KR20220103806A - 암 치료용 항-pd1 및 항-lag3 항체 - Google Patents
암 치료용 항-pd1 및 항-lag3 항체 Download PDFInfo
- Publication number
- KR20220103806A KR20220103806A KR1020227023184A KR20227023184A KR20220103806A KR 20220103806 A KR20220103806 A KR 20220103806A KR 1020227023184 A KR1020227023184 A KR 1020227023184A KR 20227023184 A KR20227023184 A KR 20227023184A KR 20220103806 A KR20220103806 A KR 20220103806A
- Authority
- KR
- South Korea
- Prior art keywords
- ser
- seq
- val
- amino acid
- thr
- Prior art date
Links
- 206010028980 Neoplasm Diseases 0.000 title claims abstract description 100
- 201000011510 cancer Diseases 0.000 title claims abstract description 53
- 238000011282 treatment Methods 0.000 title claims description 28
- 238000000034 method Methods 0.000 claims abstract description 67
- 150000007523 nucleic acids Chemical class 0.000 claims abstract description 39
- 102000039446 nucleic acids Human genes 0.000 claims abstract description 36
- 108020004707 nucleic acids Proteins 0.000 claims abstract description 36
- 125000003275 alpha amino acid group Chemical group 0.000 claims description 210
- 239000008194 pharmaceutical composition Substances 0.000 claims description 50
- 239000013604 expression vector Substances 0.000 claims description 30
- 239000002773 nucleotide Substances 0.000 claims description 28
- 125000003729 nucleotide group Chemical group 0.000 claims description 28
- 239000003814 drug Substances 0.000 claims description 24
- 101100510618 Homo sapiens LAG3 gene Proteins 0.000 claims description 20
- 229960003301 nivolumab Drugs 0.000 claims description 19
- 238000004519 manufacturing process Methods 0.000 claims description 14
- 229960002621 pembrolizumab Drugs 0.000 claims description 14
- 208000002154 non-small cell lung carcinoma Diseases 0.000 claims description 12
- 229940124597 therapeutic agent Drugs 0.000 claims description 12
- 208000029729 tumor suppressor gene on chromosome 11 Diseases 0.000 claims description 11
- 206010041067 Small cell lung cancer Diseases 0.000 claims description 8
- 239000003795 chemical substances by application Substances 0.000 claims description 8
- 208000000587 small cell lung carcinoma Diseases 0.000 claims description 8
- 206010039491 Sarcoma Diseases 0.000 claims description 6
- 201000009030 Carcinoma Diseases 0.000 claims description 5
- 229960003852 atezolizumab Drugs 0.000 claims description 5
- 230000035772 mutation Effects 0.000 claims description 5
- 229950002916 avelumab Drugs 0.000 claims description 4
- 238000012258 culturing Methods 0.000 claims description 4
- 230000015572 biosynthetic process Effects 0.000 claims description 3
- 239000003937 drug carrier Substances 0.000 claims description 3
- 201000005787 hematologic cancer Diseases 0.000 claims 3
- 208000024200 hematopoietic and lymphoid system neoplasm Diseases 0.000 claims 3
- 239000000203 mixture Substances 0.000 abstract description 28
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 abstract description 27
- 230000001225 therapeutic effect Effects 0.000 abstract description 17
- 230000027455 binding Effects 0.000 description 83
- 210000004027 cell Anatomy 0.000 description 82
- 239000003112 inhibitor Substances 0.000 description 67
- 102100035360 Cerebellar degeneration-related antigen 1 Human genes 0.000 description 64
- 108060003951 Immunoglobulin Proteins 0.000 description 61
- 102000018358 immunoglobulin Human genes 0.000 description 61
- 102100040678 Programmed cell death protein 1 Human genes 0.000 description 59
- 101710089372 Programmed cell death protein 1 Proteins 0.000 description 56
- 108020004414 DNA Proteins 0.000 description 53
- 101001137987 Homo sapiens Lymphocyte activation gene 3 protein Proteins 0.000 description 48
- 241000880493 Leptailurus serval Species 0.000 description 48
- 102000017578 LAG3 Human genes 0.000 description 47
- 241000282414 Homo sapiens Species 0.000 description 44
- 239000000427 antigen Substances 0.000 description 38
- 108091007433 antigens Proteins 0.000 description 38
- 102000036639 antigens Human genes 0.000 description 38
- 108090000623 proteins and genes Proteins 0.000 description 34
- YMTLKLXDFCSCNX-BYPYZUCNSA-N Ser-Gly-Gly Chemical compound OC[C@H](N)C(=O)NCC(=O)NCC(O)=O YMTLKLXDFCSCNX-BYPYZUCNSA-N 0.000 description 28
- 230000000694 effects Effects 0.000 description 28
- 102000004169 proteins and genes Human genes 0.000 description 27
- 101000611936 Homo sapiens Programmed cell death protein 1 Proteins 0.000 description 26
- 235000018102 proteins Nutrition 0.000 description 26
- 101100505161 Caenorhabditis elegans mel-32 gene Proteins 0.000 description 23
- 102000048362 human PDCD1 Human genes 0.000 description 23
- AIRZWUMAHCDDHR-KKUMJFAQSA-N Lys-Leu-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O AIRZWUMAHCDDHR-KKUMJFAQSA-N 0.000 description 22
- 235000001014 amino acid Nutrition 0.000 description 22
- AOHKLEBWKMKITA-IHRRRGAJSA-N Arg-Phe-Ser Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N AOHKLEBWKMKITA-IHRRRGAJSA-N 0.000 description 21
- QOIKZODVIPOPDD-AVGNSLFASA-N Tyr-Cys-Gln Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCC(N)=O)C(O)=O QOIKZODVIPOPDD-AVGNSLFASA-N 0.000 description 21
- HTONZBWRYUKUKC-RCWTZXSCSA-N Val-Thr-Val Chemical compound CC(C)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O HTONZBWRYUKUKC-RCWTZXSCSA-N 0.000 description 21
- 108010069205 aspartyl-phenylalanine Proteins 0.000 description 21
- VCHVSKNMTXWIIP-SRVKXCTJSA-N Leu-Lys-Ser Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O VCHVSKNMTXWIIP-SRVKXCTJSA-N 0.000 description 20
- 241001529936 Murinae Species 0.000 description 20
- 241000699670 Mus sp. Species 0.000 description 20
- IHCXPSYCHXFXKT-DCAQKATOSA-N Pro-Arg-Glu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(O)=O IHCXPSYCHXFXKT-DCAQKATOSA-N 0.000 description 20
- 108010087924 alanylproline Proteins 0.000 description 20
- 201000010099 disease Diseases 0.000 description 20
- MKJBPDLENBUHQU-CIUDSAMLSA-N Asn-Ser-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O MKJBPDLENBUHQU-CIUDSAMLSA-N 0.000 description 19
- 210000001744 T-lymphocyte Anatomy 0.000 description 19
- 238000003556 assay Methods 0.000 description 19
- 230000014509 gene expression Effects 0.000 description 19
- XKUKSGPZAADMRA-UHFFFAOYSA-N glycyl-glycyl-glycine Natural products NCC(=O)NCC(=O)NCC(O)=O XKUKSGPZAADMRA-UHFFFAOYSA-N 0.000 description 19
- MNQMTYSEKZHIDF-GCJQMDKQSA-N Asp-Thr-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O MNQMTYSEKZHIDF-GCJQMDKQSA-N 0.000 description 17
- AIMGJYMCTAABEN-GVXVVHGQSA-N Leu-Val-Glu Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O AIMGJYMCTAABEN-GVXVVHGQSA-N 0.000 description 17
- 241000699666 Mus <mouse, genus> Species 0.000 description 17
- FQPDRTDDEZXCEC-SVSWQMSJSA-N Thr-Ile-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O FQPDRTDDEZXCEC-SVSWQMSJSA-N 0.000 description 17
- 150000001413 amino acids Chemical class 0.000 description 17
- -1 antibody Proteins 0.000 description 17
- 108010067216 glycyl-glycyl-glycine Proteins 0.000 description 17
- 108010089804 glycyl-threonine Proteins 0.000 description 17
- 108010064235 lysylglycine Proteins 0.000 description 17
- 108090000765 processed proteins & peptides Proteins 0.000 description 17
- VKKYFICVTYKFIO-CIUDSAMLSA-N Arg-Ala-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCN=C(N)N VKKYFICVTYKFIO-CIUDSAMLSA-N 0.000 description 16
- FQCILXROGNOZON-YUMQZZPRSA-N Gln-Pro-Gly Chemical compound NC(=O)CC[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O FQCILXROGNOZON-YUMQZZPRSA-N 0.000 description 16
- BYYNJRSNDARRBX-YFKPBYRVSA-N Gly-Gln-Gly Chemical compound NCC(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O BYYNJRSNDARRBX-YFKPBYRVSA-N 0.000 description 16
- 101000692455 Homo sapiens Platelet-derived growth factor receptor beta Proteins 0.000 description 16
- KIZIOFNVSOSKJI-CIUDSAMLSA-N Leu-Ser-Cys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)O)N KIZIOFNVSOSKJI-CIUDSAMLSA-N 0.000 description 16
- 102100026547 Platelet-derived growth factor receptor beta Human genes 0.000 description 16
- YOOAQCZYZHGUAZ-KATARQTJSA-N Thr-Leu-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O YOOAQCZYZHGUAZ-KATARQTJSA-N 0.000 description 16
- 102100033177 Vascular endothelial growth factor receptor 2 Human genes 0.000 description 16
- 108010008685 alanyl-glutamyl-aspartic acid Proteins 0.000 description 16
- 125000000539 amino acid group Chemical group 0.000 description 16
- 108010050848 glycylleucine Proteins 0.000 description 16
- 108010015792 glycyllysine Proteins 0.000 description 16
- 210000004408 hybridoma Anatomy 0.000 description 16
- XQJCEKXQUJQNNK-ZLUOBGJFSA-N Ser-Ser-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O XQJCEKXQUJQNNK-ZLUOBGJFSA-N 0.000 description 15
- DWYAUVCQDTZIJI-VZFHVOOUSA-N Thr-Ala-Ser Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O DWYAUVCQDTZIJI-VZFHVOOUSA-N 0.000 description 15
- 229920001184 polypeptide Polymers 0.000 description 15
- 102000004196 processed proteins & peptides Human genes 0.000 description 15
- HAXARWKYFIIHKD-ZKWXMUAHSA-N Gly-Ile-Ser Chemical compound NCC(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O HAXARWKYFIIHKD-ZKWXMUAHSA-N 0.000 description 14
- KZNQNBZMBZJQJO-UHFFFAOYSA-N N-glycyl-L-proline Natural products NCC(=O)N1CCCC1C(O)=O KZNQNBZMBZJQJO-UHFFFAOYSA-N 0.000 description 14
- YOFKMVUAZGPFCF-IHRRRGAJSA-N Phe-Met-Asn Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(N)=O)C(O)=O YOFKMVUAZGPFCF-IHRRRGAJSA-N 0.000 description 14
- MQGGXGKQSVEQHR-KKUMJFAQSA-N Tyr-Ser-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 MQGGXGKQSVEQHR-KKUMJFAQSA-N 0.000 description 14
- 108091008605 VEGF receptors Proteins 0.000 description 14
- 108010069020 alanyl-prolyl-glycine Proteins 0.000 description 14
- 108010001064 glycyl-glycyl-glycyl-glycine Proteins 0.000 description 14
- 108010010147 glycylglutamine Proteins 0.000 description 14
- 108010003137 tyrosyltyrosine Proteins 0.000 description 14
- CREYEAPXISDKSB-FQPOAREZSA-N Ala-Thr-Tyr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O CREYEAPXISDKSB-FQPOAREZSA-N 0.000 description 13
- 108010074708 B7-H1 Antigen Proteins 0.000 description 13
- 102000008096 B7-H1 Antigen Human genes 0.000 description 13
- GGAPHLIUUTVYMX-QWRGUYRKSA-N Gly-Phe-Ser Chemical compound OC[C@@H](C([O-])=O)NC(=O)[C@@H](NC(=O)C[NH3+])CC1=CC=CC=C1 GGAPHLIUUTVYMX-QWRGUYRKSA-N 0.000 description 13
- WNZOCXUOGVYYBJ-CDMKHQONSA-N Gly-Phe-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)NC(=O)CN)O WNZOCXUOGVYYBJ-CDMKHQONSA-N 0.000 description 13
- WZBLRQQCDYYRTD-SIXJUCDHSA-N His-Ile-Trp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)NC(=O)[C@H](CC3=CN=CN3)N WZBLRQQCDYYRTD-SIXJUCDHSA-N 0.000 description 13
- 101100335081 Mus musculus Flt3 gene Proteins 0.000 description 13
- CUMXHKAOHNWRFQ-BZSNNMDCSA-N Phe-Asp-Tyr Chemical compound C([C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=CC=C1 CUMXHKAOHNWRFQ-BZSNNMDCSA-N 0.000 description 13
- QYSFWUIXDFJUDW-DCAQKATOSA-N Ser-Leu-Arg Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O QYSFWUIXDFJUDW-DCAQKATOSA-N 0.000 description 13
- YUJLIIRMIAGMCQ-CIUDSAMLSA-N Ser-Leu-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O YUJLIIRMIAGMCQ-CIUDSAMLSA-N 0.000 description 13
- OSFZCEQJLWCIBG-BZSNNMDCSA-N Ser-Tyr-Tyr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O OSFZCEQJLWCIBG-BZSNNMDCSA-N 0.000 description 13
- YOPQYBJJNSIQGZ-JNPHEJMOSA-N Thr-Tyr-Tyr Chemical compound C([C@H](NC(=O)[C@@H](N)[C@H](O)C)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=C(O)C=C1 YOPQYBJJNSIQGZ-JNPHEJMOSA-N 0.000 description 13
- VEYXZZGMIBKXCN-UBHSHLNASA-N Trp-Asp-Asp Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC(=O)O)C(=O)O)N VEYXZZGMIBKXCN-UBHSHLNASA-N 0.000 description 13
- VTFWAGGJDRSQFG-MELADBBJSA-N Tyr-Asn-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)N)NC(=O)[C@H](CC2=CC=C(C=C2)O)N)C(=O)O VTFWAGGJDRSQFG-MELADBBJSA-N 0.000 description 13
- CTDPLKMBVALCGN-JSGCOSHPSA-N Tyr-Gly-Val Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O CTDPLKMBVALCGN-JSGCOSHPSA-N 0.000 description 13
- GVJUTBOZZBTBIG-AVGNSLFASA-N Val-Lys-Arg Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N GVJUTBOZZBTBIG-AVGNSLFASA-N 0.000 description 13
- 108010010430 asparagine-proline-alanine Proteins 0.000 description 13
- 230000001105 regulatory effect Effects 0.000 description 13
- 108010045269 tryptophyltryptophan Proteins 0.000 description 13
- 108010077037 tyrosyl-tyrosyl-phenylalanine Proteins 0.000 description 13
- ZDILXFDENZVOTL-BPNCWPANSA-N Ala-Val-Tyr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O ZDILXFDENZVOTL-BPNCWPANSA-N 0.000 description 12
- PPGBXYKMUMHFBF-KATARQTJSA-N Leu-Ser-Thr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O PPGBXYKMUMHFBF-KATARQTJSA-N 0.000 description 12
- PDIDTSZKKFEDMB-UWVGGRQHSA-N Lys-Pro-Gly Chemical compound [H]N[C@@H](CCCCN)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O PDIDTSZKKFEDMB-UWVGGRQHSA-N 0.000 description 12
- 108091028043 Nucleic acid sequence Proteins 0.000 description 12
- 239000012634 fragment Substances 0.000 description 12
- 239000003446 ligand Substances 0.000 description 12
- 238000002360 preparation method Methods 0.000 description 12
- 108010070643 prolylglutamic acid Proteins 0.000 description 12
- 239000000243 solution Substances 0.000 description 12
- KVWLTGNCJYDJET-LSJOCFKGSA-N Ala-Arg-His Chemical compound C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N KVWLTGNCJYDJET-LSJOCFKGSA-N 0.000 description 11
- REAQAWSENITKJL-DDWPSWQVSA-N Ala-Met-Asp-Tyr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O REAQAWSENITKJL-DDWPSWQVSA-N 0.000 description 11
- AWNAEZICPNGAJK-FXQIFTODSA-N Ala-Met-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CO)C(O)=O AWNAEZICPNGAJK-FXQIFTODSA-N 0.000 description 11
- KLALXKYLOMZDQT-ZLUOBGJFSA-N Ala-Ser-Asn Chemical compound C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC(N)=O KLALXKYLOMZDQT-ZLUOBGJFSA-N 0.000 description 11
- GCTANJIJJROSLH-GVARAGBVSA-N Ala-Tyr-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@H](C)N GCTANJIJJROSLH-GVARAGBVSA-N 0.000 description 11
- LRCIOEVFVGXZKB-BZSNNMDCSA-N Asn-Tyr-Tyr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O LRCIOEVFVGXZKB-BZSNNMDCSA-N 0.000 description 11
- XYBJLTKSGFBLCS-QXEWZRGKSA-N Asp-Arg-Val Chemical compound NC(N)=NCCC[C@@H](C(=O)N[C@@H](C(C)C)C(O)=O)NC(=O)[C@@H](N)CC(O)=O XYBJLTKSGFBLCS-QXEWZRGKSA-N 0.000 description 11
- SAKCBXNPWDRWPE-BQBZGAKWSA-N Asp-Met-Gly Chemical compound CSCC[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CC(=O)O)N SAKCBXNPWDRWPE-BQBZGAKWSA-N 0.000 description 11
- AMRLSQGGERHDHJ-FXQIFTODSA-N Cys-Ala-Arg Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O AMRLSQGGERHDHJ-FXQIFTODSA-N 0.000 description 11
- SZQCDCKIGWQAQN-FXQIFTODSA-N Cys-Arg-Ala Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(O)=O SZQCDCKIGWQAQN-FXQIFTODSA-N 0.000 description 11
- OZHXXYOHPLLLMI-CIUDSAMLSA-N Cys-Lys-Ala Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(O)=O OZHXXYOHPLLLMI-CIUDSAMLSA-N 0.000 description 11
- SMLDOQHTOAAFJQ-WDSKDSINSA-N Gln-Gly-Ser Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)NCC(=O)N[C@@H](CO)C(O)=O SMLDOQHTOAAFJQ-WDSKDSINSA-N 0.000 description 11
- OOLCSQQPSLIETN-JYJNAYRXSA-N Gln-His-Tyr Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)O)NC(=O)[C@H](CC2=CN=CN2)NC(=O)[C@H](CCC(=O)N)N)O OOLCSQQPSLIETN-JYJNAYRXSA-N 0.000 description 11
- XZLLTYBONVKGLO-SDDRHHMPSA-N Gln-Lys-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCCN)NC(=O)[C@H](CCC(=O)N)N)C(=O)O XZLLTYBONVKGLO-SDDRHHMPSA-N 0.000 description 11
- HNAUFGBKJLTWQE-IFFSRLJSSA-N Gln-Val-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](C(C)C)NC(=O)[C@H](CCC(=O)N)N)O HNAUFGBKJLTWQE-IFFSRLJSSA-N 0.000 description 11
- NTNUEBVGKMVANB-NHCYSSNCSA-N Glu-Val-Met Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCSC)C(O)=O NTNUEBVGKMVANB-NHCYSSNCSA-N 0.000 description 11
- RMWAOBGCZZSJHE-UMNHJUIQSA-N Glu-Val-Pro Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCC(=O)O)N RMWAOBGCZZSJHE-UMNHJUIQSA-N 0.000 description 11
- UFPXDFOYHVEIPI-BYPYZUCNSA-N Gly-Gly-Asp Chemical compound NCC(=O)NCC(=O)N[C@H](C(O)=O)CC(O)=O UFPXDFOYHVEIPI-BYPYZUCNSA-N 0.000 description 11
- MIIVFRCYJABHTQ-ONGXEEELSA-N Gly-Leu-Val Chemical compound [H]NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O MIIVFRCYJABHTQ-ONGXEEELSA-N 0.000 description 11
- SOEGEPHNZOISMT-BYPYZUCNSA-N Gly-Ser-Gly Chemical compound NCC(=O)N[C@@H](CO)C(=O)NCC(O)=O SOEGEPHNZOISMT-BYPYZUCNSA-N 0.000 description 11
- NVTPVQLIZCOJFK-FOHZUACHSA-N Gly-Thr-Asp Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(O)=O NVTPVQLIZCOJFK-FOHZUACHSA-N 0.000 description 11
- JHNJNTMTZHEDLJ-NAKRPEOUSA-N Ile-Ser-Arg Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O JHNJNTMTZHEDLJ-NAKRPEOUSA-N 0.000 description 11
- WRDTXMBPHMBGIB-STECZYCISA-N Ile-Tyr-Val Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](C(C)C)C(O)=O)CC1=CC=C(O)C=C1 WRDTXMBPHMBGIB-STECZYCISA-N 0.000 description 11
- PMGDADKJMCOXHX-UHFFFAOYSA-N L-Arginyl-L-glutamin-acetat Natural products NC(=N)NCCCC(N)C(=O)NC(CCC(N)=O)C(O)=O PMGDADKJMCOXHX-UHFFFAOYSA-N 0.000 description 11
- FEHQLKKBVJHSEC-SZMVWBNQSA-N Leu-Glu-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC(C)C)C(O)=O)=CNC2=C1 FEHQLKKBVJHSEC-SZMVWBNQSA-N 0.000 description 11
- LCNASHSOFMRYFO-WDCWCFNPSA-N Leu-Thr-Gln Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CCC(N)=O LCNASHSOFMRYFO-WDCWCFNPSA-N 0.000 description 11
- LJBVRCDPWOJOEK-PPCPHDFISA-N Leu-Thr-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O LJBVRCDPWOJOEK-PPCPHDFISA-N 0.000 description 11
- GQZMPWBZQALKJO-UWVGGRQHSA-N Lys-Gly-Arg Chemical compound [H]N[C@@H](CCCCN)C(=O)NCC(=O)N[C@@H](CCCNC(N)=N)C(O)=O GQZMPWBZQALKJO-UWVGGRQHSA-N 0.000 description 11
- SKRGVGLIRUGANF-AVGNSLFASA-N Lys-Leu-Glu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O SKRGVGLIRUGANF-AVGNSLFASA-N 0.000 description 11
- SPSSJSICDYYTQN-HJGDQZAQSA-N Met-Thr-Gln Chemical compound CSCC[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CCC(N)=O SPSSJSICDYYTQN-HJGDQZAQSA-N 0.000 description 11
- ULVMNZOKDBHKKI-ACZMJKKPSA-N Ser-Gln-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O ULVMNZOKDBHKKI-ACZMJKKPSA-N 0.000 description 11
- SQBLRDDJTUJDMV-ACZMJKKPSA-N Ser-Glu-Asn Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O SQBLRDDJTUJDMV-ACZMJKKPSA-N 0.000 description 11
- UIGMAMGZOJVTDN-WHFBIAKZSA-N Ser-Gly-Ser Chemical compound OC[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O UIGMAMGZOJVTDN-WHFBIAKZSA-N 0.000 description 11
- SFTZWNJFZYOLBD-ZDLURKLDSA-N Ser-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CO SFTZWNJFZYOLBD-ZDLURKLDSA-N 0.000 description 11
- MOINZPRHJGTCHZ-MMWGEVLESA-N Ser-Ile-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CO)N MOINZPRHJGTCHZ-MMWGEVLESA-N 0.000 description 11
- ADJDNJCSPNFFPI-FXQIFTODSA-N Ser-Pro-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CO ADJDNJCSPNFFPI-FXQIFTODSA-N 0.000 description 11
- FGBLCMLXHRPVOF-IHRRRGAJSA-N Ser-Tyr-Arg Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O FGBLCMLXHRPVOF-IHRRRGAJSA-N 0.000 description 11
- WRUWXBBEFUTJOU-XGEHTFHBSA-N Thr-Met-Ser Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CO)C(=O)O)N)O WRUWXBBEFUTJOU-XGEHTFHBSA-N 0.000 description 11
- BIBYEFRASCNLAA-CDMKHQONSA-N Thr-Phe-Gly Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@H](C(=O)NCC(O)=O)CC1=CC=CC=C1 BIBYEFRASCNLAA-CDMKHQONSA-N 0.000 description 11
- MNYNCKZAEIAONY-XGEHTFHBSA-N Thr-Val-Ser Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O MNYNCKZAEIAONY-XGEHTFHBSA-N 0.000 description 11
- SVGAWGVHFIYAEE-JSGCOSHPSA-N Trp-Gly-Gln Chemical compound C1=CC=C2C(C[C@H](N)C(=O)NCC(=O)N[C@@H](CCC(N)=O)C(O)=O)=CNC2=C1 SVGAWGVHFIYAEE-JSGCOSHPSA-N 0.000 description 11
- YXSSXUIBUJGHJY-SFJXLCSZSA-N Trp-Thr-Phe Chemical compound C([C@H](NC(=O)[C@@H](NC(=O)[C@@H](N)CC=1C2=CC=CC=C2NC=1)[C@H](O)C)C(O)=O)C1=CC=CC=C1 YXSSXUIBUJGHJY-SFJXLCSZSA-N 0.000 description 11
- MBLJBGZWLHTJBH-SZMVWBNQSA-N Trp-Val-Arg Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O)=CNC2=C1 MBLJBGZWLHTJBH-SZMVWBNQSA-N 0.000 description 11
- QUILOGWWLXMSAT-IHRRRGAJSA-N Tyr-Gln-Gln Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O QUILOGWWLXMSAT-IHRRRGAJSA-N 0.000 description 11
- VYQQQIRHIFALGE-UWJYBYFXSA-N Tyr-Ser-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 VYQQQIRHIFALGE-UWJYBYFXSA-N 0.000 description 11
- ZZDYJFVIKVSUFA-WLTAIBSBSA-N Tyr-Thr-Gly Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O ZZDYJFVIKVSUFA-WLTAIBSBSA-N 0.000 description 11
- VJOWWOGRNXRQMF-UVBJJODRSA-N Val-Ala-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](C)NC(=O)[C@@H](N)C(C)C)C(O)=O)=CNC2=C1 VJOWWOGRNXRQMF-UVBJJODRSA-N 0.000 description 11
- JVYIGCARISMLMV-HOCLYGCPSA-N Val-Gly-Trp Chemical compound CC(C)[C@@H](C(=O)NCC(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)N JVYIGCARISMLMV-HOCLYGCPSA-N 0.000 description 11
- ZXYPHBKIZLAQTL-QXEWZRGKSA-N Val-Pro-Asp Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(=O)O)C(=O)O)N ZXYPHBKIZLAQTL-QXEWZRGKSA-N 0.000 description 11
- 108010081404 acein-2 Proteins 0.000 description 11
- 108010086434 alanyl-seryl-glycine Proteins 0.000 description 11
- 108010070944 alanylhistidine Proteins 0.000 description 11
- 108010008355 arginyl-glutamine Proteins 0.000 description 11
- 108010018006 histidylserine Proteins 0.000 description 11
- 108010020755 prolyl-glycyl-glycine Proteins 0.000 description 11
- 108010090894 prolylleucine Proteins 0.000 description 11
- 108010069117 seryl-lysyl-aspartic acid Proteins 0.000 description 11
- 108010044292 tryptophyltyrosine Proteins 0.000 description 11
- 239000013598 vector Substances 0.000 description 11
- ARHJJAAWNWOACN-FXQIFTODSA-N Ala-Ser-Val Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O ARHJJAAWNWOACN-FXQIFTODSA-N 0.000 description 10
- OTZMRMHZCMZOJZ-SRVKXCTJSA-N Arg-Leu-Glu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O OTZMRMHZCMZOJZ-SRVKXCTJSA-N 0.000 description 10
- SLKLLQWZQHXYSV-CIUDSAMLSA-N Asn-Ala-Lys Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCCN)C(O)=O SLKLLQWZQHXYSV-CIUDSAMLSA-N 0.000 description 10
- USNJAPJZSGTTPX-XVSYOHENSA-N Asp-Phe-Thr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O USNJAPJZSGTTPX-XVSYOHENSA-N 0.000 description 10
- OHLLDUNVMPPUMD-DCAQKATOSA-N Cys-Leu-Val Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](C(C)C)C(=O)O)NC(=O)[C@H](CS)N OHLLDUNVMPPUMD-DCAQKATOSA-N 0.000 description 10
- OYTPNWYZORARHL-XHNCKOQMSA-N Gln-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCC(=O)N)N OYTPNWYZORARHL-XHNCKOQMSA-N 0.000 description 10
- KPNWAJMEMRCLAL-GUBZILKMSA-N Gln-Ser-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CCC(=O)N)N KPNWAJMEMRCLAL-GUBZILKMSA-N 0.000 description 10
- AVZHGSCDKIQZPQ-CIUDSAMLSA-N Glu-Arg-Ala Chemical compound C[C@H](NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@@H](N)CCC(O)=O)C(O)=O AVZHGSCDKIQZPQ-CIUDSAMLSA-N 0.000 description 10
- PAQUJCSYVIBPLC-AVGNSLFASA-N Glu-Asp-Phe Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 PAQUJCSYVIBPLC-AVGNSLFASA-N 0.000 description 10
- INGJLBQKTRJLFO-UKJIMTQDSA-N Glu-Ile-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H](N)CCC(O)=O INGJLBQKTRJLFO-UKJIMTQDSA-N 0.000 description 10
- WGYHAAXZWPEBDQ-IFFSRLJSSA-N Glu-Val-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O WGYHAAXZWPEBDQ-IFFSRLJSSA-N 0.000 description 10
- XCLCVBYNGXEVDU-WHFBIAKZSA-N Gly-Asn-Ser Chemical compound NCC(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O XCLCVBYNGXEVDU-WHFBIAKZSA-N 0.000 description 10
- CQZDZKRHFWJXDF-WDSKDSINSA-N Gly-Gln-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CCC(N)=O)NC(=O)CN CQZDZKRHFWJXDF-WDSKDSINSA-N 0.000 description 10
- BHPQOIPBLYJNAW-NGZCFLSTSA-N Gly-Ile-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)CN BHPQOIPBLYJNAW-NGZCFLSTSA-N 0.000 description 10
- NNCSJUBVFBDDLC-YUMQZZPRSA-N Gly-Leu-Ser Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O NNCSJUBVFBDDLC-YUMQZZPRSA-N 0.000 description 10
- PDUHNKAFQXQNLH-ZETCQYMHSA-N Gly-Lys-Gly Chemical compound NCCCC[C@H](NC(=O)CN)C(=O)NCC(O)=O PDUHNKAFQXQNLH-ZETCQYMHSA-N 0.000 description 10
- HAOUOFNNJJLVNS-BQBZGAKWSA-N Gly-Pro-Ser Chemical compound NCC(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O HAOUOFNNJJLVNS-BQBZGAKWSA-N 0.000 description 10
- ZZWUYQXMIFTIIY-WEDXCCLWSA-N Gly-Thr-Leu Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O ZZWUYQXMIFTIIY-WEDXCCLWSA-N 0.000 description 10
- XHVONGZZVUUORG-WEDXCCLWSA-N Gly-Thr-Lys Chemical compound NCC(=O)N[C@@H]([C@H](O)C)C(=O)N[C@H](C(O)=O)CCCCN XHVONGZZVUUORG-WEDXCCLWSA-N 0.000 description 10
- TVMNTHXFRSXZGR-IHRRRGAJSA-N His-Lys-Val Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(O)=O TVMNTHXFRSXZGR-IHRRRGAJSA-N 0.000 description 10
- KIMHKBDJQQYLHU-PEFMBERDSA-N Ile-Glu-Asp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CC(=O)O)C(=O)O)N KIMHKBDJQQYLHU-PEFMBERDSA-N 0.000 description 10
- AXZGZMGRBDQTEY-SRVKXCTJSA-N Leu-Gln-Met Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCSC)C(O)=O AXZGZMGRBDQTEY-SRVKXCTJSA-N 0.000 description 10
- CQGSYZCULZMEDE-UHFFFAOYSA-N Leu-Gln-Pro Natural products CC(C)CC(N)C(=O)NC(CCC(N)=O)C(=O)N1CCCC1C(O)=O CQGSYZCULZMEDE-UHFFFAOYSA-N 0.000 description 10
- GPICTNQYKHHHTH-GUBZILKMSA-N Leu-Gln-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O GPICTNQYKHHHTH-GUBZILKMSA-N 0.000 description 10
- SBANPBVRHYIMRR-GARJFASQSA-N Leu-Ser-Pro Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CO)C(=O)N1CCC[C@@H]1C(=O)O)N SBANPBVRHYIMRR-GARJFASQSA-N 0.000 description 10
- SBANPBVRHYIMRR-UHFFFAOYSA-N Leu-Ser-Pro Natural products CC(C)CC(N)C(=O)NC(CO)C(=O)N1CCCC1C(O)=O SBANPBVRHYIMRR-UHFFFAOYSA-N 0.000 description 10
- LINKCQUOMUDLKN-KATARQTJSA-N Leu-Thr-Cys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CC(C)C)N)O LINKCQUOMUDLKN-KATARQTJSA-N 0.000 description 10
- AIQWYVFNBNNOLU-RHYQMDGZSA-N Leu-Thr-Val Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O AIQWYVFNBNNOLU-RHYQMDGZSA-N 0.000 description 10
- IXHKPDJKKCUKHS-GARJFASQSA-N Lys-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCCCN)N IXHKPDJKKCUKHS-GARJFASQSA-N 0.000 description 10
- YCCUXNNKXDGMAM-KKUMJFAQSA-N Phe-Leu-Ser Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O YCCUXNNKXDGMAM-KKUMJFAQSA-N 0.000 description 10
- JDMKQHSHKJHAHR-UHFFFAOYSA-N Phe-Phe-Leu-Tyr Natural products C=1C=C(O)C=CC=1CC(C(O)=O)NC(=O)C(CC(C)C)NC(=O)C(NC(=O)C(N)CC=1C=CC=CC=1)CC1=CC=CC=C1 JDMKQHSHKJHAHR-UHFFFAOYSA-N 0.000 description 10
- FGWUALWGCZJQDJ-URLPEUOOSA-N Phe-Thr-Ile Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O FGWUALWGCZJQDJ-URLPEUOOSA-N 0.000 description 10
- KLYYKKGCPOGDPE-OEAJRASXSA-N Phe-Thr-Leu Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O KLYYKKGCPOGDPE-OEAJRASXSA-N 0.000 description 10
- TUYWCHPXKQTISF-LPEHRKFASA-N Pro-Cys-Pro Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CS)C(=O)N2CCC[C@@H]2C(=O)O TUYWCHPXKQTISF-LPEHRKFASA-N 0.000 description 10
- MGDFPGCFVJFITQ-CIUDSAMLSA-N Pro-Glu-Asp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O MGDFPGCFVJFITQ-CIUDSAMLSA-N 0.000 description 10
- VPEVBAUSTBWQHN-NHCYSSNCSA-N Pro-Glu-Val Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O VPEVBAUSTBWQHN-NHCYSSNCSA-N 0.000 description 10
- FDMKYQQYJKYCLV-GUBZILKMSA-N Pro-Pro-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H]1NCCC1 FDMKYQQYJKYCLV-GUBZILKMSA-N 0.000 description 10
- QEDMOZUJTGEIBF-FXQIFTODSA-N Ser-Arg-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(O)=O QEDMOZUJTGEIBF-FXQIFTODSA-N 0.000 description 10
- ZOHGLPQGEHSLPD-FXQIFTODSA-N Ser-Gln-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O ZOHGLPQGEHSLPD-FXQIFTODSA-N 0.000 description 10
- GJFYFGOEWLDQGW-GUBZILKMSA-N Ser-Leu-Gln Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CO)N GJFYFGOEWLDQGW-GUBZILKMSA-N 0.000 description 10
- GZSZPKSBVAOGIE-CIUDSAMLSA-N Ser-Lys-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(O)=O GZSZPKSBVAOGIE-CIUDSAMLSA-N 0.000 description 10
- AZWNCEBQZXELEZ-FXQIFTODSA-N Ser-Pro-Ser Chemical compound OC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O AZWNCEBQZXELEZ-FXQIFTODSA-N 0.000 description 10
- HNDMFDBQXYZSRM-IHRRRGAJSA-N Ser-Val-Phe Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O HNDMFDBQXYZSRM-IHRRRGAJSA-N 0.000 description 10
- LECUEEHKUFYOOV-ZJDVBMNYSA-N Thr-Thr-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@@H](N)[C@@H](C)O LECUEEHKUFYOOV-ZJDVBMNYSA-N 0.000 description 10
- OGOYMQWIWHGTGH-KZVJFYERSA-N Thr-Val-Ala Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C)C(O)=O OGOYMQWIWHGTGH-KZVJFYERSA-N 0.000 description 10
- PKZIWSHDJYIPRH-JBACZVJFSA-N Trp-Tyr-Gln Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(N)=O)C(O)=O PKZIWSHDJYIPRH-JBACZVJFSA-N 0.000 description 10
- UJMCYJKPDFQLHX-XGEHTFHBSA-N Val-Ser-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](C(C)C)N)O UJMCYJKPDFQLHX-XGEHTFHBSA-N 0.000 description 10
- OWFGFHQMSBTKLX-UFYCRDLUSA-N Val-Tyr-Tyr Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)O)N OWFGFHQMSBTKLX-UFYCRDLUSA-N 0.000 description 10
- 230000003042 antagnostic effect Effects 0.000 description 10
- 108010052670 arginyl-glutamyl-glutamic acid Proteins 0.000 description 10
- 108010009111 arginyl-glycyl-glutamic acid Proteins 0.000 description 10
- 108010092854 aspartyllysine Proteins 0.000 description 10
- 108010049041 glutamylalanine Proteins 0.000 description 10
- 108010000434 glycyl-alanyl-leucine Proteins 0.000 description 10
- 108010050475 glycyl-leucyl-tyrosine Proteins 0.000 description 10
- 230000005764 inhibitory process Effects 0.000 description 10
- 108010044311 leucyl-glycyl-glycine Proteins 0.000 description 10
- 238000006467 substitution reaction Methods 0.000 description 10
- 108010051110 tyrosyl-lysine Proteins 0.000 description 10
- 108010052774 valyl-lysyl-glycyl-phenylalanyl-tyrosine Proteins 0.000 description 10
- 108010073969 valyllysine Proteins 0.000 description 10
- HSWYMWGDMPLTTH-FXQIFTODSA-N Asp-Glu-Gln Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O HSWYMWGDMPLTTH-FXQIFTODSA-N 0.000 description 9
- 206010009944 Colon cancer Diseases 0.000 description 9
- ASCFJMSGKUIRDU-ZPFDUUQYSA-N Ile-Arg-Gln Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(O)=O ASCFJMSGKUIRDU-ZPFDUUQYSA-N 0.000 description 9
- SYSWVVCYSXBVJG-RHYQMDGZSA-N Val-Leu-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](C(C)C)N)O SYSWVVCYSXBVJG-RHYQMDGZSA-N 0.000 description 9
- 239000003623 enhancer Substances 0.000 description 9
- 210000004962 mammalian cell Anatomy 0.000 description 9
- QNFRBNZGVVKBNJ-PEFMBERDSA-N Asp-Ile-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CC(=O)O)N QNFRBNZGVVKBNJ-PEFMBERDSA-N 0.000 description 8
- JXFLPKSDLDEOQK-JHEQGTHGSA-N Gln-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CCC(N)=O JXFLPKSDLDEOQK-JHEQGTHGSA-N 0.000 description 8
- DHMQDGOQFOQNFH-UHFFFAOYSA-N Glycine Chemical compound NCC(O)=O DHMQDGOQFOQNFH-UHFFFAOYSA-N 0.000 description 8
- 102100037850 Interferon gamma Human genes 0.000 description 8
- 108010074328 Interferon-gamma Proteins 0.000 description 8
- YKIRNDPUWONXQN-GUBZILKMSA-N Lys-Asn-Gln Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N YKIRNDPUWONXQN-GUBZILKMSA-N 0.000 description 8
- TYYBJUYSTWJHGO-ZKWXMUAHSA-N Ser-Asn-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](C(C)C)C(O)=O TYYBJUYSTWJHGO-ZKWXMUAHSA-N 0.000 description 8
- 230000005867 T cell response Effects 0.000 description 8
- 230000006870 function Effects 0.000 description 8
- 238000001727 in vivo Methods 0.000 description 8
- 239000000126 substance Substances 0.000 description 8
- PRLPSDIHSRITSF-UNQGMJICSA-N Arg-Phe-Thr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O PRLPSDIHSRITSF-UNQGMJICSA-N 0.000 description 7
- GCACQYDBDHRVGE-LKXGYXEUSA-N Asp-Thr-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H]([C@H](O)C)NC(=O)[C@@H](N)CC(O)=O GCACQYDBDHRVGE-LKXGYXEUSA-N 0.000 description 7
- 206010058467 Lung neoplasm malignant Diseases 0.000 description 7
- 101100407308 Mus musculus Pdcd1lg2 gene Proteins 0.000 description 7
- IPFXYNKCXYGSSV-KKUMJFAQSA-N Phe-Ser-Lys Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)O)N IPFXYNKCXYGSSV-KKUMJFAQSA-N 0.000 description 7
- 108700030875 Programmed Cell Death 1 Ligand 2 Proteins 0.000 description 7
- 102100024213 Programmed cell death 1 ligand 2 Human genes 0.000 description 7
- XJDMUQCLVSCRSJ-VZFHVOOUSA-N Ser-Thr-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O XJDMUQCLVSCRSJ-VZFHVOOUSA-N 0.000 description 7
- 230000000903 blocking effect Effects 0.000 description 7
- 210000004443 dendritic cell Anatomy 0.000 description 7
- 210000000987 immune system Anatomy 0.000 description 7
- 208000020816 lung neoplasm Diseases 0.000 description 7
- 238000003259 recombinant expression Methods 0.000 description 7
- YCRAFFCYWOUEOF-DLOVCJGASA-N Ala-Phe-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)C)CC1=CC=CC=C1 YCRAFFCYWOUEOF-DLOVCJGASA-N 0.000 description 6
- KNMRXHIAVXHCLW-ZLUOBGJFSA-N Asp-Asn-Ser Chemical compound C([C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CO)C(=O)O)N)C(=O)O KNMRXHIAVXHCLW-ZLUOBGJFSA-N 0.000 description 6
- 102000053602 DNA Human genes 0.000 description 6
- XTZDZAXYPDISRR-MNXVOIDGSA-N Glu-Ile-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCC(=O)O)N XTZDZAXYPDISRR-MNXVOIDGSA-N 0.000 description 6
- PABFFPWEJMEVEC-JGVFFNPUSA-N Gly-Gln-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)N)NC(=O)CN)C(=O)O PABFFPWEJMEVEC-JGVFFNPUSA-N 0.000 description 6
- KSOBNUBCYHGUKH-UWVGGRQHSA-N Gly-Val-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)CN KSOBNUBCYHGUKH-UWVGGRQHSA-N 0.000 description 6
- PEDCQBHIVMGVHV-UHFFFAOYSA-N Glycerine Chemical compound OCC(O)CO PEDCQBHIVMGVHV-UHFFFAOYSA-N 0.000 description 6
- LLZLRXBTOOFODM-QSFUFRPTSA-N Ile-Asp-Val Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](C(C)C)C(=O)O)N LLZLRXBTOOFODM-QSFUFRPTSA-N 0.000 description 6
- QUCDKEKDPYISNX-HJGDQZAQSA-N Lys-Asn-Thr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O QUCDKEKDPYISNX-HJGDQZAQSA-N 0.000 description 6
- 241000282567 Macaca fascicularis Species 0.000 description 6
- CAODKDAPYGUMLK-FXQIFTODSA-N Met-Asn-Ser Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O CAODKDAPYGUMLK-FXQIFTODSA-N 0.000 description 6
- 206010035226 Plasma cell myeloma Diseases 0.000 description 6
- UIMCLYYSUCIUJM-UWVGGRQHSA-N Pro-Gly-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H]1CCCN1 UIMCLYYSUCIUJM-UWVGGRQHSA-N 0.000 description 6
- YQHZVYJAGWMHES-ZLUOBGJFSA-N Ser-Ala-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O YQHZVYJAGWMHES-ZLUOBGJFSA-N 0.000 description 6
- BMKNXTJLHFIAAH-CIUDSAMLSA-N Ser-Ser-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O BMKNXTJLHFIAAH-CIUDSAMLSA-N 0.000 description 6
- 230000006044 T cell activation Effects 0.000 description 6
- SPVHQURZJCUDQC-VOAKCMCISA-N Thr-Lys-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(O)=O SPVHQURZJCUDQC-VOAKCMCISA-N 0.000 description 6
- UGFOSENEZHEQKX-PJODQICGSA-N Trp-Val-Ala Chemical compound CC(C)[C@H](NC(=O)[C@@H](N)Cc1c[nH]c2ccccc12)C(=O)N[C@@H](C)C(O)=O UGFOSENEZHEQKX-PJODQICGSA-N 0.000 description 6
- NKUGCYDFQKFVOJ-JYJNAYRXSA-N Tyr-Leu-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 NKUGCYDFQKFVOJ-JYJNAYRXSA-N 0.000 description 6
- VHIZXDZMTDVFGX-DCAQKATOSA-N Val-Ser-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](C(C)C)N VHIZXDZMTDVFGX-DCAQKATOSA-N 0.000 description 6
- KOSRFJWDECSPRO-UHFFFAOYSA-N alpha-L-glutamyl-L-glutamic acid Natural products OC(=O)CCC(N)C(=O)NC(CCC(O)=O)C(O)=O KOSRFJWDECSPRO-UHFFFAOYSA-N 0.000 description 6
- 102000025171 antigen binding proteins Human genes 0.000 description 6
- 108091000831 antigen binding proteins Proteins 0.000 description 6
- 108010068265 aspartyltyrosine Proteins 0.000 description 6
- 238000010494 dissociation reaction Methods 0.000 description 6
- 230000005593 dissociations Effects 0.000 description 6
- 238000005516 engineering process Methods 0.000 description 6
- 238000009472 formulation Methods 0.000 description 6
- 108010063718 gamma-glutamylaspartic acid Proteins 0.000 description 6
- 108010055341 glutamyl-glutamic acid Proteins 0.000 description 6
- 230000002163 immunogen Effects 0.000 description 6
- 230000001976 improved effect Effects 0.000 description 6
- 230000003993 interaction Effects 0.000 description 6
- 201000005202 lung cancer Diseases 0.000 description 6
- 238000013507 mapping Methods 0.000 description 6
- 239000002953 phosphate buffered saline Substances 0.000 description 6
- 108091033319 polynucleotide Proteins 0.000 description 6
- 102000040430 polynucleotide Human genes 0.000 description 6
- 239000002157 polynucleotide Substances 0.000 description 6
- 108010077112 prolyl-proline Proteins 0.000 description 6
- 229960000814 tetanus toxoid Drugs 0.000 description 6
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Chemical compound O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 6
- HDTRYLNUVZCQOY-UHFFFAOYSA-N α-D-glucopyranosyl-α-D-glucopyranoside Natural products OC1C(O)C(O)C(CO)OC1OC1C(O)C(O)C(O)C(CO)O1 HDTRYLNUVZCQOY-UHFFFAOYSA-N 0.000 description 5
- IESDGNYHXIOKRW-YXMSTPNBSA-N (2s)-2-[[(2s)-1-[(2s)-6-amino-2-[[(2s,3r)-2-amino-3-hydroxybutanoyl]amino]hexanoyl]pyrrolidine-2-carbonyl]amino]-5-(diaminomethylideneamino)pentanoic acid Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(O)=O IESDGNYHXIOKRW-YXMSTPNBSA-N 0.000 description 5
- DIBLBAURNYJYBF-XLXZRNDBSA-N (2s)-2-[[(2s)-2-[[2-[[(2s)-6-amino-2-[[(2s)-2-amino-3-methylbutanoyl]amino]hexanoyl]amino]acetyl]amino]-3-phenylpropanoyl]amino]-3-(4-hydroxyphenyl)propanoic acid Chemical compound C([C@H](NC(=O)CNC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)C(C)C)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=CC=C1 DIBLBAURNYJYBF-XLXZRNDBSA-N 0.000 description 5
- WCBVQNZTOKJWJS-ACZMJKKPSA-N Ala-Cys-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCC(O)=O)C(O)=O WCBVQNZTOKJWJS-ACZMJKKPSA-N 0.000 description 5
- SUMYEVXWCAYLLJ-GUBZILKMSA-N Ala-Leu-Gln Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O SUMYEVXWCAYLLJ-GUBZILKMSA-N 0.000 description 5
- MNZHHDPWDWQJCQ-YUMQZZPRSA-N Ala-Leu-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O MNZHHDPWDWQJCQ-YUMQZZPRSA-N 0.000 description 5
- DPNZTBKGAUAZQU-DLOVCJGASA-N Ala-Leu-His Chemical compound C[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N DPNZTBKGAUAZQU-DLOVCJGASA-N 0.000 description 5
- MEFILNJXAVSUTO-JXUBOQSCSA-N Ala-Leu-Thr Chemical compound C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O MEFILNJXAVSUTO-JXUBOQSCSA-N 0.000 description 5
- OINVDEKBKBCPLX-JXUBOQSCSA-N Ala-Lys-Thr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(O)=O OINVDEKBKBCPLX-JXUBOQSCSA-N 0.000 description 5
- MDNAVFBZPROEHO-DCAQKATOSA-N Ala-Lys-Val Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(O)=O MDNAVFBZPROEHO-DCAQKATOSA-N 0.000 description 5
- MDNAVFBZPROEHO-UHFFFAOYSA-N Ala-Lys-Val Natural products CC(C)C(C(O)=O)NC(=O)C(NC(=O)C(C)N)CCCCN MDNAVFBZPROEHO-UHFFFAOYSA-N 0.000 description 5
- DYJJJCHDHLEFDW-FXQIFTODSA-N Ala-Pro-Cys Chemical compound C[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CS)C(=O)O)N DYJJJCHDHLEFDW-FXQIFTODSA-N 0.000 description 5
- IORKCNUBHNIMKY-CIUDSAMLSA-N Ala-Pro-Glu Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O IORKCNUBHNIMKY-CIUDSAMLSA-N 0.000 description 5
- XWFWAXPOLRTDFZ-FXQIFTODSA-N Ala-Pro-Ser Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O XWFWAXPOLRTDFZ-FXQIFTODSA-N 0.000 description 5
- YJHKTAMKPGFJCT-NRPADANISA-N Ala-Val-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O YJHKTAMKPGFJCT-NRPADANISA-N 0.000 description 5
- AUFHLLPVPSMEOG-YUMQZZPRSA-N Arg-Gly-Glu Chemical compound NC(N)=NCCC[C@H](N)C(=O)NCC(=O)N[C@@H](CCC(O)=O)C(O)=O AUFHLLPVPSMEOG-YUMQZZPRSA-N 0.000 description 5
- JEOCWTUOMKEEMF-RHYQMDGZSA-N Arg-Leu-Thr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O JEOCWTUOMKEEMF-RHYQMDGZSA-N 0.000 description 5
- LRPZJPMQGKGHSG-XGEHTFHBSA-N Arg-Ser-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CCCN=C(N)N)N)O LRPZJPMQGKGHSG-XGEHTFHBSA-N 0.000 description 5
- ZJBUILVYSXQNSW-YTWAJWBKSA-N Arg-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N)O ZJBUILVYSXQNSW-YTWAJWBKSA-N 0.000 description 5
- NVGWESORMHFISY-SRVKXCTJSA-N Asn-Asn-Phe Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O NVGWESORMHFISY-SRVKXCTJSA-N 0.000 description 5
- BVLIJXXSXBUGEC-SRVKXCTJSA-N Asn-Asn-Tyr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O BVLIJXXSXBUGEC-SRVKXCTJSA-N 0.000 description 5
- OLVIPTLKNSAYRJ-YUMQZZPRSA-N Asn-Gly-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CC(=O)N)N OLVIPTLKNSAYRJ-YUMQZZPRSA-N 0.000 description 5
- WQLJRNRLHWJIRW-KKUMJFAQSA-N Asn-His-Tyr Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)O)NC(=O)[C@H](CC2=CN=CN2)NC(=O)[C@H](CC(=O)N)N)O WQLJRNRLHWJIRW-KKUMJFAQSA-N 0.000 description 5
- NYGILGUOUOXGMJ-YUMQZZPRSA-N Asn-Lys-Gly Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCCN)C(=O)NCC(O)=O NYGILGUOUOXGMJ-YUMQZZPRSA-N 0.000 description 5
- RBOBTTLFPRSXKZ-BZSNNMDCSA-N Asn-Phe-Tyr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O RBOBTTLFPRSXKZ-BZSNNMDCSA-N 0.000 description 5
- HPBNLFLSSQDFQW-WHFBIAKZSA-N Asn-Ser-Gly Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O HPBNLFLSSQDFQW-WHFBIAKZSA-N 0.000 description 5
- HNXWVVHIGTZTBO-LKXGYXEUSA-N Asn-Ser-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC(N)=O HNXWVVHIGTZTBO-LKXGYXEUSA-N 0.000 description 5
- LGCVSPFCFXWUEY-IHPCNDPISA-N Asn-Trp-Tyr Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC3=CC=C(C=C3)O)C(=O)O)NC(=O)[C@H](CC(=O)N)N LGCVSPFCFXWUEY-IHPCNDPISA-N 0.000 description 5
- KBQOUDLMWYWXNP-YDHLFZDLSA-N Asn-Val-Phe Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)NC(=O)[C@H](CC(=O)N)N KBQOUDLMWYWXNP-YDHLFZDLSA-N 0.000 description 5
- YNQIDCRRTWGHJD-ZLUOBGJFSA-N Asp-Asn-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CC(O)=O YNQIDCRRTWGHJD-ZLUOBGJFSA-N 0.000 description 5
- SNDBKTFJWVEVPO-WHFBIAKZSA-N Asp-Gly-Ser Chemical compound [H]N[C@@H](CC(O)=O)C(=O)NCC(=O)N[C@@H](CO)C(O)=O SNDBKTFJWVEVPO-WHFBIAKZSA-N 0.000 description 5
- WSGVTKZFVJSJOG-RCOVLWMOSA-N Asp-Gly-Val Chemical compound [H]N[C@@H](CC(O)=O)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O WSGVTKZFVJSJOG-RCOVLWMOSA-N 0.000 description 5
- UZFHNLYQWMGUHU-DCAQKATOSA-N Asp-Lys-Arg Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O UZFHNLYQWMGUHU-DCAQKATOSA-N 0.000 description 5
- DPNWSMBUYCLEDG-CIUDSAMLSA-N Asp-Lys-Ser Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O DPNWSMBUYCLEDG-CIUDSAMLSA-N 0.000 description 5
- CUQDCPXNZPDYFQ-ZLUOBGJFSA-N Asp-Ser-Asp Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O CUQDCPXNZPDYFQ-ZLUOBGJFSA-N 0.000 description 5
- VNXQRBXEQXLERQ-CIUDSAMLSA-N Asp-Ser-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CC(=O)O)N VNXQRBXEQXLERQ-CIUDSAMLSA-N 0.000 description 5
- YUELDQUPTAYEGM-XIRDDKMYSA-N Asp-Trp-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H](CC(=O)O)N YUELDQUPTAYEGM-XIRDDKMYSA-N 0.000 description 5
- KNDCWFXCFKSEBM-AVGNSLFASA-N Asp-Tyr-Glu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(O)=O)C(O)=O KNDCWFXCFKSEBM-AVGNSLFASA-N 0.000 description 5
- SQIARYGNVQWOSB-BZSNNMDCSA-N Asp-Tyr-Phe Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O SQIARYGNVQWOSB-BZSNNMDCSA-N 0.000 description 5
- NDUSUIGBMZCOIL-ZKWXMUAHSA-N Cys-Asn-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CS)N NDUSUIGBMZCOIL-ZKWXMUAHSA-N 0.000 description 5
- WVLZTXGTNGHPBO-SRVKXCTJSA-N Cys-Leu-Leu Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O WVLZTXGTNGHPBO-SRVKXCTJSA-N 0.000 description 5
- ZXCAQANTQWBICD-DCAQKATOSA-N Cys-Lys-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CS)N ZXCAQANTQWBICD-DCAQKATOSA-N 0.000 description 5
- SMEYEQDCCBHTEF-FXQIFTODSA-N Cys-Pro-Ala Chemical compound [H]N[C@@H](CS)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O SMEYEQDCCBHTEF-FXQIFTODSA-N 0.000 description 5
- KSMSFCBQBQPFAD-GUBZILKMSA-N Cys-Pro-Pro Chemical compound SC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 KSMSFCBQBQPFAD-GUBZILKMSA-N 0.000 description 5
- ALTQTAKGRFLRLR-GUBZILKMSA-N Cys-Val-Val Chemical compound CC(C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)O)NC(=O)[C@H](CS)N ALTQTAKGRFLRLR-GUBZILKMSA-N 0.000 description 5
- WLODHVXYKYHLJD-ACZMJKKPSA-N Gln-Asp-Ser Chemical compound C(CC(=O)N)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CO)C(=O)O)N WLODHVXYKYHLJD-ACZMJKKPSA-N 0.000 description 5
- DHNWZLGBTPUTQQ-QEJZJMRPSA-N Gln-Asp-Trp Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CCC(=O)N)N DHNWZLGBTPUTQQ-QEJZJMRPSA-N 0.000 description 5
- KCJJFESQRXGTGC-BQBZGAKWSA-N Gln-Glu-Gly Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O KCJJFESQRXGTGC-BQBZGAKWSA-N 0.000 description 5
- ZNZPKVQURDQFFS-FXQIFTODSA-N Gln-Glu-Ser Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O ZNZPKVQURDQFFS-FXQIFTODSA-N 0.000 description 5
- AQPZYBSRDRZBAG-AVGNSLFASA-N Gln-Phe-Asn Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CCC(=O)N)N AQPZYBSRDRZBAG-AVGNSLFASA-N 0.000 description 5
- HMIXCETWRYDVMO-GUBZILKMSA-N Gln-Pro-Glu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O HMIXCETWRYDVMO-GUBZILKMSA-N 0.000 description 5
- BETSEXMYBWCDAE-SZMVWBNQSA-N Gln-Trp-Lys Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCC(=O)N)N BETSEXMYBWCDAE-SZMVWBNQSA-N 0.000 description 5
- FITIQFSXXBKFFM-NRPADANISA-N Gln-Val-Ser Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O FITIQFSXXBKFFM-NRPADANISA-N 0.000 description 5
- GLWXKFRTOHKGIT-ACZMJKKPSA-N Glu-Asn-Asn Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O GLWXKFRTOHKGIT-ACZMJKKPSA-N 0.000 description 5
- CKOFNWCLWRYUHK-XHNCKOQMSA-N Glu-Asp-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)O)NC(=O)[C@H](CCC(=O)O)N)C(=O)O CKOFNWCLWRYUHK-XHNCKOQMSA-N 0.000 description 5
- RFDHKPSHTXZKLL-IHRRRGAJSA-N Glu-Gln-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCC(=O)O)N RFDHKPSHTXZKLL-IHRRRGAJSA-N 0.000 description 5
- HNVFSTLPVJWIDV-CIUDSAMLSA-N Glu-Glu-Gln Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O HNVFSTLPVJWIDV-CIUDSAMLSA-N 0.000 description 5
- KASDBWKLWJKTLJ-GUBZILKMSA-N Glu-Glu-Met Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCSC)C(O)=O KASDBWKLWJKTLJ-GUBZILKMSA-N 0.000 description 5
- QDMVXRNLOPTPIE-WDCWCFNPSA-N Glu-Lys-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(O)=O QDMVXRNLOPTPIE-WDCWCFNPSA-N 0.000 description 5
- YHOJJFFTSMWVGR-HJGDQZAQSA-N Glu-Met-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCSC)C(=O)N[C@@H]([C@@H](C)O)C(O)=O YHOJJFFTSMWVGR-HJGDQZAQSA-N 0.000 description 5
- AAJHGGDRKHYSDH-GUBZILKMSA-N Glu-Pro-Gln Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CCC(=O)O)N)C(=O)N[C@@H](CCC(=O)N)C(=O)O AAJHGGDRKHYSDH-GUBZILKMSA-N 0.000 description 5
- QOXDAWODGSIDDI-GUBZILKMSA-N Glu-Ser-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CCC(=O)O)N QOXDAWODGSIDDI-GUBZILKMSA-N 0.000 description 5
- DMYACXMQUABZIQ-NRPADANISA-N Glu-Ser-Val Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O DMYACXMQUABZIQ-NRPADANISA-N 0.000 description 5
- BPCLDCNZBUYGOD-BPUTZDHNSA-N Glu-Trp-Glu Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CCC(O)=O)N)C(=O)N[C@@H](CCC(O)=O)C(O)=O)=CNC2=C1 BPCLDCNZBUYGOD-BPUTZDHNSA-N 0.000 description 5
- ZALGPUWUVHOGAE-GVXVVHGQSA-N Glu-Val-His Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CCC(=O)O)N ZALGPUWUVHOGAE-GVXVVHGQSA-N 0.000 description 5
- VSVZIEVNUYDAFR-YUMQZZPRSA-N Gly-Ala-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)CN VSVZIEVNUYDAFR-YUMQZZPRSA-N 0.000 description 5
- GRIRDMVMJJDZKV-RCOVLWMOSA-N Gly-Asn-Val Chemical compound [H]NCC(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](C(C)C)C(O)=O GRIRDMVMJJDZKV-RCOVLWMOSA-N 0.000 description 5
- BIRKKBCSAIHDDF-WDSKDSINSA-N Gly-Glu-Cys Chemical compound NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CS)C(O)=O BIRKKBCSAIHDDF-WDSKDSINSA-N 0.000 description 5
- UUYBFNKHOCJCHT-VHSXEESVSA-N Gly-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)CN UUYBFNKHOCJCHT-VHSXEESVSA-N 0.000 description 5
- OOCFXNOVSLSHAB-IUCAKERBSA-N Gly-Pro-Pro Chemical compound NCC(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 OOCFXNOVSLSHAB-IUCAKERBSA-N 0.000 description 5
- JSLVAHYTAJJEQH-QWRGUYRKSA-N Gly-Ser-Phe Chemical compound NCC(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 JSLVAHYTAJJEQH-QWRGUYRKSA-N 0.000 description 5
- FFJQHWKSGAWSTJ-BFHQHQDPSA-N Gly-Thr-Ala Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O FFJQHWKSGAWSTJ-BFHQHQDPSA-N 0.000 description 5
- MAABHGXCIBEYQR-XVYDVKMFSA-N His-Asn-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CC1=CN=CN1)N MAABHGXCIBEYQR-XVYDVKMFSA-N 0.000 description 5
- WMKXFMUJRCEGRP-SRVKXCTJSA-N His-Asn-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC2=CN=CN2)C(=O)O)N WMKXFMUJRCEGRP-SRVKXCTJSA-N 0.000 description 5
- HIAHVKLTHNOENC-HGNGGELXSA-N His-Glu-Ala Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O HIAHVKLTHNOENC-HGNGGELXSA-N 0.000 description 5
- TTYKEFZRLKQTHH-MELADBBJSA-N His-Lys-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCCN)NC(=O)[C@H](CC2=CN=CN2)N)C(=O)O TTYKEFZRLKQTHH-MELADBBJSA-N 0.000 description 5
- ALPXXNRQBMRCPZ-MEYUZBJRSA-N His-Thr-Phe Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O ALPXXNRQBMRCPZ-MEYUZBJRSA-N 0.000 description 5
- MKWSZEHGHSLNPF-NAKRPEOUSA-N Ile-Ala-Val Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C)C(=O)N[C@@H](C(C)C)C(=O)O)N MKWSZEHGHSLNPF-NAKRPEOUSA-N 0.000 description 5
- NZGTYCMLUGYMCV-XUXIUFHCSA-N Ile-Lys-Arg Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N NZGTYCMLUGYMCV-XUXIUFHCSA-N 0.000 description 5
- 108010065920 Insulin Lispro Proteins 0.000 description 5
- RCFDOSNHHZGBOY-UHFFFAOYSA-N L-isoleucyl-L-alanine Natural products CCC(C)C(N)C(=O)NC(C)C(O)=O RCFDOSNHHZGBOY-UHFFFAOYSA-N 0.000 description 5
- OIARJGNVARWKFP-YUMQZZPRSA-N Leu-Asn-Gly Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O OIARJGNVARWKFP-YUMQZZPRSA-N 0.000 description 5
- PVMPDMIKUVNOBD-CIUDSAMLSA-N Leu-Asp-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O PVMPDMIKUVNOBD-CIUDSAMLSA-N 0.000 description 5
- HPBCTWSUJOGJSH-MNXVOIDGSA-N Leu-Glu-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O HPBCTWSUJOGJSH-MNXVOIDGSA-N 0.000 description 5
- QJUWBDPGGYVRHY-YUMQZZPRSA-N Leu-Gly-Cys Chemical compound CC(C)C[C@@H](C(=O)NCC(=O)N[C@@H](CS)C(=O)O)N QJUWBDPGGYVRHY-YUMQZZPRSA-N 0.000 description 5
- VWHGTYCRDRBSFI-ZETCQYMHSA-N Leu-Gly-Gly Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)NCC(O)=O VWHGTYCRDRBSFI-ZETCQYMHSA-N 0.000 description 5
- HYMLKESRWLZDBR-WEDXCCLWSA-N Leu-Gly-Thr Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(O)=O HYMLKESRWLZDBR-WEDXCCLWSA-N 0.000 description 5
- BKTXKJMNTSMJDQ-AVGNSLFASA-N Leu-His-Gln Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N BKTXKJMNTSMJDQ-AVGNSLFASA-N 0.000 description 5
- IAJFFZORSWOZPQ-SRVKXCTJSA-N Leu-Leu-Asn Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O IAJFFZORSWOZPQ-SRVKXCTJSA-N 0.000 description 5
- HVHRPWQEQHIQJF-AVGNSLFASA-N Leu-Lys-Glu Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(O)=O HVHRPWQEQHIQJF-AVGNSLFASA-N 0.000 description 5
- AUNMOHYWTAPQLA-XUXIUFHCSA-N Leu-Met-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCSC)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O AUNMOHYWTAPQLA-XUXIUFHCSA-N 0.000 description 5
- UHNQRAFSEBGZFZ-YESZJQIVSA-N Leu-Phe-Pro Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N2CCC[C@@H]2C(=O)O)N UHNQRAFSEBGZFZ-YESZJQIVSA-N 0.000 description 5
- DPURXCQCHSQPAN-AVGNSLFASA-N Leu-Pro-Pro Chemical compound CC(C)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 DPURXCQCHSQPAN-AVGNSLFASA-N 0.000 description 5
