CN112638944A - 抗tigit抗体 - Google Patents
抗tigit抗体 Download PDFInfo
- Publication number
- CN112638944A CN112638944A CN201980053349.2A CN201980053349A CN112638944A CN 112638944 A CN112638944 A CN 112638944A CN 201980053349 A CN201980053349 A CN 201980053349A CN 112638944 A CN112638944 A CN 112638944A
- Authority
- CN
- China
- Prior art keywords
- seq
- antibody
- amino acid
- acid sequence
- composition
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
- 230000027455 binding Effects 0.000 claims abstract description 172
- 101000831007 Homo sapiens T-cell immunoreceptor with Ig and ITIM domains Proteins 0.000 claims abstract description 135
- 102000049823 human TIGIT Human genes 0.000 claims abstract description 113
- 241000282414 Homo sapiens Species 0.000 claims abstract description 94
- 102100024834 T-cell immunoreceptor with Ig and ITIM domains Human genes 0.000 claims abstract description 30
- 108010048507 poliovirus receptor Proteins 0.000 claims abstract description 10
- 101710090983 T-cell immunoreceptor with Ig and ITIM domains Proteins 0.000 claims abstract description 9
- 125000003275 alpha amino acid group Chemical group 0.000 claims description 513
- 210000004027 cell Anatomy 0.000 claims description 288
- 239000000203 mixture Substances 0.000 claims description 258
- 206010028980 Neoplasm Diseases 0.000 claims description 150
- 238000000034 method Methods 0.000 claims description 139
- 102100035360 Cerebellar degeneration-related antigen 1 Human genes 0.000 claims description 84
- 239000000427 antigen Substances 0.000 claims description 83
- 108091007433 antigens Proteins 0.000 claims description 83
- 102000036639 antigens Human genes 0.000 claims description 83
- 239000003814 drug Substances 0.000 claims description 78
- 230000014509 gene expression Effects 0.000 claims description 76
- 229940124597 therapeutic agent Drugs 0.000 claims description 70
- 101100112922 Candida albicans CDR3 gene Proteins 0.000 claims description 68
- 102100035361 Cerebellar degeneration-related protein 2 Human genes 0.000 claims description 68
- 101000737793 Homo sapiens Cerebellar degeneration-related antigen 1 Proteins 0.000 claims description 68
- 101000737796 Homo sapiens Cerebellar degeneration-related protein 2 Proteins 0.000 claims description 68
- 210000001744 T-lymphocyte Anatomy 0.000 claims description 66
- 239000012636 effector Substances 0.000 claims description 62
- 239000003795 chemical substances by application Substances 0.000 claims description 60
- 230000004044 response Effects 0.000 claims description 58
- 201000011510 cancer Diseases 0.000 claims description 52
- 230000001965 increasing effect Effects 0.000 claims description 52
- 108090000765 processed proteins & peptides Proteins 0.000 claims description 51
- 108090000623 proteins and genes Proteins 0.000 claims description 47
- 108091033319 polynucleotide Proteins 0.000 claims description 40
- 239000002157 polynucleotide Substances 0.000 claims description 40
- 102000040430 polynucleotide Human genes 0.000 claims description 40
- -1 41BB Proteins 0.000 claims description 35
- 210000003819 peripheral blood mononuclear cell Anatomy 0.000 claims description 35
- 102000004169 proteins and genes Human genes 0.000 claims description 33
- 102000004127 Cytokines Human genes 0.000 claims description 32
- 108090000695 Cytokines Proteins 0.000 claims description 32
- 150000008267 fucoses Chemical class 0.000 claims description 32
- 108060001084 Luciferase Proteins 0.000 claims description 31
- 108700017028 mouse T cell Ig and ITIM domain Proteins 0.000 claims description 31
- 239000002773 nucleotide Substances 0.000 claims description 31
- 125000003729 nucleotide group Chemical group 0.000 claims description 31
- 206010009944 Colon cancer Diseases 0.000 claims description 30
- 101710089372 Programmed cell death protein 1 Proteins 0.000 claims description 30
- 238000004519 manufacturing process Methods 0.000 claims description 30
- 239000005089 Luciferase Substances 0.000 claims description 29
- AOJJSUZBOXZQNB-TZSSRYMLSA-N Doxorubicin Chemical compound O([C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(=O)CO)[C@H]1C[C@H](N)[C@H](O)[C@H](C)O1 AOJJSUZBOXZQNB-TZSSRYMLSA-N 0.000 claims description 28
- 102100040678 Programmed cell death protein 1 Human genes 0.000 claims description 28
- OGWKCGZFUXNPDA-XQKSVPLYSA-N vincristine Chemical compound C([N@]1C[C@@H](C[C@]2(C(=O)OC)C=3C(=CC4=C([C@]56[C@H]([C@@]([C@H](OC(C)=O)[C@]7(CC)C=CCN([C@H]67)CC5)(O)C(=O)OC)N4C=O)C=3)OC)C[C@@](C1)(O)CC)CC1=C2NC2=CC=CC=C12 OGWKCGZFUXNPDA-XQKSVPLYSA-N 0.000 claims description 28
- 239000013598 vector Substances 0.000 claims description 27
- 241000282567 Macaca fascicularis Species 0.000 claims description 26
- 229960004528 vincristine Drugs 0.000 claims description 26
- OGWKCGZFUXNPDA-UHFFFAOYSA-N vincristine Natural products C1C(CC)(O)CC(CC2(C(=O)OC)C=3C(=CC4=C(C56C(C(C(OC(C)=O)C7(CC)C=CCN(C67)CC5)(O)C(=O)OC)N4C=O)C=3)OC)CN1CCC1=C2NC2=CC=CC=C12 OGWKCGZFUXNPDA-UHFFFAOYSA-N 0.000 claims description 26
- 241001465754 Metazoa Species 0.000 claims description 25
- 208000029742 colonic neoplasm Diseases 0.000 claims description 25
- 238000003556 assay Methods 0.000 claims description 24
- 230000009260 cross reactivity Effects 0.000 claims description 24
- 210000002540 macrophage Anatomy 0.000 claims description 24
- 230000015654 memory Effects 0.000 claims description 24
- 210000001616 monocyte Anatomy 0.000 claims description 24
- 102100038077 CD226 antigen Human genes 0.000 claims description 23
- 101000884298 Homo sapiens CD226 antigen Proteins 0.000 claims description 23
- 210000000612 antigen-presenting cell Anatomy 0.000 claims description 22
- 108010002350 Interleukin-2 Proteins 0.000 claims description 20
- 102000000588 Interleukin-2 Human genes 0.000 claims description 20
- 239000003112 inhibitor Substances 0.000 claims description 20
- 239000008194 pharmaceutical composition Substances 0.000 claims description 19
- 230000005888 antibody-dependent cellular phagocytosis Effects 0.000 claims description 17
- 108010021625 Immunoglobulin Fragments Proteins 0.000 claims description 16
- 102000008394 Immunoglobulin Fragments Human genes 0.000 claims description 16
- 125000000539 amino acid group Chemical group 0.000 claims description 16
- 210000003071 memory t lymphocyte Anatomy 0.000 claims description 16
- 108010074708 B7-H1 Antigen Proteins 0.000 claims description 15
- 229930012538 Paclitaxel Natural products 0.000 claims description 15
- 102100024216 Programmed cell death 1 ligand 1 Human genes 0.000 claims description 15
- 229960001592 paclitaxel Drugs 0.000 claims description 15
- 229960004641 rituximab Drugs 0.000 claims description 15
- RCINICONZNJXQF-MZXODVADSA-N taxol Chemical compound O([C@@H]1[C@@]2(C[C@@H](C(C)=C(C2(C)C)[C@H](C([C@]2(C)[C@@H](O)C[C@H]3OC[C@]3([C@H]21)OC(C)=O)=O)OC(=O)C)OC(=O)[C@H](O)[C@@H](NC(=O)C=1C=CC=CC=1)C=1C=CC=CC=1)O)C(=O)C1=CC=CC=C1 RCINICONZNJXQF-MZXODVADSA-N 0.000 claims description 15
- ZDZOTLJHXYCWBA-VCVYQWHSSA-N N-debenzoyl-N-(tert-butoxycarbonyl)-10-deacetyltaxol Chemical compound O([C@H]1[C@H]2[C@@](C([C@H](O)C3=C(C)[C@@H](OC(=O)[C@H](O)[C@@H](NC(=O)OC(C)(C)C)C=4C=CC=CC=4)C[C@]1(O)C3(C)C)=O)(C)[C@@H](O)C[C@H]1OC[C@]12OC(=O)C)C(=O)C1=CC=CC=C1 ZDZOTLJHXYCWBA-VCVYQWHSSA-N 0.000 claims description 13
- 229960005395 cetuximab Drugs 0.000 claims description 13
- 229960003668 docetaxel Drugs 0.000 claims description 13
- 229940045513 CTLA4 antagonist Drugs 0.000 claims description 12
- 101000946889 Homo sapiens Monocyte differentiation antigen CD14 Proteins 0.000 claims description 12
- 102100035877 Monocyte differentiation antigen CD14 Human genes 0.000 claims description 12
- 208000005718 Stomach Neoplasms Diseases 0.000 claims description 12
- 238000012258 culturing Methods 0.000 claims description 12
- 206010017758 gastric cancer Diseases 0.000 claims description 12
- 229960002621 pembrolizumab Drugs 0.000 claims description 12
- BASFCYQUMIYNBI-UHFFFAOYSA-N platinum Chemical compound [Pt] BASFCYQUMIYNBI-UHFFFAOYSA-N 0.000 claims description 12
- 201000011549 stomach cancer Diseases 0.000 claims description 12
- 102100039498 Cytotoxic T-lymphocyte protein 4 Human genes 0.000 claims description 11
- 108091028043 Nucleic acid sequence Proteins 0.000 claims description 11
- 229960003301 nivolumab Drugs 0.000 claims description 11
- 230000001105 regulatory effect Effects 0.000 claims description 11
- 210000001266 CD8-positive T-lymphocyte Anatomy 0.000 claims description 10
- 108010017213 Granulocyte-Macrophage Colony-Stimulating Factor Proteins 0.000 claims description 10
- 239000000556 agonist Substances 0.000 claims description 10
- 239000002246 antineoplastic agent Substances 0.000 claims description 10
- 101001057504 Homo sapiens Interferon-stimulated gene 20 kDa protein Proteins 0.000 claims description 9
- 101001055144 Homo sapiens Interleukin-2 receptor subunit alpha Proteins 0.000 claims description 9
- 102100026878 Interleukin-2 receptor subunit alpha Human genes 0.000 claims description 9
- 206010025323 Lymphomas Diseases 0.000 claims description 9
- 229960000303 topotecan Drugs 0.000 claims description 9
- UCFGDBYHRUNTLO-QHCPKHFHSA-N topotecan Chemical compound C1=C(O)C(CN(C)C)=C2C=C(CN3C4=CC5=C(C3=O)COC(=O)[C@]5(O)CC)C4=NC2=C1 UCFGDBYHRUNTLO-QHCPKHFHSA-N 0.000 claims description 9
- 208000010839 B-cell chronic lymphocytic leukemia Diseases 0.000 claims description 8
- 206010006187 Breast cancer Diseases 0.000 claims description 8
- 208000026310 Breast neoplasm Diseases 0.000 claims description 8
- 208000031422 Lymphocytic Chronic B-Cell Leukemia Diseases 0.000 claims description 8
- 108700008625 Reporter Genes Proteins 0.000 claims description 8
- JXLYSJRDGCGARV-WWYNWVTFSA-N Vinblastine Natural products O=C(O[C@H]1[C@](O)(C(=O)OC)[C@@H]2N(C)c3c(cc(c(OC)c3)[C@]3(C(=O)OC)c4[nH]c5c(c4CCN4C[C@](O)(CC)C[C@H](C3)C4)cccc5)[C@@]32[C@H]2[C@@]1(CC)C=CCN2CC3)C JXLYSJRDGCGARV-WWYNWVTFSA-N 0.000 claims description 8
- 238000003501 co-culture Methods 0.000 claims description 8
- 229960003048 vinblastine Drugs 0.000 claims description 8
- JXLYSJRDGCGARV-XQKSVPLYSA-N vincaleukoblastine Chemical compound C([C@@H](C[C@]1(C(=O)OC)C=2C(=CC3=C([C@]45[C@H]([C@@]([C@H](OC(C)=O)[C@]6(CC)C=CCN([C@H]56)CC4)(O)C(=O)OC)N3C)C=2)OC)C[C@@](C2)(O)CC)N2CCC2=C1NC1=CC=CC=C21 JXLYSJRDGCGARV-XQKSVPLYSA-N 0.000 claims description 8
- UEJJHQNACJXSKW-UHFFFAOYSA-N 2-(2,6-dioxopiperidin-3-yl)-1H-isoindole-1,3(2H)-dione Chemical compound O=C1C2=CC=CC=C2C(=O)N1C1CCC(=O)NC1=O UEJJHQNACJXSKW-UHFFFAOYSA-N 0.000 claims description 7
- IDPUKCWIGUEADI-UHFFFAOYSA-N 5-[bis(2-chloroethyl)amino]uracil Chemical compound ClCCN(CCCl)C1=CNC(=O)NC1=O IDPUKCWIGUEADI-UHFFFAOYSA-N 0.000 claims description 7
- NMUSYJAQQFHJEW-KVTDHHQDSA-N 5-azacytidine Chemical compound O=C1N=C(N)N=CN1[C@H]1[C@H](O)[C@H](O)[C@@H](CO)O1 NMUSYJAQQFHJEW-KVTDHHQDSA-N 0.000 claims description 7
- STQGQHZAVUOBTE-UHFFFAOYSA-N 7-Cyan-hept-2t-en-4,6-diinsaeure Natural products C1=2C(O)=C3C(=O)C=4C(OC)=CC=CC=4C(=O)C3=C(O)C=2CC(O)(C(C)=O)CC1OC1CC(N)C(O)C(C)O1 STQGQHZAVUOBTE-UHFFFAOYSA-N 0.000 claims description 7
- 108010021064 CTLA-4 Antigen Proteins 0.000 claims description 7
- GAGWJHPBXLXJQN-UORFTKCHSA-N Capecitabine Chemical compound C1=C(F)C(NC(=O)OCCCCC)=NC(=O)N1[C@H]1[C@H](O)[C@H](O)[C@@H](C)O1 GAGWJHPBXLXJQN-UORFTKCHSA-N 0.000 claims description 7
- GAGWJHPBXLXJQN-UHFFFAOYSA-N Capecitabine Natural products C1=C(F)C(NC(=O)OCCCCC)=NC(=O)N1C1C(O)C(O)C(C)O1 GAGWJHPBXLXJQN-UHFFFAOYSA-N 0.000 claims description 7
- CMSMOCZEIVJLDB-UHFFFAOYSA-N Cyclophosphamide Chemical compound ClCCN(CCCl)P1(=O)NCCCO1 CMSMOCZEIVJLDB-UHFFFAOYSA-N 0.000 claims description 7
- UHDGCWIWMRVCDJ-CCXZUQQUSA-N Cytarabine Chemical compound O=C1N=C(N)C=CN1[C@H]1[C@@H](O)[C@H](O)[C@@H](CO)O1 UHDGCWIWMRVCDJ-CCXZUQQUSA-N 0.000 claims description 7
- GHASVSINZRGABV-UHFFFAOYSA-N Fluorouracil Chemical compound FC1=CNC(=O)NC1=O GHASVSINZRGABV-UHFFFAOYSA-N 0.000 claims description 7
- 108090001007 Interleukin-8 Proteins 0.000 claims description 7
- 102000004890 Interleukin-8 Human genes 0.000 claims description 7
- 208000008839 Kidney Neoplasms Diseases 0.000 claims description 7
- 239000005517 L01XE01 - Imatinib Substances 0.000 claims description 7
- 239000005411 L01XE02 - Gefitinib Substances 0.000 claims description 7
- 208000031671 Large B-Cell Diffuse Lymphoma Diseases 0.000 claims description 7
- 206010038389 Renal cancer Diseases 0.000 claims description 7
- BPEGJWRSRHCHSN-UHFFFAOYSA-N Temozolomide Chemical compound O=C1N(C)N=NC2=C(C(N)=O)N=CN21 BPEGJWRSRHCHSN-UHFFFAOYSA-N 0.000 claims description 7
- FOCVUCIESVLUNU-UHFFFAOYSA-N Thiotepa Chemical compound C1CN1P(N1CC1)(=S)N1CC1 FOCVUCIESVLUNU-UHFFFAOYSA-N 0.000 claims description 7
- 230000003213 activating effect Effects 0.000 claims description 7
- 229940009456 adriamycin Drugs 0.000 claims description 7
- 239000000611 antibody drug conjugate Substances 0.000 claims description 7
- 229940049595 antibody-drug conjugate Drugs 0.000 claims description 7
- 229960002756 azacitidine Drugs 0.000 claims description 7
- 229960002170 azathioprine Drugs 0.000 claims description 7
- LMEKQMALGUDUQG-UHFFFAOYSA-N azathioprine Chemical compound CN1C=NC([N+]([O-])=O)=C1SC1=NC=NC2=C1NC=N2 LMEKQMALGUDUQG-UHFFFAOYSA-N 0.000 claims description 7
- GXJABQQUPOEUTA-RDJZCZTQSA-N bortezomib Chemical compound C([C@@H](C(=O)N[C@@H](CC(C)C)B(O)O)NC(=O)C=1N=CC=NC=1)C1=CC=CC=C1 GXJABQQUPOEUTA-RDJZCZTQSA-N 0.000 claims description 7
- 229960001467 bortezomib Drugs 0.000 claims description 7
- 229960004117 capecitabine Drugs 0.000 claims description 7
- 208000032852 chronic lymphocytic leukemia Diseases 0.000 claims description 7
- 229960004397 cyclophosphamide Drugs 0.000 claims description 7
- 229960000684 cytarabine Drugs 0.000 claims description 7
- STQGQHZAVUOBTE-VGBVRHCVSA-N daunorubicin Chemical compound O([C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(C)=O)[C@H]1C[C@H](N)[C@H](O)[C@H](C)O1 STQGQHZAVUOBTE-VGBVRHCVSA-N 0.000 claims description 7
- 206010012818 diffuse large B-cell lymphoma Diseases 0.000 claims description 7
- 229960004679 doxorubicin Drugs 0.000 claims description 7
- 239000003937 drug carrier Substances 0.000 claims description 7
- YJGVMLPVUAXIQN-UHFFFAOYSA-N epipodophyllotoxin Natural products COC1=C(OC)C(OC)=CC(C2C3=CC=4OCOC=4C=C3C(O)C3C2C(OC3)=O)=C1 YJGVMLPVUAXIQN-UHFFFAOYSA-N 0.000 claims description 7
- 201000003444 follicular lymphoma Diseases 0.000 claims description 7
- XGALLCVXEZPNRQ-UHFFFAOYSA-N gefitinib Chemical compound C=12C=C(OCCCN3CCOCC3)C(OC)=CC2=NC=NC=1NC1=CC=C(F)C(Cl)=C1 XGALLCVXEZPNRQ-UHFFFAOYSA-N 0.000 claims description 7
- 229960002584 gefitinib Drugs 0.000 claims description 7
- 229960005277 gemcitabine Drugs 0.000 claims description 7
- SDUQYLNIPVEERB-QPPQHZFASA-N gemcitabine Chemical compound O=C1N=C(N)C=CN1[C@H]1C(F)(F)[C@H](O)[C@@H](CO)O1 SDUQYLNIPVEERB-QPPQHZFASA-N 0.000 claims description 7
- 229960001101 ifosfamide Drugs 0.000 claims description 7
- HOMGKSMUEGBAAB-UHFFFAOYSA-N ifosfamide Chemical compound ClCCNP1(=O)OCCCN1CCCl HOMGKSMUEGBAAB-UHFFFAOYSA-N 0.000 claims description 7
- KTUFNOKKBVMGRW-UHFFFAOYSA-N imatinib Chemical compound C1CN(C)CCN1CC1=CC=C(C(=O)NC=2C=C(NC=3N=C(C=CN=3)C=3C=NC=CC=3)C(C)=CC=2)C=C1 KTUFNOKKBVMGRW-UHFFFAOYSA-N 0.000 claims description 7
- 229960002411 imatinib Drugs 0.000 claims description 7
- 201000010982 kidney cancer Diseases 0.000 claims description 7
- 229960001924 melphalan Drugs 0.000 claims description 7
- SGDBTWWWUNNDEQ-LBPRGKRZSA-N melphalan Chemical compound OC(=O)[C@@H](N)CC1=CC=C(N(CCCl)CCCl)C=C1 SGDBTWWWUNNDEQ-LBPRGKRZSA-N 0.000 claims description 7
- 229950008516 olaratumab Drugs 0.000 claims description 7
- YJGVMLPVUAXIQN-XVVDYKMHSA-N podophyllotoxin Chemical compound COC1=C(OC)C(OC)=CC([C@@H]2C3=CC=4OCOC=4C=C3[C@H](O)[C@@H]3[C@@H]2C(OC3)=O)=C1 YJGVMLPVUAXIQN-XVVDYKMHSA-N 0.000 claims description 7
- 229960001237 podophyllotoxin Drugs 0.000 claims description 7
- YVCVYCSAAZQOJI-UHFFFAOYSA-N podophyllotoxin Natural products COC1=C(O)C(OC)=CC(C2C3=CC=4OCOC=4C=C3C(O)C3C2C(OC3)=O)=C1 YVCVYCSAAZQOJI-UHFFFAOYSA-N 0.000 claims description 7
- 239000002243 precursor Substances 0.000 claims description 7
- 230000002195 synergetic effect Effects 0.000 claims description 7
- 229960004964 temozolomide Drugs 0.000 claims description 7
- 229960003433 thalidomide Drugs 0.000 claims description 7
- 229960001196 thiotepa Drugs 0.000 claims description 7
- 229960000575 trastuzumab Drugs 0.000 claims description 7
- 229960001055 uracil mustard Drugs 0.000 claims description 7
- NDMPLJNOPCLANR-UHFFFAOYSA-N 3,4-dihydroxy-15-(4-hydroxy-18-methoxycarbonyl-5,18-seco-ibogamin-18-yl)-16-methoxy-1-methyl-6,7-didehydro-aspidospermidine-3-carboxylic acid methyl ester Natural products C1C(CC)(O)CC(CC2(C(=O)OC)C=3C(=CC4=C(C56C(C(C(O)C7(CC)C=CCN(C67)CC5)(O)C(=O)OC)N4C)C=3)OC)CN1CCC1=C2NC2=CC=CC=C12 NDMPLJNOPCLANR-UHFFFAOYSA-N 0.000 claims description 6
- COVZYZSDYWQREU-UHFFFAOYSA-N Busulfan Chemical compound CS(=O)(=O)OCCCCOS(C)(=O)=O COVZYZSDYWQREU-UHFFFAOYSA-N 0.000 claims description 6
- 102100021943 C-C motif chemokine 2 Human genes 0.000 claims description 6
- 102000017420 CD3 protein, epsilon/gamma/delta subunit Human genes 0.000 claims description 6
- 108050005493 CD3 protein, epsilon/gamma/delta subunit Proteins 0.000 claims description 6
- 108010017080 Granulocyte Colony-Stimulating Factor Proteins 0.000 claims description 6
- 102000004269 Granulocyte Colony-Stimulating Factor Human genes 0.000 claims description 6
- 208000017604 Hodgkin disease Diseases 0.000 claims description 6
- 208000021519 Hodgkin lymphoma Diseases 0.000 claims description 6
- 208000010747 Hodgkins lymphoma Diseases 0.000 claims description 6
- 101000815628 Homo sapiens Regulatory-associated protein of mTOR Proteins 0.000 claims description 6
- 101000652747 Homo sapiens Target of rapamycin complex 2 subunit MAPKAP1 Proteins 0.000 claims description 6
- 101000648491 Homo sapiens Transportin-1 Proteins 0.000 claims description 6
- 102000000589 Interleukin-1 Human genes 0.000 claims description 6
- 108010002352 Interleukin-1 Proteins 0.000 claims description 6
- 108010065805 Interleukin-12 Proteins 0.000 claims description 6
- 102000013462 Interleukin-12 Human genes 0.000 claims description 6
- 102000003812 Interleukin-15 Human genes 0.000 claims description 6
- 108090000172 Interleukin-15 Proteins 0.000 claims description 6
- 108010002386 Interleukin-3 Proteins 0.000 claims description 6
- 102000000646 Interleukin-3 Human genes 0.000 claims description 6
- 239000005551 L01XE03 - Erlotinib Substances 0.000 claims description 6
- 108010046938 Macrophage Colony-Stimulating Factor Proteins 0.000 claims description 6
- 102100040969 Regulatory-associated protein of mTOR Human genes 0.000 claims description 6
- 229960002092 busulfan Drugs 0.000 claims description 6
- 229960004630 chlorambucil Drugs 0.000 claims description 6
- JCKYGMPEJWAADB-UHFFFAOYSA-N chlorambucil Chemical compound OC(=O)CCCC1=CC=C(N(CCCl)CCCl)C=C1 JCKYGMPEJWAADB-UHFFFAOYSA-N 0.000 claims description 6
- 210000004292 cytoskeleton Anatomy 0.000 claims description 6
- 229960001433 erlotinib Drugs 0.000 claims description 6
- AAKJLRGGTJKAMG-UHFFFAOYSA-N erlotinib Chemical compound C=12C=C(OCCOC)C(OCCOC)=CC2=NC=NC=1NC1=CC=CC(C#C)=C1 AAKJLRGGTJKAMG-UHFFFAOYSA-N 0.000 claims description 6
- VJJPUSNTGOMMGY-MRVIYFEKSA-N etoposide Chemical compound COC1=C(O)C(OC)=CC([C@@H]2C3=CC=4OCOC=4C=C3[C@@H](O[C@H]3[C@@H]([C@@H](O)[C@@H]4O[C@H](C)OC[C@H]4O3)O)[C@@H]3[C@@H]2C(OC3)=O)=C1 VJJPUSNTGOMMGY-MRVIYFEKSA-N 0.000 claims description 6
- 229960005420 etoposide Drugs 0.000 claims description 6
- 229960002949 fluorouracil Drugs 0.000 claims description 6
- 230000003308 immunostimulating effect Effects 0.000 claims description 6
- 229960004768 irinotecan Drugs 0.000 claims description 6
- UWKQSNNFCGGAFS-XIFFEERXSA-N irinotecan Chemical compound C1=C2C(CC)=C3CN(C(C4=C([C@@](C(=O)OC4)(O)CC)C=4)=O)C=4C3=NC2=CC=C1OC(=O)N(CC1)CCC1N1CCCCC1 UWKQSNNFCGGAFS-XIFFEERXSA-N 0.000 claims description 6
- 208000032839 leukemia Diseases 0.000 claims description 6
- 229960001156 mitoxantrone Drugs 0.000 claims description 6
- KKZJGLLVHKMTCM-UHFFFAOYSA-N mitoxantrone Chemical compound O=C1C2=C(O)C=CC(O)=C2C(=O)C2=C1C(NCCNCCO)=CC=C2NCCNCCO KKZJGLLVHKMTCM-UHFFFAOYSA-N 0.000 claims description 6
- 229950010773 pidilizumab Drugs 0.000 claims description 6
- 229910052697 platinum Inorganic materials 0.000 claims description 6
- NRUKOCRGYNPUPR-QBPJDGROSA-N teniposide Chemical compound COC1=C(O)C(OC)=CC([C@@H]2C3=CC=4OCOC=4C=C3[C@@H](O[C@H]3[C@@H]([C@@H](O)[C@@H]4O[C@@H](OC[C@H]4O3)C=3SC=CC=3)O)[C@@H]3[C@@H]2C(OC3)=O)=C1 NRUKOCRGYNPUPR-QBPJDGROSA-N 0.000 claims description 6
- 229960001278 teniposide Drugs 0.000 claims description 6
- 229960003862 vemurafenib Drugs 0.000 claims description 6
- GPXBXXGIAQBQNI-UHFFFAOYSA-N vemurafenib Chemical compound CCCS(=O)(=O)NC1=CC=C(F)C(C(=O)C=2C3=CC(=CN=C3NC=2)C=2C=CC(Cl)=CC=2)=C1F GPXBXXGIAQBQNI-UHFFFAOYSA-N 0.000 claims description 6
- 229960004355 vindesine Drugs 0.000 claims description 6
- UGGWPQSBPIFKDZ-KOTLKJBCSA-N vindesine Chemical compound C([C@@H](C[C@]1(C(=O)OC)C=2C(=CC3=C([C@]45[C@H]([C@@]([C@H](O)[C@]6(CC)C=CCN([C@H]56)CC4)(O)C(N)=O)N3C)C=2)OC)C[C@@](C2)(O)CC)N2CCC2=C1N=C1[C]2C=CC=C1 UGGWPQSBPIFKDZ-KOTLKJBCSA-N 0.000 claims description 6
- KGRVJHAUYBGFFP-UHFFFAOYSA-N 2,2'-Methylenebis(4-methyl-6-tert-butylphenol) Chemical compound CC(C)(C)C1=CC(C)=CC(CC=2C(=C(C=C(C)C=2)C(C)(C)C)O)=C1O KGRVJHAUYBGFFP-UHFFFAOYSA-N 0.000 claims description 5
- WYWHKKSPHMUBEB-UHFFFAOYSA-N 6-Mercaptoguanine Natural products N1C(N)=NC(=S)C2=C1N=CN2 WYWHKKSPHMUBEB-UHFFFAOYSA-N 0.000 claims description 5
- 241000024188 Andala Species 0.000 claims description 5
- 102100034458 Hepatitis A virus cellular receptor 2 Human genes 0.000 claims description 5
- 101710091439 Major capsid protein 1 Proteins 0.000 claims description 5
- 108091005682 Receptor kinases Proteins 0.000 claims description 5
- 101710165473 Tumor necrosis factor receptor superfamily member 4 Proteins 0.000 claims description 5
- 102100022153 Tumor necrosis factor receptor superfamily member 4 Human genes 0.000 claims description 5
- 229940100198 alkylating agent Drugs 0.000 claims description 5
- 239000002168 alkylating agent Substances 0.000 claims description 5
- 150000001412 amines Chemical class 0.000 claims description 5
- XCPGHVQEEXUHNC-UHFFFAOYSA-N amsacrine Chemical compound COC1=CC(NS(C)(=O)=O)=CC=C1NC1=C(C=CC=C2)C2=NC2=CC=CC=C12 XCPGHVQEEXUHNC-UHFFFAOYSA-N 0.000 claims description 5
- 229960001220 amsacrine Drugs 0.000 claims description 5
- 239000005557 antagonist Substances 0.000 claims description 5
- 229940045799 anthracyclines and related substance Drugs 0.000 claims description 5
- 125000002603 chloroethyl group Chemical group [H]C([*])([H])C([H])([H])Cl 0.000 claims description 5
- 229960005386 ipilimumab Drugs 0.000 claims description 5
- 229940043355 kinase inhibitor Drugs 0.000 claims description 5
- GLVAUDGFNGKCSF-UHFFFAOYSA-N mercaptopurine Chemical compound S=C1NC=NC2=C1NC=N2 GLVAUDGFNGKCSF-UHFFFAOYSA-N 0.000 claims description 5
- 229960001428 mercaptopurine Drugs 0.000 claims description 5
- 239000003757 phosphotransferase inhibitor Substances 0.000 claims description 5
- 229960003087 tioguanine Drugs 0.000 claims description 5
- MNRILEROXIRVNJ-UHFFFAOYSA-N tioguanine Chemical compound N1C(N)=NC(=S)C2=NC=N[C]21 MNRILEROXIRVNJ-UHFFFAOYSA-N 0.000 claims description 5
- SQTFKIKSQNCWGJ-KCDKBNATSA-N (2s,3r,4r,5s)-2-fluoro-3,4,5-trihydroxyhexanal Chemical compound C[C@H](O)[C@@H](O)[C@@H](O)[C@H](F)C=O SQTFKIKSQNCWGJ-KCDKBNATSA-N 0.000 claims description 4
- 208000010507 Adenocarcinoma of Lung Diseases 0.000 claims description 4
- 102100022005 B-lymphocyte antigen CD20 Human genes 0.000 claims description 4
- 206010005003 Bladder cancer Diseases 0.000 claims description 4
- 101150013553 CD40 gene Proteins 0.000 claims description 4
- 108010092160 Dactinomycin Proteins 0.000 claims description 4
- 101150046249 Havcr2 gene Proteins 0.000 claims description 4
- 101000897405 Homo sapiens B-lymphocyte antigen CD20 Proteins 0.000 claims description 4
- 101000889276 Homo sapiens Cytotoxic T-lymphocyte protein 4 Proteins 0.000 claims description 4
- 101000959820 Homo sapiens Interferon alpha-1/13 Proteins 0.000 claims description 4
- 101000916644 Homo sapiens Macrophage colony-stimulating factor 1 receptor Proteins 0.000 claims description 4
- 101001109501 Homo sapiens NKG2-D type II integral membrane protein Proteins 0.000 claims description 4
- 101000692455 Homo sapiens Platelet-derived growth factor receptor beta Proteins 0.000 claims description 4
- 101001012157 Homo sapiens Receptor tyrosine-protein kinase erbB-2 Proteins 0.000 claims description 4
- 101000633784 Homo sapiens SLAM family member 7 Proteins 0.000 claims description 4
- 101150069255 KLRC1 gene Proteins 0.000 claims description 4
- FBOZXECLQNJBKD-ZDUSSCGKSA-N L-methotrexate Chemical compound C=1N=C2N=C(N)N=C(N)C2=NC=1CN(C)C1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 FBOZXECLQNJBKD-ZDUSSCGKSA-N 0.000 claims description 4
- 101150030213 Lag3 gene Proteins 0.000 claims description 4
- 101100404845 Macaca mulatta NKG2A gene Proteins 0.000 claims description 4
- 102100028198 Macrophage colony-stimulating factor 1 receptor Human genes 0.000 claims description 4
- 206010027406 Mesothelioma Diseases 0.000 claims description 4
- 102100022682 NKG2-A/NKG2-B type II integral membrane protein Human genes 0.000 claims description 4
- 102100022680 NKG2-D type II integral membrane protein Human genes 0.000 claims description 4
- 206010061902 Pancreatic neoplasm Diseases 0.000 claims description 4
- 206010035226 Plasma cell myeloma Diseases 0.000 claims description 4
- 102100026547 Platelet-derived growth factor receptor beta Human genes 0.000 claims description 4
- 206010060862 Prostate cancer Diseases 0.000 claims description 4
- 208000000236 Prostatic Neoplasms Diseases 0.000 claims description 4
- 102100030086 Receptor tyrosine-protein kinase erbB-2 Human genes 0.000 claims description 4
- 102100029198 SLAM family member 7 Human genes 0.000 claims description 4
- 101710196623 Stimulator of interferon genes protein Proteins 0.000 claims description 4
- 108091005729 TAM receptors Proteins 0.000 claims description 4
- 208000024313 Testicular Neoplasms Diseases 0.000 claims description 4
- 206010057644 Testis cancer Diseases 0.000 claims description 4
- 102000002689 Toll-like receptor Human genes 0.000 claims description 4
- 108020000411 Toll-like receptor Proteins 0.000 claims description 4
- 102100040245 Tumor necrosis factor receptor superfamily member 5 Human genes 0.000 claims description 4
- 208000007097 Urinary Bladder Neoplasms Diseases 0.000 claims description 4
- 102000005789 Vascular Endothelial Growth Factors Human genes 0.000 claims description 4
- 108010019530 Vascular Endothelial Growth Factors Proteins 0.000 claims description 4
- 229930183665 actinomycin Natural products 0.000 claims description 4
- 229960000397 bevacizumab Drugs 0.000 claims description 4
- 229960000975 daunorubicin Drugs 0.000 claims description 4
- 229960004137 elotuzumab Drugs 0.000 claims description 4
- 102000052116 epidermal growth factor receptor activity proteins Human genes 0.000 claims description 4
- 108700015053 epidermal growth factor receptor activity proteins Proteins 0.000 claims description 4
- 201000010536 head and neck cancer Diseases 0.000 claims description 4
- 208000014829 head and neck neoplasm Diseases 0.000 claims description 4
- 108010074108 interleukin-21 Proteins 0.000 claims description 4
- 201000005249 lung adenocarcinoma Diseases 0.000 claims description 4
- 208000015486 malignant pancreatic neoplasm Diseases 0.000 claims description 4
- 201000001441 melanoma Diseases 0.000 claims description 4
- 229960000485 methotrexate Drugs 0.000 claims description 4
- 201000000050 myeloid neoplasm Diseases 0.000 claims description 4
- YOHYSYJDKVYCJI-UHFFFAOYSA-N n-[3-[[6-[3-(trifluoromethyl)anilino]pyrimidin-4-yl]amino]phenyl]cyclopropanecarboxamide Chemical compound FC(F)(F)C1=CC=CC(NC=2N=CN=C(NC=3C=C(NC(=O)C4CC4)C=CC=3)C=2)=C1 YOHYSYJDKVYCJI-UHFFFAOYSA-N 0.000 claims description 4
- 239000002777 nucleoside Substances 0.000 claims description 4
- 150000003833 nucleoside derivatives Chemical class 0.000 claims description 4
- 201000002528 pancreatic cancer Diseases 0.000 claims description 4
- 208000008443 pancreatic carcinoma Diseases 0.000 claims description 4
- 229960002087 pertuzumab Drugs 0.000 claims description 4
- 201000003120 testicular cancer Diseases 0.000 claims description 4
- 201000005112 urinary bladder cancer Diseases 0.000 claims description 4
- 229960004449 vismodegib Drugs 0.000 claims description 4
- BPQMGSKTAYIVFO-UHFFFAOYSA-N vismodegib Chemical compound ClC1=CC(S(=O)(=O)C)=CC=C1C(=O)NC1=CC=C(Cl)C(C=2N=CC=CC=2)=C1 BPQMGSKTAYIVFO-UHFFFAOYSA-N 0.000 claims description 4
- VSNHCAURESNICA-NJFSPNSNSA-N 1-oxidanylurea Chemical compound N[14C](=O)NO VSNHCAURESNICA-NJFSPNSNSA-N 0.000 claims description 3
- 108010006654 Bleomycin Proteins 0.000 claims description 3
- 206010005949 Bone cancer Diseases 0.000 claims description 3
- 208000018084 Bone neoplasm Diseases 0.000 claims description 3
- 206010008342 Cervix carcinoma Diseases 0.000 claims description 3
- 208000001333 Colorectal Neoplasms Diseases 0.000 claims description 3
- WEAHRLBPCANXCN-UHFFFAOYSA-N Daunomycin Natural products CCC1(O)CC(OC2CC(N)C(O)C(C)O2)c3cc4C(=O)c5c(OC)cccc5C(=O)c4c(O)c3C1 WEAHRLBPCANXCN-UHFFFAOYSA-N 0.000 claims description 3
- 208000000461 Esophageal Neoplasms Diseases 0.000 claims description 3
- 206010017993 Gastrointestinal neoplasms Diseases 0.000 claims description 3
- VSNHCAURESNICA-UHFFFAOYSA-N Hydroxyurea Chemical compound NC(=O)NO VSNHCAURESNICA-UHFFFAOYSA-N 0.000 claims description 3
- 208000034176 Neoplasms, Germ Cell and Embryonal Diseases 0.000 claims description 3
- 206010030155 Oesophageal carcinoma Diseases 0.000 claims description 3
- 206010033128 Ovarian cancer Diseases 0.000 claims description 3
- 206010061535 Ovarian neoplasm Diseases 0.000 claims description 3
- 206010039491 Sarcoma Diseases 0.000 claims description 3
- 208000000453 Skin Neoplasms Diseases 0.000 claims description 3
- 208000024770 Thyroid neoplasm Diseases 0.000 claims description 3
- 208000006105 Uterine Cervical Neoplasms Diseases 0.000 claims description 3
- 208000002495 Uterine Neoplasms Diseases 0.000 claims description 3
- 229960000548 alemtuzumab Drugs 0.000 claims description 3
- 229960001561 bleomycin Drugs 0.000 claims description 3
- OYVAGSVQBOHSSS-UAPAGMARSA-O bleomycin A2 Chemical compound N([C@H](C(=O)N[C@H](C)[C@@H](O)[C@H](C)C(=O)N[C@@H]([C@H](O)C)C(=O)NCCC=1SC=C(N=1)C=1SC=C(N=1)C(=O)NCCC[S+](C)C)[C@@H](O[C@H]1[C@H]([C@@H](O)[C@H](O)[C@H](CO)O1)O[C@@H]1[C@H]([C@@H](OC(N)=O)[C@H](O)[C@@H](CO)O1)O)C=1N=CNC=1)C(=O)C1=NC([C@H](CC(N)=O)NC[C@H](N)C(N)=O)=NC(N)=C1C OYVAGSVQBOHSSS-UAPAGMARSA-O 0.000 claims description 3
- 229960004562 carboplatin Drugs 0.000 claims description 3
- 201000010881 cervical cancer Diseases 0.000 claims description 3
- 229960004316 cisplatin Drugs 0.000 claims description 3
- DQLATGHUWYMOKM-UHFFFAOYSA-L cisplatin Chemical compound N[Pt](N)(Cl)Cl DQLATGHUWYMOKM-UHFFFAOYSA-L 0.000 claims description 3
- 201000004101 esophageal cancer Diseases 0.000 claims description 3
- 201000003115 germ cell cancer Diseases 0.000 claims description 3
- 229940121372 histone deacetylase inhibitor Drugs 0.000 claims description 3
- 239000003276 histone deacetylase inhibitor Substances 0.000 claims description 3
- 229960001330 hydroxycarbamide Drugs 0.000 claims description 3
- 201000007270 liver cancer Diseases 0.000 claims description 3
- 208000014018 liver neoplasm Diseases 0.000 claims description 3
- 229960002450 ofatumumab Drugs 0.000 claims description 3
- 229960001756 oxaliplatin Drugs 0.000 claims description 3
- DWAFYCQODLXJNR-BNTLRKBRSA-L oxaliplatin Chemical compound O1C(=O)C(=O)O[Pt]11N[C@@H]2CCCC[C@H]2N1 DWAFYCQODLXJNR-BNTLRKBRSA-L 0.000 claims description 3
- 239000003910 polypeptide antibiotic agent Substances 0.000 claims description 3
- 229960003452 romidepsin Drugs 0.000 claims description 3
- OHRURASPPZQGQM-GCCNXGTGSA-N romidepsin Chemical compound O1C(=O)[C@H](C(C)C)NC(=O)C(=C/C)/NC(=O)[C@H]2CSSCC\C=C\[C@@H]1CC(=O)N[C@H](C(C)C)C(=O)N2 OHRURASPPZQGQM-GCCNXGTGSA-N 0.000 claims description 3
- 108010091666 romidepsin Proteins 0.000 claims description 3
- OHRURASPPZQGQM-UHFFFAOYSA-N romidepsin Natural products O1C(=O)C(C(C)C)NC(=O)C(=CC)NC(=O)C2CSSCCC=CC1CC(=O)NC(C(C)C)C(=O)N2 OHRURASPPZQGQM-UHFFFAOYSA-N 0.000 claims description 3
- 201000000849 skin cancer Diseases 0.000 claims description 3
- 201000002510 thyroid cancer Diseases 0.000 claims description 3
- 206010046766 uterine cancer Diseases 0.000 claims description 3
- GBABOYUKABKIAF-GHYRFKGUSA-N vinorelbine Chemical compound C1N(CC=2C3=CC=CC=C3NC=22)CC(CC)=C[C@H]1C[C@]2(C(=O)OC)C1=CC([C@]23[C@H]([C@]([C@H](OC(C)=O)[C@]4(CC)C=CCN([C@H]34)CC2)(O)C(=O)OC)N2C)=C2C=C1OC GBABOYUKABKIAF-GHYRFKGUSA-N 0.000 claims description 3
- 229960002066 vinorelbine Drugs 0.000 claims description 3
- WAEXFXRVDQXREF-UHFFFAOYSA-N vorinostat Chemical compound ONC(=O)CCCCCCC(=O)NC1=CC=CC=C1 WAEXFXRVDQXREF-UHFFFAOYSA-N 0.000 claims description 3
- 229960000237 vorinostat Drugs 0.000 claims description 3
- AOJJSUZBOXZQNB-VTZDEGQISA-N 4'-epidoxorubicin Chemical compound O([C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(=O)CO)[C@H]1C[C@H](N)[C@@H](O)[C@H](C)O1 AOJJSUZBOXZQNB-VTZDEGQISA-N 0.000 claims description 2
- HTIJFSOGRVMCQR-UHFFFAOYSA-N Epirubicin Natural products COc1cccc2C(=O)c3c(O)c4CC(O)(CC(OC5CC(N)C(=O)C(C)O5)c4c(O)c3C(=O)c12)C(=O)CO HTIJFSOGRVMCQR-UHFFFAOYSA-N 0.000 claims description 2
- 108010030545 N-(2(R)-2-(hydroxamidocarbonylmethyl)-4-methylpentanoyl)-L-tryptophan methylamide Proteins 0.000 claims description 2
- 229960003852 atezolizumab Drugs 0.000 claims description 2
- 229950002916 avelumab Drugs 0.000 claims description 2
- 208000025997 central nervous system neoplasm Diseases 0.000 claims description 2
- 239000003534 dna topoisomerase inhibitor Substances 0.000 claims description 2
- 229950009791 durvalumab Drugs 0.000 claims description 2
- 229960001904 epirubicin Drugs 0.000 claims description 2
- NITYDPDXAAFEIT-DYVFJYSZSA-N ilomastat Chemical compound C1=CC=C2C(C[C@@H](C(=O)NC)NC(=O)[C@H](CC(C)C)CC(=O)NO)=CNC2=C1 NITYDPDXAAFEIT-DYVFJYSZSA-N 0.000 claims description 2
- 229940127073 nucleoside analogue Drugs 0.000 claims description 2
- 229960000402 palivizumab Drugs 0.000 claims description 2
- 229940044693 topoisomerase inhibitor Drugs 0.000 claims description 2
- 102000004457 Granulocyte-Macrophage Colony-Stimulating Factor Human genes 0.000 claims 4
- 102100023990 60S ribosomal protein L17 Human genes 0.000 claims 2
- 102100028123 Macrophage colony-stimulating factor 1 Human genes 0.000 claims 2
- BICLFERWXTUOGB-UHFFFAOYSA-N nitrosourea Chemical compound N(=O)NC(=O)N.N(=O)NC(=O)N BICLFERWXTUOGB-UHFFFAOYSA-N 0.000 claims 2
- RGNOTKMIMZMNRX-XVFCMESISA-N 2-amino-1-[(2r,3r,4s,5r)-3,4-dihydroxy-5-(hydroxymethyl)oxolan-2-yl]pyrimidin-4-one Chemical compound NC1=NC(=O)C=CN1[C@H]1[C@H](O)[C@H](O)[C@@H](CO)O1 RGNOTKMIMZMNRX-XVFCMESISA-N 0.000 claims 1
- 101800002068 Galanin Proteins 0.000 claims 1
- 102000019432 Galanin Human genes 0.000 claims 1
- JBDIWCWZUDNWTL-HDICACEKSA-N [4-[(3s,4r)-4-(4-phosphonooxyphenyl)hexan-3-yl]phenyl] dihydrogen phosphate Chemical compound C1([C@H](CC)[C@H](CC)C=2C=CC(OP(O)(O)=O)=CC=2)=CC=C(OP(O)(O)=O)C=C1 JBDIWCWZUDNWTL-HDICACEKSA-N 0.000 claims 1
- 190000008236 carboplatin Chemical compound 0.000 claims 1
- OPTASPLRGRRNAP-UHFFFAOYSA-N cytosine Chemical compound NC=1C=CNC(=O)N=1 OPTASPLRGRRNAP-UHFFFAOYSA-N 0.000 claims 1
- 230000003436 cytoskeletal effect Effects 0.000 claims 1
- SLZIZIJTGAYEKK-CIJSCKBQSA-N molport-023-220-247 Chemical compound C([C@@H](C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC=1N=CNC=1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](CC=1N=CNC=1)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(N)=O)NC(=O)[C@H]1N(CCC1)C(=O)CNC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)CNC(=O)[C@H](C)NC(=O)[C@H](CO)NC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](NC(=O)[C@H](CC=1C2=CC=CC=C2NC=1)NC(=O)CN)[C@@H](C)O)C1=CNC=N1 SLZIZIJTGAYEKK-CIJSCKBQSA-N 0.000 claims 1
- 229960000513 necitumumab Drugs 0.000 claims 1
- 230000000694 effects Effects 0.000 description 88
- 238000011282 treatment Methods 0.000 description 56
- 230000003993 interaction Effects 0.000 description 47
- 235000001014 amino acid Nutrition 0.000 description 45
- 241000699666 Mus <mouse, genus> Species 0.000 description 32
- 235000018102 proteins Nutrition 0.000 description 31
- 241000699670 Mus sp. Species 0.000 description 29
- 238000004458 analytical method Methods 0.000 description 28
- 238000006467 substitution reaction Methods 0.000 description 27
- 230000010056 antibody-dependent cellular cytotoxicity Effects 0.000 description 25
- 239000000523 sample Substances 0.000 description 25
- 230000013595 glycosylation Effects 0.000 description 24
- 238000006206 glycosylation reaction Methods 0.000 description 24
- 210000000822 natural killer cell Anatomy 0.000 description 24
- 125000003295 alanine group Chemical group N[C@@H](C)C(=O)* 0.000 description 22
- 229940024606 amino acid Drugs 0.000 description 22
- 230000037361 pathway Effects 0.000 description 22
- SHZGCJCMOBCMKK-DHVFOXMCSA-N L-fucopyranose Chemical compound C[C@@H]1OC(O)[C@@H](O)[C@H](O)[C@@H]1O SHZGCJCMOBCMKK-DHVFOXMCSA-N 0.000 description 21
- KDXKERNSBIXSRK-UHFFFAOYSA-N Lysine Natural products NCCCCC(N)C(O)=O KDXKERNSBIXSRK-UHFFFAOYSA-N 0.000 description 21
- 150000001413 amino acids Chemical class 0.000 description 21
- 230000006870 function Effects 0.000 description 21
- 239000003446 ligand Substances 0.000 description 21
- 230000001404 mediated effect Effects 0.000 description 20
- 102000004196 processed proteins & peptides Human genes 0.000 description 20
- 238000002474 experimental method Methods 0.000 description 19
- 210000003289 regulatory T cell Anatomy 0.000 description 19
- 238000004166 bioassay Methods 0.000 description 18
- 239000012634 fragment Substances 0.000 description 18
- 102000009490 IgG Receptors Human genes 0.000 description 17
- 108010073807 IgG Receptors Proteins 0.000 description 17
- 238000001943 fluorescence-activated cell sorting Methods 0.000 description 17
- 238000001727 in vivo Methods 0.000 description 17
- 101710117290 Aldo-keto reductase family 1 member C4 Proteins 0.000 description 16
- 230000004913 activation Effects 0.000 description 16
- 238000009472 formulation Methods 0.000 description 16
- 230000006698 induction Effects 0.000 description 16
- SHZGCJCMOBCMKK-UHFFFAOYSA-N D-mannomethylose Natural products CC1OC(O)C(O)C(O)C1O SHZGCJCMOBCMKK-UHFFFAOYSA-N 0.000 description 15
- PNNNRSAQSRJVSB-SLPGGIOYSA-N Fucose Natural products C[C@H](O)[C@@H](O)[C@H](O)[C@H](O)C=O PNNNRSAQSRJVSB-SLPGGIOYSA-N 0.000 description 15
- 241001529936 Murinae Species 0.000 description 15
- 239000002953 phosphate buffered saline Substances 0.000 description 15
- 230000002829 reductive effect Effects 0.000 description 15
- 239000000243 solution Substances 0.000 description 15
- 240000004808 Saccharomyces cerevisiae Species 0.000 description 14
- 230000005867 T cell response Effects 0.000 description 14
- 210000000952 spleen Anatomy 0.000 description 14
- 241000701022 Cytomegalovirus Species 0.000 description 13
- 230000015572 biosynthetic process Effects 0.000 description 13
- 150000001875 compounds Chemical class 0.000 description 13
- 239000000824 cytostatic agent Substances 0.000 description 13
- 238000000684 flow cytometry Methods 0.000 description 13
- 239000000047 product Substances 0.000 description 13
- 210000001519 tissue Anatomy 0.000 description 13
- 239000011534 wash buffer Substances 0.000 description 13
- 210000000662 T-lymphocyte subset Anatomy 0.000 description 12
- 230000000903 blocking effect Effects 0.000 description 12
- 238000005259 measurement Methods 0.000 description 12
- 230000035772 mutation Effects 0.000 description 12
- 235000000346 sugar Nutrition 0.000 description 12
- 238000003786 synthesis reaction Methods 0.000 description 12
- 102100029193 Low affinity immunoglobulin gamma Fc region receptor III-A Human genes 0.000 description 11
- 101710099301 Low affinity immunoglobulin gamma Fc region receptor III-A Proteins 0.000 description 11
- 239000004698 Polyethylene Substances 0.000 description 11
- 230000001085 cytostatic effect Effects 0.000 description 11
- 238000002198 surface plasmon resonance spectroscopy Methods 0.000 description 11
- 239000012190 activator Substances 0.000 description 10
- 239000000872 buffer Substances 0.000 description 10
- 238000005516 engineering process Methods 0.000 description 10
- 238000011156 evaluation Methods 0.000 description 10
- 239000002609 medium Substances 0.000 description 10
- 239000002207 metabolite Substances 0.000 description 10
- 210000002381 plasma Anatomy 0.000 description 10
- 230000011664 signaling Effects 0.000 description 10
- 230000001225 therapeutic effect Effects 0.000 description 10
- OVRNDRQMDRJTHS-UHFFFAOYSA-N N-acelyl-D-glucosamine Natural products CC(=O)NC1C(O)OC(CO)C(O)C1O OVRNDRQMDRJTHS-UHFFFAOYSA-N 0.000 description 9
- MBLBDJOUHNCFQT-LXGUWJNJSA-N N-acetylglucosamine Natural products CC(=O)N[C@@H](C=O)[C@@H](O)[C@H](O)[C@H](O)CO MBLBDJOUHNCFQT-LXGUWJNJSA-N 0.000 description 9
- 238000012575 bio-layer interferometry Methods 0.000 description 9
- 210000004978 chinese hamster ovary cell Anatomy 0.000 description 9
- 230000016396 cytokine production Effects 0.000 description 9
- 238000010494 dissociation reaction Methods 0.000 description 9
- 230000005593 dissociations Effects 0.000 description 9
- 150000002482 oligosaccharides Chemical class 0.000 description 9
- 238000000746 purification Methods 0.000 description 9
- 241000894007 species Species 0.000 description 9
- 230000009870 specific binding Effects 0.000 description 9
- 206010057249 Phagocytosis Diseases 0.000 description 8
- 230000000259 anti-tumor effect Effects 0.000 description 8
- 230000033581 fucosylation Effects 0.000 description 8
- 230000003834 intracellular effect Effects 0.000 description 8
- 230000003278 mimic effect Effects 0.000 description 8
- 150000007523 nucleic acids Chemical class 0.000 description 8
- 230000008782 phagocytosis Effects 0.000 description 8
- 230000009467 reduction Effects 0.000 description 8
- 210000004988 splenocyte Anatomy 0.000 description 8
- 230000004083 survival effect Effects 0.000 description 8
- 238000004448 titration Methods 0.000 description 8
- 230000004614 tumor growth Effects 0.000 description 8
- MTCFGRXMJLQNBG-REOHCLBHSA-N (2S)-2-Amino-3-hydroxypropansäure Chemical group OC[C@H](N)C(O)=O MTCFGRXMJLQNBG-REOHCLBHSA-N 0.000 description 7
- NFGXHKASABOEEW-UHFFFAOYSA-N 1-methylethyl 11-methoxy-3,7,11-trimethyl-2,4-dodecadienoate Chemical compound COC(C)(C)CCCC(C)CC=CC(C)=CC(=O)OC(C)C NFGXHKASABOEEW-UHFFFAOYSA-N 0.000 description 7
- 241000283707 Capra Species 0.000 description 7
- 229930182474 N-glycoside Natural products 0.000 description 7
- 230000006044 T cell activation Effects 0.000 description 7
- 210000004369 blood Anatomy 0.000 description 7
- 239000008280 blood Substances 0.000 description 7
- 150000001720 carbohydrates Chemical class 0.000 description 7
- 238000012512 characterization method Methods 0.000 description 7
- 125000000151 cysteine group Chemical group N[C@@H](CS)C(=O)* 0.000 description 7
- 229940079593 drug Drugs 0.000 description 7
- 238000004191 hydrophobic interaction chromatography Methods 0.000 description 7
- 238000000338 in vitro Methods 0.000 description 7
- 230000005764 inhibitory process Effects 0.000 description 7
- 229920001542 oligosaccharide Polymers 0.000 description 7
- 239000000546 pharmaceutical excipient Substances 0.000 description 7
- 102000005962 receptors Human genes 0.000 description 7
- 108020003175 receptors Proteins 0.000 description 7
- 108020004414 DNA Proteins 0.000 description 6
- 238000002965 ELISA Methods 0.000 description 6
- 102000004190 Enzymes Human genes 0.000 description 6
- 108090000790 Enzymes Proteins 0.000 description 6
- 108010021472 Fc gamma receptor IIB Proteins 0.000 description 6
- 102100039620 Granulocyte-macrophage colony-stimulating factor Human genes 0.000 description 6
- OVRNDRQMDRJTHS-FMDGEEDCSA-N N-acetyl-beta-D-glucosamine Chemical compound CC(=O)N[C@H]1[C@H](O)O[C@H](CO)[C@@H](O)[C@@H]1O OVRNDRQMDRJTHS-FMDGEEDCSA-N 0.000 description 6
- 108010058846 Ovalbumin Proteins 0.000 description 6
- 229960000074 biopharmaceutical Drugs 0.000 description 6
- 238000010790 dilution Methods 0.000 description 6
- 239000012895 dilution Substances 0.000 description 6
- 229940088598 enzyme Drugs 0.000 description 6
- 230000002601 intratumoral effect Effects 0.000 description 6
- 230000000670 limiting effect Effects 0.000 description 6
- 239000000463 material Substances 0.000 description 6
- 229950006780 n-acetylglucosamine Drugs 0.000 description 6
- 102000039446 nucleic acids Human genes 0.000 description 6
- 108020004707 nucleic acids Proteins 0.000 description 6
- 229940092253 ovalbumin Drugs 0.000 description 6
- 239000008188 pellet Substances 0.000 description 6
- 238000012360 testing method Methods 0.000 description 6
- 241000392139 Astarte Species 0.000 description 5
- 102000003886 Glycoproteins Human genes 0.000 description 5
- 108090000288 Glycoproteins Proteins 0.000 description 5
- 101000917858 Homo sapiens Low affinity immunoglobulin gamma Fc region receptor III-A Proteins 0.000 description 5
- 102100026120 IgG receptor FcRn large subunit p51 Human genes 0.000 description 5
- 101710177940 IgG receptor FcRn large subunit p51 Proteins 0.000 description 5
- DCXYFEDJOCDNAF-REOHCLBHSA-N L-asparagine Chemical compound OC(=O)[C@@H](N)CC(N)=O DCXYFEDJOCDNAF-REOHCLBHSA-N 0.000 description 5
- OVRNDRQMDRJTHS-RTRLPJTCSA-N N-acetyl-D-glucosamine Chemical compound CC(=O)N[C@H]1C(O)O[C@H](CO)[C@@H](O)[C@@H]1O OVRNDRQMDRJTHS-RTRLPJTCSA-N 0.000 description 5
- 238000003559 RNA-seq method Methods 0.000 description 5
- 230000006023 anti-tumor response Effects 0.000 description 5
- 239000011230 binding agent Substances 0.000 description 5
- 239000003153 chemical reaction reagent Substances 0.000 description 5
- 230000000295 complement effect Effects 0.000 description 5
- 230000004540 complement-dependent cytotoxicity Effects 0.000 description 5
- 230000000139 costimulatory effect Effects 0.000 description 5
- 239000012228 culture supernatant Substances 0.000 description 5
- 230000003247 decreasing effect Effects 0.000 description 5
- 230000001419 dependent effect Effects 0.000 description 5
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 description 5
- 231100000673 dose–response relationship Toxicity 0.000 description 5
- 239000013604 expression vector Substances 0.000 description 5
- 150000004676 glycans Chemical class 0.000 description 5
- 238000011534 incubation Methods 0.000 description 5
- 230000014759 maintenance of location Effects 0.000 description 5
- 230000004048 modification Effects 0.000 description 5
- 238000012986 modification Methods 0.000 description 5
- 230000036961 partial effect Effects 0.000 description 5
- 235000013855 polyvinylpyrrolidone Nutrition 0.000 description 5
- 239000001267 polyvinylpyrrolidone Substances 0.000 description 5
- 229920000036 polyvinylpyrrolidone Polymers 0.000 description 5
- 238000012545 processing Methods 0.000 description 5
- 239000002904 solvent Substances 0.000 description 5
- 238000013268 sustained release Methods 0.000 description 5
- 239000012730 sustained-release form Substances 0.000 description 5
- 208000024891 symptom Diseases 0.000 description 5
- 239000012114 Alexa Fluor 647 Substances 0.000 description 4
- 102100021266 Alpha-(1,6)-fucosyltransferase Human genes 0.000 description 4
- 108700031361 Brachyury Proteins 0.000 description 4
- 102100032912 CD44 antigen Human genes 0.000 description 4
- 241000588724 Escherichia coli Species 0.000 description 4
- 101000819490 Homo sapiens Alpha-(1,6)-fucosyltransferase Proteins 0.000 description 4
- 101000868273 Homo sapiens CD44 antigen Proteins 0.000 description 4
- 101000914514 Homo sapiens T-cell-specific surface glycoprotein CD28 Proteins 0.000 description 4
- 108060003951 Immunoglobulin Proteins 0.000 description 4
- 102100029205 Low affinity immunoglobulin gamma Fc region receptor II-b Human genes 0.000 description 4
- 102000007651 Macrophage Colony-Stimulating Factor Human genes 0.000 description 4
- 102100027213 T-cell-specific surface glycoprotein CD28 Human genes 0.000 description 4
- DTQVDTLACAAQTR-UHFFFAOYSA-N Trifluoroacetic acid Chemical compound OC(=O)C(F)(F)F DTQVDTLACAAQTR-UHFFFAOYSA-N 0.000 description 4
- 239000002671 adjuvant Substances 0.000 description 4
- 230000000735 allogeneic effect Effects 0.000 description 4
- 229940034982 antineoplastic agent Drugs 0.000 description 4
- 239000011324 bead Substances 0.000 description 4
- 238000000423 cell based assay Methods 0.000 description 4
- 238000006243 chemical reaction Methods 0.000 description 4
- 238000010367 cloning Methods 0.000 description 4
- 230000024203 complement activation Effects 0.000 description 4
- 230000000875 corresponding effect Effects 0.000 description 4
- 230000009089 cytolysis Effects 0.000 description 4
- 229940127089 cytotoxic agent Drugs 0.000 description 4
- 239000010432 diamond Substances 0.000 description 4
- 201000010099 disease Diseases 0.000 description 4
- 239000000975 dye Substances 0.000 description 4
- 210000003162 effector t lymphocyte Anatomy 0.000 description 4
- 125000000404 glutamine group Chemical group N[C@@H](CCC(N)=O)C(=O)* 0.000 description 4
