WO2013157602A1 - Performance evaluation device, karaoke device, and server device - Google Patents
Performance evaluation device, karaoke device, and server device Download PDFInfo
- Publication number
- WO2013157602A1 WO2013157602A1 PCT/JP2013/061488 JP2013061488W WO2013157602A1 WO 2013157602 A1 WO2013157602 A1 WO 2013157602A1 JP 2013061488 W JP2013061488 W JP 2013061488W WO 2013157602 A1 WO2013157602 A1 WO 2013157602A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- performance
- facial expression
- data
- pitch
- music
- Prior art date
Links
- 238000011156 evaluation Methods 0.000 title claims abstract description 112
- 230000008921 facial expression Effects 0.000 claims description 176
- 230000014509 gene expression Effects 0.000 claims description 64
- 230000005236 sound signal Effects 0.000 claims description 23
- 238000013500 data storage Methods 0.000 claims 2
- 230000001747 exhibiting effect Effects 0.000 claims 1
- 238000000034 method Methods 0.000 description 40
- 230000008569 process Effects 0.000 description 23
- 239000008186 active pharmaceutical agent Substances 0.000 description 21
- 230000001755 vocal effect Effects 0.000 description 19
- 238000012854 evaluation process Methods 0.000 description 18
- 235000014196 Magnolia kobus Nutrition 0.000 description 10
- 240000005378 Magnolia kobus Species 0.000 description 10
- 241000238876 Acari Species 0.000 description 9
- 238000004891 communication Methods 0.000 description 7
- 238000010586 diagram Methods 0.000 description 7
- 230000005540 biological transmission Effects 0.000 description 5
- 230000035945 sensitivity Effects 0.000 description 5
- 238000001514 detection method Methods 0.000 description 4
- 230000003111 delayed effect Effects 0.000 description 2
- 230000000694 effects Effects 0.000 description 2
- 238000005516 engineering process Methods 0.000 description 2
- 230000001815 facial effect Effects 0.000 description 2
- 230000004044 response Effects 0.000 description 2
- 241001070941 Castanea Species 0.000 description 1
- 235000014036 Castanea Nutrition 0.000 description 1
- 238000009825 accumulation Methods 0.000 description 1
- 230000008859 change Effects 0.000 description 1
- 230000001934 delay Effects 0.000 description 1
- 235000013601 eggs Nutrition 0.000 description 1
- 230000002123 temporal effect Effects 0.000 description 1
- 230000007704 transition Effects 0.000 description 1
Images








Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10K—SOUND-PRODUCING DEVICES; METHODS OR DEVICES FOR PROTECTING AGAINST, OR FOR DAMPING, NOISE OR OTHER ACOUSTIC WAVES IN GENERAL; ACOUSTICS NOT OTHERWISE PROVIDED FOR
- G10K15/00—Acoustics not otherwise provided for
- G10K15/04—Sound-producing devices
-
- G—PHYSICS
- G09—EDUCATION; CRYPTOGRAPHY; DISPLAY; ADVERTISING; SEALS
- G09B—EDUCATIONAL OR DEMONSTRATION APPLIANCES; APPLIANCES FOR TEACHING, OR COMMUNICATING WITH, THE BLIND, DEAF OR MUTE; MODELS; PLANETARIA; GLOBES; MAPS; DIAGRAMS
- G09B15/00—Teaching music
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10H—ELECTROPHONIC MUSICAL INSTRUMENTS; INSTRUMENTS IN WHICH THE TONES ARE GENERATED BY ELECTROMECHANICAL MEANS OR ELECTRONIC GENERATORS, OR IN WHICH THE TONES ARE SYNTHESISED FROM A DATA STORE
- G10H1/00—Details of electrophonic musical instruments
- G10H1/36—Accompaniment arrangements
- G10H1/361—Recording/reproducing of accompaniment for use with an external source, e.g. karaoke systems
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L25/00—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00
- G10L25/48—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 specially adapted for particular use
- G10L25/51—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 specially adapted for particular use for comparison or discrimination
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L25/00—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00
- G10L25/90—Pitch determination of speech signals
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10H—ELECTROPHONIC MUSICAL INSTRUMENTS; INSTRUMENTS IN WHICH THE TONES ARE GENERATED BY ELECTROMECHANICAL MEANS OR ELECTRONIC GENERATORS, OR IN WHICH THE TONES ARE SYNTHESISED FROM A DATA STORE
- G10H2210/00—Aspects or methods of musical processing having intrinsic musical character, i.e. involving musical theory or musical parameters or relying on musical knowledge, as applied in electrophonic musical tools or instruments
- G10H2210/031—Musical analysis, i.e. isolation, extraction or identification of musical elements or musical parameters from a raw acoustic signal or from an encoded audio signal
- G10H2210/091—Musical analysis, i.e. isolation, extraction or identification of musical elements or musical parameters from a raw acoustic signal or from an encoded audio signal for performance evaluation, i.e. judging, grading or scoring the musical qualities or faithfulness of a performance, e.g. with respect to pitch, tempo or other timings of a reference performance
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10H—ELECTROPHONIC MUSICAL INSTRUMENTS; INSTRUMENTS IN WHICH THE TONES ARE GENERATED BY ELECTROMECHANICAL MEANS OR ELECTRONIC GENERATORS, OR IN WHICH THE TONES ARE SYNTHESISED FROM A DATA STORE
- G10H2220/00—Input/output interfacing specifically adapted for electrophonic musical tools or instruments
- G10H2220/155—User input interfaces for electrophonic musical instruments
- G10H2220/441—Image sensing, i.e. capturing images or optical patterns for musical purposes or musical control purposes
- G10H2220/455—Camera input, e.g. analyzing pictures from a video camera and using the analysis results as control data
Definitions
- This invention relates to a technique for evaluating the skill of music performance.
- karaoke apparatus for singing having a scoring function for scoring the skill of a singer's singing performance
- karaoke apparatus For example, various techniques relating to a karaoke apparatus for singing having a scoring function for scoring the skill of a singer's singing performance (hereinafter simply referred to as “karaoke apparatus” unless otherwise specified) have been proposed.
- Patent Document 1 As a document disclosing this kind of technology.
- the karaoke device disclosed in this document calculates the difference between the pitch extracted from the user's singing sound and the pitch extracted from the data prepared in advance as the guide melody for each note of the singing song, and based on this difference Calculate the basic score.
- this karaoke apparatus calculates the bonus point according to the frequency
- This karaoke device presents the total score of the basic score and bonus points to the user as the final evaluation result.
- Patent Documents 2 to 6 disclose documents that disclose a technique for detecting a singing using a technique such as vibrato or shackle from a waveform indicating a singing sound.
- Japanese Unexamined Patent Publication No. 2005-107334 Japanese Unexamined Patent Publication No. 2005-107330 Japanese Laid-Open Patent Publication No. 2005-107087 Japanese Unexamined Patent Publication No. 2008-268370 Japanese Unexamined Patent Publication No. 2005-107336 Japanese Unexamined Patent Publication No. 2008-225115
- the present invention has been made in view of such a problem, and an object of the present invention is to make it possible to present an evaluation result closer to human sensitivity in the evaluation of music performance such as karaoke singing.
- the present invention relates to the expression performance to be performed during the performance of the music and the timing at which the expression performance should be performed in the music with reference to the pronunciation start time of the note or note group included in the music.
- Facial expression performance reference data acquisition means for acquiring facial expression performance reference data to indicate
- pitch volume data generation means for generating pitch volume data indicating the pitch and volume of the performance sound from the performance sound of the music by the performer
- the pitch volume At least one characteristic of pitch and volume indicated by the pitch volume data generated by the data generation means should be performed by the facial expression performance reference data within a predetermined time range indicated by the facial expression performance reference data in the music piece. Characteristics of facial expression performance If shown, it provides a performance evaluation apparatus and a playing evaluating means to improve the evaluation of the performance of the music by the player.
- the present invention also provides the performance evaluation apparatus, accompaniment data acquisition means for acquiring accompaniment data for instructing accompaniment of music, and sound signal output means for outputting a sound signal indicating a musical sound of accompaniment according to the instruction of the accompaniment data
- the pitch volume data generation means includes the pitch and volume of the performance sound of the music performed by the performer according to the accompaniment emitted from a speaker according to the sound signal output from the sound signal output means
- a karaoke apparatus for generating pitch sound volume data indicating the above is provided.
- the present invention relates to each of the performance sounds of music by an arbitrary number of arbitrary performers, and one facial expression performance appears at one timing based on the pronunciation start time of notes or note groups included in the music
- Each of a note or a group of notes included in the music based on an expression performance appearance data acquisition means for acquiring expression performance appearance data indicating that, and an arbitrary number of expression performance appearance data acquired by the expression performance appearance data acquisition means Is performed during the performance of the musical piece according to the specified information, specifying which facial expression performance appears at which timing with reference to the sound generation start time of the note or group of notes.
- the expression of a note or a group of notes included in the music indicates the power expression performance and the timing at which the expression performance should be performed in the music
- a server apparatus comprising facial expression performance reference data generating means for generating facial expression performance reference data indicating the start time as reference, and transmitting means for transmitting facial expression performance reference data generated by the facial expression performance reference data generating means to the performance evaluation apparatus I will provide a.
- the present invention is a singing evaluation system, wherein a facial expression performance to be performed during the performance of a musical piece and a timing at which the facial expression performance is to be performed in the musical piece are determined as a pronunciation start time of a note or a note group included in the musical piece.
- Facial expression performance reference data acquisition means for acquiring first facial expression performance reference data shown as a reference; pitch volume data generation means for generating pitch volume data indicating the pitch and volume of the performance sound from the performance sound of the music by the performer; And at least one of the pitch and volume characteristics indicated by the pitch volume data generated by the pitch volume data generation means is within the predetermined time range indicated by the first facial expression performance reference data in the music. Should be done with performance reference data
- the performance evaluation means for improving the performance of the music performed by the performer and each of the performance sounds of the music performed by an arbitrary number of the performers.
- Expression performance appearance data acquisition means for acquiring expression performance appearance data indicating that one expression performance has appeared at one timing based on a pronunciation start time of a note or a group of notes included in the music, and the expression performance appearance data Based on the arbitrary number of facial expression performance appearance data acquired by the acquisition means, any timing with respect to each note or group of notes included in the musical piece by the arbitrary player based on the pronunciation start time of the notes or group of notes And which facial expression performance appears at what frequency, and according to the identified information, the arbitrary performance The facial expression performance to be performed during the performance of the musical piece by and the timing at which the facial expression performance should be performed in the musical piece by the arbitrary player, based on the pronunciation start time of the note or the note group included in the musical piece by the arbitrary player.
- a singing evaluation system comprising expression performance reference data generating means for generating second expression performance reference data to be shown.
- the present invention also provides facial expression performance reference data that indicates the facial expression performance to be performed during the performance of a musical piece and the timing at which the facial expression performance is to be performed in the musical piece, with reference to the pronunciation start time of the note or note group included in the musical piece. And generating pitch volume data indicating the pitch and volume of the performance sound from the performance sound of the music by the performer, and at least one of the characteristics of the pitch and volume indicated by the pitch volume data is A performance evaluation method for improving the performance of the music performed by the performer when the characteristics of the facial expression performance that should be performed by the expression performance reference data within a predetermined time range indicated by the expression performance reference data I will provide a.
- the present invention is a computer-executable program, in which a facial expression performance to be performed during the performance of a musical piece and a timing at which the facial expression performance should be performed in the musical piece are pronounced in a note or a group of notes included in the musical piece
- Expression performance reference data acquisition processing for acquiring expression performance reference data indicating the start time as a reference
- pitch volume data generation processing for generating pitch volume data indicating the pitch and volume of the performance sound from the performance sound of the music by the performer
- at least one of the pitch and volume characteristics indicated by the pitch volume data generated by the pitch volume data generation means is within the predetermined time range indicated by the expression performance reference data in the music piece. Should be done by When showing the characteristics of the expression performance that is, to provide a program for executing a performance evaluation process for improving the evaluation of the performance of the music by the player to the computer.
- a performance evaluation device that gives a high evaluation to the performer is realized.
- the evaluation is performed with little deviation from human sensitivity.
- FIG. 1 is a diagram showing a configuration of a singing evaluation system 1 according to an embodiment of the present invention.
- a karaoke device 10-m 1, 2,... M: M is the total number of karaoke devices
- M is the total number of karaoke devices
- One or a plurality of karaoke apparatuses 10-m are installed in each karaoke store.
- the server device 30 is installed in the system management center.
- the karaoke apparatus 10-m and the server apparatus 30 are connected to the network 90, and can transmit and receive various data to and from each other.
- the karaoke device 10-m is a device that performs singing effects through sound emission of accompaniment music that supports the user's singing and display of lyrics, and evaluation of the skill of the user's singing.
- the karaoke apparatus 10-m evaluates the skill of the singing skill by evaluating the pitch and volume of the user's singing sound and the following five types of facial expression singing.
- the score that is the evaluation result of the two evaluations is presented to the user together with the comment message.
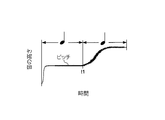
- a1. Tame This is a facial expression song that intentionally delays the singing of a specific sound in the song. As shown in FIG. 2, when this singing is performed, the time at which the pitch of the sound changes from the sound before the singing sound to that of the sound corresponds to both sounds in the score (exemplary singing).
- Vibrato This is a facial expression song that vibrates finely while maintaining the apparent pitch of a specific sound in the song. As shown in FIG. 3, when this singing is performed, the pitch of the singing sound periodically changes across the height of the note corresponding to the sound in the score.
- Kobushi This is a facial expression song that changes the tone of a specific sound in the song so that it sings during pronunciation. As shown in FIG. 4, when this singing is performed, the pitch of the singing sound rises temporarily in the middle of the note corresponding to the sound in the score. d1.
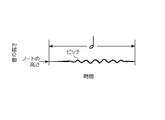
- Shakuri This is a singing technique in which a specific sound in a song is pronounced with a voice lower than the original pitch and then brought close to the original pitch.
- the pitch of the singing sound at the sounding start time is lower than the height of the note corresponding to the sound in the score. Then, the pitch of this singing sound rises slowly after the start of sounding and reaches almost the same height as the note. e1.
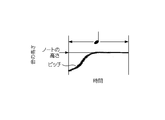
- Fall This is a singing technique in which a specific sound in a song is pronounced with a voice higher than its original height and then brought close to its original height.
- FIG. 6 when this singing is performed, the pitch of the singing sound at the sounding start time is higher than the height of the note corresponding to the sound in the score. The pitch of the singing sound gradually falls after the start of sounding and reaches almost the same height as the note.
- the karaoke apparatus 10-m includes a sound source 11, a speaker 12, a microphone 13, a display unit 14, a communication interface 15, a vocal adapter 16, a CPU 17, a RAM 18, a ROM 19, a hard disk 20, and a sequencer 21.
- Sound source 11 outputs a sound signal S A in accordance with the various messages of MIDI (Musical Instrument Digital Interface).
- the speaker 12 emits a given signal as sound.
- the microphone 13 collects sound and outputs a sound collection signal S M.
- the display unit 14 displays an image corresponding to the image signal S I.
- the communication interface 15 transmits / receives data to / from devices connected to the network 90.
- the CPU 17 executes a program stored in the ROM 19 or the hard disk 20 while using the RAM 18 as a work area. Details of the operation of the CPU 17 will be described later.
- the ROM 19 stores IPL (Initial Program Loader) and the like.
- the song data MD-n of each song is data in which the accompaniment content of the song, the lyrics of the song, and the exemplary song content of the song are recorded in SMF (Standard MIDI File) format.
- the music data MD-n has a header HD, an accompaniment track TR AC , a lyrics track TR LY , and a model song reference track TR NR .
- the header HD information such as a song number, a song title, a genre, a performance time, and a time base (the number of ticks corresponding to the time of one quarter note) is described.
- each note NT (i) in the score of the accompaniment part of singing songs indicates the order counted from the beginning of the notebook NT of the score of the relevant part (1)
- the event EV (i) ON to be turned on indicating the order counted from the beginning of the notebook NT of the score of the relevant part (1)
- the delta time DT indicating the execution time difference (number of ticks) of the succeeding events are described in chronological order.
- the lyrics track TR LY includes each data D LY indicating the lyrics of the song and the display time of each lyrics (more specifically, the time difference between the display time of each lyrics and the display time of each previous lyrics) Delta time DT indicating (number of ticks)) is described in chronological order.
- the model singing reference track TR NR includes an event EV (i) ON for instructing the sound of each note NT (i) in the singing part of the score of the song, and an event EV (i) OFF for instructing to mute the sound.
- a delta time DT indicating a difference in execution time (number of ticks) between successive events is described in chronological order.
- the reference database DBRK stores five types of facial expression singing reference data DD a1 , DD a2 , DD a3 , DD a4 , DD a5 .
- the facial expression singing reference data DD a1 is obtained when the singing is performed at each time t on the time axis with the pronunciation start time of the note NT (i) included in the singing song as the reference point t BS and at those times t. Is a data showing each pair of evaluation points VSR (t).
- the facial expression singing reference data DD a2 is obtained when the vibrato singing is performed at each time t on the time axis with the pronunciation start time of the note NT (i) included in the singing song as a reference point t BS and those times t. Is a data showing each pair of evaluation points VSR (t).
- the facial expression singing reference data DD a3 is obtained when each time t on the time axis with the pronunciation start time of the note NT (i) included in the singing song as a reference point t BS and the time t at which the singing is performed by Kobushi. Is a data showing each pair of evaluation points VSR (t).
- the facial expression singing reference data DD a4 is obtained when the singing is performed at each time t on the time axis with the pronunciation start time of the note NT (i) included in the singing song as the reference point t BS and at the time t. Is a data showing each pair of evaluation points VSR (t).
- the facial expression singing reference data DD a5 is obtained when the singing by the fall is performed at each time t on the time axis with the sound generation start time of the note NT (i) included in the singing song as the reference point t BS and at those times t Is a data showing each pair of evaluation points VSR (t).
- the five types of facial expression song reference data DD a1 , DD a2 , DD a3 , DD a4 , DD a5 are referred to as facial expression song reference data DD.
- the song evaluation program VPG has the following three functions. a2. Standard Evaluation Function This is because each note NT (determined by each event EV (i) ON and EV (i) OFF in the exemplary singing reference track TR NR indicated by the output signals S L and S P of the vocal adapter 16 This is a function for comparing the model pitch PCH REF and the model volume LV REF of i) and evaluating the skill of singing based on the result of this comparison. b2.
- Expression singing evaluation function which, each time the characteristic waveform expression singing appear in the pitch waveform indicated by the output signal S P output vocal adapter 16, the reference point pronunciation start time of notebook NT is the subject expression singing (i) The appearance time of the feature waveform of the facial expression song on the time axis as t BS is obtained, and the evaluation point VSR (t) corresponding to this appearance time is set as each evaluation point VSR of the corresponding facial expression song reference data DD in the reference database DBRK ( This is a function of selecting from t) and evaluating the skill of singing based on this evaluation point VSR (t). c2.
- Evaluation result presentation function This is a function for calculating a score from the evaluation result of the evaluation by a2 and the evaluation result of the evaluation by b2, and displaying the score on the display unit 14 together with the comment message.
- the sequencer 21 When the song data MD-n of the corresponding song is transferred from the hard disk 20 to the RAM 18 in response to the singing start operation of the song by a remote controller (not shown), the sequencer 21 performs an event EV in the song data MD-n. (I) ON , EV (i) OFF , and data DLY are supplied to each part of the apparatus. Specifically, when the music piece data MD-n is stored in the RAM 18, the sequencer 21 stores the time base described in the header HD of the music piece data MD-n and the tempo designated by the remote controller (not shown). The time length of one tick is determined based on the above, and the following three processes are performed while counting ticks as the time length elapses.
- the sequencer 21 reads out the event EV (i) ON following thereafter each time the count number of ticks matches the delta time DT in accompaniment track TR AC (or EV (i) OFF) Instrument 11 is supplied.
- the event EV (i) ON is supplied from the sequencer 21
- the sound source 11 supplies the sound signal S A specified by the event EV (i) ON to the speaker 12, and the event EV (i) OFF is supplied from the sequencer 21. Then, the supply of the sound signal S A to the speaker 12 is stopped.
- the sequencer 21 reads the subsequent data DLY and supplies it to the display unit 14 every time the tick count matches the delta time DT in the lyrics track TRLY .
- the display unit 14 converts the data D LY into a lyrics telop image, and displays the image on a display (not shown).
- the accompaniment sound is emitted from the speaker 12 and the lyrics are displayed on the display.
- the user sings the lyrics displayed on the display toward the microphone 13 while listening to the accompaniment sound emitted from the speaker 12. While the user is singing into the microphone 13, the microphone 13 outputs a collected sound signal S M of the user's singing sound, vocal adapter 16 signal S P and showing the pitch and volume of the signal S M S L is output.
- the sequencer 21 counts the number of ticks read event EV (i) ON following thereafter every time matches the delta time DT within model singing Reference track TR NR (or EV (i) OFF) To the CPU 17.
- the CPU 17 evaluates the skill of the user's singing using the events EV (i) ON and EV (i) OFF supplied from the sequencer 21 and the output signals S P and S L of the vocal adapter 16. Details will be described later.
- the server device 30 is a device that plays a role of supporting the provision of services at a karaoke store.
- the server device 30 includes a communication interface 35, a CPU 37, a RAM 38, a ROM 39, and a hard disk 40.
- the communication interface 35 transmits / receives data to / from devices connected to the network 90.
- the CPU 37 executes various programs stored in the ROM 39 and the hard disk 40 while using the RAM 38 as a work area. Details of the operation of the CPU 37 will be described later.
- the ROM 39 stores IPL and the like.
- the hard disk 40 stores a song sample database DBS, a reference database DBRS, and a song analysis program APG.
- singing sample database DBS singing sample data DS groups each corresponding to one singing song are individually stored.
- the singing sample data DS is data in which a pitch waveform and a volume waveform of a singing sound when a person who has a singing ability exceeding a certain level sings a singing song is recorded.
- the reference database DBRS stores the latest facial expression singing reference data DD to be stored in the reference database DBRK of each karaoke apparatus 10-m.
- the song analysis program APG has the following three functions. a3. Accumulation function This is a function for acquiring the song sample data DS for each song from the karaoke apparatus 10-m one by one, and accumulating the acquired song sample data DS in the song sample database DBS. b3. Rewriting function This is to search the characteristic waveform of the facial expression song from the waveform indicated by the song sample data DS for each of the song sample data DS stored in the song sample database DBS, and to be the target of the facial expression song from the search result.