- CHJKEDSZNSONPS-DCAQKATOSA-N Leu-Pro-Ser Chemical compound [H]N[C@@H](CC(C)C)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O CHJKEDSZNSONPS-DCAQKATOSA-N 0.000 description 5
- XOWMDXHFSBCAKQ-SRVKXCTJSA-N Leu-Ser-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC(C)C XOWMDXHFSBCAKQ-SRVKXCTJSA-N 0.000 description 5
- BRTVHXHCUSXYRI-CIUDSAMLSA-N Leu-Ser-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O BRTVHXHCUSXYRI-CIUDSAMLSA-N 0.000 description 5
- QWWPYKKLXWOITQ-VOAKCMCISA-N Leu-Thr-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CC(C)C QWWPYKKLXWOITQ-VOAKCMCISA-N 0.000 description 5
- VUBIPAHVHMZHCM-KKUMJFAQSA-N Leu-Tyr-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CO)C(O)=O)CC1=CC=C(O)C=C1 VUBIPAHVHMZHCM-KKUMJFAQSA-N 0.000 description 5
- YQFZRHYZLARWDY-IHRRRGAJSA-N Leu-Val-Lys Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CCCCN YQFZRHYZLARWDY-IHRRRGAJSA-N 0.000 description 5
- MPGHETGWWWUHPY-CIUDSAMLSA-N Lys-Ala-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCCN MPGHETGWWWUHPY-CIUDSAMLSA-N 0.000 description 5
- WSXTWLJHTLRFLW-SRVKXCTJSA-N Lys-Ala-Lys Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCCN)C(O)=O WSXTWLJHTLRFLW-SRVKXCTJSA-N 0.000 description 5
- NTSPQIONFJUMJV-AVGNSLFASA-N Lys-Arg-Val Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C(C)C)C(O)=O NTSPQIONFJUMJV-AVGNSLFASA-N 0.000 description 5
- NRQRKMYZONPCTM-CIUDSAMLSA-N Lys-Asp-Ser Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O NRQRKMYZONPCTM-CIUDSAMLSA-N 0.000 description 5
- KWUKZRFFKPLUPE-HJGDQZAQSA-N Lys-Asp-Thr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O KWUKZRFFKPLUPE-HJGDQZAQSA-N 0.000 description 5
- NTBFKPBULZGXQL-KKUMJFAQSA-N Lys-Asp-Tyr Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 NTBFKPBULZGXQL-KKUMJFAQSA-N 0.000 description 5
- ODUQLUADRKMHOZ-JYJNAYRXSA-N Lys-Glu-Tyr Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CCCCN)N)O ODUQLUADRKMHOZ-JYJNAYRXSA-N 0.000 description 5
- XNKDCYABMBBEKN-IUCAKERBSA-N Lys-Gly-Gln Chemical compound NCCCC[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCC(N)=O XNKDCYABMBBEKN-IUCAKERBSA-N 0.000 description 5
- GQFDWEDHOQRNLC-QWRGUYRKSA-N Lys-Gly-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CCCCN GQFDWEDHOQRNLC-QWRGUYRKSA-N 0.000 description 5
- IOQWIOPSKJOEKI-SRVKXCTJSA-N Lys-Ser-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O IOQWIOPSKJOEKI-SRVKXCTJSA-N 0.000 description 5
- CAVRAQIDHUPECU-UVOCVTCTSA-N Lys-Thr-Thr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O CAVRAQIDHUPECU-UVOCVTCTSA-N 0.000 description 5
- YFQSSOAGMZGXFT-MEYUZBJRSA-N Lys-Thr-Tyr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O YFQSSOAGMZGXFT-MEYUZBJRSA-N 0.000 description 5
- RQILLQOQXLZTCK-KBPBESRZSA-N Lys-Tyr-Gly Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)NCC(O)=O RQILLQOQXLZTCK-KBPBESRZSA-N 0.000 description 5
- QLFAPXUXEBAWEK-NHCYSSNCSA-N Lys-Val-Asp Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O QLFAPXUXEBAWEK-NHCYSSNCSA-N 0.000 description 5
- XABXVVSWUVCZST-GVXVVHGQSA-N Lys-Val-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CCCCN XABXVVSWUVCZST-GVXVVHGQSA-N 0.000 description 5
- GILLQRYAWOMHED-DCAQKATOSA-N Lys-Val-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CCCCN GILLQRYAWOMHED-DCAQKATOSA-N 0.000 description 5
- 108700018351 Major Histocompatibility Complex Proteins 0.000 description 5
- SITLTJHOQZFJGG-UHFFFAOYSA-N N-L-alpha-glutamyl-L-valine Natural products CC(C)C(C(O)=O)NC(=O)C(N)CCC(O)=O SITLTJHOQZFJGG-UHFFFAOYSA-N 0.000 description 5
- XMBSYZWANAQXEV-UHFFFAOYSA-N N-alpha-L-glutamyl-L-phenylalanine Natural products OC(=O)CCC(N)C(=O)NC(C(O)=O)CC1=CC=CC=C1 XMBSYZWANAQXEV-UHFFFAOYSA-N 0.000 description 5
- 101100068676 Neurospora crassa (strain ATCC 24698 / 74-OR23-1A / CBS 708.71 / DSM 1257 / FGSC 987) gln-1 gene Proteins 0.000 description 5
- HXSUFWQYLPKEHF-IHRRRGAJSA-N Phe-Asn-Arg Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N HXSUFWQYLPKEHF-IHRRRGAJSA-N 0.000 description 5
- CDNPIRSCAFMMBE-SRVKXCTJSA-N Phe-Asn-Ser Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O CDNPIRSCAFMMBE-SRVKXCTJSA-N 0.000 description 5
- BWTKUQPNOMMKMA-FIRPJDEBSA-N Phe-Ile-Phe Chemical compound C([C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=CC=C1 BWTKUQPNOMMKMA-FIRPJDEBSA-N 0.000 description 5
- SMFGCTXUBWEPKM-KBPBESRZSA-N Phe-Leu-Gly Chemical compound OC(=O)CNC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC1=CC=CC=C1 SMFGCTXUBWEPKM-KBPBESRZSA-N 0.000 description 5
- MSHZERMPZKCODG-ACRUOGEOSA-N Phe-Leu-Phe Chemical compound C([C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=CC=C1 MSHZERMPZKCODG-ACRUOGEOSA-N 0.000 description 5
- JLLJTMHNXQTMCK-UBHSHLNASA-N Phe-Pro-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CC1=CC=CC=C1 JLLJTMHNXQTMCK-UBHSHLNASA-N 0.000 description 5
- QARPMYDMYVLFMW-KKUMJFAQSA-N Phe-Pro-Glu Chemical compound C([C@H](N)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CCC(O)=O)C(O)=O)C1=CC=CC=C1 QARPMYDMYVLFMW-KKUMJFAQSA-N 0.000 description 5
- WWPAHTZOWURIMR-ULQDDVLXSA-N Phe-Pro-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CC1=CC=CC=C1 WWPAHTZOWURIMR-ULQDDVLXSA-N 0.000 description 5
- AFNJAQVMTIQTCB-DLOVCJGASA-N Phe-Ser-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CC=CC=C1 AFNJAQVMTIQTCB-DLOVCJGASA-N 0.000 description 5
- IIEOLPMQYRBZCN-SRVKXCTJSA-N Phe-Ser-Cys Chemical compound N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)O IIEOLPMQYRBZCN-SRVKXCTJSA-N 0.000 description 5
- SJRQWEDYTKYHHL-SLFFLAALSA-N Phe-Tyr-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=C(C=C2)O)NC(=O)[C@H](CC3=CC=CC=C3)N)C(=O)O SJRQWEDYTKYHHL-SLFFLAALSA-N 0.000 description 5
- HQVPQXMCQKXARZ-FXQIFTODSA-N Pro-Cys-Ser Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CS)C(=O)N[C@@H](CO)C(=O)O HQVPQXMCQKXARZ-FXQIFTODSA-N 0.000 description 5
- UAYHMOIGIQZLFR-NHCYSSNCSA-N Pro-Gln-Val Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(O)=O UAYHMOIGIQZLFR-NHCYSSNCSA-N 0.000 description 5
- WFHYFCWBLSKEMS-KKUMJFAQSA-N Pro-Glu-Phe Chemical compound N([C@@H](CCC(=O)O)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C(=O)[C@@H]1CCCN1 WFHYFCWBLSKEMS-KKUMJFAQSA-N 0.000 description 5
- LGSANCBHSMDFDY-GARJFASQSA-N Pro-Glu-Pro Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CCC(=O)O)C(=O)N2CCC[C@@H]2C(=O)O LGSANCBHSMDFDY-GARJFASQSA-N 0.000 description 5
- FMLRRBDLBJLJIK-DCAQKATOSA-N Pro-Leu-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H]1CCCN1 FMLRRBDLBJLJIK-DCAQKATOSA-N 0.000 description 5
- ZLXKLMHAMDENIO-DCAQKATOSA-N Pro-Lys-Asp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(O)=O ZLXKLMHAMDENIO-DCAQKATOSA-N 0.000 description 5
- ULWBBFKQBDNGOY-RWMBFGLXSA-N Pro-Lys-Pro Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CCCCN)C(=O)N2CCC[C@@H]2C(=O)O ULWBBFKQBDNGOY-RWMBFGLXSA-N 0.000 description 5
- PCWLNNZTBJTZRN-AVGNSLFASA-N Pro-Pro-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H]1NCCC1 PCWLNNZTBJTZRN-AVGNSLFASA-N 0.000 description 5
- KBUAPZAZPWNYSW-SRVKXCTJSA-N Pro-Pro-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H]1NCCC1 KBUAPZAZPWNYSW-SRVKXCTJSA-N 0.000 description 5
- OWQXAJQZLWHPBH-FXQIFTODSA-N Pro-Ser-Asn Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O OWQXAJQZLWHPBH-FXQIFTODSA-N 0.000 description 5
- GMJDSFYVTAMIBF-FXQIFTODSA-N Pro-Ser-Asp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O GMJDSFYVTAMIBF-FXQIFTODSA-N 0.000 description 5
- SEZGGSHLMROBFX-CIUDSAMLSA-N Pro-Ser-Gln Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(O)=O SEZGGSHLMROBFX-CIUDSAMLSA-N 0.000 description 5
- PRKWBYCXBBSLSK-GUBZILKMSA-N Pro-Ser-Val Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O PRKWBYCXBBSLSK-GUBZILKMSA-N 0.000 description 5
- YDTUEBLEAVANFH-RCWTZXSCSA-N Pro-Val-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H]1CCCN1 YDTUEBLEAVANFH-RCWTZXSCSA-N 0.000 description 5
- 108010076504 Protein Sorting Signals Proteins 0.000 description 5
- UEJYSALTSUZXFV-SRVKXCTJSA-N Rigin Chemical compound NCC(=O)N[C@@H](CCC(N)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCN=C(N)N)C(O)=O UEJYSALTSUZXFV-SRVKXCTJSA-N 0.000 description 5
- WDXYVIIVDIDOSX-DCAQKATOSA-N Ser-Arg-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)CO)CCCN=C(N)N WDXYVIIVDIDOSX-DCAQKATOSA-N 0.000 description 5
- QVOGDCQNGLBNCR-FXQIFTODSA-N Ser-Arg-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(O)=O QVOGDCQNGLBNCR-FXQIFTODSA-N 0.000 description 5
- HZWAHWQZPSXNCB-BPUTZDHNSA-N Ser-Arg-Trp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O HZWAHWQZPSXNCB-BPUTZDHNSA-N 0.000 description 5
- VAUMZJHYZQXZBQ-WHFBIAKZSA-N Ser-Asn-Gly Chemical compound OC[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O VAUMZJHYZQXZBQ-WHFBIAKZSA-N 0.000 description 5
- VGNYHOBZJKWRGI-CIUDSAMLSA-N Ser-Asn-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CO VGNYHOBZJKWRGI-CIUDSAMLSA-N 0.000 description 5
- UGJRQLURDVGULT-LKXGYXEUSA-N Ser-Asn-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O UGJRQLURDVGULT-LKXGYXEUSA-N 0.000 description 5
- QPFJSHSJFIYDJZ-GHCJXIJMSA-N Ser-Asp-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CO QPFJSHSJFIYDJZ-GHCJXIJMSA-N 0.000 description 5
- MOVJSUIKUNCVMG-ZLUOBGJFSA-N Ser-Cys-Ser Chemical compound C([C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CO)C(=O)O)N)O MOVJSUIKUNCVMG-ZLUOBGJFSA-N 0.000 description 5
- VQBCMLMPEWPUTB-ACZMJKKPSA-N Ser-Glu-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O VQBCMLMPEWPUTB-ACZMJKKPSA-N 0.000 description 5
- GZFAWAQTEYDKII-YUMQZZPRSA-N Ser-Gly-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CO GZFAWAQTEYDKII-YUMQZZPRSA-N 0.000 description 5
- KDGARKCAKHBEDB-NKWVEPMBSA-N Ser-Gly-Pro Chemical compound C1C[C@@H](N(C1)C(=O)CNC(=O)[C@H](CO)N)C(=O)O KDGARKCAKHBEDB-NKWVEPMBSA-N 0.000 description 5
- XXXAXOWMBOKTRN-XPUUQOCRSA-N Ser-Gly-Val Chemical compound [H]N[C@@H](CO)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O XXXAXOWMBOKTRN-XPUUQOCRSA-N 0.000 description 5
- DJACUBDEDBZKLQ-KBIXCLLPSA-N Ser-Ile-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(O)=O)C(O)=O DJACUBDEDBZKLQ-KBIXCLLPSA-N 0.000 description 5
- GDUZTEQRAOXYJS-SRVKXCTJSA-N Ser-Phe-Asn Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CO)N GDUZTEQRAOXYJS-SRVKXCTJSA-N 0.000 description 5
- MQUZANJDFOQOBX-SRVKXCTJSA-N Ser-Phe-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(O)=O MQUZANJDFOQOBX-SRVKXCTJSA-N 0.000 description 5
- CKDXFSPMIDSMGV-GUBZILKMSA-N Ser-Pro-Val Chemical compound [H]N[C@@H](CO)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(O)=O CKDXFSPMIDSMGV-GUBZILKMSA-N 0.000 description 5
- HHJFMHQYEAAOBM-ZLUOBGJFSA-N Ser-Ser-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O HHJFMHQYEAAOBM-ZLUOBGJFSA-N 0.000 description 5
- SRSPTFBENMJHMR-WHFBIAKZSA-N Ser-Ser-Gly Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O SRSPTFBENMJHMR-WHFBIAKZSA-N 0.000 description 5
- JCLAFVNDBJMLBC-JBDRJPRFSA-N Ser-Ser-Ile Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O JCLAFVNDBJMLBC-JBDRJPRFSA-N 0.000 description 5
- PYTKULIABVRXSC-BWBBJGPYSA-N Ser-Ser-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O PYTKULIABVRXSC-BWBBJGPYSA-N 0.000 description 5
- VGQVAVQWKJLIRM-FXQIFTODSA-N Ser-Ser-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O VGQVAVQWKJLIRM-FXQIFTODSA-N 0.000 description 5
- NADLKBTYNKUJEP-KATARQTJSA-N Ser-Thr-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O NADLKBTYNKUJEP-KATARQTJSA-N 0.000 description 5
- PCJLFYBAQZQOFE-KATARQTJSA-N Ser-Thr-Lys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CO)N)O PCJLFYBAQZQOFE-KATARQTJSA-N 0.000 description 5
- RCOUFINCYASMDN-GUBZILKMSA-N Ser-Val-Met Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCSC)C(O)=O RCOUFINCYASMDN-GUBZILKMSA-N 0.000 description 5
- HSWXBJCBYSWBPT-GUBZILKMSA-N Ser-Val-Val Chemical compound CC(C)[C@H](NC(=O)[C@@H](NC(=O)[C@@H](N)CO)C(C)C)C(O)=O HSWXBJCBYSWBPT-GUBZILKMSA-N 0.000 description 5
- ODSAPYVQSLDRSR-LKXGYXEUSA-N Thr-Cys-Asn Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(N)=O)C(O)=O ODSAPYVQSLDRSR-LKXGYXEUSA-N 0.000 description 5
- DSLHSTIUAPKERR-XGEHTFHBSA-N Thr-Cys-Val Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CS)C(=O)N[C@@H](C(C)C)C(O)=O DSLHSTIUAPKERR-XGEHTFHBSA-N 0.000 description 5
- LAFLAXHTDVNVEL-WDCWCFNPSA-N Thr-Gln-Lys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CCCCN)C(=O)O)N)O LAFLAXHTDVNVEL-WDCWCFNPSA-N 0.000 description 5
- GKWNLDNXMMLRMC-GLLZPBPUSA-N Thr-Glu-Gln Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N)O GKWNLDNXMMLRMC-GLLZPBPUSA-N 0.000 description 5
- FIFDDJFLNVAVMS-RHYQMDGZSA-N Thr-Leu-Met Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCSC)C(O)=O FIFDDJFLNVAVMS-RHYQMDGZSA-N 0.000 description 5
- BDGBHYCAZJPLHX-HJGDQZAQSA-N Thr-Lys-Asn Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(O)=O BDGBHYCAZJPLHX-HJGDQZAQSA-N 0.000 description 5
- XSEPSRUDSPHMPX-KATARQTJSA-N Thr-Lys-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O XSEPSRUDSPHMPX-KATARQTJSA-N 0.000 description 5
- DXPURPNJDFCKKO-RHYQMDGZSA-N Thr-Lys-Val Chemical compound CC(C)[C@H](NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)[C@@H](C)O)C(O)=O DXPURPNJDFCKKO-RHYQMDGZSA-N 0.000 description 5
- MROIJTGJGIDEEJ-RCWTZXSCSA-N Thr-Pro-Pro Chemical compound C[C@@H](O)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 MROIJTGJGIDEEJ-RCWTZXSCSA-N 0.000 description 5
- XHWCDRUPDNSDAZ-XKBZYTNZSA-N Thr-Ser-Glu Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N)O XHWCDRUPDNSDAZ-XKBZYTNZSA-N 0.000 description 5
- SGAOHNPSEPVAFP-ZDLURKLDSA-N Thr-Ser-Gly Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)NCC(O)=O SGAOHNPSEPVAFP-ZDLURKLDSA-N 0.000 description 5
- BEZTUFWTPVOROW-KJEVXHAQSA-N Thr-Tyr-Arg Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N)O BEZTUFWTPVOROW-KJEVXHAQSA-N 0.000 description 5
- LVRFMARKDGGZMX-IZPVPAKOSA-N Thr-Tyr-Thr Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@H](C(=O)N[C@@H]([C@@H](C)O)C(O)=O)CC1=CC=C(O)C=C1 LVRFMARKDGGZMX-IZPVPAKOSA-N 0.000 description 5
- FYBFTPLPAXZBOY-KKHAAJSZSA-N Thr-Val-Asp Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O FYBFTPLPAXZBOY-KKHAAJSZSA-N 0.000 description 5
- HDTRYLNUVZCQOY-WSWWMNSNSA-N Trehalose Natural products O[C@@H]1[C@@H](O)[C@@H](O)[C@@H](CO)O[C@@H]1O[C@@H]1[C@H](O)[C@@H](O)[C@@H](O)[C@@H](CO)O1 HDTRYLNUVZCQOY-WSWWMNSNSA-N 0.000 description 5
- UKINEYBQXPMOJO-UBHSHLNASA-N Trp-Asn-Ser Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CO)C(=O)O)N UKINEYBQXPMOJO-UBHSHLNASA-N 0.000 description 5
- VTHNLRXALGUDBS-BPUTZDHNSA-N Trp-Gln-Glu Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N VTHNLRXALGUDBS-BPUTZDHNSA-N 0.000 description 5
- CXPJPTFWKXNDKV-NUTKFTJISA-N Trp-Leu-Ala Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(O)=O)=CNC2=C1 CXPJPTFWKXNDKV-NUTKFTJISA-N 0.000 description 5
- NLWCSMOXNKBRLC-WDSOQIARSA-N Trp-Lys-Val Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(O)=O NLWCSMOXNKBRLC-WDSOQIARSA-N 0.000 description 5
- SSSDKJMQMZTMJP-BVSLBCMMSA-N Trp-Tyr-Val Chemical compound C([C@@H](C(=O)N[C@@H](C(C)C)C(O)=O)NC(=O)[C@@H](N)CC=1C2=CC=CC=C2NC=1)C1=CC=C(O)C=C1 SSSDKJMQMZTMJP-BVSLBCMMSA-N 0.000 description 5
- QJBWZNTWJSZUOY-UWJYBYFXSA-N Tyr-Ala-Cys Chemical compound C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N QJBWZNTWJSZUOY-UWJYBYFXSA-N 0.000 description 5
- QYSBJAUCUKHSLU-JYJNAYRXSA-N Tyr-Arg-Val Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C(C)C)C(O)=O QYSBJAUCUKHSLU-JYJNAYRXSA-N 0.000 description 5
- SLCSPPCQWUHPPO-JYJNAYRXSA-N Tyr-Glu-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 SLCSPPCQWUHPPO-JYJNAYRXSA-N 0.000 description 5
- GZUIDWDVMWZSMI-KKUMJFAQSA-N Tyr-Lys-Cys Chemical compound NCCCC[C@@H](C(=O)N[C@@H](CS)C(O)=O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 GZUIDWDVMWZSMI-KKUMJFAQSA-N 0.000 description 5
- SINRIKQYQJRGDQ-MEYUZBJRSA-N Tyr-Lys-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 SINRIKQYQJRGDQ-MEYUZBJRSA-N 0.000 description 5
- RWOKVQUCENPXGE-IHRRRGAJSA-N Tyr-Ser-Arg Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O RWOKVQUCENPXGE-IHRRRGAJSA-N 0.000 description 5
- RIVVDNTUSRVTQT-IRIUXVKKSA-N Tyr-Thr-Gln Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N)O RIVVDNTUSRVTQT-IRIUXVKKSA-N 0.000 description 5
- PWKMJDQXKCENMF-MEYUZBJRSA-N Tyr-Thr-Leu Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O PWKMJDQXKCENMF-MEYUZBJRSA-N 0.000 description 5
- 101150117115 V gene Proteins 0.000 description 5
- CGGVNFJRZJUVAE-BYULHYEWSA-N Val-Asp-Asn Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC(=O)N)C(=O)O)N CGGVNFJRZJUVAE-BYULHYEWSA-N 0.000 description 5
- QHDXUYOYTPWCSK-RCOVLWMOSA-N Val-Asp-Gly Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)NCC(=O)O)N QHDXUYOYTPWCSK-RCOVLWMOSA-N 0.000 description 5
- ZQGPWORGSNRQLN-NHCYSSNCSA-N Val-Asp-His Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N ZQGPWORGSNRQLN-NHCYSSNCSA-N 0.000 description 5
- OVLIFGQSBSNGHY-KKHAAJSZSA-N Val-Asp-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](C(C)C)N)O OVLIFGQSBSNGHY-KKHAAJSZSA-N 0.000 description 5
- SCBITHMBEJNRHC-LSJOCFKGSA-N Val-Asp-Val Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](C(C)C)C(=O)O)N SCBITHMBEJNRHC-LSJOCFKGSA-N 0.000 description 5
- JXGWQYWDUOWQHA-DZKIICNBSA-N Val-Gln-Phe Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)N JXGWQYWDUOWQHA-DZKIICNBSA-N 0.000 description 5
- OQWNEUXPKHIEJO-NRPADANISA-N Val-Glu-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CO)C(=O)O)N OQWNEUXPKHIEJO-NRPADANISA-N 0.000 description 5
- UEHRGZCNLSWGHK-DLOVCJGASA-N Val-Glu-Val Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O UEHRGZCNLSWGHK-DLOVCJGASA-N 0.000 description 5
- ZIGZPYJXIWLQFC-QTKMDUPCSA-N Val-His-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CN=CN1)NC(=O)[C@H](C(C)C)N)O ZIGZPYJXIWLQFC-QTKMDUPCSA-N 0.000 description 5
- HGJRMXOWUWVUOA-GVXVVHGQSA-N Val-Leu-Gln Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](C(C)C)N HGJRMXOWUWVUOA-GVXVVHGQSA-N 0.000 description 5
- XTDDIVQWDXMRJL-IHRRRGAJSA-N Val-Leu-His Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](C(C)C)N XTDDIVQWDXMRJL-IHRRRGAJSA-N 0.000 description 5
- SBJCTAZFSZXWSR-AVGNSLFASA-N Val-Met-His Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N SBJCTAZFSZXWSR-AVGNSLFASA-N 0.000 description 5
- FMQGYTMERWBMSI-HJWJTTGWSA-N Val-Phe-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)NC(=O)[C@H](C(C)C)N FMQGYTMERWBMSI-HJWJTTGWSA-N 0.000 description 5
- SSYBNWFXCFNRFN-GUBZILKMSA-N Val-Pro-Ser Chemical compound CC(C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O SSYBNWFXCFNRFN-GUBZILKMSA-N 0.000 description 5
- RYHUIHUOYRNNIE-NRPADANISA-N Val-Ser-Gln Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N RYHUIHUOYRNNIE-NRPADANISA-N 0.000 description 5
- SDHZOOIGIUEPDY-JYJNAYRXSA-N Val-Ser-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CO)NC(=O)[C@@H](N)C(C)C)C(O)=O)=CNC2=C1 SDHZOOIGIUEPDY-JYJNAYRXSA-N 0.000 description 5
- NZYNRRGJJVSSTJ-GUBZILKMSA-N Val-Ser-Val Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O NZYNRRGJJVSSTJ-GUBZILKMSA-N 0.000 description 5
- UVHFONIHVHLDDQ-IFFSRLJSSA-N Val-Thr-Glu Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@H](C(C)C)N)O UVHFONIHVHLDDQ-IFFSRLJSSA-N 0.000 description 5
- TVGWMCTYUFBXAP-QTKMDUPCSA-N Val-Thr-His Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](C(C)C)N)O TVGWMCTYUFBXAP-QTKMDUPCSA-N 0.000 description 5
- GVNLOVJNNDZUHS-RHYQMDGZSA-N Val-Thr-Lys Chemical compound [H]N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(O)=O GVNLOVJNNDZUHS-RHYQMDGZSA-N 0.000 description 5
- BGTDGENDNWGMDQ-KJEVXHAQSA-N Val-Tyr-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@H](C(C)C)N)O BGTDGENDNWGMDQ-KJEVXHAQSA-N 0.000 description 5
- ZLNYBMWGPOKSLW-LSJOCFKGSA-N Val-Val-Asp Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O ZLNYBMWGPOKSLW-LSJOCFKGSA-N 0.000 description 5
- ZHWZDZFWBXWPDW-GUBZILKMSA-N Val-Val-Cys Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CS)C(O)=O ZHWZDZFWBXWPDW-GUBZILKMSA-N 0.000 description 5
- LLJLBRRXKZTTRD-GUBZILKMSA-N Val-Val-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(=O)O)N LLJLBRRXKZTTRD-GUBZILKMSA-N 0.000 description 5
- JVGDAEKKZKKZFO-RCWTZXSCSA-N Val-Val-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](C(C)C)NC(=O)[C@H](C(C)C)N)O JVGDAEKKZKKZFO-RCWTZXSCSA-N 0.000 description 5
- 108010041407 alanylaspartic acid Proteins 0.000 description 5
- HDTRYLNUVZCQOY-LIZSDCNHSA-N alpha,alpha-trehalose Chemical compound O[C@@H]1[C@@H](O)[C@H](O)[C@@H](CO)O[C@@H]1O[C@@H]1[C@H](O)[C@@H](O)[C@H](O)[C@@H](CO)O1 HDTRYLNUVZCQOY-LIZSDCNHSA-N 0.000 description 5
- 108010050025 alpha-glutamyltryptophan Proteins 0.000 description 5
- 108010047857 aspartylglycine Proteins 0.000 description 5
- 210000004978 chinese hamster ovary cell Anatomy 0.000 description 5
- 238000003501 co-culture Methods 0.000 description 5
- 238000011284 combination treatment Methods 0.000 description 5
- FSXRLASFHBWESK-UHFFFAOYSA-N dipeptide phenylalanyl-tyrosine Natural products C=1C=C(O)C=CC=1CC(C(O)=O)NC(=O)C(N)CC1=CC=CC=C1 FSXRLASFHBWESK-UHFFFAOYSA-N 0.000 description 5
- 208000035475 disorder Diseases 0.000 description 5
- 239000002552 dosage form Substances 0.000 description 5
- 239000012636 effector Substances 0.000 description 5
- 102000052116 epidermal growth factor receptor activity proteins Human genes 0.000 description 5
- 108700015053 epidermal growth factor receptor activity proteins Proteins 0.000 description 5
- 238000002474 experimental method Methods 0.000 description 5
- 230000004927 fusion Effects 0.000 description 5
- 108010013768 glutamyl-aspartyl-proline Proteins 0.000 description 5
- 108010077515 glycylproline Proteins 0.000 description 5
- 108010037850 glycylvaline Proteins 0.000 description 5
- 230000001965 increasing effect Effects 0.000 description 5
- 238000001802 infusion Methods 0.000 description 5
- 238000002347 injection Methods 0.000 description 5
- 239000007924 injection Substances 0.000 description 5
- 238000001990 intravenous administration Methods 0.000 description 5
- 108010073472 leucyl-prolyl-proline Proteins 0.000 description 5
- 108010057821 leucylproline Proteins 0.000 description 5
- 108010003700 lysyl aspartic acid Proteins 0.000 description 5
- 108010017391 lysylvaline Proteins 0.000 description 5
- 201000000050 myeloid neoplasm Diseases 0.000 description 5
- YOHYSYJDKVYCJI-UHFFFAOYSA-N n-[3-[[6-[3-(trifluoromethyl)anilino]pyrimidin-4-yl]amino]phenyl]cyclopropanecarboxamide Chemical compound FC(F)(F)C1=CC=CC(NC=2N=CN=C(NC=3C=C(NC(=O)C4CC4)C=CC=3)C=2)=C1 YOHYSYJDKVYCJI-UHFFFAOYSA-N 0.000 description 5
- 108010024654 phenylalanyl-prolyl-alanine Proteins 0.000 description 5
- 108010073101 phenylalanylleucine Proteins 0.000 description 5
- 108010051242 phenylalanylserine Proteins 0.000 description 5
- 108010031719 prolyl-serine Proteins 0.000 description 5
- 108010053725 prolylvaline Proteins 0.000 description 5
- 230000002829 reductive effect Effects 0.000 description 5
- 230000020382 suppression by virus of host antigen processing and presentation of peptide antigen via MHC class I Effects 0.000 description 5
- 108010071097 threonyl-lysyl-proline Proteins 0.000 description 5
- 238000011269 treatment regimen Methods 0.000 description 5
- 108010080629 tryptophan-leucine Proteins 0.000 description 5
- 108010079202 tyrosyl-alanyl-cysteine Proteins 0.000 description 5
- 108010071635 tyrosyl-prolyl-arginine Proteins 0.000 description 5
- 108010027345 wheylin-1 peptide Proteins 0.000 description 5
- CCDFBRZVTDDJNM-GUBZILKMSA-N Ala-Leu-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O CCDFBRZVTDDJNM-GUBZILKMSA-N 0.000 description 4
- KYQNAIMCTRZLNP-QSFUFRPTSA-N Asp-Ile-Val Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C(C)C)C(O)=O KYQNAIMCTRZLNP-QSFUFRPTSA-N 0.000 description 4
- YIDFBWRHIYOYAA-LKXGYXEUSA-N Asp-Ser-Thr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O YIDFBWRHIYOYAA-LKXGYXEUSA-N 0.000 description 4
- 238000011740 C57BL/6 mouse Methods 0.000 description 4
- 208000001333 Colorectal Neoplasms Diseases 0.000 description 4
- 108010047041 Complementarity Determining Regions Proteins 0.000 description 4
- 238000002965 ELISA Methods 0.000 description 4
- 108091008794 FGF receptors Proteins 0.000 description 4
- 108010087819 Fc receptors Proteins 0.000 description 4
- 102000009109 Fc receptors Human genes 0.000 description 4
- RBWKVOSARCFSQQ-FXQIFTODSA-N Gln-Gln-Ser Chemical compound NC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O RBWKVOSARCFSQQ-FXQIFTODSA-N 0.000 description 4
- 101001117317 Homo sapiens Programmed cell death 1 ligand 1 Proteins 0.000 description 4
- GYAFMRQGWHXMII-IUKAMOBKSA-N Ile-Asp-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H]([C@@H](C)O)C(=O)O)N GYAFMRQGWHXMII-IUKAMOBKSA-N 0.000 description 4
- QGXQHJQPAPMACW-PPCPHDFISA-N Ile-Thr-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(=O)O)N QGXQHJQPAPMACW-PPCPHDFISA-N 0.000 description 4
- UGTHTQWIQKEDEH-BQBZGAKWSA-N L-alanyl-L-prolylglycine zwitterion Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O UGTHTQWIQKEDEH-BQBZGAKWSA-N 0.000 description 4
- LOGFVTREOLYCPF-RHYQMDGZSA-N Lys-Pro-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CCCCN LOGFVTREOLYCPF-RHYQMDGZSA-N 0.000 description 4
- DNDVVILEHVMWIS-LPEHRKFASA-N Met-Asp-Pro Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N1CCC[C@@H]1C(=O)O)N DNDVVILEHVMWIS-LPEHRKFASA-N 0.000 description 4
- RIIFMEBFDDXGCV-VEVYYDQMSA-N Met-Thr-Asn Chemical compound CSCC[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CC(N)=O RIIFMEBFDDXGCV-VEVYYDQMSA-N 0.000 description 4
- 241001465754 Metazoa Species 0.000 description 4
- ZOPISOXXPQNOCO-SVSWQMSJSA-N Ser-Ile-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)O)NC(=O)[C@H](CO)N ZOPISOXXPQNOCO-SVSWQMSJSA-N 0.000 description 4
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 4
- GXUWHVZYDAHFSV-FLBSBUHZSA-N Thr-Ile-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(O)=O GXUWHVZYDAHFSV-FLBSBUHZSA-N 0.000 description 4
- VRUFCJZQDACGLH-UVOCVTCTSA-N Thr-Leu-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O VRUFCJZQDACGLH-UVOCVTCTSA-N 0.000 description 4
- KZSYAEWQMJEGRZ-RHYQMDGZSA-N Thr-Leu-Val Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O KZSYAEWQMJEGRZ-RHYQMDGZSA-N 0.000 description 4
- JLNMFGCJODTXDH-WEDXCCLWSA-N Thr-Lys-Gly Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(=O)NCC(O)=O JLNMFGCJODTXDH-WEDXCCLWSA-N 0.000 description 4
- 229940124674 VEGF-R inhibitor Drugs 0.000 description 4
- 239000013543 active substance Substances 0.000 description 4
- 238000004458 analytical method Methods 0.000 description 4
- 239000005557 antagonist Substances 0.000 description 4
- 230000000259 anti-tumor effect Effects 0.000 description 4
- 230000008901 benefit Effects 0.000 description 4
- 239000000872 buffer Substances 0.000 description 4
- 230000000295 complement effect Effects 0.000 description 4
- 150000001875 compounds Chemical class 0.000 description 4
- 229910052805 deuterium Inorganic materials 0.000 description 4
- 229940121647 egfr inhibitor Drugs 0.000 description 4
- 210000003527 eukaryotic cell Anatomy 0.000 description 4
- 102000052178 fibroblast growth factor receptor activity proteins Human genes 0.000 description 4
- 102000048776 human CD274 Human genes 0.000 description 4
- 239000004615 ingredient Substances 0.000 description 4
- 201000001441 melanoma Diseases 0.000 description 4
- 206010061289 metastatic neoplasm Diseases 0.000 description 4
- 230000037361 pathway Effects 0.000 description 4
- 230000008569 process Effects 0.000 description 4
- 230000028327 secretion Effects 0.000 description 4
- 108010026333 seryl-proline Proteins 0.000 description 4
- 241000894007 species Species 0.000 description 4
- 230000000638 stimulation Effects 0.000 description 4
- 230000002195 synergetic effect Effects 0.000 description 4
- 108010072986 threonyl-seryl-lysine Proteins 0.000 description 4
- 239000008215 water for injection Substances 0.000 description 4
- 230000003442 weekly effect Effects 0.000 description 4
- DMQYDVBIPXAAJA-VHXPQNKSSA-N (3z)-5-[(1-ethylpiperidin-4-yl)amino]-3-[(3-fluorophenyl)-(5-methyl-1h-imidazol-2-yl)methylidene]-1h-indol-2-one Chemical compound C1CN(CC)CCC1NC1=CC=C(NC(=O)\C2=C(/C=3NC=C(C)N=3)C=3C=C(F)C=CC=3)C2=C1 DMQYDVBIPXAAJA-VHXPQNKSSA-N 0.000 description 3
- YABJJWZLRMPFSI-UHFFFAOYSA-N 1-methyl-5-[[2-[5-(trifluoromethyl)-1H-imidazol-2-yl]-4-pyridinyl]oxy]-N-[4-(trifluoromethyl)phenyl]-2-benzimidazolamine Chemical compound N=1C2=CC(OC=3C=C(N=CC=3)C=3NC(=CN=3)C(F)(F)F)=CC=C2N(C)C=1NC1=CC=C(C(F)(F)F)C=C1 YABJJWZLRMPFSI-UHFFFAOYSA-N 0.000 description 3
- NHBKXEKEPDILRR-UHFFFAOYSA-N 2,3-bis(butanoylsulfanyl)propyl butanoate Chemical compound CCCC(=O)OCC(SC(=O)CCC)CSC(=O)CCC NHBKXEKEPDILRR-UHFFFAOYSA-N 0.000 description 3
- QMOQBVOBWVNSNO-UHFFFAOYSA-N 2-[[2-[[2-[(2-azaniumylacetyl)amino]acetyl]amino]acetyl]amino]acetate Chemical compound NCC(=O)NCC(=O)NCC(=O)NCC(O)=O QMOQBVOBWVNSNO-UHFFFAOYSA-N 0.000 description 3
- WEVYNIUIFUYDGI-UHFFFAOYSA-N 3-[6-[4-(trifluoromethoxy)anilino]-4-pyrimidinyl]benzamide Chemical compound NC(=O)C1=CC=CC(C=2N=CN=C(NC=3C=CC(OC(F)(F)F)=CC=3)C=2)=C1 WEVYNIUIFUYDGI-UHFFFAOYSA-N 0.000 description 3
- QTBSBXVTEAMEQO-UHFFFAOYSA-N Acetic acid Chemical compound CC(O)=O QTBSBXVTEAMEQO-UHFFFAOYSA-N 0.000 description 3
- OBVSBEYOMDWLRJ-BFHQHQDPSA-N Ala-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@H](C)N OBVSBEYOMDWLRJ-BFHQHQDPSA-N 0.000 description 3
- GIVATXIGCXFQQA-FXQIFTODSA-N Arg-Ala-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCN=C(N)N GIVATXIGCXFQQA-FXQIFTODSA-N 0.000 description 3
- VJTWLBMESLDOMK-WDSKDSINSA-N Asn-Gln-Gly Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O VJTWLBMESLDOMK-WDSKDSINSA-N 0.000 description 3
- JDDYEZGPYBBPBN-JRQIVUDYSA-N Asp-Thr-Tyr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O JDDYEZGPYBBPBN-JRQIVUDYSA-N 0.000 description 3
- 229940125565 BMS-986016 Drugs 0.000 description 3
- 206010006187 Breast cancer Diseases 0.000 description 3
- 208000026310 Breast neoplasm Diseases 0.000 description 3
- 210000001666 CD4-positive, alpha-beta memory T lymphocyte Anatomy 0.000 description 3
- LFQSCWFLJHTTHZ-UHFFFAOYSA-N Ethanol Chemical compound CCO LFQSCWFLJHTTHZ-UHFFFAOYSA-N 0.000 description 3
- AFODTOLGSZQDSL-PEFMBERDSA-N Glu-Asn-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CCC(=O)O)N AFODTOLGSZQDSL-PEFMBERDSA-N 0.000 description 3
- CWSZWFILCNSNEX-CIUDSAMLSA-N His-Ser-Asn Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(=O)N)C(=O)O)N CWSZWFILCNSNEX-CIUDSAMLSA-N 0.000 description 3
- 101000979342 Homo sapiens Nuclear factor NF-kappa-B p105 subunit Proteins 0.000 description 3
- 241000701044 Human gammaherpesvirus 4 Species 0.000 description 3
- BCISUQVFDGYZBO-QSFUFRPTSA-N Ile-Val-Asp Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC(O)=O BCISUQVFDGYZBO-QSFUFRPTSA-N 0.000 description 3
- 229940076838 Immune checkpoint inhibitor Drugs 0.000 description 3
- 239000002147 L01XE04 - Sunitinib Substances 0.000 description 3
- 239000005536 L01XE08 - Nilotinib Substances 0.000 description 3
- ULUQBUKAPDUKOC-GVXVVHGQSA-N Lys-Glu-Val Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O ULUQBUKAPDUKOC-GVXVVHGQSA-N 0.000 description 3
- 241000829100 Macaca mulatta polyomavirus 1 Species 0.000 description 3
- 108010079364 N-glycylalanine Proteins 0.000 description 3
- 102100023050 Nuclear factor NF-kappa-B p105 subunit Human genes 0.000 description 3
- 229920001213 Polysorbate 20 Polymers 0.000 description 3
- VBZXFFYOBDLLFE-HSHDSVGOSA-N Pro-Trp-Thr Chemical compound N([C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H]([C@H](O)C)C(O)=O)C(=O)[C@@H]1CCCN1 VBZXFFYOBDLLFE-HSHDSVGOSA-N 0.000 description 3
- DNIAPMSPPWPWGF-UHFFFAOYSA-N Propylene glycol Chemical compound CC(O)CO DNIAPMSPPWPWGF-UHFFFAOYSA-N 0.000 description 3
- 108010008281 Recombinant Fusion Proteins Proteins 0.000 description 3
- 102000007056 Recombinant Fusion Proteins Human genes 0.000 description 3
- IYCBDVBJWDXQRR-FXQIFTODSA-N Ser-Ala-Met Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H](CCSC)C(O)=O IYCBDVBJWDXQRR-FXQIFTODSA-N 0.000 description 3
- LGIMRDKGABDMBN-DCAQKATOSA-N Ser-Val-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CO)N LGIMRDKGABDMBN-DCAQKATOSA-N 0.000 description 3
- MTCFGRXMJLQNBG-UHFFFAOYSA-N Serine Natural products OCC(N)C(O)=O MTCFGRXMJLQNBG-UHFFFAOYSA-N 0.000 description 3
- 108010003723 Single-Domain Antibodies Proteins 0.000 description 3
- 206010068771 Soft tissue neoplasm Diseases 0.000 description 3
- 208000005718 Stomach Neoplasms Diseases 0.000 description 3
- 239000005463 Tandutinib Substances 0.000 description 3
- 206010043376 Tetanus Diseases 0.000 description 3
- CDRYEAWHKJSGAF-BPNCWPANSA-N Tyr-Ala-Met Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C)C(=O)N[C@@H](CCSC)C(O)=O CDRYEAWHKJSGAF-BPNCWPANSA-N 0.000 description 3
- QARCDOCCDOLJSF-HJPIBITLSA-N Tyr-Ile-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N QARCDOCCDOLJSF-HJPIBITLSA-N 0.000 description 3
- UMSZZGTXGKHTFJ-SRVKXCTJSA-N Tyr-Ser-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 UMSZZGTXGKHTFJ-SRVKXCTJSA-N 0.000 description 3
- AZSHAZJLOZQYAY-FXQIFTODSA-N Val-Ala-Ser Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O AZSHAZJLOZQYAY-FXQIFTODSA-N 0.000 description 3
- 239000004480 active ingredient Substances 0.000 description 3
- 238000010171 animal model Methods 0.000 description 3
- 230000000890 antigenic effect Effects 0.000 description 3
- 239000002246 antineoplastic agent Substances 0.000 description 3
- RITAVMQDGBJQJZ-FMIVXFBMSA-N axitinib Chemical compound CNC(=O)C1=CC=CC=C1SC1=CC=C(C(\C=C\C=2N=CC=CC=2)=NN2)C2=C1 RITAVMQDGBJQJZ-FMIVXFBMSA-N 0.000 description 3
- 210000003719 b-lymphocyte Anatomy 0.000 description 3
- 230000001580 bacterial effect Effects 0.000 description 3
- 210000000481 breast Anatomy 0.000 description 3
- 238000012875 competitive assay Methods 0.000 description 3
- 239000003085 diluting agent Substances 0.000 description 3
- 238000001943 fluorescence-activated cell sorting Methods 0.000 description 3
- 206010017758 gastric cancer Diseases 0.000 description 3
- VPZXBVLAVMBEQI-UHFFFAOYSA-N glycyl-DL-alpha-alanine Natural products OC(=O)C(C)NC(=O)CN VPZXBVLAVMBEQI-UHFFFAOYSA-N 0.000 description 3
- 101150107276 hpd-1 gene Proteins 0.000 description 3
- 210000002865 immune cell Anatomy 0.000 description 3
- 239000012274 immune-checkpoint protein inhibitor Substances 0.000 description 3
- 230000003053 immunization Effects 0.000 description 3
- 238000002649 immunization Methods 0.000 description 3
- 230000005847 immunogenicity Effects 0.000 description 3
- 239000002955 immunomodulating agent Substances 0.000 description 3
- 238000000338 in vitro Methods 0.000 description 3
- 210000004698 lymphocyte Anatomy 0.000 description 3
- 229940124302 mTOR inhibitor Drugs 0.000 description 3
- 239000003628 mammalian target of rapamycin inhibitor Substances 0.000 description 3
- 239000000463 material Substances 0.000 description 3
- 238000005259 measurement Methods 0.000 description 3
- 230000001404 mediated effect Effects 0.000 description 3
- 230000001394 metastastic effect Effects 0.000 description 3
- 238000010172 mouse model Methods 0.000 description 3
- 229960001346 nilotinib Drugs 0.000 description 3
- HHZIURLSWUIHRB-UHFFFAOYSA-N nilotinib Chemical compound C1=NC(C)=CN1C1=CC(NC(=O)C=2C=C(NC=3N=C(C=CN=3)C=3C=NC=CC=3)C(C)=CC=2)=CC(C(F)(F)F)=C1 HHZIURLSWUIHRB-UHFFFAOYSA-N 0.000 description 3
- 210000003819 peripheral blood mononuclear cell Anatomy 0.000 description 3
- 239000002935 phosphatidylinositol 3 kinase inhibitor Substances 0.000 description 3
- 239000000256 polyoxyethylene sorbitan monolaurate Substances 0.000 description 3
- 235000010486 polyoxyethylene sorbitan monolaurate Nutrition 0.000 description 3
- 239000000843 powder Substances 0.000 description 3
- 230000035755 proliferation Effects 0.000 description 3
- 238000001959 radiotherapy Methods 0.000 description 3
- 238000012163 sequencing technique Methods 0.000 description 3
- 206010041823 squamous cell carcinoma Diseases 0.000 description 3
- 201000011549 stomach cancer Diseases 0.000 description 3
- 238000007920 subcutaneous administration Methods 0.000 description 3
- 229960001796 sunitinib Drugs 0.000 description 3
- WINHZLLDWRZWRT-ATVHPVEESA-N sunitinib Chemical compound CCN(CC)CCNC(=O)C1=C(C)NC(\C=C/2C3=CC(F)=CC=C3NC\2=O)=C1C WINHZLLDWRZWRT-ATVHPVEESA-N 0.000 description 3
- 239000006228 supernatant Substances 0.000 description 3
- 238000001356 surgical procedure Methods 0.000 description 3
- 208000024891 symptom Diseases 0.000 description 3
- 229950009893 tandutinib Drugs 0.000 description 3
- UXXQOJXBIDBUAC-UHFFFAOYSA-N tandutinib Chemical compound COC1=CC2=C(N3CCN(CC3)C(=O)NC=3C=CC(OC(C)C)=CC=3)N=CN=C2C=C1OCCCN1CCCCC1 UXXQOJXBIDBUAC-UHFFFAOYSA-N 0.000 description 3
- 238000002560 therapeutic procedure Methods 0.000 description 3
- 210000001519 tissue Anatomy 0.000 description 3
- 210000003171 tumor-infiltrating lymphocyte Anatomy 0.000 description 3
- 239000002525 vasculotropin inhibitor Substances 0.000 description 3
- YBJHBAHKTGYVGT-ZKWXMUAHSA-N (+)-Biotin Chemical compound N1C(=O)N[C@@H]2[C@H](CCCCC(=O)O)SC[C@@H]21 YBJHBAHKTGYVGT-ZKWXMUAHSA-N 0.000 description 2
- CSGQVNMSRKWUSH-IAGOWNOFSA-N (3r,4r)-4-amino-1-[[4-(3-methoxyanilino)pyrrolo[2,1-f][1,2,4]triazin-5-yl]methyl]piperidin-3-ol Chemical compound COC1=CC=CC(NC=2C3=C(CN4C[C@@H](O)[C@H](N)CC4)C=CN3N=CN=2)=C1 CSGQVNMSRKWUSH-IAGOWNOFSA-N 0.000 description 2
- NFGXHKASABOEEW-UHFFFAOYSA-N 1-methylethyl 11-methoxy-3,7,11-trimethyl-2,4-dodecadienoate Chemical compound COC(C)(C)CCCC(C)CC=CC(C)=CC(=O)OC(C)C NFGXHKASABOEEW-UHFFFAOYSA-N 0.000 description 2
- UEJJHQNACJXSKW-UHFFFAOYSA-N 2-(2,6-dioxopiperidin-3-yl)-1H-isoindole-1,3(2H)-dione Chemical compound O=C1C2=CC=CC=C2C(=O)N1C1CCC(=O)NC1=O UEJJHQNACJXSKW-UHFFFAOYSA-N 0.000 description 2
- FGTCROZDHDSNIO-UHFFFAOYSA-N 3-(4-quinolinylmethylamino)-N-[4-(trifluoromethoxy)phenyl]-2-thiophenecarboxamide Chemical compound C1=CC(OC(F)(F)F)=CC=C1NC(=O)C1=C(NCC=2C3=CC=CC=C3N=CC=2)C=CS1 FGTCROZDHDSNIO-UHFFFAOYSA-N 0.000 description 2
- QFCXANHHBCGMAS-UHFFFAOYSA-N 4-[[4-(4-chloroanilino)furo[2,3-d]pyridazin-7-yl]oxymethyl]-n-methylpyridine-2-carboxamide Chemical compound C1=NC(C(=O)NC)=CC(COC=2C=3OC=CC=3C(NC=3C=CC(Cl)=CC=3)=NN=2)=C1 QFCXANHHBCGMAS-UHFFFAOYSA-N 0.000 description 2
- CBRHYTYNUKLOBK-DDWIOCJRSA-N 4-[[5-bromo-4-[[(2R)-1-hydroxypropan-2-yl]amino]pyrimidin-2-yl]amino]benzenesulfonamide hydrochloride Chemical compound Cl.C1=C(Br)C(N[C@@H](CO)C)=NC(NC=2C=CC(=CC=2)S(N)(=O)=O)=N1 CBRHYTYNUKLOBK-DDWIOCJRSA-N 0.000 description 2
- FWMNVWWHGCHHJJ-SKKKGAJSSA-N 4-amino-1-[(2r)-6-amino-2-[[(2r)-2-[[(2r)-2-[[(2r)-2-amino-3-phenylpropanoyl]amino]-3-phenylpropanoyl]amino]-4-methylpentanoyl]amino]hexanoyl]piperidine-4-carboxylic acid Chemical compound C([C@H](C(=O)N[C@H](CC(C)C)C(=O)N[C@H](CCCCN)C(=O)N1CCC(N)(CC1)C(O)=O)NC(=O)[C@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 FWMNVWWHGCHHJJ-SKKKGAJSSA-N 0.000 description 2
- KDCGOANMDULRCW-UHFFFAOYSA-N 7H-purine Chemical compound N1=CNC2=NC=NC2=C1 KDCGOANMDULRCW-UHFFFAOYSA-N 0.000 description 2
- OONFNUWBHFSNBT-HXUWFJFHSA-N AEE788 Chemical compound C1CN(CC)CCN1CC1=CC=C(C=2NC3=NC=NC(N[C@H](C)C=4C=CC=CC=4)=C3C=2)C=C1 OONFNUWBHFSNBT-HXUWFJFHSA-N 0.000 description 2
- QTBSBXVTEAMEQO-UHFFFAOYSA-M Acetate Chemical compound CC([O-])=O QTBSBXVTEAMEQO-UHFFFAOYSA-M 0.000 description 2
- AWZKCUCQJNTBAD-SRVKXCTJSA-N Ala-Leu-Lys Chemical compound C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CCCCN AWZKCUCQJNTBAD-SRVKXCTJSA-N 0.000 description 2
- 108010088751 Albumins Proteins 0.000 description 2
- 102000009027 Albumins Human genes 0.000 description 2
- 108010032595 Antibody Binding Sites Proteins 0.000 description 2
- 206010063836 Atrioventricular septal defect Diseases 0.000 description 2
- 208000010839 B-cell chronic lymphocytic leukemia Diseases 0.000 description 2
- 102100022005 B-lymphocyte antigen CD20 Human genes 0.000 description 2
- 241000894006 Bacteria Species 0.000 description 2
- 102000004506 Blood Proteins Human genes 0.000 description 2
- 108010017384 Blood Proteins Proteins 0.000 description 2
- 101800001318 Capsid protein VP4 Proteins 0.000 description 2
- 102000000844 Cell Surface Receptors Human genes 0.000 description 2
- 108010001857 Cell Surface Receptors Proteins 0.000 description 2
- 241000282693 Cercopithecidae Species 0.000 description 2
- 230000006820 DNA synthesis Effects 0.000 description 2
- AOJJSUZBOXZQNB-TZSSRYMLSA-N Doxorubicin Chemical compound O([C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(=O)CO)[C@H]1C[C@H](N)[C@H](O)[C@H](C)O1 AOJJSUZBOXZQNB-TZSSRYMLSA-N 0.000 description 2
- 241000196324 Embryophyta Species 0.000 description 2
- 208000000461 Esophageal Neoplasms Diseases 0.000 description 2
- 201000008808 Fibrosarcoma Diseases 0.000 description 2
- IXFVOPOHSRKJNG-LAEOZQHASA-N Gln-Asp-Val Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O IXFVOPOHSRKJNG-LAEOZQHASA-N 0.000 description 2
- GPISLLFQNHELLK-DCAQKATOSA-N Gln-Gln-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCC(=O)N)N GPISLLFQNHELLK-DCAQKATOSA-N 0.000 description 2
- ULZCYBYDTUMHNF-IUCAKERBSA-N Gly-Leu-Glu Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O ULZCYBYDTUMHNF-IUCAKERBSA-N 0.000 description 2
- RYAOJUMWLWUGNW-QMMMGPOBSA-N Gly-Val-Gly Chemical compound NCC(=O)N[C@@H](C(C)C)C(=O)NCC(O)=O RYAOJUMWLWUGNW-QMMMGPOBSA-N 0.000 description 2
- 244000060234 Gmelina philippensis Species 0.000 description 2
- 241000238631 Hexapoda Species 0.000 description 2
- 241000282412 Homo Species 0.000 description 2
- 101000897405 Homo sapiens B-lymphocyte antigen CD20 Proteins 0.000 description 2
- 101001117312 Homo sapiens Programmed cell death 1 ligand 2 Proteins 0.000 description 2
- 101000894590 Homo sapiens Uncharacterized protein C20orf85 Proteins 0.000 description 2
- 102000037982 Immune checkpoint proteins Human genes 0.000 description 2
- 108091008036 Immune checkpoint proteins Proteins 0.000 description 2
- 108010021625 Immunoglobulin Fragments Proteins 0.000 description 2
- 102000008394 Immunoglobulin Fragments Human genes 0.000 description 2
- 108091082332 JAK family Proteins 0.000 description 2
- 102000042838 JAK family Human genes 0.000 description 2
- FFEARJCKVFRZRR-BYPYZUCNSA-N L-methionine Chemical compound CSCC[C@H](N)C(O)=O FFEARJCKVFRZRR-BYPYZUCNSA-N 0.000 description 2
- 239000005517 L01XE01 - Imatinib Substances 0.000 description 2
- 239000005411 L01XE02 - Gefitinib Substances 0.000 description 2
- 239000002118 L01XE12 - Vandetanib Substances 0.000 description 2
- 208000006404 Large Granular Lymphocytic Leukemia Diseases 0.000 description 2
- UWKNTTJNVSYXPC-CIUDSAMLSA-N Lys-Ala-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCCN UWKNTTJNVSYXPC-CIUDSAMLSA-N 0.000 description 2
- 241000699660 Mus musculus Species 0.000 description 2
- 101100519207 Mus musculus Pdcd1 gene Proteins 0.000 description 2
- 102100038895 Myc proto-oncogene protein Human genes 0.000 description 2
- 101710135898 Myc proto-oncogene protein Proteins 0.000 description 2
- 201000003793 Myelodysplastic syndrome Diseases 0.000 description 2
- NWIBSHFKIJFRCO-WUDYKRTCSA-N Mytomycin Chemical compound C1N2C(C(C(C)=C(N)C3=O)=O)=C3[C@@H](COC(N)=O)[C@@]2(OC)[C@@H]2[C@H]1N2 NWIBSHFKIJFRCO-WUDYKRTCSA-N 0.000 description 2
- 206010030155 Oesophageal carcinoma Diseases 0.000 description 2
- 229940116355 PI3 kinase inhibitor Drugs 0.000 description 2
- 108090000526 Papain Proteins 0.000 description 2
- 102000057297 Pepsin A Human genes 0.000 description 2
- 108090000284 Pepsin A Proteins 0.000 description 2
- ISWSIDIOOBJBQZ-UHFFFAOYSA-N Phenol Chemical compound OC1=CC=CC=C1 ISWSIDIOOBJBQZ-UHFFFAOYSA-N 0.000 description 2
- 208000006664 Precursor Cell Lymphoblastic Leukemia-Lymphoma Diseases 0.000 description 2
- VTFXTWDFPTWNJY-RHYQMDGZSA-N Pro-Leu-Thr Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O VTFXTWDFPTWNJY-RHYQMDGZSA-N 0.000 description 2
- ONIBWKKTOPOVIA-UHFFFAOYSA-N Proline Natural products OC(=O)C1CCCN1 ONIBWKKTOPOVIA-UHFFFAOYSA-N 0.000 description 2
- 206010060862 Prostate cancer Diseases 0.000 description 2
- 208000000236 Prostatic Neoplasms Diseases 0.000 description 2
- 239000004365 Protease Substances 0.000 description 2
- 102000003923 Protein Kinase C Human genes 0.000 description 2
- 108090000315 Protein Kinase C Proteins 0.000 description 2
- 108020004511 Recombinant DNA Proteins 0.000 description 2
- 102100027609 Rho-related GTP-binding protein RhoD Human genes 0.000 description 2
- DKKGAAJTDKHWOD-BIIVOSGPSA-N Ser-Asn-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)N)NC(=O)[C@H](CO)N)C(=O)O DKKGAAJTDKHWOD-BIIVOSGPSA-N 0.000 description 2
- DBIDZNUXSLXVRG-FXQIFTODSA-N Ser-Asp-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CO)N DBIDZNUXSLXVRG-FXQIFTODSA-N 0.000 description 2
- VYPSYNLAJGMNEJ-UHFFFAOYSA-N Silicium dioxide Chemical compound O=[Si]=O VYPSYNLAJGMNEJ-UHFFFAOYSA-N 0.000 description 2
- 201000008717 T-cell large granular lymphocyte leukemia Diseases 0.000 description 2
- NKANXQFJJICGDU-QPLCGJKRSA-N Tamoxifen Chemical compound C=1C=CC=CC=1C(/CC)=C(C=1C=CC(OCCN(C)C)=CC=1)/C1=CC=CC=C1 NKANXQFJJICGDU-QPLCGJKRSA-N 0.000 description 2
- MXNAOGFNFNKUPD-JHYOHUSXSA-N Thr-Phe-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O MXNAOGFNFNKUPD-JHYOHUSXSA-N 0.000 description 2
- XVHAUVJXBFGUPC-RPTUDFQQSA-N Thr-Tyr-Phe Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O XVHAUVJXBFGUPC-RPTUDFQQSA-N 0.000 description 2
- 101710150448 Transcriptional regulator Myc Proteins 0.000 description 2
- DYEGCOJHFNJBKB-UFYCRDLUSA-N Tyr-Arg-Tyr Chemical compound C([C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=C(O)C=C1 DYEGCOJHFNJBKB-UFYCRDLUSA-N 0.000 description 2
- QPOUERMDWKKZEG-HJPIBITLSA-N Tyr-Ser-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 QPOUERMDWKKZEG-HJPIBITLSA-N 0.000 description 2
- 102100021442 Uncharacterized protein C20orf85 Human genes 0.000 description 2
- JIODCDXKCJRMEH-NHCYSSNCSA-N Val-Arg-Gln Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N JIODCDXKCJRMEH-NHCYSSNCSA-N 0.000 description 2
- IQQYYFPCWKWUHW-YDHLFZDLSA-N Val-Asn-Tyr Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)O)N IQQYYFPCWKWUHW-YDHLFZDLSA-N 0.000 description 2
- PGBMPFKFKXYROZ-UFYCRDLUSA-N Val-Tyr-Phe Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC2=CC=CC=C2)C(=O)O)N PGBMPFKFKXYROZ-UFYCRDLUSA-N 0.000 description 2
- 230000002159 abnormal effect Effects 0.000 description 2
- 229940022663 acetate Drugs 0.000 description 2
- 239000008351 acetate buffer Substances 0.000 description 2
- RJURFGZVJUQBHK-UHFFFAOYSA-N actinomycin D Natural products CC1OC(=O)C(C(C)C)N(C)C(=O)CN(C)C(=O)C2CCCN2C(=O)C(C(C)C)NC(=O)C1NC(=O)C1=C(N)C(=O)C(C)=C2OC(C(C)=CC=C3C(=O)NC4C(=O)NC(C(N5CCCC5C(=O)N(C)CC(=O)N(C)C(C(C)C)C(=O)OC4C)=O)C(C)C)=C3N=C21 RJURFGZVJUQBHK-UHFFFAOYSA-N 0.000 description 2
- 230000004913 activation Effects 0.000 description 2
- 239000008186 active pharmaceutical agent Substances 0.000 description 2
- 208000009956 adenocarcinoma Diseases 0.000 description 2
- 239000002671 adjuvant Substances 0.000 description 2
- 125000001931 aliphatic group Chemical group 0.000 description 2
- 230000004075 alteration Effects 0.000 description 2
- 239000004037 angiogenesis inhibitor Substances 0.000 description 2
- 239000003242 anti bacterial agent Substances 0.000 description 2
- 229940124691 antibody therapeutics Drugs 0.000 description 2
- 239000012062 aqueous buffer Substances 0.000 description 2
- 239000007864 aqueous solution Substances 0.000 description 2
- 229960003005 axitinib Drugs 0.000 description 2
- 229960000397 bevacizumab Drugs 0.000 description 2
- 230000004071 biological effect Effects 0.000 description 2
- 210000004369 blood Anatomy 0.000 description 2
- 239000008280 blood Substances 0.000 description 2
- 210000001124 body fluid Anatomy 0.000 description 2
- 239000010839 body fluid Substances 0.000 description 2
- 238000002619 cancer immunotherapy Methods 0.000 description 2
- 229960005395 cetuximab Drugs 0.000 description 2
- 229940044683 chemotherapy drug Drugs 0.000 description 2
- OSASVXMJTNOKOY-UHFFFAOYSA-N chlorobutanol Chemical compound CC(C)(O)C(Cl)(Cl)Cl OSASVXMJTNOKOY-UHFFFAOYSA-N 0.000 description 2
- 238000004587 chromatography analysis Methods 0.000 description 2
- 208000029742 colonic neoplasm Diseases 0.000 description 2
- 230000016396 cytokine production Effects 0.000 description 2
- 229940127089 cytotoxic agent Drugs 0.000 description 2
- 229950006418 dactolisib Drugs 0.000 description 2
- JOGKUKXHTYWRGZ-UHFFFAOYSA-N dactolisib Chemical compound O=C1N(C)C2=CN=C3C=CC(C=4C=C5C=CC=CC5=NC=4)=CC3=C2N1C1=CC=C(C(C)(C)C#N)C=C1 JOGKUKXHTYWRGZ-UHFFFAOYSA-N 0.000 description 2
- 230000029087 digestion Effects 0.000 description 2
- 239000006185 dispersion Substances 0.000 description 2
- 229940088679 drug related substance Drugs 0.000 description 2
- 230000008030 elimination Effects 0.000 description 2
- 238000003379 elimination reaction Methods 0.000 description 2
- 201000004101 esophageal cancer Diseases 0.000 description 2
- 238000011156 evaluation Methods 0.000 description 2
- 230000001747 exhibiting effect Effects 0.000 description 2
- 230000005714 functional activity Effects 0.000 description 2
- 230000002538 fungal effect Effects 0.000 description 2
- 108020001507 fusion proteins Proteins 0.000 description 2
- 102000037865 fusion proteins Human genes 0.000 description 2
- 229960002584 gefitinib Drugs 0.000 description 2
- XGALLCVXEZPNRQ-UHFFFAOYSA-N gefitinib Chemical compound C=12C=C(OCCCN3CCOCC3)C(OC)=CC2=NC=NC=1NC1=CC=C(F)C(Cl)=C1 XGALLCVXEZPNRQ-UHFFFAOYSA-N 0.000 description 2
- 210000004602 germ cell Anatomy 0.000 description 2
- 230000012010 growth Effects 0.000 description 2
- 239000001963 growth medium Substances 0.000 description 2
- 206010073071 hepatocellular carcinoma Diseases 0.000 description 2
- 231100000844 hepatocellular carcinoma Toxicity 0.000 description 2
- 102000048119 human PDCD1LG2 Human genes 0.000 description 2
- 229960002411 imatinib Drugs 0.000 description 2
- KTUFNOKKBVMGRW-UHFFFAOYSA-N imatinib Chemical compound C1CN(C)CCN1CC1=CC=C(C(=O)NC=2C=C(NC=3N=C(C=CN=3)C=3C=NC=CC=3)C(C)=CC=2)C=C1 KTUFNOKKBVMGRW-UHFFFAOYSA-N 0.000 description 2
- 230000005965 immune activity Effects 0.000 description 2
- 238000003780 insertion Methods 0.000 description 2
- 230000037431 insertion Effects 0.000 description 2
- 230000003834 intracellular effect Effects 0.000 description 2
- 210000003734 kidney Anatomy 0.000 description 2
- 230000003902 lesion Effects 0.000 description 2
- 230000000670 limiting effect Effects 0.000 description 2
- 239000002502 liposome Substances 0.000 description 2
- 201000007270 liver cancer Diseases 0.000 description 2
- 208000014018 liver neoplasm Diseases 0.000 description 2
- 230000007774 longterm Effects 0.000 description 2
- 210000004072 lung Anatomy 0.000 description 2
- 230000036210 malignancy Effects 0.000 description 2
- 229950002736 marizomib Drugs 0.000 description 2
- 238000004949 mass spectrometry Methods 0.000 description 2
- 229960004452 methionine Drugs 0.000 description 2
- 108010005942 methionylglycine Proteins 0.000 description 2
- 230000004048 modification Effects 0.000 description 2
- 238000012986 modification Methods 0.000 description 2
- 238000001823 molecular biology technique Methods 0.000 description 2
- 238000002703 mutagenesis Methods 0.000 description 2
- 231100000350 mutagenesis Toxicity 0.000 description 2
- 230000000869 mutational effect Effects 0.000 description 2
- 238000006386 neutralization reaction Methods 0.000 description 2
- 210000000056 organ Anatomy 0.000 description 2
- 229940055729 papain Drugs 0.000 description 2
- 235000019834 papain Nutrition 0.000 description 2
- 229960000639 pazopanib Drugs 0.000 description 2
