JP7020909B2 - 抗-cd3抗体、活性化可能抗-cd3抗体、多重特異的抗-cd3抗体、多重特異的活性化可能抗-cd3抗体、及びそれらの使用方法 - Google Patents
抗-cd3抗体、活性化可能抗-cd3抗体、多重特異的抗-cd3抗体、多重特異的活性化可能抗-cd3抗体、及びそれらの使用方法 Download PDFInfo
- Publication number
- JP7020909B2 JP7020909B2 JP2017504058A JP2017504058A JP7020909B2 JP 7020909 B2 JP7020909 B2 JP 7020909B2 JP 2017504058 A JP2017504058 A JP 2017504058A JP 2017504058 A JP2017504058 A JP 2017504058A JP 7020909 B2 JP7020909 B2 JP 7020909B2
- Authority
- JP
- Japan
- Prior art keywords
- antibody
- multispecific
- seq
- amino acid
- acid sequence
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 230000003213 activating effect Effects 0.000 title claims description 391
- 230000027455 binding Effects 0.000 claims description 611
- 238000009739 binding Methods 0.000 claims description 610
- 239000000427 antigen Substances 0.000 claims description 318
- 239000012634 fragment Substances 0.000 claims description 317
- 108091007433 antigens Proteins 0.000 claims description 308
- 102000036639 antigens Human genes 0.000 claims description 308
- 101000946860 Homo sapiens T-cell surface glycoprotein CD3 epsilon chain Proteins 0.000 claims description 227
- 102100035794 T-cell surface glycoprotein CD3 epsilon chain Human genes 0.000 claims description 227
- 230000000873 masking effect Effects 0.000 claims description 184
- 108091005804 Peptidases Proteins 0.000 claims description 154
- 239000004365 Protease Substances 0.000 claims description 154
- 102000035195 Peptidases Human genes 0.000 claims description 147
- 239000003795 chemical substances by application Substances 0.000 claims description 137
- 102100035360 Cerebellar degeneration-related antigen 1 Human genes 0.000 claims description 133
- 239000000758 substrate Substances 0.000 claims description 112
- 206010028980 Neoplasm Diseases 0.000 claims description 110
- 108090000765 processed proteins & peptides Proteins 0.000 claims description 107
- 150000001413 amino acids Chemical group 0.000 claims description 106
- 102000004196 processed proteins & peptides Human genes 0.000 claims description 76
- 229920001184 polypeptide Polymers 0.000 claims description 68
- 210000004027 cell Anatomy 0.000 claims description 67
- 238000000034 method Methods 0.000 claims description 67
- 201000011510 cancer Diseases 0.000 claims description 55
- 150000007523 nucleic acids Chemical class 0.000 claims description 44
- 102000039446 nucleic acids Human genes 0.000 claims description 31
- 108020004707 nucleic acids Proteins 0.000 claims description 31
- -1 APRIL Proteins 0.000 claims description 24
- 239000003814 drug Substances 0.000 claims description 24
- 238000011282 treatment Methods 0.000 claims description 20
- 229940124597 therapeutic agent Drugs 0.000 claims description 17
- 239000002246 antineoplastic agent Substances 0.000 claims description 14
- 230000006870 function Effects 0.000 claims description 13
- 239000013598 vector Substances 0.000 claims description 13
- FWMNVWWHGCHHJJ-SKKKGAJSSA-N 4-amino-1-[(2r)-6-amino-2-[[(2r)-2-[[(2r)-2-[[(2r)-2-amino-3-phenylpropanoyl]amino]-3-phenylpropanoyl]amino]-4-methylpentanoyl]amino]hexanoyl]piperidine-4-carboxylic acid Chemical compound C([C@H](C(=O)N[C@H](CC(C)C)C(=O)N[C@H](CCCCN)C(=O)N1CCC(N)(CC1)C(O)=O)NC(=O)[C@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 FWMNVWWHGCHHJJ-SKKKGAJSSA-N 0.000 claims description 11
- 210000004899 c-terminal region Anatomy 0.000 claims description 10
- 239000000032 diagnostic agent Substances 0.000 claims description 10
- 229940039227 diagnostic agent Drugs 0.000 claims description 10
- 102100032702 Protein jagged-1 Human genes 0.000 claims description 9
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 claims description 9
- 238000004519 manufacturing process Methods 0.000 claims description 9
- 102100037792 Interleukin-6 receptor subunit alpha Human genes 0.000 claims description 8
- 239000008194 pharmaceutical composition Substances 0.000 claims description 8
- 102000005962 receptors Human genes 0.000 claims description 7
- 108020003175 receptors Proteins 0.000 claims description 7
- 108010028275 Leukocyte Elastase Proteins 0.000 claims description 6
- 102100033174 Neutrophil elastase Human genes 0.000 claims description 6
- 102100024216 Programmed cell death 1 ligand 1 Human genes 0.000 claims description 6
- JARGNLJYKBUKSJ-KGZKBUQUSA-N (2r)-2-amino-5-[[(2r)-1-(carboxymethylamino)-3-hydroxy-1-oxopropan-2-yl]amino]-5-oxopentanoic acid;hydrobromide Chemical compound Br.OC(=O)[C@H](N)CCC(=O)N[C@H](CO)C(=O)NCC(O)=O JARGNLJYKBUKSJ-KGZKBUQUSA-N 0.000 claims description 5
- 108010054477 Immunoglobulin Fab Fragments Proteins 0.000 claims description 5
- 102000001706 Immunoglobulin Fab Fragments Human genes 0.000 claims description 5
- 206010039509 Scab Diseases 0.000 claims description 5
- 108010044804 gamma-glutamyl-seryl-glycine Proteins 0.000 claims description 5
- 108700026078 glutathione trisulfide Proteins 0.000 claims description 5
- 229940045513 CTLA4 antagonist Drugs 0.000 claims description 4
- 239000003446 ligand Substances 0.000 claims description 4
- 108010074708 B7-H1 Antigen Proteins 0.000 claims description 3
- 102100027207 CD27 antigen Human genes 0.000 claims description 3
- 108010021064 CTLA-4 Antigen Proteins 0.000 claims description 3
- 102100039498 Cytotoxic T-lymphocyte protein 4 Human genes 0.000 claims description 3
- 102100034458 Hepatitis A virus cellular receptor 2 Human genes 0.000 claims description 3
- 101710083479 Hepatitis A virus cellular receptor 2 homolog Proteins 0.000 claims description 3
- 101000914511 Homo sapiens CD27 antigen Proteins 0.000 claims description 3
- 101000599048 Homo sapiens Interleukin-6 receptor subunit alpha Proteins 0.000 claims description 3
- 101000801234 Homo sapiens Tumor necrosis factor receptor superfamily member 18 Proteins 0.000 claims description 3
- 101000851370 Homo sapiens Tumor necrosis factor receptor superfamily member 9 Proteins 0.000 claims description 3
- 108010061593 Member 14 Tumor Necrosis Factor Receptors Proteins 0.000 claims description 3
- 101710089372 Programmed cell death protein 1 Proteins 0.000 claims description 3
- 102100032733 Protein jagged-2 Human genes 0.000 claims description 3
- 101710170213 Protein jagged-2 Proteins 0.000 claims description 3
- 229940126547 T-cell immunoglobulin mucin-3 Drugs 0.000 claims description 3
- 102100026144 Transferrin receptor protein 1 Human genes 0.000 claims description 3
- 108090001012 Transforming Growth Factor beta Proteins 0.000 claims description 3
- 102100028785 Tumor necrosis factor receptor superfamily member 14 Human genes 0.000 claims description 3
- 102100033728 Tumor necrosis factor receptor superfamily member 18 Human genes 0.000 claims description 3
- 102100038929 V-set domain-containing T-cell activation inhibitor 1 Human genes 0.000 claims description 3
- 208000024891 symptom Diseases 0.000 claims description 3
- 239000003053 toxin Substances 0.000 claims description 3
- 231100000765 toxin Toxicity 0.000 claims description 3
- 108700012359 toxins Proteins 0.000 claims description 3
- 102000018651 Epithelial Cell Adhesion Molecule Human genes 0.000 claims description 2
- 108010066687 Epithelial Cell Adhesion Molecule Proteins 0.000 claims description 2
- 101000831007 Homo sapiens T-cell immunoreceptor with Ig and ITIM domains Proteins 0.000 claims description 2
- 101000835093 Homo sapiens Transferrin receptor protein 1 Proteins 0.000 claims description 2
- 108010002350 Interleukin-2 Proteins 0.000 claims description 2
- 102000000588 Interleukin-2 Human genes 0.000 claims description 2
- 108090001005 Interleukin-6 Proteins 0.000 claims description 2
- 108700003486 Jagged-1 Proteins 0.000 claims description 2
- 102000017578 LAG3 Human genes 0.000 claims description 2
- 101150030213 Lag3 gene Proteins 0.000 claims description 2
- 108700037966 Protein jagged-1 Proteins 0.000 claims description 2
- 102100024834 T-cell immunoreceptor with Ig and ITIM domains Human genes 0.000 claims description 2
- 229960000397 bevacizumab Drugs 0.000 claims description 2
- 229960002621 pembrolizumab Drugs 0.000 claims description 2
- 239000008177 pharmaceutical agent Substances 0.000 claims description 2
- 102100037486 Reverse transcriptase/ribonuclease H Human genes 0.000 claims 7
- 102000017420 CD3 protein, epsilon/gamma/delta subunit Human genes 0.000 claims 3
- 108050005493 CD3 protein, epsilon/gamma/delta subunit Proteins 0.000 claims 3
- 102100027221 CD81 antigen Human genes 0.000 claims 2
- 102100025475 Carcinoembryonic antigen-related cell adhesion molecule 5 Human genes 0.000 claims 2
- 102100026234 Cytokine receptor common subunit gamma Human genes 0.000 claims 2
- 101000914479 Homo sapiens CD81 antigen Proteins 0.000 claims 2
- 101000914324 Homo sapiens Carcinoembryonic antigen-related cell adhesion molecule 5 Proteins 0.000 claims 2
- 101001055144 Homo sapiens Interleukin-2 receptor subunit alpha Proteins 0.000 claims 2
- 102100022337 Integrin alpha-V Human genes 0.000 claims 2
- 102100026878 Interleukin-2 receptor subunit alpha Human genes 0.000 claims 2
- 102000004357 Transferases Human genes 0.000 claims 2
- 108090000992 Transferases Proteins 0.000 claims 2
- 102000009524 Vascular Endothelial Growth Factor A Human genes 0.000 claims 2
- 229960000575 trastuzumab Drugs 0.000 claims 2
- WWUZIQQURGPMPG-UHFFFAOYSA-N (-)-D-erythro-Sphingosine Natural products CCCCCCCCCCCCCC=CC(O)C(N)CO WWUZIQQURGPMPG-UHFFFAOYSA-N 0.000 claims 1
- TZCPCKNHXULUIY-RGULYWFUSA-N 1,2-distearoyl-sn-glycero-3-phosphoserine Chemical compound CCCCCCCCCCCCCCCCCC(=O)OC[C@H](COP(O)(=O)OC[C@H](N)C(O)=O)OC(=O)CCCCCCCCCCCCCCCCC TZCPCKNHXULUIY-RGULYWFUSA-N 0.000 claims 1
- RTQWWZBSTRGEAV-PKHIMPSTSA-N 2-[[(2s)-2-[bis(carboxymethyl)amino]-3-[4-(methylcarbamoylamino)phenyl]propyl]-[2-[bis(carboxymethyl)amino]propyl]amino]acetic acid Chemical compound CNC(=O)NC1=CC=C(C[C@@H](CN(CC(C)N(CC(O)=O)CC(O)=O)CC(O)=O)N(CC(O)=O)CC(O)=O)C=C1 RTQWWZBSTRGEAV-PKHIMPSTSA-N 0.000 claims 1
- 108010068327 4-hydroxyphenylpyruvate dioxygenase Proteins 0.000 claims 1
- 102100023990 60S ribosomal protein L17 Human genes 0.000 claims 1
- 102100031585 ADP-ribosyl cyclase/cyclic ADP-ribose hydrolase 1 Human genes 0.000 claims 1
- 102100028163 ATP-binding cassette sub-family C member 4 Human genes 0.000 claims 1
- 108091006112 ATPases Proteins 0.000 claims 1
- 102000057290 Adenosine Triphosphatases Human genes 0.000 claims 1
- 102100031936 Anterior gradient protein 2 homolog Human genes 0.000 claims 1
- 102100029822 B- and T-lymphocyte attenuator Human genes 0.000 claims 1
- 102100038080 B-cell receptor CD22 Human genes 0.000 claims 1
- 102100024222 B-lymphocyte antigen CD19 Human genes 0.000 claims 1
- 102100022005 B-lymphocyte antigen CD20 Human genes 0.000 claims 1
- 108010081589 Becaplermin Proteins 0.000 claims 1
- 102100036166 C-X-C chemokine receptor type 1 Human genes 0.000 claims 1
- 102100028989 C-X-C chemokine receptor type 2 Human genes 0.000 claims 1
- 102100031650 C-X-C chemokine receptor type 4 Human genes 0.000 claims 1
- 102100025248 C-X-C motif chemokine 10 Human genes 0.000 claims 1
- 102100025277 C-X-C motif chemokine 13 Human genes 0.000 claims 1
- 102100024217 CAMPATH-1 antigen Human genes 0.000 claims 1
- 102100031171 CCN family member 1 Human genes 0.000 claims 1
- 102100031168 CCN family member 2 Human genes 0.000 claims 1
- 102100031173 CCN family member 4 Human genes 0.000 claims 1
- 101710137353 CCN family member 4 Proteins 0.000 claims 1
- 102100025215 CCN family member 5 Human genes 0.000 claims 1
- 101710137354 CCN family member 5 Proteins 0.000 claims 1
- 102100024210 CD166 antigen Human genes 0.000 claims 1
- 108010029697 CD40 Ligand Proteins 0.000 claims 1
- 101150013553 CD40 gene Proteins 0.000 claims 1
- 102100032937 CD40 ligand Human genes 0.000 claims 1
- 102100032912 CD44 antigen Human genes 0.000 claims 1
- 108010058905 CD44v6 antigen Proteins 0.000 claims 1
- 108010065524 CD52 Antigen Proteins 0.000 claims 1
- 102100025221 CD70 antigen Human genes 0.000 claims 1
- 102100029756 Cadherin-6 Human genes 0.000 claims 1
- 102100025473 Carcinoembryonic antigen-related cell adhesion molecule 6 Human genes 0.000 claims 1
- ZEOWTGPWHLSLOG-UHFFFAOYSA-N Cc1ccc(cc1-c1ccc2c(n[nH]c2c1)-c1cnn(c1)C1CC1)C(=O)Nc1cccc(c1)C(F)(F)F Chemical compound Cc1ccc(cc1-c1ccc2c(n[nH]c2c1)-c1cnn(c1)C1CC1)C(=O)Nc1cccc(c1)C(F)(F)F ZEOWTGPWHLSLOG-UHFFFAOYSA-N 0.000 claims 1
- 102100025175 Cellular communication network factor 6 Human genes 0.000 claims 1
- 101710118748 Cellular communication network factor 6 Proteins 0.000 claims 1
- 102100039496 Choline transporter-like protein 4 Human genes 0.000 claims 1
- 102100038423 Claudin-3 Human genes 0.000 claims 1
- 108090000599 Claudin-3 Proteins 0.000 claims 1
- 102100038447 Claudin-4 Human genes 0.000 claims 1
- 108090000601 Claudin-4 Proteins 0.000 claims 1
- 102000008186 Collagen Human genes 0.000 claims 1
- 108010035532 Collagen Proteins 0.000 claims 1
- 108010028773 Complement C5 Proteins 0.000 claims 1
- 108010019961 Cysteine-Rich Protein 61 Proteins 0.000 claims 1
- 101710189311 Cytokine receptor common subunit gamma Proteins 0.000 claims 1
- 102100033553 Delta-like protein 4 Human genes 0.000 claims 1
- 102100034579 Desmoglein-1 Human genes 0.000 claims 1
- 101150076616 EPHA2 gene Proteins 0.000 claims 1
- 101150097734 EPHB2 gene Proteins 0.000 claims 1
- 108700041152 Endoplasmic Reticulum Chaperone BiP Proteins 0.000 claims 1
- 102100021451 Endoplasmic reticulum chaperone BiP Human genes 0.000 claims 1
- 102100038083 Endosialin Human genes 0.000 claims 1
- 102100030340 Ephrin type-A receptor 2 Human genes 0.000 claims 1
- 102100031968 Ephrin type-B receptor 2 Human genes 0.000 claims 1
- 102000003974 Fibroblast growth factor 2 Human genes 0.000 claims 1
- 108090000379 Fibroblast growth factor 2 Proteins 0.000 claims 1
- 102100037680 Fibroblast growth factor 8 Human genes 0.000 claims 1
- 102100023593 Fibroblast growth factor receptor 1 Human genes 0.000 claims 1
- 101710182386 Fibroblast growth factor receptor 1 Proteins 0.000 claims 1
- 102100023600 Fibroblast growth factor receptor 2 Human genes 0.000 claims 1
- 101710182389 Fibroblast growth factor receptor 2 Proteins 0.000 claims 1
- 102100027842 Fibroblast growth factor receptor 3 Human genes 0.000 claims 1
- 101710182396 Fibroblast growth factor receptor 3 Proteins 0.000 claims 1
- 102100027844 Fibroblast growth factor receptor 4 Human genes 0.000 claims 1
- 102100040583 Galactosylceramide sulfotransferase Human genes 0.000 claims 1
- 101710088083 Glomulin Proteins 0.000 claims 1
- 102100041003 Glutamate carboxypeptidase 2 Human genes 0.000 claims 1
- ZWZWYGMENQVNFU-UHFFFAOYSA-N Glycerophosphorylserin Natural products OC(=O)C(N)COP(O)(=O)OCC(O)CO ZWZWYGMENQVNFU-UHFFFAOYSA-N 0.000 claims 1
- 108010017080 Granulocyte Colony-Stimulating Factor Proteins 0.000 claims 1
- 102100039619 Granulocyte colony-stimulating factor Human genes 0.000 claims 1
- 108010017213 Granulocyte-Macrophage Colony-Stimulating Factor Proteins 0.000 claims 1
- 102100039620 Granulocyte-macrophage colony-stimulating factor Human genes 0.000 claims 1
- 102100030595 HLA class II histocompatibility antigen gamma chain Human genes 0.000 claims 1
- 101150112743 HSPA5 gene Proteins 0.000 claims 1
- 102100026122 High affinity immunoglobulin gamma Fc receptor I Human genes 0.000 claims 1
- 101000777636 Homo sapiens ADP-ribosyl cyclase/cyclic ADP-ribose hydrolase 1 Proteins 0.000 claims 1
- 101000986629 Homo sapiens ATP-binding cassette sub-family C member 4 Proteins 0.000 claims 1
- 101000775021 Homo sapiens Anterior gradient protein 2 homolog Proteins 0.000 claims 1
- 101000952934 Homo sapiens Atrial natriuretic peptide-converting enzyme Proteins 0.000 claims 1
- 101000864344 Homo sapiens B- and T-lymphocyte attenuator Proteins 0.000 claims 1
- 101000884305 Homo sapiens B-cell receptor CD22 Proteins 0.000 claims 1
- 101000980825 Homo sapiens B-lymphocyte antigen CD19 Proteins 0.000 claims 1
- 101000897405 Homo sapiens B-lymphocyte antigen CD20 Proteins 0.000 claims 1
- 101000947174 Homo sapiens C-X-C chemokine receptor type 1 Proteins 0.000 claims 1
- 101000922348 Homo sapiens C-X-C chemokine receptor type 4 Proteins 0.000 claims 1
- 101000858088 Homo sapiens C-X-C motif chemokine 10 Proteins 0.000 claims 1
- 101000858064 Homo sapiens C-X-C motif chemokine 13 Proteins 0.000 claims 1
- 101000777550 Homo sapiens CCN family member 2 Proteins 0.000 claims 1
- 101000868273 Homo sapiens CD44 antigen Proteins 0.000 claims 1
- 101000934356 Homo sapiens CD70 antigen Proteins 0.000 claims 1
- 101000794604 Homo sapiens Cadherin-6 Proteins 0.000 claims 1
- 101000914326 Homo sapiens Carcinoembryonic antigen-related cell adhesion molecule 6 Proteins 0.000 claims 1
- 101000916489 Homo sapiens Chondroitin sulfate proteoglycan 4 Proteins 0.000 claims 1
- 101000872077 Homo sapiens Delta-like protein 4 Proteins 0.000 claims 1
- 101000924316 Homo sapiens Desmoglein-1 Proteins 0.000 claims 1
- 101000884275 Homo sapiens Endosialin Proteins 0.000 claims 1
- 101001027382 Homo sapiens Fibroblast growth factor 8 Proteins 0.000 claims 1
- 101000917134 Homo sapiens Fibroblast growth factor receptor 4 Proteins 0.000 claims 1
- 101000893879 Homo sapiens Galactosylceramide sulfotransferase Proteins 0.000 claims 1
- 101000892862 Homo sapiens Glutamate carboxypeptidase 2 Proteins 0.000 claims 1
- 101001082627 Homo sapiens HLA class II histocompatibility antigen gamma chain Proteins 0.000 claims 1
- 101000913074 Homo sapiens High affinity immunoglobulin gamma Fc receptor I Proteins 0.000 claims 1
- 101100232357 Homo sapiens IL13RA1 gene Proteins 0.000 claims 1
- 101100232360 Homo sapiens IL13RA2 gene Proteins 0.000 claims 1
- 101001034652 Homo sapiens Insulin-like growth factor 1 receptor Proteins 0.000 claims 1
- 101000599951 Homo sapiens Insulin-like growth factor I Proteins 0.000 claims 1
- 101001078143 Homo sapiens Integrin alpha-IIb Proteins 0.000 claims 1
- 101001046677 Homo sapiens Integrin alpha-V Proteins 0.000 claims 1
- 101001002470 Homo sapiens Interferon lambda-1 Proteins 0.000 claims 1
- 101001057504 Homo sapiens Interferon-stimulated gene 20 kDa protein Proteins 0.000 claims 1
- 101001033249 Homo sapiens Interleukin-1 beta Proteins 0.000 claims 1
- 101001076418 Homo sapiens Interleukin-1 receptor type 1 Proteins 0.000 claims 1
- 101000998146 Homo sapiens Interleukin-17A Proteins 0.000 claims 1
- 101000853012 Homo sapiens Interleukin-23 receptor Proteins 0.000 claims 1
- 101001043821 Homo sapiens Interleukin-31 Proteins 0.000 claims 1
- 101001033312 Homo sapiens Interleukin-4 receptor subunit alpha Proteins 0.000 claims 1
- 101001004865 Homo sapiens Leucine-rich repeat-containing protein 26 Proteins 0.000 claims 1
- 101000868279 Homo sapiens Leukocyte surface antigen CD47 Proteins 0.000 claims 1
- 101001043598 Homo sapiens Low-density lipoprotein receptor-related protein 4 Proteins 0.000 claims 1
- 101000916644 Homo sapiens Macrophage colony-stimulating factor 1 receptor Proteins 0.000 claims 1
- 101000694615 Homo sapiens Membrane primary amine oxidase Proteins 0.000 claims 1
- 101000628547 Homo sapiens Metalloreductase STEAP1 Proteins 0.000 claims 1
- 101000628535 Homo sapiens Metalloreductase STEAP2 Proteins 0.000 claims 1
- 101001133056 Homo sapiens Mucin-1 Proteins 0.000 claims 1
- 101000623901 Homo sapiens Mucin-16 Proteins 0.000 claims 1
- 101000934338 Homo sapiens Myeloid cell surface antigen CD33 Proteins 0.000 claims 1
- 101000581981 Homo sapiens Neural cell adhesion molecule 1 Proteins 0.000 claims 1
- 101000603877 Homo sapiens Nuclear receptor subfamily 1 group I member 2 Proteins 0.000 claims 1
- 101000897042 Homo sapiens Nucleotide pyrophosphatase Proteins 0.000 claims 1
- 101000829725 Homo sapiens Phospholipid hydroperoxide glutathione peroxidase Proteins 0.000 claims 1
- 101001136592 Homo sapiens Prostate stem cell antigen Proteins 0.000 claims 1
- 101000928535 Homo sapiens Protein delta homolog 1 Proteins 0.000 claims 1
- 101001098560 Homo sapiens Proteinase-activated receptor 2 Proteins 0.000 claims 1
- 101001012157 Homo sapiens Receptor tyrosine-protein kinase erbB-2 Proteins 0.000 claims 1
- 101000884271 Homo sapiens Signal transducer CD24 Proteins 0.000 claims 1
- 101000713170 Homo sapiens Solute carrier family 52, riboflavin transporter, member 1 Proteins 0.000 claims 1
- 101001056234 Homo sapiens Sperm mitochondrial-associated cysteine-rich protein Proteins 0.000 claims 1
- 101000914514 Homo sapiens T-cell-specific surface glycoprotein CD28 Proteins 0.000 claims 1
- 101000914484 Homo sapiens T-lymphocyte activation antigen CD80 Proteins 0.000 claims 1
- 101000831567 Homo sapiens Toll-like receptor 2 Proteins 0.000 claims 1
- 101000669447 Homo sapiens Toll-like receptor 4 Proteins 0.000 claims 1
- 101000669406 Homo sapiens Toll-like receptor 6 Proteins 0.000 claims 1
- 101000669402 Homo sapiens Toll-like receptor 7 Proteins 0.000 claims 1
- 101000800483 Homo sapiens Toll-like receptor 8 Proteins 0.000 claims 1
- 101000904724 Homo sapiens Transmembrane glycoprotein NMB Proteins 0.000 claims 1
- 101000798694 Homo sapiens Transmembrane protein 31 Proteins 0.000 claims 1
- 101000610605 Homo sapiens Tumor necrosis factor receptor superfamily member 10A Proteins 0.000 claims 1
- 101000610604 Homo sapiens Tumor necrosis factor receptor superfamily member 10B Proteins 0.000 claims 1
- 101000611023 Homo sapiens Tumor necrosis factor receptor superfamily member 6 Proteins 0.000 claims 1
- 101000851376 Homo sapiens Tumor necrosis factor receptor superfamily member 8 Proteins 0.000 claims 1
- 101000666896 Homo sapiens V-type immunoglobulin domain-containing suppressor of T-cell activation Proteins 0.000 claims 1
- 101000851018 Homo sapiens Vascular endothelial growth factor receptor 1 Proteins 0.000 claims 1
- 101000851007 Homo sapiens Vascular endothelial growth factor receptor 2 Proteins 0.000 claims 1
- 101000851030 Homo sapiens Vascular endothelial growth factor receptor 3 Proteins 0.000 claims 1
- 108010003272 Hyaluronate lyase Proteins 0.000 claims 1
- 102000001974 Hyaluronidases Human genes 0.000 claims 1
- 102000026633 IL6 Human genes 0.000 claims 1
- 102000009438 IgE Receptors Human genes 0.000 claims 1
- 108010073816 IgE Receptors Proteins 0.000 claims 1
- 108010001127 Insulin Receptor Proteins 0.000 claims 1
- 102100036721 Insulin receptor Human genes 0.000 claims 1
- 102100039688 Insulin-like growth factor 1 receptor Human genes 0.000 claims 1
- 102100037852 Insulin-like growth factor I Human genes 0.000 claims 1
- 102100025306 Integrin alpha-IIb Human genes 0.000 claims 1
- 108010041012 Integrin alpha4 Proteins 0.000 claims 1
- 108010008212 Integrin alpha4beta1 Proteins 0.000 claims 1
- 102100020990 Interferon lambda-1 Human genes 0.000 claims 1
- 102100039065 Interleukin-1 beta Human genes 0.000 claims 1
- 102100026016 Interleukin-1 receptor type 1 Human genes 0.000 claims 1
- 108090000177 Interleukin-11 Proteins 0.000 claims 1
- 102000003815 Interleukin-11 Human genes 0.000 claims 1
- 102000013462 Interleukin-12 Human genes 0.000 claims 1
- 108010065805 Interleukin-12 Proteins 0.000 claims 1
- 102100020790 Interleukin-12 receptor subunit beta-1 Human genes 0.000 claims 1
- 101710103841 Interleukin-12 receptor subunit beta-1 Proteins 0.000 claims 1
- 102000003816 Interleukin-13 Human genes 0.000 claims 1
- 108090000176 Interleukin-13 Proteins 0.000 claims 1
- 102100020791 Interleukin-13 receptor subunit alpha-1 Human genes 0.000 claims 1
- 108090000172 Interleukin-15 Proteins 0.000 claims 1
- 102000003812 Interleukin-15 Human genes 0.000 claims 1
- 102100033461 Interleukin-17A Human genes 0.000 claims 1
- 102000003810 Interleukin-18 Human genes 0.000 claims 1
- 108090000171 Interleukin-18 Proteins 0.000 claims 1
- 102100030704 Interleukin-21 Human genes 0.000 claims 1
- 102000013264 Interleukin-23 Human genes 0.000 claims 1
- 108010065637 Interleukin-23 Proteins 0.000 claims 1
- 102100036672 Interleukin-23 receptor Human genes 0.000 claims 1
- 108010066979 Interleukin-27 Proteins 0.000 claims 1
- 102100036678 Interleukin-27 subunit alpha Human genes 0.000 claims 1
- 102100021596 Interleukin-31 Human genes 0.000 claims 1
- 102000004388 Interleukin-4 Human genes 0.000 claims 1
- 108090000978 Interleukin-4 Proteins 0.000 claims 1
- 102100039078 Interleukin-4 receptor subunit alpha Human genes 0.000 claims 1
- 102100039881 Interleukin-5 receptor subunit alpha Human genes 0.000 claims 1
- 108010018951 Interleukin-8B Receptors Proteins 0.000 claims 1
- 102100025950 Leucine-rich repeat-containing protein 26 Human genes 0.000 claims 1
- 102100021747 Leukemia inhibitory factor receptor Human genes 0.000 claims 1
- 101710142062 Leukemia inhibitory factor receptor Proteins 0.000 claims 1
- 102100032913 Leukocyte surface antigen CD47 Human genes 0.000 claims 1
- 102100021918 Low-density lipoprotein receptor-related protein 4 Human genes 0.000 claims 1
- 102100028198 Macrophage colony-stimulating factor 1 receptor Human genes 0.000 claims 1
- 102100027754 Mast/stem cell growth factor receptor Kit Human genes 0.000 claims 1
- 102100027159 Membrane primary amine oxidase Human genes 0.000 claims 1
- 108090000015 Mesothelin Proteins 0.000 claims 1
- 102000003735 Mesothelin Human genes 0.000 claims 1
- 102100026712 Metalloreductase STEAP1 Human genes 0.000 claims 1
- 102100026711 Metalloreductase STEAP2 Human genes 0.000 claims 1
- 102100034256 Mucin-1 Human genes 0.000 claims 1
- 102100023123 Mucin-16 Human genes 0.000 claims 1
- 101100407308 Mus musculus Pdcd1lg2 gene Proteins 0.000 claims 1
- 101100369076 Mus musculus Tdgf1 gene Proteins 0.000 claims 1
- 102100025243 Myeloid cell surface antigen CD33 Human genes 0.000 claims 1
- 101001055320 Myxine glutinosa Insulin-like growth factor Proteins 0.000 claims 1
- 102000015336 Nerve Growth Factor Human genes 0.000 claims 1
- 108010025020 Nerve Growth Factor Proteins 0.000 claims 1
- 102100027347 Neural cell adhesion molecule 1 Human genes 0.000 claims 1
- 108010070047 Notch Receptors Proteins 0.000 claims 1
- 102000005650 Notch Receptors Human genes 0.000 claims 1
- 102100021969 Nucleotide pyrophosphatase Human genes 0.000 claims 1
- 229910019142 PO4 Inorganic materials 0.000 claims 1
- 108010035030 Platelet Membrane Glycoprotein IIb Proteins 0.000 claims 1
- 102000001393 Platelet-Derived Growth Factor alpha Receptor Human genes 0.000 claims 1
- 108010068588 Platelet-Derived Growth Factor alpha Receptor Proteins 0.000 claims 1
- 108700030875 Programmed Cell Death 1 Ligand 2 Proteins 0.000 claims 1
- 102100024213 Programmed cell death 1 ligand 2 Human genes 0.000 claims 1
- 102100023832 Prolyl endopeptidase FAP Human genes 0.000 claims 1
- 102100036735 Prostate stem cell antigen Human genes 0.000 claims 1
- 102100036467 Protein delta homolog 1 Human genes 0.000 claims 1
- 102100030086 Receptor tyrosine-protein kinase erbB-2 Human genes 0.000 claims 1
- 102100029986 Receptor tyrosine-protein kinase erbB-3 Human genes 0.000 claims 1
- 101710100969 Receptor tyrosine-protein kinase erbB-3 Proteins 0.000 claims 1
- 108091006296 SLC2A1 Proteins 0.000 claims 1
- 108091006300 SLC2A4 Proteins 0.000 claims 1
- 108091007561 SLC44A4 Proteins 0.000 claims 1
- 101100111629 Saccharomyces cerevisiae (strain ATCC 204508 / S288c) KAR2 gene Proteins 0.000 claims 1
- 102100038081 Signal transducer CD24 Human genes 0.000 claims 1
- 102100023536 Solute carrier family 2, facilitated glucose transporter member 1 Human genes 0.000 claims 1
- 102100033939 Solute carrier family 2, facilitated glucose transporter member 4 Human genes 0.000 claims 1
- 102100036863 Solute carrier family 52, riboflavin transporter, member 1 Human genes 0.000 claims 1
- 102100026503 Sperm mitochondrial-associated cysteine-rich protein Human genes 0.000 claims 1
- 102100027213 T-cell-specific surface glycoprotein CD28 Human genes 0.000 claims 1
- 102100027222 T-lymphocyte activation antigen CD80 Human genes 0.000 claims 1
- 108010060818 Toll-Like Receptor 9 Proteins 0.000 claims 1
- 102100024333 Toll-like receptor 2 Human genes 0.000 claims 1
- 102100039360 Toll-like receptor 4 Human genes 0.000 claims 1
- 102100039387 Toll-like receptor 6 Human genes 0.000 claims 1
- 102100039390 Toll-like receptor 7 Human genes 0.000 claims 1
- 102100033110 Toll-like receptor 8 Human genes 0.000 claims 1
- 102100033117 Toll-like receptor 9 Human genes 0.000 claims 1
- 102100030742 Transforming growth factor beta-1 proprotein Human genes 0.000 claims 1
- 102100023935 Transmembrane glycoprotein NMB Human genes 0.000 claims 1
- 102100032456 Transmembrane protein 31 Human genes 0.000 claims 1
- 108060008682 Tumor Necrosis Factor Proteins 0.000 claims 1
- 108060008683 Tumor Necrosis Factor Receptor Proteins 0.000 claims 1
- 102000000852 Tumor Necrosis Factor-alpha Human genes 0.000 claims 1
- 101710181056 Tumor necrosis factor ligand superfamily member 13B Proteins 0.000 claims 1
- 102100040113 Tumor necrosis factor receptor superfamily member 10A Human genes 0.000 claims 1
- 102100040112 Tumor necrosis factor receptor superfamily member 10B Human genes 0.000 claims 1
- 102100040245 Tumor necrosis factor receptor superfamily member 5 Human genes 0.000 claims 1
- 102100040403 Tumor necrosis factor receptor superfamily member 6 Human genes 0.000 claims 1
- 102100036857 Tumor necrosis factor receptor superfamily member 8 Human genes 0.000 claims 1
- 108010079206 V-Set Domain-Containing T-Cell Activation Inhibitor 1 Proteins 0.000 claims 1
- 102100038282 V-type immunoglobulin domain-containing suppressor of T-cell activation Human genes 0.000 claims 1
- 108010000134 Vascular Cell Adhesion Molecule-1 Proteins 0.000 claims 1
- 108010073929 Vascular Endothelial Growth Factor A Proteins 0.000 claims 1
- 108010073925 Vascular Endothelial Growth Factor B Proteins 0.000 claims 1
- 108010073923 Vascular Endothelial Growth Factor C Proteins 0.000 claims 1
- 108010073919 Vascular Endothelial Growth Factor D Proteins 0.000 claims 1
- 108010019530 Vascular Endothelial Growth Factors Proteins 0.000 claims 1
- 102100023543 Vascular cell adhesion protein 1 Human genes 0.000 claims 1
- 102100038217 Vascular endothelial growth factor B Human genes 0.000 claims 1
- 102100038232 Vascular endothelial growth factor C Human genes 0.000 claims 1
- 102100038234 Vascular endothelial growth factor D Human genes 0.000 claims 1
- 102100033178 Vascular endothelial growth factor receptor 1 Human genes 0.000 claims 1
- 102100033177 Vascular endothelial growth factor receptor 2 Human genes 0.000 claims 1
- 102100033179 Vascular endothelial growth factor receptor 3 Human genes 0.000 claims 1
- 229960000446 abciximab Drugs 0.000 claims 1
- 229960002964 adalimumab Drugs 0.000 claims 1
- 229960000548 alemtuzumab Drugs 0.000 claims 1
- DUKURNFHYQXCJG-JEOLMMCMSA-N alpha-L-Fucp-(1->4)-[beta-D-Galp-(1->3)]-beta-D-GlcpNAc-(1->3)-beta-D-Galp-(1->4)-D-Glcp Chemical compound O[C@H]1[C@H](O)[C@H](O)[C@H](C)O[C@H]1O[C@H]1[C@H](O[C@H]2[C@@H]([C@@H](O)[C@@H](O)[C@@H](CO)O2)O)[C@@H](NC(C)=O)[C@H](O[C@@H]2[C@H]([C@H](O[C@@H]3[C@H](OC(O)[C@H](O)[C@H]3O)CO)O[C@H](CO)[C@@H]2O)O)O[C@@H]1CO DUKURNFHYQXCJG-JEOLMMCMSA-N 0.000 claims 1
- 229960003852 atezolizumab Drugs 0.000 claims 1
- 229960004669 basiliximab Drugs 0.000 claims 1
- 229950007843 bavituximab Drugs 0.000 claims 1
- 229960000455 brentuximab vedotin Drugs 0.000 claims 1
- 229960005395 cetuximab Drugs 0.000 claims 1
- 229920001436 collagen Polymers 0.000 claims 1
- 229960002806 daclizumab Drugs 0.000 claims 1
- 229960001251 denosumab Drugs 0.000 claims 1
- 229960002224 eculizumab Drugs 0.000 claims 1
- 229960000284 efalizumab Drugs 0.000 claims 1
- 102000052116 epidermal growth factor receptor activity proteins Human genes 0.000 claims 1
- 108700015053 epidermal growth factor receptor activity proteins Proteins 0.000 claims 1
- IJJVMEJXYNJXOJ-UHFFFAOYSA-N fluquinconazole Chemical compound C=1C=C(Cl)C=C(Cl)C=1N1C(=O)C2=CC(F)=CC=C2N=C1N1C=NC=N1 IJJVMEJXYNJXOJ-UHFFFAOYSA-N 0.000 claims 1
- 102000006815 folate receptor Human genes 0.000 claims 1
- 108020005243 folate receptor Proteins 0.000 claims 1
- 229960000578 gemtuzumab Drugs 0.000 claims 1
- 229960003297 gemtuzumab ozogamicin Drugs 0.000 claims 1
- 101150028578 grp78 gene Proteins 0.000 claims 1
- 229960002773 hyaluronidase Drugs 0.000 claims 1
- 229960001001 ibritumomab tiuxetan Drugs 0.000 claims 1
- 229960000598 infliximab Drugs 0.000 claims 1
- 108010044426 integrins Proteins 0.000 claims 1
- 102000006495 integrins Human genes 0.000 claims 1
- 108040003610 interleukin-12 receptor activity proteins Proteins 0.000 claims 1
- 108010074108 interleukin-21 Proteins 0.000 claims 1
- 229960005386 ipilimumab Drugs 0.000 claims 1
- 229950001869 mapatumumab Drugs 0.000 claims 1
- YOHYSYJDKVYCJI-UHFFFAOYSA-N n-[3-[[6-[3-(trifluoromethyl)anilino]pyrimidin-4-yl]amino]phenyl]cyclopropanecarboxamide Chemical compound FC(F)(F)C1=CC=CC(NC=2N=CN=C(NC=3C=C(NC(=O)C4CC4)C=CC=3)C=2)=C1 YOHYSYJDKVYCJI-UHFFFAOYSA-N 0.000 claims 1
- 229960005027 natalizumab Drugs 0.000 claims 1
- 229960002450 ofatumumab Drugs 0.000 claims 1
- 229960000470 omalizumab Drugs 0.000 claims 1
- 229960001972 panitumumab Drugs 0.000 claims 1
- NBIIXXVUZAFLBC-UHFFFAOYSA-K phosphate Chemical compound [O-]P([O-])([O-])=O NBIIXXVUZAFLBC-UHFFFAOYSA-K 0.000 claims 1
- 239000010452 phosphate Substances 0.000 claims 1
- 108010017843 platelet-derived growth factor A Proteins 0.000 claims 1
- 229920001481 poly(stearyl methacrylate) Polymers 0.000 claims 1
- 229960003876 ranibizumab Drugs 0.000 claims 1
- 229960004641 rituximab Drugs 0.000 claims 1
- WWUZIQQURGPMPG-KRWOKUGFSA-N sphingosine Chemical compound CCCCCCCCCCCCC\C=C\[C@@H](O)[C@@H](N)CO WWUZIQQURGPMPG-KRWOKUGFSA-N 0.000 claims 1
- 101150047061 tag-72 gene Proteins 0.000 claims 1
- 229950008160 tanezumab Drugs 0.000 claims 1
- 229960005267 tositumomab Drugs 0.000 claims 1
- 102000003298 tumor necrosis factor receptor Human genes 0.000 claims 1
- 102000009816 urokinase plasminogen activator receptor activity proteins Human genes 0.000 claims 1
- 108040001269 urokinase plasminogen activator receptor activity proteins Proteins 0.000 claims 1
- 125000003275 alpha amino acid group Chemical group 0.000 description 343
- 101100112922 Candida albicans CDR3 gene Proteins 0.000 description 131
- 102100035361 Cerebellar degeneration-related protein 2 Human genes 0.000 description 131
- 101000737796 Homo sapiens Cerebellar degeneration-related protein 2 Proteins 0.000 description 131
- 101000737793 Homo sapiens Cerebellar degeneration-related antigen 1 Proteins 0.000 description 130
- 230000008878 coupling Effects 0.000 description 97
- 238000010168 coupling process Methods 0.000 description 97
- 238000005859 coupling reaction Methods 0.000 description 97
- 235000001014 amino acid Nutrition 0.000 description 88
- 229940024606 amino acid Drugs 0.000 description 80
- 238000010494 dissociation reaction Methods 0.000 description 65
- 230000005593 dissociations Effects 0.000 description 65
- 210000001744 T-lymphocyte Anatomy 0.000 description 60
- 125000005647 linker group Chemical group 0.000 description 59
- 125000002924 primary amino group Chemical group [H]N([H])* 0.000 description 56
- 210000002966 serum Anatomy 0.000 description 52
- 230000008685 targeting Effects 0.000 description 47
- 108010047041 Complementarity Determining Regions Proteins 0.000 description 41
- 208000003837 Second Primary Neoplasms Diseases 0.000 description 39
- 239000003112 inhibitor Substances 0.000 description 35
- 210000001519 tissue Anatomy 0.000 description 34
- 102000030431 Asparaginyl endopeptidase Human genes 0.000 description 31
- 108010055066 asparaginylendopeptidase Proteins 0.000 description 31
- 238000003776 cleavage reaction Methods 0.000 description 31
- 239000000203 mixture Substances 0.000 description 31
- 108090000623 proteins and genes Proteins 0.000 description 31
- 230000007017 scission Effects 0.000 description 31
- 101000642536 Apis mellifera Venom serine protease 34 Proteins 0.000 description 30
- 102000004169 proteins and genes Human genes 0.000 description 25
- 229940121354 immunomodulator Drugs 0.000 description 23
- 230000002829 reductive effect Effects 0.000 description 23
- 239000012642 immune effector Substances 0.000 description 22
- 235000018102 proteins Nutrition 0.000 description 21
- 108010021625 Immunoglobulin Fragments Proteins 0.000 description 20
- 102000008394 Immunoglobulin Fragments Human genes 0.000 description 20
- 230000009870 specific binding Effects 0.000 description 20
- 102000002274 Matrix Metalloproteinases Human genes 0.000 description 19
- 108010000684 Matrix Metalloproteinases Proteins 0.000 description 19
- 108060003951 Immunoglobulin Proteins 0.000 description 18
- 102000018358 immunoglobulin Human genes 0.000 description 18
- 125000006850 spacer group Chemical group 0.000 description 18
- 230000001225 therapeutic effect Effects 0.000 description 17
- 102000004190 Enzymes Human genes 0.000 description 16
- 108090000790 Enzymes Proteins 0.000 description 16
- 229940088598 enzyme Drugs 0.000 description 16
- 238000006467 substitution reaction Methods 0.000 description 16
- 108091033319 polynucleotide Proteins 0.000 description 15
- 102000040430 polynucleotide Human genes 0.000 description 15
- 239000002157 polynucleotide Substances 0.000 description 15
- DHMQDGOQFOQNFH-UHFFFAOYSA-N Glycine Chemical compound NCC(O)=O DHMQDGOQFOQNFH-UHFFFAOYSA-N 0.000 description 13
- 241001465754 Metazoa Species 0.000 description 12
- 230000004913 activation Effects 0.000 description 12
- 238000001994 activation Methods 0.000 description 12
- 241000894007 species Species 0.000 description 12
- 101000798702 Homo sapiens Transmembrane protease serine 4 Proteins 0.000 description 11
- 108091034117 Oligonucleotide Proteins 0.000 description 11
- 102100032471 Transmembrane protease serine 4 Human genes 0.000 description 11
- 125000003178 carboxy group Chemical group [H]OC(*)=O 0.000 description 11
- 230000000694 effects Effects 0.000 description 10
- 125000003729 nucleotide group Chemical group 0.000 description 10
- 239000000523 sample Substances 0.000 description 10
- 102100030216 Matrix metalloproteinase-14 Human genes 0.000 description 9
- 108091028043 Nucleic acid sequence Proteins 0.000 description 9
- 239000000556 agonist Substances 0.000 description 9
- 239000003638 chemical reducing agent Substances 0.000 description 9
- 230000000670 limiting effect Effects 0.000 description 9
- 102100030412 Matrix metalloproteinase-9 Human genes 0.000 description 8
- 108091008874 T cell receptors Proteins 0.000 description 8
- 102000016266 T-Cell Antigen Receptors Human genes 0.000 description 8
- 239000002773 nucleotide Substances 0.000 description 8
- 239000000126 substance Substances 0.000 description 8
- 150000003573 thiols Chemical class 0.000 description 8
- 101000994439 Danio rerio Protein jagged-1a Proteins 0.000 description 7
- 241000699666 Mus <mouse, genus> Species 0.000 description 7
- 230000006044 T cell activation Effects 0.000 description 7
- JLCPHMBAVCMARE-UHFFFAOYSA-N [3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-hydroxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methyl [5-(6-aminopurin-9-yl)-2-(hydroxymethyl)oxolan-3-yl] hydrogen phosphate Polymers Cc1cn(C2CC(OP(O)(=O)OCC3OC(CC3OP(O)(=O)OCC3OC(CC3O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c3nc(N)[nH]c4=O)C(COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3CO)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cc(C)c(=O)[nH]c3=O)n3cc(C)c(=O)[nH]c3=O)n3ccc(N)nc3=O)n3cc(C)c(=O)[nH]c3=O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)O2)c(=O)[nH]c1=O JLCPHMBAVCMARE-UHFFFAOYSA-N 0.000 description 7
- 238000012258 culturing Methods 0.000 description 7
- 229940127089 cytotoxic agent Drugs 0.000 description 7
- 238000001514 detection method Methods 0.000 description 7
- MTCFGRXMJLQNBG-REOHCLBHSA-N (2S)-2-Amino-3-hydroxypropansäure Chemical compound OC[C@H](N)C(O)=O MTCFGRXMJLQNBG-REOHCLBHSA-N 0.000 description 6
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 6
- 108091007505 ADAM17 Proteins 0.000 description 6
- 102100028728 Bone morphogenetic protein 1 Human genes 0.000 description 6
- 108090000654 Bone morphogenetic protein 1 Proteins 0.000 description 6
- 108010084457 Cathepsins Proteins 0.000 description 6
- 102000005600 Cathepsins Human genes 0.000 description 6
- 102100027995 Collagenase 3 Human genes 0.000 description 6
- 102100031111 Disintegrin and metalloproteinase domain-containing protein 17 Human genes 0.000 description 6
- 229940076838 Immune checkpoint inhibitor Drugs 0.000 description 6
- 108010076504 Protein Sorting Signals Proteins 0.000 description 6
- 108090000190 Thrombin Proteins 0.000 description 6
- 238000003745 diagnosis Methods 0.000 description 6
- 238000010586 diagram Methods 0.000 description 6
- 201000010099 disease Diseases 0.000 description 6
- 210000004408 hybridoma Anatomy 0.000 description 6
- 239000012274 immune-checkpoint protein inhibitor Substances 0.000 description 6
- 210000000265 leukocyte Anatomy 0.000 description 6
- 238000006722 reduction reaction Methods 0.000 description 6
- 125000004434 sulfur atom Chemical group 0.000 description 6
- 229960004072 thrombin Drugs 0.000 description 6
- 201000009030 Carcinoma Diseases 0.000 description 5
- 102000005927 Cysteine Proteases Human genes 0.000 description 5
- 108010005843 Cysteine Proteases Proteins 0.000 description 5
- 101001011906 Homo sapiens Matrix metalloproteinase-14 Proteins 0.000 description 5
- 101000990902 Homo sapiens Matrix metalloproteinase-9 Proteins 0.000 description 5
- 101000798700 Homo sapiens Transmembrane protease serine 3 Proteins 0.000 description 5
- 108010038501 Interleukin-6 Receptors Proteins 0.000 description 5
- CKLJMWTZIZZHCS-REOHCLBHSA-N L-aspartic acid Chemical compound OC(=O)[C@@H](N)CC(O)=O CKLJMWTZIZZHCS-REOHCLBHSA-N 0.000 description 5
- ROHFNLRQFUQHCH-YFKPBYRVSA-N L-leucine Chemical compound CC(C)C[C@H](N)C(O)=O ROHFNLRQFUQHCH-YFKPBYRVSA-N 0.000 description 5
- ROHFNLRQFUQHCH-UHFFFAOYSA-N Leucine Natural products CC(C)CC(N)C(O)=O ROHFNLRQFUQHCH-UHFFFAOYSA-N 0.000 description 5
- 241000283984 Rodentia Species 0.000 description 5
- 102100037942 Suppressor of tumorigenicity 14 protein Human genes 0.000 description 5
- 102000003990 Urokinase-type plasminogen activator Human genes 0.000 description 5
- 108090000435 Urokinase-type plasminogen activator Proteins 0.000 description 5
- 238000003556 assay Methods 0.000 description 5
- 239000003153 chemical reaction reagent Substances 0.000 description 5
- 150000001875 compounds Chemical class 0.000 description 5
- 125000000151 cysteine group Chemical group N[C@@H](CS)C(=O)* 0.000 description 5
- 230000003993 interaction Effects 0.000 description 5
- 235000005772 leucine Nutrition 0.000 description 5
- 229920000642 polymer Polymers 0.000 description 5
- YBJHBAHKTGYVGT-ZKWXMUAHSA-N (+)-Biotin Chemical compound N1C(=O)N[C@@H]2[C@H](CCCCC(=O)O)SC[C@@H]21 YBJHBAHKTGYVGT-ZKWXMUAHSA-N 0.000 description 4
- 206010006187 Breast cancer Diseases 0.000 description 4
- 208000026310 Breast neoplasm Diseases 0.000 description 4
- 108091026890 Coding region Proteins 0.000 description 4
- 108050005238 Collagenase 3 Proteins 0.000 description 4
- 108020004414 DNA Proteins 0.000 description 4
- 102000053602 DNA Human genes 0.000 description 4
- 239000004471 Glycine Substances 0.000 description 4
- 101000595925 Homo sapiens Plasminogen-like protein B Proteins 0.000 description 4
- 101000661807 Homo sapiens Suppressor of tumorigenicity 14 protein Proteins 0.000 description 4
- XUJNEKJLAYXESH-REOHCLBHSA-N L-Cysteine Chemical compound SC[C@H](N)C(O)=O XUJNEKJLAYXESH-REOHCLBHSA-N 0.000 description 4
- AGPKZVBTJJNPAG-WHFBIAKZSA-N L-isoleucine Chemical compound CC[C@H](C)[C@H](N)C(O)=O AGPKZVBTJJNPAG-WHFBIAKZSA-N 0.000 description 4
- KZSNJWFQEVHDMF-BYPYZUCNSA-N L-valine Chemical compound CC(C)[C@H](N)C(O)=O KZSNJWFQEVHDMF-BYPYZUCNSA-N 0.000 description 4
- 102100027998 Macrophage metalloelastase Human genes 0.000 description 4
- 108010076557 Matrix Metalloproteinase 14 Proteins 0.000 description 4
- 102100035195 Plasminogen-like protein B Human genes 0.000 description 4
- MTCFGRXMJLQNBG-UHFFFAOYSA-N Serine Natural products OCC(N)C(O)=O MTCFGRXMJLQNBG-UHFFFAOYSA-N 0.000 description 4
- KZSNJWFQEVHDMF-UHFFFAOYSA-N Valine Natural products CC(C)C(N)C(O)=O KZSNJWFQEVHDMF-UHFFFAOYSA-N 0.000 description 4
- 239000002253 acid Substances 0.000 description 4
- 230000010056 antibody-dependent cellular cytotoxicity Effects 0.000 description 4
- 235000003704 aspartic acid Nutrition 0.000 description 4
- OQFSQFPPLPISGP-UHFFFAOYSA-N beta-carboxyaspartic acid Natural products OC(=O)C(N)C(C(O)=O)C(O)=O OQFSQFPPLPISGP-UHFFFAOYSA-N 0.000 description 4
- 230000017531 blood circulation Effects 0.000 description 4
- 239000002299 complementary DNA Substances 0.000 description 4
- 235000018417 cysteine Nutrition 0.000 description 4
- XUJNEKJLAYXESH-UHFFFAOYSA-N cysteine Natural products SCC(N)C(O)=O XUJNEKJLAYXESH-UHFFFAOYSA-N 0.000 description 4
- 229940079593 drug Drugs 0.000 description 4
- 230000004927 fusion Effects 0.000 description 4
- 230000012010 growth Effects 0.000 description 4
- 235000014705 isoleucine Nutrition 0.000 description 4
- 229960000310 isoleucine Drugs 0.000 description 4
- AGPKZVBTJJNPAG-UHFFFAOYSA-N isoleucine Natural products CCC(C)C(N)C(O)=O AGPKZVBTJJNPAG-UHFFFAOYSA-N 0.000 description 4
- 229940043355 kinase inhibitor Drugs 0.000 description 4
- 230000001404 mediated effect Effects 0.000 description 4
- 230000004048 modification Effects 0.000 description 4
- 238000012986 modification Methods 0.000 description 4
- 210000005087 mononuclear cell Anatomy 0.000 description 4
- 230000036961 partial effect Effects 0.000 description 4
- 239000003757 phosphotransferase inhibitor Substances 0.000 description 4
- 239000000047 product Substances 0.000 description 4
- 230000009467 reduction Effects 0.000 description 4
- 235000004400 serine Nutrition 0.000 description 4
- 239000004474 valine Substances 0.000 description 4
- 235000014393 valine Nutrition 0.000 description 4
- 239000012099 Alexa Fluor family Substances 0.000 description 3
- 102000002260 Alkaline Phosphatase Human genes 0.000 description 3
- 108020004774 Alkaline Phosphatase Proteins 0.000 description 3
- 241000282472 Canis lupus familiaris Species 0.000 description 3
- 241000282326 Felis catus Species 0.000 description 3
- 241000282412 Homo Species 0.000 description 3
- 101001117317 Homo sapiens Programmed cell death 1 ligand 1 Proteins 0.000 description 3
- 108010001336 Horseradish Peroxidase Proteins 0.000 description 3
- QNAYBMKLOCPYGJ-REOHCLBHSA-N L-alanine Chemical compound C[C@H](N)C(O)=O QNAYBMKLOCPYGJ-REOHCLBHSA-N 0.000 description 3
- DCXYFEDJOCDNAF-REOHCLBHSA-N L-asparagine Chemical compound OC(=O)[C@@H](N)CC(N)=O DCXYFEDJOCDNAF-REOHCLBHSA-N 0.000 description 3
- WHUUTDBJXJRKMK-VKHMYHEASA-N L-glutamic acid Chemical compound OC(=O)[C@@H](N)CCC(O)=O WHUUTDBJXJRKMK-VKHMYHEASA-N 0.000 description 3
- ZDXPYRJPNDTMRX-VKHMYHEASA-N L-glutamine Chemical compound OC(=O)[C@@H](N)CCC(N)=O ZDXPYRJPNDTMRX-VKHMYHEASA-N 0.000 description 3
- COLNVLDHVKWLRT-QMMMGPOBSA-N L-phenylalanine Chemical compound OC(=O)[C@@H](N)CC1=CC=CC=C1 COLNVLDHVKWLRT-QMMMGPOBSA-N 0.000 description 3
- AYFVYJQAPQTCCC-GBXIJSLDSA-N L-threonine Chemical compound C[C@@H](O)[C@H](N)C(O)=O AYFVYJQAPQTCCC-GBXIJSLDSA-N 0.000 description 3
- QIVBCDIJIAJPQS-VIFPVBQESA-N L-tryptophane Chemical compound C1=CC=C2C(C[C@H](N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-VIFPVBQESA-N 0.000 description 3
- OUYCCCASQSFEME-QMMMGPOBSA-N L-tyrosine Chemical compound OC(=O)[C@@H](N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-QMMMGPOBSA-N 0.000 description 3
- 101710187853 Macrophage metalloelastase Proteins 0.000 description 3
- 241000124008 Mammalia Species 0.000 description 3
- 102100030417 Matrilysin Human genes 0.000 description 3
- 108010015302 Matrix metalloproteinase-9 Proteins 0.000 description 3
- 108010090804 Streptavidin Proteins 0.000 description 3
- AYFVYJQAPQTCCC-UHFFFAOYSA-N Threonine Natural products CC(O)C(N)C(O)=O AYFVYJQAPQTCCC-UHFFFAOYSA-N 0.000 description 3
- 239000004473 Threonine Substances 0.000 description 3
- QIVBCDIJIAJPQS-UHFFFAOYSA-N Tryptophan Natural products C1=CC=C2C(CC(N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-UHFFFAOYSA-N 0.000 description 3
- 150000007513 acids Chemical class 0.000 description 3
- 235000004279 alanine Nutrition 0.000 description 3
- 125000000539 amino acid group Chemical group 0.000 description 3
- 238000003491 array Methods 0.000 description 3
- 230000015572 biosynthetic process Effects 0.000 description 3
- 210000001185 bone marrow Anatomy 0.000 description 3
- 230000008859 change Effects 0.000 description 3
- 230000000295 complement effect Effects 0.000 description 3
- 238000010276 construction Methods 0.000 description 3
- 238000012217 deletion Methods 0.000 description 3
- 230000037430 deletion Effects 0.000 description 3
- 230000001419 dependent effect Effects 0.000 description 3
- 238000013461 design Methods 0.000 description 3
- 239000007850 fluorescent dye Substances 0.000 description 3
- ZDXPYRJPNDTMRX-UHFFFAOYSA-N glutamine Natural products OC(=O)C(N)CCC(N)=O ZDXPYRJPNDTMRX-UHFFFAOYSA-N 0.000 description 3
- 235000004554 glutamine Nutrition 0.000 description 3
- 230000001900 immune effect Effects 0.000 description 3
- 238000000099 in vitro assay Methods 0.000 description 3
- 238000005462 in vivo assay Methods 0.000 description 3
- 208000032839 leukemia Diseases 0.000 description 3
- 239000003550 marker Substances 0.000 description 3
- 235000008729 phenylalanine Nutrition 0.000 description 3
- COLNVLDHVKWLRT-UHFFFAOYSA-N phenylalanine Natural products OC(=O)C(N)CC1=CC=CC=C1 COLNVLDHVKWLRT-UHFFFAOYSA-N 0.000 description 3
- 230000000069 prophylactic effect Effects 0.000 description 3
- 238000012552 review Methods 0.000 description 3
- RCINICONZNJXQF-MZXODVADSA-N taxol Chemical compound O([C@@H]1[C@@]2(C[C@@H](C(C)=C(C2(C)C)[C@H](C([C@]2(C)[C@@H](O)C[C@H]3OC[C@]3([C@H]21)OC(C)=O)=O)OC(=O)C)OC(=O)[C@H](O)[C@@H](NC(=O)C=1C=CC=CC=1)C=1C=CC=CC=1)O)C(=O)C1=CC=CC=C1 RCINICONZNJXQF-MZXODVADSA-N 0.000 description 3
- 238000011285 therapeutic regimen Methods 0.000 description 3
- 235000008521 threonine Nutrition 0.000 description 3
- OUYCCCASQSFEME-UHFFFAOYSA-N tyrosine Natural products OC(=O)C(N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-UHFFFAOYSA-N 0.000 description 3
- 235000002374 tyrosine Nutrition 0.000 description 3
- 229960005356 urokinase Drugs 0.000 description 3
- 102100036475 Alanine aminotransferase 1 Human genes 0.000 description 2
- 108010082126 Alanine transaminase Proteins 0.000 description 2
- 108010012934 Albumin-Bound Paclitaxel Proteins 0.000 description 2
- 239000004475 Arginine Substances 0.000 description 2
- DCXYFEDJOCDNAF-UHFFFAOYSA-N Asparagine Natural products OC(=O)C(N)CC(N)=O DCXYFEDJOCDNAF-UHFFFAOYSA-N 0.000 description 2
- 108090001008 Avidin Proteins 0.000 description 2
- 229940124291 BTK inhibitor Drugs 0.000 description 2
- 108010019670 Chimeric Antigen Receptors Proteins 0.000 description 2
- 206010009944 Colon cancer Diseases 0.000 description 2
- 208000001333 Colorectal Neoplasms Diseases 0.000 description 2
- 238000009007 Diagnostic Kit Methods 0.000 description 2
- AOJJSUZBOXZQNB-TZSSRYMLSA-N Doxorubicin Chemical compound O([C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(=O)CO)[C@H]1C[C@H](N)[C@H](O)[C@H](C)O1 AOJJSUZBOXZQNB-TZSSRYMLSA-N 0.000 description 2
- 102100025137 Early activation antigen CD69 Human genes 0.000 description 2
- WHUUTDBJXJRKMK-UHFFFAOYSA-N Glutamic acid Natural products OC(=O)C(N)CCC(O)=O WHUUTDBJXJRKMK-UHFFFAOYSA-N 0.000 description 2
- BCCRXDTUTZHDEU-VKHMYHEASA-N Gly-Ser Chemical compound NCC(=O)N[C@@H](CO)C(O)=O BCCRXDTUTZHDEU-VKHMYHEASA-N 0.000 description 2
- 108010043121 Green Fluorescent Proteins Proteins 0.000 description 2
- 102000004144 Green Fluorescent Proteins Human genes 0.000 description 2
- 101000577887 Homo sapiens Collagenase 3 Proteins 0.000 description 2
- 101000934374 Homo sapiens Early activation antigen CD69 Proteins 0.000 description 2
- 101001013150 Homo sapiens Interstitial collagenase Proteins 0.000 description 2
- 101000990912 Homo sapiens Matrilysin Proteins 0.000 description 2
- 101001011887 Homo sapiens Matrix metalloproteinase-17 Proteins 0.000 description 2
- 101001011896 Homo sapiens Matrix metalloproteinase-19 Proteins 0.000 description 2
- 101000990915 Homo sapiens Stromelysin-1 Proteins 0.000 description 2
- 101000577877 Homo sapiens Stromelysin-3 Proteins 0.000 description 2
- 101000955999 Homo sapiens V-set domain-containing T-cell activation inhibitor 1 Proteins 0.000 description 2
- 108091006905 Human Serum Albumin Proteins 0.000 description 2
- 102000008100 Human Serum Albumin Human genes 0.000 description 2
- PMMYEEVYMWASQN-DMTCNVIQSA-N Hydroxyproline Chemical compound O[C@H]1CN[C@H](C(O)=O)C1 PMMYEEVYMWASQN-DMTCNVIQSA-N 0.000 description 2
- 102100040061 Indoleamine 2,3-dioxygenase 1 Human genes 0.000 description 2
- UQSXHKLRYXJYBZ-UHFFFAOYSA-N Iron oxide Chemical compound [Fe]=O UQSXHKLRYXJYBZ-UHFFFAOYSA-N 0.000 description 2
- ONIBWKKTOPOVIA-BYPYZUCNSA-N L-Proline Chemical compound OC(=O)[C@@H]1CCCN1 ONIBWKKTOPOVIA-BYPYZUCNSA-N 0.000 description 2
- ODKSFYDXXFIFQN-BYPYZUCNSA-P L-argininium(2+) Chemical compound NC(=[NH2+])NCCC[C@H]([NH3+])C(O)=O ODKSFYDXXFIFQN-BYPYZUCNSA-P 0.000 description 2
- HNDVDQJCIGZPNO-YFKPBYRVSA-N L-histidine Chemical compound OC(=O)[C@@H](N)CC1=CN=CN1 HNDVDQJCIGZPNO-YFKPBYRVSA-N 0.000 description 2
- KDXKERNSBIXSRK-YFKPBYRVSA-N L-lysine Chemical compound NCCCC[C@H](N)C(O)=O KDXKERNSBIXSRK-YFKPBYRVSA-N 0.000 description 2
- FFEARJCKVFRZRR-BYPYZUCNSA-N L-methionine Chemical compound CSCC[C@H](N)C(O)=O FFEARJCKVFRZRR-BYPYZUCNSA-N 0.000 description 2
- 239000002146 L01XE16 - Crizotinib Substances 0.000 description 2
- 239000002177 L01XE27 - Ibrutinib Substances 0.000 description 2
- 206010058467 Lung neoplasm malignant Diseases 0.000 description 2
- KDXKERNSBIXSRK-UHFFFAOYSA-N Lysine Natural products NCCCCC(N)C(O)=O KDXKERNSBIXSRK-UHFFFAOYSA-N 0.000 description 2
- 239000004472 Lysine Substances 0.000 description 2
- 230000005723 MEK inhibition Effects 0.000 description 2
- 102000000380 Matrix Metalloproteinase 1 Human genes 0.000 description 2
- 102100030219 Matrix metalloproteinase-17 Human genes 0.000 description 2
- 102100030218 Matrix metalloproteinase-19 Human genes 0.000 description 2
- 206010027476 Metastases Diseases 0.000 description 2
- 101100069392 Mus musculus Gzma gene Proteins 0.000 description 2
- 101710160107 Outer membrane protein A Proteins 0.000 description 2
- 229930012538 Paclitaxel Natural products 0.000 description 2
- 102100040678 Programmed cell death protein 1 Human genes 0.000 description 2
- ONIBWKKTOPOVIA-UHFFFAOYSA-N Proline Natural products OC(=O)C1CCCN1 ONIBWKKTOPOVIA-UHFFFAOYSA-N 0.000 description 2
- 206010060862 Prostate cancer Diseases 0.000 description 2
- 208000000236 Prostatic Neoplasms Diseases 0.000 description 2
- 108020004511 Recombinant DNA Proteins 0.000 description 2
- 108091028664 Ribonucleotide Proteins 0.000 description 2
- 206010039491 Sarcoma Diseases 0.000 description 2
- 102000012479 Serine Proteases Human genes 0.000 description 2
- 108010022999 Serine Proteases Proteins 0.000 description 2
- 102100030416 Stromelysin-1 Human genes 0.000 description 2
- 102100028847 Stromelysin-3 Human genes 0.000 description 2
- 208000029052 T-cell acute lymphoblastic leukemia Diseases 0.000 description 2
- PZBFGYYEXUXCOF-UHFFFAOYSA-N TCEP Chemical compound OC(=O)CCP(CCC(O)=O)CCC(O)=O PZBFGYYEXUXCOF-UHFFFAOYSA-N 0.000 description 2
- 101150056647 TNFRSF4 gene Proteins 0.000 description 2
- 108020000411 Toll-like receptor Proteins 0.000 description 2
- 102000002689 Toll-like receptor Human genes 0.000 description 2
- 102000004887 Transforming Growth Factor beta Human genes 0.000 description 2
- 241000700605 Viruses Species 0.000 description 2
- 229940028652 abraxane Drugs 0.000 description 2
- 238000007792 addition Methods 0.000 description 2
- 238000004458 analytical method Methods 0.000 description 2
- 239000005557 antagonist Substances 0.000 description 2
- 239000000611 antibody drug conjugate Substances 0.000 description 2
- 229940049595 antibody-drug conjugate Drugs 0.000 description 2
- 229940041181 antineoplastic drug Drugs 0.000 description 2
- ODKSFYDXXFIFQN-UHFFFAOYSA-N arginine Natural products OC(=O)C(N)CCCNC(N)=N ODKSFYDXXFIFQN-UHFFFAOYSA-N 0.000 description 2
- 235000009697 arginine Nutrition 0.000 description 2
- 235000009582 asparagine Nutrition 0.000 description 2
- 229960001230 asparagine Drugs 0.000 description 2
- VSRXQHXAPYXROS-UHFFFAOYSA-N azanide;cyclobutane-1,1-dicarboxylic acid;platinum(2+) Chemical compound [NH2-].[NH2-].[Pt+2].OC(=O)C1(C(O)=O)CCC1 VSRXQHXAPYXROS-UHFFFAOYSA-N 0.000 description 2
- 230000008901 benefit Effects 0.000 description 2
- 108010005774 beta-Galactosidase Proteins 0.000 description 2
- 102000005936 beta-Galactosidase Human genes 0.000 description 2
- 229960002685 biotin Drugs 0.000 description 2
- 235000020958 biotin Nutrition 0.000 description 2
- 239000011616 biotin Substances 0.000 description 2
- 125000004057 biotinyl group Chemical group [H]N1C(=O)N([H])[C@]2([H])[C@@]([H])(SC([H])([H])[C@]12[H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C(*)=O 0.000 description 2
- 229960004562 carboplatin Drugs 0.000 description 2
- 230000022534 cell killing Effects 0.000 description 2
- 230000001413 cellular effect Effects 0.000 description 2
- 238000006243 chemical reaction Methods 0.000 description 2
- 238000002512 chemotherapy Methods 0.000 description 2
- 239000012829 chemotherapy agent Substances 0.000 description 2
- 229960004316 cisplatin Drugs 0.000 description 2
- DQLATGHUWYMOKM-UHFFFAOYSA-L cisplatin Chemical compound N[Pt](N)(Cl)Cl DQLATGHUWYMOKM-UHFFFAOYSA-L 0.000 description 2
- 239000000470 constituent Substances 0.000 description 2
- 239000002872 contrast media Substances 0.000 description 2
- KTEIFNKAUNYNJU-GFCCVEGCSA-N crizotinib Chemical group O([C@H](C)C=1C(=C(F)C=CC=1Cl)Cl)C(C(=NC=1)N)=CC=1C(=C1)C=NN1C1CCNCC1 KTEIFNKAUNYNJU-GFCCVEGCSA-N 0.000 description 2
- 229960005061 crizotinib Drugs 0.000 description 2
- 108010082025 cyan fluorescent protein Proteins 0.000 description 2
- 231100000433 cytotoxic Toxicity 0.000 description 2
- 230000001472 cytotoxic effect Effects 0.000 description 2
- 230000003013 cytotoxicity Effects 0.000 description 2
- 231100000135 cytotoxicity Toxicity 0.000 description 2
- WBZKQQHYRPRKNJ-UHFFFAOYSA-L disulfite Chemical compound [O-]S(=O)S([O-])(=O)=O WBZKQQHYRPRKNJ-UHFFFAOYSA-L 0.000 description 2
- PMMYEEVYMWASQN-UHFFFAOYSA-N dl-hydroxyproline Natural products OC1C[NH2+]C(C([O-])=O)C1 PMMYEEVYMWASQN-UHFFFAOYSA-N 0.000 description 2
- 238000009510 drug design Methods 0.000 description 2
- 239000000975 dye Substances 0.000 description 2
- 239000012636 effector Substances 0.000 description 2
- 230000002255 enzymatic effect Effects 0.000 description 2
- 238000002474 experimental method Methods 0.000 description 2
- MHMNJMPURVTYEJ-UHFFFAOYSA-N fluorescein-5-isothiocyanate Chemical compound O1C(=O)C2=CC(N=C=S)=CC=C2C21C1=CC=C(O)C=C1OC1=CC(O)=CC=C21 MHMNJMPURVTYEJ-UHFFFAOYSA-N 0.000 description 2
- 238000005755 formation reaction Methods 0.000 description 2
- SDUQYLNIPVEERB-QPPQHZFASA-N gemcitabine Chemical compound O=C1N=C(N)C=CN1[C@H]1C(F)(F)[C@H](O)[C@@H](CO)O1 SDUQYLNIPVEERB-QPPQHZFASA-N 0.000 description 2
- 229960005277 gemcitabine Drugs 0.000 description 2
- 235000013922 glutamic acid Nutrition 0.000 description 2
- 229960002989 glutamic acid Drugs 0.000 description 2
- 239000004220 glutamic acid Substances 0.000 description 2
- 239000005090 green fluorescent protein Substances 0.000 description 2
- 230000036541 health Effects 0.000 description 2
- 235000014304 histidine Nutrition 0.000 description 2
- HNDVDQJCIGZPNO-UHFFFAOYSA-N histidine Natural products OC(=O)C(N)CC1=CN=CN1 HNDVDQJCIGZPNO-UHFFFAOYSA-N 0.000 description 2
- 229960002591 hydroxyproline Drugs 0.000 description 2
- XYFPWWZEPKGCCK-GOSISDBHSA-N ibrutinib Chemical compound C1=2C(N)=NC=NC=2N([C@H]2CN(CCC2)C(=O)C=C)N=C1C(C=C1)=CC=C1OC1=CC=CC=C1 XYFPWWZEPKGCCK-GOSISDBHSA-N 0.000 description 2
- 229960001507 ibrutinib Drugs 0.000 description 2
- 239000012216 imaging agent Substances 0.000 description 2
- 238000000338 in vitro Methods 0.000 description 2
- 238000010348 incorporation Methods 0.000 description 2
- 238000011534 incubation Methods 0.000 description 2
- 230000006698 induction Effects 0.000 description 2
- JVTAAEKCZFNVCJ-UHFFFAOYSA-N lactic acid Chemical compound CC(O)C(O)=O JVTAAEKCZFNVCJ-UHFFFAOYSA-N 0.000 description 2
- 201000005202 lung cancer Diseases 0.000 description 2
- 208000020816 lung neoplasm Diseases 0.000 description 2
- 235000018977 lysine Nutrition 0.000 description 2
- 238000005259 measurement Methods 0.000 description 2
- 201000001441 melanoma Diseases 0.000 description 2
- 230000002503 metabolic effect Effects 0.000 description 2
- 229910052751 metal Inorganic materials 0.000 description 2
- 239000002184 metal Substances 0.000 description 2
- 230000009401 metastasis Effects 0.000 description 2
- 235000006109 methionine Nutrition 0.000 description 2
- 229930182817 methionine Natural products 0.000 description 2
- 229940125374 mitogen-activated extracellular signal-regulated kinase inhibitor Drugs 0.000 description 2
- 210000004985 myeloid-derived suppressor cell Anatomy 0.000 description 2
- 210000000822 natural killer cell Anatomy 0.000 description 2
- 229960001592 paclitaxel Drugs 0.000 description 2
- 210000000496 pancreas Anatomy 0.000 description 2
- 238000002823 phage display Methods 0.000 description 2
- BASFCYQUMIYNBI-UHFFFAOYSA-N platinum Chemical compound [Pt] BASFCYQUMIYNBI-UHFFFAOYSA-N 0.000 description 2
- 238000012545 processing Methods 0.000 description 2
- 235000013930 proline Nutrition 0.000 description 2
- 238000000746 purification Methods 0.000 description 2
- 108010054624 red fluorescent protein Proteins 0.000 description 2
- 210000003289 regulatory T cell Anatomy 0.000 description 2
- 239000002336 ribonucleotide Substances 0.000 description 2
- 125000002652 ribonucleotide group Chemical group 0.000 description 2
- 238000002702 ribosome display Methods 0.000 description 2
- 230000035945 sensitivity Effects 0.000 description 2
- 206010041823 squamous cell carcinoma Diseases 0.000 description 2
- 238000010561 standard procedure Methods 0.000 description 2
- 238000001356 surgical procedure Methods 0.000 description 2
- 238000003786 synthesis reaction Methods 0.000 description 2
- ZRKFYGHZFMAOKI-QMGMOQQFSA-N tgfbeta Chemical compound C([C@H](NC(=O)[C@H](C(C)C)NC(=O)CNC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@H](CC(C)C)NC(=O)CNC(=O)[C@H](C)NC(=O)[C@H](CO)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](NC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)[C@@H](NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CCSC)C(C)C)[C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](C)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)N1[C@@H](CCC1)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O)C1=CC=C(O)C=C1 ZRKFYGHZFMAOKI-QMGMOQQFSA-N 0.000 description 2
- 238000013518 transcription Methods 0.000 description 2
- 230000035897 transcription Effects 0.000 description 2
- 230000005030 transcription termination Effects 0.000 description 2
- 238000012384 transportation and delivery Methods 0.000 description 2
- 238000011269 treatment regimen Methods 0.000 description 2
- 210000004881 tumor cell Anatomy 0.000 description 2
- 241001430294 unidentified retrovirus Species 0.000 description 2
- 108091005957 yellow fluorescent proteins Proteins 0.000 description 2
- KUHSEZKIEJYEHN-BXRBKJIMSA-N (2s)-2-amino-3-hydroxypropanoic acid;(2s)-2-aminopropanoic acid Chemical compound C[C@H](N)C(O)=O.OC[C@H](N)C(O)=O KUHSEZKIEJYEHN-BXRBKJIMSA-N 0.000 description 1
- NFGXHKASABOEEW-UHFFFAOYSA-N 1-methylethyl 11-methoxy-3,7,11-trimethyl-2,4-dodecadienoate Chemical group COC(C)(C)CCCC(C)CC=CC(C)=CC(=O)OC(C)C NFGXHKASABOEEW-UHFFFAOYSA-N 0.000 description 1
- GOJUJUVQIVIZAV-UHFFFAOYSA-N 2-amino-4,6-dichloropyrimidine-5-carbaldehyde Chemical group NC1=NC(Cl)=C(C=O)C(Cl)=N1 GOJUJUVQIVIZAV-UHFFFAOYSA-N 0.000 description 1
- BRMWTNUJHUMWMS-UHFFFAOYSA-N 3-Methylhistidine Natural products CN1C=NC(CC(N)C(O)=O)=C1 BRMWTNUJHUMWMS-UHFFFAOYSA-N 0.000 description 1
- 229940117976 5-hydroxylysine Drugs 0.000 description 1
- 102100026802 72 kDa type IV collagenase Human genes 0.000 description 1
- QNAYBMKLOCPYGJ-UHFFFAOYSA-N Alanine Chemical compound CC([NH3+])C([O-])=O QNAYBMKLOCPYGJ-UHFFFAOYSA-N 0.000 description 1
- 108020000948 Antisense Oligonucleotides Proteins 0.000 description 1
- MLDQJTXFUGDVEO-UHFFFAOYSA-N BAY-43-9006 Chemical compound C1=NC(C(=O)NC)=CC(OC=2C=CC(NC(=O)NC=3C=C(C(Cl)=CC=3)C(F)(F)F)=CC=2)=C1 MLDQJTXFUGDVEO-UHFFFAOYSA-N 0.000 description 1
- 241000894006 Bacteria Species 0.000 description 1
- 206010004146 Basal cell carcinoma Diseases 0.000 description 1
- 102000004506 Blood Proteins Human genes 0.000 description 1
- 108010017384 Blood Proteins Proteins 0.000 description 1
- 206010005949 Bone cancer Diseases 0.000 description 1
- 208000020084 Bone disease Diseases 0.000 description 1
- 208000018084 Bone neoplasm Diseases 0.000 description 1
- 101800001415 Bri23 peptide Proteins 0.000 description 1
- 125000001433 C-terminal amino-acid group Chemical group 0.000 description 1
- 101800000655 C-terminal peptide Proteins 0.000 description 1
- 102400000107 C-terminal peptide Human genes 0.000 description 1
- 102100038078 CD276 antigen Human genes 0.000 description 1
- 239000012275 CTLA-4 inhibitor Substances 0.000 description 1
- 208000024172 Cardiovascular disease Diseases 0.000 description 1
- 108090000613 Cathepsin S Proteins 0.000 description 1
- 102100035654 Cathepsin S Human genes 0.000 description 1
- 108020004705 Codon Proteins 0.000 description 1
- 150000008574 D-amino acids Chemical class 0.000 description 1
- 101150029707 ERBB2 gene Proteins 0.000 description 1
- 102400001368 Epidermal growth factor Human genes 0.000 description 1
- 101800003838 Epidermal growth factor Proteins 0.000 description 1
- 208000000461 Esophageal Neoplasms Diseases 0.000 description 1
- 241000206602 Eukaryota Species 0.000 description 1
- 150000000918 Europium Chemical class 0.000 description 1
- 101710089384 Extracellular protease Proteins 0.000 description 1
- 108091006020 Fc-tagged proteins Proteins 0.000 description 1
- 102000003886 Glycoproteins Human genes 0.000 description 1
- 108090000288 Glycoproteins Proteins 0.000 description 1
- 102000009465 Growth Factor Receptors Human genes 0.000 description 1
- 108010009202 Growth Factor Receptors Proteins 0.000 description 1
- 101000627872 Homo sapiens 72 kDa type IV collagenase Proteins 0.000 description 1
- 101000884279 Homo sapiens CD276 antigen Proteins 0.000 description 1
- 101000577881 Homo sapiens Macrophage metalloelastase Proteins 0.000 description 1
- 101001011884 Homo sapiens Matrix metalloproteinase-15 Proteins 0.000 description 1
- 101001011886 Homo sapiens Matrix metalloproteinase-16 Proteins 0.000 description 1
- 101001013139 Homo sapiens Matrix metalloproteinase-20 Proteins 0.000 description 1
- 101000627858 Homo sapiens Matrix metalloproteinase-24 Proteins 0.000 description 1
- 101000627852 Homo sapiens Matrix metalloproteinase-25 Proteins 0.000 description 1
- 101000627854 Homo sapiens Matrix metalloproteinase-26 Proteins 0.000 description 1
- 101000627860 Homo sapiens Matrix metalloproteinase-27 Proteins 0.000 description 1
- 101000990908 Homo sapiens Neutrophil collagenase Proteins 0.000 description 1
- 101001041393 Homo sapiens Serine protease HTRA1 Proteins 0.000 description 1
- 101000577874 Homo sapiens Stromelysin-2 Proteins 0.000 description 1
- 102000013463 Immunoglobulin Light Chains Human genes 0.000 description 1
- 108010065825 Immunoglobulin Light Chains Proteins 0.000 description 1
- 102000004889 Interleukin-6 Human genes 0.000 description 1
- 108010029660 Intrinsically Disordered Proteins Proteins 0.000 description 1
- 208000008839 Kidney Neoplasms Diseases 0.000 description 1
- 239000005551 L01XE03 - Erlotinib Substances 0.000 description 1
- 239000005511 L01XE05 - Sorafenib Substances 0.000 description 1
- 229940125563 LAG3 inhibitor Drugs 0.000 description 1
- 241000406668 Loxodonta cyclotis Species 0.000 description 1
- 108060001084 Luciferase Proteins 0.000 description 1
- 239000005089 Luciferase Substances 0.000 description 1
- 206010025323 Lymphomas Diseases 0.000 description 1
- 241000282567 Macaca fascicularis Species 0.000 description 1
- 108090000855 Matrilysin Proteins 0.000 description 1
- 108010091175 Matriptase Proteins 0.000 description 1
- 102100030201 Matrix metalloproteinase-15 Human genes 0.000 description 1
- 102100030200 Matrix metalloproteinase-16 Human genes 0.000 description 1
- 102100024129 Matrix metalloproteinase-24 Human genes 0.000 description 1
- 102100024131 Matrix metalloproteinase-25 Human genes 0.000 description 1
- 102100024128 Matrix metalloproteinase-26 Human genes 0.000 description 1
- 102100024132 Matrix metalloproteinase-27 Human genes 0.000 description 1
- 101150073847 Mmp23 gene Proteins 0.000 description 1
- 108090000143 Mouse Proteins Proteins 0.000 description 1
- 208000034578 Multiple myelomas Diseases 0.000 description 1
- XKCWNEVAXQCMGP-YFKPBYRVSA-N N(5)-methyl-L-arginine Chemical compound NC(=N)N(C)CCC[C@H](N)C(O)=O XKCWNEVAXQCMGP-YFKPBYRVSA-N 0.000 description 1
- DTERQYGMUDWYAZ-ZETCQYMHSA-N N(6)-acetyl-L-lysine Chemical compound CC(=O)NCCCC[C@H]([NH3+])C([O-])=O DTERQYGMUDWYAZ-ZETCQYMHSA-N 0.000 description 1
- JDHILDINMRGULE-LURJTMIESA-N N(pros)-methyl-L-histidine Chemical compound CN1C=NC=C1C[C@H](N)C(O)=O JDHILDINMRGULE-LURJTMIESA-N 0.000 description 1
- MXNRLFUSFKVQSK-UHFFFAOYSA-O N,N,N-Trimethyllysine Chemical compound C[N+](C)(C)CCCCC(N)C(O)=O MXNRLFUSFKVQSK-UHFFFAOYSA-O 0.000 description 1
- ZDZOTLJHXYCWBA-VCVYQWHSSA-N N-debenzoyl-N-(tert-butoxycarbonyl)-10-deacetyltaxol Chemical compound O([C@H]1[C@H]2[C@@](C([C@H](O)C3=C(C)[C@@H](OC(=O)[C@H](O)[C@@H](NC(=O)OC(C)(C)C)C=4C=CC=CC=4)C[C@]1(O)C3(C)C)=O)(C)[C@@H](O)C[C@H]1OC[C@]12OC(=O)C)C(=O)C1=CC=CC=C1 ZDZOTLJHXYCWBA-VCVYQWHSSA-N 0.000 description 1
- PYUSHNKNPOHWEZ-YFKPBYRVSA-N N-formyl-L-methionine Chemical compound CSCC[C@@H](C(O)=O)NC=O PYUSHNKNPOHWEZ-YFKPBYRVSA-N 0.000 description 1
- 102100030411 Neutrophil collagenase Human genes 0.000 description 1
- 206010030155 Oesophageal carcinoma Diseases 0.000 description 1
- 206010033128 Ovarian cancer Diseases 0.000 description 1
- 206010061535 Ovarian neoplasm Diseases 0.000 description 1
- 239000012270 PD-1 inhibitor Substances 0.000 description 1
- 239000012668 PD-1-inhibitor Substances 0.000 description 1
- 206010061902 Pancreatic neoplasm Diseases 0.000 description 1
- 206010035226 Plasma cell myeloma Diseases 0.000 description 1
- 102000001938 Plasminogen Activators Human genes 0.000 description 1
- 108010001014 Plasminogen Activators Proteins 0.000 description 1
- 241000288906 Primates Species 0.000 description 1
- 229940079156 Proteasome inhibitor Drugs 0.000 description 1
- 108020005067 RNA Splice Sites Proteins 0.000 description 1
- 206010038389 Renal cancer Diseases 0.000 description 1
- 241000714474 Rous sarcoma virus Species 0.000 description 1
- 102100021119 Serine protease HTRA1 Human genes 0.000 description 1
- 108010071390 Serum Albumin Proteins 0.000 description 1
- 102000007562 Serum Albumin Human genes 0.000 description 1
- 108020004682 Single-Stranded DNA Proteins 0.000 description 1
- 208000000453 Skin Neoplasms Diseases 0.000 description 1
- 208000000102 Squamous Cell Carcinoma of Head and Neck Diseases 0.000 description 1
- 208000036765 Squamous cell carcinoma of the esophagus Diseases 0.000 description 1
- 208000005718 Stomach Neoplasms Diseases 0.000 description 1
- 102100028848 Stromelysin-2 Human genes 0.000 description 1
- 229940125555 TIGIT inhibitor Drugs 0.000 description 1
- 229940123237 Taxane Drugs 0.000 description 1
- 108010033576 Transferrin Receptors Proteins 0.000 description 1
- 208000003721 Triple Negative Breast Neoplasms Diseases 0.000 description 1
- 230000002378 acidificating effect Effects 0.000 description 1
- 239000012190 activator Substances 0.000 description 1
- 230000002411 adverse Effects 0.000 description 1
- 230000009824 affinity maturation Effects 0.000 description 1
- 125000001931 aliphatic group Chemical group 0.000 description 1
- 239000002168 alkylating agent Substances 0.000 description 1
- 229940100198 alkylating agent Drugs 0.000 description 1
- 230000029936 alkylation Effects 0.000 description 1
- 238000005804 alkylation reaction Methods 0.000 description 1
- 150000001408 amides Chemical class 0.000 description 1
- 230000003321 amplification Effects 0.000 description 1
- 239000002260 anti-inflammatory agent Substances 0.000 description 1
- 229940121363 anti-inflammatory agent Drugs 0.000 description 1
- 230000000890 antigenic effect Effects 0.000 description 1
- 229940034982 antineoplastic agent Drugs 0.000 description 1
- 239000003972 antineoplastic antibiotic Substances 0.000 description 1
- 239000000074 antisense oligonucleotide Substances 0.000 description 1
- 238000012230 antisense oligonucleotides Methods 0.000 description 1
- 238000013459 approach Methods 0.000 description 1
- 125000003118 aryl group Chemical group 0.000 description 1
- 230000002238 attenuated effect Effects 0.000 description 1
- 239000011230 binding agent Substances 0.000 description 1
- 230000004071 biological effect Effects 0.000 description 1
- 239000012620 biological material Substances 0.000 description 1
- 229960000074 biopharmaceutical Drugs 0.000 description 1
- 229920001222 biopolymer Polymers 0.000 description 1
- 230000001851 biosynthetic effect Effects 0.000 description 1
- GXJABQQUPOEUTA-RDJZCZTQSA-N bortezomib Chemical compound C([C@@H](C(=O)N[C@@H](CC(C)C)B(O)O)NC(=O)C=1N=CC=NC=1)C1=CC=CC=C1 GXJABQQUPOEUTA-RDJZCZTQSA-N 0.000 description 1
- 229960001467 bortezomib Drugs 0.000 description 1
- 210000000481 breast Anatomy 0.000 description 1
- 238000004364 calculation method Methods 0.000 description 1
- 108010021331 carfilzomib Proteins 0.000 description 1
- BLMPQMFVWMYDKT-NZTKNTHTSA-N carfilzomib Chemical compound C([C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](CC(C)C)C(=O)[C@]1(C)OC1)NC(=O)CN1CCOCC1)CC1=CC=CC=C1 BLMPQMFVWMYDKT-NZTKNTHTSA-N 0.000 description 1
- 229960002438 carfilzomib Drugs 0.000 description 1
- 239000000969 carrier Substances 0.000 description 1
- 230000030833 cell death Effects 0.000 description 1
- 230000002759 chromosomal effect Effects 0.000 description 1
- 230000000112 colonic effect Effects 0.000 description 1
- 238000012875 competitive assay Methods 0.000 description 1
- 230000009918 complex formation Effects 0.000 description 1
- 239000000562 conjugate Substances 0.000 description 1
- 238000007796 conventional method Methods 0.000 description 1
- LXWYCLOUQZZDBD-LIYNQYRNSA-N csfv Chemical compound C([C@H](NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)[C@@H](C)CC)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(O)=O)C1=CC=C(O)C=C1 LXWYCLOUQZZDBD-LIYNQYRNSA-N 0.000 description 1
- 210000004748 cultured cell Anatomy 0.000 description 1
- 125000004122 cyclic group Chemical group 0.000 description 1
- 230000009089 cytolysis Effects 0.000 description 1
- 230000034994 death Effects 0.000 description 1
- YSMODUONRAFBET-UHFFFAOYSA-N delta-DL-hydroxylysine Natural products NCC(O)CCC(N)C(O)=O YSMODUONRAFBET-UHFFFAOYSA-N 0.000 description 1
- 239000005547 deoxyribonucleotide Substances 0.000 description 1
- 125000002637 deoxyribonucleotide group Chemical group 0.000 description 1
- PGUYAANYCROBRT-UHFFFAOYSA-N dihydroxy-selanyl-selanylidene-lambda5-phosphane Chemical compound OP(O)([SeH])=[Se] PGUYAANYCROBRT-UHFFFAOYSA-N 0.000 description 1
- NAGJZTKCGNOGPW-UHFFFAOYSA-K dioxido-sulfanylidene-sulfido-$l^{5}-phosphane Chemical compound [O-]P([O-])([S-])=S NAGJZTKCGNOGPW-UHFFFAOYSA-K 0.000 description 1
- 208000035475 disorder Diseases 0.000 description 1
- 239000003534 dna topoisomerase inhibitor Substances 0.000 description 1
- 229960003668 docetaxel Drugs 0.000 description 1
- 231100000673 dose–response relationship Toxicity 0.000 description 1
- 229960004679 doxorubicin Drugs 0.000 description 1
- 238000004520 electroporation Methods 0.000 description 1
- 230000008030 elimination Effects 0.000 description 1
- 238000003379 elimination reaction Methods 0.000 description 1
- 230000002708 enhancing effect Effects 0.000 description 1
- 238000006911 enzymatic reaction Methods 0.000 description 1
- 229940116977 epidermal growth factor Drugs 0.000 description 1
- 230000008472 epithelial growth Effects 0.000 description 1
- 229960001433 erlotinib Drugs 0.000 description 1
- AAKJLRGGTJKAMG-UHFFFAOYSA-N erlotinib Chemical compound C=12C=C(OCCOC)C(OCCOC)=CC2=NC=NC=1NC1=CC=CC(C#C)=C1 AAKJLRGGTJKAMG-UHFFFAOYSA-N 0.000 description 1
- YSMODUONRAFBET-UHNVWZDZSA-N erythro-5-hydroxy-L-lysine Chemical compound NC[C@H](O)CC[C@H](N)C(O)=O YSMODUONRAFBET-UHNVWZDZSA-N 0.000 description 1
- 201000004101 esophageal cancer Diseases 0.000 description 1
- 208000007276 esophageal squamous cell carcinoma Diseases 0.000 description 1
- 239000013604 expression vector Substances 0.000 description 1
- 230000002349 favourable effect Effects 0.000 description 1
- 238000009472 formulation Methods 0.000 description 1
- UIWYJDYFSGRHKR-UHFFFAOYSA-N gadolinium atom Chemical compound [Gd] UIWYJDYFSGRHKR-UHFFFAOYSA-N 0.000 description 1
- 229940075613 gadolinium oxide Drugs 0.000 description 1
- 229910001938 gadolinium oxide Inorganic materials 0.000 description 1
- UHBYWPGGCSDKFX-VKHMYHEASA-N gamma-carboxy-L-glutamic acid Chemical compound OC(=O)[C@@H](N)CC(C(O)=O)C(O)=O UHBYWPGGCSDKFX-VKHMYHEASA-N 0.000 description 1
- 206010017758 gastric cancer Diseases 0.000 description 1
- 102000054767 gene variant Human genes 0.000 description 1
- 230000002068 genetic effect Effects 0.000 description 1
- 208000005017 glioblastoma Diseases 0.000 description 1
- 229930195712 glutamate Natural products 0.000 description 1
- 229940049906 glutamate Drugs 0.000 description 1
- 150000002337 glycosamines Chemical group 0.000 description 1
- 125000003147 glycosyl group Chemical group 0.000 description 1
- 230000013595 glycosylation Effects 0.000 description 1
- 238000006206 glycosylation reaction Methods 0.000 description 1
- 201000010536 head and neck cancer Diseases 0.000 description 1
- 208000014829 head and neck neoplasm Diseases 0.000 description 1
- 201000000459 head and neck squamous cell carcinoma Diseases 0.000 description 1
- 238000009396 hybridization Methods 0.000 description 1
- 230000002209 hydrophobic effect Effects 0.000 description 1
- 230000016784 immunoglobulin production Effects 0.000 description 1
- 229940072221 immunoglobulins Drugs 0.000 description 1
- 239000002955 immunomodulating agent Substances 0.000 description 1
- 230000002584 immunomodulator Effects 0.000 description 1
- 239000003018 immunosuppressive agent Substances 0.000 description 1
- 229940125721 immunosuppressive agent Drugs 0.000 description 1
- 238000001727 in vivo Methods 0.000 description 1
- 238000011065 in-situ storage Methods 0.000 description 1
- 229910052738 indium Inorganic materials 0.000 description 1
- APFVFJFRJDLVQX-UHFFFAOYSA-N indium atom Chemical group [In] APFVFJFRJDLVQX-UHFFFAOYSA-N 0.000 description 1
- 239000004615 ingredient Substances 0.000 description 1
- 230000005764 inhibitory process Effects 0.000 description 1
- 230000002452 interceptive effect Effects 0.000 description 1
- 229940100601 interleukin-6 Drugs 0.000 description 1
- PNDPGZBMCMUPRI-UHFFFAOYSA-N iodine Chemical compound II PNDPGZBMCMUPRI-UHFFFAOYSA-N 0.000 description 1
- UWKQSNNFCGGAFS-XIFFEERXSA-N irinotecan Chemical compound C1=C2C(CC)=C3CN(C(C4=C([C@@](C(=O)OC4)(O)CC)C=4)=O)C=4C3=NC2=CC=C1OC(=O)N(CC1)CCC1N1CCCCC1 UWKQSNNFCGGAFS-XIFFEERXSA-N 0.000 description 1
- 229960004768 irinotecan Drugs 0.000 description 1
- 208000028867 ischemia Diseases 0.000 description 1
- 201000010982 kidney cancer Diseases 0.000 description 1
- 210000003292 kidney cell Anatomy 0.000 description 1
- 230000002147 killing effect Effects 0.000 description 1
- 238000002372 labelling Methods 0.000 description 1
- 239000004310 lactic acid Substances 0.000 description 1
- 235000014655 lactic acid Nutrition 0.000 description 1
- 229910052747 lanthanoid Inorganic materials 0.000 description 1
- 150000002602 lanthanoids Chemical class 0.000 description 1
- GOTYRUGSSMKFNF-UHFFFAOYSA-N lenalidomide Chemical compound C1C=2C(N)=CC=CC=2C(=O)N1C1CCC(=O)NC1=O GOTYRUGSSMKFNF-UHFFFAOYSA-N 0.000 description 1
- 229960004942 lenalidomide Drugs 0.000 description 1
- 238000001638 lipofection Methods 0.000 description 1
- 238000004020 luminiscence type Methods 0.000 description 1
- 210000004072 lung Anatomy 0.000 description 1
- 201000005243 lung squamous cell carcinoma Diseases 0.000 description 1
- 210000002540 macrophage Anatomy 0.000 description 1
- 238000012423 maintenance Methods 0.000 description 1
- 208000015486 malignant pancreatic neoplasm Diseases 0.000 description 1
- 230000035800 maturation Effects 0.000 description 1
- 229910021645 metal ion Inorganic materials 0.000 description 1
- 125000002496 methyl group Chemical group [H]C([H])([H])* 0.000 description 1
- 239000003607 modifier Substances 0.000 description 1
- 230000035772 mutation Effects 0.000 description 1
- 208000025113 myeloid leukemia Diseases 0.000 description 1
- 239000002159 nanocrystal Substances 0.000 description 1
- 230000010807 negative regulation of binding Effects 0.000 description 1
- 238000009099 neoadjuvant therapy Methods 0.000 description 1
- 230000007935 neutral effect Effects 0.000 description 1
- 229910052757 nitrogen Inorganic materials 0.000 description 1
- 229960003301 nivolumab Drugs 0.000 description 1
- 208000002154 non-small cell lung carcinoma Diseases 0.000 description 1
- 238000003199 nucleic acid amplification method Methods 0.000 description 1
- 238000002515 oligonucleotide synthesis Methods 0.000 description 1
- 230000003287 optical effect Effects 0.000 description 1
- 201000008968 osteosarcoma Diseases 0.000 description 1
- DWAFYCQODLXJNR-BNTLRKBRSA-L oxaliplatin Chemical compound O1C(=O)C(=O)O[Pt]11N[C@@H]2CCCC[C@H]2N1 DWAFYCQODLXJNR-BNTLRKBRSA-L 0.000 description 1
- 229960001756 oxaliplatin Drugs 0.000 description 1
- 230000003647 oxidation Effects 0.000 description 1
- 238000007254 oxidation reaction Methods 0.000 description 1
- 201000002528 pancreatic cancer Diseases 0.000 description 1
- 208000008443 pancreatic carcinoma Diseases 0.000 description 1
- 230000037361 pathway Effects 0.000 description 1
- 229940121655 pd-1 inhibitor Drugs 0.000 description 1
- BZQFBWGGLXLEPQ-REOHCLBHSA-N phosphoserine Chemical compound OC(=O)[C@@H](N)COP(O)(O)=O BZQFBWGGLXLEPQ-REOHCLBHSA-N 0.000 description 1
- 239000013612 plasmid Substances 0.000 description 1
- 229940127126 plasminogen activator Drugs 0.000 description 1
- 229920003023 plastic Polymers 0.000 description 1
- 239000004033 plastic Substances 0.000 description 1
- 229910052697 platinum Inorganic materials 0.000 description 1
- 230000008488 polyadenylation Effects 0.000 description 1
- 230000002265 prevention Effects 0.000 description 1
- 210000002307 prostate Anatomy 0.000 description 1
- 239000003207 proteasome inhibitor Substances 0.000 description 1
- 230000009145 protein modification Effects 0.000 description 1
- 230000017854 proteolysis Effects 0.000 description 1
- 239000002096 quantum dot Substances 0.000 description 1
- 230000005855 radiation Effects 0.000 description 1
- 230000002285 radioactive effect Effects 0.000 description 1
- 238000003653 radioligand binding assay Methods 0.000 description 1
- 238000001959 radiotherapy Methods 0.000 description 1
- 230000036647 reaction Effects 0.000 description 1
- 230000007115 recruitment Effects 0.000 description 1
- 230000001105 regulatory effect Effects 0.000 description 1
- 238000011160 research Methods 0.000 description 1
- 230000004043 responsiveness Effects 0.000 description 1
- 230000001177 retroviral effect Effects 0.000 description 1
- 206010039073 rheumatoid arthritis Diseases 0.000 description 1
- PYWVYCXTNDRMGF-UHFFFAOYSA-N rhodamine B Chemical compound [Cl-].C=12C=CC(=[N+](CC)CC)C=C2OC2=CC(N(CC)CC)=CC=C2C=1C1=CC=CC=C1C(O)=O PYWVYCXTNDRMGF-UHFFFAOYSA-N 0.000 description 1
- 230000019491 signal transduction Effects 0.000 description 1
- 230000011664 signaling Effects 0.000 description 1
- 238000002741 site-directed mutagenesis Methods 0.000 description 1
- 201000000849 skin cancer Diseases 0.000 description 1
- 201000010106 skin squamous cell carcinoma Diseases 0.000 description 1
- 150000003384 small molecules Chemical class 0.000 description 1
- 239000000243 solution Substances 0.000 description 1
- 229960003787 sorafenib Drugs 0.000 description 1
- 201000011549 stomach cancer Diseases 0.000 description 1
- DKPFODGZWDEEBT-QFIAKTPHSA-N taxane Chemical class C([C@]1(C)CCC[C@@H](C)[C@H]1C1)C[C@H]2[C@H](C)CC[C@@H]1C2(C)C DKPFODGZWDEEBT-QFIAKTPHSA-N 0.000 description 1
- 229910052713 technetium Inorganic materials 0.000 description 1
- GKLVYJBZJHMRIY-UHFFFAOYSA-N technetium atom Chemical compound [Tc] GKLVYJBZJHMRIY-UHFFFAOYSA-N 0.000 description 1
- JGVWCANSWKRBCS-UHFFFAOYSA-N tetramethylrhodamine thiocyanate Chemical compound [Cl-].C=12C=CC(N(C)C)=CC2=[O+]C2=CC(N(C)C)=CC=C2C=1C1=CC=C(SC#N)C=C1C(O)=O JGVWCANSWKRBCS-UHFFFAOYSA-N 0.000 description 1
- RYYWUUFWQRZTIU-UHFFFAOYSA-K thiophosphate Chemical compound [O-]P([O-])([O-])=S RYYWUUFWQRZTIU-UHFFFAOYSA-K 0.000 description 1
- 229940044693 topoisomerase inhibitor Drugs 0.000 description 1
- 231100000331 toxic Toxicity 0.000 description 1
- 230000002588 toxic effect Effects 0.000 description 1
- 230000001988 toxicity Effects 0.000 description 1
- 231100000419 toxicity Toxicity 0.000 description 1
- 230000009466 transformation Effects 0.000 description 1
- 238000013519 translation Methods 0.000 description 1
- 208000022679 triple-negative breast carcinoma Diseases 0.000 description 1
- 208000029729 tumor suppressor gene on chromosome 11 Diseases 0.000 description 1
- 238000011144 upstream manufacturing Methods 0.000 description 1
- VBEQCZHXXJYVRD-GACYYNSASA-N uroanthelone Chemical compound C([C@@H](C(=O)N[C@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CS)C(=O)N[C@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)NCC(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H](CO)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O)C(C)C)[C@@H](C)O)NC(=O)[C@H](CO)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CO)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](NC(=O)[C@H](CC=1NC=NC=1)NC(=O)[C@H](CCSC)NC(=O)[C@H](CS)NC(=O)[C@@H](NC(=O)CNC(=O)CNC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CS)NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)CNC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)[C@H](CO)NC(=O)[C@H](CO)NC(=O)[C@H]1N(CCC1)C(=O)[C@H](CS)NC(=O)CNC(=O)[C@H]1N(CCC1)C(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC(N)=O)C(C)C)[C@@H](C)CC)C1=CC=C(O)C=C1 VBEQCZHXXJYVRD-GACYYNSASA-N 0.000 description 1
- 229960005486 vaccine Drugs 0.000 description 1
- 229940055760 yervoy Drugs 0.000 description 1
Images