- 238000004128 high performance liquid chromatography Methods 0.000 description 4
- 210000004408 hybridoma Anatomy 0.000 description 4
- 230000001900 immune effect Effects 0.000 description 4
- 230000028993 immune response Effects 0.000 description 4
- 102000018358 immunoglobulin Human genes 0.000 description 4
- 230000001976 improved effect Effects 0.000 description 4
- 230000002401 inhibitory effect Effects 0.000 description 4
- 230000000977 initiatory effect Effects 0.000 description 4
- 239000007924 injection Substances 0.000 description 4
- 238000002347 injection Methods 0.000 description 4
- 230000002452 interceptive effect Effects 0.000 description 4
- 238000007912 intraperitoneal administration Methods 0.000 description 4
- 239000007788 liquid Substances 0.000 description 4
- 210000004698 lymphocyte Anatomy 0.000 description 4
- 238000002826 magnetic-activated cell sorting Methods 0.000 description 4
- 238000002703 mutagenesis Methods 0.000 description 4
- 231100000350 mutagenesis Toxicity 0.000 description 4
- JMUPMJGUKXYCMF-IWDIICGPSA-N n-[(2s,3r,4r,5s,6r)-2-[(2s,3s,4s,5s,6r)-2-[[(2r,3r,4s,5s,6s)-6-[(2r,3s,4r,5r,6s)-5-acetamido-6-[(2r,3s,4r,5r)-5-acetamido-1,2,4-trihydroxy-6-oxohexan-3-yl]oxy-4-hydroxy-2-(hydroxymethyl)oxan-3-yl]oxy-4-[(2r,3s,4s,5s,6r)-3-[(2s,3r,4r,5s,6r)-3-acetamido-4-h Chemical group O[C@@H]1[C@@H](NC(C)=O)[C@H](O[C@@H]([C@H](O)[C@H](C=O)NC(=O)C)[C@H](O)CO)O[C@H](CO)[C@H]1O[C@H]1[C@@H](O)[C@@H](O[C@@H]2[C@H]([C@@H](O)[C@H](O)[C@@H](CO)O2)O[C@H]2[C@@H]([C@@H](O)[C@H](O[C@H]3[C@@H]([C@@H](O)[C@@H](O)[C@@H](CO)O3)O)[C@@H](CO)O2)NC(C)=O)[C@H](O)[C@@H](CO[C@@H]2[C@H]([C@@H](O)[C@H](O)[C@@H](CO)O2)O[C@H]2[C@@H]([C@@H](O)[C@H](O[C@H]3[C@@H]([C@@H](O)[C@@H](O)[C@@H](CO)O3)O)[C@@H](CO)O2)NC(C)=O)O1 JMUPMJGUKXYCMF-IWDIICGPSA-N 0.000 description 4
- 210000000440 neutrophil Anatomy 0.000 description 4
- 230000009871 nonspecific binding Effects 0.000 description 4
- 239000013612 plasmid Substances 0.000 description 4
- 239000013641 positive control Substances 0.000 description 4
- 238000002360 preparation method Methods 0.000 description 4
- 230000037452 priming Effects 0.000 description 4
- 238000000159 protein binding assay Methods 0.000 description 4
- 230000003393 splenic effect Effects 0.000 description 4
- 210000000130 stem cell Anatomy 0.000 description 4
- 238000007920 subcutaneous administration Methods 0.000 description 4
- 230000008685 targeting Effects 0.000 description 4
- 210000004881 tumor cell Anatomy 0.000 description 4
- 230000035899 viability Effects 0.000 description 4
- 238000005406 washing Methods 0.000 description 4
- QTBSBXVTEAMEQO-UHFFFAOYSA-N Acetic acid Chemical compound CC(O)=O QTBSBXVTEAMEQO-UHFFFAOYSA-N 0.000 description 3
- WEVYAHXRMPXWCK-UHFFFAOYSA-N Acetonitrile Chemical compound CC#N WEVYAHXRMPXWCK-UHFFFAOYSA-N 0.000 description 3
- 108700028369 Alleles Proteins 0.000 description 3
- DCXYFEDJOCDNAF-UHFFFAOYSA-N Asparagine Natural products OC(=O)C(N)CC(N)=O DCXYFEDJOCDNAF-UHFFFAOYSA-N 0.000 description 3
- 238000011725 BALB/c mouse Methods 0.000 description 3
- 108091003079 Bovine Serum Albumin Proteins 0.000 description 3
- 102100036301 C-C chemokine receptor type 7 Human genes 0.000 description 3
- 241000699802 Cricetulus griseus Species 0.000 description 3
- WQZGKKKJIJFFOK-QTVWNMPRSA-N D-mannopyranose Chemical compound OC[C@H]1OC(O)[C@@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-QTVWNMPRSA-N 0.000 description 3
- IAZDPXIOMUYVGZ-UHFFFAOYSA-N Dimethylsulphoxide Chemical compound CS(C)=O IAZDPXIOMUYVGZ-UHFFFAOYSA-N 0.000 description 3
- 108010021468 Fc gamma receptor IIA Proteins 0.000 description 3
- 102000009109 Fc receptors Human genes 0.000 description 3
- 108010087819 Fc receptors Proteins 0.000 description 3
- 208000012766 Growth delay Diseases 0.000 description 3
- 241000282412 Homo Species 0.000 description 3
- 101000716065 Homo sapiens C-C chemokine receptor type 7 Proteins 0.000 description 3
- 101001043809 Homo sapiens Interleukin-7 receptor subunit alpha Proteins 0.000 description 3
- 108090000978 Interleukin-4 Proteins 0.000 description 3
- 108010002616 Interleukin-5 Proteins 0.000 description 3
- 102000000743 Interleukin-5 Human genes 0.000 description 3
- 102100021593 Interleukin-7 receptor subunit alpha Human genes 0.000 description 3
- 102100029204 Low affinity immunoglobulin gamma Fc region receptor II-a Human genes 0.000 description 3
- 108091034117 Oligonucleotide Proteins 0.000 description 3
- 229930182555 Penicillin Natural products 0.000 description 3
- JGSARLDLIJGVTE-MBNYWOFBSA-N Penicillin G Chemical compound N([C@H]1[C@H]2SC([C@@H](N2C1=O)C(O)=O)(C)C)C(=O)CC1=CC=CC=C1 JGSARLDLIJGVTE-MBNYWOFBSA-N 0.000 description 3
- DNIAPMSPPWPWGF-UHFFFAOYSA-N Propylene glycol Chemical compound CC(O)CO DNIAPMSPPWPWGF-UHFFFAOYSA-N 0.000 description 3
- 108010076504 Protein Sorting Signals Proteins 0.000 description 3
- 238000012228 RNA interference-mediated gene silencing Methods 0.000 description 3
- 239000006146 Roswell Park Memorial Institute medium Substances 0.000 description 3
- MTCFGRXMJLQNBG-UHFFFAOYSA-N Serine Natural products OCC(N)C(O)=O MTCFGRXMJLQNBG-UHFFFAOYSA-N 0.000 description 3
- 108010090804 Streptavidin Proteins 0.000 description 3
- 239000002253 acid Substances 0.000 description 3
- 230000004075 alteration Effects 0.000 description 3
- 235000009582 asparagine Nutrition 0.000 description 3
- 229960001230 asparagine Drugs 0.000 description 3
- 238000011953 bioanalysis Methods 0.000 description 3
- 230000037396 body weight Effects 0.000 description 3
- 229940098773 bovine serum albumin Drugs 0.000 description 3
- 210000004899 c-terminal region Anatomy 0.000 description 3
- 235000014633 carbohydrates Nutrition 0.000 description 3
- 238000005119 centrifugation Methods 0.000 description 3
- 230000008859 change Effects 0.000 description 3
- 239000000356 contaminant Substances 0.000 description 3
- 230000002596 correlated effect Effects 0.000 description 3
- 235000018417 cysteine Nutrition 0.000 description 3
- 238000012217 deletion Methods 0.000 description 3
- 230000037430 deletion Effects 0.000 description 3
- 210000004443 dendritic cell Anatomy 0.000 description 3
- 210000003743 erythrocyte Anatomy 0.000 description 3
- 230000009368 gene silencing by RNA Effects 0.000 description 3
- 230000011365 genetic imprinting Effects 0.000 description 3
- 210000004602 germ cell Anatomy 0.000 description 3
- 230000036541 health Effects 0.000 description 3
- 210000002865 immune cell Anatomy 0.000 description 3
- 230000001506 immunosuppresive effect Effects 0.000 description 3
- 230000002757 inflammatory effect Effects 0.000 description 3
- 238000007918 intramuscular administration Methods 0.000 description 3
- 238000001990 intravenous administration Methods 0.000 description 3
- 210000000265 leukocyte Anatomy 0.000 description 3
- 238000013507 mapping Methods 0.000 description 3
- 108020004999 messenger RNA Proteins 0.000 description 3
- 239000000178 monomer Substances 0.000 description 3
- 238000005457 optimization Methods 0.000 description 3
- 229940049954 penicillin Drugs 0.000 description 3
- 230000002093 peripheral effect Effects 0.000 description 3
- 239000012071 phase Substances 0.000 description 3
- 210000004623 platelet-rich plasma Anatomy 0.000 description 3
- 230000002265 prevention Effects 0.000 description 3
- 150000003839 salts Chemical class 0.000 description 3
- 239000007790 solid phase Substances 0.000 description 3
- 210000004989 spleen cell Anatomy 0.000 description 3
- 239000003381 stabilizer Substances 0.000 description 3
- 238000010186 staining Methods 0.000 description 3
- 239000006228 supernatant Substances 0.000 description 3
- 239000000725 suspension Substances 0.000 description 3
- 230000009885 systemic effect Effects 0.000 description 3
- 230000037317 transdermal delivery Effects 0.000 description 3
- 238000010361 transduction Methods 0.000 description 3
- 230000026683 transduction Effects 0.000 description 3
- 230000009466 transformation Effects 0.000 description 3
- 210000003171 tumor-infiltrating lymphocyte Anatomy 0.000 description 3
- 238000002255 vaccination Methods 0.000 description 3
- HBZBAMXERPYTFS-SECBINFHSA-N (4S)-2-(6,7-dihydro-5H-pyrrolo[3,2-f][1,3]benzothiazol-2-yl)-4,5-dihydro-1,3-thiazole-4-carboxylic acid Chemical compound OC(=O)[C@H]1CSC(=N1)c1nc2cc3CCNc3cc2s1 HBZBAMXERPYTFS-SECBINFHSA-N 0.000 description 2
- 108091023037 Aptamer Proteins 0.000 description 2
- CIWBSHSKHKDKBQ-JLAZNSOCSA-N Ascorbic acid Chemical compound OC[C@H](O)[C@H]1OC(=O)C(O)=C1O CIWBSHSKHKDKBQ-JLAZNSOCSA-N 0.000 description 2
- 238000011740 C57BL/6 mouse Methods 0.000 description 2
- 102100027207 CD27 antigen Human genes 0.000 description 2
- 241000282693 Cercopithecidae Species 0.000 description 2
- 102000016574 Complement C3-C5 Convertases Human genes 0.000 description 2
- 108010067641 Complement C3-C5 Convertases Proteins 0.000 description 2
- SRBFZHDQGSBBOR-IOVATXLUSA-N D-xylopyranose Chemical compound O[C@@H]1COC(O)[C@H](O)[C@H]1O SRBFZHDQGSBBOR-IOVATXLUSA-N 0.000 description 2
- QOSSAOTZNIDXMA-UHFFFAOYSA-N Dicylcohexylcarbodiimide Chemical compound C1CCCCC1N=C=NC1CCCCC1 QOSSAOTZNIDXMA-UHFFFAOYSA-N 0.000 description 2
- 241000196324 Embryophyta Species 0.000 description 2
- 101000867232 Escherichia coli Heat-stable enterotoxin II Proteins 0.000 description 2
- OYTPNWYZORARHL-XHNCKOQMSA-N Gln-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCC(=O)N)N OYTPNWYZORARHL-XHNCKOQMSA-N 0.000 description 2
- FQCILXROGNOZON-YUMQZZPRSA-N Gln-Pro-Gly Chemical compound NC(=O)CC[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O FQCILXROGNOZON-YUMQZZPRSA-N 0.000 description 2
- YQPFCZVKMUVZIN-AUTRQRHGSA-N Glu-Val-Gln Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O YQPFCZVKMUVZIN-AUTRQRHGSA-N 0.000 description 2
- MIIVFRCYJABHTQ-ONGXEEELSA-N Gly-Leu-Val Chemical compound [H]NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O MIIVFRCYJABHTQ-ONGXEEELSA-N 0.000 description 2
- PDUHNKAFQXQNLH-ZETCQYMHSA-N Gly-Lys-Gly Chemical compound NCCCC[C@H](NC(=O)CN)C(=O)NCC(O)=O PDUHNKAFQXQNLH-ZETCQYMHSA-N 0.000 description 2
- 101000690301 Homo sapiens Aldo-keto reductase family 1 member C4 Proteins 0.000 description 2
- 101000914511 Homo sapiens CD27 antigen Proteins 0.000 description 2
- 101001018097 Homo sapiens L-selectin Proteins 0.000 description 2
- 101001116548 Homo sapiens Protein CBFA2T1 Proteins 0.000 description 2
- 101000738771 Homo sapiens Receptor-type tyrosine-protein phosphatase C Proteins 0.000 description 2
- 101000596234 Homo sapiens T-cell surface protein tactile Proteins 0.000 description 2
- 101000801234 Homo sapiens Tumor necrosis factor receptor superfamily member 18 Proteins 0.000 description 2
- 101000851370 Homo sapiens Tumor necrosis factor receptor superfamily member 9 Proteins 0.000 description 2
- OAKJQQAXSVQMHS-UHFFFAOYSA-N Hydrazine Chemical compound NN OAKJQQAXSVQMHS-UHFFFAOYSA-N 0.000 description 2
- 108010054477 Immunoglobulin Fab Fragments Proteins 0.000 description 2
- 102000001706 Immunoglobulin Fab Fragments Human genes 0.000 description 2
- 102000018071 Immunoglobulin Fc Fragments Human genes 0.000 description 2
- 108010091135 Immunoglobulin Fc Fragments Proteins 0.000 description 2
- 102100040019 Interferon alpha-1/13 Human genes 0.000 description 2
- 102000008070 Interferon-gamma Human genes 0.000 description 2
- 108010074328 Interferon-gamma Proteins 0.000 description 2
- 102100030703 Interleukin-22 Human genes 0.000 description 2
- PMGDADKJMCOXHX-UHFFFAOYSA-N L-Arginyl-L-glutamin-acetat Natural products NC(=N)NCCCC(N)C(=O)NC(CCC(N)=O)C(O)=O PMGDADKJMCOXHX-UHFFFAOYSA-N 0.000 description 2
- 102100033467 L-selectin Human genes 0.000 description 2
- AYFVYJQAPQTCCC-GBXIJSLDSA-N L-threonine Chemical compound C[C@@H](O)[C@H](N)C(O)=O AYFVYJQAPQTCCC-GBXIJSLDSA-N 0.000 description 2
- FEHQLKKBVJHSEC-SZMVWBNQSA-N Leu-Glu-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC(C)C)C(O)=O)=CNC2=C1 FEHQLKKBVJHSEC-SZMVWBNQSA-N 0.000 description 2
- JGKHAFUAPZCCDU-BZSNNMDCSA-N Leu-Tyr-Leu Chemical compound CC(C)C[C@H]([NH3+])C(=O)N[C@H](C(=O)N[C@@H](CC(C)C)C([O-])=O)CC1=CC=C(O)C=C1 JGKHAFUAPZCCDU-BZSNNMDCSA-N 0.000 description 2
- AIMGJYMCTAABEN-GVXVVHGQSA-N Leu-Val-Glu Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O AIMGJYMCTAABEN-GVXVVHGQSA-N 0.000 description 2
- 101000686985 Mouse mammary tumor virus (strain C3H) Protein PR73 Proteins 0.000 description 2
- 238000005481 NMR spectroscopy Methods 0.000 description 2
- 206010061309 Neoplasm progression Diseases 0.000 description 2
- 230000004989 O-glycosylation Effects 0.000 description 2
- 241000276498 Pollachius virens Species 0.000 description 2
- DLRVVLDZNNYCBX-UHFFFAOYSA-N Polydextrose Polymers OC1C(O)C(O)C(CO)OC1OCC1C(O)C(O)C(O)C(O)O1 DLRVVLDZNNYCBX-UHFFFAOYSA-N 0.000 description 2
- 239000012980 RPMI-1640 medium Substances 0.000 description 2
- 241000700159 Rattus Species 0.000 description 2
- 102100037422 Receptor-type tyrosine-protein phosphatase C Human genes 0.000 description 2
- 108010008281 Recombinant Fusion Proteins Proteins 0.000 description 2
- 102000007056 Recombinant Fusion Proteins Human genes 0.000 description 2
- YMTLKLXDFCSCNX-BYPYZUCNSA-N Ser-Gly-Gly Chemical compound OC[C@H](N)C(=O)NCC(=O)NCC(O)=O YMTLKLXDFCSCNX-BYPYZUCNSA-N 0.000 description 2
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 2
- 229920002472 Starch Polymers 0.000 description 2
- 102100021669 Stromal cell-derived factor 1 Human genes 0.000 description 2
- 101710088580 Stromal cell-derived factor 1 Proteins 0.000 description 2
- 229930006000 Sucrose Natural products 0.000 description 2
- CZMRCDWAGMRECN-UGDNZRGBSA-N Sucrose Chemical compound O[C@H]1[C@H](O)[C@@H](CO)O[C@@]1(CO)O[C@@H]1[C@H](O)[C@@H](O)[C@H](O)[C@@H](CO)O1 CZMRCDWAGMRECN-UGDNZRGBSA-N 0.000 description 2
- 230000006052 T cell proliferation Effects 0.000 description 2
- 102100035268 T-cell surface protein tactile Human genes 0.000 description 2
- YOOAQCZYZHGUAZ-KATARQTJSA-N Thr-Leu-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O YOOAQCZYZHGUAZ-KATARQTJSA-N 0.000 description 2
- 239000004473 Threonine Substances 0.000 description 2
- MBLJBGZWLHTJBH-SZMVWBNQSA-N Trp-Val-Arg Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O)=CNC2=C1 MBLJBGZWLHTJBH-SZMVWBNQSA-N 0.000 description 2
- 102100033728 Tumor necrosis factor receptor superfamily member 18 Human genes 0.000 description 2
- 102100036856 Tumor necrosis factor receptor superfamily member 9 Human genes 0.000 description 2
- YSGAPESOXHFTQY-IHRRRGAJSA-N Tyr-Met-Asp Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N YSGAPESOXHFTQY-IHRRRGAJSA-N 0.000 description 2
- 108010066342 Virus Receptors Proteins 0.000 description 2
- 102000018265 Virus Receptors Human genes 0.000 description 2
- 239000013543 active substance Substances 0.000 description 2
- 108010069020 alanyl-prolyl-glycine Proteins 0.000 description 2
- BFNBIHQBYMNNAN-UHFFFAOYSA-N ammonium sulfate Chemical compound N.N.OS(O)(=O)=O BFNBIHQBYMNNAN-UHFFFAOYSA-N 0.000 description 2
- 229910052921 ammonium sulfate Inorganic materials 0.000 description 2
- 235000011130 ammonium sulphate Nutrition 0.000 description 2
- 108010008355 arginyl-glutamine Proteins 0.000 description 2
- 108010018691 arginyl-threonyl-arginine Proteins 0.000 description 2
- 125000000613 asparagine group Chemical group N[C@@H](CC(N)=O)C(=O)* 0.000 description 2
- 239000012131 assay buffer Substances 0.000 description 2
- VSRXQHXAPYXROS-UHFFFAOYSA-N azanide;cyclobutane-1,1-dicarboxylic acid;platinum(2+) Chemical compound [NH2-].[NH2-].[Pt+2].OC(=O)C1(C(O)=O)CCC1 VSRXQHXAPYXROS-UHFFFAOYSA-N 0.000 description 2
- 230000004888 barrier function Effects 0.000 description 2
- 230000003915 cell function Effects 0.000 description 2
- 230000001413 cellular effect Effects 0.000 description 2
- 238000004587 chromatography analysis Methods 0.000 description 2
- 238000003776 cleavage reaction Methods 0.000 description 2
- 238000000576 coating method Methods 0.000 description 2
- 210000001072 colon Anatomy 0.000 description 2
- 238000012875 competitive assay Methods 0.000 description 2
- 230000004154 complement system Effects 0.000 description 2
- 238000007906 compression Methods 0.000 description 2
- 230000006835 compression Effects 0.000 description 2
- 239000002254 cytotoxic agent Substances 0.000 description 2
- 230000003111 delayed effect Effects 0.000 description 2
- 238000013461 design Methods 0.000 description 2
- 238000011161 development Methods 0.000 description 2
- 230000018109 developmental process Effects 0.000 description 2
- 235000014113 dietary fatty acids Nutrition 0.000 description 2
- PQYUGUXEJHLOIL-UHFFFAOYSA-N diethoxysilyl triethyl silicate Chemical compound C(C)O[SiH](O[Si](OCC)(OCC)OCC)OCC PQYUGUXEJHLOIL-UHFFFAOYSA-N 0.000 description 2
- 239000008298 dragée Substances 0.000 description 2
- 230000001804 emulsifying effect Effects 0.000 description 2
- 239000000839 emulsion Substances 0.000 description 2
- 239000003623 enhancer Substances 0.000 description 2
- 230000002708 enhancing effect Effects 0.000 description 2
- 231100000655 enterotoxin Toxicity 0.000 description 2
- 230000002255 enzymatic effect Effects 0.000 description 2
- 230000007717 exclusion Effects 0.000 description 2
- 238000013265 extended release Methods 0.000 description 2
- 239000000194 fatty acid Substances 0.000 description 2
- 229930195729 fatty acid Natural products 0.000 description 2
- 238000001914 filtration Methods 0.000 description 2
- MHMNJMPURVTYEJ-UHFFFAOYSA-N fluorescein-5-isothiocyanate Chemical compound O1C(=O)C2=CC(N=C=S)=CC=C2C21C1=CC=C(O)C=C1OC1=CC(O)=CC=C21 MHMNJMPURVTYEJ-UHFFFAOYSA-N 0.000 description 2
- 108020001507 fusion proteins Proteins 0.000 description 2
- 102000037865 fusion proteins Human genes 0.000 description 2
- 229930182830 galactose Natural products 0.000 description 2
- ASUTZQLVASHGKV-JDFRZJQESA-N galanthamine Chemical compound O1C(=C23)C(OC)=CC=C2CN(C)CC[C@]23[C@@H]1C[C@@H](O)C=C2 ASUTZQLVASHGKV-JDFRZJQESA-N 0.000 description 2
- 239000000499 gel Substances 0.000 description 2
- 238000003198 gene knock in Methods 0.000 description 2
- 238000010353 genetic engineering Methods 0.000 description 2
- 125000000291 glutamic acid group Chemical group N[C@@H](CCC(O)=O)C(=O)* 0.000 description 2
- 108010067216 glycyl-glycyl-glycine Proteins 0.000 description 2
- XKUKSGPZAADMRA-UHFFFAOYSA-N glycyl-glycyl-glycine Natural products NCC(=O)NCC(=O)NCC(O)=O XKUKSGPZAADMRA-UHFFFAOYSA-N 0.000 description 2
- 108010089804 glycyl-threonine Proteins 0.000 description 2
- PCHJSUWPFVWCPO-UHFFFAOYSA-N gold Chemical compound [Au] PCHJSUWPFVWCPO-UHFFFAOYSA-N 0.000 description 2
- 229910052737 gold Inorganic materials 0.000 description 2
- 239000010931 gold Substances 0.000 description 2
- 239000008187 granular material Substances 0.000 description 2
- 239000001963 growth medium Substances 0.000 description 2
- 102000054751 human RUNX1T1 Human genes 0.000 description 2
- 210000005260 human cell Anatomy 0.000 description 2
- 238000002013 hydrophilic interaction chromatography Methods 0.000 description 2
- 229920001477 hydrophilic polymer Polymers 0.000 description 2
- 230000002209 hydrophobic effect Effects 0.000 description 2
- NPZTUJOABDZTLV-UHFFFAOYSA-N hydroxybenzotriazole Substances O=C1C=CC=C2NNN=C12 NPZTUJOABDZTLV-UHFFFAOYSA-N 0.000 description 2
- 239000001866 hydroxypropyl methyl cellulose Substances 0.000 description 2
- 235000010979 hydroxypropyl methyl cellulose Nutrition 0.000 description 2
- 229920003088 hydroxypropyl methyl cellulose Polymers 0.000 description 2
- UFVKGYZPFZQRLF-UHFFFAOYSA-N hydroxypropyl methyl cellulose Chemical compound OC1C(O)C(OC)OC(CO)C1OC1C(O)C(O)C(OC2C(C(O)C(OC3C(C(O)C(O)C(CO)O3)O)C(CO)O2)O)C(CO)O1 UFVKGYZPFZQRLF-UHFFFAOYSA-N 0.000 description 2
- 230000002998 immunogenetic effect Effects 0.000 description 2
- 230000016784 immunoglobulin production Effects 0.000 description 2
- 229940072221 immunoglobulins Drugs 0.000 description 2
- 230000002055 immunohistochemical effect Effects 0.000 description 2
- 230000006872 improvement Effects 0.000 description 2
- 238000003780 insertion Methods 0.000 description 2
- 230000037431 insertion Effects 0.000 description 2
- 229960003130 interferon gamma Drugs 0.000 description 2
- 230000004073 interleukin-2 production Effects 0.000 description 2
- 239000007928 intraperitoneal injection Substances 0.000 description 2
- 238000002955 isolation Methods 0.000 description 2
- 238000012417 linear regression Methods 0.000 description 2
- 238000011068 loading method Methods 0.000 description 2
- 239000007937 lozenge Substances 0.000 description 2
- 239000006166 lysate Substances 0.000 description 2
- 230000002101 lytic effect Effects 0.000 description 2
- 210000004962 mammalian cell Anatomy 0.000 description 2
- 239000003550 marker Substances 0.000 description 2
- 239000011159 matrix material Substances 0.000 description 2
- 125000001360 methionine group Chemical group N[C@@H](CCSC)C(=O)* 0.000 description 2
- 229920000609 methyl cellulose Polymers 0.000 description 2
- 239000001923 methylcellulose Substances 0.000 description 2
- 235000010981 methylcellulose Nutrition 0.000 description 2
- 238000007799 mixed lymphocyte reaction assay Methods 0.000 description 2
- 238000002156 mixing Methods 0.000 description 2
- OSTGTTZJOCZWJG-UHFFFAOYSA-N nitrosourea Chemical compound NC(=O)N=NO OSTGTTZJOCZWJG-UHFFFAOYSA-N 0.000 description 2
- 239000002674 ointment Substances 0.000 description 2
- 210000001672 ovary Anatomy 0.000 description 2
- LUYQYZLEHLTPBH-UHFFFAOYSA-N perfluorobutanesulfonyl fluoride Chemical compound FC(F)(F)C(F)(F)C(F)(F)C(F)(F)S(F)(=O)=O LUYQYZLEHLTPBH-UHFFFAOYSA-N 0.000 description 2
- 210000005259 peripheral blood Anatomy 0.000 description 2
- 239000011886 peripheral blood Substances 0.000 description 2
- 230000002085 persistent effect Effects 0.000 description 2
- 239000000825 pharmaceutical preparation Substances 0.000 description 2
- 229920001184 polypeptide Polymers 0.000 description 2
- 229960000688 pomalidomide Drugs 0.000 description 2
- UVSMNLNDYGZFPF-UHFFFAOYSA-N pomalidomide Chemical compound O=C1C=2C(N)=CC=CC=2C(=O)N1C1CCC(=O)NC1=O UVSMNLNDYGZFPF-UHFFFAOYSA-N 0.000 description 2
- 230000003389 potentiating effect Effects 0.000 description 2
- 239000003755 preservative agent Substances 0.000 description 2
- 210000004986 primary T-cell Anatomy 0.000 description 2
- 230000008569 process Effects 0.000 description 2
- 108010020755 prolyl-glycyl-glycine Proteins 0.000 description 2
- 230000010076 replication Effects 0.000 description 2
- 238000011160 research Methods 0.000 description 2
- 230000007017 scission Effects 0.000 description 2
- 210000002966 serum Anatomy 0.000 description 2
- 108010007375 seryl-seryl-seryl-arginine Proteins 0.000 description 2
- 230000019491 signal transduction Effects 0.000 description 2
- 150000003384 small molecules Chemical group 0.000 description 2
- 239000001488 sodium phosphate Substances 0.000 description 2
- 229910000162 sodium phosphate Inorganic materials 0.000 description 2
- 239000007787 solid Substances 0.000 description 2
- 238000012289 standard assay Methods 0.000 description 2
- 239000000126 substance Substances 0.000 description 2
- 239000005720 sucrose Substances 0.000 description 2
- 150000008163 sugars Chemical class 0.000 description 2
- 231100000617 superantigen Toxicity 0.000 description 2
- 239000003826 tablet Substances 0.000 description 2
- 238000002560 therapeutic procedure Methods 0.000 description 2
- 125000000341 threoninyl group Chemical group [H]OC([H])(C([H])([H])[H])C([H])(N([H])[H])C(*)=O 0.000 description 2
- 238000011200 topical administration Methods 0.000 description 2
- 230000000699 topical effect Effects 0.000 description 2
- 239000012096 transfection reagent Substances 0.000 description 2
- RYFMWSXOAZQYPI-UHFFFAOYSA-K trisodium phosphate Chemical compound [Na+].[Na+].[Na+].[O-]P([O-])([O-])=O RYFMWSXOAZQYPI-UHFFFAOYSA-K 0.000 description 2
- 230000005751 tumor progression Effects 0.000 description 2
- 241000701161 unidentified adenovirus Species 0.000 description 2
- 230000003827 upregulation Effects 0.000 description 2
- 230000003442 weekly effect Effects 0.000 description 2
- 238000001262 western blot Methods 0.000 description 2
- 238000002424 x-ray crystallography Methods 0.000 description 2
- 210000005253 yeast cell Anatomy 0.000 description 2
- LNAZSHAWQACDHT-XIYTZBAFSA-N (2r,3r,4s,5r,6s)-4,5-dimethoxy-2-(methoxymethyl)-3-[(2s,3r,4s,5r,6r)-3,4,5-trimethoxy-6-(methoxymethyl)oxan-2-yl]oxy-6-[(2r,3r,4s,5r,6r)-4,5,6-trimethoxy-2-(methoxymethyl)oxan-3-yl]oxyoxane Chemical compound CO[C@@H]1[C@@H](OC)[C@H](OC)[C@@H](COC)O[C@H]1O[C@H]1[C@H](OC)[C@@H](OC)[C@H](O[C@H]2[C@@H]([C@@H](OC)[C@H](OC)O[C@@H]2COC)OC)O[C@@H]1COC LNAZSHAWQACDHT-XIYTZBAFSA-N 0.000 description 1
- KYBXNPIASYUWLN-WUCPZUCCSA-N (2s)-5-hydroxypyrrolidine-2-carboxylic acid Chemical compound OC1CC[C@@H](C(O)=O)N1 KYBXNPIASYUWLN-WUCPZUCCSA-N 0.000 description 1
- IRKXGKIPOMIQOD-ZZWDRFIYSA-N (3s,4r,5s,6s)-3-fluoro-6-methyloxane-2,4,5-triol Chemical group C[C@@H]1OC(O)[C@@H](F)[C@H](O)[C@@H]1O IRKXGKIPOMIQOD-ZZWDRFIYSA-N 0.000 description 1
- 125000003088 (fluoren-9-ylmethoxy)carbonyl group Chemical group 0.000 description 1
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 1
- ASOKPJOREAFHNY-UHFFFAOYSA-N 1-Hydroxybenzotriazole Chemical compound C1=CC=C2N(O)N=NC2=C1 ASOKPJOREAFHNY-UHFFFAOYSA-N 0.000 description 1
- IXPNQXFRVYWDDI-UHFFFAOYSA-N 1-methyl-2,4-dioxo-1,3-diazinane-5-carboximidamide Chemical compound CN1CC(C(N)=N)C(=O)NC1=O IXPNQXFRVYWDDI-UHFFFAOYSA-N 0.000 description 1
- QUTSYCOAZVHGGT-UHFFFAOYSA-N 2,6-bis(bromomethyl)pyridine Chemical compound BrCC1=CC=CC(CBr)=N1 QUTSYCOAZVHGGT-UHFFFAOYSA-N 0.000 description 1
- 125000000979 2-amino-2-oxoethyl group Chemical group [H]C([*])([H])C(=O)N([H])[H] 0.000 description 1
- KZMAWJRXKGLWGS-UHFFFAOYSA-N 2-chloro-n-[4-(4-methoxyphenyl)-1,3-thiazol-2-yl]-n-(3-methoxypropyl)acetamide Chemical compound S1C(N(C(=O)CCl)CCCOC)=NC(C=2C=CC(OC)=CC=2)=C1 KZMAWJRXKGLWGS-UHFFFAOYSA-N 0.000 description 1
- HZLCGUXUOFWCCN-UHFFFAOYSA-N 2-hydroxynonadecane-1,2,3-tricarboxylic acid Chemical compound CCCCCCCCCCCCCCCCC(C(O)=O)C(O)(C(O)=O)CC(O)=O HZLCGUXUOFWCCN-UHFFFAOYSA-N 0.000 description 1
- 229940117976 5-hydroxylysine Drugs 0.000 description 1
- 101150052384 50 gene Proteins 0.000 description 1
- QTBSBXVTEAMEQO-UHFFFAOYSA-M Acetate Chemical compound CC([O-])=O QTBSBXVTEAMEQO-UHFFFAOYSA-M 0.000 description 1
- NIXOWILDQLNWCW-UHFFFAOYSA-N Acrylic acid Chemical group OC(=O)C=C NIXOWILDQLNWCW-UHFFFAOYSA-N 0.000 description 1
- 208000024893 Acute lymphoblastic leukemia Diseases 0.000 description 1
- 208000014697 Acute lymphocytic leukaemia Diseases 0.000 description 1
- 208000031261 Acute myeloid leukaemia Diseases 0.000 description 1
- 229920001817 Agar Polymers 0.000 description 1
- YYSWCHMLFJLLBJ-ZLUOBGJFSA-N Ala-Ala-Ser Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O YYSWCHMLFJLLBJ-ZLUOBGJFSA-N 0.000 description 1
- JBGSZRYCXBPWGX-BQBZGAKWSA-N Ala-Arg-Gly Chemical compound OC(=O)CNC(=O)[C@@H](NC(=O)[C@@H](N)C)CCCN=C(N)N JBGSZRYCXBPWGX-BQBZGAKWSA-N 0.000 description 1
- FXKNPWNXPQZLES-ZLUOBGJFSA-N Ala-Asn-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O FXKNPWNXPQZLES-ZLUOBGJFSA-N 0.000 description 1
- ZDILXFDENZVOTL-BPNCWPANSA-N Ala-Val-Tyr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O ZDILXFDENZVOTL-BPNCWPANSA-N 0.000 description 1
- GUBGYTABKSRVRQ-XLOQQCSPSA-N Alpha-Lactose Chemical compound O[C@@H]1[C@@H](O)[C@@H](O)[C@@H](CO)O[C@H]1O[C@@H]1[C@@H](CO)O[C@H](O)[C@H](O)[C@H]1O GUBGYTABKSRVRQ-XLOQQCSPSA-N 0.000 description 1
- 102100021761 Alpha-mannosidase 2 Human genes 0.000 description 1
- ATRRKUHOCOJYRX-UHFFFAOYSA-N Ammonium bicarbonate Chemical compound [NH4+].OC([O-])=O ATRRKUHOCOJYRX-UHFFFAOYSA-N 0.000 description 1
- 229910000013 Ammonium bicarbonate Inorganic materials 0.000 description 1
- 108091093088 Amplicon Proteins 0.000 description 1
- 108010032595 Antibody Binding Sites Proteins 0.000 description 1
- 101000642536 Apis mellifera Venom serine protease 34 Proteins 0.000 description 1
- MAISCYVJLBBRNU-DCAQKATOSA-N Arg-Asn-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CCCN=C(N)N)N MAISCYVJLBBRNU-DCAQKATOSA-N 0.000 description 1
- NTAZNGWBXRVEDJ-FXQIFTODSA-N Arg-Asp-Asp Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O NTAZNGWBXRVEDJ-FXQIFTODSA-N 0.000 description 1
- YNSGXDWWPCGGQS-YUMQZZPRSA-N Arg-Gly-Gln Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)NCC(=O)N[C@@H](CCC(N)=O)C(O)=O YNSGXDWWPCGGQS-YUMQZZPRSA-N 0.000 description 1
- PRLPSDIHSRITSF-UNQGMJICSA-N Arg-Phe-Thr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O PRLPSDIHSRITSF-UNQGMJICSA-N 0.000 description 1
- AIFHRTPABBBHKU-RCWTZXSCSA-N Arg-Thr-Arg Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O AIFHRTPABBBHKU-RCWTZXSCSA-N 0.000 description 1
- RCFGLXMZDYNRSC-CIUDSAMLSA-N Asn-Lys-Ala Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(O)=O RCFGLXMZDYNRSC-CIUDSAMLSA-N 0.000 description 1
- MYTHOBCLNIOFBL-SRVKXCTJSA-N Asn-Ser-Tyr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O MYTHOBCLNIOFBL-SRVKXCTJSA-N 0.000 description 1
- QXHVOUSPVAWEMX-ZLUOBGJFSA-N Asp-Asp-Ser Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O QXHVOUSPVAWEMX-ZLUOBGJFSA-N 0.000 description 1
- GYNUXDMCDILYIQ-QRTARXTBSA-N Asp-Val-Trp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)NC(=O)[C@H](CC(=O)O)N GYNUXDMCDILYIQ-QRTARXTBSA-N 0.000 description 1
- 241000416162 Astragalus gummifer Species 0.000 description 1
- 208000003950 B-cell lymphoma Diseases 0.000 description 1
- 208000032791 BCR-ABL1 positive chronic myelogenous leukemia Diseases 0.000 description 1
- 241000701822 Bovine papillomavirus Species 0.000 description 1
- 101710155857 C-C motif chemokine 2 Proteins 0.000 description 1
- 108010065524 CD52 Antigen Proteins 0.000 description 1
- 102000013135 CD52 Antigen Human genes 0.000 description 1
- 108010078791 Carrier Proteins Proteins 0.000 description 1
- 102000016289 Cell Adhesion Molecules Human genes 0.000 description 1
- 102000019034 Chemokines Human genes 0.000 description 1
- 108010012236 Chemokines Proteins 0.000 description 1
- 208000010833 Chronic myeloid leukaemia Diseases 0.000 description 1
- 108010047041 Complementarity Determining Regions Proteins 0.000 description 1
- 229920002261 Corn starch Polymers 0.000 description 1
- 241000557626 Corvus corax Species 0.000 description 1
- 108010069514 Cyclic Peptides Proteins 0.000 description 1
- 102000001189 Cyclic Peptides Human genes 0.000 description 1
- SZQCDCKIGWQAQN-FXQIFTODSA-N Cys-Arg-Ala Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(O)=O SZQCDCKIGWQAQN-FXQIFTODSA-N 0.000 description 1
- FBPFZTCFMRRESA-FSIIMWSLSA-N D-Glucitol Natural products OC[C@H](O)[C@H](O)[C@@H](O)[C@H](O)CO FBPFZTCFMRRESA-FSIIMWSLSA-N 0.000 description 1
- FBPFZTCFMRRESA-KVTDHHQDSA-N D-Mannitol Chemical compound OC[C@@H](O)[C@@H](O)[C@H](O)[C@H](O)CO FBPFZTCFMRRESA-KVTDHHQDSA-N 0.000 description 1
- FBPFZTCFMRRESA-JGWLITMVSA-N D-glucitol Chemical compound OC[C@H](O)[C@@H](O)[C@H](O)[C@H](O)CO FBPFZTCFMRRESA-JGWLITMVSA-N 0.000 description 1
- 241000702421 Dependoparvovirus Species 0.000 description 1
- 101100012887 Drosophila melanogaster btl gene Proteins 0.000 description 1
- 101100012878 Drosophila melanogaster htl gene Proteins 0.000 description 1
- 239000006144 Dulbecco’s modified Eagle's medium Substances 0.000 description 1
- 238000012286 ELISA Assay Methods 0.000 description 1
- 239000001856 Ethyl cellulose Substances 0.000 description 1
- ZZSNKZQZMQGXPY-UHFFFAOYSA-N Ethyl cellulose Chemical compound CCOCC1OC(OC)C(OCC)C(OCC)C1OC1C(O)C(O)C(OC)C(CO)O1 ZZSNKZQZMQGXPY-UHFFFAOYSA-N 0.000 description 1
- 108091006020 Fc-tagged proteins Proteins 0.000 description 1
- 101150050927 Fcgrt gene Proteins 0.000 description 1
- 108010045674 Fucose-1-phosphate guanylyltransferase Proteins 0.000 description 1
- 102000006471 Fucosyltransferases Human genes 0.000 description 1
- 108010019236 Fucosyltransferases Proteins 0.000 description 1
- LQEBEXMHBLQMDB-UHFFFAOYSA-N GDP-L-fucose Natural products OC1C(O)C(O)C(C)OC1OP(O)(=O)OP(O)(=O)OCC1C(O)C(O)C(N2C3=C(C(N=C(N)N3)=O)N=C2)O1 LQEBEXMHBLQMDB-UHFFFAOYSA-N 0.000 description 1
- LQEBEXMHBLQMDB-JGQUBWHWSA-N GDP-beta-L-fucose Chemical compound O[C@H]1[C@H](O)[C@H](O)[C@H](C)O[C@@H]1OP(O)(=O)OP(O)(=O)OC[C@@H]1[C@@H](O)[C@@H](O)[C@H](N2C3=C(C(NC(N)=N3)=O)N=C2)O1 LQEBEXMHBLQMDB-JGQUBWHWSA-N 0.000 description 1
- 101710203794 GDP-fucose transporter Proteins 0.000 description 1
- 108010062427 GDP-mannose 4,6-dehydratase Proteins 0.000 description 1
- 108010020034 GDPfucose synthetase Proteins 0.000 description 1
- 102000002312 GDPmannose 4,6-dehydratase Human genes 0.000 description 1
- 108010010803 Gelatin Proteins 0.000 description 1
- 108700039691 Genetic Promoter Regions Proteins 0.000 description 1
- 108700007698 Genetic Terminator Regions Proteins 0.000 description 1
- MSHXWFKYXJTLEZ-CIUDSAMLSA-N Gln-Met-Asn Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CCC(=O)N)N MSHXWFKYXJTLEZ-CIUDSAMLSA-N 0.000 description 1
- HPBKQFJXDUVNQV-FHWLQOOXSA-N Gln-Tyr-Tyr Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)O)NC(=O)[C@H](CCC(=O)N)N)O HPBKQFJXDUVNQV-FHWLQOOXSA-N 0.000 description 1
- AVZHGSCDKIQZPQ-CIUDSAMLSA-N Glu-Arg-Ala Chemical compound C[C@H](NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@@H](N)CCC(O)=O)C(O)=O AVZHGSCDKIQZPQ-CIUDSAMLSA-N 0.000 description 1
- SBCYJMOOHUDWDA-NUMRIWBASA-N Glu-Asp-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O SBCYJMOOHUDWDA-NUMRIWBASA-N 0.000 description 1
- INGJLBQKTRJLFO-UKJIMTQDSA-N Glu-Ile-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H](N)CCC(O)=O INGJLBQKTRJLFO-UKJIMTQDSA-N 0.000 description 1
- HVKAAUOFFTUSAA-XDTLVQLUSA-N Glu-Tyr-Ala Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C)C(O)=O HVKAAUOFFTUSAA-XDTLVQLUSA-N 0.000 description 1
- WQZGKKKJIJFFOK-GASJEMHNSA-N Glucose Natural products OC[C@H]1OC(O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-GASJEMHNSA-N 0.000 description 1
- KRRMJKMGWWXWDW-STQMWFEESA-N Gly-Arg-Phe Chemical compound NC(=N)NCCC[C@H](NC(=O)CN)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 KRRMJKMGWWXWDW-STQMWFEESA-N 0.000 description 1
- DTPOVRRYXPJJAZ-FJXKBIBVSA-N Gly-Arg-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CCCN=C(N)N DTPOVRRYXPJJAZ-FJXKBIBVSA-N 0.000 description 1
- BYYNJRSNDARRBX-YFKPBYRVSA-N Gly-Gln-Gly Chemical compound NCC(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O BYYNJRSNDARRBX-YFKPBYRVSA-N 0.000 description 1
- WNZOCXUOGVYYBJ-CDMKHQONSA-N Gly-Phe-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)NC(=O)CN)O WNZOCXUOGVYYBJ-CDMKHQONSA-N 0.000 description 1
- WCORRBXVISTKQL-WHFBIAKZSA-N Gly-Ser-Ser Chemical compound NCC(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O WCORRBXVISTKQL-WHFBIAKZSA-N 0.000 description 1
- TVTZEOHWHUVYCG-KYNKHSRBSA-N Gly-Thr-Thr Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O TVTZEOHWHUVYCG-KYNKHSRBSA-N 0.000 description 1
- NGBGZCUWFVVJKC-IRXDYDNUSA-N Gly-Tyr-Tyr Chemical compound C([C@H](NC(=O)CN)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=C(O)C=C1 NGBGZCUWFVVJKC-IRXDYDNUSA-N 0.000 description 1
- 102000051366 Glycosyltransferases Human genes 0.000 description 1
- 108700023372 Glycosyltransferases Proteins 0.000 description 1
- HTTJABKRGRZYRN-UHFFFAOYSA-N Heparin Chemical compound OC1C(NC(=O)C)C(O)OC(COS(O)(=O)=O)C1OC1C(OS(O)(=O)=O)C(O)C(OC2C(C(OS(O)(=O)=O)C(OC3C(C(O)C(O)C(O3)C(O)=O)OS(O)(=O)=O)C(CO)O2)NS(O)(=O)=O)C(C(O)=O)O1 HTTJABKRGRZYRN-UHFFFAOYSA-N 0.000 description 1
- 101710083479 Hepatitis A virus cellular receptor 2 homolog Proteins 0.000 description 1
- 101100005713 Homo sapiens CD4 gene Proteins 0.000 description 1
- 101000913074 Homo sapiens High affinity immunoglobulin gamma Fc receptor I Proteins 0.000 description 1
- 101001002657 Homo sapiens Interleukin-2 Proteins 0.000 description 1
- 101000917839 Homo sapiens Low affinity immunoglobulin gamma Fc region receptor III-B Proteins 0.000 description 1
- 101100369640 Homo sapiens TIGIT gene Proteins 0.000 description 1
- 101000764622 Homo sapiens Transmembrane and immunoglobulin domain-containing protein 2 Proteins 0.000 description 1
- 229920002153 Hydroxypropyl cellulose Polymers 0.000 description 1
- 108091058560 IL8 Proteins 0.000 description 1
- JHNJNTMTZHEDLJ-NAKRPEOUSA-N Ile-Ser-Arg Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O JHNJNTMTZHEDLJ-NAKRPEOUSA-N 0.000 description 1
- 102000037982 Immune checkpoint proteins Human genes 0.000 description 1
- 108091008036 Immune checkpoint proteins Proteins 0.000 description 1
- 108010067060 Immunoglobulin Variable Region Proteins 0.000 description 1
- 102000017727 Immunoglobulin Variable Region Human genes 0.000 description 1
- XUJNEKJLAYXESH-REOHCLBHSA-N L-Cysteine Chemical compound SC[C@H](N)C(O)=O XUJNEKJLAYXESH-REOHCLBHSA-N 0.000 description 1
- 102100040648 L-fucose kinase Human genes 0.000 description 1
- GUBGYTABKSRVRQ-QKKXKWKRSA-N Lactose Natural products OC[C@H]1O[C@@H](O[C@H]2[C@H](O)[C@@H](O)C(O)O[C@@H]2CO)[C@H](O)[C@@H](O)[C@H]1O GUBGYTABKSRVRQ-QKKXKWKRSA-N 0.000 description 1
- 108090001090 Lectins Proteins 0.000 description 1
- 102000004856 Lectins Human genes 0.000 description 1
- 241000880493 Leptailurus serval Species 0.000 description 1
- OVZLLFONXILPDZ-VOAKCMCISA-N Leu-Lys-Thr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(O)=O OVZLLFONXILPDZ-VOAKCMCISA-N 0.000 description 1
- KIZIOFNVSOSKJI-CIUDSAMLSA-N Leu-Ser-Cys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)O)N KIZIOFNVSOSKJI-CIUDSAMLSA-N 0.000 description 1
- SBANPBVRHYIMRR-GARJFASQSA-N Leu-Ser-Pro Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CO)C(=O)N1CCC[C@@H]1C(=O)O)N SBANPBVRHYIMRR-GARJFASQSA-N 0.000 description 1
- SBANPBVRHYIMRR-UHFFFAOYSA-N Leu-Ser-Pro Natural products CC(C)CC(N)C(=O)NC(CO)C(=O)N1CCCC1C(O)=O SBANPBVRHYIMRR-UHFFFAOYSA-N 0.000 description 1
- LCNASHSOFMRYFO-WDCWCFNPSA-N Leu-Thr-Gln Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CCC(N)=O LCNASHSOFMRYFO-WDCWCFNPSA-N 0.000 description 1
- 102100029185 Low affinity immunoglobulin gamma Fc region receptor III-B Human genes 0.000 description 1
- DGWXCIORNLWGGG-CIUDSAMLSA-N Lys-Asn-Ser Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O DGWXCIORNLWGGG-CIUDSAMLSA-N 0.000 description 1
- 239000004472 Lysine Substances 0.000 description 1
- 201000003791 MALT lymphoma Diseases 0.000 description 1
- 102000043129 MHC class I family Human genes 0.000 description 1
- 108091054437 MHC class I family Proteins 0.000 description 1
- 102000043131 MHC class II family Human genes 0.000 description 1
- 108091054438 MHC class II family Proteins 0.000 description 1
- 239000012515 MabSelect SuRe Substances 0.000 description 1
- 241000829100 Macaca mulatta polyomavirus 1 Species 0.000 description 1
- 235000019759 Maize starch Nutrition 0.000 description 1
- 241000124008 Mammalia Species 0.000 description 1
- 229930195725 Mannitol Natural products 0.000 description 1
- 108010090665 Mannosyl-Glycoprotein Endo-beta-N-Acetylglucosaminidase Proteins 0.000 description 1
- 208000025205 Mantle-Cell Lymphoma Diseases 0.000 description 1
- CAODKDAPYGUMLK-FXQIFTODSA-N Met-Asn-Ser Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O CAODKDAPYGUMLK-FXQIFTODSA-N 0.000 description 1
- 108090000143 Mouse Proteins Proteins 0.000 description 1
- 101100369641 Mus musculus Tigit gene Proteins 0.000 description 1
- 208000033761 Myelogenous Chronic BCR-ABL Positive Leukemia Diseases 0.000 description 1
- 208000033776 Myeloid Acute Leukemia Diseases 0.000 description 1
- OVRNDRQMDRJTHS-CBQIKETKSA-N N-Acetyl-D-Galactosamine Chemical compound CC(=O)N[C@H]1[C@@H](O)O[C@H](CO)[C@H](O)[C@@H]1O OVRNDRQMDRJTHS-CBQIKETKSA-N 0.000 description 1
- NQTADLQHYWFPDB-UHFFFAOYSA-N N-Hydroxysuccinimide Chemical compound ON1C(=O)CCC1=O NQTADLQHYWFPDB-UHFFFAOYSA-N 0.000 description 1
- WHNWPMSKXPGLAX-UHFFFAOYSA-N N-Vinyl-2-pyrrolidone Chemical compound C=CN1CCCC1=O WHNWPMSKXPGLAX-UHFFFAOYSA-N 0.000 description 1
- MBLBDJOUHNCFQT-UHFFFAOYSA-N N-acetyl-D-galactosamine Natural products CC(=O)NC(C=O)C(O)C(O)C(O)CO MBLBDJOUHNCFQT-UHFFFAOYSA-N 0.000 description 1
- BKAYIFDRRZZKNF-VIFPVBQESA-N N-acetylcarnosine Chemical compound CC(=O)NCCC(=O)N[C@H](C(O)=O)CC1=CN=CN1 BKAYIFDRRZZKNF-VIFPVBQESA-N 0.000 description 1
- 230000004988 N-glycosylation Effects 0.000 description 1
- 108010006232 Neuraminidase Proteins 0.000 description 1
- 102000005348 Neuraminidase Human genes 0.000 description 1
- 239000000020 Nitrocellulose Substances 0.000 description 1
- 241000283973 Oryctolagus cuniculus Species 0.000 description 1
- 108090000526 Papain Proteins 0.000 description 1
- XDMMOISUAHXXFD-SRVKXCTJSA-N Phe-Ser-Asp Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O XDMMOISUAHXXFD-SRVKXCTJSA-N 0.000 description 1
- BPIMVBKDLSBKIJ-FCLVOEFKSA-N Phe-Thr-Phe Chemical compound C([C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=CC=C1 BPIMVBKDLSBKIJ-FCLVOEFKSA-N 0.000 description 1
- 229920001100 Polydextrose Polymers 0.000 description 1
- 239000002202 Polyethylene glycol Substances 0.000 description 1
- 239000004743 Polypropylene Substances 0.000 description 1
- 229920001213 Polysorbate 20 Polymers 0.000 description 1
- 208000006664 Precursor Cell Lymphoblastic Leukemia-Lymphoma Diseases 0.000 description 1
- 206010036711 Primary mediastinal large B-cell lymphomas Diseases 0.000 description 1
- ONIBWKKTOPOVIA-UHFFFAOYSA-N Proline Natural products OC(=O)C1CCCN1 ONIBWKKTOPOVIA-UHFFFAOYSA-N 0.000 description 1
- 239000004365 Protease Substances 0.000 description 1
- 239000012083 RIPA buffer Substances 0.000 description 1
- 108020005067 RNA Splice Sites Proteins 0.000 description 1
- 108020004511 Recombinant DNA Proteins 0.000 description 1
- HQTKVSCNCDLXSX-BQBZGAKWSA-N Ser-Arg-Gly Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)NCC(O)=O HQTKVSCNCDLXSX-BQBZGAKWSA-N 0.000 description 1
- SFZKGGOGCNQPJY-CIUDSAMLSA-N Ser-Asp-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CO)N SFZKGGOGCNQPJY-CIUDSAMLSA-N 0.000 description 1
- FMDHKPRACUXATF-ACZMJKKPSA-N Ser-Gln-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O FMDHKPRACUXATF-ACZMJKKPSA-N 0.000 description 1
- QYSFWUIXDFJUDW-DCAQKATOSA-N Ser-Leu-Arg Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O QYSFWUIXDFJUDW-DCAQKATOSA-N 0.000 description 1
- UBRMZSHOOIVJPW-SRVKXCTJSA-N Ser-Leu-Lys Chemical compound OC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(O)=O UBRMZSHOOIVJPW-SRVKXCTJSA-N 0.000 description 1
- HDBOEVPDIDDEPC-CIUDSAMLSA-N Ser-Lys-Asn Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(O)=O HDBOEVPDIDDEPC-CIUDSAMLSA-N 0.000 description 1
- RHAPJNVNWDBFQI-BQBZGAKWSA-N Ser-Pro-Gly Chemical compound OC[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O RHAPJNVNWDBFQI-BQBZGAKWSA-N 0.000 description 1
- LGIMRDKGABDMBN-DCAQKATOSA-N Ser-Val-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CO)N LGIMRDKGABDMBN-DCAQKATOSA-N 0.000 description 1
- 108010071390 Serum Albumin Proteins 0.000 description 1
- 102000007562 Serum Albumin Human genes 0.000 description 1
- 101000895926 Streptomyces plicatus Endo-beta-N-acetylglucosaminidase H Proteins 0.000 description 1
- 241000282887 Suidae Species 0.000 description 1
- 229940126547 T-cell immunoglobulin mucin-3 Drugs 0.000 description 1
- 239000004098 Tetracycline Substances 0.000 description 1
- XSLXHSYIVPGEER-KZVJFYERSA-N Thr-Ala-Val Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(=O)N[C@@H](C(C)C)C(O)=O XSLXHSYIVPGEER-KZVJFYERSA-N 0.000 description 1
- LGNBRHZANHMZHK-NUMRIWBASA-N Thr-Glu-Asp Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CC(=O)O)C(=O)O)N)O LGNBRHZANHMZHK-NUMRIWBASA-N 0.000 description 1
- FQPDRTDDEZXCEC-SVSWQMSJSA-N Thr-Ile-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O FQPDRTDDEZXCEC-SVSWQMSJSA-N 0.000 description 1
- VBMOVTMNHWPZJR-SUSMZKCASA-N Thr-Thr-Glu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(O)=O VBMOVTMNHWPZJR-SUSMZKCASA-N 0.000 description 1
- LECUEEHKUFYOOV-ZJDVBMNYSA-N Thr-Thr-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@@H](N)[C@@H](C)O LECUEEHKUFYOOV-ZJDVBMNYSA-N 0.000 description 1
- MNYNCKZAEIAONY-XGEHTFHBSA-N Thr-Val-Ser Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O MNYNCKZAEIAONY-XGEHTFHBSA-N 0.000 description 1
- AYFVYJQAPQTCCC-UHFFFAOYSA-N Threonine Natural products CC(O)C(N)C(O)=O AYFVYJQAPQTCCC-UHFFFAOYSA-N 0.000 description 1
- 101710183280 Topoisomerase Proteins 0.000 description 1
- 229920001615 Tragacanth Polymers 0.000 description 1
- 102100026224 Transmembrane and immunoglobulin domain-containing protein 2 Human genes 0.000 description 1
- 101000980463 Treponema pallidum (strain Nichols) Chaperonin GroEL Proteins 0.000 description 1
- 239000013504 Triton X-100 Substances 0.000 description 1
- 229920004890 Triton X-100 Polymers 0.000 description 1
- SVGAWGVHFIYAEE-JSGCOSHPSA-N Trp-Gly-Gln Chemical compound C1=CC=C2C(C[C@H](N)C(=O)NCC(=O)N[C@@H](CCC(N)=O)C(O)=O)=CNC2=C1 SVGAWGVHFIYAEE-JSGCOSHPSA-N 0.000 description 1
- VCXWRWYFJLXITF-AUTRQRHGSA-N Tyr-Ala-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 VCXWRWYFJLXITF-AUTRQRHGSA-N 0.000 description 1
- SMLCYZYQFRTLCO-UWJYBYFXSA-N Tyr-Cys-Ala Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CS)C(=O)N[C@@H](C)C(O)=O SMLCYZYQFRTLCO-UWJYBYFXSA-N 0.000 description 1
- AZGZDDNKFFUDEH-QWRGUYRKSA-N Tyr-Gly-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CC1=CC=C(O)C=C1 AZGZDDNKFFUDEH-QWRGUYRKSA-N 0.000 description 1
- GULIUBBXCYPDJU-CQDKDKBSSA-N Tyr-Leu-Ala Chemical compound [O-]C(=O)[C@H](C)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H]([NH3+])CC1=CC=C(O)C=C1 GULIUBBXCYPDJU-CQDKDKBSSA-N 0.000 description 1
- KLQPIEVIKOQRAW-IZPVPAKOSA-N Tyr-Thr-Thr Chemical compound C[C@H]([C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N)O KLQPIEVIKOQRAW-IZPVPAKOSA-N 0.000 description 1
- BUPRFDPUIJNOLS-UFYCRDLUSA-N Tyr-Tyr-Met Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCSC)C(O)=O BUPRFDPUIJNOLS-UFYCRDLUSA-N 0.000 description 1
- RMRFSFXLFWWAJZ-HJOGWXRNSA-N Tyr-Tyr-Tyr Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=C(O)C=C1 RMRFSFXLFWWAJZ-HJOGWXRNSA-N 0.000 description 1
- DIOSYUIWOQCXNR-ONGXEEELSA-N Val-Lys-Gly Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)NCC(O)=O DIOSYUIWOQCXNR-ONGXEEELSA-N 0.000 description 1
- PZTZYZUTCPZWJH-FXQIFTODSA-N Val-Ser-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)O)N PZTZYZUTCPZWJH-FXQIFTODSA-N 0.000 description 1
- HTONZBWRYUKUKC-RCWTZXSCSA-N Val-Thr-Val Chemical compound CC(C)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O HTONZBWRYUKUKC-RCWTZXSCSA-N 0.000 description 1
- 238000005411 Van der Waals force Methods 0.000 description 1
- 241000700605 Viruses Species 0.000 description 1
- JLCPHMBAVCMARE-UHFFFAOYSA-N [3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-hydroxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methyl [5-(6-aminopurin-9-yl)-2-(hydroxymethyl)oxolan-3-yl] hydrogen phosphate Polymers Cc1cn(C2CC(OP(O)(=O)OCC3OC(CC3OP(O)(=O)OCC3OC(CC3O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c3nc(N)[nH]c4=O)C(COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3CO)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cc(C)c(=O)[nH]c3=O)n3cc(C)c(=O)[nH]c3=O)n3ccc(N)nc3=O)n3cc(C)c(=O)[nH]c3=O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)O2)c(=O)[nH]c1=O JLCPHMBAVCMARE-UHFFFAOYSA-N 0.000 description 1
- 229960000446 abciximab Drugs 0.000 description 1
- 238000002835 absorbance Methods 0.000 description 1
- 238000010521 absorption reaction Methods 0.000 description 1
- DPXJVFZANSGRMM-UHFFFAOYSA-N acetic acid;2,3,4,5,6-pentahydroxyhexanal;sodium Chemical compound [Na].CC(O)=O.OCC(O)C(O)C(O)C(O)C=O DPXJVFZANSGRMM-UHFFFAOYSA-N 0.000 description 1
- 239000000654 additive Substances 0.000 description 1
- 230000009824 affinity maturation Effects 0.000 description 1
- 239000008272 agar Substances 0.000 description 1
- 235000010419 agar Nutrition 0.000 description 1
- 229940040563 agaric acid Drugs 0.000 description 1
- 230000002776 aggregation Effects 0.000 description 1
- 238000004220 aggregation Methods 0.000 description 1
- 235000004279 alanine Nutrition 0.000 description 1
- 108010086434 alanyl-seryl-glycine Proteins 0.000 description 1
- 235000010443 alginic acid Nutrition 0.000 description 1
- 239000000783 alginic acid Substances 0.000 description 1
- 229920000615 alginic acid Polymers 0.000 description 1
- 229960001126 alginic acid Drugs 0.000 description 1
- 150000004781 alginic acids Chemical class 0.000 description 1
- WQZGKKKJIJFFOK-PHYPRBDBSA-N alpha-D-galactose Chemical compound OC[C@H]1O[C@H](O)[C@H](O)[C@@H](O)[C@H]1O WQZGKKKJIJFFOK-PHYPRBDBSA-N 0.000 description 1
- 235000012538 ammonium bicarbonate Nutrition 0.000 description 1
- 239000001099 ammonium carbonate Substances 0.000 description 1
- 238000005571 anion exchange chromatography Methods 0.000 description 1
- 230000003042 antagnostic effect Effects 0.000 description 1
- 229940124650 anti-cancer therapies Drugs 0.000 description 1
- 230000002494 anti-cea effect Effects 0.000 description 1
- 238000011091 antibody purification Methods 0.000 description 1
- 238000009175 antibody therapy Methods 0.000 description 1
- 210000000628 antibody-producing cell Anatomy 0.000 description 1
- 238000011319 anticancer therapy Methods 0.000 description 1
- 230000009464 antigen specific memory response Effects 0.000 description 1
- 239000003963 antioxidant agent Substances 0.000 description 1
- 235000006708 antioxidants Nutrition 0.000 description 1
- 230000005975 antitumor immune response Effects 0.000 description 1
- 238000013459 approach Methods 0.000 description 1
- 239000007864 aqueous solution Substances 0.000 description 1
- 239000003125 aqueous solvent Substances 0.000 description 1
- 239000008135 aqueous vehicle Substances 0.000 description 1
