WO2013157602A1 - 演奏評価装置、カラオケ装置及びサーバ装置 - Google Patents
演奏評価装置、カラオケ装置及びサーバ装置 Download PDFInfo
- Publication number
- WO2013157602A1 WO2013157602A1 PCT/JP2013/061488 JP2013061488W WO2013157602A1 WO 2013157602 A1 WO2013157602 A1 WO 2013157602A1 JP 2013061488 W JP2013061488 W JP 2013061488W WO 2013157602 A1 WO2013157602 A1 WO 2013157602A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- performance
- facial expression
- data
- pitch
- music
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images








Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10K—SOUND-PRODUCING DEVICES; METHODS OR DEVICES FOR PROTECTING AGAINST, OR FOR DAMPING, NOISE OR OTHER ACOUSTIC WAVES IN GENERAL; ACOUSTICS NOT OTHERWISE PROVIDED FOR
- G10K15/00—Acoustics not otherwise provided for
- G10K15/04—Sound-producing devices
-
- G—PHYSICS
- G09—EDUCATION; CRYPTOGRAPHY; DISPLAY; ADVERTISING; SEALS
- G09B—EDUCATIONAL OR DEMONSTRATION APPLIANCES; APPLIANCES FOR TEACHING, OR COMMUNICATING WITH, THE BLIND, DEAF OR MUTE; MODELS; PLANETARIA; GLOBES; MAPS; DIAGRAMS
- G09B15/00—Teaching music
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10H—ELECTROPHONIC MUSICAL INSTRUMENTS; INSTRUMENTS IN WHICH THE TONES ARE GENERATED BY ELECTROMECHANICAL MEANS OR ELECTRONIC GENERATORS, OR IN WHICH THE TONES ARE SYNTHESISED FROM A DATA STORE
- G10H1/00—Details of electrophonic musical instruments
- G10H1/36—Accompaniment arrangements
- G10H1/361—Recording/reproducing of accompaniment for use with an external source, e.g. karaoke systems
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L25/00—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00
- G10L25/48—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 specially adapted for particular use
- G10L25/51—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 specially adapted for particular use for comparison or discrimination
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L25/00—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00
- G10L25/90—Pitch determination of speech signals
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10H—ELECTROPHONIC MUSICAL INSTRUMENTS; INSTRUMENTS IN WHICH THE TONES ARE GENERATED BY ELECTROMECHANICAL MEANS OR ELECTRONIC GENERATORS, OR IN WHICH THE TONES ARE SYNTHESISED FROM A DATA STORE
- G10H2210/00—Aspects or methods of musical processing having intrinsic musical character, i.e. involving musical theory or musical parameters or relying on musical knowledge, as applied in electrophonic musical tools or instruments
- G10H2210/031—Musical analysis, i.e. isolation, extraction or identification of musical elements or musical parameters from a raw acoustic signal or from an encoded audio signal
- G10H2210/091—Musical analysis, i.e. isolation, extraction or identification of musical elements or musical parameters from a raw acoustic signal or from an encoded audio signal for performance evaluation, i.e. judging, grading or scoring the musical qualities or faithfulness of a performance, e.g. with respect to pitch, tempo or other timings of a reference performance
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10H—ELECTROPHONIC MUSICAL INSTRUMENTS; INSTRUMENTS IN WHICH THE TONES ARE GENERATED BY ELECTROMECHANICAL MEANS OR ELECTRONIC GENERATORS, OR IN WHICH THE TONES ARE SYNTHESISED FROM A DATA STORE
- G10H2220/00—Input/output interfacing specifically adapted for electrophonic musical tools or instruments
- G10H2220/155—User input interfaces for electrophonic musical instruments
- G10H2220/441—Image sensing, i.e. capturing images or optical patterns for musical purposes or musical control purposes
- G10H2220/455—Camera input, e.g. analyzing pictures from a video camera and using the analysis results as control data
Definitions
- This invention relates to a technique for evaluating the skill of music performance.
- karaoke apparatus for singing having a scoring function for scoring the skill of a singer's singing performance
- karaoke apparatus For example, various techniques relating to a karaoke apparatus for singing having a scoring function for scoring the skill of a singer's singing performance (hereinafter simply referred to as “karaoke apparatus” unless otherwise specified) have been proposed.
- Patent Document 1 As a document disclosing this kind of technology.
- the karaoke device disclosed in this document calculates the difference between the pitch extracted from the user's singing sound and the pitch extracted from the data prepared in advance as the guide melody for each note of the singing song, and based on this difference Calculate the basic score.
- this karaoke apparatus calculates the bonus point according to the frequency
- This karaoke device presents the total score of the basic score and bonus points to the user as the final evaluation result.
- Patent Documents 2 to 6 disclose documents that disclose a technique for detecting a singing using a technique such as vibrato or shackle from a waveform indicating a singing sound.
- Japanese Unexamined Patent Publication No. 2005-107334 Japanese Unexamined Patent Publication No. 2005-107330 Japanese Laid-Open Patent Publication No. 2005-107087 Japanese Unexamined Patent Publication No. 2008-268370 Japanese Unexamined Patent Publication No. 2005-107336 Japanese Unexamined Patent Publication No. 2008-225115
- the present invention has been made in view of such a problem, and an object of the present invention is to make it possible to present an evaluation result closer to human sensitivity in the evaluation of music performance such as karaoke singing.
- the present invention relates to the expression performance to be performed during the performance of the music and the timing at which the expression performance should be performed in the music with reference to the pronunciation start time of the note or note group included in the music.
- Facial expression performance reference data acquisition means for acquiring facial expression performance reference data to indicate
- pitch volume data generation means for generating pitch volume data indicating the pitch and volume of the performance sound from the performance sound of the music by the performer
- the pitch volume At least one characteristic of pitch and volume indicated by the pitch volume data generated by the data generation means should be performed by the facial expression performance reference data within a predetermined time range indicated by the facial expression performance reference data in the music piece. Characteristics of facial expression performance If shown, it provides a performance evaluation apparatus and a playing evaluating means to improve the evaluation of the performance of the music by the player.
- the present invention also provides the performance evaluation apparatus, accompaniment data acquisition means for acquiring accompaniment data for instructing accompaniment of music, and sound signal output means for outputting a sound signal indicating a musical sound of accompaniment according to the instruction of the accompaniment data
- the pitch volume data generation means includes the pitch and volume of the performance sound of the music performed by the performer according to the accompaniment emitted from a speaker according to the sound signal output from the sound signal output means
- a karaoke apparatus for generating pitch sound volume data indicating the above is provided.
- the present invention relates to each of the performance sounds of music by an arbitrary number of arbitrary performers, and one facial expression performance appears at one timing based on the pronunciation start time of notes or note groups included in the music
- Each of a note or a group of notes included in the music based on an expression performance appearance data acquisition means for acquiring expression performance appearance data indicating that, and an arbitrary number of expression performance appearance data acquired by the expression performance appearance data acquisition means Is performed during the performance of the musical piece according to the specified information, specifying which facial expression performance appears at which timing with reference to the sound generation start time of the note or group of notes.
