. 이 외에, 상이한 Fc영역을 갖는 클론 2-9, 즉 2-9-1 IgG1 SELF 및 2-9-2 IgG4는 기준 항체1보다 현저하게 높은 IL2 최대 방출을 나타낸다.
총적으로, 항CD137 항체는 조제량 의존적 방식으로 사이토카인 생산을 유도하였고, 두가지의 기준 항체보다 IFN-γ 및 IL2 수준이 더 높았다. IFN-γ 및 IL2는 중요한 항 종양 사이토카인이고, 데이터에 따르면 클론 2-9항체(Fc돌연변이 및 야생형)는 두가지 기준 항체보다 더 강력한 항종양 효능을 갖는 것으로 나타났다.
E.
체내 항종양 요법 연구
2-9개의 변이체는 항종양 효능을 평가하기 위해 바이오사이토젠(Biocytogen) 시설에서 체내에서 추가로 테스트되었다. 인간CD137(4-1BB라고도 함) 녹인 C57BL/6마우스 및 MC38뮤린 결장직장암 모델을 이용하여, 2-9 IgG2 wt, 2-9-1 IgG2 SELF 및 2-9-1 IgG1 SELF의 효능과 벡터 대조군을 비교하였다. MC38종양 세포는 치료 1주일 전에 이식되었다. 종양 부피가 약 100 mm3에 도달하면 치료가 시작되고, 약물은 복강 주사 형식으로 투여되고, 주당 2회 총 4주 투여되었다. 2-9-1 IgG1 SELF항체의 회당 투여 조제량은 10, 1 및 0.3 mg/kg이다. 2-9-1-IgG2 SELF 및 2-9-IgG2 항체는 회당 투여 조제량은 1 mg/kg이다. 치료 24일 후, 대조군에서 다수의 마우스의 종양 부피가 상한(2000 mm3)에 도달하면 시험이 종료된다. 다른 그룹은 계속하여 28일까지 시험되고 종양 측정된다. 치료 후 28일은 데이터 분석의 종점이다. 도 5A 및 표8에 나타낸 바와 같이, 2-9 IgG2 wt, 2-9-1 IgG1 SELF 및 2-9-1 IgG2 SELF의 치료는 벡터 대조군보다 종양 성장을 현저하게 감소시켰다. 2-9 IgG2 wt, 2-9-1 IgG1 SELF와 2-9-1 IgG2 SELF는 동일한 조제량(1 mg/kg)의 치료군을 비교하면, 종양이 100 mm3 이하로 감소된 동물의 수는 각 그룹의 총 수에서 각각 2/8, 5/8 및 5/8이다. 상이한 그룹에서 동물 체중은 연구에서 현저한 변화가 없고(도 5B), 치료가 잘 관용된 것을 나타낸다.
표 8. 예시적 항CD137 항체의 체내 항종양 효능

a: 평균값 ± 표준오차;
b: 각각의 치료군의 종양 부피와 벡터 대조군은 치료 24일 후에 T검증
이 외에, 바이오사이토젠 이전에 인간CD137(4-1BB라고도 함) 녹인 C57BL/6마우스를 이용하여 MC38뮤린 결장직장암 모델에서 전술한 2-9변이체 연구와 유사한 조건으로 유토밀루맙 유사 약물을 테스트하였다. 도 6A에 나타낸 바와 같이, 유토밀루맙 유사 약물은 1 mg/kg 및 10 mg/kg 두가지 투여 조제량으로 테스트되었다. IgG 대조 항체와 비교하여, 1 mg/kg 치료군의 종양억제는 60.0%이고, 10 mg/kg 치료군의 종양억제는 85.4%이다(상기 데이터는 www.biocytogen.com에서도 참조 가능함). 유토밀루맙은 더 안전한 독성 데이터 프로파일을 갖는 것으로 알려져 있고, 도 6B는 마우스 체중이 유토밀루맙 치료 하에서 현저한 변화가 없는 것을 나타낸다.
이 연구의 조건이 2-9 변이체에 대한 연구 조건과 유사하기 때문에, 2-9 변이체에 대한 데이터는 유토밀루맙 유사 약물에 대한 데이터와 비교할 수 있다. 구체적으로, 유토밀루맙 유사 약물과 비교하여, 임의의 투여 조제량 조건에서, 2-9변이체는 모두 더 높은 종양 억제를 유도하였다(도 5A, 6A 및 표 8). 10 mg/kg의 동일한 투여 조제량에서 비교하면, 2-9-1 IgG1 SELF의 종양억제(103.8%)는 유토밀루맙 유사 약물의 종양억제(85.4%)보다 현저하게 높았다. 이러한 데이터는 각각의 2-9변이체의 체내에서 효능이 유토밀루맙 유사 약물보다 모두 높은 것으로 나타났다.
구현예 3: 항CD137 x TAA(즉, 종양 관련 항원) 이중 특이성 항체의 구축
CD137 (4-1BB)은 T세포 및 NK세포에서 발현되어 세포 활성, 증식 및 생존을 지지하는 공동 자극 분자이다. 그러나, 현재 임상 연구에서의 기준 항체 또는 안전과 관련되거나, 효력이 부족하다. 예를 들어, II기 임상 시험에서 CD137에 대한 강력한 작용제 항체인 Urelumab은 매우 효과적이나, 조제량 ≥ 1 mg/kg일 경우 간독성의 제한을 받는다. (Segal NH, et al., Clin Cancer Res. 2017 Apr 15; 23(8): 1929-1936). II기 임상 시험 중의 다른 하나의 기준 항체 유토밀루맙(PF-05082566)은 CD137에 대한 약한 작용제 항체로 10 mg/kg까지 안전한 것으로 나타났지만, 임상에서의 효력이 제한적이다. (Tolcher AW et al., Clin Cancer Res. 2017 Sep 15; 23(18): 5349-5357.). 이러한 발견에 기반하여, 차세대 항CD137치료성 항체는 종양 부위에서만 특이적으로 높은 CD137 활성화를 구현해야 한다. 이러한 문제를 해결하기 위해, 이중 특이성 항체를 디자인하였고, 여기서 하나의 암은 CD137을 타겟팅하고, 다른 하나의 암은 종양 관련 항원을 타겟팅한다.
구현예 1 및 2에 서술된 항CD137 모노클로날 항체클론 2-9를 선택하여 단일쇄Fv (scFv)를 구축하였다. 항TAA항체는 IgG 형태로 유지된다. 이중 특이성 항체를 구축하기 위해, 항CD137 scFv는 중쇄 N말단(HC-N), 중쇄C말단(HC-C), 경쇄 N말단(LC-N)또는 경쇄C말단(LC-C)에서 링커(예를 들어, (GSG)4)에 의해 항TAA항체에 융합된다. 도 7을 참조바란다.
구체적으로, 클론 2-9로부터 유래된 항CD137 scFv는 항EGFR항체의 중쇄의 N말단 또는 C말단(HC-N, HC-C, 예컨대 2-9scFv-αEGFR-HC-C) 또는 경쇄의 N말단 또는 C말단(LC-N, LC-C)에서 링커에 의해 예시적 항EGFR전장 항체(트라스투주맙의 아미노산 서열로부터 유래됨)에 융합된다.
일부 작업 구현예에서, IgG1 (LALA돌연변이) 및 IgG4 (FALA돌연변이), 또는 S228P돌연변이를 갖는 IgG4와 같은 감소된 이펙터 기능을 갖는 Fc 백본을 사용하였다. IgG1 LALA돌연변이는 이펙터 기능을 감소시키기 위한 IgG1 Fc영역에서의 Leu234Ala 및 Leu235Ala돌연변이이다(Lund, J., et al., (1992)Mol. Immunol., 29, 53-59). IgG4 FALA돌연변이는 이펙터 기능을 약화시키는 IgG4 Fc에서의 Ser228Pro돌연변이 및 PHE234Ala 및 Leu235Ala돌연변이이다(Vafa O, et al., Methods. (2014)65: 114-26. 10.1016).
pAS puro플라스미드는 제조업체의 방안에 따라 ExpiCHO-S세포(Thermo Fischer)에서 재조합 면역글로블린 변이체를 발현시켰다. 1 : 2의 비율로 중쇄 및 경쇄를 형질감염시켰다. ExpiCHO-S세포 배양물은 통상적으로 형질감염 약 10-12일 후 수득하였다. ExpiCHO-S세포 배양물을 정화하고 여과하였다. AKTA Avant (GE Healthcare)에서 단백질A로 정제하여(MabSelect SuRe™ LX, GE Healthcare) 배양 상등액을 정제하였다. 먼저, 상기 컬럼을 PBS로 5개의 부피(CV)를 평형시켰다. 다음, 배양물 상등액을 체류 시간이 5분일때 컬럼에 로딩하였다. 다음, 칼럼을 5 CV의 고염 완충액(100 mM의 아세트산나트륨, 500 mM의 염화나트륨, pH 5.5) 및 5 CV의 저염 완충액(50 mM의 아세트산나트륨, pH 5.5)으로 세척하였다. 항체를 3 CV의 용출 완충액(100 mM의 아세트산나트륨, pH 3.5)으로 용출한 다음, 1M의 Tris-HCl, pH 8.5로 중화시켰다. 단백질 A 정제된 단백질은 체외 기능 측정에 사용되었다.
양이온 교환 정제(Capto S ImpAct, GE Healthcare)를 통해 단백질A 정제된 단백질 샘플을 추가로 정제하였다. 완충액 A는 20 mM의 아세트산나트륨이고, pH5.5이다. 완충액 B는 20 mM의 아세트산나트륨, 500 mM의 염화나트륨고, pH5.5이다. 시료 로딩 전 단백질 A 정제된 샘플을 완충액 A와 유사한 pH 및 전도율로 조절하였다. 시료 로딩 체류 시간은 4분이다. 용출 구배가 30%-80%인 완충액 B는 15 CV 동안 유지되었다. 최소 응집을 갖는 분획을 합병하였다. 두 단계 정제 단백질은 안정성 연구 및 체내 효력 모델에 사용되었다.
구현예 4: 항CD137 x EGFR이중 특이성 항체의 특성화
구현예 3에서와 같이, 클론 2-9로부터 유래된 항CD137 scFv를 항EGFR항체의 중쇄의 N말단 및 C말단(HC-N, HC-C) 및 경쇄의 N말단 및 C말단(LC-N, LC-C)에서 PCT/US 2015/033402 (국제공개 WO 2015184403로 개시됨)에 개시된 아미노산 서열로부터 유래된 항EGFR전장 항체에 융합하였다.
A. 친화력 측정
생물층 간섭 측정법을 사용하여 이중 특이성 항체의 결합 동역학의 결합 및 해리 상수를 측정하였다. 동역학은 FortieBio Octet Red 96에서 30℃에서 측정되고, FortieBio Data Analysis 9.0 소프트웨어로 분석하였다. 항 인간 IgG Fc(AHC)센서를 사용하여 이중 특이성 항체 또는 대조군 항체를 포획하였다. 이중 결합은 제1 항원에 결합된 후, 해리되고, 제2 항원에 결합되 후 해리됨으로써 이루어진다. 상이한 항체 순환에서 20 mM의 글리신, pH 1.5으로 재생 순환시켰다. 기준선의 경우, 1x 동역학 완충액(Fortie Bio)을 사용하였다. 인간CD137-His (Sino Biologicals카탈로그 번호: 10041-H08H) 및 히말라야원숭이CD137-His단백질(Sino Biologicals 카탈로그 번호: 90847-K08H)을 일련의 농도에서 동역학 완충액으로 희석하였다. 동역학 완충웰을 기준웰로 설정하고, 데이터 처리 동안 감하였다. 각각의 항체-항원 결합에 대해, Rmax연결된 전체적인 피팅법을 사용하여 결합 및 해리된 1 : 1 Langmuir 모델로 피팅하였다. 인간CD137-his는 폴리히스티딘 태그가 인간 CD137 항원의 C-말단에 융합된 재조합 CD137 단백질이다(Sino Biological, 10041-H08H). 인간EGFR-his는 폴리히스티딘 태그가 인간EGFR항원의 C말단에 융합된 재조합 EGFR 단백질이다(Acro Biosystem, EGR-H5222-100 ug).
1) 제1 CD137-His, 제2 EGFR-His, 및 2) 제1 EGFR-His, 제2 CD137-His의 2개의 순차적인 순서로 상기 실험을 반복하였다. 도 8 및 하기 표 8에 나타낸 바와 같이, 모mAb와 비교하여, 상기 이중 특이성 항체의 각각의 항원 결합 부분은 유사한 결합 친화력을 나타낸다.
표 9.

세포 표면 수용체에 대한 이중 특이성 항체의 결합 친화력은 또한 전체 세포 결합 측정에서 정량화되었다. EGFR결합 친화력을 측정하기 위하여, 10,000개의 SK-Hep1세포(ATCC) 또는 CD137에 안정적으로 형질감염된 293T세포(제작 구축)를 FACS 완충액(1 x PBS, 2% FBS)에서 일련의 농도의 이중 특이성 항체와 4℃에서 1시간 동안 인큐베이션하였다. 다음, 세포를 PBS로 2회 세척한 후, FACS완충액에서 2차Alexa Fluor® 488 AffiniPure 염소 항 인간 IgG, F(ab')2단편 특이적 항체(Jackson ImmunoResearch, 코드 109-545-006)와 4℃에서 30분 동안 인큐베이션하였다. 다음, 세포를 PBS로 2회 세척하고 FACS 완충액에 재부유시켰다. 유세포분석법(Beckman Coulter, CytoFlex)은 결합된 항체의 정량화에 사용되고, CytExpert 분석 결과를 사용하였다. GraphPad8.0을 갖는 비선형 모델을 사용하여 중간 값 형광 강도를 피팅하였다.도 9A에 나타낸 바와 같이, 항CD137 x EGFR이중 특이성 항체는 CD137-형질감염된 293T 세포에 대해 유사한 전체 세포 결합 친화력을 나타내었다. 상기 항CD137 x EGFR이중 특이성 항체는 IgG1 야생형 Fc, LALA 돌연변이를 갖는 IgG1 Fc 및 상이한 링커의 변이체를 포함한다. 도 9B에 나타낸 바와 같이, 항CD137 x EGFR이중 특이성 항체 변이체는 EGFR-양성 SK-Hep1 종양 세포에 대해 유사한 전체 세포 결합 친화력을 나타냈다. 모 항EGFR 모노클로날 항체를 양성 대조로 사용하였다.
B. CD137 리포터 측정
먼저 NF-κB리포터 측정에서 항CD137 x EGFR이중 특이성 항체의 CD137작용제 활성을 측정하였다. 종양 세포의 높은 수준의 EGFR은 이중 특이성 항체를 종양 부위에 지정하고 CD137을 인근 T 세포에 과가교시켜 강력한 T 세포 활성화를 유도할 수 있는 것으로 추측된다. 이 가설을 테스트하기 위해, 상기 측정에 CD137 및 NFκB 루시페라제 리포터 유전자로 안정적으로 형질감염된 리포터 세포주, 높은 EGFR 발현 세포주 SK-Hep1(ATCC) 및 낮은 EGFR 발현 세포주 SKBR-3(ATCC)를 사용하였다. 293T세포에서 CD137 및 NF-κB루시퍼라제 리포터 유전자로 안정적으로 형질감염된 리포터 세포주를 내부에서 구축하였다. 실험에서 높은 EGFR 발현 종양 세포주 SK-Hep1(ATCC) 및 낮은 EGFR 발현 종양 세포주 SKBR-3(ATCC)을 사용하였다. EGFR 높은 세포주 SK-Hep1은 타겟 종양 세포를 모의하는데 사용되었고, EGFR 낮은 세포주 SKBR-3은 말초 또는 비타겟 세포를 모의하는데 사용되으며, CD137/NFκB 리포터 293T 세포는 T 세포를 모의하는데 사용되었다. SK-Hep1세포는 CD137/NFκB 리포터 293T세포와 공동 인큐베이션으로 발현 높은 수준의 EGFR을 발현하는 종양 세포와 T세포가 공존하는 종양 미세환경을 모의하였다. SK-Hep1세포의 높은 수준의 EGFR은 이중 특이성 항체를 종양 부위에 지정하고 리포터 세포주에 CD137을 과가교시켜, 강력한 NFκB 신호전달 및 활성화를 유도할 수 있는 것으로 추측된다. 293T 리포터 세포와 SKBR-3 세포의 공동 인큐베이션은 이중 특이성 항체의 안전성 상황을 테스트하는데 사용되는 말초 또는 표적 외 부위를 모의하였다.
세포 배양 조건은 ATCC에서 권장하는 배지 및 조건을 사용하였다. 각각의 세포주를 96-웰플레이트에 단독으로 시딩하여 밤을 샌다. 각 웰당 100 ul의 배지는 15,000개의 SKBR-3 또는 SK-Hep1세포를 사용하여 시딩하였다. 2일째, 종양 세포를 세척하고 일련의 농도의 항체를 37℃에서 20분 동안 처리하였다. 이 후, 항체를 씻어냈다. 상기 단계는 과량의 항체를 제거하고 후크 효과를 방지하기 위한 것이다. 다음, 120,000개의 293T CD137/NFκB리포더 세포를 DMEM배지(HyClone, 카탈로그 번호16777-200)중의 암세포에 첨가하였다. 단일 특이적 모클론 2-9항체 및 항EGFR항체의 조합을 대조로 사용하였다. TNFα가 직접적인 NF-κB활성제이므로, 상기 측정에서 20 ng/ml의 TNFα를 양성대조로 사용하였다. PBS를 음성 대조로 사용하였다. 5시간 후, 제조업체의 방안에 따라, Bright-Glo™루시퍼라제 측정 시스템(Promega, 카탈로그 번호E2610)을 사용하여 루시퍼라제 활성을 측정하였다.
결과에 따르면, EGFR높은 SK-Hep1세포가 존재하는 경우, 예시적 항CD137 x EGFR이중 특이성 항체에 의한 CD137의 용량 의존적 활성화되나(도 10A), EGFR낮은 SKBR-3 세포의 존재 하에서는 그렇지 않으며(도 10B), 단일 특이성 모클론 2-9 항체와의 조합 항EGFR 항체는 어떠한 CD137 활성도 유도하지 않았다(도 10A 및 도 10B). 결과적으로, 이중 특이성 항체는 종양 부위의 효력 이점과 말초 또는 비표적 부위에서 이중특이성 항체의 안전성 상황을 나타낸다. 상이한 링커 또는 IgG1 Fc LALA돌연변이는 CD137 활성화에 영향을 미치지 않는다.
C. 사이토카인 방출 측정
EGFR의존성 T 세포 활성화에 대한 이중 특이성 항체의 효능을 사이토카인 방출에 의해 추가로 측정하였다. 실험에서 높은 EGFR 발현 종양 세포주 SK-Hep1(ATCC) 및 낮은 EGFR 발현 종양 세포주 SKBR-3(ATCC)을 사용하였다. 세포 배양 조건은 ATCC에서 권장하는 배지 및 조건을 사용하였다. 각각의 세포주를 96-웰플레이트에 단독으로 시딩하여 밤을 샌다. 각 웰당 100 ul의 배지는 15,000개의 SKBR-3 또는 SK-Hep1세포를 사용하여 시딩하였다. Ficoll-Paque® PLUS(카탈로그 번호17-1440-02, GE Healthcare)를 사용하여 인간 PBMC를 단리하였다. 단핵구가 부착될 수 있도록 적어도 3시간 동안 배양접시에서 단리된 PBMC를 배양함으로써 단핵구를 고갈시켰다. 2일째, 종양 세포를 세척하고, 37℃에서 일련의 농도의 항체를 20분 동안 처리하였다. 이 후, 항체를 씻어냈다. 상기 단계는 과량의 항체를 제거하고 후크 효과를 방지하기 위한 것이다. 다음 PBMC를 Gibco RPMI 배지 1640(카탈로그 번호 A1049101, Thermo Fischer)의 암세포에 첨가하였다. 단일 특이적 모클론 2-9항체 및 항EGFR항체의 조합을 대조로 사용하였다. 모든 측정에서 10: 1의 이펙터 세포(PBMC)와 타겟세포(암세포)의 비율을 측정하였다. 24시간 후, 배지를 수집하고, ELISA방법(인간IL-2 ELISA MAX™ Deluxe, 카탈로그 번호431804, BioLegend)을 사용하여 IL-2 수준을 측정하였다.
도 11에 나타낸 바와 같이, EGFR 높은 세포가 존재하는 경우, IL-2에 대한 효과기 세포(즉 PBMC)의 조제량 의존성 분비를 관찰되었으나, EGFR 낮은 세포가 존재하는 경우 관찰되지 않았다. 대조군으로 사용된 단일 특이성 모클론 2-9 항체와 항EGFR 항체의 조합과 비교하여, 이중 특이성 항체 변이체는 EGFR 높은 세포의 존재하에서 더 높은 사이토카인 방출을 나타내고, 이는 종양 부위에서 이중 특이성 항체의 효능 우세를 나타낸다. 이중 특이성 항체 변이체는 EGFR 낮은 세포의 존재 하에서 현저한 사이토카인 방출을 유도하지 않았고, 이는 말초 또는 비타겟 부위에서 이중 특이성 항체의 안전성 상황을 나타낸다. 상기 측정은 상이한 공여체를 사용하여 수회 반복 실험하여, 유사한 결과를 관찰하였다. 일반적으로, 상이한 링커 및 IgG1 Fc LALA돌연변이는 CD137 활성화에 영향을 미치지 않는다. 공여체 63 및 공여체 64는 두 개의 상이한 PBMC 공여체이고 반복 역할을 한다. PBMC만이 음성 대조군이고, 여기서 PBMC만 있고, 다른 항체는 없다. 총적으로, 항CD137 x EGFR 이중 특이성 항체 치료는 EGFR 의존적 방식으로 사이토카인 생산을 유도하였다.
종양 세포가 없는 상태에서 T 세포 활성화를 사이토카인 방출로 측정하였다. 상기 측정은 CD137 양성 T 세포만 존재하지만 종양 세포가 없는 말초/비타겟 부위에서 이중 특이적 항체를 모의하여 종양 부재 하에 이중 특이성 항체의 안전성 상황을 추가로 입증하는 데 사용하였다. 어떠한 종양 세포가 없이 단리된 PBMC를 상이한 항체의 존재하에 RPMI 배지 1640에서 밤새 배양하였다. 24시간 후, ELISA (인간IL-2 ELISA MAX™ Deluxe, 카탈로그 번호431804, BioLegend)로 IL-2의 수준을 측정하였다. 도 11에서 SK-Hep1세포 존재 하의 사이토카인 수준과 비교하여, 모든 항체의 IL-2 유도가 최소이다. 도 12를 참조바란다. 이는 CD137에 의한 T 세포의 강력한 활성화가 EGFR높은 종양 세포에 대한 이중 특이성 항체의 결합에 의해 유도된 수용체 응집을 필요로 하기 때문에 예측과 일치하다. 다수의 공여체로 반복 실험하고 유사한 결과를 얻었다.
D. 체내 효력 평가
LoVo/이종 이식편을 지닌 PBMC인간화ASID마우스 모델에서 상기 이중 특이성 항체의 체내 효력을 연구하였다. LoVo (인간 결장암 종양 세포주)은 상대적으로 높은 EGFR을 발현하고 KRAS-G13D돌연변이를 갖는다. 상기 모델에서, 500만개의 종양 세포를 ASID마우스에 피하 주사하였다. 종양 크기가 ~100 mm3에 달하는 경우, 금방 단리된 인간PBMC를 면역 결핍(ASID)마우스에 정맥 주사하였다. 다음 동물을 4주 동안 주당 2회씩 복강 내 주사하여 상이한 항체로 처리하였다. 1차 치료 25일 후, 조제량 의존적 방식으로 항종양 작용을 관찰하였다. 캘리퍼스로 종양 크기를 측정하고, 하기 공식으로 종양 부피(TV, mm3로 계산)를 계산하였다: TV = a × b2/2, 여기서 “a” 및 “b”는 각각 종양의 긴지름과 짧은 지름이다. TV는 하기 공식으로 종양 성장 억제(TGI, 항종양 유효성 지표) 계산에 사용된다: TGI (% = [1-(Tt-T0/(Ct-C0] × 100%, 여기서 Tt = 치료 피험자의 시간 t에서의 평균TV, T0 = 치료 피험자의 시간 0에서의 평균TV(기준선), Ct = 대조의 시간 t에서의 평균TV, 및 C0 = 대조의 시간 0에서의 평균TV(기준선).
도 13A 및 표10에 나타낸 바와 같이, IgG1 Fc(LALA돌연변이가 있음)를 갖는 항CD137 x EGFR이중 특이성 항체로 치료된 EGFR높은 종양 보유 마우스는 10 mg/kg 내지 0.2 mg/kg의 조제량 의존성 종양억제를 나타내고, 여기서 비히클 대조와 비교하여, 모든 그룹에서의 p값 < 0.05이다. 조제량 의존성 종양억제는 종양억제가 상기 이중 특이성 항체 치료와 관련되는 것을 나타낸다.
표 10.

비히클 대조군과 비교한 T검증: * p < 0.05, ** p < 0.01, *** p < 0.001, **** p < 0.0001
도 13B 및 표 11에 나타낸 바와 같이, 상기 이중 특이성 항체로 치료된 EGFR높은 종양 보유 마우스는 단일 특이성 모 항CD137 항체 및 항EGFR항체를 포함하는 조제량 매칭(몰비) 조합과 비교하여 증강된 종양억제(14일째, 97% vs 74%)를 나타내고, 이는 상기 이중 특이성 항체의 우수한 치료 효과를 나타낸다. PBMC가 없는 치료군의 경우, 각 그룹에서 종양억제의 현저한 차의가 관찰되지 않았다(데이터에 나타나지 않음). 결과적으로, 단일 특이성 항CD137 항체, 단일 특이성 항EGFR항체 및 이들의 조합과 비교하여, 항CD137 x EGFR이중 특이성 항체의 치료 효력이 우수한 것을 나타낸다.
표 11.

비히클 대조군과 비교한 T검증: * p < 0.05, ** p < 0.01, *** p < 0.001, **** p < 0.0001
또한 A431/이종 이식편을 지닌 PBMC NOD-SCID마우스 모델에서 상기 이중 특이성 항체의 체내 효력을 연구하였다. A431(인간 표피양 암 세포주)도 상대적으로 높은 수준의 EGFR을 발현한다. 상기 모델에서, 200만개의 종양 세포는 3 : 1의 비율로 100만개의 새로 단리된 인간PBMC와 공동으로 혼합된 후, 면역 결핍 (NOD-SCID)마우스에 피하 주사된다. 다음 동물을 4-5주 동안 주당 2회씩 복강 내 주사하여 상이한 항체로 처리하였다. 1차 치료 14일 후, 조제량 의존적 방식으로 항종양 효과를 관찰하였다. 캘리퍼스로 종양 크기를 측정하고, 하기 공식으로 종양 부피(TV, mm3로 계산)를 계산하였다: TV = a × b2/2, 여기서 “a” 및 “b”는 각각 종양의 긴지름과 짧은 지름이다. TV는 하기 공식으로 종양 성장 억제(TGI, 항종양 효과성의 지표)를 계산하기 위한 것이다: TGI (% = [1-(Tt-T0/(Ct-C0)]×100%. 여기서 Tt = 치료자의 시간 t에서의 평균 TV, T0 = 치료의 시간 0에서의 평균 TV(기준선), Ct = 대조의 시간 t에서의 평균 TV, 및 C0 = 대조의 시간 0에서의 평균 TV(기준선).
도 14A 및 표12에 나타낸 바와 같이, IgG1 Fc(LALA돌연변이가 있음)를 갖는 항CD137 x EGFR이중 특이성 항체로 치료된 A431 종양 보유 마우스는 0.3 mg/kg 내지 1.4 mg/kg의 조제량 의존성 종양억제를 나타내고, 여기서 비히클 대조와 비교하여, 높은 조제량군(1.4 mg/kg)에서의 p값 < 0.05이다. 조제량 의존성 종양억제는 종양억제가 이중 특이성 항체 치료와 관련되는 것을 나타낸다. 도 14B 및 표 12에 나타낸 바와 같이, 상기 이중 특이성 항체로 치료된 EGFR높은 종양 보유 마우스는 단일 특이성 모 항CD137 항체 및 항EGFR항체를 포함하는 조제량 매칭(몰비) 조합과 비교하여 증강된 종양억제(14일째, 78% vs 26%)를 나타내고, 이는 이중 특이성 항체의 우수한 치료 효과를 나타낸다. 결과적으로, 항CD137 x EGFR이중 특이성 항체는 단일 특이적 항CD137 항체, 단일 특이적 항EGFR항체 및 조합보다 우수한 치료 효력을 갖는 것을 나타낸다.
표 12.