- FIG. 7 is a flowchart showing the operation of this embodiment.
- the CPU 17 of the karaoke apparatus 10-m supplies a control signal S O to the sequencer 21 when the singing start operation of the song is performed (S100: Yes), and processes the sequencer 21 (the above-described first process).
- S100: Yes the control signal
- S120 the standard song evaluation process
- S140 a facial expression song evaluation process
- Standard song evaluation process (S130) In this processing, the CPU 17 determines the time from when the event EV (i) ON is supplied from the sequencer 21 to when the next event EV (i) OFF is supplied to the sound corresponding to the i-th note NT (i). Let the pronunciation time T NT (i).
- the difference PCH DEF of a model pitch PCH REF output signal S P output vocal adapter 16 converts the note number of the pitch and event EV (i) ON shown during the sounding time T NT (i), and in between determining a difference LV DEF of a model volume LV REF obtained by converting the volume and event EV (i) velocity oN indicated by the signal S P, notebook NT if this difference PCH DEF and differences LV DEF is within a predetermined range (i) It is determined that the singing is successful.
- the CPU 17 performs this note determination from the start to the end of the singing by the user, and divides the number of all notes TN (i) at the end of the singing by the number of the notes NT (i) determined to be acceptable.
- a value obtained by multiplying the obtained value by 100 is defined as a basic score SR BASE .
- CPU 17 determines, in a pitch waveform indicated by the output signal S P output vocal adapter 16, Tame, vibrato, fist, jerking, whether any of the expression singing features waveform fall appeared .
- Patent Document 2 details of the method for determining the feature waveform of the patent are disclosed in Patent Document 2
- Patent Document 3 details of the method for determining the characteristic waveform of the vibrato are described in Patent Document 3
- Patent Document 4 details of the method of determining the feature waveform of Kobushi are described in Patent Document 4
- Patent Document 6 for details of the fall feature waveform determination method.
- the CPU 17 performs this characteristic waveform determination from the start to the end of the singing by the user, and sets a value obtained by multiplying the number of appearances of the facial expression song at the end of the singing by a predetermined coefficient as the addition point SR ADD .
- the total of the basic score SR BASE and the addition point SR ADD is set as the standard score SR NOR .
- Expression song evaluation process (S140) In this process, the CPU 17 sets the time from the output of the sound source event EV (i) ON to the output of the next event EV (i) OFF as the sound generation time T NT (i) corresponding to the i-th note NT (i). ). Then, CPU 17, when the characteristic waveform expression singing in pitch waveform indicated by the output signal S P output vocal adapter 16 between the sounding time T NT (i) are noticed, within sounding time T NT (i) Find the appearance time of the facial expression song and the type of facial expression song that appeared. The CPU 17 generates facial expression song appearance data indicating the type and appearance time of the facial expression song specified as described above.
- the CPU 17 selects the facial expression song indicated in the generated facial expression song appearance data and the evaluation point VSR (t) corresponding to the appearance time from the series of evaluation points VSR (t) indicated by the facial expression song reference data DD. To do.
- the CPU selects such evaluation points VSR (t) from the start to the end of singing by the user, and the average value of the evaluation points VSR (t) at the end of the singing is used as the facial expression score SR EX.
- CPU17 will perform an evaluation result presentation process, after the song of the song by a user is complete
- the CPU 17 selects a higher score from the standard score SR NOR scored by the standard song evaluation process and the facial score SR EX scored by the facial expression song evaluation process. Then, CPU17 is, if you choose the standard score SR NOR, and this score SR NOR, to display a comment messages in accordance with the score SR NOR for example, such as "It is cool and refined song" on the display unit 14.
- CPU17 is, if you choose a facial expression score SR EX, this and score SR EX, for example, to display a comment message corresponding to the facial expression score such as "I have full of kindness" SR EX on the display unit 14.
- the CPU 17 performs a sample transmission process (S160).
- Sample transmission process CPU 17 is vocal signal S P and S L adapter 16 has output a singing sample data DS of the singing music piece, steps and the singing sample data DS between the start and end of singing singing voice
- a message MS1 including the basic score SR BASE (singing evaluation data) obtained in S130 is transmitted to the server device 30.
- the CPU 37 of the server device 30 obtains the message MS1 from the karaoke device 10-m (S200: Yes), the singing sample data DS and the basic score SR BASE are extracted from this message MS1, and this basic score SR BASE is obtained from the advanced player. It is compared with a reference score SR TH (for example, 80 points) that separates those who are not (S220). When the basic score SR BASE is higher than the reference score SR TH (S220: Yes), the CPU 37 accumulates the song sample data DS extracted from the message MS1 in the song sample database DBS (S230).
- a reference score SR TH for example, 80 points
- the CPU 37 performs a rewriting process (S240).
- the CPU 37 performs the following five processes.
- the CPU 37 searches for the characteristic waveform of the ticks from within the pitch waveform indicated by each singing sample data DS stored in the singing sample database DBS, and the facial expression singing appearance data indicating the search results (the appearance of the ticks). generating a note NT data indicating each time t on the time axis of the reproduction starting time of (i) a reference point t BS).
- CPU 37 based on the expression singing occurrence data generated relates Tame, expression singing at each time t and their time t on the time axis to the reproduction starting time of the notebook NT (i) as a reference point t BS "tame"
- Statistical data showing the relationship with the number of occurrences Num of the synthesizer, and the evaluation point VSR (t) corresponding to each time t in the facial expression singing reference data DD a1 is rewritten based on the contents of this statistical data.
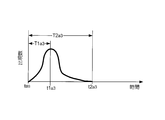
- FIG. 8 is a diagram illustrating an example of statistical data on the eggs.
- the statistics of this example the number of occurrences Num expression singing between the reference point t BS time T1 a1 only before time t1 a1 and the reference point t BS than the time T4 a1 time t4 after only a1 is distributed Yes.
- the maximum peak of the number of appearances Num appears at the time t2 a1 immediately after the reference point t BS , and the second peak of the number of appearances Num at the time t3 a1 later than the time t2 a1. Appears.
- the evaluation point VSR (t2 a1 ) at the time t2 a1 is the highest, and the evaluation point VSR (t3 a1 ) at the time t3 a1 is the second. Get higher.
- the CPU 37 searches for the characteristic waveform of vibrato from within the pitch waveform indicated by each singing sample data DS stored in the singing sample database DBS, and facial expression singing appearance data (vibrato has appeared) indicating the search result. generating a note NT data indicating each time t on the time axis of the reproduction starting time of (i) a reference point t BS). Subsequently, based on the expression song appearance data generated for the vibrato, the CPU 37 uses the time t on the time axis where the pronunciation start time of the note NT (i) is the reference point t BS and the number Num of appearances of the expression song at those times t. Is generated, and the evaluation score VSR (t) corresponding to each time t in the facial expression song reference data DD a2 is rewritten based on the contents of the statistical data.
- FIG. 9 is a diagram illustrating an example of statistical data on vibrato.
- appearance number Num expression singing between the reference point t BS and the reference point t BS than the time T2 a2 time after only t2 a2 are distributed.
- to be the reference point t BS time T1 a2 only after the time t1 a2 is the maximum peak number of occurrences Num has appeared. Therefore, in the facial expression song reference data DD a2 after rewriting by the statistical data of this example, the evaluation point VSR (t1 a2 ) at the time t1 a2 is the highest.
- the CPU 37 searches for the characteristic waveform of Kobushi from within the pitch waveform indicated by each singing sample data DS stored in the singing sample database DBS, and the facial expression singing appearance data (Kobushi appears) indicating the search result. generating a note NT data indicating each time t on the time axis of the reproduction starting time of (i) a reference point t BS). Subsequently, based on the facial expression song appearance data generated for Kobushi, the CPU 37 uses each time t on the time axis with the pronunciation start time of the note NT (i) as the reference point t BS and the number of facial expression songs at those times t. Statistical data indicating the relationship with Num is generated, and the evaluation point VSR (t) corresponding to each time t in the facial expression song reference data DD a3 is rewritten based on the contents of the statistical data.
- FIG. 10 is a diagram illustrating an example of statistical data regarding Kobushi.
- appearance number Num expression singing between the reference point t BS and the reference point t BS than the time T2 a3 time after only t2 a3 are distributed.
- to be the reference point t BS time T1 a3 only after time t1 a3 maximum peak number of occurrences Num has appeared. Therefore, in the facial expression song reference data DD a3 after rewriting by the statistical data of this example, the evaluation point VSR (t1 a3 ) at the time t1 a3 is the highest.
- the CPU 37 searches for the characteristic waveform of the crisp from the pitch waveform indicated by each singing sample data DS stored in the singing sample database DBS, and the facial expression singing appearance data indicating the search result (the appearance of the crisp appears). generating a note NT data indicating each time t on the time axis of the reproduction starting time of (i) a reference point t BS). Subsequently, based on the expression song appearance data generated for the shackle, the CPU 37 uses each time t on the time axis with the pronunciation start time of the note NT (i) as a reference point t BS and the number of appearances of the expression song at those times t. Statistical data indicating the relationship with Num is generated, and the evaluation point VSR (t) corresponding to each time t in the facial expression song reference data DD a4 is rewritten based on the contents of the statistical data.
- FIG. 11 is a diagram illustrating an example of the statistical data regarding shackle.
- appearance number Num expression singing between the reference point t BS and the reference point t BS than the time T2 a4 time after only t2 a4 are distributed.
- the statistics in this example the reference point t BS have appeared up to the peak number of occurrences Num
- the time t1 a4 than the reference point t BS delayed by time T1 a4 is a second peak number of occurrences Num Appears.
- the evaluation point VSR (t BS ) at the time t BS is the highest, and the evaluation point VSR (t 1 a4 ) at the time t1 a4 is the second. Get higher.
- the CPU 37 searches for the characteristic waveform of the fall from within the pitch waveform indicated by each singing sample data DS stored in the singing sample database DBS, and the facial expression singing appearance data (fall has appeared) indicating this search result. generating a note NT data indicating each time t on the time axis of the reproduction starting time of (i) a reference point t BS).
- CPU 37 based on the expression singing occurrence data generated relates fall, the number of occurrences of facial expression singing at each time t and their time t on the time axis to the reproduction starting time of the notebook NT (i) as a reference point t BS Statistical data indicating the relationship with Num is generated, and the evaluation point VSR (t) corresponding to each time in the facial expression song reference data DD a5 is rewritten based on the contents of the statistical data.
- FIG. 12 is a diagram illustrating an example of statistical data regarding a fall.
- the statistics of this example the number of occurrences of facial expression singing between the reference point t BS than the time T1 a5 only after the time t1 a5 and time t BS from the time T2 a5 only after the time t2 a5 of Num is distributed .
- the maximum peak of the number of occurrences Num appears at time t2 a5 . Therefore, in the facial expression song reference data DD a5 after rewriting by the statistical data of this example, the evaluation point VSR (t2 a5 ) at time t2 a5 is the highest.
- the CPU 17 of the karaoke apparatus 10-m performs inquiry processing every time a predetermined inquiry time arrives (S110: Yes) (S170). In this inquiry process, the CPU 17 transmits a message MS2 for requesting transmission of the latest data to the server device 30 (S170).
- the CPU 37 of the server device 30 receives the message MS2 from the karaoke device 10-m (S210: Yes), the facial expression singing reference in which the contents are rewritten between the previous message MS2 reception time and the current message MS2 reception time.
- the data DD is transmitted to the karaoke apparatus 10-m that is the transmission source of the message M2 (S250).
- the CPU 17 of the karaoke apparatus 10-m overwrites the facial expression song reference data DD on the reference database DBRK and updates the content (S180).
- each time the characteristic waveform of the facial expression song appears in the waveform of the output signal of the vocal adapter 16 the pronunciation of the note NT (i) that is the target of the facial expression song is started.
- the appearance time of the feature waveform of the facial expression song on the time axis with the time as the reference point is obtained, and the evaluation point VSR (t) corresponding to this appearance time is selected from the evaluation points VSR (t) in the song reference data DD.
- the skill of singing is evaluated based on the selected evaluation point VSR (t). Therefore, according to this embodiment, even if the user performs facial expression singing, good evaluation cannot be obtained unless the timing is appropriate. Therefore, according to this embodiment, it is possible to present an evaluation result closer to that based on human sensitivity.
- the facial expression song characteristic waveform is searched from the waveform indicated by the data DD, and the facial expression song is obtained from the search result.
- Statistical data indicating the relationship between each time on the time axis with the pronunciation start time of the note NT (i) as a reference point being the reference point and the number of facial expression singings appearing at those times, and singing reference data DD
- the evaluation score VSR (t) corresponding to each time at is rewritten based on the contents of the statistical data. Therefore, according to this embodiment, the change of the tendency of how to sing advanced users who are singing a song can be reflected in the evaluation result.
- the present invention may have other embodiments.
- it is as follows.
- facial expressions other than these five types may be detected.
- a song with inflection may be detected.
- the CPU 17 performs the standard singing evaluation process using both the output signals S P and S L of the vocal adapter 16 and indicates the pitch among the output signals S P and S L of the vocal adapter 16. was facial expression singing evaluation process by using only the signal S P. However, CPU 17 may perform a standard singing evaluation process using only one signal S P and S L. Further, CPU 17 may perform facial expression singing evaluation process using both signals S P and S L.
- the skill of the song was evaluated based on the appearance time of the characteristic waveform of the facial expression song.
- the evaluation may be performed in consideration of elements other than the appearance time of the feature waveform of the facial expression song (for example, the length and depth of each of the choke, vibrato, kobushi, shakuri, and fall).
- a configuration is adopted in which a facial expression song that appears in the song sound corresponding to each of the notes included in the song song is adopted, but a series of plural songs included in the song song are included.
- the structure which detects the facial expression song which appears in the song sound according to the note (note group) may be employ
- a facial expression song such as crescendo decrescendo is a facial expression song performed in a series of notes, and it is desirable that detection and evaluation of those facial expressions be performed in units of notes. Therefore, it is desirable that the facial expression song reference data DD relating to such facial expression song is also configured in units of notes.
- the singing sample data DS (pitch) including the signals SP and S L output from the vocal adapter 16 to the server device 30 from the start to the end of the singing of the singing song.
- the sound volume data is transmitted, and the server apparatus 30 employs a configuration in which each facial expression song is detected from the singing sample data DS and the timing of the appearance is specified.
- the server device 30 from the karaoke device 10 transmits a sound signal S M indicating the picked-up sound (sound waveform data indicating the singing sound) by microphones 13, the sound signal S M in the server apparatus 30 processing for generating a signal S p and the signal S L (processing vocal adapter 16 in the above embodiment does) configuration may be employed that originate.
- the karaoke device 10 transmits to the server device 30 data (facial singing appearance data) indicating the type of facial expression singing specified in the facial expression singing evaluation processing (S140) performed in accordance with the singing evaluation program VPG and the timing of its appearance.
- the server device 30 may employ a configuration in which the facial expression song reference data DD is updated based on the facial expression song appearance data transmitted from the karaoke device 10 without performing facial expression song detection processing.
- the server device 30 generates statistical data and rewrites the facial expression song reference data DD based on the statistical data.
- each of the karaoke apparatuses 10-m generates a sound signal S M indicating a singing sound generated by the own apparatus in the past, or directly from another karaoke apparatus 10-m or via the server apparatus 30, and their sound signals S
- the signal S p and the signal S L generated from M , or data (expression song appearance data) indicating the type and expression timing of the expression song specified using these signals are stored in the hard disk 20, and the CPU 17 They may be read and used to perform processing similar to the processing performed by the server device 30 in S240, that is, generation of statistical data and rewriting of facial expression song reference data DD based thereon.
- the standard score SR NOR is calculated by summing the addition point SR ADD calculated based on the number of appearances of the expression song in the standard song evaluation process (S130) with the basic score SR BASE.
- the appearance of the facial expression singing is not taken into account, and a configuration for calculating only the basic score SR BASE may be adopted.
- the higher score of the standard score SR NOR scored by the standard song evaluation process and the expression score SR EX scored by the expression song evaluation process is displayed to the singer.
- the evaluation result for the singer may be presented in other manners such as displaying both and displaying their total score.
- a singer whose basic score SR BASE is higher than the standard score SR TH is regarded as an advanced person, and the facial expression singing reference is made using only the singing sample data DS relating to the advanced person.
- a configuration for updating the data DD is employed.
- the method of selecting the singing sample data DS used for updating the facial expression singing reference data DD is not limited to this.
- the basic score instead of the SR BASE, may be used standard scoring SR NOR that the sum of the summing junction SR ADD basic score SR BASE as the basis for advanced estimation.
- an upper threshold is provided in addition to a lower threshold (reference score SR TH ).
- the singing sample data DS of a singer with a higher basic score SR BASE (or other score) may not be used for updating the facial expression song reference data DD.
- the singing sample data DS of the singer with a high basic score SR BASE is given a high weight and the facial expression singing reference data DD is updated. You may make it use for.
- a performance evaluation device that evaluates a music performance
- a performance evaluation device that is provided in a karaoke device for singing and evaluates a singing performance is shown.
- the present invention is not limited to the evaluation of singing performances, and can be applied to the evaluation of musical performances using various musical instruments. That is, the term “singing” used in the above embodiment is replaced with the more general term “performance”. Note that in a performance evaluation device that evaluates instrumental music performance, for example, choking on a guitar, and the like, evaluation regarding facial expression performance corresponding to each instrument is performed.
- the karaoke apparatus for musical instrument performance uses, for example, data indicating the score and each section of the score (for example, the song data MD instead of the lyrics track TR LY (for example, The delta time indicating the display time of 2 bars or 4 bars) is configured to include a score track which is data described in chronological order, and the sequencer 21 and the display unit 14 follow the score track to progress the music. Accordingly, an image signal indicating a musical score corresponding to the accompaniment location is output to the display.
- the image signal output processing by the sequencer 21 and the display unit 14 may not be performed.
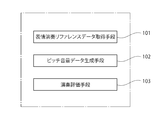
- the performance evaluation apparatus is such that, as illustrated in FIG. Facial expression performance reference data acquisition means 101 for acquiring facial expression performance reference data that indicates the timing to be performed in reference to the pronunciation start time of a note or note group included in the music, and the performance from the performance sound of the music by the performer Pitch volume data generation means 102 for generating pitch volume data indicating the pitch and volume of sound, and at least one of the characteristics of pitch and volume indicated by the pitch volume data generated by the pitch volume data generation means 102 is Within a predetermined time range indicated by the expression performance reference data in the music
- a performance evaluation means 103 for improving the performance of the music performed by the performer when the expression performance characteristics are supposed to be performed by the expression performance reference data. Expressed, the presence or absence of other elements and the specific mode of other elements are arbitrary.
- the performance evaluation device according to the present invention is not limited to a dedicated device.
- a configuration that realizes the performance evaluation device according to the present invention by causing various devices such as a personal computer, a portable information terminal (for example, a mobile phone or a smart phone), and a game device to perform processing according to a program is adopted.
- this program can be distributed by being stored in a recording medium such as a CD-ROM, or can be distributed by using an electric communication line such as the Internet.
- This application is based on Japanese Patent Application No. 2012-094853 filed on Apr. 18, 2012, the contents of which are incorporated herein by reference.
- SYMBOLS 1 Singing evaluation system, 10 ... Karaoke apparatus, 11 ... Sound source, 12 ... Speaker, 13 ... Microphone, 14 ... Display part, 15 ... Communication interface, 16 ... Vocal adapter, 17 ... CPU, 18 ... RAM, 19 ... ROM, DESCRIPTION OF SYMBOLS 20 ... Hard disk, 21 ... Sequencer, 30 ... Server apparatus, 35 ... Communication interface, 37 ... CPU, 38 ... RAM, 39 ... ROM, 40 ... Hard disk, 90 ... Network
Landscapes
- Engineering & Computer Science (AREA)
- Multimedia (AREA)
- Physics & Mathematics (AREA)
- Acoustics & Sound (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Human Computer Interaction (AREA)
- Health & Medical Sciences (AREA)
- Signal Processing (AREA)
- Computational Linguistics (AREA)
- Business, Economics & Management (AREA)
- Educational Administration (AREA)
- Educational Technology (AREA)
- General Physics & Mathematics (AREA)
- Theoretical Computer Science (AREA)
- Auxiliary Devices For Music (AREA)
- Reverberation, Karaoke And Other Acoustics (AREA)
- Electrophonic Musical Instruments (AREA)
Abstract
This performance evaluation device is provided with: an expressiveness reference data acquisition means that acquires expressiveness reference data that shows expressiveness that should be achieved during the performance of a piece of music and timing at which the expressiveness should be achieved for that piece of music with utterance start timing for notes or note groups included in the piece of music as a standard; a pitch and volume data generating means that generates pitch and volume data showing the pitch and volume of the performance sound from the performance sound of the piece of music by a performer; and a performance evaluation means that improves evaluation of the performance of the piece of music by the performer when at least one of the characteristics of pitch and volume shown by the pitch and volume data generated by the pitch and volume data generating means exhibits expressiveness characteristics that should be achieved according to the expressiveness reference data within a prescribed time range shown by the expressiveness reference data for the piece of music.
Description
この発明は、楽曲演奏の巧拙を評価する技術に関する。
This invention relates to a technique for evaluating the skill of music performance.
例えば、歌唱者の歌唱演奏の巧拙を採点する採点機能を備えた歌唱用のカラオケ装置(以下、特に断らない限り、単に「カラオケ装置」という)に関わる技術が各種提案されている。この種の技術を開示した文献として、特許文献1がある。同文献に開示されたカラオケ装置は、利用者の歌唱音から抽出したピッチとガイドメロディとしてあらかじめ準備されたデータから抽出したピッチとの差分を歌唱曲のノート毎に算出し、この差分に基づいて基本得点を算出する。また、このカラオケ装置は、ビブラートやしゃくりなどの技法を駆使した歌唱が行われた場合にはその歌唱が行われた回数に応じたボーナスポイントを算出する。このカラオケ装置は、基本得点とボーナスポイントの合計点を最終的な評価結果として利用者に提示する。この技術によると、ビブラートやしゃくりなどといった難度の高い技法を駆使した歌唱を評価結果に反映させることができる。
For example, various techniques relating to a karaoke apparatus for singing having a scoring function for scoring the skill of a singer's singing performance (hereinafter simply referred to as “karaoke apparatus” unless otherwise specified) have been proposed. There is Patent Document 1 as a document disclosing this kind of technology. The karaoke device disclosed in this document calculates the difference between the pitch extracted from the user's singing sound and the pitch extracted from the data prepared in advance as the guide melody for each note of the singing song, and based on this difference Calculate the basic score. Moreover, this karaoke apparatus calculates the bonus point according to the frequency | count that the singing was performed, when the singing using techniques, such as a vibrato and a shawl, was performed. This karaoke device presents the total score of the basic score and bonus points to the user as the final evaluation result. According to this technology, singing that makes full use of highly difficult techniques such as vibrato and shackle can be reflected in the evaluation results.