- the expression of a note or a group of notes included in the music indicates the power expression performance and the timing at which the expression performance should be performed in the music
- a server apparatus comprising facial expression performance reference data generating means for generating facial expression performance reference data indicating the start time as reference, and transmitting means for transmitting facial expression performance reference data generated by the facial expression performance reference data generating means to the performance evaluation apparatus I will provide a.
- the present invention is a singing evaluation system, wherein a facial expression performance to be performed during the performance of a musical piece and a timing at which the facial expression performance is to be performed in the musical piece are determined as a pronunciation start time of a note or a note group included in the musical piece.
- Facial expression performance reference data acquisition means for acquiring first facial expression performance reference data shown as a reference; pitch volume data generation means for generating pitch volume data indicating the pitch and volume of the performance sound from the performance sound of the music by the performer; And at least one of the pitch and volume characteristics indicated by the pitch volume data generated by the pitch volume data generation means is within the predetermined time range indicated by the first facial expression performance reference data in the music. Should be done with performance reference data
- the performance evaluation means for improving the performance of the music performed by the performer and each of the performance sounds of the music performed by an arbitrary number of the performers.
- Expression performance appearance data acquisition means for acquiring expression performance appearance data indicating that one expression performance has appeared at one timing based on a pronunciation start time of a note or a group of notes included in the music, and the expression performance appearance data Based on the arbitrary number of facial expression performance appearance data acquired by the acquisition means, any timing with respect to each note or group of notes included in the musical piece by the arbitrary player based on the pronunciation start time of the notes or group of notes And which facial expression performance appears at what frequency, and according to the identified information, the arbitrary performance The facial expression performance to be performed during the performance of the musical piece by and the timing at which the facial expression performance should be performed in the musical piece by the arbitrary player, based on the pronunciation start time of the note or the note group included in the musical piece by the arbitrary player.
- a singing evaluation system comprising expression performance reference data generating means for generating second expression performance reference data to be shown.
- the present invention also provides facial expression performance reference data that indicates the facial expression performance to be performed during the performance of a musical piece and the timing at which the facial expression performance is to be performed in the musical piece, with reference to the pronunciation start time of the note or note group included in the musical piece. And generating pitch volume data indicating the pitch and volume of the performance sound from the performance sound of the music by the performer, and at least one of the characteristics of the pitch and volume indicated by the pitch volume data is A performance evaluation method for improving the performance of the music performed by the performer when the characteristics of the facial expression performance that should be performed by the expression performance reference data within a predetermined time range indicated by the expression performance reference data I will provide a.
- the present invention is a computer-executable program, in which a facial expression performance to be performed during the performance of a musical piece and a timing at which the facial expression performance should be performed in the musical piece are pronounced in a note or a group of notes included in the musical piece
- Expression performance reference data acquisition processing for acquiring expression performance reference data indicating the start time as a reference
- pitch volume data generation processing for generating pitch volume data indicating the pitch and volume of the performance sound from the performance sound of the music by the performer
- at least one of the pitch and volume characteristics indicated by the pitch volume data generated by the pitch volume data generation means is within the predetermined time range indicated by the expression performance reference data in the music piece. Should be done by When showing the characteristics of the expression performance that is, to provide a program for executing a performance evaluation process for improving the evaluation of the performance of the music by the player to the computer.
- a performance evaluation device that gives a high evaluation to the performer is realized.
- the evaluation is performed with little deviation from human sensitivity.
- FIG. 1 is a diagram showing a configuration of a singing evaluation system 1 according to an embodiment of the present invention.
- a karaoke device 10-m 1, 2,... M: M is the total number of karaoke devices
- M is the total number of karaoke devices
- One or a plurality of karaoke apparatuses 10-m are installed in each karaoke store.
- the server device 30 is installed in the system management center.
- the karaoke apparatus 10-m and the server apparatus 30 are connected to the network 90, and can transmit and receive various data to and from each other.
- the karaoke device 10-m is a device that performs singing effects through sound emission of accompaniment music that supports the user's singing and display of lyrics, and evaluation of the skill of the user's singing.
- the karaoke apparatus 10-m evaluates the skill of the singing skill by evaluating the pitch and volume of the user's singing sound and the following five types of facial expression singing.
- the score that is the evaluation result of the two evaluations is presented to the user together with the comment message.
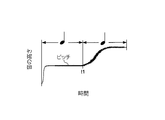
- a1. Tame This is a facial expression song that intentionally delays the singing of a specific sound in the song. As shown in FIG. 2, when this singing is performed, the time at which the pitch of the sound changes from the sound before the singing sound to that of the sound corresponds to both sounds in the score (exemplary singing).
- Vibrato This is a facial expression song that vibrates finely while maintaining the apparent pitch of a specific sound in the song. As shown in FIG. 3, when this singing is performed, the pitch of the singing sound periodically changes across the height of the note corresponding to the sound in the score.
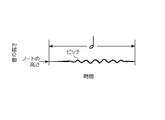
- Kobushi This is a facial expression song that changes the tone of a specific sound in the song so that it sings during pronunciation. As shown in FIG. 4, when this singing is performed, the pitch of the singing sound rises temporarily in the middle of the note corresponding to the sound in the score. d1.
- Shakuri This is a singing technique in which a specific sound in a song is pronounced with a voice lower than the original pitch and then brought close to the original pitch.
- the pitch of the singing sound at the sounding start time is lower than the height of the note corresponding to the sound in the score. Then, the pitch of this singing sound rises slowly after the start of sounding and reaches almost the same height as the note. e1.
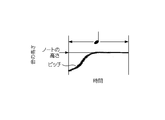
- Fall This is a singing technique in which a specific sound in a song is pronounced with a voice higher than its original height and then brought close to its original height.
- FIG. 6 when this singing is performed, the pitch of the singing sound at the sounding start time is higher than the height of the note corresponding to the sound in the score. The pitch of the singing sound gradually falls after the start of sounding and reaches almost the same height as the note.
- the karaoke apparatus 10-m includes a sound source 11, a speaker 12, a microphone 13, a display unit 14, a communication interface 15, a vocal adapter 16, a CPU 17, a RAM 18, a ROM 19, a hard disk 20, and a sequencer 21.
- Sound source 11 outputs a sound signal S A in accordance with the various messages of MIDI (Musical Instrument Digital Interface).
- the speaker 12 emits a given signal as sound.
- the microphone 13 collects sound and outputs a sound collection signal S M.
- the display unit 14 displays an image corresponding to the image signal S I.
- the communication interface 15 transmits / receives data to / from devices connected to the network 90.
- the CPU 17 executes a program stored in the ROM 19 or the hard disk 20 while using the RAM 18 as a work area. Details of the operation of the CPU 17 will be described later.