비히클 대조군과 비교한 T검증: * p < 0.05, ** p < 0.01, *** p < 0.001, **** p < 0.0001
도시되고 보호받고자 하는 다양한 실시예 외에, 개시된 주제는 또한 본문에 개시되고 보호받고자 하는 특징의 다른 조합의 다른 실시예에 관한 것이다. 이러한 방식으로, 본문에 제시된 특정 특징은 개시된 주제의 범위 내에서 다른 방식으로 서로 조합되어, 개시된 주제에 본문에 개시된 특징의 임의의 적합한 조합을 포함하도록 할 수 있다. 예시 및 설명의 목적으로 개시된 주제의 구체적인 실시예에 대한 전술한 설명을 제출하였다. 이상 설명은 개시된 주제를 개시된 실시예로 완전하게 제한하거나 제한하려는 의도가 아니다.
본 분야에서 통상의 지식을 가진 자에게 있어서, 개시된 주제의 정신 또는 범위를 벗어나지 않는 경우, 개시된 주제의 조성 및 방법에 다양한 수정 및 변형이 이루어질 수 있는 것은 명백하다. 따라서, 개시된 주제는 첨부된 청구범위 및 그 균등물의 범위 내에서 수정 및 변형을 포함하도록 의도된다.
본문은 다양한 간행물, 특허 및 특허 출원을 인용하였고, 그 전체 내용은 인용을 통해 본문에 통합된다.
SEQUENCE LISTING
<110> SHANGHAI HENLIUS BIOTECH, INC
<120> Anti-CD137 constructs, etc.
<130> SH1903-20P450298
<150> PCT/CN2020/077148
<151> 2020-02-28
<160> 282
<170> SIPOSequenceListing 1.0
<210> 1
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(5)
<223> Clone 3 VH CDR1
<400> 1
Asp Thr Tyr Ile His
1 5
<210> 2
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(17)
<223> Clone 3 VH CDR2
<400> 2
Arg Ile Asp Pro Ala Asn Gly Phe Thr Glu Tyr Ala Gln Lys Phe Gln
1 5 10 15
Gly
<210> 3
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(10)
<223> Clone 3 VH CDR3
<400> 3
Gly Asn Leu His Tyr Ala Leu Met Asp Tyr
1 5 10
<210> 4
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(11)
<223> Clone 3 VL CDR1
<400> 4
Lys Ala Ser Gln Ala Ile Asn Thr Tyr Leu Ser
1 5 10
<210> 5
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(7)
<223> Clone 3 VL CDR2
<400> 5
Arg Ala Asn Arg Met Val Asp
1 5
<210> 6
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(9)
<223> Clone 3 VL CDR3
<400> 6
Leu Gln Ser Asp Asp Phe Pro Tyr Thr
1 5
<210> 7
<211> 119
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(119)
<223> Clone 3 VH
<400> 7
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Phe Asn Pro Lys Asp Thr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Arg Ile Asp Pro Ala Asn Gly Phe Thr Glu Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Met Thr Arg Asp Thr Ser Thr Ser Thr Val Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Thr Gly Asn Leu His Tyr Ala Leu Met Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Ser Val Thr Val Ser Ser
115
<210> 8
<211> 110
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(110)
<223> Clone 3 VL
<400> 8
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Val Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Lys Ala Ser Gln Ala Ile Asn Thr Tyr
20 25 30
Leu Ser Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Arg Ala Asn Arg Met Val Asp Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln His
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln Ser Asp Asp Phe Pro Tyr
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys Arg Thr Val
100 105 110
<210> 9
<211> 445
<212> PRT
<213> Artificial Sequence
<220>
<221> CHAIN
<222> (1)..(445)
<223> Clone 3 HC
<400> 9
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Phe Asn Pro Lys Asp Thr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Arg Ile Asp Pro Ala Asn Gly Phe Thr Glu Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Met Thr Arg Asp Thr Ser Thr Ser Thr Val Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Thr Gly Asn Leu His Tyr Ala Leu Met Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Ser Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe
115 120 125
Pro Leu Ala Pro Cys Ser Arg Ser Thr Ser Glu Ser Thr Ala Ala Leu
130 135 140
Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp
145 150 155 160
Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu
165 170 175
Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser
180 185 190
Ser Asn Phe Gly Thr Gln Thr Tyr Thr Cys Asn Val Asp His Lys Pro
195 200 205
Ser Asn Thr Lys Val Asp Lys Thr Val Glu Arg Lys Cys Cys Val Glu
210 215 220
Cys Pro Pro Cys Pro Ala Pro Pro Val Ala Gly Pro Ser Val Phe Leu
225 230 235 240
Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu
245 250 255
Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Gln
260 265 270
Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys
275 280 285
Pro Arg Glu Glu Gln Phe Asn Ser Thr Phe Arg Val Val Ser Val Leu
290 295 300
Thr Val Val His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys
305 310 315 320
Val Ser Asn Lys Gly Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys
325 330 335
Thr Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser
340 345 350
Arg Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys
355 360 365
Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln
370 375 380
Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Met Leu Asp Ser Asp Gly
385 390 395 400
Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln
405 410 415
Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn
420 425 430
His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
435 440 445
<210> 10
<211> 214
<212> PRT
<213> Artificial Sequence
<220>
<221> CHAIN
<222> (1)..(214)
<223> Clone 3 LC
<400> 10
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Val Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Lys Ala Ser Gln Ala Ile Asn Thr Tyr
20 25 30
Leu Ser Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Arg Ala Asn Arg Met Val Asp Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln His
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln Ser Asp Asp Phe Pro Tyr
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 11
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(5)
<223> Clone 9 VH CDR1
<400> 11
Asp Thr Tyr Ile His
1 5
<210> 12
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(17)
<223> Clone 9 VH CDR2
<400> 12
Lys Ile Asp Pro Ala Asn Gly Asn Thr Glu Tyr Ala Gln Lys Phe Gln
1 5 10 15
Gly
<210> 13
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(10)
<223> Clone 9 VH CDR3
<400> 13
Gly Asn Leu His Tyr Ala Leu Met Asp Tyr
1 5 10
<210> 14
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(11)
<223> Clone 9 VL CDR1
<400> 14
Lys Ala Ser Gln Ala Ile Ala Thr Tyr Leu Ser
1 5 10
<210> 15
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(7)
<223> Clone 9 VL CDR2
<400> 15
Arg Ala Asn Arg Met Tyr Asp
1 5
<210> 16
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(9)
<223> Clone 9 VL CDR3
<400> 16
Leu Gln Phe Asp Asp Phe Pro Tyr Thr
1 5
<210> 17
<211> 119
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(119)
<223> Clone 9 VH
<400> 17
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Phe Asn Leu Lys Asp Thr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Lys Ile Asp Pro Ala Asn Gly Asn Thr Glu Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Met Thr Arg Asp Thr Ser Thr Ser Thr Val Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Thr Gly Asn Leu His Tyr Ala Leu Met Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Ser Val Thr Val Ser Ser
115
<210> 18
<211> 110
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(110)
<223> Clone 9 VL
<400> 18
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Val Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Lys Ala Ser Gln Ala Ile Ala Thr Tyr
20 25 30
Leu Ser Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Arg Ala Asn Arg Met Tyr Asp Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln Phe Asp Asp Phe Pro Tyr
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys Arg Thr Val
100 105 110
<210> 19
<211> 445
<212> PRT
<213> Artificial Sequence
<220>
<221> CHAIN
<222> (1)..(445)
<223> Clone 9 HC
<400> 19
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Phe Asn Leu Lys Asp Thr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Lys Ile Asp Pro Ala Asn Gly Asn Thr Glu Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Met Thr Arg Asp Thr Ser Thr Ser Thr Val Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Thr Gly Asn Leu His Tyr Ala Leu Met Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Ser Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe
115 120 125
Pro Leu Ala Pro Cys Ser Arg Ser Thr Ser Glu Ser Thr Ala Ala Leu
130 135 140
Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp
145 150 155 160
Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu
165 170 175
Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser
180 185 190
Ser Asn Phe Gly Thr Gln Thr Tyr Thr Cys Asn Val Asp His Lys Pro
195 200 205
Ser Asn Thr Lys Val Asp Lys Thr Val Glu Arg Lys Cys Cys Val Glu
210 215 220
Cys Pro Pro Cys Pro Ala Pro Pro Val Ala Gly Pro Ser Val Phe Leu
225 230 235 240
Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu
245 250 255
Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Gln
260 265 270
Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys
275 280 285
Pro Arg Glu Glu Gln Phe Asn Ser Thr Phe Arg Val Val Ser Val Leu
290 295 300
Thr Val Val His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys
305 310 315 320
Val Ser Asn Lys Gly Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys
325 330 335
Thr Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser
340 345 350
Arg Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys
355 360 365
Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln
370 375 380
Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Met Leu Asp Ser Asp Gly
385 390 395 400
Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln
405 410 415
Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn
420 425 430
His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
435 440 445
<210> 20
<211> 214
<212> PRT
<213> Artificial Sequence
<220>
<221> CHAIN
<222> (1)..(214)
<223> Clone 9 LC
<400> 20
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Val Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Lys Ala Ser Gln Ala Ile Ala Thr Tyr
20 25 30
Leu Ser Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Arg Ala Asn Arg Met Tyr Asp Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln Phe Asp Asp Phe Pro Tyr
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Glu Ser
195 200 205
Leu Asn Arg Gly Glu Cys
210
<210> 21
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(5)
<223> Clone 23 VH CDR1
<400> 21
Asp Thr Tyr Ile His
1 5
<210> 22
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(17)
<223> Clone 23 VH CDR2
<400> 22
Lys Ile Asp Pro Ala Asn Gly Gln Thr Glu Tyr Ala Gln Lys Phe Gln
1 5 10 15
Gly
<210> 23
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(10)
<223> Clone 23 VH CDR3
<400> 23
Gly Asn Leu His Tyr Ala Leu Met Asp Tyr
1 5 10
<210> 24
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(11)
<223> Clone 23 VL CDR1
<400> 24
Lys Ala Ser Gln Ala Ile Asn Thr Tyr Leu Ser
1 5 10
<210> 25
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(7)
<223> Clone 23 VL CDR2
<400> 25
Arg Ala Asn Arg Met Val Gly
1 5
<210> 26
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(9)
<223> Clone 23 VL CDR3
<400> 26
Leu Gln Tyr Arg Asp Phe Pro Tyr Thr
1 5
<210> 27
<211> 119
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(119)
<223> Clone 23 VH
<400> 27
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Phe Asn Ile Lys Asp Thr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Lys Ile Asp Pro Ala Asn Gly Gln Thr Glu Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Met Thr Arg Asp Thr Ser Thr Ser Thr Val Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Thr Gly Asn Leu His Tyr Ala Leu Met Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Ser Val Thr Val Ser Ser
115
<210> 28
<211> 110
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(110)
<223> Clone 23 VL
<400> 28
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Val Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Lys Ala Ser Gln Ala Ile Asn Thr Tyr
20 25 30
Leu Ser Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Arg Ala Asn Arg Met Val Gly Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln Tyr Arg Asp Phe Pro Tyr
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys Arg Thr Val
100 105 110
<210> 29
<211> 445
<212> PRT
<213> Artificial Sequence
<220>
<221> CHAIN
<222> (1)..(445)
<223> Clone 23 HC
<400> 29
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Phe Asn Ile Lys Asp Thr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Lys Ile Asp Pro Ala Asn Gly Gln Thr Glu Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Met Thr Arg Asp Thr Ser Thr Ser Thr Val Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Thr Gly Asn Leu His Tyr Ala Leu Met Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Ser Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe
115 120 125
Pro Leu Ala Pro Cys Ser Arg Ser Thr Ser Glu Ser Thr Ala Ala Leu
130 135 140
Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp
145 150 155 160
Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu
165 170 175
Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser
180 185 190
Ser Asn Phe Gly Thr Gln Thr Tyr Thr Cys Asn Val Asp His Lys Pro
195 200 205
Ser Asn Thr Lys Val Asp Lys Thr Val Glu Arg Lys Cys Cys Val Glu
210 215 220
Cys Pro Pro Cys Pro Ala Pro Pro Val Ala Gly Pro Ser Val Phe Leu
225 230 235 240
Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu
245 250 255
Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Gln
260 265 270
Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys
275 280 285
Pro Arg Glu Glu Gln Phe Asn Ser Thr Phe Arg Val Val Ser Val Leu
290 295 300
Thr Val Val His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys
305 310 315 320
Val Ser Asn Lys Gly Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys
325 330 335
Thr Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser
340 345 350
Arg Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys
355 360 365
Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln
370 375 380
Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Met Leu Asp Ser Asp Gly
385 390 395 400
Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln
405 410 415
Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn
420 425 430
His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
435 440 445
<210> 30
<211> 214
<212> PRT
<213> Artificial Sequence
<220>
<221> CHAIN
<222> (1)..(214)
<223> Clone 23 LC
<400> 30
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Val Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Lys Ala Ser Gln Ala Ile Asn Thr Tyr
20 25 30
Leu Ser Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Arg Ala Asn Arg Met Val Gly Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln Tyr Arg Asp Phe Pro Tyr
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 31
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(5)
<223> Clone 25 VH CDR1
<400> 31
Asp Thr Tyr Ile His
1 5
<210> 32
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(17)
<223> Clone 25 VH CDR2
<400> 32
Arg Ile Asp Pro Ala Asn Gly Asn Ser Glu Tyr Ala Gln Lys Phe Gln
1 5 10 15
Gly
<210> 33
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(10)
<223> Clone 25 VH CDR3
<400> 33
Gly Asn Leu His Tyr Gly Leu Met Asp Tyr
1 5 10
<210> 34
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(11)
<223> Clone 25 VL CDR1
<400> 34
Lys Ala Ser Gln Ala Ile Asn Thr Tyr Leu Ser
1 5 10
<210> 35
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(7)
<223> Clone 25 VL CDR2
<400> 35
Arg Asp Asn Arg Lys Val Asp
1 5
<210> 36
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(9)
<223> Clone 25 VL CDR3
<400> 36
Leu Gln Tyr Gln Asp Phe Pro Tyr Lys
1 5
<210> 37
<211> 119
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(119)
<223> Clone 25 VH
<400> 37
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Phe Asn Ile Gln Asp Thr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Arg Ile Asp Pro Ala Asn Gly Asn Ser Glu Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Met Thr Arg Asp Thr Ser Thr Ser Thr Val Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Thr Gly Asn Leu His Tyr Gly Leu Met Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Ser Val Thr Val Ser Ser
115
<210> 38
<211> 110
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(110)
<223> Clone 25 VL
<400> 38
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Val Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Lys Ala Ser Gln Ala Ile Asn Thr Tyr
20 25 30
Leu Ser Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Arg Asp Asn Arg Lys Val Asp Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln Tyr Gln Asp Phe Pro Tyr
85 90 95
Lys Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys Arg Thr Val
100 105 110
<210> 39
<211> 445
<212> PRT
<213> Artificial Sequence
<220>
<221> CHAIN
<222> (1)..(445)
<223> Clone 25 HC
<400> 39
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Phe Asn Ile Gln Asp Thr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Arg Ile Asp Pro Ala Asn Gly Asn Ser Glu Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Met Thr Arg Asp Thr Ser Thr Ser Thr Val Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Thr Gly Asn Leu His Tyr Gly Leu Met Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Ser Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe
115 120 125
Pro Leu Ala Pro Cys Ser Arg Ser Thr Ser Glu Ser Thr Ala Ala Leu
130 135 140
Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp
145 150 155 160
Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu
165 170 175
Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser
180 185 190
Ser Asn Phe Gly Thr Gln Thr Tyr Thr Cys Asn Val Asp His Lys Pro
195 200 205
Ser Asn Thr Lys Val Asp Lys Thr Val Glu Arg Lys Cys Cys Val Glu
210 215 220
Cys Pro Pro Cys Pro Ala Pro Pro Val Ala Gly Pro Ser Val Phe Leu
225 230 235 240
Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu
245 250 255
Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Gln
260 265 270
Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys
275 280 285
Pro Arg Glu Glu Gln Phe Asn Ser Thr Phe Arg Val Val Ser Val Leu
290 295 300
Thr Val Val His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys
305 310 315 320
Val Ser Asn Lys Gly Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys
325 330 335
Thr Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser
340 345 350
Arg Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys
355 360 365
Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln
370 375 380
Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Met Leu Asp Ser Asp Gly
385 390 395 400
Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln
405 410 415
Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn
420 425 430
His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
435 440 445
<210> 40
<211> 214
<212> PRT
<213> Artificial Sequence
<220>
<221> CHAIN
<222> (1)..(214)
<223> Clone 25 LC
<400> 40
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Val Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Lys Ala Ser Gln Ala Ile Asn Thr Tyr
20 25 30
Leu Ser Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Arg Asp Asn Arg Lys Val Asp Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln Tyr Gln Asp Phe Pro Tyr
85 90 95
Lys Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 41
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(5)
<223> Clone 33 VH CDR1
<400> 41
Asp Thr Tyr Ile Gln
1 5
<210> 42
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(17)
<223> Clone 33 VH CDR2
<400> 42
Lys Ile Asp Pro Ala Asn Gly Asn Thr Met Tyr Ala Gln Lys Phe Gln
1 5 10 15
Gly
<210> 43
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(10)
<223> Clone 33 VH CDR3
<400> 43
Gly Asn Leu His Tyr Ala Leu Met Asp Tyr
1 5 10
<210> 44
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(11)
<223> Clone 33 VL CDR1
<400> 44
Lys Ala Ser Gln Thr Ile Asn Thr Tyr Leu Ser
1 5 10
<210> 45
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(7)
<223> Clone 33 VL CDR2
<400> 45
Arg Ala Asn Arg Met Pro Asp
1 5
<210> 46
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(9)
<223> Clone 33 VL CDR3
<400> 46
Leu Gln Tyr Asp Asp Phe Pro Tyr Thr
1 5
<210> 47
<211> 119
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(119)
<223> Clone 33 VH
<400> 47
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Phe Asn Ile Lys Asp Thr
20 25 30
Tyr Ile Gln Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Lys Ile Asp Pro Ala Asn Gly Asn Thr Met Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Met Thr Arg Asp Thr Ser Thr Ser Thr Val Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Thr Gly Asn Leu His Tyr Ala Leu Met Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Ser Val Thr Val Ser Ser
115
<210> 48
<211> 110
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(110)
<223> Clone 33 VL
<400> 48
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Val Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Lys Ala Ser Gln Thr Ile Asn Thr Tyr
20 25 30
Leu Ser Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Arg Ala Asn Arg Met Pro Asp Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln Tyr Asp Asp Phe Pro Tyr
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys Arg Thr Val
100 105 110
<210> 49
<211> 445
<212> PRT
<213> Artificial Sequence
<220>
<221> CHAIN
<222> (1)..(445)
<223> Clone 33 HC
<400> 49
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Phe Asn Ile Lys Asp Thr
20 25 30
Tyr Ile Gln Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Lys Ile Asp Pro Ala Asn Gly Asn Thr Met Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Met Thr Arg Asp Thr Ser Thr Ser Thr Val Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Thr Gly Asn Leu His Tyr Ala Leu Met Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Ser Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe
115 120 125
Pro Leu Ala Pro Cys Ser Arg Ser Thr Ser Glu Ser Thr Ala Ala Leu
130 135 140
Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp
145 150 155 160
Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu
165 170 175
Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser
180 185 190
Ser Asn Phe Gly Thr Gln Thr Tyr Thr Cys Asn Val Asp His Lys Pro
195 200 205
Ser Asn Thr Lys Val Asp Lys Thr Val Glu Arg Lys Cys Cys Val Glu
210 215 220
Cys Pro Pro Cys Pro Ala Pro Pro Val Ala Gly Pro Ser Val Phe Leu
225 230 235 240
Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu
245 250 255
Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Gln
260 265 270
Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys
275 280 285
Pro Arg Glu Glu Gln Phe Asn Ser Thr Phe Arg Val Val Ser Val Leu
290 295 300
Thr Val Val His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys
305 310 315 320
Val Ser Asn Lys Gly Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys
325 330 335
Thr Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser
340 345 350
Arg Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys
355 360 365
Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln
370 375 380
Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Met Leu Asp Ser Asp Gly
385 390 395 400
Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln
405 410 415
Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn
420 425 430
His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
435 440 445
<210> 50
<211> 214
<212> PRT
<213> Artificial Sequence
<220>
<221> CHAIN
<222> (1)..(214)
<223> Clone 33 LC
<400> 50
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Val Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Lys Ala Ser Gln Thr Ile Asn Thr Tyr
20 25 30
Leu Ser Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Arg Ala Asn Arg Met Pro Asp Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln Tyr Asp Asp Phe Pro Tyr
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 51
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(5)
<223> Clone 35 VH CDR1
<400> 51
Asp Thr Tyr Ile His
1 5
<210> 52
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(17)
<223> Clone 35 VH CDR2
<400> 52
Arg Ile Asp Pro Ala Asn Gly Tyr Thr Glu Tyr Ala Gln Lys Phe Gln
1 5 10 15
Gly
<210> 53
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(10)
<223> Clone 35 VH CDR3
<400> 53
Gly Asn Leu His Tyr Ala Leu Met Asp Tyr
1 5 10
<210> 54
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(11)
<223> Clone 35 VL CDR1
<400> 54
Lys Ala Ser Gln Ala Ile Ala Thr Tyr Leu Ser
1 5 10
<210> 55
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(7)
<223> Clone 35 VL CDR2
<400> 55
Arg Ala Asn Arg Met Val Asp
1 5
<210> 56
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(9)
<223> Clone 35 VL CDR3
<400> 56
Leu Gln Phe Gln Asp Phe Pro Tyr Thr
1 5
<210> 57
<211> 119
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(119)
<223> Clone 35 VH
<400> 57
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Phe Asn Ile Asn Asp Thr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Arg Ile Asp Pro Ala Asn Gly Tyr Thr Glu Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Met Thr Arg Asp Thr Ser Thr Ser Thr Val Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Thr Gly Asn Leu His Tyr Ala Leu Met Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Ser Val Thr Val Ser Ser
115
<210> 58
<211> 110
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(110)
<223> Clone 35 VL
<400> 58
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Val Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Lys Ala Ser Gln Ala Ile Ala Thr Tyr
20 25 30
Leu Ser Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Arg Ala Asn Arg Met Val Asp Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln Phe Gln Asp Phe Pro Tyr
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys Arg Thr Val
100 105 110
<210> 59
<211> 445
<212> PRT
<213> Artificial Sequence
<220>
<221> CHAIN
<222> (1)..(445)
<223> Clone 35 HC
<400> 59
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Phe Asn Ile Asn Asp Thr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Arg Ile Asp Pro Ala Asn Gly Tyr Thr Glu Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Met Thr Arg Asp Thr Ser Thr Ser Thr Val Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Thr Gly Asn Leu His Tyr Ala Leu Met Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Ser Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe
115 120 125
Pro Leu Ala Pro Cys Ser Arg Ser Thr Ser Glu Ser Thr Ala Ala Leu
130 135 140
Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp
145 150 155 160
Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu
165 170 175
Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser
180 185 190
Ser Asn Phe Gly Thr Gln Thr Tyr Thr Cys Asn Val Asp His Lys Pro
195 200 205
Ser Asn Thr Lys Val Asp Lys Thr Val Glu Arg Lys Cys Cys Val Glu
210 215 220
Cys Pro Pro Cys Pro Ala Pro Pro Val Ala Gly Pro Ser Val Phe Leu
225 230 235 240
Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu
245 250 255
Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Gln
260 265 270
Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys
275 280 285
Pro Arg Glu Glu Gln Phe Asn Ser Thr Phe Arg Val Val Ser Val Leu
290 295 300
Thr Val Val His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys
305 310 315 320
Val Ser Asn Lys Gly Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys
325 330 335
Thr Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser
340 345 350
Arg Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys
355 360 365
Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln
370 375 380
Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Met Leu Asp Ser Asp Gly
385 390 395 400
Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln
405 410 415
Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn
420 425 430
His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
435 440 445
<210> 60
<211> 214
<212> PRT
<213> Artificial Sequence
<220>
<221> CHAIN
<222> (1)..(214)
<223> Clone 35 LC
<400> 60
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Val Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Lys Ala Ser Gln Ala Ile Ala Thr Tyr
20 25 30
Leu Ser Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Arg Ala Asn Arg Met Val Asp Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln Phe Gln Asp Phe Pro Tyr
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 61
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(5)
<223> Clone 5 VH CDR1
<400> 61
Asp Thr Tyr Ile His
1 5
<210> 62
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(17)
<223> Clone 5 VH CDR2
<400> 62
Lys Ile Asp Pro Ala Asn Gly Asn Thr Glu Tyr Ala Gln Lys Phe Gln
1 5 10 15
Gly
<210> 63
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(10)
<223> Clone 5 VH CDR3
<400> 63
Gly Asn Leu His Tyr Gly Leu Met Asp Tyr
1 5 10
<210> 64
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(11)
<223> Clone 5 VL CDR1
<400> 64
Lys Ala Ser Gln Ala Ile Asn Thr Tyr His Ser
1 5 10
<210> 65
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(7)
<223> Clone 5 VL CDR2
<400> 65
Arg Val Asn Arg Met Val Asp
1 5
<210> 66
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(9)
<223> Clone 5 VL CDR3
<400> 66
Leu Gln Tyr Leu Asp Phe Pro Tyr Thr
1 5
<210> 67
<211> 119
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(119)
<223> Clone 5 VH
<400> 67
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Phe Asn Ile Arg Asp Thr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Lys Ile Asp Pro Ala Asn Gly Asn Thr Glu Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Met Thr Arg Asp Thr Ser Thr Ser Thr Val Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Thr Gly Asn Leu His Tyr Gly Leu Met Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Ser Val Thr Val Ser Ser
115
<210> 68
<211> 110
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(110)
<223> Clone 5 VL
<400> 68
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Val Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Lys Ala Ser Gln Ala Ile Asn Thr Tyr
20 25 30
His Ser Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Arg Val Asn Arg Met Val Asp Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln Tyr Leu Asp Phe Pro Tyr
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys Arg Thr Val
100 105 110
<210> 69
<211> 445
<212> PRT
<213> Artificial Sequence
<220>
<221> CHAIN
<222> (1)..(445)
<223> Clone 5 HC
<400> 69
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Phe Asn Ile Arg Asp Thr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Lys Ile Asp Pro Ala Asn Gly Asn Thr Glu Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Met Thr Arg Asp Thr Ser Thr Ser Thr Val Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Thr Gly Asn Leu His Tyr Gly Leu Met Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Ser Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe
115 120 125
Pro Leu Ala Pro Cys Ser Arg Ser Thr Ser Glu Ser Thr Ala Ala Leu
130 135 140
Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp
145 150 155 160
Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu
165 170 175
Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser
180 185 190
Ser Asn Phe Gly Thr Gln Thr Tyr Thr Cys Asn Val Asp His Lys Pro
195 200 205
Ser Asn Thr Lys Val Asp Lys Thr Val Glu Arg Lys Cys Cys Val Glu
210 215 220
Cys Pro Pro Cys Pro Ala Pro Pro Val Ala Gly Pro Ser Val Phe Leu
225 230 235 240
Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu
245 250 255
Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Gln
260 265 270
Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys
275 280 285
Pro Arg Glu Glu Gln Phe Asn Ser Thr Phe Arg Val Val Ser Val Leu
290 295 300
Thr Val Val His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys
305 310 315 320
Val Ser Asn Lys Gly Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys
325 330 335
Thr Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser
340 345 350
Arg Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys
355 360 365
Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln
370 375 380
Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Met Leu Asp Ser Asp Gly