- PYMYPHUHKUWMLA-UHFFFAOYSA-N arabinose Natural products OCC(O)C(O)C(O)C=O PYMYPHUHKUWMLA-UHFFFAOYSA-N 0.000 description 1
- 238000003491 array Methods 0.000 description 1
- 125000003118 aryl group Chemical group 0.000 description 1
- 229960005070 ascorbic acid Drugs 0.000 description 1
- 235000010323 ascorbic acid Nutrition 0.000 description 1
- 239000011668 ascorbic acid Substances 0.000 description 1
- 238000011948 assay development Methods 0.000 description 1
- 230000002238 attenuated effect Effects 0.000 description 1
- OHDRQQURAXLVGJ-HLVWOLMTSA-N azane;(2e)-3-ethyl-2-[(e)-(3-ethyl-6-sulfo-1,3-benzothiazol-2-ylidene)hydrazinylidene]-1,3-benzothiazole-6-sulfonic acid Chemical compound [NH4+].[NH4+].S/1C2=CC(S([O-])(=O)=O)=CC=C2N(CC)C\1=N/N=C1/SC2=CC(S([O-])(=O)=O)=CC=C2N1CC OHDRQQURAXLVGJ-HLVWOLMTSA-N 0.000 description 1
- 230000001580 bacterial effect Effects 0.000 description 1
- 230000008901 benefit Effects 0.000 description 1
- 102000015736 beta 2-Microglobulin Human genes 0.000 description 1
- 108010081355 beta 2-Microglobulin Proteins 0.000 description 1
- SRBFZHDQGSBBOR-UHFFFAOYSA-N beta-D-Pyranose-Lyxose Natural products OC1COC(O)C(O)C1O SRBFZHDQGSBBOR-UHFFFAOYSA-N 0.000 description 1
- WQZGKKKJIJFFOK-VFUOTHLCSA-N beta-D-glucose Chemical compound OC[C@H]1O[C@@H](O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-VFUOTHLCSA-N 0.000 description 1
- SQVRNKJHWKZAKO-UHFFFAOYSA-N beta-N-Acetyl-D-neuraminic acid Natural products CC(=O)NC1C(O)CC(O)(C(O)=O)OC1C(O)C(O)CO SQVRNKJHWKZAKO-UHFFFAOYSA-N 0.000 description 1
- AFYNADDZULBEJA-UHFFFAOYSA-N bicinchoninic acid Chemical compound C1=CC=CC2=NC(C=3C=C(C4=CC=CC=C4N=3)C(=O)O)=CC(C(O)=O)=C21 AFYNADDZULBEJA-UHFFFAOYSA-N 0.000 description 1
- 230000001588 bifunctional effect Effects 0.000 description 1
- 230000031018 biological processes and functions Effects 0.000 description 1
- 230000006696 biosynthetic metabolic pathway Effects 0.000 description 1
- 238000006664 bond formation reaction Methods 0.000 description 1
- SOEBTSCUOQNNLV-UHFFFAOYSA-N butyl n-(6-aminohexyl)carbamate Chemical compound CCCCOC(=O)NCCCCCCN SOEBTSCUOQNNLV-UHFFFAOYSA-N 0.000 description 1
- 239000003560 cancer drug Substances 0.000 description 1
- 238000005251 capillar electrophoresis Methods 0.000 description 1
- 239000002775 capsule Substances 0.000 description 1
- 238000012511 carbohydrate analysis Methods 0.000 description 1
- 239000001768 carboxy methyl cellulose Substances 0.000 description 1
- 229940096529 carboxypolymethylene Drugs 0.000 description 1
- 239000000969 carrier Substances 0.000 description 1
- 238000012219 cassette mutagenesis Methods 0.000 description 1
- 230000015556 catabolic process Effects 0.000 description 1
- 230000020411 cell activation Effects 0.000 description 1
- 238000004113 cell culture Methods 0.000 description 1
- 239000006143 cell culture medium Substances 0.000 description 1
- 230000030833 cell death Effects 0.000 description 1
- 230000006037 cell lysis Effects 0.000 description 1
- 230000011748 cell maturation Effects 0.000 description 1
- 210000000170 cell membrane Anatomy 0.000 description 1
- 239000006285 cell suspension Substances 0.000 description 1
- 229920002678 cellulose Polymers 0.000 description 1
- 239000001913 cellulose Substances 0.000 description 1
- 210000003169 central nervous system Anatomy 0.000 description 1
- 239000002738 chelating agent Substances 0.000 description 1
- 239000013611 chromosomal DNA Substances 0.000 description 1
- 239000013599 cloning vector Substances 0.000 description 1
- 238000011260 co-administration Methods 0.000 description 1
- 230000004186 co-expression Effects 0.000 description 1
- 239000011248 coating agent Substances 0.000 description 1
- 230000000112 colonic effect Effects 0.000 description 1
- 238000004440 column chromatography Methods 0.000 description 1
- 238000002648 combination therapy Methods 0.000 description 1
- 230000009918 complex formation Effects 0.000 description 1
- 235000021310 complex sugar Nutrition 0.000 description 1
- 239000000562 conjugate Substances 0.000 description 1
- 238000013270 controlled release Methods 0.000 description 1
- 230000001276 controlling effect Effects 0.000 description 1
- 238000012937 correction Methods 0.000 description 1
- 230000008878 coupling Effects 0.000 description 1
- 238000010168 coupling process Methods 0.000 description 1
- 238000005859 coupling reaction Methods 0.000 description 1
- 239000006071 cream Substances 0.000 description 1
- 230000006341 curative response Effects 0.000 description 1
- 231100000433 cytotoxic Toxicity 0.000 description 1
- 230000001472 cytotoxic effect Effects 0.000 description 1
- 230000003013 cytotoxicity Effects 0.000 description 1
- 231100000135 cytotoxicity Toxicity 0.000 description 1
- 238000007405 data analysis Methods 0.000 description 1
- 230000002950 deficient Effects 0.000 description 1
- 230000022811 deglycosylation Effects 0.000 description 1
- 229940124447 delivery agent Drugs 0.000 description 1
- YSMODUONRAFBET-UHFFFAOYSA-N delta-DL-hydroxylysine Natural products NCC(O)CCC(N)C(O)=O YSMODUONRAFBET-UHFFFAOYSA-N 0.000 description 1
- 238000011033 desalting Methods 0.000 description 1
- 238000001514 detection method Methods 0.000 description 1
- 238000012631 diagnostic technique Methods 0.000 description 1
- 230000029087 digestion Effects 0.000 description 1
- 238000006471 dimerization reaction Methods 0.000 description 1
- LOKCTEFSRHRXRJ-UHFFFAOYSA-I dipotassium trisodium dihydrogen phosphate hydrogen phosphate dichloride Chemical compound P(=O)(O)(O)[O-].[K+].P(=O)(O)([O-])[O-].[Na+].[Na+].[Cl-].[K+].[Cl-].[Na+] LOKCTEFSRHRXRJ-UHFFFAOYSA-I 0.000 description 1
- 239000002270 dispersing agent Substances 0.000 description 1
- 239000002612 dispersion medium Substances 0.000 description 1
- 239000002552 dosage form Substances 0.000 description 1
- 238000012377 drug delivery Methods 0.000 description 1
- 238000009509 drug development Methods 0.000 description 1
- 230000009977 dual effect Effects 0.000 description 1
- 238000000132 electrospray ionisation Methods 0.000 description 1
- 230000008030 elimination Effects 0.000 description 1
- 238000003379 elimination reaction Methods 0.000 description 1
- 238000010828 elution Methods 0.000 description 1
- 239000003995 emulsifying agent Substances 0.000 description 1
- 230000006862 enzymatic digestion Effects 0.000 description 1
- YQGOJNYOYNNSMM-UHFFFAOYSA-N eosin Chemical compound [Na+].OC(=O)C1=CC=CC=C1C1=C2C=C(Br)C(=O)C(Br)=C2OC2=C(Br)C(O)=C(Br)C=C21 YQGOJNYOYNNSMM-UHFFFAOYSA-N 0.000 description 1
- YSMODUONRAFBET-UHNVWZDZSA-N erythro-5-hydroxy-L-lysine Chemical compound NC[C@H](O)CC[C@H](N)C(O)=O YSMODUONRAFBET-UHNVWZDZSA-N 0.000 description 1
- 150000002148 esters Chemical class 0.000 description 1
- 235000019325 ethyl cellulose Nutrition 0.000 description 1
- 229920001249 ethyl cellulose Polymers 0.000 description 1
- 210000003527 eukaryotic cell Anatomy 0.000 description 1
- 230000001747 exhibiting effect Effects 0.000 description 1
- 150000004665 fatty acids Chemical class 0.000 description 1
- 239000000945 filler Substances 0.000 description 1
- 238000001917 fluorescence detection Methods 0.000 description 1
- 230000037406 food intake Effects 0.000 description 1
- 108010083136 fucokinase Proteins 0.000 description 1
- 125000002446 fucosyl group Chemical group C1([C@@H](O)[C@H](O)[C@H](O)[C@@H](O1)C)* 0.000 description 1
- 238000002825 functional assay Methods 0.000 description 1
- 125000000524 functional group Chemical group 0.000 description 1
- 101150023212 fut8 gene Proteins 0.000 description 1
- 229960003980 galantamine Drugs 0.000 description 1
- ASUTZQLVASHGKV-UHFFFAOYSA-N galanthamine hydrochloride Natural products O1C(=C23)C(OC)=CC=C2CN(C)CCC23C1CC(O)C=C2 ASUTZQLVASHGKV-UHFFFAOYSA-N 0.000 description 1
- 210000004475 gamma-delta t lymphocyte Anatomy 0.000 description 1
- 238000001502 gel electrophoresis Methods 0.000 description 1
- 238000005227 gel permeation chromatography Methods 0.000 description 1
- 229920000159 gelatin Polymers 0.000 description 1
- 239000008273 gelatin Substances 0.000 description 1
- 235000019322 gelatine Nutrition 0.000 description 1
- 235000011852 gelatine desserts Nutrition 0.000 description 1
- 238000003197 gene knockdown Methods 0.000 description 1
- 238000003209 gene knockout Methods 0.000 description 1
- 230000002068 genetic effect Effects 0.000 description 1
- 239000008103 glucose Substances 0.000 description 1
- 108010078144 glutaminyl-glycine Proteins 0.000 description 1
- RWSXRVCMGQZWBV-WDSKDSINSA-N glutathione Chemical compound OC(=O)[C@@H](N)CCC(=O)N[C@@H](CS)C(=O)NCC(O)=O RWSXRVCMGQZWBV-WDSKDSINSA-N 0.000 description 1
- XBGGUPMXALFZOT-UHFFFAOYSA-N glycyl-L-tyrosine hemihydrate Natural products NCC(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 XBGGUPMXALFZOT-UHFFFAOYSA-N 0.000 description 1
- 108010010147 glycylglutamine Proteins 0.000 description 1
- 108010087823 glycyltyrosine Proteins 0.000 description 1
- 238000000227 grinding Methods 0.000 description 1
- 230000012010 growth Effects 0.000 description 1
- 230000007773 growth pattern Effects 0.000 description 1
- 229960002897 heparin Drugs 0.000 description 1
- 229920000669 heparin Polymers 0.000 description 1
- 102000057266 human FCGR3A Human genes 0.000 description 1
- 239000000416 hydrocolloid Substances 0.000 description 1
- 230000007062 hydrolysis Effects 0.000 description 1
- 238000006460 hydrolysis reaction Methods 0.000 description 1
- 229920001600 hydrophobic polymer Polymers 0.000 description 1
- 125000002349 hydroxyamino group Chemical group [H]ON([H])[*] 0.000 description 1
- 239000001863 hydroxypropyl cellulose Substances 0.000 description 1
- 235000010977 hydroxypropyl cellulose Nutrition 0.000 description 1
- 210000003297 immature b lymphocyte Anatomy 0.000 description 1
- 210000000987 immune system Anatomy 0.000 description 1
- 230000000899 immune system response Effects 0.000 description 1
- 230000036039 immunity Effects 0.000 description 1
- 238000003018 immunoassay Methods 0.000 description 1
- 230000002163 immunogen Effects 0.000 description 1
- 238000001114 immunoprecipitation Methods 0.000 description 1
- 230000002637 immunotoxin Effects 0.000 description 1
- 229940051026 immunotoxin Drugs 0.000 description 1
- 231100000608 immunotoxin Toxicity 0.000 description 1
- 239000002596 immunotoxin Substances 0.000 description 1
- 230000005917 in vivo anti-tumor Effects 0.000 description 1
- 230000002779 inactivation Effects 0.000 description 1
- 230000001939 inductive effect Effects 0.000 description 1
- 239000011261 inert gas Substances 0.000 description 1
- 208000015181 infectious disease Diseases 0.000 description 1
- 230000028709 inflammatory response Effects 0.000 description 1
- 238000001802 infusion Methods 0.000 description 1
- 238000011081 inoculation Methods 0.000 description 1
- 230000031261 interleukin-10 production Effects 0.000 description 1
- 229940117681 interleukin-12 Drugs 0.000 description 1
- 229940076264 interleukin-3 Drugs 0.000 description 1
- 230000017307 interleukin-4 production Effects 0.000 description 1
- 230000008863 intramolecular interaction Effects 0.000 description 1
- 108010011519 keratan-sulfate endo-1,4-beta-galactosidase Proteins 0.000 description 1
- 230000002147 killing effect Effects 0.000 description 1
- 238000012004 kinetic exclusion assay Methods 0.000 description 1
- 239000008101 lactose Substances 0.000 description 1
- 238000001499 laser induced fluorescence spectroscopy Methods 0.000 description 1
- 239000002523 lectin Substances 0.000 description 1
- 229960004942 lenalidomide Drugs 0.000 description 1
- GOTYRUGSSMKFNF-UHFFFAOYSA-N lenalidomide Chemical compound C1C=2C(N)=CC=CC=2C(=O)N1C1CCC(=O)NC1=O GOTYRUGSSMKFNF-UHFFFAOYSA-N 0.000 description 1
- 239000008206 lipophilic material Substances 0.000 description 1
- 238000004895 liquid chromatography mass spectrometry Methods 0.000 description 1
- 230000007774 longterm Effects 0.000 description 1
- 125000003588 lysine group Chemical group [H]N([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])(N([H])[H])C(*)=O 0.000 description 1
- 125000005439 maleimidyl group Chemical class C1(C=CC(N1*)=O)=O 0.000 description 1
- 239000000594 mannitol Substances 0.000 description 1
- 235000010355 mannitol Nutrition 0.000 description 1
- 102000036209 mannose binding proteins Human genes 0.000 description 1
- 108020003928 mannose binding proteins Proteins 0.000 description 1
- 108010083819 mannosyl-oligosaccharide 1,3 - 1,6-alpha-mannosidase Proteins 0.000 description 1
- 238000004949 mass spectrometry Methods 0.000 description 1
- 230000010534 mechanism of action Effects 0.000 description 1
- 230000007595 memory recall Effects 0.000 description 1
- 230000001394 metastastic effect Effects 0.000 description 1
- 208000037819 metastatic cancer Diseases 0.000 description 1
- 208000011575 metastatic malignant neoplasm Diseases 0.000 description 1
- FJQXCDYVZAHXNS-UHFFFAOYSA-N methadone hydrochloride Chemical compound Cl.C=1C=CC=CC=1C(CC(C)N(C)C)(C(=O)CC)C1=CC=CC=C1 FJQXCDYVZAHXNS-UHFFFAOYSA-N 0.000 description 1
- MYWUZJCMWCOHBA-VIFPVBQESA-N methamphetamine Chemical compound CN[C@@H](C)CC1=CC=CC=C1 MYWUZJCMWCOHBA-VIFPVBQESA-N 0.000 description 1
- 229930182817 methionine Natural products 0.000 description 1
- 125000002496 methyl group Chemical group [H]C([H])([H])* 0.000 description 1
- 239000011325 microbead Substances 0.000 description 1
- 239000003607 modifier Substances 0.000 description 1
- 238000010369 molecular cloning Methods 0.000 description 1
- 238000012544 monitoring process Methods 0.000 description 1
- 150000002772 monosaccharides Chemical class 0.000 description 1
- 239000004570 mortar (masonry) Substances 0.000 description 1
- 210000004985 myeloid-derived suppressor cell Anatomy 0.000 description 1
- 229920005615 natural polymer Polymers 0.000 description 1
- 239000013642 negative control Substances 0.000 description 1
- 230000009826 neoplastic cell growth Effects 0.000 description 1
- 229920001220 nitrocellulos Polymers 0.000 description 1
- QTILRWYIYBSLBF-UHFFFAOYSA-N nitrosourea nitrourea Chemical compound N(=O)NC(=O)N.[N+](=O)([O-])NC(=O)N QTILRWYIYBSLBF-UHFFFAOYSA-N 0.000 description 1
- 208000002154 non-small cell lung carcinoma Diseases 0.000 description 1
- 235000015097 nutrients Nutrition 0.000 description 1
- 229920002113 octoxynol Polymers 0.000 description 1
- 239000003921 oil Substances 0.000 description 1
- 238000011275 oncology therapy Methods 0.000 description 1
- 230000003287 optical effect Effects 0.000 description 1
- 229940127084 other anti-cancer agent Drugs 0.000 description 1
- 230000002018 overexpression Effects 0.000 description 1
- 238000006213 oxygenation reaction Methods 0.000 description 1
- 230000000242 pagocytic effect Effects 0.000 description 1
- 229940055729 papain Drugs 0.000 description 1
- 235000019834 papain Nutrition 0.000 description 1
- 238000007911 parenteral administration Methods 0.000 description 1
- 239000002245 particle Substances 0.000 description 1
- 230000006320 pegylation Effects 0.000 description 1
- 238000010647 peptide synthesis reaction Methods 0.000 description 1
- 239000000816 peptidomimetic Substances 0.000 description 1
- 102000013415 peroxidase activity proteins Human genes 0.000 description 1
- 108040007629 peroxidase activity proteins Proteins 0.000 description 1
- 238000002823 phage display Methods 0.000 description 1
- 229940124531 pharmaceutical excipient Drugs 0.000 description 1
- 230000000144 pharmacologic effect Effects 0.000 description 1
- 108010051242 phenylalanylserine Proteins 0.000 description 1
- 230000010399 physical interaction Effects 0.000 description 1
- 239000002504 physiological saline solution Substances 0.000 description 1
- 239000006187 pill Substances 0.000 description 1
- 210000004180 plasmocyte Anatomy 0.000 description 1
- 230000004983 pleiotropic effect Effects 0.000 description 1
- 230000008488 polyadenylation Effects 0.000 description 1
- 239000001259 polydextrose Substances 0.000 description 1
- 235000013856 polydextrose Nutrition 0.000 description 1
- 229940035035 polydextrose Drugs 0.000 description 1
- 229920001223 polyethylene glycol Polymers 0.000 description 1
- 239000000256 polyoxyethylene sorbitan monolaurate Substances 0.000 description 1
- 235000010486 polyoxyethylene sorbitan monolaurate Nutrition 0.000 description 1
- 229920001155 polypropylene Polymers 0.000 description 1
- 229920001282 polysaccharide Polymers 0.000 description 1
- 239000005017 polysaccharide Substances 0.000 description 1
- 239000011148 porous material Substances 0.000 description 1
- 229920001592 potato starch Polymers 0.000 description 1
- 229940124606 potential therapeutic agent Drugs 0.000 description 1
- 239000000843 powder Substances 0.000 description 1
- 238000001556 precipitation Methods 0.000 description 1
- 230000002335 preservative effect Effects 0.000 description 1
- 229940002612 prodrug Drugs 0.000 description 1
- 239000000651 prodrug Substances 0.000 description 1
- 239000000092 prognostic biomarker Substances 0.000 description 1
- 230000035755 proliferation Effects 0.000 description 1
- 230000001737 promoting effect Effects 0.000 description 1
- 230000000644 propagated effect Effects 0.000 description 1
- 238000002818 protein evolution Methods 0.000 description 1
- 238000001742 protein purification Methods 0.000 description 1
- 230000017854 proteolysis Effects 0.000 description 1
- 230000002797 proteolythic effect Effects 0.000 description 1
- 238000011002 quantification Methods 0.000 description 1
- 230000005855 radiation Effects 0.000 description 1
- 238000003127 radioimmunoassay Methods 0.000 description 1
- 229960002633 ramucirumab Drugs 0.000 description 1
- 230000007420 reactivation Effects 0.000 description 1
- 230000009257 reactivity Effects 0.000 description 1
- 238000003259 recombinant expression Methods 0.000 description 1
- 238000010188 recombinant method Methods 0.000 description 1
- 230000006798 recombination Effects 0.000 description 1
- 238000005215 recombination Methods 0.000 description 1
- 238000011084 recovery Methods 0.000 description 1
- 238000004064 recycling Methods 0.000 description 1
- 238000009877 rendering Methods 0.000 description 1
- 239000011347 resin Substances 0.000 description 1
- 229920005989 resin Polymers 0.000 description 1
- 108091008146 restriction endonucleases Proteins 0.000 description 1
- 230000000717 retained effect Effects 0.000 description 1
- 238000003757 reverse transcription PCR Methods 0.000 description 1
- 229940100486 rice starch Drugs 0.000 description 1
- 238000010079 rubber tapping Methods 0.000 description 1
- 239000012723 sample buffer Substances 0.000 description 1
- 238000005070 sampling Methods 0.000 description 1
- 238000007480 sanger sequencing Methods 0.000 description 1
- 238000012216 screening Methods 0.000 description 1
- 230000003248 secreting effect Effects 0.000 description 1
- 230000028327 secretion Effects 0.000 description 1
- 238000000926 separation method Methods 0.000 description 1
- 238000013207 serial dilution Methods 0.000 description 1
- 239000013605 shuttle vector Substances 0.000 description 1
- SQVRNKJHWKZAKO-OQPLDHBCSA-N sialic acid Chemical compound CC(=O)N[C@@H]1[C@@H](O)C[C@@](O)(C(O)=O)OC1[C@H](O)[C@H](O)CO SQVRNKJHWKZAKO-OQPLDHBCSA-N 0.000 description 1
- 125000005629 sialic acid group Chemical group 0.000 description 1
- 239000002002 slurry Substances 0.000 description 1
- 235000010413 sodium alginate Nutrition 0.000 description 1
- 239000000661 sodium alginate Substances 0.000 description 1
- 229940005550 sodium alginate Drugs 0.000 description 1
- 235000019812 sodium carboxymethyl cellulose Nutrition 0.000 description 1
- 229920001027 sodium carboxymethylcellulose Polymers 0.000 description 1
- 239000011780 sodium chloride Substances 0.000 description 1
- 239000012439 solid excipient Substances 0.000 description 1
- 239000000600 sorbitol Substances 0.000 description 1
- 125000006850 spacer group Chemical group 0.000 description 1
- 206010062113 splenic marginal zone lymphoma Diseases 0.000 description 1
- 230000002269 spontaneous effect Effects 0.000 description 1
- 238000010561 standard procedure Methods 0.000 description 1
- 235000019698 starch Nutrition 0.000 description 1
- 239000008107 starch Substances 0.000 description 1
- 230000004936 stimulating effect Effects 0.000 description 1
- 230000000638 stimulation Effects 0.000 description 1
- 238000003860 storage Methods 0.000 description 1
- 239000000758 substrate Substances 0.000 description 1
- BDHFUVZGWQCTTF-UHFFFAOYSA-M sulfonate Chemical compound [O-]S(=O)=O BDHFUVZGWQCTTF-UHFFFAOYSA-M 0.000 description 1
- 239000004094 surface-active agent Substances 0.000 description 1
- 238000001356 surgical procedure Methods 0.000 description 1
- 239000000375 suspending agent Substances 0.000 description 1
- 229920001059 synthetic polymer Polymers 0.000 description 1
- 239000006188 syrup Substances 0.000 description 1
- 235000020357 syrup Nutrition 0.000 description 1
- 230000009897 systematic effect Effects 0.000 description 1
- 229930184616 taxin Natural products 0.000 description 1
- KOTXAHKUCAQPQA-AAUVPWARSA-N taxine Chemical compound C1([C@@H]([C@@H](O)C(=O)O[C@@H]2C=3/C[C@@](C([C@H](O)C4=C(C)[C@@H](OC(C)=O)CC(C4(C)C)[C@@H](OC(C)=O)\C=3)=O)(C)[C@@H](O)C2)N(C)C)=CC=CC=C1 KOTXAHKUCAQPQA-AAUVPWARSA-N 0.000 description 1
- 229960002180 tetracycline Drugs 0.000 description 1
- 229930101283 tetracycline Natural products 0.000 description 1
- 235000019364 tetracycline Nutrition 0.000 description 1
- 150000003522 tetracyclines Chemical class 0.000 description 1
- 229940126622 therapeutic monoclonal antibody Drugs 0.000 description 1
- 238000009210 therapy by ultrasound Methods 0.000 description 1
- 150000003573 thiols Chemical class 0.000 description 1
- 238000013518 transcription Methods 0.000 description 1
- 230000035897 transcription Effects 0.000 description 1
- 230000002103 transcriptional effect Effects 0.000 description 1
- 230000031998 transcytosis Effects 0.000 description 1
- 238000001890 transfection Methods 0.000 description 1
- 238000012546 transfer Methods 0.000 description 1
- 230000001131 transforming effect Effects 0.000 description 1
- 238000005829 trimerization reaction Methods 0.000 description 1
- 238000009966 trimming Methods 0.000 description 1
- GPRLSGONYQIRFK-MNYXATJNSA-N triton Chemical compound [3H+] GPRLSGONYQIRFK-MNYXATJNSA-N 0.000 description 1
- 230000005909 tumor killing Effects 0.000 description 1
- 230000006433 tumor necrosis factor production Effects 0.000 description 1
- 208000029729 tumor suppressor gene on chromosome 11 Diseases 0.000 description 1
- WFKWXMTUELFFGS-UHFFFAOYSA-N tungsten Chemical compound [W] WFKWXMTUELFFGS-UHFFFAOYSA-N 0.000 description 1
- 229910052721 tungsten Inorganic materials 0.000 description 1
- 239000010937 tungsten Substances 0.000 description 1
- 108010035534 tyrosyl-leucyl-alanine Proteins 0.000 description 1
- 108010003137 tyrosyltyrosine Proteins 0.000 description 1
- 241001430294 unidentified retrovirus Species 0.000 description 1
- 229960005486 vaccine Drugs 0.000 description 1
- 235000013311 vegetables Nutrition 0.000 description 1
- 239000003981 vehicle Substances 0.000 description 1
- 239000013603 viral vector Substances 0.000 description 1
- 235000012431 wafers Nutrition 0.000 description 1
- 230000004580 weight loss Effects 0.000 description 1
- 229940100445 wheat starch Drugs 0.000 description 1
- DGVVWUTYPXICAM-UHFFFAOYSA-N β‐Mercaptoethanol Chemical compound OCCS DGVVWUTYPXICAM-UHFFFAOYSA-N 0.000 description 1
Images






































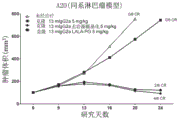


























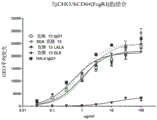


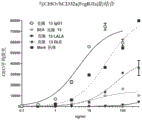


Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/50—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates
- A61K47/51—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent
- A61K47/68—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment
- A61K47/6801—Drug-antibody or immunoglobulin conjugates defined by the pharmacologically or therapeutically active agent
- A61K47/6803—Drugs conjugated to an antibody or immunoglobulin, e.g. cisplatin-antibody conjugates
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/50—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates
- A61K47/51—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent
- A61K47/68—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment
- A61K47/6835—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment the modifying agent being an antibody or an immunoglobulin bearing at least one antigen-binding site
- A61K47/6849—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment the modifying agent being an antibody or an immunoglobulin bearing at least one antigen-binding site the antibody targeting a receptor, a cell surface antigen or a cell surface determinant
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2803—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2803—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily
- C07K16/2818—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily against CD28 or CD152
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/30—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants from tumour cells
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/505—Medicinal preparations containing antigens or antibodies comprising antibodies
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/505—Medicinal preparations containing antigens or antibodies comprising antibodies
- A61K2039/507—Comprising a combination of two or more separate antibodies
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/20—Immunoglobulins specific features characterized by taxonomic origin
- C07K2317/21—Immunoglobulins specific features characterized by taxonomic origin from primates, e.g. man
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/20—Immunoglobulins specific features characterized by taxonomic origin
- C07K2317/24—Immunoglobulins specific features characterized by taxonomic origin containing regions, domains or residues from different species, e.g. chimeric, humanized or veneered
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/30—Immunoglobulins specific features characterized by aspects of specificity or valency
- C07K2317/31—Immunoglobulins specific features characterized by aspects of specificity or valency multispecific
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/30—Immunoglobulins specific features characterized by aspects of specificity or valency
- C07K2317/32—Immunoglobulins specific features characterized by aspects of specificity or valency specific for a neo-epitope on a complex, e.g. antibody-antigen or ligand-receptor
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/30—Immunoglobulins specific features characterized by aspects of specificity or valency
- C07K2317/33—Crossreactivity, e.g. for species or epitope, or lack of said crossreactivity
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/30—Immunoglobulins specific features characterized by aspects of specificity or valency
- C07K2317/34—Identification of a linear epitope shorter than 20 amino acid residues or of a conformational epitope defined by amino acid residues
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/40—Immunoglobulins specific features characterized by post-translational modification
- C07K2317/41—Glycosylation, sialylation, or fucosylation
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/52—Constant or Fc region; Isotype
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/56—Immunoglobulins specific features characterized by immunoglobulin fragments variable (Fv) region, i.e. VH and/or VL
- C07K2317/565—Complementarity determining region [CDR]
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/73—Inducing cell death, e.g. apoptosis, necrosis or inhibition of cell proliferation
- C07K2317/734—Complement-dependent cytotoxicity [CDC]
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/74—Inducing cell proliferation
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/76—Antagonist effect on antigen, e.g. neutralization or inhibition of binding
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/90—Immunoglobulins specific features characterized by (pharmaco)kinetic aspects or by stability of the immunoglobulin
- C07K2317/92—Affinity (KD), association rate (Ka), dissociation rate (Kd) or EC50 value
-
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y02—TECHNOLOGIES OR APPLICATIONS FOR MITIGATION OR ADAPTATION AGAINST CLIMATE CHANGE
- Y02A—TECHNOLOGIES FOR ADAPTATION TO CLIMATE CHANGE
- Y02A50/00—TECHNOLOGIES FOR ADAPTATION TO CLIMATE CHANGE in human health protection, e.g. against extreme weather
- Y02A50/30—Against vector-borne diseases, e.g. mosquito-borne, fly-borne, tick-borne or waterborne diseases whose impact is exacerbated by climate change
Abstract
本发明提供结合人TIGIT(具有Ig及ITIM结构域的T细胞免疫受体)的分离抗体。在一些实施方式中,该抗体对人TIGIT的结合亲和性(KD)小于5nM。在一些实施方式中,该抗TIGIT抗体阻断CD155和/或CD112与TIGIT的结合。在一些实施方式中,所述抗体是无岩藻糖基化的。
Description
相关申请的交叉援引
本申请主张于2018年8月23日提出申请的美国临时申请第62/722,063号、于2018年9月20日提出申请的美国临时申请第62/734,130号及于2019年3月22日提出申请的美国临时申请第62/822,674号的优先权的权益;每一案件出于任何目的以引用方式全文并入本文中。
技术领域
本文提供结合人TIGIT(具有Ig及ITIM结构域的T细胞免疫受体)的抗体及其用途。
背景技术
TIGIT(“具有Ig及ITIM结构域的T细胞免疫受体”)是在T细胞(例如活化、记忆及调节T细胞)及天然杀手(NK)细胞上表达的免疫受体。TIGIT是Ig蛋白超家族内的CD28家族的成员,且用作限制T细胞增殖及活化及NK细胞功能的共抑制性分子。TIGIT藉由与CD226(亦称为DNAX辅助分子-1或“DNAM-1”)竞争相同组的配体:CD155(亦称为脊髓灰白质炎病毒受体或“PVR”)及CD112(亦称为脊髓灰白质炎病毒受体相关2或“PVRL2”)介导其免疫抑制效应。参见Levin等人,Eur.J.Immunol.,2011,41:902-915。由于CD155对TIGIT的亲和性高于其对CD226的亲和性,故在TIGIT存在下,CD226信号传导受到抑制,藉此限制T细胞增殖及活化。
在患有黑色素瘤的患者中,TIGIT表达在肿瘤抗原(TA)特异性CD8+T细胞及CD8+肿瘤浸润性淋巴细胞(TIL)上上调。在表达TIGIT配体(CD155)的细胞存在下阻断TIGIT可增加TA特异性CD8+T细胞及CD8+TIL两者的增殖、细胞因子产生及去粒。参见Chauvin等人,J ClinInvest.,2015,125:2046-2058。因此,TIGIT代表用于刺激患者中的抗肿瘤T细胞反应的潜在治疗靶标,但仍然需要阻断TIGIT及促进抗肿瘤反应的改良方法。
发明内容
实施方式1.一种包含经分离抗体的组合物,所述经分离抗体结合人TIGIT(具有Ig及ITIM结构域的T细胞免疫受体),其中所述抗体对人TIGIT的结合亲和性(KD)小于5nM,且其中该组合物中至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%或至少99%的所述抗体是无岩藻糖基化的。
实施方式2.如实施方式1所述的组合物,其中所述抗体对人TIGIT的KD小于1nM。
实施方式3.如实施方式1所述的组合物,其中所述抗体对人TIGIT的KD小于100pM。
实施方式4.如实施方式1至3中任一项所述的组合物,其中所述抗体表现出与食蟹猕猴(cynomolgus monkey)TIGIT和/或小鼠TIGIT的交叉反应性。
实施方式5.如实施方式4所述的组合物,其中所述抗体表现出与食蟹猕猴TIGIT及小鼠TIGIT两者的交叉反应性。
实施方式6.如实施方式1至5中任一项所述的组合物,其中所述抗体阻断CD155与TIGIT的结合。
实施方式7.如实施方式1至5中任一项所述的组合物,其中所述抗体阻断CD112与TIGIT的结合。
实施方式8.如实施方式1至5中任一项所述的组合物,其中所述抗体阻断CD155及CD112两者与TIGIT的结合。
实施方式9.如实施方式1至8中任一项所述的组合物,其中所述抗体与包括包含SEQ ID NO:55所示氨基酸序列的重链可变区及包含SEQ ID NO:64所示氨基酸序列的轻链可变区的抗体竞争结合人TIGIT。
实施方式10.如实施方式1至9中任一项所述的组合物,其中所述抗体在结合人TIGIT时结合氨基酸位置81及82中之一或两者。
实施方式11.如实施方式10所述的组合物,其中所述抗体结合氨基酸位置81及82两者。
实施方式12.如实施方式10或实施方式11所述的组合物,其中氨基酸位置81及82是Phe81和Lys82。
实施方式13.如实施方式1至12中任一项所述的组合物,其中所述抗体结合人TIGIT上包含氨基酸位置81及82中之一或两者的表位。
实施方式14.一种包含结合人TIGIT的经分离抗体的组合物,其中所述抗体在结合人TIGIT时结合氨基酸位置81及82中之一或两者,且其中该组合物中至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%或至少99%的所述抗体是无岩藻糖基化的。
实施方式15.如实施方式14所述的组合物,其中所述抗体结合氨基酸位置81及82两者。
实施方式16.如实施方式14或实施方式15所述的组合物,其中氨基酸位置81及82是Phe81和Lys82。
实施方式17.一种包含结合人TIGIT的经分离抗体的组合物,其中所述抗体结合人TIGIT上包含氨基酸位置81及82中之一或两者的表位,且其中该组合物中至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%或至少99%的所述抗体是无岩藻糖基化的。
实施方式18.如实施方式13或实施方式17所述的组合物,其中所述表位包含第81位的Phe。
实施方式19.如实施方式13、17及18中任一项所述的组合物,其中所述表位包含第82位的Lys或Ser。
实施方式20.如实施方式13及17至19中任一项所述的组合物,其中所述表位包含第81位的Phe及第82位的Lys或Ser。
实施方式21.如实施方式20所述的组合物,其中所述表位包含Phe81和Lys82。
实施方式22.如实施方式13及17至21中任一项所述的组合物,其中所述表位是不连续表位。
实施方式23.如实施方式13及17至22中任一项所述的组合物,其中所述抗体结合人TIGIT上进一步包含氨基酸位置51、52、53、54、55、73、74、75、76、77、79、83、84、85、86、87、88、89、90、91、92或93中之一或多者的表位。
实施方式24.如实施方式23所述的组合物,其中所述表位进一步包含一个或多个选自下组的氨基酸残基:Thr51、Ala52、Gln53、Val54、Thr55、Leu73、Gly74、Trp75、His76、Ile77、Pro79、Asp83、Arg84、Val85、Ala86、Pro87、Gly88、Pro89、Gly90、Leu91、Gly92及Leu93。
实施方式25.如实施方式24所述的组合物,其中所述表位包含所述氨基酸残基Thr51、Ala52、Gln53、Val54、Thr55、Gly74、Trp75、His76、Ile77、Phe81、Lys82、Pro87、Gly88、Pro89、Gly90、Leu91、Gly92及Leu93。
实施方式26.如实施方式24所述的组合物,其中所述表位包含所述氨基酸残基Ala52、Gln53、Leu73、Gly74、Trp75、Pro79、Phe81、Lys82、Asp83、Arg84、Val85及Ala86。
实施方式27.如实施方式13及17至26中任一项所述的组合物,其中所述表位包含序列ICNADLGWHISPSFK(SEQ ID NO:258)。
实施方式28.如实施方式1至27中任一项所述的组合物,其中人TIGIT包含序列SEQID NO:218。
实施方式29.如实施方式1至28中任一项所述的组合物,其中所述抗体中之每一者包含以下之一或多者:
(a)重链CDR1,其包含选自SEQ ID NO:4、SEQ ID NO:22、SEQ ID NO:40、SEQ IDNO:58、SEQ ID NO:76、SEQ ID NO:94、SEQ ID NO:112、SEQ ID NO:130、SEQ ID NO:148、SEQID NO:166、SEQ ID NO:184、SEQ ID NO:202、SEQ ID NO:221、SEQ ID NO:224、SEQ ID NO:226、SEQ ID NO:231、SEQ ID NO:233、SEQ ID NO:239、SEQ ID NO:243、SEQ ID NO:283、SEQID NO:284、SEQ ID NO:293、SEQ ID NO:294、SEQ ID NO:289及SEQ ID NO:290的序列;
(b)重链CDR2,其包含选自SEQ ID NO:6、SEQ ID NO:24、SEQ ID NO:42、SEQ IDNO:60、SEQ ID NO:78、SEQ ID NO:96、SEQ ID NO:114、SEQ ID NO:132、SEQ ID NO:150、SEQID NO:168、SEQ ID NO:186、SEQ ID NO:204、SEQ ID NO:222、SEQ ID NO:225、SEQ ID NO:227、SEQ ID NO:229、SEQ ID NO:232、SEQ ID NO:234、SEQ ID NO:238、SEQ ID NO:240、SEQID NO:285、SEQ ID NO:297、SEQ ID NO:291及SEQ ID NO:295的序列;
(c)重链CDR3,其包含选自SEQ ID NO:8、SEQ ID NO:26、SEQ ID NO:44、SEQ IDNO:62、SEQ ID NO:80、SEQ ID NO:98、SEQ ID NO:116、SEQ ID NO:134、SEQ ID NO:152、SEQID NO:170、SEQ ID NO:188、SEQ ID NO:206、SEQ ID NO:223、SEQ ID NO:228、SEQ ID NO:230、SEQ ID NO:235、SEQ ID NO:236、SEQ ID NO:237、SEQ ID NO:241、SEQ ID NO:242、SEQID NO:244、SEQ ID NO:286、SEQ ID NO:292及SEQ ID NO:296的序列;
(d)轻链CDR1,其包含选自SEQ ID NO:13、SEQ ID NO:31、SEQ ID NO:49、SEQ IDNO:67、SEQ ID NO:85、SEQ ID NO:103、SEQ ID NO:121、SEQ ID NO:139、SEQ ID NO:157、SEQ ID NO:175、SEQ ID NO:193、SEQ ID NO:211及SEQ ID NO:287的序列;
(e)轻链CDR2,其包含选自SEQ ID NO:15、SEQ ID NO:33、SEQ ID NO:51、SEQ IDNO:69、SEQ ID NO:87、SEQ ID NO:105、SEQ ID NO:123、SEQ ID NO:141、SEQ ID NO:159、SEQ ID NO:177、SEQ ID NO:195、SEQ ID NO:213及SEQ ID NO:288的序列;或
(f)轻链CDR3,其包含选自SEQ ID NO:17、SEQ ID NO:35、SEQ ID NO:53、SEQ IDNO:71、SEQ ID NO:89、SEQ ID NO:107、SEQ ID NO:125、SEQ ID NO:143、SEQ ID NO:161、SEQ ID NO:179、SEQ ID NO:197及SEQ ID NO:215的序列。
实施方式30.如实施方式29所述的组合物,其中所述抗体中之每一者包含:
(a)重链CDR1序列,其包含选自SEQ ID NO:58、SEQ ID NO:283、SEQ ID NO:284、SEQ ID NO:224、SEQ ID NO:293、SEQ ID NO:294、SEQ ID NO:226、SEQ ID NO:289及SEQ IDNO:290的氨基酸序列;
(b)重链CDR2序列,其包含选自SEQ ID NO:60、SEQ ID NO:285、SEQ ID NO:225、SEQ ID NO:297、SEQ ID NO:227、SEQ ID NO:291、SEQ ID NO:229及SEQ ID NO:295的氨基酸序列;
(c)重链CDR3序列,其包含选自SEQ ID NO:62、SEQ ID NO:286、SEQ ID NO:228、SEQ ID NO:292、SEQ ID NO:230及SEQ ID NO:296的氨基酸序列;
(d)轻链CDR1序列,其包含选自SEQ ID NO:67及SEQ ID NO:287的氨基酸序列;
(e)轻链CDR2序列,其包含选自SEQ ID NO:69及SEQ ID NO:288的氨基酸序列;和/或
(f)轻链CDR3序列,其包含SEQ ID NO:71的氨基酸序列。
实施方式31.如实施方式29或实施方式30所述的组合物,其中所述抗体中之每一者包括包含以下序列的重链CDR1、CDR2及CDR3及轻链CDR1、CDR2及CDR3:
(a)分别为SEQ ID NO:4、6、8、13、15及17;或
(b)分别为SEQ ID NO:22、24、26、31、33及35;或
(c)分别为SEQ ID NO:40、42、44、49、51及53;或
(d)分别为SEQ ID NO:58、60、62、67、69及71;或
(e)分别为SEQ ID NO:283、285、62、287、288及71;或
(f)分别为SEQ ID NO:284、60、286、67、69及71;或
(g)分别为SEQ ID NO:76、78、80、85、87及89;或
(h)分别为SEQ ID NO:94、96、98、103、105及107;或
(i)分别为SEQ ID NO:112、114、116、121、123及125;或
(j)分别为SEQ ID NO:130、132、134、139、141及143;或
(k)分别为SEQ ID NO:148、150、152、157、159及161;或
(l)分别为SEQ ID NO:166、168、170、175、177及179;或
(m)分别为SEQ ID NO:184、186、188、193、195及197;或
(n)分别为SEQ ID NO:202、204、206、211、213及215;或
(o)分别为SEQ ID NO:221、222、223、13、15及17;或
(p)分别为SEQ ID NO:224、225、62、67、69及71;或
(q)分别为SEQ ID NO:293、297、62、287、288及71;或
(r)分别为SEQ ID NO:294、225、286、67、69及71;或
(s)分别为SEQ ID NO:226、227、228、67、69及71;或
(t)分别为SEQ ID NO:289、291、228、287、288及71;或
(u)分别为SEQ ID NO:290、227、292、67、69及71;或
(v)分别为SEQ ID NO:224、229、230、67、69及71;或
(w)分别为SEQ ID NO:293、295、230、287、288及71;或
(x)分别为SEQ ID NO:294、229、296、67、69及71;或
(y)分别为SEQ ID NO:224、227、230、67、69及71;或
(z)分别为SEQ ID NO:293、290、230、287、288及71;或
(aa)分别为SEQ ID NO:294、290、230、67、69及71;或
(bb)分别为SEQ ID NO:231、232、235、103、105及107;或
(cc)分别为SEQ ID NO:233、234、236、103、105及107;或
(dd)分别为SEQ ID NO:233、234、237、103、105及107;或
(ee)分别为SEQ ID NO:166、238、170、175、177及179;或
(ff)分别为SEQ ID NO:239、240、170、175、177及179;或
(gg)分别为SEQ ID NO:239、240、241、175、177及179;或
(hh)分别为SEQ ID NO:239、240、242、175、177及179;或
(ii)分别为SEQ ID NO:243、168、244、175、177及179。
实施方式32.如实施方式1至31中任一项所述的组合物,其中所述抗体中之每一者包括包含以下序列的重链CDR1、CDR2及CDR3及轻链CDR1、CDR2及CDR3:
(a)分别为SEQ ID NO:58、60、62、67、69及71;或
(b)分别为SEQ ID NO:283、285、62、287、288及71;或
(c)分别为SEQ ID NO:284、60、286、67、69及71。
实施方式33.如实施方式1至32中任一项所述的组合物,其中所述抗体中之每一者包含:
(a)重链可变区,其包含与SEQ ID NO:1、SEQ ID NO:19、SEQ ID NO:37、SEQ IDNO:55、SEQ ID NO:73、SEQ ID NO:91、SEQ ID NO:109、SEQ ID NO:127、SEQ ID NO:145、SEQID NO:163、SEQ ID NO:181、SEQ ID NO:199、SEQ ID NO:245、SEQ ID NO:246、SEQ ID NO:247、SEQ ID NO:248、SEQ ID NO:249、SEQ ID NO:250、SEQ ID NO:251、SEQ ID NO:252、SEQID NO:253、SEQ ID NO:254、SEQ ID NO:255、SEQ ID NO:256或SEQ ID NO:257具有至少90%序列一致性的氨基酸序列;和/或
(b)轻链可变区,其包含与SEQ ID NO:10、SEQ ID NO:28、SEQ ID NO:46、SEQ IDNO:64、SEQ ID NO:82、SEQ ID NO:100、SEQ ID NO:118、SEQ ID NO:136、SEQ ID NO:154、SEQ ID NO:172、SEQ ID NO:190或SEQ ID NO:208具有至少90%序列一致性的氨基酸序列。
实施方式34.如实施方式1至33中任一项所述的组合物,其中所述抗体中之每一者包含:
(a)包含与SEQ ID NO:1或SEQ ID NO:245具有至少90%序列一致性的氨基酸序列的重链可变区及包含与SEQ ID NO:10具有至少90%序列一致性的氨基酸序列的轻链可变区;或
(b)包含与SEQ ID NO:19具有至少90%序列一致性的氨基酸序列的重链可变区及包含与SEQ ID NO:28具有至少90%序列一致性的氨基酸序列的轻链可变区;或
(c)包含与SEQ ID NO:37具有至少90%序列一致性的氨基酸序列的重链可变区及包含与SEQ ID NO:46具有至少90%序列一致性的氨基酸序列的轻链可变区;或
(d)包含与SEQ ID NO:55、SEQ ID NO:246、SEQ ID NO:247、SEQ ID NO:248或SEQID NO:249中任一者具有至少90%序列一致性的氨基酸序列的重链可变区及包含与SEQ IDNO:64具有至少90%序列一致性的氨基酸序列的轻链可变区;或
(e)包含与SEQ ID NO:73具有至少90%序列一致性的氨基酸序列的重链可变区及包含与SEQ ID NO:82具有至少90%序列一致性的氨基酸序列的轻链可变区;或
(f)包含与SEQ ID NO:91、SEQ ID NO:250、SEQ ID NO:251或SEQ ID NO:252中任一者具有至少90%序列一致性的氨基酸序列的重链可变区及包含与SEQ ID NO:100具有至少90%序列一致性的氨基酸序列的轻链可变区;或
(g)包含与SEQ ID NO:109具有至少90%序列一致性的氨基酸序列的重链可变区及包含与SEQ ID NO:118具有至少90%序列一致性的氨基酸序列的轻链可变区;或
(h)包含与SEQ ID NO:127具有至少90%序列一致性的氨基酸序列的重链可变区及包含与SEQ ID NO:136具有至少90%序列一致性的氨基酸序列的轻链可变区;或
(i)包含与SEQ ID NO:145具有至少90%序列一致性的氨基酸序列的重链可变区及包含与SEQ ID NO:154具有至少90%序列一致性的氨基酸序列的轻链可变区;或
(j)包含与SEQ ID NO:163、SEQ ID NO:253、SEQ ID NO:254、SEQ ID NO:255、SEQID NO:256或SEQ ID NO:257中任一者具有至少90%序列一致性的氨基酸序列的重链可变区及包含与SEQ ID NO:172具有至少90%序列一致性的氨基酸序列的轻链可变区;或
(k)包含与SEQ ID NO:181具有至少90%序列一致性的氨基酸序列的重链可变区及包含与SEQ ID NO:190具有至少90%序列一致性的氨基酸序列的轻链可变区;或
(l)包含与SEQ ID NO:199具有至少90%序列一致性的氨基酸序列的重链可变区及包含与SEQ ID NO:208具有至少90%序列一致性的氨基酸序列的轻链可变区。
实施方式35.如实施方式34所述的组合物,其中所述抗体中之每一者包含:
(a)包含SEQ ID NO:1或SEQ ID NO:245所示氨基酸序列的重链可变区及包含SEQID NO:10所示氨基酸序列的轻链可变区;或
(b)包含SEQ ID NO:19所示氨基酸序列的重链可变区及包含SEQ ID NO:28所示氨基酸序列的轻链可变区;或
(c)包含SEQ ID NO:37所示氨基酸序列的重链可变区及包含SEQ ID NO:46所示氨基酸序列的轻链可变区;或
(d)包含SEQ ID NO:55、SEQ ID NO:246、SEQ ID NO:247、SEQ ID NO:248或SEQ IDNO:249中任一者所示氨基酸序列的重链可变区及包含SEQ ID NO:64所示氨基酸序列的轻链可变区;或
(e)包含SEQ ID NO:73所示氨基酸序列的重链可变区及包含SEQ ID NO:82所示氨基酸序列的轻链可变区;或
(f)包含SEQ ID NO:91、SEQ ID NO:250、SEQ ID NO:251或SEQ ID NO:252中任一者所示氨基酸序列的重链可变区及包含SEQ ID NO:100所示氨基酸序列的轻链可变区;或
(g)包含SEQ ID NO:109所示氨基酸序列的重链可变区及包含SEQ ID NO:118所示氨基酸序列的轻链可变区;或
(h)包含SEQ ID NO:127所示氨基酸序列的重链可变区及包含SEQ ID NO:136所示氨基酸序列的轻链可变区;或
(i)包含SEQ ID NO:145所示氨基酸序列的重链可变区及包含SEQ ID NO:154所示氨基酸序列的轻链可变区;或
(j)包含SEQ ID NO:163、SEQ ID NO:253、SEQ ID NO:254、SEQ ID NO:255、SEQ IDNO:256或SEQ ID NO:257中任一者所示氨基酸序列的重链可变区及包含SEQ ID NO:172所示氨基酸序列的轻链可变区;或
(k)包含SEQ ID NO:181所示氨基酸序列的重链可变区及包含SEQ ID NO:190所示氨基酸序列的轻链可变区;或
(l)包含SEQ ID NO:199所示氨基酸序列的重链可变区及包含SEQ ID NO:208所示氨基酸序列的轻链可变区。
实施方式36.如实施方式1至35中任一项所述的组合物,其中所述抗体中之每一者包括包含SEQ ID NO:55所示氨基酸序列的重链可变区及包含SEQ ID NO:64所示氨基酸序列的轻链可变区。
实施方式37.如实施方式1至36中任一项所述的组合物,其中所述抗体是IgG抗体。
实施方式38.如实施方式37所述的组合物,其中所述抗体是IgG1抗体或IgG3抗体。
实施方式39.如实施方式1至38中任一项所述的组合物,其中所述抗体中之每一者包括包含选自SEQ ID NO:260、262、264、266、268、270及272的氨基酸序列的重链及包含SEQID NO:274所示氨基酸序列的轻链。
实施方式40.如实施方式39所述的组合物,其中所述抗体中之每一者包括包含SEQID NO:260所示氨基酸序列的重链及包含SEQ ID NO:274所示氨基酸序列的轻链。
实施方式41.如实施方式39所述的组合物,其中所述抗体中之每一者包含由SEQID NO:260所示氨基酸序列组成的重链;及由SEQ ID NO:274所示氨基酸序列组成的轻链。
实施方式42.一种包含结合人TIGIT的经分离抗体的组合物,其中所述组合物中至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%或至少99%的所述抗体是无岩藻糖基化的,且其中所述抗体中之每一者包括包含SEQID NO:260所示氨基酸序列的重链及包含SEQ ID NO:274所示氨基酸序列的轻链。
实施方式43.一种包含结合人TIGIT的经分离抗体的组合物,其中所述组合物中至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%或至少99%的所述抗体是无岩藻糖基化的,且其中所述抗体中之每一者包含由SEQ IDNO:260所示氨基酸序列组成的重链及由SEQ ID NO:274所示氨基酸序列组成的轻链。
实施方式44.如实施方式1至43中任一项所述的组合物,其中所述抗体表现出与抗PD-1抗体或抗PD-L1抗体的协同作用。
实施方式45.如实施方式44所述的组合物,其中协同作用是使用包含以下所述内容的分析测定的:使包含:(i)表达PD-1、TIGIT及CD226的Jurkat效应细胞,其中所述Jurkat效应细胞包含由IL-2启动子驱动的荧光素酶报导基因;及(ii)表达TCR活化因子、PD-L1及CD155的CHO-K1人工抗原呈递细胞(aAPC)的共培养物与该组合物及抗PD-1抗体或抗PD-L1抗体接触。
实施方式46.如实施方式1至45中任一项所述的组合物,其中调节性T(Treg)细胞从与该组合物接触的人PBMC中清除(depleted)。
实施方式47.如实施方式1至46中任一项所述的组合物,MCP1、IL-8及MIP1α的表达在与该组合物接触的人PBMC中增加。
实施方式48.如实施方式1至47中任一项所述的组合物,其中单核细胞/巨噬细胞在与该组合物接触时经活化。
实施方式49.如实施方式1至48中任一项所述的组合物,其中在CD14+单核细胞/巨噬细胞与该组合物接触时,CD86及MHCII上调。
实施方式50.如实施方式1至49中任一项所述的组合物,其中与所述组合物接触的CD14+单核细胞/巨噬细胞成熟为抗原呈递细胞。
实施方式51.如实施方式1至50中任一项所述的组合物,其中与所述组合物接触的记忆T细胞响应抗原的IFNγ产生增加。
实施方式52.如实施方式1至51中任一项所述的组合物,其中与所述组合物接触的所述记忆T细胞对抗原的反应增强。
实施方式53.如实施方式1至52中任一项所述的组合物,其中效应记忆CD8+ T细胞和/或效应记忆CD4+ T细胞在与该组合物接触的肿瘤中增加。
实施方式54.如实施方式1至53中任一项所述的组合物,其中所述组合物增强给予了所述组合物的动物中的Th1反应。
实施方式55.如实施方式1至54中任一项所述的组合物,其中与未经无岩藻糖基化的相同抗TIGIT抗体相比,该组合物的所述抗体对FcγRIIa和/或FcγRIIb具有较低结合亲和性。
实施方式56.如实施方式1至55中任一项所述的组合物,其中所述组合物介导在单核细胞巨噬细胞存在下TIGIT表达细胞的抗体依赖性细胞吞噬作用(ADCP)。
实施方式57.如实施方式1至56中任一项所述的组合物,其中所述抗体是单克隆抗体。
实施方式58.如实施方式1至57中任一项所述的组合物,其中所述抗体是完全人抗体。
实施方式59.如实施方式1至58中任一项所述的组合物,其中所述抗体是嵌合抗体。
实施方式60.如实施方式1至28及44至59中任一项所述的组合物,其中所述抗体是人源化抗体。
实施方式61.如实施方式1至60中任一项所述的组合物,其中所述抗体是抗体片段。
实施方式62.如实施方式61所述的组合物,其中所述抗体片段是Fab、Fab’、F(ab’)2、scFv或双价抗体(diabodies)。
实施方式63.如实施方式1至62中任一项所述的组合物,其中所述抗体是双特异性抗体。
实施方式64.如实施方式1至63中任一项所述的组合物,其中所述抗体是抗体-药物偶联物。
实施方式65.一种结合人TIGIT(具有Ig及ITIM结构域的T细胞免疫受体)的抗体,其中所述抗体对人TIGIT的结合亲和性(KD)小于5nM,且其中所述抗体是无岩藻糖基化的。
实施方式66.如实施方式65所述的抗体,其中所述抗体对人TIGIT的KD小于1nM。
实施方式67.如实施方式66所述的抗体,其中抗体对人TIGIT的KD小于100pM。
实施方式68.如实施方式65至67中任一项所述的抗体,其中抗体表现出与食蟹猕猴TIGIT和/或小鼠TIGIT的交叉反应性。
实施方式69.如实施方式68所述的抗体,其中所述抗体表现出与食蟹猕猴TIGIT及小鼠TIGIT两者的交叉反应性。
实施方式70.如实施方式65至69中任一项所述的抗体,其中所述抗体阻断CD155与TIGIT的结合。
实施方式71.如实施方式65至70中任一项所述的抗体,其中所述抗体阻断CD112与TIGIT的结合。
实施方式72.如实施方式65至71中任一项所述的抗体,其中所述抗体阻断CD155及CD112两者与TIGIT的结合。
实施方式73.如实施方式65至72中任一项所述的抗体,其中所述抗体与包括包含SEQ ID NO:55所示氨基酸序列的重链可变区及包含SEQ ID NO:64所示氨基酸序列的轻链可变区的抗体竞争结合人TIGIT。
实施方式74.如实施方式65至73中任一项所述的抗体,其中所述抗体在结合人TIGIT时结合氨基酸位置81及82中之一或两者。
实施方式75.如实施方式74所述的抗体,其中所述抗体结合氨基酸位置81及82两者。
实施方式76.如实施方式74或实施方式75所述的抗体,其中氨基酸位置81及82是Phe81和Lys82。
实施方式77.如实施方式65至76中任一项所述的抗体,其中所述抗体结合人TIGIT上包含氨基酸位置81及82中之一或两者的表位。
实施方式78.一种结合人TIGIT的抗体,其中所述抗体在结合人TIGIT时结合氨基酸位置81及82中之一或两者,且其中所述抗体是无岩藻糖基化的。
实施方式79.如实施方式78所述的抗体,其中所述抗体结合氨基酸位置81及82两者。
实施方式80.如实施方式78或实施方式79所述的抗体,其中氨基酸位置81及82是Phe81和Lys82。
实施方式81.一种结合人TIGIT的抗体,其中所述抗体结合人TIGIT上包含氨基酸位置81及82中之一或两者的表位,且其中所述抗体是无岩藻糖基化的。
实施方式82.如实施方式77或实施方式81所述的抗体,其中所述表位包含第81位的Phe。
实施方式83.如实施方式77、81及82中任一项所述的抗体,其中所述表位包含第82位的Lys或Ser。
实施方式84.如实施方式77及81至83中任一项所述的抗体,其中所述表位包含第81位的Phe及第82位的Lys或Ser。
实施方式85.如实施方式84所述的抗体,其中所述表位包含Phe81和Lys82。
实施方式86.如实施方式77及81至85中任一项所述的抗体,其中所述表位是不连续表位。
实施方式87.如实施方式77及81至86中任一项所述的抗体,其中所述抗体结合人TIGIT上进一步包含氨基酸位置51、52、53、54、55、73、74、75、76、77、79、83、84、85、86、87、88、89、90、91、92或93中之一或多者的表位。
实施方式88.如实施方式87所述的抗体,其中所述表位进一步包含一个或多个选自下组的氨基酸残基:Thr51、Ala52、Gln53、Val54、Thr55、Leu73、Gly74、Trp75、His76、Ile77、Pro79、Asp83、Arg84、Val85、Ala86、Pro87、Gly88、Pro89、Gly90、Leu91、Gly92及Leu93。
实施方式89.如实施方式88所述的抗体,其中所述表位包含所述氨基酸残基Thr51、Ala52、Gln53、Val54、Thr55、Gly74、Trp75、His76、Ile77、Phe81、Lys82、Pro87、Gly88、Pro89、Gly90、Leu91、Gly92及Leu93。
实施方式90.如实施方式88所述的抗体,其中所述表位包含所述氨基酸残基Ala52、Gln53、Leu73、Gly74、Trp75、Pro79、Phe81、Lys82、Asp83、Arg84、Val85及Ala86。
实施方式91.如实施方式77及81至90中任一项所述的抗体,其中所述表位包含序列ICNADLGWHISPSFK(SEQ ID NO:258)。
实施方式92.如实施方式65至91中任一项所述的抗体,其中人TIGIT包含序列SEQID NO:218。
实施方式93.如实施方式65至92中任一项所述的抗体,其中所述抗体包含以下之一或多者:
(a)重链CDR1,其包含选自SEQ ID NO:4、SEQ ID NO:22、SEQ ID NO:40、SEQ IDNO:58、SEQ ID NO:76、SEQ ID NO:94、SEQ ID NO:112、SEQ ID NO:130、SEQ ID NO:148、SEQID NO:166、SEQ ID NO:184、SEQ ID NO:202、SEQ ID NO:221、SEQ ID NO:224、SEQ ID NO:226、SEQ ID NO:231、SEQ ID NO:233、SEQ ID NO:239、SEQ ID NO:243、SEQ ID NO:283、SEQID NO:284、SEQ ID NO:293、SEQ ID NO:294、SEQ ID NO:289及SEQ ID NO:290的序列;
(b)重链CDR2,其包含选自SEQ ID NO:6、SEQ ID NO:24、SEQ ID NO:42、SEQ IDNO:60、SEQ ID NO:78、SEQ ID NO:96、SEQ ID NO:114、SEQ ID NO:132、SEQ ID NO:150、SEQID NO:168、SEQ ID NO:186、SEQ ID NO:204、SEQ ID NO:222、SEQ ID NO:225、SEQ ID NO:227、SEQ ID NO:229、SEQ ID NO:232、SEQ ID NO:234、SEQ ID NO:238、SEQ ID NO:240、SEQID NO:285、SEQ ID NO:297、SEQ ID NO:291及SEQ ID NO:295的序列;
(c)重链CDR3,其包含选自SEQ ID NO:8、SEQ ID NO:26、SEQ ID NO:44、SEQ IDNO:62、SEQ ID NO:80、SEQ ID NO:98、SEQ ID NO:116、SEQ ID NO:134、SEQ ID NO:152、SEQID NO:170、SEQ ID NO:188、SEQ ID NO:206、SEQ ID NO:223、SEQ ID NO:228、SEQ ID NO:230、SEQ ID NO:235、SEQ ID NO:236、SEQ ID NO:237、SEQ ID NO:241、SEQ ID NO:242、SEQID NO:244、SEQ ID NO:286、SEQ ID NO:292及SEQ ID NO:296的序列;
(d)轻链CDR1,其包含选自SEQ ID NO:13、SEQ ID NO:31、SEQ ID NO:49、SEQ IDNO:67、SEQ ID NO:85、SEQ ID NO:103、SEQ ID NO:121、SEQ ID NO:139、SEQ ID NO:157、SEQ ID NO:175、SEQ ID NO:193、SEQ ID NO:211及SEQ ID NO:287的序列;
(e)轻链CDR2,其包含选自SEQ ID NO:15、SEQ ID NO:33、SEQ ID NO:51、SEQ IDNO:69、SEQ ID NO:87、SEQ ID NO:105、SEQ ID NO:123、SEQ ID NO:141、SEQ ID NO:159、SEQ ID NO:177、SEQ ID NO:195、SEQ ID NO:213及SEQ ID NO:288的序列;或
(f)轻链CDR3,其包含选自SEQ ID NO:17、SEQ ID NO:35、SEQ ID NO:53、SEQ IDNO:71、SEQ ID NO:89、SEQ ID NO:107、SEQ ID NO:125、SEQ ID NO:143、SEQ ID NO:161、SEQ ID NO:179、SEQ ID NO:197及SEQ ID NO:215的序列。
实施方式94.如实施方式93所述的抗体,其中所述抗体包含:
(d)重链CDR1序列,其包含选自SEQ ID NO:58、SEQ ID NO:283、SEQ ID NO:284、SEQ ID NO:224、SEQ ID NO:293、SEQ ID NO:294、SEQ ID NO:226、SEQ ID NO:289及SEQ IDNO:290的氨基酸序列;
(e)重链CDR2序列,其包含选自SEQ ID NO:60、SEQ ID NO:285、SEQ ID NO:225、SEQ ID NO:297、SEQ ID NO:227、SEQ ID NO:291、SEQ ID NO:229及SEQ ID NO:295的氨基酸序列;
(f)重链CDR3序列,其包含选自SEQ ID NO:62、SEQ ID NO:286、SEQ ID NO:228、SEQ ID NO:292、SEQ ID NO:230及SEQ ID NO:296的氨基酸序列;
(g)轻链CDR1序列,其包含选自SEQ ID NO:67及SEQ ID NO:287的氨基酸序列;
(h)轻链CDR2序列,其包含选自SEQ ID NO:69及SEQ ID NO:288的氨基酸序列;和/或
(i)轻链CDR3序列,其包含SEQ ID NO:71的氨基酸序列。
实施方式95.如实施方式94所述的抗体,其中所述抗体包括包含以下序列的重链CDR1、CDR2及CDR3及轻链CDR1、CDR2及CDR3:
(a)分别为SEQ ID NO:4、6、8、13、15及17;或
(b)分别为SEQ ID NO:22、24、26、31、33及35;或
(c)分别为SEQ ID NO:40、42、44、49、51及53;或
(d)分别为SEQ ID NO:58、60、62、67、69及71;或
(e)分别为SEQ ID NO:76、78、80、85、87及89;或
(f)分别为SEQ ID NO:94、96、98、103、105及107;或
(g)分别为SEQ ID NO:112、114、116、121、123及125;或
(h)分别为SEQ ID NO:130、132、134、139、141及143;或
(i)分别为SEQ ID NO:148、150、152、157、159及161;或
(j)分别为SEQ ID NO:166、168、170、175、177及179;或
(k)分别为SEQ ID NO:184、186、188、193、195及197;或
(l)分别为SEQ ID NO:202、204、206、211、213及215;或
(m)分别为SEQ ID NO:221、222、223、13、15及17;或
(n)分别为SEQ ID NO:224、225、62、67、69及71;或
(o)分别为SEQ ID NO:226、227、228、67、69及71;或
(p)分别为SEQ ID NO:224、229、230、67、69及71;或
(q)分别为SEQ ID NO:224、227、230、67、69及71;或
(r)分别为SEQ ID NO:231、232、235、103、105及107;或
(s)分别为SEQ ID NO:233、234、236、103、105及107;或
(t)分别为SEQ ID NO:233、234、237、103、105及107;或
(u)分别为SEQ ID NO:166、238、170、175、177及179;或
(v)分别为SEQ ID NO:239、240、170、175、177及179;或
(w)分别为SEQ ID NO:239、240、241、175、177及179;或
(x)分别为SEQ ID NO:239、240、242、175、177及179;或
(y)分别为SEQ ID NO:243、168、244、175、177及179。
实施方式96.如实施方式65至95中任一项所述的抗体,其中所述抗体包括包含以下序列的重链CDR1、CDR2及CDR3及轻链CDR1、CDR2及CDR3:
(j)分别为SEQ ID NO:58、60、62、67、69及71;或
(k)分别为SEQ ID NO:283、285、62、287、288及71;或
(l)分别为SEQ ID NO:284、60、286、67、69及71。
实施方式97.如实施方式65至96中任一项所述的抗体,其中所述抗体包含:
(a)重链可变区,其包含与SEQ ID NO:1、SEQ ID NO:19、SEQ ID NO:37、SEQ IDNO:55、SEQ ID NO:73、SEQ ID NO:91、SEQ ID NO:109、SEQ ID NO:127、SEQ ID NO:145、SEQID NO:163、SEQ ID NO:181、SEQ ID NO:199、SEQ ID NO:245、SEQ ID NO:246、SEQ ID NO:247、SEQ ID NO:248、SEQ ID NO:249、SEQ ID NO:250、SEQ ID NO:251、SEQ ID NO:252、SEQID NO:253、SEQ ID NO:254、SEQ ID NO:255、SEQ ID NO:256或SEQ ID NO:257具有至少90%序列一致性的氨基酸序列;和/或
(b)轻链可变区,其包含与SEQ ID NO:10、SEQ ID NO:28、SEQ ID NO:46、SEQ IDNO:64、SEQ ID NO:82、SEQ ID NO:100、SEQ ID NO:118、SEQ ID NO:136、SEQ ID NO:154、SEQ ID NO:172、SEQ ID NO:190或SEQ ID NO:208具有至少90%序列一致性的氨基酸序列。
实施方式98.如实施方式65至97中任一项所述的抗体,其中所述抗体包含:
(a)包含与SEQ ID NO:1或SEQ ID NO:245具有至少90%序列一致性的氨基酸序列的重链可变区及包含与SEQ ID NO:10具有至少90%序列一致性的氨基酸序列的轻链可变区;或
(b)包含与SEQ ID NO:19具有至少90%序列一致性的氨基酸序列的重链可变区及包含与SEQ ID NO:28具有至少90%序列一致性的氨基酸序列的轻链可变区;或
(c)包含与SEQ ID NO:37具有至少90%序列一致性的氨基酸序列的重链可变区及包含与SEQ ID NO:46具有至少90%序列一致性的氨基酸序列的轻链可变区;或
(d)包含与SEQ ID NO:55、SEQ ID NO:246、SEQ ID NO:247、SEQ ID NO:248或SEQID NO:249中任一者具有至少90%序列一致性的氨基酸序列的重链可变区及包含与SEQ IDNO:64具有至少90%序列一致性的氨基酸序列的轻链可变区;或
(e)包含与SEQ ID NO:73具有至少90%序列一致性的氨基酸序列的重链可变区及包含与SEQ ID NO:82具有至少90%序列一致性的氨基酸序列的轻链可变区;或
(f)包含与SEQ ID NO:91、SEQ ID NO:250、SEQ ID NO:251或SEQ ID NO:252中任一者具有至少90%序列一致性的氨基酸序列的重链可变区及包含与SEQ ID NO:100具有至少90%序列一致性的氨基酸序列的轻链可变区;或
(g)包含与SEQ ID NO:109具有至少90%序列一致性的氨基酸序列的重链可变区及包含与SEQ ID NO:118具有至少90%序列一致性的氨基酸序列的轻链可变区;或
(h)包含与SEQ ID NO:127具有至少90%序列一致性的氨基酸序列的重链可变区及包含与SEQ ID NO:136具有至少90%序列一致性的氨基酸序列的轻链可变区;或
(i)包含与SEQ ID NO:145具有至少90%序列一致性的氨基酸序列的重链可变区及包含与SEQ ID NO:154具有至少90%序列一致性的氨基酸序列的轻链可变区;或
(j)包含与SEQ ID NO:163、SEQ ID NO:253、SEQ ID NO:254、SEQ ID NO:255、SEQID NO:256或SEQ ID NO:257中任一者具有至少90%序列一致性的氨基酸序列的重链可变区及包含与SEQ ID NO:172具有至少90%序列一致性的氨基酸序列的轻链可变区;或
(k)包含与SEQ ID NO:181具有至少90%序列一致性的氨基酸序列的重链可变区及包含与SEQ ID NO:190具有至少90%序列一致性的氨基酸序列的轻链可变区;或
(l)包含与SEQ ID NO:199具有至少90%序列一致性的氨基酸序列的重链可变区及包含与SEQ ID NO:208具有至少90%序列一致性的氨基酸序列的轻链可变区。
实施方式99.如实施方式98所述的抗体,其中所述抗体包含:
(a)包含SEQ ID NO:1或SEQ ID NO:245所示氨基酸序列的重链可变区及包含SEQID NO:10所示氨基酸序列的轻链可变区;或
(b)包含SEQ ID NO:19所示氨基酸序列的重链可变区及包含SEQ ID NO:28所示氨基酸序列的轻链可变区;或
(c)包含SEQ ID NO:37所示氨基酸序列的重链可变区及包含SEQ ID NO:46所示氨基酸序列的轻链可变区;或
(d)包含SEQ ID NO:55、SEQ ID NO:246、SEQ ID NO:247、SEQ ID NO:248或SEQ IDNO:249中任一者所示氨基酸序列的重链可变区及包含SEQ ID NO:64所示氨基酸序列的轻链可变区;或
(e)包含SEQ ID NO:73所示氨基酸序列的重链可变区及包含SEQ ID NO:82所示氨基酸序列的轻链可变区;或
(f)包含SEQ ID NO:91、SEQ ID NO:250、SEQ ID NO:251或SEQ ID NO:252中任一者所示氨基酸序列的重链可变区及包含SEQ ID NO:100所示氨基酸序列的轻链可变区;或
(g)包含SEQ ID NO:109所示氨基酸序列的重链可变区及包含SEQ ID NO:118所示氨基酸序列的轻链可变区;或
(h)包含SEQ ID NO:127所示氨基酸序列的重链可变区及包含SEQ ID NO:136所示氨基酸序列的轻链可变区;或
(i)包含SEQ ID NO:145所示氨基酸序列的重链可变区及包含SEQ ID NO:154所示氨基酸序列的轻链可变区;或
(j)包含SEQ ID NO:163、SEQ ID NO:253、SEQ ID NO:254、SEQ ID NO:255、SEQ IDNO:256或SEQ ID NO:257中任一者所示氨基酸序列的重链可变区及包含SEQ ID NO:172所示氨基酸序列的轻链可变区;或
(k)包含SEQ ID NO:181所示氨基酸序列的重链可变区及包含SEQ ID NO:190所示氨基酸序列的轻链可变区;或
(l)包含SEQ ID NO:199所示氨基酸序列的重链可变区及包含SEQ ID NO:208所示氨基酸序列的轻链可变区。
实施方式100.如实施方式65至99中任一项所述的抗体,其中所述抗体包括包含SEQ ID NO:55所示氨基酸序列的重链可变区及包含SEQ ID NO:64所示氨基酸序列的轻链可变区。
实施方式101.如实施方式65至100中任一项所述的抗体,其中所述抗体是IgG抗体。
实施方式102.如实施方式101所述的抗体,其中所述抗体是IgG1抗体或IgG3抗体。
实施方式103.如实施方式65至102中任一项所述的抗体,其中所述抗体包括包含选自SEQ ID NO:260、262、264、266、268、270及272的氨基酸序列的重链及包含SEQ ID NO:274所示氨基酸序列的轻链。
实施方式104.如实施方式103所述的抗体,其中所述抗体包括包含SEQ ID NO:260所示氨基酸序列的重链及包含SEQ ID NO:274所示氨基酸序列的轻链。
实施方式105.如实施方式103所述的抗体,其中所述抗体包含由SEQ ID NO:260所示氨基酸序列组成的重链及由SEQ ID NO:274所示氨基酸序列组成的轻链。