- the ROM 19 stores IPL (Initial Program Loader) and the like.
- the song data MD-n of each song is data in which the accompaniment content of the song, the lyrics of the song, and the exemplary song content of the song are recorded in SMF (Standard MIDI File) format.
- the music data MD-n has a header HD, an accompaniment track TR AC , a lyrics track TR LY , and a model song reference track TR NR .
- the header HD information such as a song number, a song title, a genre, a performance time, and a time base (the number of ticks corresponding to the time of one quarter note) is described.
- each note NT (i) in the score of the accompaniment part of singing songs indicates the order counted from the beginning of the notebook NT of the score of the relevant part (1)
- the event EV (i) ON to be turned on indicating the order counted from the beginning of the notebook NT of the score of the relevant part (1)
- the delta time DT indicating the execution time difference (number of ticks) of the succeeding events are described in chronological order.
- the lyrics track TR LY includes each data D LY indicating the lyrics of the song and the display time of each lyrics (more specifically, the time difference between the display time of each lyrics and the display time of each previous lyrics) Delta time DT indicating (number of ticks)) is described in chronological order.
- the model singing reference track TR NR includes an event EV (i) ON for instructing the sound of each note NT (i) in the singing part of the score of the song, and an event EV (i) OFF for instructing to mute the sound.
- a delta time DT indicating a difference in execution time (number of ticks) between successive events is described in chronological order.
- the reference database DBRK stores five types of facial expression singing reference data DD a1 , DD a2 , DD a3 , DD a4 , DD a5 .
- the facial expression singing reference data DD a1 is obtained when the singing is performed at each time t on the time axis with the pronunciation start time of the note NT (i) included in the singing song as the reference point t BS and at those times t. Is a data showing each pair of evaluation points VSR (t).
- the facial expression singing reference data DD a2 is obtained when the vibrato singing is performed at each time t on the time axis with the pronunciation start time of the note NT (i) included in the singing song as a reference point t BS and those times t. Is a data showing each pair of evaluation points VSR (t).
- the facial expression singing reference data DD a3 is obtained when each time t on the time axis with the pronunciation start time of the note NT (i) included in the singing song as a reference point t BS and the time t at which the singing is performed by Kobushi. Is a data showing each pair of evaluation points VSR (t).
- the facial expression singing reference data DD a4 is obtained when the singing is performed at each time t on the time axis with the pronunciation start time of the note NT (i) included in the singing song as the reference point t BS and at the time t. Is a data showing each pair of evaluation points VSR (t).
- the facial expression singing reference data DD a5 is obtained when the singing by the fall is performed at each time t on the time axis with the sound generation start time of the note NT (i) included in the singing song as the reference point t BS and at those times t Is a data showing each pair of evaluation points VSR (t).
- the five types of facial expression song reference data DD a1 , DD a2 , DD a3 , DD a4 , DD a5 are referred to as facial expression song reference data DD.
- the song evaluation program VPG has the following three functions. a2. Standard Evaluation Function This is because each note NT (determined by each event EV (i) ON and EV (i) OFF in the exemplary singing reference track TR NR indicated by the output signals S L and S P of the vocal adapter 16 This is a function for comparing the model pitch PCH REF and the model volume LV REF of i) and evaluating the skill of singing based on the result of this comparison. b2.
- Expression singing evaluation function which, each time the characteristic waveform expression singing appear in the pitch waveform indicated by the output signal S P output vocal adapter 16, the reference point pronunciation start time of notebook NT is the subject expression singing (i) The appearance time of the feature waveform of the facial expression song on the time axis as t BS is obtained, and the evaluation point VSR (t) corresponding to this appearance time is set as each evaluation point VSR of the corresponding facial expression song reference data DD in the reference database DBRK ( This is a function of selecting from t) and evaluating the skill of singing based on this evaluation point VSR (t). c2.
- Evaluation result presentation function This is a function for calculating a score from the evaluation result of the evaluation by a2 and the evaluation result of the evaluation by b2, and displaying the score on the display unit 14 together with the comment message.
- the sequencer 21 When the song data MD-n of the corresponding song is transferred from the hard disk 20 to the RAM 18 in response to the singing start operation of the song by a remote controller (not shown), the sequencer 21 performs an event EV in the song data MD-n. (I) ON , EV (i) OFF , and data DLY are supplied to each part of the apparatus. Specifically, when the music piece data MD-n is stored in the RAM 18, the sequencer 21 stores the time base described in the header HD of the music piece data MD-n and the tempo designated by the remote controller (not shown). The time length of one tick is determined based on the above, and the following three processes are performed while counting ticks as the time length elapses.
- the sequencer 21 reads out the event EV (i) ON following thereafter each time the count number of ticks matches the delta time DT in accompaniment track TR AC (or EV (i) OFF) Instrument 11 is supplied.
- the event EV (i) ON is supplied from the sequencer 21
- the sound source 11 supplies the sound signal S A specified by the event EV (i) ON to the speaker 12, and the event EV (i) OFF is supplied from the sequencer 21. Then, the supply of the sound signal S A to the speaker 12 is stopped.
- the sequencer 21 reads the subsequent data DLY and supplies it to the display unit 14 every time the tick count matches the delta time DT in the lyrics track TRLY .
- the display unit 14 converts the data D LY into a lyrics telop image, and displays the image on a display (not shown).
- the accompaniment sound is emitted from the speaker 12 and the lyrics are displayed on the display.
- the user sings the lyrics displayed on the display toward the microphone 13 while listening to the accompaniment sound emitted from the speaker 12. While the user is singing into the microphone 13, the microphone 13 outputs a collected sound signal S M of the user's singing sound, vocal adapter 16 signal S P and showing the pitch and volume of the signal S M S L is output.
- the sequencer 21 counts the number of ticks read event EV (i) ON following thereafter every time matches the delta time DT within model singing Reference track TR NR (or EV (i) OFF) To the CPU 17.
- the CPU 17 evaluates the skill of the user's singing using the events EV (i) ON and EV (i) OFF supplied from the sequencer 21 and the output signals S P and S L of the vocal adapter 16. Details will be described later.
- the server device 30 is a device that plays a role of supporting the provision of services at a karaoke store.
- the server device 30 includes a communication interface 35, a CPU 37, a RAM 38, a ROM 39, and a hard disk 40.
- the communication interface 35 transmits / receives data to / from devices connected to the network 90.
- the CPU 37 executes various programs stored in the ROM 39 and the hard disk 40 while using the RAM 38 as a work area. Details of the operation of the CPU 37 will be described later.
- the ROM 39 stores IPL and the like.
- the hard disk 40 stores a song sample database DBS, a reference database DBRS, and a song analysis program APG.
- singing sample database DBS singing sample data DS groups each corresponding to one singing song are individually stored.
- the singing sample data DS is data in which a pitch waveform and a volume waveform of a singing sound when a person who has a singing ability exceeding a certain level sings a singing song is recorded.