また、歌唱音を示す波形から、ビブラートやしゃくりなどの技法を用いた歌唱が行われたことを検出する技術を開示した文献として、例えば特許文献2乃至6がある。
Further, for example, Patent Documents 2 to 6 disclose documents that disclose a technique for detecting a singing using a technique such as vibrato or shackle from a waveform indicating a singing sound.
しかしながら、特許文献1の技術の場合、本来であればビブラートやしゃくりなどの技法を駆使した歌唱を行うことが好ましくない歌唱箇所についてそのような歌唱が行われた場合であっても、ボーナスポイントが加算されてしまう。このため、評価結果として提示される得点が人間の感性によるものと乖離してしまうという問題があった。
However, in the case of the technique of Patent Document 1, even if such singing is performed for a singing place where it is not preferable to perform singing using techniques such as vibrato and shackle, It will be added. For this reason, there is a problem that the score presented as the evaluation result deviates from that due to human sensitivity.
本発明は、このような課題に鑑みてなされたものであり、カラオケ歌唱等の楽曲演奏の評価において、人間の感性によるものにより近い評価結果を提示できるようにすることを目的とする。
The present invention has been made in view of such a problem, and an object of the present invention is to make it possible to present an evaluation result closer to human sensitivity in the evaluation of music performance such as karaoke singing.
上記課題を解決するため、本発明は、楽曲の演奏中に行われるべき表情演奏と当該表情演奏が前記楽曲において行われるべきタイミングを前記楽曲に含まれるノートまたはノート群の発音開始時刻を基準として示す表情演奏リファレンスデータを取得する表情演奏リファレンスデータ取得手段と、演奏者による前記楽曲の演奏音から当該演奏音のピッチおよび音量を示すピッチ音量データを生成するピッチ音量データ生成手段と、前記ピッチ音量データ生成手段により生成された前記ピッチ音量データにより示されるピッチおよび音量の少なくとも一方の特性が、前記楽曲における前記表情演奏リファレンスデータにより示される所定時間範囲内において前記表情演奏リファレンスデータにより行われるべきであるとされる表情演奏の特性を示す場合、前記演奏者による前記楽曲の演奏に対する評価を向上させる演奏評価手段とを備える演奏評価装置を提供する。
In order to solve the above-mentioned problems, the present invention relates to the expression performance to be performed during the performance of the music and the timing at which the expression performance should be performed in the music with reference to the pronunciation start time of the note or note group included in the music. Facial expression performance reference data acquisition means for acquiring facial expression performance reference data to indicate, pitch volume data generation means for generating pitch volume data indicating the pitch and volume of the performance sound from the performance sound of the music by the performer, and the pitch volume At least one characteristic of pitch and volume indicated by the pitch volume data generated by the data generation means should be performed by the facial expression performance reference data within a predetermined time range indicated by the facial expression performance reference data in the music piece. Characteristics of facial expression performance If shown, it provides a performance evaluation apparatus and a playing evaluating means to improve the evaluation of the performance of the music by the player.
また、本発明は、上記の演奏評価装置と、楽曲の伴奏を指示する伴奏データを取得する伴奏データ取得手段と、前記伴奏データの指示に従い伴奏の楽音を示す音信号を出力する音信号出力手段とを備え、前記ピッチ音量データ生成手段は、前記音信号出力手段から出力された音信号に従いスピーカから放音された伴奏に応じて前記演奏者により行われた前記楽曲の演奏音のピッチおよび音量を示すピッチ音量データを生成するカラオケ装置を提供する。
The present invention also provides the performance evaluation apparatus, accompaniment data acquisition means for acquiring accompaniment data for instructing accompaniment of music, and sound signal output means for outputting a sound signal indicating a musical sound of accompaniment according to the instruction of the accompaniment data The pitch volume data generation means includes the pitch and volume of the performance sound of the music performed by the performer according to the accompaniment emitted from a speaker according to the sound signal output from the sound signal output means A karaoke apparatus for generating pitch sound volume data indicating the above is provided.
また、本発明は、任意数の任意の演奏者による楽曲の演奏音の各々に関し、前記楽曲に含まれるノートまたはノート群の発音開始時刻を基準とする一のタイミングにおいて一の表情演奏が出現したことを示す表情演奏出現データを取得する表情演奏出現データ取得手段と、前記表情演奏出現データ取得手段により取得された任意数の表情演奏出現データに基づき、前記楽曲に含まれるノートまたはノート群の各々に関し、当該ノートまたはノート群の発音開始時刻を基準とするいずれのタイミングでいずれの表情演奏がいずれの頻度で出現しているかを特定し、当該特定した情報に従い、前記楽曲の演奏中に行われるべき表情演奏と当該表情演奏が前記楽曲において行われるべきタイミングを前記楽曲に含まれるノートまたはノート群の発音開始時刻を基準として示す表情演奏リファレンスデータを生成する表情演奏リファレンスデータ生成手段と、前記表情演奏リファレンスデータ生成手段により生成された表情演奏リファレンスデータを演奏評価装置に送信する送信手段とを備えるサーバ装置を提供する。
また、本発明は、歌唱評価システムであって、楽曲の演奏中に行われるべき表情演奏と当該表情演奏が前記楽曲において行われるべきタイミングを前記楽曲に含まれるノートまたはノート群の発音開始時刻を基準として示す第一表情演奏リファレンスデータを取得する表情演奏リファレンスデータ取得手段と、 演奏者による前記楽曲の演奏音から当該演奏音のピッチおよび音量を示すピッチ音量データを生成するピッチ音量データ生成手段と、前記ピッチ音量データ生成手段により生成された前記ピッチ音量データにより示されるピッチおよび音量の少なくとも一方の特性が、前記楽曲における前記第一表情演奏リファレンスデータにより示される所定時間範囲内において前記第一表情演奏リファレンスデータにより行われるべきであるとされる表情演奏の特性を示す場合、前記演奏者による前記楽曲の演奏に対する評価を向上させる演奏評価手段と、任意数の任意の演奏者による楽曲の演奏音の各々に関し、前記任意の演奏者による前記楽曲に含まれるノートまたはノート群の発音開始時刻を基準とする一のタイミングにおいて一の表情演奏が出現したことを示す表情演奏出現データを取得する表情演奏出現データ取得手段と、前記表情演奏出現データ取得手段により取得された任意数の表情演奏出現データに基づき、前記任意の演奏者による楽曲に含まれるノートまたはノート群の各々に関し、当該ノートまたはノート群の発音開始時刻を基準とするいずれのタイミングでいずれの表情演奏がいずれの頻度で出現しているかを特定し、当該特定した情報に従い、前記任意の演奏者による楽曲の演奏中に行われるべき表情演奏と当該表情演奏が前記任意の演奏者による楽曲において行われるべきタイミングを前記任意の演奏者による楽曲に含まれるノートまたはノート群の発音開始時刻を基準として示す第二表情演奏リファレンスデータを生成する表情演奏リファレンスデータ生成手段と、を備える歌唱評価システムを提供する。
また、本発明は、楽曲の演奏中に行われるべき表情演奏と当該表情演奏が前記楽曲において行われるべきタイミングを前記楽曲に含まれるノートまたはノート群の発音開始時刻を基準として示す表情演奏リファレンスデータを取得し、演奏者による前記楽曲の演奏音から当該演奏音のピッチおよび音量を示すピッチ音量データを生成し、前記ピッチ音量データにより示されるピッチおよび音量の少なくとも一方の特性が、前記楽曲における前記表情演奏リファレンスデータにより示される所定時間範囲内において前記表情演奏リファレンスデータにより行われるべきであるとされる表情演奏の特性を示す場合、前記演奏者による前記楽曲の演奏に対する評価を向上させる演奏評価方法を提供する。
また、本発明は、コンピュータが実行可能なプログラムであって、楽曲の演奏中に行われるべき表情演奏と当該表情演奏が前記楽曲において行われるべきタイミングを前記楽曲に含まれるノートまたはノート群の発音開始時刻を基準として示す表情演奏リファレンスデータを取得する表情演奏リファレンスデータ取得処理と、演奏者による前記楽曲の演奏音から当該演奏音のピッチおよび音量を示すピッチ音量データを生成するピッチ音量データ生成処理と、前記ピッチ音量データ生成手段により生成された前記ピッチ音量データにより示されるピッチおよび音量の少なくとも一方の特性が、前記楽曲における前記表情演奏リファレンスデータにより示される所定時間範囲内において前記表情演奏リファレンスデータにより行われるべきであるとされる表情演奏の特性を示す場合、前記演奏者による前記楽曲の演奏に対する評価を向上させる演奏評価処理とを前記コンピュータに実行させるプログラムを提供する。 Further, the present invention relates to each of the performance sounds of music by an arbitrary number of arbitrary performers, and one facial expression performance appears at one timing based on the pronunciation start time of notes or note groups included in the music Each of a note or a group of notes included in the music based on an expression performance appearance data acquisition means for acquiring expression performance appearance data indicating that, and an arbitrary number of expression performance appearance data acquired by the expression performance appearance data acquisition means Is performed during the performance of the musical piece according to the specified information, specifying which facial expression performance appears at which timing with reference to the sound generation start time of the note or group of notes. The expression of a note or a group of notes included in the music indicates the power expression performance and the timing at which the expression performance should be performed in the music A server apparatus comprising facial expression performance reference data generating means for generating facial expression performance reference data indicating the start time as reference, and transmitting means for transmitting facial expression performance reference data generated by the facial expression performance reference data generating means to the performance evaluation apparatus I will provide a.
Further, the present invention is a singing evaluation system, wherein a facial expression performance to be performed during the performance of a musical piece and a timing at which the facial expression performance is to be performed in the musical piece are determined as a pronunciation start time of a note or a note group included in the musical piece. Facial expression performance reference data acquisition means for acquiring first facial expression performance reference data shown as a reference; pitch volume data generation means for generating pitch volume data indicating the pitch and volume of the performance sound from the performance sound of the music by the performer; And at least one of the pitch and volume characteristics indicated by the pitch volume data generated by the pitch volume data generation means is within the predetermined time range indicated by the first facial expression performance reference data in the music. Should be done with performance reference data The performance evaluation means for improving the performance of the music performed by the performer and each of the performance sounds of the music performed by an arbitrary number of the performers. Expression performance appearance data acquisition means for acquiring expression performance appearance data indicating that one expression performance has appeared at one timing based on a pronunciation start time of a note or a group of notes included in the music, and the expression performance appearance data Based on the arbitrary number of facial expression performance appearance data acquired by the acquisition means, any timing with respect to each note or group of notes included in the musical piece by the arbitrary player based on the pronunciation start time of the notes or group of notes And which facial expression performance appears at what frequency, and according to the identified information, the arbitrary performance The facial expression performance to be performed during the performance of the musical piece by and the timing at which the facial expression performance should be performed in the musical piece by the arbitrary player, based on the pronunciation start time of the note or the note group included in the musical piece by the arbitrary player There is provided a singing evaluation system comprising expression performance reference data generating means for generating second expression performance reference data to be shown.
The present invention also provides facial expression performance reference data that indicates the facial expression performance to be performed during the performance of a musical piece and the timing at which the facial expression performance is to be performed in the musical piece, with reference to the pronunciation start time of the note or note group included in the musical piece. And generating pitch volume data indicating the pitch and volume of the performance sound from the performance sound of the music by the performer, and at least one of the characteristics of the pitch and volume indicated by the pitch volume data is A performance evaluation method for improving the performance of the music performed by the performer when the characteristics of the facial expression performance that should be performed by the expression performance reference data within a predetermined time range indicated by the expression performance reference data I will provide a.
In addition, the present invention is a computer-executable program, in which a facial expression performance to be performed during the performance of a musical piece and a timing at which the facial expression performance should be performed in the musical piece are pronounced in a note or a group of notes included in the musical piece Expression performance reference data acquisition processing for acquiring expression performance reference data indicating the start time as a reference, and pitch volume data generation processing for generating pitch volume data indicating the pitch and volume of the performance sound from the performance sound of the music by the performer And at least one of the pitch and volume characteristics indicated by the pitch volume data generated by the pitch volume data generation means is within the predetermined time range indicated by the expression performance reference data in the music piece. Should be done by When showing the characteristics of the expression performance that is, to provide a program for executing a performance evaluation process for improving the evaluation of the performance of the music by the player to the computer.
また、本発明は、歌唱評価システムであって、楽曲の演奏中に行われるべき表情演奏と当該表情演奏が前記楽曲において行われるべきタイミングを前記楽曲に含まれるノートまたはノート群の発音開始時刻を基準として示す第一表情演奏リファレンスデータを取得する表情演奏リファレンスデータ取得手段と、 演奏者による前記楽曲の演奏音から当該演奏音のピッチおよび音量を示すピッチ音量データを生成するピッチ音量データ生成手段と、前記ピッチ音量データ生成手段により生成された前記ピッチ音量データにより示されるピッチおよび音量の少なくとも一方の特性が、前記楽曲における前記第一表情演奏リファレンスデータにより示される所定時間範囲内において前記第一表情演奏リファレンスデータにより行われるべきであるとされる表情演奏の特性を示す場合、前記演奏者による前記楽曲の演奏に対する評価を向上させる演奏評価手段と、任意数の任意の演奏者による楽曲の演奏音の各々に関し、前記任意の演奏者による前記楽曲に含まれるノートまたはノート群の発音開始時刻を基準とする一のタイミングにおいて一の表情演奏が出現したことを示す表情演奏出現データを取得する表情演奏出現データ取得手段と、前記表情演奏出現データ取得手段により取得された任意数の表情演奏出現データに基づき、前記任意の演奏者による楽曲に含まれるノートまたはノート群の各々に関し、当該ノートまたはノート群の発音開始時刻を基準とするいずれのタイミングでいずれの表情演奏がいずれの頻度で出現しているかを特定し、当該特定した情報に従い、前記任意の演奏者による楽曲の演奏中に行われるべき表情演奏と当該表情演奏が前記任意の演奏者による楽曲において行われるべきタイミングを前記任意の演奏者による楽曲に含まれるノートまたはノート群の発音開始時刻を基準として示す第二表情演奏リファレンスデータを生成する表情演奏リファレンスデータ生成手段と、を備える歌唱評価システムを提供する。
また、本発明は、楽曲の演奏中に行われるべき表情演奏と当該表情演奏が前記楽曲において行われるべきタイミングを前記楽曲に含まれるノートまたはノート群の発音開始時刻を基準として示す表情演奏リファレンスデータを取得し、演奏者による前記楽曲の演奏音から当該演奏音のピッチおよび音量を示すピッチ音量データを生成し、前記ピッチ音量データにより示されるピッチおよび音量の少なくとも一方の特性が、前記楽曲における前記表情演奏リファレンスデータにより示される所定時間範囲内において前記表情演奏リファレンスデータにより行われるべきであるとされる表情演奏の特性を示す場合、前記演奏者による前記楽曲の演奏に対する評価を向上させる演奏評価方法を提供する。
また、本発明は、コンピュータが実行可能なプログラムであって、楽曲の演奏中に行われるべき表情演奏と当該表情演奏が前記楽曲において行われるべきタイミングを前記楽曲に含まれるノートまたはノート群の発音開始時刻を基準として示す表情演奏リファレンスデータを取得する表情演奏リファレンスデータ取得処理と、演奏者による前記楽曲の演奏音から当該演奏音のピッチおよび音量を示すピッチ音量データを生成するピッチ音量データ生成処理と、前記ピッチ音量データ生成手段により生成された前記ピッチ音量データにより示されるピッチおよび音量の少なくとも一方の特性が、前記楽曲における前記表情演奏リファレンスデータにより示される所定時間範囲内において前記表情演奏リファレンスデータにより行われるべきであるとされる表情演奏の特性を示す場合、前記演奏者による前記楽曲の演奏に対する評価を向上させる演奏評価処理とを前記コンピュータに実行させるプログラムを提供する。 Further, the present invention relates to each of the performance sounds of music by an arbitrary number of arbitrary performers, and one facial expression performance appears at one timing based on the pronunciation start time of notes or note groups included in the music Each of a note or a group of notes included in the music based on an expression performance appearance data acquisition means for acquiring expression performance appearance data indicating that, and an arbitrary number of expression performance appearance data acquired by the expression performance appearance data acquisition means Is performed during the performance of the musical piece according to the specified information, specifying which facial expression performance appears at which timing with reference to the sound generation start time of the note or group of notes. The expression of a note or a group of notes included in the music indicates the power expression performance and the timing at which the expression performance should be performed in the music A server apparatus comprising facial expression performance reference data generating means for generating facial expression performance reference data indicating the start time as reference, and transmitting means for transmitting facial expression performance reference data generated by the facial expression performance reference data generating means to the performance evaluation apparatus I will provide a.
Further, the present invention is a singing evaluation system, wherein a facial expression performance to be performed during the performance of a musical piece and a timing at which the facial expression performance is to be performed in the musical piece are determined as a pronunciation start time of a note or a note group included in the musical piece. Facial expression performance reference data acquisition means for acquiring first facial expression performance reference data shown as a reference; pitch volume data generation means for generating pitch volume data indicating the pitch and volume of the performance sound from the performance sound of the music by the performer; And at least one of the pitch and volume characteristics indicated by the pitch volume data generated by the pitch volume data generation means is within the predetermined time range indicated by the first facial expression performance reference data in the music. Should be done with performance reference data The performance evaluation means for improving the performance of the music performed by the performer and each of the performance sounds of the music performed by an arbitrary number of the performers. Expression performance appearance data acquisition means for acquiring expression performance appearance data indicating that one expression performance has appeared at one timing based on a pronunciation start time of a note or a group of notes included in the music, and the expression performance appearance data Based on the arbitrary number of facial expression performance appearance data acquired by the acquisition means, any timing with respect to each note or group of notes included in the musical piece by the arbitrary player based on the pronunciation start time of the notes or group of notes And which facial expression performance appears at what frequency, and according to the identified information, the arbitrary performance The facial expression performance to be performed during the performance of the musical piece by and the timing at which the facial expression performance should be performed in the musical piece by the arbitrary player, based on the pronunciation start time of the note or the note group included in the musical piece by the arbitrary player There is provided a singing evaluation system comprising expression performance reference data generating means for generating second expression performance reference data to be shown.
The present invention also provides facial expression performance reference data that indicates the facial expression performance to be performed during the performance of a musical piece and the timing at which the facial expression performance is to be performed in the musical piece, with reference to the pronunciation start time of the note or note group included in the musical piece. And generating pitch volume data indicating the pitch and volume of the performance sound from the performance sound of the music by the performer, and at least one of the characteristics of the pitch and volume indicated by the pitch volume data is A performance evaluation method for improving the performance of the music performed by the performer when the characteristics of the facial expression performance that should be performed by the expression performance reference data within a predetermined time range indicated by the expression performance reference data I will provide a.
In addition, the present invention is a computer-executable program, in which a facial expression performance to be performed during the performance of a musical piece and a timing at which the facial expression performance should be performed in the musical piece are pronounced in a note or a group of notes included in the musical piece Expression performance reference data acquisition processing for acquiring expression performance reference data indicating the start time as a reference, and pitch volume data generation processing for generating pitch volume data indicating the pitch and volume of the performance sound from the performance sound of the music by the performer And at least one of the pitch and volume characteristics indicated by the pitch volume data generated by the pitch volume data generation means is within the predetermined time range indicated by the expression performance reference data in the music piece. Should be done by When showing the characteristics of the expression performance that is, to provide a program for executing a performance evaluation process for improving the evaluation of the performance of the music by the player to the computer.
本発明によれば、個々の楽曲の演奏において、望ましいタイミングで望ましい表情演奏が行われると、演奏者に対し高い評価を与える演奏評価装置が実現される。その結果、演奏者により表情演奏が行われた場合、人間の感性との乖離の少ない評価がなされる。
According to the present invention, when a desired facial expression performance is performed at a desired timing in the performance of each piece of music, a performance evaluation device that gives a high evaluation to the performer is realized. As a result, when an expression performance is performed by the performer, the evaluation is performed with little deviation from human sensitivity.
以下、図面を参照し、この発明の実施の形態を説明する。
図1は、本発明の一実施形態である歌唱評価システム1の構成を示す図である。この歌唱評価システム1は、カラオケ装置10-m(m=1、2…M:Mはカラオケ装置の総数)とサーバ装置30とを有する。カラオケ装置10-mは、各カラオケ店に一台または複数台ずつ設置される。サーバ装置30は、システム運営センタ内に設置される。カラオケ装置10-mとサーバ装置30はネットワーク90に接続され、互いに各種データの送受信が可能である。 Embodiments of the present invention will be described below with reference to the drawings.
FIG. 1 is a diagram showing a configuration of a singing evaluation system 1 according to an embodiment of the present invention. The singing evaluation system 1 includes a karaoke device 10-m (m = 1, 2,... M: M is the total number of karaoke devices) and a server device 30. One or a plurality of karaoke apparatuses 10-m are installed in each karaoke store. The server device 30 is installed in the system management center. The karaoke apparatus 10-m and the server apparatus 30 are connected to thenetwork 90, and can transmit and receive various data to and from each other.
図1は、本発明の一実施形態である歌唱評価システム1の構成を示す図である。この歌唱評価システム1は、カラオケ装置10-m(m=1、2…M:Mはカラオケ装置の総数)とサーバ装置30とを有する。カラオケ装置10-mは、各カラオケ店に一台または複数台ずつ設置される。サーバ装置30は、システム運営センタ内に設置される。カラオケ装置10-mとサーバ装置30はネットワーク90に接続され、互いに各種データの送受信が可能である。 Embodiments of the present invention will be described below with reference to the drawings.
