ES2901396T3 - Composiciones y métodos de ácidos nucleicos dirigidos a ácido nucleico - Google Patents
Composiciones y métodos de ácidos nucleicos dirigidos a ácido nucleico Download PDFInfo
- Publication number
- ES2901396T3 ES2901396T3 ES19188624T ES19188624T ES2901396T3 ES 2901396 T3 ES2901396 T3 ES 2901396T3 ES 19188624 T ES19188624 T ES 19188624T ES 19188624 T ES19188624 T ES 19188624T ES 2901396 T3 ES2901396 T3 ES 2901396T3
- Authority
- ES
- Spain
- Prior art keywords
- nucleic acid
- sequence
- site
- cell
- targeting
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 150000007523 nucleic acids Chemical class 0.000 title claims description 1018
- 102000039446 nucleic acids Human genes 0.000 title claims description 998
- 108020004707 nucleic acids Proteins 0.000 title claims description 997
- 230000008685 targeting Effects 0.000 title claims description 247
- 238000000034 method Methods 0.000 title description 80
- 239000000203 mixture Substances 0.000 title description 76
- 108091033409 CRISPR Proteins 0.000 claims abstract description 80
- 230000004048 modification Effects 0.000 claims abstract description 64
- 238000012986 modification Methods 0.000 claims abstract description 64
- 230000037430 deletion Effects 0.000 claims abstract description 21
- 238000012217 deletion Methods 0.000 claims abstract description 21
- 230000037431 insertion Effects 0.000 claims abstract description 15
- 238000003780 insertion Methods 0.000 claims abstract description 15
- 241000193996 Streptococcus pyogenes Species 0.000 claims abstract description 12
- 125000000539 amino acid group Chemical group 0.000 claims abstract description 5
- 210000004027 cell Anatomy 0.000 claims description 235
- 102000040430 polynucleotide Human genes 0.000 claims description 158
- 108091033319 polynucleotide Proteins 0.000 claims description 158
- 239000002157 polynucleotide Substances 0.000 claims description 158
- 230000004927 fusion Effects 0.000 claims description 49
- 125000003275 alpha amino acid group Chemical group 0.000 claims description 44
- 210000004102 animal cell Anatomy 0.000 claims description 7
- 241000251539 Vertebrata <Metazoa> Species 0.000 claims description 5
- 230000002538 fungal effect Effects 0.000 claims description 5
- 102000004533 Endonucleases Human genes 0.000 claims description 4
- 108010042407 Endonucleases Proteins 0.000 claims description 4
- 230000001580 bacterial effect Effects 0.000 claims description 4
- 210000005260 human cell Anatomy 0.000 claims description 3
- 210000004962 mammalian cell Anatomy 0.000 claims description 3
- 108020004705 Codon Proteins 0.000 claims description 2
- 108020001507 fusion proteins Proteins 0.000 claims description 2
- 102000037865 fusion proteins Human genes 0.000 claims description 2
- 239000003153 chemical reaction reagent Substances 0.000 claims 1
- 239000003550 marker Substances 0.000 claims 1
- 108090000765 processed proteins & peptides Proteins 0.000 description 370
- 102000004196 processed proteins & peptides Human genes 0.000 description 357
- 229920001184 polypeptide Polymers 0.000 description 356
- 125000003729 nucleotide group Chemical group 0.000 description 223
- 239000002773 nucleotide Substances 0.000 description 219
- 230000000694 effects Effects 0.000 description 137
- 101710163270 Nuclease Proteins 0.000 description 112
- 108090000623 proteins and genes Proteins 0.000 description 103
- 108091079001 CRISPR RNA Proteins 0.000 description 89
- 235000018102 proteins Nutrition 0.000 description 85
- 102000004169 proteins and genes Human genes 0.000 description 85
- 230000035772 mutation Effects 0.000 description 75
- 102000044158 nucleic acid binding protein Human genes 0.000 description 72
- 108700020942 nucleic acid binding protein Proteins 0.000 description 72
- 230000027455 binding Effects 0.000 description 70
- 230000002068 genetic effect Effects 0.000 description 57
- 229920002477 rna polymer Polymers 0.000 description 55
- 239000003795 chemical substances by application Substances 0.000 description 53
- 239000013598 vector Substances 0.000 description 46
- 102000002494 Endoribonucleases Human genes 0.000 description 44
- 108010093099 Endoribonucleases Proteins 0.000 description 44
- 239000012636 effector Substances 0.000 description 44
- 125000006850 spacer group Chemical group 0.000 description 39
- 125000005647 linker group Chemical group 0.000 description 36
- 108091028043 Nucleic acid sequence Proteins 0.000 description 30
- 239000000872 buffer Substances 0.000 description 26
- 238000003776 cleavage reaction Methods 0.000 description 25
- 230000007017 scission Effects 0.000 description 25
- -1 mCherry Proteins 0.000 description 23
- 102000053602 DNA Human genes 0.000 description 22
- 108020004414 DNA Proteins 0.000 description 22
- 235000001014 amino acid Nutrition 0.000 description 22
- 235000000346 sugar Nutrition 0.000 description 20
- 229940024606 amino acid Drugs 0.000 description 19
- 150000001413 amino acids Chemical class 0.000 description 19
- 238000009396 hybridization Methods 0.000 description 18
- 239000000523 sample Substances 0.000 description 18
- YBJHBAHKTGYVGT-ZKWXMUAHSA-N (+)-Biotin Chemical compound N1C(=O)N[C@@H]2[C@H](CCCCC(=O)O)SC[C@@H]21 YBJHBAHKTGYVGT-ZKWXMUAHSA-N 0.000 description 16
- 239000002585 base Substances 0.000 description 16
- 210000000130 stem cell Anatomy 0.000 description 15
- 108010008532 Deoxyribonuclease I Proteins 0.000 description 13
- 102000007260 Deoxyribonuclease I Human genes 0.000 description 13
- GNBHRKFJIUUOQI-UHFFFAOYSA-N fluorescein Chemical compound O1C(=O)C2=CC=CC=C2C21C1=CC=C(O)C=C1OC1=CC(O)=CC=C21 GNBHRKFJIUUOQI-UHFFFAOYSA-N 0.000 description 13
- 102000004190 Enzymes Human genes 0.000 description 12
- 108090000790 Enzymes Proteins 0.000 description 12
- RAXXELZNTBOGNW-UHFFFAOYSA-N imidazole Natural products C1=CNC=N1 RAXXELZNTBOGNW-UHFFFAOYSA-N 0.000 description 12
- 108090000994 Catalytic RNA Proteins 0.000 description 11
- 102000053642 Catalytic RNA Human genes 0.000 description 11
- 102000044126 RNA-Binding Proteins Human genes 0.000 description 11
- 150000001875 compounds Chemical class 0.000 description 11
- 239000002096 quantum dot Substances 0.000 description 11
- 108091092562 ribozyme Proteins 0.000 description 11
- 238000006467 substitution reaction Methods 0.000 description 11
- 230000004570 RNA-binding Effects 0.000 description 10
- OPTASPLRGRRNAP-UHFFFAOYSA-N cytosine Chemical compound NC=1C=CNC(=O)N=1 OPTASPLRGRRNAP-UHFFFAOYSA-N 0.000 description 10
- 238000013461 design Methods 0.000 description 10
- 102000034287 fluorescent proteins Human genes 0.000 description 10
- 108091006047 fluorescent proteins Proteins 0.000 description 10
- 125000004573 morpholin-4-yl group Chemical group N1(CCOCC1)* 0.000 description 10
- 238000013518 transcription Methods 0.000 description 10
- 230000035897 transcription Effects 0.000 description 10
- 229950010342 uridine triphosphate Drugs 0.000 description 10
- 239000011616 biotin Substances 0.000 description 9
- 229960002685 biotin Drugs 0.000 description 9
- 201000010099 disease Diseases 0.000 description 9
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 description 9
- UYTPUPDQBNUYGX-UHFFFAOYSA-N guanine Chemical compound O=C1NC(N)=NC2=C1N=CN2 UYTPUPDQBNUYGX-UHFFFAOYSA-N 0.000 description 9
- 125000000623 heterocyclic group Chemical group 0.000 description 9
- 230000001939 inductive effect Effects 0.000 description 9
- 102000036364 Cullin Ring E3 Ligases Human genes 0.000 description 8
- 108091007045 Cullin Ring E3 Ligases Proteins 0.000 description 8
- 108010043121 Green Fluorescent Proteins Proteins 0.000 description 8
- 102000004144 Green Fluorescent Proteins Human genes 0.000 description 8
- 235000020958 biotin Nutrition 0.000 description 8
- 230000000295 complement effect Effects 0.000 description 8
- 238000010494 dissociation reaction Methods 0.000 description 8
- 230000005593 dissociations Effects 0.000 description 8
- 239000000975 dye Substances 0.000 description 8
- 239000012530 fluid Substances 0.000 description 8
- 239000005090 green fluorescent protein Substances 0.000 description 8
- 230000003993 interaction Effects 0.000 description 8
- 239000002777 nucleoside Substances 0.000 description 8
- 108091023037 Aptamer Proteins 0.000 description 7
- 102000052510 DNA-Binding Proteins Human genes 0.000 description 7
- 241000196324 Embryophyta Species 0.000 description 7
- 125000000217 alkyl group Chemical group 0.000 description 7
- 230000002255 enzymatic effect Effects 0.000 description 7
- 238000000338 in vitro Methods 0.000 description 7
- 101710096438 DNA-binding protein Proteins 0.000 description 6
- IAZDPXIOMUYVGZ-UHFFFAOYSA-N Dimethylsulphoxide Chemical compound CS(C)=O IAZDPXIOMUYVGZ-UHFFFAOYSA-N 0.000 description 6
- 102000003960 Ligases Human genes 0.000 description 6
- 108090000364 Ligases Proteins 0.000 description 6
- 108060004795 Methyltransferase Proteins 0.000 description 6
- 102000006382 Ribonucleases Human genes 0.000 description 6
- 108010083644 Ribonucleases Proteins 0.000 description 6
- 238000003556 assay Methods 0.000 description 6
- 230000015572 biosynthetic process Effects 0.000 description 6
- 230000008859 change Effects 0.000 description 6
- 239000002105 nanoparticle Substances 0.000 description 6
- PYWVYCXTNDRMGF-UHFFFAOYSA-N rhodamine B Chemical compound [Cl-].C=12C=CC(=[N+](CC)CC)C=C2OC2=CC(N(CC)CC)=CC=C2C=1C1=CC=CC=C1C(O)=O PYWVYCXTNDRMGF-UHFFFAOYSA-N 0.000 description 6
- 238000012163 sequencing technique Methods 0.000 description 6
- 150000003384 small molecules Chemical class 0.000 description 6
- ABZLKHKQJHEPAX-UHFFFAOYSA-N tetramethylrhodamine Chemical compound C=12C=CC(N(C)C)=CC2=[O+]C2=CC(N(C)C)=CC=C2C=1C1=CC=CC=C1C([O-])=O ABZLKHKQJHEPAX-UHFFFAOYSA-N 0.000 description 6
- 210000001519 tissue Anatomy 0.000 description 6
- UHDGCWIWMRVCDJ-UHFFFAOYSA-N 1-beta-D-Xylofuranosyl-NH-Cytosine Natural products O=C1N=C(N)C=CN1C1C(O)C(O)C(CO)O1 UHDGCWIWMRVCDJ-UHFFFAOYSA-N 0.000 description 5
- ZKHQWZAMYRWXGA-KQYNXXCUSA-J ATP(4-) Chemical class C1=NC=2C(N)=NC=NC=2N1[C@@H]1O[C@H](COP([O-])(=O)OP([O-])(=O)OP([O-])([O-])=O)[C@@H](O)[C@H]1O ZKHQWZAMYRWXGA-KQYNXXCUSA-J 0.000 description 5
- UHDGCWIWMRVCDJ-PSQAKQOGSA-N Cytidine Natural products O=C1N=C(N)C=CN1[C@@H]1[C@@H](O)[C@@H](O)[C@H](CO)O1 UHDGCWIWMRVCDJ-PSQAKQOGSA-N 0.000 description 5
- 108091034117 Oligonucleotide Proteins 0.000 description 5
- 108091093037 Peptide nucleic acid Proteins 0.000 description 5
- CZPWVGJYEJSRLH-UHFFFAOYSA-N Pyrimidine Chemical compound C1=CN=CN=C1 CZPWVGJYEJSRLH-UHFFFAOYSA-N 0.000 description 5
- 241000283984 Rodentia Species 0.000 description 5
- ISAKRJDGNUQOIC-UHFFFAOYSA-N Uracil Chemical compound O=C1C=CNC(=O)N1 ISAKRJDGNUQOIC-UHFFFAOYSA-N 0.000 description 5
- JLCPHMBAVCMARE-UHFFFAOYSA-N [3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-hydroxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methyl [5-(6-aminopurin-9-yl)-2-(hydroxymethyl)oxolan-3-yl] hydrogen phosphate Polymers Cc1cn(C2CC(OP(O)(=O)OCC3OC(CC3OP(O)(=O)OCC3OC(CC3O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c3nc(N)[nH]c4=O)C(COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3CO)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cc(C)c(=O)[nH]c3=O)n3cc(C)c(=O)[nH]c3=O)n3ccc(N)nc3=O)n3cc(C)c(=O)[nH]c3=O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)O2)c(=O)[nH]c1=O JLCPHMBAVCMARE-UHFFFAOYSA-N 0.000 description 5
- 239000002253 acid Substances 0.000 description 5
- 230000004075 alteration Effects 0.000 description 5
- 150000001408 amides Chemical group 0.000 description 5
- 238000004458 analytical method Methods 0.000 description 5
- UHDGCWIWMRVCDJ-ZAKLUEHWSA-N cytidine Chemical compound O=C1N=C(N)C=CN1[C@H]1[C@H](O)[C@@H](O)[C@H](CO)O1 UHDGCWIWMRVCDJ-ZAKLUEHWSA-N 0.000 description 5
- 229940104302 cytosine Drugs 0.000 description 5
- 230000009977 dual effect Effects 0.000 description 5
- VYXSBFYARXAAKO-UHFFFAOYSA-N ethyl 2-[3-(ethylamino)-6-ethylimino-2,7-dimethylxanthen-9-yl]benzoate;hydron;chloride Chemical compound [Cl-].C1=2C=C(C)C(NCC)=CC=2OC2=CC(=[NH+]CC)C(C)=CC2=C1C1=CC=CC=C1C(=O)OCC VYXSBFYARXAAKO-UHFFFAOYSA-N 0.000 description 5
- 210000003527 eukaryotic cell Anatomy 0.000 description 5
- 150000002243 furanoses Chemical group 0.000 description 5
- 239000003446 ligand Substances 0.000 description 5
- 230000000670 limiting effect Effects 0.000 description 5
- 230000006780 non-homologous end joining Effects 0.000 description 5
- 239000008194 pharmaceutical composition Substances 0.000 description 5
- 229920000642 polymer Polymers 0.000 description 5
- 238000012216 screening Methods 0.000 description 5
- 238000003860 storage Methods 0.000 description 5
- 239000000126 substance Substances 0.000 description 5
- 125000001424 substituent group Chemical group 0.000 description 5
- 239000001226 triphosphate Substances 0.000 description 5
- 235000011178 triphosphate Nutrition 0.000 description 5
- OAKPWEUQDVLTCN-NKWVEPMBSA-N 2',3'-Dideoxyadenosine-5-triphosphate Chemical compound C1=NC=2C(N)=NC=NC=2N1[C@H]1CC[C@@H](CO[P@@](O)(=O)O[P@](O)(=O)OP(O)(O)=O)O1 OAKPWEUQDVLTCN-NKWVEPMBSA-N 0.000 description 4
- PEHVGBZKEYRQSX-UHFFFAOYSA-N 7-deaza-adenine Chemical compound NC1=NC=NC2=C1C=CN2 PEHVGBZKEYRQSX-UHFFFAOYSA-N 0.000 description 4
- LRFVTYWOQMYALW-UHFFFAOYSA-N 9H-xanthine Chemical compound O=C1NC(=O)NC2=C1NC=N2 LRFVTYWOQMYALW-UHFFFAOYSA-N 0.000 description 4
- 101710159080 Aconitate hydratase A Proteins 0.000 description 4
- 101710159078 Aconitate hydratase B Proteins 0.000 description 4
- 102000020313 Cell-Penetrating Peptides Human genes 0.000 description 4
- 108010051109 Cell-Penetrating Peptides Proteins 0.000 description 4
- LYCAIKOWRPUZTN-UHFFFAOYSA-N Ethylene glycol Chemical compound OCCO LYCAIKOWRPUZTN-UHFFFAOYSA-N 0.000 description 4
- YCKRFDGAMUMZLT-UHFFFAOYSA-N Fluorine atom Chemical compound [F] YCKRFDGAMUMZLT-UHFFFAOYSA-N 0.000 description 4
- 241000124008 Mammalia Species 0.000 description 4
- 241001465754 Metazoa Species 0.000 description 4
- 206010028980 Neoplasm Diseases 0.000 description 4
- 108091000080 Phosphotransferase Proteins 0.000 description 4
- 101710105008 RNA-binding protein Proteins 0.000 description 4
- ARLKCWCREKRROD-POYBYMJQSA-N [[(2s,5r)-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl] phosphono hydrogen phosphate Chemical compound O=C1N=C(N)C=CN1[C@@H]1O[C@H](COP(O)(=O)OP(O)(=O)OP(O)(O)=O)CC1 ARLKCWCREKRROD-POYBYMJQSA-N 0.000 description 4
- QTBSBXVTEAMEQO-UHFFFAOYSA-N acetic acid Substances CC(O)=O QTBSBXVTEAMEQO-UHFFFAOYSA-N 0.000 description 4
- 102000005421 acetyltransferase Human genes 0.000 description 4
- 108020002494 acetyltransferase Proteins 0.000 description 4
- 125000000304 alkynyl group Chemical group 0.000 description 4
- 230000006907 apoptotic process Effects 0.000 description 4
- 235000009697 arginine Nutrition 0.000 description 4
- 125000000637 arginyl group Chemical class N[C@@H](CCCNC(N)=N)C(=O)* 0.000 description 4
- 230000001413 cellular effect Effects 0.000 description 4
- 239000003431 cross linking reagent Substances 0.000 description 4
- RGWHQCVHVJXOKC-SHYZEUOFSA-J dCTP(4-) Chemical compound O=C1N=C(N)C=CN1[C@@H]1O[C@H](COP([O-])(=O)OP([O-])(=O)OP([O-])([O-])=O)[C@@H](O)C1 RGWHQCVHVJXOKC-SHYZEUOFSA-J 0.000 description 4
- 238000001514 detection method Methods 0.000 description 4
- 230000010354 integration Effects 0.000 description 4
- 239000012528 membrane Substances 0.000 description 4
- 230000015654 memory Effects 0.000 description 4
- 150000003833 nucleoside derivatives Chemical class 0.000 description 4
- 125000003835 nucleoside group Chemical group 0.000 description 4
- 239000002245 particle Substances 0.000 description 4
- 125000002467 phosphate group Chemical group [H]OP(=O)(O[H])O[*] 0.000 description 4
- 102000020233 phosphotransferase Human genes 0.000 description 4
- 229920001223 polyethylene glycol Polymers 0.000 description 4
- 238000000746 purification Methods 0.000 description 4
- 230000002829 reductive effect Effects 0.000 description 4
- 230000002441 reversible effect Effects 0.000 description 4
- 239000007787 solid Substances 0.000 description 4
- RWQNBRDOKXIBIV-UHFFFAOYSA-N thymine Chemical compound CC1=CNC(=O)NC1=O RWQNBRDOKXIBIV-UHFFFAOYSA-N 0.000 description 4
- 238000011282 treatment Methods 0.000 description 4
- 229940035893 uracil Drugs 0.000 description 4
- VGIRNWJSIRVFRT-UHFFFAOYSA-N 2',7'-difluorofluorescein Chemical compound OC(=O)C1=CC=CC=C1C1=C2C=C(F)C(=O)C=C2OC2=CC(O)=C(F)C=C21 VGIRNWJSIRVFRT-UHFFFAOYSA-N 0.000 description 3
- WCKQPPQRFNHPRJ-UHFFFAOYSA-N 4-[[4-(dimethylamino)phenyl]diazenyl]benzoic acid Chemical compound C1=CC(N(C)C)=CC=C1N=NC1=CC=C(C(O)=O)C=C1 WCKQPPQRFNHPRJ-UHFFFAOYSA-N 0.000 description 3
- SJQRQOKXQKVJGJ-UHFFFAOYSA-N 5-(2-aminoethylamino)naphthalene-1-sulfonic acid Chemical compound C1=CC=C2C(NCCN)=CC=CC2=C1S(O)(=O)=O SJQRQOKXQKVJGJ-UHFFFAOYSA-N 0.000 description 3
- KDCGOANMDULRCW-UHFFFAOYSA-N 7H-purine Chemical compound N1=CNC2=NC=NC2=C1 KDCGOANMDULRCW-UHFFFAOYSA-N 0.000 description 3
- CSCPPACGZOOCGX-UHFFFAOYSA-N Acetone Chemical compound CC(C)=O CSCPPACGZOOCGX-UHFFFAOYSA-N 0.000 description 3
- 229930024421 Adenine Natural products 0.000 description 3
- ZKHQWZAMYRWXGA-UHFFFAOYSA-N Adenosine triphosphate Natural products C1=NC=2C(N)=NC=NC=2N1C1OC(COP(O)(=O)OP(O)(=O)OP(O)(O)=O)C(O)C1O ZKHQWZAMYRWXGA-UHFFFAOYSA-N 0.000 description 3
- 108010046331 Deoxyribodipyrimidine photo-lyase Proteins 0.000 description 3
- AHCYMLUZIRLXAA-SHYZEUOFSA-N Deoxyuridine 5'-triphosphate Chemical compound O1[C@H](COP(O)(=O)OP(O)(=O)OP(O)(O)=O)[C@@H](O)C[C@@H]1N1C(=O)NC(=O)C=C1 AHCYMLUZIRLXAA-SHYZEUOFSA-N 0.000 description 3
- LFQSCWFLJHTTHZ-UHFFFAOYSA-N Ethanol Chemical compound CCO LFQSCWFLJHTTHZ-UHFFFAOYSA-N 0.000 description 3
- NYHBQMYGNKIUIF-UUOKFMHZSA-N Guanosine Chemical compound C1=NC=2C(=O)NC(N)=NC=2N1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O NYHBQMYGNKIUIF-UUOKFMHZSA-N 0.000 description 3
- 102000029812 HNH nuclease Human genes 0.000 description 3
- 108060003760 HNH nuclease Proteins 0.000 description 3
- 101000615488 Homo sapiens Methyl-CpG-binding domain protein 2 Proteins 0.000 description 3
- 102000004157 Hydrolases Human genes 0.000 description 3
- 108090000604 Hydrolases Proteins 0.000 description 3
- 102100034343 Integrase Human genes 0.000 description 3
- 108090000769 Isomerases Proteins 0.000 description 3
- 102000004195 Isomerases Human genes 0.000 description 3
- 102000004317 Lyases Human genes 0.000 description 3
- 108090000856 Lyases Proteins 0.000 description 3
- OKKJLVBELUTLKV-UHFFFAOYSA-N Methanol Chemical compound OC OKKJLVBELUTLKV-UHFFFAOYSA-N 0.000 description 3
- 102100021299 Methyl-CpG-binding domain protein 2 Human genes 0.000 description 3
- 102000016397 Methyltransferase Human genes 0.000 description 3
- 241000699666 Mus <mouse, genus> Species 0.000 description 3
- 108010077850 Nuclear Localization Signals Proteins 0.000 description 3
- 230000010718 Oxidation Activity Effects 0.000 description 3
- 102000004316 Oxidoreductases Human genes 0.000 description 3
- 108090000854 Oxidoreductases Proteins 0.000 description 3
- 102000035195 Peptidases Human genes 0.000 description 3
- 108091005804 Peptidases Proteins 0.000 description 3
- 102000004160 Phosphoric Monoester Hydrolases Human genes 0.000 description 3
- 108090000608 Phosphoric Monoester Hydrolases Proteins 0.000 description 3
- 239000002202 Polyethylene glycol Substances 0.000 description 3
- 239000004365 Protease Substances 0.000 description 3
- 108091093078 Pyrimidine dimer Proteins 0.000 description 3
- 108700020471 RNA-Binding Proteins Proteins 0.000 description 3
- 102000018120 Recombinases Human genes 0.000 description 3
- 108010091086 Recombinases Proteins 0.000 description 3
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 3
- 241000320123 Streptococcus pyogenes M1 GAS Species 0.000 description 3
- 102000004357 Transferases Human genes 0.000 description 3
- 108090000992 Transferases Proteins 0.000 description 3
- 102000008579 Transposases Human genes 0.000 description 3
- 108010020764 Transposases Proteins 0.000 description 3
- 102000006275 Ubiquitin-Protein Ligases Human genes 0.000 description 3
- 108010083111 Ubiquitin-Protein Ligases Proteins 0.000 description 3
- HDRRAMINWIWTNU-NTSWFWBYSA-N [[(2s,5r)-5-(2-amino-6-oxo-3h-purin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl] phosphono hydrogen phosphate Chemical compound C1=2NC(N)=NC(=O)C=2N=CN1[C@H]1CC[C@@H](COP(O)(=O)OP(O)(=O)OP(O)(O)=O)O1 HDRRAMINWIWTNU-NTSWFWBYSA-N 0.000 description 3
- 238000010521 absorption reaction Methods 0.000 description 3
- 229960000643 adenine Drugs 0.000 description 3
- 230000006154 adenylylation Effects 0.000 description 3
- 125000003342 alkenyl group Chemical group 0.000 description 3
- 230000029936 alkylation Effects 0.000 description 3
- 238000005804 alkylation reaction Methods 0.000 description 3
- 230000006229 amino acid addition Effects 0.000 description 3
- 238000001574 biopsy Methods 0.000 description 3
- 210000004899 c-terminal region Anatomy 0.000 description 3
- URGJWIFLBWJRMF-JGVFFNPUSA-N ddTTP Chemical compound O=C1NC(=O)C(C)=CN1[C@@H]1O[C@H](COP(O)(=O)OP(O)(=O)OP(O)(O)=O)CC1 URGJWIFLBWJRMF-JGVFFNPUSA-N 0.000 description 3
- 230000009615 deamination Effects 0.000 description 3
- 238000006481 deamination reaction Methods 0.000 description 3
- 230000006114 demyristoylation Effects 0.000 description 3
- 230000027832 depurination Effects 0.000 description 3
- 230000029180 desumoylation Effects 0.000 description 3
- 210000002472 endoplasmic reticulum Anatomy 0.000 description 3
- 239000013604 expression vector Substances 0.000 description 3
- 229910052731 fluorine Inorganic materials 0.000 description 3
- 239000011737 fluorine Substances 0.000 description 3
- 239000012634 fragment Substances 0.000 description 3
- 210000003958 hematopoietic stem cell Anatomy 0.000 description 3
- 235000014304 histidine Nutrition 0.000 description 3
- HNDVDQJCIGZPNO-UHFFFAOYSA-N histidine Natural products OC(=O)C(N)CC1=CN=CN1 HNDVDQJCIGZPNO-UHFFFAOYSA-N 0.000 description 3
- 125000002887 hydroxy group Chemical group [H]O* 0.000 description 3
- 238000001727 in vivo Methods 0.000 description 3
- 125000000325 methylidene group Chemical group [H]C([H])=* 0.000 description 3
- 230000000813 microbial effect Effects 0.000 description 3
- 210000003470 mitochondria Anatomy 0.000 description 3
- 239000000178 monomer Substances 0.000 description 3
- 230000007498 myristoylation Effects 0.000 description 3
- 210000004940 nucleus Anatomy 0.000 description 3
- 230000003285 pharmacodynamic effect Effects 0.000 description 3
- 150000004713 phosphodiesters Chemical class 0.000 description 3
- 150000003904 phospholipids Chemical class 0.000 description 3
- 125000004437 phosphorous atom Chemical group 0.000 description 3
- 210000001236 prokaryotic cell Anatomy 0.000 description 3
- 239000013635 pyrimidine dimer Substances 0.000 description 3
- 230000002285 radioactive effect Effects 0.000 description 3
- 210000002966 serum Anatomy 0.000 description 3
- 239000000243 solution Substances 0.000 description 3
- 230000010741 sumoylation Effects 0.000 description 3
- 238000010361 transduction Methods 0.000 description 3
- 230000026683 transduction Effects 0.000 description 3
- 230000005945 translocation Effects 0.000 description 3
- 125000002264 triphosphate group Chemical class [H]OP(=O)(O[H])OP(=O)(O[H])OP(=O)(O[H])O* 0.000 description 3
- PIINGYXNCHTJTF-UHFFFAOYSA-N 2-(2-azaniumylethylamino)acetate Chemical group NCCNCC(O)=O PIINGYXNCHTJTF-UHFFFAOYSA-N 0.000 description 2
- FZWGECJQACGGTI-UHFFFAOYSA-N 2-amino-7-methyl-1,7-dihydro-6H-purin-6-one Chemical compound NC1=NC(O)=C2N(C)C=NC2=N1 FZWGECJQACGGTI-UHFFFAOYSA-N 0.000 description 2
- ICSNLGPSRYBMBD-UHFFFAOYSA-N 2-aminopyridine Chemical compound NC1=CC=CC=N1 ICSNLGPSRYBMBD-UHFFFAOYSA-N 0.000 description 2
- QLHLYJHNOCILIT-UHFFFAOYSA-N 4-o-(2,5-dioxopyrrolidin-1-yl) 1-o-[2-[4-(2,5-dioxopyrrolidin-1-yl)oxy-4-oxobutanoyl]oxyethyl] butanedioate Chemical compound O=C1CCC(=O)N1OC(=O)CCC(=O)OCCOC(=O)CCC(=O)ON1C(=O)CCC1=O QLHLYJHNOCILIT-UHFFFAOYSA-N 0.000 description 2
- RYVNIFSIEDRLSJ-UHFFFAOYSA-N 5-(hydroxymethyl)cytosine Chemical compound NC=1NC(=O)N=CC=1CO RYVNIFSIEDRLSJ-UHFFFAOYSA-N 0.000 description 2
- LRSASMSXMSNRBT-UHFFFAOYSA-N 5-methylcytosine Chemical compound CC1=CNC(=O)N=C1N LRSASMSXMSNRBT-UHFFFAOYSA-N 0.000 description 2
- ZMERMCRYYFRELX-UHFFFAOYSA-N 5-{[2-(iodoacetamido)ethyl]amino}naphthalene-1-sulfonic acid Chemical compound C1=CC=C2C(S(=O)(=O)O)=CC=CC2=C1NCCNC(=O)CI ZMERMCRYYFRELX-UHFFFAOYSA-N 0.000 description 2
- LIZDKDDCWIEQIN-UHFFFAOYSA-N 6-[2-[5-(3-ethyl-1,1-dimethyl-6,8-disulfobenzo[e]indol-2-ylidene)penta-1,3-dienyl]-1,1-dimethyl-6,8-disulfobenzo[e]indol-3-ium-3-yl]hexanoate Chemical compound C1=CC2=C(S(O)(=O)=O)C=C(S(O)(=O)=O)C=C2C(C2(C)C)=C1N(CC)\C2=C\C=C\C=C\C1=[N+](CCCCCC([O-])=O)C2=CC=C(C(=CC(=C3)S(O)(=O)=O)S(O)(=O)=O)C3=C2C1(C)C LIZDKDDCWIEQIN-UHFFFAOYSA-N 0.000 description 2
- HCGHYQLFMPXSDU-UHFFFAOYSA-N 7-methyladenine Chemical compound C1=NC(N)=C2N(C)C=NC2=N1 HCGHYQLFMPXSDU-UHFFFAOYSA-N 0.000 description 2
- UJOBWOGCFQCDNV-UHFFFAOYSA-N 9H-carbazole Chemical compound C1=CC=C2C3=CC=CC=C3NC2=C1 UJOBWOGCFQCDNV-UHFFFAOYSA-N 0.000 description 2
- MSSXOMSJDRHRMC-UHFFFAOYSA-N 9H-purine-2,6-diamine Chemical compound NC1=NC(N)=C2NC=NC2=N1 MSSXOMSJDRHRMC-UHFFFAOYSA-N 0.000 description 2
- 241000251468 Actinopterygii Species 0.000 description 2
- 108020005544 Antisense RNA Proteins 0.000 description 2
- 102000007272 Apoptosis Inducing Factor Human genes 0.000 description 2
- 108010033604 Apoptosis Inducing Factor Proteins 0.000 description 2
- 239000004475 Arginine Substances 0.000 description 2
- 108090000397 Caspase 3 Proteins 0.000 description 2
- 102100029855 Caspase-3 Human genes 0.000 description 2
- 241000218631 Coniferophyta Species 0.000 description 2
- 241000195493 Cryptophyta Species 0.000 description 2
- 102220605874 Cytosolic arginine sensor for mTORC1 subunit 2_D10A_mutation Human genes 0.000 description 2
- 241000605762 Desulfovibrio vulgaris Species 0.000 description 2
- WSFSSNUMVMOOMR-UHFFFAOYSA-N Formaldehyde Chemical compound O=C WSFSSNUMVMOOMR-UHFFFAOYSA-N 0.000 description 2
- XKMLYUALXHKNFT-UUOKFMHZSA-N Guanosine-5'-triphosphate Chemical compound C1=2NC(N)=NC(=O)C=2N=CN1[C@@H]1O[C@H](COP(O)(=O)OP(O)(=O)OP(O)(O)=O)[C@@H](O)[C@H]1O XKMLYUALXHKNFT-UUOKFMHZSA-N 0.000 description 2
- 108091092195 Intron Proteins 0.000 description 2
- CKLJMWTZIZZHCS-REOHCLBHSA-N L-aspartic acid Chemical compound OC(=O)[C@@H](N)CC(O)=O CKLJMWTZIZZHCS-REOHCLBHSA-N 0.000 description 2
- 108700011259 MicroRNAs Proteins 0.000 description 2
- 108020002230 Pancreatic Ribonuclease Proteins 0.000 description 2
- 102000005891 Pancreatic ribonuclease Human genes 0.000 description 2
- WCUXLLCKKVVCTQ-UHFFFAOYSA-M Potassium chloride Chemical compound [Cl-].[K+] WCUXLLCKKVVCTQ-UHFFFAOYSA-M 0.000 description 2
- 108091008103 RNA aptamers Proteins 0.000 description 2
- 241000700159 Rattus Species 0.000 description 2
- 108020004459 Small interfering RNA Proteins 0.000 description 2
- 108010090804 Streptavidin Proteins 0.000 description 2
- 241000039733 Thermoproteus thermophilus Species 0.000 description 2
- RYYWUUFWQRZTIU-UHFFFAOYSA-N Thiophosphoric acid Chemical class OP(O)(S)=O RYYWUUFWQRZTIU-UHFFFAOYSA-N 0.000 description 2
- 108060008682 Tumor Necrosis Factor Proteins 0.000 description 2
- 108060008683 Tumor Necrosis Factor Receptor Proteins 0.000 description 2
- 240000008042 Zea mays Species 0.000 description 2
- 235000002017 Zea mays subsp mays Nutrition 0.000 description 2
- 230000021736 acetylation Effects 0.000 description 2
- 238000006640 acetylation reaction Methods 0.000 description 2
- DZBUGLKDJFMEHC-UHFFFAOYSA-N acridine Chemical compound C1=CC=CC2=CC3=CC=CC=C3N=C21 DZBUGLKDJFMEHC-UHFFFAOYSA-N 0.000 description 2
- OIRDTQYFTABQOQ-KQYNXXCUSA-N adenosine Chemical compound C1=NC=2C(N)=NC=NC=2N1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O OIRDTQYFTABQOQ-KQYNXXCUSA-N 0.000 description 2
- 239000007801 affinity label Substances 0.000 description 2
- 230000003321 amplification Effects 0.000 description 2
- 230000000692 anti-sense effect Effects 0.000 description 2
- 239000000427 antigen Substances 0.000 description 2
- 108091007433 antigens Proteins 0.000 description 2
- 102000036639 antigens Human genes 0.000 description 2
- ODKSFYDXXFIFQN-UHFFFAOYSA-N arginine Natural products OC(=O)C(N)CCCNC(N)=N ODKSFYDXXFIFQN-UHFFFAOYSA-N 0.000 description 2
- 229960003121 arginine Drugs 0.000 description 2
- 235000003704 aspartic acid Nutrition 0.000 description 2
- ZYGHJZDHTFUPRJ-UHFFFAOYSA-N benzo-alpha-pyrone Natural products C1=CC=C2OC(=O)C=CC2=C1 ZYGHJZDHTFUPRJ-UHFFFAOYSA-N 0.000 description 2
- OQFSQFPPLPISGP-UHFFFAOYSA-N beta-carboxyaspartic acid Natural products OC(=O)C(N)C(C(O)=O)C(O)=O OQFSQFPPLPISGP-UHFFFAOYSA-N 0.000 description 2
- 230000003115 biocidal effect Effects 0.000 description 2
- VYLDEYYOISNGST-UHFFFAOYSA-N bissulfosuccinimidyl suberate Chemical compound O=C1C(S(=O)(=O)O)CC(=O)N1OC(=O)CCCCCCC(=O)ON1C(=O)C(S(O)(=O)=O)CC1=O VYLDEYYOISNGST-UHFFFAOYSA-N 0.000 description 2
- 210000004369 blood Anatomy 0.000 description 2
- 239000008280 blood Substances 0.000 description 2
- 210000001185 bone marrow Anatomy 0.000 description 2
- 150000001720 carbohydrates Chemical class 0.000 description 2
- 235000014633 carbohydrates Nutrition 0.000 description 2
- 229910052799 carbon Inorganic materials 0.000 description 2
- 150000001721 carbon Chemical group 0.000 description 2
- 230000015556 catabolic process Effects 0.000 description 2
- 238000004113 cell culture Methods 0.000 description 2
- 239000013592 cell lysate Substances 0.000 description 2
- HVYWMOMLDIMFJA-DPAQBDIFSA-N cholesterol Chemical group C1C=C2C[C@@H](O)CC[C@]2(C)[C@@H]2[C@@H]1[C@@H]1CC[C@H]([C@H](C)CCCC(C)C)[C@@]1(C)CC2 HVYWMOMLDIMFJA-DPAQBDIFSA-N 0.000 description 2
- 235000012000 cholesterol Nutrition 0.000 description 2
- 239000011247 coating layer Substances 0.000 description 2
- 238000004891 communication Methods 0.000 description 2
- 239000003184 complementary RNA Substances 0.000 description 2
- 235000001671 coumarin Nutrition 0.000 description 2
- RMRCNWBMXRMIRW-BYFNXCQMSA-M cyanocobalamin Chemical compound N#C[Co+]N([C@]1([H])[C@H](CC(N)=O)[C@]\2(CCC(=O)NC[C@H](C)OP(O)(=O)OC3[C@H]([C@H](O[C@@H]3CO)N3C4=CC(C)=C(C)C=C4N=C3)O)C)C/2=C(C)\C([C@H](C/2(C)C)CCC(N)=O)=N\C\2=C\C([C@H]([C@@]/2(CC(N)=O)C)CCC(N)=O)=N\C\2=C(C)/C2=N[C@]1(C)[C@@](C)(CC(N)=O)[C@@H]2CCC(N)=O RMRCNWBMXRMIRW-BYFNXCQMSA-M 0.000 description 2
- 125000000753 cycloalkyl group Chemical group 0.000 description 2
- SUYVUBYJARFZHO-RRKCRQDMSA-N dATP Chemical compound C1=NC=2C(N)=NC=NC=2N1[C@H]1C[C@H](O)[C@@H](COP(O)(=O)OP(O)(=O)OP(O)(O)=O)O1 SUYVUBYJARFZHO-RRKCRQDMSA-N 0.000 description 2
- SUYVUBYJARFZHO-UHFFFAOYSA-N dATP Natural products C1=NC=2C(N)=NC=NC=2N1C1CC(O)C(COP(O)(=O)OP(O)(=O)OP(O)(O)=O)O1 SUYVUBYJARFZHO-UHFFFAOYSA-N 0.000 description 2
- 230000006196 deacetylation Effects 0.000 description 2
- 238000003381 deacetylation reaction Methods 0.000 description 2
- 238000006731 degradation reaction Methods 0.000 description 2
- 230000009504 deubiquitination Effects 0.000 description 2
- LOKCTEFSRHRXRJ-UHFFFAOYSA-I dipotassium trisodium dihydrogen phosphate hydrogen phosphate dichloride Chemical compound P(=O)(O)(O)[O-].[K+].P(=O)(O)([O-])[O-].[Na+].[Na+].[Cl-].[K+].[Cl-].[Na+] LOKCTEFSRHRXRJ-UHFFFAOYSA-I 0.000 description 2
- 238000009826 distribution Methods 0.000 description 2
- ZWIBGKZDAWNIFC-UHFFFAOYSA-N disuccinimidyl suberate Chemical compound O=C1CCC(=O)N1OC(=O)CCCCCCC(=O)ON1C(=O)CCC1=O ZWIBGKZDAWNIFC-UHFFFAOYSA-N 0.000 description 2
- 230000005782 double-strand break Effects 0.000 description 2
- 230000029142 excretion Effects 0.000 description 2
- 210000003722 extracellular fluid Anatomy 0.000 description 2
- 238000002866 fluorescence resonance energy transfer Methods 0.000 description 2
- 239000007850 fluorescent dye Substances 0.000 description 2
- 238000007710 freezing Methods 0.000 description 2
- 230000008014 freezing Effects 0.000 description 2
- 125000000524 functional group Chemical group 0.000 description 2
- 239000000499 gel Substances 0.000 description 2
- 235000003869 genetically modified organism Nutrition 0.000 description 2
- 229940029575 guanosine Drugs 0.000 description 2
- 125000001475 halogen functional group Chemical group 0.000 description 2
- 125000005842 heteroatom Chemical group 0.000 description 2
- 238000002744 homologous recombination Methods 0.000 description 2
- 230000006801 homologous recombination Effects 0.000 description 2
- FDGQSTZJBFJUBT-UHFFFAOYSA-N hypoxanthine Chemical compound O=C1NC=NC2=C1NC=N2 FDGQSTZJBFJUBT-UHFFFAOYSA-N 0.000 description 2
- 230000001976 improved effect Effects 0.000 description 2
- 230000001965 increasing effect Effects 0.000 description 2
- 210000003093 intracellular space Anatomy 0.000 description 2
- 150000002632 lipids Chemical class 0.000 description 2
- 239000000463 material Substances 0.000 description 2
- 230000004060 metabolic process Effects 0.000 description 2
- 239000002679 microRNA Substances 0.000 description 2
- 210000003205 muscle Anatomy 0.000 description 2
- 238000003199 nucleic acid amplification method Methods 0.000 description 2
- 210000003463 organelle Anatomy 0.000 description 2
- RDOWQLZANAYVLL-UHFFFAOYSA-N phenanthridine Chemical compound C1=CC=C2C3=CC=CC=C3C=NC2=C1 RDOWQLZANAYVLL-UHFFFAOYSA-N 0.000 description 2
- 239000002953 phosphate buffered saline Substances 0.000 description 2
- 150000008300 phosphoramidites Chemical class 0.000 description 2
- 229910052698 phosphorus Inorganic materials 0.000 description 2
- 210000001778 pluripotent stem cell Anatomy 0.000 description 2
- 229920000724 poly(L-arginine) polymer Polymers 0.000 description 2
- 229920000768 polyamine Polymers 0.000 description 2
- 229920000447 polyanionic polymer Polymers 0.000 description 2
- 108010011110 polyarginine Proteins 0.000 description 2
- KMUONIBRACKNSN-UHFFFAOYSA-N potassium dichromate Chemical compound [K+].[K+].[O-][Cr](=O)(=O)O[Cr]([O-])(=O)=O KMUONIBRACKNSN-UHFFFAOYSA-N 0.000 description 2
- 238000012545 processing Methods 0.000 description 2
- 239000000047 product Substances 0.000 description 2
- 150000003212 purines Chemical class 0.000 description 2
- BBEAQIROQSPTKN-UHFFFAOYSA-N pyrene Chemical compound C1=CC=C2C=CC3=CC=CC4=CC=C1C2=C43 BBEAQIROQSPTKN-UHFFFAOYSA-N 0.000 description 2
- 150000003230 pyrimidines Chemical class 0.000 description 2
- 102000005962 receptors Human genes 0.000 description 2
- 108020003175 receptors Proteins 0.000 description 2
- 108010054624 red fluorescent protein Proteins 0.000 description 2
- 238000007634 remodeling Methods 0.000 description 2
- 238000010839 reverse transcription Methods 0.000 description 2
- 150000003839 salts Chemical class 0.000 description 2
- 239000004055 small Interfering RNA Substances 0.000 description 2
- 230000009870 specific binding Effects 0.000 description 2
- UCSJYZPVAKXKNQ-HZYVHMACSA-N streptomycin Chemical compound CN[C@H]1[C@H](O)[C@@H](O)[C@H](CO)O[C@H]1O[C@@H]1[C@](C=O)(O)[C@H](C)O[C@H]1O[C@@H]1[C@@H](NC(N)=N)[C@H](O)[C@@H](NC(N)=N)[C@H](O)[C@H]1O UCSJYZPVAKXKNQ-HZYVHMACSA-N 0.000 description 2
- MPLHNVLQVRSVEE-UHFFFAOYSA-N texas red Chemical compound [O-]S(=O)(=O)C1=CC(S(Cl)(=O)=O)=CC=C1C(C1=CC=2CCCN3CCCC(C=23)=C1O1)=C2C1=C(CCC1)C3=[N+]1CCCC3=C2 MPLHNVLQVRSVEE-UHFFFAOYSA-N 0.000 description 2
- ZFXYFBGIUFBOJW-UHFFFAOYSA-N theophylline Chemical compound O=C1N(C)C(=O)N(C)C2=C1NC=N2 ZFXYFBGIUFBOJW-UHFFFAOYSA-N 0.000 description 2
- 229940113082 thymine Drugs 0.000 description 2
- 210000003014 totipotent stem cell Anatomy 0.000 description 2
- UNXRWKVEANCORM-UHFFFAOYSA-N triphosphoric acid Chemical compound OP(O)(=O)OP(O)(=O)OP(O)(O)=O UNXRWKVEANCORM-UHFFFAOYSA-N 0.000 description 2
- 102000003390 tumor necrosis factor Human genes 0.000 description 2
- 102000003298 tumor necrosis factor receptor Human genes 0.000 description 2
- 230000034512 ubiquitination Effects 0.000 description 2
- 238000010798 ubiquitination Methods 0.000 description 2
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 2
- 229940075420 xanthine Drugs 0.000 description 2
- 108091005957 yellow fluorescent proteins Proteins 0.000 description 2
- YIMATHOGWXZHFX-WCTZXXKLSA-N (2r,3r,4r,5r)-5-(hydroxymethyl)-3-(2-methoxyethoxy)oxolane-2,4-diol Chemical compound COCCO[C@H]1[C@H](O)O[C@H](CO)[C@H]1O YIMATHOGWXZHFX-WCTZXXKLSA-N 0.000 description 1
- BHQCQFFYRZLCQQ-UHFFFAOYSA-N (3alpha,5alpha,7alpha,12alpha)-3,7,12-trihydroxy-cholan-24-oic acid Natural products OC1CC2CC(O)CCC2(C)C2C1C1CCC(C(CCC(O)=O)C)C1(C)C(O)C2 BHQCQFFYRZLCQQ-UHFFFAOYSA-N 0.000 description 1
- QGVQZRDQPDLHHV-DPAQBDIFSA-N (3s,8s,9s,10r,13r,14s,17r)-10,13-dimethyl-17-[(2r)-6-methylheptan-2-yl]-2,3,4,7,8,9,11,12,14,15,16,17-dodecahydro-1h-cyclopenta[a]phenanthrene-3-thiol Chemical compound C1C=C2C[C@@H](S)CC[C@]2(C)[C@@H]2[C@@H]1[C@@H]1CC[C@H]([C@H](C)CCCC(C)C)[C@@]1(C)CC2 QGVQZRDQPDLHHV-DPAQBDIFSA-N 0.000 description 1
- QGKMIGUHVLGJBR-UHFFFAOYSA-M (4z)-1-(3-methylbutyl)-4-[[1-(3-methylbutyl)quinolin-1-ium-4-yl]methylidene]quinoline;iodide Chemical compound [I-].C12=CC=CC=C2N(CCC(C)C)C=CC1=CC1=CC=[N+](CCC(C)C)C2=CC=CC=C12 QGKMIGUHVLGJBR-UHFFFAOYSA-M 0.000 description 1
- 125000000008 (C1-C10) alkyl group Chemical group 0.000 description 1
- UFSCXDAOCAIFOG-UHFFFAOYSA-N 1,10-dihydropyrimido[5,4-b][1,4]benzothiazin-2-one Chemical compound S1C2=CC=CC=C2N=C2C1=CNC(=O)N2 UFSCXDAOCAIFOG-UHFFFAOYSA-N 0.000 description 1
- PTFYZDMJTFMPQW-UHFFFAOYSA-N 1,10-dihydropyrimido[5,4-b][1,4]benzoxazin-2-one Chemical compound O1C2=CC=CC=C2N=C2C1=CNC(=O)N2 PTFYZDMJTFMPQW-UHFFFAOYSA-N 0.000 description 1
- FYADHXFMURLYQI-UHFFFAOYSA-N 1,2,4-triazine Chemical class C1=CN=NC=N1 FYADHXFMURLYQI-UHFFFAOYSA-N 0.000 description 1
- VOTJUWBJENROFB-UHFFFAOYSA-N 1-[3-[[3-(2,5-dioxo-3-sulfopyrrolidin-1-yl)oxy-3-oxopropyl]disulfanyl]propanoyloxy]-2,5-dioxopyrrolidine-3-sulfonic acid Chemical compound O=C1C(S(=O)(=O)O)CC(=O)N1OC(=O)CCSSCCC(=O)ON1C(=O)C(S(O)(=O)=O)CC1=O VOTJUWBJENROFB-UHFFFAOYSA-N 0.000 description 1
- WJFKNYWRSNBZNX-UHFFFAOYSA-N 10H-phenothiazine Chemical compound C1=CC=C2NC3=CC=CC=C3SC2=C1 WJFKNYWRSNBZNX-UHFFFAOYSA-N 0.000 description 1
- TZMSYXZUNZXBOL-UHFFFAOYSA-N 10H-phenoxazine Chemical compound C1=CC=C2NC3=CC=CC=C3OC2=C1 TZMSYXZUNZXBOL-UHFFFAOYSA-N 0.000 description 1
- UHUHBFMZVCOEOV-UHFFFAOYSA-N 1h-imidazo[4,5-c]pyridin-4-amine Chemical compound NC1=NC=CC2=C1N=CN2 UHUHBFMZVCOEOV-UHFFFAOYSA-N 0.000 description 1
- VEPOHXYIFQMVHW-XOZOLZJESA-N 2,3-dihydroxybutanedioic acid (2S,3S)-3,4-dimethyl-2-phenylmorpholine Chemical compound OC(C(O)C(O)=O)C(O)=O.C[C@H]1[C@@H](OCCN1C)c1ccccc1 VEPOHXYIFQMVHW-XOZOLZJESA-N 0.000 description 1
- 125000001917 2,4-dinitrophenyl group Chemical group [H]C1=C([H])C(=C([H])C(=C1*)[N+]([O-])=O)[N+]([O-])=O 0.000 description 1
- AOTQGWFNFTVXNQ-UHFFFAOYSA-N 2-(1-adamantyl)acetic acid Chemical compound C1C(C2)CC3CC2CC1(CC(=O)O)C3 AOTQGWFNFTVXNQ-UHFFFAOYSA-N 0.000 description 1
- QSHACTSJHMKXTE-UHFFFAOYSA-N 2-(2-aminopropyl)-7h-purin-6-amine Chemical compound CC(N)CC1=NC(N)=C2NC=NC2=N1 QSHACTSJHMKXTE-UHFFFAOYSA-N 0.000 description 1
- 102100027962 2-5A-dependent ribonuclease Human genes 0.000 description 1
- 108010000834 2-5A-dependent ribonuclease Proteins 0.000 description 1
- JKMHFZQWWAIEOD-UHFFFAOYSA-N 2-[4-(2-hydroxyethyl)piperazin-1-yl]ethanesulfonic acid Chemical compound OCC[NH+]1CCN(CCS([O-])(=O)=O)CC1 JKMHFZQWWAIEOD-UHFFFAOYSA-N 0.000 description 1
- LAXVMANLDGWYJP-UHFFFAOYSA-N 2-amino-5-(2-aminoethyl)naphthalene-1-sulfonic acid Chemical compound NC1=CC=C2C(CCN)=CC=CC2=C1S(O)(=O)=O LAXVMANLDGWYJP-UHFFFAOYSA-N 0.000 description 1
- JRYMOPZHXMVHTA-DAGMQNCNSA-N 2-amino-7-[(2r,3r,4s,5r)-3,4-dihydroxy-5-(hydroxymethyl)oxolan-2-yl]-1h-pyrrolo[2,3-d]pyrimidin-4-one Chemical compound C1=CC=2C(=O)NC(N)=NC=2N1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O JRYMOPZHXMVHTA-DAGMQNCNSA-N 0.000 description 1
- WKMPTBDYDNUJLF-UHFFFAOYSA-N 2-fluoroadenine Chemical compound NC1=NC(F)=NC2=C1N=CN2 WKMPTBDYDNUJLF-UHFFFAOYSA-N 0.000 description 1
- 125000003903 2-propenyl group Chemical group [H]C([*])([H])C([H])=C([H])[H] 0.000 description 1
- OALHHIHQOFIMEF-UHFFFAOYSA-N 3',6'-dihydroxy-2',4',5',7'-tetraiodo-3h-spiro[2-benzofuran-1,9'-xanthene]-3-one Chemical compound O1C(=O)C2=CC=CC=C2C21C1=CC(I)=C(O)C(I)=C1OC1=C(I)C(O)=C(I)C=C21 OALHHIHQOFIMEF-UHFFFAOYSA-N 0.000 description 1
- XODZICXILWCPBD-UHFFFAOYSA-N 3-[18-(2-carboxyethyl)-7,12-diethyl-3,8,13,17,22-pentamethyl-23h-porphyrin-2-yl]propanoic acid Chemical compound CN1C(C=C2C(CC)=C(C)C(N2)=CC=2C(=C(CCC(O)=O)C(=C3)N=2)C)=C(C)C(CC)=C1C=C1C(C)=C(CCC(O)=O)C3=N1 XODZICXILWCPBD-UHFFFAOYSA-N 0.000 description 1
- QQHITEBEBQNARV-UHFFFAOYSA-N 3-[[2-carboxy-2-(2,5-dioxopyrrolidin-1-yl)-2-sulfoethyl]disulfanyl]-2-(2,5-dioxopyrrolidin-1-yl)-2-sulfopropanoic acid Chemical compound O=C1CCC(=O)N1C(S(O)(=O)=O)(C(=O)O)CSSCC(S(O)(=O)=O)(C(O)=O)N1C(=O)CCC1=O QQHITEBEBQNARV-UHFFFAOYSA-N 0.000 description 1
- OVONXEQGWXGFJD-UHFFFAOYSA-N 4-sulfanylidene-1h-pyrimidin-2-one Chemical compound SC=1C=CNC(=O)N=1 OVONXEQGWXGFJD-UHFFFAOYSA-N 0.000 description 1
- ZLOIGESWDJYCTF-XVFCMESISA-N 4-thiouridine Chemical compound O[C@@H]1[C@H](O)[C@@H](CO)O[C@H]1N1C(=O)NC(=S)C=C1 ZLOIGESWDJYCTF-XVFCMESISA-N 0.000 description 1
- LQLQRFGHAALLLE-UHFFFAOYSA-N 5-bromouracil Chemical compound BrC1=CNC(=O)NC1=O LQLQRFGHAALLLE-UHFFFAOYSA-N 0.000 description 1
- NJYVEMPWNAYQQN-UHFFFAOYSA-N 5-carboxyfluorescein Chemical compound C12=CC=C(O)C=C2OC2=CC(O)=CC=C2C21OC(=O)C1=CC(C(=O)O)=CC=C21 NJYVEMPWNAYQQN-UHFFFAOYSA-N 0.000 description 1
- ZLAQATDNGLKIEV-UHFFFAOYSA-N 5-methyl-2-sulfanylidene-1h-pyrimidin-4-one Chemical compound CC1=CNC(=S)NC1=O ZLAQATDNGLKIEV-UHFFFAOYSA-N 0.000 description 1
- UJBCLAXPPIDQEE-UHFFFAOYSA-N 5-prop-1-ynyl-1h-pyrimidine-2,4-dione Chemical compound CC#CC1=CNC(=O)NC1=O UJBCLAXPPIDQEE-UHFFFAOYSA-N 0.000 description 1
- KXBCLNRMQPRVTP-UHFFFAOYSA-N 6-amino-1,5-dihydroimidazo[4,5-c]pyridin-4-one Chemical compound O=C1NC(N)=CC2=C1N=CN2 KXBCLNRMQPRVTP-UHFFFAOYSA-N 0.000 description 1
- DCPSTSVLRXOYGS-UHFFFAOYSA-N 6-amino-1h-pyrimidine-2-thione Chemical compound NC1=CC=NC(S)=N1 DCPSTSVLRXOYGS-UHFFFAOYSA-N 0.000 description 1
- QNNARSZPGNJZIX-UHFFFAOYSA-N 6-amino-5-prop-1-ynyl-1h-pyrimidin-2-one Chemical compound CC#CC1=CNC(=O)N=C1N QNNARSZPGNJZIX-UHFFFAOYSA-N 0.000 description 1
- WQZIDRAQTRIQDX-UHFFFAOYSA-N 6-carboxy-x-rhodamine Chemical compound OC(=O)C1=CC=C(C([O-])=O)C=C1C(C1=CC=2CCCN3CCCC(C=23)=C1O1)=C2C1=C(CCC1)C3=[N+]1CCCC3=C2 WQZIDRAQTRIQDX-UHFFFAOYSA-N 0.000 description 1
- NJBMMMJOXRZENQ-UHFFFAOYSA-N 6H-pyrrolo[2,3-f]quinoline Chemical compound c1cc2ccc3[nH]cccc3c2n1 NJBMMMJOXRZENQ-UHFFFAOYSA-N 0.000 description 1
- LOSIULRWFAEMFL-UHFFFAOYSA-N 7-deazaguanine Chemical compound O=C1NC(N)=NC2=C1CC=N2 LOSIULRWFAEMFL-UHFFFAOYSA-N 0.000 description 1
- DKVRNHPCAOHRSI-KQYNXXCUSA-N 7-methyl-GTP Chemical compound C1=2N=C(N)NC(=O)C=2[N+](C)=CN1[C@@H]1O[C@H](COP(O)(=O)OP(O)(=O)OP(O)([O-])=O)[C@@H](O)[C@H]1O DKVRNHPCAOHRSI-KQYNXXCUSA-N 0.000 description 1
- HRYKDUPGBWLLHO-UHFFFAOYSA-N 8-azaadenine Chemical compound NC1=NC=NC2=NNN=C12 HRYKDUPGBWLLHO-UHFFFAOYSA-N 0.000 description 1
- LPXQRXLUHJKZIE-UHFFFAOYSA-N 8-azaguanine Chemical compound NC1=NC(O)=C2NN=NC2=N1 LPXQRXLUHJKZIE-UHFFFAOYSA-N 0.000 description 1
- 229960005508 8-azaguanine Drugs 0.000 description 1
- 102000021527 ATP binding proteins Human genes 0.000 description 1
- 108091011108 ATP binding proteins Proteins 0.000 description 1
- 108010013043 Acetylesterase Proteins 0.000 description 1
- GFFGJBXGBJISGV-UHFFFAOYSA-N Adenine Chemical compound NC1=NC=NC2=C1N=CN2 GFFGJBXGBJISGV-UHFFFAOYSA-N 0.000 description 1
- 235000016626 Agrimonia eupatoria Nutrition 0.000 description 1
- 241000252087 Anguilla japonica Species 0.000 description 1
- 102100021569 Apoptosis regulator Bcl-2 Human genes 0.000 description 1
- 102000008682 Argonaute Proteins Human genes 0.000 description 1
- 108010088141 Argonaute Proteins Proteins 0.000 description 1
- 101100272670 Aromatoleum evansii boxB gene Proteins 0.000 description 1
- 239000000592 Artificial Cell Substances 0.000 description 1
- 235000000832 Ayote Nutrition 0.000 description 1
- 102100026189 Beta-galactosidase Human genes 0.000 description 1
- 208000019838 Blood disease Diseases 0.000 description 1
- 241000283690 Bos taurus Species 0.000 description 1
- 241001536303 Botryococcus braunii Species 0.000 description 1
- 108091003079 Bovine Serum Albumin Proteins 0.000 description 1
- 241000195940 Bryophyta Species 0.000 description 1
- 239000002126 C01EB10 - Adenosine Substances 0.000 description 1
- 238000010356 CRISPR-Cas9 genome editing Methods 0.000 description 1
- 238000010453 CRISPR/Cas method Methods 0.000 description 1
- 102000000584 Calmodulin Human genes 0.000 description 1
- 108010041952 Calmodulin Proteins 0.000 description 1
- 241000282472 Canis lupus familiaris Species 0.000 description 1
- 241000283707 Capra Species 0.000 description 1
- OKTJSMMVPCPJKN-UHFFFAOYSA-N Carbon Chemical compound [C] OKTJSMMVPCPJKN-UHFFFAOYSA-N 0.000 description 1
- 102000014914 Carrier Proteins Human genes 0.000 description 1
- 102000004018 Caspase 6 Human genes 0.000 description 1
- 108090000425 Caspase 6 Proteins 0.000 description 1
- 108090000567 Caspase 7 Proteins 0.000 description 1
- 102100026549 Caspase-10 Human genes 0.000 description 1
- 108090000572 Caspase-10 Proteins 0.000 description 1
- 102220555352 Caspase-4_H29A_mutation Human genes 0.000 description 1
- 102100038902 Caspase-7 Human genes 0.000 description 1
- 102100026548 Caspase-8 Human genes 0.000 description 1
- 108090000538 Caspase-8 Proteins 0.000 description 1
- 102100026550 Caspase-9 Human genes 0.000 description 1
- 108090000566 Caspase-9 Proteins 0.000 description 1
- 102000011727 Caspases Human genes 0.000 description 1
- 108010076667 Caspases Proteins 0.000 description 1
- 244000201986 Cassia tora Species 0.000 description 1
- 206010050337 Cerumen impaction Diseases 0.000 description 1
- 241000195597 Chlamydomonas reinhardtii Species 0.000 description 1
- 244000249214 Chlorella pyrenoidosa Species 0.000 description 1
- 235000007091 Chlorella pyrenoidosa Nutrition 0.000 description 1
- 108020004998 Chloroplast DNA Proteins 0.000 description 1
- 239000004380 Cholic acid Substances 0.000 description 1
- 241000243321 Cnidaria Species 0.000 description 1
- KQLDDLUWUFBQHP-UHFFFAOYSA-N Cordycepin Natural products C1=NC=2C(N)=NC=NC=2N1C1OCC(CO)C1O KQLDDLUWUFBQHP-UHFFFAOYSA-N 0.000 description 1
- 229920000742 Cotton Polymers 0.000 description 1
- 108091029523 CpG island Proteins 0.000 description 1
- MIKUYHXYGGJMLM-GIMIYPNGSA-N Crotonoside Natural products C1=NC2=C(N)NC(=O)N=C2N1[C@H]1O[C@@H](CO)[C@H](O)[C@@H]1O MIKUYHXYGGJMLM-GIMIYPNGSA-N 0.000 description 1
- 240000004244 Cucurbita moschata Species 0.000 description 1
- 235000009854 Cucurbita moschata Nutrition 0.000 description 1
- 235000009804 Cucurbita pepo subsp pepo Nutrition 0.000 description 1
- 102000004127 Cytokines Human genes 0.000 description 1
- 108090000695 Cytokines Proteins 0.000 description 1
- 102100039221 Cytoplasmic polyadenylation element-binding protein 3 Human genes 0.000 description 1
- NYHBQMYGNKIUIF-UHFFFAOYSA-N D-guanosine Natural products C1=2NC(N)=NC(=O)C=2N=CN1C1OC(CO)C(O)C1O NYHBQMYGNKIUIF-UHFFFAOYSA-N 0.000 description 1
- 108091008102 DNA aptamers Proteins 0.000 description 1
- 230000033616 DNA repair Effects 0.000 description 1
- 108700020911 DNA-Binding Proteins Proteins 0.000 description 1
- 230000004568 DNA-binding Effects 0.000 description 1
- 229920002307 Dextran Polymers 0.000 description 1
- WDJUZGPOPHTGOT-OAXVISGBSA-N Digitoxin Natural products O([C@H]1[C@@H](C)O[C@@H](O[C@@H]2C[C@@H]3[C@@](C)([C@@H]4[C@H]([C@]5(O)[C@@](C)([C@H](C6=CC(=O)OC6)CC5)CC4)CC3)CC2)C[C@H]1O)[C@H]1O[C@@H](C)[C@H](O[C@H]2O[C@@H](C)[C@@H](O)[C@@H](O)C2)[C@@H](O)C1 WDJUZGPOPHTGOT-OAXVISGBSA-N 0.000 description 1
- 108700006830 Drosophila Antp Proteins 0.000 description 1
- 101100232687 Drosophila melanogaster eIF4A gene Proteins 0.000 description 1
- 241000258955 Echinodermata Species 0.000 description 1
- 108060002716 Exonuclease Proteins 0.000 description 1
- 108010002700 Exoribonucleases Proteins 0.000 description 1
- 102000004678 Exoribonucleases Human genes 0.000 description 1
- 108010039471 Fas Ligand Protein Proteins 0.000 description 1
- 241000282326 Felis catus Species 0.000 description 1
- 241000233866 Fungi Species 0.000 description 1
- 108091092512 GIR1 branching ribozyme Proteins 0.000 description 1
- 241000287828 Gallus gallus Species 0.000 description 1
- SXRSQZLOMIGNAQ-UHFFFAOYSA-N Glutaraldehyde Chemical compound O=CCCCC=O SXRSQZLOMIGNAQ-UHFFFAOYSA-N 0.000 description 1
- 244000068988 Glycine max Species 0.000 description 1
- 235000010469 Glycine max Nutrition 0.000 description 1
- 102000003886 Glycoproteins Human genes 0.000 description 1
- 108090000288 Glycoproteins Proteins 0.000 description 1
- 241000219146 Gossypium Species 0.000 description 1
- HVLSXIKZNLPZJJ-TXZCQADKSA-N HA peptide Chemical compound C([C@@H](C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H](C)C(O)=O)NC(=O)[C@H]1N(CCC1)C(=O)[C@@H](N)CC=1C=CC(O)=CC=1)C1=CC=C(O)C=C1 HVLSXIKZNLPZJJ-TXZCQADKSA-N 0.000 description 1
- 239000007995 HEPES buffer Substances 0.000 description 1
- 239000012981 Hank's balanced salt solution Substances 0.000 description 1
- MAJYPBAJPNUFPV-BQBZGAKWSA-N His-Cys Chemical compound SC[C@@H](C(O)=O)NC(=O)[C@@H](N)CC1=CN=CN1 MAJYPBAJPNUFPV-BQBZGAKWSA-N 0.000 description 1
- 102100022823 Histone RNA hairpin-binding protein Human genes 0.000 description 1
- 101000971171 Homo sapiens Apoptosis regulator Bcl-2 Proteins 0.000 description 1
- 101000741445 Homo sapiens Calcitonin Proteins 0.000 description 1
- 101000745755 Homo sapiens Cytoplasmic polyadenylation element-binding protein 3 Proteins 0.000 description 1
- 101000825762 Homo sapiens Histone RNA hairpin-binding protein Proteins 0.000 description 1
- 101001001272 Homo sapiens Prostatic acid phosphatase Proteins 0.000 description 1
- 108010001336 Horseradish Peroxidase Proteins 0.000 description 1
- UGQMRVRMYYASKQ-UHFFFAOYSA-N Hypoxanthine nucleoside Natural products OC1C(O)C(CO)OC1N1C(NC=NC2=O)=C2N=C1 UGQMRVRMYYASKQ-UHFFFAOYSA-N 0.000 description 1
- 108060003951 Immunoglobulin Proteins 0.000 description 1
- 229930010555 Inosine Natural products 0.000 description 1
- UGQMRVRMYYASKQ-KQYNXXCUSA-N Inosine Chemical compound O[C@@H]1[C@H](O)[C@@H](CO)O[C@H]1N1C2=NC=NC(O)=C2N=C1 UGQMRVRMYYASKQ-KQYNXXCUSA-N 0.000 description 1
- 101710203526 Integrase Proteins 0.000 description 1
- 108010061833 Integrases Proteins 0.000 description 1
- ODKSFYDXXFIFQN-BYPYZUCNSA-P L-argininium(2+) Chemical compound NC(=[NH2+])NCCC[C@H]([NH3+])C(O)=O ODKSFYDXXFIFQN-BYPYZUCNSA-P 0.000 description 1
- RHGKLRLOHDJJDR-BYPYZUCNSA-N L-citrulline Chemical compound NC(=O)NCCC[C@H]([NH3+])C([O-])=O RHGKLRLOHDJJDR-BYPYZUCNSA-N 0.000 description 1
- QIVBCDIJIAJPQS-VIFPVBQESA-N L-tryptophane Chemical compound C1=CC=C2C(C[C@H](N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-VIFPVBQESA-N 0.000 description 1
- KZSNJWFQEVHDMF-BYPYZUCNSA-N L-valine Chemical compound CC(C)[C@H](N)C(O)=O KZSNJWFQEVHDMF-BYPYZUCNSA-N 0.000 description 1
- JVTAAEKCZFNVCJ-UHFFFAOYSA-M Lactate Chemical compound CC(O)C([O-])=O JVTAAEKCZFNVCJ-UHFFFAOYSA-M 0.000 description 1
- 108090000004 Leadzyme Proteins 0.000 description 1
- 108090001090 Lectins Proteins 0.000 description 1
- 102000004856 Lectins Human genes 0.000 description 1
- 241000270322 Lepidosauria Species 0.000 description 1
- 239000000232 Lipid Bilayer Substances 0.000 description 1
- 108090001030 Lipoproteins Proteins 0.000 description 1
- 102000004895 Lipoproteins Human genes 0.000 description 1
- 229930183998 Lividomycin Natural products 0.000 description 1
- 108060001084 Luciferase Proteins 0.000 description 1
- 239000005089 Luciferase Substances 0.000 description 1
- 235000007688 Lycopersicon esculentum Nutrition 0.000 description 1
- 241000758962 Lycopodiopsida Species 0.000 description 1
- 241000218922 Magnoliophyta Species 0.000 description 1
- 240000003183 Manihot esculenta Species 0.000 description 1
- 235000016735 Manihot esculenta subsp esculenta Nutrition 0.000 description 1
- 241000196323 Marchantiophyta Species 0.000 description 1
- 206010027476 Metastases Diseases 0.000 description 1
- 108020005196 Mitochondrial DNA Proteins 0.000 description 1
- 102000007474 Multiprotein Complexes Human genes 0.000 description 1
- 108010085220 Multiprotein Complexes Proteins 0.000 description 1
- 241001529936 Murinae Species 0.000 description 1
- 208000023178 Musculoskeletal disease Diseases 0.000 description 1
- BAWFJGJZGIEFAR-NNYOXOHSSA-N NAD zwitterion Chemical compound NC(=O)C1=CC=C[N+]([C@H]2[C@@H]([C@H](O)[C@@H](COP([O-])(=O)OP(O)(=O)OC[C@@H]3[C@H]([C@@H](O)[C@@H](O3)N3C4=NC=NC(N)=C4N=C3)O)O2)O)=C1 BAWFJGJZGIEFAR-NNYOXOHSSA-N 0.000 description 1
- 241001250129 Nannochloropsis gaditana Species 0.000 description 1
- RHGKLRLOHDJJDR-UHFFFAOYSA-N Ndelta-carbamoyl-DL-ornithine Natural products OC(=O)C(N)CCCNC(N)=O RHGKLRLOHDJJDR-UHFFFAOYSA-N 0.000 description 1
- 241000244206 Nematoda Species 0.000 description 1
- 229930193140 Neomycin Natural products 0.000 description 1
- 206010029260 Neuroblastoma Diseases 0.000 description 1
- 244000061176 Nicotiana tabacum Species 0.000 description 1
- 235000002637 Nicotiana tabacum Nutrition 0.000 description 1
- 108091005461 Nucleic proteins Proteins 0.000 description 1
- REYJJPSVUYRZGE-UHFFFAOYSA-N Octadecylamine Chemical compound CCCCCCCCCCCCCCCCCCN REYJJPSVUYRZGE-UHFFFAOYSA-N 0.000 description 1
- 240000007594 Oryza sativa Species 0.000 description 1
- 235000007164 Oryza sativa Nutrition 0.000 description 1
- 229910019142 PO4 Inorganic materials 0.000 description 1
- 229930040373 Paraformaldehyde Natural products 0.000 description 1
- 241001494479 Pecora Species 0.000 description 1
- 102000007079 Peptide Fragments Human genes 0.000 description 1
- 108010033276 Peptide Fragments Proteins 0.000 description 1
- 108090000279 Peptidyltransferases Proteins 0.000 description 1
- 241000199919 Phaeophyceae Species 0.000 description 1
- PCNDJXKNXGMECE-UHFFFAOYSA-N Phenazine Natural products C1=CC=CC2=NC3=CC=CC=C3N=C21 PCNDJXKNXGMECE-UHFFFAOYSA-N 0.000 description 1
- ABLZXFCXXLZCGV-UHFFFAOYSA-N Phosphorous acid Chemical class OP(O)=O ABLZXFCXXLZCGV-UHFFFAOYSA-N 0.000 description 1
- 239000004952 Polyamide Substances 0.000 description 1
- 229920002732 Polyanhydride Polymers 0.000 description 1
- 108010039918 Polylysine Proteins 0.000 description 1
- 241000985694 Polypodiopsida Species 0.000 description 1
- 241000288906 Primates Species 0.000 description 1
- 206010036790 Productive cough Diseases 0.000 description 1
- XBDQKXXYIPTUBI-UHFFFAOYSA-M Propionate Chemical compound CCC([O-])=O XBDQKXXYIPTUBI-UHFFFAOYSA-M 0.000 description 1
- 102100035703 Prostatic acid phosphatase Human genes 0.000 description 1
- 241000589517 Pseudomonas aeruginosa Species 0.000 description 1
- BDJDTKYGKHEMFF-UHFFFAOYSA-M QSY7 succinimidyl ester Chemical compound [Cl-].C=1C=C2C(C=3C(=CC=CC=3)S(=O)(=O)N3CCC(CC3)C(=O)ON3C(CCC3=O)=O)=C3C=C\C(=[N+](\C)C=4C=CC=CC=4)C=C3OC2=CC=1N(C)C1=CC=CC=C1 BDJDTKYGKHEMFF-UHFFFAOYSA-M 0.000 description 1
- 102000041801 RAMP family Human genes 0.000 description 1
- 108091078765 RAMP family Proteins 0.000 description 1
- 230000007022 RNA scission Effects 0.000 description 1
- 108010092799 RNA-directed DNA polymerase Proteins 0.000 description 1
- AUNGANRZJHBGPY-SCRDCRAPSA-N Riboflavin Chemical compound OC[C@@H](O)[C@@H](O)[C@@H](O)CN1C=2C=C(C)C(C)=CC=2N=C2C1=NC(=O)NC2=O AUNGANRZJHBGPY-SCRDCRAPSA-N 0.000 description 1
- 102000003661 Ribonuclease III Human genes 0.000 description 1
- 108010057163 Ribonuclease III Proteins 0.000 description 1
- 108090000621 Ribonuclease P Proteins 0.000 description 1
- 102000004167 Ribonuclease P Human genes 0.000 description 1
- 108091007047 SCF complex Proteins 0.000 description 1
- 240000000111 Saccharum officinarum Species 0.000 description 1
- 235000007201 Saccharum officinarum Nutrition 0.000 description 1
- 241000593524 Sargassum patens Species 0.000 description 1
- 229920002125 Sokalan® Polymers 0.000 description 1
- 240000003768 Solanum lycopersicum Species 0.000 description 1
- 244000061456 Solanum tuberosum Species 0.000 description 1
- 235000002595 Solanum tuberosum Nutrition 0.000 description 1
- 102100022467 Something about silencing protein 10 Human genes 0.000 description 1
- 241000251131 Sphyrna Species 0.000 description 1
- PJANXHGTPQOBST-VAWYXSNFSA-N Stilbene Natural products C=1C=CC=CC=1/C=C/C1=CC=CC=C1 PJANXHGTPQOBST-VAWYXSNFSA-N 0.000 description 1
- UCKMPCXJQFINFW-UHFFFAOYSA-N Sulphide Chemical compound [S-2] UCKMPCXJQFINFW-UHFFFAOYSA-N 0.000 description 1
- 101710192266 Tegument protein VP22 Proteins 0.000 description 1
- 241000255588 Tephritidae Species 0.000 description 1
- 102000040945 Transcription factor Human genes 0.000 description 1
- 108091023040 Transcription factor Proteins 0.000 description 1
- 235000021307 Triticum Nutrition 0.000 description 1
- 244000098338 Triticum aestivum Species 0.000 description 1
- QIVBCDIJIAJPQS-UHFFFAOYSA-N Tryptophan Natural products C1=CC=C2C(CC(N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-UHFFFAOYSA-N 0.000 description 1
- 102100031988 Tumor necrosis factor ligand superfamily member 6 Human genes 0.000 description 1
- 102100022013 U1 small nuclear ribonucleoprotein A Human genes 0.000 description 1
- 102000044159 Ubiquitin Human genes 0.000 description 1
- 108090000848 Ubiquitin Proteins 0.000 description 1
- KZSNJWFQEVHDMF-UHFFFAOYSA-N Valine Natural products CC(C)C(N)C(O)=O KZSNJWFQEVHDMF-UHFFFAOYSA-N 0.000 description 1
- OZKXLOZHHUHGNV-UHFFFAOYSA-N Viomycin Natural products NCCCC(N)CC(=O)NC1CNC(=O)C(=CNC(=O)N)NC(=O)C(CO)NC(=O)C(CO)NC(=O)C(NC1=O)C2CC(O)NC(=N)N2 OZKXLOZHHUHGNV-UHFFFAOYSA-N 0.000 description 1
- 108010015940 Viomycin Proteins 0.000 description 1
- 241000700605 Viruses Species 0.000 description 1
- 235000005824 Zea mays ssp. parviglumis Nutrition 0.000 description 1
- 235000016383 Zea mays subsp huehuetenangensis Nutrition 0.000 description 1
- HCHKCACWOHOZIP-UHFFFAOYSA-N Zinc Chemical compound [Zn] HCHKCACWOHOZIP-UHFFFAOYSA-N 0.000 description 1
- RLXCFCYWFYXTON-JTTSDREOSA-N [(3S,8S,9S,10R,13S,14S,17R)-3-hydroxy-10,13-dimethyl-17-[(2R)-6-methylheptan-2-yl]-2,3,4,7,8,9,11,12,14,15,16,17-dodecahydro-1H-cyclopenta[a]phenanthren-16-yl] N-hexylcarbamate Chemical group C1C=C2C[C@@H](O)CC[C@]2(C)[C@@H]2[C@@H]1[C@@H]1CC(OC(=O)NCCCCCC)[C@H]([C@H](C)CCCC(C)C)[C@@]1(C)CC2 RLXCFCYWFYXTON-JTTSDREOSA-N 0.000 description 1
- NOXMCJDDSWCSIE-DAGMQNCNSA-N [[(2R,3S,4R,5R)-5-(2-amino-4-oxo-3H-pyrrolo[2,3-d]pyrimidin-7-yl)-3,4-dihydroxyoxolan-2-yl]methoxy-hydroxyphosphoryl] phosphono hydrogen phosphate Chemical compound C1=2NC(N)=NC(=O)C=2C=CN1[C@@H]1O[C@H](COP(O)(=O)OP(O)(=O)OP(O)(O)=O)[C@@H](O)[C@H]1O NOXMCJDDSWCSIE-DAGMQNCNSA-N 0.000 description 1
- AZJLCKAEZFNJDI-DJLDLDEBSA-N [[(2r,3s,5r)-5-(4-aminopyrrolo[2,3-d]pyrimidin-7-yl)-3-hydroxyoxolan-2-yl]methoxy-hydroxyphosphoryl] phosphono hydrogen phosphate Chemical compound C1=CC=2C(N)=NC=NC=2N1[C@H]1C[C@H](O)[C@@H](COP(O)(=O)OP(O)(=O)OP(O)(O)=O)O1 AZJLCKAEZFNJDI-DJLDLDEBSA-N 0.000 description 1
- AZRNEVJSOSKAOC-VPHBQDTQSA-N [[(2r,3s,5r)-5-[5-[(e)-3-[6-[5-[(3as,4s,6ar)-2-oxo-1,3,3a,4,6,6a-hexahydrothieno[3,4-d]imidazol-4-yl]pentanoylamino]hexanoylamino]prop-1-enyl]-2,4-dioxopyrimidin-1-yl]-3-hydroxyoxolan-2-yl]methoxy-hydroxyphosphoryl] phosphono hydrogen phosphate Chemical compound O1[C@H](COP(O)(=O)OP(O)(=O)OP(O)(O)=O)[C@@H](O)C[C@@H]1N1C(=O)NC(=O)C(\C=C\CNC(=O)CCCCCNC(=O)CCCC[C@H]2[C@H]3NC(=O)N[C@H]3CS2)=C1 AZRNEVJSOSKAOC-VPHBQDTQSA-N 0.000 description 1
- PGAVKCOVUIYSFO-UHFFFAOYSA-N [[5-(2,4-dioxopyrimidin-1-yl)-3,4-dihydroxyoxolan-2-yl]methoxy-hydroxyphosphoryl] phosphono hydrogen phosphate Chemical compound OC1C(O)C(COP(O)(=O)OP(O)(=O)OP(O)(O)=O)OC1N1C(=O)NC(=O)C=C1 PGAVKCOVUIYSFO-UHFFFAOYSA-N 0.000 description 1
- 108700025690 abl Genes Proteins 0.000 description 1
- 238000000862 absorption spectrum Methods 0.000 description 1
- 230000003213 activating effect Effects 0.000 description 1
- 230000004913 activation Effects 0.000 description 1
- 239000013543 active substance Substances 0.000 description 1
- 229960005305 adenosine Drugs 0.000 description 1
- 210000004504 adult stem cell Anatomy 0.000 description 1
- 239000000443 aerosol Substances 0.000 description 1
- 125000001931 aliphatic group Chemical group 0.000 description 1
- 229930013930 alkaloid Natural products 0.000 description 1
- 150000001336 alkenes Chemical class 0.000 description 1
- 125000005083 alkoxyalkoxy group Chemical group 0.000 description 1
- 125000002877 alkyl aryl group Chemical group 0.000 description 1
- 125000005600 alkyl phosphonate group Chemical group 0.000 description 1
- 125000005122 aminoalkylamino group Chemical group 0.000 description 1
- 210000004381 amniotic fluid Anatomy 0.000 description 1
- PYKYMHQGRFAEBM-UHFFFAOYSA-N anthraquinone Natural products CCC(=O)c1c(O)c2C(=O)C3C(C=CC=C3O)C(=O)c2cc1CC(=O)OC PYKYMHQGRFAEBM-UHFFFAOYSA-N 0.000 description 1
- 150000004056 anthraquinones Chemical class 0.000 description 1
- 239000003242 anti bacterial agent Substances 0.000 description 1
- 238000002617 apheresis Methods 0.000 description 1
- 230000001640 apoptogenic effect Effects 0.000 description 1
- 125000003710 aryl alkyl group Chemical group 0.000 description 1
- 239000003855 balanced salt solution Substances 0.000 description 1
- 230000037429 base substitution Effects 0.000 description 1
- 239000011324 bead Substances 0.000 description 1
- 230000008901 benefit Effects 0.000 description 1
- 108010005774 beta-Galactosidase Proteins 0.000 description 1
- 125000002619 bicyclic group Chemical group 0.000 description 1
- 239000011230 binding agent Substances 0.000 description 1
- 108091008324 binding proteins Proteins 0.000 description 1
- 229920001400 block copolymer Polymers 0.000 description 1
- 210000000988 bone and bone Anatomy 0.000 description 1
- 229910052794 bromium Inorganic materials 0.000 description 1
- 201000011510 cancer Diseases 0.000 description 1
- 125000001369 canonical nucleoside group Chemical group 0.000 description 1
- 230000000747 cardiac effect Effects 0.000 description 1
- 210000000845 cartilage Anatomy 0.000 description 1
- 230000022131 cell cycle Effects 0.000 description 1
- 230000030833 cell death Effects 0.000 description 1
- 230000006037 cell lysis Effects 0.000 description 1
- 210000000170 cell membrane Anatomy 0.000 description 1
- 210000002421 cell wall Anatomy 0.000 description 1
- 230000004700 cellular uptake Effects 0.000 description 1
- 235000013339 cereals Nutrition 0.000 description 1
- 210000001175 cerebrospinal fluid Anatomy 0.000 description 1
- 210000002939 cerumen Anatomy 0.000 description 1
- 238000007385 chemical modification Methods 0.000 description 1
- 210000004978 chinese hamster ovary cell Anatomy 0.000 description 1
- 102000021178 chitin binding proteins Human genes 0.000 description 1
- 108091011157 chitin binding proteins Proteins 0.000 description 1
- 229960005091 chloramphenicol Drugs 0.000 description 1
- WIIZWVCIJKGZOK-RKDXNWHRSA-N chloramphenicol Chemical compound ClC(Cl)C(=O)N[C@H](CO)[C@H](O)C1=CC=C([N+]([O-])=O)C=C1 WIIZWVCIJKGZOK-RKDXNWHRSA-N 0.000 description 1
- 229910052801 chlorine Inorganic materials 0.000 description 1
- 210000003763 chloroplast Anatomy 0.000 description 1
- 230000011088 chloroplast localization Effects 0.000 description 1
- 150000001841 cholesterols Chemical class 0.000 description 1
- 235000019416 cholic acid Nutrition 0.000 description 1
- BHQCQFFYRZLCQQ-OELDTZBJSA-N cholic acid Chemical compound C([C@H]1C[C@H]2O)[C@H](O)CC[C@]1(C)[C@@H]1[C@@H]2[C@@H]2CC[C@H]([C@@H](CCC(O)=O)C)[C@@]2(C)[C@@H](O)C1 BHQCQFFYRZLCQQ-OELDTZBJSA-N 0.000 description 1
- 229960002471 cholic acid Drugs 0.000 description 1
- KRVSOGSZCMJSLX-UHFFFAOYSA-L chromic acid Substances O[Cr](O)(=O)=O KRVSOGSZCMJSLX-UHFFFAOYSA-L 0.000 description 1
- 229960002173 citrulline Drugs 0.000 description 1
- 235000013477 citrulline Nutrition 0.000 description 1
- 239000003086 colorant Substances 0.000 description 1
- 230000001447 compensatory effect Effects 0.000 description 1
- 210000002808 connective tissue Anatomy 0.000 description 1
- OFEZSBMBBKLLBJ-BAJZRUMYSA-N cordycepin Chemical compound C1=NC=2C(N)=NC=NC=2N1[C@@H]1O[C@H](CO)C[C@H]1O OFEZSBMBBKLLBJ-BAJZRUMYSA-N 0.000 description 1
- OFEZSBMBBKLLBJ-UHFFFAOYSA-N cordycepine Natural products C1=NC=2C(N)=NC=NC=2N1C1OC(CO)CC1O OFEZSBMBBKLLBJ-UHFFFAOYSA-N 0.000 description 1
- 235000005822 corn Nutrition 0.000 description 1
- 230000000875 corresponding effect Effects 0.000 description 1
- 150000004775 coumarins Chemical class 0.000 description 1
- 244000038559 crop plants Species 0.000 description 1
- 229960002104 cyanocobalamin Drugs 0.000 description 1
- 235000000639 cyanocobalamin Nutrition 0.000 description 1
- 239000011666 cyanocobalamin Substances 0.000 description 1
- 125000001995 cyclobutyl group Chemical group [H]C1([H])C([H])([H])C([H])(*)C1([H])[H] 0.000 description 1
- 125000000596 cyclohexenyl group Chemical group C1(=CCCCC1)* 0.000 description 1
- 210000000172 cytosol Anatomy 0.000 description 1
- HAAZLUGHYHWQIW-KVQBGUIXSA-N dGTP Chemical compound C1=NC=2C(=O)NC(N)=NC=2N1[C@H]1C[C@H](O)[C@@H](COP(O)(=O)OP(O)(=O)OP(O)(O)=O)O1 HAAZLUGHYHWQIW-KVQBGUIXSA-N 0.000 description 1
- UFJPAQSLHAGEBL-RRKCRQDMSA-N dITP Chemical compound O1[C@H](COP(O)(=O)OP(O)(=O)OP(O)(O)=O)[C@@H](O)C[C@@H]1N1C(N=CNC2=O)=C2N=C1 UFJPAQSLHAGEBL-RRKCRQDMSA-N 0.000 description 1
- NHVNXKFIZYSCEB-XLPZGREQSA-N dTTP Chemical compound O=C1NC(=O)C(C)=CN1[C@@H]1O[C@H](COP(O)(=O)OP(O)(=O)OP(O)(O)=O)[C@@H](O)C1 NHVNXKFIZYSCEB-XLPZGREQSA-N 0.000 description 1
- KXGVEGMKQFWNSR-UHFFFAOYSA-N deoxycholic acid Natural products C1CC2CC(O)CCC2(C)C2C1C1CCC(C(CCC(O)=O)C)C1(C)C(O)C2 KXGVEGMKQFWNSR-UHFFFAOYSA-N 0.000 description 1
- 239000005549 deoxyribonucleoside Substances 0.000 description 1
- 206010012601 diabetes mellitus Diseases 0.000 description 1
- 238000003745 diagnosis Methods 0.000 description 1
- ANCLJVISBRWUTR-UHFFFAOYSA-N diaminophosphinic acid Chemical compound NP(N)(O)=O ANCLJVISBRWUTR-UHFFFAOYSA-N 0.000 description 1
- 239000005546 dideoxynucleotide Substances 0.000 description 1
- WDJUZGPOPHTGOT-XUDUSOBPSA-N digitoxin Chemical compound C1[C@H](O)[C@H](O)[C@@H](C)O[C@H]1O[C@@H]1[C@@H](C)O[C@@H](O[C@@H]2[C@H](O[C@@H](O[C@@H]3C[C@@H]4[C@]([C@@H]5[C@H]([C@]6(CC[C@@H]([C@@]6(C)CC5)C=5COC(=O)C=5)O)CC4)(C)CC3)C[C@@H]2O)C)C[C@@H]1O WDJUZGPOPHTGOT-XUDUSOBPSA-N 0.000 description 1
- 229960000648 digitoxin Drugs 0.000 description 1
- ZPTBLXKRQACLCR-XVFCMESISA-N dihydrouridine Chemical compound O[C@@H]1[C@H](O)[C@@H](CO)O[C@H]1N1C(=O)NC(=O)CC1 ZPTBLXKRQACLCR-XVFCMESISA-N 0.000 description 1
- 238000007865 diluting Methods 0.000 description 1
- 239000013024 dilution buffer Substances 0.000 description 1
- 239000006185 dispersion Substances 0.000 description 1
- NAGJZTKCGNOGPW-UHFFFAOYSA-N dithiophosphoric acid Chemical class OP(O)(S)=S NAGJZTKCGNOGPW-UHFFFAOYSA-N 0.000 description 1
- 239000003814 drug Substances 0.000 description 1
- 229940079593 drug Drugs 0.000 description 1
- 235000013399 edible fruits Nutrition 0.000 description 1
- 238000004520 electroporation Methods 0.000 description 1
- 238000000295 emission spectrum Methods 0.000 description 1
- 108010050663 endodeoxyribonuclease CreI Proteins 0.000 description 1
- 239000002158 endotoxin Substances 0.000 description 1
- 238000005516 engineering process Methods 0.000 description 1
- 239000002532 enzyme inhibitor Substances 0.000 description 1
- YQGOJNYOYNNSMM-UHFFFAOYSA-N eosin Chemical compound [Na+].OC(=O)C1=CC=CC=C1C1=C2C=C(Br)C(=O)C(Br)=C2OC2=C(Br)C(O)=C(Br)C=C21 YQGOJNYOYNNSMM-UHFFFAOYSA-N 0.000 description 1
- CHNUOJQWGUIOLD-NFZZJPOKSA-N epalrestat Chemical compound C=1C=CC=CC=1\C=C(/C)\C=C1/SC(=S)N(CC(O)=O)C1=O CHNUOJQWGUIOLD-NFZZJPOKSA-N 0.000 description 1
- 210000000981 epithelium Anatomy 0.000 description 1
- IINNWAYUJNWZRM-UHFFFAOYSA-L erythrosin B Chemical compound [Na+].[Na+].[O-]C(=O)C1=CC=CC=C1C1=C2C=C(I)C(=O)C(I)=C2OC2=C(I)C([O-])=C(I)C=C21 IINNWAYUJNWZRM-UHFFFAOYSA-L 0.000 description 1
- 229940011411 erythrosine Drugs 0.000 description 1
- 239000004174 erythrosine Substances 0.000 description 1
- 235000012732 erythrosine Nutrition 0.000 description 1
- 230000005284 excitation Effects 0.000 description 1
- 102000013165 exonuclease Human genes 0.000 description 1
- 230000001036 exonucleolytic effect Effects 0.000 description 1
- 210000001723 extracellular space Anatomy 0.000 description 1
- 208000030533 eye disease Diseases 0.000 description 1
- 108010052621 fas Receptor Proteins 0.000 description 1
- 102000018823 fas Receptor Human genes 0.000 description 1
- 210000004700 fetal blood Anatomy 0.000 description 1
- 239000012894 fetal calf serum Substances 0.000 description 1
- 210000002950 fibroblast Anatomy 0.000 description 1
- 239000000834 fixative Substances 0.000 description 1
- GVEPBJHOBDJJJI-UHFFFAOYSA-N fluoranthrene Natural products C1=CC(C2=CC=CC=C22)=C3C2=CC=CC3=C1 GVEPBJHOBDJJJI-UHFFFAOYSA-N 0.000 description 1
- 229940014144 folate Drugs 0.000 description 1
- OVBPIULPVIDEAO-LBPRGKRZSA-N folic acid Chemical compound C=1N=C2NC(N)=NC(=O)C2=NC=1CNC1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 OVBPIULPVIDEAO-LBPRGKRZSA-N 0.000 description 1
- 235000019152 folic acid Nutrition 0.000 description 1
- 239000011724 folic acid Substances 0.000 description 1
- 230000006870 function Effects 0.000 description 1
- AWJWCTOOIBYHON-UHFFFAOYSA-N furo[3,4-b]pyrazine-5,7-dione Chemical compound C1=CN=C2C(=O)OC(=O)C2=N1 AWJWCTOOIBYHON-UHFFFAOYSA-N 0.000 description 1
- 230000002496 gastric effect Effects 0.000 description 1
- 230000014509 gene expression Effects 0.000 description 1
- 238000012239 gene modification Methods 0.000 description 1
- 238000010353 genetic engineering Methods 0.000 description 1
- 230000005017 genetic modification Effects 0.000 description 1
- 235000013617 genetically modified food Nutrition 0.000 description 1
- 238000010362 genome editing Methods 0.000 description 1
- 230000000762 glandular Effects 0.000 description 1
- 101150117187 glmS gene Proteins 0.000 description 1
- JFCQEDHGNNZCLN-UHFFFAOYSA-N glutaric acid Chemical compound OC(=O)CCCC(O)=O JFCQEDHGNNZCLN-UHFFFAOYSA-N 0.000 description 1
- 150000004676 glycans Chemical class 0.000 description 1
- 125000003827 glycol group Chemical group 0.000 description 1
- 210000002288 golgi apparatus Anatomy 0.000 description 1
- 208000019622 heart disease Diseases 0.000 description 1
- 208000014951 hematologic disease Diseases 0.000 description 1
- 208000018706 hematopoietic system disease Diseases 0.000 description 1
- 125000000592 heterocycloalkyl group Chemical group 0.000 description 1
- 229920001519 homopolymer Polymers 0.000 description 1
- 235000020256 human milk Nutrition 0.000 description 1
- 210000004251 human milk Anatomy 0.000 description 1
- WGCNASOHLSPBMP-UHFFFAOYSA-N hydroxyacetaldehyde Natural products OCC=O WGCNASOHLSPBMP-UHFFFAOYSA-N 0.000 description 1
- 210000002865 immune cell Anatomy 0.000 description 1
- 102000018358 immunoglobulin Human genes 0.000 description 1
- 229940072221 immunoglobulins Drugs 0.000 description 1
- 238000011065 in-situ storage Methods 0.000 description 1
- 238000010348 incorporation Methods 0.000 description 1
- 150000002484 inorganic compounds Chemical class 0.000 description 1
- 229910010272 inorganic material Inorganic materials 0.000 description 1
- 229960003786 inosine Drugs 0.000 description 1
- 239000000138 intercalating agent Substances 0.000 description 1
- 230000002452 interceptive effect Effects 0.000 description 1
- 210000000936 intestine Anatomy 0.000 description 1
- 238000007918 intramuscular administration Methods 0.000 description 1
- 238000001990 intravenous administration Methods 0.000 description 1
- 125000001449 isopropyl group Chemical group [H]C([H])([H])C([H])(*)C([H])([H])[H] 0.000 description 1
- 238000005304 joining Methods 0.000 description 1
- 229960000318 kanamycin Drugs 0.000 description 1
- 229930027917 kanamycin Natural products 0.000 description 1
- SBUJHOSQTJFQJX-NOAMYHISSA-N kanamycin Chemical compound O[C@@H]1[C@@H](O)[C@H](O)[C@@H](CN)O[C@@H]1O[C@H]1[C@H](O)[C@@H](O[C@@H]2[C@@H]([C@@H](N)[C@H](O)[C@@H](CO)O2)O)[C@H](N)C[C@@H]1N SBUJHOSQTJFQJX-NOAMYHISSA-N 0.000 description 1
- 229930182823 kanamycin A Natural products 0.000 description 1
- 238000002372 labelling Methods 0.000 description 1
- 239000002523 lectin Substances 0.000 description 1
- 210000000265 leukocyte Anatomy 0.000 description 1
- 229920006008 lipopolysaccharide Polymers 0.000 description 1
- 239000002502 liposome Substances 0.000 description 1
- 210000004185 liver Anatomy 0.000 description 1
- 229950003076 lividomycin Drugs 0.000 description 1
- DBLVDAUGBTYDFR-SWMBIRFSSA-N lividomycin A Chemical compound O([C@@H]1[C@@H](N)C[C@@H](N)[C@H](O)[C@H]1O[C@@H]1O[C@H](CO)[C@H]([C@H]1O)O[C@H]1O[C@H]([C@H]([C@H](O)[C@H]1N)O[C@@H]1[C@H]([C@@H](O)[C@H](O)[C@@H](CO)O1)O)CN)[C@H]1O[C@H](CO)[C@@H](O)C[C@H]1N DBLVDAUGBTYDFR-SWMBIRFSSA-N 0.000 description 1
- DLBFLQKQABVKGT-UHFFFAOYSA-L lucifer yellow dye Chemical compound [Li+].[Li+].[O-]S(=O)(=O)C1=CC(C(N(C(=O)NN)C2=O)=O)=C3C2=CC(S([O-])(=O)=O)=CC3=C1N DLBFLQKQABVKGT-UHFFFAOYSA-L 0.000 description 1
- 210000004072 lung Anatomy 0.000 description 1
- 210000003712 lysosome Anatomy 0.000 description 1
- 230000001868 lysosomic effect Effects 0.000 description 1
- 229920002521 macromolecule Polymers 0.000 description 1
- 239000002122 magnetic nanoparticle Substances 0.000 description 1
- 230000014759 maintenance of location Effects 0.000 description 1
- 235000009973 maize Nutrition 0.000 description 1
- 240000004308 marijuana Species 0.000 description 1
- 210000001006 meconium Anatomy 0.000 description 1
- 239000002609 medium Substances 0.000 description 1
- 208000030159 metabolic disease Diseases 0.000 description 1
- 239000002207 metabolite Substances 0.000 description 1
- 230000009401 metastasis Effects 0.000 description 1
- WSFSSNUMVMOOMR-NJFSPNSNSA-N methanone Chemical compound O=[14CH2] WSFSSNUMVMOOMR-NJFSPNSNSA-N 0.000 description 1
- 125000000956 methoxy group Chemical group [H]C([H])([H])O* 0.000 description 1
- 239000000693 micelle Substances 0.000 description 1
- 239000011325 microbead Substances 0.000 description 1
- 230000002438 mitochondrial effect Effects 0.000 description 1
- 230000025608 mitochondrion localization Effects 0.000 description 1
- 239000003068 molecular probe Substances 0.000 description 1
- 230000000877 morphologic effect Effects 0.000 description 1
- 210000003097 mucus Anatomy 0.000 description 1
- 229960004927 neomycin Drugs 0.000 description 1
- 230000001537 neural effect Effects 0.000 description 1
- 238000007481 next generation sequencing Methods 0.000 description 1
- 229910052757 nitrogen Inorganic materials 0.000 description 1
- 238000001216 nucleic acid method Methods 0.000 description 1
- 238000001821 nucleic acid purification Methods 0.000 description 1
- IOQPZZOEVPZRBK-UHFFFAOYSA-N octan-1-amine Chemical compound CCCCCCCCN IOQPZZOEVPZRBK-UHFFFAOYSA-N 0.000 description 1
- 239000003921 oil Substances 0.000 description 1
- 235000019198 oils Nutrition 0.000 description 1
- 229920001542 oligosaccharide Polymers 0.000 description 1
- 150000002482 oligosaccharides Chemical class 0.000 description 1
- 230000003287 optical effect Effects 0.000 description 1
- 210000000056 organ Anatomy 0.000 description 1
- 150000002894 organic compounds Chemical class 0.000 description 1
- 125000001181 organosilyl group Chemical group [SiH3]* 0.000 description 1
- 229910000489 osmium tetroxide Inorganic materials 0.000 description 1
- 229910052760 oxygen Inorganic materials 0.000 description 1
- 125000004430 oxygen atom Chemical group O* 0.000 description 1
- 125000000913 palmityl group Chemical group [H]C([*])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])[H] 0.000 description 1
- 210000000496 pancreas Anatomy 0.000 description 1
- 229920002866 paraformaldehyde Polymers 0.000 description 1
- 230000037361 pathway Effects 0.000 description 1
- ONTNXMBMXUNDBF-UHFFFAOYSA-N pentatriacontane-17,18,19-triol Chemical compound CCCCCCCCCCCCCCCCC(O)C(O)C(O)CCCCCCCCCCCCCCCC ONTNXMBMXUNDBF-UHFFFAOYSA-N 0.000 description 1
- 229950000688 phenothiazine Drugs 0.000 description 1
- 150000002991 phenoxazines Chemical class 0.000 description 1
- NCAIGTHBQTXTLR-UHFFFAOYSA-N phentermine hydrochloride Chemical compound [Cl-].CC(C)([NH3+])CC1=CC=CC=C1 NCAIGTHBQTXTLR-UHFFFAOYSA-N 0.000 description 1
- 208000028591 pheochromocytoma Diseases 0.000 description 1
- 239000010452 phosphate Substances 0.000 description 1
- 239000008363 phosphate buffer Substances 0.000 description 1
- 150000008298 phosphoramidates Chemical class 0.000 description 1
- 150000008299 phosphorodiamidates Chemical class 0.000 description 1
- OXNIZHLAWKMVMX-UHFFFAOYSA-N picric acid Chemical class OC1=C([N+]([O-])=O)C=C([N+]([O-])=O)C=C1[N+]([O-])=O OXNIZHLAWKMVMX-UHFFFAOYSA-N 0.000 description 1
- 230000003169 placental effect Effects 0.000 description 1
- 210000002381 plasma Anatomy 0.000 description 1
- 239000004584 polyacrylic acid Substances 0.000 description 1
- 229920002647 polyamide Polymers 0.000 description 1
- 239000004417 polycarbonate Substances 0.000 description 1
- 229920000728 polyester Polymers 0.000 description 1
- 229920000570 polyether Polymers 0.000 description 1
- 229920000656 polylysine Polymers 0.000 description 1
- 229920001282 polysaccharide Polymers 0.000 description 1
- 239000005017 polysaccharide Substances 0.000 description 1
- 239000013641 positive control Substances 0.000 description 1
- 230000023603 positive regulation of transcription initiation, DNA-dependent Effects 0.000 description 1
- 239000001103 potassium chloride Substances 0.000 description 1
- 235000011164 potassium chloride Nutrition 0.000 description 1
- 239000012286 potassium permanganate Substances 0.000 description 1
- 235000012015 potatoes Nutrition 0.000 description 1
- 150000003141 primary amines Chemical class 0.000 description 1
- 125000002924 primary amino group Chemical group [H]N([H])* 0.000 description 1
- 230000008569 process Effects 0.000 description 1
- 230000001902 propagating effect Effects 0.000 description 1
- 102000021127 protein binding proteins Human genes 0.000 description 1
- 108091011138 protein binding proteins Proteins 0.000 description 1
- 230000002685 pulmonary effect Effects 0.000 description 1
- 235000015136 pumpkin Nutrition 0.000 description 1
- 239000012521 purified sample Substances 0.000 description 1
- IGFXRKMLLMBKSA-UHFFFAOYSA-N purine Chemical compound N1=C[N]C2=NC=NC2=C1 IGFXRKMLLMBKSA-UHFFFAOYSA-N 0.000 description 1
- UBQKCCHYAOITMY-UHFFFAOYSA-N pyridin-2-ol Chemical compound OC1=CC=CC=N1 UBQKCCHYAOITMY-UHFFFAOYSA-N 0.000 description 1
- RXTQGIIIYVEHBN-UHFFFAOYSA-N pyrimido[4,5-b]indol-2-one Chemical compound C1=CC=CC2=NC3=NC(=O)N=CC3=C21 RXTQGIIIYVEHBN-UHFFFAOYSA-N 0.000 description 1
- SRBUGYKMBLUTIS-UHFFFAOYSA-N pyrrolo[2,3-d]pyrimidin-2-one Chemical compound O=C1N=CC2=CC=NC2=N1 SRBUGYKMBLUTIS-UHFFFAOYSA-N 0.000 description 1
- 238000010188 recombinant method Methods 0.000 description 1
- 125000006853 reporter group Chemical group 0.000 description 1
- 201000009410 rhabdomyosarcoma Diseases 0.000 description 1
- 108090000446 ribonuclease T(2) Proteins 0.000 description 1
- 108020005403 ribonuclease U2 Proteins 0.000 description 1
- 239000002342 ribonucleoside Substances 0.000 description 1
- 108020004418 ribosomal RNA Proteins 0.000 description 1
- 125000000548 ribosyl group Chemical group C1([C@H](O)[C@H](O)[C@H](O1)CO)* 0.000 description 1
- 235000009566 rice Nutrition 0.000 description 1
- 210000003296 saliva Anatomy 0.000 description 1
- 230000028327 secretion Effects 0.000 description 1
- 210000000582 semen Anatomy 0.000 description 1
- 238000000926 separation method Methods 0.000 description 1
- 238000002864 sequence alignment Methods 0.000 description 1
- 230000003007 single stranded DNA break Effects 0.000 description 1
- 238000002741 site-directed mutagenesis Methods 0.000 description 1
- 210000003491 skin Anatomy 0.000 description 1
- 239000011734 sodium Substances 0.000 description 1
- 239000011780 sodium chloride Substances 0.000 description 1
- 238000001228 spectrum Methods 0.000 description 1
- 210000003594 spinal ganglia Anatomy 0.000 description 1
- 210000000952 spleen Anatomy 0.000 description 1
- 210000003802 sputum Anatomy 0.000 description 1
- 208000024794 sputum Diseases 0.000 description 1
- 230000006641 stabilisation Effects 0.000 description 1
- 238000011105 stabilization Methods 0.000 description 1
- 230000000087 stabilizing effect Effects 0.000 description 1
- 150000003431 steroids Chemical class 0.000 description 1
- PJANXHGTPQOBST-UHFFFAOYSA-N stilbene Chemical compound C=1C=CC=CC=1C=CC1=CC=CC=C1 PJANXHGTPQOBST-UHFFFAOYSA-N 0.000 description 1
- 235000021286 stilbenes Nutrition 0.000 description 1
- 210000002784 stomach Anatomy 0.000 description 1
- 229960005322 streptomycin Drugs 0.000 description 1
- 230000004960 subcellular localization Effects 0.000 description 1
- 238000007920 subcutaneous administration Methods 0.000 description 1
- 235000021092 sugar substitutes Nutrition 0.000 description 1
- 150000008163 sugars Chemical class 0.000 description 1
- IIACRCGMVDHOTQ-UHFFFAOYSA-N sulfamic acid Chemical group NS(O)(=O)=O IIACRCGMVDHOTQ-UHFFFAOYSA-N 0.000 description 1
- 150000003456 sulfonamides Chemical group 0.000 description 1
- BDHFUVZGWQCTTF-UHFFFAOYSA-M sulfonate Chemical compound [O-]S(=O)=O BDHFUVZGWQCTTF-UHFFFAOYSA-M 0.000 description 1
- 150000003457 sulfones Chemical group 0.000 description 1
- 150000003462 sulfoxides Chemical class 0.000 description 1
- 229910052717 sulfur Inorganic materials 0.000 description 1
- 239000000725 suspension Substances 0.000 description 1
- 210000004243 sweat Anatomy 0.000 description 1
- 239000003765 sweetening agent Substances 0.000 description 1
- 238000003786 synthesis reaction Methods 0.000 description 1
- IBVCSSOEYUMRLC-GABYNLOESA-N texas red-5-dutp Chemical compound O1[C@H](COP(O)(=O)OP(O)(=O)OP(O)(O)=O)[C@@H](O)C[C@@H]1N1C(=O)NC(=O)C(C#CCNS(=O)(=O)C=2C=C(C(C=3C4=CC=5CCCN6CCCC(C=56)=C4OC4=C5C6=[N+](CCC5)CCCC6=CC4=3)=CC=2)S([O-])(=O)=O)=C1 IBVCSSOEYUMRLC-GABYNLOESA-N 0.000 description 1
- 229960000278 theophylline Drugs 0.000 description 1
- 150000003568 thioethers Chemical class 0.000 description 1
- 150000003573 thiols Chemical class 0.000 description 1
- RYYWUUFWQRZTIU-UHFFFAOYSA-K thiophosphate Chemical compound [O-]P([O-])([O-])=S RYYWUUFWQRZTIU-UHFFFAOYSA-K 0.000 description 1
- ZEMGGZBWXRYJHK-UHFFFAOYSA-N thiouracil Chemical compound O=C1C=CNC(=S)N1 ZEMGGZBWXRYJHK-UHFFFAOYSA-N 0.000 description 1
- 229960000707 tobramycin Drugs 0.000 description 1
- NLVFBUXFDBBNBW-PBSUHMDJSA-N tobramycin Chemical compound N[C@@H]1C[C@H](O)[C@@H](CN)O[C@@H]1O[C@H]1[C@H](O)[C@@H](O[C@@H]2[C@@H]([C@@H](N)[C@H](O)[C@@H](CO)O2)O)[C@H](N)C[C@@H]1N NLVFBUXFDBBNBW-PBSUHMDJSA-N 0.000 description 1
- 238000011200 topical administration Methods 0.000 description 1
- 230000002103 transcriptional effect Effects 0.000 description 1
- 230000009261 transgenic effect Effects 0.000 description 1
- 230000032258 transport Effects 0.000 description 1
- ZMANZCXQSJIPKH-UHFFFAOYSA-O triethylammonium ion Chemical compound CC[NH+](CC)CC ZMANZCXQSJIPKH-UHFFFAOYSA-O 0.000 description 1
- 229960004799 tryptophan Drugs 0.000 description 1
- 125000002948 undecyl group Chemical group [H]C([*])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])[H] 0.000 description 1
- 210000002700 urine Anatomy 0.000 description 1
- 239000004474 valine Substances 0.000 description 1
- 229960004295 valine Drugs 0.000 description 1
- 235000014393 valine Nutrition 0.000 description 1
- 235000013311 vegetables Nutrition 0.000 description 1
- 229950001272 viomycin Drugs 0.000 description 1
- GXFAIFRPOKBQRV-GHXCTMGLSA-N viomycin Chemical compound N1C(=O)\C(=C\NC(N)=O)NC(=O)[C@H](CO)NC(=O)[C@H](CO)NC(=O)[C@@H](NC(=O)C[C@@H](N)CCCN)CNC(=O)[C@@H]1[C@@H]1NC(=N)N[C@@H](O)C1 GXFAIFRPOKBQRV-GHXCTMGLSA-N 0.000 description 1
- 230000003612 virological effect Effects 0.000 description 1
- 229940088594 vitamin Drugs 0.000 description 1
- 229930003231 vitamin Natural products 0.000 description 1
- 235000013343 vitamin Nutrition 0.000 description 1
- 239000011782 vitamin Substances 0.000 description 1
- 239000011534 wash buffer Substances 0.000 description 1
- 210000005253 yeast cell Anatomy 0.000 description 1
- 229910052725 zinc Inorganic materials 0.000 description 1
- 239000011701 zinc Substances 0.000 description 1
Classifications
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K38/00—Medicinal preparations containing peptides
- A61K38/16—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- A61K38/43—Enzymes; Proenzymes; Derivatives thereof
- A61K38/46—Hydrolases (3)
- A61K38/465—Hydrolases (3) acting on ester bonds (3.1), e.g. lipases, ribonucleases
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/50—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates
- A61K47/51—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent
- A61K47/54—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an organic compound
- A61K47/549—Sugars, nucleosides, nucleotides or nucleic acids
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/50—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates
- A61K47/51—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent
- A61K47/62—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being a protein, peptide or polyamino acid
- A61K47/64—Drug-peptide, drug-protein or drug-polyamino acid conjugates, i.e. the modifying agent being a peptide, protein or polyamino acid which is covalently bonded or complexed to a therapeutically active agent
- A61K47/645—Polycationic or polyanionic oligopeptides, polypeptides or polyamino acids, e.g. polylysine, polyarginine, polyglutamic acid or peptide TAT
- A61K47/6455—Polycationic oligopeptides, polypeptides or polyamino acids, e.g. for complexing nucleic acids
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P11/00—Drugs for disorders of the respiratory system
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P13/00—Drugs for disorders of the urinary system
- A61P13/12—Drugs for disorders of the urinary system of the kidneys
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P19/00—Drugs for skeletal disorders
- A61P19/02—Drugs for skeletal disorders for joint disorders, e.g. arthritis, arthrosis
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P25/00—Drugs for disorders of the nervous system
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P27/00—Drugs for disorders of the senses
- A61P27/02—Ophthalmic agents
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P29/00—Non-central analgesic, antipyretic or antiinflammatory agents, e.g. antirheumatic agents; Non-steroidal antiinflammatory drugs [NSAID]
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P31/00—Antiinfectives, i.e. antibiotics, antiseptics, chemotherapeutics
- A61P31/04—Antibacterial agents
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P9/00—Drugs for disorders of the cardiovascular system
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P9/00—Drugs for disorders of the cardiovascular system
- A61P9/10—Drugs for disorders of the cardiovascular system for treating ischaemic or atherosclerotic diseases, e.g. antianginal drugs, coronary vasodilators, drugs for myocardial infarction, retinopathy, cerebrovascula insufficiency, renal arteriosclerosis
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/10—Processes for the isolation, preparation or purification of DNA or RNA
- C12N15/102—Mutagenizing nucleic acids
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
- C12N15/52—Genes encoding for enzymes or proenzymes
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/79—Vectors or expression systems specially adapted for eukaryotic hosts
- C12N15/85—Vectors or expression systems specially adapted for eukaryotic hosts for animal cells
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/87—Introduction of foreign genetic material using processes not otherwise provided for, e.g. co-transformation
- C12N15/90—Stable introduction of foreign DNA into chromosome
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/87—Introduction of foreign genetic material using processes not otherwise provided for, e.g. co-transformation
- C12N15/90—Stable introduction of foreign DNA into chromosome
- C12N15/902—Stable introduction of foreign DNA into chromosome using homologous recombination
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/87—Introduction of foreign genetic material using processes not otherwise provided for, e.g. co-transformation
- C12N15/90—Stable introduction of foreign DNA into chromosome
- C12N15/902—Stable introduction of foreign DNA into chromosome using homologous recombination
- C12N15/907—Stable introduction of foreign DNA into chromosome using homologous recombination in mammalian cells
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N5/00—Undifferentiated human, animal or plant cells, e.g. cell lines; Tissues; Cultivation or maintenance thereof; Culture media therefor
- C12N5/0006—Modification of the membrane of cells, e.g. cell decoration
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/14—Hydrolases (3)
- C12N9/16—Hydrolases (3) acting on ester bonds (3.1)
- C12N9/22—Ribonucleases RNAses, DNAses
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q1/00—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions
- C12Q1/68—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions involving nucleic acids
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q1/00—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions
- C12Q1/68—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions involving nucleic acids
- C12Q1/6806—Preparing nucleic acids for analysis, e.g. for polymerase chain reaction [PCR] assay
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q1/00—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions
- C12Q1/68—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions involving nucleic acids
- C12Q1/6813—Hybridisation assays
- C12Q1/6816—Hybridisation assays characterised by the detection means
- C12Q1/6818—Hybridisation assays characterised by the detection means involving interaction of two or more labels, e.g. resonant energy transfer
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q1/00—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions
- C12Q1/68—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions involving nucleic acids
- C12Q1/6844—Nucleic acid amplification reactions
- C12Q1/686—Polymerase chain reaction [PCR]
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q1/00—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions
- C12Q1/68—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions involving nucleic acids
- C12Q1/6869—Methods for sequencing
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q1/00—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions
- C12Q1/68—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions involving nucleic acids
- C12Q1/6869—Methods for sequencing
- C12Q1/6874—Methods for sequencing involving nucleic acid arrays, e.g. sequencing by hybridisation
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
- C12N15/113—Non-coding nucleic acids modulating the expression of genes, e.g. antisense oligonucleotides; Antisense DNA or RNA; Triplex- forming oligonucleotides; Catalytic nucleic acids, e.g. ribozymes; Nucleic acids used in co-suppression or gene silencing
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/10—Type of nucleic acid
- C12N2310/20—Type of nucleic acid involving clustered regularly interspaced short palindromic repeats [CRISPRs]
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/50—Physical structure
- C12N2310/53—Physical structure partially self-complementary or closed
- C12N2310/531—Stem-loop; Hairpin
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/50—Physical structure
- C12N2310/53—Physical structure partially self-complementary or closed
- C12N2310/533—Physical structure partially self-complementary or closed having a mismatch or nick in at least one of the strands
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2800/00—Nucleic acids vectors
- C12N2800/80—Vectors containing sites for inducing double-stranded breaks, e.g. meganuclease restriction sites
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q2525/00—Reactions involving modified oligonucleotides, nucleic acids, or nucleotides
- C12Q2525/10—Modifications characterised by
- C12Q2525/203—Modifications characterised by incorporating a composite nucleic acid containing a polypeptide sequence other than PNA
Abstract
Una proteína CRISPR Cas9 modificada genéticamente, que comprende: una modificación en una región de una proteína CRISPR Cas9 que se corresponde con una región de los restos de aminoácidos 170-312 de una proteína Cas9 de S. pyogenes (SEQ ID NO:8), en donde la modificación comprende una inserción, una deleción o una combinación de las mismas.
Description
DESCRIPCIÓN
Composiciones y métodos de ácidos nucleicos dirigidos a ácido nucleico
Antecedentes de la invención
El diseño del genoma puede referirse a la modificación del genoma mediante la deleción, la inserción, la mutación o la sustitución de secuencias específicas de ácido nucleico. La modificación puede ser específica del gen o de la ubicación. El diseño del genoma puede usar nucleasas para cortar un ácido nucleico generando así un sitio para la modificación. También se contempla el diseño del ácido nucleico no genómico. Una proteína que contiene un dominio nucleasa puede unirse y escindir un ácido nucleico diana formando un complejo con un ácido nucleico dirigido a ácido nucleico. En un ejemplo, la escisión puede introducir roturas bicatenarias en el ácido nucleico diana. Un ácido nucleico puede ser reparado, por ejemplo, por la maquinaria endógena de unión de extremos no homólogos (NHEJ). En un ejemplo adicional, se puede insertar una pieza de ácido nucleico. Las modificaciones de ácidos nucleicos dirigidos a ácido nucleico y polipéptidos dirigidos a un sitio pueden introducir nuevas funciones para su uso en el diseño del genoma.
Jinek et al. (Science, 2012, 337(6096):816-812), Cong et al. (Science, 2013, 339(6121):819-823), Y Qi et al. (Cell, 2013, 152(5): 1173-1183 se refieren a CRISPR-Cas9 de S. pyogenes diseñados genéticamente que tienen mutaciones en los dominios HNH y/o de tipo RuvC. Las mutaciones PAM también se describen en esas referencias.
Sumario de la invención
La invención se define por las reivindicaciones adjuntas.
La divulgación proporciona un ácido nucleico dirigido a ácido nucleico diseñado, que comprende: una mutación en un dominio P del ácido nucleico dirigido a ácido nucleico. En algunas realizaciones, el dominio P comienza cadena abajo de un último nucleótido emparejado de un dúplex entre una repetición CRISPR y una secuencia de ARNcrtra del ácido nucleico dirigido a ácido nucleico. En algunas realizaciones, el ácido nucleico dirigido a ácido nucleico diseñado comprende además una secuencia enlazadora. En algunas realizaciones, la secuencia enlazadora une la repetición CRISPR y la secuencia de ARNcrtra. En algunas realizaciones, el ácido nucleico dirigido a ácido nucleico diseñado es un ácido nucleico dirigido a ácido nucleico diseñado aislado. En algunas realizaciones, el ácido nucleico dirigido a ácido nucleico diseñado es un ácido nucleico dirigido a ácido nucleico diseñado recombinante. En algunas realizaciones, el ácido nucleico dirigido a ácido nucleico diseñado está adaptado a hibridarse con un ácido nucleico diana. En algunas realizaciones, el dominio P comprende 2 nucleótidos adyacentes. En algunas realizaciones, el dominio P comprende 3 nucleótidos adyacentes. En algunas realizaciones, el dominio P comprende 4 nucleótidos adyacentes. En algunas realizaciones, el dominio P comprende 5 nucleótidos adyacentes. En algunas realizaciones, el dominio P comprende 6 o más nucleótidos adyacentes. En algunas realizaciones, el dominio P comienza 1 nucleótido cadena abajo del último nucleótido emparejado del dúplex. En algunas realizaciones, el dominio P comienza 2 nucleótidos cadena abajo del último nucleótido emparejado del dúplex. En algunas realizaciones, el dominio P comienza 3 nucleótidos cadena abajo del último nucleótido emparejado del dúplex. En algunas realizaciones, el dominio P comienza 4 nucleótidos cadena abajo del último nucleótido emparejado del dúplex. En algunas realizaciones, el dominio P comienza 5 nucleótidos cadena abajo del último nucleótido emparejado del dúplex. En algunas realizaciones, el dominio P comienza 6 o más nucleótidos cadena abajo del último nucleótido emparejado del dúplex. En algunas realizaciones, la mutación comprende una o más mutaciones. En algunas realizaciones, la una o más mutaciones son adyacentes entre sí. En algunas realizaciones, la una o más mutaciones están separadas entre sí. En algunas realizaciones, la mutación está adaptada para permitir que el ácido nucleico dirigido a ácido nucleico diseñado se hibride con un motivo adyacente al protoespaciador diferente. En algunas realizaciones, el motivo adyacente al protoespaciador diferente comprende al menos 4 nucleótidos. En algunas realizaciones, el motivo adyacente al protoespaciador diferente comprende al menos 5 nucleótidos. En algunas realizaciones, el motivo adyacente al protoespaciador diferente comprende al menos 6 nucleótidos. En algunas realizaciones, el motivo adyacente al protoespaciador diferente comprende al menos 7 o más nucleótidos. En algunas realizaciones, el motivo adyacente al protoespaciador diferente comprende dos regiones no adyacentes. En algunas realizaciones, el motivo adyacente al protoespaciador diferente comprende tres regiones no adyacentes. En algunas realizaciones, la mutación está adaptada para permitir que el ácido nucleico dirigido a ácido nucleico diseñado se una a un ácido nucleico diana con una constante de disociación menor que un ácido nucleico dirigido a ácido nucleico no diseñado. En algunas realizaciones, la mutación está adaptada para permitir que el ácido nucleico dirigido a ácido nucleico diseñado se una a un ácido nucleico diana con mayor especificidad que un ácido nucleico dirigido a ácido nucleico no diseñado. En algunas realizaciones, la mutación está adaptada para reducir la unión del ácido nucleico dirigido a ácido nucleico diseñado a una secuencia no específica en un ácido nucleico diana en comparación con un ácido nucleico dirigido a ácido nucleico no diseñado. En algunas realizaciones, el ácido nucleico dirigido a ácido nucleico diseñado comprende además dos horquillas, en donde una de las dos horquillas comprende un dúplex entre un polinucleótido que comprende al menos un 50 % de identidad con un ARN de CRISPR sobre 6 nucleótidos contiguos, y un polinucleótido que comprende al menos un 50 % de identidad con un ARNcrtra sobre 6 nucleótidos contiguos; y, en donde una de las dos horquillas está 3' de la primera horquilla, en donde la segunda horquilla comprende un dominio P diseñado. En algunas realizaciones, la segunda horquilla está adaptada para eliminar el dúplex cuando el ácido nucleico está en
contacto con un ácido nucleico diana. En algunas realizaciones, el dominio P está adaptado a: hibridarse con un primer polinucleótido, en donde el primer polinucleótido comprende una región del ácido nucleico dirigido a ácido nucleico diseñado, hibridarse con un segundo polinucleótido, en donde el segundo polinucleótido comprende un ácido nucleico diana y se hibrida específicamente con el primer o segundo polinucleótido. En algunas realizaciones, el primer polinucleótido comprende al menos un 50 % de identidad con un ARNcrtra sobre 6 nucleótidos contiguos. En algunas realizaciones, el primer polinucleótido está ubicado cadena abajo de un dúplex entre un polinucleótido que comprende al menos un 50 % de identidad con una repetición CRISPR sobre 6 nucleótidos contiguos, y un polinucleótido que comprende al menos un 50 % de identidad con una secuencia de ARNcrtra sobre 6 nucleótidos contiguos. En algunas realizaciones, el segundo polinucleótido comprende un motivo adyacente al protoespaciador. En algunas realizaciones, el ácido nucleico dirigido a ácido nucleico diseñado está adaptado a unirse a un polipéptido dirigido a un sitio. En algunas realizaciones, la mutación comprende una inserción de uno o más nucleótidos en el dominio P. En algunas realizaciones, la mutación comprende la eliminación de uno o más nucleótidos del dominio P. En algunas realizaciones, la mutación comprende la mutación de uno o más nucleótidos. En algunas realizaciones, la mutación está configurada para permitir que el ácido nucleico dirigido a ácido nucleico se hibride con un motivo adyacente al protoespaciador diferente. En algunas realizaciones, el motivo adyacente al protoespaciador diferente comprende un motivo adyacente al protoespaciador seleccionado del grupo que consiste en: 5'-NGGNG-3', 5'-NNAAAAW-3', 5'-NNNNGa Tt -3', 5'-GNNNCn Na -3' y 5-NNNACA-3', o cualquier combinación de los mismos. En algunas realizaciones, la mutación está configurada para permitir que el ácido nucleico dirigido a ácido nucleico diseñado se una con una constante de disociación menor que un ácido nucleico dirigido a ácido nucleico no diseñado. En algunas realizaciones, la mutación está configurada para permitir que el ácido nucleico dirigido a ácido nucleico diseñado se una con mayor especificidad que un ácido nucleico dirigido a ácido nucleico no diseñado. En algunas realizaciones, la mutación está configurada para reducir la unión del ácido nucleico dirigido a ácido nucleico diseñado a una secuencia no específica en un ácido nucleico diana en comparación con un ácido nucleico dirigido a ácido nucleico no diseñado.
La divulgación proporciona un método de modificación de un ácido nucleico diana que comprende poner en contacto un ácido nucleico diana con un ácido nucleico dirigido a ácido nucleico diseñado que comprende: una mutación en un dominio P del ácido nucleico dirigido a ácido nucleico, y modificar el ácido nucleico diana. En algunas realizaciones, el método comprende además insertar un polinucleótido donante en el ácido nucleico diana. En algunas realizaciones, la modificación comprende escindir el ácido nucleico diana. En algunas realizaciones, la modificación comprende modificar la transcripción del ácido nucleico diana.
La divulgación proporciona un vector que comprende una secuencia polinucleotídica que codifica un ácido nucleico dirigido a ácido nucleico diseñado que comprende: una mutación en un dominio P del ácido nucleico dirigido a ácido nucleico.
La divulgación proporciona un kit que comprende: un ácido nucleico dirigido a ácido nucleico diseñado que comprende: una mutación en un dominio P del ácido nucleico dirigido a ácido nucleico; y un tampón. En algunas realizaciones, el kit comprende además un polipéptido dirigido a un sitio. En algunas realizaciones, el kit comprende además un polinucleótido donante. En algunas realizaciones, El kit comprende además instrucciones de uso.
La divulgación proporciona un ácido nucleico dirigido a ácido nucleico diseñado que comprende: una mutación en una región protuberante de un ácido nucleico dirigido a ácido nucleico. En algunas realizaciones, la protuberancia se encuentra dentro de un dúplex entre una repetición CRISPR y una secuencia de ARNcrtra del ácido nucleico dirigido a ácido nucleico. En algunas realizaciones, el ácido nucleico dirigido a ácido nucleico diseñado comprende además una secuencia enlazadora. En algunas realizaciones, la secuencia enlazadora une la repetición CRISPR y la secuencia de ARNcrtra. En algunas realizaciones, el ácido nucleico dirigido a ácido nucleico diseñado es un ácido nucleico dirigido a ácido nucleico diseñado aislado. En algunas realizaciones, el ácido nucleico dirigido a ácido nucleico diseñado es un ácido nucleico dirigido a ácido nucleico diseñado recombinante. En algunas realizaciones, la protuberancia comprende al menos un 1 nucleótido no emparejado en la repetición CRISPR, y 1 nucleótido no emparejado en la secuencia de ARNcrtra. En algunas realizaciones, la protuberancia comprende al menos un 1 nucleótido no emparejado en la repetición CRISPR, y al menos 2 nucleótidos no emparejados en la secuencia de ARNcrtra. En algunas realizaciones, la protuberancia comprende al menos un 1 nucleótido no emparejado en la repetición CRISPR, y al menos 3 nucleótidos no emparejados en la secuencia de ARNcrtra. En algunas realizaciones, la protuberancia comprende al menos un 1 nucleótido no emparejado en la repetición CRISPR, y al menos 4 nucleótidos no emparejados en la secuencia de ARNcrtra. En algunas realizaciones, la protuberancia comprende al menos un 1 nucleótido no emparejado en la repetición CRISPR, y al menos 5 nucleótidos no emparejados en la secuencia de ARNcrtra. En algunas realizaciones, la protuberancia comprende al menos 2 nucleótidos no emparejados en la repetición CRISPR, y 1 nucleótido no emparejado en la secuencia de ARNcrtra. En algunas realizaciones, la protuberancia comprende al menos 3 nucleótidos no emparejados en la repetición CRISPR, y al menos 2 nucleótidos no emparejados en la secuencia de ARNcrtra. En algunas realizaciones, la protuberancia comprende al menos 4 nucleótidos no emparejados en la repetición CRISPR, y al menos 3 nucleótidos no emparejados en la secuencia de ARNcrtra. En algunas realizaciones, la protuberancia comprende al menos 5 nucleótidos no emparejados en la repetición CRISPR, y al menos 4 nucleótidos no emparejados en la secuencia de ARNcrtra. En algunas realizaciones, la protuberancia comprende al menos un nucleótido en la repetición CRISPR adaptado a formar un par oscilante con al menos un nucleótido en la secuencia de ARNcrtra. En algunas realizaciones, la mutación comprende una o más mutaciones. En algunas realizaciones, la una o más mutaciones son adyacentes entre sí. En algunas realizaciones,
la una o más mutaciones están separadas entre sí. En algunas realizaciones, la mutación está adaptada para permitir que el ácido nucleico dirigido a ácido nucleico diseñado se una a un polipéptido dirigido a un sitio diferente. En algunas realizaciones, el polipéptido dirigido a un sitio diferente es un homólogo de Cas9. En algunas realizaciones, el polipéptido dirigido a un sitio diferente es una versión mutada de Cas9. En algunas realizaciones, el polipéptido dirigido a un sitio diferente comprenden una identidad de secuencia de aminoácidos del 10% con Cas9 en un dominio nucleasa seleccionado del grupo que consiste en: un dominio nucleasa RuvC y un dominio nucleasa HNH, o cualquier combinación de los mismos. En algunas realizaciones, la mutación está adaptada para permitir que el ácido nucleico dirigido a ácido nucleico diseñado se hibride con un motivo adyacente al protoespaciador diferente. En algunas realizaciones, la mutación está adaptada para permitir que el ácido nucleico dirigido a ácido nucleico diseñado se una a un polipéptido dirigido a un sitio con una constante de disociación menor que un ácido nucleico dirigido a ácido nucleico no diseñado. En algunas realizaciones, la mutación está adaptada para permitir que el ácido nucleico dirigido a ácido nucleico diseñado se una a un polipéptido dirigido a un sitio con mayor especificidad que un ácido nucleico dirigido a ácido nucleico no diseñado. En algunas realizaciones, la mutación está adaptada para permitir que el ácido nucleico dirigido a ácido nucleico diseñado dirija a un polipéptido dirigido a un sitio para escindir un ácido nucleico diana con mayor especificidad que un ácido nucleico dirigido a ácido nucleico no diseñado. En algunas realizaciones, la mutación está adaptada para reducir la unión del ácido nucleico dirigido a ácido nucleico diseñado a una secuencia no específica en un ácido nucleico diana en comparación con un ácido nucleico dirigido a ácido nucleico no diseñado. En algunas realizaciones, el ácido nucleico dirigido a ácido nucleico diseñado está adaptado a hibridarse con un ácido nucleico diana. En algunas realizaciones, la mutación comprende la inserción de uno o más nucleótidos en la protuberancia. En algunas realizaciones, la mutación comprende la eliminación de uno o más nucleótidos de la protuberancia. En algunas realizaciones, la mutación comprende la mutación de uno o más nucleótidos. En algunas realizaciones, la mutación está configurada para permitir que el ácido nucleico dirigido a ácido nucleico diseñado se hibride con un motivo adyacente al protoespaciador diferente en comparación con un ácido nucleico dirigido a ácido nucleico no diseñado. En algunas realizaciones, la mutación está configurada para permitir que el ácido nucleico dirigido a ácido nucleico diseñado se una a un polipéptido dirigido a un sitio con una constante de disociación menor que un ácido nucleico dirigido a ácido nucleico no diseñado. En algunas realizaciones, la mutación está configurada para permitir que el ácido nucleico dirigido a ácido nucleico diseñado se una a un polipéptido dirigido a un sitio con mayor especificidad que un ácido nucleico dirigido a ácido nucleico no diseñado. En algunas realizaciones, la mutación está configurada para reducir la unión del ácido nucleico dirigido a ácido nucleico diseñado a una secuencia no específica en un ácido nucleico diana en comparación con un ácido nucleico dirigido a ácido nucleico no diseñado.
La divulgación proporciona un método de modificación de un ácido nucleico diana que comprende: poner en contacto el ácido nucleico diana con un ácido nucleico dirigido a ácido nucleico diseñado que comprende: una mutación en una región protuberante de un ácido nucleico dirigido a ácido nucleico; y modificar el ácido nucleico diana. En algunas realizaciones, el método comprende además insertar un polinucleótido donante en el ácido nucleico diana. En algunas realizaciones, la modificación comprende escindir el ácido nucleico diana. En algunas realizaciones, la modificación comprende modificar la transcripción del ácido nucleico diana.
La divulgación proporciona un vector que comprende una secuencia polinucleotídica que codifica un ácido nucleico dirigido a ácido nucleico diseñado que comprende: una mutación en una región protuberante de un ácido nucleico dirigido a ácido nucleico; y modificar el ácido nucleico diana.
La divulgación proporciona un kit que comprende: un ácido nucleico dirigido a ácido nucleico diseñado que comprende: una mutación en una región protuberante de un ácido nucleico dirigido a ácido nucleico; y modificar el ácido nucleico diana; y un tampón. En algunas realizaciones, el kit comprende además un polipéptido dirigido a un sitio. En algunas realizaciones, el kit comprende además un polinucleótido donante. En algunas realizaciones, El kit comprende además instrucciones de uso.
La divulgación proporciona un método de producción de una célula marcada con polinucleótido donante que comprende: escindir un ácido nucleico diana de una célula usando un complejo que comprende un polipéptido dirigido a un sitio y un ácido nucleico dirigido a ácido nucleico, insertar un polinucleótido donante en un ácido nucleico diana escindido, propagar la célula portadora del polinucleótido donante y determinar un origen de la célula marcada con el polinucleótido donante. En algunas realizaciones, el método se realiza in vivo. En algunas realizaciones, el método se realiza in vitro. En algunas realizaciones, el método se realiza in situ. En algunas realizaciones, la propagación produce una población de células. En algunas realizaciones, la propagación produce una estirpe celular. En algunas realizaciones, el método comprende además determinar una secuencia de ácido nucleico de un ácido nucleico de la célula. En algunas realizaciones, la secuencia de ácido nucleico determina un origen de la célula. En algunas realizaciones, la determinación comprende determinar un genotipo de la célula. En algunas realizaciones, la propagación comprende diferenciar la célula. En algunas realizaciones, la propagación comprende desdiferenciar la célula. En algunas realizaciones, la propagación comprende diferenciar la célula y luego desdiferenciar la célula. En algunas realizaciones, la propagación comprende diferenciar la célula. En algunas realizaciones, la propagación comprende inducir a la célula a dividirse. En algunas realizaciones, la propagación comprende inducir a la célula a entrar en el ciclo celular. En algunas realizaciones, la propagación comprende que la célula forma una metástasis. En algunas realizaciones, la propagación comprende diferenciar una célula pluripotente en una célula diferenciada. En algunas realizaciones, la célula es una célula diferenciada. En algunas realizaciones, la célula es una célula desdiferenciada. En algunas realizaciones, la célula es una célula madre. En algunas realizaciones, la célula es una
célula madre pluripotente. En algunas realizaciones, la célula es una estirpe celular eucariota. En algunas realizaciones, la célula es una estirpe celular primaria. En algunas realizaciones, la célula es una estirpe celular derivada del paciente. En algunas realizaciones, el método comprende además trasplantar la célula a un organismo. En algunas realizaciones, el organismo es un ser humano. En algunas realizaciones, el organismo es un mamífero. En algunas realizaciones, el organismo se selecciona del grupo que consiste en: un ser humano, un perro, una rata, un ratón, un pollo, un pez, un gato, una planta y un primate. En algunas realizaciones, el método comprende además seleccionar la célula. En algunas realizaciones, el polinucleótido donante se inserta en un ácido nucleico diana que se expresa en un estado celular. En algunas realizaciones, el polinucleótido donante se inserta en un ácido nucleico diana que se expresa en una pluralidad de tipos de células. En algunas realizaciones, el polinucleótido del donante se inserta en un ácido nucleico diana que se expresa en un estado pluripotente. En algunas realizaciones, el polinucleótido donante se inserta en un ácido nucleico diana que se expresa en un estado diferenciado.
La divulgación proporciona un método de creación de una estirpe celular expandida clónicamente que comprende: introducir en una célula un complejo que comprende: un polipéptido dirigido a un sitio y un ácido nucleico dirigido a ácido nucleico, poner en contacto el complejo con un ácido nucleico diana, escindir el ácido nucleico diana, en donde la escisión es realizada por el complejo, produciendo así un ácido nucleico diana escindido, insertar un polinucleótido donante en el ácido nucleico diana escindido, propagar la célula, en donde la propagación produce la estirpe celular expandida clónicamente. En algunas realizaciones, la célula se selecciona del grupo que consiste en: célula HeLa, célula de ovario de hámster chino, célula 293-T, un feocromocitoma, un fibroblasto de neuroblastomas, un rabdomiosarcoma, una célula del ganglio de la raíz dorsal, una célula NSO, CV-I (ATCC CCL 70), COS-I (ATCC CRL 1650), COS-7 (ATCC CRL 1651), CHO-K1 (ATCC CCL 61), 3T3 (ATCC CCL 92), NIH/3T3 (ATCC CRL 1658), HeLa (ATCC CCL 2), C 1271 (ATCC CRL-1616), BS-C-I (ATCC CCL 26), MRC-5 (ATCC CCL 171), células L, HEK-293 (ATCC CRL1 573) y PC 12 (ATCC CRL-1721), HEK293T (ATCC CRL-11268), RBL (ATCC CRL-1378), SH-SY5Y (ATCC CRL-2266), MDCK (ATCC CCL-34), SJ-RH30 (ATCC CRL-2061), HepG2 (ATCC HB-8065), ND7/23 (ECACC 92090903), CHO (ECACC 85050302), Vera (ATCC CCL 81), Caco-2 (ATCC HTB 37), K562 (ATCC CCL 243), Jurkat (ATCC TIB-152), Per.Có, Huvec (ATCC PCS 100-010 primaria humana, CRL 2514 de ratón, CRL 2515, CRL 2516), HuH-7D12 (ECACC 01042712), 293 (ATCC CRL 10852), A549 (ATCC CCL 185), IMR-90 (ATCC CCL 186), MCF-7 (ATC HTB-22), U-2 OS (ATCC HTB-96) y T84 (ATCC c Cl 248), o cualquier combinación de las mismas. En algunas realizaciones, la célula es una célula madre. En algunas realizaciones, la célula es una célula diferenciada. En algunas realizaciones, la célula es una célula pluripotente.
La divulgación proporciona un método para el análisis de múltiples tipos de células que comprende: escindir al menos un ácido nucleico diana de dos o más células usando un complejo que comprende un polipéptido dirigido a un sitio y un ácido nucleico dirigido a ácido nucleico, para crear dos ácidos nucleicos diana escindidos, insertar un polinucleótido donante diferente en cada uno de los ácidos nucleicos diana escindidos, y analizar las dos o más células. En algunas realizaciones, el análisis comprende analizar simultáneamente las dos o más células. En algunas realizaciones, el análisis comprende determinar una secuencia del ácido nucleico diana. En algunas realizaciones, el análisis comprende comparar las dos o más células. En algunas realizaciones, el análisis comprende determinar un genotipo de las dos o más células. En algunas realizaciones, la célula es una célula diferenciada. En algunas realizaciones, la célula es una célula desdiferenciada. En algunas realizaciones, la célula es una célula madre. En algunas realizaciones, la célula es una célula madre pluripotente. En algunas realizaciones, la célula es una estirpe celular eucariota. En algunas realizaciones, la célula es una estirpe celular primaria. En algunas realizaciones, la célula es una estirpe celular derivada del paciente. En algunas realizaciones, se inserta una pluralidad de polinucleótidos donantes en una pluralidad de ácidos nucleicos diana escindidos de la célula.
La divulgación proporciona una composición que comprende: un ácido nucleico dirigido a ácido nucleico diseñado que comprende una extensión de hibridación de 3' y un polinucleótido donante, en donde el polinucleótido donante se hibrida con la extensión de hibridación de 3'. En algunas realizaciones, la extensión de hibridación de 3' está adaptada para hibridarse con al menos 5 nucleótidos del 3' del polinucleótido donante. En algunas realizaciones, la extensión de hibridación de 3' está adaptada para hibridarse con al menos 5 nucleótidos del 5' del polinucleótido donante. En algunas realizaciones, la extensión de hibridación de 3' está adaptada para hibridarse con al menos 5 nucleótidos adyacentes en el polinucleótido donante. En algunas realizaciones, la extensión de hibridación de 3' está adaptada para hibridarse con todo el polinucleótido donante. En algunas realizaciones, la extensión de hibridación de 3' comprende una plantilla de transcripción inversa. En algunas realizaciones, la plantilla de transcripción inversa está adaptada para ser transcrita inversamente por una transcriptasa inversa. En algunas realizaciones, la composición comprende además un polinucleótido de ADN transcrito inversamente. En algunas realizaciones, el polinucleótido de ADN transcrito inversamente está adaptado a hibridarse con la plantilla de transcripción inversa. En algunas realizaciones, el polinucleótido donante es ADN. En algunas realizaciones, la extensión de hibridación de 3' es ARN. En algunas realizaciones, el ácido nucleico dirigido a ácido nucleico diseñado es un ácido nucleico dirigido a ácido nucleico diseñado aislado. En algunas realizaciones, el ácido nucleico dirigido a ácido nucleico diseñado es un ácido nucleico dirigido a ácido nucleico diseñado recombinante.
La divulgación proporciona un método de introducción de un polinucleótido donante en un ácido nucleico diana que comprende: poner en contacto el ácido nucleico diana con una composición que comprende: un ácido nucleico dirigido a ácido nucleico diseñado que comprende una extensión de hibridación de 3' y un polinucleótido donante, en donde el polinucleótido donante se hibrida con la extensión de hibridación de 3'. En algunas realizaciones, el método
comprende además escindir el ácido nucleico diana para producir un ácido nucleico diana escindido. En algunas realizaciones, la escisión se realiza mediante un polipéptido dirigido a un sitio. En algunas realizaciones, el método comprende además insertar el polinucleótido donante en el ácido nucleico diana escindido.
La divulgación proporciona una composición que comprende: una proteína efectora y un ácido nucleico, en donde el ácido nucleico comprende al menos un 50 % de identidad de secuencia con un ARNcr sobre 6 nucleótidos contiguos, al menos un 50 % de identidad de secuencia con un ARNcrtra sobre 6 nucleótidos contiguos; y una secuencia no nativa, en donde el ácido nucleico está adaptado a unirse a la proteína efectora. En algunas realizaciones, la composición comprende además un polipéptido que comprende al menos un 10% de identidad de secuencia de aminoácidos con un dominio nucleasa Cas9, en donde el ácido nucleico se une al polipéptido. En algunas realizaciones, el polipéptido comprende al menos un 60 % de identidad de secuencia de aminoácidos en un dominio nucleasa con un dominio nucleasa Cas9. En algunas realizaciones, el polipéptido es Cas9. En algunas realizaciones, el ácido nucleico comprende además una secuencia enlazadora, en donde la secuencia enlazadora une la secuencia que comprende al menos un 50 % de identidad de secuencia con un ARNcr sobre 6 nucleótidos contiguos y la secuencia que comprende al menos un 50 % de identidad de secuencia con un ARNcrtra sobre 6 nucleótidos contiguos. En algunas realizaciones, la secuencia no nativa se encuentra en una posición del ácido nucleico seleccionada del grupo que consiste en: un extremo 5' y un extremo 3', o cualquier combinación de los mismos. En algunas realizaciones, el ácido nucleico comprende dos moléculas de ácido nucleico. En algunas realizaciones, el ácido nucleico comprende una sola molécula continua de ácido nucleico. En algunas realizaciones, la secuencia no nativa comprende una secuencia de unión a proteínas de unión a ARN de CRISPR. En algunas realizaciones, la secuencia no nativa comprende una secuencia de unión seleccionada del grupo que consiste en: una secuencia de unión a ARN de Cas5, una secuencia de unión a ARN de Cas6 y una secuencia de unión a ARN de Csy4, o cualquier combinación de las mismas. En algunas realizaciones, la proteína efectora comprende una proteína de unión a ARN de CRISPR. En algunas realizaciones, la proteína efectora comprende al menos un 15 % de identidad de secuencia de aminoácidos con una proteína seleccionada del grupo que consiste en: Cas5, Cas6 y Csy4, o cualquier combinación de las mismas. En algunas realizaciones, un dominio de unión a ARN de la proteína efectora comprende al menos un 15 % de identidad de secuencia de aminoácidos con un dominio de unión a ARN de una proteína seleccionada del grupo que consiste en: Cas5, Cas6 y Csy4, o cualquier combinación de las mismas. En algunas realizaciones, la proteína efectora se selecciona del grupo que consiste en: Cas5, Cas6 y Csy4, o cualquier combinación de las mismas. En algunas realizaciones, la proteína efectora comprende además una o más secuencias no nativas. En algunas realizaciones, la secuencia no nativa confiere una actividad enzimática a la proteína efectora. En algunas realizaciones, la actividad enzimática se selecciona del grupo que consiste en: actividad de metiltransferasa, actividad de desmetilasa, actividad de acetilación, actividad de desacetilación, actividad de ubiquitinación, actividad de desubiquitinación, actividad de desaminación, actividad de dismutasa, actividad de alquilación, actividad de despurinación, actividad de oxidación, actividad de formación de dímeros de pirimidina, actividad de transposasa, actividad de recombinasa, actividad de polimerasa, actividad de ligasa, actividad de helicasa, actividad de fotoliasa o actividad de glucosilasa, actividad de acetiltransferasa, actividad de desacetilasa, actividad de quinasa, actividad de fosfatasa, actividad de ubiquitina ligasa, actividad desubiquitinante, actividad de adenilación, actividad de desadenilación, actividad de SUMOilación, actividad deSUMOilación, actividad de ribosilación, actividad de desribosilación, actividad de miristoilación, actividad de remodelación, actividad de proteasa, actividad de oxidorreductasa, actividad de transferasa, actividad de hidrolasa, actividad de liasa, actividad de isomerasa, actividad de sintasa, actividad de sintetasa y actividad de desmiristoilación, o cualquier combinación de las mismas. En algunas realizaciones, el ácido nucleico es ARN. En algunas realizaciones, la proteína efectora comprende una proteína de fusión que comprende una proteína de unión a ARN y una proteína de unión a ADN. En algunas realizaciones, la composición comprende además un polinucleótido donante. En algunas realizaciones, el polinucleótido donante se une directamente a la proteína de unión al ADN, y en donde la proteína de unión al ARN se une a ácido nucleico que se dirige a ácido nucleico. En algunas realizaciones, el extremo 5' del polinucleótido donante se une a la proteína de unión al ADN. En algunas realizaciones, el extremo 3' del polinucleótido donante se une a la proteína de unión al ADN. En algunas realizaciones, al menos 5 nucleótidos del polinucleótido donante se unen a la proteína de unión al ADN. En algunas realizaciones, el ácido nucleico es un ácido nucleico aislado. En algunas realizaciones, el ácido nucleico es un ácido nucleico recombinante.
La divulgación proporciona un método de introducción de un polinucleótido donante en un ácido nucleico diana que comprende: poner en contacto un ácido nucleico diana con un complejo que comprende un polipéptido dirigido a un sitio y una composición que comprende: una proteína efectora y un ácido nucleico, en donde el ácido nucleico comprende al menos un 50 % de identidad de secuencia con un ARNcr sobre 6 nucleótidos contiguos, al menos un 50 % de identidad de secuencia con un ARNcrtra sobre 6 nucleótidos contiguos; y una secuencia no nativa, en donde el ácido nucleico está adaptado a unirse a la proteína efectora. En algunas realizaciones, el método comprende además escindir el ácido nucleico diana. En algunas realizaciones, la escisión es realizada por el polipéptido dirigido a un sitio. En algunas realizaciones, el método comprende además insertar el polinucleótido donante en el ácido nucleico diana.
La divulgación proporciona un método de modulación de un ácido nucleico diana que comprende: poner en contacto un ácido nucleico diana con uno o más complejos, comprendiendo cada complejo un polipéptido dirigido a un sitio y una composición que comprende: una proteína efectora y un ácido nucleico, en donde el ácido nucleico comprende al menos un 50 % de identidad de secuencia con un ARNcr sobre 6 nucleótidos contiguos, al menos un 50 % de identidad
de secuencia con un ARNcrtra sobre 6 nucleótidos contiguos; y una secuencia no nativa, en donde el ácido nucleico está adaptado a unirse a la proteína efectora y modular el ácido nucleico diana. En algunas realizaciones, el polipéptido dirigido a un sitio comprende al menos un 10 % de identidad de secuencia de aminoácidos con un dominio nucleasa de Cas9. En algunas realizaciones, la modulación es realizada por la proteína efectora. En algunas realizaciones, la modulación comprende una actividad seleccionada del grupo que consiste en: actividad de metiltransferasa, actividad de desmetilasa, actividad de acetilación, actividad de desacetilación, actividad de ubiquitinación, actividad de desubiquitinación, actividad de desaminación, actividad de dismutasa, actividad de alquilación, actividad de despurinación, actividad de oxidación, actividad de formación de dímeros de pirimidina, actividad de transposasa, actividad de recombinasa, actividad de polimerasa, actividad de ligasa, actividad de helicasa, actividad de fotoliasa o actividad de glucosilasa, actividad de acetiltransferasa, actividad de desacetilasa, actividad de quinasa, actividad de fosfatasa, actividad de ubiquitina ligasa, actividad desubiquitinante, actividad de adenilación, actividad de desadenilación, actividad de SUMOilación, actividad deSUMOilación, actividad de ribosilación, actividad de desribosilación, actividad de miristoilación, actividad de remodelación, actividad de proteasa, actividad de oxidorreductasa, actividad de transferasa, actividad de hidrolasa, actividad de liasa, actividad de isomerasa, actividad de sintasa, actividad de sintetasa y actividad de desmiristoilación, o cualquier combinación de las mismas. En algunas realizaciones, la proteína efectora comprende una o más proteínas efectoras.
La divulgación proporciona un método para detectar si dos complejos están próximos entre sí, que comprende: poner en contacto un primer ácido nucleico diana con un primer complejo, en donde el primer complejo comprende un primer polipéptido dirigido a un sitio, un primer ácido nucleico dirigido a ácido nucleico modificado y una primera proteína efectora, en donde la proteína efectora está adaptada para unirse a ácido nucleico dirigido a ácido nucleico modificado, y en donde la primera proteína efectora comprende una secuencia no nativa que comprende una primera parte de un sistema dividido, y poner en contacto un segundo ácido nucleico diana con un segundo complejo, en donde el segundo complejo comprende un segundo polipéptido dirigido a un sitio, un segundo ácido nucleico dirigido a ácido nucleico modificado y una segunda proteína efectora, en donde la proteína efectora está adaptada para unirse a ácido nucleico dirigido a ácido nucleico modificado, y en donde la segunda proteína efectora comprende una secuencia no nativa que comprende una segunda parte de un sistema dividido. En algunas realizaciones, el primer ácido nucleico diana y el segundo ácido nucleico diana están en el mismo polímero polinucleotídico. En algunas realizaciones, el sistema dividido comprende dos o más fragmentos de proteínas que individualmente no son activos, pero, cuando se forman en un complejo, dan lugar a un complejo proteico activo. En algunas realizaciones, el método comprende además detectar una interacción entre la primera parte y la segunda parte. En algunas realizaciones, la detección indica que el primer y el segundo complejo están cerca uno del otro. En algunas realizaciones, el polipéptido dirigido a un sitio está adaptado a no poder escindir el ácido nucleico diana. En algunas realizaciones, la detección comprende determinar la existencia de un hecho de movilidad genética. En algunas realizaciones, el hecho de movilidad genética comprende una translocación. En algunas realizaciones, antes del hecho de movilidad genética, las dos partes del sistema dividido no interactúan. En algunas realizaciones, después del hecho de movilidad genética, las dos partes del sistema dividido interactúan. En algunas realizaciones, el hecho de movilidad genética es una translocación entre un BCR y un gen Abl. En algunas realizaciones, la interacción activa el sistema dividido. En algunas realizaciones, la interacción indica que los ácidos nucleicos diana unidos por los complejos están muy juntos entre sí. En algunas realizaciones, el sistema dividido se selecciona del grupo que consiste en: sistema de GFP dividido, un sistema de ubiquitina dividido, un sistema de factor de transcripción dividido y un sistema de marcador de afinidad dividido, o cualquier combinación de los mismos. En algunas realizaciones, el sistema dividido comprende un sistema de GFP dividido. En algunas realizaciones, la detección indica un genotipo. En algunas realizaciones, el método comprende además: determinar un curso de tratamiento para una enfermedad basada en el genotipo. En algunas realizaciones, el método comprende además tratar la enfermedad. En algunas realizaciones, el tratamiento comprende administrar un fármaco. En algunas realizaciones, el tratamiento comprende administrar un complejo que comprende un ácido nucleico dirigido a ácido nucleico y un polipéptido dirigido a un sitio, en donde el complejo puede modificar un elemento genético que participe en la enfermedad. En algunas realizaciones, la modificación se selecciona del grupo que consiste en: añadir una secuencia de ácido nucleico al elemento genético, sustituir una secuencia de ácido nucleico en el elemento genético, y eliminar una secuencia de ácido nucleico del elemento genético, o cualquier combinación de los mismos. En algunas realizaciones, el método comprende además: comunicar el genotipo de un cuidador a un paciente. En algunas realizaciones, la comunicación comprende comunicarse desde un sistema de memoria de almacenamiento a un ordenador remoto. En algunas realizaciones, la detección diagnostica una enfermedad. En algunas realizaciones, el método comprende además: comunicar el diagnóstico de un cuidador a un paciente. En algunas realizaciones, la detección indica la presencia de polimorfismo de un solo nucleótido (SNP). En algunas realizaciones, el método comprende además: comunicar la existencia de un hecho de movilidad genética de un cuidador a un paciente. En algunas realizaciones, la comunicación comprende comunicarse desde un sistema de memoria de almacenamiento a un ordenador remoto. En algunas realizaciones, el polipéptido dirigido a un sitio comprende al menos un 20 % de identidad de secuencia de aminoácidos con Cas9. En algunas realizaciones, el polipéptido dirigido a un sitio comprende al menos un 60 % de identidad de secuencia de aminoácidos con Cas9. En algunas realizaciones, el polipéptido dirigido a un sitio comprende al menos un 60 % de identidad de secuencia de aminoácidos en un dominio nucleasa con un dominio nucleasa Cas9. En algunas realizaciones, el polipéptido dirigido a un sitio es Cas9. En algunas realizaciones, el ácido nucleico dirigido a ácido nucleico modificado comprende una secuencia no nativa. En algunas realizaciones, la secuencia no nativa se encuentra en una posición del ácido nucleico dirigido a ácido nucleico modificado seleccionada del grupo que consiste en: un extremo 5' y un extremo 3', o cualquier combinación de los mismos. En algunas realizaciones, el ácido nucleico dirigido a ácido nucleico modificado
comprende dos moléculas de ácido nucleico. En algunas realizaciones, el ácido nucleico comprende una sola molécula continua de ácido nucleico que comprende una primera parte que comprende al menos un 50 % de identidad con una repetición CRISPR sobre 6 nucleótidos contiguos y una segunda parte que comprende al menos un 50 % de identidad con una secuencia de ARNcrtra sobre 6 nucleótidos contiguos. En algunas realizaciones, la primera parte y la segunda parte están unidas por un enlazador. En algunas realizaciones, la secuencia no nativa comprende una secuencia de unión a proteínas de unión a ARN de CRISPR. En algunas realizaciones, la secuencia no nativa comprende una secuencia de unión seleccionada del grupo que consiste en: una secuencia de unión a ARN de Cas5, una secuencia de unión a ARN de Cas6 y una secuencia de unión a ARN de Csy4, o cualquier combinación de las mismas. En algunas realizaciones, el ácido nucleico dirigido a ácido nucleico modificado está adaptado a unirse a una proteína efectora. En algunas realizaciones, la proteína efectora es una proteína de unión a ARN de CRISPR. En algunas realizaciones, la proteína efectora comprende al menos un 15 % de identidad de secuencia de aminoácidos con una proteína seleccionada del grupo que consiste en: Cas5, Cas6 y Csy4, o cualquier combinación de las mismas. En algunas realizaciones, un dominio de unión a ARN de la proteína efectora comprende al menos un 15 % de identidad de secuencia de aminoácidos con un dominio de unión a ARN de una proteína seleccionada del grupo que consiste en: Cas5, Cas6 y Csy4, o cualquier combinación de las mismas. En algunas realizaciones, la proteína efectora se selecciona del grupo que consiste en: Cas5, Cas6 y Csy4, o cualquier combinación de las mismas. En algunas realizaciones, el ácido nucleico dirigido a ácido nucleico es ARN. En algunas realizaciones, el ácido nucleico diana es ADN. En algunas realizaciones, la interacción comprende formar un marcador de afinidad. En algunas realizaciones, la detección comprende capturar el marcador de afinidad. En algunas realizaciones, el método comprende además secuenciar ácido nucleico unido al primer y segundo complejo. En algunas realizaciones, el método comprende además fragmentar el ácido nucleico antes de la captura. En algunas realizaciones, la interacción forma un sistema activado. En algunas realizaciones, el método comprende además alterar la transcripción de un primer ácido nucleico diana o de un segundo ácido nucleico diana, en donde la alteración es realizada por el sistema activado. En algunas realizaciones, el segundo ácido nucleico diana no se une al primer ácido nucleico diana. En algunas realizaciones, La alteración de la transcripción del segundo ácido nucleico diana se realiza en trans. En algunas realizaciones, la alteración de la transcripción del primer ácido nucleico diana se realiza en cis. En algunas realizaciones, el primer o segundo ácido nucleico diana se selecciona del grupo que consiste en: un ácido nucleico endógeno y un ácido nucleico exógeno, o cualquier combinación de los mismos. En algunas realizaciones, la alteración comprende una transcripción creciente del primer o segundo ácido nucleico diana. En algunas realizaciones, el primer o segundo ácido nucleico diana comprende un polinucleótido que codifica uno o más genes que causan la muerte celular. En algunas realizaciones, el primer o segundo ácido nucleico diana comprende un polinucleótido que codifica un péptido inductor de lisis celular. En algunas realizaciones, el primer o segundo ácido nucleico diana comprende un polinucleótido que codifica un antígeno de reclutamiento de células inmunitarias. En algunas realizaciones, el primer o segundo ácido nucleico diana comprende un polinucleótido que codifica uno o más genes implicados en la apóptosis. En algunas realizaciones, el uno o más genes implicados en la apóptosis comprende caspasas. En algunas realizaciones, el uno o más genes implicados en la apóptosis comprende citocinas. En algunas realizaciones, uno o más genes implicados en la apóptosis se seleccionan del grupo que consiste en: factor de necrosis tumoral (TNF), receptor del TNF 1 (TNFR1), receptor del TNF 2 (TNFR2), receptor de Fas, FasL, caspasa-8, caspasa-10, caspasa-3, caspasa-9, caspasa-3, caspasa-6, caspasa-7, Bcl-2 y factor inductor de la apóptosis (AIF), o cualquier combinación de los mismos. En algunas realizaciones, el primer o segundo ácido nucleico diana comprende un polinucleótido que codifica uno o más ácidos nucleicos dirigidos a ácido nucleico. En algunas realizaciones, el uno o más ácidos nucleicos dirigidos a ácido nucleico se dirigen a una pluralidad de ácidos nucleicos diana. En algunas realizaciones, la detección comprende generar datos genéticos. En algunas realizaciones, el método comprende además comunicar los datos genéticos desde un sistema de memoria de almacenamiento a un ordenador remoto. En algunas realizaciones, los datos genéticos indican un genotipo. En algunas realizaciones, los datos genéticos indican la existencia de un hecho de movilidad genética. En algunas realizaciones, los datos genéticos indican una ubicación espacial de los genes.
La divulgación proporciona un kit que comprende: un polipéptido dirigido a un sitio, un ácido nucleico dirigido a ácido nucleico modificado, en donde el ácido nucleico dirigido a ácido nucleico modificado comprende una secuencia no nativa, una proteína efectora que está adaptada para unirse a la secuencia no nativa y un tampón. En algunas realizaciones, El kit comprende además instrucciones de uso.
La divulgación proporciona un vector que comprende una secuencia polinucleotídica que codifica un ácido nucleico dirigido a ácido nucleico modificado, en donde el ácido nucleico dirigido a ácido nucleico modificado comprende una secuencia no nativa. En algunas realizaciones, la secuencia polinucleotídica está unida operativamente a un promotor. En algunas realizaciones, el promotor es un promotor inducible.
La divulgación proporciona un kit que comprende: una secuencia polinucleotídica que codifica: un ácido nucleico dirigido a ácido nucleico modificado, en donde el ácido nucleico dirigido a ácido nucleico modificado comprende una secuencia configurada para unirse a una proteína efectora, y un polipéptido dirigido a un sitio. En algunas realizaciones, la secuencia polinucleotídica está unida operativamente a un promotor. En algunas realizaciones, el promotor es un promotor inducible.
La divulgación proporciona un vector que comprende: una secuencia polinucleotídica que codifica: un ácido nucleico dirigido a ácido nucleico modificado, en donde el ácido nucleico dirigido a ácido nucleico modificado comprende una secuencia no nativa, un polipéptido dirigido a un sitio y una proteína efectora. En algunas realizaciones, la secuencia
polinucleotídica está unida operativamente a un promotor. En algunas realizaciones, el promotor es un promotor inducible.
La divulgación proporciona una célula modificada genéticamente que comprende una composición que comprende: una proteína efectora y un ácido nucleico, en donde el ácido nucleico comprende al menos un 50 % de identidad de secuencia con un ARNcr sobre 6 nucleótidos contiguos, al menos un 50 % de identidad de secuencia con un ARNcrtra sobre 6 nucleótidos contiguos; y una secuencia no nativa, en donde el ácido nucleico está adaptado a unirse a la proteína efectora.
La divulgación proporciona una célula modificada genéticamente que comprende un vector que comprende una secuencia polinucleotídica que codifica un ácido nucleico dirigido a ácido nucleico modificado, en donde el ácido nucleico dirigido a ácido nucleico modificado comprende una secuencia no nativa.
La divulgación proporciona una célula modificada genéticamente que comprende un vector que comprende: una secuencia polinucleotídica que codifica: un ácido nucleico dirigido a ácido nucleico modificado, en donde el ácido nucleico dirigido a ácido nucleico modificado comprende una secuencia configurada para unirse a una proteína efectora, y un polipéptido dirigido a un sitio.
La divulgación proporciona una célula modificada genéticamente que comprende un vector que comprende: una secuencia polinucleotídica que codifica: un ácido nucleico dirigido a ácido nucleico modificado, en donde el ácido nucleico dirigido a ácido nucleico modificado comprende una secuencia no nativa, un polipéptido dirigido a un sitio y una proteína efectora.
La divulgación proporciona un kit que comprende: un vector que comprende una secuencia polinucleotídica que codifica un ácido nucleico dirigido a ácido nucleico modificado, en donde el ácido nucleico dirigido a ácido nucleico modificado comprende una secuencia no nativa y un tampón. En algunas realizaciones, El kit comprende además instrucciones de uso.
La divulgación proporciona un kit que comprende: un vector que comprende: una secuencia polinucleotídica que codifica: un ácido nucleico dirigido a ácido nucleico modificado, en donde el ácido nucleico dirigido a ácido nucleico modificado comprende una secuencia configurada para unirse a una proteína efectora, y un polipéptido dirigido a un sitio y un tampón. En algunas realizaciones, El kit comprende además instrucciones de uso.
La divulgación proporciona un kit que comprende: un vector que comprende: una secuencia polinucleotídica que codifica: un ácido nucleico dirigido a ácido nucleico modificado, en donde el ácido nucleico dirigido a ácido nucleico modificado comprende una secuencia no nativa, un polipéptido dirigido a un sitio y una proteína efectora, y un tampón. En algunas realizaciones, El kit comprende además instrucciones de uso.
La divulgación proporciona una composición que comprende: un agente de dirección genético multiplexado, en donde el agente de dirección genético multiplexado comprende uno o más módulos de ácido nucleico, en donde el módulo de ácido nucleico comprende una secuencia no nativa, y en donde el módulo de ácido nucleico está configurado para unirse a un polipéptido que comprende al menos un 10 % de identidad de secuencia de aminoácidos con un dominio nucleasa de Cas9 y en donde el módulo de ácido nucleico está configurado para hibridarse a un ácido nucleico diana. En algunas realizaciones, el módulo de ácido nucleico comprende una primera secuencia que comprende al menos un 50 % de identidad de secuencia con un ARNcr sobre 6 nucleótidos contiguos y una segunda secuencia que comprende al menos un 50 % de identidad de secuencia con un ARNcrtra sobre 6 nucleótidos contiguos. En algunas realizaciones, la composición comprende además una secuencia enlazadora que une la primera y la segunda secuencia. En algunas realizaciones, el uno o más módulos de ácido nucleico se hibridan con uno o más ácidos nucleicos diana. En algunas realizaciones, el uno o más módulos de ácido nucleico difieren en al menos un nucleótido en una región espaciadora del uno o más módulos de ácido nucleico. En algunas realizaciones, el uno o más módulos de ácido nucleico es ARN. En algunas realizaciones, El agente de dirección genético multiplexado es ARN. En algunas realizaciones, la secuencia no nativa comprende una ribozima. En algunas realizaciones, la secuencia no nativa comprende una secuencia de unión a endorribonucleasa. En algunas realizaciones, la secuencia de unión a endorribonucleasa se encuentra en un extremo 5' del módulo de ácido nucleico. En algunas realizaciones, la secuencia de unión a endorribonucleasa se encuentra en un extremo 3' del módulo de ácido nucleico. En algunas realizaciones, la secuencia de unión a endorribonucleasa está adaptada ser unida por una endorribonucleasa CRISPR. En algunas realizaciones, la secuencia de unión a endorribonucleasa está adaptada para ser unida por una endorribonucleasa que comprende un dominio RAMP. En algunas realizaciones, la secuencia de unión a endorribonucleasa está adaptada para ser unida por una endorribonucleasa seleccionada del grupo que consiste en: una endorribonucleasa miembro de la superfamilia de Cas5 y una endorribonucleasa miembro de la superfamilia de Cas6, o cualquier combinación de las mismas. En algunas realizaciones, la secuencia de unión a endorribonucleasa está adaptada para ser unida por una endorribonucleasa que comprende al menos un 15 % de identidad de secuencia de aminoácidos con una proteína seleccionada del grupo que consiste en: Csy4, Cas5 y Cas6. En algunas realizaciones, la secuencia de unión a endorribonucleasa está adaptada para ser unida por una endorribonucleasa que comprende al menos un 15 % de identidad de secuencia de aminoácidos con un dominio nucleasa de una proteína seleccionada del grupo que consiste en: Csy4, Cas5 y Cas6. En algunas realizaciones, la secuencia de unión a endorribonucleasa comprende una
horquilla. En algunas realizaciones, la horquilla comprende al menos 4 nucleótidos consecutivos en una estructura de tallo-lazo. En algunas realizaciones, la secuencia de unión a endorribonucleasa comprende al menos un 60 % de identidad con una secuencia seleccionada del grupo que consiste en:
5'- GUUCACUGCCGUAUAGGCAGCUAAGAAA-3’,
5’- GUUGCAAGGGAUUGAGCCCCGUAAGGGGAUUGCGAC-3’,
5’- GUUGCAAACCUCGUUAGCCUCGUAGAGGAUUGAAAC-3’;
5’- GGAUCGAUACCCACCCCGAAGAAAAGGGGACGAGAAC-3’,
5’- GUCGUCAGACCCAAAACCCCGAGAGGGGACGGAAAC-3’;
5’- GAUAUAAACCUAAUUACCUCGAGAGGGGACGGAAAC-3’,
5’- CCCC AGUO ACCUCGGGAGGGGACGGAAAC-3 ’;
5’- GUUCCAAUUAAUCUUAAACCCUAUUAGGGAUUGAAAC-3’
5’-GUUGCAAGGGAUUGAGCCCCGUAAGGGGAUUGCGAC-3’,
5’- GUUGCAAACCUCGUUAGCCUCGUAGAGGAUUGAAAC-3’;
5T- GG AUCG AU ACOC ACCCCGAAG AAAAGGGG AC G AG A AC-3 ’;
5”- GUCGUCAGACCCAAAACCCCGAGAGGGGACGGAAAC-3
5’- G AU AL A A AC CU A AUU A C CUC G AG AG GGG ACGG A A AC-3 \
5’-CCCCAGUC ACCUCGGGAGGGGACGGAAAC-3’;
5 - GUUCCAAUUAAUCUUAAACCCUAUUAGGGAUUGAAAC-3
5y-GUCGCCCCCCACGCGGGGGCGUGGAUUGAAAC-3\
Sy-CCAGCCGCCUUCGGGCGGCUGUGUGUUGAAAC-3’i
5y-GUCGC ACUCUACAU GAGUGCGUGGAU UGA A A U-3 ‘;
5' -UGU CGCACCUUA UA UAGGUGCGUGGAUUGAAAU-3 ’; y
5y GUCGCGCCCCGCAUGGGGCGCGUGGAUUGAAA-3\ o cualquier
combinación de las mismas. En algunas realizaciones, el uno o más módulos de ácido nucleico están adaptados para ser unidos por diferentes endorribonucleasas. En algunas realizaciones, el agente de dirección genético multiplexado es un agente de dirección genético multiplexado aislado. En algunas realizaciones, el agente de dirección genético multiplexado es un agente de dirección genético multiplexado recombinante.
La divulgación proporciona un vector que comprende una secuencia polinucleotídica que codifica un agente de dirección genético multiplexado, en donde el agente de dirección genético multiplexado comprende uno o más módulos de ácido nucleico, en donde el módulo de ácido nucleico comprende una secuencia no nativa, y en donde el módulo de ácido nucleico está configurado para unirse a un polipéptido que comprende al menos un 10 % de identidad de secuencia de aminoácidos con un dominio nucleasa de Cas9 y en donde el módulo de ácido nucleico está configurado para hibridarse a un ácido nucleico diana. En algunas realizaciones, la secuencia polinucleotídica está unida operativamente a un promotor. En algunas realizaciones, el promotor es un promotor inducible.
La divulgación proporciona una célula modificada genéticamente que comprende un agente de dirección genético multiplexado, en donde el agente de dirección genético multiplexado comprende uno o más módulos de ácido nucleico, en donde el módulo de ácido nucleico comprende una secuencia no nativa, y en donde el módulo de ácido nucleico está configurado para unirse a un polipéptido que comprende al menos un 10% de identidad de secuencia de aminoácidos con un dominio nucleasa de Cas9 y en donde el módulo de ácido nucleico está configurado para hibridarse a un ácido nucleico diana.
La divulgación proporciona una célula modificada genéticamente que comprende un vector que comprende una
secuencia polinucleotídica que codifica un agente de dirección genético multiplexado, en donde el agente de dirección genético multiplexado comprende uno o más módulos de ácido nucleico, en donde el módulo de ácido nucleico comprende una secuencia no nativa, y en donde el módulo de ácido nucleico está configurado para unirse a un polipéptido que comprende al menos un 10 % de identidad de secuencia de aminoácidos con un dominio nucleasa de Cas9 y en donde el módulo de ácido nucleico está configurado para hibridarse a un ácido nucleico diana.
lLa divulgación proporciona un kit que comprende un agente de dirección genético multiplexado, en donde el agente de dirección genético multiplexado comprende uno o más módulos de ácido nucleico, en donde el módulo de ácido nucleico comprende una secuencia no nativa, y en donde el módulo de ácido nucleico está configurado para unirse a un polipéptido que comprende al menos un 10 % de identidad de secuencia de aminoácidos con un dominio nucleasa de Cas9 y en donde el módulo de ácido nucleico está configurado para hibridarse a un ácido nucleico diana y un tampón. En algunas realizaciones, El kit comprende además instrucciones de uso.
La divulgación proporciona un kit que comprende: un vector que comprende una secuencia polinucleotídica que codifica un agente de dirección genético multiplexado, en donde el agente de dirección genético multiplexado comprende uno o más módulos de ácido nucleico, en donde el módulo de ácido nucleico comprende una secuencia no nativa, y en donde el módulo de ácido nucleico está configurado para unirse a un polipéptido que comprende al menos un 10 % de identidad de secuencia de aminoácidos con un dominio nucleasa de Cas9 y en donde el módulo de ácido nucleico está configurado para hibridarse a un ácido nucleico diana y un tampón. En algunas realizaciones, El kit comprende además instrucciones de uso.
La divulgación proporciona un método de generación de un ácido nucleico, en donde el ácido nucleico se une a un polipéptido que comprende al menos un 10 % de identidad de secuencia de aminoácidos con un dominio nucleasa de Cas9 y se hibrida con un ácido nucleico diana que comprende: introducir un agente de dirección genético multiplexado, en donde el agente de dirección genético multiplexado comprende uno o más módulos de ácido nucleico, en donde el módulo de ácido nucleico comprende una secuencia no nativa, y en donde el módulo de ácido nucleico está configurado para unirse a un polipéptido que comprende al menos un 10 % de identidad de secuencia de aminoácidos con un dominio nucleasa de Cas9 y en donde el módulo de ácido nucleico está configurado para hibridarse a un ácido nucleico diana en una célula hospedadora, procesar el agente de dirección genético multiplexado en uno o más módulos de ácido nucleico, y poner en contacto los uno o más módulos de ácido nucleico procesados con uno o más ácidos nucleicos diana en la célula. En algunas realizaciones, el método comprende además escindir el ácido nucleico diana. En algunas realizaciones, el método comprende además modificar el ácido nucleico diana. En algunas realizaciones, la modificación comprende alterar la transcripción del ácido nucleico diana. En algunas realizaciones, la modificación comprende además insertar un polinucleótido donante en el ácido nucleico diana.
La divulgación proporciona un polipéptido dirigido a un sitio modificado que comprende: un primer dominio nucleasa, un segundo dominio nucleasa y un dominio nucleasa insertado. En algunas realizaciones, el polipéptido dirigido a un sitio comprende al menos un 15 % de identidad con un dominio nucleasa de Cas9. En algunas realizaciones, el primer dominio nucleasa comprende un dominio nucleasa seleccionado del grupo que consiste en: un dominio HNH y un dominio RuvC, o cualquier combinación de los mismos. En algunas realizaciones, el segundo dominio nucleasa comprende un dominio nucleasa seleccionado del grupo que consiste en: un dominio HNH y un dominio RuvC, o cualquier combinación de los mismos. En algunas realizaciones, el dominio nucleasa insertado comprende un dominio HNH. En algunas realizaciones, el dominio nucleasa insertado comprende un dominio RuvC. En algunas realizaciones, el dominio nucleasa insertado es N-terminal al primer dominio nucleasa. En algunas realizaciones, el dominio nucleasa insertado es N-terminal al segundo dominio nucleasa. En algunas realizaciones, el dominio nucleasa insertado es C-terminal al primer dominio nucleasa. En algunas realizaciones, el dominio nucleasa insertado es C-terminal al segundo dominio nucleasa. En algunas realizaciones, el dominio nucleasa insertado está en tándem con el primer dominio nucleasa. En algunas realizaciones, el dominio nucleasa insertado está en tándem con el segundo dominio nucleasa. En algunas realizaciones, el dominio nucleasa insertado está adaptado a escindir un ácido nucleico diana en un sitio diferente al primer o segundo dominio nucleasa. En algunas realizaciones, el dominio nucleasa insertado está adaptado a escindir un ARN en un híbrido de ADN-ARN. En algunas realizaciones, el dominio nucleasa insertado está adaptado a escindir un ADN en un híbrido de ADN-ARN. En algunas realizaciones, el dominio nucleasa insertado está adaptado a aumentar la especificidad de unión del polipéptido dirigido a un sitio modificado con un ácido nucleico diana. En algunas realizaciones, el dominio nucleasa insertado se adapta para aumentar la fuerza de unión del polipéptido dirigido a un sitio modificado con un ácido nucleico diana.
La divulgación proporciona un vector que comprende una secuencia polinucleotídica que codifica un polipéptido dirigido a un sitio modificado que comprende: un primer dominio nucleasa, un segundo dominio nucleasa y un dominio nucleasa insertado.
La divulgación proporciona un kit que comprende: un polipéptido dirigido a un sitio modificado que comprende: un primer dominio nucleasa, un segundo dominio nucleasa y un dominio nucleasa insertado, y un tampón. En algunas realizaciones, El kit comprende además instrucciones de uso.
La divulgación proporciona una composición que comprende: un polipéptido dirigido a un sitio modificado, en donde el polipéptido se modifica de modo que se adapta para dirigirse a un segundo motivo adyacente al protoespaciador en
comparación con un polipéptido dirigido a un sitio de tipo silvestre. En algunas realizaciones, el polipéptido dirigido a un sitio se modifica mediante una modificación seleccionada del grupo que consiste en: una adición de aminoácido, una sustitución de aminoácido, un reemplazo de aminoácido y una eliminación de aminoácido, o cualquier combinación de los mismos. En algunas realizaciones, el polipéptido dirigido a un sitio modificado comprende una secuencia no nativa. En algunas realizaciones, el polipéptido dirigido a un sitio modificado está adaptado a dirigirse al segundo motivo adyacente al protoespaciador con mayor especificidad que el polipéptido dirigido a un sitio de tipo silvestre. En algunas realizaciones, el polipéptido dirigido a un sitio modificado está adaptado a dirigirse al segundo motivo adyacente al protoespaciador con una constante de disociación más baja en comparación con el polipéptido dirigido a un sitio de tipo silvestre. En algunas realizaciones, el polipéptido dirigido a un sitio modificado se adapta para dirigirse al segundo motivo adyacente al protoespaciador con una constante de disociación más alta en comparación con el polipéptido dirigido a un sitio de tipo silvestre. En algunas realizaciones, el segundo motivo adyacente al protoespaciador comprende un motivo adyacente al protoespaciador seleccionado del grupo que consiste en: 5'-NGGNG-3', 5'-NNAAAAW-3', 5'-NNNNGATT-3', 5'-GNNNCNNA-3' y 5'-NNNACA-3', o cualquier combinación de los mismos.
La divulgación proporciona un vector que comprende una secuencia polinucleotídica que codifica un polipéptido dirigido a un sitio modificado, en donde el polipéptido se modifica de modo que se adapta para dirigirse a un segundo motivo adyacente al protoespaciador en comparación con un polipéptido dirigido a un sitio de tipo silvestre.
La divulgación proporciona un kit que comprende: un polipéptido dirigido a un sitio modificado, en donde el polipéptido se modifica de modo que se adapta para dirigirse a un segundo motivo adyacente al protoespaciador en comparación con un polipéptido dirigido a un sitio de tipo silvestre y un tampón. En algunas realizaciones, El kit comprende además instrucciones de uso.
La divulgación proporciona una composición que comprende: un polipéptido dirigido a un sitio modificado, en donde el polipéptido se modifica de modo que se adapta para dirigirse a un segundo ácido nucleico dirigido a ácido nucleico en comparación con un polipéptido dirigido a un sitio de tipo silvestre. En algunas realizaciones, el polipéptido dirigido a un sitio se modifica mediante una modificación seleccionada del grupo que consiste en: una adición de aminoácido, una sustitución de aminoácido, un reemplazo de aminoácido y una eliminación de aminoácido, o cualquier combinación de los mismos. En algunas realizaciones, el polipéptido dirigido a un sitio modificado comprende una secuencia no nativa. En algunas realizaciones, el polipéptido dirigido a un sitio modificado está adaptado a dirigirse al segundo ácido nucleico dirigido a ácido nucleico con una especificidad superior en comparación con el polipéptido dirigido a un sitio de tipo silvestre. En algunas realizaciones, el polipéptido dirigido a un sitio modificado está adaptado a dirigirse al segundo ácido nucleico dirigido a ácido nucleico con una constante de disociación más baja en comparación con el polipéptido dirigido a un sitio de tipo silvestre. En algunas realizaciones, el polipéptido dirigido a un sitio modificado está adaptado a dirigirse al segundo ácido nucleico dirigido a ácido nucleico con una constante de disociación más alta en comparación con el polipéptido dirigido a un sitio de tipo silvestre. En algunas realizaciones, el polipéptido dirigido a un sitio se dirige a una parte de ARNcrtra del segundo ácido nucleico dirigido a ácido nucleico.
La divulgación proporciona un vector que comprende una secuencia polinucleotídica que codifica un polipéptido dirigido a un sitio modificado, en donde el polipéptido se modifica de modo que se adapta para dirigirse a un segundo ácido nucleico dirigido a ácido nucleico en comparación con un polipéptido dirigido a un sitio de tipo silvestre.
La divulgación proporciona un kit que comprende: un polipéptido dirigido a un sitio modificado, en donde el polipéptido se modifica de modo que se adapta para dirigirse a un segundo ácido nucleico dirigido a ácido nucleico en comparación con un polipéptido dirigido a un sitio de tipo silvestre y un tampón. En algunas realizaciones, El kit comprende además instrucciones de uso.
La divulgación proporciona una composición que comprende: un polipéptido dirigido a un sitio modificado que comprende una modificación en una hélice puente en comparación con la SEQ ID: 8. En algunas realizaciones, la composición está configurada para escindir un ácido nucleico diana.
La divulgación proporciona una composición que comprende: un polipéptido dirigido a un sitio modificado que comprende una modificación en un parche muy básico en comparación con la SEQ ID: 8. En algunas realizaciones, la composición está configurada para escindir un ácido nucleico diana.
La divulgación proporciona una composición que comprende: un polipéptido dirigido a un sitio modificado que comprende una modificación en un dominio de tipo polimerasa en comparación con la SEQ ID: 8. En algunas realizaciones, la composición está configurada para escindir un ácido nucleico diana.
La divulgación proporciona una composición que comprende: un polipéptido dirigido a un sitio modificado que comprende una modificación en una hélice puente, un parche muy básico, un dominio nucleasa y un dominio polimerasa en comparación con la SEQ ID: 8, o cualquier combinación de las mismas.
La divulgación proporciona un vector que comprende una secuencia polinucleotídica que codifica un polipéptido dirigido a un sitio modificado que comprende una modificación en una hélice puente, un parche muy básico, un dominio
nucleasa y un dominio polimerasa en comparación con la SEQ ID: 8, o cualquier combinación de las mismas.
La divulgación proporciona un kit que comprende: un polipéptido dirigido a un sitio modificado que comprende una modificación en una hélice puente, un parche muy básico, un dominio nucleasa y un dominio polimerasa en comparación con la SEQ ID: 8, o cualquier combinación de las mismas y un tampón. En algunas realizaciones, El kit comprende además instrucciones de uso. En algunas realizaciones, el kit comprende además un ácido nucleico dirigido a ácido nucleico.
La divulgación proporciona a una célula modificada genéticamente un polipéptido dirigido a un sitio modificado que comprende una modificación en una hélice puente, un parche muy básico, un dominio nucleasa y un dominio polimerasa en comparación con la SEQ ID: 8, o cualquier combinación de las mismas.
La divulgación proporciona un método para el diseño del genoma que comprende: poner en contacto un ácido nucleico diana con un complejo, en donde el complejo comprende un polipéptido dirigido a un sitio modificado que comprende una modificación en una hélice puente, un parche muy básico, un dominio nucleasa y un dominio polimerasa en comparación con la SEQ ID: 8, o cualquier combinación de las mismas, y un ácido nucleico dirigido a ácido nucleico, y modificar el ácido nucleico diana. En algunas realizaciones, la puesta en contacto comprende poner en contacto el complejo con un motivo adyacente al protoespaciador en el ácido nucleico diana. En algunas realizaciones, la puesta en contacto comprende poner en contacto el complejo con una secuencia de ácido nucleico diana más larga en comparación con un polipéptido dirigido a un sitio no modificado. En algunas realizaciones, la modificación comprende escindir el ácido nucleico diana. En algunas realizaciones, el ácido nucleico diana comprende ARN. En algunas realizaciones, el ácido nucleico diana comprende ADN. En algunas realizaciones, la modificación comprende escindir la cadena de ARN de un ARN y ADN hibridado. En algunas realizaciones, la modificación comprende escindir la cadena de ADN de un ARN y ADN hibridado. En algunas realizaciones, la modificación comprende insertar en el ácido nucleico diana un polinucleótido donante, una parte de un polinucleótido donante, una copia de un polinucleótido donante, o una parte de una copia de un polinucleótido donante, o cualquier combinación de las mismas. En algunas realizaciones, la modificación comprende modificar la actividad de transcripción del ácido nucleico diana. En algunas realizaciones, la modificación comprende una eliminación de uno o más nucleótidos del ácido nucleico diana.
La divulgación proporciona una composición que comprende: un polipéptido dirigido a un sitio modificado que comprende un dominio nucleasa modificado en comparación con la SEQ ID: 8. En algunas realizaciones, la composición está configurada para escindir un ácido nucleico diana. En algunas realizaciones, el dominio nucleasa modificado comprende un dominio nucleasa de dominio RuvC. En algunas realizaciones, el dominio nucleasa modificado comprende un dominio nucleasa de HNH. En algunas realizaciones, el dominio nucleasa modificado comprende la duplicación de un dominio nucleasa de HNH. En algunas realizaciones, el dominio nucleasa modificado se adapta para aumentar la especificidad de la secuencia de aminoácidos por un ácido nucleico diana en comparación con un polipéptido dirigido a un sitio no modificado. En algunas realizaciones, el dominio nucleasa modificado se adapta para aumentar la especificidad de la secuencia de aminoácidos por un ácido nucleico dirigido a ácido nucleico en comparación con un polipéptido dirigido a un sitio no modificado. En algunas realizaciones, el dominio nucleasa modificado comprende una modificación seleccionada del grupo que consiste en: una adición de aminoácido, una sustitución de aminoácido, un reemplazo de aminoácido y una eliminación de aminoácido, o cualquier combinación de los mismos. En algunas realizaciones, el dominio nucleasa modificado comprende una secuencia no nativa insertada. En algunas realizaciones, la secuencia no nativa confiere una actividad enzimática al polipéptido dirigido a un sitio modificado. En algunas realizaciones, la actividad enzimática se selecciona del grupo que consiste en: actividad de nucleasa, actividad de metilasa, actividad de acetilasa, actividad de desmetilasa, actividad de desaminación, actividad de dismutasa, actividad de alquilación, actividad de despurinación, actividad de oxidación, actividad de formación de dímeros de pirimidina, actividad de integrasa, actividad de transposasa, actividad de recombinasa, actividad de polimerasa, actividad de ligasa, actividad de helicasa, actividad de fotoliasa o actividad de glucosilasa, actividad de acetiltransferasa, actividad de desacetilasa, actividad de quinasa, actividad de fosfatasa, actividad de ubiquitina ligasa, actividad desubiquitinante, actividad de adenilación, actividad de desadenilación, actividad de SUMOilación, actividad deSUMOilación, actividad de ribosilación, actividad de desribosilación, actividad de miristoilación, actividad de remodelación, actividad de proteasa, actividad de oxidorreductasa, actividad de transferasa, actividad de hidrolasa, actividad de liasa, actividad de isomerasa, actividad de sintasa, actividad de sintetasa y actividad de desmiristoilación, o cualquier combinación de las mismas. En algunas realizaciones, la actividad enzimática está adaptada para modular la transcripción de un ácido nucleico diana. En algunas realizaciones, el dominio nucleasa modificado está adaptado a permitir la unión de la secuencia de aminoácidos a una secuencia de motivo adyacente al protoespaciador que es diferente de una secuencia de motivo adyacente al protoespaciador con la que un polipéptido dirigido a un sitio no modificado está adaptado a unirse. En algunas realizaciones, el dominio nucleasa modificado está adaptado a permitir la unión de la secuencia de aminoácidos a un ácido nucleico dirigido a ácido nucleico que es diferente de un ácido nucleico dirigido a ácido nucleico con el que un polipéptido dirigido a un sitio no modificado está adaptado a unirse. En algunas realizaciones, el polipéptido dirigido a un sitio modificado está adaptado a unirse a una secuencia de ácido nucleico diana más larga que un polipéptido dirigido a un sitio no modificado. En algunas realizaciones, el polipéptido dirigido a un sitio modificado está adaptado a escindir ADN bicatenario. En algunas realizaciones, el polipéptido dirigido a un sitio modificado está adaptado a escindir la cadena de ARN de un ARN y un ADN hibridado. En algunas realizaciones, el polipéptido dirigido a un sitio modificado está adaptado a escindir la cadena de ADN de un ARN y un ADN hibridado. En algunas realizaciones, la composición comprende además un ácido nucleico dirigido a ácido
