ES2834741T3 - Anticuerpo anti-NR10 y uso del mismo - Google Patents
Anticuerpo anti-NR10 y uso del mismo Download PDFInfo
- Publication number
- ES2834741T3 ES2834741T3 ES16172648T ES16172648T ES2834741T3 ES 2834741 T3 ES2834741 T3 ES 2834741T3 ES 16172648 T ES16172648 T ES 16172648T ES 16172648 T ES16172648 T ES 16172648T ES 2834741 T3 ES2834741 T3 ES 2834741T3
- Authority
- ES
- Spain
- Prior art keywords
- seq
- amino acid
- antibody
- acid sequence
- antibodies
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2866—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against receptors for cytokines, lymphokines, interferons
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/395—Antibodies; Immunoglobulins; Immune serum, e.g. antilymphocytic serum
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P29/00—Non-central analgesic, antipyretic or antiinflammatory agents, e.g. antirheumatic agents; Non-steroidal antiinflammatory drugs [NSAID]
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P37/00—Drugs for immunological or allergic disorders
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N33/00—Investigating or analysing materials by specific methods not covered by groups G01N1/00 - G01N31/00
- G01N33/48—Biological material, e.g. blood, urine; Haemocytometers
- G01N33/50—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing
- G01N33/68—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing involving proteins, peptides or amino acids
- G01N33/6863—Cytokines, i.e. immune system proteins modifying a biological response such as cell growth proliferation or differentiation, e.g. TNF, CNF, GM-CSF, lymphotoxin, MIF or their receptors
- G01N33/6869—Interleukin
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/505—Medicinal preparations containing antigens or antibodies comprising antibodies
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/20—Immunoglobulins specific features characterized by taxonomic origin
- C07K2317/24—Immunoglobulins specific features characterized by taxonomic origin containing regions, domains or residues from different species, e.g. chimeric, humanized or veneered
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/56—Immunoglobulins specific features characterized by immunoglobulin fragments variable (Fv) region, i.e. VH and/or VL
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/56—Immunoglobulins specific features characterized by immunoglobulin fragments variable (Fv) region, i.e. VH and/or VL
- C07K2317/565—Complementarity determining region [CDR]
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/56—Immunoglobulins specific features characterized by immunoglobulin fragments variable (Fv) region, i.e. VH and/or VL
- C07K2317/567—Framework region [FR]
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/76—Antagonist effect on antigen, e.g. neutralization or inhibition of binding
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/90—Immunoglobulins specific features characterized by (pharmaco)kinetic aspects or by stability of the immunoglobulin
- C07K2317/92—Affinity (KD), association rate (Ka), dissociation rate (Kd) or EC50 value
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N2333/00—Assays involving biological materials from specific organisms or of a specific nature
- G01N2333/435—Assays involving biological materials from specific organisms or of a specific nature from animals; from humans
- G01N2333/705—Assays involving receptors, cell surface antigens or cell surface determinants
- G01N2333/715—Assays involving receptors, cell surface antigens or cell surface determinants for cytokines; for lymphokines; for interferons
- G01N2333/7155—Assays involving receptors, cell surface antigens or cell surface determinants for cytokines; for lymphokines; for interferons for interleukins [IL]
Abstract
Un anticuerpo anti-NR10 que tiene una actividad neutralizante, en el que el anticuerpo anti-NR10 es uno cualquiera de: (1) un anticuerpo que comprende una región variable de cadena pesada que comprende CDR1 que comprende la secuencia de aminoácidos de SEQ ID NO: 1, CDR2 que comprende la secuencia de aminoácidos de SEQ ID NO: 2 y CDR3 que comprende la secuencia de aminoácidos de SEQ ID NO: 3, y que comprende una región variable de cadena ligera que comprende CDR1 que comprende la secuencia de aminoácidos de SEQ ID NO: 5, CDR2 que comprende la secuencia de aminoácidos de SEQ ID NO: 6 y CDR3 que comprende la secuencia de aminoácidos de SEQ ID NO: 7; (2) un anticuerpo que comprende la región variable de cadena pesada de SEQ ID NO: 4 y que comprende la región variable de cadena ligera de SEQ ID NO: 8; y (3) un anticuerpo que se une al mismo epítopo que un epítopo al que se une el anticuerpo de (1) o (2), y compite con el anticuerpo de (1) o (2) por unirse a NR10.
Description
DESCRIPCIÓN
Anticuerpo anti-NR10 y uso del mismo
La presente descripción se refiere a anticuerpos anti-NR10, y a composiciones farmacéuticas que comprenden un anticuerpo anti-NR10.
Muchas citocinas se conocen como factores humorales implicados en el crecimiento y la diferenciación de diversos tipos de células, o en la activación de las funciones de las células maduras diferenciadas. Las células estimuladas con citocinas producen diferentes tipos de citocinas, y de ese modo se forman redes de múltiples citocinas en el organismo. La homeostasis biológica se mantiene mediante un equilibrio delicado de la regulación mutua entre las citocinas de estas redes. Se cree que muchas enfermedades inflamatorias son el resultado de un defecto de tales redes de citocinas. Así, la terapia anti-citocinas basada en anticuerpos monoclonales está atrayendo mucha atención. Por ejemplo, se ha demostrado que los anticuerpos anti-TNF y los anticuerpos anti-receptor de IL-6 son muy eficaces clínicamente. Por otra parte, hay muchos ejemplos de fallos en los que no se produjeron efectos terapéuticos cuando se bloqueó solamente una única citocina, tal como IL-4, debido a la activación de rutas compensadoras en condiciones patológicas reales.
Los presentes inventores han conseguido aislar un nuevo receptor de citocinas NR10, que fue sumamente homólogo a gp130, un receptor para la transducción de señales de IL-6 (Documento de Patente 1). NR10 forma un heterodímero con el receptor de oncoestatina M (OSMR) y funciona como receptor de IL-31 (Documento no de Patente 1). Con respecto a IL-31, se ha informado que los ratones transgénicos que sobreexpresan IL-31 desarrollan espontáneamente dermatitis prurítica (Documento de Patente 2).
Se ha sugerido el uso de antagonistas de IL-31 RA en la detección, diagnóstico y tratamiento de enfermedades, en particular, enfermedades que tienen una alta correlación de antígeno linfocitario cutáneo (CLA) (Documento de patente 3)
Los anticuerpos que se unen a NR10 e inhiben la unión entre NR10 e IL-31 pueden ser eficaces en el tratamiento de enfermedades inflamatorias. Para uso clínico, es necesario que los anticuerpos anti-NR10 tengan una baja inmunogenicidad. Además, para conseguir efectos terapéuticos elevados, se desean anticuerpos con una actividad intensa de unión o neutralización hacia NR10.
Los documentos de la técnica anterior de la presente invención se describen a continuación.
Documento de Patente 1: WO00/75314
Documento de Patente 2: WO03/060090
Documento de Patente 5: WO 2006/088855 A1
Documento no de Patente 1: IL-31 is associated with cutaneous lymphocyte antigen-positive skin homing T cells in patients with atopic dermatitis., J Allergy Clin Immunol. Feb de 2006; 117(2): 418-25
[Problemas que resuelve la invención]
La presente invención se llevó a cabo en vista de las circunstancias descritas anteriormente. Un objetivo de la presente descripción es proporcionar anticuerpos anti-NR10 y composiciones farmacéuticas que comprenden un anticuerpo anti-NR10.
[Medios para resolver los problemas]
La invención se refiere a las realizaciones como se definen en las reivindicaciones. Un aspecto de la invención se refiere a un anticuerpo anti-NR10 que tiene actividad neutralizante, en donde el anticuerpo anti-NR10 es uno cualquiera de:
(1) un anticuerpo que comprendeID NO una región variable de ID NOID NOID NOregión variable de la cadena pesada que comprende una CDR1 que comprende la secuencia de aminoácidos de SEQ ID NO: 1, una CDR2 que comprende la secuencia de aminoácidos de SEQ ID NO: 2, y una CDR3 que comprende la secuencia de aminoácidos de SEQ ID NO: 3, y que comprende una región variable de la cadena ligera que comprende una CDR1 que comprende la secuencia de aminoácidos de SEQ ID NO: 5, una CDR2 que comprende la secuencia de aminoácidos de SEQ ID NO: 6, y una CDR3 que comprende la secuencia de aminoácidos de SEQ ID NO: 7;
(2) un anticuerpo que comprende la región variable de cadena pesada de SEQ ID NO: 4 y que comprende la región variable de cadena ligera de SEQ ID NO: 8; y
(3) un anticuerpo que se une al mismo epítopo que un epítopo al que se une el anticuerpo de (1) o (2), y compite con el anticuerpo de (1) o (2) por unirse a NR10.
La invención también se refiere a un anticuerpo anti-NR10 que tiene actividad neutralizante, en donde el anticuerpo anti-NR10 es cualquiera de:
(1) un anticuerpo que comprende una región variable de cadena pesada que comprende CDR1 que comprende la secuencia de aminoácidos de SEQ ID NO: 17, CDR2 que comprende la secuencia de aminoácidos de SEQ ID NO: 18 y CDR3 que comprende la secuencia de aminoácidos de SEQ ID NO: 19, y que comprende una región variable de cadena ligera que comprende CDR1 que comprende la secuencia de aminoácidos de SEQ ID NO: 21, CDR2 que comprende la secuencia de aminoácidos de SEQ ID NO: 22, y CDR3 que comprende la secuencia de aminoácidos de SEQ ID NO: 23;
(2) un anticuerpo que comprende la región variable de cadena pesada de SEQ ID NO: 20 y que comprende la región variable de cadena ligera de SEQ ID NO: 24; y
(3) un anticuerpo que se une al mismo epítopo que un epítopo al que se une el anticuerpo de (1) o (2), y compite con el anticuerpo de (1) o (2) por unirse a NR10.
Según la invención, el anticuerpo anti-NR10 tal como se define anteriormente puede ser un anticuerpo humanizado. La invención también se refiere a una composición farmacéutica que comprende el anticuerpo anti-NR10 como se definió anteriormente. Un aspecto de la invención se refiere a esta composición farmacéutica para su uso en el tratamiento de una enfermedad inflamatoria.
La invención proporciona además el uso del anticuerpo anti-NR10 como se definió anteriormente en la preparación de un agente terapéutico para una enfermedad inflamatoria.
Los presentes inventores llevaron a cabo estudios especializados para alcanzar el objetivo descrito anteriormente. Los presentes inventores consiguieron obtener anticuerpos anti-NR10 que tuvieron una actividad neutralizante eficaz hacia NR10. Además, los presentes inventores consiguieron humanizar los anticuerpos a la vez que se mantenía su actividad. Los presentes inventores también produjeron con éxito anticuerpos con una farmacocinética mejorada, una actividad incrementada de unión al antígeno, una estabilidad mejorada, y/o un riesgo reducido de inmunogenicidad. Estos anticuerpos son útiles como agentes terapéuticos para enfermedades inflamatorias.
La presente descripción se refiere a anticuerpos anti-NR10, y a composiciones farmacéuticas que comprenden un anticuerpo anti-NR10. De manera más específica, la presente descripción incluye:
[1] un anticuerpo que reconoce el dominio 1 de NR10;
[2] el anticuerpo de [1], que tiene una actividad neutralizante;
[3] el anticuerpo de [1] o [2], que es un anticuerpo humanizado;
[4] un anticuerpo anti-NR10 que es cualquiera de:
(1) un anticuerpo que comprende una región variable de la cadena pesada que comprende una CDR1 que comprende la secuencia de aminoácidos de SEQ ID NO: 1, una CDR2 que comprende la secuencia de aminoácidos de SEQ ID NO: 2, y una CDR3 que comprende la secuencia de aminoácidos de SEQ ID NO: 3; (2) un anticuerpo que comprende la región variable de la cadena pesada de SEQ ID NO: 4;
(3) un anticuerpo que comprende una región variable de la cadena ligera que comprende una CDR1 que comprende la secuencia de aminoácidos de SEQ ID NO: 5, una CDR2 que comprende la secuencia de aminoácidos de SEQ ID NO: 6, y una CDR3 que comprende la secuencia de aminoácidos de SEQ ID NO: 7; (4) un anticuerpo que comprende la región variable de la cadena ligera de SEQ ID NO: 8;
(5) un anticuerpo que comprende la región variable de la cadena pesada de (1) y la región variable de la cadena ligera de (3);
(6) un anticuerpo que comprende la región variable de la cadena pesada de (2) y la región variable de la cadena ligera de (4);
(7) un anticuerpo en el que uno o más aminoácidos están sustituidos, delecionados, añadidos, y/o insertados en el anticuerpo de cualquiera de (1) a (6), que tiene una actividad equivalente a la del anticuerpo de cualquiera de (1) a (6); y
(8) un anticuerpo que se une al mismo epítopo que un epítopo unido por el anticuerpo de cualquiera de (1) a (7);
[5] un anticuerpo anti-NR10 que es cualquiera de:
(1) un anticuerpo que comprende una región variable de la cadena pesada que comprende una CDR1 que
comprende la secuencia de aminoácidos de SEQ ID NO: 9, una CDR2 que comprende la secuencia de aminoácidos de SEQ ID NO: 10, y una CDR3 que comprende la secuencia de aminoácidos de SEQ ID NO: 11; (2) un anticuerpo que comprende la región variable de la cadena pesada de SEQ ID NO: 12;
(3) un anticuerpo que comprende una región variable de la cadena ligera que comprende una CDR1 que comprende la secuencia de aminoácidos de SEQ ID NO: 13, una CDR2 que comprende la secuencia de aminoácidos de SEQ ID NO: 14, y una CDR3 que comprende la secuencia de aminoácidos de SEQ ID NO: 15; (4) un anticuerpo que comprende la región variable de la cadena ligera de SEQ ID NO: 16;
(5) un anticuerpo que comprende la región variable de la cadena pesada de (1) y la región variable de la cadena ligera de (3);
(6) un anticuerpo que comprende la región variable de la cadena pesada de (2) y la región variable de la cadena ligera de (4);
(7) un anticuerpo en el que uno o más aminoácidos están sustituidos, delecionados, añadidos, y/o insertados en el anticuerpo de cualquiera de (1) a (6), que tiene una actividad equivalente a la del anticuerpo de cualquiera de (1) a (6); y
(8) un anticuerpo que se une al mismo epítopo que un epítopo unido por el anticuerpo de cualquiera de (1) a (7);
[6] un anticuerpo anti-NR10 que es cualquiera de:
(1) un anticuerpo que comprende una región variable de la cadena pesada que comprende una CDR1 que comprende la secuencia de aminoácidos de SEQ ID NO: 17, una CDR2 que comprende la secuencia de aminoácidos de SEQ ID NO: 18, y una CDR3 que comprende la secuencia de aminoácidos de SEQ ID NO: 19; (2) un anticuerpo que comprende la región variable de la cadena pesada de SEQ ID NO: 20;
(3) un anticuerpo que comprende una región variable de la cadena ligera que comprende una CDR1 que comprende la secuencia de aminoácidos de SEQ ID NO: 21, una CDR2 que comprende la secuencia de aminoácidos de SEQ ID NO: 22, y una CDR3 que comprende la secuencia de aminoácidos de SEQ ID NO: 23; (4) un anticuerpo que comprende la región variable de la cadena ligera de SEQ ID NO: 24;
(5) un anticuerpo que comprende la región variable de la cadena pesada de (1) y la región variable de la cadena ligera de (3);
(6) un anticuerpo que comprende la región variable de la cadena pesada de (2) y la región variable de la cadena ligera de (4);
(7) un anticuerpo en el que uno o más aminoácidos están sustituidos, delecionados, añadidos, y/o insertados en el anticuerpo de cualquiera de (1) a (6), que tiene una actividad equivalente a la del anticuerpo de cualquiera de (1) a (6); y
(8) un anticuerpo que se une al mismo epítopo que un epítopo unido por el anticuerpo de cualquiera de (1) a (7);
[7] un anticuerpo anti-NR10 que es cualquiera de:
(1) un anticuerpo que comprende una región variable de la cadena pesada que comprende una CDR1 que comprende la secuencia de aminoácidos de SEQ ID NO: 25, una CDR2 que comprende la secuencia de aminoácidos de SEQ ID NO: 26, y una CDR3 que comprende la secuencia de aminoácidos de SEQ ID NO: 27; (2) un anticuerpo que comprende la región variable de la cadena pesada de SEQ ID NO: 28;
(3) un anticuerpo que comprende una región variable de la cadena ligera que comprende una CDR1 que comprende la secuencia de aminoácidos de SEQ ID NO: 29, una CDR2 que comprende la secuencia de aminoácidos de SEQ ID NO: 30, y una CDR3 que comprende la secuencia de aminoácidos de SEQ ID NO: 31; (4) un anticuerpo que comprende la región variable de la cadena ligera de SEQ ID NO: 32;
(5) un anticuerpo que comprende la región variable de la cadena pesada de (1) y la región variable de la cadena ligera de (3);
(6) un anticuerpo que comprende la región variable de la cadena pesada de (2) y la región variable de la cadena ligera de (4);
(7) un anticuerpo en el que uno o más aminoácidos están sustituidos, delecionados, añadidos, y/o insertados en
el anticuerpo de cualquiera de (1) a (6), que tiene una actividad equivalente a la del anticuerpo de cualquiera de (1) a (6); y
(8) un anticuerpo que se une al mismo epítopo que un epítopo unido por el anticuerpo de cualquiera de (1) a (7);
[8] un anticuerpo o región variable de un anticuerpo que es cualquiera de:
(1) una región variable de la cadena pesada que comprende una CDR1 de SEQ ID NO: 196, una CDR2 de SEQ ID NO: 197, y una CDR3 de SEQ ID NO: 11 (H17);
(2) una región variable de la cadena pesada que comprende una CDR1 de SEQ ID NO: 176, una CDR2 de SEQ ID NO: 197, y una CDR3 de SEQ ID NO: 11 (H19);
(3) una región variable de la cadena pesada que comprende una CDR1 de SEQ ID NO: 196, una CDR2 de SEQ ID NO: 197, y una CDR3 de SEQ ID NO: 184 (H28, H42);
(4) una región variable de la cadena pesada que comprende una CDR1 de SEQ ID NO: 9, una CDR2 de SEQ ID NO: 197, y una CDR3 de SEQ ID NO: 184 (H30, H44);
(5) una región variable de la cadena pesada que comprende una CDR1 de SEQ ID NO: 176, una CDR2 de SEQ ID NO: 197, una CDR3 de SEQ ID NO: 184 (H34, H46);
(6) una región variable de la cadena pesada que comprende una CDR1 de SEQ ID NO: 9, una CDR2 de SEQ ID NO: 198, y una CDR3 de SEQ ID NO: 184 (H57, H78);
(7) una región variable de la cadena pesada que comprende una CDR1 de SEQ ID NO: 176, una CDR2 de SEQ ID NO: 198, y una CDR3 de SEQ ID NO: 184 (H71, H92);
(8) una región variable de la cadena pesada que comprende una CDR1 de SEQ ID NO: 9, una CDR2 de SEQ ID NO: 199, y una CDR3 de SEQ ID NO: 184 (H97, H98);
(9) una región variable de la cadena ligera que comprende una CDR1 de SEQ ID NO: 200, una CDR2 de SEQ ID NO: 170, y una CDR3 de SEQ ID NO: 193 (L11);
(10) una región variable de la cadena ligera que comprende una CDR1 de SEQ ID NO: 201, una CDR2 de SEQ ID NO: 170, y una CDR3 de SEQ ID NO: 193 (L12);
(11) una región variable de la cadena ligera que comprende una CDR1 de SEQ ID NO: 202, una CDR2 de SEQ ID NO: 170, y una CDR3 de SEQ ID NO: 193 (L17);
(12) una región variable de la cadena ligera que comprende una CDR1 de SEQ ID NO: 203, una CDR2 de SEQ ID NO: 170, y una CDR3 de SEQ ID NO: 193 (L50);
(13) un anticuerpo que comprende la región variable de la cadena pesada de (3) y la región variable de la cadena ligera de (11);
(14) un anticuerpo que comprende la región variable de la cadena pesada de (4) y la región variable de la cadena ligera de (11);
(15) un anticuerpo que comprende la región variable de la cadena pesada de (5) y la región variable de la cadena ligera de (11);
(16) un anticuerpo que comprende la región variable de la cadena pesada de (6) y la región variable de la cadena ligera de (11);
(17) un anticuerpo que comprende la región variable de la cadena pesada de (7) y la región variable de la cadena ligera de (11);
(18) un anticuerpo que comprende la región variable de la cadena pesada de (8) y la región variable de la cadena ligera de (12);
(19) un anticuerpo en el que uno o más aminoácidos están sustituidos, delecionados, añadidos, y/o insertados en el anticuerpo de cualquiera de (13) a (18), que tiene una actividad equivalente a la del anticuerpo de cualquiera de (13) a (18); y
(20) un anticuerpo que se une al mismo epítopo que un epítopo unido por el anticuerpo de cualquiera de (13) a (18);
[9] un anticuerpo o región variable de un anticuerpo que es cualquiera de:
(1) una región variable de la cadena pesada que comprende la secuencia de aminoácidos de SEQ ID NO: 204 (H17);
(2) una región variable de la cadena pesada que comprende la secuencia de aminoácidos de SEQ ID NO: 205 (H19); (3) una región variable de la cadena pesada que comprende la secuencia de aminoácidos de SEQ ID NO: 206 (H28); (4) una región variable de la cadena pesada que comprende la secuencia de aminoácidos de SEQ ID NO: 207 (H30); (5) una región variable de la cadena pesada que comprende la secuencia de aminoácidos de SEQ ID NO: 208 (H34), (6) una región variable de la cadena pesada que comprende la secuencia de aminoácidos de SEQ ID NO: 209 (H42); (7) una región variable de la cadena pesada que comprende la secuencia de aminoácidos de SEQ ID NO: 210 (H44); (8) una región variable de la cadena pesada que comprende la secuencia de aminoácidos de SEQ ID NO: 211 (H46); (9) una región variable de la cadena pesada que comprende la secuencia de aminoácidos de SEQ ID NO: 212 (H57); (10) una región variable de la cadena pesada que comprende la secuencia de aminoácidos de SEQ ID NO: 213 (H71); (11) una región variable de la cadena pesada que comprende la secuencia de aminoácidos de SEQ ID NO: 214 (H78); (12) una región variable de la cadena pesada que comprende la secuencia de aminoácidos de SEQ ID NO: 215 (H92); (13) una región variable de la cadena pesada que comprende la secuencia de aminoácidos de SEQ ID NO: 216 (H97); (14) una región variable de la cadena pesada que comprende la secuencia de aminoácidos de SEQ ID NO: 217 (H98); (15) una región variable de la cadena ligera que comprende la secuencia de aminoácidos de SEQ ID NO: 218 (L11); (16) una región variable de la cadena ligera que comprende la secuencia de aminoácidos de SEQ ID NO: 219 (L12); (17) una región variable de la cadena ligera que comprende la secuencia de aminoácidos de SEQ ID NO: 220 (L17); (18) una región variable de la cadena ligera que comprende la secuencia de aminoácidos de SEQ ID NO: 221 (L50); (19) un anticuerpo que comprende la región variable de la cadena pesada de (3) y la región variable de la cadena ligera de (17) (H28L17);
(20) un anticuerpo que comprende la región variable de la cadena pesada de (4) y la región variable de la cadena ligera de (17) (H30L17);
(21) un anticuerpo que comprende la región variable de la cadena pesada de (5) y la región variable de la cadena ligera de (17) (H34L17);
(22) un anticuerpo que comprende la región variable de la cadena pesada de (6) y la región variable de la cadena ligera de (17) (H42L17);
(23) un anticuerpo que comprende la región variable de la cadena pesada de (7) y la región variable de la cadena ligera de (17) (H44L17);
(24) un anticuerpo que comprende la región variable de la cadena pesada de (8) y la región variable de la cadena ligera de (17) (H46L17);
(25) un anticuerpo que comprende la región variable de la cadena pesada de (9) y la región variable de la cadena ligera de (17) (H57L17);
(26) un anticuerpo que comprende la región variable de la cadena pesada de (10) y la región variable de la cadena ligera de (17) (H71L17);
(27) un anticuerpo que comprende la región variable de la cadena pesada de (11) y la región variable de la cadena ligera de (17) (H78L17);
(28) un anticuerpo que comprende la región variable de la cadena pesada de (12) y la región variable de la cadena ligera de (17) (H92L17);
(29) un anticuerpo que comprende la región variable de la cadena pesada de (13) y la región variable de la cadena ligera de (18) (H97L50);
(30) un anticuerpo que comprende la región variable de la cadena pesada de (14) y la región variable de la cadena ligera de (18) (H98L50),
(31) un anticuerpo en el que uno o más aminoácidos están sustituidos, delecionados, añadidos, y/o insertados en
el anticuerpo de cualquiera de (19) a (30), que tiene una actividad equivalente a la del anticuerpo de cualquiera de (19) a (30); y
(32) un anticuerpo que se une al mismo epítopo que un epítopo unido por el anticuerpo de cualquiera de (19) a (30);
[10] el anticuerpo anti-NR10 de cualquiera de [4] a [9], que es un anticuerpo humanizado;
[11] un anticuerpo, cadena pesada de anticuerpo, o cadena ligera de anticuerpo, que es cualquiera de:
(1) una cadena pesada que comprende la secuencia de aminoácidos de SEQ ID NO: 222 (H17);
(2) una cadena pesada que comprende la secuencia de aminoácidos de SEQ ID NO: 223 (H19);
(3) una cadena pesada que comprende la secuencia de aminoácidos de SEQ ID NO: 224 (H28);
(4) una cadena pesada que comprende la secuencia de aminoácidos de SEQ ID NO: 225 (H30);
(5) una cadena pesada que comprende la secuencia de aminoácidos de SEQ ID NO: 226 (H34);
(6) una cadena pesada que comprende la secuencia de aminoácidos de SEQ ID NO: 227 (H42);
(7) una cadena pesada que comprende la secuencia de aminoácidos de SEQ ID NO: 228 (H44);
(8) una cadena pesada que comprende la secuencia de aminoácidos de SEQ ID NO: 229 (H46);
(9) una cadena pesada que comprende la secuencia de aminoácidos de SEQ ID NO: 230 (H57);
(10) una cadena pesada que comprende la secuencia de aminoácidos de SEQ ID NO: 231 (H71);
(11) una cadena pesada que comprende la secuencia de aminoácidos de SEQ ID NO: 232 (H78);
(12) una cadena pesada que comprende la secuencia de aminoácidos de SEQ ID NO: 233 (H92);
(13) una cadena pesada que comprende la secuencia de aminoácidos de SEQ ID NO: 234 (H97);
(14) una cadena pesada que comprende la secuencia de aminoácidos de SEQ ID NO: 235 (H98);
(15) una cadena ligera que comprende la secuencia de aminoácidos de SEQ ID NO: 236 (L11);
(16) una cadena ligera que comprende la secuencia de aminoácidos de SEQ ID NO: 237 (L12);
(17) una cadena ligera que comprende la secuencia de aminoácidos de SEQ ID NO: 238 (L17);
(18) una cadena ligera que comprende la secuencia de aminoácidos de SEQ ID NO: 239 (L50);
(19) un anticuerpo que comprende la cadena pesada de (3) y la cadena ligera de (17) (H28L17);
(20) un anticuerpo que comprende la cadena pesada de (4) y la cadena ligera de (17) (H30L17);
(21) un anticuerpo que comprende la cadena pesada de (5) y la cadena ligera de (17) (H34L17);
(22) un anticuerpo que comprende la cadena pesada de (6) y la cadena ligera de (17) (H42L17);
(23) un anticuerpo que comprende la cadena pesada de (7) y la cadena ligera de (17) (H44L17);
(24) un anticuerpo que comprende la cadena pesada de (8) y la cadena ligera de (17) (H46L17);
(25) un anticuerpo que comprende la cadena pesada de (9) y la cadena ligera de (17) (H57L17);
(26) un anticuerpo que comprende la cadena pesada de (10) y la cadena ligera de (17) (H71L17);
(27) un anticuerpo que comprende la cadena pesada de (11) y la cadena ligera de (17) (H78L17);
(28) un anticuerpo que comprende la cadena pesada de (12) y la cadena ligera de (17) (H92L17);
(29) un anticuerpo que comprende la cadena pesada de (13) y la cadena ligera de (18) (H97L50);
(30) un anticuerpo que comprende la cadena pesada de (14) y la cadena ligera de (18) (H98L50);
(31) un anticuerpo en el que uno o más aminoácidos están sustituidos, delecionados, añadidos, y/o insertados en el anticuerpo de cualquiera de (19) a (30), que tiene una actividad equivalente a la del anticuerpo de cualquiera de (19) a (30); y
(32) un anticuerpo que se une al mismo epítopo que un epítopo unido por el anticuerpo de cualquiera de (19) a (30);
[12] una composición farmacéutica que comprende el anticuerpo de cualquiera de [1] a [11];
[13] la composición farmacéutica de [12], que es un agente para tratar una enfermedad inflamatoria;
[14] un método para tratar o prevenir una enfermedad inflamatoria, que comprende la etapa de administrar el anticuerpo de cualquiera de [1] a [11]; y
[15] el uso del anticuerpo de cualquiera de [1] a [11] en la preparación de un agente terapéutico para una enfermedad inflamatoria.
Descripción breve de los dibujos
La Fig. 1 muestra las secuencias de aminoácidos de las regiones variables de las cadenas pesadas de los anticuerpos de ratón NS18, NS22, NS23, y NS33.
La Fig. 2 muestra las secuencias de aminoácidos de las regiones variables de las cadenas ligeras de los anticuerpos de ratón NS18, NS22, NS23, y NS33.
La Fig. 3 es un gráfico que muestra la inhibición del crecimiento de células hNR10/hOSMR/BaF3 mediante sobrenadantes de cultivos de hibridomas.
La Fig. 4 es un gráfico que muestra la inhibición del crecimiento de células cynNR10/cynOSMR/BaF3 mediante sobrenadantes de cultivos de hibridomas.
La Fig. 5  n gráfico que muestra el estudio de la actividad de NS22 quimérico (BaF).
n gráfico que muestra el estudio de la actividad de NS22 quimérico (BaF).
La Fig. 6 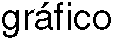 n gráfico que muestra el estudio de la actividad de NS22 quimérico (DU-145). La Fig. 7
n gráfico que muestra el estudio de la actividad de NS22 quimérico (DU-145). La Fig. 7  n gráfico que muestra el estudio de la competición de NS22 quimérico con IL-31. La Fig. 8
n gráfico que muestra el estudio de la competición de NS22 quimérico con IL-31. La Fig. 8  n gráfico que muestra la actividad de unión competitiva a NR10 de anticuerpos anti-NR10. La Fig. 9 es un grupo de gráficos que muestran el estudio de la competición de NS22 humanizado (H0L0) con IL-31. La Fig. 10 muestra el efecto de la región constante del anticuerpo anti-NR10 humanizado H0L0 sobre la heterogeneidad estudiada mediante cromatografía de intercambio catiónico.
n gráfico que muestra la actividad de unión competitiva a NR10 de anticuerpos anti-NR10. La Fig. 9 es un grupo de gráficos que muestran el estudio de la competición de NS22 humanizado (H0L0) con IL-31. La Fig. 10 muestra el efecto de la región constante del anticuerpo anti-NR10 humanizado H0L0 sobre la heterogeneidad estudiada mediante cromatografía de intercambio catiónico.
La Fig. 11 es un grupo de gráficos que muestran el estudio de la competición de mutantes del anticuerpo anti-NR10 humanizado de los cuales se reduce el punto isoeléctrico de las regiones variables sin una pérdida significativa de la unión a NR10, con IL-31.
La Fig. 12 muestra el efecto de la región constante del anticuerpo anti-receptor de IL-6 sobre la heterogeneidad estudiada mediante cromatografía de intercambio catiónico.
La Fig. 13 muestra el efecto de la región constante del anticuerpo anti-receptor de IL-6 sobre el pico de desnaturalización estudiado mediante DSC.
La Fig. 14 muestra el efecto de la región constante nueva M14 sobre la heterogeneidad en un anticuerpo anti receptor de IL-6, estudiada mediante cromatografía de intercambio catiónico.
La Fig. 15 muestra el efecto de la región constante nueva M58 sobre la heterogeneidad en un anticuerpo anti receptor de IL-6, estudiada mediante cromatografía de intercambio catiónico.
La Fig. 16 muestra el efecto de la región constante nueva M58 sobre el pico de desnaturalización en un anticuerpo anti-receptor de IL-6, estudiado mediante DSC.
La Fig. 17 muestra el resultado de ensayar la retención de huPM1-IgG1 y huPM1-M58 en el plasma de ratones transgénicos para FcRn humano.
La Fig. 18 muestra la actividad biológica de cada anticuerpo estudiada mediante el uso de BaF/NR10.
La Fig. 19 muestra el análisis de muestras aceleradas térmicamente (línea discontinua) y no aceleradas (línea continua) de cada anticuerpo modificado mediante cromatografía de intercambio catiónico para comparar la generación de productos de degradación antes y después de la aceleración térmica. La flecha indica la posición del pico del componente básico que se alteró.
La Fig. 20 es un grupo de gráficos que muestran el estudio (BaF) de la actividad de cada variante.
La Fig. 21 es un gráfico que muestra el estudio (BaF) de la actividad de Ha401 La402 y H0L0.
La Fig. 22 es un gráfico que muestra el estudio (BaF) de la actividad de H17L11 y H0L0.
La Fig. 23 es un gráfico que muestra el estudio (BaF) de la actividad de H19L12 y H0L0.
La Fig. 24 es un gráfico que muestra la actividad biológica de H0L12 y H0L17 estudiada mediante el uso de BaF/NR10.
La Fig. 25-1 es un grupo de gráficos que muestran el estudio (BaF) de la actividad de cada variante.
La Fig. 25-2 es una continuación de la Fig. 25-1.
La Fig. 26 es un diagrama esquemático para el ECD de NR10 de tipo natural y quimérico humano/de ratón.
La Fig. 27 es un grupo de fotografías que muestran la detección del dominio de unión mediante transferencia de Western. A es una fotografía que muestra el resultado de la detección mediante el uso de un anticuerpo humanizado anti-NR10 humano; B es una fotografía que muestra el resultado de la detección mediante el uso de un anticuerpo de ratón anti-NR10 humano; y C es una fotografía que muestra el resultado de la detección mediante el uso de un anticuerpo anti-Myc. Con el anticuerpo anti-NR10 humano se detectó un antígeno de unión solamente en hhh, hhm, y hmm, pero no en mmm, mmh, y mhm.
La Fig. 28-1 muestra la secuencia de aminoácidos de cada variante de H0 (SEQ ID NO: 50).
La Fig. 28-2 es una continuación de la Fig. 28-1.
La Fig. 28-3 es una continuación de la Fig. 28-2.
La Fig. 29-1 muestra la secuencia de aminoácidos de cada variante de L0 (SEQ ID NO: 52).
La Fig. 29-2 es una continuación de la Fig. 29-1.
NR10
NR10 es una proteína que forma un heterodímero con el receptor de oncoestatina M (OSMR) y funciona como un receptor de IL-31. NR10 se conoce también como glm-r (J Biol Chem 277, 16831-6, 2002), Gp L (J Biol Chem 278, 49850-9, 2003), IL31RA (Nat Immunol 5, 752-60, 2004), etc. Así, en la presente invención NR10 también incluye las proteínas denominadas mediante tales nombres.
En la presente invención, NR10 (también denominado IL31RA, GPL, o glm-r) no está limitado en particular en cuanto a su origen, e incluye los derivados de seres humanos, ratones, monos, y otros mamíferos. Se prefiere el NR10 derivado de seres humanos, ratones, y monos, y se prefiere especialmente el NR10 derivado de seres humanos. Existen múltiples variantes de corte y empalme conocidas de NR10 derivado de seres humanos (documento WO 00/075314). De las variantes de corte y empalme anteriormente descritas, NR10.1 consiste en 662 aminoácidos y contiene un dominio transmembrana. NR10.2 es una proteína similar a un receptor soluble que consiste en 252 aminoácidos sin el dominio transmembrana. Mientras tanto, las variantes de corte y empalme de NR10 conocidas que funcionan como proteínas de receptores transmembrana incluyen NR10.3 e IL-31RAv3. El NR10 humano no está limitado en particular, con tal de que forme un heterodímero con el receptor de oncoestatina M (OSMR) y funcione como un receptor de IL-31. El NR10 preferido incluye NR10.3 (también denominado ILRAv4 (Nat Immunol 5, 752-60, 2004)) e IL-31RAv3. NR 10.3 (IL31RAv4) consiste en 662 aminoácidos (documento WO 00/075314; Nat Immunol 5, 752-60, 2004) e IL31RAv3 consiste en 732 aminoácidos (N° de Acceso de GenBank: NM_139017). La secuencia de aminoácidos de IL31 RAv4 se muestra en SEQ ID NO: 79, y la secuencia de aminoácidos de IL31 RAv3 se muestra en SEQ ID NO: 80. Mientras tanto, el NR10 derivado de ratón incluye las proteínas que comprenden la secuencia de aminoácidos de SEQ ID NO: 81. Además, el NR10 derivado de mono cinomolgo incluye las proteínas que comprenden la secuencia de aminoácidos de SEQ ID NO: 66.
Anticuerpos (secuencias)
Las realizaciones preferidas del anticuerpo anti-NR10 incluyen los anticuerpos anti-NR10 de cualquiera de (1) a (8) en (A) a (D) a continuación.
(A) NS18
(1) los anticuerpos que tienen una región variable de la cadena pesada que comprende una CDR1 que tiene la secuencia de aminoácidos de SEQ ID NO: 1 (HCDR1), una CDR2 que tiene la secuencia de aminoácidos de SEQ ID NO: 2 (HCDR2), y una CDR3 que tiene la secuencia de aminoácidos de SEQ ID NO: 3 (HCDR3);
(2) los anticuerpos que tienen la región variable de la cadena pesada de SEQ ID NO: 4 (VH);
(3) los anticuerpos que tienen una región variable de la cadena ligera que comprende una CDR1 que tiene la secuencia de aminoácidos de SEQ ID NO: 5 (LCDR1), una CDR2 que tiene la secuencia de aminoácidos de SEQ ID
NO: 6 (LCDR2), y una CDR3 que tiene la secuencia de aminoácidos de SEQ ID NO: 7 (LCDR3);
(4) los anticuerpos que tienen la región variable de la cadena ligera de SEQ ID NO: 8 (VL);
(5) los anticuerpos que tienen la región variable de la cadena pesada de (1) y la región variable de la cadena ligera de (3);
(6) los anticuerpos que tienen la región variable de la cadena pesada de (2) y la región variable de la cadena ligera de (4);
(7) los anticuerpos en los que uno o más aminoácidos están sustituidos, delecionados, añadidos, y/o insertados en los anticuerpos de cualquiera de (1) a (6), que tienen una actividad equivalente a la de los anticuerpos de cualquiera de (1) a (6); y
(8) los anticuerpos que se unen al mismo epítopo que un epítopo unido por los anticuerpos de cualquiera de (1) a (7). (B) NS22
(1) los anticuerpos que tienen una región variable de la cadena pesada que comprende una CDR1 que tiene la secuencia de aminoácidos de SEQ ID NO: 9 (HCDR1), una CDR2 que tiene la secuencia de aminoácidos de SEQ ID NO: 10 (HCDR2), y una CDR3 que tiene la secuencia de aminoácidos de SEQ ID NO: 11 (HCDR3);
(2) los anticuerpos que tienen la región variable de la cadena pesada de SEQ ID NO: 12 (VH);
(3) los anticuerpos que tienen una región variable de la cadena ligera que comprende una CDR1 que tiene la secuencia de aminoácidos de SEQ ID NO: 13 (LCDR1), una CDR2 que tiene la secuencia de aminoácidos de SEQ ID NO: 14 (LCDR2), y una CDR3 que tiene la secuencia de aminoácidos de SEQ ID NO: 15 (LCDR3);
(4) los anticuerpos que tienen la región variable de la cadena ligera de SEQ ID NO: 16 (VL);
(5) los anticuerpos que tienen la región variable de la cadena pesada de (1) y la región variable de la cadena ligera de (3); (6) los anticuerpos que tienen la región variable de la cadena pesada de (2) y la región variable de la cadena ligera de (4); (7) los anticuerpos en los que uno o más aminoácidos están sustituidos, delecionados, añadidos, y/o insertados en los anticuerpos de cualquiera de (1) a (6), que tienen una actividad equivalente a la de los anticuerpos de cualquiera de (1) a (6); y
(8) los anticuerpos que se unen al mismo epítopo que un epítopo unido por los anticuerpos de cualquiera de (1) a (7). Los ejemplos específicos de la sustitución, deleción, adición, y/o inserción anteriormente descritas de uno o más aminoácidos no están limitados en particular e incluyen, por ejemplo, las modificaciones siguientes.