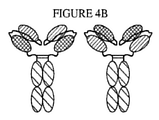











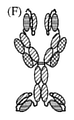




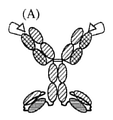






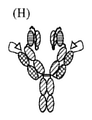























































Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2803—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily
- C07K16/2809—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily against the T-cell receptor (TcR)-CD3 complex
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/395—Antibodies; Immunoglobulins; Immune serum, e.g. antilymphocytic serum
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/50—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates
- A61K47/51—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent
- A61K47/68—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment
- A61K47/6801—Drug-antibody or immunoglobulin conjugates defined by the pharmacologically or therapeutically active agent
- A61K47/6803—Drugs conjugated to an antibody or immunoglobulin, e.g. cisplatin-antibody conjugates
- A61K47/6811—Drugs conjugated to an antibody or immunoglobulin, e.g. cisplatin-antibody conjugates the drug being a protein or peptide, e.g. transferrin or bleomycin
- A61K47/6817—Toxins
- A61K47/6831—Fungal toxins, e.g. alpha sarcine, mitogillin, zinniol or restrictocin
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/50—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates
- A61K47/51—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent
- A61K47/68—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment
- A61K47/6835—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment the modifying agent being an antibody or an immunoglobulin bearing at least one antigen-binding site
- A61K47/6845—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment the modifying agent being an antibody or an immunoglobulin bearing at least one antigen-binding site the antibody targeting a cytokine, e.g. growth factors, VEGF, TNF, a lymphokine or an interferon
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/50—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates
- A61K47/51—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent
- A61K47/68—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment
- A61K47/6835—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment the modifying agent being an antibody or an immunoglobulin bearing at least one antigen-binding site
- A61K47/6849—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment the modifying agent being an antibody or an immunoglobulin bearing at least one antigen-binding site the antibody targeting a receptor, a cell surface antigen or a cell surface determinant
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/50—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates
- A61K47/51—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent
- A61K47/68—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment
- A61K47/6835—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment the modifying agent being an antibody or an immunoglobulin bearing at least one antigen-binding site
- A61K47/6851—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment the modifying agent being an antibody or an immunoglobulin bearing at least one antigen-binding site the antibody targeting a determinant of a tumour cell
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/50—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates
- A61K47/51—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent
- A61K47/68—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment
- A61K47/6835—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment the modifying agent being an antibody or an immunoglobulin bearing at least one antigen-binding site
- A61K47/6875—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment the modifying agent being an antibody or an immunoglobulin bearing at least one antigen-binding site the antibody being a hybrid immunoglobulin
- A61K47/6879—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment the modifying agent being an antibody or an immunoglobulin bearing at least one antigen-binding site the antibody being a hybrid immunoglobulin the immunoglobulin having two or more different antigen-binding sites, e.g. bispecific or multispecific immunoglobulin
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/50—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates
- A61K47/51—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent
- A61K47/68—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment
- A61K47/6889—Conjugates wherein the antibody being the modifying agent and wherein the linker, binder or spacer confers particular properties to the conjugates, e.g. peptidic enzyme-labile linkers or acid-labile linkers, providing for an acid-labile immuno conjugate wherein the drug may be released from its antibody conjugated part in an acidic, e.g. tumoural or environment
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2863—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against receptors for growth factors, growth regulators
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/30—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants from tumour cells
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/30—Immunoglobulins specific features characterized by aspects of specificity or valency
- C07K2317/31—Immunoglobulins specific features characterized by aspects of specificity or valency multispecific
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/56—Immunoglobulins specific features characterized by immunoglobulin fragments variable (Fv) region, i.e. VH and/or VL
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/56—Immunoglobulins specific features characterized by immunoglobulin fragments variable (Fv) region, i.e. VH and/or VL
- C07K2317/565—Complementarity determining region [CDR]
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/60—Immunoglobulins specific features characterized by non-natural combinations of immunoglobulin fragments
- C07K2317/62—Immunoglobulins specific features characterized by non-natural combinations of immunoglobulin fragments comprising only variable region components
- C07K2317/622—Single chain antibody (scFv)
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/60—Immunoglobulins specific features characterized by non-natural combinations of immunoglobulin fragments
- C07K2317/64—Immunoglobulins specific features characterized by non-natural combinations of immunoglobulin fragments comprising a combination of variable region and constant region components
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/72—Increased effector function due to an Fc-modification
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/73—Inducing cell death, e.g. apoptosis, necrosis or inhibition of cell proliferation
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/90—Immunoglobulins specific features characterized by (pharmaco)kinetic aspects or by stability of the immunoglobulin
- C07K2317/92—Affinity (KD), association rate (Ka), dissociation rate (Kd) or EC50 value
Landscapes
- Health & Medical Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Immunology (AREA)
- Life Sciences & Earth Sciences (AREA)
- Medicinal Chemistry (AREA)
- General Health & Medical Sciences (AREA)
- Engineering & Computer Science (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Organic Chemistry (AREA)
- Pharmacology & Pharmacy (AREA)
- Animal Behavior & Ethology (AREA)
- Public Health (AREA)
- Veterinary Medicine (AREA)
- Epidemiology (AREA)
- Molecular Biology (AREA)
- Genetics & Genomics (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Biochemistry (AREA)
- Biophysics (AREA)
- Cell Biology (AREA)
- Microbiology (AREA)
- Mycology (AREA)
- Toxicology (AREA)
- Chemical Kinetics & Catalysis (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- General Chemical & Material Sciences (AREA)
- Peptides Or Proteins (AREA)
- Medicines Containing Antibodies Or Antigens For Use As Internal Diagnostic Agents (AREA)
- Preparation Of Compounds By Using Micro-Organisms (AREA)
- Medicinal Preparation (AREA)
- Medicines That Contain Protein Lipid Enzymes And Other Medicines (AREA)
Description
開示の分野
(VL-CL)2:(VH-CH1-CH2-CH3-L4-VH*-L3-VL*-L2-CM-L1-MM)2;(VL-CL)2:(VH-CH1-CH2-CH3-L4-VL*-L3-VH*-L2-CM-L1-MM)2;(MM-L1-CM-L2-VL-CL)2:(VH-CH1-CH2-CH3-L4-VH*-L3-VL*)2;(MM-L1-CM-L2-VL-CL)2:(VH-CH1-CH2-CH3-L4-VL*-L3-VH*)2;(VL-CL)2:(MM-L1-CM-L2-VL*-L3-VH*-L4-VH-CH1-CH2-CH3)2;(VL-CL)2:(MM-L1-CM-L2-VH*-L3-VL*-L4-VH-CH1-CH2-CH3)2;(MM-L1-CM-L2-VL-CL)2:(VL*-L3-VH*-L4-VH-CH1-CH2-CH3)2;(MM-L1-CM-L2-VL-CL)2:(VH*-L3-VL*-L4-VH-CH1-CH2-CH3)2;(VL-CL-L4-VH*-L3-VL*-L2-CM-L1-MM)2:(VH-CH1-CH2-CH3)2;(VL-CL-L4-VL*-L3-VH*-L2-CM-L1-MM)2:(VH-CH1-CH2-CH3)2;(MM-L1-CM-L2-VL*-L3-VH*-L4-VL-CL)2:(VH-CH1-CH2-CH3)2;(MM-L1-CM-L2-VH*-L3-VL*-L4-VL-CL)2:(VH-CH1-CH2-CH3)2;(VL-CL-L4-VH*-L3-VL*-L2-CM-L1-MM)2:(MM-L1-CM-L2-VL*-L3-VH*-L4-VH-CH1-CH2-CH3)2;(VL-CL-L4-VH*-L3-VL*-L2-CM-L1-MM)2:(MM-L1-CM-L2-VH*-L3-VL*-L4-VH-CH1-CH2-CH3)2;(VL-CL-L4-VL*-L3-VH*-L2-CM-L1-MM)2:(MM-L1-CM-L2-VL*-L3-VH*-L4-VH-CH1-CH2-CH3)2;(VL-CL-L4-VL*-L3-VH*-L2-CM-L1-MM)2:(MM-L1-CM-L2-VH*-L3-VL*-L4-VH-CH1-CH2-CH3)2;(VL-CL-L4-VH*-L3-VL*)2:(MM-L1-CM-L2-VL*-L3-VH*-L4-VH-CH1-CH2-CH3)2;(VL-CL-L4-VH*-L3-VL*)2:(MM-L1-CM-L2-VH*-L3-VL*-L4-VH-CH1-CH2-CH3)2;(VL-CL-L4-VL*-L3-VH*)2:(MM-L1-CM-L2-VL*-L3-VH*-L4-VH-CH1-CH2-CH3)2;(VL-CL-L4-VL*-L3-VH*)2:(MM-L1-CM-L2-VH*-L3-VL*-L4-VH-CH1-CH2-CH3)2;(VL-CL-L4-VH*-L3-VL*-L2-CM-L1-MM)2:(VL*-L3-VH*-L4-VH-CH1-CH2-CH3)2;(VL-CL-L4-VH*-L3-VL*-L2-CM-L1-MM)2:(VH*-L3-VL*-L4-VH-CH1-CH2-CH3)2;(VL-CL-L4-VL*-L3-VH*-L2-CM-L1-MM)2:(VL*-L3-VH*-L4-VH-CH1-CH2-CH3)2;又は(VL-CL-L4-VL*-L3-VH*-L2-CM-L1-MM)2:(VH*-L3-VL*-L4-VH-CH1-CH2-CH3)2、であり、ここでVL及びVHは、IgGに含まれる、第1特異性の軽及び重可変ドメインを表し;VL*及びVH*は、scFvに含まれる、第2特異性の可変ドメインを表し;L1は、マスキング部分(MM)及び切断可能部分(CM)を連結するリンカーペプチドであり;L2は、切断可能部分(CM)及び抗体を連結するリンカーペプチドであり;L3は、scFvの可変ドメインを連結するリンカーペプチドであり;L4は、第2特異性の抗体に、第1特異性の抗体を連結するリンカーペプチドであり;CLは、軽鎖定常ドメインであり;及び、CH1、CH2、CH3は、重鎖定常ドメインである。前記第1及び第2特異性は、任意の抗原又はエピトープに対するものであってもよい。
定義
多重特異的抗体及び多重特異的活性化可能抗体




CD3HvLv
EVQLVESGGGLVQPGGSLKLSCAASGFTFNKYAMNWVRQAPGKGLEWVARIRSKYNNYATYYADSVKDRFTISRDDSKNTAYLQMNNLKTEDTAVYYCVRHGNFGNSYISYWAYWGQGTLVTVSSGGGGSGGGGSGGGGSQTVVTQEPSLTVSPGGTVTLTCGSSTGAVTSGYYPNWVQQKPGQAPRGLIGGTKFLAPGTPARFSGSLLGGKAALTLSGVQPEDEAEYYCALWYSNRWVFGGGTKLTVL(配列番号587)
CD3LvHv
QTVVTQEPSLTVSPGGTVTLTCRSSTGAVTTSNYANWVQQKPGQAPRGLIGGTNKRAPGTPARFSGSLLGGKAALTLSGVQPEDEAEYYCALWYSNLWVFGGGTKLTVLGGGGSGGGGSGGGGSEVQLVESGGGLVQPGGSLKLSCAASGFTFNTYAMNWVRQAPGKGLEWVARIRSKYNNYATYYADSVKDRFTISRDDSKNTAYLQMNNLKTEDTAVYYCVRHGNFGNSYVSWFAYWGQGTLVTVSS(配列番号588)