nucleico modificado, en donde la modificación del polipéptido dirigido a un sitio está adaptada a permitir que el polipéptido dirigido a un sitio se una a ácido nucleico dirigido a ácido nucleico modificado. En algunas realizaciones, el ácido nucleico dirigido a ácido nucleico modificado y el polipéptido dirigido a un sitio modificado comprenden mutaciones compensatorias.
La divulgación proporciona un método para enriquecer un ácido nucleico diana para la secuenciación, que comprende: poner en contacto un ácido nucleico diana con un complejo que comprende un ácido nucleico dirigido a ácido nucleico y un polipéptido dirigido a un sitio, enriquecer el ácido nucleico diana usando el complejo y determinar una secuencia del ácido nucleico diana. En algunas realizaciones, el método no comprende una etapa de amplificación. En algunas realizaciones, el método comprende además analizar la secuencia del ácido nucleico diana. En algunas realizaciones, el método comprende además fragmentar el ácido nucleico diana antes del enriquecimiento. En algunas realizaciones, el ácido nucleico dirigido a ácido nucleico comprende ARN. En algunas realizaciones, el método del ácido nucleico dirigido a ácido nucleico comprende dos moléculas de ARN. En algunas realizaciones, en el método, una parte de cada una de las dos moléculas de ARN se hibridan entre sí. En algunas realizaciones, en el método, una de las dos moléculas de ARN comprende una secuencia de repetición CRISPR. En algunas realizaciones, la secuencia de repetición CRISPR es homóloga a un ARNcr sobre 6 nucleótidos contiguos. En algunas realizaciones, la secuencia de repetición CRISPR comprende al menos un 60 % de identidad con un ARNcr sobre 6 nucleótidos contiguos. En algunas realizaciones, la una de las dos moléculas de ARN comprende una secuencia de ARNcrtra. En algunas realizaciones, la secuencia de ARNcrtra es homóloga a un ARNcrtra sobre 6 nucleótidos contiguos. En algunas realizaciones, la secuencia de ARNcrtra comprende al menos un 60 % de identidad con un ARNcrtra sobre 6 nucleótidos contiguos. En algunas realizaciones, el ácido nucleico dirigido a ácido nucleico es un ácido nucleico guía doble. En algunas realizaciones, el ácido nucleico dirigido a ácido nucleico comprende una molécula de ARN continua, en donde la molécula de ARN continua comprende además dos dominios y un enlazador. En algunas realizaciones, una parte de cada uno de los dos dominios de la molécula de ARN continua se hibrida entre sí. En algunas realizaciones, la molécula de ARN continua comprende una secuencia de repetición CRISPR. En algunas realizaciones, la secuencia de repetición CRISPR es homóloga a un ARNcr sobre 6 nucleótidos contiguos. En algunas realizaciones, la secuencia de repetición CRISPR comprende al menos un 60 % de identidad con un ARNcr sobre 6 nucleótidos contiguos. En algunas realizaciones, la molécula de ARN continua comprende una secuencia de ARNcrtra. En algunas realizaciones, la secuencia de ARNcrtra es homóloga a un ARNcrtra sobre 6 nucleótidos contiguos. En algunas realizaciones, la secuencia de ARNcrtra comprende al menos un 60 % de identidad con un ARNcrtra sobre 6 nucleótidos contiguos. En algunas realizaciones, el ácido nucleico dirigido a ácido nucleico es un ácido nucleico guía sencillo. En algunas realizaciones, la puesta en contacto comprende hibridar una parte del ácido nucleico dirigido a ácido nucleico con una parte del ácido nucleico diana. En algunas realizaciones, el ácido nucleico dirigido a ácido nucleico se hibrida con el ácido nucleico diana sobre una región que comprende 6-20 nucleótidos. En algunas realizaciones, el polipéptido dirigido a un sitio comprende Cas9. En algunas realizaciones, el polipéptido dirigido a un sitio comprende al menos un 20 % de homología con un dominio nucleasa de Cas9. En algunas realizaciones, el polipéptido dirigido a un sitio comprende al menos un 60 % de homología con Cas9. En algunas realizaciones, el polipéptido dirigido a un sitio comprende un dominio nucleasa diseñado, en donde el dominio nucleasa comprende una actividad nucleasa reducida en comparación con un polipéptido dirigido a un sitio que comprende un dominio nucleasa no diseñado. En algunas realizaciones, el polipéptido dirigido a un sitio introduce una rotura monocatenaria en el ácido nucleico diana. En algunas realizaciones, el dominio nucleasa diseñado comprende la mutación de un ácido aspártico conservado. En algunas realizaciones, el dominio nucleasa diseñado comprende una mutación D10A. En algunas realizaciones, el dominio nucleasa diseñado comprende la mutación de una histidina conservada. En algunas realizaciones, el dominio nucleasa diseñado comprende una mutación H840A. En algunas realizaciones, el polipéptido dirigido a un sitio comprende un marcador de afinidad. En algunas realizaciones, el marcador de afinidad se encuentra en el extremo N del polipéptido dirigido a un sitio, el extremo C del polipéptido dirigido a un sitio, una región accesible a la superficie o cualquier combinación de los mismos. En algunas realizaciones, el marcador de afinidad se selecciona de un grupo que comprende: biotina, FLAG, His6x, His9x y una proteína fluorescente, o cualquier combinación de los mismos. En algunas realizaciones, el ácido nucleico dirigido a ácido nucleico comprende un marcador de afinidad de ácido nucleico. En algunas realizaciones, el marcador de afinidad de ácido nucleico se encuentra en el extremo 5' del ácido nucleico dirigido a ácido nucleico, el extremo 3' del ácido nucleico dirigido a ácido nucleico, una región accesible a la superficie o cualquier combinación de los mismos. En algunas realizaciones, el marcador de afinidad de ácido nucleico se selecciona del grupo que comprende una molécula pequeña, marcador fluorescente, un marcador radiactivo, o cualquier combinación de los mismos. En algunas realizaciones, el marcador de afinidad de ácido nucleico comprende una secuencia que está configurada para unirse a Csy4, Cas5, Cas6 o cualquier combinación de las mismas. En algunas realizaciones, el marcador de afinidad de ácido nucleico comprende un 50 % de identidad con 5'-GUUCACUGCCGUAUAGGCAGCUAAGAAA-3'. En algunas realizaciones, el método comprende además diagnosticar una enfermedad y tomar una decisión de tratamiento específica del paciente, o cualquier combinación de las mismas. En algunas realizaciones, la determinación comprende determinar un genotipo. En algunas realizaciones, el método comprende además comunicar la secuencia desde un sistema de memoria de almacenamiento a un ordenador remoto. En algunas realizaciones, el enriquecimiento comprende poner en contacto un marcador de afinidad del complejo con un agente de captura. En algunas realizaciones, el agente de captura comprende un anticuerpo. En algunas realizaciones, el agente de captura comprende un soporte sólido. En algunas realizaciones, el agente de captura se selecciona del grupo que comprende: Csy4, Cas5 y Cas6. En algunas realizaciones, el agente de captura comprende una actividad enzimática reducida en ausencia de imidazol. En algunas realizaciones, el agente de captura comprende un dominio enzimático activable, en donde el dominio enzimático
activable se activa al entrar en contacto con imidazol. En algunas realizaciones, el agente de captura es un miembro de la familia Cas6. En algunas realizaciones, el agente de captura comprende un marcador de afinidad. En algunas realizaciones, el agente de captura comprende una endorribonucleasa condicionalmente enzimáticamente inactiva que comprende una mutación en un dominio nucleasa. En algunas realizaciones, la mutación de una histidina conservada. En algunas realizaciones, la mutación comprende una mutación H29A. En algunas realizaciones, el ácido nucleico diana está unido al complejo. En algunas realizaciones, el ácido nucleico diana es un ácido nucleico escindido que no está unido al complejo. En algunas realizaciones, se pone en contacto una pluralidad de complejos con una pluralidad de ácidos nucleicos diana. En algunas realizaciones, la pluralidad de ácidos nucleicos diana difieren en al menos un nucleótido. En algunas realizaciones, la pluralidad de complejos comprende una pluralidad de ácidos nucleicos dirigidos a ácido nucleico que difieren en al menos un nucleótido.
La divulgación proporciona un método para escindir un ácido nucleico que comprende: poner en contacto un ácido nucleico diana con dos o más complejos, en donde cada complejo comprende un polipéptido dirigido a un sitio y un ácido nucleico dirigido a ácido nucleico, y escindir el ácido nucleico diana, en donde la escisión produce un ácido nucleico diana escindido. En algunas realizaciones, la escisión se realiza mediante un dominio nucleasa del polipéptido dirigido a un sitio. En algunas realizaciones, el método no comprende amplificación. En algunas realizaciones, el método comprende además enriquecer el ácido nucleico diana escindido. En algunas realizaciones, el método comprende además secuenciar el ácido nucleico diana escindido. En algunas realizaciones, el ácido nucleico dirigido a ácido nucleico es ARN. En algunas realizaciones, el ácido nucleico dirigido a ácido nucleico comprende dos moléculas de ARN. En algunas realizaciones, una parte de cada una de las dos moléculas de ARN se hibridan entre sí. En algunas realizaciones, una de las dos moléculas de ARN comprende una secuencia de repetición CRISPR. En algunas realizaciones, la secuencia de repetición CRISPR comprende una secuencia que es homóloga a un ARNcr sobre 6 nucleótidos contiguos. En algunas realizaciones, la secuencia de repetición CRISPR comprende una secuencia que tiene al menos un 60 % de identidad con un ARNcr sobre 6 nucleótidos contiguos. En algunas realizaciones, una de las dos moléculas de ARN comprende una secuencia de ARNcrtra. En algunas realizaciones, la secuencia de ARNcrtra es homóloga a un ARNcr sobre 6 nucleótidos contiguos. En algunas realizaciones, la secuencia de ARNcrtra comprende al menos un 60 % de identidad con un ARNcr sobre 6 nucleótidos contiguos. En algunas realizaciones, el ácido nucleico dirigido a ácido nucleico es un ácido nucleico guía doble. En algunas realizaciones, el ácido nucleico dirigido a ácido nucleico comprende una molécula de ARN continua, en donde la molécula de ARN continua comprende además dos dominios y un enlazador. En algunas realizaciones, una parte de cada uno de los dos dominios de la molécula de ARN continua se hibrida entre sí. En algunas realizaciones, la molécula de ARN continua comprende una secuencia de repetición CRISPR. En algunas realizaciones, la secuencia de repetición CRISPR es homóloga a un ARNcr sobre 6 nucleótidos contiguos. En algunas realizaciones, la secuencia de repetición CRISPR comprende al menos un 60 % de identidad con un ARNcr sobre 6 nucleótidos contiguos. En algunas realizaciones, la molécula de ARN continua comprende una secuencia de ARNcrtra. En algunas realizaciones, la secuencia de ARNcrtra es homóloga a un ARNcr sobre 6 nucleótidos contiguos. En algunas realizaciones, la secuencia de ARNcrtra comprende al menos un 60 % de identidad con un ARNcr sobre 6 nucleótidos contiguos. En algunas realizaciones, el ácido nucleico dirigido a ácido nucleico es un ácido nucleico guía sencillo. En algunas realizaciones, el ácido nucleico dirigido a ácido nucleico se hibrida con un ácido nucleico diana. En algunas realizaciones, el ácido nucleico dirigido a ácido nucleico se hibrida con un ácido nucleico diana sobre una región, en donde la región comprende al menos 6 nucleótidos y como máximo 20 nucleótidos. En algunas realizaciones, el polipéptido dirigido a un sitio es Cas9. En algunas realizaciones, el polipéptido dirigido a un sitio comprende un polipéptido que comprende al menos un 20 % de homología con un dominio nucleasa de Cas9. En algunas realizaciones, el polipéptido dirigido a un sitio comprende un polipéptido que comprende al menos un 60 % de homología con Cas9. En algunas realizaciones, el polipéptido dirigido a un sitio comprende un marcador de afinidad. En algunas realizaciones, el marcador de afinidad se encuentra en el extremo N del polipéptido dirigido a un sitio, el extremo C del polipéptido dirigido a un sitio, una región accesible a la superficie o cualquier combinación de los mismos. En algunas realizaciones, el marcador de afinidad se selecciona de un grupo que comprende: biotina, FLAG, His6x, His9x y una proteína fluorescente, o cualquier combinación de los mismos. En algunas realizaciones, el ácido nucleico dirigido a ácido nucleico comprende un marcador de afinidad de ácido nucleico. En algunas realizaciones, el marcador de afinidad de ácido nucleico se encuentra en el extremo 5' del ácido nucleico dirigido a ácido nucleico, el extremo 3' del ácido nucleico dirigido a ácido nucleico, una región accesible a la superficie o cualquier combinación de los mismos. En algunas realizaciones, el marcador de afinidad de ácido nucleico se selecciona del grupo que comprende una molécula pequeña, marcador fluorescente, un marcador radiactivo, o cualquier combinación de los mismos. En algunas realizaciones, el marcador de afinidad de ácido nucleico es una secuencia que puede unirse a Csy4, Cas5, Cas6 o cualquier combinación de las mismas. En algunas realizaciones, el marcador de afinidad de ácido nucleico comprende un 50 % de identidad con GUUCACUGCCGUAUAGGCAGCUAAGAAA. En algunas realizaciones, el ácido nucleico diana es un ácido nucleico escindido que no está unido a los dos o más complejos. En algunas realizaciones, los dos o más complejos se ponen en contacto con una pluralidad de ácidos nucleicos diana. En algunas realizaciones, la pluralidad de ácidos nucleicos diana difieren en al menos un nucleótido. En algunas realizaciones, los dos o más complejos comprenden ácidos nucleicos dirigidos a ácido nucleico que difieren en al menos un nucleótido.
La divulgación proporciona un método de generación de un banco de ácidos nucleicos diana que comprende: poner en contacto una pluralidad de ácidos nucleicos diana con un complejo que comprende un polipéptido dirigido a un sitio y un ácido nucleico dirigido a ácido nucleico, escindir la pluralidad de ácidos nucleicos diana y purificar la pluralidad de ácidos nucleicos diana para crear el banco de ácidos nucleicos diana. En algunas realizaciones, el método
comprende además el cribado del banco de ácidos nucleicos diana.
La divulgación proporciona una composición que comprende: un primer complejo que comprende: un primer polipéptido dirigido a un sitio y un primer ácido nucleico dirigido a ácido nucleico, un segundo complejo que comprende: un segundo polipéptido dirigido a un sitio y un segundo ácido nucleico dirigido a ácido nucleico, en donde, el primer y el segundo ácido nucleico dirigido a ácido nucleico son diferentes. En algunas realizaciones, la composición comprende además un ácido nucleico diana, que es unido por el primer o el segundo complejo. En algunas realizaciones, el primer polipéptido dirigido a un sitio y el segundo polipéptido dirigido a un sitio son iguales. En algunas realizaciones, el primer polipéptido dirigido a un sitio y el segundo polipéptido dirigido a un sitio son diferentes.
La divulgación proporciona un vector que comprende una secuencia polinucleotídica que codifica: dos o más ácidos nucleicos dirigidos a ácido nucleico que difieren en al menos un nucleótido y un polipéptido dirigido a un sitio.
La divulgación proporciona una célula hospedadora modificada genéticamente que comprende: un vector que comprende una secuencia polinucleotídica que codifica: dos o más ácidos nucleicos dirigidos a ácido nucleico que difieren en al menos un nucleótido y un polipéptido dirigido a un sitio.
La divulgación proporciona un kit que comprende: un vector que comprende una secuencia polinucleotídica que codifica: dos o más ácidos nucleicos dirigidos a ácido nucleico que difieren en al menos un nucleótido, un polipéptido dirigido a un sitio y un tampón adecuado. En algunas realizaciones, el kit comprende además: un agente de captura, un soporte sólido, adaptadores de secuenciación y un control positivo, o cualquier combinación de los mismos. En algunas realizaciones, El kit comprende además instrucciones de uso.
La divulgación proporciona un kit que comprende: un polipéptido dirigido a un sitio que comprende actividad enzimática reducida en comparación con un polipéptido dirigido a un sitio de tipo silvestre, un ácido nucleico dirigido a ácido nucleico y un agente de captura. En algunas realizaciones, el kit comprende además: instrucciones de uso. En algunas realizaciones, el kit comprende además un tampón seleccionado del grupo que comprende: un tampón de lavado, un tampón de estabilización, un tampón reconstituyente o un tampón diluyente.
La divulgación proporciona un método de escisión de un ácido nucleico diana usando dos o más nickasas que comprende: poner en contacto un ácido nucleico diana con un primer complejo y un segundo complejo, en donde el primer complejo comprende una primera nickasa y un primer ácido nucleico dirigido a ácido nucleico, y en donde el segundo complejo comprende una segunda nickasa y un segundo ácido nucleico dirigido a ácido nucleico, en donde el ácido nucleico diana comprende un primer motivo adyacente al protoespaciador en una primera cadena y un segundo motivo adyacente al protoespaciador en una segunda cadena, en donde los primeros ácidos nucleicos dirigidos a ácido nucleico están adaptados a hibridarse con el primer motivo adyacente al protoespaciador, y en donde el segundo ácido nucleico dirigido a ácido nucleico está adaptado a hibridarse con el segundo motivo adyacente al protoespaciador, y mellar la primera y segunda cadena del ácido nucleico diana, en donde la mella genera un ácido nucleico diana escindido. En algunas realizaciones, la primera y la segunda nickasa son iguales. En algunas realizaciones, la primera y segunda nickasa son diferentes. En algunas realizaciones, el primer y el segundo ácido nucleico dirigido a ácido nucleico son diferentes. En algunas realizaciones, hay menos de 125 nucleótidos entre el primer motivo adyacente al protoespaciador y el segundo motivo adyacente al protoespaciador. En algunas realizaciones, el primer y segundo motivo adyacente al protoespaciador forman parte de la secuencia ngG, donde N es cualquier nucleótido. En algunas realizaciones, la primera o segunda nickasa comprende al menos un dominio nucleasa esencialmente inactivo. En algunas realizaciones, la primera o segunda nickasa comprende una mutación de un ácido aspártico conservado. En algunas realizaciones, la mutación es una mutación D10A. En algunas realizaciones, la primera o segunda nickasa comprende una mutación de una histidina conservada. En algunas realizaciones, la mutación es una mutación H840A. En algunas realizaciones, hay menos de 15 nucleótidos entre el primer y el segundo motivo adyacente al protoespaciador. En algunas realizaciones, hay menos de 10 nucleótidos entre el primer y el segundo motivo adyacente al protoespaciador. En algunas realizaciones, hay menos de 5 nucleótidos entre el primer y el segundo motivo adyacente al protoespaciador. En algunas realizaciones, el primer y el segundo motivo adyacente al protoespaciador son adyacentes entre sí. En algunas realizaciones, el mellado comprende el primer mellado de la nickasa de la primera cadena y el segundo mellado de la nickasa de la segunda cadena. En algunas realizaciones, el mellado genera un corte final pegajoso. En algunas realizaciones, el mellado genera un corte final romo. En algunas realizaciones, el método comprende además insertar un polinucleótido donante en el ácido nucleico diana escindido.
La divulgación proporciona una composición que comprende: una pluralidad de moléculas de ácido nucleico, en donde cada molécula de ácido nucleico comprende un sitio de unión de proteína de unión a ácido nucleico, en donde al menos una de la pluralidad de moléculas de ácido nucleico codifica un ácido nucleico dirigido a ácido nucleico, y una de la pluralidad de moléculas de ácido nucleico codifica un polipéptido dirigido a un sitio y un polipéptido de fusión, en donde el polipéptido de fusión comprende una pluralidad de proteínas de unión a ácido nucleico, en donde la pluralidad de proteínas de unión a ácido nucleico está adaptada a unirse a su sitio de unión a proteínas de unión a ácido nucleico afín. En algunas realizaciones, una o más de la pluralidad de proteínas de unión a ácido nucleico comprenden una secuencia no nativa. En algunas realizaciones, la secuencia no nativa se encuentra en una posición seleccionada del grupo que consiste en: el extremo N, el extremo C, una región accesible a la superficie o cualquier combinación de los
mismos. En algunas realizaciones, la secuencia no nativa codifica una señal de localización nuclear. En algunas realizaciones, la pluralidad de proteínas de unión a ácido nucleico están separadas por un enlazador. En algunas realizaciones, algunas de la pluralidad de proteínas de unión a ácido nucleico son la misma proteína de unión a ácido nucleico. En algunas realizaciones, toda la pluralidad de proteínas de unión a ácido nucleico son la misma proteína de unión a ácido nucleico. En algunas realizaciones, la pluralidad de proteínas de unión a ácido nucleico son diferentes proteínas de unión a ácido nucleico. En algunas realizaciones, la pluralidad de proteínas de unión a ácido nucleico comprende proteínas de unión a ARN. En algunas realizaciones, las proteínas de unión a ARN se seleccionan del grupo que consiste en: una endorribonucleasa de sistema de grupos de repeticiones palindrómicas cortas en intervalos regulares de Tipo I, una endorribonucleasa de sistema de grupos de repeticiones palindrómicas cortas en intervalos regulares de Tipo II o una endorribonucleasa de sistema de grupos de repeticiones palindrómicas cortas en intervalos regulares Tipo III, o cualquier combinación de las mismas. En algunas realizaciones, las proteínas de unión a ARN se seleccionan del grupo que consiste en: Cas5, Cas6 y Csy4, o cualquier combinación de las mismas. En algunas realizaciones, la pluralidad de proteínas de unión a ácido nucleico comprende proteínas de unión a ADN. En algunas realizaciones, el sitio de unión a la proteína de unión a ácido nucleico está configurado para unirse a una proteína de unión a ácido nucleico seleccionada del grupo que consiste en: proteína de unión a ácido nucleico del sistema de grupos de repeticiones palindrómicas cortas en intervalos regulares de Tipo I, Tipo II y Tipo III, o cualquier combinación de los mismos. En algunas realizaciones, el sitio de unión a la proteína de unión a ácido nucleico está configurado para unirse a una proteína de unión a ácido nucleico seleccionada del grupo que consiste en: Cas6, Cas5 y Csy4, o cualquier combinación de las mismas. En algunas realizaciones, algunas de la pluralidad de moléculas de ácido nucleico comprenden el mismo sitio de unión de proteína de unión a ácido nucleico. En algunas realizaciones, la pluralidad de moléculas de ácido nucleico comprende el mismo sitio de unión de proteína de unión a ácido nucleico. En algunas realizaciones, ninguna de la pluralidad de moléculas de ácido nucleico comprenden el mismo sitio de unión de proteína de unión a ácido nucleico. En algunas realizaciones, el polipéptido dirigido a un sitio comprende al menos un 20 % de identidad de secuencia con un dominio nucleasa de Cas9. En algunas realizaciones, el polipéptido dirigido a un sitio es Cas9. En algunas realizaciones, al menos una de las moléculas de ácido nucleico codifica una endorribonucleasa de grupos de repeticiones palindrómicas cortas en intervalos regulares. En algunas realizaciones, la endorribonucleasa de grupos de repeticiones palindrómicas cortas en intervalos regulares comprende al menos un 20 % de similitud de secuencia con Csy4. En algunas realizaciones, la endorribonucleasa de grupos de repeticiones palindrómicas cortas en intervalos regulares comprende al menos un 60 % de similitud de secuencia con Csy4. En algunas realizaciones, la endorribonucleasa de grupos de repeticiones palindrómicas cortas en intervalos regulares es Csy4. En algunas realizaciones, la pluralidad de proteínas de unión a ácido nucleico comprende actividad enzimática reducida. En algunas realizaciones, la pluralidad de proteínas de unión a ácido nucleico están adaptadas a unirse al sitio de unión de proteína de unión a ácido nucleico, pero no puede escindir el sitio de unión de proteína de unión a ácido nucleico. En algunas realizaciones, el ácido nucleico dirigido a ácido nucleico comprende dos moléculas de ARN. En algunas realizaciones, una parte de cada una de las dos moléculas de ARN se hibridan entre sí. En algunas realizaciones, una primera molécula de las dos moléculas de ARN comprende una secuencia que comprende al menos el 60 % de identidad con una secuencia de ARN de grupos de repeticiones palindrómicas cortas en intervalos regulares sobre 8 nucleótidos contiguos, y una segunda molécula de las dos moléculas de ARN comprende una secuencia que comprende al menos el 60 % de identidad con una secuencia de ARN de grupos de repeticiones palindrómicas cortas en intervalos regulares de activación en trans sobre 6 nucleótidos contiguos. En algunas realizaciones, el ácido nucleico dirigido a ácido nucleico comprende una molécula de ARN continua, en donde la molécula de ARN continua comprende además dos dominios y un enlazador. En algunas realizaciones, una parte de los dos dominios de la molécula de ARN continua se hibrida entre sí. En algunas realizaciones, una primera parte de la molécula de ARN continua comprende una secuencia que comprende al menos el 60 % de identidad con una secuencia de ARN de grupos de repeticiones palindrómicas cortas en intervalos regulares sobre 8 nucleótidos contiguos, y una segunda parte de la molécula de ARN continua comprende una secuencia que comprende al menos el 60 % de identidad con una secuencia de ARN de grupos de repeticiones palindrómicas cortas en intervalos regulares de activación en trans sobre 6 nucleótidos contiguos. En algunas realizaciones, el ácido nucleico dirigido a ácido nucleico está adaptado a hibridarse con un ácido nucleico diana sobre 6-20 nucleótidos. En algunas realizaciones, la composición está configurada para ser administrada a una célula. En algunas realizaciones, la composición está configurada para administrar cantidades iguales de la pluralidad de moléculas de ácido nucleico a una célula. En algunas realizaciones, la composición comprende además una molécula de polinucleótido donante, en donde la molécula de polinucleótido donante comprende un sitio de unión de proteínas de unión a ácido nucleico, en donde el sitio de unión está unido por una proteína de unión a ácido nucleico del polipéptido de fusión.
La divulgación proporciona un método de administración de ácidos nucleicos a una ubicación subcelular en una célula que comprende: introducir en una célula una composición que comprende: una pluralidad de moléculas de ácido nucleico, en donde cada molécula de ácido nucleico comprende un sitio de unión de proteína de unión a ácido nucleico, en donde al menos una de la pluralidad de moléculas de ácido nucleico codifica un ácido nucleico dirigido a ácido nucleico, y una de la pluralidad de moléculas de ácido nucleico codifica un polipéptido dirigido a un sitio y un polipéptido de fusión, en donde el polipéptido de fusión comprende una pluralidad de proteínas de unión a ácido nucleico, en donde la pluralidad de proteínas de unión a ácido nucleico están adaptadas a unirse a sus sitios de unión de proteínas de unión a ácido nucleico afines que administran la composición a la ubicación subcelular de forma estequiométrica, formar una unidad que comprende un polipéptido dirigido a un sitio traducido de la molécula de ácido nucleico que codifica un polipéptido dirigido a un sitio y el ácido nucleico dirigido a ácido nucleico, y escindir un ácido nucleico diana, en donde el polipéptido dirigido a un sitio de la unidad escinde el ácido nucleico diana. En algunas realizaciones, la
pluralidad de proteínas de unión a ácido nucleico se unen a su sitio de unión de proteínas de unión a ácido nucleico afín. En algunas realizaciones, una endorribonucleasa escinde uno de los uno o más sitios de unión de proteínas de unión a ácido nucleico. En algunas realizaciones, una endorribonucleasa escinde los sitios de unión de proteínas de unión a ácido nucleico del ácido nucleico que codifica el ácido nucleico dirigido a ácido nucleico, liberando así el ácido nucleico dirigido a ácido nucleico. En algunas realizaciones, la ubicación subcelular se selecciona del grupo que consiste en: la nucleasa, el RE, el aparato de Golgi, las mitocondrias, la pared celular, el lisosoma y el núcleo. En algunas realizaciones, la ubicación subcelular es el núcleo.
La divulgación proporciona un kit que comprende: una secuencia polinucleotídica que codifica una composición que comprende: una pluralidad de moléculas de ácido nucleico, en donde cada molécula de ácido nucleico comprende un sitio de unión de proteína de unión a ácido nucleico, en donde al menos una de la pluralidad de moléculas de ácido nucleico codifica un ácido nucleico dirigido a ácido nucleico, y una de la pluralidad de moléculas de ácido nucleico codifica un polipéptido dirigido a un sitio; y un polipéptido de fusión, en donde el polipéptido de fusión comprende una pluralidad de proteínas de unión a ácido nucleico, en donde la pluralidad de proteínas de unión a ácido nucleico están adaptadas a unirse a sus sitios de unión de proteínas de unión a ácido nucleico afines que administran la composición a la ubicación subcelular de forma estequiométrica. En algunas realizaciones, el vector comprende además un polinucleótido que codifica un promotor. En algunas realizaciones, el promotor está unido operativamente al polinucleótido. En algunas realizaciones, el promotor es un promotor inducible.
La divulgación proporciona un organismo modificado genéticamente que comprende un vector que comprende: una secuencia polinucleotídica que codifica una pluralidad de moléculas de ácido nucleico, en donde cada molécula de ácido nucleico comprende un sitio de unión de proteína de unión a ácido nucleico, en donde al menos una de la pluralidad de moléculas de ácido nucleico codifica un ácido nucleico dirigido a ácido nucleico, y una de la pluralidad de moléculas de ácido nucleico codifica un polipéptido dirigido a un sitio y un polipéptido de fusión, en donde el polipéptido de fusión comprende una pluralidad de proteínas de unión a ácido nucleico, en donde la pluralidad de proteínas de unión a ácido nucleico están adaptadas a unirse a sus sitios de unión de proteínas de unión a ácido nucleico afines que administran la composición a la ubicación subcelular de forma estequiométrica.
La divulgación proporciona un organismo modificado genéticamente que comprende: una composición que comprende: una pluralidad de moléculas de ácido nucleico, en donde cada molécula de ácido nucleico comprende un sitio de unión de proteína de unión a ácido nucleico, en donde al menos una de la pluralidad de moléculas de ácido nucleico codifica un ácido nucleico dirigido a ácido nucleico, y una de la pluralidad de moléculas de ácido nucleico codifica un polipéptido dirigido a un sitio; y un polipéptido de fusión, en donde el polipéptido de fusión comprende una pluralidad de proteínas de unión a ácido nucleico, en donde la pluralidad de proteínas de unión a ácido nucleico está adaptada a unirse a su sitio de unión a proteínas de unión a ácido nucleico afín.
La divulgación proporciona un kit que comprende: una composición que comprende: una pluralidad de moléculas de ácido nucleico, en donde cada molécula de ácido nucleico comprende un sitio de unión de proteína de unión a ácido nucleico, en donde al menos una de la pluralidad de moléculas de ácido nucleico codifica un ácido nucleico dirigido a ácido nucleico, y una de la pluralidad de moléculas de ácido nucleico codifica un polipéptido dirigido a un sitio y un polipéptido de fusión, en donde el polipéptido de fusión comprende una pluralidad de proteínas de unión a ácido nucleico, en donde la pluralidad de proteínas de unión a ácido nucleico está adaptada a unirse a su sitio de unión a proteínas de unión a ácido nucleico afín y un tampón.
La divulgación proporciona un kit que comprende: un vector que comprende: una secuencia polinucleotídica que codifica una pluralidad de moléculas de ácido nucleico, en donde cada molécula de ácido nucleico comprende un sitio de unión de proteína de unión a ácido nucleico, en donde al menos una de la pluralidad de moléculas de ácido nucleico codifica un ácido nucleico dirigido a ácido nucleico, y una de la pluralidad de moléculas de ácido nucleico codifica un polipéptido dirigido a un sitio; y un polipéptido de fusión, en donde el polipéptido de fusión comprende una pluralidad de proteínas de unión a ácido nucleico, en donde la pluralidad de proteínas de unión a ácido nucleico están adaptadas a unirse a sus sitios de unión de proteínas de unión a ácido nucleico afines que administran la composición a la ubicación subcelular de forma estequiométrica y un tampón. En algunas realizaciones, El kit comprende además instrucciones de uso. En algunas realizaciones, el tampón se selecciona del grupo que comprende: un tampón de dilución, un tampón de reconstitución y un tampón de estabilización, o cualquier combinación de los mismos
La divulgación proporciona un polinucleótido donante que comprende: un elemento genético de interés y un elemento indicador, en donde el elemento indicador comprende una secuencia polinucleotídica que codifica un polipéptido dirigido a un sitio, y uno o más ácidos nucleicos, en donde el uno o más ácidos nucleicos comprende una secuencia que comprende al menos un 50 % de identidad de secuencia con un ARNcr sobre 6 nucleótidos contiguos y una secuencia que comprende al menos un 50 % de identidad de secuencia con un ARNcrtra sobre 6 nucleótidos contiguos. En algunas realizaciones, el elemento genético de interés comprende un gen. En algunas realizaciones, el elemento genético de interés comprende un ácido nucleico no codificante seleccionado del grupo que consiste en: un microARN, un ARNip y un ARN largo no codificante, o cualquier combinación de los mismos. En algunas realizaciones, el elemento genético de interés comprende un gen no codificante. En algunas realizaciones, el elemento genético de interés comprende un ácido nucleico no codificante seleccionado del grupo que consiste en: un microARN, un ARNip y un ARN largo no codificante, o cualquier combinación de los mismos. En algunas realizaciones, el elemento indicador
comprende un gen seleccionado del grupo que consiste en: un gen que codifica una proteína fluorescente, un gen que codifica una proteína quimioluminiscente y un gen de resistencia a antibióticos, o cualquier combinación de los mismos. En algunas realizaciones, el elemento indicador comprende un gen que codifica una proteína fluorescente. En algunas realizaciones, la proteína fluorescente comprende proteína verde fluorescente. En algunas realizaciones, el elemento indicador está unido operativamente a un promotor. En algunas realizaciones, el promotor comprende un promotor inducible. En algunas realizaciones, el promotor comprende un promotor específico del tejido. En algunas realizaciones, el polipéptido dirigido a un sitio comprende al menos un 15 % de identidad de secuencia de aminoácidos con un dominio nucleasa de Cas9. En algunas realizaciones, el polipéptido dirigido a un sitio comprende al menos un 95% de identidad de secuencia de aminoácidos sobre 10 aminoácidos para Cas9. En algunas realizaciones, el dominio nucleasa se selecciona del grupo que consiste en: un dominio HNH, un dominio de tipo HNH, un dominio RuvC y un dominio de tipo RuvC, o cualquier combinación de los mismos.
La divulgación proporciona un vector de expresión que comprende una secuencia polinucleotídica que codifica un elemento genético de interés; y un elemento indicador, en donde el elemento indicador comprende una secuencia polinucleotídica que codifica un polipéptido dirigido a un sitio, y uno o más ácidos nucleicos, en donde el uno o más ácidos nucleicos comprende una secuencia que comprende al menos un 50 % de identidad de secuencia con un ARNcr sobre 6 nucleótidos contiguos y una secuencia que comprende al menos un 50 % de identidad de secuencia con un ARNcrtra sobre 6 nucleótidos contiguos.
La divulgación proporciona una célula modificada genéticamente que comprende un polinucleótido donante que comprende: un elemento genético de interés; y un elemento indicador, en donde el elemento indicador comprende una secuencia polinucleotídica que codifica un polipéptido dirigido a un sitio, y uno o más ácidos nucleicos, en donde el uno o más ácidos nucleicos comprende una secuencia que comprende al menos un 50 % de identidad de secuencia con un ARNcr sobre 6 nucleótidos contiguos y una secuencia que comprende al menos un 50 % de identidad de secuencia con un ARNcrtra sobre 6 nucleótidos contiguos.
La divulgación proporciona un kit que comprende: un polinucleótido donante que comprende: un elemento genético de interés; y un elemento indicador, en donde el elemento indicador comprende una secuencia polinucleotídica que codifica un polipéptido dirigido a un sitio, y uno o más ácidos nucleicos, en donde el uno o más ácidos nucleicos comprende una secuencia que comprende al menos un 50 % de identidad de secuencia con un ARNcr sobre 6 nucleótidos contiguos y una secuencia que comprende al menos un 50 % de identidad de secuencia con un ARNcrtra sobre 6 nucleótidos contiguos; y un tampón. En algunas realizaciones, el kit comprende además: un polipéptido que comprende al menos un 10 % de identidad de secuencia de aminoácidos con Cas9; y un ácido nucleico, en donde el ácido nucleico se une al polipéptido y se hibrida con un ácido nucleico diana. En algunas realizaciones, El kit comprende además instrucciones de uso. En algunas realizaciones, el kit comprende además un polinucleótido que codifica un polipéptido, en donde el polipéptido comprende al menos un 15% de identidad de secuencia de aminoácidos con Cas9. En algunas realizaciones, el kit comprende además un polinucleótido que codifica un ácido nucleico, en donde el ácido nucleico comprende una secuencia que comprende al menos un 50 % de identidad de secuencia con un ARNcr sobre 6 nucleótidos contiguos y una secuencia que comprende al menos un 50 % de identidad de secuencia con un ARNcrtra sobre 6 nucleótidos contiguos.
La divulgación proporciona un método de selección de una célula usando un elemento indicador y escindiendo el elemento indicador de la célula que comprende: poner en contacto el ácido nucleico diana con un complejo que comprende un polipéptido dirigido a un sitio y un ácido nucleico dirigido a ácido nucleico; escindir el ácido nucleico diana con el polipéptido dirigido a un sitio, para generar un ácido nucleico diana escindido; insertar el polinucleótido donante que comprende un elemento genético de interés; y un elemento indicador, en donde el elemento indicador comprende una secuencia polinucleotídica que codifica un polipéptido dirigido a un sitio, y uno o más ácidos nucleicos, en donde el uno o más ácidos nucleicos comprende una secuencia que comprende al menos un 50 % de identidad de secuencia con un ARNcr sobre 6 nucleótidos contiguos y una secuencia que comprende al menos un 50 % de identidad de secuencia con un ARNcrtra sobre 6 nucleótidos contiguos en el ácido nucleico diana escindido; y seleccionar la célula basada en el polinucleótido donante para generar una célula seleccionada. En algunas realizaciones, la selección comprende seleccionar la célula de un sujeto que está siendo tratado por una enfermedad. En algunas realizaciones, la selección comprende seleccionar la célula de un sujeto que está siendo diagnosticado por una enfermedad. En algunas realizaciones, después de la selección, la célula comprende el polinucleótido donante. En algunas realizaciones, el método comprende además escindir todo, parte o nada del elemento indicador, generando así una segunda célula seleccionada. En algunas realizaciones, la escisión comprende poner en contacto el extremo 5' del elemento indicador con un complejo que comprende un polipéptido dirigido a un sitio y un ácido nucleico dirigido a ácido nucleico, en donde el complejo escinde el extremo 5'. En algunas realizaciones, la escisión comprende poner en contacto el extremo 3' del elemento indicador con un complejo que comprende un polipéptido dirigido a un sitio y un ácido nucleico dirigido a ácido nucleico, en donde el complejo escinde el extremo 3'. En algunas realizaciones, la escisión comprende el contacto del extremo 5' y 3' del elemento indicador con uno o más complejos que comprenden un polipéptido dirigido a un sitio y un ácido nucleico dirigido a ácido nucleico, en donde el complejo escinde el extremo 5' y 3'. En algunas realizaciones, el método comprende además el cribado de la segunda célula seleccionada. En algunas realizaciones, el cribado consiste en observar la ausencia de todo o parte del elemento indicador.
La divulgación proporciona una composición que comprende: un ácido nucleico que comprende: un espaciador, en donde el espaciador está entre 12-30 nucleótidos, ambos incluidos, y en donde el espaciador está adaptado a hibridarse a una secuencia que está a 5' de un PAM; un primer dúplex, en donde el primer dúplex está a 3' del espaciador; una protuberancia, en donde la protuberancia comprende al menos 3 nucleótidos no emparejados en una primera cadena del primer dúplex y al menos 1 nucleótido no emparejado en una segunda cadena del primer dúplex; un enlazador, en donde el enlazador une la primera cadena y la segunda cadena del dúplex y tiene al menos 3 nucleótidos de longitud; un dominio P; y un segundo dúplex, en donde el segundo dúplex está a 3' del dominio P y está adaptado a unirse a un polipéptido dirigido a un sitio. En algunas realizaciones, la secuencia que está a 5' de un PAM tiene al menos 18 nucleótidos de longitud. En algunas realizaciones, la secuencia que está a 5' de un PAM es adyacente al PAM. En algunas realizaciones, el PAM comprende 5'-NGG-3'. En algunas realizaciones, el primer dúplex está adyacente al espaciador. En algunas realizaciones, el dominio P comienza desde 1-5 nucleótidos cadena abajo del dúplex, comprende al menos 4 nucleótidos, y está adaptado a hibridarse con la secuencia seleccionada del grupo que consiste en: una secuencia de motivo adyacente al protoespaciador 5'-NGG-3', una secuencia que comprende al menos un 50 % de identidad con los aminoácidos 1096-1225 de Cas9 de S. pyogenes, o cualquier combinación de las mismas. En algunas realizaciones, el polipéptido dirigido a un sitio comprende al menos un 15 % de identidad con un dominio nucleasa de Cas9 de S. pyogenes. En algunas realizaciones, el ácido nucleico es ARN. En algunas realizaciones, El ácido nucleico es un ARN en forma de A. En algunas realizaciones, el primer dúplex tiene al menos 6 nucleótidos de longitud. En algunas realizaciones, los 3 nucleótidos no emparejados de la protuberancia comprenden 5'-AAG-3 '. En algunas realizaciones, adyacente a los 3 nucleótidos no emparejados hay un nucleótido que forma un par oscilante con un nucleótido en la segunda cadena del primer dúplex. En algunas realizaciones, el polipéptido se une a una región del ácido nucleico seleccionada del grupo que consiste en: el primer dúplex, el segundo dúplex y el dominio P, o cualquier combinación de los mismos.
La divulgación proporciona un método de modificación de un ácido nucleico diana que comprende: poner en contacto un ácido nucleico diana con una composición que comprende: un ácido nucleico que comprende: un espaciador, en donde el espaciador está entre 12-30 nucleótidos, ambos incluidos, y en donde el espaciador está adaptado a hibridarse a una secuencia que está a 5' de un PAM; un primer dúplex, en donde el primer dúplex está a 3' del espaciador; una protuberancia, en donde la protuberancia comprende al menos 3 nucleótidos no emparejados en una primera cadena del primer dúplex y al menos 1 nucleótido no emparejado en una segunda cadena del primer dúplex; un enlazador, en donde el enlazador une la primera cadena y la segunda cadena del dúplex y tiene al menos 3 nucleótidos de longitud; un dominio P; y un segundo dúplex, en donde el segundo dúplex está a 3' del dominio P y está adaptado a unirse a un polipéptido dirigido a un sitio; y modificar el ácido nucleico diana. En algunas realizaciones, el método comprende además entrar en contacto con un polipéptido dirigido a un sitio. En algunas realizaciones, la puesta en contacto comprende poner en contacto el espaciador con el ácido nucleico diana. En algunas realizaciones, la modificación comprende escindir el ácido nucleico diana para producir un ácido nucleico diana escindido. En algunas realizaciones, la escisión es realizada por el polipéptido dirigido a un sitio. En algunas realizaciones, el método comprende además insertar un polinucleótido donante en el ácido nucleico diana escindido. En algunas realizaciones, la modificación comprende modificar la transcripción del ácido nucleico diana.
La divulgación proporciona un vector que comprende una secuencia polinucleotídica que codifica un ácido nucleico que comprende: un espaciador, en donde el espaciador está entre 12-30 nucleótidos, ambos incluidos, y en donde el espaciador está adaptado a hibridarse a una secuencia que está a 5' de un PAM; un primer dúplex, en donde el primer dúplex está a 3' del espaciador; una protuberancia, en donde la protuberancia comprende al menos 3 nucleótidos no emparejados en una primera cadena del primer dúplex y al menos 1 nucleótido no emparejado en una segunda cadena del primer dúplex; un enlazador, en donde el enlazador une la primera cadena y la segunda cadena del dúplex y tiene al menos 3 nucleótidos de longitud; un dominio P; y un segundo dúplex, en donde el segundo dúplex está a 3' del dominio P y está adaptado a unirse a un polipéptido dirigido a un sitio.
La divulgación proporciona un kit que comprende: una composición que comprende: un ácido nucleico que comprende: un espaciador, en donde el espaciador está entre 12-30 nucleótidos, ambos incluidos, y en donde el espaciador está adaptado a hibridarse a una secuencia que está a 5' de un PAM; un primer dúplex, en donde el primer dúplex está a 3' del espaciador; una protuberancia, en donde la protuberancia comprende al menos 3 nucleótidos no emparejados en una primera cadena del primer dúplex y al menos 1 nucleótido no emparejado en una segunda cadena del primer dúplex; un enlazador, en donde el enlazador une la primera cadena y la segunda cadena del dúplex y tiene al menos 3 nucleótidos de longitud; un dominio P; y un segundo dúplex, en donde el segundo dúplex está a 3' del dominio P y está adaptado a unirse a un polipéptido dirigido a un sitio; y un tampón. En algunas realizaciones, el kit comprende además un polipéptido dirigido a un sitio. En algunas realizaciones, el kit comprende además un polinucleótido donante. En algunas realizaciones, El kit comprende además instrucciones de uso.
La divulgación proporciona un método de creación de un ácido nucleico dirigido a ácido nucleico diseñado sintéticamente que comprende: diseñar una composición que comprende: un ácido nucleico que comprende: un espaciador, en donde el espaciador está entre 12-30 nucleótidos, ambos incluidos, y en donde el espaciador está adaptado a hibridarse a una secuencia que está a 5' de un PAM; un primer dúplex, en donde el primer dúplex está a 3' del espaciador; una protuberancia, en donde la protuberancia comprende al menos 3 nucleótidos no emparejados en una primera cadena del primer dúplex y al menos 1 nucleótido no emparejado en una segunda cadena del primer dúplex; un enlazador, en donde el enlazador une la primera cadena y la segunda cadena del dúplex y tiene al menos
3 nucleótidos de longitud; un dominio P; y un segundo dúplex, en donde el segundo dúplex está a 3' del dominio P y está adaptado a unirse a un polipéptido dirigido a un sitio.
La divulgación proporciona una composición farmacéutica que comprende un ácido nucleico dirigido a ácido nucleico diseñado seleccionado del grupo que consiste en: un ácido nucleico dirigido a ácido nucleico diseñado que comprende: una mutación en un dominio P de dicho ácido nucleico dirigido a ácido nucleico; un ácido nucleico dirigido a ácido nucleico diseñado que comprende: una mutación en una región protuberante de un ácido nucleico dirigido a ácido nucleico.
La divulgación proporciona una composición farmacéutica que comprende una composición seleccionada del grupo que consiste en: una composición que comprende: un ácido nucleico dirigido a ácido nucleico diseñado que comprende una extensión de hibridación de 3' y un polinucleótido donante, en donde dicho polinucleótido donante se hibrida con dicha extensión de hibridación de 3'; una composición que comprende: una proteína efectora y un ácido nucleico, en donde dicho ácido nucleico comprende: al menos un 50 % de identidad de secuencia con un ARNcr sobre 6 nucleótidos contiguos, al menos un 50 % de identidad de secuencia con un ARNcrtra sobre 6 nucleótidos contiguos y una secuencia no nativa, en donde dicho ácido nucleico está adaptado a unirse a dicha proteína efectora; una composición que comprende: un agente de dirección genético multiplexado, en donde dicho agente de dirección genético multiplexado comprende uno o más módulos de ácido nucleico, en donde dicho módulo de ácido nucleico comprende una secuencia no nativa, y en donde dicho módulo de ácido nucleico está configurado para unirse a un polipéptido que comprende al menos un 10 % de identidad de secuencia de aminoácidos con un dominio nucleasa de Cas9 y en donde dicho módulo de ácido nucleico está configurado para hibridarse a un ácido nucleico diana; una composición que comprende: un polipéptido dirigido a un sitio modificado, en donde dicho polipéptido se modifica de modo que se adapta para dirigirse a un segundo motivo adyacente al protoespaciador en comparación con un polipéptido dirigido a un sitio de tipo silvestre; una composición que comprende: un polipéptido dirigido a un sitio modificado, en donde dicho polipéptido se modifica de modo que se adapta para dirigirse a un segundo ácido nucleico dirigido a ácido nucleico en comparación con un polipéptido dirigido a un sitio de tipo silvestre; una composición que comprende: un polipéptido dirigido a un sitio modificado que comprende una modificación en una hélice puente en comparación con la SEQ ID: 8; una composición que comprende: un polipéptido dirigido a un sitio modificado que comprende una modificación en un parche muy básico en comparación con la SEQ ID: 8; una composición que comprende: un polipéptido dirigido a un sitio modificado que comprende una modificación en un dominio de tipo polimerasa en comparación con la SEQ ID: 8; una composición que comprende: un polipéptido dirigido a un sitio modificado que comprende una modificación en una hélice puente, un parche muy básico, un dominio nucleasa y un dominio polimerasa en comparación con la SEQ ID: 8, o cualquier combinación de los mismos; una composición que comprende: un polipéptido dirigido a un sitio modificado que comprende un dominio nucleasa modificado en comparación con la s Eq ID: 8; una composición que comprende: un primer complejo que comprende: un primer polipéptido dirigido a un sitio y un primer ácido nucleico dirigido a ácido nucleico, un segundo complejo que comprende: un segundo polipéptido dirigido a un sitio y un segundo ácido nucleico dirigido a ácido nucleico, en donde, dicho primer y dicho segundo ácido nucleico dirigido a ácido nucleico son diferentes; una composición que comprende: una pluralidad de moléculas de ácido nucleico, en donde cada molécula de ácido nucleico comprende un sitio de unión de proteína de unión a ácido nucleico, en donde al menos una de dicha pluralidad de moléculas de ácido nucleico codifica un ácido nucleico dirigido a ácido nucleico, y una de dicha pluralidad de moléculas de ácido nucleico codifica un polipéptido dirigido a un sitio y un polipéptido de fusión, en donde dicho polipéptido de fusión comprende una pluralidad de dichas proteínas de unión a ácido nucleico, en donde dicha pluralidad de proteínas de unión a ácido nucleico está adaptada a unirse a su sitio de unión a proteínas de unión a ácido nucleico afín; y una composición que comprende: un ácido nucleico que comprende: un espaciador, en donde dicho espaciador está entre 12-30 nucleótidos, ambos incluidos, y en donde dicho espaciador está adaptado a hibridarse a una secuencia que está a 5' de un PAM, un primer dúplex, en donde dicho primer dúplex está a 3' de dicho espaciador, una protuberancia, en donde dicha protuberancia comprende al menos 3 nucleótidos no emparejados en dicha primera cadena del primer dúplex y al menos 1 nucleótido no emparejado en una segunda cadena de dicho primer dúplex, un enlazador, en donde dicho enlazador une dicha primera cadena y dicha segunda cadena de dicho dúplex y tiene al menos 3 nucleótidos de longitud, un dominio P y un segundo dúplex, en donde dicho segundo dúplex está a 3' de dicho dominio P y está adaptado a unirse a un polipéptido dirigido a un sitio; o cualquier combinación de los mismos.
La divulgación proporciona una composición farmacéutica que comprende un polipéptido dirigido a un sitio modificado que comprende: un primer dominio nucleasa, un segundo dominio nucleasa y un dominio nucleasa insertado.
La divulgación proporciona una composición farmacéutica que comprende un polinucleótido donante que comprende: un elemento genético de interés y un elemento indicador, en donde dicho elemento indicador comprende una secuencia polinucleotídica que codifica un polipéptido dirigido a un sitio, y uno o más ácidos nucleicos, en donde dichos uno o más ácidos nucleicos comprende una secuencia que comprende al menos un 50 % de identidad de secuencia con un ARNcr sobre 6 nucleótidos contiguos y una secuencia que comprende al menos un 50 % de identidad de secuencia con un ARNcrtra sobre 6 nucleótidos contiguos.
La divulgación proporciona una composición farmacéutica que comprende un vector seleccionado del grupo que consiste en: un vector que comprende una secuencia polinucleotídica que codifica un ácido nucleico dirigido a ácido nucleico diseñado que comprende: una mutación en un dominio P de dicho ácido nucleico dirigido a ácido nucleico;
un vector que comprende una secuencia polinucleotídica que codifica un ácido nucleico dirigido a ácido nucleico diseñado que comprende: una mutación en una región protuberante de un ácido nucleico dirigido a ácido nucleico; y modificar el ácido nucleico diana; un vector que comprende una secuencia polinucleotídica que codifica un ácido nucleico dirigido a ácido nucleico modificado, en donde el ácido nucleico dirigido a ácido nucleico modificado comprende una secuencia no nativa; un vector que comprende: una secuencia polinucleotídica que codifica: un ácido nucleico dirigido a ácido nucleico modificado, en donde el ácido nucleico dirigido a ácido nucleico modificado comprende una secuencia configurada para unirse a una proteína efectora, y un polipéptido dirigido a un sitio; un vector que comprende: una secuencia polinucleotídica que codifica: un ácido nucleico dirigido a ácido nucleico modificado, en donde el ácido nucleico dirigido a ácido nucleico modificado comprende una secuencia no nativa, un polipéptido dirigido a un sitio y una proteína efectora; un vector que comprende una secuencia polinucleotídica que codifica un agente de dirección genético multiplexado, en donde el agente de dirección genético multiplexado comprende uno o más módulos de ácido nucleico, en donde el módulo de ácido nucleico comprende una secuencia no nativa, y en donde el módulo de ácido nucleico está configurado para unirse a un polipéptido que comprende al menos un 10 % de identidad de secuencia de aminoácidos con un dominio nucleasa de Cas9 y en donde el módulo de ácido nucleico está configurado para hibridarse a un ácido nucleico diana; un vector que comprende una secuencia polinucleotídica que codifica un polipéptido dirigido a un sitio modificado que comprende una modificación en una hélice puente, un parche muy básico, un dominio nucleasa y un dominio polimerasa en comparación con la SEQ ID: 8, o cualquier combinación de los mismos; un vector que comprende una secuencia polinucleotídica que codifica: dos o más ácidos nucleicos dirigidos a ácido nucleico que difieren en al menos un nucleótido; y un polipéptido dirigido a un sitio; un vector que comprende: una secuencia polinucleotídica que codifica una composición que comprende: una pluralidad de moléculas de ácido nucleico, en donde cada molécula de ácido nucleico comprende un sitio de unión de proteína de unión a ácido nucleico, en donde al menos una de la pluralidad de moléculas de ácido nucleico codifica un ácido nucleico dirigido a ácido nucleico, y una de la pluralidad de moléculas de ácido nucleico codifica un polipéptido dirigido a un sitio; y un polipéptido de fusión, en donde el polipéptido de fusión comprende una pluralidad de proteínas de unión a ácido nucleico, en donde la pluralidad de proteínas de unión a ácido nucleico están adaptadas a unirse a sus sitios de unión de proteínas de unión a ácido nucleico afines que administran la composición a la ubicación subcelular de forma estequiométrica; un vector de expresión que comprende una secuencia polinucleotídica que codifica un elemento genético de interés; y un elemento indicador, en donde el elemento indicador comprende una secuencia polinucleotídica que codifica un polipéptido dirigido a un sitio, y uno o más ácidos nucleicos, en donde el uno o más ácidos nucleicos comprende una secuencia que comprende al menos un 50 % de identidad de secuencia con un ARNcr sobre 6 nucleótidos contiguos y una secuencia que comprende al menos un 50 % de identidad de secuencia con un ARNcrtra sobre 6 nucleótidos contiguos; y un vector que comprende una secuencia polinucleotídica que codifica un ácido nucleico que comprende: un espaciador, en donde el espaciador está entre 12-30 nucleótidos, ambos incluidos, y en donde el espaciador está adaptado a hibridarse a una secuencia que está a 5' de un PAM; un primer dúplex, en donde el primer dúplex está a 3' del espaciador; una protuberancia, en donde la protuberancia comprende al menos 3 nucleótidos no emparejados en una primera cadena del primer dúplex y al menos 1 nucleótido no emparejado en una segunda cadena del primer dúplex; un enlazador, en donde el enlazador une la primera cadena y la segunda cadena del dúplex y tiene al menos 3 nucleótidos de longitud; un dominio P; y un segundo dúplex, en donde el segundo dúplex está a 3' del dominio P y está adaptado a unirse a un polipéptido dirigido a un sitio; o cualquier combinación de los mismos.
La divulgación proporciona un método de tratamiento de una enfermedad que comprende administrar a un sujeto: un ácido nucleico dirigido a ácido nucleico diseñado que comprende: una mutación en un dominio P de dicho ácido nucleico dirigido a ácido nucleico; un ácido nucleico dirigido a ácido nucleico diseñado que comprende: una mutación en una región protuberante de un ácido nucleico dirigido a ácido nucleico; una composición que comprende: un ácido nucleico dirigido a ácido nucleico diseñado que comprende una extensión de hibridación de 3' y un polinucleótido donante, en donde dicho polinucleótido donante se hibrida con dicha extensión de hibridación de 3'; una composición que comprende: una proteína efectora y un ácido nucleico, en donde dicho ácido nucleico comprende: al menos un 50 % de identidad de secuencia con un ARNcr sobre 6 nucleótidos contiguos, al menos un 50 % de identidad de secuencia con un ARNcrtra sobre 6 nucleótidos contiguos y una secuencia no nativa, en donde dicho ácido nucleico está adaptado a unirse a dicha proteína efectora; una composición que comprende: un agente de dirección genético multiplexado, en donde dicho agente de dirección genético multiplexado comprende uno o más módulos de ácido nucleico, en donde dicho módulo de ácido nucleico comprende una secuencia no nativa, y en donde dicho módulo de ácido nucleico está configurado para unirse a un polipéptido que comprende al menos un 10% de identidad de secuencia de aminoácidos con un dominio nucleasa de Cas9 y en donde dicho módulo de ácido nucleico está configurado para hibridarse a un ácido nucleico diana; una composición que comprende: un polipéptido dirigido a un sitio modificado, en donde dicho polipéptido se modifica de modo que se adapta para dirigirse a un segundo motivo adyacente al protoespaciador en comparación con un polipéptido dirigido a un sitio de tipo silvestre; una composición que comprende: un polipéptido dirigido a un sitio modificado, en donde dicho polipéptido se modifica de modo que se adapta para dirigirse a un segundo ácido nucleico dirigido a ácido nucleico en comparación con un polipéptido dirigido a un sitio de tipo silvestre; una composición que comprende: un polipéptido dirigido a un sitio modificado que comprende una modificación en una hélice puente en comparación con la SEQ ID: 8; una composición que comprende: un polipéptido dirigido a un sitio modificado que comprende una modificación en un parche muy básico en comparación con la SEQ ID: 8; una composición que comprende: un polipéptido dirigido a un sitio modificado que comprende una modificación en un dominio de tipo polimerasa en comparación con la SEQ ID: 8; una composición que comprende: un polipéptido dirigido a un sitio modificado que comprende una modificación en una hélice puente, un parche muy
básico, un dominio nucleasa y un dominio polimerasa en comparación con la SEQ ID: 8, o cualquier combinación de los mismos; una composición que comprende: un polipéptido dirigido a un sitio modificado que comprende un dominio nucleasa modificado en comparación con la SEQ ID: 8; una composición que comprende: un primer complejo que comprende: un primer polipéptido dirigido a un sitio y un primer ácido nucleico dirigido a ácido nucleico, un segundo complejo que comprende: un segundo polipéptido dirigido a un sitio y un segundo ácido nucleico dirigido a ácido nucleico, en donde, dicho primer y dicho segundo ácido nucleico dirigido a ácido nucleico son diferentes; una composición que comprende: una pluralidad de moléculas de ácido nucleico, en donde cada molécula de ácido nucleico comprende un sitio de unión de proteína de unión a ácido nucleico, en donde al menos una de dicha pluralidad de moléculas de ácido nucleico codifica un ácido nucleico dirigido a ácido nucleico, y una de dicha pluralidad de moléculas de ácido nucleico codifica un polipéptido dirigido a un sitio y un polipéptido de fusión, en donde dicho polipéptido de fusión comprende una pluralidad de dichas proteínas de unión a ácido nucleico, en donde dicha pluralidad de proteínas de unión a ácido nucleico está adaptada a unirse a su sitio de unión a proteínas de unión a ácido nucleico afín; una composición que comprende: un ácido nucleico que comprende: un espaciador, en donde dicho espaciador está entre 12-30 nucleótidos, ambos incluidos, y en donde dicho espaciador está adaptado a hibridarse a una secuencia que está a 5' de un PAM, un primer dúplex, en donde dicho primer dúplex está a 3' de dicho espaciador, una protuberancia, en donde dicha protuberancia comprende al menos 3 nucleótidos no emparejados en dicha primera cadena del primer dúplex y al menos 1 nucleótido no emparejado en una segunda cadena de dicho primer dúplex, un enlazador, en donde dicho enlazador une dicha primera cadena y dicha segunda cadena de dicho dúplex y tiene al menos 3 nucleótidos de longitud, un dominio P y un segundo dúplex, en donde dicho segundo dúplex está a 3' de dicho dominio P y está adaptado a unirse a un polipéptido dirigido a un sitio; un polipéptido dirigido a un sitio modificado que comprende: un primer dominio nucleasa, un segundo dominio nucleasa y un dominio nucleasa insertado; un polinucleótido donante que comprende: un elemento genético de interés y un elemento indicador, en donde dicho elemento indicador comprende una secuencia polinucleotídica que codifica un polipéptido dirigido a un sitio, y uno o más ácidos nucleicos, en donde dichos uno o más ácidos nucleicos comprende una secuencia que comprende al menos un 50 % de identidad de secuencia con un ARNcr sobre 6 nucleótidos contiguos y una secuencia que comprende al menos un 50 % de identidad de secuencia con un ARNcrtra sobre 6 nucleótidos contiguos; un vector que comprende una secuencia polinucleotídica que codifica un ácido nucleico dirigido a ácido nucleico diseñado que comprende: una mutación en un dominio P de dicho ácido nucleico dirigido a ácido nucleico; un vector que comprende una secuencia polinucleotídica que codifica un ácido nucleico dirigido a ácido nucleico diseñado que comprende: una mutación en una región protuberante de un ácido nucleico dirigido a ácido nucleico; y modificar el ácido nucleico diana; un vector que comprende una secuencia polinucleotídica que codifica un ácido nucleico dirigido a ácido nucleico modificado, en donde el ácido nucleico dirigido a ácido nucleico modificado comprende una secuencia no nativa; un vector que comprende: una secuencia polinucleotídica que codifica: un ácido nucleico dirigido a ácido nucleico modificado, en donde el ácido nucleico dirigido a ácido nucleico modificado comprende una secuencia configurada para unirse a una proteína efectora, y un polipéptido dirigido a un sitio; un vector que comprende: una secuencia polinucleotídica que codifica: un ácido nucleico dirigido a ácido nucleico modificado, en donde el ácido nucleico dirigido a ácido nucleico modificado comprende una secuencia no nativa, un polipéptido dirigido a un sitio y una proteína efectora; un vector que comprende una secuencia polinucleotídica que codifica un agente de dirección genético multiplexado, en donde el agente de dirección genético multiplexado comprende uno o más módulos de ácido nucleico, en donde el módulo de ácido nucleico comprende una secuencia no nativa, y en donde el módulo de ácido nucleico está configurado para unirse a un polipéptido que comprende al menos un 10 % de identidad de secuencia de aminoácidos con un dominio nucleasa de Cas9 y en donde el módulo de ácido nucleico está configurado para hibridarse a un ácido nucleico diana; un vector que comprende una secuencia polinucleotídica que codifica un polipéptido dirigido a un sitio modificado que comprende una modificación en una hélice puente, un parche muy básico, un dominio nucleasa y un dominio polimerasa en comparación con la SEQ ID: 8, o cualquier combinación de los mismos; un vector que comprende una secuencia polinucleotídica que codifica: dos o más ácidos nucleicos dirigidos a ácido nucleico que difieren en al menos un nucleótido; y un polipéptido dirigido a un sitio; un vector que comprende: una secuencia polinucleotídica que codifica una composición que comprende: una pluralidad de moléculas de ácido nucleico, en donde cada molécula de ácido nucleico comprende un sitio de unión de proteína de unión a ácido nucleico, en donde al menos una de la pluralidad de moléculas de ácido nucleico codifica un ácido nucleico dirigido a ácido nucleico, y una de la pluralidad de moléculas de ácido nucleico codifica un polipéptido dirigido a un sitio; y un polipéptido de fusión, en donde el polipéptido de fusión comprende una pluralidad de proteínas de unión a ácido nucleico, en donde la pluralidad de proteínas de unión a ácido nucleico están adaptadas a unirse a sus sitios de unión de proteínas de unión a ácido nucleico afines que administran la composición a la ubicación subcelular de forma estequiométrica; un vector de expresión que comprende una secuencia polinucleotídica que codifica un elemento genético de interés; y un elemento indicador, en donde el elemento indicador comprende una secuencia polinucleotídica que codifica un polipéptido dirigido a un sitio, y uno o más ácidos nucleicos, en donde el uno o más ácidos nucleicos comprende una secuencia que comprende al menos un 50 % de identidad de secuencia con un ARNcr sobre 6 nucleótidos contiguos y una secuencia que comprende al menos un 50 % de identidad de secuencia con un ARNcrtra sobre 6 nucleótidos contiguos; y un vector que comprende una secuencia polinucleotídica que codifica un ácido nucleico que comprende: un espaciador, en donde el espaciador está entre 12-30 nucleótidos, ambos incluidos, y en donde el espaciador está adaptado a hibridarse a una secuencia que está a 5' de un PAM; un primer dúplex, en donde el primer dúplex está a 3' del espaciador; una protuberancia, en donde la protuberancia comprende al menos 3 nucleótidos no emparejados en una primera cadena del primer dúplex y al menos 1 nucleótido no emparejado en una segunda cadena del primer dúplex; un enlazador, en donde el enlazador une la primera cadena y la segunda cadena del dúplex y tiene al menos 3 nucleótidos de longitud; un dominio P; y un segundo dúplex, en
donde el segundo dúplex está a 3' del dominio P y está adaptado a unirse a un polipéptido dirigido a un sitio; o cualquier combinación de los mismos. En algunas realizaciones, la administración comprende administrar mediante administración vírica. En algunas realizaciones, la administración comprende administrar mediante electroporación. En algunas realizaciones, la administración comprende administrar mediante administración en nanopartículas. En algunas realizaciones, la administración comprende administrar mediante administración en liposomas. En algunas realizaciones, la administración comprende administrar mediante un método seleccionado del grupo que consiste en: administración intravenosa, subcutánea, intramuscular, oral, rectal, por aerosol, parenteral, oftálmica, pulmonar, transdérmica, vaginal, ótica, nasal y tópica, o cualquier combinación de las mismas. En algunas realizaciones, los métodos de divulgación se realizan en una célula seleccionada del grupo que consiste en: célula vegetal, célula microbiana y célula fúngica, o cualquier combinación de las mismas.
Breve descripción de los dibujos
Las figuras que no pertenecen a la invención son solo para fines ilustrativos. Las nuevas características de la invención se exponen con particularidad en las reivindicaciones adjuntas. Se obtendrá una mejor comprensión de las características y ventajas de la presente invención haciendo referencia a la siguiente descripción detallada que expone realizaciones ilustrativas, en las que se utilizan los principios de la invención y los dibujos adjuntos de los cuales:
La Figura 1A representa un ácido nucleico dirigido a ácido nucleico guía sencillo de la divulgación.
La Figura 1B representa un ácido nucleico dirigido a ácido nucleico guía sencillo de la divulgación.
La Figura 2 representa un ácido nucleico dirigido a ácido nucleico guía doble de la divulgación.
La Figura 3 representa un método de enriquecimiento de secuencias de la divulgación que utiliza la escisión del ácido nucleico diana.
La Figura 4 representa un método de enriquecimiento de secuenciad de la divulgación que utiliza el enriquecimiento del ácido nucleico diana.
La Figura 5 representa un método de la divulgación para determinar sitios de unión fuera de la diana de un polipéptido dirigido a un sitio utilizando la purificación del polipéptido dirigido a un sitio.
La Figura 6 representa un método de la divulgación para determinar sitios de unión fuera de la diana de un polipéptido dirigido a un sitio utilizando la purificación del ácido nucleico dirigido a ácido nucleico.
La Figura 7 ilustra un método de secuenciación basado en una matriz que usa un polipéptido dirigido a un sitio de la divulgación.
La Figura 8 ilustra un método de secuenciación basado en una matriz que usa un polipéptido dirigido a un sitio de la divulgación, en donde se secuencian productos escindidos.
La Figura 9 ilustra un método basado en la secuenciación de próxima generación que usa un polipéptido dirigido a un sitio de la divulgación.
La Figura 10 representa un ácido nucleico dirigido a ácido nucleico guía sencillo marcado.
La Figura 11 representa un ácido nucleico dirigido a ácido nucleico guía doble marcado.
La Figura 12 ilustra un método de uso de ácido nucleico dirigido a ácido nucleico marcado con un sistema dividido (por ejemplo, sistema fluorescente dividido).
La Figura 13 representa datos acerca del efecto de un ácido nucleico dirigido a ácido nucleico marcado en 5' sobre la escisión de ácido nucleico diana.
La Figura 14 ilustra un ácido nucleico dirigido a ácido nucleico marcado en 5' que comprende una secuencia enlazadora de marcador entre el ácido nucleico dirigido a ácido nucleico y el marcador.
La Figura 15 representa un método de escisión de ácido nucleico diana multiplexado.
La Figura 16 representa un método de administración estequiométrica de ácidos nucleicos de ARN.
La Figura 17 representa un método de administración estequiométrica de ácidos nucleicos.
La Figura 18 representa una inserción perfecta de un elemento indicador en un ácido nucleico diana usando un polipéptido dirigido a un sitio de la divulgación.
La Figura 19 representa la eliminación de un elemento indicador de un ácido nucleico diana.
La Figura 20 representa partes complementarias de las secuencias de ácido nucleico de un ácido nucleico pre-CRISPR y secuencias de ácido nucleico crtra de Streptococcus pyogenes SF370.
La Figura 21 representa una estructura secundaria de un ácido nucleico dirigido a ácido nucleico guía en una sola secuencia sintético.
Las Figuras 22A y B muestran variantes de cadena principal de ácido nucleico dirigido a ácido nucleico guía sencillo. Los nucleótidos de los recuadros corresponden a nucleótidos que han sido alterados en relación con las secuencias de CRISPR marcadas como secuencia de ARNcr-crtra de longitud completa.
La Figura 23A-C muestra datos de un ensayo de escisión in vitro. Los resultados demuestran que más de una secuencia sintética de cadena principal de ácido nucleico dirigido a ácido nucleico puede soportar la escisión por un polipéptido dirigido a un sitio (por ejemplo, Cas9).
La Figura 24 muestra secuencias sintéticas de ácido nucleico dirigido a ácido nucleico guía sencillo que contienen variantes en la región/el dúplex complementario. Los nucleótidos de los recuadros corresponden a nucleótidos que han sido alterados en relación con las secuencias de CRISPR marcadas como secuencia de ARNcr-crtra de longitud completa.
La Figura 25 muestra variantes ilustrativas de la estructura de ácido nucleico dirigido a ácido nucleico guía sencillo dentro de la región 3' con respecto a la región/al dúplex complementario. Los nucleótidos de los recuadros corresponden a nucleótidos que han sido alterados en relación con el emparejamiento de secuencias de ácido
nucleico crtra y ácido nucleico de CRISPR de S. pyogenes SF370 natural.
La Figura 26A-B muestra variantes ilustrativas de la estructura de ácido nucleico dirigido a ácido nucleico guía sencillo dentro de la región 3' con respecto a la región/al dúplex complementario. Los nucleótidos de los recuadros corresponden a nucleótidos que han sido alterados en relación con el emparejamiento de secuencias de ácido nucleico crtra y ácido nucleico de CRISPR de S. pyogenes SF370 natural.
La Figura 27A-B muestra variantes de estructuras de ácido nucleico dirigido a ácido nucleico que comprenden secuencias de horquilla adicionales derivadas de la repetición CRISPR en Pseudomonas aeruginosa (PA 14). Las secuencias de los recuadros pueden unirse a la ribonucleasa Csy4 de PAH.
La Figura 28 muestra datos de un ensayo de escisión in vitro que demuestra que múltiples secuencias de cadena principal sintéticas de ácido nucleico dirigido a ácido nucleico soportan la escisión de Cas9. Las imágenes de gel superior e inferior representan dos repeticiones independientes del ensayo.
La Figura 29 muestra datos de un ensayo de escisión in vitro que demuestra que múltiples secuencias de cadena principal sintéticas de ácido nucleico dirigido a ácido nucleico soportan la escisión de Cas9. Las imágenes de gel superior e inferior representan dos repeticiones independientes del ensayo.
La Figura 30 representa métodos de la divulgación para llevar un polinucleótido donante a un sitio de modificación en un ácido nucleico diana.
La Figura 31 muestra un sistema para almacenar y compartir información electrónica.
La Figura 32 representa dos nickasas que generan un corte terminal romo en un ácido nucleico diana. No se muestran los polipéptidos modificadores dirigidos a un sitio complejados con ácidos nucleicos dirigidos a ácido nucleico.
La Figura 33 muestra el corte escalonado de un ácido nucleico diana usando dos nickasas y generando extremos pegajosos. No se muestran los polipéptidos modificadores dirigidos a un sitio complejados con ácidos nucleicos dirigidos a ácido nucleico.
La Figura 34 representa el corte escalonado de un ácido nucleico diana usando dos nickasas y generando extremos pegajosos de tamaño medio. No se muestran los polipéptidos modificadores dirigidos a un sitio complejados con ácidos nucleicos dirigidos a ácido nucleico.
La Figura 35 ilustra una alineación de secuencias de ortólogos de Cas9. Los aminoácidos con una "X" debajo de ellos pueden considerarse similares. Los aminoácidos con una "Y" debajo de ellos pueden considerarse altamente conservados o idénticos en todas las secuencias. Los restos de aminoácidos sin una "X" o una "Y" pueden no conservarse.
La Figura 36 muestra la funcionalidad de las variantes de ácido nucleico dirigido a ácido nucleico en la escisión de ácido nucleico diana. Las variantes probadas en la Figura 36 corresponden a las variantes representadas en la Figura 22, Figura 24, y Figura 25.
La Figura 37A-D muestra ensayos de escisión in vitro usando variantes de ácidos nucleicos dirigidos a ácido nucleico.
La Figura 38 representa secuencias de aminoácidos de Csy4 de P. aeruginosa de tipo silvestre.
La Figura 39 representa secuencias de aminoácidos de una endorribonucleasa enzimáticamente inactiva (por ejemplo, Csy4).
La Figura 40 representa secuencias de aminoácidos de Csy4 de P. aeruginosa.
La Figura 41A-J representa secuencias de aminoácidos de Cas6.
La Figura 42A-C representa secuencias de aminoácidos de Cas6.
Descripción detallada de la invención
La invención se define por las reivindicaciones adjuntas.
Definiciones
Como se usa en el presente documento, "marcador de afinidad" puede referirse a cualquier marcador de afinidad peptídico o un marcador de afinidad de ácido nucleico. el marcador de afinidad se refiere, en general, a una secuencia de proteína o de ácido nucleico que puede unirse a una molécula (por ejemplo, unirse por una molécula pequeña, proteína, enlace covalente). Un marcador de afinidad puede ser una secuencia no nativa. Un marcador de afinidad peptídico puede comprender un péptido. Un marcador de afinidad peptídico puede ser aquel que pueda formar parte de un sistema dividido (por ejemplo, dos fragmentos de péptido inactivos pueden combinarse en trans para formar un marcador de afinidad activo). Un marcador de afinidad de ácido nucleico puede comprender un ácido nucleico. Un marcador de afinidad de ácido nucleico puede ser una secuencia que puede unirse selectivamente a una secuencia de ácido nucleico conocida (por ejemplo, mediante hibridación). Un marcador de afinidad de ácido nucleico puede ser una secuencia que puede unirse selectivamente a una proteína. Un marcador de afinidad puede fusionarse con una proteína nativa. Un marcador de afinidad puede fusionarse con una secuencia de nucleótidos. Algunas veces, un, dos o una pluralidad de marcadores de afinidad pueden fusionarse con una proteína nativa o secuencia de nucleótidos. Se puede introducir un marcador de afinidad en un ácido nucleico dirigido a ácido nucleico usando métodos de transcripción in vitro o in vivo. Los marcadores de afinidad de ácido nucleico pueden incluir, por ejemplo, un marcador químico, una secuencia de unión de proteínas de unión a ARN, una secuencia de unión de proteínas de unión a ADN, una secuencia hibridable a un polinucleótido marcado por afinidad, un aptámero de ARN sintético o un aptámero de ADN sintético. Los ejemplos de marcadores de afinidad de ácido nucleico químicos pueden incluir, pero sin limitación, ribo-nucleotrifosfatos que contienen biotina, colorantes fluorescentes y digoxeginina. Los ejemplos de marcadores de
afinidad de ácido nucleico que se unen a proteínas pueden incluir, pero sin limitación, la secuencia de unión a MS2, la secuencia de unión a U1A, secuencias de proteínas de unión de tallo-lazo, la secuencia de boxB, la secuencia de eIF4A, o cualquier secuencia reconocida por una proteína de unión a ARN. Los ejemplos de oligonucleótidos marcados por afinidad de ácido nucleico pueden incluir, pero sin limitación, oligonucleótidos biotinilados, oligonucleótidos de 2,4-dinitrofenilo, oligonucleótidos de fluoresceína y oligonucleótidos conjugados con amina primaria.
Un marcador de afinidad de ácido nucleico puede ser un aptámero de ARN. Los aptámeros pueden incluir, aptámeros que se unen a la teofilina, estreptavidina, dextrano B512, adenosina, guanosina, guanina/xantina, 7-metil-GTP, aptámeros de aminoácidos tales como los aptámeros que se unen a la arginina, citrulina, valina, triptófano, cianocobalamina, N-metilmesoporfirina IX, flavina, NAD, y aptámeros de antibióticos tales como los aptámeros que se unen a la tobramicina, neomicina, lividomicina, kanamicina, estreptomicina, viomicina y cloranfenicol.
Un marcador de afinidad de ácido nucleico puede comprender una secuencia de ARN que puede estar unida por un polipéptido dirigido a un sitio. El polipéptido dirigido a un sitio puede ser condicionalmente inactivo enzimáticamente. La secuencia de ARN puede comprender una secuencia que puede estar unida por un miembro de los sistemas de CRISPR de tipo I, tipo II y/o tipo III. La secuencia de ARN puede estar unida por una proteína miembro de la familia de RAMP. La secuencia de ARN puede estar unida por una proteína miembro de la familia de Cas6 (por ejemplo, Csy4, Cas6). La secuencia de ARN puede estar unida por una proteína miembro de la familia de Cas5 (por ejemplo, Cas5). Por ejemplo, Csy4 puede unirse a una secuencia de horquilla de ARN específica con alta afinidad (Kd ~50 pM) y puede escindir el en un sitio 3' con respecto a la horquilla. La proteína miembro de la familia de Cas5 o Cas6 puede unirse a una secuencia de ARN que comprenda al menos aproximadamente o como máximo aproximadamente un 30 %, 40 %, 50 %, 60 %, 70 %, 75 %, 80 %, 85 %, 90 %, 95% o 100% de identidad de secuencia y/o similitud de secuencia con las siguientes secuencias de nucleótidos:
GUUCACUGCCGUAUAGGCAGCUAAGAAA-3’;
5’- GUUCACUGCCGUAUAGGCAGCUAAGAAA-3’
5 - GUUGCAAGGGAUUGAGCCCCGUAAGGGGAUUGCGAC-3';
5 GUUGC AA ACCUCGUU AGCCUCGU AGAGGAUUGA A AC-3’:
5’- GGAUCGAUACCCACCCCGAAGAAAAGGGGACGAGAAC-3’;
5"- GUCGUCAG ACCCAAAACCCCGACAGGGGACGGAA AC-3
¥ - GAUAUAAACC UAAUUACCUCGAGAGGGG ACGG AAAC-3 ’;
5 ’ - CCCC AG UC ACCUCGGGAjGGGG ACGG A A AC-3f;
5’- GUUCCAA UUA AUCUU A A ACCCU AUUAGGGAU UG A A AC-3 ’
5'-GUUGCAAGGGAUUGAGCCCCGlJAAGGGGAUUGCGAC-3\
5’- GUUGC A A ACCUCGUU AGCCUCGU AGAGGAUUGA A AC-3 \
5*- GGAUOGAU ACCC ACCCCGA AG A A A AGGGGACOAG A AC-3 ’;
5 *- GUCGUC AGACCC AAAACCCCGAG ACGGG ACGG AA AC-3
S’- GAUAUAAACCUAAUUACCUCGAGAGGGGACGGAAAC-3\
5’- CCCCAGUCACCUCGGGAGGGGACGGAAAC-3’;
S*- GUUCCAAUUAAUCUUAAACCCUAUUAGGGAUUGAAAC-3 \
5-GUCGCCCCCCACGCGGGGGCGUGGAUUGAAAC-3’;
5’-CCAGCCGCCUUCGGGCGGCUGUGUGUUGAAAC-3
5' -GUCGC ACUCUAC AUGAGUGCGUGGAUUG A A AU-3
SCUGUCGCACCUUAUAUAJGGUGCGUGGAUUGAAAU-3y
5'-GUCGCGCCCCGCAUGGGGCGCGUGGAUUGA AA-j \
Un marcador de afinidad de ácido nucleico puede comprender una secuencia de ADN que puede unirse por un polipéptido dirigido a un sitio. El polipéptido dirigido a un sitio puede ser condicionalmente inactivo enzimáticamente. La secuencia de ADN puede comprender una secuencia que puede estar unida por un miembro del sistema de CRISPR de tipo I, tipo II y/o tipo III. La secuencia de ADN puede estar unida por una proteína Argonauta. La secuencia de ADN puede estar unida por una proteína que contenga un dominio de dedo de cinc, un dominio TALE o cualquier otro dominio de unión a ADN.
Un marcador de afinidad de ácido nucleico puede comprender una secuencia de ribozima. Las ribozimas adecuadas pueden incluir ARNr de 23S de peptidil transferasa, RnasaP, intrones del grupo I, intrones del grupo II, ribozima de ramificación de GIR1, Leadzima, ribozimas de horquilla, ribozimas de cabeza de martillo, ribozimas de HDV, ribozimas de CPEB3, ribozimas de VS, ribozima de glmS, ribozima de CoTC y ribozimas sintéticas.
Los marcadores de afinidad peptídicos pueden comprender marcadores que pueden usarse para el seguimiento o la purificación (por ejemplo, una proteína fluorescente, proteína fluorescente verde (GFP), YFP, RFP, CFP, mCherry, tdTomato, un marcador His, (por ejemplo, un marcador 6XHis), un marcador de hemaglutinina (HA), un marcador FLAG, un marcador Myc, un marcador GST, un marcador MBP y un marcador de proteína de unión a quitina, un marcador de calmodulina, un marcador V5, un marcador de unión a estreptavidina y similares).
Los marcadores de afinidad de ácido nucleico y péptido pueden comprender marcadores de molécula pequeña tales como biotina o digitoxina, marcadores fluorescentes, tales como, por ejemplo, fluoresceína, rodamina, colorantes de flúor Alexa, colorante de cianina3, colorante de cianina5.
Los marcadores de afinidad de ácido nucleico pueden ubicarse a 5' de un ácido nucleico (por ejemplo, un ácido nucleico dirigido a ácido nucleico). Los marcadores de afinidad de ácido nucleico pueden ubicarse a 3' de un ácido nucleico. Los marcadores de afinidad de ácido nucleico pueden ubicarse a 5' y 3' de un ácido nucleico. Los marcadores de afinidad de ácido nucleico pueden ubicarse dentro de un ácido nucleico. Los marcadores de afinidad de péptidos se pueden ubicar en el extremo N-terminal de una secuencia polipeptídica. Los marcadores de afinidad peptídicos pueden ubicarse en el extremo C-terminal de una secuencia polipeptídica. Los marcadores de afinidad peptídicos pueden ubicarse en el extremo N-terminal y C-terminal de una secuencia polipeptídica. Se puede fusionar una pluralidad de marcadores de afinidad con un ácido nucleico y/o una secuencia polipeptídica.
Como se usa en el presente documento, "Agente de captura" puede referirse, en general, a un agente que puede purificar un polipéptido y/o un ácido nucleico. Un agente de captura puede ser una molécula o un material biológicamente activo (por ejemplo, cualquier sustancia biológica que se encuentre en la naturaleza o sintética, e incluye, pero sin limitación, células, virus, partículas subcelulares, proteínas, incluyendo más específicamente anticuerpos, inmunoglobulinas, antígenos, lipoproteínas, glucoproteínas, péptidos, polipéptidos, complejos proteicos, complejos de (estrepto)avidina-biotina, ligandos, receptores o moléculas pequeñas, aptámeros, ácidos nucleicos, ADN, ARN, ácidos nucleicos peptídicos, oligosacáridos, polisacáridos, lipopolisacáridos, metabolitos celulares, haptenos, sustancias farmacológicamente activas, alcaloides, esteroides, vitaminas, aminoácidos y azúcares). En algunas realizaciones, el agente de captura puede comprender un marcador de afinidad. En algunas realizaciones, un agente de captura puede unirse preferentemente a un polipéptido o ácido nucleico diana de interés. Los agentes de captura pueden flotar libremente en una mezcla. Los agentes de captura pueden unirse a una partícula (por ejemplo, una perla, una microperla, una nanopartícula). Los agentes de captura pueden unirse a una superficie sólida o semisólida. En algunos casos, los agentes de captura están unidos irreversiblemente a un diana. En otros casos, los agentes de captura están unidos de forma reversible a un diana (por ejemplo, si se puede eluir un diana o mediante el uso de un compuesto químico tal como el imidizol).
Como se usa en el presente documento, "Cas5" puede referirse, en general, a un polipéptido con al menos aproximadamente un 5 %, 10 %, 20 %, 30 %, 40 %, 50 %, 60 %, 70 %, 80 %, 90 %, 100 % de identidad de secuencia y/o similitud de secuencia con un polipéptido Cas5 ilustrativo de tipo silvestre (por ejemplo, Cas5 de D. vulgaris y/o cualquier secuencia representada en la Figura 42). Cas5 puede referirse, en general, a un polipéptido con, como máximo, aproximadamente un 5 %, 10 %, 20 %, 30 %, 40 %, 50 %, 60 %, 70 %, 80 %, 90 %, 100 % de identidad de secuencia y/o similitud de secuencia con un polipéptido Cas5 ilustrativo de tipo silvestre (por ejemplo, un Cas5 de D. vulgaris). Cas5 puede referirse al tipo silvestre o a una forma modificada de la proteína Cas5 que puede comprender un cambio de aminoácido tal como una eliminación, inserción, sustitución, variante, mutación, fusión, quimera, o cualquier combinación de las mismas.
Como se usa en el presente documento, "Cas6" puede referirse, en general, a un polipéptido con al menos aproximadamente un 5 %, 10 %, 20 %, 30 %, 40 %, 50 %, 60 %, 70 %, 80 %, 90 %, 100 % de identidad de secuencia y/o similitud de secuencia con un polipéptido Cas6 ilustrativo de tipo silvestre (por ejemplo, Cas6 de T. thermophilus y/o cualquier secuencia representada en la Figura 41). Cas6 puede referirse, en general, a un polipéptido con, como máximo, aproximadamente un 5 %, 10 %, 20 %, 30 %, 40 %, 50 %, 60 %, 70 %, 80 %, 90 %, 100 % de identidad de secuencia y/o similitud de secuencia con un polipéptido Cas6 ilustrativo de tipo silvestre (por ejemplo, de T. thermophilus). Cas6 puede referirse al tipo silvestre o a una forma modificada de la proteína Cas6 que puede comprender un cambio de aminoácido tal como una eliminación, inserción, sustitución, variante, mutación, fusión, quimera, o cualquier combinación de las mismas.
Como se usa en el presente documento, "Cas9" puede referirse, en general, a un polipéptido con al menos aproximadamente un 5 %, 10 %, 20 %, 30 %, 40 %, 50 %, 60 %, 70 %, 80 %, 90 %, 100 % de identidad de secuencia y/o similitud de secuencia con un polipéptido Cas9 ilustrativo de tipo silvestre (por ejemplo, Cas9 de S. pyogenes (SEQ ID NO: 8, SEQ ID NO: 1-256, SEQ ID NO: 795-1346). Cas9 puede referirse a un polipéptido con, como máximo, aproximadamente un 5 %, 10 %, 20 %, 30 %, 40 %, 50 %, 60 %, 70 %, 80 %, 90 %, 100 % de identidad de secuencia y/o similitud de secuencia con un polipéptido Cas9 ilustrativo de tipo silvestre (por ejemplo, de S. pyogenes). Cas9 puede referirse al tipo silvestre o una forma modificada de la proteína Cas9 que puede comprender un cambio de aminoácido tal como una eliminación, inserción, sustitución, variante, mutación, fusión, quimera, o cualquier combinación de las mismas.
Como se usa en el presente documento, una "célula" puede referirse, en general, a una célula biológica. Una célula puede ser la unidad estructural, funcional y/o biológica de un organismo vivo. Una célula puede proceder de cualquier organismo que tenga una o más células. Algunos ejemplos no limitantes incluyen: una célula procariota, célula eucariota, una célula bacteriana, una célula de arquea, una célula de un organismo eucariota unicelular, una célula de protozoo, una célula de una planta (por ejemplo, células de cultivos vegetales, frutas, hortalizas, cereales, semilla de soja, maíz, maíz, trigo, semillas, tomates, arroz, yuca, caña de azúcar, calabaza, heno, patatas, algodón, cannabis, tabaco, plantas en flor, coníferas, gimnospermas, helechos, Lycopodiopsida, hornabeques, hepáticas, musgos), una célula de algas, (por ejemplo,, Botryococcus braunii, Chlamydomonas reinhardtii, Nannochloropsis gaditana, Chlorella pyrenoidosa, Sargassum patens C. Agardh, y similares), algas marinas (por ejemplo, alga parda), una célula fúngica (por ejemplo, una célula de levadura, una célula de un hongo), una célula animal, una célula de un animal invertebrado (por ejemplo, mosca de la fruta, cnidario, equinodermo, nematodo, etc.), una célula de un animal vertebrado (por ejemplo, pez, anfibio, reptil, ave, mamífero), una célula de un mamífero (por ejemplo, un cerdo, una vaca, una cabra, una oveja, un roedor, una rata, un ratón, un primate no humano, un ser humano, etc.), etcétera. A veces, una célula no procede de un organismo natural (por ejemplo, una célula puede estar hecha sintéticamente, a veces, se denomina célula artificial).
Una célula puede estar in vitro. Una célula puede estar in vivo. Una célula puede ser una célula aislada. Una célula puede ser una célula de dentro de un organismo. Una célula puede ser un organismo. Una célula puede ser una célula en un cultivo celular. Una célula puede ser una de una colección de células. Una célula puede ser una célula procariota o puede derivarse de una célula procariota. Una célula puede ser una célula bacteriana o puede derivarse de una célula bacteriana. Una célula puede ser una célula de arquea o derivada de una célula de arquea. Una célula puede ser una célula eucariota o puede derivarse de una célula eucariota. Una célula puede ser una célula vegetal o puede derivarse de una célula vegetal. Una célula puede ser una célula animal o puede derivarse de una célula animal. Una célula puede ser una célula de invertebrado o puede derivarse de una célula de invertebrado. Una célula puede ser una célula de vertebrado o puede derivarse de una célula de vertebrado. Una célula puede ser una célula de mamífero o puede derivarse de una célula de mamífero. Una célula puede ser una célula de roedor o puede derivarse de una célula de roedor. Una célula puede ser una célula humana o puede derivarse de una célula humana. Una célula puede ser una célula microbiana o puede derivarse de una célula microbiana. Una célula puede ser una célula de hongo o puede derivarse de una célula de hongo.
Una célula puede ser una célula madre o una célula progenitora. Las células pueden incluir células madre (por ejemplo, células madre adultas, células iPS) y células progenitoras (por ejemplo, células progenitoras cardíacas, células progenitoras neuronales, etc.). Las células pueden incluir células madre y células progenitoras de mamíferos, incluyendo células madre de roedores, células progenitoras de roedores, células madre humanas, células progenitoras humanas, etc. Las células clónicas pueden comprender la progenie de una célula. Una célula puede comprender un ácido nucleico diana. Una célula puede estar en un organismo vivo. Una célula puede ser una célula modificada genéticamente. Una célula puede ser una célula hospedadora.
Una célula puede ser una célula madre totipotente, sin embargo, en algunas realizaciones de la divulgación, se puede usar el término "célula", pero puede no referirse a una célula madre totipotente. Una célula puede ser una célula vegetal, pero, en algunas realizaciones de la divulgación, se puede usar el término "célula", pero puede no referirse a una célula vegetal. Una célula puede ser una célula pluripotente. Por ejemplo, una célula puede ser una célula hematopoyética pluripotente que puede diferenciarse en otras células en el linaje celular hematopoyético, pero puede no ser capaz de diferenciarse en otra célula no hematopoyética. Una célula puede convertirse en un organismo completo. Una célula puede o no ser capaz de convertirse en un organismo completo. Una célula puede ser un organismo completo.
Una célula puede ser una célula primaria. Por ejemplo, los cultivos de células primarias se pueden pasar 0 veces, 1 vez, 2 veces, 4 veces, 5 veces, 10 veces, 15 veces o más. Las células pueden ser organismos unicelulares. Las células pueden crecer en cultivo.
Una célula puede ser una célula enferma. Una célula enferma puede tener alteración del metabolismo, de la expresión génica y/o de las características morfológicas. Una célula enferma puede ser una célula cancerosa, una célula diabética y una célula apoptótica. Una célula enferma puede ser una célula de un sujeto enfermo. Las enfermedades ilustrativas pueden incluir trastornos de la sangre, cánceres, trastornos metabólicos, trastornos oculares, trastornos de
órganos, trastornos musculoesqueléticos, enfermedad cardíaca y similares.
Si las células son células primarias, pueden cosecharse de un individuo por cualquier método. Por ejemplo, los leucocitos pueden cosecharse por aféresis, leucocitaféresis, separación por gradiente de densidad, etc. Las células de tejidos tales como la piel, músculo, médula ósea, bazo, hígado, páncreas, pulmón, intestino, estómago, etc. se pueden cosechar mediante biopsia. Puede utilizarse una solución apropiada para la dispersión o suspensión de las células cosechadas. Dicha solución puede ser, en general, una solución de sal equilibrada, (por ejemplo, solución salina normal, solución salina tamponada con fosfato (PBS), solución de sal equilibrada de Hank, etc.), convenientemente complementada con suero de ternera fetal u otros factores de origen natural, junto con un tampón aceptable a baja concentración. Los tampones pueden incluir HEPES, tampones de fosfato, tampones de lactato, etc. Las células se pueden usar de inmediato o se pueden almacenar (por ejemplo, por congelación). Las células congeladas pueden descongelarse y pueden reutilizarse. Las células pueden congelarse en DMSO, suero, tampón de medio (por ejemplo, DMSO al 10 %, suero al 50 %, medio tamponado al 40 %), y/o alguna otra solución común usada para preservar las células a temperaturas de congelación.
Como se usa en el presente documento, "polipéptido dirigido a un sitio condicionalmente inactivo enzimáticamente", en general, puede referirse a un polipéptido que puede unirse a una secuencia de ácido nucleico en un polinucleótido de una manera específica de la secuencia, pero no puede escindir un polinucleótido diana, excepto en una o más condiciones que activen el dominio enzimático. Un polipéptido dirigido a un sitio condicionalmente inactivo enzimáticamente puede comprender un dominio inactivo enzimáticamente que puede activarse condicionalmente. Un polipéptido dirigido a un sitio condicionalmente inactivo enzimáticamente puede activarse condicionalmente en presencia de imidazol. Un polipéptido dirigido a un sitio condicionalmente inactivo enzimáticamente puede comprender un sitio activo mutado que no se una a su ligando afín, dando lugar a un polipéptido dirigido a un sitio inactivo enzimáticamente. El sitio activo mutado puede diseñarse para unirse a análogos de ligando, de modo que un análogo de ligando puede unirse al sitio activo mutado y reactivo al polipéptido dirigido a un sitio. Por ejemplo, las proteínas de unión a ATP pueden comprender un sitio activo mutado que puede inhibir la actividad de la proteína, sin embargo, están diseñadas para unirse específicamente a los análogos de ATP. La unión de un análogo de ATP, pero no de ATP, puede reactivar la proteína. El polipéptido dirigido a un sitio condicionalmente inactivo enzimáticamente puede comprender una o más secuencias no nativas (por ejemplo, una fusión, un marcador de afinidad).
Como se usa en el presente documento, "ARNcr" puede referirse, en general, a un ácido nucleico con al menos aproximadamente un 5 %, 10 %, 20 %, 30 %, 40 %, 50 %, 60 %, 70 %, 80 %, 90 %, 100 % de identidad de secuencia y/o similitud de secuencia con un ARNcr ilustrativo de tipo silvestre (por ejemplo, un ARNcr de S. pyogenes (por ejemplo, SEQ ID NO: 569, SEQ ID NO: 563-679). El ARNcr puede referirse, en general, a un ácido nucleico con, como máximo, aproximadamente un 5 %, 10 %, 20 %, 30 %, 40 %, 50 %, 60 %, 70 %, 80 %, 90 %, 100% de identidad de secuencia y/o similitud de secuencia con un ARNcr ilustrativo de tipo silvestre (por ejemplo, un ARNcr de S. pyogenes). El ARNcr puede referirse a una forma modificada de un ARNcr que puede comprender un cambio de nucleótido tal como una eliminación, inserción o sustitución, variante, mutación o quimera. Un ARNcr puede ser un ácido nucleico que sea al menos aproximadamente un 60 % idéntico a una secuencia de ARNcr ilustrativa de tipo silvestre (por ejemplo, un ARNcr de S. pyogenes) sobre un tramo de al menos 6 nucleótidos contiguos. Por ejemplo, una secuencia de ARNcr puede ser al menos aproximadamente un 60 % idéntica, al menos aproximadamente un 65 % idéntica, al menos aproximadamente un 70 % idéntica, al menos aproximadamente un 75 % idéntica, al menos aproximadamente un 80 % idéntica, al menos aproximadamente un 85 % idéntica, al menos aproximadamente un 90 % idéntico, al menos aproximadamente un 95 % idéntica, al menos aproximadamente un 98 % idéntica, al menos aproximadamente un 99 % idéntica o un 100 % idéntica, a una secuencia de ARNcr ilustrativa de tipo silvestre (por ejemplo, un ARNcr de S. pyogenes) en un tramo de al menos 6 nucleótidos contiguos.
Como se usa en el presente documento, "Repetición CRISPR" o "Secuencia de repetición CRISPR" puede referirse a una secuencia de repetición CRISPR mínima.
Como se usa en el presente documento, "Cas4" puede referirse, en general, a un polipéptido con, como máximo, aproximadamente un 5 %, 10 %, 20 %, 30 %, 40 %, 50 %, 60 %, 70 %, 80 %, 90 %, 100 % de identidad de secuencia y/o similitud de secuencia con un polipéptido Csy4 ilustrativo de tipo silvestre (por ejemplo, Csy4 de P. aeruginosa, véase la Figura 40). "Cas4" puede referirse, en general, a un polipéptido con al menos aproximadamente un 5 %, 10 %, 20 %, 30 %, 40 %, 50 %, 60 %, 70 %, 80 %, 90 %, 100 % de identidad de secuencia y/o similitud de secuencia con un polipéptido Csy4 ilustrativo de tipo silvestre (por ejemplo, Csy4 de P. aeruginosa). Csy4 puede referirse al tipo silvestre o una forma modificada de la proteína Csy4 que puede comprender un cambio de aminoácido tal como una eliminación, inserción, sustitución, variante, mutación, fusión, quimera, o cualquier combinación de las mismas.
Como se usa en el presente documento, La "endorribonucleasa" puede referirse, en general, a un polipéptido que puede escindir ARN. En algunas realizaciones, una endorribonucleasa puede ser un polipéptido dirigido a un sitio. Una endorribonucleasa puede ser miembro de un sistema de CRISPR (por ejemplo, Tipo I, Tipo II, Tipo III). La endorribonucleasa puede referirse a una superfamilia de proteínas misteriosas asociadas a repeticiones (RAMP) (por ejemplo, Cas6, familias Cas6, Cas5). Las endorribonucleasas también pueden incluir los miembros de las familias RNasa A, RNasa H, RNasa I, RNasa III (por ejemplo, Drosha, Dicer, RNasa N), RNasa L, RNasa P, RNasa PhyM, RNasa Tl, RNasa T2, RNasa U2, RNasa V1, RNasa V. Una endorribonucleasa puede referirse a una
endorribonucleasa condicionalmente enzimáticamente inactiva. Una endorribonucleasa puede referirse a una endorribonucleasa catalíticamente inactiva.
Como se usa en el presente documento, "polinucleótido donante" puede referirse a un ácido nucleico que puede integrarse en un sitio durante el diseño del genoma o el diseño del ácido nucleico diana.
Como se usa en el presente documento, "fijador" o "agente de entrecruzamiento" puede referirse, en general, a un agente que puede fijar o entrecruzar células. Las células fijas o entrecruzadas pueden estabilizar los complejos de proteína-ácido nucleico en la célula. Los fijadores y agentes de entrecruzamiento adecuados pueden incluir, formaldehído, glutaraldehído, fijadores a base de etanol, fijadores a base de metanol, acetona, ácido acético, tetraóxido de osmio, dicromato de potasio, ácido crómico, permanganato de potasio, mercuriales, picratos, formol, paraformaldehído, agentes de entrecruzamiento de NHS-éster reactivos con amina tales como bis[sulfosuccinimidil]suberato (BS3), 3,3'-ditiobis[sulfosuccinimidilpropionato] (DTSSP), bis[sulfosuccinimidilsuccinato de etilenglicol (sulfo-EGS), glutarato de disuccinimidilo (DSG), propionato de ditiobis[succinimidilo] (DSP), suberato de disuccinimidilo (DSS), bis[succinimidilsuccinato] de etilenglicol (EGS), agentes de entrecruzamiento de NHS-éster/diazirina tales como NHS-diazirina, NHS-LC-diazirina, NHS-SS-diazirina, sulfo-NHS-diazirina, sulfo-NHS-LC-diazirina y sulfo-NHS-SS-diazirina.
Como se usa en el presente documento, "Fusión" puede referirse a una proteína y/o a un ácido nucleico que comprende una o más secuencias no nativas (por ejemplo, fracciones). Una fusión puede comprender una o más secuencias no nativas iguales. Una fusión puede comprender una o más secuencias no nativas diferentes. Una fusión puede ser una quimera. Una fusión puede comprender un marcador de afinidad de ácido nucleico. Una fusión puede comprender un código de barras. Una fusión puede comprender un marcador de afinidad peptídico. Una fusión puede proporcionar la localización subcelular del polipéptido dirigido a un sitio (por ejemplo, una señal de localización nuclear (NLS) para dirigirse al núcleo, una señal de localización mitocondrial para dirigirse a las mitocondrias, una señal de localización de cloroplasto para dirigirse a un cloroplasto, una señal de retención del retículo endoplasmático (RE) y similares). Una fusión puede proporcionar una secuencia no nativa (por ejemplo, marcador de afinidad) que se puede usar para rastrear o purificar. Una fusión puede ser una molécula pequeña tal como biotina o un colorante tal como los colorantes de flúor alexa, colorante de cianina3, colorante de cianina5. La fusión puede proporcionar una mayor o menor estabilidad.
En algunas realizaciones, una fusión puede comprender un marcador detectable, incluyendo una fracción que puede proporcionar una señal detectable. Los marcadores y/o fracciones detectables adecuados que pueden proporcionar una señal detectable pueden incluir, pero sin limitación, una enzima, un radioisótopo, un miembro de un par de unión específico; un fluoróforo; una proteína fluorescente; un punto cuántico; y similares.
Una fusión puede comprender un miembro de un par de FRET. Los pares de FRET (donante/aceptor) adecuados para su uso pueden incluir, pero sin limitación, EDANS/fluoresceína, IAEDANS/fluoresceína, fluoresceína/tetrametilrodamina, fluoresceína/Cy 5, IEDANS/DABCYL, fluoresceína/QSY-7, fluoresceína/lC Rojo 640, fluoresceína/Cy 5.5 y fluoresceína/lC Rojo 705.
Un par de donante/aceptor de fluoróforo/punto cuántico puede usarse como fusión. Los fluoróforos adecuados ("marcador fluorescente") pueden incluir cualquier molécula que pueda detectarse a través de sus propiedades fluorescentes inherentes, que puede incluir fluorescencia detectable tras la excitación. Los marcadores fluorescentes adecuados pueden incluir, pero sin limitación, fluoresceína, rodamina, tetrametilrodamina, eosina, eritrosina, cumarina, metil-cumarinas, pireno, Verde de malacita, estilbeno, Lucifer Yellow, Cascade Blue™, Texas Red, IAEDANS, EDANS, BODIPY FL, LC Rojo 640, Cy 5, Cy 5.5, LC Rojo 705 y Oregon green.
Una fusión puede comprender una enzima. Las enzimas adecuadas pueden incluir, pero sin limitación, peroxidasa de rábano picante, luciferasa, beta-galactosidasa y similares.
Una fusión puede comprender una proteína fluorescente. Las proteínas fluorescentes adecuadas pueden incluir, pero sin limitación, una proteína fluorescente verde (GFP), (por ejemplo, una GFP de Aequoria victoria, proteínas fluorescentes de Anguilla japónica, o un mutante o derivado de las mismas), una proteína fluorescente roja, una proteína fluorescente amarilla, cualquiera de varias proteínas fluorescentes y coloreadas.
Una fusión puede comprender una nanopartícula. Las nanopartículas adecuadas pueden incluir nanopartículas fluorescentes o luminiscentes y nanopartículas magnéticas. Se puede detectar cualquier propiedad o característica óptica o magnética de la/s nanopartícula/s.
Una fusión puede comprender puntos cuánticos (QD). Los QD pueden volverse solubles en agua aplicando capas de recubrimiento que comprendan varios materiales diferentes. Por ejemplo, los QD se pueden solubilizar usando polímeros anfífilos. Los polímeros ilustrativos que se han empleado pueden incluir ácido poliacrílico de bajo peso molecular modificado con octilamina, fosfolípidos derivados de polietilenglicol (PEG), polianhídridos, copolímeros de bloque, etc. Los QD se pueden conjugar con un polipéptido a través de cualquiera de varios grupos funcionales o agentes de enlace diferentes que se pueden unir directa o indirectamente a una capa de recubrimiento. Hay QD con
una amplia variedad de espectros de absorción y emisión disponibles en el mercado, por ejemplo, de Quantum Dot Corp. (Hayward Calif.; ahora propiedad de Invitrogen) o de Evident Technologies (Troy, N.Y.). Por ejemplo, Hay QD que tienen longitudes de onda de emisión máxima de aproximadamente 525, 535, 545, 565, 585, 605, 655, 705 y 800 nm. Por lo tanto, los QD pueden tener un intervalo de colores diferentes en la parte visible del espectro y, en algunos casos, incluso más allá.
Los radioisótopos adecuados pueden incluir, pero sin limitación, 14C, 3H, 32P, 33P, 35S y 125I.
Como se usa en el presente documento, "célula modificada genéticamente" puede referirse, en general, a una célula que ha sido modificada genéticamente. Algunos ejemplos no limitantes de modificaciones genéticas pueden incluir: inserciones, eliminaciones, inversiones, translocaciones, fusiones de genes o cambio de uno o más nucleótidos. Una célula modificada genéticamente puede comprender un ácido nucleico diana con una rotura de doble cadena introducida (por ejemplo, rotura de ADN). Una célula modificada genéticamente puede comprender un ácido nucleico introducido exógenamente (por ejemplo, un vector). Una célula modificada genéticamente puede comprender un polipéptido introducido exógenamente de la divulgación y/o ácido nucleico de la divulgación. Una célula modificada genéticamente puede comprender un polinucleótido donante. Una célula modificada genéticamente puede comprender un ácido nucleico exógeno integrado en el genoma de la célula modificada genéticamente. Una célula modificada genéticamente puede comprender una eliminación de ADN. Una célula modificada genéticamente también puede referirse a una célula con ADN mitocondrial o de cloroplasto modificado.
Como se usa en el presente documento, el "diseño del genoma" puede referirse a un proceso de modificación de un ácido nucleico diana. El diseño del genoma puede referirse a la integración de ácido nucleico no nativo en ácido nucleico nativo. El diseño del genoma puede referirse a la dirección de un polipéptido dirigido a un sitio y un ácido nucleico dirigido a ácido nucleico a un ácido nucleico diana, sin una integración o una eliminación del ácido nucleico diana. El diseño del genoma puede referirse a la escisión de un ácido nucleico diana y la unión de nuevo del ácido nucleico diana sin una integración de una secuencia exógena en el ácido nucleico diana o una eliminación en el ácido nucleico diana. El ácido nucleico nativo puede comprender un gen. El ácido nucleico no nativo puede comprender un polinucleótido donante. En los métodos de la divulgación, los polipéptidos dirigidos a un sitio (por ejemplo, Cas9) pueden introducir roturas bicatenarias en ácido nucleico, (por ejemplo, ADN genómico). La rotura de doble cadena puede estimular las vías de reparación de ADN endógeno de una célula (por ejemplo, recombinación homóloga (HR) y/o la unión de extremos no homólogos (NHEJ) o A-NHEJ (unión de extremos no homólogos alternativa)). Se pueden introducir mutaciones, eliminaciones, alteraciones e integraciones de ácido nucleico foráneo, exógeno y/o alternativo en el sitio de la rotura del ADN bicatenario.
Como se usa en el presente documento, el término "aislado" puede referirse a un ácido nucleico o polipéptido que, de la mano de un ser humano, existe aparte de su entorno nativo y, por lo tanto, no es un producto de la naturaleza. Aislado puede significar esencialmente puro. Un ácido nucleico o polipéptido aislado puede existir en una forma purificada y/o puede existir en un entorno no nativo tal como, por ejemplo, en una célula transgénica.
Como se usa en el presente documento, "no nativo" puede referirse a una secuencia de ácido nucleico o polipéptido que no se encuentra en un ácido nucleico o proteína nativo. No nativo puede referirse a marcadores de afinidad. No nativo puede referirse a fusiones. No nativo puede referirse a una secuencia de ácido nucleico o polipéptido natural que comprende mutaciones, inserciones y/o eliminaciones. Una secuencia no nativa puede presentar y/o codificar una actividad (por ejemplo, actividad enzimática, actividad de metiltransferasa, actividad de acetiltransferasa, actividad de quinasa, actividad ubiquitinante, etc.) que también puede ser presentada por la secuencia de ácido nucleico y/o polipéptido a la que se fusiona la secuencia no nativa. Una secuencia de ácido nucleico o polipéptido no nativa puede unirse a una secuencia de ácido nucleico o polipéptido natural (o una variante de la misma) mediante ingeniería genética para generar una secuencia de ácido nucleico y/o polipéptido quimérica que codifique un ácido nucleico y/o polipéptido quimérico. Una secuencia no nativa puede referirse a una secuencia de extensión de la hibridación 3'.
Como se usa en el presente documento, un "ácido nucleico" puede referirse, en general, a una secuencia polinucleotídica o a un fragmento de la misma. Un ácido nucleico puede comprender nucleótidos. Un ácido nucleico puede ser exógeno o endógeno a una célula. Un ácido nucleico puede existir en un entorno libre de células. Un ácido nucleico puede ser un gen o un fragmento del mismo. Un ácido nucleico puede ser ADN. Un ácido nucleico puede ser ARN. Un ácido nucleico puede comprender uno o más análogos (por ejemplo, cadena principal alterada, azúcar o nucleobase). Algunos ejemplos no limitantes de análogos incluyen: 5-bromouracilo, ácido nucleico peptídico, ácido xenonucleico, morfolinos, ácidos nucleicos bloqueados, ácidos nucleicos de glicol, ácidos nucleicos de treosa, didesoxinucleótidos, cordicepina, 7-desaza-GTP, fluoróforos (por ejemplo, rodamina o fluoresceína unidos al azúcar), nucleótidos que contienen tiol, nucleótidos unidos a biotina, análogos de bases fluorescentes, islas CpG, metil-7-guanosina, nucleótidos metilados, inosina, tiouridina, seudourdina, dihidrouridina, queuosina y wiosina.
Como se usa en el presente documento, una "muestra de ácido nucleico" puede referirse, en general, a una muestra de una entidad biológica. Una muestra de ácido nucleico puede comprender ácido nucleico. El ácido nucleico de la muestra de ácido nucleico estar purificado y/o enriquecido. La muestra de ácido nucleico puede mostrar la naturaleza de conjunto. Las muestras de ácido nucleico pueden proceder de varias fuentes. Las muestras de ácido nucleico pueden proceder de uno o más individuos. Una o más muestras de ácido nucleico pueden proceder del mismo
individuo. Un ejemplo no limitante sería si una muestra procediera de la sangre de un individuo y una segunda muestra procediera de la biopsia tumoral de un individuo. Los ejemplos de muestras de ácido nucleico pueden incluir, entre otros, sangre, suero, plasma, hisopo nasal o hisopo nasofaringeo, saliva, orina, fluido gástrico, líquido espinal, lágrimas, deposición, mucosidad, sudor, cerumen, aceite, secreción glandular, líquido cefalorraquídeo, tejido, semen, fluido vaginal, líquidos intersticiales, incluidos los líquidos intersticiales derivados del tejido tumoral, líquidos oculares, líquido espinal, hisopo de garganta, hisopo de mejilla, aire espirado, cabello, uñas, piel, biopsia, líquido placentario, fluido amniótico, sangre de cordón umbilical, fluidos enfáticos, fluidos de cavidades, esputo, pus, micropiota, meconio, leche materna, muestras bucales, lavado nasofaríngeo, otras excreciones o cualquier combinación de las mismas. Las muestras de ácido nucleico pueden proceder de tejidos. Los ejemplos de muestras de tejido pueden incluir, entre otros, tejido conjuntivo, tejido muscular, tejido nervioso, tejido epitelial, cartílago, muestra cancerosa o tumoral, médula ósea o hueso. La muestra de ácido nucleico puede proporcionarse de un ser humano o animal. La muestra de ácido nucleico puede proporcionarse de un mamífero, vertebrado, tales como murinos, de simio, de seres humanos, de animales de granja, animales deportivos o animales domésticos. La muestra de ácido nucleico puede recogerse de un sujeto vivo o muerto. La muestra de ácido nucleico puede ser recién recogida de un sujeto o puede haber sido sometida a alguna forma de procesamiento previo, almacenamiento o transporte.
Una muestra de ácido nucleico puede comprender un ácido nucleico diana. Una muestra de ácido nucleico puede proceder de lisado celular. El lisado celular puede proceder de una célula.
Como se usa en el presente documento, "ácido nucleico dirigido a ácido nucleico" puede referirse a un ácido nucleico que puede hibridarse con otro ácido nucleico. Un ácido nucleico dirigido a ácido nucleico puede ser ARN. Un ácido nucleico dirigido a ácido nucleico puede ser ADN. El ácido nucleico dirigido a ácido nucleico puede programarse para unirse a una secuencia de ácido nucleico específica de un sitio. El ácido nucleico que se va a dirigido o el ácido nucleico diana, puede comprender nucleótidos. El ácido nucleico dirigido a ácido nucleico puede comprender nucleótidos. Una parte del ácido nucleico diana puede ser complementaria a una parte del ácido nucleico dirigido a ácido nucleico. Un ácido nucleico dirigido a ácido nucleico puede comprender una cadena polinucleotídica y puede denominarse un "ácido nucleico guía sencillo" (es decir, un "ácido nucleico dirigido a ácido nucleico guía sencillo"). Un ácido nucleico dirigido a ácido nucleico puede comprender dos cadenas polipeptídicas y puede denominarse un "ácido nucleico guía doble" (es decir, un "ácido nucleico dirigido a ácido nucleico guía doble"). Si no se especifica lo contrario, la expresión "ácido nucleico dirigido a ácido nucleico" puede ser inclusiva, refiriéndose tanto a los ácidos nucleicos guía sencillos como a los ácidos nucleicos guía dobles.
Un ácido nucleico dirigido a ácido nucleico puede comprender un segmento que puede denominarse un "segmento dirigido a ácido nucleico" o una "secuencia dirigida al ácido nucleico". Un ácido nucleico dirigido a ácido nucleico puede comprender un segmento que puede denominarse "segmento de unión a proteínas" o "secuencia de unión a proteínas".
Un ácido nucleico dirigido a ácido nucleico puede comprender una o más modificaciones (por ejemplo, una modificación de base, una modificación de la estructura principal), para proporcionar al ácido nucleico una característica nueva o mejorada (por ejemplo, estabilidad mejorada). Un ácido nucleico dirigido a ácido nucleico puede comprender un marcador de afinidad de ácido nucleico. Un nucleósido puede ser una combinación de base y azúcar. La parte de base del nucleósido puede ser una base heterocíclica. Las dos clases más comunes de dichas bases heterocíclicas son las purinas y las pirimidinas. Los nucleótidos pueden ser nucleósidos que además incluyen un grupo fosfato unido covalentemente a la parte de azúcar del nucleósido. Para aquellos nucleósidos que incluyen un azúcar pentofuranosilo, el grupo fosfato se puede unir a la fracción hidroxilo 2', 3' o 5' del azúcar. En la formación de ácidos nucleicos dirigidos a ácido nucleico, los grupos fosfato pueden unir covalentemente nucleósidos adyacentes entre sí para formar un compuesto polimérico lineal. A su vez, se pueden unir los respectivos extremos de este compuesto polimérico lineal más para formar un compuesto circular; sin embargo, en general, son adecuados los compuestos lineales. Además, los compuestos lineales pueden tener una complementariedad interna de las bases de nucleótidos y, por lo tanto, pueden plegarse de manera que se produzca un compuesto total o parcialmente bicatenario. Dentro de los ácidos nucleicos dirigidos a ácido nucleico, los grupos fosfato pueden denominarse comúnmente como la formación de la cadena principal internucleosídica del ácido nucleico dirigido a ácido nucleico. El enlace o la cadena principal del ácido nucleico dirigido a ácido nucleico puede ser un enlace fosfodiéster de 3' a 5'.
Un ácido nucleico dirigido a ácido nucleico puede comprender una cadena principal modificada y/o enlaces internucleosídicos modificados. Las cadenas principales modificadas pueden incluir aquellas que conservan un átomo de fósforo en la cadena principal y aquellas que no tienen un átomo de fósforo en la cadena principal.
Las cadenas principales de ácido nucleico dirigido a ácido nucleico modificadas adecuadas que contienen un átomo de fósforo pueden incluir, por ejemplo, fosforotioatos, fosforotioatos quirales, fosforoditioatos, fosfotriésteres, aminoalquilfosfotriésteres, metil- y otros alquil-fosfonatos tales como los 3'-alquilen-fosfonatos, 5'-alquilen-fosfonatos, fosfonatos quirales, fosfinatos, fosforamidatos que incluyen 3'-amino-fosforamidato y amino-alquilfosforamidatos, fosforodiamidatos, tionofosforamidatos, tionoalquilfosfonatos, tionoalquilfosfotriésteres, selenofosfatos y boranofosfatos que tienen enlaces 3-5' normales, análogos unidos en 2-5', y aquellos que tienen polaridad invertida, en donde uno o más enlaces internucleotídicos es un enlace de 3' a 3', de 5 'a 5' o de 2 'a 2'. Los ácidos nucleicos dirigidos a ácido nucleico adecuados que tienen polaridad invertida pueden comprender un solo enlace de 3' a 3' en
el enlace internucleotídico más a 3' (es decir, un solo resto de nucleósido invertido en donde falta la nucleobase o tiene un grupo hidroxilo en su lugar). También se pueden incluir diversas sales (por ejemplo, cloruro de potasio o cloruro de sodio), sales mixtas y formas de ácido libre.
Un ácido nucleico dirigido a ácido nucleico puede comprender uno o más enlaces internucleosídicos de fosforotioato y/o heteroátomo, en particular -CH2-NH-O-CH2-, -CH2-N(CH3)-O-CH2- (es decir, una cadena principal de metileno (metilimino) o MMI), -CH2-O-N(CH3)-CH2-, -CH2-N(CH3)-N(CH3)-CH2- y -O-N(CH3)-CH2-CH2- (en donde el enlace internucleotídico de fosfodiéster nativo se representa como -O-P(=O)(OH)-O-CH2-).
Un ácido nucleico dirigido a ácido nucleico puede comprender una estructura de cadena principal de morfolino. Por ejemplo, un ácido nucleico puede comprender un anillo de morfolino de 6 elementos en lugar de un anillo de ribosa. En algunas de estas realizaciones, un enlace fosforodiamidato u otro enlace internucleosídico no fosfodiéster puede reemplazar a un enlace fosfodiéster.
Un ácido nucleico dirigido a ácido nucleico puede comprender cadenas principales polinucleotídicas que están formadas por enlaces internucleosídicos de alquilo o cicloalquilo de cadena corta, enlaces internucleosídicos de heteroátomos mixtos y de alquilo o cicloalquilo, o uno o más enlaces internucleosídicos heteroatómicos o heterocíclicos de cadena corta. Estos pueden incluir aquellos que tienen enlaces morfolino (formados en parte a partir de la parte de azúcar de un nucleósido); cadenas principales de siloxano; cadenas principales de sulfuro, sulfóxido y sulfona; cadenas principales de formacetilo y tioformacetilo; cadenas principales de metilen formacetilo y tioformacetilo; cadenas principales de riboacetilo; cadenas principales que contienen alqueno; cadenas principales de sulfamato; cadenas principales de metilenimino y metilenhidrazino; cadenas principales de sulfonato y sulfonamida; cadenas principales de amida; y otros que tienen partes componentes de N, O, S y CH2.
Un ácido nucleico dirigido a ácido nucleico puede comprender un mimético de ácido nucleico. El término "mimético" puede incluir polinucleótidos en los que solo el anillo de furanosa o tanto el anillo de furanosa como el enlace internucleotídico se reemplazan por grupos no furanosa, el reemplazo de solo el anillo de furanosa también puede denominarse sustituto del azúcar. Se puede mantener la fracción de base heterocíclica o una fracción de base heterocíclica modificada para la hibridación con un ácido nucleico diana apropiado. Uno de dichos ácidos nucleicos puede ser un ácido nucleico peptídico (ANP). En un ANP, la cadena principal de azúcar de un polinucleótido puede reemplazarse por una cadena principal que contenga amida, en particular, una cadena principal de aminoetilglicina. Los nucleótidos pueden ser conservados y están unidos directa o indirectamente a átomos de nitrógeno aza de la parte amida de la cadena principal. La cadena principal de los compuestos de ANP puede comprender dos o más unidades de aminoetilglicina unidas que dan al ANP una cadena principal que contiene una amida. Las fracciones de base heterocíclica pueden unirse directa o indirectamente a átomos de nitrógeno aza de la parte amida de la cadena principal.
Un ácido nucleico dirigido a ácido nucleico puede comprender unidades morfolino enlazadas (es decir, ácido nucleico de morfolino) que tienen bases heterocíclicas unidas al anillo morfolino. Los grupos de enlace pueden unir las unidades monoméricas de morfolino en un ácido nucleico de morfolino. Los compuestos oligoméricos a base de morfolino no iónicos pueden tener interacciones menos indeseables con las proteínas celulares. Los polinucleótidos a base de morfolino pueden ser miméticos no iónicos de ácidos nucleicos dirigidos a ácidos nucleicos. Se puede unir varios compuestos dentro de la clase morfolino usando diferentes grupos de enlace. Una clase adicional de polinucleótido mimético se puede denominar ácidos nucleicos de ciclohexenilo (CeNA). El anillo de furanosa normalmente presente en una molécula de ácido nucleico puede reemplazarse por un anillo de ciclohexenilo. Los monómeros de fosforamidita protegidos con DMT CeNA pueden prepararse y usarse para la síntesis de compuestos oligoméricos usando química de fosforamidita. La incorporación de monómeros de CeNA a una cadena de ácido nucleico puede aumentar la estabilidad de un híbrido de ADN/ARN. Los oligoadenilatos de CeNA pueden formar complejos con complementos de ácido nucleico con una estabilidad similar a los complejos nativos. Una modificación adicional puede incluir ácidos nucleicos bloqueados (LNA) en los que el grupo 2'-hidroxilo está unido al átomo de carbono 4' del anillo de azúcar, formando así un enlace 2'-C,4'-C-oximetileno, que da lugar a una fracción de azúcar bicíclica. El enlace puede ser un metileno (-CH2-), grupo que une el átomo de oxígeno 2' y el átomo de carbono 4', en donde n es 1 o 2. Los LNA y análogos de LNA pueden mostrar estabilidades térmicas de dúplex muy altas con ácido nucleico complementario (Tf = 3 a 10 °C), estabilidad hacia la degradación exonucleolítica en 3' y buenas propiedades de solubilidad.
Un ácido nucleico dirigido a ácido nucleico puede comprender una o más fracciones de azúcar sustituidas. Los polinucleótidos adecuados pueden comprender un grupo sustituyente de azúcar seleccionado de: OH; F; O-, S- o N-alquilo; O-, S- o N-alquenilo; O-, S- o N-alquinilo; u O-alquil-O-alquilo, en donde el alquilo, alquenilo y alquinilo pueden ser alquilo C1 a C10 sustituido o no sustituido, o alquenilo y alquinilo C2 a C10. Son particularmente adecuados O((CH2)nO) mCH3 , O(CH2)nOCH3, O(CH2)nNH2 , O (C H )nCH3, O(CH2)nONH2 y O(CH2)nON((CH2)nCH3)2, en donde n y m son de 1 a aproximadamente 10. Se puede seleccionar un grupo sustituyente de azúcar entre: alquilo C1 a C10 inferior, alquilo inferior sustituido, alquenilo, alquinilo, alcarilo, aralquilo, O-alcarilo u O-aralquilo, SH, SCH3 , OCN, Cl, Br, CN, CF3, OCF3 , SOCH3 , SO2CH3 , ONO2, NO2, N3 , NH2 , heterocicloalquilo, heterocicloalcarilo, aminoalquilamino, polialquilamino, sililo sustituido, un grupo de escisión de ARN, un grupo indicador, un intercalante, un grupo para mejorar las propiedades farmacocinéticas de un ácido nucleico dirigido a ácido nucleico, o un grupo para mejorar las propiedades farmacodinámicas de un ácido nucleico dirigido a ácido nucleico y otros sustituyentes que tienen
propiedades similares. Una modificación adecuada puede incluir 2'-metoxietoxi (2'-O-CH CH2OCH3, también conocido como 2'-O-(2-metoxietilo) o 2'-MOE, es decir, un grupo alcoxialcoxi). Una modificación adecuada adicional puede incluir 2'-dimetilaminooxietoxi, (es decir, un grupo O(CH2)2ON(CH3)2, también conocido como 2'-DMAOE) y 2'-dimetilaminoetoxi-etoxi (también conocido como 2'-O-dimetil-amino-etoxi-etilo o 2'-DMAEOE), es decir, 2'-O-CH2-O-CH2-N(CH3)2.
Otros grupos sustituyentes de azúcar adecuados pueden incluir metoxi (-O-CH3), aminopropoxi (-O CH2 CH2 CH2NH2), alilo (-CH2-CH=CH2), -O-alilo (-O-CH2-CH=CH2) y flúor (F). Los grupos sustituyentes de azúcar 2' pueden estar en la posición arabino (arriba) o ribo (abajo). Una modificación adecuada de 2'-arabino es 2'-F. También se pueden hacer modificaciones similares en otras posiciones del compuesto oligomérico, particularmente, la posición 3' del azúcar del nucleósido 3' terminal o en los nucleótidos enlazados en 2'-5' y la posición 5' del nucleótido 5' terminal. Los compuestos oligoméricos también pueden tener miméticos de azúcar tales como fracciones ciclobutilo en lugar del azúcar pentofuranosilo.
Un ácido nucleico dirigido a ácido nucleico también puede incluir modificaciones o sustituciones de nucleobase (a menudo denominadas simplemente "base"). Como se usa en el presente documento, Las nucleobases "no modificadas" o "naturales" pueden incluir las bases de purina, (por ejemplo, adenina (A) y guanina (G)), y las bases de pirimidina, (por ejemplo, timina (T), citosina (C) y uracilo (U). Las nucleobases modificadas pueden incluir otras nucleobases sintéticas y naturales, tales como 5-metilcitosina (5-me-C), 5-hidroximetil-citosina, xantina, hipoxantina, 2-aminoadenina, derivados de 6-metilo y otros de alquilo de adenina y guanina, derivados de 2-propilo y otros de alquilo de adenina y guanina, 2-tiouracilo, 2-tiotimina y 2-tiocitosina, 5-halouracilo y citosina, 5-propinilo (-C = C-CH3) uracilo y citosina, y otros derivados alquinílicos de bases de pirimidina, 6-azo uracilo, citosina y timina, 5-uracilo (pseudouracilo), 4-tiouracilo, 8-halo, 8-amino, 8-tiol, 8-tioalquilo, 8-hidroxilo y otras adeninas y guaninas 8-sustituidas, 5-halo, particularmente, 5-bromo, 5-trifluorometil y otros uracilos y citosinas 5-sustituidas, 7-metilguanina y 7-metiladenina, 2-F-adenina, 2-aminoadenina, 8-azaguanina y 8-azaadenina, 7-desazaguanina y 7-desazaadenina y 3-desazaguanina y 3-desazaadenina. Las nucleobases modificadas pueden incluir pirimidinas tricíclicas tales como fenoxazina citidina (1H-pirimido(5,4-b)(1,4)benzoxazin-2(3H)-ona), fenotiazina citidina (1H-pirimido(5,4-b)(1,4)benzotiazin-2(3H)-ona), La fijación de G tal como una fenoxazina citidina sustituida (por ejemplo, 9-(2-aminoetoxi)-H-pirimido(5,4-(b)(1,4)benzoxazin-2(3H)-ona), carbazol citidina (2H-pirimido(4,5-b)indol-2-ona), piridoindol citidina (H-pirido(3',2':4,5)pirrolo(2,3-d)pirimidin-2-ona).
Las fracciones de bases heterocíclicas pueden incluir aquellas en las que la base de purina o pirimidina se reemplaza por otros heterociclos, por ejemplo, 7-desaza-adenina, 7-desazaguanosina, 2-aminopiridina y 2-piridona. Las nucleobases pueden ser útiles para aumentar la afinidad de unión de un compuesto polinucleotídico. Estas pueden incluir pirimidinas 5-sustituidas, 6-azapirimidinas y purinas N-2, N-6 y O-6-sustituidas, incluyendo 2-aminopropiladenina, 5-propiniluracilo y 5-propinilcitosina. Las sustituciones de 5-metilcitosina pueden aumentar la estabilidad del dúplex de ácido nucleico a 0,6-1,2 °C y pueden ser sustituciones de bases adecuadas (por ejemplo, cuando se combinan con modificaciones de azúcar 2'-O-metoxietilo).
Una modificación de un ácido nucleico dirigido a ácido nucleico puede comprender unir químicamente al ácido nucleico dirigido a ácido nucleico una o más fracciones o conjugados que puedan potenciar la actividad, distribución celular o absorción celular del ácido nucleico dirigido a ácido nucleico. Estas fracciones o conjugados pueden incluir grupos conjugados unidos covalentemente a grupos funcionales, tales como grupos hidroxilo primarios o secundarios. Los grupos conjugados pueden incluir, pero sin limitación, intercaladores, moléculas indicadoras, poliaminas, poliamidas, polietilenglicoles, poliéteres, grupos que potencian las propiedades farmacodinámicas de los oligómeros y grupos que pueden potenciar las propiedades farmacocinéticas de los oligómeros. Los grupos conjugados pueden incluir, pero sin limitación, colesteroles, lípidos, fosfolípidos, biotina, fenazina, folato, fenantridina, antraquinona, acridina, fluoresceínas, rodaminas, coumarinas y colorantes. Los grupos que potencian las propiedades farmacodinámicas incluyen grupos que mejoran la absorción, potencian la resistencia a la degradación y/o fortalecen la hibridación específica de secuencia con el ácido nucleico diana. Los grupos que pueden potenciar las propiedades farmacocinéticas incluyen grupos que mejoran la absorción, la distribución, el metabolismo o la excreción de un ácido nucleico. Las fracciones de conjugados pueden incluir, pero sin limitación, fracciones lipídicas tales como una fracción de colesterol, ácido cólico un tioéter, (por ejemplo, hexil-S-tritiltiol), un tiocolesterol, una cadena alifática (por ejemplo, restos de dodecandiol o de undecilo), un fosfolípido (por ejemplo, di-hexadecil-rac-glicerol o 1,2-di-0-hexadecil-racglicero-3-H-fosfonato de trietilamonio), una poliamina o una cadena de polietilenglicol o ácido adamantanoacético, una fracción de palmitilo o una fracción de octadecilamina o de hexilamino-carbonil-oxicolesterol.
Una modificación puede incluir un "dominio de transducción de proteínas" o PTD (es decir, un péptido penetrante en células (CPP)). El PTD puede referirse a un polipéptido, polinucleótido, carbohidratos, o compuestos orgánicos o inorgánicos que facilitan atravesar una bicapa lipídica, micela, membrana celular, membrana de orgánulo o membrana vesicular. Un PTD se puede unir a otra molécula, que puede variar desde una molécula polar pequeña hasta una macromolécula grande y/o una nanopartícula, y puede facilitar que la molécula atraviese una membrana, por ejemplo, pasando del espacio extracelular al espacio intracelular, o del citosol al interior de un orgánulo. Un PTD puede estar unido covalentemente al extremo amino de un polipéptido. Un PTD puede estar unido covalentemente al extremo carboxilo de un polipéptido. Un PTD puede estar unido covalentemente a un ácido nucleico. Los ejemplos de PTD pueden incluir, pero sin limitación, un dominio mínimo de transducción de proteínas y péptidos; una secuencia de
poliarginina que comprende varias argininas suficientes para dirigir la entrada a una célula (por ejemplo, 3, 4, 5, 6, 7, 8, 9, 10 o 10-50 argininas), un dominio VP22, un dominio de transducción de proteínas de Drosophila Antennapedia, un péptido de calcitonina humana truncado, polilisina y transportan, homopolímero de arginina de 3 restos de arginina a 50 restos de arginina. El PTD puede ser un CPP activable (ACPP). Los ACPP pueden comprender un CPP policatiónico (por ejemplo, Arg9 o "R9") conectado a través de un enlazador escindible a un polianión correspondiente (por ejemplo, Glu9 o "E9"), que puede reducir la carga neta a casi cero y, por lo tanto, inhibe la adhesión y la absorción en las células. Tras la escisión del enlazador, el polianión puede ser liberado, desenmascarando localmente la poliarginina y su adhesividad inherente, "activando" así el ACPP para atravesar la membrana.
"Nucleótido" puede referirse, en general, a una combinación de base-azúcar-fosfato. Un nucleótido puede comprender un nucleótido sintético. Un nucleótido puede comprender un análogo de nucleótido sintético. Los nucleótidos pueden ser unidades monoméricas de una secuencia de ácido nucleico (por ejemplo, ácido desoxirribonucleico (ADN) y ácido ribonucleico (ARN)). El término nucleótido puede incluir ribonucleósido trifosfato adenosina trifosfato (ATP), trifosfato de uridina (UTP), trifosfato de citosina (CTP), trifosfato de guanosina (GTP) y trifosfatos de desoxirribonucleósidos tales como dATP, dCTP, dITP, dUTP, dGTP, dTTP o derivados de los mismos. Dichos derivados pueden incluir, por ejemplo, [aS]dATP, 7-desaza-dGTP y 7-desaza-dATP, y derivados de nucleótidos que confieren resistencia a la nucleasa en la molécula de ácido nucleico que los contiene. El término nucleótido, como se usa en el presente documento, puede referirse a didesoxirribonucleósido trifosfatos (ddNTP) y sus derivados. Los ejemplos ilustrativos de didesoxirribonucleósidos trifosfatos pueden incluir, pero sin limitación, ddATP, ddCTP, ddGTP, ddlTP y ddTTP. Un nucleótido puede estar sin marcar o marcarse de manera detectable mediante técnicas bien conocidas. El marcaje también se puede realizar con puntos cuánticos. Los marcadores detectables pueden incluir, por ejemplo, isótopos radiactivos, marcadores fluorescentes, marcadores quimioluminiscentes, marcadores bioluminiscentes y marcadores enzimáticos. Los marcadores fluorescentes de nucleótidos pueden incluir, entre otros, fluoresceína, 5-carboxifluoresceína (FAM), 2'7'-dimetoxi-4'5-dicloro-6-carboxifluoresceína (JOE), rodamina, 6-carboxirrodamina (R6G), N,N,N',N'-tetrametil-6-carboxirrodamina (TAMRA), 6-carboxi-X-rodamina (ROX), ácido 4-(4-dimetilaminofenilazo)benzoico (DABCYL), Cascade Blue, Oregon Green, Texas Red, Cianina y ácido 5-(2'-aminoetil)aminonaftalen-1-sulfónico (EDANS). Los ejemplos específicos de nucleótidos marcados con fluorescencia pueden incluir [R6G] dUTP, [TAMRA]dUTP, [R110]dCTP, [R6G]dCTP, [TAMRA]dCTP, [JOE]ddATP, [R6G]ddATP, [FAM]ddCTP, [R110]ddCTP, [TAMRA]ddGTP, [ROX]ddTTP, [dR6G]ddATP, [dR110]ddCTP, [dTAMRA]ddGTP y [dROX]ddTTP disponibles en Perkin Elmer, Foster City, Calif FluoroLink DeoxyNucleotides, FluoroLink Cy3-dCTP, FluoroLink Cy5-dCTP, FluoroLink Fluor X-dCTP, FluoroLink Cy3-dUTP y FluoroLink Cy5-dUTP disponibles en Amersham, Arlington Heights, Ill.; Fluoresceína-15-dATP, Fluoresceína-12-dUTP, Tetrametil-rodamina-6-dUTP, IR770-9-dATP, Fluoresceína-12-ddUTP, Fluoresceína-12-UTP y Fluoresceína-15-2'-dATP disponibles en Boehringer Mannheim, Indianápolis, Ind.; y nucleótidos marcados con cromosomas, BODIPY-FL-14-UTP, BODIPY-FL-4-UTP, BODIPY-TMR-14-UTP, BODIPY-TMR-14-dUTP, BODIPY-TR-14-UTP, BODIPY-TR-14-dUTP, Cascade Blue-7-UTP, Cascade Blue-7-dUTP, fluoresceína-12-UTP, fluoresceína-12-dUTP, Oregon Green 488-5-dUTP, Rodamina Green-5 -UTP, Rodamina Green-5-dUTP, tetrametilrrodamina-6-UTP, tetrametilrrodamina-6-dUTP, Texas Red-5-UTP, Texas Red-5-dUTP y Texas Red-12-dUTP disponible en Molecular Probes, Eugene, Oreg. Los nucleótidos también se pueden marcar mediante modificación química. Un nucleótido individual modificado químicamente puede ser biotinadNTP. Algunos ejemplos no limitantes de dNTP biotinilados pueden incluir, biotina-dATP (por ejemplo, bio-N6-ddATP, biotina-14-dATP), biotina-dCTP (por ejemplo, biotina-11-dCTP, biotina-14-dCTP) y biotina-dUTP (por ejemplo, biotina-11-dUTP, biotina-16-dUTP, biotina-20-dUTP).
Como se usa en el presente documento, "Dominio P" puede referirse a una región de un ácido nucleico dirigido a ácido nucleico. El dominio P puede interactuar con un motivo adyacente al protoespaciador (PAM), polipéptido dirigido a un sitio y/o ácido nucleico dirigido a ácido nucleico. Un dominio P puede interactuar directa o indirectamente con un motivo adyacente al protoespaciador (PAM), polipéptido dirigido a un sitio y/o ácido nucleico dirigido a ácido nucleico ácido nucleico. Como se usan en el presente documento, las expresiones "región interactiva de PAM", "región adyacente anti-repetición" y "dominio P" se pueden usar indistintamente.
Como se usa en el presente documento, "purificado/a" puede referirse a una molécula (por ejemplo, polipéptido dirigido a un sitio, ácido nucleico dirigido a ácido nucleico) que comprende al menos el 50, 60, 70, 80, 90, 95, 96, 97, 98, 99 o 100 % de la composición. Por ejemplo, si una muestra que comprende el 10 % de un polipéptido dirigido a un sitio, después de una etapa de purificación comprende el 60 % del polipéptido dirigido a un sitio, entonces se puede decir que la muestra está purificada. Una muestra purificada puede referirse a una muestra enriquecida o una muestra que ha sido sometida a métodos para eliminar partículas distintas de la partícula de interés.
Como se usa en el presente documento, "agente de reactivación" puede referirse, en general, a cualquier agente que pueda convertir un polipéptido inactivo enzimáticamente en un polipéptido activo enzimáticamente. El imidazol puede ser un agente de reactivación. Un análogo de ligando puede ser un agente de reactivación.
Como se usa en el presente documento, "recombinante" puede referirse a una secuencia que procede de una fuente foránea al hospedador en particular (por ejemplo, célula) o, si procede de la misma fuente, está modificada con respecto a su forma original. Un ácido nucleico recombinante de una célula puede incluir un ácido nucleico que sea endógeno a la célula en particular, pero que se haya modificado a través de, por ejemplo, el uso de mutagénesis dirigida. El término puede incluir múltiples copias no naturales de una secuencia de ADN que se produce de forma
natural. Así pues, el término puede referirse a un ácido nucleico que sea foráneo o heterólogo a la célula, u homólogo a la célula, pero en una posición o forma dentro de la célula en la que normalmente no se encuentra el ácido nucleico. De igual manera, cuando se usa en el contexto de una secuencia polipeptídica o de aminoácidos, una secuencia polipeptídica o de aminoácidos exógena puede ser una secuencia polipeptídica o de aminoácidos que proceda de una fuente foránea para la célula en particular o, si procede de la misma fuente, está modificada con respecto a su forma original.
Como se usa en el presente documento, "polipéptidos dirigidos a un sitio" puede referirse, en general, a nucleasas, nucleasas dirigidas a un sitio, endorribonucleasas, endorribonucleasas condicionalmente inactivas enzimáticamente, proteínas argonautas y proteínas de unión a ácidos nucleico. Un polipéptido o una proteína dirigido a un sitio puede incluir nucleasas tales como endonucleasas de asentamiento tales como PI-TliII, H-DreI, I-DmoI y I-CreI, I-SceI, nucleasas de la familia LAGLIDADG, meganucleasas, nucleasas de la familia GIY-YIG, nucleasas de la familia de cajas His-Cys, nucleasas de tipo Vsr, endorribonucleasas, exorribonucleasas, endonucleasas y exonucleasas. Un polipéptido dirigido a un sitio puede referirse a un miembro de los genes Cas de los sistemas de CRISPR/Cas de Tipo I, Tipo II, Tipo III y/o Tipo U. Un polipéptido dirigido a un sitio puede referirse a un miembro de la superfamilia de proteínas misteriosas asociadas a repeticiones (RAMP) (por ejemplo, subfamilias Cas5, Cas6). Un polipéptido dirigido a un sitio puede referirse a una proteína argonauta.
Un polipéptido dirigido a un sitio puede ser un tipo de proteína. Un polipéptido dirigido a un sitio puede referirse a una nucleasa. Un polipéptido dirigido a un sitio puede referirse a una endorribonucleasa. Un polipéptido dirigido a un sitio puede referirse a cualquier secuencia polipeptídica modificada (por ejemplo, acortada, mutada, alargada) u homólogo del polipéptido dirigido a un sitio. Un polipéptido dirigido a un sitio puede ser codón optimizado. Un polipéptido dirigido a un sitio puede ser un homólogo optimizado por codones de un polipéptido dirigido a un sitio. Un polipéptido dirigido a un sitio puede ser enzimáticamente inactivo, parcialmente activo, constitutivamente activo, completamente activo, inducible activo y/o más activo, (por ejemplo, más que el homólogo de tipo silvestre de la proteína o del polipéptido). Un polipéptido dirigido a un sitio puede ser Cas9. Un polipéptido dirigido a un sitio puede ser Csy4. Un polipéptido dirigido a un sitio puede ser Cas5 o un miembro de la familia Cas5. Un polipéptido dirigido a un sitio puede ser Cas6 o un miembro de la familia Cas6.
En algunos casos, el polipéptido dirigido a un sitio (por ejemplo, polipéptido dirigido a un sitio variante, mutado, inactivo enzimáticamente y/o condicionalmente inactivo enzimáticamente) puede dirigirse a ácido nucleico. El polipéptido dirigido a un sitio (por ejemplo, endorribonucleasa variante, mutada, enzimáticamente inactiva y/o condicionalmente enzimáticamente inactiva) puede dirigirse a ARN. Las endorribonucleasas que pueden dirigirse a ARN pueden incluir miembros de otras subfamilias de CRISPR tales como Cas6 y Cas5.
Como se usa en el presente documento, el término "específico" puede referirse a la interacción de dos moléculas a través de la que una de las moléculas, a través de, por ejemplo, medios químicos o físicos, se une específicamente a la segunda molécula. Las interacciones de unión específicas ilustrativas pueden referirse a la unión de antígenoanticuerpo, unión de avidina-biotina, carbohidratos y lectinas, secuencias de ácido nucleico complementarias (por ejemplo, hibridación), secuencias peptídicas complementarias, incluyendo las formadas mediante métodos recombinantes, moléculas efectoras y receptoras, cofactores enzimáticos y enzimas, inhibidores enzimáticos y enzimas, y similares. "No específica" puede referirse a una interacción entre dos moléculas que no es específica.
Como se usa en el presente documento, "soporte sólido" puede referirse, en general, a cualquier material insoluble o parcialmente soluble. Un soporte sólido puede referirse a una tira reactiva, una placa de múltiples pocillos y similares. El soporte sólido puede comprender varias sustancias (por ejemplo, vidrio, poliestireno, cloruro de polivinilo, polipropileno, polietileno, policarbonato, dextrano, nylon, amilosa, celulosas naturales y modificadas, poliacrilamidas, agarosas y magnetita), y se pueden proporcionar en varias formas, incluyendo perlas de agarosa, perlas de poliestireno, perlas de látex, perlas magnéticas, partículas metálicas coloidales, chips y superficies de vidrio y/o silicio, tiras de nitrocelulosa, membranas de nylon, láminas, pocillos de bandejas de reacción (por ejemplo, placas de múltiples pocillos), tubos de plástico, etc. Un soporte sólido puede ser sólido, semisólido, una perla o una superficie. El soporte puede ser móvil en una solución o puede ser inmóvil. Se puede usar un soporte sólido para capturar un polipéptido. Un soporte sólido puede comprender un agente de captura.
Como se usa en el presente documento, "ácido nucleico diana" puede referirse, en general, a un ácido nucleico que se vaya a usar en los métodos de la divulgación. Un ácido nucleico diana puede referirse a una secuencia cromosómica o una secuencia extracromosómica, (por ejemplo, una secuencia episomal, una secuencia de minicírculo, una secuencia mitocondrial, una secuencia de cloroplasto, etc.). Un ácido nucleico diana puede ser ADN. Un ácido nucleico diana puede ser ARN. Un ácido nucleico diana puede usarse en el presente documento indistintamente con "polinucleótido", "secuencia de nucleótidos" y/o "polinucleótido diana". Un ácido nucleico diana puede ser una secuencia de ácido nucleico que puede no estar relacionada con ninguna otra secuencia de una muestra de ácido nucleico mediante una sustitución de un solo nucleótido. Un ácido nucleico diana puede ser una secuencia de ácido nucleico que puede no estar relacionada con ninguna otra secuencia de una muestra de ácido nucleico mediante sustituciones de 2, 3, 4, 5, 6, 7, 8, 9 o 10 nucleótidos. En algunas realizaciones, la sustitución no puede ocurrir dentro de los 5, 10, 15, 20, 25, 30 o 35 nucleótidos del extremo 5' de un ácido nucleico diana. En algunas realizaciones, la sustitución no puede ocurrir dentro de 5, 10, 15, 20, 25, 30, 35 nucleótidos del extremo 3' de un ácido nucleico diana.
Como se usa en el presente documento, "ARNcrtra" puede referirse, en general, a un ácido nucleico con al menos aproximadamente un 5 %, 10 %, 20 %, 30 %, 40 %, 50 %, 60 %, 70 %, 80 %, 90 %, 100 % de identidad de secuencia y/o similitud de secuencia con una secuencia de ARNcrtra ilustrativa de tipo silvestre (por ejemplo, un ARNcrtra de S. pyogenes (SEQ ID 433), SEQ ID 431-562). ARNcrtra puede referirse a un ácido nucleico con, como máximo, aproximadamente un 5 %, 10 %, 20 %, 30 %, 40 %, 50 %, 60 %, 70 %, 80 %, 90 %, 100 % de identidad de secuencia y/o similitud de secuencia con una secuencia de ARNcrtra ilustrativa de tipo silvestre (por ejemplo, un ARNcrtra de S. pyogenes). ARNcrtra puede referirse a una forma modificada de un ARNcrtra que puede comprender un cambio de nucleótidos tal como una eliminación, inserción o sustitución, variante, mutación o quimera. Un ARNcrtra puede referirse a un ácido nucleico que puede ser al menos aproximadamente un 60 % idéntico a una secuencia de ARNcrtra ilustrativa de tipo silvestre (por ejemplo, un ARNcrtra de S. pyogenes) en un tramo de al menos 6 nucleótidos contiguos. Por ejemplo, una secuencia de ARNcrtra puede ser al menos aproximadamente un 60 % idéntica, al menos aproximadamente un 65 % idéntica, al menos aproximadamente un 70 % idéntica, al menos aproximadamente un 75 % idéntica, al menos aproximadamente un 80 % idéntica, al menos aproximadamente un 85 % idéntica, al menos aproximadamente un 90 % idéntico, al menos aproximadamente un 95 % idéntica, al menos aproximadamente un 98% idéntica, al menos aproximadamente un 99% idéntica o un 100% idéntica, a una secuencia de ARNcrtra ilustrativa de tipo silvestre (por ejemplo, un ARNcrtra de S. pyogenes) en un tramo de al menos 6 nucleótidos contiguos. Un ARNcrtra puede referirse a un ARNcrtra medio. Un ARNcrtra puede referirse a una secuencia mínima de ARNcrtra.
Sistemas de CRISPR
Un CRISPR (grupos de repeticiones palindrómicas cortas en intervalos regulares) puede ser un locus genómico que se encuentra en los genomas de muchos procariotas (por ejemplo, bacterias y arqueas). Los locus de CRISPR pueden proporcionar resistencia a los invasores foráneos (por ejemplo, virus, fago) en procariotas. De esta manera, se puede pensar que el sistema de CRISPR funciona como un tipo de sistema inmunitario para ayudar a defender a los organismos procariotas contra los invasores foráneos. Puede haber tres etapas de la función del locus de CRISPR: integración de nuevas secuencias en el locus, biogénesis del ARN de CRISPR (ARNcr) y silenciamiento del ácido nucleico invasor foráneo. Puede haber cuatro tipos de sistemas de CRISPR (por ejemplo, Tipo I, Tipo II, Tipo III, Tipo U).
Un locus de CRISPR puede incluir una serie de secuencias repetitivas cortas denominadas "repeticiones". Las repeticiones pueden formar estructuras de horquilla y/o las repeticiones pueden ser secuencias monocatenarias no estructuradas. Las repeticiones pueden ocurrir en grupos. Las secuencias de repeticiones, con frecuencia, pueden divergir entre especies. Las repeticiones pueden estar intercaladas regularmente con secuencias intermedias únicas denominadas "espaciadores", produciendo una arquitectura de locus de repetición-espaciador-repetición. Los espaciadores pueden ser idénticos o tener una alta homología con secuencias invasoras foráneas conocidas. Una unidad de espaciador-repetición puede codificar un ARNcrispr (ARNcr). Un ARNcr puede referirse a la forma madura de la unidad de espaciador-repetición. Un ARNcr puede comprender una secuencia "semilla" que puede participar en la dirección a un ácido nucleico diana (por ejemplo, posiblemente como un mecanismo de vigilancia contra ácido nucleico foráneo). Se puede ubicar una secuencia semilla en el extremo 5' o 3' del ARNcr.
Un locus de CRISPR puede comprender secuencias polinucleotídicas que codifican genes asociados a Crispr (Cas). Los genes Cas pueden participar en las etapas de biogénesis y/o interferencia de la función de ARNcr. Los genes Cas pueden mostrar una divergencia de secuencia extrema (por ejemplo, secuencia primaria) entre especies y homólogos. Por ejemplo, los homólogos Cas1 pueden comprender menos del 10 % de identidad con la secuencia primaria entre homólogos. Algunos genes Cas pueden comprender estructuras secundarias y/o terciarias homólogas. Por ejemplo, a pesar de la divergencia de secuencia extrema, muchos miembros de la familia Cas6 de proteínas CRISPR comprenden un pliegue de tipo ferredoxina N-terminal. Los genes Cas se pueden nombrar de acuerdo con el organismo del que se derivan. Por ejemplo, los genes Cas de Staphylococcus epidermidis pueden denominarse de tipo Csm, los genes Cas de Streptococcus thermophilus pueden denominarse de tipo Csn y los genes Cas de Pyrococcus furiosus pueden denominarse de tipo Cmr.
Integración
La etapa de integración del sistema de CRISPR puede referirse a la capacidad del locus de CRISPR para integrar nuevos espaciadores en la matriz de ARNcr al ser infectado por un invasor foráneo. La adquisición de espaciadores invasores foráneos puede ayudar a conferir inmunidad a los ataques posteriores del mismo invasor foráneo. La integración puede ocurrir en el extremo líder del locus de CRISPR. Las proteínas Cas (por ejemplo, Cas1 y Cas2) pueden participar en la integración de nuevas secuencias de espaciador. La integración puede proceder de manera similar para algunos tipos de sistemas de CRISPR (por ejemplo, Tipo I-III).
Biogénesis
Los ARNcr maduros pueden procesarse a partir de una transcripción de locus de CRISPR policistrónica más larga (es decir, una matriz de pre-ARNcr). Una matriz de pre-ARNcr puede comprender una pluralidad de ARNcr. Las repeticiones de la matriz de pre-ARNcr pueden ser reconocidas por los genes Cas. Los genes Cas pueden unirse a
las repeticiones y escindir las repeticiones. Esta acción puede liberar la pluralidad de ARNcr. Los ARNcr pueden someterse a eventos adicionales para producir la forma madura de ARNcr, tales como el recorte (por ejemplo, con un exonucleasa). Un ARNcr puede comprender todas, alguna o ninguna de la secuencia de repetición de CRISPR.
Interferencia
La interferencia puede referirse a la etapa del sistema de CRISPR que es funcionalmente responsable de combatir la infección por un invasor foráneo. La interferencia de CRISPR puede seguir un mecanismo similar a la interferencia del ARN (ARNi (por ejemplo, en donde un ARN diana está dirigido (por ejemplo, hibridado) por un ARN interferente corto (ARNip)), que puede producir la degradación y/o desestabilización del ARN diana. Los sistemas de CRISPR pueden realizar LA interferencia de un ácido nucleico diana mediante el acoplamiento de ARNcr y genes Cas, formando así ribonucleoproteínas de CRISPR (RNPcr). El ARNcr de la RNPcr puede guiar al RNPcr al ácido nucleico invasor foráneo, (por ejemplo, reconociendo el ácido nucleico invasor foráneo a través de hibridación). Las unidades de ARNcr de ácido nucleico invasor foráneo diana hibridado pueden ser sometidas a escisión por proteínas Cas. La interferencia del ácido nucleico diana puede requerir un motivo adyacente al espaciador (PAM) en un ácido nucleico diana.
Tipos de sistemas de CRISPR
Puede haber cuatro tipos de sistemas de CRISPR: Tipo I, Tipo II, Tipo III y Tipo U. Se puede encontrar más de un tipo de sistema de CRISPR en un organismo. Los sistemas de CRISPR pueden ser complementarios entre sí y/o pueden prestar unidades funcionales en trans para facilitar el procesamiento del locus de CRISPR.
Sistemas de CRISPR de tipo I
La biogénesis del ARNcr en los sistemas de CRISPR de Tipo I puede comprender la escisión por endorribonucleasa de repeticiones de la matriz de pre-ARNcr, que puede producir una pluralidad de ARNcr. Los ARNcr de los sistemas de Tipo I no pueden someterse a recorte de ARNcr. Un ARNcr puede procesarse a partir de una matriz de pre-ARNcr mediante un complejo multiproteína denominado Cascade (que se origina a partir del complejo asociado a CRISPR para la defensa antivírica). Cascade puede comprender subunidades de proteínas (por ejemplo, CasA-CasE). Algunas de las subunidades pueden ser miembros de la superfamilia de proteínas misteriosas asociadas a repeticiones (RAMP) (por ejemplo, familias Cas5 y Cas6). El complejo de Cascade-ARNcr (es decir, complejo de interferencia) puede reconocer el ácido nucleico diana a través de la hibridación del ARNcr con el ácido nucleico diana. El complejo de interferencia de Cascade puede reclutar la helicasa/nucleasa Cas3 que puede actuar en trans para facilitar la escisión del ácido nucleico diana. La nucleasa Cas3 puede escindir el ácido nucleico diana (por ejemplo, con su dominio nucleasa HD). El ácido nucleico diana de un sistema de CRISPR de Tipo I puede comprender un PAM. El ácido nucleico diana de un sistema de CRISPR DE Tipo I puede ser ADN.
Los sistemas de Tipo I pueden subdividirse aún más por su especie de origen. Los sistemas de Tipo I pueden comprender: las subfamilias de los Tipos IA (Aeropyrum pernix o CASS5); IB (Thermotoga neapolitana- Haloarcula marismortui o CASS7); IC (Desulfovibrio vulgaris o CASS1); ID; IE (Escherichia coli o CASS2); e IF (Yersinia pestis o CASS3).
Sistemas de CRISPR de Tipo II
La biogénesis de ARNcr en un sistema de CRISPR de Tipo II puede comprender un ARN de CRISPR de activación en trans (ARNcrtra). Un ARNcrtra puede ser modificado por RNasaIII endógena. El ARNcrtra del complejo puede hibridarse con una repetición de ARNcr en la matriz de pre-ARNcr. RnasaIII endógena puede ser reclutada para escindir el pre-ARNcr. Los ARNcr escindidos pueden someterse a un recorte de exorribonucleasa para producir la forma madura de ARNcr (por ejemplo, recorte de 5'). El ARNcrtra puede permanecer hibridado con el ARNcr. El ARNcrtra y el ARNcr pueden asociarse con un polipéptido dirigido a un sitio (por ejemplo, Cas9). El ARNcr del complejo de ARNcr-ARNcrtra-Cas9 puede guiar al complejo a un ácido nucleico diana con el que el ARNcr puede hibridarse. La hibridación del ARNcr con el ácido nucleico diana puede activar a Cas9 para la escisión del ácido nucleico diana. El ácido nucleico diana de un sistema de CRISPR de Tipo II puede comprender un PAM. En algunas realizaciones, un PAM es esencial para facilitar la unión de un polipéptido dirigido a un sitio (por ejemplo, Cas9) a un ácido nucleico diana. Los sistemas de Tipo II se pueden subdividir en II-A (Nmeni o CASS4) y II-B (Nmeni o CASS4).
Sistemas de CRISPR de Tipo III
La biogénesis de ARNcr de los sistemas de CRISPR de Tipo III puede comprender una etapa de escisión por endorribonucleasa de repeticiones de la matriz de pre-ARNcr, que puede producir una pluralidad de ARNcr. Las repeticiones del sistema de CRISPR de Tipo III pueden ser regiones monocatenarias no estructuradas. Las repeticiones pueden ser reconocidas y escindidas por un miembro de la superfamilia de endorribonucleasas RAMP (por ejemplo, Cas6). Los ARNcr de los sistemas de Tipo III (por ejemplo, Tipo III-B) pueden someterse a recorte de ARNcr (por ejemplo, recorte de 3'). Los sistemas de Tipo III pueden comprender una proteína similar a la polimerasa (por ejemplo, Cas10). Cas10 puede comprender un dominio homólogo a un dominio de palma.
Los sistemas de Tipo III pueden procesar pre-ARNcr con un complejo que comprende una pluralidad de proteínas que forman parte de la superfamilia RAMP y una o más proteínas CRISPR de tipo polimerasa. Los sistemas de Tipo III se pueden dividir en III-A y III-B. Un complejo de interferencia del sistema DE Tipo III-A (es decir, complejo Csm) puede dirigirse a ácido nucleico plasmídico. La escisión del ácido nucleico plasmídico puede ocurrir con el dominio nucleasa HD de una proteína similar a la polimerasa en el complejo. Un complejo de interferencia del sistema de Tipo III-B (es decir, complejo Cmr) puede dirigirse a ARN.
Sistemas de CRISPR de Tipo U
Los sistemas de CRISPR de Tipo U pueden no comprender los genes distintivos de ninguno de los sistemas de CRISPR de Tipo I-III (por ejemplo, Cas3, Cas9, Cas6, Cas1, Cas2). Los ejemplos de genes Cas de CRISPR de Tipo U pueden incluir, pero sin limitación, Csf1, Csf2, Csf3, Csf4. Los genes Cas de Tipo U pueden ser homólogos muy distantes de los genes Cas de Tipo I-III. Por ejemplo, Csf3 puede ser muy divergente, pero funcionalmente similar a los miembros de la familia Cas5. Un sistema de Tipo U puede funcionar complementariamente en trans con un sistema de Tipo I-III. En algunos casos, los sistemas de tipo U pueden no estar asociados con el procesamiento de matrices de CRISPR. Los sistemas de Tipo U pueden representar un sistema alternativo de defensa contra invasores foráneos.
Superfamilia de RAMP
Las proteínas misteriosas asociadas a repeticiones (proteínas RAMP) se pueden caracterizar por un pliegue proteico que comprende un motivo pappap [beta-alfa-beta-beta-alfa-beta] de cadenas p (p) y hélices a (a). Una proteína RAMP puede comprender un motivo de reconocimiento de ARN (RRM) (que puede comprender una ferredoxina o un pliegue de tipo ferredoxina). Las proteínas RAMP pueden comprender un RRM N-terminal. El dominio C-terminal de las proteínas RAMP puede variar, pero también puede comprender un RRM. Los miembros de la familia RAMP pueden reconocer el ácido nucleico estructurado y/o no estructurado. Los miembros de la familia RAMP pueden reconocer el ácido nucleico monocatenario y/o bicatenario. Las proteínas RAMP pueden participar en la biogénesis y/o la etapa de interferencia de los sistemas de CRISPR de Tipo I y Tipo III. Los miembros de la superfamilia RAMP pueden comprender miembros de familias Cas7, Cas6 y Cas5. Los miembros de la superfamilia RAMP pueden ser endorribonucleasas.
Los dominios RRM de la superfamilia RAMP pueden ser extremadamente divergentes. Los dominios RRM pueden comprender al menos aproximadamente un 5%, al menos aproximadamente un 10%, al menos aproximadamente un 15 %, al menos aproximadamente un 20 %, al menos aproximadamente un 25 %, al menos aproximadamente un 30 %, al menos aproximadamente un 35 %, al menos aproximadamente un 40 %, al menos aproximadamente un 45 %, al menos aproximadamente un 50 %, al menos aproximadamente un 55 %, al menos aproximadamente un 60 %, al menos aproximadamente un 65 %, al menos aproximadamente un 70 %, al menos aproximadamente un 75 %, al menos aproximadamente un 80 %, al menos aproximadamente un 85 %, al menos aproximadamente un 90 %, al menos aproximadamente un 95 % o 100 % de homología de secuencia o estructural con un dominio RRM ilustrativo de tipo silvestre (por ejemplo, un dominio RRM de Cas7). Los dominios RRM pueden comprender, como máximo, aproximadamente un 5 %, como máximo, aproximadamente un 10 %, como máximo, aproximadamente un 15%, como máximo, aproximadamente un 20%, como máximo, aproximadamente un 25%, como máximo, aproximadamente un 30 %, como máximo, aproximadamente un 35 %, como máximo, aproximadamente un 40 %, como máximo, aproximadamente un 45 %, como máximo, aproximadamente un 50 %, como máximo, aproximadamente un 55 %, como máximo, aproximadamente un 60 %, como máximo, aproximadamente un 65 %, como máximo, aproximadamente un 70 %, como máximo, aproximadamente un 75 %, como máximo, aproximadamente un 80 %, como máximo, aproximadamente un 85 %, como máximo, aproximadamente un 90 %, como máximo aproximadamente un 95% o 100% de homología de secuencia o estructural con un dominio RRM ilustrativo de tipo silvestre (por ejemplo, un dominio RRM de Cas7).
Familia Cas7
Los miembros de la familia Cas7 pueden ser una subclase de proteínas de la familia RAMP. Las proteínas de la familia Cas7 se pueden clasificar en sistemas de CRISPR de Tipo I. Los miembros de la familia Cas7 pueden no comprender un bucle rico en glicina que sea familiar para algunos miembros de la familia RAMP. Los miembros de la familia Cas7 pueden comprender un dominio RRM. Los miembros de la familia Cas7 pueden incluir, pero sin limitación, Cas7 (COG1857), Cas7 (COG3649), Cas7 (CT1975), Csy3, Csm3, Cmr6, Csm5, Cmr4, Cmr1, Csf2 y Csc2.
Familia Cas6
La familia Cas6 puede ser una subfamilia de RAMP. Los miembros de la familia Cas6 pueden comprender dos dominios similares a motivos de reconocimiento de ARN (RRM). Un miembro de la familia Cas6 (por ejemplo, Cas6f) puede comprender un dominio RRM N-terminal y un dominio C-terminal distinto que puede mostrar una similitud de secuencia u homología estructural débil con un dominio RRM. Los miembros de la familia Cas6 pueden comprender una histidina catalítica que puede participar en la actividad endorribonucleasa. Se puede encontrar un motivo comparable en las familias de RAMP Cas5 y Cas7. Los miembros de la familia Cas6 pueden incluir, pero sin limitación, Cas6, Cas6e, Cas6f (por ejemplo, Csy4).
Familia Cas5
La familia Cas5 puede ser una subfamilia de RAMP. La familia Cas5 se puede dividir en dos subgrupos: un subgrupo que puede comprender dos dominios RRM y un subgrupo que puede comprender un dominio RRM. Los miembros de la familia Cas5 pueden incluir, pero sin limitación, Csm4, Csx10, Cmr3, Cas5, Cas5(BH0337), Csy2, Csc1, Csf3.
Genes Cas
Los genes Cas de CRISPR ilustrativos pueden incluir Cas1, Cas2, Cas3' (cebado de Cas3), Cas3" (cebado doble de Cas3), Cas4, Cas5, Cas6, Cas6e (anteriormente denominado CasE, Cse3), Cas6f (es decir, Csy4), Cas7, Cas8a1, Cas8a2, Cas8b, Cas8c, Cas9, Cas10, Cas10d, Csy1, Csy2, Csy3, Cse1, Cse2, Csc1, Csc2, Csa5, Csn2, Csm2, Csm3, Csm4, Csm5, Csm6, Cmr1, Cmr3, Cmr4, Cmr5, Cmr6, Csb1, Csb2, Csb3, Csx17, Csx14, Csx10, Csx16, CsaX, Csx3, Csx1, Csx15, Csf1, Csf2, Csf3, Csf4. La Tabla 1 proporciona una categorización ilustrativa de genes Cas de CRISPR según el tipo de sistema de CRISPR.
El sistema de nombramiento de los genes Cas de CRISPR ha experimentado una amplia reestructuración desde que se descubrieron los genes Cas. Para los fines de la presente solicitud, los nombres de los genes Cas usados en el presente documento se basan en el sistema de nombramiento descrito en Makarova et al. "Evolution and classification of the CRISPR-Cas systems". Nature Reviews Microbiology. Junio de 2011; 9(6): 467-477. Doi:10.1038/nrmicro2577.
T l 1: l ifi i n il r iv n RI PR n l i RI PR