385 390 395 400
Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln
405 410 415
Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn
420 425 430
His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
435 440 445
<210> 70
<211> 214
<212> PRT
<213> Artificial Sequence
<220>
<221> CHAIN
<222> (1)..(214)
<223> Clone 5 LC
<400> 70
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Val Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Lys Ala Ser Gln Ala Ile Asn Thr Tyr
20 25 30
His Ser Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Arg Val Asn Arg Met Val Asp Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln Tyr Leu Asp Phe Pro Tyr
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 71
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(5)
<223> Clone 6 VH CDR1
<400> 71
Asp Thr Tyr Ile His
1 5
<210> 72
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(17)
<223> Clone 6 VH CDR2
<400> 72
Lys Ile Asp Pro Ala Asn Gly Leu Thr Glu Tyr Ala Gln Lys Phe Gln
1 5 10 15
Gly
<210> 73
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(10)
<223> Clone 6 VH CDR3
<400> 73
Gly Asn Leu His Tyr Ala Leu Met Asp Tyr
1 5 10
<210> 74
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(11)
<223> Clone 6 VL CDR1
<400> 74
Lys Ala Ser Gln Ala Ile Ala Thr Tyr Leu Ser
1 5 10
<210> 75
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(7)
<223> Clone 6 VL CDR2
<400> 75
Arg Ala Asn Arg Met Gly Asp
1 5
<210> 76
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(9)
<223> Clone 6 VL CDR3
<400> 76
Leu Gln Tyr Leu Asp Phe Pro Tyr Thr
1 5
<210> 77
<211> 119
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(119)
<223> Clone 6 VH
<400> 77
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Phe Asn Ile Cys Asp Thr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Lys Ile Asp Pro Ala Asn Gly Leu Thr Glu Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Met Thr Arg Asp Thr Ser Thr Ser Thr Val Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Thr Gly Asn Leu His Tyr Ala Leu Met Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Ser Val Thr Val Ser Ser
115
<210> 78
<211> 110
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(110)
<223> Clone 6 VL
<400> 78
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Val Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Lys Ala Ser Gln Ala Ile Ala Thr Tyr
20 25 30
Leu Ser Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Arg Ala Asn Arg Met Gly Asp Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Leu Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln Tyr Leu Asp Phe Pro Tyr
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys Arg Thr Val
100 105 110
<210> 79
<211> 445
<212> PRT
<213> Artificial Sequence
<220>
<221> CHAIN
<222> (1)..(445)
<223> Clone 6 HC
<400> 79
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Phe Asn Ile Cys Asp Thr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Lys Ile Asp Pro Ala Asn Gly Leu Thr Glu Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Met Thr Arg Asp Thr Ser Thr Ser Thr Val Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Thr Gly Asn Leu His Tyr Ala Leu Met Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Ser Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe
115 120 125
Pro Leu Ala Pro Cys Ser Arg Ser Thr Ser Glu Ser Thr Ala Ala Leu
130 135 140
Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp
145 150 155 160
Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu
165 170 175
Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser
180 185 190
Ser Asn Phe Gly Thr Gln Thr Tyr Thr Cys Asn Val Asp His Lys Pro
195 200 205
Ser Asn Thr Lys Val Asp Lys Thr Val Glu Arg Lys Cys Cys Val Glu
210 215 220
Cys Pro Pro Cys Pro Ala Pro Pro Val Ala Gly Pro Ser Val Phe Leu
225 230 235 240
Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu
245 250 255
Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Gln
260 265 270
Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys
275 280 285
Pro Arg Glu Glu Gln Phe Asn Ser Thr Phe Arg Val Val Ser Val Leu
290 295 300
Thr Val Val His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys
305 310 315 320
Val Ser Asn Lys Gly Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys
325 330 335
Thr Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser
340 345 350
Arg Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys
355 360 365
Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln
370 375 380
Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Met Leu Asp Ser Asp Gly
385 390 395 400
Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln
405 410 415
Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn
420 425 430
His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
435 440 445
<210> 80
<211> 214
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(214)
<223> Clone 6 LC
<400> 80
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Val Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Lys Ala Ser Gln Ala Ile Ala Thr Tyr
20 25 30
Leu Ser Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Arg Ala Asn Arg Met Gly Asp Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Leu Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln Tyr Leu Asp Phe Pro Tyr
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 81
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(5)
<223> Clone 17 VH CDR1
<400> 81
Asp Thr Tyr Ile His
1 5
<210> 82
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(17)
<223> Clone 17 VH CDR2
<400> 82
Lys Ile Asp Pro Ala Asn Gly Gln Thr Glu Tyr Ala Gln Lys Phe Gln
1 5 10 15
Gly
<210> 83
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(10)
<223> Clone 17 VH CDR3
<400> 83
Gly Asn Leu His Tyr Ala Leu Met Asp Tyr
1 5 10
<210> 84
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(11)
<223> Clone 17 VL CDR1
<400> 84
Lys Ala Ser Gln Ala Thr Asn Thr Tyr Leu Ser
1 5 10
<210> 85
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(7)
<223> Clone 17 VL CDR2
<400> 85
Arg Val Asn Arg Val Val Asp
1 5
<210> 86
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(9)
<223> Clone 17 VL CDR3
<400> 86
Leu Gln Tyr Arg Asp Phe Pro Tyr Thr
1 5
<210> 87
<211> 119
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(119)
<223> Clone 17 VH
<400> 87
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Phe Cys Ile Lys Asp Thr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Lys Ile Asp Pro Ala Asn Gly Gln Thr Glu Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Met Thr Arg Asp Thr Ser Thr Ser Thr Val Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Thr Gly Asn Leu His Tyr Ala Leu Met Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Ser Val Thr Val Ser Ser
115
<210> 88
<211> 110
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(110)
<223> Clone 17 VL
<400> 88
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Val Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Lys Ala Ser Gln Ala Thr Asn Thr Tyr
20 25 30
Leu Ser Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Arg Val Asn Arg Val Val Asp Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln Tyr Arg Asp Phe Pro Tyr
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys Arg Thr Val
100 105 110
<210> 89
<211> 445
<212> PRT
<213> Artificial Sequence
<220>
<221> CHAIN
<222> (1)..(445)
<223> Clone 17 HC
<400> 89
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Phe Cys Ile Lys Asp Thr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Lys Ile Asp Pro Ala Asn Gly Gln Thr Glu Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Met Thr Arg Asp Thr Ser Thr Ser Thr Val Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Thr Gly Asn Leu His Tyr Ala Leu Met Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Ser Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe
115 120 125
Pro Leu Ala Pro Cys Ser Arg Ser Thr Ser Glu Ser Thr Ala Ala Leu
130 135 140
Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp
145 150 155 160
Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu
165 170 175
Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser
180 185 190
Ser Asn Phe Gly Thr Gln Thr Tyr Thr Cys Asn Val Asp His Lys Pro
195 200 205
Ser Asn Thr Lys Val Asp Lys Thr Val Glu Arg Lys Cys Cys Val Glu
210 215 220
Cys Pro Pro Cys Pro Ala Pro Pro Val Ala Gly Pro Ser Val Phe Leu
225 230 235 240
Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu
245 250 255
Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Gln
260 265 270
Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys
275 280 285
Pro Arg Glu Glu Gln Phe Asn Ser Thr Phe Arg Val Val Ser Val Leu
290 295 300
Thr Val Val His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys
305 310 315 320
Val Ser Asn Lys Gly Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys
325 330 335
Thr Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser
340 345 350
Arg Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys
355 360 365
Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln
370 375 380
Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Met Leu Asp Ser Asp Gly
385 390 395 400
Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln
405 410 415
Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn
420 425 430
His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
435 440 445
<210> 90
<211> 214
<212> PRT
<213> Artificial Sequence
<220>
<221> CHAIN
<222> (1)..(214)
<223> Clone 17 LC
<400> 90
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Val Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Lys Ala Ser Gln Ala Thr Asn Thr Tyr
20 25 30
Leu Ser Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Arg Val Asn Arg Val Val Asp Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln Tyr Arg Asp Phe Pro Tyr
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 91
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(5)
<223> Clone 18 VH CDR1
<400> 91
Asp Thr Tyr Ile His
1 5
<210> 92
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(17)
<223> Clone 18 VH CDR2
<400> 92
Lys Ile Asp Pro Ala Asn Gly Met Thr Glu Tyr Ala Gln Lys Phe Gln
1 5 10 15
Gly
<210> 93
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(10)
<223> Clone 18 VH CDR3
<400> 93
Gly Asn Leu His Tyr Ala Leu Met Asp Tyr
1 5 10
<210> 94
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(11)
<223> Clone 18 VL CDR1
<400> 94
Lys Ala Ser Gln Ala Pro Asn Thr Tyr Leu Ser
1 5 10
<210> 95
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(7)
<223> Clone 18 VL CDR2
<400> 95
Arg Ala Asn Arg Met Val Asp
1 5
<210> 96
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(9)
<223> Clone 18 VL CDR3
<400> 96
Leu Gln Tyr Glu Asp Phe Pro Tyr Thr
1 5
<210> 97
<211> 119
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(119)
<223> Clone 18 VH
<400> 97
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Gln Ala Ser Gly Phe Asn Ile Lys Asp Thr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Gly Trp Met
35 40 45
Gly Lys Ile Asp Pro Ala Asn Gly Met Thr Glu Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Val Thr Arg Asp Thr Ser Thr Ser Thr Val Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Thr Gly Asn Leu His Tyr Ala Leu Met Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Ser Val Thr Val Ser Ser
115
<210> 98
<211> 110
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(110)
<223> Clone 18 VL
<400> 98
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Val Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Lys Ala Ser Gln Ala Pro Asn Thr Tyr
20 25 30
Leu Ser Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Arg Ala Asn Arg Met Val Asp Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln Tyr Glu Asp Phe Pro Tyr
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys Arg Thr Val
100 105 110
<210> 99
<211> 445
<212> PRT
<213> Artificial Sequence
<220>
<221> CHAIN
<222> (1)..(445)
<223> Clone 18 HC
<400> 99
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Gln Ala Ser Gly Phe Asn Ile Lys Asp Thr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Gly Trp Met
35 40 45
Gly Lys Ile Asp Pro Ala Asn Gly Met Thr Glu Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Val Thr Arg Asp Thr Ser Thr Ser Thr Val Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Thr Gly Asn Leu His Tyr Ala Leu Met Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Ser Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe
115 120 125
Pro Leu Ala Pro Cys Ser Arg Ser Thr Ser Glu Ser Thr Ala Ala Leu
130 135 140
Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp
145 150 155 160
Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu
165 170 175
Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser
180 185 190
Ser Asn Phe Gly Thr Gln Thr Tyr Thr Cys Asn Val Asp His Lys Pro
195 200 205
Ser Asn Thr Lys Val Asp Lys Thr Val Glu Arg Lys Cys Cys Val Glu
210 215 220
Cys Pro Pro Cys Pro Ala Pro Pro Val Ala Gly Pro Ser Val Phe Leu
225 230 235 240
Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu
245 250 255
Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Gln
260 265 270
Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys
275 280 285
Pro Arg Glu Glu Gln Phe Asn Ser Thr Phe Arg Val Val Ser Val Leu
290 295 300
Thr Val Val His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys
305 310 315 320
Val Ser Asn Lys Gly Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys
325 330 335
Thr Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser
340 345 350
Arg Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys
355 360 365
Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln
370 375 380
Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Met Leu Asp Ser Asp Gly
385 390 395 400
Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln
405 410 415
Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn
420 425 430
His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
435 440 445
<210> 100
<211> 214
<212> PRT
<213> Artificial Sequence
<220>
<221> CHAIN
<222> (1)..(214)
<223> Clone 18 LC
<400> 100
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Val Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Lys Ala Ser Gln Ala Pro Asn Thr Tyr
20 25 30
Leu Ser Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Arg Ala Asn Arg Met Val Asp Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln Tyr Glu Asp Phe Pro Tyr
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 101
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(5)
<223> Clone 19 VH CDR1
<400> 101
Asp Thr Tyr Ile His
1 5
<210> 102
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(17)
<223> Clone 19 VH CDR2
<400> 102
Lys Ile Asp Pro Ala Asn Gly Ala Thr Glu Tyr Ala Gln Lys Phe Gln
1 5 10 15
Gly
<210> 103
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(10)
<223> Clone 19 VH CDR3
<400> 103
Gly Asn Leu His Tyr Gly Leu Met Asp Tyr
1 5 10
<210> 104
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(11)
<223> Clone 19 VL CDR1
<400> 104
Lys Ala Ser Gln Ala Ile Asn Thr Tyr Leu Ser
1 5 10
<210> 105
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(7)
<223> Clone 19 VL CDR2
<400> 105
Arg Ala Asn Arg Met Gly Asp
1 5
<210> 106
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(9)
<223> Clone 19 VL CDR3
<400> 106
Leu Gln Ser Asp Asp Phe Pro Tyr Thr
1 5
<210> 107
<211> 119
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(119)
<223> Clone 19 VH
<400> 107
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Phe Asn Met Lys Asp Thr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Lys Ile Asp Pro Ala Asn Gly Ala Thr Glu Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Met Thr Arg Asp Thr Ser Thr Ser Thr Val Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Thr Gly Asn Leu His Tyr Gly Leu Met Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Ser Val Thr Val Ser Ser
115
<210> 108
<211> 110
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(110)
<223> Clone 19 VL
<400> 108
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Val Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Lys Ala Ser Gln Ala Ile Asn Thr Tyr
20 25 30
Leu Ser Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Arg Ala Asn Arg Met Gly Asp Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln Ser Asp Asp Phe Pro Tyr
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys Arg Thr Val
100 105 110
<210> 109
<211> 445
<212> PRT
<213> Artificial Sequence
<220>
<221> CHAIN
<222> (1)..(445)
<223> Clone 19 HC
<400> 109
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Phe Asn Met Lys Asp Thr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Lys Ile Asp Pro Ala Asn Gly Ala Thr Glu Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Met Thr Arg Asp Thr Ser Thr Ser Thr Val Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Thr Gly Asn Leu His Tyr Gly Leu Met Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Ser Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe
115 120 125
Pro Leu Ala Pro Cys Ser Arg Ser Thr Ser Glu Ser Thr Ala Ala Leu
130 135 140
Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp
145 150 155 160
Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu
165 170 175
Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser
180 185 190
Ser Asn Phe Gly Thr Gln Thr Tyr Thr Cys Asn Val Asp His Lys Pro
195 200 205
Ser Asn Thr Lys Val Asp Lys Thr Val Glu Arg Lys Cys Cys Val Glu
210 215 220
Cys Pro Pro Cys Pro Ala Pro Pro Val Ala Gly Pro Ser Val Phe Leu
225 230 235 240
Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu
245 250 255
Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Gln
260 265 270
Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys
275 280 285
Pro Arg Glu Glu Gln Phe Asn Ser Thr Phe Arg Val Val Ser Val Leu
290 295 300
Thr Val Val His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys
305 310 315 320
Val Ser Asn Lys Gly Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys
325 330 335
Thr Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser
340 345 350
Arg Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys
355 360 365
Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln
370 375 380
Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Met Leu Asp Ser Asp Gly
385 390 395 400
Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln
405 410 415
Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn
420 425 430
His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
435 440 445
<210> 110
<211> 214
<212> PRT
<213> Artificial Sequence
<220>
<221> CHAIN
<222> (1)..(214)
<223> Clone 19 LC
<400> 110
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Val Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Lys Ala Ser Gln Ala Ile Asn Thr Tyr
20 25 30
Leu Ser Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Arg Ala Asn Arg Met Gly Asp Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln Ser Asp Asp Phe Pro Tyr
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 111
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(5)
<223> Clone 20 VH CDR1
<400> 111
Asp Thr Tyr Ile His
1 5
<210> 112
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(17)
<223> Clone 20 VH CDR2
<400> 112
Lys Ile Asp Pro Ala Asn Gly Asp Thr Glu Tyr Ala Gln Lys Phe Gln
1 5 10 15
Gly
<210> 113
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(10)
<223> Clone 20 VH CDR3
<400> 113
Gly Asn Leu His Tyr Ala Leu Met Asp Tyr
1 5 10
<210> 114
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(11)
<223> Clone 20 VL CDR1
<400> 114
Lys Ala Ser Gln Ala Ile Asn Thr Tyr Leu Ser
1 5 10
<210> 115
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(7)
<223> Clone 20 VL CDR2
<400> 115
Arg Ala Asn Arg Ala Val Asp
1 5
<210> 116
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(9)
<223> Clone 20 VL CDR3
<400> 116
Leu Gln Tyr Leu Asp Phe Pro Tyr Thr
1 5
<210> 117
<211> 119
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(119)
<223> Clone 20 VH
<400> 117
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Phe Asn Met Lys Asp Thr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Lys Ile Asp Pro Ala Asn Gly Asp Thr Glu Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Met Thr Arg Asp Thr Ser Thr Ser Thr Val Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Thr Gly Asn Leu His Tyr Ala Leu Met Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Ser Val Thr Val Ser Ser
115
<210> 118
<211> 110
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(110)
<223> Clone 20 VL
<400> 118
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Val Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Lys Ala Ser Gln Ala Ile Asn Thr Tyr
20 25 30
Leu Ser Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Arg Ala Asn Arg Ala Val Asp Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln Tyr Leu Asp Phe Pro Tyr
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys Arg Thr Val
100 105 110
<210> 119
<211> 445
<212> PRT
<213> Artificial Sequence
<220>
<221> CHAIN
<222> (1)..(445)
<223> Clone 20 HC
<400> 119
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Phe Asn Met Lys Asp Thr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Lys Ile Asp Pro Ala Asn Gly Asp Thr Glu Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Met Thr Arg Asp Thr Ser Thr Ser Thr Val Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Thr Gly Asn Leu His Tyr Ala Leu Met Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Ser Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe
115 120 125
Pro Leu Ala Pro Cys Ser Arg Ser Thr Ser Glu Ser Thr Ala Ala Leu
130 135 140
Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp
145 150 155 160
Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu
165 170 175
Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser
180 185 190
Ser Asn Phe Gly Thr Gln Thr Tyr Thr Cys Asn Val Asp His Lys Pro
195 200 205
Ser Asn Thr Lys Val Asp Lys Thr Val Glu Arg Lys Cys Cys Val Glu
210 215 220
Cys Pro Pro Cys Pro Ala Pro Pro Val Ala Gly Pro Ser Val Phe Leu
225 230 235 240
Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu
245 250 255
Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Gln
260 265 270
Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys
275 280 285
Pro Arg Glu Glu Gln Phe Asn Ser Thr Phe Arg Val Val Ser Val Leu
290 295 300
Thr Val Val His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys
305 310 315 320
Val Ser Asn Lys Gly Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys
325 330 335
Thr Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser
340 345 350
Arg Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys
355 360 365
Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln
370 375 380
Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Met Leu Asp Ser Asp Gly
385 390 395 400
Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln
405 410 415
Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn
420 425 430
His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
435 440 445
<210> 120
<211> 214
<212> PRT
<213> Artificial Sequence
<220>
<221> CHAIN
<222> (1)..(214)
<223> Clone 20 LC
<400> 120
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Val Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Lys Ala Ser Gln Ala Ile Asn Thr Tyr
20 25 30
Leu Ser Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Arg Ala Asn Arg Ala Val Asp Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln Tyr Leu Asp Phe Pro Tyr
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 121
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(5)
<223> Clone 2-9 VH CDR1
<400> 121
Asp Thr Tyr Ile His
1 5
<210> 122
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(17)
<223> Clone 2-9 VH CDR2
<400> 122
Arg Ile Asp Pro Ala Asn Gly Asn Ser Glu Tyr Ala Gln Lys Phe Gln
1 5 10 15
Gly
<210> 123
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(10)
<223> Clone 2-9 VH CDR3
<400> 123
Gly Asn Leu His Tyr Ala Leu Met Asp Tyr
1 5 10
<210> 124
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(11)
<223> Clone 2-9 VL CDR1
<400> 124
Lys Ala Ser Gln Pro Ile Asn Thr Tyr Leu Ser
1 5 10
<210> 125
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(7)
<223> Clone 2-9 VL CDR2
<400> 125
Arg Val Asn Arg Lys Val Asp
1 5
<210> 126
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(9)
<223> Clone 2-9 VL CDR3
<400> 126
Leu Gln Tyr Leu Asp Phe Pro Tyr Thr
1 5
<210> 127
<211> 119
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(119)
<223> Clone 2-9 VH
<400> 127
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Ala Ser Cys Lys Ala Ser Gly Phe Asn Ile Gln Asp Thr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Arg Ile Asp Pro Ala Asn Gly Asn Ser Glu Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Met Thr Arg Asp Thr Ser Thr Ser Thr Val Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Thr Gly Asn Leu His Tyr Ala Leu Met Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Ser Val Thr Val Ser Ser
115
<210> 128
<211> 110
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(110)
<223> Clone 2-9 VL
<400> 128
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Val Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Lys Ala Ser Gln Pro Ile Asn Thr Tyr
20 25 30
Leu Ser Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Arg Val Asn Arg Lys Val Asp Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln Tyr Leu Asp Phe Pro Tyr
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys Arg Thr Val
100 105 110
<210> 129
<211> 445
<212> PRT
<213> Artificial Sequence
<220>
<221> CHAIN
<222> (1)..(445)
<223> Clone 2-9 HC
<400> 129
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Ala Ser Cys Lys Ala Ser Gly Phe Asn Ile Gln Asp Thr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Arg Ile Asp Pro Ala Asn Gly Asn Ser Glu Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Met Thr Arg Asp Thr Ser Thr Ser Thr Val Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Thr Gly Asn Leu His Tyr Ala Leu Met Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Ser Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe
115 120 125
Pro Leu Ala Pro Cys Ser Arg Ser Thr Ser Glu Ser Thr Ala Ala Leu
130 135 140
Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp
145 150 155 160
Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu
165 170 175
Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser
180 185 190
Ser Asn Phe Gly Thr Gln Thr Tyr Thr Cys Asn Val Asp His Lys Pro
195 200 205
Ser Asn Thr Lys Val Asp Lys Thr Val Glu Arg Lys Cys Cys Val Glu
210 215 220
Cys Pro Pro Cys Pro Ala Pro Pro Val Ala Gly Pro Ser Val Phe Leu
225 230 235 240
Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu
245 250 255
Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Gln
260 265 270
Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys
275 280 285
Pro Arg Glu Glu Gln Phe Asn Ser Thr Phe Arg Val Val Ser Val Leu
290 295 300
Thr Val Val His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys
305 310 315 320
Val Ser Asn Lys Gly Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys
325 330 335
Thr Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser
340 345 350
Arg Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys
355 360 365
Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln
370 375 380
Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Met Leu Asp Ser Asp Gly
385 390 395 400
Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln
405 410 415
Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn
420 425 430
His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
435 440 445
<210> 130
<211> 214
<212> PRT
<213> Artificial Sequence
<220>
<221> CHAIN
<222> (1)..(214)
<223> Clone 2-9 LC
<400> 130
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Val Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Lys Ala Ser Gln Pro Ile Asn Thr Tyr
20 25 30
Leu Ser Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Arg Val Asn Arg Lys Val Asp Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln Tyr Leu Asp Phe Pro Tyr
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 131
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(5)
<223> Clone 2-11 VH CDR1
<400> 131
Asp Thr Tyr Ile His
1 5
<210> 132
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(17)
<223> Clone 2-11 VH CDR2
<400> 132
Lys Ile Asp Pro Ala Asn Gly Gly Thr Glu Tyr Ala Gln Lys Phe Gln
1 5 10 15
Gly
<210> 133
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(10)
<223> Clone 2-11 VH CDR3
<400> 133
Gly Asn Leu His Tyr Ala Leu Met Asp Tyr
1 5 10
<210> 134
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(11)
<223> Clone 2-11 VL CDR1
<400> 134
Lys Ala Ser Gln Pro Ile Asn Thr Tyr Leu Ser
1 5 10
<210> 135
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(7)
<223> Clone 2-11 VL CDR2
<400> 135
Arg Val Asn Arg Lys Val Asp
1 5
<210> 136
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(9)
<223> Clone 2-11 VL CDR3
<400> 136
Leu Gln Tyr Val Asp Phe Pro Tyr Thr
1 5
<210> 137
<211> 119
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(119)
<223> Clone 2-11 VH
<400> 137
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Phe Asn Ile Lys Asp Thr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Lys Ile Asp Pro Ala Asn Gly Gly Thr Glu Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Met Thr Arg Asp Thr Ser Thr Ser Thr Val Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Thr Gly Asn Leu His Tyr Ala Leu Met Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Ser Val Thr Val Ser Ser
115
<210> 138
<211> 110
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(110)
<223> Clone 2-11 VL
<400> 138
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Val Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Lys Ala Ser Gln Pro Ile Asn Thr Tyr
20 25 30
Leu Ser Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Arg Val Asn Arg Lys Val Asp Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln Tyr Val Asp Phe Pro Tyr
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys Arg Thr Val
100 105 110
<210> 139
<211> 445
<212> PRT
<213> Artificial Sequence
<220>
<221> CHAIN
<222> (1)..(445)
<223> Clone 2-11 HC
<400> 139
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Phe Asn Ile Lys Asp Thr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Lys Ile Asp Pro Ala Asn Gly Gly Thr Glu Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Met Thr Arg Asp Thr Ser Thr Ser Thr Val Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Thr Gly Asn Leu His Tyr Ala Leu Met Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Ser Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe
115 120 125
Pro Leu Ala Pro Cys Ser Arg Ser Thr Ser Glu Ser Thr Ala Ala Leu
130 135 140
Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp
145 150 155 160
Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu
165 170 175
Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser
180 185 190
Ser Asn Phe Gly Thr Gln Thr Tyr Thr Cys Asn Val Asp His Lys Pro
195 200 205
Ser Asn Thr Lys Val Asp Lys Thr Val Glu Arg Lys Cys Cys Val Glu
210 215 220
Cys Pro Pro Cys Pro Ala Pro Pro Val Ala Gly Pro Ser Val Phe Leu
225 230 235 240
Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu
245 250 255
Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Gln
260 265 270
Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys
275 280 285
Pro Arg Glu Glu Gln Phe Asn Ser Thr Phe Arg Val Val Ser Val Leu
290 295 300
Thr Val Val His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys
305 310 315 320
Val Ser Asn Lys Gly Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys
325 330 335
Thr Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser
340 345 350
Arg Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys
355 360 365
Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln
370 375 380
Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Met Leu Asp Ser Asp Gly
385 390 395 400
Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln
405 410 415
Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn
420 425 430
His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
435 440 445
<210> 140
<211> 214
<212> PRT
<213> Artificial Sequence
<220>
<221> CHAIN
<222> (1)..(214)
<223> Clone 2-11 LC
<400> 140
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Val Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Lys Ala Ser Gln Pro Ile Asn Thr Tyr
20 25 30
Leu Ser Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Arg Val Asn Arg Lys Val Asp Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln Tyr Val Asp Phe Pro Tyr
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 141
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(5)
<223> Consensus VH CDR1
<400> 141
Asp Thr Tyr Ile His
1 5
<210> 142
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(17)
<223> Consensus VH CDR2
<220>
<221> UNSURE
<222> (1)..(1)
<223> The 'Xaa' at location 1 stands for any amino acid
<220>
<221> UNSURE
<222> (8)..(8)
<223> The 'Xaa' at location 8 stands for any amino acid
<400> 142
Xaa Ile Asp Pro Ala Asn Gly Xaa Thr Glu Tyr Ala Gln Lys Phe Gln
1 5 10 15
Gly
<210> 143
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(10)
<223> Consensus VH CDR3
<220>
<221> UNSURE
<222> (6)..(6)
<223> The 'Xaa' at location 6 stands for any amino acid
<400> 143
Gly Asn Leu His Tyr Xaa Leu Met Asp Tyr
1 5 10
<210> 144
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(11)
<223> Consensus VL CDR1
<220>
<221> UNSURE
<222> (5)..(5)
<223> The 'Xaa' at location 5 stands for any amino acid
<220>
<221> UNSURE
<222> (6)..(6)
<223> The 'Xaa' at location 6 stands for any amino acid
<220>
<221> UNSURE
<222> (7)..(7)
<223> The 'Xaa' at location 7 stands for any amino acid
<220>
<221> UNSURE
<222> (10)..(10)
<223> The 'Xaa' at location 10 stands for any amino acid
<400> 144
Lys Ala Ser Gln Xaa Xaa Xaa Thr Tyr Xaa Ser
1 5 10
<210> 145
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(7)
<223> Consensus VL CDR2
<220>
<221> UNSURE
<222> (2)..(2)
<223> The 'Xaa' at location 2 stands for any amino acid
<220>
<221> UNSURE
<222> (5)..(5)
<223> The 'Xaa' at location 5 stands for any amino acid
<220>
<221> UNSURE
<222> (6)..(6)
<223> The 'Xaa' at location 6 stands for any amino acid
<400> 145
Arg Xaa Asn Arg Xaa Xaa Asp
1 5
<210> 146
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(9)
<223> Consensus VL CDR3
<220>
<221> UNSURE
<222> (4)..(4)
<223> The 'Xaa' at location 4 stands for any amino acid
<400> 146
Leu Gln Tyr Xaa Asp Phe Pro Tyr Thr
1 5
<210> 147
<211> 119
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(119)
<223> Consensus VH
<220>
<221> UNSURE
<222> (28)..(28)
<223> The 'Xaa' at location 28 stands for any amino acid
<220>
<221> UNSURE
<222> (29)..(29)
<223> The 'Xaa' at location 29 stands for any amino acid
<220>
<221> UNSURE
<222> (30)..(30)
<223> The 'Xaa' at location 30 stands for any amino acid
<220>
<221> UNSURE
<222> (50)..(50)
<223> The 'Xaa' at location 50 stands for any amino acid
<220>
<221> UNSURE
<222> (57)..(57)
<223> The 'Xaa' at location 57 stands for any amino acid
<220>
<221> UNSURE
<222> (104)..(104)
<223> The 'Xaa' at location 104 stands for any amino acid
<400> 147
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Phe Xaa Xaa Xaa Asp Thr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Xaa Ile Asp Pro Ala Asn Gly Xaa Thr Glu Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Met Thr Arg Asp Thr Ser Thr Ser Thr Val Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Thr Gly Asn Leu His Tyr Xaa Leu Met Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Ser Val Thr Val Ser Ser
115
<210> 148
<211> 110
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(110)
<223> Consensus VL
<220>
<221> UNSURE
<222> (28)..(28)
<223> The 'Xaa' at location 28 stands for any amino acid
<220>
<221> UNSURE
<222> (29)..(29)
<223> The 'Xaa' at location 29 stands for any amino acid
<220>
<221> UNSURE
<222> (30)..(30)
<223> The 'Xaa' at location 30 stands for any amino acid
<220>
<221> UNSURE
<222> (33)..(33)
<223> The 'Xaa' at location 33 stands for any amino acid
<220>
<221> UNSURE
<222> (51)..(51)
<223> The 'Xaa' at location 51 stands for any amino acid
<220>
<221> UNSURE
<222> (54)..(54)
<223> The 'Xaa' at location 54 stands for any amino acid
<220>
<221> UNSURE
<222> (55)..(55)
<223> The 'Xaa' at location 55 stands for any amino acid
<220>
<221> UNSURE
<222> (92)..(92)
<223> The 'Xaa' at location 92 stands for any amino acid
<400> 148
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Val Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Lys Ala Ser Gln Xaa Xaa Xaa Thr Tyr
20 25 30
Xaa Ser Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Arg Xaa Asn Arg Xaa Xaa Asp Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln Tyr Xaa Asp Phe Pro Tyr
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys Arg Thr Val
100 105 110
<210> 149
<211> 445
<212> PRT
<213> Artificial Sequence
<220>
<221> CHAIN
<222> (1)..(445)
<223> Consensus HC
<220>
<221> UNSURE
<222> (28)..(28)
<223> The 'Xaa' at location 28 stands for any amino acid
<220>
<221> UNSURE
<222> (29)..(29)
<223> The 'Xaa' at location 29 stands for any amino acid
<220>
<221> UNSURE
<222> (30)..(30)
<223> The 'Xaa' at location 30 stands for any amino acid
<220>
<221> UNSURE
<222> (57)..(57)
<223> The 'Xaa' at location 57 stands for any amino acid
<220>
<221> UNSURE
<222> (104)..(104)
<223> The 'Xaa' at location 104 stands for any amino acid
<400> 149
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Phe Xaa Xaa Xaa Asp Thr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Lys Ile Asp Pro Ala Asn Gly Xaa Thr Glu Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Met Thr Arg Asp Thr Ser Thr Ser Thr Val Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Thr Gly Asn Leu His Tyr Xaa Leu Met Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Ser Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe
115 120 125
Pro Leu Ala Pro Cys Ser Arg Ser Thr Ser Glu Ser Thr Ala Ala Leu
130 135 140
Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp
145 150 155 160
Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu
165 170 175
Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser
180 185 190
Ser Asn Phe Gly Thr Gln Thr Tyr Thr Cys Asn Val Asp His Lys Pro
195 200 205
Ser Asn Thr Lys Val Asp Lys Thr Val Glu Arg Lys Cys Cys Val Glu
210 215 220
Cys Pro Pro Cys Pro Ala Pro Pro Val Ala Gly Pro Ser Val Phe Leu
225 230 235 240
Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu
245 250 255
Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Gln
260 265 270
Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys
275 280 285
Pro Arg Glu Glu Gln Phe Asn Ser Thr Phe Arg Val Val Ser Val Leu
290 295 300
Thr Val Val His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys
305 310 315 320
Val Ser Asn Lys Gly Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys
325 330 335
Thr Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser
340 345 350
Arg Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys
355 360 365
Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln
370 375 380
Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Met Leu Asp Ser Asp Gly
385 390 395 400
Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln
405 410 415
Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn
420 425 430
His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
435 440 445
<210> 150
<211> 214
<212> PRT
<213> Artificial Sequence
<220>
<221> CHAIN
<222> (1)..(214)
<223> Consensus LC
<220>
<221> UNSURE
<222> (28)..(28)
<223> The 'Xaa' at location 28 stands for any amino acid
<220>
<221> UNSURE
<222> (29)..(29)
<223> The 'Xaa' at location 29 stands for any amino acid
<220>
<221> UNSURE
<222> (30)..(30)
<223> The 'Xaa' at location 30 stands for any amino acid
<220>
<221> UNSURE
<222> (33)..(33)
<223> The 'Xaa' at location 33 stands for any amino acid
<220>
<221> UNSURE
<222> (51)..(51)
<223> The 'Xaa' at location 51 stands for any amino acid
<220>
<221> UNSURE
<222> (54)..(54)
<223> The 'Xaa' at location 54 stands for any amino acid
<220>
<221> UNSURE
<222> (55)..(55)
<223> The 'Xaa' at location 55 stands for any amino acid
<220>
<221> UNSURE
<222> (92)..(92)
<223> The 'Xaa' at location 92 stands for any amino acid
<400> 150
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Val Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Lys Ala Ser Gln Xaa Xaa Xaa Thr Tyr
20 25 30
Xaa Ser Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Arg Xaa Asn Arg Xaa Xaa Asp Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln Tyr Xaa Asp Phe Pro Tyr
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 151
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(5)
<223> 29.39/44.21 VH CDR1
<400> 151
Asp Thr Tyr Ile His
1 5
<210> 152
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(5)
<223> 3.10 VH CDR1
<400> 152
Thr Tyr Asp Val Ser
1 5
<210> 153
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(5)
<223> 30.19/6.62 VH CDR1
<400> 153
Asp Tyr Ser Ile His
1 5
<210> 154
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(17)
<223> 29.39/44.21 VH CDR2
<400> 154
Lys Ile Asp Pro Ala Asn Gly Asn Thr Glu Tyr Asp Leu Asn Phe Gln
1 5 10 15
Gly
<210> 155
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(16)
<223> 3.10 VH CDR2
<400> 155
Val Ile Trp Thr Gly Gly Gly Thr Asn Tyr Asn Ser Thr Phe Met Ser
1 5 10 15
<210> 156
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(17)
<223> 30.19/6.62 VH CDR2
<400> 156
Trp Met Asn Thr Glu Thr Gly Glu Pro Ala Tyr Ala Asp Asp Phe Lys
1 5 10 15
Gly
<210> 157
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(10)
<223> 29.39/44.21 VH CDR3
<400> 157
Gly Asn Leu His Tyr Tyr Leu Met Asp Tyr
1 5 10
<210> 158
<211> 3
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(3)
<223> 3.10 VH CDR3
<400> 158
Val Asp Tyr
1
<210> 159
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(8)
<223> 30.19/6.62 VH CDR3
<400> 159
Ser Ser Tyr Gly Tyr Phe Asp Tyr
1 5
<210> 160
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(11)
<223> 29.39/30.19 VL CDR1
<400> 160
Lys Ala Ser Gln Ala Ile Asn Thr Tyr Leu Ser
1 5 10
<210> 161
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(16)
<223> 6.62 VL CDR1
<400> 161
Arg Ser Ser Gln Thr Leu Glu His Ile Asn Gly Asn Thr Tyr Leu Glu
1 5 10 15
<210> 162
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(16)
<223> 44.21 VL CDR1
<400> 162
Arg Ser Ser Gln Ser Leu Val His Ser Asn Gly Asn Thr Tyr Leu His
1 5 10 15
<210> 163
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(16)
<223> 3.10 VL CDR1
<400> 163
Arg Ser Ser Gln Ser Leu Val His Asn Asn Gly Asn Thr Tyr Leu His
1 5 10 15
<210> 164
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(7)
<223> 29.39/30.19 VL CDR2
<400> 164
Arg Ala Asn Arg Met Val Asp
1 5
<210> 165
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(7)
<223> 6.62 VL CDR2
<400> 165
Lys Val Ser Asp Arg Phe Ser
1 5
<210> 166
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(7)
<223> 44.21/3.10 VL CDR2
<400> 166
Lys Val Ser Asn Arg Phe Ser
1 5
<210> 167
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(9)
<223> 29.39/30.19 VL CDR3
<400> 167
Leu Gln Tyr Asp Asp Phe Pro Tyr Thr
1 5
<210> 168
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(9)
<223> 6.62 VL CDR3
<400> 168
Phe Gln Gly Ser His Phe Pro Leu Thr
1 5
<210> 169
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(9)
<223> 44.21/3.10 VL CDR3
<400> 169
Ser Gln Asn Ala His Val Pro Trp Thr
1 5
<210> 170
<211> 119
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(119)
<223> 29.39/44.21 VH
<400> 170
Glu Val Lys Leu Met Glu Ser Gly Ala Glu Leu Val Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Leu Ser Cys Thr Ala Ser Gly Phe Asn Ile Lys Asp Thr
20 25 30
Tyr Ile His Trp Val Lys Gln Arg Pro Glu Gln Gly Leu Glu Trp Ile
35 40 45
Gly Lys Ile Asp Pro Ala Asn Gly Asn Thr Glu Tyr Asp Leu Asn Phe
50 55 60
Gln Gly Arg Ala Thr Ile Thr Ala Asp Thr Ser Ser Asn Thr Ala Tyr
65 70 75 80
Leu Gln Leu Ser Ser Leu Thr Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Thr Gly Asn Leu His Tyr Tyr Leu Met Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Ser Val Thr Ser Leu Glu
115
<210> 171
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(117)
<223> 30.19/6.62 VH
<400> 171
Gln Ile Gln Leu Val Gln Ser Gly Pro Glu Leu Lys Lys Pro Gly Glu
1 5 10 15
Thr Val Lys Ile Ser Cys Lys Ala Ser Gly Tyr Ser Phe Thr Asp Tyr
20 25 30
Ser Ile His Trp Val Lys Gln Ala Pro Gly Lys Gly Leu Lys Trp Met
35 40 45
Gly Trp Met Asn Thr Glu Thr Gly Glu Pro Ala Tyr Ala Asp Asp Phe
50 55 60
Lys Gly Arg Phe Ala Phe Ser Leu Glu Thr Ala Ala Ser Thr Ala Tyr
65 70 75 80
Leu Gln Ile Asn His Leu Arg Asp Glu Asp Thr Ala Thr Tyr Phe Cys
85 90 95
Thr Arg Ser Ser Tyr Gly Tyr Phe Asp Tyr Trp Gly Gln Gly Thr Thr
100 105 110
Leu Thr Val Ser Ser
115
<210> 172
<211> 111
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(111)
<223> 3.10 VH
<400> 172
Glu Val Gln Leu Val Glu Ser Gly Pro Gly Leu Val Ala Pro Ser Gln
1 5 10 15
Ser Leu Ser Ile Thr Cys Thr Val Ser Gly Phe Ser Leu Thr Thr Tyr
20 25 30
Asp Val Ser Trp Ile Arg Gln Pro Pro Gly Lys Gly Leu Glu Trp Leu
35 40 45
Gly Val Ile Trp Thr Gly Gly Gly Thr Asn Tyr Asn Ser Thr Phe Met
50 55 60
Ser Arg Leu Thr Ile Ser Lys Asp Asn Ser Lys Asn Gln Val Phe Leu
65 70 75 80
Lys Met Asn Ser Leu Gln Thr Asp Asp Thr Ala Thr Tyr Tyr Cys Val
85 90 95
Arg Val Asp Tyr Trp Gly Gln Gly Thr Thr Leu Thr Val Ser Arg
100 105 110
<210> 173
<211> 108
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(108)
<223> 29.39/30.19 VL
<400> 173
Asp Ile Val Met Thr Gln Ser Pro Ser Ser Met Tyr Ala Ser Leu Gly
1 5 10 15
Glu Arg Val Thr Ile Thr Cys Lys Ala Ser Gln Ala Ile Asn Thr Tyr
20 25 30
Leu Ser Trp Phe Gln Gln Lys Pro Gly Lys Ser Pro Lys Thr Leu Ile
35 40 45
Tyr Arg Ala Asn Arg Met Val Asp Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Gln Asp Tyr Ser Leu Thr Ile Ser Ser Leu Asp Tyr
65 70 75 80
Glu Asp Met Gly Ile Tyr Tyr Cys Leu Gln Tyr Asp Asp Phe Pro Tyr
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys Arg
100 105
<210> 174
<211> 112
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(112)
<223> 6.62 VL
<400> 174
Asp Val Val Met Thr Gln Thr Pro Leu Ser Leu Pro Val Ser Leu Gly
1 5 10 15
Asp Gln Ala Ala Ile Ser Cys Arg Ser Ser Gln Thr Leu Glu His Ile
20 25 30
Asn Gly Asn Thr Tyr Leu Glu Trp Tyr Leu Gln Lys Pro Gly Gln Ser
35 40 45
Pro Lys Leu Leu Ile Tyr Lys Val Ser Asp Arg Phe Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Gly Phe Thr Leu Lys Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Leu Gly Val Tyr Tyr Cys Phe Gln Gly
85 90 95
Ser His Phe Pro Leu Thr Phe Gly Gly Gly Thr Lys Leu Glu Leu Lys
100 105 110
<210> 175
<211> 113
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(113)
<223> 3.10 VL
<400> 175
Asp Val Val Met Thr Gln Thr Pro Leu Ser Leu Pro Val Ser Leu Gly
1 5 10 15
Gly His Ala Ser Ile Ser Cys Arg Ser Ser Gln Ser Leu Val His Asn
20 25 30
Asn Gly Asn Thr Tyr Leu His Trp Phe Leu Gln Lys Pro Gly Gln Ser
35 40 45
Pro Lys Leu Leu Ile Tyr Lys Val Ser Asn Arg Phe Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Leu Gly Val Tyr Phe Cys Ser Gln Asn
85 90 95
Ala His Val Pro Trp Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
100 105 110
Arg
<210> 176
<211> 113
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(113)
<223> 44.21 VL
<400> 176
Asp Ile Val Met Thr Gln Thr Pro Leu Ser Leu Pro Val Ser Leu Gly
1 5 10 15
Asp His Ala Ser Ile Ser Cys Arg Ser Ser Gln Ser Leu Val His Ser
20 25 30
Asn Gly Asn Thr Tyr Leu His Trp Phe Leu Gln Lys Pro Gly Gln Ser
35 40 45
Pro Lys Leu Leu Ile Tyr Lys Val Ser Asn Arg Phe Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Leu Gly Val Tyr Phe Cys Ser Gln Asn
85 90 95
Ala His Val Pro Trp Thr Phe Gly Gly Gly Thr Lys Arg Lys Ser Asn
100 105 110
Glu
<210> 177
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(10)
<223> Consensus humanized 29.39 VH CDR1
GFX1X2X3DTYI X4
wherein X1=N or C; X2=I, P, L or M; X3=K, N, R, C or Q; X4=H or Q
<220>
<221> UNSURE
<222> (3)..(3)
<223> The 'Xaa' at location 3 stands for Asn or Cys
<220>
<221> UNSURE
<222> (4)..(4)
<223> The 'Xaa' at location 4 stands for Ile, Pro, Leu or Met
<220>
<221> UNSURE
<222> (5)..(5)
<223> The 'Xaa' at location 5 stands for Lys, Asn, Arg, Cys or Gln
<220>
<221> UNSURE
<222> (10)..(10)
<223> The 'Xaa' at location 10 stands for His or Gln
<400> 177
Gly Phe Xaa Xaa Xaa Asp Thr Tyr Ile Xaa
1 5 10
<210> 178
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(10)
<223> Consensus humanized 29.39 VH CDR2
X1IDPANGX2X3X4
wherein X1=K or R; X2=N, G, F, Y, A, D, L, M or Q; X3=S or T; X4=E or M
<220>
<221> UNSURE
<222> (1)..(1)
<223> The 'Xaa' at location 1 stands for Lys or Arg
<220>
<221> UNSURE
<222> (8)..(8)
<223> The 'Xaa' at location 8 stands for Asn, Gly, Phe, Tyr, Ala, Asp, Leu, Met or Gln
<220>
<221> UNSURE
<222> (9)..(9)
<223> The 'Xaa' at location 9 stands for Ser or Thr
<220>
<221> UNSURE
<222> (10)..(10)
<223> The 'Xaa' at location 10 stands for Glu or Met
<400> 178
Xaa Ile Asp Pro Ala Asn Gly Xaa Xaa Xaa
1 5 10
<210> 179
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(9)
<223> Consensus humanized 29.39 VH CDR3
GNLHYX1LMD
wherein X1=Y, A or G
<220>
<221> UNSURE
<222> (6)..(6)
<223> The 'Xaa' at location 6 stands for Tyr, Ala or Gly
<400> 179
Gly Asn Leu His Tyr Xaa Leu Met Asp
1 5
<210> 180
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(11)
<223> Consensus humanized 29.39 VL CDR1
KASQX1X2X3TYX4S
wherein X1=A, P, or T; X2=I, T, or P; X3=N or A; X4=L, G or H
<220>
<221> UNSURE
<222> (5)..(5)
<223> The 'Xaa' at location 5 stands for Ala, Pro or Thr
<220>
<221> UNSURE
<222> (6)..(6)
<223> The 'Xaa' at location 6 stands for Ile, Thr or Pro
<220>
<221> UNSURE
<222> (7)..(7)
<223> The 'Xaa' at location 7 stands for Asn or Ala
<220>
<221> UNSURE
<222> (10)..(10)
<223> The 'Xaa' at location 10 stands for Leu,Gly or His
<400> 180
Lys Ala Ser Gln Xaa Xaa Xaa Thr Tyr Xaa Ser
1 5 10
<210> 181
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(7)
<223> Consensus humanized 29.39 VL CDR2
RX1NRX2X3X4
wherein X1=A, Y, V, or D; X2=M, K, V, or A; X3=V, P, Y or G; X4=D or G
<220>
<221> UNSURE
<222> (2)..(2)
<223> The 'Xaa' at location 2 stands for Ala, Tyr, Val or Asp
<220>
<221> UNSURE
<222> (5)..(5)
<223> The 'Xaa' at location 5 stands for Met, Lys, Val or Ala
<220>
<221> UNSURE
<222> (6)..(6)
<223> The 'Xaa' at location 6 stands for Val, Pro, Tyr or Gly
<220>
<221> UNSURE
<222> (7)..(7)
<223> The 'Xaa' at location 7 stands for Asp or Gly
<400> 181
Arg Xaa Asn Arg Xaa Xaa Xaa
1 5
<210> 182
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(9)
<223> Consensus humanized 29.39 VL CDR3
LQX1X2DFPYX3
wherein X1=Y, S, or F; X2=D, V, L, R, E or Q; X3=T or K
<220>
<221> UNSURE
<222> (3)..(3)
<223> The 'Xaa' at location 3 stands for Tyr, Ser or Phe
<220>
<221> UNSURE
<222> (4)..(4)
<223> The 'Xaa' at location 4 stands for Asp, Val, Leu, Arg, Glu or Gln
<220>
<221> UNSURE
<222> (9)..(9)
<223> The 'Xaa' at location 9 stands for Thr or Lys
<400> 182
Leu Gln Xaa Xaa Asp Phe Pro Tyr Xaa
1 5
<210> 183
<211> 706
<212> PRT
<213> Artificial Sequence
<220>
<221> CHAIN
<222> (1)..(706)
<223> Anti-EGFR HC-anti-CD137 scFv-IgG1-Linker 7 (HCC)
<400> 183
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Ser Leu Thr Asn Tyr
20 25 30
Gly Val His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Leu
35 40 45
Gly Val Ile Trp Ser Gly Gly Asn Thr Asp Tyr Gly Asn Glu Phe Thr
50 55 60
Ser Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Ala Leu Asp Tyr Tyr Asp Tyr Glu Phe Ala Tyr Trp Gly Gln Gly
100 105 110
Thr Met Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe
115 120 125
Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu
130 135 140
Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp
145 150 155 160
Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu
165 170 175
Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser
180 185 190
Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro
195 200 205
Ser Asn Thr Lys Val Asp Lys Arg Val Glu Pro Lys Ser Cys Asp Lys
210 215 220
Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro
225 230 235 240
Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser
245 250 255
Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp
260 265 270
Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn
275 280 285
Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val
290 295 300
Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu
305 310 315 320
Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys
325 330 335
Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr
340 345 350
Leu Pro Pro Ser Arg Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr
355 360 365
Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu
370 375 380
Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu
385 390 395 400
Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys
405 410 415
Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu
420 425 430
Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly
435 440 445
Lys Gly Ser Gly Gly Ser Gly Gly Ser Gly Gly Ser Gly Asp Ile Gln
450 455 460
Met Thr Gln Ser Pro Ser Ser Val Ser Ala Ser Val Gly Asp Arg Val
465 470 475 480
Thr Ile Thr Cys Lys Ala Ser Gln Pro Ile Asn Thr Tyr Leu Ser Trp
485 490 495
Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile Tyr Arg Val
500 505 510
Asn Arg Lys Val Asp Gly Val Pro Ser Arg Phe Ser Gly Ser Gly Ser
515 520 525
Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro Glu Asp Phe
530 535 540
Ala Thr Tyr Tyr Cys Leu Gln Tyr Leu Asp Phe Pro Tyr Thr Phe Gly
545 550 555 560
Gly Gly Thr Lys Leu Glu Ile Lys Arg Gly Gly Gly Gly Ser Gly Gly
565 570 575
Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gln Glu Gln Leu Val
580 585 590
Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala Ser Val Lys Ala Ser
595 600 605
Cys Lys Ala Ser Gly Phe Asn Ile Gln Asp Thr Tyr Ile His Trp Val
610 615 620
Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met Gly Arg Ile Asp Pro
625 630 635 640
Ala Asn Gly Asn Ser Glu Tyr Ala Gln Lys Phe Gln Gly Arg Val Thr
645 650 655
Met Thr Arg Asp Thr Ser Thr Ser Thr Val Tyr Met Glu Leu Ser Ser
660 665 670
Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys Thr Thr Gly Asn Leu
675 680 685
His Tyr Ala Leu Met Asp Tyr Trp Gly Gln Gly Thr Ser Val Thr Val
690 695 700
Ser Ser
705
<210> 184
<211> 214
<212> PRT
<213> Artificial Sequence
<220>
<221> CHAIN
<222> (1)..(214)
<223> Anti-EGFR LC1
<400> 184
Glu Ile Val Leu Thr Gln Ser Pro Ala Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser Ile Ser Thr Asn
20 25 30
Ile His Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu Ile
35 40 45
Lys Tyr Gly Ser Glu Ser Ile Ser Gly Ile Pro Ala Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Glu Pro
65 70 75 80
Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Asn Asn Asn Trp Pro Thr
85 90 95
Ser Phe Gly Gly Gly Thr Lys Val Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 185
<211> 706
<212> PRT
<213> Artificial Sequence
<220>
<221> CHAIN
<222> (1)..(706)
<223> Anti-EGFR -HC-anti-CD137 scFv-IgG1-LALA-Linker 7 (HCC)
<400> 185
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Ser Leu Thr Asn Tyr
20 25 30
Gly Val His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Leu
35 40 45
Gly Val Ile Trp Ser Gly Gly Asn Thr Asp Tyr Gly Asn Glu Phe Thr
50 55 60
Ser Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Ala Leu Asp Tyr Tyr Asp Tyr Glu Phe Ala Tyr Trp Gly Gln Gly
100 105 110
Thr Met Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe
115 120 125
Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu
130 135 140
Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp
145 150 155 160
Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu
165 170 175
Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser
180 185 190
Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro
195 200 205
Ser Asn Thr Lys Val Asp Lys Arg Val Glu Pro Lys Ser Cys Asp Lys
210 215 220
Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Ala Ala Gly Gly Pro
225 230 235 240
Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser
245 250 255
Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp
260 265 270
Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn
275 280 285
Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val
290 295 300
Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu
305 310 315 320
Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys
325 330 335
Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr
340 345 350
Leu Pro Pro Ser Arg Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr
355 360 365
Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu
370 375 380
Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu
385 390 395 400
Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys
405 410 415
Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu
420 425 430
Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly
435 440 445
Lys Gly Ser Gly Gly Ser Gly Gly Ser Gly Gly Ser Gly Asp Ile Gln
450 455 460
Met Thr Gln Ser Pro Ser Ser Val Ser Ala Ser Val Gly Asp Arg Val
465 470 475 480
Thr Ile Thr Cys Lys Ala Ser Gln Pro Ile Asn Thr Tyr Leu Ser Trp
485 490 495
Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile Tyr Arg Val
500 505 510
Asn Arg Lys Val Asp Gly Val Pro Ser Arg Phe Ser Gly Ser Gly Ser
515 520 525
Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro Glu Asp Phe
530 535 540
Ala Thr Tyr Tyr Cys Leu Gln Tyr Leu Asp Phe Pro Tyr Thr Phe Gly
545 550 555 560
Gly Gly Thr Lys Leu Glu Ile Lys Arg Gly Gly Gly Gly Ser Gly Gly
565 570 575
Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gln Glu Gln Leu Val
580 585 590
Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala Ser Val Lys Ala Ser
595 600 605
Cys Lys Ala Ser Gly Phe Asn Ile Gln Asp Thr Tyr Ile His Trp Val
610 615 620
Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met Gly Arg Ile Asp Pro
625 630 635 640
Ala Asn Gly Asn Ser Glu Tyr Ala Gln Lys Phe Gln Gly Arg Val Thr
645 650 655
Met Thr Arg Asp Thr Ser Thr Ser Thr Val Tyr Met Glu Leu Ser Ser
660 665 670
Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys Thr Thr Gly Asn Leu
675 680 685
His Tyr Ala Leu Met Asp Tyr Trp Gly Gln Gly Thr Ser Val Thr Val
690 695 700
Ser Ser
705
<210> 186
<211> 214
<212> PRT
<213> Artificial Sequence
<220>
<221> CHAIN
<222> (1)..(214)
<223> Anti-EGFR LC2
<400> 186
Glu Ile Val Leu Thr Gln Ser Pro Ala Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser Ile Arg Thr Asn
20 25 30
Ile His Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu Ile
35 40 45
Lys Tyr Gly Ser Glu Ser Ile Ser Gly Ile Pro Ala Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Glu Pro
65 70 75 80
Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Asn Asn Asn Trp Pro Thr
85 90 95
Ser Phe Gly Gly Gly Thr Lys Val Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 187
<211> 214
<212> PRT
<213> Artificial Sequence
<220>
<221> CHAIN
<222> (1)..(214)
<223> Anti-EGFR LC3
<400> 187
Glu Ile Val Leu Thr Gln Ser Pro Ala Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser Ile Gly Thr Asn
20 25 30
Ile His Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu Ile
35 40 45
Lys Tyr Ala Ser Glu Ser Ile Ser Gly Ile Pro Ala Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Glu Pro
65 70 75 80
Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Asn Asn Asn Trp Pro Thr
85 90 95
Ser Phe Gly Gly Gly Thr Lys Val Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 188
<211> 726
<212> PRT
<213> Artificial Sequence
<220>
<221> CHAIN
<222> (1)..(726)
<223> Anti-EGFR HC-anti-CD137 scFv-IgG1-LALA- Positive Charge Linker (HCC)
<400> 188
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Ser Leu Thr Asn Tyr
20 25 30
Gly Val His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Leu
35 40 45
Gly Val Ile Trp Ser Gly Gly Asn Thr Asp Tyr Ala Thr Glu Phe Thr
50 55 60
Ser Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Ala Leu Asp Tyr Tyr Asp Tyr Glu Phe Ala Tyr Trp Gly Gln Gly
100 105 110
Thr Met Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe
115 120 125
Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu
130 135 140
Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp
145 150 155 160
Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu
165 170 175
Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser
180 185 190
Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro
195 200 205
Ser Asn Thr Lys Val Asp Lys Arg Val Glu Pro Lys Ser Cys Asp Lys
210 215 220
Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Ala Ala Gly Gly Pro
225 230 235 240
Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser
245 250 255
Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp
260 265 270
Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn
275 280 285
Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val
290 295 300
Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu
305 310 315 320
Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys
325 330 335
Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr
340 345 350
Leu Pro Pro Ser Arg Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr
355 360 365
Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu
370 375 380
Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu
385 390 395 400
Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys
405 410 415
Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu
420 425 430
Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly
435 440 445
Lys Gly Arg Pro Gly Ser Gly Arg Pro Gly Ser Gly Arg Pro Gly Ser
450 455 460
Gly Arg Pro Gly Ser Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Val
465 470 475 480
Ser Ala Ser Val Gly Asp Arg Val Thr Ile Thr Cys Lys Ala Ser Gln
485 490 495
Pro Ile Asn Thr Tyr Leu Ser Trp Tyr Gln Gln Lys Pro Gly Lys Ala
500 505 510
Pro Lys Leu Leu Ile Tyr Arg Val Asn Arg Lys Val Asp Gly Val Pro
515 520 525
Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile
530 535 540
Ser Ser Leu Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln Tyr
545 550 555 560
Leu Asp Phe Pro Tyr Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
565 570 575
Arg Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
580 585 590
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gln
595 600 605
Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala Ser
610 615 620
Val Lys Ala Ser Cys Lys Ala Ser Gly Phe Asn Ile Gln Asp Thr Tyr
625 630 635 640
Ile His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met Gly
645 650 655
Arg Ile Asp Pro Ala Asn Gly Asn Ser Glu Tyr Ala Gln Lys Phe Gln
660 665 670
Gly Arg Val Thr Met Thr Arg Asp Thr Ser Thr Ser Thr Val Tyr Met
675 680 685
Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys Thr
690 695 700
Thr Gly Asn Leu His Tyr Ala Leu Met Asp Tyr Trp Gly Gln Gly Thr
705 710 715 720
Ser Val Thr Val Ser Ser
725
<210> 189
<211> 726
<212> PRT
<213> Artificial Sequence
<220>
<221> CHAIN
<222> (1)..(726)
<223> Anti-EGFR HC-anti-CD137 scFv-IgG1-LALA-Negative Charge Linker (HCC)
<400> 189
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Ser Leu Thr Thr Tyr
20 25 30
Gly Val His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Leu
35 40 45
Gly Val Ile Trp Ser Gly Gly Asn Thr Asp Tyr Gly Asn Glu Phe Thr
50 55 60
Ser Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Ala Leu Asp Tyr Tyr Asp Tyr Glu Phe Ala Tyr Trp Gly Gln Gly
100 105 110