CAGGTGCAGCTGAAACAGAGCGGCCCGGGCCTGGTGCAGCCGAGCCAGAGCCTGAGCATTACCTGCACCGTGAGCGGCTTTAGCCTGACCAACTATGGCGTGCATTGGGTGCGCCAGAGCCCGGGCAAAGGCCTGGAATGGCTGGGCGTGATTTGGAGCGGCGGCAACACCGATTATAACACCCCGTTTACCAGCCGCCTGAGCATTAACAAAGATAACAGCAAAAGCCAGGTGTTTTTTAAAATGAACAGCCTGCAAAGCCAGGATACCGCGATTTATTATTGCGCGCGCGCGCTGACCTATTATGATTATGAATTTGCGTATTGGGGCCAGGGCACCCTGGTGACCGTGAGCGCGGCTAGCACCAAGGGCCCATCGGTCTTCCCCCTGGCACCCTCCTCCAAGAGCACCTCTGGGGGCACAGCGGCCCTGGGCTGCCTGGTCAAGGACTACTTCCCCGAACCGGTGACGGTGTCGTGGAACTCAGGCGCCCTGACCAGCGGCGTGCACACCTTCCCGGCTGTCCTACAGTCCTCAGGACTCTACTCCCTCAGCAGCGTGGTGACCGTGCCCTCCAGCAGCTTGGGCACCCAGACCTACATCTGCAACGTGAATCACAAGCCCAGCAACACCAAGGTGGACAAGAAAGTTGAGCCCAAATCTTGTGACAAAACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACAACAGCACGTACCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGGGATGAACTGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCTACAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTACACGCAGAAGAGCCTCTCCCTGTCTCCGGGTAAATGA(配列番号100)
C225v5抗体重鎖アミノ酸配列
QVQLKQSGPGLVQPSQSLSITCTVSGFSLTNYGVHWVRQSPGKGLEWLGVIWSGGNTDYNTPFTSRLSINKDNSKSQVFFKMNSLQSQDTAIYYCARALTYYDYEFAYWGQGTLVTVSAASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK*(配列番号101)
CAGATCTTGCTGACCCAGAGCCCGGTGATTCTGAGCGTGAGCCCGGGCGAACGTGTGAGCTTTAGCTGCCGCGCGAGCCAGAGCATTGGCACCAACATTCATTGGTATCAGCAGCGCACCAACGGCAGCCCGCGCCTGCTGATTAAATATGCGAGCGAAAGCATTAGCGGCATTCCGAGCCGCTTTAGCGGCAGCGGCAGCGGCACCGATTTTACCCTGAGCATTAACAGCGTGGAAAGCGAAGATATTGCGGATTATTATTGCCAGCAGAACAACAACTGGCCGACCACCTTTGGCGCGGGCACCAAACTGGAACTGAAACGTACGGTGGCTGCACCATCTGTCTTCATCTTCCCGCCATCTGATGAGCAGTTGAAATCTGGAACTGCCTCTGTTGTGTGCCTGCTGAATAACTTCTATCCCAGAGAGGCCAAAGTACAGTGGAAGGTGGATAACGCCCTCCAATCGGGTAACTCCCAGGAGAGTGTCACAGAGCAGGACAGCAAGGACAGCACCTACAGCCTCAGCAGCACCCTGACGCTGAGCAAAGCAGACTACGAGAAACACAAAGTCTACGCCTGCGAAGTCACCCATCAGGGCCTGAGCTCGCCCGTCACAAAGAGCTTCAACAGGGGAGAGTGTTAG(配列番号102)
C225v5抗体軽鎖アミノ酸配列:
QILLTQSPVILSVSPGERVSFSCRASQSIGTNIHWYQQRTNGSPRLLIKYASESISGIPSRFSGSGSGTDFTLSINSVESEDIADYYCQQNNNWPTTFGAGTKLELKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC*(配列番号103)
CAGGTGCAGCTGAAACAGAGCGGCCCGGGCCTGGTGCAGCCGAGCCAGAGCCTGAGCATTACCTGCACCGTGAGCGGCTTTAGCCTGACCAACTATGGCGTGCATTGGGTGCGCCAGAGCCCGGGCAAAGGCCTGGAATGGCTGGGCGTGATTTGGAGCGGCGGCAACACCGATTATAACACCCCGTTTACCAGCCGCCTGAGCATTAACAAAGATAACAGCAAAAGCCAGGTGTTTTTTAAAATGAACAGCCTGCAAAGCAACGATACCGCGATTTATTATTGCGCGCGCGCGCTGACCTATTATGATTATGAATTTGCGTATTGGGGCCAGGGCACCCTGGTGACCGTGAGCGCGGCTAGCACCAAGGGCCCATCGGTCTTCCCCCTGGCACCCTCCTCCAAGAGCACCTCTGGGGGCACAGCGGCCCTGGGCTGCCTGGTCAAGGACTACTTCCCCGAACCGGTGACGGTGTCGTGGAACTCAGGCGCCCTGACCAGCGGCGTGCACACCTTCCCGGCTGTCCTACAGTCCTCAGGACTCTACTCCCTCAGCAGCGTGGTGACCGTGCCCTCCAGCAGCTTGGGCACCCAGACCTACATCTGCAACGTGAATCACAAGCCCAGCAACACCAAGGTGGACAAGAAAGTTGAGCCCAAATCTTGTGACAAAACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACAACAGCACGTACCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGGGATGAACTGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCTACAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTACACGCAGAAGAGCCTCTCCCTGTCTCCGGGTAAATGA(配列番号104)
C225v4抗体重鎖アミノ酸配列:
QVQLKQSGPGLVQPSQSLSITCTVSGFSLTNYGVHWVRQSPGKGLEWLGVIWSGGNTDYNTPFTSRLSINKDNSKSQVFFKMNSLQSNDTAIYYCARALTYYDYEFAYWGQGTLVTVSAASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK*(配列番号105)
CAGGTGCAGCTGAAACAGAGCGGCCCGGGCCTGGTGCAGCCGAGCCAGAGCCTGAGCATTACCTGCACCGTGAGCGGCTTTAGCCTGACCAACTATGGCGTGCATTGGGTGCGCCAGAGCCCGGGCAAAGGCCTGGAATGGCTGGGCGTGATTTGGAGCGGCGGCAACACCGATTATAACACCCCGTTTACCAGCCGCCTGAGCATTAACAAAGATAACAGCAAAAGCCAGGTGTTTTTTAAAATGAACAGCCTGCAAAGCCAGGATACCGCGATTTATTATTGCGCGCGCGCGCTGACCTATTATGATTATGAATTTGCGTATTGGGGCCAGGGCACCCTGGTGACCGTGAGCGCGGCTAGCACCAAGGGCCCATCGGTCTTCCCCCTGGCACCCTCCTCCAAGAGCACCTCTGGGGGCACAGCGGCCCTGGGCTGCCTGGTCAAGGACTACTTCCCCGAACCGGTGACGGTGTCGTGGAACTCAGGCGCCCTGACCAGCGGCGTGCACACCTTCCCGGCTGTCCTACAGTCCTCAGGACTCTACTCCCTCAGCAGCGTGGTGACCGTGCCCTCCAGCAGCTTGGGCACCCAGACCTACATCTGCAACGTGAATCACAAGCCCAGCAACACCAAGGTGGACAAGAAAGTTGAGCCCAAATCTTGTGACAAAACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACGCCAGCACGTACCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGGGATGAACTGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCTACAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTACACGCAGAAGAGCCTCTCCCTGTCTCCGGGTAAATGA](配列番号106)
C225v6抗体重鎖アミノ酸配列
QVQLKQSGPGLVQPSQSLSITCTVSGFSLTNYGVHWVRQSPGKGLEWLGVIWSGGNTDYNTPFTSRLSINKDNSKSQVFFKMNSLQSQDTAIYYCARALTYYDYEFAYWGQGTLVTVSAASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYASTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK*(配列番号107)
QVQLKQSGPGLVQPSQSLSITCTVSGFSLTNYGVHWVRQSPGKGLEWLGVIWSGGNTDYNTPFTSRLSINKDNSKSQVFFKMNSLQSQDTAIYYCARALTYYDYEFAYWGQGTLVTVSAASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYQSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK*(配列番号523)
QVQLQESGPGLVRPSQTLSLTCTVSGYSITSDHAWSWVRQPPGRGLEWIGYISYSGITTYNPSLKSRVTISRDNSKNTLYLQMNSLRAEDTAVYYCARSLARTTAMDYWGQGSLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK(配列番号108)
DIQMTQSPSSLSASVGDRVTITCRASQDISSYLNWYQQKPGKAPKLLIYYTSRLHSGVPSRFSGSGSGTDFTFTISSLQPEDIATYYCQQGNTLPYTFGQGTKVEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC(配列番号109)
DIQMTQSPSSLSASVGDRVTITCRASQSISSYLNWYQQKPGKAPKLLIYAASSLQSGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCQQTVVAPPLFGQGTKVEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC(配列番号110)
EVQLLESGGGLVQPGGSLRLSCAASGFTFSSYAMSWVRQAPGKGLEWVSSIDPEGRQTYYADSVKGRFTISRDNSKNTLYLQMNSLRAEDTAVYYCAKDIGGRSAFDYWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK(配列番号111)
EVHLLESGGGLVQPGGSLRLSCAASGFTFSSYAMSWVRQAPGKGLEWVSSIDPEGRQTYYADSVKGRFTISRDNSKNTLYLQMNSLRAEDTAVYYCAKDIGGRSAFDYWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK(配列番号112)
DIQMTQSPSSLSASVGDRVTITCRASQSISSYLNWYQQKPGKAPKLLIYAASSLQSGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCQQTVVAPPLFGQGTKVEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLXKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC(配列番号113)
DIQMTQSPSSLSASVGDRVTITCRASQSISSYLNWYQQKPGKAPKLLIYAASSLQSGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCQQSVVAPLTFGQGTKVEIKR(配列番号114)
EVQLLESGGGLVQPGGSLRLSCAASGFTFSSYAMSWVRQAPGKGLEWVSSIEQMGWQTYYADSVKGRFTISRDNSKNTLYLQMNSLRAEDTAVYYCAKDIGGRSAFDYWGQGTLVTVSS(配列番号115)
DIQMTQSPSSLSASVGDRVTITCRASQSISSYLNWYQQKPGKAPKLLIYAASSLQSGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCQQSVVAPLTFGQGTKVEIKR(配列番号116)
EVQLLESGGGLVQPGGSLRLSCAASGFTFSSYAMSWVRQAPGKGLEWVSSIEQMGWQTYYADSVKGRFTISRDNSKNTLYLQMNSLRAEDTAVYYCAKSPPYHGQFDYWGQGTLVTVSS(配列番号117)
DIQMTQSPSSLSASVGDRVTITCRASQSISSYLNWYQQKPGKAPKLLIYAASSLQSGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCQQSVVAPLTFGQGTKVEIKR(配列番号118)
EVQLLESGGGLVQPGGSLRLSCAASGFTFSSYAMSWVRQAPGKGLEWVSSIEQMGWQTYYADSVKGRFTISRDNSKNTLYLQMNSLRAEDTAVYYCAKSPPFFGQFDYWGQGTLVTVSS(配列番号119)
DIQMTQSPSSLSASVGDRVTITCRASQSISSYLNWYQQKPGKAPKLLIYAASSLQSGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCQQSVVAPLTFGQGTKVEIKR(配列番号120)
EVQLLESGGGLVQPGGSLRLSCAASGFTFSSYAMSWVRQAPGKGLEWVSSIEQMGWQTYYADSVKGRFTISRDNSKNTLYLQMNSLRAEDTAVYYCAKHIGRTNPFDYWGQGTLVTVSS(配列番号121)
DIQMTQSPSSLSASVGDRVTITCRASQSISSYLNWYQQKPGKAPKLLIYAASSLQSGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCQQSVVAPLTFGQGTKVEIKR(配列番号122)
EVQLLESGGGLVQPGGSLRLSCAASGFTFSSYAMSWVRQAPGKGLEWVSSIEQMGWQTEYADSVKGRFTISRDNSKNTLYLQMNSLRAEDTAVYYCAKSAAAFDYWGQGTLVTVSS(配列番号123)
DIQMTQSPSSLSASVGDRVTITCRASQSISSYLNWYQQKPGKAPKLLIYAASSLQSGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCQQSVVAPLTFGQGTKVEIKR(配列番号124)
EVQLLESGGGLVQPGGSLRLSCAASGFTFSSYAMSWVRQAPGKGLEWVSSIEQMGWQTYYADSVKGRFTISRDNSKNTLYLQMNSLRAEDTAVYYCAKSPPYYGQFDYWGQGTLVTVSS(配列番号125)
DIQMTQSPSSLSASVGDRVTITCRASQSISSYLNWYQQKPGKAPKLLIYAASSLQSGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCQQSVVAPLTFGQGTKVEIKR(配列番号126)
EVQLLESGGGLVQPGGSLRLSCAASGFTFSSYAMSWVRQAPGKGLEWVSSIEQMGWQTYYADSVKGRFTISRDNSKNTLYLQMNSLRAEDTAVYYCAKSPPFFGQFDYWGQGTLVTVSS(配列番号127)
DIQMTQSPSSLSASVGDRVTITCRASQSISSYLNWYQQKPGKAPKLLIYAASSLQSGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCQQSVVAPLTFGQGTKVEIKR(配列番号128)
EVQLLESGGGLVQPGGSLRLSCAASGFTFSSYAMSWVRQAPGKGLEWVSSIEQMGWQTYYADSVKGRFTISRDNSKNTLYLQMNSLRAEDTAVYYCAKDIGGRSAFDYWGQGTLVTVSS(配列番号129)
DIQMTQSPSSLSASVGDRVTITCRASQSISSYLNWYQQKPGKAPKLLIYAASSLQSGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCQQSVVAPLTFGQGTKVEIKR(配列番号130)
EVQLLESGGGLVQPGGSLRLSCAASGFTFSSYAMSWVRQAPGKGLEWVSSIEEMGWQTLYADSVKGRFTISRDNSKNTLYLQMNSLRAEDTAVYYCAKSAAAFDYWGQGTLVTVSS(配列番号131)
DIQMTQSPSSLSASVGDRVTITCRASQSISSYLNWYQQKPGKAPKLLIYAASSLQSGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCQQSVVAPLTFGQGTKVEIKR(配列番号132)
EVQLLESGGGLVQPGGSLRLSCAASGFTFSSYAMSWVRQAPGKGLEWVSSIEQMGWQTYYADSVKGRFTISRDNSKNTLYLQMNSLRAEDTAVYYCAKDIGGRSAFDYWGQGTLVTVSS(配列番号133)
DIQMTQSPSSLSASVGDRVTITCRASQSISSYLNWYQQKPGKAPKLLIYAASSLQSGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCQQSVVAPLTFGQGTKVEIKR(配列番号134)
EVQLLESGGGLVQPGGSLRLSCAASGFTFSSYAMSWVRQAPGKGLEWVSSIEQMGWQTYYADSVKGRFTISRDNSKNTLYLQMNSLRAEDTAVYYCAKSPPFYGQFDYWGQGTLVTVSS(配列番号135)
DIQMTQSPSSLSASVGDRVTITCRASQSISSYLNWYQQKPGKAPKLLIYAASSLQSGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCQQSVVAPLTFGQGTKVEIKR(配列番号136)
EVQLLESGGGLVQPGGSLRLSCAASGFTFSSYAMSWVRQAPGKGLEWVSSIEQMGWQTYYADSVKGRFTISRDNSKNTLYLQMNSLRAEDTAVYYCAKSPPFFGQFDYWGQGTLVTVSS(配列番号137)
DIQMTQSPSSLSASVGDRVTITCRASQSISSYLNWYQQKPGKAPKLLIYAASSLQSGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCQQSVVAPLTFGQGTKVEIKR(配列番号138)
EVQLLESGGGLVQPGGSLRLSCAASGFTFSSYAMSWVRQAPGKGLEWVSSIEEMGWQTLYADSVKGRFTISRDNSKNTLYLQMNSLRAEDTAVYYAKSAAAFDYWGQGTLVTVSS(配列番号139)
DIQMTQSPSSLSASVGDRVTITCRASQSISSYLNWYQQKPGKAPKLLIYAASSLQSGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCQQSVVAPLTFGQGTKVEIKR(配列番号140)
EVQLLESGGGLVQPGGSLRLSCAASGFTFSSYAMSWVRQAPGKGLEWVSSIEQMGWQTYYADSVKGRFTISRDNSKNTLYLQMNSLRAEDTAVYYCAKDIGGRSAFDYWGQGTLVTVSS(配列番号141)
DIQMTQSPSSLSASVGDRVTITCRASQSISSYLNWYQQKPGKAPKLLIYAASSLQSGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCQQSVVAPLTFGQGTKVEIKR(配列番号142)
EVQLLESGGGLVQPGGSLRLSCAASGFTFSSYAMSWVRQAPGKGLEWVSSIDPEGWQTYYADSVKGRFTISRDNSKNTLYLQMNSLRAEDTAVYYCAKSAAAFDYWGQGTLVTVSS(配列番号143)
DIQMTQSPSSLSASVGDRVTITCRASQSISSYLNWYQQKPGKAPKLLIYAASSLQSGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCQQSVVAPLTFGQGTKVEIKR(配列番号144)
EVQLLESGGGLVQPGGSLRLSCAASGFTFSSYAMSWVRQAPGKGLEWVSSIEQMGWQTYYADSVKGRFTISRDNSKNTLYLQMNSLRAEDTAVYYCAKSPPHNGQFDYWGQGTLVTVSS(配列番号145)
DIQMTQSPSSLSASVGDRVTITCRASQSISSYLNWYQQKPGKAPKLLIYAASSLQSGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCQQSVVAPLTFGQGTKVEIKR(配列番号146)
EVQLLESGGGLVQPGGSLRLSCAASGFTFSSYAMSWVRQAPGKGLEWVSSIEQMGWQTEYADSVKGRFTISRDNSKNTLYLQMNSLRAEDTAVYYCAKSAAAFDYWGQGTLVTVSS(配列番号147)
DIQMTQSPSSLSASVGDRVTITCRASQSISSYLNWYQQKPGKAPKLLIYAASSLQSGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCQQSVVAPLTFGQGTKVEIKR(配列番号148)
EVQLLESGGGLVQPGGSLRLSCAASGFTFSSYAMSWVRQAPGKGLEWVSSIEQMGWQTYYADSVKGRFTISRDNSKNTLYLQMNSLRAEDTAVYYCAKSPPFFGQFDYWGQGTLVTVSS(配列番号149)
DIQMTQSPSSLSASVGDRVTITCRASQSISSYLNWYQQKPGKAPKLLIYAASSLQSGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCQQSVVAPLTFGQGTKVEIKR(配列番号150)
EVQLLESGGGLVQPGGSLRLSCAASGFTFSSYAMSWVRQAPGKGLEWVSSIDEMGWQTEYADSVKGRFTISRDNSKNTLYLQMNSLRAEDTAVYYCAKSAAAFDYWGQGTLVTVSS(配列番号151)
DIQMTQSPSSLSASVGDRVTITCRASQSISSYLNWYQQKPGKAPKLLIYAASSLQSGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCQQTLDAPPQFGQGTKVEIKR(配列番号152)
EVQLLESGGGLVQPGGSLRLSCAASGFTFSSYAMSWVRQAPGKGLEWVSSIEQMGWQTYYADSVKGRFTISRDNSKNTLYLQMNSLRAEDTAVYYCAKDIGGRSAFDYWGQGTLVTVSS(配列番号153)
DIQMTQSPSSLSASVGDRVTITCRASQSISSYLNWYQQKPGKAPKLLIYAASSLQSGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCQQTVVAPPLFGQGTKVEIKR(配列番号154)
EVQLLESGGGLVQPGGSLRLSCAASGFTFSSYAMSWVRQAPGKGLEWVSSIDPEGRQTYYADSVKGRFTISRDNSKNTLYLQMNSLRAEDTAVYYCAKDIGGRSAFDYWGQGTLVTVSS(配列番号155)
DIQMTQSPSSLSASVGDRVTITCRASQSISSYLNWYQQKPGKAPKLLIYAASSLQSGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCQQSLVAPLTFGQGTKVEIKR(配列番号156)
EVQLLESGGGLVQPGGSLRLSCAASGFTFSSYAMSWVRQAPGKGLEWVSSIEEMGWQTKYADSVKGRFTISRDNSKNTLYLQMNSLRAEDTAVYYCAKSAAAFDYWGQGTLVTVSS(配列番号157)
DIQMTQSPSSLSASVGDRVTITCRASQSISSYLNWYQQKPGKAPKLLIYAASSLQSGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCQQALDAPLMFGQGTKVEIKR(配列番号158)
EVQLLESGGGLVQPGGSLRLSCAASGFTFSSYAMSWVRQAPGKGLEWVSSIEPMGQLTEYADSVKGRFTISRDNSKNTLYLQMNSLRAEDTAVYYCAKDIGGRSAFDYWGQGTLVTVSS(配列番号159)
DIQMTQSPSSLSASVGDRVTITCRASQSISSYLNWYQQKPGKAPKLLIYAASSLQSGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCQQALVAPLTFGQGTKVEIKR(配列番号160)
EVQLLESGGGLVQPGGSLRLSCAASGFTFSSYAMSWVRQAPGKGLEWVSSIDEMGWQTYYADSVKGRFTISRDNSKNTLYLQMNSLRAEDTAVYYCAKSAAAFDYWGQGTLVTVSS(配列番号161)
DIQMTQSPSSLSASVGDRVTITCRASQSISSYLNWYQQKPGKAPKLLIYAASSLQSGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCQQALVAPLTFGQGTKVEIKR(配列番号162)
EVQLLESGGGLVQPGGSLRLSCAASGFTFSSYAMSWVRQAPGKGLEWVSSIDEMGWQTYYADSVKGRFTISRDNSKNTLYLQMNSLRAEDTAVYYCAKSAAAFDYWGQGTLVTVSS(配列番号163)
活性化可能抗体及び多重特異的活性化可能抗体
(MM)-(AB)
(AB)-(MM)
(MM)-L-(AB)
(AB)-L-(MM)
ここで、MMはマスキング部分であり、ABは抗体又はその抗体フラグメントであり、そしてLはリンカーである。多くの実施形態によれば、柔軟性を提供するために、組成物中に1又は2以上のリンカー、例えば柔軟リンカーを挿入することが所望される。
(MM)-(AB)
(AB)-(MM)
(MM)-L-(AB)
(AB)-L-(MM)
ここで、MMはマスキング部分であり、ABは抗体又はその抗体フラグメントであり、そしてLはリンカーである。多くの実施形態によれば、柔軟性を提供するために、組成物中に1又は2以上のリンカー、例えば柔軟リンカーを挿入することが所望される。
(MM)-(CM)-(AB)
(AB)-(CM)-(MM)
ここで、MMはマスキング成分であり、CMは切断可能部分であり、そしてABは抗体又はそのフラグメントである。MM及びCMは上記式において異なる成分として示されるが、本明細書において開示されるすべての典型的な実施形態(式を含む)によれば、MM及びCMのアミノ酸配列は、CMがMM内に完全に又は部分的に含まれるよう、オーバーラップできると考えられる。さらに、上記式は、活性化可能抗体要素に対してN末端又はC末端に位置決定され得る追加のアミノ酸配列を提供する。
(MM)-(CM)-(AB)
(AB)-(CM)-(MM)
ここで、MMはマスキング成分であり、CMは切断可能部分であり、そしてABは第1抗体又はそのフラグメントである。MM及びCMは上記式において異なる成分として示されるが、本明細書において開示されるすべての典型的な実施形態(式を含む)によれば、MM及びCMのアミノ酸配列は、CMがMM内に完全に又は部分的に含まれるよう、オーバーラップできると考えられる。さらに、上記式は、活性化可能抗体要素に対してN末端又はC末端に位置決定され得る追加のアミノ酸配列を提供する。
(MM)-L1-(CM)-(AB)
(MM)-(CM)-L2-(AB)
(MM)-L1-(CM)-L2-(AB)
ここで、MM、CM及びABは、上記に定義された通りであり;L1及びL2は、それぞれ独立して、及び任意には、存在しても又は不在であっての良く、少なくとも1つの柔軟アミノ酸(例えば、Gly)を含む同一又は異なった柔軟リンカーである。さらに、上記式は、活性化可能抗体及び/又は多重特異的活性化可能抗体要素に対してN末端又はC末端に配置され得る追加のアミノ酸配列を提供する。例として、次のものを挙げることができるが、但しそれらだけには限定されない:標的化部分(例えば、標的組織に存在する細胞の受容体のためのリガンド)及び血清半減期延長部分(例えば、血清タンパク質、例えば免疫グロブリン(すなわち、IgG)又は血清アルブミン(例えば、ヒト血清アルブミン(HAS))に結合するポリペプチド。

結合された抗体、結合された活性化可能抗体、結合された多重特異的抗体及び/又は結合された多重特異的活性化可能抗体



W-(CH2)n-Q
(式中、Wは、--NH--CH2--又は--CH2--のいずれかであり;
Qは、アミノ酸、ペプチドであり;及び
nは、0~20の整数である)

W-(CH2)n-Q
(式中、Wは、--NH--CH2--又は--CH2--のいずれかであり;
Qは、アミノ酸、ペプチドであり;及び
nは、0~20の整数である)
非結合立体部分又は非結合立体部分のための結合パートナーを有する活性化可能抗体及び多重特異的活性化可能抗体
抗-CD3ε抗体、活性化可能抗体、多重特異的抗体、及び/又は多重特異的活性化可能抗体の使用
抗-CD3ε抗体、活性化可能抗体、多重特異的抗体、及び/又は多重特異的活性化可能抗体の治療的投与及び製剤
MACS1及びMACS2選択
FACS選択
選択番号1


発現基準化結合=平均Fab蛍光/平均yPetMona蛍光
そして、それは、
平均yPetMona蛍光=ペプチド発現レベル
とされる。


ヌクレオチド配列
CAGGCTGTCGTGACACAGGAAAGCGCCCTGACCACCAGCCCTGGCGAGACAGTGACCCTGACCTGCAGATCTAGCACAGGCGCCGTGACCACAAGCAACTACGCCAACTGGGTGCAGGAAAAGCCCGACCACCTGTTCACCGGCCTGATCGGCGGCACCAACAAAAGGGCTCCAGGCGTGCCAGCCAGATTCAGCGGCAGCCTGATTGGCGATAAGGCCGCCCTGACAATCACTGGCGCCCAGACCGAGGACGAGGCCATCTACTTTTGCGCCCTGTGGTACAGCAACCTGTGGGTGTTCGGCGGAGGCACCAAGCTGACAGTGCTG(配列番号1)
アミノ酸配列
QAVVTQESALTTSPGETVTLTCRSSTGAVTTSNYANWVQEKPDHLFTGLIGGTNKRAPGVPARFSGSLIGDKAALTITGAQTEDEAIYFCALWYSNLWVFGGGTKLTVL(配列番号2)
ヌクレオチド配列
GAAGTGCAGCTGGTGGAATCTGGCGGCGGACTGGTGCAGCCTAAGGGCTCTCTGAAGCTGAGCTGTGCCGCCAGCGGCTTCACCTTCAACACCTACGCCATGAATTGGGTGCGCCAGGCCCCTGGCAAGGGACTGGAATGGGTGGCCCGGATCAGAAGCAAGTACAACAATTACGCCACCTACTACGCCGACAGCGTGAAGGACCGGTTCACCATCAGCCGGGACGACAGCCAGAGCATCCTGTATCTGCAGATGAACAACCTGAAAACCGAGGACACCGCCATGTACTACTGCGTGCGGCACGGCAACTTCGGCAACAGCTATGTGTCTTGGTTTGCCTACTGGGGCCAGGGCACCCTCGTGACAGTGTCTGCT(配列番号3)
アミノ酸配列
EVQLVESGGGLVQPKGSLKLSCAASGFTFNTYAMNWVRQAPGKGLEWVARIRSKYNNYATYYADSVKDRFTISRDDSQSILYLQMNNLKTEDTAMYYCVRHGNFGNSYVSWFAYWGQGTLVTVSA(配列番号4)
ヌクレオチド配列
CAGGCTGTCGTGACACAGGAAAGCGCCCTGACCACCAGCCCTGGCGAGACAGTGACCCTGACCTGCAGATCTAGCACAGGCGCCGTGACCACAAGCAACTACGCCAACTGGGTGCAGGAAAAGCCCGACCACCTGTTCACCGGCCTGATCGGCGGCACCAACAAAAGGGCTCCAGGCGTGCCAGCCAGATTCAGCGGCAGCCTGATTGGCGATAAGGCCGCCCTGACAATCACTGGCGCCCAGACCGAGGACGAGGCCATCTACTTTTGCGCCCTGTGGTACAGCAACCTGTGGGTGTTCGGCGGAGGCACCAAGCTGACAGTGCTGGGAGGCGGAGGATCTGGCGGAGGCGGAAGTGGCGGAGGGGGATCTGAAGTGCAGCTGGTGGAATCTGGCGGCGGACTGGTGCAGCCTAAGGGCTCTCTGAAGCTGAGCTGTGCCGCCAGCGGCTTCACCTTCAACACCTACGCCATGAATTGGGTGCGCCAGGCCCCTGGCAAGGGACTGGAATGGGTGGCCCGGATCAGAAGCAAGTACAACAATTACGCCACCTACTACGCCGACAGCGTGAAGGACCGGTTCACCATCAGCCGGGACGACAGCCAGAGCATCCTGTATCTGCAGATGAACAACCTGAAAACCGAGGACACCGCCATGTACTACTGCGTGCGGCACGGCAACTTCGGCAACAGCTATGTGTCTTGGTTTGCCTACTGGGGCCAGGGCACCCTCGTGACAGTGTCTGCT(配列番号5)
アミノ酸配列
QAVVTQESALTTSPGETVTLTCRSSTGAVTTSNYANWVQEKPDHLFTGLIGGTNKRAPGVPARFSGSLIGDKAALTITGAQTEDEAIYFCALWYSNLWVFGGGTKLTVLGGGGSGGGGSGGGGSEVQLVESGGGLVQPKGSLKLSCAASGFTFNTYAMNWVRQAPGKGLEWVARIRSKYNNYATYYADSVKDRFTISRDDSQSILYLQMNNLKTEDTAMYYCVRHGNFGNSYVSWFAYWGQGTLVTVSA(配列番号6)
ヌクレオチド配列
CAGGCTGTCGTGACACAGGAAAGCGCCCTGACCACCAGCCCTGGCGAGACAGTGACCCTGACCTGCAGATCTAGCACAGGCGCCGTGACCACAAGCAACTACGCCAACTGGGTGCAGGAAAAGCCCGACCACCTGTTCACCGGCCTGATCGGCGGCACCAACAAAAGGGCTCCAGGCGTGCCAGCCAGATTCAGCGGCAGCCTGATTGGCGATAAGGCCGCCCTGACAATCACTGGCGCCCAGACCGAGGACGAGGCCATCTACTTTTGCGCCCTGTGGTACAGCAACCTGTGGGTGTTCGGCGGAGGCACCAAGCTGACAGTGCTGGGAGGCGGAGGATCTGGCGGAGGCGGAAGTGGCGGAGGGGGATCTGAAGTGCAGCTGGTGGAATCTGGCGGCGGACTGGTGCAGCCTAAGGGCTCTCTGAAGCTGAGCTGTGCCGCCAGCGGCTTCACCTTCAACACCTACGCCATGAATTGGGTGCGCCAGGCCCCTGGCAAGGGACTGGAATGGGTGGCCCGGATCAGAAGCAAGTACAACAATTACGCCACCTACTACGCCGACAGCGTGAAGGACCGGTTCACCATCAGCCGGGACGACAGCCAGAGCATCCTGTATCTGCAGATGAACAACCTGAAAACCGAGGACACCGCCATGTACTACTGCGTGCGGCACGGCAACTTCGGCAACAGCTATGTGTCTTGGTTTGCCTACTGGGGCCAGGGCACCCTCGTGACAGTGTCTGCTGGCGGCTCCCTGGACCCTAAGTCATCTGACAAAACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACAACAGCACGTACCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGGGAGGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCTACAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTACACGCAGAAGAGCCTCTCCCTGTCTCCGGGTAAA(配列番号7)
アミノ酸配列
QAVVTQESALTTSPGETVTLTCRSSTGAVTTSNYANWVQEKPDHLFTGLIGGTNKRAPGVPARFSGSLIGDKAALTITGAQTEDEAIYFCALWYSNLWVFGGGTKLTVLGGGGSGGGGSGGGGSEVQLVESGGGLVQPKGSLKLSCAASGFTFNTYAMNWVRQAPGKGLEWVARIRSKYNNYATYYADSVKDRFTISRDDSQSILYLQMNNLKTEDTAMYYCVRHGNFGNSYVSWFAYWGQGTLVTVSAGGSLDPKSSDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK(配列番号8)
ヌクレオチド配列
[スペーサー(配列番号507)][スペーサーを有さない抗体15003-1204-SP34scFv(LvHv) (配列番号547)]
[CAAGGCCAGTCTGGCCAA][GGTTATCGGTGGGGTTGCGAGTGGAATTGCGGTGGGATTACTACTGGCTCGAGCGGTGGCAGCGGTGGCTCTGGTGGTCTGAGCGGCCGTTCCGATAATCATGGCGGCGGTTCTCAGGCTGTCGTGACACAGGAAAGCGCCCTGACCACCAGCCCTGGCGAGACAGTGACCCTGACCTGCAGATCTAGCACAGGCGCCGTGACCACAAGCAACTACGCCAACTGGGTGCAGGAAAAGCCCGACCACCTGTTCACCGGCCTGATCGGCGGCACCAACAAAAGGGCTCCAGGCGTGCCAGCCAGATTCAGCGGCAGCCTGATTGGCGATAAGGCCGCCCTGACAATCACTGGCGCCCAGACCGAGGACGAGGCCATCTACTTTTGCGCCCTGTGGTACAGCAACCTGTGGGTGTTCGGCGGAGGCACCAAGCTGACAGTGCTGGGAGGCGGAGGATCTGGCGGAGGCGGAAGTGGCGGAGGGGGATCTGAAGTGCAGCTGGTGGAATCTGGCGGCGGACTGGTGCAGCCTAAGGGCTCTCTGAAGCTGAGCTGTGCCGCCAGCGGCTTCACCTTCAACACCTACGCCATGAATTGGGTGCGCCAGGCCCCTGGCAAGGGACTGGAATGGGTGGCCCGGATCAGAAGCAAGTACAACAATTACGCCACCTACTACGCCGACAGCGTGAAGGACCGGTTCACCATCAGCCGGGACGACAGCCAGAGCATCCTGTATCTGCAGATGAACAACCTGAAAACCGAGGACACCGCCATGTACTACTGCGTGCGGCACGGCAACTTCGGCAACAGCTATGTGTCTTGGTTTGCCTACTGGGGCCAGGGCACCCTCGTGACAGTGTCTGCT](配列番号9)
アミノ酸配列
[スペーサー(配列番号87)][スペーサーを有さない抗体 15003-1204-SP34scFv(LvHv)(配列番号548)]
[QGQSGQ][GYRWGCEWNCGGITTGSSGGSGGSGGLSGRSDNHGGGSQAVVTQESALTTSPGETVTLTCRSSTGAVTTSNYANWVQEKPDHLFTGLIGGTNKRAPGVPARFSGSLIGDKAALTITGAQTEDEAIYFCALWYSNLWVFGGGTKLTVLGGGGSGGGGSGGGGSEVQLVESGGGLVQPKGSLKLSCAASGFTFNTYAMNWVRQAPGKGLEWVARIRSKYNNYATYYADSVKDRFTISRDDSQSILYLQMNNLKTEDTAMYYCVRHGNFGNSYVSWFAYWGQGTLVTVSA](配列番号10)
ヌクレオチド配列
[スペーサー(配列番号507)][スペーサーを有さない活性化可能抗体15003-1204-SP34scFv(LvHv)-Fc融合体(配列番号549)]
[CAAGGCCAGTCTGGCCAA][GGTTATCGGTGGGGTTGCGAGTGGAATTGCGGTGGGATTACTACTGGCTCGAGCGGTGGCAGCGGTGGCTCTGGTGGTCTGAGCGGCCGTTCCGATAATCATGGCGGCGGTTCTCAGGCTGTCGTGACACAGGAAAGCGCCCTGACCACCAGCCCTGGCGAGACAGTGACCCTGACCTGCAGATCTAGCACAGGCGCCGTGACCACAAGCAACTACGCCAACTGGGTGCAGGAAAAGCCCGACCACCTGTTCACCGGCCTGATCGGCGGCACCAACAAAAGGGCTCCAGGCGTGCCAGCCAGATTCAGCGGCAGCCTGATTGGCGATAAGGCCGCCCTGACAATCACTGGCGCCCAGACCGAGGACGAGGCCATCTACTTTTGCGCCCTGTGGTACAGCAACCTGTGGGTGTTCGGCGGAGGCACCAAGCTGACAGTGCTGGGAGGCGGAGGATCTGGCGGAGGCGGAAGTGGCGGAGGGGGATCTGAAGTGCAGCTGGTGGAATCTGGCGGCGGACTGGTGCAGCCTAAGGGCTCTCTGAAGCTGAGCTGTGCCGCCAGCGGCTTCACCTTCAACACCTACGCCATGAATTGGGTGCGCCAGGCCCCTGGCAAGGGACTGGAATGGGTGGCCCGGATCAGAAGCAAGTACAACAATTACGCCACCTACTACGCCGACAGCGTGAAGGACCGGTTCACCATCAGCCGGGACGACAGCCAGAGCATCCTGTATCTGCAGATGAACAACCTGAAAACCGAGGACACCGCCATGTACTACTGCGTGCGGCACGGCAACTTCGGCAACAGCTATGTGTCTTGGTTTGCCTACTGGGGCCAGGGCACCCTCGTGACAGTGTCTGCTGGCGGCTCCCTGGACCCTAAGTCATCTGACAAAACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACAACAGCACGTACCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGGGAGGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCTACAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTACACGCAGAAGAGCCTCTCCCTGTCTCCGGGTAAA](配列番号11)
アミノ酸配列
[スペーサー(配列番号407)] [スペーサーを有さない活性化可能抗体15003-1204-SP34scFv(LvHv)-Fc 融合体(配列番号550)]
[QGQSGQ][GYRWGCEWNCGGITTGSSGGSGGSGGLSGRSDNHGGGSQAVVTQESALTTSPGETVTLTCRSSTGAVTTSNYANWVQEKPDHLFTGLIGGTNKRAPGVPARFSGSLIGDKAALTITGAQTEDEAIYFCALWYSNLWVFGGGTKLTVLGGGGSGGGGSGGGGSEVQLVESGGGLVQPKGSLKLSCAASGFTFNTYAMNWVRQAPGKGLEWVARIRSKYNNYATYYADSVKDRFTISRDDSQSILYLQMNNLKTEDTAMYYCVRHGNFGNSYVSWFAYWGQGTLVTVSAGGSLDPKSSDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK](配列番号12)
ヌクレオチド配列
[スペーサー(配列番号507)][スペーサーを有さない15263-1204-SP34scFv(LvHv)(配列番号551)]
[CAAGGCCAGTCTGGCCAA][TGGTATTCGGGTGGGTGCGAGGCTTTTTGCGGTATTTTGTCGTCGGGCTCGAGCGGTGGCAGCGGTGGCTCTGGTGGTCTGAGCGGCCGTTCCGATAATCATGGCGGCGGTTCTCAGGCTGTCGTGACACAGGAAAGCGCCCTGACCACCAGCCCTGGCGAGACAGTGACCCTGACCTGCAGATCTAGCACAGGCGCCGTGACCACAAGCAACTACGCCAACTGGGTGCAGGAAAAGCCCGACCACCTGTTCACCGGCCTGATCGGCGGCACCAACAAAAGGGCTCCAGGCGTGCCAGCCAGATTCAGCGGCAGCCTGATTGGCGATAAGGCCGCCCTGACAATCACTGGCGCCCAGACCGAGGACGAGGCCATCTACTTTTGCGCCCTGTGGTACAGCAACCTGTGGGTGTTCGGCGGAGGCACCAAGCTGACAGTGCTGGGAGGCGGAGGATCTGGCGGAGGCGGAAGTGGCGGAGGGGGATCTGAAGTGCAGCTGGTGGAATCTGGCGGCGGACTGGTGCAGCCTAAGGGCTCTCTGAAGCTGAGCTGTGCCGCCAGCGGCTTCACCTTCAACACCTACGCCATGAATTGGGTGCGCCAGGCCCCTGGCAAGGGACTGGAATGGGTGGCCCGGATCAGAAGCAAGTACAACAATTACGCCACCTACTACGCCGACAGCGTGAAGGACCGGTTCACCATCAGCCGGGACGACAGCCAGAGCATCCTGTATCTGCAGATGAACAACCTGAAAACCGAGGACACCGCCATGTACTACTGCGTGCGGCACGGCAACTTCGGCAACAGCTATGTGTCTTGGTTTGCCTACTGGGGCCAGGGCACCCTCGTGACAGTGTCTGCT](配列番号13)
アミノ酸配列
[スペーサー(配列番号87)][スペーサーを有さない15263-1204-SP34scFv(LvHv)(配列番号552)]
[QGQSGQ][WYSGGCEAFCGILSSGSSGGSGGSGGLSGRSDNHGGGSQAVVTQESALTTSPGETVTLTCRSSTGAVTTSNYANWVQEKPDHLFTGLIGGTNKRAPGVPARFSGSLIGDKAALTITGAQTEDEAIYFCALWYSNLWVFGGGTKLTVLGGGGSGGGGSGGGGSEVQLVESGGGLVQPKGSLKLSCAASGFTFNTYAMNWVRQAPGKGLEWVARIRSKYNNYATYYADSVKDRFTISRDDSQSILYLQMNNLKTEDTAMYYCVRHGNFGNSYVSWFAYWGQGTLVTVSA](配列番号14)
ヌクレオチド配列
[スペーサー(配列番号507)][スペーサーを有さない活性化可能抗体15263-1204-SP34scFv(LvHv)-Fc融合体(配列番号553)]
[CAAGGCCAGTCTGGCCAA][TGGTATTCGGGTGGGTGCGAGGCTTTTTGCGGTATTTTGTCGTCGGGCTCGAGCGGTGGCAGCGGTGGCTCTGGTGGTCTGAGCGGCCGTTCCGATAATCATGGCGGCGGTTCTCAGGCTGTCGTGACACAGGAAAGCGCCCTGACCACCAGCCCTGGCGAGACAGTGACCCTGACCTGCAGATCTAGCACAGGCGCCGTGACCACAAGCAACTACGCCAACTGGGTGCAGGAAAAGCCCGACCACCTGTTCACCGGCCTGATCGGCGGCACCAACAAAAGGGCTCCAGGCGTGCCAGCCAGATTCAGCGGCAGCCTGATTGGCGATAAGGCCGCCCTGACAATCACTGGCGCCCAGACCGAGGACGAGGCCATCTACTTTTGCGCCCTGTGGTACAGCAACCTGTGGGTGTTCGGCGGAGGCACCAAGCTGACAGTGCTGGGAGGCGGAGGATCTGGCGGAGGCGGAAGTGGCGGAGGGGGATCTGAAGTGCAGCTGGTGGAATCTGGCGGCGGACTGGTGCAGCCTAAGGGCTCTCTGAAGCTGAGCTGTGCCGCCAGCGGCTTCACCTTCAACACCTACGCCATGAATTGGGTGCGCCAGGCCCCTGGCAAGGGACTGGAATGGGTGGCCCGGATCAGAAGCAAGTACAACAATTACGCCACCTACTACGCCGACAGCGTGAAGGACCGGTTCACCATCAGCCGGGACGACAGCCAGAGCATCCTGTATCTGCAGATGAACAACCTGAAAACCGAGGACACCGCCATGTACTACTGCGTGCGGCACGGCAACTTCGGCAACAGCTATGTGTCTTGGTTTGCCTACTGGGGCCAGGGCACCCTCGTGACAGTGTCTGCTGGCGGCTCCCTGGACCCTAAGTCATCTGACAAAACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACAACAGCACGTACCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGGGAGGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCTACAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTACACGCAGAAGAGCCTCTCCCTGTCTCCGGGTAAA](配列番号15)
アミノ酸配列
[スペーサー(配列番号87)][スペーサーを有さない活性化可能抗体15263-1204-SP34scFv(LvHv)-Fc 融合体(配列番号554)]]
[QGQSGQ][WYSGGCEAFCGILSSGSSGGSGGSGGLSGRSDNHGGGSQAVVTQESALTTSPGETVTLTCRSSTGAVTTSNYANWVQEKPDHLFTGLIGGTNKRAPGVPARFSGSLIGDKAALTITGAQTEDEAIYFCALWYSNLWVFGGGTKLTVLGGGGSGGGGSGGGGSEVQLVESGGGLVQPKGSLKLSCAASGFTFNTYAMNWVRQAPGKGLEWVARIRSKYNNYATYYADSVKDRFTISRDDSQSILYLQMNNLKTEDTAMYYCVRHGNFGNSYVSWFAYWGQGTLVTVSAGGSLDPKSSDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK](配列番号16)
ヌクレオチド配列
[スペーサー(配列番号507)][スペーサーを有さない15860-1204-SP34scFv(LvHv)(配列番号555)]
[CAAGGCCAGTCTGGCCAA][GTTTATTATTGCGGTGGGAATGAGAGTCTGTGCGGTGAGAGGAGGGGCTCGAGCGGTGGCAGCGGTGGCTCTGGTGGTCTGAGCGGCCGTTCCGATAATCATGGCGGCGGTTCTCAGGCTGTCGTGACACAGGAAAGCGCCCTGACCACCAGCCCTGGCGAGACAGTGACCCTGACCTGCAGATCTAGCACAGGCGCCGTGACCACAAGCAACTACGCCAACTGGGTGCAGGAAAAGCCCGACCACCTGTTCACCGGCCTGATCGGCGGCACCAACAAAAGGGCTCCAGGCGTGCCAGCCAGATTCAGCGGCAGCCTGATTGGCGATAAGGCCGCCCTGACAATCACTGGCGCCCAGACCGAGGACGAGGCCATCTACTTTTGCGCCCTGTGGTACAGCAACCTGTGGGTGTTCGGCGGAGGCACCAAGCTGACAGTGCTGGGAGGCGGAGGATCTGGCGGAGGCGGAAGTGGCGGAGGGGGATCTGAAGTGCAGCTGGTGGAATCTGGCGGCGGACTGGTGCAGCCTAAGGGCTCTCTGAAGCTGAGCTGTGCCGCCAGCGGCTTCACCTTCAACACCTACGCCATGAATTGGGTGCGCCAGGCCCCTGGCAAGGGACTGGAATGGGTGGCCCGGATCAGAAGCAAGTACAACAATTACGCCACCTACTACGCCGACAGCGTGAAGGACCGGTTCACCATCAGCCGGGACGACAGCCAGAGCATCCTGTATCTGCAGATGAACAACCTGAAAACCGAGGACACCGCCATGTACTACTGCGTGCGGCACGGCAACTTCGGCAACAGCTATGTGTCTTGGTTTGCCTACTGGGGCCAGGGCACCCTCGTGACAGTGTCTGCT](配列番号17)
アミノ酸配列
[スペーサー(配列番号87)][スペーサーを有さない15263-1204-SP34scFv(LvHv)(配列番号556)]
[QGQSGQ][VYYCGGNESLCGERRGSSGGSGGSGGLSGRSDNHGGGSQAVVTQESALTTSPGETVTLTCRSSTGAVTTSNYANWVQEKPDHLFTGLIGGTNKRAPGVPARFSGSLIGDKAALTITGAQTEDEAIYFCALWYSNLWVFGGGTKLTVLGGGGSGGGGSGGGGSEVQLVESGGGLVQPKGSLKLSCAASGFTFNTYAMNWVRQAPGKGLEWVARIRSKYNNYATYYADSVKDRFTISRDDSQSILYLQMNNLKTEDTAMYYCVRHGNFGNSYVSWFAYWGQGTLVTVSA](配列番号18)
ヌクレオチド配列
[スペーサー(配列番号507)][スペーサーを有さない活性化可能抗体15860-1204-SP34scFv(LvHv)-Fc 融合体(配列番号557)]
[CAAGGCCAGTCTGGCCAA][GTTTATTATTGCGGTGGGAATGAGAGTCTGTGCGGTGAGAGGAGGGGCTCGAGCGGTGGCAGCGGTGGCTCTGGTGGTCTGAGCGGCCGTTCCGATAATCATGGCGGCGGTTCTCAGGCTGTCGTGACACAGGAAAGCGCCCTGACCACCAGCCCTGGCGAGACAGTGACCCTGACCTGCAGATCTAGCACAGGCGCCGTGACCACAAGCAACTACGCCAACTGGGTGCAGGAAAAGCCCGACCACCTGTTCACCGGCCTGATCGGCGGCACCAACAAAAGGGCTCCAGGCGTGCCAGCCAGATTCAGCGGCAGCCTGATTGGCGATAAGGCCGCCCTGACAATCACTGGCGCCCAGACCGAGGACGAGGCCATCTACTTTTGCGCCCTGTGGTACAGCAACCTGTGGGTGTTCGGCGGAGGCACCAAGCTGACAGTGCTGGGAGGCGGAGGATCTGGCGGAGGCGGAAGTGGCGGAGGGGGATCTGAAGTGCAGCTGGTGGAATCTGGCGGCGGACTGGTGCAGCCTAAGGGCTCTCTGAAGCTGAGCTGTGCCGCCAGCGGCTTCACCTTCAACACCTACGCCATGAATTGGGTGCGCCAGGCCCCTGGCAAGGGACTGGAATGGGTGGCCCGGATCAGAAGCAAGTACAACAATTACGCCACCTACTACGCCGACAGCGTGAAGGACCGGTTCACCATCAGCCGGGACGACAGCCAGAGCATCCTGTATCTGCAGATGAACAACCTGAAAACCGAGGACACCGCCATGTACTACTGCGTGCGGCACGGCAACTTCGGCAACAGCTATGTGTCTTGGTTTGCCTACTGGGGCCAGGGCACCCTCGTGACAGTGTCTGCTGGCGGCTCCCTGGACCCTAAGTCATCTGACAAAACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACAACAGCACGTACCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGGGAGGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCTACAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTACACGCAGAAGAGCCTCTCCCTGTCTCCGGGTAAA](配列番号19)
アミノ酸配列
[スペーサー(配列番号87)][スペーサーを有さない活性化可能抗体15860-1204-SP34scFv(LvHv)-Fc融合体(配列番号558)]
[QGQSGQ][VYYCGGNESLCGERRGSSGGSGGSGGLSGRSDNHGGGSQAVVTQESALTTSPGETVTLTCRSSTGAVTTSNYANWVQEKPDHLFTGLIGGTNKRAPGVPARFSGSLIGDKAALTITGAQTEDEAIYFCALWYSNLWVFGGGTKLTVLGGGGSGGGGSGGGGSEVQLVESGGGLVQPKGSLKLSCAASGFTFNTYAMNWVRQAPGKGLEWVARIRSKYNNYATYYADSVKDRFTISRDDSQSILYLQMNNLKTEDTAMYYCVRHGNFGNSYVSWFAYWGQGTLVTVSAGGSLDPKSSDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK](配列番号20)
ヌクレオチド配列
[スペーサー(配列番号507)][スペーサーを有さない15864-1204-SP34scFv(LvHv)(配列番号559)]
[CAAGGCCAGTCTGGCCAA][TTTATGTGCCAGCAGCGGATGTGGGGGAATGAGTTTTGCCATCAGGGCTCGAGCGGTGGCAGCGGTGGCTCTGGTGGTCTGAGCGGCCGTTCCGATAATCATGGCGGCGGTTCTCAGGCTGTCGTGACACAGGAAAGCGCCCTGACCACCAGCCCTGGCGAGACAGTGACCCTGACCTGCAGATCTAGCACAGGCGCCGTGACCACAAGCAACTACGCCAACTGGGTGCAGGAAAAGCCCGACCACCTGTTCACCGGCCTGATCGGCGGCACCAACAAAAGGGCTCCAGGCGTGCCAGCCAGATTCAGCGGCAGCCTGATTGGCGATAAGGCCGCCCTGACAATCACTGGCGCCCAGACCGAGGACGAGGCCATCTACTTTTGCGCCCTGTGGTACAGCAACCTGTGGGTGTTCGGCGGAGGCACCAAGCTGACAGTGCTGGGAGGCGGAGGATCTGGCGGAGGCGGAAGTGGCGGAGGGGGATCTGAAGTGCAGCTGGTGGAATCTGGCGGCGGACTGGTGCAGCCTAAGGGCTCTCTGAAGCTGAGCTGTGCCGCCAGCGGCTTCACCTTCAACACCTACGCCATGAATTGGGTGCGCCAGGCCCCTGGCAAGGGACTGGAATGGGTGGCCCGGATCAGAAGCAAGTACAACAATTACGCCACCTACTACGCCGACAGCGTGAAGGACCGGTTCACCATCAGCCGGGACGACAGCCAGAGCATCCTGTATCTGCAGATGAACAACCTGAAAACCGAGGACACCGCCATGTACTACTGCGTGCGGCACGGCAACTTCGGCAACAGCTATGTGTCTTGGTTTGCCTACTGGGGCCAGGGCACCCTCGTGACAGTGTCTGCT](配列番号21)
アミノ酸
[スペーサー(配列番号87)][スペーサーを有さない15864-1204-SP34scFv(LvHv)(配列番号560)]
[QGQSGQ][FMCQQRMWGNEFCHQGSSGGSGGSGGLSGRSDNHGGGSQAVVTQESALTTSPGETVTLTCRSSTGAVTTSNYANWVQEKPDHLFTGLIGGTNKRAPGVPARFSGSLIGDKAALTITGAQTEDEAIYFCALWYSNLWVFGGGTKLTVLGGGGSGGGGSGGGGSEVQLVESGGGLVQPKGSLKLSCAASGFTFNTYAMNWVRQAPGKGLEWVARIRSKYNNYATYYADSVKDRFTISRDDSQSILYLQMNNLKTEDTAMYYCVRHGNFGNSYVSWFAYWGQGTLVTVSA](配列番号22)
ヌクレオチド配列
[スペーサー(配列番号507)][スペーサーを有さない活性化可能抗体15864-1204-SP34scFv(LvHv)-Fc 融合体(配列番号561)]
[CAAGGCCAGTCTGGCCAA][TTTATGTGCCAGCAGCGGATGTGGGGGAATGAGTTTTGCCATCAGGGCTCGAGCGGTGGCAGCGGTGGCTCTGGTGGTCTGAGCGGCCGTTCCGATAATCATGGCGGCGGTTCTCAGGCTGTCGTGACACAGGAAAGCGCCCTGACCACCAGCCCTGGCGAGACAGTGACCCTGACCTGCAGATCTAGCACAGGCGCCGTGACCACAAGCAACTACGCCAACTGGGTGCAGGAAAAGCCCGACCACCTGTTCACCGGCCTGATCGGCGGCACCAACAAAAGGGCTCCAGGCGTGCCAGCCAGATTCAGCGGCAGCCTGATTGGCGATAAGGCCGCCCTGACAATCACTGGCGCCCAGACCGAGGACGAGGCCATCTACTTTTGCGCCCTGTGGTACAGCAACCTGTGGGTGTTCGGCGGAGGCACCAAGCTGACAGTGCTGGGAGGCGGAGGATCTGGCGGAGGCGGAAGTGGCGGAGGGGGATCTGAAGTGCAGCTGGTGGAATCTGGCGGCGGACTGGTGCAGCCTAAGGGCTCTCTGAAGCTGAGCTGTGCCGCCAGCGGCTTCACCTTCAACACCTACGCCATGAATTGGGTGCGCCAGGCCCCTGGCAAGGGACTGGAATGGGTGGCCCGGATCAGAAGCAAGTACAACAATTACGCCACCTACTACGCCGACAGCGTGAAGGACCGGTTCACCATCAGCCGGGACGACAGCCAGAGCATCCTGTATCTGCAGATGAACAACCTGAAAACCGAGGACACCGCCATGTACTACTGCGTGCGGCACGGCAACTTCGGCAACAGCTATGTGTCTTGGTTTGCCTACTGGGGCCAGGGCACCCTCGTGACAGTGTCTGCTGGCGGCTCCCTGGACCCTAAGTCATCTGACAAAACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACAACAGCACGTACCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGGGAGGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCTACAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTACACGCAGAAGAGCCTCTCCCTGTCTCCGGGTAAA](配列番号23)
アミノ酸配列
[スペーサー(配列番号87)][スペーサーを有さない活性化可能抗体15864-1204-SP34scFv(LvHv)-Fc 融合体(配列番号562)]
[QGQSGQ][FMCQQRMWGNEFCHQGSSGGSGGSGGLSGRSDNHGGGSQAVVTQESALTTSPGETVTLTCRSSTGAVTTSNYANWVQEKPDHLFTGLIGGTNKRAPGVPARFSGSLIGDKAALTITGAQTEDEAIYFCALWYSNLWVFGGGTKLTVLGGGGSGGGGSGGGGSEVQLVESGGGLVQPKGSLKLSCAASGFTFNTYAMNWVRQAPGKGLEWVARIRSKYNNYATYYADSVKDRFTISRDDSQSILYLQMNNLKTEDTAMYYCVRHGNFGNSYVSWFAYWGQGTLVTVSAGGSLDPKSSDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK](配列番号24)
ヌクレオチド配列
[スペーサー(配列番号507)][スペーサーを有さない15865-1204-SP34scFv(LvHv)(配列番号563)]
[CAAGGCCAGTCTGGCCAA][ATGATGTATTGCGGTGGGAATGAGGTGTTGTGCGGGCCGCGGGTTGGCTCGAGCGGTGGCAGCGGTGGCTCTGGTGGTCTGAGCGGCCGTTCCGATAATCATGGCGGCGGTTCTCAGGCTGTCGTGACACAGGAAAGCGCCCTGACCACCAGCCCTGGCGAGACAGTGACCCTGACCTGCAGATCTAGCACAGGCGCCGTGACCACAAGCAACTACGCCAACTGGGTGCAGGAAAAGCCCGACCACCTGTTCACCGGCCTGATCGGCGGCACCAACAAAAGGGCTCCAGGCGTGCCAGCCAGATTCAGCGGCAGCCTGATTGGCGATAAGGCCGCCCTGACAATCACTGGCGCCCAGACCGAGGACGAGGCCATCTACTTTTGCGCCCTGTGGTACAGCAACCTGTGGGTGTTCGGCGGAGGCACCAAGCTGACAGTGCTGGGAGGCGGAGGATCTGGCGGAGGCGGAAGTGGCGGAGGGGGATCTGAAGTGCAGCTGGTGGAATCTGGCGGCGGACTGGTGCAGCCTAAGGGCTCTCTGAAGCTGAGCTGTGCCGCCAGCGGCTTCACCTTCAACACCTACGCCATGAATTGGGTGCGCCAGGCCCCTGGCAAGGGACTGGAATGGGTGGCCCGGATCAGAAGCAAGTACAACAATTACGCCACCTACTACGCCGACAGCGTGAAGGACCGGTTCACCATCAGCCGGGACGACAGCCAGAGCATCCTGTATCTGCAGATGAACAACCTGAAAACCGAGGACACCGCCATGTACTACTGCGTGCGGCACGGCAACTTCGGCAACAGCTATGTGTCTTGGTTTGCCTACTGGGGCCAGGGCACCCTCGTGACAGTGTCTGCT](配列番号25)
アミノ酸配列
[スペーサー(配列番号87)][スペーサーを有さない15865-1204-SP34scFv(LvHv)(配列番号564)]
[QGQSGQ][MMYCGGNEVLCGPRVGSSGGSGGSGGLSGRSDNHGGGSQAVVTQESALTTSPGETVTLTCRSSTGAVTTSNYANWVQEKPDHLFTGLIGGTNKRAPGVPARFSGSLIGDKAALTITGAQTEDEAIYFCALWYSNLWVFGGGTKLTVLGGGGSGGGGSGGGGSEVQLVESGGGLVQPKGSLKLSCAASGFTFNTYAMNWVRQAPGKGLEWVARIRSKYNNYATYYADSVKDRFTISRDDSQSILYLQMNNLKTEDTAMYYCVRHGNFGNSYVSWFAYWGQGTLVTVSA](配列番号26)
ヌクレオチド配列
[スペーサー(配列番号507)][スペーサーを有さない活性化可能抗体15865-1204-SP34scFv(LvHv)-Fc 融合体(配列番号565)]
[CAAGGCCAGTCTGGCCAA][ATGATGTATTGCGGTGGGAATGAGGTGTTGTGCGGGCCGCGGGTTGGCTCGAGCGGTGGCAGCGGTGGCTCTGGTGGTCTGAGCGGCCGTTCCGATAATCATGGCGGCGGTTCTCAGGCTGTCGTGACACAGGAAAGCGCCCTGACCACCAGCCCTGGCGAGACAGTGACCCTGACCTGCAGATCTAGCACAGGCGCCGTGACCACAAGCAACTACGCCAACTGGGTGCAGGAAAAGCCCGACCACCTGTTCACCGGCCTGATCGGCGGCACCAACAAAAGGGCTCCAGGCGTGCCAGCCAGATTCAGCGGCAGCCTGATTGGCGATAAGGCCGCCCTGACAATCACTGGCGCCCAGACCGAGGACGAGGCCATCTACTTTTGCGCCCTGTGGTACAGCAACCTGTGGGTGTTCGGCGGAGGCACCAAGCTGACAGTGCTGGGAGGCGGAGGATCTGGCGGAGGCGGAAGTGGCGGAGGGGGATCTGAAGTGCAGCTGGTGGAATCTGGCGGCGGACTGGTGCAGCCTAAGGGCTCTCTGAAGCTGAGCTGTGCCGCCAGCGGCTTCACCTTCAACACCTACGCCATGAATTGGGTGCGCCAGGCCCCTGGCAAGGGACTGGAATGGGTGGCCCGGATCAGAAGCAAGTACAACAATTACGCCACCTACTACGCCGACAGCGTGAAGGACCGGTTCACCATCAGCCGGGACGACAGCCAGAGCATCCTGTATCTGCAGATGAACAACCTGAAAACCGAGGACACCGCCATGTACTACTGCGTGCGGCACGGCAACTTCGGCAACAGCTATGTGTCTTGGTTTGCCTACTGGGGCCAGGGCACCCTCGTGACAGTGTCTGCTGGCGGCTCCCTGGACCCTAAGTCATCTGACAAAACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACAACAGCACGTACCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGGGAGGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCTACAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTACACGCAGAAGAGCCTCTCCCTGTCTCCGGGTAAA](配列番号27)
アミノ酸配列
[スペーサー(配列番号87)][スペーサーを有さない活性化可能抗体15865-1204-SP34scFv(LvHv)-Fc融合体(配列番号566)]
[QGQSGQ][MMYCGGNEVLCGPRVGSSGGSGGSGGLSGRSDNHGGGSQAVVTQESALTTSPGETVTLTCRSSTGAVTTSNYANWVQEKPDHLFTGLIGGTNKRAPGVPARFSGSLIGDKAALTITGAQTEDEAIYFCALWYSNLWVFGGGTKLTVLGGGGSGGGGSGGGGSEVQLVESGGGLVQPKGSLKLSCAASGFTFNTYAMNWVRQAPGKGLEWVARIRSKYNNYATYYADSVKDRFTISRDDSQSILYLQMNNLKTEDTAMYYCVRHGNFGNSYVSWFAYWGQGTLVTVSAGGSLDPKSSDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK](配列番号28)
ヌクレオチド配列
GAAGTGCAGCTGGTGGAATCTGGGGGCGGACTGGTGCAGCCTAAGGGCAGCCTGAAGCTGAGCTGTGCCGCCAGCGGCTTCACCTTCAACACCTACGCCATGAACTGGGTGCGCCAGGCCCCTGGCAAAGGCCTGGAATGGGTGGCCCGGATCAGAAGCAAGTACAACAATTACGCCACCTACTACGCCGACAGCGTGAAGGACAGATTCACCATCAGCCGGGACGACAGCCAGAGCATCCTGTACCTGCAGATGAACAACCTGAAAACCGAGGACACCGCCATGTACTACTGCGTGCGGCACGGCAACTTCGGCAACAGCTATGTGTCTTGGTTTGCCTACTGGGGCCAGGGCACCCTCGTGACAGTGTCTGCCGGTGGTGGTGGTAGTGGTGGCGGTGGTTCAGGCGGTGGCGGTAGCCAGGCTGTCGTGACACAGGAAAGCGCCCTGACCACCAGCCCTGGCGAGACAGTGACCCTGACCTGTAGAAGCAGCACAGGCGCCGTGACCACAAGCAACTACGCCAATTGGGTGCAGGAAAAGCCCGACCACCTGTTCACCGGCCTGATCGGCGGCACCAACAAAAGGGCTCCAGGCGTGCCAGCCAGATTCAGCGGCTCCCTGATCGGAGATAAGGCCGCCCTGACAATCACTGGCGCCCAGACCGAGGACGAGGCCATCTACTTTTGCGCCCTGTGGTACAGCAACCTGTGGGTGTTCGGCGGAGGCACCAAGCTGACCGTGCTG(配列番号29)
アミノ酸配列
EVQLVESGGGLVQPKGSLKLSCAASGFTFNTYAMNWVRQAPGKGLEWVARIRSKYNNYATYYADSVKDRFTISRDDSQSILYLQMNNLKTEDTAMYYCVRHGNFGNSYVSWFAYWGQGTLVTVSAGGGGSGGGGSGGGGSQAVVTQESALTTSPGETVTLTCRSSTGAVTTSNYANWVQEKPDHLFTGLIGGTNKRAPGVPARFSGSLIGDKAALTITGAQTEDEAIYFCALWYSNLWVFGGGTKLTVL(配列番号30)
ヌクレオチド配列
GAAGTGCAGCTGGTGGAATCTGGGGGCGGACTGGTGCAGCCTAAGGGCAGCCTGAAGCTGAGCTGTGCCGCCAGCGGCTTCACCTTCAACACCTACGCCATGAACTGGGTGCGCCAGGCCCCTGGCAAAGGCCTGGAATGGGTGGCCCGGATCAGAAGCAAGTACAACAATTACGCCACCTACTACGCCGACAGCGTGAAGGACAGATTCACCATCAGCCGGGACGACAGCCAGAGCATCCTGTACCTGCAGATGAACAACCTGAAAACCGAGGACACCGCCATGTACTACTGCGTGCGGCACGGCAACTTCGGCAACAGCTATGTGTCTTGGTTTGCCTACTGGGGCCAGGGCACCCTCGTGACAGTGTCTGCCGGTGGTGGTGGTAGTGGTGGCGGTGGTTCAGGCGGTGGCGGTAGCCAGGCTGTCGTGACACAGGAAAGCGCCCTGACCACCAGCCCTGGCGAGACAGTGACCCTGACCTGTAGAAGCAGCACAGGCGCCGTGACCACAAGCAACTACGCCAATTGGGTGCAGGAAAAGCCCGACCACCTGTTCACCGGCCTGATCGGCGGCACCAACAAAAGGGCTCCAGGCGTGCCAGCCAGATTCAGCGGCTCCCTGATCGGAGATAAGGCCGCCCTGACAATCACTGGCGCCCAGACCGAGGACGAGGCCATCTACTTTTGCGCCCTGTGGTACAGCAACCTGTGGGTGTTCGGCGGAGGCACCAAGCTGACCGTGCTGGGCGGCTCCCTGGACCCTAAGTCATCTGACAAAACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACAACAGCACGTACCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGGGAGGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCTACAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTACACGCAGAAGAGCCTCTCCCTGTCTCCGGGTAAA(配列番号31)
アミノ酸配列
EVQLVESGGGLVQPKGSLKLSCAASGFTFNTYAMNWVRQAPGKGLEWVARIRSKYNNYATYYADSVKDRFTISRDDSQSILYLQMNNLKTEDTAMYYCVRHGNFGNSYVSWFAYWGQGTLVTVSAGGGGSGGGGSGGGGSQAVVTQESALTTSPGETVTLTCRSSTGAVTTSNYANWVQEKPDHLFTGLIGGTNKRAPGVPARFSGSLIGDKAALTITGAQTEDEAIYFCALWYSNLWVFGGGTKLTVLGGSLDPKSSDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK(配列番号32)
ヌクレオチド配列
[スペーサー(配列番号507)][スペーサーを有さない15003-1204-SP34scFv(HvLv)(配列番号567)]
[CAAGGCCAGTCTGGCCAA][GGTTATCGGTGGGGTTGCGAGTGGAATTGCGGTGGGATTACTACTGGCTCGAGCGGTGGCAGCGGTGGCTCTGGTGGTCTGAGCGGCCGTTCCGATAATCATGGCGGCGGTTCTGAAGTGCAGCTGGTGGAATCTGGGGGCGGACTGGTGCAGCCTAAGGGCAGCCTGAAGCTGAGCTGTGCCGCCAGCGGCTTCACCTTCAACACCTACGCCATGAACTGGGTGCGCCAGGCCCCTGGCAAAGGCCTGGAATGGGTGGCCCGGATCAGAAGCAAGTACAACAATTACGCCACCTACTACGCCGACAGCGTGAAGGACAGATTCACCATCAGCCGGGACGACAGCCAGAGCATCCTGTACCTGCAGATGAACAACCTGAAAACCGAGGACACCGCCATGTACTACTGCGTGCGGCACGGCAACTTCGGCAACAGCTATGTGTCTTGGTTTGCCTACTGGGGCCAGGGCACCCTCGTGACAGTGTCTGCCGGTGGTGGTGGTAGTGGTGGCGGTGGTTCAGGCGGTGGCGGTAGCCAGGCTGTCGTGACACAGGAAAGCGCCCTGACCACCAGCCCTGGCGAGACAGTGACCCTGACCTGTAGAAGCAGCACAGGCGCCGTGACCACAAGCAACTACGCCAATTGGGTGCAGGAAAAGCCCGACCACCTGTTCACCGGCCTGATCGGCGGCACCAACAAAAGGGCTCCAGGCGTGCCAGCCAGATTCAGCGGCTCCCTGATCGGAGATAAGGCCGCCCTGACAATCACTGGCGCCCAGACCGAGGACGAGGCCATCTACTTTTGCGCCCTGTGGTACAGCAACCTGTGGGTGTTCGGCGGAGGCACCAAGCTGACCGTGCTG(配列番号33)
アミノ酸配列
[スペーサー(配列番号87)][スペーサーを有さない15003-1204-SP34scFv(HvLv)(配列番号568)]
[QGQSGQ][GYRWGCEWNCGGITTGSSGGSGGSGGLSGRSDNHGGGSEVQLVESGGGLVQPKGSLKLSCAASGFTFNTYAMNWVRQAPGKGLEWVARIRSKYNNYATYYADSVKDRFTISRDDSQSILYLQMNNLKTEDTAMYYCVRHGNFGNSYVSWFAYWGQGTLVTVSAGGGGSGGGGSGGGGSQAVVTQESALTTSPGETVTLTCRSSTGAVTTSNYANWVQEKPDHLFTGLIGGTNKRAPGVPARFSGSLIGDKAALTITGAQTEDEAIYFCALWYSNLWVFGGGTKLTVL](配列番号34)
ヌクレオチド配列
[スペーサー(配列番号507)][スペーサーを有さない活性化可能抗体15003-1204-SP34scFv(HvLv)-Fc融合体(配列番号569)]
[CAAGGCCAGTCTGGCCAA][GGTTATCGGTGGGGTTGCGAGTGGAATTGCGGTGGGATTACTACTGGCTCGAGCGGTGGCAGCGGTGGCTCTGGTGGTCTGAGCGGCCGTTCCGATAATCATGGCGGCGGTTCTGAAGTGCAGCTGGTGGAATCTGGGGGCGGACTGGTGCAGCCTAAGGGCAGCCTGAAGCTGAGCTGTGCCGCCAGCGGCTTCACCTTCAACACCTACGCCATGAACTGGGTGCGCCAGGCCCCTGGCAAAGGCCTGGAATGGGTGGCCCGGATCAGAAGCAAGTACAACAATTACGCCACCTACTACGCCGACAGCGTGAAGGACAGATTCACCATCAGCCGGGACGACAGCCAGAGCATCCTGTACCTGCAGATGAACAACCTGAAAACCGAGGACACCGCCATGTACTACTGCGTGCGGCACGGCAACTTCGGCAACAGCTATGTGTCTTGGTTTGCCTACTGGGGCCAGGGCACCCTCGTGACAGTGTCTGCCGGTGGTGGTGGTAGTGGTGGCGGTGGTTCAGGCGGTGGCGGTAGCCAGGCTGTCGTGACACAGGAAAGCGCCCTGACCACCAGCCCTGGCGAGACAGTGACCCTGACCTGTAGAAGCAGCACAGGCGCCGTGACCACAAGCAACTACGCCAATTGGGTGCAGGAAAAGCCCGACCACCTGTTCACCGGCCTGATCGGCGGCACCAACAAAAGGGCTCCAGGCGTGCCAGCCAGATTCAGCGGCTCCCTGATCGGAGATAAGGCCGCCCTGACAATCACTGGCGCCCAGACCGAGGACGAGGCCATCTACTTTTGCGCCCTGTGGTACAGCAACCTGTGGGTGTTCGGCGGAGGCACCAAGCTGACCGTGCTGGGCGGCTCCCTGGACCCTAAGTCATCTGACAAAACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACAACAGCACGTACCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGGGAGGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCTACAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTACACGCAGAAGAGCCTCTCCCTGTCTCCGGGTAAA(配列番号35)
アミノ酸配列
[スペーサー(配列番号87)][スペーサーを有さない活性化可能抗体15003-1204-SP34scFv(HvLv)-Fc 融合体(配列番号570)]
[QGQSGQ][GYRWGCEWNCGGITTGSSGGSGGSGGLSGRSDNHGGGSEVQLVESGGGLVQPKGSLKLSCAASGFTFNTYAMNWVRQAPGKGLEWVARIRSKYNNYATYYADSVKDRFTISRDDSQSILYLQMNNLKTEDTAMYYCVRHGNFGNSYVSWFAYWGQGTLVTVSAGGGGSGGGGSGGGGSQAVVTQESALTTSPGETVTLTCRSSTGAVTTSNYANWVQEKPDHLFTGLIGGTNKRAPGVPARFSGSLIGDKAALTITGAQTEDEAIYFCALWYSNLWVFGGGTKLTVLGGSLDPKSSDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK](配列番号36)
ヌクレオチド配列
[スペーサー(配列番号507)][スペーサーを有さない15263-1204-SP34scFv(HvLv)(配列番号571)]
[CAAGGCCAGTCTGGCCAA][TGGTATTCGGGTGGGTGCGAGGCTTTTTGCGGTATTTTGTCGTCGGGCTCGAGCGGTGGCAGCGGTGGCTCTGGTGGTCTGAGCGGCCGTTCCGATAATCATGGCGGCGGTTCTGAAGTGCAGCTGGTGGAATCTGGGGGCGGACTGGTGCAGCCTAAGGGCAGCCTGAAGCTGAGCTGTGCCGCCAGCGGCTTCACCTTCAACACCTACGCCATGAACTGGGTGCGCCAGGCCCCTGGCAAAGGCCTGGAATGGGTGGCCCGGATCAGAAGCAAGTACAACAATTACGCCACCTACTACGCCGACAGCGTGAAGGACAGATTCACCATCAGCCGGGACGACAGCCAGAGCATCCTGTACCTGCAGATGAACAACCTGAAAACCGAGGACACCGCCATGTACTACTGCGTGCGGCACGGCAACTTCGGCAACAGCTATGTGTCTTGGTTTGCCTACTGGGGCCAGGGCACCCTCGTGACAGTGTCTGCCGGTGGTGGTGGTAGTGGTGGCGGTGGTTCAGGCGGTGGCGGTAGCCAGGCTGTCGTGACACAGGAAAGCGCCCTGACCACCAGCCCTGGCGAGACAGTGACCCTGACCTGTAGAAGCAGCACAGGCGCCGTGACCACAAGCAACTACGCCAATTGGGTGCAGGAAAAGCCCGACCACCTGTTCACCGGCCTGATCGGCGGCACCAACAAAAGGGCTCCAGGCGTGCCAGCCAGATTCAGCGGCTCCCTGATCGGAGATAAGGCCGCCCTGACAATCACTGGCGCCCAGACCGAGGACGAGGCCATCTACTTTTGCGCCCTGTGGTACAGCAACCTGTGGGTGTTCGGCGGAGGCACCAAGCTGACCGTGCTG](配列番号37)
アミノ酸配列
[スペーサー(配列番号87)][スペーサーを有さない15263-1204-SP34scFv(HvLv)(配列番号572)]
[QGQSGQ][WYSGGCEAFCGILSSGSSGGSGGSGGLSGRSDNHGGGSEVQLVESGGGLVQPKGSLKLSCAASGFTFNTYAMNWVRQAPGKGLEWVARIRSKYNNYATYYADSVKDRFTISRDDSQSILYLQMNNLKTEDTAMYYCVRHGNFGNSYVSWFAYWGQGTLVTVSAGGGGSGGGGSGGGGSQAVVTQESALTTSPGETVTLTCRSSTGAVTTSNYANWVQEKPDHLFTGLIGGTNKRAPGVPARFSGSLIGDKAALTITGAQTEDEAIYFCALWYSNLWVFGGGTKLTVL](配列番号38)
ヌクレオチド配列
[スペーサー(配列番号507)][スペーサーを有さない活性化可能抗体15263-1204-SP34scFv(HvLv)-Fc 融合体(配列番号573)]
[CAAGGCCAGTCTGGCCAA][TGGTATTCGGGTGGGTGCGAGGCTTTTTGCGGTATTTTGTCGTCGGGCTCGAGCGGTGGCAGCGGTGGCTCTGGTGGTCTGAGCGGCCGTTCCGATAATCATGGCGGCGGTTCTGAAGTGCAGCTGGTGGAATCTGGGGGCGGACTGGTGCAGCCTAAGGGCAGCCTGAAGCTGAGCTGTGCCGCCAGCGGCTTCACCTTCAACACCTACGCCATGAACTGGGTGCGCCAGGCCCCTGGCAAAGGCCTGGAATGGGTGGCCCGGATCAGAAGCAAGTACAACAATTACGCCACCTACTACGCCGACAGCGTGAAGGACAGATTCACCATCAGCCGGGACGACAGCCAGAGCATCCTGTACCTGCAGATGAACAACCTGAAAACCGAGGACACCGCCATGTACTACTGCGTGCGGCACGGCAACTTCGGCAACAGCTATGTGTCTTGGTTTGCCTACTGGGGCCAGGGCACCCTCGTGACAGTGTCTGCCGGTGGTGGTGGTAGTGGTGGCGGTGGTTCAGGCGGTGGCGGTAGCCAGGCTGTCGTGACACAGGAAAGCGCCCTGACCACCAGCCCTGGCGAGACAGTGACCCTGACCTGTAGAAGCAGCACAGGCGCCGTGACCACAAGCAACTACGCCAATTGGGTGCAGGAAAAGCCCGACCACCTGTTCACCGGCCTGATCGGCGGCACCAACAAAAGGGCTCCAGGCGTGCCAGCCAGATTCAGCGGCTCCCTGATCGGAGATAAGGCCGCCCTGACAATCACTGGCGCCCAGACCGAGGACGAGGCCATCTACTTTTGCGCCCTGTGGTACAGCAACCTGTGGGTGTTCGGCGGAGGCACCAAGCTGACCGTGCTGGGCGGCTCCCTGGACCCTAAGTCATCTGACAAAACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACAACAGCACGTACCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGGGAGGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCTACAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTACACGCAGAAGAGCCTCTCCCTGTCTCCGGGTAAA](配列番号39)
アミノ酸配列
[スペーサー(配列番号87)][スペーサーを有さない活性化可能抗体15263-1204-SP34scFv(HvLv)-Fc融合体(配列番号574)]
[QGQSGQ][WYSGGCEAFCGILSSGSSGGSGGSGGLSGRSDNHGGGSEVQLVESGGGLVQPKGSLKLSCAASGFTFNTYAMNWVRQAPGKGLEWVARIRSKYNNYATYYADSVKDRFTISRDDSQSILYLQMNNLKTEDTAMYYCVRHGNFGNSYVSWFAYWGQGTLVTVSAGGGGSGGGGSGGGGSQAVVTQESALTTSPGETVTLTCRSSTGAVTTSNYANWVQEKPDHLFTGLIGGTNKRAPGVPARFSGSLIGDKAALTITGAQTEDEAIYFCALWYSNLWVFGGGTKLTVLGGSLDPKSSDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK](配列番号40)
ヌクレオチド配列
[スペーサー(配列番号507)][スペーサーを有さない15860-1204-SP34scFv(HvLv)(配列番号575)]
[CAAGGCCAGTCTGGCCAA][GTTTATTATTGCGGTGGGAATGAGAGTCTGTGCGGTGAGAGGAGGGGCTCGAGCGGTGGCAGCGGTGGCTCTGGTGGTCTGAGCGGCCGTTCCGATAATCATGGCGGCGGTTCTGAAGTGCAGCTGGTGGAATCTGGGGGCGGACTGGTGCAGCCTAAGGGCAGCCTGAAGCTGAGCTGTGCCGCCAGCGGCTTCACCTTCAACACCTACGCCATGAACTGGGTGCGCCAGGCCCCTGGCAAAGGCCTGGAATGGGTGGCCCGGATCAGAAGCAAGTACAACAATTACGCCACCTACTACGCCGACAGCGTGAAGGACAGATTCACCATCAGCCGGGACGACAGCCAGAGCATCCTGTACCTGCAGATGAACAACCTGAAAACCGAGGACACCGCCATGTACTACTGCGTGCGGCACGGCAACTTCGGCAACAGCTATGTGTCTTGGTTTGCCTACTGGGGCCAGGGCACCCTCGTGACAGTGTCTGCCGGTGGTGGTGGTAGTGGTGGCGGTGGTTCAGGCGGTGGCGGTAGCCAGGCTGTCGTGACACAGGAAAGCGCCCTGACCACCAGCCCTGGCGAGACAGTGACCCTGACCTGTAGAAGCAGCACAGGCGCCGTGACCACAAGCAACTACGCCAATTGGGTGCAGGAAAAGCCCGACCACCTGTTCACCGGCCTGATCGGCGGCACCAACAAAAGGGCTCCAGGCGTGCCAGCCAGATTCAGCGGCTCCCTGATCGGAGATAAGGCCGCCCTGACAATCACTGGCGCCCAGACCGAGGACGAGGCCATCTACTTTTGCGCCCTGTGGTACAGCAACCTGTGGGTGTTCGGCGGAGGCACCAAGCTGACCGTGCTG](配列番号41)
アミノ酸配列
[スペーサー(配列番号87)][スペーサーを有さない15860-1204-SP34scFv(HvLv)(配列番号576)]
[QGQSGQ][VYYCGGNESLCGERRGSSGGSGGSGGLSGRSDNHGGGSEVQLVESGGGLVQPKGSLKLSCAASGFTFNTYAMNWVRQAPGKGLEWVARIRSKYNNYATYYADSVKDRFTISRDDSQSILYLQMNNLKTEDTAMYYCVRHGNFGNSYVSWFAYWGQGTLVTVSAGGGGSGGGGSGGGGSQAVVTQESALTTSPGETVTLTCRSSTGAVTTSNYANWVQEKPDHLFTGLIGGTNKRAPGVPARFSGSLIGDKAALTITGAQTEDEAIYFCALWYSNLWVFGGGTKLTVL](配列番号42)
ヌクレオチド配列
[スペーサー(配列番号507)][スペーサーを有さない活性化可能抗体15860-1204-SP34scFv(HvLv)-Fc融合体(配列番号577)]
[CAAGGCCAGTCTGGCCAA][GTTTATTATTGCGGTGGGAATGAGAGTCTGTGCGGTGAGAGGAGGGGCTCGAGCGGTGGCAGCGGTGGCTCTGGTGGTCTGAGCGGCCGTTCCGATAATCATGGCGGCGGTTCTGAAGTGCAGCTGGTGGAATCTGGGGGCGGACTGGTGCAGCCTAAGGGCAGCCTGAAGCTGAGCTGTGCCGCCAGCGGCTTCACCTTCAACACCTACGCCATGAACTGGGTGCGCCAGGCCCCTGGCAAAGGCCTGGAATGGGTGGCCCGGATCAGAAGCAAGTACAACAATTACGCCACCTACTACGCCGACAGCGTGAAGGACAGATTCACCATCAGCCGGGACGACAGCCAGAGCATCCTGTACCTGCAGATGAACAACCTGAAAACCGAGGACACCGCCATGTACTACTGCGTGCGGCACGGCAACTTCGGCAACAGCTATGTGTCTTGGTTTGCCTACTGGGGCCAGGGCACCCTCGTGACAGTGTCTGCCGGTGGTGGTGGTAGTGGTGGCGGTGGTTCAGGCGGTGGCGGTAGCCAGGCTGTCGTGACACAGGAAAGCGCCCTGACCACCAGCCCTGGCGAGACAGTGACCCTGACCTGTAGAAGCAGCACAGGCGCCGTGACCACAAGCAACTACGCCAATTGGGTGCAGGAAAAGCCCGACCACCTGTTCACCGGCCTGATCGGCGGCACCAACAAAAGGGCTCCAGGCGTGCCAGCCAGATTCAGCGGCTCCCTGATCGGAGATAAGGCCGCCCTGACAATCACTGGCGCCCAGACCGAGGACGAGGCCATCTACTTTTGCGCCCTGTGGTACAGCAACCTGTGGGTGTTCGGCGGAGGCACCAAGCTGACCGTGCTGGGCGGCTCCCTGGACCCTAAGTCATCTGACAAAACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACAACAGCACGTACCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGGGAGGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCTACAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTACACGCAGAAGAGCCTCTCCCTGTCTCCGGGTAAA](配列番号43)
アミノ酸配列
[スペーサー(配列番号87)][スペーサーを有さない活性化可能抗体15860-1204-SP34scFv(HvLv)-Fc融合体(配列番号578)]
[QGQSGQ][VYYCGGNESLCGERRGSSGGSGGSGGLSGRSDNHGGGSEVQLVESGGGLVQPKGSLKLSCAASGFTFNTYAMNWVRQAPGKGLEWVARIRSKYNNYATYYADSVKDRFTISRDDSQSILYLQMNNLKTEDTAMYYCVRHGNFGNSYVSWFAYWGQGTLVTVSAGGGGSGGGGSGGGGSQAVVTQESALTTSPGETVTLTCRSSTGAVTTSNYANWVQEKPDHLFTGLIGGTNKRAPGVPARFSGSLIGDKAALTITGAQTEDEAIYFCALWYSNLWVFGGGTKLTVLGGSLDPKSSDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK](配列番号44)
ヌクレオチド配列
[スペーサー(配列番号507)][スペーサーを有さない15864-1204-SP34scFv(HvLv)(配列番号579)]
[CAAGGCCAGTCTGGCCAA][TTTATGTGCCAGCAGCGGATGTGGGGGAATGAGTTTTGCCATCAGGGCTCGAGCGGTGGCAGCGGTGGCTCTGGTGGTCTGAGCGGCCGTTCCGATAATCATGGCGGCGGTTCTGAAGTGCAGCTGGTGGAATCTGGGGGCGGACTGGTGCAGCCTAAGGGCAGCCTGAAGCTGAGCTGTGCCGCCAGCGGCTTCACCTTCAACACCTACGCCATGAACTGGGTGCGCCAGGCCCCTGGCAAAGGCCTGGAATGGGTGGCCCGGATCAGAAGCAAGTACAACAATTACGCCACCTACTACGCCGACAGCGTGAAGGACAGATTCACCATCAGCCGGGACGACAGCCAGAGCATCCTGTACCTGCAGATGAACAACCTGAAAACCGAGGACACCGCCATGTACTACTGCGTGCGGCACGGCAACTTCGGCAACAGCTATGTGTCTTGGTTTGCCTACTGGGGCCAGGGCACCCTCGTGACAGTGTCTGCCGGTGGTGGTGGTAGTGGTGGCGGTGGTTCAGGCGGTGGCGGTAGCCAGGCTGTCGTGACACAGGAAAGCGCCCTGACCACCAGCCCTGGCGAGACAGTGACCCTGACCTGTAGAAGCAGCACAGGCGCCGTGACCACAAGCAACTACGCCAATTGGGTGCAGGAAAAGCCCGACCACCTGTTCACCGGCCTGATCGGCGGCACCAACAAAAGGGCTCCAGGCGTGCCAGCCAGATTCAGCGGCTCCCTGATCGGAGATAAGGCCGCCCTGACAATCACTGGCGCCCAGACCGAGGACGAGGCCATCTACTTTTGCGCCCTGTGGTACAGCAACCTGTGGGTGTTCGGCGGAGGCACCAAGCTGACCGTGCTG](配列番号45)
アミノ酸配列
[スペーサー(配列番号87)][スペーサーを有さない15864-1204-SP34scFv(HvLv)(配列番号580)]
[QGQSGQ][FMCQQRMWGNEFCHQGSSGGSGGSGGLSGRSDNHGGGSEVQLVESGGGLVQPKGSLKLSCAASGFTFNTYAMNWVRQAPGKGLEWVARIRSKYNNYATYYADSVKDRFTISRDDSQSILYLQMNNLKTEDTAMYYCVRHGNFGNSYVSWFAYWGQGTLVTVSAGGGGSGGGGSGGGGSQAVVTQESALTTSPGETVTLTCRSSTGAVTTSNYANWVQEKPDHLFTGLIGGTNKRAPGVPARFSGSLIGDKAALTITGAQTEDEAIYFCALWYSNLWVFGGGTKLTVL](配列番号46)
[スペーサー(配列番号507)][スペーサーを有さない活性化可能抗体15864-1204-SP34scFv(HvLv)-Fc 融合体(配列番号581)]
[CAAGGCCAGTCTGGCCAA][TTTATGTGCCAGCAGCGGATGTGGGGGAATGAGTTTTGCCATCAGGGCTCGAGCGGTGGCAGCGGTGGCTCTGGTGGTCTGAGCGGCCGTTCCGATAATCATGGCGGCGGTTCTGAAGTGCAGCTGGTGGAATCTGGGGGCGGACTGGTGCAGCCTAAGGGCAGCCTGAAGCTGAGCTGTGCCGCCAGCGGCTTCACCTTCAACACCTACGCCATGAACTGGGTGCGCCAGGCCCCTGGCAAAGGCCTGGAATGGGTGGCCCGGATCAGAAGCAAGTACAACAATTACGCCACCTACTACGCCGACAGCGTGAAGGACAGATTCACCATCAGCCGGGACGACAGCCAGAGCATCCTGTACCTGCAGATGAACAACCTGAAAACCGAGGACACCGCCATGTACTACTGCGTGCGGCACGGCAACTTCGGCAACAGCTATGTGTCTTGGTTTGCCTACTGGGGCCAGGGCACCCTCGTGACAGTGTCTGCCGGTGGTGGTGGTAGTGGTGGCGGTGGTTCAGGCGGTGGCGGTAGCCAGGCTGTCGTGACACAGGAAAGCGCCCTGACCACCAGCCCTGGCGAGACAGTGACCCTGACCTGTAGAAGCAGCACAGGCGCCGTGACCACAAGCAACTACGCCAATTGGGTGCAGGAAAAGCCCGACCACCTGTTCACCGGCCTGATCGGCGGCACCAACAAAAGGGCTCCAGGCGTGCCAGCCAGATTCAGCGGCTCCCTGATCGGAGATAAGGCCGCCCTGACAATCACTGGCGCCCAGACCGAGGACGAGGCCATCTACTTTTGCGCCCTGTGGTACAGCAACCTGTGGGTGTTCGGCGGAGGCACCAAGCTGACCGTGCTGGGCGGCTCCCTGGACCCTAAGTCATCTGACAAAACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACAACAGCACGTACCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGGGAGGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCTACAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTACACGCAGAAGAGCCTCTCCCTGTCTCCGGGTAAA](配列番号47)
アミノ酸配列
[スペーサー(配列番号87)][スペーサーを有さない活性化可能抗体15864-1204-SP34scFv(HvLv)-Fc融合体(配列番号582)]
[QGQSGQ][FMCQQRMWGNEFCHQGSSGGSGGSGGLSGRSDNHGGGSEVQLVESGGGLVQPKGSLKLSCAASGFTFNTYAMNWVRQAPGKGLEWVARIRSKYNNYATYYADSVKDRFTISRDDSQSILYLQMNNLKTEDTAMYYCVRHGNFGNSYVSWFAYWGQGTLVTVSAGGGGSGGGGSGGGGSQAVVTQESALTTSPGETVTLTCRSSTGAVTTSNYANWVQEKPDHLFTGLIGGTNKRAPGVPARFSGSLIGDKAALTITGAQTEDEAIYFCALWYSNLWVFGGGTKLTVLGGSLDPKSSDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK](配列番号48)
ヌクレオチド配列
[スペーサー(配列番号507)][スペーサーを有さない15865-1204-SP34scFv(HvLv)(配列番号583)]
[CAAGGCCAGTCTGGCCAA][ATGATGTATTGCGGTGGGAATGAGGTGTTGTGCGGGCCGCGGGTTGGCTCGAGCGGTGGCAGCGGTGGCTCTGGTGGTCTGAGCGGCCGTTCCGATAATCATGGCGGCGGTTCTGAAGTGCAGCTGGTGGAATCTGGGGGCGGACTGGTGCAGCCTAAGGGCAGCCTGAAGCTGAGCTGTGCCGCCAGCGGCTTCACCTTCAACACCTACGCCATGAACTGGGTGCGCCAGGCCCCTGGCAAAGGCCTGGAATGGGTGGCCCGGATCAGAAGCAAGTACAACAATTACGCCACCTACTACGCCGACAGCGTGAAGGACAGATTCACCATCAGCCGGGACGACAGCCAGAGCATCCTGTACCTGCAGATGAACAACCTGAAAACCGAGGACACCGCCATGTACTACTGCGTGCGGCACGGCAACTTCGGCAACAGCTATGTGTCTTGGTTTGCCTACTGGGGCCAGGGCACCCTCGTGACAGTGTCTGCCGGTGGTGGTGGTAGTGGTGGCGGTGGTTCAGGCGGTGGCGGTAGCCAGGCTGTCGTGACACAGGAAAGCGCCCTGACCACCAGCCCTGGCGAGACAGTGACCCTGACCTGTAGAAGCAGCACAGGCGCCGTGACCACAAGCAACTACGCCAATTGGGTGCAGGAAAAGCCCGACCACCTGTTCACCGGCCTGATCGGCGGCACCAACAAAAGGGCTCCAGGCGTGCCAGCCAGATTCAGCGGCTCCCTGATCGGAGATAAGGCCGCCCTGACAATCACTGGCGCCCAGACCGAGGACGAGGCCATCTACTTTTGCGCCCTGTGGTACAGCAACCTGTGGGTGTTCGGCGGAGGCACCAAGCTGACCGTGCTG](配列番号49)
アミノ酸配列
[スペーサー(配列番号87)][スペーサーを有さない15865-1204-SP34scFv(HvLv)(配列番号584)]
[QGQSGQ][MMYCGGNEVLCGPRVGSSGGSGGSGGLSGRSDNHGGGSEVQLVESGGGLVQPKGSLKLSCAASGFTFNTYAMNWVRQAPGKGLEWVARIRSKYNNYATYYADSVKDRFTISRDDSQSILYLQMNNLKTEDTAMYYCVRHGNFGNSYVSWFAYWGQGTLVTVSAGGGGSGGGGSGGGGSQAVVTQESALTTSPGETVTLTCRSSTGAVTTSNYANWVQEKPDHLFTGLIGGTNKRAPGVPARFSGSLIGDKAALTITGAQTEDEAIYFCALWYSNLWVFGGGTKLTVL](配列番号50)
ヌクレオチド配列
[スペーサー(配列番号507)][スペーサーを有さない活性化可能抗体15865-1204-SP34scFv(HvLv)-Fc 融合体(配列番号585)]
[CAAGGCCAGTCTGGCCAA][ATGATGTATTGCGGTGGGAATGAGGTGTTGTGCGGGCCGCGGGTTGGCTCGAGCGGTGGCAGCGGTGGCTCTGGTGGTCTGAGCGGCCGTTCCGATAATCATGGCGGCGGTTCTGAAGTGCAGCTGGTGGAATCTGGGGGCGGACTGGTGCAGCCTAAGGGCAGCCTGAAGCTGAGCTGTGCCGCCAGCGGCTTCACCTTCAACACCTACGCCATGAACTGGGTGCGCCAGGCCCCTGGCAAAGGCCTGGAATGGGTGGCCCGGATCAGAAGCAAGTACAACAATTACGCCACCTACTACGCCGACAGCGTGAAGGACAGATTCACCATCAGCCGGGACGACAGCCAGAGCATCCTGTACCTGCAGATGAACAACCTGAAAACCGAGGACACCGCCATGTACTACTGCGTGCGGCACGGCAACTTCGGCAACAGCTATGTGTCTTGGTTTGCCTACTGGGGCCAGGGCACCCTCGTGACAGTGTCTGCCGGTGGTGGTGGTAGTGGTGGCGGTGGTTCAGGCGGTGGCGGTAGCCAGGCTGTCGTGACACAGGAAAGCGCCCTGACCACCAGCCCTGGCGAGACAGTGACCCTGACCTGTAGAAGCAGCACAGGCGCCGTGACCACAAGCAACTACGCCAATTGGGTGCAGGAAAAGCCCGACCACCTGTTCACCGGCCTGATCGGCGGCACCAACAAAAGGGCTCCAGGCGTGCCAGCCAGATTCAGCGGCTCCCTGATCGGAGATAAGGCCGCCCTGACAATCACTGGCGCCCAGACCGAGGACGAGGCCATCTACTTTTGCGCCCTGTGGTACAGCAACCTGTGGGTGTTCGGCGGAGGCACCAAGCTGACCGTGCTGGGCGGCTCCCTGGACCCTAAGTCATCTGACAAAACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACAACAGCACGTACCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGGGAGGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCTACAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTACACGCAGAAGAGCCTCTCCCTGTCTCCGGGTAAA](配列番号51)
アミノ酸配列
[スペーサー(配列番号87)][スペーサーを有さない活性化可能抗体15865-1204-SP34scFv(HvLv)-Fc融合体(配列番号586)]
[QGQSGQ][MMYCGGNEVLCGPRVGSSGGSGGSGGLSGRSDNHGGGSEVQLVESGGGLVQPKGSLKLSCAASGFTFNTYAMNWVRQAPGKGLEWVARIRSKYNNYATYYADSVKDRFTISRDDSQSILYLQMNNLKTEDTAMYYCVRHGNFGNSYVSWFAYWGQGTLVTVSAGGGGSGGGGSGGGGSQAVVTQESALTTSPGETVTLTCRSSTGAVTTSNYANWVQEKPDHLFTGLIGGTNKRAPGVPARFSGSLIGDKAALTITGAQTEDEAIYFCALWYSNLWVFGGGTKLTVLGGSLDPKSSDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK](配列番号52)
実施例3.性化可能抗-CD3ε抗体のインビトロ特徴づけ
実施例4.二重特異的活性化可能抗体