La sustitución de Ile en la posición 3 de la CDR1 de la cadena pesada de SEQ ID NO: 9 con otro aminoácido. El aminoácido después de la sustitución no está limitado en particular, pero los ejemplos preferidos del mismo incluyen Val. La sustitución de Met en la posición 4 de la CDR1 de la cadena pesada de SEQ ID NO: 9 con otro aminoácido. El aminoácido después de la sustitución no está limitado en particular, pero los ejemplos preferidos del mismo incluyen Ile. La sustitución de Met en la posición 4 de la CDR1 de la cadena pesada de SEQ ID NO: 9 con otro aminoácido. El aminoácido después de la sustitución no está limitado en particular, pero los ejemplos preferidos del mismo incluyen Leu. La sustitución de Ile en la posición 3 de la CDR1 de la cadena pesada de SEQ ID NO: 9 con otro aminoácido. El aminoácido después de la sustitución no está limitado en particular, pero los ejemplos preferidos del mismo incluyen Ala. La sustitución de Leu en la posición 1 de la CDR2 de la cadena pesada de SEQ ID NO: 10 con otro aminoácido. El aminoácido después de la sustitución no está limitado en particular, pero los ejemplos preferidos del mismo incluyen Glu. La sustitución de Asn en la posición 3 de la CDR2 de la cadena pesada de SEQ ID NO: 10 con otro aminoácido. El aminoácido después de la sustitución no está limitado en particular, pero los ejemplos preferidos del mismo incluyen Asp. La sustitución de Gln en la posición 13 de la CDR2 de la cadena pesada de SEQ ID NO: 10 con otro aminoácido. El aminoácido después de la sustitución no está limitado en particular, pero los ejemplos preferidos del mismo incluyen Asp. La sustitución de Lys en la posición 14 de la CDR2 de la cadena pesada de SEQ ID NO: 10 con otro aminoácido. El aminoácido después de la sustitución no está limitado en particular, pero los ejemplos preferidos del mismo incluyen Gln. La sustitución de Lys en la posición 16 de la CDR2 de la cadena pesada de SEQ ID NO: 10 con otro aminoácido. El aminoácido después de la sustitución no está limitado en particular, pero los ejemplos preferidos del mismo incluyen Gln.
La sustitución de Gly en la posición 17 de la CDR2 de la cadena pesada de SEQ ID NO: 10 con otro aminoácido. El aminoácido después de la sustitución no está limitado en particular, pero los ejemplos preferidos del mismo incluyen Asp.
La sustitución de Lys y Gly en las posiciones 16 y 17, respectivamente, de la CDR2 de la cadena pesada de SEQ ID NO: 10 con otro aminoácido. El aminoácido después de la sustitución no está limitado en particular, pero los ejemplos preferidos incluyen la sustitución de Lys en la posición 16 con Gln, y Gly en la posición 17 con Asp.
La sustitución de Lys, Lys, y Gly en las posiciones 14, 16, y 17, respectivamente, de la CDR2 de la cadena pesada de SEQ ID NO: 10 con otro aminoácido. El aminoácido después de la sustitución no está limitado en particular, pero los ejemplos preferidos incluyen la sustitución de Lys en la posición 14 con Gln, Lys en la posición 16 con Gln, y Gly en la posición 17 con Asp.
La sustitución de Gln, Lys, Lys, y Gly en las posiciones 13, 14, 16, y 17, respectivamente, de la CDR2 de la cadena pesada de SEQ ID NO: 10 con otro aminoácido. El aminoácido después de la sustitución no está limitado en particular, pero los ejemplos preferidos incluyen la sustitución de Gln en la posición 13 con Asp, Lys en la posición 14 con Gln, Lys en la posición 16 con Gln, y Gly en la posición 17 con Asp.
La sustitución de Ser en la posición 10 de la CDR2 de la cadena pesada de SEQ ID NO: 10 con otro aminoácido. El aminoácido después de la sustitución no está limitado en particular, pero los ejemplos preferidos del mismo incluyen Asp.
La sustitución de Gln en la posición 13 de la CDR2 de la cadena pesada de SEQ ID NO: 10 con otro aminoácido. El aminoácido después de la sustitución no está limitado en particular, pero los ejemplos preferidos del mismo incluyen Pro.
La sustitución de Tyr en la posición 3 de la CDR3 de la cadena pesada de SEQ ID NO: 11 con otro aminoácido. El aminoácido después de la sustitución no está limitado en particular, pero los ejemplos preferidos del mismo incluyen Leu.
La sustitución de Met en la posición 10 de la CDR3 de la cadena pesada de SEQ ID NO: 11 con otro aminoácido. El aminoácido después de la sustitución no está limitado en particular, pero los ejemplos preferidos del mismo incluyen Leu.
La sustitución de Asp en la posición 11 de la CDR3 de la cadena pesada de SEQ ID NO: 11 con otro aminoácido. El aminoácido después de la sustitución no está limitado en particular, pero los ejemplos preferidos del mismo incluyen Glu.
La sustitución de Tyr en la posición 12 de la CDR3 de la cadena pesada de SEQ ID NO: 11 con otro aminoácido. El aminoácido después de la sustitución no está limitado en particular, pero los ejemplos preferidos del mismo incluyen Thr y Ser.
La sustitución de Met, Asp, y Tyr en las posiciones 10, 11, y 12, respectivamente, de la CDR3 de la cadena pesada de SEQ ID NO: 11 con otro aminoácido. El aminoácido después de la sustitución no está limitado en particular, pero los ejemplos preferidos incluyen la sustitución de Met en la posición 10 con Leu, Asp en la posición 11 con Glu, y Tyr en la posición 12 con Thr.
La sustitución de Asp y Tyr en las posiciones 11 y 12, respectivamente, de la CDR3 de la cadena pesada de SEQ ID NO: 11 con otro aminoácido. El aminoácido después de la sustitución no está limitado en particular, pero los ejemplos preferidos incluyen la sustitución de Asp en la posición 11 con Glu, y Tyr en la posición 12 con Thr.
La sustitución de Tyr, Asp, y Tyr en las posiciones 3, 11, y 12, respectivamente, de la CDR3 de la cadena pesada de SEQ ID NO: 11 con otro aminoácido. El aminoácido después de la sustitución no está limitado en particular, pero los ejemplos preferidos incluyen la sustitución de Tyr en la posición 3 con Leu, Asp en la posición 11 con Glu, y Tyr en la posición 12 con Thr o Ser.
La sustitución de Arg en la posición 1 de la CDR1 de la cadena ligera de SEQ ID NO: 13 con otro aminoácido. El aminoácido después de la sustitución no está limitado en particular, pero los ejemplos preferidos del mismo incluyen Gln.
La sustitución de Asn en la posición 5 de la CDR1 de la cadena ligera de SEQ ID NO: 13 con otro aminoácido. El aminoácido después de la sustitución no está limitado en particular, pero los ejemplos preferidos del mismo incluyen Asp.
La sustitución de Arg y Asn en las posiciones 1 y 5, respectivamente, de la CDR1 de la cadena ligera de SEQ ID NO: 13 con otro aminoácido. El aminoácido después de la sustitución no está limitado en particular, pero los ejemplos preferidos incluyen la sustitución de Arg en la posición 1 con Gln, y Asn en la posición 5 con Asp.
La sustitución de Ser en la posición 8 de la CDR1 de la cadena ligera de SEQ ID NO: 13 con otro aminoácido. El aminoácido después de la sustitución no está limitado en particular, pero los ejemplos preferidos del mismo incluyen Arg.
La sustitución de Leu en la posición 10 de la CDR1 de la cadena ligera de SEQ ID NO: 13 con otro aminoácido. El aminoácido después de la sustitución no está limitado en particular, pero los ejemplos preferidos del mismo incluyen Val.
La sustitución de Ser y Leu en las posiciones 8 y 10, respectivamente, de la CDR1 de la cadena ligera de SEQ ID NO: 13 con otro aminoácido. El aminoácido después de la sustitución no está limitado en particular, pero los ejemplos preferidos incluyen la sustitución de Ser en la posición 8 con Arg, y Leu en la posición 10 con Val.
La sustitución de Thr en la posición 2 de la CDR1 de la cadena ligera de SEQ ID NO: 13 con otro aminoácido. El aminoácido después de la sustitución no está limitado en particular, pero los ejemplos preferidos del mismo incluyen Ala y Ser.
La sustitución de Asn en la posición 1 de la CDR2 de la cadena ligera de SEQ ID NO: 14 con otro aminoácido. El aminoácido después de la sustitución no está limitado en particular, pero los ejemplos preferidos del mismo incluyen Asp.
La sustitución de Lys en la posición 3 de la CDR2 de la cadena ligera de SEQ ID NO: 14 con otro aminoácido. El aminoácido después de la sustitución no está limitado en particular, pero los ejemplos preferidos del mismo incluyen Gln.
La sustitución de Leu en la posición 5 de la CDR2 de la cadena ligera de SEQ ID NO: 14 con otro aminoácido. El aminoácido después de la sustitución no está limitado en particular, pero los ejemplos preferidos del mismo incluyen Glu.
La sustitución de Lys en la posición 7 de la CDR2 de la cadena ligera de SEQ ID NO: 14 con otro aminoácido. El aminoácido después de la sustitución no está limitado en particular, pero los ejemplos preferidos del mismo incluyen Gln y Asp.
La sustitución de Lys, Leu, y Lys en las posiciones 3, 5, y 7, respectivamente, de la CDR2 de la cadena ligera de SEQ ID NO: 14 con otro aminoácido. El aminoácido después de la sustitución no está limitado en particular, pero los ejemplos preferidos incluyen la sustitución de Lys en la posición 3 con Gln, Leu en la posición 5 con Glu, y Lys en la posición 7 con Gln.
La sustitución de Glu en la posición 5 de la CDR3 de la cadena ligera de SEQ ID NO: 15 con otro aminoácido. El aminoácido después de la sustitución no está limitado en particular, pero los ejemplos preferidos del mismo incluyen Asp.
La sustitución de Ser en la posición 6 de la CDR3 de la cadena ligera de SEQ ID NO: 15 con otro aminoácido. El aminoácido después de la sustitución no está limitado en particular, pero los ejemplos preferidos del mismo incluyen Asp.
La sustitución de Thr en la posición 9 de la CDR3 de la cadena ligera de SEQ ID NO: 15 con otro aminoácido. El aminoácido después de la sustitución no está limitado en particular, pero los ejemplos preferidos del mismo incluyen Phe.
Cada una de las sustituciones anteriormente descritas se pueden hacer solas, o se pueden hacer múltiples sustituciones en combinación. Además, las sustituciones anteriores se pueden combinar con otras sustituciones. Estas sustituciones pueden mejorar la farmacocinética del anticuerpo (retención en el plasma), aumentar la actividad de unión al antígeno, mejorar la estabilidad, y/o reducir el riesgo de inmunogenicidad.
Los ejemplos específicos de las regiones variables que tienen una combinación de las sustituciones anteriormente descritas incluyen, por ejemplo, las regiones variables de la cadena pesada que tienen la secuencia de aminoácidos de SEQ ID NO: 167 y las regiones variables de la cadena ligera que tienen la secuencia de aminoácidos de SEQ ID NO: 168. Además, los ejemplos de los anticuerpos que tienen una combinación de las sustituciones anteriormente descritas incluyen, por ejemplo, los anticuerpos que comprenden una región variable de la cadena pesada que tiene la secuencia de aminoácidos de SEQ ID NO: 167 y una región variable de la cadena ligera que tiene la secuencia de aminoácidos de SEQ ID NO: 168.
Además, los ejemplos específicos de las regiones variables de la cadena pesada o de la cadena ligera que tienen una combinación de las sustituciones anteriormente descritas incluyen, por ejemplo, las regiones variables siguientes:
(a) las regiones variables de la cadena pesada que comprenden una CDR1 de SEQ ID NO: 196, una CDR2 de SEQ ID NO: 197, y una CDR3 de SEQ ID NO: 11 (H17);
(b) las regiones variables de la cadena pesada que comprenden una CDR1 de SEQ ID NO: 176, una CDR2 de SEQ ID NO: 197, y una CDR3 de SEQ ID NO: 11 (H19);
(c) las regiones variables de la cadena pesada que comprenden una CDR1 de SEQ ID NO: 196, una CDR2 de SEQ ID NO: 197, y una CDR3 de SEQ ID NO: 184 (H28, H42);
(d) las regiones variables de la cadena pesada que comprenden una CDR1 de SEQ ID NO: 9, una CDR2 de SEQ ID NO: 197, y una CDR3 de SEQ ID NO: 184 (H30, H44);
(e) las regiones variables de la cadena pesada que comprenden una CDR1 de SEQ ID NO: 176, una CDR2 de SEQ ID NO: 197, y una CDR3 de SEQ ID NO: 184 (H34, H46);
(f) las regiones variables de la cadena pesada que comprenden una CDR1 de SEQ ID NO: 9, una CDR2 de SEQ ID NO: 198, y una CDR3 de SEQ ID NO: 184 (H57, H78);
(g) las regiones variables de la cadena pesada que comprenden una CDR1 de SEQ ID NO: 176, una CDR2 de SEQ ID NO: 198, y una CDR3 de SEQ ID NO: 184 (H71, H92);
(h) las regiones variables de la cadena pesada que comprenden una CDR1 de SEQ ID NO: 9, una CDR2 de SEQ ID NO: 199, y una CDR3 de SEQ ID NO: 184 (H97, H98);
(i) las regiones variables de la cadena ligera que comprenden una CDR1 de SEQ ID NO: 200, una CDR2 de SEQ ID NO: 170, y una CDR3 de SEQ ID NO: 193 (L11);
(j) las regiones variables de la cadena ligera que comprenden una CDR1 de SEQ ID NO: 201, una CDR2 de SEQ ID NO: 170, y una CDR3 de SEQ ID NO: 193 (L12);
(k) las regiones variables de la cadena ligera que comprenden una CDR1 de SEQ ID NO: 202, una CDR2 de SEQ ID NO: 170, y una CDR3 de SEQ ID NO: 193 (L17); y
(l) las regiones variables de la cadena ligera que comprenden una CDR1 de SEQ ID NO: 203, una CDR2 de SEQ ID NO: 170, y una CDR3 de SEQ ID NO: 193 (L50).
Además, los ejemplos específicos de los anticuerpos que tienen una combinación de las sustituciones anteriormente descritas incluyen, por ejemplo:
(i) los anticuerpos que comprenden la región variable de la cadena pesada de (c) y la región variable de la cadena ligera de (k);
(ii) los anticuerpos que comprenden la región variable de la cadena pesada de (d) y la región variable de la cadena ligera de (k);
(iii) los anticuerpos que comprenden la región variable de la cadena pesada de (e) y la región variable de la cadena ligera de (k);
(iv) los anticuerpos que comprenden la región variable de la cadena pesada de (f) y la región variable de la cadena ligera de (k);
(v) los anticuerpos que comprenden la región variable de la cadena pesada de (g) y la región variable de la cadena ligera de (k); y
(vi) los anticuerpos que comprenden la región variable de la cadena pesada de (h) y la región variable de la cadena ligera de (l).
(C) NS23
(1) los anticuerpos que tienen una región variable de la cadena pesada que comprende una CDR1 que tiene la secuencia de aminoácidos de SEQ ID NO: 17 (HCDR1), una CDR2 que tiene la secuencia de aminoácidos de SEQ ID NO: 18 (HCDR2), y una CDR3 que tiene la secuencia de aminoácidos de SEQ ID NO: 19 (HCDR3);
(2) los anticuerpos que tienen la región variable de la cadena pesada de SEQ ID NO: 20 (VH);
(3) los anticuerpos que tienen una región variable de la cadena ligera que comprende una CDR1 que tiene la secuencia de aminoácidos de SEQ ID NO: 21 (LCDR1), una CDR2 que tiene la secuencia de aminoácidos de SEQ ID NO: 22 (LCDR2), y una CDR3 que tiene la secuencia de aminoácidos de SEQ ID NO: 23 (LCDR3);
(4) los anticuerpos que tienen la región variable de la cadena ligera de SEQ ID NO: 24 (VL);
(5) los anticuerpos que tienen la región variable de la cadena pesada de (1) y la región variable de la cadena ligera de (3);
(6) los anticuerpos que tienen la región variable de la cadena pesada de (2) y la región variable de la cadena ligera de (4);
(7) los anticuerpos en los que uno o más aminoácidos están sustituidos, delecionados, añadidos, y/o insertados en los anticuerpos de cualquiera de (1) a (6), que tienen una actividad equivalente a la de los anticuerpos de cualquiera de (1) a (6); y
(8) los anticuerpos que se unen al mismo epítopo que un epítopo unido por los anticuerpos de cualquiera de (1) a (7).
(D) NS33
(1) los anticuerpos que tienen una región variable de la cadena pesada que comprende una CDR1 que tiene la secuencia de aminoácidos de SEQ ID NO: 25 (HCDR1), una CDR2 que tiene la secuencia de aminoácidos de SEQ ID NO: 26 (HCDR2), y una CDR3 que tiene la secuencia de aminoácidos de SEQ ID NO: 27 (HCDR3);
(2) los anticuerpos que tienen la región variable de la cadena pesada de SEQ ID NO: 28 (VH);
(3) los anticuerpos que tienen una región variable de la cadena ligera que comprende una CDR1 que tiene la secuencia de aminoácidos de SEQ ID NO: 29 (LCDR1), una CDR2 que tiene la secuencia de aminoácidos de SEQ ID NO: 30 (LCDR2), y una CDR3 que tiene la secuencia de aminoácidos de SEQ ID NO: 31 (LCDR3);
(4) los anticuerpos que tienen la región variable de la cadena ligera de SEQ ID NO: 32 (VL);
(5) los anticuerpos que tienen la región variable de la cadena pesada de (1) y la región variable de la cadena ligera de (3);
(6) los anticuerpos que tienen la región variable de la cadena pesada de (2) y la región variable de la cadena ligera de (4);
(7) los anticuerpos en los que uno o más aminoácidos están sustituidos, delecionados, añadidos, y/o insertados en los anticuerpos de cualquiera de (1) a (6), que tienen una actividad equivalente a la de los anticuerpos de cualquiera de (1) a (6); y
(8) los anticuerpos que se unen al mismo epítopo que un epítopo unido por los anticuerpos de cualquiera de (1) a (7).
Se puede usar cualquier región estructural (FR) para los anticuerpos anteriormente descritos de (1) o (3); sin embargo, se usan preferiblemente las FRs derivadas de seres humanos. Además, se puede usar cualquier región constante para los anticuerpos anteriormente descritos de (1) a (8); sin embargo, se usan preferiblemente las regiones constantes derivadas de seres humanos. Para los anticuerpos de la presente invención, la secuencia de aminoácidos de la FR o región constante original se puede usar sin modificación, o después de modificarla hasta una secuencia de aminoácidos diferente mediante la sustitución, deleción, adición, y/o inserción de uno o más aminoácidos.
La secuencia de aminoácidos de la cadena pesada del NS18 anteriormente descrito se muestra en SEQ ID NO: 34 y la secuencia de nucleótidos que codifica esta secuencia de aminoácidos se muestra en SEQ ID NO: 33. Mientras tanto, la secuencia de aminoácidos de la cadena ligera se muestra en SEQ ID NO: 36 y la secuencia de nucleótidos que codifica esta secuencia de aminoácidos se muestra en SEQ ID NO: 35.
La secuencia de aminoácidos de la cadena pesada de NS22 se muestra en SEQ ID NO: 38 y la secuencia de nucleótidos que codifica esta secuencia de aminoácidos se muestra en SEQ ID NO: 37. Mientras tanto, la secuencia de aminoácidos de la cadena ligera se muestra en SEQ ID NO: 40 y la secuencia de nucleótidos que codifica esta secuencia de aminoácidos se muestra en SEQ ID NO: 39.
La secuencia de aminoácidos de la cadena pesada de NS23 se muestra en SEQ ID NO: 42 y la secuencia de nucleótidos que codifica esta secuencia de aminoácidos se muestra en SEQ ID NO: 41. Mientras tanto, la secuencia de aminoácidos de la cadena ligera se muestra en SEQ ID NO: 44 y la secuencia de nucleótidos que codifica esta secuencia de aminoácidos se muestra en SEQ ID NO: 43.
La secuencia de aminoácidos de la cadena pesada de NS33 se muestra en SEQ ID NO: 46 y la secuencia de nucleótidos que codifica esta secuencia de aminoácidos se muestra en SEQ ID NO: 45. Mientras tanto, la secuencia de aminoácidos de la cadena ligera se muestra en SEQ ID NO: 48 y la secuencia de nucleótidos que codifica esta secuencia de aminoácidos se muestra en SEQ ID NO: 47.
La expresión "actividad equivalente a la del anticuerpo de cualquiera de (1) a (6)" significa que la actividad de unión y/o neutralizante hacia NR10 (por ejemplo, NR10 humano) es equivalente. El término "equivalente" significa que la actividad no es necesariamente la misma, sino que puede estar incrementada o reducida con tal de que se conserve la actividad. Los anticuerpos con una actividad reducida incluyen, por ejemplo, los anticuerpos que tienen una actividad que es un 30% o más, preferiblemente un 50% o más, y más preferiblemente un 80% o más de la del anticuerpo original.
Los anticuerpos de cualquiera de (1) a (6) mencionados anteriormente pueden tener una sustitución, deleción, adición, y/o inserción de uno o más aminoácidos en la secuencia de aminoácidos de las regiones variables (secuencias de CDR y/o secuencias de FR), con tal de que se conserve la actividad de unión y/o neutralizante hacia NR10. Los métodos bien conocidos para los expertos en la técnica para preparar la secuencia de aminoácidos de un anticuerpo que tiene una sustitución, deleción, adición, y/o inserción de uno o más aminoácidos en la secuencia de aminoácidos y que conserva la actividad de unión y/o neutralizante hacia NR10, incluyen los métodos para introducir mutaciones en las proteínas. Por ejemplo, los expertos en la técnica pueden preparar mutantes funcionalmente equivalentes al anticuerpo que tiene actividad de unión y/o neutralizante hacia NR10 introduciendo mutaciones adecuadas en la secuencia de aminoácidos del anticuerpo que tiene actividad de unión y/o neutralizante hacia NR10 mediante el uso de mutagénesis dirigida (Hashimoto-Gotoh, T, Mizuno, T, Ogasahara, Y, y Nakagawa, M. (1995) An oligodeoxyribonucleotide-directed dual amber method for site-directed mutagenesis. Gene 152, 271-275, Zoller, MJ, y Smith, M. (1983) Oligonucleotide-directed mutagenesis of DNA fragments cloned into M13 vectors. Methods Enzymol. 100, 468-500, Kramer, W, Drutsa, V, Jansen, HW, Kramer, B, Pflugfelder, M, y Fritz, HJ (1984) The gapped duplex DNA approach to oligonucleotide-directed mutation construction. Nucleic Acids Res. 12, 9441-9456, Kramer W, y Fritz HJ (1987) Oligonucleotide-directed construction of mutations via gapped duplex DNA Methods. Enzymol.
154, 350-367, Kunkel, TA (1985) Rapid and efficient site-specific mutagenesis without phenotypic selection. Proc Natl Acad Sci USA. 82, 488-492) o similares. Así, los anticuerpos que contienen una o más mutaciones de aminoácidos en las regiones variables y que tienen actividad de unión y/o neutralizante hacia NR10 se incluyen también en el anticuerpo de la presente descripción.
Cuando se altera un residuo de aminoácido, el aminoácido se muta preferiblemente por un/varios aminoácido(s) diferente(s) que conserva(n) las propiedades de la cadena lateral del aminoácido. Los ejemplos de propiedades de las cadenas laterales de aminoácidos son: aminoácidos hidrófobos (A, I, L, M, F, P, W, Y, y V), aminoácidos hidrófilos (R, D, N, C, E, Q, G, H, K, S, y T), aminoácidos que contienen cadenas laterales alifáticas (G, A, V, L, I, y P), aminoácidos que contienen cadenas laterales que contienen grupos hidroxilo (S, T, e Y), aminoácidos que contienen cadenas laterales que contienen azufre (C y M), aminoácidos que contienen cadenas laterales que contienen ácido carboxílico y amida (D, N, E, y Q), aminoácidos que contienen cadenas laterales básicas (R, K, y H), y aminoácidos que contienen cadenas laterales aromáticas (H, F, Y, y W) (los aminoácidos se representan mediante códigos de una letra entre paréntesis). Las sustituciones de aminoácidos dentro de cada grupo se denominan sustituciones conservativas. Se sabe que un polipéptido que contiene una secuencia de aminoácidos modificada en la que uno o más residuos de aminoácidos en una secuencia de aminoácidos determinada se deleciona, añade, y/o sustituye con otros aminoácidos puede conservar la actividad biológica original (Mark, D. F. et al., Proc. Natl. Acad. Sci. USA; (1984) 81:5662-6; Zoller, M. J. y Smith, M., Nucleic Acids Res. (1982) 10:6487-500; Wang, A. et a l, Science (1984) 224:1431-3; Dalbadie-McFarland, G. et al., Proc. Natl. Acad. Sci. USA (1982) 79:6409-13). Tales mutantes tienen una identidad de aminoácidos de al menos un 70%, más preferiblemente al menos un 75%, aún más preferiblemente al menos un 80%, todavía más preferiblemente al menos un 85%, aún más preferiblemente al menos un 90%, y lo más preferiblemente al menos un 95%, con las regiones variables (por ejemplo, las secuencias CDR, secuencias FR, o las regiones variables completas) de la presente descripción. En la presente memoria, la identidad de secuencias se define como el porcentaje de residuos idénticos a los de la secuencia de aminoácidos original de la región variable de la cadena pesada o de la región variable de la cadena ligera, determinado tras alinear las secuencias e introducir huecos de manera adecuada para maximizar la identidad de secuencias según sea necesario. La identidad de las secuencias de aminoácidos se puede determinar mediante el método descrito más adelante.
De manera alternativa, las secuencias de aminoácidos de las regiones variables que tienen una sustitución, deleción, adición, y/o inserción de uno o más aminoácidos en la secuencia de aminoácidos de las regiones variables (secuencias CDR y/o secuencias FR) y que conservan la actividad de unión y/o neutralizante hacia NR10, se pueden obtener de ácidos nucleicos que hibridan en condiciones rigurosas al ácido nucleico compuesto de la secuencia de nucleótidos que codifica la secuencia de aminoácidos de las regiones variables. Las condiciones de hibridación rigurosas para aislar un ácido nucleico que hibrida en condiciones rigurosas a un ácido nucleico que incluye la secuencia de nucleótidos que codifica la secuencia de aminoácidos de las regiones variables incluyen, por ejemplo, las condiciones de urea 6 M, 0,4% de SDS, SSC 0,5x, y 37 °C, o las condiciones de hibridación con rigurosidades equivalente a estas. Con condiciones más rigurosas, por ejemplo, las condiciones de urea 6 M, 0,4% de SDS, SSC 0,1x, y 42 °C, se puede esperar el aislamiento de ácidos nucleicos con una homología mucho mayor. Las secuencias de los ácidos nucleicos aislados se pueden determinar mediante los métodos conocidos descritos más adelante. La homología global de la secuencia de nucleótidos del ácido nucleico aislado es al menos de un 50%, o una identidad de secuencias mayor, preferiblemente un 70% o mayor, más preferiblemente un 90% o mayor (por ejemplo, un 95%, 96%, 97%, 98%, 99%, o mayor).
Los ácidos nucleicos que hibridan en condiciones rigurosas a un ácido nucleico compuesto de la secuencia de nucleótidos que codifica la secuencia de aminoácidos de las regiones variables se pueden aislar también mediante el uso, en vez de los métodos anteriormente descritos que usan técnicas de hibridación, de métodos de amplificación de genes tales como la reacción en cadena de la polimerasa (PCR) con el uso de cebadores sintetizados basados en la información de la secuencia de nucleótidos que codifica la secuencia de aminoácidos de las regiones variables.
De manera específica, se puede determinar la identidad de una secuencia de nucleótidos o de una secuencia de aminoácidos respecto de otra mediante el uso del algoritmo BLAST, de Karlin y Altschul (Proc. Natl. Acad. Sci. USA (1993) 90, 5873-7). Se desarrollaron programas tales como BLASTN y BLASTX basándose en este algoritmo (Altschul et al., J. Mol. Biol. (1990) 215, 403-10). Para analizar las secuencias de nucleótidos según BLASTN basado en BLAST, los parámetros se ajustan, por ejemplo, como puntuación= 100 y longitud de palabra= 12. Por otra parte, los parámetros usados para el análisis de secuencias de aminoácidos mediante BLASTX basado en BLAST incluyen, por ejemplo, puntuación= 50 y longitud de palabra= 3. Se usan los parámetros por defecto para cada programa cuando se usan los programas BLAST y Gapped BLAST. Los métodos específicos para tales análisis se conocen en la técnica (véase el sitio de Internet del National Center for Biotechnology Information (NCBI), Basic Local Alignment Search Tool (BLAST); http://www.ncbi.nlm.nih.gov).
La presente descripción también proporciona anticuerpos que se unen al mismo epítopo que un epítopo unido por los anticuerpos de cualquiera de (1) a (7).
Se puede confirmar si un anticuerpo reconoce el mismo epítopo que el reconocido por otro anticuerpo mediante la competición entre los dos anticuerpos hacia el epítopo. La competición entre los anticuerpos se puede determinar
mediante ensayos de unión competitiva con el uso de medios tales como ELISA, un método de transferencia de energía de fluorescencia (FRET), y la tecnología de ensayo fluorimétrico con microvolúmenes (FMAT(R)). La cantidad de anticuerpos unidos a un antígeno se correlaciona indirectamente con la capacidad de unión de anticuerpos competitivos candidatos (anticuerpos de ensayo) que se unen de manera competitiva al mismo epítopo. En otras palabras, a medida que se incrementa la cantidad o la afinidad de los anticuerpos de ensayo hacia el mismo epítopo, disminuye la cantidad de anticuerpos unidos al antígeno, y se incrementa la cantidad de anticuerpos de ensayo unidos al antígeno. De manera específica, los anticuerpos marcados adecuadamente y los anticuerpos a analizar se añaden simultáneamente a los antígenos, y los anticuerpos así unidos se detectan mediante el uso del marcador. La cantidad de anticuerpos unidos al antígeno se puede determinar fácilmente marcando los anticuerpos con antelación. Este marcador no está limitado en particular, y el método de marcaje se selecciona según la técnica de ensayo usada. El método de marcaje incluye el marcaje fluorescente, el radiomarcaje, el marcaje enzimático, y similares.
Por ejemplo, los anticuerpos marcados con fluorescencia y los anticuerpos sin marcar o anticuerpos de ensayo se añaden de manera simultánea a células animales que expresan NR10, y los anticuerpos marcados se detectan mediante la tecnología de ensayo fluorimétrico con microvolúmenes.
En la presente memoria, el "anticuerpo que reconoce el mismo epítopo" se refiere a un anticuerpo que puede reducir la unión del anticuerpo marcado en al menos un 50% a una concentración que es normalmente 100 veces mayor, preferiblemente 80 veces mayor, más preferiblemente 50 veces mayor, aún más preferiblemente 30 veces mayor, y todavía más preferiblemente 10 veces mayor que una concentración a la que el anticuerpo sin marcar reduce la unión del anticuerpo marcado un 50% (CI50).
Los anticuerpos que se unen al epítopo al que se unen los anticuerpos indicados en cualquiera de los puntos (1) a (7) anteriores son útiles, ya que tienen una actividad neutralizante especialmente elevada.
Los anticuerpos expuestos en cualquiera de los puntos (1) a (8) anteriores son preferiblemente anticuerpos humanizados, pero no se limitan especialmente a ellos.
Además, la presente descripción proporciona genes que codifican los anticuerpos anti-NR10 de cualquiera de los puntos (1) a (8) de (A) a (D) anteriores. Los genes de la presente descripción pueden ser cualquier forma de genes, por ejemplo, ADNs o ARNs.
Anticuerpos (humanizados)
Las realizaciones preferidas de los anticuerpos de la presente descripción incluyen los anticuerpos humanizados que se unen a NR10. Los anticuerpos humanizados se pueden preparar mediante métodos conocidos para los expertos en la técnica.
La región variable del anticuerpo está compuesta en general de tres regiones determinantes de la complementariedad (CDRs) intercaladas en cuatro regiones estructurales (FRs). Las CDRs determinan sustancialmente la especificidad de unión del anticuerpo. Las secuencias de aminoácidos de las CDRs son muy diversas. En contraste, las secuencias de aminoácidos de las FRs exhiben a menudo una homología elevada entre anticuerpos que tienen especificidades de unión diferentes. Por lo tanto, se dice en general que la especificidad de unión de un anticuerpo se puede trasplantar a un anticuerpo diferente injertando las CDRs.
Los anticuerpos humanizados también se denominan anticuerpos humanos remodelados, y se preparan transfiriendo las CDRs de un anticuerpo derivado de un mamífero no humano, tal como un ratón, a las CDRs de un anticuerpo humano. También se conocen las técnicas generales de recombinación genética para su preparación (véase la Publicación de Solicitud de Patente Europea N° 125023 y el documento WO 96/02576).
De manera específica, por ejemplo, cuando las CDRs se obtienen de un anticuerpo de ratón, se sintetiza una secuencia de ADN diseñada de forma que las CDRs del anticuerpo de ratón se unen con regiones estructurales (FRs) de un anticuerpo humano mediante PCR con el uso, como cebadores, de varios oligonucleótidos que tienen porciones que se solapan con los extremos de las CDRs y FRs (véase el método descrito en el documento WO 98/13388). El ADN resultante se liga después a un ADN que codifica una región constante de un anticuerpo humano, se inserta en un vector de expresión, y se introduce en un hospedador para producir el anticuerpo (véase la Publicación de Solicitud de Patente Europea N° EP 239400 y la Publicación de Solicitud de Patente Internacional N° WO 96/02576).
Las regiones estructurales de un anticuerpo humano a unir con las CDRs se seleccionan de manera que las CDRs formen un sitio de unión al antígeno favorable. Si es necesario, se puede introducir la sustitución, deleción, adición, y/o inserción de aminoácidos en las regiones estructurales de la región variable del anticuerpo de manera que las CDRs del anticuerpo humano remodelado formen un sitio de unión al antígeno adecuado. Por ejemplo, se pueden introducir mutaciones en la secuencia de aminoácidos de FR aplicando el método de PCR que se usa para injertar CDRs de ratón en FRs humanas. De manera específica, se pueden introducir mutaciones en una porción de las secuencias de nucleótidos de cebadores que hibridan con las FRs. Las mutaciones se introducen en las FRs sintetizadas mediante tales cebadores. La actividad de unión al antígeno de los anticuerpos mutantes que tienen
sustituciones de aminoácidos se puede determinar y estudiar mediante el método descrito anteriormente, y de ese modo se pueden seleccionar las secuencias de FR mutantes que tienen las propiedades deseadas (Sato, K. et al., Cancer Res. (1993) 53, 851-856).
Se usan las regiones constantes (C) de anticuerpos humanos para las de los anticuerpos humanizados. Por ejemplo, se usan Cy1, Cy2, Cy3, Cy4, Cp, C5, Ca1, Ca2, y Cs para las cadenas H; y se usan Ck y CA para las cadenas L. La secuencia de aminoácidos de Ck se muestra en SEQ ID NO: 58, y la secuencia de nucleótidos que codifica esta secuencia de aminoácidos se muestra en SEQ ID NO: 57. La secuencia de aminoácidos de Cy1 se muestra en SEQ ID NO: 60, y la secuencia de nucleótidos que codifica esta secuencia de aminoácidos se muestra en SEQ ID NO: 59. La secuencia de aminoácidos de Cy2 se muestra en SEQ ID NO: 62, y la secuencia de nucleótidos que codifica esta secuencia de aminoácidos se muestra en SEQ ID NO: 61. La secuencia de aminoácidos de Cy4 se muestra en SEQ ID NO: 64, y la secuencia de nucleótidos que codifica esta secuencia de aminoácidos se muestra en SEQ ID NO: 63. Además, se pueden modificar las regiones C de un anticuerpo humano para mejorar la estabilidad del anticuerpo o la producción del anticuerpo. Las regiones C de un anticuerpo humano modificado incluyen, por ejemplo, las regiones C descritas más adelante en la presente memoria. Los anticuerpos humanos usados para la humanización pueden ser de cualquier isotipo tal como IgG, IgM, IgA, IgE, o IgD; sin embargo, se usa preferiblemente IgG en la presente invención. La IgG que se puede usar incluye IgG 1, IgG2, IgG3, IgG4, y similares.
Además, después de preparar un anticuerpo humanizado, los aminoácidos de la región variable (por ejemplo, CDR y FR) y de la región constante del anticuerpo humanizado se pueden delecionar, añadir, insertar, y/o sustituir con otros aminoácidos. Los anticuerpos de la presente descripción también incluyen tales anticuerpos humanizados con sustituciones de aminoácidos y similares.
El origen de las CDRs de un anticuerpo humanizado no está limitado en particular, y puede ser cualquier animal. Por ejemplo, es posible usar las secuencias de anticuerpos de ratón, anticuerpos de rata, anticuerpos de conejo, anticuerpos de camello, y similares. Se prefieren las secuencias de CDRs de anticuerpos de ratón.
En general, es difícil humanizar anticuerpos mientras se conservan las actividades de unión y neutralizantes de los anticuerpos originales. La presente descripción, sin embargo, consigue obtener anticuerpos humanizados que tienen actividades de unión y/o neutralizantes equivalentes a las de los anticuerpos de ratón originales. Los anticuerpos humanizados son útiles cuando se administran a seres humanos para fines terapéuticos, ya que exhiben una inmunogenicidad reducida en el cuerpo humano.