Thr Met Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe
115 120 125
Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu
130 135 140
Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp
145 150 155 160
Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu
165 170 175
Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser
180 185 190
Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro
195 200 205
Ser Asn Thr Lys Val Asp Lys Arg Val Glu Pro Lys Ser Cys Asp Lys
210 215 220
Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Ala Ala Gly Gly Pro
225 230 235 240
Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser
245 250 255
Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp
260 265 270
Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn
275 280 285
Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val
290 295 300
Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu
305 310 315 320
Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys
325 330 335
Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr
340 345 350
Leu Pro Pro Ser Arg Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr
355 360 365
Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu
370 375 380
Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu
385 390 395 400
Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys
405 410 415
Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu
420 425 430
Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly
435 440 445
Lys Gly Glu Pro Gly Ser Gly Glu Pro Gly Ser Gly Glu Pro Gly Ser
450 455 460
Gly Glu Pro Gly Ser Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Val
465 470 475 480
Ser Ala Ser Val Gly Asp Arg Val Thr Ile Thr Cys Lys Ala Ser Gln
485 490 495
Pro Ile Asn Thr Tyr Leu Ser Trp Tyr Gln Gln Lys Pro Gly Lys Ala
500 505 510
Pro Lys Leu Leu Ile Tyr Arg Val Asn Arg Lys Val Asp Gly Val Pro
515 520 525
Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile
530 535 540
Ser Ser Leu Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln Tyr
545 550 555 560
Leu Asp Phe Pro Tyr Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
565 570 575
Arg Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
580 585 590
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gln
595 600 605
Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala Ser
610 615 620
Val Lys Ala Ser Cys Lys Ala Ser Gly Phe Asn Ile Gln Asp Thr Tyr
625 630 635 640
Ile His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met Gly
645 650 655
Arg Ile Asp Pro Ala Asn Gly Asn Ser Glu Tyr Ala Gln Lys Phe Gln
660 665 670
Gly Arg Val Thr Met Thr Arg Asp Thr Ser Thr Ser Thr Val Tyr Met
675 680 685
Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys Thr
690 695 700
Thr Gly Asn Leu His Tyr Ala Leu Met Asp Tyr Trp Gly Gln Gly Thr
705 710 715 720
Ser Val Thr Val Ser Ser
725
<210> 190
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(5)
<223> 348331 CDR-H1
<400> 190
Asn Tyr Gly Val His
1 5
<210> 191
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(9)
<223> 348331 CDR-H2
<400> 191
Tyr Asn Thr Pro Phe Thr Ser Arg Phe
1 5
<210> 192
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(9)
<223> 348331 CDR-H3
<400> 192
Thr Tyr Tyr Asp Tyr Glu Phe Ala Tyr
1 5
<210> 193
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(6)
<223> 348331 CDR-L1
<400> 193
Ile Gly Thr Asn Ile His
1 5
<210> 194
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(8)
<223> 348331 CDR-L2
<400> 194
Lys Tyr Ala Ser Glu Ser Ile Ser
1 5
<210> 195
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(5)
<223> 348331 CDR-L3
<400> 195
Asn Trp Pro Thr Thr
1 5
<210> 196
<211> 119
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(119)
<223> 348331 VH
<400> 196
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Ser Leu Thr Asn Tyr
20 25 30
Gly Val His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Leu
35 40 45
Gly Val Ile Trp Ser Gly Gly Asn Thr Asp Tyr Asn Thr Pro Phe Thr
50 55 60
Ser Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Ala Leu Thr Tyr Tyr Asp Tyr Glu Phe Ala Tyr Trp Gly Gln Gly
100 105 110
Thr Met Val Thr Val Ser Ser
115
<210> 197
<211> 108
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(108)
<223> 348331 VL
<400> 197
Glu Ile Val Leu Thr Gln Ser Pro Ala Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser Ile Gly Thr Asn
20 25 30
Ile His Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu Ile
35 40 45
Lys Tyr Ala Ser Glu Ser Ile Ser Gly Ile Pro Ala Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Glu Pro
65 70 75 80
Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Asn Asn Asn Trp Pro Thr
85 90 95
Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys Arg
100 105
<210> 198
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(5)
<223> 2-68/1-26 CDR-H1
<400> 198
Asn Tyr Gly Val His
1 5
<210> 199
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(9)
<223> 2-68/1-26 CDR-H2
<400> 199
Tyr Ala Thr Glu Phe Thr Ser Arg Phe
1 5
<210> 200
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(9)
<223> 2-68/1-26 CDR-H3
<400> 200
Asp Tyr Tyr Asp Tyr Glu Phe Ala Tyr
1 5
<210> 201
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(6)
<223> 2-68/1-26 CDR-L1
<400> 201
Ile Gly Thr Asn Ile His
1 5
<210> 202
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(8)
<223> 2-68/1-26 CDR-L2
<400> 202
Lys Tyr Ala Ser Glu Ser Ile Ser
1 5
<210> 203
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(5)
<223> 2-68/1-26 CDR-L3
<400> 203
Asn Trp Pro Thr Ser
1 5
<210> 204
<211> 119
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(119)
<223> 2-68/1-26 VH
<400> 204
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Ser Leu Thr Asn Tyr
20 25 30
Gly Val His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Leu
35 40 45
Gly Val Ile Trp Ser Gly Gly Asn Thr Asp Tyr Ala Thr Glu Phe Thr
50 55 60
Ser Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Ala Leu Asp Tyr Tyr Asp Tyr Glu Phe Ala Tyr Trp Gly Gln Gly
100 105 110
Thr Met Val Thr Val Ser Ser
115
<210> 205
<211> 108
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(108)
<223> 2-68/1-26 VL
<400> 205
Glu Ile Val Leu Thr Gln Ser Pro Ala Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser Ile Gly Thr Asn
20 25 30
Ile His Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu Ile
35 40 45
Lys Tyr Ala Ser Glu Ser Ile Ser Gly Ile Pro Ala Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Glu Pro
65 70 75 80
Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Asn Asn Asn Trp Pro Thr
85 90 95
Ser Phe Gly Gly Gly Thr Lys Val Glu Ile Lys Arg
100 105
<210> 206
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(5)
<223> 3-67/1-26 CDR-H1
<400> 206
Asn Tyr Gly Val His
1 5
<210> 207
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(9)
<223> 3-67/1-26 CDR-H2
<400> 207
Tyr Gly Asn Glu Phe Thr Ser Arg Phe
1 5
<210> 208
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(9)
<223> 3-67/1-26 CDR-H3
<400> 208
Asp Tyr Tyr Asp Tyr Glu Phe Ala Tyr
1 5
<210> 209
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(6)
<223> 3-67/1-26 CDR-L1
<400> 209
Ile Gly Thr Asn Ile His
1 5
<210> 210
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(8)
<223> 3-67/1-26 CDR-L2
<400> 210
Lys Tyr Ala Ser Glu Ser Ile Ser
1 5
<210> 211
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(5)
<223> 3-67/1-26 CDR-L3
<400> 211
Asn Trp Pro Thr Ser
1 5
<210> 212
<211> 119
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(119)
<223> 3-67/1-26 VH
<400> 212
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Ser Leu Thr Asn Tyr
20 25 30
Gly Val His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Leu
35 40 45
Gly Val Ile Trp Ser Gly Gly Asn Thr Asp Tyr Gly Asn Glu Phe Thr
50 55 60
Ser Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Ala Leu Asp Tyr Tyr Asp Tyr Glu Phe Ala Tyr Trp Gly Gln Gly
100 105 110
Thr Met Val Thr Val Ser Ser
115
<210> 213
<211> 108
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(108)
<223> 3-67/1-26 VL
<400> 213
Glu Ile Val Leu Thr Gln Ser Pro Ala Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser Ile Gly Thr Asn
20 25 30
Ile His Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu Ile
35 40 45
Lys Tyr Ala Ser Glu Ser Ile Ser Gly Ile Pro Ala Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Glu Pro
65 70 75 80
Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Asn Asn Asn Trp Pro Thr
85 90 95
Ser Phe Gly Gly Gly Thr Lys Val Glu Ile Lys Arg
100 105
<210> 214
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(5)
<223> 3-67.33/3-67.8 CDR-H1
<400> 214
Thr Tyr Gly Val His
1 5
<210> 215
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(9)
<223> 3-67.33/3-67.8 CDR-H2
<400> 215
Tyr Gly Asn Glu Phe Thr Ser Arg Phe
1 5
<210> 216
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(9)
<223> 3-67.33/3-67.8 CDR-H3
<400> 216
Asp Tyr Tyr Asp Tyr Glu Phe Ala Tyr
1 5
<210> 217
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(6)
<223> 3-67.33/3-67.8 CDR-L1
<400> 217
Ile Arg Thr Asn Ile His
1 5
<210> 218
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(8)
<223> 3-67.33/3-67.8 CDR-L2
<400> 218
Lys Tyr Gly Ser Glu Ser Ile Ser
1 5
<210> 219
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(5)
<223> 3-67.33/3-67.8 CDR-L3
<400> 219
Asn Trp Pro Thr Ser
1 5
<210> 220
<211> 119
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(119)
<223> 3-67.33/3-67.8 VH
<400> 220
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Ser Leu Thr Thr Tyr
20 25 30
Gly Val His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Leu
35 40 45
Gly Val Ile Trp Ser Gly Gly Asn Thr Asp Tyr Gly Asn Glu Phe Thr
50 55 60
Ser Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Ala Leu Asp Tyr Tyr Asp Tyr Glu Phe Ala Tyr Trp Gly Gln Gly
100 105 110
Thr Met Val Thr Val Ser Ser
115
<210> 221
<211> 108
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(108)
<223> 3-67.33/3-67.8 VL
<400> 221
Glu Ile Val Leu Thr Gln Ser Pro Ala Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser Ile Arg Thr Asn
20 25 30
Ile His Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu Ile
35 40 45
Lys Tyr Gly Ser Glu Ser Ile Ser Gly Ile Pro Ala Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Glu Pro
65 70 75 80
Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Asn Asn Asn Trp Pro Thr
85 90 95
Ser Phe Gly Gly Gly Thr Lys Val Glu Ile Lys Arg
100 105
<210> 222
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(5)
<223> 3-67.33/3-67.34 CDR-H1
<400> 222
Thr Tyr Gly Val His
1 5
<210> 223
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(9)
<223> 3-67.33/3-67.34 CDR-H2
<400> 223
Tyr Gly Asn Glu Phe Thr Ser Arg Phe
1 5
<210> 224
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(9)
<223> 3-67.33/3-67.34 CDR-H3
<400> 224
Asp Tyr Tyr Asp Tyr Glu Phe Ala Tyr
1 5
<210> 225
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(6)
<223> 3-67.33/3-67.34 CDR-L1
<400> 225
Ile Ser Thr Asn Ile His
1 5
<210> 226
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(8)
<223> 3-67.33/3-67.34 CDR-L2
<400> 226
Lys Tyr Gly Ser Glu Ser Ile Ser
1 5
<210> 227
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(5)
<223> 3-67.33/3-67.34 CDR-L3
<400> 227
Asn Trp Pro Thr Ser
1 5
<210> 228
<211> 119
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(119)
<223> 3-67.33/3-67.34 VH
<400> 228
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Ser Leu Thr Thr Tyr
20 25 30
Gly Val His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Leu
35 40 45
Gly Val Ile Trp Ser Gly Gly Asn Thr Asp Tyr Gly Asn Glu Phe Thr
50 55 60
Ser Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Ala Leu Asp Tyr Tyr Asp Tyr Glu Phe Ala Tyr Trp Gly Gln Gly
100 105 110
Thr Met Val Thr Val Ser Ser
115
<210> 229
<211> 108
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(108)
<223> 3-67.33/3-67.34 VL
<400> 229
Glu Ile Val Leu Thr Gln Ser Pro Ala Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser Ile Ser Thr Asn
20 25 30
Ile His Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu Ile
35 40 45
Lys Tyr Gly Ser Glu Ser Ile Ser Gly Ile Pro Ala Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Glu Pro
65 70 75 80
Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Asn Asn Asn Trp Pro Thr
85 90 95
Ser Phe Gly Gly Gly Thr Lys Val Glu Ile Lys Arg
100 105
<210> 230
<211> 699
<212> PRT
<213> Artificial Sequence
<220>
<221> CHAIN
<222> (1)..(699)
<223> Anti-EGFR HC-anti-CD137 scFv-IgG1 LALA-Linker 10(HCC)
<400> 230
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Ser Leu Thr Asn Tyr
20 25 30
Gly Val His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Leu
35 40 45
Gly Val Ile Trp Ser Gly Gly Asn Thr Asp Tyr Gly Asn Glu Phe Thr
50 55 60
Ser Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Ala Leu Asp Tyr Tyr Asp Tyr Glu Phe Ala Tyr Trp Gly Gln Gly
100 105 110
Thr Met Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe
115 120 125
Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu
130 135 140
Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp
145 150 155 160
Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu
165 170 175
Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser
180 185 190
Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro
195 200 205
Ser Asn Thr Lys Val Asp Lys Arg Val Glu Pro Lys Ser Cys Asp Lys
210 215 220
Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Ala Ala Gly Gly Pro
225 230 235 240
Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser
245 250 255
Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp
260 265 270
Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn
275 280 285
Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val
290 295 300
Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu
305 310 315 320
Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys
325 330 335
Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr
340 345 350
Leu Pro Pro Ser Arg Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr
355 360 365
Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu
370 375 380
Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu
385 390 395 400
Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys
405 410 415
Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu
420 425 430
Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly
435 440 445
Lys Pro Ala Pro Ala Pro Asp Ile Gln Met Thr Gln Ser Pro Ser Ser
450 455 460
Val Ser Ala Ser Val Gly Asp Arg Val Thr Ile Thr Cys Lys Ala Ser
465 470 475 480
Gln Pro Ile Asn Thr Tyr Leu Ser Trp Tyr Gln Gln Lys Pro Gly Lys
485 490 495
Ala Pro Lys Leu Leu Ile Tyr Arg Val Asn Arg Lys Val Asp Gly Val
500 505 510
Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr
515 520 525
Ile Ser Ser Leu Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln
530 535 540
Tyr Leu Asp Phe Pro Tyr Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile
545 550 555 560
Lys Arg Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
565 570 575
Ser Gly Gly Gly Gln Glu Gln Leu Val Gln Ser Gly Ala Glu Val Lys
580 585 590
Lys Pro Gly Ala Ser Val Lys Ala Ser Cys Lys Ala Ser Gly Phe Asn
595 600 605
Ile Gln Asp Thr Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Gly
610 615 620
Leu Glu Trp Met Gly Arg Ile Asp Pro Ala Asn Gly Asn Ser Glu Tyr
625 630 635 640
Ala Gln Lys Phe Gln Gly Arg Val Thr Met Thr Arg Asp Thr Ser Thr
645 650 655
Ser Thr Val Tyr Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala
660 665 670
Val Tyr Tyr Cys Thr Thr Gly Asn Leu His Tyr Ala Leu Met Asp Tyr
675 680 685
Trp Gly Gln Gly Thr Ser Val Thr Val Ser Ser
690 695
<210> 231
<211> 726
<212> PRT
<213> Artificial Sequence
<220>
<221> CHAIN
<222> (1)..(726)
<223> Anti-EGFR HC-anti-CD137 scFv-IgG1-LALA- Positive Charge Linker (HCC)
<400> 231
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Ser Leu Thr Asn Tyr
20 25 30
Gly Val His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Leu
35 40 45
Gly Val Ile Trp Ser Gly Gly Asn Thr Asp Tyr Gly Asn Glu Phe Thr
50 55 60
Ser Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Ala Leu Asp Tyr Tyr Asp Tyr Glu Phe Ala Tyr Trp Gly Gln Gly
100 105 110
Thr Met Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe
115 120 125
Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu
130 135 140
Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp
145 150 155 160
Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu
165 170 175
Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser
180 185 190
Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro
195 200 205
Ser Asn Thr Lys Val Asp Lys Arg Val Glu Pro Lys Ser Cys Asp Lys
210 215 220
Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Ala Ala Gly Gly Pro
225 230 235 240
Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser
245 250 255
Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp
260 265 270
Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn
275 280 285
Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val
290 295 300
Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu
305 310 315 320
Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys
325 330 335
Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr
340 345 350
Leu Pro Pro Ser Arg Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr
355 360 365
Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu
370 375 380
Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu
385 390 395 400
Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys
405 410 415
Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu
420 425 430
Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly
435 440 445
Lys Gly Arg Pro Gly Ser Gly Arg Pro Gly Ser Gly Arg Pro Gly Ser
450 455 460
Gly Arg Pro Gly Ser Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Val
465 470 475 480
Ser Ala Ser Val Gly Asp Arg Val Thr Ile Thr Cys Lys Ala Ser Gln
485 490 495
Pro Ile Asn Thr Tyr Leu Ser Trp Tyr Gln Gln Lys Pro Gly Lys Ala
500 505 510
Pro Lys Leu Leu Ile Tyr Arg Val Asn Arg Lys Val Asp Gly Val Pro
515 520 525
Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile
530 535 540
Ser Ser Leu Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln Tyr
545 550 555 560
Leu Asp Phe Pro Tyr Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
565 570 575
Arg Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
580 585 590
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gln
595 600 605
Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala Ser
610 615 620
Val Lys Ala Ser Cys Lys Ala Ser Gly Phe Asn Ile Gln Asp Thr Tyr
625 630 635 640
Ile His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met Gly
645 650 655
Arg Ile Asp Pro Ala Asn Gly Asn Ser Glu Tyr Ala Gln Lys Phe Gln
660 665 670
Gly Arg Val Thr Met Thr Arg Asp Thr Ser Thr Ser Thr Val Tyr Met
675 680 685
Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys Thr
690 695 700
Thr Gly Asn Leu His Tyr Ala Leu Met Asp Tyr Trp Gly Gln Gly Thr
705 710 715 720
Ser Val Thr Val Ser Ser
725
<210> 232
<211> 15
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(15)
<223> Exemplary linker (Linker 7)
<400> 232
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
1 5 10 15
<210> 233
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(5)
<223> Exemplary linker233
<400> 233
Gly Gly Gly Ser Gly
1 5
<210> 234
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(10)
<223> Exemplary linker234
<400> 234
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
1 5 10
<210> 235
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(12)
<223> Exemplary linker235
<400> 235
Gly Ser Gly Gly Ser Gly Gly Ser Gly Gly Ser Gly
1 5 10
<210> 236
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(8)
<223> Exemplary linker236
<400> 236
Gly Gly Ser Gly Gly Gly Ser Gly
1 5
<210> 237
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(12)
<223> Exemplary linker237
<400> 237
Gly Gly Ser Gly Gly Gly Ser Gly Gly Gly Ser Gly
1 5 10
<210> 238
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(6)
<223> Exemplary linker238
<400> 238
Gly Ser Gly Gly Ser Gly
1 5
<210> 239
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(9)
<223> Exemplary linker239
<400> 239
Gly Ser Gly Gly Ser Gly Gly Ser Gly
1 5
<210> 240
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(7)
<223> Exemplary linker240
<400> 240
Gly Ser Gly Ser Gly Ser Gly
1 5
<210> 241
<211> 18
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(18)
<223> Exemplary linker241
<400> 241
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
1 5 10 15
Gly Gly
<210> 242
<211> 30
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(30)
<223> Exemplary linker242
<400> 242
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
1 5 10 15
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
20 25 30
<210> 243
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(5)
<223> Exemplary linker (Linker 10)
<400> 243
Pro Ala Pro Ala Pro
1 5
<210> 244
<211> 15
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(15)
<223> Exemplary linker244
<400> 244
Pro Ala Pro Ala Pro Pro Ala Pro Ala Pro Pro Ala Pro Ala Pro
1 5 10 15
<210> 245
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(7)
<223> Exemplary linker245
<400> 245
Ile Lys Arg Thr Val Ala Ala
1 5
<210> 246
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(7)
<223> Exemplary linker246
<400> 246
Val Ser Ser Ala Ser Thr Lys
1 5
<210> 247
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(7)
<223> Exemplary linker247
<400> 247
Ala Glu Ala Ala Ala Lys Ala
1 5
<210> 248
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(12)
<223> Exemplary linker248
<400> 248
Ala Glu Ala Ala Ala Lys Glu Ala Ala Ala Lys Ala
1 5 10
<210> 249
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(10)
<223> Exemplary linker249
<400> 249
Gly Arg Pro Gly Ser Gly Arg Pro Gly Ser
1 5 10
<210> 250
<211> 20
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(20)
<223> Exemplary linker250
<400> 250
Gly Arg Pro Gly Ser Gly Arg Pro Gly Ser Gly Arg Pro Gly Ser Gly
1 5 10 15
Arg Pro Gly Ser
20
<210> 251
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(10)
<223> Exemplary linker251
<400> 251
Gly Arg Gly Gly Ser Gly Arg Gly Gly Ser
1 5 10
<210> 252
<211> 20
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(20)
<223> Exemplary linker252
<400> 252
Gly Arg Gly Gly Ser Gly Arg Gly Gly Ser Gly Arg Gly Gly Ser Gly
1 5 10 15
Arg Gly Gly Ser
20
<210> 253
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(10)
<223> Exemplary linker253
<400> 253
Gly Lys Pro Gly Ser Gly Lys Pro Gly Ser
1 5 10
<210> 254
<211> 20
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(20)
<223> Exemplary linker254
<400> 254
Gly Lys Pro Gly Ser Gly Lys Pro Gly Ser Gly Lys Pro Gly Ser Gly
1 5 10 15
Lys Pro Gly Ser
20
<210> 255
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(10)
<223> Exemplary linker255
<400> 255
Gly Glu Pro Gly Ser Gly Glu Pro Gly Ser
1 5 10
<210> 256
<211> 20
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(20)
<223> Exemplary linker256
<400> 256
Gly Glu Gly Gly Ser Gly Glu Gly Gly Ser Gly Glu Gly Gly Ser Gly
1 5 10 15
Glu Gly Gly Ser
20
<210> 257
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(10)
<223> Exemplary linker257
<400> 257
Gly Asp Pro Gly Ser Gly Asp Pro Gly Ser
1 5 10
<210> 258
<211> 20
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(20)
<223> Exemplary linker258
<400> 258
Gly Asp Pro Gly Ser Gly Asp Pro Gly Ser Gly Asp Pro Gly Ser Gly
1 5 10 15
Asp Pro Gly Ser
20
<210> 259
<211> 726
<212> PRT
<213> Artificial Sequence
<220>
<221> CHAIN
<222> (1)..(726)
<223> Anti-EGFR HC-anti-CD137 scFv-IgG1-LALA-Negative Charge Linker (HCC)
<400> 259
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Ser Leu Thr Thr Tyr
20 25 30
Gly Val His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Leu
35 40 45
Gly Val Ile Trp Ser Gly Gly Asn Thr Asp Tyr Gly Asn Glu Phe Thr
50 55 60
Ser Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Ala Leu Asp Tyr Tyr Asp Tyr Glu Phe Ala Tyr Trp Gly Gln Gly
100 105 110
Thr Met Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe
115 120 125
Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu
130 135 140
Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp
145 150 155 160
Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu
165 170 175
Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser
180 185 190
Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro
195 200 205
Ser Asn Thr Lys Val Asp Lys Arg Val Glu Pro Lys Ser Cys Asp Lys
210 215 220
Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Ala Ala Gly Gly Pro
225 230 235 240
Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser
245 250 255
Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp
260 265 270
Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn
275 280 285
Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val
290 295 300
Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu
305 310 315 320
Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys
325 330 335
Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr
340 345 350
Leu Pro Pro Ser Arg Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr
355 360 365
Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu
370 375 380
Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu
385 390 395 400
Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys
405 410 415
Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu
420 425 430
Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly
435 440 445
Lys Gly Glu Pro Gly Ser Gly Glu Pro Gly Ser Gly Glu Pro Gly Ser
450 455 460
Gly Glu Pro Gly Ser Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Val
465 470 475 480
Ser Ala Ser Val Gly Asp Arg Val Thr Ile Thr Cys Lys Ala Ser Gln
485 490 495
Pro Ile Asn Thr Tyr Leu Ser Trp Tyr Gln Gln Lys Pro Gly Lys Ala
500 505 510
Pro Lys Leu Leu Ile Tyr Arg Val Asn Arg Lys Val Asp Gly Val Pro
515 520 525
Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile
530 535 540
Ser Ser Leu Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln Tyr
545 550 555 560
Leu Asp Phe Pro Tyr Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
565 570 575
Arg Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
580 585 590
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gln
595 600 605
Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala Ser
610 615 620
Val Lys Ala Ser Cys Lys Ala Ser Gly Phe Asn Ile Gln Asp Thr Tyr
625 630 635 640
Ile His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met Gly
645 650 655
Arg Ile Asp Pro Ala Ser Gly Asn Ser Glu Tyr Ala Gln Lys Phe Gln
660 665 670
Gly Arg Val Thr Met Thr Arg Asp Thr Ser Thr Ser Thr Val Tyr Met
675 680 685
Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys Thr
690 695 700
Thr Gly Asn Leu His Tyr Ala Leu Met Asp Tyr Trp Gly Gln Gly Thr
705 710 715 720
Ser Val Thr Val Ser Ser
725
<210> 260
<211> 726
<212> PRT
<213> Artificial Sequence
<220>
<221> CHAIN
<222> (1)..(726)
<223> Anti-EGFR HC-anti-CD137-1 scFv-IgG1-LALA- Positive Charge Linker (HCC)
<400> 260
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Ser Leu Thr Asn Tyr
20 25 30
Gly Val His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Leu
35 40 45
Gly Val Ile Trp Ser Gly Gly Asn Thr Asp Tyr Gly Asn Glu Phe Thr
50 55 60
Ser Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Ala Leu Asp Tyr Tyr Asp Tyr Glu Phe Ala Tyr Trp Gly Gln Gly
100 105 110
Thr Met Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe
115 120 125
Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu
130 135 140
Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp
145 150 155 160
Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu
165 170 175
Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser
180 185 190
Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro
195 200 205
Ser Asn Thr Lys Val Asp Lys Arg Val Glu Pro Lys Ser Cys Asp Lys
210 215 220
Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Ala Ala Gly Gly Pro
225 230 235 240
Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser
245 250 255
Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp
260 265 270
Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn
275 280 285
Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val
290 295 300
Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu
305 310 315 320
Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys
325 330 335
Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr
340 345 350
Leu Pro Pro Ser Arg Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr
355 360 365
Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu
370 375 380
Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu
385 390 395 400
Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys
405 410 415
Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu
420 425 430
Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly
435 440 445
Lys Gly Arg Pro Gly Ser Gly Arg Pro Gly Ser Gly Arg Pro Gly Ser
450 455 460
Gly Arg Pro Gly Ser Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Val
465 470 475 480
Ser Ala Ser Val Gly Asp Arg Val Thr Ile Thr Cys Lys Ala Ser Gln
485 490 495
Pro Ile Asn Thr Tyr Leu Ser Trp Tyr Gln Gln Lys Pro Gly Lys Ala
500 505 510
Pro Lys Leu Leu Ile Tyr Arg Val Asn Arg Lys Val Asp Gly Val Pro
515 520 525
Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile
530 535 540
Ser Ser Leu Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln Tyr
545 550 555 560
Leu Asp Phe Pro Tyr Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
565 570 575
Arg Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
580 585 590
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gln
595 600 605
Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala Ser
610 615 620
Val Lys Ala Ser Cys Lys Ala Ser Gly Phe Asn Ile Gln Asp Thr Tyr
625 630 635 640
Ile His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met Gly
645 650 655
Arg Ile Asp Pro Ala Ser Gly Asn Ser Glu Tyr Ala Gln Lys Phe Gln
660 665 670
Gly Arg Val Thr Met Thr Arg Asp Thr Ser Thr Ser Thr Val Tyr Met
675 680 685
Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys Thr
690 695 700
Thr Gly Asn Leu His Tyr Ala Leu Met Asp Tyr Trp Gly Gln Gly Thr
705 710 715 720
Ser Val Thr Val Ser Ser
725
<210> 261
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(5)
<223> Clone 2-9-1 VH CDR1
<400> 261
Asp Thr Tyr Ile His
1 5
<210> 262
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(17)
<223> Clone 2-9-1 VH CDR2
<400> 262
Arg Ile Asp Pro Ala Ser Gly Asn Ser Glu Tyr Ala Gln Lys Phe Gln
1 5 10 15
Gly
<210> 263
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(10)
<223> Clone 2-9-1 VH CDR3
<400> 263
Gly Asn Leu His Tyr Ala Leu Met Asp Tyr
1 5 10
<210> 264
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(11)
<223> Clone 2-9-1 VL CDR1
<400> 264
Lys Ala Ser Gln Pro Ile Asn Thr Tyr Leu Ser
1 5 10
<210> 265
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(7)
<223> Clone 2-9-1 VL CDR2
<400> 265
Arg Val Asn Arg Lys Val Asp
1 5
<210> 266
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(9)
<223> Clone 2-9-1 VL CDR3
<400> 266
Leu Gln Tyr Leu Asp Phe Pro Tyr Thr
1 5
<210> 268
<211> 119
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(119)
<223> Clone 2-9-1 VH
<400> 268
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Ala Ser Cys Lys Ala Ser Gly Phe Asn Ile Gln Asp Thr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Arg Ile Asp Pro Ala Ser Gly Asn Ser Glu Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Met Thr Arg Asp Thr Ser Thr Ser Thr Val Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Thr Gly Asn Leu His Tyr Ala Leu Met Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Ser Val Thr Val Ser Ser
115
<210> 268
<211> 110