pLW019: HC C225v5N297Q-CD3HvLv-H-N
ヌクレオチド配列
GAGGTGCAGCTGGTCGAGTCTGGAGGAGGATTGGTGCAGCCTGGAGGGTCATTGAAACTCTCATGTGCAGCCTCTGGATTCACCTTCAATAAGTACGCCATGAACTGGGTCCGCCAGGCTCCAGGAAAGGGTTTGGAATGGGTTGCTCGCATAAGAAGTAAATATAATAATTATGCAACATATTATGCCGATTCAGTGAAAGACAGGTTCACCATCTCCAGAGATGATTCAAAAAACACTGCCTATCTACAAATGAACAACTTGAAAACTGAGGACACTGCCGTGTACTACTGTGTGAGACATGGGAACTTCGGTAATAGCTACATATCCTACTGGGCTTACTGGGGCCAAGGGACTCTGGTCACCGTCTCCTCAGGTGGTGGTGGTTCTGGCGGCGGCGGCTCCGGTGGTGGTGGTTCTCAGACTGTTGTGACTCAGGAACCTTCACTCACCGTATCACCTGGTGGAACAGTCACACTCACTTGTGGCTCCTCGACTGGGGCTGTTACATCTGGCTACTACCCAAACTGGGTCCAACAAAAACCAGGTCAGGCACCCCGTGGTCTAATAGGTGGGACTAAGTTCCTCGCCCCCGGTACTCCTGCCAGATTCTCAGGCTCCCTGCTTGGAGGCAAGGCTGCCCTCACCCTCTCAGGGGTACAGCCAGAGGATGAGGCAGAATATTACTGTGCTCTATGGTACAGCAACCGCTGGGTGTTCGGTGGAGGAACCAAACTGACTGTCCTAGGAGGTGGTGGATCCCAGGTGCAGCTGAAACAGAGCGGCCCGGGCCTGGTGCAGCCGAGCCAGAGCCTGAGCATTACCTGCACCGTGAGCGGCTTTAGCCTGACCAACTATGGCGTGCATTGGGTGCGCCAGAGCCCGGGCAAAGGCCTGGAATGGCTGGGCGTGATTTGGAGCGGCGGCAACACCGATTATAACACCCCGTTTACCAGCCGCCTGAGCATTAACAAAGATAACAGCAAAAGCCAGGTGTTTTTTAAAATGAACAGCCTGCAAAGCCAGGATACCGCGATTTATTATTGCGCGCGCGCGCTGACCTATTATGATTATGAATTTGCGTATTGGGGCCAGGGCACCCTGGTGACCGTGAGCGCGGCTAGCACCAAGGGCCCATCGGTCTTCCCCCTGGCACCCTCCTCCAAGAGCACCTCTGGGGGCACAGCGGCCCTGGGCTGCCTGGTCAAGGACTACTTCCCCGAACCGGTGACGGTGTCGTGGAACTCAGGCGCCCTGACCAGCGGCGTGCACACCTTCCCGGCTGTCCTACAGTCCTCAGGACTCTACTCCCTCAGCAGCGTGGTGACCGTGCCCTCCAGCAGCTTGGGCACCCAGACCTACATCTGCAACGTGAATCACAAGCCCAGCAACACCAAGGTGGACAAGAAAGTTGAGCCCAAATCTTGTGACAAAACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACCAGAGCACGTACCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGGGAGGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCTACAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTACACGCAGAAGAGCCTCTCCCTGTCTCCGGGTAAATGA(配列番号445)
アミノ酸配列
EVQLVESGGGLVQPGGSLKLSCAASGFTFNKYAMNWVRQAPGKGLEWVARIRSKYNNYATYYADSVKDRFTISRDDSKNTAYLQMNNLKTEDTAVYYCVRHGNFGNSYISYWAYWGQGTLVTVSSGGGGSGGGGSGGGGSQTVVTQEPSLTVSPGGTVTLTCGSSTGAVTSGYYPNWVQQKPGQAPRGLIGGTKFLAPGTPARFSGSLLGGKAALTLSGVQPEDEAEYYCALWYSNRWVFGGGTKLTVLGGGGSQVQLKQSGPGLVQPSQSLSITCTVSGFSLTNYGVHWVRQSPGKGLEWLGVIWSGGNTDYNTPFTSRLSINKDNSKSQVFFKMNSLQSQDTAIYYCARALTYYDYEFAYWGQGTLVTVSAASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYQSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK*(配列番号446)
ヌクレオチド配列
GATATCTTGCTGACCCAGAGCCCGGTGATTCTGAGCGTGAGCCCGGGCGAACGTGTGAGCTTTAGCTGCCGCGCGAGCCAGAGCATTGGCACCAACATTCATTGGTATCAGCAGCGCACCAACGGCAGCCCGCGCCTGCTGATTAAATATGCGAGCGAAAGCATTAGCGGCATTCCGAGCCGCTTTAGCGGCAGCGGCAGCGGCACCGATTTTACCCTGAGCATTAACAGCGTGGAAAGCGAAGATATTGCGGATTATTATTGCCAGCAGAACAACAACTGGCCGACCACCTTTGGCGCGGGCACCAAACTGGAACTGAAACGTACGGTGGCTGCACCATCTGTCTTCATCTTCCCGCCATCTGATGAGCAGTTGAAATCTGGAACTGCCTCTGTTGTGTGCCTGCTGAATAACTTCTATCCCAGAGAGGCCAAAGTACAGTGGAAGGTGGATAACGCCCTCCAATCGGGTAACTCCCAGGAGAGTGTCACAGAGCAGGACAGCAAGGACAGCACCTACAGCCTCAGCAGCACCCTGACGCTGAGCAAAGCAGACTACGAGAAACACAAAGTCTACGCCTGCGAAGTCACCCATCAGGGCCTGAGCTCGCCCGTCACAAAGAGCTTCAACAGGGGAGAGTGTTAG(配列番号447)
アミノ酸配列
DILLTQSPVILSVSPGERVSFSCRASQSIGTNIHWYQQRTNGSPRLLIKYASESISGIPSRFSGSGSGTDFTLSINSVESEDIADYYCQQNNNWPTTFGAGTKLELKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC*(配列番号448)
pLW019: HC C225v5N297Q-CD3HvLv-H-N
ヌクレオチド配列
GAGGTGCAGCTGGTCGAGTCTGGAGGAGGATTGGTGCAGCCTGGAGGGTCATTGAAACTCTCATGTGCAGCCTCTGGATTCACCTTCAATAAGTACGCCATGAACTGGGTCCGCCAGGCTCCAGGAAAGGGTTTGGAATGGGTTGCTCGCATAAGAAGTAAATATAATAATTATGCAACATATTATGCCGATTCAGTGAAAGACAGGTTCACCATCTCCAGAGATGATTCAAAAAACACTGCCTATCTACAAATGAACAACTTGAAAACTGAGGACACTGCCGTGTACTACTGTGTGAGACATGGGAACTTCGGTAATAGCTACATATCCTACTGGGCTTACTGGGGCCAAGGGACTCTGGTCACCGTCTCCTCAGGTGGTGGTGGTTCTGGCGGCGGCGGCTCCGGTGGTGGTGGTTCTCAGACTGTTGTGACTCAGGAACCTTCACTCACCGTATCACCTGGTGGAACAGTCACACTCACTTGTGGCTCCTCGACTGGGGCTGTTACATCTGGCTACTACCCAAACTGGGTCCAACAAAAACCAGGTCAGGCACCCCGTGGTCTAATAGGTGGGACTAAGTTCCTCGCCCCCGGTACTCCTGCCAGATTCTCAGGCTCCCTGCTTGGAGGCAAGGCTGCCCTCACCCTCTCAGGGGTACAGCCAGAGGATGAGGCAGAATATTACTGTGCTCTATGGTACAGCAACCGCTGGGTGTTCGGTGGAGGAACCAAACTGACTGTCCTAGGAGGTGGTGGATCCCAGGTGCAGCTGAAACAGAGCGGCCCGGGCCTGGTGCAGCCGAGCCAGAGCCTGAGCATTACCTGCACCGTGAGCGGCTTTAGCCTGACCAACTATGGCGTGCATTGGGTGCGCCAGAGCCCGGGCAAAGGCCTGGAATGGCTGGGCGTGATTTGGAGCGGCGGCAACACCGATTATAACACCCCGTTTACCAGCCGCCTGAGCATTAACAAAGATAACAGCAAAAGCCAGGTGTTTTTTAAAATGAACAGCCTGCAAAGCCAGGATACCGCGATTTATTATTGCGCGCGCGCGCTGACCTATTATGATTATGAATTTGCGTATTGGGGCCAGGGCACCCTGGTGACCGTGAGCGCGGCTAGCACCAAGGGCCCATCGGTCTTCCCCCTGGCACCCTCCTCCAAGAGCACCTCTGGGGGCACAGCGGCCCTGGGCTGCCTGGTCAAGGACTACTTCCCCGAACCGGTGACGGTGTCGTGGAACTCAGGCGCCCTGACCAGCGGCGTGCACACCTTCCCGGCTGTCCTACAGTCCTCAGGACTCTACTCCCTCAGCAGCGTGGTGACCGTGCCCTCCAGCAGCTTGGGCACCCAGACCTACATCTGCAACGTGAATCACAAGCCCAGCAACACCAAGGTGGACAAGAAAGTTGAGCCCAAATCTTGTGACAAAACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACCAGAGCACGTACCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGGGAGGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCTACAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTACACGCAGAAGAGCCTCTCCCTGTCTCCGGGTAAATGA(配列番号445)
アミノ酸配列
EVQLVESGGGLVQPGGSLKLSCAASGFTFNKYAMNWVRQAPGKGLEWVARIRSKYNNYATYYADSVKDRFTISRDDSKNTAYLQMNNLKTEDTAVYYCVRHGNFGNSYISYWAYWGQGTLVTVSSGGGGSGGGGSGGGGSQTVVTQEPSLTVSPGGTVTLTCGSSTGAVTSGYYPNWVQQKPGQAPRGLIGGTKFLAPGTPARFSGSLLGGKAALTLSGVQPEDEAEYYCALWYSNRWVFGGGTKLTVLGGGGSQVQLKQSGPGLVQPSQSLSITCTVSGFSLTNYGVHWVRQSPGKGLEWLGVIWSGGNTDYNTPFTSRLSINKDNSKSQVFFKMNSLQSQDTAIYYCARALTYYDYEFAYWGQGTLVTVSAASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYQSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK*(配列番号446)
ヌクレオチド配列
[スペーサーを有さない(配列番号507)][スペーサーを有さないOPP022(配列番号509)]
[CAAGGCCAGTCTGGCCAG][TGCATCTCACCTCGTGGTTGTCCGGACGGCCCATACGTCATGTACGGCTCGAGCGGTGGCAGCGGTGGCTCTGGTGGATCCGGTCTGAGCGGCCGTTCCGATAATCATGGCAGTAGCGGTACCCAGATCTTGCTGACCCAGAGCCCGGTGATTCTGAGCGTGAGCCCGGGCGAACGTGTGAGCTTTAGCTGCCGCGCGAGCCAGAGCATTGGCACCAACATTCATTGGTATCAGCAGCGCACCAACGGCAGCCCGCGCCTGCTGATTAAATATGCGAGCGAAAGCATTAGCGGCATTCCGAGCCGCTTTAGCGGCAGCGGCAGCGGCACCGATTTTACCCTGAGCATTAACAGCGTGGAAAGCGAAGATATTGCGGATTATTATTGCCAGCAGAACAACAACTGGCCGACCACCTTTGGCGCGGGCACCAAACTGGAACTGAAACGTACGGTGGCTGCACCATCTGTCTTCATCTTCCCGCCATCTGATGAGCAGTTGAAATCTGGAACTGCCTCTGTTGTGTGCCTGCTGAATAACTTCTATCCCAGAGAGGCCAAAGTACAGTGGAAGGTGGATAACGCCCTCCAATCGGGTAACTCCCAGGAGAGTGTCACAGAGCAGGACAGCAAGGACAGCACCTACAGCCTCAGCAGCACCCTGACGCTGAGCAAAGCAGACTACGAGAAACACAAAGTCTACGCCTGCGAAGTCACCCATCAGGGCCTGAGCTCGCCCGTCACAAAGAGCTTCAACAGGGGAGAGTGTTAG](配列番号449)
アミノ酸配列
[スペーサーを有さない(配列番号87)][スペーサーを有さないOPP022(配列番号508)]
[QGQSGQ][CISPRGCPDGPYVMYGSSGGSGGSGGSGLSGRSDNHGSSGTQILLTQSPVILSVSPGERVSFSCRASQSIGTNIHWYQQRTNGSPRLLIKYASESISGIPSRFSGSGSGTDFTLSINSVESEDIADYYCQQNNNWPTTFGAGTKLELKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC]*(配列番号450)
pLW023: C225v5N297Q-15865-CD3LvHv-H-N
ヌクレオチド配列
[スペーサー(配列番号507)][スペーサーを有さないpLW023(配列番号511)]
[CAAGGCCAGTCTGGCCAA][ATGATGTATTGCGGTGGGAATGAGGTGTTGTGCGGGCCGCGGGTTGGCTCGAGCGGTGGCAGCGGTGGCTCTGGTGGTCTGAGCGGCCGTTCCGATAATCATGGCGGCGGTTCTCAGACCGTGGTCACACAGGAGCCCTCACTGACAGTGAGCCCTGGCGGGACCGTCACACTGACTTGTCGCAGTTCAACTGGCGCCGTGACTACCAGCAATTACGCTAACTGGGTCCAGCAGAAACCAGGACAGGCACCACGAGGACTGATCGGAGGAACTAATAAGAGAGCACCAGGAACCCCTGCAAGGTTCTCCGGATCTCTGCTGGGGGGAAAAGCCGCTCTGACACTGAGCGGCGTGCAGCCTGAGGACGAAGCTGAGTACTATTGCGCACTGTGGTACTCCAACCTGTGGGTGTTTGGCGGGGGAACTAAGCTGACCGTCCTGGGAGGAGGAGGAAGCGGAGGAGGAGGGAGCGGAGGAGGAGGATCCGAAGTGCAGCTGGTCGAGAGCGGAGGAGGACTGGTGCAGCCAGGAGGATCCCTGAAGCTGTCTTGTGCAGCCAGTGGCTTCACCTTCAACACTTACGCAATGAACTGGGTGCGGCAGGCACCTGGGAAGGGACTGGAATGGGTCGCCCGGATCAGATCTAAATACAATAACTATGCCACCTACTATGCTGACAGTGTGAAGGATAGGTTCACCATTTCACGCGACGATAGCAAAAACACAGCTTATCTGCAGATGAATAACCTGAAGACCGAGGATACAGCAGTGTACTATTGCGTCAGACACGGCAATTTCGGGAACTCTTACGTGAGTTGGTTTGCCTATTGGGGACAGGGGACACTGGTCACCGTCTCCTCAGGAGGTGGTGGATCCCAGGTGCAGCTGAAACAGAGCGGCCCGGGCCTGGTGCAGCCGAGCCAGAGCCTGAGCATTACCTGCACCGTGAGCGGCTTTAGCCTGACCAACTATGGCGTGCATTGGGTGCGCCAGAGCCCGGGCAAAGGCCTGGAATGGCTGGGCGTGATTTGGAGCGGCGGCAACACCGATTATAACACCCCGTTTACCAGCCGCCTGAGCATTAACAAAGATAACAGCAAAAGCCAGGTGTTTTTTAAAATGAACAGCCTGCAAAGCCAGGATACCGCGATTTATTATTGCGCGCGCGCGCTGACCTATTATGATTATGAATTTGCGTATTGGGGCCAGGGCACCCTGGTGACCGTGAGCGCGGCTAGCACCAAGGGCCCATCGGTCTTCCCCCTGGCACCCTCCTCCAAGAGCACCTCTGGGGGCACAGCGGCCCTGGGCTGCCTGGTCAAGGACTACTTCCCCGAACCGGTGACGGTGTCGTGGAACTCAGGCGCCCTGACCAGCGGCGTGCACACCTTCCCGGCTGTCCTACAGTCCTCAGGACTCTACTCCCTCAGCAGCGTGGTGACCGTGCCCTCCAGCAGCTTGGGCACCCAGACCTACATCTGCAACGTGAATCACAAGCCCAGCAACACCAAGGTGGACAAGAAAGTTGAGCCCAAATCTTGTGACAAAACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACCAGAGCACGTACCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGGGAGGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCTACAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTACACGCAGAAGAGCCTCTCCCTGTCTCCGGGTAAATGA](配列番号451)
アミノ酸配列
[スペーサー(配列番号87)][スペーサーを有さないpLW023(配列番号512)]
[QGQSGQ][MMYCGGNEVLCGPRVGSSGGSGGSGGLSGRSDNHGGGSQTVVTQEPSLTVSPGGTVTLTCRSSTGAVTTSNYANWVQQKPGQAPRGLIGGTNKRAPGTPARFSGSLLGGKAALTLSGVQPEDEAEYYCALWYSNLWVFGGGTKLTVLGGGGSGGGGSGGGGSEVQLVESGGGLVQPGGSLKLSCAASGFTFNTYAMNWVRQAPGKGLEWVARIRSKYNNYATYYADSVKDRFTISRDDSKNTAYLQMNNLKTEDTAVYYCVRHGNFGNSYVSWFAYWGQGTLVTVSSGGGGSQVQLKQSGPGLVQPSQSLSITCTVSGFSLTNYGVHWVRQSPGKGLEWLGVIWSGGNTDYNTPFTSRLSINKDNSKSQVFFKMNSLQSQDTAIYYCARALTYYDYEFAYWGQGTLVTVSAASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYQSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK]*(配列番号452)
ヌクレオチド配列
GATATCTTGCTGACCCAGAGCCCGGTGATTCTGAGCGTGAGCCCGGGCGAACGTGTGAGCTTTAGCTGCCGCGCGAGCCAGAGCATTGGCACCAACATTCATTGGTATCAGCAGCGCACCAACGGCAGCCCGCGCCTGCTGATTAAATATGCGAGCGAAAGCATTAGCGGCATTCCGAGCCGCTTTAGCGGCAGCGGCAGCGGCACCGATTTTACCCTGAGCATTAACAGCGTGGAAAGCGAAGATATTGCGGATTATTATTGCCAGCAGAACAACAACTGGCCGACCACCTTTGGCGCGGGCACCAAACTGGAACTGAAACGTACGGTGGCTGCACCATCTGTCTTCATCTTCCCGCCATCTGATGAGCAGTTGAAATCTGGAACTGCCTCTGTTGTGTGCCTGCTGAATAACTTCTATCCCAGAGAGGCCAAAGTACAGTGGAAGGTGGATAACGCCCTCCAATCGGGTAACTCCCAGGAGAGTGTCACAGAGCAGGACAGCAAGGACAGCACCTACAGCCTCAGCAGCACCCTGACGCTGAGCAAAGCAGACTACGAGAAACACAAAGTCTACGCCTGCGAAGTCACCCATCAGGGCCTGAGCTCGCCCGTCACAAAGAGCTTCAACAGGGGAGAGTGTTAG(配列番号447)
アミノ酸配列
DILLTQSPVILSVSPGERVSFSCRASQSIGTNIHWYQQRTNGSPRLLIKYASESISGIPSRFSGSGSGTDFTLSINSVESEDIADYYCQQNNNWPTTFGAGTKLELKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC*(配列番号448)
pLW022: C225v5N297Q-15865-CD3LvHv-H-N
ヌクレオチド配列
[スペーサー(配列番号507)][スペーサーを有さないpLW022(配列番号895)]
[CAAGGCCAGTCTGGCCAA][GGTTATCGGTGGGGTTGCGAGTGGAATTGCGGTGGGATTACTACTGGCTCGAGCGGTGGCAGCGGTGGCTCTGGTGGTCTGAGCGGCCGTTCCGATAATCATGGCGGCGGTTCTCAGACCGTGGTCACACAGGAGCCCTCACTGACAGTGAGCCCTGGCGGGACCGTCACACTGACTTGTCGCAGTTCAACTGGCGCCGTGACTACCAGCAATTACGCTAACTGGGTCCAGCAGAAACCAGGACAGGCACCACGAGGACTGATCGGAGGAACTAATAAGAGAGCACCAGGAACCCCTGCAAGGTTCTCCGGATCTCTGCTGGGGGGAAAAGCCGCTCTGACACTGAGCGGCGTGCAGCCTGAGGACGAAGCTGAGTACTATTGCGCACTGTGGTACTCCAACCTGTGGGTGTTTGGCGGGGGAACTAAGCTGACCGTCCTGGGAGGAGGAGGAAGCGGAGGAGGAGGGAGCGGAGGAGGAGGATCCGAAGTGCAGCTGGTCGAGAGCGGAGGAGGACTGGTGCAGCCAGGAGGATCCCTGAAGCTGTCTTGTGCAGCCAGTGGCTTCACCTTCAACACTTACGCAATGAACTGGGTGCGGCAGGCACCTGGGAAGGGACTGGAATGGGTCGCCCGGATCAGATCTAAATACAATAACTATGCCACCTACTATGCTGACAGTGTGAAGGATAGGTTCACCATTTCACGCGACGATAGCAAAAACACAGCTTATCTGCAGATGAATAACCTGAAGACCGAGGATACAGCAGTGTACTATTGCGTCAGACACGGCAATTTCGGGAACTCTTACGTGAGTTGGTTTGCCTATTGGGGACAGGGGACACTGGTCACCGTCTCCTCAGGAGGTGGTGGATCCCAGGTGCAGCTGAAACAGAGCGGCCCGGGCCTGGTGCAGCCGAGCCAGAGCCTGAGCATTACCTGCACCGTGAGCGGCTTTAGCCTGACCAACTATGGCGTGCATTGGGTGCGCCAGAGCCCGGGCAAAGGCCTGGAATGGCTGGGCGTGATTTGGAGCGGCGGCAACACCGATTATAACACCCCGTTTACCAGCCGCCTGAGCATTAACAAAGATAACAGCAAAAGCCAGGTGTTTTTTAAAATGAACAGCCTGCAAAGCCAGGATACCGCGATTTATTATTGCGCGCGCGCGCTGACCTATTATGATTATGAATTTGCGTATTGGGGCCAGGGCACCCTGGTGACCGTGAGCGCGGCTAGCACCAAGGGCCCATCGGTCTTCCCCCTGGCACCCTCCTCCAAGAGCACCTCTGGGGGCACAGCGGCCCTGGGCTGCCTGGTCAAGGACTACTTCCCCGAACCGGTGACGGTGTCGTGGAACTCAGGCGCCCTGACCAGCGGCGTGCACACCTTCCCGGCTGTCCTACAGTCCTCAGGACTCTACTCCCTCAGCAGCGTGGTGACCGTGCCCTCCAGCAGCTTGGGCACCCAGACCTACATCTGCAACGTGAATCACAAGCCCAGCAACACCAAGGTGGACAAGAAAGTTGAGCCCAAATCTTGTGACAAAACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACCAGAGCACGTACCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGGGAGGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCTACAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTACACGCAGAAGAGCCTCTCCCTGTCTCCGGGTAAATGA](配列番号453)
アミノ酸配列
[スペーサー(配列番号87)][スペーサーを有さないpLW022(配列番号510)]
[QGQSGQ][GYRWGCEWNCGGITTGSSGGSGGSGGLSGRSDNHGGGSQTVVTQEPSLTVSPGGTVTLTCRSSTGAVTTSNYANWVQQKPGQAPRGLIGGTNKRAPGTPARFSGSLLGGKAALTLSGVQPEDEAEYYCALWYSNLWVFGGGTKLTVLGGGGSGGGGSGGGGSEVQLVESGGGLVQPGGSLKLSCAASGFTFNTYAMNWVRQAPGKGLEWVARIRSKYNNYATYYADSVKDRFTISRDDSKNTAYLQMNNLKTEDTAVYYCVRHGNFGNSYVSWFAYWGQGTLVTVSSGGGGSQVQLKQSGPGLVQPSQSLSITCTVSGFSLTNYGVHWVRQSPGKGLEWLGVIWSGGNTDYNTPFTSRLSINKDNSKSQVFFKMNSLQSQDTAIYYCARALTYYDYEFAYWGQGTLVTVSAASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYQSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK]*(配列番号454)
ヌクレオチド配列
[スペーサー(配列番号507)][スペーサーを有さないOPP022(配列番号509)]
[CAAGGCCAGTCTGGCCAG][TGCATCTCACCTCGTGGTTGTCCGGACGGCCCATACGTCATGTACGGCTCGAGCGGTGGCAGCGGTGGCTCTGGTGGATCCGGTCTGAGCGGCCGTTCCGATAATCATGGCAGTAGCGGTACCCAGATCTTGCTGACCCAGAGCCCGGTGATTCTGAGCGTGAGCCCGGGCGAACGTGTGAGCTTTAGCTGCCGCGCGAGCCAGAGCATTGGCACCAACATTCATTGGTATCAGCAGCGCACCAACGGCAGCCCGCGCCTGCTGATTAAATATGCGAGCGAAAGCATTAGCGGCATTCCGAGCCGCTTTAGCGGCAGCGGCAGCGGCACCGATTTTACCCTGAGCATTAACAGCGTGGAAAGCGAAGATATTGCGGATTATTATTGCCAGCAGAACAACAACTGGCCGACCACCTTTGGCGCGGGCACCAAACTGGAACTGAAACGTACGGTGGCTGCACCATCTGTCTTCATCTTCCCGCCATCTGATGAGCAGTTGAAATCTGGAACTGCCTCTGTTGTGTGCCTGCTGAATAACTTCTATCCCAGAGAGGCCAAAGTACAGTGGAAGGTGGATAACGCCCTCCAATCGGGTAACTCCCAGGAGAGTGTCACAGAGCAGGACAGCAAGGACAGCACCTACAGCCTCAGCAGCACCCTGACGCTGAGCAAAGCAGACTACGAGAAACACAAAGTCTACGCCTGCGAAGTCACCCATCAGGGCCTGAGCTCGCCCGTCACAAAGAGCTTCAACAGGGGAGAGTGTTAG](配列番号449)
アミノ酸配列
[スペーサー(配列番号87)][スペーサーを有さないOPP022(配列番号508)]
[QGQSGQ][CISPRGCPDGPYVMYGSSGGSGGSGGSGLSGRSDNHGSSGTQILLTQSPVILSVSPGERVSFSCRASQSIGTNIHWYQQRTNGSPRLLIKYASESISGIPSRFSGSGSGTDFTLSINSVESEDIADYYCQQNNNWPTTFGAGTKLELKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC*](配列番号450)
pLW023: HC C225v5N297Q-15865-CD3LvHv-H-N
ヌクレオチド配列
[スペーサー(配列番号507)][スペーサーを有さないpLW023(配列番号511)]
[CAAGGCCAGTCTGGCCAA][ATGATGTATTGCGGTGGGAATGAGGTGTTGTGCGGGCCGCGGGTTGGCTCGAGCGGTGGCAGCGGTGGCTCTGGTGGTCTGAGCGGCCGTTCCGATAATCATGGCGGCGGTTCTCAGACCGTGGTCACACAGGAGCCCTCACTGACAGTGAGCCCTGGCGGGACCGTCACACTGACTTGTCGCAGTTCAACTGGCGCCGTGACTACCAGCAATTACGCTAACTGGGTCCAGCAGAAACCAGGACAGGCACCACGAGGACTGATCGGAGGAACTAATAAGAGAGCACCAGGAACCCCTGCAAGGTTCTCCGGATCTCTGCTGGGGGGAAAAGCCGCTCTGACACTGAGCGGCGTGCAGCCTGAGGACGAAGCTGAGTACTATTGCGCACTGTGGTACTCCAACCTGTGGGTGTTTGGCGGGGGAACTAAGCTGACCGTCCTGGGAGGAGGAGGAAGCGGAGGAGGAGGGAGCGGAGGAGGAGGATCCGAAGTGCAGCTGGTCGAGAGCGGAGGAGGACTGGTGCAGCCAGGAGGATCCCTGAAGCTGTCTTGTGCAGCCAGTGGCTTCACCTTCAACACTTACGCAATGAACTGGGTGCGGCAGGCACCTGGGAAGGGACTGGAATGGGTCGCCCGGATCAGATCTAAATACAATAACTATGCCACCTACTATGCTGACAGTGTGAAGGATAGGTTCACCATTTCACGCGACGATAGCAAAAACACAGCTTATCTGCAGATGAATAACCTGAAGACCGAGGATACAGCAGTGTACTATTGCGTCAGACACGGCAATTTCGGGAACTCTTACGTGAGTTGGTTTGCCTATTGGGGACAGGGGACACTGGTCACCGTCTCCTCAGGAGGTGGTGGATCCCAGGTGCAGCTGAAACAGAGCGGCCCGGGCCTGGTGCAGCCGAGCCAGAGCCTGAGCATTACCTGCACCGTGAGCGGCTTTAGCCTGACCAACTATGGCGTGCATTGGGTGCGCCAGAGCCCGGGCAAAGGCCTGGAATGGCTGGGCGTGATTTGGAGCGGCGGCAACACCGATTATAACACCCCGTTTACCAGCCGCCTGAGCATTAACAAAGATAACAGCAAAAGCCAGGTGTTTTTTAAAATGAACAGCCTGCAAAGCCAGGATACCGCGATTTATTATTGCGCGCGCGCGCTGACCTATTATGATTATGAATTTGCGTATTGGGGCCAGGGCACCCTGGTGACCGTGAGCGCGGCTAGCACCAAGGGCCCATCGGTCTTCCCCCTGGCACCCTCCTCCAAGAGCACCTCTGGGGGCACAGCGGCCCTGGGCTGCCTGGTCAAGGACTACTTCCCCGAACCGGTGACGGTGTCGTGGAACTCAGGCGCCCTGACCAGCGGCGTGCACACCTTCCCGGCTGTCCTACAGTCCTCAGGACTCTACTCCCTCAGCAGCGTGGTGACCGTGCCCTCCAGCAGCTTGGGCACCCAGACCTACATCTGCAACGTGAATCACAAGCCCAGCAACACCAAGGTGGACAAGAAAGTTGAGCCCAAATCTTGTGACAAAACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACCAGAGCACGTACCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGGGAGGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCTACAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTACACGCAGAAGAGCCTCTCCCTGTCTCCGGGTAAATGA](配列番号451)
アミノ酸配列
[スペーサー(配列番号87)][スペーサーを有さないpLW023(配列番号512)]
[QGQSGQ][MMYCGGNEVLCGPRVGSSGGSGGSGGLSGRSDNHGGGSQTVVTQEPSLTVSPGGTVTLTCRSSTGAVTTSNYANWVQQKPGQAPRGLIGGTNKRAPGTPARFSGSLLGGKAALTLSGVQPEDEAEYYCALWYSNLWVFGGGTKLTVLGGGGSGGGGSGGGGSEVQLVESGGGLVQPGGSLKLSCAASGFTFNTYAMNWVRQAPGKGLEWVARIRSKYNNYATYYADSVKDRFTISRDDSKNTAYLQMNNLKTEDTAVYYCVRHGNFGNSYVSWFAYWGQGTLVTVSSGGGGSQVQLKQSGPGLVQPSQSLSITCTVSGFSLTNYGVHWVRQSPGKGLEWLGVIWSGGNTDYNTPFTSRLSINKDNSKSQVFFKMNSLQSQDTAIYYCARALTYYDYEFAYWGQGTLVTVSAASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYQSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK](配列番号452)
ヌクレオチド配列
[スペーサー(配列番号507)][スペーサーを有さないOPP022(配列番号509)]
[CAAGGCCAGTCTGGCCAG][TGCATCTCACCTCGTGGTTGTCCGGACGGCCCATACGTCATGTACGGCTCGAGCGGTGGCAGCGGTGGCTCTGGTGGATCCGGTCTGAGCGGCCGTTCCGATAATCATGGCAGTAGCGGTACCCAGATCTTGCTGACCCAGAGCCCGGTGATTCTGAGCGTGAGCCCGGGCGAACGTGTGAGCTTTAGCTGCCGCGCGAGCCAGAGCATTGGCACCAACATTCATTGGTATCAGCAGCGCACCAACGGCAGCCCGCGCCTGCTGATTAAATATGCGAGCGAAAGCATTAGCGGCATTCCGAGCCGCTTTAGCGGCAGCGGCAGCGGCACCGATTTTACCCTGAGCATTAACAGCGTGGAAAGCGAAGATATTGCGGATTATTATTGCCAGCAGAACAACAACTGGCCGACCACCTTTGGCGCGGGCACCAAACTGGAACTGAAACGTACGGTGGCTGCACCATCTGTCTTCATCTTCCCGCCATCTGATGAGCAGTTGAAATCTGGAACTGCCTCTGTTGTGTGCCTGCTGAATAACTTCTATCCCAGAGAGGCCAAAGTACAGTGGAAGGTGGATAACGCCCTCCAATCGGGTAACTCCCAGGAGAGTGTCACAGAGCAGGACAGCAAGGACAGCACCTACAGCCTCAGCAGCACCCTGACGCTGAGCAAAGCAGACTACGAGAAACACAAAGTCTACGCCTGCGAAGTCACCCATCAGGGCCTGAGCTCGCCCGTCACAAAGAGCTTCAACAGGGGAGAGTGTTAG](配列番号449)
アミノ酸配列
[スペーサー(配列番号87)][スペーサーを有さないOPP022(配列番号508)]
[QGQSGQ][CISPRGCPDGPYVMYGSSGGSGGSGGSGLSGRSDNHGSSGTQILLTQSPVILSVSPGERVSFSCRASQSIGTNIHWYQQRTNGSPRLLIKYASESISGIPSRFSGSGSGTDFTLSINSVESEDIADYYCQQNNNWPTTFGAGTKLELKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC](配列番号450)
pLW006: C225v5N297Q
ヌクレオチド配列
CAGGTGCAGCTGAAACAGAGCGGCCCGGGCCTGGTGCAGCCGAGCCAGAGCCTGAGCATTACCTGCACCGTGAGCGGCTTTAGCCTGACCAACTATGGCGTGCATTGGGTGCGCCAGAGCCCGGGCAAAGGCCTGGAATGGCTGGGCGTGATTTGGAGCGGCGGCAACACCGATTATAACACCCCGTTTACCAGCCGCCTGAGCATTAACAAAGATAACAGCAAAAGCCAGGTGTTTTTTAAAATGAACAGCCTGCAAAGCCAGGATACCGCGATTTATTATTGCGCGCGCGCGCTGACCTATTATGATTATGAATTTGCGTATTGGGGCCAGGGCACCCTGGTGACCGTGAGCGCGGCTAGCACCAAGGGCCCATCGGTCTTCCCCCTGGCACCCTCCTCCAAGAGCACCTCTGGGGGCACAGCGGCCCTGGGCTGCCTGGTCAAGGACTACTTCCCCGAACCGGTGACGGTGTCGTGGAACTCAGGCGCCCTGACCAGCGGCGTGCACACCTTCCCGGCTGTCCTACAGTCCTCAGGACTCTACTCCCTCAGCAGCGTGGTGACCGTGCCCTCCAGCAGCTTGGGCACCCAGACCTACATCTGCAACGTGAATCACAAGCCCAGCAACACCAAGGTGGACAAGAAAGTTGAGCCCAAATCTTGTGACAAAACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACCAGAGCACGTACCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGGGAGGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCTACAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTACACGCAGAAGAGCCTCTCCCTGTCTCCGGGTAAATGA(配列番号455)
アミノ酸配列
QVQLKQSGPGLVQPSQSLSITCTVSGFSLTNYGVHWVRQSPGKGLEWLGVIWSGGNTDYNTPFTSRLSINKDNSKSQVFFKMNSLQSQDTAIYYCARALTYYDYEFAYWGQGTLVTVSAASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYQSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK*(配列番号456)
ヌクレオチド配列
GATATCTTGCTGACCCAGAGCCCGGTGATTCTGAGCGTGAGCCCGGGCGAACGTGTGAGCTTTAGCTGCCGCGCGAGCCAGAGCATTGGCACCAACATTCATTGGTATCAGCAGCGCACCAACGGCAGCCCGCGCCTGCTGATTAAATATGCGAGCGAAAGCATTAGCGGCATTCCGAGCCGCTTTAGCGGCAGCGGCAGCGGCACCGATTTTACCCTGAGCATTAACAGCGTGGAAAGCGAAGATATTGCGGATTATTATTGCCAGCAGAACAACAACTGGCCGACCACCTTTGGCGCGGGCACCAAACTGGAAATCAAACGTACGGTGGCTGCACCATCTGTCTTCATCTTCCCGCCATCTGATGAGCAGTTGAAATCTGGAACTGCCTCTGTTGTGTGCCTGCTGAATAACTTCTATCCCAGAGAGGCCAAAGTACAGTGGAAGGTGGATAACGCCCTCCAATCGGGTAACTCCCAGGAGAGTGTCACAGAGCAGGACAGCAAGGACAGCACCTACAGCCTCAGCAGCACCCTGACGCTGAGCAAAGCAGACTACGAGAAACACAAAGTCTACGCCTGCGAAGTCACCCATCAGGGCCTGAGCTCGCCCGTCACAAAGAGCTTCAACAGGGGAGAGTGTTAG(配列番号457)
アミノ酸配列
DILLTQSPVILSVSPGERVSFSCRASQSIGTNIHWYQQRTNGSPRLLIKYASESISGIPSRFSGSGSGTDFTLSINSVESEDIADYYCQQNNNWPTTFGAGTKLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC*(配列番号458)
pLW057: HC C225v5N297Q-CD3LvHv-H-N
ヌクレオチド配列
CAGACCGTGGTCACACAGGAGCCCTCACTGACAGTGAGCCCTGGCGGGACCGTCACACTGACTTGTCGCAGTTCAACTGGCGCCGTGACTACCAGCAATTACGCTAACTGGGTCCAGCAGAAACCAGGACAGGCACCACGAGGACTGATCGGAGGAACTAATAAGAGAGCACCAGGAACCCCTGCAAGGTTCTCCGGATCTCTGCTGGGGGGAAAAGCCGCTCTGACACTGAGCGGCGTGCAGCCTGAGGACGAAGCTGAGTACTATTGCGCACTGTGGTACTCCAACCTGTGGGTGTTTGGCGGGGGAACTAAGCTGACCGTCCTGGGAGGAGGAGGAAGCGGAGGAGGAGGGAGCGGAGGAGGAGGATCCGAAGTGCAGCTGGTCGAGAGCGGAGGAGGACTGGTGCAGCCAGGAGGATCCCTGAAGCTGTCTTGTGCAGCCAGTGGCTTCACCTTCAACACTTACGCAATGAACTGGGTGCGGCAGGCACCTGGGAAGGGACTGGAATGGGTCGCCCGGATCAGATCTAAATACAATAACTATGCCACCTACTATGCTGACAGTGTGAAGGATAGGTTCACCATTTCACGCGACGATAGCAAAAACACAGCTTATCTGCAGATGAATAACCTGAAGACCGAGGATACAGCAGTGTACTATTGCGTCAGACACGGCAATTTCGGGAACTCTTACGTGAGTTGGTTTGCCTATTGGGGACAGGGGACACTGGTCACCGTCTCCTCAGGAGGTGGTGGATCCCAGGTGCAGCTGAAACAGAGCGGCCCGGGCCTGGTGCAGCCGAGCCAGAGCCTGAGCATTACCTGCACCGTGAGCGGCTTTAGCCTGACCAACTATGGCGTGCATTGGGTGCGCCAGAGCCCGGGCAAAGGCCTGGAATGGCTGGGCGTGATTTGGAGCGGCGGCAACACCGATTATAACACCCCGTTTACCAGCCGCCTGAGCATTAACAAAGATAACAGCAAAAGCCAGGTGTTTTTTAAAATGAACAGCCTGCAAAGCCAGGATACCGCGATTTATTATTGCGCGCGCGCGCTGACCTATTATGATTATGAATTTGCGTATTGGGGCCAGGGCACCCTGGTGACCGTGAGCGCGGCTAGCACCAAGGGCCCATCGGTCTTCCCCCTGGCACCCTCCTCCAAGAGCACCTCTGGGGGCACAGCGGCCCTGGGCTGCCTGGTCAAGGACTACTTCCCCGAACCGGTGACGGTGTCGTGGAACTCAGGCGCCCTGACCAGCGGCGTGCACACCTTCCCGGCTGTCCTACAGTCCTCAGGACTCTACTCCCTCAGCAGCGTGGTGACCGTGCCCTCCAGCAGCTTGGGCACCCAGACCTACATCTGCAACGTGAATCACAAGCCCAGCAACACCAAGGTGGACAAGAAAGTTGAGCCCAAATCTTGTGACAAAACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACCAGAGCACGTACCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGGGAGGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCTACAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTACACGCAGAAGAGCCTCTCCCTGTCTCCGGGTAAATGA(配列番号459)
アミノ酸配列
QTVVTQEPSLTVSPGGTVTLTCRSSTGAVTTSNYANWVQQKPGQAPRGLIGGTNKRAPGTPARFSGSLLGGKAALTLSGVQPEDEAEYYCALWYSNLWVFGGGTKLTVLGGGGSGGGGSGGGGSEVQLVESGGGLVQPGGSLKLSCAASGFTFNTYAMNWVRQAPGKGLEWVARIRSKYNNYATYYADSVKDRFTISRDDSKNTAYLQMNNLKTEDTAVYYCVRHGNFGNSYVSWFAYWGQGTLVTVSSGGGGSQVQLKQSGPGLVQPSQSLSITCTVSGFSLTNYGVHWVRQSPGKGLEWLGVIWSGGNTDYNTPFTSRLSINKDNSKSQVFFKMNSLQSQDTAIYYCARALTYYDYEFAYWGQGTLVTVSAASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYQSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK*(配列番号460)
ヌクレオチド配列
GATATCTTGCTGACCCAGAGCCCGGTGATTCTGAGCGTGAGCCCGGGCGAACGTGTGAGCTTTAGCTGCCGCGCGAGCCAGAGCATTGGCACCAACATTCATTGGTATCAGCAGCGCACCAACGGCAGCCCGCGCCTGCTGATTAAATATGCGAGCGAAAGCATTAGCGGCATTCCGAGCCGCTTTAGCGGCAGCGGCAGCGGCACCGATTTTACCCTGAGCATTAACAGCGTGGAAAGCGAAGATATTGCGGATTATTATTGCCAGCAGAACAACAACTGGCCGACCACCTTTGGCGCGGGCACCAAACTGGAAATCAAACGTACGGTGGCTGCACCATCTGTCTTCATCTTCCCGCCATCTGATGAGCAGTTGAAATCTGGAACTGCCTCTGTTGTGTGCCTGCTGAATAACTTCTATCCCAGAGAGGCCAAAGTACAGTGGAAGGTGGATAACGCCCTCCAATCGGGTAACTCCCAGGAGAGTGTCACAGAGCAGGACAGCAAGGACAGCACCTACAGCCTCAGCAGCACCCTGACGCTGAGCAAAGCAGACTACGAGAAACACAAAGTCTACGCCTGCGAAGTCACCCATCAGGGCCTGAGCTCGCCCGTCACAAAGAGCTTCAACAGGGGAGAGTGTTAG(配列番号457)
アミノ酸配列
DILLTQSPVILSVSPGERVSFSCRASQSIGTNIHWYQQRTNGSPRLLIKYASESISGIPSRFSGSGSGTDFTLSINSVESEDIADYYCQQNNNWPTTFGAGTKLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC*(配列番号458)
pLW057: HC C225v5N297Q-CD3LvHv-H-N
ヌクレオチド配列
CAGACCGTGGTCACACAGGAGCCCTCACTGACAGTGAGCCCTGGCGGGACCGTCACACTGACTTGTCGCAGTTCAACTGGCGCCGTGACTACCAGCAATTACGCTAACTGGGTCCAGCAGAAACCAGGACAGGCACCACGAGGACTGATCGGAGGAACTAATAAGAGAGCACCAGGAACCCCTGCAAGGTTCTCCGGATCTCTGCTGGGGGGAAAAGCCGCTCTGACACTGAGCGGCGTGCAGCCTGAGGACGAAGCTGAGTACTATTGCGCACTGTGGTACTCCAACCTGTGGGTGTTTGGCGGGGGAACTAAGCTGACCGTCCTGGGAGGAGGAGGAAGCGGAGGAGGAGGGAGCGGAGGAGGAGGATCCGAAGTGCAGCTGGTCGAGAGCGGAGGAGGACTGGTGCAGCCAGGAGGATCCCTGAAGCTGTCTTGTGCAGCCAGTGGCTTCACCTTCAACACTTACGCAATGAACTGGGTGCGGCAGGCACCTGGGAAGGGACTGGAATGGGTCGCCCGGATCAGATCTAAATACAATAACTATGCCACCTACTATGCTGACAGTGTGAAGGATAGGTTCACCATTTCACGCGACGATAGCAAAAACACAGCTTATCTGCAGATGAATAACCTGAAGACCGAGGATACAGCAGTGTACTATTGCGTCAGACACGGCAATTTCGGGAACTCTTACGTGAGTTGGTTTGCCTATTGGGGACAGGGGACACTGGTCACCGTCTCCTCAGGAGGTGGTGGATCCCAGGTGCAGCTGAAACAGAGCGGCCCGGGCCTGGTGCAGCCGAGCCAGAGCCTGAGCATTACCTGCACCGTGAGCGGCTTTAGCCTGACCAACTATGGCGTGCATTGGGTGCGCCAGAGCCCGGGCAAAGGCCTGGAATGGCTGGGCGTGATTTGGAGCGGCGGCAACACCGATTATAACACCCCGTTTACCAGCCGCCTGAGCATTAACAAAGATAACAGCAAAAGCCAGGTGTTTTTTAAAATGAACAGCCTGCAAAGCCAGGATACCGCGATTTATTATTGCGCGCGCGCGCTGACCTATTATGATTATGAATTTGCGTATTGGGGCCAGGGCACCCTGGTGACCGTGAGCGCGGCTAGCACCAAGGGCCCATCGGTCTTCCCCCTGGCACCCTCCTCCAAGAGCACCTCTGGGGGCACAGCGGCCCTGGGCTGCCTGGTCAAGGACTACTTCCCCGAACCGGTGACGGTGTCGTGGAACTCAGGCGCCCTGACCAGCGGCGTGCACACCTTCCCGGCTGTCCTACAGTCCTCAGGACTCTACTCCCTCAGCAGCGTGGTGACCGTGCCCTCCAGCAGCTTGGGCACCCAGACCTACATCTGCAACGTGAATCACAAGCCCAGCAACACCAAGGTGGACAAGAAAGTTGAGCCCAAATCTTGTGACAAAACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACCAGAGCACGTACCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGGGAGGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCTACAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTACACGCAGAAGAGCCTCTCCCTGTCTCCGGGTAAATGA(配列番号459)
アミノ酸配列
QTVVTQEPSLTVSPGGTVTLTCRSSTGAVTTSNYANWVQQKPGQAPRGLIGGTNKRAPGTPARFSGSLLGGKAALTLSGVQPEDEAEYYCALWYSNLWVFGGGTKLTVLGGGGSGGGGSGGGGSEVQLVESGGGLVQPGGSLKLSCAASGFTFNTYAMNWVRQAPGKGLEWVARIRSKYNNYATYYADSVKDRFTISRDDSKNTAYLQMNNLKTEDTAVYYCVRHGNFGNSYVSWFAYWGQGTLVTVSSGGGGSQVQLKQSGPGLVQPSQSLSITCTVSGFSLTNYGVHWVRQSPGKGLEWLGVIWSGGNTDYNTPFTSRLSINKDNSKSQVFFKMNSLQSQDTAIYYCARALTYYDYEFAYWGQGTLVTVSAASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYQSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK*(配列番号460)
ヌクレオチド配列
[スペーサー(配列番号507)][スペーサーを有さないOPP022(配列番号509)]
[CAAGGCCAGTCTGGCCAG][TGCATCTCACCTCGTGGTTGTCCGGACGGCCCATACGTCATGTACGGCTCGAGCGGTGGCAGCGGTGGCTCTGGTGGATCCGGTCTGAGCGGCCGTTCCGATAATCATGGCAGTAGCGGTACCCAGATCTTGCTGACCCAGAGCCCGGTGATTCTGAGCGTGAGCCCGGGCGAACGTGTGAGCTTTAGCTGCCGCGCGAGCCAGAGCATTGGCACCAACATTCATTGGTATCAGCAGCGCACCAACGGCAGCCCGCGCCTGCTGATTAAATATGCGAGCGAAAGCATTAGCGGCATTCCGAGCCGCTTTAGCGGCAGCGGCAGCGGCACCGATTTTACCCTGAGCATTAACAGCGTGGAAAGCGAAGATATTGCGGATTATTATTGCCAGCAGAACAACAACTGGCCGACCACCTTTGGCGCGGGCACCAAACTGGAACTGAAACGTACGGTGGCTGCACCATCTGTCTTCATCTTCCCGCCATCTGATGAGCAGTTGAAATCTGGAACTGCCTCTGTTGTGTGCCTGCTGAATAACTTCTATCCCAGAGAGGCCAAAGTACAGTGGAAGGTGGATAACGCCCTCCAATCGGGTAACTCCCAGGAGAGTGTCACAGAGCAGGACAGCAAGGACAGCACCTACAGCCTCAGCAGCACCCTGACGCTGAGCAAAGCAGACTACGAGAAACACAAAGTCTACGCCTGCGAAGTCACCCATCAGGGCCTGAGCTCGCCCGTCACAAAGAGCTTCAACAGGGGAGAGTGTTAG](配列番号449)
アミノ酸配列
[スペーサー(配列番号87)][スペーサーを有さないOPP022(配列番号508)]
[QGQSGQ][CISPRGCPDGPYVMYGSSGGSGGSGGSGLSGRSDNHGSSGTQILLTQSPVILSVSPGERVSFSCRASQSIGTNIHWYQQRTNGSPRLLIKYASESISGIPSRFSGSGSGTDFTLSINSVESEDIADYYCQQNNNWPTTFGAGTKLELKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC]*(配列番号450)
pLW078: HC IL6RN297Q
ヌクレオチド配列
CAGGTGCAGCTGCAGGAGTCCGGACCAGGACTGGTCCGGCCCTCACAGACTCTGAGCCTGACATGCACTGTGTCAGGCTACAGCATCACCTCCGATCACGCCTGGAGCTGGGTCAGGCAGCCACCTGGACGCGGCCTGGAATGGATCGGCTACATTTCTTATAGTGGGATCACCACATACAACCCCTCTCTGAAGAGTCGAGTGACCATTTCCAGAGACAACTCTAAAAATACACTGTATCTGCAGATGAATAGTCTGCGGGCCGAGGATACAGCTGTGTACTATTGTGCACGGTCTCTGGCCAGAACTACCGCTATGGACTATTGGGGGCAGGGAAGCCTGGTGACCGTCAGCTCCGCTAGCACCAAGGGCCCATCGGTCTTCCCCCTGGCACCCTCCTCCAAGAGCACCTCTGGGGGCACAGCGGCCCTGGGCTGCCTGGTCAAGGACTACTTCCCCGAACCGGTGACGGTGTCGTGGAACTCAGGCGCCCTGACCAGCGGCGTGCACACCTTCCCGGCTGTCCTACAGTCCTCAGGACTCTACTCCCTCAGCAGCGTGGTGACCGTGCCCTCCAGCAGCTTGGGCACCCAGACCTACATCTGCAACGTGAATCACAAGCCCAGCAACACCAAGGTGGACAAGAAAGTTGAGCCCAAATCTTGTGACAAAACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACCAGAGCACGTACCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGGGAGGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCTACAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTACACGCAGAAGAGCCTCTCCCTGTCTCCGGGTAAATGA(配列番号465)
アミノ酸配列
QVQLQESGPGLVRPSQTLSLTCTVSGYSITSDHAWSWVRQPPGRGLEWIGYISYSGITTYNPSLKSRVTISRDNSKNTLYLQMNSLRAEDTAVYYCARSLARTTAMDYWGQGSLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYQSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK*(配列番号466)
ヌクレオチド配列
GACATCCAGATGACTCAGTCTCCTAGCTCCCTGTCCGCCTCTGTGGGGGACCGAGTCACCATCACATGCAGAGCCAGCCAGGATATTTCTAGTTACCTGAACTGGTATCAGCAGAAGCCCGGAAAAGCACCTAAGCTGCTGATCTACTATACCTCCAGGCTGCACTCTGGCGTGCCCAGTCGGTTCAGTGGCTCAGGGAGCGGAACCGACTTCACTTTTACCATCTCAAGCCTGCAGCCAGAGGATATTGCCACATACTATTGTCAGCAGGGCAATACACTGCCCTACACTTTTGGCCAGGGGACCAAGGTGGAAATCAAACGTACGGTGGCTGCACCATCTGTCTTCATCTTCCCGCCATCTGATGAGCAGTTGAAATCTGGAACTGCCTCTGTTGTGTGCCTGCTGAATAACTTCTATCCCAGAGAGGCCAAAGTACAGTGGAAGGTGGATAACGCCCTCCAATCGGGTAACTCCCAGGAGAGTGTCACAGAGCAGGACAGCAAGGACAGCACCTACAGCCTCAGCAGCACCCTGACGCTGAGCAAAGCAGACTACGAGAAACACAAAGTCTACGCCTGCGAAGTCACCCATCAGGGCCTGAGCTCGCCCGTCACAAAGAGCTTCAACAGGGGAGAGTGTTAG(配列番号467)
アミノ酸配列
DIQMTQSPSSLSASVGDRVTITCRASQDISSYLNWYQQKPGKAPKLLIYYTSRLHSGVPSRFSGSGSGTDFTFTISSLQPEDIATYYCQQGNTLPYTFGQGTKVEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC*(配列番号468)
pLW083: HC IL6RN297Q-CD3LvHv-H-N
ヌクレオチド配列
CAGACCGTGGTCACACAGGAGCCCTCACTGACAGTGAGCCCTGGCGGGACCGTCACACTGACTTGTCGCAGTTCAACTGGCGCCGTGACTACCAGCAATTACGCTAACTGGGTCCAGCAGAAACCAGGACAGGCACCACGAGGACTGATCGGAGGAACTAATAAGAGAGCACCAGGAACCCCTGCAAGGTTCTCCGGATCTCTGCTGGGGGGAAAAGCCGCTCTGACACTGAGCGGCGTGCAGCCTGAGGACGAAGCTGAGTACTATTGCGCACTGTGGTACTCCAACCTGTGGGTGTTTGGCGGGGGAACTAAGCTGACCGTCCTGGGAGGAGGAGGAAGCGGAGGAGGAGGGAGCGGAGGAGGAGGATCCGAAGTGCAGCTGGTCGAGAGCGGAGGAGGACTGGTGCAGCCAGGAGGATCCCTGAAGCTGTCTTGTGCAGCCAGTGGCTTCACCTTCAACACTTACGCAATGAACTGGGTGCGGCAGGCACCTGGGAAGGGACTGGAATGGGTCGCCCGGATCAGATCTAAATACAATAACTATGCCACCTACTATGCTGACAGTGTGAAGGATAGGTTCACCATTTCACGCGACGATAGCAAAAACACAGCTTATCTGCAGATGAATAACCTGAAGACCGAGGATACAGCAGTGTACTATTGCGTCAGACACGGCAATTTCGGGAACTCTTACGTGAGTTGGTTTGCCTATTGGGGACAGGGGACACTGGTCACCGTCTCCTCAGGAGGTGGTGGATCCCAGGTGCAGCTGCAGGAGTCCGGACCAGGACTGGTCCGGCCCTCACAGACTCTGAGCCTGACATGCACTGTGTCAGGCTACAGCATCACCTCCGATCACGCCTGGAGCTGGGTCAGGCAGCCACCTGGACGCGGCCTGGAATGGATCGGCTACATTTCTTATAGTGGGATCACCACATACAACCCCTCTCTGAAGAGTCGAGTGACCATTTCCAGAGACAACTCTAAAAATACACTGTATCTGCAGATGAATAGTCTGCGGGCCGAGGATACAGCTGTGTACTATTGTGCACGGTCTCTGGCCAGAACTACCGCTATGGACTATTGGGGGCAGGGAAGCCTGGTGACCGTCAGCTCCGCTAGCACCAAGGGCCCATCGGTCTTCCCCCTGGCACCCTCCTCCAAGAGCACCTCTGGGGGCACAGCGGCCCTGGGCTGCCTGGTCAAGGACTACTTCCCCGAACCGGTGACGGTGTCGTGGAACTCAGGCGCCCTGACCAGCGGCGTGCACACCTTCCCGGCTGTCCTACAGTCCTCAGGACTCTACTCCCTCAGCAGCGTGGTGACCGTGCCCTCCAGCAGCTTGGGCACCCAGACCTACATCTGCAACGTGAATCACAAGCCCAGCAACACCAAGGTGGACAAGAAAGTTGAGCCCAAATCTTGTGACAAAACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACCAGAGCACGTACCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGGGAGGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCTACAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTACACGCAGAAGAGCCTCTCCCTGTCTCCGGGTAAATGA(配列番号469)
アミノ酸配列
QTVVTQEPSLTVSPGGTVTLTCRSSTGAVTTSNYANWVQQKPGQAPRGLIGGTNKRAPGTPARFSGSLLGGKAALTLSGVQPEDEAEYYCALWYSNLWVFGGGTKLTVLGGGGSGGGGSGGGGSEVQLVESGGGLVQPGGSLKLSCAASGFTFNTYAMNWVRQAPGKGLEWVARIRSKYNNYATYYADSVKDRFTISRDDSKNTAYLQMNNLKTEDTAVYYCVRHGNFGNSYVSWFAYWGQGTLVTVSSGGGGSQVQLQESGPGLVRPSQTLSLTCTVSGYSITSDHAWSWVRQPPGRGLEWIGYISYSGITTYNPSLKSRVTISRDNSKNTLYLQMNSLRAEDTAVYYCARSLARTTAMDYWGQGSLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYQSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK*(配列番号470)
ヌクレオチド配列
GACATCCAGATGACTCAGTCTCCTAGCTCCCTGTCCGCCTCTGTGGGGGACCGAGTCACCATCACATGCAGAGCCAGCCAGGATATTTCTAGTTACCTGAACTGGTATCAGCAGAAGCCCGGAAAAGCACCTAAGCTGCTGATCTACTATACCTCCAGGCTGCACTCTGGCGTGCCCAGTCGGTTCAGTGGCTCAGGGAGCGGAACCGACTTCACTTTTACCATCTCAAGCCTGCAGCCAGAGGATATTGCCACATACTATTGTCAGCAGGGCAATACACTGCCCTACACTTTTGGCCAGGGGACCAAGGTGGAAATCAAACGTACGGTGGCTGCACCATCTGTCTTCATCTTCCCGCCATCTGATGAGCAGTTGAAATCTGGAACTGCCTCTGTTGTGTGCCTGCTGAATAACTTCTATCCCAGAGAGGCCAAAGTACAGTGGAAGGTGGATAACGCCCTCCAATCGGGTAACTCCCAGGAGAGTGTCACAGAGCAGGACAGCAAGGACAGCACCTACAGCCTCAGCAGCACCCTGACGCTGAGCAAAGCAGACTACGAGAAACACAAAGTCTACGCCTGCGAAGTCACCCATCAGGGCCTGAGCTCGCCCGTCACAAAGAGCTTCAACAGGGGAGAGTGTTAG(配列番号467)
アミノ酸配列
DIQMTQSPSSLSASVGDRVTITCRASQDISSYLNWYQQKPGKAPKLLIYYTSRLHSGVPSRFSGSGSGTDFTFTISSLQPEDIATYYCQQGNTLPYTFGQGTKVEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC*(配列番号468)
pLW085: HC IL6RN297Q-15865_1204-CD3LvHv-H-N
ヌクレオチド配列
[スペーサー(配列番号507)][スペーサーを有さないpLW085(配列番号513)]
[CAAGGCCAGTCTGGCCAA][ATGATGTATTGCGGTGGGAATGAGGTGTTGTGCGGGCCGCGGGTTGGCTCGAGCGGTGGCAGCGGTGGCTCTGGTGGTCTGAGCGGCCGTTCCGATAATCATGGCGGCGGTTCTCAGACCGTGGTCACACAGGAGCCCTCACTGACAGTGAGCCCTGGCGGGACCGTCACACTGACTTGTCGCAGTTCAACTGGCGCCGTGACTACCAGCAATTACGCTAACTGGGTCCAGCAGAAACCAGGACAGGCACCACGAGGACTGATCGGAGGAACTAATAAGAGAGCACCAGGAACCCCTGCAAGGTTCTCCGGATCTCTGCTGGGGGGAAAAGCCGCTCTGACACTGAGCGGCGTGCAGCCTGAGGACGAAGCTGAGTACTATTGCGCACTGTGGTACTCCAACCTGTGGGTGTTTGGCGGGGGAACTAAGCTGACCGTCCTGGGAGGAGGAGGAAGCGGAGGAGGAGGGAGCGGAGGAGGAGGATCCGAAGTGCAGCTGGTCGAGAGCGGAGGAGGACTGGTGCAGCCAGGAGGATCCCTGAAGCTGTCTTGTGCAGCCAGTGGCTTCACCTTCAACACTTACGCAATGAACTGGGTGCGGCAGGCACCTGGGAAGGGACTGGAATGGGTCGCCCGGATCAGATCTAAATACAATAACTATGCCACCTACTATGCTGACAGTGTGAAGGATAGGTTCACCATTTCACGCGACGATAGCAAAAACACAGCTTATCTGCAGATGAATAACCTGAAGACCGAGGATACAGCAGTGTACTATTGCGTCAGACACGGCAATTTCGGGAACTCTTACGTGAGTTGGTTTGCCTATTGGGGACAGGGGACACTGGTCACCGTCTCCTCAGGAGGTGGTGGATCCCAGGTGCAGCTGCAGGAGTCCGGACCAGGACTGGTCCGGCCCTCACAGACTCTGAGCCTGACATGCACTGTGTCAGGCTACAGCATCACCTCCGATCACGCCTGGAGCTGGGTCAGGCAGCCACCTGGACGCGGCCTGGAATGGATCGGCTACATTTCTTATAGTGGGATCACCACATACAACCCCTCTCTGAAGAGTCGAGTGACCATTTCCAGAGACAACTCTAAAAATACACTGTATCTGCAGATGAATAGTCTGCGGGCCGAGGATACAGCTGTGTACTATTGTGCACGGTCTCTGGCCAGAACTACCGCTATGGACTATTGGGGGCAGGGAAGCCTGGTGACCGTCAGCTCCGCTAGCACCAAGGGCCCATCGGTCTTCCCCCTGGCACCCTCCTCCAAGAGCACCTCTGGGGGCACAGCGGCCCTGGGCTGCCTGGTCAAGGACTACTTCCCCGAACCGGTGACGGTGTCGTGGAACTCAGGCGCCCTGACCAGCGGCGTGCACACCTTCCCGGCTGTCCTACAGTCCTCAGGACTCTACTCCCTCAGCAGCGTGGTGACCGTGCCCTCCAGCAGCTTGGGCACCCAGACCTACATCTGCAACGTGAATCACAAGCCCAGCAACACCAAGGTGGACAAGAAAGTTGAGCCCAAATCTTGTGACAAAACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACCAGAGCACGTACCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGGGAGGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCTACAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTACACGCAGAAGAGCCTCTCCCTGTCTCCGGGTAAATGA](配列番号471)
アミノ酸配列
[スペーサー(配列番号87)][スペーサーを有さないpLW085(配列番号514)]
[QGQSGQ][MMYCGGNEVLCGPRVGSSGGSGGSGGLSGRSDNHGGGSQTVVTQEPSLTVSPGGTVTLTCRSSTGAVTTSNYANWVQQKPGQAPRGLIGGTNKRAPGTPARFSGSLLGGKAALTLSGVQPEDEAEYYCALWYSNLWVFGGGTKLTVLGGGGSGGGGSGGGGSEVQLVESGGGLVQPGGSLKLSCAASGFTFNTYAMNWVRQAPGKGLEWVARIRSKYNNYATYYADSVKDRFTISRDDSKNTAYLQMNNLKTEDTAVYYCVRHGNFGNSYVSWFAYWGQGTLVTVSSGGGGSQVQLQESGPGLVRPSQTLSLTCTVSGYSITSDHAWSWVRQPPGRGLEWIGYISYSGITTYNPSLKSRVTISRDNSKNTLYLQMNSLRAEDTAVYYCARSLARTTAMDYWGQGSLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYQSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK]*(配列番号472)
ヌクレオチド配列
GACATCCAGATGACTCAGTCTCCTAGCTCCCTGTCCGCCTCTGTGGGGGACCGAGTCACCATCACATGCAGAGCCAGCCAGGATATTTCTAGTTACCTGAACTGGTATCAGCAGAAGCCCGGAAAAGCACCTAAGCTGCTGATCTACTATACCTCCAGGCTGCACTCTGGCGTGCCCAGTCGGTTCAGTGGCTCAGGGAGCGGAACCGACTTCACTTTTACCATCTCAAGCCTGCAGCCAGAGGATATTGCCACATACTATTGTCAGCAGGGCAATACACTGCCCTACACTTTTGGCCAGGGGACCAAGGTGGAAATCAAACGTACGGTGGCTGCACCATCTGTCTTCATCTTCCCGCCATCTGATGAGCAGTTGAAATCTGGAACTGCCTCTGTTGTGTGCCTGCTGAATAACTTCTATCCCAGAGAGGCCAAAGTACAGTGGAAGGTGGATAACGCCCTCCAATCGGGTAACTCCCAGGAGAGTGTCACAGAGCAGGACAGCAAGGACAGCACCTACAGCCTCAGCAGCACCCTGACGCTGAGCAAAGCAGACTACGAGAAACACAAAGTCTACGCCTGCGAAGTCACCCATCAGGGCCTGAGCTCGCCCGTCACAAAGAGCTTCAACAGGGGAGAGTGTTAG(配列番号467)
アミノ酸配列
DIQMTQSPSSLSASVGDRVTITCRASQDISSYLNWYQQKPGKAPKLLIYYTSRLHSGVPSRFSGSGSGTDFTFTISSLQPEDIATYYCQQGNTLPYTFGQGTKVEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC*(配列番号468)
pLW085: HC IL6RN297Q-15865_1204-CD3LvHv-H-N
ヌクレオチド配列
[スペーサー(配列番号507)][スペーサーを有さないpLW085(配列番号513)]
[CAAGGCCAGTCTGGCCAA][ATGATGTATTGCGGTGGGAATGAGGTGTTGTGCGGGCCGCGGGTTGGCTCGAGCGGTGGCAGCGGTGGCTCTGGTGGTCTGAGCGGCCGTTCCGATAATCATGGCGGCGGTTCTCAGACCGTGGTCACACAGGAGCCCTCACTGACAGTGAGCCCTGGCGGGACCGTCACACTGACTTGTCGCAGTTCAACTGGCGCCGTGACTACCAGCAATTACGCTAACTGGGTCCAGCAGAAACCAGGACAGGCACCACGAGGACTGATCGGAGGAACTAATAAGAGAGCACCAGGAACCCCTGCAAGGTTCTCCGGATCTCTGCTGGGGGGAAAAGCCGCTCTGACACTGAGCGGCGTGCAGCCTGAGGACGAAGCTGAGTACTATTGCGCACTGTGGTACTCCAACCTGTGGGTGTTTGGCGGGGGAACTAAGCTGACCGTCCTGGGAGGAGGAGGAAGCGGAGGAGGAGGGAGCGGAGGAGGAGGATCCGAAGTGCAGCTGGTCGAGAGCGGAGGAGGACTGGTGCAGCCAGGAGGATCCCTGAAGCTGTCTTGTGCAGCCAGTGGCTTCACCTTCAACACTTACGCAATGAACTGGGTGCGGCAGGCACCTGGGAAGGGACTGGAATGGGTCGCCCGGATCAGATCTAAATACAATAACTATGCCACCTACTATGCTGACAGTGTGAAGGATAGGTTCACCATTTCACGCGACGATAGCAAAAACACAGCTTATCTGCAGATGAATAACCTGAAGACCGAGGATACAGCAGTGTACTATTGCGTCAGACACGGCAATTTCGGGAACTCTTACGTGAGTTGGTTTGCCTATTGGGGACAGGGGACACTGGTCACCGTCTCCTCAGGAGGTGGTGGATCCCAGGTGCAGCTGCAGGAGTCCGGACCAGGACTGGTCCGGCCCTCACAGACTCTGAGCCTGACATGCACTGTGTCAGGCTACAGCATCACCTCCGATCACGCCTGGAGCTGGGTCAGGCAGCCACCTGGACGCGGCCTGGAATGGATCGGCTACATTTCTTATAGTGGGATCACCACATACAACCCCTCTCTGAAGAGTCGAGTGACCATTTCCAGAGACAACTCTAAAAATACACTGTATCTGCAGATGAATAGTCTGCGGGCCGAGGATACAGCTGTGTACTATTGTGCACGGTCTCTGGCCAGAACTACCGCTATGGACTATTGGGGGCAGGGAAGCCTGGTGACCGTCAGCTCCGCTAGCACCAAGGGCCCATCGGTCTTCCCCCTGGCACCCTCCTCCAAGAGCACCTCTGGGGGCACAGCGGCCCTGGGCTGCCTGGTCAAGGACTACTTCCCCGAACCGGTGACGGTGTCGTGGAACTCAGGCGCCCTGACCAGCGGCGTGCACACCTTCCCGGCTGTCCTACAGTCCTCAGGACTCTACTCCCTCAGCAGCGTGGTGACCGTGCCCTCCAGCAGCTTGGGCACCCAGACCTACATCTGCAACGTGAATCACAAGCCCAGCAACACCAAGGTGGACAAGAAAGTTGAGCCCAAATCTTGTGACAAAACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACCAGAGCACGTACCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGGGAGGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCTACAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTACACGCAGAAGAGCCTCTCCCTGTCTCCGGGTAAATGA](配列番号471)
アミノ酸配列
[スペーサー(配列番号87)][スペーサーを有さないpLW085(配列番号514)]
[QGQSGQ][MMYCGGNEVLCGPRVGSSGGSGGSGGLSGRSDNHGGGSQTVVTQEPSLTVSPGGTVTLTCRSSTGAVTTSNYANWVQQKPGQAPRGLIGGTNKRAPGTPARFSGSLLGGKAALTLSGVQPEDEAEYYCALWYSNLWVFGGGTKLTVLGGGGSGGGGSGGGGSEVQLVESGGGLVQPGGSLKLSCAASGFTFNTYAMNWVRQAPGKGLEWVARIRSKYNNYATYYADSVKDRFTISRDDSKNTAYLQMNNLKTEDTAVYYCVRHGNFGNSYVSWFAYWGQGTLVTVSSGGGGSQVQLQESGPGLVRPSQTLSLTCTVSGYSITSDHAWSWVRQPPGRGLEWIGYISYSGITTYNPSLKSRVTISRDNSKNTLYLQMNSLRAEDTAVYYCARSLARTTAMDYWGQGSLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYQSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK]*(配列番号472)
ヌクレオチド配列
[スペーサー(配列番号507)][スペーサーを有さないpLW080(配列番号515)]
[CAAGGCCAGTCTGGCCAG][TATGGGTCCTGCAGTTGGAACTATGTACACATATTCATGGATTGCGGCTCGAGCGGTGGCAGCGGTGGCTCTGGTGGTCTGAGCGGCCGTTCCGATAATCATGGCGGCGGTTCTGACATCCAGATGACTCAGTCTCCTAGCTCCCTGTCCGCCTCTGTGGGGGACCGAGTCACCATCACATGCAGAGCCAGCCAGGATATTTCTAGTTACCTGAACTGGTATCAGCAGAAGCCCGGAAAAGCACCTAAGCTGCTGATCTACTATACCTCCAGGCTGCACTCTGGCGTGCCCAGTCGGTTCAGTGGCTCAGGGAGCGGAACCGACTTCACTTTTACCATCTCAAGCCTGCAGCCAGAGGATATTGCCACATACTATTGTCAGCAGGGCAATACACTGCCCTACACTTTTGGCCAGGGGACCAAGGTGGAAATCAAACGTACGGTGGCTGCACCATCTGTCTTCATCTTCCCGCCATCTGATGAGCAGTTGAAATCTGGAACTGCCTCTGTTGTGTGCCTGCTGAATAACTTCTATCCCAGAGAGGCCAAAGTACAGTGGAAGGTGGATAACGCCCTCCAATCGGGTAACTCCCAGGAGAGTGTCACAGAGCAGGACAGCAAGGACAGCACCTACAGCCTCAGCAGCACCCTGACGCTGAGCAAAGCAGACTACGAGAAACACAAAGTCTACGCCTGCGAAGTCACCCATCAGGGCCTGAGCTCGCCCGTCACAAAGAGCTTCAACAGGGGAGAGTGTTAG](配列番号473)
アミノ酸配列
[スペーサー(配列番号87)][スペーサーを有さないpLW080(配列番号516)]
[QGQSGQ][YGSCSWNYVHIFMDCGSSGGSGGSGGLSGRSDNHGGGSDIQMTQSPSSLSASVGDRVTITCRASQDISSYLNWYQQKPGKAPKLLIYYTSRLHSGVPSRFSGSGSGTDFTFTISSLQPEDIATYYCQQGNTLPYTFGQGTKVEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC]*(配列番号474)
pLW083: HC AV1N297Q-CD3LvHv-H-N
ヌクレオチド配列
CAGACCGTGGTCACACAGGAGCCCTCACTGACAGTGAGCCCTGGCGGGACCGTCACACTGACTTGTCGCAGTTCAACTGGCGCCGTGACTACCAGCAATTACGCTAACTGGGTCCAGCAGAAACCAGGACAGGCACCACGAGGACTGATCGGAGGAACTAATAAGAGAGCACCAGGAACCCCTGCAAGGTTCTCCGGATCTCTGCTGGGGGGAAAAGCCGCTCTGACACTGAGCGGCGTGCAGCCTGAGGACGAAGCTGAGTACTATTGCGCACTGTGGTACTCCAACCTGTGGGTGTTTGGCGGGGGAACTAAGCTGACCGTCCTGGGAGGAGGAGGAAGCGGAGGAGGAGGGAGCGGAGGAGGAGGATCCGAAGTGCAGCTGGTCGAGAGCGGAGGAGGACTGGTGCAGCCAGGAGGATCCCTGAAGCTGTCTTGTGCAGCCAGTGGCTTCACCTTCAACACTTACGCAATGAACTGGGTGCGGCAGGCACCTGGGAAGGGACTGGAATGGGTCGCCCGGATCAGATCTAAATACAATAACTATGCCACCTACTATGCTGACAGTGTGAAGGATAGGTTCACCATTTCACGCGACGATAGCAAAAACACAGCTTATCTGCAGATGAATAACCTGAAGACCGAGGATACAGCAGTGTACTATTGCGTCAGACACGGCAATTTCGGGAACTCTTACGTGAGTTGGTTTGCCTATTGGGGACAGGGGACACTGGTCACCGTCTCCTCAGGAGGTGGTGGATCCCAGGTGCAGCTGCAGGAGTCCGGACCAGGACTGGTCCGGCCCTCACAGACTCTGAGCCTGACATGCACTGTGTCAGGCTACAGCATCACCTCCGATCACGCCTGGAGCTGGGTCAGGCAGCCACCTGGACGCGGCCTGGAATGGATCGGCTACATTTCTTATAGTGGGATCACCACATACAACCCCTCTCTGAAGAGTCGAGTGACCATTTCCAGAGACAACTCTAAAAATACACTGTATCTGCAGATGAATAGTCTGCGGGCCGAGGATACAGCTGTGTACTATTGTGCACGGTCTCTGGCCAGAACTACCGCTATGGACTATTGGGGGCAGGGAAGCCTGGTGACCGTCAGCTCCGCTAGCACCAAGGGCCCATCGGTCTTCCCCCTGGCACCCTCCTCCAAGAGCACCTCTGGGGGCACAGCGGCCCTGGGCTGCCTGGTCAAGGACTACTTCCCCGAACCGGTGACGGTGTCGTGGAACTCAGGCGCCCTGACCAGCGGCGTGCACACCTTCCCGGCTGTCCTACAGTCCTCAGGACTCTACTCCCTCAGCAGCGTGGTGACCGTGCCCTCCAGCAGCTTGGGCACCCAGACCTACATCTGCAACGTGAATCACAAGCCCAGCAACACCAAGGTGGACAAGAAAGTTGAGCCCAAATCTTGTGACAAAACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACCAGAGCACGTACCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGGGAGGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCTACAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTACACGCAGAAGAGCCTCTCCCTGTCTCCGGGTAAATGA(配列番号469)