FIG. 1 is a diagram showing a configuration of a singing evaluation system 1 according to an embodiment of the present invention. The singing evaluation system 1 includes a karaoke device 10-m (m = 1, 2,... M: M is the total number of karaoke devices) and a server device 30. One or a plurality of karaoke apparatuses 10-m are installed in each karaoke store. The server device 30 is installed in the system management center. The karaoke apparatus 10-m and the server apparatus 30 are connected to the
カラオケ装置10-mは、利用者の歌唱を支える伴奏曲の放音と歌詞の表示とを通じた歌唱演出と、利用者の歌唱の巧拙の評価とを行う装置である。ここで、カラオケ装置10-mは、歌唱の巧拙の評価では、利用者の歌唱音のピッチ及び音量の良否を評価対象とする評価と、以下に示す5種類の表情歌唱の良否を評価対象とする評価とを行い、2つの評価の評価結果である得点をコメントメッセージとともに利用者に提示する。
a1.タメ
これは、歌唱曲内の特定の音の歌いだしを故意に遅らせる表情歌唱である。図2に示すように、この歌唱が行われた場合、歌唱音の前の音のものから当該音のものへと音のピッチが変化する時刻が楽譜(模範的な歌唱)における両音に対応する2つのノート(音符)の遷移時刻よりも僅かな時間だけ遅れる。
b1.ビブラート
これは、歌唱曲内の特定の音を見かけのピッチを保ちつつ細かく震わせる表情歌唱である。図3に示すように、この歌唱が行われた場合、歌唱音のピッチは楽譜におけるその音に対応するノートの高さを跨いで周期的に変化する。
c1.コブシ
これは、歌唱曲内の特定の音の声色を発音の途中でうなるように変化させる表情歌唱である。図4に示すように、この歌唱が行われた場合、歌唱音のピッチは楽譜におけるその音に対応するノートの途中で一過的に上昇する。
d1.シャクリ
これは、歌唱曲内の特定の音を本来の高さよりも低い声で発音してから本来の高さに近づけていく歌唱手法である。図5に示すように、この歌唱が行われた場合、歌唱音の発音開始時刻におけるピッチは楽譜におけるその音に対応するノートの高さよりも低くなる。そして、この歌唱音のピッチは発音開始後に緩やかに上昇してノートの高さとほぼ同じ高さに達する。
e1.フォール
これは、歌唱曲内の特定の音を本来の高さよりも高い声で発音してから本来の高さに近づけていく歌唱手法である。図6に示すように、この歌唱が行われた場合、歌唱音の発音始時刻におけるピッチは楽譜におけるその音に対応するノートの高さよりも高くなる。そして、この歌唱音のピッチは発音開始後に緩やかに下降してノートの高さとほぼ同じ高さに達する。 The karaoke device 10-m is a device that performs singing effects through sound emission of accompaniment music that supports the user's singing and display of lyrics, and evaluation of the skill of the user's singing. Here, the karaoke apparatus 10-m evaluates the skill of the singing skill by evaluating the pitch and volume of the user's singing sound and the following five types of facial expression singing. The score that is the evaluation result of the two evaluations is presented to the user together with the comment message.
a1. Tame This is a facial expression song that intentionally delays the singing of a specific sound in the song. As shown in FIG. 2, when this singing is performed, the time at which the pitch of the sound changes from the sound before the singing sound to that of the sound corresponds to both sounds in the score (exemplary singing). It is delayed by a slight time from the transition time of the two notes (notes).
b1. Vibrato This is a facial expression song that vibrates finely while maintaining the apparent pitch of a specific sound in the song. As shown in FIG. 3, when this singing is performed, the pitch of the singing sound periodically changes across the height of the note corresponding to the sound in the score.
c1. Kobushi This is a facial expression song that changes the tone of a specific sound in the song so that it sings during pronunciation. As shown in FIG. 4, when this singing is performed, the pitch of the singing sound rises temporarily in the middle of the note corresponding to the sound in the score.
d1. Shakuri This is a singing technique in which a specific sound in a song is pronounced with a voice lower than the original pitch and then brought close to the original pitch. As shown in FIG. 5, when this singing is performed, the pitch of the singing sound at the sounding start time is lower than the height of the note corresponding to the sound in the score. Then, the pitch of this singing sound rises slowly after the start of sounding and reaches almost the same height as the note.
e1. Fall This is a singing technique in which a specific sound in a song is pronounced with a voice higher than its original height and then brought close to its original height. As shown in FIG. 6, when this singing is performed, the pitch of the singing sound at the sounding start time is higher than the height of the note corresponding to the sound in the score. The pitch of the singing sound gradually falls after the start of sounding and reaches almost the same height as the note.
a1.タメ
これは、歌唱曲内の特定の音の歌いだしを故意に遅らせる表情歌唱である。図2に示すように、この歌唱が行われた場合、歌唱音の前の音のものから当該音のものへと音のピッチが変化する時刻が楽譜(模範的な歌唱)における両音に対応する2つのノート(音符)の遷移時刻よりも僅かな時間だけ遅れる。
b1.ビブラート
これは、歌唱曲内の特定の音を見かけのピッチを保ちつつ細かく震わせる表情歌唱である。図3に示すように、この歌唱が行われた場合、歌唱音のピッチは楽譜におけるその音に対応するノートの高さを跨いで周期的に変化する。
c1.コブシ
これは、歌唱曲内の特定の音の声色を発音の途中でうなるように変化させる表情歌唱である。図4に示すように、この歌唱が行われた場合、歌唱音のピッチは楽譜におけるその音に対応するノートの途中で一過的に上昇する。
d1.シャクリ
これは、歌唱曲内の特定の音を本来の高さよりも低い声で発音してから本来の高さに近づけていく歌唱手法である。図5に示すように、この歌唱が行われた場合、歌唱音の発音開始時刻におけるピッチは楽譜におけるその音に対応するノートの高さよりも低くなる。そして、この歌唱音のピッチは発音開始後に緩やかに上昇してノートの高さとほぼ同じ高さに達する。
e1.フォール
これは、歌唱曲内の特定の音を本来の高さよりも高い声で発音してから本来の高さに近づけていく歌唱手法である。図6に示すように、この歌唱が行われた場合、歌唱音の発音始時刻におけるピッチは楽譜におけるその音に対応するノートの高さよりも高くなる。そして、この歌唱音のピッチは発音開始後に緩やかに下降してノートの高さとほぼ同じ高さに達する。 The karaoke device 10-m is a device that performs singing effects through sound emission of accompaniment music that supports the user's singing and display of lyrics, and evaluation of the skill of the user's singing. Here, the karaoke apparatus 10-m evaluates the skill of the singing skill by evaluating the pitch and volume of the user's singing sound and the following five types of facial expression singing. The score that is the evaluation result of the two evaluations is presented to the user together with the comment message.
a1. Tame This is a facial expression song that intentionally delays the singing of a specific sound in the song. As shown in FIG. 2, when this singing is performed, the time at which the pitch of the sound changes from the sound before the singing sound to that of the sound corresponds to both sounds in the score (exemplary singing). It is delayed by a slight time from the transition time of the two notes (notes).
b1. Vibrato This is a facial expression song that vibrates finely while maintaining the apparent pitch of a specific sound in the song. As shown in FIG. 3, when this singing is performed, the pitch of the singing sound periodically changes across the height of the note corresponding to the sound in the score.
c1. Kobushi This is a facial expression song that changes the tone of a specific sound in the song so that it sings during pronunciation. As shown in FIG. 4, when this singing is performed, the pitch of the singing sound rises temporarily in the middle of the note corresponding to the sound in the score.
d1. Shakuri This is a singing technique in which a specific sound in a song is pronounced with a voice lower than the original pitch and then brought close to the original pitch. As shown in FIG. 5, when this singing is performed, the pitch of the singing sound at the sounding start time is lower than the height of the note corresponding to the sound in the score. Then, the pitch of this singing sound rises slowly after the start of sounding and reaches almost the same height as the note.
e1. Fall This is a singing technique in which a specific sound in a song is pronounced with a voice higher than its original height and then brought close to its original height. As shown in FIG. 6, when this singing is performed, the pitch of the singing sound at the sounding start time is higher than the height of the note corresponding to the sound in the score. The pitch of the singing sound gradually falls after the start of sounding and reaches almost the same height as the note.
図1に戻り、歌唱評価システム1全体の説明を続ける。カラオケ装置10-mは、音源11、スピーカ12、マイクロホン13、表示部14、通信インターフェース15、ボーカルアダプタ16、CPU17、RAM18、ROM19、ハードディスク20、シーケンサ21を有する。音源11は、MIDI(Musical Instrument Digital Interface)の各種メッセージに従った音信号SAを出力する。スピーカ12は、与えられた信号を音として放音する。マイクロホン13は、音を収音して収音信号SMを出力する。表示部14は、画像信号SIに応じた画像を表示する。通信インターフェース15は、ネットワーク90に接続された装置との間でデータを送受信する。
Returning to FIG. 1, the explanation of the entire singing evaluation system 1 will be continued. The karaoke apparatus 10-m includes a sound source 11, a speaker 12, a microphone 13, a display unit 14, a communication interface 15, a vocal adapter 16, a CPU 17, a RAM 18, a ROM 19, a hard disk 20, and a sequencer 21. Sound source 11 outputs a sound signal S A in accordance with the various messages of MIDI (Musical Instrument Digital Interface). The speaker 12 emits a given signal as sound. The microphone 13 collects sound and outputs a sound collection signal S M. The display unit 14 displays an image corresponding to the image signal S I. The communication interface 15 transmits / receives data to / from devices connected to the network 90.
ボーカルアダプタ16は、音信号SMのピッチ及び音量を測定し、それらの時間的な変化を示すピッチ音量データを生成する。具体的には、ボーカルアダプタ16は、マイクロホン13から与えられた音信号SMのピッチを時間TS(例えば、TS=30ミリ秒とする)毎に検出し、この検出結果を信号SPとして出力する。また、ボーカルアダプタ16は、マイクロホン13から与えられた音信号SMの音量を時間TS毎に検出し、この検出結果を信号SLとして出力する。
The vocal adapter 16 measures the pitch and volume of the sound signal S M , and generates pitch volume data indicating their temporal changes. Specifically, the vocal adapter 16 detects the pitch of the sound signal S M given from the microphone 13 every time T S (for example, T S = 30 milliseconds), and the detection result is the signal S P. Output as. The vocal adapter 16 detects the volume of the sound signal S M given from the microphone 13 every time T S and outputs the detection result as a signal S L.
CPU17は、RAM18をワークエリアとして利用しつつROM19やハードディスク20に記憶されたプログラムを実行する。このCPU17の動作の詳細は後述する。ROM19には、IPL(Initial Program Loader)などが記憶されている。ハードディスク20には、各種歌唱曲の曲データMD-n(n=1~N)(Nは、歌唱曲の種類の総数)、リファレンスデータベースDBRK、及び歌唱評価プログラムVPGが記憶されている。各歌唱曲の曲データMD-nは、歌唱曲の伴奏内容、歌唱曲の歌詞、及び歌唱曲の模範的な歌唱内容をSMF(Standard MIDI File)形式で記録したデータである。
The CPU 17 executes a program stored in the ROM 19 or the hard disk 20 while using the RAM 18 as a work area. Details of the operation of the CPU 17 will be described later. The ROM 19 stores IPL (Initial Program Loader) and the like. The hard disk 20 stores song data MD-n (n = 1 to N) (N is the total number of song types), a reference database DBRK, and a song evaluation program VPG of various song songs. The song data MD-n of each song is data in which the accompaniment content of the song, the lyrics of the song, and the exemplary song content of the song are recorded in SMF (Standard MIDI File) format.
具体的に説明すると、図1の枠内に示すように、曲データMD-nは、ヘッダHD、伴奏トラックTRAC、歌詞トラックTRLY、模範歌唱リファレンストラックTRNRを有している。ヘッダHDには、曲番号、曲名、ジャンル、演奏時間、タイムベース(4分音符1つ分の時間に相当するティック数)などの情報が記述されている。
More specifically, as shown in the frame of FIG. 1, the music data MD-n has a header HD, an accompaniment track TR AC , a lyrics track TR LY , and a model song reference track TR NR . In the header HD, information such as a song number, a song title, a genre, a performance time, and a time base (the number of ticks corresponding to the time of one quarter note) is described.
伴奏トラックTRACには、歌唱曲の楽譜の伴奏パートにおける各ノートNT(i)(iは、楽譜の該当パートの先頭のノートNT(1)から数えた順番を示す)の音の発音を指示するイベントEV(i)ONとその消音を指示するイベントEV(i)OFF、及び相前後するイベントの実行時間差(ティック数)を示すデルタタイムDTが時系列順に記述されている。
The accompaniment track TR AC, each note NT (i) in the score of the accompaniment part of singing songs (i indicates the order counted from the beginning of the notebook NT of the score of the relevant part (1)) indicate the pronunciation of the sound of The event EV (i) ON to be turned on , the event EV (i) OFF instructing to mute the event EV, and the delta time DT indicating the execution time difference (number of ticks) of the succeeding events are described in chronological order.
歌詞トラックTRLYには、歌唱曲の歌詞を示す各データDLYと、各歌詞の表示時刻(より具体的には、各歌詞の表示時刻と各々の前の歌詞の表示時刻との間の時間差(ティック数))を示すデルタタイムDTが時系列順に記述されている。
The lyrics track TR LY includes each data D LY indicating the lyrics of the song and the display time of each lyrics (more specifically, the time difference between the display time of each lyrics and the display time of each previous lyrics) Delta time DT indicating (number of ticks)) is described in chronological order.
模範歌唱リファレンストラックTRNRには、歌唱曲の楽譜の歌唱パートにおける各ノートNT(i)の音の発音を指示するイベントEV(i)ONとその消音を指示するイベントEV(i)OFF、及び相前後するイベントの実行時間差(ティック数)を示すデルタタイムDTが時系列順に記述されている。
The model singing reference track TR NR includes an event EV (i) ON for instructing the sound of each note NT (i) in the singing part of the score of the song, and an event EV (i) OFF for instructing to mute the sound. A delta time DT indicating a difference in execution time (number of ticks) between successive events is described in chronological order.
リファレンスデータベースDBRKには、5種類の表情歌唱リファレンスデータDDa1、DDa2、DDa3、DDa4、DDa5が記憶されている。表情歌唱リファレンスデータDDa1は、歌唱曲に含まれるノートNT(i)の発音開始時刻を基準点tBSとする時間軸上の各時刻tとそれらの時刻tにおいてタメによる歌唱が行われた場合の評価点VSR(t)の各対を示すデータである。表情歌唱リファレンスデータDDa2は、歌唱曲に含まれるノートNT(i)の発音開始時刻を基準点tBSとする時間軸上の各時刻tとそれらの時刻tにおいてビブラートによる歌唱が行われた場合の評価点VSR(t)の各対を示すデータである。表情歌唱リファレンスデータDDa3は、歌唱曲に含まれるノートNT(i)の発音開始時刻を基準点tBSとする時間軸上の各時刻tとそれらの時刻tにおいてコブシによる歌唱が行われた場合の評価点VSR(t)の各対を示すデータである。表情歌唱リファレンスデータDDa4は、歌唱曲に含まれるノートNT(i)の発音開始時刻を基準点tBSとする時間軸上の各時刻tとそれらの時刻tにおいてシャクリによる歌唱が行われた場合の評価点VSR(t)の各対を示すデータである。表情歌唱リファレンスデータDDa5は、歌唱曲に含まれるノートNT(i)の発音開始時刻を基準点tBSとする時間軸上の各時刻tとそれらの時刻tにおいてフォールによる歌唱が行われた場合の評価点VSR(t)の各対を示すデータである。以下では、5種類の表情歌唱リファレンスデータDDa1、DDa2、DDa3、DDa4、DDa5を区別しない場合は表情歌唱リファレンスデータDDと記す。
The reference database DBRK stores five types of facial expression singing reference data DD a1 , DD a2 , DD a3 , DD a4 , DD a5 . The facial expression singing reference data DD a1 is obtained when the singing is performed at each time t on the time axis with the pronunciation start time of the note NT (i) included in the singing song as the reference point t BS and at those times t. Is a data showing each pair of evaluation points VSR (t). The facial expression singing reference data DD a2 is obtained when the vibrato singing is performed at each time t on the time axis with the pronunciation start time of the note NT (i) included in the singing song as a reference point t BS and those times t. Is a data showing each pair of evaluation points VSR (t). The facial expression singing reference data DD a3 is obtained when each time t on the time axis with the pronunciation start time of the note NT (i) included in the singing song as a reference point t BS and the time t at which the singing is performed by Kobushi. Is a data showing each pair of evaluation points VSR (t). The facial expression singing reference data DD a4 is obtained when the singing is performed at each time t on the time axis with the pronunciation start time of the note NT (i) included in the singing song as the reference point t BS and at the time t. Is a data showing each pair of evaluation points VSR (t). The facial expression singing reference data DD a5 is obtained when the singing by the fall is performed at each time t on the time axis with the sound generation start time of the note NT (i) included in the singing song as the reference point t BS and at those times t Is a data showing each pair of evaluation points VSR (t). Hereinafter, the five types of facial expression song reference data DD a1 , DD a2 , DD a3 , DD a4 , DD a5 are referred to as facial expression song reference data DD.
歌唱評価プログラムVPGは、次の3つの機能を有する。
a2.標準評価機能
これは、ボーカルアダプタ16の出力信号SL及びSPが示すピッチ及び音量と模範歌唱リファレンストラックTRNR内の各イベントEV(i)ON及びEV(i)OFFにより決まる各ノートNT(i)の模範ピッチPCHREF及び模範音量LVREFとを比較し、この比較の結果に基づいて歌唱の巧拙を評価する機能である。
b2.表情歌唱評価機能
これは、ボーカルアダプタ16の出力信号SPが示すピッチ波形に表情歌唱の特徴波形が出現する度に、表情歌唱の対象となったノートNT(i)の発音開始時刻を基準点tBSとする時間軸上における表情歌唱の特徴波形の出現時刻を求め、この出現時刻と対応する評価点VSR(t)をリファレンスデータベースDBRK内における該当の表情歌唱リファレンスデータDDの各評価点VSR(t)の中から選択し、この評価点VSR(t)に基づいて歌唱の巧拙を評価する機能である。
c2.評価結果提示機能
これは、a2による評価の評価結果及びb2による評価の評価結果から得点を算出し、この得点をコメントメッセージとともに表示部14に表示させる機能である。 The song evaluation program VPG has the following three functions.
a2. Standard Evaluation Function This is because each note NT (determined by each event EV (i) ON and EV (i) OFF in the exemplary singing reference track TR NR indicated by the output signals S L and S P of thevocal adapter 16 This is a function for comparing the model pitch PCH REF and the model volume LV REF of i) and evaluating the skill of singing based on the result of this comparison.
b2. Expression singing evaluation function which, each time the characteristic waveform expression singing appear in the pitch waveform indicated by the output signal S P outputvocal adapter 16, the reference point pronunciation start time of notebook NT is the subject expression singing (i) The appearance time of the feature waveform of the facial expression song on the time axis as t BS is obtained, and the evaluation point VSR (t) corresponding to this appearance time is set as each evaluation point VSR of the corresponding facial expression song reference data DD in the reference database DBRK ( This is a function of selecting from t) and evaluating the skill of singing based on this evaluation point VSR (t).
c2. Evaluation result presentation function This is a function for calculating a score from the evaluation result of the evaluation by a2 and the evaluation result of the evaluation by b2, and displaying the score on thedisplay unit 14 together with the comment message.
a2.標準評価機能
これは、ボーカルアダプタ16の出力信号SL及びSPが示すピッチ及び音量と模範歌唱リファレンストラックTRNR内の各イベントEV(i)ON及びEV(i)OFFにより決まる各ノートNT(i)の模範ピッチPCHREF及び模範音量LVREFとを比較し、この比較の結果に基づいて歌唱の巧拙を評価する機能である。
b2.表情歌唱評価機能
これは、ボーカルアダプタ16の出力信号SPが示すピッチ波形に表情歌唱の特徴波形が出現する度に、表情歌唱の対象となったノートNT(i)の発音開始時刻を基準点tBSとする時間軸上における表情歌唱の特徴波形の出現時刻を求め、この出現時刻と対応する評価点VSR(t)をリファレンスデータベースDBRK内における該当の表情歌唱リファレンスデータDDの各評価点VSR(t)の中から選択し、この評価点VSR(t)に基づいて歌唱の巧拙を評価する機能である。
c2.評価結果提示機能
これは、a2による評価の評価結果及びb2による評価の評価結果から得点を算出し、この得点をコメントメッセージとともに表示部14に表示させる機能である。 The song evaluation program VPG has the following three functions.
a2. Standard Evaluation Function This is because each note NT (determined by each event EV (i) ON and EV (i) OFF in the exemplary singing reference track TR NR indicated by the output signals S L and S P of the
b2. Expression singing evaluation function which, each time the characteristic waveform expression singing appear in the pitch waveform indicated by the output signal S P output
c2. Evaluation result presentation function This is a function for calculating a score from the evaluation result of the evaluation by a2 and the evaluation result of the evaluation by b2, and displaying the score on the
シーケンサ21は、リモートコントローラ(不図示)による歌唱曲の歌唱開始操作を契機として該当曲の曲データMD-nがハードディスク20からRAM18に転送された場合に、その曲データMD-n内のイベントEV(i)ON、EV(i)OFF、およびデータDLYを装置各部に供給する。具体的には、シーケンサ21は、RAM18に曲データMD-nが記憶されると、この曲データMD-nのヘッダHDに記述されたタイムベースとリモートコントローラ(不図示)により指定されたテンポとに基づいて1ティックの時間長を決定し、この時間長の経過に合わせてティックをカウントしつつ次の3つの処理を行う。
When the song data MD-n of the corresponding song is transferred from the hard disk 20 to the RAM 18 in response to the singing start operation of the song by a remote controller (not shown), the sequencer 21 performs an event EV in the song data MD-n. (I) ON , EV (i) OFF , and data DLY are supplied to each part of the apparatus. Specifically, when the music piece data MD-n is stored in the RAM 18, the sequencer 21 stores the time base described in the header HD of the music piece data MD-n and the tempo designated by the remote controller (not shown). The time length of one tick is determined based on the above, and the following three processes are performed while counting ticks as the time length elapses.
第1の処理では、シーケンサ21は、ティックのカウント数が伴奏トラックTRAC内のデルタタイムDTと一致する度にそれに後続するイベントEV(i)ON(またはEV(i)OFF)を読み出して音源11に供給する。音源11は、シーケンサ21からイベントEV(i)ONが供給されるとそのイベントEV(i)ONが指定する音信号SAをスピーカ12に供給し、シーケンサ21からイベントEV(i)OFFが供給されるとスピーカ12への音信号SAの供給を止める。
In the first processing, the sequencer 21 reads out the event EV (i) ON following thereafter each time the count number of ticks matches the delta time DT in accompaniment track TR AC (or EV (i) OFF) Instrument 11 is supplied. When the event EV (i) ON is supplied from the sequencer 21, the sound source 11 supplies the sound signal S A specified by the event EV (i) ON to the speaker 12, and the event EV (i) OFF is supplied from the sequencer 21. Then, the supply of the sound signal S A to the speaker 12 is stopped.