Los ejemplos preferidos de los anticuerpos anti-NR10 humanizados de la presente descripción incluyen, por ejemplo:
(a) los anticuerpos humanizados que comprenden una región variable de la cadena pesada que tiene la secuencia de aminoácidos de SEQ ID NO: 50 (H0-VH);
(b) los anticuerpos humanizados que comprenden una región variable de la cadena pesada que tiene la secuencia de aminoácidos de SEQ ID NO: 112 (H1-VH);
(c) los anticuerpos humanizados que comprenden una región variable de la cadena ligera que tiene la secuencia de aminoácidos de SEQ ID NO: 52 (L0-VL);
(d) los anticuerpos humanizados que comprenden una región variable de la cadena pesada que tiene la secuencia de aminoácidos de SEQ ID NO: 50 (H0-VH) y una región variable de la cadena ligera que tiene la secuencia de aminoácidos de SEQ ID NO: 52 (L0-VL); y
(e) los anticuerpos humanizados que comprenden una región variable de la cadena pesada que tiene la secuencia de aminoácidos de SEQ ID NO: 112 y una región variable de la cadena ligera que tiene la secuencia de aminoácidos de SEQ ID NO: 52.
La región variable de la cadena pesada que tiene la secuencia de aminoácidos de SEQ ID NO: 50 (H0-VH), la región variable de la cadena pesada que tiene la secuencia de aminoácidos de SEQ ID NO: 112, y la región variable de la cadena ligera que tiene la secuencia de aminoácidos de SEQ ID NO: 52 (L0-VL) pueden tener una sustitución, deleción, adición, y/o inserción de uno o más aminoácidos. La sustitución, deleción, adición, y/o inserción de aminoácidos se puede hacer en una o ambas CDRs y FRs.
Así, otras realizaciones preferidas del anticuerpo anti-NR10 humanizado de la presente descripción incluyen, por ejemplo:
(f) los anticuerpos que comprenden una región variable de la cadena pesada que tiene una secuencia de aminoácidos en la que uno o más aminoácidos están sustituidos, delecionados, añadidos, y/o insertados en la secuencia de aminoácidos de SEQ ID NO: 50 (H0-VH);
(g) los anticuerpos que comprenden una región variable de la cadena pesada que tiene una secuencia de aminoácidos en la que uno o más aminoácidos están sustituidos, delecionados, añadidos, y/o insertados en la secuencia de aminoácidos de SEQ ID NO: 112 (H1-VH);
(h) los anticuerpos que comprenden una región variable de la cadena ligera que tiene una secuencia de aminoácidos en la que uno o más aminoácidos están sustituidos, delecionados, añadidos, y/o insertados en la secuencia de aminoácidos de SEQ ID NO: 52 (L0-VL);
(i) los anticuerpos que comprenden una región variable de la cadena pesada que tiene una secuencia de aminoácidos en la que uno o más aminoácidos están sustituidos, delecionados, añadidos, y/o insertados en la secuencia de aminoácidos de SEQ ID NO: 50 (H0-VH), y una región variable de la cadena ligera que tiene una secuencia de aminoácidos en la que uno o más aminoácidos están sustituidos, delecionados, añadidos, y/o insertados en la secuencia de aminoácidos de SEQ ID NO: 52 (L0-VL);
(j) los anticuerpos que comprenden una región variable de la cadena pesada que tiene una secuencia de aminoácidos en la que uno o más aminoácidos están sustituidos, delecionados, añadidos, y/o insertados en la secuencia de aminoácidos de SEQ ID NO: 112 (H1-VH), y una región variable de la cadena ligera que tiene una secuencia de aminoácidos en la que uno o más aminoácidos están sustituidos, delecionados, añadidos, y/o insertados en la secuencia de aminoácidos de SEQ ID NO: 52 (L0-VL);
Sin una limitación particular, los anticuerpos de cualquiera de (f) a (j) tienen preferiblemente una actividad similar a la de los anticuerpos de cualquiera de (a) a (e).
La sustitución, deleción, adición, y/o inserción de aminoácidos no están limitadas en particular, y los ejemplos específicos incluyen, por ejemplo, las sustituciones de aminoácidos anteriormente descritas.
De manera más específica, por ejemplo, se pueden incluir las sustituciones de aminoácidos siguientes:
La sustitución de Ile en la posición 3 de la CDR1 (SEQ ID NO: 9) de la región variable de la cadena pesada de SEQ ID NO: 50 o 112 con Val (SEQ ID NO: 173). Así, la presente descripción proporciona regiones variables de la cadena pesada en las que una CDR1 que tiene la secuencia de aminoácidos de SEQ ID NO: 9 está sustituida con una CDR1 que tiene la secuencia de aminoácidos de SEQ ID NO: 173 en una región variable de la cadena pesada que tiene la secuencia de aminoácidos de SEQ ID NO: 50 o 112.
La sustitución de Met en la posición 4 de la CDR1 (SEQ ID NO: 9) de la región variable de la cadena pesada de SEQ ID NO: 50 o 112 con Ile (SEQ ID NO: 174). Así, la presente descripción proporciona regiones variables de la cadena pesada en las que una CDR1 que tiene la secuencia de aminoácidos de SEQ ID NO: 9 está sustituida con una CDR1 que tiene la secuencia de aminoácidos de SEQ ID NO: 174 en una región variable de la cadena pesada que tiene la secuencia de aminoácidos de SEQ ID NO: 50 o 112.
La sustitución de Met en la posición 4 de la CDR1 (SEQ ID NO: 9) de la región variable de la cadena pesada de SEQ ID NO: 50 o 112 con Leu (SEQ ID NO: 175). Así, la presente descripción proporciona regiones variables de la cadena pesada en las que una CDR1 que tiene la secuencia de aminoácidos de SEQ ID NO: 9 está sustituida con una CDR1 que tiene la secuencia de aminoácidos de SEQ ID NO: 175 en una región variable de la cadena pesada que tiene la secuencia de aminoácidos de SEQ ID NO: 50 o 112.
La sustitución de Ile en la posición 3 de la CDR1 (SEQ ID NO: 9) de la región variable de la cadena pesada de SEQ ID NO: 50 o 112 con Ala (SEQ ID NO: 176). Así, la presente descripción proporciona regiones variables de la cadena pesada en las que una CDR1 que tiene la secuencia de aminoácidos de SEQ ID NO: 9 está sustituida con una CDR1 que tiene la secuencia de aminoácidos de SEQ ID NO: 176 en una región variable de la cadena pesada que tiene la secuencia de aminoácidos de SEQ ID NO: 50 o 112.
La sustitución de Leu en la posición 1 de la CDR2 (SEQ ID NO: 10) de la región variable de la cadena pesada de SEQ ID NO: 50 o 112 con Glu (SEQ ID NO: 113). Así, la presente descripción proporciona regiones variables de la cadena pesada en las que una CDR2 que tiene la secuencia de aminoácidos de SEQ ID NO: 10 está sustituida con una CDR2 que tiene la secuencia de aminoácidos de SEQ ID NO: 113 en una región variable de la cadena pesada que tiene la secuencia de aminoácidos de SEQ ID NO: 50 o 112.
La sustitución de Asn en la posición 3 de la CDR2 (SEQ ID NO: 10) de la región variable de la cadena pesada de SEQ ID NO: 50 o 112 con Asp (SEQ ID NO: 114). Así, la presente descripción proporciona regiones variables de la cadena pesada en las que una CDR2 que tiene la secuencia de aminoácidos de SEQ ID NO: 10 está sustituida con una CDR2 que tiene la secuencia de aminoácidos de SEQ ID NO: 114 en una región variable de la cadena pesada que tiene la secuencia de aminoácidos de SEQ ID NO: 50 o 112.
La sustitución de Gln en la posición 13 de la CDR2 (SEQ ID NO: 10) de la región variable de la cadena pesada de SEQ ID NO: 50 o 112 con Asp (SEQ ID NO: 115). Así, la presente descripción proporciona regiones variables de la cadena pesada en las que una CDR2 que tiene la secuencia de aminoácidos de SEQ ID NO: 10 está sustituida con una CDR2 que tiene la secuencia de aminoácidos de SEQ ID NO: 115 en una región variable de la cadena pesada que tiene la secuencia de aminoácidos de SEQ ID NO: 50 o 112.
La sustitución de Lys en la posición 14 de la CDR2 (SEQ ID NO: 10) de la región variable de la cadena pesada de SEQ ID NO: 50 o 112 con Gln (SEQ ID NO: 116). Así, la presente descripción proporciona regiones variables de la
cadena pesada en las que una CDR2 que tiene la secuencia de aminoácidos de SEQ ID NO: 10 está sustituida con una CDR2 que tiene la secuencia de aminoácidos de SEQ ID NO: 116 en una región variable de la cadena pesada que tiene la secuencia de aminoácidos de SEQ ID NO: 50 o 112.
La sustitución de Lys en la posición 16 de la CDR2 (SEQ ID NO: 10) de la región variable de la cadena pesada de SEQ ID NO: 50 o 112 con Gln (SEQ ID NO: 117). Así, la presente descripción proporciona regiones variables de la cadena pesada en las que una CDR2 que tiene la secuencia de aminoácidos de SEQ ID NO: 10 está sustituida con una CDR2 que tiene la secuencia de aminoácidos de SEQ ID NO: 117 en una región variable de la cadena pesada que tiene la secuencia de aminoácidos de SEQ ID NO: 50 o 112.
La sustitución de Gly en la posición 17 de la CDR2 (SEQ ID NO: 10) de la región variable de la cadena pesada de SEQ ID NO: 50 o 112 con Asp (SEQ ID NO: 118). Así, la presente descripción proporciona regiones variables de la cadena pesada en las que una CDR2 que tiene la secuencia de aminoácidos de SEQ ID NO: 10 está sustituida con una CDR2 que tiene la secuencia de aminoácidos de SEQ ID NO: 118 en una región variable de la cadena pesada que tiene la secuencia de aminoácidos de SEQ ID NO: 50 o 112.
La sustitución de Lys en la posición 16 y Gly en la posición 17 de la CDR2 (SEQ ID NO: 10) de la región variable de la cadena pesada de SEQ ID NO: 50 o 112 con Gln y Asp, respectivamente (SEQ ID NO: 119). Así, la presente descripción proporciona regiones variables de la cadena pesada en las que una CDR2 que tiene la secuencia de aminoácidos de SEQ ID NO: 10 está sustituida con una CDR2 que tiene la secuencia de aminoácidos de SEQ ID NO: 119 en una región variable de la cadena pesada que tiene la secuencia de aminoácidos de SEQ ID NO: 50 o 112.
La sustitución de Lys en la posición 14, Lys en la posición 16, y Gly en la posición 17 de la CDR2 (SEQ ID NO: 10) de la región variable de la cadena pesada de SEQ ID NO: 50 o 112 con Gln, Gln, y Asp, respectivamente (SEQ ID NO: 167). Así, la presente descripción proporciona regiones variables de la cadena pesada en las que una CDR2 que tiene la secuencia de aminoácidos de SEQ ID NO: 10 está sustituida con una CDR2 que tiene la secuencia de aminoácidos de SEQ ID NO: 167 en una región variable de la cadena pesada que tiene la secuencia de aminoácidos de SEQ ID NO: 50 o 112.
La sustitución de Gln en la posición 13, Lys en la posición 14, Lys en la posición 16, y Gly en la posición 17 de la CDR2 (SEQ ID NO: 10) de la región variable de la cadena pesada de s Eq ID NO: 50 o 112 con Asp, Gln, Gln, y Asp, respectivamente (SEQ ID NO: 172). Así, la presente descripción proporciona regiones variables de la cadena pesada en las que una CDR2 que tiene la secuencia de aminoácidos de SEQ ID NO: 10 está sustituida con una CDR2 que tiene la secuencia de aminoácidos de SEQ ID NO: 172 en una región variable de la cadena pesada que tiene la secuencia de aminoácidos de SEQ ID NO: 50 o 112.
La sustitución de Ser en la posición 10 de la CDR2 (SEQ ID NO: 10) de la región variable de la cadena pesada de SEQ ID NO: 50 o 112 con Asp (SEQ ID NO: 177). Así, la presente descripción proporciona regiones variables de la cadena pesada en las que una CDR2 que tiene la secuencia de aminoácidos de SEQ ID NO: 10 está sustituida con una CDR2 que tiene la secuencia de aminoácidos de SEQ ID NO: 177 en una región variable de la cadena pesada que tiene la secuencia de aminoácidos de SEQ ID NO: 50 o 112.
La sustitución de Gln en la posición 13 de la CDR2 (SEQ ID NO: 10) de la región variable de la cadena pesada de SEQ ID NO: 50 o 112 con Pro (SEQ ID NO: 178). Así, la presente descripción proporciona regiones variables de la cadena pesada en las que una CDR2 que tiene la secuencia de aminoácidos de SEQ ID NO: 10 está sustituida con una CDR2 que tiene la secuencia de aminoácidos de SEQ ID NO: 178 en una región variable de la cadena pesada que tiene la secuencia de aminoácidos de SEQ ID NO: 50 o 112.
La sustitución de Tyr en la posición 3 de la CDR3 (SEQ ID NO: 11) de la región variable de la cadena pesada de SEQ ID NO: 50 o 112 con Leu (SEQ ID NO: 179). Así, la presente descripción proporciona regiones variables de la cadena pesada en las que una CDR3 que tiene la secuencia de aminoácidos de SEQ ID NO: 11 está sustituida con una CDR3 que tiene la secuencia de aminoácidos de SEQ ID NO: 179 en una región variable de la cadena pesada que tiene la secuencia de aminoácidos de SEQ ID NO: 50 o 112.
La sustitución de Met en la posición 10 de la CDR3 (SEQ ID NO: 11) de la región variable de la cadena pesada de SEQ ID NO: 50 o 112 con Leu (SEQ ID NO: 180). Así, la presente descripción proporciona regiones variables de la cadena pesada en las que una CDR3 que tiene la secuencia de aminoácidos de SEQ ID NO: 11 está sustituida con una CDR3 que tiene la secuencia de aminoácidos de SEQ ID NO: 180 en una región variable de la cadena pesada que tiene la secuencia de aminoácidos de SEQ ID NO: 50 o 112.
La sustitución de Asp en la posición 11 de la CDR3 (SEQ ID NO: 11) de la región variable de la cadena pesada de SEQ ID NO: 50 o 112 con Glu (SEQ ID NO: 181). Así, la presente descripción proporciona regiones variables de la cadena pesada en las que una CDR3 que tiene la secuencia de aminoácidos de SEQ ID NO: 11 está sustituida con una CDR3 que tiene la secuencia de aminoácidos de SEQ ID NO: 181 en una región variable de la cadena pesada que tiene la secuencia de aminoácidos de SEQ ID NO: 50 o 112.
La sustitución de Tyr en la posición 12 de la CDR3 (SEQ ID NO: 11) de la región variable de la cadena pesada de SEQ ID NO: 50 o 112 con Thr (SEQ ID NO: 182). Así, la presente descripción proporciona regiones variables de la
cadena pesada en las que una CDR3 que tiene la secuencia de aminoácidos de SEQ ID NO: 11 está sustituida con una CDR3 que tiene la secuencia de aminoácidos de SEQ ID NO: 182 en una región variable de la cadena pesada que tiene la secuencia de aminoácidos de SEQ ID NO: 50 o 112.
La sustitución de Tyr en la posición 12 de la CDR3 (SEQ ID NO: 11) de la región variable de la cadena pesada de SEQ ID NO: 50 o 112 con Ser (SEQ ID NO: 183). Así, la presente descripción proporciona regiones variables de la cadena pesada en las que una CDR3 que tiene la secuencia de aminoácidos de SEQ ID NO: 11 está sustituida con una CDR3 que tiene la secuencia de aminoácidos de SEQ ID NO: 183 en una región variable de la cadena pesada que tiene la secuencia de aminoácidos de SEQ ID NO: 50 o 112.
La sustitución de Met en la posición 10, Asp en la posición 11, y Tyr en la posición 12 de la CDR3 (SEQ ID NO: 11) de la región variable de la cadena pesada de SEQ ID NO: 50 o 112 con Leu, Glu, Thr, respectivamente (SEQ ID NO: 184). Así, la presente descripción proporciona regiones variables de la cadena pesada en las que una CDR3 que tiene la secuencia de aminoácidos de SEQ ID NO: 11 está sustituida con una CDR3 que tiene la secuencia de aminoácidos de SEQ ID NO: 184 en una región variable de la cadena pesada que tiene la secuencia de aminoácidos de SEQ ID NO: 50 o 112.
La sustitución de Asp en la posición 11 y Tyr en la posición 12 de la CDR3 (SEQ ID NO: 11) de la región variable de la cadena pesada de SEQ ID NO: 50 o 112 con Glu y Thr, respectivamente (SEQ ID NO: 185). Así, la presente descripción proporciona regiones variables de la cadena pesada en las que una CDR3 que tiene la secuencia de aminoácidos de SEQ ID NO: 11 está sustituida con una CDR3 que tiene la secuencia de aminoácidos de SEQ ID NO: 185 en una región variable de la cadena pesada que tiene la secuencia de aminoácidos de SEQ ID NO: 50 o 112.
La sustitución de Tyr en la posición 3, Asp en la posición 11, y Tyr en la posición 12 de la CDR3 (SEQ ID NO: 11) de la región variable de la cadena pesada de SEQ ID NO: 50 o 112 con Leu, Glu, y Thr, respectivamente (SEQ ID NO: 186) . Así, la presente descripción proporciona regiones variables de la cadena pesada en las que una CDR3 que tiene la secuencia de aminoácidos de SEQ ID NO: 11 está sustituida con una CDR3 que tiene la secuencia de aminoácidos de SEQ ID NO: 186 en una región variable de la cadena pesada que tiene la secuencia de aminoácidos de SEQ ID NO: 50 o 112.
La sustitución de Tyr en la posición 3, Asp en la posición 11, y Tyr en la posición 12 de la CDR3 (SEQ ID NO: 11) de la región variable de la cadena pesada de SEQ Id NO: 50 o 112 con Leu, Glu, y Ser, respectivamente (SEQ ID NO: 187) . Así, la presente descripción proporciona regiones variables de la cadena pesada en las que una CDR3 que tiene la secuencia de aminoácidos de SEQ ID NO: 11 está sustituida con una CDR3 que tiene la secuencia de aminoácidos de SEQ ID NO: 187 en una región variable de la cadena pesada que tiene la secuencia de aminoácidos de SEQ ID NO: 50 o 112.
La sustitución de Arg en la posición 1 de la CDR1 (SEQ ID NO: 13) de la región variable de la cadena ligera de SEQ ID NO: 52 con Gln (SEQ ID NO: 121). Así, la presente descripción proporciona regiones variables de la cadena ligera en las que una CDR1 que tiene la secuencia de aminoácidos de SEQ ID NO: 13 está sustituida con una CDR1 que tiene la secuencia de aminoácidos de SEQ ID NO: 121 en una región variable de la cadena ligera que tiene la secuencia de aminoácidos de SEQ ID NO: 52.
La sustitución de Asn en la posición 5 de la CDR1 (SEQ ID NO: 13) de la región variable de la cadena ligera de SEQ ID NO: 52 con Asp (SEQ ID NO: 122). Así, la presente descripción proporciona regiones variables de la cadena ligera en las que una CDR1 que tiene la secuencia de aminoácidos de SEQ ID NO: 13 está sustituida con una CDR1 que tiene la secuencia de aminoácidos de SEQ ID NO: 122 en una región variable de la cadena ligera que tiene la secuencia de aminoácidos de SEQ ID NO: 52.
La sustitución de Ser en la posición 8 de la CDR1 (SEQ ID NO: 13) de la región variable de la cadena ligera de SEQ ID NO: 52 con Arg (SEQ ID NO: 188). Así, la presente descripción proporciona regiones variables de la cadena ligera en las que una CDR1 que tiene la secuencia de aminoácidos de SEQ ID NO: 13 está sustituida con una CDR1 que tiene la secuencia de aminoácidos de SEQ ID NO: 188 en una región variable de la cadena ligera que tiene la secuencia de aminoácidos de SEQ ID NO: 52.
La sustitución de Leu en la posición 10 de la CDR1 (SEQ ID NO: 13) de la región variable de la cadena ligera de SEQ ID NO: 52 con Val (SEQ ID NO: 189). Así, la presente descripción proporciona regiones variables de la cadena ligera en las que una CDR1 que tiene la secuencia de aminoácidos de SEQ ID NO: 13 está sustituida con una CDR1 que tiene la secuencia de aminoácidos de SEQ ID NO: 189 en una región variable de la cadena ligera que tiene la secuencia de aminoácidos de SEQ ID NO: 52.
La sustitución de Ser en la posición 8 y Leu en la posición 10 de la CDR1 (SEQ ID NO: 13) de la región variable de la cadena ligera de SEQ ID NO: 52 con Arg y Val, respectivamente (SEQ ID NO: 190). Así, la presente descripción proporciona regiones variables de la cadena ligera en las que una CDR1 que tiene la secuencia de aminoácidos de SEQ ID NO: 13 está sustituida con una CDR1 que tiene la secuencia de aminoácidos de SEQ ID NO: 190 en una región variable de la cadena ligera que tiene la secuencia de aminoácidos de SEQ ID NO: 52.
La sustitución de Thr en la posición 2 de la CDR1 (SEQ ID NO: 13) de la región variable de la cadena ligera de SEQ
ID NO: 52 con Ala (SEQ ID NO: 191). Así, la presente descripción proporciona regiones variables de la cadena ligera en las que una CDR1 que tiene la secuencia de aminoácidos de SEQ ID NO: 13 está sustituida con una CDR1 que tiene la secuencia de aminoácidos de SEQ ID NO: 191 en una región variable de la cadena ligera que tiene la secuencia de aminoácidos de SEQ ID NO: 52.
La sustitución de Thr en la posición 2 de la CDR1 (SEQ ID NO: 13) de la región variable de la cadena ligera de SEQ ID NO: 52 con Ser (SEQ Id NO: 192). Así, la presente descripción proporciona regiones variables de la cadena ligera en las que una CDR1 que tiene la secuencia de aminoácidos de SEQ ID NO: 13 está sustituida con una CDR1 que tiene la secuencia de aminoácidos de SEQ ID NO: 192 en una región variable de la cadena ligera que tiene la secuencia de aminoácidos de SEQ ID NO: 52.
La sustitución de Asn en la posición 1 de la CDR2 (SEQ ID NO: 14) de la región variable de la cadena ligera de SEQ ID NO: 52 con Asp (SEQ ID NO: 123). Así, la presente descripción proporciona regiones variables de la cadena ligera en las que una CDR2 que tiene la secuencia de aminoácidos de SEQ ID NO: 14 está sustituida con una CDR2 que tiene la secuencia de aminoácidos de SEQ ID NO: 123 en una región variable de la cadena ligera que tiene la secuencia de aminoácidos de SEQ ID NO: 52.
La sustitución de Lys en la posición 3 de la CDR2 (SEQ ID NO: 14) de la región variable de la cadena ligera de SEQ ID NO: 52 con Gln (SEQ ID NO: 124). Así, la presente descripción proporciona regiones variables de la cadena ligera en las que una CDR2 que tiene la secuencia de aminoácidos de SEQ ID NO: 14 está sustituida con una CDR2 que tiene la secuencia de aminoácidos de SEQ ID NO: 124 en una región variable de la cadena ligera que tiene la secuencia de aminoácidos de SEQ ID NO: 52.
La sustitución de Leu en la posición 5 de la CDR2 (SEQ ID NO: 14) de la región variable de la cadena ligera de SEQ ID NO: 52 con Glu (SEQ ID NO: 125). Así, la presente descripción proporciona regiones variables de la cadena ligera en las que una CDR2 que tiene la secuencia de aminoácidos de SEQ ID NO: 14 está sustituida con una CDR2 que tiene la secuencia de aminoácidos de SEQ ID NO: 125 en una región variable de la cadena ligera que tiene la secuencia de aminoácidos de SEQ ID NO: 52.
La sustitución de Lys en la posición 7 de la CDR2 (SEQ ID NO: 14) de la región variable de la cadena ligera de SEQ ID NO: 52 con Gln (SEQ ID NO: 126). Así, la presente descripción proporciona regiones variables de la cadena ligera en las que una CDR2 que tiene la secuencia de aminoácidos de SEQ ID NO: 14 está sustituida con una CDR2 que tiene la secuencia de aminoácidos de SEQ ID NO: 126 en una región variable de la cadena ligera que tiene la secuencia de aminoácidos de SEQ ID NO: 52.
La sustitución de Lys en la posición 7 de la CDR2 (SEQ ID NO: 14) de la región variable de la cadena ligera de SEQ ID NO: 52 con Asp (SEQ ID NO: 127). Así, la presente descripción proporciona regiones variables de la cadena ligera en las que una CDR2 que tiene la secuencia de aminoácidos de SEQ ID NO: 14 está sustituida con una CDR2 que tiene la secuencia de aminoácidos de SEQ ID NO: 127 en una región variable de la cadena ligera que tiene la secuencia de aminoácidos de SEQ ID NO: 52.
La sustitución de Arg en la posición 1 y Asn en la posición 5 de la CDR1 (SEQ ID NO: 13) de la región variable de la cadena ligera de SEQ ID NO: 52 con Gln y Asp, respectivamente (SEQ ID NO: 169). Así, la presente descripción proporciona regiones variables de la cadena ligera en las que una CDR1 que tiene la secuencia de aminoácidos de SEQ ID NO: 13 está sustituida con una CDR1 que tiene la secuencia de aminoácidos de SEQ ID NO: 169 en una región variable de la cadena ligera que tiene la secuencia de aminoácidos de SEQ ID NO: 52.
La sustitución de Lys en la posición 3, Leu en la posición 5, y Lys en la posición 7 de la CDR2 (SEQ ID NO: 14) de la región variable de la cadena ligera de SEQ ID NO: 52 con Gln, Glu, y Gln, respectivamente (SEQ ID NO: 170). Así, la presente descripción proporciona regiones variables de la cadena ligera en las que una CDR2 que tiene la secuencia de aminoácidos de SEQ ID NO: 14 está sustituida con una CDR2 que tiene la secuencia de aminoácidos de SEQ ID NO: 170 en una región variable de la cadena ligera que tiene la secuencia de aminoácidos de SEQ ID NO: 52.
La sustitución de Glu en la posición 5 de la CDR3 (SEQ ID NO: 15) de la región variable de la cadena ligera de SEQ ID NO: 52 con Asp (SEQ ID NO: 193). Así, la presente descripción proporciona regiones variables de la cadena ligera en las que una CDR3 que tiene la secuencia de aminoácidos de SEQ ID NO: 15 está sustituida con una CDR3 que tiene la secuencia de aminoácidos de SEQ ID NO: 193 en una región variable de la cadena ligera que tiene la secuencia de aminoácidos de SEQ ID NO: 52.
La sustitución de Ser en la posición 6 de la CDR3 (SEQ ID NO: 15) de la región variable de la cadena ligera de SEQ ID NO: 52 con Asp (SEQ ID NO: 194). Así, la presente descripción proporciona regiones variables de la cadena ligera en las que una CDR3 que tiene la secuencia de aminoácidos de SEQ ID NO: 15 está sustituida con una CDR3 que tiene la secuencia de aminoácidos de SEQ ID NO: 194 en una región variable de la cadena ligera que tiene la secuencia de aminoácidos de SEQ ID NO: 52.
La sustitución de Thr en la posición 9 de la CDR3 (SEQ ID NO: 15) de la región variable de la cadena ligera de SEQ ID NO: 52 con Phe (SEQ ID NO: 195). Así, la presente descripción proporciona regiones variables de la cadena ligera en las que una CDR3 que tiene la secuencia de aminoácidos de SEQ ID NO: 15 está sustituida con una CDR3
que tiene la secuencia de aminoácidos de SEQ ID NO: 195 en una región variable de la cadena ligera que tiene la
secuencia de aminoácidos de SEQ ID NO: 52.
Además, las sustituciones distintas de las descritas anteriormente incluyen una sustitución de Arg en la posición 3 de
una FR2 de la cadena pesada que tiene la secuencia de aminoácidos de SEQ ID NO: 97 con otro aminoácido. El
aminoácido después de la sustitución no está limitado en particular; pero los ejemplos preferidos del mismo incluyen
Gln. Cuando la Arg de la posición 3 en SEQ ID NO: 97 se ha sustituido con Gln, la Ala de la posición 5 se puede
sustituir con Ser para producir una secuencia FR2 humana. La secuencia de aminoácidos en la que Arg y Ala en las
posiciones 3 y 5 de la secuencia de aminoácidos de SEQ ID NO: 97 se han sustituido con Gln y Ser,
respectivamente, se muestra en SEQ ID NO: 120. Así, la presente descripción proporciona regiones variables de la
cadena pesada en las que una FR2 que tiene la secuencia de aminoácidos de SEQ ID NO: 97 está sustituida con
una FR2 que tiene la secuencia de aminoácidos de SEQ ID NO: 120 en una región variable de la cadena pesada
que tiene la secuencia de aminoácidos de SEQ ID NO: 50 o 112.
Cada una de las sustituciones de aminoácidos anteriormente descritas se pueden usar solas o en combinación con
otras sustituciones de aminoácidos descritas anteriormente. También se pueden combinar con sustituciones de
aminoácidos distintas de las descritas anteriormente.
Los ejemplos específicos de los anticuerpos en los que las sustituciones anteriormente descritas se han llevado a
cabo incluyen, por ejemplo, los anticuerpos que comprenden una región variable de la cadena pesada que tiene la
secuencia de aminoácidos de SEQ ID NO: 167, los anticuerpos que comprenden una región variable de la cadena
ligera que tiene la secuencia de aminoácidos de SEQ ID NO: 168, y los anticuerpos que comprenden una región
variable de la cadena pesada que tiene la secuencia de aminoácidos de SEQ ID NO: 167 y una región variable de la
cadena ligera que tiene la secuencia de aminoácidos de SEQ ID NO: 168.
Además, los ejemplos específicos de las regiones variables de la cadena pesada en las que se han llevado a cabo
las sustituciones anteriormente descritas incluyen, por ejemplo, las regiones variables de la cadena pesada
siguientes:
(1) las regiones variables de la cadena pesada que tienen la secuencia de aminoácidos de SEQ ID NO: 204 (H17);
(2) las regiones variables de la cadena pesada que tienen la secuencia de aminoácidos de SEQ ID NO: 205 (H19);
(3) las regiones variables de la cadena pesada que tienen la secuencia de aminoácidos de SEQ ID NO: 206 (H28);
(4) las regiones variables de la cadena pesada que tienen la secuencia de aminoácidos de SEQ ID NO: 207 (H30);
(5) las regiones variables de la cadena pesada que tienen la secuencia de aminoácidos de SEQ ID NO: 208 (H34);
(6) las regiones variables de la cadena pesada que tienen la secuencia de aminoácidos de SEQ ID NO: 209 (H42);
(7) las regiones variables de la cadena pesada que tienen la secuencia de aminoácidos de SEQ ID NO: 210 (H44);
(8) las regiones variables de la cadena pesada que tienen la secuencia de aminoácidos de SEQ ID NO: 211 (H46);
(9) las regiones variables de la cadena pesada que tienen la secuencia de aminoácidos de SEQ ID NO: 212 (H57);
(10) las regiones variables de la cadena pesada que tienen la secuencia de aminoácidos de SEQ ID NO: 213 (H71) (11) las regiones variables de la cadena pesada que tienen la secuencia de aminoácidos de SEQ
ID NO: 213 (H71) (11) las regiones variables de la cadena pesada que tienen la secuencia de aminoácidos de SEQ ID NO: 214 (H78) (12) las regiones variables de la cadena pesada que tienen la secuencia de aminoácidos de SEQ
ID NO: 214 (H78) (12) las regiones variables de la cadena pesada que tienen la secuencia de aminoácidos de SEQ ID NO: 215 (H92) (13) las regiones variables de la cadena pesada que tienen la secuencia de aminoácidos de SEQ ID NO: 216 (H97); y
ID NO: 215 (H92) (13) las regiones variables de la cadena pesada que tienen la secuencia de aminoácidos de SEQ ID NO: 216 (H97); y
(14) las regiones variables de la cadena pesada que tienen la secuencia de aminoácidos de SEQ ID NO: 217 (H98) Mientras tanto, los ejemplos específicos de las regiones variables de la cadena ligera en las que se han llevado a
ID NO: 217 (H98) Mientras tanto, los ejemplos específicos de las regiones variables de la cadena ligera en las que se han llevado a
cabo las sustituciones anteriormente descritas incluyen, por ejemplo, las regiones variables de la cadena ligera
siguientes:
(15) las regiones variables de la cadena ligera que tienen la secuencia de aminoácidos de SEQ ID NO: 218 (L11);
(16) las regiones variables de la cadena ligera que tienen la secuencia de aminoácidos de SEQ ID NO: 219 (L12);
(17) las regiones variables de la cadena ligera que tienen la secuencia de aminoácidos de SEQ ID NO: 220 (L17); y
(18) las regiones variables de la cadena ligera que tienen la secuencia de aminoácidos de SEQ ID NO: 221 (L50).
Además, los ejemplos específicos de los anticuerpos que comprenden las regiones variables de la cadena pesada y
de la cadena ligera anteriormente descritas incluyen, por ejemplo, los anticuerpos siguientes:
(19) los anticuerpos que comprenden la región variable de la cadena pesada de (3) y la región variable de la cadena ligera de (17) (H28L17);
(20) los anticuerpos que comprenden la región variable de la cadena pesada de (4) y la región variable de la cadena ligera de (17) (H30L17);
(21) los anticuerpos que comprenden la región variable de la cadena pesada de (5) y la región variable de la cadena ligera de (17) (H34L17);
(22) los anticuerpos que comprenden la región variable de la cadena pesada de (6) y la región variable de la cadena ligera de (17) (H42L17);
(23) los anticuerpos que comprenden la región variable de la cadena pesada de (7) y la región variable de la cadena ligera de (17) (H44L17);
(24) los anticuerpos que comprenden la región variable de la cadena pesada de (8) y la región variable de la cadena ligera de (17) (H46L17);
(25) los anticuerpos que comprenden la región variable de la cadena pesada de (9) y la región variable de la cadena ligera de (17) (H57L17);
(26) los anticuerpos que comprenden la región variable de la cadena pesada de (10) y la región variable de la cadena ligera de (17) (H71L17);
(27) los anticuerpos que comprenden la región variable de la cadena pesada de (11 ) y la región variable de la cadena ligera de (17) (H78L17);
(28) los anticuerpos que comprenden la región variable de la cadena pesada de (12) y la región variable de la cadena ligera de (17) (H92L17);
(29) los anticuerpos que comprenden la región variable de la cadena pesada de (13) y la región variable de la cadena ligera de (18) (H97L50); y
(30) los anticuerpos que comprenden la región variable de la cadena pesada de (14) y la región variable de la cadena ligera de (18) (H98L50);
La región constante usada para los anticuerpos humanizados de la presente invención puede ser cualquier región constante derivada de un anticuerpo humano. Los ejemplos preferidos de tales regiones constantes derivadas de anticuerpos humanos incluyen, por ejemplo, las regiones constantes derivadas de IgG1 o IgG2. Además, también se pueden usar regiones constantes en las que uno o más aminoácidos están sustituidos, delecionados, añadidos, y/o insertados en la región constante derivada de un anticuerpo humano.
Las regiones constantes en las que uno o más aminoácidos están sustituidos, delecionados, añadidos, y/o insertados en la región constante derivada de un anticuerpo humano no están limitadas en particular, e incluyen, por ejemplo, las regiones constantes siguientes:
las regiones constantes que tienen la secuencia de aminoácidos de SEQ ID NO: 128 (M58);
las regiones constantes que tienen la secuencia de aminoácidos de SEQ ID NO: 129 (M14); y
las regiones constantes que tienen la secuencia de aminoácidos de SEQ ID NO: 62 (SKSC).
Los ejemplos específicos de las cadenas pesadas o anticuerpos que tienen las regiones constantes anteriormente descritas incluyen, por ejemplo:
(1) las cadenas pesadas que comprenden una región variable que tiene la secuencia de aminoácidos de SEQ ID NO: 167 y una región constante que tiene la secuencia de aminoácidos de SEQ ID NO: 128;
(2) las cadenas pesadas en las que una CDR2 que tiene la secuencia de aminoácidos de SEQ ID NO: 171 en las cadenas pesadas de (1) está sustituida con una CDR2 que tiene la secuencia de aminoácidos de SEQ ID NO: 172; (3) los anticuerpos que comprenden la cadena pesada de (1) y una cadena ligera que tiene la secuencia de aminoácidos de SEQ ID NO: 152; y
(4) los anticuerpos que comprenden la cadena pesada de (2) y una cadena ligera que tiene la secuencia de aminoácidos de SEQ ID NO: 152.
Los ejemplos más específicos de los anticuerpos anti-NR10 humanizados de la presente descripción incluyen, por
ejemplo, los anticuerpos siguientes:
(k) los anticuerpos que comprenden una cadena pesada que tiene la secuencia de aminoácidos de SEQ ID NO: 54 (H0-VH región constante);
(l) los anticuerpos que comprenden una cadena pesada que tiene la secuencia de aminoácidos de SEQ ID NO: 130 (H1-VH región constante);
(m) los anticuerpos que comprenden una cadena ligera que tiene la secuencia de aminoácidos de SEQ ID NO: 56 (L0-VL región constante);
(n) los anticuerpos que comprenden una cadena pesada que tiene la secuencia de aminoácidos de SEQ ID NO: 54 (H0-VH región constante) y una cadena ligera que tiene la secuencia de aminoácidos de SEQ ID NO: 56 (L0-VL región constante); y
(o) los anticuerpos que comprenden una cadena pesada que tiene la secuencia de aminoácidos de SEQ ID NO: 130 (H1-VH región constante) y una cadena ligera que tiene la secuencia de aminoácidos de SEQ ID NO: 56 (L0-VL región constante).
La cadena pesada que tiene la secuencia de aminoácidos de SEQ ID NO: 54 (H0-VH región constante) y la cadena ligera que tiene la secuencia de aminoácidos de SEQ ID NO: 56 (L0-VL región constante) pueden tener una sustitución, deleción, adición, y/o inserción de uno o más aminoácidos. La sustitución, deleción, adición, y/o inserción de aminoácidos se puede llevar a cabo en una o ambas regiones variables y constantes.