- CUIHSIWYWATEQL-UHFFFAOYSA-N pazopanib Chemical compound C1=CC2=C(C)N(C)N=C2C=C1N(C)C(N=1)=CC=NC=1NC1=CC=C(C)C(S(N)(=O)=O)=C1 CUIHSIWYWATEQL-UHFFFAOYSA-N 0.000 description 2
- 229940111202 pepsin Drugs 0.000 description 2
- 238000002823 phage display Methods 0.000 description 2
- 239000000546 pharmaceutical excipient Substances 0.000 description 2
- 230000000144 pharmacologic effect Effects 0.000 description 2
- 239000008363 phosphate buffer Substances 0.000 description 2
- 230000008488 polyadenylation Effects 0.000 description 2
- 230000003389 potentiating effect Effects 0.000 description 2
- 230000002265 prevention Effects 0.000 description 2
- 125000002924 primary amino group Chemical group [H]N([H])* 0.000 description 2
- 230000002062 proliferating effect Effects 0.000 description 2
- 238000000159 protein binding assay Methods 0.000 description 2
- 239000003197 protein kinase B inhibitor Substances 0.000 description 2
- 239000012460 protein solution Substances 0.000 description 2
- 238000000746 purification Methods 0.000 description 2
- 229950001626 quizartinib Drugs 0.000 description 2
- 238000003127 radioimmunoassay Methods 0.000 description 2
- 229960004836 regorafenib Drugs 0.000 description 2
- FNHKPVJBJVTLMP-UHFFFAOYSA-N regorafenib Chemical compound C1=NC(C(=O)NC)=CC(OC=2C=C(F)C(NC(=O)NC=3C=C(C(Cl)=CC=3)C(F)(F)F)=CC=2)=C1 FNHKPVJBJVTLMP-UHFFFAOYSA-N 0.000 description 2
- 230000010076 replication Effects 0.000 description 2
- 230000004044 response Effects 0.000 description 2
- 238000012552 review Methods 0.000 description 2
- NGWSFRIPKNWYAO-SHTIJGAHSA-N salinosporamide A Chemical compound C([C@@H]1[C@H](O)[C@]23C(=O)O[C@]2([C@H](C(=O)N3)CCCl)C)CCC=C1 NGWSFRIPKNWYAO-SHTIJGAHSA-N 0.000 description 2
- 210000002966 serum Anatomy 0.000 description 2
- 230000019491 signal transduction Effects 0.000 description 2
- 238000009097 single-agent therapy Methods 0.000 description 2
- 201000002314 small intestine cancer Diseases 0.000 description 2
- 150000003384 small molecules Chemical class 0.000 description 2
- 239000011780 sodium chloride Substances 0.000 description 2
- 239000007787 solid Substances 0.000 description 2
- 239000003381 stabilizer Substances 0.000 description 2
- 238000010561 standard procedure Methods 0.000 description 2
- 230000004936 stimulating effect Effects 0.000 description 2
- 235000000346 sugar Nutrition 0.000 description 2
- 150000008163 sugars Chemical class 0.000 description 2
- 230000004083 survival effect Effects 0.000 description 2
- 229950003046 tesevatinib Drugs 0.000 description 2
- HVXKQKFEHMGHSL-QKDCVEJESA-N tesevatinib Chemical compound N1=CN=C2C=C(OC[C@@H]3C[C@@H]4CN(C)C[C@@H]4C3)C(OC)=CC2=C1NC1=CC=C(Cl)C(Cl)=C1F HVXKQKFEHMGHSL-QKDCVEJESA-N 0.000 description 2
- 238000001890 transfection Methods 0.000 description 2
- 238000011830 transgenic mouse model Methods 0.000 description 2
- 210000004881 tumor cell Anatomy 0.000 description 2
- 230000004614 tumor growth Effects 0.000 description 2
- 238000010798 ubiquitination Methods 0.000 description 2
- 230000034512 ubiquitination Effects 0.000 description 2
- 241000701161 unidentified adenovirus Species 0.000 description 2
- 229960000241 vandetanib Drugs 0.000 description 2
- UHTHHESEBZOYNR-UHFFFAOYSA-N vandetanib Chemical compound COC1=CC(C(/N=CN2)=N/C=3C(=CC(Br)=CC=3)F)=C2C=C1OCC1CCN(C)CC1 UHTHHESEBZOYNR-UHFFFAOYSA-N 0.000 description 2
- 210000005253 yeast cell Anatomy 0.000 description 2
- WCWUXEGQKLTGDX-LLVKDONJSA-N (2R)-1-[[4-[(4-fluoro-2-methyl-1H-indol-5-yl)oxy]-5-methyl-6-pyrrolo[2,1-f][1,2,4]triazinyl]oxy]-2-propanol Chemical compound C1=C2NC(C)=CC2=C(F)C(OC2=NC=NN3C=C(C(=C32)C)OC[C@H](O)C)=C1 WCWUXEGQKLTGDX-LLVKDONJSA-N 0.000 description 1
- MQLNLMKPNAHPDZ-LLMUXGIESA-N (3'r,3'as,6's,6as,6bs,7'ar,9s,12as,12br)-3',6',11,12b-tetramethylspiro[2,5,6,6a,6b,7,8,10,12,12a-decahydro-1h-naphtho[2,1-a]azulene-9,2'-3a,4,5,6,7,7a-hexahydro-3h-furo[3,2-b]pyridine]-3-one Chemical compound C([C@@]1(CC(C)=C2C3)O[C@@H]4C[C@H](C)CN[C@H]4[C@H]1C)C[C@H]2[C@H]1[C@H]3[C@@]2(C)CCC(=O)C=C2CC1 MQLNLMKPNAHPDZ-LLMUXGIESA-N 0.000 description 1
- DEQANNDTNATYII-OULOTJBUSA-N (4r,7s,10s,13r,16s,19r)-10-(4-aminobutyl)-19-[[(2r)-2-amino-3-phenylpropanoyl]amino]-16-benzyl-n-[(2r,3r)-1,3-dihydroxybutan-2-yl]-7-[(1r)-1-hydroxyethyl]-13-(1h-indol-3-ylmethyl)-6,9,12,15,18-pentaoxo-1,2-dithia-5,8,11,14,17-pentazacycloicosane-4-carboxa Chemical compound C([C@@H](N)C(=O)N[C@H]1CSSC[C@H](NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](CC=2C3=CC=CC=C3NC=2)NC(=O)[C@H](CC=2C=CC=CC=2)NC1=O)C(=O)N[C@H](CO)[C@H](O)C)C1=CC=CC=C1 DEQANNDTNATYII-OULOTJBUSA-N 0.000 description 1
- FPVKHBSQESCIEP-UHFFFAOYSA-N (8S)-3-(2-deoxy-beta-D-erythro-pentofuranosyl)-3,6,7,8-tetrahydroimidazo[4,5-d][1,3]diazepin-8-ol Natural products C1C(O)C(CO)OC1N1C(NC=NCC2O)=C2N=C1 FPVKHBSQESCIEP-UHFFFAOYSA-N 0.000 description 1
- FDKXTQMXEQVLRF-ZHACJKMWSA-N (E)-dacarbazine Chemical compound CN(C)\N=N\c1[nH]cnc1C(N)=O FDKXTQMXEQVLRF-ZHACJKMWSA-N 0.000 description 1
- LKJPYSCBVHEWIU-KRWDZBQOSA-N (R)-bicalutamide Chemical compound C([C@@](O)(C)C(=O)NC=1C=C(C(C#N)=CC=1)C(F)(F)F)S(=O)(=O)C1=CC=C(F)C=C1 LKJPYSCBVHEWIU-KRWDZBQOSA-N 0.000 description 1
- UEJJHQNACJXSKW-VIFPVBQESA-N (S)-thalidomide Chemical compound O=C1C2=CC=CC=C2C(=O)N1[C@H]1CCC(=O)NC1=O UEJJHQNACJXSKW-VIFPVBQESA-N 0.000 description 1
- NWUYHJFMYQTDRP-UHFFFAOYSA-N 1,2-bis(ethenyl)benzene;1-ethenyl-2-ethylbenzene;styrene Chemical compound C=CC1=CC=CC=C1.CCC1=CC=CC=C1C=C.C=CC1=CC=CC=C1C=C NWUYHJFMYQTDRP-UHFFFAOYSA-N 0.000 description 1
- SPMVMDHWKHCIDT-UHFFFAOYSA-N 1-[2-chloro-4-[(6,7-dimethoxy-4-quinolinyl)oxy]phenyl]-3-(5-methyl-3-isoxazolyl)urea Chemical compound C=12C=C(OC)C(OC)=CC2=NC=CC=1OC(C=C1Cl)=CC=C1NC(=O)NC=1C=C(C)ON=1 SPMVMDHWKHCIDT-UHFFFAOYSA-N 0.000 description 1
- MTJHLONVHHPNSI-IBGZPJMESA-N 1-ethyl-3-[2-methoxy-4-[5-methyl-4-[[(1S)-1-(3-pyridinyl)butyl]amino]-2-pyrimidinyl]phenyl]urea Chemical compound N([C@@H](CCC)C=1C=NC=CC=1)C(C(=CN=1)C)=NC=1C1=CC=C(NC(=O)NCC)C(OC)=C1 MTJHLONVHHPNSI-IBGZPJMESA-N 0.000 description 1
- VSNHCAURESNICA-NJFSPNSNSA-N 1-oxidanylurea Chemical compound N[14C](=O)NO VSNHCAURESNICA-NJFSPNSNSA-N 0.000 description 1
- ABEXEQSGABRUHS-UHFFFAOYSA-N 16-methylheptadecyl 16-methylheptadecanoate Chemical compound CC(C)CCCCCCCCCCCCCCCOC(=O)CCCCCCCCCCCCCCC(C)C ABEXEQSGABRUHS-UHFFFAOYSA-N 0.000 description 1
- FPYJSJDOHRDAMT-KQWNVCNZSA-N 1h-indole-5-sulfonamide, n-(3-chlorophenyl)-3-[[3,5-dimethyl-4-[(4-methyl-1-piperazinyl)carbonyl]-1h-pyrrol-2-yl]methylene]-2,3-dihydro-n-methyl-2-oxo-, (3z)- Chemical compound C=1C=C2NC(=O)\C(=C/C3=C(C(C(=O)N4CCN(C)CC4)=C(C)N3)C)C2=CC=1S(=O)(=O)N(C)C1=CC=CC(Cl)=C1 FPYJSJDOHRDAMT-KQWNVCNZSA-N 0.000 description 1
- RWEVIPRMPFNTLO-UHFFFAOYSA-N 2-(2-fluoro-4-iodoanilino)-N-(2-hydroxyethoxy)-1,5-dimethyl-6-oxo-3-pyridinecarboxamide Chemical compound CN1C(=O)C(C)=CC(C(=O)NOCCO)=C1NC1=CC=C(I)C=C1F RWEVIPRMPFNTLO-UHFFFAOYSA-N 0.000 description 1
- VQCDZFWRGXFUMS-UHFFFAOYSA-N 2-[2-[4-[4-(4-tert-butylanilino)phenoxy]-6-methoxyquinolin-7-yl]oxyethylamino]ethanol Chemical compound C1=CN=C2C=C(OCCNCCO)C(OC)=CC2=C1OC(C=C1)=CC=C1NC1=CC=C(C(C)(C)C)C=C1 VQCDZFWRGXFUMS-UHFFFAOYSA-N 0.000 description 1
- KGTRXRJMKPFFHY-UHFFFAOYSA-N 2-amino-3,7-dihydropurine-6-thione;3,7-dihydropurine-6-thione Chemical compound S=C1N=CNC2=C1NC=N2.S=C1NC(N)=NC2=C1NC=N2 KGTRXRJMKPFFHY-UHFFFAOYSA-N 0.000 description 1
- 108020005345 3' Untranslated Regions Proteins 0.000 description 1
- HXHAJRMTJXHJJZ-UHFFFAOYSA-N 3-[(4-bromo-2,6-difluorophenyl)methoxy]-5-(4-pyrrolidin-1-ylbutylcarbamoylamino)-1,2-thiazole-4-carboxamide Chemical compound S1N=C(OCC=2C(=CC(Br)=CC=2F)F)C(C(=O)N)=C1NC(=O)NCCCCN1CCCC1 HXHAJRMTJXHJJZ-UHFFFAOYSA-N 0.000 description 1
- WHMXDBPHBVLYRC-OFVILXPXSA-N 3-chloro-n-[(2s)-1-[[2-(dimethylamino)acetyl]amino]-3-[4-[8-[(1s)-1-hydroxyethyl]imidazo[1,2-a]pyridin-2-yl]phenyl]propan-2-yl]-4-propan-2-yloxybenzamide Chemical compound C1=C(Cl)C(OC(C)C)=CC=C1C(=O)N[C@H](CNC(=O)CN(C)C)CC1=CC=C(C=2N=C3C([C@H](C)O)=CC=CN3C=2)C=C1 WHMXDBPHBVLYRC-OFVILXPXSA-N 0.000 description 1
- AOJJSUZBOXZQNB-VTZDEGQISA-N 4'-epidoxorubicin Chemical compound O([C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(=O)CO)[C@H]1C[C@H](N)[C@@H](O)[C@H](C)O1 AOJJSUZBOXZQNB-VTZDEGQISA-N 0.000 description 1
- XXJWYDDUDKYVKI-UHFFFAOYSA-N 4-[(4-fluoro-2-methyl-1H-indol-5-yl)oxy]-6-methoxy-7-[3-(1-pyrrolidinyl)propoxy]quinazoline Chemical compound COC1=CC2=C(OC=3C(=C4C=C(C)NC4=CC=3)F)N=CN=C2C=C1OCCCN1CCCC1 XXJWYDDUDKYVKI-UHFFFAOYSA-N 0.000 description 1
- FJKROLUGYXJWQN-UHFFFAOYSA-M 4-hydroxybenzoate Chemical compound OC1=CC=C(C([O-])=O)C=C1 FJKROLUGYXJWQN-UHFFFAOYSA-M 0.000 description 1
- GPSZYOIFQZPWEJ-UHFFFAOYSA-N 4-methyl-5-[2-(4-morpholin-4-ylanilino)pyrimidin-4-yl]-1,3-thiazol-2-amine Chemical compound N1=C(N)SC(C=2N=C(NC=3C=CC(=CC=3)N3CCOCC3)N=CC=2)=C1C GPSZYOIFQZPWEJ-UHFFFAOYSA-N 0.000 description 1
- ALKJNCZNEOTEMP-UHFFFAOYSA-N 4-n-(5-cyclopropyl-1h-pyrazol-3-yl)-6-(4-methylpiperazin-1-yl)-2-n-[(3-propan-2-yl-1,2-oxazol-5-yl)methyl]pyrimidine-2,4-diamine Chemical compound O1N=C(C(C)C)C=C1CNC1=NC(NC=2NN=C(C=2)C2CC2)=CC(N2CCN(C)CC2)=N1 ALKJNCZNEOTEMP-UHFFFAOYSA-N 0.000 description 1
- QSUPQMGDXOHVLK-FFXKMJQXSA-N 4-n-[3-chloro-4-(1,3-thiazol-2-ylmethoxy)phenyl]-6-n-[(4r)-4-methyl-4,5-dihydro-1,3-oxazol-2-yl]quinazoline-4,6-diamine;4-methylbenzenesulfonic acid Chemical compound CC1=CC=C(S(O)(=O)=O)C=C1.CC1=CC=C(S(O)(=O)=O)C=C1.C[C@@H]1COC(NC=2C=C3C(NC=4C=C(Cl)C(OCC=5SC=CN=5)=CC=4)=NC=NC3=CC=2)=N1 QSUPQMGDXOHVLK-FFXKMJQXSA-N 0.000 description 1
- CTNPALGJUAXMMC-PMFHANACSA-N 5-[(z)-(5-fluoro-2-oxo-1h-indol-3-ylidene)methyl]-n-[(2s)-2-hydroxy-3-morpholin-4-ylpropyl]-2,4-dimethyl-1h-pyrrole-3-carboxamide Chemical compound C([C@@H](O)CNC(=O)C=1C(C)=C(\C=C/2C3=CC(F)=CC=C3NC\2=O)NC=1C)N1CCOCC1 CTNPALGJUAXMMC-PMFHANACSA-N 0.000 description 1
- ZHJGWYRLJUCMRT-QGZVFWFLSA-N 5-[6-[(4-methyl-1-piperazinyl)methyl]-1-benzimidazolyl]-3-[(1R)-1-[2-(trifluoromethyl)phenyl]ethoxy]-2-thiophenecarboxamide Chemical group O([C@H](C)C=1C(=CC=CC=1)C(F)(F)F)C(=C(S1)C(N)=O)C=C1N(C1=C2)C=NC1=CC=C2CN1CCN(C)CC1 ZHJGWYRLJUCMRT-QGZVFWFLSA-N 0.000 description 1
- XAUDJQYHKZQPEU-KVQBGUIXSA-N 5-aza-2'-deoxycytidine Chemical compound O=C1N=C(N)N=CN1[C@@H]1O[C@H](CO)[C@@H](O)C1 XAUDJQYHKZQPEU-KVQBGUIXSA-N 0.000 description 1
- STQGQHZAVUOBTE-UHFFFAOYSA-N 7-Cyan-hept-2t-en-4,6-diinsaeure Natural products C1=2C(O)=C3C(=O)C=4C(OC)=CC=CC=4C(=O)C3=C(O)C=2CC(O)(C(C)=O)CC1OC1CC(N)C(O)C(C)O1 STQGQHZAVUOBTE-UHFFFAOYSA-N 0.000 description 1
- BIGPXXAUSQLTQR-UHFFFAOYSA-N 7-chloro-9-oxoindeno[1,2-b]pyrazine-2,3-dicarbonitrile Chemical group N#CC1=C(C#N)N=C2C3=CC=C(Cl)C=C3C(=O)C2=N1 BIGPXXAUSQLTQR-UHFFFAOYSA-N 0.000 description 1
- GBJVVSCPOBPEIT-UHFFFAOYSA-N AZT-1152 Chemical compound N=1C=NC2=CC(OCCCN(CC)CCOP(O)(O)=O)=CC=C2C=1NC(=NN1)C=C1CC(=O)NC1=CC=CC(F)=C1 GBJVVSCPOBPEIT-UHFFFAOYSA-N 0.000 description 1
- 102000007469 Actins Human genes 0.000 description 1
- 108010085238 Actins Proteins 0.000 description 1
- 208000024893 Acute lymphoblastic leukemia Diseases 0.000 description 1
- 208000014697 Acute lymphocytic leukaemia Diseases 0.000 description 1
- 208000031261 Acute myeloid leukaemia Diseases 0.000 description 1
- ORILYTVJVMAKLC-UHFFFAOYSA-N Adamantane Natural products C1C(C2)CC3CC1CC2C3 ORILYTVJVMAKLC-UHFFFAOYSA-N 0.000 description 1
- 206010067484 Adverse reaction Diseases 0.000 description 1
- 229940126638 Akt inhibitor Drugs 0.000 description 1
- BTYTYHBSJKQBQA-GCJQMDKQSA-N Ala-Asp-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](C)N)O BTYTYHBSJKQBQA-GCJQMDKQSA-N 0.000 description 1
- VNYMOTCMNHJGTG-JBDRJPRFSA-N Ala-Ile-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O VNYMOTCMNHJGTG-JBDRJPRFSA-N 0.000 description 1
- RGQCNKIDEQJEBT-CQDKDKBSSA-N Ala-Leu-Tyr Chemical compound C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 RGQCNKIDEQJEBT-CQDKDKBSSA-N 0.000 description 1
- AJBVYEYZVYPFCF-CIUDSAMLSA-N Ala-Lys-Asn Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(O)=O AJBVYEYZVYPFCF-CIUDSAMLSA-N 0.000 description 1
- OSRZOHXQCUFIQG-FPMFFAJLSA-N Ala-Phe-Pro Chemical compound C([C@H](NC(=O)[C@@H]([NH3+])C)C(=O)N1[C@H](CCC1)C([O-])=O)C1=CC=CC=C1 OSRZOHXQCUFIQG-FPMFFAJLSA-N 0.000 description 1
- WQKAQKZRDIZYNV-VZFHVOOUSA-N Ala-Ser-Thr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O WQKAQKZRDIZYNV-VZFHVOOUSA-N 0.000 description 1
- CLOMBHBBUKAUBP-LSJOCFKGSA-N Ala-Val-His Chemical compound C[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N CLOMBHBBUKAUBP-LSJOCFKGSA-N 0.000 description 1
- 201000003076 Angiosarcoma Diseases 0.000 description 1
- 101100186130 Arabidopsis thaliana NAC052 gene Proteins 0.000 description 1
- KWKQGHSSNHPGOW-BQBZGAKWSA-N Arg-Ala-Gly Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(=O)NCC(O)=O KWKQGHSSNHPGOW-BQBZGAKWSA-N 0.000 description 1
- XVLLUZMFSAYKJV-GUBZILKMSA-N Arg-Asp-Arg Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O XVLLUZMFSAYKJV-GUBZILKMSA-N 0.000 description 1
- PQWTZSNVWSOFFK-FXQIFTODSA-N Arg-Asp-Asn Chemical compound C(C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC(=O)N)C(=O)O)N)CN=C(N)N PQWTZSNVWSOFFK-FXQIFTODSA-N 0.000 description 1
- COXMUHNBYCVVRG-DCAQKATOSA-N Arg-Leu-Ser Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O COXMUHNBYCVVRG-DCAQKATOSA-N 0.000 description 1
- ISJWBVIYRBAXEB-CIUDSAMLSA-N Arg-Ser-Glu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(O)=O ISJWBVIYRBAXEB-CIUDSAMLSA-N 0.000 description 1
- BFYIZQONLCFLEV-DAELLWKTSA-N Aromasine Chemical compound O=C1C=C[C@]2(C)[C@H]3CC[C@](C)(C(CC4)=O)[C@@H]4[C@@H]3CC(=C)C2=C1 BFYIZQONLCFLEV-DAELLWKTSA-N 0.000 description 1
- LIJXJYGRSRWLCJ-IHRRRGAJSA-N Asp-Phe-Arg Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O LIJXJYGRSRWLCJ-IHRRRGAJSA-N 0.000 description 1
- JSNWZMFSLIWAHS-HJGDQZAQSA-N Asp-Thr-Leu Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(C)C)C(=O)O)NC(=O)[C@H](CC(=O)O)N)O JSNWZMFSLIWAHS-HJGDQZAQSA-N 0.000 description 1
- QOJJMJKTMKNFEF-ZKWXMUAHSA-N Asp-Val-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CC(O)=O QOJJMJKTMKNFEF-ZKWXMUAHSA-N 0.000 description 1
- 206010003571 Astrocytoma Diseases 0.000 description 1
- 208000023275 Autoimmune disease Diseases 0.000 description 1
- 102100029822 B- and T-lymphocyte attenuator Human genes 0.000 description 1
- 208000004736 B-Cell Leukemia Diseases 0.000 description 1
- 208000028564 B-cell non-Hodgkin lymphoma Diseases 0.000 description 1
- MLDQJTXFUGDVEO-UHFFFAOYSA-N BAY-43-9006 Chemical compound C1=NC(C(=O)NC)=CC(OC=2C=CC(NC(=O)NC=3C=C(C(Cl)=CC=3)C(F)(F)F)=CC=2)=C1 MLDQJTXFUGDVEO-UHFFFAOYSA-N 0.000 description 1
- 208000032791 BCR-ABL1 positive chronic myelogenous leukemia Diseases 0.000 description 1
- QULDDKSCVCJTPV-UHFFFAOYSA-N BIIB021 Chemical compound COC1=C(C)C=NC(CN2C3=NC(N)=NC(Cl)=C3N=C2)=C1C QULDDKSCVCJTPV-UHFFFAOYSA-N 0.000 description 1
- 206010004146 Basal cell carcinoma Diseases 0.000 description 1
- 229940118364 Bcr-Abl inhibitor Drugs 0.000 description 1
- 108010006654 Bleomycin Proteins 0.000 description 1
- COVZYZSDYWQREU-UHFFFAOYSA-N Busulfan Chemical compound CS(=O)(=O)OCCCCOS(C)(=O)=O COVZYZSDYWQREU-UHFFFAOYSA-N 0.000 description 1
- 102100024263 CD160 antigen Human genes 0.000 description 1
- 229940113310 CD4 antagonist Drugs 0.000 description 1
- 108010029697 CD40 Ligand Proteins 0.000 description 1
- 102100032937 CD40 ligand Human genes 0.000 description 1
- 229940123828 CD80 antagonist Drugs 0.000 description 1
- 108010021064 CTLA-4 Antigen Proteins 0.000 description 1
- 102000008203 CTLA-4 Antigen Human genes 0.000 description 1
- 229940045513 CTLA4 antagonist Drugs 0.000 description 1
- 101100463133 Caenorhabditis elegans pdl-1 gene Proteins 0.000 description 1
- GAGWJHPBXLXJQN-UORFTKCHSA-N Capecitabine Chemical compound C1=C(F)C(NC(=O)OCCCCC)=NC(=O)N1[C@H]1[C@H](O)[C@H](O)[C@@H](C)O1 GAGWJHPBXLXJQN-UORFTKCHSA-N 0.000 description 1
- GAGWJHPBXLXJQN-UHFFFAOYSA-N Capecitabine Natural products C1=C(F)C(NC(=O)OCCCCC)=NC(=O)N1C1C(O)C(O)C(C)O1 GAGWJHPBXLXJQN-UHFFFAOYSA-N 0.000 description 1
- DLGOEMSEDOSKAD-UHFFFAOYSA-N Carmustine Chemical compound ClCCNC(=O)N(N=O)CCCl DLGOEMSEDOSKAD-UHFFFAOYSA-N 0.000 description 1
- 206010008342 Cervix carcinoma Diseases 0.000 description 1
- JWBOIMRXGHLCPP-UHFFFAOYSA-N Chloditan Chemical compound C=1C=CC=C(Cl)C=1C(C(Cl)Cl)C1=CC=C(Cl)C=C1 JWBOIMRXGHLCPP-UHFFFAOYSA-N 0.000 description 1
- PTOAARAWEBMLNO-KVQBGUIXSA-N Cladribine Chemical compound C1=NC=2C(N)=NC(Cl)=NC=2N1[C@H]1C[C@H](O)[C@@H](CO)O1 PTOAARAWEBMLNO-KVQBGUIXSA-N 0.000 description 1
- 108020004705 Codon Proteins 0.000 description 1
- 108700010070 Codon Usage Proteins 0.000 description 1
- 241000699800 Cricetinae Species 0.000 description 1
- 241000699802 Cricetulus griseus Species 0.000 description 1
- CMSMOCZEIVJLDB-UHFFFAOYSA-N Cyclophosphamide Chemical compound ClCCN(CCCl)P1(=O)NCCCO1 CMSMOCZEIVJLDB-UHFFFAOYSA-N 0.000 description 1
- JTNKVWLMDHIUOG-IHRRRGAJSA-N Cys-Arg-Phe Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O JTNKVWLMDHIUOG-IHRRRGAJSA-N 0.000 description 1
- NRVQLLDIJJEIIZ-VZFHVOOUSA-N Cys-Thr-Ala Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](C)C(=O)O)NC(=O)[C@H](CS)N)O NRVQLLDIJJEIIZ-VZFHVOOUSA-N 0.000 description 1
- UHDGCWIWMRVCDJ-CCXZUQQUSA-N Cytarabine Chemical compound O=C1N=C(N)C=CN1[C@H]1[C@@H](O)[C@H](O)[C@@H](CO)O1 UHDGCWIWMRVCDJ-CCXZUQQUSA-N 0.000 description 1
- FBPFZTCFMRRESA-KVTDHHQDSA-N D-Mannitol Chemical compound OC[C@@H](O)[C@@H](O)[C@H](O)[C@H](O)CO FBPFZTCFMRRESA-KVTDHHQDSA-N 0.000 description 1
- 239000012623 DNA damaging agent Substances 0.000 description 1
- 108010092160 Dactinomycin Proteins 0.000 description 1
- 101100481408 Danio rerio tie2 gene Proteins 0.000 description 1
- ZBNZXTGUTAYRHI-UHFFFAOYSA-N Dasatinib Chemical compound C=1C(N2CCN(CCO)CC2)=NC(C)=NC=1NC(S1)=NC=C1C(=O)NC1=C(C)C=CC=C1Cl ZBNZXTGUTAYRHI-UHFFFAOYSA-N 0.000 description 1
- KCXVZYZYPLLWCC-UHFFFAOYSA-N EDTA Chemical compound OC(=O)CN(CC(O)=O)CCN(CC(O)=O)CC(O)=O KCXVZYZYPLLWCC-UHFFFAOYSA-N 0.000 description 1
- 101150029707 ERBB2 gene Proteins 0.000 description 1
- 102000004190 Enzymes Human genes 0.000 description 1
- 108090000790 Enzymes Proteins 0.000 description 1
- 102100031983 Ephrin type-B receptor 4 Human genes 0.000 description 1
- HTIJFSOGRVMCQR-UHFFFAOYSA-N Epirubicin Natural products COc1cccc2C(=O)c3c(O)c4CC(O)(CC(OC5CC(N)C(=O)C(C)O5)c4c(O)c3C(=O)c12)C(=O)CO HTIJFSOGRVMCQR-UHFFFAOYSA-N 0.000 description 1
- 241000588724 Escherichia coli Species 0.000 description 1
- 101100306202 Escherichia coli (strain K12) rpoB gene Proteins 0.000 description 1
- 229910052693 Europium Inorganic materials 0.000 description 1
- HKVAMNSJSFKALM-GKUWKFKPSA-N Everolimus Chemical compound C1C[C@@H](OCCO)[C@H](OC)C[C@@H]1C[C@@H](C)[C@H]1OC(=O)[C@@H]2CCCCN2C(=O)C(=O)[C@](O)(O2)[C@H](C)CC[C@H]2C[C@H](OC)/C(C)=C/C=C/C=C/[C@@H](C)C[C@@H](C)C(=O)[C@H](OC)[C@H](O)/C(C)=C/[C@@H](C)C(=O)C1 HKVAMNSJSFKALM-GKUWKFKPSA-N 0.000 description 1
- 208000006168 Ewing Sarcoma Diseases 0.000 description 1
- GHASVSINZRGABV-UHFFFAOYSA-N Fluorouracil Chemical compound FC1=CNC(=O)NC1=O GHASVSINZRGABV-UHFFFAOYSA-N 0.000 description 1
- VWUXBMIQPBEWFH-WCCTWKNTSA-N Fulvestrant Chemical compound OC1=CC=C2[C@H]3CC[C@](C)([C@H](CC4)O)[C@@H]4[C@@H]3[C@H](CCCCCCCCCS(=O)CCCC(F)(F)C(F)(F)F)CC2=C1 VWUXBMIQPBEWFH-WCCTWKNTSA-N 0.000 description 1
- KGPGFQWBCSZGEL-ZDUSSCGKSA-N GSK690693 Chemical compound C=12N(CC)C(C=3C(=NON=3)N)=NC2=C(C#CC(C)(C)O)N=CC=1OC[C@H]1CCCNC1 KGPGFQWBCSZGEL-ZDUSSCGKSA-N 0.000 description 1
- 108010010803 Gelatin Proteins 0.000 description 1
- 208000032612 Glial tumor Diseases 0.000 description 1
- 206010018338 Glioma Diseases 0.000 description 1
- RGXXLQWXBFNXTG-CIUDSAMLSA-N Gln-Arg-Ala Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(O)=O RGXXLQWXBFNXTG-CIUDSAMLSA-N 0.000 description 1
- IULKWYSYZSURJK-AVGNSLFASA-N Gln-Leu-Lys Chemical compound NC(=O)CC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(O)=O IULKWYSYZSURJK-AVGNSLFASA-N 0.000 description 1
- VNTGPISAOMAXRK-CIUDSAMLSA-N Gln-Pro-Ser Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O VNTGPISAOMAXRK-CIUDSAMLSA-N 0.000 description 1
- SYZZMPFLOLSMHL-XHNCKOQMSA-N Gln-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CCC(=O)N)N)C(=O)O SYZZMPFLOLSMHL-XHNCKOQMSA-N 0.000 description 1
- VLOLPWWCNKWRNB-LOKLDPHHSA-N Gln-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCC(=O)N)N)O VLOLPWWCNKWRNB-LOKLDPHHSA-N 0.000 description 1
- MRVYVEQPNDSWLH-XPUUQOCRSA-N Gln-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@@H](N)CCC(N)=O MRVYVEQPNDSWLH-XPUUQOCRSA-N 0.000 description 1
- WOMUDRVDJMHTCV-DCAQKATOSA-N Glu-Arg-Arg Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O WOMUDRVDJMHTCV-DCAQKATOSA-N 0.000 description 1
- QPRZKNOOOBWXSU-CIUDSAMLSA-N Glu-Asp-Arg Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CCCN=C(N)N QPRZKNOOOBWXSU-CIUDSAMLSA-N 0.000 description 1
- JPHYJQHPILOKHC-ACZMJKKPSA-N Glu-Asp-Asp Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O JPHYJQHPILOKHC-ACZMJKKPSA-N 0.000 description 1
- JVSBYEDSSRZQGV-GUBZILKMSA-N Glu-Asp-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CCC(O)=O JVSBYEDSSRZQGV-GUBZILKMSA-N 0.000 description 1
- WQZGKKKJIJFFOK-GASJEMHNSA-N Glucose Chemical compound OC[C@H]1OC(O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-GASJEMHNSA-N 0.000 description 1
- JMQFHZWESBGPFC-WDSKDSINSA-N Gly-Gln-Asp Chemical compound NCC(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O JMQFHZWESBGPFC-WDSKDSINSA-N 0.000 description 1
- UESJMAMHDLEHGM-NHCYSSNCSA-N Gly-Ile-Leu Chemical compound NCC(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(C)C)C(O)=O UESJMAMHDLEHGM-NHCYSSNCSA-N 0.000 description 1
- FFALDIDGPLUDKV-ZDLURKLDSA-N Gly-Thr-Ser Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O FFALDIDGPLUDKV-ZDLURKLDSA-N 0.000 description 1
- YGHSQRJSHKYUJY-SCZZXKLOSA-N Gly-Val-Pro Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)CN YGHSQRJSHKYUJY-SCZZXKLOSA-N 0.000 description 1
- 239000004471 Glycine Substances 0.000 description 1
- 108010069236 Goserelin Proteins 0.000 description 1
- 229940125497 HER2 kinase inhibitor Drugs 0.000 description 1
- 239000012981 Hank's balanced salt solution Substances 0.000 description 1
- 101710113864 Heat shock protein 90 Proteins 0.000 description 1
- 102100034051 Heat shock protein HSP 90-alpha Human genes 0.000 description 1
- 208000001258 Hemangiosarcoma Diseases 0.000 description 1
- 102100034458 Hepatitis A virus cellular receptor 2 Human genes 0.000 description 1
- 208000017604 Hodgkin disease Diseases 0.000 description 1
- 208000010747 Hodgkins lymphoma Diseases 0.000 description 1
- 101000600756 Homo sapiens 3-phosphoinositide-dependent protein kinase 1 Proteins 0.000 description 1
- 101000864344 Homo sapiens B- and T-lymphocyte attenuator Proteins 0.000 description 1
- 101000761938 Homo sapiens CD160 antigen Proteins 0.000 description 1
- 101001068133 Homo sapiens Hepatitis A virus cellular receptor 2 Proteins 0.000 description 1
- 101000898034 Homo sapiens Hepatocyte growth factor Proteins 0.000 description 1
- 101001076408 Homo sapiens Interleukin-6 Proteins 0.000 description 1
- 101001138062 Homo sapiens Leukocyte-associated immunoglobulin-like receptor 1 Proteins 0.000 description 1
- 101000904173 Homo sapiens Progonadoliberin-1 Proteins 0.000 description 1
- 101000868152 Homo sapiens Son of sevenless homolog 1 Proteins 0.000 description 1
- 101000831007 Homo sapiens T-cell immunoreceptor with Ig and ITIM domains Proteins 0.000 description 1
- 101000997832 Homo sapiens Tyrosine-protein kinase JAK2 Proteins 0.000 description 1
- 101000666896 Homo sapiens V-type immunoglobulin domain-containing suppressor of T-cell activation Proteins 0.000 description 1
- 101000851007 Homo sapiens Vascular endothelial growth factor receptor 2 Proteins 0.000 description 1
- 101001117146 Homo sapiens [Pyruvate dehydrogenase (acetyl-transferring)] kinase isozyme 1, mitochondrial Proteins 0.000 description 1
- XDXDZDZNSLXDNA-TZNDIEGXSA-N Idarubicin Chemical compound C1[C@H](N)[C@H](O)[C@H](C)O[C@H]1O[C@@H]1C2=C(O)C(C(=O)C3=CC=CC=C3C3=O)=C3C(O)=C2C[C@@](O)(C(C)=O)C1 XDXDZDZNSLXDNA-TZNDIEGXSA-N 0.000 description 1
- XDXDZDZNSLXDNA-UHFFFAOYSA-N Idarubicin Natural products C1C(N)C(O)C(C)OC1OC1C2=C(O)C(C(=O)C3=CC=CC=C3C3=O)=C3C(O)=C2CC(O)(C(C)=O)C1 XDXDZDZNSLXDNA-UHFFFAOYSA-N 0.000 description 1
- HDOYNXLPTRQLAD-JBDRJPRFSA-N Ile-Ala-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(=O)O)N HDOYNXLPTRQLAD-JBDRJPRFSA-N 0.000 description 1
- NBJAAWYRLGCJOF-UGYAYLCHSA-N Ile-Asp-Asn Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC(=O)N)C(=O)O)N NBJAAWYRLGCJOF-UGYAYLCHSA-N 0.000 description 1
- ADDYYRVQQZFIMW-MNXVOIDGSA-N Ile-Lys-Glu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N ADDYYRVQQZFIMW-MNXVOIDGSA-N 0.000 description 1
- VGSPNSSCMOHRRR-BJDJZHNGSA-N Ile-Ser-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)O)N VGSPNSSCMOHRRR-BJDJZHNGSA-N 0.000 description 1
- 108010054477 Immunoglobulin Fab Fragments Proteins 0.000 description 1
- 102000001706 Immunoglobulin Fab Fragments Human genes 0.000 description 1
- 102000018071 Immunoglobulin Fc Fragments Human genes 0.000 description 1
- 108010091135 Immunoglobulin Fc Fragments Proteins 0.000 description 1
- 108700005091 Immunoglobulin Genes Proteins 0.000 description 1
- 108010067060 Immunoglobulin Variable Region Proteins 0.000 description 1
- 102000017727 Immunoglobulin Variable Region Human genes 0.000 description 1
- 206010062016 Immunosuppression Diseases 0.000 description 1
- 102000006992 Interferon-alpha Human genes 0.000 description 1
- 108010047761 Interferon-alpha Proteins 0.000 description 1
- 108091092195 Intron Proteins 0.000 description 1
- 241000764238 Isis Species 0.000 description 1
- 208000007766 Kaposi sarcoma Diseases 0.000 description 1
- 241000235058 Komagataella pastoris Species 0.000 description 1
- FFEARJCKVFRZRR-UHFFFAOYSA-N L-Methionine Natural products CSCCC(N)C(O)=O FFEARJCKVFRZRR-UHFFFAOYSA-N 0.000 description 1
- 229930195722 L-methionine Natural products 0.000 description 1
- FBOZXECLQNJBKD-ZDUSSCGKSA-N L-methotrexate Chemical compound C=1N=C2N=C(N)N=C(N)C2=NC=1CN(C)C1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 FBOZXECLQNJBKD-ZDUSSCGKSA-N 0.000 description 1
- 239000005551 L01XE03 - Erlotinib Substances 0.000 description 1
- 239000005511 L01XE05 - Sorafenib Substances 0.000 description 1
- 239000002067 L01XE06 - Dasatinib Substances 0.000 description 1
- 239000002136 L01XE07 - Lapatinib Substances 0.000 description 1
- 239000003798 L01XE11 - Pazopanib Substances 0.000 description 1
- 239000002145 L01XE14 - Bosutinib Substances 0.000 description 1
- 101150030213 Lag3 gene Proteins 0.000 description 1
- WSGXUIQTEZDVHJ-GARJFASQSA-N Leu-Ala-Pro Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)N1CCC[C@@H]1C(O)=O WSGXUIQTEZDVHJ-GARJFASQSA-N 0.000 description 1
- MPSBSKHOWJQHBS-IHRRRGAJSA-N Leu-His-Met Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CCSC)C(=O)O)N MPSBSKHOWJQHBS-IHRRRGAJSA-N 0.000 description 1
- HMDDEJADNKQTBR-BZSNNMDCSA-N Leu-His-Tyr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O HMDDEJADNKQTBR-BZSNNMDCSA-N 0.000 description 1
- DSFYPIUSAMSERP-IHRRRGAJSA-N Leu-Leu-Arg Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N DSFYPIUSAMSERP-IHRRRGAJSA-N 0.000 description 1
- 102100020943 Leukocyte-associated immunoglobulin-like receptor 1 Human genes 0.000 description 1
- 108010000817 Leuprolide Proteins 0.000 description 1
- GQYIWUVLTXOXAJ-UHFFFAOYSA-N Lomustine Chemical compound ClCCN(N=O)C(=O)NC1CCCCC1 GQYIWUVLTXOXAJ-UHFFFAOYSA-N 0.000 description 1
- 102100020862 Lymphocyte activation gene 3 protein Human genes 0.000 description 1
- 208000031422 Lymphocytic Chronic B-Cell Leukemia Diseases 0.000 description 1
- 206010025323 Lymphomas Diseases 0.000 description 1
- JCFYLFOCALSNLQ-GUBZILKMSA-N Lys-Ala-Gln Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(N)=O)C(O)=O JCFYLFOCALSNLQ-GUBZILKMSA-N 0.000 description 1
- RFQATBGBLDAKGI-VHSXEESVSA-N Lys-Gly-Pro Chemical compound C1C[C@@H](N(C1)C(=O)CNC(=O)[C@H](CCCCN)N)C(=O)O RFQATBGBLDAKGI-VHSXEESVSA-N 0.000 description 1
- 206010025671 Malignant melanoma stage IV Diseases 0.000 description 1
- 229930195725 Mannitol Natural products 0.000 description 1
- 208000005410 Mediastinal Neoplasms Diseases 0.000 description 1
- 208000002030 Merkel cell carcinoma Diseases 0.000 description 1
- 206010027406 Mesothelioma Diseases 0.000 description 1
- 208000032818 Microsatellite Instability Diseases 0.000 description 1
- 101150097381 Mtor gene Proteins 0.000 description 1
- 208000034578 Multiple myelomas Diseases 0.000 description 1
- 101100510619 Mus musculus Lag3 gene Proteins 0.000 description 1
- 101100306001 Mus musculus Mst1r gene Proteins 0.000 description 1
- 101100481410 Mus musculus Tek gene Proteins 0.000 description 1
- 229940124160 Myc inhibitor Drugs 0.000 description 1
- 208000033776 Myeloid Acute Leukemia Diseases 0.000 description 1
- QJZRFPJCWMNVAV-HHHXNRCGSA-N N-(3-aminopropyl)-N-[(1R)-1-[7-chloro-4-oxo-3-(phenylmethyl)-2-quinazolinyl]-2-methylpropyl]-4-methylbenzamide Chemical compound NCCCN([C@H](C(C)C)C=1N(C(=O)C2=CC=C(Cl)C=C2N=1)CC=1C=CC=CC=1)C(=O)C1=CC=C(C)C=C1 QJZRFPJCWMNVAV-HHHXNRCGSA-N 0.000 description 1
- OUSFTKFNBAZUKL-UHFFFAOYSA-N N-(5-{[(5-tert-butyl-1,3-oxazol-2-yl)methyl]sulfanyl}-1,3-thiazol-2-yl)piperidine-4-carboxamide Chemical compound O1C(C(C)(C)C)=CN=C1CSC(S1)=CN=C1NC(=O)C1CCNCC1 OUSFTKFNBAZUKL-UHFFFAOYSA-N 0.000 description 1
- YBAFDPFAUTYYRW-UHFFFAOYSA-N N-L-alpha-glutamyl-L-leucine Natural products CC(C)CC(C(O)=O)NC(=O)C(N)CCC(O)=O YBAFDPFAUTYYRW-UHFFFAOYSA-N 0.000 description 1
- PESQCPHRXOFIPX-UHFFFAOYSA-N N-L-methionyl-L-tyrosine Natural products CSCCC(N)C(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 PESQCPHRXOFIPX-UHFFFAOYSA-N 0.000 description 1
- XKFTZKGMDDZMJI-HSZRJFAPSA-N N-[5-[(2R)-2-methoxy-1-oxo-2-phenylethyl]-4,6-dihydro-1H-pyrrolo[3,4-c]pyrazol-3-yl]-4-(4-methyl-1-piperazinyl)benzamide Chemical compound O=C([C@H](OC)C=1C=CC=CC=1)N(CC=12)CC=1NN=C2NC(=O)C(C=C1)=CC=C1N1CCN(C)CC1 XKFTZKGMDDZMJI-HSZRJFAPSA-N 0.000 description 1
- ZDZOTLJHXYCWBA-VCVYQWHSSA-N N-debenzoyl-N-(tert-butoxycarbonyl)-10-deacetyltaxol Chemical compound O([C@H]1[C@H]2[C@@](C([C@H](O)C3=C(C)[C@@H](OC(=O)[C@H](O)[C@@H](NC(=O)OC(C)(C)C)C=4C=CC=CC=4)C[C@]1(O)C3(C)C)=O)(C)[C@@H](O)C[C@H]1OC[C@]12OC(=O)C)C(=O)C1=CC=CC=C1 ZDZOTLJHXYCWBA-VCVYQWHSSA-N 0.000 description 1
- 206010029260 Neuroblastoma Diseases 0.000 description 1
- 206010029266 Neuroendocrine carcinoma of the skin Diseases 0.000 description 1
- 101100342977 Neurospora crassa (strain ATCC 24698 / 74-OR23-1A / CBS 708.71 / DSM 1257 / FGSC 987) leu-1 gene Proteins 0.000 description 1
- 208000015914 Non-Hodgkin lymphomas Diseases 0.000 description 1
- 230000005913 Notch signaling pathway Effects 0.000 description 1
- 108010016076 Octreotide Proteins 0.000 description 1
- 208000001715 Osteoblastoma Diseases 0.000 description 1
- 208000000035 Osteochondroma Diseases 0.000 description 1
- 206010033128 Ovarian cancer Diseases 0.000 description 1
- 206010061535 Ovarian neoplasm Diseases 0.000 description 1
- SUDAHWBOROXANE-SECBINFHSA-N PD 0325901 Chemical compound OC[C@@H](O)CONC(=O)C1=CC=C(F)C(F)=C1NC1=CC=C(I)C=C1F SUDAHWBOROXANE-SECBINFHSA-N 0.000 description 1
- 229940124611 PDK1 inhibitor Drugs 0.000 description 1
- OYONTEXKYJZFHA-SSHUPFPWSA-N PHA-665752 Chemical compound CC=1C(C(=O)N2[C@H](CCC2)CN2CCCC2)=C(C)NC=1\C=C(C1=C2)/C(=O)NC1=CC=C2S(=O)(=O)CC1=C(Cl)C=CC=C1Cl OYONTEXKYJZFHA-SSHUPFPWSA-N 0.000 description 1
- 229930012538 Paclitaxel Natural products 0.000 description 1
- 206010061902 Pancreatic neoplasm Diseases 0.000 description 1
- 235000019483 Peanut oil Nutrition 0.000 description 1
- KPEIBEPEUAZWNS-ULQDDVLXSA-N Phe-Leu-Met Chemical compound CSCC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC1=CC=CC=C1 KPEIBEPEUAZWNS-ULQDDVLXSA-N 0.000 description 1
- FQUUYTNBMIBOHS-IHRRRGAJSA-N Phe-Met-Ser Chemical compound CSCC[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)N FQUUYTNBMIBOHS-IHRRRGAJSA-N 0.000 description 1
- YMIZSYUAZJSOFL-SRVKXCTJSA-N Phe-Ser-Asn Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O YMIZSYUAZJSOFL-SRVKXCTJSA-N 0.000 description 1
- BPIMVBKDLSBKIJ-FCLVOEFKSA-N Phe-Thr-Phe Chemical compound C([C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=CC=C1 BPIMVBKDLSBKIJ-FCLVOEFKSA-N 0.000 description 1
- 102000003993 Phosphatidylinositol 3-kinases Human genes 0.000 description 1
- 108090000430 Phosphatidylinositol 3-kinases Proteins 0.000 description 1
- 208000007452 Plasmacytoma Diseases 0.000 description 1
- 241000276498 Pollachius virens Species 0.000 description 1
- MLQVJYMFASXBGZ-IHRRRGAJSA-N Pro-Asn-Tyr Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)O MLQVJYMFASXBGZ-IHRRRGAJSA-N 0.000 description 1
- HFNPOYOKIPGAEI-SRVKXCTJSA-N Pro-Leu-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H]1CCCN1 HFNPOYOKIPGAEI-SRVKXCTJSA-N 0.000 description 1
- BGWKULMLUIUPKY-BQBZGAKWSA-N Pro-Ser-Gly Chemical compound OC(=O)CNC(=O)[C@H](CO)NC(=O)[C@@H]1CCCN1 BGWKULMLUIUPKY-BQBZGAKWSA-N 0.000 description 1
- 102100024028 Progonadoliberin-1 Human genes 0.000 description 1
- 102000004245 Proteasome Endopeptidase Complex Human genes 0.000 description 1
- 108090000708 Proteasome Endopeptidase Complex Proteins 0.000 description 1
- 229940079156 Proteasome inhibitor Drugs 0.000 description 1
- 102000014128 RANK Ligand Human genes 0.000 description 1
- 108010025832 RANK Ligand Proteins 0.000 description 1
- 241000700159 Rattus Species 0.000 description 1
- 208000015634 Rectal Neoplasms Diseases 0.000 description 1
- 208000006265 Renal cell carcinoma Diseases 0.000 description 1
- 201000000582 Retinoblastoma Diseases 0.000 description 1
- 241000283984 Rodentia Species 0.000 description 1
- 240000004808 Saccharomyces cerevisiae Species 0.000 description 1
- 238000010266 Sephadex chromatography Methods 0.000 description 1
- RDFQNDHEHVSONI-ZLUOBGJFSA-N Ser-Asn-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O RDFQNDHEHVSONI-ZLUOBGJFSA-N 0.000 description 1
- MMAPOBOTRUVNKJ-ZLUOBGJFSA-N Ser-Asp-Ser Chemical compound C([C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CO)N)C(=O)O MMAPOBOTRUVNKJ-ZLUOBGJFSA-N 0.000 description 1
- BQWCDDAISCPDQV-XHNCKOQMSA-N Ser-Gln-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CO)N)C(=O)O BQWCDDAISCPDQV-XHNCKOQMSA-N 0.000 description 1
- JFWDJFULOLKQFY-QWRGUYRKSA-N Ser-Gly-Phe Chemical compound [H]N[C@@H](CO)C(=O)NCC(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O JFWDJFULOLKQFY-QWRGUYRKSA-N 0.000 description 1
- CLKKNZQUQMZDGD-SRVKXCTJSA-N Ser-His-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)CO)CC1=CN=CN1 CLKKNZQUQMZDGD-SRVKXCTJSA-N 0.000 description 1
- FUMGHWDRRFCKEP-CIUDSAMLSA-N Ser-Leu-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(O)=O FUMGHWDRRFCKEP-CIUDSAMLSA-N 0.000 description 1
- UBRMZSHOOIVJPW-SRVKXCTJSA-N Ser-Leu-Lys Chemical compound OC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(O)=O UBRMZSHOOIVJPW-SRVKXCTJSA-N 0.000 description 1
- JWOBLHJRDADHLN-KKUMJFAQSA-N Ser-Leu-Tyr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O JWOBLHJRDADHLN-KKUMJFAQSA-N 0.000 description 1
- FBLNYDYPCLFTSP-IXOXFDKPSA-N Ser-Phe-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O FBLNYDYPCLFTSP-IXOXFDKPSA-N 0.000 description 1
- FZXOPYUEQGDGMS-ACZMJKKPSA-N Ser-Ser-Gln Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(O)=O FZXOPYUEQGDGMS-ACZMJKKPSA-N 0.000 description 1
- ZKOKTQPHFMRSJP-YJRXYDGGSA-N Ser-Thr-Tyr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O ZKOKTQPHFMRSJP-YJRXYDGGSA-N 0.000 description 1
- LLSLRQOEAFCZLW-NRPADANISA-N Ser-Val-Gln Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O LLSLRQOEAFCZLW-NRPADANISA-N 0.000 description 1
- 208000000453 Skin Neoplasms Diseases 0.000 description 1
- VMHLLURERBWHNL-UHFFFAOYSA-M Sodium acetate Chemical compound [Na+].CC([O-])=O VMHLLURERBWHNL-UHFFFAOYSA-M 0.000 description 1
- 208000021712 Soft tissue sarcoma Diseases 0.000 description 1
- 108010090804 Streptavidin Proteins 0.000 description 1
- 229930006000 Sucrose Natural products 0.000 description 1
- CZMRCDWAGMRECN-UGDNZRGBSA-N Sucrose Chemical compound O[C@H]1[C@H](O)[C@@H](CO)O[C@@]1(CO)O[C@@H]1[C@H](O)[C@@H](O)[C@H](O)[C@@H](CO)O1 CZMRCDWAGMRECN-UGDNZRGBSA-N 0.000 description 1
- 101000996723 Sus scrofa Gonadotropin-releasing hormone receptor Proteins 0.000 description 1
- 229940046176 T-cell checkpoint inhibitor Drugs 0.000 description 1
- 239000012644 T-cell checkpoint inhibitor Substances 0.000 description 1
- 102100024834 T-cell immunoreceptor with Ig and ITIM domains Human genes 0.000 description 1
- 208000000389 T-cell leukemia Diseases 0.000 description 1
- 208000027585 T-cell non-Hodgkin lymphoma Diseases 0.000 description 1
- 208000026651 T-cell prolymphocytic leukemia Diseases 0.000 description 1
- 108010000449 TNF-Related Apoptosis-Inducing Ligand Receptors Proteins 0.000 description 1
- 102000002259 TNF-Related Apoptosis-Inducing Ligand Receptors Human genes 0.000 description 1
- NAVMQTYZDKMPEU-UHFFFAOYSA-N Targretin Chemical compound CC1=CC(C(CCC2(C)C)(C)C)=C2C=C1C(=C)C1=CC=C(C(O)=O)C=C1 NAVMQTYZDKMPEU-UHFFFAOYSA-N 0.000 description 1
- 229940123237 Taxane Drugs 0.000 description 1
- BPEGJWRSRHCHSN-UHFFFAOYSA-N Temozolomide Chemical compound O=C1N(C)N=NC2=C(C(N)=O)N=CN21 BPEGJWRSRHCHSN-UHFFFAOYSA-N 0.000 description 1
- CBPNZQVSJQDFBE-FUXHJELOSA-N Temsirolimus Chemical compound C1C[C@@H](OC(=O)C(C)(CO)CO)[C@H](OC)C[C@@H]1C[C@@H](C)[C@H]1OC(=O)[C@@H]2CCCCN2C(=O)C(=O)[C@](O)(O2)[C@H](C)CC[C@H]2C[C@H](OC)/C(C)=C/C=C/C=C/[C@@H](C)C[C@@H](C)C(=O)[C@H](OC)[C@H](O)/C(C)=C/[C@@H](C)C(=O)C1 CBPNZQVSJQDFBE-FUXHJELOSA-N 0.000 description 1
- 208000024313 Testicular Neoplasms Diseases 0.000 description 1
- 206010057644 Testis cancer Diseases 0.000 description 1
- FOCVUCIESVLUNU-UHFFFAOYSA-N Thiotepa Chemical compound C1CN1P(N1CC1)(=S)N1CC1 FOCVUCIESVLUNU-UHFFFAOYSA-N 0.000 description 1
- GFDUZZACIWNMPE-KZVJFYERSA-N Thr-Ala-Met Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(=O)N[C@@H](CCSC)C(O)=O GFDUZZACIWNMPE-KZVJFYERSA-N 0.000 description 1
- ABWNZPOIUJMNKT-IXOXFDKPSA-N Thr-Phe-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(O)=O ABWNZPOIUJMNKT-IXOXFDKPSA-N 0.000 description 1
- GXDLGHLJTHMDII-WISUUJSJSA-N Thr-Ser Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](CO)C(O)=O GXDLGHLJTHMDII-WISUUJSJSA-N 0.000 description 1
- IEZVHOULSUULHD-XGEHTFHBSA-N Thr-Ser-Val Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O IEZVHOULSUULHD-XGEHTFHBSA-N 0.000 description 1
- BBPCSGKKPJUYRB-UVOCVTCTSA-N Thr-Thr-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O BBPCSGKKPJUYRB-UVOCVTCTSA-N 0.000 description 1
- 108090000901 Transferrin Proteins 0.000 description 1
- 102000004338 Transferrin Human genes 0.000 description 1
- 208000003721 Triple Negative Breast Neoplasms Diseases 0.000 description 1
- ZHDQRPWESGUDST-JBACZVJFSA-N Trp-Phe-Gln Chemical compound C([C@H](NC(=O)[C@H](CC=1C2=CC=CC=C2NC=1)N)C(=O)N[C@@H](CCC(N)=O)C(O)=O)C1=CC=CC=C1 ZHDQRPWESGUDST-JBACZVJFSA-N 0.000 description 1
- 102000004243 Tubulin Human genes 0.000 description 1
- 108090000704 Tubulin Proteins 0.000 description 1
- 108091005906 Type I transmembrane proteins Proteins 0.000 description 1
- HSVPZJLMPLMPOX-BPNCWPANSA-N Tyr-Arg-Ala Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(O)=O HSVPZJLMPLMPOX-BPNCWPANSA-N 0.000 description 1
- UPODKYBYUBTWSV-BZSNNMDCSA-N Tyr-Phe-Cys Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](CS)C(O)=O)C1=CC=C(O)C=C1 UPODKYBYUBTWSV-BZSNNMDCSA-N 0.000 description 1
- 102100033444 Tyrosine-protein kinase JAK2 Human genes 0.000 description 1
- 208000025865 Ulcer Diseases 0.000 description 1
- 208000006105 Uterine Cervical Neoplasms Diseases 0.000 description 1
- 102100038282 V-type immunoglobulin domain-containing suppressor of T-cell activation Human genes 0.000 description 1
- PVPAOIGJYHVWBT-KKHAAJSZSA-N Val-Asn-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](C(C)C)N)O PVPAOIGJYHVWBT-KKHAAJSZSA-N 0.000 description 1
- 108010053099 Vascular Endothelial Growth Factor Receptor-2 Proteins 0.000 description 1
- 241000251539 Vertebrata <Metazoa> Species 0.000 description 1
- JXLYSJRDGCGARV-WWYNWVTFSA-N Vinblastine Natural products O=C(O[C@H]1[C@](O)(C(=O)OC)[C@@H]2N(C)c3c(cc(c(OC)c3)[C@]3(C(=O)OC)c4[nH]c5c(c4CCN4C[C@](O)(CC)C[C@H](C3)C4)cccc5)[C@@]32[C@H]2[C@@]1(CC)C=CCN2CC3)C JXLYSJRDGCGARV-WWYNWVTFSA-N 0.000 description 1
- 229940122803 Vinca alkaloid Drugs 0.000 description 1
- 241000700605 Viruses Species 0.000 description 1
- 102000013814 Wnt Human genes 0.000 description 1
- 108050003627 Wnt Proteins 0.000 description 1
- LUJZZYWHBDHDQX-QFIPXVFZSA-N [(3s)-morpholin-3-yl]methyl n-[4-[[1-[(3-fluorophenyl)methyl]indazol-5-yl]amino]-5-methylpyrrolo[2,1-f][1,2,4]triazin-6-yl]carbamate Chemical compound C=1N2N=CN=C(NC=3C=C4C=NN(CC=5C=C(F)C=CC=5)C4=CC=3)C2=C(C)C=1NC(=O)OC[C@@H]1COCCN1 LUJZZYWHBDHDQX-QFIPXVFZSA-N 0.000 description 1
- 102100024148 [Pyruvate dehydrogenase (acetyl-transferring)] kinase isozyme 1, mitochondrial Human genes 0.000 description 1
- 238000010521 absorption reaction Methods 0.000 description 1
- RJURFGZVJUQBHK-IIXSONLDSA-N actinomycin D Chemical compound C[C@H]1OC(=O)[C@H](C(C)C)N(C)C(=O)CN(C)C(=O)[C@@H]2CCCN2C(=O)[C@@H](C(C)C)NC(=O)[C@H]1NC(=O)C1=C(N)C(=O)C(C)=C2OC(C(C)=CC=C3C(=O)N[C@@H]4C(=O)N[C@@H](C(N5CCC[C@H]5C(=O)N(C)CC(=O)N(C)[C@@H](C(C)C)C(=O)O[C@@H]4C)=O)C(C)C)=C3N=C21 RJURFGZVJUQBHK-IIXSONLDSA-N 0.000 description 1
- 230000003213 activating effect Effects 0.000 description 1
- 150000003838 adenosines Chemical class 0.000 description 1
- 230000006838 adverse reaction Effects 0.000 description 1
- 239000000443 aerosol Substances 0.000 description 1
- 229960001686 afatinib Drugs 0.000 description 1
- ULXXDDBFHOBEHA-CWDCEQMOSA-N afatinib Chemical compound N1=CN=C2C=C(O[C@@H]3COCC3)C(NC(=O)/C=C/CN(C)C)=CC2=C1NC1=CC=C(F)C(Cl)=C1 ULXXDDBFHOBEHA-CWDCEQMOSA-N 0.000 description 1
- 230000009824 affinity maturation Effects 0.000 description 1
- 108010081667 aflibercept Proteins 0.000 description 1
- 239000000556 agonist Substances 0.000 description 1
- 229910052783 alkali metal Inorganic materials 0.000 description 1
- 229940100198 alkylating agent Drugs 0.000 description 1
- 239000002168 alkylating agent Substances 0.000 description 1
- 230000000735 allogeneic effect Effects 0.000 description 1
- 230000003281 allosteric effect Effects 0.000 description 1
- 229950007861 alvespimycin Drugs 0.000 description 1
- KUFRQPKVAWMTJO-LMZWQJSESA-N alvespimycin Chemical compound N1C(=O)\C(C)=C\C=C/[C@H](OC)[C@@H](OC(N)=O)\C(C)=C\[C@H](C)[C@@H](O)[C@@H](OC)C[C@H](C)CC2=C(NCCN(C)C)C(=O)C=C1C2=O KUFRQPKVAWMTJO-LMZWQJSESA-N 0.000 description 1
- 230000001668 ameliorated effect Effects 0.000 description 1
- 150000001408 amides Chemical class 0.000 description 1
- 229960001097 amifostine Drugs 0.000 description 1
- JKOQGQFVAUAYPM-UHFFFAOYSA-N amifostine Chemical compound NCCCNCCSP(O)(O)=O JKOQGQFVAUAYPM-UHFFFAOYSA-N 0.000 description 1
- 150000001412 amines Chemical class 0.000 description 1
- 229960001220 amsacrine Drugs 0.000 description 1
- XCPGHVQEEXUHNC-UHFFFAOYSA-N amsacrine Chemical compound COC1=CC(NS(C)(=O)=O)=CC=C1NC1=C(C=CC=C2)C2=NC2=CC=CC=C12 XCPGHVQEEXUHNC-UHFFFAOYSA-N 0.000 description 1
- 229960001694 anagrelide Drugs 0.000 description 1
- OTBXOEAOVRKTNQ-UHFFFAOYSA-N anagrelide Chemical compound N1=C2NC(=O)CN2CC2=C(Cl)C(Cl)=CC=C21 OTBXOEAOVRKTNQ-UHFFFAOYSA-N 0.000 description 1
- 229960002932 anastrozole Drugs 0.000 description 1
- YBBLVLTVTVSKRW-UHFFFAOYSA-N anastrozole Chemical compound N#CC(C)(C)C1=CC(C(C)(C#N)C)=CC(CN2N=CN=C2)=C1 YBBLVLTVTVSKRW-UHFFFAOYSA-N 0.000 description 1
- 238000004873 anchoring Methods 0.000 description 1
- 230000033115 angiogenesis Effects 0.000 description 1
- 239000010775 animal oil Substances 0.000 description 1
- 229940045799 anthracyclines and related substance Drugs 0.000 description 1
- 230000000844 anti-bacterial effect Effects 0.000 description 1
- 230000001093 anti-cancer Effects 0.000 description 1
- 230000003432 anti-folate effect Effects 0.000 description 1
- 230000000340 anti-metabolite Effects 0.000 description 1
- 230000005809 anti-tumor immunity Effects 0.000 description 1
- 229940088710 antibiotic agent Drugs 0.000 description 1
- 229940127074 antifolate Drugs 0.000 description 1
- 229940121375 antifungal agent Drugs 0.000 description 1
- 239000003429 antifungal agent Substances 0.000 description 1
- 239000013059 antihormonal agent Substances 0.000 description 1
- 229940100197 antimetabolite Drugs 0.000 description 1
- 239000002256 antimetabolite Substances 0.000 description 1
- 229940127079 antineoplastic immunimodulatory agent Drugs 0.000 description 1
- 210000000436 anus Anatomy 0.000 description 1
- 239000007900 aqueous suspension Substances 0.000 description 1
- 239000003886 aromatase inhibitor Substances 0.000 description 1
- 229940046844 aromatase inhibitors Drugs 0.000 description 1
- 125000003118 aryl group Chemical group 0.000 description 1
- 108010077245 asparaginyl-proline Proteins 0.000 description 1
- 108010038633 aspartylglutamate Proteins 0.000 description 1
- 229950004810 atamestane Drugs 0.000 description 1
- PEPMWUSGRKINHX-TXTPUJOMSA-N atamestane Chemical compound C1C[C@@H]2[C@@]3(C)C(C)=CC(=O)C=C3CC[C@H]2[C@@H]2CCC(=O)[C@]21C PEPMWUSGRKINHX-TXTPUJOMSA-N 0.000 description 1
- 239000005441 aurora Substances 0.000 description 1
- VSRXQHXAPYXROS-UHFFFAOYSA-N azanide;cyclobutane-1,1-dicarboxylic acid;platinum(2+) Chemical compound [NH2-].[NH2-].[Pt+2].OC(=O)C1(C(O)=O)CCC1 VSRXQHXAPYXROS-UHFFFAOYSA-N 0.000 description 1
- 229950002365 bafetinib Drugs 0.000 description 1
- 229960002938 bexarotene Drugs 0.000 description 1
- 229960000997 bicalutamide Drugs 0.000 description 1
- 201000009036 biliary tract cancer Diseases 0.000 description 1
- 208000020790 biliary tract neoplasm Diseases 0.000 description 1
- 229960002685 biotin Drugs 0.000 description 1
- 235000020958 biotin Nutrition 0.000 description 1
- 239000011616 biotin Substances 0.000 description 1
- 229960001561 bleomycin Drugs 0.000 description 1
- OYVAGSVQBOHSSS-UAPAGMARSA-O bleomycin A2 Chemical compound N([C@H](C(=O)N[C@H](C)[C@@H](O)[C@H](C)C(=O)N[C@@H]([C@H](O)C)C(=O)NCCC=1SC=C(N=1)C=1SC=C(N=1)C(=O)NCCC[S+](C)C)[C@@H](O[C@H]1[C@H]([C@@H](O)[C@H](O)[C@H](CO)O1)O[C@@H]1[C@H]([C@@H](OC(N)=O)[C@H](O)[C@@H](CO)O1)O)C=1N=CNC=1)C(=O)C1=NC([C@H](CC(N)=O)NC[C@H](N)C(N)=O)=NC(N)=C1C OYVAGSVQBOHSSS-UAPAGMARSA-O 0.000 description 1
- 230000037396 body weight Effects 0.000 description 1
- 210000000988 bone and bone Anatomy 0.000 description 1
- 229960001467 bortezomib Drugs 0.000 description 1
- GXJABQQUPOEUTA-RDJZCZTQSA-N bortezomib Chemical compound C([C@@H](C(=O)N[C@@H](CC(C)C)B(O)O)NC(=O)C=1N=CC=NC=1)C1=CC=CC=C1 GXJABQQUPOEUTA-RDJZCZTQSA-N 0.000 description 1
- 229960003736 bosutinib Drugs 0.000 description 1
- UBPYILGKFZZVDX-UHFFFAOYSA-N bosutinib Chemical compound C1=C(Cl)C(OC)=CC(NC=2C3=CC(OC)=C(OCCCN4CCN(C)CC4)C=C3N=CC=2C#N)=C1Cl UBPYILGKFZZVDX-UHFFFAOYSA-N 0.000 description 1
- 210000004556 brain Anatomy 0.000 description 1
- 229960002092 busulfan Drugs 0.000 description 1
- 239000001506 calcium phosphate Substances 0.000 description 1
- 229910000389 calcium phosphate Inorganic materials 0.000 description 1
- 235000011010 calcium phosphates Nutrition 0.000 description 1
- 238000004364 calculation method Methods 0.000 description 1
- 229940022399 cancer vaccine Drugs 0.000 description 1
- 238000009566 cancer vaccine Methods 0.000 description 1
- 230000000711 cancerogenic effect Effects 0.000 description 1
- 229960004117 capecitabine Drugs 0.000 description 1
- 229960004562 carboplatin Drugs 0.000 description 1
- 231100000315 carcinogenic Toxicity 0.000 description 1
- 108010021331 carfilzomib Proteins 0.000 description 1
- BLMPQMFVWMYDKT-NZTKNTHTSA-N carfilzomib Chemical compound C([C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](CC(C)C)C(=O)[C@]1(C)OC1)NC(=O)CN1CCOCC1)CC1=CC=CC=C1 BLMPQMFVWMYDKT-NZTKNTHTSA-N 0.000 description 1
- 229960002438 carfilzomib Drugs 0.000 description 1
- 229960005243 carmustine Drugs 0.000 description 1
- 239000000969 carrier Substances 0.000 description 1
- 239000012876 carrier material Substances 0.000 description 1
- 239000003729 cation exchange resin Substances 0.000 description 1
- 229960002412 cediranib Drugs 0.000 description 1
- 229960000590 celecoxib Drugs 0.000 description 1
- RZEKVGVHFLEQIL-UHFFFAOYSA-N celecoxib Chemical compound C1=CC(C)=CC=C1C1=CC(C(F)(F)F)=NN1C1=CC=C(S(N)(=O)=O)C=C1 RZEKVGVHFLEQIL-UHFFFAOYSA-N 0.000 description 1
- 230000020411 cell activation Effects 0.000 description 1
- 238000000423 cell based assay Methods 0.000 description 1
- 230000003915 cell function Effects 0.000 description 1
- 230000010261 cell growth Effects 0.000 description 1
- 239000013592 cell lysate Substances 0.000 description 1
- 230000004663 cell proliferation Effects 0.000 description 1
- 210000003169 central nervous system Anatomy 0.000 description 1
- 201000010881 cervical cancer Diseases 0.000 description 1
- 210000003679 cervix uteri Anatomy 0.000 description 1
- 108700008462 cetrorelix Proteins 0.000 description 1
- SBNPWPIBESPSIF-MHWMIDJBSA-N cetrorelix Chemical compound C([C@@H](C(=O)N[C@H](CCCNC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N1[C@@H](CCC1)C(=O)N[C@H](C)C(N)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](CC=1C=NC=CC=1)NC(=O)[C@@H](CC=1C=CC(Cl)=CC=1)NC(=O)[C@@H](CC=1C=C2C=CC=CC2=CC=1)NC(C)=O)C1=CC=C(O)C=C1 SBNPWPIBESPSIF-MHWMIDJBSA-N 0.000 description 1
- 229960003230 cetrorelix Drugs 0.000 description 1
- 230000008859 change Effects 0.000 description 1
- 238000012512 characterization method Methods 0.000 description 1
- JXDYOSVKVSQGJM-UHFFFAOYSA-N chembl3109738 Chemical compound N1C2=CC(Br)=CC=C2CN(C)CCCCCOC2=CC3=C1N=CN=C3C=C2OC JXDYOSVKVSQGJM-UHFFFAOYSA-N 0.000 description 1
- PIQCTGMSNWUMAF-UHFFFAOYSA-N chembl522892 Chemical compound C1CN(C)CCN1C1=CC=C(NC(=N2)C=3C(NC4=CC=CC(F)=C4C=3N)=O)C2=C1 PIQCTGMSNWUMAF-UHFFFAOYSA-N 0.000 description 1
- 229960004630 chlorambucil Drugs 0.000 description 1
- JCKYGMPEJWAADB-UHFFFAOYSA-N chlorambucil Chemical compound OC(=O)CCCC1=CC=C(N(CCCl)CCCl)C=C1 JCKYGMPEJWAADB-UHFFFAOYSA-N 0.000 description 1
- 229960004926 chlorobutanol Drugs 0.000 description 1
- 201000005217 chondroblastoma Diseases 0.000 description 1
- 230000001684 chronic effect Effects 0.000 description 1
- 229960004316 cisplatin Drugs 0.000 description 1
- DQLATGHUWYMOKM-UHFFFAOYSA-L cisplatin Chemical compound N[Pt](N)(Cl)Cl DQLATGHUWYMOKM-UHFFFAOYSA-L 0.000 description 1
- 239000007979 citrate buffer Substances 0.000 description 1
- 229960002436 cladribine Drugs 0.000 description 1
- 238000003776 cleavage reaction Methods 0.000 description 1
- BSMCAPRUBJMWDF-KRWDZBQOSA-N cobimetinib Chemical compound C1C(O)([C@H]2NCCCC2)CN1C(=O)C1=CC=C(F)C(F)=C1NC1=CC=C(I)C=C1F BSMCAPRUBJMWDF-KRWDZBQOSA-N 0.000 description 1
- 210000001072 colon Anatomy 0.000 description 1
- 238000002648 combination therapy Methods 0.000 description 1
- 230000009137 competitive binding Effects 0.000 description 1
- 239000002299 complementary DNA Substances 0.000 description 1
- 238000010276 construction Methods 0.000 description 1
- 238000007796 conventional method Methods 0.000 description 1
- 208000017763 cutaneous neuroendocrine carcinoma Diseases 0.000 description 1
- 229940043378 cyclin-dependent kinase inhibitor Drugs 0.000 description 1
- 229960004397 cyclophosphamide Drugs 0.000 description 1
- 229960000978 cyproterone acetate Drugs 0.000 description 1
- UWFYSQMTEOIJJG-FDTZYFLXSA-N cyproterone acetate Chemical compound C1=C(Cl)C2=CC(=O)[C@@H]3C[C@@H]3[C@]2(C)[C@@H]2[C@@H]1[C@@H]1CC[C@@](C(C)=O)(OC(=O)C)[C@@]1(C)CC2 UWFYSQMTEOIJJG-FDTZYFLXSA-N 0.000 description 1