- the reference database DBRS stores the latest facial expression singing reference data DD to be stored in the reference database DBRK of each karaoke apparatus 10-m.
- the song analysis program APG has the following three functions. a3. Accumulation function This is a function for acquiring the song sample data DS for each song from the karaoke apparatus 10-m one by one, and accumulating the acquired song sample data DS in the song sample database DBS. b3. Rewriting function This is to search the characteristic waveform of the facial expression song from the waveform indicated by the song sample data DS for each of the song sample data DS stored in the song sample database DBS, and to be the target of the facial expression song from the search result.
- FIG. 7 is a flowchart showing the operation of this embodiment.
- the CPU 17 of the karaoke apparatus 10-m supplies a control signal S O to the sequencer 21 when the singing start operation of the song is performed (S100: Yes), and processes the sequencer 21 (the above-described first process).
- S100: Yes the control signal
- S120 the standard song evaluation process
- S140 a facial expression song evaluation process
- Standard song evaluation process (S130) In this processing, the CPU 17 determines the time from when the event EV (i) ON is supplied from the sequencer 21 to when the next event EV (i) OFF is supplied to the sound corresponding to the i-th note NT (i). Let the pronunciation time T NT (i).
- the difference PCH DEF of a model pitch PCH REF output signal S P output vocal adapter 16 converts the note number of the pitch and event EV (i) ON shown during the sounding time T NT (i), and in between determining a difference LV DEF of a model volume LV REF obtained by converting the volume and event EV (i) velocity oN indicated by the signal S P, notebook NT if this difference PCH DEF and differences LV DEF is within a predetermined range (i) It is determined that the singing is successful.
- the CPU 17 performs this note determination from the start to the end of the singing by the user, and divides the number of all notes TN (i) at the end of the singing by the number of the notes NT (i) determined to be acceptable.
- a value obtained by multiplying the obtained value by 100 is defined as a basic score SR BASE .
- CPU 17 determines, in a pitch waveform indicated by the output signal S P output vocal adapter 16, Tame, vibrato, fist, jerking, whether any of the expression singing features waveform fall appeared .
- Patent Document 2 details of the method for determining the feature waveform of the patent are disclosed in Patent Document 2
- Patent Document 3 details of the method for determining the characteristic waveform of the vibrato are described in Patent Document 3
- Patent Document 4 details of the method of determining the feature waveform of Kobushi are described in Patent Document 4
- Patent Document 6 for details of the fall feature waveform determination method.
- the CPU 17 performs this characteristic waveform determination from the start to the end of the singing by the user, and sets a value obtained by multiplying the number of appearances of the facial expression song at the end of the singing by a predetermined coefficient as the addition point SR ADD .
- the total of the basic score SR BASE and the addition point SR ADD is set as the standard score SR NOR .
- Expression song evaluation process (S140) In this process, the CPU 17 sets the time from the output of the sound source event EV (i) ON to the output of the next event EV (i) OFF as the sound generation time T NT (i) corresponding to the i-th note NT (i). ). Then, CPU 17, when the characteristic waveform expression singing in pitch waveform indicated by the output signal S P output vocal adapter 16 between the sounding time T NT (i) are noticed, within sounding time T NT (i) Find the appearance time of the facial expression song and the type of facial expression song that appeared. The CPU 17 generates facial expression song appearance data indicating the type and appearance time of the facial expression song specified as described above.
- the CPU 17 selects the facial expression song indicated in the generated facial expression song appearance data and the evaluation point VSR (t) corresponding to the appearance time from the series of evaluation points VSR (t) indicated by the facial expression song reference data DD. To do.
- the CPU selects such evaluation points VSR (t) from the start to the end of singing by the user, and the average value of the evaluation points VSR (t) at the end of the singing is used as the facial expression score SR EX.
- CPU17 will perform an evaluation result presentation process, after the song of the song by a user is complete
- the CPU 17 selects a higher score from the standard score SR NOR scored by the standard song evaluation process and the facial score SR EX scored by the facial expression song evaluation process. Then, CPU17 is, if you choose the standard score SR NOR, and this score SR NOR, to display a comment messages in accordance with the score SR NOR for example, such as "It is cool and refined song" on the display unit 14.
- CPU17 is, if you choose a facial expression score SR EX, this and score SR EX, for example, to display a comment message corresponding to the facial expression score such as "I have full of kindness" SR EX on the display unit 14.
- the CPU 17 performs a sample transmission process (S160).
- Sample transmission process CPU 17 is vocal signal S P and S L adapter 16 has output a singing sample data DS of the singing music piece, steps and the singing sample data DS between the start and end of singing singing voice
- a message MS1 including the basic score SR BASE (singing evaluation data) obtained in S130 is transmitted to the server device 30.
- the CPU 37 of the server device 30 obtains the message MS1 from the karaoke device 10-m (S200: Yes), the singing sample data DS and the basic score SR BASE are extracted from this message MS1, and this basic score SR BASE is obtained from the advanced player. It is compared with a reference score SR TH (for example, 80 points) that separates those who are not (S220). When the basic score SR BASE is higher than the reference score SR TH (S220: Yes), the CPU 37 accumulates the song sample data DS extracted from the message MS1 in the song sample database DBS (S230).
- a reference score SR TH for example, 80 points
- the CPU 37 performs a rewriting process (S240).
- the CPU 37 performs the following five processes.
- the CPU 37 searches for the characteristic waveform of the ticks from within the pitch waveform indicated by each singing sample data DS stored in the singing sample database DBS, and the facial expression singing appearance data indicating the search results (the appearance of the ticks). generating a note NT data indicating each time t on the time axis of the reproduction starting time of (i) a reference point t BS).
- CPU 37 based on the expression singing occurrence data generated relates Tame, expression singing at each time t and their time t on the time axis to the reproduction starting time of the notebook NT (i) as a reference point t BS "tame"
- Statistical data showing the relationship with the number of occurrences Num of the synthesizer, and the evaluation point VSR (t) corresponding to each time t in the facial expression singing reference data DD a1 is rewritten based on the contents of this statistical data.
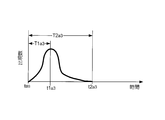
- FIG. 8 is a diagram illustrating an example of statistical data on the eggs.
- the statistics of this example the number of occurrences Num expression singing between the reference point t BS time T1 a1 only before time t1 a1 and the reference point t BS than the time T4 a1 time t4 after only a1 is distributed Yes.
- the maximum peak of the number of appearances Num appears at the time t2 a1 immediately after the reference point t BS , and the second peak of the number of appearances Num at the time t3 a1 later than the time t2 a1. Appears.
- the evaluation point VSR (t2 a1 ) at the time t2 a1 is the highest, and the evaluation point VSR (t3 a1 ) at the time t3 a1 is the second. Get higher.