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(110)
<223> Clone 2-9-1 VL
<400> 268
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Val Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Lys Ala Ser Gln Pro Ile Asn Thr Tyr
20 25 30
Leu Ser Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Arg Val Asn Arg Lys Val Asp Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln Tyr Leu Asp Phe Pro Tyr
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys Arg Thr Val
100 105 110
<210> 269
<211> 449
<212> PRT
<213> Artificial Sequence
<220>
<221> CHAIN
<222> (1)..(449)
<223> Clone 2-9-1 HC
<400> 269
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Ala Ser Cys Lys Ala Ser Gly Phe Asn Ile Gln Asp Thr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Arg Ile Asp Pro Ala Ser Gly Asn Ser Glu Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Met Thr Arg Asp Thr Ser Thr Ser Thr Val Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Thr Gly Asn Leu His Tyr Ala Leu Met Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Ser Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe
115 120 125
Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu
130 135 140
Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp
145 150 155 160
Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu
165 170 175
Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser
180 185 190
Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro
195 200 205
Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys
210 215 220
Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro
225 230 235 240
Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser
245 250 255
Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Glu His Glu Asp
260 265 270
Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn
275 280 285
Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val
290 295 300
Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu
305 310 315 320
Tyr Lys Cys Lys Val Ser Asn Lys Ala Phe Pro Ala Pro Ile Glu Lys
325 330 335
Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr
340 345 350
Leu Pro Pro Ser Arg Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr
355 360 365
Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu
370 375 380
Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu
385 390 395 400
Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys
405 410 415
Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu
420 425 430
Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly
435 440 445
Lys
<210> 270
<211> 214
<212> PRT
<213> Artificial Sequence
<220>
<221> CHAIN
<222> (1)..(214)
<223> Clone 2-9-1 LC
<400> 270
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Val Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Lys Ala Ser Gln Pro Ile Asn Thr Tyr
20 25 30
Leu Ser Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Arg Val Asn Arg Lys Val Asp Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln Tyr Leu Asp Phe Pro Tyr
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 271
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(5)
<223> Clone 2-9-2 VH CDR1
<400> 271
Asp Thr Tyr Ile His
1 5
<210> 272
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(17)
<223> Clone 2-9-2 VH CDR2
<400> 272
Arg Ile Asp Pro Ala Ser Gly Asn Ser Glu Tyr Ala Gln Lys Phe Gln
1 5 10 15
Gly
<210> 273
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(10)
<223> Clone 2-9-2 VH CDR3
<400> 273
Gly Asn Leu His Tyr Ala Leu Met Asp Tyr
1 5 10
<210> 274
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(11)
<223> Clone 2-9-2 VL CDR1
<400> 274
Lys Ala Ser Gln Pro Ile Asn Thr Tyr Leu Ser
1 5 10
<210> 275
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(7)
<223> Clone 2-9-2 VL CDR2
<400> 275
Arg Val Asn Arg Lys Val Asp
1 5
<210> 276
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(9)
<223> Clone 2-9-2 VL CDR3
<400> 276
Leu Gln Tyr Leu Asp Phe Pro Tyr Thr
1 5
<210> 277
<211> 119
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(119)
<223> Clone 2-9-2 VH
<400> 277
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Phe Asn Ile Gln Asp Thr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Arg Ile Asp Pro Ala Ser Gly Asn Ser Glu Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Met Thr Arg Asp Thr Ser Thr Ser Thr Val Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Thr Gly Asn Leu His Tyr Ala Leu Met Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Ser Val Thr Val Ser Ser
115
<210> 278
<211> 110
<212> PRT
<213> Artificial Sequence
<220>
<221> DOMAIN
<222> (1)..(110)
<223> Clone 2-9-2 VL
<400> 278
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Val Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Lys Ala Ser Gln Pro Ile Asn Thr Tyr
20 25 30
Leu Ser Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Arg Val Asn Arg Lys Val Asp Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln Tyr Leu Asp Phe Pro Tyr
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys Arg Thr Val
100 105 110
<210> 279
<211> 446
<212> PRT
<213> Artificial Sequence
<220>
<221> CHAIN
<222> (1)..(446)
<223> Clone 2-9-2 HC
<400> 279
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Phe Asn Ile Gln Asp Thr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Arg Ile Asp Pro Ala Ser Gly Asn Ser Glu Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Met Thr Arg Asp Thr Ser Thr Ser Thr Val Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Thr Gly Asn Leu His Tyr Ala Leu Met Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Ser Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe
115 120 125
Pro Leu Ala Pro Cys Ser Arg Ser Thr Ser Glu Ser Thr Ala Ala Leu
130 135 140
Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp
145 150 155 160
Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu
165 170 175
Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser
180 185 190
Ser Ser Leu Gly Thr Lys Thr Tyr Thr Cys Asn Val Asp His Lys Pro
195 200 205
Ser Asn Thr Lys Val Asp Lys Arg Val Glu Ser Lys Tyr Gly Pro Pro
210 215 220
Cys Pro Pro Cys Pro Ala Pro Glu Phe Leu Gly Gly Pro Ser Val Phe
225 230 235 240
Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro
245 250 255
Glu Val Thr Cys Val Val Val Asp Val Ser Gln Glu Asp Pro Glu Val
260 265 270
Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr
275 280 285
Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr Tyr Arg Val Val Ser Val
290 295 300
Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys
305 310 315 320
Lys Val Ser Asn Lys Gly Leu Pro Ser Ser Ile Glu Lys Thr Ile Ser
325 330 335
Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro
340 345 350
Ser Gln Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val
355 360 365
Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly
370 375 380
Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp
385 390 395 400
Gly Ser Phe Phe Leu Tyr Ser Arg Leu Thr Val Asp Lys Ser Arg Trp
405 410 415
Gln Glu Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His
420 425 430
Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Leu Gly Lys
435 440 445
<210> 280
<211> 214
<212> PRT
<213> Artificial Sequence
<220>
<221> CHAIN
<222> (1)..(214)
<223> Clone 2-9-2 LC
<400> 280
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Val Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Lys Ala Ser Gln Pro Ile Asn Thr Tyr
20 25 30
Leu Ser Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Arg Val Asn Arg Lys Val Asp Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln Tyr Leu Asp Phe Pro Tyr
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 281
<211> 699
<212> PRT
<213> Artificial Sequence
<220>
<221> CHAIN
<222> (1)..(669)
<223> Anti-EGFR HC-anti-CD137-2 scFv-IgG1 LALA-Linker 10 (HCC)
<400> 281
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Ser Leu Thr Asn Tyr
20 25 30
Gly Val His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Leu
35 40 45
Gly Val Ile Trp Ser Gly Gly Asn Thr Asp Tyr Gly Asn Glu Phe Thr
50 55 60
Ser Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Ala Leu Asp Tyr Tyr Asp Tyr Glu Phe Ala Tyr Trp Gly Gln Gly
100 105 110
Thr Met Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe
115 120 125
Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu
130 135 140
Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp
145 150 155 160
Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu
165 170 175
Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser
180 185 190
Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro
195 200 205
Ser Asn Thr Lys Val Asp Lys Arg Val Glu Pro Lys Ser Cys Asp Lys
210 215 220
Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Ala Ala Gly Gly Pro
225 230 235 240
Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser
245 250 255
Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp
260 265 270
Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn
275 280 285
Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val
290 295 300
Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu
305 310 315 320
Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys
325 330 335
Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr
340 345 350
Leu Pro Pro Ser Arg Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr
355 360 365
Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu
370 375 380
Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu
385 390 395 400
Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys
405 410 415
Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu
420 425 430
Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly
435 440 445
Lys Pro Ala Pro Ala Pro Asp Ile Gln Met Thr Gln Ser Pro Ser Ser
450 455 460
Val Ser Ala Ser Val Gly Asp Arg Val Thr Ile Thr Cys Lys Ala Ser
465 470 475 480
Gln Pro Ile Asn Thr Tyr Leu Ser Trp Tyr Gln Gln Lys Pro Gly Lys
485 490 495
Ala Pro Lys Leu Leu Ile Tyr Arg Val Asn Arg Lys Val Asp Gly Val
500 505 510
Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr
515 520 525
Ile Ser Ser Leu Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln
530 535 540
Tyr Leu Asp Phe Pro Tyr Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile
545 550 555 560
Lys Arg Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
565 570 575
Ser Gly Gly Gly Gln Glu Gln Leu Val Gln Ser Gly Ala Glu Val Lys
580 585 590
Lys Pro Gly Ala Ser Val Lys Val Ser Cys Lys Ala Ser Gly Phe Asn
595 600 605
Ile Gln Asp Thr Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Gly
610 615 620
Leu Glu Trp Met Gly Arg Ile Asp Pro Ala Ser Gly Asn Ser Glu Tyr
625 630 635 640
Ala Gln Lys Phe Gln Gly Arg Val Thr Met Thr Arg Asp Thr Ser Thr
645 650 655
Ser Thr Val Tyr Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala
660 665 670
Val Tyr Tyr Cys Thr Thr Gly Asn Leu His Tyr Ala Leu Met Asp Tyr
675 680 685
Trp Gly Gln Gly Thr Ser Val Thr Val Ser Ser
690 695
<210> 282
<211> 726
<212> PRT
<213> Artificial Sequence
<220>
<221> CHAIN
<222> (1)..(726)
<223> Anti-EGFR HC-anti-CD137-2 scFv-IgG1-LALA- Positive Charge Linker (HCC)
<400> 282
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Ser Leu Thr Asn Tyr
20 25 30
Gly Val His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Leu
35 40 45
Gly Val Ile Trp Ser Gly Gly Asn Thr Asp Tyr Gly Asn Glu Phe Thr
50 55 60
Ser Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Ala Leu Asp Tyr Tyr Asp Tyr Glu Phe Ala Tyr Trp Gly Gln Gly
100 105 110
Thr Met Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe
115 120 125
Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu
130 135 140
Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp
145 150 155 160
Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu
165 170 175
Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser
180 185 190
Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro
195 200 205
Ser Asn Thr Lys Val Asp Lys Arg Val Glu Pro Lys Ser Cys Asp Lys
210 215 220
Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Ala Ala Gly Gly Pro
225 230 235 240
Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser
245 250 255
Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp
260 265 270
Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn
275 280 285
Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val
290 295 300
Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu
305 310 315 320
Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys
325 330 335
Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr
340 345 350
Leu Pro Pro Ser Arg Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr
355 360 365
Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu
370 375 380
Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu
385 390 395 400
Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys
405 410 415
Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu
420 425 430
Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly
435 440 445
Lys Gly Arg Pro Gly Ser Gly Arg Pro Gly Ser Gly Arg Pro Gly Ser
450 455 460
Gly Arg Pro Gly Ser Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Val
465 470 475 480
Ser Ala Ser Val Gly Asp Arg Val Thr Ile Thr Cys Lys Ala Ser Gln
485 490 495
Pro Ile Asn Thr Tyr Leu Ser Trp Tyr Gln Gln Lys Pro Gly Lys Ala
500 505 510
Pro Lys Leu Leu Ile Tyr Arg Val Asn Arg Lys Val Asp Gly Val Pro
515 520 525
Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile
530 535 540
Ser Ser Leu Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln Tyr
545 550 555 560
Leu Asp Phe Pro Tyr Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
565 570 575
Arg Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
580 585 590
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gln
595 600 605
Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala Ser
610 615 620
Val Lys Val Ser Cys Lys Ala Ser Gly Phe Asn Ile Gln Asp Thr Tyr
625 630 635 640
Ile His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met Gly
645 650 655
Arg Ile Asp Pro Ala Ser Gly Asn Ser Glu Tyr Ala Gln Lys Phe Gln
660 665 670
Gly Arg Val Thr Met Thr Arg Asp Thr Ser Thr Ser Thr Val Tyr Met
675 680 685
Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys Thr
690 695 700
Thr Gly Asn Leu His Tyr Ala Leu Met Asp Tyr Trp Gly Gln Gly Thr
705 710 715 720
Ser Val Thr Val Ser Ser
725
Claims (103)
- CD137에 결합되는 제1 항체 부분 및 EGFR에 결합되는 제2 항체 부분을 포함하는 것을 특징으로 하는 CD137 및 EGFR에 결합되는 다중 특이적 항체.
- 제1항에 있어서, 상기 제1 항체 부분은 중쇄 가변 영역(VH) 및 경쇄 가변 영역(VL) 을 포함하고,
a) 상기 VH는,
i) GFX1X2X3DTYIX4(SEQ ID NO: 177)의 아미노산 서열을 포함하며, X1 = N 또는 C; X2 = I, P, L 또는 M; X3 = K, N, R, C 또는 Q; X4 = H 또는 Q인 HC-CDR1,
ii) X1IDPANGX2X3X4(SEQ ID NO: 178)의 아미노산 서열, X1 = K 또는 R; X2 = N, G, F, Y, A, D, L, M 또는 Q; X3 = S 또는 T; X4 = E 또는 M인 HC-CDR2, 및
iii) GNLHYX1LMD(SEQ ID NO: 179)의 아미노산 서열을 포함하고, X1 = Y, A 또는 G인 HC-CDR3을 포함하며;
b) 상기 VL는,
i) KASQX1X2X3TYX4S(SEQ ID NO: 180)의 아미노산 서열을 포함하고, X1 = A, P 또는 T; X2 = I, T, 또는 P; X3 = N 또는 A; X4 = L, G 또는 H인 LC-CDR1,
ii) RX1NRX2X3X4(SEQ ID NO: 181)의 아미노산 서열을 포함하며, X1 = A, Y, V 또는 D; X2 = M, K, V, 또는 A; X3 = V, P, Y 또는 G; X4 = D 또는 G인 LC-CDR2, 및
iii) LQX1X2DFPYX3(SEQ ID NO: 182)의 아미노산 서열을 포함하고, X1 = Y, S 또는 F; X2 = D, V, L, R, E 또는 Q; X3 = T 또는 K인 LC-CDR3을 포함하는 것을 특징으로 하는 다중 특이적 항체. - 제2항에 있어서,
a) 상기 HC-CDR1은 SEQ ID NO: 1, 11, 21, 31, 41, 51, 61, 71, 81, 91, 101, 111, 121, 131, 141, 261 및 271 중의 임의의 하나의 아미노산 서열을 포함하거나, 최대 약 3개의 아미노산에 의해 치환된 변이체를 포함하고;
b) 상기 HC-CDR2는 SEQ ID NO: 2, 12, 22, 32, 42, 52, 62, 72, 82, 92, 102, 112, 122, 132, 142, 262 및 272 중의 임의의 하나의 아미노산 서열을 포함하거나, 최대 약 3개의 아미노산에 의해 치환된 변이체를 포함하며;
c) 상기 HC-CDR3은 SEQ ID NO: 3, 13, 23, 33, 43, 53, 63, 73, 83, 93, 103, 113, 123, 133, 143, 263 및 273 중의 임의의 하나의 아미노산 서열을 포함하거나, 최대 약 3개의 아미노산에 의해 치환된 변이체를 포함하고;
d) 상기 LC-CDR1은 SEQ ID NO: 4, 14, 24, 34, 44, 54, 64, 74, 84, 94, 104, 114, 124, 134, 144, 264 및 274 중의 임의의 하나의 아미노산 서열을 포함하거나 최대 약 3개의 아미노산에 의해 치환된 변이체를 포함하며;
e) 상기 LC-CDR2는 SEQ ID NO: 5, 15, 25, 35, 45, 55, 65, 75, 85, 95, 105, 115, 125, 135, 145, 265 및 275 중의 임의의 하나의 아미노산 서열을 포함하거나, 최대 약 3개의 아미노산에 의해 치환된 변이체를 포함하고;
f) 상기 LC-CDR3은 SEQ ID NO: 6, 16, 26, 36, 46, 56, 66, 76, 86, 96, 106, 116, 126, 136, 146, 266 및 276 중의 임의의 하나의 아미노산 서열을 포함하거나, 최대 약 3개의 아미노산에 의해 치환된 변이체를 포함하는 것을 특징으로 하는 다중 특이적 항체. - 제1항 내지 제3항 중 어느 한 항에 있어서, 상기 제1 항체 부분은 기준 항CD137 작제물과 교차 경쟁하여 CD137에 결합되고, 상기 기준 항CD137 항체 부분은 중쇄 가변 영역(VH) 및 경쇄 가변 영역(VL)을 포함하며, 상기 중쇄 가변 영역은 HC-CDR1, HC-CDR2 및 HC-CDR3 도메인을 포함하고, 상기 경쇄 가변 영역은 LC-CDR1, LC-CDR2 및 LC-CDR3 도메인을 포함하며, 상기 중쇄 가변 영역 및 상기 경쇄 가변 영역은,
a) SEQ ID NO: 1의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 2의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 3의 아미노산 서열을 포함하는 HC-CDR3을 포함하는 상기 VH, 및 SEQ ID NO: 4의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 5의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 6의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 상기 VL;
b) SEQ ID NO: 11의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 12의 아미노산 서열을 포함하는HC-CDR2 및 SEQ ID NO: 13의 아미노산 서열을 포함하는 HC-CDR3을 포함하는 상기 VH, 및 SEQ ID NO: 14의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 15의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 16의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 상기 VL;
c) SEQ ID NO: 21의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 22의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 23의 아미노산 서열을 포함하는 HC-CDR3을 포함하는 상기 VH, 및 SEQ ID NO: 24의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 25의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 26의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 상기 VL;
d) SEQ ID NO: 31의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 32의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 33의 아미노산 서열을 포함하는 HC-CDR3을 포함하는 상기 VH, 및 SEQ ID NO: 34의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 35의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 36의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 상기 VL;
e) SEQ ID NO: 41의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 42의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 43의 아미노산 서열을 포함하는 HC-CDR3을 포함하는 상기 VH, 및 SEQ ID NO: 44의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 45의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 46의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 상기 VL;
f) SEQ ID NO: 51의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 52의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 53의 아미노산 서열을 포함하는 HC-CDR3을 포함하는 상기 VH, 및 SEQ ID NO: 54의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 55의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 56의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 VL
g) SEQ ID NO: 61의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 62의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 63의 아미노산 서열을 포함하는 HC-CDR3을 포함하는 상기 VH, 및 SEQ ID NO: 64의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 65의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 66의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 상기 VL;
h) SEQ ID NO: 71의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 72의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 73의 아미노산 서열을 포함하는 HC-CDR3을 포함하는 상기 VH, 및 SEQ ID NO: 74의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 75의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 76의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 상기 VL;
i) SEQ ID NO: 81의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 82의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 83의 아미노산 서열을 포함하는 HC-CDR3을 포함하는 상기 VH, 및 SEQ ID NO: 84의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 85의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 86의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 상기 VL;
j) SEQ ID NO: 91의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 92의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 93의 아미노산 서열을 포함하는 HC-CDR3을 포함하는 상기 VH, 및 SEQ ID NO: 94의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 95의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 96의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 상기 VL;
k) SEQ ID NO: 101의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 102의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 103의 아미노산 서열을 포함하는 HC-CDR3을 포함하는 상기 VH, 및 SEQ ID NO: 104의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 105의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 106의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 상기 VL;
l) SEQ ID NO: 111의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 112의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 113의 아미노산 서열을 포함하는 HC-CDR3을 포함하는 상기 VH, 및 SEQ ID NO: 114의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 115의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 116의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 상기 VL;
m) SEQ ID NO: 121의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 122의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 123의 아미노산 서열을 포함하는 HC-CDR3을 포함하는 상기 VH, 및 SEQ ID NO: 124의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 125의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 126의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 상기 VL;
n) SEQ ID NO: 131의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 132의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 133의 아미노산 서열을 포함하는 HC-CDR3을 포함하는 상기 VH, 및 SEQ ID NO: 134의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 135의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 136의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 상기 VL;
o) SEQ ID NO: 261의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 262의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 263의 아미노산 서열을 포함하는 HC-CDR3을 포함하는 상기 VH, 및 SEQ ID NO: 264의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 265의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 266의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 상기 VL; 및
p) SEQ ID NO: 271의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 272의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 273의 아미노산 서열을 포함하는 HC-CDR3을 포함하는 상기 VH, 및 SEQ ID NO: 274의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 275의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 276의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 상기 VL 로 이루어진 군으로부터 선택되는 것을 특징으로 하는 다중 특이적 항체. - 제1항 내지 제4항 중 어느 한 항에 있어서, 상기 제1 항체 부분은 중쇄 가변 영역(VH) 및 경쇄 가변 영역(VL)을 포함하고, 상기 중쇄 가변 영역은 HC-CDR1, HC-CDR2, 및 HC-CDR3 도메인을 포함하며, 상기 경쇄 가변 영역은 LC-CDR1, LC-CDR2, 및 LC-CDR3 도메인을 포함하고, 상기 VH 및 상기 VL 은,
a) SEQ ID NO: 1의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 2의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 3의 아미노산 서열을 포함하는 VH-CDR3을 포함하는 상기 VH, 및 SEQ ID NO: 4의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 5의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 6의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 상기 VL;
b) SEQ ID NO: 11의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 12의 아미노산 서열을 포함하는HC-CDR2 및 SEQ ID NO: 13의 아미노산 서열을 포함하는 HC-CDR3을 포함하는 상기 VH, 및 SEQ ID NO: 14의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 15의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 16의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 상기 VL;
c) SEQ ID NO: 21의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 22의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 23의 아미노산 서열을 포함하는 HC-CDR3을 포함하는 상기 VH, 및 SEQ ID NO: 24의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 25의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 26의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 상기 VL;
d) SEQ ID NO: 31의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 32의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 33의 아미노산 서열을 포함하는 HC-CDR3을 포함하는 상기 VH, 및 SEQ ID NO: 34의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 35의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 36의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 상기 VL;
e) SEQ ID NO: 41의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 42의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 43의 아미노산 서열을 포함하는 HC-CDR3을 포함하는 상기 VH, 및 SEQ ID NO: 44의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 45의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 46의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 상기 VL;
f) SEQ ID NO: 51의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 52의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 53의 아미노산 서열을 포함하는 HC-CDR3을 포함하는 상기 VH, 및 SEQ ID NO: 54의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 55의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 56의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 상기 VL;
g) SEQ ID NO: 61의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 62의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 63의 아미노산 서열을 포함하는 HC-CDR3을 포함하는 상기 VH, 및 SEQ ID NO: 64의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 65의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 66의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 상기 VL;
h) SEQ ID NO: 71의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 72의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 73의 아미노산 서열을 포함하는 HC-CDR3을 포함하는 상기 VH, 및 SEQ ID NO: 74의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 75의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 76의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 상기 VL;
i) SEQ ID NO: 81의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 82의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 83의 아미노산 서열을 포함하는 HC-CDR3을 포함하는 상기 VH, 및 SEQ ID NO: 84의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 85의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 86의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 상기 VL;
j) SEQ ID NO: 91의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 92의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 93의 아미노산 서열을 포함하는 HC-CDR3을 포함하는 상기 VH, 및 SEQ ID NO: 94의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 95의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 96의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 상기 VL;
k) SEQ ID NO: 101의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 102의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 103의 아미노산 서열을 포함하는 HC-CDR3을 포함하는 상기 VH, 및 SEQ ID NO: 104의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 105의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 106의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 상기 VL;
l) SEQ ID NO: 111의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 112의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 113의 아미노산 서열을 포함하는 HC-CDR3을 포함하는 상기 VH, 및 SEQ ID NO: 114의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 115의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 116의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 상기 VL;
m) SEQ ID NO: 121의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 122의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 123의 아미노산 서열을 포함하는 HC-CDR3을 포함하는 상기 VH, 및 SEQ ID NO: 124의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 125의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 126의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 상기 VL;
n) SEQ ID NO: 131의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 132의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 133의 아미노산 서열을 포함하는 HC-CDR3을 포함하는 상기 VH, 및 SEQ ID NO: 134의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 135의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 136의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 상기 VL;
o) SEQ ID NO: 261의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 262의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 263의 아미노산 서열을 포함하는 HC-CDR3을 포함하는 상기 VH, 및 SEQ ID NO: 264의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 265의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 266의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 상기 VL; 및
p) SEQ ID NO: 271의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 272의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 273의 아미노산 서열을 포함하는 HC-CDR3을 포함하는 상기 VH, 및 SEQ ID NO: 274의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 275의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 276의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 상기 VL 로 이루어진 군으로부터 선택되는 것을 특징으로 하는 다중 특이적 항체. - 제1항 내지 제5항 중 어느 한 항에 있어서, 상기 제1 항체 부분은 중쇄 가변 영역(VH); 및 경쇄 가변 영역(VL)을 포함하고, 상기 중쇄 가변 영역(VH)은 HC-CDR1, HC-CDR2 및 HC-CDR3 도메인을 포함하며, 상기 경쇄 가변 영역(VL)은 LC-CDR1, LC-CDR2 및 LC-CDR3 도메인을 포함하고, 상기 VH은 SEQ ID NO: 1의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 2의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 3의 아미노산 서열을 포함하는 HC-CDR3을 포함하며, 상기 VL은 SEQ ID NO: 4의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 5의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 6의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 것을 특징으로 하는 다중 특이적 항체.
- 제1항 내지 제5항 중 어느 한 항에 있어서, 상기 제1 항체 부분은 중쇄 가변 영역(VH); 및 경쇄 가변 영역(VL)을 포함하고, 상기 중쇄 가변 영역(VH)은 HC-CDR1, HC-CDR2 및 HC-CDR3 도메인을 포함하며, 상기 경쇄 가변 영역(VL)은 LC-CDR1, LC-CDR2 및 LC-CDR3 도메인을 포함하고, 상기 VH은 SEQ ID NO: 11의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 12의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 13의 아미노산 서열을 포함하는 HC-CDR3을 포함하며, 상기 VL은 SEQ ID NO: 14의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 15의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 16의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 것을 특징으로 하는 다중 특이적 항체.
- 제1항 내지 제5항 중 어느 한 항에 있어서, 상기 제1 항체 부분은 중쇄 가변 영역(VH); 및 경쇄 가변 영역(VL)을 포함하고, 상기 중쇄 가변 영역(VH)은 HC-CDR1, HC-CDR2 및 HC-CDR3 도메인을 포함하며, 상기 경쇄 가변 영역(VL)은 LC-CDR1, LC-CDR2 및 LC-CDR3 도메인을 포함하고, 상기 VH은 SEQ ID NO: 21의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 22의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 23의 아미노산 서열을 포함하는 HC-CDR3을 포함하며, 상기 VL은 SEQ ID NO: 24의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 25의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 26의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 것을 특징으로 하는 다중 특이적 항체.
- 제1항 내지 제5항 중 어느 한 항에 있어서, 상기 제1 항체 부분은 중쇄 가변 영역(VH); 및 경쇄 가변 영역(VL)을 포함하고, 상기 중쇄 가변 영역(VH)은 HC-CDR1, HC-CDR2 및 HC-CDR3 도메인을 포함하며, 상기 경쇄 가변 영역(VL)은 LC-CDR1, LC-CDR2 및 LC-CDR3 도메인을 포함하고, 상기 VH은 SEQ ID NO: 31의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 32의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 33의 아미노산 서열을 포함하는 HC-CDR3을 포함하며, 상기 VL은 SEQ ID NO: 34의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 35의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 36의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 것을 특징으로 하는 다중 특이적 항체.
- 제1항 내지 제5항 중 어느 한 항에 있어서, 상기 제1 항체 부분은 중쇄 가변 영역(VH); 및 경쇄 가변 영역(VL)을 포함하고, 상기 중쇄 가변 영역(VH)은 HC-CDR1, HC-CDR2 및 HC-CDR3 도메인을 포함하며, 상기 경쇄 가변 영역(VL)은 LC-CDR1, LC-CDR2 및 LC-CDR3 도메인을 포함하고, 상기 VH은 SEQ ID NO: 41의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 42의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 43의 아미노산 서열을 포함하는 HC-CDR3을 포함하며, 상기 VL은 SEQ ID NO: 44의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 45의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 46의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 것을 특징으로 하는 다중 특이적 항체.
- 제1항 내지 제5항 중 어느 한 항에 있어서, 상기 제1 항체 부분은 중쇄 가변 영역(VH); 및 경쇄 가변 영역(VL)을 포함하고, 상기 중쇄 가변 영역(VH)은 HC-CDR1, HC-CDR2 및 HC-CDR3 도메인을 포함하며, 상기 경쇄 가변 영역(VL)은 LC-CDR1, LC-CDR2 및 LC-CDR3 도메인을 포함하고, 상기 VH은 SEQ ID NO: 51의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 52의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 53의 아미노산 서열을 포함하는 HC-CDR3을 포함하며, 상기 VL은 SEQ ID NO: 54의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 55의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 56의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 것을 특징으로 하는 다중 특이적 항체.