第2の処理では、シーケンサ21は、ティックのカウント数が歌詞トラックTRLY内のデルタタイムDTと一致する度にそれに後続するデータDLYを読み出して表示部14に供給する。表示部14は、シーケンサ21からデータDLYが供給されるとそのデータDLYを歌詞テロップの画像に変換し、この画像をディスプレイ(不図示)に表示させる。
In the second process, the sequencer 21 reads the subsequent data DLY and supplies it to the display unit 14 every time the tick count matches the delta time DT in the lyrics track TRLY . When the data D LY is supplied from the sequencer 21, the display unit 14 converts the data D LY into a lyrics telop image, and displays the image on a display (not shown).
シーケンサ21がこの第1および第2の処理を行うことにより、スピーカ12からの伴奏音の放音とディスプレイへの歌詞の表示とが進行する。利用者は、スピーカ12から放音される伴奏音を聴きつつディスプレイに表示された歌詞をマイクロホン13に向かって歌唱する。利用者がマイクロホン13に向かって歌唱している間、マイクロホン13は利用者の歌唱音の収音信号SMを出力し、ボーカルアダプタ16はこの信号SMのピッチ及び音量を示す信号SP及びSLを出力する。
When the sequencer 21 performs the first and second processes, the accompaniment sound is emitted from the speaker 12 and the lyrics are displayed on the display. The user sings the lyrics displayed on the display toward the microphone 13 while listening to the accompaniment sound emitted from the speaker 12. While the user is singing into the microphone 13, the microphone 13 outputs a collected sound signal S M of the user's singing sound, vocal adapter 16 signal S P and showing the pitch and volume of the signal S M S L is output.
第3の処理では、シーケンサ21は、ティックのカウント数が模範歌唱リファレンストラックTRNR内のデルタタイムDTと一致する度にそれに後続するイベントEV(i)ON(またはEV(i)OFF)を読み出してCPU17に供給する。CPU17は、シーケンサ21から供給されるイベントEV(i)ON及びEV(i)OFFとボーカルアダプタ16の出力信号SP及びSLとを用いて利用者の歌唱の巧拙を評価する。詳しくは、後述する。
In the third processing, the sequencer 21, counts the number of ticks read event EV (i) ON following thereafter every time matches the delta time DT within model singing Reference track TR NR (or EV (i) OFF) To the CPU 17. The CPU 17 evaluates the skill of the user's singing using the events EV (i) ON and EV (i) OFF supplied from the sequencer 21 and the output signals S P and S L of the vocal adapter 16. Details will be described later.
サーバ装置30は、カラオケ店舗におけるサービスの提供を支援する役割を果たす装置である。サーバ装置30は、通信インターフェース35、CPU37、RAM38、ROM39、ハードディスク40を有する。通信インターフェース35は、ネットワーク90に接続された装置との間でデータを送受信する。CPU37は、RAM38をワークエリアとして利用しつつ、ROM39やハードディスク40に記憶された各種プログラムを実行する。このCPU37の動作の詳細は後述する。ROM39にはIPLなどが記憶されている。
The server device 30 is a device that plays a role of supporting the provision of services at a karaoke store. The server device 30 includes a communication interface 35, a CPU 37, a RAM 38, a ROM 39, and a hard disk 40. The communication interface 35 transmits / receives data to / from devices connected to the network 90. The CPU 37 executes various programs stored in the ROM 39 and the hard disk 40 while using the RAM 38 as a work area. Details of the operation of the CPU 37 will be described later. The ROM 39 stores IPL and the like.
ハードディスク40には、歌唱サンプルデータベースDBS、リファレンスデータベースDBRS、および歌唱分析プログラムAPGが記憶されている。歌唱サンプルデータベースDBSには、各々が1つの歌唱曲と対応する歌唱サンプルデータDS群が個別に記憶される。歌唱サンプルデータDSは、一定水準以上の歌唱力を有する者が歌唱曲を歌唱したときの歌唱音のピッチ波形及び音量波形を記録したデータである。リファレンスデータベースDBRSには、各カラオケ装置10-mのリファレンスデータベースDBRK内に格納されるべき最新の表情歌唱リファレンスデータDDが記憶される。
The hard disk 40 stores a song sample database DBS, a reference database DBRS, and a song analysis program APG. In the singing sample database DBS, singing sample data DS groups each corresponding to one singing song are individually stored. The singing sample data DS is data in which a pitch waveform and a volume waveform of a singing sound when a person who has a singing ability exceeding a certain level sings a singing song is recorded. The reference database DBRS stores the latest facial expression singing reference data DD to be stored in the reference database DBRK of each karaoke apparatus 10-m.
歌唱分析プログラムAPGは、次の3つの機能を有する。
a3.蓄積機能
これは、カラオケ装置10-mから各歌唱曲の歌唱サンプルデータDSを1曲分ずつ取得し、取得した歌唱サンプルデータDSを歌唱サンプルデータベースDBSに蓄積する機能である。
b3.書き換え機能
これは、歌唱サンプルデータベースDBSに蓄積された歌唱サンプルデータDSの各々について、当該歌唱サンプルデータDSが示す波形内から表情歌唱の特徴波形を探索し、この探索結果から表情歌唱の対象となったノートNT(i)の発音開始時刻を基準点tBSとする時間軸上の各時刻tとそれらの時刻tにおける表情歌唱の出現数Numとの関係を示す統計データを生成し、リファレンスデータベースDBR内の表情歌唱リファレンスデータDDにおける各時刻tと対応する評価点VSR(t)を統計データの内容に基づいて書き換える機能である。
c3.送信機能
これは、書き換え機能により書き換えた表情歌唱リファレンスデータDDをカラオケ装置10-mからの要求に応じてカラオケ装置10-mに送信する機能である。 The song analysis program APG has the following three functions.
a3. Accumulation function This is a function for acquiring the song sample data DS for each song from the karaoke apparatus 10-m one by one, and accumulating the acquired song sample data DS in the song sample database DBS.
b3. Rewriting function This is to search the characteristic waveform of the facial expression song from the waveform indicated by the song sample data DS for each of the song sample data DS stored in the song sample database DBS, and to be the target of the facial expression song from the search result. Statistical data indicating the relationship between each time t on the time axis with the pronunciation start time of the note NT (i) as the reference point t BS and the number of facial expression songs Num at those times t is generated, and the reference database DBR It is a function which rewrites the evaluation score VSR (t) corresponding to each time t in the facial expression song reference data DD based on the contents of the statistical data.
c3. Transmission Function This is a function for transmitting facial expression song reference data DD rewritten by the rewriting function to the karaoke apparatus 10-m in response to a request from the karaoke apparatus 10-m.
a3.蓄積機能
これは、カラオケ装置10-mから各歌唱曲の歌唱サンプルデータDSを1曲分ずつ取得し、取得した歌唱サンプルデータDSを歌唱サンプルデータベースDBSに蓄積する機能である。
b3.書き換え機能
これは、歌唱サンプルデータベースDBSに蓄積された歌唱サンプルデータDSの各々について、当該歌唱サンプルデータDSが示す波形内から表情歌唱の特徴波形を探索し、この探索結果から表情歌唱の対象となったノートNT(i)の発音開始時刻を基準点tBSとする時間軸上の各時刻tとそれらの時刻tにおける表情歌唱の出現数Numとの関係を示す統計データを生成し、リファレンスデータベースDBR内の表情歌唱リファレンスデータDDにおける各時刻tと対応する評価点VSR(t)を統計データの内容に基づいて書き換える機能である。
c3.送信機能
これは、書き換え機能により書き換えた表情歌唱リファレンスデータDDをカラオケ装置10-mからの要求に応じてカラオケ装置10-mに送信する機能である。 The song analysis program APG has the following three functions.
a3. Accumulation function This is a function for acquiring the song sample data DS for each song from the karaoke apparatus 10-m one by one, and accumulating the acquired song sample data DS in the song sample database DBS.
b3. Rewriting function This is to search the characteristic waveform of the facial expression song from the waveform indicated by the song sample data DS for each of the song sample data DS stored in the song sample database DBS, and to be the target of the facial expression song from the search result. Statistical data indicating the relationship between each time t on the time axis with the pronunciation start time of the note NT (i) as the reference point t BS and the number of facial expression songs Num at those times t is generated, and the reference database DBR It is a function which rewrites the evaluation score VSR (t) corresponding to each time t in the facial expression song reference data DD based on the contents of the statistical data.
c3. Transmission Function This is a function for transmitting facial expression song reference data DD rewritten by the rewriting function to the karaoke apparatus 10-m in response to a request from the karaoke apparatus 10-m.
次に、本実施形態の動作を説明する。図7は、本実施形態の動作を示すフローチャートである。図7において、カラオケ装置10-mのCPU17は、歌唱曲の歌唱開始操作が行われた場合(S100:Yes)、シーケンサ21に制御信号SOを供給してシーケンサ21に処理(上述した第1~第3の処理)を開始させる(S120)。CPU17は、シーケンサ21による処理が始まると、標準歌唱評価処理(S130)と表情歌唱評価処理(S140)の2つの処理を行う。この2つの処理の詳細は次の通りである。
Next, the operation of this embodiment will be described. FIG. 7 is a flowchart showing the operation of this embodiment. In FIG. 7, the CPU 17 of the karaoke apparatus 10-m supplies a control signal S O to the sequencer 21 when the singing start operation of the song is performed (S100: Yes), and processes the sequencer 21 (the above-described first process). To (third process) are started (S120). CPU17 will perform two processes, a standard song evaluation process (S130) and a facial expression song evaluation process (S140), if the process by the sequencer 21 starts. Details of these two processes are as follows.
a4.標準歌唱評価処理(S130)
この処理では、CPU17は、シーケンサ21からイベントEV(i)ONが供給されてから次のイベントEV(i)OFFが供給されるまでの時間をi番目のノートNT(i)に相当する音の発音時間TNT(i)とする。CPU17は、発音時間TNT(i)の間のボーカルアダプタ16の出力信号SPが示すピッチとイベントEV(i)ONのノートナンバを変換した模範ピッチPCHREFとの差PCHDEF、及びその間の信号SPが示す音量とイベントEV(i)ONのベロシティを変換した模範音量LVREFとの差LVDEFを求め、この差PCHDEF及び差LVDEFが所定範囲に収まる場合にノートNT(i)の歌唱が合格であると判定する。CPU17は、利用者による歌唱の開始から終了までの間に亘ってこのノート判定を行い、歌唱の終了時点における全ノートTN(i)の数を合格と判定したノートNT(i)の数で除算した値に100を乗じた値を基本得点SRBASEとする。 a4. Standard song evaluation process (S130)
In this processing, theCPU 17 determines the time from when the event EV (i) ON is supplied from the sequencer 21 to when the next event EV (i) OFF is supplied to the sound corresponding to the i-th note NT (i). Let the pronunciation time T NT (i). CPU17, the difference PCH DEF of a model pitch PCH REF output signal S P output vocal adapter 16 converts the note number of the pitch and event EV (i) ON shown during the sounding time T NT (i), and in between determining a difference LV DEF of a model volume LV REF obtained by converting the volume and event EV (i) velocity oN indicated by the signal S P, notebook NT if this difference PCH DEF and differences LV DEF is within a predetermined range (i) It is determined that the singing is successful. The CPU 17 performs this note determination from the start to the end of the singing by the user, and divides the number of all notes TN (i) at the end of the singing by the number of the notes NT (i) determined to be acceptable. A value obtained by multiplying the obtained value by 100 is defined as a basic score SR BASE .
この処理では、CPU17は、シーケンサ21からイベントEV(i)ONが供給されてから次のイベントEV(i)OFFが供給されるまでの時間をi番目のノートNT(i)に相当する音の発音時間TNT(i)とする。CPU17は、発音時間TNT(i)の間のボーカルアダプタ16の出力信号SPが示すピッチとイベントEV(i)ONのノートナンバを変換した模範ピッチPCHREFとの差PCHDEF、及びその間の信号SPが示す音量とイベントEV(i)ONのベロシティを変換した模範音量LVREFとの差LVDEFを求め、この差PCHDEF及び差LVDEFが所定範囲に収まる場合にノートNT(i)の歌唱が合格であると判定する。CPU17は、利用者による歌唱の開始から終了までの間に亘ってこのノート判定を行い、歌唱の終了時点における全ノートTN(i)の数を合格と判定したノートNT(i)の数で除算した値に100を乗じた値を基本得点SRBASEとする。 a4. Standard song evaluation process (S130)
In this processing, the
また、この処理では、CPU17は、ボーカルアダプタ16の出力信号SPが示すピッチ波形内に、タメ、ビブラート、コブシ、シャクリ、フォールのいずれかの表情歌唱の特徴波形が出現した否かを判定する。ここで、タメの特徴波形の判定手法の詳細は特許文献2を、ビブラートの特徴波形の判定手法の詳細は特許文献3を、コブシの特徴波形の判定手法の詳細は特許文献4を、シャクリの特徴波形の判定手法の詳細は特許文献5を、フォールの特徴波形の判定手法の詳細は特許文献6を参照されたい。CPU17は、利用者による歌唱の開始から終了までの間に亘ってこの特徴波形判定を行い、歌唱の終了時点における表情歌唱の出現数に所定の係数を乗じた値を加算点SRADDとする。そして、この処理では、基本得点SRBASEと加算点SRADDの合計を標準得点SRNORとする。
Further, in this process, CPU 17 determines, in a pitch waveform indicated by the output signal S P output vocal adapter 16, Tame, vibrato, fist, jerking, whether any of the expression singing features waveform fall appeared . Here, details of the method for determining the feature waveform of the patent are disclosed in Patent Document 2, details of the method for determining the characteristic waveform of the vibrato are described in Patent Document 3, details of the method of determining the feature waveform of Kobushi are described in Patent Document 4, and Refer to Patent Document 5 for details of the feature waveform determination method, and Patent Document 6 for details of the fall feature waveform determination method. The CPU 17 performs this characteristic waveform determination from the start to the end of the singing by the user, and sets a value obtained by multiplying the number of appearances of the facial expression song at the end of the singing by a predetermined coefficient as the addition point SR ADD . In this process, the total of the basic score SR BASE and the addition point SR ADD is set as the standard score SR NOR .
b4.表情歌唱評価処理(S140)
この処理では、CPU17は、音源イベントEV(i)ONの出力から次のイベントEV(i)OFFの出力までの時間をi番目のノートNT(i)に相当する音の発音時間TNT(i)とする。そして、CPU17は、発音時間TNT(i)の間のボーカルアダプタ16の出力信号SPが示すピッチ波形内に表情歌唱の特徴波形が出現した場合には、発音時間TNT(i)内における表情歌唱の出現時刻と出現した表情歌唱の種類を求める。CPU17は、そのように特定した表情歌唱の種類と出現時刻とを示す表情歌唱出現データを生成する。 b4. Expression song evaluation process (S140)
In this process, theCPU 17 sets the time from the output of the sound source event EV (i) ON to the output of the next event EV (i) OFF as the sound generation time T NT (i) corresponding to the i-th note NT (i). ). Then, CPU 17, when the characteristic waveform expression singing in pitch waveform indicated by the output signal S P output vocal adapter 16 between the sounding time T NT (i) are noticed, within sounding time T NT (i) Find the appearance time of the facial expression song and the type of facial expression song that appeared. The CPU 17 generates facial expression song appearance data indicating the type and appearance time of the facial expression song specified as described above.
この処理では、CPU17は、音源イベントEV(i)ONの出力から次のイベントEV(i)OFFの出力までの時間をi番目のノートNT(i)に相当する音の発音時間TNT(i)とする。そして、CPU17は、発音時間TNT(i)の間のボーカルアダプタ16の出力信号SPが示すピッチ波形内に表情歌唱の特徴波形が出現した場合には、発音時間TNT(i)内における表情歌唱の出現時刻と出現した表情歌唱の種類を求める。CPU17は、そのように特定した表情歌唱の種類と出現時刻とを示す表情歌唱出現データを生成する。 b4. Expression song evaluation process (S140)
In this process, the
そして、CPU17は、生成した表情歌唱出現データに示される表情歌唱およびその出現時刻に応じた評価点VSR(t)を、表情歌唱リファレンスデータDDが示す一連の評価点VSR(t)の中から選択する。CPUは、利用者による歌唱の開始から終了までの間に亘ってこのような評価点VSR(t)の選択を行い、歌唱の終了時点における評価点VSR(t)の平均値を表情得点SREXとする。
The CPU 17 selects the facial expression song indicated in the generated facial expression song appearance data and the evaluation point VSR (t) corresponding to the appearance time from the series of evaluation points VSR (t) indicated by the facial expression song reference data DD. To do. The CPU selects such evaluation points VSR (t) from the start to the end of singing by the user, and the average value of the evaluation points VSR (t) at the end of the singing is used as the facial expression score SR EX. And
CPU17は、利用者による歌唱曲の歌唱が終了すると、評価結果提示処理を行う(S150)。評価結果提示処理では、CPU17は、標準歌唱評価処理により採点した標準得点SRNORと表情歌唱評価処理により採点した表情得点SREXのうち高い方の得点を選択する。そして、CPU17は、標準得点SRNORを選択した場合、この得点SRNORと、例えば「クールで精緻な歌ですね」といった得点SRNORに応じたコメントメッセージを表示部14に表示させる。また、CPU17は、表情得点SREXを選択した場合、この得点SREXと、例えば「人情味あふれていますね」といった表情得点SREXに応じたコメントメッセージを表示部14に表示させる。
CPU17 will perform an evaluation result presentation process, after the song of the song by a user is complete | finished (S150). In the evaluation result presentation process, the CPU 17 selects a higher score from the standard score SR NOR scored by the standard song evaluation process and the facial score SR EX scored by the facial expression song evaluation process. Then, CPU17 is, if you choose the standard score SR NOR, and this score SR NOR, to display a comment messages in accordance with the score SR NOR for example, such as "It is cool and refined song" on the display unit 14. In addition, CPU17 is, if you choose a facial expression score SR EX, this and score SR EX, for example, to display a comment message corresponding to the facial expression score such as "I have full of kindness" SR EX on the display unit 14.
次に、CPU17は、サンプル送信処理を行う(S160)。サンプル送信処理では、CPU17は、歌唱曲の歌唱の開始から終了までの間にボーカルアダプタ16が出力した信号SP及びSLを当該歌唱曲の歌唱サンプルデータDSとし、この歌唱サンプルデータDSとステップS130で求めた基本得点SRBASE(歌唱評価データ)とを含むメッセージMS1をサーバ装置30に送信する。
Next, the CPU 17 performs a sample transmission process (S160). Sample transmission process, CPU 17 is vocal signal S P and S L adapter 16 has output a singing sample data DS of the singing music piece, steps and the singing sample data DS between the start and end of singing singing voice A message MS1 including the basic score SR BASE (singing evaluation data) obtained in S130 is transmitted to the server device 30.
サーバ装置30のCPU37は、カラオケ装置10-mからメッセージMS1を取得すると(S200:Yes)、このメッセージMS1から歌唱サンプルデータDSと基本得点SRBASEとを取り出し、この基本得点SRBASEを上級者とそうでない者とを分ける基準得点SRTH(たとえば、80点とする)と比較する(S220)。CPU37は、基本得点SRBASEが基準得点SRTHよりも高い場合(S220:Yes)、メッセージMS1から取り出した歌唱サンプルデータDSを歌唱サンプルデータベースDBSに蓄積する(S230)。
When the CPU 37 of the server device 30 obtains the message MS1 from the karaoke device 10-m (S200: Yes), the singing sample data DS and the basic score SR BASE are extracted from this message MS1, and this basic score SR BASE is obtained from the advanced player. It is compared with a reference score SR TH (for example, 80 points) that separates those who are not (S220). When the basic score SR BASE is higher than the reference score SR TH (S220: Yes), the CPU 37 accumulates the song sample data DS extracted from the message MS1 in the song sample database DBS (S230).
続いて、CPU37は書き換え処理を行う(S240)。書き換え処理では、CPU37は、次の5つの処理を行う。第1の処理では、CPU37は、歌唱サンプルデータベースDBSに蓄積された各歌唱サンプルデータDSが示すピッチ波形内からタメの特徴波形を探索し、この探索結果を示す表情歌唱出現データ(タメが出現したノートNT(i)の発音開始時刻を基準点tBSとする時間軸上の各時刻tを示すデータ)を生成する。続いて、CPU37はタメに関し生成した表情歌唱出現データに基づき、ノートNT(i)の発音開始時刻を基準点tBSとする時間軸上の各時刻tとそれらの時刻tにおける表情歌唱「タメ」の出現数Numとの関係を示す統計データを生成し、表情歌唱リファレンスデータDDa1における各時刻tと対応する評価点VSR(t)をこの統計データの内容に基づいて書き換える。
Subsequently, the CPU 37 performs a rewriting process (S240). In the rewriting process, the CPU 37 performs the following five processes. In the first process, the CPU 37 searches for the characteristic waveform of the ticks from within the pitch waveform indicated by each singing sample data DS stored in the singing sample database DBS, and the facial expression singing appearance data indicating the search results (the appearance of the ticks). generating a note NT data indicating each time t on the time axis of the reproduction starting time of (i) a reference point t BS). Then, CPU 37, based on the expression singing occurrence data generated relates Tame, expression singing at each time t and their time t on the time axis to the reproduction starting time of the notebook NT (i) as a reference point t BS "tame" Statistical data showing the relationship with the number of occurrences Num of the synthesizer, and the evaluation point VSR (t) corresponding to each time t in the facial expression singing reference data DD a1 is rewritten based on the contents of this statistical data.