- the CPU 37 searches for the characteristic waveform of vibrato from within the pitch waveform indicated by each singing sample data DS stored in the singing sample database DBS, and facial expression singing appearance data (vibrato has appeared) indicating the search result. generating a note NT data indicating each time t on the time axis of the reproduction starting time of (i) a reference point t BS). Subsequently, based on the expression song appearance data generated for the vibrato, the CPU 37 uses the time t on the time axis where the pronunciation start time of the note NT (i) is the reference point t BS and the number Num of appearances of the expression song at those times t. Is generated, and the evaluation score VSR (t) corresponding to each time t in the facial expression song reference data DD a2 is rewritten based on the contents of the statistical data.
- FIG. 9 is a diagram illustrating an example of statistical data on vibrato.
- appearance number Num expression singing between the reference point t BS and the reference point t BS than the time T2 a2 time after only t2 a2 are distributed.
- to be the reference point t BS time T1 a2 only after the time t1 a2 is the maximum peak number of occurrences Num has appeared. Therefore, in the facial expression song reference data DD a2 after rewriting by the statistical data of this example, the evaluation point VSR (t1 a2 ) at the time t1 a2 is the highest.
- the CPU 37 searches for the characteristic waveform of Kobushi from within the pitch waveform indicated by each singing sample data DS stored in the singing sample database DBS, and the facial expression singing appearance data (Kobushi appears) indicating the search result. generating a note NT data indicating each time t on the time axis of the reproduction starting time of (i) a reference point t BS). Subsequently, based on the facial expression song appearance data generated for Kobushi, the CPU 37 uses each time t on the time axis with the pronunciation start time of the note NT (i) as the reference point t BS and the number of facial expression songs at those times t. Statistical data indicating the relationship with Num is generated, and the evaluation point VSR (t) corresponding to each time t in the facial expression song reference data DD a3 is rewritten based on the contents of the statistical data.
- FIG. 10 is a diagram illustrating an example of statistical data regarding Kobushi.
- appearance number Num expression singing between the reference point t BS and the reference point t BS than the time T2 a3 time after only t2 a3 are distributed.
- to be the reference point t BS time T1 a3 only after time t1 a3 maximum peak number of occurrences Num has appeared. Therefore, in the facial expression song reference data DD a3 after rewriting by the statistical data of this example, the evaluation point VSR (t1 a3 ) at the time t1 a3 is the highest.
- the CPU 37 searches for the characteristic waveform of the crisp from the pitch waveform indicated by each singing sample data DS stored in the singing sample database DBS, and the facial expression singing appearance data indicating the search result (the appearance of the crisp appears). generating a note NT data indicating each time t on the time axis of the reproduction starting time of (i) a reference point t BS). Subsequently, based on the expression song appearance data generated for the shackle, the CPU 37 uses each time t on the time axis with the pronunciation start time of the note NT (i) as a reference point t BS and the number of appearances of the expression song at those times t. Statistical data indicating the relationship with Num is generated, and the evaluation point VSR (t) corresponding to each time t in the facial expression song reference data DD a4 is rewritten based on the contents of the statistical data.
- FIG. 11 is a diagram illustrating an example of the statistical data regarding shackle.
- appearance number Num expression singing between the reference point t BS and the reference point t BS than the time T2 a4 time after only t2 a4 are distributed.
- the statistics in this example the reference point t BS have appeared up to the peak number of occurrences Num
- the time t1 a4 than the reference point t BS delayed by time T1 a4 is a second peak number of occurrences Num Appears.
- the evaluation point VSR (t BS ) at the time t BS is the highest, and the evaluation point VSR (t 1 a4 ) at the time t1 a4 is the second. Get higher.
- the CPU 37 searches for the characteristic waveform of the fall from within the pitch waveform indicated by each singing sample data DS stored in the singing sample database DBS, and the facial expression singing appearance data (fall has appeared) indicating this search result. generating a note NT data indicating each time t on the time axis of the reproduction starting time of (i) a reference point t BS).
- CPU 37 based on the expression singing occurrence data generated relates fall, the number of occurrences of facial expression singing at each time t and their time t on the time axis to the reproduction starting time of the notebook NT (i) as a reference point t BS Statistical data indicating the relationship with Num is generated, and the evaluation point VSR (t) corresponding to each time in the facial expression song reference data DD a5 is rewritten based on the contents of the statistical data.
- FIG. 12 is a diagram illustrating an example of statistical data regarding a fall.
- the statistics of this example the number of occurrences of facial expression singing between the reference point t BS than the time T1 a5 only after the time t1 a5 and time t BS from the time T2 a5 only after the time t2 a5 of Num is distributed .
- the maximum peak of the number of occurrences Num appears at time t2 a5 . Therefore, in the facial expression song reference data DD a5 after rewriting by the statistical data of this example, the evaluation point VSR (t2 a5 ) at time t2 a5 is the highest.
- the CPU 17 of the karaoke apparatus 10-m performs inquiry processing every time a predetermined inquiry time arrives (S110: Yes) (S170). In this inquiry process, the CPU 17 transmits a message MS2 for requesting transmission of the latest data to the server device 30 (S170).
- the CPU 37 of the server device 30 receives the message MS2 from the karaoke device 10-m (S210: Yes), the facial expression singing reference in which the contents are rewritten between the previous message MS2 reception time and the current message MS2 reception time.
- the data DD is transmitted to the karaoke apparatus 10-m that is the transmission source of the message M2 (S250).
- the CPU 17 of the karaoke apparatus 10-m overwrites the facial expression song reference data DD on the reference database DBRK and updates the content (S180).
- each time the characteristic waveform of the facial expression song appears in the waveform of the output signal of the vocal adapter 16 the pronunciation of the note NT (i) that is the target of the facial expression song is started.
- the appearance time of the feature waveform of the facial expression song on the time axis with the time as the reference point is obtained, and the evaluation point VSR (t) corresponding to this appearance time is selected from the evaluation points VSR (t) in the song reference data DD.
- the skill of singing is evaluated based on the selected evaluation point VSR (t). Therefore, according to this embodiment, even if the user performs facial expression singing, good evaluation cannot be obtained unless the timing is appropriate. Therefore, according to this embodiment, it is possible to present an evaluation result closer to that based on human sensitivity.
- the facial expression song characteristic waveform is searched from the waveform indicated by the data DD, and the facial expression song is obtained from the search result.
- Statistical data indicating the relationship between each time on the time axis with the pronunciation start time of the note NT (i) as a reference point being the reference point and the number of facial expression singings appearing at those times, and singing reference data DD
- the evaluation score VSR (t) corresponding to each time at is rewritten based on the contents of the statistical data. Therefore, according to this embodiment, the change of the tendency of how to sing advanced users who are singing a song can be reflected in the evaluation result.
- the present invention may have other embodiments.
- it is as follows.
- facial expressions other than these five types may be detected.
- a song with inflection may be detected.