实施方式106.一种结合人TIGIT的抗体,其中所述抗体包括包含选自SEQ ID NO:260、262、264、266、268、270及272的氨基酸序列的重链及包含SEQ ID NO:274所示氨基酸序列的轻链。
实施方式107.一种结合人TIGIT的抗体,其中所述抗体包括包含SEQ ID NO:260所示氨基酸序列的重链及包含SEQ ID NO:274所示氨基酸序列的轻链。
实施方式108.一种结合人TIGIT的抗体,其中所述抗体包含由SEQ ID NO:260所示氨基酸序列组成的重链及由SEQ ID NO:274所示氨基酸序列组成的轻链。
实施方式109.如实施方式65至108中任一项所述的抗体,其中所述抗体表现出与抗PD-1抗体或抗PD-L1抗体的协同作用。
实施方式110.如实施方式109所述的抗体,其中协同作用是使用包含以下所述内容的分析测定的:使:(i)表达PD-1、TIGIT及CD226的Jurkat效应细胞,其中所述Jurkat效应细胞包含由IL-2启动子驱动的荧光素酶报导基因;及(ii)表达TCR活化因子、PD-L1及CD155的CHO-K1人工抗原呈递细胞(aAPC)的共培养物与所述抗体及抗PD-1抗体或抗PD-L1抗体接触。
实施方式111.如实施方式65至110中任一项所述的抗体,其中调节性T(Treg)细胞从与该抗体接触的人PBMC中清除。
实施方式112.如实施方式65至111中任一项所述的抗体,MCP1、IL-8及MIP1α的表达在与该抗体接触的人PBMC中增加。
实施方式113.如实施方式65至112中任一项所述的抗体,其中单核细胞/巨噬细胞在与该抗体接触时经活化。
实施方式114.如实施方式65至113中任一项所述的抗体,其中在CD14+单核细胞/巨噬细胞与该抗体接触时,CD86及MHCII上调。
实施方式115.如实施方式65至114中任一项所述的抗体,其中与该抗体接触的CD14+单核细胞/巨噬细胞成熟为抗原呈递细胞。
实施方式116.如实施方式65至115中任一项所述的抗体,其中与该抗体接触的记忆T细胞响应抗原的IFNγ产生增加。
实施方式117.如实施方式65至116中任一项所述的抗体,其中与该抗体接触的所述记忆T细胞对抗原的反应增强。
实施方式118.如实施方式65至117中任一项所述的抗体,其中效应记忆CD8+ T细胞和/或效应记忆CD4+ T细胞在与该抗体接触的肿瘤中增加。
实施方式119.如实施方式65至118中任一项所述的抗体,其中所述抗体增强给予了该抗体的动物中的Th1反应。
实施方式120.如实施方式65至119中任一项所述的抗体,其中与未经无岩藻糖基化的相同抗TIGIT抗体相比,该抗体对FcγRIIa和/或FcγRIIb具有较低结合亲和性。
实施方式121.如实施方式65至120中任一项所述的抗体,其中所述抗体介导在单核细胞巨噬细胞存在下TIGIT表达细胞的抗体依赖性细胞吞噬作用(ADCP)。
实施方式122.如实施方式65至121中任一项所述的抗体,其中所述抗体是单克隆抗体。
实施方式123.如实施方式65至122中任一项所述的抗体,其中所述抗体是完全人抗体。
实施方式124.如实施方式65至123中任一项所述的抗体,其中所述抗体是嵌合抗体。
实施方式125.如实施方式65至92及109至124中任一项所述的抗体,其中所述抗体是人源化抗体。
实施方式126.如实施方式65至125中任一项所述的抗体,其中所述抗体是抗体片段。
实施方式127.如实施方式126所述的抗体,其中所述抗体片段是Fab、Fab’、F(ab’)2、scFv或双价抗体。
实施方式128.如实施方式65至127中任一项所述的抗体,其中所述抗体是双特异性抗体。
实施方式129.如实施方式65至128中任一项所述的抗体,其中所述抗体是抗体-药物偶联物。
实施方式130.一种药物制剂,其包含如实施方式1至64中任一项所述的组合物或如实施方式65至129中任一项所述的抗体及药学上可接受的载剂。
实施方式131.一种经分离多核苷酸,其编码(i)如实施方式106至108中任一项所述抗体的重链;(ii)如实施方式106至108中任一项所述抗体的轻链;或(iii)如实施方式106至108中任一项所述抗体的重链及轻链。
实施方式132.如实施方式131所述的经分离多核苷酸,其中该多核苷酸包含(i)选自SEQ ID NO:259、261、163、265、267、269及271的核苷酸序列;或(ii)SEQ ID NO:273的核苷酸序列;或(iii)选自SEQ ID NO:259、261、263、265、267、269及271的核苷酸序列,及SEQID NO:273的核苷酸序列。
实施方式133.一种包含如实施方式131或实施方式132所述多核苷酸的载体。
实施方式134.一种经分离宿主细胞,其包含如实施方式131或实施方式132所述的经分离多核苷酸或如实施方式133所述的载体。
实施方式135.一种经分离宿主细胞,其表达如实施方式106至108中任一项所述的抗体。
实施方式136.如实施方式134或实施方式135所述的宿主细胞,其经工程改造以产生无岩藻糖基化抗体。
实施方式137.一种产生结合人TIGIT的抗体的方法,其包含在适于产生该抗体的条件下培育如实施方式134至136中任一项所述的宿主细胞。
实施方式138.如实施方式137所述的方法,其中该宿主细胞经工程改造以产生无岩藻糖基化抗体。
实施方式139.如实施方式137所述的方法,其中在适于产生无岩藻糖基化抗体的条件下在岩藻糖类似物存在下培养该宿主细胞。
实施方式140.如权利要求137至139中任一项所述的方法,其进一步包含分离所述抗体。
实施方式141.一种结合人TIGIT的经分离抗体的组合物,其中所述组合物中至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%或至少99%的所述抗体是无岩藻糖基化的,其中所述抗体是藉由如实施方式138至140中任一项所述的方法产生。
实施方式142.一种结合人TIGIT的经分离抗体的组合物,其中所述组合物中至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%或至少99%的所述抗体是无岩藻糖基化的,其中所述抗体是藉由包含以下内容的方法产生:在适于产生无岩藻糖基化抗体的条件下培育如实施方式134或实施方式135所述的宿主细胞,及分离所述抗体以形成经分离抗体的组合物。
实施方式143.如实施方式142所述的组合物,其中该宿主细胞经工程改造以产生无岩藻糖基化抗体。
实施方式144.如实施方式142所述的组合物,其中在适于产生无岩藻糖基化抗体的条件下在岩藻糖类似物存在下培养该宿主细胞。
实施方式145.一种包含多核苷酸的宿主细胞,该多核苷酸包含编码(i)如实施方式1至63中任一项所述的组合物的抗体,或(ii)如实施方式65至128中任一项所述抗体的核苷酸序列,其中该宿主细胞经工程改造以产生无岩藻糖基化抗体。
实施方式146.如实施方式145所述的宿主细胞,其中该多核苷酸是载体。
实施方式147.一种宿主细胞,其表达(i)如实施方式1至63中任一项所述的组合物的抗体,或(ii)如实施方式65至128中任一项所述的抗体,其中该宿主细胞经工程改造以产生无岩藻糖基化抗体。
实施方式148.如实施方式145至147中任一项所述的宿主细胞,其中该宿主细胞包含:
(a)SEQ ID NO:2、SEQ ID NO:20、SEQ ID NO:38、SEQ ID NO:56、SEQ ID NO:74、SEQ ID NO:92、SEQ ID NO:110、SEQ ID NO:128、SEQ ID NO:146、SEQ ID NO:164、SEQ IDNO:182、SEQ ID NO:200、SEQ ID NO:259、SEQ ID NO:265、SEQ ID NO:267、SEQ ID NO:269或SEQ ID NO:271的核苷酸序列;和/或
(b)SEQ ID NO:11、SEQ ID NO:29、SEQ ID NO:47、SEQ ID NO:65、SEQ ID NO:83、SEQ ID NO:101、SEQ ID NO:119、SEQ ID NO:137、SEQ ID NO:155、SEQ ID NO:173、SEQ IDNO:191、SEQ ID NO:209或SEQ ID NO:273的核苷酸序列。
实施方式149.一种产生结合TIGIT的无岩藻糖基化抗体的方法,其包含在适于产生所述无岩藻糖基化抗体的条件下培养如实施方式145至148中任一项所述的宿主细胞。
实施方式150.一种产生结合TIGIT的无岩藻糖基化抗体的方法,其包含在适于产生无岩藻糖基化抗体的条件下在岩藻糖类似物存在下培养宿主细胞,其中该宿主细胞包含多核苷酸,该多核苷酸包含编码(i)如实施方式1至63中任一项所述的组合物的抗体或(ii)如实施方式65至128中任一项所述抗体的核苷酸序列。
实施方式151.如实施方式150所述的方法,其中该多核苷酸是载体。
实施方式152.一种产生结合TIGIT的无岩藻糖基化抗体的方法,其包含在适于产生无岩藻糖基化抗体的条件下在岩藻糖类似物存在下培养宿主细胞,其中该宿主细胞表达(i)如实施方式1至63中任一项所述的组合物的抗体,或(ii)如实施方式65至128中任一项所述的抗体。
实施方式153.如实施方式150至152中任一项所述的方法,其中该宿主细胞包含:
(a)SEQ ID NO:2、SEQ ID NO:20、SEQ ID NO:38、SEQ ID NO:56、SEQ ID NO:74、SEQ ID NO:92、SEQ ID NO:110、SEQ ID NO:128、SEQ ID NO:146、SEQ ID NO:164、SEQ IDNO:182、SEQ ID NO:200、SEQ ID NO:259、SEQ ID NO:265、SEQ ID NO:267、SEQ ID NO:269或SEQ ID NO:271的核苷酸序列;和/或
(b)SEQ ID NO:11、SEQ ID NO:29、SEQ ID NO:47、SEQ ID NO:65、SEQ ID NO:83、SEQ ID NO:101、SEQ ID NO:119、SEQ ID NO:137、SEQ ID NO:155、SEQ ID NO:173、SEQ IDNO:191、SEQ ID NO:209或SEQ ID NO:273的核苷酸序列。
实施方式154.如实施方式150至153中任一项所述的方法,其中所述岩藻糖类似物是2-氟岩藻糖。
实施方式155.如权利要求149至154中任一项所述的方法,其进一步包含分离所述无岩藻糖基化抗体。
实施方式156.一种结合人TIGIT的经分离抗体的组合物,其中所述组合物中至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%或至少99%的所述抗体是无岩藻糖基化的,其中所述抗体是藉由如实施方式149至155中任一项所述的方法产生。
实施方式157.一种结合人TIGIT的经分离抗体的组合物,其中所述组合物中至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%或至少99%的所述抗体是无岩藻糖基化的,其中所述抗体是藉由包含以下内容的方法产生:在适于产生无岩藻糖基化抗体的条件下培育如实施方式145至147中任一项所述的宿主细胞,及分离所述抗体以形成经分离抗体的组合物。
实施方式158.一种结合人TIGIT的经分离抗体的组合物,其中所述组合物中至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%或至少99%的所述抗体是无岩藻糖基化的,其中所述抗体是藉由包含以下内容的方法产生:在适于产生无岩藻糖基化抗体的条件下在岩藻糖类似物存在下培养宿主细胞,其中该宿主细胞包含多核苷酸,该多核苷酸包含编码(i)如实施方式1至63中任一项所述的组合物的抗体或(ii)如实施方式65至128中任一项所述抗体的核苷酸序列。
实施方式159.一种结合人TIGIT的经分离抗体的组合物,其中所述组合物中至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%或至少99%的所述抗体是无岩藻糖基化的,其中所述抗体是藉由包含以下内容的方法产生:在适于产生无岩藻糖基化抗体的条件下在岩藻糖类似物存在下培养宿主细胞,其中该宿主细胞表达(i)如实施方式1至63中任一项所述的组合物的抗体,或(ii)如实施方式65至128中任一项所述的抗体。
实施方式160.一种试剂盒,其包含:
如实施方式1至64中任一项所述的组合物、如实施方式65至129中任一项所述的抗体或如实施方式130所述的药物组合物;及
其他治疗剂。
实施方式161.如实施方式160所述的试剂盒,其中所述其他治疗剂是抗癌剂。
实施方式162.如实施方式160或实施方式161所述的试剂盒,其中所述其他治疗剂是抗体。
实施方式163.如实施方式160至162中任一项所述的试剂盒,其中所述其他治疗剂是T细胞共抑制因子的拮抗剂或抑制剂;T细胞共活化因子的激动剂;免疫刺激性细胞因子;或SGN-2FF。
实施方式164.如实施方式160至163中任一项所述的试剂盒,其中所述其他治疗剂结合选自下组的蛋白质:CD25、PD-1、PD-L1、Tim3、Lag3、CTLA4、41BB、OX40、CD3、CD40、CD47M、GM-CSF、CSF1R、TLR、STING、RIGI、TAM受体激酶、NKG2A、NKG2D、GD2、HER2、EGFR、PDGFRα、SLAMF7、VEGF、CTLA-4、CD20、cCLB8、KIR及CD52。
实施方式165.如实施方式160至164中任一项所述的试剂盒,其中所述其他治疗剂选自抗CD25抗体、抗PD-1抗体、抗PD-L1抗体、抗Tim3抗体、抗Lag3抗体、抗CTLA4抗体、抗41BB抗体、抗OX40抗体、抗CD3抗体、抗CD40抗体、抗CD47M抗体、抗CSF1R抗体、抗TLR抗体、抗STING抗体、抗RIGI抗体、抗TAM受体激酶抗体、抗NKG2A抗体、抗NKG2D抗体、抗GD2抗体、抗HER2抗体、抗EGFR抗体、抗PDGFR-α-抗体、抗SLAMF7抗体、抗VEGF抗体、抗CTLA-4抗体、抗CD20抗体、抗cCLB8抗体、抗KIR抗体及抗CD52抗体。
实施方式166.如实施方式160至165中任一项所述的试剂盒,其中所述其他治疗剂包含选自IL-15、IL-21、IL-2、GM-CSF、M-CSF、G-CSF、IL-1、IL-3、IL-12及IFNγ的细胞因子。
实施方式167.如实施方式160至165中任一项所述的试剂盒,其中所述其他治疗剂选自SEA-CD40、阿维鲁单抗(avelumab)、德瓦鲁单抗(durvalumab)、尼沃鲁单抗(nivolumab)、派姆单抗(pembrolizumab)、匹利珠单抗(pidilizumab)、阿替珠单抗(atezolizumab)、Hul4.18K322A、Hu3F8、达妥昔单抗(dinituximab)、曲妥珠单抗(trastuzumab)、西妥昔单抗(cetuximab)、奥拉妥单抗(olaratumab)、奈昔木单抗(necitumumab)、埃罗妥珠单抗(elotuzumab)、雷莫芦单抗(ramucirumab)、帕妥珠单抗(pertuzumab)、伊匹单抗(ipilimumab)、贝伐珠单抗(bevacizumab)、利妥昔单抗(rituximab)、奥妥珠单抗(obinutuzumab)、司妥昔单抗(siltuximab)、奥法木单抗(ofatumumab)、利利单抗(lirilumab)及阿伦单抗(alemtuzumab)。
实施方式168.如实施方式160或实施方式161所述的试剂盒,其中所述其他治疗剂选自烷基化剂(例如环磷酰胺(cyclophosphamide)、异环磷酰胺(ifosfamide)、氮芥苯丁酸(chlorambucil)、白消安(busulfan)、美法仑(melphalan)、甲基二(氯乙基)胺(mechlorethamine)、乌拉莫司汀(uramustine)、噻替派(thiotepa)、亚硝基脲(nitrosoureas)或替莫唑胺(temozolomide))、蒽环(例如多柔比星(doxorubicin)、阿德力霉素(adriamycin)、道诺霉素(daunorubicin)、泛艾霉素(epirubicin)或米托蒽醌(mitoxantrone))、细胞骨架破坏剂(例如太平洋紫杉醇(paclitaxel)或多西他赛(docetaxel))、组织蛋白去乙酰酶抑制剂(例如伏立诺他(vorinostat)或罗米地辛(romidepsin))、拓朴异构酶抑制剂(例如伊立替康(irinotecan)、托泊替康(topotecan)、安吖啶(amsacrine)、依托泊苷(etoposide)或替尼泊苷(teniposide))、激酶抑制剂(例如硼替佐米(bortezomib)、厄洛替尼(erlotinib)、吉非替尼(gefitinib)、伊马替尼(imatinib)、威罗菲尼(vemurafenib)或维莫德吉(vismodegib))、核苷类似物或前体类似物(例如阿扎胞苷(azacitidine)、硫唑嘌呤(azathioprine)、卡培他滨(capecitabine)、阿糖胞苷(cytarabine)、氟尿嘧啶(fluorouracil)、吉西他滨(gemcitabine)、羟基脲(hydroxyurea)、巯嘌呤(mercaptopurine)、胺甲喋呤(methotrexate)或硫鸟嘌呤(thioguanine))、肽抗生素(例如放线菌素(actinomycin)或博来霉素(bleomycin))、基于铂的药剂(例如顺铂(cisplatin)、奥沙利铂(oxaloplatin)或卡铂(carboplatin))、或植物碱(例如长春新碱(vincristine)、长春碱(vinblastine)、长春瑞滨(vinorelbine)、长春地辛(vindesine)、鬼臼毒素(podophyllotoxin)、太平洋紫杉醇或多西他赛)、加拉定(galardin)、沙利窦迈(thalidomide)、雷利窦迈(lenalidomide)及泊马窦迈(pomalidomide)。
实施方式169.一种治疗对象癌症的方法,其包含给予所述对象治疗有效量的如实施方式1至64中任一项所述的组合物、如实施方式65至129中任一项所述的抗体或如实施方式130所述的药物组合物。
实施方式170.如实施方式169所述的方法,其中所述癌症是CD112或CD155表达富集的癌症。
实施方式171.如实施方式169或实施方式170所述的方法,其中所述癌症是表达TIGIT的T细胞或天然杀手(NK)细胞富集的癌症。
实施方式172.如实施方式169至171中任一项所述的方法,其中所述癌症是膀胱癌、乳癌、子宫癌、子宫颈癌、卵巢癌、前列腺癌、睪丸癌、食道癌、胃肠癌、胃癌(gastriccancer)、胰脏癌、结肠直肠癌、结肠癌、肾癌、透明细胞肾癌、头颈癌、肺癌、肺腺癌、胃癌(stomach cancer)、生殖细胞癌、骨癌、肝癌、甲状腺癌、皮肤癌、黑色素瘤、中枢神经系统赘瘤、间皮瘤、淋巴瘤、白血病、慢性淋巴细胞白血病、弥漫性大B细胞淋巴瘤、滤泡性淋巴瘤、霍奇金氏淋巴瘤(Hodgkin lymphoma)、骨髓瘤或肉瘤。
实施方式173.如实施方式172所述的方法,其中所述癌症是淋巴瘤、白血病、慢性淋巴细胞白血病、弥漫性大B细胞淋巴瘤、滤泡性淋巴瘤或霍奇金氏淋巴瘤。
实施方式174.如实施方式169至173中任一项所述的方法,其进一步包含给予所述对象治疗有效量的其他治疗剂。
实施方式175.如实施方式174所述的方法,其中所述其他治疗剂是抗癌剂。
实施方式176.如实施方式174或实施方式175所述的方法,其中所述其他治疗剂是抗体。
实施方式177.如实施方式174至176中任一项所述的方法,其中所述其他治疗剂是T细胞共抑制因子的拮抗剂或抑制剂;T细胞共活化因子的激动剂;或免疫刺激性细胞因子;或SGN-2FF。
实施方式178.如实施方式174至177中任一项所述的方法,其中所述其他治疗剂结合选自下组的蛋白质:CD25、PD-1、PD-L1、Tim3、Lag3、CTLA4、41BB、OX40、CD3、CD40、CD47M、GM-CSF、CSF1R、TLR、STING、RIGI、TAM受体激酶、NKG2A、NKG2D、GD2、HER2、EGFR、PDGFRα、SLAMF7、VEGF、CTLA-4、CD20、cCLB8、KIR及CD52。
实施方式179.如实施方式178所述的方法,其中所述其他治疗剂选自抗CD25抗体、抗PD-1抗体、抗PD-L1抗体、抗Tim3抗体、抗Lag3抗体、抗CTLA4抗体、抗41BB抗体、抗OX40抗体、抗CD3抗体、抗CD40抗体、抗CD47M抗体、抗CSF1R抗体、抗TLR抗体、抗STING抗体、抗RIGI抗体、抗TAM受体激酶抗体、抗NKG2A抗体、抗NKG2D抗体、抗GD2抗体、抗HER2抗体、抗EGFR抗体、抗PDGFR-α-抗体、抗SLAMF7抗体、抗VEGF抗体、抗CTLA-4抗体、抗CD20抗体、抗cCLB8抗体、抗KIR抗体及抗CD52抗体。
实施方式180.如实施方式174或实施方式175所述的方法,其中所述其他治疗剂包含选自IL-15、IL-21、IL-2、GM-CSF、M-CSF、G-CSF、IL-1、IL-3、IL-12及IFNγ的细胞因子。
实施方式181.如实施方式174至179中任一项所述的方法,其中所述其他治疗剂选自SEA-CD40、阿维鲁单抗、德瓦鲁单抗、尼沃鲁单抗、派姆单抗、匹利珠单抗、阿替珠单抗、Hul4.18K322A、Hu3F8、达妥昔单抗、曲妥珠单抗、西妥昔单抗、奥拉妥单抗、奈昔木单抗、埃罗妥珠单抗、雷莫芦单抗、帕妥珠单抗、伊匹单抗、贝伐珠单抗、利妥昔单抗、奥妥珠单抗、司妥昔单抗、奥法木单抗、利利单抗及阿伦单抗。
实施方式182.如实施方式174或实施方式175所述的方法,其中所述其他治疗剂选自烷基化剂(例如环磷酰胺、异环磷酰胺、氮芥苯丁酸、白消安、美法仑、甲基二(氯乙基)胺、乌拉莫司汀、噻替派、亚硝基脲或替莫唑胺)、蒽环(例如多柔比星、阿德力霉素、道诺霉素、泛艾霉素或米托蒽醌)、细胞骨架破坏剂(例如太平洋紫杉醇或多西他赛)、组织蛋白去乙酰酶抑制剂(例如伏立诺他或罗米地辛)、拓朴异构酶抑制剂(例如伊立替康、托泊替康、安吖啶、依托泊苷或替尼泊苷)、激酶抑制剂(例如硼替佐米、厄洛替尼、吉非替尼、伊马替尼、威罗菲尼或维莫德吉)、核苷类似物或前体类似物(例如阿扎胞苷、硫唑嘌呤、卡培他滨、阿糖胞苷、氟尿嘧啶、吉西他滨、羟基脲、巯嘌呤、胺甲喋呤或硫鸟嘌呤)、肽抗生素(例如放线菌素或博来霉素)、基于铂的药剂(例如顺铂、奥沙利铂或卡铂)、或植物碱(例如长春新碱、长春碱、长春瑞滨、长春地辛、鬼臼毒素、太平洋紫杉醇或多西他赛)、加拉定、沙利窦迈、雷利窦迈及泊马窦迈。
实施方式183.如实施方式174至182中任一项所述的方法,其中所述组合物、所述抗体或所述药物组合物与所述其他治疗剂同时给药。
实施方式184.如实施方式174至183中任一项所述的方法,其中所述组合物、所述抗体或所述药物组合物与所述其他治疗剂依序给药。
附图说明
图1.65个抗TIGIT抗体克隆及无关同型对照抗体与经工程改造以表达人TIGIT(顶部图)、食蟹猕猴TIGIT(中间图)及小鼠TIGIT(底部图)的HEK 293细胞的结合。
图2.65个抗TIGIT抗体克隆及无关同型对照抗体与原代人T细胞(顶部图)、食蟹猕猴T细胞(中间图)及小鼠T细胞(底部图)的结合。对于底部图,评估65个克隆中的35个。在评估的35个克隆中,35个中的5个不结合mTIGIT-Fc蛋白(克隆20、27、55、56及60),如由浅绿色柱所指示。
图3A-3D.(A-C)8个抗TIGIT抗体克隆(克隆2、5、13、16、17、20、25及54)与在HEK293细胞上表达的人(A)、小鼠(B)及食蟹猕猴(C)TIGIT的结合滴定值。显示单个孔的结果。(D)8个抗TIGIT抗体克隆(克隆2、5、13、16、17、20、25及54)与在HEK 293细胞上表达的人、小鼠及食蟹猕猴TIGIT的EC50值。
图4.抗TIGIT抗体克隆13及25与活化小鼠脾T细胞的结合滴定。显示单个孔的结果。克隆13的EC50为0.24μg/mL。克隆25的EC50为2.28μg/mL。
图5A-5B.对于与表达人TIGIT的HEK 293细胞结合的人CD155(A)及与表达小鼠TIGIT的HEK 293细胞结合的小鼠CD155(B)两者,抗TIGIT抗体阻断CD155与在HEK 293细胞上表达的TIGIT的相互作用。显示单个孔的结果。
图6.抗TIGIT抗体阻断人CD112与在HEK 293细胞上表达的人TIGIT的相互作用。显示单个孔的结果。
图7A-7B.(A)上图:所选抗TIGIT抗体有效地阻断TIGIT-CD155接合,从而引起T细胞活化,如据荧光素酶活性的>1.5诱导所量测。约12个克隆在生物分析中显示>1.5倍诱导。在ForteBio分析中,两个克隆不阻断TIGIT-CD155相互作用(粉色柱)。相对于无抗体对照量测倍数诱导。平均值及SD是一式两份实验的平均值及SD;抗体是20μg/mL。灰色柱=hIgG1同型对照。黑色柱=无抗体对照(定义为基线)。下图:TIGIT/CD155阻断生物分析对TIGIT-Fc亲和性的相关性图。生物分析中的活性与对重组蛋白的亲和性相关。(B)TIGIT/CD155阻断生物分析中12个所选抗TIGIT克隆的剂量反应。克隆13及25显示与所有三个物种的强结合,在生物分析中显示良好活性。平均值及SD是一式三份孔的平均值及SD。
图8.所选抗TIGIT抗体与抗PD-1协同作用,从而引起T细胞活化。平均值及SD是一式三份孔的平均值及SD。克隆13及克隆25两者在组合生物分析中皆显示与抗PD-1的协同作用。
图9A-9H.克隆13的完全人抗TIGIT克隆13(“c13 hIgG1”)及小鼠IgG1(“c13mIgG1”)及小鼠IgG2a(“c13 mIgG2a”)嵌合体的与在HEK 293细胞上表达的人(A)、小鼠(B)及食蟹猕猴(C)TIGIT的结合的(A-D)结合滴定(A-C)及EC50值(D)。平均值及SD是一式两份孔的平均值及SD。(E-F)对于与表达人TIGIT的HEK 293细胞结合的人CD155(E)及与表达小鼠TIGIT的HEK 293细胞结合的小鼠CD155(F)两者,抗体c13 hIgG1、c13 mIgG1及c13mIgG2a阻断CD155与在HEK 293细胞上表达的TIGIT的相互作用。结果是单个孔的结果。(G)抗体c13 hIgG1、c13mIgG1及c13 mIgG2a阻断人CD112与在HEK 293细胞上表达的人TIGIT的相互作用。结果是单个孔的结果。(H)TIGIT/CD155阻断生物分析中亲代及嵌合抗TIGIT抗体克隆c13 hIgG1、c13 mIgG1及c13 mIgG2a的剂量反应。平均值及SD是一式三份孔的平均值及SD。
图10A-10K.可接合活化Fcγ受体的抗TIGIT抗体在小鼠中的CT26同系肿瘤模型中介导抗肿瘤效能。(A)组平均肿瘤体积。(B-K)组1至10的个别动物肿瘤体积。PR=部分反应(对于三个连续量测结果,肿瘤体积是其第1天体积的50%或更小,且对于该三个量测结果中之一或多者等于或大于13.5mm3)。CR=完全反应(对于三个连续量测结果,肿瘤体积小于13.5mm3)。
图11.藉由BLI的人FcγRIIIa 158V结合滴定的抗TIGIT抗体的感测图。显示抗TIGIT克隆13 hIgG1野生型、无岩藻糖基化及LALA-PG(左图)、抗TIGIT克隆13 mIgG2a野生型、无岩藻糖基化及LALA-PG(中心图)及抗TIGIT克隆13C hIgG1野生型(右图)的结果。
图12.抗TIGIT mIgG2a抗体与表达mCD16(FcγRIVa之鼠类形式)的CHO细胞的结合。与野生型mIgG2a(黑色圆圈)或mIgG2a LALA-PG(黑色三角形)相比,无岩藻糖基化克隆13 mIgG2a(黑色正方形)以显著更大亲和性结合。结合数据概述于下表中。
图13.来自健康供体的T细胞亚组的TIGIT(顶部图)、CD226(中间图)及CD155(底部图)表达。Treg表达最高量的TIGIT,而测试的所有T细胞亚组皆表达活化受体CD226。大部分缺乏CD155表达。
图14.TIGIT阳性Treg细胞被不同浓度的克隆13 IgG1野生型(黑色圆圈)、无岩藻糖基化克隆13 IgG1(黑色正方形)、克隆13 IgG1 LALA-PG(黑色三角形)及人IgG1同型对照(灰色倒三角形)的清除。
图15.同种异体NK/Treg共培养物实验中Treg被克隆13 IgG1野生型(黑色圆圈)、无岩藻糖基化克隆13 IgG1(黑色正方形)及克隆13 IgG1 LALA-PG(黑色三角形)的清除。包括无岩藻糖基化OKT9抗体(空心圆圈)作为阳性对照。
图16.在用克隆13 IgG1野生型抗体(黑色正方形)、克隆13 IgG1无岩藻糖基化抗体(黑色菱形)或克隆13 IgG1 LALA-PG抗体(黑色圆圈)治疗后的PBMC的炎性细胞因子MCP-1(顶部图)、IL-8(中间图)及MIP1α(底部图)产生。
图17.在用克隆13 IgG1野生型抗体(灰色圆圈)、克隆13 IgG1无岩藻糖基化抗体(灰色正方形)及克隆13 IgG1 LALA-PG抗体(黑色三角形)治疗后CD14+单核细胞上CD86(左图)及MHC II类(右图)表达的剂量依赖性上调。
图18A-18C.三个不同同系肿瘤模型中抗TIGIT抗体的体内活性。图8A显示A20同系淋巴瘤模型中克隆13 IgG2a野生型、无岩藻糖基化克隆13 IgG2a及克隆13 IgG2a LALA-PG对肿瘤体积的效应。图8B显示CT26同系结肠癌模型中克隆13 IgG2a野生型、无岩藻糖基化克隆13 IgG2a及克隆13 IgG2a LALA-PG对肿瘤体积的效应。图8C显示MC38同系结肠癌模型中克隆13 IgG2a野生型、无岩藻糖基化克隆13 IgG2a及克隆13 IgG2a LALA-PG对肿瘤体积的效应。在所有3个模型中,在与克隆13 IgG2a LALPG(黑色正方形)或未治疗动物(灰色三角形)相比时,克隆13 mIgG2a野生型(黑色圆圈)及无岩藻糖基化克隆13 mIGg2a(黑色菱形)在控制肿瘤大小方面更有效。
图19.针对与单独西妥昔单抗(空心正方形)、西妥昔单抗与抗TIGIT抗体克隆13IgG1的组合(黑色正方形)及IgG1同型对照抗体(空心三角形)接触的A549细胞的ADCC活性。
图20.暴露于CMV回忆抗原且经抗PD-1抗体(派姆单抗治疗以灰色正方形显示,尼沃鲁单抗治疗以灰色菱形显示)及递增浓度的抗TIGIT抗体克隆13 IgG1处理的PBMC中CMV诱导的IFNγ表达。亦显示用单独抗TIGIT抗体克隆13 IgG1的治疗(黑色正方形)。
图21.暴露于CMB回忆抗原且经递增浓度的抗TIGIT抗体克隆13 IgG1野生型(“克隆13 IgG1”)、无岩藻糖基化克隆13 IgG1(“克隆13 SEA IgG1”)及克隆13 IgG1 LALA-PG(“克隆13 LALA IgG1”)处理的PBMC中CMV诱导的IFNγ表达。
图22.经递增浓度的抗TIGIT抗体克隆13 IgG1野生型(“克隆13 IgG1”)、无岩藻糖基化克隆13 IgG1(“克隆13 SEA IgG1”)及克隆13 IgG1 LALA-PG(“克隆13 LALA IgG1”)处理的HLA错配的共培养的PBMC中的IL2表达。
图23.响应抗TIGIT抗体的CT26结肠癌异种移植物小鼠的血浆及组织中的细胞因子诱导。将植入CT26结肠癌细胞的小鼠用1mg/kg克隆13 IgG2a野生型(“WT”)、无岩藻糖基化克隆13 IgG1(“SEA”)或克隆13 IgG2a LALA-PG(“LALA”)治疗,且在血浆、脾及肿瘤溶解物中量测细胞因子含量。
图24.在用抗TIGIT抗体克隆13 IgG2a野生型(“WT TIGIT”)、无岩藻糖基化克隆13IgG2a(“SEA TIGIT”)或克隆13 IgG2a LALA-PG(“LALA TIGIT”)治疗后CT26结肠癌异种移植物小鼠中的肿瘤内及外周CD8+ T细胞亚组的变化。
图25.经抗TIGIT抗体克隆13 IgG2a野生型(“WT TIGIT”)、无岩藻糖基化克隆13IgG2a(“SEA TIGIT”)或克隆13 IgG2a LALA-PG(“LALA TIGIT”)治疗的CT26结肠癌异种移植物小鼠中的肿瘤内及外周CD4+ T细胞亚组的变化。
图26A-B.在六个剂量的抗TIGIT抗体克隆13 IgG2a野生型(“WT TIGIT”)、无岩藻糖基化克隆13 IgG2a(“SEA TIGIT”)或克隆13 IgG2a LALA-PG(“LALA TIGIT”)后CT26结肠癌异种移植物小鼠中的脾CD8+(A)及CD4+(B)T细胞亚组的变化。显示在CD8+或CD4+上门控的活CD45+细胞的结果。
图27.经抗TIGIT抗体克隆13 IgG2a野生型(“WT TIGIT”)、无岩藻糖基化克隆13IgG2a(“SEA TIGIT”)或克隆13 IgG2a LALA-PG(“LALA TIGIT”)治疗的CT26结肠癌异种移植物小鼠的血浆及脾中的细胞因子诱导。
图28.经抗TIGIT抗体克隆13 IgG2a野生型(“WT TIGIT”)、无岩藻糖基化克隆13IgG2a(“SEA TIGIT”)或克隆13 IgG2a LALA-PG(“LALA TIGIT”)治疗的小鼠中抗原特异性T细胞反应的诱导。
图29A-C.三个不同同系肿瘤模型中抗TIGIT抗体的体内活性。图29A显示EMT6同系乳癌模型中5mg/kg克隆13 IgG2a野生型(“TIGIT”)及0.1mg/kg、1mg.kg及5mg/kg无岩藻糖基化克隆13 IgG2a(“SEA TIGIT”)对肿瘤体积的效应。图29B显示E0771同系乳癌模型中5mg/kg克隆13 IgG2a野生型(“TIGIT”)及0.1mg/kg、1mg.kg及5mg/kg无岩藻糖基化克隆13IgG2a(“SEA TIGIT”对肿瘤体积的效应。图29C显示外部保持的CT26同系结肠癌模型中1mg/ml克隆13 IgG2a野生型对肿瘤体积的效应。
图30.NK细胞(左)及活化CD8 T细胞(右)分子印记(signature)与对抗TIGIT抗体治疗的同系肿瘤模型反应的相关性。
图31.TIGIT(左)及CD155(右)表达与对抗TIGIT抗体治疗的同系肿瘤模型反应的相关性。
图32.在经OVA疫苗接种及用1mg/kg克隆13 IgG2a野生型(“WT TIGIT”)、克隆13mIgG2a无岩藻糖基化(“SEA TIGIT”)或克隆13 mIgG2a LALA-PG(“LALA TIGIT”)抗体治疗后小鼠中的抗OVA IgG1(左图)及IgG2a(右图)含量。
图33.在重新刺激经OVA疫苗接种后1mg/kg克隆13 IgG2a野生型(“WT TIGIT”)、克隆13 mIgG2a无岩藻糖基化(“SEA TIGIT”)或克隆13 mIgG2a LALA-PG(“LALA TIGIT”)抗体治疗的小鼠离体脾细胞后的细胞因子表达。
图34.在用克隆13 mIgG2a无岩藻糖基化抗体治疗后在CT26同系肿瘤模型中显示完全反应的小鼠的再攻击。
图35.抗TIGIT抗体克隆13 IgG1野生型(“WT”)、无岩藻糖基化克隆13 IgG1(“SEA克隆13 IgG1”)或克隆13 IgG1 DLE(“DLE”)所致Treg清除。
图36.抗TIGIT抗体克隆13 IgG1野生型(“WT克隆13”)、无岩藻糖基化克隆13 IgG1(“SEA克隆13 IgG1”)或克隆H5/L4 IgG1所致Treg清除。
图37.MC38小鼠肿瘤模型中抗TIGIT抗体克隆13 IgG1野生型(“WT克隆13”或“WTTIGIT”)、无岩藻糖基化克隆13 IgG1(“SEA克隆13”或“SGN-TGT”)、抗PD-1抗体以及抗PD-1抗体与克隆13 IgG1野生型或无岩藻糖基化克隆13 IgG1之组合的效能。
图38A-38B.图38A在与超抗原葡萄球菌肠毒素B肽及抗TIGIT抗体克隆13 IgG1野生型(“WT克隆13”)、无岩藻糖基化克隆13 IgG1(“SEA克隆13”)、克隆13 IgG1 DLE(“DLE”)或克隆H5/L4 IgG1接触后的IL-2表达(图38A)或IL-10表达(图38B)。
图39A-39D.抗TIGIT抗体克隆13 IgG1野生型(“克隆13 IgG1”)、无岩藻糖基化克隆13 IgG1(“SEA克隆13”)、克隆13 LALA-PG(“克隆13 LALA”)、克隆13 IgG1 DLE(“克隆13DLE”)或克隆H5/L4 IgG1与在CHO细胞表面上表达的FcγRI(图39A)、FcγRIIIa V/V(图39B)、FcγRIIb(图39C)或FcγRIIa(图39D)的结合。
图40.由抗TIGIT抗体克隆13 IgG1野生型(“克隆13”)、无岩藻糖基化克隆13 IgG1(“SEA克隆13”)及克隆13 IgG1 DLE(“克隆13 DLE”)介导的TIGIT阳性Jurkat细胞的吞噬作用。
图41.由抗TIGIT抗体克隆13 IgG1野生型(“克隆13 IgG1”)、无岩藻糖基化克隆13IgG1(“SEA克隆13”)、克隆13 LALA-PG(“克隆13 LALA-PG”)、克隆13 IgG1 DLE(“克隆13DLE”)或克隆H5/L4 IgG1以及由抗CD47抗体hB6h12.3介导的TIGIT阳性Jurkat细胞的CDC。
具体实施方式
I.导论
本文提供对人TIGIT(具有Ig及ITIM结构域的T细胞免疫受体)具有高亲和性且进一步与小鼠TIGIT及食蟹猕猴TIGIT中任一者或两者具有交叉反应性的抗体,已鉴定为抑制TIGIT与CD155之间相互作用的抗体。所述抗体亦表现出与抗PD-1抗体的协同作用。因此,本文所述抗TIGIT抗体可作为单一药剂或与另一治疗剂的组合用于多种治疗应用,例如用于治疗各种癌症。在一些实施方式中,抗TIGIT抗体是无岩藻糖基化的。
因此,在一些实施方式中,本发明提供包含结合人TIGIT的抗体的组合物、试剂盒及治疗方法,其中所述抗体是无岩藻糖基化的。
II.定义
除非另有定义,否则本文中所用技术及科学术语具有与本领域普通技术人员通常所了解相同的含义。参见(例如)Lackie,DICTIONARY OF CELL AND MOLECULAR BIOLOGY,Elsevier(第4版,2007);Sambrook等人,MOLECULAR CLONING,A LABORATORY MANUAL,ColdSprings Harbor Press(Cold Springs Harbor,NY 1989)。与本文所述内容类似或等效的任何方法、装置及材料可用于本发明的实践中。
除非上下文另外明确指出,否则本文所用单数形式“一(a、an)”及“该”包括复数个指示物。因此,例如,对“抗体”的提及可选性包括两个或更多个所述分子的组合,及诸如此类。
本文所用术语“约”指本领域技术人员容易了解的对应值的常见误差范围。
如本文所用术语“TIGIT”指“具有Ig及ITIM结构域的T细胞免疫受体”。由TIGIT基因编码的蛋白质的蛋白质Ig超家族内的CD28家族的成员。TIGIT在若干类别的T细胞上及在天然杀手(NK)细胞上表达且藉由与CD226竞争配体CD155及CD112介导其免疫抑制效应。参见Levin等人,Eur.J.Immunol.,2011,41:902-915。TIGIT在业内亦称作WUCAM(WashingtonUniversity Cell Adhesion Molecule)及VSTM3(HUGO名称)。参见Levin等人,Eur JImmunol,2011,41:902-915。因此,除非另有说明或自上下文明了,否则贯穿本申请的对“TIGIT”的提及亦包括对WUCAM和/或VSTM3的提及。人TIGIT核苷酸及蛋白质序列分别记载于(例如)GenBank登录号NM173799(SEQ ID NO:217)及NP776160(SEQ ID NO:218)中。
术语“抗体”包括完整抗体及其抗原结合片段,其中抗原结合片段包含抗原结合区及包含位于CH2中的天冬酰胺(N)297的重链恒定区的至少一部分。通常,“可变区”含有抗体的抗原结合区且参与结合的特异性及亲和性。参见Fundamental Immunology第7版,Paul编辑,Wolters Kluwer Health/Lippincott Williams&Wilkins(2013)。轻链通常分类为κ或λ。重链通常分类为γ、μ、α、δ或ε,其进而定义免疫球蛋白类别,分别为IgG、IgM、IgA、IgD及IgE。
术语“抗体”亦包括二价或双特异性分子、双价抗体、三价抗体及四价抗体。二价及双特异性分子记载于以下中:例如Kostelny等人(1992)J.Immunol.148:1547,Pack及Pluckthun(1992)Biochemistry 31:1579,Hollinger等人(1993),PNAS.USA 90:6444,Gruber等人(1994)J Immunol.152:5368,Zhu等人(1997)Protein Sci.6:781,Hu等人(1996)Cancer Res.56:3055,Adams等人(1993)Cancer Res.53:4026及McCartney,等人(1995)Protein Eng.8:301。
术语“抗体”包括抗体自身(裸抗体)或偶联至细胞毒性或细胞生长抑制药物的抗体。
“单克隆抗体”指自实质上同源的抗体群获得的抗体,即,除可能存在极少量天然存在的突变外,构成该群体的个别抗体皆相同。修饰词“单克隆”指示抗体特征是自实质上同源的抗体群获得,不应理解为需要藉由任一特定方法来产生该抗体。举例而言,欲按本发明使用的单克隆抗体可藉由首次由Kohler等人(1975)Nature 256:495阐述的杂交瘤方法来制备,或可藉由重组DNA方法来制备(例如参见美国专利第4816567号)。“单克隆抗体”亦可使用以下所述的技术自噬菌体抗体文库分离:例如,Clackson等人(1991)Nature 352:624-628及Marks等人(1991)J.Mol.Biol.,222:581-597,或可藉由其他方法制备。本文所述抗体是单克隆抗体。
单克隆抗体与其靶抗原的特异性结合意指亲和性为至少106、107、108、109或1010M-1。特异性结合在量值上可检测地高于至少一个无关靶标发生的非特异性结合且可与该非特异性结合区分。特异性结合可以是在特定官能团或特定空间配合(例如锁钥型)之间成键的结果,而非特异性结合通常是范德华力(van der Waals force)的结果。
基本抗体结构单元是亚单元的四聚体。每一四聚物包括两对相同多肽链,每一对具有一条“轻”链(约25kDa)及一条“重”链(约50-70kDa)。每一链的氨基末端部分包括主要负责抗原识别的约100个至110个或更多氨基酸的可变区。此可变区初始表达为连接至可裂解信号肽。无信号肽的可变区有时称作成熟可变区。因此,例如,轻链成熟可变区意指无轻链信号肽的轻链可变区。每一链的羧基末端部分界定主要负责效应功能的恒定区。
轻链分类为κ或λ。重链分类为γ、μ、α、δ或ε,且将抗体的同型分别定义为IgG、IgM、IgA、IgD及IgE。在轻链及重链内,可变区及恒定区藉由约包含12个或更多个氨基酸的“J”区接合,其中该重链亦包括约10个或更多个氨基酸的“D”区。(通常参见FundamentalImmunology(Paul,W.编辑,第2版Raven Press,N.Y.,1989,第7章,引用方式全文并入用于所有目的)。
每一轻链/重链对的成熟可变区形成抗体结合位点。因此,完整抗体具有两个结合位点。除在双功能或双特异性抗体中之外,两个结合位点是相同的。链皆呈现由三个超变区(亦称为互补决定区或CDR)接合的相对保守框架区(FR)的相同通用结构。每一对的两条链的CDR由框架区对准,从而能够结合特异性表位。轻链及重链两者自N末端至C末端包含结构域FR1、CDR1、FR2、CDR2、FR3、CDR3及FR4。氨基酸至各结构域中的指配按照以下定义:Kabat,Sequences of Proteins of Immunological Interest(National Institutes ofHealth,Bethesda,MD,1987及1991)、或Chothia及Lesk,J.Mol.Biol.196:901-917(1987);Chothia等人,Nature 342:878-883(1989)、或Kabat及Chothia之复合体、或IMGT(ImMunoGeneTics资讯系统)、AbM或Contact或CDR的其他常用定义。Kabat亦提供广泛使用的编号惯例(Kabat编号),其中不同重链之间或不同轻链之间的相应残基指配相同编号。除非自上下文另外明了,否则Kabat编号用于命名可变区中氨基酸的位置。除非自上下文另外明了,否则EU编号用于命名恒定区中的位置。
“人源化”抗体是保留非人抗体的反应性、但在人中免疫原性较小的抗体。此可(例如)藉由保留非人CDR区及用其人对应体置换抗体其余部分来达成。参见(例如)Morrison等人,PNAS USA,81:6851-6855(1984);Morrison及Oi,Adv.Immunol.,44:65-92(1988);Verhoeyen等人,Science,239:1534-1536(1988);Padlan,Molec.Immun.,28:489-498(1991);Padlan,Molec.Immun.,31(3):169-217(1994)。
如本文所用术语“嵌合抗体”指如下抗体分子:其中(a)恒定区或其部分被置换使得抗原结合位点(可变区、CDR或其部分)连接至不同物种的恒定区。
术语“表位”指抗原上抗体所结合的位点。表位可由一种或多种蛋白质三级折叠并置的连续氨基酸或非连续氨基酸形成。自连续氨基酸形成的表位在暴露于变性溶剂时通常保留,而在用变性溶剂处理时通常损失由三级折叠形成的表位。表位通常包括至少3个、且更通常至少5个或8-10个呈独特空间构象的氨基酸。确定表位的空间构象的方法包括(例如)x-射线晶体测量术及2-维核磁共振。参见(例如)Epitope Mapping Protocols,inMethods in Molecular Biology,第66卷,Glenn E.Morris编辑(1996)。
可在简单免疫分析中鉴定识别相同或重迭表位的抗体,该免疫分析显示一种抗体与另一抗体竞争结合靶抗原的能力。抗体的表位亦可由结合其抗原的抗体的X射线结晶测量术来界定以鉴定接触残基。或者,若降低或消除一种抗体的结合的抗原的所有氨基酸突变皆降低或消除另一抗体的结合,则两个抗体具有相同表位。若降低或消除一种抗体的结合的一些氨基酸突变降低或消除另一抗体的结合,则两个抗体具有重迭表位。
藉由如下分析测定抗体之间的竞争:其中测试抗体抑制参考抗体与共用抗原的特异性结合(例如,参见Junghans等人,Cancer Res.50:1495,1990)。若过量测试抗体(例如至少2x、5x、10x、20x或100x)将参考抗体的结合抑制至少50%、但较佳75%、90%或99%,如竞争性结合分析中所量测,则测试抗体与参考抗体竞争。藉由竞争分析鉴定的抗体(竞争抗体)包括与参考抗体结合相同表位的抗体及结合与由参考抗体结合的表位足够靠近以进行立体阻碍的毗邻表位的抗体。
片语“特异性结合”指相比分子(例如抗体或抗体片段)与非靶标化合物的结合,其以更大亲和性、亲合力、更容易和/或以更大持续时间结合样品中的靶标。在一些实施方式中,特异性结合靶标的抗体是以非靶标化合物的至少2倍的亲和性、例如至少4倍、5倍、6倍、7倍、8倍、9倍、10倍、20倍、25倍、50倍或100倍的亲和性结合靶标的抗体。举例而言,特异性结合TIGIT的抗体通常将以非TIGIT靶标的至少2倍亲和性结合TIGIT。本领域普通技术人员阅读此定义应理解,例如,特异性或优先结合第一靶标的抗体(或部分或表位)可或可不特异性或优先结合第二靶标。因此,“特异性结合”不一定需要(但其可包括)排他性结合。
术语“结合亲和性”在本文中用作两个分子(例如抗体或其片段与抗原)之间的非共价相互作用的强度的量度。术语“结合亲和性”用于描述单价相互作用(固有活性)。
经由单价相互作用的两个分子(例如抗体或其片段与抗原)之间的结合亲和性可藉由测定解离常数(KD)来量化。KD进而可藉由使用(作为非限制性实例)表面等离子体共振(SPR)方法(BiacoreTM)量测复合体形式及解离的动力学来测定。对应于单价复合体的解离及缔合的速率常数分别称为缔合速率常数ka(或kon)及解离速率常数kd(或koff)。经由等式KD=kd/ka,KD与ka及kd相关。解离常数的值可藉由熟知方法直接测定,且可甚至针对复杂混合物藉由(例如)以下文献中所述的那些方法来计算:例如Caceci等人(1984,Byte 9:340-362)。举例而言,KD可使用双过滤器硝化纤维素过滤器结合分析、例如由Wong及Lohman(1993,Proc.Natl.Acad.Sci.USA 90:5428-5432)所揭示的分析来确认。用以评估配体(例如抗体)对靶抗原的结合能力的其他标准分析为业内已知,包括(例如)ELISA、Western印迹、RIA及流式细胞术分析及本文中别处例举的其他分析。抗体的结合动力学及结合亲和性亦可藉由业内已知或如以下实施例部分中所述的标准分析来评价,例如表面等离子体共振(SPR),例如藉由使用BiacoreTM系统;动力学排除分析,例如 及生物层干涉术(例如使用
及生物层干涉术(例如使用 Octet平台)。在一些实施方式中,使用生物层干涉分析测定结合亲和性。参见(例如)Wilson等人,Biochemistry and Molecular Biology Education,38:400-407(2010);Dysinger等人,J.Immunol.Methods,379:30-41(2012);及Estep等人,Mabs,2013,5:270-278。
Octet平台)。在一些实施方式中,使用生物层干涉分析测定结合亲和性。参见(例如)Wilson等人,Biochemistry and Molecular Biology Education,38:400-407(2010);Dysinger等人,J.Immunol.Methods,379:30-41(2012);及Estep等人,Mabs,2013,5:270-278。
如本文所用术语“交叉反应”指抗体结合除抗体所针对的抗原之外的抗原的能力。在一些实施方式中,交叉反应性指抗体结合不同于抗体所针对的抗原的另一物种的抗原的能力。作为非限制性实例,针对人TIGIT抗原的如本文所述抗TIGIT抗体可表现出与来自不同物种(例如小鼠或猴)的TIGIT的交叉反应性。
“经分离”抗体是指已自其天然环境鉴定及分离和/或回收的抗体和/或重组产生的抗体。“纯化抗体”是通常去除干扰蛋白及来自其生产或纯化的其他污染物达至少50%w/w纯的抗体,但不排除单克隆抗体与过量药学上可接受的载剂或意欲促进其使用的其他载剂组合的可能性。干扰蛋白及其他污染物可包括(例如)抗体从中分离或由其重组产生的细胞的细胞组分。有时,单克隆抗体去干扰蛋白及来自其生产或纯化的污染物达至少60%、70%、80%、90%、95或99%w/w纯。本文所述抗体(包括大鼠、嵌合、胶合及人源化抗体)可以分离和/或纯化形式提供。
术语“免疫抗肿瘤剂”指增强、刺激或上调针对对象癌症的免疫反应(例如刺激免疫反应以抑制肿瘤生长)的药剂。在一些实施方式中,免疫抗肿瘤剂是小分子、抗体、肽、蛋白质、环状肽、肽模拟物、多核苷酸、抑制性RNA、适配体、药物化合物或其他化合物。在一些实施方式中,免疫抗肿瘤剂是PD-1或PD-1路径的拮抗剂或抑制剂。
“对象(Subject)”、“患者”、“个体(individual)”及类似术语可互换使用且除非另有指示,否则指哺乳动物,例如人类及非人类灵长类动物、以及兔、大鼠、小鼠、山羊、猪及其他哺乳动物物种。该术语不一定指示个体已经诊断患有特定疾病,但通常指在医学监护下的个体。
术语“疗法”、“治疗”及“改善”指症状的严重程度的任何降低。在治疗癌症的情形下,治疗可指降低(例如)肿瘤大小、癌细胞数目、生长速率、转移活性、非癌细胞的细胞死亡等。如本文所用术语“治疗”及“预防”并不意欲作为绝对术语。治疗及预防可指发作的任何延迟、症状的改善、患者存活的改良、存活时间或存活率增加等。治疗及预防可为完全(无剩余可检测症状)或部分,使得症状比在无本文所述治疗的患者中较不频繁或较不严重。治疗效应可与未接受治疗的个体或个体集或在治疗之前或在治疗期间不同时间的相同患者进行比较。在一些情形中,与(例如)给药之前的个体或未经历治疗的对照个体相比,疾病严重程度降低至少10%。在一些态样中,疾病严重程度降低至少25%、50%、75%、80%或90%,或在一些情形下,使用标准诊断技术不再可检测到。
如本文所用,药剂(例如如本文所述的抗体)的“治疗量”或“治疗有效量”是药剂预防、缓和、减少、改善或降低对象疾病(例如癌症)的症状严重程度的量。
术语“给药”和“给予”(administer、administered或administering)指向生物作用的期望位点递送药剂、化合物或组合物的方法。所述方法包括(但不限于)局部递送、胃肠外递送、静脉内递送、真皮内递送、肌内递送、结肠递送、直肠递送或腹膜内递送。可选性采用本文所述药剂及方法的给药技术包括例如如Goodman及Gilman,The PharmacologicalBasis of Therapeutics,当前版本;Pergamon;及Remington's,Pharmaceutical Sciences(当前版本),Mack Publishing Co.,Easton,PA中所论述。
III.针对TIGIT的抗体
内容之一,提供结合人TIGIT(具有Ig及ITIM结构域的T细胞免疫受体)的抗体。如本文所述,在一些实施方式中,抗TIGIT抗体抑制TIGIT与配体CD155及CD112中之一或两者之间的相互作用。在一些实施方式中,在功能生物分析中,抗TIGIT抗体抑制TIGIT与CD155之间的相互作用,从而容许发生CD155-CD226信号传导。在一些实施方式中,抗TIGIT抗体表现出与抗PD-1剂(例如抗PD-1抗体)或抗PD-L1剂(例如抗PD-L1抗体)的协同作用。
本发明者发现,出人意料地,具有增强效应功能的抗TIGIT抗体,例如可利用无岩藻糖基化IgG1抗体获得的那些,清除Treg细胞且显示改良的体内效能。因此,在各种实施方式中,提供无岩藻糖基化抗TIGIT抗体。
抗TIGIT抗体之示例性特征
在一些实施方式中,抗TIGIT抗体(例如无岩藻糖基化抗TIGIT抗体)以高亲和性结合人TIGIT蛋白(SEQ ID NO:218)或其部分。在一些实施方式中,抗体对人TIGIT的结合亲和性(KD)小于5nM、小于1nM、小于500pM、小于250pM、小于150pM、小于100pM、小于50pM、小于40pM、小于30pM、小于20pM或小于约10pM。在一些实施方式中,抗体对人TIGIT的结合亲和性(KD)小于50pM。在一些实施方式中,抗体对人TIGIT的KD在约1pM至约5nM、例如约1pM至约1nM、约1pM至约500pM、约5pM至约250pM或约10pM至约100pM范围内。
在一些实施方式中,除了以高亲和性结合人TIGIT外,无岩藻糖基化抗TIGIT抗体亦表现出与食蟹猕猴(“cyno”)TIGIT(例如具有序列SEQ ID NO:219的cyno TIGIT蛋白)和/或小鼠TIGIT(例如具有序列SEQ ID NO:220的小鼠TIGIT蛋白)的交叉反应性。在一些实施方式中,抗TIGIT抗体以100nM或更低的结合亲和性(KD)结合小鼠TIGIT(例如具有序列SEQID NO:220的小鼠TIGIT)。在一些实施方式中,抗TIGIT抗体以5nM或更低的KD结合人TIGIT,且以100nM或更低的KD与小鼠TIGIT交叉反应。在一些实施方式中,结合人TIGIT的抗TIGIT抗体亦表现出与食蟹猕猴TIGIT及小鼠TIGIT两者的交叉反应性。
在一些实施方式中,藉由检测抗TIGIT抗体与在细胞(例如表达人TIGIT、cynoTIGIT或小鼠TIGIT的细胞系;或内源表达TIGIT的原代细胞,例如内源表达人TIGIT、cynoTIGIT或小鼠TIGIT的原代T细胞)上表达的TIGIT的特异性结合测定抗体交叉反应性。在一些实施方式中,藉由检测抗TIGIT抗体与纯化或重组TIGIT(例如纯化或重组人TIGIT、纯化或重组cyno TIGIT或纯化或重组小鼠TIGIT)或包含TIGIT的嵌合蛋白(例如包含人TIGIT、cyno TIGIT或小鼠TIGIT的Fc-融合蛋白、或包含人TIGIT、cyno TIGIT或小鼠TIGIT之His标记的蛋白质)的特异性结合测定抗体结合及抗体交叉反应性。
用于分析结合亲和性、结合动力学及交叉反应性的方法为业内已知。参见(例如)Ernst等人,Determination of Equilibrium Dissociation Constants,TherapeuticMonoclonal Antibodies(Wiley&Sons编辑,2009)。所述方法包括(但不限于)固相结合分析(例如ELISA分析)、免疫沉淀、表面等离子体共振(SPR,例如BiacoreTM(GE Healthcare,Piscataway,NJ))、动力学排除分析(例如 )、流式细胞术、荧光活化细胞分选(FACS)、生物层干涉术(例如OctetTM(FortéBio,Inc.,Menlo Park,CA))及Western印迹分析。SPR技术综述于(例如)Hahnfeld等人Determination of Kinetic Data Using SPRBiosensors,Molecular Diagnosis of Infectious Diseases(2004)中。在典型SPR实验中,一种相互作用剂(靶标或靶向剂)固定于流动槽中的SPR活性金涂布的载玻片上,且引入含有另一相互作用剂的样品以横跨表面流动。当给定波长的光照射在表面上时,金的光反射率变化指示结合及结合动力学。在一些实施方式中,使用动力学排除分析来测定亲和性。此技术可见(例如)Darling等人,Assay and Drug Development Technologies第2卷,第6期647-657(2004)中。在一些实施方式中,使用生物层干涉分析来测定亲和性。此技术可见(例如)Wilson等人,Biochemistry and Molecular Biology Education,38:400-407(2010);Dysinger等人,J.Immunol.Methods,379:30-41(2012)中。
)、流式细胞术、荧光活化细胞分选(FACS)、生物层干涉术(例如OctetTM(FortéBio,Inc.,Menlo Park,CA))及Western印迹分析。SPR技术综述于(例如)Hahnfeld等人Determination of Kinetic Data Using SPRBiosensors,Molecular Diagnosis of Infectious Diseases(2004)中。在典型SPR实验中,一种相互作用剂(靶标或靶向剂)固定于流动槽中的SPR活性金涂布的载玻片上,且引入含有另一相互作用剂的样品以横跨表面流动。当给定波长的光照射在表面上时,金的光反射率变化指示结合及结合动力学。在一些实施方式中,使用动力学排除分析来测定亲和性。此技术可见(例如)Darling等人,Assay and Drug Development Technologies第2卷,第6期647-657(2004)中。在一些实施方式中,使用生物层干涉分析来测定亲和性。此技术可见(例如)Wilson等人,Biochemistry and Molecular Biology Education,38:400-407(2010);Dysinger等人,J.Immunol.Methods,379:30-41(2012)中。
在一些实施方式中,本文提供的抗TIGIT抗体抑制TIGIT与配体CD155之间的相互作用。在一些实施方式中,本文提供的抗TIGIT抗体抑制TIGIT与配体CD112之间的相互作用。在一些实施方式中,本文提供的抗TIGIT抗体抑制TIGIT与配体CD155及CD112两者之间的相互作用。
在一些实施方式中,藉由量测结合分析中TIGIT与CD155或CD112之间的物理相互作用是否降低来评估抗TIGIT抗体抑制TIGIT与CD155和/或CD112之间相互作用的能力。在一些实施方式中,结合分析是竞争性结合分析。该分析可以各种方式,例如(但不限于)ELISA分析、流式细胞术、表面等离子体共振(SPR)分析(例如BiacoreTM)或生物层干涉术(例如ForteBio OctetTM)实施。参见例如Duff等人,Biochem J.,2009,419:577-584;Dysinger等人,J.Immunol.Methods,379:30-41(2012);及Estep等人,Mabs,2013,5:270-278。
在一些实施方式中,在功能生物分析例如藉由量测细胞中CD155-CD226信号传导活化(例如经由下游报导基因的活化)评估TIGIT/CD155相互作用抑制的功能细胞分析中,抗TIGIT抗体抑制TIGIT与CD155之间的相互作用。非限制性示例性功能细胞分析可见以下实施例部分中的描述。在此示例性功能分析中,荧光素酶表达需要TCR接合及来自CD155-CD226的共刺激信号。第一细胞(亦称为“T效应细胞”)在细胞表面上表达TCR复合体、TIGIT及CD226且含有荧光素酶基因。第二细胞(亦称为“人工抗原呈递细胞”)表达TCR活化因子及CD155。细胞在抗TIGIT抗体不存在下共培养造成TIGIT-CD155相互作用,抑制效应细胞被CD155-CD226共刺激,防止效应细胞表达荧光素酶。在抑制TIGIT与CD155之间相互作用的抗TIGIT抗体存在下,CD155及CD226能够相互作用且产生驱动第一细胞中荧光素酶表达的共刺激信号。所述功能细胞分析可见业内记载,例如Cong等人,Genetic Engineering andBiotechnology News,2015,35(10):16-17,亦有市售(例如TIGIT/CD155阻断生物分析试剂盒,Promega Corp.,Madison,WI)。在一些实施方式中,与抗TIGIT抗体不存在下CD155-CD226信号传导的程度或量相比,抑制TIGIT与CD155之间相互作用的抗TIGIT抗体使CD155-CD226信号传导的活化程度或量增加(例如于细胞分析例如TIGIT/CD155阻断生物分析试剂盒中所量测)至少10%、至少20%、至少30%、至少40%、至少50%、至少60%、至少70%、至少80%、至少90%或更多。在一些实施方式中,与抗TIGIT抗体不存在下CD155-CD226信号传导的程度或量相比,抑制TIGIT与CD155之间相互作用的抗TIGIT抗体使CD155-CD226信号传导的活化程度或量增加(例如于细胞分析例如TIGIT/CD155阻断生物分析试剂盒中所量测)至少约1.2倍、至少约1.5倍、至少约2倍、至少约3倍、至少约4倍、至少约5倍、至少约6倍、至少约7倍、至少约8倍、至少约9倍、至少约10倍或更多倍。
在一些实施方式中,结合人TIGIT(且可选性地表现出与食蟹猕猴和/或小鼠TIGIT的交叉反应性和/或可选性抑制TIGIT与CD155和/或CD112之间相互作用)的抗TIGIT抗体表现出与抗PD-1剂(例如抗PD-1抗体)的协同作用。在一些实施方式中,抗TIGIT抗体将抗PD-1剂(例如抗PD-1抗体)的效应增强至少约1.2倍、至少约1.5倍、至少约2倍、至少约3倍、至少约4倍、至少约5倍、至少约6倍、至少约7倍、至少约8倍、至少约9倍、至少约10倍或更多倍。
在一些实施方式中,在功能生物分析、例如藉由量测效应细胞中信号传导活化评估TIGIT信号传导抑制及PD-1信号传导抑制的功能细胞分析中,抗TIGIT抗体表现出与抗PD-1剂(例如抗PD-1抗体)的协同作用。非限制性示例性功能细胞分析可见以下实施例部分中的描述。在此示例性功能细胞分析中,第一细胞(亦称为“T效应细胞”)在细胞表面上表达TCR复合体、TIGIT、CD226及PD-1且含有荧光素酶基因。第二细胞(亦称为“人工抗原呈递细胞”)表达TCR活化因子、CD155及PD-L1。藉由以下之任一者或两者活化效应细胞的荧光素酶基因表达:(1)TIGIT-CD155相互作用的阻断,藉此容许CD155-CD226相互作用,及随后共刺激效应细胞表达荧光素酶,或(2)PD-1/PD-L1相互作用的阻断,藉此减轻效应细胞的荧光素酶表达抑制。可量测且量化在不存在或存在抗TIGIT抗体及抗PD-1剂或抗PD-L1剂下荧光素酶表达程度用于确定抗TIGIT抗体是否表现出与抗PD-1剂或抗PD-L1剂的协同作用。所述功能细胞分析可见业内记载(例如Cong等人,Genetic Engineering and BiotechnologyNews,2015,35(10):16-17),亦有市售(例如PD-1/TIGIT组合生物分析试剂盒,PromegaCorp.,Madison,WI)。
在一些实施方式中,抗TIGIT抗体之效能以及抗TIGIT抗体是否与抗PD-1剂(例如抗PD-1抗体)或抗PD-L1剂(例如抗PD-L1抗体)协同抑制可使用体内模型、例如体内肿瘤模型来量测。举例而言,本文所述抗TIGIT抗体的效能或本文所述抗TIGIT抗体在与抗PD-1剂或抗PD-L1剂联合给药时的效能可使用同系小鼠肿瘤模型来评估。适宜同系肿瘤模型可见业内记载。参见(例如,Rios-Doria等人,Neoplasia,2015,17:661-670;及Moynihan等人,Nature Medicine,2016,doi:10.1038/nm.4200。在一些实施方式中,与对照或参照值相比(例如与未治疗对照中的肿瘤大小或肿瘤总数目相比),抗TIGIT抗体将体内模型中肿瘤大小或肿瘤总数目减少至少10%、至少20%、至少30%、至少40%、至少50%、至少60%、至少70%、至少80%、至少90%或更多。
在一些实施方式中,抗TIGIT抗体识别人TIGIT的包含参照SEQ ID NO:218编号的氨基酸位置81及82中之一或两者的表位。在一些实施方式中,抗TIGIT抗体识别包含第81位的Phe的表位。在一些实施方式中,抗TIGIT抗体识别包含第82位的Lys或Ser的表位。在一些实施方式中,抗TIGIT抗体识别包含第81位的Phe及第82位的Lys的表位。在一些实施方式中,抗TIGIT抗体识别包含第81位的Phe及第82位的Ser的表位。
在一些实施方式中,抗TIGIT抗体识别包含氨基酸位置81及82中之一或两者的线性表位(例如包含第81位的Phe及第82位的Lys或Ser的线性表位)。在一些实施方式中,抗TIGIT抗体识别包含氨基酸位置81及82中之一或两者的不连续表位(例如包含第81位的Phe及第82位的Lys或Ser的不连续表位)。
在一些实施方式中,抗TIGIT抗体结合人TIGIT上进一步包含氨基酸位置51、52、53、54、55、73、74、75、76、77、79、83、84、85、86、87、88、89、90、91、92或93中之一或多者(例如1、2、3、4、5、6、7、8、9、10、12、13、14、15或更多者)的表位。在一些实施方式中,抗TIGIT抗体结合人TIGIT上进一步包含以下之一或多者(例如1、2、3、4、5、6、7、8、9、10、12、13、14、15或更多者)的表位:第51位的Thr、第52位的Ala、第53位的Glu或Gln、第54位的Val、第55位的Thr、第73位的Leu、第74位的Gly、第75位的Trp、第76位的His、第77位的Val或Ile、第79位的Ser或Pro、第83位的Asp、第84位的Arg、第85位的Val、第86位的Val或Ala、第87位的Pro、第88位的Gly、第89位的Pro、第90位的Ser或Gly、第91位的Leu、第92位的Gly或第93位的Leu。在一些实施方式中,抗TIGIT抗体结合人TIGIT上进一步包含氨基酸残基Thr51、Ala52、Gln53、Val54、Thr55、Leu73、Gly74、Trp75、His76、Ile77、Pro79、Asp83、Arg84、Val85、Ala86、Pro87、Gly88、Pro89、Gly90、Leu91、Gly92及Leu93中之一或多者(例如1、2、3、4、5、6、7、8、9、10、12、13、14、15或更多者)的表位。
在一些实施方式中,抗TIGIT抗体识别包含第81位的Phe及第82位的Lys或Ser且进一步包含第51位的Thr、第52位的Ala、第53位的Glu或Gln、第54位的Val和/或第55位的Thr的表位。在一些实施方式中,抗TIGIT抗体识别包含第81位的Phe及第82位的Lys或Ser且进一步包含第74位的Gly、第75位的Trp、第76位的His和/或第77位的Val或Ile的表位。在一些实施方式中,抗TIGIT抗体识别包含第81位的Phe及第82位的Lys或Ser且进一步包含第87位的Pro、第88位的Gly、第89位的Pro、第90位的Ser或Gly、第91位的Leu、第92位的Gly和/或第93位的Leu的表位。在一些实施方式中,抗TIGIT抗体识别包含氨基酸残基Thr51、Ala52、Gln53、Val54、Thr55、Gly74、Trp75、His76、Ile77、Phe81、Lys82、Pro87、Gly88、Pro89、Gly90、Leu91、Gly92及Leu93的表位。
在一些实施方式中,抗TIGIT抗体识别包含第81位的Phe及第82位的Lys或Ser且进一步包含第52位的Ala和/或第53位的Glu或Gln的表位。在一些实施方式中,抗TIGIT抗体识别包含第81位的Phe及第82位的Lys或Ser且进一步包含第73位的Leu、第74位的Gly和/或第75位的Trp的表位。在一些实施方式中,抗TIGIT抗体识别包含第81位的Phe及第82位的Lys或Ser且进一步包含第83位的Asp、第84位的Arg、第85位的Val和/或第86位的Val或Ala的表位。在一些实施方式中,抗TIGIT抗体识别包含氨基酸残基Ala52、Gln53、Leu73、Gly74、Trp75、Pro79、Phe81、Lys82、Asp83、Arg84、Val85及Ala86的表位。
在一些实施方式中,抗TIGIT抗体识别包含序列ICNADLGWHISPSFK(SEQ ID NO:258)的人TIGIT的表位,其对应于人TIGIT的残基68-82(SEQ ID NO:218)。在一些实施方式中,抗TIGIT抗体识别由序列ICNADLGWHISPSFK(SEQ ID NO:258)组成的人TIGIT的表位。
某些抗TIGIT抗体序列
在一些实施方式中,结合人TIGIT且可选性表现出与食蟹猕猴TIGIT和/或小鼠TIGIT的交叉反应性的抗TIGIT抗体包含衍生自本文所述以下抗体中任一者的轻链可变区序列或其部分、和/或重链可变区序列或其部分:克隆2、克隆2C、克隆3、克隆5、克隆13、克隆13A、克隆13B、克隆13C、克隆13D、克隆14、克隆16、克隆16C、克隆16D、克隆16E、克隆18、克隆21、克隆22、克隆25、克隆25A、克隆25B、克隆25C、克隆25D、克隆25E、克隆27或克隆54。抗TIGIT抗体克隆2、克隆2C、克隆3、克隆5、克隆13、克隆13A、克隆13B、克隆13C、克隆13D、克隆14、克隆16、克隆16C、克隆16D、克隆16E、克隆18、克隆21、克隆22、克隆25、克隆25A、克隆25B、克隆25C、克隆25D、克隆25E、克隆27及克隆54的CDR、轻链可变结构域(VL)及重链可变结构域(VH)的氨基酸序列如后文序列表中所示。
在一些实施方式中,抗TIGIT抗体包含重链可变区(VH),其包含与SEQ ID NO:1、SEQ ID NO:19、SEQ ID NO:37、SEQ ID NO:55、SEQ ID NO:73、SEQ ID NO:91、SEQ ID NO:109、SEQ ID NO:127、SEQ ID NO:145、SEQ ID NO:163、SEQ ID NO:181、SEQ ID NO:199、SEQID NO:245、SEQ ID NO:246、SEQ ID NO:247、SEQ ID NO:248、SEQ ID NO:249、SEQ ID NO:250、SEQ ID NO:251、SEQ ID NO:252、SEQ ID NO:253、SEQ ID NO:254、SEQ ID NO:255、SEQID NO:256或SEQ ID NO:257具有至少90%序列一致性(例如至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%或至少99%序列一致性)的氨基酸序列。在一些实施方式中,抗TIGIT抗体包含VH,其包含SEQ ID NO:1、SEQ ID NO:19、SEQID NO:37、SEQ ID NO:55、SEQ ID NO:73、SEQ ID NO:91、SEQ ID NO:109、SEQ ID NO:127、SEQ ID NO:145、SEQ ID NO:163、SEQ ID NO:181、SEQ ID NO:199、SEQ ID NO:245、SEQ IDNO:246、SEQ ID NO:247、SEQ ID NO:248、SEQ ID NO:249、SEQ ID NO:250、SEQ ID NO:251、SEQ ID NO:252、SEQ ID NO:253、SEQ ID NO:254、SEQ ID NO:255、SEQ ID NO:256或SEQ IDNO:257的氨基酸序列。在一些实施方式中,与参照序列(例如SEQ ID NO:1、SEQ ID NO:19、SEQ ID NO:37、SEQ ID NO:55、SEQ ID NO:73、SEQ ID NO:91、SEQ ID NO:109、SEQ ID NO:127、SEQ ID NO:145、SEQ ID NO:163、SEQ ID NO:181、SEQ ID NO:199、SEQ ID NO:245、SEQID NO:246、SEQ ID NO:247、SEQ ID NO:248、SEQ ID NO:249、SEQ ID NO:250、SEQ ID NO:251、SEQ ID NO:252、SEQ ID NO:253、SEQ ID NO:254、SEQ ID NO:255、SEQ ID NO:256或SEQ ID NO:257)具有至少90%序列一致性的VH序列相对于参照序列含有1个、2个、3个、4个、5个、6个、7个、8个、9个、10个或更多个取代(例如保守取代)、插入或缺失,但保留结合人TIGIT的能力且可选性保留阻断CD155和/或CD112与TIGIT结合的能力。
在一些实施方式中,抗TIGIT抗体包含轻链可变区(VL),其包含与SEQ ID NO:10、SEQ ID NO:28、SEQ ID NO:46、SEQ ID NO:64、SEQ ID NO:82、SEQ ID NO:100、SEQ ID NO:118、SEQ ID NO:136、SEQ ID NO:154、SEQ ID NO:172、SEQ ID NO:190或SEQ ID NO:208具有至少90%序列一致性(例如至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%或至少99%序列一致性)的氨基酸序列。在一些实施方式中,抗TIGIT抗体包含VL,其包含SEQ ID NO:10、SEQ ID NO:28、SEQ ID NO:46、SEQ ID NO:64、SEQID NO:82、SEQ ID NO:100、SEQ ID NO:118、SEQ ID NO:136、SEQ ID NO:154、SEQ ID NO:172、SEQ ID NO:190或SEQ ID NO:208的氨基酸序列。在一些实施方式中,与参照序列(例如SEQ ID NO:10、SEQ ID NO:28、SEQ ID NO:46、SEQ ID NO:64、SEQ ID NO:82、SEQ ID NO:100、SEQ ID NO:118、SEQ ID NO:136、SEQ ID NO:154、SEQ ID NO:172、SEQ ID NO:190或SEQ ID NO:208)具有至少90%序列一致性的VL序列相对于参照序列含有1个、2个、3个、4个、5个、6个、7个、8个、9个、10个或更多个取代(例如保守取代)、插入或缺失,但保留结合人TIGIT的能力且可选性保留阻断CD155和/或CD112与TIGIT结合的能力。
在一些实施方式中,抗TIGIT抗体包含重链可变区,其包含与SEQ ID NO:1、SEQ IDNO:19、SEQ ID NO:37、SEQ ID NO:55、SEQ ID NO:73、SEQ ID NO:91、SEQ ID NO:109、SEQID NO:127、SEQ ID NO:145、SEQ ID NO:163、SEQ ID NO:181、SEQ ID NO:199、SEQ ID NO:245、SEQ ID NO:246、SEQ ID NO:247、SEQ ID NO:248、SEQ ID NO:249、SEQ ID NO:250、SEQID NO:251、SEQ ID NO:252、SEQ ID NO:253、SEQ ID NO:254、SEQ ID NO:255、SEQ ID NO:256或SEQ ID NO:257具有至少90%序列一致性(例如至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%或至少99%序列一致性)的氨基酸序列;且进一步包含轻链可变区,其包含与SEQ ID NO:10、SEQ ID NO:28、SEQ ID NO:46、SEQ IDNO:64、SEQ ID NO:82、SEQ ID NO:100、SEQ ID NO:118、SEQ ID NO:136、SEQ ID NO:154、SEQ ID NO:172、SEQ ID NO:190或SEQ ID NO:208具有至少90%序列一致性(例如至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%或至少99%序列一致性)的氨基酸序列。在一些实施方式中,抗TIGIT抗体包含重链可变区,其包含SEQID NO:1、SEQ ID NO:19、SEQ ID NO:37、SEQ ID NO:55、SEQ ID NO:73、SEQ ID NO:91、SEQID NO:109、SEQ ID NO:127、SEQ ID NO:145、SEQ ID NO:163、SEQ ID NO:181、SEQ ID NO:199、SEQ ID NO:245、SEQ ID NO:246、SEQ ID NO:247、SEQ ID NO:248、SEQ ID NO:249、SEQID NO:250、SEQ ID NO:251、SEQ ID NO:252、SEQ ID NO:253、SEQ ID NO:254、SEQ ID NO:255、SEQ ID NO:256或SEQ ID NO:257的氨基酸序列;且进一步包含轻链可变区,其包含SEQID NO:10、SEQ ID NO:28、SEQ ID NO:46、SEQ ID NO:64、SEQ ID NO:82、SEQ ID NO:100、SEQ ID NO:118、SEQ ID NO:136、SEQ ID NO:154、SEQ ID NO:172、SEQ ID NO:190或SEQ IDNO:208的氨基酸序列。
在一些实施方式中,抗TIGIT抗体包含:
(a)包含与SEQ ID NO:1或SEQ ID NO:245具有至少90%序列一致性(例如至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%或至少99%序列一致性)的氨基酸序列的VH及包含与SEQ ID NO:10具有至少90%序列一致性(例如至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%或至少99%序列一致性)的氨基酸序列的VL;
(b)包含与SEQ ID NO:19具有至少90%序列一致性(例如至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%或至少99%序列一致性)的氨基酸序列的VH及包含与SEQ ID NO:28具有至少90%序列一致性(例如至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%或至少99%序列一致性)的氨基酸序列的VL;
(c)包含与SEQ ID NO:37具有至少90%序列一致性(例如至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%或至少99%序列一致性)的氨基酸序列的VH及包含与SEQ ID NO:46具有至少90%序列一致性(例如至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%或至少99%序列一致性)的氨基酸序列的VL;
(d)包含与SEQ ID NO:55、SEQ ID NO:246、SEQ ID NO:247、SEQ ID NO:248或SEQID NO:249中任一者具有至少90%序列一致性(例如至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%或至少99%序列一致性)的氨基酸序列的VH及包含与SEQ ID NO:64具有至少90%序列一致性(例如至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%或至少99%序列一致性)的氨基酸序列的VL;
(e)包含与SEQ ID NO:73具有至少90%序列一致性(例如至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%或至少99%序列一致性)的氨基酸序列的VH及包含与SEQ ID NO:82具有至少90%序列一致性(例如至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%或至少99%序列一致性)的氨基酸序列的VL;
(f)包含与SEQ ID NO:91、SEQ ID NO:250、SEQ ID NO:251或SEQ ID NO:252中任一者具有至少90%序列一致性(例如至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%或至少99%序列一致性)的氨基酸序列的VH及包含与SEQ IDNO:100具有至少90%序列一致性(例如至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%或至少99%序列一致性)的氨基酸序列的VL;
(g)包含与SEQ ID NO:109具有至少90%序列一致性(例如至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%或至少99%序列一致性)的氨基酸序列的VH及包含与SEQ ID NO:118具有至少90%序列一致性(例如至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%或至少99%序列一致性)的氨基酸序列的VL;
(h)包含与SEQ ID NO:127具有至少90%序列一致性(例如至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%或至少99%序列一致性)的氨基酸序列的VH及包含与SEQ ID NO:136具有至少90%序列一致性(例如至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%或至少99%序列一致性)的氨基酸序列的VL;
(i)包含与SEQ ID NO:145具有至少90%序列一致性(例如至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%或至少99%序列一致性)的氨基酸序列的VH及包含与SEQ ID NO:154具有至少90%序列一致性(例如至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%或至少99%序列一致性)的氨基酸序列的VL;
(j)包含与SEQ ID NO:163、SEQ ID NO:253、SEQ ID NO:254、SEQ ID NO:255、SEQID NO:256或SEQ ID NO:257中任一者具有至少90%序列一致性(例如至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%或至少99%序列一致性)的氨基酸序列的VH及包含与SEQ ID NO:172具有至少90%序列一致性(例如至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%或至少99%序列一致性)的氨基酸序列的VL;
(k)包含与SEQ ID NO:181具有至少90%序列一致性(例如至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%或至少99%序列一致性)的氨基酸序列的VH及包含与SEQ ID NO:190具有至少90%序列一致性(例如至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%或至少99%序列一致性)的氨基酸序列的VL;或
(l)包含与SEQ ID NO:199具有至少90%序列一致性(例如至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%或至少99%序列一致性)的氨基酸序列的VH及包含与SEQ ID NO:208具有至少90%序列一致性(例如至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%或至少99%序列一致性)的氨基酸序列的VL。
在一些实施方式中,抗TIGIT抗体包含:
(a)包含SEQ ID NO:1所示氨基酸序列的VH及包含SEQ ID NO:10所示氨基酸序列的VL;
(b)包含SEQ ID NO:19所示氨基酸序列的VH及包含SEQ ID NO:28所示氨基酸序列的VL;
(c)包含SEQ ID NO:37所示氨基酸序列的VH及包含SEQ ID NO:46所示氨基酸序列的VL;
(d)包含SEQ ID NO:55所示氨基酸序列的VH及包含SEQ ID NO:64所示氨基酸序列的VL;
(e)包含SEQ ID NO:73所示氨基酸序列的VH及包含SEQ ID NO:82所示氨基酸序列的VL;
(f)包含SEQ ID NO:91所示氨基酸序列的VH及包含SEQ ID NO:100所示氨基酸序列的VL;
(g)包含SEQ ID NO:109所示氨基酸序列的VH及包含SEQ ID NO:118所示氨基酸序列的VL;
(h)包含SEQ ID NO:127所示氨基酸序列的VH及包含SEQ ID NO:136所示氨基酸序列的VL;
(i)包含SEQ ID NO:145所示氨基酸序列的VH及包含SEQ ID NO:154所示氨基酸序列的VL;
(j)包含SEQ ID NO:163所示氨基酸序列的VH及包含SEQ ID NO:172所示氨基酸序列的VL;
(k)包含SEQ ID NO:181所示氨基酸序列的VH及包含SEQ ID NO:190所示氨基酸序列的VL;
(l)包含SEQ ID NO:199所示氨基酸序列的VH及包含SEQ ID NO:208所示氨基酸序列的VL;或
(m)包含SEQ ID NO:245所示氨基酸序列的VH及包含SEQ ID NO:10所示氨基酸序列的VL;或
(n)包含SEQ ID NO:246所示氨基酸序列的VH及包含SEQ ID NO:64所示氨基酸序列的VL;或
(o)包含SEQ ID NO:247所示氨基酸序列的VH及包含SEQ ID NO:64所示氨基酸序列的VL;或
(p)包含SEQ ID NO:248所示氨基酸序列的VH及包含SEQ ID NO:64所示氨基酸序列的VL;
(q)包含SEQ ID NO:249所示氨基酸序列的VH及包含SEQ ID NO:64所示氨基酸序列的VL;或
(r)包含SEQ ID NO:250所示氨基酸序列的VH及包含SEQ ID NO:100所示氨基酸序列的VL;或
(s)包含SEQ ID NO:251所示氨基酸序列的VH及包含SEQ ID NO:100所示氨基酸序列的VL;或
(t)包含SEQ ID NO:252所示氨基酸序列的VH及包含SEQ ID NO:100所示氨基酸序列的VL;或
(u)包含SEQ ID NO:253所示氨基酸序列的VH及包含SEQ ID NO:172所示氨基酸序列的VL;或
(v)包含SEQ ID NO:254所示氨基酸序列的VH及包含SEQ ID NO:172所示氨基酸序列的VL;或
(w)包含SEQ ID NO:255所示氨基酸序列的VH及包含SEQ ID NO:172所示氨基酸序列的VL;或
(x)包含SEQ ID NO:256所示氨基酸序列的VH及包含SEQ ID NO:172所示氨基酸序列的VL;或
(y)包含SEQ ID NO:257所示氨基酸序列的VH及包含SEQ ID NO:172所示氨基酸序列的VL。
在一些实施方式中,抗TIGIT抗体包含重链CDR1、CDR2及CDR3及轻链CDR1、CDR2及CDR3,其中CDR中之一或多者(例如一者、两者、三者、四者、五者或六者)是选自表A、B、C、D及E中所示之重链CDR1、CDR2及CDR3及轻链CDR1、CDR2及CDR3。
表A:克隆13替代CDR定义

表B:克隆13A替代CDR定义


表C:克隆13B替代CDR定义

表D:克隆13C替代CDR定义

表E:克隆13D替代CDR定义

在一些实施方式中,抗TIGIT抗体包含以下之一或多者(例如一者、两者、三者、四者、五者或六者):
重链CDR1序列,其包含选自SEQ ID NO:58、SEQ ID NO:283、SEQ ID NO:284、SEQID NO:224、SEQ ID NO:293、SEQ ID NO:294、SEQ ID NO:226、SEQ ID NO:289及SEQ ID NO:290的氨基酸序列;
重链CDR2序列,其包含选自SEQ ID NO:60、SEQ ID NO:285、SEQ ID NO:225、SEQID NO:297、SEQ ID NO:227、SEQ ID NO:291、SEQ ID NO:229及SEQ ID NO:295的氨基酸序列;
重链CDR3序列,其包含选自SEQ ID NO:62、SEQ ID NO:286、SEQ ID NO:228、SEQID NO:292、SEQ ID NO:230及SEQ ID NO:296的氨基酸序列;
轻链CDR1序列,其包含选自SEQ ID NO:67及SEQ ID NO:287的氨基酸序列;
轻链CDR2序列,其包含选自SEQ ID NO:69及SEQ ID NO:288的氨基酸序列;和/或
轻链CDR3序列,其包含SEQ ID NO:71的氨基酸序列。
在一些实施方式中,抗TIGIT抗体包含重链CDR1序列,其包含SEQ ID NO:58、SEQID NO:283、SEQ ID NO:284、SEQ ID NO:224、SEQ ID NO:293、SEQ ID NO:294、SEQ ID NO:226、SEQ ID NO:289或SEQ ID NO:290中任一者的氨基酸序列;重链CDR2序列,其包含SEQID NO:60、SEQ ID NO:285、SEQ ID NO:225、SEQ ID NO:297、SEQ ID NO:227、SEQ ID NO:291、SEQ ID NO:229或SEQ ID NO:295中任一者的氨基酸序列;重链CDR3序列,其包含SEQID NO:62、SEQ ID NO:286、SEQ ID NO:228、SEQ ID NO:292、SEQ ID NO:230或SEQ ID NO:296中任一者的氨基酸序列;轻链CDR1序列,其包含SEQ ID NO:67或SEQ ID NO:287中任一者的氨基酸序列;轻链CDR2序列,其包含SEQ ID NO:69或SEQ ID NO:288中任一者的氨基酸序列;及轻链CDR3序列,其包含SEQ ID NO:71的氨基酸序列。
在一些实施方式中,抗TIGIT抗体包含重链CDR1序列,其包含SEQ ID NO:58、SEQID NO:283、SEQ ID NO:284、SEQ ID NO:224、SEQ ID NO:293、SEQ ID NO:294、SEQ ID NO:226、SEQ ID NO:289或SEQ ID NO:290中任一者的氨基酸序列;重链CDR2序列,其包含SEQID NO:60、SEQ ID NO:285、SEQ ID NO:225、SEQ ID NO:297、SEQ ID NO:227、SEQ ID NO:291、SEQ ID NO:229或SEQ ID NO:295中任一者的氨基酸序列;及重链CDR3序列,其包含SEQID NO:62、SEQ ID NO:286、SEQ ID NO:228、SEQ ID NO:292、SEQ ID NO:230或SEQ ID NO:296中任一者的氨基酸序列。
在一些实施方式中,抗TIGIT抗体包含轻链CDR1序列,其包含SEQ ID NO:67或SEQID NO:287中任一者的氨基酸序列;轻链CDR2序列,其包含SEQ ID NO:69或SEQ ID NO:288中任一者的氨基酸序列;及轻链CDR3序列,其包含SEQ ID NO:71的氨基酸序列。
在一些实施方式中,抗TIGIT抗体包含:(i)重链CDR1序列,其包含SEQ ID NO:58、SEQ ID NO:283或SEQ ID NO:284的氨基酸序列;(ii)重链CDR2序列,其包含SEQ ID NO:60或SEQ ID NO:285的氨基酸序列;(iii)重链CDR3序列,其包含SEQ ID NO:62或SEQ ID NO:286的氨基酸序列;(iv)轻链CDR1序列,其包含SEQ ID NO:67或SEQ ID NO:287的氨基酸序列;(v)轻链CDR2序列,其包含SEQ ID NO:69或SEQ ID NO:288的氨基酸序列;及(vi)轻链CDR3序列,其包含SEQ ID NO:71的氨基酸序列。
在一些实施方式中,抗TIGIT抗体包含:(i)重链CDR1序列,其包含SEQ ID NO:224、SEQ ID NO:293或SEQ ID NO:294的氨基酸序列;(ii)重链CDR2序列,其包含SEQ ID NO:225或SEQ ID NO:297的氨基酸序列;(iii)重链CDR3序列,其包含SEQ ID NO:62或SEQ ID NO:286的氨基酸序列;(iv)轻链CDR1序列,其包含SEQ ID NO:67或SEQ ID NO:287的氨基酸序列;(v)轻链CDR2序列,其包含SEQ ID NO:69或SEQ ID NO:288的氨基酸序列;及(vi)轻链CDR3序列,其包含SEQ ID NO:71的氨基酸序列。
在一些实施方式中,抗TIGIT抗体包含:(i)重链CDR1序列,其包含SEQ ID NO:226、SEQ ID NO:289或SEQ ID NO:290的氨基酸序列;(ii)重链CDR2序列,其包含SEQ ID NO:227或SEQ ID NO:291的氨基酸序列;(iii)重链CDR3序列,其包含SEQ ID NO:228或SEQ ID NO:292的氨基酸序列;(iv)轻链CDR1序列,其包含SEQ ID NO:67或SEQ ID NO:287的氨基酸序列;(v)轻链CDR2序列,其包含SEQ ID NO:69或SEQ ID NO:288的氨基酸序列;及(vi)轻链CDR3序列,其包含SEQ ID NO:71的氨基酸序列。
在一些实施方式中,抗TIGIT抗体包含:(i)重链CDR1序列,其包含SEQ ID NO:224、SEQ ID NO:293或SEQ ID NO:294的氨基酸序列;(ii)重链CDR2序列,其包含SEQ ID NO:229或SEQ ID NO:295的氨基酸序列;(iii)重链CDR3序列,其包含SEQ ID NO:230或SEQ ID NO:296的氨基酸序列;(iv)轻链CDR1序列,其包含SEQ ID NO:67或SEQ ID NO:287的氨基酸序列;(v)轻链CDR2序列,其包含SEQ ID NO:69或SEQ ID NO:288的氨基酸序列;及(vi)轻链CDR3序列,其包含SEQ ID NO:71的氨基酸序列。
在一些实施方式中,抗TIGIT抗体包含:(i)重链CDR1序列,其包含SEQ ID NO:224、SEQ ID NO:293或SEQ ID NO:294的氨基酸序列;(ii)重链CDR2序列,其包含SEQ ID NO:227或SEQ ID NO:290的氨基酸序列;(iii)重链CDR3序列,其包含SEQ ID NO:230或SEQ ID NO:296的氨基酸序列;(iv)轻链CDR1序列,其包含SEQ ID NO:67或SEQ ID NO:287的氨基酸序列;(v)轻链CDR2序列,其包含SEQ ID NO:69或SEQ ID NO:288的氨基酸序列;及(vi)轻链CDR3序列,其包含SEQ ID NO:71的氨基酸序列。
在一些实施方式中,抗TIGIT抗体包含以下之一或多者(例如一者、两者、三者、四者、五者或六者):
重链CDR1序列,其包含SEQ ID NO:4、SEQ ID NO:22、SEQ ID NO:40、SEQ ID NO:58、SEQ ID NO:76、SEQ ID NO:94、SEQ ID NO:112、SEQ ID NO:130、SEQ ID NO:148、SEQ IDNO:166、SEQ ID NO:184、SEQ ID NO:202、SEQ ID NO:221、SEQ ID NO:224、SEQ ID NO:226、SEQ ID NO:231、SEQ ID NO:233、SEQ ID NO:239、SEQ ID NO:243、SEQ ID NO:283、SEQ IDNO:284、SEQ ID NO:293、SEQ ID NO:294、SEQ ID NO:289或SEQ ID NO:290中任一者的氨基酸序列;
重链CDR2序列,其包含SEQ ID NO:6、SEQ ID NO:24、SEQ ID NO:42、SEQ ID NO:60、SEQ ID NO:78、SEQ ID NO:96、SEQ ID NO:114、SEQ ID NO:132、SEQ ID NO:150、SEQ IDNO:168、SEQ ID NO:186、SEQ ID NO:204、SEQ ID NO:222、SEQ ID NO:225、SEQ ID NO:227、SEQ ID NO:229、SEQ ID NO:232、SEQ ID NO:234、SEQ ID NO:238、SEQ ID NO:240、SEQ IDNO:285、SEQ ID NO:297、SEQ ID NO:291或SEQ ID NO:295中任一者的氨基酸序列;
重链CDR3序列,其包含SEQ ID NO:8、SEQ ID NO:26、SEQ ID NO:44、SEQ ID NO:62、SEQ ID NO:80、SEQ ID NO:98、SEQ ID NO:116、SEQ ID NO:134、SEQ ID NO:152、SEQ IDNO:170、SEQ ID NO:188、SEQ ID NO:206、SEQ ID NO:223、SEQ ID NO:228、SEQ ID NO:230、SEQ ID NO:235、SEQ ID NO:236、SEQ ID NO:237、SEQ ID NO:241、SEQ ID NO:242、SEQ IDNO:244、SEQ ID NO:286、SEQ ID NO:292或SEQ ID NO:296中任一者的氨基酸序列;
轻链CDR1序列,其包含SEQ ID NO:13、SEQ ID NO:31、SEQ ID NO:49、SEQ ID NO:67、SEQ ID NO:85、SEQ ID NO:103、SEQ ID NO:121、SEQ ID NO:139、SEQ ID NO:157、SEQID NO:175、SEQ ID NO:193、SEQ ID NO:211或SEQ ID NO:287中任一者的氨基酸序列;
轻链CDR2序列,其包含SEQ ID NO:15、SEQ ID NO:33、SEQ ID NO:51、SEQ ID NO:69、SEQ ID NO:87、SEQ ID NO:105、SEQ ID NO:123、SEQ ID NO:141、SEQ ID NO:159、SEQID NO:177、SEQ ID NO:195、SEQ ID NO:213或SEQ ID NO:288中任一者的氨基酸序列;和/或
轻链CDR3序列,其包含SEQ ID NO:17、SEQ ID NO:35、SEQ ID NO:53、SEQ ID NO:71、SEQ ID NO:89、SEQ ID NO:107、SEQ ID NO:125、SEQ ID NO:143、SEQ ID NO:161、SEQID NO:179、SEQ ID NO:197或SEQ ID NO:215中任一者的氨基酸序列。
在一些实施方式中,抗TIGIT抗体包含重链CDR1序列,其包含SEQ ID NO:4、SEQ IDNO:22、SEQ ID NO:40、SEQ ID NO:58、SEQ ID NO:76、SEQ ID NO:94、SEQ ID NO:112、SEQID NO:130、SEQ ID NO:148、SEQ ID NO:166、SEQ ID NO:184、SEQ ID NO:202、SEQ ID NO:221、SEQ ID NO:224、SEQ ID NO:226、SEQ ID NO:231、SEQ ID NO:233、SEQ ID NO:239、SEQID NO:243、SEQ ID NO:283、SEQ ID NO:284、SEQ ID NO:293、SEQ ID NO:294、SEQ ID NO:289或SEQ ID NO:290中任一者的氨基酸序列;重链CDR2序列,其包含SEQ ID NO:6、SEQ IDNO:24、SEQ ID NO:42、SEQ ID NO:60、SEQ ID NO:78、SEQ ID NO:96、SEQ ID NO:114、SEQID NO:132、SEQ ID NO:150、SEQ ID NO:168、SEQ ID NO:186、SEQ ID NO:204、SEQ ID NO:222、SEQ ID NO:225、SEQ ID NO:227、SEQ ID NO:229、SEQ ID NO:232、SEQ ID NO:234、SEQID NO:238、SEQ ID NO:240、SEQ ID NO:285、SEQ ID NO:297、SEQ ID NO:291或SEQ ID NO:295中任一者的氨基酸序列;及重链CDR3序列,其包含SEQ ID NO:8、SEQ ID NO:26、SEQ IDNO:44、SEQ ID NO:62、SEQ ID NO:80、SEQ ID NO:98、SEQ ID NO:116、SEQ ID NO:134、SEQID NO:152、SEQ ID NO:170、SEQ ID NO:188、SEQ ID NO:206、SEQ ID NO:223、SEQ ID NO:228、SEQ ID NO:230、SEQ ID NO:235、SEQ ID NO:236、SEQ ID NO:237、SEQ ID NO:241、SEQID NO:242、SEQ ID NO:244、SEQ ID NO:286、SEQ ID NO:292或SEQ ID NO:296中任一者的氨基酸序列。
在一些实施方式中,抗TIGIT抗体包含轻链CDR1序列,其包含SEQ ID NO:13、SEQID NO:31、SEQ ID NO:49、SEQ ID NO:67、SEQ ID NO:85、SEQ ID NO:103、SEQ ID NO:121、SEQ ID NO:139、SEQ ID NO:157、SEQ ID NO:175、SEQ ID NO:193、SEQ ID NO:211或SEQ IDNO:287中任一者的氨基酸序列;轻链CDR2序列,其包含SEQ ID NO:15、SEQ ID NO:33、SEQID NO:51、SEQ ID NO:69、SEQ ID NO:87、SEQ ID NO:105、SEQ ID NO:123、SEQ ID NO:141、SEQ ID NO:159、SEQ ID NO:177、SEQ ID NO:195、SEQ ID NO:213或SEQ ID NO:288中任一者的氨基酸序列;及轻链CDR3序列,其包含SEQ ID NO:17、SEQ ID NO:35、SEQ ID NO:53、SEQ ID NO:71、SEQ ID NO:89、SEQ ID NO:107、SEQ ID NO:125、SEQ ID NO:143、SEQ IDNO:161、SEQ ID NO:179、SEQ ID NO:197或SEQ ID NO:215中任一者的氨基酸序列。
在一些实施方式中,抗TIGIT抗体包含:
(i)重链CDR1序列,其包含SEQ ID NO:4、SEQ ID NO:22、SEQ ID NO:40、SEQ IDNO:58、SEQ ID NO:76、SEQ ID NO:94、SEQ ID NO:112、SEQ ID NO:130、SEQ ID NO:148、SEQID NO:166、SEQ ID NO:184、SEQ ID NO:202、SEQ ID NO:221、SEQ ID NO:224、SEQ ID NO:226、SEQ ID NO:231、SEQ ID NO:233、SEQ ID NO:239、SEQ ID NO:243、SEQ ID NO:283、SEQID NO:284、SEQ ID NO:293、SEQ ID NO:294、SEQ ID NO:289或SEQ ID NO:290中任一者的氨基酸序列;及
(ii)重链CDR2序列,其包含SEQ ID NO:6、SEQ ID NO:24、SEQ ID NO:42、SEQ IDNO:60、SEQ ID NO:78、SEQ ID NO:96、SEQ ID NO:114、SEQ ID NO:132、SEQ ID NO:150、SEQID NO:168、SEQ ID NO:186、SEQ ID NO:204、SEQ ID NO:222、SEQ ID NO:225、SEQ ID NO:227、SEQ ID NO:229、SEQ ID NO:232、SEQ ID NO:234、SEQ ID NO:238、SEQ ID NO:240、SEQID NO:285、SEQ ID NO:297、SEQ ID NO:291或SEQ ID NO:295中任一者的氨基酸序列;及
(iii)重链CDR3序列,其包含SEQ ID NO:8、SEQ ID NO:26、SEQ ID NO:44、SEQ IDNO:62、SEQ ID NO:80、SEQ ID NO:98、SEQ ID NO:116、SEQ ID NO:134、SEQ ID NO:152、SEQID NO:170、SEQ ID NO:188、SEQ ID NO:206、SEQ ID NO:223、SEQ ID NO:228、SEQ ID NO:230、SEQ ID NO:235、SEQ ID NO:236、SEQ ID NO:237、SEQ ID NO:241、SEQ ID NO:242、SEQID NO:244、SEQ ID NO:286、SEQ ID NO:292或SEQ ID NO:296中任一者的氨基酸序列;及
(iv)轻链CDR1序列,其包含SEQ ID NO:13、SEQ ID NO:31、SEQ ID NO:49、SEQ IDNO:67、SEQ ID NO:85、SEQ ID NO:103、SEQ ID NO:121、SEQ ID NO:139、SEQ ID NO:157、SEQ ID NO:175、SEQ ID NO:193、SEQ ID NO:211或SEQ ID NO:287中任一者的氨基酸序列;及
(v)轻链CDR2序列,其包含SEQ ID NO:15、SEQ ID NO:33、SEQ ID NO:51、SEQ IDNO:69、SEQ ID NO:87、SEQ ID NO:105、SEQ ID NO:123、SEQ ID NO:141、SEQ ID NO:159、SEQ ID NO:177、SEQ ID NO:195、SEQ ID NO:213或SEQ ID NO:288中任一者的氨基酸序列;及
(vi)轻链CDR3序列,其包含SEQ ID NO:17、SEQ ID NO:35、SEQ ID NO:53、SEQ IDNO:71、SEQ ID NO:89、SEQ ID NO:107、SEQ ID NO:125、SEQ ID NO:143、SEQ ID NO:161、SEQ ID NO:179、SEQ ID NO:197或SEQ ID NO:215中任一者的氨基酸序列。
在一些实施方式中,抗TIGIT抗体包含:(i)重链CDR1序列,其包含SEQ ID NO:4或SEQ ID NO:221的氨基酸序列;(ii)重链CDR2序列,其包含SEQ ID NO:6或SEQ ID NO:222的氨基酸序列;(iii)重链CDR3序列,其包含SEQ ID NO:8或SEQ ID NO:223的氨基酸序列;(iv)轻链CDR1序列,其包含SEQ ID NO:13的氨基酸序列;(v)轻链CDR2序列,其包含SEQ IDNO:15的氨基酸序列;及(vi)轻链CDR3序列,其包含SEQ ID NO:17的氨基酸序列。
在一些实施方式中,抗TIGIT抗体包含:(i)重链CDR1序列,其包含SEQ ID NO:58、SEQ ID NO:224或SEQ ID NO:226中任一者的氨基酸序列;(ii)重链CDR2序列,其包含SEQID NO:60、SEQ ID NO:225、SEQ ID NO:227或SEQ ID NO:229中任一者的氨基酸序列;(iii)重链CDR3序列,其包含SEQ ID NO:62、SEQ ID NO:228或SEQ ID NO:230中任一者的氨基酸序列;(iv)轻链CDR1序列,其包含SEQ ID NO:67的氨基酸序列;(v)轻链CDR2序列,其包含SEQ ID NO:69的氨基酸序列;及(vi)轻链CDR3序列,其包含SEQ ID NO:71的氨基酸序列。
在一些实施方式中,抗TIGIT抗体包含:(i)重链CDR1序列,其包含SEQ ID NO:94、SEQ ID NO:231或SEQ ID NO:233中任一者的氨基酸序列;(ii)重链CDR2序列,其包含SEQID NO:96、SEQ ID NO:232或SEQ ID NO:234中任一者的氨基酸序列;(iii)重链CDR3序列,其包含SEQ ID NO:98、SEQ ID NO:235、SEQ ID NO:236或SEQ ID NO:237中任一者的氨基酸序列;(iv)轻链CDR1序列,其包含SEQ ID NO:103的氨基酸序列;(v)轻链CDR2序列,其包含SEQ ID NO:105的氨基酸序列;及(vi)轻链CDR3序列,其包含SEQ ID NO:107的氨基酸序列。
在一些实施方式中,抗TIGIT抗体包含:(i)重链CDR1序列,其包含SEQ ID NO:166、SEQ ID NO:239或SEQ ID NO:243中任一者的氨基酸序列;(ii)重链CDR2序列,其包含SEQID NO:168、SEQ ID NO:238或SEQ ID NO:240中任一者的氨基酸序列;(iii)重链CDR3序列,其包含SEQ ID NO:170、SEQ ID NO:241、SEQ ID NO:242或SEQ ID NO:244中任一者的氨基酸序列;(iv)轻链CDR1序列,其包含SEQ ID NO:175的氨基酸序列;(v)轻链CDR2序列,其包含SEQ ID NO:177的氨基酸序列;及(vi)轻链CDR3序列,其包含SEQ ID NO:179的氨基酸序列。
在一些实施方式中,抗TIGIT抗体包含重链CDR1-3及轻链CDR1-3,其包含以下氨基酸序列:
(a)分别为SEQ ID NO:4、6、8、13、15及17;
(b)分别为SEQ ID NO:22、24、26、31、33及35;
(c)分别为SEQ ID NO:40、42、44、49、51及53;
(d)分别为SEQ ID NO:58、60、62、67、69及71;
(e)分别为SEQ ID NO:76、78、80、85、87及89;
(f)分别为SEQ ID NO:94、96、98、103、105及107;
(g)分别为SEQ ID NO:112、114、116、121、123及125;
(h)分别为SEQ ID NO:130、132、134、139、141及143;
(i)分别为SEQ ID NO:148、150、152、157、159及161;
(j)分别为SEQ ID NO:166、168、170、175、177及179;
(k)分别为SEQ ID NO:184、186、188、193、195及197;
(l)分别为SEQ ID NO:202、204、206、211、213及215;或
(m)分别为SEQ ID NO:221、222、223、13、15及17;或
(n)分别为SEQ ID NO:224、225、62、67、69及71;或
(o)分别为SEQ ID NO:226、227、228、67、69及71;或
(p)分别为SEQ ID NO:224、229、230、67、69及71;或
(q)分别为SEQ ID NO:224、227、230、67、69及71;或
(r)分别为SEQ ID NO:231、232、235、103、105及107;或
(s)分别为SEQ ID NO:233、234、236、103、105及107;或
(t)分别为SEQ ID NO:233、234、237、103、105及107;或
(u)分别为SEQ ID NO:166、238、170、175、177及179;或
(v)分别为SEQ ID NO:239、240、170、175、177及179;或
(w)分别为SEQ ID NO:239、240、241、175、177及179;或
(x)分别为SEQ ID NO:239、240、242、175、177及179;或
(y)分别为SEQ ID NO:243、168、244、175、177及179。
在一些实施方式中,抗TIGIT抗体包含一个或多个重链框架区(FR1、FR2、FR3和/或FR4),其包含SEQ ID NO:3、SEQ ID NO:5、SEQ ID NO:7、SEQ ID NO:9、SEQ ID NO:21、SEQID NO:23、SEQ ID NO:25、SEQ ID NO:27、SEQ ID NO:39、SEQ ID NO:41、SEQ ID NO:43、SEQID NO:45、SEQ ID NO:57、SEQ ID NO:59、SEQ ID NO:61、SEQ ID NO:63、SEQ ID NO:75、SEQID NO:77、SEQ ID NO:79、SEQ ID NO:81、SEQ ID NO:93、SEQ ID NO:95、SEQ ID NO:97、SEQID NO:99、SEQ ID NO:111、SEQ ID NO:113、SEQ ID NO:115、SEQ ID NO:117、SEQ ID NO:129、SEQ ID NO:131、SEQ ID NO:133、SEQ ID NO:135、SEQ ID NO:147、SEQ ID NO:149、SEQID NO:151、SEQ ID NO:153、SEQ ID NO:165、SEQ ID NO:167、SEQ ID NO:169、SEQ ID NO:171、SEQ ID NO:183、SEQ ID NO:185、SEQ ID NO:187、SEQ ID NO:189、SEQ ID NO:201、SEQID NO:203、SEQ ID NO:205或SEQ ID NO:207的氨基酸序列。