図8は、タメについての統計データの一例を示す図である。この例の統計データでは、基準点tBSより時間T1a1だけ前の時刻t1a1と基準点tBSより時間T4a1だけ後の時刻t4a1との間に表情歌唱の出現数Numが分布している。そして、この例の統計データでは、基準点tBSの直後の時刻t2a1に出現数Numの最大ピークが表れており、時刻t2a1よりも遅れた時刻t3a1に出現数Numの2番目のピークが表れている。よって、この例の統計データによる書き換え後の表情歌唱リファレンスデータDDa1では、時刻t2a1の評価点VSR(t2a1)が最も高くなり、時刻t3a1の評価点VSR(t3a1)が2番目に高くなる。
FIG. 8 is a diagram illustrating an example of statistical data on the eggs. The statistics of this example, the number of occurrences Num expression singing between the reference point t BS time T1 a1 only before time t1 a1 and the reference point t BS than the time T4 a1 time t4 after only a1 is distributed Yes. In the statistical data of this example, the maximum peak of the number of appearances Num appears at the time t2 a1 immediately after the reference point t BS , and the second peak of the number of appearances Num at the time t3 a1 later than the time t2 a1. Appears. Therefore, in the facial expression song reference data DD a1 after rewriting by the statistical data of this example, the evaluation point VSR (t2 a1 ) at the time t2 a1 is the highest, and the evaluation point VSR (t3 a1 ) at the time t3 a1 is the second. Get higher.
第2の処理では、CPU37は、歌唱サンプルデータベースDBSに蓄積された各歌唱サンプルデータDSが示すピッチ波形内からビブラートの特徴波形を探索し、この探索結果を示す表情歌唱出現データ(ビブラートが出現したノートNT(i)の発音開始時刻を基準点tBSとする時間軸上の各時刻tを示すデータ)を生成する。続いて、CPU37はビブラートに関し生成した表情歌唱出現データに基づき、ノートNT(i)の発音開始時刻を基準点tBSする時間軸上の各時刻tとそれらの時刻tにおける表情歌唱の出現数Numとの関係を示す統計データを生成し、表情歌唱リファレンスデータDDa2における各時刻tと対応する評価点VSR(t)をこの統計データの内容に基づいて書き換える。
In the second process, the CPU 37 searches for the characteristic waveform of vibrato from within the pitch waveform indicated by each singing sample data DS stored in the singing sample database DBS, and facial expression singing appearance data (vibrato has appeared) indicating the search result. generating a note NT data indicating each time t on the time axis of the reproduction starting time of (i) a reference point t BS). Subsequently, based on the expression song appearance data generated for the vibrato, the CPU 37 uses the time t on the time axis where the pronunciation start time of the note NT (i) is the reference point t BS and the number Num of appearances of the expression song at those times t. Is generated, and the evaluation score VSR (t) corresponding to each time t in the facial expression song reference data DD a2 is rewritten based on the contents of the statistical data.
図9は、ビブラートについての統計データの一例を示す図である。この例の統計データでは、基準点tBSと基準点tBSより時間T2a2だけ後の時刻t2a2との間に表情歌唱の出現数Numが分布している。そして、この例の統計データでは、基準点tBSよりも時間T1a2だけ後の時刻t1a2に出現数Numの最大ピークが表れている。よって、この例の統計データによる書き換え後の表情歌唱リファレンスデータDDa2では、時刻t1a2の評価点VSR(t1a2)が最も高くなる。
FIG. 9 is a diagram illustrating an example of statistical data on vibrato. In the statistics example, appearance number Num expression singing between the reference point t BS and the reference point t BS than the time T2 a2 time after only t2 a2 are distributed. Then, in the statistical data example, to be the reference point t BS time T1 a2 only after the time t1 a2 is the maximum peak number of occurrences Num has appeared. Therefore, in the facial expression song reference data DD a2 after rewriting by the statistical data of this example, the evaluation point VSR (t1 a2 ) at the time t1 a2 is the highest.
第3の処理では、CPU37は、歌唱サンプルデータベースDBSに蓄積された各歌唱サンプルデータDSが示すピッチ波形内からコブシの特徴波形を探索し、この探索結果を示す表情歌唱出現データ(コブシが出現したノートNT(i)の発音開始時刻を基準点tBSとする時間軸上の各時刻tを示すデータ)を生成する。続いて、CPU37はコブシに関し生成した表情歌唱出現データに基づき、ノートNT(i)の発音開始時刻を基準点tBSとする時間軸上の各時刻tとそれらの時刻tにおける表情歌唱の出現数Numとの関係を示す統計データを生成し、表情歌唱リファレンスデータDDa3における各時刻tと対応する評価点VSR(t)をこの統計データの内容に基づいて書き換える。
In the third process, the CPU 37 searches for the characteristic waveform of Kobushi from within the pitch waveform indicated by each singing sample data DS stored in the singing sample database DBS, and the facial expression singing appearance data (Kobushi appears) indicating the search result. generating a note NT data indicating each time t on the time axis of the reproduction starting time of (i) a reference point t BS). Subsequently, based on the facial expression song appearance data generated for Kobushi, the CPU 37 uses each time t on the time axis with the pronunciation start time of the note NT (i) as the reference point t BS and the number of facial expression songs at those times t. Statistical data indicating the relationship with Num is generated, and the evaluation point VSR (t) corresponding to each time t in the facial expression song reference data DD a3 is rewritten based on the contents of the statistical data.
図10は、コブシについての統計データの一例を示す図である。この例の統計データでは、基準点tBSと基準点tBSより時間T2a3だけ後の時刻t2a3との間に表情歌唱の出現数Numが分布している。そして、この例の統計データでは、基準点tBSよりも時間T1a3だけ後の時刻t1a3に出現数Numの最大ピークが表れている。よって、この例の統計データによる書き換え後の表情歌唱リファレンスデータDDa3では、時刻t1a3の評価点VSR(t1a3)が最も高くなる。
FIG. 10 is a diagram illustrating an example of statistical data regarding Kobushi. In the statistics example, appearance number Num expression singing between the reference point t BS and the reference point t BS than the time T2 a3 time after only t2 a3 are distributed. Then, in the statistical data example, to be the reference point t BS time T1 a3 only after time t1 a3 maximum peak number of occurrences Num has appeared. Therefore, in the facial expression song reference data DD a3 after rewriting by the statistical data of this example, the evaluation point VSR (t1 a3 ) at the time t1 a3 is the highest.
第4の処理では、CPU37は、歌唱サンプルデータベースDBSに蓄積された各歌唱サンプルデータDSが示すピッチ波形内からシャクリの特徴波形を探索し、この探索結果を示す表情歌唱出現データ(シャクリが出現したノートNT(i)の発音開始時刻を基準点tBSとする時間軸上の各時刻tを示すデータ)を生成する。続いて、CPU37はシャクリに関し生成した表情歌唱出現データに基づき、ノートNT(i)の発音開始時刻を基準点tBSとする時間軸上の各時刻tとそれらの時刻tにおける表情歌唱の出現数Numとの関係を示す統計データを生成し、表情歌唱リファレンスデータDDa4における各時刻tと対応する評価点VSR(t)をこの統計データの内容に基づいて書き換える。
In the fourth process, the CPU 37 searches for the characteristic waveform of the crisp from the pitch waveform indicated by each singing sample data DS stored in the singing sample database DBS, and the facial expression singing appearance data indicating the search result (the appearance of the crisp appears). generating a note NT data indicating each time t on the time axis of the reproduction starting time of (i) a reference point t BS). Subsequently, based on the expression song appearance data generated for the shackle, the CPU 37 uses each time t on the time axis with the pronunciation start time of the note NT (i) as a reference point t BS and the number of appearances of the expression song at those times t. Statistical data indicating the relationship with Num is generated, and the evaluation point VSR (t) corresponding to each time t in the facial expression song reference data DD a4 is rewritten based on the contents of the statistical data.
図11は、シャクリについての統計データの一例を示す図である。この例の統計データでは、基準点tBSと基準点tBSより時間T2a4だけ後の時刻t2a4との間に表情歌唱の出現数Numが分布している。そして、この例の統計データでは、基準点tBSに出現数Numの最大ピークが表れており、基準点tBSよりも時間T1a4だけ遅れた時刻t1a4に出現数Numの2番目のピークが表れている。よって、この例の統計データによる書き換え後の表情歌唱リファレンスデータDDa4では、時刻tBSの評価点VSR(tBS)が最も高くなり、時刻t1a4の評価点VSR(t1a4)が2番目に高くなる。
FIG. 11 is a diagram illustrating an example of the statistical data regarding shackle. In the statistics example, appearance number Num expression singing between the reference point t BS and the reference point t BS than the time T2 a4 time after only t2 a4 are distributed. Then, the statistics in this example, the reference point t BS have appeared up to the peak number of occurrences Num, the time t1 a4 than the reference point t BS delayed by time T1 a4 is a second peak number of occurrences Num Appears. Therefore, in the facial expression song reference data DD a4 after rewriting by the statistical data of this example, the evaluation point VSR (t BS ) at the time t BS is the highest, and the evaluation point VSR (t 1 a4 ) at the time t1 a4 is the second. Get higher.
第5の処理では、CPU37は、歌唱サンプルデータベースDBSに蓄積された各歌唱サンプルデータDSが示すピッチ波形内からフォールの特徴波形を探索し、この探索結果を示す表情歌唱出現データ(フォールが出現したノートNT(i)の発音開始時刻を基準点tBSとする時間軸上の各時刻tを示すデータ)を生成する。続いて、CPU37はフォールに関し生成した表情歌唱出現データに基づき、ノートNT(i)の発音開始時刻を基準点tBSとする時間軸上の各時刻tとそれらの時刻tにおける表情歌唱の出現数Numとの関係を示す統計データを生成し、表情歌唱リファレンスデータDDa5における各時刻と対応する評価点VSR(t)をこの統計データの内容に基づいて書き換える。
In the fifth process, the CPU 37 searches for the characteristic waveform of the fall from within the pitch waveform indicated by each singing sample data DS stored in the singing sample database DBS, and the facial expression singing appearance data (fall has appeared) indicating this search result. generating a note NT data indicating each time t on the time axis of the reproduction starting time of (i) a reference point t BS). Then, CPU 37, based on the expression singing occurrence data generated relates fall, the number of occurrences of facial expression singing at each time t and their time t on the time axis to the reproduction starting time of the notebook NT (i) as a reference point t BS Statistical data indicating the relationship with Num is generated, and the evaluation point VSR (t) corresponding to each time in the facial expression song reference data DD a5 is rewritten based on the contents of the statistical data.
図12は、フォールについての統計データの一例を示す図である。この例の統計データでは、基準点tBSより時間T1a5だけ後の時刻t1a5と時刻tBSから時間T2a5だけ後の時刻t2a5との間に表情歌唱の出現数Numが分布している。そして、この例の統計データでは、時刻t2a5に出現数Numの最大ピークが表れている。よって、この例の統計データによる書き換え後の表情歌唱リファレンスデータDDa5では、時刻t2a5の評価点VSR(t2a5)が最も高くなる。
FIG. 12 is a diagram illustrating an example of statistical data regarding a fall. The statistics of this example, the number of occurrences of facial expression singing between the reference point t BS than the time T1 a5 only after the time t1 a5 and time t BS from the time T2 a5 only after the time t2 a5 of Num is distributed . In the statistical data of this example, the maximum peak of the number of occurrences Num appears at time t2 a5 . Therefore, in the facial expression song reference data DD a5 after rewriting by the statistical data of this example, the evaluation point VSR (t2 a5 ) at time t2 a5 is the highest.
図7において、カラオケ装置10-mのCPU17は、予め決められた問合せ時刻が到来する度に(S110:Yes)、問合せ処理を行う(S170)。この問合せ処理では、CPU17は、最新データの送信を求めるメッセージMS2をサーバ装置30に送信する(S170)。サーバ装置30のCPU37は、カラオケ装置10-mからメッセージMS2を受信すると(S210:Yes)、前回のメッセージMS2の受信時刻から今回のメッセージMS2の受信時刻までの間に内容を書き換えた表情歌唱リファレンスデータDDをメッセージM2の送信元のカラオケ装置10-mに送信する(S250)。カラオケ装置10-mのCPU17は、サーバ装置30から表情歌唱リファレンスデータDDを受信すると、この表情歌唱リファレンスデータDDをリファレンスデータベースDBRKに上書きしてその内容を更新する(S180)。
In FIG. 7, the CPU 17 of the karaoke apparatus 10-m performs inquiry processing every time a predetermined inquiry time arrives (S110: Yes) (S170). In this inquiry process, the CPU 17 transmits a message MS2 for requesting transmission of the latest data to the server device 30 (S170). When the CPU 37 of the server device 30 receives the message MS2 from the karaoke device 10-m (S210: Yes), the facial expression singing reference in which the contents are rewritten between the previous message MS2 reception time and the current message MS2 reception time. The data DD is transmitted to the karaoke apparatus 10-m that is the transmission source of the message M2 (S250). When receiving the facial expression song reference data DD from the server device 30, the CPU 17 of the karaoke apparatus 10-m overwrites the facial expression song reference data DD on the reference database DBRK and updates the content (S180).
以上が、本実施形態の構成の詳細である。本実施形態によると、次の効果が得られる。
第1に、本実施形態の表情付け歌唱評価処理では、ボーカルアダプタ16の出力信号の波形に表情歌唱の特徴波形が出現する度に、表情歌唱の対象となったノートNT(i)の発音開始時刻を基準点とする時間軸上における表情歌唱の特徴波形の出現時刻を求め、この出現時刻と対応する評価点VSR(t)を歌唱リファレンスデータDD内の各評価点VSR(t)の中から選択し、この選択した評価点VSR(t)に基づいて歌唱の巧拙を評価する。よって、本実施形態によると、利用者が表情歌唱を行ったとしても、そのタイミングが適切でなければ良好な評価が得られないことになる。従って、本実施形態によると、人の感性によるものにより近い評価結果を提示することができる。 The above is the details of the configuration of the present embodiment. According to this embodiment, the following effects can be obtained.
First, in the facial expression singing evaluation process according to the present embodiment, each time the characteristic waveform of the facial expression song appears in the waveform of the output signal of thevocal adapter 16, the pronunciation of the note NT (i) that is the target of the facial expression song is started. The appearance time of the feature waveform of the facial expression song on the time axis with the time as the reference point is obtained, and the evaluation point VSR (t) corresponding to this appearance time is selected from the evaluation points VSR (t) in the song reference data DD. The skill of singing is evaluated based on the selected evaluation point VSR (t). Therefore, according to this embodiment, even if the user performs facial expression singing, good evaluation cannot be obtained unless the timing is appropriate. Therefore, according to this embodiment, it is possible to present an evaluation result closer to that based on human sensitivity.
第1に、本実施形態の表情付け歌唱評価処理では、ボーカルアダプタ16の出力信号の波形に表情歌唱の特徴波形が出現する度に、表情歌唱の対象となったノートNT(i)の発音開始時刻を基準点とする時間軸上における表情歌唱の特徴波形の出現時刻を求め、この出現時刻と対応する評価点VSR(t)を歌唱リファレンスデータDD内の各評価点VSR(t)の中から選択し、この選択した評価点VSR(t)に基づいて歌唱の巧拙を評価する。よって、本実施形態によると、利用者が表情歌唱を行ったとしても、そのタイミングが適切でなければ良好な評価が得られないことになる。従って、本実施形態によると、人の感性によるものにより近い評価結果を提示することができる。 The above is the details of the configuration of the present embodiment. According to this embodiment, the following effects can be obtained.
First, in the facial expression singing evaluation process according to the present embodiment, each time the characteristic waveform of the facial expression song appears in the waveform of the output signal of the
第2に、本実施形態では、歌唱サンプルデータベースDBS内に蓄積された表情歌唱リファレンスデータDDの各々について、当該データDDが示す波形内から表情歌唱の特徴波形を探索し、この探索結果から表情歌唱の対象となったノートNT(i)の発音開始時刻を基準点とする時間軸上の各時刻とそれらの時刻における表情歌唱の出現数との関係を示す統計データを生成し、歌唱リファレンスデータDDにおける各時刻と対応する評価点VSR(t)を統計データの内容に基づいて書き換える。よって、本実施形態によると、歌唱曲を歌い込んでいる上級者らの歌い方の傾向の変化を評価結果に反映させることができる。
Secondly, in the present embodiment, for each of the facial expression song reference data DD stored in the song sample database DBS, the facial expression song characteristic waveform is searched from the waveform indicated by the data DD, and the facial expression song is obtained from the search result. Statistical data indicating the relationship between each time on the time axis with the pronunciation start time of the note NT (i) as a reference point being the reference point and the number of facial expression singings appearing at those times, and singing reference data DD The evaluation score VSR (t) corresponding to each time at is rewritten based on the contents of the statistical data. Therefore, according to this embodiment, the change of the tendency of how to sing advanced users who are singing a song can be reflected in the evaluation result.
以上、この発明の一実施形態について説明したが、この発明には他にも実施形態があり得る。例えば、以下の通りである。
(1)上記実施形態では、CPU17は、タメ、ビブラート、コブシ、シャクリ、フォールの5種類の表情歌唱をボーカルアダプタ16の出力信号SPから検出した。しかし、この5種類以外の表情歌唱を検出してもよい。たとえば、抑揚をつけた歌唱を検出してもよい。 Although one embodiment of the present invention has been described above, the present invention may have other embodiments. For example, it is as follows.
(1) In the above embodiment,CPU 17 has detected Tame, vibrato, fist, jerking, five types of expressions singing fall from the output signal S P output vocal adapter 16. However, facial expressions other than these five types may be detected. For example, a song with inflection may be detected.
(1)上記実施形態では、CPU17は、タメ、ビブラート、コブシ、シャクリ、フォールの5種類の表情歌唱をボーカルアダプタ16の出力信号SPから検出した。しかし、この5種類以外の表情歌唱を検出してもよい。たとえば、抑揚をつけた歌唱を検出してもよい。 Although one embodiment of the present invention has been described above, the present invention may have other embodiments. For example, it is as follows.
(1) In the above embodiment,
(2)上記実施形態では、CPU17は、ボーカルアダプタ16の出力信号SP及びSLの両方を用いて標準歌唱評価処理を行い、ボーカルアダプタ16の出力信号SP及びSLのうちピッチを示す信号SPのみを用いて表情歌唱評価処理を行った。しかし、CPU17は、信号SP及びSLの一方のみを用いて標準歌唱評価処理を行ってもよい。また、CPU17は、信号SP及びSLの両方を用いて表情歌唱評価処理を行ってもよい。
(2) In the above embodiment, the CPU 17 performs the standard singing evaluation process using both the output signals S P and S L of the vocal adapter 16 and indicates the pitch among the output signals S P and S L of the vocal adapter 16. was facial expression singing evaluation process by using only the signal S P. However, CPU 17 may perform a standard singing evaluation process using only one signal S P and S L. Further, CPU 17 may perform facial expression singing evaluation process using both signals S P and S L.
(3)上記実施形態の表情歌唱評価処理では、表情歌唱の特徴波形の出現時刻に基づいて歌唱の巧拙を評価した。しかし、表情歌唱の特徴波形の出現時刻以外の要素(たとえば、タメ、ビブラート、コブシ、シャクリ、フォールの各々の長さや深さなど)を加味した評価を行ってもよい。
(3) In the facial expression song evaluation process of the above embodiment, the skill of the song was evaluated based on the appearance time of the characteristic waveform of the facial expression song. However, the evaluation may be performed in consideration of elements other than the appearance time of the feature waveform of the facial expression song (for example, the length and depth of each of the choke, vibrato, kobushi, shakuri, and fall).
(4)上記実施形態の表情歌唱評価処理では、歌唱曲に含まれるノートの各々に応じた歌唱音において出現する表情歌唱を検出する構成が採用されているが、歌唱曲に含まれる一連の複数のノート(ノート群)に応じた歌唱音において出現する表情歌唱を検出する構成が採用されてもよい。例えば、クレッシェンド・デクレッシェンドのような表情歌唱は、一連の複数のノートの歌唱において行われる表情歌唱であるため、それらの表情歌唱の検出および評価はノート群を単位として行われる方が望ましい。従って、そのような表情歌唱に関する表情歌唱リファレンスデータDDもまたノート群単位で構成されることが望ましい。
(4) In the facial expression song evaluation process of the above embodiment, a configuration is adopted in which a facial expression song that appears in the song sound corresponding to each of the notes included in the song song is adopted, but a series of plural songs included in the song song are included. The structure which detects the facial expression song which appears in the song sound according to the note (note group) may be employ | adopted. For example, a facial expression song such as crescendo decrescendo is a facial expression song performed in a series of notes, and it is desirable that detection and evaluation of those facial expressions be performed in units of notes. Therefore, it is desirable that the facial expression song reference data DD relating to such facial expression song is also configured in units of notes.
(5)上記実施形態では、カラオケ装置10からサーバ装置30に対し、歌唱曲の歌唱の開始から終了までの間にボーカルアダプタ16が出力した信号SP及びSLを含む歌唱サンプルデータDS(ピッチ音量データ)を送信し、サーバ装置30においては歌唱サンプルデータDSから各表情歌唱の検出およびその出現のタイミングの特定処理が行われる構成が採用されている。これに代えて、カラオケ装置10からサーバ装置30に対し、マイクロホン13により収音された音を示す音信号SM(歌唱音を示す音声波形データ)を送信し、サーバ装置30において音信号SMから信号Spおよび信号SLを生成する処理(上記実施形態におけるボーカルアダプタ16が行う処理)が行われる構成が採用されてもよい。また、カラオケ装置10からサーバ装置30に対し、歌唱評価プログラムVPGに従い行われる表情歌唱評価処理(S140)に際し特定した表情歌唱の種別およびその出現のタイミングを示すデータ(表情歌唱出現データ)を送信し、サーバ装置30においては表情歌唱の検出処理は行わずカラオケ装置10から送信されてくる表情歌唱出現データに基づき表情歌唱リファレンスデータDDの更新処理が行われる構成が採用されてもよい。
(5) In the above embodiment, the singing sample data DS (pitch) including the signals SP and S L output from the vocal adapter 16 to the server device 30 from the start to the end of the singing of the singing song. The sound volume data) is transmitted, and the server apparatus 30 employs a configuration in which each facial expression song is detected from the singing sample data DS and the timing of the appearance is specified. Alternatively, to the server device 30 from the karaoke device 10, transmits a sound signal S M indicating the picked-up sound (sound waveform data indicating the singing sound) by microphones 13, the sound signal S M in the server apparatus 30 processing for generating a signal S p and the signal S L (processing vocal adapter 16 in the above embodiment does) configuration may be employed that originate. Further, the karaoke device 10 transmits to the server device 30 data (facial singing appearance data) indicating the type of facial expression singing specified in the facial expression singing evaluation processing (S140) performed in accordance with the singing evaluation program VPG and the timing of its appearance. The server device 30 may employ a configuration in which the facial expression song reference data DD is updated based on the facial expression song appearance data transmitted from the karaoke device 10 without performing facial expression song detection processing.