- the CPU 17 performs the standard singing evaluation process using both the output signals S P and S L of the vocal adapter 16 and indicates the pitch among the output signals S P and S L of the vocal adapter 16. was facial expression singing evaluation process by using only the signal S P. However, CPU 17 may perform a standard singing evaluation process using only one signal S P and S L. Further, CPU 17 may perform facial expression singing evaluation process using both signals S P and S L.
- the skill of the song was evaluated based on the appearance time of the characteristic waveform of the facial expression song.
- the evaluation may be performed in consideration of elements other than the appearance time of the feature waveform of the facial expression song (for example, the length and depth of each of the choke, vibrato, kobushi, shakuri, and fall).
- a configuration is adopted in which a facial expression song that appears in the song sound corresponding to each of the notes included in the song song is adopted, but a series of plural songs included in the song song are included.
- the structure which detects the facial expression song which appears in the song sound according to the note (note group) may be employ
- a facial expression song such as crescendo decrescendo is a facial expression song performed in a series of notes, and it is desirable that detection and evaluation of those facial expressions be performed in units of notes. Therefore, it is desirable that the facial expression song reference data DD relating to such facial expression song is also configured in units of notes.
- the singing sample data DS (pitch) including the signals SP and S L output from the vocal adapter 16 to the server device 30 from the start to the end of the singing of the singing song.
- the sound volume data is transmitted, and the server apparatus 30 employs a configuration in which each facial expression song is detected from the singing sample data DS and the timing of the appearance is specified.
- the server device 30 from the karaoke device 10 transmits a sound signal S M indicating the picked-up sound (sound waveform data indicating the singing sound) by microphones 13, the sound signal S M in the server apparatus 30 processing for generating a signal S p and the signal S L (processing vocal adapter 16 in the above embodiment does) configuration may be employed that originate.
- the karaoke device 10 transmits to the server device 30 data (facial singing appearance data) indicating the type of facial expression singing specified in the facial expression singing evaluation processing (S140) performed in accordance with the singing evaluation program VPG and the timing of its appearance.
- the server device 30 may employ a configuration in which the facial expression song reference data DD is updated based on the facial expression song appearance data transmitted from the karaoke device 10 without performing facial expression song detection processing.
- the server device 30 generates statistical data and rewrites the facial expression song reference data DD based on the statistical data.
- each of the karaoke apparatuses 10-m generates a sound signal S M indicating a singing sound generated by the own apparatus in the past, or directly from another karaoke apparatus 10-m or via the server apparatus 30, and their sound signals S
- the signal S p and the signal S L generated from M , or data (expression song appearance data) indicating the type and expression timing of the expression song specified using these signals are stored in the hard disk 20, and the CPU 17 They may be read and used to perform processing similar to the processing performed by the server device 30 in S240, that is, generation of statistical data and rewriting of facial expression song reference data DD based thereon.
- the standard score SR NOR is calculated by summing the addition point SR ADD calculated based on the number of appearances of the expression song in the standard song evaluation process (S130) with the basic score SR BASE.
- the appearance of the facial expression singing is not taken into account, and a configuration for calculating only the basic score SR BASE may be adopted.
- the higher score of the standard score SR NOR scored by the standard song evaluation process and the expression score SR EX scored by the expression song evaluation process is displayed to the singer.
- the evaluation result for the singer may be presented in other manners such as displaying both and displaying their total score.
- a singer whose basic score SR BASE is higher than the standard score SR TH is regarded as an advanced person, and the facial expression singing reference is made using only the singing sample data DS relating to the advanced person.
- a configuration for updating the data DD is employed.
- the method of selecting the singing sample data DS used for updating the facial expression singing reference data DD is not limited to this.
- the basic score instead of the SR BASE, may be used standard scoring SR NOR that the sum of the summing junction SR ADD basic score SR BASE as the basis for advanced estimation.
- an upper threshold is provided in addition to a lower threshold (reference score SR TH ).
- the singing sample data DS of a singer with a higher basic score SR BASE (or other score) may not be used for updating the facial expression song reference data DD.
- the singing sample data DS of the singer with a high basic score SR BASE is given a high weight and the facial expression singing reference data DD is updated. You may make it use for.
- a performance evaluation device that evaluates a music performance
- a performance evaluation device that is provided in a karaoke device for singing and evaluates a singing performance is shown.
- the present invention is not limited to the evaluation of singing performances, and can be applied to the evaluation of musical performances using various musical instruments. That is, the term “singing” used in the above embodiment is replaced with the more general term “performance”. Note that in a performance evaluation device that evaluates instrumental music performance, for example, choking on a guitar, and the like, evaluation regarding facial expression performance corresponding to each instrument is performed.
- the karaoke apparatus for musical instrument performance uses, for example, data indicating the score and each section of the score (for example, the song data MD instead of the lyrics track TR LY (for example, The delta time indicating the display time of 2 bars or 4 bars) is configured to include a score track which is data described in chronological order, and the sequencer 21 and the display unit 14 follow the score track to progress the music. Accordingly, an image signal indicating a musical score corresponding to the accompaniment location is output to the display.
- the image signal output processing by the sequencer 21 and the display unit 14 may not be performed.
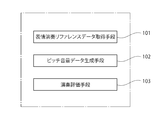
- the performance evaluation apparatus is such that, as illustrated in FIG. Facial expression performance reference data acquisition means 101 for acquiring facial expression performance reference data that indicates the timing to be performed in reference to the pronunciation start time of a note or note group included in the music, and the performance from the performance sound of the music by the performer Pitch volume data generation means 102 for generating pitch volume data indicating the pitch and volume of sound, and at least one of the characteristics of pitch and volume indicated by the pitch volume data generated by the pitch volume data generation means 102 is Within a predetermined time range indicated by the expression performance reference data in the music
- a performance evaluation means 103 for improving the performance of the music performed by the performer when the expression performance characteristics are supposed to be performed by the expression performance reference data. Expressed, the presence or absence of other elements and the specific mode of other elements are arbitrary.
- the performance evaluation device according to the present invention is not limited to a dedicated device.
- a configuration that realizes the performance evaluation device according to the present invention by causing various devices such as a personal computer, a portable information terminal (for example, a mobile phone or a smart phone), and a game device to perform processing according to a program is adopted.
- this program can be distributed by being stored in a recording medium such as a CD-ROM, or can be distributed by using an electric communication line such as the Internet.
- This application is based on Japanese Patent Application No. 2012-094853 filed on Apr. 18, 2012, the contents of which are incorporated herein by reference.