- 제1항 내지 제5항 중 어느 한 항에 있어서, 상기 제1 항체 부분은 중쇄 가변 영역(VH); 및 경쇄 가변 영역(VL)을 포함하고, 상기 중쇄 가변 영역(VH)은 HC-CDR1, HC-CDR2 및 HC-CDR3 도메인을 포함하며, 상기 경쇄 가변 영역(VL)은 LC-CDR1, LC-CDR2 및 LC-CDR3 도메인을 포함하고, 상기 VH은 SEQ ID NO: 61의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 62의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 63의 아미노산 서열을 포함하는 HC-CDR3을 포함하며, 상기 VL은 SEQ ID NO: 64의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 65의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 66의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 것을 특징으로 하는 다중 특이적 항체.
- 제1항 내지 제5항 중 어느 한 항에 있어서, 상기 제1 항체 부분은 중쇄 가변 영역(VH); 및 경쇄 가변 영역(VL)을 포함하고, 상기 중쇄 가변 영역(VH)은 HC-CDR1, HC-CDR2 및 HC-CDR3 도메인을 포함하며, 상기 경쇄 가변 영역(VL)은 LC-CDR1, LC-CDR2 및 LC-CDR3 도메인을 포함하고, 상기 VH은 SEQ ID NO: 71의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 72의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 73의 아미노산 서열을 포함하는 HC-CDR3을 포함하며, 상기 VL은 SEQ ID NO: 74의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 75의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 76의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 것을 특징으로 하는 다중 특이적 항체.
- 제1항 내지 제5항 중 어느 한 항에 있어서, 상기 제1 항체 부분은 중쇄 가변 영역(VH); 및 경쇄 가변 영역(VL)을 포함하고, 상기 중쇄 가변 영역(VH)은 HC-CDR1, HC-CDR2 및 HC-CDR3 도메인을 포함하며, 상기 경쇄 가변 영역(VL)은 LC-CDR1, LC-CDR2 및 LC-CDR3 도메인을 포함하고, 상기 VH은 SEQ ID NO: 81의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 82의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 83의 아미노산 서열을 포함하는 HC-CDR3을 포함하며, 상기 VL은 SEQ ID NO: 84의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 85의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 86의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 것을 특징으로 하는 다중 특이적 항체.
- 제1항 내지 제5항 중 어느 한 항에 있어서, 상기 제1 항체 부분은 중쇄 가변 영역(VH); 및 경쇄 가변 영역(VL)을 포함하고, 상기 중쇄 가변 영역(VH)은 HC-CDR1, HC-CDR2 및 HC-CDR3 도메인을 포함하며, 상기 경쇄 가변 영역(VL)은 LC-CDR1, LC-CDR2 및 LC-CDR3 도메인을 포함하고, 상기 VH은 SEQ ID NO: 91의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 92의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 93의 아미노산 서열을 포함하는 HC-CDR3을 포함하며, 상기 VL은 SEQ ID NO: 94의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 95의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 96의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 것을 특징으로 하는 다중 특이적 항체.
- 제1항 내지 제5항 중 어느 한 항에 있어서, 상기 제1 항체 부분은 중쇄 가변 영역(VH); 및 경쇄 가변 영역(VL)을 포함하고, 상기 중쇄 가변 영역(VH)은 HC-CDR1, HC-CDR2 및 HC-CDR3 도메인을 포함하며, 상기 경쇄 가변 영역(VL)은 LC-CDR1, LC-CDR2 및 LC-CDR3 도메인을 포함하고, 상기 VH은 SEQ ID NO: 101의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 102의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 103의 아미노산 서열을 포함하는 HC-CDR3을 포함하며, 상기 VL은 SEQ ID NO: 104의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 105의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 106의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 것을 특징으로 하는 다중 특이적 항체.
- 제1항 내지 제5항 중 어느 한 항에 있어서, 상기 제1 항체 부분은 중쇄 가변 영역(VH); 및 경쇄 가변 영역(VL)을 포함하고, 상기 중쇄 가변 영역(VH)은 HC-CDR1, HC-CDR2 및 HC-CDR3 도메인을 포함하며, 상기 경쇄 가변 영역(VL)은 LC-CDR1, LC-CDR2 및 LC-CDR3 도메인을 포함하고, 상기 VH은 SEQ ID NO: 111의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 112의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 113의 아미노산 서열을 포함하는 HC-CDR3을 포함하며, 상기 VL은 SEQ ID NO: 114의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 115의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 116의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 것을 특징으로 하는 다중 특이적 항체.
- 제1항 내지 제5항 중 어느 한 항에 있어서, 상기 제1 항체 부분은 중쇄 가변 영역(VH); 및 경쇄 가변 영역(VL)을 포함하고, 상기 중쇄 가변 영역(VH)은 HC-CDR1, HC-CDR2 및 HC-CDR3 도메인을 포함하며, 상기 경쇄 가변 영역(VL)은 LC-CDR1, LC-CDR2 및 LC-CDR3 도메인을 포함하고, 상기 VH은 SEQ ID NO: 121의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 122의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 123의 아미노산 서열을 포함하는 HC-CDR3을 포함하며, 상기 VL은 SEQ ID NO: 124의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 125의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 126의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 것을 특징으로 하는 다중 특이적 항체.
- 제1항 내지 제5항 중 어느 한 항에 있어서, 상기 제1 항체 부분은 중쇄 가변 영역(VH); 및 경쇄 가변 영역(VL)을 포함하고, 상기 중쇄 가변 영역(VH)은 HC-CDR1, HC-CDR2 및 HC-CDR3 도메인을 포함하며, 상기 경쇄 가변 영역(VL)은 LC-CDR1, LC-CDR2 및 LC-CDR3 도메인을 포함하고, 상기 VH은 SEQ ID NO: 131의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 132의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 133의 아미노산 서열을 포함하는 HC-CDR3을 포함하며, 상기 VL은 SEQ ID NO: 134의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 135의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 136의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 것을 특징으로 하는 다중 특이적 항체.
- 제1항 내지 제5항 중 어느 한 항에 있어서, 상기 제1 항체 부분은 중쇄 가변 영역(VH); 및 경쇄 가변 영역(VL)을 포함하고, 상기 중쇄 가변 영역(VH)은 HC-CDR1, HC-CDR2 및 HC-CDR3 도메인을 포함하며, 상기 경쇄 가변 영역(VL)은 LC-CDR1, LC-CDR2 및 LC-CDR3 도메인을 포함하고, 상기 VH은 SEQ ID NO: 141의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 142의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 143의 아미노산 서열을 포함하는 HC-CDR3을 포함하며, 상기 VL은 SEQ ID NO: 144의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 145의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 146의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 것을 특징으로 하는 다중 특이적 항체.
- 제1항 내지 제5항 중 어느 한 항에 있어서, 상기 제1 항체 부분은 중쇄 가변 영역(VH); 및 경쇄 가변 영역(VL)을 포함하고, 상기 중쇄 가변 영역(VH)은 HC-CDR1, HC-CDR2 및 HC-CDR3 도메인을 포함하며, 상기 경쇄 가변 영역(VL)은 LC-CDR1, LC-CDR2 및 LC-CDR3 도메인을 포함하고, 상기 VH은 SEQ ID NO: 261의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 262의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 263의 아미노산 서열을 포함하는 HC-CDR3을 포함하며, 상기 VL은 SEQ ID NO: 264의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 265의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 266의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 것을 특징으로 하는 다중 특이적 항체.
- 제1항 내지 제5항 중 어느 한 항에 있어서, 상기 제1 항체 부분은 중쇄 가변 영역(VH); 및 경쇄 가변 영역(VL)을 포함하고, 상기 중쇄 가변 영역(VH)은 HC-CDR1, HC-CDR2 및 HC-CDR3 도메인을 포함하며, 상기 경쇄 가변 영역(VL)은 LC-CDR1, LC-CDR2 및 LC-CDR3 도메인을 포함하고, 상기 VH은 SEQ ID NO: 271의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 272의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 273의 아미노산 서열을 포함하는 HC-CDR3을 포함하며, 상기 VL은 SEQ ID NO: 274의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 275의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 276의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 것을 특징으로 하는 다중 특이적 항체.
- 제1항 내지 제22항 중 어느 한 항에 있어서, 상기 제1 항체 부분은,
a) SEQ ID NO: 7로 표시되는 서열을 갖는 VH쇄 영역 내의 CDR1, CDR2 및 CDR3의 아미노산 서열을 각각 포함하는 HC-CDR1, HC-CDR2 및 HC-CDR3; 및 SEQ ID NO: 8로 표시되는 서열을 갖는 VL쇄 영역 내의 CDR1, CDR2 및 CDR3의 아미노산 서열을 각각 포함하는 LC-CDR1, LC-CDR2 및 LC-CDR3;
b) SEQ ID NO: 17로 표시되는 서열을 갖는 VH쇄 영역 내의 CDR1, CDR2 및 CDR3의 아미노산 서열을 각각 포함하는 HC-CDR1, HC-CDR2 및 HC-CDR3; 및 SEQ ID NO: 18로 표시되는 서열을 갖는 VL쇄 영역 내의 CDR1, CDR2 및 CDR3의 아미노산 서열을 각각 포함하는 LC-CDR1, LC-CDR2 및 LC-CDR3;
c) SEQ ID NO: 27로 표시되는 서열을 갖는 VH쇄 영역 내의 CDR1, CDR2 및 CDR3의 아미노산 서열을 각각 포함하는 HC-CDR1, HC-CDR2 및 HC-CDR3; 및 SEQ ID NO: 28로 표시되는 서열을 갖는 VL쇄 영역 내의 CDR1, CDR2 및 CDR3의 아미노산 서열을 각각 포함하는 LC-CDR1, LC-CDR2 및 LC-CDR3;
d) SEQ ID NO: 37로 표시되는 서열을 갖는 VH쇄 영역 내의 CDR1, CDR2 및 CDR3의 아미노산 서열을 각각 포함하는 HC-CDR1, HC-CDR2 및 HC-CDR3; 및 SEQ ID NO: 38로 표시되는 서열을 갖는 VL쇄 영역 내의 CDR1, CDR2 및 CDR3의 아미노산 서열을 각각 포함하는 LC-CDR1, LC-CDR2 및 LC-CDR3;
e) SEQ ID NO: 47로 표시되는 서열을 갖는 VH쇄 영역 내의 CDR1, CDR2 및 CDR3의 아미노산 서열을 각각 포함하는 HC-CDR1, HC-CDR2 및 HC-CDR3; 및 SEQ ID NO: 48로 표시되는 서열을 갖는 VL쇄 영역 내의 CDR1, CDR2 및 CDR3의 아미노산 서열을 각각 포함하는 LC-CDR1, LC-CDR2 및 LC-CDR3;
f) SEQ ID NO: 57로 표시되는 서열을 갖는 VH쇄 영역 내의 CDR1, CDR2 및 CDR3의 아미노산 서열을 각각 포함하는 HC-CDR1, HC-CDR2 및 HC-CDR3; 및 SEQ ID NO: 58로 표시되는 서열을 갖는 VL쇄 영역 내의 CDR1, CDR2 및 CDR3의 아미노산 서열을 각각 포함하는 LC-CDR1, LC-CDR2 및 LC-CDR3;
g) SEQ ID NO: 67로 표시되는 서열을 갖는 VH쇄 영역 내의 CDR1, CDR2 및 CDR3의 아미노산 서열을 각각 포함하는 HC-CDR1, HC-CDR2 및 HC-CDR3; 및 SEQ ID NO: 68로 표시되는 서열을 갖는 VL쇄 영역 내의 CDR1, CDR2 및 CDR3의 아미노산 서열을 각각 포함하는 LC-CDR1, LC-CDR2 및 LC-CDR3;
h) SEQ ID NO: 77로 표시되는 서열을 갖는 VH쇄 영역 내의 CDR1, CDR2 및 CDR3의 아미노산 서열을 각각 포함하는 HC-CDR1, HC-CDR2 및 HC-CDR3; 및 SEQ ID NO: 78로 표시되는 서열을 갖는 VL쇄 영역 내의 CDR1, CDR2 및 CDR3의 아미노산 서열을 각각 포함하는 LC-CDR1, LC-CDR2 및 LC-CDR3;
i) SEQ ID NO: 87로 표시되는 서열을 갖는 VH쇄 영역 내의 CDR1, CDR2 및 CDR3의 아미노산 서열을 각각 포함하는 HC-CDR1, HC-CDR2 및 HC-CDR3; 및 SEQ ID NO: 88로 표시되는 서열을 갖는 VL쇄 영역 내의 CDR1, CDR2 및 CDR3의 아미노산 서열을 각각 포함하는 LC-CDR1, LC-CDR2 및 LC-CDR3;
j) SEQ ID NO: 97로 표시되는 서열을 갖는 VH쇄 영역 내의 CDR1, CDR2 및 CDR3의 아미노산 서열을 각각 포함하는 HC-CDR1, HC-CDR2 및 HC-CDR3; 및 SEQ ID NO: 98로 표시되는 서열을 갖는 VL쇄 영역 내의 CDR1, CDR2 및 CDR3의 아미노산 서열을 각각 포함하는 LC-CDR1, LC-CDR2 및 LC-CDR3;
k) SEQ ID NO: 107로 표시되는 서열을 갖는 VH쇄 영역 내의 CDR1, CDR2 및 CDR3의 아미노산 서열을 각각 포함하는 HC-CDR1, HC-CDR2 및 HC-CDR3; 및 SEQ ID NO: 108로 표시되는 서열을 갖는 VL쇄 영역 내의 CDR1, CDR2 및 CDR3의 아미노산 서열을 각각 포함하는 LC-CDR1, LC-CDR2 및 LC-CDR3;
l) SEQ ID NO: 117로 표시되는 서열을 갖는 VH쇄 영역 내의 CDR1, CDR2 및 CDR3의 아미노산 서열을 각각 포함하는 HC-CDR1, HC-CDR2 및 HC-CDR3; 및 SEQ ID NO: 118로 표시되는 서열을 갖는 VL쇄 영역 내의 CDR1, CDR2 및 CDR3의 아미노산 서열을 각각 포함하는 LC-CDR1, LC-CDR2 및 LC-CDR3;
m) SEQ ID NO: 127로 표시되는 서열을 갖는 VH쇄 영역 내의 CDR1, CDR2 및 CDR3의 아미노산 서열을 각각 포함하는 HC-CDR1, HC-CDR2 및 HC-CDR3; 및 SEQ ID NO: 128로 표시되는 서열을 갖는 VL쇄 영역 내의 CDR1, CDR2 및 CDR3의 아미노산 서열을 각각 포함하는 LC-CDR1, LC-CDR2 및 LC-CDR3;
n) SEQ ID NO: 137로 표시되는 서열을 갖는 VH쇄 영역 내의 CDR1, CDR2 및 CDR3의 아미노산 서열을 각각 포함하는 HC-CDR1, HC-CDR2 및 HC-CDR3; 및 SEQ ID NO: 138로 표시되는 서열을 갖는 VL쇄 영역 내의 CDR1, CDR2 및 CDR3의 아미노산 서열을 각각 포함하는 LC-CDR1, LC-CDR2 및 LC-CDR3;
o) SEQ ID NO: 267로 표시되는 서열을 갖는 VH쇄 영역 내의 CDR1, CDR2 및 CDR3의 아미노산 서열을 각각 포함하는 HC-CDR1, HC-CDR2 및 HC-CDR3; 및 SEQ ID NO: 268로 표시되는 서열을 갖는 VL쇄 영역 내의 CDR1, CDR2 및 CDR3의 아미노산 서열을 각각 포함하는 LC-CDR1, LC-CDR2 및 LC-CDR3; 또는
p) SEQ ID NO: 277로 표시되는 서열을 갖는 VH쇄 영역 내의 CDR1, CDR2 및 CDR3의 아미노산 서열을 각각 포함하는 HC-CDR1, HC-CDR2 및 HC-CDR3; 및 SEQ ID NO: 278로 표시되는 서열을 갖는 VL쇄 영역 내의 CDR1, CDR2 및 CDR3의 아미노산 서열을 각각 포함하는 LC-CDR1, LC-CDR2 및 LC-CDR3;을 포함하는 것을 특징으로 하는 다중 특이적 항체. - 제1항 내지 제23항 중 어느 한 항에 있어서, 상기 제1 항체 부분은,
(a) SEQ ID NO: 7로 표시되는 서열을 갖는 아미노산을 포함하는 중쇄 가변 영역; 및 SEQ ID NO: 8로 표시되는 서열을 갖는 아미노산을 포함하는 경쇄 가변 영역;
(b) SEQ ID NO: 17로 표시되는 서열을 갖는 아미노산을 포함하는 중쇄 가변 영역; 및 SEQ ID NO: 18로 표시되는 서열을 갖는 아미노산을 포함하는 경쇄 가변 영역;
(c) SEQ ID NO: 27로 표시되는 서열을 갖는 아미노산을 포함하는 중쇄 가변 영역; 및 SEQ ID NO: 28로 표시되는 서열을 갖는 아미노산을 포함하는 경쇄 가변 영역;
(d) SEQ ID NO: 37로 표시되는 서열을 갖는 아미노산을 포함하는 중쇄 가변 영역; 및 SEQ ID NO: 38로 표시되는 서열을 갖는 아미노산을 포함하는 경쇄 가변 영역;
(e) SEQ ID NO: 47로 표시되는 서열을 갖는 아미노산을 포함하는 중쇄 가변 영역; 및 SEQ ID NO: 48로 표시되는 서열을 갖는 아미노산을 포함하는 경쇄 가변 영역;
(f) SEQ ID NO: 57로 표시되는 서열을 갖는 아미노산을 포함하는 중쇄 가변 영역; 및 SEQ ID NO: 58로 표시되는 서열을 갖는 아미노산을 포함하는 경쇄 가변 영역;
(g) SEQ ID NO: 67로 표시되는 서열을 갖는 아미노산을 포함하는 중쇄 가변 영역; 및 SEQ ID NO: 68로 표시되는 서열을 갖는 아미노산을 포함하는 경쇄 가변 영역;
(h) SEQ ID NO: 77로 표시되는 서열을 갖는 아미노산을 포함하는 중쇄 가변 영역; 및 SEQ ID NO: 78로 표시되는 서열을 갖는 아미노산을 포함하는 경쇄 가변 영역;
(i) SEQ ID NO: 87로 표시되는 서열을 갖는 아미노산을 포함하는 중쇄 가변 영역; 및 SEQ ID NO: 88로 표시되는 서열을 갖는 아미노산을 포함하는 경쇄 가변 영역;
(j) SEQ ID NO: 97로 표시되는 서열을 갖는 아미노산을 포함하는 중쇄 가변 영역; 및 SEQ ID NO: 98로 표시되는 서열을 갖는 아미노산을 포함하는 경쇄 가변 영역;
(k) SEQ ID NO: 107로 표시되는 서열을 갖는 아미노산을 포함하는 중쇄 가변 영역; 및 SEQ ID NO: 108로 표시되는 서열을 갖는 아미노산을 포함하는 경쇄 가변 영역;
(l) SEQ ID NO: 117로 표시되는 서열을 갖는 아미노산을 포함하는 중쇄 가변 영역; 및 SEQ ID NO: 118로 표시되는 서열을 갖는 아미노산을 포함하는 경쇄 가변 영역;
(m) SEQ ID NO: 127로 표시되는 서열을 갖는 아미노산을 포함하는 중쇄 가변 영역; 및 SEQ ID NO: 128로 표시되는 서열을 갖는 아미노산을 포함하는 경쇄 가변 영역;
(n) SEQ ID NO: 137로 표시되는 서열을 갖는 아미노산을 포함하는 중쇄 가변 영역; 및 SEQ ID NO: 138로 표시되는 서열을 갖는 아미노산을 포함하는 경쇄 가변 영역;
(o) SEQ ID NO: 267로 표시되는 서열을 갖는 아미노산을 포함하는 중쇄 가변 영역; 및 SEQ ID NO: 268로 표시되는 서열을 갖는 아미노산을 포함하는 경쇄 가변 영역; 또는
(p) SEQ ID NO: 277로 표시되는 서열을 갖는 아미노산을 포함하는 중쇄 가변 영역; 및 SEQ ID NO: 278로 표시되는 서열을 갖는 아미노산을 포함하는 경쇄 가변 영역; 을 포함하는 것을 특징으로 하는 다중 특이적 항체. - 제1항 내지 제24항 중 어느 한 항에 있어서, 상기 제1 항체 부분은 중쇄 가변 영역(VH) 및 경쇄 가변 영역(VL)을 포함하고,
a) 상기 VH는,
i) SEQ ID NO: 151-153 중의 임의의 하나의 아미노산 서열을 포함하거나, 최대 약 3개의 아미노산에 의해 치환된 변이체를 포함하는 HC-CDR1;
ii) SEQ ID NO: 154-156 중의 임의의 하나의 아미노산 서열을 포함하거나, 최대 약 3개의 아미노산에 의해 치환된 변이체를 포함하는 HC-CDR2;
iii) SEQ ID NO: 157-159 중의 임의의 하나의 아미노산 서열을 포함하거나, 최대 약 3개의 아미노산에 의해 치환된 변이체를 포함하는 HC-CDR3;을 포함하고,
b) 상기 VL는,
i) SEQ ID NO: 160-163 중의 임의의 하나의 아미노산 서열을 포함하거나, 최대 약 3개의 아미노산에 의해 치환된 변이체를 포함하는 LC-CDR1;
ii) SEQ ID NO: 164-166 중의 임의의 하나의 아미노산 서열을 포함하거나, 최대 약 3개의 아미노산에 의해 치환된 변이체를 포함하는 LC-CDR2;
iii) SEQ ID NO: 167-169 중의 임의의 하나의 아미노산 서열을 포함하거나, 최대 약 3개의 아미노산에 의해 치환된 변이체를 포함하는 LC-CDR3;을 포함하는 것을 특징으로 하는 다중 특이적 항체. - 제1항 내지 제25항 중 어느 한 항에 있어서, 상기 제1 항체 부분은 중쇄 가변 영역(VH) 및 경쇄 가변 영역(VL)을 포함하고,
a) 상기 VH는 SEQ ID NO: 151의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 154의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 157의 아미노산 서열을 포함하는 HC-CDR3을 포함하며, 상기 VL은 SEQ ID NO: 160의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 164의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 167의 아미노산 서열을 포함하는 LC-CDR3을 포함하고;
b) 상기 VH는 SEQ ID NO: 151의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 154의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 157의 아미노산 서열을 포함하는 HC-CDR3을 포함하며, 상기 VL은 SEQ ID NO: 162의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 166의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 169의 아미노산 서열을 포함하는 LC-CDR3을 포함하고;
c) 상기 VH는 SEQ ID NO: 152의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 155의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 158의 아미노산 서열을 포함하는 HC-CDR3을 포함하며, 상기 VL은 SEQ ID NO: 163의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 166의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 169의 아미노산 서열을 포함하는 LC-CDR3을 포함하고;
d) 상기 VH는 SEQ ID NO: 153의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 156의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 159의 아미노산 서열을 포함하는 HC-CDR3을 포함하며, 상기 VL은 SEQ ID NO: 160의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 164의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 167의 아미노산 서열을 포함하는 LC-CDR3을 포함하거나; 또는
e) 상기 VH는 SEQ ID NO: 153의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 156의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 159의 아미노산 서열을 포함하는 HC-CDR3을 포함하며, 상기 VL은 SEQ ID NO: 161의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 165의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 168의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 것을 특징으로 하는 다중 특이적 항체. - 제1항 내지 제26항 중 어느 한 항에 있어서, 상기 제1 항체 부분은, 전장 항체, 다중 특이적 항체(예를 들어 이중 특이성 항체), 단일쇄Fv(scFv), Fab단편, Fab’단편, F(ab’)2, Fv단편, 이황화 결합이 안정적인 Fv단편(dsFv), (dsFv)2, VHH, Fv-Fc융합체, scFv-Fc융합체, scFv-Fv융합체, 디아바디, 트리바디, 및 테트라바디로 이루어진 군으로부터 선택되는 항체 또는 이의 항원 결합 단편을 포함하는 것을 특징으로 하는 다중 특이적 항체.
- 제1항 내지 제27항 중 어느 한 항에 있어서, 상기 제1 항체 부분은 인간화된 항CD137 전장 항체를 포함하는 것을 특징으로 하는 다중 특이적 항체.
- 제1항 내지 제28항 중 어느 한 항에 있어서, 상기 제1 항체 부분은 인간화된 항CD137 단일쇄 Fv단편(scFv)을 포함하는 것을 특징으로 하는 다중 특이적 항체.
- 제1항 내지 제29항 중 어느 한 항에 있어서, 상기 제1 항체 부분은 CD137작용제 항체인 것을 특징으로 하는 다중 특이적 항체.
- 제1항 내지 제30항 중 어느 한 항에 있어서, 상기 제1 항체 부분은 항CD137 항체 부분을 포함하고, 상기 항CD137 항체 부분은 인간 면역 글로불린의 Fc영역을 포함하는 것을 특징으로 하는 다중 특이적 항체.
- 제31항에 있어서, 상기 Fc영역은, IgG, IgA, IgD, IgE 및 IgM의 Fc영역으로 이루어진 군으로부터 선택되는 것을 특징으로 하는 다중 특이적 항체.
- 제32항에 있어서, 상기 Fc영역은, IgG1, IgG2, IgG3 및 IgG4의 Fc영역으로 이루어진 군으로부터 선택되는 것을 특징으로 하는 다중 특이적 항체.
- 제1항 내지 제33항 중 어느 한 항에 있어서, 상기 제1 항체 부분은 인간CD137 및 유인원CD137에 결합되는 것을 특징으로 하는 다중 특이적 항체.
- 제1항 내지 제34항 중 어느 한 항에 있어서, 상기 제1 항체 부분은 마우스 CD137에 결합되지 않는 것을 특징으로 하는 다중 특이적 항체.
- 제1항 내지 제35항 중 어느 한 항에 있어서,
상기 제1 항체 부분은 중쇄 가변 영역(VH) 및 경쇄 가변 영역(V L)을 포함하는 항CD137 단일쇄 Fv단편을 함유하고,
상기 제2 항체 부분은 EGFR에 결합되고 두 가닥의 항체 중쇄 및 두 가닥의 항체 경쇄를 포함하는 전장 항체를 포함하며, 상기 중쇄는 각각 제2 중쇄 가변영역 (VH-2)을 포함하고, 상기 경쇄는 각각 제2 경쇄 가변영역 (V L-2)을 포함하며,
상기 항CD137 단일쇄 Fv단편은 전장 항체의 중쇄 또는 경쇄 중 적어도 한 가닥에 융합되는 것을 특징으로 하는 다중 특이적 항체. - 제36항에 있어서, 상기 항CD137 단일쇄 Fv단편은 전장 항체의 각 가닥의 중쇄의 C말단에 융합되는 것을 특징으로 하는 다중 특이적 항체.
- 제36항에 있어서, 상기 항CD137 단일쇄 Fv단편은 전장 항체의 각 가닥의 중쇄의 N말단에 융합되는 것을 특징으로 하는 다중 특이적 항체.
- 제36항에 있어서, 상기 항CD137 단일쇄 Fv단편은 전장 항체의 각 가닥의 경쇄의 C말단에 융합되는 것을 특징으로 하는 다중 특이적 항체.
- 제36항에 있어서, 상기 항CD137 단일쇄 Fv단편은 전장 항체의 각 가닥의 경쇄의 N말단에 융합되는 것을 특징으로 하는 다중 특이적 항체.
- 제1항 내지 제40항 중 어느 한 항에 있어서, 상기 항CD137 단일쇄 Fv단편의 VH 및 VL은 제1 펩티드 링커에 의해 융합되는 것을 특징으로 하는 다중 특이적 항체.
- 제41항에 있어서, 상기 제1 펩티드 링커는 약 4개 내지 약 15개의 아미노산을 포함하는 것을 특징으로 하는 다중 특이적 항체.
- 제41항 또는 제42항에 있어서, 상기 제1 펩티드 링커는 링커를 포함하고, 상기 링커는 SEQ ID NO: 232-260 중의 임의의 하나의 서열을 포함하는 것을 특징으로 하는 다중 특이적 항체.
- 제1항 내지 제43항 중 어느 한 항에 있어서, 상기 항CD137 단일쇄 Fv단편은 제2 펩티드 링커에 의해 전장 항체에 융합되는 것을 특징으로 하는 다중 특이적 항체.
- 제44항에 있어서, 상기 제2펩티드 링커는 약 4개 내지 약 15개의 아미노산을 포함하는 것을 특징으로 하는 다중 특이적 항체.
- 제44항 또는 제45항에 있어서, 상기 제2 펩티드 링커는 링커를 포함하고, 상기 링커는 SEQ ID NO: 232-260 중의 임의의 하나의 서열을 포함하는 것을 특징으로 하는 다중 특이적 항체.