Polipéptidos dirigidos a un sitio
Un polipéptido dirigido a un sitio puede ser un polipéptido que puede unirse a un ácido nucleico diana. Un polipéptido dirigido a un sitio puede ser una nucleasa.
Un polipéptido dirigido a un sitio puede comprender un dominio de unión a ácido nucleico. El dominio de unión a ácido nucleico puede comprender una región que está en contacto con un ácido nucleico. Un dominio de unión a ácido nucleico puede comprender un ácido nucleico. Un dominio de unión a ácido nucleico puede comprender un material proteico. Un dominio de unión a ácido nucleico puede comprender ácido nucleico y un material proteico. Un dominio de unión a ácido nucleico puede comprender ARN. Puede haber un solo dominio de unión a ácido nucleico. Los ejemplos de dominios de unión a ácido nucleico pueden incluir, pero sin limitación, un dominio hélice-vuelta-hélice, un dominio de dedo de cinc, un dominio de cremallera de leucina (bZIP), un dominio de hélice alada, un dominio de hélice alada-vuelta-hélice, un dominio hélice-lazo-hélice, un dominio de caja HMG, un dominio Wor3, un dominio de inmunoglobulina, un dominio B3, un dominio TALE, un dominio de motivo de reconocimiento de ARN, un dominio de motivo de unión a ARN bicatenario, un dominio de unión a ácido nucleico bicatenario, un dominio de unión a ácido nucleico monocatenario, un dominio KH, un dominio PUF, un dominio de caja RGG, un dominio de caja DEAD/DEAH, un dominio PAZ, un dominio Piwi y un dominio de choque frío.
Un dominio de unión a ácido nucleico puede ser un dominio de una proteína argonauta. Una proteína argonauta puede
ser una argonauta eucariota o una argonauta procariota. Una proteína argonauta puede unirse a ARN, ADN, o tanto a ARN como a ADN. Una proteína argonauta puede escindir a Rn o ADN, o tanto ARN como ADN. En algunos casos, una proteína argonauta se une a un ADN y escinde un ADN diana.
En algunos casos, dos o más dominios de unión a ácido nucleico pueden estar unidos entre sí. La unión de una pluralidad de dominios de unión a ácido nucleico entre sí puede proporcionar una mayor especificidad dirigida a un polinucleótido. Dos o más dominios de unión a ácido nucleico pueden unirse mediante uno o más enlazadores. El enlazador puede ser un enlazador flexible. Los enlazadores pueden comprender 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11,12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 30, 35, 40 o más aminoácidos de longitud. Los enlazadores pueden comprender al menos el 5 %, 10 %, 15 %, 20 %, 25 %, 30 %, 35 %, 40 %, 45 %, 50 %, 55 %, 60 %, 65 %, 70 %, 75 %, 80 %, 85 %, 90 %, 95 % o 100 % de contenido de glicina. Los enlazadores pueden comprender, como máximo, el 5 %, 10 %, 15 %, 20 %, 25 %, 30 %, 35 %, 40 %, 45 %, 50 %, 55 %, 60 %, 65 %, 70 %, 75 %, 80 %, 85 %, 90 %, 95 % o 100 % de contenido de glicina. Los enlazadores pueden comprender al menos el 5 %, 10 %, 15 %, 20 %, 25 %, 30 %, 35 %, 40 %, 45 %, 50 %, 55 %, 60 %, 65 %, 70 %, 75 %, 80 %, 85 %, 90 %, 95 % o 100 % de contenido de serina. Los enlazadores pueden comprender, como máximo, el 5 %, 10 %, 15 %, 20 %, 25 %, 30 %, 35 %, 40 %, 45 %, 50 %, 55 %, 60 %, 65 %, 70 %, 75 %, 80 %, 85 %, 90 %, 95 % o 100 % de contenido de serina.
Los dominios de unión a ácido nucleico pueden unirse a secuencias de ácido nucleico. Los dominios de unión a ácido nucleico pueden unirse a ácidos nucleicos mediante hibridación. Los dominios de unión a ácido nucleico pueden ser diseñados (por ejemplo, diseñados para hibridarse con una secuencia en un genoma). Un dominio de unión a ácido nucleico puede diseñarse mediante técnicas de clonación molecular (por ejemplo, evolución dirigida, mutación específica y mutagénesis racional).
Un polipéptido dirigido a un sitio puede comprender un dominio de escisión de ácido nucleico. El dominio de escisión de ácido nucleico puede ser un dominio de escisión de ácido nucleico de cualquier proteína de escisión de ácido nucleico. El dominio de escisión de ácido nucleico puede proceder de una nucleasa. Los dominios de escisión de ácido nucleico adecuados incluyen el dominio de escisión de ácido nucleico de endonucleasas (por ejemplo, endonucleasa AP, enonucleasa RecBCD, endonucleasa T7, endonucleasa T4 IV, endonucleasa Bal 31, Endonucleasa I (endo I), Nucleasa microcócica, Endonucleasa II (endo VI, exo III)), exonucleasas, nucleasas de restricción, endorribonucleasas, exorribonucleasas, RNasas (por ejemplo, ARNasa I, II o III). En algunos casos, el dominio de escisión de ácido nucleico puede proceder de la endonucleasa FokI. Un polipéptido dirigido a un sitio puede comprender una pluralidad de dominios de escisión de ácido nucleico. Los dominios de escisión de ácido nucleico pueden estar unidos entre sí. Dos o más dominios de escisión de ácido nucleico se pueden unir mediante un enlazador. En algunas realizaciones, el enlazador puede ser un enlazador flexible. Los enlazadores pueden comprender 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 30, 35, 40 o más aminoácidos de longitud. En algunas realizaciones, un polipéptido dirigido a un sitio puede comprender la pluralidad de dominios de escisión de ácido nucleico.
Un polipéptido dirigido a un sitio (por ejemplo, Cas9, argonauta) puede comprender dos o más dominios nucleasa. Cas9 puede comprender un dominio nucleasa de tipo HNH o HNH y/o un dominio nucleasa de tipo RuvC o RuvC. Los dominios de tipo HNH o HNH pueden comprender un pliegue de tipo McrA. Los dominios de tipo HNH o HNH pueden comprender dos cadenas p paralelas y una hélice a. Los dominios de tipo HNH o HNH pueden comprender un sitio de unión a metal (por ejemplo, sitio de unión a cationes divalentes). Los dominios de tipo HNH o HNH pueden escindir una cadena de un ácido nucleico diana (por ejemplo, cadena complementaria de la cadena dirigida a ARNcr). Las proteínas que comprenden un dominio de tipo HNH o HNH pueden incluir endonucleasas, clicinas, endonucleasas de restricción, transposasas y factores de empaquetamiento de ADN.
Los dominios RuvC o de tipo RuvC pueden comprender un pliegue de RNasaH o de tipo RNasaH. Los dominios RuvC/RNasaH pueden participar en un conjunto diverso de funciones basadas en ácidos nucleicos, incluyendo la actuación sobre ARN y ADN. El dominio RNasaH puede comprender 5 cadenas p rodeadas por una pluralidad de hélices a. Los dominios RuvC/RNasaH o de tipo RuvC/RNasaH pueden comprender un sitio de unión a metal (por ejemplo, sitio de unión a cationes divalentes). Los dominios RuvC/RNasaH o de tipo RuvC/RNasaH pueden escindir una cadena de un ácido nucleico diana (por ejemplo, cadena no complementaria de la cadena dirigida a ARNcr). Las proteínas que comprenden un dominio RuvC, de tipo RuvC o de tipo RNasaH pueden incluir RNasaH, RuvC, transposasas de ADN, integrasas retrovíricas y proteínas argonautas).
El polipéptido dirigido a un sitio puede ser una endorribonucleasa. El polipéptido dirigido a un sitio puede ser un polipéptido dirigido a un sitio inactivo enzimáticamente. El polipéptido dirigido a un sitio puede ser un polipéptido dirigido a un sitio condicionalmente inactivo enzimáticamente. Los polipéptidos dirigidos a un sitio pueden introducir roturas bicatenarias o roturas monocatenarias en ácido nucleico, (por ejemplo, ADN genómico). La rotura bicatenaria puede estimular las vías de reparación del ADN endógenas de una célula (por ejemplo, recombinación homóloga y unión de extremos no homólogos (NHEJ) o unión de extremos no homólogos alternativa (A-NHEJ)). La NHEJ puede reparar el ácido nucleico escindido sin la necesidad de una plantilla homóloga. Esto puede producir eliminaciones del ácido nucleico diana. La recombinación homóloga (HR) puede ocurrir con una plantilla homóloga. La plantilla homóloga puede comprender secuencias que son homólogas a las secuencias que flanquean el sitio de escisión del ácido nucleico diana. Una vez escindido un ácido nucleico diana por un polipéptido dirigido a un sitio, el sitio de escisión
puede destruirse (por ejemplo, el sitio puede no ser accesible para otra serie de escisión con el ácido nucleico dirigido a ácido nucleico y el polipéptido dirigido a un sitio originales).
En algunos casos, la recombinación homóloga puede introducir una secuencia polinucleotídica exógena en el sitio de escisión del ácido nucleico diana. Una secuencia polinucleotídica exógena puede denominarse polinucleótido donante. En algunos casos de los métodos de divulgación, se puede insertar el polinucleótido donante, una parte de un polinucleótido donante, una copia del polinucleótido donante o una parte de la copia del polinucleótido donante en el sitio de escisión del ácido nucleico diana. Un polinucleótido donante puede ser una secuencia polinucleotídica exógena. Un polinucleótido donante puede ser una secuencia no natural en el sitio de escisión del ácido nucleico diana. Un vector puede comprender un polinucleótido donante. Las modificaciones del ADN diana debidas a la NHEJ y/o HR pueden conducir a, por ejemplo, mutaciones, eliminaciones, alteraciones, integraciones, corrección genética, reemplazo de genes, marcaje de genes, inserción de transgenes, eliminación de nucleótidos, disrupción genética y/o mutación genética. El proceso de integración de ácido nucleico no nativo en el ADN genómico puede denominarse diseño genómico.
En algunos casos, el polipéptido dirigido a un sitio puede comprender una secuencia de aminoácidos que tenga, como máximo, un 10%, como máximo, un 15 %, como máximo, un 20 %, como máximo, un 30 %, como máximo, un 40 %, como máximo, un 50 %, como máximo, un 60 %, como máximo, un 70 %, como máximo, un 75 %, como máximo, un 80 %, como máximo, un 85 %, como máximo, un 90 %, como máximo, un 95 %, como máximo, un 99 % o un 100 % de identidad de secuencia de aminoácidos con un polipéptido dirigido a un sitio ilustrativo de tipo silvestre (por ejemplo, Cas9 de S. pyogenes, SEQ ID NO: 8).
En algunos casos, el polipéptido dirigido a un sitio puede comprender una secuencia de aminoácidos que tenga al menos un 10 %, al menos un 15 %, 20 %, al menos un 30 %, al menos un 40 %, al menos un 50 %, al menos un 60 %, al menos un 70 %, al menos un 75 %, al menos un 80 %, al menos un 85 %, al menos un 90 %, al menos un 95 %, al menos un 99 % o 100 %, de identidad de secuencia de aminoácidos con un polipéptido dirigido a un sitio ilustrativo de tipo silvestre (por ejemplo, Cas9 de S. pyogenes, SEQ ID NO: 8).
En algunos casos, el polipéptido dirigido a un sitio puede comprender una secuencia de aminoácidos que tenga, como máximo, un 10%, como máximo, un 15 %, como máximo, un 20 %, como máximo, un 30 %, como máximo, un 40 %, como máximo, un 50 %, como máximo, un 60 %, como máximo, un 70 %, como máximo, un 75 %, como máximo, un 80 %, como máximo, un 85 %, como máximo, un 90 %, como máximo, un 95 %, como máximo, un 99 % o un 100 % de identidad de secuencia de aminoácidos con el dominio nucleasa de un polipéptido dirigido a un sitio ilustrativo de tipo silvestre (por ejemplo, Cas9 de S. pyogenes, SEQ ID NO: 8).
Un polipéptido dirigido a un sitio puede comprender al menos un 70, 75, 80, 85, 90, 95, 97, 99 o 100 % de identidad con el polipéptido dirigido a un sitio de tipo silvestre (por ejemplo, Cas9 de S. pyogenes, SEQ ID NO: 8) sobre 10 aminoácidos contiguos. Un polipéptido dirigido a un sitio puede comprender, como máximo, un 70, 75, 80, 85, 90, 95, 97, 99 o 100 % de identidad con el polipéptido dirigido a un sitio de tipo silvestre (por ejemplo, Cas9 de S. pyogenes, SEQ ID NO: 8) sobre 10 aminoácidos contiguos. Un polipéptido dirigido a un sitio puede comprender al menos un 70, 75, 80, 85, 90, 95, 97, 99 o 100 % de identidad con un polipéptido dirigido a un sitio de tipo silvestre (por ejemplo, Cas9 de S. pyogenes, SEQ ID NO: 8) sobre 10 aminoácidos contiguos en un dominio nucleasa HNH del polipéptido dirigido a un sitio. Un polipéptido dirigido a un sitio puede comprender, como máximo, un 70, 75, 80, 85, 90, 95, 97, 99 o 100 % de identidad con un polipéptido dirigido a un sitio de tipo silvestre (por ejemplo, Cas9 de S. pyogenes, SEQ ID NO: 8) sobre 10 aminoácidos contiguos en un dominio nucleasa HNH del polipéptido dirigido a un sitio. Un polipéptido dirigido a un sitio puede comprender al menos un 70, 75, 80, 85, 90, 95, 97, 99 o 100 % de identidad con un polipéptido dirigido a un sitio de tipo silvestre (por ejemplo, Cas9 de S. pyogenes, SEQ ID NO: 8) sobre 10 aminoácidos contiguos en un dominio nucleasa RuvC del polipéptido dirigido a un sitio. Un polipéptido dirigido a un sitio puede comprender, como máximo, un 70, 75, 80, 85, 90, 95, 97, 99 o 100% de identidad con un polipéptido dirigido a un sitio de tipo silvestre (por ejemplo, Cas9 de S. pyogenes, SEQ ID NO: 8) sobre 10 aminoácidos contiguos en un dominio nucleasa RuvC del polipéptido dirigido a un sitio.
En algunos casos, el polipéptido dirigido a un sitio puede comprender una secuencia de aminoácidos que tenga al menos un 10 %, al menos un 15 %, al menos un 20 %, al menos un 30 %, al menos un 40 %, al menos un 50 %, al menos un 60 %, al menos un 70 %, al menos un 75 %, al menos un 80 %, al menos un 85 %, al menos un 90 %, al menos un 95 %, al menos un 99 % o 100 % de identidad de secuencia de aminoácidos con el dominio nucleasa de un polipéptido dirigido a un sitio ilustrativo de tipo silvestre (por ejemplo, Cas9 de S. pyogenes).
El polipéptido dirigido a un sitio puede comprender una forma modificada de un polipéptido dirigido a un sitio ilustrativo de tipo silvestre. La forma modificada del polipéptido dirigido a un sitio ilustrativo de tipo silvestre puede comprender un cambio de aminoácido (por ejemplo, eliminación, inserción o sustitución) que reduzca la actividad de escisión de ácido nucleico del polipéptido dirigido a un sitio. Por ejemplo, la forma modificada del polipéptido dirigido a un sitio ilustrativo de tipo silvestre puede tener menos del 90 %, menos del 80 %, menos del 70 %, menos del 60 %, menos del 50 %, menos del 40 %, menos del 30 %, menos del 20 %, menos del 10 %, menos del 5 % o menos del 1 % de la actividad de escisión de ácido nucleico del polipéptido dirigido a un sitio ilustrativo de tipo silvestre (por ejemplo, Cas9 de S. pyogenes). La forma modificada del polipéptido dirigido a un sitio puede no tener actividad de escisión de ácido
nucleico sustancial. Cuando un polipéptido dirigido a un sitio es una forma modificada que no tiene actividad de escisión de ácido nucleico sustancial, se puede denominar "inactivo enzimáticamente".
La forma modificada del polipéptido dirigido a un sitio ilustrativo de tipo silvestre puede tener más del 90 %, más del 80 %, más del 70 %, más del 60 %, más del 50 %, más del 40 %, más del 30 %, más del 20 %, más del 10 %, más del 5 % o más del 1 % de la actividad de escisión de ácido nucleico del polipéptido dirigido a un sitio ilustrativo de tipo silvestre (por ejemplo, Cas9 de S. pyogenes).
La forma modificada del polipéptido dirigido a un sitio puede comprender una mutación. La forma modificada del polipéptido dirigido a un sitio puede comprender una mutación que le permita inducir una rotura monocatenaria (SSB) en un ácido nucleico diana (por ejemplo, cortando solo una de las cadenas principales de azúcar-fosfato del ácido nucleico diana). La mutación puede dar lugar a menos del 90 %, menos del 80 %, menos del 70 %, menos del 60 %, menos del 50 %, menos del 40 %, menos del 30 %, menos del 20 %, menos del 10 %, menos del 5 % o menos del 1 % de la actividad de escisión de ácido nucleico en uno o más de la pluralidad de dominios de escisión de ácido nucleico del polipéptido dirigido a un sitio de tipo silvestre (por ejemplo, Cas9 de S. pyogenes). La mutación puede hacer que uno o más de la pluralidad de dominios de escisión de ácido nucleico conserve la capacidad de escindir la cadena complementaria del ácido nucleico diana, pero que tenga una menor capacidad de escindir la cadena no complementaria del ácido nucleico diana. La mutación puede hacer que uno o más de la pluralidad de dominios de escisión de ácido nucleico conserve la capacidad de escindir la cadena no complementaria del ácido nucleico diana, pero que tenga una menor capacidad de escindir la cadena complementaria del ácido nucleico diana. Por ejemplo, los restos del polipéptido Cas9 ilustrativo de tipo silvestre de S. pyogenes tales como Asp10, His840, Asn854 y Asn856 pueden mutarse para inactivar uno o más de la pluralidad de dominios de escisión de ácido nucleico (por ejemplo, dominios nucleasa). Los restos que se mutarán pueden corresponder a los restos Asp10, His840, Asn854 y Asn856 del polipéptido Cas9 ilustrativo de S. pyogenes de tipo silvestre (por ejemplo, según lo determinado por alineamiento de secuencia y/o estructural). Los ejemplos no limitantes de mutaciones pueden incluir D10A, H840A, N854A o N856A. Un experto en la materia reconocerá que son adecuadas las mutaciones distintas de las sustituciones de alanina.
Una mutación D10A se puede combinar con una o más de las mutaciones H840A, N854A o N856A para producir un polipéptido dirigido a un sitio que carezca sustancialmente de actividad de escisión de ADN. Una mutación H840A se puede combinar con una o más de las mutaciones D10A, N854A o N856A para producir un polipéptido dirigido a un sitio que carezca sustancialmente de actividad de escisión de ADN. Una mutación N854A se puede combinar con una o más de las mutaciones H840A, D10A o N856A para producir un polipéptido dirigido a un sitio que carezca sustancialmente de actividad de escisión de ADN. Una mutación N856A se puede combinar con una o más de las mutaciones H840A, N854A o D10A para producir un polipéptido dirigido a un sitio que carezca sustancialmente de actividad de escisión de ADN. Los polipéptidos dirigidos a un sitio que comprenden un dominio nucleasa sustancialmente inactivo pueden denominarse nickasas.
Las mutaciones de la divulgación se pueden producir por mutación dirigida a un sitio. Las mutaciones pueden incluir sustituciones, adiciones y eliminaciones, o cualquier combinación de las mismas. En algunos casos, la mutación convierte al aminoácido mutado en alanina. En algunos casos, la mutación convierte al aminoácido mutado en otro aminoácido (por ejemplo, glicina, serina, treonina, cisteína, valina, leucina, isoleucina, metionina, prolina, fenilalanina, tirosina, triptófano, ácido aspártico, ácido glutámico, asparaginas, glutamina, histidina, lisina o arginina). La mutación puede convertir al aminoácido mutado en un aminoácido no natural (por ejemplo, selenometionina). La mutación puede convertir al aminoácido mutado en miméticos de aminoácidos (por ejemplo, fosfomiméticos). La mutación puede ser una mutación conservativa. Por ejemplo, la mutación puede convertir al aminoácido mutado en aminoácidos que se parecen en tamaño, forma, carga, polaridad, configuración y/o rotámeros de los aminoácidos mutados (por ejemplo, mutación de cisteína/serina, mutación de lisina/asparagina, mutación de histidina/fenilalanina).
En algunos casos, el polipéptido dirigido a un sitio (por ejemplo, el polipéptido dirigido a un sitio variante, mutado, inactivo enzimáticamente y/o condicionalmente inactivo enzimáticamente) puede dirigirse al ácido nucleico. El polipéptido dirigido a un sitio (por ejemplo, endorribonucleasa variante, mutada, enzimáticamente inactiva y/o condicionalmente enzimáticamente inactiva) puede dirigirse a ARN. Los polipéptidos dirigidos a un sitio que pueden dirigirse al ARN pueden incluir miembros de otras subfamilias de CRISPR tales como Cas6 y Cas5.
El polipéptido dirigido a un sitio puede comprender una o más secuencias no nativas (por ejemplo, una fusión).
Un polipéptido dirigido a un sitio puede comprender una secuencia de aminoácidos que comprenda al menos un 15 % de identidad de aminoácidos con una Cas9 de una bacteria (por ejemplo, S. pyogenes), un dominio de unión a ácido nucleico y dos dominios de escisión de ácido nucleico (es decir, un dominio h Nh y un dominio RuvC).
Un polipéptido dirigido a un sitio puede comprender una secuencia de aminoácidos que comprenda al menos un 15 % de identidad de aminoácidos con una Cas9 de una bacteria (por ejemplo, S. pyogenes) y dos dominios de escisión de ácido nucleico (es decir, un dominio HNH y un dominio RuvC).
Un polipéptido dirigido a un sitio puede comprender una secuencia de aminoácidos que comprenda al menos un 15 % de identidad de aminoácidos con una Cas9 de una bacteria (por ejemplo, S. pyogenes) y dos dominios de escisión de
ácido nucleico, en donde uno o ambos dominios de escisión de ácido nucleico comprenden al menos un 50 % de identidad de aminoácidos con un dominio nucleasa de Cas9 de una bacteria (por ejemplo, S. pyogenes).
Un polipéptido dirigido a un sitio puede comprender una secuencia de aminoácidos que comprenda al menos un 15 % de identidad de aminoácidos con una Cas9 de una bacteria (por ejemplo, S. pyogenes), dos dominios de escisión de ácido nucleico (es decir, un dominio HNH y un dominio RuvC) y un enlazador que una al polipéptido dirigido a un sitio con una secuencia no nativa.
Un polipéptido dirigido a un sitio puede comprender una secuencia de aminoácidos que comprenda al menos un 15 % de identidad de aminoácidos con una Cas9 de una bacteria (por ejemplo, S. pyogenes), dos dominios de escisión de ácido nucleico (es decir, un dominio HNH y un dominio RuvC), en donde el polipéptido dirigido a un sitio comprende una mutación en uno o ambos dominios de escisión de ácido nucleico que reduce la actividad de escisión de los dominios nucleasa en al menos un 50 %.
Un polipéptido dirigido a un sitio puede comprender una secuencia de aminoácidos que comprenda al menos un 15 % de identidad de aminoácidos con una Cas9 de una bacteria (por ejemplo, S. pyogenes), y dos dominios de escisión de ácido nucleico (es decir, un dominio HNH y un dominio RuvC), en donde uno de los dominios nucleasa comprende la mutación de ácido aspártico 10 y/o en donde uno de los dominios nucleasa comprende la mutación de histidina 840, y en donde la mutación reduce la actividad de escisión de los dominios nucleasa en al menos un 50 %.
Endorribonucleasas
En algunas realizaciones, un polipéptido dirigido a un sitio puede ser una endorribonucleasa.
En algunos casos, la endorribonucleasa puede comprender una secuencia de aminoácidos que tenga, como máximo, aproximadamente un 20 %, como máximo, aproximadamente un 30 %, como máximo, aproximadamente un 40 %, como máximo, aproximadamente un 50 %, como máximo, aproximadamente un 60 %, como máximo, aproximadamente un 70 %, como máximo, aproximadamente un 75 %, como máximo, aproximadamente un 80 %, como máximo, aproximadamente un 85 %, como máximo, aproximadamente un 90 %, como máximo, aproximadamente un 95%, como máximo, aproximadamente un 99% o 100% de identidad y/u homología de secuencia de aminoácidos con una endorribonucleasa de referencia de tipo silvestre. La endorribonucleasa puede comprender una secuencia de aminoácidos que tenga al menos aproximadamente un 20 %, al menos aproximadamente un 30 %, al menos aproximadamente un 40 %, al menos aproximadamente un 50 aproximadamente un 60 %, al  menos aproximadamente un 70
menos aproximadamente un 70 menos aproximadamente un 75 aproximadamente un 80 %, al menos aproximadamente un 85 %, al menos aproximadamente un 90 aproximadamente un 95 %, al menos aproximadamente un 99 % o un 100 % de identidad y/u homología de secuencia de aminoácidos con una endorribonucleasa de referencia de tipo silvestre (por ejemplo, Csy4 de P. aeruginosa). La endorribonucleasa de referencia puede ser un miembro de la familia Cas6 (por ejemplo, Csy4, Cas6). La endorribonucleasa de referencia puede ser un miembro de la familia Cas5 (por ejemplo, Cas5 de familia D. vulgaris).
menos aproximadamente un 75 aproximadamente un 80 %, al menos aproximadamente un 85 %, al menos aproximadamente un 90 aproximadamente un 95 %, al menos aproximadamente un 99 % o un 100 % de identidad y/u homología de secuencia de aminoácidos con una endorribonucleasa de referencia de tipo silvestre (por ejemplo, Csy4 de P. aeruginosa). La endorribonucleasa de referencia puede ser un miembro de la familia Cas6 (por ejemplo, Csy4, Cas6). La endorribonucleasa de referencia puede ser un miembro de la familia Cas5 (por ejemplo, Cas5 de familia D. vulgaris).
La endorribonucleasa de referencia puede ser un miembro de la familia CRISPR de Tipo I (por ejemplo, Cas3). Las endorribonucleasas de referencia pueden ser un miembro de la familia de Tipo II. La endorribonucleasa de referencia puede ser un miembro de la familia de Tipo III (por ejemplo, Cas6). Una endorribonucleasa de referencia puede ser miembro de la superfamilia de proteínas misteriosas asociadas con repeticiones (RAMP) (por ejemplo, Cas7).
La endorribonucleasa puede comprender modificaciones de aminoácidos (por ejemplo, sustituciones, eliminaciones, adiciones, etc.). La endorribonucleasa puede comprender una o más secuencias no nativas (por ejemplo, una fusión, un marcador de afinidad). Las modificaciones de aminoácidos pueden no alterar sustancialmente la actividad de la endorribonucleasa. Una endorribonucleasa que comprende modificaciones y/o fusiones de aminoácidos puede conservar al menos aproximadamente un 75 %, al menos aproximadamente un 80 %, al menos aproximadamente un
85 %, al menos aproximadamente un 90 %, al menos aproximadamente un 95 %, al menos aproximadamente 97 % o
100 % de actividad de la endorribonucleasa de tipo silvestre.
La modificación puede producir la alteración de la actividad enzimática de la endorribonucleasa. La modificación puede dar lugar a menos del 90 %, menos del 80 %, menos del 70 %, menos del 60 %, menos del 50 %, menos del 40 %, menos del 30 %, menos del 20 %, menos del 10 %, menos del 5 % o menos del 1 % de la endorribonucleasa. En algunos casos, la modificación se produce en el dominio nucleasa de una endorribonucleasa. Dichas modificaciones pueden dar lugar a menos del 90 %, menos del 80 %, menos del 70 %, menos del 60 %, menos del 50 %, menos del
40 %, menos del 30 %, menos del 20 %, menos del 10 %, menos del 5 % o menos del 1 % de la capacidad de escisión de ácido nucleico en uno o más de la pluralidad de dominios de escisión de ácido nucleico de la endorribonucleasa de tipo silvestre.
Endorribonucleasas condicionalmente inactivas enzimáticamente
En algunas realizaciones, una endorribonucleasa puede ser condicionalmente enzimáticamente inactiva. Una endorribonucleasa condicionalmente enzimáticamente inactiva puede unirse a un polinucleótido de una manera específica de la secuencia. Una endorribonucleasa condicionalmente enzimáticamente inactiva puede unirse a un
polinucleótido de una manera específica de la secuencia, pero no puede escindir el polirribonucleótido diana.
En algunos casos, la endorribonucleasa condicionalmente enzimáticamente inactiva puede comprender una secuencia de aminoácidos que tenga hasta aproximadamente un 20 %, hasta aproximadamente un 30 %, hasta aproximadamente un 40 %, hasta aproximadamente un 50 %, hasta aproximadamente un 60 %, hasta aproximadamente un 70 %, hasta aproximadamente un 75 %, hasta aproximadamente un 80 %, hasta aproximadamente un 85 %, hasta aproximadamente un 90 %, hasta aproximadamente un 95 %, hasta aproximadamente un 99% o un 100% de identidad y/u homología de secuencia de aminoácidos con una endorribonucleasa condicionalmente enzimáticamente inactiva de referencia (por ejemplo, Csy4 de P. aeruginosa). En algunos casos, la endorribonucleasa condicionalmente enzimáticamente inactiva puede comprender una secuencia de aminoácidos que tenga al menos aproximadamente un 20 %, al menos aproximadamente un 30 %, al menos aproximadamente un 40 %, al menos aproximadamente un 50 %, al menos aproximadamente un 60 %, al menos aproximadamente un 70 %, al menos aproximadamente un 75 %, al menos aproximadamente un 80 %, al menos aproximadamente un 85 %, al menos aproximadamente un 90 %, al menos aproximadamente un 95 %, al menos aproximadamente un 99% o un 100% de identidad y/u homología de secuencia de aminoácidos con una endorribonucleasa condicionalmente enzimáticamente inactiva de referencia (por ejemplo, Csy4 de P. aeruginosa).
La endorribonucleasa condicionalmente enzimáticamente inactiva puede comprender una forma modificada de una endorribonucleasa. La forma modificada de la endorribonucleasa puede comprender un cambio de aminoácido (por ejemplo, eliminación, inserción o sustitución) que reduzca la actividad de escisión de ácido nucleico de la endorribonucleasa. Por ejemplo, la forma modificada de la endorribonucleasa condicionalmente enzimáticamente inactiva puede tener menos del 90 %, menos del 80 %, menos del 70 %, menos del 60 %, menos del 50 %, menos del 40 %, menos del 30 %, menos del 20 %, menos del 10 %, menos del 5 % o menos del 1 % de la actividad de escisión de ácido nucleico de la endorribonucleasa condicionalmente enzimáticamente inactiva de referencia (por ejemplo, tipo silvestre) (por ejemplo, Csy4 de P. aeruginosa). La forma modificada de la endorribonucleasa condicionalmente enzimáticamente inactiva puede no tener actividad sustancial de escisión de ácido nucleico. Cuando una endorribonucleasa condicionalmente enzimáticamente inactiva es una forma modificada que no tiene una actividad sustancial de escisión de ácido nucleico, se puede denominar "inactiva enzimáticamente".
La forma modificada de la endorribonucleasa condicionalmente enzimáticamente inactiva puede comprender una mutación que puede dar lugar a una capacidad reducida de escisión de ácido nucleico (es decir, de modo que la endorribonucleasa condicionalmente enzimáticamente inactiva puede ser enzimáticamente inactiva en uno o más de los dominios de escisión de ácido nucleico). La mutación puede dar lugar a menos del 90 %, menos del 80 %, menos del 70 %, menos del 60 %, menos del 50 %, menos del 40 %, menos del 30 %, menos del 20 %, menos del 10 %, menos del 5 % o menos del 1 % de la capacidad de escisión de ácido nucleico en uno o más de la pluralidad de dominios de escisión de ácido nucleico de la endorribonucleasa de tipo silvestre (por ejemplo, Csy4 de P. aeruginosa). La mutación puede ocurrir en el dominio nucleasa de la endorribonucleasa. La mutación puede ocurrir en un pliegue de tipo ferredoxina. La mutación puede comprender la mutación de un aminoácido aromático conservado. La mutación puede comprender la mutación de un aminoácido catalítico. La mutación puede comprender la mutación de una histidina. Por ejemplo, la mutación puede comprender una mutación H29a en Csy4 (por ejemplo, Csy4 de P. aeruginosa) o cualquier resto correspondiente a H29A según lo determinado por la alineación de secuencia y/o estructural. Se pueden mutar otros restos para lograr el mismo efecto (es decir, inactivar uno o más de la pluralidad de dominios nucleasa).
Las mutaciones pueden producirse por mutación dirigida a un sitio. Las mutaciones pueden incluir sustituciones, adiciones y eliminaciones, o cualquier combinación de las mismas. En algunos casos, la mutación convierte al aminoácido mutado en alanina. En algunos casos, la mutación convierte al aminoácido mutado en otro aminoácido (por ejemplo, glicina, serina, treonina, cisteína, valina, leucina, isoleucina, metionina, prolina, fenilalanina, tirosina, triptófano, ácido aspártico, ácido glutámico, asparaginas, glutamina, histidina, lisina o arginina). La mutación puede convertir al aminoácido mutado en un aminoácido no natural (por ejemplo, selenometionina). La mutación puede convertir al aminoácido mutado en miméticos de aminoácidos (por ejemplo, fosfomiméticos). La mutación puede ser una mutación conservativa. Por ejemplo, la mutación puede convertir al aminoácido mutado en aminoácidos que se parecen en tamaño, forma, carga, polaridad, configuración y/o rotámeros de los aminoácidos mutados (por ejemplo, mutación de cisteína/serina, mutación de lisina/asparagina, mutación de histidina/fenilalanina).
Una endorribonucleasa condicionalmente enzimáticamente inactiva puede ser enzimáticamente inactiva en ausencia de un agente de reactivación (por ejemplo, imidazol). Un agente de reactivación puede ser un agente que imite a un resto de histidina (por ejemplo, puede tener un anillo de imidazol). Una endorribonucleasa condicionalmente enzimáticamente inactiva puede activarse mediante el contacto con un agente de reactivación. El agente de reactivación puede comprender imidazol. Por ejemplo, la endorribonucleasa condicionalmente enzimáticamente inactiva puede activarse enzimáticamente poniendo en contacto la endorribonucleasa condicionalmente enzimáticamente inactiva con imidazol a una concentración de aproximadamente 100 mM a aproximadamente 500 mM. El imidazol puede estar a una concentración de aproximadamente 100 mM, aproximadamente 150 mM, aproximadamente 200 mM, aproximadamente 250 mM, aproximadamente 300 mM, aproximadamente 350 mM, aproximadamente 400 mM, aproximadamente 450 mM, aproximadamente 500 mM, aproximadamente 550 mM o aproximadamente 600 mM. La presencia de imidazol (por ejemplo, en un intervalo de concentración de
aproximadamente 100 mM a aproximadamente 500 mM) puede reactivar la endorribonucleasa condicionalmente enzimáticamente inactiva de modo que la endorribonucleasa condicionalmente enzimáticamente inactiva se vuelva enzimáticamente activa, por ejemplo, la endorribonucleasa condicionalmente enzimáticamente inactiva presente al menos aproximadamente un 50 %, al menos aproximadamente un 60 %, al menos aproximadamente un 70 %, al menos aproximadamente un 80 %, al menos aproximadamente un 90 %, al menos aproximadamente el 95 % o más de un 95 % de la capacidad de escisión de ácido nucleico de una endorribonucleasa condicionalmente enzimáticamente inactiva (por ejemplo, Csy4 de P. aeruginosa que comprende la mutación H29A).
Una endorribonucleasa condicionalmente enzimáticamente inactiva puede comprender al menos un 20 % de identidad de aminoácidos con Csy4 de P. aeruginosa, una mutación de histidina 29, en donde la mutación produce al menos un 50 % de reducción de la actividad de nucleasa de la endorribonucleasa, y en donde al menos el 50 % de la actividad de nucleasa perdida puede restablecerse mediante la incubación de la endorribonucleasa con al menos 100 mM de imidazol.
Optimización de codones
Un polinucleótido que codifica un polipéptido dirigido a un sitio y/o una endorribonucleasa puede someterse a una optimización de codones. Este tipo de optimización puede implicar la mutación del ADN extraído (por ejemplo, recombinante) para imitar las preferencias de codones del organismo o de la célula hospedadora previsto mientras codifica la misma proteína. Así pues, los codones se pueden cambiar, pero la proteína codificada permanece sin cambios. Por ejemplo, si la célula diana prevista fuera una célula humana, podría usarse un polinucleótido Cas9 con optimización de codones humano para producir un polipéptido dirigido a un sitio adecuado. Como otro ejemplo no limitante, si la célula hospedadora prevista fuera una célula de ratón, entonces un polinucleótido con optimización de codones de ratón que codifica Cas9 podría ser un polipéptido dirigido a un sitio adecuado. Un polinucleótido que codifica un polipéptido dirigido a un sitio puede estar optimizado en cuanto a los codones para muchas células hospedadoras de interés. Una célula hospedadora puede ser una célula de cualquier organismo (por ejemplo, una célula bacteriana, una célula de arquea, una célula de un organismo eucariota unicelular, una célula vegetal, una célula de algas, por ejemplo, Botryococcus braunii, Chlamydomonas reinhardtii, Nannochloropsis gaditana, Chlorella pyrenoidosa, Sargassum patens C. Agardh, y similares, una célula fúngica (por ejemplo, una célula de levadura), una célula animal, una célula de un animal invertebrado (por ejemplo, mosca de la fruta, cnidario, equinodermo, nematodo, etc.), una célula de un animal vertebrado (por ejemplo, pez, anfibio, reptil, ave, mamífero), una célula de un mamífero (por ejemplo, un cerdo, una vaca, una cabra, una oveja, un roedor, una rata, un ratón, un primate no humano, un ser humano, etc.), etc. La optimización de codones puede no ser necesaria. En algunos casos, la optimización de codones puede ser preferible.
Ácido nucleico dirigido a ácido nucleico
La presente divulgación proporciona un ácido nucleico dirigido a ácido nucleico que puede dirigir las actividades de un polipéptido asociado (por ejemplo, un polipéptido dirigido a un sitio) a una secuencia diana específica dentro de un ácido nucleico diana. El ácido nucleico dirigido a ácido nucleico puede comprender nucleótidos. El ácido nucleico dirigido a ácido nucleico puede ser ARN. Un ácido nucleico dirigido a ácido nucleico puede comprender un ácido nucleico dirigido a ácido nucleico guía sencillo. Un ejemplo de ácido nucleico guía sencillo se representa en la FIGURA 1A. La extensión del espaciador 105 y la extensión del ARNcrtra 135 pueden comprender elementos que pueden aportar funcionalidad adicional (por ejemplo, estabilidad) al ácido nucleico dirigido a ácido nucleico. En algunas realizaciones, la extensión del espaciador 105 y la extensión de ARNcrtra 135 son opcionales. Una secuencia de espaciador 110 puede comprender una secuencia que puede hibridarse con una secuencia de ácido nucleico diana. La secuencia de espaciador 110 puede ser una parte variable del ácido nucleico dirigido a ácido nucleico. La secuencia de la secuencia de espaciador 110 puede diseñarse para hibridarse con la secuencia de ácido nucleico diana. La repetición CRISPR 115 (es decir, en la presente realización ilustrativa, como una repetición CRISPR mínima) puede comprender nucleótidos que pueden hibridarse con una secuencia de ARNcrtra 125 (es decir, en la presente realización ilustrativa, como una secuencia mínima de ARNcrtra). La repetición CRISPR mínima 115 y la secuencia mínima de ARNcrtra 125 pueden interactuar, comprendiendo las moléculas que interactúan una estructura bicatenaria de bases emparejadas. Conjuntamente, la repetición CRISPR mínima 115 y la secuencia mínima de ARNcrtra 125 pueden facilitar la unión al polipéptido dirigido a un sitio. La repetición mínima CRISPR 115 y la secuencia mínima de ARNcrtra 125 pueden unirse para formar una estructura de horquilla a través del enlazador guía sencillo 120. La secuencia de ARNcrtra 130 3' puede comprender una secuencia de reconocimiento de motivos adyacentes protoespaciadores. La secuencia de ARNcrtra 130 3' puede ser idéntica o similar a parte de una secuencia de ARNcrtra. En algunas realizaciones, la secuencia de ARNcrtra 1303' puede comprender una o más horquillas.
En algunas realizaciones, un ácido nucleico dirigido a ácido nucleico puede comprender un ácido nucleico dirigido a ácido nucleico guía sencillo como se representa en la FIGURA 1B. Un ácido nucleico dirigido a ácido nucleico puede comprender una secuencia de espaciador 140. Una secuencia de espaciador 140 puede comprender una secuencia que puede hibridarse con la secuencia de ácido nucleico diana. La secuencia de espaciador 140 puede ser una parte variable del ácido nucleico dirigido a ácido nucleico. La secuencia de espaciador 140 puede estar a 5' de un primer dúplex 145. El primer dúplex 145 comprende una región de hibridación entre una repetición CRISPR mínima 146 y una secuencia mínima de ARNcrtra 147. El primer dúplex 145 puede ser interrumpido por una protuberancia 150. La
protuberancia 150 puede comprender nucleótidos no emparejados. La protuberancia 150 puede facilitar el reclutamiento de un polipéptido dirigido a un sitio hacia el ácido nucleico dirigido a ácido nucleico. La protuberancia 150 puede estar seguida de un primer lazo 155. El primer lazo 155 comprende una secuencia enlazadora que une la repetición CRISPR mínima 146 y la secuencia mínima de ARNcrtra 147. El último nucleótido emparejado en el extremo 3' del primer dúplex 145 se puede conectar a una segunda secuencia enlazadora 160. El segundo enlazador 160 puede comprender un dominio P. El segundo enlazador 160 puede enlazar el primer dúplex 145 a un ARNcrtra medio 165. El ARNcrtra medio 165 puede, en algunas realizaciones, comprender una o más regiones de horquilla. Por ejemplo, el ARNcrtra medio 165 puede comprender un segundo lazo 170 y un tercer lazo 175.
En algunas realizaciones, el ácido nucleico dirigido a ácido nucleico puede comprender una estructura de ácido nucleico guía doble. La FIGURA 2 representa una estructura ilustrativa de ácido nucleico dirigido a ácido nucleico guía doble. Similar a la estructura de ácido nucleico guía sencillo de la FIGURA 1, la estructura de ácido nucleico guía doble puede comprender una extensión del espaciador 205, un espaciador 210, una repetición CRISPR mínima 215, una secuencia mínima de ARNcrtra 230, una secuencia de ARNcrtra 3' 235 y una extensión de ARNcrtra 240. Sin embargo, un ácido nucleico dirigido a ácido nucleico guía doble puede no comprender el enlazador guía sencillo 120. En cambio, la secuencia de repetición CRISPR mínima 215 puede comprender una secuencia de repetición CRISPR 2203' que puede ser similar o idéntica a parte de una repetición CRISPR. De igual manera, la secuencia mínima de ARNcrtra 230 puede comprender una secuencia de ARNcrtra 5' 225 que puede ser similar o idéntica a parte de un ARNcrtra. Los ARN guía dobles pueden hibridarse entre sí a través de la repetición CRISPR mínima 215 y la secuencia mínima de ARNcrtra 230.
En algunas realizaciones, el primer segmento (es decir, el segmento dirigido a ácido nucleico) puede comprender la extensión del espaciador (por ejemplo, 105/205) y el espaciador (por ejemplo, 110/210). El ácido nucleico dirigido a ácido nucleico puede guiar al polipéptido unido a una secuencia de nucleótidos específica dentro del ácido nucleico diana a través del segmento dirigido a ácido nucleico mencionado anteriormente.
En algunas realizaciones, el segundo segmento (es decir, el segmento de unión a proteínas) puede comprender la repetición CRISPR mínima (por ejemplo, 115/215), la secuencia mínima de ARNcrtra (por ejemplo, 125/230), la secuencia de ARNcrtra 3' (por ejemplo, 130/235) y/o la secuencia de extensión de ARNcrtra (por ejemplo, 135/240). El segmento de unión a proteínas de un ácido nucleico dirigido a ácido nucleico puede interactuar con un polipéptido dirigido a un sitio. El segmento de unión a proteínas de un ácido nucleico dirigido a ácido nucleico puede comprender dos tramos de nucleótidos que pueden hibridarse entre sí. Los nucleótidos del segmento de unión a proteínas pueden hibridarse para formar un dúplex de ácido nucleico bicatenario. El dúplex de ácido nucleico bicatenario puede ser ARN. El dúplex de ácido nucleico bicatenario puede ser ADN.
En algunos casos, un ácido nucleico dirigido a ácido nucleico puede comprender, en el orden de 5' a 3', una extensión del espaciador, un espaciador, una repetición CRISPR mínima, un enlazador guía sencillo, un ARNcrtra mínimo, una secuencia de ARNcrtra 3' y una extensión de ARNcrtra. En algunos casos, un ácido nucleico dirigido a ácido nucleico puede comprender, una extensión de ARNcrtra, una secuencia de ARNcrtra 3', un ARNcrtra mínimo, un enlazador guía sencillo, una repetición CRISPR mínima, un espaciador y una extensión del espaciador en cualquier orden.
Un ácido nucleico dirigido a ácido nucleico y un polipéptido dirigido a un sitio pueden formar un complejo. El ácido nucleico dirigido a ácido nucleico puede proporcionar especificidad por una diana al complejo al comprender una secuencia de nucleótidos que puede hibridarse con una secuencia de un ácido nucleico diana. En otras palabras, el polipéptido dirigido a un sitio puede guiarse a una secuencia de ácido nucleico en virtud de su asociación con al menos el segmento de unión a proteínas del ácido nucleico dirigido a ácido nucleico. El ácido nucleico dirigido a ácido nucleico puede dirigir la actividad de una proteína Cas9. El ácido nucleico dirigido a ácido nucleico puede dirigir la actividad de una proteína Cas9 enzimáticamente inactiva.
Los métodos de la divulgación pueden proporcionar una célula modificada genéticamente. Una célula modificada genéticamente puede comprender un ácido nucleico dirigido a ácido nucleico exógeno y/o un ácido nucleico exógeno que comprende una secuencia de nucleótidos que codifica un ácido nucleico dirigido a ácido nucleico.
Secuencia de extensión del espaciador
Una secuencia de extensión del espaciador puede proporcionar estabilidad y/o proporcionar una ubicación para modificaciones de un ácido nucleico dirigido a ácido nucleico. Una secuencia de extensión del espaciador puede tener una longitud de aproximadamente 1 nucleótido a aproximadamente 400 nucleótidos. Una secuencia de extensión del espaciador puede tener una longitud de más de 1, 5, 10, 15, 20, 25, 30, 35, 40, 45, 50, 60, 70, 80, 90, 100, 120, 140, 160, 180, 200, 220, 240, 260, 280, 300, 320, 340, 360, 380, 40,1000, 2000, 3000, 4000, 5000, 6000 o 7000, o más nucleótidos. Una secuencia de extensión del espaciador puede tener una longitud de menos de 1, 5, 10, 15, 20, 25, 30, 35, 40, 45, 50, 60, 70, 80, 90, 100, 120, 140, 160, 180, 200, 220, 240, 260, 280, 300, 320, 340, 360, 380, 400, 1000, 2000, 3000, 4000, 5000, 6000, 7000 o más nucleótidos. Una secuencia de extensión del espaciador puede tener menos de 10 nucleótidos de longitud. Una secuencia de extensión del espaciador puede tener entre 10 y 30 nucleótidos de longitud. Una secuencia de extensión del espaciador puede tener entre 30 y 70 nucleótidos de longitud.
La secuencia de extensión del espaciador puede comprender una fracción (por ejemplo, una secuencia de control de la estabilidad, una secuencia de unión a endorribonucleasa, una ribozima). Una fracción puede influir en la estabilidad de un ácido nucleico dirigido al ARN. Una fracción puede ser un segmento terminador de la transcripción (es decir, una secuencia de terminación de la transcripción). Una fracción de un ácido nucleico dirigido a ácido nucleico puede tener una longitud total de aproximadamente 10 nucleótidos a aproximadamente 100 nucleótidos, de aproximadamente 10 nucleótidos (nt) a aproximadamente 20 nt, de aproximadamente 20 nt a aproximadamente 30 nt, de aproximadamente 30 nt a aproximadamente 40 nt, de aproximadamente 40 nt a aproximadamente 50 nt, de aproximadamente 50 nt a aproximadamente 60 nt, de aproximadamente 60 nt a aproximadamente 70 nt, de aproximadamente 70 nt a aproximadamente 80 nt, de aproximadamente 80 nt a aproximadamente 90 nt, o de aproximadamente 90 nt a aproximadamente 100 nt, de aproximadamente 15 nucleótidos (nt) a aproximadamente 80 nt, de aproximadamente 15 nt a aproximadamente 50 nt, de aproximadamente 15 nt a aproximadamente 40 nt, de aproximadamente 15 nt a aproximadamente 30 nt o de aproximadamente 15 nt a aproximadamente 25 nt. La fracción puede ser aquella que pueda funcionar en una célula eucariota. En algunos casos, la fracción puede ser aquella que pueda funcionar en una célula procariota. La fracción puede ser aquella que pueda funcionar tanto en una célula eucariota como en una célula procariota.
Los ejemplos no limitantes de fracciones adecuadas pueden incluir: caperuza de 5' (por ejemplo, una caperuza de 7-metilguanilato (m7 G)), una secuencia riboswitch (por ejemplo, para permitir una estabilidad regulada y/o accesibilidad regulada por proteínas y complejos de proteínas), una secuencia que forma un dúplex de ARNbc (es decir, una horquilla), una secuencia que dirige el ARN a una ubicación subcelular (por ejemplo, núcleo, mitocondrias, cloroplastos y similares), una modificación o secuencia que proporciona el seguimiento (por ejemplo, conjugación directa a una molécula fluorescente, conjugación a una fracción que facilita la detección fluorescente, una secuencia que permite la detección fluorescente, etc.), una modificación o secuencia que proporciona un sitio de unión para proteínas (por ejemplo, proteínas que actúan sobre el ADN, incluyendo activadores de la transcripción, represores de la transcripción, ADN metiltransferasas, ADN desmetilasas, histona acetiltransferasas, histona desacetilasas y similares), una modificación o secuencia que proporciona una estabilidad aumentada, disminuida y/o controlable, o cualquier combinación de los mismos. Una secuencia de extensión del espaciador puede comprender un sitio de unión al cebador, un índice molecular (por ejemplo, secuencia de código de barras). La secuencia de extensión del espaciador puede comprender un marcador de afinidad de ácido nucleico.
Espaciador
El segmento de dirección a ácido nucleico de un ácido nucleico dirigido a ácido nucleico puede comprender una secuencia de nucleótidos (por ejemplo, un espaciador) que puede hibridarse con una secuencia de un ácido nucleico diana. El espaciador de un ácido nucleico dirigido a ácido nucleico puede interactuar con un ácido nucleico diana de una manera específica de la secuencia mediante hibridación (es decir, emparejamiento de bases). Por tanto, la secuencia de nucleótidos del espaciador puede variar y puede determinar la ubicación dentro del ácido nucleico diana en donde el ácido nucleico dirigido a ácido nucleico y el ácido nucleico diana pueden interactuar.
La secuencia de espaciador puede hibridarse con un ácido nucleico diana que se encuentra a 5' del motivo adyacente al espaciador (PAM). Diferentes organismos pueden comprender diferentes secuencias de PAM. Por ejemplo, en S. pyogenes, el PAM puede ser una secuencia del ácido nucleico diana que comprenda la secuencia 5-XRR-3', donde R puede ser A o G, donde X es cualquier nucleótido y X está a inmediatamente 3' de la secuencia de ácido nucleico diana de la secuencia de espaciador.
La secuencia de ácido nucleico diana puede ser de 20 nucleótidos. El ácido nucleico diana puede tener menos de 20 nucleótidos. El ácido nucleico diana puede tener al menos 5, 10, 15, 16, 17, 18, 19, 20, 21,22, 23, 24, 25, 30 o más nucleótidos. El ácido nucleico diana puede tener, como máximo, 5, 10, 15, 16, 17, 18, 19, 20, 21,22, 23, 24, 25, 30 o más nucleótidos. La secuencia de ácido nucleico diana puede tener 20 bases a inmediatamente 5' del primer nucleótido del PAM. Por ejemplo, en una secuencia que comprende 5'-NNNNNNNNNNNNNNNNNNNNXRR-3', el ácido nucleico diana puede ser la secuencia que corresponde a los N, en donde N es cualquier nucleótido.
La secuencia dirigida a ácido nucleico del espaciador que puede hibridarse con el ácido nucleico diana puede tener una longitud de al menos aproximadamente 6 nt. Por ejemplo, la secuencia de espaciador que puede hibridarse con el ácido nucleico diana puede tener una longitud de al menos aproximadamente 6 nt, al menos aproximadamente 10 nt, al menos aproximadamente 15 nt, al menos aproximadamente 18 nt, al menos aproximadamente 19 nt, al menos aproximadamente 20 nt, al menos aproximadamente 25 nt, al menos aproximadamente 30 nt, al menos aproximadamente 35 nt o al menos aproximadamente 40 nt, de aproximadamente 6 nt a aproximadamente 80 nt, de aproximadamente 6 nt a aproximadamente 50nt, de aproximadamente 6 nt a aproximadamente 45 nt, de aproximadamente 6 nt a aproximadamente 40 nt, de aproximadamente 6 nt a aproximadamente 35 nt, de aproximadamente 6 nt a aproximadamente 30 nt, de aproximadamente 6 nt a aproximadamente 25 nt, de aproximadamente 6 nt a aproximadamente 20 nt, de aproximadamente 6 nt a aproximadamente 19 nt, de aproximadamente 10 nt a aproximadamente 50nt, de aproximadamente 10 nt a aproximadamente 45 nt, de aproximadamente 10 nt a aproximadamente 40 nt, de aproximadamente 10 nt a aproximadamente 35 nt, de aproximadamente 10 nt a aproximadamente 30 nt, de aproximadamente 10 nt a aproximadamente 25 nt, de
aproximadamente 10 nt a aproximadamente 20 nt, de aproximadamente 10 nt a aproximadamente 19 nt, de aproximadamente 19 nt a aproximadamente 25 nt, de aproximadamente 19 nt a aproximadamente 30 nt, de aproximadamente 19 nt a aproximadamente 35 nt, de aproximadamente 19 nt a aproximadamente 40 nt, de aproximadamente 19 nt a aproximadamente 45 nt, de aproximadamente 19 nt a aproximadamente 50 nt, de aproximadamente 19 nt a aproximadamente 60 nt, de aproximadamente 20 nt a aproximadamente 25 nt, de aproximadamente 20 nt a aproximadamente 30 nt, de aproximadamente 20 nt a aproximadamente 35 nt, de aproximadamente 20 nt a aproximadamente 40 nt, de aproximadamente 20 nt a aproximadamente 45 nt, de aproximadamente 20 nt a aproximadamente 50 nt o de aproximadamente 20 nt a aproximadamente 60 nt. En algunos casos, la secuencia de espaciador que puede hibridarse con el ácido nucleico diana puede tener 20 nucleótidos de longitud. El espaciador que puede hibridarse con el ácido nucleico diana puede tener 19 nucleótidos de longitud.
El porcentaje de complementariedad entre la secuencia de espaciador del ácido nucleico diana puede ser de al menos aproximadamente 30 %, al menos aproximadamente 40 %, al menos aproximadamente 50 %, al menos aproximadamente 60 %, al menos aproximadamente 65 %, al menos aproximadamente 70 %, al menos aproximadamente 75 %, al menos aproximadamente 80 %, al menos aproximadamente 85 %, al menos aproximadamente 90 %, al menos aproximadamente 95 %, al menos aproximadamente 97 %, al menos aproximadamente 98%, al menos aproximadamente 99% o 100%. El porcentaje de complementariedad entre la secuencia de espaciador del ácido nucleico diana puede ser, como máximo, de aproximadamente 30 %, como máximo, aproximadamente 40 %, como máximo, aproximadamente 50 %, como máximo, aproximadamente 60 %, como máximo, aproximadamente 65 %, como máximo, aproximadamente 70 %, como máximo, aproximadamente 75 %, como máximo, aproximadamente 80 %, como máximo, aproximadamente 85 %, como máximo, aproximadamente 90 %, como máximo, aproximadamente 95 %, como máximo, aproximadamente 97 %, como máximo, aproximadamente 98 %, como máximo, aproximadamente 99 % o 100 %. En algunos casos, el porcentaje de complementariedad entre la secuencia de espaciador y el ácido nucleico diana puede ser del 100 % sobre los seis nucleótidos contiguos más a 5' de la secuencia diana de la cadena complementaria del ácido nucleico diana. En algunos casos, el porcentaje de complementariedad entre la secuencia de espaciador y el ácido nucleico diana puede ser al menos del 60 % sobre aproximadamente 20 nucleótidos contiguos. En algunos casos, el porcentaje de complementariedad entre la secuencia de espaciador y el ácido nucleico diana puede ser del 100 % sobre los catorce nucleótidos contiguos más a 5' de la secuencia diana de la cadena complementaria del ácido nucleico diana y tan bajo como del 0 % en el resto. En dicho caso, se puede considerar que la secuencia de espaciador tiene 14 nucleótidos de longitud. En algunos casos, el porcentaje de complementariedad entre la secuencia de espaciador y el ácido nucleico diana puede ser del 100% sobre los seis nucleótidos contiguos más a 5' de la secuencia diana de la cadena complementaria del ácido nucleico diana y tan bajo como del 0 % en el resto. En dicho caso, se puede considerar que la secuencia de espaciador 6 nucleótidos de longitud. El ácido nucleico diana puede ser más de aproximadamente el 50 %, 60 %, 70 %, 80 %, 90 % o 100 % complementario a la región semilla del ARNcr. El ácido nucleico diana puede ser menos del aproximadamente 50%, 60%, 70%, 80%, 90% o 100% complementario a la región semilla del ARNcr.
El segmento espaciador de un ácido nucleico dirigido a ácido nucleico puede modificarse (por ejemplo, mediante ingeniería genética) para que se hibride con cualquier secuencia deseada dentro de un ácido nucleico diana. Por ejemplo, se puede diseñar un espaciador (por ejemplo, diseñar, programar) para que se hibride con una secuencia en ácido nucleico diana que participe en el cáncer, el crecimiento celular, la replicación del ADN, la reparación del ADN, genes HLA, proteínas de la superficie celular, receptores de linfocitos T, genes de la superfamilia de inmunoglobulinas, genes supresores de tumores, genes de microARN, genes de ARN no codificantes largos, factores de transcripción, globinas, proteínas víricas, genes mitocondriales y similares.
Se puede identificar una secuencia de espaciador usando un programa informático (por ejemplo, código legible por máquina). El programa informático puede usar variables tales como la temperatura de fusión prevista, formación de estructuras secundarias y temperatura de hibridación previstas, identidad de secuencia, contexto genómico, accesibilidad a la cromatina, % de GC, frecuencia de aparición genómica, estado de metilación, presencia de SNP y similares.
Secuencia de repeticiones CRISPR mínima
Una secuencia de repetición CRISPR mínima puede ser una secuencia de al menos aproximadamente un 30 %, 40 %, 50%, 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95% o 100% de identidad de secuencia y/o homología de secuencia con una secuencia de repetición CRISPR de referencia (por ejemplo, ARNcr de S. pyogenes). Una secuencia de repetición CRISPR mínima puede ser una secuencia con, como máximo, un 30 %, 40 %, 50 %, 60 %, 65 %, 70 %, 75 %, 80 %, 85 %, 90 %, 95 % o 100 % de identidad de secuencia y/u homología de secuencia con una secuencia de repetición CRISPR de referencia (por ejemplo, ARNcr de S. pyogenes). Una repetición CRISPR mínima puede comprender nucleótidos que pueden hibridarse con una secuencia mínima de ARNcrtra. Una repetición CRISPR mínima y una secuencia mínima de ARNcrtra pueden formar una estructura bicatenaria de bases emparejadas. Conjuntamente, la repetición CRISPR mínima y la secuencia mínima de ARNcrtra pueden facilitar la unión al polipéptido dirigido a un sitio. Una parte de la secuencia de repetición CRISPR mínima puede hibridarse con la secuencia mínima de ARNcrtra. Una parte de la secuencia de repetición CRISPR mínima puede ser al menos aproximadamente un 30 %, 40 %, 50 %, 60 %, 65 %, 70 %, 75 %, 80 %, 85 %, 90 %, 95 % o 100 % complementaria
a la secuencia mínima de ARNcrtra. Una parte de la secuencia de repetición CRISPR mínima puede ser, como máximo, un 30%, 40%, 50%, 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95% o 100% complementaria a la secuencia mínima de ARNcrtra.
Una secuencia de repetición CRISPR mínima puede tener una longitud de aproximadamente 6 nucleótidos a aproximadamente 100 nucleótidos. Por ejemplo, la secuencia de repetición CRISPR mínima puede tener una longitud de aproximadamente 6 nucleótidos (nt) a aproximadamente 50 nt, de aproximadamente 6 nt a aproximadamente 40 nt, de aproximadamente 6 nt a aproximadamente 30 nt, de aproximadamente 6 nt a aproximadamente 25 nt, de aproximadamente 6 nt a aproximadamente 20 nt, de aproximadamente 6 nt a aproximadamente 15 nt, de aproximadamente 8 nt a aproximadamente 40 nt, de aproximadamente 8 nt a aproximadamente 30 nt, de aproximadamente 8 nt a aproximadamente 25 nt, de aproximadamente 8 nt a aproximadamente 20 nt o de aproximadamente 8 nt a aproximadamente 15 nt, de aproximadamente 15 nt a aproximadamente 100 nt, de aproximadamente 15 nt a aproximadamente 80 nt, de aproximadamente 15 nt a aproximadamente 50 nt, de aproximadamente 15 nt a aproximadamente 40 nt, de aproximadamente 15 nt a aproximadamente 30 nt o de aproximadamente 15 nt a aproximadamente 25 nt. En algunas realizaciones, la secuencia de repetición CRISPR mínima tiene una longitud de aproximadamente 12 nucleótidos.
La secuencia de repetición CRISPR mínima puede ser al menos aproximadamente un 60 % idéntica a una secuencia de repetición CRISPR mínima de referencia (por ejemplo, ARNc de tipo silvestre de S. pyogenes) en un tramo de al menos 6, 7 u 8 nucleótidos contiguos. La secuencia de repetición CRISPR mínima puede ser al menos aproximadamente un 60 % idéntica a una secuencia de repetición CRISPR mínima de referencia (por ejemplo, ARNc de tipo silvestre de S. pyogenes) en un tramo de al menos 6, 7 u 8 nucleótidos contiguos. Por ejemplo, La secuencia de repetición CRISPR mínima puede ser al menos aproximadamente un 65 % idéntica, al menos aproximadamente un 70 % idéntica, al menos aproximadamente un 75 % idéntica, al menos aproximadamente un 80 % idéntica, al menos aproximadamente un 85 % idéntica, al menos aproximadamente un 90 % idéntico, al menos aproximadamente un 95 % idéntica, al menos aproximadamente un 98 % idéntica, al menos aproximadamente un 99 % idéntica o un 100% idéntica a una secuencia de repetición CRISPR mínima de referencia en un tramo de al menos 6, 7 u 8 nucleótidos contiguos.
Secuencia mínima de ARNcrtra
Una secuencia mínima de ARNcrtra puede ser una secuencia con al menos aproximadamente un 30 %, 40 %, 50 %, 60 %, 65 %, 70 %, 75 %, 80 %, 85 %, 90 %, 95 % o 100 % de identidad de secuencia y/o homología de secuencia con una secuencia de ARNcrtra de referencia (por ejemplo, ARNcrtra de tipo silvestre de S. pyogenes). Una secuencia mínima de ARNcrtra puede ser una secuencia con, como máximo, aproximadamente un 30 %, 40 %, 50 %, 60 %, 65 %, 70 %, 75 %, 80 %, 85 %, 90 %, 95 % o 100 % de identidad de secuencia y/o homología de secuencia con una secuencia de ARNcrtra de referencia (por ejemplo, ARNcrtra de tipo silvestre de S. pyogenes). Una secuencia mínima de ARNcrtra puede comprender nucleótidos que se pueden hibridar con una secuencia de repetición de CRISPR mínima. Una secuencia mínima de ARNcrtra y una secuencia de repetición CRISPR mínima pueden formar una estructura bicatenaria de bases emparejadas. Conjuntamente, la secuencia mínima de ARNcrtra y la secuencia de repetición CRISPR mínima pueden facilitar la unión al polipéptido dirigido a un sitio. Una parte de la secuencia mínima de ARNcrtra se puede hibridar con la secuencia de repetición CRISPR mínima. Una parte de la secuencia mínima de ARNcrtra puede ser un 30 %, 40 %, 50 %, 60 %, 65 %, 70 %, 75 %, 80 %, 85 %, 90 %, 95 % o 100 % complementaria a la secuencia de repetición CRISPR mínima.
La secuencia mínima de ARNcrtra puede tener una longitud de aproximadamente 6 nucleótidos a aproximadamente 100 nucleótidos. Por ejemplo, la secuencia mínima de ARNcrtra puede tener una longitud de aproximadamente 6 nucleótidos (nt) a aproximadamente 50 nt, de aproximadamente 6 nt a aproximadamente 40 nt, de aproximadamente 6 nt a aproximadamente 30 nt, de aproximadamente 6 nt a aproximadamente 25 nt, de aproximadamente 6 nt a aproximadamente 20 nt, de aproximadamente 6 nt a aproximadamente 15 nt, de aproximadamente 8 nt a aproximadamente 40 nt, de aproximadamente 8 nt a aproximadamente 30 nt, de aproximadamente 8 nt a aproximadamente 25 nt, de aproximadamente 8 nt a aproximadamente 20 nt o de aproximadamente 8 nt a aproximadamente 15 nt, de aproximadamente 15 nt a aproximadamente 100 nt, de aproximadamente 15 nt a aproximadamente 80 nt, de aproximadamente 15 nt a aproximadamente 50 nt, de aproximadamente 15 nt a aproximadamente 40 nt, de aproximadamente 15 nt a aproximadamente 30 nt o de aproximadamente 15 nt a aproximadamente 25 nt. En algunas realizaciones, la secuencia mínima de ARNcrtra tiene una longitud de aproximadamente 14 nucleótidos.
La secuencia mínima de ARNcrtra puede ser al menos aproximadamente un 60 % idéntica a una secuencia mínima de ARNcrtra de referencia (por ejemplo, ARNcrtra de tipo silvestre de S. pyogenes) en un tramo de al menos 6, 7 u 8 nucleótidos contiguos. La secuencia mínima de ARNcrtra puede ser al menos aproximadamente un 60 % idéntica a una secuencia mínima de ARNcrtra de referencia (por ejemplo, ARNcrtra de tipo silvestre de S. pyogenes) en un tramo de al menos 6, 7 u 8 nucleótidos contiguos. Por ejemplo, la secuencia mínima de ARNcrtra puede ser al menos aproximadamente un 65 % idéntica, al menos aproximadamente un 70 % idéntica, al menos aproximadamente un 75 % idéntica, al menos aproximadamente un 80 % idéntica, al menos aproximadamente un 85 % idéntica, al menos aproximadamente un 90 % idéntico, al menos aproximadamente un 95 % idéntica, al menos aproximadamente un
98 % idéntica, al menos aproximadamente 99 % idéntica o 100 % idéntica a una secuencia mínima de ARNcrtra de referencia en un tramo de al menos 6, 7 u 8 nucleótidos contiguos.
El dúplex (es decir, el primer dúplex de la Figura 1B) entre el ARN de CRISPR mínimo y el ARNcrtra mínimo puede comprender una doble hélice. La primera base de la primera cadena del dúplex (por ejemplo, la repetición CRISPR mínima de la Figura 1B) puede ser una guanina. La primera base de la primera cadena del dúplex (por ejemplo, la repetición CRISPR mínima de la Figura 1B) puede ser una adenina. El dúplex (es decir, el primer dúplex de la Figura 1B) entre el ARN de CRISPR mínimo y el ARNcrtra mínimo puede comprender al menos aproximadamente 1,2, 3, 4, 5, 6, 7, 8, 9 o 10, o más nucleótidos. El dúplex (es decir, el primer dúplex de la Figura 1B) entre el ARN de CRISPR mínimo y el ARNcrtra mínimo puede comprender, como máximo, aproximadamente 1, 2, 3, 4, 5, 6, 7, 8, 9 o 10 o más nucleótidos.
El dúplex puede comprender una falta de coincidencia. El dúplex puede comprender al menos aproximadamente 1, 2, 3, 4, 5 o más faltas de coincidencia. El dúplex puede comprender, como máximo, aproximadamente 1, 2, 3, 4 o 5 faltas de coincidencia. En algunos casos, el dúplex comprende no más de 2 faltas de coincidencia.
Protuberancia
Una protuberancia puede referirse a una región no emparejada de nucleótidos dentro del dúplex formado por la repetición CRISPR mínima y la secuencia mínima de ARNcrtra. La protuberancia puede ser importante en la unión al polipéptido dirigido a un sitio. una protuberancia puede comprender, a un lado del dúplex, un 5-XXXY-3' no emparejado, donde X es cualquier purina e Y puede ser un nucleótido que puede formar un par oscilante con un nucleótido en la cadena opuesta, y una región de nucleótidos no emparejados en el otro lado del dúplex.
Por ejemplo, la protuberancia puede comprender una purina no emparejada (por ejemplo, adenina) en la cadena de repetición CRISPR mínima de la protuberancia. En algunas realizaciones, una protuberancia puede comprender un 5-AAGY-3' no emparejado de la cadena de secuencia de ARNcrtra mínima de la protuberancia, donde Y puede ser un nucleótido que puede formar un emparejamiento oscilante con un nucleótido en la cadena de repetición CRISPR mínima.
Una protuberancia en un primer lado del dúplex (por ejemplo, el lado de la repetición CRISPR mínima) puede comprender al menos 1, 2, 3, 4 o 5, o más nucleótidos no emparejados. Una protuberancia en un primer lado del dúplex (por ejemplo, el lado de la repetición CRISPR mínima) puede comprender, como máximo, 1,2, 3, 4 o 5, o más nucleótidos no emparejados. Una protuberancia en el primer lado del dúplex (por ejemplo, el lado de la repetición CRISPR mínima) puede comprender 1 nucleótido no emparejado.
Una protuberancia en un segundo lado del dúplex (por ejemplo, el lado de la secuencia mínima de ARNcrtra del dúplex) puede comprender al menos 1, 2, 3, 4, 5, 6, 7, 8, 9 o 10, o más nucleótidos no emparejados. Una protuberancia en un segundo lado del dúplex (por ejemplo, el lado de la secuencia mínima de ARNcrtra del dúplex) puede comprender, como máximo, 1,2, 3, 4, 5, 6, 7, 8, 9 o 10, o más nucleótidos no emparejados. Una protuberancia en un segundo lado del dúplex (por ejemplo, el lado de la secuencia mínima de ARNcrtra del dúplex) puede comprender 4 nucleótidos no emparejados.
Las regiones de diferentes números de nucleótidos no emparejados en cada cadena del dúplex se pueden emparejar entre sí. Por ejemplo, una protuberancia puede comprender 5 nucleótidos no emparejados de una primera cadena y 1 nucleótido no emparejado de una segunda cadena. Una protuberancia puede comprender 4 nucleótidos no emparejados de una primera cadena y 1 nucleótido no emparejado de una segunda cadena. Una protuberancia puede comprender 3 nucleótidos no emparejados de una primera cadena y 1 nucleótido no emparejado de una segunda cadena. Una protuberancia puede comprender 2 nucleótidos no emparejados de una primera cadena y 1 nucleótido no emparejado de una segunda cadena. Una protuberancia puede comprender 1 nucleótido no emparejado de una primera cadena y 1 nucleótido no emparejado de una segunda cadena. Una protuberancia puede comprender 1 nucleótido no emparejado de una primera cadena y 2 nucleótidos no emparejados de una segunda cadena. Una protuberancia puede comprender 1 nucleótido no emparejado de una primera cadena y 3 nucleótido no emparejado de una segunda cadena. Una protuberancia puede comprender 1 nucleótido no emparejado de una primera cadena y 4 nucleótidos no emparejados de una segunda cadena. una protuberancia puede comprender 1 nucleótido no emparejado de una primera cadena y 5 nucleótidos no emparejados de una segunda cadena.
En algunos casos, una protuberancia puede comprender al menos un emparejamiento oscilante. En algunos casos, una protuberancia puede comprender, como máximo, un emparejamiento oscilante. Una secuencia de protuberancia puede comprender al menos un nucleótido de purina. Una secuencia de protuberancia puede comprender al menos 3 nucleótidos de purina. Una secuencia de protuberancia puede comprender al menos 5 nucleótidos de purina. Una secuencia de protuberancia puede comprender al menos un nucleótido de guanina. Una secuencia de protuberancia puede comprender al menos un nucleótido de adenina.
Dominio P (DOMINIO P)
Un dominio P puede referirse a una región de un ácido nucleico dirigido a un ácido nucleico que puede reconocer un motivo adyacente al protoespaciador (PAM) en un ácido nucleico diana. Un dominio P puede hibridarse con un PAM en un ácido nucleico diana. Por tanto, un dominio P puede comprender una secuencia que sea complementaria a un PAM. Un dominio P puede ubicarse a 3' de la secuencia mínima de ARNcrtra. Un dominio P puede ubicarse dentro de una secuencia de ARNcrtra de 3' (es decir, una secuencia de ARNcrtra media).
Un P comienza al menos aproximadamente 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 15 o 20, o más nucleótidos 3' del último nucleótido emparejado del dúplex de repetición CRISPR mínima y secuencia mínima de ARNcrtra. Un dominio P puede comenzar, como máximo, aproximadamente 1, 2, 3, 4, 5, 6, 7, 8, 9 o 10, o más nucleótidos a 3' del último nucleótido emparejado del dúplex de repetición CRISPR mínima y secuencia mínima de ARNcrtra.
Un dominio P puede comprender al menos aproximadamente 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 15 o 20, o más nucleótidos consecutivos. Un dominio P puede comprender, como máximo, aproximadamente 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 15 o 20, o más nucleótidos consecutivos.
En algunos casos, un dominio P puede comprender un dinucleótido CC (es decir, dos nucleótidos de citosina consecutivos). El dinucleótido CC puede interactuar con el dinucleótido GG de un PAM, en donde el PAM comprende una secuencia 5'-XGG-3'.
Un dominio P puede ser una secuencia de nucleótidos ubicada en la secuencia de ARNcrtra 3' (es decir, la secuencia de ARNcrtra media). Un dominio P puede comprender nucleótidos duplicados (por ejemplo, nucleótidos de una horquilla, hibridados entre sí. Por ejemplo, un dominio P puede comprender un dinucleótido CC que se hibrida con un dinucleótido GG en un dúplex en horquilla de la secuencia de ARNcrtra 3' (es decir, la secuencia de ARNcrtra media). La actividad del dominio P (por ejemplo, la capacidad del ácido nucleico dirigido a ácido nucleico para dirigirse a un ácido nucleico diana) puede estar regulada por el estado de hibridación del DOMINIO P. Por ejemplo, si el dominio P se hibrida, el ácido nucleico dirigido a ácido nucleico puede no reconocer su diana. Si el dominio P no se hibrida, el ácido nucleico dirigido a ácido nucleico puede reconocer su diana.
El dominio P puede interactuar con regiones que interactúan con el dominio P dentro del polipéptido dirigido a un sitio. El dominio P puede interactuar con un parche básico rico en arginina en el polipéptido dirigido a un sitio. Las regiones que interactúan con el dominio P pueden interactuar con una secuencia de PAM. El dominio P puede comprender un tallo-lazo. El dominio P puede comprender una protuberancia.
Secuencia de ARNcrtra de 3'
Una secuencia de ARNcrtra de 3' puede ser una secuencia con al menos aproximadamente un 30 %, 40 %, 50 %, 60 %, 65 %, 70 %, 75 %, 80 %, 85 %, 90 %, 95 % o 100 % de identidad de secuencia y/u homología de secuencia con una secuencia de ARNcrtra de referencia (por ejemplo, ARNcrtra de S. pyogenes). Una secuencia de ARNcrtra de 3' puede ser una secuencia con, como máximo, un 30 %, 40 %, 50 %, 60 %, 65 %, 70 %, 75 %, 80 %, 85 %, 90 %, 95 % o 100 % de identidad de secuencia y/u homología de secuencia con una secuencia de ARNcrtra de referencia (por ejemplo, ARNcrtra de S. pyogenes).
La secuencia de ARNcrtra de 3' puede tener una longitud de aproximadamente 6 nucleótidos a aproximadamente 100 nucleótidos. Por ejemplo, la secuencia de ARNcrtra de 3' puede tener una longitud de aproximadamente 6 nucleótidos (nt) a aproximadamente 50 nt, de aproximadamente 6 nt a aproximadamente 40 nt, de aproximadamente 6 nt a aproximadamente 30 nt, de aproximadamente 6 nt a aproximadamente 25 nt, de aproximadamente 6 nt a aproximadamente 20 nt, de aproximadamente 6 nt a aproximadamente 15 nt, de aproximadamente 8 nt aproximadamente 40 nt, de aproximadamente 8 nt a aproximadamente 30 nt, de aproximadamente 8 nt aproximadamente 25 nt, de aproximadamente 8 nt a aproximadamente 20 nt o de aproximadamente 8 nt aproximadamente 15 nt, de aproximadamente 15 nt a aproximadamente 100 nt, de aproximadamente 15 nt aproximadamente 80 nt, de aproximadamente 15 nt a aproximadamente 50 nt, de aproximadamente 15 nt aproximadamente 40 nt, de aproximadamente 15 nt a aproximadamente 30 nt o de aproximadamente 15 nt aproximadamente 25 nt. En algunas realizaciones, la secuencia de ARNcrtra de 3' tiene una longitud de aproximadamente 14 nucleótidos.
La secuencia de ARNcrtra de 3' puede ser al menos aproximadamente un 60 % idéntica a una secuencia de ARNcrtra de 3' de referencia (por ejemplo, la secuencia de ARNcrtra de 3' de tipo silvestre de S. pyogenes) sobre un tramo de al menos 6, 7 u 8 nucleótidos contiguos. Por ejemplo, la secuencia de ARNcrtra de 3' puede ser al menos aproximadamente un 60 % idéntica, al menos aproximadamente un 65 % idéntica, al menos aproximadamente un 70 % idéntica, al menos aproximadamente un 75 % idéntica, al menos aproximadamente un 80 % idéntica, al menos aproximadamente un 85 % idéntica, al menos aproximadamente un 90 % idéntico, al menos aproximadamente un 95 % idéntica, al menos aproximadamente un 98 % idéntica, al menos aproximadamente un 99 % idéntica o un 100 % idéntica, a una secuencia de ARNcrtra de 3' de referencia (por ejemplo, secuencia de ARNcrtra de 3' de tipo silvestre de S. pyogenes) en un tramo de al menos 6, 7 u 8 nucleótidos contiguos.
Una secuencia de ARNcrtra de 3' puede comprender más de una región duplexada (por ejemplo, horquilla, región
hibridada). Una secuencia de ARNcrtra de 3' puede comprender dos regiones duplexadas.
La secuencia de ARNcrtra de 3' también puede denominarse ARNcrtra media (véase la Figura 1B). La secuencia de ARNcrtra media puede comprender una estructura de tallo-lazo. En otras palabras, la secuencia del ARNcrtra media puede comprender una horquilla que sea diferente de un segundo o tercer tallo, como se muestra en la Figura 1B. Una estructura de tallo-lazo de ARNcrtra medio (es decir, el ARNcrtra de 3') puede comprender al menos 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 15 o 20, o más nucleótidos. Una estructura de tallo-lazo en el ARNcrtra medio (es decir, el ARNcrtra de 3') puede comprender, como máximo, 1, 2, 3, 4, 5, 6, 7, 8, 9 o 10, o más nucleótidos. La estructura de tallo-lazo puede comprender una fracción funcional. Por ejemplo, la estructura de tallo-lazo puede comprender un aptámero, una ribozima, una horquilla que interactúa con proteínas, una matriz CRISPR, un intrón y un exón. La estructura de tallolazo puede comprender al menos aproximadamente 1, 2, 3, 4 o 5 fracciones funcionales. La estructura de tallo-lazo puede comprender, como máximo, aproximadamente 1,2, 3, 4 o 5, o más fracciones funcionales.
La horquilla de la secuencia de ARNcrtra medio puede comprender un dominio P. El dominio P puede comprender una región bicatenaria en la horquilla.
Secuencia de extensión de ARNcrtra
Una secuencia de extensión del ARNcrtra puede proporcionar estabilidad y/o proporcionar una ubicación para modificaciones de un ácido nucleico dirigido a ácido nucleico. Una secuencia de extensión del ARNcrtra puede tener una longitud de aproximadamente 1 nucleótido a aproximadamente 400 nucleótidos. Una secuencia de extensión del ARNcrtra puede tener una longitud de más de 1, 5, 10, 15, 20, 25, 30, 35, 40, 45, 50, 60, 70, 80, 90, 100, 120, 140, 160, 180, 200, 220, 240, 260, 280, 300, 320, 340, 360, 380, 400 o más nucleótidos. Una secuencia de extensión del ARNcrtra puede tener una longitud de aproximadamente 20 a aproximadamente 5000 o más nucleótidos. Una secuencia de extensión del ARNcrtra puede tener una longitud de más de 1000 nucleótidos. Una secuencia de extensión del ARNcrtra puede tener una longitud de menos de 1, 5, 10, 15, 20, 25, 30, 35, 40, 45, 50, 60, 70, 80, 90, 100, 120, 140, 160, 180, 200, 220, 240, 260, 280, 300, 320, 340, 360, 380, 400 nucleótidos. Una secuencia de extensión del ARNcrtra puede tener una longitud de menos de 1000 nucleótidos. Una secuencia de extensión del ARNcrtra puede tener menos de 10 nucleótidos de longitud. Una secuencia de extensión del ARNcrtra puede tener entre 10 y 30 nucleótidos de longitud. Una secuencia de extensión del ARNcrtra puede tener entre 30 y 70 nucleótidos de longitud.
La secuencia de extensión del ARNcrtra puede comprender una fracción (por ejemplo, secuencia de control de la estabilidad, ribozima, secuencia de unión a endorribonucleasa). Una fracción puede influir en la estabilidad de un ácido nucleico dirigido al ARN. Una fracción puede ser un segmento terminador de la transcripción (es decir, una secuencia de terminación de la transcripción). Una fracción de un ácido nucleico dirigido a ácido nucleico puede tener una longitud total de aproximadamente 10 nucleótidos a aproximadamente 100 nucleótidos, de aproximadamente 10 nucleótidos (nt) a aproximadamente 20 nt, de aproximadamente 20 nt a aproximadamente 30 nt, de aproximadamente 30 nt a aproximadamente 40 nt, de aproximadamente 40 nt a aproximadamente 50 nt, de aproximadamente 50 nt a aproximadamente 60 nt, de aproximadamente 60 nt a aproximadamente 70 nt, de aproximadamente 70 nt a aproximadamente 80 nt, de aproximadamente 80 nt a aproximadamente 90 nt, o de aproximadamente 90 nt a aproximadamente 100 nt, de aproximadamente 15 nucleótidos (nt) a aproximadamente 80 nt, de aproximadamente 15 nt a aproximadamente 50 nt, de aproximadamente 15 nt a aproximadamente 40 nt, de aproximadamente 15 nt a aproximadamente 30 nt o de aproximadamente 15 nt a aproximadamente 25 nt. La fracción puede ser aquella que pueda funcionar en una célula eucariota. En algunos casos, la fracción puede ser aquella que pueda funcionar en una célula procariota. La fracción puede ser aquella que pueda funcionar tanto en una célula eucariota como en una célula procariota.
Los ejemplos no limitantes de fracciones de extensión de ARNcrtra adecuadas incluyen: una cola 3' poli-adenilada, una secuencia riboswitch (por ejemplo, para permitir una estabilidad regulada y/o accesibilidad regulada por proteínas y complejos de proteínas), una secuencia que forma un dúplex de ARNbc (es decir, una horquilla), una secuencia que dirige el ARN a una ubicación subcelular (por ejemplo, núcleo, mitocondrias, cloroplastos y similares), una modificación o secuencia que proporciona el seguimiento (por ejemplo, conjugación directa a una molécula fluorescente, conjugación a una fracción que facilita la detección fluorescente, una secuencia que permite la detección fluorescente, etc.), una modificación o secuencia que proporciona un sitio de unión para proteínas (por ejemplo, proteínas que actúan sobre el ADN, incluyendo activadores de la transcripción, represores de la transcripción, ADN metiltransferasas, ADN desmetilasas, histona acetiltransferasas, histona desacetilasas y similares), una modificación o secuencia que proporciona una estabilidad aumentada, disminuida y/o controlable, o cualquier combinación de los mismos. Una secuencia de extensión del ARNcrtra puede comprender un sitio de unión al cebador, un índice molecular (por ejemplo, secuencia de código de barras). En algunas realizaciones de la divulgación, la secuencia de extensión del ARNcrtra puede comprender uno o más marcadores de afinidad.
Ácido nucleico guía sencillo
El ácido nucleico dirigido a ácido nucleico puede ser un ácido nucleico guía sencillo. El ácido nucleico guía sencillo puede ser ARN. Un ácido nucleico guía sencillo puede comprender un enlazador (es decir, el elemento 120 de la
Figura 1A) entre la secuencia de repetición CRISPR mínima y la secuencia de ARNcrtra mínima, que puede denominarse secuencia de enlazador guía sencillo.
El enlazador guía sencillo de un ácido nucleico guía sencillo puede tener una longitud de aproximadamente 3 nucleótidos a aproximadamente 100 nucleótidos. Por ejemplo, el enlazador puede tener una longitud de aproximadamente 3 nucleótidos (nt) a aproximadamente 90 nt, de aproximadamente 3 nt a aproximadamente 80 nt, de aproximadamente 3 nt a aproximadamente 70 nt, de aproximadamente 3 nt a aproximadamente 60 nt, de aproximadamente 3 nt a aproximadamente 50 nt, de aproximadamente 3 nt a aproximadamente 40 nt, de aproximadamente 3 nt a aproximadamente 30 nt, de aproximadamente 3 nt a aproximadamente 20 nt o de aproximadamente 3 nt a aproximadamente 10 nt. Por ejemplo, El enlazador puede tener una longitud de aproximadamente 3 nt a aproximadamente 5 nt, de aproximadamente 5 nt a aproximadamente 10 nt, de aproximadamente 10 nt a aproximadamente 15 nt, de aproximadamente 15 nt a aproximadamente 20 nt, de aproximadamente 20 nt a aproximadamente 25 nt, de aproximadamente 25 nt a aproximadamente 30 nt, de aproximadamente 30 nt a aproximadamente 35 nt, de aproximadamente 35 nt a aproximadamente 40 nt, de aproximadamente 40 nt a aproximadamente 50 nt, de aproximadamente 50 nt a aproximadamente 60 nt, de aproximadamente 60 nt a aproximadamente 70 nt, de aproximadamente 70 nt a aproximadamente 80 nt, de aproximadamente 80 nt a aproximadamente 90 nt. de aproximadamente 90 nt a aproximadamente 100 nt. En algunas realizaciones, El enlazador de un ácido nucleico guía sencillo es de entre 4 y 40 nucleótidos. Un enlazador puede tener una longitud de al menos aproximadamente 100, 500, 1000, 1500, 2000, 2500, 3000, 3500, 4000, 4500, 5000, 5500, 6000, 6500 o 7000, o más nucleótidos. Un enlazador puede tener una longitud, como máximo, de 100, 500, 1000, 1500, 2000, 2500, 3000, 3500, 4000, 4500, 5000, 5500, 6000, 6500 o 7000, o más nucleótidos.
La secuencia enlazadora puede comprender una fracción funcional. Por ejemplo, la secuencia enlazadora puede comprender un aptámero, una ribozima, una horquilla que interactúa con proteínas, una matriz CRISPR, un intrón y un exón. La secuencia enlazadora puede comprender al menos aproximadamente 1, 2, 3, 4 o 5, o más fracciones funcionales. La secuencia enlazadora puede comprender, como máximo, aproximadamente 1, 2, 3, 4 o 5, o más fracciones funcionales.
En algunas realizaciones, el enlazador guía simple puede conectar el extremo 3' de la repetición CRISPR mínima al extremo 5' de la secuencia mínima de ARNcrtra. Como alternativa, el enlazador guía sencillo puede conectar el extremo 3' de la secuencia de ARNcrtra con el extremo 5' de la repetición CRISPR mínima. Es decir, un ácido nucleico guía sencillo puede comprender un segmento de unión a ADN de 5' unido a un segmento de unión a proteínas de 3'. Un ácido nucleico guía sencillo puede comprender un segmento de unión a proteínas de 5' unido a un segmento de unión a ADN de 3'.
Un ácido nucleico dirigido a ácido nucleico puede comprender una secuencia de extensión del espaciador de 10 5000 nucleótidos de longitud; una secuencia de espaciador de 12-30 nucleótidos de longitud, en donde el espaciador es al menos un 50 % complementario a un ácido nucleico diana; una repetición CRISPR mínima que comprende al menos un 60 % de identidad con un ARNcr de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6, 7 u 8 nucleótidos contiguos y en donde la repetición CRISPR mínima tiene una longitud de 5-30 nucleótidos; una secuencia mínima de ARNcrtra que comprende al menos un 60 % de identidad con un ARNcrtra de una bacteria (por ejemplo, S. pyogenes) sobre 6, 7 u 8 nucleótidos contiguos y en donde la secuencia mínima de ARNcrtra tiene una longitud de 5-30 nucleótidos; una secuencia enlazadora que une la repetición CRISPR mínima y el ARNcrtra mínimo y comprende una longitud de 3-5000 nucleótidos; un ARNcrtra 3' que comprende al menos un 60 % de identidad con un ARNcrtra de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6, 7 u 8 nucleótidos contiguos y en donde el ARNcrtra 3' comprende una longitud de 10-20 nucleótidos, y comprende una región duplexada; y/o una extensión de ARNcrtra que comprende 10-5000 nucleótidos de longitud, o cualquier combinación de los mismos. Este ácido nucleico dirigido a ácido nucleico puede denominarse ácido nucleico dirigido a ácido nucleico guía sencillo.
Un ácido nucleico dirigido a ácido nucleico puede comprender una secuencia de extensión del espaciador de 10 5000 nucleótidos de longitud; una secuencia de espaciador de 12-30 nucleótidos de longitud, en donde el espaciador es al menos un 50 % complementario a un ácido nucleico diana; un dúplex que comprende 1) una repetición CRISPR mínima que comprende al menos un 60 % de identidad con un ARNcr de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6 nucleótidos contiguos y en donde la repetición CRISPR mínima tiene una longitud de 5-30 nucleótidos; 2 ) una secuencia mínima de ARNcrtra que comprende al menos un 60 % de identidad con un ARNcrtra de una bacteria (por ejemplo, S. pyogenes) sobre 6 nucleótidos contiguos y en donde la secuencia mínima de ARNcrtra tiene una longitud de 5-30 nucleótidos; y 3) una protuberancia en donde la protuberancia comprende al menos 3 nucleótidos no emparejados en la cadena de repetición CRISPR mínima del dúplex y al menos 1 nucleótido no emparejado en la cadena de secuencia mínima de ARNcrtra del dúplex; una secuencia enlazadora que une la repetición CRISPR mínima y el ARNcrtra mínimo y comprende una longitud de 3-5000 nucleótidos; un ARNcrtra 3' que comprende al menos un 60 % de identidad con un ARNcrtra de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6 nucleótidos contiguos, en donde el ARNcrtra 3' comprende una longitud de 10-20 nucleótidos y comprende una región duplexada; un dominio P que comienza desde 1-5 nucleótidos cadena abajo del dúplex que comprende la repetición CRISPR mínima y el ARNcrtra mínimo, comprende 1-10 nucleótidos, comprende una secuencia que puede hibridarse con un motivo adyacente al protoespaciador en un ácido nucleico diana, puede formar una horquilla y se encuentra en la región de ARNcrtra 3'; y/o una extensión de ARNcrtra que comprende 10-5000 nucleótidos de longitud, o cualquier
combinación de los mismos.
Ácido nucleico guía doble
Un ácido nucleico dirigido a ácido nucleico puede ser un ácido nucleico guía doble. El ácido nucleico guía doble puede ser ARN. El ácido nucleico guía doble puede comprender dos moléculas de ácido nucleico separadas (es decir, polinucleótidos). Cada una de las dos moléculas de ácido nucleico de un ácido nucleico dirigido a ácido nucleico guía doble puede comprender un tramo de nucleótidos que pueden hibridarse entre sí de manera que los nucleótidos complementarios de las dos moléculas de ácido nucleico se hibridan para formar el dúplex bicatenario del segmento de unión a proteínas. Si no se especifica lo contrario, la expresión "ácido nucleico dirigido a ácido nucleico" puede ser inclusiva, refiriéndose tanto a los ácidos nucleicos dirigidos a ácido nucleico de una sola molécula como a los ácidos nucleicos dirigidos a ácido nucleico de doble molécula.
Un ácido nucleico dirigido a ácido nucleico guía doble puede comprender 1) una primera molécula de ácido nucleico que comprende una secuencia de extensión del espaciador de 10-5000 nucleótidos de longitud; una secuencia de espaciador de 12-30 nucleótidos de longitud, en donde el espaciador es al menos un 50 % complementario a un ácido nucleico diana; y una repetición CRISPR mínima que comprende al menos un 60 % de identidad con un ARNc de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6 nucleótidos contiguos y en donde la repetición CRISPR mínima tiene una longitud de 5-30 nucleótidos; y 2) una segunda molécula de ácido nucleico del ácido nucleico dirigido a ácido nucleico guía doble puede comprender una secuencia mínima de ARNcrtra que comprende al menos un 60 % de identidad con un ARNcrtra de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6 nucleótidos contiguos y en donde la secuencia mínima de ARNcrtra tiene una longitud de 5-30 nucleótidos; un ARNcrtra 3' que comprende al menos un 60 % de identidad con un ARNcrtra de una bacteria (por ejemplo, S. pyogenes) sobre 6 nucleótidos contiguos y en donde el ARNcrtra 3' comprende una longitud de 10-20 nucleótidos, y comprende una región duplexada; y/o una extensión de ARNcrtra que comprende 10-5000 nucleótidos de longitud, o cualquier combinación de los mismos.
En algunos casos, un ácido nucleico dirigido a ácido nucleico guía doble puede comprender 1) una primera molécula de ácido nucleico que comprende una secuencia de extensión del espaciador de 10-5000 nucleótidos de longitud; una secuencia de espaciador de 12-30 nucleótidos de longitud, en donde el espaciador es al menos un 50% complementario a un ácido nucleico diana; una repetición CRISPR mínima que comprende al menos un 60 % de identidad con un ARNc de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6 nucleótidos contiguos y en donde la repetición CRISPR mínima tiene una longitud de 5-30 nucleótidos y al menos 3 nucleótidos no emparejados de una protuberancia; y 2) una segunda molécula de ácido nucleico del ácido nucleico dirigido a ácido nucleico guía doble puede comprender una secuencia mínima de ARNcrtra que comprende al menos un 60 % de identidad con un ARNcrtra de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6 nucleótidos contiguos y en donde la secuencia mínima de ARNcrtra tiene una longitud de 5-30 nucleótidos y al menos 1 nucleótido no emparejado de una protuberancia, en donde el 1 nucleótido no emparejado de la protuberancia está ubicado en la misma protuberancia que los 3 nucleótidos no emparejados de la repetición CRISPR mínima; un ARNcrtra 3' que comprende al menos un 60 % de identidad con un ARNcrtra de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6 nucleótidos contiguos y en donde el ARNcrtra 3' comprende una longitud de 10-20 nucleótidos, y comprende una región duplexada; un dominio P que comienza desde 1-5 nucleótidos cadena abajo del dúplex que comprende la repetición CRISPR mínima y el ARNcrtra mínimo, comprende 1-10 nucleótidos, comprende una secuencia que puede hibridarse con un motivo adyacente al protoespaciador en un ácido nucleico diana, puede formar una horquilla y se encuentra en la región de ARNcrtra 3'; y/o una extensión de ARNcrtra que comprende 10-5000 nucleótidos de longitud, o cualquier combinación de los mismos.
Complejo de un ácido nucleico dirigido a ácido nucleico y un polipéptido dirigido a un sitio
Un ácido nucleico dirigido a ácido nucleico puede interactuar con un polipéptido dirigido a un sitio (por ejemplo, una nucleasa guiada por ácido nucleico, Cas9), formando así un complejo. El ácido nucleico dirigido a ácido nucleico puede guiar al polipéptido dirigido a un sitio a un ácido nucleico diana.
En algunas realizaciones, un ácido nucleico dirigido a ácido nucleico puede modificarse de forma tal que el complejo (por ejemplo, que comprende un polipéptido dirigido a un sitio y un ácido nucleico dirigido a ácido nucleico) pueda unirse fuera del sitio de escisión del polipéptido dirigido a un sitio. En este caso, el ácido nucleico diana puede no interactuar con el complejo, y el ácido nucleico diana se puede escindir (por ejemplo, libre del complejo).
En algunas realizaciones, un ácido nucleico dirigido a ácido nucleico puede diseñado de modo que el complejo pueda unirse dentro del sitio de escisión del polipéptido dirigido a un sitio. En este caso, el ácido nucleico diana puede interactuar con el complejo y el ácido nucleico diana puede unirse (por ejemplo, unirse al complejo).
En algunos casos, un complejo puede comprender un polipéptido dirigido a un sitio, en donde el polipéptido dirigido a un sitio puede comprender una secuencia de aminoácidos que comprenda al menos un 15 % de identidad de aminoácidos con un Cas9 de S. pyogenes, y dos dominios de escisión de ácido nucleico (es decir, un dominio HNH y un dominio RuvC); y un ácido nucleico dirigido a ácido nucleico guía doble que comprende 1) una primera molécula
de ácido nucleico que comprende una secuencia de extensión del espaciador de 10-5000 nucleótidos de longitud; una secuencia de espaciador de 12-30 nucleótidos de longitud, en donde el espaciador es al menos un 50% complementario a un ácido nucleico diana; y una repetición CRISPR mínima que comprende al menos un 60 % de identidad con un ARNc de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6 nucleótidos contiguos y en donde la repetición CRISPR mínima tiene una longitud de 5-30 nucleótidos; y 2) una segunda molécula de ácido nucleico del ácido nucleico dirigido a ácido nucleico guía doble puede comprender una secuencia mínima de ARNcrtra que comprenda al menos un 60 % de identidad con un ARNcrtra de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6 nucleótidos contiguos y en donde la secuencia mínima de ARNcrtra tiene una longitud de 5 30 nucleótidos; un ARNcrtra 3' que comprende al menos un 60 % de identidad con un ARNcrtra de una bacteria (por ejemplo, S. pyogenes) sobre 6 nucleótidos contiguos y en donde el ARNcrtra 3' comprende una longitud de 10 20 nucleótidos, y comprende una región duplexada; y/o una extensión de ARNcrtra que comprende 10 5000 nucleótidos de longitud, o cualquier combinación de los mismos.
En algunos casos, un complejo puede comprender un polipéptido dirigido a un sitio, en donde el polipéptido dirigido a un sitio puede comprender una secuencia de aminoácidos que comprenda al menos un 15 % de identidad de aminoácidos con un Cas9 de S. pyogenes, y dos dominios de escisión de ácido nucleico (es decir, un dominio HNH y un dominio RuvC); y, un ácido nucleico dirigido a ácido nucleico guía doble que comprende 1) una primera molécula de ácido nucleico que comprende una secuencia de extensión del espaciador de 10-5000 nucleótidos de longitud; una secuencia de espaciador de 12-30 nucleótidos de longitud, en donde el espaciador es al menos un 50% complementario a un ácido nucleico diana; una repetición CRISPR mínima que comprende al menos un 60 % de identidad con un ARNc de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6 nucleótidos contiguos y en donde la repetición CRISPR mínima tiene una longitud de 5-30 nucleótidos y al menos 3 nucleótidos no emparejados de una protuberancia; y 2) una segunda molécula de ácido nucleico del ácido nucleico dirigido a ácido nucleico guía doble puede comprender una secuencia mínima de ARNcrtra que comprende al menos un 60 % de identidad con un ARNcrtra de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6 nucleótidos contiguos y en donde la secuencia mínima de ARNcrtra tiene una longitud de 5-30 nucleótidos y al menos 1 nucleótido no emparejado de una protuberancia, en donde el 1 nucleótido no emparejado de la protuberancia está ubicado en la misma protuberancia que los 3 nucleótidos no emparejados de la repetición CRISPR mínima; un ARNcrtra 3' que comprende al menos un 60 % de identidad con un ARNcrtra de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6 nucleótidos contiguos y en donde el ARNcrtra 3' comprende una longitud de 10-20 nucleótidos, y comprende una región duplexada; un dominio P que comienza desde 1-5 nucleótidos cadena abajo del dúplex que comprende la repetición CRISPR mínima y el ARNcrtra mínimo, comprende 1-10 nucleótidos, comprende una secuencia que puede hibridarse con un motivo adyacente al protoespaciador en un ácido nucleico diana, puede formar una horquilla y se encuentra en la región de ARNcrtra 3'; y/o una extensión de ARNcrtra que comprende 10-5000 nucleótidos de longitud, o cualquier combinación de los mismos.
En algunos casos, un complejo puede comprender un polipéptido dirigido a un sitio, en donde el polipéptido dirigido a un sitio puede comprender una secuencia de aminoácidos que comprende al menos un 15 % de identidad de aminoácidos con un Cas9 de S. pyogenes y, dos dominios de escisión de ácido nucleico (es decir, un dominio HNH y un dominio RuvC); y, un ácido nucleico dirigido a ácido nucleico que comprende una secuencia de extensión del espaciador de 10-5000 nucleótidos de longitud; una secuencia de espaciador de 12-30 nucleótidos de longitud, en donde el espaciador es al menos un 50 % complementario a un ácido nucleico diana; una repetición CRISPR mínima que comprende al menos un 60 % de identidad con un ARNcr de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6, 7 u 8 nucleótidos contiguos y en donde la repetición CRISPR mínima tiene una longitud de 5-30 nucleótidos; una secuencia mínima de ARNcrtra que comprende al menos un 60 % de identidad con un ARNcrtra de una bacteria (por ejemplo, S. pyogenes) sobre 6, 7 u 8 nucleótidos contiguos y en donde la secuencia mínima de ARNcrtra tiene una longitud de 5-30 nucleótidos; una secuencia enlazadora que une la repetición CRISPR mínima y el ARNcrtra mínimo y comprende una longitud de 3-5000 nucleótidos; un ARNcrtra 3' que comprende al menos un 60 % de identidad con un ARNcrtra de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6, 7 u 8 nucleótidos contiguos y en donde el ARNcrtra 3' comprende una longitud de 10-20 nucleótidos, y comprende una región duplexada; y/o una extensión de ARNcrtra que comprende 10-5000 nucleótidos de longitud, o cualquier combinación de los mismos. Este ácido nucleico dirigido a ácido nucleico puede denominarse ácido nucleico dirigido a ácido nucleico guía sencillo.
En algunos casos, un complejo puede comprender un polipéptido dirigido a un sitio, en donde el polipéptido dirigido a un sitio puede comprender una secuencia de aminoácidos que comprenda al menos un 15 % de identidad de aminoácidos con un Cas9 de S. pyogenes, y dos dominios de escisión de ácido nucleico (es decir, un dominio HNH y un dominio RuvC); y, un ácido nucleico dirigido a ácido nucleico puede comprender una secuencia de extensión del espaciador de 10-5000 nucleótidos de longitud; una secuencia de espaciador de 12-30 nucleótidos de longitud, en donde el espaciador es al menos un 50 % complementario a un ácido nucleico diana; un dúplex que comprende 1) una repetición CRISPR mínima que comprende al menos un 60 % de identidad con un ARNcr de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6 nucleótidos contiguos y en donde la repetición CRISPR mínima tiene una longitud de 5-30 nucleótidos; 2 ) una secuencia mínima de ARNcrtra que comprende al menos un 60 % de identidad con un ARNcrtra de una bacteria (por ejemplo, S. pyogenes) sobre 6 nucleótidos contiguos y en donde la secuencia mínima de ARNcrtra tiene una longitud de 5-30 nucleótidos; y 3) una protuberancia en donde la protuberancia comprende al menos 3 nucleótidos no emparejados en la cadena de repetición CRISPR mínima del dúplex y al menos 1 nucleótido no emparejado en la cadena de secuencia mínima de ARNcrtra del dúplex; una secuencia enlazadora
que une la repetición CRISPR mínima y el ARNcrtra mínimo y comprende una longitud de 3-5000 nucleótidos; un ARNcrtra 3' que comprende al menos un 60 % de identidad con un ARNcrtra de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6 nucleótidos contiguos, en donde el ARNcrtra 3' comprende una longitud de 10 20 nucleótidos y comprende una región duplexada; un dominio P que comienza desde 1-5 nucleótidos cadena abajo del dúplex que comprende la repetición CRISPR mínima y el ARNcrtra mínimo, comprende 1-10 nucleótidos, comprende una secuencia que puede hibridarse con un motivo adyacente al protoespaciador en un ácido nucleico diana, puede formar una horquilla y se encuentra en la región de ARNcrtra 3'; y/o una extensión de ARNcrtra que comprende 10-5000 nucleótidos de longitud, o cualquier combinación de los mismos. En algunos casos, un complejo puede comprender un polipéptido dirigido a un sitio, en donde el polipéptido dirigido a un sitio comprende una secuencia de aminoácidos que comprende al menos un 15 % de identidad de aminoácidos con un Cas9 de S. pyogenes, dos dominios de escisión de ácido nucleico (es decir, un dominio HNH y un dominio RuvC) y un enlazador que une al polipéptido dirigido a un sitio con una secuencia no nativa; y un ácido nucleico dirigido a ácido nucleico guía doble que comprende 1) una primera molécula de ácido nucleico que comprende una secuencia de extensión del espaciador de 10-5000 nucleótidos de longitud; una secuencia de espaciador de 12-30 nucleótidos de longitud, en donde el espaciador es al menos un 50 % complementario a un ácido nucleico diana; y una repetición CRISPR mínima que comprende al menos un 60 % de identidad con un ARNc de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6 nucleótidos contiguos y en donde la repetición CRISPR mínima tiene una longitud de 5-30 nucleótidos; y 2) una segunda molécula de ácido nucleico del ácido nucleico dirigido a ácido nucleico guía doble puede comprender una secuencia mínima de ARNcrtra que comprende al menos un 60 % de identidad con un ARNcrtra de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6 nucleótidos contiguos y en donde la secuencia mínima de ARNcrtra tiene una longitud de 5-30 nucleótidos; un ARNcrtra 3' que comprende al menos un 60 % de identidad con un ARNcrtra de una bacteria (por ejemplo, S. pyogenes) sobre 6 nucleótidos contiguos y en donde el ARNcrtra 3' comprende una longitud de 10-20 nucleótidos, y comprende una región duplexada; y/o una extensión de ARNcrtra que comprende 10 5000 nucleótidos de longitud, o cualquier combinación de los mismos.
En algunos casos, un complejo puede comprender un polipéptido dirigido a un sitio, en donde el polipéptido dirigido a un sitio comprende una secuencia de aminoácidos que comprende al menos un 15 % de identidad de aminoácidos con un Cas9 de S. pyogenes, dos dominios de escisión de ácido nucleico (es decir, un dominio HNH y un dominio RuvC) y un enlazador que une al polipéptido dirigido a un sitio con una secuencia no nativa; y un ácido nucleico dirigido a ácido nucleico guía doble que comprende 1) una primera molécula de ácido nucleico que comprende una secuencia de extensión del espaciador de 10-5000 nucleótidos de longitud; una secuencia de espaciador de 12-30 nucleótidos de longitud, en donde el espaciador es al menos un 50 % complementario a un ácido nucleico diana; una repetición CRISPR mínima que comprende al menos un 60 % de identidad con un ARNc de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6 nucleótidos contiguos y en donde la repetición CRISPR mínima tiene una longitud de 5 30 nucleótidos y al menos 3 nucleótidos no emparejados de una protuberancia; y 2) una segunda molécula de ácido nucleico del ácido nucleico dirigido a ácido nucleico guía doble puede comprender una secuencia mínima de ARNcrtra que comprende al menos un 60 % de identidad con un ARNcrtra de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6 nucleótidos contiguos y en donde la secuencia mínima de ARNcrtra tiene una longitud de 5-30 nucleótidos y al menos 1 nucleótido no emparejado de una protuberancia, en donde el 1 nucleótido no emparejado de la protuberancia está ubicado en la misma protuberancia que los 3 nucleótidos no emparejados de la repetición CRISPR mínima; un ARNcrtra 3' que comprende al menos un 60 % de identidad con un ARNcrtra de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6 nucleótidos contiguos y en donde el ARNcrtra 3' comprende una longitud de 10 20 nucleótidos, y comprende una región duplexada; un dominio P que comienza desde 1-5 nucleótidos cadena abajo del dúplex que comprende la repetición CRISPR mínima y el ARNcrtra mínimo, comprende 1-10 nucleótidos, comprende una secuencia que puede hibridarse con un motivo adyacente al protoespaciador en un ácido nucleico diana, puede formar una horquilla y se encuentra en la región de ARNcrtra 3'; y/o una extensión de ARNcrtra que comprende 10-5000 nucleótidos de longitud, o cualquier combinación de los mismos.
En algunos casos, un complejo puede comprender un polipéptido dirigido a un sitio, en donde el polipéptido dirigido a un sitio comprende una secuencia de aminoácidos que comprende al menos un 15 % de identidad de aminoácidos con un Cas9 de S. pyogenes, dos dominios de escisión de ácido nucleico (es decir, un dominio HNH y un dominio RuvC) y un enlazador que une al polipéptido dirigido a un sitio con una secuencia no nativa; y un ácido nucleico dirigido a ácido nucleico que comprende una secuencia de extensión del espaciador de 10-5000 nucleótidos de longitud; una secuencia de espaciador de 12-30 nucleótidos de longitud, en donde el espaciador es al menos un 50% complementario a un ácido nucleico diana; una repetición CRISPR mínima que comprende al menos un 60 % de identidad con un ARNcr de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6, 7 u 8 nucleótidos contiguos y en donde la repetición CRISPR mínima tiene una longitud de 5-30 nucleótidos; una secuencia mínima de ARNcrtra que comprende al menos un 60 % de identidad con un ARNcrtra de una bacteria (por ejemplo, S. pyogenes) sobre 6, 7 u 8 nucleótidos contiguos y en donde la secuencia mínima de ARNcrtra tiene una longitud de 5-30 nucleótidos; una secuencia enlazadora que une la repetición CRISPR mínima y el ARNcrtra mínimo y comprende una longitud de 3 5000 nucleótidos; un ARNcrtra 3' que comprende al menos un 60 % de identidad con un ARNcrtra de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6, 7 u 8 nucleótidos contiguos y en donde el ARNcrtra 3' comprende una longitud de 10-20 nucleótidos, y comprende una región duplexada; y/o una extensión de ARNcrtra que comprende 10 5000 nucleótidos de longitud, o cualquier combinación de los mismos. Este ácido nucleico dirigido a ácido nucleico puede denominarse ácido nucleico dirigido a ácido nucleico guía sencillo.
En algunos casos, un complejo puede comprender un polipéptido dirigido a un sitio, en donde el polipéptido dirigido a un sitio comprende una secuencia de aminoácidos que comprende al menos un 15 % de identidad de aminoácidos con un Cas9 de S. pyogenes, dos dominios de escisión de ácido nucleico (es decir, un dominio HNH y un dominio RuvC) y un enlazador que une al polipéptido dirigido a un sitio con una secuencia no nativa; y el ácido nucleico dirigido a ácido nucleico puede comprender una secuencia de extensión del espaciador de 10-5000 nucleótidos de longitud; una secuencia de espaciador de 12-30 nucleótidos de longitud, en donde el espaciador es al menos un 50% complementario a un ácido nucleico diana; un dúplex que comprende 1) una repetición CRISPR mínima que comprende al menos un 60 % de identidad con un ARNcr de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6 nucleótidos contiguos y en donde la repetición CRISPR mínima tiene una longitud de 5-30 nucleótidos; 2) una secuencia mínima de ARNcrtra que comprende al menos un 60 % de identidad con un ARNcrtra de una bacteria (por ejemplo, S. pyogenes) sobre 6 nucleótidos contiguos y en donde la secuencia mínima de ARNcrtra tiene una longitud de 5-30 nucleótidos; y 3) una protuberancia en donde la protuberancia comprende al menos 3 nucleótidos no emparejados en la cadena de repetición CRISPR mínima del dúplex y al menos 1 nucleótido no emparejado en la cadena de secuencia mínima de ARNcrtra del dúplex; una secuencia enlazadora que une la repetición CRISPR mínima y el ARNcrtra mínimo y comprende una longitud de 3-5000 nucleótidos; un ARNcrtra 3' que comprende al menos un 60 % de identidad con un ARNcrtra de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6 nucleótidos contiguos, en donde el ARNcrtra 3' comprende una longitud de 10-20 nucleótidos y comprende una región duplexada; un dominio P que comienza desde 1-5 nucleótidos cadena abajo del dúplex que comprende la repetición CRISPR mínima y el ARNcrtra mínimo, comprende 1-10 nucleótidos, comprende una secuencia que puede hibridarse con un motivo adyacente al protoespaciador en un ácido nucleico diana, puede formar una horquilla y se encuentra en la región de ARNcrtra 3'; y/o una extensión de ARNcrtra que comprende 10-5000 nucleótidos de longitud, o cualquier combinación de los mismos.
En algunos casos, un complejo puede comprender un polipéptido dirigido a un sitio, en donde el polipéptido dirigido a un sitio comprende al menos un 15 % de identidad de aminoácidos con una Cas9 de S. pyogenes, dos dominios de escisión de ácido nucleico (es decir, un dominio HNH y un dominio RuvC), en donde el polipéptido dirigido a un sitio comprende una mutación en uno o ambos dominios de escisión de ácido nucleico que reduce la actividad de escisión de los dominios nucleasa en al menos un 50 %; y un ácido nucleico dirigido a ácido nucleico guía doble que comprende 1) una primera molécula de ácido nucleico que comprende una secuencia de extensión del espaciador de 10 5000 nucleótidos de longitud; una secuencia de espaciador de 12-30 nucleótidos de longitud, en donde el espaciador es al menos un 50 % complementario a un ácido nucleico diana; y una repetición CRISPR mínima que comprende al menos un 60 % de identidad con un ARNc de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6 nucleótidos contiguos y en donde la repetición CRISPR mínima tiene una longitud de 5-30 nucleótidos; y 2) una segunda molécula de ácido nucleico del ácido nucleico dirigido a ácido nucleico guía doble puede comprender una secuencia mínima de ARNcrtra que comprende al menos un 60 % de identidad con un ARNcrtra de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6 nucleótidos contiguos y en donde la secuencia mínima de ARNcrtra tiene una longitud de 5 30 nucleótidos; un ARNcrtra 3' que comprende al menos un 60 % de identidad con un ARNcrtra de una bacteria (por ejemplo, S. pyogenes) sobre 6 nucleótidos contiguos y en donde el ARNcrtra 3' comprende una longitud de 10 20 nucleótidos, y comprende una región duplexada; y/o una extensión de ARNcrtra que comprende 10 5000 nucleótidos de longitud, o cualquier combinación de los mismos.
En algunos casos, un complejo puede comprender un polipéptido dirigido a un sitio, en donde el polipéptido dirigido a un sitio comprende al menos un 15 % de identidad de aminoácidos con una Cas9 de S. pyogenes, dos dominios de escisión de ácido nucleico (es decir, un dominio HNH y un dominio RuvC), en donde el polipéptido dirigido a un sitio comprende una mutación en uno o ambos dominios de escisión de ácido nucleico que reduce la actividad de escisión de los dominios nucleasa en al menos un 50 %; y un ácido nucleico dirigido a ácido nucleico guía doble que comprende 1) una primera molécula de ácido nucleico que comprende una secuencia de extensión del espaciador de 10 5000 nucleótidos de longitud; una secuencia de espaciador de 12-30 nucleótidos de longitud, en donde el espaciador es al menos un 50 % complementario a un ácido nucleico diana; una repetición CRISPR mínima que comprende al menos un 60 % de identidad con un ARNc de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6 nucleótidos contiguos y en donde la repetición CRISPR mínima tiene una longitud de 5-30 nucleótidos y al menos 3 nucleótidos no emparejados de una protuberancia; y 2) una segunda molécula de ácido nucleico del ácido nucleico dirigido a ácido nucleico guía doble puede comprender una secuencia mínima de ARNcrtra que comprende al menos un 60 % de identidad con un ARNcrtra de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6 nucleótidos contiguos y en donde la secuencia mínima de ARNcrtra tiene una longitud de 5-30 nucleótidos y al menos 1 nucleótido no emparejado de una protuberancia, en donde el 1 nucleótido no emparejado de la protuberancia está ubicado en la misma protuberancia que los 3 nucleótidos no emparejados de la repetición CRISPR mínima; un ARNcrtra 3' que comprende al menos un 60 % de identidad con un ARNcrtra de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6 nucleótidos contiguos y en donde el ARNcrtra 3' comprende una longitud de 10-20 nucleótidos, y comprende una región duplexada; un dominio P que comienza desde 1-5 nucleótidos cadena abajo del dúplex que comprende la repetición CRISPR mínima y el ARNcrtra mínimo, comprende 1-10 nucleótidos, comprende una secuencia que puede hibridarse con un motivo adyacente al protoespaciador en un ácido nucleico diana, puede formar una horquilla y se encuentra en la región de ARNcrtra 3'; y/o una extensión de ARNcrtra que comprende 10-5000 nucleótidos de longitud, o cualquier combinación de los mismos.
En algunos casos, un complejo puede comprender un polipéptido dirigido a un sitio, en donde el polipéptido dirigido a
un sitio comprende al menos un 15 % de identidad de aminoácidos con una Cas9 de S. pyogenes, dos dominios de escisión de ácido nucleico (es decir, un dominio HNH y un dominio RuvC), en donde el polipéptido dirigido a un sitio comprende una mutación en uno o ambos dominios de escisión de ácido nucleico que reduce la actividad de escisión de los dominios nucleasa en al menos un 50 %; y ácido nucleico dirigido a ácido nucleico que comprende una secuencia de extensión del espaciador de 10-5000 nucleótidos de longitud; una secuencia de espaciador de 12 30 nucleótidos de longitud, en donde el espaciador es al menos un 50 % complementario a un ácido nucleico diana; una repetición CRISPR mínima que comprende al menos un 60 % de identidad con un ARNcr de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6, 7 u 8 nucleótidos contiguos y en donde la repetición CRISPR mínima tiene una longitud de 5-30 nucleótidos; una secuencia mínima de ARNcrtra que comprende al menos un 60 % de identidad con un ARNcrtra de una bacteria (por ejemplo, S. pyogenes) sobre 6, 7 u 8 nucleótidos contiguos y en donde la secuencia mínima de ARNcrtra tiene una longitud de 5-30 nucleótidos; una secuencia enlazadora que une la repetición CRISPR mínima y el ARNcrtra mínimo y comprende una longitud de 3-5000 nucleótidos; un ARNcrtra 3' que comprende al menos un 60 % de identidad con un ARNcrtra de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6, 7 u 8 nucleótidos contiguos y en donde el ARNcrtra 3' comprende una longitud de 10-20 nucleótidos, y comprende una región duplexada; y/o una extensión de ARNcrtra que comprende 10-5000 nucleótidos de longitud, o cualquier combinación de los mismos. Este ácido nucleico dirigido a ácido nucleico puede denominarse ácido nucleico dirigido a ácido nucleico guía sencillo.
En algunos casos, un complejo puede comprender un polipéptido dirigido a un sitio, en donde el polipéptido dirigido a un sitio comprende al menos un 15 % de identidad de aminoácidos con una Cas9 de S. pyogenes, dos dominios de escisión de ácido nucleico (es decir, un dominio HNH y un dominio RuvC), en donde el polipéptido dirigido a un sitio comprende una mutación en uno o ambos dominios de escisión de ácido nucleico que reduce la actividad de escisión de los dominios nucleasa en al menos un 50 %; y el ácido nucleico dirigido a ácido nucleico puede comprender una secuencia de extensión del espaciador de 10-5000 nucleótidos de longitud; una secuencia de espaciador de 12 30 nucleótidos de longitud, en donde el espaciador es al menos un 50 % complementario a un ácido nucleico diana; un dúplex que comprende 1) una repetición CRISPR mínima que comprende al menos un 60 % de identidad con un ARNcr de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6 nucleótidos contiguos y en donde la repetición CRISPR mínima tiene una longitud de 5-30 nucleótidos; 2 ) una secuencia mínima de ARNcrtra que comprende al menos un 60 % de identidad con un ARNcrtra de una bacteria (por ejemplo, S. pyogenes) sobre 6 nucleótidos contiguos y en donde la secuencia mínima de ARNcrtra tiene una longitud de 5-30 nucleótidos; y 3) una protuberancia en donde la protuberancia comprende al menos 3 nucleótidos no emparejados en la cadena de repetición CRISPR mínima del dúplex y al menos 1 nucleótido no emparejado en la cadena de secuencia mínima de ARNcrtra del dúplex; una secuencia enlazadora que une la repetición Cr iSp R mínima y el ARNcrtra mínimo y comprende una longitud de 3-5000 nucleótidos; un ARNcrtra 3' que comprende al menos un 60 % de identidad con un ARNcrtra de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6 nucleótidos contiguos, en donde el ARNcrtra 3' comprende una longitud de 10-20 nucleótidos y comprende una región duplexada; un dominio P que comienza desde 1-5 nucleótidos cadena abajo del dúplex que comprende la repetición CRISPR mínima y el ARNcrtra mínimo, comprende 1-10 nucleótidos, comprende una secuencia que puede hibridarse con un motivo adyacente al protoespaciador en un ácido nucleico diana, puede formar una horquilla y se encuentra en la región de ARNcrtra 3'; y/o una extensión de ARNcrtra que comprende 10-5000 nucleótidos de longitud, o cualquier combinación de los mismos.
En algunos casos, un complejo puede comprender un polipéptido dirigido a un sitio, en donde el polipéptido dirigido a un sitio comprende al menos un 15 % de identidad de aminoácidos con una Cas9 de S. pyogenes, dos dominios de escisión de ácido nucleico (es decir, un dominio HNH y un dominio RuvC), en donde el polipéptido dirigido a un sitio comprende una mutación en uno o ambos dominios de escisión de ácido nucleico que reduce la actividad de escisión de los dominios nucleasa en al menos un 50 %; y un ácido nucleico dirigido a ácido nucleico guía doble que comprende 1) una primera molécula de ácido nucleico que comprende una secuencia de extensión del espaciador de 10 5000 nucleótidos de longitud; una secuencia de espaciador de 12-30 nucleótidos de longitud, en donde el espaciador es al menos un 50 % complementario a un ácido nucleico diana; y una repetición CRISPR mínima que comprende al menos un 60 % de identidad con un ARNc de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6 nucleótidos contiguos y en donde la repetición CRISPR mínima tiene una longitud de 5-30 nucleótidos; y 2) una segunda molécula de ácido nucleico del ácido nucleico dirigido a ácido nucleico guía doble puede comprender una secuencia mínima de ARNcrtra que comprende al menos un 60 % de identidad con un ARNcrtra de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6 nucleótidos contiguos y en donde la secuencia mínima de ARNcrtra tiene una longitud de 5 30 nucleótidos; un ARNcrtra 3' que comprende al menos un 60 % de identidad con un ARNcrtra de una bacteria (por ejemplo, S. pyogenes) sobre 6 nucleótidos contiguos y en donde el ARNcrtra 3' comprende una longitud de 10 20 nucleótidos, y comprende una región duplexada; y/o una extensión de ARNcrtra que comprende 10 5000 nucleótidos de longitud, o cualquier combinación de los mismos.
En algunos casos, un complejo puede comprender un polipéptido dirigido a un sitio, en donde el polipéptido dirigido a un sitio comprende al menos un 15 % de identidad de aminoácidos con una Cas9 de S. pyogenes, dos dominios de escisión de ácido nucleico (es decir, un dominio HNH y un dominio RuvC), en donde el polipéptido dirigido a un sitio comprende una mutación en uno o ambos dominios de escisión de ácido nucleico que reduce la actividad de escisión de los dominios nucleasa en al menos un 50 %; y un ácido nucleico dirigido a ácido nucleico guía doble que comprende 1) una primera molécula de ácido nucleico que comprende una secuencia de extensión del espaciador de 10 5000 nucleótidos de longitud; una secuencia de espaciador de 12-30 nucleótidos de longitud, en donde el espaciador
es al menos un 50 % complementario a un ácido nucleico diana; una repetición CRISPR mínima que comprende al menos un 60 % de identidad con un ARNc de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6 nucleótidos contiguos y en donde la repetición CRISPR mínima tiene una longitud de 5-30 nucleótidos y al menos 3 nucleótidos no emparejados de una protuberancia; y 2) una segunda molécula de ácido nucleico del ácido nucleico dirigido a ácido nucleico guía doble puede comprender una secuencia mínima de ARNcrtra que comprende al menos un 60 % de identidad con un ARNcrtra de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6 nucleótidos contiguos y en donde la secuencia mínima de ARNcrtra tiene una longitud de 5-30 nucleótidos y al menos 1 nucleótido no emparejado de una protuberancia, en donde el 1 nucleótido no emparejado de la protuberancia está ubicado en la misma protuberancia que los 3 nucleótidos no emparejados de la repetición CRISPR mínima; un ARNcrtra 3' que comprende al menos un 60 % de identidad con un ARNcrtra de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6 nucleótidos contiguos y en donde el ARNcrtra 3' comprende una longitud de 10-20 nucleótidos, y comprende una región duplexada; un dominio P que comienza desde 1-5 nucleótidos cadena abajo del dúplex que comprende la repetición CRISPR mínima y el ARNcrtra mínimo, comprende 1-10 nucleótidos, comprende una secuencia que puede hibridarse con un motivo adyacente al protoespaciador en un ácido nucleico diana, puede formar una horquilla y se encuentra en la región de ARNcrtra 3'; y/o una extensión de ARNcrtra que comprende 10-5000 nucleótidos de longitud, o cualquier combinación de los mismos.
En algunos casos, un complejo puede comprender un polipéptido dirigido a un sitio, en donde el polipéptido dirigido a un sitio comprende al menos un 15 % de identidad de aminoácidos con una Cas9 de S. pyogenes, dos dominios de escisión de ácido nucleico (es decir, un dominio HNH y un dominio RuvC), en donde el polipéptido dirigido a un sitio comprende una mutación en uno o ambos dominios de escisión de ácido nucleico que reduce la actividad de escisión de los dominios nucleasa en al menos un 50 %; y ácido nucleico dirigido a ácido nucleico que comprende una secuencia de extensión del espaciador de 10-5000 nucleótidos de longitud; una secuencia de espaciador de 12 30 nucleótidos de longitud, en donde el espaciador es al menos un 50 % complementario a un ácido nucleico diana; una repetición CRISPR mínima que comprende al menos un 60 % de identidad con un ARNcr de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6, 7 u 8 nucleótidos contiguos y en donde la repetición CRISPR mínima tiene una longitud de 5-30 nucleótidos; una secuencia mínima de ARNcrtra que comprende al menos un 60 % de identidad con un ARNcrtra de una bacteria (por ejemplo, S. pyogenes) sobre 6, 7 u 8 nucleótidos contiguos y en donde la secuencia mínima de ARNcrtra tiene una longitud de 5-30 nucleótidos; una secuencia enlazadora que une la repetición CRISPR mínima y el ARNcrtra mínimo y comprende una longitud de 3-5000 nucleótidos; un ARNcrtra 3' que comprende al menos un 60 % de identidad con un ARNcrtra de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6, 7 u 8 nucleótidos contiguos y en donde el ARNcrtra 3' comprende una longitud de 10-20 nucleótidos, y comprende una región duplexada; y/o una extensión de ARNcrtra que comprende 10-5000 nucleótidos de longitud, o cualquier combinación de los mismos. Este ácido nucleico dirigido a ácido nucleico puede denominarse ácido nucleico dirigido a ácido nucleico guía sencillo.
En algunos casos, un complejo puede comprender un polipéptido dirigido a un sitio, en donde el polipéptido dirigido a un sitio comprende al menos un 15 % de identidad de aminoácidos con una Cas9 de S. pyogenes, dos dominios de escisión de ácido nucleico (es decir, un dominio HNH y un dominio RuvC), en donde el polipéptido dirigido a un sitio comprende una mutación en uno o ambos dominios de escisión de ácido nucleico que reduce la actividad de escisión de los dominios nucleasa en al menos un 50 %; y el ácido nucleico dirigido a ácido nucleico puede comprender una secuencia de extensión del espaciador de 10-5000 nucleótidos de longitud; una secuencia de espaciador de 12 30 nucleótidos de longitud, en donde el espaciador es al menos un 50 % complementario a un ácido nucleico diana; un dúplex que comprende 1) una repetición CRISPR mínima que comprende al menos un 60 % de identidad con un ARNcr de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6 nucleótidos contiguos y en donde la repetición CRISPR mínima tiene una longitud de 5-30 nucleótidos; 2 ) una secuencia mínima de ARNcrtra que comprende al menos un 60 % de identidad con un ARNcrtra de una bacteria (por ejemplo, S. pyogenes) sobre 6 nucleótidos contiguos y en donde la secuencia mínima de ARNcrtra tiene una longitud de 5-30 nucleótidos; y 3) una protuberancia en donde la protuberancia comprende al menos 3 nucleótidos no emparejados en la cadena de repetición CRISPR mínima del dúplex y al menos 1 nucleótido no emparejado en la cadena de secuencia mínima de ARNcrtra del dúplex; una secuencia enlazadora que une la repetición CRISPR mínima y el ARNcrtra mínimo y comprende una longitud de 3-5000 nucleótidos; un ARNcrtra 3' que comprende al menos un 60 % de identidad con un ARNcrtra de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6 nucleótidos contiguos, en donde el ARNcrtra 3' comprende una longitud de 10-20 nucleótidos y comprende una región duplexada; un dominio P que comienza desde 1-5 nucleótidos cadena abajo del dúplex que comprende la repetición CRISPR mínima y el ARNcrtra mínimo, comprende 1-10 nucleótidos, comprende una secuencia que puede hibridarse con un motivo adyacente al protoespaciador en un ácido nucleico diana, puede formar una horquilla y se encuentra en la región de ARNcrtra 3'; y/o una extensión de ARNcrtra que comprende 10-5000 nucleótidos de longitud, o cualquier combinación de los mismos.
En algunos casos, un complejo puede comprender un polipéptido dirigido a un sitio, en donde el polipéptido dirigido a un sitio comprende al menos un 15 % de identidad de aminoácidos con una Cas9 de S. pyogenes, dos dominios de escisión de ácido nucleico (es decir, un dominio HNH y un dominio RuvC), en donde el polipéptido dirigido a un sitio comprende una mutación en uno o ambos dominios de escisión de ácido nucleico que reduce la actividad de escisión de los dominios nucleasa en al menos un 50 %; y un ácido nucleico dirigido a ácido nucleico guía doble que comprende 1) una primera molécula de ácido nucleico que comprende una secuencia de extensión del espaciador de 10 5000 nucleótidos de longitud; una secuencia de espaciador de 12-30 nucleótidos de longitud, en donde el espaciador
es al menos un 50 % complementario a un ácido nucleico diana; y una repetición CRISPR mínima que comprende al menos un 60 % de identidad con un ARNc de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6 nucleótidos contiguos y en donde la repetición CRISPR mínima tiene una longitud de 5-30 nucleótidos; y 2) una segunda molécula de ácido nucleico del ácido nucleico dirigido a ácido nucleico guía doble puede comprender una secuencia mínima de ARNcrtra que comprende al menos un 60 % de identidad con un ARNcrtra de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6 nucleótidos contiguos y en donde la secuencia mínima de ARNcrtra tiene una longitud de 5 30 nucleótidos; un ARNcrtra 3' que comprende al menos un 60 % de identidad con un ARNcrtra de una bacteria (por ejemplo, S. pyogenes) sobre 6 nucleótidos contiguos y en donde el ARNcrtra 3' comprende una longitud de 10 20 nucleótidos, y comprende una región duplexada; y/o una extensión de ARNcrtra que comprende 10 5000 nucleótidos de longitud, o cualquier combinación de los mismos.
En algunos casos, un complejo puede comprender un polipéptido dirigido a un sitio, en donde el polipéptido dirigido a un sitio comprende al menos un 15 % de identidad de aminoácidos con una Cas9 de S. pyogenes y dos dominios de escisión de ácido nucleico, en donde uno o ambos dominios de escisión de ácido nucleico comprenden al menos un 50 % de identidad de aminoácidos con un dominio nucleasa de Cas9 de S. pyogenes; y un ácido nucleico dirigido a ácido nucleico guía doble que comprende 1) una primera molécula de ácido nucleico que comprende una secuencia de extensión del espaciador de 10-5000 nucleótidos de longitud; una secuencia de espaciador de 12-30 nucleótidos de longitud, en donde el espaciador es al menos un 50 % complementario a un ácido nucleico diana; una repetición CRISPR mínima que comprende al menos un 60 % de identidad con un ARNc de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6 nucleótidos contiguos y en donde la repetición CRISPR mínima tiene una longitud de 5 30 nucleótidos y al menos 3 nucleótidos no emparejados de una protuberancia; y 2) una segunda molécula de ácido nucleico del ácido nucleico dirigido a ácido nucleico guía doble puede comprender una secuencia mínima de ARNcrtra que comprende al menos un 60 % de identidad con un ARNcrtra de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6 nucleótidos contiguos y en donde la secuencia mínima de ARNcrtra tiene una longitud de 5-30 nucleótidos y al menos 1 nucleótido no emparejado de una protuberancia, en donde el 1 nucleótido no emparejado de la protuberancia está ubicado en la misma protuberancia que los 3 nucleótidos no emparejados de la repetición CRISPR mínima; un ARNcrtra 3' que comprende al menos un 60 % de identidad con un ARNcrtra de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6 nucleótidos contiguos y en donde el ARNcrtra 3' comprende una longitud de 10 20 nucleótidos, y comprende una región duplexada; un dominio P que comienza desde 1-5 nucleótidos cadena abajo del dúplex que comprende la repetición CRISPR mínima y el ARNcrtra mínimo, comprende 1-10 nucleótidos, comprende una secuencia que puede hibridarse con un motivo adyacente al protoespaciador en un ácido nucleico diana, puede formar una horquilla y se encuentra en la región de ARNcrtra 3'; y/o una extensión de ARNcrtra que comprende 10-5000 nucleótidos de longitud, o cualquier combinación de los mismos.
En algunos casos, un complejo puede comprender un polipéptido dirigido a un sitio, en donde el polipéptido dirigido a un sitio comprende al menos un 15 % de identidad de aminoácidos con una Cas9 de S. pyogenes y dos dominios de escisión de ácido nucleico, en donde uno o ambos dominios de escisión de ácido nucleico comprenden al menos un 50 % de identidad de aminoácidos con un dominio nucleasa de Cas9 de S. pyogenes; y ácido nucleico dirigido a ácido nucleico que comprende una secuencia de extensión del espaciador de 10-5000 nucleótidos de longitud; una secuencia de espaciador de 12-30 nucleótidos de longitud, en donde el espaciador es al menos un 50% complementario a un ácido nucleico diana; una repetición CRISPR mínima que comprende al menos un 60 % de identidad con un ARNcr de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6, 7 u 8 nucleótidos contiguos y en donde la repetición CRISPR mínima tiene una longitud de 5-30 nucleótidos; una secuencia mínima de ARNcrtra que comprende al menos un 60 % de identidad con un ARNcrtra de una bacteria (por ejemplo, S. pyogenes) sobre 6, 7 u 8 nucleótidos contiguos y en donde la secuencia mínima de ARNcrtra tiene una longitud de 5-30 nucleótidos; una secuencia enlazadora que une la repetición CRISPR mínima y el ARNcrtra mínimo y comprende una longitud de 3 5000 nucleótidos; un ARNcrtra 3' que comprende al menos un 60 % de identidad con un ARNcrtra de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6, 7 u 8 nucleótidos contiguos y en donde el ARNcrtra 3' comprende una longitud de 10-20 nucleótidos, y comprende una región duplexada; y/o una extensión de ARNcrtra que comprende 10 5000 nucleótidos de longitud, o cualquier combinación de los mismos. Este ácido nucleico dirigido a ácido nucleico puede denominarse ácido nucleico dirigido a ácido nucleico guía sencillo.
En algunos casos, un complejo puede comprender un polipéptido dirigido a un sitio, en donde el polipéptido dirigido a un sitio comprende al menos un 15 % de identidad de aminoácidos con una Cas9 de S. pyogenes y dos dominios de escisión de ácido nucleico, en donde uno o ambos dominios de escisión de ácido nucleico comprenden al menos un 50 % de identidad de aminoácidos con un dominio nucleasa de Cas9 de S. pyogenes; y el ácido nucleico dirigido a ácido nucleico puede comprender una secuencia de extensión del espaciador de 10-5000 nucleótidos de longitud; una secuencia de espaciador de 12-30 nucleótidos de longitud, en donde el espaciador es al menos un 50% complementario a un ácido nucleico diana; un dúplex que comprende 1) una repetición CRISPR mínima que comprende al menos un 60 % de identidad con un ARNcr de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6 nucleótidos contiguos y en donde la repetición CRISPR mínima tiene una longitud de 5-30 nucleótidos; 2) una secuencia mínima de ARNcrtra que comprende al menos un 60 % de identidad con un ARNcrtra de una bacteria (por ejemplo, S. pyogenes) sobre 6 nucleótidos contiguos y en donde la secuencia mínima de ARNcrtra tiene una longitud de 5-30 nucleótidos; y 3) una protuberancia en donde la protuberancia comprende al menos 3 nucleótidos no emparejados en la cadena de repetición CRISPR mínima del dúplex y al menos 1 nucleótido no emparejado en la cadena de secuencia mínima de ARNcrtra del dúplex; una secuencia enlazadora que une la repetición CRISPR mínima
y el ARNcrtra mínimo y comprende una longitud de 3-5000 nucleótidos; un ARNcrtra 3' que comprende al menos un 60 % de identidad con un ARNcrtra de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6 nucleótidos contiguos, en donde el ARNcrtra 3' comprende una longitud de 10-20 nucleótidos y comprende una región duplexada; un dominio P que comienza desde 1-5 nucleótidos cadena abajo del dúplex que comprende la repetición CRISPR mínima y el ARNcrtra mínimo, comprende 1-10 nucleótidos, comprende una secuencia que puede hibridarse con un motivo adyacente al protoespaciador en un ácido nucleico diana, puede formar una horquilla y se encuentra en la región de ARNcrtra 3'; y/o una extensión de ARNcrtra que comprende 10-5000 nucleótidos de longitud, o cualquier combinación de los mismos.
Cualquier ácido nucleico dirigido a ácido nucleico de la divulgación, un polipéptido dirigido a un sitio de la divulgación, una proteína efectora, un agente de dirección genético multiplexado, un polinucleótido donante, una proteína de fusión en tándem, un elemento indicador, un elemento genético de interés, un componente de un sistema dividido y/o cualquier ácido nucleico o molécula proteica que se necesite para llevar a cabo las realizaciones de los métodos de la divulgación puede ser recombinante, purificado y/o aislado.
Ácidos nucleicos que codifican un ácido nucleico dirigido a ácido nucleico y/o un polipéptido dirigido a un sitio
La presente divulgación proporciona un ácido nucleico que comprende una secuencia de nucleótidos que codifica un ácido nucleico dirigido a ácido nucleico de la divulgación, un polipéptido dirigido a un sitio de la divulgación, una proteína efectora, un agente de dirección genético multiplexado, un polinucleótido donante, una proteína de fusión en tándem, un elemento indicador, un elemento genético de interés, un componente de un sistema dividido y/o cualquier ácido nucleico o molécula proteica que se necesite para llevar a cabo las realizaciones de los métodos de la divulgación. En algunas realizaciones, el ácido nucleico que codifica un ácido nucleico dirigido a ácido nucleico de la divulgación, un polipéptido dirigido a un sitio de la divulgación, una proteína efectora, un agente de dirección genético multiplexado, un polinucleótido donante, una proteína de fusión en tándem, un elemento indicador, un elemento genético de interés, un componente de un sistema dividido y/o cualquier ácido nucleico o molécula proteica que se necesite para llevar a cabo las realizaciones de los métodos de la divulgación puede ser un vector (por ejemplo, un vector de expresión recombinante).
En algunas realizaciones, el vector de expresión recombinante puede ser una construcción vírica, (por ejemplo, una construcción de virus adenoasociado recombinante), una construcción adenovírica recombinante, una construcción lentivírica recombinante, una construcción retrovírica recombinante, etc.
Los vectores de expresión adecuados pueden incluir, pero sin limitación, vectores víricos (por ejemplo, vectores víricos basados en virus vaccinia, poliovirus, adenovirus, virus adenoasociados, SV40, virus del herpes simple, virus de la inmunodeficiencia humana, un vector retrovírico (por ejemplo, virus de la leucemia murina, virus de la necrosis del bazo y vectores procedentes de retrovirus, tales como el virus del sarcoma de Rous, virus del sarcoma de Harvey, virus de la leucosis aviar, un lentivirus, virus de la inmunodeficiencia humana, virus del sarcoma mieloproliferativo y virus del tumor mamario), vectores de plantas (por ejemplo, vector de ADN-T) y similares. Los siguientes vectores se pueden proporcionar, a modo de ejemplo, para las células hospedadoras eucariotas: pXT1, pSG5, pSVK3, pBPV, pMSG y pSVLSV40 (Pharmacia). Se pueden usar otros vectores siempre que sean compatibles con la célula hospedadora.
En algunos casos, un vector puede ser un vector linealizado. Un vector linealizado puede comprender un polipéptido dirigido a un sitio y/o un ácido nucleico dirigido a ácido nucleico. Un vector linealizado puede no ser un plásmido circular. Un vector linealizado puede comprender una rotura bicatenaria. Un vector linealizado puede comprender una secuencia que codifica una proteína fluorescente (por ejemplo, proteína fluorescente naranja (OFP)). Un vector linealizado puede comprender una secuencia que codifica un antígeno (por ejemplo, CD4). Un vector linealizado se puede linealizar (por ejemplo, cortar) en una región del vector que codifica partes del ácido nucleico dirigido a ácido nucleico. Por ejemplo, un vector linealizado se puede linealizar (por ejemplo, cortar) en una región del ácido nucleico dirigido a ácido nucleico a 5' a la parte de ARNcr del ácido nucleico dirigido a ácido nucleico. Un vector linealizado se puede linealizar (por ejemplo, cortar) en una región del ácido nucleico dirigido a ácido nucleico a 3' de la secuencia de extensión del espaciador del ácido nucleico dirigido a ácido nucleico. Un vector linealizado se puede linealizar (por ejemplo, cortar) en una región del ácido nucleico dirigido a ácido nucleico que codifica la secuencia de ARNcr del ácido nucleico dirigido a ácido nucleico. En algunos casos, un vector linealizado o un vector superenrollado cerrado comprende una secuencia que codifica un polipéptido dirigido a un sitio (por ejemplo, Cas9), un promotor que impulsa la expresión de la secuencia que codifica el polipéptido dirigido a un sitio (por ejemplo, promotor CMV), una secuencia que codifica un enlazador (por ejemplo, 2A), una secuencia que codifica un marcador (por ejemplo, CD4 u OFP), una secuencia que codifica la parte de un ácido nucleico dirigido a ácido nucleico, un promotor que impulsa la expresión de la secuencia que codifica una parte del ácido nucleico dirigido a ácido nucleico, y una secuencia que codifica un marcador seleccionable (por ejemplo, ampicilina), o cualquier combinación de las mismas.
Un vector puede comprender un elemento de control de la transcripción y/o de la traducción. Dependiendo del hospedador/sistema de vector utilizado, se puede usar cualquiera de una serie de elementos de control de la transcripción y de la traducción adecuados, Incluyendo promotores constitutivos e inducibles, elementos potenciadores
de la transcripción, terminadores de la transcripción, etc. en el vector de expresión.
En algunas realizaciones, una secuencia de nucleótidos que codifica un ácido nucleico dirigido a ácido nucleico de la divulgación, un polipéptido dirigido a un sitio de la divulgación, una proteína efectora, un agente de dirección genético multiplexado, un polinucleótido donante, una proteína de fusión en tándem, un elemento indicador, un elemento genético de interés, un componente de un sistema dividido y/o cualquier ácido nucleico o molécula proteica que se necesite para llevar a cabo las realizaciones de los métodos de la divulgación se puede unir operativamente a un elemento de control (por ejemplo, un elemento de control de la transcripción), tal como un promotor. El elemento de control de la transcripción puede ser funcional en una célula eucariota, (por ejemplo, una célula de mamífero), una célula procariota (por ejemplo, una célula bacteriana o de arquea). En algunas realizaciones, una secuencia de nucleótidos que codifica un ácido nucleico dirigido a ácido nucleico de la divulgación, un polipéptido dirigido a un sitio de la divulgación, una proteína efectora, un agente de dirección genético multiplexado, un polinucleótido donante, una proteína de fusión en tándem, un elemento indicador, un elemento genético de interés, un componente de un sistema dividido y/o cualquier ácido nucleico o molécula proteica que se necesite para llevar a cabo las realizaciones de los métodos de la divulgación se puede unir operativamente a múltiples elementos de control. El unión operativa a múltiples elementos de control puede permitir la expresión de la secuencia de nucleótidos que codifica un ácido nucleico dirigido a ácido nucleico de la divulgación, un polipéptido dirigido a un sitio de la divulgación, una proteína efectora, un agente de dirección genético multiplexado, un polinucleótido donante, una proteína de fusión en tándem, un elemento indicador, un elemento genético de interés, un componente de un sistema dividido y/o cualquier ácido nucleico o molécula proteica que se necesite para llevar a cabo las realizaciones de los métodos de la divulgación en células procariotas o eucariotas.
Los ejemplos no limitantes de promotores eucariotas adecuados (es decir, promotores funcionales en una célula eucariota) pueden incluir los procedentes de citomegalovirus (CMV) inmediato precoz, timidina quinasa del virus del herpes simple (VHS), SV40 precoz y tardío, repeticiones terminales largas (LTR) de retrovirus, promotor del factor de elongación humano-1 (EF1), una construcción híbrida que comprende el potenciador del citomegalovirus (CMV) fusionado con el promotor activo beta (CAG) de pollo, promotor del virus de células madre murinas (MSCV), promotor de locus de fosfoglicerato quinasa 1 (PGK) y metalotioneína I de ratón. El promotor puede ser un promotor fúngico. El promotor puede ser un promotor vegetal. Se puede encontrar una base de datos de promotores vegetales (por ejemplo, PlantProm). El vector de expresión también puede contener un sitio de unión a ribosomas para el inicio de la traducción y un terminador de la transcripción. El vector de expresión también puede incluir secuencias apropiadas para amplificar la expresión. El vector de expresión también puede incluir secuencias de nucleótidos que codifican marcadores no nativos (por ejemplo, marcador 6xHis, marcador de hemaglutinina, proteína verde fluorescente, etc.) que se fusionan con el polipéptido dirigido a un sitio, dando lugar así a una proteína de fusión.
En algunas realizaciones, una secuencia o secuencias de nucleótidos que codifican un ácido nucleico dirigido a ácido nucleico de la divulgación, un polipéptido dirigido a un sitio de la divulgación, una proteína efectora, un agente de dirección genético multiplexado, un polinucleótido donante, una proteína de fusión en tándem, un elemento indicador, un elemento genético de interés, un componente de un sistema dividido y/o cualquier ácido nucleico o molécula proteica que se necesite para llevar a cabo las realizaciones de los métodos de la divulgación se puede unir operativamente a un promotor inducible (por ejemplo, promotor de choque térmico, promotor regulado por tetraciclina, promotor regulado por esteroides, promotor regulado por metales, promotor regulado por el receptor de estrógenos, etc.). En algunas realizaciones, una secuencia de nucleótidos que codifica un ácido nucleico dirigido a ácido nucleico de la divulgación, un polipéptido dirigido a un sitio de la divulgación, una proteína efectora, un agente de dirección genético multiplexado, un polinucleótido donante, una proteína de fusión en tándem, un elemento indicador, un elemento genético de interés, un componente de un sistema dividido y/o cualquier ácido nucleico o molécula proteica que se necesiten para llevar a cabo las realizaciones de los métodos de la divulgación un polipéptido de la divulgación se puede unir operativamente a un promotor constitutivo (por ejemplo, promotor CMV, promotor UBC). En algunas realizaciones, la secuencia de nucleótidos puede estar unida operativamente a un promotor restringido espacialmente y/o temporalmente (por ejemplo, un promotor específico del tejido, un promotor específico del tipo de célula, etc.).
Una secuencia o secuencias de nucleótidos que codifican un ácido nucleico dirigido a ácido nucleico de la divulgación, un polipéptido dirigido a un sitio de la divulgación, una proteína efectora, un agente de dirección genético multiplexado, un polinucleótido donante, una proteína de fusión en tándem, un elemento indicador, un elemento genético de interés, un componente de un sistema dividido y/o cualquier ácido nucleico o molécula proteica que se necesite para llevar a cabo las realizaciones de los métodos de la divulgación se puede empaquetar dentro o sobre la superficie de los compartimentos biológicos para la administración a las células. Los compartimentos biológicos pueden incluir, pero sin limitación, virus (lentivirus, adenovirus), nanoesferas, liposomas, puntos cuánticos, nanopartículas, partículas de polietilenglicol, hidrogeles y micelas.
La introducción de los complejos, los polipéptidos y los ácidos nucleicos de la divulgación en las células pueden ocurrir por infección vírica o bacteriófaga, transfección, conjugación, fusión de protoplastos, lipofección, electroporación, precipitación con fosfato de calcio, transfección mediada por polietilenimina (PEI), transfección mediada con DEAE-dextrano, transfección mediada por liposomas, tecnología de pistola de partículas, precipitación con fosfato de calcio, microinyección directa, administración de ácido nucleico mediada por nanopartículas, y similares.
Células y organismos transgénicos
La divulgación proporciona células y organismos transgénicos. El ácido nucleico de una célula hospedadora modificada genéticamente y/u organismo transgénico puede ser objeto de ingeniería genómica.
Las células ilustrativas que pueden usarse para generar células transgénicas de acuerdo con los métodos de la divulgación pueden incluir, pero sin limitación, célula HeLa, célula de ovario de hámster chino, célula 293-T, un feocromocitoma, un fibroblasto de neuroblastomas, un rabdomiosarcoma, una célula del ganglio de la raíz dorsal, una célula NSO, Tobacco BY-2, CV-I (ATCC CCL 70), COS-I (ATCC CRL 1650), COS-7 (ATCC CRL 1651), CHO-K1 (ATCC CCL 61), 3T3 (ATCC CCL 92), NIH/3T3 (ATCC CRL 1658), HeLa (ATCC CCL 2), C 1271 (ATCC CRL 1616), BS-C-I (ATCC CCL 26), MRC-5 (ATCC CCL 171), células L, HEK-293 (ATCC CRL1 573) y PC 12 (ATCC CRL-1721), HEK293T (ATCC CRL-11268), RBL (ATCC CRL-1378), SH-SY5Y (ATCC CRL-2266), MDCK (ATCC CCL-34), SJ-RH30 (ATCC CRL-2061), HepG2 (ATCC HB-8065), ND7/23 (ECACC 92090903), CHO (ECACC 85050302), Vera (ATCC CCL 81), Caco-2 (ATCC HTB 37), K562 (ATCC CCL 243), Jurkat (ATCC TIB-152), Per.Có, Huvec (ATCC PCS 100-010 primaria humana, CRL 2514 de ratón, CRL 2515, CRL 2516), HuH-7D12 (ECACC 01042712), 293 (ATCC CRL 10852), A549 (ATCC CCL 185), IMR-90 (ATCC CCL 186), MCF-7 (ATC HTB-22), U-2 OS (ATCC HTB-96) y T84 (ATCC CCL 248), o cualquier célula disponible en la colección Americana de Cultivos Tipo (ATCC), o cualquier combinación de las mismas.
Los organismos que pueden ser transgénicos pueden incluir bacterias, arqueas, eucariotas unicelulares, plantas, algas, hongos (por ejemplo, levadura), invertebrados (por ejemplo, mosca de la fruta, cnidario, equinodermo, nematodo, etc.), Vertebrados (por ejemplo, pez, anfibio, reptil, ave, mamífero), mamíferos (por ejemplo, un cerdo, una vaca, una cabra, una oveja, un roedor, una rata, un ratón, un primate no humano, un ser humano, etc.), etc.
Los organismos transgénicos pueden comprender células modificadas genéticamente. Los organismos transgénicos y/o las células modificadas genéticamente pueden comprender organismos y/o células que se han modificado genéticamente con un ácido nucleico exógeno que comprende una secuencia de nucleótidos que codifica el ácido nucleico dirigido a ácido nucleico de la divulgación, una proteína efectora y/o un polipéptido dirigido a un sitio, o cualquier combinación de los mismos.
Una célula modificada genéticamente puede comprender un polipéptido dirigido a un sitio exógeno y/o un ácido nucleico exógeno que comprende una secuencia de nucleótidos que codifica un polipéptido dirigido a un sitio. La expresión del polipéptido dirigido a un sitio en la célula puede llevar 0,1, 0,2, 0,5, 1,2, 3, 4, 5, 6 o más días. Las células, introducidas con el polipéptido dirigido a un sitio, se pueden cultivar durante 0,1, 0,2, 0,5, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 o incluso más días antes de que las células puedan retirarse del cultivo celular y/o del organismo hospedador.
Sujetos
La divulgación proporciona la realización de los métodos de divulgación en un sujeto. Un sujeto puede ser un ser humano. Un sujeto puede ser un mamífero (por ejemplo, rata, ratón, vaca, perro, cerdo, oveja, caballo). Un sujeto puede ser un vertebrado o un invertebrado. Un sujeto puede ser un animal de laboratorio. Un sujeto puede ser un paciente. Un sujeto puede estar padeciendo una enfermedad. Un sujeto puede mostrar síntomas de una enfermedad. Un sujeto puede no mostrar síntomas de una enfermedad, pero,aún así, tener una enfermedad. Un sujeto puede estar bajo la atención médica de un cuidador (por ejemplo, el sujeto está hospitalizado y es tratado por un médico). Un sujeto puede ser una planta o un cultivo.
Kits
La presente divulgación proporciona kits para llevar a cabo los métodos de la divulgación. Un kit puede incluir uno o más de: un ácido nucleico dirigido a ácido nucleico de la divulgación, un polinucleótido que codifica un ácido nucleico dirigido a ácido nucleico, un polipéptido dirigido a un sitio de la divulgación, un polinucleótido que codifica un polipéptido dirigido a un sitio, una proteína efectora, un polinucleótido que codifica una proteína efectora, un agente de dirección genético multiplexado, un polinucleótido que codifica un agente de dirección genético multiplexado, un polinucleótido donante, una proteína de fusión en tándem, un polinucleótido que codifica una proteína de fusión en tándem, un elemento indicador, un elemento genético de interés, un componente de un sistema dividido y/o cualquier ácido nucleico o molécula proteica que se necesite para llevar a cabo las realizaciones de los métodos de la divulgación, o cualquier combinación de los mismos.
Un ácido nucleico dirigido a ácido nucleico de la divulgación, un polinucleótido que codifica un ácido nucleico dirigido a ácido nucleico, un polipéptido dirigido a un sitio de la divulgación, un polinucleótido que codifica un polipéptido dirigido a un sitio, una proteína efectora, un polinucleótido que codifica una proteína efectora, un agente de dirección genético multiplexado, un polinucleótido que codifica un agente de dirección genético multiplexado, un polinucleótido donante, una proteína de fusión en tándem, un polinucleótido que codifica una proteína de fusión en tándem, un elemento indicador, un elemento genético de interés, un componente de un sistema dividido y/o cualquier ácido nucleico o molécula proteica que se necesite para llevar a cabo las realizaciones de los métodos de la divulgación se han descrito en detalle anteriormente.
Un kit puede comprender: (1) un vector que comprende una secuencia de nucleótidos que codifica un ácido nucleico dirigido a ácido nucleico; y (2) un vector que comprende una secuencia de nucleótidos que codifica el polipéptido dirigido a un sitio y (2) un reactivo para la reconstitución y/o dilución de los vectores.
Un kit puede comprender: (1) un vector que comprende (i) una secuencia de nucleótidos que codifica un ácido nucleico dirigido un ácido nucleico, e (ii) una secuencia de nucleótidos que codifica el polipéptido dirigido a un sitio; y (2) un reactivo para la reconstitución y/o dilución del vector.
Un kit puede comprender: (1) un vector que comprende una secuencia de nucleótidos que codifica un ácido nucleico dirigido a ácido nucleico; (2) un vector que comprende una secuencia de nucleótidos que codifica el polipéptido dirigido a un sitio; (3) un vector que comprende una secuencia de nucleótidos que codifica una proteína efectora, un agente de dirección genético multiplexado, un polinucleótido donante, una proteína de fusión en tándem, un elemento indicador, un elemento genético de interés, un componente de un sistema dividido y/o cualquier ácido nucleico o molécula proteica que se necesite para llevar a cabo las realizaciones de los métodos de la divulgación; y (4) un reactivo para la reconstitución y/o dilución de los vectores.
Un kit puede comprender: (1) un vector que comprende (i) una secuencia de nucleótidos que codifica un ácido nucleico dirigido a ácido nucleico, (ii) una secuencia de nucleótidos que codifica un polipéptido dirigido a un sitio; (2) un vector que comprende una secuencia de nucleótidos que codifica una proteína efectora, un agente de dirección genético multiplexado, un polinucleótido donante, una proteína de fusión en tándem, un elemento indicador, un elemento genético de interés, un componente de un sistema dividido y/o cualquier ácido nucleico o molécula proteica que se necesite para llevar a cabo las realizaciones de los métodos de la divulgación; y (3) un reactivo para la reconstitución y/o dilución de los vectores de expresión recombinantes.
En algunos casos, un kit puede comprender un polipéptido dirigido a un sitio (y/o un ácido nucleico que lo codifica), en donde el polipéptido dirigido a un sitio puede comprender una secuencia de aminoácidos que comprenda al menos un 15 % de identidad de aminoácidos con un Cas9 de S. pyogenes, y dos dominios de escisión de ácido nucleico (es decir, un dominio HNH y un dominio RuvC); y un ácido nucleico dirigido a ácido nucleico guía doble (y/o un ácido nucleico que lo codifica) que comprende 1) una primera molécula de ácido nucleico que comprende una secuencia de extensión del espaciador de 10-5000 nucleótidos de longitud; una secuencia de espaciador de 12-30 nucleótidos de longitud, en donde el espaciador es al menos un 50 % complementario a un ácido nucleico diana; y una repetición CRISPR mínima que comprende al menos un 60 % de identidad con un ARNc de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6 nucleótidos contiguos y en donde la repetición CRISPR mínima tiene una longitud de 5 30 nucleótidos; y 2) una segunda molécula de ácido nucleico del ácido nucleico dirigido a ácido nucleico guía doble puede comprender una secuencia mínima de ARNcrtra que comprende al menos un 60 % de identidad con un ARNcrtra de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6 nucleótidos contiguos y en donde la secuencia mínima de ARNcrtra tiene una longitud de 5-30 nucleótidos; un ARNcrtra 3' que comprende al menos un 60 % de identidad con un ARNcrtra de una bacteria (por ejemplo, S. pyogenes) sobre 6 nucleótidos contiguos y en donde el ARNcrtra 3' comprende una longitud de 10-20 nucleótidos, y comprende una región duplexada; y/o una extensión de ARNcrtra que comprende 10-5000 nucleótidos de longitud, o cualquier combinación de los mismos.
En algunos casos, un kit puede comprender un polipéptido dirigido a un sitio (y/o un ácido nucleico que lo codifica), en donde el polipéptido dirigido a un sitio puede comprender una secuencia de aminoácidos que comprenda al menos un 15 % de identidad de aminoácidos con un Cas9 de S. pyogenes, y dos dominios de escisión de ácido nucleico (es decir, un dominio HNH y un dominio RuvC); y, un ácido nucleico dirigido a ácido nucleico guía doble (y/o un ácido nucleico que lo codifica) que comprende 1) una primera molécula de ácido nucleico que comprende una secuencia de extensión del espaciador de 10-5000 nucleótidos de longitud; una secuencia de espaciador de 12-30 nucleótidos de longitud, en donde el espaciador es al menos un 50 % complementario a un ácido nucleico diana; una repetición CRISPR mínima que comprende al menos un 60 % de identidad con un ARNc de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6 nucleótidos contiguos y en donde la repetición CRISPR mínima tiene una longitud de 5 30 nucleótidos y al menos 3 nucleótidos no emparejados de una protuberancia; y 2) una segunda molécula de ácido nucleico del ácido nucleico dirigido a ácido nucleico guía doble puede comprender una secuencia mínima de ARNcrtra que comprende al menos un 60 % de identidad con un ARNcrtra de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6 nucleótidos contiguos y en donde la secuencia mínima de ARNcrtra tiene una longitud de 5-30 nucleótidos y al menos 1 nucleótido no emparejado de una protuberancia, en donde el 1 nucleótido no emparejado de la protuberancia está ubicado en la misma protuberancia que los 3 nucleótidos no emparejados de la repetición CRISPR mínima; un ARNcrtra 3' que comprende al menos un 60 % de identidad con un ARNcrtra de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6 nucleótidos contiguos y en donde el ARNcrtra 3' comprende una longitud de 10 20 nucleótidos, y comprende una región duplexada; un dominio P que comienza desde 1-5 nucleótidos cadena abajo del dúplex que comprende la repetición CRISPR mínima y el ARNcrtra mínimo, comprende 1-10 nucleótidos, comprende una secuencia que puede hibridarse con un motivo adyacente al protoespaciador en un ácido nucleico diana, puede formar una horquilla y se encuentra en la región de ARNcrtra 3'; y/o una extensión de ARNcrtra que comprende 10-5000 nucleótidos de longitud, o cualquier combinación de los mismos.
En algunos casos, un kit puede comprender un polipéptido dirigido a un sitio (y/o un ácido nucleico que lo codifica), en
donde el polipéptido dirigido a un sitio puede comprender una secuencia de aminoácidos que comprende al menos un 15 % de identidad de aminoácidos con un Cas9 de S. pyogenes y, dos dominios de escisión de ácido nucleico (es decir, un dominio HNH y un dominio RuvC); y, un ácido nucleico dirigido a ácido nucleico (y/o un ácido nucleico que lo codifica) que comprende una secuencia de extensión del espaciador de 10-5000 nucleótidos de longitud; una secuencia de espaciador de 12-30 nucleótidos de longitud, en donde el espaciador es al menos un 50% complementario a un ácido nucleico diana; una repetición CRISPR mínima que comprende al menos un 60 % de identidad con un ARNcr de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6, 7 u 8 nucleótidos contiguos y en donde la repetición CRISPR mínima tiene una longitud de 5-30 nucleótidos; una secuencia mínima de ARNcrtra que comprende al menos un 60 % de identidad con un ARNcrtra de una bacteria (por ejemplo, S. pyogenes) sobre 6, 7 u 8 nucleótidos contiguos y en donde la secuencia mínima de ARNcrtra tiene una longitud de 5-30 nucleótidos; una secuencia enlazadora que une la repetición CRISPR mínima y el ARNcrtra mínimo y comprende una longitud de 3 5000 nucleótidos; un ARNcrtra 3' que comprende al menos un 60 % de identidad con un ARNcrtra de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6, 7 u 8 nucleótidos contiguos y en donde el ARNcrtra 3' comprende una longitud de 10-20 nucleótidos, y comprende una región duplexada; y/o una extensión de ARNcrtra que comprende 10 5000 nucleótidos de longitud, o cualquier combinación de los mismos. Este ácido nucleico dirigido a ácido nucleico puede denominarse ácido nucleico dirigido a ácido nucleico guía sencillo.
En algunos casos, un kit puede comprender un polipéptido dirigido a un sitio (y/o un ácido nucleico que lo codifica), en donde el polipéptido dirigido a un sitio puede comprender una secuencia de aminoácidos que comprenda al menos un 15 % de identidad de aminoácidos con un Cas9 de S. pyogenes, y dos dominios de escisión de ácido nucleico (es decir, un dominio HNH y un dominio RuvC); y, un ácido nucleico dirigido a ácido nucleico (y/o un ácido nucleico que lo codifica) que comprende una secuencia de extensión del espaciador de 10-5000 nucleótidos de longitud; una secuencia de espaciador de 12-30 nucleótidos de longitud, en donde el espaciador es al menos un 50% complementario a un ácido nucleico diana; un dúplex que comprende 1) una repetición CRISPR mínima que comprende al menos un 60 % de identidad con un ARNcr de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6 nucleótidos contiguos y en donde la repetición CRISPR mínima tiene una longitud de 5-30 nucleótidos; 2) una secuencia mínima de ARNcrtra que comprende al menos un 60 % de identidad con un ARNcrtra de una bacteria (por ejemplo, S. pyogenes) sobre 6 nucleótidos contiguos y en donde la secuencia mínima de ARNcrtra tiene una longitud de 5-30 nucleótidos; y 3) una protuberancia en donde la protuberancia comprende al menos 3 nucleótidos no emparejados en la cadena de repetición CRISPR mínima del dúplex y al menos 1 nucleótido no emparejado en la cadena de secuencia mínima de ARNcrtra del dúplex; una secuencia enlazadora que une la repetición CRISPR mínima y el ARNcrtra mínimo y comprende una longitud de 3-5000 nucleótidos; un ARNcrtra 3' que comprende al menos un 60 % de identidad con un ARNcrtra de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6 nucleótidos contiguos, en donde el ARNcrtra 3' comprende una longitud de 10-20 nucleótidos y comprende una región duplexada; un dominio P que comienza desde 1-5 nucleótidos cadena abajo del dúplex que comprende la repetición CRISPR mínima y el ARNcrtra mínimo, comprende 1-10 nucleótidos, comprende una secuencia que puede hibridarse con un motivo adyacente al protoespaciador en un ácido nucleico diana, puede formar una horquilla y se encuentra en la región de ARNcrtra 3'; y/o una extensión de ARNcrtra que comprende 10-5000 nucleótidos de longitud, o cualquier combinación de los mismos.
En algunos casos, un kit puede comprender un polipéptido dirigido a un sitio (y/o un ácido nucleico que lo codifica), en donde el polipéptido dirigido a un sitio comprende una secuencia de aminoácidos que comprende al menos un 15 % de identidad de aminoácidos con un Cas9 de S. pyogenes, dos dominios de escisión de ácido nucleico (es decir, un dominio HNH y un dominio RuvC) y un enlazador que une al polipéptido dirigido a un sitio con una secuencia no nativa; y un ácido nucleico dirigido a ácido nucleico guía doble (y/o un ácido nucleico que lo codifica) que comprende 1) una primera molécula de ácido nucleico que comprende una secuencia de extensión del espaciador de 10 5000 nucleótidos de longitud; una secuencia de espaciador de 12-30 nucleótidos de longitud, en donde el espaciador es al menos un 50 % complementario a un ácido nucleico diana; y una repetición CRISPR mínima que comprende al menos un 60 % de identidad con un ARNc de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6 nucleótidos contiguos y en donde la repetición CRISPR mínima tiene una longitud de 5-30 nucleótidos; y 2) una segunda molécula de ácido nucleico del ácido nucleico dirigido a ácido nucleico guía doble puede comprender una secuencia mínima de ARNcrtra que comprende al menos un 60 % de identidad con un ARNcrtra de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6 nucleótidos contiguos y en donde la secuencia mínima de ARNcrtra tiene una longitud de 5 30 nucleótidos; un ARNcrtra 3' que comprende al menos un 60 % de identidad con un ARNcrtra de una bacteria (por ejemplo, S. pyogenes) sobre 6 nucleótidos contiguos y en donde el ARNcrtra 3' comprende una longitud de 10 20 nucleótidos, y comprende una región duplexada; y/o una extensión de ARNcrtra que comprende 10 5000 nucleótidos de longitud, o cualquier combinación de los mismos.
En algunos casos, un kit puede comprender un polipéptido dirigido a un sitio (y/o un ácido nucleico que lo codifica), en donde el polipéptido dirigido a un sitio comprende una secuencia de aminoácidos que comprende al menos un 15 % de identidad de aminoácidos con un Cas9 de S. pyogenes, dos dominios de escisión de ácido nucleico (es decir, un dominio HNH y un dominio RuvC) y un enlazador que une al polipéptido dirigido a un sitio con una secuencia no nativa; y un ácido nucleico dirigido a ácido nucleico guía doble (y/o un ácido nucleico que lo codifica) que comprende 1) una primera molécula de ácido nucleico que comprende una secuencia de extensión del espaciador de 10 5000 nucleótidos de longitud; una secuencia de espaciador de 12-30 nucleótidos de longitud, en donde el espaciador es al menos un 50 % complementario a un ácido nucleico diana; una repetición CRISPR mínima que comprende al
menos un 60 % de identidad con un ARNc de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6 nucleótidos contiguos y en donde la repetición CRISPR mínima tiene una longitud de 5-30 nucleótidos y al menos 3 nucleótidos no emparejados de una protuberancia; y 2) una segunda molécula de ácido nucleico del ácido nucleico dirigido a ácido nucleico guía doble puede comprender una secuencia mínima de ARNcrtra que comprende al menos un 60 % de identidad con un ARNcrtra de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6 nucleótidos contiguos y en donde la secuencia mínima de ARNcrtra tiene una longitud de 5-30 nucleótidos y al menos 1 nucleótido no emparejado de una protuberancia, en donde el 1 nucleótido no emparejado de la protuberancia está ubicado en la misma protuberancia que los 3 nucleótidos no emparejados de la repetición CRISPR mínima; un ARNcrtra 3' que comprende al menos un 60 % de identidad con un ARNcrtra de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6 nucleótidos contiguos y en donde el ARNcrtra 3' comprende una longitud de 10-20 nucleótidos, y comprende una región duplexada; un dominio P que comienza desde 1-5 nucleótidos cadena abajo del dúplex que comprende la repetición CRISPR mínima y el ARNcrtra mínimo, comprende 1-10 nucleótidos, comprende una secuencia que puede hibridarse con un motivo adyacente al protoespaciador en un ácido nucleico diana, puede formar una horquilla y se encuentra en la región de ARNcrtra 3'; y/o una extensión de ARNcrtra que comprende 10-5000 nucleótidos de longitud, o cualquier combinación de los mismos.
En algunos casos, un kit puede comprender un polipéptido dirigido a un sitio (y/o un ácido nucleico que lo codifica), en donde el polipéptido dirigido a un sitio comprende una secuencia de aminoácidos que comprende al menos un 15 % de identidad de aminoácidos con un Cas9 de S. pyogenes, dos dominios de escisión de ácido nucleico (es decir, un dominio HNH y un dominio RuvC) y un enlazador que une al polipéptido dirigido a un sitio con una secuencia no nativa; y un ácido nucleico dirigido a ácido nucleico (y/o un ácido nucleico que lo codifica) que comprende una secuencia de extensión del espaciador de 10-5000 nucleótidos de longitud; una secuencia de espaciador de 12-30 nucleótidos de longitud, en donde el espaciador es al menos un 50 % complementario a un ácido nucleico diana; una repetición CRISPR mínima que comprende al menos un 60 % de identidad con un ARNcr de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6, 7 u 8 nucleótidos contiguos y en donde la repetición CRISPR mínima tiene una longitud de 5-30 nucleótidos; una secuencia mínima de ARNcrtra que comprende al menos un 60 % de identidad con un ARNcrtra de una bacteria (por ejemplo, S. pyogenes) sobre 6, 7 u 8 nucleótidos contiguos y en donde la secuencia mínima de ARNcrtra tiene una longitud de 5-30 nucleótidos; una secuencia enlazadora que une la repetición CRISPR mínima y el ARNcrtra mínimo y comprende una longitud de 3-5000 nucleótidos; un ARNcrtra 3' que comprende al menos un 60 % de identidad con un ARNcrtra de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6, 7 u 8 nucleótidos contiguos y en donde el ARNcrtra 3' comprende una longitud de 10-20 nucleótidos, y comprende una región duplexada; y/o una extensión de ARNcrtra que comprende 10-5000 nucleótidos de longitud, o cualquier combinación de los mismos. Este ácido nucleico dirigido a ácido nucleico puede denominarse ácido nucleico dirigido a ácido nucleico guía sencillo.
En algunos casos, un kit puede comprender un polipéptido dirigido a un sitio (y/o un ácido nucleico que lo codifica), en donde el polipéptido dirigido a un sitio comprende una secuencia de aminoácidos que comprende al menos un 15 % de identidad de aminoácidos con un Cas9 de S. pyogenes, dos dominios de escisión de ácido nucleico (es decir, un dominio HNH y un dominio RuvC) y un enlazador que une al polipéptido dirigido a un sitio con una secuencia no nativa; y ácido nucleico dirigido a ácido nucleico (y/o un ácido nucleico que lo codifica) que comprende una secuencia de extensión del espaciador de 10-5000 nucleótidos de longitud; una secuencia de espaciador de 12-30 nucleótidos de longitud, en donde el espaciador es al menos un 50 % complementario a un ácido nucleico diana; un dúplex que comprende 1) una repetición CRISPR mínima que comprende al menos un 60 % de identidad con un ARNcr de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6 nucleótidos contiguos y en donde la repetición CRISPR mínima tiene una longitud de 5-30 nucleótidos; 2) una secuencia mínima de ARNcrtra que comprende al menos un 60 % de identidad con un ARNcrtra de una bacteria (por ejemplo, S. pyogenes) sobre 6 nucleótidos contiguos y en donde la secuencia mínima de ARNcrtra tiene una longitud de 5-30 nucleótidos; y 3) una protuberancia en donde la protuberancia comprende al menos 3 nucleótidos no emparejados en la cadena de repetición CRISPR mínima del dúplex y al menos 1 nucleótido no emparejado en la cadena de secuencia mínima de ARNcrtra del dúplex; una secuencia enlazadora que une la repetición CRISPR mínima y el ARNcrtra mínimo y comprende una longitud de 3 5000 nucleótidos; un ARNcrtra 3' que comprende al menos un 60 % de identidad con un ARNcrtra de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6 nucleótidos contiguos, en donde el ARNcrtra 3' comprende una longitud de 10-20 nucleótidos y comprende una región duplexada; un dominio P que comienza desde 1-5 nucleótidos cadena abajo del dúplex que comprende la repetición CRISPR mínima y el ARNcrtra mínimo, comprende 1-10 nucleótidos, comprende una secuencia que puede hibridarse con un motivo adyacente al protoespaciador en un ácido nucleico diana, puede formar una horquilla y se encuentra en la región de ARNcrtra 3'; y/o una extensión de ARNcrtra que comprende 10-5000 nucleótidos de longitud, o cualquier combinación de los mismos.
En algunos casos, un kit puede comprender un polipéptido dirigido a un sitio (y/o un ácido nucleico que lo codifica), en donde el polipéptido dirigido a un sitio comprende al menos un 15 % de identidad de aminoácidos con una Cas9 de S. pyogenes, dos dominios de escisión de ácido nucleico (es decir, un dominio HNH y un dominio RuvC), en donde el polipéptido dirigido a un sitio comprende una mutación en uno o ambos dominios de escisión de ácido nucleico que reduce la actividad de escisión de los dominios nucleasa en al menos un 50 %; y un ácido nucleico dirigido a ácido nucleico guía doble (y/o un ácido nucleico que lo codifica) que comprende 1) una primera molécula de ácido nucleico que comprende una secuencia de extensión del espaciador de 10-5000 nucleótidos de longitud; una secuencia de espaciador de 12-30 nucleótidos de longitud, en donde el espaciador es al menos un 50 % complementario a un ácido
nucleico diana; y una repetición CRISPR mínima que comprende al menos un 60 % de identidad con un ARNc de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6 nucleótidos contiguos y en donde la repetición CRISPR mínima tiene una longitud de 5-30 nucleótidos; y 2) una segunda molécula de ácido nucleico del ácido nucleico dirigido a ácido nucleico guía doble puede comprender una secuencia mínima de ARNcrtra que comprenda al menos un 60 % de identidad con un ARNcrtra de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6 nucleótidos contiguos y en donde la secuencia mínima de ARNcrtra tiene una longitud de 5-30 nucleótidos; un ARNcrtra 3' que comprende al menos un 60 % de identidad con un ARNcrtra de una bacteria (por ejemplo, S. pyogenes) sobre 6 nucleótidos contiguos y en donde el ARNcrtra 3' comprende una longitud de 10-20 nucleótidos, y comprende una región duplexada; y/o una extensión de ARNcrtra que comprende 10-5000 nucleótidos de longitud, o cualquier combinación de los mismos.
En algunos casos, un kit puede comprender un polipéptido dirigido a un sitio (y/o un ácido nucleico que lo codifica), en donde el polipéptido dirigido a un sitio comprende al menos un 15 % de identidad de aminoácidos con una Cas9 de S. pyogenes, dos dominios de escisión de ácido nucleico (es decir, un dominio HNH y un dominio RuvC), en donde el polipéptido dirigido a un sitio comprende una mutación en uno o ambos dominios de escisión de ácido nucleico que reduce la actividad de escisión de los dominios nucleasa en al menos un 50 %; y un ácido nucleico dirigido a ácido nucleico guía doble (y/o un ácido nucleico que lo codifica) que comprende 1) una primera molécula de ácido nucleico que comprende una secuencia de extensión del espaciador de 10-5000 nucleótidos de longitud; una secuencia de espaciador de 12-30 nucleótidos de longitud, en donde el espaciador es al menos un 50 % complementario a un ácido nucleico diana; una repetición CRISPR mínima que comprende al menos un 60 % de identidad con un ARNc de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6 nucleótidos contiguos y en donde la repetición CRISPR mínima tiene una longitud de 5-30 nucleótidos y al menos 3 nucleótidos no emparejados de una protuberancia; y 2) una segunda molécula de ácido nucleico del ácido nucleico dirigido a ácido nucleico guía doble puede comprender una secuencia mínima de ARNcrtra que comprende al menos un 60 % de identidad con un ARNcrtra de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6 nucleótidos contiguos y en donde la secuencia mínima de ARNcrtra tiene una longitud de 5-30 nucleótidos y al menos 1 nucleótido no emparejado de una protuberancia, en donde el 1 nucleótido no emparejado de la protuberancia está ubicado en la misma protuberancia que los 3 nucleótidos no emparejados de la repetición CRISPR mínima; un ARNcrtra 3' que comprende al menos un 60 % de identidad con un ARNcrtra de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6 nucleótidos contiguos y en donde el ARNcrtra 3' comprende una longitud de 10-20 nucleótidos, y comprende una región duplexada; un dominio P que comienza desde 1-5 nucleótidos cadena abajo del dúplex que comprende la repetición CRISPR mínima y el ARNcrtra mínimo, comprende 1-10 nucleótidos, comprende una secuencia que puede hibridarse con un motivo adyacente al protoespaciador en un ácido nucleico diana, puede formar una horquilla y se encuentra en la región de ARNcrtra 3'; y/o una extensión de ARNcrtra que comprende 10-5000 nucleótidos de longitud, o cualquier combinación de los mismos.
En algunos casos, un kit puede comprender un polipéptido dirigido a un sitio (y/o un ácido nucleico que lo codifica), en donde el polipéptido dirigido a un sitio comprende al menos un 15 % de identidad de aminoácidos con una Cas9 de S. pyogenes, dos dominios de escisión de ácido nucleico (es decir, un dominio HNH y un dominio RuvC), en donde el polipéptido dirigido a un sitio comprende una mutación en uno o ambos dominios de escisión de ácido nucleico que reduce la actividad de escisión de los dominios nucleasa en al menos un 50 %; y ácido nucleico dirigido a ácido nucleico (y/o un ácido nucleico que lo codifica) que comprende una secuencia de extensión del espaciador de 10 5000 nucleótidos de longitud; una secuencia de espaciador de 12-30 nucleótidos de longitud, en donde el espaciador es al menos un 50 % complementario a un ácido nucleico diana; una repetición CRISPR mínima que comprende al menos un 60 % de identidad con un ARNcr de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6, 7 u 8 nucleótidos contiguos y en donde la repetición CRISPR mínima tiene una longitud de 5-30 nucleótidos; una secuencia mínima de ARNcrtra que comprende al menos un 60 % de identidad con un ARNcrtra de una bacteria (por ejemplo, S. pyogenes) sobre 6, 7 u 8 nucleótidos contiguos y en donde la secuencia mínima de ARNcrtra tiene una longitud de 5-30 nucleótidos; una secuencia enlazadora que une la repetición CRISPR mínima y el ARNcrtra mínimo y comprende una longitud de 3-5000 nucleótidos; un ARNcrtra 3' que comprende al menos un 60 % de identidad con un ARNcrtra de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6, 7 u 8 nucleótidos contiguos y en donde el ARNcrtra 3' comprende una longitud de 10-20 nucleótidos, y comprende una región duplexada; y/o una extensión de ARNcrtra que comprende 10-5000 nucleótidos de longitud, o cualquier combinación de los mismos. Este ácido nucleico dirigido a ácido nucleico puede denominarse ácido nucleico dirigido a ácido nucleico guía sencillo.
En algunos casos, un kit puede comprender un polipéptido dirigido a un sitio (y/o un ácido nucleico que lo codifica), en donde el polipéptido dirigido a un sitio comprende al menos un 15 % de identidad de aminoácidos con una Cas9 de S. pyogenes, dos dominios de escisión de ácido nucleico (es decir, un dominio HNH y un dominio RuvC), en donde el polipéptido dirigido a un sitio comprende una mutación en uno o ambos dominios de escisión de ácido nucleico que reduce la actividad de escisión de los dominios nucleasa en al menos un 50 %; y ácido nucleico dirigido a ácido nucleico (y/o un ácido nucleico que lo codifica) que comprende una secuencia de extensión del espaciador de 10 5000 nucleótidos de longitud; una secuencia de espaciador de 12-30 nucleótidos de longitud, en donde el espaciador es al menos un 50 % complementario a un ácido nucleico diana; un dúplex que comprende 1) una repetición CRISPR mínima que comprende al menos un 60 % de identidad con un ARNcr de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6 nucleótidos contiguos y en donde la repetición CRISPR mínima tiene una longitud de 5-30 nucleótidos; 2) una secuencia mínima de ARNcrtra que comprende al menos un 60 % de identidad con un ARNcrtra de una bacteria
(por ejemplo, S. pyogenes) sobre 6 nucleótidos contiguos y en donde la secuencia mínima de ARNcrtra tiene una longitud de 5-30 nucleótidos; y 3) una protuberancia en donde la protuberancia comprende al menos 3 nucleótidos no emparejados en la cadena de repetición CRISPR mínima del dúplex y al menos 1 nucleótido no emparejado en la cadena de secuencia mínima de ARNcrtra del dúplex; una secuencia enlazadora que une la repetición CRISPR mínima y el ARNcrtra mínimo y comprende una longitud de 3-5000 nucleótidos; un ARNcrtra 3' que comprende al menos un 60 % de identidad con un ARNcrtra de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6 nucleótidos contiguos, en donde el ARNcrtra 3' comprende una longitud de 10-20 nucleótidos y comprende una región duplexada; un dominio P que comienza desde 1-5 nucleótidos cadena abajo del dúplex que comprende la repetición CRISPR mínima y el ARNcrtra mínimo, comprende 1-10 nucleótidos, comprende una secuencia que puede hibridarse con un motivo adyacente al protoespaciador en un ácido nucleico diana, puede formar una horquilla y se encuentra en la región de ARNcrtra 3'; y/o una extensión de ARNcrtra que comprende 10-5000 nucleótidos de longitud, o cualquier combinación de los mismos.
En algunos casos, un kit puede comprender un polipéptido dirigido a un sitio (y/o un ácido nucleico que lo codifica), en donde el polipéptido dirigido a un sitio comprende al menos un 15 % de identidad de aminoácidos con una Cas9 de S. pyogenes, dos dominios de escisión de ácido nucleico (es decir, un dominio HNH y un dominio RuvC), en donde el polipéptido dirigido a un sitio comprende una mutación en uno o ambos dominios de escisión de ácido nucleico que reduce la actividad de escisión de los dominios nucleasa en al menos un 50 %; y un ácido nucleico dirigido a ácido nucleico guía doble (y/o un ácido nucleico que lo codifica) que comprende 1) una primera molécula de ácido nucleico que comprende una secuencia de extensión del espaciador de 10-5000 nucleótidos de longitud; una secuencia de espaciador de 12-30 nucleótidos de longitud, en donde el espaciador es al menos un 50 % complementario a un ácido nucleico diana; y una repetición CRISPR mínima que comprende al menos un 60 % de identidad con un ARNc de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6 nucleótidos contiguos y en donde la repetición CRISPR mínima tiene una longitud de 5-30 nucleótidos; y 2) una segunda molécula de ácido nucleico del ácido nucleico dirigido a ácido nucleico guía doble puede comprender una secuencia mínima de ARNcrtra que comprenda al menos un 60 % de identidad con un ARNcrtra de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6 nucleótidos contiguos y en donde la secuencia mínima de ARNcrtra tiene una longitud de 5-30 nucleótidos; un ARNcrtra 3' que comprende al menos un 60 % de identidad con un ARNcrtra de una bacteria (por ejemplo, S. pyogenes) sobre 6 nucleótidos contiguos y en donde el ARNcrtra 3' comprende una longitud de 10-20 nucleótidos, y comprende una región duplexada; y/o una extensión de ARNcrtra que comprende 10-5000 nucleótidos de longitud, o cualquier combinación de los mismos.
En algunos casos, un kit puede comprender un polipéptido dirigido a un sitio (y/o un ácido nucleico que lo codifica), en donde el polipéptido dirigido a un sitio comprende al menos un 15 % de identidad de aminoácidos con una Cas9 de S. pyogenes, dos dominios de escisión de ácido nucleico (es decir, un dominio HNH y un dominio RuvC), en donde el polipéptido dirigido a un sitio comprende una mutación en uno o ambos dominios de escisión de ácido nucleico que reduce la actividad de escisión de los dominios nucleasa en al menos un 50 %; y un ácido nucleico dirigido a ácido nucleico guía doble (y/o un ácido nucleico que lo codifica) que comprende 1) una primera molécula de ácido nucleico que comprende una secuencia de extensión del espaciador de 10-5000 nucleótidos de longitud; una secuencia de espaciador de 12-30 nucleótidos de longitud, en donde el espaciador es al menos un 50 % complementario a un ácido nucleico diana; una repetición CRISPR mínima que comprende al menos un 60 % de identidad con un ARNc de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6 nucleótidos contiguos y en donde la repetición CRISPR mínima tiene una longitud de 5-30 nucleótidos y al menos 3 nucleótidos no emparejados de una protuberancia; y 2) una segunda molécula de ácido nucleico del ácido nucleico dirigido a ácido nucleico guía doble puede comprender una secuencia mínima de ARNcrtra que comprende al menos un 60 % de identidad con un ARNcrtra de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6 nucleótidos contiguos y en donde la secuencia mínima de ARNcrtra tiene una longitud de 5-30 nucleótidos y al menos 1 nucleótido no emparejado de una protuberancia, en donde el 1 nucleótido no emparejado de la protuberancia está ubicado en la misma protuberancia que los 3 nucleótidos no emparejados de la repetición CRISPR mínima; un ARNcrtra 3' que comprende al menos un 60 % de identidad con un ARNcrtra de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6 nucleótidos contiguos y en donde el ARNcrtra 3' comprende una longitud de 10-20 nucleótidos, y comprende una región duplexada; un dominio P que comienza desde 1-5 nucleótidos cadena abajo del dúplex que comprende la repetición CRISPR mínima y el ARNcrtra mínimo, comprende 1-10 nucleótidos, comprende una secuencia que puede hibridarse con un motivo adyacente al protoespaciador en un ácido nucleico diana, puede formar una horquilla y se encuentra en la región de ARNcrtra 3'; y/o una extensión de ARNcrtra que comprende 10-5000 nucleótidos de longitud, o cualquier combinación de los mismos.
En algunos casos, un kit puede comprender un polipéptido dirigido a un sitio (y/o un ácido nucleico que lo codifica), en donde el polipéptido dirigido a un sitio comprende al menos un 15 % de identidad de aminoácidos con una Cas9 de S. pyogenes, dos dominios de escisión de ácido nucleico (es decir, un dominio HNH y un dominio RuvC), en donde el polipéptido dirigido a un sitio comprende una mutación en uno o ambos dominios de escisión de ácido nucleico que reduce la actividad de escisión de los dominios nucleasa en al menos un 50 %; y ácido nucleico dirigido a ácido nucleico (y/o un ácido nucleico que lo codifica) que comprende una secuencia de extensión del espaciador de 10 5000 nucleótidos de longitud; una secuencia de espaciador de 12-30 nucleótidos de longitud, en donde el espaciador es al menos un 50 % complementario a un ácido nucleico diana; una repetición CRISPR mínima que comprende al menos un 60 % de identidad con un ARNcr de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6, 7 u
8 nucleótidos contiguos y en donde la repetición CRISPR mínima tiene una longitud de 5-30 nucleótidos; una secuencia mínima de ARNcrtra que comprende al menos un 60 % de identidad con un ARNcrtra de una bacteria (por ejemplo, S. pyogenes) sobre 6, 7 u 8 nucleótidos contiguos y en donde la secuencia mínima de ARNcrtra tiene una longitud de 5-30 nucleótidos; una secuencia enlazadora que une la repetición CRISPR mínima y el ARNcrtra mínimo y comprende una longitud de 3-5000 nucleótidos; un ARNcrtra 3' que comprende al menos un 60 % de identidad con un ARNcrtra de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6, 7 u 8 nucleótidos contiguos y en donde el ARNcrtra 3' comprende una longitud de 10-20 nucleótidos, y comprende una región duplexada; y/o una extensión de ARNcrtra que comprende 10-5000 nucleótidos de longitud, o cualquier combinación de los mismos. Este ácido nucleico dirigido a ácido nucleico puede denominarse ácido nucleico dirigido a ácido nucleico guía sencillo.
En algunos casos, un kit puede comprender un polipéptido dirigido a un sitio (y/o un ácido nucleico que lo codifica), en donde el polipéptido dirigido a un sitio comprende al menos un 15 % de identidad de aminoácidos con una Cas9 de S. pyogenes, dos dominios de escisión de ácido nucleico (es decir, un dominio HNH y un dominio RuvC), en donde el polipéptido dirigido a un sitio comprende una mutación en uno o ambos dominios de escisión de ácido nucleico que reduce la actividad de escisión de los dominios nucleasa en al menos un 50 %; y un ácido nucleico dirigido a ácido nucleico (y/o un ácido nucleico que lo codifica) que comprende una secuencia de extensión del espaciador de 10 5000 nucleótidos de longitud; una secuencia de espaciador de 12-30 nucleótidos de longitud, en donde el espaciador es al menos un 50 % complementario a un ácido nucleico diana; un dúplex que comprende 1) una repetición CRISPR mínima que comprende al menos un 60 % de identidad con un ARNcr de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6 nucleótidos contiguos y en donde la repetición CRISPR mínima tiene una longitud de 5-30 nucleótidos; 2 ) una secuencia mínima de ARNcrtra que comprende al menos un 60 % de identidad con un ARNcrtra de una bacteria (por ejemplo, S. pyogenes) sobre 6 nucleótidos contiguos y en donde la secuencia mínima de ARNcrtra tiene una longitud de 5-30 nucleótidos; y 3) una protuberancia en donde la protuberancia comprende al menos 3 nucleótidos no emparejados en la cadena de repetición CRISPR mínima del dúplex y al menos 1 nucleótido no emparejado en la cadena de secuencia mínima de ARNcrtra del dúplex; una secuencia enlazadora que une la repetición CRISPR mínima y el ARNcrtra mínimo y comprende una longitud de 3-5000 nucleótidos; un ARNcrtra 3' que comprende al menos un 60 % de identidad con un ARNcrtra de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6 nucleótidos contiguos, en donde el ARNcrtra 3' comprende una longitud de 10-20 nucleótidos y comprende una región duplexada; un dominio P que comienza desde 1-5 nucleótidos cadena abajo del dúplex que comprende la repetición CRISPR mínima y el ARNcrtra mínimo, comprende 1-10 nucleótidos, comprende una secuencia que puede hibridarse con un motivo adyacente al protoespaciador en un ácido nucleico diana, puede formar una horquilla y se encuentra en la región de ARNcrtra 3'; y/o una extensión de ARNcrtra que comprende 10-5000 nucleótidos de longitud, o cualquier combinación de los mismos.
En algunos casos, un kit puede comprender un polipéptido dirigido a un sitio (y/o un ácido nucleico que lo codifica), en donde el polipéptido dirigido a un sitio comprende al menos un 15 % de identidad de aminoácidos con una Cas9 de S. pyogenes, dos dominios de escisión de ácido nucleico (es decir, un dominio HNH y un dominio RuvC), en donde el polipéptido dirigido a un sitio comprende una mutación en uno o ambos dominios de escisión de ácido nucleico que reduce la actividad de escisión de los dominios nucleasa en al menos un 50 %; y un ácido nucleico dirigido a ácido nucleico guía doble (y/o un ácido nucleico que lo codifica) que comprende 1) una primera molécula de ácido nucleico que comprende una secuencia de extensión del espaciador de 10-5000 nucleótidos de longitud; una secuencia de espaciador de 12-30 nucleótidos de longitud, en donde el espaciador es al menos un 50 % complementario a un ácido nucleico diana; y una repetición CRISPR mínima que comprende al menos un 60 % de identidad con un ARNc de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6 nucleótidos contiguos y en donde la repetición CRISPR mínima tiene una longitud de 5-30 nucleótidos; y 2) una segunda molécula de ácido nucleico del ácido nucleico dirigido a ácido nucleico guía doble puede comprender una secuencia mínima de ARNcrtra que comprenda al menos un 60 % de identidad con un ARNcrtra de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6 nucleótidos contiguos y en donde la secuencia mínima de ARNcrtra tiene una longitud de 5-30 nucleótidos; un ARNcrtra 3' que comprende al menos un 60 % de identidad con un ARNcrtra de una bacteria (por ejemplo, S. pyogenes) sobre 6 nucleótidos contiguos y en donde el ARNcrtra 3' comprende una longitud de 10-20 nucleótidos, y comprende una región duplexada; y/o una extensión de ARNcrtra que comprende 10-5000 nucleótidos de longitud, o cualquier combinación de los mismos.
En algunos casos, un kit puede comprender un polipéptido dirigido a un sitio (y/o un ácido nucleico que lo codifica), en donde el polipéptido dirigido a un sitio comprende al menos un 15 % de identidad de aminoácidos con una Cas9 de S. pyogenes y dos dominios de escisión de ácido nucleico, en donde uno o ambos dominios de escisión de ácido nucleico comprenden al menos un 50 % de identidad de aminoácidos con un dominio nucleasa de Cas9 de S. pyogenes; y un ácido nucleico dirigido a ácido nucleico guía doble (y/o un ácido nucleico que lo codifica) que comprende: 1) una primera molécula de ácido nucleico que comprende una secuencia de extensión del espaciador de 10 5000 nucleótidos de longitud; una secuencia de espaciador de 12-30 nucleótidos de longitud, en donde el espaciador es al menos un 50 % complementario a un ácido nucleico diana; una repetición CRISPR mínima que comprende al menos un 60 % de identidad con un ARNc de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6 nucleótidos contiguos y en donde la repetición CRISPR mínima tiene una longitud de 5-30 nucleótidos y al menos 3 nucleótidos no emparejados de una protuberancia; y 2) una segunda molécula de ácido nucleico del ácido nucleico dirigido a ácido nucleico guía doble puede comprender una secuencia mínima de ARNcrtra que comprende al menos un 60 % de identidad con un ARNcrtra de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6 nucleótidos contiguos y en
donde la secuencia mínima de ARNcrtra tiene una longitud de 5-30 nucleótidos y al menos 1 nucleótido no emparejado de una protuberancia, en donde el 1 nucleótido no emparejado de la protuberancia está ubicado en la misma protuberancia que los 3 nucleótidos no emparejados de la repetición CRISPR mínima; un ARNcrtra 3' que comprende al menos un 60 % de identidad con un ARNcrtra de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6 nucleótidos contiguos y en donde el ARNcrtra 3' comprende una longitud de 10-20 nucleótidos, y comprende una región duplexada; un dominio P que comienza desde 1-5 nucleótidos cadena abajo del dúplex que comprende la repetición CRISPR mínima y el ARNcrtra mínimo, comprende 1-10 nucleótidos, comprende una secuencia que puede hibridarse con un motivo adyacente al protoespaciador en un ácido nucleico diana, puede formar una horquilla y se encuentra en la región de ARNcrtra 3'; y/o una extensión de ARNcrtra que comprende 10-5000 nucleótidos de longitud, o cualquier combinación de los mismos.
En algunos casos, un kit puede comprender un polipéptido dirigido a un sitio (y/o un ácido nucleico que lo codifica), en donde el polipéptido dirigido a un sitio comprende al menos un 15 % de identidad de aminoácidos con una Cas9 de S. pyogenes y dos dominios de escisión de ácido nucleico, en donde uno o ambos dominios de escisión de ácido nucleico comprenden al menos un 50 % de identidad de aminoácidos con un dominio nucleasa de Cas9 de S. pyogenes; y ácido nucleico dirigido a ácido nucleico (y/o un ácido nucleico que codifica el mismo) que comprende una secuencia de extensión del espaciador de 10-5000 nucleótidos de longitud; una secuencia de espaciador de 12-30 nucleótidos de longitud, en donde el espaciador es al menos un 50 % complementario a un ácido nucleico diana; una repetición CRISPR mínima que comprende al menos un 60 % de identidad con un ARNcr de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6, 7 u 8 nucleótidos contiguos y en donde la repetición CRISPR mínima tiene una longitud de 5-30 nucleótidos; una secuencia mínima de ARNcrtra que comprende al menos un 60 % de identidad con un ARNcrtra de una bacteria (por ejemplo, S. pyogenes) sobre 6, 7 u 8 nucleótidos contiguos y en donde la secuencia mínima de ARNcrtra tiene una longitud de 5-30 nucleótidos; una secuencia enlazadora que une la repetición CRISPR mínima y el ARNcrtra mínimo y comprende una longitud de 3-5000 nucleótidos; un ARNcrtra 3' que comprende al menos un 60 % de identidad con un ARNcrtra de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6, 7 u 8 nucleótidos contiguos y en donde el ARNcrtra 3' comprende una longitud de 10-20 nucleótidos, y comprende una región duplexada; y/o una extensión de ARNcrtra que comprende 10-5000 nucleótidos de longitud, o cualquier combinación de los mismos. Este ácido nucleico dirigido a ácido nucleico puede denominarse ácido nucleico dirigido a ácido nucleico guía sencillo.
En algunos casos, un kit puede comprender un polipéptido dirigido a un sitio (y/o un ácido nucleico que lo codifica), en donde el polipéptido dirigido a un sitio comprende al menos un 15 % de identidad de aminoácidos con una Cas9 de S. pyogenes y dos dominios de escisión de ácido nucleico, en donde uno o ambos dominios de escisión de ácido nucleico comprenden al menos un 50 % de identidad de aminoácidos con un dominio nucleasa de Cas9 de S. pyogenes; y un ácido nucleico dirigido a ácido nucleico (y/o un ácido nucleico que lo codifica) que comprende una secuencia de extensión del espaciador de 10-5000 nucleótidos de longitud; una secuencia de espaciador de 12-30 nucleótidos de longitud, en donde el espaciador es al menos un 50 % complementario a un ácido nucleico diana; un dúplex que comprende: 1) una repetición CRISPR mínima que comprende al menos un 60 % de identidad con un ARNcr de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6 nucleótidos contiguos y en donde la repetición CRISPR mínima tiene una longitud de 5-30 nucleótidos; 2 ) una secuencia mínima de ARNcrtra que comprende al menos un 60 % de identidad con un ARNcrtra de una bacteria (por ejemplo, S. pyogenes) sobre 6 nucleótidos contiguos y en donde la secuencia mínima de ARNcrtra tiene una longitud de 5-30 nucleótidos; y 3) una protuberancia en donde la protuberancia comprende al menos 3 nucleótidos no emparejados en la cadena de repetición CRISPR mínima del dúplex y al menos 1 nucleótido no emparejado en la cadena de secuencia mínima de ARNcrtra del dúplex; una secuencia enlazadora que une la repetición CRISPR mínima y el ARNcrtra mínimo y comprende una longitud de 3 5000 nucleótidos; un ARNcrtra 3' que comprende al menos un 60 % de identidad con un ARNcrtra de un procariota (por ejemplo, S. pyogenes) o un fago sobre 6 nucleótidos contiguos, en donde el ARNcrtra 3' comprende una longitud de 10-20 nucleótidos y comprende una región duplexada; un dominio P que comienza desde 1-5 nucleótidos cadena abajo del dúplex que comprende la repetición CRISPR mínima y el ARNcrtra mínimo, comprende 1-10 nucleótidos, comprende una secuencia que puede hibridarse con un motivo adyacente al protoespaciador en un ácido nucleico diana, puede formar una horquilla y se encuentra en la región de ARNcrtra 3'; y/o una extensión de ARNcrtra que comprende 10-5000 nucleótidos de longitud, o cualquier combinación de los mismos.
En algunas realizaciones de cualquiera de los kits anteriores, el kit puede comprender un ácido nucleico dirigido a ácido nucleico guía sencillo. En algunas realizaciones de cualquiera de los kits anteriores, el kit puede comprender un ácido nucleico dirigido a ácido nucleico guía doble. En algunas realizaciones de cualquiera de los kits anteriores, el kit puede comprender dos o más ácidos nucleicos dirigidos a ácido nucleicos guía dobles o sencillos. En algunas realizaciones, un vector puede codificar un ácido nucleico dirigido a ácido nucleico.
En algunas realizaciones de cualquiera de los kits anteriores, el kit puede comprender además un polinucleótido donante o una secuencia polinucleotídica que codifica el polinucleótido donante, para efectuar la modificación genética deseada. Los componentes de un kit pueden estar en recipientes separados; o se pueden combinar en un solo recipiente.
Un kit descrito anteriormente comprende además uno o más reactivos adicionales, donde dichos reactivos adicionales se pueden seleccionar entre: un tampón, un tampón para introducir un elemento polipeptídico o polinucleótido del kit
en una célula, un tampón de lavado, un reactivo de control, un vector de control, un polinucleótido de ARN de control, un reactivo para la producción in vitro del polipéptido a partir de ADN, adaptadores para la secuenciación y similares. Un tampón puede ser un tampón de estabilización, un tampón reconstituyente o un tampón diluyente.
En algunos casos, un kit puede comprender uno o más reactivos adicionales específicos para plantas y/u hongos. Los uno o más reactivos adicionales para plantas y/u hongos pueden incluir, por ejemplo, suelo, nutrientes, plantas, semillas, esporas, agrobacterias, vector de ADN-T y un vector pBINAR.
Además de los componentes mencionados anteriormente, un kit puede incluir además instrucciones para usar los componentes del kit para poner en práctica los métodos. Las instrucciones para poner en práctica los métodos se registran generalmente en un medio de grabación adecuado. Por ejemplo, las instrucciones pueden imprimirse sobre un sustrato, tal como papel o plástico, etc. Las instrucciones pueden estar presentes en los kits en forma de prospecto, en la etiqueta del envase del kit o los componentes del mismo (es decir, asociado al envase o envase secundario), etc. Las instrucciones pueden estar presentes en forma de un archivo de datos almacenado electrónicamente presente en un medio de almacenamiento legible por ordenador adecuado, por ejemplo, CD-ROM, disquete, unidad flash, etc. En algunos casos, las instrucciones reales no están presentes en el kit, pero se proporcionan medios para obtener las instrucciones de una fuente remota (por ejemplo, a través de Internet). Un ejemplo de esta realización es un kit que incluye una página web donde pueden verse las instrucciones y/o a través de la cual pueden descargarse las instrucciones. Al igual que con las instrucciones, esto significa que, para obtenerse las instrucciones, puede registrarse en un sustrato adecuado.
En algunas realizaciones, un kit puede comprender un vector linealizado. Un vector linealizado puede comprender un plásmido que comprenda un polipéptido dirigido a un sitio y/o un ácido nucleico dirigido a ácido nucleico que esté linealizado (por ejemplo, que no sea circular). Un vector linealizado puede almacenarse en un tampón que comprenda Tris-HCl 10 mM, pH 8,0 y EDTA 1 mM, pH 8,0. Un kit puede comprender aproximadamente 20 microlitros del vector de nucleasa CRISPR linealizado. En algunas realizaciones, un kit puede comprender uno o más vectores circulares.
En algunas realizaciones, un kit puede comprender un tampón de hibridación de oligonucleótidos. Un tampón de hibridación de oligonucleótidos puede ser un tampón usado para hibridar oligos de ADN entre sí para generar un ADN bicatenario que codifique un ácido nucleico dirigido a ácido nucleico. Un tampón de hibridación de oligonucleótidos puede estar al menos aproximadamente 1,2, 3, 4, 5, 6, 7, 8, 9 o 10, o más concentrado que la concentración de uso. Un tampón de hibridación de oligonucleótidos puede estar 10 veces más concentrado que la concentración cuando se usa. Un tampón de hibridación de oligonucleótidos puede comprender Tris-HCl 100 mM, pH 8,0, EDTA 10 mM, pH 8,0 y NaCl 1 M. Un kit puede comprender 250 microlitros del tampón de hibridación de oligonucleótidos.
Un kit puede comprender agua exenta de DNasa. Un kit puede comprender agua exenta de ARNasa. Un kit puede comprender al menos 1,5 mililitros de agua exenta de RNasa y/o DNAsa.
Un kit puede comprender un tampón de ligadura. Se puede usar un tampón de ligadura para ligar oligonucleótidos al vector de nucleasa CRISPR linealizado. Un tampón de ligadura puede estar al menos aproximadamente 1, 2, 3, 4, 5, 6, 7, 8, 9 o 10, o más concentrado que la concentración de uso. Un tampón de ligadura puede ser 5 veces más concentrado que la concentración de uso. Un tampón de ligadura x5 puede comprender Tris-HCl 250 mM, pH 7,6, MgCh 50 mM, ATP 5 mM, DTT 5 mM, y polietilenglicol-8000 al 25 % (p/v). Un kit puede comprender aproximadamente 80 microlitros de un tampón de ligadura.
Un kit puede comprender una ADN ligasa. Se puede usar una ADN ligasa para ligar los oligonucleótidos al vector de nucleasa CRISPR linealizado. Una ADN ligasa puede comprender Tris-HCl 10 mM, pH 7,5, KCl 50 mM, DTT 1 mM y glicerol al 50 % (v/v). Un kit puede comprender 20 microlitros de una ADN ligasa.
Un kit puede comprender un cebador de secuenciación. El cebador de secuenciación puede usarse para secuenciar el vector una vez que los oligonucleótidos se han ligado en un vector linealizado. Un cebador de secuenciación se puede diluir en tampón Tris-EDTA a pH 8,0. Un kit puede comprender 20 microlitros de un cebador de secuenciación.
Un kit puede comprender un oligonucleótido de control. Un oligonucleótido de control puede ser un oligonucleótido que se vaya a ligar en un vector linealizado, pero que no codifica un ácido nucleico dirigido a ácido nucleico. Un oligonucleótido de control puede diluirse a una concentración x1 del tampón de hibridación de oligonucleótidos. Un kit puede comprender 10 microlitros de un oligonucleótido de control.
En algunos casos, un kit puede comprender un vector linealizado que comprenda un polipéptido dirigido a un sitio y un ácido nucleico dirigido a ácido nucleico, un tampón de hibridación de oligonucleótidos, agua exenta de DNAsa/RNAsa, un tampón de ligadura, una enzima ligasa, un cebador de secuenciación y un oligonucleótido de control, o cualquier combinación de los mismos.
Composiciones farmacéuticas
Las moléculas, tales como un ácido nucleico dirigido a ácido nucleico de la divulgación como el descrito en el presente
documento, un polinucleótido que codifica un ácido nucleico dirigido a ácido nucleico, un polipéptido dirigido a un sitio de la divulgación, un polinucleótido que codifica un polipéptido dirigido a un sitio, una proteína efectora, un polinucleótido que codifica una proteína efectora, un agente de dirección genético multiplexado, un polinucleótido que codifica un agente de dirección genético multiplexado, un polinucleótido donante, una proteína de fusión en tándem, un polinucleótido que codifica una proteína de fusión en tándem, un elemento indicador, un elemento genético de interés, un componente de un sistema dividido y/o cualquier ácido nucleico o molécula proteica que se necesite para llevar a cabo las realizaciones de los métodos de la divulgación, se pueden formular en una composición farmacéutica.
Una composición farmacéutica puede comprender una combinación de cualquier molécula descrita en el presente documento con otros componentes químicos, tales como vehículos, estabilizantes, diluyentes, agentes dispersantes, agentes de suspensión, agentes espesantes y/o excipientes. La composición farmacéutica puede facilitar la administración de la molécula a un organismo. Las composiciones farmacéuticas pueden administrarse en cantidades terapéuticamente eficaces como composiciones farmacéuticas mediante diversas formas y vías que incluyen, por ejemplo, administración intravenosa, subcutánea, intramuscular, oral, rectal, aerosol, parenteral, oftálmica, pulmonar, transdérmica, vaginal, ótica, nasal y tópica.
Una composición farmacéutica puede administrarse de manera local o sistémica, por ejemplo, mediante la inyección de la molécula directamente en un órgano, opcionalmente, en una formulación en depósito o de liberación sostenida. Las composiciones farmacéuticas pueden proporcionarse en forma de una formulación de liberación rápida, en forma de una formulación de liberación prolongada o en forma de una formulación de liberación intermedia. Una forma de liberación rápida puede proporcionar una liberación inmediata. Una formulación de liberación prolongada puede proporcionar una liberación controlada o una liberación retardada sostenida.
Para la administración oral, las composiciones farmacéuticas pueden formularse fácilmente combinando las moléculas con vehículos o excipientes farmacéuticamente aceptables. Dichos vehículos pueden usarse para formular comprimidos, polvos, píldoras, grageas, cápsulas, líquidos, geles, jarabes, elixires, pastas, suspensiones y similares, para la ingestión oral por parte de un sujeto.
Se pueden obtener preparados farmacéuticos para uso oral mezclando uno o más excipientes sólidos con una o más de las moléculas descritas en el presente documento, moliendo opcionalmente la mezcla resultante y procesando la mezcla de gránulos, después de añadir adyuvantes adecuados, si se desea, para obtenerse comprimidos o núcleos de grageas. Los núcleos se pueden proporcionar con recubrimientos adecuados. Para este fin, pueden usarse soluciones de azúcar concentradas, que pueden contener un excipiente tal como goma arábiga, talco, polivinilpirrolidona, gel de carbopol, polietilenglicol y/o dióxido de titanio, soluciones de laca y disolventes orgánicos adecuados o mezclas de disolventes. Se pueden añadir colorantes o pigmentos a los comprimidos o recubrimientos de grageas, por ejemplo, para identificar o para caracterizar diferentes combinaciones de dosis de compuestos activos.
Los preparados farmacéuticos que se pueden usar por vía oral incluyen cápsulas de ajuste por presión hechas de gelatina, así como cápsulas blandas, selladas fabricadas de gelatina y un plastificante, tal como glicerol o sorbitol. En algunas realizaciones, la cápsula comprende una cápsula de gelatina dura que comprende uno o más productos farmacéuticos, gelatinas bovinas y vegetales. Una gelatina puede ser procesada en condiciones alcalinas. Las cápsulas de ajuste a presión pueden comprender los principios activos mezclados con carga, tal como lactosa, aglutinantes, tales como almidones y/o lubricantes, tales como talco o estearato de magnesio y, estabilizantes. En las cápsulas blandas, la molécula puede disolverse o suspenderse en líquidos adecuados, tales como aceites grasos, parafina líquida o polietilenglicoles líquidos. Pueden añadirse estabilizantes. Todas las formulaciones para administración oral se proporcionan en dosis adecuadas para dicha administración.
Para la administración bucal o sublingual, las composiciones pueden ser comprimidos, pastillas para chupar o geles.
Las inyecciones parentales pueden formularse para inyección en bolo o infusión continua. Las composiciones farmacéuticas pueden estar en una forma adecuada para inyección parenteral tal como una suspensión, solución o emulsión estéril en vehículos aceitosos o acuosos, y pueden contener agentes de formulación tales como agentes de suspensión, estabilizantes y/o dispersantes. Las formulaciones farmacéuticas para su administración parenteral pueden incluir soluciones acuosas de los compuestos activos en forma hidrosoluble.
Se pueden preparar suspensiones de las moléculas en forma de suspensiones oleosos para inyección. Los disolventes o vehículos lipófilos adecuados incluyen aceites grasos, tales como aceite de sésamo, o ésteres de ácidos grasos sintéticos, tales como oleato de etilo o triglicéridos, o liposomas. Las suspensiones de inyección acuosa pueden contener sustancias que aumentan la viscosidad de la emulsión, tales como carboximetilcelulosa sódica, sorbitol o dextrano. La suspensión también puede contener estabilizantes o agentes adecuados que aumenten la solubilidad de las moléculas para permitir la preparación de soluciones muy concentradas. Como alternativa, el principio activo se puede encontrar en forma de polvo para su constitución con un vehículo adecuado, por ejemplo, agua apirógena estéril, antes de su uso.
Los compuestos activos pueden administrarse por vía tópica y pueden formularse en varias composiciones que se pueden administrar por vía tópica, tales como soluciones, suspensiones, lociones, geles, pastas, palos medicinales,
bálsamos, cremas y pomadas. Dichas composiciones farmacéuticas pueden comprender solubilizantes, estabilizantes, agentes potenciadores de la tonicidad, tampones y conservantes.
Las formulaciones adecuadas para la administración transdérmica de las moléculas pueden emplear dispositivos de administración transdérmica y parches de administración transdérmica, y pueden ser emulsiones lipófilas o soluciones acuosas tamponadas, disueltas y/o dispersadas en un polímero o un adhesivo. Dichos parches pueden construirse para la administración continua, pulsátil o a demanda de moléculas. La administración transdérmica se puede lograr por medio de parches iontoforéticos y similares. Además, los parches transdérmicos pueden proporcionar una administración controlada. Se puede reducir la velocidad de absorción usando membranas de control de la velocidad o atrapando el compuesto dentro de una matriz de polímero o gel. Por el contrario, se pueden usar potenciadores de la absorción para aumentar la absorción. Un potenciador o vehículo de absorción puede incluir disolventes absorbibles farmacéuticamente aceptables para ayudar al paso a través de la piel. Por ejemplo, los dispositivos transdérmicos pueden tener la forma de un vendaje que comprenda un miembro de soporte, un depósito que contenga compuestos y vehículos, una barrera de control de la velocidad para administrar los compuestos en la piel del sujeto a una velocidad controlada y predeterminada durante un período prolongado de tiempo, y adhesivos para fijar el dispositivo a la piel.
Para la administración por inhalación, la molécula puede estar en forma de aerosol, una nebulización o un polvo. Las composiciones farmacéuticas pueden administrarse en forma de presentación en aerosol a partir de envases presurizados o un nebulizador, con el uso de un propulsor adecuado, por ejemplo, diclorodifluorometano, triclorofluorometano, diclorotetrafluoroetano, dióxido de carbono u otro gas adecuado. En el caso de un aerosol presurizado, la unidad de dosificación se puede determinar proporcionando una válvula para administrar una cantidad medida. Las cápsulas y los cartuchos de, por ejemplo, gelatina para su uso en un inhalador o insuflador pueden formularse para que contengan una mezcla de polvo de los compuestos y una base de polvo adecuada, tal como lactosa o almidón.
Las moléculas también se pueden formular en composiciones rectales tales como enemas, geles rectales, espumas rectales, aerosoles rectales, supositorios, supositorios de gelatina o enemas de retención, que contiene bases para supositorio convencionales, tales como manteca de cacao u otros glicéridos, así como polímeros sintéticos tales como polivinilpirrolidona y PEG. En las formas en supositorio de las composiciones, se puede usar una cera de bajo punto de fusión, tal como una mezcla de glicéridos de ácidos grasos o manteca de cacao.
Al poner en práctica los métodos de la divulgación, se pueden administrar cantidades terapéuticamente eficaces de los compuestos descritos en el presente documento en composiciones farmacéuticas a un sujeto que tenga una enfermedad o afección que haya que tratar. Una cantidad terapéuticamente eficaz puede variar ampliamente dependiendo de la gravedad de la enfermedad, la edad y salud relativa del sujeto, la potencia de los compuestos usados, así como de otros factores. Los compuestos se pueden usar solos o en combinación con uno o más agentes terapéuticos como componentes de mezclas.
Las composiciones farmacéuticas pueden formularse usando uno o más vehículos fisiológicamente aceptables que comprenden excipientes y adyuvantes, que faciliten el procesamiento de la molécula en preparados que pueden usarse farmacéuticamente. La formulación puede modificarse dependiendo de la vía de administración escogida. Las composiciones farmacéuticas que comprenden una molécula descrita en el presente documento pueden fabricarse, por ejemplo, mediante procesos de mezcla, disolución, granulación, preparación de grageas, levigación, emulsionado, encapsulación, atrapamiento o compresión.
Las composiciones farmacéuticas pueden incluir al menos un vehículo, diluyente o excipiente farmacéuticamente aceptable, y la molécula descrita en el presente documento en forma de base libre o de sal farmacéuticamente aceptable. Los métodos y las composiciones farmacéuticas descritos en el presente documento incluyen el uso de formas cristalinas (también conocidas como polimorfos) y metabolitos activos de estos compuestos que tienen el mismo tipo de actividad.
Los métodos para la preparación de composiciones que comprenden los compuestos descritos en el presente documento pueden incluir la formulación de la molécula con uno o más excipientes o vehículos farmacéuticamente aceptables, inertes, para formar una composición sólida, semisólida o líquida. Las composiciones sólidas pueden incluir, por ejemplo, polvos, comprimidos, gránulos dispersables, cápsulas, obleas y supositorios. Las composiciones líquidas pueden incluir, por ejemplo, soluciones en las que hay disuelto un compuesto, emulsiones que comprenden un compuesto o una solución que contiene liposomas, micelas o nanopartículas que comprenden un compuesto tal como se ha desvelado en el presente documento. Las composiciones semisólidas pueden incluir, por ejemplo, geles, suspensiones y cremas. Las composiciones pueden estar en soluciones o suspensiones líquidas, en formas sólidas adecuadas para su disolución o suspensión en un líquido antes de su uso o como emulsiones. Estas composiciones también pueden contener cantidades menores de sustancias auxiliares, no tóxicas, tales como agentes humectantes o emulsionantes, agentes tamponadores de pH y otros aditivos farmacéuticamente aceptables.
Los ejemplos no limitantes de formas farmacéuticas pueden incluir piensos, alimentos, microgránulo, pastilla para chupar, líquido, elixir, aerosol, inhalador, pulverización, polvo, comprimido, píldora, cápsula, gel, comprimidos de gel, nanosuspensión, nanopartícula, microgel, trociscos en supositorio, suspensiones acuosas u oleosas, pomada, parche,
loción, dentífrico, emulsión, cremas, gotas, polvos o gránulos dispersables, emulsión en cápsulas de gel duras o blandas, jarabes, fitofármacos y nutracéuticos, o cualquier combinación de los mismos.
Los ejemplos no limitantes de excipientes farmacéuticamente aceptables pueden incluir agentes de granulación, agentes aglutinantes, agentes lubricantes, agentes disgregantes, agentes edulcorantes, sustancias de deslizamiento, antiadherentes, agentes antiestáticos, tensioactivos, antioxidantes, gomas, agentes de recubrimiento, agentes colorantes, agentes aromatizantes, agentes de recubrimiento, plastificantes, conservantes, agentes de suspensión, agentes emulsionantes, material celulósico vegetal y agentes de esferonización, o cualquier combinación de los mismos.
Una composición puede ser, por ejemplo, una forma de liberación inmediata o una formulación de liberación controlada. Se puede formular una formulación de liberación inmediata para permitir que las moléculas actúen rápidamente. Los ejemplos no limitantes de formulaciones de liberación inmediata pueden incluir formulaciones fácilmente solubles. Una formulación de liberación controlada puede ser una formulación farmacéutica que se haya adaptado para que las velocidades de liberación del fármaco y los perfiles de liberación del fármaco sean acordes a las necesidades fisiológicas y cronoterapéuticas o, como alternativa, que se haya formulado para efectuar la liberación de un fármaco a una velocidad programada. Los ejemplos no limitantes de formulaciones de liberación controlada pueden incluir gránulos, gránulos de liberación retardada, hidrogeles (por ejemplo, de origen sintético o natural), otros agentes gelificantes (por ejemplo, fibras dietéticas formadoras de gel), formulaciones basadas en matriz (por ejemplo, formulaciones que comprenden un material polimérico que tiene al menos un principio activo disperso), gránulos dentro de una matriz, mezclas poliméricas, masas granulares y similares.
Una formulación de liberación controlada puede ser una forma de liberación retardada. Se puede formular una forma de liberación retardada para retrasar la acción de una molécula durante un período prolongado de tiempo. Se puede formular una forma de liberación retardada para retrasar la liberación de una dosis eficaz de una o más moléculas, por ejemplo, durante aproximadamente 4, aproximadamente 8, aproximadamente 12, aproximadamente 16 o aproximadamente 24 horas.
Una formulación de liberación controlada puede ser una forma de liberación sostenida. Se puede formular una forma de liberación sostenida para mantener, por ejemplo, la acción de la molécula durante un período prolongado de tiempo. Se puede formular una forma de liberación sostenida para proporcionar una dosis eficaz de cualquier molécula descrita en el presente documento (por ejemplo, proporcionar un perfil sanguíneo fisiológicamente eficaz) durante aproximadamente 4, aproximadamente 8, aproximadamente 12, aproximadamente 16 o aproximadamente 24 horas.
Métodos de administración y métodos de tratamiento.
Las composiciones farmacéuticas que contienen moléculas descritas en el presente documento pueden administrarse para tratamientos profilácticos y/o terapéuticos. En las aplicaciones terapéuticas, las composiciones pueden administrarse a un sujeto que ya padece una enfermedad o afección, en una cantidad suficiente para curar o al menos detener parcialmente los síntomas de la enfermedad o afección, o para curar, sanar, o mejorar la afección. Las cantidades eficaces para este uso pueden variar según la gravedad y el curso de la enfermedad o afección, la terapia previa, el estado de salud del sujeto, el peso y la respuesta a los fármacos y el juicio del médico tratante.
Se pueden administrar múltiples agentes terapéuticos en cualquier orden o simultáneamente. Si se administran simultáneamente, los múltiples agentes terapéuticos se pueden proporcionar en una sola forma unificada o en múltiples formas, por ejemplo, como múltiples píldoras separadas. Las moléculas se pueden acondicionar juntas o por separado, en un solo envase o en una pluralidad de envases. Uno o todos los agentes terapéuticos pueden administrarse en múltiples dosis. Si no se administran simultáneamente, el tiempo entre las múltiples dosis puede variar hasta aproximadamente un mes.
Las moléculas descritas en el presente documento pueden administrarse antes, durante o después de la aparición de una enfermedad o afección, y el momento de la administración de la composición que contiene un compuesto puede variar. Por ejemplo, las composiciones farmacéuticas pueden usarse como composiciones profilácticas y pueden administrarse de manera continua a sujetos con una propensión a afecciones o enfermedades a fin de prevenir la aparición de la enfermedad o afección. Las moléculas y las composiciones farmacéuticas se pueden administrar a un sujeto durante o tan pronto como sea posible tras el inicio de los síntomas. La administración de las moléculas puede iniciarse dentro de las primeras 48 horas del inicio de los síntomas, dentro de las primeras 24 horas del inicio de los síntomas, dentro de las primeras 6 horas del inicio de los síntomas o dentro de las 3 horas del inicio de los síntomas. La administración inicial puede ser por cualquier vía práctica, tal como por cualquier vía descrita en el presente documento usando cualquier formulación descrita en el presente documento. Se puede administrar una molécula tan pronto como sea posible tras la detección o sospecha del inicio de una enfermedad o afección, y durante el tiempo necesario para el tratamiento de la enfermedad, tal como, por ejemplo, de aproximadamente 1 mes a aproximadamente 3 meses. La duración del tratamiento puede variar para cada sujeto.
Una molécula se puede acondicionar en un compartimento biológico. Un compartimento biológico que comprende la molécula puede administrarse a un sujeto. Los compartimentos biológicos pueden incluir, pero sin limitación, virus
(lentivirus, adenovirus), nanoesferas, liposomas, puntos cuánticos, nanopartículas, micropartículas, nanocápsulas, vesículas, partículas de polietilenglicol, hidrogeles y micelas.
Por ejemplo, un compartimento biológico puede comprender un liposoma. Un liposoma puede ser una estructura de autoensamblaje que comprenda una o más bicapas lipídicas, pudiendo comprender cada una de las cuales dos monocapas que contengan moléculas de lípidos anfipáticos con orientación opuesta. Los lípidos anfipáticos pueden comprender un grupo de cabeza polar (hidrófilo) unido covalentemente a una o dos o más cadenas de acilo o alquilo no polares (hidrófobas). Los contactos energéticamente desfavorables entre las cadenas de acilo hidrófobas y un medio acuoso circundante inducen a las moléculas de lípidos anfipáticos a organizarse de manera que los grupos de cabeza polares puedan orientarse hacia la superficie de la bicapa y las cadenas de acilo estén orientadas hacia el interior de la bicapa, protegiendo de manera eficaz las cadenas de acilo del contacto con el ambiente acuoso.
Los ejemplos de compuestos anfipáticos preferidos usados en liposomas pueden incluir fosfoglicéridos y esfingolípidos, cuyos ejemplos representativos incluyen fosfatidilcolina, fosfatidiletanolamina, fosfatidilserina, fosfatidilinositol, ácido fosfatídico, fosfatidilglicerol, palmitoiloleoil fosfatidilcolina, lisofosfatidilcolina, lisofosfatidiletanolamina, dimiristoilfosfatidilcolina (DMPC), dipalmitoilfosfatidilcolina (DPPC), dioleoilfosfatidilcolina, diestearoilfosfatidilcolina (DSPC), dilinoleoilfosfatidilcolina y esfingomielina de huevo, o cualquier combinación de los mismos.
Un compartimento biológico puede comprender una nanopartícula. Una nanopartícula puede comprender un diámetro de aproximadamente 40 nanómetros a aproximadamente 1,5 micrómetros, de aproximadamente 50 nanómetros a aproximadamente 1,2 micrómetros, de aproximadamente 60 nanómetros a aproximadamente 1 micrómetro, de aproximadamente 70 nanómetros a aproximadamente 800 nanómetros, de aproximadamente 80 nanómetros a aproximadamente 600 nanómetros, de aproximadamente 90 nanómetros a aproximadamente 400 nanómetros, de aproximadamente 100 nanómetros a aproximadamente 200 nanómetros.
En algunos casos, a medida que aumenta el tamaño de la nanopartícula, puede reducirse o prolongarse la velocidad de liberación, y a medida que disminuye el tamaño de la nanopartícula, se puede aumentar la velocidad de liberación.
La cantidad de albúmina en las nanopartículas puede variar del aproximadamente 5 % al aproximadamente 85 % de albúmina (v/v), del aproximadamente 10% al aproximadamente 80%, del aproximadamente 15% al aproximadamente 80 %, del aproximadamente 20 % al aproximadamente 70 % de albúmina (v/v), del aproximadamente 25 % al aproximadamente 60 %, del aproximadamente 30 % al aproximadamente 50 % o del aproximadamente 35 % al aproximadamente 40 %. La composición farmacéutica puede comprender hasta 30, 40, 50, 60, 70 u 80 % o más de nanopartícula. En algunos casos, las moléculas de ácido nucleico de la divulgación pueden unirse a la superficie de la nanopartícula.
Un compartimento biológico puede comprender un virus. El virus puede ser un sistema de administración para las composiciones farmacéuticas de la divulgación. Los virus ilustrativos pueden incluir lentivirus, retrovirus, adenovirus, virus del herpes simple I o II, parvovirus, virus de la reticuloendoteliosis y virus adenoasociados (AAV). Las composiciones farmacéuticas de la divulgación pueden administrarse a una célula usando un virus. El virus puede infectar y transducir la célula in vivo, ex vivo o in vitro. En la administración ex vivo e in vitro, las células transducidas pueden administrarse a un sujeto que necesite terapia.
Las composiciones farmacéuticas se pueden acondicionar en sistemas de administración vírica. Por ejemplo, las composiciones pueden acondicionarse en viriones mediante un sistema de acondicionamiento libre de virus auxiliar HSV-1.
Los sistemas de administración vírica (por ejemplo, los virus que comprenden las composiciones farmacéuticas de la divulgación) se pueden administrar mediante inyección directa, inyección estereotáxica, vía intracerebroventricular, mediante sistemas de infusión de minibomba, por convección, catéteres, administración intravenosa, parenteral, inyección intraperitoneal y/o subcutánea, a una célula, un tejido o un órgano de un sujeto necesitado. En algunos casos, las células pueden transducirse in vitro o ex vivo con sistemas de administración vírica. Las células transducidas pueden administrarse a un sujeto que tenga una enfermedad. Por ejemplo, se puede transducir una célula madre con un sistema de administración vírica que comprenda una composición farmacéutica, y la célula madre puede implantarse en el paciente para tratar una enfermedad. En algunos casos, la dosis de células transducidas administrada a un sujeto puede ser de aproximadamente 1*105 células/kg, aproximadamente 5*105 células/kg, aproximadamente 1*10® células/kg, aproximadamente 2*10® células/kg, aproximadamente 3*10® células/kg, aproximadamente 4*10® células/kg, aproximadamente 5*10® células/kg, aproximadamente 6*10® células/kg, aproximadamente 7*10® células/kg, aproximadamente 8*10® células/kg, aproximadamente 9*10® células/kg, aproximadamente 1*107 células/kg, aproximadamente 5*107 células/kg, aproximadamente 1*108 células/kg o más en una sola dosis.
Las composiciones farmacéuticas en compartimentos biológicos pueden usarse para tratar enfermedades inflamatorias tales como artritis, cánceres, tales como, por ejemplo, cáncer de hueso, cáncer de mama, cáncer de piel, cáncer de próstata, cáncer de hígado, cáncer de pulmón, cáncer de garganta y cáncer de riñón, infecciones
bacterianas, para tratar el daño nervioso, enfermedades pulmonares, hepáticas y renales, tratamiento de los ojos, lesiones de la médula espinal, cardiopatía, enfermedad arterial.
La introducción de los compartimentos biológicos en las células puede ocurrir por infección vírica o bacteriófaga, transfección, conjugación, fusión de protoplastos, lipofección, electroporación, precipitación con fosfato de calcio, transfección mediada por polietilenimina (PEI), transfección mediada con DEAE-dextrano, transfección mediada por liposomas, tecnología de pistola de partículas, precipitación con fosfato de calcio, microinyección directa, administración de ácido nucleico mediada por nanopartículas, y similares.
Dosificación
Las composiciones farmacéuticas descritas en el presente documento pueden estar en formas de dosificación unitarias adecuadas para la administración única de dosis precisas. En la forma de dosificación unitaria, la formulación se puede dividir en dosis unitarias que contengan cantidades apropiadas de uno o más compuestos. La dosis unitaria puede estar en forma de un envase que contenga cantidades diferenciadas de la formulación. Los ejemplos no limitantes pueden incluir comprimidos o cápsulas acondicionados y polvos en viales o ampollas. Las composiciones de suspensión acuosa se pueden acondicionar en recipientes monodosis no reutilizables. Se pueden usar recipientes reutilizables multidosis, por ejemplo, en combinación con un conservante. Las formulaciones para inyección parenteral se pueden presentar en forma de dosificación unitaria, por ejemplo, en ampollas o en envases multidosis con un conservante.
Una molécula descrita en el presente documento puede estar presente en una composición en un intervalo de aproximadamente 1 mg a aproximadamente 2000 mg; de aproximadamente 5 mg a aproximadamente 1000 mg, de aproximadamente 10 mg a aproximadamente 25 mg a 500 mg, de aproximadamente 50 mg a aproximadamente 250 mg, de aproximadamente 100 mg a aproximadamente 200 mg, de aproximadamente 1 mg a aproximadamente 50 mg, de aproximadamente 50 mg a aproximadamente 100 mg, de aproximadamente 100 mg a aproximadamente 150 mg, de aproximadamente 150 mg a aproximadamente 200 mg, de aproximadamente 200 mg a aproximadamente 250 mg, de aproximadamente 250 mg a aproximadamente 300 mg, de aproximadamente 300 mg a aproximadamente 350 mg, de aproximadamente 350 mg a aproximadamente 400 mg, de aproximadamente 400 mg a aproximadamente 450 mg, de aproximadamente 450 mg a aproximadamente 500 mg, de aproximadamente 500 mg a aproximadamente 550 mg, de aproximadamente 550 mg a aproximadamente 600 mg, de aproximadamente 600 mg a aproximadamente 650 mg, de aproximadamente 650 mg a aproximadamente 700 mg, de aproximadamente 700 mg a aproximadamente 750 mg, de aproximadamente 750 mg a aproximadamente 800 mg, de aproximadamente 800 mg a aproximadamente 850 mg, de aproximadamente 850 mg a aproximadamente 900 mg, de aproximadamente 900 mg a aproximadamente 950 mg o de aproximadamente 950 mg a aproximadamente 1000 mg.
Una molécula descrita en el presente documento puede estar presente en una composición en una cantidad de aproximadamente 1 mg, aproximadamente 2 mg, aproximadamente 3 mg, aproximadamente 4 mg, aproximadamente 5 mg, aproximadamente 10 mg, aproximadamente 15 mg, aproximadamente 20 mg, aproximadamente 25 mg, aproximadamente 30 mg, aproximadamente 35 mg, aproximadamente 40 mg, aproximadamente 45 mg, aproximadamente 50 mg, aproximadamente 55 mg, aproximadamente 60 mg, aproximadamente 65 mg, aproximadamente 70 mg, aproximadamente 75 mg, aproximadamente 80 mg, aproximadamente 85 mg, aproximadamente 90 mg, aproximadamente 95 mg, aproximadamente 100 mg, aproximadamente 125 mg, aproximadamente 150 mg, aproximadamente 175 mg, aproximadamente 200 mg, aproximadamente 250 mg, aproximadamente 300 mg, aproximadamente 350 mg, aproximadamente 400 mg, aproximadamente 450 mg, aproximadamente 500 mg, aproximadamente 550 mg, aproximadamente 600 mg, aproximadamente 650 mg, aproximadamente 700 mg, aproximadamente 750 mg, aproximadamente 800 mg, aproximadamente 850 mg, aproximadamente 900 mg, aproximadamente 950 mg, aproximadamente 1000 mg, aproximadamente 1050 mg, aproximadamente 1100 mg, aproximadamente 1150 mg, aproximadamente 1200 mg, aproximadamente 1250 mg, aproximadamente 1300 mg, aproximadamente 1350 mg, aproximadamente 1400 mg, aproximadamente 1450 mg, aproximadamente 1500 mg, aproximadamente 1550 mg, aproximadamente 1600 mg, aproximadamente 1650 mg, aproximadamente 1700 mg, aproximadamente 1750 mg, aproximadamente 1800 mg, aproximadamente 1850 mg, aproximadamente 1900 mg, aproximadamente 1950 mg o aproximadamente 2000 mg.
Una molécula (por ejemplo, un polipéptido dirigido a un sitio, ácido nucleico dirigido a ácido nucleico y/o complejo de un polipéptido dirigido a un sitio y un ácido nucleico dirigido a ácido nucleico) descrita en el presente documento puede estar presente en una composición que proporcione al menos 0,1, 0,5, 1, 1,5, 2, 2,53, 3,5, 4, 4,5, 5, 5,5, 6, 6,5, 10 o más unidades de actividad/mg de molécula. En algunas realizaciones, el número total de unidades de actividad de la molécula administrada a un sujeto es de al menos 25.000, 30.000, 35.000, 40.000, 45.000, 50.000, 60.000, 70.000, 80.000, 90.000, 110.000, 120.000, 130.000, 140.000, 150.000, 160.000, 170.000, 180.000, 190.000, 200.000, 210.000, 220.000, 230.000 o 250.000, o más unidades. En algunas realizaciones, el número total de unidades de actividad de la molécula administrada a un sujeto es, como máximo, de 25.000, 30.000, 35.000, 40.000, 45.000, 50.000, 60.000, 70.000, 80.000, 90.000, 110.000, 120.000, 130.000, 140.000, 150.000, 160.000, 170.000, 180.000, 190.000, 200.000, 210.000, 220.000, 230.000 o 250.000, o más unidades.
En algunas realizaciones, se administran al menos aproximadamente 10.000 unidades de actividad a un sujeto,
normalizadas por 50 kg de peso corporal. En algunas realizaciones, se administran al menos aproximadamente 10.000, 15.000, 25.000, 30.000, 35.000, 40.000, 45.000, 50.000, 60.000, 70.000, 80.000, 90.000, 110.000, 120.000, 130.000, 140.000, 150.000, 160.000, 170.000, 180.000, 190.000, 200.000, 210.000, 220.000, 230.000 o 250.000 unidades o más de actividad de la molécula al sujeto, normalizadas por 50 kg de peso corporal. En algunas realizaciones, una dosis terapéuticamente eficaz comprende al menos 5 x 105, 1 x 106, 2 x 106, 3 x 106, 4, 106, 5 x 106, 6 x 106, 7 x 106, 8 x 106, 9 x 106, 1 x 107, 1,1 x 107, 1,2 x 107, 1,5 x 107, 1,6 x 107, 1,7 x 107, 1,8 x 107, 1,9 x 107, 2 x 107, 2,1 x 107, o 3 x 107 o más unidades de actividad de la molécula. En algunas realizaciones, una dosis terapéuticamente eficaz comprende, como máximo, 5 x 105, 1 x 106, 2 x 106, 3 x 106, 4, 106, 5 x 106, 6 x 106, 7 x 106, 8 x 106, 9 x 106, 1 x 107, 1,1 x 107, 1,2 x 107, 1,5 x 107, 1,6 x 107, 1,7 x 107, 1,8 x 107, 1,9 x 107, 2 x 107, 2,1 x 107, o 3 x 107 o más unidades de actividad de la molécula.
En algunas realizaciones, una dosis terapéuticamente eficaz es de al menos aproximadamente 10.000, 15.000, 20.000, 22.000, 24.000, 25.000, 30.000, 40.000, 50.000, 60.000, 70.000, 80.000, 90.000, 100.000, 125.000, 150.000, 200.000 o 500.000 unidades/kg de peso corporal. En algunas realizaciones, una dosis terapéuticamente eficaz es como máximo de aproximadamente 10.000, 15.000, 20.000, 22.000, 24.000, 25.000, 30.000, 40.000, 50.000, 60.000, 70.000, 80.000, 90.000, 100.000, 125.000, 150.000, 200.000 o 500.000 unidades/kg de peso corporal.
En algunas realizaciones, la actividad de la molécula administrada a un sujeto es de al menos 10.000, 11.000, 12.000, 13.000, 14,000, 20.000, 21.000, 22.000, 23.000, 24.000, 25.000, 26.000, 27.000, 28.000, 30.000, 32.000, 34.000, 35.000, 36.000, 37.000, 40.000, 45.000 o 50.000, o más U/mg de molécula. En algunas realizaciones, la actividad de la molécula administrada a un sujeto es como máximo de 10.000, 11.000, 12.000, 13.000, 14,000, 20.000, 21.000, 22.000, 23.000, 24.000, 25.000, 26.000, 27.000, 28.000, 30.000, 32.000, 34.000, 35.000, 36.000, 37.000, 40.000, 45.000 o 50.000, o más U/mg de molécula.
Mediciones farmacocinéticas y farmacodinámicas
Los datos farmacocinéticos y farmacodinámicos se pueden obtener mediante diversas técnicas experimentales. Los componentes apropiados del perfil farmacocinético y farmacodinámico que describen una determinada composición pueden variar debido a variaciones en el metabolismo del fármaco en los sujetos humanos. Los perfiles farmacocinéticos y farmacodinámicos pueden basarse en la determinación de los parámetros medios de un grupo de sujetos. El grupo de sujetos incluye cualquier número razonable de sujetos adecuados para determinar una media representativa, por ejemplo, 5 sujetos, 10 sujetos, 15 sujetos, 20 sujetos, 25 sujetos, 30 sujetos, 35 sujetos o más. La media se puede determinar calculando el promedio de las mediciones de todos los sujetos para cada parámetro medido. Se puede modular una dosis para lograr un perfil farmacocinético o farmacodinámico deseado, tal como un perfil sanguíneo deseado o eficaz, como se describe en el presente documento.
Los parámetros farmacocinéticos pueden ser cualquier parámetro adecuado para describir una molécula. Por ejemplo, la Cmáx puede ser, por ejemplo, de no menos de aproximadamente 25 ng/ml; no menos de aproximadamente 50 ng/ml; no menos de aproximadamente 75 ng/ml; no menos de aproximadamente 100 ng/ml; no menos de aproximadamente 200 ng/ml; no menos de aproximadamente 300 ng/ml; no menos de aproximadamente 400 ng/ml; no menos de aproximadamente 500 ng/ml; no menos de aproximadamente 600 ng/ml; no menos de aproximadamente 700 ng/ml; no menos de aproximadamente 800 ng/ml; no menos de aproximadamente 900 ng/ml; no menos de aproximadamente 1000 ng/ml; no menos de aproximadamente 1250 ng/ml; no menos de aproximadamente 1500 ng/ml; no menos de aproximadamente 1750 ng/ml; no menos de aproximadamente 2000 ng/ml; o cualquier otra Cmáx apropiada para describir un perfil farmacocinético de una molécula descrita en el presente documento.
El Tmáx de una molécula descrita en el presente documento puede ser, por ejemplo, de no más de aproximadamente 0,5 horas, no más de aproximadamente 1 horas, no más de aproximadamente 1,5 horas, no más de aproximadamente 2 horas, no más de aproximadamente 2,5 horas, no más de aproximadamente 3 horas, no más de aproximadamente 3,5 horas, no más de aproximadamente 4 horas, no más de aproximadamente 4,5 horas, no más de aproximadamente 5 horas, o cualquier otro Tmáx apropiado para describir un perfil farmacocinético de una molécula descrita en el presente documento.
La ABC(ü-inf) de una molécula descrita en el presente documento puede ser, por ejemplo, de no menos de aproximadamente 50 ng^h/ml, no menos de aproximadamente 100ng/h/ml, no menos de aproximadamente 150 ng/h/ml, no menos de aproximadamente 200 ng^h/ml, no menos de aproximadamente 250 ng/h/ml, no menos de aproximadamente 300 ng/h/ml, no menos de aproximadamente 350 ng/h/ml, no menos de aproximadamente 400 ng/h/ml, no menos de aproximadamente 450 ng/h/ml, no menos de aproximadamente 500 ng/h/ml, no menos de aproximadamente 600 ng/h/ml, no menos de aproximadamente 700 ng/h/ml, no menos de aproximadamente 800 ng/h/ml, no menos de aproximadamente 900 ng/h/ml, no menos de aproximadamente 1000 ng^h/ml, no menos de aproximadamente 1250 ng/h/ml, no menos de aproximadamente 1500 ng/h/ml, no menos de aproximadamente 1750 ng/h/ml, no menos de aproximadamente 2000 ng/h/ml, no menos de aproximadamente 2500 ng/h/ml, no menos de aproximadamente 3000 ng/h/ml, no menos de aproximadamente 3500 ng/h/ml, no menos de aproximadamente 4000 ng/h/ml, no menos de aproximadamente 5000 ng/h/ml, no menos de aproximadamente 6000 ng/h/ml, no menos de aproximadamente 7000 ng/h/ml, no menos de aproximadamente 8000 ng/h/ml, no menos de aproximadamente 9000 ng/h/ml, no menos de aproximadamente 10.000 ng/h/ml, o cualquier otro valor de ABC(0-¡nf) apropiado para
describir un perfil farmacocinético de una molécula descrita en el presente documento.
La concentración en plasma de una molécula descrita en el presente documento aproximadamente una hora después de la administración puede ser, por ejemplo, de no menos de aproximadamente 25 ng/ml, no menos de aproximadamente 50 ng/ml, no menos de aproximadamente 75 ng/ml, no menos de aproximadamente 100 ng/ml, no menos de aproximadamente 150 ng/ml, no menos de aproximadamente 200 ng/ml, no menos de aproximadamente 300 ng/ml, no menos de aproximadamente 400 ng/ml, no menos de aproximadamente 500 ng/ml, no menos de aproximadamente 600 ng/ml, no menos de aproximadamente 700 ng/ml, no menos de aproximadamente 800 ng/ml, no menos de aproximadamente 900 ng/ml, no menos de aproximadamente 1000 ng/ml, no menos de aproximadamente 1200 ng/ml, o cualquier otra concentración en plasma de una molécula descrita en el presente documento.
Los parámetros farmacodinámicos pueden ser cualquier parámetro adecuado para describir las composiciones farmacéuticas de la descripción. Por ejemplo, el perfil farmacodinámico puede presentar disminuciones en los factores asociados con la inflamación después de, por ejemplo, aproximadamente 2 horas, aproximadamente 4 horas, aproximadamente 8 horas, aproximadamente 12 horas o aproximadamente 24 horas.
Sales farmacéuticamente aceptables
La divulgación proporciona el uso de sales farmacéuticamente aceptables de cualquier molécula descrita en el presente documento. Las sales farmacéuticamente aceptables pueden incluir, por ejemplo, sales de adición de ácido y sales de adición de base. El ácido que se añade al compuesto para formar una sal de adición de ácido puede ser un ácido orgánico o un ácido inorgánico. Una base que se añade al compuesto para formar una sal de adición de base puede ser una base orgánica o una base inorgánica. En algunas realizaciones, una sal farmacéuticamente aceptable es una sal metálica. En algunas realizaciones, una sal farmacéuticamente aceptable es una sal de amonio.
Las sales metálicas pueden surgir de la adición de una base inorgánica a un compuesto de la invención. La base inorgánica consiste en un catión metálico emparejado con un contraión básico, tal como, por ejemplo, hidróxido, carbonato, bicarbonato o fosfato. El metal puede ser un metal alcalino, metal alcalinotérreo, metal de transición o metal del grupo principal. En algunas realizaciones, el metal es litio, sodio, potasio, cesio, cerio, magnesio, manganeso, hierro, calcio, estroncio, cobalto, titanio, aluminio, cobre, cadmio o cinc.
En algunas realizaciones, una sal de metal es una sal de litio, una sal de sodio, una sal de potasio, una sal de cesio, una sal de cerio, una sal de magnesio, una sal de manganeso, una sal de hierro, una sal de calcio, una sal de estroncio, una sal de cobalto, una sal de titanio, una sal de aluminio, una sal de cobre, una sal de cadmio o una sal de cinc, o cualquier combinación de las mismas.
Las sales de amonio pueden surgir de la adición de amoniaco o una amina orgánica a un compuesto de la invención. En algunas realizaciones, la amina orgánica es trietilamina, diisopropilamina, etanolamina, dietanolamina, trietanolamina, morfolina, W-metilmorfolina, piperidina, /V-metilpiperidina, W-etilpiperidina, dibencilamina, piperazina, piridina, pirrazol, pipirrazol, imidazol, pirazina o pipirazina, o cualquier combinación de las mismas.
En algunas realizaciones, una sal de amonio es una sal de trietilamina, una sal de diisopropilamina, una sal de etanolamina, una sal de dietanolamina, una sal de trietanolamina, una sal de morfolina, una sal de W-metilmorfolina, una sal de piperidina, una sal de W-metilpiperidina, una sal de W-etilpiperidina, una sal de dibencilamina, una sal de piperazina, una sal de piridina, una sal de pirrazol, una sal de pipirrazol, una sal de imidazol, una sal de pirazina o una sal de pipirazina, o cualquier combinación de las mismas.
Las sales de adición de ácido pueden surgir de la adición de un ácido a una molécula de la divulgación. En algunas realizaciones, el ácido es orgánico. En algunas realizaciones, el ácido es inorgánico. En algunas realizaciones, el ácido es ácido clorhídrico, ácido bromhídrico, ácido yodhídrico, ácido nítrico, ácido nitroso, ácido sulfúrico, ácido sulfuroso, un ácido fosfórico, ácido isonicotínico, ácido láctico, ácido salicílico, ácido tartárico, ácido ascórbico, ácido gentisínico, ácido glucónico, ácido glucarónico, ácido sacarínico, ácido fórmico, ácido benzoico, ácido glutámico, ácido pantoténico, ácido acético, ácido propiónico, ácido butírico, ácido fumárico, ácido succínico, ácido metanosulfónico, ácido etanosulfónico, ácido bencenosulfónico, ácido p-toluenosulfónico, ácido cítrico, ácido oxálico o ácido maleico, o cualquier combinación de los mismos.
En algunas realizaciones, la sal es una sal de clorhidrato, una sal de bromhidrato, una sal de yodhidrato, una sal de nitrato, una sal de nitrito, una sal de sulfato, una sal de sulfito, una sal de fosfato, sal de isonicotinato, una sal de lactato, una sal de salicilato, una sal de tartrato, una sal de ascorbato, una sal de gentisinato, una sal de gluconato, una sal de glucaronato, una sal de sacarato, una sal de formiato, una sal de benzoato, una sal de glutamato, una sal de pantotenato, una sal de acetato, una sal de propionato, una sal de butirato, una sal de fumarato, una sal succinato, una sal de metanosulfonato, una sal de etanosulfonato, una sal de bencenosulfonato, una sal de p-toluenosulfonato, una sal de citrato, una sal de oxalato o una sal de maleato, o cualquier combinación de las mismas.
Polipéptidos dirigidos a un sitio diseñados
Visión general
La divulgación describe métodos, composiciones, sistemas y/o kits para modificar polipéptidos dirigidos a un sitio (por ejemplo, Cas9, Csy4, Cas5, Cas6, Argonauta, etc.) y/o enzimas relacionadas. Las modificaciones pueden incluir cualquier modificación covalente o no covalente en los polipéptidos dirigidos a un sitio. En algunos casos, esto puede incluir modificaciones químicas en una o más regiones del polipéptido dirigido a un sitio. En algunos casos, las modificaciones pueden incluir sustituciones de aminoácidos conservativas o no conservativas del polipéptido dirigido a un sitio. En algunos casos, las modificaciones pueden incluir la adición, eliminación o sustitución de cualquier parte del polipéptido dirigido a un sitio con aminoácidos, péptidos o dominios que no se encuentran en el polipéptido nativo dirigido a un sitio. En algunos casos, uno o más dominios no nativos se pueden añadir, eliminar o sustituir en el polipéptido dirigido a un sitio. En algunos casos, el polipéptido dirigido a un sitio puede existir como una proteína de fusión.
En algunos casos, la presente divulgación proporciona el diseño a de polipéptidos dirigidos a un sitio para reconocer una secuencia de ácido nucleico diana deseada con especificidad y/o actividad enzimática deseadas. Las modificaciones en un polipéptido dirigido a un sitio se pueden realizar mediante el diseño de proteínas. El diseño de proteínas puede incluir la fusión de dominios funcionales a dicho polipéptido dirigido a un sitio diseñado que puede usarse para modificar el estado funcional del polipéptido dirigido a un sitio global o la secuencia de ácido nucleico diana real de un locus celular endógeno. El polipéptido dirigido a un sitio de la divulgación puede usarse para regular la expresión de genes endógenos, tanto a través de la activación como de la represión de la transcripción de genes endógenos.
Las fusiones de polipéptidos dirigidos al sitio también se pueden unir a otros dominios reguladores o funcionales, por ejemplo, nucleasas, transposasas o metilasas, para modificar secuencias cromosómicas endógenas. En algunos casos, el polipéptido dirigido a un sitio puede estar unido a al menos uno o más dominios reguladores, descritos en el presente documento. Los ejemplos no limitantes de dominios reguladores o funcionales incluyen dominios represores o activadores de factores de transcripción tales como KRAB y VP 16, dominios co-represores y co-activadores, metil transferasas de ADN, histona acetiltransferasas, histona desacetolasas y dominios de escisión de ADN tal como el dominio de escisión de la endonucleasa FokI.
En algunos casos, uno o más dominios específicos, regiones o elementos estructurales del polipéptido dirigido a un sitio pueden modificarse juntos. Pueden producirse modificaciones en el polipéptido dirigido a un sitio, pero no se limitan a los elementos del polipéptido dirigido a un sitio, tales como regiones que reconocen o se unen al motivo adyacente al espaciador (pA m ), y/o regiones que se unen a o reconocen el ácido nucleico dirigido a ácido nucleico. Dichos elementos de unión o reconocimiento pueden incluir una hélice de puente conservada, región altamente básica, región de N-terminal, región C-terminal, motivos RuvC (por ejemplo, dominios nucleasa de tipo RuvC y/o RuvC) y uno o más dominios nucleasa, tales como HNH y/o dominios de tipo HNH. Se pueden realizar modificaciones en dominios adicionales, elementos estructurales, secuencia o aminoácidos dentro del polipéptido dirigido a un sitio.
Se pueden realizar modificaciones en una o más regiones del polipéptido dirigido a un sitio para alterar diversas propiedades del polipéptido dirigido a un sitio. En algunos casos, las modificaciones pueden alterar el reconocimiento de unión para ciertas secuencias diana de ácido nucleico. Esto puede incluir, pero sin limitación, aumentar la afinidad y/o especificidad de unión a ciertas secuencias o preferentemente la dirección de ciertas secuencias de ácido nucleico/elementos de reconocimiento. En algunos casos, se pueden usar modificaciones para alterar la función de la nucleasa nativa. En algunos casos, las modificaciones realizadas en el polipéptido dirigido a un sitio pueden alterar la especificidad hacia PAM, la especificidad de ARNcrtra, la especificidad de ARNcr o la especificidad para elementos de ácido nucleico adicionales, tales como un ácido nucleico dirigido a ácido nucleico.
En el presente documento, también se describen composiciones y métodos que incluyen proteínas de fusión que comprenden un polipéptido dirigido a un sitio (por ejemplo, Cas9) y uno o más dominios o regiones diseñados para la edición genómica (por ejemplo, escisión de genes; alteración de genes, por ejemplo, mediante escisión seguida de inserción (inserción física o inserción mediante reparación dirigida por homología) de una secuencia exógena y/o escisión seguida de NHEJ; inactivación parcial o total de uno o más genes; generación de alelos con estados funcionales alterados de genes endógenos, inserción de elementos reguladores; etc.) y alteraciones del genoma que se portan a la línea germinal. También se desvelan métodos de fabricación y uso de estas composiciones (es decir, reactivos), por ejemplo, para editar (es decir, alterar) uno o más genes de una célula diana. Así pues, los métodos y las composiciones descritos en el presente documento proporcionan métodos altamente eficaces para la alteración genética dirigida (por ejemplo, inserción) y/o desactivación (parcial o total ) de uno o más genes y/o para la mutación aleatoria de la secuencia de cualquier alelo diana y, por tanto, permiten la generación de modelos animales de enfermedades humanas. Un experto en la materia reconocerá que, aunque la expresión "diseño del genoma" o "edición genómica" se suele usar para describir los métodos del presente documento, los métodos y las composiciones descritos en el presente documento también pueden usarse para alterar cualquier ácido nucleico diana que puede no estar, estrictamente hablando, en el genoma de una célula (por ejemplo, se puede usar en un ácido nucleico sintético, un plásmido, un vector, un ácido nucleico vírico, un ácido nucleico recombinante, etc.).
Los métodos y las composiciones descritos en el presente documento permiten nuevas aplicaciones terapéuticas, (por ejemplo, prevención y/o tratamiento de: enfermedades genéticas, cáncer, Infecciones fúngicas, protozoarias, bacterianas y víricas, isquemia, enfermedad vascular, artritis, trastornos inmunológicos, etc.), diagnósticos novedosos (por ejemplo, predicción y/o diagnóstico de una afección), así como proporcionar herramientas de investigación (por ejemplo kits, ensayos de genómica funcional, y generación de estirpes celulares diseñadas y modelos animales diseñados para investigación y detección de fármacos), y medios para desarrollar plantas con fenotipos alterados, incluyendo, pero sin limitación, aumento de la resistencia a enfermedades y alteración de las características de maduración de la fruta, composición de azúcar y aceite, rendimiento y color. Los métodos y las composiciones descritos en el presente documento permiten nuevos estudios epigenéticos.
Modificaciones y diseño de proteínas
Alteraciones de aminoácidos
Los polipéptidos dirigidos a un sitio, como se desvela en el presente documento, pueden modificarse. La modificación puede comprender modificaciones en un aminoácido del polipéptido dirigido a un sitio desvelado en el presente documento. Las modificaciones pueden alterar la secuencia de aminoácidos primaria y/o la estructura de aminoácidos secundaria, terciaria y cuaternaria. En algunos casos, algunas secuencias de aminoácidos de un polipéptido dirigido a un sitio pueden variarse sin un efecto significativo sobre la estructura ni la función de la proteína. El tipo de mutación puede ser completamente irrelevante si la alteración ocurre en algunas regiones (por ejemplo, una región no fundamental) de la proteína. En algunos casos, dependiendo de la ubicación del reemplazo, la mutación puede no tener un efecto importante en las propiedades biológicas de la variante resultante. Por ejemplo, las propiedades y funciones de las variantes de Cas9 pueden ser del mismo tipo que Cas9 de tipo silvestre. En algunos casos, la mutación puede tener un impacto crítico en la estructura y/o función del polipéptido dirigido a un sitio.
La ubicación de dónde modificar un polipéptido dirigido a un sitio (por ejemplo, una variante de Cas9) puede determinarse usando la alineación de secuencias y/o estructuras. La alineación de secuencias puede identificar regiones de un polipéptido que sean similares y/o no similares (por ejemplo, conservadas, no conservadas, hidrófobas, hidrófilas, etc.). En algunos casos, una región de la secuencia de interés que es similar a otras secuencias es adecuada para la modificación. En algunos casos, una región de la secuencia de interés que es diferente de otras secuencias es adecuada para la modificación. Por ejemplo, la alineación de secuencias se puede realizar mediante búsqueda en bases de datos, alineación por pares, alineación de múltiples secuencias, análisis genómico, búsqueda de motivos, evaluación comparativa y/o programas tales como BLAST, CS-BLAST, HHPRED, psi-BLAST, LALIGN, PyMOL y SEQALN. La alineación estructural puede realizarse mediante programas tales como Dali, PHYRE, Chimera, COOT, O y PyMOL. La alineación se puede realizar mediante búsqueda en bases de datos, alineación por pares, alineación de múltiples secuencias, análisis genómico, búsqueda de motivos o evaluación comparativa, o cualquier combinación de los mismos.
Un polipéptido dirigido a un sitio puede modificarse para aumentar la especificidad de unión a un ácido nucleico dirigido a ácido nucleico y/o un ácido nucleico diana. Un polipéptido dirigido a un sitio puede modificarse para aumentar la unión a regiones específicas de un ácido nucleico dirigido a ácido nucleico (por ejemplo, la extensión del espaciador, el espaciador, la repetición CRISPR mínima, la secuencia mínima de ARNcrtra, la secuencia de ARNcrtra de 3', la extensión de ARNcrtra) y/o un ácido nucleico diana.
En algunos casos, la modificación puede comprender una modificación conservativa. Un cambio conservativo de aminoácidos puede implicar la sustitución de uno de una familia de aminoácidos que están relacionados en sus cadenas laterales (por ejemplo, cisteína/serina).
En algunos casos, los cambios de aminoácidos en la proteína Cas9 descritos en el presente documento son cambios de aminoácidos no conservativos (es decir, sustituciones de aminoácidos con carga o sin carga similares). Un cambio de aminoácido no conservativo puede implicar la sustitución de uno de una familia de aminoácidos que pueden no estar relacionados en sus cadenas laterales o una sustitución que altere la actividad biológica del polipéptido dirigido a un sitio.
La mutación de los aminoácidos también puede cambiar la selectividad de la unión a un ácido nucleico diana. La mutación puede dar lugar a un cambio que puede comprender un cambio en la constante de disociación (Kd) de la unión entre un polipéptido mutado dirigido a un sitio y un ácido nucleico diana. El cambio en la Kd de unión entre un polipéptido mutado dirigido a un sitio y un ácido nucleico diana puede ser más de 1000 veces, más de 500 veces, más de 100 veces, más de 50 veces, más de 25 veces, más de 10 veces, más de 5 veces, más de 4 veces, más de 3 veces, más de 2 veces superior o inferior a la Kd de la unión entre un polipéptido no mutado dirigido a un sitio y una ácido nucleico diana. El cambio en la Kd de la unión entre un polipéptido mutado dirigido a un sitio y un ácido nucleico diana puede ser menos de 1000 veces, menos de 500 veces, menos de 100 veces, menos de 50 veces, menos de 25 veces, menos de 10 veces, menos de 5 veces, menos de 4 veces, menos de 3 veces, menos de 2 veces superior o inferior a la Kd de la unión entre un polipéptido no mutado dirigido a un sitio y un ácido nucleico diana.
La mutación puede dar lugar a un cambio que puede comprender un cambio en la Kd de unión entre un polipéptido mutado dirigido a un sitio y un motivo PAM. El cambio en la Kd de unión entre un polipéptido mutado dirigido a un sitio y un motivo PAM puede ser más de 1000 veces, más de 500 veces, más de 100 veces, más de 50 veces, más de 25 veces, más de 10 veces, más de 5 veces, más de 4 veces, más de 3 veces, más de 2 veces superior o inferior a la Kd de unión entre un polipéptido no mutado dirigido a un sitio y un motivo PAM. El cambio en la Kd de la unión entre un polipéptido mutado dirigido a un sitio y un motivo PAM puede ser menos de 1000 veces, menos de 500 veces, menos de 100 veces, menos de 50 veces, menos de 25 veces, menos de 10 veces, menos de 5 veces, menos de 4 veces, menos de 3 veces, menos de 2 veces superior o inferior a la Kd de la unión entre un polipéptido no mutado dirigido a un sitio y un motivo PAM.
La mutación puede dar lugar a un cambio que puede comprender un cambio en la Kd de unión entre un polipéptido mutado dirigido a un sitio y un ácido nucleico dirigido a ácido nucleico. El cambio en la Kd de unión entre un polipéptido mutado dirigido a un sitio y un ácido nucleico dirigido a ácido nucleico puede ser más de 1000 veces, más de 500 veces, más de 100 veces, más de 50 veces, más de 25 veces, más de 10 veces, más de 5 veces, más de 4 veces, más de 3 veces, más de 2 veces superior o inferior a la Kd de unión entre un polipéptido no mutado dirigido a un sitio y un ácido nucleico dirigido a ácido nucleico. El cambio en la Kd de la unión entre un polipéptido mutado dirigido a un sitio y un ácido nucleico dirigido a ácido nucleico puede ser menos de 1000 veces, menos de 500 veces, menos de 100 veces, menos de 50 veces, menos de 25 veces, menos de 10 veces, menos de 5 veces, menos de 4 veces, menos de 3 veces, menos de 2 veces superior o inferior a la Kd de la unión entre un polipéptido no mutado dirigido a un sitio y un ácido nucleico dirigido a ácido nucleico.
La mutación de un polipéptido dirigido a un sitio también puede cambiar la cinética de la acción enzimática del polipéptido dirigido a un sitio. La mutación puede dar lugar a un cambio que puede comprender un cambio en la Km del polipéptido mutado dirigido a un sitio. El cambio en la Km del polipéptido mutado dirigido a un sitio puede ser más de 1000 veces, más de 500 veces, más de 100 veces, más de 50 veces, más de 25 veces, más de 10 veces, más de 5 veces, más de 4 veces, más de 3 veces, más de 2 veces superior o inferior a la Km de un polipéptido no mutado dirigido a un sitio. El cambio en la Km de un polipéptido mutado dirigido a un sitio puede ser menos de 1000 veces, menos de 500 veces, menos de 100 veces, menos de 50 veces, menos de 25 veces, menos de 10 veces, menos de 5 veces, menos de 4 veces, menos de 3 veces, menos de 2 veces superior o inferior a la Km de un polipéptido no mutado dirigido a un sitio.
La mutación de un polipéptido dirigido a un sitio puede producir un cambio que puede comprender un cambio en el recambio del polipéptido dirigido a un sitio. El cambio en el recambio del polipéptido mutado dirigido a un sitio puede ser más de 1000 veces, más de 500 veces, más de 100 veces, más de 50 veces, más de 25 veces, más de 10 veces, más de 5 veces, más de 4 veces, más de 3 veces, más de 2 veces superior o inferior al recambio de un polipéptido no mutado dirigido a un sitio. El cambio en el recambio de un polipéptido mutado dirigido a un sitio puede ser menos de 1000 veces, menos de 500 veces, menos de 100 veces, menos de 50 veces, menos de 25 veces, menos de 10 veces, menos de 5 veces, menos de 4 veces, menos de 3 veces, menos de 2 veces superior o inferior al recambio de un polipéptido no mutado dirigido a un sitio.
La mutación puede producir un cambio que puede comprender un cambio en AG de la acción enzimática del polipéptido dirigido a un sitio. El cambio en AG del polipéptido mutado dirigido a un sitio puede ser más de 1000 veces, más de 500 veces, más de 100 veces, más de 50 veces, más de 25 veces, más de 10 veces, más de 5 veces, más de 4 veces, más de 3 veces, más de 2 veces superior o inferior a AG de un polipéptido no mutado dirigido a un sitio. El cambio en el recambio de un polipéptido mutado dirigido a un sitio puede ser menos de 1000 veces, menos de 500 veces, menos de 100 veces, menos de 50 veces, menos de 25 veces, menos de 10 veces, menos de 5 veces, menos de 4 veces, menos de 3 veces, menos de 2 veces superior o inferior a AG de un polipéptido no mutado dirigido a un sitio.
La mutación puede producir un cambio que puede comprender un cambio en Vmáx de la acción enzimática del polipéptido dirigido a un sitio. El cambio en Vmáx del polipéptido mutado dirigido a un sitio puede ser más de 1000 veces, más de 500 veces, más de 100 veces, más de 50 veces, más de 25 veces, más de 10 veces, más de 5 veces, más de 4 veces, más de 3 veces, más de 2 veces superior o inferior a Vmáx de un polipéptido no mutado dirigido a un sitio. El cambio en el recambio de un polipéptido mutado dirigido a un sitio puede ser menos de 1000 veces, menos de 500 veces, menos de 100 veces, menos de 50 veces, menos de 25 veces, menos de 10 veces, menos de 5 veces, menos de 4 veces, menos de 3 veces, menos de 2 veces superior o inferior a Vmáx de un polipéptido no mutado dirigido a un sitio.
La mutación puede producir un cambio que puede comprender un cambio en cualquier parámetro cinético del polipéptido dirigido a un sitio. La mutación puede producir un cambio que puede comprender un cambio en cualquier parámetro termodinámico del polipéptido dirigido a un sitio. La mutación puede producir un cambio que puede comprender un cambio en la carga superficial, el área superficial enterrada y/o la cinética de plegamiento del polipéptido dirigido a un sitio y/o la acción enzimática del polipéptido dirigido a un sitio.
Los aminoácidos del polipéptido dirigido a un sitio de la presente divulgación que son esenciales para la función pueden identificarse mediante métodos tales como mutagénesis dirigida, mutagénesis de barrido de alanina, análisis de
estructura de proteínas, resonancia magnética nuclear, mareaje de fotoafinidad y tomografía de electrones, cribado de alto rendimiento, ELISA, ensayos bioquímicos, ensayos de unión, ensayos de escisión (por ejemplo, ensayo Surveyor), ensayos de indicadores y similares.
Otras alteraciones de aminoácidos también pueden incluir aminoácidos con formas glicosiladas, conjugados agregativos con otras moléculas y conjugados covalentes con fracciones químicas no relacionadas (por ejemplo, moléculas pegiladas). Las variantes covalentes pueden prepararse uniendo funcionalidades a grupos que se encuentran en la cadena de aminoácidos o en el resto N o C-terminal. En algunos casos, los polipéptidos mutados dirigidos a un sitio también pueden incluir variantes alélicas y variantes de especies.
Se pueden diseñar truncamientos de regiones que no afecten a la actividad funcional de las proteínas Cas9. Se pueden diseñar truncamientos de regiones que afecten a la actividad funcional de la proteína Cas9. Un truncamiento puede comprender un truncamiento de menos de 5, menos de 10, menos de 15, menos de 20, menos de 25, menos de 30, menos de 35, menos de 40, menos de 45, menos de 50, menos de 60, menos de 70, menos de 80, menos de 90, menos de 100 o más aminoácidos. Un truncamiento puede comprender un truncamiento de más de 5, más de 10, más de 15, más de 20, más de 25, más de 30, más de 35, más de 40, más de 45, más de 50, más de 60, más de 70, más de 80, más de 90, más de 100 o más aminoácidos. Un truncamiento puede comprender un truncamiento del aproximadamente 5 %, 10 %, 15 %, 20 %, 25 %, 30 %, 35 %, 40 %, 45 %, 50 %, 55 %, 60 %, 65 %, 70 %, 75 %, 80 %, 85 %, 90 %, 95 % o 100 % del polipéptido dirigido a un sitio.
Se pueden diseñar eliminaciones de regiones que no afecten a la actividad funcional de las proteínas Cas9. Se pueden diseñar eliminaciones de regiones que afecten a la actividad funcional de la proteína Cas9. Una eliminación puede comprender una eliminación de menos de 5, menos de 10, menos de 15, menos de 20, menos de 25, menos de 30, menos de 35, menos de 40, menos de 45, menos de 50, menos de 60, menos de 70, menos de 80, menos de 90, menos de 100 o más aminoácidos. Una eliminación puede comprender un eliminación de más de 5, más de 10, más de 15, más de 20, más de 25, más de 30, más de 35, más de 40, más de 45, más de 50, más de 60, más de 70, más de 80, más de 90, más de 100 o más aminoácidos. Una eliminación puede comprender una eliminación del aproximadamente 5 %, 10 %, 15 %, 20 %, 25 %, 30 %, 35 %, 40 %, 45 %, 50 %, 55 %, 60 %, 65 %, 70 %, 75 %, 80 %, 85 %, 90 %, 95 % o 100 % del polipéptido dirigido a un sitio. Una eliminación puede ocurrir en el extremo N, el extremo C o en cualquier región de la cadena polipeptídica.
Cribados
La divulgación proporciona métodos de diseño de un polipéptido dirigido a un sitio. Se pueden usar cribados para diseñar un polipéptido dirigido a un sitio. Por ejemplo, se puede configurar un cribado para detectar el efecto de las mutaciones en una región del polipéptido dirigido a un sitio. Por ejemplo, se puede configurar un cribado para probar modificaciones del parche altamente básico en la afinidad por la estructura de ARN (por ejemplo, la estructura del ácido nucleico dirigida a ácido nucleico) o la capacidad de procesamiento (por ejemplo, la escisión de ácido nucleico diana). Los métodos de cribado ilustrativos pueden incluir, pero sin limitación, métodos de clasificación celular, presentación en ARNm, presentación en fagos y evolución dirigida.
Fusiones
En algunos casos, el polipéptido dirigido a un sitio se modifica de modo que comprenda una secuencia no nativa (es decir, el polipéptido tenga una modificación que lo altera con respecto al alelo o de la secuencia de la que se deriva) (por ejemplo, el polipéptido puede denominarse fusión). La secuencia no nativa también puede incluir una o más proteínas adicionales, dominios de proteínas, subdominios o polipéptidos. Por ejemplo, Cas9 puede fusionarse con cualquier proteína y/o dominio de unión a ácido nucleico normativo adicional adecuado, incluyendo, pero sin limitación, dominios de factor de transcripción, dominios nucleasa, dominios de polimerización de ácido nucleico. La secuencia no nativa puede comprender una secuencia de Cas9 y/o un homólogo de Cas9.
La secuencia no nativa puede conferir nuevas funciones a la proteína de fusión. Estas funciones pueden incluir, por ejemplo, escisión del a Dn , metilación del ADN, daño del ADN, reparación del ADN, modificación de un polipéptido diana asociado con el ADN diana (por ejemplo, una histona, una proteína de unión al ADN, etc.), lo que lleva a, por ejemplo, la metilación de histonas, acetilación de histonas, ubiquitinación de histonas y similares. Otras funciones conferidas por una proteína de fusión pueden incluir actividad de metiltransferasa, actividad de desmetilasa, actividad de desaminación, actividad de dismutasa, actividad de alquilación, actividad de despurinación, actividad de oxidación, actividad de formación de dímeros de pirimidina, actividad integrasa, actividad de transposasa, actividad de recombinasa, actividad polimerasa, actividad de ligasa, actividad de helicasa, actividad de fotoliasa o actividad de glucosilasa, actividad de acetiltransferasa, actividad de desacetilasa, actividad de quinasa, actividad fosfatasa, actividad de ubiquitina ligasa, actividad desubiquitinante, actividad de adenilación, actividad de desadenilación, actividad de SUMOilación, actividad deSUMOilación, actividad de ribosilación, actividad de desribosilación, actividad de miristoilación, actividad de remodelación, actividad de proteasa, actividad de oxidorreductasa, actividad de transferasa, actividad de hidrolasa, actividad de liasa, actividad de isomerasa, actividad de sintasa, actividad de sintetasa y actividad de desmiristoilación, o cualquier combinación de las mismas.
Modificaciones en la hélice puente
En algunos casos, se puede modificar la región de la hélice puente de Cas9 (por ejemplo, para alterar la especificidad hacia PAM). En algunos casos, la hélice puente puede compartir homología con la hélice puente identificada en la proteína Cas9 de S.pyogenes (restos 551-566). En algunos casos, la hélice puente puede compartir al menos un 5 %, 10 %, 15 %, 20 %, 25 %, 30 %, 35 %, 40 %, 45 %, 50 %, 55 %, 60 %, 65 %, 70 %, 75 %, 80 %, 85 %, 90 %, 95 %, 98 %, 99 % o 100 % de homología con los restos 551-556 de la hélice puente de Cas9 de S. pyogenes. En algunos casos, la hélice puente puede compartir, como máximo, un 5 %, 10 %, 15 %, 20 %, 25 %, 30 %, 35 %, 40 %, 45 %, 50 %, 55 %, 60 %, 65 %, 70 %, 75 %, 80 %, 85 %, 90 %, 95 %, 98 %, 99 % o 100 % de homología con los restos 551 556 de la hélice puente de Cas9 de S. pyogenes.
En algunos casos, las modificaciones en la hélice puente pueden incluir, pero sin limitación, modificaciones de aminoácidos individuales, como se describe en el presente documento. En algunos casos, la modificación de la hélice puente puede incluir, pero sin limitación, inserciones, eliminaciones o sustituciones de aminoácidos o polipéptidos individuales, tales como otros elementos proteicos (por ejemplo, dominios, motivos estructurales, proteínas).
Las modificaciones pueden incluir modificaciones de al menos 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20 o más aminoácidos de la hélice puente. Las modificaciones pueden incluir modificaciones, como máximo, en 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20 o más aminoácidos de la hélice puente. Las modificaciones también pueden incluir al menos un 5 %, 10 %, 15 %, 20 %, 25 %, 30 %, 35 %, 40 %, 45 %, 50 %, 55 %, 60 %, 65 %, 70 %, 75 %, 80 %, 85 %, 90 %, 95 %, 98 %, 99 % o 100 % de la hélice puente. Las modificaciones también pueden incluir, como máximo, un 5 %, 10 %, 15 %, 20 %, 25 %, 30 %, 35 %, 40 %, 45 %, 50 %, 55 %, 60 %, 65 %, 70 %, 75 %, 80 %, 85 %, 90 %, 95 %, 98 %, 99 % o 100 % de la hélice puente.
En algunos casos, las modificaciones en las secuencias de la hélice puente del polipéptido dirigido a un sitio pueden incluir determinados motivos estructurales del polipéptido, incluyendo, aunque sin limitación, la hélice alfa, cadena beta, lámina beta, hélice 310, hélice pi, motivo de polipropolina I, motivo de polipropolina II, motivo de poliprolina III, vuelta beta, alfa-vuelta-alfa, o acodamientos o bisagras de hélice. Por ejemplo, las sustituciones en la hélice puente del polipéptido dirigido a un sitio pueden incluir la sustitución o adición con uno o más restos de aminoácidos de prolina. La inserción de restos de prolina puede introducir acodamientos en la hélice puente que pueden alterar la especificidad de unión de la hélice puente por el PAM. En otro ejemplo, la sustitución o adición puede incluir uno o más restos de aminoácidos de glicina. La inserción o sustitución de restos de glicina puede introducir una mayor flexibilidad en la hélice puente o "bisagras" que también pueden alterar la especificidad de unión de la hélice puente por el PAM. La alteración de la especificidad de unión puede o no afectar a la actividad enzimática de la proteína Cas9.
En algunos casos, las modificaciones en las secuencias de la hélice puente del polipéptido dirigido a un sitio pueden incluir la eliminación de al menos un 1 %, 5 %, 10 %, 15 %, 20 %, 25 %, 30 %, 35 %, 40 %, 45 %, 50 %, 55 %, 60 %, 65%, 70%, 75%, 80%, 85%, 90%, 95%, 98%, 99% o 100% de la hélice puente. En algunos casos, las modificaciones en las secuencias de la hélice puente del polipéptido dirigido a un sitio pueden incluir la eliminación de, como máximo, un 1 %, 5 %, 10 %, 15 %, 20 %, 25 %, 30 %, 35 %, 40 %, 45 %, 50 %, 55 %, 60 %, 65 %, 70 %, 75 %, 80 %, 85 %, 90 %, 95 %, 98 %, 99 % o 100 % de la hélice puente.
En algunos casos, las modificaciones en las secuencias de la hélice puente del polipéptido dirigido a un sitio pueden incluir la adición o sustitución de al menos un 1 %, 5 %, 10 %, 15 %, 20 %, 25 %, 30 %, 35 %, 40 %, 45 %, 50 %, 55 %, 60 %, 65 %, 70 %, 75 %, 80 %, 85 %, 90 %, 95 %, 98 %, 99 % o 100 % de una hélice puente del polipéptido dirigido a un sitio homóloga. En algunos casos, las modificaciones en las secuencias de la hélice puente del polipéptido dirigido a un sitio pueden incluir la adición o sustitución de, como máximo, un 1 %, 5 %, 10 %, 15 %, 20 %, 25 %, 30 %, 35 %, 40 %, 45 %, 50 %, 55 %, 60 %, 65 %, 70 %, 75 %, 80 %, 85 %, 90 %, 95 %, 98 %, 99 % o 100 % de una hélice puente del polipéptido dirigido a un sitio homóloga.
Por ejemplo, se pueden derivar hélices puente de Cas9 no nativas de cualquier organismo adecuado. En algunos casos, la proteína Cas9 y la hélice puente pueden derivarse de organismos procariotas, incluyendo, pero sin limitación, arqueas, bacterias, protistas (por ejemplo,, E. coli, S. pyogenes, S. thermophilus, P.furiosus, etc.).
Por ejemplo, la hélice puente de la enzima Cas9 de S. pyogenes puede sustituirse o insertarse con la hélice puente, o fragmento de la misma, derivada de otra enzima Cas9 de una especie diferente.
En algunos casos, un polipéptido dirigido a un sitio comprende una secuencia de aminoácidos que comprende al menos un 15 % de identidad de aminoácidos con un Cas9 de S. pyogenes, dos dominios de escisión de ácido nucleico (es decir, un dominio HNH y un dominio RuvC) y una hélice puente modificada.
Modificaciones del parche altamente básico
La unión y especificidad hacia PAM también pueden verse afectadas por regiones adicionales dentro de la proteína Cas9. En algunos casos, un parche altamente básico o una región altamente básica, que comprende restos de aminoácidos básicos adyacentes a un sitio de unión a PAM, también puede modificarse para alterar la especificidad
hacia PAM. En algunos casos, el parche o la región altamente básico puede compartir homología con el parche altamente básico identificado en la Cas9 de S. pyogenes contenida dentro de la región N-terminal, o los restos de aminoácidos 1-270 del Cas9 de S. pyogenes. En algunos casos, el parche altamente básico puede compartir al menos un 5 %, 10 %, 15 %, 20 %, 25 %, 30 %, 35 %, 40 %, 45 %, 50 %, 55 %, 60 %, 65 %, 70 %, 75 %, 80 %, 85 %, 90 %, 95 %, 98 %, 99 % o 100 % de homología con el parche altamente básico de Cas9 de S. pyogenes. En algunos casos, el parche altamente básico puede compartir, como máximo, un 5 %, 10 %, 15 %, 20 %, 25 %, 30 %, 35 %, 40 %, 45 %, 50 %, 55 %, 60 %, 65 %, 70 %, 75 %, 80 %, 85 %, 90 %, 95 %, 98 %, 99 % o 100 % de homología con el parche altamente básico de Cas9 de S. pyogenes.
En algunos casos, las modificaciones en el parche altamente básico pueden incluir, pero sin limitación, modificaciones de aminoácidos individuales, como se describe en el presente documento. En algunos casos, la modificación en el parche altamente básico puede incluir, pero sin limitación, inserciones, eliminaciones o sustituciones de aminoácidos o polipéptidos individuales, tales como otros elementos proteicos (por ejemplo, dominios, motivos estructurales, proteínas).
Las modificaciones pueden incluir modificaciones de al menos 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37,38, 39, 40, 21, 42, 43, 44, 45, 46, 47, 48, 49, 50 o más aminoácidos del parche altamente básico. Las modificaciones pueden incluir modificaciones de, como máximo, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 21, 42, 43, 44, 45, 46, 47, 48, 49, 50 o más aminoácidos del parche altamente básico. Las modificaciones también pueden incluir al menos un 5 %, 10 %, 15 %, 20 %, 25 %, 30 %, 35 %, 40 %, 45 %, 50 %, 55 %, 60 %, 65 %, 70 %, 75 %, 80 %, 85 %, 90 %, 95 %, 98 %, 99 % o 100 % del parche altamente básico. Las modificaciones también pueden incluir, como máximo, un 5%, 10%, 15%, 20%, 25%, 30%, 35%, 40%, 45%, 50 %, 55 %, 60 %, 65 %, 70 %, 75 %, 80 %, 85 %, 90 %, 95 %, 98 %, 99 % o 100 % del parche altamente básico.
En algunos casos, las modificaciones de la secuencia del parche altamente básico del polipéptido dirigido a un sitio pueden incluir determinados motivos estructurales del polipéptido, incluyendo, aunque sin limitación, la hélice alfa, cadena beta, lámina beta, hélice 310, hélice pi, motivo de polipropolina I, motivo de polipropolina II, motivo de poliprolina III, vuelta beta, alfa-vuelta-alfa, o acodamientos o bisagras de hélice.
Las sustituciones del parche altamente básico del polipéptido dirigido a un sitio pueden incluir la sustitución o adición con uno o más restos de aminoácidos ácidos. La inserción de restos ácidos puede disminuir la carga básica general de esta área del polipéptido dirigido a un sitio y puede alterar la especificidad de unión del parche altamente básico hacia el PAM. En otro ejemplo, la sustitución o adición puede incluir uno o más restos de aminoácidos básicos. La inserción o sustitución de restos básicos puede aumentar el área de carga o la fuerza iónica de interacción entre el polipéptido y el ácido nucleico, y también puede alterar la especificidad de unión del parche altamente básico hacia el PAM. La alteración de la especificidad de unión puede o no afectar a la actividad enzimática del polipéptido dirigido a un sitio.
En algunos casos, las modificaciones de las secuencias de parche altamente básico del polipéptido dirigido a un sitio pueden incluir la eliminación de al menos un 1 %, 5 %, 10 %, 15 %, 20 %, 25 %, 30 %, 35 %, 40 %, 45 %, 50 %, 55 %, 60 %, 65 %, 70 %, 75 %, 80 %, 85 %, 90 %, 95 %, 98 %, 99 % o 100 % del parche altamente básico. En algunos casos, las modificaciones de las secuencias de parches altamente básicos del polipéptido dirigido a un sitio pueden incluir la eliminación de, como máximo, un 1 %, 5 %, 10 %, 15 %, 20 %, 25 %, 30 %, 35 %, 40 %, 45 %, 50 %, 55 %, 60 %, 65 %, 70 %, 75 %, 80 %, 85 %, 90 %, 95 %, 98 %, 99 % o 100 % del parche altamente básico.
En algunos casos, las modificaciones de las secuencias de parches altamente básicos del polipéptido dirigido a un sitio pueden incluir la adición o sustitución de al menos un 1 %, 5 %, 10 %, 15 %, 20 %, 25 %, 30 %, 35 %, 40 %, 45 %, 50 %, 55 %, 60 %, 65 %, 70 %, 75 %, 80 %, 85 %, 90 %, 95 %, 98 %, 99 % o 100 % de un parche altamente básico de Cas9 homólogo. En algunos casos, las modificaciones de las secuencias de parches altamente básicos del polipéptido dirigido a un sitio pueden incluir la adición o sustitución de, como máximo, un 1 %, 5 %, 10 %, 15 %, 20 %, 25 %, 30 %, 35 %, 40 %, 45 %, 50 %, 55 %, 60 %, 65 %, 70 %, 75 %, 80 %, 85 %, 90 %, 95 %, 98 %, 99 % o 100 % de un parche altamente básico de Cas9 homólogo.
Las secuencias de parches altamente básicos de Cas9 homólogos pueden derivarse de cualquier organismo adecuado. En algunos casos, la proteína Cas9 puede derivarse de organismos procariotas tales como arqueas, bacterias, protistas (por ejemplo,, E. coli, S. pyogenes, S. thermophilus, P.furiosus, etc.).Por ejemplo, el parche altamente básico de la enzima Cas9 de S. pyogenes puede ser sustituido con o modificado mediante la inserción del parche altamente básico, o fragmento del mismo, derivado de una Cas9 de otra especie.
En algunos casos, un polipéptido dirigido a un sitio comprende una secuencia de aminoácidos que comprende al menos un 15 % de identidad de aminoácidos con un Cas9 de S. pyogenes, dos dominios de escisión de ácido nucleico (es decir, un dominio HNH y un dominio RuvC) y un parche altamente básico modificado.
Modificaciones del dominio HNH
En algunos casos, el dominio HNH de un polipéptido dirigido a un sitio puede modificarse para alterar la especificidad hacia PAM. En algunos casos, el dominio HNH puede compartir homología con el dominio HNH identificado en el dominio C-terminal de la proteína Cas9 de S. pyogenes (restos 860-1100). En algunos casos, el dominio HNH puede compartir al menos un 5 %, 10 %, 15 %, 20 %, 25 %, 30 %, 35 %, 40 %, 45 %, 50 %, 55 %, 60 %, 65 %, 70 %, 75 %, 80 %, 85 %, 90 %, 95 %, 98 %, 99 % o 100 % de homología con los restos 551-556 del dominio NHN de Cas9 de S. pyogenes. En algunos casos, el dominio HNH puede compartir, como máximo, un 5 %, 10 %, 15 %, 20 %, 25 %, 30 %, 35 %, 40 %, 45 %, 50 %, 55 %, 60 %, 65 %, 70 %, 75 %, 80 %, 85 %, 90 %, 95 %, 98 %, 99 % o 100 % de homología con los restos 860-1100 del dominio HNH de Cas9 de S. pyogenes.
En algunos casos, las modificaciones en el dominio HNH pueden incluir, pero sin limitación, modificaciones de aminoácidos individuales, como se describe en el presente documento. En algunos casos, la modificación en el dominio HNH puede incluir, pero sin limitación, inserciones, eliminaciones o sustituciones de aminoácidos o polipéptidos individuales, tales como otros elementos proteicos (por ejemplo, dominios, motivos estructurales, proteínas).
Las modificaciones pueden incluir modificaciones de al menos 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20 o más aminoácidos del dominio HNH. Las modificaciones pueden incluir modificaciones, como máximo, en 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20 o más aminoácidos del dominio HNH. Las modificaciones también pueden incluir al menos un 5 %, 10 %, 15 %, 20 %, 25 %, 30 %, 35 %, 40 %, 45 %, 50 %, 55 %, 60 %, 65 %, 70 %, 75 %, 80 %, 85 %, 90 %, 95 %, 98 %, 99 % o 100 % del dominio HNH. Las modificaciones también pueden incluir, como máximo, un 5 %, 10 %, 15 %, 20 %, 25 %, 30 %, 35 %, 40 %, 45 %, 50 %, 55 %, 60 %, 65 %, 70 %, 75 %, 80 %, 85 %, 90 %, 95 %, 98 %, 99 % o 100 % del dominio HNH.
En algunos casos, las modificaciones en las secuencias del dominio HNH del polipéptido dirigido a un sitio pueden incluir determinados motivos estructurales del polipéptido, incluyendo, aunque sin limitación, la hélice alfa, cadena beta, lámina beta, hélice 310, hélice pi, motivo de polipropolina I, motivo de polipropolina II, motivo de poliprolina III, vuelta beta, alfa-vuelta-alfa, o acodamientos o bisagras de hélice.
Las sustituciones del dominio HNH del polipéptido dirigido a un sitio pueden incluir la sustitución o adición con uno o más restos de aminoácidos. En algunos casos, el dominio HNH puede reemplazarse o fusionarse con otros dominios de unión a ácido nucleico adecuados. Un dominio de unión a ácido nucleico puede comprender ARN. Puede haber un solo dominio de unión a ácido nucleico. Los ejemplos de dominios de unión a ácido nucleico pueden incluir, pero sin limitación, un dominio hélice-vuelta-hélice, un dominio de dedo de cinc, un dominio de cremallera de leucina (bZIP), un dominio de hélice alada, un dominio de hélice alada-vuelta-hélice, un dominio hélice-lazo-hélice, un dominio de caja HMG, un dominio Wor3, un dominio de inmunoglobulina, un dominio B3, un dominio TALE, un dominio de dedo de cinc, un dominio de motivo de reconocimiento de ARN, un dominio de motivo de unión a ARN bicatenario, un dominio de unión a ácido nucleico bicatenario, un dominio de unión a ácido nucleico monocatenario, un dominio KH, un dominio PUF, un dominio de caja RGG, un dominio de caja DEAD/DEAH, un dominio PAZ, un dominio Piwi y un dominio de choque frío, un dominio RNAsaH, un dominio HNH, un dominio de tipo RuvC, un dominio RAMP, un dominio Cas5, un dominio Cas6.
En algunos casos, las modificaciones en las secuencias del dominio HNH del polipéptido dirigido a un sitio pueden incluir la eliminación de al menos un 1 %, 5 %, 10 %, 15 %, 20 %, 25 %, 30 %, 35 %, 40 %, 45 %, 50 %, 55 %, 60 %, 65%, 70%, 75%, 80%, 85%, 90%, 95%, 98%, 99% o 100% del dominio HNH. En algunos casos, las modificaciones en las secuencias del dominio HNH del polipéptido dirigido a un sitio pueden incluir la eliminación de, como máximo, un 1 %, 5 %, 10 %, 15 %, 20 %, 25 %, 30 %, 35 %, 40 %, 45 %, 50 %, 55 %, 60 %, 65 %, 70 %, 75 %, 80 %, 85 %, 90 %, 95 %, 98 %, 99 % o 100 % del dominio HNH.
En algunos casos, las modificaciones en las secuencias del dominio HNH del polipéptido dirigido a un sitio pueden incluir la adición o sustitución de al menos un 1 %, 5 %, 10 %, 15 %, 20 %, 25 %, 30 %, 35 %, 40 %, 45 %, 50 %, 55 %, 60 %, 65 %, 70 %, 75 %, 80 %, 85 %, 90 %, 95 %, 98 %, 99 % o 100 % de un dominio HNH de Cas9 homólogo. En algunos casos, las modificaciones en las secuencias del dominio HNH del polipéptido dirigido a un sitio pueden incluir la adición o sustitución de, como máximo, un 1 %, 5 %, 10 %, 15 %, 20 %, 25 %, 30 %, 35 %, 40 %, 45 %, 50 %, 55 %, 60 %, 65 %, 70 %, 75 %, 80 %, 85 %, 90 %, 95 %, 98 %, 99 % o 100 % de un dominio HNH de Cas9 homólogo.
Los dominios HNH homólogos de Cas9 pueden derivarse de cualquier organismo adecuado. En algunos casos, la proteína Cas9 puede derivarse de organismos procariotas tales como arqueas, bacterias, protistas (por ejemplo, E. cob, S. pyogenes, S. thermophilus, P.furiosus, etc.). Por ejemplo, el dominio HNH de la enzima Cas9 de S. pyogenes puede ser sustituido con o modificado mediante la inserción del dominio HNH, o fragmento del mismo, derivado de una enzima Cas9 de otra especie. En algunos casos, se puede insertar al menos un dominio HNH homólogo de Cas9 en el dominio HNH. En algunos casos, el al menos un dominio HNH homólogo de Cas9 puede formar una matriz de dominios HNH, que comprende al menos dos dominios HNH. En algunos casos, una matriz de dominio HNH puede comprender al menos un dominio HNH de Cas9 y al menos un segundo dominio HNH.
En algunos casos, la modificación del dominio HNH o de tipo HNH puede comprender la inserción del mismo dominio HNH o de tipo HNH, o de uno similar, en tándem (por ejemplo, adyacente) al dominio HNH de Cas9. El dominio HNH
o de tipo HNH puede insertarse en el extremo N y/o extremo C del dominio HNH en Cas9. La inserción de uno o más dominios HNH o de tipo HNH en Cas9 puede ser útil para ampliar la especificidad en un ácido nucleico diana. La inserción de uno o más dominios HNH o de tipo HNH en Cas9 puede ser útil para duplicar la especificidad en un ácido nucleico diana. Por ejemplo, la inserción de uno o más dominios HNH o de tipo HNH puede configurar Cas9 para reconocer un tramo más largo de ácido nucleico diana, reconocer un híbrido de ARN-ADN diferente y/o reconocer un ácido nucleico diana con mayor afinidad de unión.
En algunos casos, un polipéptido dirigido a un sitio comprende una secuencia de aminoácidos que comprende al menos un 15 % de identidad de aminoácidos con un Cas9 de S. pyogenes, dos dominios de escisión de ácido nucleico (es decir, un dominio HNH y un dominio RuvC) y un dominio HNH modificado.
Modificaciones de los dominios RuvC o de tipo RuvC
En algunos casos, el dominio RuvC o de tipo RuvC del polipéptido dirigido a un sitio puede modificarse para alterar la especificidad hacia PAM. En algunos casos, el dominio RuvC o de tipo RuvC puede compartir homología con el dominio RuvC o de tipo RuvC identificado en la proteína Cas9 de S. pyogenes (restos 1-270). En algunos casos, el dominio RuvC o de tipo RuvC puede compartir al menos un 5 %, 10 %, 15 %, 20 %, 25 %, 30 %, 35 %, 40 %, 45 %, 50 %, 55 %, 60 %, 65 %, 70 %, 75 %, 80 %, 85 %, 90 %, 95 %, 98 %, 99 % o 100 % de homología con los restos 551 556 del dominio RuvC o de tipo RuvC de Cas9 de S. pyogenes. En algunos casos, el dominio RuvC o de tipo RuvC puede compartir, como máximo, un 5 %, 10 %, 15 %, 20 %, 25 %, 30 %, 35 %, 40 %, 45 %, 50 %, 55 %, 60 %, 65 %, 70 %, 75 %, 80 %, 85 %, 90 %, 95 %, 98 %, 99 % o 100 % de homología con los restos 1-270 del dominio RuvC o de tipo RuvC de Cas9 de S. pyogenes.
En algunos casos, las modificaciones en el dominio RuvC o de tipo RuvC pueden incluir, pero sin limitación, modificaciones de aminoácidos individuales, como se describe en el presente documento. En algunos casos, las modificaciones del dominio RuvC o de tipo RuvC pueden incluir, pero sin limitación, eliminaciones o sustituciones de aminoácidos o polipéptidos individuales, tales como otros elementos proteicos (por ejemplo, dominios, motivos estructurales, proteínas).
Las modificaciones pueden incluir modificaciones de al menos 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20 o más aminoácidos del dominio RuvC o de tipo RuvC. Las modificaciones pueden incluir modificaciones, como máximo, en 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20 o más aminoácidos del dominio RuvC o de tipo RuvC. Las modificaciones también pueden incluir al menos un 5 %, 10 %, 15 %, 20 %, 25 %, 30 %, 35 %, 40 %, 45 %, 50 %, 55 %, 60 %, 65 %, 70 %, 75 %, 80 %, 85 %, 90 %, 95 %, 98 %, 99 % o 100 % del dominio RuvC o de tipo RuvC. Las modificaciones también pueden incluir, como máximo, un 5 %, 10 %, 15 %, 20 %, 25 %, 30 %, 35 %, 40 %, 45 %, 50 %, 55 %, 60 %, 65 %, 70 %, 75 %, 80 %, 85 %, 90 %, 95 %, 98 %, 99 % o 100 % del dominio RuvC o de tipo RuvC.
En algunos casos, las modificaciones de las secuencias de dominio RuvC o de tipo RuvC del polipéptido dirigido a un sitio pueden incluir determinados motivos estructurales del polipéptido, incluyendo, aunque sin limitación, la hélice alfa, cadena beta, lámina beta, hélice 310, hélice pi, motivo de polipropolina I, motivo de polipropolina II, motivo de poliprolina III, vuelta beta, alfa-vuelta-alfa, o acodamientos o bisagras de hélice.
Las sustituciones del dominio RuvC o de tipo RuvC del polipéptido dirigido a un sitio pueden incluir la sustitución o adición con uno o más restos de aminoácidos. En algunos casos, el dominio RuvC o de tipo RuvC puede reemplazarse o fusionarse con otros dominios de unión a ácido nucleico adecuados. Un dominio de unión a ácido nucleico puede comprender ARN. Puede haber un solo dominio de unión a ácido nucleico. Los ejemplos de dominios de unión a ácido nucleico pueden incluir, pero sin limitación, un dominio hélice-vuelta-hélice, un dominio de dedo de cinc, un dominio de cremallera de leucina (bZIP), un dominio de hélice alada, un dominio de hélice alada-vuelta-hélice, un dominio hélice-lazo-hélice, un dominio de caja HMG, un dominio Wor3, un dominio de inmunoglobulina, un dominio B3, un dominio TALE, un dominio de dedo de cinc, un dominio de motivo de reconocimiento de ARN, un dominio de motivo de unión a ARN bicatenario, un dominio de unión a ácido nucleico bicatenario, un dominio de unión a ácido nucleico monocatenario, un dominio KH, un dominio PUF, un dominio de caja RGG, un dominio de caja DEAD/DEAH, un dominio PAZ, un dominio Piwi, un dominio de choque frío, un dominio RNAsaH, un dominio HNH, un dominio de tipo RuvC, un dominio RAMP, un dominio Cas5 y un dominio Cas6.
En algunos casos, las modificaciones en las secuencias del dominio RuvC o de tipo RuvC del polipéptido dirigido a un sitio pueden incluir la eliminación de al menos un 1 %, 5 %, 10 %, 15 %, 20 %, 25 %, 30 %, 35 %, 40 %, 45 %, 50 %, 55 %, 60 %, 65 %, 70 %, 75 %, 80 %, 85 %, 90 %, 95 %, 98 %, 99 % o 100 % del dominio RuvC o de tipo RuvC. En algunos casos, las modificaciones en las secuencias del dominio RuvC o de tipo RuvC del polipéptido dirigido a un sitio pueden incluir la eliminación de, como máximo, un 1 %, 5 %, 10 %, 15 %, 20 %, 25 %, 30 %, 35 %, 40 %, 45 %, 50 %, 55 %, 60 %, 65 %, 70 %, 75 %, 80 %, 85 %, 90 %, 95 %, 98 %, 99 % o 100 % del dominio RuvC o de tipo RuvC.
En algunos casos, las modificaciones en las secuencias del dominio RuvC o de tipo RuvC del polipéptido dirigido a un sitio pueden incluir la adición o sustitución de al menos un 1 %, 5 %, 10 %, 15 %, 20 %, 25 %, 30 %, 35 %, 40 %, 45 %, 50 %, 55 %, 60 %, 65 %, 70 %, 75 %, 80 %, 85 %, 90 %, 95 %, 98 %, 99 % o 100 % del dominio RuvC o de tipo
RuvC de Cas9 homólogo. En algunos casos, las modificaciones en las secuencias del dominio RuvC o de tipo RuvC del polipéptido dirigido a un sitio pueden incluir la adición o sustitución de, como máximo, un 1 %, 5 %, 10 %, 15 %, 20 %, 25 %, 30 %, 35 %, 40 %, 45 %, 50 %, 55 %, 60 %, 65 %, 70 %, 75 %, 80 %, 85 %, 90 %, 95 %, 98 %, 99 % o 100 % del dominio RuvC o de tipo RuvC de Cas9 homólogo.
Los dominios RuvC o de tipo RuvC de Cas9 homólogos se pueden derivar de cualquier organismo adecuado. En algunos casos, la proteína Cas9 puede derivarse de organismos procariotas tales como arqueas, bacterias, protistas (por ejemplo, E. coli, S. pyogenes, S. thermophilus, P.furiosus, etc.). Por ejemplo, el dominio RuvC o de tipo RuvC de la enzima Cas9 de S. pyogenes puede ser sustituido con o modificado mediante la inserción del dominio RuvC o de tipo RuvC, o un fragmento del mismo, derivado de otra enzima Cas9, tal como uno de otra especie.
En algunos casos, la modificación del dominio RuvC o de tipo RuvC puede comprender la inserción del mismo dominio RuvC o de tipo RuvC, o de uno similar, en tándem (por ejemplo, adyacente) al dominio RuvC de Cas9. El dominio RuvC o de tipo RuvC se puede insertar en el extremo N y/o extremo C del dominio RuvC o de tipo RuvC de Cas9. La inserción de uno o más dominios RuvC o de tipo RuvC en Cas9 puede ser útil para ampliar la especificidad en un ácido nucleico diana. La inserción de uno o más dominios RuvC o de tipo RuvC en Cas9 puede ser útil para duplicar la especificidad en un ácido nucleico diana. Por ejemplo, la inserción de uno o más dominios RuvC o de tipo RuvC puede configurar Cas9 para reconocer un tramo más largo de ácido nucleico diana, reconocer un híbrido de ARN-ADN diferente y/o reconocer un ácido nucleico diana con mayor afinidad de unión.
En algunos casos, un polipéptido dirigido a un sitio comprende una secuencia de aminoácidos que comprende al menos un 15 % de identidad de aminoácidos con un Cas9 de S. pyogenes, dos dominios de escisión de ácido nucleico (es decir, un dominio HNH y un dominio RuvC) y un dominio RuvC modificado.
Modificaciones de los dominios Cas9 que contienen regiones homólogas de ARN polimerasa
En algunos casos, un polipéptido dirigido a un sitio puede compartir homología con la ARN polimerasa. Ambas proteínas pueden compartir dominios funcionalmente homólogos similares que participe en la catálisis de unión y manipulación de ácidos nucleicos. Por ejemplo, la ARN polimerasa puede comprender regiones de secuencia polipeptídica que participe en la unión de los dúplex de ARN-ADN. En algunos casos, estas regiones pueden ayudar a fundir el dúplex.
En algunos casos, un polipéptido dirigido a un sitio también puede comprender ciertas regiones que afectan a la especificidad de unión de la enzima hacia los ácidos nucleicos. En algunos casos, estas regiones pueden compartir secuencia u homología funcional con dominios o regiones como las encontradas en la ARN polimerasa. En algunos casos, la región básica del extremo N del polipéptido dirigido a un sitio puede unirse al ARNcrtra y al ARNcr o a un solo ARN (ARNgs). En S. pyogenes, esto puede corresponder a una región de restos 50-100.
En general, la presente divulgación proporciona cualquier modificación adecuada de esta región o regiones adyacentes. En algunos casos, la región de unión a ARNcrtra/ARNcr (por ejemplo, la región de unión a ácido nucleico dirigida a ácido nucleico) del polipéptido dirigido a un sitio puede modificarse para alterar la especificidad hacia el ácido nucleico. En algunos casos, la región de unión a ARNcrtra/ARNcr puede compartir homología con la región de unión a ARNcrtra/ARNcr identificada en la proteína Cas9 de S. pyogenes (restos 50-100). En algunos casos, la región de unión a ARNcrtra/ARNcr puede compartir al menos un 5 %, 10 %, 15 %, 20 %, 25 %, 30 %, 35 %, 40 %, 45 %, 50 %, 55 %, 60 %, 65 %, 70 %, 75 %, 80 %, 85 %, 90 %, 95 %, 98 %, 99 % o 100 % de homología con los restos 50-100 de la región de unión a ARNcrtra/ARNcr de Cas9 de S. pyogenes. En algunos casos, la región de unión a ARNcrtra/ARNcr puede compartir, como máximo, un 5 %, 10 %, 15 %, 20 %, 25 %, 30 %, 35 %, 40 %, 45 %, 50 %, 55 %, 60 %, 65 %, 70 %, 75 %, 80 %, 85 %, 90 %, 95 %, 98 %, 99 % o 100 % de homología con los restos 50-100 de la región de unión a ARNcrtra/ARNcr de Cas9 de S. pyogenes.
En algunos casos, las modificaciones en la región de unión a ARNcrtra/ARNcr pueden incluir, pero sin limitación, modificaciones de aminoácidos individuales, como se describe en el presente documento. En algunos casos, la modificación de la región de unión a ARNcrtra/ARNcr puede incluir, pero sin limitación, inserciones, eliminaciones o sustituciones de aminoácidos o polipéptidos individuales, tales como otros elementos proteicos (por ejemplo, dominios, motivos estructurales, proteínas).
Las modificaciones pueden incluir modificaciones de al menos 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20 o más aminoácidos de la región de unión a ARNcrtra/ARNcr. Las modificaciones pueden incluir modificaciones, como máximo, en 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20 o más aminoácidos de la región de unión a ARNcrtra/ARNcr. Las modificaciones también pueden incluir al menos un 5 %, 10 %, 15 %, 20 %, 25 %, 30 %, 35 %, 40 %, 45 %, 50 %, 55 %, 60 %, 65 %, 70 %, 75 %, 80 %, 85 %, 90 %, 95 %, 98 %, 99 % o 100 % de la región de unión a ARNcrtra/ARNcr. Las modificaciones también pueden incluir, como máximo, un 5 %, 10 %, 15 %, 20 %, 25 %, 30 %, 35 %, 40 %, 45 %, 50 %, 55 %, 60 %, 65 %, 70 %, 75 %, 80 %, 85 %, 90 %, 95 %, 98 %, 99 % o 100 % de la región de unión a ARNcrtra/ARNcr.
En algunos casos, las modificaciones de las secuencias de la región de unión a ARNcrtra/ARNcr del polipéptido dirigido
a un sitio pueden incluir determinados motivos estructurales del polipéptido, incluyendo, aunque sin limitación, la hélice alfa, cadena beta, lámina beta, hélice 310, hélice pi, motivo de polipropolina I, motivo de polipropolina II, motivo de poliprolina III, vuelta beta, alfa-vuelta-alfa, o acodamientos o bisagras de hélice.
Por ejemplo, las sustituciones en la región de unión del ARNcrtra/ARNcr del polipéptido dirigido a un sitio pueden incluir la sustitución o adición con una o más proteínas o fragmentos de las mismas. Por ejemplo, la región de unión a ARNcrtra/ARNcr podría ser sustituida con el dominio de unión a ARN de cualquiera de los miembros del sistema CRISPR de Tipo I, Tipo II o Tipo III de unión al ARN conocidos. La región de unión a ARNcrtra/ARNcr podría ser sustituida con el dominio de unión a ARN de cualquiera de los miembros de unión al ARN de la superfamilia RAMP. La región de unión a ARNcrtra/ARNcr podría sustituirse con el dominio de unión a ARN de cualquiera de los miembros de unión a ARN conocidos de las familias Cas7, Cas6, Cas5. En un ejemplo, el requisito de ARNcrtra puede reemplazarse con el requisito de una secuencia de horquilla 5' con la secuencia del espaciador colocada cadeba abajo de la horquilla para el reconocimiento de ADN.
En algunos casos, las modificaciones de las secuencias de la región de unión del ARNcrtra/ARNcr del polipéptido dirigido a un sitio pueden incluir la eliminación de al menos un 1 %, 5 %, 10 %, 15 %, 20 %, 25 %, 30 %, 35 %, 40 %, 45 %, 50 %, 55 %, 60 %, 65 %, 70 %, 75 %, 80 %, 85 %, 90 %, 95 %, 98 %, 99 % o 100 % de la región de unión a ARNcrtra/ARNcr. En algunos casos, las modificaciones de las secuencias de la región de unión a ARNcrtra/ARNcr del polipéptido dirigido a un sitio pueden incluir la eliminación de, como máximo, un 1 %, 5 %, 10 %, 15 %, 20 %, 25 %, 30 %, 35 %, 40 %, 45 %, 50 %, 55 %, 60 %, 65 %, 70 %, 75 %, 80 %, 85 %, 90 %, 95 %, 98 %, 99 % o 100 % de la región de unión a ARNcrtra/ARNcr.
En algunos casos, las modificaciones de las secuencias de la región de unión del ARNcrtra/ARNcr del polipéptido dirigido a un sitio pueden incluir la adición o sustitución de al menos un 1 %, 5 %, 10 %, 15 %, 20 %, 25 %, 30 %, 35 %, 40 %, 45 %, 50 %, 55 %, 60 %, 65 %, 70 %, 75 %, 80 %, 85 %, 90 %, 95 %, 98 %, 99 % o 100 % de la región de unión a ARNcrtra/ARNcr de Cas9 homóloga. En algunos casos, las modificaciones de las secuencias de la región de unión del ARNcrtra/ARNcr del polipéptido dirigido a un sitio pueden incluir la adición o sustitución de, como máximo, un 1 %, 5 %, 10 %, 15 %, 20 %, 25 %, 30 %, 35 %, 40 %, 45 %, 50 %, 55 %, 60 %, 65 %, 70 %, 75 %, 80 %, 85 %, 90 %, 95 %, 98 %, 99 % o 100 % de la región de unión a ARNcrtra/ARNcr de Cas9 homóloga.
Las regiones de unión a ARNcrtra/ARNcr de polipéptido dirigido a un sitio homólogas pueden derivarse de cualquier organismo adecuado. En algunos casos, la región de unión a ARNcrtra/ARNcr puede derivarse de organismos procariotas, incluyendo, pero sin limitación, arqueas, bacterias, protistas (por ejemplo,, E. coli, S. pyogenes, S. thermophilus, P.furiosus, etc.).Por ejemplo, la región de unión a ARNcrtra/ARNcr de Cas9 de S. pyogenes puede sustituirse con o modificarse mediante la inserción de la región de unión a ARNcrtra/ARNcr, o un fragmento de la misma, derivada de otra Cas9, tal como una derivada de otra especie.
En algunos casos, un polipéptido dirigido a un sitio comprende una secuencia de aminoácidos que comprende al menos un 15 % de identidad de aminoácidos con un Cas9 de S. pyogenes, dos dominios de escisión de ácido nucleico (es decir, un dominio HNH y un dominio RuvC) y un dominio de tipo polimerasa modificado.
Modificaciones para alterar la especificidad hacia PAM
En algunos casos, un polipéptido dirigido a un sitio puede reconocer un motivo adyacente al protoespaciador (PAM). Un PAM puede ser cualquier secuencia de un ácido nucleico diana que es reconocido por un polipéptido dirigido a un sitio y que está inmediatamente a 3' de la secuencia de ácido nucleico diana dirigida por el espaciador de un ácido nucleico dirigido a ácido nucleico. Por ejemplo, un PAM puede comprender 5-NGG-3' o 5'-NGg Ng -3', 5'-NNAAAAW-3', 5'-NNNNGATT-3', 5'-GNNNCNNA-3', 5-NNNACA-3' donde N es cualquier nucleótido y N está a inmediatamente a 3' de la secuencia de ácido nucleico diana de la secuencia de espaciador.
Un polipéptido dirigido a un sitio puede modificarse para alterar la especificidad hacia PAM. Por ejemplo, un polipéptido dirigido a un sitio puede modificarse de manera que, antes de la modificación, el polipéptido se dirija a un primer motivo adyacente al protoespaciador y, después de la modificación, el polipéptido dirigido a un sitio se dirija a un segundo motivo adyacente al protoespaciador. En algunos casos, la especificidad hacia PAM alterada puede comprender un cambio en la especificidad de unión (por ejemplo, unión aumentada, unión disminuida) y/o un cambio en la constante de unión (por ejemplo, aumento de Kd, disminución de Kd).
Un polipéptido dirigido a un sitio puede modificarse de manera que el polipéptido dirigido a un sitio pueda reconocer un nuevo tipo de PAM diferente del tipo que reconoce el polipéptido dirigido a un sitio de tipo silvestre. Por ejemplo, un polipéptido dirigido a un sitio que reconoce el PAM 5'-Ng G-3' puede modificarse de modo que pueda reconocer el PAM 5'-NGGNG-3', 5'-NNAAAAW-3', 5'-NNNNGATT-3', 5'-GNNNCNNA-3' 5'-NNNACA-3'.
Se puede diseñar cualquier región de un polipéptido dirigido a un sitio (por ejemplo, hélice puente, dominio HNH y/o dominio de tipo HNH, dominio RuvC y/o dominio de tipo RuvC, parche básico) para alterar la especificidad hacia pA m de acuerdo con los métodos de la divulgación.
Las regiones correspondientes a los restos 445-507, 446-497, 1096-1225, 1105-1138 de un polipéptido dirigido a un sitio de tipo silvestre (por ejemplo, Cas9 de S. pyogenes, SEQ ID NO: 8) pueden modificarse para modificar el reconocimiento de PAM. El diseño de estas regiones puede comprender mutaciones introductoras, reemplazando con regiones correspondientes de otras Cas9 ortólogas, eliminaciones, inserciones, etc. Las regiones correspondientes a los restos 718-757, 22-49, 65-95, 445-507, 446-497, 1096-1225, 1105-1138 puede diseñarse para modificar el reconocimiento del ácido nucleico dirigido a ácido nucleico. Se pueden diseñar regiones correspondientes a los restos 445-507 y 1105-1138 para modificar el reconocimiento del dominio P.
En algunos casos, un polipéptido dirigido a un sitio comprende una secuencia de aminoácidos que comprende al menos un 15 % de identidad de aminoácidos con un Cas9 de S. pyogenes, dos dominios de escisión de ácido nucleico (es decir, un dominio HNH y un dominio RuvC) y una modificación, en donde, antes de la introducción de la modificación, el polipéptido dirigido a un sitio se adapta para unirse a un primer PAM y, después de la introducción de la modificación, el polipéptido dirigido a un sitio se adapta para unirse a un PAM diferente.
Modificaciones para alterar la especificidad del ácido nucleico dirigido a ácido nucleico
En algunos casos, un polipéptido dirigido a un sitio puede reconocer a un ácido nucleico dirigido a ácido nucleico. Un polipéptido dirigido a un sitio puede modificarse para alterar una especificidad hacia el ácido nucleico dirigida a ácido nucleico. Por ejemplo, un polipéptido dirigido a un sitio puede modificarse de manera que, antes de la modificación, el polipéptido se dirija aun primer ácido nucleico dirigido a ácido nucleico y, después de la modificación, el polipéptido dirigido a un sitio se dirija un segundo ácido nucleico dirigido a ácido nucleico. En algunos casos, la especificidad hacia el ácido nucleico dirigido a ácido nucleico alterada puede comprender un cambio en la especificidad de unión (por ejemplo, unión aumentada, unión disminuida) y/o un cambio en la constante de unión (por ejemplo, aumento de Kd, disminución de Kd ).
Un polipéptido dirigido a un sitio puede modificarse de manera que el polipéptido dirigido a un sitio pueda reconocer un nuevo tipo de ácido nucleico dirigido a ácido nucleico diferente del tipo que reconoce el polipéptido dirigido a un sitio de tipo silvestre. Se puede diseñar cualquier región de un polipéptido dirigido a un sitio (por ejemplo, hélice puente, dominio HNH y/o dominio de tipo HNH, dominio RuvC y/o dominio de tipo RuvC, parche básico) para alterar la especificidad hacia PAM de acuerdo con los métodos de la divulgación.
En algunos casos, un polipéptido dirigido a un sitio comprende una secuencia de aminoácidos que comprende al menos un 15 % de identidad de aminoácidos con un Cas9 de S. pyogenes, dos dominios de escisión de ácido nucleico (es decir, un dominio HNH y un dominio RuvC) y una modificación, en donde, antes de la introducción de la modificación, el polipéptido dirigido a un sitio se adapta para unirse a un primer ácido nucleico dirigido a ácido nucleico y, después de la introducción de la modificación, el polipéptido dirigido a un sitio está adaptado para unirse a un ácido nucleico dirigido a ácido nucleico diferente.
Modificaciones para alterar los requisitos de hibridación
Inserciones
Un polipéptido dirigido a un sitio puede modificarse para aumentar la especificidad de unión a un ácido nucleico diana. Se puede insertar una secuencia en el polipéptido dirigido a un sitio. En algunos casos, se puede insertar un dominio HNH y/o de tipo HNH en un polipéptido dirigido a un sitio. La secuencia no nativa (por ejemplo, dominio HNH y/o de tipo HNH) puede proceder de cualquier especie. La inserción puede tener lugar en cualquier lugar del polipéptido dirigido a un sitio. La inserción puede ocurrir en tándem (por ejemplo, adyacente) al dominio nativo HNH y/o de tipo HNH del polipéptido dirigido a un sitio. El dominio HNH y/o de tipo HNH insertado puede comprender una mutación. El dominio HNH y/o de tipo HNH insertado puede comprender una mutación que reduzca la actividad nucleasa del dominio. En algunos casos, se puede insertar un dominio RuvC y/o de tipo RuvC en un polipéptido dirigido a un sitio. La inserción puede tener lugar en cualquier lugar del polipéptido dirigido a un sitio. La inserción puede ocurrir en tándem (por ejemplo, adyacente) al dominio nativo RuvC y/o de tipo RuvC del polipéptido dirigido a un sitio. El dominio RuvC y/o de tipo RuvC insertado puede comprender una mutación. El dominio RuvC y/o de tipo RuvC insertado puede comprender una mutación que reduzca la actividad nucleasa del dominio.
Un polipéptido dirigido a un sitio puede modificarse para aumentar la especificidad de unión a un ácido nucleico dirigido a ácido nucleico. Se puede insertar una secuencia en el polipéptido dirigido a un sitio. Se puede insertar un dominio HNH y/o de tipo HNH en un polipéptido dirigido a un sitio. La secuencia no nativa (por ejemplo, dominio HNH y/o de tipo HNH) puede proceder de cualquier especie. La inserción puede tener lugar en cualquier lugar del polipéptido dirigido a un sitio. La inserción puede ocurrir en tándem (por ejemplo, adyacente) al dominio nativo HNH y/o de tipo HNH del polipéptido dirigido a un sitio. El dominio HNH y/o de tipo HNH insertado puede comprender una mutación. El dominio HNH y/o de tipo HNH insertado puede comprender una mutación que reduzca la actividad nucleasa del dominio. Se puede insertar un dominio RuvC y/o de tipo RuvC en un polipéptido dirigido a un sitio. La inserción puede tener lugar en cualquier lugar del polipéptido dirigido a un sitio. La inserción puede ocurrir en tándem (por ejemplo, adyacente) al dominio nativo RuvC y/o de tipo RuvC del polipéptido dirigido a un sitio. El dominio RuvC y/o de tipo RuvC insertado puede comprender una mutación. El dominio RuvC y/o de tipo RuvC insertado puede comprender una
mutación que reduzca la actividad nucleasa del dominio.
Un polipéptido dirigido a un sitio puede diseñarse para comprender un dominio de polipéptido que puedA unirse a híbridos de ARN-ADN (por ejemplo, dominio RNasa, dominio de dedo de cinc). Por ejemplo, un polipéptido dirigido a un sitio se puede diseñar para comprender un dominio RNasaH. El dominio RNasaH insertado puede comprender una mutación. El dominio RNasaH insertado puede comprender una mutación que reduzca la actividad nucleasa del dominio.
Se puede diseñar un polipéptido dirigido a un sitio para que comprenda un dominio de polipéptido que pueda unirse a ADN bicatenario (por ejemplo, dominios que comprenden motivos de hélice-vuelta-hélice, dominios que comprenden motivos de cremallera de leucina, dominios que comprenden motivos de hélice-lazo-hélice, dominios que comprenden motivos de dedos de cinc). Por ejemplo, un polipéptido dirigido a un sitio puede diseñarse para comprender un motivo hélice-vuelta-hélice. Los ejemplos no limitantes de motivos de hélice-giro-hélice incluyen los de dnaB, TetR, MuB, P2R, CysB, BirA, el bacteriófago lambda represor, Engrailed, Myb, LuxR, MarR, ETS, ZNF10a, Kox-1. El motivo hélicelazo-hélice puede ser dihelicoidal, trihelicoidal, tetrahelicoidal, hélice-vuelta-hélice alado u otro hélice-lazo-hélice modificado. El dominio insertado puede comprender una mutación. El dominio insertado puede comprender una mutación que reduzca la actividad nucleasa del dominio.
Mutaciones compensatorias
Un polipéptido dirigido a un sitio puede comprender una mutación y/o estar diseñado de manera que pueda unirse preferentemente a un ácido nucleico dirigido a ácido nucleico mutado y/o diseñado. Dicha mutación de un par de polipéptido dirigido a un sitio y ácido nucleico dirigido a ácido nucleico se puede denominar mutación compensatoria. Por ejemplo, se puede diseñar un polipéptido dirigido a un sitio de manera que su dominio nucleasa (por ejemplo, HNH y/o de tipo HNH, RuvC y/o de tipo RuvC) se reemplaza por un dominio de unión a ácido nucleico (por ejemplo, dominio de unión a ácido nucleico Csy4, Cas5, Cas6). Se puede diseñar un polipéptido dirigido a un sitio de manera que un dominio de unión a ácido nucleico (por ejemplo, dominio de unión al ácido nucleico Csy4, Cas5, Cas6) se inserta en el polipéptido dirigido a un sitio. El polipéptido dirigido a un sitio resultante puede unirse a un ácido nucleico dirigido a ácido nucleico que está mutado y/o diseñado para comprender un sitio de unión al dominio de unión a ácido nucleico (por ejemplo, sitio de unión para los dominios de unión a ácido nucleico Csy4, Cas5, Cas6). El ácido nucleico dirigido a ácido nucleico puede mutarse y/o diseñarse para que comprenda un sitio de unión al dominio de unión a ácido nucleico en la secuencia mínima de ARNcrtra. El ácido nucleico dirigido a ácido nucleico puede mutarse y/o diseñarse para que comprenda un sitio de unión al dominio de unión a ácido nucleico en la secuencia de ARNcrtra de 3'. El ácido nucleico dirigido a ácido nucleico puede mutarse y/o diseñarse para que comprenda un sitio de unión al dominio de unión a ácido nucleico en la extensión de ARNcrtra.
En algunos casos, un polipéptido dirigido a un sitio comprende una secuencia de aminoácidos que comprende al menos un 15 % de identidad de aminoácidos con un Cas9 de S. pyogenes, dos dominios de escisión de ácido nucleico (es decir, un dominio HNH y un dominio RuvC) y una mutación compensatoria, en donde el polipéptido dirigido a un sitio es tal que puede unirse a un ácido nucleico dirigido a ácido nucleico diseñado, pero no a un ácido nucleico dirigido a ácido nucleico no modificado.
Métodos de generación de extremos adhesivos y cortes romos
En algunos casos, se pueden usar una o más nickasas (es decir, un polipéptido dirigido a un sitio que comprende un dominio nucleasa sustancialmente inactivo) para generar cortes bicatenarios dirigidos en ácido nucleico diana. Cada nickasa de una o más nickasas puede dirigirse a una cadena del ácido nucleico diana bicatenario. En algunos casos, se pueden usar dos nickasas para generar un corte bicatenario diana.
Las dos nickasas pueden cortar el ácido nucleico diana generando un corte de extremo romo (en donde los sitios de corte del ácido nucleico diana están en la misma ubicación en cada cadena). Las dos nickasas pueden cortar el ácido nucleico diana en diferentes ubicaciones dentro de cada cadena de manera que permanezcan algunos nucleótidos monocatenarios, generando así un extremo adhesivo.
La escisión del ácido nucleico diana por dos polipéptidos modificados dirigidos a un sitio que tienen actividad de nickasa puede usarse para incurrir en eliminaciones o inserciones de material de ácido nucleico de un ácido nucleico diana escindiendo el ácido nucleico diana y permitiendo que la célula repare la secuencia en ausencia de un polinucleótido donante proporcionado exógenamente. En algunos casos, los métodos de la divulgación pueden usarse para desactivar un gen. Si un ácido nucleico dirigido a ácido nucleico y dos polipéptidos modificados dirigidos a un sitio que tienen actividad de nickasa se administran conjuntamente a las células con una secuencia de polinucleótido donante que incluye al menos un segmento con homología con el ácido nucleico diana, se puede obtener un nuevo material de ácido nucleico insertado/copiado en el sitio. Dichos métodos se pueden usar para agregar, es decir, insertar o reemplazar, material de ácido nucleico a un ácido nucleico diana (por ejemplo, "insertar" un ácido nucleico que codifica una proteína, un ARNip, un miARN, etc.), para agregar un marcador (por ejemplo, 6xHis, una proteína fluorescente (por ejemplo, una proteína fluorescente verde; una proteína fluorescente amarilla, etc.), hemaglutinina (HA), FLAG, etc.), para agregar una secuencia reguladora a un gen (por ejemplo, promotor, señal de poliadenilación,
secuencia interna de entrada al ribosoma (IRES), péptido 2A, codón de inicio, codón de terminación, señal de corte y empalme, señal de localización, etc.), para modificar una secuencia de ácido nucleico (por ejemplo, introducir una mutación) y similares.
La Figura 32 muestra un método para la generación extremos romos por nickasas. El dúplex 3210 de ácido nucleico diana puede comprender una pluralidad de secuencias 3215 de PAM (recuadro), en donde un PAM está en una cadena del ácido nucleico diana 3210 y un PAM está en la otra cadena del ácido nucleico diana 3210. Un ácido nucleico dirigido a ácido nucleico 3205 como parte de un complejo con la nickasa (no se muestra la nickasa) puede hibridarse con la secuencia del espaciador adyacente al PAM 3215 en cada cadena del ácido nucleico diana 3210. La nickasa puede escindir una cadena del ácido nucleico diana 3210. La escisión se indica por los triángulos. Si los PAM están espaciados adecuadamente, las nickasas pueden cortar el ácido nucleico diana en sustancialmente el mismo lugar de cada cadena, lo que da lugar a un extremo romo. Las secuencias de PAM pueden estar separadas por al menos aproximadamente 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 20, 30, 40 o 50, o más, nucleótidos. Las secuencias de PAM pueden estar separadas, como máximo, por 1,2, 3, 4, 5, 6, 7, 8, 9, 10, 20, 30, 40 o 50, o más, nucleótidos. En algunos casos, los PAM están separados por 6 nucleótidos (es decir, hay 6 nucleótidos entre cada PAM). En algunos casos, el ácido nucleico dirigido a ácido nucleico escinde aproximadamente 3 nucleótidos de 5' del PAM.
En algunas realizaciones, se pueden emplear dos o más nickasas para generar extremos adhesivos. La Figura 33 ilustra cómo dos nickasas dirigidas a regiones superpuestas en un ácido nucleico diana pueden producir una rotura bicatenaria escalonada que da lugar a extremos adhesivos. El dúplex 3310 de ácido nucleico diana puede comprender una pluralidad de secuencias 3315 de PAM (recuadro). Un ácido nucleico dirigido a ácido nucleico 3305 como parte de un complejo con la nickasa (no se muestra la nickasa) puede hibridarse con la secuencia del espaciador adyacente al PAM 3315 en cada cadena del ácido nucleico diana 3310. La nickasa puede escindir una cadena del ácido nucleico diana 3310. La escisión se indica por los triángulos. Si los PAM están espaciados adecuadamente, las nickasas pueden cortar el ácido nucleico diana en ubicaciones escalonadas, lo que da lugar a un extremo adhesivo. Las secuencias de PAM pueden estar separadas por al menos aproximadamente 1, 2, 3, 4, 5, 6, 7, 8, 9 o 10, o más, nucleótidos. Las secuencias de PAM pueden estar separadas, como máximo, por 1, 2, 3, 4, 5, 6, 7, 8, 9 o 10, o más, nucleótidos. La distancia de las secuencias de PAM puede estar relacionada con la longitud del extremo adhesivo generado. Por ejemplo, cuanto más alejados estén los PAM entre sí, más largo será el extremo adhesivo.
Un método para generar extremos adhesivos usando dos o más nickasas puede implicar secuencias de PAM sustancialmente adyacentes entre sí (aunque en cadenas opuestas). En algunos casos, las secuencias de PAM están separadas por al menos aproximadamente 1, 2, 3, 4, 5, 6, 7, 8, 9 o 10, o más, nucleótidos. En algunos casos, las secuencias de PAM están, como máximo, por 1, 2, 3, 4, 5, 6, 7, 8, 9 o 10, o más, nucleótidos. En algunos casos, las secuencias de PAM están separadas por un nucleótido. En algunos casos, las secuencias de PAM no están separadas por ningún nucleótido.
Métodos de enriquecimiento y secuenciación de ácidos nucleicos diana
Visión general
La secuenciación puede ser útil para diagnosticar enfermedades mediante la identificación de mutaciones y/u otras variantes de secuencia (por ejemplo, polimorfismos). Los métodos de la divulgación proporcionan métodos, kits y composiciones para enriquecer una secuencia de ácido nucleico diana sin el uso de metodologías de amplificación. Un ácido nucleico diana puede ser enriquecido con el uso de un polipéptido dirigido a un sitio y un ácido nucleico dirigido a ácido nucleico.
La FIGURA 3 representa una realización a modo de ejemplo de los métodos de la divulgación. Un polipéptido dirigido a un sitio 305 puede unirse a un ácido nucleico dirigido a ácido nucleico 310, formando así un complejo 306. El ácido nucleico diana de ácido nucleico 310 puede comprender un marcador de afinidad hacia ácido nucleico 311. El polipéptido dirigido a un sitio 305 puede comprender un dominio nucleasa. El polipéptido 305 dirigido a un sitio puede ser enzimáticamente activo. El polipéptido dirigido a un sitio 305 puede comprender un marcador de afinidad 315. El ácido nucleico dirigido a ácido nucleico 310 puede hibridarse con un ácido nucleico diana 320. En algunas realizaciones, una pluralidad de complejos 306 puede hibridarse con una pluralidad de ubicaciones dentro de un ácido nucleico diana 320. En una etapa de escisión 325, el dominio nucleasa de un polipéptido dirigido a un sitio 305 puede escindir o cortar 330 el ácido nucleico diana 320. El ácido nucleico diana cortado 340 puede purificarse en una etapa de purificación 335. Los adaptadores 345 pueden ligarse al ácido nucleico diana escindido. Los adaptadores pueden facilitar la secuenciación del ácido nucleico diana escindido.
La FIGURA 4 representa un una realización a modo de ejemplo de los métodos de la divulgación. Un polipéptido dirigido a un sitio 405 puede interactuar con un ácido nucleico dirigido a ácido nucleico 410, formando así un complejo 406. El polipéptido dirigido a un sitio 405 puede comprender un dominio nucleasa. En algunas realizaciones, el dominio nucleasa del polipéptido dirigido a un sitio 405 puede ser enzimáticamente inactivo. El polipéptido dirigido a un sitio 405 puede comprender un marcador de afinidad 415. El ácido nucleico dirigido a ácido nucleico 410 puede hibridarse con un ácido nucleico diana 420. El ácido nucleico diana de ácido nucleico 410 puede comprender un marcador de afinidad hacia ácido nucleico 411. El marcador de afinidad 411 del ácido nucleico dirigido a ácido nucleico puede
comprender una estructura de horquilla. Una pluralidad de complejos 406 puede hibridarse con una pluralidad de ubicaciones dentro de un ácido nucleico diana 420. En una etapa de fragmentación 225, el ácido nucleico diana 420 puede fragmentarse en el fragmento de ácido nucleico diana 445 (también denominado en el presente documento "ácido nucleico diana"). El polipéptido dirigido a un sitio 405 puede purificarse mediante un agente de captura 440 que puede unirse al marcador de afinidad 415 del polipéptido dirigido a un sitio 405. El ácido nucleico diana fragmentado 445 puede eluirse del complejo 406 en una etapa de purificación 450. En la misma etapa, u opcionalmente, en un etapa diferente, los adaptadores 455 pueden ligarse al ácido nucleico diana escindido. Los adaptadores pueden facilitar la secuenciación del ácido nucleico diana.
Complejo de un ácido nucleico dirigido a ácido nucleico y un polipéptido dirigido a un sitio
Un ácido nucleico dirigido a ácido nucleico puede interactuar con un polipéptido dirigido a un sitio (por ejemplo, una nucleasa guiada a ácido nucleico, por ejemplo, Cas9), formando así un complejo. El ácido nucleico dirigido a ácido nucleico puede guiar al polipéptido dirigido a un sitio a un ácido nucleico diana.
En algunas realizaciones, un ácido nucleico dirigido a ácido nucleico puede modificarse de forma tal que el complejo (por ejemplo, que comprende un polipéptido dirigido a un sitio y un ácido nucleico dirigido a ácido nucleico) pueda unirse fuera del sitio de escisión del polipéptido dirigido a un sitio. En este caso, el ácido nucleico diana puede no interactuar con el complejo, y el ácido nucleico diana se puede escindir (por ejemplo, libre del complejo).
En algunas realizaciones, un ácido nucleico dirigido a ácido nucleico puede diseñado de modo que el complejo pueda unirse dentro del sitio de escisión del polipéptido dirigido a un sitio. En este caso, el ácido nucleico diana puede interactuar con el complejo y el ácido nucleico diana puede unirse (por ejemplo, unirse al complejo).
El ácido nucleico dirigido a ácido nucleico se puede diseñar de manera que el complejo (por ejemplo, que comprende un polipéptido dirigido a un sitio y/o un ácido nucleico dirigido a ácido nucleico) pueda hibridarse en una pluralidad de ubicaciones dentro de una muestra de ácido nucleico.
Se puede poner en contacto una pluralidad de complejos con una muestra de ácido nucleico. La pluralidad de complejos puede comprender ácidos nucleicos dirigidos a ácido nucleico diseñados para hibridarse con la misma secuencia. La pluralidad de complejos puede comprender ácidos nucleicos dirigidos a ácido nucleico diseñados para hibridarse con las diferentes secuencias.
Las secuencias pueden estar en diferentes ubicaciones dentro de un ácido nucleico diana. Las ubicaciones pueden comprender las mismas secuencias de ácido nucleico diana, o similares. Las ubicaciones pueden comprender diferentes secuencias de ácido nucleico diana. Las ubicaciones pueden estar a una distancia definida entre sí. Las ubicaciones pueden estar separadas por menos de 10 kilobases (Kb), menos de 8 Kb, menos de 6 Kb, menos de 4 Kb, menos de 2 Kb, menos de 1 Kb, menos de 900 nucleótidos, menos de 800 nucleótidos, menos de 700 nucleótidos, menos de 600 nucleótidos, menos de 500 nucleótidos, menos de 400 nucleótidos, menos de 300 nucleótidos, menos de 200 nucleótidos, menos de 100 nucleótidos.
Los complejos pueden escindir el ácido nucleico diana que puede producir un ácido nucleico diana escindido que puede tener menos de 10 kilobases (Kb) de longitud, menos de 8 Kb de longitud, menos de 6 Kb de longitud, menos de 4 Kb de longitud, menos de 2 Kb de longitud, menos de 1 Kb de longitud, menos de 900 nucleótidos de longitud, menos de 800 nucleótidos de longitud, menos de 700 nucleótidos de longitud, menos de 600 nucleótidos de longitud, menos de 500 nucleótidos de longitud, menos de 400 nucleótidos de longitud, menos de 300 nucleótidos de longitud, menos de 200 nucleótidos de longitud, menos de 100 nucleótidos de longitud.
Los complejos se pueden unir a un ácido nucleico diana fragmentado que puede tener menos de 10 kilobases (Kb) de longitud, menos de 8 Kb de longitud, menos de 6 Kb de longitud, menos de 4 Kb de longitud, menos de 2 Kb de longitud, menos de 1 Kb de longitud, menos de 900 nucleótidos de longitud, menos de 800 nucleótidos de longitud, menos de 700 nucleótidos de longitud, menos de 600 nucleótidos de longitud, menos de 500 nucleótidos de longitud, menos de 400 nucleótidos de longitud, menos de 300 nucleótidos de longitud, menos de 200 nucleótidos de longitud, menos de 100 nucleótidos de longitud.
Métodos de detección de sitios de unión fuera de la diana de polipéptidos dirigidos a un sitio
Visión general
La presente divulgación describe métodos, composiciones, sistemas y/o kits de determinación de sitios de unión fuera de la diana de polipéptidos dirigidos a un sitio. En algunas realizaciones de la divulgación, un polipéptido dirigido a un sitio puede comprender un ácido nucleico dirigido a ácido nucleico, formando así un complejo. El complejo puede ponerse en contacto con un ácido nucleico diana. El ácido nucleico diana puede capturarse con agentes de captura que pueden unirse a los marcadores de afinidad del complejo. La identidad del ácido nucleico diana se puede determinar mediante secuenciación. La secuenciación (por ejemplo, secuenciación de alto rendimiento, por ejemplo, Illumina, Ion Torrent) también puede identificar la frecuencia de sitios de unión fuera de la diana del polipéptido dirigido
a un sitio y/o complejo, contando el número de veces que se lee un determinado sitio de unión. Los métodos, las composiciones, los sistemas y/o los kits de la divulgación pueden facilitar el desarrollo de polipéptidos dirigidos a un sitio de manera más precisa y específica.
La FIGURA 5 representa un método ilustrativo de la divulgación. Un polipéptido dirigido a un sitio 505 puede comprender un marcador de afinidad 510. El polipéptido dirigido a un sitio puede comprender un dominio de unión a ácido nucleico 515. El dominio de unión a ácido nucleico 515 puede ser un ácido nucleico. En algunas realizaciones, el dominio de unión a ácido nucleico 515 y el polipéptido 505 dirigido a un sitio forman un complejo 531. El complejo 531 puede ponerse en contacto 525 con un ácido nucleico diana 530. En un aspecto preferido, el ácido nucleico diana 530 es ADN (por ejemplo, ADN genómico o ADNg). El complejo puede purificarse por afinidad 535 con un agente de captura 540. El agente de captura 540 puede unirse al marcador de afinidad 510 del polipéptido dirigido a un sitio 505. El agente de captura 540 puede comprender un segundO marcador de afinidad 545. El agente de captura 540 puede ser purificado por afinidad 550 uniéndose a un soporte sólido 555. En algunas realizaciones, el soporte sólido 555 es una perla recubierta con un reactivo de afinidad que puede unirse al marcador de afinidad 545 del agente de captura. Opcionalmente, el soporte sólido 555 puede unirse al marcador de afinidad 510 del polipéptido dirigido a un sitio 505 para facilitar la purificación. En algunas realizaciones, se pueden producir una o más series de purificación. Cada serie puede comprender poner en contacto un soporte sólido 555 con los marcadores de afinidad del polipéptido dirigido a un sitio 510 y/o el agente de captura 545. El complejo purificado por afinidad puede eluirse del ácido nucleico diana 530. El ácido nucleico diana puede prepararse posteriormente para su posterior procesamiento. El procesamiento puede incluir métodos de análisis cadena abajo, por ejemplo, secuenciación.
La FIGURA 6 representa un método ilustrativo de la divulgación. Un polipéptido dirigido a un sitio 605 puede comprender un marcador de afinidad 610. El polipéptido dirigido a un sitio 605 puede comprender un dominio de unión a ácido nucleico 615. El dominio de unión a ácido nucleico 615 puede ser un ácido nucleico. En algunas realizaciones, el dominio de unión a ácido nucleico 615 puede comprender un marcador de afinidad 620. En algunas realizaciones, el dominio de unión a ácido nucleico 615 y el polipéptido específico del sitio 605 pueden formar un complejo 631. El complejo 631 puede ponerse en contacto 625 con un ácido nucleico diana 630. En un aspecto preferido, el ácido nucleico diana 630 es ADN. El complejo 631 puede purificarse por afinidad 635 con un agente de captura 640. El agente de captura 640 puede ser un polipéptido dirigido a un sitio condicionalmente enzimáticamente inactivo. El agente de captura 640 puede ser una variante condicionalmente enzimáticamente inactiva de Csy4. El agente de captura 640 puede unirse al marcador de afinidad 620. El agente de captura 640 puede comprender un marcador de afinidad 645. El agente de captura 640 puede ser purificado por afinidad 650 uniéndose a un soporte sólido 655. En algunas realizaciones, el soporte sólido es una perla recubierta con un reactivo de afinidad que puede unirse al marcador de afinidad 645 del agente de captura 640. Opcionalmente, el soporte sólido 655 puede unirse al marcador de afinidad 610 del polipéptido dirigido a un sitio 605 para facilitar la purificación. En algunas realizaciones, pueden producirse dos series de purificación, comprendiendo cada serie poner en contacto un soporte sólido 655 con los marcadores de afinidad del polipéptido dirigido a un sitio 610 y/o el agente de captura 640. La escisión del marcador de afinidad 620 puede facilitar la elución 660 del ácido nucleico diana 630 del soporte sólido 655. El ácido nucleico diana 630 puede prepararse posteriormente para métodos de análisis posteriores cadena abajo tales como secuenciación.
Métodos
La divulgación proporciona métodos para la inmunoprecipitación y secuenciación de nucleasas (NIP-Seq). En algunas realizaciones, el método puede comprender a) poner en contacto una muestra de ácido nucleico con un complejo que comprende un polipéptido dirigido a un sitio enzimáticamente inactivo, un polipéptido dirigido a un sitio y un ácido nucleico dirigido a ácido nucleico. El complejo puede hibridarse con un ácido nucleico diana. El complejo puede capturarse con un agente de captura, y el ácido nucleico diana unido al complejo puede secuenciarse. En algunas realizaciones, el método puede comprender además determinar la identidad del sitio de unión fuera de la diana. El método se puede realizar usando cualquiera de los polipéptidos dirigidos a un sitio, ácidos nucleicos dirigidos a ácido nucleico y complejos de polipéptidos dirigidos a un sitio y ácidos nucleicos dirigidos a ácido nucleico tales como los descritos en el presente documento.
Los métodos se pueden realizar fuera de una célula. Por ejemplo, una muestra puede comprender ADN genómico purificado, lisado de células, tejido homogeneizado, plasma y similares. Los métodos se pueden realizar en células.
Los complejos de polipéptido dirigido a un sitio-ácido nucleico dirigido a ácido nucleico se pueden fijar o entrecruzar para formar complejos. Las células se pueden entrecruzar antes del lisado. Las células fijas o entrecruzadas pueden estabilizar los complejos de proteína-ADN en la célula. Los fijadores y agentes de entrecruzamiento adecuados pueden incluir, formaldehído, glutaraldehído, fijadores a base de etanol, fijadores a base de metanol, acetona, ácido acético, tetraóxido de osmio, dicromato de potasio, ácido crómico, permanganato de potasio, mercuriales, picratos, formol, paraformaldehído, agentes de entrecruzamiento de NHS-éster reactivos con amina tales como bis[sulfosuccinimidil]suberato (BS3), 3,3'-ditiobis[sulfosuccinimidilpropionato] (DTSSP), bis[sulfosuccinimidilsuccinato de etilenglicol (sulfo-EGS), glutarato de disuccinimidilo (DSG), propionato de ditiobis[succinimidilo] (DSP), suberato de disuccinimidilo (DSS), bis[succinimidilsuccinato] de etilenglicol (EGS), agentes de entrecruzamiento de NHS-éster/diazirina tales como NHS-diazirina, NHS-LC-diazirina, NHS-SS-diazirina, sulfo-NHS-diazirina, sulfo-NHS-LCdiazirina y sulfo-NHS-SS-diazirina.
El ácido nucleico (por ejemplo, ADN genómico) puede tratarse para fragmentar el ADN antes de la purificación por afinidad. La fragmentación se puede realizar a través de métodos físicos, mecánicos o enzimáticos. La fragmentación física puede incluir la exposición de un polinucleótido diana al calor o a la luz ultravioleta (UV). La disrupción mecánica puede usarse para cortar mecánicamente un polinucleótido diana en fragmentos del intervalo deseado. La cizalla mecánica se puede lograr a través de varios métodos conocidos en la técnica, que incluyen pipeteo repetitivo del polinucleótido diana, sonicación y nebulización. Los polinucleótidos diana también pueden fragmentarse usando métodos enzimáticos. En algunos casos, se puede realizar la digestión enzimática usando enzimas tales como las enzimas de restricción. Las enzimas de restricción pueden usarse para realizar una fragmentación específica o no específica de polinucleótidos diana. Los métodos pueden usar uno o más tipos de enzimas de restricción, descritas en general como enzimas de Tipo I, enzimas de Tipo II y/o enzimas de Tipo III. Las enzimas de Tipo II y Tipo III, en general, están disponibles en el mercado, y son bien conocidas en la técnica. Las enzimas de Tipo II y de Tipo III reconocen secuencias específicas de nucleótidos nucleotídicos dentro de una secuencia polinucleotídica bicatenaria (una "secuencia de reconocimiento" o "sitio de reconocimiento"). Tras la unión y el reconocimiento de estas secuencias, las enzimas de Tipo II y Tipo III escinden la secuencia de polinucleótidos. En algunos casos, la escisión dará lugar a un fragmento de polinucleótido con una parte de ADN monocatenario saliente, denominada "extremo adhesivo". En otros casos, la escisión no dará lugar a un fragmento con un saliente, creando un "extremo romo". Los métodos pueden comprender el uso de enzimas de restricción que generen extremos adhesivos o extremos romos. Los fragmentos de ácidos nucleicos también se pueden generar mediante técnicas de amplificación (por ejemplo, reacción en cadena de la polimerasa, reacción en cadena de la polimerasa de largo alcance, reacción en cadena de la polimerasa lineal, etc.).
Una vez fragmentados, los complejos que comprenden el polipéptido dirigido a un sitio pueden purificarse mediante incubación con un soporte sólido. Por ejemplo, si el polipéptido dirigido a un sitio comprende un marcador de biotina, el soporte sólido puede recubrirse con avidina o estreptavidina para unirse al marcador de biotina.
En algunas realizaciones, Una vez fragmentados, los complejos que comprenden el polipéptido dirigido a un sitio, el ácido nucleico diana y/o el ácido nucleico dirigido a ácido nucleico se purifican por incubación con un agente de captura. Un agente de captura puede referirse a cualquier agente que pueda unirse a un marcador de afinidad fusionado con el polipéptido dirigido a un sitio. Los ejemplos de agentes de captura pueden incluir biotina, estreptavidina y anticuerpos. Por ejemplo, si el marcador de afinidad fusionado con el polipéptido dirigido a un sitio es un marcador FLAG, entonces el agente de captura será un anticuerpo anti-marcador FLAG. En algunas realizaciones, el agente de captura puede comprender un marcador de afinidad (por ejemplo, biotina,estreptavidina).
En algunos casos, el agente de captura es una endorribonucleasa enzimáticamente inactiva. Por ejemplo, un agente de captura puede ser un polipéptido dirigido a un sitio enzimáticamente inactivo, una Csy4, Cas5 o Cas6 enzimáticamente inactiva.
El agente de captura se puede purificar con un soporte sólido. Por ejemplo, si el agente de captura comprende un marcador de biotina, la perla puede recubrirse con avidina o estreptavidina para unirse al agente de captura biotinilado.
En algunas realizaciones del método, se pueden realizar dos o más series de purificación. Se pueden realizar al menos 1, 2, 3, 4, 5, 6, 7 o más series de purificación. Se pueden realizar, como máximo, 1, 2, 3, 4, 5, 6, 7 o más series de purificación. Una primera serie de purificación puede comprender la purificación con un soporte sólido que pueda unirse al marcador de afinidad del agente de captura, y una segunda serie de purificación puede comprender la purificación con un soporte sólido que pueda unirse al marcador de afinidad del polipéptido dirigido a un sitio. Una primera serie de purificación puede comprender la purificación con un soporte sólido que pueda unirse al marcador de afinidad del polipéptido dirigido a un sitio, y una segunda serie de purificación puede comprender la purificación con un soporte sólido que se unirá al marcador de afinidad del agente de captura. El método puede usarse para optimizar la especificidad de unión de un polipéptido dirigido a un sitio realizando el método más de una vez.
El complejo capturado puede comprender un polipéptido dirigido a un sitio y un ácido nucleico diana. El ácido nucleico diana se puede eluir del complejo del polipéptido dirigido a un sitio mediante métodos tales como lavado con alto contenido de sal, precipitación en etanol, ebullición y purificación en gel.
El ADN eluido puede prepararse para el análisis de secuenciación (por ejemplo, cizalla, ligadura de adaptadores). La preparación para el análisis de secuenciación puede incluir la generación de bancos de secuenciación del ácido nucleico diana eluido. El análisis de secuenciación puede determinar la identidad y frecuencia de los sitios de unión fuera de la diana de los polipéptidos dirigidos a un sitio. La determinación de las secuencias también se realizará usando métodos que determinen muchas secuencias de ácido nucleico (normalmente, de miles a miles de millones) de una manera intrínsecamente paralela, donde se leen muchas secuencias preferentemente en paralelo mediante un proceso en serie de alto rendimiento. Dichos métodos incluyen, pero sin limitación, pirosecuenciación (por ejemplo, como la comercializada por 454 Life Sciences, Inc., Branford, Conn.); secuenciación por ligadura (por ejemplo, como la comercializada en la tecnología SOLiD™, Life Technology, Inc., Carlsbad, Calif.); La secuenciación por síntesis usando nucleótidos modificados (tales como los comercializados en la tecnología TruSeq™ y HiSeq™ por Illumina,
Inc., San Diego, Calif., HeliScope™ de Helicos Biosciences Corporation, Cambridge, Mass. y PacBio RS de Pacific Biosciences of California, Inc., Menlo Park, Calif.), secuenciación mediante tecnologías de detección de iones (Ion Torrent, Inc., South San Francisco, Calif.); secuenciación de nanobolas de ADN (Complete Genomics, Inc., Mountain View, Calif.); tecnologías de secuenciación basadas en nanoporos (por ejemplo, las desarrolladas por Oxford Nanopore Technologies, LTD, Oxford, Reino Unido) y otros métodos de secuenciación altamente paralelizados conocidos.
En algunas realizaciones, el método comprende además recopilar datos y almacenar datos. Los datos pueden ser legibles por máquina y pueden almacenarse y/o recopilarse en el servidor de un ordenador (por ejemplo, Figura 31 y Ejemplo 27).
Métodos de detección de variantes de secuencia en ácidos nucleicos
Visión general
En algunas realizaciones, los métodos de la divulgación proporcionan la detección de variantes de secuencia en ácidos nucleicos. El método se puede realizar usando cualquiera de los polipéptidos dirigidos a un sitio, ácidos nucleicos dirigidos a ácido nucleico y complejos de polipéptidos dirigidos a un sitio y ácidos nucleicos dirigidos a ácido nucleico tales como los descritos en el presente documento. Como se representa en la Figura 7, una muestra de ácido nucleico 705 se puede ligar 720 con un marcador de ácido nucleico 710. El marcador de ácido nucleico puede ser un ARN guía sencillo. El marcador de ácido nucleico puede comprender un ARNcr. El marcador de ácido nucleico puede comprender un marcador detectable 715. En conjunto, la muestra de ácido nucleico 705 ligada al marcador de ácido nucleico 710 puede denominarse muestra de prueba marcada 721. La muestra de prueba marcada 721 puede ponerse en contacto 725 con una matriz 740 que comprenda oligonucleótidos inmovilizados 735. Los oligonucleótidos inmovilizados 735 pueden denominarse banco de ácido nucleico. Los oligonucleótidos 735 pueden ser ADN bicatenario. Los oligonucleótidos 735 pueden comprender un marcador detectable 730. Los miembros individuales de la muestra de prueba marcada 721 pueden hibridarse 745 con los oligonucleótidos 735 con los que comparten suficiente complementariedad para facilitar la hibridación. La cantidad de hibridación puede cuantificarse comparando las intensidades de los dos marcadores detectables 715 y 730. Por ejemplo, los oligonucleótidos hibridados pueden mostrar dos marcadores detectables. Los oligonucleótidos no hibridados pueden mostrar un marcador detectable 730. La muestra hibridada puede ponerse en contacto con un polipéptido dirigido a un sitio 750. El polipéptido dirigido a un sitio puede escindir 755 los oligonucleótidos 735 en la matriz 740 que se han hibridado con miembros de la muestra de prueba marcada 721. La escisión por el polipéptido dirigido a un sitio puede permitir que los miembros hibridados de la muestra de prueba marcada 721 sean eliminados. Tras la escisión por el polipéptido dirigido a un sitio 750, solo permanecerán en la matriz los marcadores detectables 760 de oligonucleótidos no hibridados. El marcador detectable 760 restante puede cuantificarse. La cuantificación de los marcadores detectables 760 restantes se puede correlacionar con qué secuencias se representaron en la muestra de ácido nucleico 705 y cuáles no. Los oligonucleótidos que no muestran un marcador detectable 760 restante corresponden a secuencias representadas en la muestra de ácido nucleico 705. Los oligonucleótidos que muestran un marcador detectable 760 restante corresponden a secuencias que no estaban representadas en la muestra de ácido nucleico 705.
En algunas realizaciones, una muestra de ácido nucleico 805 se puede ligar 820 con un marcador de ácido nucleico 810. El marcador de ácido nucleico puede ser un ARN guía sencillo. El marcador de ácido nucleico puede comprender un ARNcr. El marcador de ácido nucleico puede comprender un marcador detectable 815. En conjunto, la muestra de ácido nucleico ligada al marcador de ácido nucleico puede denominarse muestra de prueba marcada 821. La muestra de prueba marcada 821 puede ponerse en contacto 825 con una matriz 840 que comprenda oligonucleótidos inmovilizados 835. Los oligonucleótidos inmovilizados pueden denominarse banco de ácido nucleico. Los oligonucleótidos 835 pueden ser ADN bicatenario. Los miembros individuales de la muestra de prueba marcada 821 pueden hibridarse 845 con los oligonucleótidos 835 con los que comparten suficiente complementariedad para facilitar la hibridación. La muestra hibridada puede ponerse en contacto con un polipéptido dirigido a un sitio 850. El polipéptido dirigido a un sitio puede escindir 855 los oligonucleótidos 835 en la matriz 840 que se han hibridado con miembros de la muestra de prueba marcada 821. La escisión por el polipéptido dirigido 850 a un sitio puede permitir que los miembros hibridados de la muestra de prueba marcada 821 sean eliminados. La escisión por el polipéptido dirigido a un sitio 850 puede permitir que una parte del oligonucleótido inmovilizado sea escindida y separada de la matriz 860. Los oligonucleótidos escindidos separados 860 pueden ligarse 865 a los adaptadores apropiados 870 para la secuenciación. La secuenciación de los oligonucleótidos escindidos 860 puede determinar las secuencias representadas en la muestra de ácido nucleico 805.
En algunas realizaciones, se puede generar un banco de ácido nucleico para el análisis de secuenciación usando plataformas de secuenciación de alto rendimiento disponibles en el mercado. El banco puede comprender ácidos nucleicos que pueden comprender una o más marcadores de secuenciación 930 y una secuencia diana 945. La secuencia diana 945 puede ser una secuencia que se puede representar en una muestra de ácido nucleico 905. Una secuencia diana 945 puede comprender una secuencia de motivo adyacente al protoespaciador (PAM). Opcionalmente, los ácidos nucleicos de un banco de ácido nucleico pueden comprender una o más secuencias de polinucleótidos de identificación 935, y una o más secuencias de extensión 940. En este aspecto, una muestra de ácido nucleico 905 se puede ligar 920 con un marcador de ácido nucleico 910. El marcador de ácido nucleico puede
ser un ARN guía sencillo. El marcador de ácido nucleico puede comprender un ARNcr. Opcionalmente, el marcador de ácido nucleico puede comprender un marcador de afinidad 915. En conjunto, la muestra de ácido nucleico ligada al marcador de ácido nucleico puede denominarse muestra de prueba marcada 921. La muestra de prueba marcada 921 puede ponerse en contacto 925 con un banco de ácido nucleico. La muestra de prueba marcada 921 puede hibridarse con un ácido nucleico en el banco de ácido nucleico, formando un complejo 946. La muestra de prueba marcada hibridada y el banco de ácido nucleico pueden ponerse en contacto con un polipéptido dirigido a un sitio 950. El polipéptido dirigido a un sitio 950 puede escindir los miembros del banco de ácido nucleico hibridado. Los miembros del banco de ácido nucleico escindidos 965 pueden separarse de los miembros no escindidos. Los miembros no escindidos pueden ser sometidos a análisis de secuencia. El análisis de secuenciación puede determinar qué secuencias se representaron en la muestra de ácido nucleico 905. Por ejemplo, las secuencias de los miembros no escindidos pueden corresponder a secuencias que no se representaron en la muestra de ácido nucleico 905. Estas secuencias se pueden eliminar de las secuencias conocidas del banco de ácido nucleico. Las secuencias resultantes pueden ser las secuencias de los miembros escindidos 965 del banco de ácido nucleico que pueden corresponder a secuencias que se representaron en la muestra de ácido nucleico 905.
El polipéptido dirigido a un sitio 950 puede comprender un marcador de afinidad 955. Opcionalmente, el polipéptido dirigido a un sitio 950 puede ser una variante enzimáticamente inactiva de un polipéptido dirigido a un sitio. En algunas realizaciones, un polipéptido dirigido a un sitio enzimáticamente inactivo puede ponerse en contacto con un banco de ácido nucleico hibridado (por ejemplo, complejo 946). El polipéptido dirigido a un sitio puede unirse pero no puede escindir los miembros del banco de ácido nucleico hibridado. El polipéptido dirigido a un sitio puede purificarse por afinidad 970 con un agente de captura 975 que puede unirse al marcador de afinidad 955. Opcionalmente, el complejo 946 puede purificarse por afinidad con un agente de captura que pueda unirse al marcador de afinidad 915. Los miembros del banco de ácido nucleico purificado por afinidad pueden someterse a análisis de secuenciación. En este aspecto, los miembros del banco de ácido nucleico secuenciados pueden corresponder a secuencias que están representadas en la muestra de ácido nucleico 905.
Secuenciación
Los métodos de detección de variantes de secuencia pueden comprender la secuenciación de las variantes. La determinación de las secuencias también se puede realizar usando métodos que determinen muchas secuencias de ácido nucleico (normalmente, de miles a miles de millones) de una manera intrínsecamente paralela, donde se leen muchas secuencias preferentemente en paralelo mediante un proceso en serie de alto rendimiento. Dichos métodos pueden incluir, pero sin limitación, pirosecuenciación (por ejemplo, como la comercializada por 454 Life Sciences, Inc., Branford, Conn.); secuenciación por ligadura (por ejemplo, como la comercializada en la tecnología SOLiD™, Life Technology, Inc., Carlsbad, Calif.); La secuenciación por síntesis usando nucleótidos modificados (tales como los comercializados en la tecnología TruSeq™ y HiSeq™ por Illumina, Inc., San Diego, Calif., HeliScope™ de Helicos Biosciences Corporation, Cambridge, Mass. y PacBio r S de Pacific Biosciences of California, Inc., Menlo Park, Calif.), secuenciación mediante tecnologías de detección de iones (Ion Torrent, Inc., South San Francisco, Calif.); secuenciación de nanobolas de ADN (Complete Genomics, Inc., Mountain View, Calif.); tecnologías de secuenciación basadas en nanoporos (por ejemplo, las desarrolladas por Oxford Nanopore Technologies, LTD, Oxford, Reino Unido), secuenciación capilar (por ejemplo, comercializada en MegaBACE por Molecular Dynamics), secuenciación electrónica, secuenciación de moléculas individuales (por ejemplo, tal como la comercializada en tecnología SMRT™ de Pacific Biosciences, Menlo Park, Calif.), secuenciación microfluídica de gotas, secuenciación por hibridación (tal como la comercializada por Affymetrix, Santa Clara, California), secuenciación de bisulfato y otros métodos de secuenciación altamente paralelizados conocidos.
PCR en tiempo real
Los métodos de detección de variantes de secuencia pueden comprender la detección de las variantes usando PCR en tiempo real. La determinación de la secuencia se puede realizar mediante una reacción en cadena de la polimerasa en tiempo real (RT-PCR, también conocida como PCR cuantitativa (QPCR)) que puede detectar una cantidad de ácido nucleico amplificable presente en una muestra. La QPCR es una técnica basada en la reacción en cadena de la polimerasa, y puede usarse para amplificar y cuantificar simultáneamente un ácido nucleico diana. La QPCR puede permitir tanto la detección como la cuantificación de una secuencia específica de una muestra de ácido nucleico diana. El procedimiento puede seguir el principio general de la reacción en cadena de la polimerasa, con la característica adicional de que el ácido nucleico diana amplificado puede cuantificarse a medida que se va acumulando en la reacción en tiempo real tras cada ciclo de amplificación. Puede haber métodos de cuantificación: (1) el uso de colorantes fluorescentes que se intercalan con ácido nucleico diana bicatenario; y (2) sondas de oligonucleótidos de ADN modificadas que producen fluorescencia cuando se hibridan con un ácido nucleico diana complementario. En el primer método, un colorante de unión a ácido nucleico diana puede unirse a todos los ácidos nucleicos bicatenarios (bc) en la PCR, produciendo la fluorescencia del colorante. Por lo tanto, un aumento en el producto de ácido nucleico durante la PCR puede conducir a un aumento en la intensidad de fluorescencia y puede medirse en cada ciclo, permitiendo así que se cuantifiquen las concentraciones de ácido nucleico. La reacción se puede preparar de manera similar a una reacción de PCR convencional, con la adición de colorante fluorescente de ácido nucleico (bc). La reacción se puede ejecutar en un termociclador, y tras cada ciclo, se pueden medir los niveles de fluorescencia con un detector; el colorante solo puede emitir fluorescencia cuando se una al ácido nucleico (bc) (es decir, el producto de PCR). Con
referencia a una dilución patrón, se puede determinar la concentración de ácido nucleico (bc) en la PCR. Los valores obtenidos no pueden tener unidades absolutas asociadas. La comparación de una muestra de ADN/ARN medida con una dilución patrón puede dar una fracción o proporción de la muestra con respecto al patrón, lo que permite comparaciones relativas entre diferentes tejidos o condiciones experimentales. Para garantizar la precisión de la cuantificación, se puede normalizar la expresión de un gen diana con respecto a un gen expresado de forma estable. Esto puede permitir la corrección de posibles diferencias en la cantidad o calidad de ácido nucleico entre muestras. El segundo método puede usar una sonda basada en ARN o ADN específica de la secuencia para cuantificar solo el ácido nucleico que contiene la secuencia de la sonda; por tanto, el uso de la sonda indicadora puede aumentar la especificidad y puede permitir la cuantificación incluso en presencia de alguna amplificación de ácido nucleico no específica. Esto puede permitir la multiplexación (es decir, analizar varios genes en la misma reacción usando sondas específicas con marcadores de diferentes colores), siempre que todos los genes se amplifiquen con una eficiencia similar. Este método puede llevarse a cabo con una sonda basada en ácido nucleico con un indicador fluorescente (por ejemplo, 6-carboxifluoresceína) en un extremo y un inhibidor (por ejemplo, 6-carboxitetrametilrodamina) de la fluorescencia en el extremo opuesto de la sonda. La proximidad del indicador al desactivador puede evitar la detección de su fluorescencia. La rotura de la sonda por la actividad exonucleasa de 5' a 3' de una polimerasa (por ejemplo, la polimerasa Taq) puede romper la proximidad entre el indicador el desactivador y, por lo tanto, puede permitir que no se apague la emisión de fluorescencia, que se puede detectar. Un aumento en el producto diana de la sonda indicadora en cada ciclo de PCR puede producir un aumento proporcional de la fluorescencia debido a la rotura de la sonda y a la liberación del indicador.
La reacción se puede preparar de manera similar a una reacción de PCR convencional, y se puede añadir la sonda indicadora. A medida que comienza la reacción, durante la etapa de hibridación de la PCR, tanto la sonda como los cebadores pueden hibridarse al ácido nucleico diana. La polimerización de una nueva cadena de ADN se puede iniciar a partir de los cebadores, y una vez que la polimerasa alcanza a la sonda, su exonucleasa 5'-3' puede degradar la sonda, separando físicamente el indicador fluorescente del desactivador, lo que produce un aumento de la fluorescencia. La fluorescencia se puede detectar y medir en un termociclador de PCR en tiempo real, y el aumento geométrico de la fluorescencia puede corresponder al aumento exponencial del producto que se usa para determinar el ciclo umbral en cada reacción. Las concentraciones relativas de ADN presentes durante la fase exponencial de la reacción se pueden determinar rep'representando la fluorescencia frente al número de ciclos en una escala logarítmica (por lo que una cantidad que aumenta exponencialmente puede dar una línea recta). Se puede determinar un umbral para la detección de la fluorescencia por encima del fondo. El ciclo en el que la fluorescencia de una muestra atraviesa el umbral se puede denominar umbral de ciclo, Ct. Dado que la cantidad de ADN puede duplicarse en cada ciclo durante la fase exponencial, se pueden calcular cantidades relativas de ADN (por ejemplo, una muestra con un Ct de 3 ciclos antes que otro tiene 23 = 8 veces más plantilla). Las cantidades de ácido nucleico (por ejemplo, ARN o ADN) se pueden determinar comparando los resultados con una curva patrón producida por una PCR en tiempo real de diluciones en serie (por ejemplo, sin diluir, 1:4, 1:16, 1:64) de un cantidad conocida de ácido nucleico. La reacción de QPCR puede implicar un enfoque de fluoróforo doble que aprovecha la transferencia de energía de resonancia de fluorescencia (FRET), (por ejemplo, sondas de hibridación LIGHTCYCLER, en donde dos sondas oligonucleotídicas pueden hibridarse con el amplicón). Los oligonucleótidos pueden diseñarse para hibridarse en una orientación de cabeza a cola con los fluoróforos separados a una distancia que sea compatible con la transferencia eficaz de energía. Otros ejemplos de oligonucleótidos marcados que están estructurados para emitir una señal cuando se unen a un ácido nucleico o que se incorporan a un producto de extensión incluyen: sondas SCORPIONS, cebadores Sunrise (o AMPLIFLOUR) y cebadores LUX y sondas MOLECULAR BEACONS. La reacción de QPCR puede usar la metodología fluorescente Taqman y un instrumento capaz de medir la fluorescencia en tiempo real (por ejemplo, ABI Prism 7700 Sequence Detector). La reacción de Taqman puede usar una sonda de hibridación marcada con dos colorantes fluorescentes diferentes. Un colorante puede ser un colorante indicador (6-carboxifluoresceína), el otro puede ser un colorante desactivador (6-carboxi-tetrametilrodamina). Cuando la sonda está intacta, puede producirse una transferencia de energía fluorescente, y la emisión fluorescente del colorante indicador puede ser absorbida por el colorante desactivador. Durante la fase de extensión del ciclo de PCR, la sonda de hibridación fluorescente se puede escindir mediante actividad nucleolítica 5'-3' de la ADN polimerasa. En la escisión de la sonda, la emisión de colorante indicador ya no puede transferirse eficazmente al colorante desactivador, lo que produce un aumento de los espectros de emisión fluorescente del colorante indicador. Se puede usar cualquier método de cuantificación de ácido nucleico, incluyendo los métodos en tiempo real o los métodos de detección de un solo punto para cuantificar la cantidad de ácido nucleico en la muestra. La detección se puede realizar con varias metodologías diferentes (por ejemplo, tinción, hibridación con una sonda marcada; incorporación de cebadores biotinilados seguidos de detección de conjugado de avidina-enzima; incorporación de trifosfatos desoxinucleotídicos marcados con 32P, tales como dCTP o dATP, en el segmento amplificado. La cuantificación puede o no incluir un etapa de amplificación. La cuantificación no puede ser experimental.
Micromatriz
Los métodos de detección de variantes de secuencia pueden comprender secuenciar y/o detectar las variantes usando una micromatriz. Las micromatrices pueden usarse para determinar el nivel de expresión de una pluralidad de genes en una muestra de ácido nucleico. Las micromatrices se pueden usar para determinar la identidad de secuencia de una pluralidad de secuencias de una muestra de ácido nucleico.
Una micromatriz puede comprender un sustrato. Los sustratos pueden incluir, pero sin limitación, vidrio y vidrio modificado o funcionalizado, plásticos (incluidos acrílicos, poliestireno y copolímeros de estireno y otros materiales, polipropileno, polietileno, polibutileno, poliuretanos, Teflon™ y similares), polisacáridos, nailon y nitrocelulosa, resinas, sílice o materiales a base de sílice, incluidos el silicio y el silicio modificado, carbono, metales, vidrios inorgánicos y plásticos.
Las micromatrices pueden comprender una pluralidad de sondas polinucleotídicas. Una micromatriz puede comprender aproximadamente 1, 10, 100, 1000, 5000, 10000, 20000, 30000, 40000, 50000, 60000, 70000, 80000, 90000, 100000, 110000, 120000 o más sondas.
Las sondas pueden tener al menos 10, 20, 30, 40, 50, 60, 70, 80, 90, 100, 110, 120, 130, 140 nucleótidos o más de longitud.
En algunas realizaciones, las sondas pueden comprender información de secuencia para un conjunto específico de genes y/o especies. Una sonda puede ser complementaria a una secuencia de ácido nucleico que codifica una proteína hospedadora. Una sonda puede ser complementaria a una secuencia de ácido nucleico no codificante. Una sonda puede ser complementaria a una secuencia de ADN. Una sonda puede ser complementaria a una secuencia de ARN.
Las sondas se pueden inmovilizar en una micromatriz. La inmovilización de polinucleótidos en un sustrato sólido se puede realizar mediante la síntesis directa (por ejemplo, síntesis fotolitográfica) de polinucleótidos en un sustrato sólido o por inmovilización (manchado) de polinucleótidos sintetizados previamente en regiones predeterminadas de un sustrato sólido. Los polinucleótidos se pueden inmovilizar en un sustrato de micromatriz activando una superficie de un sustrato sólido con un grupo funcional nucleófilo (por ejemplo, un grupo amino), acoplando biomoléculas (por ejemplo, polinucleótidos) activadas con un buen grupo saliente al sustrato sólido activado superficialmente, y eliminando los reactivos no reaccionados. Las sondas se pueden inmovilizar en una perla conjugada además a través de una unión covalente o iónica a un soporte sólido. Las sondas se pueden inmovilizar sobre un sustrato usando una película específica que tenga una baja conductividad y una temperatura de fusión baja, es decir, una película de oro. Una radiación electromagnética aplicada puede fundirse y puede ablacionar la película en el sitio de impacto. La película puede estar en contacto con una dispersión coloidal y, al fundirse, puede generar un flujo de convección en el sitio de reacción, lo que conduce a la adhesión de una partícula insoluble en la dispersión a un sitio fundido específicamente.
Una micromatriz puede analizar una muestra de ácido nucleico que comprenda ácidos nucleicos de identidad desconocida (por ejemplo, muestra de prueba) comparando la muestra de ácido nucleico de identidad desconocida con una muestra de referencia. Se puede preparar una muestra de ácido nucleico a partir de ADN (por ejemplo, ADN aislado, ADN genómico, ADN extracromasómico). Se puede preparar una muestra de ácido nucleico a partir de ARN. El ARN se puede transcribir inversamente en ADN con un cebador específico del gen o un cebador universal. El ADN transcrito inversamente (por ejemplo, ADNc) puede tratarse con Rnasa o una base (por ejemplo, NaOH) para hidrolizar el ARN. El ADNc puede marcarse con un colorante (por ejemplo, Cy3, Cy5) con química de W-hidroxisuccinimida o químicas de marcaje similares. Los colorantes fluorescentes adecuados pueden incluir varios colorantes comerciales y derivados de colorantes tales como los que se denominan Alexa, Fluoresceína, Rodamina, FAM, TAMRA, Joe, ROX, Texas Red, BODIPY, FITC, Oregon Green, Lisamina y otros. La muestra de referencia se puede marcar con un colorante diferente al de la muestra de prueba.
La muestra de prueba y la muestra de referencia se pueden aplicar a una micromatriz para poner en contacto múltiples puntos simultáneamente. La muestra de prueba y la muestra de referencia se pueden aplicar a la micromatriz en condiciones de hibridación que pueden permitir que los ácidos nucleicos de la muestra de ácido nucleico se unan a una sonda complementaria o en la micromatriz. Se pueden realizar varias etapas de reacción con las moléculas unidas en la micromatriz, incluyendo la exposición de moléculas reactivas unidas a las etapas de lavado. Se puede controlar el progreso o el resultado de la reacción en cada punto (por ejemplo, sonda) en la micromatriz para caracterizar la muestra de ácido nucleico inmovilizada en el chip. En general, el análisis de micromatrices puede requerir un período de incubación que puede variar de minutos a horas. La duración del período de incubación puede depender del ensayo, y puede determinarse por varios factores, tales como el tipo de reactivo, el grado de mezcla, el volumen de la muestra, el número de copias diana y la densidad de la matriz. Durante el período de incubación, los ácidos nucleicos de la muestra de ácido nucleico pueden estar en contacto íntimo con las sondas de micromatrices.
La detección se puede realizar usando un instrumento de barrindo confocal con excitación láser y detección de tubo fotomultiplicador, tal como el ScanArray 3000 proporcionado por GSI Lumonics (Bellerica, MA). Para implementar el método, se pueden usar sistemas de detección fluorescente confocales y no confocales tales como los proporcionados por Axon Instruments (Foster City, CA), Genetic MicroSystems (Santa Clara, CA), Molecular Dynamics (Sunnyvale, CA) y Virtek (Woburn, MA). Los sistemas de detección alternativos pueden incluir sistemas de barrido que usan láseres en estado gaseoso, diodo y sólido, así como aquellos que usan otros varios tipos de fuentes de iluminación, tales como bombillas de xenón y halógenas. Además de los tubos fotomultiplicadores, los detectores pueden incluir cámaras que usan dispositivos de acoplamiento de carga (CCD) y chips complementarios de silicio de óxido de metal (CMOS).
Se puede comparar la proporción de las intensidades de los dos colorantes de la muestra de prueba y la muestra de
referencia para cada sonda. La intensidad de la señal detectada procedente de un punto de micromatriz dado puede ser directamente proporcional al grado de hibridación de un ácido nucleico de la muestra a la sonda en un punto dado (por ejemplo, un punto comprende una sonda). El análisis de las intensidades de fluorescencia de las micromatrices hibridadas puede incluir la segmentación de los puntos, la determinación del fondo (y la posible sustracción), la eliminación de puntos malos, seguido de un método de normalización para corregir cualquier ruido restante. Las técnicas de normalización pueden incluir la normalización global en todos los puntos o un subconjunto de los puntos, tal como los genes constitutivos, el desplazamiento prelogarítmico para obtener mejores coincidencias de referencia, o en el caso de dos (o más) hibridaciones de canales que encuentran el mejor ajuste que ayuda a dar una gráfica de M frente a A centrada en torno a M = 0 y/o que ayuda a dar una gráfica del log (Rojo) frente al log (Verde) centrada en torno A LA diagonal con la menor propagación. La gráfica de M frente a A también se puede denominar gráfica de R frente a I, en la que R es una proporción, tal como R = log2(Rojo/Verde) e I es una intensidad, tal como I = log VRcd* Verde. La escala, el desplazamiento, los mejores ajustes a través de diagramas de dispersión, etc. pueden ser técnicas usadas para normalizar conjuntos de datos de micromatrices y proporcionar una mejor base para el análisis posterior. La mayoría de estos métodos de normalización pueden tener algunas hipótesis subyacentes (tales como "la mayoría de los genes dentro del estudio no varían mucho").
Ácidos nucleicos marcados y métodos de uso
Visión general
La divulgación proporciona kits, métodos y composiciones para ácidos nucleicos dirigidos a ácido nucleico marcados, como se describe en el presente documento. La Figura 10 representa un ejemplo de ácido nucleico dirigido a ácido nucleico 1005 de la divulgación. Un ácido nucleico dirigido a ácido nucleico puede comprender una o más secuencias no nativas (por ejemplo, marcadores) 1010/1015. Un ácido nucleico dirigido a ácido nucleico puede comprender una secuencia no nativa 1010/1015 en el extremo 3', el extremo 5' o ambos extremos 3' y 5' del ácido nucleico dirigido a ácido nucleico.
En algunos casos, un ácido nucleico dirigido a ácido nucleico puede ser ácido nucleico dirigido a ácido nucleico tal como se describe en el presente documento, y comprender una o más secuencias no nativas, tales como en el extremo 3', el extremo 5' o ambos extremos 3' y 5' del ácido nucleico dirigido a ácido nucleico.
En algunos casos, el ácido nucleico dirigido a ácido nucleico es un ácido nucleico dirigido a ácido nucleico guía doble tal como se describe en el presente documento, y tal como se representa en la Figura 11. Un ácido nucleico dirigido a ácido nucleico guía doble puede comprender dos moléculas de ácido nucleico 1101/1110. Un ácido nucleico dirigido a ácido nucleico guía doble puede comprender una pluralidad de secuencias no nativas 1115/1120/1125/1130. La secuencia no nativa se puede ubicar en el extremo 3', el extremo 5' o ambos extremos 3' y 5' de cada molécula del ácido nucleico dirigido a ácido nucleico. Por ejemplo, la secuencia no nativa puede estar situada en el extremo 3', extremo 5' o en ambos extremos 3' y 5' de la primera molécula de ácido nucleico 1105. La secuencia no nativa se puede ubicar en el extremo 3', extremo 5' o ambos extremos 3' y 5' de la segunda molécula 1110. Un ácido nucleico dirigido a ácido nucleico puede comprender una o más secuencias no nativas en cualquiera de las configuraciones enumeradas en la Figura 11.
La divulgación proporciona métodos de uso de ácidos nucleicos dirigidos a ácido nucleico marcados. El método se puede realizar usando cualquiera de los polipéptidos dirigidos a un sitio, ácidos nucleicos dirigidos a ácido nucleico y complejos de polipéptidos dirigidos a un sitio y ácidos nucleicos dirigidos a ácido nucleico tales como los descritos en el presente documento. En algunos casos, una pluralidad de ácidos nucleicos dirigidos a ácido nucleico marcados pueden ponerse en contacto con una pluralidad de ácidos nucleicos diana. La Figura 12 representa un método de uso ilustrativo para los ácidos nucleicos dirigidos a ácido nucleico marcados. Un ácido nucleico dirigido a ácido nucleico marcado puede comprender un espaciador 1210 que puede hibridarse con un ácido nucleico diana 1205. El ácido nucleico dirigido a ácido nucleico puede comprender una secuencia no nativa (por ejemplo, marcador) 1220. La secuencia no nativa 1220 puede ser una secuencia de unión de proteínas de unión a ARN. En algunos casos, la secuencia no nativa 1220 puede ser una secuencia de unión de proteína de unión a RNA CRISPR. La secuencia no nativa 1220 puede estar unida por una proteína de unión a ARN 1215. La proteína de unión a ARN 1215 puede comprender una secuencia no nativa 1225 (por ejemplo, una fusión, es decir, la proteína de unión a ARN 1215 puede ser un polipéptido de fusión). La secuencia no nativa (por ejemplo, fusión) 1225 puede alterar la transcripción del ácido nucleico diana y/o un ácido nucleico exógeno. La secuencia no nativa (por ejemplo, fusión) 1225 puede comprender una primera parte de un sistema dividido.
En algunas realizaciones, un segundo ácido nucleico dirigido a ácido nucleico, que comprende un segundo espaciador 1240, que puede hibridarse con un segundo ácido nucleico diana 1245, puede comprender una segunda secuencia no nativa (por ejemplo, marcador) 1250. La segunda secuencia no nativa (por ejemplo, marcador) 1250 puede ser una secuencia de unión de proteínas de unión a ARN. La segunda secuencia no nativa (por ejemplo, marcador) 1250 puede ser una secuencia de unión de proteínas de unión a ARN CRISPR. La segunda secuencia no nativa 1250 puede estar unida por una proteína de unión a ARN 1235. La proteína de unión a ARN puede comprender una secuencia no nativa 1230 (por ejemplo, fusión, es decir, la proteína de unión a ARN 1235 puede ser una fusión). La secuencia no nativa 1230 (por ejemplo, fusión) puede ser una segunda parte de un sistema dividido.
En algunos casos, la primera parte del sistema dividido 1225 y la segunda parte del sistema dividido 1230 pueden estar cercanas entre sí en el espacio, de manera que la primera parte del sistema dividido 1225 y la segunda parte del sistema dividido 1230 interactúan 1255 para formar un sistema dividido activo 1260. Un sistema dividido activo 1260 puede referirse a un sistema no dividido, en donde la primera parte y la segunda parte forman una pieza completa del sistema dividido. La activación del sistema dividido puede indicar que dos ácidos nucleicos diana 1205/1245 están muy juntos entre sí en el espacio.
Métodos
La divulgación proporciona métodos para poner en contacto un ácido nucleico diana con un complejo que comprende un polipéptido dirigido a un sitio y un ácido nucleico dirigido a ácido nucleico, e introducir una o más proteínas efectoras, en donde la una o más proteínas efectoras comprenden una secuencia no nativa y pueden unirse al ácido nucleico dirigido a ácido nucleico modificado. Una proteína efectora puede referirse a cualquier proteína con un efecto funcional. Por ejemplo, una proteína efectora puede comprender actividad enzimática, remodelar moléculas biológicas (por ejemplo, chaperonas plegables), ser una proteína de armazón y/o unirse a una molécula pequeña o metabolito. La proteína efectora puede modificar el ácido nucleico diana (por ejemplo, por escisión, modificación enzimática, modificación de la transcripción). Los métodos de la divulgación proporcionan el uso de las composiciones de la divulgación tales como biosensores. Por ejemplo, los complejos (por ejemplo, los que comprenden un ácido nucleico dirigido a ácido nucleico modificado, un polipéptido dirigido a un sitio y/o una proteína efectora) se pueden usar para controlar los eventos de movilidad genética, detectar cuándo las secuencias están muy juntas en un espacio tridimensional, y alterar condicionalmente la transcripción.
Evento de movilidad genética
La divulgación proporciona métodos para determinar la existencia de un evento de movilidad genética. El método se puede realizar usando cualquiera de los polipéptidos dirigidos a un sitio, ácidos nucleicos dirigidos a ácido nucleico y complejos de polipéptidos dirigidos a un sitio y ácidos nucleicos dirigidos a ácido nucleico tales como los descritos en el presente documento. Un evento de movilidad genética puede comprender, por ejemplo, una translocación, una recombinación, una integración, una transposición, un evento horizontal de transferencia génica, una transformación, una transducción, una conjugación, un evento de conversión génica, una duplicación, una translocación, una inversión, una eliminación, una sustitución o cualquier combinación de los mismos.
Un evento de movilidad genética puede comprender una recombinación entre genes. La recombinación puede conducir a productos génicos perjudiciales (por ejemplo, la recombinación BCR-ABL que puede contribuir al cáncer de mama). La recombinación puede incluir, por ejemplo, recombinación homóloga, recombinación no homóloga (por ejemplo, unión de extremos no homólogos) y la recombinación V(D)J. La recombinación puede referirse al cruce cromosómico. La recombinación puede ocurrir durante la profase I de la meiosis (por ejemplo, sinapsis). La recombinación puede comprender la rotura bicatenaria de las cadenas de ADN de ácido nucleico, seguida de la formación de una unión de holliday por recombinasas que pueden catalizar el intercambio de las cadenas de ADN.
Los eventos de movilidad genética pueden causar enfermedades. Por ejemplo, la leucemia mielógena crónica puede ser el resultado de un evento de movilidad genética. La translocación entre los cromosomas 9 y 22 puede producir un gen de fusión BCR-Abl1, que puede provocar el alargamiento de un cromosoma (por ejemplo, 9) y el acortamiento de otro cromosoma (por ejemplo, 22, es decir, el cromosoma Filadelfia). La translocación de BCR-Abl1 puede conducir a la producción de una proteína de fusión BCR-Abl que puede interactuar con los receptores (por ejemplo, el receptor de interleucina-3) para potenciar la división celular, lo que conduce a la leucemia mielógena crónica (LMC). Otros eventos de movilidad genética ilustrativos no limitantes incluyen BRD3-NUT, BRD4-NUT, KIAA1549-BRAF, FIG/GOPC-ROS1, ETV6-NTRK3, BCAS4-BCAS3, TBL1XR1-RGS17, ODZ4-NRG1, MALAT1-TFEB, APSCR1-TFE3, PRCC-TFE3, CLTC-TFE3, NONO-TFE3, SFPQ-TFE3, ETV6-NRTK3, EML4-ALK, EWSR1-ATF1, MN1-ETV6, CTNNB1-PLAG1, LIFR-PLAG1, TCEA1-PLAG1, FGFr1-PLAG1, CHCHD7-PLAG1, HMGA2-FHIT, HMGA-NFIB, CRTC1-MAMl2, CRCT3-MAML2, EWSR1-POUF5F1, TMPRSS1-ERG, TMPRSS2-ETV4, TMPRSS2-ETV5, HNRNPA2B1 -ETV1, HERV-K-ETV1, C150RF21-ETV1, SLC45A3-ETV1, SLC45A3-ETV5, SLC45A3-ELK4, KLK2-ETV4, CANT1-ETV4, RET-PTC1/CCDC6, RET-PTC2/PRKAR1A, RET-PTC3,4/NCOA4, RET-PTC5/GOLGA5, RET-PTC6/TRIM24, RET-PTC7/TRIM33, RET-PTC8/KTN1, RET-PTC9/RFG9, RET-PTCM1, TFG-NTRK1, TPM3-NRTK1, TPR-NRTK1, RET-D10S170, ELKS-RET, HOOKS3-RET, RFP-RET, AKAP9-BRAF y PAX8-PPARG.
Las enfermedades que pueden ser causadas por eventos de movilidad genética pueden incluir la enfermedad de Charcot-Marie-Tooth de tipo 1A (CMT1A), nefronofisis juvenil (NPH), ictiosis ligada al cromosoma X, deficiencia de hormona de crecimiento familiar de tipo 1 A, distrofia muscular fascioescapulohumeral (FSHD), a-talasemia, hemofilia A, síndrome de Hunter (es decir, mucopolisacaridosis II), distrofia muscular de Emery-Dreifuss, Síndrome de hemoglobina Lepore, deficiencia de esteroides 21-hidroxilasa, hiperaldosteronismo supresor de glucocorticoides (GSH), daltonismo (por ejemplo, dicromato visual), atrofia muscular espinal (AME), cáncer, leucemia linfoblástica aguda de linfocitos T (LLA-T), carcinoma agresivo de línea media, Astrocitoma, Carcinoma de mama secretor, Cáncer de mama, Carcinoma de riñón, Nefroma mesoblástico, Adenocarcinoma de pulmón, Melanoma, Meningioma, adenoma pleomórfico, cáncer mucoepidermoide, Carcinoma de próstata, carcinoma de tiroides y leucemia
promielocítica aguda.
Los métodos de la divulgación proporcionan la determinación de la existencia de un evento de movilidad genética en donde un ácido nucleico diana puede ponerse en contacto con dos complejos, comprendiendo cada complejo un polipéptido dirigido a un sitio y un ácido nucleico dirigido a ácido nucleico modificado, y se pueden introducir dos o más proteínas efectoras, en donde las dos o más proteínas efectoras pueden unirse a los ácidos nucleicos dirigidos a ácido nucleico modificados, en donde una de las dos o más proteínas efectoras comprende una secuencia no nativa que es una primera pieza de un sistema dividido y una de las dos o más proteínas efectoras comprende una secuencia no nativa que es una segunda pieza del sistema dividido. Un sistema dividido puede referirse a un complejo de proteínas compuesto por dos o más fragmentos de proteínas que individualmente no son fluorescentes, pero que, cuando se forman en un complejo, producen un complejo de proteínas fluorescentes funcional (es decir, que produce fluorescencia). Los fragmentos de proteínas individuales de un sistema dividido (por ejemplo, proteína fluorescente dividida) pueden denominarse "fragmentos de complementariedad" o "fragmentos complementarios". Los fragmentos complementarios que pueden ensamblarse espontáneamente en un complejo proteico fluorescente funcional se conocen como fragmentos complementarios de autocomplementación, autoensamblaje o asociación espontánea. Por ejemplo, un sistema dividido puede comprender GFP. En un sistema dividido de GFP, los fragmentos complementarios se derivan de la estructura tridimensional de GFP, que incluye once cadenas beta externas antiparalelas y una cadena alfa interna. Un primer fragmento puede comprender una de las once cadenas beta de la molécula de GFP (por ejemplo, GFP S11), y un segundo fragmento puede comprender las cadenas restantes (por ejemplo, GFP S1-10).
Antes del evento de movilidad genética, la secuencia de ácido nucleico diana que puede ser dirigida por un complejo puede estar muy separada de la secuencia de ácido nucleico diana que puede ser dirigida por otra secuencia. La distancia entre las dos secuencias de ácido nucleico diana puede comprender al menos aproximadamente 0,1, 0,5, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 o más Kb. La distancia entre las dos secuencias de ácido nucleico diana puede comprender, como máximo, aproximadamente 0,1, 0,5, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 o más Kb. Las dos secuencias de ácido nucleico diana pueden ubicarse en diferentes cromosomas. Las dos secuencias de ácido nucleico diana pueden ubicarse en el mismo cromosoma.
Antes del evento de movilidad genética, las proteínas efectoras que comprenden partes del sistema dividido pueden no ser capaces de interactuar entre sí (por ejemplo, el sistema dividido puede estar inactivo). Tras el evento de movilidad genética, la secuencia de ácido nucleico diana que puede ser dirigida por un complejo puede ubicarse muy cerca de la secuencia de ácido nucleico diana que puede ser dirigida por el otro complejo. Tras el evento de movilidad genética, las proteínas efectoras que comprenden partes del sistema dividido pueden interactuar entre sí, activando así el sistema dividido.
El sistema dividido activado puede indicar la existencia del evento de movilidad genética. Por ejemplo, si el sistema dividido activado es un sistema dividido de proteína fluorescente, entonces, antes del evento de movilidad genética, puede no detectarse fluorescencia en la muestra. En algunos casos, los niveles de fluorescencia del sistema dividido inactivo (por ejemplo, niveles de fondo) pueden ser 0,01, 0,05, 0,1, 0,5, 1, 1,5, 2, 2,5, 3, 3,5 o más veces menos fluorescentes en comparación con una muestra de control (por ejemplo, célula) que no comprende el sistema dividido. En algunos casos, los niveles de fluorescencia del sistema dividido inactivo (por ejemplo, nivel de fondo) pueden ser 0,01, 0,05, 0,1, 0,5, 1, 1,5, 2, 2,5, 3, 3,5 o más veces más fluorescentes que una muestra de control (por ejemplo, célula) que no comprende el sistema dividido.
Tras el evento de movilidad genética, las dos piezas divididas pueden unirse para formar una proteína fluorescente activa, y se puede detectar fluorescencia en la muestra. Un sistema dividido activo puede producir un aumento de fluorescencia de al menos aproximadamente 0,1, 0,5, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 o más veces. Un sistema dividido activo puede producir un aumento de la fluorescencia de 0,1, 0,5, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 o más veces.
La detección de una movilidad genética se puede usar para genotipar un sujeto (por ejemplo, un paciente). Un genotipo puede ser indicativo de una enfermedad. La detección de un evento de movilidad genética se puede usar para diagnosticar un sujeto. La información genética y de diagnóstico obtenida de los métodos descritos en el presente documento se puede comunicar a un sujeto. La información genética y de diagnóstico obtenida a partir de los métodos descritos en el presente documento se puede usar para desarrollar un plan de tratamiento específico del sujeto. Por ejemplo, si los datos obtenidos a partir de los métodos de la divulgación indican que un paciente tiene un genotipo que le hace resistente a un régimen terapéutico en particular, se puede hacer un nuevo plan de tratamiento para el sujeto.
Alteración de la transcripción
Los métodos de la divulgación pueden proporcionar la alteración de la transcripción de un ácido nucleico. El método se puede realizar usando cualquiera de los polipéptidos dirigidos a un sitio, ácidos nucleicos dirigidos a ácido nucleico y complejos de polipéptidos dirigidos a un sitio y ácidos nucleicos dirigidos a ácido nucleico tales como los descritos en el presente documento. El método proporciona el contacto de un ácido nucleico diana con dos complejos, comprendiendo cada complejo un polipéptido dirigido a un sitio y un ácido nucleico dirigido a ácido nucleico modificado,y la introducción de dos o más proteínas efectoras, en donde las dos o más proteínas efectoras pueden unirse a los ácidos nucleicos dirigidos a ácido nucleico modificados, en donde una de las dos o más proteínas efectoras
comprende una secuencia no nativa que es una primera pieza de un sistema de factor de transcripción dividido y una de las dos o más proteínas efectoras comprende una secuencia no nativa que es una segunda pieza del sistema de factor de transcripción dividido, y en donde una interacción entre la primera pieza y la segunda pieza del sistema dividido forma un factor de transcripción que altera la transcripción del ácido nucleico.
El factor de transcripción puede alterar los niveles de transcripción de un ácido nucleico y/o un ácido nucleico diana. La transcripción alterada puede incluir niveles de transcripción aumentados y/o niveles de transcripción disminuidos. Un factor de transcripción puede alterar los niveles de transcripción más de 2 veces, 3 veces, 5 veces, 10 veces, 50 veces, 100 veces, 1000 veces o más superior o inferior que los niveles de transcripción no alterados. Un factor de transcripción puede alterar los niveles de transcripción menos de 2 veces, 3 veces, 5 veces, 10 veces, 50 veces, 100 veces, 1000 veces o más superior o inferior que los niveles de transcripción no alterados.
El factor de transcripción puede alterar la transcripción de un ácido nucleico diana y/o un ácido nucleico exógeno. Un ácido nucleico diana puede ser el ácido nucleico que está en contacto con el complejo que comprende el polipéptido dirigido a un sitio y el ácido nucleico dirigido a ácido nucleico. Un ácido nucleico exógeno puede comprender un polinucleótido donante, un plásmido y/o un ácido nucleico diana.
Un ácido nucleico exógeno puede comprender un polinucleótido que codifica genes implicados en la apóptosis. Los genes adecuados implicados en la apóptosis pueden incluir factor de necrosis tumoral (TNF), TNF-R1, TNF-R2, dominio de muerte asociado al receptor de TNF (TRADD), receptor Fas y ligando Fas, caspasas (por ejemplo, caspasa-3, caspasa-8, caspasa-10), APAF-1, FADD y factor inductor de apóptosis (AIF). Un ácido nucleico exógeno puede comprender un polinucleótido que codifica genes que producen la lisis celular. Los genes adecuados pueden incluir la proteína de muerte de Adenovirus (ADP), defensinas, péptidos líticos permeabilizantes de membrana derivados de c-FLIP, procaspasas, péptidos penetrantes de células, por ejemplo, VIH TAT. Un ácido nucleico exógeno puede comprender un polinucleótido que codifica un antígeno que puede producir el reclutamiento de células inmunitarias en la ubicación celular (por ejemplo, péptidos de clase MHC). Un ácido nucleico exógeno puede comprender un polinucleótido que codifica un ácido nucleico dirigido a ácido nucleico que se dirige a secuencias que ocurren muchas veces dentro del genoma (por ejemplo, microsatélites, repeticiones en tándem), produciendo una fragmentación del genoma a gran escala y la muerte celular.
Modificación del ácido nucleico diana
La divulgación proporciona métodos para modificar un ácido nucleico diana usando el ácido nucleico dirigido a ácido nucleico de la divulgación. El método se puede realizar usando cualquiera de los polipéptidos dirigidos a un sitio, ácidos nucleicos dirigidos a ácido nucleico y complejos de polipéptidos dirigidos a un sitio y ácidos nucleicos dirigidos a ácido nucleico tales como los descritos en el presente documento. Por ejemplo, un ácido nucleico diana puede ponerse en contacto con un complejo que comprenda un polipéptido dirigido a un sitio, un ácido nucleico dirigido a ácido nucleico y una o más proteínas efectoras, en donde la una o más proteínas efectoras comprenden una secuencia no nativa y pueden unirse al ácido nucleico dirigido a ácido nucleico modificado. La secuencia no nativa puede conferir una actividad enzimática y/o la actividad de transcripción de la proteína efectora puede modificar el ácido nucleico diana. Por ejemplo, si la proteína efectora comprende una secuencia no nativa correspondiente a una metiltransferasa, entonces la metiltransferasa puede ser capaz de metilar el ácido nucleico diana. La modificación del ácido nucleico diana puede ocurrir al menos 1,2, 3, 4, 5, 6, 7, 8, 9, 10, 20, 30, 40, 50, 60, 70, 80, 90, 100 o más nucleótidos lejos del extremo 5' o 3 'del ácido nucleico diana. La modificación del ácido nucleico diana puede ocurrir, como máximo, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 20, 30, 40, 50, 60, 70, 80, 90, 100 o más nucleótidos lejos del extremo 5' o 3' del ácido nucleico diana. La modificación puede ocurrir en un ácido nucleico separado que no comprenda el ácido nucleico diana (por ejemplo, otro cromosoma).
Las modificaciones ilustrativas pueden comprender metilación, desmetilación, acetilación, desacetilación, ubiquitinación, desubiquitinación, desaminación, alquilación, despurinación, oxidación, formación de dímeros de pirimidina, transposición, recombinación, alargamiento de cadena, ligamiento, glicosilación, fosforilación, desfosforilación, adenilación, desadenilación, SUMOilación, deSUMOilación, ribosilación, desribosilación, miristoilación, remodelación, escisión, oxidorreducción, hidrolación e isomerización.
Determinación de un genotipo y tratamiento
La divulgación proporciona métodos para tratar una enfermedad usando el ácido nucleico dirigido a ácido nucleico de la divulgación. El método se puede realizar usando cualquiera de los polipéptidos dirigidos a un sitio, ácidos nucleicos dirigidos a ácido nucleico y complejos de polipéptidos dirigidos a un sitio y ácidos nucleicos dirigidos a ácido nucleico tales como los descritos en el presente documento. Por ejemplo, usando el sistema dividido descrito en el presente documento, la presencia de dos o más ácidos nucleicos diana juntos en el espacio (por ejemplo, en un evento de movilidad genética, en la estructura de la cromatina o en un ácido nucleico lineal) puede ser indicativo de un genotipo (por ejemplo, de un sujeto). Un genotipo puede referirse a la presencia o ausencia de una determinada secuencia de ácido nucleico, un polimorfismo de nucleótidos (es decir, un polimorfismo de un solo nucleótido o un polimorfismo de múltiples nucleótidos), una variante alélica o cualquier otra indicación de la secuencia de un ácido nucleico. El genotipo puede indicar si un paciente padece una enfermedad y/o está predispuesto a contraer una enfermedad.
La determinación de un genotipo puede incluir, por ejemplo, determinar si un sujeto comprende una secuencia mutante (por ejemplo, una secuencia de ácido nucleico que comprende una mutación). En algunos casos, un primer ácido nucleico dirigido a ácido nucleico que comprende los componentes apropiados tal como se describe en el presente documento para comprender una primera parte de un sistema dividido puede diseñarse para dirigirse a una región cerca de una secuencia mutante predicha. En algunos casos, un segundo ácido nucleico dirigido a ácido nucleico que comprende los componentes apropiados tal como se describe en el presente documento para comprender una segunda parte del sistema dividido puede diseñarse para dirigirse a una región que comprenda la secuencia mutante predicha. Si la secuencia mutante existe, el segundo ácido nucleico dirigido a ácido nucleico puede unirse a ella, y las dos partes del sistema dividido pueden interactuar. La interacción puede generar una señal que puede ser indicativa de la presencia de una secuencia mutante.
Un genotipo puede ser identificado por un biomarcador. A biomarcador puede ser indicativo de cualquier proceso fisiológico. Un biomarcador puede servir como indicador de la eficacia de un tratamiento (por ejemplo, tratamiento con fármacos). Un biomarcador puede ser un ácido nucleico, un polipéptido, un analito, un soluto, una molécula pequeña, un ion, un átomo, una modificación de un ácido nucleico y/o polipéptido y/o un producto de degradación. Un biomarcador puede referirse a niveles de expresión relativos de un ácido nucleico y/o un polipéptido.
Se puede identificar un plan de tratamiento específico del sujeto a partir de la determinación del genotipo del sujeto usando los métodos de la divulgación. Por ejemplo, si un sujeto comprende un cierto genotipo que se sabe que no responde a una terapia en particular, entonces el sujeto puede ser tratado con una terapia diferente. La determinación del genotipo puede permitir que un sujeto sea seleccionado o excluido para un ensayo clínico.
La determinación del genotipo puede ser comunicada por un cuidador a un sujeto (por ejemplo, por un médico a un paciente o por una persona que realiza el análisis del genotipo a un cliente). La comunicación puede ocurrir en persona (por ejemplo, en un consultorio médico), por teléfono, por escrito o electrónicamente. La comunicación puede informar además al sujeto de un régimen de tratamiento específico del sujeto, determinado a partir del genotipo del sujeto.
El método se puede realizar más de una vez (por ejemplo, iterativamente) en un sujeto. Por ejemplo, se puede determinar el genotipo de un sujeto, se puede prescribir un curso de tratamiento para el sujeto, se puede determinar nuevamente el genotipo del sujeto. Los dos genotipos se pueden comparar para determinar la efectividad del curso del tratamiento. El plan de tratamiento puede modificarse en función de la comparación de los genotipos.
Localización de secuencias en el espacio tridimensional
En algunos casos, la divulgación proporciona un método para determinar la ubicación de secuencias en un espacio tridimensional en una célula. El método se puede realizar usando cualquiera de los polipéptidos dirigidos a un sitio, ácidos nucleicos dirigidos a ácido nucleico y complejos de polipéptidos dirigidos a un sitio y ácidos nucleicos dirigidos a ácido nucleico tales como los descritos en el presente documento. La determinación de la organización tridimensional de la cromatina y el ácido nucleico puede ser importante para comprender la regulación génica, tal como la activación de la transcripción y/o la represión de genes. En algunos casos, el método comprende poner en contacto un ácido nucleico diana con dos complejos, en donde cada complejo se une a su ácido nucleico diana afín. Los complejos pueden comprender un polipéptido dirigido a un sitio y un ácido nucleico dirigido a ácido nucleico de la divulgación. Se pueden introducir dos o más proteínas efectoras, en donde cada una de las dos o más proteínas efectoras se une a un complejo. Las proteínas efectoras pueden ser similares al sistema dividido descrito anteriormente, en donde cada proteína efectora puede comprender un fragmento inactivo de un polipéptido completo. Cuando las proteínas efectoras están muy separadas en el espacio, las proteínas efectoras están inactivas (por ejemplo, no se detecta señal). Cuando las proteínas efectoras están lo suficientemente cerca en el espacio para interactuar, pueden formar un polipéptido activo detectable.
Las proteínas efectoras pueden ser parte de un sistema de marcador de afinidad dividido. En un sistema de marcador de afinidad dividido, los dos fragmentos polipeptídicos inactivos del sistema pueden corresponder a dos fragmentos inactivos de un marcador de afinidad. Cuando los dos fragmentos se unen, se restablece el marcador de afinidad completo, de modo que el marcador de afinidad puede ser detectado por un agente de unión. Un agente de unión puede referirse a una molécula que puede unirse y purificar el marcador de afinidad. Los ejemplos de agentes de unión pueden incluir anticuerpos, perlas conjugadas con anticuerpos y perlas conjugadas de molécula pequeña.
La introducción de los complejos y polipéptidos de la divulgación puede ocurrir por infección vírica o bacteriófaga, transfección, conjugación, fusión de protoplastos, lipofección, electroporación, precipitación con fosfato de calcio, transfección mediada por polietilenimina (PEI), transfección mediada con DEAE-dextrano, transfección mediada por liposomas, tecnología de pistola de partículas, precipitación con fosfato de calcio, microinyección directa, administración de ácido nucleico mediada por nanopartículas, y similares.
Las células pueden cultivarse con los complejos durante al menos 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 o más días. Las células pueden cultivarse con los complejos, como máximo, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 o más días. Tras un período de tiempo apropiado (por ejemplo, un período de tiempo para permitir que los complejos se unan a su ácido nucleico diana), las
células se pueden lisar.
Las células se pueden entrecruzar antes del lisado. Las células fijas o entrecruzadas pueden estabilizar los complejos de proteína-ADN en la célula. Los fijadores y agentes de entrecruzamiento adecuados pueden incluir, formaldehído, glutaraldehído, fijadores a base de etanol, fijadores a base de metanol, acetona, ácido acético, tetraóxido de osmio, dicromato de potasio, ácido crómico, permanganato de potasio, mercuriales, picratos, formol, paraformaldehído, agentes de entrecruzamiento de NHS-éster reactivos con amina tales como bis[sulfosuccinimidil]suberato (BS3), 3,3'-ditiobis[sulfosuccinimidilpropionato] (DTSSP), bis[sulfosuccinimidilsuccinato de etilenglicol (sulfo-EGS), glutarato de disuccinimidilo (DSG), propionato de ditiobis[succinimidilo] (DSP), suberato de disuccinimidilo (DSS), bis[succinimidilsuccinato] de etilenglicol (EGS), agentes de entrecruzamiento de NHS-éster/diazirina tales como NHS-diazirina, NHS-LC-diazirina, NHS-SS-diazirina, sulfo-NHS-diazirina, sulfo-NHS-LC-diazirina y sulfo-NHS-SS-diazirina.
Las células lisadas pueden ponerse en contacto con un agente de unión (por ejemplo, un anticuerpo) que se dirija a unirse al marcador de afinidad. El contacto puede ocurrir en un tubo de ensayo. El contacto puede ocurrir en un entorno cromatográfico (por ejemplo, una columna de cromatografía de afinidad). El contacto con el agente aglutinante puede ocurrir durante al menos 1 minuto, 5 minutos, 10 minutos, 15 minutos, 20 minutos, 25 minutos, 30 minutos, 1 hora, 2 horas, 3 horas, 4 horas, 5 horas, 6 horas, 7 horas, 8 horas, 9 horas, 10 horas, 15 horas, 20 horas, 25 horas, 30 horas, 35 horas, 40 horas, 45 o más horas. El contacto con el agente aglutinante puede ocurrir, como máximo, durante 1 minuto, 5 minutos, 10 minutos, 15 minutos, 20 minutos, 25 minutos, 30 minutos, 1 hora, 2 horas, 3 horas, 4 horas, 5 horas, 6 horas, 7 horas, 8 horas, 9 horas, 10 horas, 15 horas, 20 horas, 25 horas, 30 horas, 35 horas, 40 horas, 45 o más horas. En algunos casos, el contacto con un agente de unión ocurre antes de la lisis celular.
Los complejos se pueden purificar con el agente aglutinante. Los complejos purificados pueden someterse a técnicas de purificación de ácido nucleico para separar el ácido nucleico diana de los complejos. Las técnicas de purificación de ácido nucleico pueden incluir separación en columna de centrifugación, precipitación y electroforesis.
El ácido nucleico (por ejemplo, el ácido nucleico que compre el ácido nucleico diana) puede someterse a metodologías de secuenciación. El ácido nucleico puede prepararse para el análisis de secuenciación mediante ligadura de uno o más adaptadores. Los ácidos nucleicos secuenciados se pueden analizar para identificar polimorfismos, diagnosticar una enfermedad, determinar un curso de tratamiento para una enfermedad y/o determinar la estructura tridimensional del genoma.
Ácidos nucleicos dirigidos a ácido nucleico marcados con enlazadores
La divulgación proporciona composiciones y métodos para generar y usar ácidos nucleicos dirigidos a ácido nucleico marcados. La Figura 13A representa un ejemplo de ácido nucleico dirigido a ácido nucleico sin marcar. Un ácido nucleico dirigido a ácido nucleico sin marcar puede comprender un protoespaciador (PS), una repetición CRISPR mínima (MCR), un conector guía sencillo (SGC), una secuencia mínima de ARNcrtra (MtS), una secuencia de ARNcrtra de 3' (3TS) y extensión de ARNcrtra (TE). Un ácido nucleico dirigido a ácido nucleico marcado que comprende un enlazador puede referirse a cualquiera de los ácidos nucleicos dirigidos a ácido nucleico descritos en el presente documento y que comprende un enlazador en el extremo 5', el extremo 3' o tanto el extremo 5' como 3' del ácido nucleico dirigido a ácido nucleico.
Un ácido nucleico dirigido a ácido nucleico puede comprender una secuencia no nativa como se representa en la Figura 13B. La secuencia no nativa se puede denominar marcador. El marcador puede fusionarse con el extremo 5', el extremo 3' o tanto el extremo 5' como 3' del ácido nucleico dirigido a ácido nucleico. La secuencia no nativa puede comprender una secuencia de unión para una proteína de unión a ARN. La proteína de unión a ARN puede ser Csy4. La secuencia no nativa se puede fusionar con la secuencia del protoespaciador del ácido nucleico dirigido a ácido nucleico.
La fusión no nativa se puede separar del ácido nucleico dirigido a ácido nucleico mediante un enlazador. La Figura 14 representa un enlazador ilustrativo (por ejemplo, enlazador Tag), que separa la secuencia no nativa (por ejemplo, horquilla Csy4) del protoespaciador del ácido nucleico dirigido a ácido nucleico. La secuencia enlazadora puede ser complementaria al ácido nucleico diana. La secuencia enlazadora puede comprender al menos 1,2, 3, 4, 5, 6, 7, 8, 9, 10 o más emparejamientos erróneos con el ácido nucleico diana. La secuencia enlazadora puede comprender, como máximo, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 o más emparejamientos erróneos con el ácido nucleico diana. En algunos casos, cuanto menos emparejamientos erróneos haya entre el enlazador y el ácido nucleico diana, mejor será la eficacia de escisión del complejo de Cas9:ácido nucleico dirigido a ácido nucleico.
La secuencia enlazadora puede ser de al menos 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 25, 30, 35, 40, 45, 50, 55, 60 o más nucleótidos de longitud. La secuencia enlazadora puede ser, como máximo, de 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 25, 30, 35, 40, 45, 50, 55, 60 o más nucleótidos de longitud.
Agentes de dirección genéticos multiplexados
Visión general
La presente divulgación describe métodos, composiciones, sistemas y/o kits para la ingeniería genómica multiplexada. En algunas realizaciones de la divulgación, un polipéptido dirigido a un sitio puede comprender un ácido nucleico dirigido a ácido nucleico, formando así un complejo. El complejo puede ponerse en contacto con un ácido nucleico diana. El ácido nucleico diana puede ser escindido y/o modificado por el complejo. Los métodos, las composiciones, los sistemas y/o los kits de la divulgación pueden ser útiles para modificar múltiples ácidos nucleicos diana de forma rápida, eficaz y/o simultánea. El método se puede realizar usando cualquiera de los polipéptidos dirigidos a un sitio, ácidos nucleicos dirigidos a ácido nucleico y complejos de polipéptidos dirigidos a un sitio y ácidos nucleicos dirigidos a ácido nucleico tales como los descritos en el presente documento.
La FIGURA 15 representa una realización ilustrativa de los métodos de la divulgación. Un ácido nucleico (por ejemplo, un ácido nucleico dirigido a ácido nucleico) 1505 puede fusionarse con una secuencia no nativa (por ejemplo, una fracción, una secuencia de unión a endorribonucleasa, ribozima) 1510, formando así un módulo 1512 de ácido nucleico. El módulo 1512 de ácido nucleico (por ejemplo, que comprende el ácido nucleico fusionado a una secuencia no nativa) puede conjugarse en tándem, formando así un agente de dirección genético multiplexado (por ejemplo, polimódulo, por ejemplo, matriz) 1511. El agente de dirección genético multiplexado 1511 puede comprender ARN. El agente de dirección genético multiplexado puede ponerse en contacto 1515 con una o más endorribonucleasas 1520. Las endorribonucleasas pueden unirse a la secuencia no nativa 1510. La endorribonucleasa unida puede escindir un módulo de ácido nucleico 1512 del agente de dirección genético multiplexado 1511 en una ubicación prescrita definida por la secuencia no nativa 1510. La escisión 1525 puede procesar (por ejemplo, liberar) módulos de ácido nucleico individuales 1512. En algunas realizaciones, los módulos de ácido nucleico 1512 procesados pueden comprender la totalidad, una parte o nada de la secuencia no nativa 1510. Los módulos de ácido nucleico 1512 procesados pueden estar unidos por un polipéptido dirigido a un sitio 1530, formando de este modo un complejo 1531. El complejo 1531 se puede dirigir 1535 a un ácido nucleico diana 1540. El ácido nucleico diana 1540 puede ser escindido y/o modificado por el complejo 1531.
Agentes de dirección genéticos multiplexados
Se puede usar un agente de dirección genético multiplexado para modificar múltiples ácidos nucleicos diana al mismo tiempo y/o en cantidades estequiométricas. Un agente de dirección genético multiplexado puede ser cualquier ácido nucleico dirigido a ácido nucleico como se describe en el presente documento en tándem. Un agente de dirección genético multiplexado puede referirse a una molécula continua de ácido nucleico que comprenda uno o más módulos de ácido nucleico. Un módulo de ácido nucleico puede comprender un ácido nucleico y una secuencia no nativa (por ejemplo, una fracción, secuencia de unión endorribonucleasa, ribozima). El ácido nucleico puede ser ARN no codificante tal como microARN (miARN), ARN de interferencia pequeño (ARNip), ARN largo no codificante (ARNlnc o ARNlinc), ARNip endógeno (endo-ARNip), ARN de interferente con piwi (ARNpiwi), ARN interferente corto de acción trans (ARNiptra), ARN interferente pequeño asociado a repetición (ARNipar), ARN nucleolar pequeño (ARNpno), ARN nuclear pequeño (ARNnp), ARN de transferencia (ARNt) y ARN ribosómico (ARNr), o cualquier combinación de los mismos. El ácido nucleico puede ser un ARN codificante (por ejemplo, un ARNm). El ácido nucleico puede ser cualquier tipo de ARN. En algunas realizaciones, el ácido nucleico puede ser un ácido nucleico dirigido a ácido nucleico.
La secuencia no nativa puede ubicarse en el extremo 3' del módulo de ácido nucleico. La secuencia no nativa puede ubicarse en el extremo 5' del módulo de ácido nucleico. La secuencia no nativa puede ubicarse tanto en el extremo 3' como en el extremo 5' del módulo de ácido nucleico. La secuencia no nativa puede comprender una secuencia que puede unirse a una endorribonucleasa (por ejemplo, secuencia de unión a endorribonucleasa). La secuencia no nativa puede ser una secuencia reconocida con especificidad de secuencia por una endorribonucleasa (por ejemplo, RNasa T1 escinde bases de G no emparejadas, RNasa T2 escinde el extremo 3' de As, RNasa U2 escinde el extremo 3' de bases de A no emparejadas). La secuencia no nativa puede ser una secuencia que sea estructuralmente reconocida por una endorribonucleasa (por ejemplo, estructura de horquilla, uniones monocatenarias y bicatenarias, por ejemplo, Drosha reconoce una unión monocatenaria-bicatenaria dentro de una horquilla). La secuencia no nativa puede comprender una secuencia que puede unirse a una endorribonucleasa del sistema CRISPR (por ejemplo, proteína Csy4, Cas5 y/o Cas6). La secuencia no nativa puede comprender una secuencia de nucleótidos que tenga al menos o como máximo aproximadamente un 40 %, 50 %, 60 %, 70 %, 80 %, 85 %, 90 %, 95 %, 98 %, 99 % o 100 % de identidad de secuencia y/o similitud de secuencia de nucleótidos con una de las siguientes secuencias:
5'- GUUCACUGCCGUAUAGGCAGCUAAGAAA-3 ’;
5 ’ - GUU GC A AGGGAUUGAGC C C CGUAAGGGGAUU GC G AC -3 ’,
5’- GUUGCAAACCUCGUUAGCCUCGUAGAGGAUUGAAAC-j’;
5’- GGAUCGAUACCCACCCCGAAGAAAAGGGGACGAGAAC-3’;
5’- GUCGUCAGACCCAAAACCCCGAGAGGGGACGGAAAC-3’,
5’- GAU AU AA ACC U AA U U ACCUCGAGAGGGGACGGA A AC-3';
5*-CCCCAGUCACCUCGGGAGGGGACGGAAAC-3T;
5’- GU UCC A A U U A A UC UU A A ACCC U AUU AGGGAUUGA A AC-3
5f- GU U GCA AGGG A U UGAGCCCCGU A AGGGGAU U GCGAC-3
5T- GUlí GC A A ACCUCGUU AGOC UCGU AG AGGAU UGA A AC-3 *;
5*- GGAUCGAU ACCC ACCCCGA AGA A A AGGGGACGAGA AG3*;
5 - GUCGUCAGACCCAAAACCCCGAGAGGGGACGGAAAC-3';
5’- GAU AUAAACCUAAUUACCUCGAGAGGGG ACGG AAAC-3
5'- CCCCAGUCACCUCGGGAGGGGACGCAAAC-3’,
S’- GUUCCAAUUAAUCUUAAACCCUAUUAGGGAUUGAAAC-3’,
5 -GUCGCCCCCC ACGCGGGGGCGUGG A ULJGA A AC-31;
5T-CCAGCCGCCUUCGGGCGGCUGUGUGUUGAAAC-3’;
S -^GUCGC ACUC U AC A UGAGUGCGUGGA UUGA A AU-3 *;
S ’ -UGUCGC AOC UU AU AU AGGUGCGUGG AU UGA A A U-3 ’; y
5-GUCGCGCCCCGCAUGGGGCGCGUGGAUUGAAA-31.
En algunas realizaciones, en donde la secuencia no nativa comprende una secuencia de unión a endorribonucleasa, los módulos de ácido nucleico pueden estar unidos por la misma endorribonucleasa. Los módulos de ácido nucleico pueden no comprender la misma secuencia de unión a endorribonucleasa. Los módulos de ácido nucleico pueden comprender diferentes secuencias de unión a endorribonucleasa. Las diferentes secuencias de unión a endorribonucleasa pueden estar unidas por la misma endorribonucleasa. En algunas realizaciones, los módulos de ácido nucleico pueden estar unidos por diferentes endorribonucleasas.
La fracción puede comprender una ribozima. La ribozima puede escindirse, liberando así cada módulo del agente de dirección genético multiplexado. Las ribozimas adecuadas pueden incluir ARNr de 23S de peptidil transferasa, RnasaP, intrones del grupo I, intrones del grupo II, ribozima de ramificación de GIR1, Leadzima, ribozimas de horquilla, ribozimas de cabeza de martillo, ribozimas de HDV, ribozimas de CPEB3, ribozimas de VS, ribozima de glmS, ribozima de CoTC y ribozimas sintéticas.
Los ácidos nucleicos de los módulos de ácido nucleico del agente de dirección genético multiplexado pueden ser idénticos. Los módulos de ácido nucleico pueden diferir en 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 15, 20, 25, 30, 35, 40, 45, 50 o más nucleótidos. Por ejemplo, los diferentes módulos de ácido nucleico pueden diferir en la región espaciadora del módulo de ácido nucleico, dirigiendo así el módulo de ácido nucleico a un ácido nucleico diana diferente. En algunos casos, los diferentes módulos de ácido nucleico pueden diferir en la región espaciadora del módulo de ácido nucleico, y aún así dirigirse al mismo ácido nucleico diana. Los módulos de ácido nucleico pueden dirigirse al mismo ácido nucleico diana. Los módulos de ácido nucleico pueden dirigirse a uno o más ácidos nucleicos diana.
Un módulo de ácido nucleico puede comprender una secuencia reguladora que puede permitir la traducción o amplificación apropiada del módulo de ácido nucleico. Por ejemplo, un módulo de ácido nucleico puede comprender un promotor, una caja de TATA, un elemento potenciador, un elemento de terminación de la transcripción, un sitio de unión al ribosoma, una región 3' sin traducir, una región 5' sin traducir, una secuencia de capuchón en 5', una secuencia de poliadenilación en 3', un elemento de estabilidad del ARN y similares.
Métodos
La divulgación proporciona métodos para la modificación de múltiples ácidos nucleicos diana, de forma simultánea, mediante el uso de un agente de dirección genético multiplexado. Un polipéptido dirigido a un sitio, una endorribonucleasa y un agente de dirección genético multiplexado se pueden introducir en una célula hospedadora. Se puede introducir un vector de la divulgación (por ejemplo, uno que comprende un agente de dirección genético multiplexado, una endorribonucleasa y/o un polipéptido dirigido a un sitio) en una célula hospedadora. En algunos casos, se puede introducir más de una endorribonucleasa y/o de un agente de dirección genético multiplexado en las
células. Si un agente de dirección genético multiplexado comprende diferentes tipos de fracciones, donde los fracciones son diferentes secuencias de unión a endorribonucleasa, entonces una o más endorribonucleasas correspondientes a los tipos de secuencias de unión del agente de dirección genético multiplexado pueden introducirse en las células.
La introducción se puede producir mediante cualquier medio de introducción de un ácido nucleico en una célula, tal como infección vírica o bacteriófaga, transfección, conjugación, fusión de protoplastos, lipofección, electroporación, precipitación con fosfato de calcio, transfección mediada por polietilenimina (PEI), transfección mediada con DEAE-dextrano, transfección mediada por liposomas, tecnología de pistola de partículas, precipitación con fosfato de calcio, microinyección directa, administración de ácido nucleico mediada por nanopartículas, y similares. El vector puede expresarse transitoriamente en la célula hospedadora. El vector puede expresarse de manera estable en la célula hospedadora (por ejemplo, mediante la integración estable en el genoma de la célula hospedadora).
En los casos en los que un fracción comprende una secuencia de unión a endorribonucleasa, se puede expresar una endorribonucleasa y puede unirse a un sitio de unión a endorribonucleasa en el agente de dirección genético multiplexado. La endorribonucleasa puede escindir el agente de dirección genético multiplexado en módulos de ácido nucleico individuales.
En los casos en los que un fracción comprende una ribozima, es posible que no se requiera la expresión de una endorribonucleasa en una célula hospedadora. La ribozima puede escindirse, lo que produce la escisión del agente de dirección genético multiplexado en módulos de ácido nucleico individuales.
Los módulos de ácido nucleico individuales (por ejemplo, escindidos) pueden comprender toda, una parte o nada de la fracción (por ejemplo, secuencia de unión a endorribonucleasa). Por ejemplo, el módulo de ácido nucleico liberado (por ejemplo, procesado) puede someterse a un recorte y/o una degradación por exonucleasa que puede producir la eliminación del extremo 5' y/o 3' del módulo de ácido nucleico. En dichos casos, el recorte y/o la degradación por exonucleasa puede producir la eliminación de toda, parte o nada de la fracción (por ejemplo, secuencia de unión a endorribonucleasa).
El módulo de ácido nucleico liberado (por ejemplo, procesado) puede unirse a un polipéptido dirigido a un sitio, formando así un complejo. El complejo puede ser guiado a un ácido nucleico diana por el ácido nucleico dirigido a ácido nucleico que puede hibridarse con el ácido nucleico diana de una manera específica de la secuencia. Una vez hibridado, el polipéptido dirigido a un sitio del complejo puede modificar el ácido nucleico diana (por ejemplo, escindir el ácido nucleico diana). En algunos casos, la modificación comprende la introducción de una rotura bicatenaria en el ácido nucleico diana. En algunos casos, la modificación comprende la introducción de una rotura monocatenaria en el ácido nucleico diana.
En algunas realizaciones, uno o más polinucleótidos y/o vectores donantes que codifican los mismos pueden introducirse en la célula. Se pueden incorporar uno o más polinucleótidos donantes en los ácidos nucleicos diana modificados (por ejemplo, escindidos), lo que produce una inserción. El mismo polinucleótido donante puede incorporarse en múltiples sitios de escisión de ácidos nucleicos diana. Se pueden incorporar uno o más polinucleótidos donantes en uno o más sitios de escisión de ácidos nucleicos diana. Esto se puede denominar ingeniería de genoma multiplex. En algunos casos, no se puede introducir en las células ningún polinucleótido ni/o vector donante que lo codifique. En estos casos, el ácido nucleico diana modificado puede comprender una eliminación.
Administración estequiométrica de ácidos nucleicos
Visión general
La divulgación proporciona composiciones, métodos y kits para la administración estequiométrica de un ácido nucleico a una ubicación celular y/o subcelular. La administración estequiométrica puede estar mediada por un complejo. La Figura 16 representa un complejo ilustrativo para la administración estequiométrica de una pluralidad de ácidos nucleicos a una célula y/o ubicación subcelular. El complejo puede comprender una pluralidad de ácidos nucleicos 1605. Cada ácido nucleico puede comprender un sitio de unión de proteínas de unión a ácido nucleico 1610. Los sitios de unión de proteínas de unión a ácido nucleico 1610 pueden ser todas las mismas secuencias, secuencias diferentes, o algunas pueden ser las mismas secuencias y algunas pueden ser secuencias diferentes. En algunas realizaciones, los sitios de unión de proteínas de unión a ácido nucleico pueden unirse a un miembro de la familia Cas6, Cas5 o Csy4. El complejo puede comprender un polipéptido de fusión en tándem 1630. El polipéptido de fusión en tándem puede comprender proteínas de unión a ácido nucleico 1625 fusionadas entre sí en tándem. Las proteínas de unión a ácido nucleico pueden estar separadas por un enlazador 1620. Las proteínas de unión a ácido nucleico 1625 pueden ser la misma proteína, pueden ser proteínas diferentes, o algunas pueden ser las mismas proteínas y algunas pueden ser proteínas diferentes. Las proteínas de unión a ácido nucleico 1625 pueden ser proteínas Csy4. Las proteínas de unión a ácido nucleico 1625 pueden unirse a un sitio de unión de proteína de unión a ácido nucleico 1610 sobre el ácido nucleico 1605. El polipéptido de fusión en tándem 1630 puede comprender una secuencia no nativa 1615. En algunos casos, la secuencia no nativa es una secuencia de ubicación subcelular (por ejemplo, nuclear). En algunas realizaciones, el ácido nucleico 1605 puede codificar una secuencia no nativa (por ejemplo, una secuencia de
ubicación subcelular (por ejemplo, nuclear)). El complejo se puede introducir 1635 en las células, en donde uno o más de los ácidos nucleicos 105 se pueden traducir en los polipéptidos 1640. Un polipéptido traducido 1640 puede unirse y escindir el sitio de unión de la proteína de unión a ácido nucleico 1610 en el ácido nucleico 1605. La escisión 1645 puede liberar el ácido nucleico 1650 que puede ser un ácido nucleico dirigido a ácido nucleico. El ácido nucleico liberado 1650 puede unirse a un polipéptido traducido 1645 (por ejemplo, un polipéptido dirigido a un sitio), formando así una unidad. El polipéptido traducido 1645 puede comprender una señal de localización nuclear. La unidad puede translocarse al núcleo, en donde la unidad puede guiarse a un ácido nucleico diana hibridable con el espaciador del ácido nucleico liberado 1650. La unidad puede hibridarse a un ácido nucleico diana. El polipéptido dirigido a un sitio de la unidad puede escindir el ácido nucleico diana. La escisión del ácido nucleico diana puede denominarse ingeniería genómica. El método se puede realizar usando cualquiera de los polipéptidos dirigidos a un sitio, ácidos nucleicos dirigidos a ácido nucleico y complejos de polipéptidos dirigidos a un sitio y ácidos nucleicos dirigidos a ácido nucleico tales como los descritos en el presente documento.
En algunas realizaciones, los múltiples ácidos nucleicos dirigidos a ácido nucleico pueden administrarse estequiométricamente en una ubicación celular y/o subcelular. La Figura 17 representa un complejo ilustrativo para la administración estequiométrica de una pluralidad de ácidos nucleicos. El complejo puede comprender una pluralidad de ácidos nucleicos 1705. Cada ácido nucleico puede comprender una pluralidad de sitios de unión de proteínas de unión a ácido nucleico 1710/1711. Los sitios de unión de proteínas de unión a ácido nucleico 1710/1711 pueden ser todas las mismas secuencias, secuencias diferentes, o algunas pueden ser las mismas secuencias y algunas pueden ser secuencias diferentes. En algunas realizaciones, los sitios de unión de proteínas de unión a ácido nucleico 1710/1711 pueden unirse a un miembro de la familia Cas6, Cas5 o Csy4. El complejo puede comprender un polipéptido de fusión en tándem 1730. El polipéptido de fusión en tándem puede comprender proteínas de unión a ácido nucleico 1725 fusionadas entre sí en tándem. Las proteínas de unión a ácido nucleico pueden estar separadas por un enlazador 1720. Las proteínas de unión a ácido nucleico 1725 pueden ser la misma proteína, pueden ser proteínas diferentes, o algunas pueden ser las mismas proteínas y algunas pueden ser proteínas diferentes. Las proteínas de unión a ARN 1725 pueden ser una combinación de polipéptidos Csy4, Cas5 y Cas6. Las proteínas de unión a ácido nucleico 1725 pueden unirse a un sitio de unión de proteína de unión a ácido nucleico 1710 sobre el ácido nucleico 1705. El polipéptido de fusión en tándem 1730 puede comprender una secuencia no nativa 1715. En algunos casos, la secuencia no nativa es una secuencia de ubicación subcelular (por ejemplo, nuclear). En algunas realizaciones, el ácido nucleico 1705 puede codificar una secuencia no nativa (por ejemplo, una secuencia de ubicación subcelular (por ejemplo, nuclear)). El complejo puede introducirse en las células 1735, en donde uno o más de los ácidos nucleicos pueden traducirse en los polipéptidos 1740/1750. Un polipéptido traducido 1740 puede unirse y escindir el sitio de unión de la proteína de unión a ácido nucleico 1711 en el ácido nucleico 1705. La escisión 1745 puede liberar el ácido nucleico 1755, que puede ser un ácido nucleico dirigido a ácido nucleico y/o un polinucleótido donante. El ácido nucleico liberado 1755 puede unirse a un polipéptido traducido 1750 (por ejemplo, un polipéptido dirigido a un sitio), formando así una unidad. En algunos casos, El polipéptido traducido 1750 comprende una señal de localización nuclear. La unidad puede translocarse al núcleo, en donde la unidad puede guiarse a un ácido nucleico diana hibridable con el espaciador del ARN liberado 1755. La unidad puede hibridarse a un ácido nucleico diana. El polipéptido dirigido a un sitio de la unidad puede escindir el ácido nucleico diana.
Métodos
La divulgación proporciona métodos para la administración estequiométrica de ácidos nucleicos a una célula (por ejemplo, ácidos nucleicos administrables estequiométricamente). El método puede comprender la unión de un polipéptido de fusión en tándem a una pluralidad de ácidos nucleicos administrables estequiométricamente, formando así un complejo. El complejo puede comprender cantidades estequiométricas de los ácidos nucleicos (por ejemplo, el complejo puede comprender la pluralidad de ácidos nucleicos en una proporción y/o cantidad prescrita). Se pueden administrar 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 o más ácidos nucleicos estequiométricamente. En algunos casos, se pueden administrar 3 ácidos nucleicos administrables estequiométricamente. En algunos casos, se pueden administrar 4 ácidos nucleicos administrables estequiométricamente.
El ácido nucleico administrable estequiométricamente puede codificar un polipéptido o un ARN no codificante. El polipéptido puede ser un polipéptido del sistema CRISPR (por ejemplo, un polipéptido dirigido a un sitio, una endorribonucleasa). El ácido nucleico administrable estequiométricamente puede codificar más de un polipéptido. El ácido nucleico administrable estequiométricamente puede comprender una pluralidad de ácidos nucleicos administrables estequiométricamente (por ejemplo, en una matriz). El ácido nucleico administrable estequiométricamente puede codificar un ARN no codificante. Los ejemplos de ARN no codificantes pueden incluir microARN (miARN), ARN de interferencia pequeño (ARNip), ARN largo no codificante (ARNlnc o ARNlinc), ARNip endógeno (endo-ARNip), ARN de interferente con piwi (ARNpiwi), ARN interferente corto de acción trans (ARNiptra), ARN interferente pequeño asociado a repetición (ARNipar), ARN nucleolar pequeño (ARNpno), ARN nuclear pequeño (ARNnp), ARN de transferencia (ARNt) y ARN ribosómico (ARNr). El ácido nucleico administrable estequiométricamente puede ser ARN.
El ácido nucleico administrable estequiométricamente puede codificar una secuencia no nativa. En algunos casos, el ácido nucleico administrable estequiométricamente codifica una secuencia no nativa de modo que cuando un polipéptido se traduce de un ácido nucleico administrable estequiométricamente que codifica un polipéptido, el
polipéptido se fusiona con la secuencia no nativa (por ejemplo, generando una proteína de fusión). La secuencia no nativa puede ser un marcador de afinidad peptídico. La secuencia no nativa (por ejemplo, marcador de afinidad peptídico) se puede ubicar en el extremo N del polipéptido, el extremo C del polipéptido o cualquier ubicación dentro del polipéptido (por ejemplo, un lazo accesible desde la superficie). En algunas realizaciones, la secuencia no nativa es una señal de localización nuclear (NLS). Una NLS puede ser secuencia monopartita o bipartita. La NLS puede ser reconocida por la maquinaria de importación nuclear (por ejemplo, las importinas). Una NLS puede ser un péptido pequeño (por ejemplo, PKKKRKV del antígeno t grande del SV40). Una NLS puede ser un dominio polipeptídico (por ejemplo, dominio M9 ácido de hnRNP A1).
La secuencia no nativa puede ser un marcador de afinidad de ácido nucleico (por ejemplo, señal de localización de ácido nucleico). Por ejemplo, un ácido nucleico administrable estequiométricamente que codifica un ADN (por ejemplo, un polinucleótido donante) puede comprender una señal de localización de ácido nucleico que puede localizar el ADN en el núcleo. Dichas señales de localización de ácido nucleico pueden incluir, por ejemplo, secuencias de ácido nucleico peptídico (PNA).
Los ácidos nucleicos administrables estequiométricamente pueden comprender secuencias reguladoras que pueden permitir la traducción o amplificación apropiada del ácido nucleico. Por ejemplo, un ácido nucleico puede comprender un promotor, una caja de TATA, un elemento potenciador, un elemento de terminación de la transcripción, un elemento de estabilidad del a Dn , un sitio de unión al ribosoma, una región 3' sin traducir, una región 5' sin traducir, una secuencia de capuchón en 5', una secuencia de poliadenilación en 3', un elemento de estabilidad del ARN y similares.
El ácido nucleico puede comprender un sitio de unión de proteínas de unión a ácido nucleico. El sitio de unión de proteína de unión a ácido nucleico puede estar unido por un una proteína de unión a ácido nucleico. El sitio de unión de proteína de unión a ácido nucleico puede estar unido por un polipéptido CRISPR (por ejemplo, polipéptido dirigido a un sitio, una endorribonucleasa). El sitio de unión de proteína de unión a ácido nucleico puede estar unido por un polipéptido de la familia Cas5 o Cas6. El sitio de unión de proteína de unión a ácido nucleico puede estar unido por un polipéptido Csy4, Cas5 o Cas6. Algunos ejemplos de sitios de unión de proteínas de unión a ácido nucleico pueden incluir, por ejemplo, secuencias que pueden ser unidas por proteínas de unión a ARN tales como la secuencia de unión a MS2, la secuencia de unión a U1A, la secuencia de boxB, la secuencia de eIF4A, horquillas, secuencias que pueden ser unidas por dominios de motivos de reconocimiento de ARN (RRM) (por ejemplo, U1A), secuencias que pueden estar unidas por dominios de unión a ARN bicatenarios (dsRBD) (por ejemplo, Staufen), secuencias que pueden estar unidas por dominios PAZ (por ejemplo, PAZ, Argonauta), secuencias que pueden estar unidas por dominios PIWI (por ejemplo, PIWI, MILI, MIWI, Argonauta) y similares,. Algunos ejemplos de sitios de unión de proteínas de unión a ácido nucleico pueden incluir, por ejemplo, secuencias que pueden estar unidas por proteínas de unión a ADN tales como dedos de cinc, un dominio hélice-vuelta-hélice, un dominio de dedo de cinc, un dominio de cremallera de leucina (bZIP), un dominio de hélice alada, un dominio de hélice alada-vuelta-hélice, un dominio hélicelazo-hélice, un dominio de caja HMG, un dominio Wor3, un dominio de inmunoglobulina, un dominio B3, un dominio TALE y similares.
El ácido nucleico puede comprender uno o más sitios de unión de proteínas de unión a ácido nucleico. El ácido nucleico puede comprender 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 o más sitios de unión de proteínas de unión a ácido nucleico. El uno o más sitios de unión de proteínas de unión a ácido nucleico pueden ser iguales. El uno o más sitios de unión de proteínas de unión a ácido nucleico pueden ser diferentes. Por ejemplo, el ácido nucleico puede comprender un sitio de unión a Csy4 y un sitio de unión a MS2. El uno o más sitios de unión de proteínas de unión a ácido nucleico pueden estar separados por 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 20, 30, 40, 50, 60, 70, 80, 90, 100, 110, 120, 130, 140, 150, 160, 170, 180, 190, 200, 250, 300, 350, 400, 450, 500 o más nucleótidos. En algunas realizaciones, el sitio de unión de la proteína de unión al ácido nucleico más a 3' puede estar unido por un polipéptido de fusión en tándem de la divulgación.
Polipéptido de fusión en tándem
En algunas realizaciones, el método de la divulgación proporciona la unión de una pluralidad de ácidos nucleicos a un polipéptido de fusión en tándem. Un polipéptido de fusión en tándem puede comprender una pluralidad de proteínas de unión a ácido nucleico fusionadas en una cadena polipeptídica. Un polipéptido de fusión en tándem puede comprender 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 o más proteínas de unión a ácido nucleico. Las proteínas de unión a ácido nucleico del polipéptido de fusión en tándem pueden unirse a los sitios de unión de proteína de unión a ácido nucleico de los ácidos nucleicos de la divulgación. Los ejemplos de proteínas de unión a ácido nucleico pueden incluir MS2, U1A, proteínas de unión a secuencia de boxB (por ejemplo, dedos de cinc), eIF4A, Staufen, PAZ, Argonauta, PIWI, MILI, MIWI, dedos de cinc, un dominio hélice-vuelta-hélice, un dominio de dedo de cinc, un dominio de cremallera de leucina (bZIP), un dominio de hélice alada, un dominio de hélice alada-vuelta-hélice, un dominio hélice-lazo-hélice, un dominio de caja HMG, un dominio Wor3, un dominio de inmunoglobulina, un dominio B3, un dominio TALE y similares. En algunas realizaciones, la proteína de unión a ácido nucleico es una proteína de unión a ARN. La proteína de unión a ARN puede ser miembro de un sistema CRISPR. En algunas realizaciones, la proteína de unión a ARN puede ser un miembro de la familia de proteínas Cas5 o Cas6. En algunas realizaciones, la proteína de unión a ARN puede ser Csy4, Cas5, Cas6 o cualquier combinación de las mismas. En algunas realizaciones, la proteína de unión a ácido nucleico es una proteína de unión a ADN (por ejemplo, un dedo de cinc).
En algunos casos, Las proteínas de unión a ácido nucleico están separadas por un enlazador. Un enlazador puede comprender aproximadamente 1, 2, 3,4, 5, 6, 7, 8, 9, 10, 20, 30, 40, 50, 60, 70, 80, 90, 100 o más aminoácidos.
Un polipéptido de fusión en tándem puede comprender una secuencia no nativa (por ejemplo, marcador de afinidad peptídico). La secuencia no nativa puede comprender una señal de localización nuclear (NLS) que puede dirigir el polipéptido de fusión en tándem a una ubicación subcelular (por ejemplo, núcleo).
Cada proteína de unión a ácido nucleico del polipéptido de fusión en tándem puede comprender su propia secuencia no nativa. La secuencia no nativa de cada proteína de unión a ácido nucleico puede ser la misma. La secuencia no nativa de cada proteína de unión a ácido nucleico puede ser diferente. La secuencia no nativa de algunas de las proteínas de unión a ácido nucleico del polipéptido de fusión en tándem puede ser la misma y la secuencia no nativa de algunas de las proteínas de unión a ácido nucleico del polipéptido de fusión en tándem puede ser diferente.
En algunos casos, los métodos de la divulgación pueden proporcionar la formación de un complejo que comprenda un polipéptido de fusión en tándem y una pluralidad de ácidos nucleicos de la divulgación. La formación del complejo puede comprender la unión de las proteínas de unión a ácido nucleico del polipéptido de fusión en tándem a su secuencia de unión a proteína de unión a ácido nucleico afín en los ácidos nucleicos de la divulgación. Por ejemplo, un ácido nucleico administrable estequiométricamente que comprende un sitio de unión a Csy4, puede unirse a la subunidad de proteína Csy4 en la proteína de fusión en tándem. El complejo puede formarse fuera de las células (por ejemplo, in vitro). El complejo puede formarse en células (por ejemplo, in vivo). Cuando se forma un complejo in vitro,se puede introducir en una célula mediante, por ejemplo, transfección, transformación, transducción vírica, electroporación, inyección y similares.
Los métodos de la divulgación proporcionan la administración terapéutica de múltiples ácidos nucleicos in vivo, in vitro y ex vivo. Los ácidos nucleicos administrados pueden usarse para tratar una enfermedad. Por ejemplo, los ácidos nucleicos administrados pueden usarse en terapia génica y/o pueden integrarse en el genoma de la célula, proporcionando así un resultado terapéutico. Un resultado terapéutico puede referirse al aumento o a la disminución de los niveles de una proteína, ácido nucleico o cualquier molécula biológica relacionada con una enfermedad, tal como un producto de degradación, una molécula pequeña y/o un ion. Por ejemplo, un resultado terapéutico puede comprender aumentar los niveles de un gen antiinflamatorio o disminuir los niveles de una proteína en una vía relacionada con una enfermedad. Un resultado terapéutico puede referirse a un efecto fisiológico. Los efectos fisiológicos pueden incluir cambios morfológicos, cambios metabólicos y/o cambios estructurales en una célula. Un resultado terapéutico puede referirse a cambios en las modificaciones de una proteína y/o un ácido nucleico, tales como glicosilación, acetilación, metilación, desmetilación, despurinación, ubiquitinilación y similares.
Un resultado terapéutico puede medirse mediante cambios en la composición genética de la célula, los niveles de biomoléculas de interés en la célula y/o los cambios fisiológicos en la célula. Las mediciones se pueden realizar usando técnicas de biología molecular, tales como espectroscopia, espectrometría, secuenciación, ELISA, microscopía y/o cristalografía de rayos X. Las mediciones se pueden realizar usando modelos animales, tales como ratón, ratas, perros y primates. Por ejemplo, las células modificadas genéticamente de la divulgación pueden introducirse en ratones y evaluarse para detectar cambios biológicos y fisiológicos tales como, por ejemplo, la capacidad de hacer metástasis y/o diferenciarse.
Espaciadores para trastornos de la sangre
La presente divulgación proporciona composiciones, métodos y kits para la ingeniería genética de células madre hematopoyéticas (HSC).
Composiciones
Una HSC puede comprender un polipéptido dirigido a un sitio (por ejemplo, Cas9).
Una HSC puede comprender un ácido nucleico dirigido a ácido nucleico. El ácido nucleico dirigido a ácido nucleico de la divulgación puede dirigirse a un gen implicado en un trastorno genético.
La Tabla 1 enumera genes ilustrativos que participan en trastornos. Los genes enumerados en la Tabla 1 pueden ser genes que pueden ser la diana de un ácido nucleico dirigido a ácido nucleico. El ácido nucleico dirigido a ácido nucleico de la divulgación puede comprender un espaciador que puede dirigirse a un gen enumerado en la Tabla 2.
La Tabla 2 representa separadores ilustrativos de los ácidos nucleicos dirigidos a ácidos nucleicos de la divulgación. Cada espaciador de la Tabla 2 puede ser un espaciador que se puede insertar en un ácido nucleico dirigido a ácido nucleico. Los espaciadores ilustrativos están acompañados por el nombre del trastorno y el gen que participa en el trastorno que es la diana de los espaciadores.
Tabla 2. Es aciadores de los trastornos san uíneos.

Métodos
La divulgación proporciona métodos para introducir un ácido nucleico dirigido a ácido nucleico y un polipéptido dirigido a un sitio en una HSC. En algunas realizaciones, la HSC se extrae de un paciente antes de la introducción. La HSC extraída se puede purificar (por ejemplo, por aféresis). El polipéptido dirigido a un sitio y/o el ácido nucleico dirigido a ácido nucleico pueden ser introducidos en una HSC que haya sido purificada. El polipéptido dirigido a un sitio y/o el ácido nucleico dirigido a ácido nucleico se pueden introducir en una HSC que no se haya purificado. La introducción puede ocurrir en una HSC in vitro (por ejemplo, fuera del paciente, célula extraída). En algunos casos, la introducción ocurre en una HSC in vivo (por ejemplo, dentro de un paciente, célula no extraída).
La introducción del polipéptido dirigido a un sitio y/o del ácido nucleico dirigido a ácido nucleico de la divulgación puede ocurrir, por ejemplo, transducción vírica, transfección, electroporación, transfección óptica y/o transfección química.
Una vez introducido en una HSC, el ácido nucleico dirigido a ácido nucleico de la divulgación y el polipéptido dirigido a un sitio pueden formar un complejo. El complejo puede ser guiado a un ácido nucleico diana (por ejemplo, los genes enumerados en la Tabla 3) por el ácido nucleico dirigido a ácido nucleico. El ácido nucleico dirigido a ácido nucleico puede hibridarse con el ácido nucleico diana. El polipéptido dirigido a un sitio puede modificar el ácido nucleico diana (por ejemplo, mediante la escisión del ácido nucleico diana).
En algunos casos, el ácido nucleico diana modificado comprende una eliminación. En algunos casos, el ácido nucleico diana modificado comprende una eliminación comprende una inserción de un polinucleótido donante. Un polinucleótido donante, una parte de un polinucleótido donante, una copia de un polinucleótido donante o una parte de una copia de un polinucleótido donante en un ácido nucleico diana. El método se puede realizar usando cualquiera de los polipéptidos dirigidos a un sitio, ácidos nucleicos dirigidos a ácido nucleico y complejos de polipéptidos dirigidos a un sitio y ácidos nucleicos dirigidos a ácido nucleico tales como los descritos en el presente documento.

continuación

Métodos computacionales
La divulgación proporciona métodos computacionales para identificar espaciadores para ácidos nucleicos dirigidos a ácido nucleico. El método computacional puede comprender el barrido de la secuencia de ácido nucleico de un genoma en busca de un motivo adyacente al protoespaciador. Al encontrar un motivo adyacente al protoespaciador, el programa puede contar automáticamente entre 10-30 nucleótidos cadena arriba del motivo adyacente al protoespaciador. Los 10-30 nucleótidos cadena arriba del motivo adyacente al protoespaciador pueden constituir una secuencia espaciadora putativa. En otras palabras, los 10-30 nucleótidos cadena arriba del motivo adyacente al protoespaciador en el genoma pueden corresponder a un ácido nucleico diana, y una secuencia complementaria al ácido nucleico diana puede denominarse espaciador.
El programa puede probar cada iteración de secuencia de la secuencia espaciadora putativa para determinar la eficacia de la secuencia como espaciador en un ácido nucleico dirigido a ácido nucleico. Por ejemplo, el programa puede tomar cada iteración de la secuencia espaciadora putativa y realizar una predicción de estructura secundaria in silico en la secuencia. La predicción de la estructura secundaria puede comprender agregar las secuencias espaciadoras putativas a una cadena principal de ácido nucleico dirigido a ácido nucleico (por ejemplo, el ácido nucleico dirigido a ácido nucleico sin el espaciador). La predicción de la estructura secundaria puede realizar un análisis de predicción de la estructura secundaria de la secuencia espaciadora putativa acoplada en la cadena principal de ácido nucleico dirigido a ácido nucleico. El análisis de predicción de la estructura secundaria puede comprender, por ejemplo, predecir qué nucleótidos pueden formar dúplex, horquillas, qué nucleótidos no están estructurados y/o qué nucleótidos pueden estar desapareados.
El método computacional puede comprender implementar una prueba de plegamiento en cada secuencia espaciadora putativa que haya sido sometida a un análisis de predicción de la estructura secundaria. La prueba de plegamiento puede comprender el plegamiento in silico del ácido nucleico dirigido a ácido nucleico que comprende la secuencia espaciadora putativa. El ácido nucleico dirigido a ácido nucleico y la secuencia espaciadora putativa pueden pasar o no la prueba de plegamiento.
Para pasar la prueba de plegamiento, la estructura secundaria de la cadena principal de ácido nucleico dirigido a ácido nucleico puede necesitar conservarse, menos de 5, 4, 3, 2 o 1 nucleótidos en el espaciador se hibridan con nucleótidos fuera del espaciador y otra segunda estructura del espaciador está contenida dentro del espaciador.
Selección perfecta del indicador
Visión general
La presente divulgación describe métodos, composiciones, sistemas y kits para la modificación genética de células y la selección de dichas células modificadas genéticamente mediante la incorporación, detección y escisión perfectas de un elemento indicador. En algunas realizaciones de la divulgación, un polinucleótido donante puede comprender un ácido nucleico que se va a introducir en el genoma de una célula (en el presente documento denominado elemento genético de interés), así como una secuencia de ácido nucleico que codifica un elemento indicador (por ejemplo, GFP), un polipéptido dirigido a un sitio y dos ácidos nucleicos dirigidos a ácido nucleico. El polipéptido dirigido a un sitio, los ácidos nucleicos dirigidos a ácido nucleico y/o los tres pueden ser controlados por un promotor inducible. Un
polipéptido dirigido a un sitio y un ácido nucleico dirigido a ácido nucleico pueden formar un complejo que puede dirigirse a un sitio en el genoma celular por hibridación del ácido nucleico dirigido a ácido nucleico con un ácido nucleico diana en el genoma. El polipéptido dirigido a un sitio del complejo puede escindir el ácido nucleico diana. El polinucleótido donante puede insertarse en el ácido nucleico diana escindido. Tras la introducción de una rotura bicatenaria (o rotura monocatenaria) en el sitio diana en presencia del polinucleótido donante, la población de células receptoras puede cribarse para detectar la presencia de la molécula indicadora como un indicador de la presencia del elemento genético de interés. Tras el aislamiento de las células que contienen moléculas indicadoras, el elemento indicador se puede eliminar mediante la inducción de la expresión del polipéptido dirigido a un sitio y/o de ácido nucleico dirigido a ácido nucleico. Los ácidos nucleicos dirigios a ácido nucleico pueden dirigirse a los extremos 5' y 3' del elemento indicador y pueden provocar la escisión del elemento indicador. El método se puede realizar usando cualquiera de los polipéptidos dirigidos a un sitio, ácidos nucleicos dirigidos a ácido nucleico y complejos de polipéptidos dirigidos a un sitio y ácidos nucleicos dirigidos a ácido nucleico tales como los descritos en el presente documento.
La FIGURA 18 representa una realización a modo de ejemplo de los métodos de la divulgación. Un ácido nucleico puede comprender una pluralidad de elementos genéticos 1805/1810. Los elementos genéticos 1805 y 1810 pueden ser, por ejemplo, genes, ácidos nucleicos no codificantes, intrones, exones, ADN y/o ARN. Los elementos genéticos 1805 y 1810 pueden ser partes del mismo gen. Entre los elementos genéticos puede haber un ácido nucleico diana 106 adecuado para la ingeniería genética. Un polipéptido dirigido a un sitio y un ácido nucleico dirigido a ácido nucleico de la divulgación pueden formar un complejo que puede dirigirse a 1815 al ácido nucleico diana 1806. El polipéptido dirigido a un sitio del complejo puede escindir 1820 el ácido nucleico diana 1806. Un polinucleótido donante puede insertarse 1825 en el ácido nucleico diana escindido 1806. El polinucleótido donante puede comprender un elemento genético de interés 1830. El elemento genético de interés 1830 puede ser un gen. El polinucleótido donante también puede comprender un elemento indicador 1835. El polinucleótido donante también puede comprender una secuencia polinucleotídica que codifica un polipéptido dirigido a un sitio y uno o más ácidos nucleicos dirigidos a ácido nucleico. En algunos casos, el polinucleótido que codifica el polipéptido dirigido a un sitio y el uno o más ácidos nucleicos dirigidos a ácido nucleico codifica dos ácidos nucleicos dirigidos a ácido nucleico. La secuencia polinucleotídica que codifica el polipéptido dirigido a un sitio y el ácido nucleico dirigido a ácido nucleico puede unirse operativamente a un promotor inducible. La inserción del polinucleótido donante en el ácido nucleico diana 1806 puede producir la expresión del elemento indicador 1835. El elemento indicador 1835 puede usarse como una forma de seleccionar células que comprenden el polinucleótido donante.
La FIGURA 19 representa una realización a modo de ejemplo para la eliminación del elemento indicador 1915 del ácido nucleico diana. Un ácido nucleico diana puede comprender una pluralidad de elementos genéticos 1905/1920. El elemento indicador 1915 puede fusionarse con un elemento genético de interés 1910. La expresión del gen indicador 1915 puede inducirse, lo que puede producir la producción de un polipéptido dirigido a un sitio y uno o más ácidos nucleicos dirigidos a ácido nucleico. El polipéptido dirigido a un sitio puede formar complejos con los ácidos nucleicos dirigidos a ácido nucleico. Los complejos pueden ser guiados al elemento indicador 1915 por el ácido nucleico dirigido a ácido nucleico del complejo. Uno de los dos ácidos nucleicos dirigidos a ácido nucleico puede dirigirse 1925 al extremo 5' del elemento indicador 1915. Uno de los dos ácidos nucleicos dirigidos a ácido nucleico pueden dirigirse 1930 al extremo 3' del elemento indicador 1915. Los extremos diana del elemento indicador 1915 pueden ser escindidos por el polipéptido dirigido a un sitio del complejo, eliminando 1935 así el elemento indicador 1915. El ácido nucleico diana puede comprender la parte del elemento genético de interés 1910 del polinucleótido donante. Los ácidos nucleicos dirigidos a ácido nucleico pueden diseñarse de modo que se escinda el polinucleótido donante (incluyendo el elemento genético de interés).
Métodos
La presente divulgación proporciona métodos para seleccionar células usando un elemento indicador y la escisión del elemento indicador. Un polipéptido dirigido a un sitio, una endorribonucleasa, un ácido nucleico dirigido a ácido nucleico, un polinucleótido donante y/o un ácido nucleico dirigido a un ácido nucleico pueden introducirse en una célula. El polinucleótido donante puede incluir uno o más elementos genéticos de interés. El polinucleótido donante puede incluir uno o más elementos indicadores. El polinucleótido donante incluye uno o más elementos genéticos de interés y uno o más elementos indicadores. Se puede introducir en una célula más de un polipéptido dirigido a un sitio, endorribonucleasa, polinucleótido donante y/o ácido nucleico dirigido a ácido nucleico. En algunos casos, la célula expresa ya un polipéptido dirigido a un sitio y/o un ácido nucleico dirigido a ácido nucleico. En algunos casos, el polipéptido dirigido a un sitio y/o el ácido nucleico dirigido a ácido nucleico son codificados en un plásmido. En algunos casos, el polipéptido dirigido a un sitio y/o el ácido nucleico dirigido a ácido nucleico está codificado en más de un plásmido. En algunos casos, se introduce en la célula más de un polipéptido dirigido a un sitio o ácido nucleico dirigido que codifica un polipéptido dirigido a un sitio. En algunos casos, la célula es un lisado celular.
La introducción se puede producir mediante cualquier medio de introducción de un ácido nucleico en una célula, tal como infección vírica o bacteriófaga, transfección, conjugación, fusión de protoplastos, lipofección, electroporación, transfección con fosfato de calcio, transfección mediada por polietilenimina (PEI), transfección mediada con DEAE-dextrano, transfección mediada por liposomas, tecnología de pistola de partículas, precipitación con fosfato de calcio, microinyección directa, administración de ácido nucleico mediada por nanopartículas, y similares. El vector puede
expresarse transitoriamente en la célula hospedadora. El vector puede expresarse de manera estable en la célula hospedadora (por ejemplo, mediante la integración estable en el genoma de la célula hospedadora).
Un ácido nucleico dirigido a ácido nucleico puede unirse a un ácido nucleico caracterizado por una secuencia diana particular y/o cualquier secuencia homóloga a una secuencia particular. La secuencia diana puede ser parte o la totalidad de un gen, un extremo 5' de un gen, un extremo 3' de un gen, un elemento regulador (por ejemplo, promotor, potenciador), un pseudogén, ADN no codificante, un microsatélite, un intrón, un exón, ADN cromosómico, ADN mitrocondrial, ADN sensible, ADN no codificante, ADN nucleoide, ADN o ARN de cloroplasto entre otras entidades de ácido nucleico.
El polipéptido dirigido a un sitio puede escindir el ácido nucleico diana unido por un ácido nucleico dirigido a ácido nucleico. El polipéptido dirigido a un sitio puede no escindir el ácido nucleico diana. En algunos casos, una endorribonucleasa escinde el ácido nucleico diana. La endorribonucleasa puede ser codificada por el vector. La endorribonucleasa puede ser codificada por el polinucleótido donante. La endorribonucleasa puede estar presente en la célula. La expresión de la endorribonucleasa y/o del polipéptido dirigido a un sitio puede ser inducida por un promotor condicional. Se puede incorporar un polinucleótido donante al ácido nucleico diana en el sitio donde se escindió.
Escisión
Los métodos desvelados en el presente documento pueden comprender además la escisión de todo, parte o nada del elemento indicador. Un primer ácido nucleico dirigido a ácido nucleico del elemento indicador puede dirigirse al extremo 5' del elemento indicador. Un segundo ácido nucleico dirigido a ácido nucleico del elemento indicador puede dirigirse al extremo 3' del elemento indicador. Un ácido nucleico dirigido a ácido nucleico puede dirigirse a los extremos 5' y 3' del elemento indicador. Un ácido nucleico dirigido a ácido nucleico puede dirigirse a dos secuencias en del elemento indicador y/o del polinucleótido donante. Las dos secuencias diana pueden ser al menos aproximadamente un 70, 75, 80, 85, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99 o 100 % idénticas. Las dos secuencias diana pueden ser, como máximo, aproximadamente un 70, 75, 80, 85, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99 o 100 % idénticas. Cuando se expresan los ácidos nucleicos dirigidos a ácido nucleico del elemento indicador, pueden formar un complejo con un polipéptido dirigido a un sitio y dirigirse a los extremos 5' y 3' del elemento indicador hibridándose a una región complementaria en los extremos 5' y 3' del elemento indicador. La hibridación del complejo con el elemento indicador puede producir la escisión de todo, parte o nada del elemento indicador. El ácido nucleico escindido se puede volver a unir mediante, por ejemplo, unión de extremos no homólogos. El ácido nucleico unido de nuevo puede no introducir una eliminación o inserción. El ácido nucleico unido de nuevo puede introducir una eliminación o inserción. El ácido nucleico escindido se puede volver a unir mediante, por ejemplo, recombinación homóloga. La recombinación homóloga puede usarse para volver a unir un ácido nucleico escindido cuando los sitios del ácido nucleico diana son sustancialmente idénticos.
Cribado
Los métodos desvelados en el presente documento pueden comprender además la escisión de un elemento indicador de una célula seleccionada, formando así una segunda célula; y el cribado de la segunda célula. El cribado puede comprender la detección de la ausencia de todo o parte del elemento indicador. El cribado puede incluir la clasificación de células activadas por fluorescencia (FACS), en donde las células que expresan una proteína fluorescente codificada por el elemento indicador se separan de las células que no expresan una proteína fluorescente. Las células pueden ponerse en contacto con proteínas fluorescentes, sondas fluorescentes o anticuerpos conjugados con fluorocromo que se unen a proteínas codificadas por el elemento indicador o elemento genético, y posteriormente seleccionarse por FACS. Los fluorocromos pueden incluir, pero sin limitación, Cascade Blue, Pacific Blue, Pacific Orange, Lucifer yellow, NBD, R-Ficoeritrina (PE), conjugados de PE-Cy5, conjugados de PE-Cy7, Red 613, PerCP, TruRed, FluorX, Fluoresceína, BODIPY-FL, TRITC, Texas Red, Aloficocianina, conjugados de APC-Cy7 (PharRed), diversos colorantes Alexa Fluor, Cy2, Cy3, Cy3B, Cy3.5, Cy5, Cy5.5, Cy7, diversos DyLights, Y66H, Y66F, EBFP, EBFP2, Azurita, GFPuv, T-Zafiro, TagBFP, Ceruleano, mCFP, ECFP, CyPet, Y66W, dKeima-Red, mKeima-Red, TagCFP, AmCyan1, mTFP1, S65A, Midoriishi-Cyan, GFP, Turbo GFP, TagGFP, TagGFP2, AcGFP1, S65L, Esmeralda, S65T, S65C, EGFP, Azami-Green, ZaGreen1, Dronpa-Green, TagYFP, EYFP, Topaz, Venus, mCitirine, YPet, Turbo YFP, PhiYFP, PhiYFPm, ZaYellow1, mBanana, Kusabira-Orange, mOrange, mOrane2, mKO, TurboRFP, tdTomato, DsRed-Express2, TagRFP, monómero de DsRed, DsRed2, mStrawberry, Turbo FP602, AsRed2, mRFP1, J-Red, mCherry, HcRed1, mKate2, Katushka, mKate, TurboFP635, mPlum, mRaspberry, mNeptune, E2-Crimson.
Las células pueden ponerse en contacto con anticuerpos que se unen a marcadores de afinidad peptídicos codificados por el elemento indicador o elemento genético y, posteriormente, pueden seleccionarse mediante perlas inmunomagnéticas que reconocen los anticuerpos. El cribado puede comprender la tinción de células mediante la adición de X-gal cuando el elemento indicador o el elemento genético codifica b-galactosidasa. El cribado puede comprender una clasificación manual (por ejemplo, suspensiones celulares diluidas) y microscopía (por ejemplo, microscopía de fluorescencia). El cribado puede comprender un cribado de alto contenido.
Los elementos indicadores pueden codificar genes de resistencia a fármacos, lo que permite la selección de células que contienen el elemento indicador mediante la adición de fármacos, que destruyen las células que no expresan el elemento indicador. Dicho fármaco puede incluir, pero sin limitación, eritromicina, clindamicina, cloranfenicol,
gentamicina, kanamicina, estreptomicina, tetraciclina, la combinación de quinupristina-dalfopristina, enrofloxacina, vancomicina, oxacilina, penicilina, sulfisoxazol sulfonamida, trimetoprima, sulfoximina metoinina, metotrexato, puromicina, blasticidina, histidinol, higromicina, zeocina, bleomicina y neomicina.
Bancos
La presente divulgación proporciona un banco de vectores de expresión que comprenden polinucleótidos donantes. En algunas realizaciones, el banco puede comprender vectores de expresión que comprenden secuencias de polinucleótidos que codifican diferentes elementos genéticos de interés, pero los mismos elementos indicadores. En algunas realizaciones, el banco puede comprender vectores de expresión que comprenden secuencias de polinucleótidos que codifican diferentes elementos genéticos de interés y diferentes elementos indicadores. Los elementos indicadores pueden diferir en sus secuencias de dirección de ácido nucleico (ARNcr y ARNcrtra). Los elementos indicadores pueden diferir en sus genes indicadores (por ejemplo, genes que codifican proteínas fluorescentes). La presente divulgación proporciona métodos para usar el banco para generar una pluralidad de células modificadas genéticamente. La presente divulgación proporciona métodos para usar el banco para un cribado genético de alto rendimiento. Estos bancos pueden permitir analizar grandes cantidades de genes individuales para inferir la función del gen. Los bancos pueden comprender de aproximadamente 10 miembros individuales a aproximadamente 1012 miembros individuales; por ejemplo, un banco puede comprender de aproximadamente 10 miembros individuales a aproximadamente 102 miembros individuales, de aproximadamente 102 miembros individuales a aproximadamente 103 miembros individuales, de aproximadamente 103 miembros individuales a aproximadamente 105 miembros individuales, de aproximadamente 105 miembros individuales a aproximadamente 107 miembros individuales, de aproximadamente 107 miembros individuales a aproximadamente 109 miembros individuales o de aproximadamente 109 miembros individuales a aproximadamente 1012 miembros individuales.
Modificación de células (transfección/infección)
Los métodos de la divulgación proporcionan la selección de células que comprenden el polinucleótido donante. En algunas realizaciones, un método puede implicar poner en contacto un ácido nucleico diana o introducir en una célula (o una población de células) uno o más ácidos nucleicos que comprenden secuencias de nucleótidos que codifican un ácido nucleico dirigido a ácido nucleico, un polipéptido dirigido a un sitio y/o polinucleótido donante de la divulgación. Los métodos para introducir un ácido nucleico en una célula pueden incluir infección vírica o bacteriófaga, transfección, conjugación, fusión de protoplastos, lipofección, electroporación, precipitación con fosfato de calcio, transfección mediada por polietilenimina (PEI), transfección mediada con DEAE-dextrano, transfección mediada por liposomas, tecnología de pistola de partículas, precipitación con fosfato de calcio, microinyección directa, administración de ácido nucleico mediada por nanopartículas, y similares. En algunas realizaciones, la puesta en contacto con un ácido nucleico diana o la introducción en una célula (o una población de células) de uno o más ácidos nucleicos puede no comprender una infección vírica. En algunas realizaciones, la puesta en contacto con un ácido nucleico diana o la introducción en una célula (o una población de células) de uno o más ácidos nucleicos puede no comprender la infección por bacteriófagos. En algunas realizaciones, la puesta en contacto con un ácido nucleico diana o la introducción en una célula (o una población de células) de uno o más ácidos nucleicos puede no comprender la transfección.
Ácidos nucleicos dirigidos a ácido nucleico diseñados
Dominios P diseñados
Se puede diseñar un ácido nucleico dirigido a ácido nucleico (por ejemplo, comprender modificaciones). Un ácido nucleico dirigido a ácido nucleico diseñado puede referirse a cualquiera de los ácidos nucleicos dirigidos a ácido nucleico diseñados como se describe en el presente documento. Por ejemplo, un ácido nucleico dirigido a ácido nucleico diseñado puede comprender una repetición CRISPR mínima, un ARNcrtra mínimo y un ARNcrtra 3'. Un dominio P de un ácido nucleico dirigido a ácido nucleico puede interactuar con la región de un polipéptido dirigido a un sitio. Un dominio P puede interactuar con una pluralidad de regiones de un polipéptido dirigido a un sitio. Un dominio P puede interactuar con una pluralidad de regiones de un polipéptido dirigido a un sitio, en donde al menos una de las regiones interactúa con un PAM en un motivo adyacente al protoespaciador. Los ejemplos de estas regiones pueden incluir los aminoácidos 1096-1225 y 1105-1138 de Cas9 en S. pyogenes.
Se puede introducir una modificación en el dominio P. Un dominio P puede comprender al menos aproximadamente 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 15, 20, 25 o 30, o más, nucleótidos adyacentes. Un dominio P puede comprender, como máximo, aproximadamente 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 15, 20, 25 o 30, o más, nucleótidos adyacentes. Un dominio P puede iniciar un nucleótido 3' del último nucleótido emparejado en el dúplex que comprende la repetición CRISPR mínima y la secuencia mínima de ARNcrtra. Un dominio P puede iniciar al menos aproximadamente 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 15, 20, 25 o 30, o más, nucleótidos a 3' del último nucleótido emparejado en el dúplex que comprende la repetición CRISPR mínima y la secuencia mínima de ARNcrtra. Un dominio P puede iniciar, como máximo, aproximadamente 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 15, 20, 25 o 30, o más, nucleótidos a 3' del último nucleótido emparejado en el dúplex que comprende la repetición CRISPR mínima y la secuencia mínima de ARNcrtra.
Un dominio P diseñado puede comprender al menos aproximadamente 1, 2, 3, 4, 5, 6, 7, 8, 9 o 10, o más mutaciones. Un dominio P diseñado puede comprender, como máximo, aproximadamente 1, 2, 3, 4, 5, 6, 7, 8, 9 o 10, o más, mutaciones. Las mutaciones pueden ser adyacentes entre sí (por ejemplo, secuenciales). Las mutaciones pueden estar separadas entre sí. Las mutaciones pueden estar separadas por al menos aproximadamente 1, 2, 3, 4, 5, 6, 7, 8, 9 o 10, o más, nucleótidos. Las mutaciones pueden estar separadas por al menos aproximadamente 1,2, 3, 4, 5, 6, 7, 8, 9 o 10, o más, nucleótidos. Las mutaciones en un ácido nucleico dirigido a ácido nucleico pueden comprender inserciones, eliminaciones y sustituciones de nucleótidos en el ácido nucleico dirigido a ácido nucleico.
En algunos casos, un ácido nucleico dirigido a ácido nucleico diseñado comprende, como máximo, aproximadamente un 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30 % o más de identidad y/o similitud de nucleótidos con un ácido nucleico dirigido a ácido nucleico de tipo silvestre. En algunos casos, un ácido nucleico dirigido a ácido nucleico diseñado comprende al menos aproximadamente un 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21,22, 23, 24, 25, 26, 27, 28, 29, 30 % o más de identidad y/o similitud de nucleótidos con un ácido nucleico dirigido a ácido nucleico de tipo silvestre.
En algunos casos, una parte de ácido nucleico de CRISPR del ácido nucleico dirigido a ácido nucleico diseñado comprende, como máximo, aproximadamente un 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30 % o más de identidad y/o similitud de nucleótidos con un ácido nucleico de CRISPR de tipo silvestre. En algunos casos, una parte de ácido nucleico de CRISPR del ácido nucleico dirigido a ácido nucleico diseñado comprende al menos aproximadamente un 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30 % o más de identidad y/o similitud de nucleótidos con un ácido nucleico de CRISPR de tipo silvestre.
Una parte de ácido nucleico de ARNcrtra del ácido nucleico dirigido a ácido nucleico diseñado puede comprender, como máximo, aproximadamente un 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30 % o más de identidad y/o similitud de nucleótidos con un ácido nucleico ARNcrtra de tipo silvestre. Una parte de ácido nucleico de ARNcrtra del ácido nucleico dirigido a ácido nucleico diseñado puede comprender al menos aproximadamente un 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30 % o más de identidad y/o similitud de nucleótidos con un ácido nucleico ARNcrtra de tipo silvestre.
Las modificaciones en el dominio P pueden ser tales que el ácido nucleico dirigido a ácido nucleico diseñado se configure de nuevo para hibridarse con una nueva secuencia de PAM en un ácido nucleico diana. La modificación del dominio P puede ser complementaria a PAM en el ácido nucleico diana. La modificación del dominio P puede comprender el complemento inverso de PAM en el ácido nucleico diana. El nuevo PAM puede comprender al menos aproximadamente 1, 2, 3, 4, 5, 6, 7, 8, 9 o 10, o más, nucleótidos. El nuevo PAM puede comprender, como máximo, aproximadamente 1,2, 3, 4, 5, 6, 7, 8, 9 o 10, o más, nucleótidos. Las modificaciones en el dominio P pueden ocurrir en concierto con modificaciones en una región de unión al dominio P y unión a PAM de un polipéptido dirigido a un sitio. Estas modificaciones pueden ser compensatorias, en donde un dominio P modificado se modifica específicamente para unirse a un polipéptido dirigido a un sitio modificado, en donde la modificación permite que el polipéptido dirigido a un sitio se una al dominio P diseñado con mayor especificidad.
Un dominio P diseñado puede diseñarse para unirse a un nuevo PAM (por ejemplo, el dominio P diseñado puede hibridarse con un nuevo PAM). El nuevo PAM (por ejemplo, PAM diferente) puede ser bimodal (es decir, un PAM bimodal puede comprender dos regiones separadas del PAM). Las dos regiones separadas de un PAM bimodal pueden estar separadas por al menos aproximadamente 1, 2, 3, 4, 5, 6, 7, 8, 9 o 10, o más, nucleótidos. Las dos regiones separadas de un PAM bimodal pueden estar separadas, como máximo, por 1, 2, 3, 4, 5, 6, 7, 8, 9 o 10, o más, nucleótidos.
Un dominio P diseñado se puede diseñar para unirse a un nuevo PAM (por ejemplo, un PAM diferente), en donde el nuevo PAM es trimodal. Una PAM trimodal puede comprender tres regiones separadas de una secuencia de PAM (por ejemplo, tres regiones separadas que se pueden usar para dirigir un ácido nucleico dirigido a ácido nucleico a un ácido nucleico diana). Las tres regiones separadas de un PAM trimodal pueden estar separadas por al menos aproximadamente 1, 2, 3, 4, 5, 6, 7, 8, 9 o 10, o más, nucleótidos. Las tres regiones separadas de un PAM trimodal pueden estar separadas, como máximo, por 1, 2, 3, 4, 5, 6, 7, 8, 9 o 10, o más, nucleótidos.
Un ácido nucleico dirigido a ácido nucleico diseñado puede comprender al menos dos horquillas. Una primera horquilla puede comprender un dúplex entre la repetición CRISPR mínima y la secuencia mínima de ARNcrtra. La segunda horquilla puede estar cadena abajo de la primera horquilla. La segunda horquilla puede comenzar al menos 1, 2, 3, 4, 5, 6, 7, 8, 9 o 10, o más, nucleótidos cadena abajo del último nucleótido emparejado del primer dúplex. La segunda horquilla puede comenzar, como máximo, 1, 2, 3, 4, 5, 6, 7, 8, 9 o 10, o más, nucleótidos cadena abajo del último nucleótido emparejado del primer dúplex. La segunda horquilla puede comprender un dominio P diseñado.
El dominio P diseñado de la segunda horquilla puede ubicarse en un lado de la horquilla del dúplex. El dominio P diseñado de la segunda horquilla puede ubicarse en ambos lados de la horquilla del dúplex. El dominio P diseñado de la segunda horquilla puede comprender al menos aproximadamente un 1, 2, 3, 4, 5, 10 o 20 % de los nucleótidos en la segunda horquilla. El dominio P diseñado de la segunda horquilla puede comprender, como máximo,
aproximadamente un 1, 2, 3, 4, 5, 10 o 20 % de los nucleótidos en la segunda horquilla.
La segunda horquilla puede comprender un ARNcrtra (por ejemplo, el ARNcrtra medio o el ARNcrtra de 3' de un ácido nucleico dirigido a ácido nucleico). La segunda horquilla puede comprender al menos un 1, 5, 10, 15, 20, 25, 30, 35, 40, 45 o 50 %, o más, de identidad con un ARNcrtra. La segunda horquilla puede comprender, como máximo, aproximadamente un 1, 5, 10, 15, 20, 25, 30, 35, 40, 45 o 50 %, o más, de identidad con un ARNcrtra.
La segunda horquilla que comprende el dominio P diseñado puede configurarse para que elimine el dúplex (por ejemplo, se funda, se desenrolle). La segunda horquilla puede eliminar el dúplex cuando está en contacto con un ácido nucleico diana. La segunda horquilla puede eliminar el dúplex cuando está en contacto con un motivo adyacente al protoespaciador de un ácido nucleico diana.
En algunos casos, un dominio P modificado se puede configurar para hibridarse a una región en un ácido nucleico dirigido a ácido nucleico (por ejemplo, el mismo ácido nucleico dirigido a ácido nucleico que comprende el dominio P diseñado) y el dominio P diseñado se puede configurar para hibridarse con un ácido nucleico diana. En otras palabras, el dominio P diseñado puede comprender una secuencia conmutable, en la que, en algunos casos, el dominio P se hibrida con el ácido nucleico dirigido a ácido nucleico, formando así una horquilla, y, en algunos casos, el dominio P se hibrida a un PAM en un ácido nucleico diana.
Un ácido nucleico dirigido a ácido nucleico diseñado que comprende un dominio P modificado se puede diseñar para unirse a un PAM con una constante de disociación más baja que la de un ácido nucleico dirigido a ácido nucleico que no comprende un dominio P modificado (por ejemplo, ácido nucleico dirigido a ácido nucleico de tipo silvestre). Un ácido nucleico dirigido a ácido nucleico diseñado que comprende un dominio P modificado puede diseñarse para unirse a un PAM con una constante de disociación de al menos aproximadamente un 10, 50, 100, 150, 200, 250, 300, 350, 400, 450, 500, 550 o 600 %, o más inferior o superior a la de un ácido nucleico dirigido a ácido nucleico que no comprende un dominio P modificado.
Un ácido nucleico dirigido a ácido nucleico diseñado que comprende un dominio P modificado puede diseñarse para unirse a un PAM con una constante de disociación, como máximo, aproximadamente un 10, 50, 100, 150, 200, 250, 300, 350, 400, 450, 500, 550 o 600%, o más inferior o superior a la de un ácido nucleico dirigido a ácido nucleico que no comprende un dominio P modificado. Un ácido nucleico dirigido a ácido nucleico diseñado que comprende un dominio P modificado puede diseñarse para unirse a un PAM con una constante de disociación al menos aproximadamente 1 vez, 2 veces, 3 veces, 4 veces, 5 veces, 10 veces, 20 veces, 30 veces, 40 veces o 50 veces, o más, inferior o superior a la de un ácido nucleico dirigido a ácido nucleico que no comprende un dominio P modificado. Un ácido nucleico dirigido a ácido nucleico diseñado que comprende un dominio P modificado puede diseñarse para unirse a un PAM con una constante de disociación, como máximo, aproximadamente 1 vez, 2 veces, 3 veces, 4 veces, 5 veces, 10 veces, 20 veces, 30 veces, 40 veces o 50 veces, o más, inferior o superior a la de un ácido nucleico dirigido a ácido nucleico que no comprende un dominio P modificado.
Un ácido nucleico dirigido a ácido nucleico diseñado que comprende un dominio P modificado se puede diseñar para unirse a un PAM con una especificidad superior a la de un ácido nucleico dirigido a ácido nucleico que no comprende un dominio P modificado (por ejemplo, ácido nucleico dirigido a ácido nucleico de tipo silvestre). Una mayor especificidad puede referirse a una reducción de la unión fuera de la diana (por ejemplo, la unión del ácido nucleico dirigido a ácido nucleico a una secuencia de PAM o de tipo PAM incorrecta). Por ejemplo, un ácido nucleico dirigido a ácido nucleico diseñado que comprende un dominio P modificado se puede diseñar para reducir la unión no específica en al menos aproximadamente un 10, 50, 100, 150, 200, 250, 300, 350, 400, 450, 500, 550 o 600 %, o más, en comparación con la de un ácido nucleico dirigido a ácido nucleico que no comprende un dominio P modificado. Un ácido nucleico dirigido a ácido nucleico diseñado que comprende un dominio P modificado se puede diseñar para reducir la unión no específica, como máximo, en aproximadamente un 10, 50, 100, 150, 200, 250, 300, 350, 400, 450, 500, 550 o 600 %, o más, con respecto a la de un ácido nucleico dirigido a ácido nucleico que no comprende un dominio P modificado. Un ácido nucleico dirigido a ácido nucleico diseñado que comprende un dominio P modificado se puede diseñar para reducir la unión no específica, como máximo, aproximadamente 1 vez, 2 veces, 3 veces, 4 veces, 5 veces, 10 veces, 20 veces, 30 veces, 40 veces o 50 veces, en comparación con la de un ácido nucleico dirigido a ácido nucleico que no comprende un dominio P modificado. Un ácido nucleico dirigido a ácido nucleico diseñado que comprende un dominio P modificado se puede diseñar para reducir la unión no específica en, como máximo, aproximadamente 1 vez, 2 veces, 3 veces, 4 veces, 5 veces, 10 veces, 20 veces, 30 veces, 40 veces o 50 veces, o más, en comparación con la de un ácido nucleico dirigido a ácido nucleico que no comprende un dominio P modificado.
Protuberancias diseñadas
Se puede diseñar un ácido nucleico dirigido a ácido nucleico diseñado de manera que se pueda introducir una modificación en la región protuberante del ácido nucleico dirigido a ácido nucleico. Una protuberancia es un elemento típico del ácido nucleico que comprende nucleótidos no emparejados. Una protuberancia puede comprender nucleótidos no emparejados en cada cadena del dúplex que comprende la protuberancia. En otras palabras, una protuberancia puede comprender un nucleótido no emparejado en la cadena de repetición CRISPR mínima del dúplex
y un nucleótido no emparejado en la cadena de secuencia mínima de ARNcrtra del dúplex.
Una protuberancia puede comprender al menos aproximadamente 1, 2, 3, 4, 5, 6, 7, 8, 9 o 10, o más, nucleótidos no emparejados en una primera cadena de un dúplex en un ácido nucleico dirigido a ácido nucleico (es decir, la cadena de repetición CRISPR mínima del dúplex que comprende la repetición CRISPR mínima y la secuencia mínima de ARNcrtra). Una protuberancia puede comprender, como máximo, aproximadamente 1, 2, 3, 4, 5, 6, 7, 8, 9 o 10, o más, nucleótidos no emparejados en una primera cadena de un dúplex en un ácido nucleico dirigido a ácido nucleico (es decir, cadena de repetición CRISPR mínima del dúplex que comprende la repetición mínima de CRISPR y la secuencia mínima de ARNcrtra). Una protuberancia puede comprender al menos aproximadamente 1, 2, 3, 4, 5, 6, 7, 8, 9 o 10, o más, nucleótidos no emparejados en una segunda cadena de un dúplex en un ácido nucleico dirigido a ácido nucleico (es decir, la cadena de la secuencia mínima de ARNcrtra del dúplex que comprende la repetición mínima de CRISPR y la secuencia mínima de ARNcrtra). Una protuberancia puede comprender, como máximo, aproximadamente 1, 2, 3, 4, 5, 6, 7, 8, 9 o 10, o más, nucleótidos no emparejados en una segunda cadena de un dúplex en un ácido nucleico dirigido a ácido nucleico (es decir, la cadena de la secuencia mínima de ARNcrtra del dúplex que comprende la repetición mínima de CRISPR y la secuencia mínima de ARNcrtra). Una protuberancia puede comprender un nucleótido no emparejado en la secuencia mínima de ARN de CRISPR y 3 nucleótidos no emparejados en la cadena de secuencia mínima de ARNcrtra.
Los nucleótidos adyacentes a un nucleótido no emparejado pueden ser un nucleótido que forma una interacción de emparejamiento de bases oscilantes. Las interacciones de emparejamiento de bases oscilantes pueden incluir guanina-uracilo, hipoantina-uracilo, hipoxantina-adenina e hipoxantina-citosina. Al menos 1, 2, 3, 4 o 5 o más nucleótidos adyacentes a un nucleótido no emparejado pueden formar un emparejamiento oscilante. Como máximo, 1, 2, 3, 4 o 5, o más, nucleótidos adyacentes a un nucleótido no emparejado pueden formar un emparejamiento oscilante.
Una protuberancia diseñada puede comprender al menos aproximadamente 1, 2, 3, 4, 5, 6, 7, 8, 9 o 10, o más, mutaciones. Una protuberancia diseñada puede comprender, como máximo, aproximadamente 1, 2, 3, 4, 5, 6, 7, 8, 9 o 10, o más, mutaciones. Las mutaciones pueden ser adyacentes entre sí (por ejemplo, secuenciales). Las mutaciones pueden estar separadas entre sí. Las mutaciones pueden estar separadas por al menos aproximadamente 1,2, 3, 4, 5, 6, 7, 8, 9 o 10, o más, nucleótidos. Las mutaciones pueden estar separadas por al menos aproximadamente 1, 2, 3, 4, 5, 6, 7, 8, 9 o 10, o más, nucleótidos. Las mutaciones en un ácido nucleico dirigido a ácido nucleico pueden comprender inserciones, eliminaciones y sustituciones de nucleótidos en el ácido nucleico dirigido a ácido nucleico.
Una protuberancia un ácido nucleico dirigido a ácido nucleico diseñado puede comprender, como máximo, aproximadamente un 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30 % o más de identidad y/o similitud de nucleótidos con un ácido nucleico dirigido a ácido nucleico de tipo silvestre. Una protuberancia un ácido nucleico dirigido a ácido nucleico diseñado puede comprender al menos aproximadamente un 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21,22, 23, 24, 25, 26, 27, 28, 29, 30 %, o más, de identidad y/o similitud de nucleótidos con un ácido nucleico dirigido a ácido nucleico de tipo silvestre.
Una cadena de la protuberancia puede estar mutada y la otra cadena no estar mutada. En otras palabras, en algunos casos, la secuencia de la protuberancia de la cadena mínima de ARN de CRISPR es la misma que la de un ácido nucleico dirigido a ácido nucleico de tipo silvestre, y la secuencia de la protuberancia de la secuencia mínima de ARNcr está mutada. En otras palabras, la secuencia de la protuberancia de la cadena mínima de ARN de CRISPR está mutada, y la secuencia de la protuberancia de la secuencia mínima de ARNcrtra es la misma que un ácido nucleico dirigido a ácido nucleico de tipo silvestre.
Las modificaciones en la protuberancia pueden ser tales que el ácido nucleico dirigido a ácido nucleico diseñado se configure de nuevo para unirse a un nuevo polipéptido dirigido a un sitio. El nuevo polipéptido dirigido a un sitio puede comprender al menos aproximadamente un 5, 10, 15, 20, 25, 30, 35, 40, 45 o 50 %, o más, de identidad de secuencia de aminoácidos con un polipéptido dirigido a un sitio de tipo silvestre. El nuevo polipéptido dirigido a un sitio puede comprender, como máximo, aproximadamente un 5, 10, 15, 20, 25, 30, 35, 40, 45 o 50 %, o más, de identidad de secuencia de aminoácidos con un polipéptido dirigido a un sitio de tipo silvestre. El nuevo polipéptido dirigido a un sitio puede ser un homólogo de Cas9. El nuevo polipéptido dirigido a un sitio puede ser un ortólogo de Cas9. El nuevo polipéptido dirigido a un sitio puede ser una quimera de dos polipéptidos diferentes dirigidos a un sitio. El nuevo polipéptido dirigido a un sitio puede comprender una mutación como se desvela en el presente documento.
Un ácido nucleico dirigido a ácido nucleico diseñado que comprende una protuberancia modificada puede diseñarse para unirse a un polipéptido dirigido a un sitio con una constante de disociación inferior o superior a la de un ácido nucleico dirigido a ácido nucleico que no comprende una protuberancia modificada (por ejemplo, ácido nucleico dirigido a ácido nucleico de tipo silvestre). Un ácido nucleico dirigido a ácido nucleico diseñado que comprende una protuberancia modificada puede diseñarse para unirse a un polipéptido dirigido a un sitio con una constante de disociación de al menos aproximadamente un 10, 50, 100, 150, 200, 250, 300, 350, 400, 450, 500, 550 o 600 %, o más, inferior o superior a la de un ácido nucleico dirigido a ácido nucleico que no comprende la protuberancia modificada. Un ácido nucleico dirigido a ácido nucleico diseñado que comprende una protuberancia modificada puede diseñarse para unirse a un polipéptido dirigido a un sitio con una constante de disociación, como máximo,
aproximadamente un 10, 50, 100, 150, 200, 250, 300, 350, 400, 450, 500, 550 o 600 %, o más inferior o superior a la de un ácido nucleico dirigido a ácido nucleico que no comprende una protuberancia modificada. Un ácido nucleico dirigido a ácido nucleico diseñado que comprende una protuberancia modificada puede diseñarse para unirse a un polipéptido dirigido a un sitio con una constante de disociación al menos aproximadamente 1 vez, 2 veces, 3 veces, 4 veces, 5 veces, 10 veces, 20 veces, 30 veces, 40 veces o 50 veces, o más, inferior o superior a la de un ácido nucleico dirigido a ácido nucleico que no comprende una protuberancia modificada. Un ácido nucleico dirigido a ácido nucleico diseñado que comprende una protuberancia modificada puede diseñarse para unirse a un polipéptido dirigido a un sitio con una constante de disociación, como máximo, aproximadamente 1 vez, 2 veces, 3 veces, 4 veces, 5 veces, 10 veces, 20 veces, 30 veces, 40 veces o 50 veces, o más, inferior o superior a la de un ácido nucleico dirigido a ácido nucleico que no comprende una protuberancia modificada.
Métodos
La divulgación proporciona métodos para diseñar ácidos nucleicos dirigidos a ácido nucleico. Los métodos pueden comprender la modificación de un ácido nucleico dirigido a ácido nucleico. La modificación puede comprender insertar, eliminar, sustituir y mutar los nucleótidos en el ácido nucleico dirigido a ácido nucleico. La modificación puede comprender modificar el ácido nucleico dirigido a ácido nucleico de manera que el ácido nucleico dirigido a ácido nucleico pueda unirse a nuevos motivos adyacentes al protoespaciador y/o nuevos polipéptidos dirigidos a un sitio en comparación con un ácido nucleico dirigido a ácido nucleico de tipo silvestre. El método se puede realizar usando cualquiera de los polipéptidos dirigidos a un sitio, ácidos nucleicos dirigidos a ácido nucleico y complejos de polipéptidos dirigidos a un sitio y ácidos nucleicos dirigidos a ácido nucleico tales como los descritos en el presente documento.
Se puede usar un ácido nucleico dirigido a ácido nucleico diseñado para escindir un ácido nucleico diana. Un ácido nucleico dirigido a ácido nucleico diseñado puede introducirse en células con un polipéptido dirigido a un sitio, formando así un complejo. El complejo puede hibridarse con un ácido nucleico diana, en donde el ácido nucleico diana comprende un motivo adyacente al protoespaciador. El polipéptido dirigido a un sitio del complejo puede escindir el ácido nucleico diana.
Las partes complementarias de las secuencias de ácido nucleico del ácido nucleico pre-CRISPR y las secuencias de ácido nucleico crtra de Streptococcus pyogenes SF370 se muestran en la Figura 20.
La Figura 21 representa una estructura ilustrativa del dúplex (por ejemplo, horquilla) que comprende la repetición CRISPR mínima y la secuencia mínima de ARNcrtra y una parte de la secuencia de ARNcrtra de 3'. El dúplex comprende una región de protuberancia.
La Tabla 4 contiene las secuencias de plantillas de ADN usadas para sintetizar los ácidos nucleicos dirigidos a un ácido nucleico guía sencillos de la divulgación.








La Tabla 2 muestra las secuencias de ARN de las plantillas de ADN de la Tabla 1.
Tabla 2. Secuencias de ARN de los ácidos nucleicos dirigidos a ácido nucleico guía sencillos de la divulgación




O ) o CM co
■*— Tt CN CN OJ ÍM ÍM
> > > > > > ¿ t ¿ ¿ I T C¿ ¿ 0 O 0 O
a i en en O 0 0 en eo




La Tabla 5 indica la actividad y el propósito de variantes adicionales de ácido nucleico dirigido a ácido nucleico. se refiere a activo, - se refiere a inactivo. Los datos experimentales de estas variantes se muestran en la Figura 37.
Tabla 5. Variantes de ácido nucleico diri ido a ácido nucleico su actividad

(co n tin u a c ió n )

(co n tin u a c ió n )
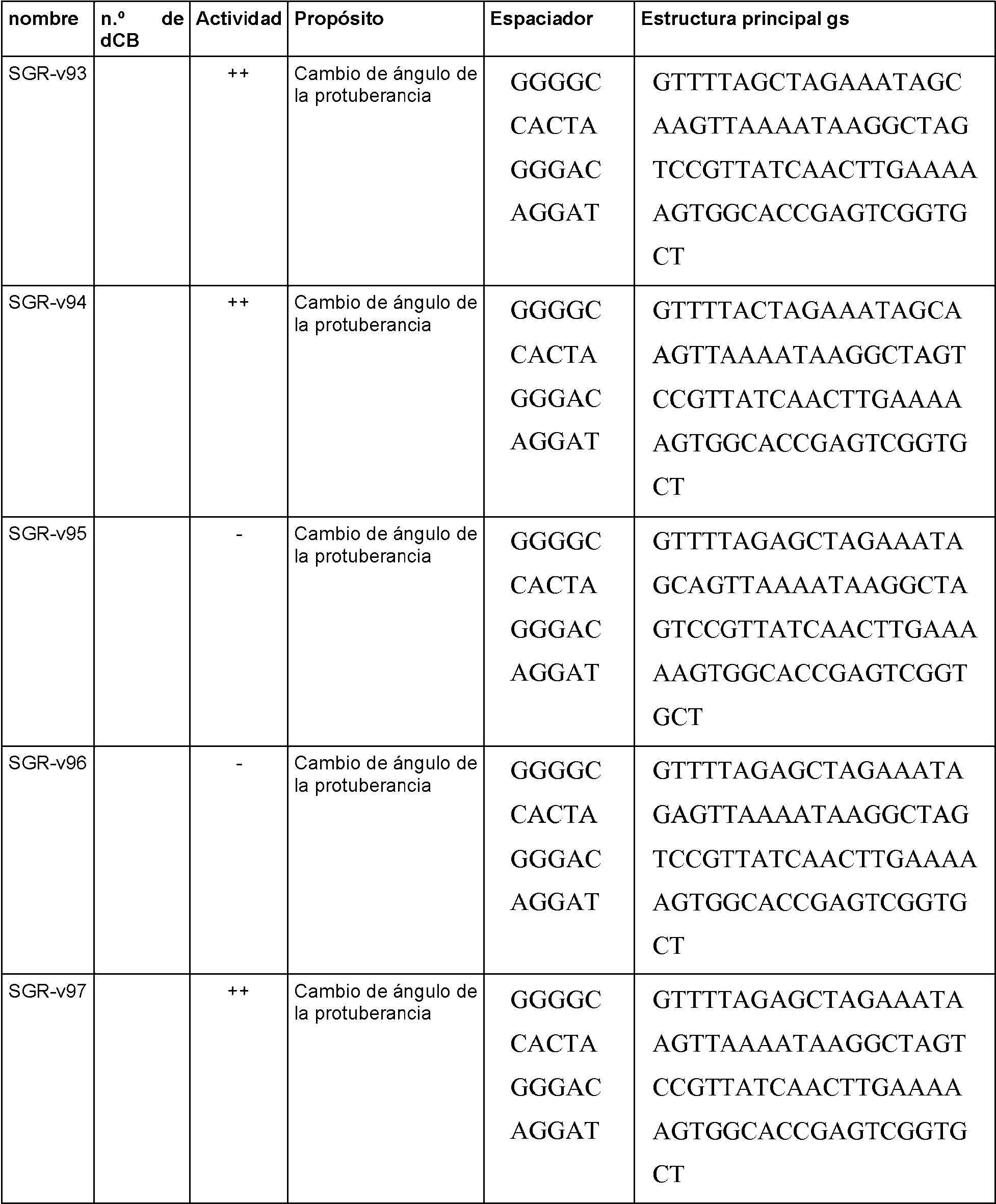
(co n tin u a c ió n )

(co n tin u a c ió n )

(continuación)

(co n tin u a c ió n )

(co n tin u a c ió n )

(c o n tin u a c ió n )

(co n tin u a c ió n )

Métodos para la generación de estirpes celulares marcadas usando un ácido nucleico dirigido a ácido nucleico Los métodos de la divulgación proporcionan el mareaje de una célula con un polinucleótido donante, en donde el polinucleótido donante puede dividirse y/o diferenciarse, y el polinucleótido donante puede transmitirse a cada célula hija durante la división celular. El método se puede realizar usando cualquiera de los polipéptidos dirigidos a un sitio, ácidos nucleicos dirigidos a ácido nucleico y complejos de polipéptidos dirigidos a un sitio y ácidos nucleicos dirigidos a ácido nucleico tales como los descritos en el presente documento.
Se puede generar una célula marcada poniendo en contacto la célula con un polinucleótido donante y un complejo que comprenda un polipéptido dirigido a un sitio y un ácido nucleico dirigido a ácido nucleico. El polinucleótido donante puede insertarse en el ácido nucleico diana escindido, generando así una célula marcada. La célula marcada se puede propagar, tal como en una estirpe celular, o para producir una población propagada de células.
Se puede introducir un polinucleótido donante en el sitio de corte mediante el uso de un casete donante para la recombinación homóloga que comprende extremos homólogos a secuencias a ambos lados de la rotura bicatenaria. El polinucleótido donante puede comprender una secuencia adicional entre los dos extremos. La secuencia adicional puede ser una secuencia de ácido nucleico. La secuencia adicional puede codificar un gen. La secuencia adicional puede codificar un elemento de ácido nucleico no codificante.
El polinucleótido donante (por ejemplo, la secuencia adicional de un polinucleótido donante entre dos extremos homólogos) puede comprender un marcador. Un marcador puede comprender un marcador de visualización (por ejemplo, un marcador fluorescente tal como GFP). Un marcador puede comprender una secuencia de polinucleótido aleatoria (por ejemplo, tal como una secuencia de hexámero aleatoria). Un marcador puede ser un código de barras.
La NHEJ puede introducir una firma de secuencia única en cada sitio de corte. El mecanismo de reparación puede producir la introducción de inserciones (por ejemplo, inserción de un polinucleótido donante), eliminaciones o mutaciones en un sitio de corte. Una célula que se somete a NHEJ para reparar una rotura bicatenaria puede comprender una secuencia única una vez que haya tenido lugar la reparación (por ejemplo, se puede insertar una secuencia única en la rotura bicatenaria). Si se corta más de un sitio dentro de una célula, la reparación puede introducir el polinucleótido donante en cada sitio, agregando así diversidad de secuencia a esa célula. El sitio reparado puede proporcionar una secuencia de código de barras única a la célula, que puede conservarse durante la división celular y transmitirse a toda la progenie de la célula modificada. Se puede insertar un polinucleótido donante en al menos aproximadamente 1,2, 3, 4, 5, 6, 7, 8, 9 o 10 o más sitios (por ejemplo, ácidos nucleicos diana escindidos). Se puede insertar un polinucleótido donante, como máximo, en aproximadamente 1, 2, 3, 4, 5, 6, 7, 8, 9 o 10 o más sitios (por ejemplo, ácidos nucleicos diana escindidos).
La recombinación homóloga (HR) puede usarse para introducir secuencias de códigos de barras en una célula y/o una población de células (por ejemplo, una célula humana, una célula de mamífero, una levadura, un hongo, un protozoo, una arquea). Se puede preparar un banco de plásmidos donantes (por ejemplo, que comprenden el polinucleótido donante) con secuencias aleatorizadas en el casete donante. El banco puede estar hecho de oligonucleótidos, una pieza de ADN bicatenario, un plásmido y/o un minicírculo.
Las secuencias de polinucleótidos donantes pueden introducirse en los genomas de células individuales con el fin de rastrear el linaje celular. Los sitios se pueden elegir para su modificación en regiones silenciosas o de "puerto seguro" del genoma, distantes de los genes y elementos reguladores, para minimizar los efectos potencialmente nocivos sobre la función celular. Los sitios dentro de elementos genéticos funcionales también se pueden usar para rastrear el destino celular.
Por ejemplo, los polinucleótidos donantes pueden introducirse en células madre y/o poblaciones de células madre. Los métodos de la divulgación se pueden usar para rastrear el desarrollo del linaje celular en modelos animales. Por ejemplo, se puede rastrear el desarrollo del destino celular y/o la diferenciación en la hematopoyesis usando los métodos de la divulgación. Los métodos de la divulgación pueden usarse para terapias basadas en ingeniería de células terapéuticas. Por ejemplo, una célula puede marcarse con un polinucleótido donante que codifique una proteína terapéutica. La célula se puede propagar. La célula propagada se puede introducir en un sujeto. Como otro ejemplo, una célula diferenciada puede retirarse de un sujeto. La célula diferenciada puede marcarse con dos marcadores: uno expresado cuando la célula está diferenciada, otro expresado cuando la célula está desdiferenciada. La identificación de los marcadores puede ser útil para determinar los eventos de diferenciación. En otro ejemplo, se puede obtener una célula diferenciada de un sujeto. La célula diferenciada se puede desdiferenciar en una célula pluripotente. La célula pluripotente puede marcarse con un polinucleótido donante que codifique una proteína terapéutica. La célula se puede volver a diferenciar en un nuevo tipo celular mientras se expresa la proteína terapéutica, creando así una célula terapéutica específica del paciente. Las células marcadas pueden dividirse y diferenciarse, y las modificaciones realizadas en su genoma pueden transmitirse a cada célula hija durante la división celular.
En algunos casos, se pueden marcar dos células con dos marcadores de polinucleótido donante diferentes. Las dos células se pueden combinar. La mezcla combinada se puede analizar simultáneamente. Los polinucleótidos donantes pueden permitir el análisis multiplex de las dos células, porque el polinucleótido donante puede usarse para distinguir las dos células.
Se puede elegir una población celular para introducir roturas bicatenarias o generar firmas celulares. Las células pueden ser purificadas o seleccionadas. Por ejemplo, una población de células madre hematopoyéticas (CD45 positivas) puede seleccionarse mediante FACS o purificación de perlas magnéticas. La médula ósea se puede tratar ex vivo con la nucleasa. Las células pueden ser atacadas in vivo mediante el uso de virus con un tropismo particular. Las células pueden seleccionarse mediante el uso de virus diseñados para dirigirse a células que portan un receptor particular.
Las células marcadas pueden analizarse mediante secuenciación de alto rendimiento a nivel de población o a nivel de célula individual. A nivel de población, se puede lisar una colección de células. El ADN genómico se puede extraer. Se pueden diseñar cebadores de PCR para amplificar la región genómica que ha sido modificada por la nucleasa. Las
secuencias pueden enriquecerse por hibridación. Se puede preparar un banco de secuencias a partir del ADN genómico y enriquecerla. Se puede enriquecer la región de interés y se puede preparar un banco de secuencias. Se puede preparar un banco de secuencias simultáneamente durante el enriquecimiento usando cebadores que comprendan marcadores de secuencia apropiados para su uso con tecnologías de secuenciación de ácido nucleico. Si la rotura bicatenaria se realiza dentro de una región que se puede transcribir, se puede usar ARN para preparar bancos de secuencias.
Una vez que se han obtenido los datos de la secuencia de ácido nucleico, se pueden analizar las secuencias para determinar la estructura clónica. Esto puede llevarse a cabo reuniendo secuencias comunes y contando esas secuencias.
Las células se pueden subseleccionar mediante esquemas de clasificación basados en marcadores de superficie celular usando citometría de flujo o métodos de purificación por afinidad. Los marcadores de superficie celular se pueden usar para definir estados celulares y, si se comparan los estados celulares con la estructura clónica, se puede determinar el destino de las poblaciones celulares modificadas.
A nivel de una sola célula, las células pueden aislarse. Los productos de PCR se pueden generar a partir de cada célula individual. Esto se puede lograr en matrices de micropocillos, dispositivos microfluídicos y/o emulsiones. Cuando se realiza más de una modificación genómica por célula, los productos de PCR se pueden acoplar entre sí, ya sea física o químicamente, para garantizar su relación con la célula madre.
Métodos para cuantificar eventos de edición del genoma
Para las nucleasas dependientes del ARN, tales como Cas9, se pueden unir la funcionalidad de reconocimiento de ácido nucleico y las actividades nucleasa. En algunos casos, la funcionalidad de reconocimiento de ácido nucleico y las actividades nucleasa pueden no estar enlazadas. Los sitios de nucleasa pueden ubicarse dentro de la secuencia específica reconocida por la nucleasa.
La unión de extremos no homólogos puede ser un proceso de reparación imperfecto que puede producir en la inserción de múltiples bases en el sitio de la rotura bicatenaria. La NHEJ puede producir la introducción de inserciones, eliminaciones y/o mutaciones en un sitio de corte. La NHEJ puede interrumpir significativamente la secuencia original. Se puede usar la interrupción de la secuencia nativa como consecuencia de los mecanismos de reparación para evaluar la eficiencia de los enfoques de edición del genoma.
La recombinación homóloga puede permitir una reparación más completa de la rotura del ácido nucleico diana mediante el intercambio de secuencias de nucleótidos entre moléculas de ácido nucleico similares o idénticas. Se puede introducir una secuencia adicional en el ácido nucleico diana en el sitio de corte mediante el uso de un casete donante (por ejemplo, polinucleótido donante) que comprenda extremos homólogos a las secuencias a ambos lados de la rotura bicatenaria y una secuencia adicional entre los dos extremos.
La presente divulgación describe un enfoque para evaluar la actividad de rotura bicatenaria y las inserciones/eliminaciones mediadas por la NHEJ introducidas por nucleasas dependientes de ácido nucleico, tales como Cas9. El método aprovecha el hecho de que los sitios de un ácido nucleico diana reconocido por Cas9 durante el reconocimiento inicial de la nucleasa y la actividad de escisión de ácido nucleico pueden destruirse durante el proceso de NHEJ, ya sea mediante la introducción de inserciones o eliminaciones.
En algunos casos, el método proporciona el diseño de un ácido nucleico dirigido a ácido nucleico para dirigir un sitio de interés en un ácido nucleico diana (por ejemplo, genoma). Se puede diseñar una plantilla de ácido nucleico que codifica el ácido nucleico dirigido a ácido nucleico con una secuencia promotora añadida en el extremo 5' del ácido nucleico dirigido a ácido nucleico para permitir la síntesis in vitro del ácido nucleico dirigido a ácido nucleico.
Los cebadores pueden diseñarse en posiciones que flanquean el sitio de escisión. El sitio de escisión (y/o regiones de ácido nucleico alrededor del sitio de escisión) puede amplificarse (por ejemplo, a partir de ácido nucleico genómico), generando así un producto (por ejemplo, producto de p Cr amplificado). El producto (por ejemplo, producto de PCR amplificado) puede tener al menos aproximadamente 100, 200, 300, 400, 500, 600, 700, 800, 900, 1000, 1100, 1200 o más bases de longitud. El producto (por ejemplo, producto de PCR amplificado) puede tener, como máximo, aproximadamente 100, 200, 300, 400, 500, 600, 700, 800, 900, 1000, 1100, 1200 o más bases de longitud. El producto (por ejemplo, producto de PCR amplificado) puede tener aproximadamente 200-600 pares de bases de longitud.
Los productos pueden ser purificados. Los productos pueden ser incubados con una nucleasa dependiente del ARN (por ejemplo, Cas9) y ácido nucleico dirigido a ácido nucleico. Esas moléculas que han sido amplificadas a partir de ácido nucleico genómico que no han sido modificadas por NHEJ pueden comprender la secuencia correcta que puede ser reconocida y escindida por Cas9. Las moléculas que se han amplificado a partir del ácido nucleico genómico que ha sido modificado por NHEJ pueden no comprender sitios que puedan ser reconocidos y/o cortados por Cas9.
Los productos digeridos pueden analizarse luego mediante métodos tales como electroforesis en gel, electroforesis
capilar, secuenciación de alto rendimiento y/o PCR cuantitativa (por ejemplo, qPCR). En el caso de la electroforesis en gel, se puede obtener una imagen de un gel. Una vez que se ha tomado una imagen de un gel, se puede estimar el porcentaje de células modificadas por NHEJ midiendo la intensidad de las bandas correspondientes a los productos digeridos y comparando la intensidad de las bandas correspondientes a los productos no digeridos.
Métodos para administrar el polinucleótido donante a una rotura bicatenaria para su inserción en la rotura bicatenaria
La presente divulgación describe métodos para acercar un polinucleótido donante a una rotura de ácido nucleico diana dirigido a un sitio para mejorar la inserción (por ejemplo, recombinación homóloga) del polinucleótido donante en el sitio de la rotura bicatenaria. El método se puede realizar usando cualquiera de los polipéptidos dirigidos a un sitio, ácidos nucleicos dirigidos a ácido nucleico y complejos de polipéptidos dirigidos a un sitio y ácidos nucleicos dirigidos a ácido nucleico tales como los descritos en el presente documento.
En algunos casos, los métodos de la divulgación prevén llevar un polinucleótido donante cerca del sitio de una rotura bicatenaria en un ácido nucleico diana, uniéndolo a la nucleasa que genera la rotura bicatenaria (por ejemplo, Cas9).
Un complejo que comprende un polipéptido dirigido a un sitio, un ácido nucleico dirigido a ácido nucleico y un polinucleótido donante pueden administrarse a un ácido nucleico diana. La Figura 30 ilustra métodos ilustrativos para acercar un polinucleótido donante a un sitio de una rotura bicatenaria en un ácido nucleico diana. Por ejemplo, un ácido nucleico dirigido a ácido nucleico puede comprender una secuencia de extensión de hibridación de 3', que puede ser parte de una secuencia de extensión de ARNcrtra (mostrada en la línea punteada clara unida al ácido nucleico dirigido a ácido nucleico). Una secuencia de extensión de hibridación de 3' puede ser una secuencia no nativa. La Figura 30A ilustra que la secuencia de extensión de ARNcrtra en el extremo 3' del ácido nucleico dirigido a ácido nucleico puede incluir una secuencia que puede hibridarse con un extremo del polinucleótido donante (por ejemplo, el extremo 3') (el polinucleótido donante se muestra en línea punteada gruesa en negrita). La secuencia de extensión de hibridación de 3' puede tener al menos aproximadamente 1,2, 3, 4, 5, 6, 7, 8, 9 o 10 o más nucleótidos de longitud. La secuencia de extensión de hibridación de 3' puede tener, como máximo, 1, 2, 3, 4, 5, 6, 7, 8, 9 o 10, o más, nucleótidos de longitud. La secuencia de hibridación de 3' puede hibridarse con al menos aproximadamente 1,2, 3, 4, 5, 5, 6, 7, 8, 9 o 10, o más, nucleótidos del polinucleótido donante. La secuencia de hibridación de 3' puede hibridarse, como máximo, con 1, 2, 3, 4, 5, 5, 6, 7, 8, 9 o 10, o más, nucleótidos del polinucleótido donante. La secuencia de hibridación de 3' puede hibridarse con el polinucleótido donante con al menos 1, 2, 3, 4, 5, 6, 7, 8, 9 o 10, o más, emparejamientos erróneos. La secuencia de hibridación de 3' puede hibridarse con el polinucleótido donante con, como máximo, 1, 2, 3, 4, 5, 6, 7, 8, 9 o 10 o más emparejamientos erróneos.
La extensión de hibridación de 3' puede hibridarse con el extremo 3' del polinucleótido donante. La extensión de hibridación de 3' puede hibridarse con al menos 1, 2, 3, 4, 5, 6, 7, 8, 9 o 10, o más, nucleótidos más a 3' del polinucleótido donante. La extensión de hibridación de 3' puede hibridarse, como máximo, con 1, 2, 3, 4, 5, 6, 7, 8, 9 o 10, o más, nucleótidos más a 3' del polinucleótido donante.
Como se representa en la Figura 30B, la extensión de ácido nucleico crtra en el extremo 3' del ácido nucleico dirigido a ácido nucleico puede incluir una secuencia que puede hibridarse con el extremo 5' del ADN donante. La extensión de hibridación de 3' puede hibridarse con al menos 1, 2, 3, 4, 5, 6, 7, 8, 9 o 10, o más, nucleótidos más a 5' del polinucleótido donante. La extensión de hibridación de 3' puede hibridarse, como máximo, con 1, 2, 3, 4, 5, 6, 7, 8, 9 o 10, o más, nucleótidos más a 5' del polinucleótido donante.
La extensión de ácido nucleico crtra en el extremo 3' del ácido nucleico dirigido a ácido nucleico puede incluir una secuencia que puede hibridarse a una región entre el extremo 3' y el extremo 5' del polinucleótido donante, como se muestra en la Figura 30C. La extensión de hibridación de 3' puede hibridarse con al menos 1, 2, 3, 4, 5, 6, 7, 8, 9 o 10, o más, nucleótidos entre el extremo 3' y 5' del polinucleótido donante. La extensión de hibridación de 3' puede hibridarse, como máximo, con 1,2, 3, 4, 5, 6, 7, 8, 9 o 10, o más, nucleótidos entre el extremo 3' y 5' del polinucleótido donante.
La extensión de ácido nucleico crtra en el extremo 3' del ácido nucleico dirigido a ácido nucleico puede incluir una secuencia que puede hibridarse a lo largo del polinucleótido donante, como se muestra en la Figura 30D. El ácido nucleico dirigido a ácido nucleico puede hibridarse a lo largo de al menos aproximadamente un 20, 30, 40, 50, 60, 70, 80, 90 o 100 % del polinucleótido donante. El ácido nucleico dirigido a ácido nucleico puede hibridarse a lo largo de aproximadamente un 20, 30, 40, 50, 60, 70, 80, 90 o 100 % del polinucleótido donante. La secuencia de extensión de hibridación de 3' puede hibridarse a lo largo de la longitud completa del polinucleótido donante con al menos aproximadamente 1, 2, 3, 4, 5, 6, 7, 8, 9 o 10, o más, emparejamientos erróneos. La secuencia de extensión de hibridación de 3' puede hibridarse a lo largo de toda la longitud del polinucleótido donante con, como máximo, aproximadamente 1, 2, 3, 4, 5, 6, 7, 8, 9 o 10, o más, emparejamientos erróneos.
La extensión de ácido nucleico crtra en el extremo 3' del ácido nucleico dirigido a ácido nucleico (por ejemplo, extensión de hibridación de 3') puede comprender una secuencia que puede usarse como plantilla y ser convertida, por ejemplo, por una transcriptasa inversa para generar ácido nucleico híbrido (por ejemplo, el ácido nucleico resultante es un
híbrido de ARN-ADN, en donde el ácido nucleico recién transcrito puede ser ADN), como se muestra en la Figura 30E. Los ejemplos de transcriptasas inversas incluyen SuperScript, ThermoScript, transcriptasa inversa de VIH y transcriptasa inversa de MMLV. La transcriptasa inversa puede extender la secuencia de polinucleótido donante a partir de la plantilla de extensión de hibridación de 3'.
La extensión de ácido nucleico crtra en el extremo 3' del ácido nucleico dirigido a ácido nucleico puede incorporar una secuencia de ácido nucleico que puede unirse a una proteína de unión a ARN (RBP). La proteína de unión a ARN puede fusionarse con una proteína de unión a ADN (DBP), como se muestra en la Figura 30F. La proteína de unión al ADN puede unirse al polinucleótido donante.
Las secuencias usadas para acercar el polinucleótido donante a una rotura bicatenaria se pueden unir al extremo 5' del ácido nucleico dirigido a ácido nucleico (por ejemplo, La extensión del espaciador). Las secuencias usadas para acercar el polinucleótido donante a una rotura bicatenaria se pueden unir tanto al extremo 5' como al extremo 3' del ácido nucleico dirigido a ácido nucleico.
La nucleasa usada en los métodos de la divulgación (por ejemplo, Cas9) puede comprender actividad nickasa, en donde la nucleasa puede introducir roturas monocatenarias en un ácido nucleico diana. Los pares de nucleasas con actividad nickasa pueden dirigirse a regiones cercanas entre sí. Una primera nucleasa puede unirse a un primer ácido nucleico dirigido a ácido nucleico que puede interactuar con un primer polinucleótido donante. Una segunda nucleasa puede unirse a un segundo ácido nucleico dirigido a ácido nucleico que puede interactuar con un segundo polinucleótido donante. El primer y segundo polinucleótido donante se pueden diseñar para hibridarse entre sí a fin de crear un polinucleótido donante bicatenario. Se pueden llevar dos polinucleótidos donante separados a un sitio de nucleasa.
En algunas realizaciones, el polinucleótido donante puede ser monocatenario. En algunas realizaciones, el polinucleótido donante puede ser bicatenario. En algunas realizaciones, el ADN donante puede ser un minicírculo. En algunas realizaciones, el polinucleótido donante puede ser un plásmido. En algunas realizaciones, el plásmido puede estar superenrollado. En algunas realizaciones, el polinucleótido donante puede estar metilado. En algunas realizaciones, el polinucleótido donante puede no estar metilado. El polinucleótido donante puede comprender una modificación. Las modificaciones pueden incluir las descritas en el presente documento, que incluyen, aunque sin limitación, biotinilación, conjugado químico y nucleótidos sintéticos.
Métodos para clonar y expresar un vector que comprende un polipéptido dirigido a un sitio y un ácido nucleico dirigido a ácido nucleico
La divulgación proporciona métodos para clonar un ácido nucleico dirigido a ácido nucleico diseñado en un vector (por ejemplo, un vector linealizado). El método se puede realizar usando cualquiera de los polipéptidos dirigidos a un sitio, ácidos nucleicos dirigidos a ácido nucleico y complejos de polipéptidos dirigidos a un sitio y ácidos nucleicos dirigidos a ácido nucleico tales como los descritos en el presente documento.
Un usuario (por ejemplo, un científico) puede diseñar oligonucleótidos de ADN monocatenarios. Los oligonucleótidos de ADN monocatenarios pueden, cuando se hibridan entre sí, codificar una secuencia espacial para dirigirse a un ácido nucleico diana. Los oligonucleótidos de ADN monocatenarios pueden tener al menos aproximadamente 5, 10, 15, 20, 25, 30, o más, nucleótidos de longitud. Los oligonucleótidos de ADN monocatenarios pueden tener, como máximo, aproximadamente 5, 10, 15, 20, 25, 30, o más, nucleótidos de longitud. Los oligonucleótidos de ADN monocatenarios pueden tener 19-20 nucleótidos de longitud.
Un oligonucleótido de ADN monocatenario puede diseñarse de modo que pueda hibridarse con un ácido nucleico diana (por ejemplo, una secuencia adyacente a un motivo adyacente al protoespaciador, tal como el extremo 3' o 5' del motivo adyacente al protoespaciador). El oligonucleótido de ADN puede codificar una secuencia correspondiente a la cadena codificante o no codificante de la secuencia de ácido nucleico diana.
Los oligonucleótidos monocatenarios pueden comprender una primera parte que puede hibridarse y/o es complementaria a un ácido nucleico diana. Los oligonucleótidos monocatenarios pueden comprender una primera parte que puede hibridarse y/o es complementaria a otro oligonucleótido monocatenario. El oligonucleótido monocatenario puede comprender una segunda parte que puede hibridarse con una secuencia en el vector linealizado. En otras palabras, un par de oligonucleótidos monocatenarios puede comprender una primera parte que se hibrida entre sí y una segunda parte que comprende salientes monocatenarios, en donde los salientes pueden hibridarse a extremos adhesivos en el vector linealizado. En algunos casos, un saliente comprende 5'-GTTTT-3'. En algunos casos, un saliente comprende 5'-CGGTG-3'.
Los nucleótidos de ADN monocatenarios se pueden hibridar entre sí para generar un oligonucleótido bicatenario. Los nucleótidos de ADN monocatenarios se pueden hibridar entre sí en un tampón de hibridación de oligonucleótidos (por ejemplo, que comprende Tris-HCl, EDTA y NaCl). El oligonucleótido bicatenario se puede diluir a una concentración de trabajo (por ejemplo, una concentración adecuada para la unión a un plásmido linealizado). El oligonucleótido bicatenario diluido puede ligarse en un vector linealizado. La ligadura puede realizarse en un tampón de ligadura (por
ejemplo, que comprende Tris-HCl, MgCh, ATP) y con una ligasa (por ejemplo, ADN ligasa de T4). El oligonucleótido bicatenario se puede ligar en un vector linealizado en una región dentro de la secuencia que codifica el ácido nucleico dirigido a ácido nucleico. En otras palabras, el vector linealizado puede linealizarse en un punto dentro de la región que codifica el ácido nucleico dirigido a ácido nucleico, en donde la linealización genera extremos adhesivos que son complementarios a los extremos adhesivos del oligonucleótido bicatenario. Cuando el oligonucleótido bicatenario se liga al vector, puede generar una secuencia que codifica un ácido nucleico dirigido a ácido nucleico diseñado que comprende una secuencia espaciadora correspondiente a la secuencia oligonucleotídica bicatenaria.
El vector ligado puede transformarse en células químicamente competentes (por ejemplo, DH5-alfa, Top10) y seleccionarse para la expresión del vector ligado correctamente (por ejemplo, mediante cribado con antibiótico). Los transformantes seleccionados pueden analizarse para detectar la presencia de una inserción mediante secuenciación. La secuenciación puede realizarse usando un cebador de secuenciación que pueda hibridarse con una parte del vector.
El vector ligado correctamente puede prepararse (por ejemplo, mediante preparación de ADN a gran escala, maxiprep) y purificarse. El vector, que comprende un polipéptido dirigido a un sitio, un ácido nucleico dirigido a ácido nucleico, en donde el ácido nucleico ácido dirigido a ácido nucleico comprende los oligonucleótidos de ADN bicatenarios, se puede introducir (por ejemplo, transfectar) en una estirpe celular de elección (por ejemplo, estirpe celular de mamífero).
Ejemplos
Los ejemplos que no pertenecen a la invención son solo para fines ilustrativos.
EJEMPLO 1: MODIFICACIÓN DE UN POLIPÉPTIDO DIRIGIDO A UN SITIO PARA ALTERAR LA ESPECIFICIDAD HACIA PAM
En algunas realizaciones, la divulgación proporciona un polipéptido modificado dirigido a un sitio que se modifica para alterar la especificidad hacia PAM. Un ácido nucleico que codifica un polipéptido dirigido a un sitio modificado se introduce en las células mediante transfección. El polipéptido dirigido a un sitio modificado comprende un dominio nucleasa HNH o RuvC insertado. El polipéptido modificado dirigido a un sitio comprende un parche altamente básico modificado. Un ácido nucleico dirigido a ácido nucleico que comprende un espaciador que puede hibridarse con el ácido nucleico diana también se introduce en las células mediante transfección. El polipéptido modificado dirigido a un sitio y el ácido nucleico dirigido a ácido nucleico forman un complejo. El complejo es guiado al ácido nucleico diana por el ácido nucleico dirigido a ácido nucleico. Una vez hibridado con el ácido nucleico dirigido a ácido nucleico, el ácido nucleico diana es escindido por los dominios nucleasa del polipéptido dirigido a un sitio. En algunas realizaciones, el polipéptido modificado dirigido a un sitio se une al ácido nucleico diana con una Kd inferior.
En algunas realizaciones, también se introduce un polinucleótido donante en las células. En algunos casos, el polinucleótido donante, una parte de un polinucleótido donante, una copia del polinucleótido donante o una parte de una copia del polinucleótido donante se inserta en el ácido nucleico diana escindido.
EJEMPLO 2: MODIFICACIÓN DE UN POLIPÉPTIDO DIRIGIDO A UN SITIO PARA ALTERAR LA ESPECIFICIDAD HACIA EL ÁCIDO NUCLEICO DIANA
En algunas realizaciones, la divulgación proporciona un polipéptido modificado dirigido a un sitio que se modifica para alterar la especificidad hacia ácido nucleico diana. Se introduce un polipéptido modificado dirigido a un sitio en células. El polipéptido modificado dirigido a un sitio comprende una modificación en el parche altamente básico y/o el dominio de tipo HNH. Un ácido nucleico dirigido a ácido nucleico que comprende un espaciador que puede hibridarse con el ácido nucleico diana también se introduce en las células. El polipéptido modificado dirigido a un sitio y el ácido nucleico dirigido a ácido nucleico forman un complejo. El complejo es guiado al ácido nucleico diana por el ácido nucleico dirigido a ácido nucleico. Una vez hibridado con el ácido nucleico dirigido a ácido nucleico, el ácido nucleico diana es escindido por el polipéptido dirigido a un sitio. En algunas realizaciones, el polipéptido modificado dirigido a un sitio se une al ácido nucleico diana con una Kd inferior.
En algunas realizaciones, también se introduce un polinucleótido donante en las células. En algunos casos, el polinucleótido donante, una parte de un polinucleótido donante, una copia del polinucleótido donante o una parte de una copia del polinucleótido donante se inserta en el ácido nucleico diana escindido.
EJEMPLO 3: EXPRESIÓN RECOMBINANTE DE UN POLIPÉPTIDO DIRIGIDO A UN SITIO
Se puede ensamblar una secuencia de ADN recombinante que codifica un polipéptido modificado dirigido a un sitio, y permite la expresión del polipéptido modificado dirigido a un sitio en un organismo hospedador. La secuencia de ADN recombinante comprende una secuencia promotora, y puede comprender además un marcador de afinidad para la purificación, o un marcador de epítopo. En un ejemplo no limitante, un plásmido comprende la secuencia de ADN recombinante para la expresión del polipéptido dirigido a un sitio modificado.
Producción de proteína recombinante.
Un plásmido que codifica el polipéptido modificado dirigido a un sitio se introduce en células bacterianas (por ejemplo, E. coli). El polipéptido se expresa en células bacterianas y luego se purifica del lisado celular usando métodos de cromatografía. La actividad del polipéptido dirigido a un sitio modificado se mide usando métodos de ensayo diseñados para determinar la especificidad del polipéptido modificado, la secuencia de PAM, el perfil de especificidad del polipéptido dirigido a un sitio y la preferencia del ácido nucleico (por ejemplo, ADN o ARN, o ácidos nucleicos modificados) para el polipéptido.
El software está diseñado para elegir sitios que puedan cortarse usando el polipéptido modificado dirigido a un sitio. Las secuencias de ARN guía están diseñadas para dirigir la actividad del polipéptido dirigido a un sitio. Una vez diseñado, el polipéptido dirigido a un sitio se usa para escindir ácidos nucleicos.
Introducción del polipéptido modificado dirigido a un sitio en las células
El péptido modificado se introduce en las células para dirigirse a los sitios de ácido nucleico. Un polipéptido que conserva la actividad nucleasa se usa para introducir roturas de ADN monocatenarias o bicatenarias en el a Dn diana. Se usa un polipéptido con actividad de unión al ADN, pero no de corte del ADN, para unir el ADN bicatenario a una célula. Esto puede usarse para efectuar la activación o represión de la transcripción.
EJEMPLO 4: SELECCIÓN DE SITIOS PARA MODIFICACIÓN DENTRO DE SECUENCIAS DE CAS9
Como se ha descrito anteriormente, los sistemas CRISPR de Tipo II que contienen ortólogos de Cas9 se pueden clasificar en tres grupos (Tipo II-A, Tipo II-B y Tipo II-C) según el análisis de sus locus de Cas de CRISPR. Los ortólogos de Cas9 dentro de estos grupos pueden definirse en términos generales por dos clados que comprenden secuencias más cortas (tipo Cas9/ Csn1) y más largas (tipo Cas9/Csx 12). Además de estos grupos más grandes, puede haber dos familias adicionales de homólogos que comprenden dominios HNH y RuvC dispuestos con una topología de tipo Cas9, pero con diferencias significativas en la longitud y secuencia de inserciones entre elementos de secuencia conservados. Las predicciones de estructura secundaria y las alineaciones de secuencia se usan para definir regiones del polipéptido para modificación. Las regiones que se encuentran entre elementos de estructura secundaria o entre regiones de alta conservación de secuencia se seleccionan como candidatos para inserciones o eliminaciones. Las regiones que tienen similitud con dominios de estructura conocida se analizan para identificar regiones específicas para insertar o eliminar secuencias.
La Figura 35 muestra la secuencia de alineación de CDD TIGR0185 para un pequeño número de diversos ortólogos de Cas9. Los aminoácidos con una "X" debajo de ellos se consideran similares. Los aminoácidos con una "Y" debajo de ellos pueden considerarse altamente conservados o idénticos en todas las secuencias. Los restos de aminoácidos sin una "X" o una "Y" no se conservan. Esta alineación no incluye la región C-terminal (que corresponde aproximadamente a los restos de aminoácidos 1100-1350) de los ortólogos de Cas9 más largos. Las secuencias enumeradas en la Figura 35 se enumeran en la Tabla 6.
T l . n i n m r n l Fi r .

Las ubicaciones para la inserción de nuevos dominios funcionales, regiones para la inserción de secuencias alternativas, o para la eliminación o reducción del tamaño de la región que modifican la actividad de Cas9 pueden incluir, pero sin limitación, las regiones resaltadas en la Tabla 7. Los números representan los números de secuencia de aminoácidos basados en la secuencia de Cas9 de Ml GAS de Streptococcus pyogenes.
Tabla 7. Ubicaciones ilustrativas para modificar Cas9

Una vez que se ha identificado una región como una ubicación potencial para insertar una nueva secuencia de polipéptido en la proteína, o eliminar una región de la proteína, la secuencia de ADN que codifica la proteína se modifica para incorporar la modificación.
EJEMPLO 5: ENRIQUECIMIENTO DE SECUENCIA DEL ÁCIDO NUCLEICO DIANA UNIDO AL POLIPEPTIDO DIRIGIDO A UN SITIO
La divulgación proporciona métodos para el enriquecimiento de secuencias sin amplificación usando polipéptidos dirigidos a un sitio.
En algunas realizaciones, el método comprenderá a) poner en contacto un ácido nucleico diana con un complejo que comprende un ácido nucleico dirigido a ácido nucleico y un polipéptido dirigido a un sitio; b) escindir el ácido nucleico diana; c) purificar el ácido nucleico diana; y d ) secuenciar el ácido nucleico diana, en donde dicho ácido nucleico diana es enriquecido.
En algunas realizaciones, el polipéptido dirigido a un sitio estará enzimáticamente inactivo. El uso de un polipéptido dirigido a un sitio enzimáticamente inactivo facilitará la unión del ácido nucleico diana al complejo del polipéptido dirigido a un sitio. En algunas realizaciones, el polipéptido dirigido a un sitio será enzimáticamente activo.
En algunas realizaciones, el enriquecimiento de secuencia se realiza fuera de las células (por ejemplo, muestra libre de células). Por ejemplo, una muestra comprenderá ADN genómico purificado. En algunas realizaciones, el enriquecimiento de secuencia se realizará en una muestra celular (por ejemplo, células, lisado celular).
En algunos casos, los complejos de polipéptido dirigido a un sitio-ácido nucleico dirigido a ácido nucleico se fijarán o entrecruzarán para formar complejos. Si el método se realiza en células, las células se lisarán. Las condiciones de lisis se elegirán para mantener intactos los complejos de proteína-ADN.
La muestra de ácido nucleico se tratará para fragmentar el ácido nucleico diana antes de la purificación por afinidad. La fragmentación se puede realizar a través de métodos físicos, mecánicos o enzimáticos. La fragmentación física
incluirá la exposición de un polinucleótido diana al calor o a la luz ultravioleta (UV). La disrupción mecánica se usará para cortar mecánicamente un polinucleótido diana en fragmentos del intervalo deseado. La cizalla mecánica se realizará a través de varios métodos, que incluyen pipeteo repetitivo del polinucleótido diana, sonicación y nebulización. Los ácidos nucleicos diana también se fragmentarán usando métodos enzimáticos. En algunos casos, se realizará la digestión enzimática usando enzimas tales como las enzimas de restricción. Las enzimas de restricción se usarán para realizar una fragmentación específica o no específica de polinucleótidos diana. Los métodos usarán uno o más tipos de enzimas de restricción, descritas en general como enzimas de Tipo I, enzimas de Tipo II y/o enzimas de Tipo III. Las enzimas de Tipo II y de Tipo III reconocen secuencias específicas de nucleótidos dentro de una secuencia polinucleotídica bicatenaria (una "secuencia de reconocimiento" o "sitio de reconocimiento"). Tras la unión y el reconocimiento de estas secuencias, las enzimas de Tipo II y Tipo III escinden la secuencia de polinucleótidos. En algunos casos, la escisión dará lugar a un fragmento de polinucleótido con una parte de ácido nucleico monocatenario saliente, denominada "extremo adhesivo". En otros casos, la escisión no dará lugar a un fragmento con un saliente, creando un "extremo romo". Los métodos pueden comprender el uso de enzimas de restricción que generen extremos adhesivos o extremos romos.
Una vez fragmentados, los complejos que comprenden el polipéptido dirigido a un sitio se purificarán mediante incubación con un soporte sólido. Por ejemplo, si el polipéptido dirigido a un sitio comprende un marcador de biotina, el soporte sólido se recubrirá con avidina o estreptavidina para unirse al marcador de biotina.
En un aspecto alternativo, Una vez fragmentados, los complejos que comprenden el polipéptido dirigido a un sitio, el ácido nucleico diana y/o el ácido nucleico dirigido a ácido nucleico, se purificarán mediante incubación con un agente de captura. El agente de captura se unirá al marcador de afinidad fusionado con el polipéptido dirigido a un sitio. El agente de captura comprenderá un anticuerpo. Por ejemplo, si el marcador de afinidad fusionado con el polipéptido dirigido a un sitio es un marcador FLAG, entonces el agente de captura será un anticuerpo anti-marcador FLAG.
En algunas realizaciones, el agente de captura se purificará con un soporte sólido. Por ejemplo, si el agente de captura comprende un marcador de biotina, el soporte sólido se recubrirá con avidina o estreptavidina para unirse al agente de captura biotinilado.
En algunas realizaciones, el ácido nucleico dirigido a ácido nucleico comprenderá un marcador de afinidad. El marcador de afinidad comprenderá una secuencia que pueda unirse a una endorribonucleasa. En algunos casos, el marcador de afinidad comprenderá una secuencia que pueda unirse a una endorribonucleasa condicionalmente inactiva enzimáticamente. La endorribonucleasa condicionalmente enzimáticamente inactiva se unirá al, pero no escindirá, el marcador de afinidad.
En algunas realizaciones, la endorribonucleasa y/o la endorribonucleasa condicionalmente enzimáticamente inactiva comprenderán un marcador de afinidad.
La endorribonucleasa condicionalmente enzimáticamente inactiva se purificará con un soporte sólido. El soporte sólido se unirá al marcador de afinidad de la endorribonucleasa condicionalmente enzimáticamente inactiva. Por ejemplo, si la endorribonucleasa condicionalmente enzimáticamente inactiva comprende un marcador de biotina, el soporte sólido se recubrirá con avidina o estreptavidina para unirse al agente de captura biotinilado.
En algunas realizaciones, la endorribonucleasa condicionalmente enzimáticamente inactiva se inmovilizará en cualquiera de varios soportes insolubles.
En algunas realizaciones del método, se realizarán dos series de purificación. En algunos casos, una primera serie de purificación comprenderá la purificación con un soporte sólido que se unirá al marcador de afinidad del agente de captura, y una segunda serie de purificación comprenderá la purificación con un soporte sólido que se unirá al marcador de afinidad del polipéptido dirigido a un sitio. En algunos casos, una primera serie de purificación comprenderá la purificación con un soporte sólido que se unirá al marcador de afinidad del polipéptido dirigido a un sitio, y una segunda serie de purificación comprenderá la purificación con un soporte sólido que se unirá al marcador de afinidad del agente de captura.
En algunas realizaciones, los métodos de la divulgación se usarán para el enriquecimiento de múltiples secuencias. En este aspecto, se puede poner en contacto una pluralidad de ácidos nucleicos dirigidos a ácido nucleico con una muestra de ácido nucleico, en donde cada ácido nucleico dirigido a ácido nucleico está diseñado para dirigirse un ácido nucleico diana diferente (por ejemplo, una secuencia de un genoma) dentro de la muestra de ácido nucleico.
Los complejos capturados comprenderán un ácido nucleico diana. El ácido nucleico diana se eluirá del complejo del polipéptido dirigido a un sitio mediante métodos convencionales que incluyen el lavado con alto contenido de sal, precipitación en etanol, ebullición, purificación en gel y similares.
El ADN eluido se preparará para el análisis de secuenciación mediante ligadura de uno o más adaptadores.
Los bancos de secuenciación se secuenciarán como se describe en el presente documento. Los bancos secuenciados
se analizarán para identificar los polimorfismos, diagnosticar una enfermedad, determinar un curso de tratamiento para una enfermedad y/o generar bancos de anticuerpos.
EJEMPLO 6: ENRIQUECIMIENTO DE SECUENCIA DEL ÁCIDO NUCLEICO DIANA NO UNIDO A UN COMPLEJO QUE COMPRENDE UN POLIPÉPTIDO DIRIGIDO A UN SITIO
En algunas realizaciones, el enriquecimiento de secuencia se realizará con un polipéptido dirigido enzimáticamente a un sitio. En algunos casos, el polipéptido dirigido a un sitio será enzimáticamente activo. En este caso, el ácido nucleico diana no se unirá a un polipéptido dirigido a un sitio, sino que se escindirá.
Se identificará un ácido nucleico diana, y los ácidos nucleicos dirigidos a ácido nucleico se diseñarán para dirigir el polipéptido dirigido a un sitio a secuencias que flanqueen el ácido nucleico diana. La muestra se incubará con un complejo que comprenda un ácido nucleico dirigido a ácido nucleico diseñado y el polipéptido dirigido a un sitio, de modo que el polipéptido dirigido a un sitio escindirá el ADN en ambos extremos del ácido nucleico diana. Tras la escisión del ácido nucleico diana, el ácido nucleico diana se escindirá del ácido nucleico original. Se purificará el ácido nucleico diana escindido (por ejemplo, mediante electroforesis en gel, la elución de tamaño selectivo a partir de perlas, u otras perlas derivatizadas de carboxilato, o mediante la precipitación con concentraciones apropiadas de sal y PEG para precipitar preferentemente el ADN más grande o más pequeño).
En algunas realizaciones, el enriquecimiento de secuencia se realiza fuera de las células (por ejemplo, muestra libre de células). Por ejemplo, una muestra comprenderá ADN genómico purificado. En algunas realizaciones, el enriquecimiento de secuencia se realizará en una muestra celular (por ejemplo, células, lisado celular).
Si el método se realiza en células, las células se lisarán. Las condiciones de lisis se elegirán para mantener intactos los complejos de proteína-ADN.
En algunas realizaciones, el ácido nucleico diana que se va a secuenciar no estará unido a un ácido nucleico dirigido a ácido nucleico ni/o a un polipéptido dirigido a un sitio. En este aspecto, el ácido nucleico unido al polipéptido dirigido a un sitio y/o al ácido nucleico dirigido a ácido nucleico se purificará. La purificación del polipéptido dirigido a un sitio procederá como se describe anteriormente en el presente documento. Brevemente, los complejos que comprenden el polipéptido dirigido a un sitio se purificarán mediante incubación con un soporte sólido. Por ejemplo, si el polipéptido dirigido a un sitio comprende un marcador de biotina, el soporte sólido se recubrirá con avidina o estreptavidina para unirse al marcador de biotina.
En un aspecto alternativo, Una vez fragmentados, los complejos que comprenden el polipéptido dirigido a un sitio, ácido nucleico dirigido a ácido nucleico y ácido nucleico no diana, se purificarán mediante incubación con un agente de captura. El agente de captura se unirá al marcador de afinidad fusionado con el polipéptido dirigido a un sitio. El agente de captura comprenderá un anticuerpo. Por ejemplo, si el marcador de afinidad fusionado con el polipéptido dirigido a un sitio es un marcador FLAG, entonces el agente de captura será un anticuerpo anti-marcador FLAG.
El agente de captura se purificará con un soporte sólido. Por ejemplo, si el agente de captura comprende un marcador de biotina, el soporte sólido se recubrirá con avidina o estreptavidina para unirse al agente de captura biotinilado.
En algunas realizaciones, los métodos de la divulgación se usarán para el enriquecimiento de múltiples secuencias. En este aspecto, se puede introducir una pluralidad de ácidos nucleicos dirigidos a ácido nucleico en una célula, en donde cada ácido nucleico dirigido a ácido nucleico está diseñado para dirigirse un ácido nucleico diana diferente (por ejemplo, una secuencia de un genoma).
El complejo capturado no comprenderá un ácido nucleico diana.
El ácido nucleico diana comprenderá el ácido nucleico que no está unido a los complejos que comprenden el polipéptido dirigido a un sitio. El ácido nucleico diana puede recogerse mediante métodos patrón de purificación de ácido nucleico (por ejemplo, un kit de purificación por PCR disponible en el mercado, un gel de agarosa).
El ácido nucleico diana recogido se preparará para el análisis de secuenciación (por ejemplo, secuenciación profunda) mediante ligadura de uno o más adaptadores como se describe en el presente documento.
El ácido nucleico diana secuenciado se analizará para identificar polimorfismos, diagnosticar una enfermedad, determinar un curso de tratamiento para una enfermedad y/o generar bancos de anticuerpos.
EJEMPLO 7: SECUENCIACIÓN
Los ácidos nucleicos diana eluidos se prepararán para el análisis de secuenciación. La preparación para el análisis de secuenciación incluirá la generación de bancos de secuenciación del ácido nucleico diana eluido. El análisis de secuenciación determinará la identidad y frecuencia de los sitios de unión fuera de la diana de los polipéptidos dirigidos a un sitio.
La determinación de las secuencias se realizará usando métodos que determinen muchas secuencias de ácido nucleico (normalmente, de miles a miles de millones) de una manera intrínsecamente paralela, donde se leen muchas secuencias preferentemente en paralelo mediante un proceso en serie de alto rendimiento. Dichos métodos pueden incluir, pero sin limitación, pirosecuenciación (por ejemplo, como la comercializada por 454 Life Sciences, Inc., Branford, Conn.); secuenciación por ligadura (por ejemplo, como la comercializada en la tecnología SOLiD™, Life Technology, Inc., Carlsbad, Calif.); La secuenciación por síntesis usando nucleótidos modificados (tales como los comercializados en la tecnología TruSeq™ y HiSeq™ por Illumina, Inc., San Diego, Calif., HeliScope™ de Helicos Biosciences Corporation, Cambridge, Mass. yPacBio RS de Pacific Bio sciences of California, Inc., Menlo Park, Calif.), secuenciación mediante tecnologías de detección de iones (Ion Torrent, Inc., South San Francisco, Calif.); secuenciación de nanobolas de ADN (Complete Genomics, Inc., Mountain View, Calif.); tecnologías de secuenciación basadas en nanoporos (por ejemplo, las desarrolladas por Oxford Nanopore Technologies, LTD, Oxford, Reino Unido), secuenciación capilar (por ejemplo, comercializada en MegaBACE por Molecular Dynamics), secuenciación electrónica, secuenciación de moléculas individuales (por ejemplo, tal como la comercializada en tecnología SMRT™ de Pacific Biosciences, Menlo Park, Calif.), secuenciación microfluídica de gotas, secuenciación por hibridación (tal como la comercializada por Affymetrix, Santa Clara, California), secuenciación de bisulfato y otros métodos de secuenciación altamente paralelizados conocidos.
En algunas realizaciones, la secuenciación se realizará mediante análisis de micromatrices.
EJEMPLO 8: GENERACIÓN DE BANCOS ANTICUERPOS
Los métodos descritos en el presente documento se usarán para generar bancos de proteínas (por ejemplo, bancos de anticuerpos). Los bancos de proteínas serán útiles para preparar bancos de expresión, que se usarán para seleccionar proteínas (por ejemplo, anticuerpos) para uso en agentes terapéuticos, reactivos y/o de diagnóstico. Los bancos de proteínas también serán útiles para sintetizar y/o clonar anticuerpos adicionales.
Los bancos de proteínas se generarán mediante el diseño de un ácido nucleico dirigido a ácido nucleico para hibridarse con secuencias de ácido nucleico diana que codifican inmunoglobulinas. Los complejos que comprenden un polipéptido dirigido a un sitio y el ácido nucleico dirigido a ácido nucleico se purificarán usando los métodos descritos en el presente documento. En algunas realizaciones, el ácido nucleico que se hibrida con el ácido nucleico dirigido a ácido nucleico será el ácido nucleico diana, y se eluirá y secuenciará, usando los métodos que se describen en el presente documento. En algunas realizaciones, el ácido nucleico que se hibrida con el ácido nucleico dirigido a ácido nucleico no será el ácido nucleico diana. El ácido nucleico diana será el ácido nucleico que se escinda entre los sitios de escisión de una pluralidad de complejos (por ejemplo, complejos que comprenden un polipéptido dirigido a un sitio y ácido nucleico dirigido a ácido nucleico). El ácido nucleico diana escindido se purificará y secuenciará, usando los métodos que se describen en el presente documento.
EJEMPLO 9: GENOTIPADO
Los métodos descritos en el presente documento se usarán para realizar la tipificación del antígeno leucocitario humano (HLA). Los genes HLA son algunos de los genes más polimórficos de los seres humanos. Comprender los genotipos de estas regiones será importante para obtener una buena coincidencia para los trasplantes de tejidos y órganos.
Para realizar la tipificación de HLA, se diseñará un ácido nucleico dirigido a ácido nucleico para hibridarse con secuencias de ácido nucleico diana en genes HLA. Los complejos que comprenden un polipéptido dirigido a un sitio y el ácido nucleico dirigido a ácido nucleico se purificarán usando los métodos descritos en el presente documento. En algunas realizaciones, el ácido nucleico que se hibrida con el ácido nucleico dirigido a ácido nucleico será el ácido nucleico diana, y se eluirá y secuenciará, usando los métodos que se describen en el presente documento. En algunas realizaciones, el ácido nucleico que se hibrida con el ácido nucleico dirigido a ácido nucleico no será el ácido nucleico diana. El ácido nucleico diana será el ácido nucleico que se escinda entre los sitios de escisión de una pluralidad de complejos (por ejemplo, complejos que comprenden un polipéptido dirigido a un sitio y ácido nucleico dirigido a ácido nucleico). El ácido nucleico diana escindido se purificará y secuenciará, usando los métodos que se describen en el presente documento.
EJEMPLO 10: INMUNOPRECIPITACIÓN DE POLIPÉPTIDO DIRIGIDO A UN SITIO
La divulgación proporciona métodos para la inmunoprecipitación y secuenciación de nucleasas (NIP-Seq). En algunas realizaciones, el método comprenderá a) poner en contacto una muestra de ácido nucleico con un polipéptido dirigido a un sitio enzimáticamente inactivo, en donde polipéptido dirigido a un o enzimáticamente inactivo se une a un ácido nucleico diana, formando así un complejo; b) capturar el complejo con un agente de captura; y c) secuenciar el ácido nucleico diana. En algunas realizaciones, el método comprenderá además d) determinar la identidad del sitio de unión fuera de la diana.
En algunas realizaciones, los métodos de la divulgación se realizarán fuera de las células. Por ejemplo, una muestra
comprenderá ADN genómico purificado.
Los complejos de polipéptido dirigido a un sitio-ácido nucleico dirigido a ácido nucleico se fijarán o entrecruzarán para formar complejos.
El ácido nucleico (por ejemplo, ADN genómico) se tratará para fragmentar el ADN antes de la purificación por afinidad. La fragmentación se puede realizar a través de métodos físicos, mecánicos o enzimáticos. La fragmentación física puede incluir la exposición de un polinucleótido diana al calor o a la luz ultravioleta (UV). La disrupción mecánica puede usarse para cortar mecánicamente un polinucleótido diana en fragmentos del intervalo deseado. La cizalla mecánica se puede lograr a través de varios métodos conocidos en la técnica, que incluyen pipeteo repetitivo del polinucleótido diana, sonicación y nebulización. Los polinucleótidos diana también pueden fragmentarse usando métodos enzimáticos. En algunos casos, se puede realizar la digestión enzimática usando enzimas tales como las enzimas de restricción. Las enzimas de restricción pueden usarse para realizar una fragmentación específica o no específica de polinucleótidos diana. Los métodos pueden usar uno o más tipos de enzimas de restricción, descritas en general como enzimas de Tipo I, enzimas de Tipo II y/o enzimas de Tipo III. Las enzimas de Tipo II y Tipo III, en general, están disponibles en el mercado, y son bien conocidas en la técnica. Las enzimas de Tipo II y de Tipo III reconocen secuencias específicas de nucleótidos nucleotídicos dentro de una secuencia polinucleotídica bicatenaria (una "secuencia de reconocimiento" o "sitio de reconocimiento"). Tras la unión y el reconocimiento de estas secuencias, las enzimas de Tipo II y Tipo III escinden la secuencia de polinucleótidos. En algunos casos, la escisión dará lugar a un fragmento de polinucleótido con una parte de ADN monocatenario saliente, denominada "extremo adhesivo". En otros casos, la escisión no dará lugar a un fragmento con un saliente, creando un "extremo romo". Los métodos pueden comprender el uso de enzimas de restricción que generen extremos adhesivos o extremos romos.
Una vez fragmentados, los complejos que comprenden el polipéptido dirigido a un sitio se purificarán mediante incubación con un soporte sólido. Por ejemplo, si el polipéptido dirigido a un sitio comprende un marcador de biotina, el soporte sólido se recubrirá con avidina o estreptavidina para unirse al marcador de biotina.
En un aspecto alternativo, Una vez fragmentados, los complejos que comprenden el polipéptido dirigido a un sitio, el ácido nucleico diana y/o el ácido nucleico dirigido a ácido nucleico, se purificarán mediante incubación con un agente de captura. El agente de captura se unirá al marcador de afinidad fusionado con el polipéptido dirigido a un sitio. El agente de captura comprenderá un anticuerpo. Por ejemplo, si el marcador de afinidad fusionado con el polipéptido dirigido a un sitio es un marcador FLAG, entonces el agente de captura será un anticuerpo anti-marcador FLAG.
El agente de captura se purificará con un soporte sólido. Por ejemplo, si el agente de captura comprende un marcador de biotina, la perla se recubrirá con avidina o estreptavidina para unirse al agente de captura biotinilado.
En algunas realizaciones del método, se realizarán dos o más series de purificación. Una primera serie de purificación comprenderá la purificación con un soporte sólido que se puede unir al marcador de afinidad del agente de captura, y una segunda serie de purificación comprenderá la purificación con un soporte sólido que se puede unir al marcador de afinidad del polipéptido dirigido a un sitio. Una primera serie de purificación comprenderá la purificación con un soporte sólido que se unirá al marcador de afinidad del polipéptido dirigido a un sitio, y una segunda serie de purificación comprenderá la purificación con un soporte sólido que se unirá al marcador de afinidad del agente de captura.
En algunas realizaciones, el método se usará para optimizar la especificidad de unión de un polipéptido dirigido a un sitio realizando el método más de una vez.
El complejo capturado comprenderá un polipéptido dirigido a un sitio y un ácido nucleico diana. El ácido nucleico diana se eluirá del complejo del polipéptido dirigido a un sitio mediante métodos convencionales que incluyen el lavado con alto contenido de sal, precipitación en etanol, ebullición, purificación en gel y similares.
El ADN eluido se preparará para el análisis de secuenciación usando métodos patrón. Los bancos de secuenciación se secuenciarán y analizarán para identificar la secuencia y la frecuencia de los sitios de unión a nucleasas.
En algunas realizaciones, el método se realizará una pluralidad de veces. En algunas realizaciones, el método comprende además recopilar datos y almacenar datos. Los datos pueden almacenarse recopilados y almacenados en un servidor informático.
EJEMPLO 11: INMUNOPRECIPTIACIÓN IN VIVO DE POLIPÉPTIDO DIRIGIDO A UN SITIO
En algunas realizaciones, el método comprenderá: a) introducir un polipéptido dirigido a un sitio enzimáticamente inactivo en una célula, en donde polipéptido dirigido a un o enzimáticamente inactivo se une a un ácido nucleico diana, formando así un complejo; b) capturar el complejo con un agente de captura; y c) secuenciar el ácido nucleico diana. En algunas realizaciones, el método comprenderá además d) determinar la identidad del sitio de unión fuera de la diana.
En algunos casos, el polipéptido dirigido a un sitio comprenderá un marcador de afinidad. Los polipéptidos que comprenden un marcador de afinidad se han descrito en el presente documento.
Las células se fijarán o entrecruzarán. Las células fijadas y/o entrecruzadas se lisarán. Las condiciones de lisis se elegirán para mantener intactos los complejos de proteína-ADN. El lisado se tratará para fragmentar el ADN antes de la purificación por afinidad. Las técnicas de fragmentación adecuadas se describen en el presente documento.
Una vez fragmentados, los complejos que comprenden el polipéptido dirigido a un sitio, el ácido nucleico diana y/o el ácido nucleico dirigido a ácido nucleico, se purificarán del lisado mediante incubación con un soporte sólido. Por ejemplo, si el polipéptido dirigido a un sitio comprende un marcador de biotina, el soporte sólido se recubrirá con avidina o estreptavidina para unirse al marcador de biotina.
En un aspecto alternativo, Una vez fragmentados, los complejos que comprenden el polipéptido dirigido a un sitio, se purificarán del lisado mediante incubación con un agente de captura. El agente de captura se unirá al marcador de afinidad fusionado con el polipéptido dirigido a un sitio. El agente de captura comprenderá un anticuerpo. Por ejemplo, si el marcador de afinidad fusionado con el polipéptido dirigido a un sitio es un marcador FLAG, entonces el agente de captura será un anticuerpo anti-marcador FLAG.
En algunas realizaciones, el agente de captura comprenderá un marcador de afinidad. El agente de captura se purificará con un soporte sólido. El soporte sólido se unirá al marcador de afinidad del agente de captura. Por ejemplo, si el agente de captura comprende un marcador de biotina, la perla se recubrirá con avidina o estreptavidina para unirse al agente de captura biotinilado.
En algunas realizaciones del método, se realizarán dos series de purificación. En algunos casos, una primera serie de purificación comprenderá la purificación con un soporte sólido que se unirá al marcador de afinidad del agente de captura, y una segunda serie de purificación comprenderá la purificación con un soporte sólido que se unirá al marcador de afinidad del polipéptido dirigido a un sitio. En algunos casos, una primera serie de purificación comprenderá la purificación con un soporte sólido que se unirá al marcador de afinidad del polipéptido dirigido a un sitio, y una segunda serie de purificación comprenderá la purificación con un soporte sólido que se unirá al marcador de afinidad del agente de captura.
En algunas realizaciones, el método se usará para optimizar la especificidad de unión de un polipéptido dirigido a un sitio realizando el método más de una vez.
El complejo capturado comprenderá un polipéptido dirigido a un sitio y un ácido nucleico diana. El ácido nucleico diana se eluirá del complejo del polipéptido dirigido a un sitio mediante métodos convencionales que incluyen el lavado con alto contenido de sal, precipitación en etanol, ebullición, purificación en gel y similares.
El ADN eluido se preparará para el análisis de secuenciación. Los bancos de secuenciación se crearán a partir del ácido nucleico diana eluido. Los bancos de secuenciación se secuenciarán y analizarán para identificar la secuencia y la frecuencia de los sitios de unión a nucleasas.
EJEMPLO 12: INMUNOPRECIPITACIÓN CON UN AGENTE DE CAPTURA DE ENDORRIBONULEASA ENZIMÁTICAMENTE INACTIVO
Un método para determinar la identidad de un sitio de unión fuera de la diana de una nucleasa comprenderá: a) poner en contacto una muestra de ácido nucleico con un polipéptido dirigido a un sitio enzimáticamente inactivo y un ácido nucleico ácido dirigido a ácido nucleico, en donde el polipéptido dirigido a un sitio enzimáticamente inactivo y el ácido nucleico ácido dirigido a ácido nucleico se unen a un ácido nucleico diana, formando así un complejo; b) capturar el complejo con un agente de captura, en donde el agente de captura comprende un polipéptido dirigido a un sitio condicionalmente enzimáticamente inactivo; c) secuenciar el ácido nucleico diana; y d) determinar la identidad del sitio de unión fuera de la diana. Este método está diseñado para realizarse en una muestra de ácido nucleico libre de células, y/o una muestra de ácido nucleico procedente de una célula.
Los complejos de polipéptido dirigido a un sitio-ácido nucleico dirigido a ácido nucleico se fijarán o entrecruzarán para formar complejos.
Si la muestra de ácido nucleico procede de células, los complejos fijos y/o entrecruzados se lisarán. Las condiciones de lisis se pueden escoger para mantener intactos los complejos de proteína-ADN. El lisado se tratará para fragmentar el ADN antes de la purificación por afinidad. Si la muestra de ácido nucleico procede de una muestra libre de células, el ácido nucleico libre de células se tratará para fragmentar el ADN. Las técnicas de fragmentación adecuadas se describen en el presente documento.
En algunas realizaciones, el ácido nucleico dirigido a ácido nucleico comprenderá un marcador de afinidad. El marcador de afinidad comprenderá una secuencia que puede unirse a un polipéptido dirigido a un sitio condicionalmente enzimáticamente inactivo. En algunos casos, el marcador de afinidad comprenderá una secuencia
que pueda unirse a una endorribonucleasa condicionalmente inactiva enzimáticamente. En algunos casos, el marcador de afinidad comprenderá una secuencia que pueda unirse a una proteína Csy4 condicionalmente inactiva enzimáticamente. El polipéptido dirigido a un sitio condicionalmente enzimáticamente inactivo se unirá, pero no escindirá, el marcador de afinidad. El marcador de afinidad comprenderá la secuencia de nucleótidos 5'-GUUCACUGCCGUAUAGGCAGCUAAGAAA-3'. El marcador de afinidad se introducirá en un ácido nucleico usando métodos recombinantes convencionales.
Una vez fragmentados, los complejos que comprenden el polipéptido dirigido a un sitio, el ácido nucleico diana y/o el ácido nucleico dirigido a ácido nucleico se purificarán mediante incubación con un polipéptido dirigido a un sitio condicionalmente enzimáticamente inactivo (por ejemplo, la variante Csy4).
En algunas realizaciones, el polipéptido dirigido a un sitio condicionalmente enzimáticamente inactivo comprenderá un marcador de afinidad.
El polipéptido dirigido a un sitio condicionalmente enzimáticamente inactivo se purificará con un soporte sólido. El soporte sólido se unirá al marcador de afinidad del polipéptido dirigido a un sitio condicionalmente enzimáticamente inactivo. Por ejemplo, si el polipéptido dirigido a un sitio condicionalmente enzimáticamente inactivo comprende un marcador de biotina, la perla se recubrirá con avidina o estreptavidina para unirse al agente de captura biotinilado.
En algunas realizaciones, el polipéptido dirigido a un sitio enzimáticamente inactivo se inmovilizará en cualquiera de varios soportes insolubles. En algunas realizaciones del método, se realizarán dos series de purificación.
En algunas realizaciones del método, se realizarán dos series de purificación. En algunos casos, una primera serie de purificación comprenderá la purificación con un soporte sólido que se unirá al marcador de afinidad del polipéptido dirigido a un sitio condicionalmente enzimáticamente inactivo (por ejemplo, variante Csy4), y una segunda serie de purificación comprenderá la purificación con un soporte sólido que se unirá al marcador de afinidad del polipéptidos dirigido a un sitio. En algunos casos, una primera serie de purificación comprenderá la purificación con un soporte sólido que se unirá al marcador de afinidad del polipéptido dirigido a un sitio, y una segunda serie de purificación comprenderá la purificación con un soporte sólido que se unirá al marcador de afinidad del polipéptido dirigido a un sitio condicionalmente enzimáticamente inactivo (por ejemplo, variante Csy4).
En algunas realizaciones, el método se usará para optimizar la especificidad de unión de un polipéptido dirigido a un sitio realizando el método más de una vez.
El complejo capturado comprenderá un polipéptido dirigido a un sitio y un ácido nucleico diana. El ácido nucleico diana se eluirá del complejo del polipéptido dirigido a un sitio mediante métodos convencionales que incluyen el lavado con alto contenido de sal, precipitación en etanol, ebullición, purificación en gel y similares.
El ADN eluido se preparará para el análisis de secuenciación. Los bancos de secuenciación se secuenciarán y analizarán para identificar la secuencia y la frecuencia de los sitios de unión a nucleasas.
EJEMPLO 13: SECUENCIACIÓN
Los ácidos nucleicos diana eluidos se prepararán para el análisis de secuenciación. La preparación para el análisis de secuenciación incluirá la generación de bancos de secuenciación del ácido nucleico diana eluido. El análisis de secuenciación determinará la identidad y frecuencia de los sitios de unión fuera de la diana de los polipéptidos dirigidos a un sitio.
La determinación de las secuencias también se realizará usando métodos que determinen muchas secuencias de ácido nucleico (normalmente, de miles a miles de millones) de una manera intrínsecamente paralela, donde se leen muchas secuencias preferentemente en paralelo mediante un proceso en serie de alto rendimiento. Dichos métodos incluyen, pero sin limitación, pirosecuenciación (por ejemplo, como la comercializada por 454 Life Sciences, Inc., Branford, Conn.); secuenciación por ligadura (por ejemplo, como la comercializada en la tecnología SOLiD™, Life Technology, Inc., Carlsbad, Calif.); La secuenciación por síntesis usando nucleótidos modificados (tales como los comercializados en la tecnología TruSeq™ y HiSeq™ por Illumina, Inc., San Diego, Calif., HeliScope™ de Helicos Biosciences Corporation, Cambridge, Mass. y PacBio r S de Pacific Biosciences of California, Inc., Menlo Park, Calif.), secuenciación mediante tecnologías de detección de iones (Ion Torrent, Inc., South San Francisco, Calif.); secuenciación de nanobolas de ADN (Complete Genomics, Inc., Mountain View, Calif.); tecnologías de secuenciación basadas en nanoporos (por ejemplo, las desarrolladas por Oxford Nanopore Technologies, LTD, Oxford, Reino Unido) y otros métodos de secuenciación altamente paralelizados conocidos.
EJEMPLO 14: Modificación de un ácido nucleico diana con una proteína efectora
Un vector que comprende un polipéptido dirigido a un sitio, un ácido nucleico dirigido a ácido nucleico y/o una proteína efectora se introduce en una célula. Una vez dentro de la célula, se forma un complejo que comprende los elementos codificados en el vector. El ácido nucleico dirigido a ácido nucleico se modifica con una secuencia de unión a la
proteína Csy4. La proteína efectora, Csy4, se une al ácido nucleico dirigido a ácido nucleico modificado. Csy4 comprende una secuencia no nativa (por ejemplo, una fusión), que modifica un ácido nucleico diana. La secuencia no nativa es una secuencia que modifica la transcripción del ácido nucleico diana. La secuencia no nativa es un factor de transcripción. El factor de transcripción aumenta el nivel de transcripción del ácido nucleico diana. En algunos casos, la secuencia no nativa es una metilasa. La metilasa produce aumentos en la metilación del ácido nucleico diana. En algunos casos, la secuencia no nativa es una desmetilasa. La desmetilasa produce una disminución en la metilación del ácido nucleico diana. En algunos casos, la secuencia no nativa es un péptido de reclutamiento de Rad51. El péptido de reclutamiento de Rad51 aumenta el nivel de recombinación homóloga en el sitio diana. En algunos casos, la secuencia no nativa es un péptido de reclutamiento de BCRA-2. El péptido de reclutamiento de BRCA-2 aumenta el nivel de recombinación homóloga en el sitio diana.
EJEMPLO 15: Uso de un polipéptido dirigido a un sitio como biosensor para un evento de movilidad genética
Uno o varios vectores que comprenden un polipéptido dirigido a un sitio, un ácido nucleico dirigido a ácido nucleico y/o una proteína efectora se introduce en una célula. El polipéptido dirigido a un sitio y las proteínas efectoras se fusionan con las secuencias de ubicación celular (por ejemplo, una señal de localización nuclear). Una vez dentro de la célula, se forma un complejo que comprende los elementos codificados en el/los vector/es. En algunos casos, se introducen dos vectores en la célula. El/los vector/es codifica/n una primera proteína efectora (Csy4) que comprende una primera parte inactiva de una proteína fluorescente verde (GFP) dividida y se une a un primer ácido nucleico dirigido a ácido nucleico y una segunda proteína efectora (Csy4, Cas5 o Cas6) que comprende una segunda parte inactiva de la GFP dividida y se une a un segundo ácido nucleico dirigido a ácido nucleico. El primer ácido nucleico dirigido a ácido nucleico se modifica con una primera secuencia de unión a la proteína Csy4, Cas5 o Cas6 que puede unirse por una primera proteína Csy4, Cas5 o Cas6. El segundo ácido nucleico dirigido a ácido nucleico se modifica con una primera secuencia de unión a la proteína Csy4, Cas5 o Cas6 que puede unirse por una segunda proteína Csy4, Cas5 o Cas6. En algunas realizaciones, la primera proteína Csy4, Cas5 o Cas6 interactúa con la primera secuencia de unión a la proteína Csy4, Cas5 o Cas6, y la segunda proteína Csy4, Cas5 o Cas6 interactúa con la segunda secuencia de unión a la proteína Csy4, Cas5 o Cas6. Cuando el primer y el segundo ácido nucleico que se dirigen a ácido nucleico dirigen el polipéptido dirigido a un sitio para que se una a dos secuencias que están muy próximas, la primera proteína efectora y la segunda proteína efectora pondrán en contacto la primera parte inactiva de la GFP dividida con la segunda parte inactiva de la GFP dividida, para generar una GFP activa. Los ácidos nucleicos dirigidos a ácido nucleico del complejo están diseñados de manera que un ácido nucleico dirigido a ácido nucleico guía el complejo a, por ejemplo, una región en o cerca del gen Bcr, y otro ácido nucleico dirigido a ácido nucleico guía al complejo a, por ejemplo, una región en o cerca del gen Abl. Si no se ha producido un evento de translocación, el gen Bcr está en el cromosoma 22 y el gen Abl está en el cromosoma 9, y las secuencias de ácido nucleico diana están lo suficientemente separadas como para que las dos partes inactivas del sistema GFP dividido no puedan interactuar, no generando, por tanto, una señal. Si se ha producido un evento de translocación, el gen Bcr y el gen Abl se translocan de manera que los genes estén muy juntos. En este caso, las secuencias de ácido nucleico diana están lo suficientemente juntas como para que las dos partes inactivas del sistema GFP dividido se unan para formar una GFP activa. Una señal GFP puede ser detectada por un fluorómetro. La señal es indicativa de un genotipo particular resultante del evento de movilidad genética.
EJEMPLO 16: Uso de un polipéptido dirigido a un sitio como biosensor para un evento de mutación genética
El sistema descrito en el Ejemplo 2 también puede usarse para detectar la presencia de una mutación específica dentro de una célula. En este ejemplo, se elige un primer ácido nucleico dirigido a ácido nucleico para dirigir el polinucleótido dirigido a un sitio a una secuencia nativa ubicada cerca de un sitio de mutación. El segundo ácido nucleico dirigido a ácido nucleico se elige para reconocer una secuencia mutante (por ejemplo, la secuencia mutante que se ha identificado mediante secuenciación de ADN). El ácido nucleico dirigido a ácido nucleico se elige de manera que la secuencia mutante se produzca dentro de los 12 primeros ácidos nucleicos inmediatamente 5' de la secuencia PAM en el sitio. En este caso, las secuencias de ácido nucleico diana están lo suficientemente juntas como para que las dos partes inactivas del sistema GFP dividido se unan para formar una GFP activa. Una señal GFP puede ser detectada por un fluorómetro. ro.La señal es indicativa de un genotipo particular.
EJEMPLO 17: Uso de un polipéptido dirigido a un sitio como agente terapéutico para enfermedades que comprenden un evento de movilidad genética
Uno o varios vectores que comprenden un polipéptido dirigido a un sitio, un ácido nucleico dirigido a ácido nucleico y/o una proteína efectora, un ácido nucleico que comprende un péptido inductor de lisis celular (por ejemplo, proteína de muerte de Adenovirus) unido operativamente a un primer promotor también se introducirán en la célula. Una vez dentro de la célula, se forma un complejo que comprende los elementos codificados en el/los vector/es. En algunos casos, se introducen dos vectores en la célula. El/los vector/es codifica/n una primera proteína efectora (que comprende una primera secuencia de proteína Csy4, Cas5 o Cas6) que se une a un primer ácido nucleico dirigido a ácido nucleico y comprende un dominio activador para un primer factor de transcripción que se une al primer promotor y una segunda proteína efectora (que comprende una segunda secuencia de proteína Csy4, Cas5 o Cas6) que se une a un segundo ácido nucleico dirigido a ácido nucleico y comprende el dominio de unión al ADN para el primer factor de transcripción. El primer ácido nucleico dirigido a ácido nucleico se modifica con una primera secuencia de unión a
la proteína Csy4, Cas5 o Cas6 que puede unirse por una primera secuencia de proteína Csy4, Cas5 o Cas6. El segundo ácido nucleico dirigido a ácido nucleico se modifica con una primera secuencia de unión a la proteína Csy4, Cas5 o Cas6 que puede unirse por una segunda proteína Csy4, Cas5 o Cas6. En algunas realizaciones, la primera proteína Csy4, Cas5 o Cas6 interactúa preferentemente con la primera secuencia de unión a la proteína Csy4, Cas5 o Cas6, y la segunda proteína Csy4, Cas5 o Cas6 interactúa preferentemente con la segunda secuencia de unión a la proteína Csy4, Cas5 o Cas6. Si una célula enferma comprende un genoma que contiene un evento de movilidad genética, cuando el primer y el segundo ácido nucleico que se dirigen a ácido nucleico dirigen el polipéptido dirigido a un sitio para que se una a dos secuencias que están muy próximas, la primera proteína efectora y la segunda proteína efectora acercarán el dominio activador y el dominio de unión al ADN del primer factor de transcripción. El dominio de unión al ADN del primer factor de transcripción puede unirse al primer promotor unido operativamente al péptido inductor de la lisis celular, y el dominio activador proximal inducirá la transcripción del ARN que codifica el péptido inductor de la lisis celular. En una célula no enferma, que no comprende el evento movilidad genética, el dominio de unión a ADN y los dominios de activador del primer factor de transcripción no se acercan estrechamente, y no habrá ninguna transcripción del péptido inductor de la lisis celular.
Los ácidos nucleicos dirigidos a ácido nucleico del complejo están diseñados de manera que un ácido nucleico dirigido a ácido nucleico guía el complejo a, por ejemplo, una región en o cerca del gen Bcr, y otro ácido nucleico dirigido a ácido nucleico guía al complejo a, por ejemplo, una región en o cerca del gen Abl. En una célula no enferma, no se ha producido un evento de translocación, el gen Bcr está en el cromosoma 22 y el gen Abl está en el cromosoma 9, y las secuencias de ácido nucleico diana están lo suficientemente separadas como para que las dos partes inactivas del sistema de factores de transcripción no puedan interactuar y no puedan inducir la transcripción del péptido inductor de la lisis celular. En una célula enferma, en donde se ha producido un evento de translocación, el gen Bcr y el gen Abl se translocan de manera que los genes estén muy juntos. En este caso, las secuencias de ácido nucleico diana están lo suficientemente juntas como para que las dos partes inactivas del sistema del factor de transcripción se unan para inducir la transcripción del péptido inductor de la muerte celular. La lisis celular dependerá de un genotipo particular resultante del evento de movilidad genética.
EJEMPLO 18: Uso de un polipéptido dirigido a un sitio como agente terapéutico para enfermedades que comprenden un evento de mutación genética
El sistema descrito en el Ejemplo 4 también puede usarse para detectar la presencia de una mutación específica dentro de una célula. En este ejemplo, se elige el primer ácido nucleico dirigido a ácido nucleico para dirigir el polinucleótido dirigido a un sitio a una secuencia nativa ubicada cerca de un sitio de mutación. El segundo ácido nucleico dirigido a ácido nucleico se elige para reconocer una secuencia mutante (por ejemplo, la secuencia mutante que se ha identificado mediante secuenciación de ADN). El ácido nucleico dirigido a ácido nucleico se elige de manera que la secuencia mutante se produzca dentro de los 12 primeros ácidos nucleicos inmediatamente 5' de la secuencia PAM en el sitio. En este caso, las secuencias de ácido nucleico diana están lo suficientemente juntas como para que las dos partes inactivas del factor de transcripción se unan para permitir la transcripción de un péptido inductor de la lisis celular.
EJEMPLO 19: Reclutamiento del sistema inmunitario para atacar el tejido enfermo que contiene un evento de movilidad genética o una mutación genética.
El sistema descrito en el Ejemplo 4 y/o 5 también se puede usar para dirigir la transcripción mediante el sistema de factor de transcripción dividido que dará como resultado la visualización de un antígeno en la superficie celular. En algunos casos, el antígeno es un péptido presentado por moléculas de MHC de clase II. En algunos casos, el antígeno es una proteína de la superficie celular que recluta células efectoras inmunitarias en un sitio.
EJEMPLO 20: Detección de la posición tridimensional de los ácidos nucleicos
Uno o varios vectores que comprenden un polipéptido dirigido a un sitio, un ácido nucleico dirigido a ácido nucleico y/o una proteína efectora se introduce en una célula. Una vez dentro de la célula, se forma un complejo que comprende los elementos codificados en el/los vector/es. Se introducen dos vectores en la célula. Un vector codifica una proteína efectora (Csy4) que comprende una primera parte inactiva de un sistema de marcador de afinidad dividido. Un segundo vector codifica una proteína efectora (Csy4, Cas5 o Cas6) que comprende una segunda parte inactiva del marcador de afinidad dividido. El ácido nucleico dirigido a ácido nucleico de los complejos se modifica con una secuencia de unión a proteínas Csy4, Cas5 o Cas6. Las proteínas efectoras se unen al ácido nucleico dirigido a ácido nucleico modificado. Los ácidos nucleicos dirigidos a ácido nucleico están diseñados para guiar los complejos a regiones de interés en una estructura de ácido nucleico tridimensional (por ejemplo, cromatina). Si las secuencias diana no están juntas en el espacio, las dos partes inactivas del marcador de afinidad dividido no pueden interactuar. Si las secuencias diana están juntas en el espacio, entonces las dos partes inactivas del marcador de afinidad dividido pueden unirse para formar el marcador de afinidad completo.
Las células se lisan y la lisis celular se incuba con un anticuerpo que se une al marcador de afinidad. El anticuerpo se purifica, purificando así el marcador de afinidad y el ácido nucleico al que se unen los complejos. El ácido nucleico purificado se disocia de los complejos usando un lavado con alto contenido de sal. El ácido nucleico purificado
disociado se prepara para el análisis de secuenciación y se secuencia. Los resultados de la secuencia corresponden a regiones de cromatina que están juntas en un espacio tridimensional. Los resultados de la secuencia se pueden usar para comprender mejor la expresión génica y tratar la enfermedad.
EJEMPLO 21: INGENIERÍA MULTIPLEX DE GENOMA
Se introduce un vector que comprende un agente de dirección genético multiplexado que comprende módulos de ácido nucleico que comprenden un ácido nucleico dirigido a ácido nucleico y una secuencia de unión a endorribonucleasa en una célula. En algunas realizaciones, la célula ya comprende un polipéptido dirigido a un sitio y una endorribonucleasa. En algunos casos, la célula se pone en contacto con un vector que comprende una secuencia de polinucleótido que codifica un polipéptido dirigido a un sitio y un vector que comprende una secuencia de polinucleótido que codifica una endorribonucleasa. En algunos casos, la célula se pone en contacto con un vector que comprende una secuencia de polinucleótido que codifica tanto el polipéptido dirigido a un sitio como la endorribonucleasa. En algunas realizaciones, el vector comprende una secuencia de polinucleótido que codifica una o más endorribonucleasas. En algunas realizaciones, el vector comprende una secuencia polinucleotídica que codifica un agente de dirección genético multiplexado, un polipéptido dirigido a un sitio y una o más endorribonucleasas. La matriz se transcribe en ARN. La una o más endorribonucleasas se unen a una o más secuencias de unión a endorribonucleasas en el agente de dirección genético multiplexado. La una o más endorribonucleasas escinden la una o más secuencias de unión a endorribonucleasas en el agente de dirección genético multiplexado, liberando así los módulos individuales de ácido nucleico. En algunas realizaciones, los módulos de ácido nucleico comprenden la totalidad, una parte o nada de la secuencia de unión a endorribonucleasa.
Los módulos de ácido nucleico liberados se unen a polipéptidos dirigidos a un sitio, formando así complejos. Los complejos están dirigidos a uno o más ácidos nucleicos diana. El uno o más módulos de ácido nucleico se hibridan con uno o más ácidos nucleicos diana. El uno o más polipéptidos dirigidos a un sitio escinden el uno o más ácidos nucleicos diana en un sitio de escisión definido por el módulo de ácido nucleico, dando como resultado uno o más ácidos nucleicos diana modificados.
En algunas realizaciones, uno o más polinucleótidos y/o vectores donantes que codifican los mismos se introducen en la célula. Se incorporan uno o más polinucleótidos donantes en el uno o más ácidos nucleicos diana escindidos, dando lugar a uno o más ácidos nucleicos diana modificados (por ejemplo, adición). En algunos casos, el mismo polinucleótido donante se incorpora a múltiples sitios de escisión. En algunos casos, se incorporan uno o más polinucleótidos donantes a múltiples sitios de escisión. En algunos casos, no se introduce en las células ningún polinucleótido ni/o vector donante que lo codifique. En estos casos, el ácido nucleico diana modificado puede comprender una eliminación.
EJEMPLO 22: MÉTODO DE ADMINISTRACIÓN ESTOQUIOMÉTRICA DE ARN A UNA CÉLULA
En algunas realizaciones, la divulgación proporciona un método para la administración estequiométrica de ácidos nucleicos al núcleo de una célula. En algunas realizaciones, se usan tres ácidos nucleicos administrables estequiométricamente: uno que codifica Cas9, uno que codifica un ácido nucleico dirigido a ácido nucleico y otro que codifica Csy4. Cada uno de los tres ácidos nucleicos comprende un sitio de unión a Csy4.
En algunas realizaciones, el método proporciona un polipéptido de fusión en tándem. El polipéptido de fusión comprende tres polipéptidos Csy4. Los tres polipéptidos Csy4 están separados por un enlazador. Los tres polipéptidos Csy4 se unen a los sitios de unión a Csy4 en cada una de las tres moléculas de ácido nucleico, formando así un complejo.
En algunas realizaciones, el complejo se forma fuera de una célula y se introduce en la célula. El complejo se forma mezclando los tres ácidos nucleicos administrables estequiométricamente y la proteína de fusión, y dejando que ocurra la reacción para permitir la unión entre el polipéptido de fusión en tándem y los tres sitios de unión a Csy4. El complejo se introduce por inyección, electroporación, transfección, transformación, transducción vírica y similares. En el interior de la célula, se traducen algunos de los ácidos nucleicos del complejo. En algunas realizaciones, los productos de traducción resultantes son Csy4 y NLS-Cas9 (por ejemplo, Cas9 que comprende una NLS. La NLS puede que no tenga que estar en el extremo N). El Csy4 escinde el sitio de unión a Csy4 en el ácido nucleico que codifica el ácido nucleico dirigido a ácido nucleico, liberando así el ácido nucleico dirigido a ácido nucleico del polipéptido de fusión en tándem. NLS-Cas9 se une al ácido nucleico dirigido a ácido nucleico liberado, formando así una unidad. Esta unidad se transloca al núcleo. Dentro del núcleo, la unidad es guiada a un ácido nucleico diana que se hibrida con el espaciador del ácido nucleico dirigido a ácido nucleico. La Cas9 de la unidad escinde el ácido nucleico diana. La escisión del ácido nucleico diana por Cas9 se denomina ingeniería genómica.
En algunas realizaciones, el complejo se forma dentro de una célula. Se introduce en la célula un vector que codifica los tres ácidos nucleicos administrables estequiométricamente. Se introducen tres vectores diferentes que codifican uno de cada uno de los tres ácidos nucleicos administrables estequiométricamente en la célula. Se introducen dos vectores en la célula, en donde uno de los dos vectores codifica dos ácidos nucleicos administrables estequiométricamente y uno de los dos vectores codifica un ácido nucleico administrable estequiométricamente.
Cualquiera de los vectores puede codificar el polipéptido de fusión en tándem.
En el interior de la célula, el ácido nucleico del vector que codifica el ARN o un polipéptido se transcribe en ARN. Se forma un complejo que comprende los tres ácidos nucleicos y el polipéptido de fusión en tándem, mediante el que cada una de las proteínas de unión a Csy4 se une a un sitio de unión a Csy4 en cada uno de los tres ácidos nucleicos. Se traducen los ácidos nucleicos del complejo. En algunas realizaciones, los productos de traducción resultantes son Csy4 y NLS-Cas9 (por ejemplo, Cas9 que comprende una NLS. La NLS puede que no tenga que estar en el extremo N). El Csy4 escinde el sitio de unión a Csy4 en el ácido nucleico que codifica el ácido nucleico dirigido a ácido nucleico, liberando así el ácido nucleico dirigido a ácido nucleico del polipéptido de fusión en tándem. NLS-Cas9 se une al ácido nucleico dirigido a ácido nucleico liberado, formando así una unidad. Esta unidad se transloca al núcleo. Dentro del núcleo, la unidad es guiada a un ácido nucleico diana que se hibrida con el espaciador del ácido nucleico dirigido a ácido nucleico. La Cas9 de la unidad escinde el ácido nucleico diana.
EJEMPLO 23: MÉTODO DE ADMINISTRACIÓN ESTOQUIOMÉTRICA DE MÚLTIPLES ÁCIDOS NUCLEICOS DIRIGIDOS A ÁCIDO NUCLEICO A UNA CÉLULA
En algunas realizaciones, la divulgación proporciona un método para la administración estequiométrica de una pluralidad de ácidos nucleicos a una célula, en donde parte de la pluralidad de ácidos nucleicos son ácidos nucleicos dirigidos a ácido nucleico. En algunas realizaciones, la pluralidad de ácidos nucleicos comprende cuatro ácidos nucleicos: uno que codifica Cas9, dos que codifican ácidos nucleicos dirigidos a ácido nucleico y uno que codifica Csy4.
Los ácidos nucleicos pueden comprender dos o más sitios de unión de proteínas de unión a ácido nucleico. En algunos casos, el primer sitio de unión de proteínas de unión a ácido nucleico (por ejemplo, el sitio más 5') comprende un sitio de unión a Csy4. En algunos casos, el segundo sitio de unión de proteínas de unión a ácido nucleico (por ejemplo, el sitio más 3') comprende un sitio de unión de proteínas de unión a ácido nucleico diferente (por ejemplo, sitio de unión a MS2). En algunos casos, el segundo sitio de unión de proteínas de unión a ácido nucleico de cada uno de los ácidos nucleicos administrables estequiométricamente es diferente. Por ejemplo, el segundo sitio de unión de proteínas de unión a ácido nucleico puede ser un sitio que se une a uno de un polipéptido CRISPR (por ejemplo, Cas5, Cas6). En algunos casos, el ácido nucleico que codifica Cas9 también comprende una señal de localización nuclear (NLS).
En algunas realizaciones, el polipéptido de fusión en tándem comprende tres proteínas de unión a ácido nucleico. Las tres proteínas de unión a ácido nucleico son Csy4, Cas5, Cas6. El polipéptido de fusión en tándem comprende una señal de localización nuclear. Los polipéptidos de fusión en tándem comprenden más de una copia de una proteína de unión a ácido nucleico (por ejemplo, 2 copias de Csy4, una copia de Cas5, una copia de Cas6).
En algunas realizaciones, un complejo que comprende la proteína de fusión en tándem y los cuatro ácidos nucleicos se forma fuera de una célula. El complejo se forma mezclando los cuatro ácidos nucleicos y la proteína de fusión en tándem y dejando que la reacción ocurra para permitir la unión entre el polipéptido de fusión en tándem y los cuatro sitios de unión a la proteína de unión a ácido nucleico. El complejo se introduce en la célula. La introducción se produce por transformación, transfección, transducción vírica, microinyección o electroporación, o cualquier técnica capaz de introducir biomoléculas a través de una membrana celular. El complejo se forma dentro de la célula (por ejemplo, tras la introducción de vectores que comprenden secuencias de ácido nucleico que codifican los ácidos nucleicos y la proteína de fusión en tándem).
En el interior de la célula, los ácidos nucleicos que codifican Csy4 y Cas9 se traducen, resultando en Csy4 y NLS-Cas9 (por ejemplo, Cas9 que comprende una NLS. La NLS puede que no tenga que estar en el extremo N). Csy4 escinde el sitio de unión a Csy4 en los ácidos nucleicos que codifican los ácidos nucleicos dirigidos a ácido nucleico, liberándolos así del polipéptido de fusión en tándem.
NLS-Cas9 se une a los ácidos nucleicos dirigidos a ácido nucleico liberados, formando así una pluralidad de unidades. Las unidades pueden translocarse al núcleo. Dentro del núcleo, las unidades son guiadas a un ácido nucleico diana que se hibrida con el espaciador del ácido nucleico dirigido a ácido nucleico. La Cas9 de la unidad escinde el ácido nucleico diana.
EJEMPLO 24: MÉTODO DE ADMINISTRACIÓN ESTOQUIOMÉTRICA DE ARN Y UN POLINUCLEÓTIDO DONANTE
La divulgación proporciona un método de administración estequiométrica de componentes de ARN que se puede usar en el diseño del genoma. El método también puede comprender la administración de un polinucleótido donante que puede insertarse en un sitio de diseño del genoma.
La divulgación proporciona un método para la administración estequiométrica de una pluralidad de ARN y un polinucleótido donante a una célula. En algunas realizaciones, la pluralidad de ARN comprende tres ARN y un ADN. En algunos casos, los tres ARN son: uno que codifica Cas9, uno que codifica Csy4 y uno que codifica un ácido nucleico dirigido a ácido nucleico. El ADN es un a Dn que codifica un polinucleótido donante.
En algunos casos, los ARN comprenden una pluralidad de sitios de unión a proteínas de unión a ácidos nucleicos (por ejemplo, dos sitios de unión a proteínas de unión a ácidos nucleicos). El primer sitio de unión de proteínas de unión a ácido nucleico (por ejemplo, el sitio más 5') comprende un sitio de unión a Csy4. El segundo sitio de unión de proteínas de unión a ácido nucleico (por ejemplo, el sitio más 3' comprende un sitio de unión de proteínas de unión a ácido nucleico diferente). El segundo sitio de unión de proteínas de unión a ácido nucleico en cada uno de los ácidos nucleicos de la divulgación es diferente. Por ejemplo, el segundo sitio de unión a la proteína de unión a ácido nucleico se une a un polipéptido CRISPR (por ejemplo, Cas5, Cas6) y/o una proteína de unión a ADN (por ejemplo, una proteína de dedo de cinc). Los ácidos nucleicos del método también comprenden una secuencia que codifica una señal de localización nuclear (por ejemplo, el ARN que codifica Cas9 y el ADN que codifica un polinucleótido donante).
En algunas realizaciones, el polipéptido de fusión en tándem comprende cuatro proteínas de unión a ácido nucleico (por ejemplo, proteínas de unión a ARN y proteínas de unión a ADN). En algunos casos, tres proteínas de unión a ácido nucleico son Csy4, Cas5, Cas6, y la cuarta proteína de unión a ácido nucleico es una proteína de unión a ADN (por ejemplo, proteína de dedo de cinc). En algunos casos, el polipéptido de fusión en tándem comprende una señal de localización nuclear.
En algunas realizaciones, un complejo que comprende la proteína de fusión en tándem y los ácidos nucleicos (por ejemplo, tres ARN y un ADN) se forma fuera de una célula. El complejo se forma mezclando los ácidos nucleicos (por ejemplo, tres ARN y un ADN) y la proteína de fusión en tándem, y permitiendo que se produzca la reacción para permitir la unión entre el polipéptido de fusión en tándem y cuatro sitios de unión de la proteína de unión a ARN. El complejo se puede introducir en la célula. El complejo se forma dentro de la célula (por ejemplo, tras la introducción de vectores que comprenden secuencias de ácido nucleico que codifican los ácidos nucleicos y la proteína de fusión en tándem).
En el interior de la célula, los ARN que codifican Csy4 y Cas9 se traducen, resultando en Csy4 y NLS-Cas9 (por ejemplo, Cas9 que comprende una NLS. La NLS puede que no tenga que estar en el extremo N como se escribe aquí). Csy4 puede escindir el sitio de unión a Csy4 en los ARN que codifican el ácido nucleico dirigido a ácido nucleico y el ADN, liberándolos así del polipéptido de fusión en tándem. En algunos casos, el polinucleótido donante liberado es traslocalizado al núcleo por su señal de localización nuclear.
NLS-Cas9 se une al ácido nucleico dirigido a ácido nucleico liberado, formando así una unidad. La unidad puede translocarse al núcleo. Dentro del núcleo, la unidad es guiada a un ácido nucleico diana que se hibrida con el espaciador del ácido nucleico dirigido a ácido nucleico de la unidad. La Cas9 de la unidad escinde el ácido nucleico diana. El polinucleótido donante, una parte de un polinucleótido donante, una copia del polinucleótido donante o una parte de una copia del polinucleótido donante se puede insertar en el ácido nucleico diana escindido.
EJEMPLO 25: Selección perfecta de células modificadas genéticamente
Se pone en contacto una pluralidad de células con un vector que comprende secuencias que codifican un polipéptido homólogo a Cas9, un ácido nucleico dirigido a ácido nucleico y un polinucleótido donante. En algunos casos, una o más de las secuencias que codifican el polipéptido homólogo a Cas9, el ácido nucleico dirigido a ácido nucleico y el polinucleótido donante se encuentran en diferentes vectores, y las células se transfectan con el vector. En algunos casos, las células están infectadas con un virus que porta el vector. En algunos casos, la célula ya contiene una proteína homóloga a Cas9 y el vector no codifica este polipéptido. En algunos casos, la célula ya comprende un sistema CRISPR (por ejemplo, proteínas Cas, ARNcr y ARNcrtra) y el vector solo codifica el polinucleótido donante. El polinucleótido donante comprende secuencias que codifican un elemento genético de interés y un elemento indicador. El elemento indicador comprende secuencias de ácido nucleico dirigidas a ácido nucleico, una proteína homóloga a Cas9 y una proteína fluorescente. El ácido nucleico dirigido a ácido nucleico guía a Cas9 a un ácido nucleico diana (por ejemplo, un sitio en el genoma de la célula hospedadora), lo que produce una rotura de ADN bicatenaria del ácido nucleico diana y la inserción del polinucleótido donante. La inserción del polinucleótido del donante se criba mediante la detección del indicador. En algunos casos, el cribado comprende la clasificación de células activadas por fluorescencia. El cribado comprende múltiples métodos de selección. Cas9 y/o los ácidos nucleicos dirigidos a ácido nucleico están controlados por un promotor inducible. Tras seleccionar una población de células que comprende la señal indicadora, el elemento indicador se elimina activando el promotor inducible, que transcribe los ácidos nucleicos dirigidos a ácido nucleico y el polipéptido dirigido a un sitio del polinucleótido donante. El ácido nucleico dirigido a ácido nucleico transcrito y el polipéptido dirigido a un sitio transcrito pueden formar complejos. Un complejo puede dirigirse al extremo 3' del elemento indicador del polinucleótido donante. Un complejo puede dirigirse al extremo 5' del elemento indicador del polinucleótido donante. Los extremos 3' y 5' del elemento indicador pueden escindirse. El ácido nucleico diana escindido puede volverse a unir por mecanismos celulares, dando como resultado una secuencia de ácido nucleico en fase que codifica la misma secuencia de ácido nucleico que antes de la inserción del polinucleótido donante. De esta manera, el elemento indicador se inserta perfectamente y se elimina de las células.
EJEMPLO 26: Método para la escisión de Cas9 usando ácidos nucleicos dirigidos a ácido nucleico diseñados
Reactivos
Se digirió el plásmido pCB002 que contiene la secuencia de ADN diana temp3 con 1 U de AscI por 1 ug de ADN para linealizar el vector. La reacción se detuvo mediante la incubación de la mezcla de reacción a 80 °C durante 20 min. La reacción se purificó luego usando el kit de limpieza Qiagen de PCR.
El ácido nucleico guía sencillo se generó usando el kit de síntesis de ARN de alto rendimiento de T7 (n.° de cat. E2040S), usando la mitad del volumen de reactivos recomendados por los fabricantes para ARN de > 300 nucleótidos. En general, se usaron entre 200-350 ng de plantilla en una reacción de 20 pl que se incuba durante 16 horas. Las muestras se trataron con ADNasa y se purificaron usando el kit de purificación de ARN Thermo GeneJet (n.° de cat. K0732), y se eluyeron en 20 ul. Los rendimientos típicos varían de 1,4 a 2 ug/ul.
Al comienzo de la configuración del ensayo de escisión, todos los ARNgs se diluyeron a una concentración de 3500 nM y se sometieron a choque térmico a 80 °C durante 15 minutos. Las muestras se retiraron del elemento calefactor y se dejaron equilibrar a temperatura ambiente. Una parte alícuota de 4 pl de ácido nucleico dirigido a ácido nucleico guía sencillo puede extenderse en un gel de agarosa para confirmar la integridad del ARN.
Se retiraron alícuotas de Cas9 a 2-2,5 mg/ml del congelador y se descongelaron lo más rápido posible, y luego se diluyeron en tampón de escisión x1 hasta la concentración de reserva apropiada.
Ensayo de escisión
Se formaron alícuotas de una mezcla maestra de agua, tampón de escisión x5 (HEPES 100 mM, KCl 500 mM, MgCh 25 mM, DTT 5 mM y glicerol al 25 % a pH 7,4), y Cas9 a 250 nM en tubos de PCR de pared fina. Se añadió ARNgs a los tubos apropiados a una concentración final de 250 nM.
La reacción se incubó a 37 °C durante 10 minutos, se añadió plásmido linealizado 10 nM y se incubaron las reacciones (volumen de reacción final de 20 ul) a 37 °C durante y hora. La reacción se terminó calentando la reacción a 60 °C durante 20 minutos. Se mezclaron alícuotas de 10 ul con 2 ul de colorante de carga de ADN x6, y se analizaron por electroforesis en un gel de agarosa al 1,5 % teñido con SYBR seguro. La aparición de fragmentos de ~2800 pb y ~1300 pb fue indicativa de la escisión mediada por Cas9.
Los resultados de los experimentos se muestran en la Figura 6, 10 y 11. Todas las secuencias de ARN guía sintéticas diseñadas y mostradas en la Figura 5 soportaron la escisión de ARNgs, excepto SGRv8, en donde se invirtió toda la región complementaria. Estos resultados indican que diferentes regiones del ARNgs pueden ser susceptibles de modificarse y aún conservan la función.
Los ácidos nucleicos dirigidos a ácido nucleico diseñados se probaron en el ensayo descrito anteriormente. Las Figuras 22A y 22B muestran los diseños de un conjunto inicial de variantes de dúplex en variantes de cadena principal de ácido nucleico dirigido a ácido nucleico guía sencillo usadas para probar la actividad de escisión y dirección.
La Figura 23A y la 23B ilustran un segundo conjunto de variantes de dúplex con modificaciones más pequeñas en el dúplex. V28 comprende una inserción de 2 bases 3' en la región complementaria; V29 comprende una eliminación de 3 bases 3' en la región complementaria.
La Figura 24A y la 24B ilustran variantes de crtra que comprenden mutaciones en la parte de ARNcrtra del ácido nucleico dirigido a ácido nucleico (es decir, secuencia mínima de ARNcrtra y secuencia de ARNcrtra de 3'). V38-V41 comprenden fusiones entre la región complementaria/dúplex y los extremos 3' de las secuencias de ácido nucleico crtra de 163K de M. mobile (v38), FMD-9 de S. thermophilus (V39), C. jejuni (V40) y N. meningitides.
La Figura 25A y la Figura 25B representan variantes que comprenden modificaciones para permitir la unión de Csy4 al ácido nucleico dirigido a ácido nucleico. Se derivan secuencias de horquilla adicionales de la repetición CRISPR en PA14 de Pseudomonas aeruginosa.
La Figura 26A-C muestran datos del ensayo de escisión in vitro que demuestran la actividad de las variantes de ácido nucleico dirigido a ácido nucleico en la escisión de Cas9. La variante SGRv8 no pudo soportar la escisión del ácido nucleico diana (Figura 26B, carril 9).
La Figura 27 y la Figura 28 muestran dos repeticiones independientes del ensayo de escisión de Cas9 que prueba las variantes representadas en las Figuras 23-25.
Se prepararon ácidos nucleicos dirigidos a ácido nucleico diseñados adicionales como se enumeran en la Tabla 2, y se probaron en el mismo ensayo. Los resultados del ensayo se muestran en la Figura 37, y se enumeran en la columna de actividad de la Tabla 2.
Los resultados de estos experimentos indican la importancia de las regiones de protuberancia y dominio P para efectuar la escisión del ácido nucleico diana. La funcionalidad de las variantes 42-45 indica que la adición de una
secuencia de unión a Csy4 a un ácido nucleico dirigido a ácido nucleico no interrumpe la escisión del ácido nucleico diana.
EJEMPLO 27: SISTEMAS DE ANÁLISIS DE SECUENCIACIÓN
La FIGURA 30 representa un sistema que está configurado para implementar los métodos de la divulgación. El sistema puede incluir un servidor informático ("servidor") que está programado para implementar los métodos descritos en el presente documento. La FIGURA 30 representa un sistema 3000 adaptado para permitir que un usuario detecte, analice y comunique resultados de secuenciación de, por ejemplo, ácidos nucleicos enriquecidos dirigidos a nucleasas, ácidos nucleicos diana secuenciados, datos relativos a los métodos de divulgación, diagnostique una enfermedad, genotipe un paciente, tome una decisión de tratamiento específica del paciente, o cualquier combinación de los mismos. El sistema 3000 incluye un servidor informático central 3001 que está programado para implementar métodos ilustrativos descritos en el presente documento. El servidor 3001 incluye una unidad central de procesamiento (CPU, también "procesador") 3005 que puede ser un procesador de un solo núcleo, un procesador de múltiples núcleos o una pluralidad de procesadores para el procesamiento en paralelo. El servidor 3001 también incluye una memoria 3010 (por ejemplo, memoria de acceso aleatorio, memoria de solo lectura, memoria flash); unidad de almacenamiento electrónico 3015 (por ejemplo, disco duro); interfaz de comunicaciones 3020 (por ejemplo, adaptador de red) para comunicarse con uno o más sistemas; y dispositivos periféricos 3025 que pueden incluir memoria caché, otra memoria, almacenamiento de datos y/o adaptadores de presentación electrónica. La memoria 3010, la unidad de almacenamiento 3015, la interfaz 3020 y los dispositivos periféricos 3025 están en comunicación con el procesador 3005 a través de un bus de comunicaciones (líneas continuas), tales como una placa base. La unidad de almacenamiento 3015 puede ser una unidad de almacenamiento de datos para almacenar datos. El servidor 3001 está acoplado operativamente a una red informática ("red") 3030 con la ayuda de la interfaz de comunicaciones 3020. La red 3030 puede ser Internet, una intranet y/o una extranet, una intranet y/o extranet que está en comunicación con Internet, una red de telecomunicaciones o datos. La red 3030, en algunos casos, con la ayuda del servidor 3001, puede implementar una red de igual a igual, que puede permitir que los dispositivos acoplados al servidor 3001 se comporten como un cliente o un servidor. El microscopio y el micromanipulador pueden ser dispositivos periféricos 3025 o sistemas informáticos remotos 3040.
La unidad de almacenamiento 3015 puede almacenar archivos, tales como los resultados de la secuenciación, sitios de unión a dianas, datos genéticos personalizados, genotipos, imágenes, análisis de datos de imágenes y/o resultados de secuenciación, o cualquier aspecto de los datos asociados con la divulgación.
El servidor puede comunicarse con uno o más sistemas informáticos remotos a través de la red 3030. El uno o más sistemas informáticos remotos pueden ser, por ejemplo, ordenadores personales, ordenadores portátiles, tablets, teléfonos, teléfonos inteligentes o asistentes digitales personales.
En algunas situaciones, el sistema 3000 incluye un único servidor 3001. En otras situaciones, el sistema incluye múltiples servidores en comunicación entre sí a través de una intranet, extranet y/o Internet.
El servidor 3001 se puede adaptar para almacenar resultados de secuenciación, sitios de unión a dianas, datos genéticos personalizados y/u otra información de posible relevancia. Dicha información puede almacenarse en la unidad de almacenamiento 3015 o en el servidor 3001 y dichos datos pueden transmitirse a través de una red.
Los métodos descritos en el presente documento pueden implementarse mediante un código ejecutable (o software) de la máquina (o procesador informático) almacenado en una ubicación de almacenamiento electrónico del servidor 3001, tal como, por ejemplo, en la memoria 3010 o la unidad de almacenamiento electrónico 3015. Durante su uso, el procesador 3005 puede ejecutar el código. En algunos casos, el código puede recuperarse de la unidad de almacenamiento 3015 y almacenarse en la memoria 3010 para que el procesador 3005 pueda acceder fácilmente. En algunas situaciones, la unidad de almacenamiento electrónico 3015 puede excluirse, y las instrucciones ejecutables por la máquina se almacenan en la memoria 3010. Como alternativa, el código puede ejecutarse en un segundo sistema informático 3040.
Los aspectos de los sistemas y métodos proporcionados en el presente documento, tales como el servidor 3001, pueden incorporarse en programación. Varios aspectos de la tecnología pueden considerarse "productos" o "artículos de fabricación" normalmente en forma de código ejecutable por la máquina (o procesador) y/o datos asociados que se llevan a cabo o se incorporan en un tipo de medio de lectura automática. El código ejecutable automáticamente puede almacenarse en una unidad de almacenamiento electrónico, tal como la memoria (por ejemplo, memoria de solo lectura, memoria de acceso aleatorio, memoria flash) o un disco duro. Los medios de tipo "almacenamiento" pueden incluir una parte o la totalidad de la memoria tangible de los ordenadores, procesadores o similares, o módulos asociados de los mismos, tales como varias memorias de semiconductores, unidades de cinta, unidades de disco y similares, que pueden proporcionar almacenamiento no transitorio en cualquier momento para la programación del software. Todo o partes del software a veces se pueden comunicar a través de Internet u otras redes de telecomunicaciones. Dichas comunicaciones, por ejemplo, pueden permitir la carga del software desde un ordenador o un procesador a otro, por ejemplo, desde un servidor de administración u ordenador Host a la plataforma informática de un servidor de aplicaciones. Así pues, otro tipo de medio que puede contener los elementos del software incluye
ondas ópticas, eléctricas y electromagnéticas, tales como las que se usan a través de interfaces físicas entre dispositivos locales, a través de redes fijas alámbricas y ópticas, y a través de varios enlaces aéreos. Los elementos físicos que transportan dichas ondas, tales como los alámbricos o inalámbricos, los enlaces ópticos o similares, también pueden considerarse medios portadores del software. Como se usa en el presente documento, a menos que estén restringidos a medios de "almacenamiento" tangibles no transitorios, las expresiones tales como "medio legible" por ordenador o máquina se refieren a cualquier medio que participe en proporcionar instrucciones a un procesador para su ejecución.
Por lo tanto, un medio de lectura automática, tal como el código ejecutable por un ordenador, puede adoptar muchas formas, incluyendo, pero sin limitación, un medio de almacenamiento tangible, un medio de onda portadora o un medio de transmisión físico. Los medios de almacenamiento no volátiles pueden incluir, por ejemplo, discos ópticos o magnéticos, tal como cualquiera de los dispositivos de almacenamiento en cualquier ordenador o similares, que se pueden usar para implementar el sistema. Los medios de transmisión tangibles pueden incluir: cables coaxiales, cables de cobre y fibra óptica (incluyendo los cables que comprenden un bus dentro de un sistema informático). Los medios de transmisión de onda portadora pueden tomar la forma de señales eléctricas o electromagnéticas, u ondas acústicas o de luz, como las generadas durante las comunicaciones de datos por radiofrecuencia (RF) e infrarrojos (IR). Las formas comunes de medios legibles por ordenador incluyen, por tanto, por ejemplo: un disquete, un disco flexible, disco duro, cinta magnética, cualquier otro medio magnético, un CD-ROM, DVD, DVD-ROM, cualquier otro medio óptico, tarjetas perforadas, cinta de papel, cualquier otro medio de almacenamiento físico con patrones de orificios, una RAM, una Ro m , una PROM y una EPROM, una FLASH-EPROM, cualquier otro chip o cartucho de memoria, una onda portadora que transmita datos o instrucciones, cables o enlaces que transporten dicha onda portadora, o cualquier otro medio desde el cual un ordenador pueda leer código y/o datos de programación. Muchas de estas formas de medios legibles por ordenador pueden estar implicadas en llevar una o más secuencias de una o más instrucciones a un procesador para su ejecución.
EJEMPLO 28: SECUENCIACIÓN BASADA EN MATRICES USANDO UN POLIPÉPTIDO DIRIGIDO A UN SITIO.
Una muestra de ácido nucleico se liga con un marcador de ácido nucleico que comprende un solo ARN guía y un marcador detectable. En conjunto, la muestra de ácido nucleico ligada al marcador de ácido nucleico se denomina muestra de prueba marcada. La muestra de prueba marcada se pone en contacto con una micromatriz que comprende oligonucleótidos inmovilizados. Los oligonucleótidos inmovilizados son un banco de ácidos nucleicos bicatenarios. Los oligonucleótidos comprenden un marcador detectable (por ejemplo, marcador fluorescente). Los miembros individuales de la muestra de prueba marcada pueden hibridarse con los oligonucleótidos con los que comparten suficiente complementariedad para facilitar la hibridación. La cantidad de hibridación puede cuantificarse comparando las intensidades de los dos marcadores detectables del banco de muestras y los oligonucleótidos inmovilizados. Por ejemplo, los oligonucleótidos hibridados pueden mostrar dos marcadores detectables (el del banco de muestras y el oligonucleótido). Los oligonucleótidos no hibridados pueden mostrar un marcador detectable (el del oligonucleótido). Las sondas hibridadas se ponen en contacto con Cas9. Cas9 escinde los oligonucleótidos de la micromatriz que se han hibridado con miembros de la muestra de prueba marcada. La escisión por el polipéptido dirigido a un sitio permite que los miembros hibridados de la muestra de prueba marcada sean eliminados. Tras la escisión por el polipéptido dirigido a un sitio, solo quedan en la micromatriz los marcadores detectables de oligonucleótidos no hibridados. El marcador detectable restante se cuantifica. La cuantificación de los marcadores detectables restantes se correlaciona con qué secuencias se representaron en la muestra de ácido nucleico y cuáles no (por ejemplo, mediante cartografía de posición). Los oligonucleótidos que no muestran un marcador detectable restante corresponden a secuencias representadas en la muestra de ácido nucleico. Los oligonucleótidos que muestran un marcador detectable restante corresponden a secuencias que no estaban representadas en la muestra de ácido nucleico.
EJEMPLO 29: ESCISIÓN DE UN ÁCIDO NUCLEICO DIANA CON UN ÁCIDO NUCLEICO DIRIGIDO A ÁCIDO NUCLEICO MARCADO
Este ejemplo describe los resultados de la escisión del ácido nucleico diana con un ácido nucleico dirigido a ácido nucleico que comprende una secuencia de unión a Csy4 en el extremo 5' del ácido nucleico dirigido a ácido nucleico. Se incubó Cas9 con o sin un ARN guía dirigido a un solo sitio en una secuencia de ADN lineal bicatenaria. Después de 1 hora, se separaron los productos de escisión y se visualizaron en un gel de agarosa. La Figura 13D ilustra que la escisión de Cas9 mediada por un ácido nucleico dirigido a ácido nucleico marcado (carril 3) fue menos eficaz que la escisión de Cas9 mediada por un ácido nucleico dirigido a ácido nucleico sin marcar (carril 1). Después de 1 hora, aprox. el 100 % de la diana fue escindido por Cas9 guiada por el ácido nucleico dirigido a ácido nucleico sin marcar, donde solo fue escindida una pequeña fracción de la diana en el mismo tiempo por Cas9 guiada por el ácido nucleico dirigido a ácido nucleico marcado. Estos experimentos indican que se puede usar la ubicación de la secuencia no nativa para ajustar la eficacia de la escisión del complejo de Cas9: ácido nucleico dirigido a ácido nucleico. Por ejemplo, La Figura 27, y Figura 29 muestran la funcionalidad de la adición de una secuencia de unión a Csy4 en varias ubicaciones del ácido nucleico dirigido a ácido nucleico que conservan la actividad.
EJEMPLO 30: GENES DE DISEÑO DEL GENOMA EN TRASTORNOS DE LA SANGRE
Un ácido nucleico dirigido a ácido nucleico que comprende una secuencia espaciadora descrita en la Figura XX se
introduce en una célula con un polipéptido dirigido a un sitio, formando así un complejo. El complejo se dirige al gen que participa en un trastorno sanguíneo que tiene una complementariedad sustancial con la secuencia espadadora del ácido nucleico dirigido a ácido nucleico. Una vez que el ácido nucleico dirigido a ácido nucleico se hibrida con el ácido nucleico diana, el polipéptido dirigido a un sitio escinde el ácido nucleico diana. El ácido nucleico diana escindido se puede diseñar con un polinucleótido donante.
EJEMPLO 31: PROTOCOLO PARA DETERMINAR LA ESCISIÓN Y LA MODIFICACIÓN DEL ÁCIDO NUCLEICO DIANA
Este protocolo puede usarse para determinar si un ácido nucleico diana se ha escindido o si el ácido nucleico diana se ha modificado, tal como con una inserción o eliminación. Los cebadores que rodean el sitio diana se usan para amplificar por PCR, en una reacción de 25 pl, un producto de 500-600 nt de ADNg. Los cebadores comprenden al menos 100 nt a cada lado del sitio de corte. Los productos resultantes del ensayo de escisión son de aproximadamente más de 100 nt.
Se procesan aproximadamente 5 pl de producto de PCR en un gel de agarosa para determinar si la amplificación está limpia. Con el producto de PCR restante, el protocolo de fusión e hibridación es el siguiente:
°C 10 min
de °C a °C (-2,0 °C/s)
85 °C 1 min
de °C a 75 °C (-0,3 °C/s)
75 °C 1 min
de °C a °C (-0,3 °C/s)
65 °C 1 min
de °C a °C (-0,3 °C/s)
55 °C 1 min
de °C a 45 °C (-0,3 °C/s)
45 °C 1 min
de °C a 35 °C (-0,3 °C/s)
35 °C 1 min
de 35 °C a °C (-0,3 °C/s)
25 °C 1 min
4 °C Mantener
Se prepara una mezcla maestra T7E1 de agua, tampón NEB2 y enzima T7E1. Se multiplica por cada reacción, más extra. La Tabla 8 muestra los componentes de la mezcla maestra T7E1.
Tabla 8. Compo a maestra T7E1.

A cada reacción, en un tubo de tapa de tira de 200 pl, se añaden los siguientes reactivos: mezcla maestra T7E1 (10 pl) y muestra de PCR (10 pl). La reacción se incuba a 37 °C durante 25 minutos.
Se añade tampón de carga a la muestra y la muestra completa se procesa en un gel al 3 % a 120 V durante 20 minutos. El gel puede procesarse durante más tiempo si se requiere una mayor resolución. Se fotografía y se guarda la imagen del gel.
Se cuantifica la imagen para determinar la cantidad de escisión del ácido nucleico diana.
EJEMPLO 31: PRUEBA CELULAR DE VARIANTES DE ÁCIDO NUCLEICO DIRIGIDO A ÁCIDO NUCLEICO
Este ejemplo muestra que las variantes de ácido nucleico dirigido a ácido nucleico representadas en la Figura 22, 24, y 25 y el Ejemplo 26 se probaron en un ensayo basado en células para determinar si la funcionalidad in vitro determinada en el Ejemplo 26 coincidía con la funcionalidad in vivo. Las células HEK293 se cultivaron hasta 60-70 %
de confluencia en placas de 10 cm. Las células se eliminaron por tripsinización, se contaron usando un hemocitómetro y luego se separaron en alícuotas de 7 x 104 células para cada pocillo por transfectar. Para cada pocillo, se mezclaron 250 ng de plásmido pCB045 que expresa Cas9 optimizada con codón de mamífero con 30 ng de ARN guía y 40 ng de ADN copGFP y 0,5 ul de Lipofectamina 2000 en un volumen final de 50 ul de DMEM. El ADN y los lípidos se incubaron durante 15 minutos antes de la transfección. Las transfecciones se llevaron a cabo en el momento de la colocación en placa, añadiendo la mezcla de lípido:ADN a 450 pl de DMEM 10% de suero bovino fetal que contenía 7 x 104 células. La mezcla de transfección/células se añadió a placas de cultivo de tejidos de 96 pocillos recubiertas con colágeno de cola de rata I. Las células se incubaron a 37 °C en una incubadora con CO2 al 5 % durante 40 horas.
Se retiraron los medios de cada uno de los pocillos y se lisaron las células usando solución Quickextract (Epicentro) de acuerdo con las instrucciones del fabricante. El a Dn cosechado de la lisis con QuickExtract se diluyó 1:10 y se usó como plantilla en reacciones de PCR para ensayos de T7E1 como se describe en el Ejemplo 30.
La Figura 36 indica que todas las variantes, excepto v8 y v9, pudieron escindir el ácido nucleico diana. La variante de ácido nucleico dirigida a ácido nucleico v8 también fue sustancialmente inactiva en ensayos in vitro tal como se representa en la Figura 23B. La variante de ácido nucleico dirigido a ácido nucleico v9 fue muy débilmente activa en el ensayo in vitro representado en la Figura 23B.
EJEMPLO 32: DETERMINACIÓN DEL DESTINO CELULAR CON UNA CÉLULA MARCADA
Este ejemplo describe cómo rastrear una célula que se desarrolla a partir de un linaje celular. Una célula madre hematopoyética (por ejemplo, Un hemocitoblasto) se pone en contacto con un polipéptido dirigido a un sitio, un ácido nucleico dirigido a ácido nucleico y un polinucleótido donante. El polipéptido dirigido a un sitio y el ácido nucleico dirigido a ácido nucleico forman un complejo y se dirigen a una región del genoma hematopoyético para la escisión. Una vez escindido, el polinucleótido donante se inserta en el sitio escindido Del genoma de la célula hepatopoyética. La célula madre hematopoyética se induce a diferenciarse mediante procesos de diferenciación normales. En diferentes etapas de diferenciación, se puede analizar la muestra que comprende las células hematopoyéticas diferenciadas para determinar la presencia del polinucleótido donante. De esta manera, se puede rastrear el proceso de diferenciación de una célula.
EJEMPLO 33: CLONACIÓN DE OLIGONUCLEOTIDO BICATENARIO QUE CODIFICA UN ÁCIDO NUCLEICO DIRIGIDO A ÁCIDO NUCLEICO EN UN VECTOR LINEALIZADO
El presente ejemplo describe cómo generar un oligonucleótido bicatenario que codifica una parte de ácido nucleico dirigido a ácido nucleico (por ejemplo, un espaciador) e insertarlo en un vector linealizado. El vector linealizado o un vector superenrollado cerrado comprende una secuencia que codifica un polipéptido dirigido a un sitio (por ejemplo, Cas9), un promotor que impulsa la expresión de la secuencia que codifica el polipéptido dirigido a un sitio (por ejemplo, promotor CMV), una secuencia que codifica un enlazador (por ejemplo, 2A), una secuencia que codifica un marcador (por ejemplo, CD4 u OFP), una secuencia que codifica la parte de un ácido nucleico dirigido a ácido nucleico, un promotor que impulsa la expresión de la secuencia que codifica una parte del ácido nucleico dirigido a ácido nucleico, y una secuencia que codifica un marcador seleccionable (por ejemplo, ampicilina), o cualquier combinación de las mismas.
Se recogen cantidades iguales de dos oligonucleótidos monocatenarios juntos (por ejemplo, 50 micromolar). Los dos oligonucleótidos monocatenarios pueden hibridarse entre sí. Al menos uno de los dos oligonucleótidos monocatenarios es complementario a un ácido nucleico diana (por ejemplo, una región de 10-30 nucleótidos adyacente a un motivo adyacente al protoespaciador en una diana). Al menos uno de los dos nucleótidos monocatenarios comprende una secuencia de saliente 3' que comprende la secuencia 5-GTTT-3'. Al menos uno de los dos oligonucleótidos monocatenarios comprende un saliente 3' que comprende la secuencia 5-CGGTG-3'. En algunos casos, uno de los dos oligonucleótidos monocatenarios comprende un saliente 5'-GTTT-3' y el otro de los dos oligonucleótidos monocatenarios comprende 5' -CGGTG-3'. El hibridación se realiza en un tampón de hibridación que comprende al menos Tris HCl 10 mM pH 8,0, EDTA1 mM, pH 8,0, y NaCl 100 mM. El hibridación se lleva a cabo calentando la mezcla de oligonucleótidos a 95 °C durante 3-5 minutos, retirando la mezcla de oligonucleótidos de la fuente de calor, y dejando que la mezcla se enfríe a temperatura ambiente durante 5-10 minutos. La mezcla de oligonucleótidos bicatenarios se centrifuga suavemente. Tras la hibridación, la mezcla puede almacenarse a 4 °C o -20 °C. La mezcla, ahora de oligonucleótidos bicatenarios, se diluye para preparar dos soluciones madre de 500 nanomolar y 5 nanomolar. Las soluciones madre se preparan diluyendo la mezcla de oligonucleótidos en agua.
El oligonucleótido bicatenario (Oligonucleótidobc) se liga en un vector linealizado. El vector linealizado comprende una secuencia que codifica un polipéptido dirigido a un sitio (por ejemplo, Cas9), una proteína marcadora (por ejemplo, proteína fluorescente naranja) y/o una secuencia que codifica un ácido nucleico dirigido a ácido nucleico, en donde el vector linealizado está linealizado en una región de la secuencia que codifica el ácido nucleico dirigido a ácido nucleico, de modo que los extremos adhesivos generados coinciden con los extremos salientes del oligonucleótido bc. La reacción de ligación puede comprender un tampón de ligación x1 (por ejemplo, Tris-HCl 50 mM, pH 7,6, MgCh 5 mM, ATP 1 mM, DTT 1 mM y/o PEG 8000 al 5 %), 30 nanogramos vector linealizado, Oligonucleótido bc 5 Nm y ADN ligasa (por ejemplo, 4 microlitros de tampón e ligadura x5, 2 microlitros de vector linealizado a 15 nanogramos/microlitro,
2 microlitros de Oligonucleótido bc 5 nanomolar, 11 microlitros de agua, 1 microlitro de ADN ligasa de T4). Se mezcla la reacción. La reacción se incuba a temperatura ambiente durante 2 horas y 10 minutos. La reacción se coloca en hielo y se transforma en células competentes.
La transformación en células competentes comprende la transformación en células TOP 10 E. coli químicamente competentes. Las células competentes se descongelan en hielo. Se añaden 3 microlitros de la mezcla de reacción a las células competentes y se mezclan suavemente. Las células se incuban en hielo durante 10-30 minutos. Las células son sometidas a choque térmico durante 30 segundos a 42 °C. Las células se transfieren a hielo durante 2 minutos. Se añaden 250 microlitros de medio (SOC o LB) a las células. Las células se agitan a 200 rpm durante 1 hora a 37 °C. Luego, las células se extienden sobre una placa de agar que comprende 100 microgramos/mililitro de ampicilina y se almacenan durante la noche a 37 °C.
Se analizan los transformantes. Por ejemplo, los transformantes se analizan para determinar la identidad del Oligonucleótido bc ligado al vector y/o confirmar que la ligadura no es un falso positivo. Para analizar los transformantes, las colonias se recogen y se cultivan durante la noche en medio LB que comprende 100 microgramos/mililitro de amplicilina a 37 °C. El plásmido que comprende el polipéptido dirigido a un sitio y el Oligonucleótido bc se aisla (por ejemplo, mediante un kit miniprep). Se realiza una reacción de secuenciación sobre el plásmido aislado. La reacción de secuenciación usa un cebador de secuenciación diseñado para secuenciar el Oligonucleótido bc (por ejemplo, el cebador de secuenciación es un cebador de secuenciación U6 que se une al promotor U6 que se encuentra cadena arriba de la secuencia que codifica el Oligonucleótido bc.
Una vez que se identifica la inserción deseada de un oligonucleótido bc, el plásmido se puede almacenar a -20 °C o en una reserva de glicerol a -80 °C. Para preparar una reserva de glicerol, se siembra en estrías la colonia original que comprende el plásmido deseado en una placa de agar que comprende 100 microgramos/mililitro de ampicilina y se incuba durante la noche a 37 °C. Se aísla una sola colonia cultivada en LB que comprende 100 microgramos/mililitro de ampicilina hasta que el cultivo alcanza la fase estacionaria. El cultivo se mezcla con glicerol y se congela instantáneamente en nitrógeno líquido (por ejemplo, se mezclan 0,85 ml de cultivo con 0,15 ml de glicerol).
El plásmido purificado que comprende el Oligonucleótido bc deseado se inserta en una estirpe celular (por ejemplo, estirpe celular de mamífero, HeLa) mediante transfección. Para transfectar el plásmido, el plásmido se purifica a altas concentraciones usando, por ejemplo, un kit maxi prep. El plásmido se transfecta con tampón basado en lípidos (por ejemplo, Lipofectamina 2000) en las células que se siembran al 70 % de confluencia. Se transfectan 3 microgramos del vector en las células.
EJEMPLO 34: ADMINISTRACIÓN DE NANOPARTÍCULAS DE UN ÁCIDO NUCLEICO DIRIGIDO A ÁCIDO NUCLEICO DISEÑADO
Se preparará una nanopartícula que encapsula un ácido nucleico que codifica un ácido nucleico dirigido a ácido nucleico diseñado y un polipéptido dirigido a un sitio. Las nanopartículas se prepararán mezclando DOPE, Chol, DSPE-PEG y C16mPEG-Ceramida en una proporción molar de 18:60:20:1:1 en 10 ml de etanol al 90 % (30 pmol de lípido total). El ácido nucleico se disolverá en 10 ml de tampón Tris 20 mM (pH 7,4-7,6). Tras calentar a 37 °C, las dos soluciones se mezclarán entre sí a través de una bomba de jeringa de duelo, y la solución mezclada se diluirá posteriormente con 20 ml de tampón Tris 20 mM (NaCl 300 mM, pH 7,4-7,6). La mezcla se incubará a 37 °C durante 30 minutos y se dializará en tampón PBS 10 mM (NaCl 138 mM, KCl 2,7 mM, a pH 7,4). Se obtendrán partículas estables tras la eliminación del etanol de la mezcla por diálisis. La solución de nanopartículas se concentra por centrifugación a 3.000 rpm y una temperatura de 4°C.La suspensión concentrada se recogerá tras un tiempo determinado y se esterilizará por filtración a través de un filtro de jeringa de 0,22 pm (Millex-GV, Millipore, EE.UU.). Se obtendrá una suspensión homogénea de las nanopartículas que comprenden el ácido nucleico que codifica el ácido nucleico dirigido a ácido nucleico diseñado y el polipéptido dirigido a un sitio.
Se pondrán las nanopartículas en contacto con una célula. La nanopartícula entrará en la célula. En el interior de la célula, la nanopartícula liberará el ácido nucleico que codifica el ácido nucleico dirigido a ácido nucleico diseñado y el polipéptido dirigido a un sitio. El ácido nucleico se transcribirá y/o traducirá para producir un ácido nucleico dirigido a ácido nucleico diseñado que se une a una proteína de polipéptido dirigido a un sitio, formando así un complejo. El complejo se dirigirá a un ácido nucleico diana que se hibrida con el ácido nucleico dirigido a ácido nucleico diseñado. El complejo escindirá el ácido nucleico diana.
En algunos casos, la nanopartícula comprenderá además un ácido nucleico que codifica un polinucleótido donante. Cuando el ácido nucleico diana es escindido por el polipéptido dirigido a un sitio, el polinucleótido donante se insertará en el sitio del ácido nucleico diana escindido.
Claims (15)
1. Una proteína CRISPR Cas9 modificada genéticamente, que comprende:
una modificación en una región de una proteína CRISPR Cas9 que se corresponde con una región de los restos de aminoácidos 170-312 de una proteína Cas9 de S. pyogenes (SEQ ID NO:8), en donde la modificación comprende una inserción, una deleción o una combinación de las mismas.
2. La proteína CRISPR Cas9 modificada genéticamente de la reivindicación 1, en donde la modificación se hace en regiones identificadas de similitud de secuencia entre la proteína Cas9 y la proteína Cas9 de S. pyogenes (SEQ ID NO:8).
3. La proteína CRISPR Cas9 modificada genéticamente de las reivindicaciones 1 o 2, en donde la modificación comprende una deleción.
4. La proteína CRISPR Cas9 modificada genéticamente de la reivindicación 3, en donde la modificación comprende una deleción de más de 5 restos de aminoácidos, o en donde la modificación comprende una deleción de más de 100 restos de aminoácidos.
5. La proteína CRISPR Cas9 modificada genéticamente de una cualquiera de las reivindicaciones 1 a 4, en donde la modificación comprende una deleción y una inserción de una secuencia de aminoácidos no natural.
6. La proteína CRISPR Cas9 modificada genéticamente de las reivindicaciones 1 o 2, en donde la modificación comprende una inserción de una secuencia de aminoácidos no natural para formar una proteína de fusión, y en donde la secuencia de aminoácidos no natural comprende opcionalmente un dominio funcional.
7. La proteína CRISPR Cas9 modificada genéticamente de las reivindicaciones 1 o 2, en donde la proteína CRISPR Cas9 es una fusión.
8. La proteína CRISPR Cas9 modificada genéticamente de la reivindicación 7, en donde la fusión de CRISPR Cas9 modificada genéticamente comprende un marcador detectable.
9. La proteína CRISPR Cas9 modificada genéticamente de la reivindicación 7, en donde la fusión de CRISPR Cas9 modificada genéticamente comprende la proteína CRISPR Cas9 modificada genéticamente y una endonucleasa, en donde la endonucleasa es preferentemente Fokl.
10. La proteína CRISPR Cas9 modificada genéticamente de cualquiera de las reivindicaciones anteriores, en donde la proteína CRISPR Cas9 modificada genéticamente es enzimáticamente inactiva.
11. La proteína CRISPR Cas9 modificada genéticamente de cualquiera de las reivindicaciones anteriores, en donde la proteína CRISPR Cas9 modificada genéticamente está optimizada por codón para una célula hospedadora de interés.
12. La proteína CRISPR Cas9 modificada genéticamente de la reivindicación 11, en donde la célula hospedadora de interés es una célula bacteriana, una célula de arquea, una célula de un organismo eucariota unicelular, una célula vegetal, una célula de alga, una célula fúngica, una célula animal, una célula de un animal invertebrado, una célula de un animal vertebrado o una célula de un mamífero, preferentemente, una célula humana.
13. Un polinucleótido que codifica la proteína CRISPR Cas9 modificada genéticamente de una cualquiera de las reivindicaciones 1 a 12.
14. Un complejo que comprende:
la proteína CRISPR Cas9 modificada genéticamente de una cualquiera de las reivindicaciones 1 a 12, y un ácido nucleico dirigido a un ácido nucleico.
15. Un kit que comprende:
la proteína CRISPR Cas9 modificada genéticamente de una cualquiera de las reivindicaciones 1 a 12, o un polinucleótido que codifica la proteína CRISPR Cas9 modificada genéticamente; y
un reactivo, y que comprende opcionalmente:
un ácido nucleico dirigido a un ácido nucleico o un polinucleótido que codifica un ácido nucleico dirigido a un un ácido nucleico.
Applications Claiming Priority (18)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201361781598P | 2013-03-14 | 2013-03-14 | |
| US201361818386P | 2013-05-01 | 2013-05-01 | |
| US201361818382P | 2013-05-01 | 2013-05-01 | |
| US201361822002P | 2013-05-10 | 2013-05-10 | |
| US201361832690P | 2013-06-07 | 2013-06-07 | |
| US201361845714P | 2013-07-12 | 2013-07-12 | |
| US201361858767P | 2013-07-26 | 2013-07-26 | |
| US201361859661P | 2013-07-29 | 2013-07-29 | |
| US201361865743P | 2013-08-14 | 2013-08-14 | |
| US201361883804P | 2013-09-27 | 2013-09-27 | |
| US201361899712P | 2013-11-04 | 2013-11-04 | |
| US201361900311P | 2013-11-05 | 2013-11-05 | |
| US201361902723P | 2013-11-11 | 2013-11-11 | |
| US201361903232P | 2013-11-12 | 2013-11-12 | |
| US201361906211P | 2013-11-19 | 2013-11-19 | |
| US201361906335P | 2013-11-19 | 2013-11-19 | |
| US201361907216P | 2013-11-21 | 2013-11-21 | |
| US201361907777P | 2013-11-22 | 2013-11-22 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| ES2901396T3 true ES2901396T3 (es) | 2022-03-22 |
Family
ID=51580795
Family Applications (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| ES14771135T Active ES2749624T3 (es) | 2013-03-14 | 2014-03-12 | Composiciones y métodos de ácidos nucleicos dirigidos a ácido nucleico |
| ES19188624T Active ES2901396T3 (es) | 2013-03-14 | 2014-03-12 | Composiciones y métodos de ácidos nucleicos dirigidos a ácido nucleico |
Family Applications Before (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| ES14771135T Active ES2749624T3 (es) | 2013-03-14 | 2014-03-12 | Composiciones y métodos de ácidos nucleicos dirigidos a ácido nucleico |
Country Status (19)
| Country | Link |
|---|---|
| US (16) | US9260752B1 (es) |
| EP (2) | EP3620534B1 (es) |
| JP (3) | JP2016519652A (es) |
| KR (2) | KR20170108172A (es) |
| CN (2) | CN105980575A (es) |
| AU (3) | AU2014235794A1 (es) |
| BR (1) | BR112015022061B8 (es) |
| CA (1) | CA2905432C (es) |
| DK (2) | DK3620534T3 (es) |
| ES (2) | ES2749624T3 (es) |
| GB (1) | GB2527450A (es) |
| HK (1) | HK1213023A1 (es) |
| IL (1) | IL241563B (es) |
| MX (1) | MX2015013057A (es) |
| NZ (1) | NZ712727A (es) |
| RU (2) | RU2662932C2 (es) |
| SG (1) | SG11201507378UA (es) |
| WO (1) | WO2014150624A1 (es) |
| ZA (1) | ZA201507006B (es) |
Families Citing this family (289)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8399643B2 (en) | 2009-02-26 | 2013-03-19 | Transposagen Biopharmaceuticals, Inc. | Nucleic acids encoding hyperactive PiggyBac transposases |
| CA2853829C (en) | 2011-07-22 | 2023-09-26 | President And Fellows Of Harvard College | Evaluation and improvement of nuclease cleavage specificity |
| US11021737B2 (en) | 2011-12-22 | 2021-06-01 | President And Fellows Of Harvard College | Compositions and methods for analyte detection |
| IN2014DN09261A (es) | 2012-04-25 | 2015-07-10 | Regeneron Pharma | |
| KR101656237B1 (ko) * | 2012-10-23 | 2016-09-12 | 주식회사 툴젠 | 표적 DNA에 특이적인 가이드 RNA 및 Cas 단백질을 암호화하는 핵산 또는 Cas 단백질을 포함하는, 표적 DNA를 절단하기 위한 조성물 및 이의 용도 |
| SG10202107423UA (en) | 2012-12-06 | 2021-08-30 | Sigma Aldrich Co Llc | Crispr-based genome modification and regulation |
| ES2883590T3 (es) | 2012-12-12 | 2021-12-09 | Broad Inst Inc | Suministro, modificación y optimización de sistemas, métodos y composiciones para la manipulación de secuencias y aplicaciones terapéuticas |
| ES2701749T3 (es) | 2012-12-12 | 2019-02-25 | Broad Inst Inc | Métodos, modelos, sistemas y aparatos para identificar secuencias diana para enzimas Cas o sistemas CRISPR-Cas para secuencias diana y transmitir resultados de los mismos |
| SG11201504621RA (en) * | 2012-12-17 | 2015-07-30 | Harvard College | Rna-guided human genome engineering |
| AU2014207618A1 (en) | 2013-01-16 | 2015-08-06 | Emory University | Cas9-nucleic acid complexes and uses related thereto |
| EP2971184B1 (en) | 2013-03-12 | 2019-04-17 | President and Fellows of Harvard College | Method of generating a three-dimensional nucleic acid containing matrix |
| NZ712727A (en) | 2013-03-14 | 2017-05-26 | Caribou Biosciences Inc | Compositions and methods of nucleic acid-targeting nucleic acids |
| JP6980380B2 (ja) | 2013-03-15 | 2021-12-15 | ザ ジェネラル ホスピタル コーポレイション | 短縮ガイドRNA(tru−gRNA)を用いたRNA誘導型ゲノム編集の特異性の増大 |
| US10760064B2 (en) | 2013-03-15 | 2020-09-01 | The General Hospital Corporation | RNA-guided targeting of genetic and epigenomic regulatory proteins to specific genomic loci |
| CN115261411A (zh) | 2013-04-04 | 2022-11-01 | 哈佛学院校长同事会 | 利用CRISPR/Cas系统的基因组编辑的治疗性用途 |
| US9902973B2 (en) | 2013-04-11 | 2018-02-27 | Caribou Biosciences, Inc. | Methods of modifying a target nucleic acid with an argonaute |
| PT3456831T (pt) | 2013-04-16 | 2021-09-10 | Regeneron Pharma | Modificação alvejada do genoma de rato |
| EP3004339B1 (en) * | 2013-05-29 | 2021-07-07 | Cellectis | New compact scaffold of cas9 in the type ii crispr system |
| EP3004349B1 (en) * | 2013-05-29 | 2018-03-28 | Cellectis S.A. | A method for producing precise dna cleavage using cas9 nickase activity |
| US9873907B2 (en) | 2013-05-29 | 2018-01-23 | Agilent Technologies, Inc. | Method for fragmenting genomic DNA using CAS9 |
| US9267135B2 (en) | 2013-06-04 | 2016-02-23 | President And Fellows Of Harvard College | RNA-guided transcriptional regulation |
| MY197877A (en) * | 2013-06-04 | 2023-07-22 | Harvard College | Rna-guided transcriptional regulation |
| BR112015031608A2 (pt) | 2013-06-17 | 2017-08-22 | Massachusetts Inst Technology | Aplicação e uso dos sistemas crispr-cas, vetores e composições para direcionamento e terapia hepáticos |
| EP3725885A1 (en) | 2013-06-17 | 2020-10-21 | The Broad Institute, Inc. | Functional genomics using crispr-cas systems, compositions methods, screens and applications thereof |
| EP3011034B1 (en) | 2013-06-17 | 2019-08-07 | The Broad Institute, Inc. | Delivery, use and therapeutic applications of the crispr-cas systems and compositions for targeting disorders and diseases using viral components |
| DK3011029T3 (da) | 2013-06-17 | 2020-03-16 | Broad Inst Inc | Administration, modificering og optimering af tandem-guidesystemer, fremgangsmåder og sammensætninger til sekvensmanipulering |
| CA2915837A1 (en) | 2013-06-17 | 2014-12-24 | The Broad Institute, Inc. | Optimized crispr-cas double nickase systems, methods and compositions for sequence manipulation |
| US10011850B2 (en) | 2013-06-21 | 2018-07-03 | The General Hospital Corporation | Using RNA-guided FokI Nucleases (RFNs) to increase specificity for RNA-Guided Genome Editing |
| JP2016528890A (ja) | 2013-07-09 | 2016-09-23 | プレジデント アンド フェローズ オブ ハーバード カレッジ | CRISPR/Cas系を用いるゲノム編集の治療用の使用 |
| US10563225B2 (en) | 2013-07-26 | 2020-02-18 | President And Fellows Of Harvard College | Genome engineering |
| US20150044192A1 (en) | 2013-08-09 | 2015-02-12 | President And Fellows Of Harvard College | Methods for identifying a target site of a cas9 nuclease |
| US9359599B2 (en) | 2013-08-22 | 2016-06-07 | President And Fellows Of Harvard College | Engineered transcription activator-like effector (TALE) domains and uses thereof |
| BR112016003561B8 (pt) | 2013-08-22 | 2022-11-01 | Du Pont | Método para a produção de uma modificação genética, método para a introdução de um polinucleotídeo de interesse no genoma de uma planta, método para a edição de um segundo gene em um genoma de planta e método para gerar uma planta de milho resistente ao glifosato |
| US9322037B2 (en) | 2013-09-06 | 2016-04-26 | President And Fellows Of Harvard College | Cas9-FokI fusion proteins and uses thereof |
| US9526784B2 (en) | 2013-09-06 | 2016-12-27 | President And Fellows Of Harvard College | Delivery system for functional nucleases |
| US9228207B2 (en) | 2013-09-06 | 2016-01-05 | President And Fellows Of Harvard College | Switchable gRNAs comprising aptamers |
| CN105637087A (zh) | 2013-09-18 | 2016-06-01 | 科马布有限公司 | 方法、细胞与生物体 |
| WO2015066119A1 (en) | 2013-10-30 | 2015-05-07 | North Carolina State University | Compositions and methods related to a type-ii crispr-cas system in lactobacillus buchneri |
| EP3066201B1 (en) | 2013-11-07 | 2018-03-07 | Editas Medicine, Inc. | Crispr-related methods and compositions with governing grnas |
| CA2930877A1 (en) * | 2013-11-18 | 2015-05-21 | Crispr Therapeutics Ag | Crispr-cas system materials and methods |
| US9074199B1 (en) * | 2013-11-19 | 2015-07-07 | President And Fellows Of Harvard College | Mutant Cas9 proteins |
| US9546384B2 (en) | 2013-12-11 | 2017-01-17 | Regeneron Pharmaceuticals, Inc. | Methods and compositions for the targeted modification of a mouse genome |
| WO2015089364A1 (en) | 2013-12-12 | 2015-06-18 | The Broad Institute Inc. | Crystal structure of a crispr-cas system, and uses thereof |
| EP3653229A1 (en) | 2013-12-12 | 2020-05-20 | The Broad Institute, Inc. | Delivery, use and therapeutic applications of the crispr-cas systems and compositions for genome editing |
| US11053481B2 (en) | 2013-12-12 | 2021-07-06 | President And Fellows Of Harvard College | Fusions of Cas9 domains and nucleic acid-editing domains |
| CA2932472A1 (en) | 2013-12-12 | 2015-06-18 | Massachusetts Institute Of Technology | Compositions and methods of use of crispr-cas systems in nucleotide repeat disorders |
| WO2015089486A2 (en) | 2013-12-12 | 2015-06-18 | The Broad Institute Inc. | Systems, methods and compositions for sequence manipulation with optimized functional crispr-cas systems |
| US10787654B2 (en) | 2014-01-24 | 2020-09-29 | North Carolina State University | Methods and compositions for sequence guiding Cas9 targeting |
| HUE049634T2 (hu) | 2014-02-11 | 2020-09-28 | Univ Colorado Regents | A CRISPR által lehetõvé tett multiplex génmanipuláció |
| CA3194412A1 (en) | 2014-02-27 | 2015-09-03 | Monsanto Technology Llc | Compositions and methods for site directed genomic modification |
| WO2015134812A1 (en) | 2014-03-05 | 2015-09-11 | Editas Medicine, Inc. | Crispr/cas-related methods and compositions for treating usher syndrome and retinitis pigmentosa |
| US11339437B2 (en) | 2014-03-10 | 2022-05-24 | Editas Medicine, Inc. | Compositions and methods for treating CEP290-associated disease |
| US11141493B2 (en) | 2014-03-10 | 2021-10-12 | Editas Medicine, Inc. | Compositions and methods for treating CEP290-associated disease |
| EP3116997B1 (en) | 2014-03-10 | 2019-05-15 | Editas Medicine, Inc. | Crispr/cas-related methods and compositions for treating leber's congenital amaurosis 10 (lca10) |
| US11242525B2 (en) | 2014-03-26 | 2022-02-08 | Editas Medicine, Inc. | CRISPR/CAS-related methods and compositions for treating sickle cell disease |
| US11439712B2 (en) * | 2014-04-08 | 2022-09-13 | North Carolina State University | Methods and compositions for RNA-directed repression of transcription using CRISPR-associated genes |
| CN106687601A (zh) * | 2014-05-28 | 2017-05-17 | 株式会社图尔金 | 使用靶特异性核酸酶灵敏检测靶dna的方法 |
| EP3149171A1 (en) | 2014-05-30 | 2017-04-05 | The Board of Trustees of The Leland Stanford Junior University | Compositions and methods of delivering treatments for latent viral infections |
| WO2015188056A1 (en) * | 2014-06-05 | 2015-12-10 | Sangamo Biosciences, Inc. | Methods and compositions for nuclease design |
| CA2951707A1 (en) * | 2014-06-10 | 2015-12-17 | Massachusetts Institute Of Technology | Method for gene editing |
| KR102598819B1 (ko) * | 2014-06-23 | 2023-11-03 | 더 제너럴 하스피탈 코포레이션 | 서열결정에 의해 평가된 DSB의 게놈 전체에 걸친 비편향된 확인 (GUIDE-Seq) |
| WO2016022363A2 (en) | 2014-07-30 | 2016-02-11 | President And Fellows Of Harvard College | Cas9 proteins including ligand-dependent inteins |
| JP6806668B2 (ja) * | 2014-08-19 | 2021-01-06 | プレジデント アンド フェローズ オブ ハーバード カレッジ | 核酸をプロービングおよびマッピングするためのrna誘導型システム |
| US10435685B2 (en) | 2014-08-19 | 2019-10-08 | Pacific Biosciences Of California, Inc. | Compositions and methods for enrichment of nucleic acids |
| EP3633047B1 (en) | 2014-08-19 | 2022-12-28 | Pacific Biosciences of California, Inc. | Method of sequencing nucleic acids based on an enrichment of nucleic acids |
| NZ728437A (en) | 2014-08-27 | 2018-02-23 | Caribou Biosciences Inc | Methods for increasing cas9-mediated engineering efficiency |
| EP3186375A4 (en) | 2014-08-28 | 2019-03-13 | North Carolina State University | NEW CAS9 PROTEINS AND GUIDING ELEMENTS FOR DNA TARGETING AND THE GENOME EDITION |
| CA2956487A1 (en) | 2014-09-12 | 2016-03-17 | E. I. Du Pont De Nemours And Company | Generation of site-specific-integration sites for complex trait loci in corn and soybean, and methods of use |
| US20170306306A1 (en) * | 2014-10-24 | 2017-10-26 | Life Technologies Corporation | Compositions and Methods for Enhancing Homologous Recombination |
| WO2016070037A2 (en) * | 2014-10-31 | 2016-05-06 | Massachusetts Institute Of Technology | Massively parallel combinatorial genetics for crispr |
| EP3215617A2 (en) | 2014-11-07 | 2017-09-13 | Editas Medicine, Inc. | Methods for improving crispr/cas-mediated genome-editing |
| AU2015349692B2 (en) | 2014-11-21 | 2021-10-28 | Regeneron Pharmaceuticals, Inc. | Methods and compositions for targeted genetic modification using paired guide RNAs |
| AU2015355546B2 (en) | 2014-12-03 | 2021-10-14 | Agilent Technologies, Inc. | Guide RNA with chemical modifications |
| AU2015360502A1 (en) | 2014-12-10 | 2017-06-29 | Regents Of The University Of Minnesota | Genetically modified cells, tissues, and organs for treating disease |
| WO2016094872A1 (en) * | 2014-12-12 | 2016-06-16 | The Broad Institute Inc. | Dead guides for crispr transcription factors |
| WO2016094867A1 (en) | 2014-12-12 | 2016-06-16 | The Broad Institute Inc. | Protected guide rnas (pgrnas) |
| JP2017538427A (ja) | 2014-12-18 | 2017-12-28 | インテグレイテッド ディーエヌエイ テクノロジーズ インコーポレイテッド | Crispr系組成物及び使用方法 |
| CA2971444A1 (en) | 2014-12-20 | 2016-06-23 | Arc Bio, Llc | Compositions and methods for targeted depletion, enrichment, and partitioning of nucleic acids using crispr/cas system proteins |
| EP3245232B1 (en) | 2015-01-12 | 2021-04-21 | The Regents of The University of California | Heterodimeric cas9 and methods of use thereof |
| HRP20231022T1 (hr) | 2015-01-28 | 2023-12-08 | Caribou Biosciences, Inc. | Hibridni polinukleotidi crispr dna/rna i načini uporabe |
| WO2016123243A1 (en) | 2015-01-28 | 2016-08-04 | The Regents Of The University Of California | Methods and compositions for labeling a single-stranded target nucleic acid |
| KR20160103953A (ko) * | 2015-02-25 | 2016-09-02 | 연세대학교 산학협력단 | Crispr 시스템을 이용한 다중 위치 염기서열의 동시 포획 방법 |
| WO2016141224A1 (en) | 2015-03-03 | 2016-09-09 | The General Hospital Corporation | Engineered crispr-cas9 nucleases with altered pam specificity |
| US10066256B2 (en) | 2015-03-17 | 2018-09-04 | Bio-Rad Laboratories, Inc. | Detection of genome editing |
| BR112017017260A2 (pt) | 2015-03-27 | 2018-04-17 | Du Pont | construções de dna, vetor, célula, plantas, semente, método de expressão de rna e método de modificação de local alvo |
| WO2016161207A1 (en) | 2015-03-31 | 2016-10-06 | Exeligen Scientific, Inc. | Cas 9 retroviral integrase and cas 9 recombinase systems for targeted incorporation of a dna sequence into a genome of a cell or organism |
| CA2981715A1 (en) | 2015-04-06 | 2016-10-13 | The Board Of Trustees Of The Leland Stanford Junior University | Chemically modified guide rnas for crispr/cas-mediated gene regulation |
| KR102535217B1 (ko) | 2015-04-24 | 2023-05-19 | 에디타스 메디신, 인코포레이티드 | Cas9 분자/가이드 rna 분자 복합체의 평가 |
| WO2016182959A1 (en) | 2015-05-11 | 2016-11-17 | Editas Medicine, Inc. | Optimized crispr/cas9 systems and methods for gene editing in stem cells |
| US10136649B2 (en) | 2015-05-29 | 2018-11-27 | North Carolina State University | Methods for screening bacteria, archaea, algae, and yeast using CRISPR nucleic acids |
| US10117911B2 (en) | 2015-05-29 | 2018-11-06 | Agenovir Corporation | Compositions and methods to treat herpes simplex virus infections |
| EP3303585A4 (en) | 2015-06-03 | 2018-10-31 | Board of Regents of the University of Nebraska | Dna editing using single-stranded dna |
| WO2016196655A1 (en) | 2015-06-03 | 2016-12-08 | The Regents Of The University Of California | Cas9 variants and methods of use thereof |
| WO2016201047A1 (en) | 2015-06-09 | 2016-12-15 | Editas Medicine, Inc. | Crispr/cas-related methods and compositions for improving transplantation |
| US20160362667A1 (en) | 2015-06-10 | 2016-12-15 | Caribou Biosciences, Inc. | CRISPR-Cas Compositions and Methods |
| WO2016201138A1 (en) | 2015-06-12 | 2016-12-15 | The Regents Of The University Of California | Reporter cas9 variants and methods of use thereof |
| DK3307872T3 (da) | 2015-06-15 | 2023-10-23 | Univ North Carolina State | Fremgangsmåder og sammensætninger til effektiv indgivelse af nukleinsyrer og rna-baserede antimikrober |
| IL284808B (en) | 2015-06-18 | 2022-07-01 | Broad Inst Inc | Mutations in the crispr enzyme that reduce unintended effects |
| US9790490B2 (en) | 2015-06-18 | 2017-10-17 | The Broad Institute Inc. | CRISPR enzymes and systems |
| WO2016205759A1 (en) | 2015-06-18 | 2016-12-22 | The Broad Institute Inc. | Engineering and optimization of systems, methods, enzymes and guide scaffolds of cas9 orthologs and variants for sequence manipulation |
| US10456452B2 (en) | 2015-07-02 | 2019-10-29 | Poseida Therapeutics, Inc. | Compositions and methods for improved encapsulation of functional proteins in polymeric vesicles |
| US20170000743A1 (en) * | 2015-07-02 | 2017-01-05 | Vindico NanoBio Technology Inc. | Compositions and Methods for Delivery of Gene Editing Tools Using Polymeric Vesicles |
| WO2017023803A1 (en) | 2015-07-31 | 2017-02-09 | Regents Of The University Of Minnesota | Modified cells and methods of therapy |
| EP3331905B1 (en) | 2015-08-06 | 2022-10-05 | Dana-Farber Cancer Institute, Inc. | Targeted protein degradation to attenuate adoptive t-cell therapy associated adverse inflammatory responses |
| US9580727B1 (en) | 2015-08-07 | 2017-02-28 | Caribou Biosciences, Inc. | Compositions and methods of engineered CRISPR-Cas9 systems using split-nexus Cas9-associated polynucleotides |
| US9512446B1 (en) | 2015-08-28 | 2016-12-06 | The General Hospital Corporation | Engineered CRISPR-Cas9 nucleases |
| JP6799586B2 (ja) | 2015-08-28 | 2020-12-16 | ザ ジェネラル ホスピタル コーポレイション | 遺伝子操作CRISPR−Cas9ヌクレアーゼ |
| US9926546B2 (en) | 2015-08-28 | 2018-03-27 | The General Hospital Corporation | Engineered CRISPR-Cas9 nucleases |
| WO2017040709A1 (en) | 2015-08-31 | 2017-03-09 | Caribou Biosciences, Inc. | Directed nucleic acid repair |
| WO2017044776A1 (en) * | 2015-09-10 | 2017-03-16 | Texas Tech University System | Single-guide rna (sgrna) with improved knockout efficiency |
| KR20180043369A (ko) | 2015-09-11 | 2018-04-27 | 더 제너럴 하스피탈 코포레이션 | 뉴클레아제 dsb의 완전한 호출 및 시퀀싱(find-seq) |
| CN105177110A (zh) * | 2015-09-11 | 2015-12-23 | 中国科学院微生物研究所 | 核酸的检测方法 |
| CA2999500A1 (en) | 2015-09-24 | 2017-03-30 | Editas Medicine, Inc. | Use of exonucleases to improve crispr/cas-mediated genome editing |
| EP3353309A4 (en) * | 2015-09-25 | 2019-04-10 | Tarveda Therapeutics, Inc. | COMPOSITIONS AND METHOD FOR GENERIC EDITING |
| EP3356533A1 (en) | 2015-09-28 | 2018-08-08 | North Carolina State University | Methods and compositions for sequence specific antimicrobials |
| JP2018529353A (ja) | 2015-09-30 | 2018-10-11 | ザ ジェネラル ホスピタル コーポレイション | 配列決定法による切断事象の包括的生体外報告(CIRCLE−seq) |
| WO2017062855A1 (en) * | 2015-10-09 | 2017-04-13 | Monsanto Technology Llc | Novel rna-guided nucleases and uses thereof |
| US10167457B2 (en) | 2015-10-23 | 2019-01-01 | President And Fellows Of Harvard College | Nucleobase editors and uses thereof |
| EP3350327B1 (en) | 2015-10-23 | 2018-09-26 | Caribou Biosciences, Inc. | Engineered crispr class 2 cross-type nucleic-acid targeting nucleic acids |
| JP6882282B2 (ja) | 2015-11-03 | 2021-06-02 | プレジデント アンド フェローズ オブ ハーバード カレッジ | 三次元核酸含有マトリックスの立体撮像のための方法と装置 |
| US9771600B2 (en) * | 2015-12-04 | 2017-09-26 | Caribou Biosciences, Inc. | Engineered nucleic acid-targeting nucleic acids |
| WO2017112620A1 (en) | 2015-12-22 | 2017-06-29 | North Carolina State University | Methods and compositions for delivery of crispr based antimicrobials |
| MY194127A (en) | 2016-01-11 | 2022-11-14 | Univ Leland Stanford Junior | Chimeric proteins and methods of immunotherapy |
| MY196175A (en) | 2016-01-11 | 2023-03-20 | Univ Leland Stanford Junior | Chimeric Proteins And Methods Of Regulating Gene Expression |
| CN108934169A (zh) | 2016-01-20 | 2018-12-04 | 维特里萨医疗公司 | 用于抑制因子d的组合物和方法 |
| US20170218398A1 (en) * | 2016-01-30 | 2017-08-03 | Markus Alexander Brown | Method to selectively target cancerous cells for genetic manipulation |
| CN109072224B (zh) * | 2016-01-30 | 2022-07-15 | 株式会社博纳克 | 人工单导rna及其用途 |
| US10876129B2 (en) | 2016-02-12 | 2020-12-29 | Ceres, Inc. | Methods and materials for high throughput testing of mutagenized allele combinations |
| US20190249172A1 (en) | 2016-02-18 | 2019-08-15 | The Regents Of The University Of California | Methods and compositions for gene editing in stem cells |
| EP3881857A1 (en) | 2016-02-18 | 2021-09-22 | The Penn State Research Foundation | Generating gabaergic neurons in brains |
| EP3420080B1 (en) * | 2016-02-22 | 2019-08-21 | Caribou Biosciences, Inc. | Methods for modulating dna repair outcomes |
| WO2017149139A1 (en) * | 2016-03-03 | 2017-09-08 | Curevac Ag | Rna analysis by total hydrolysis |
| CN109414414A (zh) | 2016-03-16 | 2019-03-01 | 戴维·格拉德斯通研究所 | 用于治疗肥胖症和/或糖尿病以及用于鉴定候选治疗剂的方法和组合物 |
| WO2017165826A1 (en) | 2016-03-25 | 2017-09-28 | Editas Medicine, Inc. | Genome editing systems comprising repair-modulating enzyme molecules and methods of their use |
| EP3433364A1 (en) | 2016-03-25 | 2019-01-30 | Editas Medicine, Inc. | Systems and methods for treating alpha 1-antitrypsin (a1at) deficiency |
| CA3020317A1 (en) * | 2016-04-08 | 2017-10-12 | Cold Spring Harbor Laboratory | Multiplexed analysis of neuron projections by sequencing |
| MA45478A (fr) * | 2016-04-11 | 2019-02-20 | Arbutus Biopharma Corp | Compositions de conjugués d'acides nucléiques ciblés |
| US11236313B2 (en) | 2016-04-13 | 2022-02-01 | Editas Medicine, Inc. | Cas9 fusion molecules, gene editing systems, and methods of use thereof |
| CA3022290A1 (en) | 2016-04-25 | 2017-11-02 | President And Fellows Of Harvard College | Hybridization chain reaction methods for in situ molecular detection |
| ES2865481T3 (es) | 2016-04-29 | 2021-10-15 | Poseida Therapeutics Inc | Micelas basadas en poli(histidina) para la complejación y el aporte de proteínas y ácidos nucleicos |
| WO2017186550A1 (en) * | 2016-04-29 | 2017-11-02 | Basf Plant Science Company Gmbh | Improved methods for modification of target nucleic acids |
| EP4269611A3 (en) * | 2016-05-11 | 2024-01-17 | Illumina, Inc. | Polynucleotide enrichment and amplification using argonaute systems |
| EP3907286A1 (en) | 2016-06-02 | 2021-11-10 | Sigma-Aldrich Co., LLC | Using programmable dna binding proteins to enhance targeted genome modification |
| US10767175B2 (en) | 2016-06-08 | 2020-09-08 | Agilent Technologies, Inc. | High specificity genome editing using chemically modified guide RNAs |
| US10337051B2 (en) | 2016-06-16 | 2019-07-02 | The Regents Of The University Of California | Methods and compositions for detecting a target RNA |
| EP3472311A4 (en) * | 2016-06-17 | 2020-03-04 | Montana State University | BIDIRECTIONAL TARGETING FOR GENOMEDITATION |
| US10017760B2 (en) | 2016-06-24 | 2018-07-10 | Inscripta, Inc. | Methods for generating barcoded combinatorial libraries |
| BR112019001887A2 (pt) | 2016-08-02 | 2019-07-09 | Editas Medicine Inc | composições e métodos para o tratamento de doença associada a cep290 |
| IL308426A (en) | 2016-08-03 | 2024-01-01 | Harvard College | Adenosine nuclear base editors and their uses |
| CN109804066A (zh) | 2016-08-09 | 2019-05-24 | 哈佛大学的校长及成员们 | 可编程cas9-重组酶融合蛋白及其用途 |
| WO2018031950A1 (en) | 2016-08-12 | 2018-02-15 | Caribou Biosciences, Inc. | Protein engineering methods |
| US20190309288A1 (en) * | 2016-08-18 | 2019-10-10 | The Board Of Trustees Of The Leland Stanford Junior University | Targeted mutagenesis |
| WO2018039438A1 (en) | 2016-08-24 | 2018-03-01 | President And Fellows Of Harvard College | Incorporation of unnatural amino acids into proteins using base editing |
| WO2018048194A1 (ko) * | 2016-09-07 | 2018-03-15 | 울산대학교 산학협력단 | dCas9 단백질 및 표적 핵산 서열에 결합하는 gRNA를 이용한 핵산 검출의 민감도 및 특이도 향상용 조성물 및 방법 |
| EP3512535A4 (en) * | 2016-09-13 | 2020-05-06 | The Jackson Laboratory | TARGETED IMPROVED DNA DEMETHYLATION |
| WO2018053053A1 (en) * | 2016-09-13 | 2018-03-22 | The Broad Institute, Inc. | Proximity-dependent biotinylation and uses thereof |
| KR20230169449A (ko) | 2016-09-30 | 2023-12-15 | 더 리젠츠 오브 더 유니버시티 오브 캘리포니아 | Rna-가이드된 핵산 변형 효소 및 이의 사용 방법 |
| EA201990861A1 (ru) | 2016-09-30 | 2019-09-30 | Те Риджентс Оф Те Юниверсити Оф Калифорния | Рнк-направляемые модифицирующие нуклеиновые кислоты ферменты и способы их применения |
| US10669539B2 (en) | 2016-10-06 | 2020-06-02 | Pioneer Biolabs, Llc | Methods and compositions for generating CRISPR guide RNA libraries |
| AU2017342543A1 (en) | 2016-10-14 | 2019-05-02 | President And Fellows Of Harvard College | AAV delivery of nucleobase editors |
| GB2605540B (en) | 2016-10-18 | 2022-12-21 | Univ Minnesota | Tumor infiltrating lymphocytes and methods of therapy |
| US10829729B2 (en) * | 2016-11-03 | 2020-11-10 | President And Fellows Of Harvard College | Cellular poration using laser radiation |
| US9816093B1 (en) | 2016-12-06 | 2017-11-14 | Caribou Biosciences, Inc. | Engineered nucleic acid-targeting nucleic acids |
| WO2018209712A1 (en) * | 2017-05-19 | 2018-11-22 | Tsinghua University | Engineering of a minimal sacas9 crispr/cas system for gene editing and transcriptional regulation optimized by enhanced guide rna |
| EP3336546B1 (en) * | 2016-12-13 | 2020-07-01 | Miltenyi Biotec B.V. & Co. KG | Reversible cell labelling with conjugates having two releasable binding sites |
| US10975388B2 (en) | 2016-12-14 | 2021-04-13 | Ligandal, Inc. | Methods and compositions for nucleic acid and protein payload delivery |
| WO2018119359A1 (en) | 2016-12-23 | 2018-06-28 | President And Fellows Of Harvard College | Editing of ccr5 receptor gene to protect against hiv infection |
| EP3342868B1 (en) | 2016-12-30 | 2019-12-25 | Systasy Bioscience GmbH | Constructs and screening methods |
| US20190352710A1 (en) * | 2017-01-05 | 2019-11-21 | Virginia Commonwealth University | System, method, computer-accessible medium and apparatus for dna mapping |
| WO2018136827A1 (en) | 2017-01-20 | 2018-07-26 | Vitrisa Therapeutics, Inc. | Stem-loop compositions and methods for inhibiting factor d |
| CN110475866A (zh) * | 2017-01-30 | 2019-11-19 | 科沃施种子欧洲股份两合公司 | 用于基因组工程的与核酸内切酶相连的修复模板 |
| TW201839136A (zh) | 2017-02-06 | 2018-11-01 | 瑞士商諾華公司 | 治療血色素異常症之組合物及方法 |
| CA3052635A1 (en) | 2017-02-06 | 2018-11-08 | Zymergen Inc. | Engineered biosynthetic pathways for production of tyramine by fermentation |
| CN111386263A (zh) | 2017-02-08 | 2020-07-07 | 达纳-法伯癌症研究所有限公司 | 调节嵌合抗原受体 |
| US11739333B2 (en) * | 2017-03-02 | 2023-08-29 | Meiragtx Uk Ii Limited | Regulation of gene expression by aptamer-modulated RNase p cleavage |
| US11898179B2 (en) | 2017-03-09 | 2024-02-13 | President And Fellows Of Harvard College | Suppression of pain by gene editing |
| US11542496B2 (en) | 2017-03-10 | 2023-01-03 | President And Fellows Of Harvard College | Cytosine to guanine base editor |
| EP3596217A1 (en) | 2017-03-14 | 2020-01-22 | Editas Medicine, Inc. | Systems and methods for the treatment of hemoglobinopathies |
| JP7191388B2 (ja) | 2017-03-23 | 2022-12-19 | プレジデント アンド フェローズ オブ ハーバード カレッジ | 核酸によってプログラム可能なdna結合蛋白質を含む核酸塩基編集因子 |
| WO2018172556A1 (en) | 2017-03-24 | 2018-09-27 | Curevac Ag | Nucleic acids encoding crispr-associated proteins and uses thereof |
| PT3526324T (pt) | 2017-03-28 | 2021-10-20 | Locanabio Inc | Proteína associada a crispr (cas) |
| US11299779B2 (en) * | 2017-04-13 | 2022-04-12 | Imba—Insiiiut Für Molekulare Biotechnologie Gmbh | Nucleic acid modification and identification method |
| US11591589B2 (en) | 2017-04-21 | 2023-02-28 | The General Hospital Corporation | Variants of Cpf1 (Cas12a) with altered PAM specificity |
| WO2018200653A1 (en) * | 2017-04-25 | 2018-11-01 | The Johns Hopkins University | A yeast two-hybrid rna protein interaction system based on catalytically inactivated crispr-dcas9 |
| WO2018201086A1 (en) | 2017-04-28 | 2018-11-01 | Editas Medicine, Inc. | Methods and systems for analyzing guide rna molecules |
| EP3622070A2 (en) | 2017-05-10 | 2020-03-18 | Editas Medicine, Inc. | Crispr/rna-guided nuclease systems and methods |
| US11560566B2 (en) | 2017-05-12 | 2023-01-24 | President And Fellows Of Harvard College | Aptazyme-embedded guide RNAs for use with CRISPR-Cas9 in genome editing and transcriptional activation |
| CN111093714A (zh) | 2017-05-25 | 2020-05-01 | 通用医疗公司 | 使用分割型脱氨酶限制不需要的脱靶碱基编辑器脱氨 |
| US20200263186A1 (en) * | 2017-05-26 | 2020-08-20 | North Carolina State University | Altered guide rnas for modulating cas9 activity and methods of use |
| AU2018279829B2 (en) | 2017-06-09 | 2024-01-04 | Editas Medicine, Inc. | Engineered Cas9 nucleases |
| US9982279B1 (en) | 2017-06-23 | 2018-05-29 | Inscripta, Inc. | Nucleic acid-guided nucleases |
| US10011849B1 (en) | 2017-06-23 | 2018-07-03 | Inscripta, Inc. | Nucleic acid-guided nucleases |
| JP2020530307A (ja) | 2017-06-30 | 2020-10-22 | インティマ・バイオサイエンス,インコーポレーテッド | 遺伝子治療のためのアデノ随伴ウイルスベクター |
| CA3069296A1 (en) * | 2017-07-07 | 2019-01-10 | Toolgen Incorporated | Target-specific crispr mutant |
| US11866726B2 (en) | 2017-07-14 | 2024-01-09 | Editas Medicine, Inc. | Systems and methods for targeted integration and genome editing and detection thereof using integrated priming sites |
| WO2019036140A1 (en) | 2017-07-17 | 2019-02-21 | Zymergen Inc. | METALLO-ORGANIC STRESS MATERIALS |
| WO2019022986A1 (en) * | 2017-07-24 | 2019-01-31 | Vitrisa Therapeutics, Inc. | NUCLEIC ACID COMPOSITIONS AND METHODS OF INHIBITING D-FACTOR |
| EP3658573A1 (en) | 2017-07-28 | 2020-06-03 | President and Fellows of Harvard College | Methods and compositions for evolving base editors using phage-assisted continuous evolution (pace) |
| IL271283B2 (en) * | 2017-08-04 | 2024-04-01 | Syngenta Participations Ag | Methods and compositions for targeted genomic insertion |
| JP2020532967A (ja) | 2017-08-23 | 2020-11-19 | ザ ジェネラル ホスピタル コーポレイション | 変更されたPAM特異性を有する遺伝子操作されたCRISPR−Cas9ヌクレアーゼ |
| US11319532B2 (en) | 2017-08-30 | 2022-05-03 | President And Fellows Of Harvard College | High efficiency base editors comprising Gam |
| US11649442B2 (en) | 2017-09-08 | 2023-05-16 | The Regents Of The University Of California | RNA-guided endonuclease fusion polypeptides and methods of use thereof |
| CN111315889A (zh) * | 2017-09-08 | 2020-06-19 | 生命技术公司 | 提高同源重组的方法和其组合物 |
| WO2019060469A2 (en) * | 2017-09-19 | 2019-03-28 | Massachusetts Institute Of Technology | CAS9 STREPTOCOCCUS CANIS AS A GENOMIC ENGINEERING PLATFORM WITH NEW PAM SPECIFICITY |
| WO2019074841A1 (en) * | 2017-10-09 | 2019-04-18 | Pioneer Hi-Bred International, Inc. | TYPE I-E CRISPR-CAS SYSTEMS FOR EUCARYOTE GENOME EDITION |
| WO2019075197A1 (en) | 2017-10-11 | 2019-04-18 | The General Hospital Corporation | METHODS OF DETECTION OF INDIVIDUAL SITE-SPECIFIC PARASITE GENOMIC DEAMINATION BY BASE EDITING TECHNOLOGIES |
| EP3697906A1 (en) | 2017-10-16 | 2020-08-26 | The Broad Institute, Inc. | Uses of adenosine base editors |
| RU2020117711A (ru) * | 2017-11-01 | 2021-12-02 | Те Риджентс Оф Те Юниверсити Оф Калифорния | КОМПОЗИЦИИ И СПОСОБЫ ПРИМЕНЕНИЯ CasZ |
| WO2019090237A1 (en) * | 2017-11-03 | 2019-05-09 | Genus Plc | Selectively targeted dna edits in livestock |
| EP3720453A1 (en) | 2017-12-05 | 2020-10-14 | Caribou Biosciences, Inc. | Modified lymphocytes |
| CA3084263A1 (en) | 2017-12-07 | 2019-06-13 | Zymergen Inc. | Engineered biosynthetic pathways for production of (6e)-8-hydroxygeraniol by fermentation |
| US11661599B1 (en) | 2017-12-14 | 2023-05-30 | National Technology & Engineering Solutions Of Sandia, Llc | CRISPR-Cas based system for targeting single-stranded sequences |
| WO2019126037A1 (en) * | 2017-12-19 | 2019-06-27 | City Of Hope | Modified tracrrnas grnas, and uses thereof |
| RU2652899C1 (ru) * | 2017-12-28 | 2018-05-03 | Федеральное бюджетное учреждение науки "Центральный научно-исследовательский институт эпидемиологии" Федеральной службы по надзору в сфере защиты прав потребителей и благополучия человека (ФБУН ЦНИИ Эпидемиологии Роспотребнадзора) | РНК-проводники для подавления репликации вируса гепатита B и для элиминации вируса гепатита B из клетки-хозяина |
| US20210093679A1 (en) | 2018-02-05 | 2021-04-01 | Novome Biotechnologies, Inc. | Engineered gut microbes and uses thereof |
| US20210032612A1 (en) * | 2018-02-22 | 2021-02-04 | Avellino Lab Usa, Inc. | CRISPR/Cas9 Systems, and Methods of Use Thereof |
| WO2019173248A1 (en) | 2018-03-07 | 2019-09-12 | Caribou Biosciences, Inc. | Engineered nucleic acid-targeting nucleic acids |
| WO2019178346A1 (en) * | 2018-03-14 | 2019-09-19 | The Trustees Of The University Of Pennsylvania | Enrichment of nucleic acids |
| US20190284553A1 (en) | 2018-03-15 | 2019-09-19 | KSQ Therapeutics, Inc. | Gene-regulating compositions and methods for improved immunotherapy |
| US20190345479A1 (en) * | 2018-04-16 | 2019-11-14 | University Of Massachusetts | Compositions and methods for improved gene editing |
| CN112313241A (zh) | 2018-04-17 | 2021-02-02 | 总医院公司 | 核酸结合、修饰、和切割试剂的底物偏好和位点的灵敏体外试验 |
| US11160260B2 (en) | 2018-04-17 | 2021-11-02 | The Curators Of The University Of Missouri | Methods for protecting porcine fetuses from infection with porcine reproductive and respiratory syndrome virus (PRRSV) |
| CN108588123A (zh) * | 2018-05-07 | 2018-09-28 | 南京医科大学 | CRISPR/Cas9载体组合在制备基因敲除猪的血液制品中的应用 |
| KR20210045360A (ko) | 2018-05-16 | 2021-04-26 | 신테고 코포레이션 | 가이드 rna 설계 및 사용을 위한 방법 및 시스템 |
| US10227576B1 (en) | 2018-06-13 | 2019-03-12 | Caribou Biosciences, Inc. | Engineered cascade components and cascade complexes |
| CN112272704A (zh) | 2018-06-13 | 2021-01-26 | 卡里布生物科学公司 | 改造的cascade组分和cascade复合体 |
| EP3814488A4 (en) * | 2018-06-26 | 2022-06-22 | The Regents of The University of California | RNA-GUIDED EFFECTIVE PROTEINS AND METHODS OF USE THEREOF |
| EP3821012A4 (en) | 2018-07-13 | 2022-04-20 | The Regents of The University of California | RETROTRANSPOSON-BASED DELIVERY VEHICLE AND METHOD OF USE THEREOF |
| WO2020028729A1 (en) | 2018-08-01 | 2020-02-06 | Mammoth Biosciences, Inc. | Programmable nuclease compositions and methods of use thereof |
| WO2020047531A1 (en) * | 2018-08-31 | 2020-03-05 | The Children's Hospital Of Philadelphia | Scalable tagging of endogenous genes by homology-independent intron targeting |
| WO2020068643A1 (en) * | 2018-09-25 | 2020-04-02 | Excision Biotherapeutics, Inc. | CRISPRs WITH IMPROVED SPECIFICITY |
| WO2020072248A1 (en) | 2018-10-01 | 2020-04-09 | North Carolina State University | Recombinant type i crispr-cas system |
| CA3116555A1 (en) * | 2018-10-15 | 2020-04-23 | University Of Massachusetts | Programmable dna base editing by nme2cas9-deaminase fusion proteins |
| US11407995B1 (en) | 2018-10-26 | 2022-08-09 | Inari Agriculture Technology, Inc. | RNA-guided nucleases and DNA binding proteins |
| US11434477B1 (en) | 2018-11-02 | 2022-09-06 | Inari Agriculture Technology, Inc. | RNA-guided nucleases and DNA binding proteins |
| KR20210104068A (ko) | 2018-12-14 | 2021-08-24 | 파이어니어 하이 부렛드 인터내쇼날 인코포레이팃드 | 게놈 편집을 위한 신규한 crispr-cas 시스템 |
| CA3124395A1 (en) | 2018-12-20 | 2020-06-25 | Basf Plant Science Company Gmbh | Native delivery of biomolecules into plant cells using ionic complexes with cell-penetrating peptides |
| RU2714380C1 (ru) * | 2018-12-28 | 2020-02-14 | Федеральное государственное бюджетное учреждение науки институт биоорганической химии им. академиков М.М. Шемякина и Ю.А. Овчинникова Российской академии наук (ИБХ РАН) | Способ получения цитотоксических т-лимфоцитов, экспрессирующих химерные рецепторы |
| EP3931313A2 (en) | 2019-01-04 | 2022-01-05 | Mammoth Biosciences, Inc. | Programmable nuclease improvements and compositions and methods for nucleic acid amplification and detection |
| WO2020163396A1 (en) | 2019-02-04 | 2020-08-13 | The General Hospital Corporation | Adenine dna base editor variants with reduced off-target rna editing |
| US20220145330A1 (en) | 2019-02-10 | 2022-05-12 | The J. David Gladstone Institutes, a testamentary trust established under the Will of J. David Glads | Modified mitochondrion and methods of use thereof |
| US20220290120A1 (en) | 2019-02-25 | 2022-09-15 | Novome Biotechnologies, Inc. | Plasmids for gene editing |
| WO2020181101A1 (en) | 2019-03-07 | 2020-09-10 | The Regents Of The University Of California | Crispr-cas effector polypeptides and methods of use thereof |
| DE112020001342T5 (de) | 2019-03-19 | 2022-01-13 | President and Fellows of Harvard College | Verfahren und Zusammensetzungen zum Editing von Nukleotidsequenzen |
| EP3979831A4 (en) * | 2019-06-06 | 2023-06-14 | Tata Consultancy Services Limited | SYSTEM AND METHODS TO COMBAT INFECTION DUE TO ANTIBIOTIC-INDUCED PATHOGENS |
| US20220380786A1 (en) * | 2019-06-06 | 2022-12-01 | Tata Consultancy Services Limited | System and method for combating mycobacterium tuberculosis infections |
| WO2020245758A2 (en) * | 2019-06-06 | 2020-12-10 | Tata Consultancy Services Limited | System and method for combating infections due to pathogens belonging to phylum proteobacteria |
| EP3979829A4 (en) * | 2019-06-06 | 2023-06-28 | Tata Consultancy Services Limited | System and method for combating pseudomonas aeruginosa and staphylococcus aureus infrctions |
| CN113939313A (zh) * | 2019-06-06 | 2022-01-14 | 电化株式会社 | 以肽核酸为基础的佐剂 |
| EP3987024A4 (en) | 2019-06-20 | 2023-11-01 | University Of Massachusetts | COMPOSITIONS AND METHODS FOR IMPROVED GENE EDITING |
| US20230000908A1 (en) * | 2019-09-11 | 2023-01-05 | Ohio State Innovation Foundation | Engineered cells and uses thereof |
| JP2022169813A (ja) * | 2019-09-30 | 2022-11-10 | 国立研究開発法人産業技術総合研究所 | Cas9ヌクレアーゼのDNA切断活性を制御する方法 |
| US20240125764A1 (en) * | 2019-11-08 | 2024-04-18 | The Regents Of The University Of California | Compositions and methods for temporal control of cell modulation |
| US20220403357A1 (en) * | 2019-11-12 | 2022-12-22 | The Broad Institute, Inc. | Small type ii cas proteins and methods of use thereof |
| BR112022009803A2 (pt) | 2019-11-20 | 2022-08-16 | Corbion Biotech Inc | Variantes de sacarose invertase |
| WO2021105191A1 (en) | 2019-11-29 | 2021-06-03 | Basf Se | Increasing resistance against fungal infections in plants |
| US20230075913A1 (en) | 2019-12-16 | 2023-03-09 | BASF Agricultural Solutions Seed US LLC | Codon-optimized cas9 endonuclease encoding polynucleotide |
| CA3161898A1 (en) | 2019-12-19 | 2021-06-24 | Basf Se | Increasing space-time-yield, carbon-conversion-efficiency and carbon substrate flexibility in the production of fine chemicals |
| BR112022011895A2 (pt) | 2019-12-20 | 2022-09-06 | Basf Se | Diminuição da toxidez de terpenos e aumento da produção potencial em microrganismos |
| WO2021151073A2 (en) * | 2020-01-24 | 2021-07-29 | The General Hospital Corporation | Unconstrained genome targeting with near-pamless engineered crispr-cas9 variants |
| US20230086782A1 (en) * | 2020-01-27 | 2023-03-23 | Eth Zurich | Base editor lacking hnh and use thereof |
| KR20220149567A (ko) | 2020-03-04 | 2022-11-08 | 바스프 에스이 | 이. 콜라이 및 바실루스에서의 발현을 위한 셔틀 벡터 |
| EP4114954A1 (en) | 2020-03-04 | 2023-01-11 | Basf Se | Method for the production of constitutive bacterial promoters conferring low to medium expression |
| WO2021188840A1 (en) * | 2020-03-19 | 2021-09-23 | Rewrite Therapeutics, Inc. | Methods and compositions for directed genome editing |
| US20230134582A1 (en) * | 2020-04-09 | 2023-05-04 | Verve Therapeutics, Inc. | Chemically modified guide rnas for genome editing with cas12b |
| JP2023525304A (ja) | 2020-05-08 | 2023-06-15 | ザ ブロード インスティテュート,インコーポレーテッド | 標的二本鎖ヌクレオチド配列の両鎖同時編集のための方法および組成物 |
| US20240060110A1 (en) | 2020-10-07 | 2024-02-22 | Basf Se | Bacillus cell with reduced lipase and/or esterase side activities |
| JP2023546597A (ja) | 2020-10-21 | 2023-11-06 | マサチューセッツ インスティテュート オブ テクノロジー | 部位特異的標的化エレメントによるプログラム可能な付加(paste)を使用した部位特異的遺伝子操作のためのシステム、方法及び組成物 |
| CA3200855A1 (en) | 2020-11-16 | 2022-05-19 | Pig Improvement Company Uk Limited | Influenza a-resistant animals having edited anp32 genes |
| TW202246497A (zh) * | 2021-01-20 | 2022-12-01 | 美商阿伯生物技術公司 | Cas12i2融合分子及其用途 |
| CN117460518A (zh) * | 2021-04-30 | 2024-01-26 | 宾夕法尼亚大学理事会 | Cd-90靶向的脂质纳米颗粒 |
| IL308806A (en) | 2021-06-01 | 2024-01-01 | Arbor Biotechnologies Inc | Gene editing systems including nuclease crisper and their uses |
| EP4359423A1 (en) | 2021-06-24 | 2024-05-01 | Basf Se | Bacillus licheniformis host cell for production of a compound of interest with increased purity |
| EP4359546A1 (en) | 2021-06-24 | 2024-05-01 | Basf Se | Improved bacillus host cell with altered rema/remb protein |
| US11884915B2 (en) | 2021-09-10 | 2024-01-30 | Agilent Technologies, Inc. | Guide RNAs with chemical modification for prime editing |
| CA3229091A1 (en) | 2021-10-26 | 2023-05-04 | Caribou Biosciences, Inc. | Exonuclease-coupled real-time endonuclease activity assay |
| WO2023081756A1 (en) | 2021-11-03 | 2023-05-11 | The J. David Gladstone Institutes, A Testamentary Trust Established Under The Will Of J. David Gladstone | Precise genome editing using retrons |
| WO2023102329A2 (en) * | 2021-11-30 | 2023-06-08 | Mammoth Biosciences, Inc. | Effector proteins and uses thereof |
| WO2023107899A2 (en) | 2021-12-07 | 2023-06-15 | Caribou Biosciences, Inc. | A method of capturing crispr endonuclease cleavage products |
| US20230279442A1 (en) | 2021-12-15 | 2023-09-07 | Versitech Limited | Engineered cas9-nucleases and method of use thereof |
| WO2023117970A1 (en) | 2021-12-20 | 2023-06-29 | Basf Se | Method for improved production of intracellular proteins in bacillus |
| WO2023141602A2 (en) | 2022-01-21 | 2023-07-27 | Renagade Therapeutics Management Inc. | Engineered retrons and methods of use |
| WO2023173062A2 (en) * | 2022-03-11 | 2023-09-14 | Intima Bioscience, Inc. | Nucleic acid editing systems, methods, and uses thereof |
| WO2023230529A1 (en) | 2022-05-26 | 2023-11-30 | Caribou Biosciences, Inc. | Cytokine-receptor fusions for immune cell stimulation |
| WO2023230316A1 (en) * | 2022-05-27 | 2023-11-30 | The Broad Institute, Inc. | Ribozyme-assisted circular rnas and compositions and methods of use there of |
| WO2023240042A1 (en) | 2022-06-06 | 2023-12-14 | Caribou Biosciences, Inc. | Treatment of autoimmune diseases with engineered immune cells |
| WO2024020346A2 (en) | 2022-07-18 | 2024-01-25 | Renagade Therapeutics Management Inc. | Gene editing components, systems, and methods of use |
| WO2024044723A1 (en) | 2022-08-25 | 2024-02-29 | Renagade Therapeutics Management Inc. | Engineered retrons and methods of use |
| WO2024073583A1 (en) | 2022-09-30 | 2024-04-04 | Caribou Biosciences, Inc. | Anti-ror1 chimeric antigen receptors (cars), car-nk cells and related methods |
Family Cites Families (149)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5034506A (en) | 1985-03-15 | 1991-07-23 | Anti-Gene Development Group | Uncharged morpholino-based polymers having achiral intersubunit linkages |
| WO1988008450A1 (en) | 1987-05-01 | 1988-11-03 | Birdwell Finlayson | Gene therapy for metabolite disorders |
| US5350689A (en) | 1987-05-20 | 1994-09-27 | Ciba-Geigy Corporation | Zea mays plants and transgenic Zea mays plants regenerated from protoplasts or protoplast-derived cells |
| US5767367A (en) | 1990-06-23 | 1998-06-16 | Hoechst Aktiengesellschaft | Zea mays (L.) with capability of long term, highly efficient plant regeneration including fertile transgenic maize plants having a heterologous gene, and their preparation |
| US5489677A (en) | 1990-07-27 | 1996-02-06 | Isis Pharmaceuticals, Inc. | Oligonucleoside linkages containing adjacent oxygen and nitrogen atoms |
| US5602240A (en) | 1990-07-27 | 1997-02-11 | Ciba Geigy Ag. | Backbone modified oligonucleotide analogs |
| FR2688514A1 (fr) | 1992-03-16 | 1993-09-17 | Centre Nat Rech Scient | Adenovirus recombinants defectifs exprimant des cytokines et medicaments antitumoraux les contenant. |
| US5625048A (en) | 1994-11-10 | 1997-04-29 | The Regents Of The University Of California | Modified green fluorescent proteins |
| US5968738A (en) | 1995-12-06 | 1999-10-19 | The Board Of Trustees Of The Leland Stanford Junior University | Two-reporter FACS analysis of mammalian cells using green fluorescent proteins |
| US20020182673A1 (en) | 1998-05-15 | 2002-12-05 | Genentech, Inc. | IL-17 homologous polypedies and therapeutic uses thereof |
| US6306610B1 (en) | 1998-09-18 | 2001-10-23 | Massachusetts Institute Of Technology | Biological applications of quantum dots |
| JP2002535995A (ja) | 1999-02-03 | 2002-10-29 | ザ チルドレンズ メディカル センター コーポレイション | 染色体標的部位での二本鎖dna切断の誘導を含む遺伝子修復 |
| JP5002105B2 (ja) | 1999-12-28 | 2012-08-15 | リボノミックス, インコーポレイテッド | 内因性のmRNAタンパク質(mRNP)複合体の単離および特徴付けの方法 |
| EP1152058A1 (en) * | 2000-05-03 | 2001-11-07 | Institut Curie | Methods and compositions for effecting homologous recombination |
| WO2002026967A2 (en) | 2000-09-25 | 2002-04-04 | Thomas Jefferson University | Targeted gene correction by single-stranded oligodeoxynucleotides |
| EP2284183A1 (en) | 2000-10-27 | 2011-02-16 | Novartis Vaccines and Diagnostics S.r.l. | Nucleic acids and proteins from streptococcus groups A and B |
| US20060253913A1 (en) | 2001-12-21 | 2006-11-09 | Yue-Jin Huang | Production of hSA-linked butyrylcholinesterases in transgenic mammals |
| BR0307383A (pt) | 2002-01-23 | 2005-04-26 | Univ Utah Res Found | Mutagênese cromossomica alvo utilizando nucleases de ramificações de zinco |
| EP1334979A1 (en) * | 2002-02-08 | 2003-08-13 | Kweek-en Researchbedrijf Agrico B.V. | Gene conferring resistance to Phytophthera infestans (late-blight) in Solanaceae |
| EP1504092B2 (en) | 2002-03-21 | 2014-06-25 | Sangamo BioSciences, Inc. | Methods and compositions for using zinc finger endonucleases to enhance homologous recombination |
| WO2003087993A2 (en) | 2002-04-09 | 2003-10-23 | Beattie Kenneth L | Oligonucleotide probes for genosensor chips |
| EP2806025B1 (en) | 2002-09-05 | 2019-04-03 | California Institute of Technology | Use of zinc finger nucleases to stimulate gene targeting |
| US20120196370A1 (en) | 2010-12-03 | 2012-08-02 | Fyodor Urnov | Methods and compositions for targeted genomic deletion |
| WO2005030999A1 (en) * | 2003-09-25 | 2005-04-07 | Dana-Farber Cancer Institute, Inc | Methods to detect lineage-specific cells |
| US7282333B2 (en) | 2003-10-20 | 2007-10-16 | Promega Corporation | Methods and compositions for nucleic acid analysis |
| US7972854B2 (en) | 2004-02-05 | 2011-07-05 | Sangamo Biosciences, Inc. | Methods and compositions for targeted cleavage and recombination |
| US7919277B2 (en) | 2004-04-28 | 2011-04-05 | Danisco A/S | Detection and typing of bacterial strains |
| US7892224B2 (en) | 2005-06-01 | 2011-02-22 | Brainlab Ag | Inverse catheter planning |
| CA2615532C (en) | 2005-07-26 | 2016-06-28 | Sangamo Biosciences, Inc. | Targeted integration and expression of exogenous nucleic acid sequences |
| DK2341149T3 (en) | 2005-08-26 | 2017-02-27 | Dupont Nutrition Biosci Aps | Use of CRISPR-associated genes (Cas) |
| US9193974B2 (en) | 2006-05-10 | 2015-11-24 | Deinove | Process for chromosomal engineering using a novel dna repair system |
| ATE530669T1 (de) | 2006-05-19 | 2011-11-15 | Danisco | Markierte mikroorganismen und entsprechende markierungsverfahren |
| CA2651499C (en) | 2006-05-25 | 2015-06-30 | Sangamo Biosciences, Inc. | Methods and compositions for ccr-5 gene inactivation |
| WO2007144770A2 (en) | 2006-06-16 | 2007-12-21 | Danisco A/S | Bacterium |
| EP2518155B1 (en) | 2006-08-04 | 2014-07-23 | Georgia State University Research Foundation, Inc. | Enzyme sensors, methods for preparing and using such sensors, and methods of detecting protease activity |
| DE102006051516A1 (de) * | 2006-10-31 | 2008-05-08 | Curevac Gmbh | (Basen-)modifizierte RNA zur Expressionssteigerung eines Proteins |
| HUE025412T2 (en) | 2007-03-02 | 2016-02-29 | Dupont Nutrition Biosci Aps | Cultures with improved phage resistance |
| WO2008124104A1 (en) | 2007-04-04 | 2008-10-16 | Network Biosystems Inc. | Integrated nucleic acid analysis |
| FR2925918A1 (fr) | 2007-12-28 | 2009-07-03 | Pasteur Institut | Typage et sous-typage moleculaire de salmonella par identification des sequences nucleotidiques variables des loci crispr |
| US8546553B2 (en) | 2008-07-25 | 2013-10-01 | University Of Georgia Research Foundation, Inc. | Prokaryotic RNAi-like system and methods of use |
| KR101759586B1 (ko) | 2008-08-22 | 2017-07-19 | 상가모 테라퓨틱스, 인코포레이티드 | 표적화된 단일가닥 분할 및 표적화된 통합을 위한 방법 및 조성물 |
| WO2010030963A2 (en) | 2008-09-15 | 2010-03-18 | Children's Medical Center Corporation | Modulation of bcl11a for treatment of hemoglobinopathies |
| US20100076057A1 (en) | 2008-09-23 | 2010-03-25 | Northwestern University | TARGET DNA INTERFERENCE WITH crRNA |
| US9404098B2 (en) | 2008-11-06 | 2016-08-02 | University Of Georgia Research Foundation, Inc. | Method for cleaving a target RNA using a Cas6 polypeptide |
| DK2362915T3 (en) | 2008-11-07 | 2017-03-27 | Dupont Nutrition Biosci Aps | CRISPR SEQUENCES OF BIFIDOBACTERIA |
| US8129149B1 (en) * | 2008-11-12 | 2012-03-06 | The United States Of America As Represented By The Secretary Of The Army | Rapid and sensitive method to measure endonuclease activity |
| PL2367938T3 (pl) | 2008-12-12 | 2014-11-28 | Dupont Nutrition Biosci Aps | Klaster genetyczny szczepów Streptococcus thermophilus mających unikalne właściwości reologiczne dla fermentacji nabiału |
| WO2010075424A2 (en) | 2008-12-22 | 2010-07-01 | The Regents Of University Of California | Compositions and methods for downregulating prokaryotic genes |
| AU2010235161B2 (en) | 2009-04-09 | 2015-01-22 | Sangamo Therapeutics, Inc. | Targeted integration into stem cells |
| SG175839A1 (en) | 2009-04-30 | 2011-12-29 | San Raffaele Centro Fond | Gene vector |
| US20120149115A1 (en) | 2009-06-11 | 2012-06-14 | Snu R&Db Foundation | Targeted genomic rearrangements using site-specific nucleases |
| WO2011011767A1 (en) | 2009-07-24 | 2011-01-27 | Sigma-Aldrich Co. | Method for genome editing |
| US20120192298A1 (en) | 2009-07-24 | 2012-07-26 | Sigma Aldrich Co. Llc | Method for genome editing |
| AU2010281705B2 (en) | 2009-07-28 | 2015-02-05 | Sangamo Therapeutics, Inc. | Methods and compositions for treating trinucleotide repeat disorders |
| CA2770312A1 (en) | 2009-08-11 | 2011-02-17 | Sangamo Biosciences, Inc. | Organisms homozygous for targeted modification |
| EP2292731B1 (en) | 2009-08-13 | 2018-04-04 | DuPont Nutrition Biosciences ApS | Method for preparing complex cultures |
| EP3118320A1 (en) | 2009-09-25 | 2017-01-18 | BASF Plant Science Company GmbH | Plants having enhanced yield-related traits and a method for making the same |
| WO2011053987A1 (en) | 2009-11-02 | 2011-05-05 | Nugen Technologies, Inc. | Compositions and methods for targeted nucleic acid sequence selection and amplification |
| WO2011064751A1 (en) | 2009-11-27 | 2011-06-03 | Basf Plant Science Company Gmbh | Chimeric endonucleases and uses thereof |
| US20110294114A1 (en) | 2009-12-04 | 2011-12-01 | Cincinnati Children's Hospital Medical Center | Optimization of determinants for successful genetic correction of diseases, mediated by hematopoietic stem cells |
| KR102110725B1 (ko) | 2009-12-10 | 2020-05-13 | 리전츠 오브 더 유니버스티 오브 미네소타 | Tal 이펙터-매개된 dna 변형 |
| US20110203012A1 (en) | 2010-01-21 | 2011-08-18 | Dotson Stanton B | Methods and compositions for use of directed recombination in plant breeding |
| AU2011215557B2 (en) | 2010-02-09 | 2016-03-10 | Sangamo Therapeutics, Inc. | Targeted genomic modification with partially single-stranded donor molecules |
| US10087431B2 (en) | 2010-03-10 | 2018-10-02 | The Regents Of The University Of California | Methods of generating nucleic acid fragments |
| EP2553122B1 (en) | 2010-03-31 | 2017-08-09 | Spartan Bioscience Inc. | Direct nucleic acid analysis |
| KR20130055588A (ko) | 2010-04-13 | 2013-05-28 | 시그마-알드리치 컴퍼니., 엘엘씨 | 이형 단백질을 발현시키기 위한 내생 프로모터의 용도 |
| SG185481A1 (en) * | 2010-05-10 | 2012-12-28 | Univ California | Endoribonuclease compositions and methods of use thereof |
| AU2011256838B2 (en) | 2010-05-17 | 2014-10-09 | Sangamo Therapeutics, Inc. | Novel DNA-binding proteins and uses thereof |
| WO2011156430A2 (en) | 2010-06-07 | 2011-12-15 | Fred Hutchinson Cancer Research Center | Generation and expression of engineered i-onui endonuclease and its homologues and uses thereof |
| WO2011159369A1 (en) * | 2010-06-14 | 2011-12-22 | Iowa State University Research Foundation, Inc. | Nuclease activity of tal effector and foki fusion protein |
| SG187075A1 (en) | 2010-07-23 | 2013-03-28 | Sigma Aldrich Co Llc | Genome editing using targeting endonucleases and single-stranded nucleic acids |
| DK2601611T3 (da) | 2010-08-02 | 2021-02-01 | Integrated Dna Tech Inc | Fremgangsmåder til forudsigelse af stabilitet og smeltetemperaturer for nukleinsyreduplekser |
| EP2630156B1 (en) | 2010-10-20 | 2018-08-22 | DuPont Nutrition Biosciences ApS | Lactococcus crispr-cas sequences |
| WO2012092259A1 (en) | 2010-12-27 | 2012-07-05 | Ibis Biosciences, Inc. | Quantitating high titer samples by digital pcr |
| WO2012105176A1 (ja) | 2011-01-31 | 2012-08-09 | 株式会社 日立ハイテクノロジーズ | 核酸検査装置 |
| KR20120096395A (ko) | 2011-02-22 | 2012-08-30 | 주식회사 툴젠 | 뉴클레아제에 의해 유전자 변형된 세포를 농축시키는 방법 |
| US9315788B2 (en) * | 2011-04-05 | 2016-04-19 | Cellectis, S.A. | Method for the generation of compact TALE-nucleases and uses thereof |
| CN102943107A (zh) | 2011-04-08 | 2013-02-27 | 蒂莫西·刘 | 分析生物样本的目标核酸序列的方法 |
| BR112013025567B1 (pt) | 2011-04-27 | 2021-09-21 | Amyris, Inc | Métodos para modificação genômica |
| WO2012164565A1 (en) | 2011-06-01 | 2012-12-06 | Yeda Research And Development Co. Ltd. | Compositions and methods for downregulating prokaryotic genes |
| US8927218B2 (en) | 2011-06-27 | 2015-01-06 | Flir Systems, Inc. | Methods and compositions for segregating target nucleic acid from mixed nucleic acid samples |
| CA2853829C (en) * | 2011-07-22 | 2023-09-26 | President And Fellows Of Harvard College | Evaluation and improvement of nuclease cleavage specificity |
| IL277027B (en) | 2011-09-21 | 2022-07-01 | Sangamo Therapeutics Inc | Methods and preparations for regulating transgene expression |
| US8450107B1 (en) | 2011-11-30 | 2013-05-28 | The Broad Institute Inc. | Nucleotide-specific recognition sequences for designer TAL effectors |
| CN104080462B (zh) | 2011-12-16 | 2019-08-09 | 塔尔盖特基因生物技术有限公司 | 用于修饰预定的靶核酸序列的组合物和方法 |
| GB201122458D0 (en) | 2011-12-30 | 2012-02-08 | Univ Wageningen | Modified cascade ribonucleoproteins and uses thereof |
| US20130196323A1 (en) | 2012-02-01 | 2013-08-01 | The University Of North Carolina At Greensboro | Methods Of Nucleic Acid Analysis |
| RU2018109507A (ru) | 2012-02-24 | 2019-02-28 | Фред Хатчинсон Кэнсер Рисерч Сентер | Композиции и способы лечения гемоглобинопатии |
| WO2013130824A1 (en) | 2012-02-29 | 2013-09-06 | Sangamo Biosciences, Inc. | Methods and compositions for treating huntington's disease |
| US9637739B2 (en) * | 2012-03-20 | 2017-05-02 | Vilnius University | RNA-directed DNA cleavage by the Cas9-crRNA complex |
| WO2013141680A1 (en) | 2012-03-20 | 2013-09-26 | Vilnius University | RNA-DIRECTED DNA CLEAVAGE BY THE Cas9-crRNA COMPLEX |
| AU2013204327B2 (en) | 2012-04-20 | 2016-09-01 | Aviagen | Cell transfection method |
| EP2841581B2 (en) | 2012-04-23 | 2023-03-08 | BASF Agricultural Solutions Seed US LLC | Targeted genome engineering in plants |
| US9523098B2 (en) | 2012-05-02 | 2016-12-20 | Dow Agrosciences Llc | Targeted modification of malate dehydrogenase |
| CA2871524C (en) | 2012-05-07 | 2021-07-27 | Sangamo Biosciences, Inc. | Methods and compositions for nuclease-mediated targeted integration of transgenes |
| US11120889B2 (en) | 2012-05-09 | 2021-09-14 | Georgia Tech Research Corporation | Method for synthesizing a nuclease with reduced off-site cleavage |
| PE20190844A1 (es) * | 2012-05-25 | 2019-06-17 | Emmanuelle Charpentier | Modulacion de transcripcion con arn de direccion a adn generico |
| US20140056868A1 (en) | 2012-05-30 | 2014-02-27 | University of Washington Center for Commercialization | Supercoiled MiniVectors as a Tool for DNA Repair, Alteration and Replacement |
| US9102936B2 (en) | 2012-06-11 | 2015-08-11 | Agilent Technologies, Inc. | Method of adaptor-dimer subtraction using a CRISPR CAS6 protein |
| EP2858486A4 (en) | 2012-06-12 | 2016-04-13 | Hoffmann La Roche | METHODS AND COMPOSITIONS FOR GENERATING ALLLETS WITH CONDITIONAL INACTIVATION |
| EP2674501A1 (en) | 2012-06-14 | 2013-12-18 | Agence nationale de sécurité sanitaire de l'alimentation,de l'environnement et du travail | Method for detecting and identifying enterohemorrhagic Escherichia coli |
| WO2013188638A2 (en) | 2012-06-15 | 2013-12-19 | The Regents Of The University Of California | Endoribonucleases and methods of use thereof |
| US20150225734A1 (en) | 2012-06-19 | 2015-08-13 | Regents Of The University Of Minnesota | Gene targeting in plants using dna viruses |
| EP2872154B1 (en) | 2012-07-11 | 2017-05-31 | Sangamo BioSciences, Inc. | Methods and compositions for delivery of biologics |
| DK3444342T3 (da) | 2012-07-11 | 2020-08-24 | Sangamo Therapeutics Inc | Fremgangsmåder og sammensætninger til behandlingen af lysosomale aflejringssygdomme |
| JP2015527889A (ja) * | 2012-07-25 | 2015-09-24 | ザ ブロード インスティテュート, インコーポレイテッド | 誘導可能なdna結合タンパク質およびゲノム撹乱ツール、ならびにそれらの適用 |
| WO2014022702A2 (en) | 2012-08-03 | 2014-02-06 | The Regents Of The University Of California | Methods and compositions for controlling gene expression by rna processing |
| UA118957C2 (uk) | 2012-08-29 | 2019-04-10 | Сангамо Біосайєнсиз, Інк. | Спосіб і композиція для лікування генетичного захворювання |
| UA119135C2 (uk) | 2012-09-07 | 2019-05-10 | ДАУ АГРОСАЙЄНСІЗ ЕлЕлСі | Спосіб отримання трансгенної рослини |
| UA118090C2 (uk) | 2012-09-07 | 2018-11-26 | ДАУ АГРОСАЙЄНСІЗ ЕлЕлСі | Спосіб інтегрування послідовності нуклеїнової кислоти, що представляє інтерес, у ген fad2 у клітині сої та специфічний для локусу fad2 білок, що зв'язується, здатний індукувати спрямований розрив |
| US9914930B2 (en) | 2012-09-07 | 2018-03-13 | Dow Agrosciences Llc | FAD3 performance loci and corresponding target site specific binding proteins capable of inducing targeted breaks |
| EP3789405A1 (en) | 2012-10-12 | 2021-03-10 | The General Hospital Corporation | Transcription activator-like effector (tale) - lysine-specific demethylase 1 (lsd1) fusion proteins |
| KR101656237B1 (ko) | 2012-10-23 | 2016-09-12 | 주식회사 툴젠 | 표적 DNA에 특이적인 가이드 RNA 및 Cas 단백질을 암호화하는 핵산 또는 Cas 단백질을 포함하는, 표적 DNA를 절단하기 위한 조성물 및 이의 용도 |
| EP2914714A4 (en) | 2012-10-30 | 2016-09-21 | Recombinetics Inc | CONTROLLING GENDER TREATMENT IN ANIMALS |
| CA2890160A1 (en) | 2012-10-31 | 2014-05-08 | Cellectis | Coupling herbicide resistance with targeted insertion of transgenes in plants |
| US20140127752A1 (en) | 2012-11-07 | 2014-05-08 | Zhaohui Zhou | Method, composition, and reagent kit for targeted genomic enrichment |
| SG10202107423UA (en) * | 2012-12-06 | 2021-08-30 | Sigma Aldrich Co Llc | Crispr-based genome modification and regulation |
| ES2883590T3 (es) | 2012-12-12 | 2021-12-09 | Broad Inst Inc | Suministro, modificación y optimización de sistemas, métodos y composiciones para la manipulación de secuencias y aplicaciones terapéuticas |
| US20140310830A1 (en) | 2012-12-12 | 2014-10-16 | Feng Zhang | CRISPR-Cas Nickase Systems, Methods And Compositions For Sequence Manipulation in Eukaryotes |
| US8993233B2 (en) | 2012-12-12 | 2015-03-31 | The Broad Institute Inc. | Engineering and optimization of systems, methods and compositions for sequence manipulation with functional domains |
| EP2931899A1 (en) * | 2012-12-12 | 2015-10-21 | The Broad Institute, Inc. | Functional genomics using crispr-cas systems, compositions, methods, knock out libraries and applications thereof |
| EP2848690B1 (en) | 2012-12-12 | 2020-08-19 | The Broad Institute, Inc. | Crispr-cas component systems, methods and compositions for sequence manipulation |
| US8697359B1 (en) | 2012-12-12 | 2014-04-15 | The Broad Institute, Inc. | CRISPR-Cas systems and methods for altering expression of gene products |
| SG10201801969TA (en) | 2012-12-12 | 2018-04-27 | Broad Inst Inc | Engineering and Optimization of Improved Systems, Methods and Enzyme Compositions for Sequence Manipulation |
| US20140242664A1 (en) | 2012-12-12 | 2014-08-28 | The Broad Institute, Inc. | Engineering of systems, methods and optimized guide compositions for sequence manipulation |
| ES2701749T3 (es) | 2012-12-12 | 2019-02-25 | Broad Inst Inc | Métodos, modelos, sistemas y aparatos para identificar secuencias diana para enzimas Cas o sistemas CRISPR-Cas para secuencias diana y transmitir resultados de los mismos |
| EP3252160B1 (en) | 2012-12-12 | 2020-10-28 | The Broad Institute, Inc. | Crispr-cas component systems, methods and compositions for sequence manipulation |
| SG11201504621RA (en) | 2012-12-17 | 2015-07-30 | Harvard College | Rna-guided human genome engineering |
| EP2938184B1 (en) | 2012-12-27 | 2018-10-31 | Keygene N.V. | Method for removing genetic linkage in a plant |
| AU2014207618A1 (en) | 2013-01-16 | 2015-08-06 | Emory University | Cas9-nucleic acid complexes and uses related thereto |
| CN103233028B (zh) | 2013-01-25 | 2015-05-13 | 南京徇齐生物技术有限公司 | 一种无物种限制无生物安全性问题的真核生物基因打靶方法及螺旋结构dna序列 |
| JP5954808B2 (ja) * | 2013-02-14 | 2016-07-20 | 国立大学法人大阪大学 | 内在性dna配列特異的結合分子を用いる特定ゲノム領域の単離方法 |
| NZ712727A (en) | 2013-03-14 | 2017-05-26 | Caribou Biosciences Inc | Compositions and methods of nucleic acid-targeting nucleic acids |
| US11332719B2 (en) | 2013-03-15 | 2022-05-17 | The Broad Institute, Inc. | Recombinant virus and preparations thereof |
| JP6980380B2 (ja) | 2013-03-15 | 2021-12-15 | ザ ジェネラル ホスピタル コーポレイション | 短縮ガイドRNA(tru−gRNA)を用いたRNA誘導型ゲノム編集の特異性の増大 |
| US9902973B2 (en) * | 2013-04-11 | 2018-02-27 | Caribou Biosciences, Inc. | Methods of modifying a target nucleic acid with an argonaute |
| CN103224947B (zh) | 2013-04-28 | 2015-06-10 | 陕西师范大学 | 一种基因打靶系统 |
| EP3730615A3 (en) | 2013-05-15 | 2020-12-09 | Sangamo Therapeutics, Inc. | Methods and compositions for treatment of a genetic condition |
| WO2014190181A1 (en) * | 2013-05-22 | 2014-11-27 | Northwestern University | Rna-directed dna cleavage and gene editing by cas9 enzyme from neisseria meningitidis |
| CA2915837A1 (en) * | 2013-06-17 | 2014-12-24 | The Broad Institute, Inc. | Optimized crispr-cas double nickase systems, methods and compositions for sequence manipulation |
| CN103343120B (zh) | 2013-07-04 | 2015-03-04 | 中国科学院遗传与发育生物学研究所 | 一种小麦基因组定点改造方法 |
| WO2015089364A1 (en) | 2013-12-12 | 2015-06-18 | The Broad Institute Inc. | Crystal structure of a crispr-cas system, and uses thereof |
| WO2015089486A2 (en) * | 2013-12-12 | 2015-06-18 | The Broad Institute Inc. | Systems, methods and compositions for sequence manipulation with optimized functional crispr-cas systems |
| BR112016013213A2 (pt) | 2013-12-12 | 2017-12-05 | Massachusetts Inst Technology | administração, uso e aplicações terapêuticas dos sistemas crispr-cas e composições para visar distúrbios e doenças usando componentes de administração de partículas |
| KR20160097327A (ko) | 2013-12-12 | 2016-08-17 | 더 브로드 인스티튜트, 인코퍼레이티드 | 유전자 산물, 구조 정보 및 유도성 모듈형 cas 효소의 발현의 변경을 위한 crispr-cas 시스템 및 방법 |
| EP3080259B1 (en) | 2013-12-12 | 2023-02-01 | The Broad Institute, Inc. | Engineering of systems, methods and optimized guide compositions with new architectures for sequence manipulation |
| WO2015134812A1 (en) * | 2014-03-05 | 2015-09-11 | Editas Medicine, Inc. | Crispr/cas-related methods and compositions for treating usher syndrome and retinitis pigmentosa |
| US20150376586A1 (en) | 2014-06-25 | 2015-12-31 | Caribou Biosciences, Inc. | RNA Modification to Engineer Cas9 Activity |
| US9512446B1 (en) * | 2015-08-28 | 2016-12-06 | The General Hospital Corporation | Engineered CRISPR-Cas9 nucleases |
-
2014
- 2014-03-12 NZ NZ712727A patent/NZ712727A/en unknown
- 2014-03-12 CN CN201480028062.1A patent/CN105980575A/zh active Pending
- 2014-03-12 KR KR1020177026013A patent/KR20170108172A/ko not_active Application Discontinuation
- 2014-03-12 CA CA2905432A patent/CA2905432C/en active Active
- 2014-03-12 BR BR112015022061A patent/BR112015022061B8/pt active IP Right Grant
- 2014-03-12 US US14/416,338 patent/US9260752B1/en active Active
- 2014-03-12 CN CN202010276646.8A patent/CN111454951A/zh active Pending
- 2014-03-12 WO PCT/US2014/023828 patent/WO2014150624A1/en active Application Filing
- 2014-03-12 SG SG11201507378UA patent/SG11201507378UA/en unknown
- 2014-03-12 EP EP19188624.1A patent/EP3620534B1/en active Active
- 2014-03-12 AU AU2014235794A patent/AU2014235794A1/en not_active Abandoned
- 2014-03-12 RU RU2015140276A patent/RU2662932C2/ru active
- 2014-03-12 DK DK19188624.1T patent/DK3620534T3/da active
- 2014-03-12 GB GB1517172.1A patent/GB2527450A/en not_active Withdrawn
- 2014-03-12 MX MX2015013057A patent/MX2015013057A/es active IP Right Grant
- 2014-03-12 ES ES14771135T patent/ES2749624T3/es active Active
- 2014-03-12 ES ES19188624T patent/ES2901396T3/es active Active
- 2014-03-12 EP EP14771135.2A patent/EP2971167B1/en active Active
- 2014-03-12 US US14/206,319 patent/US20140315985A1/en not_active Abandoned
- 2014-03-12 DK DK14771135T patent/DK2971167T3/da active
- 2014-03-12 RU RU2018122288A patent/RU2018122288A/ru not_active Application Discontinuation
- 2014-03-12 KR KR1020157028606A patent/KR101780885B1/ko active IP Right Grant
- 2014-03-12 JP JP2016501357A patent/JP2016519652A/ja active Pending
-
2015
- 2015-06-24 US US14/749,599 patent/US20160046949A1/en not_active Abandoned
- 2015-06-24 US US14/749,594 patent/US20160046962A1/en not_active Abandoned
- 2015-06-25 US US14/751,058 patent/US20160076020A1/en not_active Abandoned
- 2015-06-25 US US14/751,088 patent/US20160046963A1/en not_active Abandoned
- 2015-06-25 US US14/751,055 patent/US9410198B2/en active Active
- 2015-06-25 US US14/751,070 patent/US20160068887A1/en not_active Abandoned
- 2015-09-10 IL IL241563A patent/IL241563B/en active IP Right Grant
- 2015-09-21 ZA ZA2015/07006A patent/ZA201507006B/en unknown
- 2015-09-29 AU AU2015101418A patent/AU2015101418A6/en not_active Expired
- 2015-12-21 US US14/977,514 patent/US9909122B2/en active Active
-
2016
- 2016-01-29 HK HK16100993.9A patent/HK1213023A1/zh unknown
- 2016-05-19 US US15/159,619 patent/US9725714B2/en active Active
- 2016-05-19 US US15/159,776 patent/US10125361B2/en active Active
- 2016-07-05 US US15/202,518 patent/US9803194B2/en active Active
- 2016-11-04 US US15/344,487 patent/US11312953B2/en active Active
-
2017
- 2017-01-09 AU AU2017200138A patent/AU2017200138A1/en not_active Abandoned
- 2017-07-26 US US15/660,906 patent/US9809814B1/en active Active
- 2017-12-27 JP JP2017250680A patent/JP2018075026A/ja active Pending
-
2018
- 2018-02-23 US US15/904,285 patent/US20180237770A1/en active Pending
-
2021
- 2021-02-12 JP JP2021020373A patent/JP7008850B2/ja active Active
- 2021-08-20 US US17/407,928 patent/US20220282244A1/en active Pending
Also Published As
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| ES2901396T3 (es) | Composiciones y métodos de ácidos nucleicos dirigidos a ácido nucleico | |
| EP2984175B1 (en) | Dna-guided dna interference by a prokaryotic argonaute |