- SYMBOLS 1 Singing evaluation system, 10 ... Karaoke apparatus, 11 ... Sound source, 12 ... Speaker, 13 ... Microphone, 14 ... Display part, 15 ... Communication interface, 16 ... Vocal adapter, 17 ... CPU, 18 ... RAM, 19 ... ROM, DESCRIPTION OF SYMBOLS 20 ... Hard disk, 21 ... Sequencer, 30 ... Server apparatus, 35 ... Communication interface, 37 ... CPU, 38 ... RAM, 39 ... ROM, 40 ... Hard disk, 90 ... Network
Landscapes
- Engineering & Computer Science (AREA)
- Multimedia (AREA)
- Physics & Mathematics (AREA)
- Acoustics & Sound (AREA)
- Computational Linguistics (AREA)
- Educational Technology (AREA)
- General Physics & Mathematics (AREA)
- Theoretical Computer Science (AREA)
- Educational Administration (AREA)
- Signal Processing (AREA)
- Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Human Computer Interaction (AREA)
- Business, Economics & Management (AREA)
- Auxiliary Devices For Music (AREA)
- Reverberation, Karaoke And Other Acoustics (AREA)
- Electrophonic Musical Instruments (AREA)
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201380015347.7A CN104170006B (zh) | 2012-04-18 | 2013-04-18 | 演奏评价装置、卡拉ok装置及服务器装置 |
| KR1020147025532A KR101666535B1 (ko) | 2012-04-18 | 2013-04-18 | 연주 평가 장치, 노래방 장치 및 서버 장치 |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2012-094853 | 2012-04-18 | ||
| JP2012094853A JP5958041B2 (ja) | 2012-04-18 | 2012-04-18 | 表情演奏リファレンスデータ生成装置、演奏評価装置、カラオケ装置及び装置 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2013157602A1 true WO2013157602A1 (ja) | 2013-10-24 |
Family
ID=49383554
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2013/061488 Ceased WO2013157602A1 (ja) | 2012-04-18 | 2013-04-18 | 演奏評価装置、カラオケ装置及びサーバ装置 |
Country Status (5)
| Country | Link |
|---|---|
| JP (1) | JP5958041B2 (enExample) |
| KR (1) | KR101666535B1 (enExample) |
| CN (1) | CN104170006B (enExample) |
| TW (1) | TWI497484B (enExample) |
| WO (1) | WO2013157602A1 (enExample) |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2020122948A (ja) * | 2019-01-31 | 2020-08-13 | 株式会社第一興商 | カラオケ装置 |
| JP2020122949A (ja) * | 2019-01-31 | 2020-08-13 | 株式会社第一興商 | カラオケ装置 |
| JP2020166162A (ja) * | 2019-03-29 | 2020-10-08 | 株式会社第一興商 | カラオケ装置 |
Families Citing this family (21)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR101459324B1 (ko) * | 2013-08-28 | 2014-11-07 | 이성호 | 음원 평가방법 및 이를 이용한 음원의 평가장치 |
| JP6428066B2 (ja) * | 2014-09-05 | 2018-11-28 | オムロン株式会社 | 採点装置及び採点方法 |
| JP6352164B2 (ja) * | 2014-11-28 | 2018-07-04 | 株式会社第一興商 | 聴取者評価を考慮したカラオケ採点システム |
| CN104392731A (zh) * | 2014-11-30 | 2015-03-04 | 陆俊 | 一种练习唱歌的方法和系统 |
| CN104485090B (zh) * | 2014-12-12 | 2020-01-17 | 上海斐讯数据通信技术有限公司 | 乐谱生成方法及装置、移动终端 |
| JP5715296B1 (ja) * | 2014-12-16 | 2015-05-07 | 行秘 大田 | 替え歌通信カラオケサーバ及び替え歌通信カラオケシステム |
| US10380657B2 (en) | 2015-03-04 | 2019-08-13 | International Business Machines Corporation | Rapid cognitive mobile application review |
| JP6113231B2 (ja) * | 2015-07-15 | 2017-04-12 | 株式会社バンダイ | 歌唱力評価装置及び記憶装置 |
| JP6701864B2 (ja) * | 2016-03-25 | 2020-05-27 | ヤマハ株式会社 | 音評価装置および音評価方法 |
| WO2018016582A1 (ja) * | 2016-07-22 | 2018-01-25 | ヤマハ株式会社 | 演奏解析方法、自動演奏方法および自動演奏システム |
| JP6776788B2 (ja) * | 2016-10-11 | 2020-10-28 | ヤマハ株式会社 | 演奏制御方法、演奏制御装置およびプログラム |
| CN108665747A (zh) * | 2017-04-01 | 2018-10-16 | 上海伍韵钢琴有限公司 | 一种在线钢琴陪练系统及使用方法 |
| JP6867900B2 (ja) * | 2017-07-03 | 2021-05-12 | 株式会社第一興商 | カラオケ装置 |
| JP6708180B2 (ja) * | 2017-07-25 | 2020-06-10 | ヤマハ株式会社 | 演奏解析方法、演奏解析装置およびプログラム |
| CN108694384A (zh) * | 2018-05-14 | 2018-10-23 | 芜湖岭上信息科技有限公司 | 一种基于图像和声音的观众满意度调查装置和方法 |
| CN109903778B (zh) * | 2019-01-08 | 2020-09-25 | 北京雷石天地电子技术有限公司 | 实时演唱评分的方法与系统 |
| CN109887524A (zh) * | 2019-01-17 | 2019-06-14 | 深圳壹账通智能科技有限公司 | 一种演唱评分方法、装置、计算机设备及存储介质 |
| CN110083772A (zh) * | 2019-04-29 | 2019-08-02 | 北京小唱科技有限公司 | 基于演唱技巧的歌手推荐方法及装置 |
| CN110120216B (zh) * | 2019-04-29 | 2021-11-12 | 北京小唱科技有限公司 | 用于演唱评价的音频数据处理方法及装置 |
| CN115210803B (zh) * | 2020-03-04 | 2025-03-28 | 雅马哈株式会社 | 信息处理方法、信息处理系统及记录介质 |
| CN112037609B (zh) * | 2020-08-26 | 2022-10-11 | 怀化学院 | 一种基于物联网的音乐教学装置 |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2005241848A (ja) * | 2004-02-25 | 2005-09-08 | Daiichikosho Co Ltd | 通信カラオケシステムにおける投稿作品編集式の模範ボーカル提供装置 |
| JP2007271977A (ja) * | 2006-03-31 | 2007-10-18 | Yamaha Corp | 評価基準判定装置、制御方法及びプログラム |
| JP2007334364A (ja) * | 2007-08-06 | 2007-12-27 | Yamaha Corp | カラオケ装置 |
| JP2008139426A (ja) * | 2006-11-30 | 2008-06-19 | Yamaha Corp | 評価用データのデータ構造、カラオケ装置及び記録媒体 |
Family Cites Families (18)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2915773B2 (ja) * | 1993-12-25 | 1999-07-05 | 日本コロムビア株式会社 | カラオケ装置 |