- 125000000151 cysteine group Chemical group N[C@@H](CS)C(=O)* 0.000 description 1
- 229960000684 cytarabine Drugs 0.000 description 1
- 229960003901 dacarbazine Drugs 0.000 description 1
- 229960000640 dactinomycin Drugs 0.000 description 1
- 229960002448 dasatinib Drugs 0.000 description 1
- 229960000975 daunorubicin Drugs 0.000 description 1
- STQGQHZAVUOBTE-VGBVRHCVSA-N daunorubicin Chemical compound O([C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(C)=O)[C@H]1C[C@H](N)[C@H](O)[C@H](C)O1 STQGQHZAVUOBTE-VGBVRHCVSA-N 0.000 description 1
- 230000034994 death Effects 0.000 description 1
- 229960003603 decitabine Drugs 0.000 description 1
- 238000012217 deletion Methods 0.000 description 1
- 230000037430 deletion Effects 0.000 description 1
- 229960001251 denosumab Drugs 0.000 description 1
- 238000001514 detection method Methods 0.000 description 1
- 239000003599 detergent Substances 0.000 description 1
- 238000011161 development Methods 0.000 description 1
- 235000005911 diet Nutrition 0.000 description 1
- 230000037213 diet Effects 0.000 description 1
- UGMCXQCYOVCMTB-UHFFFAOYSA-K dihydroxy(stearato)aluminium Chemical compound CCCCCCCCCCCCCCCCCC(=O)O[Al](O)O UGMCXQCYOVCMTB-UHFFFAOYSA-K 0.000 description 1
- 238000010790 dilution Methods 0.000 description 1
- 239000012895 dilution Substances 0.000 description 1
- 239000000539 dimer Substances 0.000 description 1
- LOKCTEFSRHRXRJ-UHFFFAOYSA-I dipotassium trisodium dihydrogen phosphate hydrogen phosphate dichloride Chemical compound P(=O)(O)(O)[O-].[K+].P(=O)(O)([O-])[O-].[Na+].[Na+].[Cl-].[K+].[Cl-].[Na+] LOKCTEFSRHRXRJ-UHFFFAOYSA-I 0.000 description 1
- 208000037765 diseases and disorders Diseases 0.000 description 1
- 239000002270 dispersing agent Substances 0.000 description 1
- 238000004090 dissolution Methods 0.000 description 1
- 238000009826 distribution Methods 0.000 description 1
- 239000003534 dna topoisomerase inhibitor Substances 0.000 description 1
- 229960003668 docetaxel Drugs 0.000 description 1
- 231100000673 dose–response relationship Toxicity 0.000 description 1
- 229960004679 doxorubicin Drugs 0.000 description 1
- 239000006196 drop Substances 0.000 description 1
- 229940079593 drug Drugs 0.000 description 1
- 230000009977 dual effect Effects 0.000 description 1
- 239000012893 effector ligand Substances 0.000 description 1
- 238000001211 electron capture detection Methods 0.000 description 1
- 238000004520 electroporation Methods 0.000 description 1
- 239000003995 emulsifying agent Substances 0.000 description 1
- 239000000839 emulsion Substances 0.000 description 1
- 210000000750 endocrine system Anatomy 0.000 description 1
- 230000002708 enhancing effect Effects 0.000 description 1
- 230000007613 environmental effect Effects 0.000 description 1
- 229940088598 enzyme Drugs 0.000 description 1
- 229960001904 epirubicin Drugs 0.000 description 1
- 229930013356 epothilone Natural products 0.000 description 1
- HESCAJZNRMSMJG-HGYUPSKWSA-N epothilone A Natural products O=C1[C@H](C)[C@H](O)[C@H](C)CCC[C@H]2O[C@H]2C[C@@H](/C(=C\c2nc(C)sc2)/C)OC(=O)C[C@H](O)C1(C)C HESCAJZNRMSMJG-HGYUPSKWSA-N 0.000 description 1
- HESCAJZNRMSMJG-KKQRBIROSA-N epothilone A Chemical class C/C([C@@H]1C[C@@H]2O[C@@H]2CCC[C@@H]([C@@H]([C@@H](C)C(=O)C(C)(C)[C@@H](O)CC(=O)O1)O)C)=C\C1=CSC(C)=N1 HESCAJZNRMSMJG-KKQRBIROSA-N 0.000 description 1
- QXRSDHAAWVKZLJ-TYFQHMATSA-N epothilone b Chemical compound C/C([C@@H]1C[C@@H]2O[C@@]2(C)CCC[C@@H]([C@H]([C@H](C)C(=O)C(C)(C)[C@H](O)CC(=O)O1)O)C)=C\C1=CSC(C)=N1 QXRSDHAAWVKZLJ-TYFQHMATSA-N 0.000 description 1
- 229960001433 erlotinib Drugs 0.000 description 1
- AAKJLRGGTJKAMG-UHFFFAOYSA-N erlotinib Chemical compound C=12C=C(OCCOC)C(OCCOC)=CC2=NC=NC=1NC1=CC=CC(C#C)=C1 AAKJLRGGTJKAMG-UHFFFAOYSA-N 0.000 description 1
- 210000003238 esophagus Anatomy 0.000 description 1
- 229960001842 estramustine Drugs 0.000 description 1
- FRPJXPJMRWBBIH-RBRWEJTLSA-N estramustine Chemical compound ClCCN(CCCl)C(=O)OC1=CC=C2[C@H]3CC[C@](C)([C@H](CC4)O)[C@@H]4[C@@H]3CCC2=C1 FRPJXPJMRWBBIH-RBRWEJTLSA-N 0.000 description 1
- 238000012869 ethanol precipitation Methods 0.000 description 1
- BEFDCLMNVWHSGT-UHFFFAOYSA-N ethenylcyclopentane Chemical compound C=CC1CCCC1 BEFDCLMNVWHSGT-UHFFFAOYSA-N 0.000 description 1
- 229960005420 etoposide Drugs 0.000 description 1
- VJJPUSNTGOMMGY-MRVIYFEKSA-N etoposide Chemical compound COC1=C(O)C(OC)=CC([C@@H]2C3=CC=4OCOC=4C=C3[C@@H](O[C@H]3[C@@H]([C@@H](O)[C@@H]4O[C@H](C)OC[C@H]4O3)O)[C@@H]3[C@@H]2C(OC3)=O)=C1 VJJPUSNTGOMMGY-MRVIYFEKSA-N 0.000 description 1
- LIQODXNTTZAGID-OCBXBXKTSA-N etoposide phosphate Chemical compound COC1=C(OP(O)(O)=O)C(OC)=CC([C@@H]2C3=CC=4OCOC=4C=C3[C@@H](O[C@H]3[C@@H]([C@@H](O)[C@@H]4O[C@H](C)OC[C@H]4O3)O)[C@@H]3[C@@H]2C(OC3)=O)=C1 LIQODXNTTZAGID-OCBXBXKTSA-N 0.000 description 1
- 229960000752 etoposide phosphate Drugs 0.000 description 1
- OGPBJKLSAFTDLK-UHFFFAOYSA-N europium atom Chemical compound [Eu] OGPBJKLSAFTDLK-UHFFFAOYSA-N 0.000 description 1
- 229960005167 everolimus Drugs 0.000 description 1
- 229960000255 exemestane Drugs 0.000 description 1
- 230000002349 favourable effect Effects 0.000 description 1
- 229950000133 filanesib Drugs 0.000 description 1
- LLXISKGBWFTGEI-FQEVSTJZSA-N filanesib Chemical compound C1([C@]2(CCCN)SC(=NN2C(=O)N(C)OC)C=2C(=CC=C(F)C=2)F)=CC=CC=C1 LLXISKGBWFTGEI-FQEVSTJZSA-N 0.000 description 1
- 229960004039 finasteride Drugs 0.000 description 1
- DBEPLOCGEIEOCV-WSBQPABSSA-N finasteride Chemical compound N([C@@H]1CC2)C(=O)C=C[C@]1(C)[C@@H]1[C@@H]2[C@@H]2CC[C@H](C(=O)NC(C)(C)C)[C@@]2(C)CC1 DBEPLOCGEIEOCV-WSBQPABSSA-N 0.000 description 1
- 230000009969 flowable effect Effects 0.000 description 1
- 229960000390 fludarabine Drugs 0.000 description 1
- GIUYCYHIANZCFB-FJFJXFQQSA-N fludarabine phosphate Chemical compound C1=NC=2C(N)=NC(F)=NC=2N1[C@@H]1O[C@H](COP(O)(O)=O)[C@@H](O)[C@@H]1O GIUYCYHIANZCFB-FJFJXFQQSA-N 0.000 description 1
- 229960002949 fluorouracil Drugs 0.000 description 1
- YLRFCQOZQXIBAB-RBZZARIASA-N fluoxymesterone Chemical compound C1CC2=CC(=O)CC[C@]2(C)[C@]2(F)[C@@H]1[C@@H]1CC[C@](C)(O)[C@@]1(C)C[C@@H]2O YLRFCQOZQXIBAB-RBZZARIASA-N 0.000 description 1
- 229960001751 fluoxymesterone Drugs 0.000 description 1
- IJJVMEJXYNJXOJ-UHFFFAOYSA-N fluquinconazole Chemical compound C=1C=C(Cl)C=C(Cl)C=1N1C(=O)C2=CC(F)=CC=C2N=C1N1C=NC=N1 IJJVMEJXYNJXOJ-UHFFFAOYSA-N 0.000 description 1
- 229960002074 flutamide Drugs 0.000 description 1
- MKXKFYHWDHIYRV-UHFFFAOYSA-N flutamide Chemical compound CC(C)C(=O)NC1=CC=C([N+]([O-])=O)C(C(F)(F)F)=C1 MKXKFYHWDHIYRV-UHFFFAOYSA-N 0.000 description 1
- 239000011888 foil Substances 0.000 description 1
- 239000004052 folic acid antagonist Substances 0.000 description 1
- 229960004421 formestane Drugs 0.000 description 1
- OSVMTWJCGUFAOD-KZQROQTASA-N formestane Chemical compound O=C1CC[C@]2(C)[C@H]3CC[C@](C)(C(CC4)=O)[C@@H]4[C@@H]3CCC2=C1O OSVMTWJCGUFAOD-KZQROQTASA-N 0.000 description 1
- 238000005194 fractionation Methods 0.000 description 1
- 238000013467 fragmentation Methods 0.000 description 1
- 238000006062 fragmentation reaction Methods 0.000 description 1
- 238000004108 freeze drying Methods 0.000 description 1
- 229960002258 fulvestrant Drugs 0.000 description 1
- 108010074605 gamma-Globulins Proteins 0.000 description 1
- 230000002496 gastric effect Effects 0.000 description 1
- 210000001035 gastrointestinal tract Anatomy 0.000 description 1
- 229920000159 gelatin Polymers 0.000 description 1
- 239000008273 gelatin Substances 0.000 description 1
- 235000019322 gelatine Nutrition 0.000 description 1
- 235000011852 gelatine desserts Nutrition 0.000 description 1
- 229960005277 gemcitabine Drugs 0.000 description 1
- SDUQYLNIPVEERB-QPPQHZFASA-N gemcitabine Chemical compound O=C1N=C(N)C=CN1[C@H]1C(F)(F)[C@H](O)[C@@H](CO)O1 SDUQYLNIPVEERB-QPPQHZFASA-N 0.000 description 1
- 238000003197 gene knockdown Methods 0.000 description 1
- 238000012239 gene modification Methods 0.000 description 1
- 230000005017 genetic modification Effects 0.000 description 1
- 235000013617 genetically modified food Nutrition 0.000 description 1
- 239000011521 glass Substances 0.000 description 1
- 229950007540 glesatinib Drugs 0.000 description 1
- 208000005017 glioblastoma Diseases 0.000 description 1
- 108010057083 glutamyl-aspartyl-leucine Proteins 0.000 description 1
- 150000002334 glycols Chemical class 0.000 description 1
- 230000013595 glycosylation Effects 0.000 description 1
- 238000006206 glycosylation reaction Methods 0.000 description 1
- XLXSAKCOAKORKW-UHFFFAOYSA-N gonadorelin Chemical compound C1CCC(C(=O)NCC(N)=O)N1C(=O)C(CCCN=C(N)N)NC(=O)C(CC(C)C)NC(=O)CNC(=O)C(NC(=O)C(CO)NC(=O)C(CC=1C2=CC=CC=C2NC=1)NC(=O)C(CC=1NC=NC=1)NC(=O)C1NC(=O)CC1)CC1=CC=C(O)C=C1 XLXSAKCOAKORKW-UHFFFAOYSA-N 0.000 description 1
- 229960003690 goserelin acetate Drugs 0.000 description 1
- 210000003128 head Anatomy 0.000 description 1
- 201000010536 head and neck cancer Diseases 0.000 description 1
- 208000014829 head and neck neoplasm Diseases 0.000 description 1
- 230000036541 health Effects 0.000 description 1
- 239000003481 heat shock protein 90 inhibitor Substances 0.000 description 1
- 210000002443 helper t lymphocyte Anatomy 0.000 description 1
- 230000002489 hematologic effect Effects 0.000 description 1
- HNDVDQJCIGZPNO-UHFFFAOYSA-N histidine Natural products OC(=O)C(N)CC1=CN=CN1 HNDVDQJCIGZPNO-UHFFFAOYSA-N 0.000 description 1
- 108010025306 histidylleucine Proteins 0.000 description 1
- 229960002193 histrelin Drugs 0.000 description 1
- 108700020746 histrelin Proteins 0.000 description 1
- HHXHVIJIIXKSOE-QILQGKCVSA-N histrelin Chemical compound CCNC(=O)[C@@H]1CCCN1C(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)[C@H](CO)NC(=O)[C@H](CC=1C2=CC=CC=C2NC=1)NC(=O)[C@H](CC=1N=CNC=1)NC(=O)[C@H]1NC(=O)CC1)CC(N=C1)=CN1CC1=CC=CC=C1 HHXHVIJIIXKSOE-QILQGKCVSA-N 0.000 description 1
- 229940088597 hormone Drugs 0.000 description 1
- 239000005556 hormone Substances 0.000 description 1
- 239000003668 hormone analog Substances 0.000 description 1
- 208000027706 hormone receptor-positive breast cancer Diseases 0.000 description 1
- 210000004754 hybrid cell Anatomy 0.000 description 1
- 229950006359 icrucumab Drugs 0.000 description 1
- 229960000908 idarubicin Drugs 0.000 description 1
- 229960001101 ifosfamide Drugs 0.000 description 1
- HOMGKSMUEGBAAB-UHFFFAOYSA-N ifosfamide Chemical compound ClCCNP1(=O)OCCCN1CCCl HOMGKSMUEGBAAB-UHFFFAOYSA-N 0.000 description 1
- 238000005417 image-selected in vivo spectroscopy Methods 0.000 description 1
- 230000002519 immonomodulatory effect Effects 0.000 description 1
- 230000001900 immune effect Effects 0.000 description 1
- 230000036737 immune function Effects 0.000 description 1
- 230000028993 immune response Effects 0.000 description 1
- 238000003018 immunoassay Methods 0.000 description 1
- 229940072221 immunoglobulins Drugs 0.000 description 1
- 229940121354 immunomodulator Drugs 0.000 description 1
- 230000001506 immunosuppresive effect Effects 0.000 description 1
- 238000009169 immunotherapy Methods 0.000 description 1
- 238000000099 in vitro assay Methods 0.000 description 1
- 238000005462 in vivo assay Methods 0.000 description 1
- 230000002779 inactivation Effects 0.000 description 1
- 230000006698 induction Effects 0.000 description 1
- 230000002401 inhibitory effect Effects 0.000 description 1
- 108091008042 inhibitory receptors Proteins 0.000 description 1
- 238000012739 integrated shape imaging system Methods 0.000 description 1
- 230000002452 interceptive effect Effects 0.000 description 1
- 229960003130 interferon gamma Drugs 0.000 description 1
- 238000007918 intramuscular administration Methods 0.000 description 1
- 238000005342 ion exchange Methods 0.000 description 1
- 229960004768 irinotecan Drugs 0.000 description 1
- UWKQSNNFCGGAFS-XIFFEERXSA-N irinotecan Chemical compound C1=C2C(CC)=C3CN(C(C4=C([C@@](C(=O)OC4)(O)CC)C=4)=O)C=4C3=NC2=CC=C1OC(=O)N(CC1)CCC1N1CCCCC1 UWKQSNNFCGGAFS-XIFFEERXSA-N 0.000 description 1
- 239000007951 isotonicity adjuster Substances 0.000 description 1
- 229950007344 ispinesib Drugs 0.000 description 1
- 229960002014 ixabepilone Drugs 0.000 description 1
- FABUFPQFXZVHFB-CFWQTKTJSA-N ixabepilone Chemical compound C/C([C@@H]1C[C@@H]2O[C@]2(C)CCC[C@@H]([C@@H]([C@H](C)C(=O)C(C)(C)[C@H](O)CC(=O)N1)O)C)=C\C1=CSC(C)=N1 FABUFPQFXZVHFB-CFWQTKTJSA-N 0.000 description 1
- 210000003292 kidney cell Anatomy 0.000 description 1
- 229960004891 lapatinib Drugs 0.000 description 1
- BCFGMOOMADDAQU-UHFFFAOYSA-N lapatinib Chemical compound O1C(CNCCS(=O)(=O)C)=CC=C1C1=CC=C(N=CN=C2NC=3C=C(Cl)C(OCC=4C=C(F)C=CC=4)=CC=3)C2=C1 BCFGMOOMADDAQU-UHFFFAOYSA-N 0.000 description 1
- 229950005692 larotaxel Drugs 0.000 description 1
- SEFGUGYLLVNFIJ-QDRLFVHASA-N larotaxel dihydrate Chemical compound O.O.O([C@@H]1[C@@]2(C[C@@H](C(C)=C(C2(C)C)[C@H](C([C@@]23[C@H]1[C@@]1(CO[C@@H]1C[C@@H]2C3)OC(C)=O)=O)OC(=O)C)OC(=O)[C@H](O)[C@@H](NC(=O)OC(C)(C)C)C=1C=CC=CC=1)O)C(=O)C1=CC=CC=C1 SEFGUGYLLVNFIJ-QDRLFVHASA-N 0.000 description 1
- 230000002045 lasting effect Effects 0.000 description 1
- 229960004942 lenalidomide Drugs 0.000 description 1
- GOTYRUGSSMKFNF-UHFFFAOYSA-N lenalidomide Chemical compound C1C=2C(N)=CC=CC=2C(=O)N1C1CCC(=O)NC1=O GOTYRUGSSMKFNF-UHFFFAOYSA-N 0.000 description 1
- 229960003784 lenvatinib Drugs 0.000 description 1
- WOSKHXYHFSIKNG-UHFFFAOYSA-N lenvatinib Chemical compound C=12C=C(C(N)=O)C(OC)=CC2=NC=CC=1OC(C=C1Cl)=CC=C1NC(=O)NC1CC1 WOSKHXYHFSIKNG-UHFFFAOYSA-N 0.000 description 1
- 229960003881 letrozole Drugs 0.000 description 1
- HPJKCIUCZWXJDR-UHFFFAOYSA-N letrozole Chemical compound C1=CC(C#N)=CC=C1C(N1N=CN=C1)C1=CC=C(C#N)C=C1 HPJKCIUCZWXJDR-UHFFFAOYSA-N 0.000 description 1
- 108010034529 leucyl-lysine Proteins 0.000 description 1
- 208000032839 leukemia Diseases 0.000 description 1
- GFIJNRVAKGFPGQ-LIJARHBVSA-N leuprolide Chemical compound CCNC(=O)[C@@H]1CCCN1C(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](CC(C)C)NC(=O)[C@@H](NC(=O)[C@H](CO)NC(=O)[C@H](CC=1C2=CC=CC=C2NC=1)NC(=O)[C@H](CC=1N=CNC=1)NC(=O)[C@H]1NC(=O)CC1)CC1=CC=C(O)C=C1 GFIJNRVAKGFPGQ-LIJARHBVSA-N 0.000 description 1
- 229960004338 leuprorelin Drugs 0.000 description 1
- MPVGZUGXCQEXTM-UHFFFAOYSA-N linifanib Chemical compound CC1=CC=C(F)C(NC(=O)NC=2C=CC(=CC=2)C=2C=3C(N)=NNC=3C=CC=2)=C1 MPVGZUGXCQEXTM-UHFFFAOYSA-N 0.000 description 1
- 210000004185 liver Anatomy 0.000 description 1
- 229960002247 lomustine Drugs 0.000 description 1
- 238000011866 long-term treatment Methods 0.000 description 1
- 201000005296 lung carcinoma Diseases 0.000 description 1
- 208000003747 lymphoid leukemia Diseases 0.000 description 1
- 239000006166 lysate Substances 0.000 description 1
- 108010038320 lysylphenylalanine Proteins 0.000 description 1
- 238000012423 maintenance Methods 0.000 description 1
- 208000015486 malignant pancreatic neoplasm Diseases 0.000 description 1
- 239000000594 mannitol Substances 0.000 description 1
- 235000010355 mannitol Nutrition 0.000 description 1
- 229950001869 mapatumumab Drugs 0.000 description 1
- 239000003550 marker Substances 0.000 description 1
- 108010082117 matrigel Proteins 0.000 description 1
- 229950008001 matuzumab Drugs 0.000 description 1
- 229960004961 mechlorethamine Drugs 0.000 description 1
- HAWPXGHAZFHHAD-UHFFFAOYSA-N mechlorethamine Chemical compound ClCCN(C)CCCl HAWPXGHAZFHHAD-UHFFFAOYSA-N 0.000 description 1
- 229960004616 medroxyprogesterone Drugs 0.000 description 1
- FRQMUZJSZHZSGN-HBNHAYAOSA-N medroxyprogesterone Chemical compound C([C@@]12C)CC(=O)C=C1[C@@H](C)C[C@@H]1[C@@H]2CC[C@]2(C)[C@@](O)(C(C)=O)CC[C@H]21 FRQMUZJSZHZSGN-HBNHAYAOSA-N 0.000 description 1
- 229960004296 megestrol acetate Drugs 0.000 description 1
- RQZAXGRLVPAYTJ-GQFGMJRRSA-N megestrol acetate Chemical compound C1=C(C)C2=CC(=O)CC[C@]2(C)[C@@H]2[C@@H]1[C@@H]1CC[C@@](C(C)=O)(OC(=O)C)[C@@]1(C)CC2 RQZAXGRLVPAYTJ-GQFGMJRRSA-N 0.000 description 1
- 229960001924 melphalan Drugs 0.000 description 1
- SGDBTWWWUNNDEQ-LBPRGKRZSA-N melphalan Chemical compound OC(=O)[C@@H](N)CC1=CC=C(N(CCCl)CCCl)C=C1 SGDBTWWWUNNDEQ-LBPRGKRZSA-N 0.000 description 1
- 201000008806 mesenchymal cell neoplasm Diseases 0.000 description 1
- 229910052751 metal Inorganic materials 0.000 description 1
- 239000002184 metal Substances 0.000 description 1
- 229930182817 methionine Natural products 0.000 description 1
- 229960000485 methotrexate Drugs 0.000 description 1
- 244000005700 microbiome Species 0.000 description 1
- 238000000520 microinjection Methods 0.000 description 1
- 239000002480 mineral oil Substances 0.000 description 1
- 230000033607 mismatch repair Effects 0.000 description 1
- CFCUWKMKBJTWLW-BKHRDMLASA-N mithramycin Chemical compound O([C@@H]1C[C@@H](O[C@H](C)[C@H]1O)OC=1C=C2C=C3C[C@H]([C@@H](C(=O)C3=C(O)C2=C(O)C=1C)O[C@@H]1O[C@H](C)[C@@H](O)[C@H](O[C@@H]2O[C@H](C)[C@H](O)[C@H](O[C@@H]3O[C@H](C)[C@@H](O)[C@@](C)(O)C3)C2)C1)[C@H](OC)C(=O)[C@@H](O)[C@@H](C)O)[C@H]1C[C@@H](O)[C@H](O)[C@@H](C)O1 CFCUWKMKBJTWLW-BKHRDMLASA-N 0.000 description 1
- 239000002829 mitogen activated protein kinase inhibitor Substances 0.000 description 1
- 229960004857 mitomycin Drugs 0.000 description 1
- 229960000350 mitotane Drugs 0.000 description 1
- 230000017205 mitotic cell cycle checkpoint Effects 0.000 description 1
- 229960001156 mitoxantrone Drugs 0.000 description 1
- KKZJGLLVHKMTCM-UHFFFAOYSA-N mitoxantrone Chemical compound O=C1C2=C(O)C=CC(O)=C2C(=O)C2=C1C(NCCNCCO)=CC=C2NCCNCCO KKZJGLLVHKMTCM-UHFFFAOYSA-N 0.000 description 1
- 238000010369 molecular cloning Methods 0.000 description 1
- 239000000178 monomer Substances 0.000 description 1
- 229950003968 motesanib Drugs 0.000 description 1
- RAHBGWKEPAQNFF-UHFFFAOYSA-N motesanib Chemical compound C=1C=C2C(C)(C)CNC2=CC=1NC(=O)C1=CC=CN=C1NCC1=CC=NC=C1 RAHBGWKEPAQNFF-UHFFFAOYSA-N 0.000 description 1
- 210000000214 mouth Anatomy 0.000 description 1
- 210000004400 mucous membrane Anatomy 0.000 description 1
- 208000025113 myeloid leukemia Diseases 0.000 description 1
- LGXVKMDGSIWEHL-UHFFFAOYSA-N n,2-dimethyl-6-[7-(2-morpholin-4-ylethoxy)quinolin-4-yl]oxy-1-benzofuran-3-carboxamide Chemical compound C=1C=C2C(C(=O)NC)=C(C)OC2=CC=1OC(C1=CC=2)=CC=NC1=CC=2OCCN1CCOCC1 LGXVKMDGSIWEHL-UHFFFAOYSA-N 0.000 description 1
- SMFXSYMLJDHGIE-UHFFFAOYSA-N n-(3-aminopropyl)-n-[1-(5-benzyl-3-methyl-4-oxo-[1,2]thiazolo[5,4-d]pyrimidin-6-yl)-2-methylpropyl]-4-methylbenzamide Chemical compound N=1C=2SN=C(C)C=2C(=O)N(CC=2C=CC=CC=2)C=1C(C(C)C)N(CCCN)C(=O)C1=CC=C(C)C=C1 SMFXSYMLJDHGIE-UHFFFAOYSA-N 0.000 description 1
- WPHXYKUPFJRJDK-AHWVRZQESA-N n-[(3s,5s)-1-(1,3-benzodioxol-5-ylmethyl)-5-(piperazine-1-carbonyl)pyrrolidin-3-yl]-n-[(3-methoxyphenyl)methyl]-3,3-dimethylbutanamide Chemical compound COC1=CC=CC(CN([C@@H]2CN(CC=3C=C4OCOC4=CC=3)[C@@H](C2)C(=O)N2CCNCC2)C(=O)CC(C)(C)C)=C1 WPHXYKUPFJRJDK-AHWVRZQESA-N 0.000 description 1
- BLCLNMBMMGCOAS-UHFFFAOYSA-N n-[1-[[1-[[1-[[1-[[1-[[1-[[1-[2-[(carbamoylamino)carbamoyl]pyrrolidin-1-yl]-5-(diaminomethylideneamino)-1-oxopentan-2-yl]amino]-4-methyl-1-oxopentan-2-yl]amino]-3-[(2-methylpropan-2-yl)oxy]-1-oxopropan-2-yl]amino]-3-(4-hydroxyphenyl)-1-oxopropan-2-yl]amin Chemical compound C1CCC(C(=O)NNC(N)=O)N1C(=O)C(CCCN=C(N)N)NC(=O)C(CC(C)C)NC(=O)C(COC(C)(C)C)NC(=O)C(NC(=O)C(CO)NC(=O)C(CC=1C2=CC=CC=C2NC=1)NC(=O)C(CC=1NC=NC=1)NC(=O)C1NC(=O)CC1)CC1=CC=C(O)C=C1 BLCLNMBMMGCOAS-UHFFFAOYSA-N 0.000 description 1
- FDMQDKQUTRLUBU-UHFFFAOYSA-N n-[3-[2-[4-(4-methylpiperazin-1-yl)anilino]thieno[3,2-d]pyrimidin-4-yl]oxyphenyl]prop-2-enamide Chemical compound C1CN(C)CCN1C(C=C1)=CC=C1NC1=NC(OC=2C=C(NC(=O)C=C)C=CC=2)=C(SC=C2)C2=N1 FDMQDKQUTRLUBU-UHFFFAOYSA-N 0.000 description 1
- YRCHYHRCBXNYNU-UHFFFAOYSA-N n-[[3-fluoro-4-[2-[5-[(2-methoxyethylamino)methyl]pyridin-2-yl]thieno[3,2-b]pyridin-7-yl]oxyphenyl]carbamothioyl]-2-(4-fluorophenyl)acetamide Chemical compound N1=CC(CNCCOC)=CC=C1C1=CC2=NC=CC(OC=3C(=CC(NC(=S)NC(=O)CC=4C=CC(F)=CC=4)=CC=3)F)=C2S1 YRCHYHRCBXNYNU-UHFFFAOYSA-N 0.000 description 1
- 239000007922 nasal spray Substances 0.000 description 1
- 210000000822 natural killer cell Anatomy 0.000 description 1
- 210000003739 neck Anatomy 0.000 description 1
- 230000010807 negative regulation of binding Effects 0.000 description 1
- 229950008835 neratinib Drugs 0.000 description 1
- JWNPDZNEKVCWMY-VQHVLOKHSA-N neratinib Chemical compound C=12C=C(NC(=O)\C=C\CN(C)C)C(OCC)=CC2=NC=C(C#N)C=1NC(C=C1Cl)=CC=C1OCC1=CC=CC=N1 JWNPDZNEKVCWMY-VQHVLOKHSA-N 0.000 description 1
- 230000001272 neurogenic effect Effects 0.000 description 1
- 230000003472 neutralizing effect Effects 0.000 description 1
- 229960002653 nilutamide Drugs 0.000 description 1
- XWXYUMMDTVBTOU-UHFFFAOYSA-N nilutamide Chemical compound O=C1C(C)(C)NC(=O)N1C1=CC=C([N+]([O-])=O)C(C(F)(F)F)=C1 XWXYUMMDTVBTOU-UHFFFAOYSA-N 0.000 description 1
- 229950010203 nimotuzumab Drugs 0.000 description 1
- 229960004378 nintedanib Drugs 0.000 description 1
- XZXHXSATPCNXJR-ZIADKAODSA-N nintedanib Chemical compound O=C1NC2=CC(C(=O)OC)=CC=C2\C1=C(C=1C=CC=CC=1)\NC(C=C1)=CC=C1N(C)C(=O)CN1CCN(C)CC1 XZXHXSATPCNXJR-ZIADKAODSA-N 0.000 description 1
- OSTGTTZJOCZWJG-UHFFFAOYSA-N nitrosourea Chemical compound NC(=O)N=NO OSTGTTZJOCZWJG-UHFFFAOYSA-N 0.000 description 1
- 230000009871 nonspecific binding Effects 0.000 description 1
- 229960002700 octreotide Drugs 0.000 description 1
- 229960002450 ofatumumab Drugs 0.000 description 1
- 239000003921 oil Substances 0.000 description 1
- 235000019198 oils Nutrition 0.000 description 1
- 229950008516 olaratumab Drugs 0.000 description 1
- 229950000778 olmutinib Drugs 0.000 description 1
- 238000001543 one-way ANOVA Methods 0.000 description 1
- 229960003278 osimertinib Drugs 0.000 description 1
- DUYJMQONPNNFPI-UHFFFAOYSA-N osimertinib Chemical compound COC1=CC(N(C)CCN(C)C)=C(NC(=O)C=C)C=C1NC1=NC=CC(C=2C3=CC=CC=C3N(C)C=2)=N1 DUYJMQONPNNFPI-UHFFFAOYSA-N 0.000 description 1
- 201000008968 osteosarcoma Diseases 0.000 description 1
- 210000001672 ovary Anatomy 0.000 description 1
- 229960001756 oxaliplatin Drugs 0.000 description 1
- DWAFYCQODLXJNR-BNTLRKBRSA-L oxaliplatin Chemical compound O1C(=O)C(=O)O[Pt]11N[C@@H]2CCCC[C@H]2N1 DWAFYCQODLXJNR-BNTLRKBRSA-L 0.000 description 1
- 229960001592 paclitaxel Drugs 0.000 description 1
- 201000002528 pancreatic cancer Diseases 0.000 description 1
- 208000008443 pancreatic carcinoma Diseases 0.000 description 1
- 229960001972 panitumumab Drugs 0.000 description 1
- 238000007911 parenteral administration Methods 0.000 description 1
- 239000002245 particle Substances 0.000 description 1
- 229950007460 patupilone Drugs 0.000 description 1
- 239000000312 peanut oil Substances 0.000 description 1
- 230000006320 pegylation Effects 0.000 description 1
- 229960005079 pemetrexed Drugs 0.000 description 1
- QOFFJEBXNKRSPX-ZDUSSCGKSA-N pemetrexed Chemical compound C1=N[C]2NC(N)=NC(=O)C2=C1CCC1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 QOFFJEBXNKRSPX-ZDUSSCGKSA-N 0.000 description 1
- 229960002340 pentostatin Drugs 0.000 description 1
- FPVKHBSQESCIEP-JQCXWYLXSA-N pentostatin Chemical compound C1[C@H](O)[C@@H](CO)O[C@H]1N1C(N=CNC[C@H]2O)=C2N=C1 FPVKHBSQESCIEP-JQCXWYLXSA-N 0.000 description 1
- SZFPYBIJACMNJV-UHFFFAOYSA-N perifosine Chemical compound CCCCCCCCCCCCCCCCCCOP([O-])(=O)OC1CC[N+](C)(C)CC1 SZFPYBIJACMNJV-UHFFFAOYSA-N 0.000 description 1
- 229950010632 perifosine Drugs 0.000 description 1
- 229960002087 pertuzumab Drugs 0.000 description 1
- 239000008177 pharmaceutical agent Substances 0.000 description 1
- 239000000825 pharmaceutical preparation Substances 0.000 description 1
- 239000002831 pharmacologic agent Substances 0.000 description 1
- 210000003800 pharynx Anatomy 0.000 description 1
- 229960003742 phenol Drugs 0.000 description 1
- 108010070409 phenylalanyl-glycyl-glycine Proteins 0.000 description 1
- 229960004403 pixantrone Drugs 0.000 description 1
- PEZPMAYDXJQYRV-UHFFFAOYSA-N pixantrone Chemical compound O=C1C2=CN=CC=C2C(=O)C2=C1C(NCCN)=CC=C2NCCN PEZPMAYDXJQYRV-UHFFFAOYSA-N 0.000 description 1
- 230000036470 plasma concentration Effects 0.000 description 1
- 239000013612 plasmid Substances 0.000 description 1
- 239000004033 plastic Substances 0.000 description 1
- 150000003057 platinum Chemical class 0.000 description 1
- 229960003171 plicamycin Drugs 0.000 description 1
- 235000010482 polyoxyethylene sorbitan monooleate Nutrition 0.000 description 1
- 229920000136 polysorbate Polymers 0.000 description 1
- 229950008882 polysorbate Drugs 0.000 description 1
- 229940068977 polysorbate 20 Drugs 0.000 description 1
- 229920000053 polysorbate 80 Polymers 0.000 description 1
- UVSMNLNDYGZFPF-UHFFFAOYSA-N pomalidomide Chemical compound O=C1C=2C(N)=CC=CC=2C(=O)N1C1CCC(=O)NC1=O UVSMNLNDYGZFPF-UHFFFAOYSA-N 0.000 description 1
- 238000001556 precipitation Methods 0.000 description 1
- 239000003755 preservative agent Substances 0.000 description 1
- 230000002335 preservative effect Effects 0.000 description 1
- 229960000624 procarbazine Drugs 0.000 description 1
- CPTBDICYNRMXFX-UHFFFAOYSA-N procarbazine Chemical compound CNNCC1=CC=C(C(=O)NC(C)C)C=C1 CPTBDICYNRMXFX-UHFFFAOYSA-N 0.000 description 1
- 230000000750 progressive effect Effects 0.000 description 1
- 210000001236 prokaryotic cell Anatomy 0.000 description 1
- 108010029020 prolylglycine Proteins 0.000 description 1
- 238000011321 prophylaxis Methods 0.000 description 1
- 210000002307 prostate Anatomy 0.000 description 1
- 239000003207 proteasome inhibitor Substances 0.000 description 1
- 238000001742 protein purification Methods 0.000 description 1
- 238000001273 protein sequence alignment Methods 0.000 description 1
- 230000002797 proteolythic effect Effects 0.000 description 1
- 210000001938 protoplast Anatomy 0.000 description 1
- 150000003230 pyrimidines Chemical class 0.000 description 1
- WOQIDNWTQOYDLF-RPWUZVMVSA-N quarfloxin Chemical group CN1CCC[C@H]1CCNC(=O)C(C1=O)=CN2C3=C1C=C(F)C(N1C[C@@H](CC1)C=1N=CC=NC=1)=C3OC1=CC3=CC=CC=C3C=C12 WOQIDNWTQOYDLF-RPWUZVMVSA-N 0.000 description 1
- 229960004622 raloxifene Drugs 0.000 description 1
- GZUITABIAKMVPG-UHFFFAOYSA-N raloxifene Chemical compound C1=CC(O)=CC=C1C1=C(C(=O)C=2C=CC(OCCN3CCCCC3)=CC=2)C2=CC=C(O)C=C2S1 GZUITABIAKMVPG-UHFFFAOYSA-N 0.000 description 1
- 229960002633 ramucirumab Drugs 0.000 description 1
- 230000007420 reactivation Effects 0.000 description 1
- 229940044601 receptor agonist Drugs 0.000 description 1
- 239000000018 receptor agonist Substances 0.000 description 1
- 229940075993 receptor modulator Drugs 0.000 description 1
- 102000005962 receptors Human genes 0.000 description 1
- 108020003175 receptors Proteins 0.000 description 1
- 206010038038 rectal cancer Diseases 0.000 description 1
- 201000001275 rectum cancer Diseases 0.000 description 1
- 230000009467 reduction Effects 0.000 description 1
- 238000011160 research Methods 0.000 description 1
- OAKGNIRUXAZDQF-TXHRRWQRSA-N retaspimycin Chemical compound N1C(=O)\C(C)=C\C=C/[C@H](OC)[C@@H](OC(N)=O)\C(C)=C\[C@H](C)[C@@H](O)[C@@H](OC)C[C@H](C)CC2=C(O)C1=CC(O)=C2NCC=C OAKGNIRUXAZDQF-TXHRRWQRSA-N 0.000 description 1
- 238000004007 reversed phase HPLC Methods 0.000 description 1
- 201000009410 rhabdomyosarcoma Diseases 0.000 description 1
- 229960004641 rituximab Drugs 0.000 description 1
- 150000003839 salts Chemical class 0.000 description 1
- 229950009919 saracatinib Drugs 0.000 description 1
- OUKYUETWWIPKQR-UHFFFAOYSA-N saracatinib Chemical compound C1CN(C)CCN1CCOC1=CC(OC2CCOCC2)=C(C(NC=2C(=CC=C3OCOC3=2)Cl)=NC=N2)C2=C1 OUKYUETWWIPKQR-UHFFFAOYSA-N 0.000 description 1
- 229960005399 satraplatin Drugs 0.000 description 1
- 190014017285 satraplatin Chemical compound 0.000 description 1
- 238000012216 screening Methods 0.000 description 1
- 230000003248 secreting effect Effects 0.000 description 1
- CYOHGALHFOKKQC-UHFFFAOYSA-N selumetinib Chemical compound OCCONC(=O)C=1C=C2N(C)C=NC2=C(F)C=1NC1=CC=C(Br)C=C1Cl CYOHGALHFOKKQC-UHFFFAOYSA-N 0.000 description 1
- 230000035945 sensitivity Effects 0.000 description 1
- 239000000377 silicon dioxide Substances 0.000 description 1
- 210000003491 skin Anatomy 0.000 description 1
- 210000000813 small intestine Anatomy 0.000 description 1
- 239000001632 sodium acetate Substances 0.000 description 1
- 235000017281 sodium acetate Nutrition 0.000 description 1
- 239000002904 solvent Substances 0.000 description 1
- 229960003787 sorafenib Drugs 0.000 description 1
- 229960000487 sorafenib tosylate Drugs 0.000 description 1
- IVDHYUQIDRJSTI-UHFFFAOYSA-N sorafenib tosylate Chemical compound [H+].CC1=CC=C(S([O-])(=O)=O)C=C1.C1=NC(C(=O)NC)=CC(OC=2C=CC(NC(=O)NC=3C=C(C(Cl)=CC=3)C(F)(F)F)=CC=2)=C1 IVDHYUQIDRJSTI-UHFFFAOYSA-N 0.000 description 1
- 239000004334 sorbic acid Substances 0.000 description 1
- 229940075582 sorbic acid Drugs 0.000 description 1
- 235000010199 sorbic acid Nutrition 0.000 description 1
- 235000012424 soybean oil Nutrition 0.000 description 1
- 239000003549 soybean oil Substances 0.000 description 1
- 230000009870 specific binding Effects 0.000 description 1
- 239000007921 spray Substances 0.000 description 1
- 230000010473 stable expression Effects 0.000 description 1
- 238000000528 statistical test Methods 0.000 description 1
- 239000008174 sterile solution Substances 0.000 description 1
- 239000008223 sterile water Substances 0.000 description 1
- 230000001954 sterilising effect Effects 0.000 description 1
- 238000004659 sterilization and disinfection Methods 0.000 description 1
- 238000003860 storage Methods 0.000 description 1
- 229960001052 streptozocin Drugs 0.000 description 1
- ZSJLQEPLLKMAKR-GKHCUFPYSA-N streptozocin Chemical compound O=NN(C)C(=O)N[C@H]1[C@@H](O)O[C@H](CO)[C@@H](O)[C@@H]1O ZSJLQEPLLKMAKR-GKHCUFPYSA-N 0.000 description 1
- 239000006190 sub-lingual tablet Substances 0.000 description 1
- 238000010254 subcutaneous injection Methods 0.000 description 1
- 239000007929 subcutaneous injection Substances 0.000 description 1
- 239000008362 succinate buffer Substances 0.000 description 1
- 239000005720 sucrose Substances 0.000 description 1
- 150000005846 sugar alcohols Polymers 0.000 description 1
- 239000000829 suppository Substances 0.000 description 1
- 239000004094 surface-active agent Substances 0.000 description 1
- 239000000725 suspension Substances 0.000 description 1
- 229960001603 tamoxifen Drugs 0.000 description 1
- 229950007866 tanespimycin Drugs 0.000 description 1
- AYUNIORJHRXIBJ-TXHRRWQRSA-N tanespimycin Chemical compound N1C(=O)\C(C)=C\C=C/[C@H](OC)[C@@H](OC(N)=O)\C(C)=C\[C@H](C)[C@@H](O)[C@@H](OC)C[C@H](C)CC2=C(NCC=C)C(=O)C=C1C2=O AYUNIORJHRXIBJ-TXHRRWQRSA-N 0.000 description 1
- 230000008685 targeting Effects 0.000 description 1
- RCINICONZNJXQF-MZXODVADSA-N taxol Chemical compound O([C@@H]1[C@@]2(C[C@@H](C(C)=C(C2(C)C)[C@H](C([C@]2(C)[C@@H](O)C[C@H]3OC[C@]3([C@H]21)OC(C)=O)=O)OC(=O)C)OC(=O)[C@H](O)[C@@H](NC(=O)C=1C=CC=CC=1)C=1C=CC=CC=1)O)C(=O)C1=CC=CC=C1 RCINICONZNJXQF-MZXODVADSA-N 0.000 description 1
- 229950004186 telatinib Drugs 0.000 description 1
- 229960004964 temozolomide Drugs 0.000 description 1
- 229960000235 temsirolimus Drugs 0.000 description 1
- QFJCIRLUMZQUOT-UHFFFAOYSA-N temsirolimus Natural products C1CC(O)C(OC)CC1CC(C)C1OC(=O)C2CCCCN2C(=O)C(=O)C(O)(O2)C(C)CCC2CC(OC)C(C)=CC=CC=CC(C)CC(C)C(=O)C(OC)C(O)C(C)=CC(C)C(=O)C1 QFJCIRLUMZQUOT-UHFFFAOYSA-N 0.000 description 1
- NRUKOCRGYNPUPR-QBPJDGROSA-N teniposide Chemical compound COC1=C(O)C(OC)=CC([C@@H]2C3=CC=4OCOC=4C=C3[C@@H](O[C@H]3[C@@H]([C@@H](O)[C@@H]4O[C@@H](OC[C@H]4O3)C=3SC=CC=3)O)[C@@H]3[C@@H]2C(OC3)=O)=C1 NRUKOCRGYNPUPR-QBPJDGROSA-N 0.000 description 1
- 229960001278 teniposide Drugs 0.000 description 1
- 201000003120 testicular cancer Diseases 0.000 description 1
- 238000012360 testing method Methods 0.000 description 1
- 229960003433 thalidomide Drugs 0.000 description 1
- 229960001196 thiotepa Drugs 0.000 description 1
- 108010061238 threonyl-glycine Proteins 0.000 description 1
- 229940044693 topoisomerase inhibitor Drugs 0.000 description 1
- 229960000303 topotecan Drugs 0.000 description 1
- UCFGDBYHRUNTLO-QHCPKHFHSA-N topotecan Chemical compound C1=C(O)C(CN(C)C)=C2C=C(CN3C4=CC5=C(C3=O)COC(=O)[C@]5(O)CC)C4=NC2=C1 UCFGDBYHRUNTLO-QHCPKHFHSA-N 0.000 description 1
- 229960005026 toremifene Drugs 0.000 description 1
- XFCLJVABOIYOMF-QPLCGJKRSA-N toremifene Chemical compound C1=CC(OCCN(C)C)=CC=C1C(\C=1C=CC=CC=1)=C(\CCCl)C1=CC=CC=C1 XFCLJVABOIYOMF-QPLCGJKRSA-N 0.000 description 1
- 239000003053 toxin Substances 0.000 description 1
- 231100000765 toxin Toxicity 0.000 description 1
- 238000003151 transfection method Methods 0.000 description 1
- 239000012581 transferrin Substances 0.000 description 1
- 230000009261 transgenic effect Effects 0.000 description 1
- 230000010474 transient expression Effects 0.000 description 1
- 238000012384 transportation and delivery Methods 0.000 description 1
- 229960000575 trastuzumab Drugs 0.000 description 1
- QORWJWZARLRLPR-UHFFFAOYSA-H tricalcium bis(phosphate) Chemical compound [Ca+2].[Ca+2].[Ca+2].[O-]P([O-])([O-])=O.[O-]P([O-])([O-])=O QORWJWZARLRLPR-UHFFFAOYSA-H 0.000 description 1
- 208000022679 triple-negative breast carcinoma Diseases 0.000 description 1
- 208000036907 triple-positive breast carcinoma Diseases 0.000 description 1
- VXKHXGOKWPXYNA-PGBVPBMZSA-N triptorelin Chemical compound C([C@@H](C(=O)N[C@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N1[C@@H](CCC1)C(=O)NCC(N)=O)NC(=O)[C@H](CO)NC(=O)[C@H](CC=1C2=CC=CC=C2NC=1)NC(=O)[C@H](CC=1N=CNC=1)NC(=O)[C@H]1NC(=O)CC1)C1=CC=C(O)C=C1 VXKHXGOKWPXYNA-PGBVPBMZSA-N 0.000 description 1
- 229960004824 triptorelin Drugs 0.000 description 1
- 230000036269 ulceration Effects 0.000 description 1
- 241001430294 unidentified retrovirus Species 0.000 description 1
- 238000001291 vacuum drying Methods 0.000 description 1
- 229950000578 vatalanib Drugs 0.000 description 1
- YCOYDOIWSSHVCK-UHFFFAOYSA-N vatalanib Chemical compound C1=CC(Cl)=CC=C1NC(C1=CC=CC=C11)=NN=C1CC1=CC=NC=C1 YCOYDOIWSSHVCK-UHFFFAOYSA-N 0.000 description 1
- 235000015112 vegetable and seed oil Nutrition 0.000 description 1
- 239000008158 vegetable oil Substances 0.000 description 1
- 229960003862 vemurafenib Drugs 0.000 description 1
- GPXBXXGIAQBQNI-UHFFFAOYSA-N vemurafenib Chemical compound CCCS(=O)(=O)NC1=CC=C(F)C(C(=O)C=2C3=CC(=CN=C3NC=2)C=2C=CC(Cl)=CC=2)=C1F GPXBXXGIAQBQNI-UHFFFAOYSA-N 0.000 description 1
- 229960003048 vinblastine Drugs 0.000 description 1
- JXLYSJRDGCGARV-XQKSVPLYSA-N vincaleukoblastine Chemical compound C([C@@H](C[C@]1(C(=O)OC)C=2C(=CC3=C([C@]45[C@H]([C@@]([C@H](OC(C)=O)[C@]6(CC)C=CCN([C@H]56)CC4)(O)C(=O)OC)N3C)C=2)OC)C[C@@](C2)(O)CC)N2CCC2=C1NC1=CC=CC=C21 JXLYSJRDGCGARV-XQKSVPLYSA-N 0.000 description 1
- 229960004528 vincristine Drugs 0.000 description 1
- OGWKCGZFUXNPDA-XQKSVPLYSA-N vincristine Chemical compound C([N@]1C[C@@H](C[C@]2(C(=O)OC)C=3C(=CC4=C([C@]56[C@H]([C@@]([C@H](OC(C)=O)[C@]7(CC)C=CCN([C@H]67)CC5)(O)C(=O)OC)N4C=O)C=3)OC)C[C@@](C1)(O)CC)CC1=C2NC2=CC=CC=C12 OGWKCGZFUXNPDA-XQKSVPLYSA-N 0.000 description 1
- OGWKCGZFUXNPDA-UHFFFAOYSA-N vincristine Natural products C1C(CC)(O)CC(CC2(C(=O)OC)C=3C(=CC4=C(C56C(C(C(OC(C)=O)C7(CC)C=CCN(C67)CC5)(O)C(=O)OC)N4C=O)C=3)OC)CN1CCC1=C2NC2=CC=CC=C12 OGWKCGZFUXNPDA-UHFFFAOYSA-N 0.000 description 1
- NMDYYWFGPIMTKO-HBVLKOHWSA-N vinflunine Chemical compound C([C@@](C1=C(C2=CC=CC=C2N1)C1)(C2=C(OC)C=C3N(C)[C@@H]4[C@@]5(C3=C2)CCN2CC=C[C@]([C@@H]52)([C@H]([C@]4(O)C(=O)OC)OC(C)=O)CC)C(=O)OC)[C@H]2C[C@@H](C(C)(F)F)CN1C2 NMDYYWFGPIMTKO-HBVLKOHWSA-N 0.000 description 1
- 229960000922 vinflunine Drugs 0.000 description 1
- GBABOYUKABKIAF-GHYRFKGUSA-N vinorelbine Chemical compound C1N(CC=2C3=CC=CC=C3NC=22)CC(CC)=C[C@H]1C[C@]2(C(=O)OC)C1=CC([C@]23[C@H]([C@]([C@H](OC(C)=O)[C@]4(CC)C=CCN([C@H]34)CC2)(O)C(=O)OC)N2C)=C2C=C1OC GBABOYUKABKIAF-GHYRFKGUSA-N 0.000 description 1
- 229960002066 vinorelbine Drugs 0.000 description 1
- 239000013603 viral vector Substances 0.000 description 1
- 230000000007 visual effect Effects 0.000 description 1
- 229950009002 zanolimumab Drugs 0.000 description 1
Images
















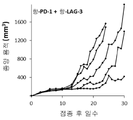





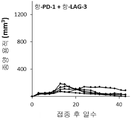
Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2803—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/395—Antibodies; Immunoglobulins; Immune serum, e.g. antilymphocytic serum
- A61K39/39533—Antibodies; Immunoglobulins; Immune serum, e.g. antilymphocytic serum against materials from animals
- A61K39/3955—Antibodies; Immunoglobulins; Immune serum, e.g. antilymphocytic serum against materials from animals against proteinaceous materials, e.g. enzymes, hormones, lymphokines
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K45/00—Medicinal preparations containing active ingredients not provided for in groups A61K31/00 - A61K41/00
- A61K45/06—Mixtures of active ingredients without chemical characterisation, e.g. antiphlogistics and cardiaca
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P43/00—Drugs for specific purposes, not provided for in groups A61P1/00-A61P41/00
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2803—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily
- C07K16/2818—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily against CD28 or CD152
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2803—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily
- C07K16/2827—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily against B7 molecules, e.g. CD80, CD86
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/79—Vectors or expression systems specially adapted for eukaryotic hosts
- C12N15/85—Vectors or expression systems specially adapted for eukaryotic hosts for animal cells
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/505—Medicinal preparations containing antigens or antibodies comprising antibodies
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/505—Medicinal preparations containing antigens or antibodies comprising antibodies
- A61K2039/507—Comprising a combination of two or more separate antibodies
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/20—Immunoglobulins specific features characterized by taxonomic origin
- C07K2317/24—Immunoglobulins specific features characterized by taxonomic origin containing regions, domains or residues from different species, e.g. chimeric, humanized or veneered
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/30—Immunoglobulins specific features characterized by aspects of specificity or valency
- C07K2317/34—Identification of a linear epitope shorter than 20 amino acid residues or of a conformational epitope defined by amino acid residues
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/52—Constant or Fc region; Isotype
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/56—Immunoglobulins specific features characterized by immunoglobulin fragments variable (Fv) region, i.e. VH and/or VL
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/56—Immunoglobulins specific features characterized by immunoglobulin fragments variable (Fv) region, i.e. VH and/or VL
- C07K2317/565—Complementarity determining region [CDR]
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/73—Inducing cell death, e.g. apoptosis, necrosis or inhibition of cell proliferation
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/76—Antagonist effect on antigen, e.g. neutralization or inhibition of binding
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/90—Immunoglobulins specific features characterized by (pharmaco)kinetic aspects or by stability of the immunoglobulin
- C07K2317/92—Affinity (KD), association rate (Ka), dissociation rate (Kd) or EC50 value
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2800/00—Nucleic acids vectors
- C12N2800/10—Plasmid DNA
- C12N2800/106—Plasmid DNA for vertebrates
- C12N2800/107—Plasmid DNA for vertebrates for mammalian
Abstract
본 발명은 신규한 항-PD1 및 항-LAG3 항체 분자에 관한 것이다. 본 발명은 또한 상기 항체 분자를 코딩하는 핵산; 그러한 항체 분자를 제조하는 방법; 이러한 항체 분자를 발현하거나 발현할 수 있는 숙주 세포; 그러한 항체 분자를 포함하는 조성물; 및 그러한 항체 분자 또는 조성물의 용도, 특히 암 질환 분야의 치료 목적을 위한 그의 용도에 관한 것이다.
Description
본 발명은 신규한 항-PD1 및 항-LAG3 항체 분자에 관한 것이다. 본 발명은 또한 상기 항체 분자를 코딩하는 핵산; 그러한 항체 분자를 제조하는 방법; 이러한 항체 분자를 발현하거나 발현할 수 있는 숙주 세포; 그러한 항체 분자를 포함하는 조성물; 및 그러한 항체 분자 또는 조성물의 용도, 특히 암 질환 분야의 치료 목적을 위한 그의 용도에 관한 것이다.
암은 신체 전체로 퍼질 가능성이 있는 비정상의 국소적인 세포 성장을 특징으로 하는 질환이다. 선진국에서는 두 번째로 흔한 사망 원인이다. 남성에서 가장 흔한 암 유형은 폐암, 전립선암, 결장직장암 및 위암이며 여성에서 가장 흔한 유형은 유방암, 결장직장암, 폐암 및 자궁경부암이다. 생존의 기회는 주로 암의 유형과 확인 단계에 달려있지만, 폐암의 경우는 전체 10년 생존율이 5% 정도이다.
과거 종양 암을 치료하는 가장 흔한 수단 (종양학)은 수술, 방사선 치료 또는 화학요법 약물의 사용이었다. 그러나, 최근에 암 면역요법이 종양학의 치료법으로서 많은 가능성을 제시하는 것으로 입증되었다.
암 면역요법은 종양이 직접 절제되거나 치료되는 기존의 일반적인 치료 방법과는 아주 대조적으로 암 치료에 면역계가 사용되는 종양학의 한 분야이다. 이 치료 개념은 이들 세포의 면역 기능을 저해하도록 작용하는 T 세포의 표면에 있는 많은 단백질의 동정에 기초한다. 이 단백질 중에 PD1이 있다.
PD1 (예정된 세포사 (Programmed cell death) 1)은 T 세포에서 발현되는 세포 표면 수용체 단백질이다. 단백질은 "면역 체크포인트 (immun checkpoint)" 억제제로서 기능하며, 즉 면역계에서 세포의 활성을 조절하여 자가면역 질환을 조절 및 제한한다. 최근 많은 암이 "면역 체크포인트" 억제제를 변형시킴으로써 면역계로부터 스스로를 보호하여 검출을 피할 수 있는 것으로 이해되고 있다.
PD1과 관련하여, 이 단백질은 세포 표면 수용체와 상호 작용하는 두개의 리간드 PD-L1 및 PD-L2를 갖는다. 결합시, PD-1은 T-세포 반응을 음성적으로 조절하는 세포 내 신호를 유도한다.
상기에서 상세히 설명한 바와 같이, PD1은 T-세포 활성의 중요한 조절 인자이다. 최근 여러 종류의 상이한 암세포에서 길항적 PD-1 항체 분자인 니볼루맵과 펨브롤리주맵이 면역계를 자극하여 암을 치료할 수 있다는 것이 밝혀졌다.
림프구 활성화 유전자-3 (LAG3; CD223)은 활성화된 T 세포의 세포 표면에서 주로 발현되지만, NK 및 수지상 세포의 서브세트에서도 발견되는 타입 Ⅰ 막관통 단백질이다. LAG3는 T 헬퍼 세포 활성화를 위한 공동 수용체인 CD4와 밀접한 관련이 있다. 두 분자는 4개의 세포 외 Ig-유사 도메인을 가지며 그의 기능적 활성화를 위해 그의 리간드인 주요 조직적합성 복합체 (MHC) 클래스 II와의 결합을 필요로 한다. MHC-II에 결합할 때, LAG3은 T-세포 반응을 음성적으로 조절하는 세포 내 신호를 유도한다. 최근 연구에 따르면 LAG3와 PD1이 종양 침윤 림프구 (tumor infiltrating lymphocyte, TIL)에서 공동 발현되어 종양 매개성 면역 억제에 기여할 수 있다고 한다. 항원에 만성적으로 노출되면 "고갈"이라는 과정을 통해 T 세포가 점진적인 불활성화에 이를 것으로 생각된다. 고갈된 T 세포는 종종 PD1 및 LAG3과 같은 음성 조절 수용체를 공동 발현한다.
PD1 길항성 모노클로날 항체인 니볼루맵과 펨브롤리주맵의 임상 결과가 고무적이지만, 치료 환자의 70% 이하는 치료에 반응하지 않았다. 동종의 종양 마우스 모델뿐만 아니라 환자 유래 T 세포에서의 전임상 데이터는 종양 유래 T 세포가 PD1 이외에 다른 억제 수용체를 종종 발현한다는 것을 입증하였다. 길항성 모노클로날 항체 분자를 이용한 PD1 및 LAG3의 중화 결합은 시험관 내 및 생체 내 모델에서 PD1 중화 단독에 비해 T 세포의 재활성화를 증가시키고 종양 거부를 향상시켰다. 이러한 결과에 기초하여, LAG3의 중화가 길항적 PD1 mAb의 효능을 향상시킬 것으로 기대된다.
그러나, 기존의 항-PD1 항체 분자는 많은 수의 환자가 치료에 반응하지 않는다는 문제점을 안고 있다. 따라서, 단독으로 또는 다른 치료 분자, 특히 추가의 T-세포 체크포인트 억제제에 대한 추가적인 길항 분자와 조합하여 사용되는 경우, 기존의 선행 항체 약제와 비교할 때, 관리가능한 부작용 프로파일을 갖는 보다 효과적인 PD1 길항성 모노클로날 항체를 동정하는 것이 필요하다.
이러한 배경에서, 본 발명자들은 공지 분자에 비해 개선된 치료 프로파일을 가지는 추가의 항-PD1 및 항-LAG3 항체를 생성하고자 하였다.
발명의 개요
제1 측면에 따라, 항-PD1 항체 분자가 제공된다. 본원에 추가로 기재된 바와 같이, 본 발명의 항-PD1 항체 분자는 다른 항-PD1 항체에 비해 놀랍고 유리한 성질을 갖는다. 특히, 이들은 기준 항-PD1 항체 분자보다 더 긴 종말 반감기와 개선된 T 세포 활성화를 입증한다. 인식할 수 있는 바와 같이, 이러한 특성은 암을 치료하는데 사용하기 위한 항-PD1 항체 분자에 바람직하다.
항-PD1 항체 분자를 코딩하는 핵산 분자, 발현 벡터, 숙주 세포 및 본 발명의 항-PD1 항체 분자의 제조 방법이 또한 제공된다. 본 발명의 항-PD1 항체 분자를 포함하는 약학적 조성물도 제공된다. 본원에 개시된 항-PD-1 항체 분자는 고형 및 연조직 종양을 비롯한 암성 질병을 치료하는데 사용될 수 있다.
보다 구체적으로, 본 발명의 항-PD1 항체 분자는 (a) 서열번호 1 (hcCDR1), 서열번호 2 (hcCDR2) 및 서열번호 3 (hcCDR3)의 아미노산 서열을 포함하는 중쇄 CDR 및 서열번호 4 (lcCDR1), 서열번호 5 (lcCDR2) 및 서열번호 6 (lcCDR3)의 아미노산 서열을 포함하는 경쇄 CDR; 또는, b) 서열번호 7 (hcCDR1), 서열번호 8 (hcCDR2) 및 서열번호 9 (hcCDR3)의 아미노산 서열을 포함하는 중쇄 CDR 및 서열번호 10 (lcCDR1), 서열번호 11 (lcCDR2) 및 서열번호 12 (lcCDR3)의 아미노산 서열을 포함하는 경쇄 CDR; 또는 (c) 서열번호 13 (hcCDR1), 서열번호 14 (hcCDR2) 및 서열번호 15 (hcCDR3)의 아미노산 서열을 포함하는 중쇄 CDR 및 서열번호 16 (lcCDR1), 서열번호 17 (lcCDR2) 및 서열번호 18 (lcCDR3)의 아미노산 서열을 포함하는 경쇄 CDR을 포함한다.
본 발명의 또 다른 측면에 따라, 항-LAG3 항체 분자가 제공된다. 본원에 추가로 기재된 바와 같이, 본 발명의 항-LAG3 항체 분자는 다른 항-LAG3 항체 분자에 비해 놀랍고 유리한 성질을 갖는다. 특히, 이들은 본 발명의 항-PD1 항체 분자와 함께 사용되는 경우 기준 항-PD1 항체 분자 및 항-LAG3 항체 분자보다 T 세포의 개선된 활성화를 입증한다. 인식할 수 있는 바와 같이, 이러한 특성은 암을 치료하는데 사용하기 위한 항-LAG3 항체 분자에 바람직하다.
항체 분자를 코딩하는 핵산 분자, 발현 벡터, 숙주 세포 및 항-LAG3 항체 분자의 제조 방법이 또한 제공된다. 본 발명의 항-LAG3 항체 분자를 포함하는 약학적 조성물도 제공된다. 본원에 개시된 항-LAG3 항체 분자는 고형 및 연조직 종양을 비롯한 암성 질병을 치료하는데 사용될 수 있다.
바람직한 실시양태에 따라, 본 발명의 항-LAG3 항체 분자는 아미노산 서열 LLRRAGVT (서열번호 111) 및/또는 YRAAVHLRDRA (서열번호 112)를 포함하는 인간 LAG3의 에피토프와 결합한다. 항체가 결합하는 에피토프를 결정하는 방법이 본원에 제공된다.
바람직한 실시양태에 따라, 본 발명의 항-LAG3 항체 분자는 (a) 서열번호 39 (hcCDR1), 서열번호 40 (hcCDR2) 및 서열번호 41 (hcCDR3)의 아미노산 서열을 포함하는 중쇄 CDR 및 서열번호 42 (lcCDR1), 서열번호 43 (lcCDR2) 및 서열번호 44 (lcCDR3)의 아미노산 서열을 포함하는 경쇄 CDR; 또는 (b) 서열번호 45 (hcCDR1), 서열번호 46 (hcCDR2) 및 서열번호 47 (hcCDR3)의 아미노산 서열을 포함하는 중쇄 CDR 및 서열번호 48 (lcCDR1), 서열번호 49 (lcCDR2) 및 서열번호 50 (lcCDR3)의 아미노산 서열을 포함하는 경쇄 CDR을 포함한다.
본 발명의 또 다른 측면에 따라, 본 발명의 항-PD1 항체 분자가 본 발명의 항-LAG3 항체 분자와 조합하여 사용될 수 있는 암의 치료 방법이 또한 제공된다. 본 발명의 이들 측면의 실시양태는 항-LAG3 항체가 항-PD1 항체 분자와 동시에, 동반하여, 순차적으로, 연속적으로, 교대로 또는 별도로 투여되는 것을 포함한다.
본 발명의 이들 측면의 추가의 실시양태는 항-PD1 항체 분자가 항-LAG3 항체 분자와 동시에, 동반하여, 순차적으로, 연속적으로, 교대로 또는 별도로 투여되는 것을 포함한다. 본 발명의 이들 측면의 추가의 실시양태는 본 발명의 항체 분자의 상기 사용이 다른 치료제와 조합될 수 있는 것을 포함한다.
본 발명의 항체 분자를 포함하는 추가의 측면, 실시양태, 용도 및 방법은 하기 발명의 상세한 설명 및 첨부된 청구 범위로부터 명백해질 것이다.
본 발명은 폐암, 특히 NSCLC와 같은 몇몇 암 유형의 보다 효과적인 치료를 가능하게 하는 신규 항체 분자를 제공한다.
도면 범례
도 1: 항-PD1 항체 분자의 가변 도메인의 아미노산 서열. 77E11은 뮤린 선조 항체의 명칭이다. PD1-1, PD1-2, PD1-3, PD1-4 및 PD1-5는 본원에서 정의된 바와 같은 항-PD1 항체이다. CDR 서열은 밑줄쳐 친다. VK 77E11 (서열번호 113); VK PD1-1 (서열번호 20); VK PD1-2; (서열번호 22); VK PD1-3 (서열번호 24); VK PD1-4, (서열번호 26); VK PD1-5 (서열번호 28); VH 77E11 (서열번호 114); VH PD1-1 (서열번호 19); VH PD1-2; (서열번호 21); VH PD1-3 (서열번호 23); VH PD1-4, (서열번호 25); VH PD1-5 (서열번호 27).
도 2: 항-PD1 항체 분자에 의한 PD1에 대한 인간 PD1-L1/L2 결합의 저해. (A) 본 발명의 항-PD1 항체가 CHO 세포의 표면상에 발현된 인간 PD-1에 대한 PD-L1 결합의 차단을 유도함을 나타낸다. (B) 본 발명의 항-PD1 항체가 CHO 세포의 표면상에 발현된 인간 PD-1에 대한 PD-L2 결합의 차단을 유도함을 나타낸다.
도 3: 항-PD1 항체 분자에 의한 항원-특이적 T 세포 반응의 자극. 4 명의 개별 공여자로부터의 파상풍 특이적 CD4 기억 T 세포의 인터페론-γ (IFN-γ) 생산을 자극하기 위한 본 발명의 항-PD1 항체의 능력을 나타낸다. 이 분석을 위해, 건강한 공여자로부터 유래된 PBMC로부터의 T 세포를 파상풍 톡소이드의 존재하에 확장시키고 파상풍 톡소이드를 로딩한 자가 성숙 수지상 세포 (DC)와 함께 2일 동안 공-배양하였다. 공-배양 단계는 PD1-1 및 PD1-3 존재하에서 유사한 방식으로 두 번 반복되었다. 두 번째 공-배양 단계 끝에 상등액을 ELISA에 의해 IFN-감마 수준에 대해 평가하였다.
도 4: hPD-1 녹-인 마우스 모델에서의 항-PD1 항체 분자의 생체 내 효능. 결장암종 세포주 (MC38)를 지닌 마우스로부터의 개별적인 종양 성장 곡선을 보여준다. 마우스를 (A) PBS q3or4d, (B) 아이소타입 q3or4d, (C) PD1-3q3or4d 또는 (D) PD1-3으로 단일 용량으로 처리하였다. PD1-3 및 아이소타입은 10 mg/kg을 투여하였다.
도 5: 항-PD1 항체 분자의 전임상 약물동력학. 정맥 투여시 PD1 항체의 약물 동력학적 파라미터가 사이노몰거스 원숭이에 투여된 용량에 대해 플롯팅된다. (A) 곡선 아래 면적 (AUC), (B) 최대 혈장 농도 (cmax), (C), 혈장 클리어런스 (CL), (D) 말기에서의 제거 반감기 (t1/2, z).
도 6: 항-LAG3 항체 분자의 가변 도메인의 아미노산 서열. 496G6은 뮤린 선조 항체의 명칭이다. LAG3-1, LAG3-2, LAG3-3, LAG3-4 및 LAG3-5는 본원에서 정의된 바와 같은 항-LAG3 항체이다. VK 496G6 (서열번호 117); VK LAG3-1 (서열번호 52); VK LAG3-2; (서열번호 54); VK LAG3-3 (서열번호 56); VK LAG3-4, (서열번호 58); VK LAG3-5 (서열번호 60); VH 496G6 (서열번호 118); VH LAG3-1 (서열번호 51); VH LAG3-2; (서열번호 53); VH LAG3-3 (서열번호 55); VH LAG3-4, (서열번호 57); VH LAG3-5 (서열번호 59).
도 7: 항-LAG3 항체 분자에 의한 MHCII에 대한 인간 LAG3 결합의 저해. Raji 세포의 표면상에 발현된 MHCII에 대한 재조합 LAG3의 결합을 차단하기 위한 제시된 LAG3 mAb 및 대조군 mAb의 효력을 나타낸다.
도 8: 항-PD1 및 항-LAG3 항체 분자에 의한 항원-특이적 T 세포 반응의 자극. (A) 펨브롤리주맵 (Keytruda (R))의 포화량에 대한 PD1/LAG3 mAb 조합의 배수 증가%를 나타낸다. 고정된 100 nM 농도의 PD1-3 및 니볼루맵 (Opdivo (R))이 증가량의 LAG3 mAb와 조합되었다 (검은선으로 나타낸 LAG3-1, 또는 점선으로 나타낸 BMS-986016과 동일한 아미노산 서열을 갖는 기준 항체 분자, 길항성 LAG3 항체). (B) 펨브롤리주맵 (Keytruda (R)) 활성에 대한 본 발명의 조합물의 PD1/LAG3 mAb 분자의 배수 증가%를 나타낸다. 조합 mAb 활성 수준은 PD1에 대해 100 nM, LAG3 mAb에 대해 200 nM에서 평가되었다. 통계 시험은 Graph Pad Prism을 사용하여 일원 분산 분석 (one-way ANOVA)에 이어 터키 사후 검정 (Tukey post hoc)으로 수행하였다.
도 9: 동계 종양 모델에서 PD1 및 LAG3 항체의 병용 요법의 생체 내 효능. 10 mg/kg의 용량으로 주 2회 도구 항체로 처리된 종양을 가진 마우스의 개별 성장 곡선을 나타낸다. (A) 결장암종 (MC38)을 가진 마우스를 PBS, 항-LAG3, 항-PD1 또는 항-PD1과 항-LAG3의 조합으로 처리하였다. 흑색종 (B16-F10) (B), 폐암종 (LL/2) (C), 결장암종 (Colon-26) (D) 또는 유방암 (4T1) (E) 종양을 가진 마우스를 PD1 아이소타입, 항-PD1 또는 항-PD1과 항-LAG3의 조합으로 처리하였다.
도 1: 항-PD1 항체 분자의 가변 도메인의 아미노산 서열. 77E11은 뮤린 선조 항체의 명칭이다. PD1-1, PD1-2, PD1-3, PD1-4 및 PD1-5는 본원에서 정의된 바와 같은 항-PD1 항체이다. CDR 서열은 밑줄쳐 친다. VK 77E11 (서열번호 113); VK PD1-1 (서열번호 20); VK PD1-2; (서열번호 22); VK PD1-3 (서열번호 24); VK PD1-4, (서열번호 26); VK PD1-5 (서열번호 28); VH 77E11 (서열번호 114); VH PD1-1 (서열번호 19); VH PD1-2; (서열번호 21); VH PD1-3 (서열번호 23); VH PD1-4, (서열번호 25); VH PD1-5 (서열번호 27).
도 2: 항-PD1 항체 분자에 의한 PD1에 대한 인간 PD1-L1/L2 결합의 저해. (A) 본 발명의 항-PD1 항체가 CHO 세포의 표면상에 발현된 인간 PD-1에 대한 PD-L1 결합의 차단을 유도함을 나타낸다. (B) 본 발명의 항-PD1 항체가 CHO 세포의 표면상에 발현된 인간 PD-1에 대한 PD-L2 결합의 차단을 유도함을 나타낸다.
도 3: 항-PD1 항체 분자에 의한 항원-특이적 T 세포 반응의 자극. 4 명의 개별 공여자로부터의 파상풍 특이적 CD4 기억 T 세포의 인터페론-γ (IFN-γ) 생산을 자극하기 위한 본 발명의 항-PD1 항체의 능력을 나타낸다. 이 분석을 위해, 건강한 공여자로부터 유래된 PBMC로부터의 T 세포를 파상풍 톡소이드의 존재하에 확장시키고 파상풍 톡소이드를 로딩한 자가 성숙 수지상 세포 (DC)와 함께 2일 동안 공-배양하였다. 공-배양 단계는 PD1-1 및 PD1-3 존재하에서 유사한 방식으로 두 번 반복되었다. 두 번째 공-배양 단계 끝에 상등액을 ELISA에 의해 IFN-감마 수준에 대해 평가하였다.
도 4: hPD-1 녹-인 마우스 모델에서의 항-PD1 항체 분자의 생체 내 효능. 결장암종 세포주 (MC38)를 지닌 마우스로부터의 개별적인 종양 성장 곡선을 보여준다. 마우스를 (A) PBS q3or4d, (B) 아이소타입 q3or4d, (C) PD1-3q3or4d 또는 (D) PD1-3으로 단일 용량으로 처리하였다. PD1-3 및 아이소타입은 10 mg/kg을 투여하였다.
도 5: 항-PD1 항체 분자의 전임상 약물동력학. 정맥 투여시 PD1 항체의 약물 동력학적 파라미터가 사이노몰거스 원숭이에 투여된 용량에 대해 플롯팅된다. (A) 곡선 아래 면적 (AUC), (B) 최대 혈장 농도 (cmax), (C), 혈장 클리어런스 (CL), (D) 말기에서의 제거 반감기 (t1/2, z).
도 6: 항-LAG3 항체 분자의 가변 도메인의 아미노산 서열. 496G6은 뮤린 선조 항체의 명칭이다. LAG3-1, LAG3-2, LAG3-3, LAG3-4 및 LAG3-5는 본원에서 정의된 바와 같은 항-LAG3 항체이다. VK 496G6 (서열번호 117); VK LAG3-1 (서열번호 52); VK LAG3-2; (서열번호 54); VK LAG3-3 (서열번호 56); VK LAG3-4, (서열번호 58); VK LAG3-5 (서열번호 60); VH 496G6 (서열번호 118); VH LAG3-1 (서열번호 51); VH LAG3-2; (서열번호 53); VH LAG3-3 (서열번호 55); VH LAG3-4, (서열번호 57); VH LAG3-5 (서열번호 59).
도 7: 항-LAG3 항체 분자에 의한 MHCII에 대한 인간 LAG3 결합의 저해. Raji 세포의 표면상에 발현된 MHCII에 대한 재조합 LAG3의 결합을 차단하기 위한 제시된 LAG3 mAb 및 대조군 mAb의 효력을 나타낸다.
도 8: 항-PD1 및 항-LAG3 항체 분자에 의한 항원-특이적 T 세포 반응의 자극. (A) 펨브롤리주맵 (Keytruda (R))의 포화량에 대한 PD1/LAG3 mAb 조합의 배수 증가%를 나타낸다. 고정된 100 nM 농도의 PD1-3 및 니볼루맵 (Opdivo (R))이 증가량의 LAG3 mAb와 조합되었다 (검은선으로 나타낸 LAG3-1, 또는 점선으로 나타낸 BMS-986016과 동일한 아미노산 서열을 갖는 기준 항체 분자, 길항성 LAG3 항체). (B) 펨브롤리주맵 (Keytruda (R)) 활성에 대한 본 발명의 조합물의 PD1/LAG3 mAb 분자의 배수 증가%를 나타낸다. 조합 mAb 활성 수준은 PD1에 대해 100 nM, LAG3 mAb에 대해 200 nM에서 평가되었다. 통계 시험은 Graph Pad Prism을 사용하여 일원 분산 분석 (one-way ANOVA)에 이어 터키 사후 검정 (Tukey post hoc)으로 수행하였다.
도 9: 동계 종양 모델에서 PD1 및 LAG3 항체의 병용 요법의 생체 내 효능. 10 mg/kg의 용량으로 주 2회 도구 항체로 처리된 종양을 가진 마우스의 개별 성장 곡선을 나타낸다. (A) 결장암종 (MC38)을 가진 마우스를 PBS, 항-LAG3, 항-PD1 또는 항-PD1과 항-LAG3의 조합으로 처리하였다. 흑색종 (B16-F10) (B), 폐암종 (LL/2) (C), 결장암종 (Colon-26) (D) 또는 유방암 (4T1) (E) 종양을 가진 마우스를 PD1 아이소타입, 항-PD1 또는 항-PD1과 항-LAG3의 조합으로 처리하였다.
발명의 상세한 설명
정의
본 발명의 상기 및 다른 측면 및 실시양태들이 본원의 추가 설명으로부터 명백해질 것이다.
지시되지 않거나 달리 정의되지 않는 한, 사용된 모든 용어는 당해 기술 분야에서 당업자에게 명백한 통상의 의미를 가질 것이다. 표준 핸드북, 예컨대 [Sambrook et al, "Molecular Cloning: A Laboratory Manual" (2nd Ed.), VoIs. 1-3, Cold Spring Harbor Laboratory Press (1989); Lewin, "Genes IV", Oxford University Press, New York, (1990), 및 Roitt et al., "Immunology" (2nd Ed.), Gower Medical Publishing, London, New York (1989)], 뿐만 아니라 여기에 인용된 일반적인 배경기술을 참고할 수 있다. 또한, 달리 언급하지 않는 한, 상세하게 구체적으로 기술되지 않은 모든 방법, 단계, 기술 및 조작은 당업자에게 명백한 바와 같이 그 자체로 공지된 방식으로 수행될 수 있고 또한 수행되었다. 예를 들어, 표준 핸드북, 위에서 언급한 일반적인 배경기술 및 그 안에 인용된 다른 참고 문헌을 다시 참조할 수 있다.
본원에서 사용된 "하나 (a 및 an)"라는 용어는 관사의 문법적 대상 중 하나 또는 복수개 (예를 들어, 적어도 하나)를 지칭한다.
본원에서 " 또는"이라는 용어는 문맥상 달리 명시하지 않는 한, " 및/또는"이라는 용어를 의미하도록 사용되고, 상호교환적으로 사용된다.
"약" 및 "대략"은 일반적으로 측정의 성질 또는 정밀도를 고려하여 측정된 양에 대한 허용 오차 정도를 의미한다. 전형적인 오차 정도는 주어진 값 또는 값 범위의 20% (%) 이내, 전형적으로 10% 이내, 보다 전형적으로 5% 이내이다.
"항체 분자" 또는 "항체" (본원에서 동의어로 사용됨)는 척추동물의 혈액 또는 기타 체액에서 발견할 수 있는 감마 글로불린 단백질로서, 박테리아나 바이러스와 같은 이물질을 식별하고 중화시키기 위해 면역계에 의해 사용된다. 이들은 전형적으로 하나의 유닛을 갖는 단량체, 2개의 유닛을 갖는 이량체 또는 5개의 유닛을 갖는 오량체를 형성하기 위해 각각 2개의 큰 중쇄 및 2개의 작은 경쇄를 갖는 기본 구조 단위로 만들어진다. 항체 분자는 비공유 상호작용에 의해 항원으로 알려진 다른 분자 또는 구조에 결합할 수 있다. 이러한 결합은 항체 분자가 높은 친화력으로 특정 구조에만 결합한다는 의미에서 특이하다. 항체 분자에 의해 인식되는 항원의 독특한 부분을 에피토프 또는 항원 결정자라고 한다. 에피토프에 결합하는 항체 분자의 부분은 때로 파라토프 (paratope)라고 불리고 항체의 소위 가변 도메인 또는 가변 영역 (Fv)에 존재한다. 가변 도메인은 프레임워크 영역 (FR's)에 의해 이격된 3개의 소위 상보성 결정 영역 (CDR's)을 포함한다.
본 발명과 관련하여 CDR's에 대한 언급은 Chothia (Chothia and Lesk, J. Mol. Biol. 1987, 196: 901-917)와 Kabat (E.A. Kabat, T.T. Wu, H. Bilofsky, M. Reid-Miller and H. Perry, Sequence of Proteins of Immunological Interest, National Institutes of Health, Bethesda (1983))의 정의에 기초한다.