在一些实施方式中,抗TIGIT抗体包含一个或多个轻链框架区(FR1、FR2、FR3和/或FR4),其包含SEQ ID NO:12、SEQ ID NO:14、SEQ ID NO:16、SEQ ID NO:18、SEQ ID NO:30、SEQ ID NO:32、SEQ ID NO:34、SEQ ID NO:36、SEQ ID NO:48、SEQ ID NO:50、SEQ ID NO:52、SEQ ID NO:54、SEQ ID NO:66、SEQ ID NO:68、SEQ ID NO:70、SEQ ID NO:72、SEQ IDNO:84、SEQ ID NO:86、SEQ ID NO:88、SEQ ID NO:90、SEQ ID NO:102、SEQ ID NO:104、SEQID NO:106、SEQ ID NO:108、SEQ ID NO:120、SEQ ID NO:122、SEQ ID NO:124、SEQ ID NO:126、SEQ ID NO:138、SEQ ID NO:140、SEQ ID NO:142、SEQ ID NO:144、SEQ ID NO:156、SEQID NO:158、SEQ ID NO:160、SEQ ID NO:162、SEQ ID NO:174、SEQ ID NO:176、SEQ ID NO:178、SEQ ID NO:180、SEQ ID NO:192、SEQ ID NO:194、SEQ ID NO:196、SEQ ID NO:198、SEQID NO:210、SEQ ID NO:212、SEQ ID NO:214或SEQ ID NO:216的氨基酸序列。
在一些实施方式中,抗TIGIT抗体包括包含选自SEQ ID NO:260、266、268、270及272的氨基酸序列的重链及包含SEQ ID NO:274所示氨基酸序列的轻链。
在一些实施方式中,本发明的抗TIGIT抗体不与US 2009/0258013、US 2016/0176963、US 2016/0376365或WO 2016/028656中所述的抗体竞争结合。在一些实施方式中,本发明的抗TIGIT抗体不与US 2009/0258013、US 2016/0176963、US 2016/0376365或WO2016/028656中所述的抗体结合相同的表位。
抗体的制备
为了制备结合TIGIT的抗体,可使用业内所知的诸多技术。参见(例如)Kohler及Milstein,Nature 256:495-497(1975);Kozbor等人,Immunology Today 4:72(1983);Cole等人,第77-96页,Monoclonal Antibodies and Cancer Therapy,Alan R.Liss,Inc.(1985);Coligan,Current Protocols in Immunology(1991);Harlow及Lane,Antibodies,A Laboratory Manual(1988);及Goding,Monoclonal Antibodies:Principles andPractice(第2版,1986))。
编码所关注抗体重链及轻链的基因可自细胞克隆,例如,编码单克隆抗体的基因可自表达抗体的杂交瘤克隆且用于产生重组单克隆抗体。编码单克隆抗体重链及轻链基因文库亦可自杂交瘤或浆细胞制得。另外,可使用噬菌体或酵母展示技术以鉴定特异性结合所选抗原抗体及异聚Fab片段(例如,参见McCafferty等人,Nature 348:552-554(1990);Marks等人,Biotechnology 10:779-783(1992);Lou等人(2010)PEDS 23:311;及Chao等人,Nature Protocols,1:755-768(2006))。或者,可使用(例如)以下文献中所揭示的基于酵母的抗体呈递系统分离和/或鉴定抗体及抗体序列:例如Xu等人,Protein Eng Des Sel,2013,26:663-670;WO 2009/036379;WO 2010/105256;及WO 2012/009568。重链及轻链基因产物的随机组合产生具有不同抗原特异性的大量抗体(例如,参见Kuby,Immunology(第3版,1997))。用于产生单链抗体或重组抗体的技术(美国专利4,946,778、美国专利第4,816,567号)亦可适于产生抗体。亦可使得抗体具有双特异性,亦即能够识别两种不同抗原(例如,参见WO 93/08829,Traunecker等人,EMBO J.10:3655-3659(1991);及Suresh等人,Methods in Enzymology 121:210(1986))。抗体亦可为异质偶联物,例如,两个共价接合的抗体或共价结合至免疫毒素的抗体(例如,参见美国专利第4,676,980号、WO 91/00360;及WO 92/200373)。
抗体可使用任何数目的表达系统(包括原核及真核表达系统)来产生。在一些实施方式中,表达系统是哺乳动物细胞,例如杂交瘤或CHO细胞。许多所述系统可自商业供应商广泛获得。在抗体包含重链及轻链两者的实施方式中,重链及轻链可使用单一载体、例如在二顺反子表达单位中、或在不同启动子控制下表达。在其他实施例中,重链及轻链区可使用单独载体表达。如本文所述的重链及轻链可可选性在N-末端包含甲硫氨酸。
在一些实施方式中,生成抗体片段(例如Fab、Fab’、F(ab’)2、scFv或双价抗体)。已研发各种技术用于产生抗体片段。传统上,所述片段由完整抗体经蛋白水解降解得到(例如,参见Morimoto等人,J.Biochem.Biophys.Meth.,24:107-117(1992);及Brennan等人,Science,229:81(1985))。然而,所述片段现可使用重组宿主细胞直接产生。举例而言,抗体片段可分离自抗体噬菌体文库。或者,Fab’-SH片段可直接自大肠杆菌细胞回收且化学偶合以形成F(ab’)2片段(例如,参见Carter等人,BioTechnology,10:163-167(1992))。根据另一方法,F(ab’)2片段可直接分离自重组宿主细胞培养物。用于产生抗体片段的其他技术为本领域普通技术人员所明了。在其他实施例中,所选抗体是单链Fv片段(scFv)。参见(例如)PCT公开第WO 93/16185号;及美国专利第5,571,894号及第5,587,458号。抗体片段亦可为线性抗体,如例如美国专利第5,641,870号中所述。
在一些实施方式中,抗体或抗体片段可偶联至另一分子(例如聚乙二醇(聚乙二醇化)或血清白蛋白),以延长体内半衰期。抗体片段聚乙二醇化的实例提供于以下文献中:Knight等人Platelets 15:409,2004(对于阿昔单抗);Pedley等人,Br.J.Cancer 70:1126,1994(对于抗CEA抗体);Chapman等人,Nature Biotech.17:780,1999;及Humphreys,等人,Protein Eng.Des.20:227,2007)。
在一些实施方式中,提供包含如本文所述抗TIGIT抗体的多特异性抗体,例如双特异性抗体。多特异性抗体是对至少两个不同位点具有结合特异性的抗体。在一些实施方式中,多特异性抗体对TIGIT(例如人TIGIT)具有结合特异性且对至少一种其他抗原具有结合特异性。制备多特异性抗体的方法包括(但不限于)两对重链及轻链在宿主细胞中重组共表达(例如,参见Zuo等人,Protein Eng Des Sel,2000,13:361-367);“杵臼结构”工程改造(例如,参见Ridgway等人,Protein Eng Des Sel,1996,9:617-721);“双价抗体”技术(例如,参见Hollinger等人,PNAS(USA),1993,90:6444-6448);及分子内三聚化(例如,参见Alvarez-Cienfuegos等人,Scientific Reports,2016,doi:/10.1038/srep28643);亦参见Spiess等人,Molecular Immunology,2015,67(2),部分A:95-106。
在一些实施方式中,提供包含本文所述抗TIGIT抗体的抗体-药物偶联物。在抗体-药物偶联物中,对抗原(例如TIGIT)具有结合特异性的单克隆抗体共价连接细胞毒性药物。用于制备抗体-药物偶联物的方法可见(例如)Chudasama等人,Nature Chemistry,2016,8:114-119;WO 2013/068874;及US 8,535,678中。
恒定区的选择
本文所述抗TIGIT抗体的重链及轻链可变区可连接至人恒定区的至少一部分。恒定区的选择部分取决于是否期望抗体依赖性细胞介导的细胞毒性、抗体依赖性细胞吞噬作用和/或补体依赖性细胞毒性。举例而言,人同型IgG1及IgG3具有强补体依赖性细胞毒性、人同型IgG2具有弱补体依赖性细胞毒性且人IgG4无补体依赖性细胞毒性。人IgG1及IgG3亦比人IgG2及IgG4诱导较强的细胞介导的效应功能。轻链恒定区可为λ或κ。抗体可表达为含有两条轻链及两条重链的四聚体;表达为单独重链、轻链;表达为Fab、Fab'、F(ab')2及Fv;或表达为单链抗体,其中重链及轻链可变结构域经由间隔体连接。
人恒定区在不同个体之间显示同种异型变异和同族同种异型变异,亦即不同个体之间的恒定区可在一个或多个多态性位置有差异。同族同种异型与同种异型的区别在于识别同族同种异型的血清结合一个或多个其他同型的非多态区。
轻链和/或重链氨基或羧基末端的一个或若干个氨基酸、例如重链C-末端的赖氨酸可在一定比例或全部分子中丢失或衍生化。可在恒定区中进行取代以降低或增加效应功能,例如补体介导的细胞毒性或ADCC(例如,参见Winter等人,美国专利第5,624,821号;Tso等人,美国专利第5,834,597号;及Lazar等人,Proc.Natl.Acad.Sci.USA 103:4005,2006),或延长人体类中的半衰期(例如,参见Hinton等人,J.Biol.Chem.279:6213,2004)。
示例性取代包括在人IgG1同型中在氨基酸位置234、235、237、239、267、298、299、326、330或332处引入天然氨基酸至半胱氨酸残基的氨基酸取代、优选S239C突变(根据EU索引编号(Kabat,Sequences of Proteins of Immunological Interest(NationalInstitutes of Health,Bethesda,MD,1987及1991);参见US20100158909,其以引用方式并入本文中)。额外半胱氨酸残基的存在可容许链间二硫键形成。该链间二硫键形成可引起立体阻碍,藉此降低Fc区-FcγR结合相互作用的亲和性。引入IgG恒定区的Fc区中或邻近IgG恒定区的Fc区的半胱氨酸残基亦可用作偶联至治疗剂的位点(即,使用硫醇特异性试剂(例如药物的马来酰亚胺衍生物)偶联细胞毒性药物)。治疗剂的存在引起立体阻碍,藉此进一步降低Fc区-FcγR结合相互作用的亲和性。位置234,235,236和/或237中任一者的其他取代降低对Fcγ受体、具体而言FcγRI受体的亲和性(例如,参见US 6,624,821、US 5,624,821)。突变的优选组合是S239D、A330L及I332E,其增加Fc结构域对FcγRIIIA的亲和性且因此增加ADCC。
抗体的体内半衰期亦可影响其效应功能。可增加或减少抗体的半衰期以修饰其治疗活性。FcRn是结构上类似于与β2-微球蛋白非共价缔合的MHC I类抗原的受体。FcRn调控IgG的分解代谢及其跨组织的转胞吞作用(Ghetie及Ward,2000,Annu.Rev.Immunol.18:739-766;Ghetie及Ward,2002,Immunol.Res.25:97-113)。IgG-FcRn相互作用发生在pH 6.0(细胞内囊泡之pH)下,而不发生在pH 7.4(血液之pH)下;此相互作用使得IgG能够循环回循环(Ghetie及Ward,2000,Ann.Rev.Immunol.18:739-766;Ghetie及Ward,2002,Immunol.Res.25:97-113)。已定位人IgG1上参与FcRn结合的区(Shields等人,2001,J.Biol.Chem.276:6591-604)。人IgG1的Pro238、Thr256、Thr307、Gln311、Asp312、Glu380、Glu382或Asn434位处的丙氨酸取代增强FcRn结合(Shields等人,2001,J.Biol.Chem.276:6591-604)。带有所述取代的IgG1分子具有更长血清半衰期。因此,所述经修饰的IgG1分子与未经修饰的IgG1相比能够更长时间地发挥其效应功能,并由此发挥其治疗效能。用于增加与FcRn结合的其他示例性取代包括250位处的Gln和/或428位处的Leu。EU编号用于恒定区中的所有位置。
共价附接至保守Asn297的寡糖参与IgG的Fc区结合FcγR的能力(Lund等人,1996,J.Immunol.157:4963-69;Wright及Morrison,1997,Trends Biotechnol.15:26-31)。IgG上此糖型的工程改造可显著改良IgG介导的ADCC。向此糖型中添加平分型N-乙酰基葡糖胺修饰(Umana等人,1999,Nat.Biotechnol.17:176-180;Davies等人,2001,Biotech.Bioeng.74:288-94)或自此糖型去除岩藻糖(Shields等人,2002,J.Biol.Chem.277:26733-40;Shinkawa等人,2003,J.Biol.Chem.278:6591-604;Niwa等人,2004,Cancer Res.64:2127-33)是IgG Fc工程改造的两个实例,其改良IgG Fc与FcγR之间的结合,藉此增强Ig介导的ADCC活性。
人IgG1 Fc区的溶剂暴露氨基酸的系统性取代生成具有FcγR结合亲和性改变的IgG变体(Shields等人,2001,J.Biol.Chem.276:6591-604)。在与亲代IgG1比较时,涉及Thr256/Ser298、Ser298/Glu333、Ser298/Lys334或Ser298/Glu333/Lys334处至Ala取代的所述变体亚组展现对FcγR的结合亲和性及ADCC活性两者皆增加(Shields等人,2001,J.Biol.Chem.276:6591-604;Okazaki等人,2004,J.Mol.Biol.336:1239-49)。
抗体补体结合活性(C1q结合及CDC活性两者)可由Lys326及Glu333的取代得以改良(Idusogie等人,2001,J.Immunol.166:2571-2575)。人IgG2主链上的相同取代可将与C1q较弱结合且补体活化活性严重缺乏的抗体同型转化为既可结合C1q亦可介导CDC者(Idusogie等人,2001,J.Immunol.166:2571-75)。亦可应用若干其他方法以改良抗体的补体结合活性。举例而言,IgM的18-氨基酸羧基-末端尾片接枝至IgG的羧基末端大大增强其CDC活性。此甚至利用IgG4可观察到,该IgG4通常无可检测CDC活性(Smith等人,1995,J.Immunol.154:2226-36)。而且,用Cys取代位于IgG1重链羧基末端附近的Ser444诱导IgG1的尾对尾二聚化,且CDC活性相对于单体IgG1增加200倍(Shopes等人,1992,J.Immunol.148:2918-22)。另外,对C1q具有特异性的双特异性双价抗体构筑体亦赋予CDC活性(Kontermann等人,1997,Nat.Biotech.15:629-31)。
可藉由将重链氨基酸残基318、320及322中至少一者突变成具有不同侧链的残基(例如Ala)来降低补体活性。用其他烷基取代的非离子残基(例如Gly、Ile、Leu或Val)、或诸如Phe、Tyr、Trp及Pro等芳香族非极性残基代替三个残基中任一者亦降低或消除C1q结合。Ser、Thr、Cys及Met可在残基320及322、而非318处用于降低或消除C1q结合活性。由极性残基置换318(Glu)残基可修饰而非消除C1q结合活性。用Ala置换残基297(Asn)可去除溶解活性,但仅稍微降低对C1q的亲和性(弱约三倍)。此改变破坏糖基化位点及补体活化所需碳水化合物的存在。此位点任何其他取代亦破坏糖基化位点。以下突变及其任何组合亦降低C1q结合:D270A、K322A、P329A及P311S(参见WO 06/036291)。
提及人恒定区时包括具有任何天然同种异型或占据天然同种异型中多形体位置之残基的任何排列的恒定区。相对于天然人恒定区,亦可存在高达1、2、5或10个突变,例如上文指示降低Fcγ受体结合或增加与FcRN的结合的那些。
核酸、载体及宿主细胞
在一些实施方式中,使用重组方法产生本文所述抗TIGIT抗体。因此,在一些态样中,本发明提供包含编码本文所述抗TIGIT抗体中任一者(例如本文所述CDR中任一者)的核酸序列的经分离核酸;包含所述核酸的载体;及其中引入核酸的宿主细胞,其用于复制编码抗体的核酸和/或表达抗体。在一些实施方式中,宿主细胞是真核细胞,例如中国仓鼠卵巢(CHO)细胞;或人细胞。
在一些实施方式中,多核苷酸(例如经分离多核苷酸)包含编码本文所述抗体的核苷酸序列。在一些实施方式中,多核苷酸包含编码序列表中所揭示的一个或多个氨基酸序列(例如CDR、重链、轻链和/或框架区)的核苷酸序列。在一些实施方式中,多核苷酸包含编码与以下序列表中所揭示的序列(例如CDR、重链、轻链或框架区序列)具有至少85%序列一致性(例如至少85%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%或至少99%序列一致性)的氨基酸序列的核苷酸序列。
在一些实施方式中,多核苷酸(例如经分离多核苷酸)包含编码本文所述的重链可变区的核苷酸序列。在一些实施方式中,多核苷酸包含编码包含与SEQ ID NO:1、SEQ IDNO:19、SEQ ID NO:37、SEQ ID NO:55、SEQ ID NO:73、SEQ ID NO:91、SEQ ID NO:109、SEQID NO:127、SEQ ID NO:145、SEQ ID NO:163、SEQ ID NO:181、SEQ ID NO:199、SEQ ID NO:245、SEQ ID NO:246、SEQ ID NO:247、SEQ ID NO:248、SEQ ID NO:249、SEQ ID NO:250、SEQID NO:251、SEQ ID NO:252、SEQ ID NO:253、SEQ ID NO:254、SEQ ID NO:255、SEQ ID NO:256或SEQ ID NO:257具有至少90%序列一致性的氨基酸序列的重链可变区的核苷酸序列。在一些实施方式中,多核苷酸包含与SEQ ID NO:2、SEQ ID NO:20、SEQ ID NO:38、SEQ IDNO:56、SEQ ID NO:74、SEQ ID NO:92、SEQ ID NO:110、SEQ ID NO:128、SEQ ID NO:146、SEQID NO:164、SEQ ID NO:182、SEQ ID NO:200、SEQ ID NO:259、SEQ ID NO:265、SEQ ID NO:267、SEQ ID NO:269或SEQ ID NO:271具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%序列一致性的核苷酸序列。
在一些实施方式中,多核苷酸(例如经分离多核苷酸)包含编码本文所述的轻链可变区的核苷酸序列。在一些实施方式中,多核苷酸包含编码包含与SEQ ID NO:10、SEQ IDNO:28、SEQ ID NO:46、SEQ ID NO:64、SEQ ID NO:82、SEQ ID NO:100、SEQ ID NO:118、SEQID NO:136、SEQ ID NO:154、SEQ ID NO:172、SEQ ID NO:190或SEQ ID NO:208具有至少90%序列一致性的氨基酸序列的轻链可变区的核苷酸序列。在一些实施方式中,多核苷酸包含与SEQ ID NO:11、SEQ ID NO:29、SEQ ID NO:47、SEQ ID NO:65、SEQ ID NO:83、SEQ IDNO:101、SEQ ID NO:119、SEQ ID NO:137、SEQ ID NO:155、SEQ ID NO:173、SEQ ID NO:191、SEQ ID NO:209或SEQ ID NO:273具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%序列一致性的核苷酸序列。
在一些实施方式中,多核苷酸包含编码本文所述的重链可变区及轻链可变区的核苷酸序列。在一些实施方式中,多核苷酸包含核苷酸序列,其编码包含与SEQ ID NO:1、SEQID NO:19、SEQ ID NO:37、SEQ ID NO:55、SEQ ID NO:73、SEQ ID NO:91、SEQ ID NO:109、SEQ ID NO:127、SEQ ID NO:145、SEQ ID NO:163、SEQ ID NO:181、SEQ ID NO:199、SEQ IDNO:245、SEQ ID NO:246、SEQ ID NO:247、SEQ ID NO:248、SEQ ID NO:249、SEQ ID NO:250、SEQ ID NO:251、SEQ ID NO:252、SEQ ID NO:253、SEQ ID NO:254、SEQ ID NO:255、SEQ IDNO:256或SEQ ID NO:257具有至少90%序列一致性的氨基酸序列的重链可变区,且编码包含与SEQ ID NO:10、SEQ ID NO:28、SEQ ID NO:46、SEQ ID NO:64、SEQ ID NO:82、SEQ IDNO:100、SEQ ID NO:118、SEQ ID NO:136、SEQ ID NO:154、SEQ ID NO:172、SEQ ID NO:190或SEQ ID NO:208具有至少90%序列一致性的氨基酸序列的轻链可变区。在一些实施方式中,多核苷酸包含与SEQ ID NO:2、SEQ ID NO:20、SEQ ID NO:38、SEQ ID NO:56、SEQ IDNO:74、SEQ ID NO:92、SEQ ID NO:110、SEQ ID NO:128、SEQ ID NO:146、SEQ ID NO:164、SEQ ID NO:182、SEQ ID NO:200、SEQ ID NO:259、SEQ ID NO:265、SEQ ID NO:267、SEQ IDNO:269或SEQ ID NO:271具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%序列一致性的核苷酸序列,且进一步包含与SEQ ID NO:11、SEQ ID NO:29、SEQID NO:47、SEQ ID NO:65、SEQ ID NO:83、SEQ ID NO:101、SEQ ID NO:119、SEQ ID NO:137、SEQ ID NO:155、SEQ ID NO:173、SEQ ID NO:191、SEQ ID NO:209或SEQ ID NO:273具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%序列一致性的核苷酸序列。
在另一方面,提供制备本文所述抗TIGIT抗体的方法。在一些实施方式中,该方法包括在适于抗体表达的条件下培养本文所述的宿主细胞(例如表达本文所述多核苷酸或载体的宿主细胞)。在一些实施方式中,随后自宿主细胞(或宿主细胞培养基)回收抗体。
含有编码本发明抗体或其片段的多核苷酸的适宜载体包括克隆载体及表达载体。尽管所选克隆载体可根据预期使用的宿主细胞而变化,但有用的克隆载体通常具有自我复制能力,可具有特定限制性酸酶内切酶的单一靶标,和/或可携带可用于选择含有载体的克隆的标记物的基因。实例包括质粒及细菌病毒,例如pUC18、pUC19、Bluescript(例如pBS SK+)及其衍生物、mp18、mp19、pBR322、pMB9、ColE1、pCR1、RP4、噬菌体DNA及穿梭载体(例如pSA3及pAT28)。克隆载体可自商业供应商(例如BioRad、Stratagene及Invitrogen)获得。
表达载体通常是含有本发明核酸的可复制多核苷酸构筑体。表达载体可在宿主细胞中作为游离基因体或作为染色体DNA的整合部分而复制。适宜表达载体包括(但不限于)质粒、病毒载体(包括腺病毒、腺相关病毒、反转录病毒)及任何其他载体。
重组抗体的表达
抗体通常是重组表达产生。重组多核苷酸构筑体通常包括可操作性连接至抗体链编码序列的表达控制序列,包括天然缔合或异源启动子区。较佳地,表达控制序列是载体中能够转化或转染真核宿主细胞的真核启动子系统。一旦将载体纳入适当宿主中,宿主即维持于适于核苷酸序列高量表达、及交叉反应抗体收集及纯化的条件下。
哺乳动物细胞是用于表达编码免疫球蛋白或其片段的核苷酸区段的较佳宿主。参见Winnacker,From Genes to Clones,(VCH出版商,NY,1987)。业内已研发多种能够分泌完整异源蛋白质的适宜宿主细胞系,且包括CHO细胞系(例如DG44)、各种COS细胞系、HeLa细胞、HEK293细胞、L细胞及非抗体产生骨髓瘤(包括Sp2/0及NS0)。较佳地,细胞是非人细胞。所述细胞的表达载体可包括表达控制序列,例如复制起点、启动子、增强子(Queen等人,Immunol.Rev.89:49(1986));及必需处理资讯位点,例如核糖体结合位点、RNA剪接位点、多聚腺苷酸化位点及转录终止子序列。较佳表达控制序列衍生自内源基因、巨细胞病毒、SV40、腺病毒、牛乳头瘤病毒及诸如此类的启动子。参见Co等人,J.Immunol.148:1149(1992)。
一旦表达,抗体即可根据业内的标准程序(包括HPLC纯化、管柱层析、凝胶电泳及诸如此类)纯化(通常参见Scopes,Protein Purification(Springer-Verlag,NY,1982))。
糖基化变体
抗体可在其恒定区中之保守位置糖基化(Jefferis及Lund,(1997)Chem.Immunol.65:111-128;Wright及Morrison,(1997)TibTECH 15:26-32)。免疫球蛋白的寡糖侧链影响蛋白质的功能(Boyd等人,(1996)Mol.Immunol.32:1311-1318;Wittwe及Howard,(1990)Biochem.29:4175-4180),及糖蛋白各部分之间可影响构形且呈现糖蛋白三维表面的分子内相互作用(Hefferis及Lund,上文文献;Wyss及Wagner,(1996)CurrentOpin.Biotech.7:409-416)。寡糖亦可用于将给定糖蛋白靶向基于特定识别结构的某些分子。举例而言,已报导,在无半乳糖基化IgG中,寡糖部分自CH2间空间“翻转出”,且末端N-乙酰基葡糖胺残基可用于结合甘露糖结合蛋白(Malhotra等人,(1995)Nature Med.1:237-243)。用糖肽酶去除中国仓鼠卵巢(CHO)细胞中产生的CAMPATH-1H(一种重组人源化鼠类单克隆IgG1抗体,其识别人淋巴细胞的CDw52抗原)的寡糖可引起补体介导的溶解的完全降低(CMCL)(Boyd等人,(1996)Mol.Immunol.32:1311-1318),而使用神经氨酸酶选择性去除唾液酸残基不引起DMCL损失。亦已报导抗体的糖基化可影响抗体依赖性细胞毒性(ADCC)。具体而言,据报导,具有四环素调控的β(1,4)-N-乙酰基葡糖氨基转移酶III(GnTIII)(一种催化平分型GlcNAc形成的糖基转移酶)表达的CHO细胞具有改良的ADCC活性(Umana等人(1999)Mature Biotech.17:176-180)。
抗体的糖基化通常是N-连接的或O-连接的。N-连接指碳水化合物部分与天冬酰胺残基的侧链附接。三肽序列天冬酰胺-X-丝氨酸及天冬酰胺-X-苏氨酸(其中X是除脯氨酸外的任何氨基酸)是碳水化合物部分与天冬酰胺侧链酶促附接的识别序列。因此,多肽中存在所述三肽序列中任一者均可产生潜在糖基化位点。O-连接的糖基化指糖N-乙酰基半乳糖胺、半乳糖或木糖中之一与羟基氨基酸(最常见为丝氨酸或苏氨酸,但亦可使用5-羟基脯氨酸或5-羟基赖氨酸)附接。
抗体的糖基化变体是抗体的糖基化型式改变之变体。改变意指缺失抗体中发现之一个或多个碳水化合物部分、向抗体添加一个或多个碳水化合物部分、改变糖基化之组成(糖基化型式)、糖基化程度等。
可藉由改变氨基酸序列以使其含有上述三肽序列中之一或多者(对于N连接的糖基化位点)向抗体添加糖基化位点。亦可藉由向初始抗体序列中添加一个或多个丝氨酸或苏氨酸残基或用一个或多个丝氨酸或苏氨酸残基实施取代(对于O-连接的糖基化位点)来达成该改变。类似地,可藉由抗体的天然糖基化位点内的氨基酸改变去除糖基化位点。
通常藉由改变基本核酸序列改变氨基酸序列。所述方法包括(但不限于)自天然来源分离(在天然氨基酸序列变体的情形下)或藉由先前制备的变体或非变体形式抗体的寡核苷酸介导(或定向)的诱变、PCR诱变或盒式诱变来制备。
亦可改变抗体的糖基化(包括糖基化型式),而不改变氨基酸序列或基本核苷酸序列。糖基化在很大程度上取决于用于表达抗体的宿主细胞。由于用于表达作为潜在治疗剂的重组糖蛋白(例如抗体)的细胞类型很少为天然细胞,故可预计抗体的糖基化型式的显著变化。参见(例如)Hse等人,(1997)J.Biol.Chem.272:9062-9070。除宿主细胞的选择外,在抗体重组产生期间影响糖基化的因素包括生长模式、培养基配方、培养密度、氧合、pH、纯化方案及诸如此类。已提出改变特定宿主生物体中所得糖基化型式的各种方法(包括引入参与寡糖产生的某些酶或使其过表达)(美国专利第5047335号;第5510261号;第5278299号)。可使用(例如)内切糖苷酶H(Endo H)以酶促方式去除糖蛋白的糖基化或某些类型的糖基化。另外,可遗传改造重组宿主细胞,例如,使某些类型多糖的处理产生缺陷。所述及类似技术为业内已知。
可藉由常用碳水化合物分析技术(包括凝集素层析、NMR、质谱法、HPLC、GPC、单糖组成分析、依序酶消化、及基于电荷使用高pH阴离子交换层析分离寡糖之HPAEC-PAD)容易地分析抗体的糖基化结构。出于分析目的释放寡糖的方法亦已知,且包括(但不限于)酶处理(通常使用肽-N-糖苷酶F/内-β-半乳糖苷酶实施)、使用苛刻碱性环境以主要释放O-连接结构的消除及使用无水肼释放N-连接及O-连接寡糖之化学方法。
抗体糖基化修饰的较佳形式是降低核心岩藻糖基化。“核心岩藻糖基化”指在N连接聚糖的还原末端向N-乙酰基葡糖胺(“GlcNAc”)添加岩藻糖(“岩藻糖基化”)。
“复杂N-糖苷连接糖链”通常结合至天冬酰胺297(根据Kabat之编号)。如本文所用,复杂N-糖苷连接的糖链具有二天线复合糖链,其主要具有以下结构:

其中±表示糖分子可存在或不存在,且数字指示糖分子之间的链接位置。在上述结构中,结合天冬酰胺的糖链末端称为还原末端(在右侧),且相对链称为非还原末端。岩藻糖通常藉由(通常)α1,6键结合至还原末端的N-乙酰基葡糖胺(“GlcNAc”)(GlcNAc之6位连接至岩藻糖之1位)。“Gal”指半乳糖,且“Man”指甘露糖。
“复杂N-糖苷连接糖链”包括1)复杂类型,其中核心结构的非还原末端侧具有0个、一个或更多个半乳糖-N-乙酰基葡糖胺(亦称为gal-GlcNAc”)分支,且gal-GlcNAc的非还原末端侧可选性具有唾液酸、平分型N-乙酰基葡糖胺或诸如此类;及2)杂合类型,其中核心结构的非还原末端侧具有高甘露糖N-糖苷连接的糖链及复杂N-糖苷连接的糖链这样两个分支。
根据本发明方法,通常仅微量岩藻糖纳入抗TIGIT抗体的复杂N-糖苷连接糖链中。举例而言,在各个实施例中,组合物中小于约60%、小于约50%、小于约40%、小于约30%、小于约20%、小于约15%、小于约10%、小于约5%或小于约3%的抗体被岩藻糖核心岩藻糖基化。在一些实施方式中,组合物中约2%的抗体被岩藻糖核心岩藻糖基化。在各个实施例中,当组合物中小于60%的抗体被岩藻糖核心岩藻糖基化时,组合物的抗体可称为“非岩藻糖基化”或“无岩藻糖基化”。在一些实施方式中,组合物中至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%或至少99%的抗体是无岩藻糖基化的。
在某些实施例中,仅微量岩藻糖类似物(或岩藻糖类似物的代谢物或产物)纳入复杂N-糖苷连接糖链中。举例而言,在各个实施例中,小于约60%、小于约50%、小于约40%、小于约30%、小于约20%、小于约15%、小于约10%、小于约5%或小于约3%的抗TIGIT抗体被岩藻糖类似物或岩藻糖类似物的代谢物或产物核心岩藻糖基化。在一些实施方式中,约2%的抗TIGIT抗体被岩藻糖类似物或岩藻糖类似物的代谢物或产物核心岩藻糖基化。
在一些实施方式中,组合物中小于约60%、小于约50%、小于约40%、小于约30%、小于约20%、小于约15%、小于约10%、小于约5%、或小于约3%的抗体在G0、G1或G2聚糖结构上具有岩藻糖残基。(例如,参见Raju等人,2012,MAbs4:385-391,图3)。在一些实施方式中,组合物中约2%的抗体在G0、G1或G2聚糖结构上具有岩藻糖残基。在各个实施例中,当组合物中小于60%的抗体在G0、G1或G2聚糖结构上具有岩藻糖残基时,组合物的抗体可称为“无岩藻糖基化的”。在一些实施方式中,组合物中至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%或至少99%的抗体在G0、G1或G2聚糖结构上无岩藻糖。应注意,G0聚糖包括G0-GN聚糖。G0-GN聚糖是具有一个末端GlcNAc残基的单天线聚糖。G1聚糖包括G1-GN聚糖。G1-GN聚糖是具有一个末端半乳糖残基的单天线聚糖。G0-GN及G1-GN聚糖可为岩藻糖基化的或非岩藻糖基化的。
用岩藻糖类似物培育产生抗体的细胞来制备无岩藻糖基化抗体的方法记载于(例如)WO2009/135181中。简言之,在岩藻糖类似物或岩藻糖类似物的细胞内代谢物或产物存在下培育经工程改造以表达抗TIGIT抗体的细胞。细胞内代谢物可为(例如)GDP修饰的类似物或完全或部分去酯化类似物。产物可为(例如)完全或部分去酯化类似物。在一些实施方式中,岩藻糖类似物可抑制岩藻糖再利用路径中的酶。举例而言,岩藻糖类似物(或岩藻糖类似物的细胞内代谢物或产物)可抑制岩藻糖激酶或GDP-岩藻糖-焦磷酸化酶的活性。在一些实施方式中,岩藻糖类似物(或岩藻糖类似物的细胞内代谢物或产物)抑制岩藻糖基转移酶(较佳1,6-岩藻糖基转移酶,例如FUT8蛋白)。在一些实施方式中,岩藻糖类似物(或岩藻糖类似物的细胞内代谢物或产物)可抑制重新合成路径中酶对岩藻糖的活性。举例而言,岩藻糖类似物(或岩藻糖类似物的细胞内代谢物或产物)可抑制GDP-甘露糖4,6-去水酶和/或GDP-岩藻糖合成酶的活性。在一些实施方式中,岩藻糖类似物(或岩藻糖类似物的细胞内代谢物或产物)可抑制岩藻糖转运蛋白(例如GDP-岩藻糖转运蛋白)。
在一个实施例中,岩藻糖类似物是2-氟岩藻糖。使用生长培养基中的岩藻糖类似物及其他岩藻糖类似物的方法记载于(例如)WO 2009/135181中,该公开文本以引用方式并入本文中。
工程改造细胞系以减少核心岩藻糖基化的其他方法包括基因剔除、基因敲入及RNA干扰(RNAi)。在基因剔除中,使编码FUT8(α1,6-岩藻糖基转移酶)的基因灭活。FUT8催化岩藻糖基残基自GDP-岩藻糖转移至N-聚糖的Asn连接(N连接)GlcNac的6位。据报导FUT8是负责将岩藻糖添加至Asn297处N-连接二天线碳水化合物的唯一酶。基因敲入添加编码酶(例如GNTIII或高尔基α甘露糖苷酶II)的基因。细胞中所述酶含量的增加将单克隆抗体自岩藻糖基化路径转向(导致核心岩藻糖基化降低),且平分型N-乙酰基葡糖胺的量增加。RNAi通常亦靶向FUT8基因表达,从而导致mRNA转录本含量降低或完全敲除基因表达。所述方法中任一者可用于生成能够产生无岩藻糖基化抗体(例如抗TIGIT抗体)的细胞系。
许多方法可用于测定抗体上岩藻糖基化的量。方法包括(例如)经由PLRP-S层析的LC-MS、电喷雾离子化四极TOF MS、利用雷射诱导的荧光毛细管电泳(CE-LIF)及利用荧光检测的亲水相互作用层析(HILIC)。
IV.使用抗TIGIT抗体的治疗方法
在一些实施方式中,提供治疗或预防个体癌症的方法。在一些实施方式中,方法包含向个体给予治疗量的抗TIGIT抗体。在一些实施方式中,抗TIGIT抗体是无岩藻糖基化的。在一些实施方式中,方法包含向个体给予治疗量的包含抗TIGIT抗体的药物组合物,其中组合物中至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%或至少99%的抗体是无岩藻糖基化的。在某些实施例中,个体是人。
在一些实施方式中,癌症是CD112和/或CD155表达富集的癌症或癌细胞。在一些实施方式中,使用对CD112或CD155具有特异性的抗体对肿瘤样品进行免疫组织化学评价来鉴别CD112-和/或CD155富集的癌症。在一些实施方式中,CD112或CD155表达在肿瘤细胞或肿瘤浸润白血球中富集或增加。在一些实施方式中,基于肿瘤样品中CD112和/或CD155 mRNA含量的评价(例如藉由业内已知的方法,例如定量RT-PCR)鉴别癌症。在一些实施方式中,自癌症患者获得的血样中可溶性CD112或CD155的量测可用于鉴别CD112和/或CD155表达富集的癌症。在一些实施方式中,方法包含自个体获得样品(例如肿瘤样品或血样)、量测个体样品中CD112和/或CD155的含量及比较个体样品中CD112和/或CD155的含量与对照值(例如健康对照个体的样品或针对健康对照群体测定的CD112和/或CD155表达量)。在一些实施方式中,方法包含确定个体样品中CD112和/或CD155的含量是否高于对照值,且随后向个体给予本文所述抗TIGIT抗体。
在一些实施方式中,癌症是表达TIGIT的T细胞或天然杀手(NK)细胞富集的癌症或癌细胞。在一些实施方式中,使用对TIGIT具有特异性的抗体对肿瘤样品进行免疫组织化学评价来鉴别TIGIT富集的癌症。在一些实施方式中,对T细胞或NK细胞具有特异性的抗体(例如抗CD3、抗CD4、抗CD8、抗CD25或抗CD56)用于测定表达TIGIT的肿瘤浸润细胞的一个或多个亚组。在一些实施方式中,藉由肿瘤样品中TIGIT mRNA含量的评价来鉴别癌症。在一些实施方式中,自癌症患者获得的血样中可溶性TIGIT的量测可用于(可选性与对T细胞或NK细胞具有特异性的抗体组合)鉴别表达TIGIT的T细胞或NK细胞富集的癌症。在一些实施方式中,方法包含自个体获得样品(例如肿瘤样品或血样)、量测个体样品中TIGIT的含量、可选性检测T细胞或NK细胞的存在(例如使用对T细胞或NK细胞具有特异性的抗体,例如抗CD3、抗CD4、抗CD8、抗CD25或抗CD56)及比较个体样品中TIGIT的含量与对照值(例如健康对照个体的样品或针对健康对照群体测定的TIGIT表达量)。在一些实施方式中,方法包含确定个体样品中TIGIT的含量是否高于对照值,且随后向个体给予本文所述抗TIGIT抗体。
在一些实施方式中,癌症是膀胱癌、乳癌、子宫癌、子宫颈癌、卵巢癌、前列腺癌、睪丸癌、食道癌、胃肠癌、胃癌(gastric cancer)、胰脏癌、结肠直肠癌、结肠癌、肾癌、透明细胞肾癌、头颈癌、肺癌、肺腺癌、胃癌(stomach cancer)、生殖细胞癌、骨癌、肝癌、甲状腺癌、皮肤癌、黑色素瘤、中枢神经系统赘瘤、间皮瘤、淋巴瘤、白血病、慢性淋巴细胞白血病、弥漫性大B细胞淋巴瘤、滤泡性淋巴瘤、霍奇金氏淋巴瘤、骨髓瘤或肉瘤。在一些实施方式中,癌症是选自胃癌、睪丸癌、胰脏癌、肺腺癌、膀胱癌、头颈癌、前列腺癌、乳癌、间皮瘤及透明细胞肾癌。在一些实施方式中,癌症是淋巴瘤或白血病,包括(但不限于)急性骨髓性、慢性骨髓性、急性淋巴细胞性或慢性淋巴细胞白血病、弥漫性大B细胞淋巴瘤、滤泡性淋巴瘤、外套细胞淋巴瘤、小淋巴细胞性淋巴瘤、原发性纵膈大B细胞淋巴瘤、脾边缘区B细胞淋巴瘤或结节外边缘区B细胞淋巴瘤。在一些实施方式中,癌症是选自慢性淋巴细胞白血病、弥漫性大B细胞淋巴瘤、滤泡性淋巴瘤及霍奇金氏淋巴瘤。在一些实施方式中,癌症是转移癌。
在一些实施方式中,方法进一步包含向个体给予治疗量的其他治疗剂。在一些实施方式中,其他治疗剂是免疫抗肿瘤剂。在一些实施方式中,免疫抗肿瘤剂是拮抗或抑制免疫检查点路径(例如PD-1路径、CTLA-4路径、Lag3路径或TIM-3路径)的组份的试剂(例如抗体、小分子或肽)。在一些实施方式中,免疫抗肿瘤剂是藉由靶向OX-40路径、4-1BB(CD137)路径、CD27路径、ICOS路径或GITR路径的T细胞共活化因子的激动剂(即,刺激T细胞活化的蛋白质的激动剂)。
在一些实施方式中,免疫抗肿瘤剂是PD-1路径抑制剂。在一些实施方式中,PD-1路径抑制剂是抗PD-1抗体或抗PD-L1抗体,例如但不限于派姆单抗、尼沃鲁单抗、德瓦鲁单抗、匹利珠单抗、阿维鲁单抗或阿替珠单抗。业内阐述PD-1路径抑制剂。参见(例如)Dolan等人,Cancer Control,2014,21:231-237;Luke等人,Oncotarget,2014,6:3479-3492;US 2016/0222113;US 2016/0272708;US 016/0272712;及US 2016/0319019。
在一些实施方式中,免疫抗肿瘤剂是T细胞共活化因子的激动剂。在一些实施方式中,免疫抗肿瘤剂是CD28、CD28H、CD3、4-1BB(CD137)、ICOS、OX40、GITR、CD27或CD40的激动剂。在一些实施方式中,免疫抗肿瘤剂是免疫刺激性细胞因子。在一些实施方式中,免疫刺激性细胞因子是粒细胞-巨噬细胞群落刺激因子(GM-CSF)、巨噬细胞群落刺激因子(M-CSF)、粒细胞群落刺激因子(G-CSF)、白介素1(IL-1)、白介素2(IL-2)、白介素3(IL-3)、白介素12(IL-12)、白介素15(IL-15)或干扰素γ(IFN-γ)。在一些实施方式中,免疫抗肿瘤剂是SGN-2FF(Seattle Genetics;参见(例如)WO 2009/135181 A2、WO 2012/019165 A2及WO2017/096274 A1)。
在一些实施方式中,其他治疗剂选自抗CD25抗体、抗PD-1抗体、抗PD-L1抗体、抗Tim3抗体、抗Lag3抗体、抗CTLA4抗体、抗41BB抗体、抗OX40抗体、抗CD3抗体、抗CD40抗体、抗CD47M抗体、抗CSF1R抗体、抗TLR抗体、抗STING抗体、抗RIGI抗体、抗TAM受体激酶抗体、抗NKG2A抗体、抗NKG2D抗体、抗GD2抗体、抗HER2抗体、抗EGFR抗体、抗PDGFR-α-抗体、抗SLAMF7抗体、抗VEGF抗体、抗CTLA-4抗体、抗CD20抗体、抗cCLB8抗体、抗KIR抗体及抗CD52抗体。在一些实施方式中,其他治疗剂选自SEA-CD40(Seattle Genetics;参见(例如)WO 2006/128103 A2及WO 2016/069919 A1)、阿维鲁单抗、德瓦鲁单抗、尼沃鲁单抗、派姆单抗、匹利珠单抗、阿替珠单抗、Hul4.18K322A(抗GD2抗体,St.Jude)、Hu3F8(抗GD2抗体,MSKCC)、达妥昔单抗、曲妥珠单抗、西妥昔单抗、奥拉妥单抗、奈昔木单抗、埃罗妥珠单抗、雷莫芦单抗、帕妥珠单抗、伊匹单抗、贝伐珠单抗、利妥昔单抗、奥妥珠单抗、司妥昔单抗、奥法木单抗及阿伦单抗。
在一些实施方式中,用如本文所述抗TIGIT抗体的治疗与一种或多种其他抗癌治疗(例如手术或辐射)组合。用如本文所述抗TIGIT抗体的治疗与一种或多种其他抗癌剂(例如化学治疗剂)组合。非限制性示例性化学治疗剂包括烷基化剂(例如环磷酰胺、异环磷酰胺、氮芥苯丁酸、白消安、美法仑、甲基二(氯乙基)胺、乌拉莫司汀、噻替派、亚硝基脲或替莫唑胺)、蒽环(例如多柔比星、阿德力霉素、道诺霉素、泛艾霉素或米托蒽醌)、细胞骨架破坏剂(例如太平洋紫杉醇或多西他赛)、组织蛋白去乙酰酶抑制剂(例如伏立诺他或罗米地辛)、拓朴异构酶抑制剂(例如伊立替康、托泊替康、安吖啶、依托泊苷或替尼泊苷)、激酶抑制剂(例如硼替佐米、厄洛替尼、吉非替尼、伊马替尼、威罗菲尼或维莫德吉)、核苷类似物或前体类似物(例如阿扎胞苷、硫唑嘌呤、卡培他滨、阿糖胞苷、氟尿嘧啶、吉西他滨、羟基脲、巯嘌呤、胺甲喋呤或硫鸟嘌呤)、肽抗生素(例如放线菌素或博来霉素)、基于铂的药剂(例如顺铂、奥沙利铂或卡铂)或植物碱(例如长春新碱、长春碱、长春瑞滨、长春地辛、鬼臼毒素、太平洋紫杉醇或多西他赛)、加拉定、沙利窦迈、雷利窦迈及泊马窦迈。
在一些实施方式中,抗TIGIT抗体(及可选性其他治疗剂)以治疗有效量或剂量给药。可使用约0.01mg/kg至约500mg/kg、或约0.1mg/kg至约200mg/kg、或约1mg/kg至约100mg/kg、或约10mg/kg至约50mg/kg的日剂量范围。然而,剂量可根据若干因素变化,所述因素包括所选给药途径、组合物配方、患者反应、病况严重程度、个体重量及开处医师的判断。剂量可随时间增加或减少,视个别患者所需要。在某些情况下,最初给予患者低剂量,随后增加至患者可耐受的有效剂量。有效量的测定一定在本领域普通技术人员的能力范围内。
抗TIGIT抗体或包含抗TIGIT抗体(及可选性免疫抗肿瘤剂或其他治疗性治疗)的药物组合物的给药途径可为经口、腹膜内、经皮、皮下、静脉内、肌内、吸入、局部、病灶内、直肠、支气管内、经鼻、经粘膜、经肠、经眼或经耳递送或业内已知的任何其他方法。在一些实施方式中,抗TIGIT抗体(及可选性免疫抗肿瘤剂)经口、静脉内或腹膜内给药。
共同给药的治疗剂(例如抗TIGIT抗体及其他治疗剂)可一起或分开、同时或在不同时间给予。在给药时,治疗剂可独立地每日给药一次、两次、三次、四次或视需要更多次或更少次。在一些实施方式中,给予的治疗剂每日给药一次。在一些实施方式中,给予的治疗剂是在一个或多个相同时间、例如作为混合物给药。在一些实施方式中,治疗剂中之一或多者以持续释放制剂给药。
在一些实施方式中,抗TIGIT抗体及其他治疗剂同时给药。在一些实施方式中,抗TIGIT抗体及其他治疗剂依序给药。举例而言,在一些实施方式中,首先给予抗TIGIT抗体达(例如)约1、2、3、4、5、6、7、8、9、10、15、20、25、30、40、50、60、70、80、90、100天或更多天,之后给予其他治疗剂。在一些实施方式中,首先给予其他治疗剂达(例如)约1、2、3、4、5、6、7、8、9、10、15、20、25、30、40、50、60、70、80、90、100天或更多天,之后给予抗TIGIT抗体。
在一些实施方式中,在延长时间段内、例如持续至少30、40、50、60、70、80、90、100、150、200、250、300、350天或更长时间,向个体给予抗TIGIT抗体(及可选性的其他治疗剂)。
V.组合物及试剂盒
在另一方面,提供包含用于治疗个体癌症的抗TIGIT抗体组合物及试剂盒。
药物组合物
在一些实施方式中,提供用于向患有癌症的个体给药的包含抗TIGIT抗体的药物组合物。在一些实施方式中,抗TIGIT抗体如本文所述,例如具有本文所述结合亲和性、活性、交叉反应性、表位识别和/或CDR、VH和/或VL序列中之一或多者的抗TIGIT抗体。在一些实施方式中,抗TIGIT抗体是无岩藻糖基化的。
在一些实施方式中,抗TIGIT抗体及其他治疗剂如本文所述一起或分开调配成药物组合物。在一些实施方式中,其他治疗剂是免疫抗肿瘤剂,例如PD-1路径抑制剂或CTLA-4路径抑制剂。在一些实施方式中,免疫抗肿瘤剂是T细胞共活化因子的激动剂。在一些实施方式中,PD-1路径抑制剂是抗PD-1抗体或抗PD-L1抗体,例如但不限于派姆单抗、尼沃鲁单抗、德瓦鲁单抗、匹利珠单抗或阿替珠单抗。
制备用于本发明制剂的指南参见(例如)Remington:The Science and Practiceof Pharmacy,第21版,2006,上文文献;Martindale:The Complete Drug Reference,Sweetman,2005,London:Pharmaceutical Press;Niazi,Handbook of PharmaceuticalManufacturing Formulations,2004,CRC Press;及Gibson,PharmaceuticalPreformulation and Formulation:A Practical Guide from Candidate DrugSelection to Commercial Dosage Form,2001,Interpharm Press,其以引用方式并入本文中。本文所述药物组合物可以本领域普通技术人员已知的方式制造,例如,藉助常用混合、溶解、颗粒化、制糖衣、乳化、囊封、包裹或冻干制程。以下方法及赋形剂仅具有例示性且决不具有限制性。
在一些实施方式中,制备抗TIGIT抗体(及可选性其他治疗剂)以持续释放、控制释放、延长释放、定时释放或延迟释放制剂、例如以含有治疗剂的固体疏水聚合物的半渗透基质来递送。各种类型的持续释放材料已确立且为本领域普通技术人员所熟知。当前延长释放制剂包括膜包衣的锭剂、多微粒或团粒系统、使用亲水或亲脂性材料及基质技术、及具有孔形成赋形剂的基于蜡的锭剂(参见(例如)Huang等人Drug Dev.Ind.Pharm.29:79(2003);Pearnchob等人Drug Dev.Ind.Pharm.29:925(2003);Maggi等人Eur.J.Pharm.Biopharm.55:99(2003);Khanvilkar等人,Drug Dev.Ind.Pharm.228:601(2002);及Schmidt,等人,Int.J.Pharm.216:9(2001))。持续释放递送系统根据其设计可在数小时或数天的过程中、例如在4、6、8、10、12、16、20、24小时或更多小时内释放化合物。通常,持续释放制剂可使用天然或合成聚合物(例如聚合乙烯基吡咯啶酮,例如聚乙烯吡咯啶酮(PVP);羧基乙烯基亲水聚合物;疏水和/或亲水性水胶体,例如甲基纤维素、乙基纤维素、羟丙基纤维素及羟丙基甲基纤维素;及羧基聚亚甲基)来制备。
对于经口给药,抗TIGIT抗体(及可选性其他治疗剂)可藉由与业内熟知的药学上可接受的载剂组合容易地调配成制剂。所述载剂使得能够将化合物配制为锭剂、丸剂、糖衣锭、胶囊、乳液、亲脂性及亲水性悬浮液、液体、凝胶、糖浆、浆液、悬浮液及诸如此类,用于待治疗患者经口摄取。用于经口使用的医药制剂可藉由混合化合物与固体赋形剂、可选性研磨所得混合物及在添加适宜辅助剂(若期望)后处理颗粒的混合物以获得锭剂或糖衣锭核来获得。适宜赋形剂包括(例如)填充剂,例如糖,包括乳糖、蔗糖、甘露醇或山梨醇;纤维素制剂,例如玉米淀粉、小麦淀粉、水稻淀粉、马铃薯淀粉、明胶、黄蓍胶、甲基纤维素、羟丙基甲基纤维素、羧甲基纤维素钠和/或聚乙烯基吡咯啶酮(PVP)。若期望,可添加崩解剂,例如交联聚乙烯吡咯啶酮、琼脂或海藻酸或其盐(例如海藻酸钠)。
抗TIGIT抗体(及可选性其他治疗剂)可配制成用于藉由注射、例如藉由浓注注射或连续输注来胃肠外给药。对于注射,一种或多种化合物可藉由将其溶解、悬浮或乳化于水性或非水性溶剂(例如植物油或其他类似油、合成脂肪酸甘油酯、高级脂肪酸或丙二醇之酯)及(若期望)与常用添加剂(例如增溶剂、等渗剂、悬浮剂、乳化剂、稳定剂及防腐剂)一起调配成制剂。在一些实施例,化合物可配制于水溶液、较佳生理上相容的缓冲液(例如汉克氏溶液(Hanks’s solution)、林格氏溶液(Ringer’s solution)或生理盐水缓冲液)中。用于注射的制剂可以单位剂型存在,例如存于安瓿瓶或存于多剂量容器中,同时添加有防腐剂。所述组合物可呈诸如于油性或水性载剂中的悬浮液、溶液或乳液等形式,且可含有诸如悬乳剂、稳定剂和/或分散剂等调配剂。
抗TIGIT抗体(及可选性其他治疗剂)可藉由经粘膜或经皮方式全身给药。对于经粘膜或经皮给药,在制剂中使用适于透过障壁的渗透剂。对于局部给药,将试剂配制成软膏剂、乳霜、油膏、粉剂及凝胶。在一个实施例中,经皮递送剂可为DMSO。经皮递送系统可包括(例如)贴剂。对于经粘膜给药,在制剂中使用适于透过障壁的渗透剂。所述渗透剂通常为业内已知。示例性经皮递送制剂包括以下中所述的那些:美国专利第6,589,549号;第6,544,548号;第6,517,864号;第6,512,010号;第6,465,006号;第6,379,696号;第6,312,717号及第6,310,177号,其各自以引用方式并入本文中。
在一些实施方式中,药物组合物包含可接受的载剂和/或赋形剂。药学上可接受的载剂包括生理上相容且较佳不干扰或以其他方式抑制治疗剂活性的任何溶剂、分散介质或包衣。在一些实施方式中,载剂适于静脉内、肌内、经口、腹膜内、经皮、局部或皮下给药。药学上可接受的载剂可含有一种或多种生理上可接受的化合物,其用于(例如)稳定组合物或增加或减少活性剂的吸收。生理上可接受的化合物可包括(例如)碳水化合物,例如葡萄糖、蔗糖或聚葡萄糖;抗氧化剂,例如抗坏血酸或麸胱甘肽;螯合剂;低分子量蛋白;减少活性剂或赋形剂或其他稳定剂和/或缓冲剂的清除或水解的组合物。其他药学上可接受的载剂及其制剂众所周知且通常记载于以下中:例如Remington:The Science and Practice ofPharmacy,第21版,Philadelphia,PA.Lippincott Williams&Wilkins,2005。各种药学上可接受的赋形剂为业内所熟知且可参见(例如)Handbook of Pharmaceutical Excipients(第5版,Ed.Rowe等人,Pharmaceutical Press,Washington,D.C.)。
本发明药物组合物的剂量及期望药物浓度可根据所设想的特定用途而变。适当剂量或给药途径的确定一定在本领域普通技术人员的能力范围内。本文亦阐述适宜剂量。
试剂盒
在一些实施方式中,提供用于治疗患有癌症的个体的试剂盒。在一些实施方式中,试剂盒包含:
抗TIGIT抗体;及
其他治疗剂。
在一些实施方式中,抗TIGIT抗体如本文所述,例如具有结合亲和性、活性、交叉反应性、表位识别和/或如本文揭示的CDR、VH和/或VL序列中之一或多者的抗TIGIT抗体。在一些实施方式中,抗TIGIT抗体是无岩藻糖基化的。在一些实施方式中,其他治疗剂是免疫抗肿瘤剂,例如PD-1路径抑制剂或CTLA-4路径抑制剂。在一些实施方式中,免疫抗肿瘤剂是T细胞共活化因子的激动剂。在一些实施方式中,PD-1路径抑制剂是抗PD-1抗体或抗PD-L1抗体。在一些实施方式中,免疫抗肿瘤剂是派姆单抗、尼沃鲁单抗、德瓦鲁单抗、匹利珠单抗或阿替珠单抗。
在一些实施方式中,试剂盒可进一步包含含有实践本发明方法的指导(即方案)的说明材料(例如,使用试剂盒治疗癌症的说明书)。尽管说明材料通常包含书面或印刷材料,但其不限于此。本发明涵盖能够储存所述说明并将其传达给最终使用的任何介质。所述介质包括(但不限于)电子储存介质(例如磁盘、磁带、盒带、晶片)、光学介质(例如CD ROM)及诸如此类。所述介质可包括提供所述说明材料的网际网路站点地址。
VI.实施例
下文论述的实施例仅对本发明具有示例性,不应认为以任何方式限制本发明。所述实施例不欲表示下文实验是所有实验或唯一实验。已努力确保关于所用数字(例如量、温度等)的准确度,但应虑及一些实验误差及偏差。除非另外指明,否则份数是重量份数,分子量是平均分子量,温度以℃表示,且压力为大气压力或接近大气压力。
实施例1:抗TIGIT抗体的生成
使用基于酵母的抗体呈递系统生成完全人抗TIGIT单克隆抗体(例如,参见Xu等人,“Addressing polyspecificity of antibodies selected from an in vitro yeastpresentation system:a FACS-based,high-throughput selection and analyticaltool,”PEDS,2013,26:663-670;WO 2009/036379;WO 2010/105256;及WO 2012/009568)。筛选八个初始人合成酵母文库,各自为约109多样性。对于前两轮选择,实施利用MiltenyiMACS系统的磁珠分选技术,如先前所述(例如,参见Siegel等人,“High efficiencyrecovery and epitope-specific sorting of an scFv yeast display library,”JImmunol Methods,2004,286:141-153)。简言之,将酵母细胞(约1010个细胞/文库)与5mL10nM生物素化Fc-融合抗原于30℃下在洗涤缓冲液(磷酸盐缓冲盐水(PBS)/0.1%牛血清白蛋白(BSA))中一起培育30分钟。用40mL冰冷洗涤缓冲液洗涤一次后,将细胞团粒再悬浮于20mL洗涤缓冲液中,且向酵母中添加链霉抗生物素蛋白微珠粒(500μL)且于4℃下培育15分钟。接下来,使酵母成团粒,再悬浮于20mL洗涤缓冲液中,且装载至Miltenyi LS管柱上。装载20mL后,将管柱用3mL洗涤缓冲液洗涤3次。随后自磁场移出管柱,且将酵母用5mL生长培养基洗脱且随后生长过夜。使用流式细胞术实施以下轮的选择。使约2×107个酵母成团粒,用洗涤缓冲液洗涤三次,且于30℃下与10nM Fc-融合抗原及递减浓度的生物素化单体抗原(100至1nM)在平衡条件下培育、与10nM生物素化Fc-融合抗原或100nM不同物种的单体抗原一起培育以获得物种交叉反应性、或与多特异性清除试剂(depletion agent)(PSR)一起培育从而由选择去除非特异性抗体。对于PSR清除,将文库与生物素化PSR试剂的1:10稀释物一起培育,如先前所述(例如,参见Xu等人,上文文献)。随后将酵母用洗涤缓冲液洗涤两次且于4℃下用LC-FITC(1:100稀释)及SA-633(1:500稀释)或EA-PE(extravidin-R-PE,1:50稀释)第二试剂染色15分钟。在用洗涤缓冲液洗涤两次后,将细胞团粒再悬浮于0.3mL洗涤缓冲液中且转移至粗滤器封盖的分选管中。分选是使用FACS ARIA分选仪(BDBiosciences)实施且确定分选门以选择具有期望特征的抗体。重复选择轮直至获得具有所有期望特征的群体。在最后一轮分选后,接种酵母且挑选各个群落进行表征。
抗原包括重组二聚体人TIGIT-Fc(Acro Biosystems TIT-H5254)、单体人TIGIT(Sino Biological 10917-H08H)、二聚体小鼠TIGIT-Fc(R&D Systems,7267-TG)及单体小鼠TIGIT(Sino Biologics 50939-M08H)。
初始活动:对744个克隆进行测序,从而产生345个独特克隆(独特CDRH3)。在克隆中呈现了18个VH种系。
轻链分批多样化活动:经由粉碎及抓取自酵母中提取来自第六轮初始发现选择富集的结合者池(binder pool)的重链(VH)质粒,在大肠杆菌中繁殖,且随后自大肠杆菌中纯化,且然后转化至具有107多样性的轻链文库中。
选择是在与初始发现基本相同的条件下实施。简言之,进行一轮磁珠富集,之后藉由流式细胞术进行三轮选择。在磁珠富集轮中,使用10nM生物素化Fc-融合抗原。利用流式细胞计数器的第一轮由使用100nM生物素化单价抗原的正向选择轮组成。接下来是第二轮,由用于PSR清除的负向选择轮组成。最后一轮(第三轮)由正向选择轮组成,其中以100nM、10nM、1nM滴定单价抗原。对于所有文库,接种来自第三轮的1nM分选物的酵母,挑选并表征各个群落。总共对728个克隆进行测序,从而产生350个独特HC/LC组合(93个独特CDRH3)。
在初始及轻链分批混洗活动之间鉴定了总共695个独特克隆。
实施例2:抗TIGIT抗体的表征
选择65个克隆进行生产及进一步评估,代表12个VH种系及9个VL种系。
抗体产生及纯化
使酵母克隆生长至饱和,然后在振荡下于30℃下诱导48h。诱导后,使酵母细胞成团粒并收获上清液用于纯化。使用蛋白质A管柱纯化IgG,并用pH 2.0的乙酸洗脱。藉由木瓜酶消化生成Fab片段且在KappaSelect(GE Healthcare LifeSciences)上纯化。
抗TIGIT抗体与重组人及小鼠蛋白的结合
如先前所述,对Octet RED384实施ForteBio亲和性量测(参见(例如)Estep等人,“High throughput solution-based measurement of antibody-antigen affinity andepitope binning,”Mabs,2013,5:270-278)。简言之,藉由将IgG在线装载至AHQ感测器上来实施ForteBio亲和性量测。将感测器在分析缓冲液中离线平衡30分钟,然后在线监测60秒用于基线确立。将装载有IgG的感测器暴露于100nM抗原(二聚体Fc-融合抗原或单体抗原)中3分钟,然后转移至分析缓冲液中3分钟以进行解离率量测。使用1:1结合模型分析所有结合及解离动力学。
在65个IgG克隆中,有43个对TIGIT单体的亲和性<100nM。在65个IgG克隆中,有34个与小鼠TIGIT-Fc交叉反应。后文表1中显示所选克隆的结合亲和性。
表位分仓/配体竞争分析
在ForteBio Octet RED384系统上使用标准夹心方式交叉阻断分析实施表位分仓(epitope binning)/配体阻断。将对照抗靶标IgG装载至AHQ感测器上,且用无关人IgG1抗体阻断感测器上未占用的Fc结合位点。然后将感测器暴露于100nM靶抗原,之后暴露于第二抗靶抗体或配体(人CD155-Fc(Sino Biological,10109-H02H))。抗原缔合后由第二抗体或配体的其他结合指示未占用的表位(非竞争者),而无结合指示表位阻断(竞争者或配体阻断)。
使用四个分仓抗体(非互斥)进行分仓评价,且鉴别五个重迭特性。65个抗TIGIT抗体中有63个与配体竞争结合hTIGIT-Fc。下表1中显示所选克隆的分仓特性及配体竞争结果。
表1.所选抗TIGIT克隆的表位结合、配体竞争及亲和性数据


注释:
N.B.=该试验分析条件下的非结合者
使用如实施例2中所述的标准夹心方式交叉阻断分析在ForteBio Octet RED384系统上生成仓代码及CD155竞争数据。
如实施例2中所述在ForteBio Octet RED384系统上生成KD亲和性数据。
抗TIGIT抗体与HEK
293细胞中过表达的人、小鼠及食蟹猕猴TIGIT的结合
HEK 293细胞藉由慢病毒转导经工程改造以稳定表达高水平的人、小鼠或食蟹猕猴TIGIT。于室温下将约100,000个亲代HEK 293(TIGIT阴性)细胞或过表达人、小鼠或食蟹猕猴的HEK 293细胞用100nM每一抗TIGIT抗体染色5分钟。然后将细胞用洗涤缓冲液洗涤两次,且与偶联至PE的抗人IgG一起在冰上培育15分钟。然后将细胞用洗涤缓冲液洗涤两次,且在FACS Canto II仪器(BD Biosciences)上藉由流式细胞术进行分析。将超过背景的倍数(FOB)计算为与靶阳性细胞结合的抗TIGIT克隆的中值荧光强度(MFI)除以与靶阴性细胞结合的抗TIGIT克隆之MFI。
如图1中所示,所有65个抗体皆显示与293-hTIGIT系特异性结合(FOB>10,如图中水平黑线所指示)。53个克隆特异性结合293-cyTIGIT系,而31个克隆特异性结合293-mTIGIT系。
多特异性试剂(PSR)分析
如先前所述实施与多特异性试剂的结合的评价以确定对TIGIT的特异性(例如,参见Xu等人,上文文献)。简言之,将自原液1:10稀释的生物素化PSR试剂与IgG呈递酵母在冰上一起培育20分钟。洗涤细胞并用EA-PE(extravidin-R-PE)标记,并在FACS分析仪上读取。多特异性结合的评分在0至1的量表内,且与具有低、中及高非特异性结合的对照IgG相关,其中评分为0指示无结合,评分为1指示极高的非特异性结合。
65个克隆中有62个被评定为PSR评分<0.10的非多特异性结合者。三个克隆被评定为低多特异性结合者(PSR评分为0.10–0.33)。
疏水性相互作用层析分析
如先前所述实施疏水相互作用层析(HIC)(Estep等人,上文文献)。简言之,在5μgIgG样品中加入移动相A溶液(1.8M硫酸铵及0.1M磷酸钠,pH 6.6),以在分析前达到约1M的最终硫酸铵浓度。使用Sepax Proteomix HIC butyl-NP5管柱,在20分钟内以移动相A及移动相B溶液(0.1M磷酸钠,pH 6.5)之线性梯度、1mL/分钟的流速且在280nM下UV吸光度监测。
抗体在疏水性管柱上的滞留增加与纯化期间疏水性增加及表达不佳、聚集或沉淀倾向相关。65个克隆中有5个具有>11.5分钟的高HIC滞留时间,10个克隆具有10.5-11.5分钟的中等HIC滞留时间,且其余克隆具有低HIC滞留时间。
实施例3:抗TIGIT抗体与在原代T细胞上内源表达的人、小鼠及食蟹猕猴TIGIT的结合
评估显示对人TIGIT重组蛋白及在HEK 293细胞上表达的人TIGIT具有特异性的65个抗体结合人原代人外周血T细胞上的内源TIGIT的能力。亦评估抗体与外周血T细胞上的食蟹猕猴TIGIT的交叉反应性,且评估65个克隆中35个与活化脾T细胞上的小鼠TIGIT的交叉反应性。
自白血球分离产物中负向分离人泛T细胞至99%纯度。用20μg/mL的各抗TIGIT抗体将100,000个细胞在4℃染色30分钟。用偶联至PE的多克隆山羊抗人IgG(JacksonImmunoResearch 109-116-098)检测抗TIGIT抗体。在CytoFLEX流式细胞计数器上分析样品。仅使用抗人IgG-PE染色测定对各抗体的FSC/SSC门控淋巴细胞群体的TIGIT+百分比,以确定阳性的临限值。
藉由红血球溶解(eBioscience 00-4300)自全血中分离食蟹猕猴白血球。用20μg/mL的各抗TIGIT抗体将200,000个细胞在4℃染色30分钟。用针对偶联至AlexaFluor647的猴免疫球蛋白吸附的多克隆山羊抗人IgG(SouthernBiotech 2049-31)检测抗TIGIT抗体且藉由用FITC偶联的抗CD3克隆SP34(BD Pharmingen 556611)复染鉴别T细胞。在CytoFLEX流式细胞计数器上分析样品。仅使用抗人IgG-PE染色测定对各抗体的CD3+群体的TIGIT+百分比,以确定阳性的临限值。
藉由负向选择(Stem Cell Technologies 19851A)自脾中分离BALB/c小鼠T细胞至>99%纯度。用板结合的抗CD3克隆145-2C11(BioLegend 100302)将细胞活化24小时,以上调TIGIT。用20μg/mL的各抗TIGIT抗体(测试之65个克隆中的35个)将200,000个活化细胞在4℃染色30分钟。用偶联至PE的多克隆山羊抗人IgG(Jackson Immuno Research 109-116-098)检测抗TIGIT抗体。在FACSCalibur流式细胞计数器上分析样品。测定对各抗的之FSC/SSC门控淋巴细胞群体的中值荧光强度。
图2显示65个抗TIGIT抗体克隆及无关同型对照抗体与原代人、食蟹猕猴及小鼠T细胞的结合。克隆13及25两者皆显示与所有三种T细胞强结合。
抗TIGIT抗体与细胞表面表达的TIGIT的可滴定结合
HEK 293细胞由慢病毒转导工程改造的稳定表达高水平的人、小鼠或食蟹猕猴TIGIT。用各抗TIGIT抗体的10点3倍滴定(30至0.002μg/mL)将200,000个293-TIGIT细胞在4℃染色30分钟。用偶联至PE的多克隆山羊抗人IgG(Jackson ImmunoResearch 109-116-098)检测抗TIGIT抗体。在CytoFLEX流式细胞计数器上分析样品。测定对各抗体浓度的FSC/SSC门控群体的中值荧光强度。使用Log(X)转变数据的非线性回归在GraphPad Prism 6中产生EC50值。所有抗TIGIT抗体皆不显示结合亲代HEK 293细胞(TIGIT-)(数据未显示)。图3A-C显示结合滴定,且图3D显示8个抗TIGIT抗体克隆(克隆2、克隆5、克隆13、克隆16、克隆17、克隆20、克隆25及克隆54)与HEK 293细胞上表达的人、食蟹猕猴及小鼠TIGIT结合的EC50。
藉由负向选择(Stem Cell Technologies 19851A)自脾中分离C57BL/6小鼠T细胞至>99%纯度。用板结合的抗CD3克隆145-2C11(BioLegend 100302)将细胞活化24小时,以上调TIGIT。用每一抗TIGIT抗体的8点3倍滴定物(30至0.014μg/mL)将200,000个细胞在4℃下染色30分钟。用偶联至PE的多克隆山羊抗人IgG(Jackson ImmunoResearch 109-116-098)检测抗TIGIT抗体。在FACSCalibur流式细胞计数器上分析样品。测定每一抗体的FSC/SSC门控淋巴细胞群体的中值荧光强度。使用Log(X)转变数据的非线性回归在GraphPadPrism 6中生成EC50值。图4显示抗TIGIT克隆13及25与活化的小鼠脾T细胞的结合滴定及EC50。
实施例4:抗TIGIT抗体阻断CD155及CD112配体与细胞表面表达的TIGIT的结合
HEK 293细胞藉由慢病毒转导经工程改造以稳定表达高水平的人或小鼠TIGIT。将hCD155-Fc(Sino Biological 10109-H02H)、hCD112-Fc(Sino Biological 10005-H02H)及mCD155-Fc(Sino Biological 50259-M03H)偶联至AlexaFluor647(ThermoFisherA30009)。将200,000个293-hTIGIT或293-mTIGIT细胞与1μg/mL CD155-Fc-AlexaFluor647或5μg/mL CD112-Fc-AlexaFluor647及每一抗TIGIT抗体或同型对照抗体的12点2倍滴定物(10至0.005μg/mL)共培育。在CytoFLEX流式细胞计数器上分析样品。测定每一抗体浓度的FSC/SSC门控群体的中值荧光强度。相对于无抗体对照的MFI计算阻断百分比。在GraphPadPrism 6中实施Log(X)转化数据的非线性回归。
如图5A-B中所示,测试6个抗TIGIT抗体克隆(克隆2、克隆5、克隆13、克隆17、克隆25及克隆55),其中对于人CD155/人TIGIT及对于小鼠CD155/小鼠TIGIT两者,6个克隆中的5个(克隆2、克隆5、克隆13、克隆17及克隆25)显著阻断CD155与在HEK 293细胞上表达的TIGIT相互作用。在ForteBio Octet配体竞争分析中,克隆55特异性结合人TIGIT,但不与hCD155-Fc竞争结合hTIGIT-Fc。类似地,克隆55未有效地阻断hCD155与293-hTIGIT细胞系的相互作用。克隆2、克隆5、克隆13、克隆17及克隆25亦能够中断人CD112与人TIGIT的结合。正如对CD155所观察,克隆55在阻断CD112-TIGIT相互作用方面低效得多。参见图6。
实施例5:TIGIT/CD155阻断生物分析中抗TIGIT抗体的体外(in vitro)活性
抗TIGIT抗体的活性可使用TIGIT/CD155间接生物分析(例如TIGIT/CD155阻断生物分析试剂盒,Promega Corp.,Madison,WI)来功能化表征,其中当抗体阻断TIGIT/CD155相互作用时,诱导或增强报导基因的表达。TIGIT/CD155阻断生物分析包含两种细胞类型:在细胞表面上表达TIGIT、CD226及TCR复合体且含有荧光素酶报导基因的效应细胞;及在细胞表面上表达CD155及TCR活化因子的人工抗原呈递细胞。在此生物分析中,荧光素酶表达需要TCR接合加上共刺激信号。CD155-TIGIT相互作用具有比CD155-CD226相互作用更高的亲和性,从而产生净抑制性信号途径,且无荧光素酶表达。CD155-TIGIT相互作用的阻断使CD155-CD226共刺激驱动荧光素酶表达。
将表达TIGIT及CD226两者的Jurkat效应细胞与表达TCR活化因子及CD155的CHO-K1人工抗原呈递细胞(aAPC)共培养。Jurkat效应细胞含有由IL-2启动子驱动的荧光素酶报导基因。在缺乏抗TIGIT抗体阻断的情况下,CD155-TIGIT接合会导致T细胞共抑制,而无IL-2启动子活性。在添加抗TIGIT抗体时,中断CD155-TIGIT相互作用,使CD155与CD226缔合以发送共刺激信号并驱动荧光素酶表达。
将aAPC接种于96孔板中并使其粘附过夜。次日,将20μg/mL的每一抗TIGIT抗体或同型对照抗体及Jurkat效应细胞添加至板中。在37℃下培育6小时后,使细胞溶解并添加荧光素酶受质。在读板仪上量化荧光素酶活性。荧光素酶活性计算为相对于无抗体对照中信号的倍数。
如图7A-7B中所示,12个抗TIGIT抗体克隆在此生物分析中展现功能性阻断。
实施例6:TIGIT/PD-1组合生物分析中抗TIGIT抗体的体外活性
抗TIGIT抗体与抗PD-1剂(例如抗PD-1抗体)的组合的协同活性可使用TIGIT/PD-1组合生物分析功能地表征,其中当抗体阻断TIGIT/CD155相互作用及PD-1/PD-L1相互作用两者时,增强报导基因的表达。生物分析包含两种细胞类型:在细胞表面上表达TIGIT、CD226、PD-1及TCR复合体且含有荧光素酶报导基因的效应细胞;及在细胞表面上表达CD155、PD-L1及TCR活化因子的人工抗原呈递细胞。在此生物分析中,荧光素酶表达需要TCR接合加上共刺激信号。CD155-TIGIT相互作用具有比CD155-CD226相互作用更高的亲和性,从而产生净抑制性信号途径,且无荧光素酶表达。另外,PD-L1与PD-1的结合抑制荧光素酶表达。CD155-TIGIT相互作用及PD-1/PD-L1相互作用两者皆减轻抑制且允许CD155-CD226共刺激荧光素酶表达。
将表达PD-1、TIGIT及CD226的Jurkat效应细胞与表达TCR活化因子、PD-L1及CD155的CHO-K1人工抗原呈递细胞(aAPC)共培养。Jurkat效应细胞含有由IL-2启动子驱动的荧光素酶报导基因。在缺乏抗TIGIT抗体阻断的情况下,PD-L1-PD-1及CD155-TIGIT接合会导致T细胞共抑制,而无IL-2启动子活性。在添加抗PD-1及抗TIGIT抗体时,阻断PD-L1-PD-1相互作用,从而释放一个共抑制信号,并中断CD155-TIGIT相互作用,从而允许CD155与CD226缔合以发送共刺激信号并驱动荧光素酶产生。
将aAPC接种于96孔板中并使其粘附过夜。次日,向板中单独添加各抗TIGIT抗体、或抗PD-1抗体(克隆EH12.2H7,BioLegend,San Diego,CA)、或各抗TIGIT抗体+抗PD-1抗体(1:1比率)及Jurkat效应细胞的10点2.5倍滴定(100至0.03μg/mL)。在37℃下培育6小时后,使细胞溶解并添加荧光素酶受质。在读板仪上量化荧光素酶活性。荧光素酶活性计算为相对于无抗体对照中信号的倍数。如图8中所示,单独抗TIGIT及抗PD-1皆不导致显著Jurkat活化,然而,抗TIGIT克隆13或克隆25与抗PD-1的组合产生强活化。
实施例7:BALB/c小鼠中CT26同系肿瘤模型中抗TIGIT抗体的体内活性
基于对鼠类TIGIT的亲和性,选择抗TIGIT克隆13在鼠类同系肿瘤模型中进行评估。生成亲代完全人抗TIGIT克隆13的小鼠IgG1及小鼠IgG2a嵌合体进行体内实验以确定Fc同型是否对拮抗性TIGIT抗体的体内效能具有效应。在体外,嵌合抗体显示与亲代hIgG1抗体类似的以相关活性:(1)与人、小鼠及食蟹猕猴TIGIT的结合,(2)CD155及CD112配体与细胞表面表达的TIGIT的结合的阻断,及(3)CD155-TIGIT阻断生物分析中的活性。参见图9A-9H。
自Charles River Laboratories获得平均体重为19g的8周龄BALB/c小鼠。在小鼠右肋腹皮下植入300,000个CT26结肠癌细胞。使肿瘤进展,直至接种肿瘤后第7天,组平均肿瘤体积为72mm3(范围为48-88mm3)。藉由配对将动物指配为n=10的10个治疗组,使得该组的平均肿瘤体积在所有治疗组中皆类似。量测肿瘤长度及宽度且使用下式计算肿瘤体积:体积(mm3)=0.5*长度*宽度2,其中长度是最长尺寸。将抗TIGIT克隆13 mIgG1、抗TIGIT克隆13mIgG2a及抗PD-1克隆RMP1-14(BioXCell)稀释至适当浓度,以在无菌PBS中给药。使用无菌PBS作为载剂对照。每周两次经由腹膜内注射给予5或20mg/kg的TIGIT抗体,持续3周(总共6个剂量)。每周两次经由腹膜内注射给予5mg/kg的抗PD-1抗体,持续2周(总共4个剂量)。在指配当天(研究第1天)开始给药。每周两次收集肿瘤体积及体重量测值,直至小鼠达到2000mm3的肿瘤体积截止值为止。相对于给药前的体重,没有动物体重减轻,指示所有测试剂的超常耐受性。
如图10A中所示,单独抗mPD-1对肿瘤进展无任何效应。克隆13的mIgG1抗TIGIT嵌合体(“13-1”)(其不能有效地接合活化Fcγ受体)作为单一试剂或与抗PD-1组合皆不会介导任何抗肿瘤活性,相比之下,克隆13的mIgG2a嵌合体(“13-2”)(其能结合活化Fcγ受体)显示肿瘤进展(在第18天86.5%(5mg/kg)或74.4%(20mg/kg)肿瘤生长抑制)。5mg/kg 13-2单一试剂组中的十只动物中有三只显示完全肿瘤消退,其稳定直至研究结束(研究第46天)。在20mg/kg 13-2单一试剂组中,十只动物中有两只显示部分肿瘤消退(定义为连续三次量测的肿瘤体积<初始体积的50%)。图10A显示,相对于单独13-2,向mIgG2a克隆13嵌合体(13-2)中添加抗PD-1不增加效能(第18天的肿瘤生长抑制为53.8%(5mg/kg抗TIGIT+5mg/kg抗PD-1)对86.5%(5mg/kg单独抗TIGIT)及89.6%(20mg/kg抗TIGIT+5mg/kg抗PD-1)对74.4%(20mg/kg单独抗TIGIT)。在组合组中观察到相似数量的完全及部分反应者。参见(例如)图10B-10K。
实施例8:抗体优化及优化抗体的表征
自主要发现输出中选择抗体克隆2、13、16及25用于进一步亲和力成熟。经由向重链可变区中引入多样性来实施抗体的优化。将两个循环的优化应用于上述谱系。第一循环包括CDRH1及CDRH2多样化方法,而在第二循环中,应用CDRH3诱变方法。
CDRH1及CDRH2方法:将单一抗体的CDRH3重组至具有多样性为1×108的CDRH1及CDRH2变体的预制文库中。然后利用一轮MACS及四轮FACS实施选择,如针对初始发现所述。
在第一轮FACS中,针对1nM单体TIGIT结合分选文库。第二轮FACS是PSR清除轮以减少多特异性。最后两轮是使用亲代Fab或IgG加压以获得高亲和性的正向选择轮。如下实施Fab/IgG加压:将抗原与10倍亲代Fab或IgG一起培育,然后与酵母文库一起培育。选择富集于比亲代Fab或IgG具有更好亲和性的IgG。在最后两轮FACS中检查物种交叉反应性。
CDRH3诱变:藉由使CDRH3中的位置随机化而产生具有CDRH3多样性的文库。如先前所述,使用一轮MACS及三轮FACS进行选择。进行PSR负向选择、物种交叉反应性、亲和性压力及分选以获得具有期望特征的群体。
MSD-SET KD量测
通常如先前所述进行平衡亲和性量测(Estep等人,上文文献)。简言之,在PBS+0.1%不含IgG的BSA(PBSF)中利用于50pM下保持恒定的生物素化人TIGIT-His单体进行溶液平衡滴定(SET),并与以约5nM开始的抗体的3至5倍系列稀释物一起培育。将抗体(20nM,于PBS中)在标准结合的MSD-ECL板上于4℃下涂覆过夜或在室温下涂覆30min。然后将板用1%BSA在700rpm振荡下封阻30min,之后用洗涤缓冲液(PBSF+0.05%Tween 20)洗涤3次。施加SET样品,且在700rpm振荡下在板上培育150s,之后洗涤一次。藉由在板上培育3min,用PBSF中250ng/ml sulfotag标记的链霉抗生物素蛋白检测板上捕获的抗原。将板用洗涤缓冲液洗涤3次,然后在MSD扇形成像仪2400仪器上使用具有表面活性剂的1倍读取缓冲液T读取。在Prism中绘制游离抗原的百分比随着滴定的抗体变化的图,并拟合至二次方程以提取KD。为了提高通量,在整个MSD-SET实验(包括SET样品制备)中使用液体处理机器人。
如上所述使用ForteBio系统量测优化抗体与His标记的人TIGIT、cyno TIGIT-Fc及小鼠TIGIT-Fc的结合。如上所述,测试优化抗体在CD155配体竞争分析中的配体阻断、以及与人TIGIT HEK、cyno TIGIT HEK、小鼠TIGIT HEK及亲代HEK细胞系的结合。
亲和性优化抗体的亲和性数据及细胞结合数据示于下表2中。

实施例9:表位定位
由肽阵列表征本文所述单克隆抗体中两者、即克隆13及克隆25的表位。为了重新构筑靶分子的表位,使用固相Fmoc合成来合成基于肽的表位模拟物文库。氨基官能化聚丙烯载体通过以下所述获得:与专有的亲水聚合物制剂接枝、之后使用二环己基碳二亚胺(DCC)及N羟基苯并三唑(HOBt)与第三丁基氧基羰基-六亚甲基二胺(BocHMDA)反应且随后使用三氟乙酸(TFA)使Boc-基团裂解。由定制的改进JANUS液体处理站(Perkin Elmer)使用标准Fmoc-肽合成在氨基官能化固体载体上合成肽。
使用支架上的专有化学连接肽(CLIPS)技术(Pepscan)进行结构模拟物的合成。CLIPS技术允许将肽结构化为单环、双环、三环、片状折叠、螺旋状折叠及其组合。将CLIPS模板与半胱氨酸残基偶合。使肽中多个半胱氨酸的侧链与一个或两个CLIPS模板偶合。举例而言,将0.5mM P2 CLIPS(2,6-双(溴甲基)吡啶)溶液溶解于碳酸氢铵(20mM,pH 7.8)/乙腈(1:3(v/v))中。将此溶液添加至肽阵列上。CLIPS模板将结合至肽阵列(455孔板,具有3μl孔)的固相结合肽中存在的两个半胱氨酸的侧链。在溶液中完全覆盖的同时,将肽阵列在溶液中轻轻振荡30至60分钟。最后,将肽阵列用过量H2O充分洗涤且于70℃下在PBS(pH 7.2)中的1%SDS/0.1%β-巯基乙醇的破坏缓冲液中超音波处理30分钟,之后在H2O中再超音波处理45分钟。携带T3 CLIPS的肽以类似方法制备,但具有三个半胱氨酸。
根据以下设计合成不同组的肽。组1包含一组长度为15个氨基酸的衍生自人TIGIT的靶序列的线性肽,具有一个残基偏移。组2包含组1的一组线性肽,但10及11位上的残基由Ala置换。当天然Ala将在任一位置上出现时,其由Gly置换。组3包含组1的一组线性肽,其含有Cys残基。在此组中,天然Cys由Cys-乙酰氨基甲基(“Cys-acm”)置换。组4包含一组长度为17个氨基酸的衍生自人TIGIT的靶序列的线性肽,具有一个残基偏移。在1及17位上是用于藉助mP2 CLIPS生成成环模拟物的Cys残基。天然Cys经Cys-acm置换。组6包含一组长度为22个氨基酸的衍生自人TIGIT的靶序列的线性肽,具有一个残基偏移。11及12位上的残基经“PG”基序置换,而Cys残基放置于1及22位上以生成具有mP2的受限模拟物。天然Cys残基经Cys-acm置换。组7含有一组长度为27个氨基酸的线性肽。在1-11及17-27位上是11聚体肽序列,其衍生自靶序列且经由“GGSGG”(SEQ ID NO:309)连接体接合。基于UniProt info在人TIGIT的二硫键桥接上进行组合。组8包含一组长度为33个氨基酸的组合肽。在2-16及18-32位上是衍生自人TIGIT的靶序列的15聚体肽。在1、17及33位上是用于藉助T3 CLIPS生成中断模拟物的Cys残基。
在基于肽扫描的ELISA中测试抗体与每一合成肽的结合。将肽阵列与一级抗体溶液一起培育(于4℃下过夜)。洗涤后,于25℃下将肽阵列与山羊抗人HRP偶联物(SouthernBiotech)的1/1000稀释物一起培育1小时。洗涤后,添加过氧化酶受质2,2’-连氮基-二-3-乙基苯并噻唑啉磺酸盐(ABTS)及20μl/ml 3%H2O2。1小时后,量测显色。用电荷耦合装置(CCD)-照相机及影像处理系统对显色进行量化。与标准96孔板ELISA读数器相似,自CCD照相机获得的值范围为0至3000mAU。
为了验证合成肽的品质,平行合成一个单独的阳性及阴性对照肽。用市售抗体3C9及57.9筛选所述肽(Posthumus等人,J.Virol.,1990,64:3304-3309)。
对于克隆13,当在高严谨条件下测试时,克隆13弱结合不连续表位模拟物。亦在中等严谨条件下测试抗体,并观察到该抗体的可检测结合。用含有核心延伸片段68ICNADLGWHISPSFK82(SEQ ID NO:258)、42ILQCHLSSTTAQV54(SEQ ID NO:298)、108CIYHTYPDGTYT GRI122(SEQ ID NO:299)的不连续表位模拟物记录最高信号强度。用含有肽延伸片段80SFKDRVAPGPG90(SEQ ID NO:300)的肽观察到额外较弱的结合。抗体与线性及简单构形表位模拟物的结合通常较低,且仅在基序基序68ICNADLGWHISPSFK82(SEQ ID NO:258)、108CIYHTYPDG TYTGRI122(SEQ ID NO:299)及80SFKDRVAPGPG90(SEQ ID NO:300)中观察到。
对于克隆25,当在高严谨条件下测试时,克隆25可检测地结合所有组的肽。用不连续表位模拟物观察到最强结合。尽管在其他组中亦观察到与在延伸片段68ICNADLGWHISPSFK82(SEQ ID NO:258)内含有残基的肽的结合,但仅在与68ICNADLGWHISPSFK82(SEQ ID NO:258)的组合中观察到与肽延伸片段50TTAQVTQ56(SEQ IDNO:301)的结合。用含有肽延伸片段80SFKDRVAPGPGLGL93(SEQ ID NO:300)的肽亦观察到额外较弱的结合。
基于克隆13及克隆25的所述表位定位结果,使用上述方法使用以下肽组对克隆13及克隆25的表位进行精细定位。组1包含基于序列CILQ2HLSSTTAQVTQCI2NADLGWHISPSFKC(SEQ ID NO:302)的单一残基表位突变体的文库。残基ADHIQRY(SEQ ID NO:304)经受置换。位置1、17、19、30及33未经置换。天然Cys残基由Cys-acm置换(贯穿全文表示“2”)。组2包含衍生自序列CILQ2HLSSTTAQVTQCI2N ADLGWHISPSFKC(SEQ ID NO:302)的双向行走的Ala突变体的文库。1、17及33位未经置换。天然Cys残基由Cys-acm置换。组3包含基于序列CKDRVAPGPGLGLTLQCI2NADLGWHISPSFKC(SEQ ID NO:303)的单一残基表位突变体的文库。使用残基ADHIQRY(SEQ ID NO:304)进行置换。1、2、17、19、30及33位未经置换。组4包含衍生自序列CKDRVAPGPGLGLTLQCI2NADLGWHISPSFKC(SEQ ID NO:303)的双向行走的Ala突变体的文库。1、17及33位未经置换。
在高及中等严谨条件下利用衍生自肽CILQ2HLSSTTAQVTQCI2NADLGWHISPSFKC(SEQID NO:302)及CKDRVAPGPGLGLTLQCI2NADLGWHISPSFKC(SEQ ID NO:303)的不连续表位突变体的四个系列测试克隆13。数据分析指示,在所有情况下,残基81FK82经单个残基或双Ala置换会损害克隆13的结合。不连续表位模拟物中其他残基的单一突变对结合无明显效应。相反,在与相应不连续模拟物一系列单一残基突变体相比时,双Ala表位突变体对结合展示更明显的效应。亦发现CILQ2HLSSTTAQVTQCI2NADLGWHISPSFKC(SEQ ID NO:302)内残基51TAQVT55(SEQ ID NO:305)的双Ala置换显著影响克隆13的结合。对于克隆13,用衍生自序列CKDRVAPGPGLGLT LQCI2NADLGWHISPSFKC(SEQ ID NO:303)的表位模拟物记录的信号强度低于用CILQ2HLSSTTAQVTQCI2NADLGWHISPSFKC(SEQ ID NO:302)记录的那些信号强度。进一步发现,除81FK82外,74GWHI77(SEQ ID NO:306)的双Ala置换显著降低克隆13的结合。另外,延伸片段87PGPGLGL93(SEQ ID NO:307)内的双Ala突变在某种程度上减弱结合。
在高及中等严谨条件下对衍生自肽CILQ2HLSSTTAQVTQCI2NADLGWHISPSFKC(SEQID NO:302)及CKDRVAPGPGLGLTLQCI2NADLGWHISPSFKC(SEQ ID NO:303)的不连续表位突变体的四个系列测试克隆25。对自表位突变体各组收集的数据分析指示,残基81FK82的单置换或双置换极大地影响结合。CILQ2HLSSTTA QVTQCI2NADLGWHISPSFKC(SEQ ID NO:302)及CKDRVAPGPGLG LTLQCI2NADLGWHISPSFKC(SEQ ID NO:303)内其他残基的单残基取代不会导致信号强度显著减少。一系列双向行走Ala突变体对克隆25与模拟物的结合展示更明显的效应。除81FK82外,残基52AQ53及P79的双Ala置换亦轻度影响抗体与表位模拟物CILQ2HLSSTTAQVTQCI2NADLGWHISPSFKC(SEQ ID NO:302)的结合。分析克隆25与衍生自CKDRVAPGPGLGLTLQCI2NADLGWHISPSFKC(SEQ ID NO:303)的双Ala突变体系列的结合再次确认81FK82的重要性,但亦指示残基73LGW75及82KDRVA86(SEQ ID NO:308)的双Ala置换中度影响结合。
总而言之,对于单克隆抗体克隆13及克隆25,发现残基81FK82对于两种抗体与TIGIT表位模拟物的结合是至关重要的。对于克隆13,亦发现残基51TAQVT55(SEQ ID NO:305)、74GWHI77(SEQ ID NO:306)及87PGPGLGL93(SEQ ID NO:307)有助于结合。对于克隆25,亦发现残基52AQ53、73LGW75、P79及82KDRVA86(SEQ ID NO:308)有助于结合。
实施例10:主链改变的抗TIGIT抗体
为了潜在地改良当前一代抗TIGIT抗体,研发具有降低的效应功能的无岩藻糖基化抗TIGIT抗体及抗TIGIT抗体的Fc突变形式(IgG1 LALA-PG)。预计无岩藻糖基化及LALA-PG抗体仍将阻断CD155及CD112与TIGIT的相互作用。不受任何特定理论限制,假设无岩藻糖基化抗TIGIT抗体可直接结合至肿瘤浸润的Treg,且导致更大的Fc介导的ADCC和/或ADCP,且最终引发更大的抗肿瘤免疫反应,或者假设,效应功能可导致效应T细胞清除,因此无效应抗体可允许保留活化的CD8 T细胞。
DNA及载体生成(Genewiz):
使用非模板PCR合成抗体可变及恒定结构域序列。使用Genewiz的生物资讯学工具将虚拟基因序列转化为寡核苷酸序列。使用PCR合成、汇集并扩增寡核苷酸。将PCR反应的全长扩增子克隆至载体中,然后将产物转化至大肠杆菌并分离出独特群落。使群落在液体培养基中生长过夜,且分离质粒DNA、纯化,并使用Sanger测序验证序列。将轻链及重链克隆至pcDNA3.4载体中。
抗体表达(Seattle Genetics):
将1:1比率的抗体重链及轻链载体用ExpiFectamine CHO转染试剂稀释至ThermoFisher OptiPRO SFM培养基中。然后将DNA/转染试剂添加至ThermoFisher ExpiCHO表达培养基中的ExpiCHO培养物中且培养9天,第一天添加ExpiCHO增强子,且第一天及第二天添加ExpiCHO进料。为了制备在N297聚糖上具有降低的核心岩藻糖基化的抗体(无岩藻糖基化抗体),在转染的前一天及转染当天将岩藻糖类似物2-氟岩藻糖添加至ExpiCHO培养物中。藉由离心及0.2μm过滤收获培养物。
抗体纯化(Seattle Genetics):
GE HiTrap mAb Select SuRe管柱用于每一IgG的纯化。洗脱之前,用5CV PBS+0.1%Triton、5CV PBS+0.5M NaCl及7.5CV PBS洗涤树脂。使用25mM乙酸pH3缓冲液洗脱IgG。使用26/60HiPrep脱盐管柱将样品缓冲液更换为PBS。然后将样品过滤灭菌,之后取样用于表征。表征包括A280浓度、aSEC HPLC、aHIC HPLC及降低糖基化及去糖基化PLRP-MS(QToF)。
实施例11:主链改变的抗体表征
在体内,单核细胞、巨噬细胞、嗜中性细胞、树突细胞及NK细胞可经由FcγRI、FcγRIIa、FcγRI及FcγRIIIa介导ADCP(抗体依赖性细胞介导的吞噬作用)及ADCC(抗体依赖性细胞介导的细胞毒性)。尽管所有三个受体皆可参与ADCP,但据信FcγRIIIa是参与ADCC的主要Fcγ受体。IgG1抗体抗体的无岩藻糖基化会导致更高的与FcγRIIIa及b的亲和性结合,且因此可增加ADCC及ADCP活性。
利用生物层共振(BLI)评价人FcγRIIIa 158V与各种抗TIGIT抗体的结合动力学,以了解在30℃下无岩藻糖基化抗体及LALA-PG突变的效应。在300秒感测器检查后,将N-羟基琥珀酰亚胺(NHS)-酯生物素化人FcγRIIIa 158V-单Fc N297A融合蛋白(在SeattleGenetics表达)以3μg/mL装载至高精密度链霉抗生物素蛋白生物感测器(Pall ForteBio)上达300秒。在200秒的基线后,使滴定的抗TIGIT抗体缔合50秒且解离200秒。在分析之前,在每一分析中减去参考值。在缔合开始时用Y轴对准、步骤间解离校正及Savitzky-Golay过滤对数据进行校正。使用1:1Langmuir等温线全域拟合模型拟合曲线。
代表性数据示于图10中。TIGIT hIgG1变体的感测图类似于藉由BLI针对hFcγRIIIa结合通常所观察到的感测图:野生型IgG1在100-200nM范围内,且由于hFcγRIIIa与hIgG1之间的焓增加或相互作用增加导致kon增加10倍,无岩藻糖基化IgG1为约10-20nM。hIgG1 LALA-PG即使在5000nM的最高浓度下亦没有可定量的结合。结果概述于表3中。
表3.使用1:1Langmuir等温线模型藉由BLI对结合人FcγRIIIa 158V的抗TIGIT抗体进行全域拟合分析。

*NB(未结合)。在20μM之浓度下,未观察到hFcγRIIIa 158V与抗TIGIT克隆13hIgG1 LALA-PG的结合
为了评估抗TIGIT抗体的Fc修饰对抗肿瘤活性的影响,制备包括野生型中人CDR及鼠类IgG2a主链、或具有无岩藻糖基化或LALA-PG修饰的嵌合抗体。鼠IgG2a抗体的无岩藻糖基化类似于无岩藻糖基化人IgG1主链的产生,并导致与鼠FcγRIV、即人FcγRIV之同系受体的结合增加。为了评价改变的FcγRIV结合的程度,使用抗小鼠IgG FITC藉由FACS测定与CHO细胞上表达的FcγRIV的抗体亲和性。如图12中所示,未岩藻糖基化克隆13 mIgG2a的结合程度明显高于野生型或LALA-PG修饰的主链两者。与以33.4的KD结合的野生型克隆13mIgG2a相比,无岩藻糖基化克隆13 mIgG2a以KD为2.37nM的亲和性结合。
实施例12:健康供体T细胞中T细胞亚组上之TIGIT表达.
藉由流式细胞术评估健康供体中T细胞亚组上的TIGIT表达。来自12名健康供体的冷冻PBMC购自Astarte Biologics(Bothell,Washington)及Folio Conversant(Huntsville,Alabama)。供体年龄在21至74岁范围内,中值年龄为48岁。在Fc受体阻断后,将细胞用存活性染料及以下抗人抗体染色:CD3、CD96、CD226、CCR7、CD25、CD127、CD45RA、CD8、CD4、CD226、CD155(Biolegend)及TIGIT(eBioscience)。然后在Attune Nxt流式细胞计数器(Life Technologies)上分析染色的细胞。Treg亚组藉由CD4、CD25及CD127(CD4+CD25+CD127lo)的适当表达来定义。CD4+及CD8+效应记忆(TEM;CD45RA-CCR7-)、CD45RA+效应记忆(TEMRA;CD45RA+CCR7-)、中枢记忆(TCM;CD45RA-CCR7+)及初始(TN;CD45RA+CCR7+)细胞亚组根据CD45RA及CCR7表达定义。如图3中所示,TIGIT表达在Treg上最高,而活化受体CD226表达在记忆及初始CD8 T细胞亚组上皆较低,且显示与初始CD4T细胞亚组类似的程度。T细胞中大部分不存在CD155表达,但在抗原呈递细胞中可见。
实施例13:抗TIGIT抗体克隆13驱动Treg的清除
为了评估抗TIGIT抗体对正常PBMC中Treg及其他T细胞亚组的绝对数目的效应,分离来自表达FcγRIII受体V/F等位基因的供体的健康供体PBMC(Astarte Biologics)。在存在各种浓度的野生型、LALA-PG或无岩藻糖基化型式的克隆13抗TIGIT抗体或人IgG1同型对照(Biolegend)下培养细胞。将冷冻保存的PBMC(Astarte Biologics)在具有10%FBS的RPMI 1640中于96孔圆底板中于37℃下培育。将每孔接种2.5×105个PBMC,以一式三份孔,滴定抗TIGIT或对照抗体。24小时后,洗涤细胞,进行Fc受体阻断,并将细胞用存活性染色剂及以下抗人抗体染色:CD3、CD4、CD8、CD25、CD127及CD45RA(Biolegend)。在Attune NxT流式细胞计数器上分析染色的细胞,并如上所述表征T细胞亚组。如图14中所示,在分析开始时,Treg对TIGIT呈73%阳性。培养24小时后,野生型型式的克隆13 IgG1抗体(黑色实心圆圈)引发TIGIT阳性Treg的剂量依赖性减少,且最大清除发生在1μg/ml下。无岩藻糖基化型式的克隆13(黑色实心正方形)赋予更大的活性,且最大Treg清除发生在200pg/ml下。LALA-PG型式的克隆13(黑色实心三角形)及人IgG1同型对照(灰色倒三角形)在此分析中未显示明显活性。
除了评估野生型、无岩藻糖基化及LALA-PG型式的克隆13抗TIGIT抗体外,亦制备包含具有S293D/A330L/I332E(“DLE”)突变的IgG1恒定区的型式,所述涂布先前曾报导可增强对Fcγ受体的亲和性。参见Lazar,2006,PNAS 103:4005-4010。基本上如上文就来自表达FcγRIII受体高亲和性V/V等位基因供体的健康供体PBMC中所述,评价野生型、无岩藻糖基化、LALA-PG及DLE型式的克隆13之Treg清除。
如图35中所示,克隆13 IgG1野生型抗体(三角形)以约0.024μg/ml的IC50清除Treg,而克隆13 IgG1 DLE抗体(正方形)及克隆13 IgG1无岩藻糖基化抗体(圆圈)两者以大得多的功效清除Treg,IC50分别为0.0006μg/ml及0.0005μg/ml。(在图35中,IgG1野生型数据来自使用同一供体的PBMC的先前实验。)
亦测试另一抗TIGIT抗体H5/L4 IgG1(参见WO 2016/028656A1)清除来自表达FcγRIII受体高亲和性V/V等位基因供体的健康供体PBMC中Treg的能力。如图36中所示,克隆13IgG1无岩藻糖基化抗体在诱导Treg清除方面最有效,而两种IgG1野生型抗体显示极为类似的功效及清除曲线。(在图36中,克隆13 IgG1野生型数据来自使用同一供体的PBMC的先前实验。)
实施例14:同种异体NK/Treg共培养物中Treg清除之评价
为了在Treg/NK细胞共培养物中寻找潜在的抗体依赖性细胞介导的细胞毒性(ADCC),将冷冻保存的人CD4+CD25+T细胞(Stem Cell Technologies)解冻并用CD3/CD28MACS iBead粒子(Miltenyi Biotec)以1:2珠粒:细胞比率在补充有20ng/ml重组人IL-2(R&D systems)的RPMI 10%FBS培养基中刺激3天,以增加TIGIT表达。3天后,经由流式细胞术评价Treg的细胞表面TIGIT表达,发现约40%阳性。然后洗涤Treg,并用CFSE(LifeTechnologies)标记,以将其与共培养后的NK细胞区分开。同一天,将纯化的人NK细胞(Astarte Biologics)解冻并在存在200ng/ml IL-2下预活化2小时。将NK:Treg比率为2.5:1的NK细胞及Treg的共培养物设置于存在100ng/ml IL-2的96孔板中的具有10%FBS的RPMI1640中。于37℃下将细胞与一式三份孔中的野生型、LALA-PG或无岩藻糖基化型式的克隆13抗TIGIT抗体或人IgG1同型对照(Biolegend)、或无岩藻糖基化抗OKT9抗体(其用作阳性对照)一起培育。24小时后,洗涤细胞,用存活性染料染色,并在Attune Nxt流式细胞计数器上经由FACS进行分析。根据存活性染料及CFSE染色对Treg进行鉴别及列举。
结果示于图15中。利用克隆13 IgG1野生型处理(黑色实心圆圈),Treg含量降低,展现清除可能部分是由于直接NK介导的ADCC。克隆13 IgG1野生型清除T细胞的能力似乎在1μg/ml处理下最大。克隆13 IgG1无岩藻糖基化型式(黑色实心正方形)的Treg清除比例更大,且最大活性出现在40ng/ml下。无效应LALA-PG型式的克隆13 IgG1(黑色实心三角形)及人IgG1同型对照(灰色倒三角形)显示对Treg数目无明显影响,而阳性对照SEA OKT9抗体(空心圆圈)显示最大清除。结果与TIGIT表达数据(图4)一致,显示Treg表达高水平的TIGIT。
实施例15:抗TIGIT抗体诱导细胞因子产生
无岩藻糖基化抗体除了与NK细胞上的FcγRIIIa以更高的亲和性结合并驱动ADCC外,亦与抗原呈递细胞及嗜中性细胞上的FcγRIIIa及FcγRIIIb以更高的亲和性结合且可增强ADCP及抗原呈递细胞活化。
为了研究抗TIGIT抗体及Fc变体对抗原呈递细胞的影响,如下分离PBMC。将来自3个独特人供体的血液收集至肝素管中,且在收集约四小时内将其等分至50ml锥形管(Falcon)中,并在25℃下于Eppendorf 5810R(A-4-62转子)中在无制动情况下以200g离心20分钟,以分离富含血小板的部分。离心后,形成三个不同层:底层,红血球(占总体积的50-80%);中间层,非常细的白血球带(亦称为“血沉棕黄层法(buffy coat)”);顶层,稻草色之富含血小板之血浆(PRP)。用1ml移液管移除富含血小板之稻草色上层并丢弃。一旦移除富含血小板的血浆,即将剩余部分用等体积的无菌PBS(Gibco)稀释。将15ml加热至室温的Histopaque-1077(Sigma)置于稀释部分之下。将样品在25℃下在无制动情况下以1500rpm离心25分钟。离心后,再次形成三层:底层,红血球(占总体积的50-80%);中间层,粗白血球带;顶层,PBS及剩余的血小板。用1ml移液管移除PBS/血小板上层并丢弃。轻轻移除粗白血球带,并放入洁净50ml无菌锥形管中。将管填充至50ml,且将细胞以800g离心10分钟。移除洗涤溶液,并将沉淀物重新悬浮于10ml ACK红血球溶解缓冲液(Gibco)中达10分钟。添加35ml无菌PBS,且将细胞以800g离心10分钟。移除洗涤溶液,并将沉淀重新悬浮于50ml PBS中。移出500μl样品,并用Vi-cell-XR(Beckman Coulter)对PBMC进行计数。将细胞再次以800g离心10分钟。
将细胞以100万细胞/ml重新悬浮于含有10%热灭活FBS(Atlantica Biologics)及1X青霉素/strepA及1X麸酰氨酸的完全DMEM中,且以100,000细胞/孔接种在96孔板中。将PBMC暴露于递增浓度(10、1.0、0.1、0.01、0.001、0.0001或0μg/ml)的克隆13 IgG1野生型、无岩藻糖基化克隆13 IgG1或克隆13 IgG1 LALA-PG中24小时。收集组织培养上清液并根据制造商的说明使用Luminex Multiplex(Millipore)进行处理用于细胞因子产生。
结果示于图16中。用克隆13 IgG1野生型抗体(黑色实心正方形)及克隆13 IgG1无岩藻糖基化抗体(黑色实心菱形)处理PBMC导致炎性细胞因子产生,包括与单核细胞/巨噬细胞活化相关的那些,例如MCP1、IL-8及MIP1α。将细胞暴露于无岩藻糖基化克隆13 IgG1引发的细胞因子反应更强,而LALA-PG Fc无效应形式导致细胞因子的产生极少。
实施例16:抗TIGIT抗体诱导APC上的活化标记物
为了评估抗TIGIT抗体对PBMC中存在的抗原呈递细胞的效应,对上述细胞因子分析中剩余细胞团粒的共刺激分子的表达进行评价。将细胞团粒重新悬浮于50ml BD FACS缓冲液中并转移至96孔圆底微量滴定板中。将Fc受体在冰上用人100μg/ml Fc片段(Millipore)封阻30分钟。在含有100mg/ml人Fc片段的BD FACS缓冲液中制备以1:100稀释的由抗CD14抗体(BD)、抗CD86抗体(BD)及抗MHCII抗体(泛抗DR、DP、DQ抗体,BD)构成的混合母液。将5μl混合母液添加至含有90μl重新悬浮细胞的每一孔中,并将样品在冰上培育1小时。然后将细胞在预冷却的Eppendorf 5810R离心机中以400g离心5分钟。移除上清液,并用200μl BD FACS缓冲液洗涤细胞。将细胞洗涤两次,然后重新悬浮于200μl FACS缓冲液中。在具有DIVA软体(BD biosciences)的LSRII流式细胞计数器(BD Biosciences)上收集样品。使用FlowJo软体分析CD14+单核细胞/巨噬细胞上的CD86及MHCII的平均荧光强度(MFI)。
该实验的结果示于图17中。用抗TIGIT抗体克隆13 IgG1野生型或无岩藻糖基化克隆13 IgG1处理CD14+单核细胞/巨噬细胞导致活化标记物CD86(左图)及MHCII(右图)上调,指示抗原呈递细胞成熟。用克隆13 IgG1 LALA-PG处理不会增加CD14+细胞的CD86或MHCII表达。
实施例17:同系肿瘤模型中具有差异Fc亲和性的抗TIGIT抗体的体内评价.
研究无岩藻糖基化抗TIGIT抗体对包含LALA-PG突变的无效应功能的抗TIGIT抗体的抗肿瘤效能。此实验经设计以确定抗TIGIT抗体的效应功能(在无岩藻糖基化型式中增强,而在LALA-PG型式中消除)是否参与抗肿瘤作用机制。生成具有三个不同Fc结构域的抗TIGIT抗体克隆13的鼠类型式:1)野生型mIgG2a;2)无岩藻糖基化mIgG2a;3)mIgG2a LALA-PG(降低的效应功能)。在CT26(结肠)、A20(B细胞淋巴瘤)及MC38(结肠)同系肿瘤模型中评估抗体,每个肿瘤模型每个抗体组有六只小鼠。一旦肿瘤达到100mm3,以每三天给予5mg/kg的剂量经腹膜内(i.p.)给予各抗体,共六个剂量。使用数位卡尺量测皮下肿瘤的长度及宽度,且使用式V=(L x W2)/2计算肿瘤体积。
该实验的结果显示在图18中。每行代表中值肿瘤体积(mm3)(每组N=6)。图18A显示,用抗TIGIT抗体无岩藻糖基化克隆13 mIgG2a、克隆13 mIgG2a野生型及克隆13 mIgG2aLALA-PG处理A20(同系淋巴瘤模型)模型分别导致4/6、2/6及0/6完全反应。图18B显示,用抗TIGIT抗体无岩藻糖基化克隆13 mIgG2a、克隆13 mIgG2a野生型及克隆13 mIgG2a LALA-PG处理CT26WT(鼠类结肠癌)模型分别导致4/6、3/6及0/6完全反应。图18C显示,用抗TIGIT抗体无岩藻糖基化克隆13mIgG2a、克隆13 mIgG2a野生型及克隆13 mIgG2a LALA-PG处理MC38(鼠类结肠癌)模型分别导致1/6、1/6及0/6完全反应。
在不同的同系模型中诱导的反应中的两分性鉴于其报导的不同免疫状况是值得关注的。据报导,CT26及A20肿瘤模型被NK及T细胞浸润的程度更高,而已知MC38模型被髓样源抑制细胞浸润的程度更高(Mosely等人,2017,Canc.Immunol.Res.5(1):29-41)。A20及CT26肿瘤模型中抗TIGIT抗体的增加活性支持所述抗体的T细胞调节活性,且表明浸润的T细胞可用作此疗法的阳性预测生物标记。此数据共同展现,鼠抗TIGIT抗体的体内抗肿瘤活性依赖于Fc效应功能,且与野生型相比,无岩藻糖基化IgG2a具有增强的效能。
实施例18:抗TIGIT抗体的组合活性.
TIGIT不仅在T细胞上表达,并且还在NK及抗原呈递细胞上表达。鉴于多向性表达,TIGIT功能可潜在地驱动多因素活性,且抗TIGIT抗体可能对多种细胞功能(包括例如NK细胞ADCC活性、T细胞活化及最佳抗原回忆反应)产生影响。除单一药剂活性外,抗TIGIT抗体亦可与其他疗法组合放大T细胞、NK或抗原呈递细胞的活性。TIGIT及CD226在NK细胞上表达,且TIGIT表达不仅可主动抑制最佳NK活性及ADCC效力,且亦可阻止CD226介导的活化。因此,TIGIT阻断可能会扩大NK介导的人IgG1靶向剂的ADCC,且ADCC定向的治疗剂在与抗TIGIT抗体组合时可显示增强的活性。
为了研究此可能性,将非小细胞肺癌细胞系A549用Na2[51Cr]O4(100μCi,添加至细胞中)放射标记,洗涤并与单独西妥昔单抗、或西妥昔单抗与10μg/mL抗TIGIT抗体克隆13hIgG1野生型的组合的滴定物混合。实验中亦包括10μg/mL的同型对照。使用EasySep人NK细胞富集试剂盒(Stem Cell Technologies)自冷冻保存的正常供体PBMC中分离出效应细胞。供体细胞为FcγRIIIa 158V/V基因型。效应细胞系以10:1(50,000:5000)的效应物-对-靶细胞比率添加。培育4小时后,量测释放至培养清液中的放射性,且特异性细胞溶解百分比计算为(测样品品cpm-自发cpm)/(总cpm-自发cpm)×100。分别自在单独培养基中培育的靶细胞的上清液及自用1%Triton X-100溶解的靶细胞测定自发及总cpm值。
如图19中所示,仅用抗TIGIT抗体克隆13 IgG1抗体处理A549靶细胞未驱动ADCC活性,但当A549靶细胞与西妥昔单抗及抗TIGIT抗体克隆13 IgG1的组合接触时,最大溶解活性相对于单独利用西妥昔单抗观察到的活性增加。
除了调节NK活性外,TIGIT阻断亦可增加T细胞中的抗原特异性记忆反应。因此,靶向T细胞上存在的检查点蛋白的抗体在与抗TIGIT抗体组合时可显示增强的活性。
为了研究此可能性,实施响应巨细胞病毒(CMV)的抗原回忆分析。来自CMV反应性供体的人PBMC购自Astarte Bio。可利用CMV抗原在体外重新活化来自此供体的记忆T细胞,以评估其抗原特异性反应。将PBMC重新悬浮于含有10%FBS(Atlanta Biologics)的X-vivo10(Lonza)中,且将100,000个细胞接种至圆底96孔板中。在存在或不存在抗TIGIT抗体和/或抗PD-1定向抗体下,将细胞暴露于10μg/ml的CMV抗原。为了评价组合活性,将PBMC用1μg/ml的次最佳剂量的抗PD-1抗体(派姆单抗或尼沃鲁单抗)处理且添加递增浓度的抗TIGIT抗体克隆13IgG1野生型(1pg/ml至1μg/ml)。使对CMV抗原的记忆回忆反应进行5天,之后收获组织培养上清液,且根据制造商的说明由Luminex分析评价(Millipore)测定细胞因子反应。
如图20中所示,抗TIGIT抗体克隆13 IgG1以剂量依赖性方式加强用抗PD-1抗体处理且暴露于CMV抗原的PBMC的IFNγ分泌。
为了研究体内组合活性,使用同系小鼠肿瘤模型。向C57BL/6小鼠(每组8只)的肋腹皮下植入1×106个MC38肿瘤细胞。当肿瘤达到约100mm3时,将动物随机分为三组,且用0.3mg/kg抗TIGIT抗体克隆13 hIgG1野生型、无岩藻糖基化克隆13 IgG1、1mg/kg抗PD-1抗体(抗小鼠PD-1抗体克隆29F.1A12)、克隆13 hIgG1野生型/抗PD-1抗体的组合、或无岩藻糖基化克隆13 IgG1/抗PD-1抗体的组合治疗,每三天一次共3个剂量(Q3dx3)。随着时间流逝监测肿瘤体积,且当肿瘤负荷达到>1000mm3时,将动物安乐死。
在此实验中,克隆13 hIgG1野生型及无岩藻糖基化克隆13 IgG1两者皆展现良好肿瘤生长延迟,野生型及无岩藻糖基化抗体分别为4/8及3/8完全反应。参见图37,左上图。抗PD-1抗体在此实验中亦显示良好效能。组合疗法显示比单独的单一药剂更快的肿瘤消退,如由第15天量测之肿瘤体积所证明。图37,右上图及底部图。
实施例19:体外抗TIGIT抗体对人T细胞反应的活性.
为了研究记忆T细胞重新活化,进行抗原回忆实验。将先前显示对CMV肽有反应的HLA-A2供体的人PBMC(100,000个细胞)重新悬浮于含有10%FBS、1X青霉素及1X麸酰氨酸的RPMI中,并接种至96孔板的圆底孔中。在存在或不存在递增浓度的抗TIGIT抗体克隆13hIgG1野生型、无岩藻糖基化克隆13 IgG1或克隆13 hIgG1 LALA-PG下,用CMV肽刺激细胞五天。收集组织培养上清液,并根据制造商的说明藉由Luminex多工分析评价细胞因子产生。
如图21中所示,抗TIGIT抗体刺激的培养物显示增加的对CMV抗原的反应,如藉由IFNγ产生的增加所见。低至1pg/ml的无岩藻糖基化克隆13 IgG1导致扩大的抗原特异性T细胞反应,且此活性比与克隆13 IgG1野生型相关的反应更稳健。无效应克隆13 IgG1LALA-PG抗体在驱动记忆T细胞反应方面无效。
为了研究初始效应T细胞反应的诱导,进行单向混合淋巴细胞反应(MLR)。将来自HLA-A2供体的人PBMC(100,000个细胞)重新悬浮于含有10%FBS、1X青霉素及1X麸酰氨酸的RPMI中,且与辐照的HLA错配同种异体PBMC以1:1比率在圆底96孔板中培养。用递增浓度的克隆13 hIgG1野生型、无岩藻糖基化克隆13 hIgG1或克隆13 IgG1 LALA-PG刺激细胞五天。收集组织培养上清液,并根据制造商的说明藉由Luminex多工分析评价细胞因子产生。
如图22中所示,用抗TIGIT抗体刺激的培养物显示增加的同种异体效应T细胞反应,如IL2产生的增加所见。低至100pg/ml的无岩藻糖基化克隆13 IgG1导致扩大的抗原特异性T细胞反应,且此活性比与克隆13 IgG1野生型相关的反应更稳健。无效应克隆13 IgG1LALA-PG抗体在驱动记忆T细胞反应方面无效。
除了研究抗原初始及记忆分析中T细胞的活化外,亦使用葡萄球菌肠毒素B肽与克隆13 hIgG1野生型、无岩藻糖基化克隆13 hIgG1、克隆13 IgG1 DLE及另一抗TIGIT抗体H5/L4 IgG1的组合作为超抗原。无岩藻糖基化克隆13 hIgG1能够诱导T细胞的活化,如藉由IL-2的诱导所测定的,比克隆13 hIgG1野生型或H5/L4更稳健。图38A。克隆13 IgG1 DLE能够诱导IL-2产生,与克隆13 hIgG1野生型及无岩藻糖基化克隆13 hIgG1两者大致相当。与其他抗体相比,发现克隆13 IgG1 DLE同时诱导IL-10产生。图38B。此结果与FcγRIIb受体接合导致IL-10诱导的报导一致。预计IgG1 DLE接合FcγRIIb。
实施例20:鼠类肿瘤模型中抗TIGIT抗体的活性.