アミノ酸配列
QTVVTQEPSLTVSPGGTVTLTCRSSTGAVTTSNYANWVQQKPGQAPRGLIGGTNKRAPGTPARFSGSLLGGKAALTLSGVQPEDEAEYYCALWYSNLWVFGGGTKLTVLGGGGSGGGGSGGGGSEVQLVESGGGLVQPGGSLKLSCAASGFTFNTYAMNWVRQAPGKGLEWVARIRSKYNNYATYYADSVKDRFTISRDDSKNTAYLQMNNLKTEDTAVYYCVRHGNFGNSYVSWFAYWGQGTLVTVSSGGGGSQVQLQESGPGLVRPSQTLSLTCTVSGYSITSDHAWSWVRQPPGRGLEWIGYISYSGITTYNPSLKSRVTISRDNSKNTLYLQMNSLRAEDTAVYYCARSLARTTAMDYWGQGSLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYQSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK*(配列番号470)
ヌクレオチド配列
[スペーサー(配列番号507)][スペーサーを有さないpLW080(配列番号515)]
[CAAGGCCAGTCTGGCCAG][TATGGGTCCTGCAGTTGGAACTATGTACACATATTCATGGATTGCGGCTCGAGCGGTGGCAGCGGTGGCTCTGGTGGTCTGAGCGGCCGTTCCGATAATCATGGCGGCGGTTCTGACATCCAGATGACTCAGTCTCCTAGCTCCCTGTCCGCCTCTGTGGGGGACCGAGTCACCATCACATGCAGAGCCAGCCAGGATATTTCTAGTTACCTGAACTGGTATCAGCAGAAGCCCGGAAAAGCACCTAAGCTGCTGATCTACTATACCTCCAGGCTGCACTCTGGCGTGCCCAGTCGGTTCAGTGGCTCAGGGAGCGGAACCGACTTCACTTTTACCATCTCAAGCCTGCAGCCAGAGGATATTGCCACATACTATTGTCAGCAGGGCAATACACTGCCCTACACTTTTGGCCAGGGGACCAAGGTGGAAATCAAACGTACGGTGGCTGCACCATCTGTCTTCATCTTCCCGCCATCTGATGAGCAGTTGAAATCTGGAACTGCCTCTGTTGTGTGCCTGCTGAATAACTTCTATCCCAGAGAGGCCAAAGTACAGTGGAAGGTGGATAACGCCCTCCAATCGGGTAACTCCCAGGAGAGTGTCACAGAGCAGGACAGCAAGGACAGCACCTACAGCCTCAGCAGCACCCTGACGCTGAGCAAAGCAGACTACGAGAAACACAAAGTCTACGCCTGCGAAGTCACCCATCAGGGCCTGAGCTCGCCCGTCACAAAGAGCTTCAACAGGGGAGAGTGTTAG](配列番号473)
アミノ酸配列
[スペーサー(配列番号87)][スペーサーを有さないpLW080(配列番号516)]
[QGQSGQ][YGSCSWNYVHIFMDCGSSGGSGGSGGLSGRSDNHGGGSDIQMTQSPSSLSASVGDRVTITCRASQDISSYLNWYQQKPGKAPKLLIYYTSRLHSGVPSRFSGSGSGTDFTFTISSLQPEDIATYYCQQGNTLPYTFGQGTKVEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC]*(配列番号474)
pLW101: HC C225v5N297Q-15865-2001-CD3LvHv-H-N
ヌクレオチド配列
[スペーサー(配列番号: 507)][スペーサーを有さないpLW101(配列番号517)]
[CAAGGCCAGTCTGGCCAA][ATGATGTATTGCGGTGGGAATGAGGTGTTGTGCGGGCCGCGGGTTGGCTCGAGCGGTGGCAGCGGTGGCTCTGGTGGTATCTCTTCCGGACTGCTGTCCGGCAGATCCGACAATCACGGCGGCGGTTCTCAGACCGTGGTCACACAGGAGCCCTCACTGACAGTGAGCCCTGGCGGGACCGTCACACTGACTTGTCGCAGTTCAACTGGCGCCGTGACTACCAGCAATTACGCTAACTGGGTCCAGCAGAAACCAGGACAGGCACCACGAGGACTGATCGGAGGAACTAATAAGAGAGCACCAGGAACCCCTGCAAGGTTCTCCGGATCTCTGCTGGGGGGAAAAGCCGCTCTGACACTGAGCGGCGTGCAGCCTGAGGACGAAGCTGAGTACTATTGCGCACTGTGGTACTCCAACCTGTGGGTGTTTGGCGGGGGAACTAAGCTGACCGTCCTGGGAGGAGGAGGAAGCGGAGGAGGAGGGAGCGGAGGAGGAGGATCCGAAGTGCAGCTGGTCGAGAGCGGAGGAGGACTGGTGCAGCCAGGAGGATCCCTGAAGCTGTCTTGTGCAGCCAGTGGCTTCACCTTCAACACTTACGCAATGAACTGGGTGCGGCAGGCACCTGGGAAGGGACTGGAATGGGTCGCCCGGATCAGATCTAAATACAATAACTATGCCACCTACTATGCTGACAGTGTGAAGGATAGGTTCACCATTTCACGCGACGATAGCAAAAACACAGCTTATCTGCAGATGAATAACCTGAAGACCGAGGATACAGCAGTGTACTATTGCGTCAGACACGGCAATTTCGGGAACTCTTACGTGAGTTGGTTTGCCTATTGGGGACAGGGGACACTGGTCACCGTCTCCTCAGGAGGTGGTGGATCCCAGGTGCAGCTGAAACAGAGCGGCCCGGGCCTGGTGCAGCCGAGCCAGAGCCTGAGCATTACCTGCACCGTGAGCGGCTTTAGCCTGACCAACTATGGCGTGCATTGGGTGCGCCAGAGCCCGGGCAAAGGCCTGGAATGGCTGGGCGTGATTTGGAGCGGCGGCAACACCGATTATAACACCCCGTTTACCAGCCGCCTGAGCATTAACAAAGATAACAGCAAAAGCCAGGTGTTTTTTAAAATGAACAGCCTGCAAAGCCAGGATACCGCGATTTATTATTGCGCGCGCGCGCTGACCTATTATGATTATGAATTTGCGTATTGGGGCCAGGGCACCCTGGTGACCGTGAGCGCGGCTAGCACCAAGGGCCCATCGGTCTTCCCCCTGGCACCCTCCTCCAAGAGCACCTCTGGGGGCACAGCGGCCCTGGGCTGCCTGGTCAAGGACTACTTCCCCGAACCGGTGACGGTGTCGTGGAACTCAGGCGCCCTGACCAGCGGCGTGCACACCTTCCCGGCTGTCCTACAGTCCTCAGGACTCTACTCCCTCAGCAGCGTGGTGACCGTGCCCTCCAGCAGCTTGGGCACCCAGACCTACATCTGCAACGTGAATCACAAGCCCAGCAACACCAAGGTGGACAAGAAAGTTGAGCCCAAATCTTGTGACAAAACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACCAGAGCACGTACCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGGGAGGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCTACAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTACACGCAGAAGAGCCTCTCCCTGTCTCCGGGTAAATGA](配列番号479)
アミノ酸配列
[スペーサー(配列番号87)][スペーサーを有さないpLW101(配列番号518)]
[QGQSGQ][MMYCGGNEVLCGPRVGSSGGSGGSGGISSGLLSGRSDNHGGGSQTVVTQEPSLTVSPGGTVTLTCRSSTGAVTTSNYANWVQQKPGQAPRGLIGGTNKRAPGTPARFSGSLLGGKAALTLSGVQPEDEAEYYCALWYSNLWVFGGGTKLTVLGGGGSGGGGSGGGGSEVQLVESGGGLVQPGGSLKLSCAASGFTFNTYAMNWVRQAPGKGLEWVARIRSKYNNYATYYADSVKDRFTISRDDSKNTAYLQMNNLKTEDTAVYYCVRHGNFGNSYVSWFAYWGQGTLVTVSSGGGGSQVQLKQSGPGLVQPSQSLSITCTVSGFSLTNYGVHWVRQSPGKGLEWLGVIWSGGNTDYNTPFTSRLSINKDNSKSQVFFKMNSLQSQDTAIYYCARALTYYDYEFAYWGQGTLVTVSAASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYQSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK]*(配列番号480)
ヌクレオチド配列
[スペーサー(配列番号507)][スペーサーを有さない3954-2001-C225v5(配列番号519)]
[CAAGGCCAGTCTGGCCAG][TGCATCTCACCTCGTGGTTGTCCGGACGGCCCATACGTCATGTACGGCTCGAGCGGTGGCAGCGGTGGCTCTGGTGGATCCGGTATTAGCAGTGGTCTGTTAAGCGGTCGTAGCGATAATCATGGCAGTAGCGGTACCCAGATCTTGCTGACCCAGAGCCCGGTGATTCTGAGCGTGAGCCCGGGCGAACGTGTGAGCTTTAGCTGCCGCGCGAGCCAGAGCATTGGCACCAACATTCATTGGTATCAGCAGCGCACCAACGGCAGCCCGCGCCTGCTGATTAAATATGCGAGCGAAAGCATTAGCGGCATTCCGAGCCGCTTTAGCGGCAGCGGCAGCGGCACCGATTTTACCCTGAGCATTAACAGCGTGGAAAGCGAAGATATTGCGGATTATTATTGCCAGCAGAACAACAACTGGCCGACCACCTTTGGCGCGGGCACCAAACTGGAACTGAAACGTACGGTGGCTGCACCATCTGTCTTCATCTTCCCGCCATCTGATGAGCAGTTGAAATCTGGAACTGCCTCTGTTGTGTGCCTGCTGAATAACTTCTATCCCAGAGAGGCCAAAGTACAGTGGAAGGTGGATAACGCCCTCCAATCGGGTAACTCCCAGGAGAGTGTCACAGAGCAGGACAGCAAGGACAGCACCTACAGCCTCAGCAGCACCCTGACGCTGAGCAAAGCAGACTACGAGAAACACAAAGTCTACGCCTGCGAAGTCACCCATCAGGGCCTGAGCTCGCCCGTCACAAAGAGCTTCAACAGGGGAGAGTGTTAG](配列番号481)
アミノ酸配列
[スペーサー(配列番号87)][スペーサーを有さないpLW080(配列番号520)]
[QGQSGQ][CISPRGCPDGPYVMYGSSGGSGGSGGSGISSGLLSGRSDNHGSSGTQILLTQSPVILSVSPGERVSFSCRASQSIGTNIHWYQQRTNGSPRLLIKYASESISGIPSRFSGSGSGTDFTLSINSVESEDIADYYCQQNNNWPTTFGAGTKLELKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC]*(配列番号482)
pLW057: HC C225v5N297Q-CD3LvHv-H-N
ヌクレオチド配列
CAGACCGTGGTCACACAGGAGCCCTCACTGACAGTGAGCCCTGGCGGGACCGTCACACTGACTTGTCGCAGTTCAACTGGCGCCGTGACTACCAGCAATTACGCTAACTGGGTCCAGCAGAAACCAGGACAGGCACCACGAGGACTGATCGGAGGAACTAATAAGAGAGCACCAGGAACCCCTGCAAGGTTCTCCGGATCTCTGCTGGGGGGAAAAGCCGCTCTGACACTGAGCGGCGTGCAGCCTGAGGACGAAGCTGAGTACTATTGCGCACTGTGGTACTCCAACCTGTGGGTGTTTGGCGGGGGAACTAAGCTGACCGTCCTGGGAGGAGGAGGAAGCGGAGGAGGAGGGAGCGGAGGAGGAGGATCCGAAGTGCAGCTGGTCGAGAGCGGAGGAGGACTGGTGCAGCCAGGAGGATCCCTGAAGCTGTCTTGTGCAGCCAGTGGCTTCACCTTCAACACTTACGCAATGAACTGGGTGCGGCAGGCACCTGGGAAGGGACTGGAATGGGTCGCCCGGATCAGATCTAAATACAATAACTATGCCACCTACTATGCTGACAGTGTGAAGGATAGGTTCACCATTTCACGCGACGATAGCAAAAACACAGCTTATCTGCAGATGAATAACCTGAAGACCGAGGATACAGCAGTGTACTATTGCGTCAGACACGGCAATTTCGGGAACTCTTACGTGAGTTGGTTTGCCTATTGGGGACAGGGGACACTGGTCACCGTCTCCTCAGGAGGTGGTGGATCCCAGGTGCAGCTGAAACAGAGCGGCCCGGGCCTGGTGCAGCCGAGCCAGAGCCTGAGCATTACCTGCACCGTGAGCGGCTTTAGCCTGACCAACTATGGCGTGCATTGGGTGCGCCAGAGCCCGGGCAAAGGCCTGGAATGGCTGGGCGTGATTTGGAGCGGCGGCAACACCGATTATAACACCCCGTTTACCAGCCGCCTGAGCATTAACAAAGATAACAGCAAAAGCCAGGTGTTTTTTAAAATGAACAGCCTGCAAAGCCAGGATACCGCGATTTATTATTGCGCGCGCGCGCTGACCTATTATGATTATGAATTTGCGTATTGGGGCCAGGGCACCCTGGTGACCGTGAGCGCGGCTAGCACCAAGGGCCCATCGGTCTTCCCCCTGGCACCCTCCTCCAAGAGCACCTCTGGGGGCACAGCGGCCCTGGGCTGCCTGGTCAAGGACTACTTCCCCGAACCGGTGACGGTGTCGTGGAACTCAGGCGCCCTGACCAGCGGCGTGCACACCTTCCCGGCTGTCCTACAGTCCTCAGGACTCTACTCCCTCAGCAGCGTGGTGACCGTGCCCTCCAGCAGCTTGGGCACCCAGACCTACATCTGCAACGTGAATCACAAGCCCAGCAACACCAAGGTGGACAAGAAAGTTGAGCCCAAATCTTGTGACAAAACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACCAGAGCACGTACCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGGGAGGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCTACAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTACACGCAGAAGAGCCTCTCCCTGTCTCCGGGTAAATGA(配列番号882)
アミノ酸配列
QTVVTQEPSLTVSPGGTVTLTCRSSTGAVTTSNYANWVQQKPGQAPRGLIGGTNKRAPGTPARFSGSLLGGKAALTLSGVQPEDEAEYYCALWYSNLWVFGGGTKLTVLGGGGSGGGGSGGGGSEVQLVESGGGLVQPGGSLKLSCAASGFTFNTYAMNWVRQAPGKGLEWVARIRSKYNNYATYYADSVKDRFTISRDDSKNTAYLQMNNLKTEDTAVYYCVRHGNFGNSYVSWFAYWGQGTLVTVSSGGGGSQVQLKQSGPGLVQPSQSLSITCTVSGFSLTNYGVHWVRQSPGKGLEWLGVIWSGGNTDYNTPFTSRLSINKDNSKSQVFFKMNSLQSQDTAIYYCARALTYYDYEFAYWGQGTLVTVSAASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYQSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK*(配列番号883)
ヌクレオチド配列
[スペーサー(配列番号507)][スペーサーを有さない3954-2001-C225v5(配列番号519)]
[CAAGGCCAGTCTGGCCAG][TGCATCTCACCTCGTGGTTGTCCGGACGGCCCATACGTCATGTACGGCTCGAGCGGTGGCAGCGGTGGCTCTGGTGGATCCGGTATTAGCAGTGGTCTGTTAAGCGGTCGTAGCGATAATCATGGCAGTAGCGGTACCCAGATCTTGCTGACCCAGAGCCCGGTGATTCTGAGCGTGAGCCCGGGCGAACGTGTGAGCTTTAGCTGCCGCGCGAGCCAGAGCATTGGCACCAACATTCATTGGTATCAGCAGCGCACCAACGGCAGCCCGCGCCTGCTGATTAAATATGCGAGCGAAAGCATTAGCGGCATTCCGAGCCGCTTTAGCGGCAGCGGCAGCGGCACCGATTTTACCCTGAGCATTAACAGCGTGGAAAGCGAAGATATTGCGGATTATTATTGCCAGCAGAACAACAACTGGCCGACCACCTTTGGCGCGGGCACCAAACTGGAACTGAAACGTACGGTGGCTGCACCATCTGTCTTCATCTTCCCGCCATCTGATGAGCAGTTGAAATCTGGAACTGCCTCTGTTGTGTGCCTGCTGAATAACTTCTATCCCAGAGAGGCCAAAGTACAGTGGAAGGTGGATAACGCCCTCCAATCGGGTAACTCCCAGGAGAGTGTCACAGAGCAGGACAGCAAGGACAGCACCTACAGCCTCAGCAGCACCCTGACGCTGAGCAAAGCAGACTACGAGAAACACAAAGTCTACGCCTGCGAAGTCACCCATCAGGGCCTGAGCTCGCCCGTCACAAAGAGCTTCAACAGGGGAGAGTGTTAG](配列番号481)
アミノ酸配列
[スペーサー(配列番号87)][スペーサーを有さないpLW080(配列番号520)]
[QGQSGQ][CISPRGCPDGPYVMYGSSGGSGGSGGSGISSGLLSGRSDNHGSSGTQILLTQSPVILSVSPGERVSFSCRASQSIGTNIHWYQQRTNGSPRLLIKYASESISGIPSRFSGSGSGTDFTLSINSVESEDIADYYCQQNNNWPTTFGAGTKLELKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC]*(配列番号482)
pLW047: HC C225v5N297Q-15003-CD3HvLv-H-N
ヌクレオチド配列
[スペーサー(配列番号507)][スペーサーを有さないpLW047(配列番号522)]
[CAAGGCCAGTCTGGCCAA][GGTTATCGGTGGGGTTGCGAGTGGAATTGCGGTGGGATTACTACTGGCTCGAGCGGTGGCAGCGGTGGCTCTGGTGGTCTGAGCGGCCGTTCCGATAATCATGGCGGCGGTTCTGAGGTGCAGCTGGTCGAGTCTGGAGGAGGATTGGTGCAGCCTGGAGGGTCATTGAAACTCTCATGTGCAGCCTCTGGATTCACCTTCAATAAGTACGCCATGAACTGGGTCCGCCAGGCTCCAGGAAAGGGTTTGGAATGGGTTGCTCGCATAAGAAGTAAATATAATAATTATGCAACATATTATGCCGATTCAGTGAAAGACAGGTTCACCATCTCCAGAGATGATTCAAAAAACACTGCCTATCTACAAATGAACAACTTGAAAACTGAGGACACTGCCGTGTACTACTGTGTGAGACATGGGAACTTCGGTAATAGCTACATATCCTACTGGGCTTACTGGGGCCAAGGGACTCTGGTCACCGTCTCCTCAGGTGGTGGTGGTTCTGGCGGCGGCGGCTCCGGTGGTGGTGGTTCTCAGACTGTTGTGACTCAGGAACCTTCACTCACCGTATCACCTGGTGGAACAGTCACACTCACTTGTGGCTCCTCGACTGGGGCTGTTACATCTGGCTACTACCCAAACTGGGTCCAACAAAAACCAGGTCAGGCACCCCGTGGTCTAATAGGTGGGACTAAGTTCCTCGCCCCCGGTACTCCTGCCAGATTCTCAGGCTCCCTGCTTGGAGGCAAGGCTGCCCTCACCCTCTCAGGGGTACAGCCAGAGGATGAGGCAGAATATTACTGTGCTCTATGGTACAGCAACCGCTGGGTGTTCGGTGGAGGAACCAAACTGACTGTCCTAGGAGGTGGTGGATCCCAGGTGCAGCTGAAACAGAGCGGCCCGGGCCTGGTGCAGCCGAGCCAGAGCCTGAGCATTACCTGCACCGTGAGCGGCTTTAGCCTGACCAACTATGGCGTGCATTGGGTGCGCCAGAGCCCGGGCAAAGGCCTGGAATGGCTGGGCGTGATTTGGAGCGGCGGCAACACCGATTATAACACCCCGTTTACCAGCCGCCTGAGCATTAACAAAGATAACAGCAAAAGCCAGGTGTTTTTTAAAATGAACAGCCTGCAAAGCCAGGATACCGCGATTTATTATTGCGCGCGCGCGCTGACCTATTATGATTATGAATTTGCGTATTGGGGCCAGGGCACCCTGGTGACCGTGAGCGCGGCTAGCACCAAGGGCCCATCGGTCTTCCCCCTGGCACCCTCCTCCAAGAGCACCTCTGGGGGCACAGCGGCCCTGGGCTGCCTGGTCAAGGACTACTTCCCCGAACCGGTGACGGTGTCGTGGAACTCAGGCGCCCTGACCAGCGGCGTGCACACCTTCCCGGCTGTCCTACAGTCCTCAGGACTCTACTCCCTCAGCAGCGTGGTGACCGTGCCCTCCAGCAGCTTGGGCACCCAGACCTACATCTGCAACGTGAATCACAAGCCCAGCAACACCAAGGTGGACAAGAAAGTTGAGCCCAAATCTTGTGACAAAACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACCAGAGCACGTACCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGGGAGGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCTACAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTACACGCAGAAGAGCCTCTCCCTGTCTCCGGGTAAATGA](配列番号461)
アミノ酸配列
[スペーサー(配列番号87)][スペーサーを有さないpLW047(配列番号524)]
[QGQSGQ][GYRWGCEWNCGGITTGSSGGSGGSGGLSGRSDNHGGGSEVQLVESGGGLVQPGGSLKLSCAASGFTFNKYAMNWVRQAPGKGLEWVARIRSKYNNYATYYADSVKDRFTISRDDSKNTAYLQMNNLKTEDTAVYYCVRHGNFGNSYISYWAYWGQGTLVTVSSGGGGSGGGGSGGGGSQTVVTQEPSLTVSPGGTVTLTCGSSTGAVTSGYYPNWVQQKPGQAPRGLIGGTKFLAPGTPARFSGSLLGGKAALTLSGVQPEDEAEYYCALWYSNRWVFGGGTKLTVLGGGGSQVQLKQSGPGLVQPSQSLSITCTVSGFSLTNYGVHWVRQSPGKGLEWLGVIWSGGNTDYNTPFTSRLSINKDNSKSQVFFKMNSLQSQDTAIYYCARALTYYDYEFAYWGQGTLVTVSAASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYQSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK]*(配列番号462)
ヌクレオチド配列
GATATCTTGCTGACCCAGAGCCCGGTGATTCTGAGCGTGAGCCCGGGCGAACGTGTGAGCTTTAGCTGCCGCGCGAGCCAGAGCATTGGCACCAACATTCATTGGTATCAGCAGCGCACCAACGGCAGCCCGCGCCTGCTGATTAAATATGCGAGCGAAAGCATTAGCGGCATTCCGAGCCGCTTTAGCGGCAGCGGCAGCGGCACCGATTTTACCCTGAGCATTAACAGCGTGGAAAGCGAAGATATTGCGGATTATTATTGCCAGCAGAACAACAACTGGCCGACCACCTTTGGCGCGGGCACCAAACTGGAAATCAAACGTACGGTGGCTGCACCATCTGTCTTCATCTTCCCGCCATCTGATGAGCAGTTGAAATCTGGAACTGCCTCTGTTGTGTGCCTGCTGAATAACTTCTATCCCAGAGAGGCCAAAGTACAGTGGAAGGTGGATAACGCCCTCCAATCGGGTAACTCCCAGGAGAGTGTCACAGAGCAGGACAGCAAGGACAGCACCTACAGCCTCAGCAGCACCCTGACGCTGAGCAAAGCAGACTACGAGAAACACAAAGTCTACGCCTGCGAAGTCACCCATCAGGGCCTGAGCTCGCCCGTCACAAAGAGCTTCAACAGGGGAGAGTGTTAG(配列番号457)
アミノ酸配列
DILLTQSPVILSVSPGERVSFSCRASQSIGTNIHWYQQRTNGSPRLLIKYASESISGIPSRFSGSGSGTDFTLSINSVESEDIADYYCQQNNNWPTTFGAGTKLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC*(配列番号458)
pLW048: HC C225v5N297Q-15865-CD3HvLv-H-N
ヌクレオチド配列
[スペーサー(配列番号507)][スペーサーを有さないpLW048(配列番号525)]
[CAAGGCCAGTCTGGCCAA][ATGATGTATTGCGGTGGGAATGAGGTGTTGTGCGGGCCGCGGGTTGGCTCGAGCGGTGGCAGCGGTGGCTCTGGTGGTCTGAGCGGCCGTTCCGATAATCATGGCGGCGGTTCTGAGGTGCAGCTGGTCGAGTCTGGAGGAGGATTGGTGCAGCCTGGAGGGTCATTGAAACTCTCATGTGCAGCCTCTGGATTCACCTTCAATAAGTACGCCATGAACTGGGTCCGCCAGGCTCCAGGAAAGGGTTTGGAATGGGTTGCTCGCATAAGAAGTAAATATAATAATTATGCAACATATTATGCCGATTCAGTGAAAGACAGGTTCACCATCTCCAGAGATGATTCAAAAAACACTGCCTATCTACAAATGAACAACTTGAAAACTGAGGACACTGCCGTGTACTACTGTGTGAGACATGGGAACTTCGGTAATAGCTACATATCCTACTGGGCTTACTGGGGCCAAGGGACTCTGGTCACCGTCTCCTCAGGTGGTGGTGGTTCTGGCGGCGGCGGCTCCGGTGGTGGTGGTTCTCAGACTGTTGTGACTCAGGAACCTTCACTCACCGTATCACCTGGTGGAACAGTCACACTCACTTGTGGCTCCTCGACTGGGGCTGTTACATCTGGCTACTACCCAAACTGGGTCCAACAAAAACCAGGTCAGGCACCCCGTGGTCTAATAGGTGGGACTAAGTTCCTCGCCCCCGGTACTCCTGCCAGATTCTCAGGCTCCCTGCTTGGAGGCAAGGCTGCCCTCACCCTCTCAGGGGTACAGCCAGAGGATGAGGCAGAATATTACTGTGCTCTATGGTACAGCAACCGCTGGGTGTTCGGTGGAGGAACCAAACTGACTGTCCTAGGAGGTGGTGGATCCCAGGTGCAGCTGAAACAGAGCGGCCCGGGCCTGGTGCAGCCGAGCCAGAGCCTGAGCATTACCTGCACCGTGAGCGGCTTTAGCCTGACCAACTATGGCGTGCATTGGGTGCGCCAGAGCCCGGGCAAAGGCCTGGAATGGCTGGGCGTGATTTGGAGCGGCGGCAACACCGATTATAACACCCCGTTTACCAGCCGCCTGAGCATTAACAAAGATAACAGCAAAAGCCAGGTGTTTTTTAAAATGAACAGCCTGCAAAGCCAGGATACCGCGATTTATTATTGCGCGCGCGCGCTGACCTATTATGATTATGAATTTGCGTATTGGGGCCAGGGCACCCTGGTGACCGTGAGCGCGGCTAGCACCAAGGGCCCATCGGTCTTCCCCCTGGCACCCTCCTCCAAGAGCACCTCTGGGGGCACAGCGGCCCTGGGCTGCCTGGTCAAGGACTACTTCCCCGAACCGGTGACGGTGTCGTGGAACTCAGGCGCCCTGACCAGCGGCGTGCACACCTTCCCGGCTGTCCTACAGTCCTCAGGACTCTACTCCCTCAGCAGCGTGGTGACCGTGCCCTCCAGCAGCTTGGGCACCCAGACCTACATCTGCAACGTGAATCACAAGCCCAGCAACACCAAGGTGGACAAGAAAGTTGAGCCCAAATCTTGTGACAAAACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACCAGAGCACGTACCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGGGAGGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCTACAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTACACGCAGAAGAGCCTCTCCCTGTCTCCGGGTAAATGA](配列番号463)
アミノ酸配列
[スペーサー(配列番号87)][スペーサーを有さないpLW048(配列番号526)]
[QGQSGQ][MMYCGGNEVLCGPRVGSSGGSGGSGGLSGRSDNHGGGSEVQLVESGGGLVQPGGSLKLSCAASGFTFNKYAMNWVRQAPGKGLEWVARIRSKYNNYATYYADSVKDRFTISRDDSKNTAYLQMNNLKTEDTAVYYCVRHGNFGNSYISYWAYWGQGTLVTVSSGGGGSGGGGSGGGGSQTVVTQEPSLTVSPGGTVTLTCGSSTGAVTSGYYPNWVQQKPGQAPRGLIGGTKFLAPGTPARFSGSLLGGKAALTLSGVQPEDEAEYYCALWYSNRWVFGGGTKLTVLGGGGSQVQLKQSGPGLVQPSQSLSITCTVSGFSLTNYGVHWVRQSPGKGLEWLGVIWSGGNTDYNTPFTSRLSINKDNSKSQVFFKMNSLQSQDTAIYYCARALTYYDYEFAYWGQGTLVTVSAASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYQSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK]*(配列番号464)
ヌクレオチド配列
GATATCTTGCTGACCCAGAGCCCGGTGATTCTGAGCGTGAGCCCGGGCGAACGTGTGAGCTTTAGCTGCCGCGCGAGCCAGAGCATTGGCACCAACATTCATTGGTATCAGCAGCGCACCAACGGCAGCCCGCGCCTGCTGATTAAATATGCGAGCGAAAGCATTAGCGGCATTCCGAGCCGCTTTAGCGGCAGCGGCAGCGGCACCGATTTTACCCTGAGCATTAACAGCGTGGAAAGCGAAGATATTGCGGATTATTATTGCCAGCAGAACAACAACTGGCCGACCACCTTTGGCGCGGGCACCAAACTGGAAATCAAACGTACGGTGGCTGCACCATCTGTCTTCATCTTCCCGCCATCTGATGAGCAGTTGAAATCTGGAACTGCCTCTGTTGTGTGCCTGCTGAATAACTTCTATCCCAGAGAGGCCAAAGTACAGTGGAAGGTGGATAACGCCCTCCAATCGGGTAACTCCCAGGAGAGTGTCACAGAGCAGGACAGCAAGGACAGCACCTACAGCCTCAGCAGCACCCTGACGCTGAGCAAAGCAGACTACGAGAAACACAAAGTCTACGCCTGCGAAGTCACCCATCAGGGCCTGAGCTCGCCCGTCACAAAGAGCTTCAACAGGGGAGAGTGTTAG(配列番号457)
アミノ酸配列
DILLTQSPVILSVSPGERVSFSCRASQSIGTNIHWYQQRTNGSPRLLIKYASESISGIPSRFSGSGSGTDFTLSINSVESEDIADYYCQQNNNWPTTFGAGTKLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC*(配列番号458)
pLW047: HC C225v5N297Q-15003-CD3HvLv-H-N
ヌクレオチド配列
[スペーサー(配列番号507)][スペーサーを有さないpLW047(配列番号522)]
[CAAGGCCAGTCTGGCCAA][GGTTATCGGTGGGGTTGCGAGTGGAATTGCGGTGGGATTACTACTGGCTCGAGCGGTGGCAGCGGTGGCTCTGGTGGTCTGAGCGGCCGTTCCGATAATCATGGCGGCGGTTCTGAGGTGCAGCTGGTCGAGTCTGGAGGAGGATTGGTGCAGCCTGGAGGGTCATTGAAACTCTCATGTGCAGCCTCTGGATTCACCTTCAATAAGTACGCCATGAACTGGGTCCGCCAGGCTCCAGGAAAGGGTTTGGAATGGGTTGCTCGCATAAGAAGTAAATATAATAATTATGCAACATATTATGCCGATTCAGTGAAAGACAGGTTCACCATCTCCAGAGATGATTCAAAAAACACTGCCTATCTACAAATGAACAACTTGAAAACTGAGGACACTGCCGTGTACTACTGTGTGAGACATGGGAACTTCGGTAATAGCTACATATCCTACTGGGCTTACTGGGGCCAAGGGACTCTGGTCACCGTCTCCTCAGGTGGTGGTGGTTCTGGCGGCGGCGGCTCCGGTGGTGGTGGTTCTCAGACTGTTGTGACTCAGGAACCTTCACTCACCGTATCACCTGGTGGAACAGTCACACTCACTTGTGGCTCCTCGACTGGGGCTGTTACATCTGGCTACTACCCAAACTGGGTCCAACAAAAACCAGGTCAGGCACCCCGTGGTCTAATAGGTGGGACTAAGTTCCTCGCCCCCGGTACTCCTGCCAGATTCTCAGGCTCCCTGCTTGGAGGCAAGGCTGCCCTCACCCTCTCAGGGGTACAGCCAGAGGATGAGGCAGAATATTACTGTGCTCTATGGTACAGCAACCGCTGGGTGTTCGGTGGAGGAACCAAACTGACTGTCCTAGGAGGTGGTGGATCCCAGGTGCAGCTGAAACAGAGCGGCCCGGGCCTGGTGCAGCCGAGCCAGAGCCTGAGCATTACCTGCACCGTGAGCGGCTTTAGCCTGACCAACTATGGCGTGCATTGGGTGCGCCAGAGCCCGGGCAAAGGCCTGGAATGGCTGGGCGTGATTTGGAGCGGCGGCAACACCGATTATAACACCCCGTTTACCAGCCGCCTGAGCATTAACAAAGATAACAGCAAAAGCCAGGTGTTTTTTAAAATGAACAGCCTGCAAAGCCAGGATACCGCGATTTATTATTGCGCGCGCGCGCTGACCTATTATGATTATGAATTTGCGTATTGGGGCCAGGGCACCCTGGTGACCGTGAGCGCGGCTAGCACCAAGGGCCCATCGGTCTTCCCCCTGGCACCCTCCTCCAAGAGCACCTCTGGGGGCACAGCGGCCCTGGGCTGCCTGGTCAAGGACTACTTCCCCGAACCGGTGACGGTGTCGTGGAACTCAGGCGCCCTGACCAGCGGCGTGCACACCTTCCCGGCTGTCCTACAGTCCTCAGGACTCTACTCCCTCAGCAGCGTGGTGACCGTGCCCTCCAGCAGCTTGGGCACCCAGACCTACATCTGCAACGTGAATCACAAGCCCAGCAACACCAAGGTGGACAAGAAAGTTGAGCCCAAATCTTGTGACAAAACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACCAGAGCACGTACCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGGGAGGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCTACAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTACACGCAGAAGAGCCTCTCCCTGTCTCCGGGTAAATGA](配列番号461)
アミノ酸配列
[スペーサー(配列番号87)][スペーサーを有さないpLW047(配列番号524)]
[QGQSGQ][GYRWGCEWNCGGITTGSSGGSGGSGGLSGRSDNHGGGSEVQLVESGGGLVQPGGSLKLSCAASGFTFNKYAMNWVRQAPGKGLEWVARIRSKYNNYATYYADSVKDRFTISRDDSKNTAYLQMNNLKTEDTAVYYCVRHGNFGNSYISYWAYWGQGTLVTVSSGGGGSGGGGSGGGGSQTVVTQEPSLTVSPGGTVTLTCGSSTGAVTSGYYPNWVQQKPGQAPRGLIGGTKFLAPGTPARFSGSLLGGKAALTLSGVQPEDEAEYYCALWYSNRWVFGGGTKLTVLGGGGSQVQLKQSGPGLVQPSQSLSITCTVSGFSLTNYGVHWVRQSPGKGLEWLGVIWSGGNTDYNTPFTSRLSINKDNSKSQVFFKMNSLQSQDTAIYYCARALTYYDYEFAYWGQGTLVTVSAASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYQSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK]*(配列番号462)
ヌクレオチド配列
[スペーサー(配列番号507)][スペーサーを有さないOPP022(配列番号509)]
[CAAGGCCAGTCTGGCCAG][TGCATCTCACCTCGTGGTTGTCCGGACGGCCCATACGTCATGTACGGCTCGAGCGGTGGCAGCGGTGGCTCTGGTGGATCCGGTCTGAGCGGCCGTTCCGATAATCATGGCAGTAGCGGTACCCAGATCTTGCTGACCCAGAGCCCGGTGATTCTGAGCGTGAGCCCGGGCGAACGTGTGAGCTTTAGCTGCCGCGCGAGCCAGAGCATTGGCACCAACATTCATTGGTATCAGCAGCGCACCAACGGCAGCCCGCGCCTGCTGATTAAATATGCGAGCGAAAGCATTAGCGGCATTCCGAGCCGCTTTAGCGGCAGCGGCAGCGGCACCGATTTTACCCTGAGCATTAACAGCGTGGAAAGCGAAGATATTGCGGATTATTATTGCCAGCAGAACAACAACTGGCCGACCACCTTTGGCGCGGGCACCAAACTGGAACTGAAACGTACGGTGGCTGCACCATCTGTCTTCATCTTCCCGCCATCTGATGAGCAGTTGAAATCTGGAACTGCCTCTGTTGTGTGCCTGCTGAATAACTTCTATCCCAGAGAGGCCAAAGTACAGTGGAAGGTGGATAACGCCCTCCAATCGGGTAACTCCCAGGAGAGTGTCACAGAGCAGGACAGCAAGGACAGCACCTACAGCCTCAGCAGCACCCTGACGCTGAGCAAAGCAGACTACGAGAAACACAAAGTCTACGCCTGCGAAGTCACCCATCAGGGCCTGAGCTCGCCCGTCACAAAGAGCTTCAACAGGGGAGAGTGTTAG](配列番号449)
アミノ酸配列
[スペーサー(配列番号87)][スペーサーを有さないOPP022(配列番号508)]
[QGQSGQ][CISPRGCPDGPYVMYGSSGGSGGSGGSGLSGRSDNHGSSGTQILLTQSPVILSVSPGERVSFSCRASQSIGTNIHWYQQRTNGSPRLLIKYASESISGIPSRFSGSGSGTDFTLSINSVESEDIADYYCQQNNNWPTTFGAGTKLELKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC]*(配列番号450)
pLW048: HC C225v5N297Q-15865-CD3HvLv-H-N
ヌクレオチド配列
[スペーサー(配列番号507)][スペーサーを有さないpLW048(配列番号525)]
[CAAGGCCAGTCTGGCCAA][ATGATGTATTGCGGTGGGAATGAGGTGTTGTGCGGGCCGCGGGTTGGCTCGAGCGGTGGCAGCGGTGGCTCTGGTGGTCTGAGCGGCCGTTCCGATAATCATGGCGGCGGTTCTGAGGTGCAGCTGGTCGAGTCTGGAGGAGGATTGGTGCAGCCTGGAGGGTCATTGAAACTCTCATGTGCAGCCTCTGGATTCACCTTCAATAAGTACGCCATGAACTGGGTCCGCCAGGCTCCAGGAAAGGGTTTGGAATGGGTTGCTCGCATAAGAAGTAAATATAATAATTATGCAACATATTATGCCGATTCAGTGAAAGACAGGTTCACCATCTCCAGAGATGATTCAAAAAACACTGCCTATCTACAAATGAACAACTTGAAAACTGAGGACACTGCCGTGTACTACTGTGTGAGACATGGGAACTTCGGTAATAGCTACATATCCTACTGGGCTTACTGGGGCCAAGGGACTCTGGTCACCGTCTCCTCAGGTGGTGGTGGTTCTGGCGGCGGCGGCTCCGGTGGTGGTGGTTCTCAGACTGTTGTGACTCAGGAACCTTCACTCACCGTATCACCTGGTGGAACAGTCACACTCACTTGTGGCTCCTCGACTGGGGCTGTTACATCTGGCTACTACCCAAACTGGGTCCAACAAAAACCAGGTCAGGCACCCCGTGGTCTAATAGGTGGGACTAAGTTCCTCGCCCCCGGTACTCCTGCCAGATTCTCAGGCTCCCTGCTTGGAGGCAAGGCTGCCCTCACCCTCTCAGGGGTACAGCCAGAGGATGAGGCAGAATATTACTGTGCTCTATGGTACAGCAACCGCTGGGTGTTCGGTGGAGGAACCAAACTGACTGTCCTAGGAGGTGGTGGATCCCAGGTGCAGCTGAAACAGAGCGGCCCGGGCCTGGTGCAGCCGAGCCAGAGCCTGAGCATTACCTGCACCGTGAGCGGCTTTAGCCTGACCAACTATGGCGTGCATTGGGTGCGCCAGAGCCCGGGCAAAGGCCTGGAATGGCTGGGCGTGATTTGGAGCGGCGGCAACACCGATTATAACACCCCGTTTACCAGCCGCCTGAGCATTAACAAAGATAACAGCAAAAGCCAGGTGTTTTTTAAAATGAACAGCCTGCAAAGCCAGGATACCGCGATTTATTATTGCGCGCGCGCGCTGACCTATTATGATTATGAATTTGCGTATTGGGGCCAGGGCACCCTGGTGACCGTGAGCGCGGCTAGCACCAAGGGCCCATCGGTCTTCCCCCTGGCACCCTCCTCCAAGAGCACCTCTGGGGGCACAGCGGCCCTGGGCTGCCTGGTCAAGGACTACTTCCCCGAACCGGTGACGGTGTCGTGGAACTCAGGCGCCCTGACCAGCGGCGTGCACACCTTCCCGGCTGTCCTACAGTCCTCAGGACTCTACTCCCTCAGCAGCGTGGTGACCGTGCCCTCCAGCAGCTTGGGCACCCAGACCTACATCTGCAACGTGAATCACAAGCCCAGCAACACCAAGGTGGACAAGAAAGTTGAGCCCAAATCTTGTGACAAAACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACCAGAGCACGTACCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGGGAGGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCTACAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTACACGCAGAAGAGCCTCTCCCTGTCTCCGGGTAAATGA](配列番号463)
アミノ酸配列
[スペーサー(配列番号87)][スペーサーを有さないpLW048(配列番号526)]
[QGQSGQ][MMYCGGNEVLCGPRVGSSGGSGGSGGLSGRSDNHGGGSEVQLVESGGGLVQPGGSLKLSCAASGFTFNKYAMNWVRQAPGKGLEWVARIRSKYNNYATYYADSVKDRFTISRDDSKNTAYLQMNNLKTEDTAVYYCVRHGNFGNSYISYWAYWGQGTLVTVSSGGGGSGGGGSGGGGSQTVVTQEPSLTVSPGGTVTLTCGSSTGAVTSGYYPNWVQQKPGQAPRGLIGGTKFLAPGTPARFSGSLLGGKAALTLSGVQPEDEAEYYCALWYSNRWVFGGGTKLTVLGGGGSQVQLKQSGPGLVQPSQSLSITCTVSGFSLTNYGVHWVRQSPGKGLEWLGVIWSGGNTDYNTPFTSRLSINKDNSKSQVFFKMNSLQSQDTAIYYCARALTYYDYEFAYWGQGTLVTVSAASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYQSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK]*(配列番号464)
ヌクレオチド配列
[スペーサー(配列番号507)][スペーサーを有さないOPP022(配列番号509)]
[CAAGGCCAGTCTGGCCAG][TGCATCTCACCTCGTGGTTGTCCGGACGGCCCATACGTCATGTACGGCTCGAGCGGTGGCAGCGGTGGCTCTGGTGGATCCGGTCTGAGCGGCCGTTCCGATAATCATGGCAGTAGCGGTACCCAGATCTTGCTGACCCAGAGCCCGGTGATTCTGAGCGTGAGCCCGGGCGAACGTGTGAGCTTTAGCTGCCGCGCGAGCCAGAGCATTGGCACCAACATTCATTGGTATCAGCAGCGCACCAACGGCAGCCCGCGCCTGCTGATTAAATATGCGAGCGAAAGCATTAGCGGCATTCCGAGCCGCTTTAGCGGCAGCGGCAGCGGCACCGATTTTACCCTGAGCATTAACAGCGTGGAAAGCGAAGATATTGCGGATTATTATTGCCAGCAGAACAACAACTGGCCGACCACCTTTGGCGCGGGCACCAAACTGGAACTGAAACGTACGGTGGCTGCACCATCTGTCTTCATCTTCCCGCCATCTGATGAGCAGTTGAAATCTGGAACTGCCTCTGTTGTGTGCCTGCTGAATAACTTCTATCCCAGAGAGGCCAAAGTACAGTGGAAGGTGGATAACGCCCTCCAATCGGGTAACTCCCAGGAGAGTGTCACAGAGCAGGACAGCAAGGACAGCACCTACAGCCTCAGCAGCACCCTGACGCTGAGCAAAGCAGACTACGAGAAACACAAAGTCTACGCCTGCGAAGTCACCCATCAGGGCCTGAGCTCGCCCGTCACAAAGAGCTTCAACAGGGGAGAGTGTTAG](配列番号449)
アミノ酸配列
[スペーサー(配列番号87)][スペーサーを有さないOPP022(配列番号508)]
[QGQSGQ][CISPRGCPDGPYVMYGSSGGSGGSGGSGLSGRSDNHGSSGTQILLTQSPVILSVSPGERVSFSCRASQSIGTNIHWYQQRTNGSPRLLIKYASESISGIPSRFSGSGSGTDFTLSINSVESEDIADYYCQQNNNWPTTFGAGTKLELKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC]*(配列番号450)
pLW085: HC IL6RN297Q-15865_1204-CD3LvHv-H-N
ヌクレオチド配列
[スペーサー(配列番号507)][スペーサーを有さないpLW085(配列番号513)]
[CAAGGCCAGTCTGGCCAA][ATGATGTATTGCGGTGGGAATGAGGTGTTGTGCGGGCCGCGGGTTGGCTCGAGCGGTGGCAGCGGTGGCTCTGGTGGTCTGAGCGGCCGTTCCGATAATCATGGCGGCGGTTCTCAGACCGTGGTCACACAGGAGCCCTCACTGACAGTGAGCCCTGGCGGGACCGTCACACTGACTTGTCGCAGTTCAACTGGCGCCGTGACTACCAGCAATTACGCTAACTGGGTCCAGCAGAAACCAGGACAGGCACCACGAGGACTGATCGGAGGAACTAATAAGAGAGCACCAGGAACCCCTGCAAGGTTCTCCGGATCTCTGCTGGGGGGAAAAGCCGCTCTGACACTGAGCGGCGTGCAGCCTGAGGACGAAGCTGAGTACTATTGCGCACTGTGGTACTCCAACCTGTGGGTGTTTGGCGGGGGAACTAAGCTGACCGTCCTGGGAGGAGGAGGAAGCGGAGGAGGAGGGAGCGGAGGAGGAGGATCCGAAGTGCAGCTGGTCGAGAGCGGAGGAGGACTGGTGCAGCCAGGAGGATCCCTGAAGCTGTCTTGTGCAGCCAGTGGCTTCACCTTCAACACTTACGCAATGAACTGGGTGCGGCAGGCACCTGGGAAGGGACTGGAATGGGTCGCCCGGATCAGATCTAAATACAATAACTATGCCACCTACTATGCTGACAGTGTGAAGGATAGGTTCACCATTTCACGCGACGATAGCAAAAACACAGCTTATCTGCAGATGAATAACCTGAAGACCGAGGATACAGCAGTGTACTATTGCGTCAGACACGGCAATTTCGGGAACTCTTACGTGAGTTGGTTTGCCTATTGGGGACAGGGGACACTGGTCACCGTCTCCTCAGGAGGTGGTGGATCCCAGGTGCAGCTGCAGGAGTCCGGACCAGGACTGGTCCGGCCCTCACAGACTCTGAGCCTGACATGCACTGTGTCAGGCTACAGCATCACCTCCGATCACGCCTGGAGCTGGGTCAGGCAGCCACCTGGACGCGGCCTGGAATGGATCGGCTACATTTCTTATAGTGGGATCACCACATACAACCCCTCTCTGAAGAGTCGAGTGACCATTTCCAGAGACAACTCTAAAAATACACTGTATCTGCAGATGAATAGTCTGCGGGCCGAGGATACAGCTGTGTACTATTGTGCACGGTCTCTGGCCAGAACTACCGCTATGGACTATTGGGGGCAGGGAAGCCTGGTGACCGTCAGCTCCGCTAGCACCAAGGGCCCATCGGTCTTCCCCCTGGCACCCTCCTCCAAGAGCACCTCTGGGGGCACAGCGGCCCTGGGCTGCCTGGTCAAGGACTACTTCCCCGAACCGGTGACGGTGTCGTGGAACTCAGGCGCCCTGACCAGCGGCGTGCACACCTTCCCGGCTGTCCTACAGTCCTCAGGACTCTACTCCCTCAGCAGCGTGGTGACCGTGCCCTCCAGCAGCTTGGGCACCCAGACCTACATCTGCAACGTGAATCACAAGCCCAGCAACACCAAGGTGGACAAGAAAGTTGAGCCCAAATCTTGTGACAAAACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACCAGAGCACGTACCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGGGAGGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCTACAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTACACGCAGAAGAGCCTCTCCCTGTCTCCGGGTAAATGA](配列番号471)
アミノ酸配列
[スペーサー(配列番号87)][スペーサーを有さないpLW085(配列番号514)]
[QGQSGQ][MMYCGGNEVLCGPRVGSSGGSGGSGGLSGRSDNHGGGSQTVVTQEPSLTVSPGGTVTLTCRSSTGAVTTSNYANWVQQKPGQAPRGLIGGTNKRAPGTPARFSGSLLGGKAALTLSGVQPEDEAEYYCALWYSNLWVFGGGTKLTVLGGGGSGGGGSGGGGSEVQLVESGGGLVQPGGSLKLSCAASGFTFNTYAMNWVRQAPGKGLEWVARIRSKYNNYATYYADSVKDRFTISRDDSKNTAYLQMNNLKTEDTAVYYCVRHGNFGNSYVSWFAYWGQGTLVTVSSGGGGSQVQLQESGPGLVRPSQTLSLTCTVSGYSITSDHAWSWVRQPPGRGLEWIGYISYSGITTYNPSLKSRVTISRDNSKNTLYLQMNSLRAEDTAVYYCARSLARTTAMDYWGQGSLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYQSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK]*(配列番号472)
ヌクレオチド配列
[スペーサー(配列番号507)][スペーサーを有さないpLW079(配列番号527)]
[CAAGGCCAGTCTGGCCAG][TATGGGTCCTGCAGTTGGAACTATGTACACATATTCATGGATTGCGGCTCGAGCGGTGGCAGCGGTGGCTCTGGTGGCTCAGGTGGAGGCTCGGGCGGTGGGAGCGGCGGTTCTGACATCCAGATGACTCAGTCTCCTAGCTCCCTGTCCGCCTCTGTGGGGGACCGAGTCACCATCACATGCAGAGCCAGCCAGGATATTTCTAGTTACCTGAACTGGTATCAGCAGAAGCCCGGAAAAGCACCTAAGCTGCTGATCTACTATACCTCCAGGCTGCACTCTGGCGTGCCCAGTCGGTTCAGTGGCTCAGGGAGCGGAACCGACTTCACTTTTACCATCTCAAGCCTGCAGCCAGAGGATATTGCCACATACTATTGTCAGCAGGGCAATACACTGCCCTACACTTTTGGCCAGGGGACCAAGGTGGAAATCAAACGTACGGTGGCTGCACCATCTGTCTTCATCTTCCCGCCATCTGATGAGCAGTTGAAATCTGGAACTGCCTCTGTTGTGTGCCTGCTGAATAACTTCTATCCCAGAGAGGCCAAAGTACAGTGGAAGGTGGATAACGCCCTCCAATCGGGTAACTCCCAGGAGAGTGTCACAGAGCAGGACAGCAAGGACAGCACCTACAGCCTCAGCAGCACCCTGACGCTGAGCAAAGCAGACTACGAGAAACACAAAGTCTACGCCTGCGAAGTCACCCATCAGGGCCTGAGCTCGCCCGTCACAAAGAGCTTCAACAGGGGAGAGTGTTAG](配列番号880)
アミノ酸配列
[スペーサー(配列番号87)][スペーサーを有さないpLW079(配列番号528)]
[QGQSGQ][YGSCSWNYVHIFMDCGSSGGSGGSGGSGGGSGGGSGGSDIQMTQSPSSLSASVGDRVTITCRASQDISSYLNWYQQKPGKAPKLLIYYTSRLHSGVPSRFSGSGSGTDFTFTISSLQPEDIATYYCQQGNTLPYTFGQGTKVEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC]*(配列番号881)
pLW087: HC IL6RN297Q-15865_Nsub-CD3LvHv-H-N
ヌクレオチド配列
[スペーサー(配列番号507)][スペーサーを有さないpLW087(配列番号529)]
[CAAGGCCAGTCTGGCCAA][ATGATGTATTGCGGTGGGAATGAGGTGTTGTGCGGGCCGCGGGTTGGCTCGAGCGGTGGCAGCGGTGGCTCTGGTGGTGGTGGAGGCTCGGGCGGTGGGAGCGGCGGCGGTTCTCAGACCGTGGTCACACAGGAGCCCTCACTGACAGTGAGCCCTGGCGGGACCGTCACACTGACTTGTCGCAGTTCAACTGGCGCCGTGACTACCAGCAATTACGCTAACTGGGTCCAGCAGAAACCAGGACAGGCACCACGAGGACTGATCGGAGGAACTAATAAGAGAGCACCAGGAACCCCTGCAAGGTTCTCCGGATCTCTGCTGGGGGGAAAAGCCGCTCTGACACTGAGCGGCGTGCAGCCTGAGGACGAAGCTGAGTACTATTGCGCACTGTGGTACTCCAACCTGTGGGTGTTTGGCGGGGGAACTAAGCTGACCGTCCTGGGAGGAGGAGGAAGCGGAGGAGGAGGGAGCGGAGGAGGAGGATCCGAAGTGCAGCTGGTCGAGAGCGGAGGAGGACTGGTGCAGCCAGGAGGATCCCTGAAGCTGTCTTGTGCAGCCAGTGGCTTCACCTTCAACACTTACGCAATGAACTGGGTGCGGCAGGCACCTGGGAAGGGACTGGAATGGGTCGCCCGGATCAGATCTAAATACAATAACTATGCCACCTACTATGCTGACAGTGTGAAGGATAGGTTCACCATTTCACGCGACGATAGCAAAAACACAGCTTATCTGCAGATGAATAACCTGAAGACCGAGGATACAGCAGTGTACTATTGCGTCAGACACGGCAATTTCGGGAACTCTTACGTGAGTTGGTTTGCCTATTGGGGACAGGGGACACTGGTCACCGTCTCCTCAGGAGGTGGTGGATCCCAGGTGCAGCTGCAGGAGTCCGGACCAGGACTGGTCCGGCCCTCACAGACTCTGAGCCTGACATGCACTGTGTCAGGCTACAGCATCACCTCCGATCACGCCTGGAGCTGGGTCAGGCAGCCACCTGGACGCGGCCTGGAATGGATCGGCTACATTTCTTATAGTGGGATCACCACATACAACCCCTCTCTGAAGAGTCGAGTGACCATTTCCAGAGACAACTCTAAAAATACACTGTATCTGCAGATGAATAGTCTGCGGGCCGAGGATACAGCTGTGTACTATTGTGCACGGTCTCTGGCCAGAACTACCGCTATGGACTATTGGGGGCAGGGAAGCCTGGTGACCGTCAGCTCCGCTAGCACCAAGGGCCCATCGGTCTTCCCCCTGGCACCCTCCTCCAAGAGCACCTCTGGGGGCACAGCGGCCCTGGGCTGCCTGGTCAAGGACTACTTCCCCGAACCGGTGACGGTGTCGTGGAACTCAGGCGCCCTGACCAGCGGCGTGCACACCTTCCCGGCTGTCCTACAGTCCTCAGGACTCTACTCCCTCAGCAGCGTGGTGACCGTGCCCTCCAGCAGCTTGGGCACCCAGACCTACATCTGCAACGTGAATCACAAGCCCAGCAACACCAAGGTGGACAAGAAAGTTGAGCCCAAATCTTGTGACAAAACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACCAGAGCACGTACCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGGGAGGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCTACAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTACACGCAGAAGAGCCTCTCCCTGTCTCCGGGTAAATGA](配列番号477)
アミノ酸配列
[スペーサー(配列番号87)][スペーサーを有さないpLW087(配列番号530)]
[QGQSGQ][MMYCGGNEVLCGPRVGSSGGSGGSGGGGGSGGGSGGGSQTVVTQEPSLTVSPGGTVTLTCRSSTGAVTTSNYANWVQQKPGQAPRGLIGGTNKRAPGTPARFSGSLLGGKAALTLSGVQPEDEAEYYCALWYSNLWVFGGGTKLTVLGGGGSGGGGSGGGGSEVQLVESGGGLVQPGGSLKLSCAASGFTFNTYAMNWVRQAPGKGLEWVARIRSKYNNYATYYADSVKDRFTISRDDSKNTAYLQMNNLKTEDTAVYYCVRHGNFGNSYVSWFAYWGQGTLVTVSSGGGGSQVQLQESGPGLVRPSQTLSLTCTVSGYSITSDHAWSWVRQPPGRGLEWIGYISYSGITTYNPSLKSRVTISRDNSKNTLYLQMNSLRAEDTAVYYCARSLARTTAMDYWGQGSLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYQSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK]*(配列番号478)
ヌクレオチド配列
GACATCCAGATGACTCAGTCTCCTAGCTCCCTGTCCGCCTCTGTGGGGGACCGAGTCACCATCACATGCAGAGCCAGCCAGGATATTTCTAGTTACCTGAACTGGTATCAGCAGAAGCCCGGAAAAGCACCTAAGCTGCTGATCTACTATACCTCCAGGCTGCACTCTGGCGTGCCCAGTCGGTTCAGTGGCTCAGGGAGCGGAACCGACTTCACTTTTACCATCTCAAGCCTGCAGCCAGAGGATATTGCCACATACTATTGTCAGCAGGGCAATACACTGCCCTACACTTTTGGCCAGGGGACCAAGGTGGAAATCAAACGTACGGTGGCTGCACCATCTGTCTTCATCTTCCCGCCATCTGATGAGCAGTTGAAATCTGGAACTGCCTCTGTTGTGTGCCTGCTGAATAACTTCTATCCCAGAGAGGCCAAAGTACAGTGGAAGGTGGATAACGCCCTCCAATCGGGTAACTCCCAGGAGAGTGTCACAGAGCAGGACAGCAAGGACAGCACCTACAGCCTCAGCAGCACCCTGACGCTGAGCAAAGCAGACTACGAGAAACACAAAGTCTACGCCTGCGAAGTCACCCATCAGGGCCTGAGCTCGCCCGTCACAAAGAGCTTCAACAGGGGAGAGTGTTAG(配列番号467)
アミノ酸配列
DIQMTQSPSSLSASVGDRVTITCRASQDISSYLNWYQQKPGKAPKLLIYYTSRLHSGVPSRFSGSGSGTDFTFTISSLQPEDIATYYCQQGNTLPYTFGQGTKVEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC*(配列番号468)
pLW087: HC IL6RN297Q-15865_Nsub-CD3LvHv-H-N
ヌクレオチド配列
[スペーサー(配列番号507)][スペーサーを有さないpLW087(配列番号529)]
[CAAGGCCAGTCTGGCCAA][ATGATGTATTGCGGTGGGAATGAGGTGTTGTGCGGGCCGCGGGTTGGCTCGAGCGGTGGCAGCGGTGGCTCTGGTGGTGGTGGAGGCTCGGGCGGTGGGAGCGGCGGCGGTTCTCAGACCGTGGTCACACAGGAGCCCTCACTGACAGTGAGCCCTGGCGGGACCGTCACACTGACTTGTCGCAGTTCAACTGGCGCCGTGACTACCAGCAATTACGCTAACTGGGTCCAGCAGAAACCAGGACAGGCACCACGAGGACTGATCGGAGGAACTAATAAGAGAGCACCAGGAACCCCTGCAAGGTTCTCCGGATCTCTGCTGGGGGGAAAAGCCGCTCTGACACTGAGCGGCGTGCAGCCTGAGGACGAAGCTGAGTACTATTGCGCACTGTGGTACTCCAACCTGTGGGTGTTTGGCGGGGGAACTAAGCTGACCGTCCTGGGAGGAGGAGGAAGCGGAGGAGGAGGGAGCGGAGGAGGAGGATCCGAAGTGCAGCTGGTCGAGAGCGGAGGAGGACTGGTGCAGCCAGGAGGATCCCTGAAGCTGTCTTGTGCAGCCAGTGGCTTCACCTTCAACACTTACGCAATGAACTGGGTGCGGCAGGCACCTGGGAAGGGACTGGAATGGGTCGCCCGGATCAGATCTAAATACAATAACTATGCCACCTACTATGCTGACAGTGTGAAGGATAGGTTCACCATTTCACGCGACGATAGCAAAAACACAGCTTATCTGCAGATGAATAACCTGAAGACCGAGGATACAGCAGTGTACTATTGCGTCAGACACGGCAATTTCGGGAACTCTTACGTGAGTTGGTTTGCCTATTGGGGACAGGGGACACTGGTCACCGTCTCCTCAGGAGGTGGTGGATCCCAGGTGCAGCTGCAGGAGTCCGGACCAGGACTGGTCCGGCCCTCACAGACTCTGAGCCTGACATGCACTGTGTCAGGCTACAGCATCACCTCCGATCACGCCTGGAGCTGGGTCAGGCAGCCACCTGGACGCGGCCTGGAATGGATCGGCTACATTTCTTATAGTGGGATCACCACATACAACCCCTCTCTGAAGAGTCGAGTGACCATTTCCAGAGACAACTCTAAAAATACACTGTATCTGCAGATGAATAGTCTGCGGGCCGAGGATACAGCTGTGTACTATTGTGCACGGTCTCTGGCCAGAACTACCGCTATGGACTATTGGGGGCAGGGAAGCCTGGTGACCGTCAGCTCCGCTAGCACCAAGGGCCCATCGGTCTTCCCCCTGGCACCCTCCTCCAAGAGCACCTCTGGGGGCACAGCGGCCCTGGGCTGCCTGGTCAAGGACTACTTCCCCGAACCGGTGACGGTGTCGTGGAACTCAGGCGCCCTGACCAGCGGCGTGCACACCTTCCCGGCTGTCCTACAGTCCTCAGGACTCTACTCCCTCAGCAGCGTGGTGACCGTGCCCTCCAGCAGCTTGGGCACCCAGACCTACATCTGCAACGTGAATCACAAGCCCAGCAACACCAAGGTGGACAAGAAAGTTGAGCCCAAATCTTGTGACAAAACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACCAGAGCACGTACCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGGGAGGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCTACAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTACACGCAGAAGAGCCTCTCCCTGTCTCCGGGTAAATGA](配列番号477)
アミノ酸配列
[スペーサー(配列番号87)][スペーサーを有さないpLW087(配列番号530)]
[QGQSGQ][MMYCGGNEVLCGPRVGSSGGSGGSGGGGGSGGGSGGGSQTVVTQEPSLTVSPGGTVTLTCRSSTGAVTTSNYANWVQQKPGQAPRGLIGGTNKRAPGTPARFSGSLLGGKAALTLSGVQPEDEAEYYCALWYSNLWVFGGGTKLTVLGGGGSGGGGSGGGGSEVQLVESGGGLVQPGGSLKLSCAASGFTFNTYAMNWVRQAPGKGLEWVARIRSKYNNYATYYADSVKDRFTISRDDSKNTAYLQMNNLKTEDTAVYYCVRHGNFGNSYVSWFAYWGQGTLVTVSSGGGGSQVQLQESGPGLVRPSQTLSLTCTVSGYSITSDHAWSWVRQPPGRGLEWIGYISYSGITTYNPSLKSRVTISRDNSKNTLYLQMNSLRAEDTAVYYCARSLARTTAMDYWGQGSLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYQSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK]*(配列番号478)
ヌクレオチド配列
[スペーサー(配列番号507)][スペーサーを有さないpLW079(配列番号527)]
[CAAGGCCAGTCTGGCCAG][TATGGGTCCTGCAGTTGGAACTATGTACACATATTCATGGATTGCGGCTCGAGCGGTGGCAGCGGTGGCTCTGGTGGCTCAGGTGGAGGCTCGGGCGGTGGGAGCGGCGGTTCTGACATCCAGATGACTCAGTCTCCTAGCTCCCTGTCCGCCTCTGTGGGGGACCGAGTCACCATCACATGCAGAGCCAGCCAGGATATTTCTAGTTACCTGAACTGGTATCAGCAGAAGCCCGGAAAAGCACCTAAGCTGCTGATCTACTATACCTCCAGGCTGCACTCTGGCGTGCCCAGTCGGTTCAGTGGCTCAGGGAGCGGAACCGACTTCACTTTTACCATCTCAAGCCTGCAGCCAGAGGATATTGCCACATACTATTGTCAGCAGGGCAATACACTGCCCTACACTTTTGGCCAGGGGACCAAGGTGGAAATCAAACGTACGGTGGCTGCACCATCTGTCTTCATCTTCCCGCCATCTGATGAGCAGTTGAAATCTGGAACTGCCTCTGTTGTGTGCCTGCTGAATAACTTCTATCCCAGAGAGGCCAAAGTACAGTGGAAGGTGGATAACGCCCTCCAATCGGGTAACTCCCAGGAGAGTGTCACAGAGCAGGACAGCAAGGACAGCACCTACAGCCTCAGCAGCACCCTGACGCTGAGCAAAGCAGACTACGAGAAACACAAAGTCTACGCCTGCGAAGTCACCCATCAGGGCCTGAGCTCGCCCGTCACAAAGAGCTTCAACAGGGGAGAGTGTTAG](配列番号880)
アミノ酸配列
[スペーサー(配列番号87)][スペーサーを有さないpLW079(配列番号528)]
[QGQSGQ][YGSCSWNYVHIFMDCGSSGGSGGSGGSGGGSGGGSGGSDIQMTQSPSSLSASVGDRVTITCRASQDISSYLNWYQQKPGKAPKLLIYYTSRLHSGVPSRFSGSGSGTDFTFTISSLQPEDIATYYCQQGNTLPYTFGQGTKVEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC]*(配列番号881)
pLW087: HC IL6RN297Q-15865_Nsub-CD3LvHv-H-N
ヌクレオチド配列
[スペーサー(配列番号507)][スペーサーを有さないpLW087(配列番号529)]
[CAAGGCCAGTCTGGCCAA][ATGATGTATTGCGGTGGGAATGAGGTGTTGTGCGGGCCGCGGGTTGGCTCGAGCGGTGGCAGCGGTGGCTCTGGTGGTGGTGGAGGCTCGGGCGGTGGGAGCGGCGGCGGTTCTCAGACCGTGGTCACACAGGAGCCCTCACTGACAGTGAGCCCTGGCGGGACCGTCACACTGACTTGTCGCAGTTCAACTGGCGCCGTGACTACCAGCAATTACGCTAACTGGGTCCAGCAGAAACCAGGACAGGCACCACGAGGACTGATCGGAGGAACTAATAAGAGAGCACCAGGAACCCCTGCAAGGTTCTCCGGATCTCTGCTGGGGGGAAAAGCCGCTCTGACACTGAGCGGCGTGCAGCCTGAGGACGAAGCTGAGTACTATTGCGCACTGTGGTACTCCAACCTGTGGGTGTTTGGCGGGGGAACTAAGCTGACCGTCCTGGGAGGAGGAGGAAGCGGAGGAGGAGGGAGCGGAGGAGGAGGATCCGAAGTGCAGCTGGTCGAGAGCGGAGGAGGACTGGTGCAGCCAGGAGGATCCCTGAAGCTGTCTTGTGCAGCCAGTGGCTTCACCTTCAACACTTACGCAATGAACTGGGTGCGGCAGGCACCTGGGAAGGGACTGGAATGGGTCGCCCGGATCAGATCTAAATACAATAACTATGCCACCTACTATGCTGACAGTGTGAAGGATAGGTTCACCATTTCACGCGACGATAGCAAAAACACAGCTTATCTGCAGATGAATAACCTGAAGACCGAGGATACAGCAGTGTACTATTGCGTCAGACACGGCAATTTCGGGAACTCTTACGTGAGTTGGTTTGCCTATTGGGGACAGGGGACACTGGTCACCGTCTCCTCAGGAGGTGGTGGATCCCAGGTGCAGCTGCAGGAGTCCGGACCAGGACTGGTCCGGCCCTCACAGACTCTGAGCCTGACATGCACTGTGTCAGGCTACAGCATCACCTCCGATCACGCCTGGAGCTGGGTCAGGCAGCCACCTGGACGCGGCCTGGAATGGATCGGCTACATTTCTTATAGTGGGATCACCACATACAACCCCTCTCTGAAGAGTCGAGTGACCATTTCCAGAGACAACTCTAAAAATACACTGTATCTGCAGATGAATAGTCTGCGGGCCGAGGATACAGCTGTGTACTATTGTGCACGGTCTCTGGCCAGAACTACCGCTATGGACTATTGGGGGCAGGGAAGCCTGGTGACCGTCAGCTCCGCTAGCACCAAGGGCCCATCGGTCTTCCCCCTGGCACCCTCCTCCAAGAGCACCTCTGGGGGCACAGCGGCCCTGGGCTGCCTGGTCAAGGACTACTTCCCCGAACCGGTGACGGTGTCGTGGAACTCAGGCGCCCTGACCAGCGGCGTGCACACCTTCCCGGCTGTCCTACAGTCCTCAGGACTCTACTCCCTCAGCAGCGTGGTGACCGTGCCCTCCAGCAGCTTGGGCACCCAGACCTACATCTGCAACGTGAATCACAAGCCCAGCAACACCAAGGTGGACAAGAAAGTTGAGCCCAAATCTTGTGACAAAACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACCAGAGCACGTACCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGGGAGGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCTACAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTACACGCAGAAGAGCCTCTCCCTGTCTCCGGGTAAATGA](配列番号477)
アミノ酸配列
[スペーサー(配列番号87)][スペーサーを有さないpLW087(配列番号530)]
[QGQSGQ][MMYCGGNEVLCGPRVGSSGGSGGSGGGGGSGGGSGGGSQTVVTQEPSLTVSPGGTVTLTCRSSTGAVTTSNYANWVQQKPGQAPRGLIGGTNKRAPGTPARFSGSLLGGKAALTLSGVQPEDEAEYYCALWYSNLWVFGGGTKLTVLGGGGSGGGGSGGGGSEVQLVESGGGLVQPGGSLKLSCAASGFTFNTYAMNWVRQAPGKGLEWVARIRSKYNNYATYYADSVKDRFTISRDDSKNTAYLQMNNLKTEDTAVYYCVRHGNFGNSYVSWFAYWGQGTLVTVSSGGGGSQVQLQESGPGLVRPSQTLSLTCTVSGYSITSDHAWSWVRQPPGRGLEWIGYISYSGITTYNPSLKSRVTISRDNSKNTLYLQMNSLRAEDTAVYYCARSLARTTAMDYWGQGSLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYQSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK]*(配列番号478)
ヌクレオチド配列
[スペーサー(配列番号507)][スペーサーを有さないpLW080(配列番号515)]
[CAAGGCCAGTCTGGCCAG][TATGGGTCCTGCAGTTGGAACTATGTACACATATTCATGGATTGCGGCTCGAGCGGTGGCAGCGGTGGCTCTGGTGGTCTGAGCGGCCGTTCCGATAATCATGGCGGCGGTTCTGACATCCAGATGACTCAGTCTCCTAGCTCCCTGTCCGCCTCTGTGGGGGACCGAGTCACCATCACATGCAGAGCCAGCCAGGATATTTCTAGTTACCTGAACTGGTATCAGCAGAAGCCCGGAAAAGCACCTAAGCTGCTGATCTACTATACCTCCAGGCTGCACTCTGGCGTGCCCAGTCGGTTCAGTGGCTCAGGGAGCGGAACCGACTTCACTTTTACCATCTCAAGCCTGCAGCCAGAGGATATTGCCACATACTATTGTCAGCAGGGCAATACACTGCCCTACACTTTTGGCCAGGGGACCAAGGTGGAAATCAAACGTACGGTGGCTGCACCATCTGTCTTCATCTTCCCGCCATCTGATGAGCAGTTGAAATCTGGAACTGCCTCTGTTGTGTGCCTGCTGAATAACTTCTATCCCAGAGAGGCCAAAGTACAGTGGAAGGTGGATAACGCCCTCCAATCGGGTAACTCCCAGGAGAGTGTCACAGAGCAGGACAGCAAGGACAGCACCTACAGCCTCAGCAGCACCCTGACGCTGAGCAAAGCAGACTACGAGAAACACAAAGTCTACGCCTGCGAAGTCACCCATCAGGGCCTGAGCTCGCCCGTCACAAAGAGCTTCAACAGGGGAGAGTGTTAG](配列番号473)
アミノ酸配列
[スペーサー(配列番号87)][スペーサーを有さないpLW080(配列番号516)]
[QGQSGQ][YGSCSWNYVHIFMDCGSSGGSGGSGGLSGRSDNHGGGSDIQMTQSPSSLSASVGDRVTITCRASQDISSYLNWYQQKPGKAPKLLIYYTSRLHSGVPSRFSGSGSGTDFTFTISSLQPEDIATYYCQQGNTLPYTFGQGTKVEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC]*(配列番号474)
HC C225v5N297Q-*CD3LvHv-H-N
ヌクレオチド配列
CAAGGCCAGTCTGGCCAAATGATGTATTGCGGTGGGAATGAGGTGTTGTGCGGGCCGCGGGTTGGCTCGAGCGGTGGCAGCGGTGGCTCTGGTGGTCTGAGCGGCCGTTCCGATAATCATGGCGGCGGTTCTCAGACCGTGGTCACACAGGAGCCCTCACTGACAGTGAGCCCTGGCGGGACCGTCACACTGACTTGTCGCAGTTCAACTGGCGCCGTGACTACCAGCAATTACGCTAACTGGGTCCAGCAGAAACCAGGACAGGCACCACGAGGACTGATCGGAGGAACTAATAAGAGAGCACCAGGAACCCCTGCAAGGTTCTCCGGATCTCTGCTGGGGGGAAAAGCCGCTCTGACACTGAGCGGCGTGCAGCCTGAGGACGAAGCTGAGTACTATTGCGCACTGTGGTACTCCAACCTGTGGGTGTTTGGCGGGGGAACTAAGCTGACCGTCCTGGGAGGAGGAGGAAGCGGAGGAGGAGGGAGCGGAGGAGGAGGATCCGAAGTGCAGCTGGTCGAGAGCGGAGGAGGACTGGTGCAGCCAGGAGGATCCCTGAAGCTGTCTTGTGCAGCCAGTGGCTTCACCTTCAACACTTACGCAATGAACTGGGTGCGGCAGGCACCTGGGAAGGGACTGGAATGGGTCGCCCGGATCAGATCTAAATACAATAACTATGCCACCTACTATGCTGACAGTGTGAAGGATAGGTTCACCATTTCACGCGACGATAGCAAAAACACAGCTTATCTGCAGATGAATAACCTGAAGACCGAGGATACAGCAGTGTACTATTGCGTCAGACACGGCAATTTCGGGAACTCTTACGTGAGTTGGTTTGCCTATTGGGGACAGGGGACACTGGTCACCGTCTCCTCAGGAGGTGGTGGATCCCAGGTGCAGCTGAAACAGAGCGGCCCGGGCCTGGTGCAGCCGAGCCAGAGCCTGAGCATTACCTGCACCGTGAGCGGCTTTAGCCTGACCAACTATGGCGTGCATTGGGTGCGCCAGAGCCCGGGCAAAGGCCTGGAATGGCTGGGCGTGATTTGGAGCGGCGGCAACACCGATTATAACACCCCGTTTACCAGCCGCCTGAGCATTAACAAAGATAACAGCAAAAGCCAGGTGTTTTTTAAAATGAACAGCCTGCAAAGCCAGGATACCGCGATTTATTATTGCGCGCGCGCGCTGACCTATTATGATTATGAATTTGCGTATTGGGGCCAGGGCACCCTGGTGACCGTGAGCGCGGCTAGCACCAAGGGCCCATCGGTCTTCCCCCTGGCACCCTCCTCCAAGAGCACCTCTGGGGGCACAGCGGCCCTGGGCTGCCTGGTCAAGGACTACTTCCCCGAACCGGTGACGGTGTCGTGGAACTCAGGCGCCCTGACCAGCGGCGTGCACACCTTCCCGGCTGTCCTACAGTCCTCAGGACTCTACTCCCTCAGCAGCGTGGTGACCGTGCCCTCCAGCAGCTTGGGCACCCAGACCTACATCTGCAACGTGAATCACAAGCCCAGCAACACCAAGGTGGACAAGAAAGTTGAGCCCAAATCTTGTGACAAAACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACCAGAGCACGTACCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGGGAGGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCTACAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTACACGCAGAAGAGCCTCTCCCTGTCTCCGGGTAAATGA(配列番号878)
アミノ酸配列
SDNHGGGSQTVVTQEPSLTVSPGGTVTLTCRSSTGAVTTSNYANWVQQKPGQAPRGLIGGTNKRAPGTPARFSGSLLGGKAALTLSGVQPEDEAEYYCALWYSNLWVFGGGTKLTVLGGGGSGGGGSGGGGSEVQLVESGGGLVQPGGSLKLSCAASGFTFNTYAMNWVRQAPGKGLEWVARIRSKYNNYATYYADSVKDRFTISRDDSKNTAYLQMNNLKTEDTAVYYCVRHGNFGNSYVSWFAYWGQGTLVTVSSGGGGSQVQLKQSGPGLVQPSQSLSITCTVSGFSLTNYGVHWVRQSPGKGLEWLGVIWSGGNTDYNTPFTSRLSINKDNSKSQVFFKMNSLQSQDTAIYYCARALTYYDYEFAYWGQGTLVTVSAASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYQSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK(配列番号879)
ヌクレオチド配列