일부 실시양태에서, 항체 분자는 예를 들어 IgG1, IgG2, IgG3, IgG4, IgM, IgA1, IgA2, IgD, 및 IgE의 중쇄 불변 영역; 특히 IgG1, IgG2, IgG3 및 IgG4 (예를 들어, 인간)의 중쇄 불변 영역으로부터 선택된다. 또 다른 실시양태에서, 항체 분자는 카파 또는 람다 (예를 들어, 인간)의 경쇄 불변 영역으로부터 선택된 경쇄 불변 영역을 갖는다. (예를 들어, Fc 수용체 결합, 항체 당질화, 시스테인 잔기의 수, 이펙터 세포 기능 및/또는 보체 기능의 특성 중 하나 이상을 증가시키거나 감소시키기 위해) 항체의 특성을 변형시키기 위해 불변 영역을 변경, 예를 들어 돌연변이화시킬 수 있다. 일부 실시양태에서, 항체는 이펙터 기능을 갖고 보체를 고정시킬 수 있다. 다른 실시양태에서, 항체는 이펙터 세포를 동원하거나 보체를 고정시키지 않는다. 특정 실시양태에서, 항체는 Fc 수용체에 결합하는 능력이 감소되었거나 또는 결합 능력이 없다. 예를 들어, 이는 Fc 수용체에 대한 결합을 지지하지 않는 아이소타입 또는 서브 타입, 단편 또는 다른 돌연변이체일 수 있으며, 예를 들어 이는 돌연변이화되거나 결실된 Fc 수용체 결합 영역을 갖는다.
항체 불변 영역은 일부 실시양태에서 변경된다. 항체 불변 영역을 변경시키는 방법은 당 업계에 공지되어 있다. 기능이 변경된, 예를 들어 세포상의 FcR 또는 보체의 C1 성분과 같이 이펙터 리간드에 대해 변경된 친화도를 가지는 항체는 항체의 불변 부분의 적어도 하나의 아미노산 잔기를 상이한 잔기로 대체함으로써 생성될 수 있다 (예를 들어, 그 전체가 본원에 참고로 포함되는 EP 388, 151 A1, 미국 특허 제5,624,821호 및 미국 특허 제5,648,260호 참조). 인간 IgG4에서 S228P (EU 명명법, Kabat 명명법으로 S241P)와 같은 항체 구조를 안정화시키는 아미노산 돌연변이 또한 고려된다. 뮤린이나 다른 종에 적용되는 경우, 면역글로불린이 이들 기능을 감소시키거나 제거하는 유사한 유형의 변경이 기술될 수 있다.
본원에 사용된 용어 "가변 도메인"은 당 업계에 공지되어 있고 이하 각각 "프레임워크 영역 1" 또는 "FR1"; "프레임워크 영역 2" 또는 "FR2"; "프레임워크 영역 3" 또는 "FR3"; 및 "프레임워크 영역 4" 또는 "FR4"로서 후술되는 4개의 "프레임워크 영역"으로 기본적으로 이루어진 항체 분자의 영역을 의미한다 (여기서, 프레임워크 영역은 당 업계에 공지되어 있고 이하 각각 "상보성 결정 영역 1" 또는 "CDR1", "상보성 결정 영역 2" 또는 "CDR2" 및 "상보성 결정 영역 3" 또는 "CDR3"으로서 후술되는 3개의 "상보성 결정 영역" 또는 "CDR"에 의해 차단된다). 따라서, 면역글로불린 가변 도메인의 일반 구조 또는 순서는 다음과 같이 표시할 수 있다: FR1 - CDR1 - FR2 - CDR2 - FR3 - CDR3 - FR4. 항원-결합 부위를 운반함으로써 항원에 대한 항체에 특이성을 부여하는 것은 면역글로불린 가변 도메인(들)이다.
"가변 중 (또는 VH)" 및 "가변 경 (또는 VL)"이란 항체 분자의 중쇄 또는 경쇄의 가변 도메인을 각각 지칭한다.
업계에서는 항체 분자를 추가로 개발하여 의학 및 기술 분야에서 다목적 도구로 만들었다. 따라서, 본 발명과 관련하여, 용어 "항체 분자" 또는 "항체"는 예를 들어, 2개의 경쇄 및 2개의 중쇄를 포함하는 자연계에서 발견될 수 있는 항체를 포함할 뿐만 아니라, 항원에 대한 결합 특이성 및 항체 분자의 가변 도메인에 대한 구조적 유사성을 갖는 적어도 하나의 파라토프를 포함하는 모든 분자를 포괄한다.
따라서, 본 발명에 따른 항체 분자는 모노클로날 항체, 인간 항체, 인간화 항체, 키메라 항체, 항체의 단편, 특히 Fv, Fab, Fab', 또는 F(ab')2 단편, 단일 사슬 항체, 특히 단일 사슬 가변 단편 (scFv), 소형 모듈 면역 약제 (SMIP), 도메인 항체, 나노바디, 디아바디를 포함한다.
모노클로날 항체 (mAb)는 아미노산 서열이 동일한 단일특이적 항체이다. 이들은 골수종 (B 세포 암) 세포와 특이적 항체-생성 B 세포의 융합 클론을 나타내는 하이브리드 세포주 (하이브리도마라고 칭한다)로부터 하이브리도마 기술에 의해 제조할 수 있다 [Kohler G, Milstein C. Continuous cultures of fused cells secreting antibody of predefined specificity. Nature 1975; 256:495-7]. 대안으로, 모노클로날 항체는 숙주 세포에서 재조합 발현에 의해 제조될 수 있다 [Norderhaug L, Olafsen T, Michaelsen TE, Sandlie I. (May 1997). "Versatile vectors for transient and stable expression of recombinant antibody molecules in mammalian cells.". J Immunol Methods 204 (1): 77-87].
사람에게 적용하는 경우, 마우스와 같은 다른 종으로부터 최초 유래된 항체의 면역원성을 감소시키는 것이 종종 바람직하다. 이것은 키메라 항체의 작제 또는 "인간화"라고 하는 과정에 의해 달성될 수 있다. 본 문맥에서, "키메라 항체"는 상이한 종 (예를 들면, 사람)으로부터 유도된 서열 부분 (예를 들면, 불변 도메인)에 융합된, 한 종 (예를 들면, 마우스)으로부터 유도된 서열 부분 (예를 들면, 가변 도메인)을 포함하는 항체인 것으로 이해된다. "인간화 항체"는 비인간 종으로부터 최초 유도된 가변 도메인을 포함하고, 여기서, 특정 아미노산들은 가변 도메인의 전체 서열이 인간 가변 도메인의 서열과 보다 가깝게 유사하도록 돌연변이화된 항체이다. 항체를 키메라화 및 인간화하는 방법은 본 분야에 잘 알려져 있다 [Billetta R, Lobuglio AF. "Chimeric antibodies". Int Rev Immunol. 1993;10(2-3):165-76; Riechmann L, Clark M, Waldmann H, Winter G (1988). "Reshaping human antibodies for therapy". Nature: 332:323].
또한, 인간 게놈으로부터 유도된 서열을 기초로 항체를 생성하는 기술이 개발되었고, 예로는 파아지 디스플레이 또는 유전자이식 동물의 사용을 들 수 있다 [WO 90/05144; D. Marks, H.R. Hoogenboom, T.P. Bonnert, J. McCafferty, A.D. Griffiths and G. Winter (1991) "By-passing immunisation. Human antibodies from V-gene libraries displayed on phage." J.Mol.Biol., 222, 581-597; Knappik et al., J. Mol. Biol. 296: 57-86, 2000; S. Carmen and L. Jermutus, "Concepts in antibody phage display". Briefings in Functional Genomics and Proteomics 2002 1(2):189-203; Lonberg N, Huszar D. "Human antibodies from transgenic mice". Int Rev Immunol. 1995;13(1):65-93.; Brueggemann M, Taussig MJ. "Production of human antibody repertoires in transgenic mice". Curr Opin Biotechnol. 1997 Aug;8(4):455-8]. 이러한 항체는 본 발명의 맥락에서 "인간 항체"이다.
본 발명에 따른 항체 분자는 또한 항원 결합 성질을 보유하는 분자의 단편, 예를 들면, Fab, Fab' 또는 F(ab')2 단편을 포함한다. 이와 같은 단편은 항체 분자의 단편화에 의해, 예를 들면, 단백질분해성 소화에 의해, 또는 이러한 단편의 재조합 발현에 의해 수득할 수 있다. 예를 들면, 항체 분자 소화는 통상적인 기술의 수단에 의해, 예를 들면, 파파인 또는 펩신을 사용하여 달성할 수 있다 (WO 94/29348 참조). 항체의 파파인은 전형적으로 각각 단일 항원 결합 부위를 갖는 두 개의 동일한 항원 결합 단편, 소위 Fab 단편과 나머지 Fc 단편을 생성한다. 펩신 처리는 F(ab')2를 생성한다. Fab 분자에서, 가변 도메인은 각각 바람직하게는 인간 기원의 면역글로불린 불변 도메인에 융합된다. 따라서, 중쇄 가변 도메인은 CH1 도메인 (소위 Fd 단편)에 융합될 수 있고, 경쇄 가변 도메인은 CL 도메인에 융합될 수 있다. Fab 분자는 숙주 세포에서 각각의 핵산의 재조합 발현에 의해 생성될 수 있다 (하기 참조).
항체 분자의 가변 도메인 또는 이러한 가변 도메인으로부터 유도된 분자를 상이한 분자 상황에 도입하는 다수의 기술이 개발되었다. 이러한 것들도 또한 본 발명에 따른 "항체"로서 고려되어야 한다. 일반적으로, 이들 항체 분자들은 천연 항체 분자에 비하여 크기가 작으며 단일 아미노산 쇄를 포함하거나 다수의 아미노산 쇄로 구성될 수 있다. 예를 들면, 단일쇄 가변 단편(scFv)은 항체 분자의 중쇄와 경쇄의 가변 영역들이 짧은 링커, 보통 세린(S) 또는 글리신(G)과 함께 연결된 융합체이다 [WO 88/01649; WO 91/17271; Huston et al; International Reviews of Immunology, Volume 10, 1993, 195-217]. "단일 도메인 항체" 또는 "나노바디"는 단일 Ig-유사 도메인에서 항원-결합 부위를 갖는다 [WO 94/04678; WO 03/050531, Ward et al., Nature. 1989 Oct 12;341(6242):544-6; Revets et al., Expert Opin Bioi Ther. 5(1): 111-24, 2005]. 동일하거나 상이한 항원에 대해 결합 특이성을 갖는 하나 이상의 단일 도메인 항체는 함께 연결될 수 있다. 디아바디는 2개의 가변 도메인을 포함한 2개의 아미노산 쇄로 구성된 2가 항체 분자이다 [WO 94/13804, Holliger et al., Proc Natl Acad Sci U S A. 1993 Jul 15;90(14):6444-8]. 항체-유사 분자의 다른 예는 면역글로불린 상과(superfamily) 항체이다 [IgSF; Srinivasan and Roeske, Current Protein Pept. Sci. 2005, 6(2): 185-96]. 상이한 개념에 의해 소위 소형 모듈 면역약제(SMIP)가 제공되었고, 이것은 단일쇄 힌지(hinge)에 연결된 Fv 도메인, 및 불변 도메인 CH1이 결여된 이펙터 도메인을 포함한다 [WO 02/056910].
항체 분자는 항체 분자의 특성에 목적하는 영향을 갖는 다른 분자 실체(entity)에 (융합 단백질로서) 융합되거나 (공유 또는 비공유 결합에 의해) 결합될 수 있다. 예를 들어, 특히 단일쇄 항체 또는 도메인 항체의 경우에, 예를 들면, 혈액과 같은 체액에서의 항체 분자의 약동학적 성질인 안정성을 향상시키는 것이 필요할 수 있다. 이와 관련하여 다수의 기술이 개발되었고, 특히 순환에서 항체 분자들의 반감기를 연장하는 기술이 개발되었으며, 이러한 기술의 예로는 페길화 [WO 98/25971; WO 98/48837; WO 2004081026], 항체 분자를 알부민과 같은 혈청 단백질에 대해 친화력을 갖는 다른 항체 분자에 융합 또는 공유 부착시키는 것 [WO 2004041865; WO 2004003019] 또는 항체 분자를 알부민 또는 트랜스페린과 같은 혈청 단백질의 전부 또는 일부와의 융합 단백질로서 발현시키는 것 [WO 01/79258]이 포함된다.
교환 가능하게 사용될 수 있는 용어 "에피토프" 및 "항원 결정자"는 본 발명의 항체 분자와 같은 항원-결합 분자, 특히 상기 분자의 항원-결합 부위에 의해 인식되는 폴리펩티드와 같은 거대 분자 부분을 지칭한다. 에피토프는 항체 분자에 대한 최소 결합 부위를 정의하며, 따라서 항체 분자의 특이성 표적을 나타낸다.
특정 에피토프, 항원 또는 단백질에 대해 (또는 그의 적어도 일부분, 단편 또는 에피토프에 대해) "친화력을 가지고" 및/또는 "특이성을 가지며", "그와 결합", "그에 결합", "특이적으로 결합" 또는 "그에 특이적으로 결합"할 수 있는 항체 분자는 상기 에피토프, 항원 또는 단백질에 대해 "대한" 또는 "대향한다"고 언급되거나, 또는 그러한 에피토프, 항원 또는 단백질에 대해 "결합하는" 분자이다.
일반적으로, 용어 "특이성"은 특정 항원 결합 분자 또는 항원 결합 단백질 (예컨대 면역글로불린, 항체, 면역글로불린 단일 가변 도메인)이 결합할 수 있는 상이한 타입의 항원 또는 에피토프의 수를 지칭한다. 항원-결합 단백질의 특이성은 그의 친화력 및/또는 결합력에 기초하여 결정될 수 있다. 항원과 항원 결합 단백질의 해리에 대한 평형 상수 (KD)로 표시되는 친화력은 항원 결합 단백질상의 항원 결합 부위와 에피토프 사이의 결합 강도를 측정하기 위한 척도이다; KD 값이 작을수록 에피토프와 항원-결합 분자 사이의 결합 강도가 강해진다 (대안적으로, 친화력은 또한 1/KD인 친화력 상수 (KA)로서 표시될 수 있다). 당업자에게 명백한 바와 같이 (예를 들어, 본원에서의 추가적인 개시에 기초하여), 친화도는 관심있는 특정 항원에 따라 그 자체로 공지된 방식으로 결정될 수 있다. 결합도는 항원-결합 분자 (본 발명의 항체와 같은)와 관련 항원 사이의 결합 강도의 척도이다. 결합도는 항원 결합 분자상의 에피토프와 그것의 항원 결합 부위 사이의 친화력 및 항원 결합 분자 상에 존재하는 관련 결합 부위의 수 모두에 관련된다.
전형적으로, 항원-결합 단백질 (본 발명의 항체 분자와 같은)은 10E-5 내지 10E-14 몰/리터 (M) 이하, 바람직하게는 10E-7 내지 10E-14 몰/리터 (M) 이하, 보다 바람직하게는 10E-8 내지 10E-14 몰/리터, 보다 더 바람직하게는 10E-11 내지 10E-13의 해리 상수 (KD) (예를 들어 당 업계에 공지되어 있는 Kinexa 분석에서 측정된 경우), 및/또는 적어도 10E7 ME-1, 바람직하게는 적어도 10E8 ME-1, 보다 바람직하게는 적어도 10E9 ME-1, 예컨대 적어도 10E11 ME-1의 결합 상수 (KA)로 결합할 것이다. 10E-4 M보다 큰 모든 KD 값은 일반적으로 비특이적 결합을 나타내는 것으로 간주된다. 바람직하게는, 본 발명의 항체는 500 nM 미만, 바람직하게는 200 nM 미만, 보다 바람직하게는 10 nM 미만, 예를 들어 500 pM 미만의 KD로 원하는 항원에 결합할 것이다. 항원-결합 단백질의 항원 또는 에피토프에 대한 특이적 결합은 예를 들어 본원에 기술된 분석, 스캐차드 (Scatchard) 분석 및/또는 방사 면역 측정법 (RIA), 효소 면역 분석법 (EIA) 및 샌드위치 경쟁 분석법과 같은 경쟁적 결합 분석, 및 업계에 그 자체로 공지된 그의 다양한 변형을 비롯해, 그 자체로 알려진 임의의 적합한 방법으로 결정될 수 있다.
항체 분자의 결합 친화력은 친화력 성숙으로 알려진 방법 [Marks et al., 1992, Biotechnology 10:779-783; Barbas, et al., 1994, Proc. Nat. Acad. Sci, USA 91:3809-3813; Shier et al., 1995, Gene 169:147-155]에 의해 증가시킬 수 있다. 따라서, 친화력 성숙 항체 또한 본 발명에 포함된다.
"경쟁" 또는 "교차 경쟁"이라는 용어는 항체 분자, 예를 들어, 본 발명의 항-PD1 또는 LAG3 항체 분자의 표적, 예를 들어, 인간 PD1 또는 LAG3에 대한 결합을 방해하는 항체 분자의 능력을 지칭하기 위해 본원에서 상호 교환적으로 사용된다. 결합에 대한 방해는 직접적 또는 간접적일 수 있다 (예를 들어, 항체 분자 또는 표적의 알로스테릭 조절을 통해). 항체 분자가 다른 항체 분자의 표적에 대한 결합을 방해할 수 있는 정도, 따라서 경쟁할 수 있는지의 여부는 경쟁 결합 분석, 예를 들어 FACS 분석, ELISA 또는 BIACORE 분석을 시용하여 결정할 수 있다. 일부 실시양태에서, 경쟁 결합 분석은 정량적 경쟁 분석이다. 일부 실시양태에서, 제1 항-PD1 또는 LAG3 항체 분자는 제1 항체 분자의 표적에 대한 결합이 경쟁 결합 분석 (예를 들어, 본원에 기재된 경쟁 분석)에서 10% 이상, 예를 들어 20% 이상, 30% 이상, 40% 이상, 50% 이상, 55% 이상, 60% 이상, 65% 이상, 70% 이상, 75% 이상, 80% 이상, 85% 이상, 90% 이상, 95% 이상, 98% 이상, 99% 이상 감소되는 경우 제2 항-PD1 또는 LAG3 항체 분자와 표적에 대한 결합에 대해 경쟁한다고 언급된다.
본원에 개시된 조성물 및 방법은 특정된 서열을 가지거나, 또는 특정된 서열과 실질적으로 동일하거나 유사한 서열, 예를 들어, 특정된 서열과 적어도 85%, 90%, 95% 이상 동일한 서열을 갖는 폴리펩티드 및 핵산을 포함한다. 아미노산 서열과 관련하여, 용어 "실질적으로 동일한"은 제1 및 제2 아미노산 서열이 공통 구조적 도메인 및/또는 공통 기능 활성을 가질 수 있도록 제2 아미노산 서열에 정렬된 아미노산 잔기와 i) 동일하거나 또는 ii) 그에 보존적 치환인 충분하거나 최소 수의 아미노산 잔기를 함유하는 제1 아미노산을 지칭하기 위해 본원에서 사용된다. 예를 들어, 기준 서열, 예를 들어 아미노산 서열은 본원에 제공된 서열과 적어도 약 85%, 90%. 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% 또는 99% 동일성을 가지는 공통 구조 도메인을 함유한다. 뉴클레오티드 서열과 관련하여, 용어 "실질적으로 동일한"은 제1 및 제2 뉴클레오티드 서열이 공통 기능 활성을 갖는 폴리펩티드를 코딩하거나 공통 구조적 폴리펩티드 도메인 또는 공통 기능적 폴리펩티드 활성을 코딩하도록 제2 핵산 서열에서 정렬된 뉴클레오티드와 동일한 충분하거나 최소 수의 뉴클레오티드를 함유하는 제1 핵산 서열을 지칭하는데 사용된다. 예를 들어, 뉴클레오티드 서열은 기준 서열에 대해 적어도 약 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% 또는 99% 동일성을 가진다.
2 이상의 핵산 또는 폴리펩티드 서열의 문맥에서 "동일" 또는 "퍼센트 동일성"이란 용어는 비교하였을 때 동일하고 최대한 대응되도록 정렬된, 특정된 퍼센트의 뉴클레오티드 또는 아미노산 잔기를 가지거나 동일한 2 이상의 서열 또는 부분 서열들을 지칭한다. 퍼센트 동일성을 결정하기 위해, 서열은 최적의 비교 목적을 위해 정렬된다 (예를 들어, 제2 아미노 또는 핵산 서열과의 최적 정렬을 위해 제1 아미노산의 서열 또는 핵산 서열에 갭이 도입될 수 있다). 이어서, 상응하는 아미노산 위치 또는 뉴클레오티드 위치의 아미노산 잔기 또는 뉴클레오티드를 비교한다. 제1 서열의 위치가 제2 서열의 상응하는 위치와 동일한 아미노산 잔기 또는 뉴클레오티드에 의해 점유된 경우, 분자는 그 위치에서 동일하다. 두 서열 간의 퍼센트 동일성은 서열에 의해 공유되는 동일한 위치의 수의 함수이다 (즉, % 동일성 = 동일한 위치의 수/전체 위치의 수 (예를 들어, 중첩 위치)×100). 일부 실시양태에서, 비교되는 2개의 서열은 적합하다면 갭이 서열 내에 도입된 후 동일한 길이이다 (예를 들어, 비교되는 서열을 넘어서 연장되는 추가 서열을 배제한다). 예를 들어, 가변 영역 서열이 비교될 때, 선도 및/또는 불변 도메인 서열은 고려되지 않는다. 두 서열 간의 서열 비교를 위해, "상응하는" CDR은 양 서열에서 동일한 위치에 있는 CDR을 의미한다 (예를 들어, 각 서열의 CDR-H1).
두 서열 간의 % 동일성 또는 % 유사성의 결정은 수학적 알고리즘을 사용하여 수행할 수 있다. 두 서열의 비교에 이용되는 수학적 알고리즘의 바람직한 비제한적인 예는 [Karlin and Altschul, 1990, Proc. Natl. Acad. Sci. USA 87:2264-2268, modified as in Karlin and Altschul, 1993, Proc. Natl. Acad. Sci. USA 90:5873-5877]이다. 이러한 알고리즘은 [Altschul et al., 1990, J. Mol. Biol. 215:403-410]의 NBLAST 및 XBLAST 프로그램에 통합되어 있다. 관심있는 단백질을 코딩하는 핵산에 상동인 뉴클레오티드 서열을 얻기 위해 NBLAST 프로그램, score = 100, wordlength = 12로 BLAST 뉴클레오티드 검색을 수행할 수 있다. 관심있는 단백질과 상동인 아미노산 서열을 얻기 위해 XBLAST 프로그램, score = 50, wordlength = 3으로 BLAST 단백질 검색을 수행할 수 있다. 비교 목적을 위한 갭 정렬을 얻기 위해, Gapped BLAST를 [Altschul et al., 1997, Nucleic Acids Res. 25:3389-3402]에 기재된 바와 같이 이용할 수 있다. 대안적으로, PSI-Blast를 사용하여 분자 간의 거리 관계를 검출하는 반복 검색을 수행할 수 있다 (상동). BLAST, Gapped BLAST 및 PSI-Blast 프로그램을 사용하는 경우, 각 프로그램 (예: XBLAST 및 NBLAST)의 디폴트 파라미터가 이용될 수 있다. 서열의 비교에 이용되는 수학적 알고리즘의 또 다른 바람직한 비제한적 예는 Myers and Miller, CABIOS (1989)의 알고리즘이다. 이러한 알고리즘은 GCG 서열 정렬 소프트웨어 패키지의 일부인 ALIGN 프로그램 (버전 2.0)에 통합된다. 아미노산 서열을 비교하기 위한 ALIGN 프로그램을 이용하는 경우, PAM120 중량 잔기 표, 갭 길이 패널티 12 및 갭 패널티 4가 사용될 수 있다. 서열 분석을 위한 추가적인 알고리즘은 당 업계에 공지되어 있으며 [Torellis and Robotti, 1994, Comput. Appl. Biosci. 10:3-5]에 기술된 바와 같은 ADVANCE 및 ADAM; 및 [Pearson and Lipman, 1988, Proc. Natl. Acad. Sci. USA 85:2444-8]에 기술된 바와 같은 FASTA를 포함한다. FASTA 내에서, ktup은 검색의 민감도와 속도를 설정하는 제어 옵션이다. ktup = 2인 경우, 비교되는 두 서열의 유사한 영역은 정렬된 잔기의 쌍을 관찰함으로써 발견된다; ktup = 1이면 단일 정렬된 아미노산을 조사한다. ktup은 단백질 서열의 경우 2 또는 1로, DNA 서열의 경우 1에서 6까지 설정할 수 있다. ktup을 지정하지 않으면 디폴트값은 단백질의 경우 2이고 DNA의 경우 6이다. 대안적으로, 단백질 서열 정렬은 [Higgins et al., 1996, Methods Enzymol. 266:383-402]에 기술된 바와 같은 CLUSTAL W 알고리즘을 사용하여 수행할 수 있다.
아미노산 잔기는 당 업계에 일반적으로 공지되고 합의된 표준 3 문자 또는 1 문자 아미노산 코드에 따라 표시될 것이다. 2개의 아미노산 서열을 비교할 때, 용어 "아미노산 차이"는 제2 서열과 비교하여 기준 서열의 위치에서 지시된 수의 아미노산 잔기의 삽입, 결실 또는 치환을 의미한다. 치환(들)의 경우, 그러한 치환(들)은 바람직하게는 보존적 아미노산 치환(들)일 것이며, 이는 아미노산 잔기가 유사한 화학 구조의 다른 아미노산 잔기로 대체되고 폴리펩티드의 기능, 활성 또는 다른 생물학적 성질에 관해 영향을 거의 또는 실질적으로 갖지 않음을 의미한다. 이러한 보존적 아미노산 치환은 당 분야에, 예를 들어 W01998/49185호로부터 잘 알려져 있으며, 여기서 보존적 아미노산 치환은 바람직하게는 하기 그룹 (i) 내지 (v) 내의 하나의 아미노산이 동일한 그룹 내의 다른 아미노산 잔기에 의해 치환된 치환이다 (i) 작은 지방족, 비극성 또는 약간 극성인 잔기: Ala, Ser, Thr, Pro 및 Gly; (ii) 극성의 음으로 하전된 잔기 및 그들의 (비하전된) 아미드: Asp, Asn, Glu 및 Gin; (iii) 극성의 양으로 하전된 잔기: His, Arg 및 Lys; (iv) 큰 지방족 비극성 잔기: Met, Leu, lie, Val 및 Cys; 및 (v) 방향족 잔기: Phe, Tyr 및 Trp. 특히 바람직한 보존적 아미노산 치환은 다음과 같다: Ala에서 Gly 또는 Ser로; Arg에서 Lys로; Asn에서 Gln 또는 His로; Asp에서 Glu로; Cys에서 Ser로; Gln에서 Asn으로; Glu에서 Asp로; Gly에서 Ala 또는 Pro로; His에서 Asn 또는 Gln으로; Iel에서 Leu 또는 Val로; Leu에서 lle 또는 Val로; Lys에서 Arg, Gln 또는 Glu로; Met에서 Leu, Tyr 또는 lle로; Phe에서 Met, Leu 또는 Tyr로; Ser에서 Thr로; Thr에서 Ser로; Trp에서 Tyr로; Tyr에서 Trp 또는 Phe로; Val에서 Ile 또는 Leu로.
용어 "폴리펩티드", "펩티드" 및 "단백질"(단일 사슬인 경우)은 본원에서 상호 교환적으로 사용된다.
용어 "핵산", "핵산 서열", "뉴클레오티드 서열" 또는 "폴리뉴클레오티드 서열" 및 "폴리뉴클레오티드"는 상호 교환적으로 사용된다.
본원에 사용된 용어 "단리된 (isolated)"은 원래 또는 자연 환경 (예를 들어, 자연 발생인 경우 천연 환경)으로부터 제거되는 물질을 지칭한다. 예를 들어, 살아있는 동물에 존재하는 자연 발생 폴리뉴클레오티드 또는 폴리펩티드는 단리된 것이 아니지만, 인간이 개입하여 자연계에서 공존하는 물질의 일부 또는 전부로부터 분리된 동일한 폴리뉴클레오티드 또는 폴리펩티드는 단리된 것이다. 그러한 폴리뉴클레오티드는 벡터의 일부일 수 있고/있거나 그러한 폴리뉴클레오티드 또는 폴리펩티드는 조성물의 일부일 수 있고, 그러한 벡터 또는 조성물은 자연계에서 발견되는 환경의 일부가 아니라는 점에서 여전히 단리된 것일 수 있다.
바람직하게는, 핵산은 이 핵산 분자가 적어도 하나의 조절 서열에 작동 가능하게 연결된 발현 벡터의 일부일 것이며, 여기서 조절 서열은 프로모터, 인핸서 또는 종결 서열, 가장 바람직하게는 이종 프로모터, 인핸서 또는 종결 서열일 수 있다.
발명의 상세한 설명
항-PD1 항체에 관한 본 발명의 실시양태
상기에서 상세히 설명한 바와 같이, PD1은 T-세포 활성 및 따라서 면역계 활성을 조절하는데 중요한 역할을 한다. 상이한 광범위 암 환경에서 길항성 항-PD1 항체 분자가 T 세포 활성을 증가시켜 면역계를 활성화시킴으로써 종양을 공격하게 되고 이에 따라 암을 치료할 수 있는 것으로 나타났다.
그러나, 기존의 항-PD1 항체 분자는 부작용과 관련된 문제를 겪고 있으며 상당 비율의 환자가 치료에 반응하지 않는다. 따라서, 종래 기술과 비교할 때 개선된 치료 지수를 갖는 다른 항-PD1 항체 분자를 동정할 필요가 있다. 이러한 분자는 단일 요법에서, 그리고 추가적인 치료제, 특히 T-세포 활성의 다른 조절제와 함께 사용될 수 있다.
이러한 배경으로, 본 발명자들은 추가의 항-PD1 항체를 생성하고자 하였다. PD1에 대한 선조 뮤린 항체 (77E11이라 칭함)로부터 시작하여, 본 발명의 대상 항-PD1 항체 분자인 5개의 인간화된 유도체를 제조하였다. 본 발명의 항-PD1 항체 분자는 PD1-1, PD1-2, PD1-3, PD1-4 및 PD1-5로 칭해진다.
시험관 내 T-세포 활성화 검정 (실시예 4에서 추가로 기술됨)을 사용하여 본 발명의 대표적인 항-PD1 항체의 기능적 특성을 조사하였다. 실시예 12 및 도 8에서 알 수 있는 바와 같이, 시험된 항체는 항-LAG3 항체와 조합하였을 때 기준 항-PD1/LAG3 항체 조합물과 비교하여 더 높은 수준으로 T-세포 활성화를 유도할 수 있었고, 이는 기준 항-PD1 항체보다 더 바람직한 치료 활성을 가짐을 제시한다.
인식할 수 있는 바와 같이, 선행 기술의 기준 항-PD1 항체보다 T-세포 활성화를 보다 효과적으로 유도하는 본 발명의 항-PD1 항체의 이러한 놀라운 능력은 선행 기술의 기준 항-PD1 항체보다 더 낮은 투여량에서 암을 치료할 수 있고 따라서 원치 않는 부작용을 덜 나타내는 치료적 응용을 가능케 할 수 있음을 시사한다.
본 발명자들은 상기 데이터에 고무되어, 본 발명의 항-PD1 항체 분자의 다양한 다른 기능적 특성을 추가로 조사하였다. 이 평가에 생체 내 약동학적 성질의 결정이 포함되었다. 실시예 7에 요약되고 도 5에 도시된 바와 같이, 사이노몰거스 원숭이에서 측정되었을 때, 1 mg/kg의 정맥 내 용량에서 본 발명의 항-PD1 항체의 실시예에서 관찰된 종말 제거 반감기는 선행 기술의 항-PD1 항체보다 1.5 내지 2배 더 높았다.
당 업계에 공지된 항-PD1 항체와 대조적으로, 이는 본 발명의 항-PD1 항체가 11일의 혈청 반감기를 갖는다는 것을 제시한다. 이것은 이하 실시예에서 알 수 있는 바와 같이, 전형적으로 0.3-3 mg/kg의 용량 범위에서 4 내지 6일의 반감기를 갖는 공지된 기준 항-PD1 항체 분자와 대조적이다. 청구된 항체 분자의 이러한 놀라운 특징은 환자가 선행 기술의 것으로 처리되는 것보다 덜 빈번하게 본 발명의 항체로 처리되는 것을 허용할 수 있으며, 이것은 감소된 투여 빈도의 형태 또는 사용되는 항체의 감소된 양으로서 공급될 항체 양의 감소를 의미할 수 있다. 항-PD1 항체 분자가 상기에서 논의된 바와 같이 환자에게 원하지 않는 부작용을 유도할 수 있다는 것을 감안하면, 본 발명의 항-PD1 항체는 선행 기술에 비해 유의적이고 놀라운 임상 이점을 가질 수 있다.
따라서, 본 발명의 제1 측면은
(a) 서열번호 1 (hcCDR1), 서열번호 2 (hcCDR2) 및 서열번호 3 (hcCDR3)의 아미노산 서열을 포함하는 중쇄 CDR 및 서열번호 4 (lcCDR1), 서열번호 5 (lcCDR2) 및 서열번호 6 (lcCDR3)의 아미노산 서열을 포함하는 경쇄 CDR; 또는,
(b) 서열번호 7 (hcCDR1), 서열번호 8 (hcCDR2) 및 서열번호 9 (hcCDR3)의 아미노산 서열을 포함하는 중쇄 CDR 및 서열번호 10 (lcCDR), 서열번호 11 (lcCDR2) 및 서열번호 12 (lcCDR3)의 아미노산 서열을 포함하는 경쇄 CDR; 또는,
(c) 서열번호 13 (hcCDR1), 서열번호 14 (hcCDR2) 및 서열번호 15 (hcCDR3)의 아미노산 서열을 포함하는 중쇄 CDR 및 서열번호 16 (lcCDR1), 서열번호 17 (lcCDR2) 및 서열번호 18 (lcCDR3)의 아미노산 서열을 포함하는 경쇄 CDR;
을 포함하는 항-PD1 항체 분자를 제공한다.
상기한 바와 같이, 본 발명의 항-PD1 항체 분자는 PD1-1, PD1-2, PD1-3, PD1-4 및 PD1-5로 칭해진다. 본 발명의 특정 항-PD1 항체 분자에 대한 개별 아미노산 서열의 확인을 용이하게 하는 서열 표가 본원에 제공된다. 이것은 실시예 2의 표 1에 요약되어 있다.
본원에 기재된 바와 같은 CDR 서열에 추가하여, 본 발명의 항체 분자는 면역글로불린 프레임워크 영역 (FR) 서열을 포함한다. 이들 서열은 바람직하게는 인간에서 면역원성이 아니며, 따라서 바람직하게는 인간 또는 인간화된 FR 서열이다. 적합한 인간 또는 인간화된 FR 서열은 당 업계에 공지되어 있다. 특히 바람직한 FR 서열은 완전한 항체 분자 및 이로써 CDR 서열뿐만 아니라 FR 서열을 개시하는, 본원에 나타낸 실시양태로부터 취할 수 있다.
본 발명의 제1 측면의 항체 분자를 제조하는 방법은 당해 분야에 잘 공지되어 있으며, 당업자는 본 발명의 제1 측면의 특징을 갖는 항체 분자를 용이하게 제조할 수 있다. 그러한 방법의 예가 아래에 제공된다.
IgG1 또는 IgG4 타입의 것과 같은 2개의 완전한 중쇄 및 2개의 완전한 경쇄를 포함하는 항체 생산에 대해 [Norderhaug et al., J Immunol Methods 1997, 204 (1): 77-87; Kipriyanow and Le Gall, Molecular Biotechnology 26: 39-60, 2004; Shukla et al., 2007, J. Chromatography B, 848(1): 28-39]이 참조된다.
기능적 scFv 분자를 산출하기 위해 숙주 세포 (E. coli, Pichia pastoris, 또는 포유동물 세포주, 예를 들면 CHO 또는 NS0)에서 scFv 작제물을 코딩하는 핵산의 재조합 발현에 의해 scFv 항체를 제조하는 방법이 또한 공지되었다 [Rippmann et al., Applied and Environmental Microbiology 1998, 64(12): 4862-4869; Yamawaki et al., J. Biosci. Bioeng. 2007, 104(5): 403-407; Sonoda et al., Protein Expr. Purif. 2010, 70(2): 248-253].
오해를 피하기 위해, 본 발명의 제1 측면에 대해 이하에 열거된 각 특정 실시양태들은 또한 본 발명의 독립적인 측면으로 간주될 수 있다.
본 발명의 제1 측면의 바람직한 실시양태는 상기 항체 분자가 인간화 항체 분자인 것이다.
본 발명의 제1 측면의 추가의 바람직한 측면은 상기 항체 분자가 모노클로날 항체, Fab, F(ab')2, Fv 또는 scFv인 것이다.
용어 "인간화된", "Fab", "F(ab')2", "Fv" 및 "scFv"는 당 업계에 잘 공지되어 있으며 본 명세서의 정의 섹션에서 더 논의된다.
바람직한 실시양태에서, 항-PD1 항체 분자는 IgG1, IgG2, IgG3, IgG4, IgM, IgA 및 IgE 불변 영역으로 구성된 군으로부터 선택된 중쇄 불변 영역을 갖는다. 바람직하게는 중쇄 불변 영역은 S241P 돌연변이를 갖는 IgG4이다.
바람직한 실시양태에서, 항-PD1 항체 분자는 카파 또는 람다인 경쇄 불변 영역을 갖는다.
바람직한 실시양태에서, 항-PD1 항체 분자는 서열번호 19, 21, 23, 25 및 27 중 어느 하나와 적어도 85% 동일한 아미노산 서열을 포함하는 중쇄 가변 도메인을 갖는다. 바람직하게는 상기 항체 분자는 서열번호 19, 21, 23, 25 및 27 중 어느 하나의 아미노산 서열을 포함하는 중쇄 가변 도메인을 갖는다.
바람직한 실시양태에서, 항-PD1 항체 분자는 서열번호 20, 22, 24, 26 및 28 중 어느 하나와 적어도 85% 동일한 아미노산 서열을 포함하는 경쇄 가변 도메인을 갖는다. 바람직하게는 상기 항체 분자는 빛 서열번호 20, 22, 24, 26 및 28의 아미노산 서열을 포함하는 경쇄 가변 도메인을 갖는다.
아미노산 서열 동일성을 계산하는 방법은 당 업계에 잘 알려져 있으며 본 명세서의 정의 섹션에서 더 논의된다.
바람직한 실시양태에서, 항-PD1 항체 분자는 서열번호 19의 아미노산 서열을 포함하는 중쇄 가변 도메인을 갖는다.
바람직한 실시양태에서, 항-PD1 항체 분자는 서열번호 29의 아미노산 서열을 포함하는 중쇄를 갖는다.
바람직한 실시양태에서, 항-PD1 항체 분자는 서열번호 21의 아미노산 서열을 포함하는 중쇄 가변 도메인을 갖는다.
바람직한 실시양태에서, 항-PD1 항체 분자는 서열번호 31의 아미노산 서열을 포함하는 중쇄를 갖는다.
바람직한 실시양태에서, 항-PD1 항체 분자는 서열번호 23의 아미노산 서열을 포함하는 중쇄 가변 도메인을 갖는다.
바람직한 실시양태에서, 항-PD1 항체 분자는 서열번호 33의 아미노산 서열을 포함하는 중쇄를 갖는다.
바람직한 실시양태에서, 항-PD1 항체 분자는 서열번호 25의 아미노산 서열을 포함하는 중쇄 가변 도메인을 갖는다.
바람직한 실시양태에서, 항-PD1 항체 분자는 서열번호 35의 아미노산 서열을 포함하는 중쇄를 갖는다.
바람직한 실시양태에서, 항-PD1 항체 분자는 서열번호 27의 아미노산 서열을 포함하는 중쇄 가변 도메인을 갖는다.
바람직한 실시양태에서, 항-PD1 항체 분자는 서열번호 37의 아미노산 서열을 포함하는 중쇄를 갖는다.
바람직한 실시양태에서, 항-PD1 항체 분자는 서열번호 20의 아미노산 서열을 포함하는 경쇄 가변 도메인을 갖는다.
바람직한 실시양태에서, 항-PD1 항체 분자는 서열번호 30의 아미노산 서열을 포함하는 경쇄를 갖는다.
바람직한 실시양태에서, 항-PD1 항체 분자는 서열번호 22의 아미노산 서열을 포함하는 경쇄 가변 도메인을 갖는다.
바람직한 실시양태에서, 항-PD1 항체 분자는 서열번호 32의 아미노산 서열을 포함하는 경쇄를 갖는다.
바람직한 실시양태에서, 항-PD1 항체 분자는 서열번호 24의 아미노산 서열을 포함하는 경쇄 가변 도메인을 갖는다.
바람직한 실시양태에서, 항-PD1 항체 분자는 서열번호 34의 아미노산 서열을 포함하는 경쇄를 갖는다.
바람직한 실시양태에서, 항-PD1 항체 분자는 서열번호 26의 아미노산 서열을 포함하는 경쇄 가변 도메인을 갖는다.
바람직한 실시양태에서, 항-PD1 항체 분자는 서열번호 36의 아미노산 서열을 포함하는 경쇄를 갖는다.
바람직한 실시양태에서, 항-PD1 항체 분자는 서열번호 28의 아미노산 서열을 포함하는 경쇄 가변 도메인을 갖는다.
바람직한 실시양태에서, 항-PD1 항체 분자는 서열번호 38의 아미노산 서열을 포함하는 경쇄를 갖는다.
바람직한 실시양태에서, 항-PD1 항체 분자는 서열번호 19의 아미노산 서열을 포함하는 중쇄 가변 도메인 및 서열번호 20의 아미노산 서열을 포함하는 경쇄 가변 도메인을 갖는다.
바람직한 실시양태에서, 항-PD1 항체 분자는 서열번호 21의 아미노산 서열을 포함하는 중쇄 가변 도메인 및 서열번호 22의 아미노산 서열을 포함하는 경쇄 가변 도메인을 갖는다.
바람직한 실시양태에서, 항-PD1 항체 분자는 서열번호 23의 아미노산 서열을 포함하는 중쇄 가변 도메인 및 서열번호 24의 아미노산 서열을 포함하는 경쇄 가변 도메인을 갖는다.
바람직한 실시양태에서, 항-PD1 항체 분자는 서열번호 25의 아미노산 서열을 포함하는 중쇄 가변 도메인 및 서열번호 26의 아미노산 서열을 포함하는 경쇄 가변 도메인을 갖는다.
바람직한 실시양태에서, 항-PD1 항체 분자는 서열번호 27의 아미노산 서열을 포함하는 중쇄 가변 도메인 및 서열번호 28의 아미노산 서열을 포함하는 경쇄 가변 도메인을 갖는다.
바람직한 실시양태에서, 항-PD1 항체 분자는 서열번호 29의 아미노산 서열을 포함하는 중쇄 및 서열번호 30의 아미노산 서열을 포함하는 경쇄를 갖는다.
바람직한 실시양태에서, 항-PD1 항체 분자는 서열번호 31의 아미노산 서열을 포함하는 중쇄 및 서열번호 32의 아미노산 서열을 포함하는 경쇄를 갖는다.
바람직한 실시양태에서, 항-PD1 항체 분자는 서열번호 33의 아미노산 서열을 포함하는 중쇄 및 서열번호 34의 아미노산 서열을 포함하는 경쇄를 갖는다.
바람직한 실시양태에서, 항-PD1 항체 분자는 서열번호 35의 아미노산 서열을 포함하는 중쇄 및 서열번호 36의 아미노산 서열을 포함하는 경쇄를 갖는다.
바람직한 실시양태에서, 항-PD1 항체 분자는 서열번호 37의 아미노산 서열을 포함하는 중쇄 및 서열번호 38의 아미노산 서열을 포함하는 경쇄를 갖는다.
상기 모든 실시양태에 있어서, "포함하는"이라는 용어를 사용함으로써, 각각의 도메인 또는 분자가 지시된 바와 같은 아미노산 서열로 "구성되는" 실시양태를 또한 포함하는 것으로 이해해야 할 것이다.
바람직한 실시양태에서, 항-PD1 항체 분자는 10 nM 미만의 해리 상수 (KD)로 인간 PD1에 결합할 수 있다.
일부 실시양태에서, 항-PD1 항체 분자는 높은 친화력으로 인간 PD1 및 사이 노몰거스 원숭이 PD1에 결합할 수 있다. 일부 실시양태에서, 높은 친화도는 SPR에 의해 측정되어 10 nM 미만, 예를 들어 9, 8, 7, 6 또는 그 아래의 KD를 지칭한다. SPR을 사용하여 KD를 결정하기 위한 프로토콜은 이하 실시예에서 제공된다.
바람직한 실시양태에서, 항-PD1 항체 분자는 마우스 PD1에 결합하지 않는다.
바람직한 실시양태에서, 항-PD1 항체 분자는 인간 PD1과 인간 PD-L1/L2의 결합을 감소시킬 수 있다. 인간 PD1과 인간 PD-L1/L2의 결합을 결정하기 위한 분석은 이하 실시예에서 제공된다.
일부 실시양태에서, 항-PD1 항체 분자는 10 nM 미만, 9, 8, 7, 6, 5 또는 4 nM 이하의 IC90으로 PD1에 대한 리간드 PD-L1 및 PD-L2의 결합을 억제할 수 있다. IC90을 결정하기 위한 프로토콜은 이하 실시예에서 제공된다.
바람직한 실시양태에서, 항-PD1 항체 분자는 항원 특이적 T 세포 반응을 증강시킬 수 있다. 항원-특이적 T 세포 반응을 결정하기 위한 분석은 실시예 4에서 제공된다.
본 발명의 추가 측면은 본 발명의 제1 측면 중 어느 하나의 항-PD1 항체 분자의 중쇄 가변 도메인 및/또는 경쇄 가변 도메인을 코딩하는 단리된 핵산 분자를 제공한다.
바람직하게는, 핵산 분자는 서열번호 19, 21, 23, 25 또는 27의 중쇄 가변 도메인을 각각 코딩하는 서열번호 71, 73, 75, 77 또는 79 의 뉴클레오티드 서열을 포함한다. 바람직하게는, 핵산 분자는 서열번호 20, 22, 24, 26 또는 28의 경쇄 가변 도메인을 각각 코딩하는 서열번호 72, 74, 76, 78 또는 80의 뉴클레오티드 서열을 포함한다.
본 발명의 또 다른 측면은 본 발명의 항-PD1 항체 분자의 중쇄 가변 도메인 및/또는 경쇄 가변 도메인을 코딩하는 뉴클레오티드 서열을 포함하는 DNA 분자를 함유하는 발현 벡터를 제공한다. 바람직하게는, 발현 벡터는 서열번호 71 및/또는 서열번호 72의 뉴클레오티드 서열을 포함하거나, 서열번호 73 및/또는 서열번호 74의 뉴클레오티드 서열을 포함하거나, 서열번호 75 및/또는 서열번호 76의 뉴클레오티드 서열을 포함하거나, 서열번호 77 및/또는 서열번호 78의 뉴클레오티드 서열을 포함하거나, 서열번호 79 및/또는 서열번호 80의 뉴클레오티드 서열을 포함하는 DNA 분자를 함유한다.
바람직하게는, 발현 벡터는 또한 각각 중쇄 가변 도메인 및/또는 경쇄 가변 도메인을 코딩하는 핵산 분자, 바람직하게는 DNA 분자에 연결된 중쇄의 불변 도메인 및/또는 경쇄의 불변 도메인을 코딩하는 핵산 분자, 바람직하게는 DNA 분자를 포함한다.
특히 바람직한 실시양태에서, 두개의 발현 벡터를 사용할 수 있는데, 그 중 하나는 중쇄의 발현을 위한 것이고 다른 하나는 경쇄의 발현을 위한 것으로서, 두 발현 벡터는 재조합 단백질 발현을 위해 숙주 세포 내로 형질감염될 수 있다.
바람직하게는, 발현 벡터는 적어도 하나의 조절 서열에 작동 가능하게 연결된 상기 핵산 분자 또는 핵산 분자들을 포함하는 벡터일 것이며, 상기 조절 서열은 프로모터, 인핸서 또는 종결 서열, 가장 바람직하게는 이종 프로모터, 인핸서, 또는 종결 서열일 수 있다.
본 발명의 핵산은 본원에서 주어진 본 발명의 항체에 대한 아미노산 서열에 대한 정보에 기초하여 그 자체로 공지된 방식으로 (예를 들어, 자동화된 DNA 합성 및/또는 재조합 DNA 기술에 의해) 제조되거나 수득될 수 있다.
다른 측면에서, 본 발명은 본 발명의 항-PD1 항체 분자의 중쇄를 코딩하는 발현 벡터 및 본 발명의 항-PD1 항체 분자의 경쇄를 코딩하는 발현 벡터를 갖는 숙주 세포에 관한 것이다.
특히 바람직한 실시양태에 따라, 상기 숙주 세포는 포유동물 세포와 같은 진핵 세포이다. 또 다른 실시양태에서, 그러한 숙주 세포는 박테리아 세포이다. 다른 유용한 세포는 효모 세포 또는 다른 진균 세포이다.
적합한 포유동물 세포는 예를 들어 CHO 세포, BHK 세포, HeLa 세포, COS 세포 등을 포함한다. 그러나, 양서 세포, 곤충 세포, 식물 세포 및 이종 단백질의 발현을 위해 당 업계에서 사용되는 임의의 다른 세포가 또한 사용될 수 있다.
항-LAG3 항체 분자 및 항-PD1 항체와의 조합에 관한 본 발명의 실시양태
상기에서 설명한 바와 같이, PD1은 T-세포 활성 및 따라서 면역계 활성을 조절하는데 중요한 역할을 한다. 상이한 광범위 암 환경에서 길항성 항-PD1 항체 분자가 T 세포 활성을 증가시켜 면역계를 활성화시킴으로써 종양을 공격하고 이에 따라 암을 치료할 수 있는 것으로 나타났다.
길항성 항-PD1 항체와 추가 면역 세포 체크포인트 억제제를 표적으로 하는 항체 분자의 조합은 길항성 항-PD1 항체의 항암 특성을 강화시킬 수 있다는 것이 또한 밝혀졌다. 그러한 체크포인트 억제제 중 하나가 LAG3으로 불린다.
PD1과 마찬가지로, LAG3는 T 세포 활성을 매개하는데 역할을 하는 것으로 보인다. 또한, PD1 경로 및 LAG3의 이중 차단이 분자 단독을 차단하는 것보다 항-종양 면역에 더 효과적이라는 것이 당 업계에 공지되어 있다.
이러한 배경으로, 본 발명자들은 단독으로 또는 본 발명의 항-PD1 항체 분자와 조합하여 사용될 수 있는 추가의 항-LAG3 항체 분자를 생성하고자 하였다. LAG3에 대한 전구 뮤린 항체 (496G6으로 명명됨)로 시작하여, 본 발명의 대상 항-LAG3 항체 분자인 5개의 인간화된 유도체를 제조하였다. 본 발명의 항-LAG3 항체 분자는 LAG3-1, LAG3-2, LAG3-3, LAG3-4 및 LAG3-5로 지칭된다.
시험관 내 T-세포 활성화 검정 (실시예 12에서 추가로 기술됨)을 사용하여 본 발명의 대표적인 항-LAG3 항체 분자의 기능적 특성을 조사하였다. 실시예 12 및 도 8에서 알 수 있는 바와 같이, 본 발명의 항-LAG3 항체 분자와 본 발명의 항-PD1 항체 분자의 조합은 놀랍게도 당 업계에 공지된 기준 항-PD1/LAG3 항체 조합보다 우수하다.
인식할 수 있는 바와 같이, 본 발명의 항-LAG3 항체 분자와 본 발명의 항-PD1 항체 분자의 조합의 이러한 우월성은 이들이 선행 기술의 항체 치료제보다 낮은 투여량 수준에서 암을 치료할 수 있고 따라서 원치 않는 부작용을 덜 나타내는 치료적 응용을 가능케 할 수 있음을 시사한다.
항-PD1 및 항-LAG3 항체 분자가 상기 논의한 바와 같이 환자에서 바람직하지 않은 부작용을 유도할 수 있음을 감안한다면, 본 발명의 항-PD1 항체 및 항-LAG3 항체는 낮은 투여량 및/또는 덜 빈번한 투여 체제를 사용함으로써 선행 기술에 비해 유의적이고 놀라운 임상적 이점을 가질 수 있다.
본 발명자들은 상기 데이터에 고무되어, 본 발명의 항-LAG3 항체 분자의 다양한 다른 기능적 특성을 추가로 조사하였다. 이 평가에 본 발명의 항-LAG3 항체 분자의 실시예에 의해 결합된 에피토프의 결정이 포함되었다. 실시예 11에서 알 수 있는 바와 같이, 본 발명자들은 본 발명의 항-LAG3 항체 분자가 인간 LAG-3, LLRRAGVT (서열번호 111) 및/또는 YRAAVHLRDRA (서열번호 112)의 두 상이한 영역에 결합할 수 있다고 결정하였다.
발명자들이 아는 한, 공지된 선행 기술의 항-LAG3 항체는 본 발명의 항-LAG3 항체 분자와 동일한 항원 결정자 결합 프로파일을 갖지 않는다. 어떤 특정 이론에 얽매임이 없이, 본 발명자들은 선행 기술 분자와 비교할 때 본 발명의 항-LAG3 항체 분자와 본 발명의 항-PD1 항체의 조합의 놀라운 개선된 효과는 본 발명의 항-LAG3 항체 분자의 에피토프 결합 프로파일에 기인할 수 있다고 추측하고 있다.
따라서, 본 발명의 또 다른 측면은 아미노산 서열 아미노산 서열 LLRRAGVT (서열번호 111) 및/또는 YRAAVHLRDRA (서열번호 112)를 포함하는 인간 LAG3의 에피토프에 결합하는 단리된 항-LAG3 항체 분자를 제공한다. 이러한 분자는 본원에서 "본 발명의 항-LAG3 항체 분자"로서 칭해진다.
본 발명의 에피토프 결합 특성을 갖는 항-LAG3 항체 분자를 제조하는 방법은 당 업계에 익히 공지되었다.
항체 및 항체 단편을 생성하는 방법은 당 업계에 잘 알려져 있다. 예를 들어, 항체는 항체 분자의 생체 내 생산의 유도, 면역글로불린 라이브러리의 스크리닝 (Orlandi et al, 1989. Proc. Natl. Acad. Sci. U.S.A. 86:3833-3837; Winter et al 1991, Nature 349:293-299) 또는 배양물에서 세포주에 의한 모노클로날 항체 분자의 생성을 이용하는 몇몇 방법 중 어느 한 방법으로 생성할 수 있다. 이들은 하이브리도마 기술, 인간 B-세포 하이브리도마 기술, 및 엡스타인-바 바이러스 (EBV)-하이브리도마 기술을 포함하나 이에 한정되지 않는다 (Kohler et al 1975. Nature 256:4950497; Kozbor et al 1985. J. Immunol. Methods 81: 31-42; Cote et al 1983. Proc. Natl. Acad. Sci. USA 80:2026-2030; Cole et al 1984. Mol. Cell. Biol. 62:109-120).
이들 방법을 사용하여 당업자가 LAG3에 대해 필요한 특이성을 갖는 결합 부위를 가지는 항체를 제조하는 것은 일상적인 것이다. 이어 후보 항체 분자를 본 발명의 항-LAG3 항체가 요구하는 것과 동일한 에피토프 서열에 결합하는지를 결정하기 위해 에피토프 맵핑을 사용하여 스크리닝할 수 있다. 이러한 에피토프 맵핑 방법은 당 업계에 잘 알려져 있고 당업자에 의해 용이하게 채택될 수 있다. 또한, 이러한 방법론의 예가 본 명세서의 실시예 11에 제공된다.
오해를 피하기 위해, 본 발명의 항-LAG3 항체에 대해 이하에 열거된 각 특정 실시양태들은 또한 본 발명의 독립적인 측면으로 간주될 수 있다.
본 발명의 제1 측면의 바람직한 실시양태는 상기 항체 분자가 인간화 항체 분자인 것이다.
추가의 바람직한 실시양태는 상기 항체 분자가 모노클로날 항체, Fab, F(ab')2, Fv 또는 scFv인 것이다.
용어 "인간화된", "Fab", "F(ab')2", "Fv" 및 "scFv"는 당 업계에 잘 알려져 있으며 본 명세서의 정의 섹션에서 더 논의된다.
바람직한 실시양태에서, 항-LAG3 항체 분자는 IgG1, IgG2, IgG3, IgG4, IgM, IgA 및 IgE 불변 영역으로 구성된 군으로부터 선택된 중쇄 불변 영역을 갖는다. 바람직하게는 중쇄 불변 영역은 S241P 돌연변이를 갖는 IgG4이다.
바람직한 실시양태에서, 항-LAG3 항체 분자는 카파 또는 람다인 경쇄 불변 영역을 갖는다.
추가의 바람직한 실시양태는 상기 항-LAG3 항체 분자가
(a) 서열번호 39 (hcCDR1), 서열번호 40 (hcCDR2) 및 서열번호 41 (hcCDR3)의 아미노산 서열을 포함하는 중쇄 CDR 및 서열번호 42 (lcCDR1), 서열번호 43 (lcCDR2) 및 서열번호 44 (lcCDR3)의 아미노산 서열을 포함하는 경쇄 CDR; 또는
(b) 서열번호 45 (hcCDR1), 서열번호 46 (hcCDR2) 및 서열번호 47 (hcCDR3)의 아미노산 서열을 포함하는 중쇄 CDR 및 서열번호 48 (lcCDR1), 서열번호 49 (lcCDR2) 및 서열번호 50 (lcCDR3)의 아미노산 서열을 포함하는 경쇄 CDR을 포함하는 것이다.
상기한 바와 같이, 본 발명의 항-LAG3 항체 분자는 LAG3-1, LAG3-2, LAG3-3, LAG3-4 및 LAG3-5로 칭해진다. 본 발명의 특정 항-LAG3 항체 분자에 대한 개별 아미노산 서열의 확인을 용이하게 하는 서열 표가 본원에 제공된다. 이것은 실시예 9의 표 6에 요약되어 있다.
본 발명의 항-LAG3 항체 분자를 제조하는 방법은 당 업계에 잘 알려져 있으며, 당업자는 항체 분자를 용이하게 제조할 수 있다. 그러한 방법의 예는 본 발명의 제1 측면과 관련하여 상기에 제공되었다.
바람직한 실시양태에서, 항-LAG3 항체 분자는 서열번호 51, 53, 55, 57 및 59 중 어느 하나와 적어도 85% 동일한 아미노산 서열을 포함하는 중쇄 가변 도메인을 갖는다. 바람직하게는 상기 항체 분자는 서열번호 51, 53, 55, 57 및 59 중 어느 하나의 아미노산 서열을 포함하는 중쇄 가변 도메인을 갖는다.
바람직한 실시양태에서, 항-LAG3 항체 분자는 서열번호 52, 54, 56, 58 및 60 중 어느 하나와 적어도 85% 동일한 아미노산 서열을 포함하는 경쇄 가변 도메인을 갖는다. 바람직하게는 상기 항체 분자는 서열번호 52, 54, 56, 58 및 60의 아미노산 서열을 포함하는 경쇄 가변 도메인을 갖는다.
아미노산 서열 동일성을 계산하는 방법은 당 업계에 잘 알려져 있으며 본 명세서의 정의 섹션에서 더 논의된다.
바람직한 실시양태에서, 항-LAG3 항체 분자는 서열번호 51의 아미노산 서열을 포함하는 중쇄 가변 도메인을 갖는다.
바람직한 실시양태에서, 항-LAG3 항체 분자는 서열번호 61의 아미노산 서열을 포함하는 중쇄를 갖는다.
바람직한 실시양태에서, 항-LAG3 항체 분자는 서열번호 53의 아미노산 서열을 포함하는 중쇄 가변 도메인을 갖는다.
바람직한 실시양태에서, 항-LAG3 항체 분자는 서열번호 63의 아미노산 서열을 포함하는 중쇄를 갖는다.
바람직한 실시양태에서, 항-LAG3 항체 분자는 서열번호 55의 아미노산 서열을 포함하는 중쇄 가변 도메인을 갖는다.
바람직한 실시양태에서, 항-LAG3 항체 분자는 서열번호 65의 아미노산 서열을 포함하는 중쇄를 갖는다.
바람직한 실시양태에서, 항-LAG3 항체 분자는 서열번호 57의 아미노산 서열을 포함하는 중쇄 가변 도메인을 갖는다.
바람직한 실시양태에서, 항-LAG3 항체 분자는 서열번호 67의 아미노산 서열을 포함하는 중쇄를 갖는다.
바람직한 실시양태에서, 항-LAG3 항체 분자는 서열번호 59의 아미노산 서열을 포함하는 중쇄 가변 도메인을 갖는다.
바람직한 실시양태에서, 항-LAG3 항체 분자는 서열번호 69의 아미노산 서열을 포함하는 중쇄를 갖는다.
바람직한 실시양태에서, 항-LAG3 항체 분자는 서열번호 52의 아미노산 서열을 포함하는 경쇄 가변 도메인을 갖는다.
바람직한 실시양태에서, 항-LAG3 항체 분자는 서열번호 62의 아미노산 서열을 포함하는 경쇄를 갖는다.
바람직한 실시양태에서, 항-LAG3 항체는 서열번호 54의 아미노산 서열을 포함하는 경쇄 가변 도메인을 갖는다.
바람직한 실시양태에서, 항-LAG3 항체 분자는 서열번호 64의 아미노산 서열을 포함하는 경쇄를 갖는다.
바람직한 실시양태에서, 항-LAG3 항체 분자는 서열번호 56의 아미노산 서열을 포함하는 경쇄 가변 도메인을 갖는다.
바람직한 실시양태에서, 항-LAG3 항체 분자는 서열번호 66의 아미노산 서열을 포함하는 경쇄를 갖는다.
바람직한 실시양태에서, 항-LAG3 항체 분자는 서열번호 58의 아미노산 서열을 포함하는 경쇄 가변 도메인을 갖는다.
바람직한 실시양태에서, 항-LAG3 항체 분자는 서열번호 68의 아미노산 서열을 포함하는 경쇄를 갖는다.
바람직한 실시양태에서, 항-LAG3 항체 분자는 서열번호 60의 아미노산 서열을 포함하는 경쇄 가변 도메인을 갖는다.
바람직한 실시양태에서, 항-LAG3 항체 분자는 서열번호 70의 아미노산 서열을 포함하는 경쇄를 갖는다.
바람직한 실시양태에서, 항-LAG3 항체 분자는 서열번호 51의 아미노산 서열을 포함하는 중쇄 가변 도메인 및 서열번호 52의 아미노산 서열을 포함하는 경쇄 가변 도메인을 갖는다.
바람직한 실시양태에서, 항-LAG3 항체 분자는 서열번호 53의 아미노산 서열을 포함하는 중쇄 가변 도메인 및 서열번호 54의 아미노산 서열을 포함하는 경쇄 가변 도메인을 갖는다.
바람직한 실시양태에서, 항-LAG3 항체 분자는 서열번호 55의 아미노산 서열을 포함하는 중쇄 가변 도메인 및 서열번호 56의 아미노산 서열을 포함하는 경쇄 가변 도메인을 갖는다.
바람직한 실시양태에서, 항-LAG3 항체 분자는 서열번호 57의 아미노산 서열을 포함하는 중쇄 가변 도메인 및 서열번호 58의 아미노산 서열을 포함하는 경쇄 가변 도메인을 갖는다.
바람직한 실시양태에서, 항-LAG3 항체 분자는 서열번호 59의 아미노산 서열을 포함하는 중쇄 가변 도메인 및 서열번호 60의 아미노산 서열을 포함하는 경쇄 가변 도메인을 갖는다.
바람직한 실시양태에서, 항-LAG3 항체 분자는 서열번호 61의 아미노산 서열을 포함하는 중쇄 및 서열번호 62의 아미노산 서열을 포함하는 경쇄를 갖는다.
바람직한 실시양태에서, 항-LAG3 항체 분자는 서열번호 63의 아미노산 서열을 포함하는 중쇄 및 서열번호 64의 아미노산 서열을 포함하는 경쇄를 갖는다.
바람직한 실시양태에서, 항-LAG3 항체 분자는 서열번호 65의 아미노산 서열을 포함하는 중쇄 및 서열번호 66의 아미노산 서열을 포함하는 경쇄를 갖는다.
바람직한 실시양태에서, 항-LAG3 항체 분자는 서열번호 67의 아미노산 서열을 포함하는 중쇄 및 서열번호 68의 아미노산 서열을 포함하는 경쇄를 갖는다.
바람직한 실시양태에서, 항-LAG3 항체 분자는 서열번호 69의 아미노산 서열을 포함하는 중쇄 및 서열번호 70의 아미노산 서열을 포함하는 경쇄를 갖는다.
상기 모든 실시양태에 있어서, "포함하는"이라는 용어를 사용함으로써, 각각의 분자 또는 도메인이 지시된 바와 같은 아미노산 서열로 구성되는 실시양태를 또한 포함하고자 한다.
바람직한 실시양태에서, 항-LAG3 항체 분자는 1 nM 미만의 해리 상수 (KD)로 인간 LAG3에 결합할 수 있다.
일부 실시양태에서, 항-LAG3 항체 분자는 인간 LAG3 및 사이노몰거스 원숭이 LAG3에 고친화력으로 결합할 수 있다. 일부 실시양태에서, 높은 친화도는 0.5 nM 미만, 예를 들어 0.4, 0.3, 0.2, 0.1, 0.09, 0.08, 0.07 또는 그 아래의 KD를 지칭한다. SPR을 사용하여 KD를 결정하기 위한 프로토콜은 이하 실시예에서 제공된다.
추가의 실시양태에서, 항-LAG3 항체 분자는 마우스 LAG3에 결합하지 않는다.
추가의 실시양태에서, 항-LAG3 항체 분자는 하기 특성 중 적어도 하나를 가질 수 있다: (i) 사이노몰거스 원숭이 LAG3에 결합; (ii) 뮤린 LAG3에 대한 결합의 결여; (iii) LAG3의 MHC II에 대한 결합 억제; 및 (iv) 면역 반응 자극.
본 발명의 추가의 측면은 의약에 사용하기 위한 본 발명의 항-LAG3 항체 분자를 제공한다.
본 발명의 또 다른 측면은 본 발명의 항-LAG3 항체 분자의 중쇄 가변 도메인 및/또는 경쇄 가변 도메인을 코딩하는 단리된 핵산 분자를 제공한다. 바람직하게는, 핵산 분자는 서열번호 51, 53, 55, 57 또는 59의 중쇄 가변 도메인을 각각 코딩하는 서열번호 91, 93, 95, 97 또는 99의 뉴클레오티드 서열을 포함한다. 바람직하게는, 핵산 분자는 서열번호 52, 54, 56, 58 또는 60의 경쇄 가변 도메인을 각각 코딩하는 서열번호 92, 94, 96, 98 또는 100의 뉴클레오티드 서열을 포함한다.
본 발명의 또 다른 측면은 본 발명의 항-LAG3 항체 분자의 중쇄 및/또는 경쇄를 코딩하는 뉴클레오티드 서열을 포함하는 DNA 분자를 함유하는 발현 벡터를 제공한다. 바람직하게는 발현 벡터는 서열번호 101 및/또는 서열번호 102의 뉴클레오티드 서열을 포함하거나, 서열번호 103 및/또는 서열번호 104의 뉴클레오티드 서열을 포함하거나, 서열번호 105 및/또는 서열번호 106의 뉴클레오티드 서열을 포함하거나, 서열번호 107 및/또는 서열번호 108의 뉴클레오티드 서열을 포함하거나, 서열번호 109 및/또는 서열번호 110의 뉴클레오티드 서열을 포함하는 DNA 분자를 함유한다.
특히 바람직한 실시양태에서, 두개의 발현 벡터를 사용할 수 있는데, 그 중 하나는 중쇄의 발현을 위한 것이고 다른 하나는 경쇄의 발현을 위한 것으로서, 두 발현 벡터는 재조합 단백질 발현을 위해 숙주 세포 내로 형질감염될 수 있다.
바람직하게는, 발현 벡터는 적어도 하나의 조절 서열에 작동 가능하게 연결된 상기 핵산 분자를 포함하는 벡터일 것이며, 상기 조절 서열은 프로모터, 인핸서 또는 종결 서열, 가장 바람직하게는 이종 프로모터, 인핸서, 또는 종결 서열일 수 있다.
본 발명의 핵산은 본 발명의 항-PD1 항체와 관련하여 추가로 상술된 바와 같이, 본원에서 주어진 본 발명의 항체에 대한 아미노산 서열에 대한 정보에 기초하여 그 자체로 공지된 방식으로 (예를 들어, 자동화 DNA 합성 및/또는 재조합 DNA 기술에 의해) 제조되거나 수득될 수 있다.
다른 측면에서, 본 발명은 본 발명의 항-LAG3 항체 분자의 중쇄를 코딩하는 발현 벡터 및 본 발명의 항-LAG3 항체 분자의 경쇄를 코딩하는 발현 벡터를 갖는 숙주 세포에 관한 것이다.
특히 바람직한 실시양태에 따라, 상기 숙주 세포는 포유동물 세포와 같은 진핵 세포, 예를 들면 항-PD1 항체 실시양태와 관련하여 상기에서 이미 개시된 것들이다. 또 다른 실시양태에서, 그러한 숙주 세포는 박테리아 세포이다. 다른 유용한 세포는 효모 세포 또는 다른 진균 세포이다.
항-PD1 및 항-LAG3 항체를 포함하는 약학적 조성물, 요소들의 키트, 방법 및 용도에 관한 본 발명의 실시양태.
본 발명의 또 다른 측면은 본 발명의 항-PD1 항체 분자 및 항-LAG3 항체 분자를 포함하는 요소들의 키트를 제공한다. 바람직하게는, 항-LAG3 항체 분자는 본 발명의 항-LAG3 항체 분자이다.
본 발명의 또 다른 측면은 본 발명의 항-LAG3 항체 분자 및 항-PD1 항체 분자를 포함하는 요소들의 키트를 제공한다. 바람직하게는, 항-PD1 항체 분자는 본 발명의 항-PD1 항체 분자이다. 대안적으로, 펨브롤리주맵 또는 니볼루맵과 같은 다른 항-PD1 항체를 이러한 요소들의 키트에 사용할 수 있다.
본 발명의 추가의 측면은 본 발명의 항-PD1 항체 분자를 포함하는 약학적 조성물을 제공한다. 본 발명의 일 실시양태는 약학적 조성물이 항-LAG3 항체 분자를 추가로 포함하는 것이다. 바람직하게는, 항-LAG3 항체 분자는 본 발명의 항-LAG3 항체 분자이다.
본 발명의 추가의 측면은 본 발명의 항-LAG3 항체 분자를 포함하는 약학적 조성물을 제공한다. 본 발명의 일 실시양태는 약학적 조성물이 항-PD1 항체 분자를 추가로 포함하는 것이다. 바람직하게는, 항-PD1 항체 분자는 본 발명의 항-PD1 항체 분자이다. 대안적으로, 또 다른 항-PD1 항체, 예컨대 펨브롤리주맵 또는 니볼루맵이 이러한 약학적 조성물에 사용될 수 있다.
당업자에게 자명한 바와 같이 상기 내용에 기초하여 상기한 본 발명의 항체 분자를 사용한 질환 (하기에 상세히 기술됨) 치료를 위한 약학적 조성물 및 본 발명의 이러한 약학적 조성물 또는 항체 분자를 사용한 질환 (하기에 상세히 기술됨)의 치료 방법이 개시된다.
오해를 피하기 위해, 본 발명의 요소들의 키트 및 약학적 조성물은 전술한 바와 같은 본 발명의 특정 항-PD1 항체 분자 및/또는 항-LAG3 항체 분자 중 임의의 것을 포함할 수 있다.
본 발명의 항-PD1 항체 분자 및 본 발명의 항-LAG3 항체 분자가 동일한 투여 경로를 통해 동시에 투여되는 경우, 이들은 상이한 약학 제제 또는 조성물로서, 또는 조합된 약학적 제형 또는 조성물의 일부로서 투여될 수 있다. 또한, 본 발명의 항-PD1 항체 분자 및 본 발명의 항-LAG3 항체 분자를 병용 치료 계획의 일부로서 사용하는 경우, 각 항체는 항체 중 하나가 자체 사용되는 경우와 동일한 계획에 따라 동일한 양으로 투여될 수 있으며, 이러한 병용 사용은 시너지 효과를 일으킬 수도 있고 그렇지 않을 수도 있다. 그러나, 항체의 병용 사용이 상승 효과를 유발하는 경우에, 여전히 원하는 치료 작용을 달성하면서, 항체 중 하나 또는 둘 모두의 양을 감소시키는 것이 가능할 수 있다. 이는 예를 들어 원하는 약리학적 또는 치료학적 효과를 얻으면서도 항체가 그의 일반적인 양으로 사용될 경우 항체 중 어느 하나 또는 양자의 사용과 관련된 어떤 바람직하지 않은 부작용을 회피, 제한 또는 감소시키는데 유용할 수 있다.