(6)上記実施形態では、サーバ装置30が統計データの生成とこれに基づく表情歌唱リファレンスデータDDの書き換えを行った。しかし、各カラオケ装置10-mが過去に自機により生成、もしくは他のカラオケ装置10-mから直接またはサーバ装置30を介して取得した歌唱音を示す音信号SMや、それらの音信号SMから生成した信号Spおよび信号SL、もしくはそれらの信号を用いて特定した表情歌唱の種別およびその出現のタイミングを示すデータ(表情歌唱出現データ)をハードディスク20に記憶しておき、CPU17がそれらを読み出して用いて、サーバ装置30がS240で行う処理と同様の処理、すなわち統計データの生成とこれに基づく表情歌唱リファレンスデータDDの書き換えを行うようにしてもよい。
(6) In the above-described embodiment, the server device 30 generates statistical data and rewrites the facial expression song reference data DD based on the statistical data. However, each of the karaoke apparatuses 10-m generates a sound signal S M indicating a singing sound generated by the own apparatus in the past, or directly from another karaoke apparatus 10-m or via the server apparatus 30, and their sound signals S The signal S p and the signal S L generated from M , or data (expression song appearance data) indicating the type and expression timing of the expression song specified using these signals are stored in the hard disk 20, and the CPU 17 They may be read and used to perform processing similar to the processing performed by the server device 30 in S240, that is, generation of statistical data and rewriting of facial expression song reference data DD based thereon.
(7)上記実施形態における歌唱の評価の方法および評価結果の歌唱者への提示の態様は様々に変更可能である。例えば、上記実施形態においては、標準歌唱評価処理(S130)にて表情歌唱の出現回数に基づき算出される加算点SRADDを基本得点SRBASEと合計することで標準得点SRNORを算出する構成が採用されているが、標準歌唱評価処理においては表情歌唱の出現は考慮せず、基本得点SRBASEのみを算出する構成が採用されてもよい。また、上記実施形態においては、歌唱者に対し、標準歌唱評価処理により採点した標準得点SRNORと表情歌唱評価処理により採点した表情得点SREXのうち高い方の得点が表示されるが、それらの両方を表示する、それらの合計点数を表示するなど、他の態様で歌唱者に対する評価結果の提示が行われてもよい。
(7) The method of singing evaluation in the above embodiment and the manner of presenting the evaluation result to the singer can be variously changed. For example, in the above-described embodiment, the standard score SR NOR is calculated by summing the addition point SR ADD calculated based on the number of appearances of the expression song in the standard song evaluation process (S130) with the basic score SR BASE. Although adopted, in the standard singing evaluation process, the appearance of the facial expression singing is not taken into account, and a configuration for calculating only the basic score SR BASE may be adopted. In the above embodiment, the higher score of the standard score SR NOR scored by the standard song evaluation process and the expression score SR EX scored by the expression song evaluation process is displayed to the singer. The evaluation result for the singer may be presented in other manners such as displaying both and displaying their total score.
(8)上記実施形態では、表情歌唱リファレンスデータDDの更新に際し、基本得点SRBASEが基準得点SRTHよりも高い歌唱者を上級者とし、上級者に関する歌唱サンプルデータDSのみを用いて表情歌唱リファレンスデータDDの更新を行う構成が採用されている。表情歌唱リファレンスデータDDの更新に用いる歌唱サンプルデータDSの選択方法はこれに限られない。例えば、基本得点SRBASEに代えて、基本得点SRBASEに加算点SRADDを合計した標準得点SRNORを上級者の推定の基準として用いてもよい。また、全く表情歌唱を行わないために基本得点SRBASEが高得点となっている上級者を除外するために、下側の閾値(基準得点SRTH)に加え上側の閾値を設け、上側の閾値より高い基本得点SRBASE(またはその他の得点)の歌唱者の歌唱サンプルデータDSは表情歌唱リファレンスデータDDの更新には用いない、という構成が採用されてもよい。また、上記のように歌唱者を上級者とそれ以外の者に2分する代わりに、例えば基本得点SRBASEが高い歌唱者の歌唱サンプルデータDSに大きい重み付けを付けて表情歌唱リファレンスデータDDの更新に用いるようにしてもよい。
(8) In the above embodiment, when updating the facial expression singing reference data DD, a singer whose basic score SR BASE is higher than the standard score SR TH is regarded as an advanced person, and the facial expression singing reference is made using only the singing sample data DS relating to the advanced person. A configuration for updating the data DD is employed. The method of selecting the singing sample data DS used for updating the facial expression singing reference data DD is not limited to this. For example, the basic score instead of the SR BASE, may be used standard scoring SR NOR that the sum of the summing junction SR ADD basic score SR BASE as the basis for advanced estimation. In addition, in order to exclude an advanced player who has a high basic score SR BASE because no facial expression singing is performed, an upper threshold is provided in addition to a lower threshold (reference score SR TH ). The singing sample data DS of a singer with a higher basic score SR BASE (or other score) may not be used for updating the facial expression song reference data DD. Also, instead of dividing the singer into the advanced and the others as described above, for example, the singing sample data DS of the singer with a high basic score SR BASE is given a high weight and the facial expression singing reference data DD is updated. You may make it use for.
(9)上記実施形態では、楽曲演奏を評価する演奏評価装置の一例として、歌唱用のカラオケ装置に設けられ、歌唱演奏を評価する演奏評価装置を示したが、本発明にかかる演奏評価装置は歌唱演奏の評価に限定されず、各種楽器を用いた楽曲演奏の評価にも適用可能である。すなわち、上記実施形態において用いた「歌唱」という言葉は、より一般的な「演奏」という言葉で置き換えられる。なお、器楽演奏を評価する演奏評価装置においては、例えばギターにおけるチョーキングなど、個々の楽器に応じた表情演奏に関する評価が行われることになる。また、楽曲が歌唱曲でなく楽器用の楽曲である場合、楽器演奏用のカラオケ装置は、曲データMDは歌詞トラックTRLYに代えて、例えば楽譜を示すデータと、楽譜の各区間(例えば、2小節もしくは4小節のブロックなど)の表示時刻を示すデルタタイムが時系列順に記述されたデータである楽譜トラックを含むように構成され、シーケンサ21および表示部14は楽譜トラックに従い、楽曲の進行に伴い伴奏箇所に応じた楽譜を示す画像信号をディスプレイに出力するように構成されることになる。なお、歌唱用のカラオケ装置および楽器演奏用のカラオケ装置において、歌詞もしくは楽譜の表示が不要な場合は、シーケンサ21および表示部14による画像信号の出力処理は行われなくてもよい。
(10)以上の例示から理解される通り、本発明の好適な態様に係る演奏評価装置は、図13に例示される通り、楽曲の演奏中に行われるべき表情演奏と当該表情演奏が前記楽曲において行われるべきタイミングを前記楽曲に含まれるノートまたはノート群の発音開始時刻を基準として示す表情演奏リファレンスデータを取得する表情演奏リファレンスデータ取得手段101と、演奏者による前記楽曲の演奏音から当該演奏音のピッチおよび音量を示すピッチ音量データを生成するピッチ音量データ生成手段102と、前記ピッチ音量データ生成手段102により生成された前記ピッチ音量データにより示されるピッチおよび音量の少なくとも一方の特性が、前記楽曲における前記表情演奏リファレンスデータにより示される所定時間範囲内において前記表情演奏リファレンスデータにより行われるべきであるとされる表情演奏の特性を示す場合、前記演奏者による前記楽曲の演奏に対する評価を向上させる演奏評価手段103と、を備える装置として包括的に表現され、他の要素の有無や他の要素の具体的な態様は任意である。 (9) In the above embodiment, as an example of a performance evaluation device that evaluates a music performance, a performance evaluation device that is provided in a karaoke device for singing and evaluates a singing performance is shown. The present invention is not limited to the evaluation of singing performances, and can be applied to the evaluation of musical performances using various musical instruments. That is, the term “singing” used in the above embodiment is replaced with the more general term “performance”. Note that in a performance evaluation device that evaluates instrumental music performance, for example, choking on a guitar, and the like, evaluation regarding facial expression performance corresponding to each instrument is performed. When the music is not a song but a music for a musical instrument, the karaoke apparatus for musical instrument performance uses, for example, data indicating the score and each section of the score (for example, the song data MD instead of the lyrics track TR LY (for example, The delta time indicating the display time of 2 bars or 4 bars) is configured to include a score track which is data described in chronological order, and thesequencer 21 and the display unit 14 follow the score track to progress the music. Accordingly, an image signal indicating a musical score corresponding to the accompaniment location is output to the display. In the karaoke apparatus for singing and the karaoke apparatus for playing musical instruments, if display of lyrics or score is unnecessary, the image signal output processing by the sequencer 21 and the display unit 14 may not be performed.
(10) As understood from the above examples, the performance evaluation apparatus according to a preferred aspect of the present invention is such that, as illustrated in FIG. Facial expression performance reference data acquisition means 101 for acquiring facial expression performance reference data that indicates the timing to be performed in reference to the pronunciation start time of a note or note group included in the music, and the performance from the performance sound of the music by the performer Pitch volume data generation means 102 for generating pitch volume data indicating the pitch and volume of sound, and at least one of the characteristics of pitch and volume indicated by the pitch volume data generated by the pitch volume data generation means 102 is Within a predetermined time range indicated by the expression performance reference data in the music And a performance evaluation means 103 for improving the performance of the music performed by the performer when the expression performance characteristics are supposed to be performed by the expression performance reference data. Expressed, the presence or absence of other elements and the specific mode of other elements are arbitrary.
(10)以上の例示から理解される通り、本発明の好適な態様に係る演奏評価装置は、図13に例示される通り、楽曲の演奏中に行われるべき表情演奏と当該表情演奏が前記楽曲において行われるべきタイミングを前記楽曲に含まれるノートまたはノート群の発音開始時刻を基準として示す表情演奏リファレンスデータを取得する表情演奏リファレンスデータ取得手段101と、演奏者による前記楽曲の演奏音から当該演奏音のピッチおよび音量を示すピッチ音量データを生成するピッチ音量データ生成手段102と、前記ピッチ音量データ生成手段102により生成された前記ピッチ音量データにより示されるピッチおよび音量の少なくとも一方の特性が、前記楽曲における前記表情演奏リファレンスデータにより示される所定時間範囲内において前記表情演奏リファレンスデータにより行われるべきであるとされる表情演奏の特性を示す場合、前記演奏者による前記楽曲の演奏に対する評価を向上させる演奏評価手段103と、を備える装置として包括的に表現され、他の要素の有無や他の要素の具体的な態様は任意である。 (9) In the above embodiment, as an example of a performance evaluation device that evaluates a music performance, a performance evaluation device that is provided in a karaoke device for singing and evaluates a singing performance is shown. The present invention is not limited to the evaluation of singing performances, and can be applied to the evaluation of musical performances using various musical instruments. That is, the term “singing” used in the above embodiment is replaced with the more general term “performance”. Note that in a performance evaluation device that evaluates instrumental music performance, for example, choking on a guitar, and the like, evaluation regarding facial expression performance corresponding to each instrument is performed. When the music is not a song but a music for a musical instrument, the karaoke apparatus for musical instrument performance uses, for example, data indicating the score and each section of the score (for example, the song data MD instead of the lyrics track TR LY (for example, The delta time indicating the display time of 2 bars or 4 bars) is configured to include a score track which is data described in chronological order, and the
(10) As understood from the above examples, the performance evaluation apparatus according to a preferred aspect of the present invention is such that, as illustrated in FIG. Facial expression performance reference data acquisition means 101 for acquiring facial expression performance reference data that indicates the timing to be performed in reference to the pronunciation start time of a note or note group included in the music, and the performance from the performance sound of the music by the performer Pitch volume data generation means 102 for generating pitch volume data indicating the pitch and volume of sound, and at least one of the characteristics of pitch and volume indicated by the pitch volume data generated by the pitch volume data generation means 102 is Within a predetermined time range indicated by the expression performance reference data in the music And a performance evaluation means 103 for improving the performance of the music performed by the performer when the expression performance characteristics are supposed to be performed by the expression performance reference data. Expressed, the presence or absence of other elements and the specific mode of other elements are arbitrary.
(11)上記実施形態では、いわゆる専用機としてのカラオケ装置に本発明にかかる演奏評価装置が設けられている例を示したが、本発明にかかる演奏評価装置は専用機に限られない。例えば、パーソナルコンピュータや携帯情報端末(例えば携帯電話機やスマートホン)やゲーム装置等の各種装置にプログラムに従った処理を行わせることによって本発明にかかる演奏評価装置を実現する構成が採用されてもよい。また、このプログラムは、CD-ROM等の記録媒体に格納して配布したり、インターネット等の電気通信回線を利用して配布したりすることも可能である。
本出願は、2012年4月18日出願の日本特許出願、特願2012-094853に基づくものであり、その内容はここに参照として取り込まれる。 (11) In the above embodiment, an example in which the performance evaluation device according to the present invention is provided in a karaoke device as a so-called dedicated device is shown, but the performance evaluation device according to the present invention is not limited to a dedicated device. For example, even if a configuration that realizes the performance evaluation device according to the present invention by causing various devices such as a personal computer, a portable information terminal (for example, a mobile phone or a smart phone), and a game device to perform processing according to a program is adopted. Good. Further, this program can be distributed by being stored in a recording medium such as a CD-ROM, or can be distributed by using an electric communication line such as the Internet.
This application is based on Japanese Patent Application No. 2012-094853 filed on Apr. 18, 2012, the contents of which are incorporated herein by reference.
本出願は、2012年4月18日出願の日本特許出願、特願2012-094853に基づくものであり、その内容はここに参照として取り込まれる。 (11) In the above embodiment, an example in which the performance evaluation device according to the present invention is provided in a karaoke device as a so-called dedicated device is shown, but the performance evaluation device according to the present invention is not limited to a dedicated device. For example, even if a configuration that realizes the performance evaluation device according to the present invention by causing various devices such as a personal computer, a portable information terminal (for example, a mobile phone or a smart phone), and a game device to perform processing according to a program is adopted. Good. Further, this program can be distributed by being stored in a recording medium such as a CD-ROM, or can be distributed by using an electric communication line such as the Internet.
This application is based on Japanese Patent Application No. 2012-094853 filed on Apr. 18, 2012, the contents of which are incorporated herein by reference.
本発明によれば、演奏者により表情演奏が行われた場合、人間の感性との乖離の少ない評価を行うことが可能である。
According to the present invention, when an expression performance is performed by a performer, it is possible to perform an evaluation with little deviation from human sensitivity.
1…歌唱評価システム、10…カラオケ装置、11…音源、12…スピーカ、13…マイクロホン、14…表示部、15…通信インターフェース、16…ボーカルアダプタ、17…CPU、18…RAM、19…ROM、20…ハードディスク、21…シーケンサ、30…サーバ装置、35…通信インターフェース、37…CPU、38…RAM、39…ROM、40…ハードディスク、90…ネットワーク
DESCRIPTION OF SYMBOLS 1 ... Singing evaluation system, 10 ... Karaoke apparatus, 11 ... Sound source, 12 ... Speaker, 13 ... Microphone, 14 ... Display part, 15 ... Communication interface, 16 ... Vocal adapter, 17 ... CPU, 18 ... RAM, 19 ... ROM, DESCRIPTION OF SYMBOLS 20 ... Hard disk, 21 ... Sequencer, 30 ... Server apparatus, 35 ... Communication interface, 37 ... CPU, 38 ... RAM, 39 ... ROM, 40 ... Hard disk, 90 ... Network
Claims (12)
- 楽曲の演奏中に行われるべき表情演奏と当該表情演奏が前記楽曲において行われるべきタイミングを前記楽曲に含まれるノートまたはノート群の発音開始時刻を基準として示す表情演奏リファレンスデータを取得する表情演奏リファレンスデータ取得手段と、
演奏者による前記楽曲の演奏音から当該演奏音のピッチおよび音量を示すピッチ音量データを生成するピッチ音量データ生成手段と、
前記ピッチ音量データ生成手段により生成された前記ピッチ音量データにより示されるピッチおよび音量の少なくとも一方の特性が、前記楽曲における前記表情演奏リファレンスデータにより示される所定時間範囲内において前記表情演奏リファレンスデータにより行われるべきであるとされる表情演奏の特性を示す場合、前記演奏者による前記楽曲の演奏に対する評価を向上させる演奏評価手段と
を備える演奏評価装置。 A facial expression performance reference that acquires facial expression performance reference data that indicates the facial expression performance to be performed during the performance of the musical piece and the timing at which the facial expression performance is to be performed in the musical piece, based on the pronunciation start time of the note or note group included in the musical piece Data acquisition means;
Pitch volume data generating means for generating pitch volume data indicating the pitch and volume of the performance sound from the performance sound of the music by the performer;
At least one of the pitch and volume characteristics indicated by the pitch volume data generated by the pitch volume data generation means is performed by the facial expression performance reference data within a predetermined time range indicated by the facial expression performance reference data in the music. A performance evaluation device comprising performance evaluation means for improving the performance of the music performed by the performer when exhibiting the characteristics of facial expression performance that should be performed. - 任意数の任意の演奏者による楽曲の演奏音の各々に関し、当該演奏音のピッチおよび音量を示すピッチ音量データを取得するピッチ音量データ取得手段と、
前記ピッチ音量データ取得手段により取得された音量ピッチデータにより示されるピッチおよび音量の少なくとも一方の特性が、前記楽曲における任意のタイミングにおいて予め定められた1以上の表情演奏の特性のうちの一の特性を示す場合、当該表情演奏と、前記楽曲に含まれるノートまたはノート群の発音開始時刻を基準とする当該タイミングとの対を示す表情演奏出現データを生成する表情演奏出現データ生成手段と、
前記表情演奏出現データ生成手段により生成された任意数の表情演奏出現データに基づき、前記楽曲に含まれるノートまたはノート群の各々に関し、当該ノートまたはノート群の発音開始時刻を基準とするいずれのタイミングでいずれの表情演奏がいずれの頻度で出現しているかを特定し、当該特定した情報に従い表情演奏リファレンスデータを生成する表情演奏リファレンスデータ生成手段と
を備える請求項1に記載の演奏評価装置。 Pitch volume data acquisition means for acquiring pitch volume data indicating the pitch and volume of the performance sound for each of the performance sounds of the music by an arbitrary number of arbitrary players,
The characteristic of at least one of the pitch and volume indicated by the volume pitch data acquired by the pitch volume data acquisition means is one of the characteristics of one or more facial expression performances predetermined at an arbitrary timing in the music The expression performance appearance data generating means for generating expression performance appearance data indicating a pair of the expression performance and the timing based on the pronunciation start time of the note or note group included in the music;
Based on any number of facial expression performance appearance data generated by the facial expression appearance data generation means, any timing with respect to each note or group of notes included in the music based on the pronunciation start time of the note or group of notes The performance evaluation device according to claim 1, further comprising: facial expression performance reference data generating means for identifying which facial expression performance appears at what frequency and generating facial expression performance reference data according to the identified information. - 表情演奏リファレンスデータを記憶する表情演奏リファレンスデータ記憶手段
を備え、
前記表情演奏リファレンスデータ生成手段によって生成された前記表情演奏リファレンスデータに基づき、前記表情演奏リファレンスデータ記憶手段に記憶される前記表情演奏リファレンスデータは書き換えられる
請求項2に記載の演奏評価装置。 A facial expression performance reference data storage means for storing facial expression performance reference data;
The performance evaluation device according to claim 2, wherein the facial expression performance reference data stored in the facial expression performance reference data storage means is rewritten based on the facial expression performance reference data generated by the facial expression performance reference data generation means. - 前記楽曲の模範となるピッチを示す模範演奏リファレンスデータを取得する模範演奏リファレンスデータ取得手段
を備え、
前記演奏評価手段は、前記ピッチ音量データ生成手段により生成されたピッチ音量データにより示されるピッチと、前記模範演奏リファレンスデータにより示されるピッチとの比較の結果に基づき前記演奏者による前記楽曲の演奏に対する評価を行う
請求項1乃至3のいずれかに記載の演奏評価装置。 An exemplary performance reference data acquisition means for acquiring exemplary performance reference data indicating a pitch as an exemplary musical piece;
The performance evaluation unit is configured to perform the performance of the music by the performer based on a result of comparison between the pitch indicated by the pitch volume data generated by the pitch volume data generation unit and the pitch indicated by the model performance reference data. The performance evaluation apparatus according to any one of claims 1 to 3, wherein the evaluation is performed. - 前記楽曲の模範となるピッチを示す模範演奏リファレンスデータを取得する模範演奏リファレンスデータ取得手段
を備え、
前記演奏評価手段は、前記ピッチ音量データ生成手段により生成されたピッチ音量データにより示されるピッチと、前記模範演奏リファレンスデータにより示されるピッチとの比較の結果に基づき前記演奏者による前記楽曲の演奏に対する評価を行い、
前記ピッチ音量データ取得手段により取得されるピッチ音量データは、前記演奏評価手段により前記模範演奏リファレンスデータを用いて行われた評価の結果、もしくは前記演奏評価手段と同様の手段を備える他機により前記模範演奏リファレンスデータと同様のデータを用いて行われた評価の結果を示す演奏評価データを伴い、
前記表情演奏リファレンスデータ生成手段は、前記ピッチ音量データ取得手段により取得されるピッチ音量データのうち所定の条件を満たす演奏評価データを伴うピッチ音量データを用いて前記表情演奏出現データ生成手段により生成された表情演奏出現データに基づき、前記表情演奏リファレンスデータを生成する
請求項2に記載の演奏評価装置。 An exemplary performance reference data acquisition means for acquiring exemplary performance reference data indicating a pitch as an exemplary musical piece;
The performance evaluation unit is configured to perform the performance of the music by the performer based on a result of comparison between the pitch indicated by the pitch volume data generated by the pitch volume data generation unit and the pitch indicated by the model performance reference data. Make an assessment,
The pitch volume data acquired by the pitch volume data acquisition means is the result of the evaluation performed by the performance evaluation means using the model performance reference data, or by the other device including the same means as the performance evaluation means. Accompanied by performance evaluation data indicating the results of evaluation performed using data similar to the model performance reference data,
The expression performance reference data generation means is generated by the expression performance appearance data generation means using pitch volume data with performance evaluation data satisfying a predetermined condition among pitch volume data acquired by the pitch volume data acquisition means. The performance evaluation device according to claim 2, wherein the facial expression performance reference data is generated based on the facial expression performance appearance data. - 請求項1乃至5のいずれかに記載の演奏評価装置と、