TCCGATAATCATGGCAGTAGCGGTACCCAGATCTTGCTGACCCAGAGCCCGGTGATTCTGAGCGTGAGCCCGGGCGAACGTGTGAGCTTTAGCTGCCGCGCGAGCCAGAGCATTGGCACCAACATTCATTGGTATCAGCAGCGCACCAACGGCAGCCCGCGCCTGCTGATTAAATATGCGAGCGAAAGCATTAGCGGCATTCCGAGCCGCTTTAGCGGCAGCGGCAGCGGCACCGATTTTACCCTGAGCATTAACAGCGTGGAAAGCGAAGATATTGCGGATTATTATTGCCAGCAGAACAACAACTGGCCGACCACCTTTGGCGCGGGCACCAAACTGGAACTGAAACGTACGGTGGCTGCACCATCTGTCTTCATCTTCCCGCCATCTGATGAGCAGTTGAAATCTGGAACTGCCTCTGTTGTGTGCCTGCTGAATAACTTCTATCCCAGAGAGGCCAAAGTACAGTGGAAGGTGGATAACGCCCTCCAATCGGGTAACTCCCAGGAGAGTGTCACAGAGCAGGACAGCAAGGACAGCACCTACAGCCTCAGCAGCACCCTGACGCTGAGCAAAGCAGACTACGAGAAACACAAAGTCTACGCCTGCGAAGTCACCCATCAGGGCCTGAGCTCGCCCGTCACAAAGAGCTTCAACAGGGGAGAGTGTTAG(配列番号483)
アミノ酸配列
SDNHGSSGTQILLTQSPVILSVSPGERVSFSCRASQSIGTNIHWYQQRTNGSPRLLIKYASESISGIPSRFSGSGSGTDFTLSINSVESEDIADYYCQQNNNWPTTFGAGTKLELKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC(配列番号484)
pLW100: HC C225v5N297Q-mCD3-H-N
ヌクレオチド配列
GAAGTGCAGCTGGTGGAATCTGGGGGCGGACTGGTGCAGCCTGGCAAGTCTCTGAAGCTGAGCTGCGAGGCCAGCGGCTTCACCTTTAGCGGCTACGGCATGCACTGGGTGCGCCAGGCACCTGGCAGAGGCCTGGAAAGCGTGGCCTACATCACCAGCAGCAGCATCAACATTAAGTACGCCGACGCCGTGAAGGGCCGGTTCACCGTGTCCAGAGACAACGCCAAGAACCTGCTGTTCCTGCAGATGAACATCCTGAAGTCCGAGGACACCGCCATGTACTACTGCGCCAGATTCGACTGGGACAAGAACTACTGGGGCCAGGGCACAATGGTCACAGTGTCCAGCGGTGGAGGTGGTAGTGGTGGAGGAAGTGGAGGTTCAGGAGGTGGAAGCGGTGGTGGTGGTAGTGACATCCAGATGACCCAGAGCCCCAGCAGCCTGCCTGCCTCTCTGGGCGATAGAGTGACCATCAACTGCCAGGCCAGCCAGGACATCAGCAACTACCTGAACTGGTATCAGCAGAAGCCCGGCAAGGCCCCCAAGCTGCTGATCTACTACACCAACAAGCTGGCCGACGGTGTGCCCAGCAGATTCAGCGGCAGCGGTAGCGGCAGAGACAGCAGCTTCACCATCAGCTCCCTGGAATCCGAGGATATCGGCAGCTACTACTGCCAGCAGTACTACAACTACCCCTGGACCTTCGGCCCTGGCACCAAGCTGGAAATCAAAAGAGGAGGTGGTGGATCCCAGGTGCAGCTGAAACAGAGCGGCCCGGGCCTGGTGCAGCCGAGCCAGAGCCTGAGCATTACCTGCACCGTGAGCGGCTTTAGCCTGACCAACTATGGCGTGCATTGGGTGCGCCAGAGCCCGGGCAAAGGCCTGGAATGGCTGGGCGTGATTTGGAGCGGCGGCAACACCGATTATAACACCCCGTTTACCAGCCGCCTGAGCATTAACAAAGATAACAGCAAAAGCCAGGTGTTTTTTAAAATGAACAGCCTGCAAAGCCAGGATACCGCGATTTATTATTGCGCGCGCGCGCTGACCTATTATGATTATGAATTTGCGTATTGGGGCCAGGGCACCCTGGTGACCGTGAGCGCGGCTAGCACCAAGGGCCCATCGGTCTTCCCCCTGGCACCCTCCTCCAAGAGCACCTCTGGGGGCACAGCGGCCCTGGGCTGCCTGGTCAAGGACTACTTCCCCGAACCGGTGACGGTGTCGTGGAACTCAGGCGCCCTGACCAGCGGCGTGCACACCTTCCCGGCTGTCCTACAGTCCTCAGGACTCTACTCCCTCAGCAGCGTGGTGACCGTGCCCTCCAGCAGCTTGGGCACCCAGACCTACATCTGCAACGTGAATCACAAGCCCAGCAACACCAAGGTGGACAAGAAAGTTGAGCCCAAATCTTGTGACAAAACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACCAGAGCACGTACCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGGGAGGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCTACAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTACACGCAGAAGAGCCTCTCCCTGTCTCCGGGTAAATGA(配列番号491)
アミノ酸配列
EVQLVESGGGLVQPGKSLKLSCEASGFTFSGYGMHWVRQAPGRGLESVAYITSSSINIKYADAVKGRFTVSRDNAKNLLFLQMNILKSEDTAMYYCARFDWDKNYWGQGTMVTVSSGGGGSGGGSGGSGGGSGGGGSDIQMTQSPSSLPASLGDRVTINCQASQDISNYLNWYQQKPGKAPKLLIYYTNKLADGVPSRFSGSGSGRDSSFTISSLESEDIGSYYCQQYYNYPWTFGPGTKLEIKRGGGGSQVQLKQSGPGLVQPSQSLSITCTVSGFSLTNYGVHWVRQSPGKGLEWLGVIWSGGNTDYNTPFTSRLSINKDNSKSQVFFKMNSLQSQDTAIYYCARALTYYDYEFAYWGQGTLVTVSAASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYQSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK*(配列番号492)
ヌクレオチド配列
GATATCTTGCTGACCCAGAGCCCGGTGATTCTGAGCGTGAGCCCGGGCGAACGTGTGAGCTTTAGCTGCCGCGCGAGCCAGAGCATTGGCACCAACATTCATTGGTATCAGCAGCGCACCAACGGCAGCCCGCGCCTGCTGATTAAATATGCGAGCGAAAGCATTAGCGGCATTCCGAGCCGCTTTAGCGGCAGCGGCAGCGGCACCGATTTTACCCTGAGCATTAACAGCGTGGAAAGCGAAGATATTGCGGATTATTATTGCCAGCAGAACAACAACTGGCCGACCACCTTTGGCGCGGGCACCAAACTGGAAATCAAACGTACGGTGGCTGCACCATCTGTCTTCATCTTCCCGCCATCTGATGAGCAGTTGAAATCTGGAACTGCCTCTGTTGTGTGCCTGCTGAATAACTTCTATCCCAGAGAGGCCAAAGTACAGTGGAAGGTGGATAACGCCCTCCAATCGGGTAACTCCCAGGAGAGTGTCACAGAGCAGGACAGCAAGGACAGCACCTACAGCCTCAGCAGCACCCTGACGCTGAGCAAAGCAGACTACGAGAAACACAAAGTCTACGCCTGCGAAGTCACCCATCAGGGCCTGAGCTCGCCCGTCACAAAGAGCTTCAACAGGGGAGAGTGTTAG(配列番号457)
アミノ酸配列
DILLTQSPVILSVSPGERVSFSCRASQSIGTNIHWYQQRTNGSPRLLIKYASESISGIPSRFSGSGSGTDFTLSINSVESEDIADYYCQQNNNWPTTFGAGTKLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC*(配列番号458)
pLW117: HC C225v5N297Q-MC01-2001-mCD3-H-N
ヌクレオチド配列
[スペーサー(配列番号507)][スペーサーを有さないpLW117(配列番号531)]
[CAAGGCCAGTCTGGCCAA][TTGCATCCTATGTGCCATCCTGAGGGTCTGTGCAAGTTTACTCCTGGAGGTGGCTCGAGCGGTGGCAGCGGTGGCTCTGGTGGTATTAGCAGTGGTCTGTTAAGCGGTCGTAGCGATAATCATGGCGGCGGTTCTGAAGTGCAGCTGGTGGAATCTGGGGGCGGACTGGTGCAGCCTGGCAAGTCTCTGAAGCTGAGCTGCGAGGCCAGCGGCTTCACCTTTAGCGGCTACGGCATGCACTGGGTGCGCCAGGCACCTGGCAGAGGCCTGGAAAGCGTGGCCTACATCACCAGCAGCAGCATCAACATTAAGTACGCCGACGCCGTGAAGGGCCGGTTCACCGTGTCCAGAGACAACGCCAAGAACCTGCTGTTCCTGCAGATGAACATCCTGAAGTCCGAGGACACCGCCATGTACTACTGCGCCAGATTCGACTGGGACAAGAACTACTGGGGCCAGGGCACAATGGTCACAGTGTCCAGCGGTGGAGGTGGTAGTGGTGGAGGAAGTGGAGGTTCAGGAGGTGGAAGCGGTGGTGGTGGTAGTGACATCCAGATGACCCAGAGCCCCAGCAGCCTGCCTGCCTCTCTGGGCGATAGAGTGACCATCAACTGCCAGGCCAGCCAGGACATCAGCAACTACCTGAACTGGTATCAGCAGAAGCCCGGCAAGGCCCCCAAGCTGCTGATCTACTACACCAACAAGCTGGCCGACGGTGTGCCCAGCAGATTCAGCGGCAGCGGTAGCGGCAGAGACAGCAGCTTCACCATCAGCTCCCTGGAATCCGAGGATATCGGCAGCTACTACTGCCAGCAGTACTACAACTACCCCTGGACCTTCGGCCCTGGCACCAAGCTGGAAATCAAAAGAGGAGGTGGTGGATCCCAGGTGCAGCTGAAACAGAGCGGCCCGGGCCTGGTGCAGCCGAGCCAGAGCCTGAGCATTACCTGCACCGTGAGCGGCTTTAGCCTGACCAACTATGGCGTGCATTGGGTGCGCCAGAGCCCGGGCAAAGGCCTGGAATGGCTGGGCGTGATTTGGAGCGGCGGCAACACCGATTATAACACCCCGTTTACCAGCCGCCTGAGCATTAACAAAGATAACAGCAAAAGCCAGGTGTTTTTTAAAATGAACAGCCTGCAAAGCCAGGATACCGCGATTTATTATTGCGCGCGCGCGCTGACCTATTATGATTATGAATTTGCGTATTGGGGCCAGGGCACCCTGGTGACCGTGAGCGCGGCTAGCACCAAGGGCCCATCGGTCTTCCCCCTGGCACCCTCCTCCAAGAGCACCTCTGGGGGCACAGCGGCCCTGGGCTGCCTGGTCAAGGACTACTTCCCCGAACCGGTGACGGTGTCGTGGAACTCAGGCGCCCTGACCAGCGGCGTGCACACCTTCCCGGCTGTCCTACAGTCCTCAGGACTCTACTCCCTCAGCAGCGTGGTGACCGTGCCCTCCAGCAGCTTGGGCACCCAGACCTACATCTGCAACGTGAATCACAAGCCCAGCAACACCAAGGTGGACAAGAAAGTTGAGCCCAAATCTTGTGACAAAACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACCAGAGCACGTACCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGGGAGGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCTACAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTACACGCAGAAGAGCCTCTCCCTGTCTCCGGGTAAATGA](配列番号493)
アミノ酸配列
[スペーサー(配列番号87)][スペーサーを有さないpLW117(配列番号532)]
[QGQSGQ][LHPMCHPEGLCKFTPGGGSSGGSGGSGGISSGLLSGRSDNHGGGSEVQLVESGGGLVQPGKSLKLSCEASGFTFSGYGMHWVRQAPGRGLESVAYITSSSINIKYADAVKGRFTVSRDNAKNLLFLQMNILKSEDTAMYYCARFDWDKNYWGQGTMVTVSSGGGGSGGGSGGSGGGSGGGGSDIQMTQSPSSLPASLGDRVTINCQASQDISNYLNWYQQKPGKAPKLLIYYTNKLADGVPSRFSGSGSGRDSSFTISSLESEDIGSYYCQQYYNYPWTFGPGTKLEIKRGGGGSQVQLKQSGPGLVQPSQSLSITCTVSGFSLTNYGVHWVRQSPGKGLEWLGVIWSGGNTDYNTPFTSRLSINKDNSKSQVFFKMNSLQSQDTAIYYCARALTYYDYEFAYWGQGTLVTVSAASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYQSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK]*(配列番号494)
ヌクレオチド配列
[スペーサー(配列番号507)][スペーサーを有さないOPP022(配列番号509)]
[CAAGGCCAGTCTGGCCAG][TGCATCTCACCTCGTGGTTGTCCGGACGGCCCATACGTCATGTACGGCTCGAGCGGTGGCAGCGGTGGCTCTGGTGGATCCGGTCTGAGCGGCCGTTCCGATAATCATGGCAGTAGCGGTACCCAGATCTTGCTGACCCAGAGCCCGGTGATTCTGAGCGTGAGCCCGGGCGAACGTGTGAGCTTTAGCTGCCGCGCGAGCCAGAGCATTGGCACCAACATTCATTGGTATCAGCAGCGCACCAACGGCAGCCCGCGCCTGCTGATTAAATATGCGAGCGAAAGCATTAGCGGCATTCCGAGCCGCTTTAGCGGCAGCGGCAGCGGCACCGATTTTACCCTGAGCATTAACAGCGTGGAAAGCGAAGATATTGCGGATTATTATTGCCAGCAGAACAACAACTGGCCGACCACCTTTGGCGCGGGCACCAAACTGGAACTGAAACGTACGGTGGCTGCACCATCTGTCTTCATCTTCCCGCCATCTGATGAGCAGTTGAAATCTGGAACTGCCTCTGTTGTGTGCCTGCTGAATAACTTCTATCCCAGAGAGGCCAAAGTACAGTGGAAGGTGGATAACGCCCTCCAATCGGGTAACTCCCAGGAGAGTGTCACAGAGCAGGACAGCAAGGACAGCACCTACAGCCTCAGCAGCACCCTGACGCTGAGCAAAGCAGACTACGAGAAACACAAAGTCTACGCCTGCGAAGTCACCCATCAGGGCCTGAGCTCGCCCGTCACAAAGAGCTTCAACAGGGGAGAGTGTTAG](配列番号449)
アミノ酸配列
[スペーサー(配列番号87)][スペーサーを有さないOPP022(配列番号508)]
[QGQSGQ][CISPRGCPDGPYVMYGSSGGSGGSGGSGLSGRSDNHGSSGTQILLTQSPVILSVSPGERVSFSCRASQSIGTNIHWYQQRTNGSPRLLIKYASESISGIPSRFSGSGSGTDFTLSINSVESEDIADYYCQQNNNWPTTFGAGTKLELKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC]*(配列番号450)
pLW118: HC C225v5N297Q-MC02-2001-mCD3-H-N
ヌクレオチド配列
[スペーサー(配列番号521)][スペーサーを有さないpLW118(配列番号533)]
[CAAGGCCAGTCTGGCCAAGGT][GCTTGCTCTGATATGGTTTATTGGGGTTCGTGCAGTTGGTTGGGAGGTGGCTCGAGCGGTGGCAGCGGTGGCTCTGGTGGTATTAGCAGTGGTCTGTTAAGCGGTCGTAGCGATAATCATGGCGGCGGTTCTGAAGTGCAGCTGGTGGAATCTGGGGGCGGACTGGTGCAGCCTGGCAAGTCTCTGAAGCTGAGCTGCGAGGCCAGCGGCTTCACCTTTAGCGGCTACGGCATGCACTGGGTGCGCCAGGCACCTGGCAGAGGCCTGGAAAGCGTGGCCTACATCACCAGCAGCAGCATCAACATTAAGTACGCCGACGCCGTGAAGGGCCGGTTCACCGTGTCCAGAGACAACGCCAAGAACCTGCTGTTCCTGCAGATGAACATCCTGAAGTCCGAGGACACCGCCATGTACTACTGCGCCAGATTCGACTGGGACAAGAACTACTGGGGCCAGGGCACAATGGTCACAGTGTCCAGCGGTGGAGGTGGTAGTGGTGGAGGAAGTGGAGGTTCAGGAGGTGGAAGCGGTGGTGGTGGTAGTGACATCCAGATGACCCAGAGCCCCAGCAGCCTGCCTGCCTCTCTGGGCGATAGAGTGACCATCAACTGCCAGGCCAGCCAGGACATCAGCAACTACCTGAACTGGTATCAGCAGAAGCCCGGCAAGGCCCCCAAGCTGCTGATCTACTACACCAACAAGCTGGCCGACGGTGTGCCCAGCAGATTCAGCGGCAGCGGTAGCGGCAGAGACAGCAGCTTCACCATCAGCTCCCTGGAATCCGAGGATATCGGCAGCTACTACTGCCAGCAGTACTACAACTACCCCTGGACCTTCGGCCCTGGCACCAAGCTGGAAATCAAAAGAGGAGGTGGTGGATCCCAGGTGCAGCTGAAACAGAGCGGCCCGGGCCTGGTGCAGCCGAGCCAGAGCCTGAGCATTACCTGCACCGTGAGCGGCTTTAGCCTGACCAACTATGGCGTGCATTGGGTGCGCCAGAGCCCGGGCAAAGGCCTGGAATGGCTGGGCGTGATTTGGAGCGGCGGCAACACCGATTATAACACCCCGTTTACCAGCCGCCTGAGCATTAACAAAGATAACAGCAAAAGCCAGGTGTTTTTTAAAATGAACAGCCTGCAAAGCCAGGATACCGCGATTTATTATTGCGCGCGCGCGCTGACCTATTATGATTATGAATTTGCGTATTGGGGCCAGGGCACCCTGGTGACCGTGAGCGCGGCTAGCACCAAGGGCCCATCGGTCTTCCCCCTGGCACCCTCCTCCAAGAGCACCTCTGGGGGCACAGCGGCCCTGGGCTGCCTGGTCAAGGACTACTTCCCCGAACCGGTGACGGTGTCGTGGAACTCAGGCGCCCTGACCAGCGGCGTGCACACCTTCCCGGCTGTCCTACAGTCCTCAGGACTCTACTCCCTCAGCAGCGTGGTGACCGTGCCCTCCAGCAGCTTGGGCACCCAGACCTACATCTGCAACGTGAATCACAAGCCCAGCAACACCAAGGTGGACAAGAAAGTTGAGCCCAAATCTTGTGACAAAACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACCAGAGCACGTACCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGGGAGGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCTACAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTACACGCAGAAGAGCCTCTCCCTGTCTCCGGGTAAATGA](配列番号495)
アミノ酸配列
[スペーサー(配列番号407)][スペーサーを有さないpLW118(配列番号534)]
[QGQSGQG][ACSDMVYWGSCSWLGGGSSGGSGGSGGISSGLLSGRSDNHGGGSEVQLVESGGGLVQPGKSLKLSCEASGFTFSGYGMHWVRQAPGRGLESVAYITSSSINIKYADAVKGRFTVSRDNAKNLLFLQMNILKSEDTAMYYCARFDWDKNYWGQGTMVTVSSGGGGSGGGSGGSGGGSGGGGSDIQMTQSPSSLPASLGDRVTINCQASQDISNYLNWYQQKPGKAPKLLIYYTNKLADGVPSRFSGSGSGRDSSFTISSLESEDIGSYYCQQYYNYPWTFGPGTKLEIKRGGGGSQVQLKQSGPGLVQPSQSLSITCTVSGFSLTNYGVHWVRQSPGKGLEWLGVIWSGGNTDYNTPFTSRLSINKDNSKSQVFFKMNSLQSQDTAIYYCARALTYYDYEFAYWGQGTLVTVSAASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYQSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK]*(配列番号496)
ヌクレオチド配列
[スペーサー(配列番号507)][スペーサーを有さないOPP022(配列番号509)]
[CAAGGCCAGTCTGGCCAG][TGCATCTCACCTCGTGGTTGTCCGGACGGCCCATACGTCATGTACGGCTCGAGCGGTGGCAGCGGTGGCTCTGGTGGATCCGGTCTGAGCGGCCGTTCCGATAATCATGGCAGTAGCGGTACCCAGATCTTGCTGACCCAGAGCCCGGTGATTCTGAGCGTGAGCCCGGGCGAACGTGTGAGCTTTAGCTGCCGCGCGAGCCAGAGCATTGGCACCAACATTCATTGGTATCAGCAGCGCACCAACGGCAGCCCGCGCCTGCTGATTAAATATGCGAGCGAAAGCATTAGCGGCATTCCGAGCCGCTTTAGCGGCAGCGGCAGCGGCACCGATTTTACCCTGAGCATTAACAGCGTGGAAAGCGAAGATATTGCGGATTATTATTGCCAGCAGAACAACAACTGGCCGACCACCTTTGGCGCGGGCACCAAACTGGAACTGAAACGTACGGTGGCTGCACCATCTGTCTTCATCTTCCCGCCATCTGATGAGCAGTTGAAATCTGGAACTGCCTCTGTTGTGTGCCTGCTGAATAACTTCTATCCCAGAGAGGCCAAAGTACAGTGGAAGGTGGATAACGCCCTCCAATCGGGTAACTCCCAGGAGAGTGTCACAGAGCAGGACAGCAAGGACAGCACCTACAGCCTCAGCAGCACCCTGACGCTGAGCAAAGCAGACTACGAGAAACACAAAGTCTACGCCTGCGAAGTCACCCATCAGGGCCTGAGCTCGCCCGTCACAAAGAGCTTCAACAGGGGAGAGTGTTAG](配列番号449)
アミノ酸配列
[スペーサー(配列番号87)][スペーサーを有さないOPP022(配列番号508)]
[QGQSGQ][CISPRGCPDGPYVMYGSSGGSGGSGGSGLSGRSDNHGSSGTQILLTQSPVILSVSPGERVSFSCRASQSIGTNIHWYQQRTNGSPRLLIKYASESISGIPSRFSGSGSGTDFTLSINSVESEDIADYYCQQNNNWPTTFGAGTKLELKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC]*(配列番号450)
pLW119: HC C225v5N297Q-MC03-2001-mCD3-H-N
ヌクレオチド配列
[スペーサー(配列番号507)][スペーサーを有さないpLW119(配列番号535)]
[CAAGGCCAGTCTGGCCAA][GATTGCATTGGATTGGATCATTATTTTCTTGGACCGTGCAGTTCTGGAGGTGGCTCGAGCGGTGGCAGCGGTGGCTCTGGTGGTATTAGCAGTGGTCTGTTAAGCGGTCGTAGCGATAATCATGGCGGCGGTTCTGAAGTGCAGCTGGTGGAATCTGGGGGCGGACTGGTGCAGCCTGGCAAGTCTCTGAAGCTGAGCTGCGAGGCCAGCGGCTTCACCTTTAGCGGCTACGGCATGCACTGGGTGCGCCAGGCACCTGGCAGAGGCCTGGAAAGCGTGGCCTACATCACCAGCAGCAGCATCAACATTAAGTACGCCGACGCCGTGAAGGGCCGGTTCACCGTGTCCAGAGACAACGCCAAGAACCTGCTGTTCCTGCAGATGAACATCCTGAAGTCCGAGGACACCGCCATGTACTACTGCGCCAGATTCGACTGGGACAAGAACTACTGGGGCCAGGGCACAATGGTCACAGTGTCCAGCGGTGGAGGTGGTAGTGGTGGAGGAAGTGGAGGTTCAGGAGGTGGAAGCGGTGGTGGTGGTAGTGACATCCAGATGACCCAGAGCCCCAGCAGCCTGCCTGCCTCTCTGGGCGATAGAGTGACCATCAACTGCCAGGCCAGCCAGGACATCAGCAACTACCTGAACTGGTATCAGCAGAAGCCCGGCAAGGCCCCCAAGCTGCTGATCTACTACACCAACAAGCTGGCCGACGGTGTGCCCAGCAGATTCAGCGGCAGCGGTAGCGGCAGAGACAGCAGCTTCACCATCAGCTCCCTGGAATCCGAGGATATCGGCAGCTACTACTGCCAGCAGTACTACAACTACCCCTGGACCTTCGGCCCTGGCACCAAGCTGGAAATCAAAAGAGGAGGTGGTGGATCCCAGGTGCAGCTGAAACAGAGCGGCCCGGGCCTGGTGCAGCCGAGCCAGAGCCTGAGCATTACCTGCACCGTGAGCGGCTTTAGCCTGACCAACTATGGCGTGCATTGGGTGCGCCAGAGCCCGGGCAAAGGCCTGGAATGGCTGGGCGTGATTTGGAGCGGCGGCAACACCGATTATAACACCCCGTTTACCAGCCGCCTGAGCATTAACAAAGATAACAGCAAAAGCCAGGTGTTTTTTAAAATGAACAGCCTGCAAAGCCAGGATACCGCGATTTATTATTGCGCGCGCGCGCTGACCTATTATGATTATGAATTTGCGTATTGGGGCCAGGGCACCCTGGTGACCGTGAGCGCGGCTAGCACCAAGGGCCCATCGGTCTTCCCCCTGGCACCCTCCTCCAAGAGCACCTCTGGGGGCACAGCGGCCCTGGGCTGCCTGGTCAAGGACTACTTCCCCGAACCGGTGACGGTGTCGTGGAACTCAGGCGCCCTGACCAGCGGCGTGCACACCTTCCCGGCTGTCCTACAGTCCTCAGGACTCTACTCCCTCAGCAGCGTGGTGACCGTGCCCTCCAGCAGCTTGGGCACCCAGACCTACATCTGCAACGTGAATCACAAGCCCAGCAACACCAAGGTGGACAAGAAAGTTGAGCCCAAATCTTGTGACAAAACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACCAGAGCACGTACCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGGGAGGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCTACAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTACACGCAGAAGAGCCTCTCCCTGTCTCCGGGTAAATGA](配列番号497)
アミノ酸配列
[スペーサー(配列番号87)][スペーサーを有さないpLW119(配列番号536)]
[QGQSGQ][DCIGLDHYFLGPCSSGGGSSGGSGGSGGISSGLLSGRSDNHGGGSEVQLVESGGGLVQPGKSLKLSCEASGFTFSGYGMHWVRQAPGRGLESVAYITSSSINIKYADAVKGRFTVSRDNAKNLLFLQMNILKSEDTAMYYCARFDWDKNYWGQGTMVTVSSGGGGSGGGSGGSGGGSGGGGSDIQMTQSPSSLPASLGDRVTINCQASQDISNYLNWYQQKPGKAPKLLIYYTNKLADGVPSRFSGSGSGRDSSFTISSLESEDIGSYYCQQYYNYPWTFGPGTKLEIKRGGGGSQVQLKQSGPGLVQPSQSLSITCTVSGFSLTNYGVHWVRQSPGKGLEWLGVIWSGGNTDYNTPFTSRLSINKDNSKSQVFFKMNSLQSQDTAIYYCARALTYYDYEFAYWGQGTLVTVSAASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYQSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK]*(配列番号498)
ヌクレオチド配列
[スペーサー(配列番号507)][スペーサーを有さないOPP022(配列番号509)]
[CAAGGCCAGTCTGGCCAG][TGCATCTCACCTCGTGGTTGTCCGGACGGCCCATACGTCATGTACGGCTCGAGCGGTGGCAGCGGTGGCTCTGGTGGATCCGGTCTGAGCGGCCGTTCCGATAATCATGGCAGTAGCGGTACCCAGATCTTGCTGACCCAGAGCCCGGTGATTCTGAGCGTGAGCCCGGGCGAACGTGTGAGCTTTAGCTGCCGCGCGAGCCAGAGCATTGGCACCAACATTCATTGGTATCAGCAGCGCACCAACGGCAGCCCGCGCCTGCTGATTAAATATGCGAGCGAAAGCATTAGCGGCATTCCGAGCCGCTTTAGCGGCAGCGGCAGCGGCACCGATTTTACCCTGAGCATTAACAGCGTGGAAAGCGAAGATATTGCGGATTATTATTGCCAGCAGAACAACAACTGGCCGACCACCTTTGGCGCGGGCACCAAACTGGAACTGAAACGTACGGTGGCTGCACCATCTGTCTTCATCTTCCCGCCATCTGATGAGCAGTTGAAATCTGGAACTGCCTCTGTTGTGTGCCTGCTGAATAACTTCTATCCCAGAGAGGCCAAAGTACAGTGGAAGGTGGATAACGCCCTCCAATCGGGTAACTCCCAGGAGAGTGTCACAGAGCAGGACAGCAAGGACAGCACCTACAGCCTCAGCAGCACCCTGACGCTGAGCAAAGCAGACTACGAGAAACACAAAGTCTACGCCTGCGAAGTCACCCATCAGGGCCTGAGCTCGCCCGTCACAAAGAGCTTCAACAGGGGAGAGTGTTAG](配列番号449)
アミノ酸配列
[スペーサー(配列番号87)][スペーサーを有さないOPP022(配列番号508)]
[QGQSGQ][CISPRGCPDGPYVMYGSSGGSGGSGGSGLSGRSDNHGSSGTQILLTQSPVILSVSPGERVSFSCRASQSIGTNIHWYQQRTNGSPRLLIKYASESISGIPSRFSGSGSGTDFTLSINSVESEDIADYYCQQNNNWPTTFGAGTKLELKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC]*(配列番号450)
pLW120: HC C225v5N297Q-MC04-2001-mCD3-H-N
ヌクレオチド配列
[スペーサー(配列番号507)][スペーサーを有さないpLW120(配列番号537)]
[CAAGGCCAGTCTGGCCAA][TCTATGTGCACTGAGCAGCAGTGGATTGTGAATCATTGCATTAGTGGAGGTGGCTCGAGCGGTGGCAGCGGTGGCTCTGGTGGTATTAGCAGTGGTCTGTTAAGCGGTCGTAGCGATAATCATGGCGGCGGTTCTGAAGTGCAGCTGGTGGAATCTGGGGGCGGACTGGTGCAGCCTGGCAAGTCTCTGAAGCTGAGCTGCGAGGCCAGCGGCTTCACCTTTAGCGGCTACGGCATGCACTGGGTGCGCCAGGCACCTGGCAGAGGCCTGGAAAGCGTGGCCTACATCACCAGCAGCAGCATCAACATTAAGTACGCCGACGCCGTGAAGGGCCGGTTCACCGTGTCCAGAGACAACGCCAAGAACCTGCTGTTCCTGCAGATGAACATCCTGAAGTCCGAGGACACCGCCATGTACTACTGCGCCAGATTCGACTGGGACAAGAACTACTGGGGCCAGGGCACAATGGTCACAGTGTCCAGCGGTGGAGGTGGTAGTGGTGGAGGAAGTGGAGGTTCAGGAGGTGGAAGCGGTGGTGGTGGTAGTGACATCCAGATGACCCAGAGCCCCAGCAGCCTGCCTGCCTCTCTGGGCGATAGAGTGACCATCAACTGCCAGGCCAGCCAGGACATCAGCAACTACCTGAACTGGTATCAGCAGAAGCCCGGCAAGGCCCCCAAGCTGCTGATCTACTACACCAACAAGCTGGCCGACGGTGTGCCCAGCAGATTCAGCGGCAGCGGTAGCGGCAGAGACAGCAGCTTCACCATCAGCTCCCTGGAATCCGAGGATATCGGCAGCTACTACTGCCAGCAGTACTACAACTACCCCTGGACCTTCGGCCCTGGCACCAAGCTGGAAATCAAAAGAGGAGGTGGTGGATCCCAGGTGCAGCTGAAACAGAGCGGCCCGGGCCTGGTGCAGCCGAGCCAGAGCCTGAGCATTACCTGCACCGTGAGCGGCTTTAGCCTGACCAACTATGGCGTGCATTGGGTGCGCCAGAGCCCGGGCAAAGGCCTGGAATGGCTGGGCGTGATTTGGAGCGGCGGCAACACCGATTATAACACCCCGTTTACCAGCCGCCTGAGCATTAACAAAGATAACAGCAAAAGCCAGGTGTTTTTTAAAATGAACAGCCTGCAAAGCCAGGATACCGCGATTTATTATTGCGCGCGCGCGCTGACCTATTATGATTATGAATTTGCGTATTGGGGCCAGGGCACCCTGGTGACCGTGAGCGCGGCTAGCACCAAGGGCCCATCGGTCTTCCCCCTGGCACCCTCCTCCAAGAGCACCTCTGGGGGCACAGCGGCCCTGGGCTGCCTGGTCAAGGACTACTTCCCCGAACCGGTGACGGTGTCGTGGAACTCAGGCGCCCTGACCAGCGGCGTGCACACCTTCCCGGCTGTCCTACAGTCCTCAGGACTCTACTCCCTCAGCAGCGTGGTGACCGTGCCCTCCAGCAGCTTGGGCACCCAGACCTACATCTGCAACGTGAATCACAAGCCCAGCAACACCAAGGTGGACAAGAAAGTTGAGCCCAAATCTTGTGACAAAACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACCAGAGCACGTACCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGGGAGGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCTACAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTACACGCAGAAGAGCCTCTCCCTGTCTCCGGGTAAATGA(配列番号499)
アミノ酸配列
[スペーサー(配列番号87)][スペーサーを有さないpLW120(配列番号538)]
[QGQSGQ][SMCTEQQWIVNHCISGGGSSGGSGGSGGISSGLLSGRSDNHGGGSEVQLVESGGGLVQPGKSLKLSCEASGFTFSGYGMHWVRQAPGRGLESVAYITSSSINIKYADAVKGRFTVSRDNAKNLLFLQMNILKSEDTAMYYCARFDWDKNYWGQGTMVTVSSGGGGSGGGSGGSGGGSGGGGSDIQMTQSPSSLPASLGDRVTINCQASQDISNYLNWYQQKPGKAPKLLIYYTNKLADGVPSRFSGSGSGRDSSFTISSLESEDIGSYYCQQYYNYPWTFGPGTKLEIKRGGGGSQVQLKQSGPGLVQPSQSLSITCTVSGFSLTNYGVHWVRQSPGKGLEWLGVIWSGGNTDYNTPFTSRLSINKDNSKSQVFFKMNSLQSQDTAIYYCARALTYYDYEFAYWGQGTLVTVSAASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYQSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK]*(配列番号500)
ヌクレオチド配列
[スペーサー(配列番号507)][スペーサーを有さないOPP022(配列番号509)]
[CAAGGCCAGTCTGGCCAG][TGCATCTCACCTCGTGGTTGTCCGGACGGCCCATACGTCATGTACGGCTCGAGCGGTGGCAGCGGTGGCTCTGGTGGATCCGGTCTGAGCGGCCGTTCCGATAATCATGGCAGTAGCGGTACCCAGATCTTGCTGACCCAGAGCCCGGTGATTCTGAGCGTGAGCCCGGGCGAACGTGTGAGCTTTAGCTGCCGCGCGAGCCAGAGCATTGGCACCAACATTCATTGGTATCAGCAGCGCACCAACGGCAGCCCGCGCCTGCTGATTAAATATGCGAGCGAAAGCATTAGCGGCATTCCGAGCCGCTTTAGCGGCAGCGGCAGCGGCACCGATTTTACCCTGAGCATTAACAGCGTGGAAAGCGAAGATATTGCGGATTATTATTGCCAGCAGAACAACAACTGGCCGACCACCTTTGGCGCGGGCACCAAACTGGAACTGAAACGTACGGTGGCTGCACCATCTGTCTTCATCTTCCCGCCATCTGATGAGCAGTTGAAATCTGGAACTGCCTCTGTTGTGTGCCTGCTGAATAACTTCTATCCCAGAGAGGCCAAAGTACAGTGGAAGGTGGATAACGCCCTCCAATCGGGTAACTCCCAGGAGAGTGTCACAGAGCAGGACAGCAAGGACAGCACCTACAGCCTCAGCAGCACCCTGACGCTGAGCAAAGCAGACTACGAGAAACACAAAGTCTACGCCTGCGAAGTCACCCATCAGGGCCTGAGCTCGCCCGTCACAAAGAGCTTCAACAGGGGAGAGTGTTAG](配列番号449)
アミノ酸配列
[スペーサー(配列番号87)][スペーサーを有さないOPP022(配列番号508)]
[QGQSGQ][CISPRGCPDGPYVMYGSSGGSGGSGGSGLSGRSDNHGSSGTQILLTQSPVILSVSPGERVSFSCRASQSIGTNIHWYQQRTNGSPRLLIKYASESISGIPSRFSGSGSGTDFTLSINSVESEDIADYYCQQNNNWPTTFGAGTKLELKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC]*(配列番号450)
pLW121: HC C225v5N297Q-MC05-2001-mCD3-H-N
ヌクレオチド配列
[スペーサー(配列番号507)][スペーサーを有さないpLW121(配列番号539)]
[CAAGGCCAGTCTGGCCAA][ATTCATCCGATGTGCCATCCTGAGGGTGTTTGCGTTGCTCTGGATGGAGGTGGCTCGAGCGGTGGCAGCGGTGGCTCTGGTGGTATTAGCAGTGGTCTGTTAAGCGGTCGTAGCGATAATCATGGCGGCGGTTCTGAAGTGCAGCTGGTGGAATCTGGGGGCGGACTGGTGCAGCCTGGCAAGTCTCTGAAGCTGAGCTGCGAGGCCAGCGGCTTCACCTTTAGCGGCTACGGCATGCACTGGGTGCGCCAGGCACCTGGCAGAGGCCTGGAAAGCGTGGCCTACATCACCAGCAGCAGCATCAACATTAAGTACGCCGACGCCGTGAAGGGCCGGTTCACCGTGTCCAGAGACAACGCCAAGAACCTGCTGTTCCTGCAGATGAACATCCTGAAGTCCGAGGACACCGCCATGTACTACTGCGCCAGATTCGACTGGGACAAGAACTACTGGGGCCAGGGCACAATGGTCACAGTGTCCAGCGGTGGAGGTGGTAGTGGTGGAGGAAGTGGAGGTTCAGGAGGTGGAAGCGGTGGTGGTGGTAGTGACATCCAGATGACCCAGAGCCCCAGCAGCCTGCCTGCCTCTCTGGGCGATAGAGTGACCATCAACTGCCAGGCCAGCCAGGACATCAGCAACTACCTGAACTGGTATCAGCAGAAGCCCGGCAAGGCCCCCAAGCTGCTGATCTACTACACCAACAAGCTGGCCGACGGTGTGCCCAGCAGATTCAGCGGCAGCGGTAGCGGCAGAGACAGCAGCTTCACCATCAGCTCCCTGGAATCCGAGGATATCGGCAGCTACTACTGCCAGCAGTACTACAACTACCCCTGGACCTTCGGCCCTGGCACCAAGCTGGAAATCAAAAGAGGAGGTGGTGGATCCCAGGTGCAGCTGAAACAGAGCGGCCCGGGCCTGGTGCAGCCGAGCCAGAGCCTGAGCATTACCTGCACCGTGAGCGGCTTTAGCCTGACCAACTATGGCGTGCATTGGGTGCGCCAGAGCCCGGGCAAAGGCCTGGAATGGCTGGGCGTGATTTGGAGCGGCGGCAACACCGATTATAACACCCCGTTTACCAGCCGCCTGAGCATTAACAAAGATAACAGCAAAAGCCAGGTGTTTTTTAAAATGAACAGCCTGCAAAGCCAGGATACCGCGATTTATTATTGCGCGCGCGCGCTGACCTATTATGATTATGAATTTGCGTATTGGGGCCAGGGCACCCTGGTGACCGTGAGCGCGGCTAGCACCAAGGGCCCATCGGTCTTCCCCCTGGCACCCTCCTCCAAGAGCACCTCTGGGGGCACAGCGGCCCTGGGCTGCCTGGTCAAGGACTACTTCCCCGAACCGGTGACGGTGTCGTGGAACTCAGGCGCCCTGACCAGCGGCGTGCACACCTTCCCGGCTGTCCTACAGTCCTCAGGACTCTACTCCCTCAGCAGCGTGGTGACCGTGCCCTCCAGCAGCTTGGGCACCCAGACCTACATCTGCAACGTGAATCACAAGCCCAGCAACACCAAGGTGGACAAGAAAGTTGAGCCCAAATCTTGTGACAAAACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACCAGAGCACGTACCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGGGAGGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCTACAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTACACGCAGAAGAGCCTCTCCCTGTCTCCGGGTAAATGA](配列番号485)
アミノ酸配列
[スペーサー(配列番号87)][スペーサーを有さないpLW121(配列番号540)]
[QGQSGQ][IHPMCHPEGVCVALDGGGSSGGSGGSGGISSGLLSGRSDNHGGGSEVQLVESGGGLVQPGKSLKLSCEASGFTFSGYGMHWVRQAPGRGLESVAYITSSSINIKYADAVKGRFTVSRDNAKNLLFLQMNILKSEDTAMYYCARFDWDKNYWGQGTMVTVSSGGGGSGGGSGGSGGGSGGGGSDIQMTQSPSSLPASLGDRVTINCQASQDISNYLNWYQQKPGKAPKLLIYYTNKLADGVPSRFSGSGSGRDSSFTISSLESEDIGSYYCQQYYNYPWTFGPGTKLEIKRGGGGSQVQLKQSGPGLVQPSQSLSITCTVSGFSLTNYGVHWVRQSPGKGLEWLGVIWSGGNTDYNTPFTSRLSINKDNSKSQVFFKMNSLQSQDTAIYYCARALTYYDYEFAYWGQGTLVTVSAASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYQSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK]*(配列番号486)
ヌクレオチド配列
[スペーサー(配列番号507)][スペーサーを有さないOPP022(配列番号509)]
[CAAGGCCAGTCTGGCCAG][TGCATCTCACCTCGTGGTTGTCCGGACGGCCCATACGTCATGTACGGCTCGAGCGGTGGCAGCGGTGGCTCTGGTGGATCCGGTCTGAGCGGCCGTTCCGATAATCATGGCAGTAGCGGTACCCAGATCTTGCTGACCCAGAGCCCGGTGATTCTGAGCGTGAGCCCGGGCGAACGTGTGAGCTTTAGCTGCCGCGCGAGCCAGAGCATTGGCACCAACATTCATTGGTATCAGCAGCGCACCAACGGCAGCCCGCGCCTGCTGATTAAATATGCGAGCGAAAGCATTAGCGGCATTCCGAGCCGCTTTAGCGGCAGCGGCAGCGGCACCGATTTTACCCTGAGCATTAACAGCGTGGAAAGCGAAGATATTGCGGATTATTATTGCCAGCAGAACAACAACTGGCCGACCACCTTTGGCGCGGGCACCAAACTGGAACTGAAACGTACGGTGGCTGCACCATCTGTCTTCATCTTCCCGCCATCTGATGAGCAGTTGAAATCTGGAACTGCCTCTGTTGTGTGCCTGCTGAATAACTTCTATCCCAGAGAGGCCAAAGTACAGTGGAAGGTGGATAACGCCCTCCAATCGGGTAACTCCCAGGAGAGTGTCACAGAGCAGGACAGCAAGGACAGCACCTACAGCCTCAGCAGCACCCTGACGCTGAGCAAAGCAGACTACGAGAAACACAAAGTCTACGCCTGCGAAGTCACCCATCAGGGCCTGAGCTCGCCCGTCACAAAGAGCTTCAACAGGGGAGAGTGTTAG](配列番号449)
アミノ酸配列
[スペーサー(配列番号87)][スペーサーを有さないOPP022(配列番号508)]
[QGQSGQ][CISPRGCPDGPYVMYGSSGGSGGSGGSGLSGRSDNHGSSGTQILLTQSPVILSVSPGERVSFSCRASQSIGTNIHWYQQRTNGSPRLLIKYASESISGIPSRFSGSGSGTDFTLSINSVESEDIADYYCQQNNNWPTTFGAGTKLELKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC]*(配列番号450)
pLW122: HC C225v5N297Q-MC06-2001-mCD3-H-N
ヌクレオチド配列
[スペーサー(配列番号507)][スペーサーを有さないpLW122(配列番号541)]
[CAAGGCCAGTCTGGCCAA][GATTGCTTTGTGCCTGGGTGGTATTTGGCGGGTCCGTGCGCTCAGGGAGGTGGCTCGAGCGGTGGCAGCGGTGGCTCTGGTGGTATTAGCAGTGGTCTGTTAAGCGGTCGTAGCGATAATCATGGCGGCGGTTCTGAAGTGCAGCTGGTGGAATCTGGGGGCGGACTGGTGCAGCCTGGCAAGTCTCTGAAGCTGAGCTGCGAGGCCAGCGGCTTCACCTTTAGCGGCTACGGCATGCACTGGGTGCGCCAGGCACCTGGCAGAGGCCTGGAAAGCGTGGCCTACATCACCAGCAGCAGCATCAACATTAAGTACGCCGACGCCGTGAAGGGCCGGTTCACCGTGTCCAGAGACAACGCCAAGAACCTGCTGTTCCTGCAGATGAACATCCTGAAGTCCGAGGACACCGCCATGTACTACTGCGCCAGATTCGACTGGGACAAGAACTACTGGGGCCAGGGCACAATGGTCACAGTGTCCAGCGGTGGAGGTGGTAGTGGTGGAGGAAGTGGAGGTTCAGGAGGTGGAAGCGGTGGTGGTGGTAGTGACATCCAGATGACCCAGAGCCCCAGCAGCCTGCCTGCCTCTCTGGGCGATAGAGTGACCATCAACTGCCAGGCCAGCCAGGACATCAGCAACTACCTGAACTGGTATCAGCAGAAGCCCGGCAAGGCCCCCAAGCTGCTGATCTACTACACCAACAAGCTGGCCGACGGTGTGCCCAGCAGATTCAGCGGCAGCGGTAGCGGCAGAGACAGCAGCTTCACCATCAGCTCCCTGGAATCCGAGGATATCGGCAGCTACTACTGCCAGCAGTACTACAACTACCCCTGGACCTTCGGCCCTGGCACCAAGCTGGAAATCAAAAGAGGAGGTGGTGGATCCCAGGTGCAGCTGAAACAGAGCGGCCCGGGCCTGGTGCAGCCGAGCCAGAGCCTGAGCATTACCTGCACCGTGAGCGGCTTTAGCCTGACCAACTATGGCGTGCATTGGGTGCGCCAGAGCCCGGGCAAAGGCCTGGAATGGCTGGGCGTGATTTGGAGCGGCGGCAACACCGATTATAACACCCCGTTTACCAGCCGCCTGAGCATTAACAAAGATAACAGCAAAAGCCAGGTGTTTTTTAAAATGAACAGCCTGCAAAGCCAGGATACCGCGATTTATTATTGCGCGCGCGCGCTGACCTATTATGATTATGAATTTGCGTATTGGGGCCAGGGCACCCTGGTGACCGTGAGCGCGGCTAGCACCAAGGGCCCATCGGTCTTCCCCCTGGCACCCTCCTCCAAGAGCACCTCTGGGGGCACAGCGGCCCTGGGCTGCCTGGTCAAGGACTACTTCCCCGAACCGGTGACGGTGTCGTGGAACTCAGGCGCCCTGACCAGCGGCGTGCACACCTTCCCGGCTGTCCTACAGTCCTCAGGACTCTACTCCCTCAGCAGCGTGGTGACCGTGCCCTCCAGCAGCTTGGGCACCCAGACCTACATCTGCAACGTGAATCACAAGCCCAGCAACACCAAGGTGGACAAGAAAGTTGAGCCCAAATCTTGTGACAAAACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACCAGAGCACGTACCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGGGAGGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCTACAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTACACGCAGAAGAGCCTCTCCCTGTCTCCGGGTAAATGA](配列番号487)
アミノ酸配列
[スペーサー(配列番号87)][スペーサーを有さないpLW122(配列番号542)]
[QGQSGQ][DCFVPGWYLAGPCAQGGGSSGGSGGSGGISSGLLSGRSDNHGGGSEVQLVESGGGLVQPGKSLKLSCEASGFTFSGYGMHWVRQAPGRGLESVAYITSSSINIKYADAVKGRFTVSRDNAKNLLFLQMNILKSEDTAMYYCARFDWDKNYWGQGTMVTVSSGGGGSGGGSGGSGGGSGGGGSDIQMTQSPSSLPASLGDRVTINCQASQDISNYLNWYQQKPGKAPKLLIYYTNKLADGVPSRFSGSGSGRDSSFTISSLESEDIGSYYCQQYYNYPWTFGPGTKLEIKRGGGGSQVQLKQSGPGLVQPSQSLSITCTVSGFSLTNYGVHWVRQSPGKGLEWLGVIWSGGNTDYNTPFTSRLSINKDNSKSQVFFKMNSLQSQDTAIYYCARALTYYDYEFAYWGQGTLVTVSAASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYQSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK]*(配列番号488)
ヌクレオチド配列
[スペーサー(配列番号507)][スペーサーを有さないOPP022(配列番号509)]
[CAAGGCCAGTCTGGCCAG][TGCATCTCACCTCGTGGTTGTCCGGACGGCCCATACGTCATGTACGGCTCGAGCGGTGGCAGCGGTGGCTCTGGTGGATCCGGTCTGAGCGGCCGTTCCGATAATCATGGCAGTAGCGGTACCCAGATCTTGCTGACCCAGAGCCCGGTGATTCTGAGCGTGAGCCCGGGCGAACGTGTGAGCTTTAGCTGCCGCGCGAGCCAGAGCATTGGCACCAACATTCATTGGTATCAGCAGCGCACCAACGGCAGCCCGCGCCTGCTGATTAAATATGCGAGCGAAAGCATTAGCGGCATTCCGAGCCGCTTTAGCGGCAGCGGCAGCGGCACCGATTTTACCCTGAGCATTAACAGCGTGGAAAGCGAAGATATTGCGGATTATTATTGCCAGCAGAACAACAACTGGCCGACCACCTTTGGCGCGGGCACCAAACTGGAACTGAAACGTACGGTGGCTGCACCATCTGTCTTCATCTTCCCGCCATCTGATGAGCAGTTGAAATCTGGAACTGCCTCTGTTGTGTGCCTGCTGAATAACTTCTATCCCAGAGAGGCCAAAGTACAGTGGAAGGTGGATAACGCCCTCCAATCGGGTAACTCCCAGGAGAGTGTCACAGAGCAGGACAGCAAGGACAGCACCTACAGCCTCAGCAGCACCCTGACGCTGAGCAAAGCAGACTACGAGAAACACAAAGTCTACGCCTGCGAAGTCACCCATCAGGGCCTGAGCTCGCCCGTCACAAAGAGCTTCAACAGGGGAGAGTGTTAG](配列番号449)
アミノ酸配列
[スペーサー(配列番号87)][スペーサーを有さないOPP022(配列番号508)]
[QGQSGQ][CISPRGCPDGPYVMYGSSGGSGGSGGSGLSGRSDNHGSSGTQILLTQSPVILSVSPGERVSFSCRASQSIGTNIHWYQQRTNGSPRLLIKYASESISGIPSRFSGSGSGTDFTLSINSVESEDIADYYCQQNNNWPTTFGAGTKLELKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC]*(配列番号450)
pLW123: HC C225v5N297Q-MC07-2001-mCD3-H-N
ヌクレオチド配列
[スペーサー(配列番号521)][スペーサーを有さないpLW123(配列番号543)]
[CAAGGCCAGTCTGGCCAAGGT][GTGTGCCATTCTCGGTTGGAGTGGCTTCTGGGTTGCCAAGGAGGAGGTGGCTCGAGCGGTGGCAGCGGTGGCTCTGGTGGTATTAGCAGTGGTCTGTTAAGCGGTCGTAGCGATAATCATGGCGGCGGTTCTGAAGTGCAGCTGGTGGAATCTGGGGGCGGACTGGTGCAGCCTGGCAAGTCTCTGAAGCTGAGCTGCGAGGCCAGCGGCTTCACCTTTAGCGGCTACGGCATGCACTGGGTGCGCCAGGCACCTGGCAGAGGCCTGGAAAGCGTGGCCTACATCACCAGCAGCAGCATCAACATTAAGTACGCCGACGCCGTGAAGGGCCGGTTCACCGTGTCCAGAGACAACGCCAAGAACCTGCTGTTCCTGCAGATGAACATCCTGAAGTCCGAGGACACCGCCATGTACTACTGCGCCAGATTCGACTGGGACAAGAACTACTGGGGCCAGGGCACAATGGTCACAGTGTCCAGCGGTGGAGGTGGTAGTGGTGGAGGAAGTGGAGGTTCAGGAGGTGGAAGCGGTGGTGGTGGTAGTGACATCCAGATGACCCAGAGCCCCAGCAGCCTGCCTGCCTCTCTGGGCGATAGAGTGACCATCAACTGCCAGGCCAGCCAGGACATCAGCAACTACCTGAACTGGTATCAGCAGAAGCCCGGCAAGGCCCCCAAGCTGCTGATCTACTACACCAACAAGCTGGCCGACGGTGTGCCCAGCAGATTCAGCGGCAGCGGTAGCGGCAGAGACAGCAGCTTCACCATCAGCTCCCTGGAATCCGAGGATATCGGCAGCTACTACTGCCAGCAGTACTACAACTACCCCTGGACCTTCGGCCCTGGCACCAAGCTGGAAATCAAAAGAGGAGGTGGTGGATCCCAGGTGCAGCTGAAACAGAGCGGCCCGGGCCTGGTGCAGCCGAGCCAGAGCCTGAGCATTACCTGCACCGTGAGCGGCTTTAGCCTGACCAACTATGGCGTGCATTGGGTGCGCCAGAGCCCGGGCAAAGGCCTGGAATGGCTGGGCGTGATTTGGAGCGGCGGCAACACCGATTATAACACCCCGTTTACCAGCCGCCTGAGCATTAACAAAGATAACAGCAAAAGCCAGGTGTTTTTTAAAATGAACAGCCTGCAAAGCCAGGATACCGCGATTTATTATTGCGCGCGCGCGCTGACCTATTATGATTATGAATTTGCGTATTGGGGCCAGGGCACCCTGGTGACCGTGAGCGCGGCTAGCACCAAGGGCCCATCGGTCTTCCCCCTGGCACCCTCCTCCAAGAGCACCTCTGGGGGCACAGCGGCCCTGGGCTGCCTGGTCAAGGACTACTTCCCCGAACCGGTGACGGTGTCGTGGAACTCAGGCGCCCTGACCAGCGGCGTGCACACCTTCCCGGCTGTCCTACAGTCCTCAGGACTCTACTCCCTCAGCAGCGTGGTGACCGTGCCCTCCAGCAGCTTGGGCACCCAGACCTACATCTGCAACGTGAATCACAAGCCCAGCAACACCAAGGTGGACAAGAAAGTTGAGCCCAAATCTTGTGACAAAACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACCAGAGCACGTACCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGGGAGGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCTACAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTACACGCAGAAGAGCCTCTCCCTGTCTCCGGGTAAATGA](配列番号489)
アミノ酸配列
[スペーサー(配列番号407)][スペーサーを有さないpLW123(配列番号544)]
[QGQSGQG][VCHSRLEWLLGCQGGGGSSGGSGGSGGISSGLLSGRSDNHGGGSEVQLVESGGGLVQPGKSLKLSCEASGFTFSGYGMHWVRQAPGRGLESVAYITSSSINIKYADAVKGRFTVSRDNAKNLLFLQMNILKSEDTAMYYCARFDWDKNYWGQGTMVTVSSGGGGSGGGSGGSGGGSGGGGSDIQMTQSPSSLPASLGDRVTINCQASQDISNYLNWYQQKPGKAPKLLIYYTNKLADGVPSRFSGSGSGRDSSFTISSLESEDIGSYYCQQYYNYPWTFGPGTKLEIKRGGGGSQVQLKQSGPGLVQPSQSLSITCTVSGFSLTNYGVHWVRQSPGKGLEWLGVIWSGGNTDYNTPFTSRLSINKDNSKSQVFFKMNSLQSQDTAIYYCARALTYYDYEFAYWGQGTLVTVSAASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYQSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK]*(配列番号490)
ヌクレオチド配列
[スペーサー(配列番号507)][スペーサーを有さないOPP022(配列番号509)]
[CAAGGCCAGTCTGGCCAG][TGCATCTCACCTCGTGGTTGTCCGGACGGCCCATACGTCATGTACGGCTCGAGCGGTGGCAGCGGTGGCTCTGGTGGATCCGGTCTGAGCGGCCGTTCCGATAATCATGGCAGTAGCGGTACCCAGATCTTGCTGACCCAGAGCCCGGTGATTCTGAGCGTGAGCCCGGGCGAACGTGTGAGCTTTAGCTGCCGCGCGAGCCAGAGCATTGGCACCAACATTCATTGGTATCAGCAGCGCACCAACGGCAGCCCGCGCCTGCTGATTAAATATGCGAGCGAAAGCATTAGCGGCATTCCGAGCCGCTTTAGCGGCAGCGGCAGCGGCACCGATTTTACCCTGAGCATTAACAGCGTGGAAAGCGAAGATATTGCGGATTATTATTGCCAGCAGAACAACAACTGGCCGACCACCTTTGGCGCGGGCACCAAACTGGAACTGAAACGTACGGTGGCTGCACCATCTGTCTTCATCTTCCCGCCATCTGATGAGCAGTTGAAATCTGGAACTGCCTCTGTTGTGTGCCTGCTGAATAACTTCTATCCCAGAGAGGCCAAAGTACAGTGGAAGGTGGATAACGCCCTCCAATCGGGTAACTCCCAGGAGAGTGTCACAGAGCAGGACAGCAAGGACAGCACCTACAGCCTCAGCAGCACCCTGACGCTGAGCAAAGCAGACTACGAGAAACACAAAGTCTACGCCTGCGAAGTCACCCATCAGGGCCTGAGCTCGCCCGTCACAAAGAGCTTCAACAGGGGAGAGTGTTAG](配列番号449)
アミノ酸配列
[スペーサー(配列番号87)][スペーサーを有さないOPP022(配列番号508)]
[QGQSGQ][CISPRGCPDGPYVMYGSSGGSGGSGGSGLSGRSDNHGSSGTQILLTQSPVILSVSPGERVSFSCRASQSIGTNIHWYQQRTNGSPRLLIKYASESISGIPSRFSGSGSGTDFTLSINSVESEDIADYYCQQNNNWPTTFGAGTKLELKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC]*(配列番号450)
pLW124: HC C225v5N297Q-MC08-2001-mCD3-H-N
ヌクレオチド配列
[スペーサー(配列番号507)][スペーサーを有さないpLW124(配列番号545)]
[CAAGGCCAGTCTGGCCAA][GTGGGTGAGTGCGTTCCGGGTCCGCATGGGTGCTGGATGGCTTATGGAGGTGGCTCGAGCGGTGGCAGCGGTGGCTCTGGTGGTATTAGCAGTGGTCTGTTAAGCGGTCGTAGCGATAATCATGGCGGCGGTTCTGAAGTGCAGCTGGTGGAATCTGGGGGCGGACTGGTGCAGCCTGGCAAGTCTCTGAAGCTGAGCTGCGAGGCCAGCGGCTTCACCTTTAGCGGCTACGGCATGCACTGGGTGCGCCAGGCACCTGGCAGAGGCCTGGAAAGCGTGGCCTACATCACCAGCAGCAGCATCAACATTAAGTACGCCGACGCCGTGAAGGGCCGGTTCACCGTGTCCAGAGACAACGCCAAGAACCTGCTGTTCCTGCAGATGAACATCCTGAAGTCCGAGGACACCGCCATGTACTACTGCGCCAGATTCGACTGGGACAAGAACTACTGGGGCCAGGGCACAATGGTCACAGTGTCCAGCGGTGGAGGTGGTAGTGGTGGAGGAAGTGGAGGTTCAGGAGGTGGAAGCGGTGGTGGTGGTAGTGACATCCAGATGACCCAGAGCCCCAGCAGCCTGCCTGCCTCTCTGGGCGATAGAGTGACCATCAACTGCCAGGCCAGCCAGGACATCAGCAACTACCTGAACTGGTATCAGCAGAAGCCCGGCAAGGCCCCCAAGCTGCTGATCTACTACACCAACAAGCTGGCCGACGGTGTGCCCAGCAGATTCAGCGGCAGCGGTAGCGGCAGAGACAGCAGCTTCACCATCAGCTCCCTGGAATCCGAGGATATCGGCAGCTACTACTGCCAGCAGTACTACAACTACCCCTGGACCTTCGGCCCTGGCACCAAGCTGGAAATCAAAAGAGGAGGTGGTGGATCCCAGGTGCAGCTGAAACAGAGCGGCCCGGGCCTGGTGCAGCCGAGCCAGAGCCTGAGCATTACCTGCACCGTGAGCGGCTTTAGCCTGACCAACTATGGCGTGCATTGGGTGCGCCAGAGCCCGGGCAAAGGCCTGGAATGGCTGGGCGTGATTTGGAGCGGCGGCAACACCGATTATAACACCCCGTTTACCAGCCGCCTGAGCATTAACAAAGATAACAGCAAAAGCCAGGTGTTTTTTAAAATGAACAGCCTGCAAAGCCAGGATACCGCGATTTATTATTGCGCGCGCGCGCTGACCTATTATGATTATGAATTTGCGTATTGGGGCCAGGGCACCCTGGTGACCGTGAGCGCGGCTAGCACCAAGGGCCCATCGGTCTTCCCCCTGGCACCCTCCTCCAAGAGCACCTCTGGGGGCACAGCGGCCCTGGGCTGCCTGGTCAAGGACTACTTCCCCGAACCGGTGACGGTGTCGTGGAACTCAGGCGCCCTGACCAGCGGCGTGCACACCTTCCCGGCTGTCCTACAGTCCTCAGGACTCTACTCCCTCAGCAGCGTGGTGACCGTGCCCTCCAGCAGCTTGGGCACCCAGACCTACATCTGCAACGTGAATCACAAGCCCAGCAACACCAAGGTGGACAAGAAAGTTGAGCCCAAATCTTGTGACAAAACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACCAGAGCACGTACCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGGGAGGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCTACAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTACACGCAGAAGAGCCTCTCCCTGTCTCCGGGTAAATGA](配列番号501)
アミノ酸配列
[スペーサー(配列番号87)][スペーサーを有さないpLW124(配列番号546)]
[QGQSGQ][VGECVPGPHGCWMAYGGGSSGGSGGSGGISSGLLSGRSDNHGGGSEVQLVESGGGLVQPGKSLKLSCEASGFTFSGYGMHWVRQAPGRGLESVAYITSSSINIKYADAVKGRFTVSRDNAKNLLFLQMNILKSEDTAMYYCARFDWDKNYWGQGTMVTVSSGGGGSGGGSGGSGGGSGGGGSDIQMTQSPSSLPASLGDRVTINCQASQDISNYLNWYQQKPGKAPKLLIYYTNKLADGVPSRFSGSGSGRDSSFTISSLESEDIGSYYCQQYYNYPWTFGPGTKLEIKRGGGGSQVQLKQSGPGLVQPSQSLSITCTVSGFSLTNYGVHWVRQSPGKGLEWLGVIWSGGNTDYNTPFTSRLSINKDNSKSQVFFKMNSLQSQDTAIYYCARALTYYDYEFAYWGQGTLVTVSAASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYQSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK]*(配列番号502)
ヌクレオチド配列
[スペーサー(配列番号507)][スペーサーを有さないOPP022(配列番号509)]
[CAAGGCCAGTCTGGCCAG][TGCATCTCACCTCGTGGTTGTCCGGACGGCCCATACGTCATGTACGGCTCGAGCGGTGGCAGCGGTGGCTCTGGTGGATCCGGTCTGAGCGGCCGTTCCGATAATCATGGCAGTAGCGGTACCCAGATCTTGCTGACCCAGAGCCCGGTGATTCTGAGCGTGAGCCCGGGCGAACGTGTGAGCTTTAGCTGCCGCGCGAGCCAGAGCATTGGCACCAACATTCATTGGTATCAGCAGCGCACCAACGGCAGCCCGCGCCTGCTGATTAAATATGCGAGCGAAAGCATTAGCGGCATTCCGAGCCGCTTTAGCGGCAGCGGCAGCGGCACCGATTTTACCCTGAGCATTAACAGCGTGGAAAGCGAAGATATTGCGGATTATTATTGCCAGCAGAACAACAACTGGCCGACCACCTTTGGCGCGGGCACCAAACTGGAACTGAAACGTACGGTGGCTGCACCATCTGTCTTCATCTTCCCGCCATCTGATGAGCAGTTGAAATCTGGAACTGCCTCTGTTGTGTGCCTGCTGAATAACTTCTATCCCAGAGAGGCCAAAGTACAGTGGAAGGTGGATAACGCCCTCCAATCGGGTAACTCCCAGGAGAGTGTCACAGAGCAGGACAGCAAGGACAGCACCTACAGCCTCAGCAGCACCCTGACGCTGAGCAAAGCAGACTACGAGAAACACAAAGTCTACGCCTGCGAAGTCACCCATCAGGGCCTGAGCTCGCCCGTCACAAAGAGCTTCAACAGGGGAGAGTGTTAG](配列番号449)
アミノ酸配列
[スペーサー(配列番号87)][スペーサーを有さないOPP022(配列番号508)]
[QGQSGQ][CISPRGCPDGPYVMYGSSGGSGGSGGSGLSGRSDNHGSSGTQILLTQSPVILSVSPGERVSFSCRASQSIGTNIHWYQQRTNGSPRLLIKYASESISGIPSRFSGSGSGTDFTLSINSVESEDIADYYCQQNNNWPTTFGAGTKLELKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC]*(配列番号450)
pLW125: HC C225v5N297Q-MC09-2001-mCD3-H-N
ヌクレオチド配列
[スペーサー(配列番号507)][スペーサーを有さないpLW125(配列番号475)]
[CAAGGCCAGTCTGGCCAA][TGGACGTGCGGAGGTATGGTGTATCTTGCGGGATTCTGCATGGCGGGAGGTGGCTCGAGCGGTGGCAGCGGTGGCTCTGGTGGTATTAGCAGTGGTCTGTTAAGCGGTCGTAGCGATAATCATGGCGGCGGTTCTGAAGTGCAGCTGGTGGAATCTGGGGGCGGACTGGTGCAGCCTGGCAAGTCTCTGAAGCTGAGCTGCGAGGCCAGCGGCTTCACCTTTAGCGGCTACGGCATGCACTGGGTGCGCCAGGCACCTGGCAGAGGCCTGGAAAGCGTGGCCTACATCACCAGCAGCAGCATCAACATTAAGTACGCCGACGCCGTGAAGGGCCGGTTCACCGTGTCCAGAGACAACGCCAAGAACCTGCTGTTCCTGCAGATGAACATCCTGAAGTCCGAGGACACCGCCATGTACTACTGCGCCAGATTCGACTGGGACAAGAACTACTGGGGCCAGGGCACAATGGTCACAGTGTCCAGCGGTGGAGGTGGTAGTGGTGGAGGAAGTGGAGGTTCAGGAGGTGGAAGCGGTGGTGGTGGTAGTGACATCCAGATGACCCAGAGCCCCAGCAGCCTGCCTGCCTCTCTGGGCGATAGAGTGACCATCAACTGCCAGGCCAGCCAGGACATCAGCAACTACCTGAACTGGTATCAGCAGAAGCCCGGCAAGGCCCCCAAGCTGCTGATCTACTACACCAACAAGCTGGCCGACGGTGTGCCCAGCAGATTCAGCGGCAGCGGTAGCGGCAGAGACAGCAGCTTCACCATCAGCTCCCTGGAATCCGAGGATATCGGCAGCTACTACTGCCAGCAGTACTACAACTACCCCTGGACCTTCGGCCCTGGCACCAAGCTGGAAATCAAAAGAGGAGGTGGTGGATCCCAGGTGCAGCTGAAACAGAGCGGCCCGGGCCTGGTGCAGCCGAGCCAGAGCCTGAGCATTACCTGCACCGTGAGCGGCTTTAGCCTGACCAACTATGGCGTGCATTGGGTGCGCCAGAGCCCGGGCAAAGGCCTGGAATGGCTGGGCGTGATTTGGAGCGGCGGCAACACCGATTATAACACCCCGTTTACCAGCCGCCTGAGCATTAACAAAGATAACAGCAAAAGCCAGGTGTTTTTTAAAATGAACAGCCTGCAAAGCCAGGATACCGCGATTTATTATTGCGCGCGCGCGCTGACCTATTATGATTATGAATTTGCGTATTGGGGCCAGGGCACCCTGGTGACCGTGAGCGCGGCTAGCACCAAGGGCCCATCGGTCTTCCCCCTGGCACCCTCCTCCAAGAGCACCTCTGGGGGCACAGCGGCCCTGGGCTGCCTGGTCAAGGACTACTTCCCCGAACCGGTGACGGTGTCGTGGAACTCAGGCGCCCTGACCAGCGGCGTGCACACCTTCCCGGCTGTCCTACAGTCCTCAGGACTCTACTCCCTCAGCAGCGTGGTGACCGTGCCCTCCAGCAGCTTGGGCACCCAGACCTACATCTGCAACGTGAATCACAAGCCCAGCAACACCAAGGTGGACAAGAAAGTTGAGCCCAAATCTTGTGACAAAACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACCAGAGCACGTACCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGGGAGGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCTACAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTACACGCAGAAGAGCCTCTCCCTGTCTCCGGGTAAATGA](配列番号503)
アミノ酸配列
[スペーサー(配列番号87)][スペーサーを有さないpLW087(配列番号476)]
[QGQSGQ][WTCGGMVYLAGFCMAGGGSSGGSGGSGGISSGLLSGRSDNHGGGSEVQLVESGGGLVQPGKSLKLSCEASGFTFSGYGMHWVRQAPGRGLESVAYITSSSINIKYADAVKGRFTVSRDNAKNLLFLQMNILKSEDTAMYYCARFDWDKNYWGQGTMVTVSSGGGGSGGGSGGSGGGSGGGGSDIQMTQSPSSLPASLGDRVTINCQASQDISNYLNWYQQKPGKAPKLLIYYTNKLADGVPSRFSGSGSGRDSSFTISSLESEDIGSYYCQQYYNYPWTFGPGTKLEIKRGGGGSQVQLKQSGPGLVQPSQSLSITCTVSGFSLTNYGVHWVRQSPGKGLEWLGVIWSGGNTDYNTPFTSRLSINKDNSKSQVFFKMNSLQSQDTAIYYCARALTYYDYEFAYWGQGTLVTVSAASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYQSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK]*(配列番号504)
ヌクレオチド配列
[スペーサー(配列番号507)][スペーサーを有さないOPP022(配列番号509)]
[CAAGGCCAGTCTGGCCAG][TGCATCTCACCTCGTGGTTGTCCGGACGGCCCATACGTCATGTACGGCTCGAGCGGTGGCAGCGGTGGCTCTGGTGGATCCGGTCTGAGCGGCCGTTCCGATAATCATGGCAGTAGCGGTACCCAGATCTTGCTGACCCAGAGCCCGGTGATTCTGAGCGTGAGCCCGGGCGAACGTGTGAGCTTTAGCTGCCGCGCGAGCCAGAGCATTGGCACCAACATTCATTGGTATCAGCAGCGCACCAACGGCAGCCCGCGCCTGCTGATTAAATATGCGAGCGAAAGCATTAGCGGCATTCCGAGCCGCTTTAGCGGCAGCGGCAGCGGCACCGATTTTACCCTGAGCATTAACAGCGTGGAAAGCGAAGATATTGCGGATTATTATTGCCAGCAGAACAACAACTGGCCGACCACCTTTGGCGCGGGCACCAAACTGGAACTGAAACGTACGGTGGCTGCACCATCTGTCTTCATCTTCCCGCCATCTGATGAGCAGTTGAAATCTGGAACTGCCTCTGTTGTGTGCCTGCTGAATAACTTCTATCCCAGAGAGGCCAAAGTACAGTGGAAGGTGGATAACGCCCTCCAATCGGGTAACTCCCAGGAGAGTGTCACAGAGCAGGACAGCAAGGACAGCACCTACAGCCTCAGCAGCACCCTGACGCTGAGCAAAGCAGACTACGAGAAACACAAAGTCTACGCCTGCGAAGTCACCCATCAGGGCCTGAGCTCGCCCGTCACAAAGAGCTTCAACAGGGGAGAGTGTTAG](配列番号449)
アミノ酸配列
[スペーサー(配列番号87)][スペーサーを有さないOPP022(配列番号508)]
[QGQSGQ][CISPRGCPDGPYVMYGSSGGSGGSGGSGLSGRSDNHGSSGTQILLTQSPVILSVSPGERVSFSCRASQSIGTNIHWYQQRTNGSPRLLIKYASESISGIPSRFSGSGSGTDFTLSINSVESEDIADYYCQQNNNWPTTFGAGTKLELKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC]*(配列番号450)
BiTE420
ヌクレオチド配列
GACATCTTGCTGACTCAGTCTCCAGTCATCCTGTCTGTGAGTCCAGGAGAAAGAGTCAGTTTCTCCTGCAGGGCCAGTCAGAGCATTGGCACAAACATACACTGGTATCAGCAAAGAACAAATGGTTCTCCAAGGCTTCTCATAAAGTATGCTTCTGAGTCTATCTCTGGGATCCCTTCCAGGTTTAGTGGCAGTGGATCAGGGACAGATTTTACTCTTAGCATCAACAGTGTGGAGTCTGAAGATATTGCAGATTATTACTGTCAACAAAATAATAACTGGCCAACCACATTTGGTGCAGGAACAAAGCTGGAACTGAAAGGTGGTGGTGGTTCTGGCGGCGGCGGCTCCGGTGGTGGTGGTTCTCAGGTGCAGCTGAAGCAGTCAGGACCTGGCCTAGTGCAGCCCTCACAGAGCCTGTCCATCACCTGCACAGTCTCTGGTTTCTCATTAACTAACTATGGAGTACACTGGGTTCGCCAGTCTCCAGGAAAGGGTCTGGAGTGGCTGGGAGTGATATGGAGTGGTGGAAACACAGACTATAATACACCTTTCACATCCAGACTGAGCATCAACAAGGACAATTCCAAGAGCCAAGTTTTCTTTAAAATGAACAGTCTGCAATCTAATGACACAGCCATATATTACTGTGCCAGAGCCCTGACCTATTATGACTACGAGTTCGCCTATTGGGGTCAGGGAACCCTGGTTACCGTGTCTTCCGGAGGTGGTGGATCCGAGGTGCAGCTGGTCGAGTCTGGAGGAGGATTGGTGCAGCCTGGAGGGTCATTGAAACTCTCATGTGCAGCCTCTGGATTCACCTTCAATAAGTACGCCATGAACTGGGTCCGCCAGGCTCCAGGAAAGGGTTTGGAATGGGTTGCTCGCATAAGAAGTAAATATAATAATTATGCAACATATTATGCCGATTCAGTGAAAGACAGGTTCACCATCTCCAGAGATGATTCAAAAAACACTGCCTATCTACAAATGAACAACTTGAAAACTGAGGACACTGCCGTGTACTACTGTGTGAGACATGGGAACTTCGGTAATAGCTACATATCCTACTGGGCTTACTGGGGCCAAGGGACTCTGGTCACCGTCTCCTCAGGTGGTGGTGGTTCTGGCGGCGGCGGCTCCGGTGGTGGTGGTTCTCAGACTGTTGTGACTCAGGAACCTTCACTCACCGTATCACCTGGTGGAACAGTCACACTCACTTGTGGCTCCTCGACTGGGGCTGTTACATCTGGCTACTACCCAAACTGGGTCCAACAAAAACCAGGTCAGGCACCCCGTGGTCTAATAGGTGGGACTAAGTTCCTCGCCCCCGGTACTCCTGCCAGATTCTCAGGCTCCCTGCTTGGAGGCAAGGCTGCCCTCACCCTCTCAGGGGTACAGCCAGAGGATGAGGCAGAATATTACTGTGCTCTATGGTACAGCAACCGCTGGGTGTTCGGTGGAGGAACCAAACTGACTGTCCTACACCATCACCACCATCATCACCACTAG(配列番号505)
アミノ酸配列
DILLTQSPVILSVSPGERVSFSCRASQSIGTNIHWYQQRTNGSPRLLIKYASESISGIPSRFSGSGSGTDFTLSINSVESEDIADYYCQQNNNWPTTFGAGTKLELKGGGGSGGGGSGGGGSQVQLKQSGPGLVQPSQSLSITCTVSGFSLTNYGVHWVRQSPGKGLEWLGVIWSGGNTDYNTPFTSRLSINKDNSKSQVFFKMNSLQSNDTAIYYCARALTYYDYEFAYWGQGTLVTVSSGGGGSEVQLVESGGGLVQPGGSLKLSCAASGFTFNKYAMNWVRQAPGKGLEWVARIRSKYNNYATYYADSVKDRFTISRDDSKNTAYLQMNNLKTEDTAVYYCVRHGNFGNSYISYWAYWGQGTLVTVSSGGGGSGGGGSGGGGSQTVVTQEPSLTVSPGGTVTLTCGSSTGAVTSGYYPNWVQQKPGQAPRGLIGGTKFLAPGTPARFSGSLLGGKAALTLSGVQPEDEAEYYCALWYSNRWVFGGGTKLTVL*(配列番号506)
実施例6.CD3εJurkat細胞への活性化可能抗-CD3ε抗体の結合
実施例7.EGFR+HT-29細胞及びCD3ε+Jurkat細胞への二重マスキングされた多重特異的活性化可能抗体の結合
実施例8.EGFR+HT-29細胞及びCD3ε+Jurkat細胞に対する二重マスキングされた多重特異的活性化可能抗体の細胞毒性
実施例9.EGFR+HT-29細胞及びCD3ε+Jurkat細胞への一重及び二重マスキングされた多重特異的活性化可能抗体の結合
実施例10.一重及び二重マスキングされた多重特異的活性化可能抗体のEGFR依存性細胞毒性
実施例11.一重及び二重マスキングされた多重特異的活性化可能抗体のEGFR依存性初代T細胞活性化
実施例12.一重及び二重マスキングされた多重特異的活性化可能抗体のEGFR非依存性初代T細胞活性化
実施例13.多重特異的活性化可能抗体のuPA消化がEGFR+HT-29luc2細胞及びCD3+Jurkat細胞への結合及びEGFR+HT-29luc2細胞に対する細胞毒性を回復する
実施例14.異なる基質を取り込む二重マスキングされた多重特異的活性化可能抗体
実施例15.本実施形態の多重特異的抗体及び多重特異的活性化可能抗体はマウスにおおけるHT-29Luc2腫瘍増殖を妨げる
表13.HT-29Luc2異種移植研究についてのグループ及び用量。*BiTEは、0.5mg/kg/日で投与された。