약학적 조성물, 투여 방법, 투여량
본 발명은 또한 본 발명의 적어도 하나의 항체 분자를 포함하는 하기에 상세히 설명되는 질환 치료용 약학적 조성물에 관한 것이다. 본 발명은 추가로 본 발명의 적어도 하나의 항체 분자 또는 전술한 바와 같은 약학적 조성물을 사용하여 질환 (하기에 상세히 기술됨)을 치료하는 방법을 포함하고, 추가로 본 발명의 항체 분자(들) 또는 약학적 조성물을 사용하여 이러한 질환을 치료하기 위한 약제의 제조를 포함한다.
본 발명의 항체 분자 및/또는 이를 포함하는 조성물은 사용하고자 하는 특정 약학적 제형 또는 조성물에 따라 임의의 적합한 방식으로 이를 필요로 하는 환자에게 투여될 수 있다. 따라서, 본 발명의 항체 분자 및/또는 이를 포함하는 조성물은 예를 들어, 정맥 내 (iv), 피하 (sc), 근육 내 (im), 복강 내 (ip), 경피 내, 경구로, 설하 (예를 들어, 혀 아래 위치하고 점막을 통해 혀 아래의 모세 혈관망으로 흡수되는 설하용 정제, 스프레이 또는 드롭제의 형태), 비강(내) (비강 분무 형태 및/또는 에어로졸 형태), 국소적으로, 좌제에 의해, 흡입에 의해, 또는 임의의 다른 적절한 방법으로 유효한 양 또는 용량으로 투여될 수 있다.
본 발명의 항체 분자 및/또는 이를 포함하는 조성물은 치료되거나 완화될 질환, 장애 또는 상태를 치료 및/또는 완화시키기에 적합한 치료 계획에 따라 투여된다. 임상의는 일반적으로 치료되거나 완화될 질환, 장애 또는 상태, 질환의 중증도, 그 증상의 중증도, 사용되는 본 발명의 특정 항체 분자, 특정 투여 경로 및 사용되는 약학적 제형 또는 조성물, 환자의 연령, 성별, 체중, 식이, 일반 상태 및 임상의에게 잘 알려진 유사한 인자와 같은 인자에 따라 적합한 치료 계획을 결정할 수 있을 것이다. 일반적으로, 치료 계획은 치료적으로 유효한 양 또는 용량으로 본 발명의 하나 이상의 항체 분자 또는 이를 포함하는 하나 이상의 조성물의 투여를 포함할 것이다.
일반적으로, 본원에서 언급된 질환, 장애 및 상태의 치료 및/또는 완화를 위하고 치료할 특정 질환, 장애 또는 상태, 본 발명의 특정 항체 분자의 효력, 특정 투여 경로 및 사용된 특정 약학적 제형 또는 조성물에 따라, 본 발명의 항체 분자는 일반적으로 체중 1 킬로그램 당 0.005 내지 20.0 mg의 양, 바람직하게는 0.05 내지 10.0 mg/kg/용량, 보다 바람직하게는 0.5 내지 10 mg/kg/용량의 용량으로 연속적으로 (예를 들어, 주입에 의해) 또는 보다 바람직하게는 단일 용량으로서 (예컨대, 주 2 회, 주간 또는 월간 용량; 하기 참조)로 투여될 수 있지만, 특히 앞에서 언급한 파라미터에 따라서 상당히 달라질 수 있다. 따라서, 일부 경우에는 위에 주어진 최소 용량보다 적게 사용하는 것이 충분할 수도 있지만, 다른 경우에는 상한을 초과해야 할 수도 있다. 많은 양을 투여할 때는 하루 동안 다수의 소 용량으로 나누는 것이 권장된다.
본 발명의 특정 항체 분자 및 이의 특이적 약동학 및 다른 특성에 따라, 매일, 매초, 3, 4, 5 또는 6 일, 주간, 월간 등으로 투여될 수 있다. 투여 요법은 장기간, 주간 치료를 포함할 수 있다. "장기간"이란 적어도 2 주, 바람직하게는 수개월 또는 수 년 동안 지속되는 것을 의미한다.
본 발명의 항체 분자 및 이를 포함하는 조성물의 효능은 관련된 특정 질병에 따라서 임의의 적합한 시험관 내 분석, 세포-기반 분석, 생체 내 분석 및/또는 그 자체로 공지된 동물 모델, 또는 이들의 임의의 조합을 사용하여 시험될 수 있다. 적합한 분석 및 동물 모델은 당업자에게 명백할 것이며, 예를 들어 하기 실시예에서 사용되는 분석 및 동물 모델을 포함한다.
제형
약학적 용도로, 본 발명의 항체 분자는 (i) 본 발명의 적어도 하나의 항체 (즉, 본 발명의 항-PD1 항체 또는 본 발명의 항-LAG3 항체 또는 본 발명의 양 항체를 함께) 및 (ii) 적어도 하나의 약학적으로 허용가능한 담체, 희석제, 부형제, 애쥬번트 및/또는 안정화제, 및 (iii) 임의로 하나 이상의 추가의 약리학적 활성 폴리펩티드 및/또는 화합물을 포함하는 약학적 제제로서 제형화될 수 있다. "약학적으로 허용가능한"이란 각각의 물질이 개체에게 투여될 때 어떠한 생물학적 또는 달리 바람직하지 않은 효과를 나타내지 않으며 함유되어 있는 약학적 조성물의 다른 성분들 (예를 들어 약학적 활성 성분) 중 어느 하나와 유해한 방식으로 상호 작용하지 않는다는 것을 의미한다. 특정 예는 표준 핸드북, 예컨대 Remington's Pharmaceutical Sciences, 18th Ed., Mack Publishing Company, USA (1990)에서 찾을 수 있다. 예를 들어, 본 발명의 항체는 통상적인 항체 및 항체 단편 및 다른 약학적으로 활성인 단백질에 대해 그 자체로 공지된 임의의 방식으로 제형화되고 투여될 수 있다. 따라서, 또 다른 실시양태에 따라, 본 발명은 적어도 하나의 본 발명의 항체 및 적어도 하나의 약학적으로 허용가능한 담체, 희석제, 부형제, 애쥬번트 및/또는 안정화제, 및 임의로 하나 이상의 추가의 약리학적 활성 물질을 함유하는 약학적 조성물 또는 제제에 관한 것이다.
정맥 내, 근육 내, 피하 주사 또는 정맥 내 주입과 같은 비경구 투여용 약학적 제제는 예를 들어, 활성 성분을 포함하며 임의로 추가의 용해 또는 희석 단계 후에 주입 또는 주사에 적합한 멸균 용액, 현탁액, 분산액, 유제 또는 분말일 수 있다. 이러한 제제를 위한 적합한 담체 또는 희석제는 예를 들어 멸균수 및 생리 학적 인산염 완충 염수, 링거액, 덱스트로스 용액 및 행크 용액과 같은 약학적으로 허용가능한 수성 완충액 및 용액; 물 오일; 글리세롤; 에탄올; 글리콜, 예컨대 프로필렌 글리콜뿐만 아니라 미네랄 오일, 동물성 오일 및 식물성 오일, 예를 들어 땅콩유, 대두유 및 이들의 적합한 혼합물을 제한없이 포함한다.
또한, 본 발명의 항체 분자의 용액은 항균 및 항진균제, 예를 들어, p-하이드록시벤조에이트, 파라벤, 클로로부탄올, 페놀, 소르브산, 티오메살, 에틸렌디아민 테트라아세트산 (의 알칼리 금속 염) 등과 같은 미생물의 증식을 방지하기 위한 방부제를 함유할 수 있다. 많은 경우에, 당, 완충액 또는 염화나트륨과 같은 등장제를 포함하는 것이 바람직할 것이다. 임의로, 유화제 및/또는 분산제가 사용될 수 있다. 적절한 유동성은 예를 들어, 리포솜의 형성, 분산액의 경우에 필요한 입자 크기의 유지 또는 계면활성제의 사용에 의해 유지될 수 있다. 흡수를 지연시키는 다른 제제, 예를 들면, 알루미늄 모노스테아레이트 및 젤라틴이 또한 첨가될 수 있다. 용액은 주사 바이알, 앰풀, 주입 병 등에 채울 수 있다.
모든 경우에 있어서 최종 투여 형태는 제조 및 저장 조건하에서 무균, 유동성 및 안정해야 한다. 멸균 주사 용액은 활성 화합물을 필요에 따라 상기 열거한 여러 가지 다른 성분과 적절한 용매에 도입한 다음 필터 멸균하여 제조한다. 멸균 주사 용액의 제조를 위한 멸균 분말의 경우, 바람직한 제조 방법은 사전 멸균 여과된 용액에 존재하는 활성 성분과 임의의 추가의 원하는 성분의 분말을 생성하는 진공 건조 및 동결 건조 기술이다.
보통, 수용액 또는 현탁액이 바람직할 것이다. 일반적으로, 본 발명의 항체와 같은 치료 단백질에 적합한 제형은 완충된 단백질 용액, 예컨대 적절한 농도 (예를 들어, 0.001 내지 400 mg/ml, 바람직하게는 0.005 내지 200 mg/ml, 보다 많은 바람직하게는 0.01 내지 200 mg/ml, 보다 바람직하게는 1.0 내지 100 mg/ml, 예컨대 1.0 mg/ml (iv 투여) 또는 100 mg/ml (sc 투여)의 단백질을 포함하는 용액 및 다음과 같은 수성 완충액:
- 포스페이트 완충 염수, pH 7.4,
- 다른 인산염 완충액, pH 6.2 내지 8.2,
- 아세트산염 완충액, pH 3.2 내지 7.5, 바람직하게는 pH 4.8 내지 5.5
- 히스티딘 완충액, pH 5.5 내지 7.0,
- 숙신산염 완충액, pH 3.2 내지 6.6,
- 시트르산염 완충액, pH 2.1 내지 6.2,
및 임의로 용액의 등장성을 제공하기 위한 염 (예, NaCl) 및/또는 당 (예컨대, 수크로스 및 트레할로스) 및/또는 다른 폴리알콜 (예: 만니톨 및 글리세롤)을 포함하는 용액이다.
바람직한 완충 단백질 용액은 220 mM 트레할로스를 첨가함으로써 등장성으로 조정된 25 mM 인산염 완충액, pH 6.5에 용해된 본 발명의 항체를 약 0.05 mg/ml로 포함하는 용액이다. 또한, 다른 제제, 예를 들면, 세제, 예를 들어, 0.02% Tween-20 또는 Tween-80이 이러한 용액에 포함될 수 있다. 피하 적용을 위한 제형은 본 발명의 항체를 상당히 더 높은 농도로, 예컨대 최대 100 mg/ml 또는 심지어 100 mg/ml 초과로 포함할 수 있다. 그러나, 상기 주어진 성분 및 그 양은 오로지 하나의 바람직한 옵션을 나타내고자 한다는 것이 당업자에게는 명백할 것이다. 이들의 대안 및 변형은 당업자에게 아주 분명할 것이거나, 또는 상기 개시 내용으로부터 출발하여 용이하게 구상될 수 있다.
본 발명의 또 다른 측면에 따라, 본 발명의 항체 분자는 주사기, 주입기 펜, 마이크로펌프 또는 다른 장치와 같이 항체의 투여에 유용한 장치와 조합하여 사용될 수 있다.
치료적 사용
본 발명의 추가의 측면은 치료적 유효량의 본 발명의 항-PD1 항체 분자를 이를 필요로 하는 환자에게 투여하는 것을 포함하는 암 치료 방법을 제공한다. 바람직한 실시양태에서, 상기 방법은 상기 환자에게 항-LAG3 항체 분자를 투여하는 것을 추가로 포함한다. 바람직하게는, 항-LAG3 항체 분자는 본 발명의 항-LAG3 항체 분자이다.
본 발명의 추가의 측면은 암 치료 방법에 사용하기 위한 본 발명의 항-PD1 항체 분자를 제공한다. 바람직한 실시양태에서, 본 측면은 항-LAG3 항체 분자의 추가적인 사용을 추가로 포함한다. 바람직하게는, 항-LAG3 항체 분자는 본 발명의 항-LAG3 항체 분자이다.
본 발명의 또 다른 측면은 암 치료용 약학적 조성물을 제조하기 위한 본 발명의 항-PD1 항체 분자의 용도이다. 바람직한 실시양태에서, 본 측면은 항-LAG3 항체 분자의 추가적인 사용을 추가로 포함한다. 바람직하게는, 항-LAG3 항체 분자는 본 발명의 항-LAG3 항체 분자이다.
일 실시양태에서, 항-PD1 항체 분자는 항-LAG3 항체 분자와 동시에, 동반하여, 순차적으로, 연속적으로, 교대로 또는 별도로 투여될 것이다.
본 발명의 추가의 측면은 치료적 유효량의 본 발명의 항-LAG3 항체 분자를 이를 필요로 하는 환자에게 투여하는 것을 포함하는 암 치료 방법을 제공한다. 바람직한 실시양태에서, 상기 방법은 상기 환자에게 항-PD1 항체 분자를 투여하는 것을 추가로 포함한다. 바람직하게는, 항-LAG3 항체 분자는 본 발명의 항-PD1 항체 분자이다.
본 발명의 또 다른 측면은 암 치료 방법에 사용하기 위한 본 발명의 항-LAG3 항체 분자를 제공한다. 바람직한 실시양태에서, 본 측면은 항-PD1 항체 분자의 추가적인 사용을 추가로 포함한다. 바람직하게는, 항-PD1 항체 분자는 본 발명의 항-PD1 항체 분자이다.
본 발명의 또 다른 측면은 암 치료용 약학적 조성물을 제조하기 위한 본 발명의 항-LAG3 항체 분자의 용도이다. 바람직한 실시양태에서, 본 측면은 항-PD1 항체 분자의 추가적인 사용을 추가로 포함한다. 바람직하게는, 항-PD1 항체 분자는 본 발명의 항-PD1 항체 분자이다.
일 실시양태에서, 항-LAG3 항체 분자는 항-PD1 항체 분자와 동시에, 동반하여, 순차적으로, 연속적으로, 교대로 또는 별도로 투여될 것이다.
오해를 피하기 위해, 본 발명의 의학적 용도 측면은 전술한 바와 같은 본 발명의 특정 항-PD1 항체 분자 및/또는 항-LAG3 항체 분자 중 임의의 것을 포함할 수 있다.
그의 생물학적 특성으로 인해, 본 발명의 항체는 암과 같은 과도하거나 비정상적인 세포 증식을 특징으로 하는 질환을 치료하는데 적합하다.
본원에 사용된 용어 "암"은 조직병리학적 유형 또는 침범 단계와 무관하게 모든 유형의 암성 증식 또는 발암 과정, 전이 조직 또는 악성으로 형질전환된 세포, 조직 또는 기관을 포함하는 것을 의미한다. 암성 질환의 예는 고형 종양, 혈액암, 연조직 종양 및 전이성 병변을 포함하나 이에 한정되지 않는다. 고형 종양의 예로는 악성 종양, 예를 들어 간, 폐, 유방, 림프구, 위장 (예: 결장), 비뇨생식관 (예: 신장, 요로상피세포), 전립선 및 인두에 영향을 미치는 것과 같은 다양한 장기 계통의 육종 및 암종 (선암종 및 편평세포 암종 포함)을 들 수 있으나 이들로만 한정되지 않는다. 선암종에는 대부분의 결장암, 직장암, 신세포 암종, 간암, 비소세포 폐암종, 소장암 및 식도암과 같은 악성 종양이 포함된다. 편평세포 암종에는 예를 들어 폐, 식도, 피부, 두경부, 구강, 항문 및 자궁 경부에서의 악성 종양을 포함한다. 일 실시양태에서, 암은 흑색종, 예를 들어, 진행 단계의 흑색종이다. 상기 언급된 암의 전이성 병변이 또한 본원에 기술된 방법 및 조성물을 사용하여 치료 또는 예방될 수 있다.
본원에 개시된 항체 분자를 사용하여 증식이 저해될 수 있는 예시적인 암은 전형적으로 면역요법에 반응하는 암을 포함한다.
예를 들어, 하기 비제한적인 암, 종양 및 기타 증식성 질환이 본 발명에 따른 항체로 치료될 수 있다: 두경부암; 예를 들어 비소세포 폐암 (NSCLC) 및 소세포 폐암 (SCLC)과 같은 폐암; 예를 들어 신경성 종양 및 중간엽 종양과 같은 종격 신생물; 예를 들어 식도암, 위암 (위장암), 췌장암, 간암 및 담도계암 (예를 들어 간세포 암종 (HCC) 포함) 및 소장 및 대장암 (예: 직장결장암 포함)과 같은 위장 (GI)관 암; 전립선암; 고환암; 부인과 암, 예를 들어 난소암; 예를 들어 유방암종, 호르몬 수용체 양성 유방암, Her2 양성 유방암 및 삼중 음성 유방암과 같은 유방의 암; 내분비계 암; 예를 들어 섬유육종, 횡문근육종, 혈관육종, 카포시육종과 같은 연조직 육종; 예를 들어. 골수종, 골육종, 유잉 종양, 섬유육종, 골연골종, 골아세포종 및 연골모세포종과 같은 뼈의 육종; 중피종; 예를 들어 기저세포 암종, 편평세포 암종, 메르켈 세포 암종 및 흑색종과 같은 피부암; 예를 들어 성상세포종, 교모세포종, 신경교종, 신경아세포종 및 망막아세포종과 같은 중추 신경계 및 뇌의 신생물; 예를 들어 B-세포 비호지킨 림프종 (NHL), T-세포 비호지킨 림프종, 만성 B-세포 림프성 백혈병 (B-CLL), 만성 T-세포 림프성 백혈병 (T-CLL), 호지킨병 (HD), 대형 과립성 림프성 백혈병 (LGL), 만성 골수성 백혈병 (CML), 급성 골수양/골수성 백혈병 (AML), 급성 림프성/림프아성 백혈병 (ALL), 다발성 골수종 (MM), 형질세포종 및 골수이형성 증후군 (MDS)과 같은 림프종 및 백혈병; 및 원발 부위 불명 암.
본 발명의 바람직한 실시양태에서, 암은 폐암, 바람직하게는 비-소세포 폐암 (NSCLC)이다.
신체에서의 특정 위치/기원을 특징으로 하는 상기 언급된 모든 암, 종양, 신생물 등은 원발성 종양 및 이로부터 유래된 전이성 종양 모두를 포함하는 의미이다.
환자가 PD-L1의 고 발현을 특징으로 하는 암을 갖고/거나 암이 항종양 면역 세포, 예를 들어 종양 침윤 림프구에 의해 침투된 경우 환자는 본 발명의 항체 분자 (본원에 기술된 바와 같이) 치료에 더 잘 반응할 가능성이 있다. 따라서, 본 발명의 일 실시양태는 치료될 환자가 PD-L1의 고 발현을 특징으로 하는 암을 갖고/거나 암이 항-종양 면역 세포에 의해 침윤된 것이다.
또한, 환자가 고-돌연변이 부담을 특징으로 하는 암을 갖는 경우 환자는 본 발명의 항체 분자 (본원에 기술된 바와 같이) 치료에 더 잘 반응할 가능성이 있다. 돌연변이 부담이 얼마나 높은지를 평가할 수 있는 예는 암이 미세위성 불안정성 또는 좋지 않은 DNA 미스매치 복구 효율을 갖는 것이 특징인지를 결정하는 것을 포함한다. 그러한 암은 면역원성이 더 강하고, 따라서 본 발명의 항체 분자와 같은 면역 조절 요법에 반응할 가능성이 더 높다고 생각된다. 따라서, 본 발명의 일 실시양태는 치료될 환자가 고 돌연변이 부담을 특징으로 하는 암을 가지고 있는 것이다.
본 발명의 항체 분자는 제1 라인, 제2 라인 또는 임의의 추가 라인 치료와 관련하여 치료 계획에 사용될 수 있다.
본 발명의 항체 분자는 상기 언급된 질환의 예방, 단기간 또는 장기간 치료에, 임의로는 또한 방사선요법 및/또는 수술과 병용하여 사용될 수 있다.
물론, 상기한 것은 또한 치료적 유효 용량을 이를 필요로 하는 환자에게 투여함으로써 상기 질환을 치료하는 다양한 방법에서의 본 발명의 항체 분자의 용도, 이러한 질환 치료용 약제의 제조를 위한 이들 항체 분자의 용도, 이러한 본 발명의 항체 분자를 포함하는 약학적 조성물, 및 본 발명의 이러한 항체를 포함하는 약제의 제제 및/또는 제조 등을 포함한다.
다른 활성 물질 또는 처리와의 병용
본 발명의 항체 분자, 또는 본 발명의 항-PD1 항체와 본 발명의 항-LAG3 항체의 조합물은 단독으로 또는 하나 이상의 추가의 치료제, 특히 DNA 손상제 또는 암 세포에서 혈관신생, 신호 전달 경로 또는 유사 분열 체크포인트을 억제하는 치료적 활성 화합물 등의 화학요법제로부터 선택되는 것과 조합하여 사용될 수 있다.
추가의 치료제는 임의로 동일한 약학 제제의 성분으로서, 항체 분자의 투여와 동시에, 또는 그의 투여 전후에 투여될 수 있다.
특정 실시양태에서, 추가의 치료제는 제한없이 EGFR, VEGFR, HER2-neu, Her3, 오로라A, 오로라B, PLK 및 PI3 키나제, FGFR, PDGFR, Raf, Ras, KSP, PDK1, PTK2, IGF-R 또는 IR의 억제제의 군으로부터 선택된 하나 이상의 억제제일 수 있다.
추가적인 치료제의 추가 예는 CDK, Akt, src/bcr abl, cKit, cMet/HGF, c-Myc, Flt3, HSP90, 헤지호그 길항제, JAK/STAT의 억제제, Mek, mTor, NFkappaB, 프로테아좀, Rho, wnt 신호 전달 억제제 또는 유비퀴틴화 경로의 억제제 또는 Notch 신호 전달 경로의 또 다른 억제제와 같은 억제제들이다.
오로라 억제제의 예로는 PHA-739358, AZD-1152, AT 9283, CYC-116, R-763, VX-680, VX-667, MLN-8045, PF-3814735가 있다.
PLK 억제제의 예로는 GSK-461364이 있다.
raf 억제제의 예로는 BAY-73-4506 (또한 VEGFR 억제제), PLX 4032, RAF 265 (또한 VEGFR 억제제), 소라페닙 (또한 VEGFR 억제제) 및 XL 281이 있다.
KSP 억제제의 예로는 이스피네십, ARRY-520, AZD-4877, CK-1122697, GSK 246053A, GSK-923295, MK-0731, 및 SB-743921이 있다.
src 및/또는 bcr-abl 억제제의 예로는 다사티닙, AZD-0530, 보수티닙, XL 228 (또한 IGF-1R 억제제), 닐로티닙 (또한 PDGFR 및 cKit 억제제), 이마티닙 (또한 cKit 억제제), 및 NS-187이 있다.
PDK1 억제제의 예로는 BX-517이 있다.
Rho 억제제의 예로는 BA-210이 있다.
PI3 키나제 억제제의 예로는 PX-866, BEZ-235 (또한 mTor 억제제), XL 418 (또한 Akt 억제제), XL-147 및 XL 765 (또한 mTor 억제제)가 있다.
cMet 또는 HGF의 억제제의 예로는 XL-184 (또한 VEGFR, cKit, Flt3의 억제제), PF-2341066, MK-2461, XL-880 (또한 VEGFR의 억제제), MGCD-265 (또한 VEGFR, Ron, Tie2의 억제제), SU-11274, PHA-665752, AMG-102, 및 AV-299이 있다.
c-Myc 억제제의 예로는 CX-3543이 있다.
Flt3 억제제의 예로는 AC-220 (또한 cKit 및 PDGFR의 억제제), KW 2449, 레스타우르티닙 (또한 VEGFR, PDGFR, PKC의 억제제), TG-101348 (또한 JAK2의 억제제), XL-999 (또한 cKit. FGFR, PDGFR 및 VEGFR의 억제제), 수니티닙 (또한 PDGFR, VEGFR 및 cKit의 억제제) 및 탄두티닙 (또한 PDGFR 및 cKit의 억제제)이 있다.
HSP90 억제제의 예로는 타네스피마이신, 알베스피마이신, IPI-504 및 CNF 2024가 있다.
JAK/STAT 억제제의 예로는 CYT-997 (또한 튜불린과 상호작용 함), TG 101348 (또한 Flt3의 억제제) 및 XL-019이 있다.
Mek 억제제의 예로는 ARRY-142886, PD-325901, AZD-8330, 및 XL 518이 있다.
mTor 억제제의 예로는 템시롤리무스, AP-23573 (VEGF 억제제로도 작용함), 에베롤리무스 (또한 VEGF 억제제), XL-765 (또한 PI3 키나제 억제제) 및 BEZ-235 (또한 PI3 키나제 억제제)가 있다.
Akt 억제제의 예로는 페리포신, GSK-690693, RX-0201 및 트리시리빈이 있다.
cKit 억제제의 예로는 AB-1010, OSI-930 (VEGFR 억제제로도 작용함), AC-220 (또한 Flt3 및 PDGFR의 억제제), 탄두티닙 (또한 Flt3 및 PDGFR 억제제), 악시티닙 (또한 VEGFR 및 PDGFR의 억제제), XL-999 (또한 Flt3, PDGFR, VEGFR, FGFR의 억제제), 수니티닙 (또한 Flt3, PDGFR, VEGFR의 억제제) 및 XL-820 (VEGFR 및 PDGFR 억제제로서 작용함), 이마티닙 (또한 bcr-abl 억제제), 닐로티닙 (또한 bcr-abl 및 PDGFR의 억제제)이 있다.
헤지호그 길항제의 예로는 IPI-609 및 CUR-61414이 있다.
CDK 억제제의 예로는 셀리시클립, AT-7519, P-276, ZK-CDK (또한 VEGFR2 및 PDGFR을 억제함), PD-332991, R-547, SNS-032, PHA-690509, 및 AG 024322가 있다.
프로테아좀 저해제의 예로는 보르테조밉, 카필조밉 및 NPI-0052 (NF카파B의 억제제)가 있다.
NFkappaB 경로 억제제의 예로는 NPI-0052이 있다.
유비퀴틴화 경로 억제제의 예로는 HBX-41108이 있다.
바람직한 실시양태에서, 추가의 치료제는 항-혈관신생제이다.
항-혈관신생제의 예로는 FGFR, PDGFR 및 VEGFR의 억제제 또는 각각의 리간드의 억제제 (예를 들어, 페가타닙 또는 항-VEGF 항체 베바시주맵과 같은 VEGF 억제제) 및 탈리도미드 (이러한 제제는 닌테다닙, 베바시주맵, 모테사닙, CDP-791, SU-14813, 텔라티닙, KRN-951, ZK-CDK (또한 CDK의 억제제), ABT-869, BMS-690514, RAF-265, IMC-KDR, IMC-18F1, IMiDs (면역조절약), 탈리도미드 유도체 CC-4047, 레날리도미드, ENMD 0995, IMC-D11, Ki 23057, 브리바닙, 세디라닙, XL-999 (또한 cKit 및 Flt3의 억제제), 1B3, CP 868596, IMC 3G3, R-1530 (또한 Flt3의 억제제), 수니티닙 (또한 cKit 및 Flt3의 억제제), 악시티닙 (또한 cKit의 억제제), 레스타우르티닙 (또한 Flt3 및 PKC의 억제제), 바탈라닙, 탄두티닙 (또한 Flt3 및 cKit의 억제제), 파조파닙, GW 786034, PF-337210, IMC-1121B, AVE-0005, AG-13736, E-7080, CHIR 258, 소라페닙 토실레이트 (또한 Raf의 억제제), RAF-265 (또한 Raf의 억제제), 반데타닙, CP-547632, OSI-930, AEE-788 (또한 EGFR 및 Her2의 억제제), BAY-57-9352 (또한 Raf의 억제제), BAY-73-4506 (또한 Raf의 억제제), XL 880 (또한 cMet의 억제제), XL-647 (또한 EGFR 및 EphB4의 억제제), XL 820 (또한 cKit의 억제제), 및 닐로티닙 (또한 cKit 및 brc-abl의 억제제)이 있다.
추가적인 치료제는 또한 EGFR 억제제로부터 선택될 수 있으며, 이는 소분자 EGFR 억제제 또는 항-EGFL 항체일 수 있다. 항-EGFL 항체의 예에는 제한없이 세툭시맵, 파니투무맵, 마투주맵이 있고; 소분자 EGFR 억제제의 예에는 제한없이 게피티닙, 아파티닙, 오시메르티닙 및 올무티닙이 있다. EGFR 조절제에 대한 또 다른 예는 EGF 융합 독소이다.
본 발명의 항체 분자와의 조합에 유용한 EGFR 및 Her2 억제제 중에는 라파티닙, 게피티닙, 에를로티닙, 세툭시맵, 트라스투주맵, 니모투주맵, 잘루투주맵, 반데타닙 (또한 VEGFR의 억제제), 페르투주맵, XL-647, HKI-272, BMS-599626 ARRY-334543, AV 412, mAB-806, BMS-690514, JNJ-26483327, AEE-788 (또한 VEGFR의 억제제), ARRY-333786, IMC-11F8, 제맵이 있다.
본 발명의 항체 분자와의 치료에서 유리하게 병용될 수 있는 다른 약제는 토시투무맵 및 이브리투모맵 티욱세탄 (2개의 방사성 표지된 항-CD20 항체), 알레투주맵 (항-CD52 항체), 데노수맵 (파골세포 분화 인자 리간드 억제제), 갈릭시맵 (CD80 길항제), 오파투무맵 (CD20 억제제), 자놀리무맵 (CD4 길항제), SGN40 (CD40 리간드 수용체 조절제), 리툭시맵 (CD20 억제제) 또는 마파투무맵 (TRAIL-1 수용체 작용제) 등이 있다.
본 발명의 항체 분자와 조합하여 사용될 수 있는 다른 화학요법 약물은 호르몬, 호르몬 유사체 및 항호르몬제 (예를 들어, 타목시펜, 토레미펜, 랄록시펜, 풀베스트란트, 메게스트롤 아세테이트, 플루타미드, 닐루타미드, 비칼루타미드, 사이프로테론 아세테이트, 피나스테리드, 부세렐린 아세테이트, 플루드코르티손, 플루옥시메스테론, 메드록시프로게스테론, 옥트레오티드, 아르족시펜, 파시레오티드, 바프레오티드), 아로마타제 억제제 (예를 들어, 아나스트로졸, 레트로졸, 리아로졸, 엑세메스탄, 아타메스탄, 포르메스탄), LHRH 작용제 및 길항제 (예를 들어, 고세렐린 아세테이트, 류프롤리드, 아바렐릭스, 세트로렐릭스, 데슬로렐린, 히스트렐린, 트립토렐린), 항대사제 (예를 들어, 메토트렉세이트, 페메트렉시드 등의 항엽산제, 5 플루오로우라실, 카페시타빈, 데시타빈, 넬라라빈 및 겜시타빈 등의 피리미딘 유사체, 머캅토퓨린 티오구아닌, 클라드리빈 및 펜토스타틴, 시타라빈, 플루다라빈과 같은 퓨린 및 아데노신 유사체); 항종양 항생제 (예를 들어, 독소루비신, 다우노루비신, 에피루비신 및 이다루비신과 같은 안트라사이클린, 미토마이신-C, 블레오마이신, 닥티노마이신, 플리카마이신, 미톡산트론, 픽산트론, 스트렙토조신); 백금 유도체 (예를 들어, 시스플라틴, 옥살리플라틴, 카보플라틴, 로바플라틴, 사트라플라틴); 알킬화제 (예를 들어, 에스트라무스틴, 메클로레타민, 멜팔란, 클로람부실, 부설판, 다카바진, 사이클로포스파미드, 이포스파미드, 하이드록시우레아, 테모졸로미드, 니트로소우레아, 예컨대 카르무스틴 및 로무스틴, 티오테파); 항분열제 (예를 들어, 빈블라스틴, 빈덴신, 비노렐빈, 빈플루닌 및 빈크리스틴 등의 빈카 알칼로이드류; 및 시모탁셀, 및 파클리탁셀, 도세탁셀 및 이들의 제제, 라로탁셀 등의 탁산류; 익사베필론, 파투필론, ZK EPO 등의 에포틸론류); 토포이소머라제 억제제 (예를 들어, 에피도필로톡신류, 예컨대 에토포시드 및 에토포포스, 테니포시드, 암사크린, 토포테칸, 이리노테칸); 및 아미포스틴, 아나그렐리드, 인터페론 알파, 프로카바진, 미토탄, 및 포르피머, 벡사로텐, 셀레콕시브와 같은 기타 화학요법제 중에서 제한없이 선택된다.
특정 실시양태에서, 추가의 치료제는 TIM3, PD-L1 (예를 들어, 아테졸리주맵, 아벨루맵 또는 듀발루맵), PD-L2, CTLA-4, VISTA, BTLA, TIGIT, CD160, LAIR1, 2B4, CEACAM의 체크포인트 억제제의 조절제와 같은 추가 면역요법제일 수 있다.
다른 실시양태에서, 면역요법제는 암 백신일 수 있다.
두 가지 이상의 물질 또는 원리가 병용 치료 계획의 일부로 사용되는 경우, 이들은 동일한 투여 경로 또는 상이한 투여 경로를 통해, 실질적으로 동시에 (즉, 동시에, 동반하여) 또는 상이한 시점에 (예를 들어, 순차적으로, 연속적으로, 교대로, 연달아서 또는 다른 종류의 교대 요법에 따라) 투여될 수 있다.
물질 또는 원리가 동일한 투여 경로를 통해 동시에 투여되는 경우, 이들은 상이한 약학 제형 또는 조성물로서, 또는 조합된 약학 제형 또는 조성물의 일부로서 투여될 수 있다. 또한, 두 가지 이상의 활성 물질 또는 원리가 병합 치료 계획의 일부로 사용되는 경우, 각 물질 또는 원칙은 화합물 또는 원리가 자체로 사용되는 것과 동일한 양과 동일한 계획에 따라 투여될 수 있으며, 그러한 병용 사용은 시너지 효과를 이끌어 낼 수도 있고 그렇지 않을 수도 있다. 그러나, 두 가지 이상의 활성 물질 또는 원리의 병용 사용이 시너지 효과를 이끌어 내는 경우는, 원하는 치료 작용을 유지한 채로 투여될 물질 또는 원리의 하나 또는 그 이상 또는 그 전부의 양을 감소시키는 것이 가능할 수 있다. 이는 예를 들어 원하는 약리학적 또는 치료학적 효과를 얻으면서, 하나 이상의 물질 또는 원칙을 그의 통상적인 양으로 사용하는 것과 관련하여 원치 않는 부작용을 회피, 제한 또는 감소시키는데 유용할 수 있다.
물론, 상기에는 상기 병용 파트너와 함께 사용하기 위한 본 발명의 항체의 제제 및 제조 방법이 포함된다. 또한, 본 발명의 항체와 함께 사용하기 위한 상기 언급된 조합 파트너의 제제 및 제조 방법도 포함된다.
본 발명의 항체 분자는 그 자체로 또는 다른 치료 계획, 예를 들어 수술 및/또는 방사선 요법과 조합하여 사용될 수 있다.
키트 및 제조 및 정제 방법
본 발명은 또한 적어도 하나의 본 발명의 항체 및 전술한 바와 같은 질환 및 장애의 치료에 사용되는 다른 약물로 구성된 군으로부터 선택된 하나 이상의 다른 성분을 포함하는 키트를 포함한다.
일 실시양태에서, 키트는 유효량의 본 발명의 항-PD1 항체 분자를 단위 투약 형태로 함유하는 조성물을 포함한다. 또 다른 실시양태에서, 키트는 본 발명의 유효량의 항-LAG3 항체 분자를 단위 투약 형태로 함유하는 조성물을 포함한다. 추가의 실시양태에서 키트는 유효량의 본 발명의 항-PD1 항체 분자를 단위 투약 형태로 함유하는 조성물 및 본 발명의 유효량의 항-LAG3 항체 분자를 단위 투약 형태로 함유하는 조성물을 모두 포함한다.
일부 실시양태에서, 키트는 이러한 조성물을 함유하는 멸균된 용기를 포함하고; 그러한 용기는 상자, 앰플, 병, 바이알, 튜브, 백, 파우치, 블리스터-팩 또는 당 업계에 공지된 다른 적합한 용기 형태일 수 있다. 이러한 용기는 플라스틱, 유리, 라미네이트지 (laminated paper), 금속 호일, 또는 약제를 보유하기에 적합한 다른 재료로 제조될 수 있다.
필요에 따라, 본 발명의 항체 분자 또는 본 발명의 항체 양 유형의 조합이 암을 갖는 대상에게 항체/항체들을 투여하기 위한 설명서와 함께 제공된다. 설명서에는 일반적으로 암의 치료 또는 예방을 위한 조성물의 사용에 대한 정보가 포함된다. 다른 실시양태에서, 설명서는 다음 중 적어도 하나를 포함한다: 치료제의 설명; 암 또는 그의 증상의 치료 또는 예방을 위한 투여 스케쥴 및 투여; 예방 조치; 경고; 증상; 금지 사항; 과량투여 정보; 이상 반응; 동물 약리학; 임상 연구; 및/또는 참고 문헌. 설명서는 용기 (있는 경우)에 직접 인쇄되거나 용기에 붙인 라벨 또는 용기 안에 또는 그와 함께 제공되는 별도의 시트, 팜플렛, 카드 또는 폴더로서 인쇄될 수 있다.
본 발명은 또한 본 발명의 항체 분자를 제조하는 방법을 제공하며, 상기 방법은 일반적으로 하기 단계를 포함한다:
- 본 발명의 항체의 형성을 허용하는 조건하에 본 발명의 항체 분자를 코딩하는 핵산을 포함하는 발현 벡터를 포함하는 숙주 세포를 배양하는 단계;
- 배양물로부터 숙주 세포에 의해 발현된 항체 분자를 회수하는 단계; 및
- 임의로 추가로 본 발명의 항체 분자를 정제 및/또는 변형 및/또는 제형화하는 단계.
본 발명의 핵산은 예를 들어, 코딩 서열 및 조절 서열 및 임의로 천연 또는 인공 인트론을 포함하는 DNA 분자일 수 있거나, cDNA 분자일 수 있다. 이것은 원래의 코돈을 가질 수 있거나, 또는 의도된 숙주 세포 또는 숙주 생물에서 발현되도록 특이적으로 적응된 최적화된 코돈 사용을 가질 수도 있다. 본 발명의 일 실시양태에 따라, 본 발명의 핵산은 상기 정의한 바와 같이 본질적으로 단리된 형태이다.
본 발명의 핵산은 전형적으로 발현 벡터, 즉 적합한 숙주 세포 또는 다른 발현 시스템으로 형질감염될 때 폴리펩티드의 발현을 제공할 수 있는 벡터에 혼입될 것이다.
본 발명의 항체를 제조하기 위해, 당업자는 예를 들어 [Kipriyanow and Le Gall, 2004]에 의해 검토된 것과 같이, 당 업계에 익히 공지된 다양한 발현 시스템으로부터 선택할 수 있다.
발현 벡터는 플라스미드, 레트로바이러스, 코스미드, EBV 유래 에피솜 등을 포함한다. 발현 벡터 및 발현 조절 서열은 숙주 세포와 양립할 수 있도록 선택된다. 항체 경쇄 유전자 및 항체 중쇄 유전자는 별개의 벡터에 삽입될 수 있다. 특정 실시양태에서, 두 DNA 서열은 동일한 발현 벡터에 삽입된다.
편리한 벡터는 상술한 바와 같이 임의의 VH (가변 중) 또는 VL (가변 경) 서열이 용이하게 삽입되고 발현될 수 있도록 조작된 적절한 제한 부위를 갖는, 기능적으로 완전한 인간 CH (불변 중) 또는 CL (불변 경) 면역글로불린 서열을 코딩하는 것이다. 항체 중쇄의 경우, 이는 임의의 IgG 아이소타입 (IgG1, IgG2, IgG3, IgG4) 또는 대립유전자 변이체를 포함하는 다른 면역글로불린일 수 있으나, 이에 한정되지 않는다.
재조합 발현 벡터는 또한 숙주 세포로부터 항체 사슬의 분비를 촉진시키는 신호 펩티드를 코딩할 수 있다. 항체 사슬을 코딩하는 DNA는 신호 펩티드가 성숙한 항체 사슬 DNA의 아미노 말단에 인-프레임 (in-frame)으로 연결되도록 벡터 내로 클로닝될 수 있다. 신호 펩티드는 면역글로불린 신호 펩티드 또는 비-면역글로불린 단백질 유래의 이종 펩티드일 수 있다. 대안으로, 항체 사슬을 코딩하는 DNA 서열은 이미 신호 펩티드 서열을 함유하고 있을 수 있다.
항체 사슬 DNA 서열 이외에, 재조합 발현 벡터는 전형적으로 프로모터, 인핸서, 종결 및 폴리아데닐화 신호 및 숙주 세포에서 항체 사슬의 발현을 조절하는 다른 발현 조절 요소를 포함하는 조절 서열, 임의로 이종 조절 서열을 가진다. (포유동물 세포에서의 발현을 위해 예시된) 프로모터 서열의 예로는 CMV 유래의 프로모터 및/또는 인핸서 (예컨대, CMV 유인원 바이러스 40 (SV40) 프로모터/인핸서), 아데노바이러스 (예를 들어, 아데노바이러스 주요 후기 프로모터 (AdMLP)), 폴리오마 및 천연 면역글로불린 및 액틴 프로모터와 같은 강한 포유동물 프로모터이다. 폴리아데닐화 신호의 예로서 BGH polyA, SV40 후기 또는 초기 polyA; 또는, 면역글로불린 유전자의 3'UTR 등이 사용될 수 있다.
재조합 발현 벡터는 또한 숙주 세포에서 벡터의 복제 (예를 들어, 복제 기원) 및 선별 마커 유전자를 조절하는 서열을 보유할 수 있다. 본 발명의 항체의 중쇄 또는 그의 항원-결합 부분 및/또는 경쇄 또는 그의 항원-결합 부분을 코딩하는 핵산 분자, 및 이들 DNA 분자를 포함하는 벡터는 리포좀-매개 형질감염, 폴리양이온-매개 형질감염, 원형질체 융합, 마이크로주입, 인산칼슘 침전법, 전기천공 또는 바이러스 벡터에 의한 전달을 비롯한 당 업계에 공지된 형질감염 방법에 따라 숙주 세포, 예를 들어 박테리아 세포 또는 고등 진핵 세포, 예를 들면, 포유동물 세포 내로 도입될 수 있다.
바람직하게는, 중쇄 및 경쇄를 코딩하는 DNA 분자는 숙주 세포, 바람직하게는 포유동물 세포 내로 동시-형질감염된 2개의 발현 벡터 상에 존재한다.
발현을 위한 숙주로서 이용가능한 포유동물 세포주는 당 업계에 잘 알려져 있으며, 특히 중국 햄스터 난소 (CHO) 세포, NS0, SP2/0 세포, HeLa 세포, 베이비 햄스터 신장 (BHK) 세포, 원숭이 신장 세포 COS), 인간 암종 세포 (예: Hep G2 및 A-549 세포), 3T3 세포 또는 임의의 그러한 세포주의 유도체/자손을 포함한다. 인간, 마우스, 래트, 원숭이 및 설치류 세포주를 예로 들 수 있으나 이에 한정되지 않는 다른 포유동물 세포, 또는 효모, 곤충 및 식물 세포를 예로 들 수 있으나 이에 한정되지 않는 다른 진핵 세포 또는 박테리아와 같은 원핵 세포가 사용될 수 있다.
본 발명의 항체 분자는 숙주 세포를 숙주 세포에서 항체 분자의 발현을 허용하기에 충분한 시간 동안 배양함으로써 생산된다. 항체 분자는 바람직하게는 분비된 폴리펩티드로서 배양 배지로부터 회수되거나, 예를 들어 분비 신호없이 발현되는 경우 숙주 세포 용해물로부터 회수될 수 있다. 실질적으로 균질한 항체 제제가 얻어지는 방식으로 재조합 단백질 및 숙주 세포 단백질에 사용되는 표준 단백질 정제 방법을 사용하여 항체 분자를 정제하는 것이 필요하다. 예로서, 본 발명의 항체 분자를 수득하는데 유용한 최첨단 정제 방법은 제1 단계로서 배양 배지 또는 용해물로부터 세포 및/또는 미립자 세포 파편을 제거하는 단계를 포함한다. 이어서 항체는 예를 들어 면역친화성 또는 이온-교환 컬럼, 에탄올 침전, 역상 HPLC, Sephadex 크로마토그래피, 실리카상의 크로마토그래피 또는 양이온 교환 수지상의 분획화에 의해 오염된 가용 단백질, 폴리펩티드 및 핵산으로부터 정제된다. 항체 분자 제제를 얻는 공정의 최종 단계로서, 정제된 항체 분자를 치료적 적용을 위해 하기 기술된 바와 같이, 예를 들면, 건조, 예를 들면 동결 건조시킬 수 있다.
실시예
실시예 1: PD1에 결합하는 마우스 항체의 생성 및 PD1에 대한 PDL-1의 결합 차단.
인간 PD1 단백질 (GenBank 수탁 번호 AAO63583.1의 아미노산 21-170)의 세포 외 도메인 (ECD)을 합성하고 면역원으로서 제제화하였다. 이어서, 마우스를 면역화시킨 후 표준 실험실 면역화 기술에 따라 인간 PD1 ECD 단백질로 부스팅시켰다.
혈장을 면역화된 마우스로부터 수확하고, 항-PD1 면역글로불린의 충분한 역가를 가진 개체를 동정하기 위해 스크리닝하였다. 표준 실험 방법에 따라, 선택된 마우스로부터의 림프구를 수확하고 마우스 골수종 세포와 융합시켜 하이브리도마를 생성시켰다. 이어서, 이들 하이브리도마를 이하 본원에 기술된 분석법을 사용하여 낮은 nM 친화력 범위에서 인간 PD1 (ECD)에 대한 결합을 나타내는 항체 분자를 생산하는 하이브리도마주를 동정하기 위해 스크리닝하고, PDD1에 대한 인간 PD-L1의 결합을 차단하였다.
인간 PD1에 결합하고 인간 PD-L1에 대한 결합을 차단하는 항체를 생산하는 몇몇 하이브리도마를 선택하고, 항체 가변 도메인을 단리하고 표준 PCR 프라이머 세트를 사용하여 클로닝하였다.
이 연구로부터, 인간 PD1 (ECD)에 대해 낮은 nM의 결합 친화력을 나타내고 또한 PD-L1과 PD1의 결합을 차단하는 모노클로날 항체를 생성하는 77E11로 명명된 뮤린 하이브리도마주가 동정되었다.
77E11에 의해 생산된 모노클로날 항체의 가변 도메인의 아미노산 서열을 도 1에 나타내었다.
실시예 2: 인간화 항-PD1 항체의 생성
뮤린 77E11 하이브리도마 세포주의 V-유전자를 당 업계에 공지된 PCR 및 시퀀싱 프로토콜에 따라 동정하였다. 그런 다음 V 유전자를 표준 분자 생물학 기술을 사용하여 가장 가까이 일치하는 인간 생식세포계 유전자에 융합시켰다. 77E11의 경우, 이로서 마우스 Vk 및 Vh 아미노산 잔기가 인간 Ck 및 Ch1 아미노산 잔기에 융합된 키메라 뮤린/인간 항체 분자가 생성되었다.
제조되면, 키메라 뮤린/인간 항체를 "인간화" 프로토콜에 적용하였다. 이때, 키메라 77E11 Fab 클론의 돌연변이화 아미노산 라이브러리를 제조하였다. 서열 장애 (즉, 면역원성이거나 잠재적인 제조 문제를 일으키는 것으로 알려진 아미노산 잔기)를 제거하도록 추가의 라이브러리 위치를 또한 제조하였다. 이들 돌연변이화 라이브러리는 보통 V-영역 당 5-10 바이너리 (마우스 대 인간) 위치를 가진다. 좀 더 복잡한 V-영역의 특정 장애를 해결하기 위해 몇몇 소규모 라이브러리를 구축할 수 있다. 이러한 라이브러리는 당 업계의 표준 방법을 사용하여 제조되며 당업자가 용이하게 이용할 수 있다.
이 단계가 완료되고 나면, 원래의 뮤린 77E11 Fab 서열로부터 유래된 다수의 상이한 "인간화된" Fab를 제조하였다. 이들 인간화된 Fab에 대해 인간 PD1에 결합시키는 능력 및 PD-L1과 PD1의 상호 작용을 차단하는 능력을 시험하였다. 이어서, 상응하는 키메라 Fab와 동등하거나 더 우수한 성능을 갖는 유전자 조작된 Fab를 선택하였다. 그들의 아미노산 서열을 인간 서열 비율, 예상되는 면역원성 및 제거된 서열 장애에 대해 분석하였다.
가장 바람직한 인간화된 Fab의 선택 후, 이들을 인간 IgG4 (Pro) 또는 IgG1KO 면역글로불린 포맷에 두었다. IgG4 (Pro)는 세린 241이 프롤린으로 변경됨으로써 표준 인간 IgG4 서열과 다르며, 이러한 변경은 IgG4 분자 사이의 동적 Fab 암 교환을 최소화하는 것으로 입증되었다. IgG1KO는 항체 분자의 이펙터 기능을 최소화하는 것으로 알려진 2개의 아미노산 치환 (L234A, L235A)에 의해 표준 인간 IgG1 서열과 상이하다.
이 연구를 완료하고 원래의 키메라 뮤린/인간 77E11 Fab의 5 가지 상이한 인간화 버전이 제조되었다. 이들은 PD1-1, PD1-2, PD1-3, PD1-4 및 PD1-5로 칭하였다.
PD1-1, PD1-2, PD1-3, PD1-4 및 PD1-5에 대한 CDR의 아미노산 서열, VH 및 VL 서열 및 완전 HC 및 LC 서열은 본 출원 명세서 마지막 표에 제시되어 있다. 오해를 피하기 위해, 항체와 그들의 서열번호 사이의 상호 관계를 또한 하기 표에 제시하였다:
| 항-PD1 항체 | CDR 서열 | VH 서열 | VL 서열 | HC 서열 | LC 서열 |
| PD1-1 | 1-6 | 19 | 20 | 29 | 30 |
| PD1-2 | 7-12 | 21 | 22 | 31 | 32 |
| PD1-3 | 13-18 | 23 | 24 | 33 | 34 |
| PD1-4 | 13-18 | 25 | 26 | 35 | 36 |
| PD1-5 | 13-18 | 27 | 28 | 37 | 38 |
실시예 3 : 인간 PD1에 결합하는 항체 및 PD1 리간드 상호 작용의 차단
뮤린 77E11 하이브리도마로부터 유래된 대표적인 인간화 항-PD1 항체 (실시예 2에 기재됨)의 인간 PD1에 대한 결합을 측정하였다.
재조합 단량체 인간 PD1에 대한 결합 친화력을 ProteOn XPR36 장비를 사용하여 SPR로 측정하였다. PD1-1, PD1-2 및 PD1-3 항체는 표면에 아민 결합된 단백질 A/G 표면에 포획되었다. 인간 PD1 ECD를 포획된 항체에 600초 동안 30 ul/분의 유속 및 1200sec 동안의 해리로 주입하였다. 인간 PD1 ECD의 농도는 0 nM, 6.25 nM, 12.5 nM, 25 nM, 50 nM 및 100 nM이었다. 원 데이터에서 백그라운드를 뺀 다음 센서그램을 1:1 랭뮤어 (Langmuir) 결합에 전체적으로 맞춰 친화력 (KD) 값을 제공하였다.
상기 프로토콜을 사용하여, 항체 PD1-1, PD1-2 및 PD1-3이 하기 표에 제시된 바와 같이 인간 PD1에 결합하는 것으로 결정되었다.
| 항체 | KD, nM |
| PD1-1 | 16.6 |
| PD1-2 | 61.8 |
| PD1-3 | 6.0 |
이어서, 본 발명의 PD1 항체를 표면 CHO 세포에서 발현된 인간 PD1에 대한 인간 PD-L1/2의 결합을 차단하는 능력에 대해 시험하였다. PD1 발현 CHO 세포를 본 발명의 항-PD1 항체 (PD1 내지 PD1-5)의 존재하에 고정 농도의 재조합 비오틴으로 표지된 PD-L1 또는 PD-L2와 인큐베이션하였다. 혼합물을 37 ℃에서 1시간 동안 인큐베이션하였다. 유로퓸으로 표지된 스트렙타비딘으로 세포 결합된 PD-L1/L2를 검출하고 Perkin Elmer Victor X4 플레이트 판독기를 사용하여 형광을 측정하였다. 데이터는 억제 백분율로 표시된다. 0% 억제는 항체가 없는 리간드와 함께 인큐베이션된 세포의 형광값으로 정의되며, 100% 억제는 표지된 리간드 및 항체가 없는 세포로 얻어진 신호로서 정의된다. 백분율 억제값을 엑셀로 계산하고 GraphPad Prism으로 곡선 피팅을 수행하였다. 곡선의 데이터 포인트는 3회 측정의 평균값이다.
리간드 차단의 90% 억제 (IC90)를 달성하는데 필요한 억제 곡선 및 mab 농도를 도 2 및 표 3에 나타내었다.
| 항체 | PD-L1 IC90 (nM) | PD-L2 IC90 (nM) |
| PD1-1 | 2.12 | 2.09 |
| PD1-2 | 2.97 | 3.64 |
| PD1-3 | 1.68 | 1.95 |
| PD1-4 | 2.04 | 2.71 |
| PD1-5 | 2.09 | 3.31 |
이 분석으로부터, 본 발명의 인간화 PD1 항체가 PD1에 대해 강력한 결합 특성을 나타내고, 또한 PD-1과 PD-L1 및 PD-L2의 상호 작용을 효과적으로 억제한다는 것이 명백하다.
실시예 4: 항-PD1 항체에 의한 항원-특이적 T 세포 반응의 자극
이어서 전술한 방법에 따라 제조된 인간화 항-PD1 항체를 파상풍 특이적 CD4 기억 T 세포의 사이토카인 생성을 자극하는 능력에 대해 시험하였다.
이 분석을 위해, 건강한 공여자로부터 유래된 PBMC로부터의 T 세포를 파상풍 톡소이드의 존재하에 확장시키고 파상풍 톡소이드를 로딩한 자가 성숙 수지상 세포 (DC)와 함께 2일 동안 공-배양하였다. 공-배양 단계를 본 발명의 대표적인 항-PD1 항체의 존재하에 유사한 방식으로 2회 반복하였다. 두 번째 공-배양 단계 끝에, 상등액을 ELISA에 의해 IFN-γ에 대해 분석하고 그 결과를 도 3에 나타내었다.
시험된 본 발명의 모든 PD1 항체는 IFN-감마 방출에 의해 측정된 바와 같이 매우 강력한 T 세포 활성화를 명백한 용량 의존 방식으로 나타낸다. 본 발명의 PD1 항체가 항-LAG3 항체와 결합되는 경우, 기준이 되는 선행 기술의 항-PD1 항체 조합과 비교할 때 우수한 활성을 관찰할 수 있었다 (실시예 12 및 도 8 참조).
실시예 5: 인간화된 항-PD1 모노클로날 항체의 에피토프 맵핑.
본 발명의 대표적인 항-PD1 항체 및 니볼루맵과 동일한 아미노산 서열을 갖는 기준 선행 기술 항체 분자의 에피토프를 항체 에피토프들의 개별 아미노산 수준에서 에피토프 차이를 나타내는 수소-중수소 교환 (HDX) 실험으로 분석하였다.
HDX 분석은 본 발명의 항-PD1 항체 및 기준 선행 기술 항체 분자가 인간 PD1의 유사 및 중첩 영역에 결합한다는 것을 보여 주었다. 그러나, 본 발명의 대표적인 PD1 항체는 표 4에 기재된 바와 같이 추가적인 서열 요소에 결합하므로, 에피토프는 동일하지 않다.
| 항체 | PD-1 결합 영역 (aa *) |
에피토프 |
| 니볼루맵에 대한 기준 항체 |
125-138 | A125ISLAPKA Q I KES L **(서열번호 115) |
| PD1-3 | 80-95, 125-138 | AAFPEDRSQPGQDCRF (서열번호 116) A125ISLAPKA Q I KES L ** (서열번호 115) |
* 넘버링에 사용된 PD1: GenBank AAO63583.1
** 결합에 관여하는 아미노산은 굵은 글씨체로 표시되어 있으며, 차이는 밑줄로 표시되었다.
실시예 6: hPD-1 녹인 마우스 모델에서 본 발명의 항-PD1 항체 분자의 생체 내 효능
본 연구의 목적은 마우스 PD1의 세포 외 도메인을 인간 PD1의 상응하는 영역으로 대체한 유전적 변형을 포함하는 완전 면역성 마우스를 사용하여 본 발명의 항-PD1 항체 분자의 효능을 측정하는 것이다. 이 실험에 사용된 마우스 C57BL/6NTac-PDCD1 tm(PDCD1)Arte 는 영국 옥스포드의 ISIS INNOVATION LIMITED에서 공급받았으며 이하 "hPD1 녹인 마우스"라고 한다.
MC-38 세포를 hPD1 녹인 (knock-in) 마우스의 옆구리에 피하 주사하고 세포 주사 후 6일째에 처리를 시작하였다. 마우스는 PBS, 아이소타입 대조군 또는 본 발명의 항-PD1 항체 분자를 주 2회 (q3or4d) 10 mg/kg의 용량으로 투여받았거나, PD1-3을 한 번만 투여받았다.
도 4는 MC38이 이식된 각각의 hPD1 녹인 마우스에 대한 시간 경과에 따른 종양 체적을 나타내고, 표 5는 세포 주사 후 23일째의 종양 성장 억제 (TGI) 및 연구 종료시 관찰된 완전한 반응을 요약한다.
완전 반응 (CR)은 (i) 종양 크기가 최초 측정과 같거나 더 작고, (ii) 잔류 담체 물질 (matrigel)의 육안 검사로 종양 조직을 나타내지 않는 경우로 정의된다. PD1-3의 단일 투약 계획은 주 2회 투약 계획과 비교하여 동등하고 강력한 항종양 효과 (TGI = 90%, 2마리의 마우스가 CR을 나타냄)를 나타냄을 입증할 수 있었다. 이 연구는 본 발명의 항-PD1 항체 분자의 단일 용량으로도 효능을 달성하기에 충분하며, 이는 보다 긴 반감기의 결과일 수 있음을 보여준다.
| TGI [%] |
CR [n/10] | |
| PBS | - | 0 |
| PD-1 아이소타입 | 12 | 0 |
| PD1-3 (q3or4d) | 83 | 3 |
| PD1-3 (한 번) | 90 | 2 |
실시예 7: 본 발명의 항-PD1 항체 분자의 전임상 약물동력학.
본 발명의 항-PD1 항체 분자의 약물동력학 (PK) 특성을 사이노몰거스 원숭이에서 단일 용량 i.v. PK 연구로 결정하였다.
1 mg/kg i.v.의 용량으로 투여된 본 발명의 항-PD1 항체 분자는 0.28 ml/h/kg의 평균 혈장 클리어런스 (CL)를 나타내었다. PD1-3에 대한 평균 분포 용적 (Vss)은 58 ml/kg이었다. PD1-3의 평균 종말 반감기는 11일이었다.
사이노몰거스 원숭이에서 1 mg/kg에서 PD1-3의 AUC 및 cmax는 IgG4Pro PD-1 항체인 니볼루맵 (BMS-936558, Wang, C. et al., Cancer Immunol. Res. 2:846-856, 2014에서 공개됨) 및 펨브롤리주맵 (MK-3475, FDA BLA document 125514Orig1s000 Pharmacology Review, 2014에서 공개됨)의 대응 파라미터와 비교할만한 용량 범위에서 거의 동일하였다.
놀랍고도 예기치 않게도, PD1-3에 대해 관찰된 종말 반감기는 도 5에 나타낸 바와 같이 니볼루맵에 비해 1.5-2 배 더 높았다. 이는 본 발명의 항-PD1 항체가 11일의 혈청 반감기를 가짐을 제시한다. 이것은 전형적으로 0.3-3 mg/kg의 용량 범위에서 4 내지 6일의 반감기를 갖는 공지된 기준 항-PD1 항체 분자와 대조적이다. 본 발명의 항체 분자의 이러한 놀라운 특징은 환자를 본 발명의 항체 분자로 당해 기술 분야의 것보다 덜 빈번하게 투여하는 것이 가능하고, 이는 감소된 투여 빈도 또는 사용되는 항체의 감소된 양 중 어느 하나의 형태로 공급될 항체의 양을 감소시키는 것을 의미할 수 있다. 항-PD1 항체 분자가 상기에서 논의된 바와 같이 환자에게 원하지 않는 부작용을 유도할 수 있다는 것을 감안하면, 본 발명의 항-PD1 항체는 당해 기술에 비해 유의하고 놀라운 임상 이점을 가질 수 있다.
실시예 8: LAG3에 결합하는 마우스 항체의 동정
인간 LAG3 단백질의 세포 외 도메인 (ECD) (GenBank 수여 번호 NP_002277의 아미노산 23-450)을 합성하고 면역원으로서 제조하였다. 이어서 마우스를 면역화시킨 후 표준 실험실 면역화 기술에 따라 인간 LAG3 ECD 단백질로 부스팅시켰다.
이어서, 면역화된 마우스로부터 혈장을 수확하고, 충분한 역가의 항-LAG3 면역글로불린을 가진 개체를 스크리닝하였다. 표준 실험 방법에 따라, 선택된 마우스의 림프구를 수확하고 마우스 골수종 세포와 융합시켜 하이브리도마를 생성시켰다.
인간 LAG3에 특이적으로 결합하는 항체를 생산하는 몇 개의 하이브리도마를 선택하고, 항체 가변 도메인을 단리하고 표준 PCR 프라이머 세트를 사용하여 클로닝하였다.
이 연구로부터, 인간 LAG3 (ECD)에 대해 낮은 nM의 결합 친화력을 나타내는 모노클로날 항체를 생산하는 496G6이라 명명된 뮤린 하이브리도마주를 동정하고 추가 연구를 위해 선택하였다.
496G6에 의해 생산된 모노클로날 항체의 가변 도메인의 아미노산 서열을 도 6에 나타내었다.
실시예 9: 인간화 항-LAG3 항체의 생성
이 실시예에서는, 실시예 8에 기술된 뮤린 하이브리도마주 496G6에 의해 생성된 모노클로날 항체의 인간화 유도체의 개발 방법 및 결과를 제공한다.
뮤린 496G6 하이브리도마의 V-유전자를 당 업계에 널리 공지된 PCR 및 시퀀싱 프로토콜에 따라 동정하였다. 그런 다음 V-유전자를 표준 분자 생물학 기숭을 사용하여 가장 가까이 일치하는 인간 생식계 유전자에 융합시켰다. 496G6의 경우, 이에 따라 마우스 Vk 및 Vh 아미노산 잔기가 인간 Ck 및 Ch1 아미노산 잔기에 융합된 키메라 뮤린/인간 항체가 생성되었다.
제조되었으면, 키메라 뮤린/인간 항체를 당 업계에 널리 공지된 표준 "인간화" 프로토콜에 적용하였다.이 방법에서는, 키메라 496G6 Fab 클론의 돌연변이화 아미노산 라이브러리를 제조하였다. 서열 장애 (즉, 면역원성이거나 잠재적인 제조 문제를 일으키는 것으로 알려진 아미노산 잔기)를 제거하도록 추가의 라이브러리 위치를 또한 제조하였다. 이 돌연변이화 라이브러리는 보통 V-영역 당 5-10 바이너리 (마우스 대 인간) 위치를 가진다. 좀 더 복잡한 V-영역의 특정 장애를 해결하기 위해 몇몇 소규모 라이브러리를 구축할 수 있다. 이러한 라이브러리는 당 업계의 표준 방법을 사용하여 제조되며 당업자가 용이하게 이용할 수 있다.
이 단계가 완료되고 나면, 원래의 뮤린 496G6 Fab 서열로부터 유래된 다수의 상이한 "인간화된" Fab를 제조하였다. 이들 인간화된 Fab에 대해 인간 LAG3에 결합하는 능력 및 MHCII와 LAG3의 상호 작용을 차단하는 능력을 시험하였다. 이어서, 상응하는 키메라 Fab와 동등하거나 더 우수한 성능을 수행하는 유전자 조작된 Fab를 선택하였다. 그들의 아미노산 서열을 인간 서열의 비율, 예상되는 면역원성 및 제거된 서열 장애에 대해 분석하였다.
가장 바람직한 인간화 Fab의 선택 후, 이들을 인간 IgG4 (Pro) 면역글로불린 포맷에 두었다. IgG4 (Pro)는 세린 241이 프롤린으로 변경됨으로써 표준 인간 IgG4 서열과 다르며, 이러한 변경은 IgG4 분자 사이의 동적 Fab 암 교환을 최소화하는 것으로 입증되었다.
이 연구를 완료하고 원래의 키메라 뮤린/인간 496G6 Fab의 5 가지 상이한 인간화 버전이 제조되었다. 이들은 LAG3-1, LAG3-2, LAG3-3, LAG3-4 및 LAG3-5로 칭하였다.
LAG3-1, LAG3-2, LAG3-3, LAG3-4, LAG3-5에 대한 CDR의 아미노산 서열, VH 및 VL 서열 및 전체 HC 및 LC 서열은 본 출원 명세서 마지막 표에 제시되어 있다. 오해를 피하기 위해, 항체와 그들의 서열번호 간 상호 관계를 또한 하기 표에 제시하였다:
| 항-LAG3 항체 |
CDR 서열 | VH 서열 | VL 서열 | HC 서열 | LC 서열 |
| LAG3-1 | 39-44 | 51 | 52 | 61 | 62 |
| LAG3-2 | 39-44 | 53 | 54 | 63 | 64 |
| LAG3-3 | 39-44 | 55 | 56 | 65 | 66 |
| LAG3-4 | 39-44 | 57 | 58 | 67 | 68 |
| LAG3-5 | 45-50 | 59 | 60 | 69 | 70 |
실시예 10: 인간 LAG3에 결합하는 항체 및 LAG3 리간드 상호 작용의 차단
재조합 단량체 인간 LAG3에 대한 결합 친화력을 SPR을 사용하여 측정하였다.
LAG3-1, LAG3-2, LAG3-3, LAG3-4 및 LAG3-5 항체를 단백질 A/G 표면에 포획하였다. 인간 LAG3 ECD-Fc를 포획된 항체에 300초 동안 30 ul/분의 유속 및 1800sec 동안의 해리로 주입하였다. 인간 LAG3 ECD의 농도는 0 nM, 0.625 nM, 1.25 nM, 2.5 nM 및 5 nM이었다. 원 데이터에서 백그라운드를 뺀 다음 센서그램을 1:1 랭뮤어 (Langmuir) 결합에 전체적으로 맞춰 친화력 (KD) 값을 제공하였다.
상기 프로토콜을 사용하여 항체 LAG3-1, LAG3-2, LAG3-3, LAG3-4 및 LAG-3-5이 하기 표에 제시된 바와 같이 높은 친화력으로 인간 LAG-3에 결합하는 것으로 결정되었다.
| 항체 | KD, nM |
| LAG3-1 | 0.125 |
| LAG3-2 | 0.09 |
| LAG3-3 | 0.12 |
| LAG3-4 | 0.1 |
| LAG3-5 | 0.07 |
본 발명의 LAG3 항체를, 그의 리간드 MHC II를 발현하는 Raji 세포에 대한 재조합 인간 LAG3 단백질의 결합을 차단하는 것에 대해 FACS를 사용하여 시험하였다. 인간 Fc에 융합된 재조합 인간 LAG3 세포 외 도메인 (hLAG3-hIgFc)을 실온 (RT)에서 LAG3 항체 LAG3-1, LAG3-2, LAG3-3, LAG3-4 및 LAG3-5와 함께 15분 동안 인큐베이션한 후, Raji 세포에 첨가하고, 4 ℃에서 30분 동안 추가 인큐베이션하였다. 세포를 3회 세척하였다. Raji 세포에 대한 HLAG3-mIgFc 결합을 PE 표지된 항-인간 IgG를 사용하여 검출하였다. HLAG3-mIgFc 결합 분석을 FACS Canto I (BD Bioscience)로 수행하였다. 그 결과는 도 7에 요약되어 있으며, 본 발명의 모든 LAG3 항체는 LAG3의 MHC II에 대한 결합을 선택적이면서 효과적으로 억제하는 것으로 입증되었다.
실시예 11: 인간화 항-LAG3 모노클로날 항체의 에피토프 맵핑.
본 발명의 대표적인 항-LAG3 항체 및 BMS-986016 (선행 기술의 기준 항-LAG3 항체 분자)과 동일한 아미노산 서열을 갖는 기준 항체 분자의 에피토프를 "경쟁 결합" 분석을 사용하여 분석하였다. 그 결과 LAG3에 대한 결합에 경쟁을 나타내지 않았고, 이는 본 발명의 항-LAG3 항체가 선행 기술의 기준 항-LAG3 항체 분자와 상이한 에피토프에 결합함을 나타낸다.
본 발명의 대표적인 항-LAG3 항체의 에피토프를 항체 에피토프들의 개별 아미노산 수준에서 에피토프 차이를 나타내는 수소-중수소 교환 (HDX) 실험으로 추가 정련하였다.
HDX 분석은 본 발명의 대표적인 항-LAG3 항체가 표 8에 기재된 바와 같이 인간 LAG3의 두 상이한 영역에 결합한다는 것을 보여 주었다.
| 항체 | LAG3 결합 영역 (aa*) | 에피토프 |
| LAG3-1 | 33-40 and 125-135 | LLRRAGVT (서열번호 111) 및 YRAAVHLRDRA (서열번호 112) |
* 넘버링에 사용된 LAG-3: GenBank NP_002277
실시예 12: 항-PD1 항체 및 항-LAG3 항체로 항원 특이적 T 세포 반응의 자극.
본 발명의 개별 항-PD1 및 항-LAG3 항체 및 이들 항체의 조합을 ELISA에 의해 파상풍 특이적 CD4 기억 T 세포의 사이토카인 생성을 자극하는 능력에 대해 시험하고, 선행 기술의 항-PD1 및 항-LAG3 항체와 비교하였다.
이 분석을 위해, 건강한 공여자 PBMC로부터의 T 세포를 파상풍 톡소이드의 존재하에 확장시키고 파상풍 톡소이드를 로딩한 자가 성숙 수지상 세포 (DC)와 함께 2일 동안 공-배양하였다. 공-배양 단계를 항-PD1, 항-LAG3 및 항-PD1과 항-LAG3 항체 분자의 조합물의 존재하에서 항-PD1 mAb (200 nM)의 양을 고정시키고 항-LAG3 항체의 양을 증가시켜 유사한 방식으로 2회 반복하였다. 두 번째 공-배양 단계를 마치고, 상등액을 IFN-γ 분비에 대해 분석하였다.
이 분석을 사용하여, 본 발명의 항-PD1 및 항-LAG3 항체의 조합을, 니볼루맵 (Opdivo (R)) (PD1 mAb) + 4명의 다른 공여자에서의 BMS-986016와 동일한 아미노산 서열을 갖는 항체 (LAG3 mAb)와 비교하였다. 증가하는 양의 항-LAG3 항체를 고정된 용량의 항-PD1 mAb와 조합 사용하였다. 제시된 데이터를 100%로 표시된 포화 농도에서 사용된 항-PD1 항체로 표준화하고, 그 결과를 도 8에 나타내었다.
이 데이터는 본 발명의 항-PD1 항체 및 항-LAG3 항체의 조합이 항-PD1 mAb 단독에 비해 IFN-감마 생산의 1.5-2배 증가를 유도한다는 것을 입증한다. 놀랍게도, 본 발명의 항-PD1 및 항-LAG3 항체의 조합은 선행 기술의 항-PD1 및 항-LAG3 항체의 것보다 우수하다.
또한, 매우 낮은 항-LAG3 mAB 수준에서 IFN-감마 분비 수준이 매우 높은 것으로 알 수 있는 바와 같이, 데이터는 4명의 공여자 중 3명에게서 항-PD1-3 (본 발명의 대표적인 PD1 항체)이 니볼루맵 (Opdivo (R) 보다 우수하다고 나타내었다 (도 8).
인식할 수 있는 바와 같이, 본 발명의 항-LAG3 항체 분자와 본 발명의 항-PD1 항체 분자의 조합의 이러한 우월성은 이들이 선행 기술의 항체 치료제보다 낮은 용량 수준에서 암을 치료할 수 있고 따라서 원치 않는 부작용을 덜 나타내는 치료적 응용을 가능케 할 수 있음을 시사한다.