楽曲の伴奏を指示する伴奏データを取得する伴奏データ取得手段と、
前記伴奏データの指示に従い伴奏の楽音を示す音信号を出力する音信号出力手段と
を備え、
前記ピッチ音量データ生成手段は、前記音信号出力手段から出力された音信号に従いスピーカから放音された伴奏に応じて前記演奏者により行われた前記楽曲の演奏音のピッチおよび音量を示すピッチ音量データを生成する
カラオケ装置。 A performance evaluation apparatus according to any one of claims 1 to 5,
Accompaniment data acquisition means for acquiring accompaniment data instructing the accompaniment of the music;
Sound signal output means for outputting a sound signal indicating the musical sound of the accompaniment according to the instruction of the accompaniment data,
The pitch volume data generating means is a pitch volume indicating the pitch and volume of the performance sound of the music performed by the performer according to the accompaniment emitted from a speaker according to the sound signal output from the sound signal output means Karaoke device that generates data. - 前記楽曲は歌唱曲であり、
前記歌唱曲の歌詞を示す歌詞データを取得する歌詞データ取得手段と、
前記歌詞データにより示される歌詞であって、前記音信号出力手段により現在出力されている音信号が示す伴奏とともに歌唱されるべき歌詞を示す画像信号を出力する画像信号出力手段と
を備える請求項6に記載のカラオケ装置。 The music is a song,
Lyrics data acquisition means for acquiring lyrics data indicating the lyrics of the song;
The image signal output means which outputs the image signal which shows the lyrics which are the lyrics shown by the said lyric data, and which should be sung with the accompaniment which the sound signal currently output by the said sound signal output means shows. Karaoke apparatus as described in 1. - 前記楽曲は楽器により演奏される楽曲であり、
前記楽曲の楽譜を示す楽譜データを取得する楽譜データ取得手段と、
前記楽譜データにより示される楽譜であって、前記音信号出力手段により現在出力されている音信号が示す伴奏とともに行われるべき演奏を指示する楽譜を示す画像信号を出力する画像信号出力手段と
を備える請求項6に記載のカラオケ装置。 The music is a music played by a musical instrument,
Score data acquisition means for acquiring score data indicating the score of the music;
Image signal output means for outputting an image signal indicating a score which is a score indicated by the score data and which indicates a performance to be performed together with an accompaniment indicated by the sound signal currently output by the sound signal output means; The karaoke apparatus according to claim 6. - 任意数の任意の演奏者による楽曲の演奏音の各々に関し、前記楽曲に含まれるノートまたはノート群の発音開始時刻を基準とする一のタイミングにおいて一の表情演奏が出現したことを示す表情演奏出現データを取得する表情演奏出現データ取得手段と、
前記表情演奏出現データ取得手段により取得された任意数の表情演奏出現データに基づき、前記楽曲に含まれるノートまたはノート群の各々に関し、当該ノートまたはノート群の発音開始時刻を基準とするいずれのタイミングでいずれの表情演奏がいずれの頻度で出現しているかを特定し、当該特定した情報に従い、前記楽曲の演奏中に行われるべき表情演奏と当該表情演奏が前記楽曲において行われるべきタイミングを前記楽曲に含まれるノートまたはノート群の発音開始時刻を基準として示す表情演奏リファレンスデータを生成する表情演奏リファレンスデータ生成手段と、
前記表情演奏リファレンスデータ生成手段により生成された表情演奏リファレンスデータを演奏評価装置に送信する送信手段と
を備えるサーバ装置。 An expression performance appearance indicating that one expression performance has appeared at one timing on the basis of the pronunciation start time of a note or a group of notes included in the music for each of the performance sounds of an arbitrary number of performers Facial expression appearance data acquisition means for acquiring data;
Based on an arbitrary number of facial expression performance appearance data acquired by the facial expression appearance data acquisition means, any timing with respect to each note or group of notes included in the music, based on the pronunciation start time of the note or group of notes And the frequency at which the expression performance appears, and the expression performance to be performed during the performance of the music and the timing at which the expression performance should be performed in the music according to the specified information. A facial expression performance reference data generating means for generating facial expression performance reference data indicating a pronunciation start time of a note or a group of notes included in
A server device comprising: transmitting means for transmitting the expression performance reference data generated by the expression performance reference data generating means to a performance evaluation device. - 歌唱評価システムであって、
楽曲の演奏中に行われるべき表情演奏と当該表情演奏が前記楽曲において行われるべきタイミングを前記楽曲に含まれるノートまたはノート群の発音開始時刻を基準として示す第一表情演奏リファレンスデータを取得する表情演奏リファレンスデータ取得手段と、
演奏者による前記楽曲の演奏音から当該演奏音のピッチおよび音量を示すピッチ音量データを生成するピッチ音量データ生成手段と、
前記ピッチ音量データ生成手段により生成された前記ピッチ音量データにより示されるピッチおよび音量の少なくとも一方の特性が、前記楽曲における前記第一表情演奏リファレンスデータにより示される所定時間範囲内において前記第一表情演奏リファレンスデータにより行われるべきであるとされる表情演奏の特性を示す場合、前記演奏者による前記楽曲の演奏に対する評価を向上させる演奏評価手段と、
任意数の任意の演奏者による楽曲の演奏音の各々に関し、前記任意の演奏者による前記楽曲に含まれるノートまたはノート群の発音開始時刻を基準とする一のタイミングにおいて一の表情演奏が出現したことを示す表情演奏出現データを取得する表情演奏出現データ取得手段と、
前記表情演奏出現データ取得手段により取得された任意数の表情演奏出現データに基づき、前記任意の演奏者による楽曲に含まれるノートまたはノート群の各々に関し、当該ノートまたはノート群の発音開始時刻を基準とするいずれのタイミングでいずれの表情演奏がいずれの頻度で出現しているかを特定し、当該特定した情報に従い、前記任意の演奏者による楽曲の演奏中に行われるべき表情演奏と当該表情演奏が前記任意の演奏者による楽曲において行われるべきタイミングを前記任意の演奏者による楽曲に含まれるノートまたはノート群の発音開始時刻を基準として示す第二表情演奏リファレンスデータを生成する表情演奏リファレンスデータ生成手段と、
を備える。 A singing evaluation system,
A facial expression for obtaining first facial expression performance reference data indicating a facial expression performance to be performed during the performance of a musical piece and a timing at which the facial expression performance is to be performed in the musical piece with reference to a pronunciation start time of a note or a group of notes included in the musical piece Performance reference data acquisition means;
Pitch volume data generating means for generating pitch volume data indicating the pitch and volume of the performance sound from the performance sound of the music by the performer;
At least one of the pitch and the volume indicated by the pitch volume data generated by the pitch volume data generation means has the first facial expression performance within a predetermined time range indicated by the first facial expression performance reference data in the music piece. Performance evaluation means for improving the performance of the music performed by the performer when indicating the characteristics of facial expression performance that should be performed by reference data;
With respect to each of the performance sounds of the music by an arbitrary number of arbitrary performers, one facial expression performance appeared at one timing based on the pronunciation start time of the notes or note groups included in the music by the arbitrary performers Facial expression appearance data acquisition means for acquiring facial expression performance appearance data indicating that;
Based on an arbitrary number of facial expression performance appearance data acquired by the facial expression performance appearance data acquisition means, with respect to each note or note group included in the music by the arbitrary player, the pronunciation start time of the note or note group is used as a reference The expression performance and the expression performance to be performed during the performance of the music by the arbitrary player are determined according to the specified information. Facial expression performance reference data generating means for generating second facial expression performance reference data indicating the timing to be performed in the music by the arbitrary player based on the pronunciation start time of a note or note group included in the music by the arbitrary player When,
Is provided. - 楽曲の演奏中に行われるべき表情演奏と当該表情演奏が前記楽曲において行われるべきタイミングを前記楽曲に含まれるノートまたはノート群の発音開始時刻を基準として示す表情演奏リファレンスデータを取得し、
演奏者による前記楽曲の演奏音から当該演奏音のピッチおよび音量を示すピッチ音量データを生成し、
前記ピッチ音量データにより示されるピッチおよび音量の少なくとも一方の特性が、前記楽曲における前記表情演奏リファレンスデータにより示される所定時間範囲内において前記表情演奏リファレンスデータにより行われるべきであるとされる表情演奏の特性を示す場合、前記演奏者による前記楽曲の演奏に対する評価を向上させる
演奏評価方法。 Obtaining facial expression performance reference data indicating the facial expression performance to be performed during the performance of the musical piece and the timing at which the facial expression performance is to be performed in the musical piece with reference to the pronunciation start time of the note or note group included in the musical piece,
Generate pitch volume data indicating the pitch and volume of the performance sound from the performance sound of the music by the performer,
A facial expression performance that is to be performed by the facial expression performance reference data within a predetermined time range indicated by the facial expression performance reference data in the musical piece, at least one of the pitch and volume characteristics indicated by the pitch volume data. A performance evaluation method for improving the performance of the music player by the performer when the characteristic is exhibited. - コンピュータが実行可能なプログラムであって、
楽曲の演奏中に行われるべき表情演奏と当該表情演奏が前記楽曲において行われるべきタイミングを前記楽曲に含まれるノートまたはノート群の発音開始時刻を基準として示す表情演奏リファレンスデータを取得する表情演奏リファレンスデータ取得処理と、
演奏者による前記楽曲の演奏音から当該演奏音のピッチおよび音量を示すピッチ音量データを生成するピッチ音量データ生成処理と、
前記ピッチ音量データ生成手段により生成された前記ピッチ音量データにより示されるピッチおよび音量の少なくとも一方の特性が、前記楽曲における前記表情演奏リファレンスデータにより示される所定時間範囲内において前記表情演奏リファレンスデータにより行われるべきであるとされる表情演奏の特性を示す場合、前記演奏者による前記楽曲の演奏に対する評価を向上させる演奏評価処理と
を前記コンピュータに実行させるプログラム。 A computer executable program,
A facial expression performance reference that acquires facial expression performance reference data that indicates the facial expression performance to be performed during the performance of the musical piece and the timing at which the facial expression performance is to be performed in the musical piece, based on the pronunciation start time of the note or note group included in the musical piece Data acquisition processing,
Pitch volume data generation processing for generating pitch volume data indicating the pitch and volume of the performance sound from the performance sound of the music by the performer;
At least one of the pitch and volume characteristics indicated by the pitch volume data generated by the pitch volume data generation means is performed by the facial expression performance reference data within a predetermined time range indicated by the facial expression performance reference data in the music. A program for causing the computer to execute performance evaluation processing for improving the performance of the music performed by the performer when the performance of the facial expression performance to be performed is indicated.
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020147025532A KR101666535B1 (en) | 2012-04-18 | 2013-04-18 | Performance evaluation device, karaoke device, and server device |
| CN201380015347.7A CN104170006B (en) | 2012-04-18 | 2013-04-18 | Performance evaluation device, karaoke device, and server device |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2012094853A JP5958041B2 (en) | 2012-04-18 | 2012-04-18 | Expression performance reference data generation device, performance evaluation device, karaoke device and device |
| JP2012-094853 | 2012-04-18 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2013157602A1 true WO2013157602A1 (en) | 2013-10-24 |
Family
ID=49383554
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2013/061488 WO2013157602A1 (en) | 2012-04-18 | 2013-04-18 | Performance evaluation device, karaoke device, and server device |
Country Status (5)
| Country | Link |
|---|---|
| JP (1) | JP5958041B2 (en) |
| KR (1) | KR101666535B1 (en) |
| CN (1) | CN104170006B (en) |
| TW (1) | TWI497484B (en) |
| WO (1) | WO2013157602A1 (en) |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2020122949A (en) * | 2019-01-31 | 2020-08-13 | 株式会社第一興商 | Karaoke device |
| JP2020122948A (en) * | 2019-01-31 | 2020-08-13 | 株式会社第一興商 | Karaoke device |
| JP2020166162A (en) * | 2019-03-29 | 2020-10-08 | 株式会社第一興商 | Karaoke device |
Families Citing this family (21)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR101459324B1 (en) * | 2013-08-28 | 2014-11-07 | 이성호 | Evaluation method of sound source and Apparatus for evaluating sound using it |
| JP6428066B2 (en) * | 2014-09-05 | 2018-11-28 | オムロン株式会社 | Scoring device and scoring method |
| JP6352164B2 (en) * | 2014-11-28 | 2018-07-04 | 株式会社第一興商 | Karaoke scoring system considering listener evaluation |
| CN104392731A (en) * | 2014-11-30 | 2015-03-04 | 陆俊 | Singing practicing method and system |
| CN104485090B (en) * | 2014-12-12 | 2020-01-17 | 上海斐讯数据通信技术有限公司 | Music score generation method and device and mobile terminal |
| JP5715296B1 (en) * | 2014-12-16 | 2015-05-07 | 行秘 大田 | Akatsuki communication karaoke server and a karaoke communication karaoke system |
| US10380657B2 (en) | 2015-03-04 | 2019-08-13 | International Business Machines Corporation | Rapid cognitive mobile application review |
| JP6113231B2 (en) * | 2015-07-15 | 2017-04-12 | 株式会社バンダイ | Singing ability evaluation device and storage device |
| JP6701864B2 (en) * | 2016-03-25 | 2020-05-27 | ヤマハ株式会社 | Sound evaluation device and sound evaluation method |
| WO2018016582A1 (en) * | 2016-07-22 | 2018-01-25 | ヤマハ株式会社 | Musical performance analysis method, automatic music performance method, and automatic musical performance system |
| JP6776788B2 (en) * | 2016-10-11 | 2020-10-28 | ヤマハ株式会社 | Performance control method, performance control device and program |
| CN108665747A (en) * | 2017-04-01 | 2018-10-16 | 上海伍韵钢琴有限公司 | A kind of online piano training mate system and application method |
| JP6867900B2 (en) * | 2017-07-03 | 2021-05-12 | 株式会社第一興商 | Karaoke equipment |
| JP6708180B2 (en) * | 2017-07-25 | 2020-06-10 | ヤマハ株式会社 | Performance analysis method, performance analysis device and program |
| CN108694384A (en) * | 2018-05-14 | 2018-10-23 | 芜湖岭上信息科技有限公司 | A kind of viewer satisfaction investigation apparatus and method based on image and sound |
| CN109903778B (en) * | 2019-01-08 | 2020-09-25 | 北京雷石天地电子技术有限公司 | Method and system for scoring singing in real time |
| CN109887524A (en) * | 2019-01-17 | 2019-06-14 | 深圳壹账通智能科技有限公司 | A kind of singing marking method, device, computer equipment and storage medium |
| CN110083772A (en) * | 2019-04-29 | 2019-08-02 | 北京小唱科技有限公司 | Singer's recommended method and device based on singing skills |
| CN110120216B (en) * | 2019-04-29 | 2021-11-12 | 北京小唱科技有限公司 | Audio data processing method and device for singing evaluation |
| WO2021176925A1 (en) * | 2020-03-04 | 2021-09-10 | ヤマハ株式会社 | Method, system and program for inferring audience evaluation of performance data |
| CN112037609B (en) * | 2020-08-26 | 2022-10-11 | 怀化学院 | Music teaching device based on thing networking |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2005241848A (en) * | 2004-02-25 | 2005-09-08 | Daiichikosho Co Ltd | Model vocal offer system of contribution work editing type in online karaoke system |
| JP2007271977A (en) * | 2006-03-31 | 2007-10-18 | Yamaha Corp | Evaluation standard decision device, control method, and program |
| JP2007334364A (en) * | 2007-08-06 | 2007-12-27 | Yamaha Corp | Karaoke machine |
| JP2008139426A (en) * | 2006-11-30 | 2008-06-19 | Yamaha Corp | Data structure of data for evaluation, karaoke machine, and recording medium |
Family Cites Families (18)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2915773B2 (en) * | 1993-12-25 | 1999-07-05 | 日本コロムビア株式会社 | Karaoke equipment |
| JP3299890B2 (en) * | 1996-08-06 | 2002-07-08 | ヤマハ株式会社 | Karaoke scoring device |
| JP3293745B2 (en) * | 1996-08-30 | 2002-06-17 | ヤマハ株式会社 | Karaoke equipment |
| JP3690224B2 (en) * | 2000-01-13 | 2005-08-31 | ヤマハ株式会社 | Mobile phone and mobile phone system |
| CN1380642A (en) * | 2001-04-11 | 2002-11-20 | 华邦电子股份有限公司 | Single-following learning scoring device and method |
| JP2003058155A (en) * | 2001-08-13 | 2003-02-28 | Casio Comput Co Ltd | Musical performance practicing device and program for musical performance practicing process |
| JP4222915B2 (en) * | 2003-09-30 | 2009-02-12 | ヤマハ株式会社 | Singing voice evaluation device, karaoke scoring device and programs thereof |
| JP4163584B2 (en) | 2003-09-30 | 2008-10-08 | ヤマハ株式会社 | Karaoke equipment |
| JP4204941B2 (en) | 2003-09-30 | 2009-01-07 | ヤマハ株式会社 | Karaoke equipment |
| JP4209751B2 (en) * | 2003-09-30 | 2009-01-14 | ヤマハ株式会社 | Karaoke equipment |
| TWI232430B (en) * | 2004-03-19 | 2005-05-11 | Sunplus Technology Co Ltd | Automatic grading method and device for audio source |
| JP2007256617A (en) * | 2006-03-23 | 2007-10-04 | Yamaha Corp | Musical piece practice device and musical piece practice system |
| JP2008015388A (en) * | 2006-07-10 | 2008-01-24 | Dds:Kk | Singing skill evaluation method and karaoke machine |
| JP2008026622A (en) * | 2006-07-21 | 2008-02-07 | Yamaha Corp | Evaluation apparatus |
| JP4865607B2 (en) | 2007-03-13 | 2012-02-01 | ヤマハ株式会社 | Karaoke apparatus, singing evaluation method and program |
| JP4910854B2 (en) | 2007-04-17 | 2012-04-04 | ヤマハ株式会社 | Fist detection device, fist detection method and program |
| TWI394141B (en) * | 2009-03-04 | 2013-04-21 | Wen Hsin Lin | Karaoke song accompaniment automatic scoring method |
| JP5244738B2 (en) * | 2009-08-24 | 2013-07-24 | 株式会社エクシング | Singing evaluation device, singing evaluation method, and computer program |
-
2012
- 2012-04-18 JP JP2012094853A patent/JP5958041B2/en not_active Expired - Fee Related
-
2013
- 2013-04-18 TW TW102113839A patent/TWI497484B/en not_active IP Right Cessation
- 2013-04-18 KR KR1020147025532A patent/KR101666535B1/en active IP Right Grant
- 2013-04-18 CN CN201380015347.7A patent/CN104170006B/en not_active Expired - Fee Related
- 2013-04-18 WO PCT/JP2013/061488 patent/WO2013157602A1/en active Application Filing
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2005241848A (en) * | 2004-02-25 | 2005-09-08 | Daiichikosho Co Ltd | Model vocal offer system of contribution work editing type in online karaoke system |
| JP2007271977A (en) * | 2006-03-31 | 2007-10-18 | Yamaha Corp | Evaluation standard decision device, control method, and program |
| JP2008139426A (en) * | 2006-11-30 | 2008-06-19 | Yamaha Corp | Data structure of data for evaluation, karaoke machine, and recording medium |
| JP2007334364A (en) * | 2007-08-06 | 2007-12-27 | Yamaha Corp | Karaoke machine |
Cited By (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2020122949A (en) * | 2019-01-31 | 2020-08-13 | 株式会社第一興商 | Karaoke device |
| JP2020122948A (en) * | 2019-01-31 | 2020-08-13 | 株式会社第一興商 | Karaoke device |
| JP7232653B2 (en) | 2019-01-31 | 2023-03-03 | 株式会社第一興商 | karaoke device |
| JP7232654B2 (en) | 2019-01-31 | 2023-03-03 | 株式会社第一興商 | karaoke equipment |
| JP2020166162A (en) * | 2019-03-29 | 2020-10-08 | 株式会社第一興商 | Karaoke device |
| JP7169243B2 (en) | 2019-03-29 | 2022-11-10 | 株式会社第一興商 | karaoke device |
Also Published As
| Publication number | Publication date |
|---|---|
| JP2013222140A (en) | 2013-10-28 |
| TWI497484B (en) | 2015-08-21 |
| KR101666535B1 (en) | 2016-10-14 |
| CN104170006B (en) | 2017-05-17 |
| CN104170006A (en) | 2014-11-26 |
| KR20140124843A (en) | 2014-10-27 |
| TW201407602A (en) | 2014-02-16 |
| JP5958041B2 (en) | 2016-07-27 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP5958041B2 (en) | Expression performance reference data generation device, performance evaluation device, karaoke device and device | |
| JP2012103603A (en) | Information processing device, musical sequence extracting method and program | |
| JP6060867B2 (en) | Information processing apparatus, data generation method, and program | |
| JP2009104097A (en) | Scoring device and program | |
| JP6288197B2 (en) | Evaluation apparatus and program | |
| JP6102076B2 (en) | Evaluation device | |
| JP5428459B2 (en) | Singing evaluation device | |
| JP6944357B2 (en) | Communication karaoke system | |
| JP2008003483A (en) | Karaoke device | |
| JP5994343B2 (en) | Performance evaluation device and karaoke device | |
| JP6459162B2 (en) | Performance data and audio data synchronization apparatus, method, and program | |
| JP5618743B2 (en) | Singing voice evaluation device | |
| JP3879524B2 (en) | Waveform generation method, performance data processing method, and waveform selection device | |
| JP6365483B2 (en) | Karaoke device, karaoke system, and program | |
| JP6074835B2 (en) | Music practice support device | |
| JP5585320B2 (en) | Singing voice evaluation device | |
| JP6011506B2 (en) | Information processing apparatus, data generation method, and program | |
| JP5416396B2 (en) | Singing evaluation device and program | |
| JP2007233078A (en) | Evaluation device, control method, and program | |
| JP2004184506A (en) | Karaoke machine and program | |
| JP2004279462A (en) | Karaoke machine | |
| JP6514868B2 (en) | Karaoke apparatus and karaoke scoring system | |
| JP2017181661A (en) | Support device | |
| JP5012269B2 (en) | Performance clock generating device, data reproducing device, performance clock generating method, data reproducing method and program | |
| JP2017067998A (en) | Singing evaluation system |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 13777807 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 20147025532 Country of ref document: KR Kind code of ref document: A |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 13777807 Country of ref document: EP Kind code of ref document: A1 |