Así, la presente descripción proporciona:
(f) los anticuerpos que comprenden una cadena pesada que tiene una secuencia de aminoácidos en la que uno o más aminoácidos están sustituidos, delecionados, añadidos, y/o insertados en la secuencia de aminoácidos de SEQ ID NO: 54 (H0-VH región constante);
(q) los anticuerpos que comprenden una cadena pesada que tiene una secuencia de aminoácidos en la que uno o más aminoácidos están sustituidos, delecionados, añadidos, y/o insertados en la secuencia de aminoácidos de SEQ ID NO: 130 (H1-VH región constante);
(r) los anticuerpos que comprenden una cadena ligera que tiene una secuencia de aminoácidos en la que uno o más aminoácidos están sustituidos, delecionados, añadidos, y/o insertados en la secuencia de aminoácidos de SEQ ID NO: 56 (L0-VL región constante);
(s) los anticuerpos que comprenden una cadena pesada que tiene una secuencia de aminoácidos en la que uno o más aminoácidos están sustituidos, delecionados, añadidos, y/o insertados en la secuencia de aminoácidos de SEQ ID NO: 54 (H0-VH región constante) y una cadena ligera que tiene una secuencia de aminoácidos en la que uno o más aminoácidos están sustituidos, delecionados, añadidos, y/o insertados en la secuencia de aminoácidos de SEQ ID NO: 56 (L0-VL región constante); y
(t) los anticuerpos que comprenden una cadena pesada que tiene una secuencia de aminoácidos en la que uno o más aminoácidos están sustituidos, delecionados, añadidos, y/o insertados en la secuencia de aminoácidos de SEQ ID NO: 130 (H1-VH región constante) y una cadena ligera que tiene una secuencia de aminoácidos en la que uno o más aminoácidos están sustituidos, delecionados, añadidos, y/o insertados en la secuencia de aminoácidos de SEQ ID NO: 56 (L0-VL región constante).
Sin una limitación particular, los anticuerpos de cualquiera de (p) a (t) tienen preferiblemente una actividad similar a la de los anticuerpos de cualquiera de (k) a (o).
La sustitución, deleción, adición, y/o inserción de aminoácidos no están limitadas en particular, y los ejemplos específicos de las mismas incluyen, por ejemplo, las sustituciones de aminoácidos anteriormente descritas.
Además, la secuencia de nucleótidos que codifica la secuencia de aminoácidos de la región variable de la cadena pesada humanizada anteriormente descrita (SEQ ID NO: 50) se muestra en SEQ ID NO: 49. La secuencia de nucleótidos que codifica la secuencia de aminoácidos de la región variable de la cadena ligera humanizada (SEQ ID NO: 52) se muestra en SEQ ID NO: 51. La secuencia de nucleótidos que codifica la secuencia de aminoácidos de la cadena pesada humanizada (SEQ ID NO: 54) se muestra en SEQ ID NO: 53. La secuencia de nucleótidos que codifica la secuencia de aminoácidos de la cadena ligera humanizada (SEQ ID NO: 56) se muestra en SEQ ID NO: 55.
Además, la presente descripción proporciona anticuerpos que reconocen el mismo epítopo que el reconocido por los anticuerpos de cualquiera de (a) a (t) anteriores. La unión al mismo epítopo es como ya se describió anteriormente.
Además, la presente descripción proporciona los anticuerpos siguientes:
(u) los anticuerpos que comprenden una cadena pesada que tiene la secuencia de aminoácidos de SEQ ID NO: 151;
(v) los anticuerpos que comprenden una cadena ligera que comprende la secuencia de aminoácidos de SEQ ID NO:
152; y
(w) los anticuerpos que comprenden la cadena pesada de (u) y la cadena ligera de (v).
Además, la presente descripción proporciona las siguientes cadenas pesadas y ligeras y anticuerpos:
(1) las cadenas pesadas que tienen la secuencia de aminoácidos de SEQ  : 222 (H17);
: 222 (H17);
(2) las cadenas pesadas que tienen la secuencia de aminoácidos de SEQ  : 223 (H19);
: 223 (H19);
(3) las cadenas pesadas que tienen la secuencia de aminoácidos de SEQ  : 224 (H28);
: 224 (H28);
(4) las cadenas pesadas que tienen la secuencia de aminoácidos de SEQ  : 225 (H30);
: 225 (H30);
(5) las cadenas pesadas que tienen la secuencia de aminoácidos de SEQ  : 226 (H34);
: 226 (H34);
(6) las cadenas pesadas que tienen la secuencia de aminoácidos de SEQ  : 227 (H42);
: 227 (H42);
(7) las cadenas pesadas que tienen la secuencia de aminoácidos de SEQ  : 228 (H44);
: 228 (H44);
(8) las cadenas pesadas que tienen la secuencia de aminoácidos de SEQ  : 229 (H46);
: 229 (H46);
(9) las cadenas pesadas que tienen la secuencia de aminoácidos de SEQ  : 230 (H57);
: 230 (H57);
(10) las cadenas pesadas que tienen la  secuencia de aminoácidos de SEQ ID NO: 231 (H71);
secuencia de aminoácidos de SEQ ID NO: 231 (H71);
(11) las cadenas pesadas que tienen la secuencia de aminoácidos de SEQ ID NO: 232 (H78); (12) las cadenas pesadas que tienen la secuencia de aminoácidos de SEQ ID NO: 233 (H92); (13) las cadenas pesadas que tienen la secuencia de aminoácidos de SEQ ID NO: 234 (H97); (14) las cadenas pesadas que tienen la secuencia de aminoácidos de SEQ ID NO: 235 (H98); (15) las cadenas ligeras que tienen la secuencia de aminoácidos de SEQ ID NO: 236 (L11);
(16) las cadenas ligeras que tienen la secuencia de aminoácidos de SEQ ID NO: 237 (L12);
(17) las cadenas ligeras que tienen la secuencia de aminoácidos de SEQ ID NO: 238 (L17);
(18) las cadenas ligeras que tienen la secuencia de aminoácidos de SEQ I O: 239 (L50);
O: 239 (L50);
(19) los anticuerpos que comprenden la cadena pesada de (3) y la cadena ligera de (17) (H28L17);
(20) los anticuerpos que comprenden la cadena pesada de (4) y la cadena ligera de (17) (H30L17);
(21) los anticuerpos que comprenden la cadena pesada de (5) y la cadena ligera de (17) (H34L17);
(22) los anticuerpos que comprenden la cadena pesada de (6) y la cadena ligera de (17) (H42L17);
(23) los anticuerpos que comprenden la cadena pesada de (7) y la cadena ligera de (17) (H44L17);
(24) los anticuerpos que comprenden la cadena pesada de (8) y la cadena ligera de (17) (H46L17);
(25) los anticuerpos que comprenden la cadena pesada de (9) y la cadena ligera de (17) (H57L17);
(26) los anticuerpos que comprenden la cadena pesada de (10) y la cadena ligera de (17) (H71L17);
(27) los anticuerpos que comprenden la cadena pesada de (11) y la cadena ligera de (17) (H78L17);
(28) los anticuerpos que comprenden la cadena pesada de (12) y la cadena ligera de (17) (H92L17);
(29) los anticuerpos que comprenden la cadena pesada de (13) y la cadena ligera de (18) (H97L50);
(30) los anticuerpos que comprenden la cadena pesada de (14) y la cadena ligera de (18) (H98L50);
(31) las cadenas pesadas que tienen una secuencia de aminoácidos en la que uno o más aminoácidos están
sustituidos, delecionados, añadidos y/o insertados en las cadenas pesadas de cualquiera de (1) a (14);
(32) las cadenas ligeras que tienen una secuencia de aminoácidos en la que uno o más aminoácidos están
sustituidos, delecionados, añadidos y/o insertados en las cadenas ligeras de cualquiera de (15) a (18);
(33) los anticuerpos que tienen una secuencia de aminoácidos en la que uno o más aminoácidos están sustituidos, delecionados, añadidos y/o insertados en los anticuerpos de cualquiera de (19) a (30); y
(34) los anticuerpos que reconocen el mismo epítopo que el reconocido por los anticuerpos de cualquiera de (19) a (33). La sustitución, deleción, adición, y/o inserción de aminoácidos son como se describió anteriormente. También se describieron anteriormente los anticuerpos que reconocen el mismo epítopo que el reconocido por un anticuerpo. La presente descripción también proporciona los genes que codifican las regiones variables, las cadenas pesadas, las cadenas ligeras, o los anticuerpos descritos en la presente memoria.
La presente descripción también proporciona vectores que portan los genes anteriormente descritos.
La presente descripción también proporciona células hospedadoras transformadas con los vectores anteriormente descritos.
La presente descripción también se refiere a los métodos para producir las regiones variables, las cadenas pesadas, las cadenas ligeras, o los anticuerpos descritos en la presente memoria, que comprenden la etapa de cultivar las células hospedadoras anteriormente descritas.
Los vectores, las células hospedadoras, y el cultivo de células hospedadoras se describen más adelante en la presente memoria.
Anticuerpos que reconocen dominios
Las realizaciones preferidas del anticuerpo anti-NR10 de la presente descripción incluyen los anticuerpos que reconocen el dominio 1 o el dominio 2. En la presente invención, el dominio 1 se refiere a la región de aminoácidos en las posiciones 21 a 120 (LPAKP a LENIA) de la secuencia de aminoácidos de NR10 humano de SEQ ID NO: 76, en la que la numeración de los aminoácidos se basa en la secuencia que incluye el péptido señal. Además, en la presente descripción, el dominio 2 se refiere a la región de aminoácidos en las posiciones 121 a 227 (KTEPP a EEEAP) de la secuencia de aminoácidos de NR10 humano de SEQ ID NO: 76, en la que la numeración de los aminoácidos se basa en la secuencia que incluye el péptido señal.
Tales anticuerpos no están limitados en particular; sin embargo, en general, tienen una actividad neutralizante, y preferiblemente son anticuerpos humanizados.
Los ejemplos de los anticuerpos preferidos en la presente descripción incluyen los anticuerpos que reconocen el dominio 1. Los anticuerpos que reconocen el dominio 1 tienen una actividad neutralizante intensa, y así son especialmente útiles como productos farmacéuticos.
Anticuerpos (actividad neutralizante)
La presente descripción también proporciona anticuerpos anti-NR10 que tienen una actividad neutralizante.
En la presente invención, la actividad neutralizante hacia NR10 se refiere a una actividad de inhibición de la unión entre NR10 y su ligando IL-31, y preferiblemente una actividad de inhibición de una actividad biológica basada en NR10.
Los anticuerpos que tienen una actividad neutralizante hacia NR10 se pueden seleccionar, por ejemplo, añadiendo anticuerpos candidatos a una línea celular dependiente de IL-31 y observando su efecto inhibidor del crecimiento sobre la línea celular. En este método, los anticuerpos que inhiben el crecimiento de la línea celular dependiente de IL-31 se determinan como anticuerpos que tienen una actividad neutralizante hacia NR10.
Anticuerpos (general)
Los anticuerpos de la presente descripción no están limitados con respecto a su origen, y se pueden obtener de cualquier animal, tal como seres humanos, ratones, y ratas. Además, los anticuerpos pueden ser anticuerpos recombinantes tales como anticuerpos quiméricos y anticuerpos humanizados. Como se describió anteriormente, los anticuerpos preferidos de la presente invención incluyen anticuerpos humanizados.
Los anticuerpos quiméricos contienen, por ejemplo, las regiones constantes de la cadena pesada y ligera de un anticuerpo humano, y las regiones variables de la cadena pesada y ligera de un anticuerpo de un mamífero no humano, tal como un ratón. Los anticuerpos quiméricos se pueden producir mediante métodos conocidos. Por ejemplo, los anticuerpos se pueden producir clonando un gen de un anticuerpo a partir de hibridomas, insertándolo en un vector adecuado, e introduciendo la construcción en hospedadores (véase, por ejemplo, Carl, A. K. Borrebaeck, James, W. Larrick, THERAPEUTIC MONOCLONAL a Nt IBODIES, publicado en el Reino Unido por MACMILLAN PUBLISHERS LTD, 1990). De manera específica, se sintetizan cADNs de las regiones variables (regiones V) de un anticuerpo a partir del mARN de hibridomas mediante el uso de una transcriptasa inversa. Una vez que se obtienen ADNs que codifican las regiones V de un anticuerpo de interés, se unen a ADNs que codifican las regiones constantes (regiones C) de un anticuerpo humano deseado. Las construcciones resultantes se insertan
en vectores de expresión. De manera alternativa, los ADNs que codifican las regiones V de un anticuerpo se pueden insertar en vectores de expresión que comprenden ADNs que codifican las regiones C de un anticuerpo humano. Los ADNs se insertan en vectores de expresión de forma que se expresan bajo la regulación de las regiones reguladoras de la expresión, por ejemplo, potenciadores y promotores. En la siguiente etapa, se pueden transformar células hospedadoras con los vectores de expresión para permitir la expresión de los anticuerpos quiméricos.
También se conocen métodos para obtener anticuerpos humanos. Por ejemplo, se pueden obtener anticuerpos humanos deseados con actividad de unión al antígeno (1) sensibilizando linfocitos humanos con los antígenos de interés o células que expresan los antígenos de interés in vitro; y (2) fusionando los linfocitos sensibilizados con células de mieloma humano tales como U266 (véase la Solicitud de Patente Japonesa (Publicación Kokoku) N° (JP-13) H01-59878 (solicitud de patente japonesa examinada y aprobada, publicada para oposición)). De manera alternativa, el anticuerpo humano deseado se puede obtener también inmunizando un animal transgénico que tiene un repertorio completo de genes de anticuerpos humanos con un antígeno deseado (véanse las Publicaciones de Solicitudes de Patentes Internacionales N2s WO 93/12227, WO 92/03918, WO 94/02602, WO 94/25585, WO 96/34096, y WO 96/33735).
Además, se conocen las técnicas para obtener anticuerpos humanos mediante cribado con una biblioteca de expresión en fagos de anticuerpos humanos. Por ejemplo, la región variable de un anticuerpo humano se expresa en forma de un anticuerpo de cadena simple (scFv) sobre la superficie de un fago, mediante el uso de un método de expresión en fagos, y se pueden seleccionar los fagos que se unen al antígeno. Analizando los genes de los fagos seleccionados, se pueden determinar las secuencias de ADN que codifican las regiones variables de los anticuerpos humanos que se unen al antígeno. Si se identifican las secuencias de ADN de los scFvs que se unen al antígeno, se pueden construir vectores de expresión adecuados que comprenden estas secuencias para obtener anticuerpos humanos. Tales métodos son muy conocidos. Se puede hacer referencia a los documentos WO 92/01047, WO 92/20791, WO 93/06213, WO 93/11236, WO 93/19172, WO 95/01438, WO 95/15388, y similares.
Los anticuerpos de la presente descripción incluyen no solamente anticuerpos divalentes tal como representa IgG, sino también anticuerpos monovalentes, anticuerpos multivalentes representados por IgM, y anticuerpos biespecíficos capaces de unirse a antígenos diferentes, con tal de que tengan una actividad de unión a NR10 y/o actividad neutralizante. Los anticuerpos multivalentes de la presente descripción incluyen anticuerpos multivalentes en los que todos los sitios de unión al antígeno son idénticos, y anticuerpos multivalentes en los que todos o algunos de los sitios de unión al antígeno son diferentes. Los anticuerpos de la presente invención no se limitan a las moléculas de anticuerpos de longitud completa, sino que también pueden ser anticuerpos de bajo peso molecular o productos modificados de los mismos, con tal de que se unan a la proteína NR10.
De manera alternativa, los anticuerpos de la presente descripción pueden ser anticuerpos de bajo peso molecular. Tales anticuerpos de bajo peso molecular son anticuerpos que incluyen fragmentos de anticuerpos que carecen de algunas porciones de un anticuerpo completo (por ejemplo, IgG completa), y no están limitados en particular, con tal de que conserven la actividad de unión y/o neutralizante hacia NR10. En la presente descripción, los anticuerpos de bajo peso molecular no están limitados en particular, con tal de que contengan una porción de los anticuerpos completos. Los anticuerpos de bajo peso molecular contienen preferiblemente una región variable de la cadena pesada (VH) o una región variable de la cadena ligera (VL). Los anticuerpos de bajo peso molecular especialmente preferidos contienen tanto VH como VL. Además, los ejemplos preferidos de los anticuerpos de bajo peso molecular de la presente descripción incluyen anticuerpos de bajo peso molecular que contienen las CDRs de un anticuerpo. Las CDRs contenidas en los anticuerpos de bajo peso molecular pueden incluir algunas CDRs o las seis CDRs de un anticuerpo.
Los anticuerpos de bajo peso molecular de la presente descripción tienen preferiblemente un peso molecular más pequeño que los anticuerpos completos. Sin embargo, los anticuerpos de bajo peso molecular pueden formar multímeros, por ejemplo, dímeros, trímeros, o tetrámeros, y así sus pesos moleculares pueden ser mayores que los de los anticuerpos completos.
Los ejemplos específicos de los fragmentos de anticuerpos incluyen, por ejemplo, Fab, Fab', F(ab')2, y Fv. Mientras tanto, los ejemplos específicos de los anticuerpos de bajo peso molecular incluyen, por ejemplo, Fab, Fab', F(ab')2, Fv, scFv (Fv de cadena simple), diacuerpos, y sc(Fv)2 ((Fv)2 de cadena simple). También se incluyen los multímeros (por ejemplo, dímeros, trímeros, tetrámeros, y polímeros) de estos anticuerpos en los anticuerpos de bajo peso molecular.
Los fragmentos de anticuerpos se pueden obtener, por ejemplo, tratando anticuerpos con enzimas para producir fragmentos de anticuerpos. Las enzimas que se sabe que generan fragmentos de anticuerpos incluyen, por ejemplo, papaína, pepsina, y plasmina. De manera alternativa, se puede construir un gen que codifica tal fragmento de anticuerpo, introducirlo en un vector de expresión, y expresarlo en células hospedadoras adecuadas (véase, por ejemplo, Co, M.S. et al., J. Immunol. (1994)152, 2968-2976; Better, M. y Horwitz, A. H. Methods in Enzymology (1989)178, 476-496; Plueckthun, A. y Skerra, A. Methods in Enzymology (1989)178, 476-496; Lamoyi, E., Methods in Enzymology (1989)121, 652-663; Rousseaux, J. et al., Methods in Enzymology (1989)121,663-669; Bird, R. E. et al., TIBTECH (1991)9, 132-137).
Las enzimas digestivas escinden un sitio específico de un fragmento de anticuerpo, lo que produce fragmentos de
anticuerpos de las estructuras específicas mostradas más adelante. Se pueden aplicar técnicas de ingeniería genética a tales fragmentos de anticuerpos obtenidos enzimáticamente para delecionar una porción arbitraria del anticuerpo.
Los fragmentos de anticuerpos obtenidos mediante el uso de las enzimas digestivas anteriormente descritas son los siguientes:
Digestión con papaína: F(ab)2 o Fab
Digestión con pepsina: F(ab')2 o Fab'
Digestión con plasmina: Facb
Los anticuerpos de bajo peso molecular de la presente descripción incluyen fragmentos de anticuerpo que carecen de una región arbitraria, con tal de que tengan una actividad de unión y/o neutralizante hacia NR10.
"Diacuerpo" se refiere a un fragmento de anticuerpo bivalente construido mediante fusión génica (Holliger P et al., Proc. Natl. Acad. Sci. USA 90: 6444-6448 (1993); documento EP 404.097; documento WO 93/11161, etc.). Los diacuerpos son dímeros compuestos de dos cadenas polipeptídicas. En cada una de las cadenas polipeptídicas que forman un dímero, una VL y una VH están unidas normalmente por un conector en la misma cadena. En general, el conector en un diacuerpo es lo suficientemente corto como para que las VL y VH no se puedan unir entre sí. De manera específica, el número de residuos de aminoácidos que constituyen el conector es, por ejemplo, de alrededor de cinco residuos. Así, las VL y VH codificadas en el mismo polipéptido no pueden formar un fragmento de región variable de cadena simple, y formarán un dímero con otro fragmento de región variable de cadena simple. Como resultado, el diacuerpo tiene dos sitios de unión al antígeno.
Los anticuerpos ScFv son polipéptidos de cadena simple producidos mediante la unión de una región variable de la cadena pesada ([VH]) y una región variable de la cadena ligera ([VL]) por medio de un conector o similar (Huston, J. S. et al., Proc. Natl. Acad. Sci. U.S.A. (1988) 85, 5879-5883; Pluckthun "The Pharmacology of Monoclonal Antibodies" Vol. 113, eds., Resenburg y Moore, Springer Verlag, Nueva York, págs. 269-315, (1994)). La región V de la cadena H y la región V de la cadena L de scFv se pueden obtener de cualquier anticuerpo descrito en la presente memoria. El conector peptídico para unir las regiones V no está limitado en particular. Por ejemplo, se puede usar un péptido de cadena simple arbitrario que contiene alrededor de tres a 25 residuos como conector. De manera específica, es posible usar los conectores peptídicos o similares descritos más adelante.
Las regiones V de ambas cadenas se pueden unir, por ejemplo, mediante PCR como se describió anteriormente. Primero, entre los ADNs siguientes, se usa un ADN que codifica una secuencia de aminoácidos completa o parcial deseada como molde para unir las regiones V mediante PCR:
la secuencia de ADN que codifica una cadena H o región V de la cadena H de un anticuerpo, y
la secuencia de ADN que codifica una cadena L o región V de la cadena L de un anticuerpo.
Los ADNs que codifican las regiones V de la cadena H y de la cadena L se amplifican mediante PCR con el uso de un par de cebadores que tienen secuencias que corresponden a los dos extremos del ADN a amplificar. Después, se prepara un ADN que codifica la porción del conector peptídico. El ADN que codifica el conector peptídico también se puede sintetizar mediante PCR. En la presente memoria, las secuencias de nucleótidos que se pueden ligar a los productos de amplificación de las regiones V sintetizadas por separado se añaden al extremo 5' de los cebadores a usar. Después, se lleva a cabo una PCR mediante el uso de cada ADN de [ADN de la región V de la cadena H] -[ADN del conector peptídico] -[ADN de la región V de la cadena L], y cebadores de PCR de ensamblaje.
Los cebadores de PCR de ensamblaje están compuestos de una combinación de un cebador que hibrida al extremo 5' del [ADN de la región V de la cadena H] y un cebador que hibrida al extremo 3' del [ADN de la región V de la cadena L]. En otras palabras, los cebadores de PCR de ensamblaje son un grupo de cebadores que se pueden usar para amplificar un ADN que codifica la secuencia de longitud completa de scFv a sintetizar. Mientras tanto, se han añadido las secuencias de nucleótidos que se pueden ligar a los ADNs de la región V al [ADN del conector peptídico]. Así, estos ADNs se unen entre sí, y después se genera finalmente el scFv completo como producto de amplificación mediante los cebadores de PCR de ensamblaje. Una vez se generan ADNs que codifican el scFv, se pueden obtener vectores de expresión que portan estos ADNs y células recombinantes transformadas con estos vectores de expresión mediante métodos convencionales. Además, el scFv se puede obtener cultivando las células recombinantes resultantes para que expresen los ADNs que codifican el scFv.
El orden de las regiones variables de la cadena pesada y de la cadena ligera a unirse entre sí no está limitado en particular, y se pueden disponer en cualquier orden. Los ejemplos de la disposición se enumeran a continuación.
[VH] conector [VL]
[VL] conector [VH]
sc(Fv)2 es un anticuerpo de bajo peso molecular de cadena simple producido uniendo dos VHs y dos VLs mediante el uso de conectores y similares (Hudson et al., J Immunol. Methods 1999; 231: 177-189). Por ejemplo, se puede producir un sc(Fv)2 uniendo scFvs por medio de un conector.
Se prefieren los anticuerpos en los que dos VHs y dos VLs están dispuestas en el orden VH-VL-VH-VL ([VH] conector [VL] conector [VH] conector [VL]) desde el extremo N-terminal del polipéptido de cadena simple. Sin embargo, el orden de las dos VHs y de las dos VLs no se limita a la disposición anterior, y pueden estar dispuestas en cualquier orden. Los ejemplos de la disposición se enumeran a continuación:
[VL] conector [VH] conector [VH] conector [VL]
[VH] conector [VL] conector [VL] conector [VH]
[VH] conector [VH] conector [VL] conector [VL]
[VL] conector [VL] conector [VH] conector [VH]
[VL] conector [VH] conector [VL] conector [VH]
La secuencia de aminoácidos de la región variable de la cadena pesada o de la región variable de la cadena ligera en un anticuerpo de bajo peso molecular puede contener una sustitución, deleción, adición, y/o inserción. Además, la región variable de la cadena pesada y la región variable de la cadena ligera también pueden carecer de algunas porciones o tener añadidos otros polipéptidos, con tal de que tengan la capacidad de unirse al antígeno cuando se unen entre sí. De manera alternativa, las regiones variables se pueden quimerizar o humanizar.
En la presente descripción, los conectores que se unen a las regiones variables del anticuerpo incluyen conectores peptídicos arbitrarios que se pueden introducir mediante el uso de ingeniería genética, o conectores sintéticos tales como los descritos en Protein Engineering, 9(3), 299-305, 1996.
Los conectores preferidos en la presente descripción son conectores peptídicos. Las longitudes de los conectores peptídicos no están limitadas en particular, y los expertos en la técnica pueden seleccionar de manera adecuada las longitudes dependiendo del propósito. Las longitudes típicas son de uno a 100 aminoácidos, preferiblemente 3 a 50 aminoácidos, más preferiblemente 5 a 30 aminoácidos, y en particular preferiblemente 12 a 18 aminoácidos (por ejemplo, 15 aminoácidos).
Las secuencias de aminoácidos de tales conectores peptídicos incluyen, por ejemplo:
Ser;
Gly-Ser;
Gly-Gly-Ser;
Ser-Gly-Gly;
Gly-Gly-Gly-Ser (SEQ ID NO: 82);
Ser-Gly-Gly-Gly (SEQ ID NO: 83);
Gly-Gly-Gly-Gly-Ser (SEQ ID NO: 84);
Ser-Gly-Gly-Gly-Gly (SEQ ID NO: 85);
Gly-Gly-Gly-Gly-Gly-Ser (SEQ ID NO: 86);
Ser-Gly-Gly-Gly-Gly-Gly (SEQ ID NO: 87);
Gly-Gly-Gly-Gly-Gly-Gly-Ser (SEQ ID NO: 88);
Ser-Gly-Gly-Gly-Gly-Gly-Gly (SEQ ID NO: 89);
(Gly-Gly-Gly-Gly-Ser (SEQ ID NO: 84))n; y
(Ser-Gly-Gly-Gly-Gly (SEQ ID NO: 85))n,
en las que n es un número entero de 1 o mayor.
Los expertos en la técnica pueden seleccionar de manera adecuada la secuencia de aminoácidos del conector peptídico dependiendo del propósito. Por ejemplo, la "n" mencionada anteriormente, que determina la longitud del conector peptídico, es normalmente de 1 a 5, preferiblemente 1 a 3, y más preferiblemente 1 o 2.
Los conectores sintéticos (agentes de entrecruzamiento químico) incluyen agentes de entrecruzamiento que se usan de manera rutinaria para entrecruzar péptidos, por ejemplo, N-hidroxi succinimida (NHS), suberato de disuccinimidilo (DSS), suberato de bis(sulfosuccinimidilo) (BS3), ditiobis(propionato de succinimidilo) (DSP), ditiobis(propionato de sulfosuccinimidilo) (DTSSP), etilen glicol bis(succinato de succinimidilo) (EGS), etilen glicol bis(succinato de sulfosuccinimidilo) (sulfo-EGS), tartrato de disuccinimidilo (DST), tartrato de disulfosuccinimidilo (sulfo-DST), bis[2-(succinimidoxicarboniloxi)etil]sulfona (BSOCOES), y bis[2-(sulfosuccinimidoxicarboniloxi)etil]sulfona (sulfo-BSOCOES). Estos agentes de entrecruzamiento están disponibles comercialmente.
Cuando se unen cuatro regiones variables de anticuerpos, normalmente son necesarios tres conectores. Tales conectores múltiples pueden ser iguales o diferentes.
Los anticuerpos de la presente descripción incluyen anticuerpos en los que se han añadido uno o más residuos de aminoácidos a la secuencia de aminoácidos de un anticuerpo descrito en la presente memoria. Además, en la presente descripción se incluyen las proteínas de fusión que son el resultado de una fusión entre uno de los anticuerpos anteriores y un segundo péptido o proteína. Las proteínas de fusión se pueden preparar ligando un polinucleótido que codifica un anticuerpo de la presente descripción y un polinucleótido que codifica un segundo péptido o polipéptido en el marco de lectura, insertando esto en un vector de expresión, y expresando la construcción de fusión en un hospedador. Algunas técnicas conocidas para los expertos en la técnica están disponibles para este fin. El péptido o polipéptido secundario a fusionar con un anticuerpo de la presente descripción puede ser un péptido conocido, por ejemplo, FLAG (Hopp, T. P. et al., BioTechnology 6, 1204-1210 (1988)), 6x His que consiste en seis residuos de His (histidina), 10x His, hemaglutinina de la gripe (HA), fragmento c-myc humano, fragmento VSV-GP, fragmento p18HIV, marcador T7, marcador HSV, marcador E, fragmento del antígeno T de SV40, marcador lck, fragmento de a-tubulina, marcador B, fragmento de la Proteína C. Otros polipéptidos secundarios a fusionar con los anticuerpos de la presente descripción incluyen, por ejemplo, GST (glutation-S-transferasa), HA (hemaglutinina de la gripe), región constante de inmunoglobulinas, p-galactosidasa, y MBP (proteína de unión a maltosa). Un polinucleótido que codifica uno de estos péptidos o polipéptidos comercialmente disponibles se puede fusionar con un polinucleótido que codifica un anticuerpo descrito en la presente memoria. El polipéptido de fusión se puede preparar expresando la construcción de fusión.
Además, los anticuerpos de la presente descripción pueden ser anticuerpos conjugados que están unidos a cualquiera de diversas moléculas, que incluyen sustancias poliméricas tales como polietilen glicol (PEG) y ácido hialurónico, sustancias radiactivas, sustancias fluorescentes, sustancias luminiscentes, enzimas, y toxinas. Tales anticuerpos conjugados se pueden obtener modificando químicamente los anticuerpos obtenidos. Los métodos para modificar anticuerpos se han establecido en este campo (por ejemplo, documentos US 5057313 y US 5156840). Los "anticuerpos" aquí descritos también incluyen dichos anticuerpos conjugados.
Además, los anticuerpos usados en la presente memoria pueden ser anticuerpos biespecíficos. El anticuerpo biespecífico se refiere a un anticuerpo que tiene regiones variables que reconocen epítopos diferentes en la misma molécula de anticuerpo. En la presente descripción, los anticuerpos biespecíficos pueden reconocer epítopos diferentes en una molécula de NR10, o reconocer NR10 con un sitio de unión al antígeno y una sustancia diferente con el otro sitio de unión al antígeno.
Se conocen los métodos para producir anticuerpos biespecíficos. Los anticuerpos biespecíficos se pueden preparar, por ejemplo, uniendo dos anticuerpos que reconocen antígenos diferentes. Los anticuerpos a unir entre sí pueden ser mitades de moléculas, cada una de las cuales contiene una cadena H y una cadena L, o cuartos de moléculas que consisten solamente en una cadena H. De manera alternativa, se pueden fusionar hibridomas que producen anticuerpos monoclonales diferentes para producir una célula fusionada que produce anticuerpos biespecíficos. Además, se pueden producir anticuerpos biespecíficos mediante técnicas de ingeniería genética.
Los anticuerpos de la presente descripción pueden diferir en la secuencia de aminoácidos, el peso molecular, el punto isoeléctrico, la presencia/ausencia de cadenas de carbohidratos, y la conformación dependiendo de la célula u hospedador que produce el anticuerpo o el método de purificación como se describe más adelante. Sin embargo, se incluye un anticuerpo resultante en la presente descripción, con tal de que sea funcionalmente equivalente a un anticuerpo de la presente descripción. Por ejemplo, cuando se expresa un anticuerpo de la presente descripción en células procarióticas, por ejemplo E. coli, se añade un residuo de metionina en el extremo N-terminal de la secuencia de aminoácidos del anticuerpo original. Tales anticuerpos se incluyen en la presente descripción.
Producción de anticuerpos
Los anticuerpos de la presente invención pueden ser anticuerpos policlonales o monoclonales. Tales anticuerpos monoclonales que tienen actividad de unión y/o neutralizante hacia NR10 se pueden obtener, por ejemplo, mediante el procedimiento siguiente: los anticuerpos monoclonales anti-NR10 se preparan mediante el uso como antígeno de NR10 o un fragmento del mismo que se obtiene de un mamífero tal como un ser humano o ratón mediante métodos conocidos, y después se seleccionan los anticuerpos que tienen actividad de unión y/o neutralizante hacia NR10 de los anticuerpos monoclonales anti-NR10 así obtenidos. De manera específica, el antígeno deseado o las células que expresan el antígeno deseado se usan como antígeno sensibilizante para la inmunización según métodos de inmunización convencionales. Los anticuerpos monoclonales anti-NR10 se pueden preparar fusionando las células
inmunitarias obtenidas con células progenitoras conocidas mediante el uso de métodos convencionales de fusión celular, y cribándolas en busca de las células productoras de anticuerpos monoclonales (hibridomas) mediante métodos convencionales de cribado. Los animales a inmunizar incluyen, por ejemplo, mamíferos tales como ratones, ratas, conejos, ovejas, monos, cabras, asnos, vacas, caballos, y cerdos. El antígeno se puede preparar mediante el uso de la secuencia conocida del gen de NR10 según métodos conocidos, por ejemplo, mediante métodos que usan baculovirus (por ejemplo, documento WO 98/46777).
Se pueden preparar hibridomas, por ejemplo, según el método de Milstein et al. (Kohler, G. y Milstein, C., Methods Enzymol. (1981) 73: 3-46) o similares. Cuando la inmunogenicidad de un antígeno es baja, la inmunización se puede llevar a cabo después de unir el antígeno con una macromolécula que tiene inmunogenicidad, tal como albúmina.
Las realizaciones de los anticuerpos de la presente invención que tienen una actividad de unión y/o neutralizante hacia NR10 incluyen los anticuerpos monoclonales que tienen una actividad de unión y/o neutralizante hacia NR10 humano. Los antígenos usados para preparar los anticuerpos monoclonales que tienen una actividad de unión y/o neutralizante hacia NR10 humano no están limitados en particular, con tal de que permitan la preparación de anticuerpos que tienen una actividad de unión y/o neutralizante hacia NR10 humano. Por ejemplo, se sabe que existen varias variantes de NR10 humano, y se puede usar cualquier variante como inmunógeno con tal de que permita la preparación de anticuerpos que tengan una actividad de unión y/o neutralizante hacia NR10 humano. De manera alternativa, con la misma condición, se puede usar un fragmento peptídico de NR10 o una proteína en la que se han introducido mutaciones artificiales en la secuencia de NR10 natural como inmunógeno. NR10.3 humano es uno de los inmunógenos preferidos en la preparación de anticuerpos que tienen una actividad de unión y neutralizante hacia NR10 en la presente invención.
Además, la actividad de unión y/o neutralizante del anticuerpo hacia NR10 se puede medir, por ejemplo, observando el efecto de inhibición del crecimiento de la línea celular dependiente de IL-31 como se describe en los Ejemplos.
Mientras tanto, también se pueden obtener anticuerpos monoclonales mediante la inmunización con ADN. La inmunización con ADN es un método en el que un vector de ADN construido de forma que el gen que codifica una proteína antigénica se puede expresar en un animal a inmunizar se administra al animal, y el inmunógeno se expresa dentro del cuerpo del animal para proporcionar la inmunoestimulación. En comparación con los métodos de inmunización habituales basados en la administración de antígenos proteicos, se espera que la inmunización con ADN sea ventajosa ya que:
- permite la inmunoestimulación a la vez que se conserva la estructura de una proteína de membrana; y
- no es necesario purificar el inmunógeno.
Por otra parte, es difícil combinar la inmunización con ADN con un medio inmunoestimulador tal como un adyuvante.
Para obtener un anticuerpo monoclonal mediante la inmunización con ADN, primero, se administra un ADN que codifica NR10 a un animal para inmunizarlo. El ADN que codifica NR10 se puede sintetizar mediante métodos conocidos tales como PCR. El ADN resultante se inserta en un vector de expresión adecuado, y se administra al animal a inmunizar. Los vectores de expresión que se pueden usar incluyen vectores de expresión disponibles comercialmente, tales como pcDNA3.1. El vector se puede administrar al organismo vivo mediante métodos convencionales. Por ejemplo, la inmunización con ADN se puede llevar a cabo introduciendo partículas de oro revestidas con el vector de expresión en las células mediante una pistola de genes. El refuerzo mediante el uso de células que expresan NR10 tras la inmunización con ADN es un método preferido para producir un anticuerpo monoclonal.
Una vez que se inmuniza al mamífero como se describió anteriormente y se confirma que se ha incrementado el nivel sérico de un anticuerpo deseado, se recogen las células inmunitarias del mamífero y se someten a fusión celular. Las células inmunitarias preferidas son las células de bazo, en particular.
Se usan células de mieloma de mamífero para la fusión con las células inmunitarias anteriores. Se prefiere que las células de mieloma tengan marcadores de selección adecuados para el cribado. El marcador de selección se refiere a un fenotipo que permite (o que no permite) la supervivencia en condiciones de cultivo particulares. Los marcadores de selección conocidos incluyen la deficiencia de hipoxantina-guanina fosforribosiltransferasa (más adelante en la presente memoria abreviada como "deficiencia de HGPRT") y la deficiencia de timidina quinasa (más adelante en la presente memoria abreviada como "deficiencia de TK"). Las células deficientes de HGPRT o TK exhiben sensibilidad a hipoxantina-aminopterina-timidina (más adelante en la presente memoria abreviada como "sensibilidad a HAT"). En el medio de selección HAT, las células sensibles a HAT no pueden sintetizar ADN, y por tanto morirán. Sin embargo, cuando se fusionan con células normales, pueden continuar sintetizando ADN por medio de la ruta de rescate de las células normales, y así pueden crecer incluso en medio de selección HAT.
Las células deficientes de HGPRT o TK se pueden seleccionar mediante el uso de un medio que contiene 6-tioguanina, 8-azaguanina (más adelante en la presente memoria abreviada como "8AG"), o 5'-bromodesoxiuridina. Mientras las células normales son destruidas debido a la incorporación de estos análogos de pirimidina en el ADN, las células que carecen de estas enzimas pueden sobrevivir en el medio de selección, ya que no pueden incorporar estos análogos de pirimidina. Otro marcador de selección denominado resistencia G418 confiere resistencia a
antibióticos de 2-desoxiestreptamina (análogos de gentamicina) debido al gen de resistencia a neomicina. Se conocen diversas células de mieloma adecuadas para la fusión celular.
La fusión celular entre las células inmunitarias y las células de mieloma se puede llevar a cabo básicamente según métodos conocidos, por ejemplo, el método de Kohler y Milstein (Kohler. G. y Milstein, C., Methods Enzymol. (1981) 73, 3-46).
De manera más específica, la fusión celular se puede llevar a cabo, por ejemplo, en un medio de cultivo habitual en presencia de un agente estimulador de la fusión celular. El agente estimulador de la fusión incluye, por ejemplo, polietilen glicol (PEG) y el virus Sendai (HVJ). Si es necesario, también se puede añadir un agente auxiliar tal como sulfóxido de dimetilo para mejorar la eficacia de la fusión.