| JP3299890B2 (ja) * | 1996-08-06 | 2002-07-08 | ヤマハ株式会社 | カラオケ採点装置 |
| JP3293745B2 (ja) * | 1996-08-30 | 2002-06-17 | ヤマハ株式会社 | カラオケ装置 |
| JP3690224B2 (ja) * | 2000-01-13 | 2005-08-31 | ヤマハ株式会社 | 携帯電話機および携帯電話システム |
| CN1380642A (zh) * | 2001-04-11 | 2002-11-20 | 华邦电子股份有限公司 | 跟唱学习评分装置及方法 |
| JP2003058155A (ja) * | 2001-08-13 | 2003-02-28 | Casio Comput Co Ltd | 演奏教習装置及び演奏教習処理のプログラム |
| JP4163584B2 (ja) | 2003-09-30 | 2008-10-08 | ヤマハ株式会社 | カラオケ装置 |
| JP4222915B2 (ja) * | 2003-09-30 | 2009-02-12 | ヤマハ株式会社 | 歌唱音声評価装置、カラオケ採点装置及びこれらのプログラム |
| JP4204941B2 (ja) | 2003-09-30 | 2009-01-07 | ヤマハ株式会社 | カラオケ装置 |
| JP4209751B2 (ja) * | 2003-09-30 | 2009-01-14 | ヤマハ株式会社 | カラオケ装置 |
| TWI232430B (en) * | 2004-03-19 | 2005-05-11 | Sunplus Technology Co Ltd | Automatic grading method and device for audio source |
| JP2007256617A (ja) * | 2006-03-23 | 2007-10-04 | Yamaha Corp | 楽曲練習装置および楽曲練習システム |
| JP2008015388A (ja) * | 2006-07-10 | 2008-01-24 | Dds:Kk | 歌唱力評価方法及びカラオケ装置 |
| JP2008026622A (ja) * | 2006-07-21 | 2008-02-07 | Yamaha Corp | 評価装置 |
| JP4865607B2 (ja) | 2007-03-13 | 2012-02-01 | ヤマハ株式会社 | カラオケ装置、歌唱評価方法およびプログラム |
| JP4910854B2 (ja) | 2007-04-17 | 2012-04-04 | ヤマハ株式会社 | こぶし検出装置、こぶし検出方法及びプログラム |
| TWI394141B (zh) * | 2009-03-04 | 2013-04-21 | Wen Hsin Lin | Karaoke song accompaniment automatic scoring method |
| JP5244738B2 (ja) * | 2009-08-24 | 2013-07-24 | 株式会社エクシング | 歌唱評価装置、歌唱評価方法及びコンピュータプログラム |
-
2012
- 2012-04-18 JP JP2012094853A patent/JP5958041B2/ja not_active Expired - Fee Related
-
2013
- 2013-04-18 WO PCT/JP2013/061488 patent/WO2013157602A1/ja not_active Ceased
- 2013-04-18 KR KR1020147025532A patent/KR101666535B1/ko not_active Expired - Fee Related
- 2013-04-18 CN CN201380015347.7A patent/CN104170006B/zh not_active Expired - Fee Related
- 2013-04-18 TW TW102113839A patent/TWI497484B/zh not_active IP Right Cessation
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2005241848A (ja) * | 2004-02-25 | 2005-09-08 | Daiichikosho Co Ltd | 通信カラオケシステムにおける投稿作品編集式の模範ボーカル提供装置 |
| JP2007271977A (ja) * | 2006-03-31 | 2007-10-18 | Yamaha Corp | 評価基準判定装置、制御方法及びプログラム |
| JP2008139426A (ja) * | 2006-11-30 | 2008-06-19 | Yamaha Corp | 評価用データのデータ構造、カラオケ装置及び記録媒体 |
| JP2007334364A (ja) * | 2007-08-06 | 2007-12-27 | Yamaha Corp | カラオケ装置 |
Cited By (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2020122948A (ja) * | 2019-01-31 | 2020-08-13 | 株式会社第一興商 | カラオケ装置 |
| JP2020122949A (ja) * | 2019-01-31 | 2020-08-13 | 株式会社第一興商 | カラオケ装置 |
| JP7232654B2 (ja) | 2019-01-31 | 2023-03-03 | 株式会社第一興商 | カラオケ装置 |
| JP7232653B2 (ja) | 2019-01-31 | 2023-03-03 | 株式会社第一興商 | カラオケ装置 |
| JP2020166162A (ja) * | 2019-03-29 | 2020-10-08 | 株式会社第一興商 | カラオケ装置 |
| JP7169243B2 (ja) | 2019-03-29 | 2022-11-10 | 株式会社第一興商 | カラオケ装置 |
Also Published As
| Publication number | Publication date |
|---|---|
| JP2013222140A (ja) | 2013-10-28 |
| TWI497484B (zh) | 2015-08-21 |
| KR101666535B1 (ko) | 2016-10-14 |
| TW201407602A (zh) | 2014-02-16 |
| CN104170006B (zh) | 2017-05-17 |
| JP5958041B2 (ja) | 2016-07-27 |
| CN104170006A (zh) | 2014-11-26 |
| KR20140124843A (ko) | 2014-10-27 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP5958041B2 (ja) | 表情演奏リファレンスデータ生成装置、演奏評価装置、カラオケ装置及び装置 | |
| CN102568482A (zh) | 信息处理设备,乐曲片段提取方法和程序 | |
| JP2009104097A (ja) | 採点装置及びプログラム | |
| JP2015069082A (ja) | 情報処理装置,データ生成方法,及びプログラム | |
| JP6102076B2 (ja) | 評価装置 | |
| JP6288197B2 (ja) | 評価装置及びプログラム | |
| JP5428459B2 (ja) | 歌唱評価装置 | |
| JP6365483B2 (ja) | カラオケ装置,カラオケシステム,及びプログラム | |
| JP6944357B2 (ja) | 通信カラオケシステム | |
| JP5994343B2 (ja) | 演奏評価装置及びカラオケ装置 | |
| JP3879524B2 (ja) | 波形生成方法、演奏データ処理方法および波形選択装置 | |
| JP6459162B2 (ja) | 演奏データとオーディオデータの同期装置、方法、およびプログラム | |
| JP5618743B2 (ja) | 歌唱音声評価装置 | |
| JP5585320B2 (ja) | 歌唱音声評価装置 | |
| JP6074835B2 (ja) | 楽曲練習支援装置 | |
| JP6011506B2 (ja) | 情報処理装置,データ生成方法,及びプログラム | |
| JP6432478B2 (ja) | 歌唱評価システム | |
| JP2007233078A (ja) | 評価装置、制御方法及びプログラム | |
| JP2008003483A (ja) | カラオケ装置 | |
| JP6514868B2 (ja) | カラオケ装置及びカラオケ採点システム | |
| JP5012269B2 (ja) | 演奏クロック生成装置、データ再生装置、演奏クロック生成方法、データ再生方法およびプログラム | |
| JP2017181661A (ja) | 支援装置 | |
| JP2023033877A (ja) | カラオケ装置 | |
| JP2015106061A (ja) | カラオケ装置 | |
| JP2014174293A (ja) | 歌唱音声評価装置および歌唱音声評価システム |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 13777807 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 20147025532 Country of ref document: KR Kind code of ref document: A |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 13777807 Country of ref document: EP Kind code of ref document: A1 |