- 제1항 내지 제46항 중 어느 한 항에 있어서, 상기 제2 항체 부분은, IgG, IgA, IgD, IgE, IgM으로부터 유래된 Fc영역 및 이의 임의의 조합 및 이형 접합체로부터 선택되는 Fc영역을 포함하는 것을 특징으로 하는 다중 특이적 항체.
- 제47항에 있어서, 상기 Fc영역은 인간 Fc영역을 포함하는 것을 특징으로 하는 다중 특이적 항체.
- 제47항 또는 제48항에 있어서, 상기 Fc영역은 IgG1, IgG2, IgG3, IgG4로부터 유래된 Fc영역 및 이의 임의의 조합 및 이형 접합체로부터 선택되는 것을 특징으로 하는 다중 특이적 항체.
- 제49항에 있어서, 상기 Fc영역은 IgG1 Fc영역을 포함하는 것을 특징으로 하는 다중 특이적 항체.
- 제50항에 있어서, 상기 IgG1 Fc영역은 L234A돌연변이 및 L235A돌연변이를 포함하는 것을 특징으로 하는 다중 특이적 항체.
- 제49항에 있어서, 상기 Fc영역은 IgG4 Fc영역을 포함하는 것을 특징으로 하는 다중 특이적 항체.
- 제52항에 있어서, 상기 IgG4 Fc영역은 F234A돌연변이 및 L235A돌연변이를 포함하는 것을 특징으로 하는 다중 특이적 항체.
- 제52항 또는 제53항에 있어서, 상기 IgG4 Fc영역은 S228P돌연변이를 포함하는 것을 특징으로 하는 다중 특이적 항체.
- 제1항 내지 제54항 중 어느 한 항에 있어서, 상기 EGFR은 인간 EGFR인 것을 특징으로 하는 다중 특이적 항체.
- 제1항 내지 제55항 중 어느 한 항에 있어서, 상기 제2 항체 부분은 EGFR에 결합되고 제3 중쇄 가변영역(VH-3) 및 제3 경쇄 가변영역(V L-3)을 포함하는 항체 또는 항체 단편과 EGFR의 결합 에피토프를 경쟁하는 전장 항체를 포함하고,
a) 상기 V H-3는 SEQ ID NO: 190의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 191의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 192의 아미노산 서열을 포함하는 HC-CDR3을 포함하며; 상기 V L-3는 SEQ ID NO: 193의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 194의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 195의 아미노산 서열을 포함하는 LC-CDR3을 포함하고;
b) 상기 V H-3는 SEQ ID NO: 198의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 199의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 200의 아미노산 서열을 포함하는 HC-CDR3을 포함하며; 상기 V L-3는 SEQ ID NO: 201의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 202의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 203의 아미노산 서열을 포함하는 LC-CDR3을 포함하고;
c) 상기 V H-3는 SEQ ID NO: 206의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 207의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 208의 아미노산 서열을 포함하는 HC-CDR3을 포함하며; 상기 V L-3는 SEQ ID NO: 209의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 210의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 211의 아미노산 서열을 포함하는 LC-CDR3을 포함하고;
d) 상기 V H-3는 SEQ ID NO: 214의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 215의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 216의 아미노산 서열을 포함하는 HC-CDR3을 포함하며; 상기 V L-3는 SEQ ID NO: 217의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 218의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 219의 아미노산 서열을 포함하는 LC-CDR3을 포함하거나; 또는
e) 상기 V H-3는 SEQ ID NO: 222의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 223의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 224의 아미노산 서열을 포함하는 HC-CDR3을 포함하며; 상기 V L-3는 SEQ ID NO: 225의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 226의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 227의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 것을 특징으로 하는 다중 특이적 항체. - 제1항 내지 제56항 중 어느 한 항에 있어서, 상기 제2 항체 부분은 EGFR에 결합되는 전장 항체를 포함하고, 제2 중쇄 가변영역 (VH-2) 및 제2 경쇄 가변영역 (V L-2)을 포함하며,
a) 상기 V H-2는 SEQ ID NO: 190의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 191의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 192의 아미노산 서열을 포함하는 HC-CDR3을 포함하고; 및 b) 상기 V L-2는 SEQ ID NO: 193의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 194의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 195의 아미노산 서열을 포함하는 LC-CDR3을 포함하며;
b) 상기 V H-2는 SEQ ID NO: 198의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 199의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 200의 아미노산 서열을 포함하는 HC-CDR3을 포함하고; 및 b) 상기 V L-2는 SEQ ID NO: 201의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 202의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 203의 아미노산 서열을 포함하는 LC-CDR3을 포함하며;
c) 상기 V H-2는 SEQ ID NO: 206의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 207의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 208의 아미노산 서열을 포함하는 HC-CDR3을 포함하고; 및 b) 상기 V L-2는 SEQ ID NO: 209의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 210의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 211의 아미노산 서열을 포함하는 LC-CDR3을 포함하며;
d) 상기 V H-2는 SEQ ID NO: 214의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 215의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 216의 아미노산 서열을 포함하는 HC-CDR3을 포함하고; 및 b) 상기 V L-2는 SEQ ID NO: 217의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 218의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 219의 아미노산 서열을 포함하는 LC-CDR3을 포함하거나; 또는
e) 상기 V H-2는 SEQ ID NO: 222의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 223의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 224의 아미노산 서열을 포함하는 HC-CDR3을 포함하고; 및 b) V L-2는 SEQ ID NO: 225의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 226의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 227의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 것을 특징으로 하는 다중 특이적 항체. - 제1항 내지 제57항에 있어서, 상기 VH-2는 SEQ ID NO: 190의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 191의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 192의 아미노산 서열을 포함하는 HC-CDR3을 포함하고; 상기 VL-2는 SEQ ID NO: 193의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 194의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 195의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 것을 특징으로 하는 다중 특이적 항체.
- 제1항 내지 제57항에 있어서, 상기 VH-2는 SEQ ID NO: 198의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 199의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 200의 아미노산 서열을 포함하는 HC-CDR3을 포함하고; 상기 VL-2는 SEQ ID NO: 201의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 202의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 203의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 것을 특징으로 하는 다중 특이적 항체.
- 제1항 내지 제57항에 있어서, 상기 VH-2는 SEQ ID NO: 206의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 207의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 208의 아미노산 서열을 포함하는 HC-CDR3을 포함하고; 상기 VL-2는 SEQ ID NO: 209의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 210의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 211의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 것을 특징으로 하는 다중 특이적 항체.
- 제1항 내지 제57항에 있어서, 상기 VH-2는 SEQ ID NO: 214의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 215의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 216의 아미노산 서열을 포함하는 HC-CDR3을 포함하고; 상기 VL-2는 SEQ ID NO: 217의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 218의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 219의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 것을 특징으로 하는 다중 특이적 항체.
- 제1항 내지 제57항에 있어서, 상기 VH-2는 SEQ ID NO: 222의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 223의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 224의 아미노산 서열을 포함하는 HC-CDR3을 포함하고; 상기 VL-2는 SEQ ID NO: 225의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 226의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 227의 아미노산 서열을 포함하는 LC-CDR3을 포함하는 것을 특징으로 하는 다중 특이적 항체.
- 제1항 내지 제62항 중 어느 한 항에 있어서,
a) 상기 VH-2는 SEQ ID NO: 196과 적어도 약 90%의 서열 동일성을 갖는 아미노산 서열을 포함하고; 및/또는 상기 VL-2는 SEQ ID NO: 197과 적어도 약 90%의 서열 동일성을 갖는 아미노산 서열을 포함하며;
b) 상기 VH-2는 SEQ ID NO: 204와 적어도 약 90%의 서열 동일성을 갖는 아미노산 서열을 포함하고; 및/또는 상기 VL-2는 SEQ ID NO: 205와 적어도 약 90%의 서열 동일성을 갖는 아미노산 서열을 포함하며;
c) 상기 VH-2는 SEQ ID NO: 212와 적어도 약 90%의 서열 동일성을 갖는 아미노산 서열을 포함하고; 및/또는 상기 VL-2는 SEQ ID NO: 213과 적어도 약 90%의 서열 동일성을 갖는 아미노산 서열을 포함하며;
d) 상기 VH-2는 SEQ ID NO: 220과 적어도 약 90%의 서열 동일성을 갖는 아미노산 서열을 포함하고; 및/또는 상기 VL-2는 SEQ ID NO: 221과 적어도 약 90%의 서열 동일성을 갖는 아미노산 서열을 포함하거나; 또는
e) 상기 VH-2는 SEQ ID NO: 228과 적어도 약 90%의 서열 동일성을 갖는 아미노산 서열을 포함하고; 및/또는 상기 VL-2는 SEQ ID NO: 229와 적어도 약 90%의 서열 동일성을 갖는 아미노산 서열을 포함하는 것을 특징으로 하는 다중 특이적 항체. - 제1항 내지 제63항 중 어느 한 항에 있어서,
a) 상기 VH-2는 SEQ ID NO: 196의 아미노산 서열을 포함하고; 상기 VL-2는 SEQ ID NO: 197의 아미노산 서열을 포함하며;
b) 상기 VH-2는 SEQ ID NO: 204의 아미노산 서열을 포함하고; 상기 VL-2는 SEQ ID NO: 205의 아미노산 서열을 포함하며;
c) 상기 VH-2는 SEQ ID NO: 212의 아미노산 서열을 포함하고; 상기 VL-2는 SEQ ID NO: 213의 아미노산 서열을 포함하며;
d) 상기 VH-2는 SEQ ID NO: 220의 아미노산 서열을 포함하고; 상기 VL-2는 SEQ ID NO: 221의 아미노산 서열을 포함하거나; 또는
e) 상기 VH-2는 SEQ ID NO: 228의 아미노산 서열을 포함하고; 상기 VL-2는 SEQ ID NO: 229의 아미노산 서열을 포함하는 것을 특징으로 하는 다중 특이적 항체. - 제1항 내지 제64항 중 어느 한 항에 있어서,
a) 상기 제1 항체 부분은 중쇄 가변 영역(VH) 및 경쇄 가변 영역(VL)을 포함하고, 상기 VH는 SEQ ID NO: 121의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 122의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 123의 아미노산 서열을 포함하는 HC-CDR3을 포함하며; 상기 VL는 SEQ ID NO: 124의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 125의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 126의 아미노산 서열을 포함하는 LC-CDR3을 포함하고;
b) 상기 제2 항체 부분은 제2 중쇄 가변영역 (VH-2) 및 제2 경쇄 가변영역 (V L-2)을 포함하며, 상기 VH-2는 SEQ ID NO: 206의 아미노산 서열을 포함하는 제2 HC-CDR1, SEQ ID NO: 207의 아미노산 서열을 포함하는 제2 HC-CDR2 및 SEQ ID NO: 208의 아미노산 서열을 포함하는 제2 HC-CDR3을 포함하고; 상기 VL-2는 SEQ ID NO: 209의 아미노산 서열을 포함하는 제2 LC-CDR1, SEQ ID NO: 210의 아미노산 서열을 포함하는 제2 LC-CDR2 및 SEQ ID NO: 211의 아미노산 서열을 포함하는 제2 LC-CDR3을 포함하는 것을 특징으로 하는 다중 특이적 항체. - 제1항 내지 제64항 중 어느 한 항에 있어서,
a) 상기 제1 항체 부분은 중쇄 가변 영역(VH) 및 경쇄 가변 영역(VL)을 포함하고, 상기 VH는 SEQ ID NO: 261의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 262의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 263의 아미노산 서열을 포함하는 HC-CDR3을 포함하며; 상기 VL는 SEQ ID NO: 264의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 265의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 266의 아미노산 서열을 포함하는 LC-CDR3을 포함하고;
b) 상기 제2 항체 부분는 제2 중쇄 가변영역 (VH-2) 및 제2 경쇄 가변영역 (V L-2)을 포함하며, 상기 VH-2는 SEQ ID NO: 206의 아미노산 서열을 포함하는 제2 HC-CDR1, SEQ ID NO: 207의 아미노산 서열을 포함하는 제2 HC-CDR2 및 SEQ ID NO: 208의 아미노산 서열을 포함하는 제2 HC-CDR3을 포함하고; 상기 VL-2는 SEQ ID NO: 209의 아미노산 서열을 포함하는 제2 LC-CDR1, SEQ ID NO: 210의 아미노산 서열을 포함하는 제2 LC-CDR2 및 SEQ ID NO: 211의 아미노산 서열을 포함하는 제2 LC-CDR3을 포함하는 것을 특징으로 하는 다중 특이적 항체. - 제1항 내지 제64항 중 어느 한 항에 있어서,
a) 상기 제1 항체 부분은 중쇄 가변 영역(VH) 및 경쇄 가변 영역(VL)을 포함하고, 상기 VH는 SEQ ID NO: 271의 아미노산 서열을 포함하는 HC-CDR1, SEQ ID NO: 272의 아미노산 서열을 포함하는 HC-CDR2 및 SEQ ID NO: 273의 아미노산 서열을 포함하는 HC-CDR3을 포함하며; 상기 VL은 SEQ ID NO: 274의 아미노산 서열을 포함하는 LC-CDR1, SEQ ID NO: 275의 아미노산 서열을 포함하는 LC-CDR2 및 SEQ ID NO: 276의 아미노산 서열을 포함하는 LC-CDR3을 포함하고;
b) 상기 제2 항체 부분은 제2 중쇄 가변영역 (VH-2) 및 제2 경쇄 가변영역 (V L-2)을 포함하며, 상기 VH-2는 SEQ ID NO: 206의 아미노산 서열을 포함하는 제2 HC-CDR1, SEQ ID NO: 207의 아미노산 서열을 포함하는 제2 HC-CDR2 및 SEQ ID NO: 208의 아미노산 서열을 포함하는 제2 HC-CDR3을 포함하고; 상기 VL-2는 SEQ ID NO: 209의 아미노산 서열을 포함하는 제2 LC-CDR1, SEQ ID NO: 210의 아미노산 서열을 포함하는 제2 LC-CDR2 및 SEQ ID NO: 211의 아미노산 서열을 포함하는 제2 LC-CDR3을 포함하는 것을 특징으로 하는 다중 특이적 항체. - 제1항 내지 제67항 중 어느 한 항에 있어서, 상기 항 CD137 단일쇄 Fv 단편은 항EGFR 전장 항체의 중쇄에 융합되고, 항CD137 단일쇄 Fv단편에 융합된 항EGFR 전장 항체의 중쇄는 SEQ ID NO: 183, 185, 188, 189, 230, 231, 259, 260, 281 또는 282 중의 임의의 하나의 아미노산 서열과 적어도 약 90%의 서열 동일성을 갖는 아미노산 서열을 포함하는 것을 특징으로 하는 다중 특이적 항체.
- 제1항 내지 제68항 중 어느 한 항에 있어서, 상기 항 CD137 단일쇄 Fv 단편은 항EGFR 전장 항체의 중쇄에 융합되고, 항CD137 단일쇄 Fv단편에 융합된 항EGFR 전장 항체의 중쇄는 SEQ ID NO: 183, 185, 188, 189, 230, 231, 259, 260, 281 또는 282 중의 임의의 하나의 아미노산 서열을 포함하는 것을 특징으로 하는 다중 특이적 항체.
- 제1항 내지 제69항 중 어느 한 항에 있어서, 상기 항 CD137 단일쇄 Fv 단편은 항EGFR 전장 항체의 중쇄에 융합되고, 항CD137 단일쇄 Fv단편에 융합된 항EGFR 전장 항체의 중쇄는 SEQ ID NO: 183의 아미노산 서열을 포함하는 것을 특징으로 하는 다중 특이적 항체.
- 제1항 내지 제69항 중 어느 한 항에 있어서, 상기 항 CD137 단일쇄 Fv 단편은 항EGFR 전장 항체의 중쇄에 융합되고, 항CD137 단일쇄 Fv단편에 융합된 항EGFR 전장 항체의 중쇄는 SEQ ID NO: 185의 아미노산 서열을 포함하는 것을 특징으로 하는 다중 특이적 항체.
- 제1항 내지 제69항 중 어느 한 항에 있어서, 상기 항 CD137 단일쇄 Fv 단편은 항EGFR 전장 항체의 중쇄에 융합되고, 항CD137 단일쇄 Fv단편에 융합된 항EGFR 전장 항체의 중쇄는 SEQ ID NO: 188의 아미노산 서열을 포함하는 것을 특징으로 하는 다중 특이적 항체.
- 제1항 내지 제69항 중 어느 한 항에 있어서, 상기 항 CD137 단일쇄 Fv 단편은 항EGFR 전장 항체의 중쇄에 융합되고, 항CD137 단일쇄 Fv단편에 융합된 항EGFR 전장 항체의 중쇄는 SEQ ID NO: 189의 아미노산 서열을 포함하는 것을 특징으로 하는 다중 특이적 항체.
- 제1항 내지 제69항 중 어느 한 항에 있어서, 상기 항 CD137 단일쇄 Fv 단편은 항EGFR 전장 항체의 중쇄에 융합되고, 항CD137 단일쇄 Fv단편에 융합된 항EGFR 전장 항체의 중쇄는 SEQ ID NO: 230의 아미노산 서열을 포함하는 것을 특징으로 하는 다중 특이적 항체.
- 제1항 내지 제69항 중 어느 한 항에 있어서, 상기 항 CD137 단일쇄 Fv 단편은 항EGFR 전장 항체의 중쇄에 융합되고, 항CD137 단일쇄 Fv단편에 융합된 항EGFR 전장 항체의 중쇄는 SEQ ID NO: 231의 아미노산 서열을 포함하는 것을 특징으로 하는 다중 특이적 항체.
- 제1항 내지 제69항 중 어느 한 항에 있어서, 상기 항 CD137 단일쇄 Fv 단편은 항EGFR 전장 항체의 중쇄에 융합되고, 항CD137 단일쇄 Fv단편에 융합된 항EGFR 전장 항체의 중쇄는 SEQ ID NO: 259의 아미노산 서열을 포함하는 것을 특징으로 하는 다중 특이적 항체.
- 제1항 내지 제69항 중 어느 한 항에 있어서, 상기 항 CD137 단일쇄 Fv 단편은 항EGFR 전장 항체의 중쇄에 융합되고, 항CD137 단일쇄 Fv단편에 융합된 항EGFR 전장 항체의 중쇄는 SEQ ID NO: 260의 아미노산 서열을 포함하는 것을 특징으로 하는 다중 특이적 항체.
- 제1항 내지 제69항 중 어느 한 항에 있어서, 상기 항 CD137 단일쇄 Fv 단편은 항EGFR 전장 항체의 중쇄에 융합되고, 항CD137 단일쇄 Fv단편에 융합된 항EGFR 전장 항체의 중쇄는 SEQ ID NO: 281의 아미노산 서열을 포함하는 것을 특징으로 하는 다중 특이적 항체.
- 제1항 내지 제69항 중 어느 한 항에 있어서, 상기 항 CD137 단일쇄 Fv 단편은 항EGFR 전장 항체의 중쇄에 융합되고, 항CD137 단일쇄 Fv단편에 융합된 항EGFR 전장 항체의 중쇄는 SEQ ID NO: 282의 아미노산 서열을 포함하는 것을 특징으로 하는 다중 특이적 항체.
- 제1항 내지 제79항 중 어느 한 항에 있어서, 포함된 항EGFR 전장 항체는 SEQ ID NO: 184, 186 또는 187의 아미노산 서열과 적어도 약 90%의 서열 동일성을 갖는 아미노산 서열을 포함하는 경쇄를 함유하는 것을 특징으로 하는 다중 특이적 항체.
- 제1항 내지 제80항 중 어느 한 항에 있어서, 상기 항EGFR 전장 항체는 SEQ ID NO: 184의 아미노산 서열을 포함하는 경쇄를 함유하는 것을 특징으로 하는 다중 특이적 항체.
- 제1항 내지 제80항 중 어느 한 항에 있어서, 상기 항EGFR 전장 항체는 SEQ ID NO: 186의 아미노산 서열을 포함하는 경쇄를 함유하는 것을 특징으로 하는 다중 특이적 항체.
- 제1항 내지 제80항 중 어느 한 항에 있어서, 상기 항EGFR 전장 항체는 SEQ ID NO: 187의 아미노산 서열을 포함하는 경쇄를 함유하는 것을 특징으로 하는 다중 특이적 항체.
- 치료제 또는 표지에 연결된 제1항 내지 제83항 중 어느 한 항에 따른 다중 특이적 항체를 포함하는 것을 특징으로 하는 면역 접합체.
- 제84항에 있어서, 상기 표지는 방사성 동위원소, 형광 염료 및 효소로 이루어진 군으로부터 선택되는 것을 특징으로 하는 면역 접합체.
- 제1항 내지 제80항 중 어느 한 항에 따른 다중 특이적 항체 또는 제84항 또는 제85항에 따른 면역 접합체 및 약학적으로 허용 가능한 담체를 포함하는 것을 특징으로 하는 약물 조성물.
- 제1항 내지 제83항 중 어느 한 항에 따른 다중 특이적 항체를 코딩하는 것을 특징으로 하는 단리된 핵산.
- 제87항에 따른 단리된 핵산을 포함하는 것을 특징으로 하는 벡터.
- 제87항에 따른 단리된 핵산 또는 제88항에 따른 벡터를 포함하는 것을 특징으로 하는 단리된 숙주 세포.
- 다중 특이적 항체를 생산하는 방법에 있어서,
a) 상기 다중 특이적 항체를 효과적으로 발현하는 조건 하에서, 제89항에 따른 단리된 숙주 세포를 배양하는 단계; 및
b) 상기 숙주 세포에서 발현된 다중 특이적 항체를 얻는 단계를 포함하는 것을 특징으로 하는 다중 특이적 항체를 생산하는 방법. - 대상체에 유효량의 제1항 내지 제83항 중 어느 한 항에 따른 다중 특이적 항체, 제84항 또는 제85항에 따른 면역 접합체, 또는 제86항에 따른 약물 조성물을 투여하는 단계를 포함하는 것을 특징으로 하는 대상체 질환을 치료 또는 예방하는 방법.
- 제91항에 있어서, 상기 질환은 암 또는 종양인 것을 특징으로 하는 방법.
- 제92항에 있어서, 상기 암은 유방암, 위암, 난소암, 폐암, 중피종, 자궁내막암, 자궁경부암, 식도암, 방광암, 침샘암, 고환암, 선암, 간암, 췌장암, 결장직장암, 피부암, 흉선암, 부신암, 두경부암, 뇌암, 갑상선암, 육종, 골수종 및 백혈병으로 이루어진 군으로부터 선택되는 것을 특징으로 하는 방법.
- 제92항 또는 제93항에 있어서, 상기 암 또는 종양은 EGFR 양성인 것을 특징으로 하는 방법.
- 제92항 내지 제94항 중 어느 한 항에 있어서, 상기 암은 폐암, 결장직장암 또는 두경부암인 것을 특징으로 하는 방법.
- 제91항 내지 제95항 중 어느 한 항에 있어서, 상기 다중 특이적 항체, 면역 접합체 또는약물 조성물은 상기 대상체에 비경구적으로 투여되는 것을 특징으로 하는 방법.
- 제96항에 있어서, 상기 다중 특이적 항체, 면역 접합체 또는 약물 조성물은 상기 대상체에 정맥내 투여되는 것을 특징으로 하는 방법.
- 제91항 내지 제97항 중 어느 한 항에 있어서, 상기 대상체는 인간인 것을 특징으로 하는 방법.
- 제1항 내지 제83항 중 어느 한 항에 있어서, 약물로서 사용되는 것을 특징으로 하는 다중 특이적 항체.
- 제1항 내지 제83항 중 어느 한 항에 있어서, 암 치료에 사용되는 것을 특징으로 하는 다중 특이적 항체.
- 제100항에 있어서, 상기 암은 유방암, 위암, 난소암, 폐암, 중피종, 자궁내막암, 자궁경부암, 식도암, 방광암, 침샘암, 고환암, 선암, 간암, 췌장암, 결장직장암, 피부암, 흉선암, 부신암, 두경부암, 뇌암, 갑상선 암, 육종, 골수종 및 백혈병으로 이루어진 군으로부터 선택되는 것을 특징으로 하는 다중 특이적 항체.
- 제1항 내지 제83항 중 어느 한 항에 따른 다중 특이적 항체, 제84항 또는 제85항에 따른 면역 접합체, 제86항에 따른 약물 조성물, 제87항에 따른 핵산, 제88항에 따른 벡터 또는 제89항에 따른 숙주 세포를 포함하는 것을 특징으로 하는 키트.
- 제102항에 있어서, 상기 키트는 암 또는 종양을 치료 및/또는 예방하기 위한 서면 명세서를 더 포함하는 것을 특징으로 하는 키트.
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN2020077148 | 2020-02-28 | ||
| CNPCT/CN2020/077148 | 2020-02-28 | ||
| PCT/CN2021/078051 WO2021170068A1 (en) | 2020-02-28 | 2021-02-26 | Anti-cd137 constructs, multispecific antibody and uses thereof |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20220148228A true KR20220148228A (ko) | 2022-11-04 |
Family
ID=77489868
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020227033169A KR20220148228A (ko) | 2020-02-28 | 2021-02-26 | 항cd137 작제물, 다중 특이적 항체 및 그 용도 |
Country Status (9)
| Country | Link |
|---|---|
| US (1) | US20230067770A1 (ko) |
| EP (1) | EP4110827A1 (ko) |
| JP (1) | JP2023516004A (ko) |
| KR (1) | KR20220148228A (ko) |
| CN (1) | CN115190889A (ko) |
| AU (1) | AU2021228077A1 (ko) |
| CA (1) | CA3169943A1 (ko) |
| WO (1) | WO2021170068A1 (ko) |
| ZA (1) | ZA202210626B (ko) |
Families Citing this family (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CA3216342A1 (en) * | 2021-04-23 | 2022-10-27 | Hassan ISSAFRAS | Anti-gpc3 antibodies, multispecific antibodies and methods of use |
| WO2024040194A1 (en) | 2022-08-17 | 2024-02-22 | Capstan Therapeutics, Inc. | Conditioning for in vivo immune cell engineering |
Family Cites Families (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP3613433B1 (en) * | 2014-05-30 | 2022-01-05 | Shanghai Henlius Biotech, Inc. | Anti-epidermal growth factor receptor (egfr) antibodies |
| EP3470428A1 (en) * | 2017-10-10 | 2019-04-17 | Numab Innovation AG | Antibodies targeting cd137 and methods of use thereof |
-
2021
- 2021-02-26 AU AU2021228077A patent/AU2021228077A1/en active Pending
- 2021-02-26 EP EP21761044.3A patent/EP4110827A1/en active Pending
- 2021-02-26 CA CA3169943A patent/CA3169943A1/en active Pending
- 2021-02-26 JP JP2022551742A patent/JP2023516004A/ja active Pending
- 2021-02-26 KR KR1020227033169A patent/KR20220148228A/ko unknown
- 2021-02-26 CN CN202180015561.7A patent/CN115190889A/zh active Pending
- 2021-02-26 WO PCT/CN2021/078051 patent/WO2021170068A1/en unknown
-
2022
- 2022-08-26 US US17/822,737 patent/US20230067770A1/en active Pending
- 2022-09-26 ZA ZA2022/10626A patent/ZA202210626B/en unknown
Also Published As
| Publication number | Publication date |
|---|---|
| CA3169943A1 (en) | 2021-09-02 |
| AU2021228077A1 (en) | 2022-09-22 |
| ZA202210626B (en) | 2023-11-29 |
| US20230067770A1 (en) | 2023-03-02 |
| CN115190889A (zh) | 2022-10-14 |
| EP4110827A1 (en) | 2023-01-04 |
| WO2021170068A1 (en) | 2021-09-02 |
| JP2023516004A (ja) | 2023-04-17 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11613587B2 (en) | Combination therapy of T cell activating bispecific antigen binding molecules and PD-1 axis binding antagonists | |
| KR20220131258A (ko) | 항tigit항체 및 사용 방법 | |
| CN111699200B (zh) | 针对pd-1的单域抗体和其变体 | |
| WO2019096121A1 (en) | Single-domain antibodies and variants thereof against pd-l1 | |
| KR20200055758A (ko) | 신규 항-cd19 항체 | |
| US20230067770A1 (en) | Anti-cd137 constructs, multispecific antibody and uses thereof | |
| US20220403040A1 (en) | Anti-cd137 constructs, multispecific antibody and uses thereof | |
| KR20220131260A (ko) | 항tigit항체, 이를 포함하는 다중 특이적 항체 및 그 사용 방법 | |
| KR20220131261A (ko) | 항tigit항체, 이를 포함하는 다중 특이적 항체 및 그 사용 방법 | |
| US20240076395A1 (en) | Anti-cd137 constructs and uses thereof | |
| TW202302646A (zh) | 抗vista構築體及其用途 | |
| WO2021164701A1 (en) | Fusion proteins and uses thereof | |
| JP2023543031A (ja) | 抗cd93構築物およびその使用 | |
| JP2024511424A (ja) | 抗igfbp7構築物およびその使用 | |
| TW202210515A (zh) | 抗cd39之構築體及其用途 | |
| TW202221029A (zh) | 抗cd93之構築體及其用途 |