Las células inmunitarias y las células de mieloma se pueden usar en una proporción determinada de manera arbitraria. Por ejemplo, la proporción de células inmunitarias respecto de las células de mieloma es preferiblemente de 1 a 10. Los medios de cultivo a usar para la fusión celular incluyen, por ejemplo, los medios que son adecuados para el crecimiento de células de una línea celular de mieloma, tales como RPMI 1640 y MEM, y otros medios de cultivo habituales usados para este tipo de cultivo celular. Además, los medios de cultivo se pueden complementar también con un complemento sérico, tal como suero bovino fetal (FCS).
Se mezclan bien cantidades predeterminadas de células inmunitarias y células de mieloma en el medio de cultivo, y después se mezclan con una disolución de PEG precalentada a 37 °C para producir células fusionadas (hibridomas). En el método de fusión celular, por ejemplo, se puede añadir PEG con un peso molecular medio de alrededor de 1.000-6.000 a las células en general a una concentración del 30% al 60% (p/v). Después, la adición sucesiva del medio de cultivo adecuado enumerado anteriormente y la extracción del sobrenadante mediante centrifugación se repite para eliminar el agente de fusión celular y similares, que son desfavorables para el crecimiento de los hibridomas.
Los hibridomas resultantes se pueden cribar mediante el uso de un medio de selección según el marcador de selección poseído por las células de mieloma usadas en la fusión celular. Por ejemplo, se pueden cribar células deficientes de HGPRT o TK cultivándolas en un medio HAT (un medio que contiene hipoxantina, aminopterina, y timidina). De manera específica, cuando se usan células de mieloma sensibles a HAT en la fusión celular, las células fusionadas con éxito con células normales se pueden cultivar selectivamente en el medio HAT. El cultivo celular mediante el uso del medio HAT anterior continúa durante un periodo suficiente de tiempo para permitir que mueran todas las células excepto los hibridomas deseados (células sin fusionar). De manera específica, en general, los hibridomas deseados se pueden seleccionar cultivando las células durante un tiempo de varios días a varias semanas. Después, se puede realizar el cribado y la clonación simple de los hibridomas que producen un anticuerpo de interés llevando a cabo métodos habituales de dilución limitante. De manera alternativa, se pueden preparar anticuerpos que reconocen NR10 mediante el método descrito en el documento WO 03/104453.
El cribado y la clonación simple de un anticuerpo de interés se pueden llevar a cabo de manera adecuada mediante métodos de cribado conocidos basados en la reacción antígeno-anticuerpo. Por ejemplo, un antígeno se une a un portador tal como microesferas hechas de poliestireno o similares, y placas de microtitulación de 96 pocillos disponibles comercialmente, y después se hace reaccionar con el sobrenadante de cultivo del hibridoma. A continuación, el portador se lava y después se hace reaccionar con un anticuerpo secundario marcado con una enzima o similar. Cuando el sobrenadante de cultivo contiene un anticuerpo de interés reactivo hacia el antígeno sensibilizante, el anticuerpo secundario se une al portador por medio de este anticuerpo. Finalmente, el anticuerpo secundario unido al portador se detecta para determinar si el sobrenadante de cultivo contiene el anticuerpo de interés. Los hibridomas que producen un anticuerpo deseado capaz de unirse al antígeno se pueden clonar mediante el método de dilución limitante o similar. Preferiblemente, se puede usar no solamente el antígeno usado para la inmunización, sino también una proteína NR10 sustancialmente equivalente a él como antígeno para este fin. Por ejemplo, se puede usar como antígeno una línea celular que expresa NR10, el dominio extracelular de NR10, o un oligopéptido compuesto de una secuencia de aminoácidos parcial que constituye el dominio.
Además del método anteriormente descrito para preparar hibridomas por medio de la inmunización de un animal no humano con un antígeno, los anticuerpos de interés se pueden obtener también sensibilizando linfocitos humanos con un antígeno. De manera específica, primero, los linfocitos humanos se sensibilizan con una proteína NR10 in vitro. Después, los linfocitos sensibilizados se fusionan con una pareja de fusión adecuada. Por ejemplo, se pueden usar células de mieloma derivadas de seres humanos con la capacidad de dividirse permanentemente como pareja de fusión (véase la Solicitud de Patente Japonesa (Publicación Kokoku) N° (JP-B) H1-59878 (solicitud de patente japonesa examinada y aprobada, publicada para oposición). Los anticuerpos obtenidos mediante este método son anticuerpos humanos que tienen una actividad de unión a la proteína NR10.
La secuencia de nucleótidos que codifica un anticuerpo anti-NR10 obtenido mediante el método anteriormente descrito o similar, y su secuencia de aminoácidos, se pueden obtener mediante métodos conocidos para los expertos en la técnica.
Basándose en la secuencia obtenida del anticuerpo anti-NR10, el anticuerpo anti-NR10 se puede preparar, por
ejemplo, mediante técnicas de recombinación genética conocidas para los expertos en la técnica. De manera específica, se puede construir un polinucleótido que codifica un anticuerpo basándose en la secuencia del anticuerpo que reconoce NR10, insertarlo en un vector de expresión, y después expresarlo en células hospedadoras adecuadas (véase, por ejemplo, Co, M. S. et al., J. Immunol. (1994)152, 2968-2976; Better, M. y Horwitz, A. H., Methods Enzymol. (1989) 178, 476-496; Pluckthun, A. y Skerra, A., Methods Enzymol. (1989) 178, 497-515; Lamoyi, E., Methods Enzymol. (1986) 121, 652-663; Rousseaux, J. et al., Methods Enzymol. (1986) 121, 663-669; Bird, R. E. y Walker, B. W., Trends Biotechnol. (1991) 9, 132-137).
Los vectores incluyen vectores M13, vectores pUC, pBR322, pBluescript, y pCR-Script. De manera alternativa, cuando se desea subclonar y escindir el cADN, los vectores incluyen, por ejemplo, pGEM-T, pDIRECT, y pT7, además de los vectores descritos anteriormente. Los vectores de expresión son especialmente útiles cuando se usan los vectores para producir los anticuerpos de la presente invención. Por ejemplo, cuando se desea expresarlos en E. coli tal como JM109, DH5a, HB101, y XL1-Blue, los vectores de expresión no solamente tienen las características anteriormente descritas que permiten la amplificación de los vectores en E. coli, sino que también deben portar un promotor que permita la expresión eficaz en E. coli, por ejemplo, el promotor lacZ (Ward et al., Nature (1989) 341,544-546; FASEB J. (1992) 6, 2422-2427), promotor araB (Better et al., Science (1988) 240, 1041 -1043), promotor T7 o similares. Tales vectores incluyen pGEX-5X-1 (Pharmacia), "sistema QIAexpress" (Qiagen), pEGFP, o pET (en este caso, el hospedador es preferiblemente BL21 que expresa la ARN polimerasa de T7), además de los vectores descritos anteriormente.
Los vectores pueden contener secuencias señal para la secreción del anticuerpo. Como secuencia señal para la secreción del anticuerpo, se puede usar una secuencia señal pelB (Lei, S. P. et al J. Bacteriol. (1987) 169, 4379) cuando se secreta una proteína en el periplasma de E. coli. El vector se puede introducir en las células hospedadoras mediante métodos que usan cloruro cálcico o electroporación, por ejemplo.
Además de los vectores para E. coli, los vectores para producir los anticuerpos de la presente invención incluyen vectores de expresión en mamíferos (por ejemplo, pcDNA3 (Invitrogen), pEF-BOS (Nucleic Acids. Res. 1990, 18(17), p5322), pEF, y pCDM8), vectores de expresión derivados de células de insecto (por ejemplo, el "sistema de expresión de baculovirus Bac-to-BAC" (Gibco-BRL) y pBacPAK8), vectores de expresión derivados de plantas (por ejemplo, pMH1 y pMH2), vectores de expresión derivados de virus animales (por ejemplo, pHSV, pMV, y pAdexLcw), vectores de expresión retrovirales (por ejemplo, pZIPneo), vectores de expresión de levaduras (por ejemplo, "Pichia Expression Kit" (Invitrogen), pNV11, y SP-Q01), y vectores de expresión de Bacillus subtilis (por ejemplo, pPL608 y pKTH50), por ejemplo.
Cuando se desea la expresión en células animales tales como las células CHO, COS, y NIH3T3, los vectores deben tener un promotor esencial para la expresión en las células, por ejemplo, el promotor de SV40 (Mulligan et al., Nature (1979) 277, 108), el promotor de MMLV-LTR, el promotor de EF1a (Mizushima et al., Nucleic Acids Res. (1990) 18, 5322), y el promotor de CMV, y más preferiblemente tienen un gen para seleccionar las células transformadas (por ejemplo, un gen de resistencia a fármacos que permite el análisis mediante el uso de un agente (neomicina, G418, o similares). Los vectores con tales características incluyen pMAM, pDR2, pBK-RSV, pBK-CMV, pOPRSV, y pOP13, por ejemplo.
Además, se puede usar el siguiente método para la expresión génica y amplificación génica estable en células: Se introduce en células CHO deficientes de una ruta de síntesis de ácidos nucleicos un vector (por ejemplo, pSV2-dhfr (Molecular Cloning, 2a edición, Cold Spring Harbor Laboratory Press, 1989)) que porta un gen DHFr que compensa la deficiencia, y el vector se amplifica mediante el uso de metotrexato (MTX). De manera alternativa, se puede usar el siguiente método para la expresión génica transitoria: Se transforman células COS con un gen que expresa el antígeno T de SV40 en su cromosoma con un vector (pcD y similares) con un origen de replicación de SV40. También se pueden usar orígenes de replicación derivados de poliomavirus, adenovirus, papilomavirus bovino (BPV), y similares. Para amplificar el número de copias del gen en las células hospedadoras, los vectores de expresión pueden portar además marcadores de selección tales como el gen de aminoglicósido transferasa (APH), el gen de timidina quinasa (TK), el gen de xantina-guanina fosforribosiltransferasa (Ecogpt) de E. coli, y el gen de dihidrofolato reductasa (dhfr).
Los anticuerpos de la presente invención obtenidos mediante los métodos descritos anteriormente se pueden aislar del interior de las células hospedadoras o del exterior de las células (el medio, o similares), y purificarlos hasta homogeneidad. Los anticuerpos se pueden aislar y purificar mediante métodos rutinarios usados para aislar y purificar anticuerpos, y el tipo de método no está limitado. Por ejemplo, los anticuerpos se pueden aislar y purificar seleccionando y combinando de manera adecuada la cromatografía en columna, filtración, ultrafiltración, desalación, precipitación con disolventes, extracción con disolventes, destilación, inmunoprecipitación, electroforesis en gel de SDS-poliacrilamida, isoelectroenfoque, diálisis, recristalización, y similares.
Las cromatografías incluyen, por ejemplo, cromatografía de afinidad, cromatografía de intercambio iónico, cromatografía hidrófoba, filtración en gel, cromatografía en fase inversa, y cromatografía de adsorción (Strategies for Protein Purification and Characterization: A Laboratory Course Manual. Ed Daniel R. Marshak et al., Cold Spring Harbor Laboratory Press, 1996). Los métodos cromatográficos descritos anteriormente se pueden llevar a cabo mediante el uso de cromatografía líquida, por ejemplo, HPLC y FPLC. Las columnas que se pueden usar para la
cromatografía de afinidad incluyen las columnas de proteína A y las columnas de proteína G. Las columnas que usan la proteína A incluyen, por ejemplo, Hyper D, POROS, y Sepharose FF (GE Amersham Biosciences). La presente invención incluye los anticuerpos sumamente purificados mediante el uso de estos métodos de purificación.
La actividad de unión a NR10 de los anticuerpos obtenidos se puede determinar mediante métodos conocidos para los expertos en la técnica. Los métodos para determinar la actividad de unión al antígeno de un anticuerpo incluyen, por ejemplo, ELISA (ensayo de inmunoabsorción ligado a enzimas), EIA (inmunoensayo enzimático), RIA (radioinmunoensayo), y un método con anticuerpos fluorescentes. Por ejemplo, cuando se usa un inmunoensayo enzimático, se añaden las muestras que contienen el anticuerpo, tales como los anticuerpos purificados y los sobrenadantes del cultivo de células productoras de anticuerpos, a placas revestidas de antígenos. Se añade un anticuerpo secundario marcado con una enzima, tal como fosfatasa alcalina, y se incuban las placas. Después de lavar se añade un sustrato enzimático, tal como fosfato de p-nitrofenilo, y se mide la absorbancia para determinar la actividad de unión al antígeno.
Composiciones farmacéuticas
La presente descripción también proporciona composiciones farmacéuticas que comprenden el anticuerpo mencionado anteriormente como ingrediente activo. Además, la presente descripción proporciona agentes terapéuticos para enfermedades inflamatorias que comprenden el anticuerpo mencionado anteriormente como ingrediente activo.
En la presente invención, la enfermedad inflamatoria se refiere a enfermedades con características patológicas implicadas en reacciones citológicas e histológicas que se dan en los vasos sanguíneos afectados y los tejidos adyacentes en respuesta a una lesión o estimulación anormal provocada por agentes físicos, químicos, o biológicos (Stedman's Medical Dictionary, 5a Ed., MEDICAL VIEW CO., 2005). En general, las enfermedades inflamatorias incluyen dermatitis (dermatitis atópica, dermatitis crónica, y similares), enfermedades inflamatorias intestinales (colitis y similares), asma, artritis (artritis reumatoide, osteoartritis, y similares), bronquitis, enfermedades autoinmunitarias Th2, lupus eritematoso sistémico, miastenia gravis, GVHD crónica, enfermedad de Crohn, espondilitis anquilosante, dolor lumbar, gota, inflamación tras cirugía o lesión, edema, neuralgia, laringofaringitis, cistitis, hepatitis (esteatohepatitis no alcohólica, hepatitis alcohólica, y similares), hepatitis B, hepatitis C, arteriosclerosis, y prurito.
Los ejemplos preferidos de enfermedades inflamatorias que son objeto de la presente invención incluyen la dermatitis atópica, dermatitis crónica, reumatismo, osteoartritis, asma crónica, y prurito.
La frase "comprende(n) un anticuerpo anti-NR10 como ingrediente activo" significa que comprende(n) un anticuerpo anti-NR10 como al menos uno de los ingredientes activos, y no se limita la proporción del anticuerpo. Además, los agentes terapéuticos para las enfermedades inflamatorias de la presente invención pueden comprender también, en combinación con el anticuerpo anti-NR10 mencionado anteriormente, otros ingredientes que mejoran el tratamiento de las enfermedades inflamatorias.
Los agentes terapéuticos de la presente invención se pueden usar también con fines preventivos.
El anticuerpo anti-NR10 de la presente invención se puede preparar en forma de formulaciones según los métodos habituales (véase, por ejemplo, Remington's Pharmaceutical Science, última edición, Mark Publishing Company, Easton, EE.UU.). Además, pueden contener vehículos y/o aditivos farmacéuticamente aceptables si es necesario. Por ejemplo, pueden contener tensioactivos (por ejemplo, PEG y Tween), excipientes, antioxidantes (por ejemplo, ácido ascórbico), agentes colorantes, agentes aromatizantes, conservantes, estabilizantes, agentes tamponadores (por ejemplo, ácido fosfórico, ácido cítrico, y otros ácidos orgánicos), agentes quelantes (por ejemplo, EDTA), agentes de suspensión, agentes isotónicos, aglutinantes, disgregantes, lubricantes, promotores de la fluidez, y correctores. Sin embargo, sin limitarse a estos, los agentes para prevenir o tratar las enfermedades inflamatorias de la presente invención pueden contener otros vehículos usados habitualmente. Tales vehículos incluyen de manera específica ácido silícico anhidro ligero, lactosa, celulosa cristalina, manitol, almidón, carmelosa cálcica, carmelosa sódica, hidroxipropilcelulosa, hidroxipropilmetilcelulosa, polivinilacetaldietilaminoacetato, polivinilpirrolidona, gelatina, triglicérido de ácidos grasos de cadena media, aceite de ricino hidrogenado y polioxietilenado 60, sacarosa, carboximetilcelulosa, almidón de maíz, y sal inorgánica. Los agentes pueden contener también otros polipéptidos de bajo peso molecular, proteínas tales como albúmina de suero, gelatina, e inmunoglobulina, y aminoácidos tales como glicina, glutamina, asparagina, arginina, y lisina. Cuando se prepara el anticuerpo anti-NR10 en forma de una disolución acuosa para inyección, el anticuerpo anti-NR10 se puede disolver en una disolución isotónica que contiene, por ejemplo, solución salina fisiológica, dextrosa, u otros adyuvantes. Los adyuvantes pueden incluir, por ejemplo, D-sorbitol, D-manosa, D-manitol, y cloruro sódico. Además, se pueden usar de manera simultánea agentes solubilizantes adecuados, por ejemplo, alcoholes (por ejemplo, etanol), polialcoholes (por ejemplo, propilen glicoles y PEGs), y detergentes no iónicos (polisorbato 80 y HCO-50).
Si es necesario, los anticuerpos anti-NR10 se pueden encapsular en microcápsulas (microcápsulas hechas de hidroximetilcelulosa, gelatina, poli(metacrilato de metilo), y similares), y transformarlos en componentes de sistemas de administración de fármacos coloidales (liposomas, microesferas de albúmina, microemulsiones, nanopartículas, y
nanocápsulas) (por ejemplo, véase "Remington's Pharmaceutical Science 16a edición" &, Oslo Ed. (1980)). Además, se conocen los métodos para producir fármacos de liberación sostenida, y se pueden aplicar a los anticuerpos anti-NR10 (Langer et al., J. Biomed. Mater. Res. (1981) 15, 167-277; Langer, Chem. Tech. (1982) 12, 98-105; Patente de EE.UU. N° 3.773.919; Solicitud de Patente Europea (EP) N° 58.481; Sidman et al., Biopolymers (1983) 22, 547-56; documento EP 133.988).
Las composiciones farmacéuticas de la presente invención se pueden administrar de manera oral o parenteral, pero preferiblemente se administran de manera parenteral. De manera específica, los agentes se administran a los pacientes mediante inyección o administración percutánea. Las inyecciones incluyen, por ejemplo, inyecciones intravenosas, inyecciones intramusculares, e inyecciones subcutáneas, para la administración sistémica o local. Los agentes se pueden administrar en sitios en los que se debe inhibir la inflamación, o las áreas alrededor de los sitios mediante infusión local, en particular inyección intramuscular. Los métodos de administración se pueden seleccionar de manera adecuada según la edad y el estado del paciente. Se puede seleccionar la dosis de administración individual, por ejemplo, dentro del intervalo de 0,0001 a 100 mg del ingrediente activo por kg de peso corporal. De manera alternativa, por ejemplo, cuando los agentes se administran a pacientes humanos, la dosis del ingrediente activo se puede seleccionar dentro del intervalo de 0,001 a 1.000 mg/kg de peso corporal. La dosis de administración individual contiene preferiblemente, por ejemplo, alrededor de 0,01 a 50 mg/kg de peso corporal del anticuerpo de la presente invención. Sin embargo, la dosis de un agente para prevenir o tratar las enfermedades inflamatorias de la presente invención no se limita a estos ejemplos.
[Ejemplos]
[Ejemplo 1] Preparación de hibridomas
1.1. Preparación de plásmidos de NR10 para ser humano y mono cinomolgo para la inmunización con ADN
1.1.1. Preparación de vectores de expresión para hNR10 y cynNR10
Se insertó NR10 humano (secuencia de nucleótidos, SEQ ID NO: 75; secuencia de aminoácidos, SEQ ID NO: 76) en el vector de expresión pMaclI, que expresa una proteína bajo control del promotor de p-actina de ratón (documento WO2005/054467), para preparar un vector de expresión para hNR10. De la misma manera, se construyó un vector de expresión para cynNR10 de NR10 de mono cinomolgo (secuencia de nucleótidos, SEQ ID NO: 65; secuencia de aminoácidos, SEQ ID NO: 66).
1.1.2. Preparación de un cartucho de ADN
Para usar el vector de expresión de hNR10 o cynNR10 preparado en 1.1.1 para la inmunización de ratones con ADN, se usó el kit Helios Gene Gun Cartridge (BIO-RAD) para producir un cartucho de ADN para cada ADN que permitiese la inmunización con 1 gg de ADN cada vez.
1.2. Preparación de hibridomas productores de anticuerpo anti-NR10 humano
1.2.1. Preparación de hibridomas mediante el uso de ratones inmunizados con NR10 humano o de mono cinomolgo
Se inmunizaron diez ratones Balb/c (hembras; seis semanas de edad al comienzo de la inmunización; Charles River Laboratories, Japón) con NR10 humano o de mono cinomolgo mediante el siguiente procedimiento. Para la inmunización primaria, los ratones se inmunizaron con el cartucho de ADN preparado con el vector de expresión hNR10 mediante el uso del sistema Helios Gene Gun (BIO-RAD). Una semana más tarde, se llevó a cabo una inmunización secundaria mediante el sistema Helios Gene Gun (BIO-RAD) mediante el uso del cartucho de ADN preparado con el vector de expresión cynNR10. La tercera y posteriores inmunizaciones se llevaron a cabo a intervalos de una semana mediante el uso de los vectores de expresión hNR10 y cynNR10 alterativamente. Después de confirmar que el título de anticuerpos séricos hacia NR10 humano fue elevado, se administró de manera intravenosa una proteína humana NR10 (dominio extracelular) (Ejemplo de Referencia 4) diluida con PBS(-) a 10 gg/cabeza como inmunización final. Cuatro días tras la inmunización final, las células de bazo de ratón se fusionaron con células P3X63Ag8U.1 de mieloma de ratón (abreviadas como P3U1; ATCC CRL-1597) mediante un método convencional con el uso de PEG1500 (Roche Diagnostics). Las células fusionadas resultantes, es decir, los hibridomas, se cultivaron en RPMI1640 complementado con un 10% de FBS (abreviado más adelante en la presente memoria como 10% de FBS/RPMI1640).
1.2.2. Selección de hibridomas
Al día siguiente de la fusión, las células fusionadas se suspendieron en un medio semisólido (StemCells), y se cultivaron para la selección así como para la colonización de hibridomas.
Después de nueve o diez días desde la fusión, se recogieron las colonias de hibridomas y cada colonia se sembró en cada pocillo de placas de 96 pocillos que contenían el medio de selección HAT (10% de FBS/RPMI1640, 2 %vol de concentrado 50x de HAT (Dainippon Pharmaceutical), y 5 %vol de BM-Condimed H1 (Roche Diagnostics)). Después de tres a cuatro días de cultivo, se recogió el sobrenadante de cultivo de cada pocillo para determinar la
concentración de IgG de ratón en el sobrenadante. Los sobrenadantes de cultivo en los que se detectó la IgG de ratón se analizaron en busca de una actividad neutralizante mediante el uso de una línea de células dependientes de IL-31 humana (células hNR10/hOSMR/BaF3; Ejemplo de Referencia 2), y se obtuvieron varios clones que tenían una actividad neutralizante intensa hacia NR10 (Fig. 3). Se obtuvieron clones que inhibían el crecimiento inducido por IL-31 humana de las células de una manera dependiente de la concentración e inhibían el crecimiento inducido por IL-31 de mono cinomolgo de las células (células cynNR10/cynOSMR/BaF3; Ejemplo de Referencia 2) de una manera dependiente de la concentración (Fig. 4).
[Ejemplo 2] Preparación de anticuerpos quiméricos
Preparación de vectores de expresión para anticuerpos quiméricos
Se extrajeron los ARNs totales de los hibridomas mediante el uso de kits RNeasy Mini (QIAGEN), y se sintetizaron cADNs a partir de ellos mediante el uso del kit de amplificación de cADN SMART RACE (BD Biosciences). Los genes de la región variable del anticuerpo se aislaron mediante PCR con el uso de la ADN polimerasa PrimeSTAR HS (TaKaRa), mezcla de cebadores universales A 10x adjuntados con el kit de amplificación de cADN SMART RACE (BD Biosciences), y cebadores diseñados para cada región constante del anticuerpo (cadena H, mIgG1-rnot; cadena L, mIgK-rnot). La secuencia de nucleótidos de cada fragmento de ADN aislado se determinó con el secuenciador de ADN ABI PRISM 3730xL o con el secuenciador de ADN ABI PRISM 3700 (Applied Biosystems), mediante el uso del kit BigDye Terminator Cycle Sequencing (Applied Biosystems) según el método descrito en el manual de instrucciones adjunto. Las secuencias de aminoácidos determinadas de la cadena H y de las regiones variables de la cadena L de los anticuerpos de ratón NS18, NS22, NS23, y NS33 se muestran en las Figs. 1 y 2, respectivamente.
Cada uno de los fragmentos de la cadena H y L resultantes se sometieron a PCR mediante el uso de la ADN Polimerasa PrimeSTAR HS (TaKaRa) y los grupos de cebadores mostrados en la Tabla 1. Los fragmentos amplificados resultantes se ligaron con la región constante (y1 o y2 humanas, y k humana, respectivamente), y después se insertaron en un vector de expresión de células animales. La secuencia de nucleótidos de cada fragmento de ADN se determinó con el secuenciador de ADN ABI PRISM 3730xL o con el secuenciador de ADN ABI PRISM 3700 (Applied Biosystems), mediante el uso del kit BigDye Terminator Cycle Sequencing (Applied Biosystems) según el método descrito en el manual de instrucciones adjunto.
Tabla 1


Preparación de anticuerpos quiméricos
Se suspendió la línea celular de cáncer de riñón embrionario humano HEK293H (Invitrogen) en DMEM (Invitrogen) complementado con un 10% de suero bovino fetal (Invitrogen), y se sembraron 10 ml de células en placas para células adherentes (10 cm de diámetro; CORNING) a una densidad celular de 6 x 105 células/ml. Las células se incubaron en un incubador de CO2 (37 °C, 5% de CO2) durante todo un día y una noche. Después, se eliminó el
medio mediante aspiración, y se añadieron 6,9 ml de medio CHO-S-SFMII (Invitrogen). El medio CHO-S-SFMII se añadió a la mezcla preparada de ADN plasmídico (13,8 gg en total) hasta un volumen de 700 gl. Esto se mezcló con 20,7 gl de 1 gg/ml de polietilenimina (Polysciences Inc.), y se dejó reposar a temperatura ambiente durante 10 minutos. La disolución se añadió a las células en cada placa. Las células se incubaron en un incubador de CO2 (37 °C, 5% de CO2) durante cuatro a cinco horas. Después, se añadieron 6,9 ml de medio CHO-S-SFMII (Invitrogen), y las células se incubaron en un incubador de CO2 durante tres a cuatro días. Los sobrenadantes de cultivo se recogieron y después se centrifugaron (aprox. 2000 g, cinco minutos, temperatura ambiente) para eliminar las células. Los sobrenadantes se filtraron a través de un filtro de 0,22 gm MILLEX®-GV (Millipore). Cada muestra se almacenó a 4 °C hasta su uso. Los anticuerpos se purificaron a partir de los sobrenadantes mediante el uso de Proteína G-Sepharose (Amersham Biosciences). Los anticuerpos purificados se concentraron con Amicon Ultra 15 (Millipore), y después el disolvente se sustituyó con PBS(-) que contenía un 0,05% de NaN3 mediante el uso de columnas de desalación PD-10 (Amersham Biosciences). Se midió la absorbancia a 280 nm con un espectrofotómetro ND-1000 (NanoDrop), y se determinaron las concentraciones mediante el método de Pace et al. (Protein Science (1995) 4: 2411-2423).
Estudio de la actividad de NS22 quimérico
Se estudió la actividad de neutralización de hIL-31 mediante el uso de la línea celular hNR10/hOSMR/BaF3, que crece de una manera dependiente de la dosis de hIL-31, como se describe más adelante.
Se prepararon las células hNR10/hOSMR/BaF3 a 1,5 x 105 células/ml mediante el uso de un medio RPMI1640 (GiBc O) que contenía un 10% de FBS (MOREGATE) y 1% de Penicilina-Estreptomicina (Invitrogen). Se añadió hIL-31 (R&D Systems) a una alícuota de las células hasta una concentración final de 4 ng/ml (IL-31 (+); conc. final: 2 ng/ml). La suspensión celular restante se usó como IL-31 (-). El NS22 purificado se ajustó a 2 gg/ml mediante el uso del medio, y se prepararon ocho diluciones en serie a una proporción de dilución común de 3 (conc. final: 1 gg/ml o menos). Se añadieron 50 gl de la suspensión celular y de la dilución de NS22 quimérico (y1, k humanas) a cada pocillo de placas de fondo plano de 96 pocillos (CORNING), y las células se cultivaron en un incubador de CO2 al 5% a 37 °C durante dos días. Tras el cultivo, se añadieron 20 gl de una mezcla de cantidades iguales del kit de recuento celular 8 (Dojindo) y PBS a cada pocillo, y se midió la absorbancia (450 nm/620 nm) (TECAN, SUNRISE CLASSIC). Después de dejar que la reacción continuase durante dos horas en un incubador de CO2 al 5% a 37 °C, se midió de nuevo la absorbancia. La actividad neutralizante de NS22 se presentó como una tasa de inhibición mediante el uso de un valor obtenido restando el valor en la hora 0 del valor en la hora 2. El resultado mostró que NS22 inhibió el crecimiento inducido por IL-31 de la línea celular hNR10/hOSMR/BaF3 de una manera dependiente de la concentración. Esto demuestra que NS22 tiene una actividad neutralizante hacia la señalización de IL-31 humana (Fig. 5).
La actividad neutralizante de IL-31 se estudió como se describe más adelante mediante el uso de la línea celular DU145 (línea celular de cáncer de próstata humano), en la que se induce la producción de IL-6 tras la estimulación con IL-31.
Se prepararon células DU145 a 2,5 x 105 células/ml en MEM (Invitrogen) que contenía un 10% de FBS (MOREGATE), 2 mmol/l de L-glutamina (Invitrogen), y 1 mmol/l de piruvato sódico (SIGMA), y se dispensaron alícuotas de 200 gl en cada pocillo de placas de 48 pocillos (CORNING). Las células se incubaron a 37 °C con un 5% de CO2 durante la noche. El NS22 quimérico purificado (y1, k humanas) se diluyó hasta 100 gg/ml con MEM que contenía un 10% de FBS, 2 mmol/l de L-glutamina, y piruvato sódico. Mediante el uso de esta disolución, se prepararon seis diluciones en serie a una proporción de dilución común de 5. Cada dilución se combinó con 100 ng/ml de interleucina humana 31 (R&D Systems) a una proporción de 1:1, y se añadió una alícuota de 50 gl a cada pocillo. Después de dos días de cultivo a 37 °C con un 5% de CO2, se determinó la concentración de IL-6 en el sobrenadante de cultivo mediante el uso del kit de revelado de ELISA DuoSet (R&D Systems). La actividad neutralizante de NS22 se estudió determinando la tasa de inhibición (%). De manera específica, suponiendo la concentración de IL-6 en ausencia de IL-31 (A) como la actividad inhibitoria máxima (100% de inhibición) y la concentración de IL-6 en presencia de IL-31 sin NS22 (B) como sin actividad inhibitoria (0% de inhibición), se determinó la concentración de IL-6 en presencia de IL-31 y NS22 (C) según la fórmula siguiente:
Tasa de inhibición (%) = (B-C)/(B-A) x 100
El resultado mostró que NS22 inhibió la producción de IL-6 inducida por IL-31 en la línea celular DU145 de una manera dependiente de la concentración, y así demostró que NS22 tuvo una actividad neutralizante hacia la señalización con IL-31 humana (Fig. 6).
Estudio de la competición del anticuerpo anti-NR10 quimérico con IL-31
Se marcó IL-31 humana (R&D Systems) con el tinte reactivo monofuncional azul FMAT (Applied Biosystems). Se mezclaron 100 gl de hIL-31 preparados a 0,5 mg/ml mediante el uso de tampón de fosfato sódico 50 mM (pH 8,0) con 5,25 gl de 25 nmoles de azul FMAT disueltos en DMSO (Junsei). Después de agitar en vórtex, la mezcla se dejó reposar a temperatura ambiente durante 15 minutos. La reacción de conjugación de azul FMAT con hIL-31 se terminó añadiendo 5 gl de Tris-HCl 1 M (pH 7,4) y 1,1 gl de un 10% de Tween20, y después la hIL-31 marcada con
azul FMAT y el azul FMAT sin reaccionar se separaron mediante filtración en gel con el uso de una columna Superdex 75 (GE Healthcare, 17-0771-01) con una disolución de revelado del 0,1% de Tween20/PBS.
Se analizaron los anticuerpos por su actividad de inhibición de la unión IL-31/NR10 mediante el uso de células CHO que expresaban hNR10 como se describe más adelante.
NS22 y NA633 (la región constante de cada uno es y1, k) se diluyeron a una concentración adecuada mediante el uso de tampón de ensayo (HEPES 10 mM, NaCl 140 mM, CaCl22,5 mM, MgCl23 mM, 2% de FBS, 0,01% de NaN3), y después se prepararon siete diluciones en serie a una proporción de dilución común de 2. Las diluciones se añadieron a 40 pl/pocillo a las placas (placas FMAT de 96 pocillos; Applied Biosystems). Después, la hIL-31 marcada con azul FMAT se diluyó 400 veces con tampón de ensayo y se añadió a 20 pl/pocillo. Finalmente, las suspensiones celulares ajustadas a 2,5 x 105 células/ml mediante el uso de tampón de ensayo se añadieron a 40 pl/pocillo (final 1 x 104 células/pocillo). Dos horas tras la adición de las células, se determinó la fluorescencia (FL1) mediante el uso del sistema de detección celular 8200 (Applied Biosystems). El resultado mostró que NS22 inhibió la unión de hIL-31/hNR10 de una manera dependiente de la dosis, y demostró que su actividad fue superior a la de NA633 (Fig. 7).
[Ejemplo 3] Competición del anticuerpo anti-NR10 hacia NR10
El anticuerpo NS22 purificado a partir de un sobrenadante de cultivo de hibridomas se marcó con azul FMAT (Applied Biosystems, 4328853). Se mezclaron 170 pl de NS22 preparado a 1 mg/ml en PBS con 17 pl de disolución de NaHCO3 1 M y 3,4 pl de azul FMAT (17 nmoles) disuelto en DMSO. Después de agitar en vórtex, la mezcla se dejó reposar a temperatura ambiente durante 30 minutos. La reacción de conjugación de azul FMAT con NS22 se terminó añadiendo 8 pl de Tris-HCl 1 M (pH 7,4) y 1,9 pl de un 1% de Tween20, y después el NS22 marcado con azul FMAT (azul FMAT-NS22) y el azul FMAT sin reaccionar se separaron mediante filtración en gel con el uso de una columna Superdex 75 (GE Healthcare, 17-0771-01) con una disolución de revelado del 0,01% de Tween20/PBS.
Cada anticuerpo se examinó en función de la inhibición de la unión del azul FMAT-NS22 preparado a células CHO que expresaban hNR10 (Ejemplo de Referencia 3) mediante el uso del sistema de detección celular 8200 (Applied Biosystems, 4342920). Los anticuerpos anti-NR10 quiméricos (la región constante de cada uno es y1, k) se añadieron a diversas concentraciones a cada pocillo que contenía 7500 células y 8,8 x 10-2 pg/ml de azul FMAT-NS22. Las células se dejaron reposar en la oscuridad durante cuatro horas, y después se midió la señal fluorescente del azul FMAT unido a las células. La reacción se llevó a cabo en Hepes-KOH 10 mM que contenía CaCl22,5 mM, MgCl2 3 mM, NaCl 140 mM, 2% de FBS, y 0,01% de NaNO3. El resultado se muestra en la Fig. 8. El valor de fluorescencia FL1, que representa la unión de azul FMAT-NS22 a las células que expresaban NR10, se redujo con el incremento de la concentración de anticuerpo NS22 o NS23. Por otra parte, FL1 apenas se redujo con el incremento de la concentración del anticuerpo NA633 (Ejemplo de Referencia 6) (Fig. 8).
[Ejemplo 4] Humanización del anticuerpo NS22
Selección de cada secuencia estructural
Las regiones variables del anticuerpo NS22 de ratón se compararon con las secuencias de la línea germinal humana. Las secuencias FR usadas para la humanización se resumen en la Tabla 2. Se determinaron las CDRs y FRs basándose en la numeración de Kabat. Las secuencias de la región variable humanizada de la cadena H compuestas de FR1, FR2, FR3_1, y FR4, y compuestas de FR1, FR2, FR3_2, y FR4, que se enumeran en la Tabla 2, se denominan H0-VH (SEQ ID NO: 50) y H1-VH (SEQ ID NO: 112), respectivamente. Mientras tanto, la secuencia de la cadena L compuesta de FR1, FR2, FR3, y Fr4 se denomina L0 (SeQ ID NO: 52).
Preparación de la región variable para el NS22 humanizado H0L0
Se diseñaron oligo ADNs sintéticos para cada una de las cadenas H y L para construir las regiones variables del NS22 humanizado en las que las CDRs de NS22 se injertan en las FRs usadas para la humanización. Los oligo ADNs sintéticos respectivos se mezclaron, y después se sometieron a PCR de ensamblaje para construir un gen que codificaba la región variable del NS22 humanizado. La PCR de ensamblaje se llevó a cabo mediante el uso de KOD-Plus (TOYOBO) según las condiciones siguientes. Una mezcla de reacción que contenía 10 pmol de oligo ADNs sintéticos y el tampón de PCR adjunto, dNTPs, MgSO4, y KOD-Plus se calentó a 94 °C durante cinco minutos. La mezcla se sometió después a dos ciclos de PCR de 94 °C durante dos minutos, 55 °C durante dos minutos, y 68 °C durante dos minutos. Después, se añadieron 10 pmol de un cebador en el que se había añadido un sitio de restricción y una secuencia Kozak en el extremo 5' de la región variable, y de un cebador en el que se había añadido un sitio de restricción en el extremo 3' de la región variable, y se sometió a 35 ciclos de PCR de 94 °C durante 30 segundos, 55 °C durante 30 segundos, y 68 °C durante un minuto para producir un fragmento amplificado. El fragmento amplificado resultante se clonó en un vector de clonación TOPO TA (TOYOBO), y se determinó su secuencia de nucleótidos mediante secuenciación. Las regiones variables construidas se combinaron con las regiones constantes para preparar H0-SKSC (SEQ ID NO: 54) y L0 (SEQ ID NO: 56). La construcción resultante se insertó en un vector de expresión capaz de expresar el gen insertado en las células animales. La secuencia de nucleótidos de cada fragmento de ADN se determinó mediante el uso del kit BigDye Terminator Cycle Sequencing (Applied Biosystems) con el secuenciador de ADN ABI PRISM 3730xL o con el secuenciador de ADN ABI PRISM
3700 (Applied Biosystems), según el método descrito en el manual de Instrucciones adjunto.
Preparación de la región variable para el NS22 humanizado H1
Se generó H1-SKSC (SEQ ID NO: 130) sustituyendo la glutamina (E) de la posición de numeración de Kabat 73 de FR3 de H0-SKSC (SEQ ID NO: 54) con lisina (K). El mutante se preparó mediante el uso del kit de mutagénesis dirigida QuikChange disponible comercialmente (Stratagene) según el manual de instrucciones adjunto.
Expresión del anticuerpo convertido en IgG
La expresión del anticuerpo se llevó a cabo mediante el método descrito más adelante. La línea celular derivada de células de cáncer renal fetal humano HEK293H (Invitrogen) se suspendió en DMEM (Invitrogen) que contenía un 10% de suero bovino fetal (Invitrogen), y se sembraron 10 ml de células a una densidad de 5-6 x 105 células/ml en placas para células adherentes (10 cm de diámetro; CORNING). Las células se incubaron en un incubador de CO2 (37 °C, 5% de CO2) durante todo un día y una noche. Después, se eliminó el medio mediante aspiración, y se añadieron 6,9 ml de medio CHO-S-SFMII (Invitrogen) a las células. La mezcla de ADN plasmídico preparado (13,8 gg en total) se mezcló con 20,7 gl de 1 gg/ml de polietilenimina (Polysciences Inc.) y 690 gl de medio CHO-S-SFMII, y se dejó reposar a temperatura ambiente durante 10 minutos. La mezcla se añadió a las células en cada placa, y las células se incubaron en un incubador de CO2 (5% de CO2 , 37 °C) durante cuatro a cinco horas. Después, se añadieron 6,9 ml de medio CHO-S-SFMII (Invitrogen), y las células se incubaron en un incubador de CO2 durante tres días. El sobrenadante de cultivo se recogió y se centrifugó (aprox. 2000 g, cinco minutos, temperatura ambiente) para eliminar las células. El sobrenadante se esterilizó después mediante filtración a través de un filtro de 0,22 gm MILLEX®-GV (Millipore). Cada muestra se almacenó a 4 °C hasta su uso.
Purificación del anticuerpo convertido en IgG
Se añadieron 50 gl de rProtein A Sepharose™ Fast Flow (Amersham Biosciences) suspendido en TBS al sobrenadante de cultivo obtenido, y se mezcló mediante inversión a 4 °C durante cuatro horas o más. La disolución se transfirió a un cono de filtración de 0,22 gm de Ultrafree®-MC (Millipore). Después de tres lavados con 500 gl de TBS, la resina de rProtein A Sepharose™ se suspendió en 100 gl de disolución acuosa de acetato sódico 50 mM (pH 3,3), y se dejó reposar durante tres minutos para eluir el anticuerpo. La disolución se neutralizó inmediatamente añadiendo 6,7 gl de Tris-HCl 1,5 M (pH 7,8). La elución se llevó a cabo dos veces, y se obtuvieron 200 gl de anticuerpo purificado. 2 gl de la disolución que contenía anticuerpo se sometieron a análisis en el espectrofotómetro ND-1000 (NanoDrop) (Espectrofotómetro Thermo Scientific NanoDrop™ 1000 (Thermo Scientific)) o 50 gl se sometieron a análisis en el espectrofotómetro DU-600 (BECKMAN) para medir la absorbancia a 280 nm, y se calculó la concentración de anticuerpo mediante el método de Pace et al. (Protein Science (1995) 4: 2411 -2423).
Medida de la competición con IL-31 mediante el uso de FMAT
Se analizaron los anticuerpos por su actividad de inhibición de la unión IL-31/NR10 mediante el uso de células CHO que expresaban hNR10 como se describe más adelante. El anticuerpo NS22 quimérico y NS22_H0L0 (cadena H, H0 -SKSC/SEQ ID NO: 54; cadena L, L0/SEQ ID NO: 56) se diluyeron a una concentración adecuada mediante el uso de tampón de ensayo (HEPES 10 mM, NaCl 140 mM, CaCl22,5 mM, MgCl23 mM, 2% de FBS, 0,01% de NaN3, pH 7,4), y además se prepararon ocho diluciones en serie a una proporción de dilución común de 2. Las diluciones se añadieron a 40 gl/pocillo a placas (placas FMAT de 96 pocillos, Applied Biosystems). Después, la hIL-31 marcada con azul FMAT se diluyó 400 veces con tampón de ensayo, y se añadió a 20 gl/pocillo. Finalmente, una suspensión celular ajustada a 2,5 x 105 células/ml mediante el uso de tampón de ensayo se añadió a 40 gl/pocillo (final 1 x 104 células/pocillo). Dos horas tras la adición de las células, se midió la fluorescencia (FL1) mediante el uso del sistema de detección celular 8200 (Applied Biosystems).
El resultado mostró que, como se muestra en la Fig. 9, los anticuerpos NS22 humanizados H0L0 (cadena H, H0-SKSC/SEQ ID NO: 54; cadena L, L0/SEQ ID NO: 56), y H1L0 (cadena H, H1-SKSC/SEQ ID NO: 130; cadena L, L0/SEQ ID NO: 56) exhibieron una actividad competitiva comparable a la del anticuerpo quimérico, lo que sugiere que tanto H0L0 como H1L0 son anticuerpos humanizados anti-receptor de IL-31. Además, se considera que las FRs usadas para H0L0 y H1L0 se pueden usar para la humanización.
Por lo tanto, todas las mutaciones en las CDRs descritas en los Ejemplos más adelante en la presente memoria se pueden introducir en H0 y H1.
Tabla 2



[Ejemplo 5] Efecto reductor de la heterogeneidad de las regiones constantes nuevas M14 y M58 en el anticuerpo humanizado anti-receptor de IL31
Como se muestra en los Ejemplos de Referencia 7 a 9, se demostró que la conversión de la región constante de IgG2 a M14 o M58 en el anticuerpo huPM1, un anticuerpo humanizado anti-receptor de IL-6, podría reducir la heterogeneidad derivada de la región de la bisagra de IgG2 sin una pérdida de estabilidad. Así, los anticuerpos humanizados anti-receptor de IL-31 también se ensayaron para estudiar si la heterogeneidad se puede reducir convirtiendo sus regiones constantes desde IgG2 de tipo natural hasta M14 o M58.
H0-M14, H0-M58, H0-IgG1, y H0-IgG2, que se generaron combinando IgG1 (SEQ ID NO: 60), IgG2 (SEQ ID NO: 132), M14 (SEQ ID NO: 129) y M58 (s Eq ID NO: 128) generados en los Ejemplos de Referencia 8 y 9, con la región variable de la cadena H H0 (H0-VH/SEQ ID NO: 50) del anticuerpo humanizado anti-receptor de IL-31 generado en el Ejemplo 4, se usaron como cadenas H, y L0 (L0/SEQ ID NO: 56) producido en el Ejemplo 4 se usó como cadena L, para generar H0L0-IgG1 (cadena H, H0-IgG1/SEQ ID NO: 133; cadena L, L0/SEQ ID NO: 56), H0L0-IgG2 (cadena H, H0-IgG2/SEQ ID NO: 134; cadena L, L0/SEQ ID NO: 56), H0L0-M14 (cadena H, H0-M14/SEQ ID NO: 135; cadena L, L0/SEQ ID NO: 56), y H0L0-M58 (cadena H, H0-M58/SEQ ID NO: 136; cadena L, L0/SEQ ID NO: 56). Cada anticuerpo se expresó y se purificó mediante el método descrito en el Ejemplo 4.
La heterogeneidad se estudió mediante cromatografía de intercambio catiónico. Los anticuerpos preparados se estudiaron en cuanto a su heterogeneidad mediante el uso de una columna ProPac WCX-10 (Dionex), acetato sódico 20 mM (pH 5,0) como fase móvil A, y acetato sódico 20 mM/NaCl 1 M (pH 5,0) como fase móvil B, con un caudal y gradiente adecuados. El resultado del análisis mediante cromatografía de intercambio catiónico (IEC) se muestra en la Fig. 10.
Como se muestra en la Fig. 10, la heterogeneidad se incrementó mediante la conversión de la región constante de IgG1 a IgG2 en el anticuerpo anti-receptor de IL-31, y la heterogeneidad se puede reducir mediante la conversión de la región constante a M14 o M58 en cualquier anticuerpo.
[Ejemplo 6] Efecto de mejora de la farmacocinética de la región constante nueva M58 en anticuerpos anti-receptor de IL-31
Como se muestra en el Ejemplo de Referencia 9, se descubrió que la conversión de la región constante de IgG1 a M58 en el anticuerpo anti-receptor de IL-6 huPM1 mejora su actividad de unión a FcRn humano y la farmacocinética en ratones transgénicos con FcRn humano. Así, los anticuerpos anti-receptor de IL-31 se ensayaron también para estudiar si la conversión de la región constante a M58 mejora su farmacocinética.
H0L0-IgG1 (cadena H: H0-IgG1/SEQ ID NO: 133; cadena L: L0/SEQ ID NO: 56) y H0L0-M58 (cadena H: H0-M58/SEQ iD NO: 136; cadena L L0/SEQ ID NO: 56) preparados como se describió en los Ejemplos 4 y 5 se estudiaron en cuanto a la actividad de unión a FcRn humano mediante el método descrito en el Ejemplo de Referencia 9. El resultado se muestra en la Tabla 3.
Tabla 3
KD (uM)
H0L0-IgG1 1,07
H0L0-M58 0,91
Como se muestra en la Tabla 3, la conversión de la región constante de IgG1 a M58 también mejoró la actividad de unión a FcRn humano del anticuerpo anti-receptor de IL-31 H0L0 como en el anticuerpo anti-receptor de IL-6 hPM1. Esto sugiere que la conversión de la región constante de IgG 1 a M58 puede mejorar la farmacocinética del anticuerpo anti-receptor de IL-31 en humanos.
[Ejemplo 7] Identificación de sitios de mutación que reducen el punto isoeléctrico
Producción de mutantes
Cada mutante se produjo mediante el método descrito en el Ejemplo 4 o mediante PCR de ensamblaje. En el método que usa PCR de ensamblaje, se sintetizan oligo ADNs basados en secuencias directas e inversas que incluyen un sitio alterado. Se combinaron los oligo ADN directos que incluyen un sitio alterado y los oligo ADN inversos que se unen al vector en el que se insertó el gen a alterar, y se combinaron los oligo a Dn inversos que incluyen un sitio alterado y los oligo ADN directos que se unen al vector en el que se insertó el gen a alterar. Se llevó a cabo una PCR mediante el uso de PrimeSTAR (Takara) para producir fragmentos de los extremos 5' y 3' que incluían el sitio alterado. Los dos fragmentos se ensamblaron mediante PCR de ensamblaje para producir cada mutante. Los mutantes producidos se insertaron en un vector de expresión capaz de expresar el gen insertado en células animales. La secuencia de nucleótidos del vector de expresión resultante se determinó mediante un método conocido para los expertos en la técnica. Los anticuerpos se produjeron y se purificaron mediante el método descrito en el Ejemplo 4.
Identificación de sitios de mutación
Para mejorar la farmacocinética de H0L0 (cadena H, H0-SKSC/SEQ ID NO: 54; cadena L, L0/SEQ ID NO: 56), se examinaron los sitios alterados capaces de reducir el punto isoeléctrico de la región variable. El cribado de los sitios de mutación en las regiones variables predichas del modelo de estructura tridimensional reveló sitios de mutación que disminuirían el punto isoeléctrico de las regiones variables sin reducir significativamente su unión a NR10. Estos se resumen en la Tabla 4 (Hp5-VH/SEQ ID NO: 137, Hp7-VH/SEQ ID NO: 138, Hp8-VH/SEQ ID NO: 139, Hp6-VH/SEQ ID NO: 140, Hp9-VH/SEQ ID NO: 141, Hp1-VH/SEQ ID NO: 142, Hp13-VH/SEQ ID NO: 143, Lp1-VL/SEQ ID NO: 144, Lp2-VL/SEQ ID NO: 145, Lp3-VL/SEQ ID NO: 146, Lp4-VL/SEQ ID NO: 147, Lp7-VL/SEQ ID NO: 148, Lp5-VL/SEQ ID NO: 149, Lp6-VL/SEQ ID NO: 150). Cada variante se produjo y se purificó mediante el método descrito en el Ejemplo 4.
Cada variante se ensayó con respecto a la actividad de inhibición de la unión hIL-31/hNR10 mediante el uso de FMAT. El ensayo se llevó a cabo según el método descrito en el Ejemplo 4. Como se muestra en la Fig. 11, la actividad competitiva de cada variante no se redujo mucho en comparación con la de H0L0.
Tabla 4
Nombre Tipo Secuencia de H0 Sitio de Secuencia Aminoácido Secuencia tras la mutación de H0 tras la mutación (N2 de mutación
kabat)
Hp5 FR2 WVRQAPGQGLEWMG 38 R Q WVQQSPGQGLEWMG (SEQ ID NO: 97) 40 *A S (SEQ ID NO:120) Hp7 CDR2 LINPYNGGTSYNQKFKG(SEQ 50 L E EINPYNGGTSYNQKFKG ID NO:10) (SEQ ID NO:113) Hp8 CDR2 LINPYNGGTSYNQKFKG 52 N D LIDPYNGGTSYNQKFKG (SEQ ID NO:10) (SEQ ID NO:114) Hp6 CDR2 LINPYNGGTSYNQKFKG 61 Q D LINPYNGGTSYNDKFKG (SEQ ID NO:10) (SEQ ID NO:115) Hp9 CDR2 LINPYNGGTSYNQKFKG 62 K Q LINPYNGGTSYNQQFKG (SEQ ID NO:10) (SEQ ID NO:116) Hp1 CDR2 LINPYNGGTSYNQKFKG 64 K Q LINPYNGGTSYNQKFQG (SEQ ID NO:10) (SEQ ID NO:117) Hp13 CDR2 LINPYNGGTSYNQKFKG(SEQ 64 K Q LINPYNGGTSYNQKFQD ID NO:10) 65 G D (SEQ ID NO: 119)
Nombre Tipo Secuencia de L0 Sitio de Secuencia Aminoácido Secuencia tras la mutación de L0 tras la mutación (N2 de mutación
kabat)
Lp1 CDR1 RTSENIYSFLA 24 R Q QTSENIYSFLA (SEQ ID NO:13) (SEQ ID NO:121) Lp2 CDR1 RTSENIYSFLA 28 N D RTSEDIYSFLA (SEQ ID NO:13) (SEQ ID NO:122) Lp3 CDR2 NAKTLAK 50 N D DAKTLAK (SEQ ID NO:14) (SEQ ID NO:123) Lp4 CDR2 NAKTLAK 52 K Q NAQTLAK (SEQ ID NO:14) (SEQ ID NO:124) Lp7 CDR2 NAKTLAK 54 L E NAKTEAK (SEQ ID NO:14) (SEQ ID NO:125) Lp5 CDR2 NAKTLAK 56 K Q NAKTLAQ (SEQ ID NO:14) (SEQ ID NO:126) Lp6 CDR2 NAKTLAK 56 K D NAKTLAD (SEQ ID NO:14) (SEQ ID NO:127)
El asterisco (*) en la Tabla 4 anterior indica un sitio que no fue relevante para el punto isoeléctrico, pero se alteró para la conversión en una secuencia humana.
Los ejemplos de los anticuerpos NS22 humanizados cuyo punto isoeléctrico se ha reducido combinando estas alteraciones incluyen Hp3Lp15 (cadena H: Hp3-SKSC/SEQ ID NO: 151 ; cadena L: Lp15/SEQ ID NO: 152). Se comparó la afinidad hacia NR10, el punto isoeléctrico, y la retención plasmática en ratones entre Hp3Lp15 y H0L0. Medida de la afinidad
La afinidad de cada anticuerpo hacia NR10 se determinó mediante el método descrito en el Ejemplo de Referencia 10. El resultado de la medida de afinidad se muestra en la Tabla 5. Se demostró que la afinidad de Hp3Lp15 fue casi la misma que la de H0L0.
Tabla 5
ka (1/Ms) kd (1/s) KD (M) H0L0 3,7E+05 1,2E-03 3,3E-09 Hp3Lp15 4,2E+05 1,6E-03 3,9E-09
Medida del punto isoeléctrico
Cada anticuerpo se analizó mediante isoelectroenfoque para estudiar los cambios en el punto isoeléctrico del anticuerpo completo debidos a las alteraciones de aminoácidos en su región variable. El isoelectroenfoque se llevó a cabo mediante el método siguiente.
Se hidrató un gel Phast-Gel Dry IEF (Amersham Biosciences) en un Phastsystem Cassette (Amersham Biosciences) durante alrededor de 30 minutos mediante el uso de la disolución de hidratación mostrada a continuación.
Agua MilliQ 1,5 ml
Pharmalyte 5-8 para IEF (Amersham Biosciences) 100 pl
La electroforesis se llevó a cabo en PhastSystem (Amersham Biosciences) mediante el uso del gel hidratado según el programa indicado más adelante. Las muestras se cargaron en el gel en la Etapa 2. Se usó el kit de calibración para pI (Amersham Biosciences) como marcador del pI.
Etapa 1: 2000 V 2,5 mA 3,5 W 15 °C 75 Vh
Etapa 2: 200 V 2,5 mA 3,5 W 15 °C 15 Vh
Etapa 3: 2000 V 2,5 mA 3,5 W 15 °C 410 Vh
Tras la electroforesis, el gel se fijó con un 20% de TCA, y después se tiñó con plata mediante el uso del kit de tinción con plata, proteína (Amersham Biosciences), según el protocolo adjunto al kit. Tras la tinción, se calculó el punto isoeléctrico de la muestra (el anticuerpo completo) a partir de los puntos isoeléctricos conocidos de los marcadores de pI.
El resultado de la medida del punto isoeléctrico mediante isoelectroenfoque mostró que el punto isoeléctrico de H0L0 fue de alrededor de 7,8, y el punto isoeléctrico de Hp3Lp15 fue de alrededor de 5,5, lo que muestra que el punto isoeléctrico de Hp3Lp15 disminuyó alrededor de 2,3 en comparación con H0L0. Cuando se calculó el punto isoeléctrico teórico de la región variable VH/VL mediante GENETYX (GENETYX CORPORATION), los puntos isoeléctricos teóricos de las regiones variables de H0L0 y Hp3Lp15 fueron 7,76 y 4,63, respectivamente. Así, el punto isoeléctrico teórico de Hp3Lp15 disminuyó 3,13 en comparación con H0L0.
Estudio de la farmacocinética del anticuerpo con un punto isoeléctrico reducido mediante el uso de ratones
Para estudiar la retención plasmática de Hp3Lp15, un anticuerpo modificado con un punto isoeléctrico reducido, se comparó la retención plasmática de H0L0 y Hp3Lp15 en ratones normales. Se administró de manera intravenosa una única dosis de H0L0 o Hp3Lp15 a 1 mg/kg a ratones (C57BL/6J, Charles River Japan, Inc.) para comparar la evolución a lo largo del tiempo de la concentración plasmática. Las concentraciones plasmáticas se determinaron mediante ELISA. Las concentraciones adecuadas de una muestra de calibración y de muestras plasmáticas de ensayo se dispensaron en inmunoplacas (Nunc-Immuno Plate, MaxiSorp (Nalge Nunc International)) revestidas con anticuerpo anti-IgG humana (específico de Fc) (Sigma). Las muestras se dejaron reposar a temperatura ambiente durante una hora. Tras la reacción con anticuerpo de cabra anti-IgG humana-ALP (Sigma) a temperatura ambiente durante una hora, la reacción de desarrollo de color se llevó a cabo mediante el uso del sistema de sustratos de fosfatasa para micropocillos BluePhos (Kirkegaard & Perry Laboratories) como sustrato. La absorbancia a 650 nm se midió con un lector de microplacas. Las concentraciones plasmáticas se determinaron basándose en la absorbancia de la curva de calibración mediante el uso del programa informático analítico SOFTmax PRO (Molecular Devices).
Los parámetros farmacocinéticos (ABC y aclaramiento sistémico (CL)) se calcularon a partir de los datos obtenidos a lo largo del tiempo de la concentración plasmática mediante el uso del programa informático de análisis farmacocinético WinNonlin (Pharsight). Los parámetros se muestran en la Tabla 6. El ABC y el aclaramiento de Hp3Lp15 tras la administración intravenosa se incrementaron alrededor del 14% y se redujeron alrededor del 12%, respectivamente, en comparación con H0L0. Así, se demostró que Hp3Lp15, en el que se ha reducido el punto isoeléctrico de H0L0, tuvo una farmacocinética mejorada.
Tabla 6

[Ejemplo 8] Efecto de las combinaciones de la región variable y la región constante sobre la actividad biológica
Para estudiar los efectos de las diferentes regiones constantes sobre la actividad biológica, se produjeron las siguientes variantes.
SKSC (SEQ ID NO: 62) y M58 (SEQ ID NO: 128), las regiones constantes preparadas en los Ejemplos de Referencia 7 y 9, se combinaron con Hp3 (Hp3-VH/SEQ ID NO: 167), una región variable preparada en el Ejemplo 7, para producir Hp3-M58 (SEQ ID NO: 240) y Hp3-SKSC (SEQ iD NO: 151) como cadenas H. Las cadenas H preparadas se combinaron con Lp15 (Lp15/SEQ ID NO: 152), una cadena L preparada en el Ejemplo 7, para producir Hp3Lp15-SKSC (cadena H, Hp3-SKSC/SEQ ID NO: 151; cadena L, Lp15/SEQ ID NO: 152) y Hp3Lp15-M58 (cadena H, Hp3-M58/SEQ ID NO: 240; cadena L, Lp15/SEQ ID NO: 152). Cada anticuerpo se expresó y se purificó mediante el método descrito en el Ejemplo 4.
Los anticuerpos producidos como se describió anteriormente, H0L0-SKSC (cadena H, H0-SKSC/SEQ ID NO: 54; cadena L, L0/SEQ ID NO: 56) preparado mediante el uso de la región constante SKSC (SEQ ID NO: 62) descrito en el Ejemplo de Referencia 7, y H0L0-M58 (cadena H, H0-M58/SEQ ID NO: 136; cadena L, L0/SEQ iD NO: 56) y H0L0-IgG2 (cadena H, H0-IgG2/SEQ ID NO: 134; cadena L, L0/SEQ ID NO: 56) preparado en el Ejemplo 5, se estudiaron con respecto a la actividad biológica mediante el método descrito en el Ejemplo 2 con el uso de BaF/NR10. El resultado se resume en la Fig. 18.
Como se muestra en la Fig. 18, no se detectó una diferencia significativa en la actividad biológica entre las regiones constantes. Debido a que la actividad biológica no se vio afectada al combinar las dos regiones variables H0 y Hp3 con cada región constante, el combinar las regiones variables creadas en el futuro con cualquier región constante no
daría como resultado la alteración de la actividad biológica.
[Ejemplo 9] Identificación de los sitios de mutación que inhiben la degradación mediante un estudio de aceleración térmica
Los anticuerpos usados para los productos farmacéuticos tienen heterogeneidad incluso aunque sean anticuerpos monoclonales obtenidos de clones derivados de células productoras de anticuerpos individuales. Se sabe que tal heterogeneidad de los anticuerpos es el resultado de la modificación, tal como la oxidación o desamidación, y se incrementa durante el almacenamiento a largo plazo o tras la exposición a condiciones de estrés, tales como estrés térmico o estrés luminoso (véase "Heterogeneity of Monoclonal Antibodies", Journal of pharmaceutical sciences, vol.
97, N° 7, 2426-2447). Sin embargo, cuando se desarrolla un anticuerpo como producto farmacéutico, las propiedades físicas de la proteína, en particular la homogeneidad y la estabilidad, son muy importantes. Así, se desea que se reduzca la heterogeneidad de las sustancias deseadas/relacionadas y que la sustancia esté compuesta por una única sustancia tanto como sea posible. En este contexto, se llevó a cabo el experimento descrito más adelante para estudiar la heterogeneidad de un anticuerpo en condiciones de estrés, y para reducir la heterogeneidad.
Para estudiar los productos de degradación, se preparó una muestra acelerada de H0L0 (cadena H, H0-SKSC/SEQ ID NO: 54; cadena L, L0/SEQ ID NO: 56) mediante el método descrito más adelante. La muestra acelerada preparada y la muestra no acelerada (inicial) se analizaron mediante cromatografía de intercambio catiónico con el uso del método descrito más adelante.
- Método para preparar muestras aceleradas
Tampón: PBS
Concentración de anticuerpo: 0,2 a 1,0 mg/ml
Temperatura de aceleración: 60 °C
Periodo de aceleración: un día
- Método para el análisis mediante cromatografía de intercambio catiónico
Columna: ProPac WCX-10, 4 x 250 mm (Dionex)
Fase móvil: (A) 25 mmol/l de MES/NaOH, pH 6,1
(B) 25 mmol/l de MES/NaOH, 250 mmol/l de NaCl, pH 6,1
Caudal: 0,5 ml/min
Temperatura de la columna: 40 °C
Gradiente: %B 0 a 0 (0-5 m in)^0 a 30 (5-80 min)
Detección: 280 nm
Los cromatogramas resultantes para las muestras de H0L0 antes y después de la aceleración se muestran en la Fig. 19. La muestra de H0L0 después de la aceleración tuvo tendencia a mostrar un pico básico incrementado.
Después, se llevó a cabo un cribado para reducir este pico. Como resultado, se hallaron Ha355, Ha356, Ha360, y Ha362. Estas variantes de cadena H se combinaron con L0 para producir Ha355L0 (cadena H, Ha355-SKSC/SEQ ID NO: 242; cadena L, L0/SEQ ID NO: 56), Ha356L0 (cadena H, Ha356-SKSC/SEQ ID NO: 243; cadena L, L0/SEQ ID NO: 56), Ha360L0 (cadena H, Ha360-SKSC/SEQ ID NO: 244; cadena L, L0/SEQ ID NO: 56), y Ha362L0 (cadena H, Ha362-SKSC/SEQ ID NO: 245; cadena L, L0/SEQ ID NO: 56). La secuencia de cada variante se muestra en la Tabla 7.
Tabla 7
Nombre Tipo Secuencia de H0 Sitio de mutación Secuencia Aminoácido tras Secuencia tras la (N° de kabat) de H0 la mutación mutación Ha355 CDR3 DGYDDGPYTMDY 100d M L DGYDDGPYTLET (SEQ ID NO:265) 101 D E (SEQ ID NO:266)
102 Y T
Ha356 CDR3 DGYDDGPYTMDY 101 D E DGYDDGPYTMET (SEQ ID NO:265) 102 Y T (SEQ ID NO:267) Ha360 CDR3 DGYDDGPYTMDY 97 Y L DGLDDGPYTMET
(SEQ ID NO:265) 101 D E (SEQ ID NO:268)
102 Y T
Ha362 CDR3 DGYDDGPYTMDY 97 Y L DGLDDGPYTMES (SEQ ID NO:265) 101 D E (SEQ ID NO:269)
102 Y S
Cada uno de los anticuerpos identificados se expresó y se purificó mediante el método descrito en el Ejemplo 4. Como con H0L0, se preparó una muestra acelerada de cada anticuerpo preparado, y se analizó mediante cromatografía de intercambio catiónico. El resultado se muestra en la Fig. 19.
El resultado mostró que la generación del pico básico incrementado tras la aceleración se redujo en el anticuerpo modificado que contenía una sustitución de ácido aspártico con ácido glutámico en la posición 101 de la cadena H, en comparación con H0L0. Los anticuerpos modificados se estudiaron con respecto a la actividad biológica mediante el método descrito en el Ejemplo 2 con el uso de BaF/NR10. El resultado se muestra en la Fig. 20. Como se muestra en la Fig. 20, las actividades biológicas de los anticuerpos modificados fueron comparables o más intensas que las de H0L0. Estos hallazgos demostraron que las modificaciones de Ha355, Ha356, Ha360, y Ha362 inhibieron la generación de productos de degradación mediante aceleración, y por lo tanto son eficaces para mejorar la estabilidad del anticuerpo.
[Ejemplo 10] Identificación de sitios de mutación que incrementan la afinidad
Se construyó una biblioteca en la que se introdujeron mutaciones en las secuencias de CDRs y se examinó para mejorar la afinidad de H0L0 hacia NR10. Como resultado del cribado de la biblioteca en la que se introdujeron las mutaciones en las CDRs, se hallaron las mutaciones que mejoran la afinidad hacia NR10. Las mutaciones se muestran en la Tabla 8. Cada una de las variantes de la cadena H Ha101-SKSC (SEQ ID NO: 246), Ha103-SKSC (SEQ ID NO: 247), Ha111-SKSC (SEQ ID NO: 248), Ha204-SKSC (SEQ ID NO: 249), y Ha219-SKSC (SEQ ID NO: 250) se combinó con L0 (L0/SEQ ID NO: 56); y cada una de las cadenas L modificadas La134 (SEQ ID NO: 251), La130 (SEQ ID NO: 252), La303 (SEQ ID NO: 253), y La328 (SEQ ID NO: 254) se combinó con H0 (H0-SKSC/SEQ ID NO: 54), para construir un anticuerpo. Cada variante se produjo y se purificó mediante el método descrito en el Ejemplo 4.
La afinidad de cada anticuerpo hacia NR10 se estudió mediante el uso de Biacore. El resultado se muestra en la Tabla 9. El ensayo se llevó a cabo mediante el uso del método descrito en el Ejemplo de Referencia 10. Como se muestra en la Tabla 9, se descubrió que el valor de KD hacia cada variante mejoró en comparación con el de H0L0 (cadena H, H0-SKSC/SEQ ID NO: 54; cadena L, L0/SEQ ID NO: 56).
Tabla 8
Nombre Tipo Secuencia de H0 Sitio de Secuencia Aminoácido Secuencia tras la mutación de H0 tras la mutación
(N° de kabat) mutación

Ha204 CD R2 LINPYNGGTSYNQKFKG 58 S D LINPYNGGTDYNQKFKG (SEQ ID NO:271) (SEQ ID NO:275) Ha219 CD R2 LINPYNGGTSYNQKFKG 61 Q P LINPYNGGTSYNPKFKG (SEQ ID NO:271) (SEQ ID NO:276)
Nombre Tipo Secuencia de L0 Sitio de Secuencia Aminoácido Secuencia tras la mutación de L0 tras la mutación (N° de kabat) mutación
La134 CD R1 RTSENIYSFLA 31 S R RTSENIYRFLA (SEQ ID NO:277) (SEQ ID NO:279) La130 CD R1 RTSENIYSFLA 31 S R RTSENIYRFVA (SEQ ID NO:277) 33 L V (SEQ ID NO:280) Ls303 CD R3 QHHYESPLT 93 E D QHHYDSPLT (SEQ ID NO:278) (SEQ ID NO:281) La328 CD R3 QHHYESPLT 94 S D QHHYEDPLT (SEQ ID NO:278) (SEQ ID NO:282) La326 CD R3 QHHYESPLT 97 T F QHHYESPLF (SEQ ID NO:278) (SEQ ID NO:283)
Tabla 9
Nombre ka (1/Ms) kd (1/s) KD (M)
H0L0 1,9E+05 6,2E-04 3,2E-09
Ha101L0 2,0E+05 3,1 E-04 1,5E-09
Ha103L0 2,2E+05 5,3E-04 2,4E-09
Ha111L0 2,6E+05 5,6E-04 2,1 E-09
Ha204L0 3,7E+05 4,8E-04 1,3E-09
Ha219L0 3,2E+05 9,6E-04 3,0E-09
Nombre ka (1/Ms) kd (1/s) KD (M)
H0L0 1,5E+05 7,4E-04 5,1 E-09
H0La134 2,5E+05 4,4E-04 1,8E-09
H0La130 2,6E+05 4,0E-04 1,5E-09
H0La303 2,2E+05 4,6E-04 2,1 E-09
H0La328 1,8E+05 5,2E-04 2,9E-09
H0La326 1,4E+05 5,2E-04 3,7E-09
Los ejemplos de combinaciones de estas mutaciones que mejoraron la afinidad con las mutaciones que redujeron el punto isoeléctrico generadas en el Ejemplo 7 incluyen, por ejemplo, Ha401La402 (cadena H, Ha401-SKSC/SEQ ID NO: 255; cadena L, La402/SEQ ID NO: 256) y H17L11 (cadena H, H17-M58/SEQ ID NO: 222; cadena L, L11/SEQ ID NO: 236). Cada variante se produjo y se purificó mediante el método descrito en el Ejemplo 4.
Ha401La402 (cadena H, Ha401-SKSC/SEQ ID NO: 255; cadena L, La402/SEQ ID NO: 256) se estudió con respecto a la afinidad hacia NR10 y su actividad biológica mediante el método descrito en el Ejemplo de Referencia 10, y el método que usó BaF/NR10 como se describió en el Ejemplo 2, respectivamente, y se compararon con los de H0L0 (cadena H, H0-SKSC/SEQ ID NO: 54; cadena L, L0/SEQ ID NO: 56). El resultado de la medida de afinidad se muestra en la Tabla 10, y la actividad biológica determinada mediante el uso de BaF/NR10 se muestra en la Fig. 21. Se descubrió que tanto la afinidad como la actividad biológica mejoraron en comparación con las de H0L0 (cadena H, H0-SKSC/SEQ ID NO: 54; cadena L, L0/SEQ ID NO: 56).
Tabla 10
ka (1/Ms) kd (1/s) KD (M) H0L0 2,9E+05 9,1 E-04 3,2E-09 Ha401La402 5,8E+05 2,9E-04 5,0E-10
Además, H17L11 (cadena H, H17-M58/SEQ ID NO: 222; cadena L, L11/SEQ ID NO: 236) se estudió con respecto a la afinidad hacia NR10 y la actividad biológica mediante el método descrito en el Ejemplo 7 y el método que usó BaF/NR10 como se describió en el Ejemplo 2, respectivamente, y se compararon con los de H0L0 (cadena H, H0-M58/SEQ ID NO: 136; cadena L, L0/SEQ ID NO: 56). El resultado de la medida de afinidad se muestra en la Tabla 11, y la actividad biológica determinada mediante el uso de BaF/NR10 se muestra en la Fig. 22. Se descubrió que tanto la afinidad como la actividad biológica mejoraron en comparación con las de H0L0 (cadena H, H0-M58/SEQ ID NO: 136; cadena L, L0/SEQ ID NO: 56).
Tabla 11
ka (1/Ms) kd (1/s) KD (M) H0L0 1,4E+05 6,9E-04 4,8E-09 H17L11 4,3E+05 2,6E-04 6,2E-10 [Ejemplo 11] Identificación de sitios de mutación que reducen el riesgo de inmunogenicidad
Reducción del riesgo de inmunogenicidad en la CDR1 de la cadena H
Se analizaron los epítopos de células T presentes en la secuencia de la región variable de H0L0 mediante el uso de TEPITOPE (Methods, dic. de 2004; 34(4): 468-75). Como resultado, se predijo que la CDR1 de la cadena H tenía muchos epítopos de células T que se unen a HLA (es decir, tienen secuencias con un riesgo elevado de inmunogenicidad). Después, se llevó a cabo un análisis TEPITOPE para examinar las sustituciones que reducirían el riesgo de inmunogenicidad de la CDR1 de la cadena H. Como resultado, se descubrió que el riesgo de inmunogenicidad se reducía enormemente sustituyendo la isoleucina de la posición 33 en la numeración de kabat con alanina (A) (Tabla 12). Después, se añadió esta alteración a H17 generado en el Ejemplo 10 para producir H19 (H19-M58/SEQ ID NO: 223). El H19 generado se combinó con L12 para producir H19L12 (cadena H, H19-M58/SEQ ID NO: 223; cadena L, L12/SEQ ID NO: 237). Cada variante se produjo y se purificó mediante el método descrito en el Ejemplo 4.
El anticuerpo se estudió con respecto a la afinidad hacia NR10 y la actividad biológica mediante el método descrito en el Ejemplo de Referencia 10 y el método que usó BaF/NR10 como se describió en el Ejemplo 2, respectivamente, y se compararon con los de H0 L0 (cadena H, H0-M58/SEQ ID NO: 136; cadena L, L0/SEQ ID NO: 56). El resultado de la medida de afinidad se muestra en la Tabla 13, y la actividad biológica determinada mediante el uso de BaF/NR10 se muestra en la Fig. 23. Se mostró que tanto la afinidad como la actividad biológica son casi iguales a las de H0L0.
Tabla 12
Nombre Tipo Secuencia de H0 Sitio de Secuencia Aminoácido tras Secuencia tras la mutación (N° de de H0 la mutación mutación kabat)

Tabla 13
ka (1/Ms) kd (1/s) KD (M)
H0L0 1,8E+05 8,7E-04 4,8E-09
H19L12 2,3E+05 1,2E-03 5,1 E-09
Reducción del riesgo de inmunogenicidad en la CDR1 de la cadena L
La treonina (T) presente en la posición 25 de la numeración de kabat de la CDR1 de la cadena L corresponde a alanina (A) o serina (S) en la secuencia de la línea germinal. Así, se predice que el riesgo de inmunogenicidad se reduce sustituyendo la treonina (T) de la posición 25 con alanina (A) o serina (S) (Tabla 14). Por lo tanto, se añadió
la sustitución anterior a L12 para producir L17 (SEQ ID NO: 238). El L17 producido se combinó con H0 para producir H0L17 (cadena H, H0-M58/SEQ ID NO: 136; cadena L, L17/SEQ ID NO: 238). Cada variante se produjo y se purificó mediante el método descrito en el Ejemplo 4.
Cada variante se estudió con respecto a la afinidad hacia NR10 y la actividad biológica mediante el método descrito en el Ejemplo de Referencia 10 y el método que usó BaF/NR10 como se describió en el Ejemplo 2, respectivamente, y se compararon con los de H0L0 (cadena H, H0-M58/SEQ ID NO: 136; cadena L, L0/SEQ ID NO: 56) y H0L12 (cadena H, H0-M58/SEQ ID NO: 136; cadena L, L12/SEQ ID NO: 237). Debido a que L12 contiene una secuencia que mejora la afinidad, exhibe una afinidad alrededor de dos veces mayor que la de H0L0. El resultado de la medida de afinidad se muestra en la Tabla 15, y la actividad biológica determinada mediante el uso de BaF/NR10 se muestra en la Fig. 24. Se mostró que tanto la afinidad como la actividad biológica son casi iguales a las de H0L12.
Tabla 14
Nombre Tipo Secuencia de L0 Sitio de Secuencia Aminoácido tras la Secuencia tras la mutación de L0 mutación mutación (N° de kabat)
Ld-1 CDR1 RTSENIYSFLA 25 T A RASENIYSFLA (SEQ ID NO:277) (SEQ ID NO:285) Ld-2 CDR1 RTSENIYSFLA 25 T S RSSENIYSFLA (SEQ ID NO:277) (SEQ ID NO:286)
Tabla 15
ka (1/Ms) kd (1/s) KD (M) H0L0 1,6E+05 7,8E-04 4,8E-09 H0L12 3,8E+05 7,4E-04 2,0E-09 H0L17 3,9E+05 8,1 E-04 2,1 E-09
[Ejemplo 12] Preparación del anticuerpo NS22 completamente humanizado
Se prepararon las regiones variables de variantes NS22 combinando las múltiples mutaciones que reducen el pI, incrementan la afinidad, inhiben la degradación de la cadena H, y reducen el riesgo de inmunogenicidad, todas las cuales se hallaron en los Ejemplos anteriores, en H0 (H0-M58/SEQ ID NO: 136), H1 (H1-M58/SEQ ID NO: 257), o L0 (L0/SEQ ID NO: 56), y se sometieron a diversos procedimientos de cribado. Como resultado, se halló H28L17 (cadena H, H28-M58/SEQ ID NO: 224; cadena L, L17/SEQ ID NO: 238), H30L17 (cadena H, H30-M58/SEQ ID NO: 225; cadena L, L17/SEQ ID NO: 238), H34L17 (cadena H, H34-M58/SEQ ID NO: 226, cadena L, L17/SEQ ID NO: 238), H42L17 (cadena H, H42-M58/SEQ ID NO: 227; cadena L, L17/SEQ ID NO: 238), H44L17 (cadena H, H44-M58/SEQ ID NO: 228; cadena L, L17/SEQ ID NO: 238), H46L17 (cadena H, H46-M58/SEQ ID NO: 229; cadena L, L17/SEQ ID NO: 238), H57L17 (cadena H, H57-M58/SEQ ID NO: 230; cadena L, L17/SEQ ID NO: 238), H71L17 (cadena H, H71-M58/SEQ ID NO: 231; cadena L, L17/SEQ ID NO: 238), H78L17 (cadena H, H78-M58/SEQ ID NO: 232; cadena L, L17/SEQ ID NO: 238), H92L17 (cadena H, H92-M58/SEQ ID NO: 233; cadena L, L17/SEQ ID NO: 238), H97L50 (cadena H, H97-M58/SEQ ID NO: 234; cadena L, L50/SEQ ID NO: 239), y H98L50 (cadena H, H98-M58/SEQ ID NO: 235; cadena L, L50/SEQ ID NO: 239). Cada variante se produjo y se purificó mediante el método descrito en el Ejemplo 4.
Cada variante se estudió con respecto a la afinidad hacia NR10 y la actividad biológica mediante el método descrito en el Ejemplo de Referencia 10 y el método que usó BaF/NR10 como se describió en el Ejemplo 2, respectivamente, y se compararon con los de H0 L0 (cadena H, H0-M58/SEQ ID NO: 136; cadena L, L0/SEQ ID NO: 56). El resultado de la medida de afinidad se muestra en la Tabla 16, y la actividad biológica determinada mediante el uso de BaF/NR10 se muestra en la Fig. 25-1 y 25-2. Se mostró que la afinidad y la actividad biológica de cada anticuerpo fueron casi iguales o mayores de las de H0L0.
Tabla 16
Muestra ka (1/Ms) kd (1/s) KD (M) H0L0 2,1 E+05 8,8E-04 4,2E-09 H28L17 6,4E+05 3,3E-04 5,2E-10 H30L17 6,8E+05 5,7E-04 8,3E-10
H34L17 3,4E+05 1,2E-03 3,6E-09 H42L17 5,7E+05 3,7E-04 6,5E-10 H44L17 6,1 E+05 7,2E-04 1,2E-09 H46L17 2,9E+05 1,3E-03 4,6E-09 H57L17 7,1 E+05 5,5E-04 7,7E-10 H71L17 3,7E+05 1,2E-03 3,3E-09 H78L17 6,1 E+05 7,0E-04 1,1 E-09 H92L17 3,1 E+05 1,3E-03 4,1 E-09 H97L50 3,6E+05 1,3E-03 3,5E-09 H98L50 2,9E+05 1,3E-03 4,6E-09
[Ejemplo 13] Análisis del dominio de unión del anticuerpo neutralizante anti-NR10
(1) Preparación de antígenos de tipo natural y quiméricos humanos/de ratón
Los genes que codifican los dominios extracelulares de tipo natural humanos y de ratón y los dominios extracelulares quiméricos de NR10 (hhh (SEQ ID NO: 258), mmm (SEQ ID NO: 259), hhm (SEQ ID NO: 260), mmh (SEQ ID NO: 261), hmm (SEQ ID NO: 262), mhm (SEQ iD NO: 263), y mhh (SEQ iD NO: 264)), se fusionaron a un marcador de His y a un marcador de Myc (HHHHHHEQKLISEEDL/SEQ ID NO: 287) en sus extremos C-terminales, se insertaron en un vector de expresión animal, y se expresaron de manera transitoria mediante el uso del sistema de expresión FreeStyle 293 (Invitrogen™). Los diagramas esquemáticos para los ECDs de NR10 de tipo natural y quiméricos humanos/de ratón se muestran en la Fig. 26.
Los antígenos de tipo natural y quiméricos humanos/de ratón (hhh, mmm, hhm, mmh, hmm, mhm, y mhh) se purificaron a partir de los sobrenadantes de cultivo mediante cromatografía en columna Ni-NTA Superflow. De manera específica, se cargó 1 ml de Ni-NTA Superflow (QIAGEN) en una columna vacía Poly-Prep (BioRad), y se le añadieron 30 ml de cada sobrenadante de cultivo. Después de lavar con D-PBS (solución salina tamponada con fosfato de Dulbecco) que contenía cloruro sódico 150 mM e imidazol 20 mM, la columna se eluyó con D-PBS que contenía cloruro sódico 150 mM e imidazol 250 mM. Se intercambió el tampón en las fracciones eluidas con D-PBS y se concentraron mediante el uso de Amicon-Ultra (Millipore) con un umbral de peso molecular de 10.000.
(2) Detección del antígeno de unión mediante transferencia de Western
Cada uno de los antígenos preparados de tipo natural y quiméricos humanos/de ratón se sometieron a electroforesis a 0,5 pg/carril en tres geles del 4-20% de poliacrilamida (Daiichi Pure Chemicals Co.). Las proteínas se electrotransfirieron a membranas de PVDF (Millipore) en un aparato de transferencia semi-seca, y las membranas se bloquearon con TBS que contenía un 5% de leche descremada. Una membrana se incubó con 5 pg/ml de H44M58L17 (sistema de detección para anticuerpo humanizado anti-NR10 humano); otra con 5 pg/ml de ND41 (sistema de detección para anticuerpo de ratón anti-NR10 humano); y la otra con el anticuerpo anti-Myc (SantaCruz, n° de cat. sc-789) diluido 500 veces con TBS que contenía un 5% de leche descremada (sistema de detección para marcador Myc) a temperatura ambiente durante una hora.
Después de lavar tres veces con TBS que contenía un 0,05% de Tween™ 20, los anticuerpos secundarios se incubaron con las membranas. Se usó el anticuerpo de cabra anti-IgGY humana marcado con fosfatasa alcalina (BIOSOURCE, N° de Cat. AHI0305) para detectar el anticuerpo humanizado anti-NR10 humano; se usó el anticuerpo de cabra anti-IgG de ratón marcado con fosfatasa alcalina (SantaCruz, N° de Cat. sc-2008) para detectar el anticuerpo de ratón anti-NR10 humano; y se usó el anticuerpo de cabra anti-IgG de conejo marcado con fosfatasa alcalina (SantaCruz, N° de Cat. sc-2057) para detectar el marcador Myc. La reacción se llevó a cabo a temperatura ambiente durante una hora. Después de lavar cuatro veces con TBS que contenía un 0,05% de Tween™ 20 durante tres minutos, se llevó a cabo el desarrollo de color mediante el uso del sustrato de fosfatasa BCIP/NBT, sistema de 1 componente (KPL). El TBS (solución salina tamponada con Tris) usado en este caso se preparó disolviendo un envase de TBS (solución salina tamponada con Tris) en polvo (TaKaRa) en 1 L de agua destilada. El resultado se muestra en la Fig. 27.
Cuando se usó el anticuerpo humanizado o el anticuerpo de ratón, la unión se detectó solamente para hhh, hhm, y hmm, que son dominios extracelulares de NR10.
[Ejemplo de Referencia 1] Aislamiento de genes de NR10, OSMR, e IL-31 de mono cinomolgo
Debido a que la reactividad cruzada y la actividad neutralizante en los monos cinomolgos se consideraron importantes para el estudio de la seguridad en una etapa pre-clínica, se aislaron los genes de NR10 y OSMR de mono cinomolgo. Se diseñaron cebadores basándose en la información publicada del genoma del mono Rhesus y otros, y los genes de NR10 y OSMR se amplificaron con éxito mediante PCR a partir de cADN pancreático de mono
cinomolgo. Las secuencias de los genes aislados de NR10, OSMR, e IL-31 de mono cinomolgo se muestran en SEQ ID NOs: 65, 69, y 67, respectivamente, y las secuencias de aminoácidos de NR10, OSMR, e IL-31 de mono cinomolgo se muestran en SEQ ID NOs: 66, 70, y 68, respectivamente.
[Ejemplo de Referencia 2] Establecimiento de líneas de células Ba/F3 que expresan NR10 y OSMR
El cADN de NR10 humano de longitud completa (SEQ ID NO: 75) se insertó en el vector de expresión pCOS1 (Biochem. Biophys. Res. Commun. 228, p838-45, 1996), y el vector resultante se denominó pCosNR10.3. Se aisló un cADN de receptor de oncoestatina M (OSMR, N° de acceso de GenBank NM003999) mediante PCR a partir de una biblioteca placentaria humana, y se construyó el vector de expresión pCos1-hOSMR de la misma manera. Se introdujeron simultáneamente 10 gg de cada uno de los vectores en la línea de células Ba/F3 derivadas de células pro-B dependientes de IL-3 de ratón mediante electroporación (BioRad Gene Pulser, 960 gF, 0,33 kV). Tras la introducción, se añadió IL-31 humana (R&D Systems), y las células se cultivaron para obtener una línea celular (células hNR10/hOSMR/BaF3) que prolifera de una manera dependiente de IL-31. Además, el gen de IL-31 de mono cinomolgo (SEQ ID NO: 67) se insertó en un vector de expresión en células de mamífero y se introdujo en la línea de células CHO DG44. El sobrenadante del cultivo resultante se obtuvo como IL-31 de mono cinomolgo. Como con hNR10/hOSMR/BaF3, los genes de NR10 y OSMR de mono cinomolgo de longitud completa se insertaron en el vector de expresión pCOS1 y se expresaron en células Ba/F3, y se estableció una línea de células dependientes de IL-31 de mono cinomolgo (célula cynNR10/cynOSMR/BaF3) mediante el uso del sobrenadante de cultivo descrito anteriormente.
[Ejemplo de Referencia 3] Establecimiento de líneas de células CHO que expresan NR10
Los genes de NR10 humano que carece del dominio citoplasmático (SEQ ID NO: 73) y de NR10 de mono cinomolgo que carece del dominio citoplasmático (SEQ ID NO: 71) se insertaron cada uno en un vector de expresión en células de mamífero. Los vectores resultantes se linealizaron con una enzima de restricción, y después se introdujeron en la línea de células CHO DG44 mediante electroporación (BioRad Gene Pulser, 25 gF, 1,5 kV). Tras la selección mediante fármacos, se seleccionaron las células que expresaban NR10 y se establecieron mediante análisis FCM con el uso de un anticuerpo anti-NR10 humano. La secuencia de aminoácidos codificada por la secuencia de nucleótidos del gen de NR10 humano que carece del dominio citoplasmático (SEQ ID NO: 73) se muestra en SEQ ID NO: 74, y la secuencia de aminoácidos codificada por la secuencia de nucleótidos del gen de NR10 de mono cinomolgo que carece del dominio citoplasmático (SEQ ID NO: 71) se muestra en SEQ ID NO: 72.
[Ejemplo de Referencia 4] Preparación de la proteína NR10 (dominio extracelular)
El cADN de NR10 humano se usó como molde para amplificar solamente el dominio extracelular mediante PCR. La región amplificada se fusionó después a una secuencia del marcador FLAG en el extremo C-terminal y se insertó en un vector de expresión en células de mamífero. Se introdujeron diez gg del vector linealizado en la línea de células de ovario de hámster chino DG44 mediante electroporación (BioRad Gene PulserII, 25 gF, 1,5 kV). Se obtuvo una línea celular que mostró una expresión elevada. El sobrenadante de la línea celular cultivada a gran escala se purificó mediante el uso de una columna de anticuerpos anti-FLAG (Sigma) y filtración en gel para obtener NR10 soluble. La secuencia de nucleótidos de NR10 soluble se muestra en SEQ ID NO: 77, y la secuencia de aminoácidos se muestra en SEQ ID NO: 78.
[Ejemplo de Referencia 5] Preparación de anticuerpos anti-NR10 humano
Se inmunizaron ratones con proteína NR10 humana (dominio extracelular) (descrita en el Ejemplo de Referencia 4), y se prepararon hibridomas mediante un método convencional. Los sobrenadantes del cultivo de estos hibridomas se analizaron con respecto a la actividad neutralizante mediante el uso de la línea celular dependiente de IL-31 humana (células hNR10/hOSMR/BaF3) descrita en el Ejemplo de Referencia 2, y de ese modo se obtuvo NA633 que tiene una actividad neutralizante hacia NR10.
Además, se llevó a cabo la inmunización con ADN mediante una pistola de genes accionada por gas He con el uso de un vector de expresión en mamíferos que portaba el gen de NR10 humano de longitud completa (SEQ ID NO: 75), y se prepararon hibridomas mediante un método convencional. Los sobrenadantes del cultivo de estos hibridomas se analizaron con respecto a la actividad neutralizante mediante el uso de la línea celular dependiente de IL-31 humana (células hNR10/hOSMR/BaF3) descrita en el Ejemplo de Referencia 2, y de ese modo se obtuvo ND41 que tiene una actividad neutralizante hacia NR10.
[Ejemplo de Referencia 6] Preparación de un anticuerpo quimérico humano
Las secuencias de aminoácidos de las regiones variables de la cadena pesada y de la cadena ligera de NA633 se muestran en SEQ ID NOs: 104 y 108, respectivamente. Las secuencias de aminoácidos de CDR1, CDR2, y CDR3 de la región variable de la cadena pesada de NA633 se muestran en SEQ ID NOs: 105, 106, y 107, respectivamente, mientras las de CDR1, CDR2, y CDR3 de la región variable de la cadena ligera se muestran en SEQ ID NOs: 109, 110, y 111, respectivamente. Además, se produjo un anticuerpo quimérico entre estas regiones variables de ratón y la región constante humana (cadena H, y1 ; cadena L, k) mediante un método convencional.
[Ejemplo de Referencia 7] Preparación de huPMI-SKSC en la que la heterogeneidad de IgG2 de tipo natural se reduce sin pérdida de estabilidad
Debido a que el anticuerpo NS22 es un anticuerpo neutralizante de NR10, su unión al receptor Fcy puede ser desfavorable considerando la inmunogenicidad y los efectos adversos. Un posible método para reducir la unión al receptor Fcy es seleccionar IgG2 o IgG4 en vez de IgG 1 como el isotipo de la región constante (Ann Hematol. junio de 1998; 76(6): 231-48.). Desde el punto de vista del receptor Fcy I y la retención en el plasma, IgG2 se ha considerado más deseable que IgG4 (Nat Biotechnol. dic. de 2007; 25(12): 1369-72). Mientras tanto, cuando se desarrolla un anticuerpo como producto farmacéutico, las propiedades de la proteína, en particular la homogeneidad y la estabilidad, son muy importantes. Se ha informado que el isotipo IgG2 tiene una heterogeneidad muy elevada que es el resultado de los enlaces disulfuro de la región de la bisagra (J Biol Chem. 6 de junio de 2008; 283(23): 16206-15.). No es fácil y sería más costoso fabricarlo como un producto farmacéutico a gran escala a la vez que se mantiene la diferencia en la heterogeneidad de las sustancias deseadas/relacionadas entre los productos resultantes de lo anterior. Por lo tanto, se desea que la sustancia esté compuesta de una única sustancia tanto como sea posible. Así, cuando los anticuerpos del isotipo IgG2 se desarrollan como productos farmacéuticos, se prefiere reducir la heterogeneidad resultante de los enlaces disulfuro, sin reducir la estabilidad.
Para reducir la heterogeneidad de la IgG2 de tipo natural, se sustituyeron las cisteínas de la región de la bisagra y el dominio CH1 de IgG2. Como resultado del examen de las diversas variantes, SKSC (SEQ ID NO: 62), que es una región constante obtenida alterando la cisteína de la posición 131 y la arginina de la posición 133 de la numeración EU (Secuencias de proteínas de interés inmunológico, Publicación del NIH N° 91-3242) dentro del dominio CH1 de la cadena H de la secuencia de la región constante de IgG2 de tipo natural a serina y lisina, respectivamente, y alterando la cisteína de la posición 219 de la numeración EU en la bisagra superior de la cadena H a serina, podría reducir la heterogeneidad sin disminuir la estabilidad. Mientras tanto, otros métodos posibles para disminuir la heterogeneidad son alterar solamente la cisteína de la posición 219 de la numeración EU en la bisagra superior de la cadena H a serina, y alterar solamente la cisteína de la posición 220 de la numeración EU a serina. Así, se produjo la región constante SC (SEQ ID NO: 153) en la que la cisteína de la posición 219 de la numeración EU en IgG2 se ha alterado a serina, y la región constante CS (SEQ ID NO: 154) en la que la cisteína de la posición 220 de la numeración EU en IgG2 se ha alterado a serina.
huPM1-SC (SEQ ID NO: 157), huPM1-CS (SEQ ID NO: 158), huPM1-IgG1 (SEQ ID NO: 159), huPM1-IgG2 (SEQ ID NO: 160), y huPM1-SKSC (SEQ ID NO: 161), que se prepararon combinando las regiones constantes producidas como anteriormente, IgG1 (SEQ ID NO: 60), e IgG2 (SEQ ID NO: 132) con la región variable del anticuerpo humanizado anti-receptor de IL-6 (región variable de la cadena H, huPM1-VH/SEQ ID NO: 155; región variable de la cadena L huPM1-VL/SEQ ID NO: 156) (Cancer Res. 15 de feb. de 1993;53(4): 851-6.), se usaron como cadena H, y huPM1-L (SEQ ID NO: 162) se usó como cadena L, para producir cada anticuerpo. Cada anticuerpo se expresó y se purificó mediante el método descrito en el Ejemplo 4.
Los anticuerpos se compararon entre sí con respecto a la heterogeneidad. Se estudió la heterogeneidad de huPM1-IgG1, huPM1-IgG2, huPM1-SC, huPM1-CS, y huPM1-SKSC mediante cromatografía de intercambio catiónico. La cromatografía se llevó a cabo mediante el uso de una columna ProPac WCX-10 (Dionex), acetato sódico 20 mM (pH 5,0) como fase móvil A, y acetato sódico 20 mM/NaCl 1 M (pH 5,0) como fase móvil B, con un caudal y gradiente adecuados. El resultado del análisis mediante cromatografía de intercambio catiónico se muestra en la Fig. 12.
Como se muestra en la Fig. 12, la conversión de la región constante de IgG1 en IgG2 incrementó la heterogeneidad. En contraste, la heterogeneidad se redujo notablemente convirtiendo la región constante en SKSC. Aunque la región constante SC dio como resultado una reducción considerable de la heterogeneidad como en SKSC, la región constante CS no mejoró suficientemente la heterogeneidad.
Cuando se desarrolla un anticuerpo como producto farmacéutico, en general se desea que el anticuerpo tenga una estabilidad elevada además de una heterogeneidad baja, para la producción de preparaciones estables. Así, para estudiar la estabilidad, se determinó la temperatura en el punto medio de desnaturalización térmica (valor de Tm) mediante calorimetría de barrido diferencial (DSC) (VP-DSC; Microcal). La temperatura en el punto medio de desnaturalización térmica (valor de Tm) sirve como indicador de la estabilidad. Para preparar preparaciones estables como productos farmacéuticos, se prefiere una temperatura mayor en el punto medio de desnaturalización térmica (valor de Tm) (J Pharm Sci., abril de 2008; 97(4): 1414-26.). Así, huPM1-IgG1, huPM1-IgG2, huPM1-SC, huPM1-CS, y huPM1-SKSC se dializaron con una disolución de acetato sódico 20 mM/NaCl 150 mM (pH 6,0) (EasySEP; TOMY), y la medida de DSC se llevó a cabo mediante el uso de alrededor de 0,1 mg/ml de proteína a una velocidad de calentamiento de 1 °C/min entre 40 y 100 °C. Las curvas de desnaturalización obtenidas mediante DSC se muestran en la Fig. 13. Los valores de Tm de los dominios Fab se enumeran en la Tabla 17 siguiente.
Tabla 17
Nombre Tm/°C
huPM1-IgG1 94,8
huPM1-IgG2 93,9
huPM1-SC 86,7
huPM1-CS 86,4
huPM1-SKSC 93,7
Los valores de Tm de huPM1-IgG1 y huPM1-IgG2 fueron casi iguales, concretamente, alrededor de 94 °C (la IgG2 fue inferior en alrededor de 1 °C). Mientras tanto, los valores de Tm de huPM1-SC y huPM1-CS fueron de alrededor de 86 °C, que fueron significativamente inferiores a los de huPM1-IgG1 y huPM1-IgG2. Por otra parte, el valor de Tm de huPM1-SKSC fue de alrededor de 94 °C, y casi igual que el de huPM1-IgG1 y huPM1-IgG2. Debido a que la estabilidad de huPM1-SC y huPM1-CS fue notablemente inferior a la de IgG2, se puede preferir más huPM1-SKSC, en el que la cisteína del dominio CH1 también se ha alterado a serina, en el desarrollo de productos farmacéuticos. La disminución significativa en el valor de Tm de huPM1-SC y huPM1-CS en comparación con IgG2 se puede deber al patrón de enlaces disulfuro de huPM1-SC y huPM1-CS, que es diferente del de IgG2.
Además, la comparación de las curvas de desnaturalización de DSC mostró que el pico de desnaturalización para el dominio Fab fue agudo en huPM1-IgG1 y huPM1-SKSC, mientras que fue más ancho en huPM1-SC y huPM1-CS que los dos anteriores, y huPM1-IgG2 proporcionó un pico secundario en el lado de la temperatura inferior del pico de desnaturalización del dominio Fab. El pico de desnaturalización en DSC se agudiza en general en el caso de un único componente, pero se puede ensanchar cuando hay presentes dos o más componentes con diferentes valores de Tm (concretamente, heterogeneidad). Así, se propuso que huPM1-IgG2, huPM1-SC, y huPM1-CS contuvieron dos o más componentes, y la heterogeneidad de IgG2 natural no se redujo en huPM1-SC y huPM1-CS. Este hallazgo sugiere que las cisteínas presentes en la región de la bisagra y en el dominio CH1 están implicadas en la heterogeneidad de la IgG2 natural, y es necesario alterar no solamente la cisteína de la región de la bisagra, sino también la del dominio CH1, para disminuir la heterogeneidad en DSC. Además, como se describió anteriormente, solamente es posible conseguir una estabilidad equivalente a la de la IgG2 natural alterando no solamente la cisteína de la región de la bisagra, sino también la del dominio CH1.
Como se describió anteriormente, como para las regiones constantes en las que la heterogeneidad resultante de la región de la bisagra de IgG2 se ha reducido, se descubrió que SC y CS, que son regiones constantes en las que se ha sustituido solamente la cisteína de la región de la bisagra con serina, pueden ser insuficientes desde el punto de vista de la heterogeneidad y la estabilidad, y que solamente es posible reducir significativamente la heterogeneidad mientras se mantiene una estabilidad comparable a IgG2 sustituyendo además la cisteína de la posición 131 de la numeración EU en el dominio CH1 con serina. Tales regiones constantes incluyen SKSC.
[Ejemplo de Referencia 8] Producción y estudio de la región constante M14 optimizada, sin unión al receptor Fcy
En el dominio de unión al receptor Fcy de la región constante de IgG2, los residuos en las posiciones 233, 234, 235, y 236 de la numeración EU son de tipo sin unión, mientras los residuos en las posiciones 327, 330, y 331 de la numeración EU son diferentes de los de IgG4, que son de tipo sin unión. Así, es necesario alterar los aminoácidos en las posiciones 327, 330, y 331 de la numeración EU a la secuencia de IgG4 (G2Aa en Eur J Immunol. ago. de 1999; 29(8):2613-24). Sin embargo, debido a que el aminoácido de la posición 339 de la numeración EU es alanina en IgG4 mientras es treonina en IgG2, la simple alteración de los aminoácidos en las posiciones 327, 330, y 331 de la numeración EU a la secuencia de IgG4 generará una nueva secuencia peptídica de 9 aminoácidos que no se da de manera natural que podría ser un péptido epitópico de células T, por lo que se provoca un riesgo de inmunogenicidad. Así, se descubrió que se podría prevenir la existencia de la secuencia peptídica nueva alterando la treonina de la posición 339 de la numeración EU en IgG2 a alanina, además de las alteraciones descritas anteriormente. Además de las mutaciones descritas anteriormente, la metionina de la posición 397 de la numeración EU se mutó a valina para mejorar la estabilidad de la IgG2 en condiciones ácidas. Además, en SKSC (SEQ ID NO: 62) producido en el Ejemplo de Referencia 7, en el que se ha mejorado la heterogeneidad resultante de los enlaces disulfuro en la región de la bisagra, la introducción de mutaciones en las posiciones 131 y 133 generará una nueva secuencia peptídica de 9 aminoácidos que no se da de manera natural que podría ser un péptido epitópico de células T, por lo que se provoca un riesgo de inmunogenicidad. Así, la secuencia peptídica alrededor de las posiciones 131 a 139 se convirtió en la misma de IgG1 mutando el ácido glutámico de la posición 137 de la numeración EU a glicina y mutando la serina de la posición 138 de la numeración EU a glicina. La secuencia de la región constante M14 (SEQ ID NO: 129) se produjo introduciendo todas las mutaciones anteriores.
La expresión y purificación de huPM1-M14, preparado mediante el uso de huPM1-M14 como cadena H y huPM1-L (SEQ ID NO: 162) como cadena L, se llevó a cabo mediante el método descrito en el Ejemplo de Referencia 7. El huPM1-M14 preparado (SEQ ID NO: 163), huPM1-IgG1, y huPM1-IgG2 se estudiaron con respecto a la heterogeneidad mediante el uso de cromatografía de intercambio catiónico con el método descrito en el Ejemplo de
Referencia 7.
Como se muestra en la Fig. 14, la heterogeneidad también se redujo en huPM1-M14 como en huPMI-SKSC.
[Ejemplo de Referencia 9] Preparación de huPM1-M58 con una heterogeneidad C-terminal reducida de la cadena H y una farmacocinética mejorada
Preparación de la molécula huPM1-M58
huPM1 es un anticuerpo IgG1. Para la heterogeneidad en la secuencia C-terminal de la cadena H del anticuerpo IgG, se ha informado de la deleción del residuo de lisina C-terminal y la amidación del grupo amino C-terminal debido a la deleción de los dos aminoácidos C-terminales, glicina y lisina (Anal Biochem. 1 de ene. de 2007;360(1): 75-83). Además en huPM1, aunque el componente principal es una secuencia en la que la lisina C-terminal codificada por la secuencia de nucleótidos se ha delecionado mediante una modificación postraduccional, también hay un componente menor en el que permanece la lisina y un componente menor en el que el grupo amino C-terminal está amidado debido a la deleción de la glicina y lisina, que contribuyen a la heterogeneidad. La fabricación de un producto farmacéutico a gran escala a la vez que se mantiene la diferencia en la heterogeneidad de las sustancias deseadas/relacionadas entre los productos no es sencilla, y da como resultado un incremento del coste, y así se desea que la sustancia esté compuesta de una única sustancia tanto como sea posible. Cuando un anticuerpo se desarrolla como producto farmacéutico, se desea la reducción de la heterogeneidad. Así, se desea que el extremo C-terminal de la cadena H no tenga heterogeneidad cuando se desarrolla como producto farmacéutico. También es deseable prolongar la semivida plasmática del anticuerpo para reducir la dosis del anticuerpo.
Así, las alteraciones descritas más adelante se introdujeron para preparar una región constante nueva en la que se ha reducido la heterogeneidad en el extremo C-terminal de la cadena H, se ha mejorado la farmacocinética en comparación con huPM1-IgG1, y la heterogeneidad derivada de IgG2 de tipo natural también se ha reducido sin pérdida de estabilidad.
De manera específica, en huPM1-SKSC, que tiene una estabilidad elevada y en la que la heterogeneidad anteriormente mencionada relacionada con los anticuerpos con regiones constantes del isotipo IgG2 está reducida, se sustituyó el ácido glutámico de la posición 137 de la numeración EU con glicina; la serina de la posición 138 con glicina; la histidina de la posición 268 con glutamina; la arginina de la posición 355 con glutamina; y la glutamina de la posición 419 con ácido glutámico. Además de las sustituciones anteriores, la glicina y lisina de las posiciones 446 y 447 se delecionaron para reducir la heterogeneidad del extremo C-terminal de la cadena H, por lo que se obtuvo huPM1-M58 (SEQ ID No : 164). El huPM1-M58 preparado mediante el uso de huPM1-M58 como una cadena H y huPM1-L (SEQ ID NO: 162) como una cadena L se expresó y se purificó mediante el método descrito en el Ejemplo 4.
Los huPM1-M58, huPM1-IgG1, y huPM1-IgG2 se estudiaron con respecto a la heterogeneidad y la estabilidad mediante los métodos descritos en el Ejemplo 5 con el uso de cromatografía de intercambio catiónico y DSC, respectivamente.
El resultado de DSC se muestra en la Tabla 18. Como se muestra en las Figs. 13 y 16, se descubrió que huPM1-M58 mostró una heterogeneidad reducida sin pérdida de estabilidad como en huPM1-SKSC.
Tabla 18
Nombre Tm/°C
huPM1-IgG1 94,8
huPM1-IgG2 93,9
huPM1-SKSC 93,7
huPM1-M58 93,7
Estudio de huPM1-M58 con respecto a la retención plasmática
La retención prolongada (eliminación lenta) de la molécula de IgG en el plasma se debe a la función de FcRn, que se conoce como un receptor de rescate de la molécula de IgG (Nat Rev Immunol. sep. de 2007;7(9): 715-25). Cuando se incorporan a los endosomas por medio de pinocitosis, las moléculas de IgG se unen al FcRn expresado en los endosomas en las condiciones ácidas dentro del endosoma (aprox. pH 6,0). Mientras las moléculas de IgG que no están unidas a FcRn se transfieren y se degradan en los lisosomas, las unidas a FcRn se translocan a la superficie de la célula y después se liberan desde el FcRn al plasma de nuevo en las condiciones neutras del plasma (aprox. pH 7,4).
Se sabe que los anticuerpos de tipo IgG incluyen los isotipos IgG1, IgG2, IgG3, e IgG4. Se informa que las semividas plasmáticas de estos isotipos en los seres humanos son alrededor de 36 días para IgG1 e IgG2; alrededor de 29 días para IgG3; y 16 días para IgG4 (Nat. Biotechnol. dic. de 2007; 25(12): 1369-72). Así, se cree que la retención de IgG 1 e IgG2 en el plasma es la más larga. En general, los isotipos de los anticuerpos usados como agentes farmacéuticos son IgG 1, IgG2, e IgG4. Los métodos informados para mejorar adicionalmente la
farmacocinética de estos anticuerpos IgG incluyen métodos para mejorar la actividad de unión anteriormente descrita a FcRn humano alterando la secuencia de la región constante de IgG (J. Biol. Chem., 19 de ene. de 2007;282(3): 1709-17; J. Immunol. 1 de ene. de 2006;176(1): 346-56).
Existen diferencias entre especies entre FcRn de ratón y FcRn humano (Proc. Natl. Acad. Sci. USA. 5 de dic. de 2006;103(49): 18709-14). Por lo tanto, para predecir la retención de los anticuerpos IgG que tienen una secuencia de la región constante alterada en el plasma humano, puede ser deseable estudiar la unión a FcRn humano y la retención plasmática en ratones transgénicos para FcRn humano (Int. Immunol. dic. de 2006;18(12): 1759-69).
Estudio de la unión a FcRn humano
FcRn es un complejo de FcRn y p2-microglobulina. Se prepararon cebadores de oligo-ADN basándose en la secuencia publicada del gen de FcRn humano (J. Exp. Med. (1994) 180 (6), 2377-2381). Se preparó un fragmento de ADN que codificaba el gen completo mediante PCR con el uso de cADN humano (Human Placenta Marathon-Ready cDNA, Clontech) como molde y los cebadores preparados. Mediante el uso del fragmento de ADN obtenido como molde, se amplificó un fragmento de ADN que codificaba el dominio extracelular que contenía la región de la señal (Met1-Leu290) mediante PCR, y se insertó en un vector de expresión en células animales (la secuencia de aminoácidos de FcRn humano/SEQ ID NO: 165). De forma similar, se prepararon cebadores de oligo-ADN basándose en la secuencia publicada del gen de p2-microglobulina humana (Proc. Natl. Acad. Sci. U.S.A. 99 (26), 16899-16903 (2002)). Se preparó un fragmento de ADN que codificaba el gen completo mediante PCR con el uso de cADN humano (Hu-Placenta Marathon-Ready cDNA, CLONTECH) como molde y los cebadores preparados. Mediante el uso del fragmento de ADN obtenido como molde, se amplificó un fragmento de ADN que codificaba la p2-microglobulina completa que contenía la región de la señal (Met1-Met119) mediante PCR, y se insertó en un vector de expresión en células animales (la secuencia de aminoácidos de p2-microglobulina humana/SEQ ID NO: 166).
Se expresó el FcRn humano soluble mediante el siguiente procedimiento. Los plásmidos preparados para FcRn y p2-microglobulina humana se introdujeron en la línea celular derivada de cáncer de riñón embrionario humano HEK293H (Invitrogen) mediante el uso de un 10% de suero bovino fetal (Invitrogen) mediante lipofección. El sobrenadante de cultivo resultante se recogió y se purificó mediante el uso de IgG Sepharose 6 Fast Flow (Amersham Biosciences) con el método descrito en J. Immunol. 1 de nov. de 2002; 169(9):5171 -80. Después, se llevó a cabo una purificación adicional mediante el uso de HiTrap Q HP (GE Healthcare).
Se estudió la unión a FcRn humano mediante el uso de Biacore 3000. Se unió un anticuerpo a Proteína L o anticuerpo anti-cadena Kappa de IgG humana de conejo inmovilizado sobre un chip sensor, se añadió FcRn humano como analito para la interacción con el anticuerpo, y se calculó la afinidad (KD) a partir de la cantidad de FcRn humano unido. De manera específica, se inmovilizó Proteína L sobre un chip sensor CM5 (BIACORE) mediante el método de acoplamiento con amina con el uso de tampón Na-fosfato 50 mM (pH 6,0) que contenía NaCl 150 mM como tampón de análisis. Después, se diluyó un anticuerpo con el tampón de análisis que contenía un 0,02% de Tween20, y se inyectó y se dejó unirse al chip. Después se inyectó FcRn humano para estudiar la actividad de unión del anticuerpo al FcRn humano.
Se calculó la afinidad mediante el uso del programa informático BIAevaluation. El sensorgrama obtenido se usó para calcular la cantidad de hFcRn unido al anticuerpo inmediatamente antes del final de la inyección de FcRn humano. Este se ajustó mediante el método de afinidad en estado estacionario para calcular la afinidad del FcRn humano hacia el anticuerpo.
Estudio predictivo de la retención plasmática de huPM1-IgG1 y huPM1-M58 en humanos mediante el uso de FcRn humano
Las actividades de unión de huPM1-IgG1 y huPM1-M58 a FcRn humano se estudiaron mediante el uso de BIAcore. Como se muestra en la Tabla 19, la actividad de unión de huPM1-M58 fue mayor que la de huPM1-IgG1 en alrededor de 1,4 veces.
Tabla 19
KD (uM)
huPM1-IgG1 162
huPM1-M58 1,17
Estudio de la retención plasmática en ratones transgénicos para FcRn humano
Se estudió la farmacocinética en ratones transgénicos para FcRn humano (ratones 276 /+, línea B6.mFcRn-/-.hFcRn Tg; Jackson Laboratories) mediante el siguiente procedimiento. Se administró un anticuerpo de manera intravenosa una vez a una dosis de 1 mg/kg a los ratones, y se recogió sangre en los momentos adecuados. La sangre recogida se centrifugó inmediatamente a 15.000 rpm durante 15 minutos a 4 °C para obtener el plasma. El plasma separado se almacenó en un congelador a -20 °C o menos hasta el uso. La concentración plasmática se determinó mediante ELISA.
Claims (6)
1. Un anticuerpo anti-NR10 que tiene una actividad neutralizante, en el que el anticuerpo anti-NR10 es uno cualquiera de:
(1) un anticuerpo que comprende una región variable de cadena pesada que comprende CDR1 que comprende la secuencia de aminoácidos de SEQ ID NO: 1, CDR2 que comprende la secuencia de aminoácidos de SEQ ID NO: 2 y CDR3 que comprende la secuencia de aminoácidos de SEQ ID NO: 3, y que comprende una región variable de cadena ligera que comprende CDR1 que comprende la secuencia de aminoácidos de SEQ ID NO: 5, CDR2 que comprende la secuencia de aminoácidos de SEQ ID NO: 6 y CDR3 que comprende la secuencia de aminoácidos de SEQ ID NO: 7;
(2) un anticuerpo que comprende la región variable de cadena pesada de SEQ ID NO: 4 y que comprende la región variable de cadena ligera de SEQ ID NO: 8; y
(3) un anticuerpo que se une al mismo epítopo que un epítopo al que se une el anticuerpo de (1) o (2), y compite con el anticuerpo de (1) o (2) por unirse a NR10.
2. Un anticuerpo anti-NR10 que tiene una actividad neutralizante, en el que el anticuerpo anti-NR10 es uno cualquiera de:
(1) un anticuerpo que comprende una región variable de cadena pesada que comprende CDR1 que comprende la secuencia de aminoácidos de SEC ID NO: 17, CDR2 que comprende la secuencia de aminoácidos de SEQ ID NO: 18 y CDR3 que comprende la secuencia de aminoácidos de SEQ ID NO: 19, y que comprende una región variable de cadena ligera que comprende CDR1 que comprende la secuencia de aminoácidos de SEQ ID NO: 21, CDR2 que comprende la secuencia de aminoácidos de SEQ ID NO: 22, y CDR3 que comprende la secuencia de aminoácidos de SEQ ID NO: 23;
(2) un anticuerpo que comprende la región variable de cadena pesada de SEQ ID NO: 20 y que comprende la región variable de cadena ligera de SEQ ID NO: 24; y
(3) un anticuerpo que se une al mismo epítopo que un epítopo al que se une el anticuerpo de (1) o (2), y compite con el anticuerpo de (1) o (2) por unirse a NR10.
3. El anticuerpo anti-NR10 de la reivindicación 1 o 2, que es un anticuerpo humanizado.
4. Una composición farmacéutica que comprende el anticuerpo anti-NR10 de cualquiera de las reivindicaciones 1 a 3.
5. La composición farmacéutica de la reivindicación 4, para uso en el tratamiento de una enfermedad inflamatoria.
6. Uso del anticuerpo anti-NR10 de la reivindicación 1 o 2 en la preparación de un agente terapéutico para el tratamiento de una enfermedad inflamatoria.
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2007315143 | 2007-12-05 | ||
| JP2008247425 | 2008-09-26 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| ES2834741T3 true ES2834741T3 (es) | 2021-06-18 |
Family
ID=40717782
Family Applications (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| ES16172648T Active ES2834741T3 (es) | 2007-12-05 | 2008-12-05 | Anticuerpo anti-NR10 y uso del mismo |
| ES08857126.0T Active ES2585480T3 (es) | 2007-12-05 | 2008-12-05 | Anticuerpo anti-NR10 y uso del mismo |
Family Applications After (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| ES08857126.0T Active ES2585480T3 (es) | 2007-12-05 | 2008-12-05 | Anticuerpo anti-NR10 y uso del mismo |
Country Status (17)
| Country | Link |
|---|---|
| US (6) | US20110129459A1 (es) |
| EP (2) | EP2236604B1 (es) |
| JP (1) | JP5682995B2 (es) |
| KR (3) | KR101643005B1 (es) |
| CN (2) | CN101939424B (es) |
| AU (2) | AU2008332271C1 (es) |
| BR (1) | BRPI0821110B8 (es) |
| CA (2) | CA2708532C (es) |
| DK (1) | DK2236604T3 (es) |
| ES (2) | ES2834741T3 (es) |
| HR (1) | HRP20151215T1 (es) |
| HU (1) | HUE025958T2 (es) |
| MX (2) | MX337081B (es) |
| MY (1) | MY177564A (es) |
| RU (1) | RU2531521C2 (es) |
| TW (2) | TW201634479A (es) |
| WO (1) | WO2009072604A1 (es) |
Families Citing this family (50)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP3050963B1 (en) | 2005-03-31 | 2019-09-18 | Chugai Seiyaku Kabushiki Kaisha | Process for production of polypeptide by regulation of assembly |
| EP4218801A3 (en) | 2006-03-31 | 2023-08-23 | Chugai Seiyaku Kabushiki Kaisha | Antibody modification method for purifying bispecific antibody |
| WO2007114319A1 (ja) | 2006-03-31 | 2007-10-11 | Chugai Seiyaku Kabushiki Kaisha | 抗体の血中動態を制御する方法 |
| BRPI0712426B1 (pt) | 2006-06-08 | 2021-10-26 | Chugai Seiyaku Kabushiki Kaisha | Usos de um anticorpo anti-nr10/il-31ra com atividade neutralizante de nr10/il-31ra, de um fragmento e/ou um fragmento quimicamente modificado do anticorpo e de um agente |
| TWI464262B (zh) | 2007-09-26 | 2014-12-11 | 中外製藥股份有限公司 | 抗體固定區的變異 |
| JP5334319B2 (ja) | 2007-09-26 | 2013-11-06 | 中外製薬株式会社 | Cdrのアミノ酸置換により抗体の等電点を改変する方法 |
| EP2236604B1 (en) | 2007-12-05 | 2016-07-06 | Chugai Seiyaku Kabushiki Kaisha | Anti-nr10 antibody and use thereof |
| EP2241332A4 (en) | 2007-12-05 | 2011-01-26 | Chugai Pharmaceutical Co Ltd | THERAPEUTIC AGENT AGAINST PRITURE |
| PL2708558T3 (pl) | 2008-04-11 | 2018-09-28 | Chugai Seiyaku Kabushiki Kaisha | Cząsteczka wiążąca antygen zdolna do wiązania dwóch lub więcej cząsteczek antygenu w sposób powtarzalny |
| TWI440469B (zh) | 2008-09-26 | 2014-06-11 | Chugai Pharmaceutical Co Ltd | Improved antibody molecules |
| JP5139517B2 (ja) * | 2008-12-05 | 2013-02-06 | 中外製薬株式会社 | 抗nr10抗体、およびその利用 |
| JP2010210772A (ja) * | 2009-03-13 | 2010-09-24 | Dainippon Screen Mfg Co Ltd | 液晶表示装置の製造方法 |
| JP5717624B2 (ja) | 2009-03-19 | 2015-05-13 | 中外製薬株式会社 | 抗体定常領域改変体 |
| TWI682995B (zh) | 2009-03-19 | 2020-01-21 | 日商中外製藥股份有限公司 | 抗體恆定區域改變體 |
| JP5837821B2 (ja) | 2009-09-24 | 2015-12-24 | 中外製薬株式会社 | 抗体定常領域改変体 |
| US20120322085A1 (en) | 2009-11-05 | 2012-12-20 | Osaka University | Therapeutic agent for autoimmune diseases or allergy, and method for screening for the therapeutic agent |
| AR080428A1 (es) | 2010-01-20 | 2012-04-11 | Chugai Pharmaceutical Co Ltd | Formulaciones liquidas estabilizadas contentivas de anticuerpos |
| EP2543730B1 (en) | 2010-03-04 | 2018-10-31 | Chugai Seiyaku Kabushiki Kaisha | Antibody constant region variant |
| AU2011253101A1 (en) * | 2010-05-11 | 2013-01-10 | Aveo Pharmaceuticals, Inc. | Anti-FGFR2 antibodies |
| WO2012073992A1 (ja) | 2010-11-30 | 2012-06-07 | 中外製薬株式会社 | 複数分子の抗原に繰り返し結合する抗原結合分子 |
| KR101903208B1 (ko) * | 2010-12-28 | 2018-10-01 | 추가이 세이야쿠 가부시키가이샤 | 동물 세포의 배양 방법 |
| WO2013012022A1 (ja) | 2011-07-19 | 2013-01-24 | 中外製薬株式会社 | アルギニンアミドまたはその類似化合物を含む安定なタンパク質含有製剤 |
| MY182178A (en) | 2011-09-01 | 2021-01-18 | Chugai Pharmaceutical Co Ltd | Method for preparing a composition comprising highly concentrated antibodies by ultrafiltration |
| CN104334581B (zh) * | 2012-05-09 | 2018-02-02 | 伊莱利利公司 | 抗‑c‑Met抗体 |
| AU2013306390B2 (en) | 2012-08-24 | 2018-07-05 | The Regents Of The University Of California | Antibodies and vaccines for use in treating ROR1 cancers and inhibiting metastasis |
| US11124576B2 (en) | 2013-09-27 | 2021-09-21 | Chungai Seiyaku Kabushiki Kaisha | Method for producing polypeptide heteromultimer |
| KR102344170B1 (ko) | 2013-12-27 | 2021-12-27 | 추가이 세이야쿠 가부시키가이샤 | 등전점이 낮은 항체의 정제방법 |
| EP3185004A4 (en) | 2014-08-20 | 2018-05-30 | Chugai Seiyaku Kabushiki Kaisha | Method for measuring viscosity of protein solution |
| CA2968382A1 (en) | 2014-11-21 | 2016-05-26 | Bristol-Myers Squibb Company | Antibodies comprising modified heavy constant regions |
| UY36404A (es) | 2014-11-21 | 2016-06-01 | Bristol Myers Squibb Company Una Corporación Del Estado De Delaware | ANTICUERPOS MONOCLONALES (Ab) COMO DETECTORES DE CD73 E INHIBIDORES DE SU ACTIVIDAD ENZIMÁTICA, Y COMPOSICIONES QUE LOS CONTIENEN |
| US10774148B2 (en) | 2015-02-27 | 2020-09-15 | Chugai Seiyaku Kabushiki Kaisha | Composition for treating IL-6-related diseases |
| US11142587B2 (en) | 2015-04-01 | 2021-10-12 | Chugai Seiyaku Kabushiki Kaisha | Method for producing polypeptide hetero-oligomer |
| KR102641898B1 (ko) * | 2015-04-14 | 2024-02-27 | 추가이 세이야쿠 가부시키가이샤 | Il-31 안타고니스트를 유효 성분으로서 함유하는 아토피성 피부염의 예방용 및/또는 치료용 의약 조성물 |
| WO2016167263A1 (ja) | 2015-04-14 | 2016-10-20 | 中外製薬株式会社 | Il-31アンタゴニストを有効成分として含有する、アトピー性皮膚炎の予防用及び/又は治療用医薬組成物 |
| CN105331703B (zh) * | 2015-11-16 | 2018-08-17 | 中国农业科学院北京畜牧兽医研究所 | 一种鉴定或辅助鉴定猪100kg体重眼肌面积的方法及其专用试剂盒 |
| US11649262B2 (en) | 2015-12-28 | 2023-05-16 | Chugai Seiyaku Kabushiki Kaisha | Method for promoting efficiency of purification of Fc region-containing polypeptide |
| CA3010612A1 (en) * | 2016-01-08 | 2017-07-13 | Oncobiologics, Inc. | Methods for separating isoforms of monoclonal antibodies |
| KR20190022752A (ko) | 2016-06-27 | 2019-03-06 | 더 리젠츠 오브 더 유니버시티 오브 캘리포니아 | 암 치료 조합 |
| SG10201607778XA (en) | 2016-09-16 | 2018-04-27 | Chugai Pharmaceutical Co Ltd | Anti-Dengue Virus Antibodies, Polypeptides Containing Variant Fc Regions, And Methods Of Use |
| JP7185884B2 (ja) | 2017-05-02 | 2022-12-08 | 国立研究開発法人国立精神・神経医療研究センター | Il-6及び好中球の関連する疾患の治療効果の予測及び判定方法 |
| CN112119090B (zh) | 2018-03-15 | 2023-01-13 | 中外制药株式会社 | 对寨卡病毒具有交叉反应性的抗登革热病毒抗体及使用方法 |
| US20210196568A1 (en) | 2018-05-21 | 2021-07-01 | Chugai Seiyaku Kabushiki Kaisha | Lyophilized formulation sealed in glass container |
| JP6955098B2 (ja) | 2018-05-28 | 2021-10-27 | 中外製薬株式会社 | 充填ノズル |
| AU2020387034A1 (en) * | 2019-11-20 | 2022-06-02 | Chugai Seiyaku Kabushiki Kaisha | Antibody-containing preparation |
| CN113637073B (zh) * | 2020-05-11 | 2024-04-12 | 上海赛比曼生物科技有限公司 | Bcma抗体及其制备和应用 |
| WO2022025030A1 (ja) | 2020-07-28 | 2022-02-03 | 中外製薬株式会社 | 新規改変型抗体を含む、針シールドを備えた針付プレフィルドシリンジ製剤 |
| KR102269716B1 (ko) | 2020-09-01 | 2021-06-28 | 추가이 세이야쿠 가부시키가이샤 | Il-31 안타고니스트를 유효 성분으로서 함유하는, 투석 소양증의 예방용 및/또는 치료용 의약 조성물 |
| KR20240050407A (ko) * | 2021-08-30 | 2024-04-18 | 갈더마 홀딩 소시에떼 아노님 | 아토피성 피부염 치료 |
| TW202333781A (zh) | 2021-10-08 | 2023-09-01 | 日商中外製藥股份有限公司 | 抗hla-dq2﹒5抗體製劑 |
| JPWO2023120561A1 (es) * | 2021-12-22 | 2023-06-29 |
Family Cites Families (149)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US3773919A (en) | 1969-10-23 | 1973-11-20 | Du Pont | Polylactide-drug mixtures |
| IE52535B1 (en) | 1981-02-16 | 1987-12-09 | Ici Plc | Continuous release pharmaceutical compositions |
| US5156840A (en) | 1982-03-09 | 1992-10-20 | Cytogen Corporation | Amine-containing porphyrin derivatives |
| JPS58201994A (ja) | 1982-05-21 | 1983-11-25 | Hideaki Hagiwara | 抗原特異的ヒト免疫グロブリンの生産方法 |
| US4816567A (en) | 1983-04-08 | 1989-03-28 | Genentech, Inc. | Recombinant immunoglobin preparations |
| JPS59162441U (ja) | 1983-04-14 | 1984-10-31 | 千代田紙業株式会社 | 吹込口を有する重包包装 |
| HUT35524A (en) | 1983-08-02 | 1985-07-29 | Hoechst Ag | Process for preparing pharmaceutical compositions containing regulatory /regulative/ peptides providing for the retarded release of the active substance |
| US5057313A (en) | 1986-02-25 | 1991-10-15 | The Center For Molecular Medicine And Immunology | Diagnostic and therapeutic antibody conjugates |
| GB8607679D0 (en) | 1986-03-27 | 1986-04-30 | Winter G P | Recombinant dna product |
| US5260203A (en) * | 1986-09-02 | 1993-11-09 | Enzon, Inc. | Single polypeptide chain binding molecules |
| US5670373A (en) * | 1988-01-22 | 1997-09-23 | Kishimoto; Tadamitsu | Antibody to human interleukin-6 receptor |
| US5322678A (en) * | 1988-02-17 | 1994-06-21 | Neorx Corporation | Alteration of pharmacokinetics of proteins by charge modification |
| DE3920358A1 (de) | 1989-06-22 | 1991-01-17 | Behringwerke Ag | Bispezifische und oligospezifische, mono- und oligovalente antikoerperkonstrukte, ihre herstellung und verwendung |
| CA2109602C (en) | 1990-07-10 | 2002-10-01 | Gregory P. Winter | Methods for producing members of specific binding pairs |
| GB9015198D0 (en) | 1990-07-10 | 1990-08-29 | Brien Caroline J O | Binding substance |
| ES2108048T3 (es) | 1990-08-29 | 1997-12-16 | Genpharm Int | Produccion y utilizacion de animales inferiores transgenicos capaces de producir anticuerpos heterologos. |
| EP0628639B1 (en) * | 1991-04-25 | 1999-06-23 | Chugai Seiyaku Kabushiki Kaisha | Reconstituted human antibody against human interleukin 6 receptor |
| US6136310A (en) | 1991-07-25 | 2000-10-24 | Idec Pharmaceuticals Corporation | Recombinant anti-CD4 antibodies for human therapy |
| WO1993006213A1 (en) | 1991-09-23 | 1993-04-01 | Medical Research Council | Production of chimeric antibodies - a combinatorial approach |
| ATE207080T1 (de) | 1991-11-25 | 2001-11-15 | Enzon Inc | Multivalente antigen-bindende proteine |
| WO1993011236A1 (en) | 1991-12-02 | 1993-06-10 | Medical Research Council | Production of anti-self antibodies from antibody segment repertoires and displayed on phage |
| EP0746609A4 (en) | 1991-12-17 | 1997-12-17 | Genpharm Int | NON-HUMAN TRANSGENIC ANIMALS CAPABLE OF PRODUCING HETEROLOGOUS ANTIBODIES |
| JPH0767688B2 (ja) | 1992-01-21 | 1995-07-26 | 近畿コンクリート工業株式会社 | Pcコンクリートパネル |
| EP0656941B1 (en) | 1992-03-24 | 2005-06-01 | Cambridge Antibody Technology Limited | Methods for producing members of specific binding pairs |
| WO1994002602A1 (en) | 1992-07-24 | 1994-02-03 | Cell Genesys, Inc. | Generation of xenogeneic antibodies |
| US5639641A (en) | 1992-09-09 | 1997-06-17 | Immunogen Inc. | Resurfacing of rodent antibodies |
| BR9204244A (pt) | 1992-10-26 | 1994-05-03 | Cofap | Ferro fundido cinzento |
| KR100371784B1 (ko) | 1992-12-01 | 2003-07-22 | 프로테인 디자인랩스, 인코포레이티드 | L-셀렉틴과반응성인인체화된항체 |
| AU6819494A (en) | 1993-04-26 | 1994-11-21 | Genpharm International, Inc. | Transgenic non-human animals capable of producing heterologous antibodies |
| GB9313509D0 (en) | 1993-06-30 | 1993-08-11 | Medical Res Council | Chemisynthetic libraries |
| IL107742A0 (en) | 1993-11-24 | 1994-02-27 | Yeda Res & Dev | Chemically-modified binding proteins |
| JPH09506508A (ja) | 1993-12-03 | 1997-06-30 | メディカル リサーチ カウンシル | 組換え結合タンパク質およびペプチド |
| US5945311A (en) | 1994-06-03 | 1999-08-31 | GSF--Forschungszentrumfur Umweltund Gesundheit | Method for producing heterologous bi-specific antibodies |
| DE4419399C1 (de) | 1994-06-03 | 1995-03-09 | Gsf Forschungszentrum Umwelt | Verfahren zur Herstellung von heterologen bispezifischen Antikörpern |
| US8017121B2 (en) * | 1994-06-30 | 2011-09-13 | Chugai Seiyaku Kabushika Kaisha | Chronic rheumatoid arthritis therapy containing IL-6 antagonist as effective component |
| CA2194907A1 (en) | 1994-07-13 | 1996-02-01 | Kouji Matsushima | Reshaped human antibody against human interleukin-8 |
| ATE552012T1 (de) | 1994-10-07 | 2012-04-15 | Chugai Pharmaceutical Co Ltd | Hemmung des abnormalen wachstums von synovialzellen durch il-6-antagonisten als wirkstoff |
| EP0791359A4 (en) | 1994-10-21 | 2002-09-11 | Chugai Pharmaceutical Co Ltd | MEDICINE AGAINST IL-6 PRODUCTION IN DISEASES |
| FR2729855A1 (fr) | 1995-01-26 | 1996-08-02 | Oreal | Utilisation d'un antagoniste de cgrp dans une composition cosmetique, pharmaceutique ou dermatologique et composition obtenue |
| US5876950A (en) | 1995-01-26 | 1999-03-02 | Bristol-Myers Squibb Company | Monoclonal antibodies specific for different epitopes of human GP39 and methods for their use in diagnosis and therapy |
| US5731168A (en) | 1995-03-01 | 1998-03-24 | Genentech, Inc. | Method for making heteromultimeric polypeptides |
| AU5632296A (en) | 1995-04-27 | 1996-11-18 | Abgenix, Inc. | Human antibodies derived from immunized xenomice |
| WO1996034096A1 (en) | 1995-04-28 | 1996-10-31 | Abgenix, Inc. | Human antibodies derived from immunized xenomice |
| US6018032A (en) | 1995-09-11 | 2000-01-25 | Kyowa Hakko Kogyo Co., Ltd. | Antibody against human interleukin-5-receptor α chain |
| CZ399A3 (cs) | 1996-07-19 | 1999-06-16 | Amgen Inc. | Polypeptidová analoga kationaktivních polypeptidů |
| BR9713294A (pt) | 1996-09-26 | 2000-10-17 | Chugai Pharmaceutical Co Ltd | "anticorpos contra proteìna relacionada a hormÈnio de paratiróide humano" |
| US7365166B2 (en) * | 1997-04-07 | 2008-04-29 | Genentech, Inc. | Anti-VEGF antibodies |
| FR2761994B1 (fr) | 1997-04-11 | 1999-06-18 | Centre Nat Rech Scient | Preparation de recepteurs membranaires a partir de baculovirus extracellulaires |
| US20020187150A1 (en) * | 1997-08-15 | 2002-12-12 | Chugai Seiyaku Kabushiki Kaisha | Preventive and/or therapeutic agent for systemic lupus erythematosus comprising anti-IL-6 receptor antibody as an active ingredient |
| KR100473836B1 (ko) | 1997-10-03 | 2005-03-07 | 츄가이 세이야꾸 가부시키가이샤 | 천연 인간형화 항체 |
| JP4124573B2 (ja) * | 1998-03-17 | 2008-07-23 | 中外製薬株式会社 | Il−6アンタゴニストを有効成分として含有する炎症性腸疾患の予防又は治療剤 |
| US6677436B1 (en) | 1998-04-03 | 2004-01-13 | Chugai Seiyaku Kabushiki Kaisha | Humanized antibody against human tissue factor (TF) and process of production of the humanized antibody |
| ATE314396T1 (de) | 1998-04-30 | 2006-01-15 | Tanox Inc | G-csf-rezeptoragonist-antikörper und methode zu ihrer isolierung mittels durchmusterung |
| GB9809951D0 (en) | 1998-05-08 | 1998-07-08 | Univ Cambridge Tech | Binding molecules |
| FR2780062B1 (fr) | 1998-06-17 | 2000-07-28 | Rhone Poulenc Rorer Sa | Anticorps monoclonaux diriges contre la proteine g3bp, et leurs utilisations |
| WO2000009560A2 (en) | 1998-08-17 | 2000-02-24 | Abgenix, Inc. | Generation of modified molecules with increased serum half-lives |
| MXPA01005515A (es) * | 1998-12-01 | 2003-07-14 | Protein Design Labs Inc | Anticuerpos humanizados para gamma-interferon. |
| CN1202128C (zh) | 1998-12-08 | 2005-05-18 | 拜奥威神有限公司 | 修饰蛋白的免疫原性 |
| US6737056B1 (en) | 1999-01-15 | 2004-05-18 | Genentech, Inc. | Polypeptide variants with altered effector function |
| US6972125B2 (en) | 1999-02-12 | 2005-12-06 | Genetics Institute, Llc | Humanized immunoglobulin reactive with B7-2 and methods of treatment therewith |
| PT1188830E (pt) * | 1999-06-02 | 2010-04-09 | Chugai Pharmaceutical Co Ltd | Nova proteína nr10 receptora da hemopoietina |
| SK782002A3 (en) * | 1999-07-21 | 2003-08-05 | Lexigen Pharm Corp | FC fusion proteins for enhancing the immunogenicity of protein and peptide antigens |
| SE9903895D0 (sv) | 1999-10-28 | 1999-10-28 | Active Biotech Ab | Novel compounds |
| EP1278512A2 (en) | 2000-05-03 | 2003-01-29 | MBT Munich Biotechnology AG | Cationic diagnostic, imaging and therapeutic agents associated with activated vascular sites |
| US20030096339A1 (en) * | 2000-06-26 | 2003-05-22 | Sprecher Cindy A. | Cytokine receptor zcytor17 |
| AU2000279625A1 (en) * | 2000-10-27 | 2002-05-15 | Chugai Seiyaku Kabushiki Kaisha | Blood mmp-3 level-lowering agent containing il-6 antgonist as the active ingredient |
| AU2002248571B2 (en) | 2001-03-07 | 2007-01-18 | Merck Patent Gmbh | Expression technology for proteins containing a hybrid isotype antibody moiety |
| UA80091C2 (en) | 2001-04-02 | 2007-08-27 | Chugai Pharmaceutical Co Ltd | Remedies for infant chronic arthritis-relating diseases and still's disease which contain an interleukin-6 (il-6) antagonist |
| JP4230776B2 (ja) | 2001-04-05 | 2009-02-25 | 株式会社 免疫生物研究所 | 抗オステオポンチン抗体およびその用途 |
| CZ303450B6 (cs) | 2001-04-13 | 2012-09-19 | Biogen Idec Ma Inc. | Protilátky k VLA-1, kompozice je obsahující a nukleové kyseliny, které je kódují, zpusob stanovení hladiny VLA-1 a použití pri lécení imunologického onemocnení |
| JP4281869B2 (ja) | 2001-06-22 | 2009-06-17 | 中外製薬株式会社 | 抗グリピカン3抗体を含む細胞増殖抑制剤 |
| ES2546797T3 (es) * | 2002-01-18 | 2015-09-28 | Zymogenetics, Inc. | Multímeros Zcytor17 receptores de citocinas |
| CA2473686C (en) | 2002-01-18 | 2011-09-20 | Zymogenetics, Inc. | Novel cytokine zcytor17 ligand |
| WO2005056606A2 (en) | 2003-12-03 | 2005-06-23 | Xencor, Inc | Optimized antibodies that target the epidermal growth factor receptor |
| US20050130224A1 (en) | 2002-05-31 | 2005-06-16 | Celestar Lexico- Sciences, Inc. | Interaction predicting device |
| US7750204B2 (en) | 2002-06-05 | 2010-07-06 | Chugai Seiyaku Kabushiki Kaisha | Methods for producing antibody |
| AU2003256266A1 (en) | 2002-06-12 | 2003-12-31 | Genencor International, Inc. | Methods and compositions for milieu-dependent binding of a targeted agent to a target |
| TW200407335A (en) * | 2002-07-22 | 2004-05-16 | Chugai Pharmaceutical Co Ltd | Non-neutralizing antibody to inhibit the inactivation of activated protein C |
| AU2003264009A1 (en) | 2002-08-15 | 2004-03-03 | Epitomics, Inc. | Humanized rabbit antibodies |
| US7217797B2 (en) | 2002-10-15 | 2007-05-15 | Pdl Biopharma, Inc. | Alteration of FcRn binding affinities or serum half-lives of antibodies by mutagenesis |
| KR100499989B1 (ko) | 2002-12-27 | 2005-07-07 | 네오바이오다임 주식회사 | 아사이알로 α1-산 당단백질에 대한 단일클론 항체, 이 항체를 포함하는 아사이알로 α1-산 당단백질에 대한 단일클론 항체, 이 항체를 포함하는 면역크로마토그래피 스트립 및 이 스트립를 이용한 아사이알로 α1-산 당단백질 측정방법 |
| CA2515081A1 (en) | 2003-02-07 | 2004-08-19 | Protein Design Labs, Inc. | Amphiregulin antibodies and their use to treat cancer and psoriasis |
| US20040223970A1 (en) * | 2003-02-28 | 2004-11-11 | Daniel Afar | Antibodies against SLC15A2 and uses thereof |
| CA2517926A1 (en) | 2003-03-04 | 2004-10-28 | Alexion Pharmaceuticals, Inc. | Method of treating autoimmune disease by inducing antigen presentation by tolerance inducing antigen presenting cells |
| DE602004028347D1 (de) | 2003-03-24 | 2010-09-09 | Zymogenetics Inc | Anti-il-22ra antikörper und bindungspartner und verwendungsmethoden bei entzündung |
| GB2401040A (en) | 2003-04-28 | 2004-11-03 | Chugai Pharmaceutical Co Ltd | Method for treating interleukin-6 related diseases |
| EP1636264A2 (en) | 2003-06-24 | 2006-03-22 | MERCK PATENT GmbH | Tumour necrosis factor receptor molecules with reduced immunogenicity |
| AU2003271174A1 (en) | 2003-10-10 | 2005-04-27 | Chugai Seiyaku Kabushiki Kaisha | Double specific antibodies substituting for functional protein |
| EP1693448A4 (en) * | 2003-10-14 | 2008-03-05 | Chugai Pharmaceutical Co Ltd | DOUBLE SPECIFICITY ANTIBODY FOR FUNCTIONAL PROTEIN SUBSTITUTION |
| WO2005047327A2 (en) | 2003-11-12 | 2005-05-26 | Biogen Idec Ma Inc. | NEONATAL Fc RECEPTOR (FcRn)-BINDING POLYPEPTIDE VARIANTS, DIMERIC Fc BINDING PROTEINS AND METHODS RELATED THERETO |
| KR20060123413A (ko) | 2003-12-03 | 2006-12-01 | 추가이 세이야쿠 가부시키가이샤 | 포유류 β 액틴 프로모터를 이용한 발현계 |
| AR048210A1 (es) | 2003-12-19 | 2006-04-12 | Chugai Pharmaceutical Co Ltd | Un agente preventivo para la vasculitis. |
| CA2552523C (en) | 2004-01-09 | 2019-11-26 | Pfizer Inc. | Monoclonal antibodies to mucosal addressin cell adhesion molecule(madcam) |
| AR048335A1 (es) | 2004-03-24 | 2006-04-19 | Chugai Pharmaceutical Co Ltd | Agentes terapeuticos para trastornos del oido interno que contienen un antagonista de il- 6 como un ingrediente activo |
| AU2005227326B2 (en) * | 2004-03-24 | 2009-12-03 | Xencor, Inc. | Immunoglobulin variants outside the Fc region |
| AR049390A1 (es) | 2004-06-09 | 2006-07-26 | Wyeth Corp | Anticuerpos contra la interleuquina-13 humana y usos de los mismos |
| JP2008504289A (ja) | 2004-06-25 | 2008-02-14 | メディミューン,インコーポレーテッド | 部位特異的突然変異誘発による哺乳動物細胞における組換え抗体の産生の増加 |
| EP3342782B1 (en) | 2004-07-15 | 2022-08-17 | Xencor, Inc. | Optimized fc variants |
| CA2580319A1 (en) | 2004-09-14 | 2006-03-23 | National Institute For Biological Standards And Control | Vaccine |
| US7563443B2 (en) | 2004-09-17 | 2009-07-21 | Domantis Limited | Monovalent anti-CD40L antibody polypeptides and compositions thereof |
| WO2006047350A2 (en) | 2004-10-21 | 2006-05-04 | Xencor, Inc. | IgG IMMUNOGLOBULIN VARIANTS WITH OPTIMIZED EFFECTOR FUNCTION |
| NZ554520A (en) * | 2004-10-22 | 2010-03-26 | Amgen Inc | Methods for refolding of recombinant antibodies |
| AU2005335714B2 (en) * | 2004-11-10 | 2012-07-26 | Macrogenics, Inc. | Engineering Fc antibody regions to confer effector function |
| WO2006067847A1 (ja) | 2004-12-22 | 2006-06-29 | Chugai Seiyaku Kabushiki Kaisha | フコーストランスポーターの機能が阻害された細胞を用いた抗体の作製方法 |
| US20090087478A1 (en) | 2004-12-27 | 2009-04-02 | Progenics Pharmaceuticals (Nevada), Inc. | Orally Deliverable and Anti-Toxin Antibodies and Methods for Making and Using Them |
| DK1831258T4 (en) * | 2004-12-28 | 2023-08-28 | Innate Pharma Sa | Monoklonale antistoffer mod NKG2A |
| US8716451B2 (en) | 2005-01-12 | 2014-05-06 | Kyowa Hakko Kirin Co., Ltd | Stabilized human IgG2 and IgG3 antibodies |
| EP1858925A2 (en) * | 2005-01-12 | 2007-11-28 | Xencor, Inc. | Antibodies and fc fusion proteins with altered immunogenicity |
| MX2007009718A (es) | 2005-02-14 | 2007-09-26 | Zymogenetics Inc | Metodos para tratar trastornos cutaneos utilizando un antagonista il-31ra. |
| EP3050963B1 (en) | 2005-03-31 | 2019-09-18 | Chugai Seiyaku Kabushiki Kaisha | Process for production of polypeptide by regulation of assembly |
| PL1876236T3 (pl) * | 2005-04-08 | 2015-01-30 | Chugai Pharmaceutical Co Ltd | Przeciwciała zastępujące czynność czynnika krzepnięcia VIII |
| PE20061323A1 (es) | 2005-04-29 | 2007-02-09 | Rinat Neuroscience Corp | Anticuerpos dirigidos contra el peptido amiloide beta y metodos que utilizan los mismos |
| US8003108B2 (en) | 2005-05-03 | 2011-08-23 | Amgen Inc. | Sclerostin epitopes |
| CA2622772A1 (en) | 2005-09-29 | 2007-04-12 | Viral Logic Systems Technology Corp. | Immunomodulatory compositions and uses therefor |
| EP1941907B1 (en) | 2005-10-14 | 2016-03-23 | Fukuoka University | Inhibitor of transplanted islet dysfunction in islet transplantation |
| US8945558B2 (en) | 2005-10-21 | 2015-02-03 | Chugai Seiyaku Kabushiki Kaisha | Methods for treating myocardial infarction comprising administering an IL-6 inhibitor |
| EP2001906A2 (en) * | 2006-01-10 | 2008-12-17 | Zymogenetics, Inc. | Methods of treating pain and inflammation in neuronal tissue using il-31ra and osmrb antagonists |
| KR20140091765A (ko) * | 2006-01-12 | 2014-07-22 | 알렉시온 파마슈티칼스, 인코포레이티드 | Ox-2/cd200에 대한 항체 및 이들의 용도 |
| NZ567888A (en) * | 2006-03-23 | 2010-08-27 | Bioarctic Neuroscience Ab | Improved protofibril selective antibodies and the use thereof |
| CA2644663A1 (en) * | 2006-03-23 | 2007-09-27 | Kirin Pharma Kabushiki Kaisha | Agonist antibody to human thrombopoietin receptor |
| EP4218801A3 (en) | 2006-03-31 | 2023-08-23 | Chugai Seiyaku Kabushiki Kaisha | Antibody modification method for purifying bispecific antibody |
| WO2007114319A1 (ja) | 2006-03-31 | 2007-10-11 | Chugai Seiyaku Kabushiki Kaisha | 抗体の血中動態を制御する方法 |
| JP5754875B2 (ja) * | 2006-04-07 | 2015-07-29 | 国立大学法人大阪大学 | 筋再生促進剤 |
| BRPI0712426B1 (pt) * | 2006-06-08 | 2021-10-26 | Chugai Seiyaku Kabushiki Kaisha | Usos de um anticorpo anti-nr10/il-31ra com atividade neutralizante de nr10/il-31ra, de um fragmento e/ou um fragmento quimicamente modificado do anticorpo e de um agente |
| EP2032602B1 (en) * | 2006-06-15 | 2013-03-27 | The Board of Trustees of the University of Arkansas | Monoclonal antibodies that selectively recognize methamphetamine and methamphetamine like compounds |
| US20100034194A1 (en) | 2006-10-11 | 2010-02-11 | Siemens Communications Inc. | Eliminating unreachable subscribers in voice-over-ip networks |
| WO2008092117A2 (en) | 2007-01-25 | 2008-07-31 | Xencor, Inc. | Immunoglobulins with modifications in the fcr binding region |
| EP2069404B1 (en) * | 2007-02-14 | 2011-01-05 | Vaccinex, Inc. | Humanized anti-cd100 antibodies |
| NZ579158A (en) | 2007-02-23 | 2012-01-12 | Schering Corp | Engineered anti-il-23p19 antibodies |
| JPWO2008114733A1 (ja) * | 2007-03-16 | 2010-07-01 | 協和発酵キリン株式会社 | 抗Claudin−4抗体 |
| GB0708002D0 (en) | 2007-04-25 | 2007-06-06 | Univ Sheffield | Antibodies |
| EP2155790A1 (en) | 2007-05-31 | 2010-02-24 | Genmab A/S | Method for extending the half-life of exogenous or endogenous soluble molecules |
| EP2031064A1 (de) | 2007-08-29 | 2009-03-04 | Boehringer Ingelheim Pharma GmbH & Co. KG | Verfahren zur Steigerung von Proteintitern |
| AU2008304756B8 (en) | 2007-09-26 | 2015-02-12 | Chugai Seiyaku Kabushiki Kaisha | Anti-IL-6 receptor antibody |
| TWI464262B (zh) | 2007-09-26 | 2014-12-11 | 中外製藥股份有限公司 | 抗體固定區的變異 |
| JP5334319B2 (ja) * | 2007-09-26 | 2013-11-06 | 中外製薬株式会社 | Cdrのアミノ酸置換により抗体の等電点を改変する方法 |
| MY148637A (en) | 2007-09-28 | 2013-05-15 | Chugai Pharmaceutical Co Ltd | Anti-glypican-3 antibody having improved kinetics in plasma |
| JO3076B1 (ar) | 2007-10-17 | 2017-03-15 | Janssen Alzheimer Immunotherap | نظم العلاج المناعي المعتمد على حالة apoe |
| EP2236604B1 (en) | 2007-12-05 | 2016-07-06 | Chugai Seiyaku Kabushiki Kaisha | Anti-nr10 antibody and use thereof |
| EP2241332A4 (en) | 2007-12-05 | 2011-01-26 | Chugai Pharmaceutical Co Ltd | THERAPEUTIC AGENT AGAINST PRITURE |
| HUE028958T2 (en) | 2008-02-08 | 2017-01-30 | Medimmune Llc | Anti-IFNAR1 antibodies with reduced Fc ligand affinity |
| PL2708558T3 (pl) | 2008-04-11 | 2018-09-28 | Chugai Seiyaku Kabushiki Kaisha | Cząsteczka wiążąca antygen zdolna do wiązania dwóch lub więcej cząsteczek antygenu w sposób powtarzalny |
| EP2294087B1 (en) | 2008-05-01 | 2014-05-14 | Amgen, Inc. | Anti-hepcidin antibodies and methods of use |
| TWI440469B (zh) | 2008-09-26 | 2014-06-11 | Chugai Pharmaceutical Co Ltd | Improved antibody molecules |
| TWI682995B (zh) | 2009-03-19 | 2020-01-21 | 日商中外製藥股份有限公司 | 抗體恆定區域改變體 |
| JP5717624B2 (ja) * | 2009-03-19 | 2015-05-13 | 中外製薬株式会社 | 抗体定常領域改変体 |
| JP5837821B2 (ja) * | 2009-09-24 | 2015-12-24 | 中外製薬株式会社 | 抗体定常領域改変体 |
| EP2543730B1 (en) * | 2010-03-04 | 2018-10-31 | Chugai Seiyaku Kabushiki Kaisha | Antibody constant region variant |
| CN105218674A (zh) | 2010-03-11 | 2016-01-06 | 瑞纳神经科学公司 | 呈pH依赖性抗原结合的抗体 |
-
2008
- 2008-12-05 EP EP08857126.0A patent/EP2236604B1/en active Active
- 2008-12-05 TW TW105118884A patent/TW201634479A/zh unknown
- 2008-12-05 RU RU2010127292/10A patent/RU2531521C2/ru active
- 2008-12-05 KR KR1020107014698A patent/KR101643005B1/ko active IP Right Grant
- 2008-12-05 ES ES16172648T patent/ES2834741T3/es active Active
- 2008-12-05 ES ES08857126.0T patent/ES2585480T3/es active Active
- 2008-12-05 KR KR1020177031058A patent/KR101840994B1/ko active IP Right Grant
- 2008-12-05 AU AU2008332271A patent/AU2008332271C1/en active Active
- 2008-12-05 MX MX2010006096A patent/MX337081B/es active IP Right Grant
- 2008-12-05 BR BRPI0821110A patent/BRPI0821110B8/pt active IP Right Grant
- 2008-12-05 KR KR1020167016319A patent/KR20160074019A/ko active Application Filing
- 2008-12-05 US US12/745,781 patent/US20110129459A1/en not_active Abandoned
- 2008-12-05 CA CA2708532A patent/CA2708532C/en active Active
- 2008-12-05 TW TW097147385A patent/TWI548418B/zh active
- 2008-12-05 WO PCT/JP2008/072152 patent/WO2009072604A1/ja active Application Filing
- 2008-12-05 MY MYPI2010002565A patent/MY177564A/en unknown
- 2008-12-05 DK DK08857126.0T patent/DK2236604T3/en active
- 2008-12-05 EP EP16172648.4A patent/EP3095862B9/en active Active
- 2008-12-05 JP JP2009544736A patent/JP5682995B2/ja active Active
- 2008-12-05 CN CN200880126539.4A patent/CN101939424B/zh active Active
-
2009
- 2009-12-04 AU AU2009323249A patent/AU2009323249B2/en active Active
- 2009-12-04 US US12/809,138 patent/US8575317B2/en active Active
- 2009-12-04 CN CN200980106176.2A patent/CN101952318B/zh active Active
- 2009-12-04 CA CA2710264A patent/CA2710264C/en active Active
- 2009-12-04 MX MX2010007936A patent/MX2010007936A/es active IP Right Grant
- 2009-12-04 HU HUE09830463A patent/HUE025958T2/en unknown
-
2013
- 2013-10-07 US US14/047,316 patent/US9399680B2/en active Active
-
2014
- 2014-07-25 US US14/340,883 patent/US20150175704A1/en not_active Abandoned
-
2015
- 2015-11-12 HR HRP20151215TT patent/HRP20151215T1/hr unknown
-
2019
- 2019-09-04 US US16/560,143 patent/US20200002429A1/en not_active Abandoned
-
2022
- 2022-10-28 US US17/975,865 patent/US20230183363A1/en active Pending
Also Published As
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US20230183363A1 (en) | Anti-nr10 antibody and use thereof | |
| EP2354161B1 (en) | Anti-nr10 antibody, and use thereof | |
| EP2371393B1 (en) | Preventive or remedy for inflammatory disease | |
| TWI432209B (zh) | Anti-NR10 antibody and its use | |
| JP5139517B2 (ja) | 抗nr10抗体、およびその利用 |