항-PD1 및 항-LAG3 항체 분자가 상기 논의한 바와 같이 환자에서 바람직하지 않은 부작용을 유도할 수 있음을 감안한다면, 본 발명의 항-PD1 항체 및 항-LAG3 항체는 낮은 투여량 및/또는 덜 빈번한 투여 체제를 사용함으로써 선행 기술에 비해 유의적이고 놀라운 임상적 이점을 가질 수 있다.
실시예 13: 동계 종양 모델에서 항-PD1 및 항-LAG3 항체의 조합 치료의 생체 내 효능
본 발명의 항-PD1 항체 및 항-LAG3 항체의 조합 치료가 생체 내에서 우수한 효능으로 이어지는지를 시험하기 위해, 여러 전임상 종양 모델을 항-PD1 및 항-LAG3 항체로 처리하였다. 모든 마우스 종양 세포주 (MC38, Colon-26 결장암, B16F10 흑색종, LL/2 (LLC1) Lewis 폐암 및 4T1 유방암)를 마우스 종양 세포주의 기원에 따라 C57BL/6 또는 BALB/c에 피하 주사하였다. 세포 주사 후 3일째에, 마우스를 매주 2회 투여로 복강 내 (ip) 처리하였다. 모든 항체는 10 mg/kg로 투여되었고, 본 발명의 항-LAG3 및 항-PD1 항체의 조합은 각각 10 mg/kg으로 투여되었다. 본 연구에 사용된 항체는 모두 미국 뉴햄프셔주 웨스트 레바논 소재의 BioXCell에서 입수한 것이다. 대조군은 래트 IgG2a 항체 (클론 2A3)로 처리하였고, 사용된 항-PD1 항체는 래트 IgG2a Fc 부분 (클론 RMP1-14)을 가지며 연구에 사용된 항-LAG3는 래트 IgG1 Fc 부분 (클론 C9B7W)을 가졌다. 종양 크기를 2차원 (길이×폭)으로 주당 적어도 3회 측정하고, 종양 체적을 계산하였다. 종양 용적이 1500 mm3에 도달하거나 종양이 궤양을 일으키면 동물을 안락사시켰다.
표 9 및 도 9에 요약된 TGI 및 CR의 결과는 개별 마우스에 대한 시간 경과에 따른 종양 용적을 나타낸다. 결론적으로, 본 연구는 항-PD1 처리 단독이 MC 38에서 효능을 나타내었지만 시험된 다른 모델에서는 그렇지 않음을 보여준다. 그러나, LL/2 모델을 제외하고, 본 발명의 항-PD1 항체 및 항-LAG3 항체의 조합 치료는 항-PD1 단독 요법의 효능을 실질적으로 개선시켰으며, 몇몇 마우스는 MC-38, Colon-26 및 4T1 모델에서 연구 종료 시점에 종양이 없었다. 특히, PD1 내성 4T1 모델에서 이 조합은 5 마리 마우스 중 3 마리가 종양이 완전히 없는 것으로 나타남으로써 종양 증식에 우수한 효과를 나타낸 것으로 관찰되었다.
| 세포주 | MC38 | B16-F10 | LL/2 (LLC1) | Colon-26 | 4T1 |
| 마우스 종 | C57BL/6 | C57BL/6 | C57BL/6 | BALB/c | BALB/c |
| TGI 계산일 | 19 | 22 | 22 | 24 | 31 |
| PD1에 대한 TGI [%] | 81 | 38 | 0 | 42 | 5 |
| LAG3에 대한 TGI [%] | 47 | 시험되지 않음 | 시험되지 않음 | 시험되지 않음 | 시험되지 않음 |
| PD1 + LAG3에 대한 TGI [%] | 99 | 58 | 29 | 99 | 99 |
| PD1에 대한 CR | 1 (10) | 0 (10) | 0 (10) | 1 (10) | 0 (10) |
| LAG3에 대한 CR | 0 (10) | 시험되지 않음 | 시험되지 않음 | 시험되지 않음 | 시험되지 않음 |
| PD-1 + LAG3에 대한 CR | 4 (10) | 0 (10) | 0 (10) | 3 (5) | 3 (5) |
실시예 14: s.c. 투여를 위한 약학적 제형
본 발명의 상기 임의의 항체 분자를 다음과 같은 조성을 갖는 피하 적용을 위한 약학적 제형의 제조용으로 선택할 수 있다:
약 물질: 100 mg/ml (1 내지 3 nmol/ml)
아세트산염 완충액 : 25 mM
트레할로스: 220 mM
Tween-20: 0.02%
약 물질을 상기 조성을 가지는 용액으로 제형화하고 멸균처리하여 2 내지 8 ℃에서 저장하였다.
실시예 15: i.v. 투여를 위한 약학적 제형
본 발명의 상기 임의의 항체 분자를 i.v. 적용을 위한 약학적 제형의 제조용으로 선택할 수 있다. 본 발명의 항체에 적합한 약학적 제형의 일례는 다음과 같다.
21.5 mM 아세트산나트륨, 3.5 mM 아세트산, 240 mM 트레할로스, 0.67 mM L-메티오닌, 0.04% w/v 폴리소르베이트 및 주사용수 (WFI)로 이루어진 완충액 중에 본 발명의 항-PD1 항체가 20 mg/mL로 20 mL 바이알에 함유되어 있다.
25 mM 아세테이트, 240 mM 트레할로스, 0.67 mM 메티오닌, 0.04% (w/v) 폴리소르베이트 20, pH 5.5 및 주사용수 (WFI)로 이루어진 완충액 중에 본 발명의 항-LAG3 항체가 20 mg/mL로 20 mL 바이알에 함유되어 있다.
실시예 16: 사람에서의 약학적 사용
상기 실시예 15에 기술된 용액이 이를 필요로 하는 환자, 예컨대 암을 앓고 있는 사람에게 2 내지 4주마다 정맥 내 주입 (100 내지 200 mg의 용량)으로 적용된다.




























SEQUENCE LISTING
<110> Boehringer Ingelheim International GmbH
<120> Antibodies
<130> P12-0402
<160> 118
<170> PatentIn version 3.5
<210> 1
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR sequence
<400> 1
Gly Phe Thr Phe Ser Ala Ser Ala Met Ser
1 5 10
<210> 2
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR sequence
<400> 2
Tyr Ile Ser Gly Gly Gly Gly Asp Thr Tyr Tyr Ser Ser Ser Val Lys
1 5 10 15
Gly
<210> 3
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR sequence
<400> 3
His Ser Asn Val Asn Tyr Tyr Ala Met Asp Tyr
1 5 10
<210> 4
<211> 15
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR sequence
<400> 4
Arg Ala Ser Glu Asn Ile Asp Thr Ser Gly Ile Ser Phe Met Asn
1 5 10 15
<210> 5
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR sequence
<400> 5
Val Ala Ser Asn Gln Gly Ser
1 5
<210> 6
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR sequence
<400> 6
Gln Gln Ser Lys Glu Val Pro Trp Thr
1 5
<210> 7
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR sequence
<400> 7
Gly Phe Thr Phe Ser Ala Ser Ala Met Ser
1 5 10
<210> 8
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR sequence
<400> 8
Tyr Ile Ser Gly Gly Gly Gly Asp Thr Tyr Tyr Ser Ser Ser Val Lys
1 5 10 15
Gly
<210> 9
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR sequence
<400> 9
His Ser Asn Pro Asn Tyr Tyr Ala Met Asp Tyr
1 5 10
<210> 10
<211> 15
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR sequence
<400> 10
Arg Ala Ser Glu Asn Ile Asp Thr Ser Gly Ile Ser Phe Met Asn
1 5 10 15
<210> 11
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR sequence
<400> 11
Val Ala Ser Asn Gln Gly Ser
1 5
<210> 12
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR sequence
<400> 12
Gln Gln Ser Lys Glu Val Pro Trp Thr
1 5
<210> 13
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR sequence
<400> 13
Gly Phe Thr Phe Ser Lys Ser Ala Met Ser
1 5 10
<210> 14
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR sequence
<400> 14
Tyr Ile Ser Gly Gly Gly Gly Asp Thr Tyr Tyr Ser Ser Ser Val Lys
1 5 10 15
Gly
<210> 15
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR sequence
<400> 15
His Ser Asn Val Asn Tyr Tyr Ala Met Asp Tyr
1 5 10
<210> 16
<211> 15
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR sequence
<400> 16
Arg Ala Ser Glu Asn Ile Asp Val Ser Gly Ile Ser Phe Met Asn
1 5 10 15
<210> 17
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR sequence
<400> 17
Val Ala Ser Asn Gln Gly Ser
1 5
<210> 18
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR sequence
<400> 18
Gln Gln Ser Lys Glu Val Pro Trp Thr
1 5
<210> 19
<211> 120
<212> PRT
<213> Artificial Sequence
<220>
<223> Immunoglobulin domain
<400> 19
Glu Val Met Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Thr Ala Ser Gly Phe Thr Phe Ser Ala Ser
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Tyr Ile Ser Gly Gly Gly Gly Asp Thr Tyr Tyr Ser Ser Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg His Ser Asn Val Asn Tyr Tyr Ala Met Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 20
<211> 111
<212> PRT
<213> Artificial Sequence
<220>
<223> Immunoglobulin domain
<400> 20
Glu Ile Val Leu Thr Gln Ser Pro Ala Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Met Ser Cys Arg Ala Ser Glu Asn Ile Asp Thr Ser
20 25 30
Gly Ile Ser Phe Met Asn Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro
35 40 45
Lys Leu Leu Ile Tyr Val Ala Ser Asn Gln Gly Ser Gly Ile Pro Ala
50 55 60
Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser
65 70 75 80
Arg Leu Glu Pro Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Ser Lys
85 90 95
Glu Val Pro Trp Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys
100 105 110
<210> 21
<211> 120
<212> PRT
<213> Artificial Sequence
<220>
<223> Immunoglobulin domain
<400> 21
Glu Val Met Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Thr Ala Ser Gly Phe Thr Phe Ser Ala Ser
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Tyr Ile Ser Gly Gly Gly Gly Asp Thr Tyr Tyr Ser Ser Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg His Ser Asn Pro Asn Tyr Tyr Ala Met Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 22
<211> 111
<212> PRT
<213> Artificial Sequence
<220>
<223> Immunoglobulin domain
<400> 22
Glu Ile Val Leu Thr Gln Ser Pro Ala Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Met Ser Cys Arg Ala Ser Glu Asn Ile Asp Thr Ser
20 25 30
Gly Ile Ser Phe Met Asn Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro
35 40 45
Lys Leu Leu Ile Tyr Val Ala Ser Asn Gln Gly Ser Gly Ile Pro Ala
50 55 60
Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser
65 70 75 80
Arg Leu Glu Pro Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Ser Lys
85 90 95
Glu Val Pro Trp Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys
100 105 110
<210> 23
<211> 120
<212> PRT
<213> Artificial Sequence
<220>
<223> Immunoglobulin domain
<400> 23
Glu Val Met Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Thr Ala Ser Gly Phe Thr Phe Ser Lys Ser
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Tyr Ile Ser Gly Gly Gly Gly Asp Thr Tyr Tyr Ser Ser Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg His Ser Asn Val Asn Tyr Tyr Ala Met Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 24
<211> 111
<212> PRT
<213> Artificial Sequence
<220>
<223> Immunoglobulin domain
<400> 24
Glu Ile Val Leu Thr Gln Ser Pro Ala Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Met Ser Cys Arg Ala Ser Glu Asn Ile Asp Val Ser
20 25 30
Gly Ile Ser Phe Met Asn Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro
35 40 45
Lys Leu Leu Ile Tyr Val Ala Ser Asn Gln Gly Ser Gly Ile Pro Ala
50 55 60
Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser
65 70 75 80
Arg Leu Glu Pro Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Ser Lys
85 90 95
Glu Val Pro Trp Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys
100 105 110
<210> 25
<211> 120
<212> PRT
<213> Artificial Sequence
<220>
<223> Immunoglobulin domain
<400> 25
Glu Val Met Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Thr Ala Ser Gly Phe Thr Phe Ser Lys Ser
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Tyr Ile Ser Gly Gly Gly Gly Asp Thr Tyr Tyr Ser Ser Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg His Ser Asn Val Asn Tyr Tyr Ala Met Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 26
<211> 111
<212> PRT
<213> Artificial Sequence
<220>
<223> Immunoglobulin domain
<400> 26
Glu Ile Val Leu Thr Gln Ser Pro Ala Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Met Ser Cys Arg Ala Ser Glu Asn Ile Asp Val Ser
20 25 30
Gly Ile Ser Phe Met Asn Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro
35 40 45
Lys Leu Leu Ile Tyr Val Ala Ser Asn Gln Gly Ser Gly Ile Pro Ala
50 55 60
Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser
65 70 75 80
Arg Leu Glu Pro Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Ser Lys
85 90 95
Glu Val Pro Trp Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys
100 105 110
<210> 27
<211> 120
<212> PRT
<213> Artificial Sequence
<220>
<223> Immunoglobulin domain
<400> 27
Glu Val Met Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Thr Ala Ser Gly Phe Thr Phe Ser Lys Ser
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Tyr Ile Ser Gly Gly Gly Gly Asp Thr Tyr Tyr Ser Ser Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg His Ser Asn Val Asn Tyr Tyr Ala Met Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 28
<211> 111
<212> PRT
<213> Artificial Sequence
<220>
<223> Immunoglobulin domain
<400> 28
Glu Ile Val Leu Thr Gln Ser Pro Ala Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Met Ser Cys Arg Ala Ser Glu Asn Ile Asp Val Ser
20 25 30
Gly Ile Ser Phe Met Asn Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro
35 40 45
Lys Leu Leu Ile Tyr Val Ala Ser Asn Gln Gly Ser Gly Ile Pro Ala
50 55 60
Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser
65 70 75 80
Arg Leu Glu Pro Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Ser Lys
85 90 95
Glu Val Pro Trp Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys
100 105 110
<210> 29
<211> 446
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody chain
<400> 29
Glu Val Met Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Thr Ala Ser Gly Phe Thr Phe Ser Ala Ser
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Tyr Ile Ser Gly Gly Gly Gly Asp Thr Tyr Tyr Ser Ser Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg His Ser Asn Val Asn Tyr Tyr Ala Met Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val
115 120 125
Phe Pro Leu Ala Pro Cys Ser Arg Ser Thr Ser Glu Ser Thr Ala Ala
130 135 140
Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser
145 150 155 160
Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val
165 170 175
Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro
180 185 190
Ser Ser Ser Leu Gly Thr Lys Thr Tyr Thr Cys Asn Val Asp His Lys
195 200 205
Pro Ser Asn Thr Lys Val Asp Lys Arg Val Glu Ser Lys Tyr Gly Pro
210 215 220
Pro Cys Pro Pro Cys Pro Ala Pro Glu Phe Leu Gly Gly Pro Ser Val
225 230 235 240
Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr
245 250 255
Pro Glu Val Thr Cys Val Val Val Asp Val Ser Gln Glu Asp Pro Glu
260 265 270
Val Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys
275 280 285
Thr Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr Tyr Arg Val Val Ser
290 295 300
Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys
305 310 315 320
Cys Lys Val Ser Asn Lys Gly Leu Pro Ser Ser Ile Glu Lys Thr Ile
325 330 335
Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro
340 345 350
Pro Ser Gln Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu
355 360 365
Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn
370 375 380
Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser
385 390 395 400
Asp Gly Ser Phe Phe Leu Tyr Ser Arg Leu Thr Val Asp Lys Ser Arg
405 410 415
Trp Gln Glu Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu
420 425 430
His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Leu Gly
435 440 445
<210> 30
<211> 218
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody chain
<400> 30
Glu Ile Val Leu Thr Gln Ser Pro Ala Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Met Ser Cys Arg Ala Ser Glu Asn Ile Asp Thr Ser
20 25 30
Gly Ile Ser Phe Met Asn Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro
35 40 45
Lys Leu Leu Ile Tyr Val Ala Ser Asn Gln Gly Ser Gly Ile Pro Ala
50 55 60
Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser
65 70 75 80
Arg Leu Glu Pro Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Ser Lys
85 90 95
Glu Val Pro Trp Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys Arg
100 105 110
Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln
115 120 125
Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr
130 135 140
Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser
145 150 155 160
Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr
165 170 175
Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys
180 185 190
His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro
195 200 205
Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
210 215
<210> 31
<211> 446
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody chain
<400> 31
Glu Val Met Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Thr Ala Ser Gly Phe Thr Phe Ser Ala Ser
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Tyr Ile Ser Gly Gly Gly Gly Asp Thr Tyr Tyr Ser Ser Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg His Ser Asn Pro Asn Tyr Tyr Ala Met Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val
115 120 125
Phe Pro Leu Ala Pro Cys Ser Arg Ser Thr Ser Glu Ser Thr Ala Ala
130 135 140
Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser
145 150 155 160
Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val
165 170 175
Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro
180 185 190
Ser Ser Ser Leu Gly Thr Lys Thr Tyr Thr Cys Asn Val Asp His Lys
195 200 205
Pro Ser Asn Thr Lys Val Asp Lys Arg Val Glu Ser Lys Tyr Gly Pro
210 215 220
Pro Cys Pro Pro Cys Pro Ala Pro Glu Phe Leu Gly Gly Pro Ser Val
225 230 235 240
Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr
245 250 255
Pro Glu Val Thr Cys Val Val Val Asp Val Ser Gln Glu Asp Pro Glu
260 265 270
Val Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys
275 280 285
Thr Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr Tyr Arg Val Val Ser
290 295 300
Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys
305 310 315 320
Cys Lys Val Ser Asn Lys Gly Leu Pro Ser Ser Ile Glu Lys Thr Ile
325 330 335
Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro
340 345 350
Pro Ser Gln Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu
355 360 365
Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn
370 375 380
Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser
385 390 395 400
Asp Gly Ser Phe Phe Leu Tyr Ser Arg Leu Thr Val Asp Lys Ser Arg
405 410 415
Trp Gln Glu Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu
420 425 430
His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Leu Gly
435 440 445
<210> 32
<211> 218
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody chain
<400> 32
Glu Ile Val Leu Thr Gln Ser Pro Ala Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Met Ser Cys Arg Ala Ser Glu Asn Ile Asp Thr Ser
20 25 30
Gly Ile Ser Phe Met Asn Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro
35 40 45
Lys Leu Leu Ile Tyr Val Ala Ser Asn Gln Gly Ser Gly Ile Pro Ala
50 55 60
Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser
65 70 75 80
Arg Leu Glu Pro Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Ser Lys
85 90 95
Glu Val Pro Trp Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys Arg
100 105 110
Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln
115 120 125
Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr
130 135 140
Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser
145 150 155 160
Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr
165 170 175
Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys
180 185 190
His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro
195 200 205
Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
210 215
<210> 33
<211> 446
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody chain
<400> 33
Glu Val Met Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Thr Ala Ser Gly Phe Thr Phe Ser Lys Ser
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Tyr Ile Ser Gly Gly Gly Gly Asp Thr Tyr Tyr Ser Ser Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg His Ser Asn Val Asn Tyr Tyr Ala Met Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val
115 120 125
Phe Pro Leu Ala Pro Cys Ser Arg Ser Thr Ser Glu Ser Thr Ala Ala
130 135 140
Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser
145 150 155 160
Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val
165 170 175
Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro
180 185 190
Ser Ser Ser Leu Gly Thr Lys Thr Tyr Thr Cys Asn Val Asp His Lys
195 200 205
Pro Ser Asn Thr Lys Val Asp Lys Arg Val Glu Ser Lys Tyr Gly Pro
210 215 220
Pro Cys Pro Pro Cys Pro Ala Pro Glu Phe Leu Gly Gly Pro Ser Val
225 230 235 240
Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr
245 250 255
Pro Glu Val Thr Cys Val Val Val Asp Val Ser Gln Glu Asp Pro Glu
260 265 270
Val Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys
275 280 285
Thr Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr Tyr Arg Val Val Ser
290 295 300
Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys
305 310 315 320
Cys Lys Val Ser Asn Lys Gly Leu Pro Ser Ser Ile Glu Lys Thr Ile
325 330 335
Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro
340 345 350
Pro Ser Gln Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu
355 360 365
Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn
370 375 380
Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser
385 390 395 400
Asp Gly Ser Phe Phe Leu Tyr Ser Arg Leu Thr Val Asp Lys Ser Arg
405 410 415
Trp Gln Glu Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu
420 425 430
His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Leu Gly
435 440 445
<210> 34
<211> 218
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody chain
<400> 34
Glu Ile Val Leu Thr Gln Ser Pro Ala Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Met Ser Cys Arg Ala Ser Glu Asn Ile Asp Val Ser
20 25 30
Gly Ile Ser Phe Met Asn Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro
35 40 45
Lys Leu Leu Ile Tyr Val Ala Ser Asn Gln Gly Ser Gly Ile Pro Ala
50 55 60
Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser
65 70 75 80
Arg Leu Glu Pro Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Ser Lys
85 90 95
Glu Val Pro Trp Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys Arg
100 105 110
Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln
115 120 125
Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr
130 135 140
Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser
145 150 155 160
Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr
165 170 175
Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys
180 185 190
His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro
195 200 205
Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
210 215
<210> 35
<211> 446
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody chain
<400> 35
Glu Val Met Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Thr Ala Ser Gly Phe Thr Phe Ser Lys Ser
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Tyr Ile Ser Gly Gly Gly Gly Asp Thr Tyr Tyr Ser Ser Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg His Ser Asn Val Asn Tyr Tyr Ala Met Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val
115 120 125
Phe Pro Leu Ala Pro Cys Ser Arg Ser Thr Ser Glu Ser Thr Ala Ala
130 135 140
Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser
145 150 155 160
Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val
165 170 175
Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro
180 185 190
Ser Ser Ser Leu Gly Thr Lys Thr Tyr Thr Cys Asn Val Asp His Lys
195 200 205
Pro Ser Asn Thr Lys Val Asp Lys Arg Val Glu Ser Lys Tyr Gly Pro
210 215 220
Pro Cys Pro Pro Cys Pro Ala Pro Glu Phe Leu Gly Gly Pro Ser Val
225 230 235 240
Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr
245 250 255
Pro Glu Val Thr Cys Val Val Val Asp Val Ser Gln Glu Asp Pro Glu
260 265 270
Val Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys
275 280 285
Thr Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr Tyr Arg Val Val Ser
290 295 300
Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys
305 310 315 320
Cys Lys Val Ser Asn Lys Gly Leu Pro Ser Ser Ile Glu Lys Thr Ile
325 330 335
Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro
340 345 350
Pro Ser Gln Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu
355 360 365
Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn
370 375 380
Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser
385 390 395 400
Asp Gly Ser Phe Phe Leu Tyr Ser Arg Leu Thr Val Asp Lys Ser Arg
405 410 415
Trp Gln Glu Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu
420 425 430
His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Leu Gly
435 440 445
<210> 36
<211> 218
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody chain
<400> 36
Glu Ile Val Leu Thr Gln Ser Pro Ala Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Met Ser Cys Arg Ala Ser Glu Asn Ile Asp Val Ser
20 25 30
Gly Ile Ser Phe Met Asn Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro
35 40 45
Lys Leu Leu Ile Tyr Val Ala Ser Asn Gln Gly Ser Gly Ile Pro Ala
50 55 60
Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser
65 70 75 80
Arg Leu Glu Pro Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Ser Lys
85 90 95
Glu Val Pro Trp Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys Arg
100 105 110
Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln
115 120 125
Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr
130 135 140
Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser
145 150 155 160
Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr
165 170 175
Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys
180 185 190
His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro
195 200 205
Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
210 215
<210> 37
<211> 446
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody chain
<400> 37
Glu Val Met Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Thr Ala Ser Gly Phe Thr Phe Ser Lys Ser
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Tyr Ile Ser Gly Gly Gly Gly Asp Thr Tyr Tyr Ser Ser Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg His Ser Asn Val Asn Tyr Tyr Ala Met Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val
115 120 125
Phe Pro Leu Ala Pro Cys Ser Arg Ser Thr Ser Glu Ser Thr Ala Ala
130 135 140
Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser
145 150 155 160
Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val
165 170 175
Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro
180 185 190
Ser Ser Ser Leu Gly Thr Lys Thr Tyr Thr Cys Asn Val Asp His Lys
195 200 205
Pro Ser Asn Thr Lys Val Asp Lys Arg Val Glu Ser Lys Tyr Gly Pro
210 215 220
Pro Cys Pro Pro Cys Pro Ala Pro Glu Phe Leu Gly Gly Pro Ser Val
225 230 235 240
Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr
245 250 255
Pro Glu Val Thr Cys Val Val Val Asp Val Ser Gln Glu Asp Pro Glu
260 265 270
Val Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys
275 280 285
Thr Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr Tyr Arg Val Val Ser
290 295 300
Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys
305 310 315 320
Cys Lys Val Ser Asn Lys Gly Leu Pro Ser Ser Ile Glu Lys Thr Ile
325 330 335
Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro
340 345 350
Pro Ser Gln Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu
355 360 365
Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn
370 375 380
Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser
385 390 395 400
Asp Gly Ser Phe Phe Leu Tyr Ser Arg Leu Thr Val Asp Lys Ser Arg
405 410 415
Trp Gln Glu Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu
420 425 430
His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Leu Gly
435 440 445
<210> 38
<211> 218
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody chain
<400> 38
Glu Ile Val Leu Thr Gln Ser Pro Ala Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Met Ser Cys Arg Ala Ser Glu Asn Ile Asp Val Ser
20 25 30
Gly Ile Ser Phe Met Asn Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro
35 40 45
Lys Leu Leu Ile Tyr Val Ala Ser Asn Gln Gly Ser Gly Ile Pro Ala
50 55 60
Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser
65 70 75 80
Arg Leu Glu Pro Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Ser Lys
85 90 95
Glu Val Pro Trp Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys Arg
100 105 110
Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln
115 120 125
Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr
130 135 140
Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser
145 150 155 160
Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr
165 170 175
Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys
180 185 190
His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro
195 200 205
Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
210 215
<210> 39
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR sequence
<400> 39
Gly Phe Ser Leu Ser Thr Ser Asp Met Gly Val Gly
1 5 10
<210> 40
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR sequence
<400> 40
His Ile Trp Trp Asp Asp Val Lys Arg Tyr Asn Pro Ala Leu Lys Ser
1 5 10 15
<210> 41
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR sequence
<400> 41
Ile Glu Asp Tyr Gly Val Ser Tyr Tyr Phe Asp Tyr
1 5 10
<210> 42
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR sequence
<400> 42
Lys Ala Ser Gln Asp Val Ser Thr Ala Val Ala
1 5 10
<210> 43
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR sequence
<400> 43
Ser Ala Ser Tyr Arg Tyr Thr
1 5
<210> 44
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR sequence
<400> 44
Gln Gln His Tyr Ser Ile Pro Leu Thr
1 5
<210> 45
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR sequence
<400> 45
Gly Phe Ser Leu Ser Thr Ser Asp Met Gly Val Gly
1 5 10
<210> 46
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR sequence
<400> 46
His Ile Trp Trp Asp Asp Val Lys Arg Tyr Asn Pro Ala Leu Lys Ser
1 5 10 15
<210> 47
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR sequence
<400> 47
Ile Val Asp Tyr Gly Val Ser Tyr Tyr Phe Asp Tyr
1 5 10
<210> 48
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR sequence
<400> 48
Lys Ala Ser Gln Asp Val Ser Thr Ala Val Ala
1 5 10
<210> 49
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR sequence
<400> 49
Ser Ala Ser Tyr Arg Tyr Thr
1 5
<210> 50
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR sequence
<400> 50
Gln Gln His Tyr Ser Ile Pro Leu Thr
1 5
<210> 51
<211> 122
<212> PRT
<213> Artificial Sequence
<220>
<223> Immunoglobulin domain
<400> 51
Gln Val Thr Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Arg
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Phe Ser Gly Phe Ser Leu Ser Thr Ser
20 25 30
Asp Met Gly Val Gly Trp Ile Arg Gln Ala Pro Gly Lys Gly Leu Glu
35 40 45
Trp Val Ala His Ile Trp Trp Asp Asp Val Lys Arg Tyr Asn Pro Ala
50 55 60
Leu Lys Ser Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu
65 70 75 80
Tyr Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Phe
85 90 95
Cys Ala Arg Ile Glu Asp Tyr Gly Val Ser Tyr Tyr Phe Asp Tyr Trp
100 105 110
Gly Gln Gly Thr Thr Val Thr Val Ser Ser
115 120
<210> 52
<211> 107
<212> PRT
<213> Artificial Sequence
<220>
<223> Immunoglobulin domain
<400> 52
Asp Ile Gln Met Thr Gln Ser Pro Ser Phe Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Ser Ile Thr Cys Lys Ala Ser Gln Asp Val Ser Thr Ala
20 25 30
Val Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Ser Ala Ser Tyr Arg Tyr Thr Gly Val Pro Asp Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln His Tyr Ser Ile Pro Leu
85 90 95
Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys
100 105
<210> 53
<211> 122
<212> PRT
<213> Artificial Sequence
<220>
<223> Immunoglobulin domain
<400> 53
Gln Val Thr Leu Lys Glu Ser Gly Pro Thr Leu Val Lys Pro Thr Gln
1 5 10 15
Thr Leu Thr Leu Thr Cys Ser Phe Ser Gly Phe Ser Leu Ser Thr Ser
20 25 30
Asp Met Gly Val Gly Trp Ile Arg Gln Pro Pro Gly Lys Ala Leu Glu
35 40 45
Trp Leu Ala His Ile Trp Trp Asp Asp Val Lys Arg Tyr Asn Pro Ala
50 55 60
Leu Lys Ser Arg Leu Thr Ile Thr Lys Asp Thr Ser Lys Asn Gln Val
65 70 75 80
Val Leu Thr Met Thr Asn Met Asp Pro Val Asp Thr Ala Thr Tyr Phe
85 90 95
Cys Ala Arg Ile Glu Asp Tyr Gly Val Ser Tyr Tyr Phe Asp Tyr Trp
100 105 110
Gly Gln Gly Thr Thr Val Thr Val Ser Ser
115 120
<210> 54
<211> 107
<212> PRT
<213> Artificial Sequence
<220>
<223> Immunoglobulin domain
<400> 54
Asp Ile Gln Met Thr Gln Ser Pro Ser Phe Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Phe Thr Cys Lys Ala Ser Gln Asp Val Ser Thr Ala
20 25 30
Val Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Ser Ala Ser Tyr Arg Tyr Thr Gly Val Pro Asp Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln His Tyr Ser Ile Pro Leu
85 90 95
Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys
100 105
<210> 55
<211> 122
<212> PRT
<213> Artificial Sequence
<220>
<223> Immunoglobulin domain
<400> 55
Gln Val Thr Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Arg
1 5 10 15
Ser Leu Ser Leu Ser Cys Ala Phe Ser Gly Phe Ser Leu Ser Thr Ser
20 25 30
Asp Met Gly Val Gly Trp Val Arg Gln Pro Pro Gly Lys Gly Leu Glu
35 40 45
Trp Val Ala His Ile Trp Trp Asp Asp Val Lys Arg Tyr Asn Pro Ala
50 55 60
Leu Lys Ser Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu
65 70 75 80
Tyr Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Thr Tyr Tyr
85 90 95
Cys Ala Arg Ile Glu Asp Tyr Gly Val Ser Tyr Tyr Phe Asp Tyr Trp
100 105 110
Gly Gln Gly Thr Thr Val Thr Val Ser Ser
115 120
<210> 56
<211> 107
<212> PRT
<213> Artificial Sequence
<220>
<223> Immunoglobulin domain
<400> 56
Asp Ile Gln Met Thr Gln Ser Pro Ser Phe Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Lys Ala Ser Gln Asp Val Ser Thr Ala
20 25 30
Val Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Ser Ala Ser Tyr Arg Tyr Thr Gly Val Pro Asp Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln His Tyr Ser Ile Pro Leu
85 90 95
Thr Phe Gly Ala Gly Thr Lys Leu Glu Ile Lys
100 105
<210> 57
<211> 122
<212> PRT
<213> Artificial Sequence
<220>
<223> Immunoglobulin domain
<400> 57
Gln Val Thr Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Arg
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Phe Ser Gly Phe Ser Leu Ser Thr Ser
20 25 30
Asp Met Gly Val Gly Trp Ile Arg Gln Ala Pro Gly Lys Gly Leu Glu
35 40 45
Trp Val Ala His Ile Trp Trp Asp Asp Val Lys Arg Tyr Asn Pro Ala
50 55 60
Leu Lys Ser Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu
65 70 75 80
Tyr Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Thr Tyr Phe
85 90 95
Cys Ala Arg Ile Glu Asp Tyr Gly Val Ser Tyr Tyr Phe Asp Tyr Trp
100 105 110
Gly Gln Gly Thr Thr Val Thr Val Ser Ser
115 120
<210> 58
<211> 107
<212> PRT
<213> Artificial Sequence
<220>
<223> Immunoglobulin domain
<400> 58
Asp Ile Val Met Thr Gln Ser Pro Ser Phe Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Lys Ala Ser Gln Asp Val Ser Thr Ala
20 25 30
Val Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Ser Ala Ser Tyr Arg Tyr Thr Gly Val Pro Asp Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln His Tyr Ser Ile Pro Leu
85 90 95
Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys
100 105
<210> 59
<211> 122
<212> PRT
<213> Artificial Sequence
<220>
<223> Immunoglobulin domain
<400> 59
Gln Val Thr Leu Lys Glu Ser Gly Pro Thr Leu Val Lys Pro Thr Gln
1 5 10 15
Thr Leu Thr Leu Thr Cys Ser Phe Ser Gly Phe Ser Leu Ser Thr Ser
20 25 30
Asp Met Gly Val Gly Trp Ile Arg Gln Pro Pro Gly Lys Ala Leu Glu
35 40 45
Trp Leu Ala His Ile Trp Trp Asp Asp Val Lys Arg Tyr Asn Pro Ala
50 55 60
Leu Lys Ser Arg Leu Thr Ile Thr Lys Asp Thr Ser Lys Asn Gln Val
65 70 75 80
Val Leu Thr Met Thr Asn Met Asp Pro Val Asp Thr Ala Thr Tyr Phe
85 90 95
Cys Ala Arg Ile Val Asp Tyr Gly Val Ser Tyr Tyr Phe Asp Tyr Trp
100 105 110
Gly Gln Gly Thr Thr Val Thr Val Ser Ser
115 120
<210> 60
<211> 107
<212> PRT
<213> Artificial Sequence
<220>
<223> Immunoglobulin domain
<400> 60
Asp Ile Gln Met Thr Gln Ser Pro Ser Phe Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Ser Ile Thr Cys Lys Ala Ser Gln Asp Val Ser Thr Ala
20 25 30
Val Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Ser Ala Ser Tyr Arg Tyr Thr Gly Val Pro Asp Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln His Tyr Ser Ile Pro Leu
85 90 95
Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys
100 105
<210> 61
<211> 448
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody chain
<400> 61
Gln Val Thr Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Arg
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Phe Ser Gly Phe Ser Leu Ser Thr Ser
20 25 30
Asp Met Gly Val Gly Trp Ile Arg Gln Ala Pro Gly Lys Gly Leu Glu
35 40 45
Trp Val Ala His Ile Trp Trp Asp Asp Val Lys Arg Tyr Asn Pro Ala
50 55 60
Leu Lys Ser Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu
65 70 75 80
Tyr Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Phe
85 90 95
Cys Ala Arg Ile Glu Asp Tyr Gly Val Ser Tyr Tyr Phe Asp Tyr Trp
100 105 110
Gly Gln Gly Thr Thr Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro
115 120 125
Ser Val Phe Pro Leu Ala Pro Cys Ser Arg Ser Thr Ser Glu Ser Thr
130 135 140
Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr
145 150 155 160
Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro
165 170 175
Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr
180 185 190
Val Pro Ser Ser Ser Leu Gly Thr Lys Thr Tyr Thr Cys Asn Val Asp
195 200 205
His Lys Pro Ser Asn Thr Lys Val Asp Lys Arg Val Glu Ser Lys Tyr
210 215 220
Gly Pro Pro Cys Pro Pro Cys Pro Ala Pro Glu Phe Leu Gly Gly Pro
225 230 235 240
Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser
245 250 255
Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser Gln Glu Asp
260 265 270
Pro Glu Val Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn
275 280 285
Ala Lys Thr Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr Tyr Arg Val
290 295 300
Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu
305 310 315 320
Tyr Lys Cys Lys Val Ser Asn Lys Gly Leu Pro Ser Ser Ile Glu Lys
325 330 335
Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr
340 345 350
Leu Pro Pro Ser Gln Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr
355 360 365
Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu
370 375 380
Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu
385 390 395 400
Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Arg Leu Thr Val Asp Lys
405 410 415
Ser Arg Trp Gln Glu Gly Asn Val Phe Ser Cys Ser Val Met His Glu
420 425 430
Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Leu Gly
435 440 445
<210> 62
<211> 214
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody chain
<400> 62
Asp Ile Gln Met Thr Gln Ser Pro Ser Phe Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Ser Ile Thr Cys Lys Ala Ser Gln Asp Val Ser Thr Ala
20 25 30
Val Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Ser Ala Ser Tyr Arg Tyr Thr Gly Val Pro Asp Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln His Tyr Ser Ile Pro Leu
85 90 95
Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 63
<211> 448
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody chain
<400> 63
Gln Val Thr Leu Lys Glu Ser Gly Pro Thr Leu Val Lys Pro Thr Gln
1 5 10 15
Thr Leu Thr Leu Thr Cys Ser Phe Ser Gly Phe Ser Leu Ser Thr Ser
20 25 30
Asp Met Gly Val Gly Trp Ile Arg Gln Pro Pro Gly Lys Ala Leu Glu
35 40 45
Trp Leu Ala His Ile Trp Trp Asp Asp Val Lys Arg Tyr Asn Pro Ala
50 55 60
Leu Lys Ser Arg Leu Thr Ile Thr Lys Asp Thr Ser Lys Asn Gln Val
65 70 75 80
Val Leu Thr Met Thr Asn Met Asp Pro Val Asp Thr Ala Thr Tyr Phe
85 90 95
Cys Ala Arg Ile Glu Asp Tyr Gly Val Ser Tyr Tyr Phe Asp Tyr Trp
100 105 110
Gly Gln Gly Thr Thr Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro
115 120 125
Ser Val Phe Pro Leu Ala Pro Cys Ser Arg Ser Thr Ser Glu Ser Thr
130 135 140
Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr
145 150 155 160
Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro
165 170 175
Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr
180 185 190
Val Pro Ser Ser Ser Leu Gly Thr Lys Thr Tyr Thr Cys Asn Val Asp
195 200 205
His Lys Pro Ser Asn Thr Lys Val Asp Lys Arg Val Glu Ser Lys Tyr
210 215 220
Gly Pro Pro Cys Pro Pro Cys Pro Ala Pro Glu Phe Leu Gly Gly Pro
225 230 235 240
Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser
245 250 255
Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser Gln Glu Asp
260 265 270
Pro Glu Val Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn
275 280 285
Ala Lys Thr Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr Tyr Arg Val
290 295 300
Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu
305 310 315 320
Tyr Lys Cys Lys Val Ser Asn Lys Gly Leu Pro Ser Ser Ile Glu Lys
325 330 335
Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr
340 345 350
Leu Pro Pro Ser Gln Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr
355 360 365
Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu
370 375 380
Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu
385 390 395 400
Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Arg Leu Thr Val Asp Lys
405 410 415
Ser Arg Trp Gln Glu Gly Asn Val Phe Ser Cys Ser Val Met His Glu
420 425 430
Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Leu Gly
435 440 445
<210> 64
<211> 214
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody chain
<400> 64
Asp Ile Gln Met Thr Gln Ser Pro Ser Phe Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Phe Thr Cys Lys Ala Ser Gln Asp Val Ser Thr Ala
20 25 30
Val Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Ser Ala Ser Tyr Arg Tyr Thr Gly Val Pro Asp Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln His Tyr Ser Ile Pro Leu
85 90 95
Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 65
<211> 448
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody chain
<400> 65
Gln Val Thr Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Arg
1 5 10 15
Ser Leu Ser Leu Ser Cys Ala Phe Ser Gly Phe Ser Leu Ser Thr Ser
20 25 30
Asp Met Gly Val Gly Trp Val Arg Gln Pro Pro Gly Lys Gly Leu Glu
35 40 45
Trp Val Ala His Ile Trp Trp Asp Asp Val Lys Arg Tyr Asn Pro Ala
50 55 60
Leu Lys Ser Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu
65 70 75 80
Tyr Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Thr Tyr Tyr
85 90 95
Cys Ala Arg Ile Glu Asp Tyr Gly Val Ser Tyr Tyr Phe Asp Tyr Trp
100 105 110
Gly Gln Gly Thr Thr Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro
115 120 125
Ser Val Phe Pro Leu Ala Pro Cys Ser Arg Ser Thr Ser Glu Ser Thr
130 135 140
Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr
145 150 155 160
Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro
165 170 175
Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr
180 185 190
Val Pro Ser Ser Ser Leu Gly Thr Lys Thr Tyr Thr Cys Asn Val Asp
195 200 205
His Lys Pro Ser Asn Thr Lys Val Asp Lys Arg Val Glu Ser Lys Tyr
210 215 220
Gly Pro Pro Cys Pro Pro Cys Pro Ala Pro Glu Phe Leu Gly Gly Pro
225 230 235 240
Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser
245 250 255
Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser Gln Glu Asp
260 265 270
Pro Glu Val Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn
275 280 285
Ala Lys Thr Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr Tyr Arg Val
290 295 300
Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu
305 310 315 320
Tyr Lys Cys Lys Val Ser Asn Lys Gly Leu Pro Ser Ser Ile Glu Lys
325 330 335
Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr
340 345 350
Leu Pro Pro Ser Gln Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr
355 360 365
Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu
370 375 380
Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu
385 390 395 400
Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Arg Leu Thr Val Asp Lys
405 410 415
Ser Arg Trp Gln Glu Gly Asn Val Phe Ser Cys Ser Val Met His Glu
420 425 430
Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Leu Gly
435 440 445
<210> 66
<211> 214
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody chain
<400> 66
Asp Ile Gln Met Thr Gln Ser Pro Ser Phe Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Lys Ala Ser Gln Asp Val Ser Thr Ala
20 25 30
Val Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Ser Ala Ser Tyr Arg Tyr Thr Gly Val Pro Asp Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln His Tyr Ser Ile Pro Leu
85 90 95
Thr Phe Gly Ala Gly Thr Lys Leu Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 67
<211> 448
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody chain
<400> 67
Gln Val Thr Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Arg
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Phe Ser Gly Phe Ser Leu Ser Thr Ser
20 25 30
Asp Met Gly Val Gly Trp Ile Arg Gln Ala Pro Gly Lys Gly Leu Glu
35 40 45
Trp Val Ala His Ile Trp Trp Asp Asp Val Lys Arg Tyr Asn Pro Ala
50 55 60
Leu Lys Ser Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu
65 70 75 80
Tyr Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Thr Tyr Phe
85 90 95
Cys Ala Arg Ile Glu Asp Tyr Gly Val Ser Tyr Tyr Phe Asp Tyr Trp
100 105 110
Gly Gln Gly Thr Thr Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro
115 120 125
Ser Val Phe Pro Leu Ala Pro Cys Ser Arg Ser Thr Ser Glu Ser Thr
130 135 140
Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr
145 150 155 160
Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro
165 170 175
Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr
180 185 190
Val Pro Ser Ser Ser Leu Gly Thr Lys Thr Tyr Thr Cys Asn Val Asp
195 200 205
His Lys Pro Ser Asn Thr Lys Val Asp Lys Arg Val Glu Ser Lys Tyr
210 215 220
Gly Pro Pro Cys Pro Pro Cys Pro Ala Pro Glu Phe Leu Gly Gly Pro
225 230 235 240
Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser
245 250 255
Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser Gln Glu Asp
260 265 270
Pro Glu Val Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn
275 280 285
Ala Lys Thr Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr Tyr Arg Val
290 295 300
Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu
305 310 315 320
Tyr Lys Cys Lys Val Ser Asn Lys Gly Leu Pro Ser Ser Ile Glu Lys
325 330 335
Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr
340 345 350
Leu Pro Pro Ser Gln Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr
355 360 365
Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu
370 375 380
Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu
385 390 395 400
Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Arg Leu Thr Val Asp Lys
405 410 415
Ser Arg Trp Gln Glu Gly Asn Val Phe Ser Cys Ser Val Met His Glu
420 425 430
Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Leu Gly
435 440 445
<210> 68
<211> 214
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody chain
<400> 68
Asp Ile Val Met Thr Gln Ser Pro Ser Phe Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Lys Ala Ser Gln Asp Val Ser Thr Ala
20 25 30
Val Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Ser Ala Ser Tyr Arg Tyr Thr Gly Val Pro Asp Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln His Tyr Ser Ile Pro Leu
85 90 95
Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 69
<211> 448
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody chain
<400> 69
Gln Val Thr Leu Lys Glu Ser Gly Pro Thr Leu Val Lys Pro Thr Gln
1 5 10 15
Thr Leu Thr Leu Thr Cys Ser Phe Ser Gly Phe Ser Leu Ser Thr Ser
20 25 30
Asp Met Gly Val Gly Trp Ile Arg Gln Pro Pro Gly Lys Ala Leu Glu
35 40 45
Trp Leu Ala His Ile Trp Trp Asp Asp Val Lys Arg Tyr Asn Pro Ala
50 55 60
Leu Lys Ser Arg Leu Thr Ile Thr Lys Asp Thr Ser Lys Asn Gln Val
65 70 75 80
Val Leu Thr Met Thr Asn Met Asp Pro Val Asp Thr Ala Thr Tyr Phe
85 90 95
Cys Ala Arg Ile Val Asp Tyr Gly Val Ser Tyr Tyr Phe Asp Tyr Trp
100 105 110
Gly Gln Gly Thr Thr Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro
115 120 125
Ser Val Phe Pro Leu Ala Pro Cys Ser Arg Ser Thr Ser Glu Ser Thr
130 135 140
Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr
145 150 155 160
Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro
165 170 175
Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr
180 185 190
Val Pro Ser Ser Ser Leu Gly Thr Lys Thr Tyr Thr Cys Asn Val Asp
195 200 205
His Lys Pro Ser Asn Thr Lys Val Asp Lys Arg Val Glu Ser Lys Tyr
210 215 220
Gly Pro Pro Cys Pro Pro Cys Pro Ala Pro Glu Phe Leu Gly Gly Pro
225 230 235 240
Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser
245 250 255
Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser Gln Glu Asp
260 265 270
Pro Glu Val Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn
275 280 285
Ala Lys Thr Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr Tyr Arg Val
290 295 300
Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu
305 310 315 320
Tyr Lys Cys Lys Val Ser Asn Lys Gly Leu Pro Ser Ser Ile Glu Lys
325 330 335
Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr
340 345 350
Leu Pro Pro Ser Gln Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr
355 360 365
Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu
370 375 380
Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu
385 390 395 400
Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Arg Leu Thr Val Asp Lys
405 410 415
Ser Arg Trp Gln Glu Gly Asn Val Phe Ser Cys Ser Val Met His Glu
420 425 430
Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Leu Gly
435 440 445
<210> 70
<211> 214
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody chain
<400> 70
Asp Ile Gln Met Thr Gln Ser Pro Ser Phe Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Ser Ile Thr Cys Lys Ala Ser Gln Asp Val Ser Thr Ala
20 25 30
Val Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Ser Ala Ser Tyr Arg Tyr Thr Gly Val Pro Asp Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln His Tyr Ser Ile Pro Leu
85 90 95
Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 71
<211> 360
<212> DNA
<213> Artificial Sequence
<220>
<223> Immunoglobulin domain
<400> 71
gaggtgatgc tggtcgagag cggcggcggt ctcgtgcagc caggcggtag cctgcgcctc 60
agctgcaccg ccagcggctt caccttcagc gctagcgcca tgagctgggt gcgccaagcc 120
ccaggcaagg gcctggagtg ggtggcctac atcagcggcg gcggcggcga cacctactac 180
agctccagcg tgaagggccg cttcaccatc agccgcgaca acgccaaaaa cagcctgtac 240
ctgcaaatga acagcctgcg cgccgaggac accgccgtgt actactgcgc ccgccacagc 300
aacgtcaact actacgccat ggactactgg ggccagggca ccctggtgac cgtgagcagc 360
<210> 72
<211> 333
<212> DNA
<213> Artificial Sequence
<220>
<223> Immunoglobulin domain
<400> 72
gagatcgtgc tgacccagag cccagccacc ctgagcctga gcccaggcga gcgcgccacc 60
atgagctgcc gcgccagcga gaacatcgac accagcggca tcagcttcat gaactggtac 120
cagcagaagc caggccaggc cccaaagctg ctgatctacg tggccagcaa ccagggcagc 180
ggcatcccag cccgcttcag cggcagcggc agcggcaccg acttcaccct gaccatcagc 240
cgcctggagc cagaggactt cgccgtgtac tactgccagc agagcaagga agtcccatgg 300
accttcggcc aaggtactaa gctggagatc aag 333
<210> 73
<211> 360
<212> DNA
<213> Artificial Sequence
<220>
<223> Immunoglobulin domain
<400> 73
gaggtgatgc tggtcgagag cggcggcggt ctcgtgcagc caggcggtag cctgcgcctc 60
agctgcaccg ccagcggctt caccttcagc gctagcgcca tgagctgggt gcgccaagcc 120
ccaggcaagg gcctggagtg ggtggcctac atcagcggcg gcggcggcga cacctactac 180
agctccagcg tgaagggccg cttcaccatc agccgcgaca acgccaaaaa cagcctgtac 240
ctgcaaatga acagcctgcg cgccgaggac accgccgtgt actactgcgc ccgccacagc 300
aacccaaact actacgccat ggactactgg ggccagggca ccctggtgac cgtgagcagc 360
<210> 74
<211> 333
<212> DNA
<213> Artificial Sequence
<220>
<223> Immunoglobulin domain
<400> 74
gagatcgtgc tgacccagag cccagccacc ctgagcctga gcccaggcga gcgcgccacc 60
atgagctgcc gcgccagcga gaacatcgac accagcggca tcagcttcat gaactggtac 120
cagcagaagc caggccaggc cccaaagctg ctgatctacg tggccagcaa ccagggcagc 180
ggcatcccag cccgcttcag cggcagcggc agcggcaccg acttcaccct gaccatcagc 240
cgcctggagc cagaggactt cgccgtgtac tactgccagc agagcaagga agtcccatgg 300
accttcggcc aaggtactaa gctggagatc aag 333
<210> 75
<211> 360
<212> DNA
<213> Artificial Sequence
<220>
<223> Immunoglobulin domain
<400> 75
gaggtgatgc tggtcgagag cggcggcggt ctcgtgcagc caggcggtag cctgcgcctc 60
agctgcaccg ccagcggctt caccttcagc aagagcgcca tgagctgggt gcgccaagcc 120
ccaggcaagg gcctggagtg ggtggcctac atcagcggcg gcggcggcga cacctactac 180
agctccagcg tgaagggccg cttcaccatc agccgcgaca acgccaagaa cagcctgtac 240
ctgcaaatga acagcctgcg cgccgaggac accgccgtgt actactgcgc ccgccacagc 300
aacgtcaact actacgccat ggactactgg ggccagggca ccctggtgac cgtgagcagc 360
<210> 76
<211> 333
<212> DNA
<213> Artificial Sequence
<220>
<223> Immunoglobulin domain
<400> 76
gagatcgtgc tgacccagag cccagccacc ctaagcctga gcccaggcga gcgcgccacc 60
atgagctgcc gcgccagcga gaacatcgac cacagcggca tcagcttcat gaactggtac 120
cagcagaagc caggccaggc cccaaagctg ctgatctacg tggccagcaa ccagggcagc 180
ggcatcccag cccgcttcag cggcagcggc agcggcaccg acttcaccct gaccatcagc 240
cgcctggagc cagaggactt cgccgtgtac tactgccagc agagcaagga agtcccatgg 300
accttcggcc aaggtactaa gctggagatc aag 333
<210> 77
<211> 360
<212> DNA
<213> Artificial Sequence
<220>
<223> Immunoglobulin domain
<400> 77
gaggtgatgc tggtcgagag cggcggcggt ctcgtgcagc caggcggtag cctgcgcctc 60
agctgcaccg ccagcggctt caccttcagc aagagcgcca tgagctgggt gcgccaagcc 120
ccaggcaagg gcctggagtg ggtggcctac atcagcggcg gcggcggcga cacctactac 180
agctccagcg tgaagggccg cttcaccatc agccgcgaca acgccaagaa cagcctgtac 240
ctgcaaatga acagcctgcg cgccgaggac accgccgtgt actactgcgc ccgccacagc 300
aacgtcaact actacgccat ggactactgg ggccagggca ccctggtgac cgtgagcagc 360
<210> 78
<211> 333
<212> DNA
<213> Artificial Sequence
<220>
<223> Immunoglobulin domain
<400> 78
gagatcgtgc tgacccagag cccagccacc ctaagcctga gcccaggcga gcgcgccacc 60
atgagctgcc gcgccagcga gaacatcgac cacagcggca tcagcttcat gaactggtac 120
cagcagaagc caggccaggc cccaaagctg ctgatctacg tggccagcaa ccagggcagc 180
ggcatcccag cccgcttcag cggcagcggc agcggcaccg acttcaccct gaccatcagc 240
cgcctggagc cagaggactt cgccgtgtac tactgccagc agagcaagga agtcccatgg 300
accttcggcc aaggtactaa gctggagatc aag 333
<210> 79
<211> 360
<212> DNA
<213> Artificial Sequence
<220>
<223> Immunoglobulin domain
<400> 79
gaggtgatgc tggtcgagag cggcggcggt ctcgtgcagc caggcggtag cctgcgcctc 60
agctgcaccg ccagcggctt caccttcagc aagagcgcca tgagctgggt gcgccaagcc 120
ccaggcaagg gcctggagtg ggtggcctac atcagcggcg gcggcggcga cacctactac 180
agctccagcg tgaagggccg cttcaccatc agccgcgaca acgccaagaa cagcctgtac 240
ctgcaaatga acagcctgcg cgccgaggac accgccgtgt actactgcgc ccgccacagc 300
aacgtcaact actacgccat ggactactgg ggccagggca ccctggtgac cgtgagcagc 360
<210> 80
<211> 333
<212> DNA
<213> Artificial Sequence
<220>
<223> Immunoglobulin domain
<400> 80
gagatcgtgc tgacccagag cccagccacc ctgagcctga gcccaggcga gcgcgccacc 60
atgagctgcc gcgccagcga gaacatcgac gtaagcggca tcagcttcat gaactggtac 120
cagcagaagc caggccaggc cccaaagctg ctgatctacg tggccagcaa ccagggcagc 180
ggcatcccag cccgcttcag cggcagcggc agcggcaccg acttcaccct gaccatcagc 240
cgcctggagc cagaggactt cgccgtgtac tactgccagc agagcaagga agtcccatgg 300
accttcggcc aaggtactaa gctggaaatc aag 333
<210> 81
<211> 1338
<212> DNA
<213> Artificial Sequence
<220>
<223> Antibody chain
<400> 81
gaggtgatgc tggtcgagag cggcggcggt ctcgtgcagc caggcggtag cctgcgcctc 60
agctgcaccg ccagcggctt caccttcagc gctagcgcca tgagctgggt gcgccaagcc 120
ccaggcaagg gcctggagtg ggtggcctac atcagcggcg gcggcggcga cacctactac 180
agctccagcg tgaagggccg cttcaccatc agccgcgaca acgccaaaaa cagcctgtac 240
ctgcaaatga acagcctgcg cgccgaggac accgccgtgt actactgcgc ccgccacagc 300
aacgtcaact actacgccat ggactactgg ggccagggca ccctggtgac cgtgagcagc 360
gcctccacaa agggcccttc cgtgttcccc ctggcccctt gctcccggtc cacctccgag 420
tctaccgccg ctctgggctg cctggtcaag gactacttcc ccgagcccgt gaccgtgtcc 480
tggaactctg gcgccctgac ctccggcgtg cacaccttcc ctgctgtgct gcagtcctcc 540
ggcctgtact ccctgtcctc cgtcgtgacc gtgccctcct ctagcctggg caccaagacc 600
tacacctgta acgtggacca caagccctcc aacaccaagg tggacaagcg ggtggaatct 660
aagtacggcc ctccctgccc cccctgccct gcccctgaat ttctgggcgg accctccgtg 720
ttcctgttcc ccccaaagcc caaggacacc ctgatgatct cccggacccc cgaagtgacc 780
tgcgtggtgg tggacgtgtc ccaggaagat cccgaggtcc agtttaattg gtacgtggac 840
ggcgtggaag tgcacaacgc caagaccaag cccagagagg aacagttcaa ctccacctac 900
cgggtggtgt ccgtgctgac cgtgctgcac caggactggc tgaacggcaa agagtacaag 960
tgcaaggtgt ccaacaaggg cctgccctcc agcatcgaaa agaccatctc caaggccaag 1020
ggccagcccc gcgagcccca ggtgtacacc ctgcctccaa gccaggaaga gatgaccaag 1080
aaccaggtgt ccctgacctg tctggtcaag ggcttctacc cctccgatat cgccgtggaa 1140
tgggagtcca acggccagcc cgagaacaac tacaagacca ccccccctgt gctggactcc 1200
gacggctcct tcttcctgta ctctcggctg accgtggaca agtcccggtg gcaggaaggc 1260
aacgtcttct cctgctccgt gatgcacgag gccctgcaca accactacac ccagaagtcc 1320
ctgtccctga gcctgggc 1338
<210> 82
<211> 654
<212> DNA
<213> Artificial Sequence
<220>
<223> Antibody chain
<400> 82
gagatcgtgc tgacccagag cccagccacc ctgagcctga gcccaggcga gcgcgccacc 60
atgagctgcc gcgccagcga gaacatcgac accagcggca tcagcttcat gaactggtac 120
cagcagaagc caggccaggc cccaaagctg ctgatctacg tggccagcaa ccagggcagc 180
ggcatcccag cccgcttcag cggcagcggc agcggcaccg acttcaccct gaccatcagc 240
cgcctggagc cagaggactt cgccgtgtac tactgccagc agagcaagga agtcccatgg 300
accttcggcc aaggtactaa gctggagatc aagcgtactg tggctgcacc atctgtcttc 360
atcttcccgc catctgatga gcaattgaaa tctggaactg cctctgttgt gtgcctgctg 420
aataacttct atcccagaga ggccaaagta cagtggaagg tggataacgc cctccaatcg 480
ggtaactccc aggagagtgt cacagagcag gacagcaagg acagcaccta cagcctcagc 540
agcaccctga cgctgagcaa agcagactac gagaaacaca aagtctacgc ctgcgaagtc 600
acccatcagg gcctgagctc gcccgtcaca aagagcttca acaggggaga gtgt 654
<210> 83
<211> 1338
<212> DNA
<213> Artificial Sequence
<220>
<223> Antibody chain
<400> 83
gaggtgatgc tggtcgagag cggcggcggt ctcgtgcagc caggcggtag cctgcgcctc 60
agctgcaccg ccagcggctt caccttcagc gctagcgcca tgagctgggt gcgccaagcc 120
ccaggcaagg gcctggagtg ggtggcctac atcagcggcg gcggcggcga cacctactac 180
agctccagcg tgaagggccg cttcaccatc agccgcgaca acgccaaaaa cagcctgtac 240
ctgcaaatga acagcctgcg cgccgaggac accgccgtgt actactgcgc ccgccacagc 300
aacccaaact actacgccat ggactactgg ggccagggca ccctggtgac cgtgagcagc 360
gcctccacaa agggcccttc cgtgttcccc ctggcccctt gctcccggtc cacctccgag 420
tctaccgccg ctctgggctg cctggtcaag gactacttcc ccgagcccgt gaccgtgtcc 480
tggaactctg gcgccctgac ctccggcgtg cacaccttcc ctgctgtgct gcagtcctcc 540
ggcctgtact ccctgtcctc cgtcgtgacc gtgccctcct ctagcctggg caccaagacc 600
tacacctgta acgtggacca caagccctcc aacaccaagg tggacaagcg ggtggaatct 660
aagtacggcc ctccctgccc cccctgccct gcccctgaat ttctgggcgg accctccgtg 720
ttcctgttcc ccccaaagcc caaggacacc ctgatgatct cccggacccc cgaagtgacc 780
tgcgtggtgg tggacgtgtc ccaggaagat cccgaggtcc agtttaattg gtacgtggac 840
ggcgtggaag tgcacaacgc caagaccaag cccagagagg aacagttcaa ctccacctac 900
cgggtggtgt ccgtgctgac cgtgctgcac caggactggc tgaacggcaa agagtacaag 960
tgcaaggtgt ccaacaaggg cctgccctcc agcatcgaaa agaccatctc caaggccaag 1020
ggccagcccc gcgagcccca ggtgtacacc ctgcctccaa gccaggaaga gatgaccaag 1080
aaccaggtgt ccctgacctg tctggtcaag ggcttctacc cctccgatat cgccgtggaa 1140
tgggagtcca acggccagcc cgagaacaac tacaagacca ccccccctgt gctggactcc 1200
gacggctcct tcttcctgta ctctcggctg accgtggaca agtcccggtg gcaggaaggc 1260
aacgtcttct cctgctccgt gatgcacgag gccctgcaca accactacac ccagaagtcc 1320
ctgtccctga gcctgggc 1338
<210> 84
<211> 654
<212> DNA
<213> Artificial Sequence
<220>
<223> Antibody chain
<400> 84
gagatcgtgc tgacccagag cccagccacc ctgagcctga gcccaggcga gcgcgccacc 60
atgagctgcc gcgccagcga gaacatcgac accagcggca tcagcttcat gaactggtac 120
cagcagaagc caggccaggc cccaaagctg ctgatctacg tggccagcaa ccagggcagc 180
ggcatcccag cccgcttcag cggcagcggc agcggcaccg acttcaccct gaccatcagc 240
cgcctggagc cagaggactt cgccgtgtac tactgccagc agagcaagga agtcccatgg 300
accttcggcc aaggtactaa gctggagatc aagcgtactg tggctgcacc atctgtcttc 360
atcttcccgc catctgatga gcaattgaaa tctggaactg cctctgttgt gtgcctgctg 420
aataacttct atcccagaga ggccaaagta cagtggaagg tggataacgc cctccaatcg 480
ggtaactccc aggagagtgt cacagagcag gacagcaagg acagcaccta cagcctcagc 540
agcaccctga cgctgagcaa agcagactac gagaaacaca aagtctacgc ctgcgaagtc 600
acccatcagg gcctgagctc gcccgtcaca aagagcttca acaggggaga gtgt 654
<210> 85
<211> 1338
<212> DNA
<213> Artificial Sequence
<220>
<223> Antibody chain
<400> 85
gaggtgatgc tggtcgagag cggcggcggt ctcgtgcagc caggcggtag cctgcgcctc 60
agctgcaccg ccagcggctt caccttcagc aagagcgcca tgagctgggt gcgccaagcc 120
ccaggcaagg gcctggagtg ggtggcctac atcagcggcg gcggcggcga cacctactac 180
agctccagcg tgaagggccg cttcaccatc agccgcgaca acgccaagaa cagcctgtac 240
ctgcaaatga acagcctgcg cgccgaggac accgccgtgt actactgcgc ccgccacagc 300
aacgtcaact actacgccat ggactactgg ggccagggca ccctggtgac cgtgagcagc 360
gcctccacaa agggcccttc cgtgttcccc ctggcccctt gctcccggtc cacctccgag 420
tctaccgccg ctctgggctg cctggtcaag gactacttcc ccgagcccgt gaccgtgtcc 480
tggaactctg gcgccctgac ctccggcgtg cacaccttcc ctgctgtgct gcagtcctcc 540
ggcctgtact ccctgtcctc cgtcgtgacc gtgccctcct ctagcctggg caccaagacc 600
tacacctgta acgtggacca caagccctcc aacaccaagg tggacaagcg ggtggaatct 660
aagtacggcc ctccctgccc cccctgccct gcccctgaat ttctgggcgg accctccgtg 720
ttcctgttcc ccccaaagcc caaggacacc ctgatgatct cccggacccc cgaagtgacc 780
tgcgtggtgg tggacgtgtc ccaggaagat cccgaggtcc agtttaattg gtacgtggac 840
ggcgtggaag tgcacaacgc caagaccaag cccagagagg aacagttcaa ctccacctac 900
cgggtggtgt ccgtgctgac cgtgctgcac caggactggc tgaacggcaa agagtacaag 960
tgcaaggtgt ccaacaaggg cctgccctcc agcatcgaaa agaccatctc caaggccaag 1020
ggccagcccc gcgagcccca ggtgtacacc ctgcctccaa gccaggaaga gatgaccaag 1080
aaccaggtgt ccctgacctg tctggtcaag ggcttctacc cctccgatat cgccgtggaa 1140
tgggagtcca acggccagcc cgagaacaac tacaagacca ccccccctgt gctggactcc 1200
gacggctcct tcttcctgta ctctcggctg accgtggaca agtcccggtg gcaggaaggc 1260
aacgtcttct cctgctccgt gatgcacgag gccctgcaca accactacac ccagaagtcc 1320
ctgtccctga gcctgggc 1338
<210> 86
<211> 654
<212> DNA
<213> Artificial Sequence
<220>
<223> Antibody chain
<400> 86
gagatcgtgc tgacccagag cccagccacc ctgagcctga gcccaggcga gcgcgccacc 60
atgagctgcc gcgccagcga gaacatcgac gtaagcggca tcagcttcat gaactggtac 120
cagcagaagc caggccaggc cccaaagctg ctgatctacg tggccagcaa ccagggcagc 180
ggcatcccag cccgcttcag cggcagcggc agcggcaccg acttcaccct gaccatcagc 240
cgcctggagc cagaggactt cgccgtgtac tactgccagc agagcaagga agtcccatgg 300
accttcggcc aaggtactaa gctggaaatc aagcgtactg tggctgcacc atctgtcttc 360
atcttcccgc catctgatga gcaattgaaa tctggaactg cctctgttgt gtgcctgctg 420
aataacttct atcccagaga ggccaaagta cagtggaagg tggataacgc cctccaatcg 480
ggtaactccc aggagagtgt cacagagcag gacagcaagg acagcaccta cagcctcagc 540
agcaccctga cgctgagcaa agcagactac gagaaacaca aagtctacgc ctgcgaagtc 600
acccatcagg gcctgagctc gcccgtcaca aagagcttca acaggggaga gtgt 654
<210> 87
<211> 1347
<212> DNA
<213> Artificial Sequence
<220>
<223> Antibody chain
<400> 87
gaggtgatgc tggtcgagag cggcggcggt ctcgtgcagc caggcggtag cctgcgcctc 60
agctgcaccg ccagcggctt caccttcagc cgcagcgcca tgagctgggt gcgccaagcc 120
ccaggcaagg gcctggagtg ggtggcctac atcagcggcg gcggcggcga cacctactac 180
agcgtcagcg tgaagggccg cttcaccatc agccgcgaca acgccaagaa cagcctgtac 240
ctgcaaatga acagcctgcg cgccgaggac accgccgtgt actactgcgc ccgccacagc 300
aactacaact actacgccat ggactactgg ggccagggca ccctggtgac cgtgagcagc 360
gcctccacca agggcccatc ggtcttcccg ctagcaccct cctccaagag cacctctggg 420
ggcacagcgg ccctgggctg cctggtcaag gactacttcc ccgaaccggt gacggtgtcg 480
tggaactcag gcgccctgac cagcggcgtg cacaccttcc cggctgtcct acagtcctca 540
ggactctact ccctcagcag cgtggtgacc gtgccctcca gcagcttggg cacccagacc 600
tacatctgca acgtgaatca caagcccagc aacaccaagg tggacaagcg cgttgagccc 660
aaatcttgtg acaaaactca cacatgccca ccgtgcccag cacctgaagc cgctggggga 720
ccgtcagtct tcctcttccc cccaaaaccc aaggacaccc tcatgatctc ccggacccct 780
gaggtcacat gcgtggtggt ggacgtgagc cacgaagacc ctgaggtcaa gttcaactgg 840
tacgtggacg gcgtggaggt gcataatgcc aagacaaagc cgcgggagga gcagtacaac 900
agcacgtacc gtgtggtcag cgtcctcacc gtcctgcacc aggactggct gaatggcaag 960
gagtacaagt gcaaggtctc caacaaagcc ctcccagccc ccatcgagaa aaccatctcc 1020
aaagccaaag ggcagccccg agaaccacag gtgtacaccc tgcccccatc ccgcgaggag 1080
atgaccaaga accaggtaag tttgacctgc ctggtcaaag gcttctatcc cagcgacatc 1140
gccgtggagt gggagagcaa tgggcagccg gagaacaact acaagaccac gcctcccgtg 1200
ctggactccg acggctcctt cttcctctat agcaagctca ccgtggacaa gagcaggtgg 1260
cagcagggga acgtcttctc atgctccgtg atgcatgagg ctctgcacaa ccactacacg 1320
cagaagagcc tctccctgtc tccgggt 1347
<210> 88
<211> 654
<212> DNA
<213> Artificial Sequence
<220>
<223> Antibody chain
<400> 88
gagatcgtgc tgacccagag cccagccacc ctaagcctga gcccaggcga gcgcgccacc 60
atgagctgcc gcgccagcga gaacatcgac cacagcggca tcagcttcat gaactggtac 120
cagcagaagc caggccaggc cccaaagctg ctgatctacg tggccagcaa ccagggcagc 180
ggcatcccag cccgcttcag cggcagcggc agcggcaccg acttcaccct gaccatcagc 240
cgcctggagc cagaggactt cgccgtgtac tactgccagc agagcaagga agtcccatgg 300
accttcggcc aaggtactaa gctggagatc aagcgtactg tggctgcacc atctgtcttc 360
atcttcccgc catctgatga gcaattgaaa tctggaactg cctctgttgt gtgcctgctg 420
aataacttct atcccagaga ggccaaagta cagtggaagg tggataacgc cctccaatcg 480
ggtaactccc aggagagtgt cacagagcag gacagcaagg acagcaccta cagcctcagc 540
agcaccctga cgctgagcaa agcagactac gagaaacaca aagtctacgc ctgcgaagtc 600
acccatcagg gcctgagctc gcccgtcaca aagagcttca acaggggaga gtgt 654
<210> 89
<211> 1338
<212> DNA
<213> Artificial Sequence
<220>
<223> Antibody chain
<400> 89
gaggtgatgc tggtcgagag cggcggcggt ctcgtgcagc caggcggtag cctgcgcctc 60
agctgcaccg ccagcggctt caccttcagc cgcagcgcca tgagctgggt gcgccaagcc 120
ccaggcaagg gcctggagtg ggtggcctac atcagcggcg gcggcggcga cacctactac 180
agcgtcagcg tgaagggccg cttcaccatc agccgcgaca acgccaagaa cagcctgtac 240
ctgcaaatga acagcctgcg cgccgaggac accgccgtgt actactgcgc ccgccacagc 300
aactacaact actacgccat ggactactgg ggccagggca ccctggtgac cgtgagcagc 360
gcctccacaa agggcccttc cgtgttcccc ctggcccctt gctcccggtc cacctccgag 420
tctaccgccg ctctgggctg cctggtcaag gactacttcc ccgagcccgt gaccgtgtcc 480
tggaactctg gcgccctgac ctccggcgtg cacaccttcc ctgctgtgct gcagtcctcc 540
ggcctgtact ccctgtcctc cgtcgtgacc gtgccctcct ctagcctggg caccaagacc 600
tacacctgta acgtggacca caagccctcc aacaccaagg tggacaagcg ggtggaatct 660
aagtacggcc ctccctgccc cccctgccct gcccctgaat ttctgggcgg accctccgtg 720
ttcctgttcc ccccaaagcc caaggacacc ctgatgatct cccggacccc cgaagtgacc 780
tgcgtggtgg tggacgtgtc ccaggaagat cccgaggtcc agtttaattg gtacgtggac 840
ggcgtggaag tgcacaacgc caagaccaag cccagagagg aacagttcaa ctccacctac 900
cgggtggtgt ccgtgctgac cgtgctgcac caggactggc tgaacggcaa agagtacaag 960
tgcaaggtgt ccaacaaggg cctgccctcc agcatcgaaa agaccatctc caaggccaag 1020
ggccagcccc gcgagcccca ggtgtacacc ctgcctccaa gccaggaaga gatgaccaag 1080
aaccaggtgt ccctgacctg tctggtcaag ggcttctacc cctccgatat cgccgtggaa 1140
tgggagtcca acggccagcc cgagaacaac tacaagacca ccccccctgt gctggactcc 1200
gacggctcct tcttcctgta ctctcggctg accgtggaca agtcccggtg gcaggaaggc 1260
aacgtcttct cctgctccgt gatgcacgag gccctgcaca accactacac ccagaagtcc 1320
ctgtccctga gcctgggc 1338
<210> 90
<211> 654
<212> DNA
<213> Artificial Sequence
<220>
<223> Antibody chain
<400> 90
gagatcgtgc tgacccagag cccagccacc ctaagcctga gcccaggcga gcgcgccacc 60
atgagctgcc gcgccagcga gaacatcgac cacagcggca tcagcttcat gaactggtac 120
cagcagaagc caggccaggc cccaaagctg ctgatctacg tggccagcaa ccagggcagc 180
ggcatcccag cccgcttcag cggcagcggc agcggcaccg acttcaccct gaccatcagc 240
cgcctggagc cagaggactt cgccgtgtac tactgccagc agagcaagga agtcccatgg 300
accttcggcc aaggtactaa gctggagatc aagcgtactg tggctgcacc atctgtcttc 360
atcttcccgc catctgatga gcaattgaaa tctggaactg cctctgttgt gtgcctgctg 420
aataacttct atcccagaga ggccaaagta cagtggaagg tggataacgc cctccaatcg 480
ggtaactccc aggagagtgt cacagagcag gacagcaagg acagcaccta cagcctcagc 540
agcaccctga cgctgagcaa agcagactac gagaaacaca aagtctacgc ctgcgaagtc 600
acccatcagg gcctgagctc gcccgtcaca aagagcttca acaggggaga gtgt 654
<210> 91
<211> 255
<212> DNA
<213> Artificial Sequence
<220>
<223> Immunoglobulin domain
<400> 91
caggtcaccc tgaaggagag cggcccaacc ctggtgaagc caacccagac cctgaccctg 60
acctgcagct tcagcggctt ctccctgagc accagcgaca tgggcgtggg ctggattcgc 120
caaccaccag gcaaggccct ggagtggctg gcccacatct ggtgggacga cgtgaagcgc 180
tacaacccag ccctgaagag ccgcctgacc atcaccaagg acaccagcaa gaaccaggtg 240
gtgctgacca tgacc 255
<210> 92
<211> 255
<212> DNA
<213> Artificial Sequence
<220>
<223> Immunoglobulin domain
<400> 92
gacatccaga tgacccagag ccctagcttc ctgagcgcca gcgtcggcga ccgcgtgacc 60
ttcacctgca aggccagcca ggacgtgagc accgccgtcg cctggtatca gcagaagcct 120
ggcaaggccc caaagctgct gatctacagc gccagctacc gctacaccgg cgtgccagac 180
cgcttcagcg gcagcggcag cggcaccgac ttcaccctga ccatcagcag cctgcaacca 240
gaggacttcg ccacc 255
<210> 93
<211> 255
<212> DNA
<213> Artificial Sequence
<220>
<223> Immunoglobulin domain
<400> 93
caggtgaccc tggtggagag cggcggcggc gtcgtgcagc caggccgcag cctgagcctg 60
agctgcgctt tcagcggctt cagcctcagc accagcgaca tgggcgtggg ctgggtccgc 120
caaccaccag gcaagggcct ggagtgggtg gcccacatct ggtgggacga cgtgaagcgc 180
tacaacccag ccctgaagag ccgctttacc atcagccgcg acaacagcaa gaacaccctg 240
tacctgcaaa tgaac 255
<210> 94
<211> 254
<212> DNA
<213> Artificial Sequence
<220>
<223> Immunoglobulin domain
<400> 94
acatccagat gacccagagc cctagcttcc tgagcgccag cgtcggcgac cgcgtgacga 60
tcacctgcaa ggccagccag gacgtgagca ccgccgtcgc ctggtatcag cagaagcctg 120
gcaaggcccc aaagctgctg atctacagcg ccagctaccg ctacaccggc gtgccagacc 180
gcttcagcgg cagcggcagc ggcaccgact tcaccctgac catcagcagc ctgcaaccag 240
aggacttcgc cacc 254
<210> 95
<211> 255
<212> DNA
<213> Artificial Sequence
<220>
<223> Immunoglobulin domain
<400> 95
caggtgaccc tggtggagag cggcggcggc gtcgtgcagc caggccgcag cctgcgcctg 60
agctgcgctt tcagcggctt cagcctcagc accagcgaca tgggcgtggg ctggatccgc 120
caagccccag gcaagggcct ggagtgggtg gcccacatct ggtgggacga cgtgaagcgc 180
tacaacccag ccctgaagag ccgctttacc atcagccgcg acaacagcaa gaacaccctg 240
tacctgcaaa tgaac 255
<210> 96
<211> 255
<212> DNA
<213> Artificial Sequence
<220>
<223> Immunoglobulin domain
<400> 96
gacatcgtga tgacccagag ccctagcttc ctgagcgcca gcgtcggcga ccgcgtgacc 60
atcacctgca aggccagcca ggacgtgagc accgccgtcg cctggtatca gcagaagcct 120
ggcaaggccc caaagctgct gatctacagc gccagctacc gctacaccgg cgtgccagac 180
cgcttcagcg gcagcggcag cggcaccgac ttcaccctga ccatcagcag cctgcaacca 240
gaggacttcg ccacc 255
<210> 97
<211> 255
<212> DNA
<213> Artificial Sequence
<220>
<223> Immunoglobulin domain
<400> 97
caggtgaccc tggtggagag cggcggcggc gtcgtgcagc caggccgcag cctgcgcctg 60
agctgcgctt tcagcggctt cagcctcagc accagcgaca tgggcgtggg ctggatccgc 120
caagccccag gcaagggcct ggagtgggtg gcccacatct ggtgggacga cgtgaagcgc 180
tacaacccag ccctgaagag ccgctttacc atcagccgcg acaacagcaa gaacaccctg 240
tacctgcaaa tgaac 255
<210> 98
<211> 255
<212> DNA
<213> Artificial Sequence
<220>
<223> Immunoglobulin domain
<400> 98
gacatccaga tgacccagag ccctagcttc ctgagcgcca gcgtcggcga ccgcgtgagc 60
atcacctgca aggccagcca ggacgtgagc accgccgtcg cctggtatca gcagaagcct 120
ggcaaggccc caaagctgct gatctacagc gccagctacc gctacaccgg cgtgccagac 180
cgcttcagcg gcagcggcag cggcaccgac ttcaccctga ccatcagcag cctgcaacca 240
gaggacttcg ccacc 255
<210> 99
<211> 255
<212> DNA
<213> Artificial Sequence
<220>
<223> Immunoglobulin domain
<400> 99
caggtcaccc tgaaggagag cggcccaacc ctggtgaagc caacccagac cctgaccctg 60
acctgcagct tcagcggctt ctccctgagc accagcgaca tgggcgtggg ctggattcgc 120
caaccaccag gcaaggccct ggagtggctg gcccacatct ggtgggacga cgtgaagcgc 180
tacaacccag ccctgaagag ccgcctgacc atcaccaagg acaccagcaa gaaccaggtg 240
gtgctgacca tgacc 255
<210> 100
<211> 255
<212> DNA
<213> Artificial Sequence
<220>
<223> Immunoglobulin domain
<400> 100
gacatccaga tgacccagag ccctagcttc ctgagcgcca gcgtcggcga ccgcgtgagc 60
atcacctgca aggccagcca ggacgtgagc accgccgtcg cctggtatca gcagaagcct 120
ggcaaggccc caaagctgct gatctacagc gccagctacc gctacaccgg cgtgccagac 180
cgcttcagcg gcagcggcag cggcaccgac ttcaccctga ccatcagcag cctgcaacca 240
gaggacttcg ccgtg 255
<210> 101
<211> 1344
<212> DNA
<213> Artificial Sequence
<220>
<223> Antibody chain
<400> 101
caggtcaccc tgaaggagag cggcccaacc ctggtgaagc caacccagac cctgaccctg 60
acctgcagct tcagcggctt ctccctgagc accagcgaca tgggcgtggg ctggattcgc 120
caaccaccag gcaaggccct ggagtggctg gcccacatct ggtgggacga cgtgaagcgc 180
tacaacccag ccctgaagag ccgcctgacc atcaccaagg acaccagcaa gaaccaggtg 240
gtgctgacca tgaccaacat ggacccagtg gacaccgcca cctacttctg cgcccgcatc 300
gaggactacg gcgtgagcta ctacttcgac tactggggcc agggcaccac cgtgaccgtg 360
agcagcgcct ccacaaaggg cccttccgtg ttccccctgg ccccttgctc ccggtccacc 420
tccgagtcta ccgccgctct gggctgcctg gtcaaggact acttccccga gcccgtgacc 480
gtgtcctgga actctggcgc cctgacctcc ggcgtgcaca ccttccctgc tgtgctgcag 540
tcctccggcc tgtactccct gtcctccgtc gtgaccgtgc cctcctctag cctgggcacc 600
aagacctaca cctgtaacgt ggaccacaag ccctccaaca ccaaggtgga caagcgggtg 660
gaatctaagt acggccctcc ctgccccccc tgccctgccc ctgaatttct gggcggaccc 720
tccgtgttcc tgttcccccc aaagcccaag gacaccctga tgatctcccg gacccccgaa 780
gtgacctgcg tggtggtgga cgtgtcccag gaagatcccg aggtccagtt taattggtac 840
gtggacggcg tggaagtgca caacgccaag accaagccca gagaggaaca gttcaactcc 900
acctaccggg tggtgtccgt gctgaccgtg ctgcaccagg actggctgaa cggcaaagag 960
tacaagtgca aggtgtccaa caagggcctg ccctccagca tcgaaaagac catctccaag 1020
gccaagggcc agccccgcga gccccaggtg tacaccctgc ctccaagcca ggaagagatg 1080
accaagaacc aggtgtccct gacctgtctg gtcaagggct tctacccctc cgatatcgcc 1140
gtggaatggg agtccaacgg ccagcccgag aacaactaca agaccacccc ccctgtgctg 1200
gactccgacg gctccttctt cctgtactct cggctgaccg tggacaagtc ccggtggcag 1260
gaaggcaacg tcttctcctg ctccgtgatg cacgaggccc tgcacaacca ctacacccag 1320
aagtccctgt ccctgagcct gggc 1344
<210> 102
<211> 642
<212> DNA
<213> Artificial Sequence
<220>
<223> Antibody chain
<400> 102
gacatccaga tgacccagag ccctagcttc ctgagcgcca gcgtcggcga ccgcgtgacc 60
ttcacctgca aggccagcca ggacgtgagc accgccgtcg cctggtatca gcagaagcct 120
ggcaaggccc caaagctgct gatctacagc gccagctacc gctacaccgg cgtgccagac 180
cgcttcagcg gcagcggcag cggcaccgac ttcaccctga ccatcagcag cctgcaacca 240
gaggacttcg ccacctacta ctgccagcag cactacagca tcccactgac ctttggccag 300
ggcaccaagc tggagatcaa gcgtactgtg gctgcaccat ctgtcttcat cttcccgcca 360
tctgatgagc aattgaaatc tggaactgcc tctgttgtgt gcctgctgaa taacttctat 420
cccagagagg ccaaagtaca gtggaaggtg gataacgccc tccaatcggg taactcccag 480
gagagtgtca cagagcagga cagcaaggac agcacctaca gcctcagcag caccctgacg 540
ctgagcaaag cagactacga gaaacacaaa gtctacgcct gcgaagtcac ccatcagggc 600
ctgagctcgc ccgtcacaaa gagcttcaac aggggagagt gt 642
<210> 103
<211> 1344
<212> DNA
<213> Artificial Sequence
<220>
<223> Antibody chain
<400> 103
caggtgaccc tggtggagag cggcggcggc gtcgtgcagc caggccgcag cctgagcctg 60
agctgcgctt tcagcggctt cagcctcagc accagcgaca tgggcgtggg ctgggtccgc 120
caaccaccag gcaagggcct ggagtgggtg gcccacatct ggtgggacga cgtgaagcgc 180
tacaacccag ccctgaagag ccgctttacc atcagccgcg acaacagcaa gaacaccctg 240
tacctgcaaa tgaacagcct gcgcgccgag gacaccgcca cctactactg cgcccgcatc 300
gaggactacg gcgtgagcta ctacttcgac tactggggcc agggcaccac cgtgaccgtg 360
agcagcgcct ccacaaaggg cccttccgtg ttccccctgg ccccttgctc ccggtccacc 420
tccgagtcta ccgccgctct gggctgcctg gtcaaggact acttccccga gcccgtgacc 480
gtgtcctgga actctggcgc cctgacctcc ggcgtgcaca ccttccctgc tgtgctgcag 540
tcctccggcc tgtactccct gtcctccgtc gtgaccgtgc cctcctctag cctgggcacc 600
aagacctaca cctgtaacgt ggaccacaag ccctccaaca ccaaggtgga caagcgggtg 660
gaatctaagt acggccctcc ctgccccccc tgccctgccc ctgaatttct gggcggaccc 720
tccgtgttcc tgttcccccc aaagcccaag gacaccctga tgatctcccg gacccccgaa 780
gtgacctgcg tggtggtgga cgtgtcccag gaagatcccg aggtccagtt taattggtac 840
gtggacggcg tggaagtgca caacgccaag accaagccca gagaggaaca gttcaactcc 900
acctaccggg tggtgtccgt gctgaccgtg ctgcaccagg actggctgaa cggcaaagag 960
tacaagtgca aggtgtccaa caagggcctg ccctccagca tcgaaaagac catctccaag 1020
gccaagggcc agccccgcga gccccaggtg tacaccctgc ctccaagcca ggaagagatg 1080
accaagaacc aggtgtccct gacctgtctg gtcaagggct tctacccctc cgatatcgcc 1140
gtggaatggg agtccaacgg ccagcccgag aacaactaca agaccacccc ccctgtgctg 1200
gactccgacg gctccttctt cctgtactct cggctgaccg tggacaagtc ccggtggcag 1260
gaaggcaacg tcttctcctg ctccgtgatg cacgaggccc tgcacaacca ctacacccag 1320
aagtccctgt ccctgagcct gggc 1344
<210> 104
<211> 642
<212> DNA
<213> Artificial Sequence
<220>
<223> Antibody chain
<400> 104
gacatccaga tgacccagag ccctagcttc ctgagcgcca gcgtcggcga ccgcgtgacg 60
atcacctgca aggccagcca ggacgtgagc accgccgtcg cctggtatca gcagaagcct 120
ggcaaggccc caaagctgct gatctacagc gccagctacc gctacaccgg cgtgccagac 180
cgcttcagcg gcagcggcag cggcaccgac ttcaccctga ccatcagcag cctgcaacca 240
gaggacttcg ccacctacta ctgccagcag cactacagca tcccactgac ctttggcgcc 300
ggcaccaagc tggagatcaa gcgtactgtg gctgcaccat ctgtcttcat cttcccgcca 360
tctgatgagc aattgaaatc tggaactgcc tctgttgtgt gcctgctgaa taacttctat 420
cccagagagg ccaaagtaca gtggaaggtg gataacgccc tccaatcggg taactcccag 480
gagagtgtca cagagcagga cagcaaggac agcacctaca gcctcagcag caccctgacg 540
ctgagcaaag cagactacga gaaacacaaa gtctacgcct gcgaagtcac ccatcagggc 600
ctgagctcgc ccgtcacaaa gagcttcaac aggggagagt gt 642
<210> 105
<211> 1344
<212> DNA
<213> Artificial Sequence
<220>
<223> Antibody chain
<400> 105
caggtgaccc tggtggagag cggcggcggc gtcgtgcagc caggccgcag cctgcgcctg 60
agctgcgctt tcagcggctt cagcctcagc accagcgaca tgggcgtggg ctggatccgc 120
caagccccag gcaagggcct ggagtgggtg gcccacatct ggtgggacga cgtgaagcgc 180
tacaacccag ccctgaagag ccgctttacc atcagccgcg acaacagcaa gaacaccctg 240
tacctgcaaa tgaacagcct gcgcgccgag gacaccgcca cctacttctg cgcccgcatc 300
gaggactacg gcgtgagcta ctacttcgac tactggggcc agggcaccac cgtgaccgtg 360
agcagcgcct ccacaaaggg cccttccgtg ttccccctgg ccccttgctc ccggtccacc 420
tccgagtcta ccgccgctct gggctgcctg gtcaaggact acttccccga gcccgtgacc 480
gtgtcctgga actctggcgc cctgacctcc ggcgtgcaca ccttccctgc tgtgctgcag 540
tcctccggcc tgtactccct gtcctccgtc gtgaccgtgc cctcctctag cctgggcacc 600
aagacctaca cctgtaacgt ggaccacaag ccctccaaca ccaaggtgga caagcgggtg 660
gaatctaagt acggccctcc ctgccccccc tgccctgccc ctgaatttct gggcggaccc 720
tccgtgttcc tgttcccccc aaagcccaag gacaccctga tgatctcccg gacccccgaa 780
gtgacctgcg tggtggtgga cgtgtcccag gaagatcccg aggtccagtt taattggtac 840
gtggacggcg tggaagtgca caacgccaag accaagccca gagaggaaca gttcaactcc 900
acctaccggg tggtgtccgt gctgaccgtg ctgcaccagg actggctgaa cggcaaagag 960
tacaagtgca aggtgtccaa caagggcctg ccctccagca tcgaaaagac catctccaag 1020
gccaagggcc agccccgcga gccccaggtg tacaccctgc ctccaagcca ggaagagatg 1080
accaagaacc aggtgtccct gacctgtctg gtcaagggct tctacccctc cgatatcgcc 1140
gtggaatggg agtccaacgg ccagcccgag aacaactaca agaccacccc ccctgtgctg 1200
gactccgacg gctccttctt cctgtactct cggctgaccg tggacaagtc ccggtggcag 1260
gaaggcaacg tcttctcctg ctccgtgatg cacgaggccc tgcacaacca ctacacccag 1320
aagtccctgt ccctgagcct gggc 1344
<210> 106
<211> 642
<212> DNA
<213> Artificial Sequence
<220>
<223> Antibody chain
<400> 106
gacatcgtga tgacccagag ccctagcttc ctgagcgcca gcgtcggcga ccgcgtgacc 60
atcacctgca aggccagcca ggacgtgagc accgccgtcg cctggtatca gcagaagcct 120
ggcaaggccc caaagctgct gatctacagc gccagctacc gctacaccgg cgtgccagac 180
cgcttcagcg gcagcggcag cggcaccgac ttcaccctga ccatcagcag cctgcaacca 240
gaggacttcg ccacctacta ctgccagcag cactacagca tcccactgac ctttggccag 300
ggcaccaagc tggagatcaa gcgtactgtg gctgcaccat ctgtcttcat cttcccgcca 360
tctgatgagc aattgaaatc tggaactgcc tctgttgtgt gcctgctgaa taacttctat 420
cccagagagg ccaaagtaca gtggaaggtg gataacgccc tccaatcggg taactcccag 480
gagagtgtca cagagcagga cagcaaggac agcacctaca gcctcagcag caccctgacg 540
ctgagcaaag cagactacga gaaacacaaa gtctacgcct gcgaagtcac ccatcagggc 600
ctgagctcgc ccgtcacaaa gagcttcaac aggggagagt gt 642
<210> 107
<211> 1344
<212> DNA
<213> Artificial Sequence
<220>
<223> Antibody chain
<400> 107
caggtgaccc tggtggagag cggcggcggc gtcgtgcagc caggccgcag cctgcgcctg 60
agctgcgctt tcagcggctt cagcctcagc accagcgaca tgggcgtggg ctggatccgc 120
caagccccag gcaagggcct ggagtgggtg gcccacatct ggtgggacga cgtgaagcgc 180
tacaacccag ccctgaagag ccgctttacc atcagccgcg acaacagcaa gaacaccctg 240
tacctgcaaa tgaacagcct gcgcgccgag gacaccgccg tgtacttctg cgcccgcatc 300
gaggactacg gcgtgagcta ctacttcgac tactggggcc agggcaccac cgtgaccgtg 360
agcagcgcct ccacaaaggg cccttccgtg ttccccctgg ccccttgctc ccggtccacc 420
tccgagtcta ccgccgctct gggctgcctg gtcaaggact acttccccga gcccgtgacc 480
gtgtcctgga actctggcgc cctgacctcc ggcgtgcaca ccttccctgc tgtgctgcag 540
tcctccggcc tgtactccct gtcctccgtc gtgaccgtgc cctcctctag cctgggcacc 600
aagacctaca cctgtaacgt ggaccacaag ccctccaaca ccaaggtgga caagcgggtg 660
gaatctaagt acggccctcc ctgccccccc tgccctgccc ctgaatttct gggcggaccc 720
tccgtgttcc tgttcccccc aaagcccaag gacaccctga tgatctcccg gacccccgaa 780
gtgacctgcg tggtggtgga cgtgtcccag gaagatcccg aggtccagtt taattggtac 840
gtggacggcg tggaagtgca caacgccaag accaagccca gagaggaaca gttcaactcc 900
acctaccggg tggtgtccgt gctgaccgtg ctgcaccagg actggctgaa cggcaaagag 960
tacaagtgca aggtgtccaa caagggcctg ccctccagca tcgaaaagac catctccaag 1020
gccaagggcc agccccgcga gccccaggtg tacaccctgc ctccaagcca ggaagagatg 1080
accaagaacc aggtgtccct gacctgtctg gtcaagggct tctacccctc cgatatcgcc 1140
gtggaatggg agtccaacgg ccagcccgag aacaactaca agaccacccc ccctgtgctg 1200
gactccgacg gctccttctt cctgtactct cggctgaccg tggacaagtc ccggtggcag 1260
gaaggcaacg tcttctcctg ctccgtgatg cacgaggccc tgcacaacca ctacacccag 1320
aagtccctgt ccctgagcct gggc 1344
<210> 108
<211> 642
<212> DNA
<213> Artificial Sequence
<220>
<223> Antibody chain
<400> 108
gacatccaga tgacccagag ccctagcttc ctgagcgcca gcgtcggcga ccgcgtgagc 60
atcacctgca aggccagcca ggacgtgagc accgccgtcg cctggtatca gcagaagcct 120
ggcaaggccc caaagctgct gatctacagc gccagctacc gctacaccgg cgtgccagac 180
cgcttcagcg gcagcggcag cggcaccgac ttcaccctga ccatcagcag cctgcaacca 240
gaggacttcg ccacctacta ctgccagcag cactacagca tcccactgac ctttggccag 300
ggcaccaagc tggagatcaa gcgtactgtg gctgcaccat ctgtcttcat cttcccgcca 360
tctgatgagc aattgaaatc tggaactgcc tctgttgtgt gcctgctgaa taacttctat 420
cccagagagg ccaaagtaca gtggaaggtg gataacgccc tccaatcggg taactcccag 480
gagagtgtca cagagcagga cagcaaggac agcacctaca gcctcagcag caccctgacg 540
ctgagcaaag cagactacga gaaacacaaa gtctacgcct gcgaagtcac ccatcagggc 600
ctgagctcgc ccgtcacaaa gagcttcaac aggggagagt gt 642
<210> 109
<211> 1344
<212> DNA
<213> Artificial Sequence
<220>
<223> Antibody chain
<400> 109
caggtcaccc tgaaggagag cggcccaacc ctggtgaagc caacccagac cctgaccctg 60
acctgcagct tcagcggctt ctccctgagc accagcgaca tgggcgtggg ctggattcgc 120
caaccaccag gcaaggccct ggagtggctg gcccacatct ggtgggacga cgtgaagcgc 180
tacaacccag ccctgaagag ccgcctgacc atcaccaagg acaccagcaa gaaccaggtg 240
gtgctgacca tgaccaacat ggacccagtg gacaccgcca cctacttctg cgcccgcatc 300
gtggactacg gcgtgagcta ctacttcgac tactggggcc agggcaccac cgtgaccgtg 360
agcagcgcct ccacaaaggg cccttccgtg ttccccctgg ccccttgctc ccggtccacc 420
tccgagtcta ccgccgctct gggctgcctg gtcaaggact acttccccga gcccgtgacc 480
gtgtcctgga actctggcgc cctgacctcc ggcgtgcaca ccttccctgc tgtgctgcag 540
tcctccggcc tgtactccct gtcctccgtc gtgaccgtgc cctcctctag cctgggcacc 600
aagacctaca cctgtaacgt ggaccacaag ccctccaaca ccaaggtgga caagcgggtg 660
gaatctaagt acggccctcc ctgccccccc tgccctgccc ctgaatttct gggcggaccc 720
tccgtgttcc tgttcccccc aaagcccaag gacaccctga tgatctcccg gacccccgaa 780
gtgacctgcg tggtggtgga cgtgtcccag gaagatcccg aggtccagtt taattggtac 840
gtggacggcg tggaagtgca caacgccaag accaagccca gagaggaaca gttcaactcc 900
acctaccggg tggtgtccgt gctgaccgtg ctgcaccagg actggctgaa cggcaaagag 960
tacaagtgca aggtgtccaa caagggcctg ccctccagca tcgaaaagac catctccaag 1020
gccaagggcc agccccgcga gccccaggtg tacaccctgc ctccaagcca ggaagagatg 1080
accaagaacc aggtgtccct gacctgtctg gtcaagggct tctacccctc cgatatcgcc 1140
gtggaatggg agtccaacgg ccagcccgag aacaactaca agaccacccc ccctgtgctg 1200
gactccgacg gctccttctt cctgtactct cggctgaccg tggacaagtc ccggtggcag 1260
gaaggcaacg tcttctcctg ctccgtgatg cacgaggccc tgcacaacca ctacacccag 1320
aagtccctgt ccctgagcct gggc 1344
<210> 110
<211> 642
<212> DNA
<213> Artificial Sequence
<220>
<223> Antibody chain
<400> 110
gacatccaga tgacccagag ccctagcttc ctgagcgcca gcgtcggcga ccgcgtgagc 60
atcacctgca aggccagcca ggacgtgagc accgccgtcg cctggtatca gcagaagcct 120
ggcaaggccc caaagctgct gatctacagc gccagctacc gctacaccgg cgtgccagac 180
cgcttcagcg gcagcggcag cggcaccgac ttcaccctga ccatcagcag cctgcaacca 240
gaggacttcg ccgtgtacta ctgccagcag cactacagca tcccactgac ctttggccag 300
ggcaccaagc tggagatcaa gcgtactgtg gctgcaccat ctgtcttcat cttcccgcca 360
tctgatgagc aattgaaatc tggaactgcc tctgttgtgt gcctgctgaa taacttctat 420
cccagagagg ccaaagtaca gtggaaggtg gataacgccc tccaatcggg taactcccag 480
gagagtgtca cagagcagga cagcaaggac agcacctaca gcctcagcag caccctgacg 540
ctgagcaaag cagactacga gaaacacaaa gtctacgcct gcgaagtcac ccatcagggc 600
ctgagctcgc ccgtcacaaa gagcttcaac aggggagagt gt 642
<210> 111
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> Epitope sequence
<400> 111
Leu Leu Arg Arg Ala Gly Val Thr
1 5
<210> 112
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> Epitope sequence
<400> 112
Tyr Arg Ala Ala Val His Leu Arg Asp Arg Ala
1 5 10
<210> 113
<211> 111
<212> PRT
<213> Artificial Sequence
<220>
<223> Immunoglobulin domain
<400> 113
Asp Ile Val Leu Thr Gln Ser Pro Ala Ser Leu Ala Val Ser Leu Gly
1 5 10 15
Gln Arg Ala Thr Met Ser Cys Arg Ala Ser Glu Asn Ile Asp Asn Ser
20 25 30
Gly Ile Ser Phe Met Asn Trp Phe Gln Gln Lys Pro Gly Gln Pro Pro
35 40 45
Lys Leu Leu Ile Tyr Val Ala Ser Asn Gln Gly Ser Gly Val Pro Ala
50 55 60
Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Arg Leu Thr Ile His
65 70 75 80
Pro Leu Glu Glu Asp Asp Thr Ala Met Tyr Phe Cys Gln Gln Ser Lys
85 90 95
Glu Val Pro Trp Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
100 105 110
<210> 114
<211> 120
<212> PRT
<213> Artificial Sequence
<220>
<223> Immunoglobulin domain
<400> 114
Glu Val Met Leu Val Glu Ser Gly Gly Gly Leu Val Lys Pro Gly Gly
1 5 10 15
Ser Leu Lys Leu Ser Cys Thr Ala Ser Gly Phe Thr Phe Ser Asn Ser
20 25 30
Ala Met Ser Trp Val Arg Gln Thr Pro Glu Arg Arg Leu Glu Trp Val
35 40 45
Ala Tyr Ile Ser Gly Gly Gly Gly Asp Thr Tyr Tyr Ser Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asp Thr Leu Tyr
65 70 75 80
Leu His Met Ser Ser Leu Arg Ser Glu Asp Thr Ala Leu His Tyr Cys
85 90 95
Ala Arg His Ser Asn Ser Asn Tyr Tyr Ala Met Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Ser Val Thr Val Ser Ser
115 120
<210> 115
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> Epitope sequence
<400> 115
Ala Ile Ser Leu Ala Pro Lys Ala Gln Ile Lys Glu Ser Leu
1 5 10
<210> 116
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> Epitope sequence
<400> 116
Ala Ala Phe Pro Glu Asp Arg Ser Gln Pro Gly Gln Asp Cys Arg Phe
1 5 10 15
<210> 117
<211> 107
<212> PRT
<213> Artificial Sequence
<220>
<223> Immunoglobulin domain
<400> 117
Asp Ile Val Met Thr Gln Ser His Lys Phe Met Ser Thr Ser Val Gly
1 5 10 15
Asp Arg Val Ser Phe Thr Cys Lys Ala Ser Gln Asp Val Asn Thr Ala
20 25 30
Val Ala Trp Tyr Gln Gln Lys Pro Gly Gln Ser Pro Lys Leu Leu Ile
35 40 45
Tyr Ser Ala Ser Tyr Arg Tyr Thr Gly Val Pro Asp Arg Phe Thr Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Phe Thr Ile Ser Ser Val Gln Ala
65 70 75 80
Glu Asp Leu Ala Leu Tyr Tyr Cys Gln Gln His Tyr Ser Ile Pro Leu
85 90 95
Thr Phe Gly Ala Gly Thr Lys Leu Glu Leu Lys
100 105
<210> 118
<211> 122
<212> PRT
<213> Artificial Sequence
<220>
<223> Immunoglobulin domain
<400> 118
Gln Val Thr Leu Lys Glu Ser Gly Pro Gly Ile Leu Gln Pro Ser Gln
1 5 10 15
Thr Leu Ser Leu Thr Cys Ser Phe Ser Gly Phe Ser Leu Ser Thr Ser
20 25 30
Asp Met Gly Val Gly Trp Ile Arg Gln Pro Ser Gly Lys Gly Leu Glu
35 40 45
Trp Leu Ala His Ile Trp Trp Asp Asp Val Lys Arg Tyr Asn Pro Ala
50 55 60
Leu Lys Ser Arg Leu Thr Ile Ser Lys Asp Thr Ser Ser Ser Gln Val
65 70 75 80
Phe Leu Met Ile Ala Ser Val Asp Thr Ala Asp Thr Ala Thr Tyr Phe
85 90 95
Cys Ala Arg Ile Glu Asp Tyr Gly Val Ser Tyr Tyr Phe Asp Tyr Trp
100 105 110
Gly Gln Gly Thr Thr Leu Thr Val Ser Ser
115 120
Claims (30)
- 아미노산 서열 LLRRAGVT(서열번호 111) 및 아미노산 서열 YRAAVHLRDRA(서열번호 112)로부터 선택되는 적어도 하나를 포함하는 인간 LAG3의 에피토프에 결합하는 항-LAG3 항체 분자.
- 제1항에 있어서,
(a) 서열번호 39(hcCDR1), 서열번호 40(hcCDR2) 및 서열번호 41(hcCDR3)의 아미노산 서열을 포함하는 중쇄 CDR 및 서열번호 42(lcCDR1), 서열번호 43(lcCDR2) 및 서열번호 44(lcCDR3)의 아미노산 서열을 포함하는 경쇄 CDR; 또는
(b) 서열번호 45(hcCDR1), 서열번호 46(hcCDR2) 및 서열번호 47(hcCDR3)의 아미노산 서열을 포함하는 중쇄 CDR 및 서열번호 48(lcCDR1), 서열번호 49(lcCDR2) 및 서열번호 50(lcCDR3)의 아미노산 서열을 포함하는 경쇄 CDR;을 포함하는,
항-LAG3 항체 분자. - 제1항에 있어서, IgG1, IgG2, IgG3, IgG4, IgM, IgA 및 IgE 불변 영역으로 구성된 군으로부터 선택된 중쇄 불변 영역을 포함하는, 항-LAG3 항체 분자.
- 제3항에 있어서, 중쇄 불변 영역이 IgG4인, 항-LAG3 항체 분자.
- 제3항에 있어서, 중쇄 불변 영역이 S241P 돌연변이를 갖는 IgG4인, 항-LAG3 항체 분자.
- 제1항에 있어서,
- 서열번호 51의 아미노산 서열을 포함하는 중쇄 가변 도메인 및 서열번호 52의 아미노산 서열을 포함하는 경쇄 가변 도메인, 또는
- 서열번호 53의 아미노산 서열을 포함하는 중쇄 가변 도메인 및 서열번호 54의 아미노산 서열을 포함하는 경쇄 가변 도메인, 또는
- 서열번호 55의 아미노산 서열을 포함하는 중쇄 가변 도메인 및 서열번호 56의 아미노산 서열을 포함하는 경쇄 가변 도메인, 또는
- 서열번호 57의 아미노산 서열을 포함하는 중쇄 가변 도메인 및 서열번호 58의 아미노산 서열을 포함하는 경쇄 가변 도메인, 또는
- 서열번호 59의 아미노산 서열을 포함하는 중쇄 가변 도메인 및 서열번호 60의 아미노산 서열을 포함하는 경쇄 가변 도메인을 가지는,
항-LAG3 항체 분자. - 제1항에 있어서,
- 서열번호 61의 아미노산 서열을 포함하는 중쇄 및 서열번호 62의 아미노산 서열을 포함하는 경쇄, 또는
- 서열번호 63의 아미노산 서열을 포함하는 중쇄 및 서열번호 64의 아미노산 서열을 포함하는 경쇄, 또는
- 서열번호 65의 아미노산 서열을 포함하는 중쇄 및 서열번호 66의 아미노산 서열을 포함하는 경쇄, 또는
- 서열번호 67의 아미노산 서열을 포함하는 중쇄 및 서열번호 68의 아미노산 서열을 포함하는 경쇄, 또는
- 서열번호 69의 아미노산 서열을 포함하는 중쇄 및 서열번호 70의 아미노산 서열을 포함하는 경쇄를 가지는,
항-LAG3 항체 분자. - 제1항 내지 제7항 중 어느 한 항의 항체 분자의 중쇄 가변 도메인 및 경쇄 가변 도메인으로부터 선택되는 적어도 하나를 코딩하는, 단리된 핵산 분자.
- 제1항 내지 제7항 중 어느 한 항의 항체 분자의 중쇄 가변 도메인 및 경쇄 가변 도메인으로부터 선택되는 적어도 하나를 코딩하는 뉴클레오티드 서열을 포함하는 핵산 분자를 함유하는, 발현 벡터.
- 제1항 내지 제7항 중 어느 한 항의 항체 분자의 중쇄 가변 도메인 및 경쇄 가변 도메인으로부터 선택되는 적어도 하나를 코딩하는 뉴클레오티드 서열을 포함하는 핵산 분자를 함유하는 발현 벡터로 형질감염된, 숙주 세포.
- - 제1항 내지 제7항 중 어느 한 항의 항체 분자의 형성을 허용하는 조건하에서, 제1항 내지 제7항 중 어느 한 항의 항체 분자의 중쇄 가변 도메인 및 경쇄 가변 도메인으로부터 선택되는 적어도 하나를 코딩하는 뉴클레오티드 서열을 포함하는 핵산 분자를 함유하는 발현 벡터로 형질감염된 숙주 세포를 배양하는 단계, 및
- 상기 항체 분자를 회수하는 단계;를 포함하는,
제1항 내지 제7항 중 어느 한 항의 항체 분자의 제조 방법. - 제11항에 있어서, 상기 항체 분자를 정제하는 단계 및 선택적으로 상기 항체 분자를 약학적 조성물로 제형화하는 단계를 추가로 포함하는, 방법.
- 제1항 내지 제7항 중 어느 한 항의 항-LAG3 항체 분자를 포함하는 암 치료용 약제.
- 제13항에 있어서, 상기 암이 비소세포 폐암(NSCLC), 소세포 폐암(SCLC), 육종, 암종, 및 조혈계 암으로 구성된 군으로부터 선택되는, 약제.
- 제13항에 있어서, 항-PD1 항체 분자 또는 항-PDL1 항체 분자와 병용하여 투여되는 약제.
- 제15항에 있어서, 상기 항-PD1 항체 분자가 하기로 구성된 그룹으로부터 선택되는, 약제:
- 펨브롤리주맵,
- 니볼루맵,
- 서열번호 29의 아미노산 서열을 포함하는 중쇄 및 서열번호 30의 아미노산 서열을 포함하는 경쇄를 갖는 항체 분자,
- 서열번호 31의 아미노산 서열을 포함하는 중쇄 및 서열번호 32의 아미노산 서열을 포함하는 경쇄를 갖는 항체 분자,
- 서열번호 33의 아미노산 서열을 포함하는 중쇄 및 서열번호 34의 아미노산 서열을 포함하는 경쇄를 갖는 항체 분자,
- 서열번호 35의 아미노산 서열을 포함하는 중쇄 및 서열번호 36의 아미노산 서열을 포함하는 경쇄를 갖는 항체 분자, 및
서열번호 37의 아미노산 서열을 포함하는 중쇄 및 서열번호 38의 아미노산 서열을 포함하는 경쇄를 갖는 항체 분자. - 제15항에 있어서, 상기 항-PDL1 항체 분자가 아테졸리주맵, 아벨루맵 및 듀발루맵으로 구성된 그룹으로부터 선택되는, 약제.
- 제15항에 있어서, 상기 항-PD1 항체 분자 또는 상기 항-PDL1 항체 분자와 동시에, 동반하여, 순차적으로, 연속적으로, 교대로, 또는 별도로 투여되는, 약제.
- 제1항 내지 제7항 중 어느 한 항의 항-LAG3 항체 분자 및 약학적으로 허용가능한 담체를 포함하는, 암 치료용 약학적 조성물.
- 제19항에 있어서, 상기 암이 비소세포 폐암(NSCLC), 소세포 폐암(SCLC), 육종, 암종, 및 조혈계 암으로 구성된 군으로부터 선택되는, 약학적 조성물.
- 제19항에 있어서, 항-PD1 항체 분자 또는 항-PDL1 항체 분자와 병용하여 투여되는 약학적 조성물.
- 제21항에 있어서, 상기 항-PD1 항체 분자가 하기로 구성된 그룹으로부터 선택되는, 약학적 조성물:
- 펨브롤리주맵,
- 니볼루맵,
- 서열번호 29의 아미노산 서열을 포함하는 중쇄 및 서열번호 30의 아미노산 서열을 포함하는 경쇄를 갖는 항체 분자,
- 서열번호 31의 아미노산 서열을 포함하는 중쇄 및 서열번호 32의 아미노산 서열을 포함하는 경쇄를 갖는 항체 분자,
- 서열번호 33의 아미노산 서열을 포함하는 중쇄 및 서열번호 34의 아미노산 서열을 포함하는 경쇄를 갖는 항체 분자,
- 서열번호 35의 아미노산 서열을 포함하는 중쇄 및 서열번호 36의 아미노산 서열을 포함하는 경쇄를 갖는 항체 분자, 및
서열번호 37의 아미노산 서열을 포함하는 중쇄 및 서열번호 38의 아미노산 서열을 포함하는 경쇄를 갖는 항체 분자. - 제21항에 있어서, 상기 항-PDL1 항체 분자가 아테졸리주맵, 아벨루맵 및 듀발루맵으로 구성된 그룹으로부터 선택되는, 약학적 조성물.
- 제19항에 있어서, 항-PD1 항체 분자 또는 항-PDL1 항체 분자를 추가로 포함하는 약학적 조성물.
- 제24항에 있어서, 상기 항-PD1 항체 분자가 하기로 구성된 그룹으로부터 선택되는, 약학적 조성물:
- 펨브롤리주맵,
- 니볼루맵,
- 서열번호 29의 아미노산 서열을 포함하는 중쇄 및 서열번호 30의 아미노산 서열을 포함하는 경쇄를 갖는 항체 분자,
- 서열번호 31의 아미노산 서열을 포함하는 중쇄 및 서열번호 32의 아미노산 서열을 포함하는 경쇄를 갖는 항체 분자,
- 서열번호 33의 아미노산 서열을 포함하는 중쇄 및 서열번호 34의 아미노산 서열을 포함하는 경쇄를 갖는 항체 분자,
- 서열번호 35의 아미노산 서열을 포함하는 중쇄 및 서열번호 36의 아미노산 서열을 포함하는 경쇄를 갖는 항체 분자, 및
서열번호 37의 아미노산 서열을 포함하는 중쇄 및 서열번호 38의 아미노산 서열을 포함하는 경쇄를 갖는 항체 분자. - 제24항에 있어서, 상기 항-PDL1 항체 분자가 아테졸리주맵, 아벨루맵 및 듀발루맵으로 구성된 그룹으로부터 선택되는, 약학적 조성물.
- 제19항에 있어서, 하나 이상의 추가의 치료제를 추가로 포함하는 약학적 조성물.
- 제1항 내지 제7항 중 어느 한 항의 항-LAG3 항체 분자 및 하기로 구성된 그룹으로부터 선택되는 항체 분자를 포함하는, 암 치료용 부품 키트(kit of parts):
- 펨브롤리주맵,
- 니볼루맵,
- 아테졸리주맵,
- 아벨루맵,
- 듀발루맵,
- 서열번호 29의 아미노산 서열을 포함하는 중쇄 및 서열번호 30의 아미노산 서열을 포함하는 경쇄를 갖는 항체 분자,
- 서열번호 31의 아미노산 서열을 포함하는 중쇄 및 서열번호 32의 아미노산 서열을 포함하는 경쇄를 갖는 항체 분자,
- 서열번호 33의 아미노산 서열을 포함하는 중쇄 및 서열번호 34의 아미노산 서열을 포함하는 경쇄를 갖는 항체 분자,
- 서열번호 35의 아미노산 서열을 포함하는 중쇄 및 서열번호 36의 아미노산 서열을 포함하는 경쇄를 갖는 항체 분자, 및
서열번호 37의 아미노산 서열을 포함하는 중쇄 및 서열번호 38의 아미노산 서열을 포함하는 경쇄를 갖는 항체 분자. - 제28항에 있어서, 상기 암이 비소세포 폐암(NSCLC), 소세포 폐암(SCLC), 육종, 암종, 및 조혈계 암으로 구성된 군으로부터 선택되는, 부품 키트.
- 제28항에 있어서, 하나 이상의 추가의 치료제를 추가로 포함하는 부품 키트.
Applications Claiming Priority (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP16170174 | 2016-05-18 | ||
| EPEP16170174.3 | 2016-05-18 | ||
| KR1020187033938A KR102419412B1 (ko) | 2016-05-18 | 2017-05-17 | 암 치료용 항-pd1 및 항-lag3 항체 |
| PCT/EP2017/061901 WO2017198741A1 (en) | 2016-05-18 | 2017-05-17 | Anti pd-1 and anti-lag3 antibodies for cancer treatment |
Related Parent Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020187033938A Division KR102419412B1 (ko) | 2016-05-18 | 2017-05-17 | 암 치료용 항-pd1 및 항-lag3 항체 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20220103806A true KR20220103806A (ko) | 2022-07-22 |
Family
ID=56014918
Family Applications (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020187033938A KR102419412B1 (ko) | 2016-05-18 | 2017-05-17 | 암 치료용 항-pd1 및 항-lag3 항체 |
| KR1020227023184A KR20220103806A (ko) | 2016-05-18 | 2017-05-17 | 암 치료용 항-pd1 및 항-lag3 항체 |
Family Applications Before (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020187033938A KR102419412B1 (ko) | 2016-05-18 | 2017-05-17 | 암 치료용 항-pd1 및 항-lag3 항체 |
Country Status (31)
| Country | Link |
|---|---|
| US (2) | US11028169B2 (ko) |
| EP (2) | EP3458478B1 (ko) |
| JP (3) | JP6585860B2 (ko) |
| KR (2) | KR102419412B1 (ko) |
| CN (2) | CN109415439B (ko) |
| AR (1) | AR108516A1 (ko) |
| AU (1) | AU2017266298B2 (ko) |
| BR (1) | BR112018072986A2 (ko) |
| CA (1) | CA3020649A1 (ko) |
| CL (2) | CL2018003153A1 (ko) |
| CO (1) | CO2018012374A2 (ko) |
| CY (1) | CY1123977T1 (ko) |
| DK (1) | DK3458478T3 (ko) |
| EA (1) | EA201892616A1 (ko) |
| ES (1) | ES2857813T3 (ko) |
| HU (1) | HUE053452T2 (ko) |
| IL (1) | IL262892B2 (ko) |
| LT (1) | LT3458478T (ko) |
| MA (2) | MA55697A (ko) |
| MX (2) | MX2018014102A (ko) |
| MY (1) | MY193112A (ko) |
| PE (1) | PE20190108A1 (ko) |
| PH (1) | PH12018502429A1 (ko) |
| PL (1) | PL3458478T3 (ko) |
| RS (1) | RS61510B1 (ko) |
| SA (1) | SA518400424B1 (ko) |
| SG (1) | SG11201809627QA (ko) |
| SI (1) | SI3458478T1 (ko) |
| TW (2) | TW202307002A (ko) |
| UA (1) | UA127200C2 (ko) |
| WO (1) | WO2017198741A1 (ko) |
Families Citing this family (88)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| BR112018000768A2 (pt) | 2015-07-13 | 2018-09-25 | Cytomx Therapeutics Inc | anticorpos anti-pd-1, anticorpos anti-pd-1 ativáveis e métodos de uso dos mesmos |
| TWI756187B (zh) | 2015-10-09 | 2022-03-01 | 美商再生元醫藥公司 | 抗lag3抗體及其用途 |
| JO3744B1 (ar) | 2015-11-18 | 2021-01-31 | Merck Sharp & Dohme | مواد ربط لـpd1 و/ أو lag3 |
| DK3458478T3 (da) | 2016-05-18 | 2021-03-22 | Boehringer Ingelheim Int | Anti-pd-1- og anti-lag3-antistoffer til cancerbehandling |
| IL265800B2 (en) | 2016-10-11 | 2023-10-01 | Agenus Inc | Anti-LAG-3 antibodies and methods of using them |
| BR112019006876A2 (pt) | 2016-10-13 | 2019-06-25 | Symphogen As | anticorpos e composições anti-lag-3 |
| US11359018B2 (en) | 2016-11-18 | 2022-06-14 | Symphogen A/S | Anti-PD-1 antibodies and compositions |
| EP3360898A1 (en) | 2017-02-14 | 2018-08-15 | Boehringer Ingelheim International GmbH | Bispecific anti-tnf-related apoptosis-inducing ligand receptor 2 and anti-cadherin 17 binding molecules for the treatment of cancer |
| AU2018219909A1 (en) | 2017-02-10 | 2019-09-12 | Regeneron Pharmaceuticals, Inc. | Radiolabeled anti-LAG3 antibodies for immuno-PET imaging |
| JP2020513009A (ja) | 2017-04-05 | 2020-04-30 | シムフォゲン・アクティーゼルスカブSymphogen A/S | Pd−1、tim−3、およびlag−3を標的とする併用治療 |
| CA3057558A1 (en) * | 2017-04-05 | 2018-10-11 | Boehringer Ingelheim International Gmbh | Anticancer combination therapy |
| JOP20190260A1 (ar) | 2017-05-02 | 2019-10-31 | Merck Sharp & Dohme | صيغ ثابتة لأجسام مضادة لمستقبل الموت المبرمج 1 (pd-1) وطرق استخدامها |
| RU2019138507A (ru) | 2017-05-02 | 2021-06-02 | Мерк Шарп И Доум Корп. | Составы антител против lag3 и совместные составы антител против lag3 и антител против pd-1 |
| BR112019020610A2 (pt) | 2017-05-30 | 2020-04-22 | Bristol-Myers Squibb Company | tratamento de tumores positivos para o lag-3 |
| CA3065304A1 (en) | 2017-05-30 | 2018-12-06 | Bristol-Myers Squibb Company | Compositions comprising an anti-lag-3 antibody or an anti-lag-3 antibody and an anti-pd-1 or anti-pd-l1 antibody |
| MX2019012038A (es) | 2017-05-30 | 2019-11-18 | Bristol Myers Squibb Co | Composiciones que comprenden una combinacion de un anticuerpo anti gen 3 de activacion del linfocito (lag-3), un inhibidor de la trayectoria del receptor de muerte programada 1 (pd-1), y un agente inmunoterapeutico. |
| KR20200013231A (ko) * | 2017-06-02 | 2020-02-06 | 베링거 인겔하임 인터내셔날 게엠베하 | 항암 조합 요법 |
| EP3714901A4 (en) * | 2017-12-22 | 2022-03-02 | Jiangsu Hengrui Medicine Co., Ltd. | ANTI-LAG-3 ANTIBODY PHARMACEUTICAL COMPOSITION AND USE THEREOF |
| CN109970856B (zh) | 2017-12-27 | 2022-08-23 | 信达生物制药(苏州)有限公司 | 抗lag-3抗体及其用途 |
| US11713353B2 (en) | 2018-01-15 | 2023-08-01 | Nanjing Legend Biotech Co., Ltd. | Single-domain antibodies and variants thereof against PD-1 |
| US20210363243A1 (en) * | 2018-02-01 | 2021-11-25 | Merck Sharp & Dohme Corp. | Methods for treating cancer or infection using a combination of an anti-pd-1 antibody, an anti-lag3 antibody, and an anti-tigit antibody |
| US20210085650A1 (en) * | 2018-02-22 | 2021-03-25 | The Board Of Regents Of The University Of Texas System | Combination therapy for the treatment of cancer |
| FR3078536A1 (fr) * | 2018-03-05 | 2019-09-06 | Peptinov Sas | Composition vaccinale anti-pd-1 |
| JP2021519298A (ja) | 2018-03-27 | 2021-08-10 | ブリストル−マイヤーズ スクイブ カンパニーBristol−Myers Squibb Company | 紫外線シグナルを使用した力価のリアルタイムモニタリング |
| EP3790584A4 (en) | 2018-05-07 | 2022-03-30 | Genmab A/S | METHOD OF TREATMENT OF CANCER WITH A COMBINATION OF AN ANTI-PD-1 ANTIBODY AND AN ANTI-TISSUE FACTOR ANTIBODY-DUG CONJUGATE |
| EP3569618A1 (en) | 2018-05-19 | 2019-11-20 | Boehringer Ingelheim International GmbH | Antagonizing cd73 antibody |
| TW202016151A (zh) | 2018-06-09 | 2020-05-01 | 德商百靈佳殷格翰國際股份有限公司 | 針對癌症治療之多特異性結合蛋白 |
| EP3802922B1 (en) * | 2018-06-11 | 2023-04-26 | Yale University | Novel immune checkpoint inhibitors |
| EP3826660A1 (en) * | 2018-07-26 | 2021-06-02 | Bristol-Myers Squibb Company | Lag-3 combination therapy for the treatment of cancer |
| CN113286611A (zh) | 2018-10-19 | 2021-08-20 | 百时美施贵宝公司 | 用于黑色素瘤的组合疗法 |
| US20210347889A1 (en) * | 2018-11-05 | 2021-11-11 | Merck Sharp & Dohme Corp. | Dosing regimen of anti-lag3 antibody and combination therapy with anti-pd-1 antibody for treating cancer |
| EP3876978A4 (en) | 2018-11-07 | 2022-09-28 | Merck Sharp & Dohme Corp. | STABLE FORMULATIONS OF PROGRAMMED DEATH RECEPTOR 1 (MP-1) ANTIBODIES AND THEIR METHODS OF USE |
| MX2021005394A (es) * | 2018-11-07 | 2021-07-06 | Merck Sharp & Dohme Llc | Co-formulaciones de anticuerpos anti-gen de activacion de linfocitos 3 (anti-lag3) y anticuerpos anti-muerte programada-1 (anti-pd-1). |
| TW202043466A (zh) | 2019-01-25 | 2020-12-01 | 德商百靈佳殷格翰國際股份有限公司 | 編碼ccl21之重組棒狀病毒 |
| US20220135619A1 (en) | 2019-02-24 | 2022-05-05 | Bristol-Myers Squibb Company | Methods of isolating a protein |
| WO2020200998A1 (en) * | 2019-03-29 | 2020-10-08 | Boehringer Ingelheim International Gmbh | Anticancer combination therapy |
| EP3969040A1 (en) * | 2019-05-13 | 2022-03-23 | Regeneron Pharmaceuticals, Inc. | Combination of pd-1 inhibitors and lag-3 inhibitors for enhanced efficacy in treating cancer |
| US20220220430A1 (en) | 2019-05-23 | 2022-07-14 | Bristol-Myers Squibb Company | Methods of monitoring cell culture media |
| JP2022534967A (ja) | 2019-05-30 | 2022-08-04 | ブリストル-マイヤーズ スクイブ カンパニー | 多腫瘍遺伝子シグネチャーおよびその使用 |
| JP2022534981A (ja) | 2019-05-30 | 2022-08-04 | ブリストル-マイヤーズ スクイブ カンパニー | 細胞局在化シグネチャーおよび組み合わせ治療 |
| EP3976832A1 (en) | 2019-05-30 | 2022-04-06 | Bristol-Myers Squibb Company | Methods of identifying a subject suitable for an immuno-oncology (i-o) therapy |
| CN114008080B (zh) * | 2019-06-12 | 2023-06-09 | 南京金斯瑞生物科技有限公司 | 抗pd-l1/抗lag-3多抗原结合蛋白及其使用方法 |
| CN112121169B (zh) * | 2019-06-24 | 2023-10-24 | 广州再极医药科技有限公司 | 用于治疗具有高间质压力的肿瘤受试者的癌症的小分子抑制剂 |
| TWI809286B (zh) | 2019-07-05 | 2023-07-21 | 日商小野藥品工業股份有限公司 | 以pd-1/cd3雙特異性蛋白質所進行之血液性癌症治療 |
| WO2021024020A1 (en) | 2019-08-06 | 2021-02-11 | Astellas Pharma Inc. | Combination therapy involving antibodies against claudin 18.2 and immune checkpoint inhibitors for treatment of cancer |
| EP4011918A4 (en) | 2019-08-08 | 2023-08-23 | ONO Pharmaceutical Co., Ltd. | DUAL SPECIFIC PROTEIN |
| TW202114637A (zh) * | 2019-08-22 | 2021-04-16 | 俄羅斯聯邦商拜奧卡德聯合股份公司 | 抗pd-1抗體prolgolimab的水性藥物組合物及其用途 |
| AU2020350795A1 (en) | 2019-09-22 | 2022-03-31 | Bristol-Myers Squibb Company | Quantitative spatial profiling for LAG-3 antagonist therapy |
| TW202128756A (zh) | 2019-10-02 | 2021-08-01 | 德商百靈佳殷格翰國際股份有限公司 | 用於癌症治療之多重專一性結合蛋白 |
| WO2021092221A1 (en) | 2019-11-06 | 2021-05-14 | Bristol-Myers Squibb Company | Methods of identifying a subject with a tumor suitable for a checkpoint inhibitor therapy |
| WO2021092220A1 (en) | 2019-11-06 | 2021-05-14 | Bristol-Myers Squibb Company | Methods of identifying a subject with a tumor suitable for a checkpoint inhibitor therapy |
| BR112022008191A2 (pt) | 2019-11-08 | 2022-07-12 | Bristol Myers Squibb Co | Terapia com antagonista de lag-3 para melanoma |
| CN110950966B (zh) * | 2019-12-13 | 2020-12-11 | 启辰生生物科技(珠海)有限公司 | 融合蛋白、编码核酸和细胞及用途 |
| CN115362167A (zh) | 2020-02-06 | 2022-11-18 | 百时美施贵宝公司 | Il-10及其用途 |
| IL298648A (en) | 2020-06-03 | 2023-01-01 | Boehringer Ingelheim Int | Recombinant rhabdovirus coding for a fc fusion protein with a cd80 extracellular site |
| CN111808192B (zh) * | 2020-06-05 | 2022-02-15 | 北京天广实生物技术股份有限公司 | 结合lag3的抗体及其用途 |
| JP2023532768A (ja) | 2020-07-07 | 2023-07-31 | バイオエヌテック エスエー | Hpv陽性癌の治療用rna |
| WO2022047189A1 (en) | 2020-08-28 | 2022-03-03 | Bristol-Myers Squibb Company | Lag-3 antagonist therapy for hepatocellular carcinoma |
| EP4204453A1 (en) | 2020-08-31 | 2023-07-05 | Bristol-Myers Squibb Company | Cell localization signature and immunotherapy |
| IL301533A (en) | 2020-09-24 | 2023-05-01 | Merck Sharp ַ& Dohme Llc | Stable compositions of programmed death receptor 1 (PD-1) antibodies and hyaluronidase variants and parts thereof and methods of using them |
| CN116406369A (zh) | 2020-10-05 | 2023-07-07 | 百时美施贵宝公司 | 用于浓缩蛋白质的方法 |
| US20240101666A1 (en) | 2020-10-23 | 2024-03-28 | Bristol-Myers Squibb Company | Lag-3 antagonist therapy for lung cancer |
| CA3200671A1 (en) | 2020-11-17 | 2022-05-27 | Seagen Inc. | Methods of treating cancer with a combination of tucatinib and an anti-pd-1/anti-pd-l1 antibody |
| WO2022120179A1 (en) | 2020-12-03 | 2022-06-09 | Bristol-Myers Squibb Company | Multi-tumor gene signatures and uses thereof |
| WO2022135666A1 (en) | 2020-12-21 | 2022-06-30 | BioNTech SE | Treatment schedule for cytokine proteins |
| WO2022135667A1 (en) | 2020-12-21 | 2022-06-30 | BioNTech SE | Therapeutic rna for treating cancer |
| TW202245808A (zh) | 2020-12-21 | 2022-12-01 | 德商拜恩迪克公司 | 用於治療癌症之治療性rna |
| AU2021416156A1 (en) | 2020-12-28 | 2023-06-22 | Bristol-Myers Squibb Company | Methods of treating tumors |
| JP2024503265A (ja) | 2020-12-28 | 2024-01-25 | ブリストル-マイヤーズ スクイブ カンパニー | 抗体組成物およびその使用の方法 |
| IL307262A (en) | 2021-03-29 | 2023-11-01 | Juno Therapeutics Inc | METHODS FOR DOSAGE AND THERAPY IN COMBINATION OF CHECKPOINT INHIBITOR AND CAR T CELL THERAPY |
| WO2022240741A1 (en) | 2021-05-12 | 2022-11-17 | Dana-Farber Cancer Institute, Inc. | Lag3 and gal3 inhibitory agents, xbp1, cs1, and cd138 peptides, and methods of use thereof |
| EP4355778A1 (en) | 2021-06-17 | 2024-04-24 | Boehringer Ingelheim International GmbH | Novel tri-specific binding molecules |
| WO2023285552A1 (en) | 2021-07-13 | 2023-01-19 | BioNTech SE | Multispecific binding agents against cd40 and cd137 in combination therapy for cancer |
| WO2023057534A1 (en) | 2021-10-06 | 2023-04-13 | Genmab A/S | Multispecific binding agents against pd-l1 and cd137 in combination |
| TW202333802A (zh) | 2021-10-11 | 2023-09-01 | 德商拜恩迪克公司 | 用於肺癌之治療性rna(二) |
| AU2022375806A1 (en) | 2021-10-29 | 2023-12-14 | Bristol-Myers Squibb Company | Lag-3 antagonist therapy for hematological cancer |
| WO2023083439A1 (en) | 2021-11-09 | 2023-05-19 | BioNTech SE | Tlr7 agonist and combinations for cancer treatment |
| WO2023147371A1 (en) | 2022-01-26 | 2023-08-03 | Bristol-Myers Squibb Company | Combination therapy for hepatocellular carcinoma |
| WO2023164638A1 (en) | 2022-02-25 | 2023-08-31 | Bristol-Myers Squibb Company | Combination therapy for colorectal carcinoma |
| WO2023168404A1 (en) | 2022-03-04 | 2023-09-07 | Bristol-Myers Squibb Company | Methods of treating a tumor |
| WO2023170606A1 (en) | 2022-03-08 | 2023-09-14 | Alentis Therapeutics Ag | Use of anti-claudin-1 antibodies to increase t cell availability |
| WO2023173011A1 (en) | 2022-03-09 | 2023-09-14 | Bristol-Myers Squibb Company | Transient expression of therapeutic proteins |
| WO2023178329A1 (en) | 2022-03-18 | 2023-09-21 | Bristol-Myers Squibb Company | Methods of isolating polypeptides |
| WO2023183317A2 (en) * | 2022-03-21 | 2023-09-28 | Ab Therapeutics, Inc. | Multispecific antibodies and uses thereof |
| WO2023218046A1 (en) | 2022-05-12 | 2023-11-16 | Genmab A/S | Binding agents capable of binding to cd27 in combination therapy |
| WO2023235847A1 (en) | 2022-06-02 | 2023-12-07 | Bristol-Myers Squibb Company | Antibody compositions and methods of use thereof |
| US20240052065A1 (en) | 2022-07-15 | 2024-02-15 | Boehringer Ingelheim International Gmbh | Binding molecules for the treatment of cancer |
| CN115960834B (zh) * | 2023-03-07 | 2023-06-09 | 浙江省肿瘤医院 | 一种pd-1/ptx联合pd-1耐药模型建立的方法 |
Family Cites Families (37)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| DE3785186T2 (de) | 1986-09-02 | 1993-07-15 | Enzon Lab Inc | Bindungsmolekuele mit einzelpolypeptidkette. |
| DE3883899T3 (de) | 1987-03-18 | 1999-04-22 | Sb2 Inc | Geänderte antikörper. |
| AU634186B2 (en) | 1988-11-11 | 1993-02-18 | Medical Research Council | Single domain ligands, receptors comprising said ligands, methods for their production, and use of said ligands and receptors |
| GB8905669D0 (en) | 1989-03-13 | 1989-04-26 | Celltech Ltd | Modified antibodies |
| US5427908A (en) | 1990-05-01 | 1995-06-27 | Affymax Technologies N.V. | Recombinant library screening methods |
| DK0656946T4 (da) | 1992-08-21 | 2010-07-26 | Univ Bruxelles | Immunoglobuliner uden lette kæder |
| EP0672142B1 (en) | 1992-12-04 | 2001-02-28 | Medical Research Council | Multivalent and multispecific binding proteins, their manufacture and use |
| ES2138662T3 (es) | 1993-06-03 | 2000-01-16 | Therapeutic Antibodies Inc | Produccion de fragmentos de anticuerpos. |
| GB9625640D0 (en) | 1996-12-10 | 1997-01-29 | Celltech Therapeutics Ltd | Biological products |
| US6329516B1 (en) | 1997-04-28 | 2001-12-11 | Fmc Corporation | Lepidopteran GABA-gated chloride channels |
| CA2288994C (en) | 1997-04-30 | 2011-07-05 | Enzon, Inc. | Polyalkylene oxide-modified single chain polypeptides |
| JP2003530839A (ja) | 2000-04-12 | 2003-10-21 | プリンシピア ファーマスーティカル コーポレイション | アルブミン融合タンパク質 |
| EP2706116A1 (en) | 2001-01-17 | 2014-03-12 | Emergent Product Development Seattle, LLC | Binding domain-immunoglobulin fusion proteins |
| WO2003050531A2 (en) | 2001-12-11 | 2003-06-19 | Algonomics N.V. | Method for displaying loops from immunoglobulin domains in different contexts |
| JP2006512895A (ja) | 2002-06-28 | 2006-04-20 | ドマンティス リミテッド | リガンド |
| EP2336179A1 (en) | 2002-11-08 | 2011-06-22 | Ablynx N.V. | Stabilized single domain antibodies |
| CN1753912B (zh) | 2002-12-23 | 2011-11-02 | 惠氏公司 | 抗pd-1抗体及其用途 |
| CA2529819A1 (en) | 2003-06-30 | 2004-09-23 | Domantis Limited | Pegylated single domain antibodies |
| AR072999A1 (es) * | 2008-08-11 | 2010-10-06 | Medarex Inc | Anticuerpos humanos que se unen al gen 3 de activacion linfocitaria (lag-3) y los usos de estos |
| TW201134488A (en) | 2010-03-11 | 2011-10-16 | Ucb Pharma Sa | PD-1 antibodies |
| KR101937733B1 (ko) | 2012-05-24 | 2019-01-11 | 마운트게이트 그룹 리미티드 | 광견병 감염의 방지 및 치료에 관한 조성물 및 방법 |
| AR091649A1 (es) * | 2012-07-02 | 2015-02-18 | Bristol Myers Squibb Co | Optimizacion de anticuerpos que se fijan al gen de activacion de linfocitos 3 (lag-3) y sus usos |
| UA118750C2 (uk) * | 2013-03-15 | 2019-03-11 | Ґлаксосмітклайн Інтеллектуал Проперті Дивелопмент Лімітед | Антитіло до lag-3 |
| PT2992017T (pt) * | 2013-05-02 | 2021-01-29 | Anaptysbio Inc | Anticorpos dirigidos contra a morte programada 1 (pd-1) |
| KR20240033088A (ko) * | 2013-09-20 | 2024-03-12 | 브리스톨-마이어스 스큅 컴퍼니 | 종양을 치료하기 위한 항-lag-3 항체 및 항-pd-1 항체의 조합물 |
| CA2928199A1 (en) | 2013-11-05 | 2015-05-14 | Bavarian Nordic A/S | Combination therapy for treating cancer with a poxvirus expressing a tumor antigen and an antagonist and/or agonist of an immune checkpoint inhibitor |
| RS59480B1 (sr) | 2013-12-12 | 2019-12-31 | Shanghai hengrui pharmaceutical co ltd | Pd-1 antitelo, njegov fragment koji se vezuje na antigen, i njegova medicinska primena |
| LT3116909T (lt) * | 2014-03-14 | 2020-02-10 | Novartis Ag | Antikūno molekulės prieš lag-3 ir jų panaudojimas |
| JP6749312B2 (ja) * | 2014-07-31 | 2020-09-02 | アムゲン リサーチ (ミュンヘン) ゲーエムベーハーAMGEN Research(Munich)GmbH | 最適化された種間特異的二重特異性単鎖抗体コンストラクト |
| JO3663B1 (ar) * | 2014-08-19 | 2020-08-27 | Merck Sharp & Dohme | الأجسام المضادة لمضاد lag3 وأجزاء ربط الأنتيجين |
| MA41044A (fr) | 2014-10-08 | 2017-08-15 | Novartis Ag | Compositions et procédés d'utilisation pour une réponse immunitaire accrue et traitement contre le cancer |
| PE20171067A1 (es) | 2014-10-14 | 2017-07-24 | Novartis Ag | Moleculas de anticuerpo que se unen a pd-l1 y usos de las mismas |
| TWI595006B (zh) | 2014-12-09 | 2017-08-11 | 禮納特神經系統科學公司 | 抗pd-1抗體類和使用彼等之方法 |
| BR112017021688A2 (pt) | 2015-04-17 | 2018-08-14 | Bristol-Myers Squibb Company | composições compreendendo uma combinação de um anticorpo anti-pd-1 e outro anticorpo |
| TWI773646B (zh) | 2015-06-08 | 2022-08-11 | 美商宏觀基因股份有限公司 | 結合lag-3的分子和其使用方法 |
| TWI756187B (zh) | 2015-10-09 | 2022-03-01 | 美商再生元醫藥公司 | 抗lag3抗體及其用途 |
| DK3458478T3 (da) | 2016-05-18 | 2021-03-22 | Boehringer Ingelheim Int | Anti-pd-1- og anti-lag3-antistoffer til cancerbehandling |
-
2017
- 2017-05-17 DK DK17726862.0T patent/DK3458478T3/da active
- 2017-05-17 PE PE2018002814A patent/PE20190108A1/es unknown
- 2017-05-17 SI SI201730636T patent/SI3458478T1/sl unknown
- 2017-05-17 WO PCT/EP2017/061901 patent/WO2017198741A1/en active Application Filing
- 2017-05-17 UA UAA201812215A patent/UA127200C2/uk unknown
- 2017-05-17 PL PL17726862T patent/PL3458478T3/pl unknown
- 2017-05-17 MY MYPI2018001836A patent/MY193112A/en unknown
- 2017-05-17 MA MA055697A patent/MA55697A/fr unknown
- 2017-05-17 KR KR1020187033938A patent/KR102419412B1/ko active IP Right Grant
- 2017-05-17 EP EP17726862.0A patent/EP3458478B1/en active Active
- 2017-05-17 HU HUE17726862A patent/HUE053452T2/hu unknown
- 2017-05-17 CN CN201780030891.7A patent/CN109415439B/zh active Active
- 2017-05-17 LT LTEP17726862.0T patent/LT3458478T/lt unknown
- 2017-05-17 CA CA3020649A patent/CA3020649A1/en active Pending
- 2017-05-17 IL IL262892A patent/IL262892B2/en unknown
- 2017-05-17 MA MA45029A patent/MA45029B1/fr unknown
- 2017-05-17 AU AU2017266298A patent/AU2017266298B2/en active Active
- 2017-05-17 RS RS20210218A patent/RS61510B1/sr unknown
- 2017-05-17 TW TW111115384A patent/TW202307002A/zh unknown
- 2017-05-17 ES ES17726862T patent/ES2857813T3/es active Active
- 2017-05-17 CN CN202210993045.8A patent/CN115340608A/zh active Pending
- 2017-05-17 BR BR112018072986-8A patent/BR112018072986A2/pt unknown
- 2017-05-17 JP JP2018555176A patent/JP6585860B2/ja active Active
- 2017-05-17 EP EP20216343.2A patent/EP3848393A1/en active Pending
- 2017-05-17 EA EA201892616A patent/EA201892616A1/ru unknown
- 2017-05-17 AR ARP170101335A patent/AR108516A1/es unknown
- 2017-05-17 MX MX2018014102A patent/MX2018014102A/es unknown
- 2017-05-17 KR KR1020227023184A patent/KR20220103806A/ko not_active Application Discontinuation
- 2017-05-17 SG SG11201809627QA patent/SG11201809627QA/en unknown
- 2017-05-17 TW TW106116226A patent/TWI762484B/zh active
- 2017-05-18 US US15/598,356 patent/US11028169B2/en active Active
-
2018
- 2018-10-22 JP JP2018198362A patent/JP6585801B2/ja active Active
- 2018-11-07 CL CL2018003153A patent/CL2018003153A1/es unknown
- 2018-11-13 SA SA518400424A patent/SA518400424B1/ar unknown
- 2018-11-16 MX MX2022008184A patent/MX2022008184A/es unknown
- 2018-11-16 CO CONC2018/0012374A patent/CO2018012374A2/es unknown
- 2018-11-19 PH PH12018502429A patent/PH12018502429A1/en unknown
-
2019
- 2019-09-05 JP JP2019161854A patent/JP2020007340A/ja active Pending
-
2020
- 2020-05-11 US US16/871,382 patent/US11795219B2/en active Active
-
2021
- 2021-03-22 CY CY20211100246T patent/CY1123977T1/el unknown
- 2021-08-10 CL CL2021002094A patent/CL2021002094A1/es unknown
Also Published As
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR102419412B1 (ko) | 암 치료용 항-pd1 및 항-lag3 항체 | |
| KR102473028B1 (ko) | 항-tim-3 항체 및 조성물 | |
| CN111788225A (zh) | 抗cd38抗体及与抗cd3和抗cd28抗体的组合 | |
| KR20180048684A (ko) | 암의 치료에 사용하기 위한 5-브로모-2,6-디-(1h-피라졸-1-일)피리미딘-4-아민 | |
| CA3007033A1 (en) | Anti-dr5 antibodies and methods of use thereof | |
| BR112020017676A2 (pt) | Anticorpo antagonizante cd73 | |
| AU2017384687A1 (en) | Bispecific anti-TNF-related apoptosis-inducing ligand receptor 2 and anti-cadherin 17 binding molecules for the treatment of cancer | |
| US11685787B2 (en) | Treatment of cancer with anti-GITR agonist antibodies | |
| US20240124581A1 (en) | Antibody molecules for cancer treatment | |
| US20230416388A1 (en) | Treatment of cancer with anti-gitr agonist antibodies | |
| US20240052065A1 (en) | Binding molecules for the treatment of cancer | |
| RU2811477C2 (ru) | Мультиспецифические антитела и способы их получения и применения | |
| EA042707B1 (ru) | Антитело к pd1, способы его получения и применения для лечения злокачественного новообразования | |
| AU2022219681A1 (en) | Antibodies against cd112r and uses thereof | |
| BR112020010336A2 (pt) | composições e métodos para terapia de câncer |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A107 | Divisional application of patent | ||
| A201 | Request for examination | ||
| E902 | Notification of reason for refusal | ||
| E601 | Decision to refuse application |