用各种形式的抗TIGIT抗体野生型IgG2a、无效应IgG2a LALA-PG或无岩藻糖基化IgG2a治疗带有肿瘤(CT26结肠癌)的小鼠,导致系统性及组织特异性细胞因子诱导两者。为了检查用抗TIGIT抗体治疗的潜在系统性及组织效应,向6只Balb/c小鼠的肋侧植入CT26结肠癌细胞,并用1mg/kg抗TIGIT抗体克隆13 IgG2a野生型、无岩藻糖基化克隆13 IgG2a、克隆13 IgG2a LALA-PG治疗,每三天一次共六个剂量,或在肿瘤达到100mm3后,不再治疗。在第3剂量的抗TIGIT抗体后24小时,处死半数小鼠,且收集血浆、脾及肿瘤组织。将各脾脏及肿瘤的一半在RIPA缓冲液中溶解,且进行机械破坏。然后使用Milipore 25预混合Luminex多工试剂盒分析血浆及组织溶解物的细胞因子,该试剂盒容许分析25种不同炎性细胞因子。经由BCA(二辛可宁酸分析)-测定的蛋白质含量将组织细胞因子含量彼此归一化。
如图23中所示,细胞因子分析未显示响应任何抗体治疗的血浆中细胞因子的急剧增加(此将指示系统反应)或组织中细胞因子的急剧增加。在未经治疗的小鼠血浆及肿瘤中观察到有限的细胞因子,且在以下抗TIGIT治疗后仅观察到中度变化,指示即使利用无岩藻糖基化抗体,TIGIT治疗亦未引发整体炎性反应。
除了分析抗TIGIT诱导的细胞因子含量外,亦藉由流式细胞术分析在第三剂量的抗TIGIT抗体后24小时收集的肿瘤及外周样品的各种T细胞亚组比例的总体变化。如上文针对图23所述,将来自同一Balb/c小鼠的肿瘤及脾单细胞悬液及PBMC进行多种细胞表面标记染色,以描绘初始/记忆T细胞的CD8+、CD4+亚组(CD62L+CD44-初始、CD62L-CD44-效应物、CD44+CD62L+中枢记忆及CD44+CD62L-效应记忆)及Treg(CD25+CD127-)。样品在Attune声学聚焦细胞计数器上运行,并使用FlowJo进行分析。将门控设置在CD45+活细胞上。
如图24中所示,在与未治疗的动物比较时,观察到响应抗TIGIT抗体克隆13mIgG2a野生型及无岩藻糖基化克隆13 mIgG2a抗体、而非无效应克隆13 mIgG2a LALA-PG的肿瘤中CD8+ T细胞增加(图24顶部图)。在抗TIGIT抗体治疗后,在PBMC及脾中观察到CD8+细胞百分比更适度增加。亦注意到初始、效应物及记忆T细胞的肿瘤内变化。具体而言,在用克隆13 mIgG2a野生型及无岩藻糖基化克隆13 mIgG2a处理后,肿瘤内初始CD8+ T细胞的含量降低,而用克隆13 mIgG2a LALA-PG处理则降低较少(图24,左下图)。在肿瘤中响应克隆13mIgG2a野生型及无岩藻糖基化抗体、而非响应克隆13 mIgG2a LALA-PG抗体观察到CD8+CD44+CD62L-效应记忆细胞(图24,右上图)及CD8+CD44+CD62L+中枢记忆细胞(图24,左上角图)比例增加。在脾或PBMC中未注意到所述变化,但在所述组织中确实发生了一些轻度变化。
亦藉由流式细胞术分析CD4+ T细胞亚组的变化,所述变化是使用与如上文针对CD8+细胞所述类似的策略由抗TIGIT抗体处理诱导。如图25(左上图)中所示,与用克隆13mIgG2a LALA-PG抗体治疗或未经治疗的动物相比,克隆13 mIgG2a野生型及无岩藻糖基化抗体治疗诱导肿瘤内CD4+细胞轻度减少。在PBMC或脾中未观察到此效应。亦在CD4+ Treg群体中观察到响应克隆13 mIgG2a野生型及无岩藻糖基化抗体、而非克隆13 LALA-PG抗体的肿瘤内减少至小的程度,表明抗TIGIT抗体治疗正减少肿瘤而非正常组织中的免疫抑制性Treg群体。与CD8+ T细胞的结果相似,与未经处理的相比,用克隆13 mIgG2a野生型及无岩藻糖基化抗体处理后,肿瘤内CD4+初始T细胞减少(图25,左下图),且此发现与肿瘤中效应记忆CD4+ T细胞的比例增加同时发生(图25,中间右图)。效应记忆CD4+及CD8+ T细胞参与引发抗肿瘤反应,且TIGIT定向抗体的升高可有助于抗肿瘤反应。所述显著肿瘤内T细胞群体变化中的许多并没有伴随外周中所述群体大的变化。
在六个剂量的抗TIGIT抗体后,在开始治疗后约20天,肿瘤减少并且几乎无法检测。自所述小鼠中收获脾及血浆,且如上所述制备用于流式细胞术的细胞。如图26A-B中所示,来自所述小鼠脾的各种T细胞亚组的分析展现,各组之间的CD8+或CD4+亚组无急剧变化。
使用多工分析评价用抗TIGIT抗体治疗的小鼠脾及血浆中细胞因子的诱导,且结果示于图27中。在与未经治疗的动物相比时,在经治疗的动物脾中未观察到细胞因子产生升高,且通常在血浆中检测到低含量的细胞因子,趋化因子LIX(鼠类IL8同系物)及伊红趋素除外,其在未经治疗及经某些抗TIGIT抗体治疗的动物中升高。
使用经抗TIGIT抗体开始治疗后约20天收集的脾细胞评估所述动物中针对肿瘤的抗原特异性记忆细胞生成。将上述用抗TIGIT抗体治疗的小鼠脾细胞重新悬浮于培养基中,且一式两份接种于96孔板的孔中。使细胞未经刺激或用1μg/ml AH1肽重新刺激,AH1肽是针对CT26结肠癌肿瘤的CD8+ T细胞反应的主要靶标。48小时后,收集培养上清液并藉由多工分析来分析细胞因子产生。
如图28中所示,在不存在肽下产生极少细胞因子。有趣的例外是观察到来自无岩藻糖基化克隆13 mIgG2a治疗的动物的未刺激脾细胞所产生的IL5及IL4含量升高(图28,下图)。然而,用CT-26特异性肽刺激脾细胞会在克隆13 mIgG2a野生型及无岩藻糖基化抗体治疗的动物中、而非在克隆13 mIgG2a LALA-PG抗体治疗的动物中产生稳健的IFNγ及TNFα产生(图28,顶部图),指示克隆13 mIgG2a野生型及无岩藻糖基化抗体治疗能够刺激持久的抗原特异性记忆CD8+ T细胞反应。记忆T细胞反应的产生参与驱动长期抗肿瘤反应。亦观察到在用肽重新刺激克隆13 mIgG2a野生型及无岩藻糖基化抗体处理的脾细胞之后IL4产生增加(图28,右下图)。在未重新刺激情况下无岩藻糖基化克隆13 mIgG2a组中未刺激脾细胞中IL4及IL5的产生可表明该抗体诱导TH2反应。
实施例21:其他鼠类肿瘤模型中抗TIGIT抗体的活性
用5mg/kg包含野生型mIgG2a抗TIGIT克隆13抗体或0.1mg/kg,1mg/kg或5mg/kg包含无岩藻糖基化mIgG2a抗TIGIT克隆13抗体处理两个鼠类同系肿瘤模型,即EMT6及E0771乳癌。给药时间表为q4dx4(每四天一剂;总共四个剂量)。量测肿瘤长度及宽度且使用下式计算肿瘤体积:体积(mm3)=0.5*长度*宽度2,其中长度是最长尺寸。
如图29A-29B中所示,乳癌模型中的抗肿瘤反应显示肿瘤生长延迟,但治愈性反应最小。在EMT6模型中,5mg/kg的克隆13 mIgG2a野生型及无岩藻糖基化抗体两者皆显示良好肿瘤生长延迟,平均存活期自30.5天分别增加至37天及39天(图29A)。克隆13 mIgG2a无岩藻糖基化抗体的其他剂量组展现在较低剂量下活性损失,且利用1及0.1mg/kg剂量观察到仅35.2及36.8天的平均总体存活期,但与未经处理的对照相比,肿瘤生长仍延迟(图29A)。
在E0771模型中,针对5mg/kg的克隆13 mIgG2a野生型及无岩藻糖基化抗体两者皆观察到更适度的肿瘤生长延迟,平均存活期自38.6天分别增加至44及42天(图29B)。此外,用1mg/kg及5mg/kg剂量的克隆13 mIgG2a无岩藻糖基化抗体似乎治愈六只小鼠中的一只。1mg/kg及0.1mg/kg的克隆13 mIgG2a无岩藻糖基化抗体的较低剂量组产生39天的平均总体存活期(图29B)。
另外,在第二CT26结肠癌模型中评估1mg/kg克隆13 mIgG2a野生型抗体,该模型是自外部实验室(MI Bioresearch)获得。如图29C中所示,在此CT26结肠癌模型中,克隆13mIgG2a野生型抗体展现在治疗情况下平均总体存活期自30天增加至40天,但仅诱导一个完全消退(16%)。如图18B中所示,Seattle Genetics所维护的CT26结肠癌模型显示利用1mg/kg克隆13 IgG2a野生型抗体具有50%(3/6)的完全消退。
实施例22:RNA-Seq分析及体内反应与分子印记之相关性
为了评估两个CT26结肠癌模型以及其他同系癌症模型的反应差异,使用RNA-seq分析来鉴别模型之间转录体中潜在的基础变化。获得每一模型的代表性未治疗肿瘤的RNA-seq原始读数(fastq格式),如下所示。
A20(于Seattle Genetics维持),2个复制物
CT26(于Seattle Genetics维持),2个复制物
CT26(自MIBio获得),1个复制物
E0771(自MIBio获得),1个复制物
EMT-6(自MIBio获得),1个复制物
MC38(于Seattle Genetics维持),1个复制物
在由适配体修整(cutadapt)、与小鼠基因组/转录体比对(STAR)及转录本量化(RSEM)组成的标准管线上处理样品的RNA-seq读数。使用归一化至FPKM(片段/千碱基/百万读数)的基因表达值进行随后分析。基于体内反应曲线的检查,按照对WT TIGIT处理的整体反应,将模型分类如下:完全反应者=A20(Seattle Genetics;图18A)、CT26(SeattleGenetics;图18B)及部分反应=CT26(MIBio;图29C)、EMT-6(MIBio;图29A)、E0771(MIBio;图29B)、MC38(Seattle Genetics;图18C)。在转录水准上观察到两个CT26结肠癌模型之间的差异,表明对用于效能研究的模型进行表征可能是重要的。
亦藉由编译来自两个公开来源的与免疫系统及免疫反应有关的基因印记来确定与可能与反应相关的肿瘤微环境(TME)有关的分子印记:Mosely等人,“Rationalselection of syngeneic preclinical tumor models for immunotherapeutic drugdiscovery,”Cancer Immunol Res 2017;5:29-41;及TCIA,The Cancer Immunome Atlas(tcia.at/home),其中印记取自Charoentong等人,“Pan-cancer Immunogenomic AnalysesReveal Genotype-Immunophenotype Relationships and Predictors of Response toCheckpoint Blockade,”Cell Rep 2017年1月3日;18(1):248-262。来自所述来源的基因印记由一系列在特定生物学背景下、例如在CD8+ T细胞中表达较高的基因组成。TCIA基因印记是源自人的,因此使用R文库biomaRt将这些印迹中每一个的基因映射至小鼠直向同系物。总共考虑约50个基因印记,且藉由对印记中基因的样品FPKM值求和,针对50个印记中的每一个对8个RNA-seq未处理的肿瘤样品中的每一个进行评分。
为了定量评估哪个基因印记评分将强反应者与弱反应者分开,将所有样品中印记评分的向量与反应向量相关联(Pearson相关性,弱反应者为0,强反应者为1)。与反应尤其高度相关的印记包括NK细胞及活化CD8 T细胞(图30)。在两种情形下,与较弱的反应者相比,较强反应者对免疫亚组评分较高。表4显示某些免疫细胞亚组之间的相关性及肿瘤细胞对抗TIGIT抗体的反应。
表4:
| 基因印记 | 相关性 | P值 |
| γδT细胞 | 0.9262 | 0.0009 |
| NK细胞 | 0.9200 | 0.0012 |
| 活化CD8 T细胞 | 0.8535 | 0.0070 |
| 活化DC | -0.8437 | 0.0085 |
| 不成熟B细胞 | 0.7875 | 0.0203 |
| CD96 | 0.7569 | 0.0297 |
| CD8 T细胞 | 0.7569 | 0.0297 |
| CD56<sup>亮</sup>天然杀手细胞 | 0.7319 | 0.0390 |
| T辅助17细胞 | 0.7139 | 0.0467 |
| 活化CD4 T细胞 | 0.7092 | 0.0488 |
不受任何特定理论限制,由于TIGIT阻断可刺激NK细胞及CD8 T细胞介导的肿瘤杀死,因此TME中所述免疫细胞群体的更大可用池可解释那些亚组中评分更高的模型中的较强反应。
有趣的是,TIGIT表达并非此评估中反应的有力区分者,CD155表达也不是(图31)。举例而言,Seattle Genetics CT26结肠癌模型显示所有模型的最高CD155表达,而A20淋巴瘤模型具有最低表达,但两者皆是强反应者。
实施例23:抗TIGIT抗体增强Th1反应
为了评价克隆13抗TIGIT抗体是否有助于驱动初始抗原特异性T细胞反应,在完全弗氏佐剂(CFA)存在下向balb/c小鼠(每组5只)皮下接种100μg的模型抗原卵白蛋白(OVA)一次。同时,向小鼠给予1mg/kg克隆13 IgG2a野生型、无岩藻糖基化克隆13 mIgG2a或克隆13 mIgG2a LALA-PG抗体,然后再三个剂量,间隔三天(q3dx4)。疫苗接种后14天,使用抗OVAIgG1及IgG2a ELISA诱导抗原特异性免疫性来分析小鼠。重新刺激脾细胞并评价细胞因子诱导。
抗OVA ELISA显示,在小鼠经历疫苗诱导的抗原特异性引发的同时,共同给予克隆13 IgG2a野生型或克隆13 mIgG2a LALA-PG抗体将产生的IgG1抗体的含量提高约1.5倍。在该实验中,克隆13 mIgG2a无岩藻糖基化抗体未提高抗原特异性IgG1抗体含量(图32,右图)。所述数据表明TIGIT阻断能够增加CD4/Th2反应的引发,但增强的效应功能消除此效应。TIGIT阻断亦提高IgG2a抗原特异性抗体的含量(图32,右图),但在此情形下,克隆13mIgG2a无岩藻糖基化抗体显示最大效应。总之,在IgG1含量与增强的效应功能之间观察到反向相关性,而IgG2a含量与增强的效应功能直接相关,克隆13 mIgG2a无岩藻糖基化抗体使抗OVA IgG2a含量增加9倍以上。克隆13 IgG2a野生型及克隆13 mIgG2a LALA-PG抗体亦提高IgG2a含量,但仅提高约4倍(图32,右图)。尽管在此实验中单独TIGIT阻断不足以使此高度Th2偏好的系统(由所用小鼠品系及佐剂驱动)偏向Th1,但TIGITβ阻断显示可增强Th1反应,且反应与效应功能相关。
除了分析抗原特异性抗体产生外,亦评估抗原特异性T细胞的诱导。用1μg全蛋白(OVA)将来自每一小鼠的相等数目的脾细胞重新离体刺激72小时,之后进行T效应细胞因子分析。如所预计,经活化T细胞的细胞因子IL-2响应抗原重新刺激(“1μg/ml OVA”)的产生在抗原/佐剂治疗组中相对于未治疗的动物有所增加,且这在引发期间在经效应功能启动(克隆13 IgG2a野生型)或增强(无岩藻糖基化克隆13 mIgG2a)抗TIGIT抗体治疗的动物的脾细胞中进一步增加(图33,右下图)。所述结果与TIGIT阻断增强初始抗原特异性T细胞反应产生的能力一致。Th2效应细胞因子IL-5及IL-4的分析显示,在抗原重新刺激后相对于仅抗原/佐剂的情形自经抗TIGIT抗体治疗的动物产生一些额外细胞因子诱导,但观察到效应功能与反应之间的较不明显相关性(图33,左图)。对于Th1/CD8 T细胞的细胞因子IFNγ,抗原引发事件期间的TIGIT阻断更加显著地增强抗原特异性T细胞的产生(图33,右上图)。在经效应物增强的克隆13 mIgG2a无岩藻糖基化抗体治疗的动物的脾细胞中观察到最明显的加强。
实施例24:抗TIGIT抗体诱导持久的抗肿瘤记忆CD8 T细胞
用无岩藻糖基化克隆13 mIgG2a或未经修饰的抗体治疗后在CT26结肠癌同系肿瘤模型中显示完全反应的小鼠及四只未经治疗的小鼠用CT26结肠癌细胞再攻击。如图34中所示,在用1mg/kg或5mg/kg无岩藻糖基化克隆13 mIgG2a或未经修饰的抗体治疗后显示完全反应的小鼠似乎具有持久的抗肿瘤记忆CD8 T细胞,其能够排斥再攻击的肿瘤细胞。
尽管为了清楚理解起见,藉助说明及实施例对上述发明进行了一些详细阐述,但本领域普通技术人员应明了,可在不脱离本发明的精神及范畴的情况下对本发明作出许多修改及变化。本文所述的具体实施例仅藉助实施例提供,且并不意指以任何方式进行限制。本说明书及实施例仅可视为示例性,且本发明的实际范围及精神如权利要求所述。
实施例25:结合至Fcγ受体的抗TIGIT抗体
在体内,单核细胞、巨噬细胞、嗜中性细胞、树突细胞及天然杀手细胞可经由FcγRI、FcγRII及FcγRIIIa介导ADCP、ADCC及CDC。为了评价细胞FcγR结合,用人FcγRI、FcγIIa、FcγIIB或高亲和性FcγRIIIa V/V受体转染CHO细胞。将细胞暴露于递增浓度的野生型、无岩藻糖基化、LALA-PG或DLE型式的克隆13IgG1抗TIGIT抗体或另一抗TIGIT抗体H5L4。使用荧光标记的抗人Fc二抗及流式细胞术监测结合。
如图39A中所示,除IgG1 LALA-PG灭活主链外,所有抗体皆与CHO细胞表面上的FcγRI实质上相等地结合。无岩藻糖基化IgG1及IgG1 DLE主链展现与CHO细胞表面上FcγRIIIa的结合增加。图39B。野生型IgG1主链及IgG1 DLE效应物增强的主链与CHO细胞表面的FcyRIIa及FcγRIIb的结合最高。图39C及图39D。在与IgG1野生型主链相比时,无岩藻糖基化IgG1主链与FcγRIIa及FcγRIIb的结合亲和性较低,但其结合亲和性大于IgG1 LALA-PG主链。图39C及图39D。与抑制性FcγRIIb受体的结合减少可影响由无岩藻糖基化IgG1主链介导的免疫反应。
实施例26:抗TIGIT抗体介导的吞噬作用
术语“抗体依赖性细胞吞噬作用”或“ADCP”指由结合至抗体的Fc区的吞噬性免疫细胞(例如巨噬细胞、嗜中性细胞及或树突细胞)全部或部分内化抗体结合的细胞的过程。
使用人单核细胞/巨噬细胞及TIGIT阳性Jurkat T细胞分析野生型、无岩藻糖基化及DLE型式的克隆13 IgG1抗TIGIT抗体的抗体介导的吞噬作用。用递增浓度的抗TIGIT抗体将经荧光红PKH染料标记的人TIGIT阳性Jurkat T细胞调理30分钟。洗涤细胞并与单核细胞巨噬细胞以10:1的比率一起培育18小时。将样品洗涤3次,并经受流式细胞术评价吞噬作用。
如图40中所示,野生型及无岩藻糖基化IgG1克隆13抗TIGIT抗体介导的吞噬作用程度相近,而克隆13 IgG1 DLE抗体对介导吞噬活性效力较低。
除了ADCC及ADCP外,细胞结合的抗体的Fc区亦可活化补体经典路径且引发CDC。当补体系统与抗原复合时,补体系统的C1q结合至抗体的Fc区。C1q与细胞结合抗体的结合可引发涉及C4及C2的蛋白水解活化以产生C3转化酶的事件级联。C3由C3转化酶裂解成C3b能够活化末端补体组分,包括C5b、C6、C7、C8及C9。所述蛋白质共同地在抗体包被的细胞上形成攻膜复合孔。所述孔破坏细胞膜的完整性,从而经由补体依赖性细胞毒性或“CDC”杀死靶细胞。
使用TIGIT+Jurkat T细胞作为靶细胞分析的野生型、无岩藻糖基化、LALA-PG及DLE型式的克隆13 IgG1抗TIGIT抗体以及H5/L4的CDC活性。在人血清(未热灭活)存在下于37℃下在含有 绿(其自活细胞排除,但在活化CDC及溶解时吸收)的培养基中将Jurkat细胞与递增剂量的抗体一起培育2小时。培育后,在读板仪上分析样品,减去背景信号,并藉由确定用1%Triton X溶液杀死的细胞的最大信号来计算最大溶解%。
绿(其自活细胞排除,但在活化CDC及溶解时吸收)的培养基中将Jurkat细胞与递增剂量的抗体一起培育2小时。培育后,在读板仪上分析样品,减去背景信号,并藉由确定用1%Triton X溶液杀死的细胞的最大信号来计算最大溶解%。
如图41中所示,抗TIGIT抗体皆未测试到介导的CDC活性。相反地,在此系统中,抗CD47抗体hB6H12.3介导稳健的CDC活性。抗体对CDC的诱导具有构形依赖性,且通常取决于其结合的表位。所述结果表明,由抗体结合的TIGIT表位不允许适当C1q结合。
本文引用的所有出版物、专利、专利申请或其他文献皆以引用方式全文并入本文用于所有目的,其并入程度如同出于所有目的将每一个别出版物、专利、专利申请或其他文件个别指明以引用方式并入一般。
序列表

























序列表
<110> 西进公司(SEAGEN INC.)
<120> 抗TIGIT抗体
<130> 01218-0001-00PCT
<150> US 62/722,063
<151> 2018-08-23
<150> US 62/734,130
<151> 2018-09-20
<150> US 62/822,674
<151> 2019-03-22
<160> 309
<170> PatentIn version 3.5
<210> 1
<211> 128
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆2 VH蛋白
<400> 1
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Asp His
20 25 30
Tyr Met Asp Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Gly Arg Thr Arg Asn Lys Ala Asn Ser Tyr Thr Thr Glu Tyr Ala Ala
50 55 60
Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asp Ser Lys Asn Ser
65 70 75 80
Leu Tyr Leu Gln Met Asn Ser Leu Lys Thr Glu Asp Thr Ala Val Tyr
85 90 95
Tyr Cys Ala Arg Gly Gln Tyr Tyr Tyr Gly Ser Ser Ser Arg Gly Tyr
100 105 110
Tyr Tyr Met Asp Val Trp Gly Gln Gly Thr Thr Val Thr Val Ser Ser
115 120 125
<210> 2
<211> 384
<212> DNA
<213> 人工序列
<220>
<223> 合成:克隆2 VH DNA
<400> 2
gaggtgcagc tggtggagtc tgggggaggc ttggtccagc ctggagggtc cctgagactc 60
tcctgtgcag cctctggatt caccttcagt gaccactaca tggactgggt ccgccaggct 120
ccagggaagg ggctggagtg ggttggccgt actagaaaca aagctaacag ttacaccaca 180
gaatacgccg cgtctgtgaa aggcagattc accatctcaa gagatgattc aaagaactca 240
ctgtatctgc aaatgaacag cctgaaaacc gaggacacgg cggtgtacta ctgcgccaga 300
ggccagtact actacggcag cagcagcaga ggttactact acatggacgt atggggccag 360
ggaacaaccg tcaccgtctc ctca 384
<210> 3
<211> 26
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆2 VH FR1
<400> 3
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly
20 25
<210> 4
<211> 9
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆2 VH CDR1
<400> 4
Phe Thr Phe Ser Asp His Tyr Met Asp
1 5
<210> 5
<211> 14
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆2 VH FR2
<400> 5
Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val Gly
1 5 10
<210> 6
<211> 19
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆2 VH CDR2
<400> 6
Arg Thr Arg Asn Lys Ala Asn Ser Tyr Thr Thr Glu Tyr Ala Ala Ser
1 5 10 15
Val Lys Gly
<210> 7
<211> 30
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆2 VH FR3
<400> 7
Arg Phe Thr Ile Ser Arg Asp Asp Ser Lys Asn Ser Leu Tyr Leu Gln
1 5 10 15
Met Asn Ser Leu Lys Thr Glu Asp Thr Ala Val Tyr Tyr Cys
20 25 30
<210> 8
<211> 19
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆2 VH CDR3
<400> 8
Ala Arg Gly Gln Tyr Tyr Tyr Gly Ser Ser Ser Arg Gly Tyr Tyr Tyr
1 5 10 15
Met Asp Val
<210> 9
<211> 11
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆2 VH FR4
<400> 9
Trp Gly Gln Gly Thr Thr Val Thr Val Ser Ser
1 5 10
<210> 10
<211> 108
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆2及2C VL蛋白
<400> 10
Glu Ile Val Leu Thr Gln Ser Pro Gly Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser Val Ser Ser Ser
20 25 30
Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu
35 40 45
Ile Tyr Gly Ala Ser Ser Arg Ala Thr Gly Ile Pro Asp Arg Phe Ser
50 55 60
Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Arg Leu Glu
65 70 75 80
Pro Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Ala Val Pro Ser Pro
85 90 95
Leu Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
100 105
<210> 11
<211> 324
<212> DNA
<213> 人工序列
<220>
<223> 合成:克隆2 VL DNA
<400> 11
gaaattgtgt tgacgcagtc tccaggcacc ctgtctttgt ctccagggga aagagccacc 60
ctctcctgca gggccagtca gagtgttagc agcagctact tagcctggta ccagcagaaa 120
cctggccagg ctcccaggct cctcatctat ggtgcatcca gcagggccac tggcatccca 180
gacaggttca gtggcagtgg gtctgggaca gacttcactc tcaccatcag cagactggag 240
cctgaagatt ttgcagtgta ttactgtcag caggccgtcc ccagtcctct cacttttggc 300
ggagggacca aggttgagat caaa 324
<210> 12
<211> 23
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆2 VL FR1
<400> 12
Glu Ile Val Leu Thr Gln Ser Pro Gly Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys
20
<210> 13
<211> 12
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆2及2C VL CDR1
<400> 13
Arg Ala Ser Gln Ser Val Ser Ser Ser Tyr Leu Ala
1 5 10
<210> 14
<211> 15
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆2 VL FR2
<400> 14
Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu Ile Tyr
1 5 10 15
<210> 15
<211> 7
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆2及2C VL CDR2
<400> 15
Gly Ala Ser Ser Arg Ala Thr
1 5
<210> 16
<211> 32
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆2 VL FR3
<400> 16
Gly Ile Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr
1 5 10 15
Leu Thr Ile Ser Arg Leu Glu Pro Glu Asp Phe Ala Val Tyr Tyr Cys
20 25 30
<210> 17
<211> 9
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆2及2CVL CDR3
<400> 17
Gln Gln Ala Val Pro Ser Pro Leu Thr
1 5
<210> 18
<211> 10
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆2 VL FR4
<400> 18
Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
1 5 10
<210> 19
<211> 128
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆3 VH蛋白
<400> 19
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Asp His
20 25 30
Tyr Met Asp Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Gly Arg Thr Arg Asn Lys Ala Asn Ser Tyr Thr Thr Glu Tyr Ala Ala
50 55 60
Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asp Ser Lys Asn Ser
65 70 75 80
Leu Tyr Leu Gln Met Asn Ser Leu Lys Thr Glu Asp Thr Ala Val Tyr
85 90 95
Tyr Cys Ala Arg Gly Gln Tyr Tyr Tyr Gly Ser Ser Ser Arg Gly Tyr
100 105 110
Tyr Tyr Met Asp Val Trp Gly Gln Gly Thr Thr Val Thr Val Ser Ser
115 120 125
<210> 20
<211> 384
<212> DNA
<213> 人工序列
<220>
<223> 合成:克隆3 VH DNA
<400> 20
gaggtgcagc tggtggagtc tgggggaggc ttggtccagc ctggagggtc cctgagactc 60
tcctgtgcag cctctggatt caccttcagt gaccactaca tggactgggt ccgccaggct 120
ccagggaagg ggctggagtg ggttggccgt actagaaaca aagctaacag ttacaccaca 180
gaatacgccg cgtctgtgaa aggcagattc accatctcaa gagatgattc aaagaactca 240
ctgtatctgc aaatgaacag cctgaaaacc gaggacacgg cggtgtacta ctgcgccaga 300
ggccagtact actacggcag cagcagcaga ggttactact acatggacgt atggggccag 360
ggaacaaccg tcaccgtctc ctca 384
<210> 21
<211> 26
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆3 VH FR1
<400> 21
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly
20 25
<210> 22
<211> 9
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆3 VH CDR1
<400> 22
Phe Thr Phe Ser Asp His Tyr Met Asp
1 5
<210> 23
<211> 14
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆3 VH FR2
<400> 23
Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val Gly
1 5 10
<210> 24
<211> 19
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆3 VH CDR2
<400> 24
Arg Thr Arg Asn Lys Ala Asn Ser Tyr Thr Thr Glu Tyr Ala Ala Ser
1 5 10 15
Val Lys Gly
<210> 25
<211> 30
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆3 VH FR3
<400> 25
Arg Phe Thr Ile Ser Arg Asp Asp Ser Lys Asn Ser Leu Tyr Leu Gln
1 5 10 15
Met Asn Ser Leu Lys Thr Glu Asp Thr Ala Val Tyr Tyr Cys
20 25 30
<210> 26
<211> 19
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆3 VH CDR3
<400> 26
Ala Arg Gly Gln Tyr Tyr Tyr Gly Ser Ser Ser Arg Gly Tyr Tyr Tyr
1 5 10 15
Met Asp Val
<210> 27
<211> 11
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆3 VH FR4
<400> 27
Trp Gly Gln Gly Thr Thr Val Thr Val Ser Ser
1 5 10
<210> 28
<211> 107
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆3 VL蛋白
<400> 28
Glu Ile Val Leu Thr Gln Ser Pro Gly Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser Val Arg Ser Ser
20 25 30
Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu
35 40 45
Ile Tyr Gly Ala Ser Ser Arg Ala Thr Gly Ile Pro Asp Arg Phe Ser
50 55 60
Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Arg Leu Glu
65 70 75 80
Pro Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Val Gly Pro Pro Leu
85 90 95
Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
100 105
<210> 29
<211> 321
<212> DNA
<213> 人工序列
<220>
<223> 合成:克隆3 VL DNA
<400> 29
gaaattgtgt tgacgcagtc tccaggcacc ctgtctttgt ctccagggga aagagccacc 60
ctctcctgca gggccagtca gagtgttagg agcagctact tagcctggta ccagcagaaa 120
cctggccagg ctcccaggct cctcatctat ggtgcatcca gcagggccac tggcatccca 180
gacaggttca gtggcagtgg gtctgggaca gacttcactc tcaccatcag cagactggag 240
cctgaagatt ttgcagtgta ttactgtcag caggtcggac cccccctcac ttttggcgga 300
gggaccaagg ttgagatcaa a 321
<210> 30
<211> 23
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆3 VL FR1
<400> 30
Glu Ile Val Leu Thr Gln Ser Pro Gly Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys
20
<210> 31
<211> 12
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆3 VL CDR1
<400> 31
Arg Ala Ser Gln Ser Val Arg Ser Ser Tyr Leu Ala
1 5 10
<210> 32
<211> 15
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆3 VL FR2
<400> 32
Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu Ile Tyr
1 5 10 15
<210> 33
<211> 7
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆3 VL CDR2
<400> 33
Gly Ala Ser Ser Arg Ala Thr
1 5
<210> 34
<211> 32
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆3 VL FR3
<400> 34
Gly Ile Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr
1 5 10 15
Leu Thr Ile Ser Arg Leu Glu Pro Glu Asp Phe Ala Val Tyr Tyr Cys
20 25 30
<210> 35
<211> 8
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆3 VL CDR3
<400> 35
Gln Gln Val Gly Pro Pro Leu Thr
1 5
<210> 36
<211> 10
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆3 VL FR4
<400> 36
Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
1 5 10
<210> 37
<211> 121
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆5 VH蛋白
<400> 37
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Thr Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ser Gly Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Gly Pro Arg Tyr Gln Asp Arg Ala Gly Met Asp Val Trp Gly
100 105 110
Gln Gly Thr Thr Val Thr Val Ser Ser
115 120
<210> 38
<211> 363
<212> DNA
<213> 人工序列
<220>
<223> 合成:克隆5 VH DNA
<400> 38
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgagactc 60
tcctgtgcag cctctggatt cacctttagc acctatgcca tgagctgggt ccgccaggct 120
ccagggaagg ggctggagtg ggtctcagct attagtggta gtggtggtag cacatactac 180
gcagactccg tgaagggccg gttcaccatc tccagagaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgag agccgaggac acggcggtgt actactgcgc caagggcccc 300
agataccaag acagggcagg aatggacgta tggggccagg gaacaactgt caccgtctcc 360
tca 363
<210> 39
<211> 26
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆5 VH FR1
<400> 39
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly
20 25
<210> 40
<211> 9
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆5 VH CDR1
<400> 40
Phe Thr Phe Ser Thr Tyr Ala Met Ser
1 5
<210> 41
<211> 14
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆5 VH FR2
<400> 41
Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val Ser
1 5 10
<210> 42
<211> 17
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆5 VH CDR2
<400> 42
Ala Ile Ser Gly Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val Lys
1 5 10 15
Gly
<210> 43
<211> 30
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆5 VH FR3
<400> 43
Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr Leu Gln
1 5 10 15
Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
20 25 30
<210> 44
<211> 14
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆5 VH CDR3
<400> 44
Ala Lys Gly Pro Arg Tyr Gln Asp Arg Ala Gly Met Asp Val
1 5 10
<210> 45
<211> 11
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆5 VH FR4
<400> 45
Trp Gly Gln Gly Thr Thr Val Thr Val Ser Ser
1 5 10
<210> 46
<211> 107
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆5 VL蛋白
<400> 46
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Ser Ile Ser Ser Tyr
20 25 30
Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Ala Ala Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ser Leu Ala Thr Pro Tyr
85 90 95
Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
100 105
<210> 47
<211> 321
<212> DNA
<213> 人工序列
<220>
<223> 合成:克隆5 VL DNA
<400> 47
gacatccaga tgacccagtc tccatcctcc ctgtctgcat ctgtaggaga cagagtcacc 60
atcacttgcc gggcaagtca gagcattagc agctatttaa attggtatca gcagaaacca 120
gggaaagccc ctaagctcct gatctatgct gcatccagtt tgcaaagtgg ggtcccatca 180
aggttcagtg gcagtggatc tgggacagat ttcactctca ccatcagcag tctgcaacct 240
gaagattttg caacttacta ctgtcagcaa agcctcgcca ctccttacac ttttggcgga 300
gggaccaagg ttgagatcaa a 321
<210> 48
<211> 23
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆5 VL FR1
<400> 48
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys
20
<210> 49
<211> 11
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆5 VL CDR1
<400> 49
Arg Ala Ser Gln Ser Ile Ser Ser Tyr Leu Asn
1 5 10
<210> 50
<211> 15
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆5 VL FR2
<400> 50
Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile Tyr
1 5 10 15
<210> 51
<211> 7
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆5 VL CDR2
<400> 51
Ala Ala Ser Ser Leu Gln Ser
1 5
<210> 52
<211> 32
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆5 VL FR3
<400> 52
Gly Val Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr
1 5 10 15
Leu Thr Ile Ser Ser Leu Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys
20 25 30
<210> 53
<211> 9
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆5 VL CDR3
<400> 53
Gln Gln Ser Leu Ala Thr Pro Tyr Thr
1 5
<210> 54
<211> 10
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆5 VL FR4
<400> 54
Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
1 5 10
<210> 55
<211> 125
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆13 VH蛋白
<400> 55
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ser
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Gly Thr Phe Ser Ser Tyr
20 25 30
Ala Ile Ser Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Ser Ile Ile Pro Ile Phe Gly Thr Ala Asn Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Ile Thr Ala Asp Glu Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Pro Ser Glu Val Gly Ala Ile Leu Gly Tyr Val Trp Phe
100 105 110
Asp Pro Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120 125
<210> 56
<211> 375
<212> DNA
<213> 人工序列
<220>
<223> 合成:克隆13 VH DNA
<400> 56
caggtgcagc tggtgcagtc tggggctgag gtgaagaagc ctgggtcctc ggtgaaggtc 60
tcctgcaagg cttctggagg caccttcagc agctatgcta tcagctgggt gcgacaggcc 120
cctggacaag ggcttgagtg gatgggaagc atcatcccta tctttggtac agcaaactac 180
gcacagaagt tccagggcag agtcacgatt accgcggacg aatccacgag cacagcctac 240
atggagctga gcagcctgag atctgaggac acggcggtgt actactgcgc cagaggccct 300
tctgaagtag gagcaatact cggatatgta tggttcgacc catggggaca gggtacattg 360
gtcaccgtct cctca 375
<210> 57
<211> 26
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆13 VH FR1
<400> 57
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ser
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly
20 25
<210> 58
<211> 9
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆13 VH CDR1
<400> 58
Gly Thr Phe Ser Ser Tyr Ala Ile Ser
1 5
<210> 59
<211> 14
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆13 VH FR2
<400> 59
Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met Gly
1 5 10
<210> 60
<211> 17
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆13 VH CDR2
<400> 60
Ser Ile Ile Pro Ile Phe Gly Thr Ala Asn Tyr Ala Gln Lys Phe Gln
1 5 10 15
Gly
<210> 61
<211> 30
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆13 VH FR3
<400> 61
Arg Val Thr Ile Thr Ala Asp Glu Ser Thr Ser Thr Ala Tyr Met Glu
1 5 10 15
Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
20 25 30
<210> 62
<211> 18
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆13及13A VH CDR3
<400> 62
Ala Arg Gly Pro Ser Glu Val Gly Ala Ile Leu Gly Tyr Val Trp Phe
1 5 10 15
Asp Pro
<210> 63
<211> 11
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆13 VH FR4
<400> 63
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
1 5 10
<210> 64
<211> 112
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆13、13A、13B、13C及13D VL蛋白
<400> 64
Asp Ile Val Met Thr Gln Ser Pro Leu Ser Leu Pro Val Thr Pro Gly
1 5 10 15
Glu Pro Ala Ser Ile Ser Cys Arg Ser Ser Gln Ser Leu Leu His Ser
20 25 30
Asn Gly Tyr Asn Tyr Leu Asp Trp Tyr Leu Gln Lys Pro Gly Gln Ser
35 40 45
Pro Gln Leu Leu Ile Tyr Leu Gly Ser Asn Arg Ala Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Met Gln Ala
85 90 95
Arg Arg Ile Pro Ile Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
100 105 110
<210> 65
<211> 336
<212> DNA
<213> 人工序列
<220>
<223> 合成:克隆13 VL DNA
<400> 65
gatattgtga tgactcagtc tccactctcc ctgcccgtca cccctggaga gccggcctcc 60
atctcctgca ggtctagtca gagcctcctg catagtaatg gatacaacta tttggattgg 120
tacctgcaga agccagggca gtctccacag ctcctgatct atttgggttc taatcgggcc 180
tccggggtcc ctgacaggtt cagtggcagt ggatcaggca cagattttac actgaaaatc 240
agcagagtgg aggctgagga tgttggggtt tattactgca tgcaggcaag acgaatccct 300
atcacttttg gcggagggac caaggttgag atcaaa 336
<210> 66
<211> 23
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆13 VL FR1
<400> 66
Asp Ile Val Met Thr Gln Ser Pro Leu Ser Leu Pro Val Thr Pro Gly
1 5 10 15
Glu Pro Ala Ser Ile Ser Cys
20
<210> 67
<211> 16
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆13、13A、13B、13C及13D VL CDR1
<400> 67
Arg Ser Ser Gln Ser Leu Leu His Ser Asn Gly Tyr Asn Tyr Leu Asp
1 5 10 15
<210> 68
<211> 15
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆13 VL FR2
<400> 68
Trp Tyr Leu Gln Lys Pro Gly Gln Ser Pro Gln Leu Leu Ile Tyr
1 5 10 15
<210> 69
<211> 7
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆13、13A、13B、13C及13D VL CDR2
<400> 69
Leu Gly Ser Asn Arg Ala Ser
1 5
<210> 70
<211> 32
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆13 VL FR3
<400> 70
Gly Val Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr
1 5 10 15
Leu Lys Ile Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys
20 25 30
<210> 71
<211> 9
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆13、13A、13B、13C及13D VL CDR3
<400> 71
Met Gln Ala Arg Arg Ile Pro Ile Thr
1 5
<210> 72
<211> 10
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆13 VL FR4
<400> 72
Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
1 5 10
<210> 73
<211> 125
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆14 VH蛋白
<400> 73
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ser
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Gly Thr Phe Ser Ser Tyr
20 25 30
Ala Ile Ser Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Ser Ile Ile Pro Ile Phe Gly Thr Ala Asn Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Ile Thr Ala Asp Glu Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Pro Ser Glu Val Gly Ala Ile Leu Gly Tyr Val Trp Phe
100 105 110
Asp Pro Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120 125
<210> 74
<211> 375
<212> DNA
<213> 人工序列
<220>
<223> 合成:克隆14 VH DNA
<400> 74
caggtgcagc tggtgcagtc tggggctgag gtgaagaagc ctgggtcctc ggtgaaggtc 60
tcctgcaagg cttctggagg caccttcagc agctatgcta tcagctgggt gcgacaggcc 120
cctggacaag ggcttgagtg gatgggaagc atcatcccta tctttggtac agcaaactac 180
gcacagaagt tccagggcag agtcacgatt accgcggacg aatccacgag cacagcctac 240
atggagctga gcagcctgag atctgaggac acggcggtgt actactgcgc cagaggccct 300
tctgaagtag gagcaatact cggatatgta tggttcgacc catggggaca gggtacattg 360
gtcaccgtct cctca 375
<210> 75
<211> 26
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆14 VH FR1
<400> 75
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ser
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly
20 25
<210> 76
<211> 9
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆14 VH CDR1
<400> 76
Gly Thr Phe Ser Ser Tyr Ala Ile Ser
1 5
<210> 77
<211> 14
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆14 VH FR2
<400> 77
Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met Gly
1 5 10
<210> 78
<211> 17
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆14 VH CDR2
<400> 78
Ser Ile Ile Pro Ile Phe Gly Thr Ala Asn Tyr Ala Gln Lys Phe Gln
1 5 10 15
Gly
<210> 79
<211> 30
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆14 VH FR3
<400> 79
Arg Val Thr Ile Thr Ala Asp Glu Ser Thr Ser Thr Ala Tyr Met Glu
1 5 10 15
Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
20 25 30
<210> 80
<211> 18
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆14 VH CDR3
<400> 80
Ala Arg Gly Pro Ser Glu Val Gly Ala Ile Leu Gly Tyr Val Trp Phe
1 5 10 15
Asp Pro
<210> 81
<211> 11
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆14 VH FR4
<400> 81
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
1 5 10
<210> 82
<211> 112
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆14 VL蛋白
<400> 82
Asp Ile Val Met Thr Gln Ser Pro Leu Ser Leu Pro Val Thr Pro Gly
1 5 10 15
Glu Pro Ala Ser Ile Ser Cys Arg Ser Ser Gln Ser Leu Leu His Ser
20 25 30
Asn Gly Tyr Asn Tyr Leu Asp Trp Tyr Leu Gln Lys Pro Gly Gln Ser
35 40 45
Pro Gln Leu Leu Ile Tyr Leu Gly Ser Asn Arg Ala Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Met Gln Ala
85 90 95
Lys Arg Leu Pro Leu Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
100 105 110
<210> 83
<211> 336
<212> DNA
<213> 人工序列
<220>
<223> 合成:克隆14 VL DNA
<400> 83
gatattgtga tgactcagtc tccactctcc ctgcccgtca cccctggaga gccggcctcc 60
atctcctgca ggtctagtca gagcctcctg catagtaatg gatacaacta tttggattgg 120
tacctgcaga agccagggca gtctccacag ctcctgatct atttgggttc taatcgggcc 180
tccggggtcc ctgacaggtt cagtggcagt ggatcaggca cagattttac actgaaaatc 240
agcagagtgg aggctgagga tgttggggtt tattactgca tgcaggcaaa acgactccct 300
ctcacttttg gcggagggac caaggttgag atcaaa 336
<210> 84
<211> 23
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆14 VL FR1
<400> 84
Asp Ile Val Met Thr Gln Ser Pro Leu Ser Leu Pro Val Thr Pro Gly
1 5 10 15
Glu Pro Ala Ser Ile Ser Cys
20
<210> 85
<211> 16
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆14 VL CDR1
<400> 85
Arg Ser Ser Gln Ser Leu Leu His Ser Asn Gly Tyr Asn Tyr Leu Asp
1 5 10 15
<210> 86
<211> 15
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆14 VL FR2
<400> 86
Trp Tyr Leu Gln Lys Pro Gly Gln Ser Pro Gln Leu Leu Ile Tyr
1 5 10 15
<210> 87
<211> 7
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆14 VL CDR2
<400> 87
Leu Gly Ser Asn Arg Ala Ser
1 5
<210> 88
<211> 32
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆14 VL FR3
<400> 88
Gly Val Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr
1 5 10 15
Leu Lys Ile Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys
20 25 30
<210> 89
<211> 9
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆14 VL CDR3
<400> 89
Met Gln Ala Lys Arg Leu Pro Leu Thr
1 5
<210> 90
<211> 10
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆14 VL FR4
<400> 90
Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
1 5 10
<210> 91
<211> 121
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆16 VH蛋白
<400> 91
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ser
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Gly Thr Phe Ser Ser Tyr
20 25 30
Ala Ile Ser Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Gly Ile Ile Pro Ile Phe Gly Thr Ala Ser Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Ile Thr Ala Asp Glu Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gln Ser Thr Trp His Lys Leu Tyr Gly Thr Asp Val Trp Gly
100 105 110
Gln Gly Thr Thr Val Thr Val Ser Ser
115 120
<210> 92
<211> 363
<212> DNA
<213> 人工序列
<220>
<223> 合成:克隆16 VH DNA
<400> 92
caggtgcagc tggtgcagtc tggggctgag gtgaagaagc ctgggtcctc ggtgaaggtc 60
tcctgcaagg cttctggagg caccttcagc agctatgcta tcagctgggt gcgacaggcc 120
cctggacaag ggcttgagtg gatgggaggg atcatcccta tctttggtac agcaagctac 180
gcacagaagt tccagggcag agtcacgatt accgcggacg aatccacgag cacagcctac 240
atggagctga gcagcctgag atctgaggac acggcggtgt actactgcgc aagacagagc 300
acctggcaca aattgtacgg aacggacgta tggggccagg gaacaactgt caccgtctcc 360
tca 363
<210> 93
<211> 26
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆16 VH FR1
<400> 93
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ser
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly
20 25
<210> 94
<211> 9
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆16 VH CDR1
<400> 94
Gly Thr Phe Ser Ser Tyr Ala Ile Ser
1 5
<210> 95
<211> 14
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆16 VH FR2
<400> 95
Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met Gly
1 5 10
<210> 96
<211> 17
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆16 VH CDR2
<400> 96
Gly Ile Ile Pro Ile Phe Gly Thr Ala Ser Tyr Ala Gln Lys Phe Gln
1 5 10 15
Gly
<210> 97
<211> 30
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆16 VH FR3
<400> 97
Arg Val Thr Ile Thr Ala Asp Glu Ser Thr Ser Thr Ala Tyr Met Glu
1 5 10 15
Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
20 25 30
<210> 98
<211> 14
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆16 VH CDR3
<400> 98
Ala Arg Gln Ser Thr Trp His Lys Leu Tyr Gly Thr Asp Val
1 5 10
<210> 99
<211> 11
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆16 VH FR4
<400> 99
Trp Gly Gln Gly Thr Thr Val Thr Val Ser Ser
1 5 10
<210> 100
<211> 107
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆16、16C、16D及16E VL蛋白
<400> 100
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Val Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Gly Ile Ser Ser Trp
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Ala Ala Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Gly Asp Ser Leu Pro Pro
85 90 95
Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
100 105
<210> 101
<211> 321
<212> DNA
<213> 人工序列
<220>
<223> 合成:克隆16 VL DNA
<400> 101
gacatccaga tgacccagtc tccatcttcc gtgtctgcat ctgtaggaga cagagtcacc 60
atcacttgtc gggcgagtca gggtattagc agctggttag cctggtatca gcagaaacca 120
gggaaagccc ctaagctcct gatctatgct gcatccagtt tgcaaagtgg ggtcccatca 180
aggttcagcg gcagtggatc tgggacagat ttcactctca ccatcagcag cctgcagcct 240
gaagattttg caacttatta ctgtcagcag ggagacagtc tccctcctac ttttggcgga 300
gggaccaagg ttgagatcaa a 321
<210> 102
<211> 23
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆16 VL FR1
<400> 102
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Val Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys
20
<210> 103
<211> 11
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆16、16C、16D及16E VL CDR1
<400> 103
Arg Ala Ser Gln Gly Ile Ser Ser Trp Leu Ala
1 5 10
<210> 104
<211> 15
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆16 VL FR2
<400> 104
Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile Tyr
1 5 10 15
<210> 105
<211> 7
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆16、16C、16D及16E VL CDR2
<400> 105
Ala Ala Ser Ser Leu Gln Ser
1 5
<210> 106
<211> 32
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆16 VL FR3
<400> 106
Gly Val Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr
1 5 10 15
Leu Thr Ile Ser Ser Leu Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys
20 25 30
<210> 107
<211> 9
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆16、16C、16D及16E VL CDR3
<400> 107
Gln Gln Gly Asp Ser Leu Pro Pro Thr
1 5
<210> 108
<211> 10
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆16 VL FR4
<400> 108
Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
1 5 10
<210> 109
<211> 120
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆18 VH蛋白
<400> 109
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr
20 25 30
Tyr Met Ser Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Ile Ile Asn Pro Ser Gly Gly Ser Thr Ser Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Met Thr Arg Asp Thr Ser Thr Ser Thr Val Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Val Arg Tyr Gly Tyr Ala Asp Gly Met Asp Val Trp Gly Gln
100 105 110
Gly Thr Thr Val Thr Val Ser Ser
115 120
<210> 110
<211> 360
<212> DNA
<213> 人工序列
<220>
<223> 合成:克隆18 VH DNA
<400> 110
caggtgcagc tggtgcagtc tggggctgag gtgaagaagc ctggggcctc agtgaaggtt 60
tcctgcaagg catctggata caccttcacc agctactata tgtcatgggt gcgacaggcc 120
cctggacaag ggcttgagtg gatgggaata atcaacccta gtggtggtag cacaagctac 180
gcacagaagt tccagggcag agtcaccatg accagggaca cgtccacgag cacagtctac 240
atggagctga gcagcctgag atctgaggac acggcggtgt actactgcgc cagagtgagg 300
tacggatacg cagacggaat ggacgtatgg ggccagggaa caactgtcac cgtctcctca 360
<210> 111
<211> 26
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆18 VH FR1
<400> 111
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly
20 25
<210> 112
<211> 9
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆18 VH CDR1
<400> 112
Tyr Thr Phe Thr Ser Tyr Tyr Met Ser
1 5
<210> 113
<211> 14
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆18 VH FR2
<400> 113
Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met Gly
1 5 10
<210> 114
<211> 17
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆18 VH CDR2
<400> 114
Ile Ile Asn Pro Ser Gly Gly Ser Thr Ser Tyr Ala Gln Lys Phe Gln
1 5 10 15
Gly
<210> 115
<211> 30
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆18 VH FR3
<400> 115
Arg Val Thr Met Thr Arg Asp Thr Ser Thr Ser Thr Val Tyr Met Glu
1 5 10 15
Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
20 25 30
<210> 116
<211> 13
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆18 VH CDR3
<400> 116
Ala Arg Val Arg Tyr Gly Tyr Ala Asp Gly Met Asp Val
1 5 10
<210> 117
<211> 11
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆18 VH FR4
<400> 117
Trp Gly Gln Gly Thr Thr Val Thr Val Ser Ser
1 5 10
<210> 118
<211> 107
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆18 VL蛋白
<400> 118
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Ser Ile Ser Ser Tyr
20 25 30
Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Gly Ala Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Val Tyr His Leu Pro Phe
85 90 95
Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
100 105
<210> 119
<211> 321
<212> DNA
<213> 人工序列
<220>
<223> 合成:克隆18 VL DNA
<400> 119
gacatccaga tgacccagtc tccatcctcc ctgtctgcat ctgtaggaga cagagtcacc 60
atcacttgcc gggcaagtca gagcattagc agctatttaa attggtatca gcagaaacca 120
gggaaagccc ctaagctcct gatctatggt gcatccagtt tgcaaagtgg ggtcccatca 180
aggttcagtg gcagtggatc tgggacagat ttcactctca ccatcagcag tctgcaacct 240
gaagattttg caacttacta ctgtcagcaa gtataccacc tccctttcac ttttggcgga 300
gggaccaagg ttgagatcaa a 321
<210> 120
<211> 23
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆18 VL FR1
<400> 120
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys
20
<210> 121
<211> 11
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆18 VL CDR1
<400> 121
Arg Ala Ser Gln Ser Ile Ser Ser Tyr Leu Asn
1 5 10
<210> 122
<211> 15
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆18 VL FR2
<400> 122
Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile Tyr
1 5 10 15
<210> 123
<211> 7
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆18 VL CDR2
<400> 123
Gly Ala Ser Ser Leu Gln Ser
1 5
<210> 124
<211> 32
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆18 VL FR3
<400> 124
Gly Val Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr
1 5 10 15
Leu Thr Ile Ser Ser Leu Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys
20 25 30
<210> 125
<211> 9
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆18 VL CDR3
<400> 125
Gln Gln Val Tyr His Leu Pro Phe Thr
1 5
<210> 126
<211> 10
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆18 VL FR4
<400> 126
Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
1 5 10
<210> 127
<211> 121
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆21 VH蛋白
<400> 127
Gln Leu Gln Leu Gln Glu Ser Gly Pro Gly Leu Val Lys Pro Ser Glu
1 5 10 15
Thr Leu Ser Leu Thr Cys Thr Val Ser Gly Gly Ser Ile Ser Ser Ser
20 25 30
Ser Tyr Tyr Trp Gly Trp Ile Arg Gln Pro Pro Gly Lys Gly Leu Glu
35 40 45
Trp Ile Gly Ser Ile Tyr Tyr Ser Gly Ser Thr Tyr Tyr Asn Pro Ser
50 55 60
Leu Lys Ser Arg Val Thr Ile Ser Val Asp Thr Ser Lys Asn Gln Phe
65 70 75 80
Ser Leu Lys Leu Ser Ser Val Thr Ala Ala Asp Thr Ala Val Tyr Tyr
85 90 95
Cys Ala Arg Asp Pro Leu Tyr Gln Asp Ala Pro Phe Asp Tyr Trp Gly
100 105 110
Gln Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 128
<211> 363
<212> DNA
<213> 人工序列
<220>
<223> 合成:克隆21 VH DNA
<400> 128
cagctgcagc tgcaggagtc gggcccagga ctggtgaagc cttcggagac cctgtccctc 60
acctgcactg tctctggtgg ctccatcagc agtagtagtt actactgggg ctggatccgc 120
cagcccccag ggaaggggct ggagtggatt gggagtatct attatagtgg gagcacctac 180
tacaacccgt ccctcaagag tcgagtcacc atatccgtag acacgtccaa gaaccagttc 240
tccctgaagc tgagttctgt gaccgccgca gacacggcgg tgtactactg cgccagagat 300
cctttgtacc aagacgctcc cttcgactat tggggacagg gtacattggt caccgtctcc 360
tca 363
<210> 129
<211> 26
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆21 VH FR1
<400> 129
Gln Leu Gln Leu Gln Glu Ser Gly Pro Gly Leu Val Lys Pro Ser Glu
1 5 10 15
Thr Leu Ser Leu Thr Cys Thr Val Ser Gly
20 25
<210> 130
<211> 11
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆21 VH CDR1
<400> 130
Gly Ser Ile Ser Ser Ser Ser Tyr Tyr Trp Gly
1 5 10
<210> 131
<211> 14
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆21 VH FR2
<400> 131
Trp Ile Arg Gln Pro Pro Gly Lys Gly Leu Glu Trp Ile Gly
1 5 10
<210> 132
<211> 16
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆21 VH CDR2
<400> 132
Ser Ile Tyr Tyr Ser Gly Ser Thr Tyr Tyr Asn Pro Ser Leu Lys Ser
1 5 10 15
<210> 133
<211> 30
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆21 VH FR3
<400> 133
Arg Val Thr Ile Ser Val Asp Thr Ser Lys Asn Gln Phe Ser Leu Lys
1 5 10 15
Leu Ser Ser Val Thr Ala Ala Asp Thr Ala Val Tyr Tyr Cys
20 25 30
<210> 134
<211> 13
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆21 VH CDR3
<400> 134
Ala Arg Asp Pro Leu Tyr Gln Asp Ala Pro Phe Asp Tyr
1 5 10
<210> 135
<211> 11
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆21 VH FR4
<400> 135
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
1 5 10
<210> 136
<211> 106
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆21 VL蛋白
<400> 136
Glu Ile Val Leu Thr Gln Ser Pro Ala Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser Val Ser Ser Tyr
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu Ile
35 40 45
Tyr Asp Ala Ser Asn Arg Ala Thr Gly Ile Pro Ala Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Glu Pro
65 70 75 80
Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Arg Ala Asn Phe Pro Thr
85 90 95
Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
100 105
<210> 137
<211> 318
<212> DNA
<213> 人工序列
<220>
<223> 合成:克隆21 VL DNA
<400> 137
gaaattgtgt tgacacagtc tccagccacc ctgtctttgt ctccagggga aagagccacc 60
ctctcctgca gggccagtca gagtgttagc agctacttag cctggtacca acagaaacct 120
ggccaggctc ccaggctcct catctatgat gcatccaaca gggccactgg catcccagcc 180
aggttcagtg gcagtgggtc tgggacagac ttcactctca ccatcagcag cctagagcct 240
gaagattttg cagtttatta ctgtcagcag agagccaact tccctacttt tggcggaggg 300
accaaggttg agatcaaa 318
<210> 138
<211> 23
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆21 VL FR1
<400> 138
Glu Ile Val Leu Thr Gln Ser Pro Ala Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys
20
<210> 139
<211> 11
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆21 VL CDR1
<400> 139
Arg Ala Ser Gln Ser Val Ser Ser Tyr Leu Ala
1 5 10
<210> 140
<211> 15
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆21 VL FR2
<400> 140
Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu Ile Tyr
1 5 10 15
<210> 141
<211> 7
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆21 VL CDR2
<400> 141
Asp Ala Ser Asn Arg Ala Thr
1 5
<210> 142
<211> 32
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆21 VL FR3
<400> 142
Gly Ile Pro Ala Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr
1 5 10 15
Leu Thr Ile Ser Ser Leu Glu Pro Glu Asp Phe Ala Val Tyr Tyr Cys
20 25 30
<210> 143
<211> 8
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆21 VL CDR3
<400> 143
Gln Gln Arg Ala Asn Phe Pro Thr
1 5
<210> 144
<211> 10
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆21 VL FR4
<400> 144
Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
1 5 10
<210> 145
<211> 124
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆22 VH蛋白
<400> 145
Gln Val Gln Leu Gln Glu Ser Gly Pro Gly Leu Val Lys Pro Ser Glu
1 5 10 15
Thr Leu Ser Leu Thr Cys Ala Val Ser Gly Tyr Ser Ile Ser Ser Gly
20 25 30
Tyr Tyr Trp Ala Trp Ile Arg Gln Pro Pro Gly Lys Gly Leu Glu Trp
35 40 45
Ile Gly Ser Ile Tyr His Ser Gly Ser Thr Tyr Tyr Asn Pro Ser Leu
50 55 60
Lys Ser Arg Val Thr Ile Ser Val Asp Thr Ser Lys Asn Gln Phe Ser
65 70 75 80
Leu Lys Leu Ser Ser Val Thr Ala Ala Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gln Gly Tyr Tyr Tyr Gly Ser Ser Gly Ser Val Asp Phe Asp
100 105 110
Leu Trp Gly Arg Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 146
<211> 372
<212> DNA
<213> 人工序列
<220>
<223> 合成:克隆22 VH DNA
<400> 146
caggtgcagc tgcaggagtc gggcccagga ctggtgaagc cttcggagac cctgtccctc 60
acctgcgctg tctctggtta ctccatcagc agtggttact actgggcttg gatccggcag 120
cccccaggga aggggctgga gtggattggg agtatctatc atagtgggag cacctactac 180
aacccgtccc tcaagagtcg agtcaccata tcagtagaca cgtccaagaa ccagttctcc 240
ctgaagctga gttctgtgac cgccgcagac acggcggtgt actactgcgc caggcaggga 300
tactactacg gcagcagcgg cagtgtagac ttcgacctat gggggagagg taccttggtc 360
accgtctcct ca 372
<210> 147
<211> 26
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆22 VH FR1
<400> 147
Gln Val Gln Leu Gln Glu Ser Gly Pro Gly Leu Val Lys Pro Ser Glu
1 5 10 15
Thr Leu Ser Leu Thr Cys Ala Val Ser Gly
20 25
<210> 148
<211> 10
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆22 VH CDR1
<400> 148
Tyr Ser Ile Ser Ser Gly Tyr Tyr Trp Ala
1 5 10
<210> 149
<211> 14
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆22 VH FR2
<400> 149
Trp Ile Arg Gln Pro Pro Gly Lys Gly Leu Glu Trp Ile Gly
1 5 10
<210> 150
<211> 16
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆22 VH CDR2
<400> 150
Ser Ile Tyr His Ser Gly Ser Thr Tyr Tyr Asn Pro Ser Leu Lys Ser
1 5 10 15
<210> 151
<211> 30
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆22 VH FR3
<400> 151
Arg Val Thr Ile Ser Val Asp Thr Ser Lys Asn Gln Phe Ser Leu Lys
1 5 10 15
Leu Ser Ser Val Thr Ala Ala Asp Thr Ala Val Tyr Tyr Cys
20 25 30
<210> 152
<211> 17
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆22 VH CDR3
<400> 152
Ala Arg Gln Gly Tyr Tyr Tyr Gly Ser Ser Gly Ser Val Asp Phe Asp
1 5 10 15
Leu
<210> 153
<211> 11
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆22 VH FR4
<400> 153
Trp Gly Arg Gly Thr Leu Val Thr Val Ser Ser
1 5 10
<210> 154
<211> 108
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆22 VL蛋白
<400> 154
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Val Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Gly Ile Ser Ser Trp
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Ala Ala Ser Asn Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ala Asn Ser Leu Pro Pro
85 90 95
Trp Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
100 105
<210> 155
<211> 324
<212> DNA
<213> 人工序列
<220>
<223> 合成:克隆22 VL DNA
<400> 155
gacatccaga tgacccagtc tccatcttcc gtgtctgcat ctgtaggaga cagagtcacc 60
atcacttgtc gggcgagtca gggtattagc agctggttag cctggtatca gcagaaacca 120
gggaaagccc ctaagctcct gatctatgct gcatccaatt tgcaaagtgg ggtcccatca 180
aggttcagcg gcagtggatc tgggacagat ttcactctca ccatcagcag cctgcagcct 240
gaagattttg caacttatta ctgtcaacag gcaaatagtc tccctccttg gacttttggc 300
ggagggacca aggttgagat caaa 324
<210> 156
<211> 23
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆22 VL FR1
<400> 156
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Val Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys
20
<210> 157
<211> 11
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆22 VL CDR1
<400> 157
Arg Ala Ser Gln Gly Ile Ser Ser Trp Leu Ala
1 5 10
<210> 158
<211> 15
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆22 VL FR2
<400> 158
Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile Tyr
1 5 10 15
<210> 159
<211> 7
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆22 VL CDR2
<400> 159
Ala Ala Ser Asn Leu Gln Ser
1 5
<210> 160
<211> 32
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆22 VL FR3
<400> 160
Gly Val Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr
1 5 10 15
Leu Thr Ile Ser Ser Leu Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys
20 25 30
<210> 161
<211> 10
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆22 VL CDR3
<400> 161
Gln Gln Ala Asn Ser Leu Pro Pro Trp Thr
1 5 10
<210> 162
<211> 10
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆22 VL FR4
<400> 162
Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
1 5 10
<210> 163
<211> 125
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆25 VH蛋白
<400> 163
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr
20 25 30
Ala Ile Ser Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Trp Ile Ser Ala Tyr Asn Gly Asn Thr Asn Tyr Ala Gln Lys Leu
50 55 60
Gln Gly Arg Val Thr Met Thr Thr Asp Thr Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Arg Ser Leu Arg Ser Asp Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Leu Ser Ser Phe Trp Ser Gly Asp Val Leu Gly Ala Phe
100 105 110
Asp Ile Trp Gly Gln Gly Thr Met Val Thr Val Ser Ser
115 120 125
<210> 164
<211> 375
<212> DNA
<213> 人工序列
<220>
<223> 合成:克隆25 VH DNA
<400> 164
caggttcagc tggtgcagtc tggagctgag gtgaagaagc ctggggcctc agtgaaggtc 60
tcctgcaagg cttctggtta cacctttacc agctatgcca tcagctgggt gcgacaggcc 120
cctggacaag ggcttgagtg gatgggatgg atcagcgctt acaatggtaa cacaaactat 180
gcacagaagc tccagggcag agtcaccatg accacagaca catccacgag cacagcctac 240
atggagctga ggagcctgag atctgacgac acggcggtgt actactgcgc aagggatttg 300
tctagcttct ggagcggaga cgtgttagga gccttcgaca tatggggtca gggtacaatg 360
gtcaccgtct cctca 375
<210> 165
<211> 26
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆25 VH FR1
<400> 165
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly
20 25
<210> 166
<211> 9
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆25及25A VH CDR1
<400> 166
Tyr Thr Phe Thr Ser Tyr Ala Ile Ser
1 5
<210> 167
<211> 14
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆25 VH FR2
<400> 167
Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met Gly
1 5 10
<210> 168
<211> 17
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆25及25E VH CDR2
<400> 168
Trp Ile Ser Ala Tyr Asn Gly Asn Thr Asn Tyr Ala Gln Lys Leu Gln
1 5 10 15
Gly
<210> 169
<211> 30
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆25 VH FR3
<400> 169
Arg Val Thr Met Thr Thr Asp Thr Ser Thr Ser Thr Ala Tyr Met Glu
1 5 10 15
Leu Arg Ser Leu Arg Ser Asp Asp Thr Ala Val Tyr Tyr Cys
20 25 30
<210> 170
<211> 18
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆25、25A及25B VH CDR3
<400> 170
Ala Arg Asp Leu Ser Ser Phe Trp Ser Gly Asp Val Leu Gly Ala Phe
1 5 10 15
Asp Ile
<210> 171
<211> 11
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆25 VH FR4
<400> 171
Trp Gly Gln Gly Thr Met Val Thr Val Ser Ser
1 5 10
<210> 172
<211> 106
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆25、25A、25B、25C、25D及25E VL蛋白
<400> 172
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Ser Ile Ser Ser Tyr
20 25 30
Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Ala Ala Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ser Val Pro Pro Arg Thr
85 90 95
Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
100 105
<210> 173
<211> 318
<212> DNA
<213> 人工序列
<220>
<223> 合成:克隆25 VL DNA
<400> 173
gacatccaga tgacccagtc tccatcctcc ctgtctgcat ctgtaggaga cagagtcacc 60
atcacttgcc gggcaagtca gagcattagc agctatttaa attggtatca gcagaaacca 120
gggaaagccc ctaagctcct gatctatgct gcatccagtt tgcaaagtgg ggtcccatca 180
aggttcagtg gcagtggatc tgggacagat ttcactctca ccatcagcag tctgcaacct 240
gaagattttg caacttacta ctgtcagcaa agcgtccccc ccaggacttt tggcggaggg 300
accaaggttg agatcaaa 318
<210> 174
<211> 23
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆25 VL FR1
<400> 174
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys
20
<210> 175
<211> 11
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆25、25A、25B、25C、25D及25E VL CDR1
<400> 175
Arg Ala Ser Gln Ser Ile Ser Ser Tyr Leu Asn
1 5 10
<210> 176
<211> 15
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆25 VL FR2
<400> 176
Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile Tyr
1 5 10 15
<210> 177
<211> 7
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆25、25A、25B、25C、25D及25E VL CDR2
<400> 177
Ala Ala Ser Ser Leu Gln Ser
1 5
<210> 178
<211> 32
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆25 VL FR3
<400> 178
Gly Val Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr
1 5 10 15
Leu Thr Ile Ser Ser Leu Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys
20 25 30
<210> 179
<211> 8
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆25、25A、25B、25C、25D及25E VL CDR3
<400> 179
Gln Gln Ser Val Pro Pro Arg Thr
1 5
<210> 180
<211> 10
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆25 VL FR4
<400> 180
Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
1 5 10
<210> 181
<211> 125
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆27 VH蛋白
<400> 181
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr
20 25 30
Ala Ile Ser Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Trp Ile Ser Ala Tyr Asn Gly Asn Thr Asn Tyr Ala Gln Lys Leu
50 55 60
Gln Gly Arg Val Thr Met Thr Thr Asp Thr Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Arg Ser Leu Arg Ser Asp Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Leu Ser Ser Phe Trp Ser Gly Asp Val Leu Gly Ala Phe
100 105 110
Asp Ile Trp Gly Gln Gly Thr Met Val Thr Val Ser Ser
115 120 125
<210> 182
<211> 375
<212> DNA
<213> 人工序列
<220>
<223> 合成:克隆27 VH DNA
<400> 182
caggttcagc tggtgcagtc tggagctgag gtgaagaagc ctggggcctc agtgaaggtc 60
tcctgcaagg cttctggtta cacctttacc agctatgcca tcagctgggt gcgacaggcc 120
cctggacaag ggcttgagtg gatgggatgg atcagcgctt acaatggtaa cacaaactat 180
gcacagaagc tccagggcag agtcaccatg accacagaca catccacgag cacagcctac 240
atggagctga ggagcctgag atctgacgac acggcggtgt actactgcgc aagggatttg 300
tctagcttct ggagcggaga cgtgttagga gccttcgaca tatggggtca gggtacaatg 360
gtcaccgtct cctca 375
<210> 183
<211> 26
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆27 VH FR1
<400> 183
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly
20 25
<210> 184
<211> 9
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆27 VH CDR1
<400> 184
Tyr Thr Phe Thr Ser Tyr Ala Ile Ser
1 5
<210> 185
<211> 14
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆27 VH FR2
<400> 185
Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met Gly
1 5 10
<210> 186
<211> 17
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆27 VH CDR2
<400> 186
Trp Ile Ser Ala Tyr Asn Gly Asn Thr Asn Tyr Ala Gln Lys Leu Gln
1 5 10 15
Gly
<210> 187
<211> 30
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆27 VH FR3
<400> 187
Arg Val Thr Met Thr Thr Asp Thr Ser Thr Ser Thr Ala Tyr Met Glu
1 5 10 15
Leu Arg Ser Leu Arg Ser Asp Asp Thr Ala Val Tyr Tyr Cys
20 25 30
<210> 188
<211> 18
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆27 VH CDR3
<400> 188
Ala Arg Asp Leu Ser Ser Phe Trp Ser Gly Asp Val Leu Gly Ala Phe
1 5 10 15
Asp Ile
<210> 189
<211> 11
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆27 VH FR4
<400> 189
Trp Gly Gln Gly Thr Met Val Thr Val Ser Ser
1 5 10
<210> 190
<211> 106
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆27 VL蛋白
<400> 190
Glu Ile Val Met Thr Gln Ser Pro Ala Thr Leu Ser Val Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser Val Ser Ser Asn
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu Ile
35 40 45
Tyr Gly Ala Ser Thr Arg Ala Thr Gly Ile Pro Ala Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Glu Phe Thr Leu Thr Ile Ser Ser Leu Gln Ser
65 70 75 80
Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln His Ala Asn His Ile Thr
85 90 95
Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
100 105
<210> 191
<211> 318
<212> DNA
<213> 人工序列
<220>
<223> 合成:克隆27 VL DNA
<400> 191
gaaatagtga tgacgcagtc tccagccacc ctgtctgtgt ctccagggga aagagccacc 60
ctctcctgca gggccagtca gagtgttagc agcaacttag cctggtacca gcagaaacct 120
ggccaggctc ccaggctcct catctatggt gcatccacca gggccactgg tatcccagcc 180
aggttcagtg gcagtgggtc tgggacagag ttcactctca ccatcagcag cctgcagtct 240
gaagattttg cagtttatta ctgtcagcag cacgccaatc acatcacttt tggcggaggg 300
accaaggttg agatcaaa 318
<210> 192
<211> 23
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆27 VL FR1
<400> 192
Glu Ile Val Met Thr Gln Ser Pro Ala Thr Leu Ser Val Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys
20
<210> 193
<211> 11
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆27 VL CDR1
<400> 193
Arg Ala Ser Gln Ser Val Ser Ser Asn Leu Ala
1 5 10
<210> 194
<211> 15
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆27 VL FR2
<400> 194
Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu Ile Tyr
1 5 10 15
<210> 195
<211> 7
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆27 VL CDR2
<400> 195
Gly Ala Ser Thr Arg Ala Thr
1 5
<210> 196
<211> 32
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆27 VL FR3
<400> 196
Gly Ile Pro Ala Arg Phe Ser Gly Ser Gly Ser Gly Thr Glu Phe Thr
1 5 10 15
Leu Thr Ile Ser Ser Leu Gln Ser Glu Asp Phe Ala Val Tyr Tyr Cys
20 25 30
<210> 197
<211> 8
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆27 VL CDR3
<400> 197
Gln Gln His Ala Asn His Ile Thr
1 5
<210> 198
<211> 10
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆27 VL FR4
<400> 198
Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
1 5 10
<210> 199
<211> 124
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆54 VH蛋白
<400> 199
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr
20 25 30
Tyr Met His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Ile Ile Asn Pro Ser Gly Gly Ser Thr Ser Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Met Thr Arg Asp Thr Ser Thr Ser Thr Val Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Ala Ser Asp Ser Tyr Gly Val Gly Leu Tyr Tyr Gly Met Asp
100 105 110
Val Trp Gly Gln Gly Thr Thr Val Thr Val Ser Ser
115 120
<210> 200
<211> 372
<212> DNA
<213> 人工序列
<220>
<223> 合成:克隆54 VH DNA
<400> 200
caggtgcagc tggtgcagtc tggggctgag gtgaagaagc ctggggcctc agtgaaggtt 60
tcctgcaagg catctggata caccttcacc agctactata tgcactgggt gcgacaggcc 120
cctggacaag ggcttgagtg gatgggaata atcaacccta gtggtggtag cacaagctac 180
gcacagaagt tccagggcag agtcaccatg accagggaca cgtccacgag cacagtctac 240
atggagctga gcagcctgag atctgaggac acggcggtgt actactgcgc tagggcatct 300
gactcctacg gagtgggcct ctactacgga atggacgtat ggggccaggg aacaactgtc 360
accgtctcct ca 372
<210> 201
<211> 26
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆54 VH FR1
<400> 201
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly
20 25
<210> 202
<211> 9
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆54 VH CDR1
<400> 202
Tyr Thr Phe Thr Ser Tyr Tyr Met His
1 5
<210> 203
<211> 14
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆54 VH FR2
<400> 203
Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met Gly
1 5 10
<210> 204
<211> 17
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆54 VH CDR2
<400> 204
Ile Ile Asn Pro Ser Gly Gly Ser Thr Ser Tyr Ala Gln Lys Phe Gln
1 5 10 15
Gly
<210> 205
<211> 30
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆54 VH FR3
<400> 205
Arg Val Thr Met Thr Arg Asp Thr Ser Thr Ser Thr Val Tyr Met Glu
1 5 10 15
Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
20 25 30
<210> 206
<211> 17
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆54 VH CDR3
<400> 206
Ala Arg Ala Ser Asp Ser Tyr Gly Val Gly Leu Tyr Tyr Gly Met Asp
1 5 10 15
Val
<210> 207
<211> 11
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆54 VH FR4
<400> 207
Trp Gly Gln Gly Thr Thr Val Thr Val Ser Ser
1 5 10
<210> 208
<211> 108
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆54 VL蛋白
<400> 208
Glu Ile Val Leu Thr Gln Ser Pro Gly Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser Val Arg Ser Ser
20 25 30
Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu
35 40 45
Ile Tyr Gly Ala Ser Ser Arg Ala Thr Gly Ile Pro Asp Arg Phe Ser
50 55 60
Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Arg Leu Glu
65 70 75 80
Pro Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Tyr Tyr Val Ser Pro
85 90 95
Leu Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
100 105
<210> 209
<211> 324
<212> DNA
<213> 人工序列
<220>
<223> 合成:克隆54 VL DNA
<400> 209
gaaattgtgt tgacgcagtc tccaggcacc ctgtctttgt ctccagggga aagagccacc 60
ctctcctgca gggccagtca gagtgttagg agcagctact tagcctggta ccagcagaaa 120
cctggccagg ctcccaggct cctcatctat ggtgcatcca gcagggccac tggcatccca 180
gacaggttca gtggcagtgg gtctgggaca gacttcactc tcaccatcag cagactggag 240
cctgaagatt ttgcagtgta ttactgtcag cagtactacg tcagtcctct cacttttggc 300
ggagggacca aggttgagat caaa 324
<210> 210
<211> 23
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆54 VL FR1
<400> 210
Glu Ile Val Leu Thr Gln Ser Pro Gly Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys
20
<210> 211
<211> 12
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆54 VL CDR1
<400> 211
Arg Ala Ser Gln Ser Val Arg Ser Ser Tyr Leu Ala
1 5 10
<210> 212
<211> 15
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆54 VL FR2
<400> 212
Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu Ile Tyr
1 5 10 15
<210> 213
<211> 7
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆54 VL CDR2
<400> 213
Gly Ala Ser Ser Arg Ala Thr
1 5
<210> 214
<211> 32
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆54 VL FR3
<400> 214
Gly Ile Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr
1 5 10 15
Leu Thr Ile Ser Arg Leu Glu Pro Glu Asp Phe Ala Val Tyr Tyr Cys
20 25 30
<210> 215
<211> 9
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆54 VL CDR3
<400> 215
Gln Gln Tyr Tyr Val Ser Pro Leu Thr
1 5
<210> 216
<211> 10
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆54 VL FR4
<400> 216
Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
1 5 10
<210> 217
<211> 2978
<212> DNA
<213> 智人(Homo sapiens)
<220>
<221> misc_feature
<223> 人TIGIT cDNA序列
<400> 217
cgtcctatct gcagtcggct actttcagtg gcagaagagg ccacatctgc ttcctgtagg 60
ccctctgggc agaagcatgc gctggtgtct cctcctgatc tgggcccagg ggctgaggca 120
ggctcccctc gcctcaggaa tgatgacagg cacaatagaa acaacgggga acatttctgc 180
agagaaaggt ggctctatca tcttacaatg tcacctctcc tccaccacgg cacaagtgac 240
ccaggtcaac tgggagcagc aggaccagct tctggccatt tgtaatgctg acttggggtg 300
gcacatctcc ccatccttca aggatcgagt ggccccaggt cccggcctgg gcctcaccct 360
ccagtcgctg accgtgaacg atacagggga gtacttctgc atctatcaca cctaccctga 420
tgggacgtac actgggagaa tcttcctgga ggtcctagaa agctcagtgg ctgagcacgg 480
tgccaggttc cagattccat tgcttggagc catggccgcg acgctggtgg tcatctgcac 540
agcagtcatc gtggtggtcg cgttgactag aaagaagaaa gccctcagaa tccattctgt 600
ggaaggtgac ctcaggagaa aatcagctgg acaggaggaa tggagcccca gtgctccctc 660
acccccagga agctgtgtcc aggcagaagc tgcacctgct gggctctgtg gagagcagcg 720
gggagaggac tgtgccgagc tgcatgacta cttcaatgtc ctgagttaca gaagcctggg 780
taactgcagc ttcttcacag agactggtta gcaaccagag gcatcttctg gaagatacac 840
ttttgtcttt gctattatag atgaatatat aagcagctgt actctccatc agtgctgcgt 900
gtgtgtgtgt gtgtgtatgt gtgtgtgtgt tcagttgagt gaataaatgt catcctcttc 960
tccatcttca tttccttggc cttttcgttc tattccattt tgcattatgg caggcctagg 1020
gtgagtaacg tggatcttga tcataaatgc aaaattaaaa aatatcttga cctggtttta 1080
aatctggcag tttgagcaga tcctatgtct ctgagagaca cattcctcat aatggccagc 1140
attttgggct acaaggtttt gtggttgatg atgaggatgg catgactgca gagccatcct 1200
catctcattt tttcacgtca ttttcagtaa ctttcactca ttcaaaggca ggttataagt 1260
aagtcctggt agcagcctct atggggagat ttgagagtga ctaaatcttg gtatctgccc 1320
tcaagaactt acagttaaat ggggagacaa tgttgtcatg aaaaggtatt atagtaagga 1380
gagaaggaga catacacagg ccttcaggaa gagacgacag tttggggtga ggtagttggc 1440
ataggcttat ctgtgatgaa gtggcctggg agcaccaagg ggatgttgag gctagtctgg 1500
gaggagcagg agttttgtct agggaacttg taggaaattc ttggagctga aagtcccaca 1560
aagaaggccc tggcaccaag ggagtcagca aacttcagat tttattctct gggcaggcat 1620
ttcaagtttc cttttgctgt gacatactca tccattagac agcctgatac aggcctgtag 1680
cctcttccgg ccgtgtgtgc tggggaagcc ccaggaaacg cacatgccca cacagggagc 1740
caagtcgtag catttgggcc ttgatctacc ttttctgcat caatacactc ttgagccttt 1800
gaaaaaagaa cgtttcccac taaaaagaaa atgtggattt ttaaaatagg gactcttcct 1860
aggggaaaaa ggggggctgg gagtgataga gggtttaaaa aataaacacc ttcaaactaa 1920
cttcttcgaa cccttttatt cactccctga cgactttgtg ctggggttgg ggtaactgaa 1980
ccgcttattt ctgtttaatt gcattcaggc tggatcttag aagactttta tccttccacc 2040
atctctctca gaggaatgag cggggaggtt ggatttactg gtgactgatt ttctttcatg 2100
ggccaaggaa ctgaaagaga atgtgaagca aggttgtgtc ttgcgcatgg ttaaaaataa 2160
agcattgtcc tgcttcctaa gacttagact ggggttgaca attgttttag caacaagaca 2220
attcaactat ttctcctagg atttttatta ttattatttt ttcacttttc taccaaatgg 2280
gttacatagg aagaatgaac tgaaatctgt ccagagctcc aagtcctttg gaagaaagat 2340
tagatgaacg taaaaatgtt gttgtttgct gtggcagttt acagcatttt tcttgcaaaa 2400
ttagtgcaaa tctgttggaa atagaacaca attcacaaat tggaagtgaa ctaaaatgta 2460
atgacgaaaa gggagtagtg ttttgatttg gaggaggtgt atattcggca gaggttggac 2520
tgagagttgg gtgttattta acataattat ggtaattggg aaacatttat aaacactatt 2580
gggatggtga taaaatacaa aagggcctat agatgttaga aatgggtcag gttactgaaa 2640
tgggattcaa tttgaaaaaa atttttttaa atagaactca ctgaactaga ttctcctctg 2700
agaaccagag aagaccattt catagttgga ttcctggaga catgcgctat ccaccacgta 2760
gccactttcc acatgtggcc atcaaccact taagatgggg ttagtttaaa tcaagatgtg 2820
ctgttataat tggtataagc ataaaatcac actagattct ggagatttaa tatgaataat 2880
aagaatacta tttcagtagt tttggtatat tgtgtgtcaa aaatgataat attttggatg 2940
tattgggtga aataaaatat taacattaaa aaaaaaaa 2978
<210> 218
<211> 244
<212> PRT
<213> 智人(Homo sapiens)
<220>
<221> misc_feature
<223> 人TIGIT蛋白
<400> 218
Met Arg Trp Cys Leu Leu Leu Ile Trp Ala Gln Gly Leu Arg Gln Ala
1 5 10 15
Pro Leu Ala Ser Gly Met Met Thr Gly Thr Ile Glu Thr Thr Gly Asn
20 25 30
Ile Ser Ala Glu Lys Gly Gly Ser Ile Ile Leu Gln Cys His Leu Ser
35 40 45
Ser Thr Thr Ala Gln Val Thr Gln Val Asn Trp Glu Gln Gln Asp Gln
50 55 60
Leu Leu Ala Ile Cys Asn Ala Asp Leu Gly Trp His Ile Ser Pro Ser
65 70 75 80
Phe Lys Asp Arg Val Ala Pro Gly Pro Gly Leu Gly Leu Thr Leu Gln
85 90 95
Ser Leu Thr Val Asn Asp Thr Gly Glu Tyr Phe Cys Ile Tyr His Thr
100 105 110
Tyr Pro Asp Gly Thr Tyr Thr Gly Arg Ile Phe Leu Glu Val Leu Glu
115 120 125
Ser Ser Val Ala Glu His Gly Ala Arg Phe Gln Ile Pro Leu Leu Gly
130 135 140
Ala Met Ala Ala Thr Leu Val Val Ile Cys Thr Ala Val Ile Val Val
145 150 155 160
Val Ala Leu Thr Arg Lys Lys Lys Ala Leu Arg Ile His Ser Val Glu
165 170 175
Gly Asp Leu Arg Arg Lys Ser Ala Gly Gln Glu Glu Trp Ser Pro Ser
180 185 190
Ala Pro Ser Pro Pro Gly Ser Cys Val Gln Ala Glu Ala Ala Pro Ala
195 200 205
Gly Leu Cys Gly Glu Gln Arg Gly Glu Asp Cys Ala Glu Leu His Asp
210 215 220
Tyr Phe Asn Val Leu Ser Tyr Arg Ser Leu Gly Asn Cys Ser Phe Phe
225 230 235 240
Thr Glu Thr Gly
<210> 219
<211> 312
<212> PRT
<213> 长尾猕猴(Macaca fascicularis)
<220>
<221> misc_feature
<223> 食蟹猕猴TIGIT蛋白
<400> 219
Met Ala Phe Leu Val Ala Pro Pro Met Gln Phe Val Tyr Leu Leu Lys
1 5 10 15
Thr Leu Cys Val Phe Asn Met Val Phe Ala Lys Pro Gly Phe Ser Glu
20 25 30
Thr Val Phe Ser His Arg Leu Ser Phe Thr Val Leu Ser Ala Val Gly
35 40 45
Tyr Phe Arg Trp Gln Lys Arg Pro His Leu Leu Pro Val Ser Pro Leu
50 55 60
Gly Arg Ser Met Arg Trp Cys Leu Phe Leu Ile Trp Ala Gln Gly Leu
65 70 75 80
Arg Gln Ala Pro Leu Ala Ser Gly Met Met Thr Gly Thr Ile Glu Thr
85 90 95
Thr Gly Asn Ile Ser Ala Lys Lys Gly Gly Ser Val Ile Leu Gln Cys
100 105 110
His Leu Ser Ser Thr Met Ala Gln Val Thr Gln Val Asn Trp Glu Gln
115 120 125
His Asp His Ser Leu Leu Ala Ile Arg Asn Ala Glu Leu Gly Trp His
130 135 140
Ile Tyr Pro Ala Phe Lys Asp Arg Val Ala Pro Gly Pro Gly Leu Gly
145 150 155 160
Leu Thr Leu Gln Ser Leu Thr Met Asn Asp Thr Gly Glu Tyr Phe Cys
165 170 175
Thr Tyr His Thr Tyr Pro Asp Gly Thr Tyr Arg Gly Arg Ile Phe Leu
180 185 190
Glu Val Leu Glu Ser Ser Val Ala Glu His Ser Ala Arg Phe Gln Ile
195 200 205
Pro Leu Leu Gly Ala Met Ala Met Met Leu Val Val Ile Cys Ile Ala
210 215 220
Val Ile Val Val Val Val Leu Ala Arg Lys Lys Lys Ser Leu Arg Ile
225 230 235 240
His Ser Val Glu Ser Gly Leu Gln Arg Lys Ser Thr Gly Gln Glu Glu
245 250 255
Gln Ile Pro Ser Ala Pro Ser Pro Pro Gly Ser Cys Val Gln Ala Glu
260 265 270
Ala Ala Pro Ala Gly Leu Cys Gly Glu Gln Gln Gly Asp Asp Cys Ala
275 280 285
Glu Leu His Asp Tyr Phe Asn Val Leu Ser Tyr Arg Ser Leu Gly Ser
290 295 300
Cys Ser Phe Phe Thr Glu Thr Gly
305 310
<210> 220
<211> 241
<212> PRT
<213> 小家鼠(Mus musculus)
<220>
<221> misc_feature
<223> 小鼠TIGIT蛋白
<400> 220
Met His Gly Trp Leu Leu Leu Val Trp Val Gln Gly Leu Ile Gln Ala
1 5 10 15
Ala Phe Leu Ala Thr Gly Ala Thr Ala Gly Thr Ile Asp Thr Lys Arg
20 25 30
Asn Ile Ser Ala Glu Glu Gly Gly Ser Val Ile Leu Gln Cys His Phe
35 40 45
Ser Ser Asp Thr Ala Glu Val Thr Gln Val Asp Trp Lys Gln Gln Asp
50 55 60
Gln Leu Leu Ala Ile Tyr Ser Val Asp Leu Gly Trp His Val Ala Ser
65 70 75 80
Val Phe Ser Asp Arg Val Val Pro Gly Pro Ser Leu Gly Leu Thr Phe
85 90 95
Gln Ser Leu Thr Met Asn Asp Thr Gly Glu Tyr Phe Cys Thr Tyr His
100 105 110
Thr Tyr Pro Gly Gly Ile Tyr Lys Gly Arg Ile Phe Leu Lys Val Gln
115 120 125
Glu Ser Ser Val Ala Gln Phe Gln Thr Ala Pro Leu Gly Gly Thr Met
130 135 140
Ala Ala Val Leu Gly Leu Ile Cys Leu Met Val Thr Gly Val Thr Val
145 150 155 160
Leu Ala Arg Lys Lys Ser Ile Arg Met His Ser Ile Glu Ser Gly Leu
165 170 175
Gly Arg Thr Glu Ala Glu Pro Gln Glu Trp Asn Leu Arg Ser Leu Ser
180 185 190
Ser Pro Gly Ser Pro Val Gln Thr Gln Thr Ala Pro Ala Gly Pro Cys
195 200 205
Gly Glu Gln Ala Glu Asp Asp Tyr Ala Asp Pro Gln Glu Tyr Phe Asn
210 215 220
Val Leu Ser Tyr Arg Ser Leu Glu Ser Phe Ile Ala Val Ser Lys Thr
225 230 235 240
Gly
<210> 221
<211> 9
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆2C VH CDR1
<400> 221
Phe Thr Phe Thr Asp Tyr Tyr Met Asp
1 5
<210> 222
<211> 19
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆2C VH CDR2
<400> 222
Arg Thr Arg Asn Lys Val Asn Ser Tyr Tyr Thr Glu Tyr Ala Ala Ser
1 5 10 15
Val Lys Gly
<210> 223
<211> 19
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆2C VH CDR3
<400> 223
Ala Arg Gly Gln Tyr Tyr Tyr Gly Ser Asp Arg Arg Gly Tyr Tyr Tyr
1 5 10 15
Met Asp Val
<210> 224
<211> 9
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆13A、13C及13D VH CDR1
<400> 224
Gly Thr Phe Leu Ser Ser Ala Ile Ser
1 5
<210> 225
<211> 17
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆13A VH CDR2
<400> 225
Ser Leu Ile Pro Tyr Phe Gly Thr Ala Asn Tyr Ala Gln Lys Phe Gln
1 5 10 15
Gly
<210> 226
<211> 9
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆13B VH CDR1
<400> 226
Gly Thr Phe Ser Ala Trp Ala Ile Ser
1 5
<210> 227
<211> 17
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆13B及13D VH CDR2
<400> 227
Ser Ile Ile Pro Tyr Phe Gly Lys Ala Asn Tyr Ala Gln Lys Phe Gln
1 5 10 15
Gly
<210> 228
<211> 18
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆13B VH CDR3
<400> 228
Ala Arg Gly Pro Ser Glu Val Ser Gly Ile Leu Gly Tyr Val Trp Phe
1 5 10 15
Asp Pro
<210> 229
<211> 17
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆13C VH CDR2
<400> 229
Ser Ile Ile Pro Leu Phe Gly Lys Ala Asn Tyr Ala Gln Lys Phe Gln
1 5 10 15
Gly
<210> 230
<211> 18
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆13C及13D VH CDR3
<400> 230
Ala Arg Gly Pro Ser Glu Val Lys Gly Ile Leu Gly Tyr Val Trp Phe
1 5 10 15
Asp Pro
<210> 231
<211> 9
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆16C VH CDR1
<400> 231
Gly Thr Phe Arg Glu Tyr Ala Ile Ser
1 5
<210> 232
<211> 17
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆16C VH CDR2
<400> 232
Gly Ile His Pro Ile Phe Gly Thr Ala Arg Tyr Ala Gln Lys Phe Gln
1 5 10 15
Gly
<210> 233
<211> 9
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆16D及16E VH CDR1
<400> 233
Gly Thr Phe Ser Asp Tyr Pro Ile Ser
1 5
<210> 234
<211> 17
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆16B、16D及16E VH CDR2
<400> 234
Gly Ile Ile Pro Ile Val Gly Gly Ala Asn Tyr Ala Gln Lys Phe Gln
1 5 10 15
Gly
<210> 235
<211> 14
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆16C VH CDR3
<400> 235
Thr Arg Gln Ser Thr Trp His Lys Leu Tyr Gly Thr Asp Val
1 5 10
<210> 236
<211> 14
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆16D VH CDR3
<400> 236
Thr Arg Gln Ser Thr Trp His Lys Leu Phe Gly Thr Asp Val
1 5 10
<210> 237
<211> 14
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆16E VH CDR3
<400> 237
Ala Arg Gln Ser Thr Trp His Lys Val Tyr Gly Thr Asp Val
1 5 10
<210> 238
<211> 17
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆25A VH CDR2
<400> 238
Trp Ile Ser Ala Tyr Asn Gly Asn Thr Lys Tyr Ala Gln Lys Leu Gln
1 5 10 15
Gly
<210> 239
<211> 9
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆25B、25C及25D VH CDR1
<400> 239
Tyr Thr Phe Thr Ser Tyr Pro Ile Gly
1 5
<210> 240
<211> 17
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆25B、25C及25D VH CDR2
<400> 240
Trp Ile Ser Ser Tyr Asn Gly Asn Thr Asn Tyr Ala Gln Lys Leu Gln
1 5 10 15
Gly
<210> 241
<211> 18
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆25C VH CDR3
<400> 241
Ala Arg Gly Ala Ser Ser Phe Trp Ser Gly Asp Val Leu Gly Ala Phe
1 5 10 15
Asp Ile
<210> 242
<211> 18
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆25D VH CDR3
<400> 242
Ala Arg Asp Leu Lys Ser Phe Trp Ser Gly Asp Val Leu Gly Ala Phe
1 5 10 15
Asp Ile
<210> 243
<211> 9
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆25E VH CDR1
<400> 243
Tyr Thr Phe Thr Ser Tyr Ala Ile Ala
1 5
<210> 244
<211> 18
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆25E VH CDR3
<400> 244
Ala Arg Ser Gly Ser Ser Phe Trp Ser Gly Asp Val Leu Gly Ala Phe
1 5 10 15
Asp Ile
<210> 245
<211> 128
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆2C VH
<400> 245
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Thr Asp Tyr
20 25 30
Tyr Met Asp Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Gly Arg Thr Arg Asn Lys Val Asn Ser Tyr Tyr Thr Glu Tyr Ala Ala
50 55 60
Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asp Ser Lys Asn Ser
65 70 75 80
Leu Tyr Leu Gln Met Asn Ser Leu Lys Thr Glu Asp Thr Ala Val Tyr
85 90 95
Tyr Cys Ala Arg Gly Gln Tyr Tyr Tyr Gly Ser Asp Arg Arg Gly Tyr
100 105 110
Tyr Tyr Met Asp Val Trp Gly Gln Gly Thr Thr Val Thr Val Ser Ser
115 120 125
<210> 246
<211> 125
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆13A VH
<400> 246
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ser
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Gly Thr Phe Leu Ser Ser
20 25 30
Ala Ile Ser Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Ser Leu Ile Pro Tyr Phe Gly Thr Ala Asn Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Ile Thr Ala Asp Glu Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Pro Ser Glu Val Gly Ala Ile Leu Gly Tyr Val Trp Phe
100 105 110
Asp Pro Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120 125
<210> 247
<211> 125
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆13B VH
<400> 247
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ser
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Gly Thr Phe Ser Ala Trp
20 25 30
Ala Ile Ser Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Ser Ile Ile Pro Tyr Phe Gly Lys Ala Asn Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Ile Thr Ala Asp Glu Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Pro Ser Glu Val Ser Gly Ile Leu Gly Tyr Val Trp Phe
100 105 110
Asp Pro Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120 125
<210> 248
<211> 125
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆13C VH
<400> 248
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ser
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Gly Thr Phe Leu Ser Ser
20 25 30
Ala Ile Ser Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Ser Ile Ile Pro Leu Phe Gly Lys Ala Asn Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Ile Thr Ala Asp Glu Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Pro Ser Glu Val Lys Gly Ile Leu Gly Tyr Val Trp Phe
100 105 110
Asp Pro Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120 125
<210> 249
<211> 125
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆13D VH
<400> 249
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ser
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Gly Thr Phe Leu Ser Ser
20 25 30
Ala Ile Ser Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Ser Ile Ile Pro Tyr Phe Gly Lys Ala Asn Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Ile Thr Ala Asp Glu Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Pro Ser Glu Val Lys Gly Ile Leu Gly Tyr Val Trp Phe
100 105 110
Asp Pro Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120 125
<210> 250
<211> 121
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆16C VH
<400> 250
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ser
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Gly Thr Phe Arg Glu Tyr
20 25 30
Ala Ile Ser Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Gly Ile His Pro Ile Phe Gly Thr Ala Arg Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Ile Thr Ala Asp Glu Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Arg Gln Ser Thr Trp His Lys Leu Tyr Gly Thr Asp Val Trp Gly
100 105 110
Gln Gly Thr Thr Val Thr Val Ser Ser
115 120
<210> 251
<211> 121
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆16D VH
<400> 251
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ser
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Gly Thr Phe Ser Asp Tyr
20 25 30
Pro Ile Ser Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Gly Ile Ile Pro Ile Val Gly Gly Ala Asn Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Ile Thr Ala Asp Glu Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Arg Gln Ser Thr Trp His Lys Leu Phe Gly Thr Asp Val Trp Gly
100 105 110
Gln Gly Thr Thr Val Thr Val Ser Ser
115 120
<210> 252
<211> 121
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆16E VH
<400> 252
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ser
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Gly Thr Phe Ser Asp Tyr
20 25 30
Pro Ile Ser Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Gly Ile Ile Pro Ile Val Gly Gly Ala Asn Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Ile Thr Ala Asp Glu Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gln Ser Thr Trp His Lys Val Tyr Gly Thr Asp Val Trp Gly
100 105 110
Gln Gly Thr Thr Val Thr Val Ser Ser
115 120
<210> 253
<211> 125
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆25A VH
<400> 253
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr
20 25 30
Ala Ile Ser Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Trp Ile Ser Ala Tyr Asn Gly Asn Thr Lys Tyr Ala Gln Lys Leu
50 55 60
Gln Gly Arg Val Thr Met Thr Thr Asp Thr Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Arg Ser Leu Arg Ser Asp Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Leu Ser Ser Phe Trp Ser Gly Asp Val Leu Gly Ala Phe
100 105 110
Asp Ile Trp Gly Gln Gly Thr Met Val Thr Val Ser Ser
115 120 125
<210> 254
<211> 125
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆25B VH
<400> 254
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr
20 25 30
Pro Ile Gly Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Trp Ile Ser Ser Tyr Asn Gly Asn Thr Asn Tyr Ala Gln Lys Leu
50 55 60
Gln Gly Arg Val Thr Met Thr Thr Asp Thr Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Arg Ser Leu Arg Ser Asp Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Leu Ser Ser Phe Trp Ser Gly Asp Val Leu Gly Ala Phe
100 105 110
Asp Ile Trp Gly Gln Gly Thr Met Val Thr Val Ser Ser
115 120 125
<210> 255
<211> 125
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆25C VH
<400> 255
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr
20 25 30
Pro Ile Gly Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Trp Ile Ser Ser Tyr Asn Gly Asn Thr Asn Tyr Ala Gln Lys Leu
50 55 60
Gln Gly Arg Val Thr Met Thr Thr Asp Thr Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Arg Ser Leu Arg Ser Asp Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Ala Ser Ser Phe Trp Ser Gly Asp Val Leu Gly Ala Phe
100 105 110
Asp Ile Trp Gly Gln Gly Thr Met Val Thr Val Ser Ser
115 120 125
<210> 256
<211> 125
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆25D VH
<400> 256
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr
20 25 30
Pro Ile Gly Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Trp Ile Ser Ser Tyr Asn Gly Asn Thr Asn Tyr Ala Gln Lys Leu
50 55 60
Gln Gly Arg Val Thr Met Thr Thr Asp Thr Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Arg Ser Leu Arg Ser Asp Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Leu Lys Ser Phe Trp Ser Gly Asp Val Leu Gly Ala Phe
100 105 110
Asp Ile Trp Gly Gln Gly Thr Met Val Thr Val Ser Ser
115 120 125
<210> 257
<211> 125
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆25E VH
<400> 257
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr
20 25 30
Ala Ile Ala Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Trp Ile Ser Ala Tyr Asn Gly Asn Thr Asn Tyr Ala Gln Lys Leu
50 55 60
Gln Gly Arg Val Thr Met Thr Thr Asp Thr Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Arg Ser Leu Arg Ser Asp Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Ser Gly Ser Ser Phe Trp Ser Gly Asp Val Leu Gly Ala Phe
100 105 110
Asp Ile Trp Gly Gln Gly Thr Met Val Thr Val Ser Ser
115 120 125
<210> 258
<211> 15
<212> PRT
<213> 智人(Homo sapiens)
<220>
<221> misc_feature
<223> hTIGIT 68-82表位
<400> 258
Ile Cys Asn Ala Asp Leu Gly Trp His Ile Ser Pro Ser Phe Lys
1 5 10 15
<210> 259
<211> 1365
<212> DNA
<213> 人工序列
<220>
<223> 合成:克隆13重链hIgG1 (及无岩藻糖基化hIgG1)核苷酸序列
<400> 259
caggtgcagc tggtgcagtc tggggctgag gtgaagaagc ctgggtcctc tgtgaaggtc 60
tcctgcaagg cttctggagg caccttcagc agctatgcta tcagctgggt gcgacaggcc 120
cctggacaag ggcttgagtg gatgggaagc atcatcccta tctttggtac agcaaactac 180
gcacagaagt tccagggcag agtcaccatt actgctgatg aatccaccag cacagcctac 240
atggagctga gcagcctgag atctgaggac actgctgtgt actactgtgc cagaggccct 300
tctgaagtag gagcaatact gggatatgta tggtttgacc catggggaca gggtacattg 360
gtcaccgtct cctcagctag caccaagggc ccatctgtct tccccctggc accctcctcc 420
aagagcacct ctgggggcac agctgccctg ggctgcctgg tcaaggacta cttccctgaa 480
cctgtgacag tgtcctggaa ctcaggagcc ctgaccagcg gcgtgcacac cttcccggct 540
gtcctacagt cctcaggact ctactccctc agcagcgtgg tgaccgtgcc ctccagcagc 600
ttgggcaccc agacctacat ctgcaacgtg aatcacaagc ccagcaacac caaggtggac 660
aagaaagttg agcccaaatc ttgtgacaaa actcacacat gcccaccgtg cccagcacct 720
gaactcctgg ggggaccgtc agtcttcctc ttccccccaa aacccaagga caccctcatg 780
atctcccgga cccctgaggt cacatgcgtg gtggtggacg tgagccacga agaccctgag 840
gtcaagttca actggtacgt ggacggcgtg gaggtgcata atgccaagac aaagccgcgg 900
gaggagcagt acaacagcac gtaccgtgtg gtcagcgtcc tcaccgtcct gcaccaggac 960
tggctgaatg gcaaggagta caagtgcaag gtctccaaca aagccctccc agcccccatc 1020
gagaaaacca tctccaaagc caaagggcag ccccgagaac cacaggttta caccctgccc 1080
ccatcccggg atgagctgac caagaaccag gtcagcctga cctgcctggt caaaggcttc 1140
tatcccagcg acatcgccgt ggagtgggag agcaatgggc agccggagaa caactacaag 1200
accacgcctc ccgtgctgga ctccgacggc tccttcttcc tctacagcaa gctcaccgtg 1260
gacaagagca ggtggcagca ggggaacgtc ttctcatgct ccgtgatgca tgaggctctg 1320
cacaaccact acacacagaa gagcctctcc ctgtctccgg gcaaa 1365
<210> 260
<211> 455
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆13重链hIgG1 (及无岩藻糖基化hIgG1)氨基酸序列
<400> 260
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ser
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Gly Thr Phe Ser Ser Tyr
20 25 30
Ala Ile Ser Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Ser Ile Ile Pro Ile Phe Gly Thr Ala Asn Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Ile Thr Ala Asp Glu Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Pro Ser Glu Val Gly Ala Ile Leu Gly Tyr Val Trp Phe
100 105 110
Asp Pro Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr
115 120 125
Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser
130 135 140
Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu
145 150 155 160
Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His
165 170 175
Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser
180 185 190
Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys
195 200 205
Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu
210 215 220
Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro
225 230 235 240
Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys
245 250 255
Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val
260 265 270
Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp
275 280 285
Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr
290 295 300
Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp
305 310 315 320
Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu
325 330 335
Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg
340 345 350
Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys
355 360 365
Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp
370 375 380
Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys
385 390 395 400
Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser
405 410 415
Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser
420 425 430
Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser
435 440 445
Leu Ser Leu Ser Pro Gly Lys
450 455
<210> 261
<211> 1365
<212> DNA
<213> 人工序列
<220>
<223> 合成:克隆13重链hIgG1 LALA-PG核苷酸序列
<400> 261
caggtgcagc tggtgcagtc tggggctgag gtgaagaagc ctgggtcctc tgtgaaggtc 60
tcctgcaagg cttctggagg caccttcagc agctatgcta tcagctgggt gcgacaggcc 120
cctggacaag ggcttgagtg gatgggaagc atcatcccta tctttggtac agcaaactac 180
gcacagaagt tccagggcag agtcaccatt actgctgatg aatccaccag cacagcctac 240
atggagctga gcagcctgag atctgaggac actgctgtgt actactgtgc cagaggccct 300
tctgaagtag gagcaatact gggatatgta tggtttgacc catggggaca gggtacattg 360
gtcaccgtct cctcagctag caccaagggc ccatctgtct tccccctggc accctcctcc 420
aagagcacct ctgggggcac agctgccctg ggctgcctgg tcaaggacta cttccctgaa 480
cctgtgacag tgtcctggaa ctcaggagcc ctgaccagcg gcgtgcacac cttcccggct 540
gtcctacagt cctcaggact ctactccctc agcagcgtgg tgaccgtgcc ctccagcagc 600
ttgggcaccc agacctacat ctgcaacgtg aatcacaagc ccagcaacac caaggtggac 660
aagaaagttg agcccaaatc ttgtgacaaa actcacacat gcccaccgtg cccagcacct 720
gaagctgctg ggggaccgtc agtcttcctc ttccccccaa aacccaagga caccctcatg 780
atctcccgga cccctgaggt cacatgcgtg gtggtggacg tgagccacga agaccctgag 840
gtcaagttca actggtacgt ggacggcgtg gaggtgcata atgccaagac aaagccgcgg 900
gaggagcagt acaacagcac gtaccgtgtg gtcagcgtcc tcaccgtcct gcaccaggac 960
tggctgaatg gcaaggagta caagtgcaag gtctccaaca aagccctcgg ggcccccatc 1020
gagaaaacca tctccaaagc caaagggcag ccccgagaac cacaggttta caccctgccc 1080
ccatcccggg atgagctgac caagaaccag gtcagcctga cctgcctggt caaaggcttc 1140
tatcccagcg acatcgccgt ggagtgggag agcaatgggc agccggagaa caactacaag 1200
accacgcctc ccgtgctgga ctccgacggc tccttcttcc tctacagcaa gctcaccgtg 1260
gacaagagca ggtggcagca ggggaacgtc ttctcatgct ccgtgatgca tgaggctctg 1320
cacaaccact acacacagaa gagcctctcc ctgtctccgg gcaaa 1365
<210> 262
<211> 455
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆13重链hIgG1 LALA-PG氨基酸序列
<400> 262
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ser
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Gly Thr Phe Ser Ser Tyr
20 25 30
Ala Ile Ser Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Ser Ile Ile Pro Ile Phe Gly Thr Ala Asn Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Ile Thr Ala Asp Glu Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Pro Ser Glu Val Gly Ala Ile Leu Gly Tyr Val Trp Phe
100 105 110
Asp Pro Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr
115 120 125
Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser
130 135 140
Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu
145 150 155 160
Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His
165 170 175
Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser
180 185 190
Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys
195 200 205
Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu
210 215 220
Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro
225 230 235 240
Glu Ala Ala Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys
245 250 255
Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val
260 265 270
Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp
275 280 285
Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr
290 295 300
Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp
305 310 315 320
Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu
325 330 335
Gly Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg
340 345 350
Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys
355 360 365
Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp
370 375 380
Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys
385 390 395 400
Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser
405 410 415
Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser
420 425 430
Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser
435 440 445
Leu Ser Leu Ser Pro Gly Lys
450 455
<210> 263
<211> 1356
<212> DNA
<213> 人工序列
<220>
<223> 合成:克隆13重链hIgG4 S228P核苷酸序列
<400> 263
caggtgcagc tggtgcagtc tggggctgag gtgaagaagc ctgggtcctc tgtgaaggtc 60
tcctgcaagg cttctggagg caccttcagc agctatgcta tcagctgggt gcgacaggcc 120
cctggacaag ggcttgagtg gatgggaagc atcatcccta tctttggtac agcaaactac 180
gcacagaagt tccagggcag agtcaccatt actgctgatg aatccaccag cacagcctac 240
atggagctga gcagcctgag atctgaggac actgctgtgt actactgtgc cagaggccct 300
tctgaagtag gagcaatact gggatatgta tggtttgacc catggggaca gggtacattg 360
gtcaccgtct cctcagctag caccaagggc ccatctgtct tccccctggc cccttgctcc 420
agaagcacat ctgagagcac agcggccctg ggatgcctgg tcaaggacta tttccctgag 480
ccggtgaccg taagctggaa ctctggagcc ctgaccagcg gcgtgcacac cttcccagct 540
gtcctgcagt cttcagggct ctactccctc agcagtgtgg tgactgtacc ctccagcagc 600
ttgggcacca agacctacac ctgcaacgta gatcacaagc ccagcaacac caaggtggac 660
aagagagttg agtccaaata tggtccccca tgcccaccct gcccagcacc agagttcctg 720
gggggaccat ctgtcttcct cttcccccca aaacccaagg ataccctcat gatctcccgg 780
acccctgagg tcacatgtgt ggtggtggac gtgagccagg aggaccccga ggtccagttc 840
aactggtatg tggatggcgt ggaagtgcat aatgctaaga caaagccacg ggaggagcag 900
ttcaacagca cctaccgtgt ggtcagcgtc ctcacagtgc tgcaccagga ctggctgaat 960
ggcaaggagt acaaatgcaa ggtctccaac aaaggcctcc catcctccat cgagaaaacc 1020
atctccaaag ccaaagggca accccgggaa ccacaggtat acaccctgcc tccatcccaa 1080
gaagagatga ccaagaacca ggtcagcctg acctgcctgg tcaaaggctt ctacccctct 1140
gacattgccg tggagtggga gagcaatggg cagccagaga acaactacaa gaccacacct 1200
cccgtgctgg actccgatgg ctccttcttc ctgtactccc ggctcacagt ggacaagagc 1260
aggtggcagg agggaaatgt cttctcctgc tccgtgatgc atgaggctct gcacaaccac 1320
tacacacaga agagcctctc cctgtctctg ggcaaa 1356
<210> 264
<211> 452
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆13重链hIgG4 S228P氨基酸序列
<400> 264
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ser
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Gly Thr Phe Ser Ser Tyr
20 25 30
Ala Ile Ser Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Ser Ile Ile Pro Ile Phe Gly Thr Ala Asn Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Ile Thr Ala Asp Glu Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Pro Ser Glu Val Gly Ala Ile Leu Gly Tyr Val Trp Phe
100 105 110
Asp Pro Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr
115 120 125
Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Cys Ser Arg Ser Thr Ser
130 135 140
Glu Ser Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu
145 150 155 160
Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His
165 170 175
Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser
180 185 190
Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Lys Thr Tyr Thr Cys
195 200 205
Asn Val Asp His Lys Pro Ser Asn Thr Lys Val Asp Lys Arg Val Glu
210 215 220
Ser Lys Tyr Gly Pro Pro Cys Pro Pro Cys Pro Ala Pro Glu Phe Leu
225 230 235 240
Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu
245 250 255
Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser
260 265 270
Gln Glu Asp Pro Glu Val Gln Phe Asn Trp Tyr Val Asp Gly Val Glu
275 280 285
Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr
290 295 300
Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn
305 310 315 320
Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Gly Leu Pro Ser Ser
325 330 335
Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln
340 345 350
Val Tyr Thr Leu Pro Pro Ser Gln Glu Glu Met Thr Lys Asn Gln Val
355 360 365
Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val
370 375 380
Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro
385 390 395 400
Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Arg Leu Thr
405 410 415
Val Asp Lys Ser Arg Trp Gln Glu Gly Asn Val Phe Ser Cys Ser Val
420 425 430
Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu
435 440 445
Ser Leu Gly Lys
450
<210> 265
<211> 1365
<212> DNA
<213> 人工序列
<220>
<223> 合成:克隆13A重链hIgG1 (及无岩藻糖基化hIgG1)核苷酸序列
<400> 265
caggtgcagc tggtgcagtc tggggctgag gtgaagaagc ctgggtcctc tgtgaaggtc 60
tcctgcaagg cttctggagg caccttcctt agctctgcta tcagctgggt gcgacaggcc 120
cctggacaag ggcttgagtg gatgggatct ctcatccctt attttggtac agcaaactac 180
gcacagaagt tccagggcag agtcaccatt actgctgatg aatccaccag cacagcctac 240
atggagctga gcagcctgag atctgaggac actgctgtgt actactgtgc cagaggccct 300
tctgaagtag gagcaatact gggatatgta tggtttgacc catggggaca gggtacattg 360
gtcaccgtct cctcagctag caccaagggc ccatctgtct tccccctggc accctcctcc 420
aagagcacct ctgggggcac agctgccctg ggctgcctgg tcaaggacta cttccctgaa 480
cctgtgacag tgtcctggaa ctcaggagcc ctgaccagcg gcgtgcacac cttcccggct 540
gtcctacagt cctcaggact ctactccctc agcagcgtgg tgaccgtgcc ctccagcagc 600
ttgggcaccc agacctacat ctgcaacgtg aatcacaagc ccagcaacac caaggtggac 660
aagaaagttg agcccaaatc ttgtgacaaa actcacacat gcccaccgtg cccagcacct 720
gaactcctgg ggggaccgtc agtcttcctc ttccccccaa aacccaagga caccctcatg 780
atctcccgga cccctgaggt cacatgcgtg gtggtggacg tgagccacga agaccctgag 840
gtcaagttca actggtacgt ggacggcgtg gaggtgcata atgccaagac aaagccgcgg 900
gaggagcagt acaacagcac gtaccgtgtg gtcagcgtcc tcaccgtcct gcaccaggac 960
tggctgaatg gcaaggagta caagtgcaag gtctccaaca aagccctccc agcccccatc 1020
gagaaaacca tctccaaagc caaagggcag ccccgagaac cacaggttta caccctgccc 1080
ccatcccggg atgagctgac caagaaccag gtcagcctga cctgcctggt caaaggcttc 1140
tatcccagcg acatcgccgt ggagtgggag agcaatgggc agccggagaa caactacaag 1200
accacgcctc ccgtgctgga ctccgacggc tccttcttcc tctacagcaa gctcaccgtg 1260
gacaagagca ggtggcagca ggggaacgtc ttctcatgct ccgtgatgca tgaggctctg 1320
cacaaccact acacacagaa gagcctctcc ctgtctccgg gcaaa 1365
<210> 266
<211> 455
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆13A重链hIgG1 (及无岩藻糖基化hIgG1)氨基酸序列
<400> 266
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ser
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Gly Thr Phe Leu Ser Ser
20 25 30
Ala Ile Ser Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Ser Leu Ile Pro Tyr Phe Gly Thr Ala Asn Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Ile Thr Ala Asp Glu Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Pro Ser Glu Val Gly Ala Ile Leu Gly Tyr Val Trp Phe
100 105 110
Asp Pro Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr
115 120 125
Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser
130 135 140
Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu
145 150 155 160
Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His
165 170 175
Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser
180 185 190
Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys
195 200 205
Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu
210 215 220
Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro
225 230 235 240
Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys
245 250 255
Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val
260 265 270
Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp
275 280 285
Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr
290 295 300
Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp
305 310 315 320
Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu
325 330 335
Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg
340 345 350
Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys
355 360 365
Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp
370 375 380
Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys
385 390 395 400
Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser
405 410 415
Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser
420 425 430
Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser
435 440 445
Leu Ser Leu Ser Pro Gly Lys
450 455
<210> 267
<211> 1365
<212> DNA
<213> 人工序列
<220>
<223> 合成:克隆13B重链hIgG1 (及无岩藻糖基化hIgG1)核苷酸序列
<400> 267
caggtgcagc tggtgcagtc tggggctgag gtgaagaagc ctgggtcctc tgtgaaggtc 60
tcctgcaagg cttctggagg caccttctct gcctgggcta tcagctgggt gcgacaggcc 120
cctggacaag ggcttgagtg gatgggatcc atcatccctt attttggtaa ggcaaactac 180
gcacagaagt tccagggcag agtcaccatt actgctgatg aatccaccag cacagcctac 240
atggagctga gcagcctgag atctgaggac actgctgtgt actactgtgc cagaggccct 300
tctgaagtaa gtggtatact gggatatgta tggtttgacc catggggaca gggtacattg 360
gtcaccgtct cctcagctag caccaagggc ccatctgtct tccccctggc accctcctcc 420
aagagcacct ctgggggcac agctgccctg ggctgcctgg tcaaggacta cttccctgaa 480
cctgtgacag tgtcctggaa ctcaggagcc ctgaccagcg gcgtgcacac cttcccggct 540
gtcctacagt cctcaggact ctactccctc agcagcgtgg tgaccgtgcc ctccagcagc 600
ttgggcaccc agacctacat ctgcaacgtg aatcacaagc ccagcaacac caaggtggac 660
aagaaagttg agcccaaatc ttgtgacaaa actcacacat gcccaccgtg cccagcacct 720
gaactcctgg ggggaccgtc agtcttcctc ttccccccaa aacccaagga caccctcatg 780
atctcccgga cccctgaggt cacatgcgtg gtggtggacg tgagccacga agaccctgag 840
gtcaagttca actggtacgt ggacggcgtg gaggtgcata atgccaagac aaagccgcgg 900
gaggagcagt acaacagcac gtaccgtgtg gtcagcgtcc tcaccgtcct gcaccaggac 960
tggctgaatg gcaaggagta caagtgcaag gtctccaaca aagccctccc agcccccatc 1020
gagaaaacca tctccaaagc caaagggcag ccccgagaac cacaggttta caccctgccc 1080
ccatcccggg atgagctgac caagaaccag gtcagcctga cctgcctggt caaaggcttc 1140
tatcccagcg acatcgccgt ggagtgggag agcaatgggc agccggagaa caactacaag 1200
accacgcctc ccgtgctgga ctccgacggc tccttcttcc tctacagcaa gctcaccgtg 1260
gacaagagca ggtggcagca ggggaacgtc ttctcatgct ccgtgatgca tgaggctctg 1320
cacaaccact acacacagaa gagcctctcc ctgtctccgg gcaaa 1365
<210> 268
<211> 455
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆13B重链hIgG1 (及无岩藻糖基化hIgG1)氨基酸序列
<400> 268
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ser
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Gly Thr Phe Ser Ala Trp
20 25 30
Ala Ile Ser Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Ser Ile Ile Pro Tyr Phe Gly Lys Ala Asn Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Ile Thr Ala Asp Glu Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Pro Ser Glu Val Ser Gly Ile Leu Gly Tyr Val Trp Phe
100 105 110
Asp Pro Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr
115 120 125
Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser
130 135 140
Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu
145 150 155 160
Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His
165 170 175
Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser
180 185 190
Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys
195 200 205
Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu
210 215 220
Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro
225 230 235 240
Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys
245 250 255
Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val
260 265 270
Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp
275 280 285
Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr
290 295 300
Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp
305 310 315 320
Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu
325 330 335
Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg
340 345 350
Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys
355 360 365
Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp
370 375 380
Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys
385 390 395 400
Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser
405 410 415
Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser
420 425 430
Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser
435 440 445
Leu Ser Leu Ser Pro Gly Lys
450 455
<210> 269
<211> 1365
<212> DNA
<213> 人工序列
<220>
<223> 合成:克隆13C重链hIgG1 (及无岩藻糖基化hIgG1)核苷酸序列
<400> 269
caggtgcagc tggtgcagtc tggggctgag gtgaagaagc ctgggtcctc tgtgaaggtc 60
tcctgcaagg cttctggagg caccttcctt agctctgcta tcagctgggt gcgacaggcc 120
cctggacaag ggcttgagtg gatgggaagt atcatccctc tgtttggtaa ggcaaactac 180
gcacagaagt tccagggcag agtcaccatt actgctgatg aatccaccag cacagcctac 240
atggagctga gcagcctgag atctgaggac actgctgtgt actactgtgc cagaggccct 300
tctgaagtaa agggtatact gggatatgta tggtttgacc catggggaca gggtacattg 360
gtcaccgtct cctcagctag caccaagggc ccatctgtct tccccctggc accctcctcc 420
aagagcacct ctgggggcac agctgccctg ggctgcctgg tcaaggacta cttccctgaa 480
cctgtgacag tgtcctggaa ctcaggagcc ctgaccagcg gcgtgcacac cttcccggct 540
gtcctacagt cctcaggact ctactccctc agcagcgtgg tgaccgtgcc ctccagcagc 600
ttgggcaccc agacctacat ctgcaacgtg aatcacaagc ccagcaacac caaggtggac 660
aagaaagttg agcccaaatc ttgtgacaaa actcacacat gcccaccgtg cccagcacct 720
gaactcctgg ggggaccgtc agtcttcctc ttccccccaa aacccaagga caccctcatg 780
atctcccgga cccctgaggt cacatgcgtg gtggtggacg tgagccacga agaccctgag 840
gtcaagttca actggtacgt ggacggcgtg gaggtgcata atgccaagac aaagccgcgg 900
gaggagcagt acaacagcac gtaccgtgtg gtcagcgtcc tcaccgtcct gcaccaggac 960
tggctgaatg gcaaggagta caagtgcaag gtctccaaca aagccctccc agcccccatc 1020
gagaaaacca tctccaaagc caaagggcag ccccgagaac cacaggttta caccctgccc 1080
ccatcccggg atgagctgac caagaaccag gtcagcctga cctgcctggt caaaggcttc 1140
tatcccagcg acatcgccgt ggagtgggag agcaatgggc agccggagaa caactacaag 1200
accacgcctc ccgtgctgga ctccgacggc tccttcttcc tctacagcaa gctcaccgtg 1260
gacaagagca ggtggcagca ggggaacgtc ttctcatgct ccgtgatgca tgaggctctg 1320
cacaaccact acacacagaa gagcctctcc ctgtctccgg gcaaa 1365
<210> 270
<211> 455
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆13C重链hIgG1 (及无岩藻糖基化hIgG1)氨基酸序列
<400> 270
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ser
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Gly Thr Phe Leu Ser Ser
20 25 30
Ala Ile Ser Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Ser Ile Ile Pro Leu Phe Gly Lys Ala Asn Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Ile Thr Ala Asp Glu Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Pro Ser Glu Val Lys Gly Ile Leu Gly Tyr Val Trp Phe
100 105 110
Asp Pro Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr
115 120 125
Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser
130 135 140
Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu
145 150 155 160
Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His
165 170 175
Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser
180 185 190
Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys
195 200 205
Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu
210 215 220
Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro
225 230 235 240
Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys
245 250 255
Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val
260 265 270
Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp
275 280 285
Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr
290 295 300
Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp
305 310 315 320
Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu
325 330 335
Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg
340 345 350
Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys
355 360 365
Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp
370 375 380
Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys
385 390 395 400
Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser
405 410 415
Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser
420 425 430
Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser
435 440 445
Leu Ser Leu Ser Pro Gly Lys
450 455
<210> 271
<211> 1365
<212> DNA
<213> 人工序列
<220>
<223> 合成:克隆13D重链hIgG1 (及无岩藻糖基化hIgG1)核苷酸序列
<400> 271
caggtgcagc tggtgcagtc tggggctgag gtgaagaagc ctgggtcctc tgtgaaggtc 60
tcctgcaagg cttctggagg caccttcctt agctctgcta tcagctgggt gcgacaggcc 120
cctggacaag ggcttgagtg gatgggatcc atcatccctt attttggtaa ggcaaactac 180
gcacagaagt tccagggcag agtcaccatt actgctgatg aatccaccag cacagcctac 240
atggagctga gcagcctgag atctgaggac actgctgtgt actactgtgc cagaggccct 300
tctgaagtaa agggtatact gggatatgta tggtttgacc catggggaca gggtacattg 360
gtcaccgtct cctcagctag caccaagggc ccatctgtct tccccctggc accctcctcc 420
aagagcacct ctgggggcac agctgccctg ggctgcctgg tcaaggacta cttccctgaa 480
cctgtgacag tgtcctggaa ctcaggagcc ctgaccagcg gcgtgcacac cttcccggct 540
gtcctacagt cctcaggact ctactccctc agcagcgtgg tgaccgtgcc ctccagcagc 600
ttgggcaccc agacctacat ctgcaacgtg aatcacaagc ccagcaacac caaggtggac 660
aagaaagttg agcccaaatc ttgtgacaaa actcacacat gcccaccgtg cccagcacct 720
gaactcctgg ggggaccgtc agtcttcctc ttccccccaa aacccaagga caccctcatg 780
atctcccgga cccctgaggt cacatgcgtg gtggtggacg tgagccacga agaccctgag 840
gtcaagttca actggtacgt ggacggcgtg gaggtgcata atgccaagac aaagccgcgg 900
gaggagcagt acaacagcac gtaccgtgtg gtcagcgtcc tcaccgtcct gcaccaggac 960
tggctgaatg gcaaggagta caagtgcaag gtctccaaca aagccctccc agcccccatc 1020
gagaaaacca tctccaaagc caaagggcag ccccgagaac cacaggttta caccctgccc 1080
ccatcccggg atgagctgac caagaaccag gtcagcctga cctgcctggt caaaggcttc 1140
tatcccagcg acatcgccgt ggagtgggag agcaatgggc agccggagaa caactacaag 1200
accacgcctc ccgtgctgga ctccgacggc tccttcttcc tctacagcaa gctcaccgtg 1260
gacaagagca ggtggcagca ggggaacgtc ttctcatgct ccgtgatgca tgaggctctg 1320
cacaaccact acacacagaa gagcctctcc ctgtctccgg gcaaa 1365
<210> 272
<211> 455
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆13D重链hIgG1 (及无岩藻糖基化hIgG1)氨基酸序列
<400> 272
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ser
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Gly Thr Phe Leu Ser Ser
20 25 30
Ala Ile Ser Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Ser Ile Ile Pro Tyr Phe Gly Lys Ala Asn Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Ile Thr Ala Asp Glu Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Pro Ser Glu Val Lys Gly Ile Leu Gly Tyr Val Trp Phe
100 105 110
Asp Pro Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr
115 120 125
Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser
130 135 140
Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu
145 150 155 160
Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His
165 170 175
Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser
180 185 190
Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys
195 200 205
Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu
210 215 220
Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro
225 230 235 240
Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys
245 250 255
Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val
260 265 270
Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp
275 280 285
Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr
290 295 300
Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp
305 310 315 320
Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu
325 330 335
Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg
340 345 350
Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys
355 360 365
Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp
370 375 380
Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys
385 390 395 400
Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser
405 410 415
Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser
420 425 430
Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser
435 440 445
Leu Ser Leu Ser Pro Gly Lys
450 455
<210> 273
<211> 657
<212> DNA
<213> 人工序列
<220>
<223> 合成:克隆13、13A、13B、13C及13D轻链κ (及无岩藻糖基化)核苷酸序列
<400> 273
gatattgtga tgactcagtc tccactctcc ctgcccgtca cccctggaga gccggcctcc 60
atctcctgca ggtctagtca gagcctcctg catagtaatg gatacaacta tttggattgg 120
tacctgcaga agccagggca gtctccacag ctcctgatct atttgggttc taatcgggcc 180
tccggggtcc ctgacaggtt cagtggcagt ggatcaggca cagattttac actgaaaatc 240
agcagagtgg aggctgagga tgttggggtt tattactgca tgcaggcaag acgaatccct 300
atcacttttg gcggagggac caaggttgag atcaaacgta cggtggctgc accatctgtc 360
ttcatcttcc cgccatctga tgagcagttg aaatctggaa ctgcctctgt tgtgtgcctg 420
ctgaataact tctatcccag agaggccaaa gtacagtgga aggtggataa cgccctccaa 480
tcgggtaact cccaggagag tgtcacagag caggacagca aggacagcac ctacagcctc 540
agcagcaccc tgacgctgag caaagcagac tacgagaaac acaaagtcta cgcctgcgaa 600
gtcacccatc agggcctgag ctcgcccgtc acaaagagct tcaacagggg agagtgt 657
<210> 274
<211> 219
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆13、13A、13B、13C及13D轻链κ (及无岩藻糖基化)氨基酸序列
<400> 274
Asp Ile Val Met Thr Gln Ser Pro Leu Ser Leu Pro Val Thr Pro Gly
1 5 10 15
Glu Pro Ala Ser Ile Ser Cys Arg Ser Ser Gln Ser Leu Leu His Ser
20 25 30
Asn Gly Tyr Asn Tyr Leu Asp Trp Tyr Leu Gln Lys Pro Gly Gln Ser
35 40 45
Pro Gln Leu Leu Ile Tyr Leu Gly Ser Asn Arg Ala Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Met Gln Ala
85 90 95
Arg Arg Ile Pro Ile Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
100 105 110
Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu
115 120 125
Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe
130 135 140
Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln
145 150 155 160
Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser
165 170 175
Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu
180 185 190
Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser
195 200 205
Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
210 215
<210> 275
<211> 1365
<212> DNA
<213> 人工序列
<220>
<223> 合成:克隆13重链mIgG2a (及无岩藻糖基化)核苷酸序列
<400> 275
caggtgcagc tggtgcagtc tggggctgag gtgaagaagc ctgggtcctc tgtgaaggtc 60
tcctgcaagg cttctggagg caccttcagc agctatgcta tcagctgggt gcgacaggcc 120
cctggacaag ggcttgagtg gatgggaagc atcatcccta tctttggtac agcaaactac 180
gcacagaagt tccagggcag agtcaccatt actgctgatg aatccaccag cacagcctac 240
atggagctga gcagcctgag atctgaggac actgctgtgt actactgtgc cagaggccct 300
tctgaagtag gagcaatact gggatatgta tggtttgacc catggggaca gggtacattg 360
gtcaccgtct cctcagctaa aacaacagcc ccatcggtct atccgctagc ccctgtgtgt 420
ggagatacaa ctggctcctc ggtgactcta ggatgcctgg tcaagggtta tttccctgag 480
ccagtgacct tgacctggaa ctctggatcc ctgtccagtg gtgtgcacac cttcccagct 540
gtcctgcagt ctgacctcta caccctcagc agctcagtga ctgtaacctc tagcacctgg 600
cccagccagt ccatcacctg caatgtggcc cacccggcaa gcagcaccaa ggtggacaag 660
aaaattgagc ccagagggcc cacaatcaag ccctgtcctc catgcaaatg cccagcacct 720
aacgctgctg gtggaccatc cgtcttcatc ttccctccaa agatcaagga tgtactcatg 780
atctccctga gccccatagt cacatgtgtg gtggtggatg tgagcgagga tgacccagat 840
gtccagatca gctggtttgt gaacaacgtg gaagtacaca cagctcagac acaaacccat 900
agagaggatt acaacagtac tctccgggtg gtcagtgccc tccccatcca gcaccaggac 960
tggatgagtg gcaaggagtt caaatgcaag gtcaacaaca aagacctcgg ggcgcccatc 1020
gagagaacca tctcaaaacc caaaggctca gtaagagctc cacaggtata tgtcttgcct 1080
ccaccagaag aagagatgac taagaaacag gtcactctga cctgcatggt cacagacttc 1140
atgcctgaag acatttacgt ggagtggacc aacaacggga aaacagagct aaactacaag 1200
aacactgaac cagtcctgga ctctgatggt tcttacttca tgtacagcaa gctgagagtg 1260
gaaaagaaga actgggtgga aagaaatagc tactcctgtt cagtggtcca cgagggtctg 1320
cacaatcacc acacgactaa gagcttctcc cggactccgg gcaaa 1365
<210> 276
<211> 455
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆13重链mIgG2a (及无岩藻糖基化)氨基酸序列
<400> 276
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ser
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Gly Thr Phe Ser Ser Tyr
20 25 30
Ala Ile Ser Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Ser Ile Ile Pro Ile Phe Gly Thr Ala Asn Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Ile Thr Ala Asp Glu Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Pro Ser Glu Val Gly Ala Ile Leu Gly Tyr Val Trp Phe
100 105 110
Asp Pro Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ala Lys Thr
115 120 125
Thr Ala Pro Ser Val Tyr Pro Leu Ala Pro Val Cys Gly Asp Thr Thr
130 135 140
Gly Ser Ser Val Thr Leu Gly Cys Leu Val Lys Gly Tyr Phe Pro Glu
145 150 155 160
Pro Val Thr Leu Thr Trp Asn Ser Gly Ser Leu Ser Ser Gly Val His
165 170 175
Thr Phe Pro Ala Val Leu Gln Ser Asp Leu Tyr Thr Leu Ser Ser Ser
180 185 190
Val Thr Val Thr Ser Ser Thr Trp Pro Ser Gln Ser Ile Thr Cys Asn
195 200 205
Val Ala His Pro Ala Ser Ser Thr Lys Val Asp Lys Lys Ile Glu Pro
210 215 220
Arg Gly Pro Thr Ile Lys Pro Cys Pro Pro Cys Lys Cys Pro Ala Pro
225 230 235 240
Asn Ala Ala Gly Gly Pro Ser Val Phe Ile Phe Pro Pro Lys Ile Lys
245 250 255
Asp Val Leu Met Ile Ser Leu Ser Pro Ile Val Thr Cys Val Val Val
260 265 270
Asp Val Ser Glu Asp Asp Pro Asp Val Gln Ile Ser Trp Phe Val Asn
275 280 285
Asn Val Glu Val His Thr Ala Gln Thr Gln Thr His Arg Glu Asp Tyr
290 295 300
Asn Ser Thr Leu Arg Val Val Ser Ala Leu Pro Ile Gln His Gln Asp
305 310 315 320
Trp Met Ser Gly Lys Glu Phe Lys Cys Lys Val Asn Asn Lys Asp Leu
325 330 335
Gly Ala Pro Ile Glu Arg Thr Ile Ser Lys Pro Lys Gly Ser Val Arg
340 345 350
Ala Pro Gln Val Tyr Val Leu Pro Pro Pro Glu Glu Glu Met Thr Lys
355 360 365
Lys Gln Val Thr Leu Thr Cys Met Val Thr Asp Phe Met Pro Glu Asp
370 375 380
Ile Tyr Val Glu Trp Thr Asn Asn Gly Lys Thr Glu Leu Asn Tyr Lys
385 390 395 400
Asn Thr Glu Pro Val Leu Asp Ser Asp Gly Ser Tyr Phe Met Tyr Ser
405 410 415
Lys Leu Arg Val Glu Lys Lys Asn Trp Val Glu Arg Asn Ser Tyr Ser
420 425 430
Cys Ser Val Val His Glu Gly Leu His Asn His His Thr Thr Lys Ser
435 440 445
Phe Ser Arg Thr Pro Gly Lys
450 455
<210> 277
<211> 1365
<212> DNA
<213> 人工序列
<220>
<223> 合成:克隆13重链mIgG2a LALA-PG核苷酸序列
<400> 277
caggtgcagc tggtgcagtc tggggctgag gtgaagaagc ctgggtcctc tgtgaaggtc 60
tcctgcaagg cttctggagg caccttcagc agctatgcta tcagctgggt gcgacaggcc 120
cctggacaag ggcttgagtg gatgggaagc atcatcccta tctttggtac agcaaactac 180
gcacagaagt tccagggcag agtcaccatt actgctgatg aatccaccag cacagcctac 240
atggagctga gcagcctgag atctgaggac actgctgtgt actactgtgc cagaggccct 300
tctgaagtag gagcaatact gggatatgta tggtttgacc catggggaca gggtacattg 360
gtcaccgtct cctcagctaa aacaacagcc ccatcggtct atccgctagc ccctgtgtgt 420
ggagatacaa ctggctcctc ggtgactcta ggatgcctgg tcaagggtta tttccctgag 480
ccagtgacct tgacctggaa ctctggatcc ctgtccagtg gtgtgcacac cttcccagct 540
gtcctgcagt ctgacctcta caccctcagc agctcagtga ctgtaacctc tagcacctgg 600
cccagccagt ccatcacctg caatgtggcc cacccggcaa gcagcaccaa ggtggacaag 660
aaaattgagc ccagagggcc cacaatcaag ccctgtcctc catgcaaatg cccagcacct 720
aacgctgctg gtggaccatc cgtcttcatc ttccctccaa agatcaagga tgtactcatg 780
atctccctga gccccatagt cacatgtgtg gtggtggatg tgagcgagga tgacccagat 840
gtccagatca gctggtttgt gaacaacgtg gaagtacaca cagctcagac acaaacccat 900
agagaggatt acaacagtac tctccgggtg gtcagtgccc tccccatcca gcaccaggac 960
tggatgagtg gcaaggagtt caaatgcaag gtcaacaaca aagacctcgg ggcgcccatc 1020
gagagaacca tctcaaaacc caaaggctca gtaagagctc cacaggtata tgtcttgcct 1080
ccaccagaag aagagatgac taagaaacag gtcactctga cctgcatggt cacagacttc 1140
atgcctgaag acatttacgt ggagtggacc aacaacggga aaacagagct aaactacaag 1200
aacactgaac cagtcctgga ctctgatggt tcttacttca tgtacagcaa gctgagagtg 1260
gaaaagaaga actgggtgga aagaaatagc tactcctgtt cagtggtcca cgagggtctg 1320
cacaatcacc acacgactaa gagcttctcc cggactccgg gcaaa 1365
<210> 278
<211> 455
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆13重链mIgG2a LALA-PG氨基酸序列
<400> 278
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ser
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Gly Thr Phe Ser Ser Tyr
20 25 30
Ala Ile Ser Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Ser Ile Ile Pro Ile Phe Gly Thr Ala Asn Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Ile Thr Ala Asp Glu Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Pro Ser Glu Val Gly Ala Ile Leu Gly Tyr Val Trp Phe
100 105 110
Asp Pro Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ala Lys Thr
115 120 125
Thr Ala Pro Ser Val Tyr Pro Leu Ala Pro Val Cys Gly Asp Thr Thr
130 135 140
Gly Ser Ser Val Thr Leu Gly Cys Leu Val Lys Gly Tyr Phe Pro Glu
145 150 155 160
Pro Val Thr Leu Thr Trp Asn Ser Gly Ser Leu Ser Ser Gly Val His
165 170 175
Thr Phe Pro Ala Val Leu Gln Ser Asp Leu Tyr Thr Leu Ser Ser Ser
180 185 190
Val Thr Val Thr Ser Ser Thr Trp Pro Ser Gln Ser Ile Thr Cys Asn
195 200 205
Val Ala His Pro Ala Ser Ser Thr Lys Val Asp Lys Lys Ile Glu Pro
210 215 220
Arg Gly Pro Thr Ile Lys Pro Cys Pro Pro Cys Lys Cys Pro Ala Pro
225 230 235 240
Asn Ala Ala Gly Gly Pro Ser Val Phe Ile Phe Pro Pro Lys Ile Lys
245 250 255
Asp Val Leu Met Ile Ser Leu Ser Pro Ile Val Thr Cys Val Val Val
260 265 270
Asp Val Ser Glu Asp Asp Pro Asp Val Gln Ile Ser Trp Phe Val Asn
275 280 285
Asn Val Glu Val His Thr Ala Gln Thr Gln Thr His Arg Glu Asp Tyr
290 295 300
Asn Ser Thr Leu Arg Val Val Ser Ala Leu Pro Ile Gln His Gln Asp
305 310 315 320
Trp Met Ser Gly Lys Glu Phe Lys Cys Lys Val Asn Asn Lys Asp Leu
325 330 335
Gly Ala Pro Ile Glu Arg Thr Ile Ser Lys Pro Lys Gly Ser Val Arg
340 345 350
Ala Pro Gln Val Tyr Val Leu Pro Pro Pro Glu Glu Glu Met Thr Lys
355 360 365
Lys Gln Val Thr Leu Thr Cys Met Val Thr Asp Phe Met Pro Glu Asp
370 375 380
Ile Tyr Val Glu Trp Thr Asn Asn Gly Lys Thr Glu Leu Asn Tyr Lys
385 390 395 400
Asn Thr Glu Pro Val Leu Asp Ser Asp Gly Ser Tyr Phe Met Tyr Ser
405 410 415
Lys Leu Arg Val Glu Lys Lys Asn Trp Val Glu Arg Asn Ser Tyr Ser
420 425 430
Cys Ser Val Val His Glu Gly Leu His Asn His His Thr Thr Lys Ser
435 440 445
Phe Ser Arg Thr Pro Gly Lys
450 455
<210> 279
<211> 1347
<212> DNA
<213> 人工序列
<220>
<223> 合成:克隆13重链mIgG1核苷酸序列
<400> 279
caggtgcagc tggtgcagtc tggggctgag gtgaagaagc ctgggtcctc tgtgaaggtc 60
tcctgcaagg cttctggagg caccttcagc agctatgcta tcagctgggt gcgacaggcc 120
cctggacaag ggcttgagtg gatgggaagc atcatcccta tctttggtac agcaaactac 180
gcacagaagt tccagggcag agtcaccatt actgctgatg aatccaccag cacagcctac 240
atggagctga gcagcctgag atctgaggac actgctgtgt actactgtgc cagaggccct 300
tctgaagtag gagcaatact gggatatgta tggtttgacc catggggaca gggtacattg 360
gtcaccgtct cctcagccaa aacgacaccc ccatctgtct atccgctagc ccctggatct 420
gctgcccaaa ctaactccat ggtgaccctg ggatgcctgg tcaagggcta tttccctgag 480
ccagtgacag tgacctggaa ctctggatcc ctgtccagcg gtgtgcacac cttcccagct 540
gtcctggagt ctgacctcta cactctgagc agctcagtga ctgtcccctc cagccctcgg 600
cccagcgaga ccgtcacctg caacgttgcc cacccggcca gcagcaccaa ggtggacaag 660
aaaattgtgc ccagggattg tggttgtaag ccttgcatct gtacagtccc agaagtatca 720
tctgtcttca tcttcccccc aaagcccaag gatgtgctca ccattactct gactcctaag 780
gtcacgtgtg ttgtggtaga catcagcaag gatgatcccg aggtccagtt cagctggttt 840
gtagatgatg tggaggtgca cacagctcag acgcaacccc gggaggagca gttcaacagc 900
actttccgct cagtcagtga acttcccatc atgcaccagg actggctcaa tggcaaggag 960
ttcaaatgca gggtcaacag tgcagctttc cctgccccca tcgagaaaac catctccaaa 1020
accaaaggca gaccgaaggc tccacaggtg tacaccattc cacctcccaa ggagcagatg 1080
gccaaggata aagtcagtct gacctgcatg ataacagact tcttccctga agacattact 1140
gtggagtggc agtggaatgg gcagccagcg gagaactaca agaacactca gcccatcatg 1200
aacacgaatg gctcttactt cgtctacagc aagctcaatg tgcagaagag caactgggag 1260
gcaggaaata ctttcacctg ctctgtgtta catgagggcc tgcacaacca ccatactgag 1320
aagagcctct cccactctcc tggcaaa 1347
<210> 280
<211> 449
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆13重链mIgG1氨基酸序列
<400> 280
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ser
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Gly Thr Phe Ser Ser Tyr
20 25 30
Ala Ile Ser Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Ser Ile Ile Pro Ile Phe Gly Thr Ala Asn Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Ile Thr Ala Asp Glu Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Pro Ser Glu Val Gly Ala Ile Leu Gly Tyr Val Trp Phe
100 105 110
Asp Pro Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ala Lys Thr
115 120 125
Thr Pro Pro Ser Val Tyr Pro Leu Ala Pro Gly Ser Ala Ala Gln Thr
130 135 140
Asn Ser Met Val Thr Leu Gly Cys Leu Val Lys Gly Tyr Phe Pro Glu
145 150 155 160
Pro Val Thr Val Thr Trp Asn Ser Gly Ser Leu Ser Ser Gly Val His
165 170 175
Thr Phe Pro Ala Val Leu Glu Ser Asp Leu Tyr Thr Leu Ser Ser Ser
180 185 190
Val Thr Val Pro Ser Ser Pro Arg Pro Ser Glu Thr Val Thr Cys Asn
195 200 205
Val Ala His Pro Ala Ser Ser Thr Lys Val Asp Lys Lys Ile Val Pro
210 215 220
Arg Asp Cys Gly Cys Lys Pro Cys Ile Cys Thr Val Pro Glu Val Ser
225 230 235 240
Ser Val Phe Ile Phe Pro Pro Lys Pro Lys Asp Val Leu Thr Ile Thr
245 250 255
Leu Thr Pro Lys Val Thr Cys Val Val Val Asp Ile Ser Lys Asp Asp
260 265 270
Pro Glu Val Gln Phe Ser Trp Phe Val Asp Asp Val Glu Val His Thr
275 280 285
Ala Gln Thr Gln Pro Arg Glu Glu Gln Phe Asn Ser Thr Phe Arg Ser
290 295 300
Val Ser Glu Leu Pro Ile Met His Gln Asp Trp Leu Asn Gly Lys Glu
305 310 315 320
Phe Lys Cys Arg Val Asn Ser Ala Ala Phe Pro Ala Pro Ile Glu Lys
325 330 335
Thr Ile Ser Lys Thr Lys Gly Arg Pro Lys Ala Pro Gln Val Tyr Thr
340 345 350
Ile Pro Pro Pro Lys Glu Gln Met Ala Lys Asp Lys Val Ser Leu Thr
355 360 365
Cys Met Ile Thr Asp Phe Phe Pro Glu Asp Ile Thr Val Glu Trp Gln
370 375 380
Trp Asn Gly Gln Pro Ala Glu Asn Tyr Lys Asn Thr Gln Pro Ile Met
385 390 395 400
Asn Thr Asn Gly Ser Tyr Phe Val Tyr Ser Lys Leu Asn Val Gln Lys
405 410 415
Ser Asn Trp Glu Ala Gly Asn Thr Phe Thr Cys Ser Val Leu His Glu
420 425 430
Gly Leu His Asn His His Thr Glu Lys Ser Leu Ser His Ser Pro Gly
435 440 445
Lys
<210> 281
<211> 657
<212> DNA
<213> 人工序列
<220>
<223> 合成:克隆13轻链mκ核苷酸序列
<400> 281
gatattgtga tgactcagtc tccactctcc ctgcccgtca cccctggaga gccggcctcc 60
atctcctgca ggtctagtca gagcctcctg catagtaatg gatacaacta tttggattgg 120
tacctgcaga agccagggca gtctccacag ctcctgatct atttgggttc taatcgggcc 180
tccggggtcc ctgacaggtt cagtggcagt ggatcaggca cagattttac actgaaaatc 240
agcagagtgg aggctgagga tgttggggtt tattactgca tgcaggcaag acgaatccct 300
atcacttttg gcggagggac caaggttgag atcaaacgtg cagatgcggc gccaactgta 360
tccatcttcc caccatccag tgagcagtta acatctggag gtgcctcagt cgtgtgcttc 420
ttgaacaact tctaccccaa agacatcaat gtcaagtgga agattgatgg cagtgaacga 480
caaaatggcg tcctgaacag ttggactgat caggacagca aagacagcac ctacagcatg 540
agcagcaccc tcacgttgac caaggacgag tatgaacgac ataacagcta tacctgtgag 600
gccactcaca agacatcaac ttcacccatt gtcaagagct tcaacaggaa tgagtgt 657
<210> 282
<211> 219
<212> PRT
<213> 人工序列
<220>
<223> 合成:克隆13轻链mκ氨基酸序列
<400> 282
Asp Ile Val Met Thr Gln Ser Pro Leu Ser Leu Pro Val Thr Pro Gly
1 5 10 15
Glu Pro Ala Ser Ile Ser Cys Arg Ser Ser Gln Ser Leu Leu His Ser
20 25 30
Asn Gly Tyr Asn Tyr Leu Asp Trp Tyr Leu Gln Lys Pro Gly Gln Ser
35 40 45
Pro Gln Leu Leu Ile Tyr Leu Gly Ser Asn Arg Ala Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Met Gln Ala
85 90 95
Arg Arg Ile Pro Ile Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
100 105 110
Arg Ala Asp Ala Ala Pro Thr Val Ser Ile Phe Pro Pro Ser Ser Glu
115 120 125
Gln Leu Thr Ser Gly Gly Ala Ser Val Val Cys Phe Leu Asn Asn Phe
130 135 140
Tyr Pro Lys Asp Ile Asn Val Lys Trp Lys Ile Asp Gly Ser Glu Arg
145 150 155 160
Gln Asn Gly Val Leu Asn Ser Trp Thr Asp Gln Asp Ser Lys Asp Ser
165 170 175
Thr Tyr Ser Met Ser Ser Thr Leu Thr Leu Thr Lys Asp Glu Tyr Glu
180 185 190
Arg His Asn Ser Tyr Thr Cys Glu Ala Thr His Lys Thr Ser Thr Ser
195 200 205
Pro Ile Val Lys Ser Phe Asn Arg Asn Glu Cys
210 215
<210> 283
<211> 8
<212> PRT
<213> 人工序列
<220>
<223> 合成
<400> 283
Gly Gly Thr Phe Ser Ser Tyr Ala
1 5
<210> 284
<211> 5
<212> PRT
<213> 人工序列
<220>
<223> 合成
<400> 284
Ser Tyr Ala Ile Ser
1 5
<210> 285
<211> 8
<212> PRT
<213> 人工序列
<220>
<223> 合成
<400> 285
Ile Ile Pro Ile Phe Gly Thr Ala
1 5
<210> 286
<211> 16
<212> PRT
<213> 人工序列
<220>
<223> 合成
<400> 286
Gly Pro Ser Glu Val Gly Ala Ile Leu Gly Tyr Val Trp Phe Asp Pro
1 5 10 15
<210> 287
<211> 11
<212> PRT
<213> 人工序列
<220>
<223> 合成
<400> 287
Gln Ser Leu Leu His Ser Asn Gly Tyr Asn Tyr
1 5 10
<210> 288
<211> 3
<212> PRT
<213> 人工序列
<220>
<223> 合成
<400> 288
Leu Gly Ser
1
<210> 289
<211> 8
<212> PRT
<213> 人工序列
<220>
<223> 合成
<400> 289
Gly Gly Thr Phe Ser Ala Trp Ala
1 5
<210> 290
<211> 5
<212> PRT
<213> 人工序列
<220>
<223> 合成
<400> 290
Ala Trp Ala Ile Ser
1 5
<210> 291
<211> 8
<212> PRT
<213> 人工序列
<220>
<223> 合成
<400> 291
Ile Ile Pro Tyr Phe Gly Lys Ala
1 5
<210> 292
<211> 16
<212> PRT
<213> 人工序列
<220>
<223> 合成
<400> 292
Gly Pro Ser Glu Val Ser Gly Ile Leu Gly Tyr Val Trp Phe Asp Pro
1 5 10 15
<210> 293
<211> 8
<212> PRT
<213> 人工序列
<220>
<223> 合成
<400> 293
Gly Gly Thr Phe Leu Ser Ser Ala
1 5
<210> 294
<211> 5
<212> PRT
<213> 人工序列
<220>
<223> 合成
<400> 294
Ser Ser Ala Ile Ser
1 5
<210> 295
<211> 8
<212> PRT
<213> 人工序列
<220>
<223> 合成
<400> 295
Ile Ile Pro Leu Phe Gly Lys Ala
1 5
<210> 296
<211> 16
<212> PRT
<213> 人工序列
<220>
<223> 合成
<400> 296
Gly Pro Ser Glu Val Lys Gly Ile Leu Gly Tyr Val Trp Phe Asp Pro
1 5 10 15
<210> 297
<211> 8
<212> PRT
<213> 人工序列
<220>
<223> 合成
<400> 297
Leu Ile Pro Tyr Phe Gly Thr Ala
1 5
<210> 298
<211> 13
<212> PRT
<213> 人工序列
<220>
<223> 合成
<400> 298
Ile Leu Gln Cys His Leu Ser Ser Thr Thr Ala Gln Val
1 5 10
<210> 299
<211> 15
<212> PRT
<213> 人工序列
<220>
<223> 合成
<400> 299
Cys Ile Tyr His Thr Tyr Pro Asp Gly Thr Tyr Thr Gly Arg Ile
1 5 10 15
<210> 300
<211> 11
<212> PRT
<213> 人工序列
<220>
<223> 合成
<400> 300
Ser Phe Lys Asp Arg Val Ala Pro Gly Pro Gly
1 5 10
<210> 301
<211> 7
<212> PRT
<213> 人工序列
<220>
<223> 合成
<400> 301
Thr Thr Ala Gln Val Thr Gln
1 5
<210> 302
<211> 33
<212> PRT
<213> 人工序列
<220>
<223> 合成
<220>
<221> misc_feature
<222> (5)..(5)
<223> Xaa是Cys-acm
<220>
<221> misc_feature
<222> (19)..(19)
<223> Xaa是Cys-acm
<400> 302
Cys Ile Leu Gln Xaa His Leu Ser Ser Thr Thr Ala Gln Val Thr Gln
1 5 10 15
Cys Ile Xaa Asn Ala Asp Leu Gly Trp His Ile Ser Pro Ser Phe Lys
20 25 30
Cys
<210> 303
<211> 33
<212> PRT
<213> 人工序列
<220>
<223> 合成
<220>
<221> misc_feature
<222> (19)..(19)
<223> Xaa是Cys-acm
<400> 303
Cys Lys Asp Arg Val Ala Pro Gly Pro Gly Leu Gly Leu Thr Leu Gln
1 5 10 15
Cys Ile Xaa Asn Ala Asp Leu Gly Trp His Ile Ser Pro Ser Phe Lys
20 25 30
Cys
<210> 304
<211> 7
<212> PRT
<213> 人工序列
<220>
<223> 合成
<400> 304
Ala Asp His Ile Gln Arg Tyr
1 5
<210> 305
<211> 5
<212> PRT
<213> 人工序列
<220>
<223> 合成
<400> 305
Thr Ala Gln Val Thr
1 5
<210> 306
<211> 4
<212> PRT
<213> 人工序列
<220>
<223> 合成
<400> 306
Gly Trp His Ile
1
<210> 307
<211> 7
<212> PRT
<213> 人工序列
<220>
<223> 合成
<400> 307
Pro Gly Pro Gly Leu Gly Leu
1 5
<210> 308
<211> 5
<212> PRT
<213> 人工序列
<220>
<223> 合成
<400> 308
Lys Asp Arg Val Ala
1 5
<210> 309
<211> 5
<212> PRT
<213> 人工序列
<220>
<223> 合成
<400> 309
Gly Gly Ser Gly Gly
1 5
Claims (184)
1.一种组合物,其包含结合人TIGIT(具有Ig及ITIM结构域的T细胞免疫受体)的分离抗体,其中所述抗体对人TIGIT的结合亲和性(KD)小于5nM,且其中所述组合物中至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%或至少99%的所述抗体是无岩藻糖基化的。
2.如权利要求1所述的组合物,其中所述抗体对人TIGIT的KD小于1nM。
3.如权利要求1所述的组合物,其中所述抗体对人TIGIT的KD小于100pM。
4.如权利要求1至3中任一项所述的组合物,其中所述抗体表现出与食蟹猕猴TIGIT和/或小鼠TIGIT的交叉反应性。
5.如权利要求4所述的组合物,其中所述抗体表现出与食蟹猕猴TIGIT及小鼠TIGIT两者的交叉反应性。
6.如权利要求1至5中任一项所述的组合物,其中所述抗体阻断CD155与TIGIT的结合。
7.如权利要求1至5中任一项所述的组合物,其中所述抗体阻断CD112与TIGIT的结合。
8.如权利要求1至5中任一项所述的组合物,其中所述抗体阻断CD155及CD112两者与TIGIT的结合。
9.如权利要求1至8中任一项所述的组合物,其中所述抗体与包括包含SEQ ID NO:55所示氨基酸序列的重链可变区及包含SEQ ID NO:64所示氨基酸序列的轻链可变区的抗体竞争结合人TIGIT。
10.如权利要求1至9中任一项所述的组合物,其中所述抗体在结合人TIGIT时结合氨基酸位置81及82中之一或两者。
11.如权利要求10所述的组合物,其中所述抗体结合氨基酸位置81及82两者。
12.如权利要求10或11所述的组合物,其中氨基酸位置81及82是Phe81和Lys82。
13.如权利要求1至12中任一项所述的组合物,其中所述抗体结合人TIGIT上包含氨基酸位置81及82中之一或两者的表位。
14.一种组合物,其包含结合人TIGIT的分离抗体,其中所述抗体在结合人TIGIT时结合氨基酸位置81及82中之一或两者,且其中所述组合物中至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%或至少99%的所述抗体是无岩藻糖基化的。
15.如权利要求14所述的组合物,其中所述抗体结合氨基酸位置81及82两者。
16.如权利要求14或15所述的组合物,其中氨基酸位置81及82是Phe81和Lys82。
17.一种组合物,其包含结合人TIGIT的分离抗体,其中所述抗体结合人TIGIT上包含氨基酸位置81及82中之一或两者的表位,且其中所述组合物中至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%或至少99%的所述抗体是无岩藻糖基化的。
18.如权利要求13或17所述的组合物,其中所述表位包含第81位的Phe。
19.如权利要求13、17及18中任一项所述的组合物,其中所述表位包含第82位的Lys或Ser。
20.如权利要求13及17至19中任一项所述的组合物,其中所述表位包含第81位的Phe及第82位的Lys或Ser。
21.如权利要求20所述的组合物,其中所述表位包含Phe81和Lys82。
22.如权利要求13及17至21中任一项所述的组合物,其中所述表位是不连续表位。
23.如权利要求13及17至22中任一项所述的组合物,其中所述抗体结合人TIGIT上进一步包含氨基酸位置51、52、53、54、55、73、74、75、76、77、79、83、84、85、86、87、88、89、90、91、92或93中之一或多者的表位。
24.如权利要求23所述的组合物,其中所述表位进一步包含一个或多个选自下组的氨基酸残基:Thr51、Ala52、Gln53、Val54、Thr55、Leu73、Gly74、Trp75、His76、Ile77、Pro79、Asp83、Arg84、Val85、Ala86、Pro87、Gly88、Pro89、Gly90、Leu91、Gly92及Leu93。
25.如权利要求24所述的组合物,其中所述表位包含氨基酸残基Thr51、Ala52、Gln53、Val54、Thr55、Gly74、Trp75、His76、Ile77、Phe81、Lys82、Pro87、Gly88、Pro89、Gly90、Leu91、Gly92及Leu93。
26.如权利要求24所述的组合物,其中所述表位包含氨基酸残基Ala52、Gln53、Leu73、Gly74、Trp75、Pro79、Phe81、Lys82、Asp83、Arg84、Val85及Ala86。
27.如权利要求13及17至26中任一项所述的组合物,其中所述表位包含序列ICNADLGWHISPSFK(SEQ ID NO:258)。
28.如权利要求1至27中任一项所述的组合物,其中人TIGIT包含序列SEQ ID NO:218。
29.如权利要求1至28中任一项所述的组合物,其中各抗体包含以下之一或多者:
(a)重链CDR1,其包含选自SEQ ID NO:4、SEQ ID NO:22、SEQ ID NO:40、SEQ ID NO:58、SEQ ID NO:76、SEQ ID NO:94、SEQ ID NO:112、SEQ ID NO:130、SEQ ID NO:148、SEQ IDNO:166、SEQ ID NO:184、SEQ ID NO:202、SEQ ID NO:221、SEQ ID NO:224、SEQ ID NO:226、SEQ ID NO:231、SEQ ID NO:233、SEQ ID NO:239、SEQ ID NO:243、SEQ ID NO:283、SEQ IDNO:284、SEQ ID NO:293、SEQ ID NO:294、SEQ ID NO:289及SEQ ID NO:290的序列;
(b)重链CDR2,其包含选自SEQ ID NO:6、SEQ ID NO:24、SEQ ID NO:42、SEQ ID NO:60、SEQ ID NO:78、SEQ ID NO:96、SEQ ID NO:114、SEQ ID NO:132、SEQ ID NO:150、SEQ IDNO:168、SEQ ID NO:186、SEQ ID NO:204、SEQ ID NO:222、SEQ ID NO:225、SEQ ID NO:227、SEQ ID NO:229、SEQ ID NO:232、SEQ ID NO:234、SEQ ID NO:238、SEQ ID NO:240、SEQ IDNO:285、SEQ ID NO:297、SEQ ID NO:291及SEQ ID NO:295的序列;
(c)重链CDR3,其包含选自SEQ ID NO:8、SEQ ID NO:26、SEQ ID NO:44、SEQ ID NO:62、SEQ ID NO:80、SEQ ID NO:98、SEQ ID NO:116、SEQ ID NO:134、SEQ ID NO:152、SEQ IDNO:170、SEQ ID NO:188、SEQ ID NO:206、SEQ ID NO:223、SEQ ID NO:228、SEQ ID NO:230、SEQ ID NO:235、SEQ ID NO:236、SEQ ID NO:237、SEQ ID NO:241、SEQ ID NO:242、SEQ IDNO:244、SEQ ID NO:286、SEQ ID NO:292及SEQ ID NO:296的序列;
(d)轻链CDR1,其包含选自SEQ ID NO:13、SEQ ID NO:31、SEQ ID NO:49、SEQ ID NO:67、SEQ ID NO:85、SEQ ID NO:103、SEQ ID NO:121、SEQ ID NO:139、SEQ ID NO:157、SEQID NO:175、SEQ ID NO:193、SEQ ID NO:211及SEQ ID NO:287的序列;
(e)轻链CDR2,其包含选自SEQ ID NO:15、SEQ ID NO:33、SEQ ID NO:51、SEQ ID NO:69、SEQ ID NO:87、SEQ ID NO:105、SEQ ID NO:123、SEQ ID NO:141、SEQ ID NO:159、SEQID NO:177、SEQ ID NO:195、SEQ ID NO:213及SEQ ID NO:288的序列;或
(f)轻链CDR3,其包含选自SEQ ID NO:17、SEQ ID NO:35、SEQ ID NO:53、SEQ ID NO:71、SEQ ID NO:89、SEQ ID NO:107、SEQ ID NO:125、SEQ ID NO:143、SEQ ID NO:161、SEQID NO:179、SEQ ID NO:197及SEQ ID NO:215的序列。
30.如权利要求29所述的组合物,其中各抗体包含:
(a)重链CDR1序列,其包含选自SEQ ID NO:58、SEQ ID NO:283、SEQ ID NO:284、SEQ IDNO:224、SEQ ID NO:293、SEQ ID NO:294、SEQ ID NO:226、SEQ ID NO:289及SEQ ID NO:290的氨基酸序列;
(b)重链CDR2序列,其包含选自SEQ ID NO:60、SEQ ID NO:285、SEQ ID NO:225、SEQ IDNO:297、SEQ ID NO:227、SEQ ID NO:291、SEQ ID NO:229及SEQ ID NO:295的氨基酸序列;
(c)重链CDR3序列,其包含选自SEQ ID NO:62、SEQ ID NO:286、SEQ ID NO:228、SEQ IDNO:292、SEQ ID NO:230及SEQ ID NO:296的氨基酸序列;
(d)轻链CDR1序列,其包含选自SEQ ID NO:67及SEQ ID NO:287的氨基酸序列;
(e)轻链CDR2序列,其包含选自SEQ ID NO:69及SEQ ID NO:288的氨基酸序列;和/或
(f)轻链CDR3序列,其包含SEQ ID NO:71的氨基酸序列。
31.如权利要求29或30所述的组合物,其中各抗体包括包含以下序列的重链CDR1、CDR2及CDR3及轻链CDR1、CDR2及CDR3:
(a)分别为SEQ ID NO:4、6、8、13、15及17;或
(b)分别为SEQ ID NO:22、24、26、31、33及35;或
(c)分别为SEQ ID NO:40、42、44、49、51及53;或
(d)分别为SEQ ID NO:58、60、62、67、69及71;或
(e)分别为SEQ ID NO:283、285、62、287、288及71;或
(f)分别为SEQ ID NO:284、60、286、67、69及71;或
(g)分别为SEQ ID NO:76、78、80、85、87及89;或
(h)分别为SEQ ID NO:94、96、98、103、105及107;或
(i)分别为SEQ ID NO:112、114、116、121、123及125;或
(j)分别为SEQ ID NO:130、132、134、139、141及143;或
(k)分别为SEQ ID NO:148、150、152、157、159及161;或
(l)分别为SEQ ID NO:166、168、170、175、177及179;或
(m)分别为SEQ ID NO:184、186、188、193、195及197;或
(n)分别为SEQ ID NO:202、204、206、211、213及215;或
(o)分别为SEQ ID NO:221、222、223、13、15及17;或
(p)分别为SEQ ID NO:224、225、62、67、69及71;或
(q)分别为SEQ ID NO:293、297、62、287、288及71;或
(r)分别为SEQ ID NO:294、225、286、67、69及71;或
(s)分别为SEQ ID NO:226、227、228、67、69及71;或
(t)分别为SEQ ID NO:289、291、228、287、288及71;或
(u)分别为SEQ ID NO:290、227、292、67、69及71;或
(v)分别为SEQ ID NO:224、229、230、67、69及71;或
(w)分别为SEQ ID NO:293、295、230、287、288及71;或
(x)分别为SEQ ID NO:294、229、296、67、69及71;或
(y)分别为SEQ ID NO:224、227、230、67、69及71;或
(z)分别为SEQ ID NO:293、290、230、287、288及71;或
(aa)分别为SEQ ID NO:294、290、230、67、69及71;或
(bb)分别为SEQ ID NO:231、232、235、103、105及107;或
(cc)分别为SEQ ID NO:233、234、236、103、105及107;或
(dd)分别为SEQ ID NO:233、234、237、103、105及107;或
(ee)分别为SEQ ID NO:166、238、170、175、177及179;或
(ff)分别为SEQ ID NO:239、240、170、175、177及179;或
(gg)分别为SEQ ID NO:239、240、241、175、177及179;或
(hh)分别为SEQ ID NO:239、240、242、175、177及179;或
(ii)分别为SEQ ID NO:243、168、244、175、177及179。
32.如权利要求1至31中任一项所述的组合物,其中各抗体包括包含以下序列的重链CDR1、CDR2及CDR3及轻链CDR1、CDR2及CDR3:
(a)分别为SEQ ID NO:58、60、62、67、69及71;或
(b)分别为SEQ ID NO:283、285、62、287、288及71;或
(c)分别为SEQ ID NO:284、60、286、67、69及71。
33.如权利要求1至32中任一项所述的组合物,其中各抗体包含:
(a)重链可变区,其包含与SEQ ID NO:1、SEQ ID NO:19、SEQ ID NO:37、SEQ ID NO:55、SEQ ID NO:73、SEQ ID NO:91、SEQ ID NO:109、SEQ ID NO:127、SEQ ID NO:145、SEQ IDNO:163、SEQ ID NO:181、SEQ ID NO:199、SEQ ID NO:245、SEQ ID NO:246、SEQ ID NO:247、SEQ ID NO:248、SEQ ID NO:249、SEQ ID NO:250、SEQ ID NO:251、SEQ ID NO:252、SEQ IDNO:253、SEQ ID NO:254、SEQ ID NO:255、SEQ ID NO:256或SEQ ID NO:257具有至少90%序列一致性的氨基酸序列;和/或
(b)轻链可变区,其包含与SEQ ID NO:10、SEQ ID NO:28、SEQ ID NO:46、SEQ ID NO:64、SEQ ID NO:82、SEQ ID NO:100、SEQ ID NO:118、SEQ ID NO:136、SEQ ID NO:154、SEQID NO:172、SEQ ID NO:190或SEQ ID NO:208具有至少90%序列一致性的氨基酸序列。
34.如权利要求1至33中任一项所述的组合物,其中各抗体包含:
(a)包含与SEQ ID NO:1或SEQ ID NO:245具有至少90%序列一致性的氨基酸序列的重链可变区及包含与SEQ ID NO:10具有至少90%序列一致性的氨基酸序列的轻链可变区;或
(b)包含与SEQ ID NO:19具有至少90%序列一致性的氨基酸序列的重链可变区及包含与SEQ ID NO:28具有至少90%序列一致性的氨基酸序列的轻链可变区;或
(c)包含与SEQ ID NO:37具有至少90%序列一致性的氨基酸序列的重链可变区及包含与SEQ ID NO:46具有至少90%序列一致性的氨基酸序列的轻链可变区;或
(d)包含与SEQ ID NO:55、SEQ ID NO:246、SEQ ID NO:247、SEQ ID NO:248或SEQ IDNO:249中任一者具有至少90%序列一致性的氨基酸序列的重链可变区及包含与SEQ IDNO:64具有至少90%序列一致性的氨基酸序列的轻链可变区;或
(e)包含与SEQ ID NO:73具有至少90%序列一致性的氨基酸序列的重链可变区及包含与SEQ ID NO:82具有至少90%序列一致性的氨基酸序列的轻链可变区;或
(f)包含与SEQ ID NO:91、SEQ ID NO:250、SEQ ID NO:251或SEQ ID NO:252中任一者具有至少90%序列一致性的氨基酸序列的重链可变区及包含与SEQ ID NO:100具有至少90%序列一致性的氨基酸序列的轻链可变区;或
(g)包含与SEQ ID NO:109具有至少90%序列一致性的氨基酸序列的重链可变区及包含与SEQ ID NO:118具有至少90%序列一致性的氨基酸序列的轻链可变区;或
(h)包含与SEQ ID NO:127具有至少90%序列一致性的氨基酸序列的重链可变区及包含与SEQ ID NO:136具有至少90%序列一致性的氨基酸序列的轻链可变区;或
(i)包含与SEQ ID NO:145具有至少90%序列一致性的氨基酸序列的重链可变区及包含与SEQ ID NO:154具有至少90%序列一致性的氨基酸序列的轻链可变区;或
(j)包含与SEQ ID NO:163、SEQ ID NO:253、SEQ ID NO:254、SEQ ID NO:255、SEQ IDNO:256或SEQ ID NO:257中任一者具有至少90%序列一致性的氨基酸序列的重链可变区及包含与SEQ ID NO:172具有至少90%序列一致性的氨基酸序列的轻链可变区;或
(k)包含与SEQ ID NO:181具有至少90%序列一致性的氨基酸序列的重链可变区及包含与SEQ ID NO:190具有至少90%序列一致性的氨基酸序列的轻链可变区;或
(l)包含与SEQ ID NO:199具有至少90%序列一致性的氨基酸序列的重链可变区及包含与SEQ ID NO:208具有至少90%序列一致性的氨基酸序列的轻链可变区。
35.如权利要求34所述的组合物,其中各抗体包含:
(a)包含SEQ ID NO:1或SEQ ID NO:245所示氨基酸序列的重链可变区及包含SEQ IDNO:10所示氨基酸序列的轻链可变区;或
(b)包含SEQ ID NO:19所示氨基酸序列的重链可变区及包含SEQ ID NO:28所示氨基酸序列的轻链可变区;或
(c)包含SEQ ID NO:37所示氨基酸序列的重链可变区及包含SEQ ID NO:46所示氨基酸序列的轻链可变区;或
(d)包含SEQ ID NO:55、SEQ ID NO:246、SEQ ID NO:247、SEQ ID NO:248或SEQ ID NO:249中任一者所示氨基酸序列的重链可变区及包含SEQ ID NO:64所示氨基酸序列的轻链可变区;或
(e)包含SEQ ID NO:73所示氨基酸序列的重链可变区及包含SEQ ID NO:82所示氨基酸序列的轻链可变区;或
(f)包含SEQ ID NO:91、SEQ ID NO:250、SEQ ID NO:251或SEQ ID NO:252中任一者所示氨基酸序列的重链可变区及包含SEQ ID NO:100所示氨基酸序列的轻链可变区;或
(g)包含SEQ ID NO:109所示氨基酸序列的重链可变区及包含SEQ ID NO:118所示氨基酸序列的轻链可变区;或
(h)包含SEQ ID NO:127所示氨基酸序列的重链可变区及包含SEQ ID NO:136所示氨基酸序列的轻链可变区;或
(i)包含SEQ ID NO:145所示氨基酸序列的重链可变区及包含SEQ ID NO:154所示氨基酸序列的轻链可变区;或
(j)包含SEQ ID NO:163、SEQ ID NO:253、SEQ ID NO:254、SEQ ID NO:255、SEQ ID NO:256或SEQ ID NO:257中任一者所示氨基酸序列的重链可变区及包含SEQ ID NO:172所示氨基酸序列的轻链可变区;或
(k)包含SEQ ID NO:181所示氨基酸序列的重链可变区及包含SEQ ID NO:190所示氨基酸序列的轻链可变区;或
(l)包含SEQ ID NO:199所示氨基酸序列的重链可变区及包含SEQ ID NO:208所示氨基酸序列的轻链可变区。
36.如权利要求1至35中任一项所述的组合物,其中各抗体包括包含SEQ ID NO:55所示氨基酸序列的重链可变区及包含SEQ ID NO:64所示氨基酸序列的轻链可变区。
37.如权利要求1至36中任一项所述的组合物,其中所述抗体是IgG抗体。
38.如权利要求37所述的组合物,其中所述抗体是IgG1抗体或IgG3抗体。
39.如权利要求1至38中任一项所述的组合物,其中各抗体包括包含选自SEQ ID NO:260、262、264、266、268、270及272的氨基酸序列的重链及包含SEQ ID NO:274所示氨基酸序列的轻链。
40.如权利要求39所述的组合物,其中各抗体包括包含SEQ ID NO:260所示氨基酸序列的重链及包含SEQ ID NO:274所示氨基酸序列的轻链。
41.如权利要求39所述的组合物,其中各抗体包含由SEQ ID NO:260所示氨基酸序列组成的重链;及由SEQ ID NO:274所示氨基酸序列组成的轻链。
42.一种组合物,其包含结合人TIGIT的分离抗体,其中所述组合物中至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%或至少99%的所述抗体是无岩藻糖基化的,且其中各抗体包括包含SEQ ID NO:260所示氨基酸序列的重链及包含SEQ ID NO:274所示氨基酸序列的轻链。
43.一种组合物,其包含结合人TIGIT的分离抗体,其中所述组合物中至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%或至少99%的所述抗体是无岩藻糖基化的,且其中各抗体包含由SEQ ID NO:260所示氨基酸序列组成的重链及由SEQ ID NO:274所示氨基酸序列组成的轻链。
44.如权利要求1至43中任一项所述的组合物,其中所述抗体表现出与抗PD-1抗体或抗PD-L1抗体的协同作用。
45.如权利要求44所述的组合物,其中协同作用是使用包含以下所述内容的分析测定的:使包含:(i)表达PD-1、TIGIT及CD226的Jurkat效应细胞,其中所述Jurkat效应细胞包含由IL-2启动子驱动的荧光素酶报导基因;及(ii)表达TCR活化因子、PD-L1及CD155的CHO-K1人工抗原呈递细胞(aAPC)的共培养物与所述组合物及抗PD-1抗体或抗PD-L1抗体接触。
46.如权利要求1至45中任一项所述的组合物,其中调节性T(Treg)细胞从与所述组合物接触的人PBMC中清除。
47.如权利要求1至46中任一项所述的组合物,MCP1、IL-8及MIP1α的表达在与所述组合物接触的人PBMC中增加。
48.如权利要求1至47中任一项所述的组合物,其中单核细胞/巨噬细胞在与所述组合物接触时活化。
49.如权利要求1至48中任一项所述的组合物,其中在CD14+单核细胞/巨噬细胞与所述组合物接触时,CD86及MHCII上调。
50.如权利要求1至49中任一项所述的组合物,其中与所述组合物接触的CD14+单核细胞/巨噬细胞成熟为抗原呈递细胞。
51.如权利要求1至50中任一项所述的组合物,其中与所述组合物接触的记忆T细胞响应抗原的IFNγ产生增加。
52.如权利要求1至51中任一项所述的组合物,其中与所述组合物接触的记忆T细胞对抗原的反应增强。
53.如权利要求1至52中任一项所述的组合物,其中效应记忆CD8+T细胞和/或效应记忆CD4+T细胞在与所述组合物接触的肿瘤中增加。
54.如权利要求1至53中任一项所述的组合物,其中所述组合物在给予了所述组合物的动物中增强Th1反应。
55.如权利要求1至54中任一项所述的组合物,其中与未经无岩藻糖基化的相同抗TIGIT抗体相比,所述组合物的抗体对FcγRIIa和/或FcγRIIb具有较低结合亲和性。
56.如权利要求1至55中任一项所述的组合物,其中所述组合物介导在单核细胞巨噬细胞存在下TIGIT表达细胞的抗体依赖性细胞吞噬作用(ADCP)。
57.如权利要求1至56中任一项所述的组合物,其中所述抗体是单克隆抗体。
58.如权利要求1至57中任一项所述的组合物,其中所述抗体是完全人抗体。
59.如权利要求1至58中任一项所述的组合物,其中所述抗体是嵌合抗体。
60.如权利要求1至28及44至59中任一项所述的组合物,其中所述抗体是人源化抗体。
61.如权利要求1至60中任一项所述的组合物,其中所述抗体是抗体片段。
62.如权利要求61所述的组合物,其中所述抗体片段是Fab、Fab’、F(ab’)2、scFv或双价抗体。
63.如权利要求1至62中任一项所述的组合物,其中所述抗体是双特异性抗体。
64.如权利要求1至63中任一项所述的组合物,其中所述抗体是抗体-药物偶联物。
65.一种结合人TIGIT(具有Ig及ITIM结构域的T细胞免疫受体)的抗体,其中所述抗体对人TIGIT的结合亲和性(KD)小于5nM,且其中所述抗体是无岩藻糖基化的。
66.如权利要求65所述的抗体,其中所述抗体对人TIGIT的KD小于1nM。
67.如权利要求66所述的抗体,其中抗体对人TIGIT的KD小于100pM。
68.如权利要求65至67中任一项所述的抗体,其中抗体表现出与食蟹猕猴TIGIT和/或小鼠TIGIT的交叉反应性。
69.如权利要求68所述的抗体,其中所述抗体表现出与食蟹猕猴TIGIT及小鼠TIGIT两者的交叉反应性。
70.如权利要求65至69中任一项所述的抗体,其中所述抗体阻断CD155与TIGIT的结合。
71.如权利要求65至70中任一项所述的抗体,其中所述抗体阻断CD112与TIGIT的结合。
72.如权利要求65至71中任一项所述的抗体,其中所述抗体阻断CD155及CD112两者与TIGIT的结合。
73.如权利要求65至72中任一项所述的抗体,其中所述抗体与包括包含SEQ ID NO:55所示氨基酸序列的重链可变区及包含SEQ ID NO:64所示氨基酸序列的轻链可变区的抗体竞争结合人TIGIT。
74.如权利要求65至73中任一项所述的抗体,其中所述抗体在结合人TIGIT时结合氨基酸位置81及82中之一或两者。
75.如权利要求74所述的抗体,其中所述抗体结合氨基酸位置81及82两者。
76.如权利要求74或75所述的抗体,其中氨基酸位置81及82是Phe81和Lys82。
77.如权利要求65至76中任一项所述的抗体,其中所述抗体结合人TIGIT上包含氨基酸位置81及82中之一或两者的表位。
78.一种结合人TIGIT的抗体,其中所述抗体在结合人TIGIT时结合氨基酸位置81及82中之一或两者,且其中所述抗体是无岩藻糖基化的。
79.如权利要求78所述的抗体,其中所述抗体结合氨基酸位置81及82两者。
80.如权利要求78或79所述的抗体,其中氨基酸位置81及82是Phe81和Lys82。
81.一种结合人TIGIT的抗体,其中所述抗体结合人TIGIT上包含氨基酸位置81及82中之一或两者的表位,且其中所述抗体是无岩藻糖基化的。
82.如权利要求77或81所述的抗体,其中所述表位包含第81位的Phe。
83.如权利要求77、81及82中任一项所述的抗体,其中所述表位包含第82位的Lys或Ser。
84.如权利要求77及81至83中任一项所述的抗体,其中所述表位包含第81位的Phe及第82位的Lys或Ser。
85.如权利要求84所述的抗体,其中所述表位包含Phe81和Lys82。
86.如权利要求77及81至85中任一项所述的抗体,其中所述表位是不连续表位。
87.如权利要求77及81至86中任一项所述的抗体,其中所述抗体结合人TIGIT上进一步包含氨基酸位置51、52、53、54、55、73、74、75、76、77、79、83、84、85、86、87、88、89、90、91、92或93中之一或多者的表位。
88.如权利要求87所述的抗体,其中所述表位进一步包含一个或多个选自下组的氨基酸残基:Thr51、Ala52、Gln53、Val54、Thr55、Leu73、Gly74、Trp75、His76、Ile77、Pro79、Asp83、Arg84、Val85、Ala86、Pro87、Gly88、Pro89、Gly90、Leu91、Gly92及Leu93。
89.如权利要求88所述的抗体,其中所述表位包含氨基酸残基Thr51、Ala52、Gln53、Val54、Thr55、Gly74、Trp75、His76、Ile77、Phe81、Lys82、Pro87、Gly88、Pro89、Gly90、Leu91、Gly92及Leu93。
90.如权利要求88所述的抗体,其中所述表位包含氨基酸残基Ala52、Gln53、Leu73、Gly74、Trp75、Pro79、Phe81、Lys82、Asp83、Arg84、Val85及Ala86。
91.如权利要求77及81至90中任一项所述的抗体,其中所述表位包含序列ICNADLGWHISPSFK(SEQ ID NO:258)。
92.如权利要求65至91中任一项所述的抗体,其中人TIGIT包含序列SEQ ID NO:218。
93.如权利要求65至92中任一项所述的抗体,其中所述抗体包含以下之一或多者:
(a)重链CDR1,其包含选自SEQ ID NO:4、SEQ ID NO:22、SEQ ID NO:40、SEQ ID NO:58、SEQ ID NO:76、SEQ ID NO:94、SEQ ID NO:112、SEQ ID NO:130、SEQ ID NO:148、SEQ IDNO:166、SEQ ID NO:184、SEQ ID NO:202、SEQ ID NO:221、SEQ ID NO:224、SEQ ID NO:226、SEQ ID NO:231、SEQ ID NO:233、SEQ ID NO:239、SEQ ID NO:243、SEQ ID NO:283、SEQ IDNO:284、SEQ ID NO:293、SEQ ID NO:294、SEQ ID NO:289及SEQ ID NO:290的序列;
(b)重链CDR2,其包含选自SEQ ID NO:6、SEQ ID NO:24、SEQ ID NO:42、SEQ ID NO:60、SEQ ID NO:78、SEQ ID NO:96、SEQ ID NO:114、SEQ ID NO:132、SEQ ID NO:150、SEQ IDNO:168、SEQ ID NO:186、SEQ ID NO:204、SEQ ID NO:222、SEQ ID NO:225、SEQ ID NO:227、SEQ ID NO:229、SEQ ID NO:232、SEQ ID NO:234、SEQ ID NO:238、SEQ ID NO:240、SEQ IDNO:285、SEQ ID NO:297、SEQ ID NO:291及SEQ ID NO:295的序列;
(c)重链CDR3,其包含选自SEQ ID NO:8、SEQ ID NO:26、SEQ ID NO:44、SEQ ID NO:62、SEQ ID NO:80、SEQ ID NO:98、SEQ ID NO:116、SEQ ID NO:134、SEQ ID NO:152、SEQ IDNO:170、SEQ ID NO:188、SEQ ID NO:206、SEQ ID NO:223、SEQ ID NO:228、SEQ ID NO:230、SEQ ID NO:235、SEQ ID NO:236、SEQ ID NO:237、SEQ ID NO:241、SEQ ID NO:242、SEQ IDNO:244、SEQ ID NO:286、SEQ ID NO:292及SEQ ID NO:296的序列;
(d)轻链CDR1,其包含选自SEQ ID NO:13、SEQ ID NO:31、SEQ ID NO:49、SEQ ID NO:67、SEQ ID NO:85、SEQ ID NO:103、SEQ ID NO:121、SEQ ID NO:139、SEQ ID NO:157、SEQID NO:175、SEQ ID NO:193、SEQ ID NO:211及SEQ ID NO:287的序列;
(e)轻链CDR2,其包含选自SEQ ID NO:15、SEQ ID NO:33、SEQ ID NO:51、SEQ ID NO:69、SEQ ID NO:87、SEQ ID NO:105、SEQ ID NO:123、SEQ ID NO:141、SEQ ID NO:159、SEQID NO:177、SEQ ID NO:195、SEQ ID NO:213及SEQ ID NO:288的序列;或
(f)轻链CDR3,其包含选自SEQ ID NO:17、SEQ ID NO:35、SEQ ID NO:53、SEQ ID NO:71、SEQ ID NO:89、SEQ ID NO:107、SEQ ID NO:125、SEQ ID NO:143、SEQ ID NO:161、SEQID NO:179、SEQ ID NO:197及SEQ ID NO:215的序列。
94.如权利要求93所述的抗体,其中所述抗体包含:
(a)重链CDR1序列,其包含选自SEQ ID NO:58、SEQ ID NO:283、SEQ ID NO:284、SEQ IDNO:224、SEQ ID NO:293、SEQ ID NO:294、SEQ ID NO:226、SEQ ID NO:289及SEQ ID NO:290的氨基酸序列;
(b)重链CDR2序列,其包含选自SEQ ID NO:60、SEQ ID NO:285、SEQ ID NO:225、SEQ IDNO:297、SEQ ID NO:227、SEQ ID NO:291、SEQ ID NO:229及SEQ ID NO:295的氨基酸序列;
(c)重链CDR3序列,其包含选自SEQ ID NO:62、SEQ ID NO:286、SEQ ID NO:228、SEQ IDNO:292、SEQ ID NO:230及SEQ ID NO:296的氨基酸序列;
(d)轻链CDR1序列,其包含选自SEQ ID NO:67及SEQ ID NO:287的氨基酸序列;
(e)轻链CDR2序列,其包含选自SEQ ID NO:69及SEQ ID NO:288的氨基酸序列;和/或
(f)轻链CDR3序列,其包含SEQ ID NO:71的氨基酸序列。
95.如权利要求94所述的抗体,其中所述抗体包括包含以下序列的重链CDR1、CDR2及CDR3及轻链CDR1、CDR2及CDR3:
(a)分别为SEQ ID NO:4、6、8、13、15及17;或
(b)分别为SEQ ID NO:22、24、26、31、33及35;或
(c)分别为SEQ ID NO:40、42、44、49、51及53;或
(d)分别为SEQ ID NO:58、60、62、67、69及71;或
(e)分别为SEQ ID NO:76、78、80、85、87及89;或
(f)分别为SEQ ID NO:94、96、98、103、105及107;或
(g)分别为SEQ ID NO:112、114、116、121、123及125;或
(h)分别为SEQ ID NO:130、132、134、139、141及143;或
(i)分别为SEQ ID NO:148、150、152、157、159及161;或
(j)分别为SEQ ID NO:166、168、170、175、177及179;或
(k)分别为SEQ ID NO:184、186、188、193、195及197;或
(l)分别为SEQ ID NO:202、204、206、211、213及215;或
(m)分别为SEQ ID NO:221、222、223、13、15及17;或
(n)分别为SEQ ID NO:224、225、62、67、69及71;或
(o)分别为SEQ ID NO:226、227、228、67、69及71;或
(p)分别为SEQ ID NO:224、229、230、67、69及71;或
(q)分别为SEQ ID NO:224、227、230、67、69及71;或
(r)分别为SEQ ID NO:231、232、235、103、105及107;或
(s)分别为SEQ ID NO:233、234、236、103、105及107;或
(t)分别为SEQ ID NO:233、234、237、103、105及107;或
(u)分别为SEQ ID NO:166、238、170、175、177及179;或
(v)分别为SEQ ID NO:239、240、170、175、177及179;或
(w)分别为SEQ ID NO:239、240、241、175、177及179;或
(x)分别为SEQ ID NO:239、240、242、175、177及179;或
(y)分别为SEQ ID NO:243、168、244、175、177及179。
96.如权利要求65至95中任一项所述的抗体,其中所述抗体包括包含以下序列的重链CDR1、CDR2及CDR3及轻链CDR1、CDR2及CDR3:
(a)分别为SEQ ID NO:58、60、62、67、69及71;或
(b)分别为SEQ ID NO:283、285、62、287、288及71;或
(c)分别为SEQ ID NO:284、60、286、67、69及71。
97.如权利要求65至96中任一项所述的抗体,其中所述抗体包含:
(a)重链可变区,其包含与SEQ ID NO:1、SEQ ID NO:19、SEQ ID NO:37、SEQ ID NO:55、SEQ ID NO:73、SEQ ID NO:91、SEQ ID NO:109、SEQ ID NO:127、SEQ ID NO:145、SEQ IDNO:163、SEQ ID NO:181、SEQ ID NO:199、SEQ ID NO:245、SEQ ID NO:246、SEQ ID NO:247、SEQ ID NO:248、SEQ ID NO:249、SEQ ID NO:250、SEQ ID NO:251、SEQ ID NO:252、SEQ IDNO:253、SEQ ID NO:254、SEQ ID NO:255、SEQ ID NO:256或SEQ ID NO:257具有至少90%序列一致性的氨基酸序列;和/或
(b)轻链可变区,其包含与SEQ ID NO:10、SEQ ID NO:28、SEQ ID NO:46、SEQ ID NO:64、SEQ ID NO:82、SEQ ID NO:100、SEQ ID NO:118、SEQ ID NO:136、SEQ ID NO:154、SEQID NO:172、SEQ ID NO:190或SEQ ID NO:208具有至少90%序列一致性的氨基酸序列。
98.如权利要求65至97中任一项所述的抗体,其中所述抗体包含:
(a)包含与SEQ ID NO:1或SEQ ID NO:245具有至少90%序列一致性的氨基酸序列的重链可变区及包含与SEQ ID NO:10具有至少90%序列一致性的氨基酸序列的轻链可变区;或
(b)包含与SEQ ID NO:19具有至少90%序列一致性的氨基酸序列的重链可变区及包含与SEQ ID NO:28具有至少90%序列一致性的氨基酸序列的轻链可变区;或
(c)包含与SEQ ID NO:37具有至少90%序列一致性的氨基酸序列的重链可变区及包含与SEQ ID NO:46具有至少90%序列一致性的氨基酸序列的轻链可变区;或
(d)包含与SEQ ID NO:55、SEQ ID NO:246、SEQ ID NO:247、SEQ ID NO:248或SEQ IDNO:249中任一者具有至少90%序列一致性的氨基酸序列的重链可变区及包含与SEQ IDNO:64具有至少90%序列一致性的氨基酸序列的轻链可变区;或
(e)包含与SEQ ID NO:73具有至少90%序列一致性的氨基酸序列的重链可变区及包含与SEQ ID NO:82具有至少90%序列一致性的氨基酸序列的轻链可变区;或
(f)包含与SEQ ID NO:91、SEQ ID NO:250、SEQ ID NO:251或SEQ ID NO:252中任一者具有至少90%序列一致性的氨基酸序列的重链可变区及包含与SEQ ID NO:100具有至少90%序列一致性的氨基酸序列的轻链可变区;或
(g)包含与SEQ ID NO:109具有至少90%序列一致性的氨基酸序列的重链可变区及包含与SEQ ID NO:118具有至少90%序列一致性的氨基酸序列的轻链可变区;或
(h)包含与SEQ ID NO:127具有至少90%序列一致性的氨基酸序列的重链可变区及包含与SEQ ID NO:136具有至少90%序列一致性的氨基酸序列的轻链可变区;或
(i)包含与SEQ ID NO:145具有至少90%序列一致性的氨基酸序列的重链可变区及包含与SEQ ID NO:154具有至少90%序列一致性的氨基酸序列的轻链可变区;或
(j)包含与SEQ ID NO:163、SEQ ID NO:253、SEQ ID NO:254、SEQ ID NO:255、SEQ IDNO:256或SEQ ID NO:257中任一者具有至少90%序列一致性的氨基酸序列的重链可变区及包含与SEQ ID NO:172具有至少90%序列一致性的氨基酸序列的轻链可变区;或
(k)包含与SEQ ID NO:181具有至少90%序列一致性的氨基酸序列的重链可变区及包含与SEQ ID NO:190具有至少90%序列一致性的氨基酸序列的轻链可变区;或
(l)包含与SEQ ID NO:199具有至少90%序列一致性的氨基酸序列的重链可变区及包含与SEQ ID NO:208具有至少90%序列一致性的氨基酸序列的轻链可变区。
99.如权利要求98所述的抗体,其中所述抗体包含:
(a)包含SEQ ID NO:1或SEQ ID NO:245所示氨基酸序列的重链可变区及包含SEQ IDNO:10所示氨基酸序列的轻链可变区;或
(b)包含SEQ ID NO:19所示氨基酸序列的重链可变区及包含SEQ ID NO:28所示氨基酸序列的轻链可变区;或
(c)包含SEQ ID NO:37所示氨基酸序列的重链可变区及包含SEQ ID NO:46所示氨基酸序列的轻链可变区;或
(d)包含SEQ ID NO:55、SEQ ID NO:246、SEQ ID NO:247、SEQ ID NO:248或SEQ ID NO:249中任一者所示氨基酸序列的重链可变区及包含SEQ ID NO:64所示氨基酸序列的轻链可变区;或
(e)包含SEQ ID NO:73所示氨基酸序列的重链可变区及包含SEQ ID NO:82所示氨基酸序列的轻链可变区;或
(f)包含SEQ ID NO:91、SEQ ID NO:250、SEQ ID NO:251或SEQ ID NO:252中任一者所示氨基酸序列的重链可变区及包含SEQ ID NO:100所示氨基酸序列的轻链可变区;或
(g)包含SEQ ID NO:109所示氨基酸序列的重链可变区及包含SEQ ID NO:118所示氨基酸序列的轻链可变区;或
(h)包含SEQ ID NO:127所示氨基酸序列的重链可变区及包含SEQ ID NO:136所示氨基酸序列的轻链可变区;或
(i)包含SEQ ID NO:145所示氨基酸序列的重链可变区及包含SEQ ID NO:154所示氨基酸序列的轻链可变区;或
(j)包含SEQ ID NO:163、SEQ ID NO:253、SEQ ID NO:254、SEQ ID NO:255、SEQ ID NO:256或SEQ ID NO:257中任一者所示氨基酸序列的重链可变区及包含SEQ ID NO:172所示氨基酸序列的轻链可变区;或
(k)包含SEQ ID NO:181所示氨基酸序列的重链可变区及包含SEQ ID NO:190所示氨基酸序列的轻链可变区;或
(l)包含SEQ ID NO:199所示氨基酸序列的重链可变区及包含SEQ ID NO:208所示氨基酸序列的轻链可变区。
100.如权利要求65至99中任一项所述的抗体,其中所述抗体包括包含SEQ ID NO:55所示氨基酸序列的重链可变区及包含SEQ ID NO:64所示氨基酸序列的轻链可变区。
101.如权利要求65至100中任一项所述的抗体,其中所述抗体是IgG抗体。
102.如权利要求101所述的抗体,其中所述抗体是IgG1抗体或IgG3抗体。
103.如权利要求65至102中任一项所述的抗体,其中所述抗体包括包含选自SEQ IDNO:260、262、264、266、268、270及272的氨基酸序列的重链及包含SEQ ID NO:274所示氨基酸序列的轻链。
104.如权利要求103所述的抗体,其中所述抗体包括包含SEQ ID NO:260所示氨基酸序列的重链及包含SEQ ID NO:274所示氨基酸序列的轻链。
105.如权利要求103所述的抗体,其中所述抗体包含由SEQ ID NO:260所示氨基酸序列组成的重链及由SEQ ID NO:274所示氨基酸序列组成的轻链。
106.一种结合人TIGIT的抗体,其中所述抗体包括包含选自SEQ ID NO:260、262、264、266、268、270及272的氨基酸序列的重链及包含SEQ ID NO:274所示氨基酸序列的轻链。
107.一种结合人TIGIT的抗体,其中所述抗体包括包含SEQ ID NO:260所示氨基酸序列的重链及包含SEQ ID NO:274所示氨基酸序列的轻链。
108.一种结合人TIGIT的抗体,其中所述抗体包含由SEQ ID NO:260所示氨基酸序列组成的重链及由SEQ ID NO:274所示氨基酸序列组成的轻链。
109.如权利要求65至108中任一项所述的抗体,其中所述抗体表现出与抗PD-1抗体或抗PD-L1抗体的协同作用。
110.如权利要求109所述的抗体,其中协同作用是使用包含以下所述内容的分析测定的:使包含:(i)表达PD-1、TIGIT及CD226的Jurkat效应细胞,其中所述Jurkat效应细胞包含由IL-2启动子驱动的荧光素酶报导基因;及(ii)表达TCR活化因子、PD-L1及CD155的CHO-K1人工抗原呈递细胞(aAPC)的共培养物与所述抗体及抗PD-1抗体或抗PD-L1抗体接触。
111.如权利要求65至110中任一项所述的抗体,其中调节性T(Treg)细胞从与所述抗体接触的人PBMC中清除。
112.如权利要求65至111中任一项所述的抗体,MCP1、IL-8及MIP1α的表达在与所述抗体接触的人PBMC中增加。
113.如权利要求65至112中任一项所述的抗体,其中单核细胞/巨噬细胞在与所述抗体接触时活化。
114.如权利要求65至113中任一项所述的抗体,其中在CD14+单核细胞/巨噬细胞与所述抗体接触时,CD86及MHCII上调。
115.如权利要求65至114中任一项所述的抗体,其中与所述抗体接触的CD14+单核细胞/巨噬细胞成熟为抗原呈递细胞。
116.如权利要求65至115中任一项所述的抗体,其中与所述抗体接触的记忆T细胞响应抗原的IFNγ产生增加。
117.如权利要求65至116中任一项所述的抗体,其中与所述抗体接触的记忆T细胞对抗原的反应增强。
118.如权利要求65至117中任一项所述的抗体,其中效应记忆CD8+T细胞和/或效应记忆CD4+T细胞在与所述抗体接触的肿瘤中增加。
119.如权利要求65至118中任一项所述的抗体,其中所述抗体增强给予了所述抗体的动物中的Th1反应。
120.如权利要求65至119中任一项所述的抗体,其中与未经无岩藻糖基化的相同抗TIGIT抗体相比,所述抗体对FcγRIIa和/或FcγRIIb具有较低结合亲和性。
121.如权利要求65至120中任一项所述的抗体,其中所述抗体介导在单核细胞巨噬细胞存在下TIGIT表达细胞的抗体依赖性细胞吞噬作用(ADCP)。
122.如权利要求65至121中任一项所述的抗体,其中所述抗体是单克隆抗体。
123.如权利要求65至122中任一项所述的抗体,其中所述抗体是完全人抗体。
124.如权利要求65至123中任一项所述的抗体,其中所述抗体是嵌合抗体。
125.如权利要求65至92及109至124中任一项所述的抗体,其中所述抗体是人源化抗体。
126.如权利要求65至125中任一项所述的抗体,其中所述抗体是抗体片段。
127.如权利要求126所述的抗体,其中所述抗体片段是Fab、Fab’、F(ab’)2、scFv或双价抗体。
128.如权利要求65至127中任一项所述的抗体,其中所述抗体是双特异性抗体。
129.如权利要求65至128中任一项所述的抗体,其中所述抗体是抗体-药物偶联物。
130.一种药物制剂,其包含如权利要求1至64中任一项所述的组合物或如权利要求65至129中任一项所述的抗体及药学上可接受的载剂。
131.一种经分离的多核苷酸,其编码(i)如权利要求106至108中任一项所述抗体的重链;(ii)如权利要求106至108中任一项所述抗体的轻链;或(iii)如权利要求106至108中任一项所述抗体的重链及轻链。
132.如权利要求131所述的经分离的多核苷酸,其中所述多核苷酸包含(i)选自SEQ IDNO:259、261、163、265、267、269及271的核苷酸序列;或(ii)SEQ ID NO:273的核苷酸序列;或(iii)选自SEQ ID NO:259、261、263、265、267、269及271的核苷酸序列,及SEQ ID NO:273的核苷酸序列。
133.一种包含如权利要求131或132所述多核苷酸的载体。
134.一种经分离的宿主细胞,其包含如权利要求131或132所述的经分离的多核苷酸或如权利要求133所述的载体。
135.一种经分离的宿主细胞,其表达如权利要求106至108中任一项所述的抗体。
136.如权利要求134或135所述的宿主细胞,其经工程改造以产生无岩藻糖基化抗体。
137.一种产生结合人TIGIT的抗体的方法,其包含在适于产生所述抗体的条件下培育如权利要求134至136中任一项所述的宿主细胞。
138.如权利要求137所述的方法,其中所述宿主细胞经工程改造以产生无岩藻糖基化抗体。
139.如权利要求137所述的方法,其中在适于产生无岩藻糖基化抗体的条件下在岩藻糖类似物存在下培养所述宿主细胞。
140.如权利要求137至139中任一项所述的方法,其进一步包含分离所述抗体。
141.一种结合人TIGIT的分离抗体的组合物,其中所述组合物中至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%或至少99%的所述抗体是无岩藻糖基化的,其中所述抗体是藉由如权利要求138至140中任一项所述的方法产生。
142.一种结合人TIGIT的分离抗体的组合物,其中所述组合物中至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%或至少99%的所述抗体是无岩藻糖基化的,其中所述抗体是藉由包含以下内容的方法产生:在适于产生无岩藻糖基化抗体的条件下培育如权利要求134或135所述的宿主细胞,及分离所述抗体以形成分离抗体的组合物。
143.如权利要求142所述的组合物,其中所述宿主细胞经工程改造以产生无岩藻糖基化抗体。
144.如权利要求142所述的组合物,其中在适于产生无岩藻糖基化抗体的条件下在岩藻糖类似物存在下培养所述宿主细胞。
145.一种宿主细胞,其包括包含编码(i)如权利要求1至63中任一项所述的组合物的抗体或(ii)如权利要求65至128中任一项所述抗体的核苷酸序列的多核苷酸,其中所述宿主细胞经工程改造以产生无岩藻糖基化抗体。
146.如权利要求145所述的宿主细胞,其中所述多核苷酸是载体。
147.一种宿主细胞,其表达(i)如权利要求1至63中任一项所述的组合物的抗体,或(ii)如权利要求65至128中任一项所述的抗体,其中所述宿主细胞经工程改造以产生无岩藻糖基化抗体。
148.如权利要求145至147中任一项所述的宿主细胞,其中所述宿主细胞包含:
(a)SEQ ID NO:2、SEQ ID NO:20、SEQ ID NO:38、SEQ ID NO:56、SEQ ID NO:74、SEQ IDNO:92、SEQ ID NO:110、SEQ ID NO:128、SEQ ID NO:146、SEQ ID NO:164、SEQ ID NO:182、SEQ ID NO:200、SEQ ID NO:259、SEQ ID NO:265、SEQ ID NO:267、SEQ ID NO:269或SEQ IDNO:271的核苷酸序列;和/或
(b)SEQ ID NO:11、SEQ ID NO:29、SEQ ID NO:47、SEQ ID NO:65、SEQ ID NO:83、SEQID NO:101、SEQ ID NO:119、SEQ ID NO:137、SEQ ID NO:155、SEQ ID NO:173、SEQ ID NO:191、SEQ ID NO:209或SEQ ID NO:273的核苷酸序列。
149.一种产生结合TIGIT的无岩藻糖基化抗体的方法,其包含在适于产生所述无岩藻糖基化抗体的条件下培养如权利要求145至148中任一项所述的宿主细胞。
150.一种产生结合TIGIT的无岩藻糖基化抗体的方法,其包含在适于产生无岩藻糖基化抗体的条件下在岩藻糖类似物存在下培养宿主细胞,其中所述宿主细胞包括包含编码(i)如权利要求1至63中任一项所述的组合物的抗体或(ii)如权利要求65至128中任一项所述抗体的核苷酸序列的多核苷酸。
151.如权利要求150所述的方法,其中所述多核苷酸是载体。
152.一种产生结合TIGIT的无岩藻糖基化抗体的方法,其包含在适于产生无岩藻糖基化抗体的条件下在岩藻糖类似物存在下培养宿主细胞,其中所述宿主细胞表达(i)如权利要求1至63中任一项所述的组合物的抗体,或(ii)如权利要求65至128中任一项所述的抗体。
153.如权利要求150至152中任一项所述的方法,其中所述宿主细胞包含:
(a)SEQ ID NO:2、SEQ ID NO:20、SEQ ID NO:38、SEQ ID NO:56、SEQ ID NO:74、SEQ IDNO:92、SEQ ID NO:110、SEQ ID NO:128、SEQ ID NO:146、SEQ ID NO:164、SEQ ID NO:182、SEQ ID NO:200、SEQ ID NO:259、SEQ ID NO:265、SEQ ID NO:267、SEQ ID NO:269或SEQ IDNO:271的核苷酸序列;和/或
(b)SEQ ID NO:11、SEQ ID NO:29、SEQ ID NO:47、SEQ ID NO:65、SEQ ID NO:83、SEQID NO:101、SEQ ID NO:119、SEQ ID NO:137、SEQ ID NO:155、SEQ ID NO:173、SEQ ID NO:191、SEQ ID NO:209或SEQ ID NO:273的核苷酸序列。
154.如权利要求150至153中任一项所述的方法,其中所述岩藻糖类似物是2-氟岩藻糖。
155.如权利要求149至154中任一项所述的方法,其进一步包含分离所述无岩藻糖基化抗体。
156.一种结合人TIGIT的分离抗体的组合物,其中所述组合物中至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%或至少99%的所述抗体是无岩藻糖基化的,其中所述抗体是藉由如权利要求149至155中任一项所述的方法产生。
157.一种结合人TIGIT的分离抗体的组合物,其中所述组合物中至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%或至少99%的所述抗体是无岩藻糖基化的,其中所述抗体是藉由包含以下内容的方法产生:在适于产生无岩藻糖基化抗体的条件下培育如权利要求145至147中任一项所述的宿主细胞,及分离所述抗体以形成分离抗体的组合物。
158.一种结合人TIGIT的分离抗体的组合物,其中所述组合物中至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%或至少99%的所述抗体是无岩藻糖基化的,其中所述抗体是藉由包含以下内容的方法产生:在适于产生无岩藻糖基化抗体的条件下在岩藻糖类似物存在下培养宿主细胞,其中所述宿主细胞包括包含编码(i)如权利要求1至63中任一项所述的组合物的抗体或(ii)如权利要求65至128中任一项所述抗体的核苷酸序列的多核苷酸。
159.一种结合人TIGIT的分离抗体的组合物,其中所述组合物中至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%或至少99%的所述抗体是无岩藻糖基化的,其中所述抗体是藉由包含以下内容的方法产生:在适于产生无岩藻糖基化抗体的条件下在岩藻糖类似物存在下培养宿主细胞,其中所述宿主细胞表达(i)如权利要求1至63中任一项所述的组合物的抗体,或(ii)如权利要求65至128中任一项所述的抗体。
160.一种试剂盒,其包含:
如权利要求1至64中任一项所述的组合物、如权利要求65至129中任一项所述的抗体或如权利要求130所述的药物组合物;及
其他治疗剂。
161.如权利要求160所述的试剂盒,其中所述其他治疗剂是抗癌剂。
162.如权利要求160或161所述的试剂盒,其中所述其他治疗剂是抗体。
163.如权利要求160至162中任一项所述的试剂盒,其中所述其他治疗剂是T细胞共抑制因子的拮抗剂或抑制剂;T细胞共活化因子的激动剂;免疫刺激性细胞因子;或SGN-2FF。
164.如权利要求160至163中任一项所述的试剂盒,其中所述其他治疗剂结合选自下组的蛋白质:CD25、PD-1、PD-L1、Tim3、Lag3、CTLA4、41BB、OX40、CD3、CD40、CD47M、GM-CSF、CSF1R、TLR、STING、RIGI、TAM受体激酶、NKG2A、NKG2D、GD2、HER2、EGFR、PDGFRα、SLAMF7、VEGF、CTLA-4、CD20、cCLB8、KIR及CD52。
165.如权利要求160至164中任一项所述的试剂盒,其中所述其他治疗剂选自抗CD25抗体、抗PD-1抗体、抗PD-L1抗体、抗Tim3抗体、抗Lag3抗体、抗CTLA4抗体、抗41BB抗体、抗OX40抗体、抗CD3抗体、抗CD40抗体、抗CD47M抗体、抗CSF1R抗体、抗TLR抗体、抗STING抗体、抗RIGI抗体、抗TAM受体激酶抗体、抗NKG2A抗体、抗NKG2D抗体、抗GD2抗体、抗HER2抗体、抗EGFR抗体、抗PDGFR-α-抗体、抗SLAMF7抗体、抗VEGF抗体、抗CTLA-4抗体、抗CD20抗体、抗cCLB8抗体、抗KIR抗体及抗CD52抗体。
166.如权利要求160至165中任一项所述的试剂盒,其中所述其他治疗剂包含选自IL-15、IL-21、IL-2、GM-CSF、M-CSF、G-CSF、IL-1、IL-3、IL-12及IFNγ的细胞因子。
167.如权利要求160至165中任一项所述的试剂盒,其中所述其他治疗剂选自SEA-CD40、阿维鲁单抗(avelumab)、德瓦鲁单抗(durvalumab)、尼沃鲁单抗(nivolumab)、派姆单抗(pembrolizumab)、匹利珠单抗(pidilizumab)、阿替珠单抗(atezolizumab)、Hul4.18K322A、Hu3F8、达妥昔单抗(dinituximab)、曲妥珠单抗(trastuzumab)、西妥昔单抗(cetuximab)、奥拉妥单抗(olaratumab)、奈昔木单抗(necitumumab)、埃罗妥珠单抗(elotuzumab)、雷莫芦单抗(ramucirumab)、帕妥珠单抗(pertuzumab)、伊匹单抗(ipilimumab)、贝伐珠单抗(bevacizumab)、利妥昔单抗(rituximab)、奥妥珠单抗(obinutuzumab)、司妥昔单抗(siltuximab)、奥法木单抗(ofatumumab)、利利单抗(lirilumab)及阿伦单抗(alemtuzumab)。
168.如权利要求160或161所述的试剂盒,其中所述其他治疗剂选自烷基化剂(例如环磷酰胺(cyclophosphamide)、异环磷酰胺(ifosfamide)、氮芥苯丁酸(chlorambucil)、白消安(busulfan)、美法仑(melphalan)、甲基二(氯乙基)胺(mechlorethamine)、乌拉莫司汀(uramustine)、噻替派(thiotepa)、亚硝基脲(nitrosoureas)或替莫唑胺(temozolomide))、蒽环(例如多柔比星(doxorubicin)、阿德力霉素(adriamycin)、道诺霉素(daunorubicin)、泛艾霉素(epirubicin)或米托蒽醌(mitoxantrone))、细胞骨架破坏剂(例如太平洋紫杉醇(paclitaxel)或多西他赛(docetaxel))、组织蛋白去乙酰酶抑制剂(例如伏立诺他(vorinostat)或罗米地辛(romidepsin))、拓朴异构酶抑制剂(例如伊立替康(irinotecan)、托泊替康(topotecan)、安吖啶(amsacrine)、依托泊苷(etoposide)或替尼泊苷(teniposide))、激酶抑制剂(例如硼替佐米(bortezomib)、厄洛替尼(erlotinib)、吉非替尼(gefitinib)、伊马替尼(imatinib)、威罗菲尼(vemurafenib)或维莫德吉(vismodegib))、核苷类似物或前体类似物(例如阿扎胞苷(azacitidine)、硫唑嘌呤(azathioprine)、卡培他滨(capecitabine)、阿糖胞苷(cytarabine)、氟尿嘧啶(fluorouracil)、吉西他滨(gemcitabine)、羟基脲(hydroxyurea)、巯嘌呤(mercaptopurine)、胺甲喋呤(methotrexate)或硫鸟嘌呤(thioguanine))、肽抗生素(例如放线菌素(actinomycin)或博来霉素(bleomycin))、基于铂的药剂(例如顺铂(cisplatin)、奥沙利铂(oxaloplatin)或卡铂(carboplatin))、或植物碱(例如长春新碱(vincristine)、长春碱(vinblastine)、长春瑞滨(vinorelbine)、长春地辛(vindesine)、鬼臼毒素(podophyllotoxin)、太平洋紫杉醇或多西他赛)、加拉定(galardin)、沙利窦迈(thalidomide)、雷利窦迈(lenalidomide)及泊马窦迈(pomalidomide)。
169.一种治疗对象癌症的方法,其包含给予所述对象治疗有效量的如权利要求1至64中任一项所述的组合物、如权利要求65至129中任一项所述的抗体或如权利要求130所述的药物组合物。
170.如权利要求169所述的方法,其中所述癌症是CD112或CD155表达富集的癌症。
171.如权利要求169或170所述的方法,其中所述癌症是表达TIGIT的T细胞或天然杀手(NK)细胞富集的癌症。
172.如权利要求169至171中任一项所述的方法,其中所述癌症是膀胱癌、乳癌、子宫癌、子宫颈癌、卵巢癌、前列腺癌、睪丸癌、食道癌、胃肠癌、胃癌(gastric cancer)、胰脏癌、结肠直肠癌、结肠癌、肾癌、透明细胞肾癌、头颈癌、肺癌、肺腺癌、胃癌(stomach cancer)、生殖细胞癌、骨癌、肝癌、甲状腺癌、皮肤癌、黑色素瘤、中枢神经系统赘瘤、间皮瘤、淋巴瘤、白血病、慢性淋巴细胞白血病、弥漫性大B细胞淋巴瘤、滤泡性淋巴瘤、霍奇金氏淋巴瘤(Hodgkin lymphoma)、骨髓瘤或肉瘤。
173.如权利要求172所述的方法,其中所述癌症是淋巴瘤、白血病、慢性淋巴细胞白血病、弥漫性大B细胞淋巴瘤、滤泡性淋巴瘤或霍奇金氏淋巴瘤。
174.如权利要求169至173中任一项所述的方法,其进一步包含给予所述对象治疗有效量的其他治疗剂。
175.如权利要求174所述的方法,其中所述其他治疗剂是抗癌剂。
176.如权利要求174或175所述的方法,其中所述其他治疗剂是抗体。
177.如权利要求174至176中任一项所述的方法,其中所述其他治疗剂是T细胞共抑制因子的拮抗剂或抑制剂;T细胞共活化因子的激动剂;或免疫刺激性细胞因子;或SGN-2FF。
178.如权利要求174至177中任一项所述的方法,其中所述其他治疗剂结合选自下组的蛋白质:CD25、PD-1、PD-L1、Tim3、Lag3、CTLA4、41BB、OX40、CD3、CD40、CD47M、GM-CSF、CSF1R、TLR、STING、RIGI、TAM受体激酶、NKG2A、NKG2D、GD2、HER2、EGFR、PDGFRα、SLAMF7、VEGF、CTLA-4、CD20、cCLB8、KIR及CD52。
179.如权利要求178所述的方法,其中所述其他治疗剂选自抗CD25抗体、抗PD-1抗体、抗PD-L1抗体、抗Tim3抗体、抗Lag3抗体、抗CTLA4抗体、抗41BB抗体、抗OX40抗体、抗CD3抗体、抗CD40抗体、抗CD47M抗体、抗CSF1R抗体、抗TLR抗体、抗STING抗体、抗RIGI抗体、抗TAM受体激酶抗体、抗NKG2A抗体、抗NKG2D抗体、抗GD2抗体、抗HER2抗体、抗EGFR抗体、抗PDGFR-α-抗体、抗SLAMF7抗体、抗VEGF抗体、抗CTLA-4抗体、抗CD20抗体、抗cCLB8抗体、抗KIR抗体及抗CD52抗体。
180.如权利要求174或175所述的方法,其中所述其他治疗剂包含选自IL-15、IL-21、IL-2、GM-CSF、M-CSF、G-CSF、IL-1、IL-3、IL-12及IFNγ的细胞因子。
181.如权利要求174至179中任一项所述的方法,其中所述其他治疗剂选自SEA-CD40、阿维鲁单抗、德瓦鲁单抗、尼沃鲁单抗、派姆单抗、匹利珠单抗、阿替珠单抗、Hul4.18K322A、Hu3F8、达妥昔单抗、曲妥珠单抗、西妥昔单抗、奥拉妥单抗、奈昔木单抗、埃罗妥珠单抗、雷莫芦单抗、帕妥珠单抗、伊匹单抗、贝伐珠单抗、利妥昔单抗、奥妥珠单抗、司妥昔单抗、奥法木单抗、利利单抗及阿伦单抗。
182.如权利要求174或175所述的方法,其中所述其他治疗剂选自烷基化剂(例如环磷酰胺、异环磷酰胺、氮芥苯丁酸、白消安、美法仑、甲基二(氯乙基)胺、乌拉莫司汀、噻替派、亚硝基脲或替莫唑胺)、蒽环(例如多柔比星、阿德力霉素、道诺霉素、泛艾霉素或米托蒽醌)、细胞骨架破坏剂(例如太平洋紫杉醇或多西他赛)、组织蛋白去乙酰酶抑制剂(例如伏立诺他或罗米地辛)、拓朴异构酶抑制剂(例如伊立替康、托泊替康、安吖啶、依托泊苷或替尼泊苷)、激酶抑制剂(例如硼替佐米、厄洛替尼、吉非替尼、伊马替尼、威罗菲尼或维莫德吉)、核苷类似物或前体类似物(例如阿扎胞苷、硫唑嘌呤、卡培他滨、阿糖胞苷、氟尿嘧啶、吉西他滨、羟基脲、巯嘌呤、胺甲喋呤或硫鸟嘌呤)、肽抗生素(例如放线菌素或博来霉素)、基于铂的药剂(例如顺铂、奥沙利铂或卡铂)、或植物碱(例如长春新碱、长春碱、长春瑞滨、长春地辛、鬼臼毒素、太平洋紫杉醇或多西他赛)、加拉定、沙利窦迈、雷利窦迈及泊马窦迈。
183.如权利要求174至182中任一项所述的方法,其中所述组合物、所述抗体或所述药物组合物与所述其他治疗剂同时给药。
184.如权利要求174至183中任一项所述的方法,其中所述组合物、所述抗体或所述药物组合物与所述其他治疗剂依序给药。
Applications Claiming Priority (7)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201862722063P | 2018-08-23 | 2018-08-23 | |
| US62/722,063 | 2018-08-23 | ||
| US201862734130P | 2018-09-20 | 2018-09-20 | |
| US62/734,130 | 2018-09-20 | ||
| US201962822674P | 2019-03-22 | 2019-03-22 | |
| US62/822,674 | 2019-03-22 | ||
| PCT/US2019/047607 WO2020041541A2 (en) | 2018-08-23 | 2019-08-22 | Anti-tigit antibodies |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN112638944A true CN112638944A (zh) | 2021-04-09 |
Family
ID=67841280
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201980053349.2A Pending CN112638944A (zh) | 2018-08-23 | 2019-08-22 | 抗tigit抗体 |
Country Status (14)
| Country | Link |
|---|---|
| US (2) | US11401339B2 (zh) |
| EP (1) | EP3841123A2 (zh) |
| JP (2) | JP2021534196A (zh) |
| KR (1) | KR20210057053A (zh) |
| CN (1) | CN112638944A (zh) |
| AU (1) | AU2019324170A1 (zh) |
| BR (1) | BR112021003156A2 (zh) |
| CA (1) | CA3107596A1 (zh) |
| IL (1) | IL280780A (zh) |
| MA (1) | MA53434A (zh) |
| MX (1) | MX2021002002A (zh) |
| SG (1) | SG11202101429YA (zh) |
| TW (1) | TW202023625A (zh) |
| WO (1) | WO2020041541A2 (zh) |
Families Citing this family (17)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2021113831A1 (en) | 2019-12-05 | 2021-06-10 | Compugen Ltd. | Anti-pvrig and anti-tigit antibodies for enhanced nk-cell based tumor killing |
| IL297167A (en) | 2020-04-10 | 2022-12-01 | Seagen Inc | Charging variant connectors |
| MX2022015157A (es) | 2020-06-02 | 2023-01-16 | Arcus Biosciences Inc | Anticuerpos para tigit. |
| EP4168118A1 (en) | 2020-06-18 | 2023-04-26 | Genentech, Inc. | Treatment with anti-tigit antibodies and pd-1 axis binding antagonists |
| CN111718415B (zh) * | 2020-07-03 | 2021-02-23 | 上海洛启生物医药技术有限公司 | 一种抗tigit纳米抗体及其应用 |
| TW202216778A (zh) | 2020-07-15 | 2022-05-01 | 美商安進公司 | Tigit及cd112r阻斷 |
| CN111763660A (zh) * | 2020-08-07 | 2020-10-13 | 南京大学 | 一种重组溶瘤痘苗病毒及其制备方法和应用 |
| WO2022217026A1 (en) | 2021-04-09 | 2022-10-13 | Seagen Inc. | Methods of treating cancer with anti-tigit antibodies |
| KR20230171980A (ko) | 2021-04-20 | 2023-12-21 | 씨젠 인크. | 항체 의존성 세포 독성의 조절 |
| EP4333894A1 (en) * | 2021-05-04 | 2024-03-13 | Agenus Inc. | Anti-tigit antibodies and methods of use thereof |
| CA3221398A1 (en) | 2021-05-28 | 2022-12-01 | Seagen Inc. | Anthracycline antibody conjugates |
| WO2023010094A2 (en) | 2021-07-28 | 2023-02-02 | Genentech, Inc. | Methods and compositions for treating cancer |
| TW202321308A (zh) | 2021-09-30 | 2023-06-01 | 美商建南德克公司 | 使用抗tigit抗體、抗cd38抗體及pd—1軸結合拮抗劑治療血液癌症的方法 |
| WO2023178289A2 (en) | 2022-03-17 | 2023-09-21 | Seagen Inc. | Camptothecin conjugates |
| WO2023215719A1 (en) | 2022-05-02 | 2023-11-09 | Arcus Biosciences, Inc. | Anti-tigit antibodies and uses of the same |
| WO2023240058A2 (en) | 2022-06-07 | 2023-12-14 | Genentech, Inc. | Prognostic and therapeutic methods for cancer |
| KR20230171885A (ko) * | 2022-06-10 | 2023-12-21 | 메디맵바이오 주식회사 | 항-tigit 항체, 인터류킨-15, 및 인터류킨-15 수용체 알파 스시 도메인을 포함하는 융합 단백질 및 이의 용도 |
Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN108290936A (zh) * | 2015-08-14 | 2018-07-17 | 默沙东公司 | 抗tigit抗体 |
Family Cites Families (187)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US4816567A (en) | 1983-04-08 | 1989-03-28 | Genentech, Inc. | Recombinant immunoglobin preparations |
| US4676980A (en) | 1985-09-23 | 1987-06-30 | The United States Of America As Represented By The Secretary Of The Department Of Health And Human Services | Target specific cross-linked heteroantibodies |
| US4946778A (en) | 1987-09-21 | 1990-08-07 | Genex Corporation | Single polypeptide chain binding molecules |
| JPH0742304B2 (ja) | 1986-12-05 | 1995-05-10 | 財団法人微生物化学研究会 | 新規なアンスラサイクリン誘導体およびその製造法 |
| EP0307434B2 (en) | 1987-03-18 | 1998-07-29 | Scotgen Biopharmaceuticals, Inc. | Altered antibodies |
| DE3712350A1 (de) | 1987-04-11 | 1988-10-20 | Behringwerke Ag | Semisynthetische rhodomycine, verfahren zu ihrer herstellung und ihre verwendung als zytostatika |
| EP0335369A3 (en) | 1988-03-29 | 1990-03-28 | Zaidan Hojin Biseibutsu Kagaku Kenkyu Kai | New anthracycline derivatives and processes for the preparation of the same |
| US5047335A (en) | 1988-12-21 | 1991-09-10 | The Regents Of The University Of Calif. | Process for controlling intracellular glycosylation of proteins |
| DE69029036T2 (de) | 1989-06-29 | 1997-05-22 | Medarex Inc | Bispezifische reagenzien für die aids-therapie |
| CA2085120A1 (en) | 1990-06-11 | 1991-12-12 | Biochem Pharma Inc. | Heterocyclic anthracyclinone and anthracycline analogs |
| JPH06500011A (ja) | 1990-06-29 | 1994-01-06 | ラージ スケール バイオロジー コーポレイション | 形質転換された微生物によるメラニンの製造 |
| MY106399A (en) | 1990-07-24 | 1995-05-30 | Pfizer | Cephalosporins and homologeus, preparation and pharmaceutical composition |
| US5192880A (en) | 1990-11-13 | 1993-03-09 | Nec Corporation | High-speed emitter coupled logic circuit with large current driving capability |
| KR100211417B1 (ko) | 1990-11-30 | 1999-10-01 | 유충식 | L-탈로피라노시드 유도체 및 그의 제조방법 |
| US5571894A (en) | 1991-02-05 | 1996-11-05 | Ciba-Geigy Corporation | Recombinant antibodies specific for a growth factor receptor |
| NZ241606A (en) | 1991-02-28 | 1994-08-26 | Iaf Biochem Int | Heteroanthracycline antitumor analogs, preparation and pharmaceutical compositions thereof; intermediates therefor |
| JP3025056B2 (ja) | 1991-03-12 | 2000-03-27 | 財団法人微生物化学研究会 | 2,6−ジデオキシ−2−フルオロ−l−タロピラノース誘導体の製造法 |
| US5278299A (en) | 1991-03-18 | 1994-01-11 | Scripps Clinic And Research Foundation | Method and composition for synthesizing sialylated glycosyl compounds |
| JPH04290891A (ja) | 1991-03-19 | 1992-10-15 | Yasumitsu Tamura | 新規なアンスラサイクリン系化合物 |
| DE4111971C1 (zh) | 1991-04-12 | 1992-03-12 | Wolf-Dieter Dr. 7803 Gundelfingen De Fessner | |
| US5552534A (en) | 1991-08-22 | 1996-09-03 | The Trustees Of The University Of Pennsylvania | Non-Peptide peptidomimetics |
| US5587458A (en) | 1991-10-07 | 1996-12-24 | Aronex Pharmaceuticals, Inc. | Anti-erbB-2 antibodies, combinations thereof, and therapeutic and diagnostic uses thereof |
| JPH07500248A (ja) | 1991-10-15 | 1995-01-12 | ザ スクリップス リサーチ インスティテュート | 糖ヌクレオチドの酵素的フコシル化合成によるフコシル化炭水化物の生産、及びGDP−フコースのin situ 再生 |
| WO1993008829A1 (en) | 1991-11-04 | 1993-05-13 | The Regents Of The University Of California | Compositions that mediate killing of hiv-infected cells |
| WO1993010260A1 (en) | 1991-11-21 | 1993-05-27 | The Board Of Trustees Of The Leland Stanford Junior University | Controlling degradation of glycoprotein oligosaccharides by extracellular glycosisases |
| AU675929B2 (en) | 1992-02-06 | 1997-02-27 | Curis, Inc. | Biosynthetic binding protein for cancer marker |
| US5278311A (en) | 1992-06-05 | 1994-01-11 | E. R. Squibb & Sons, Inc. | Nonionic radiographic contrast agents |
| US5736523A (en) | 1992-11-09 | 1998-04-07 | Biochem Pharma Inc. | Antineoplastic heteronapthoquinones |
| DK76193D0 (da) | 1993-06-25 | 1993-06-25 | Astra Ab | Kulhydratderivater |
| ATE207966T1 (de) | 1993-09-13 | 2001-11-15 | Canon Kk | Bestimmung von nukleinsäuren durch pcr, messung der anzahl von mikrobiellen zellen, genen oder genkopien durch pcr und kit zu ihrer verwendung |
| GB9418260D0 (en) | 1994-09-09 | 1994-10-26 | Erba Carlo Spa | Anthracycline derivatives |
| US5641870A (en) | 1995-04-20 | 1997-06-24 | Genentech, Inc. | Low pH hydrophobic interaction chromatography for antibody purification |
| JPH08286368A (ja) | 1995-04-14 | 1996-11-01 | Toyo Ink Mfg Co Ltd | 着色画像形成材料およびそれを用いた着色画像形成媒体と着色画像形成方法 |
| US6245347B1 (en) | 1995-07-28 | 2001-06-12 | Zars, Inc. | Methods and apparatus for improved administration of pharmaceutically active compounds |
| ES2134576T3 (es) | 1995-09-08 | 1999-10-01 | Zaidan Hojin Biseibutsu | Derivados de antraciclina que contienen fluor, que tienen grupo(s) hidroxilo mono- o di-o-aminoalquilados en su radical de azucar. |
| DE19541260A1 (de) | 1995-11-06 | 1997-05-07 | Lohmann Therapie Syst Lts | Therapeutische Zubereitung zur transdermalen Applikation von Wirkstoffen durch die Haut |
| US5834597A (en) | 1996-05-20 | 1998-11-10 | Protein Design Labs, Inc. | Mutated nonactivating IgG2 domains and anti CD3 antibodies incorporating the same |
| US6512010B1 (en) | 1996-07-15 | 2003-01-28 | Alza Corporation | Formulations for the administration of fluoxetine |
| PL182601B1 (pl) | 1996-07-17 | 2002-02-28 | Waldpharm Sp Z Oo | Sposób otrzymywania antybiotyków antracyklinowych |
| DE19640969A1 (de) | 1996-10-04 | 1998-04-16 | Bayer Ag | 20-0-verknüpfte Glycokonjugate von Camptothecin |
| US5770407A (en) | 1996-12-10 | 1998-06-23 | The Scripps Research Institute | Process for preparing nucleotide inhibitors of glycosyltransferases |
| FR2764304B1 (fr) | 1997-06-06 | 1999-07-16 | Rhone Poulenc Rorer Sa | Nouvelle classe d'agents transfectants cationiques des acides nucleiques |
| JPH1135593A (ja) | 1997-07-18 | 1999-02-09 | Daikin Ind Ltd | 2−フルオロフコシル−n−アロイルグルコサミン誘導体及びその中間物、並びにそれらの製造方法 |
| US6248864B1 (en) | 1997-12-31 | 2001-06-19 | Adherex Technologies, Inc. | Compounds and methods and modulating tissue permeability |
| AU3657899A (en) | 1998-04-20 | 1999-11-08 | James E. Bailey | Glycosylation engineering of antibodies for improving antibody-dependent cellular cytotoxicity |
| US6312717B1 (en) | 1998-07-07 | 2001-11-06 | Bristol-Myers Squibb Company | Method for treatment of anxiety and depression |
| SE9802864D0 (sv) | 1998-08-27 | 1998-08-27 | Pharmacia & Upjohn Ab | Transdermally administered tolterodine as antimuscarinic agent for the treatment of overactive bladder |
| CN100405399C (zh) | 1999-02-05 | 2008-07-23 | 三星电子株式会社 | 图像纹理恢复方法及其装置 |
| EP2275540B1 (en) | 1999-04-09 | 2016-03-23 | Kyowa Hakko Kirin Co., Ltd. | Method for controlling the activity of immunologically functional molecule |
| US6544548B1 (en) | 1999-09-13 | 2003-04-08 | Keraplast Technologies, Ltd. | Keratin-based powders and hydrogel for pharmaceutical applications |
| US20080050809A1 (en) | 1999-09-28 | 2008-02-28 | Alejandro Abuin | Novel human kinases and polynucleotides encoding the same |
| US20040219521A1 (en) | 2000-01-21 | 2004-11-04 | Tang Y. Tom | Novel nucleic acids and polypeptides |
| FR2807767B1 (fr) | 2000-04-12 | 2005-01-14 | Lab Francais Du Fractionnement | Anticorps monoclonaux anti-d |
| US6589549B2 (en) | 2000-04-27 | 2003-07-08 | Macromed, Incorporated | Bioactive agent delivering system comprised of microparticles within a biodegradable to improve release profiles |
| US6670330B1 (en) | 2000-05-01 | 2003-12-30 | Theodore J. Lampidis | Cancer chemotherapy with 2-deoxy-D-glucose |
| US6696081B2 (en) | 2000-06-09 | 2004-02-24 | Duke University | Carbohydrate based lipid compositions and supramolecular structures comprising same |
| WO2002000669A2 (de) | 2000-06-26 | 2002-01-03 | Basf Aktiengesellschaft | Phosphacyclohexane und ihre verwendung in der hydroformylierung von olefinen |
| US6946292B2 (en) | 2000-10-06 | 2005-09-20 | Kyowa Hakko Kogyo Co., Ltd. | Cells producing antibody compositions with increased antibody dependent cytotoxic activity |
| NZ592087A (en) | 2001-08-03 | 2012-11-30 | Roche Glycart Ag | Antibody glycosylation variants having increased antibody-dependent cellular cytotoxicity |
| AU2002366951A1 (en) | 2001-12-10 | 2003-07-09 | Nuvelo,Inc. | Novel nucleic acids and polypeptides |
| WO2003068943A2 (en) | 2002-02-13 | 2003-08-21 | Incyte Corporation | Secreted proteins |
| CA2476518A1 (en) | 2002-02-22 | 2003-09-04 | Genentech, Inc. | Compositions and methods for the treatment of immune related diseases |
| US7193069B2 (en) | 2002-03-22 | 2007-03-20 | Research Association For Biotechnology | Full-length cDNA |
| AUPS247502A0 (en) | 2002-05-22 | 2002-06-13 | Griffith University | An antimicrobial agent |
| WO2004024072A2 (en) | 2002-09-11 | 2004-03-25 | Genentech, Inc. | Novel compositions and methods for the treatment of immune related diseases |
| JP5401001B2 (ja) | 2002-09-11 | 2014-01-29 | ジェネンテック, インコーポレイテッド | 免疫関連疾患の治療のための新規組成物と方法 |
| AU2003279809A1 (en) | 2002-10-07 | 2004-05-04 | Encore Pharmaceuticals, Inc. | R-nsaid esters and their use |
| JP5356648B2 (ja) | 2003-02-20 | 2013-12-04 | シアトル ジェネティックス, インコーポレイテッド | 抗cd70抗体−医薬結合体、ならびに癌および免疫障害の処置のためのそれらの使用 |
| US7691603B2 (en) | 2003-04-09 | 2010-04-06 | Novo Nordisk A/S | Intracellular formation of peptide conjugates |
| US7772192B2 (en) | 2003-06-03 | 2010-08-10 | The Regents Of The University Of California | Compositions and methods for treatment of disease with acetylated disaccharides |
| FR2858235B1 (fr) | 2003-07-31 | 2006-02-17 | Lab Francais Du Fractionnement | Utilisation d'anticorps optimises en adcc pour traiter les patients faibles repondeurs |
| US20070274928A1 (en) | 2003-11-17 | 2007-11-29 | Sergey Selifonov | Novel Cyclic Oxygenated Compounds Having Cooling, Fragrance, and Flavor Properties, and Uses Thereof |
| EP1699806A1 (en) | 2003-12-23 | 2006-09-13 | Progen Industries Limited | Glycosaminoglycan (gag) mimetics |
| PL369253A1 (pl) | 2004-07-23 | 2006-02-06 | Zakład Badawczo-Produkcyjny SYNTEX Sp.z o.o. | Sposób otrzymywania złożonych 2-deoksy-2-jodopiranozydów o wysokiej czystości, szczególnie Annamycyny o czystości farmaceutycznej |
| EA016357B1 (ru) | 2004-07-30 | 2012-04-30 | Ринат Ньюросайенс Корп. | Антитела, направленные против бета-амилоидного пептида, и способы их применения |
| WO2006040558A1 (en) | 2004-10-15 | 2006-04-20 | Astrazeneca Ab | Substituted adenines and the use thereof |
| US7632497B2 (en) | 2004-11-10 | 2009-12-15 | Macrogenics, Inc. | Engineering Fc Antibody regions to confer effector function |
| WO2006124667A2 (en) | 2005-05-12 | 2006-11-23 | Zymogenetics, Inc. | Compositions and methods for modulating immune responses |
| US8303955B2 (en) | 2005-05-26 | 2012-11-06 | Seattle Genetics, Inc. | Humanized anti-CD40 antibodies and their methods of use |
| CA2634146A1 (en) | 2005-12-19 | 2007-06-28 | Genizon Biosciences Inc. | Genemap of the human genes associated with crohn's disease |
| WO2007101148A2 (en) | 2006-02-24 | 2007-09-07 | Board Of Regents, The University Of Texas System | Hexose compounds to treat cancer |
| CN101426508A (zh) | 2006-02-24 | 2009-05-06 | 得克萨斯系统大学评议会 | 治疗癌症的己糖化合物 |
| US20100075377A1 (en) | 2006-04-13 | 2010-03-25 | West James W | Tetramerizing polypeptides and methods of use |
| AU2007240491A1 (en) | 2006-04-13 | 2007-11-01 | Zymogenetics, Inc. | Tetramerizing polypeptides and methods of use |
| US9149489B2 (en) | 2006-04-27 | 2015-10-06 | Board Of Regents, University Of Texas System | Inhibitors of glycolysis useful in the treatment of brain tumors |
| US8586006B2 (en) | 2006-08-09 | 2013-11-19 | Institute For Systems Biology | Organ-specific proteins and methods of their use |
| DE102006053635B4 (de) | 2006-11-14 | 2011-06-30 | Sanofi-Aventis Deutschland GmbH, 65929 | Neue mit Benzylresten substituierte 1,4-Benzothiepin-1,1-Dioxidderivate, diese Verbindungen enthaltende Arzneimittel und deren Verwendung |
| DE102006053637B4 (de) | 2006-11-14 | 2011-06-30 | Sanofi-Aventis Deutschland GmbH, 65929 | Neue mit Fluor substituierte 1,4-Benzothiepin-1,1-Dioxidderivate, diese Verbindungen enthaltende Arzneimittel und deren Verwendung |
| US8455622B2 (en) | 2006-12-01 | 2013-06-04 | Seattle Genetics, Inc. | Variant target binding agents and uses thereof |
| WO2008131024A1 (en) | 2007-04-17 | 2008-10-30 | Board Of Regents, The University Of Texas System | Iodo-hexose compounds useful to treat cancer |
| GB0714514D0 (en) * | 2007-07-26 | 2007-09-05 | Univ City | Computer system |
| US8877688B2 (en) | 2007-09-14 | 2014-11-04 | Adimab, Llc | Rationally designed, synthetic antibody libraries and uses therefor |
| EP2193146B1 (en) | 2007-09-14 | 2016-05-25 | Adimab, LLC | Rationally designed, synthetic antibody libraries and uses therefor |
| WO2009046407A2 (en) | 2007-10-04 | 2009-04-09 | Zymogenetics, Inc. | B7 FAMILY MEMBER zB7H6 AND RELATED COMPOSITIONS AND METHODS |
| US8293720B2 (en) | 2007-12-20 | 2012-10-23 | Dogwood Pharmaceuticals, Inc. | Substituted 4-{3-[6-amino-9-(3, 4-dihydroxy-tetrahydro-furan-2-yl)-9H-purin-2-yl]-prop-2-ynyl}-piperidine-1-carboxylic acid esters as A2AR agonists |
| ES2601518T3 (es) | 2008-02-12 | 2017-02-15 | Dow Agrosciences Llc | Composiciones plaguicidas |
| JP5260093B2 (ja) | 2008-03-10 | 2013-08-14 | クラレノリタケデンタル株式会社 | 重合性単量体、重合性組成物及び歯科用材料 |
| CA2978149C (en) | 2008-03-21 | 2019-02-12 | The General Hospital Corporation | Inositol derivatives for the detection and treatment of alzheimer's disease and related disorders |
| CN101555262A (zh) | 2008-04-08 | 2009-10-14 | 中国科学院生态环境研究中心 | 六水合三氯化铁(FeCl3·6H2O)选择性脱除糖类化合物异头碳酰基的方法 |
| SG10201402815VA (en) | 2008-04-09 | 2014-09-26 | Genentech Inc | Novel compositions and methods for the treatment of immune related diseases |
| ES2458541T3 (es) | 2008-05-02 | 2014-05-06 | Seattle Genetics, Inc. | Métodos y composiciones para elaborar anticuerpos y derivados de anticuerpos con fucosilación del núcleo reducida |
| US20110183926A1 (en) | 2008-05-23 | 2011-07-28 | University Of Miami | Treatment using continuous low dose application of sugar analogs |
| ES2456873T3 (es) | 2009-02-11 | 2014-04-23 | Dow Agrosciences Llc | Composiciones pesticidas |
| AU2010225456B2 (en) | 2009-03-18 | 2016-03-17 | Carina Biotech Pty Ltd | Biomarkers and uses thereof |
| EP2411529A4 (en) | 2009-03-27 | 2012-09-19 | Zacharon Pharmaceuticals Inc | MODULATORS OF BIOSYNTHESIS OF N-BOUND GLYCANS |
| BRPI1015019A2 (pt) | 2009-04-20 | 2018-02-14 | Pfizer | controle de glicosilação de proteína e composições e métodos relacionada a ele. |
| US9624255B2 (en) | 2009-08-11 | 2017-04-18 | Arizona Board Of Regents | Carbohydrate-mediated tumor targeting |
| US9198972B2 (en) | 2010-01-28 | 2015-12-01 | Alnylam Pharmaceuticals, Inc. | Monomers and oligonucleotides comprising cycloaddition adduct(s) |
| US20150259371A1 (en) | 2010-05-06 | 2015-09-17 | Simon Fraser University | Methods and compounds for inhibiting glycosyltransferases |
| EP2580238A1 (en) | 2010-06-09 | 2013-04-17 | Zymogenetics, Inc. | Dimeric vstm3 fusion proteins and related compositions and methods |
| EP4219805A1 (en) | 2010-07-16 | 2023-08-02 | Adimab, LLC | Antibody libraries |
| MX356671B (es) | 2010-08-05 | 2018-06-08 | Seattle Genetics Inc | Métodos para inhibir fucosilación de proteína in vivo utilizando análogos de fucosa. |
| US9057086B2 (en) | 2010-08-12 | 2015-06-16 | Novozymes, Inc. | Compositions comprising a polypeptide having cellulolytic enhancing activity and a bicycle compound and uses thereof |
| TWI410431B (zh) | 2010-12-22 | 2013-10-01 | Ind Tech Res Inst | 齊敦果酸衍生物在製備預防或治療c型肝炎之藥物的用途 |
| US8923278B2 (en) | 2011-01-10 | 2014-12-30 | Vtech Telecommunications Limited | Peer-to-peer, internet protocol telephone system with system-wide configuration data |
| JP2014505058A (ja) | 2011-01-11 | 2014-02-27 | ザ・ユニバーシティ・オブ・テキサス・エム・ディー・アンダーソン・キャンサー | 増殖性および炎症性皮膚疾患の治療用単糖ベース化合物 |
| US9493452B2 (en) | 2011-03-24 | 2016-11-15 | Southern Methodist University | Compounds and derivatives of 2H-pyrido (3,2-b)(1, 4) oxazin 3)4H)-ones as raf kinase and LRRK2 inhibitors |
| US9518068B2 (en) | 2011-05-31 | 2016-12-13 | Merck Patent Gmbh | Compounds containing hydrido-tricyano-borate anions |
| WO2013010641A1 (en) | 2011-07-15 | 2013-01-24 | Merck Patent Gmbh | Compounds containing alkyl-cyano-borate or alkyl-cyano-fluoroborate anions |
| WO2013068874A1 (en) | 2011-11-11 | 2013-05-16 | Pfizer Inc. | Antibody-drug conjugates |
| CN104411826A (zh) | 2012-03-13 | 2015-03-11 | 萨克生物研究学院 | 使用腺病毒和化学二聚体的选择性细胞寻靶 |
| CA2868398A1 (en) | 2012-04-02 | 2013-10-10 | Moderna Therapeutics, Inc. | Modified polynucleotides for the production of cosmetic proteins and peptides |
| US9283287B2 (en) | 2012-04-02 | 2016-03-15 | Moderna Therapeutics, Inc. | Modified polynucleotides for the production of nuclear proteins |
| US9878056B2 (en) | 2012-04-02 | 2018-01-30 | Modernatx, Inc. | Modified polynucleotides for the production of cosmetic proteins and peptides |
| DK2854850T3 (da) | 2012-05-25 | 2021-08-30 | Sloan Kettering Inst Cancer Res | Sammensætninger til behandling eller forebyggelse af strålingssygdom og gi-syndrom |
| CA2875980A1 (en) | 2012-06-06 | 2013-12-12 | Oncomed Pharmaceuticals, Inc. | Binding agents that modulate the hippo pathway and uses thereof |
| RS58528B1 (sr) | 2012-12-03 | 2019-04-30 | Bristol Myers Squibb Co | Poboljšanje anti-kancerske aktivnosti imunomodulatornih fc fuzionih proteina |
| AR093788A1 (es) | 2012-12-04 | 2015-06-24 | Oncomed Pharm Inc | Inmunoterapia con agentes de enlace |
| CN104250302B (zh) | 2013-06-26 | 2017-11-14 | 上海君实生物医药科技股份有限公司 | 抗pd‑1抗体及其应用 |
| KR20160030936A (ko) | 2013-07-16 | 2016-03-21 | 제넨테크, 인크. | Pd-1 축 결합 길항제 및 tigit 억제제를 사용한 암을 치료하는 방법 |
| WO2015036394A1 (en) | 2013-09-10 | 2015-03-19 | Medimmune Limited | Antibodies against pd-1 and uses thereof |
| EP3060581A4 (en) | 2013-10-25 | 2017-06-07 | Dana-Farber Cancer Institute, Inc. | Anti-pd-l1 monoclonal antibodies and fragments thereof |
| WO2015073682A1 (en) | 2013-11-13 | 2015-05-21 | Oregon Health And Science University | Methods of detecting cells latently infected with hiv |
| PL3712174T3 (pl) * | 2013-12-24 | 2022-07-04 | Janssen Pharmaceutica Nv | Przeciwciała i fragmenty anty-vista |
| US20170107300A1 (en) | 2014-03-21 | 2017-04-20 | The Brigham And Women's Hospital, Inc. | Methods and compositions for treatment of immune-related diseases or disorders and/or therapy monitoring |
| WO2016011264A1 (en) | 2014-07-16 | 2016-01-21 | Genentech, Inc. | Methods of treating cancer using tigit inhibitors and anti-cancer agents |
| IL250583B (en) | 2014-08-19 | 2022-07-01 | Merck Sharp & Dohme | Anti-tigit antibodies |
| SG11201702598XA (en) | 2014-10-29 | 2017-05-30 | Seattle Genetics Inc | Dosage and administration of non-fucosylated anti-cd40 antibodies |
| RU2017119428A (ru) | 2014-11-06 | 2018-12-06 | Дженентек, Инк. | Комбинированная терапия, включающая применение агонистов, связывающихся с ох40, и ингибиторов tigit |
| WO2016073879A2 (en) | 2014-11-06 | 2016-05-12 | Scholar Rock, Inc. | Transforming growth factor-related antibodies and uses thereof |
| AU2015343048A1 (en) | 2014-11-06 | 2017-05-18 | Children's Research Institute, Children's National Medical Center | Immunotherapeutics for cancer and autoimmune diseases |
| PT3220927T (pt) | 2014-11-20 | 2022-02-07 | Promega Corp | Sistemas e métodos para avaliar moduladores de pontos de verificação imunitária |
| TWI595006B (zh) | 2014-12-09 | 2017-08-11 | 禮納特神經系統科學公司 | 抗pd-1抗體類和使用彼等之方法 |
| US10239942B2 (en) | 2014-12-22 | 2019-03-26 | Pd-1 Acquisition Group, Llc | Anti-PD-1 antibodies |
| TWI708786B (zh) | 2014-12-23 | 2020-11-01 | 美商必治妥美雅史谷比公司 | 針對tigit之抗體 |
| EP3247408A4 (en) | 2015-01-20 | 2018-08-22 | Immunexcite, Inc. | Compositions and methods for cancer immunotherapy |
| US10550173B2 (en) | 2015-02-19 | 2020-02-04 | Compugen, Ltd. | PVRIG polypeptides and methods of treatment |
| CN107580500B (zh) | 2015-02-19 | 2023-05-30 | 康姆普根有限公司 | 抗pvrig抗体和使用方法 |
| WO2016166139A1 (en) | 2015-04-14 | 2016-10-20 | Eberhard Karls Universität Tübingen | Bispecific fusion proteins for enhancing immune responses of lymphocytes against tumor cells |
| CN107969128A (zh) | 2015-04-17 | 2018-04-27 | 高山免疫科学股份有限公司 | 具有可调的亲和力的免疫调节蛋白 |
| WO2016179288A1 (en) | 2015-05-04 | 2016-11-10 | University Of Florida Research Foundation, Inc. | Novel regulatory-cells, method for their isolation and uses |
| TWI715587B (zh) | 2015-05-28 | 2021-01-11 | 美商安可美德藥物股份有限公司 | Tigit結合劑和彼之用途 |
| US11078278B2 (en) | 2015-05-29 | 2021-08-03 | Bristol-Myers Squibb Company | Treatment of renal cell carcinoma |
| EP3302548A4 (en) | 2015-06-03 | 2019-01-02 | Dana Farber Cancer Institute, Inc. | Methods to induce conversion of regulatory t cells into effector t cells for cancer immunotherapy |
| JO3620B1 (ar) | 2015-08-05 | 2020-08-27 | Amgen Res Munich Gmbh | مثبطات نقطة فحص مناعية للاستخدام في علاج سرطانات محمولة عبر الدم |
| US20180244783A1 (en) | 2015-08-31 | 2018-08-30 | Oncomed Pharmaceuticals, Inc. | Combination therapy for treatment of disease |
| WO2017040660A1 (en) | 2015-08-31 | 2017-03-09 | Oncomed Pharmaceuticals, Inc. | Combination therapy for treatment of disease |
| ES2924071T3 (es) | 2015-09-02 | 2022-10-04 | Yissum Res Dev Co Of Hebrew Univ Jerusalem Ltd | Anticuerpos específicos para inmunoglobulina de células T humanas y dominio ITIM (TIGIT) |
| CA2997551A1 (en) | 2015-09-04 | 2017-03-09 | Memorial Sloan Kettering Cancer Center | Immune cell compositions and methods of use |
| JP2018534245A (ja) | 2015-09-14 | 2018-11-22 | アルパイン イミューン サイエンシズ インコーポレイテッド | 調整可能なバリアント免疫グロブリンスーパーファミリードメインおよび改変細胞療法 |
| EP3349792A1 (en) | 2015-09-14 | 2018-07-25 | Compass Therapeutics LLC | Compositions and methods for treating cancer via antagonism of the cd155/tigit pathway and tgf- |
| CR20220186A (es) | 2015-09-25 | 2022-07-07 | Genentech Inc | ANTICUERPOS ANTI-TIGIT Y MÉTODOS DE USO (divisional 2018-0225) |
| KR20180051651A (ko) | 2015-10-01 | 2018-05-16 | 히트 바이오로직스, 인코퍼레이티드 | 비상동성 키메라 단백질로서의 i형 및 ii형 세포외 도메인을 인접시키기 위한 조성물 및 방법 |
| CN108368176B (zh) | 2015-10-01 | 2022-06-07 | 波滕扎治疗公司 | 抗tigit抗原结合蛋白及其使用方法 |
| BR112018008904A2 (pt) | 2015-11-03 | 2018-11-27 | Janssen Biotech Inc | anticorpos que se ligam especificamente a tim-3 e seus usos |
| US20180353524A1 (en) | 2015-12-04 | 2018-12-13 | Seattle Genetics, Inc. | Cancer treatment using 2-deoxy-2-fluoro-l-fucose in combination with a checkpoint inhibitor |
| WO2017100428A1 (en) | 2015-12-09 | 2017-06-15 | Memorial Sloan Kettering Cancer Center | Immune cell compositions and methods of using same |
| WO2017149538A1 (en) | 2016-03-01 | 2017-09-08 | Yissum Research Development Company Of The Hebrew University Of Jerusalem Ltd. | Antibodies specific to human poliovirus receptor (pvr) |
| WO2017152088A1 (en) | 2016-03-04 | 2017-09-08 | JN Biosciences, LLC | Antibodies to tigit |
| US11446398B2 (en) | 2016-04-11 | 2022-09-20 | Obsidian Therapeutics, Inc. | Regulated biocircuit systems |
| KR20190006495A (ko) | 2016-04-15 | 2019-01-18 | 알파인 이뮨 사이언시즈, 인코포레이티드 | Cd80 변이체 면역조절 단백질 및 그의 용도 |
| KR20230051602A (ko) | 2016-04-15 | 2023-04-18 | 알파인 이뮨 사이언시즈, 인코포레이티드 | Icos 리간드 변이체 면역조절 단백질 및 그의 용도 |
| EP3452101A2 (en) | 2016-05-04 | 2019-03-13 | CureVac AG | Rna encoding a therapeutic protein |
| US11400116B2 (en) | 2016-05-06 | 2022-08-02 | The Regents Of The University Of California | Systems and methods for targeting cancer cells |
| JP7358047B2 (ja) | 2016-05-16 | 2023-10-10 | チェックマブ エス.アール.エル. | 腫瘍浸潤制御性t細胞において選択的に脱制御されたマーカー |
| TWI784957B (zh) | 2016-06-20 | 2022-12-01 | 英商克馬伯有限公司 | 免疫細胞介素 |
| WO2018022945A1 (en) | 2016-07-28 | 2018-02-01 | Alpine Immune Sciences, Inc. | Cd112 variant immunomodulatory proteins and uses thereof |
| CN110088127A (zh) | 2016-07-28 | 2019-08-02 | 高山免疫科学股份有限公司 | Cd155变体免疫调节蛋白及其用途 |
| EP3617232A1 (en) | 2016-08-17 | 2020-03-04 | Compugen Ltd. | Anti-tigit antibodies, anti-pvrig antibodies and combinations thereof |
| EP3507361A1 (en) | 2016-08-30 | 2019-07-10 | Memorial Sloan Kettering Cancer Center | Immune cell compositions and methods of use for treating viral and other infections |
| WO2018041120A1 (en) | 2016-08-31 | 2018-03-08 | Beijing Biocytogen Co., Ltd | Genetically modified non-human animal with human or chimeric tigit |
| WO2018047178A1 (en) | 2016-09-10 | 2018-03-15 | Yeda Research And Development Co. Ltd. | Reducing systemic regulatory t cell levels or activity for treatment of disease and injury of the cns |
| EP3293271A1 (en) | 2016-09-12 | 2018-03-14 | The Provost, Fellows, Foundation Scholars, & the other members of Board, of the College of the Holy & Undiv. Trinity of Queen Elizabeth near Dublin | Marker and target as a diagnostic variable and target for therapy of metastatic cancer |
| US20190225701A1 (en) | 2016-09-26 | 2019-07-25 | The Brigham And Women's Hospital, Inc. | Regulators of b cell-mediated immunosuppression |
| WO2018102746A1 (en) | 2016-12-02 | 2018-06-07 | Rigel Pharmaceuticals, Inc. | Antigen binding molecules to tigit |
| SG11201907278VA (en) | 2017-02-28 | 2019-09-27 | Seattle Genetics Inc | Anti-tigit antibodies |
| JOP20190203A1 (ar) | 2017-03-30 | 2019-09-03 | Potenza Therapeutics Inc | بروتينات رابطة لمولد ضد مضادة لـ tigit وطرق استخدامها |
-
2019
- 2019-08-22 US US16/547,824 patent/US11401339B2/en active Active
- 2019-08-22 BR BR112021003156-1A patent/BR112021003156A2/pt unknown
- 2019-08-22 JP JP2021509776A patent/JP2021534196A/ja active Pending
- 2019-08-22 EP EP19762646.8A patent/EP3841123A2/en active Pending
- 2019-08-22 AU AU2019324170A patent/AU2019324170A1/en active Pending
- 2019-08-22 WO PCT/US2019/047607 patent/WO2020041541A2/en unknown
- 2019-08-22 MX MX2021002002A patent/MX2021002002A/es unknown
- 2019-08-22 CN CN201980053349.2A patent/CN112638944A/zh active Pending
- 2019-08-22 CA CA3107596A patent/CA3107596A1/en active Pending
- 2019-08-22 KR KR1020217008379A patent/KR20210057053A/ko unknown
- 2019-08-22 MA MA053434A patent/MA53434A/fr unknown
- 2019-08-22 TW TW108130031A patent/TW202023625A/zh unknown
- 2019-08-22 SG SG11202101429YA patent/SG11202101429YA/en unknown
-
2021
- 2021-02-10 IL IL280780A patent/IL280780A/en unknown
-
2022
- 2022-06-10 US US17/837,589 patent/US20230050440A1/en active Pending
-
2023
- 2023-10-27 JP JP2023184802A patent/JP2023182854A/ja active Pending
Patent Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN108290936A (zh) * | 2015-08-14 | 2018-07-17 | 默沙东公司 | 抗tigit抗体 |
Non-Patent Citations (1)
| Title |
|---|
| 任海龙等: "NK细胞应用于肿瘤免疫治疗的研究进展", 《现代免疫学》, no. 03, pages 61 - 65 * |
Also Published As
| Publication number | Publication date |
|---|---|
| AU2019324170A1 (en) | 2021-02-18 |
| JP2021534196A (ja) | 2021-12-09 |
| US20200062859A1 (en) | 2020-02-27 |
| EP3841123A2 (en) | 2021-06-30 |
| MX2021002002A (es) | 2021-05-31 |
| CA3107596A1 (en) | 2020-02-27 |
| BR112021003156A2 (pt) | 2021-05-11 |
| WO2020041541A3 (en) | 2020-03-26 |
| TW202023625A (zh) | 2020-07-01 |
| SG11202101429YA (en) | 2021-03-30 |
| WO2020041541A9 (en) | 2020-08-06 |
| MA53434A (fr) | 2021-12-01 |
| WO2020041541A2 (en) | 2020-02-27 |
| JP2023182854A (ja) | 2023-12-26 |
| US11401339B2 (en) | 2022-08-02 |
| US20230050440A1 (en) | 2023-02-16 |
| KR20210057053A (ko) | 2021-05-20 |
| IL280780A (en) | 2021-04-29 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN112638944A (zh) | 抗tigit抗体 | |
| KR102379464B1 (ko) | 항-pd-l1 항체 | |
| JP7212821B2 (ja) | 抗lag-3抗体および組成物 | |
| KR102536145B1 (ko) | 항-pd-1 항체 및 이의 용도 | |
| AU2014268298B2 (en) | Anti-B7-H5 antibodies and their uses | |
| JP2023519254A (ja) | がんを処置するための抗ccr8抗体 | |
| JP6976322B2 (ja) | 新規抗ctla4抗体 | |
| TW201605901A (zh) | Pd-1抗體、其抗原結合片段及其醫藥用途 | |
| CN110267989B (zh) | 抗cd40抗体、其抗原结合片段及其医药用途 | |
| JP2021508467A (ja) | 抗lag−3抗体及びその使用 | |
| CN113508139B (zh) | 结合人lag-3的抗体、其制备方法和用途 | |
| TW202039564A (zh) | 抗cd96抗體及其使用方法 | |
| KR20220008820A (ko) | Cd40과 fap에 결합하는 이중 특이적 항체 | |
| TW201121569A (en) | Treatment of cancer involving mutated KRAS or BRAF genes | |
| TWI806870B (zh) | 抗pd-1抗體及其用途 | |
| WO2022148412A1 (zh) | 特异性结合cd47的抗体及其抗原结合片段 | |
| RU2779128C2 (ru) | Антитело к cd40, его антигенсвязывающий фрагмент и его медицинское применение | |
| KR20230110523A (ko) | 델타-유사 리간드 3(dll3) 항원 결합 영역을 포함하는 단백질 및 그의 용도 | |
| AU2021400733A1 (en) | Cd40 binding molecules and uses thereof | |
| TW202305007A (zh) | 靶向pd-l1和cd73的特異性結合蛋白 | |
| JP2022523145A (ja) | 抗trem1抗体及び関連方法 | |
| TW202411252A (zh) | 抗pd-1抗體及其用途 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| REG | Reference to a national code |
Ref country code: HK Ref legal event code: DE Ref document number: 40045749 Country of ref document: HK |
|
| CB02 | Change of applicant information |
Address after: Washington State Applicant after: Sijin Co. Address before: Washington State Applicant before: Xijin Co. |
|
| CB02 | Change of applicant information |