表14.HT-29Luc2異種移植予防研究のためのグループ及び用量

実施例16.本実施形態の多重特異的抗体及び多重特異的活性化可能抗体は、マウスにおける確立されたHT-29Luc2腫瘍の退縮を誘発した
表15.用量依存性HT-29Luc2異種移植研究のためのグループ及び用量

表16.追加の用量依存性HT-29Luc2異種移植アドオン研究のためのグループ及び用量

実施例17.カニクイザルにおける多重特異的抗体及び多重特異的活性化可能抗体についての最大耐性用量(MTD)の決定
実施例18.EGFR+HT-29細胞及びマウスCD3ε+TK1細胞への二重マスキングされた多重特異的活性化可能抗体の結合
実施例19.二重マスキングされた多重特異的活性化可能抗体を標的化するIL6Rの特徴付け
他の実施態様
Claims (22)
- 活性化された状態で、CD3のイプシロン鎖(CD3ε)及び第2標的に結合する、多重特異的活性化可能抗体であって、前記多重特異的活性化可能抗体が:
CD3εに特異的に結合する第1抗体又はその抗原結合フラグメント(AB1)、及び、第2標的に結合する第2抗体又はその抗原結合フラグメント(AB2)[ここで、前記AB1が、アミノ酸配列TYAMN(配列番号53)を含むVH CDR1;アミノ酸配列RIRSKYNNYATYYADSVKD(配列番号54)を含むVH CDR2;アミノ酸配列HGNFGNSYVSWFAY(配列番号55)を含むVH CDR3;アミノ酸配列RSSTGAVTTSNYAN(配列番号56)を含むVL CDR1;アミノ酸配列GTNKRAP(配列番号57)を含むVL CDR2;及びアミノ酸配列ALWYSNLWV(配列番号58)を含むVL CDR3を含む];
前記多重特異的活性化可能抗体が未切断状態にある場合に、前記AB1のCD3εへの結合を阻害するマスキング部分(MM1)であって、ここで前記MM1は、配列番号371~391から成る群から選択されるアミノ酸配列を含む、マスキング部分(MM1);
前記AB1にカップリングされた切断可能部分(CM1)であって、ここで前記CM1はプロテアーゼの基質として機能するポリペプチドである、切断可能部分(CM1)、
前記多重特異的活性化可能抗体が未切断状態にある場合に、前記AB2の前記第2標的への結合を阻害するマスキング部分(MM2);及び
前記AB2にカップリングされた切断可能部分(CM2)であって、ここで前記CM2はプロテアーゼの基質として機能するポリペプチドである、切断可能部分(CM2)
を含む、多重特異的活性化可能抗体。 - 多重特異的活性化可能抗体が、少なくとも1つの以下の特徴:
(a)配列番号588のアミノ酸配列を含む;
(c)配列番号452、454、464、472、480、510、512、514、及び518から成る群から選択される重鎖配列を含む;
(d)配列番号450、468、474、482、508、516、881及び520から成る群から選択される軽鎖配列を含む;
(e)配列番号452、454、464、480、510、512、514、及び518から成る群から選択される重鎖配列と、配列番号448、450、482、508及び520から成る群から選択される軽鎖配列とを含む;
(f)配列番号472の重鎖配列と、配列番号474、及び516から成る群から選択される軽鎖配列とを含む;並びに
(g)配列番号456、460、466、470、448、458、及び484から成る群から選択されるアミノ酸配列を含む、
を有する、請求項1に記載の多重特異的活性化可能抗体。 - 多重特異的活性化可能抗体が、少なくとも1つの以下の特徴:
(a)前記AB1の抗原結合フラグメントが、Fabフラグメント、F(ab’)2フラグメント、scFv、及びscabから成る群から選択される;
(b)前記MM1が、前記多重特異的活性化可能抗体が切断された状態にある場合、前記標的へ結合する前記AB1を妨害しないか、又は競合しない;
(c)前記MM1が40個以下の長さのアミノ酸のポリペプチドである;
(d)前記CM1が15個までの長さのアミノ酸のポリペプチドである;
(e)前記CM1が、表9:

に示されるプロテアーゼから成る群から選択されるプロテアーゼの基質である、又は、前記CM1が、配列番号67~86、321~341、及び896~926から成る群から選択されるアミノ酸を含む;
(f)前記多重特異的活性化可能抗体が、前記MM1と前記CM1との間に連結ペプチドを含む;
(g)前記多重特異的活性化可能抗体が、前記CM1と前記AB1との間に連結ペプチドを含む、
を有する、請求項1又は2に記載の多重特異的活性化可能抗体。 - 多重特異的活性化可能抗体が、少なくとも1つの以下の特徴:
(a)前記AB2の標的が、以下:
1-92-LFA-3、α-4インテグリン、α-Vインテグリン、α4β1インテグリン、α4β7インテグリン、AGR2、抗-ルイス-Y、アペリンJ受容体、APRIL、B7-H4、BAFF、BTLA、C5補体、C-242、CA9、CA19-9 (ルイスa)、炭酸脱水酵素9、CD2、CD3、CD6、CD9、CD11a、CD19、CD20、CD22、CD24、CD25、CD27、CD28、CD30、CD33、CD38、CD40、CD40L、CD41、CD44、CD44v6、CD47、CD51、CD52、CD56、CD64、CD70、CD71、CD74、CD80、CD81、CD86、CD95、CD117、CD125、CD132 (IL-2RG)、CD133、CD137、CD138、CD166、CD172A、CD248、CDH6、CEACAM5 (CEA)、CEACAM6 (NCA-90)、CLAUDIN-3、CLAUDIN-4、cMet、コラーゲン、Cripto、CSFR、CSFR-1、CTLA-4、CTGF、CXCL10、CXCL13、CXCR1、CXCR2、CXCR4、CYR61、DL44、DLK1、DLL4、DPP-4、DSG1、EGFR、EGFRviii、エンドセリンB受容体(ETBR)、ENPP3、EpCAM、EPHA2、EPHB2、ERBB3、RSVのFタンパク、FAP、FGF-2、FGF8、FGFR1、FGFR2、FGFR3、FGFR4、葉酸受容体、GAL3ST1、G-CSF、G-CSFR、GD2、GITR、GLUT1、GLUT4、GM-CSF、GM-CSFR、GP IIb/IIIa受容体、Gp130、GPIIB/IIIA、GPNMB、GRP78、HER2/neu、HGF、hGH、HVEM、ヒアルロニダーゼ、ICOS、IFNα、IFNβ、IFNγ、IgE、IgE受容体(FceRI)、IGF、IGF1R、IL1B、IL1R、IL2、IL11、IL12、IL12p40、IL-12R、IL-12Rβ1、IL13、IL13R、IL15、IL17、IL18、IL21、IL23、IL23R、IL27/IL27R (wsx1)、IL29、IL-31R、IL31/IL31R、IL2R、IL4、IL4R、IL6、IL6R、インスリン受容体、Jagged リガンド、Jagged 1、Jagged 2、LAG-3、LIF-R、ルイス X、LIGHT、LRP4、LRRC26、MCSP、メソテリン、MRP4、MUC1、ムチン-16 (MUC16 CA-125)、Na/K ATPアーゼ、好中球エラスターゼ、NGF、ニカストリン、ノッチ受容体、ノッチ 1、ノッチ 2、ノッチ 3、ノッチ 4、NOV、OSM-R、OX-40、PAR2、PDGF-AA、PDGF-BB、PDGFRα、PDGFRβ、PD-1、PD-L1、PD-L2、ホスファチジル-セリン、P1GF、PSCA、PSMA、RAAG12、RAGE、SLC44A4、スフィンゴシン1リン酸、STEAP1、STEAP2、TAG-72、TAPA1、TGFβ、TIGIT、TIM-3、TLR2、TLR4、TLR6、TLR7、TLR8、TLR9、TMEM31、TNFα、TNFR、TNFRS12A、TRAIL-R1、TRAIL-R2、トランスフェリン、トランスフェリン受容体、TRK-A、TRK- B、uPAR、VAP1、VCAM-1、VEGF、VEGF-A、VEGF-B、VEGF-C、VEGF-D、VEGFR1、VEGFR2、VEGFR3、VISTA、WISP-1、WISP-2、及びWISP-3、
から成る群から選択される;
(b)前記AB2は、以下:
ベバシズマブ、ラニビズマブ、セツキシマブ、パニツムマブ、インフリキシマブ、アダリムマブ、ナタリズマブ、バシリキシマブ、エクリズマブ、エファリズマブ、トシツモマブ、イブリツモマブ チウキセタン、リツキシマブ、オファツムマブ、オビヌツズマブ ダクリズマブ、ブレンツキシマブ ベドチン、ゲムツズマブ、ゲムツズマブ オゾガミシン、アレムツズマブ、アブシキシマブ、オマリズマブ、トラスツズマブ、トラスツズ マブエムタシン、パリビズマブ、イピリムマブ、トレメリムマブ、Hu5c8、ペルツズマブ、エルタマキソマブ、タネズマブ、バビツキシマブ、ザルツムマブ、マパツムマブ、マツズマブ、ニモツズマブ、ICR62、mAb 528、CH806、MDX-447、エドレコロマブ、RAV12、huJ591、GC1008、アデカツムマブ、フィギツムマブ、トシリズマブ、アステキヌマブ、デノスマブ、ペンブロリズマブ、ニボルムマブ、及びアテゾリズマブ、
から成る群から選択される抗体であるか、又はその抗体に由来する;
(c)前記AB2の抗原結合フラグメントが、Fabフラグメント、F(ab’)2 フラグメント、scFv、及びscAbから成る群から選択される;
(d)前記MM2が、多重特異的活性化可能抗体が切断された状態にある場合、前記標的へ結合する前記AB2を妨害しないか、又は競合しない;
(e)前記MM2が、40個以下の長さのアミノ酸のポリペプチドである;
(f)前記MM2ポリペプチド配列が、AB2の標的とは異なる;
(g)前記CM2が、15個までの長さのアミノ酸のポリペプチドである;
(h)前記CM2が、表6:

に示されるプロテアーゼから成る群から選択されるプロテアーゼの基質である、又は、前記CM2が、配列番号67~86、321~341、及び896~926から成る群から選択されるアミノ酸配列を含む;
(i)前記多重特異的活性化可能抗体が、前記MM2と前記CM2との間に連結ペプチドを含む;及び
(j)前記多重特異的活性化可能抗体が、前記CM2と前記AB2との間に連結ペプチドを含む、
を有する、請求項1~3のいずれか一項に記載の多重特異的活性化可能抗体。 - 前記プロテアーゼが、組織においてCD3εを発現する細胞に近接する腫瘍により生成される、及び/又は組織においてAB2の標的と共局在される腫瘍により生成されるものであって、ここで、前記プロテアーゼは、前記多重特異的活性化可能抗体が前記プロテアーゼに暴露される場合、前記多重特異的活性化可能抗体における前記CM1又はCM2を切断する、請求項1~4のいずれか一項に記載の多重特異的活性化可能抗体。
- 前記多重特異的活性化可能抗体が、第1連結ペプチド(LP1)と第2連結ペプチド(LP2)とを含み、ここで;
(a)未切断状態における前記多重特異的活性化可能抗体が、次のようなN-末端からC-末端への構造配置:MM1-LP1-CM1-LP2-AB1を有する;
(b)前記2つの連結ペプチドが互いに同一ではない;
(c)LP1及びLP2のそれぞれが、1~20個の長さのアミノ酸のペプチドである;及び/又は
(d)LP1又はLP2の少なくとも1つが、(GS)n、(GGS)n、(GSGGS)n(配列番号59)及び(GGGS)n(配列番号60)、GGSG(配列番号61)、GGSGG(配列番号62)、GSGSG(配列番号63)、GSGGG(配列番号64)、GGGSG(配列番号65)、及びGSSSG(配列番号66)(式中、nは少なくとも1の整数である)から成る群から選択されたアミノ酸配列を含む、
請求項1~5のいずれか1項に記載の多重特異的活性化可能抗体。 - 前記多重特異的活性化可能抗体が、第1連結ペプチド(LP1)と第2連結ペプチド(LP2)とを含み、ここで:
(a)未切断状態における前記多重特異的活性化可能抗体が、次のようなN-末端からC-末端への構造配置:MM2-LP1-CM2-LP2-AB2を有する;
(b)前記2つの連結ペプチドが互いに同一ではない;
(c)LP1及びLP2のそれぞれが、1~20個の長さのアミノ酸のペプチドである;及び/又は
(d)LP1又はLP2の少なくとも1つが、(GS)n、(GGS)n、(GSGGS)n(配列番号59)及び(GGGS)n(配列番号60)、GGSG(配列番号61)、GGSGG(配列番号62)、GSGSG(配列番号63)、GSGGG(配列番号64)、GGGSG(配列番号65)、及びGSSSG(配列番号66)(式中、nは少なくとも1の整数である)から成る群から選択されるアミノ酸配列を含む、
請求項1~6のいずれか一項に記載の多重特異的活性化可能抗体。 - 前記多重特異的活性化可能抗体が、少なくとも1つの以下の特徴:
(a)前記AB1が、配列番号4のアミノ酸配列を含む可変重鎖(Hv)、及び配列番号2のアミノ酸配列を含む可変軽鎖(Lv)を含む;
(b)前記AB1及び/又はAB2が、scFvフラグメントを含む;
(c)前記AB1が、scFvフラグメントを含む;
(d)前記AB1が、配列番号6のアミノ酸配列、又は配列番号30のアミノ酸配列を含むscFvフラグメントを含む;及び
(e)前記AB1が、配列番号588のアミノ酸配列を含む、
を有する、請求項1~7の何れか1項に記載の多重特異的活性化可能抗体。 - 前記AB2が、以下:NYGVH(配列番号94)のアミノ酸配列を含むVH CDR1;VIWSGGNTDYNTPFTS(配列番号95)のアミノ酸配列を含むVH CDR2;ALTYYDYEFAY(配列番号96)のアミノ酸配列を含むVH CDR3;RASQSIGTNIH(配列番号97)のアミノ酸配列を含むVL CDR1;KYASESIS(配列番号98)のアミノ酸配列を含むVL CDR2;及び、QQNNNWPTT(配列番号99)のアミノ酸配列を含むVL CDR3、を含む、請求項1に記載の多重特異的活性化可能抗体。
- 前記多重特異的活性化可能抗体が、Fcドメインを含む、請求項1~9のいずれか1項に記載の多重特異的活性化可能抗体。
- AB1及びAB2の少なくとも1つに結合された剤を含み、
ここで前記剤が、治療剤、抗腫瘍剤、トキシン又はそのフラグメント、検出可能成分又は診断剤である、及び/又は、前記剤が、リンカーを介してAB1及びAB2の少なくとも1つに結合されており、ここで前記リンカーが、切断可能リンカー又は非切断可能リンカーである、請求項1~10のいずれか1項に記載の多重特異的活性化可能抗体。 - 前記多重特異的活性化可能抗体が、二重特異的である、請求項1~11のいずれか1項に記載の多重特異的活性化可能抗体。
- 請求項1~12の何れか1項に記載の多重特異的活性化可能抗体、及び担体を含む医薬組成物。
- 追加の剤を含む、請求項13に記載の医薬組成物。
- 前記追加の剤が治療剤である、請求項14に記載の医薬組成物。
- 請求項1~12のいずれか1項に記載の多重特異的活性化可能抗体をコードする単離された核酸分子。
- 請求項16に記載の単離された核酸分子を含むベクター。
- 少なくともCD3のイプシロン鎖(CD3ε)を特異的に結合する多重特異的活性化可能抗体の生成方法であって、前記方法が、多重特異的活性化可能抗体の発現をもたらす条件下で、細胞を培養することを含むものであって、ここで、前記細胞が、請求項16に記載の核酸分子又は請求項17に記載のベクターを含む、方法。
- 癌の治療に使用するための、請求項1~12のいずれか1項に記載の多重特異的活性化可能抗体、又は請求項18に従って産生される多重特異的活性化可能抗体、又は請求項13~15のいずれか1項に記載の医薬組成物。
- 対象における障害に関連する臨床適応症の症状を緩和するための医薬の製造における、請求項1~12のいずれか1項に記載の多重特異的活性化可能抗体、又は請求項18に従って産生される多重特異的活性化可能抗体、又は請求項13~15のいずれか1項に記載の医薬組成物の使用。
- 前記対象がヒトである、請求項20に記載の使用。
- 前記障害が癌である、請求項20又は21に記載の使用。
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201462029325P | 2014-07-25 | 2014-07-25 | |
| US62/029,325 | 2014-07-25 | ||
| PCT/US2015/042053 WO2016014974A2 (en) | 2014-07-25 | 2015-07-24 | Anti-cd3 antibodies, activatable anti-cd3 antibodies, multispecific anti-cd3 antibodies, multispecific activatable anti-cd3 antibodies, and methods of using the same |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2021012481A Division JP7168702B2 (ja) | 2014-07-25 | 2021-01-28 | 抗-cd3抗体、活性化可能抗-cd3抗体、多重特異的抗-cd3抗体、多重特異的活性化可能抗-cd3抗体、及びそれらの使用方法 |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| JP2017523176A JP2017523176A (ja) | 2017-08-17 |
| JP2017523176A5 JP2017523176A5 (ja) | 2018-09-06 |
| JP7020909B2 true JP7020909B2 (ja) | 2022-02-16 |
Family
ID=53765629
Family Applications (3)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2017504058A Active JP7020909B2 (ja) | 2014-07-25 | 2015-07-24 | 抗-cd3抗体、活性化可能抗-cd3抗体、多重特異的抗-cd3抗体、多重特異的活性化可能抗-cd3抗体、及びそれらの使用方法 |
| JP2021012481A Active JP7168702B2 (ja) | 2014-07-25 | 2021-01-28 | 抗-cd3抗体、活性化可能抗-cd3抗体、多重特異的抗-cd3抗体、多重特異的活性化可能抗-cd3抗体、及びそれらの使用方法 |
| JP2022171196A Active JP7564853B2 (ja) | 2014-07-25 | 2022-10-26 | 抗-cd3抗体、活性化可能抗-cd3抗体、多重特異的抗-cd3抗体、多重特異的活性化可能抗-cd3抗体、及びそれらの使用方法 |
Family Applications After (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2021012481A Active JP7168702B2 (ja) | 2014-07-25 | 2021-01-28 | 抗-cd3抗体、活性化可能抗-cd3抗体、多重特異的抗-cd3抗体、多重特異的活性化可能抗-cd3抗体、及びそれらの使用方法 |
| JP2022171196A Active JP7564853B2 (ja) | 2014-07-25 | 2022-10-26 | 抗-cd3抗体、活性化可能抗-cd3抗体、多重特異的抗-cd3抗体、多重特異的活性化可能抗-cd3抗体、及びそれらの使用方法 |
Country Status (8)
| Country | Link |
|---|---|
| US (3) | US10669337B2 (ja) |
| EP (1) | EP3172235A2 (ja) |
| JP (3) | JP7020909B2 (ja) |
| CN (1) | CN107108738A (ja) |
| AU (2) | AU2015292406B2 (ja) |
| BR (1) | BR112017001579A2 (ja) |
| CA (1) | CA2955947A1 (ja) |
| WO (1) | WO2016014974A2 (ja) |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US12060654B2 (en) | 2016-11-28 | 2024-08-13 | Chugai Seiyaku Kabushiki Kaisha | Ligand-binding molecule having adjustable ligand binding activity |
| US12077577B2 (en) | 2018-05-30 | 2024-09-03 | Chugai Seiyaku Kabushiki Kaisha | Polypeptide comprising aggrecan binding domain and carrying moiety |
Families Citing this family (141)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| GB201203442D0 (en) | 2012-02-28 | 2012-04-11 | Univ Birmingham | Immunotherapeutic molecules and uses |
| US10000567B2 (en) * | 2012-06-14 | 2018-06-19 | Therapix Biosciences Ltd. | Humanized antibodies to cluster of differentiation 3 (CD3) |
| WO2014153164A1 (en) | 2013-03-14 | 2014-09-25 | The California Institute For Biomedical Research | Targeting agent antibody conjugates and uses thereof |
| EP3024851B1 (en) | 2013-07-25 | 2018-05-09 | CytomX Therapeutics, Inc. | Multispecific antibodies, multispecific activatable antibodies and methods of using the same |
| CN118146306A (zh) | 2013-09-25 | 2024-06-07 | 西托姆克斯治疗公司 | 基质金属蛋白酶底物和其它可切割部分及其使用方法 |
| DK3736292T3 (da) | 2013-12-17 | 2024-07-22 | Genentech Inc | Anti-CD3-antistoffer og fremgangsmåder til anvendelse |
| IL302642A (en) | 2014-01-31 | 2023-07-01 | Cytomx Therapeutics Inc | Polypeptide substrates that activate matriptase and U-plasminogen and other cleavable groups, preparations containing them and their uses |
| CN107108738A (zh) | 2014-07-25 | 2017-08-29 | 西托姆克斯治疗公司 | 抗cd3抗体、可活化抗cd3抗体、多特异性抗cd3抗体、多特异性可活化抗cd3抗体及其使用方法 |
| RS60615B1 (sr) | 2014-11-20 | 2020-08-31 | Hoffmann La Roche | Zajednički laki lanci i postupci upotrebe |
| MA41374A (fr) * | 2015-01-20 | 2017-11-28 | Cytomx Therapeutics Inc | Substrats clivables par métalloprotéase matricielle et clivables par sérine protéase et procédés d'utilisation de ceux-ci |
| US11400157B2 (en) | 2015-05-13 | 2022-08-02 | Chugai Seiyaku Kabushiki Kaisha | Multiple antigen binding molecular fusion, pharmaceutical composition, method for identifying linear epitope, and method for preparing multiple antigen binding molecular fusion |
| EP3297672B1 (en) | 2015-05-21 | 2021-09-01 | Harpoon Therapeutics, Inc. | Trispecific binding proteins and methods of use |
| SG10201913303XA (en) * | 2015-07-13 | 2020-03-30 | Cytomx Therapeutics Inc | Anti-pd-1 antibodies, activatable anti-pd-1 antibodies, and methods of use thereof |
| TWI744247B (zh) | 2015-08-28 | 2021-11-01 | 美商亞穆尼克斯製藥公司 | 嵌合多肽組合體以及其製備及使用方法 |
| EP3352760A4 (en) * | 2015-09-21 | 2019-03-06 | Aptevo Research and Development LLC | CD3 BINDING POLYPEPTIDES |
| EP3370771A4 (en) * | 2015-11-03 | 2019-06-19 | Ambrx, Inc. | ANTI-CD3-FOLATE CONJUGATES AND USES THEREOF |
| WO2017087789A1 (en) | 2015-11-19 | 2017-05-26 | Revitope Limited | Functional antibody fragment complementation for a two-components system for redirected killing of unwanted cells |
| AU2016368469B2 (en) | 2015-12-09 | 2023-11-02 | F. Hoffmann-La Roche Ag | Type II anti-CD20 antibody for reducing formation of anti-drug antibodies |
| KR20180104157A (ko) * | 2016-02-04 | 2018-09-19 | 더 캘리포니아 인스티튜트 포 바이오메디칼 리써치 | 인간화 항-cd3 항체, 접합체 및 이의 용도 |
| CA3053242A1 (en) * | 2016-02-19 | 2017-08-24 | Dignity Health | Antibody fusion protein and related compositions for targeting cancer |
| BR112018016281A2 (pt) * | 2016-03-22 | 2019-01-02 | Hoffmann La Roche | molécula biespecífica ativadora de célula t ativável por protease, polipeptídeo idiotipo-específico, composição farmacêutica, usos da molécula biespecífica e método de tratamento de uma doença em um indivíduo |
| SI3433280T1 (sl) * | 2016-03-22 | 2023-07-31 | F. Hoffmann-La Roche Ag | S proteazo aktivirane bispecifične molekule celic T |
| RU2764201C2 (ru) | 2016-03-25 | 2022-01-14 | Биомюнё Фармасьютикалз | Связывающиеся с cd38 и pd-l1 молекулы |
| ES2952951T3 (es) | 2016-04-28 | 2023-11-07 | Biomunex Pharmaceuticals | Anticuerpos biespecíficos dirigidos a EGFR y HER2 |
| CN110603266A (zh) | 2016-06-02 | 2019-12-20 | 豪夫迈·罗氏有限公司 | 用于治疗癌症的ii型抗cd20抗体和抗cd20/cd3双特异性抗体 |
| EP3252078A1 (en) | 2016-06-02 | 2017-12-06 | F. Hoffmann-La Roche AG | Type ii anti-cd20 antibody and anti-cd20/cd3 bispecific antibody for treatment of cancer |
| EP3471753A1 (en) | 2016-06-20 | 2019-04-24 | Kymab Limited | Anti-pd-l1 and il-2 cytokines |
| EP3474901A1 (en) | 2016-06-27 | 2019-05-01 | Tagworks Pharmaceuticals B.V. | Cleavable tetrazine used in bio-orthogonal drug activation |
| EP3484518B1 (en) | 2016-07-07 | 2024-08-14 | The Board of Trustees of the Leland Stanford Junior University | Antibody adjuvant conjugates |
| CR20220408A (es) * | 2016-09-14 | 2022-10-20 | Teneobio Inc | ANTICUERPOS DE UNIÓN A CD3(Divisional del Expediente 2019-198) |
| CN106632681B (zh) * | 2016-10-11 | 2017-11-14 | 北京东方百泰生物科技有限公司 | 抗egfr和抗cd3双特异抗体及其应用 |
| WO2018085555A1 (en) * | 2016-11-03 | 2018-05-11 | Bristol-Myers Squibb Company | Activatable anti-ctla-4 antibodies and uses thereof |
| MX2019005438A (es) | 2016-11-15 | 2019-08-16 | Genentech Inc | Dosificacion para tratamiento con anticuerpos bispecificos anti-cd20 / anti-cd3. |
| EP3546574A4 (en) | 2016-11-28 | 2020-09-09 | Chugai Seiyaku Kabushiki Kaisha | ANTIGEN AND POLYPEPTIDE BINDING AREA INCLUDING A TRANSPORT SECTION |
| EP4252629A3 (en) | 2016-12-07 | 2023-12-27 | Biora Therapeutics, Inc. | Gastrointestinal tract detection methods, devices and systems |
| EP3555620A1 (en) * | 2016-12-13 | 2019-10-23 | H. Hoffnabb-La Roche Ag | Method to determine the presence of a target antigen in a tumor sample |
| IL267485B2 (en) | 2016-12-21 | 2024-01-01 | Teneobio Inc | Antibodies against BCMA containing only heavy chains and their uses |
| CN110637033A (zh) * | 2017-02-22 | 2019-12-31 | 艾丽塔生物治疗剂公司 | 用于治疗癌症的组合物和方法 |
| WO2018156180A1 (en) | 2017-02-24 | 2018-08-30 | Kindred Biosciences, Inc. | Anti-il31 antibodies for veterinary use |
| BR112019019998A2 (pt) | 2017-03-27 | 2020-04-28 | Biomunex Pharmaceuticals | anticorpos multiespecíficos estáveis |
| EP4108183A1 (en) | 2017-03-30 | 2022-12-28 | Biora Therapeutics, Inc. | Treatment of a disease of the gastrointestinal tract with an immune modulatory agent released using an ingestible device |
| AU2018250641A1 (en) | 2017-04-11 | 2019-10-31 | Inhibrx Biosciences, Inc. | Multispecific polypeptide constructs having constrained CD3 binding and methods of using the same |
| EP3409322A1 (en) | 2017-06-01 | 2018-12-05 | F. Hoffmann-La Roche AG | Treatment method |
| WO2018224441A1 (en) * | 2017-06-05 | 2018-12-13 | Numab Innovation Ag | Novel anti-cd3 antibodies |
| AU2018280681A1 (en) | 2017-06-05 | 2019-12-05 | Numab Therapeutics AG | Novel anti-CD3 antibodies |
| CN110945026B (zh) | 2017-06-20 | 2024-03-19 | 特纳奥尼股份有限公司 | 仅有重链的抗bcma抗体 |
| IL312322A (en) | 2017-06-20 | 2024-06-01 | Teneobio Inc | Anti-BCMA antibodies containing only heavy chains |
| WO2019005637A2 (en) * | 2017-06-25 | 2019-01-03 | Systimmune, Inc. | MULTIPECIFIC ANTIBODIES AND METHODS OF PRODUCTION AND USE THEREOF |
| WO2019018828A1 (en) * | 2017-07-20 | 2019-01-24 | Cytomx Therapeutics, Inc. | METHODS OF QUALITATIVE AND / OR QUANTITATIVE ANALYSIS OF ACTIVATABLE ANTIBODY PROPERTIES AND USES THEREOF |
| CN111511762A (zh) | 2017-08-21 | 2020-08-07 | 天演药业公司 | 抗cd137分子及其用途 |
| EP3676294A4 (en) * | 2017-08-28 | 2021-12-22 | Systimmune, Inc. | ANTI-CD3 ANTIBODIES AND METHOD OF MANUFACTURING AND USING THEREOF |
| IL302613A (en) | 2017-09-08 | 2023-07-01 | Maverick Therapeutics Inc | Binding proteins are activated under limited conditions |
| JP7066837B2 (ja) | 2017-10-13 | 2022-05-13 | ハープーン セラピューティクス,インク. | B細胞成熟抗原結合タンパク質 |
| JP7438106B2 (ja) * | 2017-10-14 | 2024-02-26 | シートムエックス セラピューティクス,インコーポレイテッド | 抗体、活性化可能抗体、二重特異性抗体、および二重特異性活性化可能抗体ならびにその使用方法 |
| MX2020005220A (es) * | 2017-11-28 | 2020-08-24 | Chugai Pharmaceutical Co Ltd | Polipeptido que incluye dominio de union al antigeno y seccion de transporte. |
| US20210206845A1 (en) | 2017-11-28 | 2021-07-08 | Chugai Seiyaku Kabushiki Kaisha | Ligand-binding molecule having adjustable ligand-binding activity |
| JOP20200157A1 (ar) | 2017-12-22 | 2022-10-30 | Teneobio Inc | أجسام مضادة ذات سلسلة ثقيلة ترتبط بـ cd22 |
| CN107880129B (zh) * | 2017-12-28 | 2021-01-15 | 广州市鲁诚生物科技有限公司 | 一种重组抗体及其制备方法 |
| WO2019148445A1 (en) * | 2018-02-02 | 2019-08-08 | Adagene Inc. | Precision/context-dependent activatable antibodies, and methods of making and using the same |
| WO2019148444A1 (en) | 2018-02-02 | 2019-08-08 | Adagene Inc. | Anti-ctla4 antibodies and methods of making and using the same |
| US11685781B2 (en) | 2018-02-15 | 2023-06-27 | Macrogenics, Inc. | Variant CD3-binding domains and their use in combination therapies for the treatment of disease |
| US20210020264A1 (en) | 2018-03-20 | 2021-01-21 | Cytomx Therapeutics, Inc. | Systems and methods for quantitative pharmacological modeling of activatable antibody species in mammalian subjects |
| CN110305217B (zh) | 2018-03-27 | 2022-03-29 | 广州爱思迈生物医药科技有限公司 | 双特异性抗体及其应用 |
| EP3788077A1 (en) | 2018-05-02 | 2021-03-10 | CytomX Therapeutics, Inc. | Antibodies, activatable antibodies, bispecific antibodies, and bispecific activatable antibodies and methods of use thereof |
| CN113840832A (zh) | 2018-05-14 | 2021-12-24 | 狼人治疗公司 | 可活化白介素-2多肽及其使用方法 |
| WO2019222294A1 (en) | 2018-05-14 | 2019-11-21 | Werewolf Therapeutics, Inc. | Activatable cytokine polypeptides and methods of use thereof |
| SG11202010580TA (en) * | 2018-05-23 | 2020-12-30 | Pfizer | Antibodies specific for cd3 and uses thereof |
| JPWO2019230868A1 (ja) | 2018-05-30 | 2021-06-24 | 中外製薬株式会社 | 単ドメイン抗体含有リガンド結合分子 |
| US20210198370A1 (en) * | 2018-05-31 | 2021-07-01 | Board Of Regents, The University Of Texas System | Bi-specific antibodies and use thereof |
| CN112513081A (zh) * | 2018-06-14 | 2021-03-16 | 生物蛋白有限公司 | 多重特异性抗体构建体 |
| US20230041197A1 (en) | 2018-06-20 | 2023-02-09 | Progenity, Inc. | Treatment of a disease of the gastrointestinal tract with an immunomodulator |
| US20230009902A1 (en) | 2018-06-20 | 2023-01-12 | Progenity, Inc. | Treatment of a disease or condition in a tissue orginating from the endoderm |
| TW202016144A (zh) * | 2018-06-21 | 2020-05-01 | 日商第一三共股份有限公司 | 包括cd3抗原結合片段之組成物及其用途 |
| EP3827019A1 (en) | 2018-07-24 | 2021-06-02 | Inhibrx, Inc. | Multispecific polypeptide constructs containing a constrained cd3 binding domain and a receptor binding region and methods of using the same |
| MX2021001085A (es) | 2018-07-31 | 2021-03-31 | Amgen Inc | Formulaciones y composiciones farmaceuticas que comprenden una proteina de union a antigeno enmascarada. |
| WO2020069028A1 (en) | 2018-09-25 | 2020-04-02 | Harpoon Therapeutics, Inc. | Dll3 binding proteins and methods of use |
| CA3115082A1 (en) | 2018-10-11 | 2020-04-16 | Inhibrx, Inc. | B7h3 single domain antibodies and therapeutic compositions thereof |
| US20210380679A1 (en) | 2018-10-11 | 2021-12-09 | Inhibrx, Inc. | Dll3 single domain antibodies and therapeutic compositions thereof |
| CA3114693A1 (en) | 2018-10-11 | 2020-04-16 | Inhibrx, Inc. | 5t4 single domain antibodies and therapeutic compositions thereof |
| WO2020077257A1 (en) | 2018-10-11 | 2020-04-16 | Inhibrx, Inc. | Pd-1 single domain antibodies and therapeutic compositions thereof |
| KR20210095165A (ko) | 2018-11-19 | 2021-07-30 | 프로제너티, 인크. | 바이오의약품으로 질환을 치료하기 위한 방법 및 디바이스 |
| US12049505B2 (en) | 2018-12-06 | 2024-07-30 | Cytomx Therapeutics, Inc. | Matrix metalloprotease-cleavable and serine or cysteine protease-cleavable substrates and methods of use thereof |
| CN116178547A (zh) * | 2019-02-22 | 2023-05-30 | 武汉友芝友生物制药股份有限公司 | Cd3抗原结合片段及其应用 |
| CN114390938A (zh) | 2019-03-05 | 2022-04-22 | 武田药品工业有限公司 | 受约束的条件性活化的结合蛋白 |
| CN113993549A (zh) | 2019-03-15 | 2022-01-28 | 博尔特生物治疗药物有限公司 | 靶向her2的免疫缀合物 |
| WO2020225805A2 (en) * | 2019-05-07 | 2020-11-12 | Immunorizon Ltd. | Precursor tri-specific antibody constructs and methods of use thereof |
| SG11202112541RA (en) | 2019-05-14 | 2021-12-30 | Werewolf Therapeutics Inc | Separation moieties and methods and use thereof |
| MX2021014433A (es) | 2019-06-05 | 2022-03-11 | Chugai Pharmaceutical Co Ltd | Molecula de union a sitio de escision de anticuerpo. |
| JP2022535924A (ja) * | 2019-06-06 | 2022-08-10 | ジャナックス セラピューティクス,インク. | 腫瘍活性化t細胞エンゲージャーに関する組成物および方法 |
| CA3140816A1 (en) | 2019-06-14 | 2020-12-17 | Nathan Trinklein | Multispecific heavy chain antibodies binding to cd22 and cd3 |
| BR112021026089A2 (pt) * | 2019-06-26 | 2022-03-22 | Amunix Pharmaceuticals Inc | Fragmentos de ligação ao antígeno de cd3 e composições compreendendo os mesmos |
| KR20220030956A (ko) | 2019-07-05 | 2022-03-11 | 오노 야꾸힝 고교 가부시키가이샤 | Pd-1/cd3 이중 특이성 단백질에 의한 혈액암 치료 |
| WO2021061867A1 (en) * | 2019-09-23 | 2021-04-01 | Cytomx Therapeutics, Inc. | Anti-cd47 antibodies, activatable anti-cd47 antibodies, and methods of use thereof |
| CN118459602A (zh) * | 2019-11-06 | 2024-08-09 | 西雅图免疫公司 | 制导和导航控制蛋白及其制备和使用方法 |
| KR20220101147A (ko) | 2019-11-14 | 2022-07-19 | 웨어울프 세라퓨틱스, 인크. | 활성화가능한 사이토카인 폴리펩티드 및 이의 사용 방법 |
| CN115666704A (zh) | 2019-12-13 | 2023-01-31 | 比奥拉治疗股份有限公司 | 用于将治疗剂递送至胃肠道的可摄取装置 |
| CN114945597A (zh) * | 2020-01-17 | 2022-08-26 | 艾提欧生物疗法有限公司 | 降低脱靶毒性的前抗体 |
| MX2022009306A (es) | 2020-01-29 | 2022-09-26 | Inhibrx Inc | Loseta de nucleo de espuma densificada (dfc) con linea de anticuerpos de dominio individual de cd28 y constructos multivalentes y multiespecíficas de los mismos. |
| TW202140561A (zh) * | 2020-02-14 | 2021-11-01 | 日商協和麒麟股份有限公司 | 與cd3結合之雙特異性抗體 |
| MX2022010915A (es) * | 2020-03-03 | 2022-10-07 | Systimmune Inc | Anticuerpos anti-cd19, metodos de uso y fabricacion de los mismos. |
| TW202200619A (zh) * | 2020-03-17 | 2022-01-01 | 美商西雅圖免疫公司 | 引導及導航控制(gnc)抗體樣蛋白質及製造與使用其之方法 |
| AU2021254279A1 (en) | 2020-04-09 | 2022-11-10 | Cytomx Therapeutics, Inc. | Compositions containing activatable antibodies |
| JP2023526774A (ja) | 2020-04-29 | 2023-06-23 | テネオバイオ, インコーポレイテッド | 重鎖定常領域が修飾された多重特異性重鎖抗体 |
| US20230312753A1 (en) * | 2020-05-04 | 2023-10-05 | Immunorizon Ltd. | Precursor tri-specific antibody constructs and methods of use thereof |
| KR20230080399A (ko) | 2020-08-11 | 2023-06-07 | 재눅스 테라퓨틱스 인크. | 절단 가능한 링커 조성물 및 방법 |
| JP2023538891A (ja) | 2020-08-19 | 2023-09-12 | ゼンコア インコーポレイテッド | 抗cd28組成物 |
| WO2022046658A1 (en) * | 2020-08-24 | 2022-03-03 | Janux Therapeutics, Inc. | Antibodies targeting trop2 and cd3 and uses thereof |
| US12116411B2 (en) * | 2020-11-03 | 2024-10-15 | Abzyme Therapeutics Llc | Antibodies binding to human CD3 at acidic pH |
| JP2023548249A (ja) * | 2020-11-10 | 2023-11-15 | 上海齊魯制藥研究中心有限公司 | クローディン18a2及びcd3に対する二重特異性抗体及びその使用 |
| MX2023006817A (es) | 2020-12-09 | 2023-08-14 | Janux Therapeutics Inc | Composiciones y metodos relacionados con anticuerpos activados por tumores dirigidos a psma y antigenos de celulas efectoras. |
| WO2022170619A1 (en) * | 2021-02-11 | 2022-08-18 | Adagene Pte. Ltd. | Anti-cd3 antibodies and methods of use thereof |
| KR102671734B1 (ko) * | 2021-04-13 | 2024-06-04 | 건국대학교 글로컬산학협력단 | 개과 동물의 CD3ε 특이적 항체 또는 그의 항원 결합 단편 |
| AU2021443318A1 (en) | 2021-04-30 | 2023-09-07 | F. Hoffmann-La Roche Ag | Dosing for combination treatment with anti-cd20/anti-cd3 bispecific antibody and anti-cd79b antibody drug conjugate |
| JP2024509664A (ja) | 2021-04-30 | 2024-03-05 | エフ・ホフマン-ラ・ロシュ・アクチェンゲゼルシャフト | 抗cd20/抗cd3二重特異性抗体による治療のための投薬 |
| WO2022266341A1 (en) * | 2021-06-16 | 2022-12-22 | Regents Of The University Of Minnesota | Targeted adam17 blocker compounds, anti-adam17 antibodies, methods of making, and methods of using |
| EP4359443A2 (en) * | 2021-06-25 | 2024-05-01 | Harpoon Therapeutics, Inc. | Extended-release immune cell engaging proteins and methods of treatment |
| WO2023028548A2 (en) * | 2021-08-25 | 2023-03-02 | Systimmune, Inc. | Bispecific tetravalent antibody targeting egfr and her3 |
| WO2023051727A1 (zh) * | 2021-09-30 | 2023-04-06 | 上海君实生物医药科技股份有限公司 | 结合cd3的抗体及其用途 |
| MX2024004563A (es) | 2021-10-15 | 2024-04-30 | Cytomx Therapeutics Inc | Complejo polipeptidico activable. |
| AU2022367525A1 (en) | 2021-10-15 | 2024-05-02 | Amgen Inc. | Activatable polypeptide complex |
| WO2023064955A1 (en) | 2021-10-15 | 2023-04-20 | Cytomx Therapeutics, Inc. | Activatable anti-cd3, anti-egfr, heteromultimeric bispecific polypeptide complex |
| KR20240113514A (ko) | 2021-11-30 | 2024-07-22 | 다이이찌 산쿄 가부시키가이샤 | 프로테아제 분해성 마스크 항체 |
| CN118401555A (zh) * | 2021-12-09 | 2024-07-26 | 信华生物药业(广州)有限公司 | 抗体掩蔽物及其用途 |
| AU2023218678A1 (en) | 2022-02-09 | 2024-08-01 | Daiichi Sankyo Company, Limited | Environmentally responsive masked antibody and use thereof |
| US20240116997A1 (en) | 2022-02-23 | 2024-04-11 | Bright Peak Therapeutics Ag | Activatable il-18 polypeptides |
| WO2023180353A1 (en) | 2022-03-23 | 2023-09-28 | F. Hoffmann-La Roche Ag | Combination treatment of an anti-cd20/anti-cd3 bispecific antibody and chemotherapy |
| WO2023183888A1 (en) | 2022-03-23 | 2023-09-28 | Cytomx Therapeutics, Inc. | Activatable antigen-binding protein constructs and uses of the same |
| WO2023183923A1 (en) | 2022-03-25 | 2023-09-28 | Cytomx Therapeutics, Inc. | Activatable dual-anchored masked molecules and methods of use thereof |
| WO2023192606A2 (en) | 2022-04-01 | 2023-10-05 | Cytomx Therapeutics, Inc. | Cd3-binding proteins and methods of use thereof |
| WO2023192973A1 (en) | 2022-04-01 | 2023-10-05 | Cytomx Therapeutics, Inc. | Activatable multispecific molecules and methods of use thereof |
| TW202404637A (zh) | 2022-04-13 | 2024-02-01 | 瑞士商赫孚孟拉羅股份公司 | 抗cd20/抗cd3雙特異性抗體之醫藥組成物及使用方法 |
| WO2024030843A1 (en) | 2022-08-01 | 2024-02-08 | Cytomx Therapeutics, Inc. | Protease-cleavable moieties and methods of use thereof |
| WO2024030850A1 (en) | 2022-08-01 | 2024-02-08 | Cytomx Therapeutics, Inc. | Protease-cleavable substrates and methods of use thereof |
| TW202426637A (zh) | 2022-08-01 | 2024-07-01 | 美商Cytomx生物製藥公司 | 蛋白酶可切割受質及其使用方法 |
| WO2024030845A1 (en) | 2022-08-01 | 2024-02-08 | Cytomx Therapeutics, Inc. | Protease-cleavable moieties and methods of use thereof |
| WO2024030847A1 (en) | 2022-08-01 | 2024-02-08 | Cytomx Therapeutics, Inc. | Protease-cleavable moieties and methods of use thereof |
| GB202214132D0 (en) * | 2022-09-27 | 2022-11-09 | Coding Bio Ltd | CLL1 binding molecules |
| WO2024088987A1 (en) | 2022-10-26 | 2024-05-02 | F. Hoffmann-La Roche Ag | Combination therapy for the treatment of cancer |
| WO2024102723A2 (en) * | 2022-11-10 | 2024-05-16 | Janux Therapeutics, Inc. | Antibodies targeting egfr and cd3 and uses thereof |
| WO2024150175A1 (en) | 2023-01-11 | 2024-07-18 | Bright Peak Therapeutics Ag | Conditionally activated proteins and methods of use |
| WO2024150174A1 (en) | 2023-01-11 | 2024-07-18 | Bright Peak Therapeutics Ag | Conditionally activated immunocytokines and methods of use |
Citations (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2009511521A (ja) | 2005-10-11 | 2009-03-19 | ミクロメット・アクチェンゲゼルシャフト | 交差種特異的(cross−species−specific)抗体を含む組成物および該組成物の使用 |
| JP2010524435A (ja) | 2007-04-03 | 2010-07-22 | マイクロメット アーゲー | 種間特異的二重特異性バインダー |
| JP2012504403A (ja) | 2008-10-01 | 2012-02-23 | マイクロメット アーゲー | 異種間特異的psma×cd3二重特異性単鎖抗体 |
| JP2012514982A (ja) | 2009-01-12 | 2012-07-05 | サイトムエックス セラピューティクス,エルエルシー | 改変した抗体組成物、それを作製および使用する方法 |
| WO2013128194A1 (en) | 2012-02-28 | 2013-09-06 | The University Of Birmingham | Immunotherapeutic molecules and uses |
| WO2013192546A1 (en) | 2012-06-22 | 2013-12-27 | Cytomx Therapeutics, Inc. | Activatable antibodies having non-binding steric moieties and mehtods of using the same |
| WO2014047231A1 (en) | 2012-09-21 | 2014-03-27 | Regeneron Pharmaceuticals, Inc. | Anti-cd3 antibodies, bispecific antigen-binding molecules that bind cd3 and cd20, and uses thereof |
Family Cites Families (94)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US3773919A (en) | 1969-10-23 | 1973-11-20 | Du Pont | Polylactide-drug mixtures |
| US4361549A (en) | 1979-04-26 | 1982-11-30 | Ortho Pharmaceutical Corporation | Complement-fixing monoclonal antibody to human T cells, and methods of preparing same |
| US4485045A (en) | 1981-07-06 | 1984-11-27 | Research Corporation | Synthetic phosphatidyl cholines useful in forming liposomes |
| US4522811A (en) | 1982-07-08 | 1985-06-11 | Syntex (U.S.A.) Inc. | Serial injection of muramyldipeptides and liposomes enhances the anti-infective activity of muramyldipeptides |
| US4544545A (en) | 1983-06-20 | 1985-10-01 | Trustees University Of Massachusetts | Liposomes containing modified cholesterol for organ targeting |
| WO1988001513A1 (en) | 1986-08-28 | 1988-03-10 | Teijin Limited | Cytocidal antibody complex and process for its preparation |
| WO1991001752A1 (en) | 1989-07-27 | 1991-02-21 | Fred Hutchinson Cancer Research Center | Immunosuppressive monoclonal antibodies, hybridomas and methods of transplantation |
| US5013556A (en) | 1989-10-20 | 1991-05-07 | Liposome Technology, Inc. | Liposomes with enhanced circulation time |
| GB8928874D0 (en) | 1989-12-21 | 1990-02-28 | Celltech Ltd | Humanised antibodies |
| US5151510A (en) | 1990-04-20 | 1992-09-29 | Applied Biosystems, Inc. | Method of synethesizing sulfurized oligonucleotide analogs |
| GB9021679D0 (en) | 1990-10-05 | 1990-11-21 | Gorman Scott David | Antibody preparation |
| US5968509A (en) | 1990-10-05 | 1999-10-19 | Btp International Limited | Antibodies with binding affinity for the CD3 antigen |
| WO1992022653A1 (en) | 1991-06-14 | 1992-12-23 | Genentech, Inc. | Method for making humanized antibodies |
| US5733743A (en) | 1992-03-24 | 1998-03-31 | Cambridge Antibody Technology Limited | Methods for producing members of specific binding pairs |
| GB9206422D0 (en) | 1992-03-24 | 1992-05-06 | Bolt Sarah L | Antibody preparation |
| US7381803B1 (en) | 1992-03-27 | 2008-06-03 | Pdl Biopharma, Inc. | Humanized antibodies against CD3 |
| DE69329503T2 (de) | 1992-11-13 | 2001-05-03 | Idec Pharma Corp | Therapeutische Verwendung von chimerischen und markierten Antikörpern, die gegen ein Differenzierung-Antigen gerichtet sind, dessen Expression auf menschliche B Lymphozyt beschränkt ist, für die Behandlung von B-Zell-Lymphoma |
| US5885573A (en) | 1993-06-01 | 1999-03-23 | Arch Development Corporation | Methods and materials for modulation of the immunosuppressive activity and toxicity of monoclonal antibodies |
| IT1271461B (it) | 1993-12-01 | 1997-05-28 | Menarini Ricerche Sud Spa | Anticorpo monoclonale bispecifico anti-cd3/anti-egfr,processo per la produzione e suo uso. |
| US5834597A (en) | 1996-05-20 | 1998-11-10 | Protein Design Labs, Inc. | Mutated nonactivating IgG2 domains and anti CD3 antibodies incorporating the same |
| NZ507381A (en) | 1998-04-21 | 2003-12-19 | Micromet Ag | CD19xCD3 specific polypeptides and uses thereof |
| GB9815909D0 (en) | 1998-07-21 | 1998-09-16 | Btg Int Ltd | Antibody preparation |
| EP1286700A2 (en) | 2000-06-01 | 2003-03-05 | Universite Catholique De Louvain | Tumor activated prodrug compounds |
| US7465790B2 (en) | 2000-10-09 | 2008-12-16 | Isis Innovation, Inc. | Therapeutic antibodies |
| CA2423850C (en) | 2000-10-09 | 2017-07-04 | Isis Innovation Limited | Therapeutic antibodies |
| DK1517921T3 (da) | 2002-06-28 | 2006-10-09 | Domantis Ltd | Immunglobulin-enkeltvariable antigen-bindende domæner og dobbeltspecifikke konstruktioner deraf |
| US20040109855A1 (en) | 2002-07-23 | 2004-06-10 | Herman Waldmann | Therapeutic antibodies with reduced side effect |
| AU2003265866A1 (en) | 2002-09-03 | 2004-03-29 | Vit Lauermann | Targeted release |
| EP1629011B1 (en) | 2003-05-31 | 2010-01-13 | Micromet AG | Human anti-human cd3 binding molecules |
| ATE447611T1 (de) | 2003-08-18 | 2009-11-15 | Univ California | Polypeptid-display-bibliotheken und verfahren zur herstellung und verwendung davon |
| CA2542239C (en) | 2003-10-16 | 2014-12-30 | Micromet Ag | Multispecific deimmunized cd3-binders |
| AU2006232310B9 (en) | 2005-04-06 | 2011-07-21 | Ibc Pharmaceuticals, Inc. | Improved stably tethered structures of defined compositions with multiple functions or binding specificities |
| US20070041905A1 (en) | 2005-08-19 | 2007-02-22 | Hoffman Rebecca S | Method of treating depression using a TNF-alpha antibody |
| AU2006284651C1 (en) | 2005-08-31 | 2013-09-12 | The Regents Of The University Of California | Cellular libraries of peptide sequences (CLiPS) and methods of using the same |
| CA2625815A1 (en) | 2005-09-12 | 2007-03-22 | Novimmune S.A. | Anti-cd3 antibody formulations |
| EP1993608A1 (en) | 2006-03-10 | 2008-11-26 | Diatos | Anticancer drugs conjugated to antibody via an enzyme cleavable linker |
| JP5374359B2 (ja) | 2006-03-17 | 2013-12-25 | バイオジェン・アイデック・エムエイ・インコーポレイテッド | 安定化されたポリペプチド化合物 |
| CA2654317A1 (en) | 2006-06-12 | 2007-12-21 | Trubion Pharmaceuticals, Inc. | Single-chain multivalent binding proteins with effector function |
| KR20090021298A (ko) | 2006-06-14 | 2009-03-02 | 임클론 시스템즈 인코포레이티드 | 항-egfr 항체의 동결건조 제제 |
| WO2008119567A2 (en) * | 2007-04-03 | 2008-10-09 | Micromet Ag | Cross-species-specific cd3-epsilon binding domain |
| PL2155788T3 (pl) * | 2007-04-03 | 2013-02-28 | Amgen Res Munich Gmbh | Swoiste międzygatunkowe bispecyficzne czynniki wiążące |
| CA2683370C (en) | 2007-04-03 | 2022-12-13 | Micromet Ag | Cross-species-specific binding domain |
| US8293685B2 (en) | 2007-07-26 | 2012-10-23 | The Regents Of The University Of California | Methods for enhancing bacterial cell display of proteins and peptides |
| WO2009018386A1 (en) | 2007-07-31 | 2009-02-05 | Medimmune, Llc | Multispecific epitope binding proteins and uses thereof |
| CA2697032C (en) | 2007-08-22 | 2021-09-14 | The Regents Of The University Of California | Activatable binding polypeptides and methods of identification and use thereof |
| FR2920686B1 (fr) | 2007-09-12 | 2010-01-15 | Aldebaran Robotics | Robot apte a echanger des programmes informatiques codant pour des comportements |
| US10981998B2 (en) * | 2008-10-01 | 2021-04-20 | Amgen Research (Munich) Gmbh | Cross-species-specific single domain bispecific single chain antibody |
| US20110217302A1 (en) | 2008-10-10 | 2011-09-08 | Emergent Product Development Seattle, Llc | TCR Complex Immunotherapeutics |
| WO2010077643A1 (en) | 2008-12-08 | 2010-07-08 | Tegopharm Corporation | Masking ligands for reversible inhibition of multivalent compounds |
| US8895702B2 (en) | 2008-12-08 | 2014-11-25 | City Of Hope | Development of masked therapeutic antibodies to limit off-target effects; application to anti-EGFR antibodies |
| PL3903829T3 (pl) | 2009-02-13 | 2023-08-14 | Immunomedics, Inc. | Immunokoniugaty z połączeniem rozszczepialnym wewnątrzkomórkowo |
| US8399219B2 (en) | 2009-02-23 | 2013-03-19 | Cytomx Therapeutics, Inc. | Protease activatable interferon alpha proprotein |
| US9315584B2 (en) | 2009-03-25 | 2016-04-19 | Tohoku University | LH-type bispecific antibody |
| AU2010242830C1 (en) | 2009-05-01 | 2014-02-13 | Abbvie Inc. | Dual variable domain immunoglobulins and uses thereof |
| WO2010129609A2 (en) | 2009-05-07 | 2010-11-11 | The Regents Of The University Of California | Antibodies and methods of use thereof |
| NZ598929A (en) | 2009-09-01 | 2014-05-30 | Abbvie Inc | Dual variable domain immunoglobulins and uses thereof |
| DK2542590T4 (da) | 2010-03-05 | 2020-07-13 | Univ Johns Hopkins | Sammensætninger og fremgangsmåde til målrettede immunomodulatoriske antistof-fer og fusionproteiner |
| TWI653333B (zh) * | 2010-04-01 | 2019-03-11 | 安進研究(慕尼黑)有限責任公司 | 跨物種專一性之PSMAxCD3雙專一性單鏈抗體 |
| BR112013002167A2 (pt) | 2010-08-24 | 2016-05-31 | Roche Glycart Ag | anticorpo biespecífico, composição farmacêutica, uso, método de tratamento de um paciente que sofre de câncer e de um paciente que sofre de inflamação |
| US9249217B2 (en) | 2010-12-03 | 2016-02-02 | Secretary, DHHS | Bispecific EGFRvIII x CD3 antibody engaging molecules |
| TWI838039B (zh) | 2011-03-28 | 2024-04-01 | 法商賽諾菲公司 | 具有交叉結合區定向之雙重可變區類抗體結合蛋白 |
| EP2710042A2 (en) | 2011-05-16 | 2014-03-26 | Fabion Pharmaceuticals, Inc. | Multi-specific fab fusion proteins and methods of use |
| BR122016016837A2 (pt) | 2011-05-21 | 2019-08-27 | Macrogenics Inc | moléculas de ligação a cd3; anticorpos de ligação a cd3; composições farmacêuticas; e usos da molécula de ligação a cd3 |
| PE20141521A1 (es) | 2011-08-23 | 2014-10-25 | Roche Glycart Ag | Moleculas biespecificas de union a antigeno activadoras de celulas t |
| KR101886983B1 (ko) | 2011-08-23 | 2018-08-08 | 로슈 글리카트 아게 | 2 개의 fab 단편을 포함하는 fc-부재 항체 및 이용 방법 |
| EP2747781B1 (en) | 2011-08-23 | 2017-11-15 | Roche Glycart AG | Bispecific antibodies specific for t-cell activating antigens and a tumor antigen and methods of use |
| WO2013026837A1 (en) | 2011-08-23 | 2013-02-28 | Roche Glycart Ag | Bispecific t cell activating antigen binding molecules |
| HUE033245T2 (hu) | 2011-12-19 | 2017-11-28 | Synimmune Gmbh | Bispecifikus ellenanyag molekula |
| CN104379601B (zh) | 2012-02-03 | 2021-04-09 | 霍夫曼-拉罗奇有限公司 | 双特异性抗体分子和抗原-转染的t-细胞以及它们在医药中的用途 |
| AU2013249267A1 (en) | 2012-04-20 | 2014-10-23 | Aptevo Research And Development Llc | CD3 binding polypeptides |
| RU2713121C2 (ru) | 2012-04-27 | 2020-02-03 | Сайтомкс Терапьютикс, Инк. | Активируемые антитела, которые связываются с рецептором эпидермального фактора роста, и способы их применения |
| US10000567B2 (en) | 2012-06-14 | 2018-06-19 | Therapix Biosciences Ltd. | Humanized antibodies to cluster of differentiation 3 (CD3) |
| WO2013188693A1 (en) | 2012-06-15 | 2013-12-19 | Imaginab, Inc. | Antigen binding constructs to cd3 |
| AU2013278075B2 (en) | 2012-06-22 | 2018-05-17 | Cytomx Therapeutics, Inc. | Anti-jagged 1/Jagged 2 cross-reactive antibodies, activatable anti-Jagged antibodies and methods of use thereof |
| CN104640562A (zh) * | 2012-07-13 | 2015-05-20 | 酵活有限公司 | 包含抗-cd3构建体的双特异性不对称异二聚体 |
| US9487590B2 (en) | 2012-09-25 | 2016-11-08 | Cytomx Therapeutics, Inc. | Activatable antibodies that bind interleukin-6 receptor and methods of use thereof |
| JP6571527B2 (ja) | 2012-11-21 | 2019-09-04 | ウーハン ワイゼットワイ バイオファルマ カンパニー リミテッドWuhan Yzy Biopharma Co., Ltd. | 二重特異性抗体 |
| WO2014107599A2 (en) | 2013-01-04 | 2014-07-10 | Cytomx Therapeutics, Inc. | Compositions and methods for detecting protease activity in biological systems |
| US10738132B2 (en) | 2013-01-14 | 2020-08-11 | Xencor, Inc. | Heterodimeric proteins |
| US10968276B2 (en) | 2013-03-12 | 2021-04-06 | Xencor, Inc. | Optimized anti-CD3 variable regions |
| US20140302037A1 (en) | 2013-03-15 | 2014-10-09 | Amgen Inc. | BISPECIFIC-Fc MOLECULES |
| US20140308285A1 (en) | 2013-03-15 | 2014-10-16 | Amgen Inc. | Heterodimeric bispecific antibodies |
| US9517276B2 (en) | 2013-06-04 | 2016-12-13 | Cytomx Therapeutics, Inc. | Compositions and methods for conjugating activatable antibodies |
| CN113248615A (zh) | 2013-07-05 | 2021-08-13 | 根马布股份公司 | 人源化或嵌合cd3抗体 |
| EP3024851B1 (en) | 2013-07-25 | 2018-05-09 | CytomX Therapeutics, Inc. | Multispecific antibodies, multispecific activatable antibodies and methods of using the same |
| CA2938626A1 (en) | 2013-07-26 | 2015-01-29 | John Rothman | Compositions to improve the therapeutic benefit of bisantrene |
| US9540440B2 (en) | 2013-10-30 | 2017-01-10 | Cytomx Therapeutics, Inc. | Activatable antibodies that bind epidermal growth factor receptor and methods of use thereof |
| IL302642A (en) | 2014-01-31 | 2023-07-01 | Cytomx Therapeutics Inc | Polypeptide substrates that activate matriptase and U-plasminogen and other cleavable groups, preparations containing them and their uses |
| CN107108738A (zh) | 2014-07-25 | 2017-08-29 | 西托姆克斯治疗公司 | 抗cd3抗体、可活化抗cd3抗体、多特异性抗cd3抗体、多特异性可活化抗cd3抗体及其使用方法 |
| MA40894A (fr) * | 2014-11-04 | 2017-09-12 | Glenmark Pharmaceuticals Sa | Immunoglobulines hétéro-dimères reciblant des lymphocytes t cd3/cd38 et leurs procédés de production |
| MA41374A (fr) | 2015-01-20 | 2017-11-28 | Cytomx Therapeutics Inc | Substrats clivables par métalloprotéase matricielle et clivables par sérine protéase et procédés d'utilisation de ceux-ci |
| BR112017023862A2 (pt) | 2015-05-04 | 2018-07-17 | Cytomx Therapeutics Inc | anticorpos anti-cd71, anticorpos anti-cd71 ativáveis, e métodos de uso destes |
| US10870701B2 (en) | 2016-03-15 | 2020-12-22 | Generon (Shanghai) Corporation Ltd. | Multispecific fab fusion proteins and use thereof |
| JP7438106B2 (ja) | 2017-10-14 | 2024-02-26 | シートムエックス セラピューティクス,インコーポレイテッド | 抗体、活性化可能抗体、二重特異性抗体、および二重特異性活性化可能抗体ならびにその使用方法 |
-
2015
- 2015-07-24 CN CN201580051713.3A patent/CN107108738A/zh active Pending
- 2015-07-24 CA CA2955947A patent/CA2955947A1/en active Pending
- 2015-07-24 WO PCT/US2015/042053 patent/WO2016014974A2/en active Application Filing
- 2015-07-24 US US14/808,711 patent/US10669337B2/en active Active
- 2015-07-24 AU AU2015292406A patent/AU2015292406B2/en active Active
- 2015-07-24 JP JP2017504058A patent/JP7020909B2/ja active Active
- 2015-07-24 BR BR112017001579A patent/BR112017001579A2/pt not_active Application Discontinuation
- 2015-07-24 EP EP15745116.2A patent/EP3172235A2/en active Pending
-
2020
- 2020-04-24 US US16/858,480 patent/US11802158B2/en active Active
-
2021
- 2021-01-28 JP JP2021012481A patent/JP7168702B2/ja active Active
- 2021-06-10 AU AU2021203876A patent/AU2021203876A1/en active Pending
-
2022
- 2022-10-26 JP JP2022171196A patent/JP7564853B2/ja active Active
-
2023
- 2023-09-22 US US18/472,748 patent/US20240084010A1/en active Pending
Patent Citations (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2009511521A (ja) | 2005-10-11 | 2009-03-19 | ミクロメット・アクチェンゲゼルシャフト | 交差種特異的(cross−species−specific)抗体を含む組成物および該組成物の使用 |
| JP2010524435A (ja) | 2007-04-03 | 2010-07-22 | マイクロメット アーゲー | 種間特異的二重特異性バインダー |
| JP2012504403A (ja) | 2008-10-01 | 2012-02-23 | マイクロメット アーゲー | 異種間特異的psma×cd3二重特異性単鎖抗体 |
| JP2012514982A (ja) | 2009-01-12 | 2012-07-05 | サイトムエックス セラピューティクス,エルエルシー | 改変した抗体組成物、それを作製および使用する方法 |
| WO2013128194A1 (en) | 2012-02-28 | 2013-09-06 | The University Of Birmingham | Immunotherapeutic molecules and uses |
| WO2013192546A1 (en) | 2012-06-22 | 2013-12-27 | Cytomx Therapeutics, Inc. | Activatable antibodies having non-binding steric moieties and mehtods of using the same |
| WO2014047231A1 (en) | 2012-09-21 | 2014-03-27 | Regeneron Pharmaceuticals, Inc. | Anti-cd3 antibodies, bispecific antigen-binding molecules that bind cd3 and cd20, and uses thereof |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US12060654B2 (en) | 2016-11-28 | 2024-08-13 | Chugai Seiyaku Kabushiki Kaisha | Ligand-binding molecule having adjustable ligand binding activity |
| US12077577B2 (en) | 2018-05-30 | 2024-09-03 | Chugai Seiyaku Kabushiki Kaisha | Polypeptide comprising aggrecan binding domain and carrying moiety |
Also Published As
| Publication number | Publication date |
|---|---|
| AU2015292406B2 (en) | 2021-03-11 |
| US20240084010A1 (en) | 2024-03-14 |
| US11802158B2 (en) | 2023-10-31 |
| WO2016014974A2 (en) | 2016-01-28 |
| CA2955947A1 (en) | 2016-01-28 |
| CN107108738A (zh) | 2017-08-29 |
| EP3172235A2 (en) | 2017-05-31 |
| AU2015292406A1 (en) | 2017-02-09 |
| US10669337B2 (en) | 2020-06-02 |
| JP2017523176A (ja) | 2017-08-17 |
| JP7564853B2 (ja) | 2024-10-09 |
| JP2021087429A (ja) | 2021-06-10 |
| AU2021203876A1 (en) | 2021-07-08 |
| US20210047406A1 (en) | 2021-02-18 |
| JP7168702B2 (ja) | 2022-11-09 |
| JP2022191494A (ja) | 2022-12-27 |
| BR112017001579A2 (pt) | 2017-11-21 |
| US20160194399A1 (en) | 2016-07-07 |
| WO2016014974A3 (en) | 2016-03-17 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP7020909B2 (ja) | 抗-cd3抗体、活性化可能抗-cd3抗体、多重特異的抗-cd3抗体、多重特異的活性化可能抗-cd3抗体、及びそれらの使用方法 | |
| JP7036860B2 (ja) | 多重特異性抗体、多重特異性活性化可能抗体、及びそれらの使用方法 | |
| US11174316B2 (en) | Anti-PDL1 antibodies, activatable anti-PDL1 antibodies, and methods of use thereof | |
| US20190309072A1 (en) | Anti-itga3 antibodies, activatable anti-itga3 antibodies, and methods of use thereof | |
| AU2018231127A1 (en) | CD147 antibodies, activatable CD147 antibodies, and methods of making and use thereof | |
| EA039736B1 (ru) | Анти-pdl1-антитела, активируемые анти-pdl1-антитела и способы их применения | |
| NZ736142B2 (en) | Anti-pdl1 antibodies, activatable anti-pdl1 antibodies, and methods of use thereof |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20180724 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20180724 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20190709 |
|
| A601 | Written request for extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A601 Effective date: 20191008 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20200109 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20200728 |
|
| A601 | Written request for extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A601 Effective date: 20201026 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20210128 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20210323 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20210803 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20211102 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20211116 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20211214 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20220104 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20220203 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 7020909 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |