KR20230022246A - 치료 항체 및 그의 용도 - Google Patents
치료 항체 및 그의 용도 Download PDFInfo
- Publication number
- KR20230022246A KR20230022246A KR1020237001331A KR20237001331A KR20230022246A KR 20230022246 A KR20230022246 A KR 20230022246A KR 1020237001331 A KR1020237001331 A KR 1020237001331A KR 20237001331 A KR20237001331 A KR 20237001331A KR 20230022246 A KR20230022246 A KR 20230022246A
- Authority
- KR
- South Korea
- Prior art keywords
- seq
- amino acid
- acid sequence
- antibody
- chain comprises
- Prior art date
Links
- 230000001225 therapeutic effect Effects 0.000 title description 26
- 238000000034 method Methods 0.000 claims abstract description 151
- 239000002157 polynucleotide Substances 0.000 claims abstract description 83
- 102000040430 polynucleotide Human genes 0.000 claims abstract description 83
- 108091033319 polynucleotide Proteins 0.000 claims abstract description 83
- 101000955999 Homo sapiens V-set domain-containing T-cell activation inhibitor 1 Proteins 0.000 claims abstract description 39
- 239000008194 pharmaceutical composition Substances 0.000 claims abstract description 37
- 125000003275 alpha amino acid group Chemical group 0.000 claims description 850
- 108010047041 Complementarity Determining Regions Proteins 0.000 claims description 274
- 230000027455 binding Effects 0.000 claims description 193
- 239000000427 antigen Substances 0.000 claims description 147
- 108091007433 antigens Proteins 0.000 claims description 143
- 102000036639 antigens Human genes 0.000 claims description 143
- 241000282414 Homo sapiens Species 0.000 claims description 141
- 206010028980 Neoplasm Diseases 0.000 claims description 79
- 108090000765 processed proteins & peptides Proteins 0.000 claims description 76
- 102000004196 processed proteins & peptides Human genes 0.000 claims description 68
- 229920001184 polypeptide Polymers 0.000 claims description 65
- 150000001413 amino acids Chemical class 0.000 claims description 58
- 238000006467 substitution reaction Methods 0.000 claims description 55
- 239000012634 fragment Substances 0.000 claims description 50
- 125000000539 amino acid group Chemical group 0.000 claims description 43
- 239000013598 vector Substances 0.000 claims description 43
- 239000003814 drug Substances 0.000 claims description 41
- 201000011510 cancer Diseases 0.000 claims description 39
- 102000055298 human VTCN1 Human genes 0.000 claims description 33
- 102100038929 V-set domain-containing T-cell activation inhibitor 1 Human genes 0.000 claims description 28
- 108700026244 Open Reading Frames Proteins 0.000 claims description 22
- 230000003211 malignant effect Effects 0.000 claims description 20
- 238000011282 treatment Methods 0.000 claims description 18
- NFGXHKASABOEEW-UHFFFAOYSA-N 1-methylethyl 11-methoxy-3,7,11-trimethyl-2,4-dodecadienoate Chemical compound COC(C)(C)CCCC(C)CC=CC(C)=CC(=O)OC(C)C NFGXHKASABOEEW-UHFFFAOYSA-N 0.000 claims description 14
- 230000004614 tumor growth Effects 0.000 claims description 12
- 206010006187 Breast cancer Diseases 0.000 claims description 11
- 208000026310 Breast neoplasm Diseases 0.000 claims description 11
- 230000005751 tumor progression Effects 0.000 claims description 10
- 206010033128 Ovarian cancer Diseases 0.000 claims description 8
- 206010061535 Ovarian neoplasm Diseases 0.000 claims description 8
- 230000002401 inhibitory effect Effects 0.000 claims description 8
- 230000005764 inhibitory process Effects 0.000 claims description 7
- 206010005003 Bladder cancer Diseases 0.000 claims description 6
- 208000007097 Urinary Bladder Neoplasms Diseases 0.000 claims description 6
- 208000002495 Uterine Neoplasms Diseases 0.000 claims description 6
- 239000003937 drug carrier Substances 0.000 claims description 6
- 201000005112 urinary bladder cancer Diseases 0.000 claims description 6
- 206010046766 uterine cancer Diseases 0.000 claims description 6
- 206010004593 Bile duct cancer Diseases 0.000 claims description 4
- 208000026900 bile duct neoplasm Diseases 0.000 claims description 4
- 208000006990 cholangiocarcinoma Diseases 0.000 claims description 4
- 230000006698 induction Effects 0.000 claims description 3
- 108010079206 V-Set Domain-Containing T-Cell Activation Inhibitor 1 Proteins 0.000 claims 25
- OAICVXFJPJFONN-UHFFFAOYSA-N Phosphorus Chemical compound [P] OAICVXFJPJFONN-UHFFFAOYSA-N 0.000 claims 1
- 229910052698 phosphorus Inorganic materials 0.000 claims 1
- 239000011574 phosphorus Substances 0.000 claims 1
- 230000004069 differentiation Effects 0.000 abstract description 2
- 210000004027 cell Anatomy 0.000 description 181
- 108090000623 proteins and genes Proteins 0.000 description 105
- 101100112922 Candida albicans CDR3 gene Proteins 0.000 description 87
- 235000001014 amino acid Nutrition 0.000 description 75
- 102000004169 proteins and genes Human genes 0.000 description 58
- 229940024606 amino acid Drugs 0.000 description 57
- 235000018102 proteins Nutrition 0.000 description 56
- 239000000203 mixture Substances 0.000 description 51
- 108020004414 DNA Proteins 0.000 description 50
- -1 ICOS Proteins 0.000 description 49
- 239000000556 agonist Substances 0.000 description 36
- 239000003795 chemical substances by application Substances 0.000 description 34
- 230000014509 gene expression Effects 0.000 description 31
- 108060003951 Immunoglobulin Proteins 0.000 description 29
- 102000018358 immunoglobulin Human genes 0.000 description 29
- 230000004048 modification Effects 0.000 description 29
- 238000012986 modification Methods 0.000 description 29
- 102000002689 Toll-like receptor Human genes 0.000 description 28
- 108020000411 Toll-like receptor Proteins 0.000 description 28
- 210000001744 T-lymphocyte Anatomy 0.000 description 27
- 238000001727 in vivo Methods 0.000 description 25
- 238000013459 approach Methods 0.000 description 23
- 238000003556 assay Methods 0.000 description 23
- 239000003112 inhibitor Substances 0.000 description 23
- 125000003729 nucleotide group Chemical group 0.000 description 23
- 239000013078 crystal Substances 0.000 description 22
- 230000000694 effects Effects 0.000 description 22
- 230000006870 function Effects 0.000 description 22
- 239000012636 effector Substances 0.000 description 21
- 102000005962 receptors Human genes 0.000 description 21
- 108020003175 receptors Proteins 0.000 description 21
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 20
- 239000002773 nucleotide Substances 0.000 description 20
- 201000010099 disease Diseases 0.000 description 19
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 description 19
- 239000013604 expression vector Substances 0.000 description 19
- 210000004408 hybridoma Anatomy 0.000 description 19
- 238000004519 manufacturing process Methods 0.000 description 19
- 125000002496 methyl group Chemical group [H]C([H])([H])* 0.000 description 19
- 239000000872 buffer Substances 0.000 description 18
- 238000005516 engineering process Methods 0.000 description 18
- 230000035772 mutation Effects 0.000 description 18
- 238000002198 surface plasmon resonance spectroscopy Methods 0.000 description 18
- 102000004127 Cytokines Human genes 0.000 description 17
- 108090000695 Cytokines Proteins 0.000 description 17
- LOKCTEFSRHRXRJ-UHFFFAOYSA-I dipotassium trisodium dihydrogen phosphate hydrogen phosphate dichloride Chemical compound P(=O)(O)(O)[O-].[K+].P(=O)(O)([O-])[O-].[Na+].[Na+].[Cl-].[K+].[Cl-].[Na+] LOKCTEFSRHRXRJ-UHFFFAOYSA-I 0.000 description 17
- 239000002953 phosphate buffered saline Substances 0.000 description 17
- 230000013595 glycosylation Effects 0.000 description 16
- 238000006206 glycosylation reaction Methods 0.000 description 16
- 239000000243 solution Substances 0.000 description 16
- 238000009472 formulation Methods 0.000 description 15
- 238000002560 therapeutic procedure Methods 0.000 description 15
- 101000643024 Homo sapiens Stimulator of interferon genes protein Proteins 0.000 description 14
- 102100035533 Stimulator of interferon genes protein Human genes 0.000 description 14
- 238000010494 dissociation reaction Methods 0.000 description 14
- 230000005593 dissociations Effects 0.000 description 14
- 230000004927 fusion Effects 0.000 description 14
- 230000001976 improved effect Effects 0.000 description 14
- 150000007523 nucleic acids Chemical class 0.000 description 14
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 13
- 102000012064 NLR Proteins Human genes 0.000 description 13
- 108091005686 NOD-like receptors Proteins 0.000 description 13
- 108091005685 RIG-I-like receptors Proteins 0.000 description 13
- 230000010056 antibody-dependent cellular cytotoxicity Effects 0.000 description 13
- 238000000338 in vitro Methods 0.000 description 13
- 208000023275 Autoimmune disease Diseases 0.000 description 12
- 108091028043 Nucleic acid sequence Proteins 0.000 description 12
- 230000000295 complement effect Effects 0.000 description 12
- 239000000463 material Substances 0.000 description 12
- 102000039446 nucleic acids Human genes 0.000 description 12
- 108020004707 nucleic acids Proteins 0.000 description 12
- 210000003819 peripheral blood mononuclear cell Anatomy 0.000 description 12
- 238000012360 testing method Methods 0.000 description 12
- 229940124597 therapeutic agent Drugs 0.000 description 12
- 238000012546 transfer Methods 0.000 description 12
- 238000002965 ELISA Methods 0.000 description 11
- 229940079593 drug Drugs 0.000 description 11
- 125000005647 linker group Chemical group 0.000 description 11
- 102000007863 pattern recognition receptors Human genes 0.000 description 11
- 108010089193 pattern recognition receptors Proteins 0.000 description 11
- 239000011780 sodium chloride Substances 0.000 description 11
- 235000000346 sugar Nutrition 0.000 description 11
- 210000004881 tumor cell Anatomy 0.000 description 11
- 241000699666 Mus <mouse, genus> Species 0.000 description 10
- 241000700159 Rattus Species 0.000 description 10
- 239000002253 acid Substances 0.000 description 10
- 238000002474 experimental method Methods 0.000 description 10
- 230000001900 immune effect Effects 0.000 description 10
- 230000002100 tumorsuppressive effect Effects 0.000 description 10
- PEDCQBHIVMGVHV-UHFFFAOYSA-N Glycerine Chemical compound OCC(O)CO PEDCQBHIVMGVHV-UHFFFAOYSA-N 0.000 description 9
- 229940127089 cytotoxic agent Drugs 0.000 description 9
- 239000000839 emulsion Substances 0.000 description 9
- 230000003308 immunostimulating effect Effects 0.000 description 9
- 230000001404 mediated effect Effects 0.000 description 9
- 238000002703 mutagenesis Methods 0.000 description 9
- 231100000350 mutagenesis Toxicity 0.000 description 9
- 239000000546 pharmaceutical excipient Substances 0.000 description 9
- 238000013207 serial dilution Methods 0.000 description 9
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 9
- IJGRMHOSHXDMSA-UHFFFAOYSA-N Atomic nitrogen Chemical compound N#N IJGRMHOSHXDMSA-UHFFFAOYSA-N 0.000 description 8
- 108090000342 C-Type Lectins Proteins 0.000 description 8
- 102000003930 C-Type Lectins Human genes 0.000 description 8
- 108010087819 Fc receptors Proteins 0.000 description 8
- 102000009109 Fc receptors Human genes 0.000 description 8
- ZHNUHDYFZUAESO-UHFFFAOYSA-N Formamide Chemical compound NC=O ZHNUHDYFZUAESO-UHFFFAOYSA-N 0.000 description 8
- 241001465754 Metazoa Species 0.000 description 8
- 101000956000 Mus musculus V-set domain containing T-cell activation inhibitor 1 Proteins 0.000 description 8
- 241000699670 Mus sp. Species 0.000 description 8
- 238000002835 absorbance Methods 0.000 description 8
- 238000007792 addition Methods 0.000 description 8
- 150000001720 carbohydrates Chemical class 0.000 description 8
- 230000028993 immune response Effects 0.000 description 8
- 210000000987 immune system Anatomy 0.000 description 8
- 230000001965 increasing effect Effects 0.000 description 8
- NOESYZHRGYRDHS-UHFFFAOYSA-N insulin Chemical compound N1C(=O)C(NC(=O)C(CCC(N)=O)NC(=O)C(CCC(O)=O)NC(=O)C(C(C)C)NC(=O)C(NC(=O)CN)C(C)CC)CSSCC(C(NC(CO)C(=O)NC(CC(C)C)C(=O)NC(CC=2C=CC(O)=CC=2)C(=O)NC(CCC(N)=O)C(=O)NC(CC(C)C)C(=O)NC(CCC(O)=O)C(=O)NC(CC(N)=O)C(=O)NC(CC=2C=CC(O)=CC=2)C(=O)NC(CSSCC(NC(=O)C(C(C)C)NC(=O)C(CC(C)C)NC(=O)C(CC=2C=CC(O)=CC=2)NC(=O)C(CC(C)C)NC(=O)C(C)NC(=O)C(CCC(O)=O)NC(=O)C(C(C)C)NC(=O)C(CC(C)C)NC(=O)C(CC=2NC=NC=2)NC(=O)C(CO)NC(=O)CNC2=O)C(=O)NCC(=O)NC(CCC(O)=O)C(=O)NC(CCCNC(N)=N)C(=O)NCC(=O)NC(CC=3C=CC=CC=3)C(=O)NC(CC=3C=CC=CC=3)C(=O)NC(CC=3C=CC(O)=CC=3)C(=O)NC(C(C)O)C(=O)N3C(CCC3)C(=O)NC(CCCCN)C(=O)NC(C)C(O)=O)C(=O)NC(CC(N)=O)C(O)=O)=O)NC(=O)C(C(C)CC)NC(=O)C(CO)NC(=O)C(C(C)O)NC(=O)C1CSSCC2NC(=O)C(CC(C)C)NC(=O)C(NC(=O)C(CCC(N)=O)NC(=O)C(CC(N)=O)NC(=O)C(NC(=O)C(N)CC=1C=CC=CC=1)C(C)C)CC1=CN=CN1 NOESYZHRGYRDHS-UHFFFAOYSA-N 0.000 description 8
- 239000002502 liposome Substances 0.000 description 8
- 102000027540 membrane-bound PRRs Human genes 0.000 description 8
- 108091008872 membrane-bound PRRs Proteins 0.000 description 8
- 238000002823 phage display Methods 0.000 description 8
- 239000000126 substance Substances 0.000 description 8
- 239000003981 vehicle Substances 0.000 description 8
- DHMQDGOQFOQNFH-UHFFFAOYSA-N Glycine Chemical compound NCC(O)=O DHMQDGOQFOQNFH-UHFFFAOYSA-N 0.000 description 7
- 102000006496 Immunoglobulin Heavy Chains Human genes 0.000 description 7
- 108010019476 Immunoglobulin Heavy Chains Proteins 0.000 description 7
- 241001529936 Murinae Species 0.000 description 7
- 230000004988 N-glycosylation Effects 0.000 description 7
- 108091034117 Oligonucleotide Proteins 0.000 description 7
- 210000003719 b-lymphocyte Anatomy 0.000 description 7
- 230000015572 biosynthetic process Effects 0.000 description 7
- 239000007975 buffered saline Substances 0.000 description 7
- 239000000969 carrier Substances 0.000 description 7
- 150000001875 compounds Chemical class 0.000 description 7
- 230000021615 conjugation Effects 0.000 description 7
- 235000018417 cysteine Nutrition 0.000 description 7
- 239000002254 cytotoxic agent Substances 0.000 description 7
- 231100000599 cytotoxic agent Toxicity 0.000 description 7
- 238000012217 deletion Methods 0.000 description 7
- 230000037430 deletion Effects 0.000 description 7
- 238000003018 immunoassay Methods 0.000 description 7
- 229940072221 immunoglobulins Drugs 0.000 description 7
- 239000007788 liquid Substances 0.000 description 7
- 239000002609 medium Substances 0.000 description 7
- 239000004405 propyl p-hydroxybenzoate Substances 0.000 description 7
- 235000010232 propyl p-hydroxybenzoate Nutrition 0.000 description 7
- 230000002829 reductive effect Effects 0.000 description 7
- 238000012216 screening Methods 0.000 description 7
- 239000007787 solid Substances 0.000 description 7
- 210000000130 stem cell Anatomy 0.000 description 7
- 150000008163 sugars Chemical class 0.000 description 7
- 208000024891 symptom Diseases 0.000 description 7
- 238000003786 synthesis reaction Methods 0.000 description 7
- GHASVSINZRGABV-UHFFFAOYSA-N Fluorouracil Chemical compound FC1=CNC(=O)NC1=O GHASVSINZRGABV-UHFFFAOYSA-N 0.000 description 6
- 108010021625 Immunoglobulin Fragments Proteins 0.000 description 6
- 102000008394 Immunoglobulin Fragments Human genes 0.000 description 6
- 239000002202 Polyethylene glycol Substances 0.000 description 6
- WCUXLLCKKVVCTQ-UHFFFAOYSA-M Potassium chloride Chemical compound [Cl-].[K+] WCUXLLCKKVVCTQ-UHFFFAOYSA-M 0.000 description 6
- 239000004480 active ingredient Substances 0.000 description 6
- 238000004458 analytical method Methods 0.000 description 6
- 229940022399 cancer vaccine Drugs 0.000 description 6
- 238000009566 cancer vaccine Methods 0.000 description 6
- 235000014633 carbohydrates Nutrition 0.000 description 6
- 238000006243 chemical reaction Methods 0.000 description 6
- 238000010790 dilution Methods 0.000 description 6
- 239000012895 dilution Substances 0.000 description 6
- 239000004403 ethyl p-hydroxybenzoate Substances 0.000 description 6
- 229960002949 fluorouracil Drugs 0.000 description 6
- 108020001507 fusion proteins Proteins 0.000 description 6
- 102000037865 fusion proteins Human genes 0.000 description 6
- 230000036541 health Effects 0.000 description 6
- 230000001939 inductive effect Effects 0.000 description 6
- 238000002347 injection Methods 0.000 description 6
- 239000007924 injection Substances 0.000 description 6
- 238000001990 intravenous administration Methods 0.000 description 6
- 239000002105 nanoparticle Substances 0.000 description 6
- 229920001223 polyethylene glycol Polymers 0.000 description 6
- 230000008569 process Effects 0.000 description 6
- 230000009467 reduction Effects 0.000 description 6
- 150000003839 salts Chemical class 0.000 description 6
- 241000894007 species Species 0.000 description 6
- 230000008685 targeting Effects 0.000 description 6
- 238000001890 transfection Methods 0.000 description 6
- MTCFGRXMJLQNBG-REOHCLBHSA-N (2S)-2-Amino-3-hydroxypropansäure Chemical compound OC[C@H](N)C(O)=O MTCFGRXMJLQNBG-REOHCLBHSA-N 0.000 description 5
- 108700028369 Alleles Proteins 0.000 description 5
- 229940045513 CTLA4 antagonist Drugs 0.000 description 5
- 102000053602 DNA Human genes 0.000 description 5
- 102000004190 Enzymes Human genes 0.000 description 5
- 108090000790 Enzymes Proteins 0.000 description 5
- 102000003886 Glycoproteins Human genes 0.000 description 5
- 108090000288 Glycoproteins Proteins 0.000 description 5
- 108010017213 Granulocyte-Macrophage Colony-Stimulating Factor Proteins 0.000 description 5
- 102100039620 Granulocyte-macrophage colony-stimulating factor Human genes 0.000 description 5
- XUJNEKJLAYXESH-REOHCLBHSA-N L-Cysteine Chemical compound SC[C@H](N)C(O)=O XUJNEKJLAYXESH-REOHCLBHSA-N 0.000 description 5
- ZDXPYRJPNDTMRX-VKHMYHEASA-N L-glutamine Chemical compound OC(=O)[C@@H](N)CCC(N)=O ZDXPYRJPNDTMRX-VKHMYHEASA-N 0.000 description 5
- KDXKERNSBIXSRK-UHFFFAOYSA-N Lysine Natural products NCCCCC(N)C(O)=O KDXKERNSBIXSRK-UHFFFAOYSA-N 0.000 description 5
- 241000283984 Rodentia Species 0.000 description 5
- 108060008682 Tumor Necrosis Factor Proteins 0.000 description 5
- 102000000852 Tumor Necrosis Factor-alpha Human genes 0.000 description 5
- 241000700605 Viruses Species 0.000 description 5
- 150000007513 acids Chemical class 0.000 description 5
- 230000003213 activating effect Effects 0.000 description 5
- 230000009286 beneficial effect Effects 0.000 description 5
- 230000004071 biological effect Effects 0.000 description 5
- 230000022534 cell killing Effects 0.000 description 5
- 239000002738 chelating agent Substances 0.000 description 5
- 210000004978 chinese hamster ovary cell Anatomy 0.000 description 5
- 238000010367 cloning Methods 0.000 description 5
- 230000004540 complement-dependent cytotoxicity Effects 0.000 description 5
- XUJNEKJLAYXESH-UHFFFAOYSA-N cysteine Natural products SCC(N)C(O)=O XUJNEKJLAYXESH-UHFFFAOYSA-N 0.000 description 5
- 230000009089 cytolysis Effects 0.000 description 5
- 230000001419 dependent effect Effects 0.000 description 5
- 229940088598 enzyme Drugs 0.000 description 5
- 238000001415 gene therapy Methods 0.000 description 5
- 239000000710 homodimer Substances 0.000 description 5
- 210000002865 immune cell Anatomy 0.000 description 5
- 230000002163 immunogen Effects 0.000 description 5
- 238000011534 incubation Methods 0.000 description 5
- 239000004615 ingredient Substances 0.000 description 5
- 230000003993 interaction Effects 0.000 description 5
- 229910052757 nitrogen Inorganic materials 0.000 description 5
- 244000052769 pathogen Species 0.000 description 5
- 239000013612 plasmid Substances 0.000 description 5
- 238000000159 protein binding assay Methods 0.000 description 5
- 238000000746 purification Methods 0.000 description 5
- 238000010188 recombinant method Methods 0.000 description 5
- 238000012552 review Methods 0.000 description 5
- 150000003384 small molecules Chemical class 0.000 description 5
- 239000003826 tablet Substances 0.000 description 5
- 206010063836 Atrioventricular septal defect Diseases 0.000 description 4
- 208000031212 Autoimmune polyendocrinopathy Diseases 0.000 description 4
- 102100024222 B-lymphocyte antigen CD19 Human genes 0.000 description 4
- 102100038078 CD276 antigen Human genes 0.000 description 4
- 101150013553 CD40 gene Proteins 0.000 description 4
- 108010021064 CTLA-4 Antigen Proteins 0.000 description 4
- 101150023944 CXCR5 gene Proteins 0.000 description 4
- 102000000905 Cadherin Human genes 0.000 description 4
- 108050007957 Cadherin Proteins 0.000 description 4
- GAGWJHPBXLXJQN-UORFTKCHSA-N Capecitabine Chemical compound C1=C(F)C(NC(=O)OCCCCC)=NC(=O)N1[C@H]1[C@H](O)[C@H](O)[C@@H](C)O1 GAGWJHPBXLXJQN-UORFTKCHSA-N 0.000 description 4
- 241000283707 Capra Species 0.000 description 4
- 108010019670 Chimeric Antigen Receptors Proteins 0.000 description 4
- 102100039498 Cytotoxic T-lymphocyte protein 4 Human genes 0.000 description 4
- SRBFZHDQGSBBOR-IOVATXLUSA-N D-xylopyranose Chemical compound O[C@@H]1COC(O)[C@H](O)[C@H]1O SRBFZHDQGSBBOR-IOVATXLUSA-N 0.000 description 4
- KCXVZYZYPLLWCC-UHFFFAOYSA-N EDTA Chemical compound OC(=O)CN(CC(O)=O)CCN(CC(O)=O)CC(O)=O KCXVZYZYPLLWCC-UHFFFAOYSA-N 0.000 description 4
- 102000001301 EGF receptor Human genes 0.000 description 4
- 108060006698 EGF receptor Proteins 0.000 description 4
- 241000588724 Escherichia coli Species 0.000 description 4
- WQZGKKKJIJFFOK-GASJEMHNSA-N Glucose Chemical compound OC[C@H]1OC(O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-GASJEMHNSA-N 0.000 description 4
- 239000004471 Glycine Substances 0.000 description 4
- 101000980825 Homo sapiens B-lymphocyte antigen CD19 Proteins 0.000 description 4
- 101000914514 Homo sapiens T-cell-specific surface glycoprotein CD28 Proteins 0.000 description 4
- 108090001061 Insulin Proteins 0.000 description 4
- 102000004877 Insulin Human genes 0.000 description 4
- 108010050904 Interferons Proteins 0.000 description 4
- 108010002350 Interleukin-2 Proteins 0.000 description 4
- 102000000588 Interleukin-2 Human genes 0.000 description 4
- KDXKERNSBIXSRK-YFKPBYRVSA-N L-lysine Chemical compound NCCCC[C@H](N)C(O)=O KDXKERNSBIXSRK-YFKPBYRVSA-N 0.000 description 4
- FBOZXECLQNJBKD-ZDUSSCGKSA-N L-methotrexate Chemical compound C=1N=C2N=C(N)N=C(N)C2=NC=1CN(C)C1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 FBOZXECLQNJBKD-ZDUSSCGKSA-N 0.000 description 4
- 239000012515 MabSelect SuRe Substances 0.000 description 4
- 206010027476 Metastases Diseases 0.000 description 4
- 108010004729 Phycoerythrin Proteins 0.000 description 4
- 206010035226 Plasma cell myeloma Diseases 0.000 description 4
- MTCFGRXMJLQNBG-UHFFFAOYSA-N Serine Natural products OCC(N)C(O)=O MTCFGRXMJLQNBG-UHFFFAOYSA-N 0.000 description 4
- PXIPVTKHYLBLMZ-UHFFFAOYSA-N Sodium azide Chemical compound [Na+].[N-]=[N+]=[N-] PXIPVTKHYLBLMZ-UHFFFAOYSA-N 0.000 description 4
- QAOWNCQODCNURD-UHFFFAOYSA-N Sulfuric acid Chemical compound OS(O)(=O)=O QAOWNCQODCNURD-UHFFFAOYSA-N 0.000 description 4
- 102100027213 T-cell-specific surface glycoprotein CD28 Human genes 0.000 description 4
- 102100040245 Tumor necrosis factor receptor superfamily member 5 Human genes 0.000 description 4
- 125000000217 alkyl group Chemical group 0.000 description 4
- 150000001412 amines Chemical group 0.000 description 4
- 229920000249 biocompatible polymer Polymers 0.000 description 4
- 238000004113 cell culture Methods 0.000 description 4
- 238000007796 conventional method Methods 0.000 description 4
- 125000000151 cysteine group Chemical group N[C@@H](CS)C(=O)* 0.000 description 4
- 230000006378 damage Effects 0.000 description 4
- 238000000113 differential scanning calorimetry Methods 0.000 description 4
- 239000002552 dosage form Substances 0.000 description 4
- 230000003828 downregulation Effects 0.000 description 4
- 238000001211 electron capture detection Methods 0.000 description 4
- 239000003623 enhancer Substances 0.000 description 4
- 210000004602 germ cell Anatomy 0.000 description 4
- ZDXPYRJPNDTMRX-UHFFFAOYSA-N glutamine Natural products OC(=O)C(N)CCC(N)=O ZDXPYRJPNDTMRX-UHFFFAOYSA-N 0.000 description 4
- 239000003102 growth factor Substances 0.000 description 4
- 238000009396 hybridization Methods 0.000 description 4
- 230000003053 immunization Effects 0.000 description 4
- 229940127121 immunoconjugate Drugs 0.000 description 4
- 229940125396 insulin Drugs 0.000 description 4
- 238000013507 mapping Methods 0.000 description 4
- 230000009401 metastasis Effects 0.000 description 4
- 229960000485 methotrexate Drugs 0.000 description 4
- 239000003094 microcapsule Substances 0.000 description 4
- 201000000050 myeloid neoplasm Diseases 0.000 description 4
- 150000002482 oligosaccharides Polymers 0.000 description 4
- 229960004390 palbociclib Drugs 0.000 description 4
- AHJRHEGDXFFMBM-UHFFFAOYSA-N palbociclib Chemical compound N1=C2N(C3CCCC3)C(=O)C(C(=O)C)=C(C)C2=CN=C1NC(N=C1)=CC=C1N1CCNCC1 AHJRHEGDXFFMBM-UHFFFAOYSA-N 0.000 description 4
- 239000002245 particle Substances 0.000 description 4
- 230000037361 pathway Effects 0.000 description 4
- 150000003904 phospholipids Chemical class 0.000 description 4
- 239000006187 pill Substances 0.000 description 4
- 239000000843 powder Substances 0.000 description 4
- RXWNCPJZOCPEPQ-NVWDDTSBSA-N puromycin Chemical compound C1=CC(OC)=CC=C1C[C@H](N)C(=O)N[C@H]1[C@@H](O)[C@H](N2C3=NC=NC(=C3N=C2)N(C)C)O[C@@H]1CO RXWNCPJZOCPEPQ-NVWDDTSBSA-N 0.000 description 4
- 230000002285 radioactive effect Effects 0.000 description 4
- ZAHRKKWIAAJSAO-UHFFFAOYSA-N rapamycin Natural products COCC(O)C(=C/C(C)C(=O)CC(OC(=O)C1CCCCN1C(=O)C(=O)C2(O)OC(CC(OC)C(=CC=CC=CC(C)CC(C)C(=O)C)C)CCC2C)C(C)CC3CCC(O)C(C3)OC)C ZAHRKKWIAAJSAO-UHFFFAOYSA-N 0.000 description 4
- 239000000523 sample Substances 0.000 description 4
- 229960002930 sirolimus Drugs 0.000 description 4
- QFJCIRLUMZQUOT-HPLJOQBZSA-N sirolimus Chemical compound C1C[C@@H](O)[C@H](OC)C[C@@H]1C[C@@H](C)[C@H]1OC(=O)[C@@H]2CCCCN2C(=O)C(=O)[C@](O)(O2)[C@H](C)CC[C@H]2C[C@H](OC)/C(C)=C/C=C/C=C/[C@@H](C)C[C@@H](C)C(=O)[C@H](OC)[C@H](O)/C(C)=C/[C@@H](C)C(=O)C1 QFJCIRLUMZQUOT-HPLJOQBZSA-N 0.000 description 4
- 239000001509 sodium citrate Substances 0.000 description 4
- NLJMYIDDQXHKNR-UHFFFAOYSA-K sodium citrate Chemical compound O.O.[Na+].[Na+].[Na+].[O-]C(=O)CC(O)(CC([O-])=O)C([O-])=O NLJMYIDDQXHKNR-UHFFFAOYSA-K 0.000 description 4
- 210000000952 spleen Anatomy 0.000 description 4
- 238000010561 standard procedure Methods 0.000 description 4
- 239000000758 substrate Substances 0.000 description 4
- 230000005760 tumorsuppression Effects 0.000 description 4
- 230000003442 weekly effect Effects 0.000 description 4
- MZOFCQQQCNRIBI-VMXHOPILSA-N (3s)-4-[[(2s)-1-[[(2s)-1-[[(1s)-1-carboxy-2-hydroxyethyl]amino]-4-methyl-1-oxopentan-2-yl]amino]-5-(diaminomethylideneamino)-1-oxopentan-2-yl]amino]-3-[[2-[[(2s)-2,6-diaminohexanoyl]amino]acetyl]amino]-4-oxobutanoic acid Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CC(O)=O)NC(=O)CNC(=O)[C@@H](N)CCCCN MZOFCQQQCNRIBI-VMXHOPILSA-N 0.000 description 3
- JKMHFZQWWAIEOD-UHFFFAOYSA-N 2-[4-(2-hydroxyethyl)piperazin-1-yl]ethanesulfonic acid Chemical compound OCC[NH+]1CCN(CCS([O-])(=O)=O)CC1 JKMHFZQWWAIEOD-UHFFFAOYSA-N 0.000 description 3
- FPQQSJJWHUJYPU-UHFFFAOYSA-N 3-(dimethylamino)propyliminomethylidene-ethylazanium;chloride Chemical compound Cl.CCN=C=NCCCN(C)C FPQQSJJWHUJYPU-UHFFFAOYSA-N 0.000 description 3
- 101000840545 Bacillus thuringiensis L-isoleucine-4-hydroxylase Proteins 0.000 description 3
- 241000894006 Bacteria Species 0.000 description 3
- WVDDGKGOMKODPV-UHFFFAOYSA-N Benzyl alcohol Chemical compound OCC1=CC=CC=C1 WVDDGKGOMKODPV-UHFFFAOYSA-N 0.000 description 3
- 101710149863 C-C chemokine receptor type 4 Proteins 0.000 description 3
- 102100036305 C-C chemokine receptor type 8 Human genes 0.000 description 3
- 102100032976 CCR4-NOT transcription complex subunit 6 Human genes 0.000 description 3
- 101710185679 CD276 antigen Proteins 0.000 description 3
- GAGWJHPBXLXJQN-UHFFFAOYSA-N Capecitabine Natural products C1=C(F)C(NC(=O)OCCCCC)=NC(=O)N1C1C(O)C(O)C(C)O1 GAGWJHPBXLXJQN-UHFFFAOYSA-N 0.000 description 3
- 102100025474 Carcinoembryonic antigen-related cell adhesion molecule 7 Human genes 0.000 description 3
- 102100028757 Chondroitin sulfate proteoglycan 4 Human genes 0.000 description 3
- CMSMOCZEIVJLDB-UHFFFAOYSA-N Cyclophosphamide Chemical compound ClCCN(CCCl)P1(=O)NCCCO1 CMSMOCZEIVJLDB-UHFFFAOYSA-N 0.000 description 3
- 241000196324 Embryophyta Species 0.000 description 3
- 108010066687 Epithelial Cell Adhesion Molecule Proteins 0.000 description 3
- 102000018651 Epithelial Cell Adhesion Molecule Human genes 0.000 description 3
- LYCAIKOWRPUZTN-UHFFFAOYSA-N Ethylene glycol Chemical compound OCCO LYCAIKOWRPUZTN-UHFFFAOYSA-N 0.000 description 3
- 102000004269 Granulocyte Colony-Stimulating Factor Human genes 0.000 description 3
- 108010017080 Granulocyte Colony-Stimulating Factor Proteins 0.000 description 3
- 239000007995 HEPES buffer Substances 0.000 description 3
- 101000716063 Homo sapiens C-C chemokine receptor type 8 Proteins 0.000 description 3
- 101000914324 Homo sapiens Carcinoembryonic antigen-related cell adhesion molecule 5 Proteins 0.000 description 3
- 101000914321 Homo sapiens Carcinoembryonic antigen-related cell adhesion molecule 7 Proteins 0.000 description 3
- 101000916489 Homo sapiens Chondroitin sulfate proteoglycan 4 Proteins 0.000 description 3
- 101000961156 Homo sapiens Immunoglobulin heavy constant gamma 1 Proteins 0.000 description 3
- 101000961146 Homo sapiens Immunoglobulin heavy constant gamma 2 Proteins 0.000 description 3
- 101000961149 Homo sapiens Immunoglobulin heavy constant gamma 4 Proteins 0.000 description 3
- 101001037256 Homo sapiens Indoleamine 2,3-dioxygenase 1 Proteins 0.000 description 3
- 101001082073 Homo sapiens Interferon-induced helicase C domain-containing protein 1 Proteins 0.000 description 3
- 101001057504 Homo sapiens Interferon-stimulated gene 20 kDa protein Proteins 0.000 description 3
- 101001055144 Homo sapiens Interleukin-2 receptor subunit alpha Proteins 0.000 description 3
- 101000623901 Homo sapiens Mucin-16 Proteins 0.000 description 3
- 101000831007 Homo sapiens T-cell immunoreceptor with Ig and ITIM domains Proteins 0.000 description 3
- 101000801234 Homo sapiens Tumor necrosis factor receptor superfamily member 18 Proteins 0.000 description 3
- 101000851376 Homo sapiens Tumor necrosis factor receptor superfamily member 8 Proteins 0.000 description 3
- 101000851370 Homo sapiens Tumor necrosis factor receptor superfamily member 9 Proteins 0.000 description 3
- 108010073807 IgG Receptors Proteins 0.000 description 3
- 102100026120 IgG receptor FcRn large subunit p51 Human genes 0.000 description 3
- 101710177940 IgG receptor FcRn large subunit p51 Proteins 0.000 description 3
- 208000033229 Immune-mediated cerebellar ataxia Diseases 0.000 description 3
- 108010067060 Immunoglobulin Variable Region Proteins 0.000 description 3
- 102000017727 Immunoglobulin Variable Region Human genes 0.000 description 3
- 102100039345 Immunoglobulin heavy constant gamma 1 Human genes 0.000 description 3
- 102100039346 Immunoglobulin heavy constant gamma 2 Human genes 0.000 description 3
- 102100039347 Immunoglobulin heavy constant gamma 4 Human genes 0.000 description 3
- 102100040061 Indoleamine 2,3-dioxygenase 1 Human genes 0.000 description 3
- 108010074328 Interferon-gamma Proteins 0.000 description 3
- 102100027353 Interferon-induced helicase C domain-containing protein 1 Human genes 0.000 description 3
- 102000014150 Interferons Human genes 0.000 description 3
- 102100026878 Interleukin-2 receptor subunit alpha Human genes 0.000 description 3
- WHUUTDBJXJRKMK-VKHMYHEASA-N L-glutamic acid Chemical compound OC(=O)[C@@H](N)CCC(O)=O WHUUTDBJXJRKMK-VKHMYHEASA-N 0.000 description 3
- 102000003855 L-lactate dehydrogenase Human genes 0.000 description 3
- 108700023483 L-lactate dehydrogenases Proteins 0.000 description 3
- 108010000817 Leuprolide Proteins 0.000 description 3
- 239000007987 MES buffer Substances 0.000 description 3
- 102000007651 Macrophage Colony-Stimulating Factor Human genes 0.000 description 3
- 108010046938 Macrophage Colony-Stimulating Factor Proteins 0.000 description 3
- 102100023123 Mucin-16 Human genes 0.000 description 3
- 108091061960 Naked DNA Proteins 0.000 description 3
- 229910019142 PO4 Inorganic materials 0.000 description 3
- 102100030090 Probable ATP-dependent RNA helicase DHX58 Human genes 0.000 description 3
- 101710120463 Prostate stem cell antigen Proteins 0.000 description 3
- 102100036735 Prostate stem cell antigen Human genes 0.000 description 3
- 108010076504 Protein Sorting Signals Proteins 0.000 description 3
- 229940044665 STING agonist Drugs 0.000 description 3
- 240000004808 Saccharomyces cerevisiae Species 0.000 description 3
- 101001037255 Saccharomyces cerevisiae (strain ATCC 204508 / S288c) Indoleamine 2,3-dioxygenase Proteins 0.000 description 3
- 102100029215 Signaling lymphocytic activation molecule Human genes 0.000 description 3
- 102220497176 Small vasohibin-binding protein_T47D_mutation Human genes 0.000 description 3
- 102100024834 T-cell immunoreceptor with Ig and ITIM domains Human genes 0.000 description 3
- FOCVUCIESVLUNU-UHFFFAOYSA-N Thiotepa Chemical compound C1CN1P(N1CC1)(=S)N1CC1 FOCVUCIESVLUNU-UHFFFAOYSA-N 0.000 description 3
- 102000008235 Toll-Like Receptor 9 Human genes 0.000 description 3
- 108010060818 Toll-Like Receptor 9 Proteins 0.000 description 3
- 102100033728 Tumor necrosis factor receptor superfamily member 18 Human genes 0.000 description 3
- 102100022153 Tumor necrosis factor receptor superfamily member 4 Human genes 0.000 description 3
- 101710165473 Tumor necrosis factor receptor superfamily member 4 Proteins 0.000 description 3
- 102100036857 Tumor necrosis factor receptor superfamily member 8 Human genes 0.000 description 3
- 102100036856 Tumor necrosis factor receptor superfamily member 9 Human genes 0.000 description 3
- JLCPHMBAVCMARE-UHFFFAOYSA-N [3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-hydroxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methyl [5-(6-aminopurin-9-yl)-2-(hydroxymethyl)oxolan-3-yl] hydrogen phosphate Polymers Cc1cn(C2CC(OP(O)(=O)OCC3OC(CC3OP(O)(=O)OCC3OC(CC3O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c3nc(N)[nH]c4=O)C(COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3CO)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cc(C)c(=O)[nH]c3=O)n3cc(C)c(=O)[nH]c3=O)n3ccc(N)nc3=O)n3cc(C)c(=O)[nH]c3=O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)O2)c(=O)[nH]c1=O JLCPHMBAVCMARE-UHFFFAOYSA-N 0.000 description 3
- 230000001270 agonistic effect Effects 0.000 description 3
- 239000005557 antagonist Substances 0.000 description 3
- 230000000890 antigenic effect Effects 0.000 description 3
- PYMYPHUHKUWMLA-UHFFFAOYSA-N arabinose Natural products OCC(O)C(O)C(O)C=O PYMYPHUHKUWMLA-UHFFFAOYSA-N 0.000 description 3
- SRBFZHDQGSBBOR-UHFFFAOYSA-N beta-D-Pyranose-Lyxose Natural products OC1COC(O)C(O)C1O SRBFZHDQGSBBOR-UHFFFAOYSA-N 0.000 description 3
- 229960000397 bevacizumab Drugs 0.000 description 3
- 238000004166 bioassay Methods 0.000 description 3
- 210000004899 c-terminal region Anatomy 0.000 description 3
- 229960004117 capecitabine Drugs 0.000 description 3
- 230000010261 cell growth Effects 0.000 description 3
- 238000005119 centrifugation Methods 0.000 description 3
- 229960005395 cetuximab Drugs 0.000 description 3
- 230000008859 change Effects 0.000 description 3
- 229960004316 cisplatin Drugs 0.000 description 3
- DQLATGHUWYMOKM-UHFFFAOYSA-L cisplatin Chemical compound N[Pt](N)(Cl)Cl DQLATGHUWYMOKM-UHFFFAOYSA-L 0.000 description 3
- KRKNYBCHXYNGOX-UHFFFAOYSA-N citric acid Chemical compound OC(=O)CC(O)(C(O)=O)CC(O)=O KRKNYBCHXYNGOX-UHFFFAOYSA-N 0.000 description 3
- 239000002299 complementary DNA Substances 0.000 description 3
- 239000003636 conditioned culture medium Substances 0.000 description 3
- 239000000562 conjugate Substances 0.000 description 3
- 229920001577 copolymer Polymers 0.000 description 3
- 238000010168 coupling process Methods 0.000 description 3
- 229960004397 cyclophosphamide Drugs 0.000 description 3
- 230000001086 cytosolic effect Effects 0.000 description 3
- 238000009792 diffusion process Methods 0.000 description 3
- RDYMFSUJUZBWLH-UHFFFAOYSA-N endosulfan Chemical compound C12COS(=O)OCC2C2(Cl)C(Cl)=C(Cl)C1(Cl)C2(Cl)Cl RDYMFSUJUZBWLH-UHFFFAOYSA-N 0.000 description 3
- 238000001914 filtration Methods 0.000 description 3
- MHMNJMPURVTYEJ-UHFFFAOYSA-N fluorescein-5-isothiocyanate Chemical compound O1C(=O)C2=CC(N=C=S)=CC=C2C21C1=CC=C(O)C=C1OC1=CC(O)=CC=C21 MHMNJMPURVTYEJ-UHFFFAOYSA-N 0.000 description 3
- 238000001943 fluorescence-activated cell sorting Methods 0.000 description 3
- SDUQYLNIPVEERB-QPPQHZFASA-N gemcitabine Chemical compound O=C1N=C(N)C=CN1[C@H]1C(F)(F)[C@H](O)[C@@H](CO)O1 SDUQYLNIPVEERB-QPPQHZFASA-N 0.000 description 3
- 238000001476 gene delivery Methods 0.000 description 3
- 239000008103 glucose Substances 0.000 description 3
- 229910052739 hydrogen Inorganic materials 0.000 description 3
- 239000001257 hydrogen Substances 0.000 description 3
- 239000012216 imaging agent Substances 0.000 description 3
- 229940121354 immunomodulator Drugs 0.000 description 3
- 238000001802 infusion Methods 0.000 description 3
- 230000015788 innate immune response Effects 0.000 description 3
- 238000003780 insertion Methods 0.000 description 3
- 230000037431 insertion Effects 0.000 description 3
- UWKQSNNFCGGAFS-XIFFEERXSA-N irinotecan Chemical compound C1=C2C(CC)=C3CN(C(C4=C([C@@](C(=O)OC4)(O)CC)C=4)=O)C=4C3=NC2=CC=C1OC(=O)N(CC1)CCC1N1CCCCC1 UWKQSNNFCGGAFS-XIFFEERXSA-N 0.000 description 3
- 239000003446 ligand Substances 0.000 description 3
- 238000012417 linear regression Methods 0.000 description 3
- 238000012423 maintenance Methods 0.000 description 3
- 239000003550 marker Substances 0.000 description 3
- 238000002483 medication Methods 0.000 description 3
- 229910052751 metal Inorganic materials 0.000 description 3
- 239000002184 metal Substances 0.000 description 3
- 239000003921 oil Substances 0.000 description 3
- 235000019198 oils Nutrition 0.000 description 3
- 229920001542 oligosaccharide Polymers 0.000 description 3
- 229960001972 panitumumab Drugs 0.000 description 3
- 230000001717 pathogenic effect Effects 0.000 description 3
- 235000021317 phosphate Nutrition 0.000 description 3
- 239000001103 potassium chloride Substances 0.000 description 3
- 235000011164 potassium chloride Nutrition 0.000 description 3
- 238000002360 preparation method Methods 0.000 description 3
- 239000000047 product Substances 0.000 description 3
- 230000000069 prophylactic effect Effects 0.000 description 3
- 239000012460 protein solution Substances 0.000 description 3
- 230000002797 proteolythic effect Effects 0.000 description 3
- 210000002966 serum Anatomy 0.000 description 3
- 239000011734 sodium Substances 0.000 description 3
- 239000003381 stabilizer Substances 0.000 description 3
- 230000004936 stimulating effect Effects 0.000 description 3
- 239000004094 surface-active agent Substances 0.000 description 3
- 239000000725 suspension Substances 0.000 description 3
- 238000013268 sustained release Methods 0.000 description 3
- 239000012730 sustained-release form Substances 0.000 description 3
- ABZLKHKQJHEPAX-UHFFFAOYSA-N tetramethylrhodamine Chemical compound C=12C=CC(N(C)C)=CC2=[O+]C2=CC(N(C)C)=CC=C2C=1C1=CC=CC=C1C([O-])=O ABZLKHKQJHEPAX-UHFFFAOYSA-N 0.000 description 3
- 108700012359 toxins Proteins 0.000 description 3
- 241000701161 unidentified adenovirus Species 0.000 description 3
- 230000035899 viability Effects 0.000 description 3
- 230000003612 virological effect Effects 0.000 description 3
- YBJHBAHKTGYVGT-ZKWXMUAHSA-N (+)-Biotin Chemical compound N1C(=O)N[C@@H]2[C@H](CCCCC(=O)O)SC[C@@H]21 YBJHBAHKTGYVGT-ZKWXMUAHSA-N 0.000 description 2
- OZFAFGSSMRRTDW-UHFFFAOYSA-N (2,4-dichlorophenyl) benzenesulfonate Chemical compound ClC1=CC(Cl)=CC=C1OS(=O)(=O)C1=CC=CC=C1 OZFAFGSSMRRTDW-UHFFFAOYSA-N 0.000 description 2
- 102000040650 (ribonucleotides)n+m Human genes 0.000 description 2
- SPMVMDHWKHCIDT-UHFFFAOYSA-N 1-[2-chloro-4-[(6,7-dimethoxy-4-quinolinyl)oxy]phenyl]-3-(5-methyl-3-isoxazolyl)urea Chemical compound C=12C=C(OC)C(OC)=CC2=NC=CC=1OC(C=C1Cl)=CC=C1NC(=O)NC=1C=C(C)ON=1 SPMVMDHWKHCIDT-UHFFFAOYSA-N 0.000 description 2
- HZAXFHJVJLSVMW-UHFFFAOYSA-N 2-Aminoethan-1-ol Chemical compound NCCO HZAXFHJVJLSVMW-UHFFFAOYSA-N 0.000 description 2
- JHALWMSZGCVVEM-UHFFFAOYSA-N 2-[4,7-bis(carboxymethyl)-1,4,7-triazonan-1-yl]acetic acid Chemical compound OC(=O)CN1CCN(CC(O)=O)CCN(CC(O)=O)CC1 JHALWMSZGCVVEM-UHFFFAOYSA-N 0.000 description 2
- VPFUWHKTPYPNGT-UHFFFAOYSA-N 3-(3,4-dihydroxyphenyl)-1-(5-hydroxy-2,2-dimethylchromen-6-yl)propan-1-one Chemical compound OC1=C2C=CC(C)(C)OC2=CC=C1C(=O)CCC1=CC=C(O)C(O)=C1 VPFUWHKTPYPNGT-UHFFFAOYSA-N 0.000 description 2
- VVIAGPKUTFNRDU-UHFFFAOYSA-N 6S-folinic acid Natural products C1NC=2NC(N)=NC(=O)C=2N(C=O)C1CNC1=CC=C(C(=O)NC(CCC(O)=O)C(O)=O)C=C1 VVIAGPKUTFNRDU-UHFFFAOYSA-N 0.000 description 2
- STQGQHZAVUOBTE-UHFFFAOYSA-N 7-Cyan-hept-2t-en-4,6-diinsaeure Natural products C1=2C(O)=C3C(=O)C=4C(OC)=CC=CC=4C(=O)C3=C(O)C=2CC(O)(C(C)=O)CC1OC1CC(N)C(O)C(C)O1 STQGQHZAVUOBTE-UHFFFAOYSA-N 0.000 description 2
- 229940126253 ADU-S100 Drugs 0.000 description 2
- 108010066676 Abrin Proteins 0.000 description 2
- 102100037435 Antiviral innate immune response receptor RIG-I Human genes 0.000 description 2
- CIWBSHSKHKDKBQ-JLAZNSOCSA-N Ascorbic acid Chemical compound OC[C@H](O)[C@H]1OC(=O)C(O)=C1O CIWBSHSKHKDKBQ-JLAZNSOCSA-N 0.000 description 2
- 108091008875 B cell receptors Proteins 0.000 description 2
- 102100038080 B-cell receptor CD22 Human genes 0.000 description 2
- 102100022005 B-lymphocyte antigen CD20 Human genes 0.000 description 2
- 108091003079 Bovine Serum Albumin Proteins 0.000 description 2
- 102100031151 C-C chemokine receptor type 2 Human genes 0.000 description 2
- 101710149815 C-C chemokine receptor type 2 Proteins 0.000 description 2
- 102100031650 C-X-C chemokine receptor type 4 Human genes 0.000 description 2
- 239000002126 C01EB10 - Adenosine Substances 0.000 description 2
- 102100024217 CAMPATH-1 antigen Human genes 0.000 description 2
- 108010058905 CD44v6 antigen Proteins 0.000 description 2
- 108010065524 CD52 Antigen Proteins 0.000 description 2
- 102100025222 CD63 antigen Human genes 0.000 description 2
- KLWPJMFMVPTNCC-UHFFFAOYSA-N Camptothecin Natural products CCC1(O)C(=O)OCC2=C1C=C3C4Nc5ccccc5C=C4CN3C2=O KLWPJMFMVPTNCC-UHFFFAOYSA-N 0.000 description 2
- 241000282472 Canis lupus familiaris Species 0.000 description 2
- 102000000844 Cell Surface Receptors Human genes 0.000 description 2
- 108010001857 Cell Surface Receptors Proteins 0.000 description 2
- 241000282693 Cercopithecidae Species 0.000 description 2
- 108010009685 Cholinergic Receptors Proteins 0.000 description 2
- 108091026890 Coding region Proteins 0.000 description 2
- 108020004705 Codon Proteins 0.000 description 2
- 108090000266 Cyclin-dependent kinases Proteins 0.000 description 2
- 102000003903 Cyclin-dependent kinases Human genes 0.000 description 2
- UHDGCWIWMRVCDJ-CCXZUQQUSA-N Cytarabine Chemical compound O=C1N=C(N)C=CN1[C@H]1[C@@H](O)[C@H](O)[C@@H](CO)O1 UHDGCWIWMRVCDJ-CCXZUQQUSA-N 0.000 description 2
- FBPFZTCFMRRESA-FSIIMWSLSA-N D-Glucitol Natural products OC[C@H](O)[C@H](O)[C@@H](O)[C@H](O)CO FBPFZTCFMRRESA-FSIIMWSLSA-N 0.000 description 2
- FBPFZTCFMRRESA-KVTDHHQDSA-N D-Mannitol Chemical compound OC[C@@H](O)[C@@H](O)[C@H](O)[C@H](O)CO FBPFZTCFMRRESA-KVTDHHQDSA-N 0.000 description 2
- FBPFZTCFMRRESA-JGWLITMVSA-N D-glucitol Chemical compound OC[C@H](O)[C@@H](O)[C@H](O)[C@H](O)CO FBPFZTCFMRRESA-JGWLITMVSA-N 0.000 description 2
- 108010092160 Dactinomycin Proteins 0.000 description 2
- 241000702421 Dependoparvovirus Species 0.000 description 2
- 102100034573 Desmoglein-4 Human genes 0.000 description 2
- 101710183213 Desmoglein-4 Proteins 0.000 description 2
- 229920002307 Dextran Polymers 0.000 description 2
- RTZKZFJDLAIYFH-UHFFFAOYSA-N Diethyl ether Chemical compound CCOCC RTZKZFJDLAIYFH-UHFFFAOYSA-N 0.000 description 2
- AOJJSUZBOXZQNB-TZSSRYMLSA-N Doxorubicin Chemical compound O([C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(=O)CO)[C@H]1C[C@H](N)[C@H](O)[C@H](C)O1 AOJJSUZBOXZQNB-TZSSRYMLSA-N 0.000 description 2
- 239000012591 Dulbecco’s Phosphate Buffered Saline Substances 0.000 description 2
- 101150029707 ERBB2 gene Proteins 0.000 description 2
- 241000283086 Equidae Species 0.000 description 2
- 108010021472 Fc gamma receptor IIB Proteins 0.000 description 2
- 241000282326 Felis catus Species 0.000 description 2
- 102100041003 Glutamate carboxypeptidase 2 Human genes 0.000 description 2
- 235000010469 Glycine max Nutrition 0.000 description 2
- 208000035186 Hemolytic Autoimmune Anemia Diseases 0.000 description 2
- 102100034458 Hepatitis A virus cellular receptor 2 Human genes 0.000 description 2
- 101710083479 Hepatitis A virus cellular receptor 2 homolog Proteins 0.000 description 2
- 241000282412 Homo Species 0.000 description 2
- 101000952099 Homo sapiens Antiviral innate immune response receptor RIG-I Proteins 0.000 description 2
- 101000884305 Homo sapiens B-cell receptor CD22 Proteins 0.000 description 2
- 101000897405 Homo sapiens B-lymphocyte antigen CD20 Proteins 0.000 description 2
- 101000922348 Homo sapiens C-X-C chemokine receptor type 4 Proteins 0.000 description 2
- 101000934368 Homo sapiens CD63 antigen Proteins 0.000 description 2
- 101000851181 Homo sapiens Epidermal growth factor receptor Proteins 0.000 description 2
- 101000892862 Homo sapiens Glutamate carboxypeptidase 2 Proteins 0.000 description 2
- 101000868279 Homo sapiens Leukocyte surface antigen CD47 Proteins 0.000 description 2
- 101000628547 Homo sapiens Metalloreductase STEAP1 Proteins 0.000 description 2
- 101001133081 Homo sapiens Mucin-2 Proteins 0.000 description 2
- 101000972284 Homo sapiens Mucin-3A Proteins 0.000 description 2
- 101000972286 Homo sapiens Mucin-4 Proteins 0.000 description 2
- 101000972282 Homo sapiens Mucin-5AC Proteins 0.000 description 2
- 101000972276 Homo sapiens Mucin-5B Proteins 0.000 description 2
- 101000972273 Homo sapiens Mucin-7 Proteins 0.000 description 2
- 101000934338 Homo sapiens Myeloid cell surface antigen CD33 Proteins 0.000 description 2
- 101001125026 Homo sapiens Nucleotide-binding oligomerization domain-containing protein 2 Proteins 0.000 description 2
- 101001012157 Homo sapiens Receptor tyrosine-protein kinase erbB-2 Proteins 0.000 description 2
- 101000633786 Homo sapiens SLAM family member 6 Proteins 0.000 description 2
- 101000633784 Homo sapiens SLAM family member 7 Proteins 0.000 description 2
- 101000633782 Homo sapiens SLAM family member 8 Proteins 0.000 description 2
- 101000934346 Homo sapiens T-cell surface antigen CD2 Proteins 0.000 description 2
- 101000914484 Homo sapiens T-lymphocyte activation antigen CD80 Proteins 0.000 description 2
- 101000831496 Homo sapiens Toll-like receptor 3 Proteins 0.000 description 2
- 101000669402 Homo sapiens Toll-like receptor 7 Proteins 0.000 description 2
- 101000800483 Homo sapiens Toll-like receptor 8 Proteins 0.000 description 2
- 101000666896 Homo sapiens V-type immunoglobulin domain-containing suppressor of T-cell activation Proteins 0.000 description 2
- 206010020751 Hypersensitivity Diseases 0.000 description 2
- 102000009490 IgG Receptors Human genes 0.000 description 2
- 108010009817 Immunoglobulin Constant Regions Proteins 0.000 description 2
- 102000009786 Immunoglobulin Constant Regions Human genes 0.000 description 2
- 108010054477 Immunoglobulin Fab Fragments Proteins 0.000 description 2
- 102000013463 Immunoglobulin Light Chains Human genes 0.000 description 2
- 108010065825 Immunoglobulin Light Chains Proteins 0.000 description 2
- 102100037850 Interferon gamma Human genes 0.000 description 2
- 102000006992 Interferon-alpha Human genes 0.000 description 2
- 108010047761 Interferon-alpha Proteins 0.000 description 2
- 102000000589 Interleukin-1 Human genes 0.000 description 2
- 108010002352 Interleukin-1 Proteins 0.000 description 2
- 102000003814 Interleukin-10 Human genes 0.000 description 2
- 108090000174 Interleukin-10 Proteins 0.000 description 2
- 102000013462 Interleukin-12 Human genes 0.000 description 2
- 108010065805 Interleukin-12 Proteins 0.000 description 2
- 102000003812 Interleukin-15 Human genes 0.000 description 2
- 102000003810 Interleukin-18 Human genes 0.000 description 2
- 108090000171 Interleukin-18 Proteins 0.000 description 2
- 102100030703 Interleukin-22 Human genes 0.000 description 2
- 102000004889 Interleukin-6 Human genes 0.000 description 2
- 108090001005 Interleukin-6 Proteins 0.000 description 2
- 102000015696 Interleukins Human genes 0.000 description 2
- 108010063738 Interleukins Proteins 0.000 description 2
- 108091092195 Intron Proteins 0.000 description 2
- 241001138401 Kluyveromyces lactis Species 0.000 description 2
- DCXYFEDJOCDNAF-REOHCLBHSA-N L-asparagine Chemical compound OC(=O)[C@@H](N)CC(N)=O DCXYFEDJOCDNAF-REOHCLBHSA-N 0.000 description 2
- AYFVYJQAPQTCCC-GBXIJSLDSA-N L-threonine Chemical compound C[C@@H](O)[C@H](N)C(O)=O AYFVYJQAPQTCCC-GBXIJSLDSA-N 0.000 description 2
- 239000002147 L01XE04 - Sunitinib Substances 0.000 description 2
- 102000017578 LAG3 Human genes 0.000 description 2
- 101150030213 Lag3 gene Proteins 0.000 description 2
- 102100032913 Leukocyte surface antigen CD47 Human genes 0.000 description 2
- 102100029205 Low affinity immunoglobulin gamma Fc region receptor II-b Human genes 0.000 description 2
- 102100029185 Low affinity immunoglobulin gamma Fc region receptor III-B Human genes 0.000 description 2
- 108060001084 Luciferase Proteins 0.000 description 2
- 239000005089 Luciferase Substances 0.000 description 2
- 102100033486 Lymphocyte antigen 75 Human genes 0.000 description 2
- 239000004472 Lysine Substances 0.000 description 2
- 102100025354 Macrophage mannose receptor 1 Human genes 0.000 description 2
- TWRXJAOTZQYOKJ-UHFFFAOYSA-L Magnesium chloride Chemical compound [Mg+2].[Cl-].[Cl-] TWRXJAOTZQYOKJ-UHFFFAOYSA-L 0.000 description 2
- 241000124008 Mammalia Species 0.000 description 2
- 229930195725 Mannitol Natural products 0.000 description 2
- 108010031099 Mannose Receptor Proteins 0.000 description 2
- 108010087870 Mannose-Binding Lectin Proteins 0.000 description 2
- 102000009112 Mannose-Binding Lectin Human genes 0.000 description 2
- 229930126263 Maytansine Natural products 0.000 description 2
- 108090000015 Mesothelin Proteins 0.000 description 2
- 102000003735 Mesothelin Human genes 0.000 description 2
- 102100026712 Metalloreductase STEAP1 Human genes 0.000 description 2
- 102100034256 Mucin-1 Human genes 0.000 description 2
- 102100034263 Mucin-2 Human genes 0.000 description 2
- 102100022497 Mucin-3A Human genes 0.000 description 2
- 102100022693 Mucin-4 Human genes 0.000 description 2
- 102100022496 Mucin-5AC Human genes 0.000 description 2
- 102100022494 Mucin-5B Human genes 0.000 description 2
- 102100022492 Mucin-7 Human genes 0.000 description 2
- 101100407308 Mus musculus Pdcd1lg2 gene Proteins 0.000 description 2
- 102100025243 Myeloid cell surface antigen CD33 Human genes 0.000 description 2
- NWIBSHFKIJFRCO-WUDYKRTCSA-N Mytomycin Chemical compound C1N2C(C(C(C)=C(N)C3=O)=O)=C3[C@@H](COC(N)=O)[C@@]2(OC)[C@@H]2[C@H]1N2 NWIBSHFKIJFRCO-WUDYKRTCSA-N 0.000 description 2
- QPCDCPDFJACHGM-UHFFFAOYSA-N N,N-bis{2-[bis(carboxymethyl)amino]ethyl}glycine Chemical compound OC(=O)CN(CC(O)=O)CCN(CC(=O)O)CCN(CC(O)=O)CC(O)=O QPCDCPDFJACHGM-UHFFFAOYSA-N 0.000 description 2
- 102100038082 Natural killer cell receptor 2B4 Human genes 0.000 description 2
- 102100029441 Nucleotide-binding oligomerization domain-containing protein 2 Human genes 0.000 description 2
- 230000004989 O-glycosylation Effects 0.000 description 2
- 239000008118 PEG 6000 Substances 0.000 description 2
- 208000031845 Pernicious anaemia Diseases 0.000 description 2
- 206010057249 Phagocytosis Diseases 0.000 description 2
- ISWSIDIOOBJBQZ-UHFFFAOYSA-N Phenol Natural products OC1=CC=CC=C1 ISWSIDIOOBJBQZ-UHFFFAOYSA-N 0.000 description 2
- NBIIXXVUZAFLBC-UHFFFAOYSA-N Phosphoric acid Chemical compound OP(O)(O)=O NBIIXXVUZAFLBC-UHFFFAOYSA-N 0.000 description 2
- 241000224016 Plasmodium Species 0.000 description 2
- 239000004698 Polyethylene Substances 0.000 description 2
- 229920002584 Polyethylene Glycol 6000 Polymers 0.000 description 2
- 239000004743 Polypropylene Substances 0.000 description 2
- 239000004793 Polystyrene Substances 0.000 description 2
- 241000288906 Primates Species 0.000 description 2
- 108700030875 Programmed Cell Death 1 Ligand 2 Proteins 0.000 description 2
- 102100024213 Programmed cell death 1 ligand 2 Human genes 0.000 description 2
- 102100030086 Receptor tyrosine-protein kinase erbB-2 Human genes 0.000 description 2
- 108020004511 Recombinant DNA Proteins 0.000 description 2
- 108010083644 Ribonucleases Proteins 0.000 description 2
- 102000006382 Ribonucleases Human genes 0.000 description 2
- 108010039491 Ricin Proteins 0.000 description 2
- 102100029197 SLAM family member 6 Human genes 0.000 description 2
- 102100029198 SLAM family member 7 Human genes 0.000 description 2
- 102100029214 SLAM family member 8 Human genes 0.000 description 2
- 229920005654 Sephadex Polymers 0.000 description 2
- 239000012507 Sephadex™ Substances 0.000 description 2
- 108010074687 Signaling Lymphocytic Activation Molecule Family Member 1 Proteins 0.000 description 2
- VMHLLURERBWHNL-UHFFFAOYSA-M Sodium acetate Chemical compound [Na+].CC([O-])=O VMHLLURERBWHNL-UHFFFAOYSA-M 0.000 description 2
- CZMRCDWAGMRECN-UGDNZRGBSA-N Sucrose Chemical compound O[C@H]1[C@H](O)[C@@H](CO)O[C@@]1(CO)O[C@@H]1[C@H](O)[C@@H](O)[C@H](O)[C@@H](CO)O1 CZMRCDWAGMRECN-UGDNZRGBSA-N 0.000 description 2
- 229930006000 Sucrose Natural products 0.000 description 2
- QAOWNCQODCNURD-UHFFFAOYSA-L Sulfate Chemical compound [O-]S([O-])(=O)=O QAOWNCQODCNURD-UHFFFAOYSA-L 0.000 description 2
- 229940126547 T-cell immunoglobulin mucin-3 Drugs 0.000 description 2
- 102100025237 T-cell surface antigen CD2 Human genes 0.000 description 2
- 102100027222 T-lymphocyte activation antigen CD80 Human genes 0.000 description 2
- 239000006180 TBST buffer Substances 0.000 description 2
- NKANXQFJJICGDU-QPLCGJKRSA-N Tamoxifen Chemical compound C=1C=CC=CC=1C(/CC)=C(C=1C=CC(OCCN(C)C)=CC=1)/C1=CC=CC=C1 NKANXQFJJICGDU-QPLCGJKRSA-N 0.000 description 2
- 239000004473 Threonine Substances 0.000 description 2
- 208000031981 Thrombocytopenic Idiopathic Purpura Diseases 0.000 description 2
- 102100024324 Toll-like receptor 3 Human genes 0.000 description 2
- 102100039390 Toll-like receptor 7 Human genes 0.000 description 2
- 102100033110 Toll-like receptor 8 Human genes 0.000 description 2
- DRTQHJPVMGBUCF-XVFCMESISA-N Uridine Chemical compound O[C@@H]1[C@H](O)[C@@H](CO)O[C@H]1N1C(=O)NC(=O)C=C1 DRTQHJPVMGBUCF-XVFCMESISA-N 0.000 description 2
- 102100038282 V-type immunoglobulin domain-containing suppressor of T-cell activation Human genes 0.000 description 2
- 102000005789 Vascular Endothelial Growth Factors Human genes 0.000 description 2
- 108010019530 Vascular Endothelial Growth Factors Proteins 0.000 description 2
- 102100033177 Vascular endothelial growth factor receptor 2 Human genes 0.000 description 2
- 230000021736 acetylation Effects 0.000 description 2
- 238000006640 acetylation reaction Methods 0.000 description 2
- 102000034337 acetylcholine receptors Human genes 0.000 description 2
- DZBUGLKDJFMEHC-UHFFFAOYSA-N acridine Chemical compound C1=CC=CC2=CC3=CC=CC=C3N=C21 DZBUGLKDJFMEHC-UHFFFAOYSA-N 0.000 description 2
- RJURFGZVJUQBHK-UHFFFAOYSA-N actinomycin D Natural products CC1OC(=O)C(C(C)C)N(C)C(=O)CN(C)C(=O)C2CCCN2C(=O)C(C(C)C)NC(=O)C1NC(=O)C1=C(N)C(=O)C(C)=C2OC(C(C)=CC=C3C(=O)NC4C(=O)NC(C(N5CCCC5C(=O)N(C)CC(=O)N(C)C(C(C)C)C(=O)OC4C)=O)C(C)C)=C3N=C21 RJURFGZVJUQBHK-UHFFFAOYSA-N 0.000 description 2
- 239000013543 active substance Substances 0.000 description 2
- 125000002252 acyl group Chemical group 0.000 description 2
- OIRDTQYFTABQOQ-KQYNXXCUSA-N adenosine Chemical compound C1=NC=2C(N)=NC=NC=2N1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O OIRDTQYFTABQOQ-KQYNXXCUSA-N 0.000 description 2
- 229960005305 adenosine Drugs 0.000 description 2
- 230000009824 affinity maturation Effects 0.000 description 2
- 229940100198 alkylating agent Drugs 0.000 description 2
- 239000002168 alkylating agent Substances 0.000 description 2
- SRHNADOZAAWYLV-XLMUYGLTSA-N alpha-L-Fucp-(1->2)-beta-D-Galp-(1->4)-[alpha-L-Fucp-(1->3)]-beta-D-GlcpNAc Chemical compound O[C@H]1[C@H](O)[C@H](O)[C@H](C)O[C@H]1O[C@H]1[C@H](O[C@H]2[C@@H]([C@@H](NC(C)=O)[C@H](O)O[C@@H]2CO)O[C@H]2[C@H]([C@H](O)[C@H](O)[C@H](C)O2)O)O[C@H](CO)[C@H](O)[C@@H]1O SRHNADOZAAWYLV-XLMUYGLTSA-N 0.000 description 2
- 230000004075 alteration Effects 0.000 description 2
- 229960003437 aminoglutethimide Drugs 0.000 description 2
- ROBVIMPUHSLWNV-UHFFFAOYSA-N aminoglutethimide Chemical compound C=1C=C(N)C=CC=1C1(CC)CCC(=O)NC1=O ROBVIMPUHSLWNV-UHFFFAOYSA-N 0.000 description 2
- 230000003321 amplification Effects 0.000 description 2
- 239000003242 anti bacterial agent Substances 0.000 description 2
- 229940088710 antibiotic agent Drugs 0.000 description 2
- 238000009175 antibody therapy Methods 0.000 description 2
- 229940049595 antibody-drug conjugate Drugs 0.000 description 2
- 210000000628 antibody-producing cell Anatomy 0.000 description 2
- 210000000612 antigen-presenting cell Anatomy 0.000 description 2
- 239000002246 antineoplastic agent Substances 0.000 description 2
- 125000003118 aryl group Chemical group 0.000 description 2
- 230000002238 attenuated effect Effects 0.000 description 2
- 201000003710 autoimmune thrombocytopenic purpura Diseases 0.000 description 2
- 230000008901 benefit Effects 0.000 description 2
- WQZGKKKJIJFFOK-VFUOTHLCSA-N beta-D-glucose Chemical compound OC[C@H]1O[C@@H](O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-VFUOTHLCSA-N 0.000 description 2
- 229960003008 blinatumomab Drugs 0.000 description 2
- 229940098773 bovine serum albumin Drugs 0.000 description 2
- 210000000481 breast Anatomy 0.000 description 2
- RFCBNSCSPXMEBK-INFSMZHSSA-N c-GMP-AMP Chemical compound C([C@H]1O2)OP(O)(=O)O[C@H]3[C@@H](O)[C@H](N4C5=NC=NC(N)=C5N=C4)O[C@@H]3COP(O)(=O)O[C@H]1[C@@H](O)[C@@H]2N1C(N=C(NC2=O)N)=C2N=C1 RFCBNSCSPXMEBK-INFSMZHSSA-N 0.000 description 2
- 239000001506 calcium phosphate Substances 0.000 description 2
- 229930195731 calicheamicin Natural products 0.000 description 2
- 229940127093 camptothecin Drugs 0.000 description 2
- VSJKWCGYPAHWDS-FQEVSTJZSA-N camptothecin Chemical compound C1=CC=C2C=C(CN3C4=CC5=C(C3=O)COC(=O)[C@]5(O)CC)C4=NC2=C1 VSJKWCGYPAHWDS-FQEVSTJZSA-N 0.000 description 2
- 239000002775 capsule Substances 0.000 description 2
- YCIMNLLNPGFGHC-UHFFFAOYSA-N catechol Chemical compound OC1=CC=CC=C1O YCIMNLLNPGFGHC-UHFFFAOYSA-N 0.000 description 2
- 238000002659 cell therapy Methods 0.000 description 2
- 239000003153 chemical reaction reagent Substances 0.000 description 2
- 229960004630 chlorambucil Drugs 0.000 description 2
- JCKYGMPEJWAADB-UHFFFAOYSA-N chlorambucil Chemical compound OC(=O)CCCC1=CC=C(N(CCCl)CCCl)C=C1 JCKYGMPEJWAADB-UHFFFAOYSA-N 0.000 description 2
- HVYWMOMLDIMFJA-DPAQBDIFSA-N cholesterol Chemical compound C1C=C2C[C@@H](O)CC[C@]2(C)[C@@H]2[C@@H]1[C@@H]1CC[C@H]([C@H](C)CCCC(C)C)[C@@]1(C)CC2 HVYWMOMLDIMFJA-DPAQBDIFSA-N 0.000 description 2
- 238000000576 coating method Methods 0.000 description 2
- 230000024203 complement activation Effects 0.000 description 2
- 238000010276 construction Methods 0.000 description 2
- 230000008878 coupling Effects 0.000 description 2
- 238000005859 coupling reaction Methods 0.000 description 2
- 238000004132 cross linking Methods 0.000 description 2
- 239000003431 cross linking reagent Substances 0.000 description 2
- 238000002425 crystallisation Methods 0.000 description 2
- 230000008025 crystallization Effects 0.000 description 2
- 150000001945 cysteines Chemical class 0.000 description 2
- 210000001151 cytotoxic T lymphocyte Anatomy 0.000 description 2
- STQGQHZAVUOBTE-VGBVRHCVSA-N daunorubicin Chemical compound O([C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(C)=O)[C@H]1C[C@H](N)[C@H](O)[C@H](C)O1 STQGQHZAVUOBTE-VGBVRHCVSA-N 0.000 description 2
- 230000034994 death Effects 0.000 description 2
- 230000007423 decrease Effects 0.000 description 2
- 230000002950 deficient Effects 0.000 description 2
- 210000004443 dendritic cell Anatomy 0.000 description 2
- 201000001981 dermatomyositis Diseases 0.000 description 2
- 229960002086 dextran Drugs 0.000 description 2
- 238000003745 diagnosis Methods 0.000 description 2
- 206010013023 diphtheria Diseases 0.000 description 2
- VSJKWCGYPAHWDS-UHFFFAOYSA-N dl-camptothecin Natural products C1=CC=C2C=C(CN3C4=CC5=C(C3=O)COC(=O)C5(O)CC)C4=NC2=C1 VSJKWCGYPAHWDS-UHFFFAOYSA-N 0.000 description 2
- 229930188854 dolastatin Natural products 0.000 description 2
- 229960004679 doxorubicin Drugs 0.000 description 2
- 238000012377 drug delivery Methods 0.000 description 2
- 229960005501 duocarmycin Drugs 0.000 description 2
- 229930184221 duocarmycin Natural products 0.000 description 2
- 238000004520 electroporation Methods 0.000 description 2
- 239000012055 enteric layer Substances 0.000 description 2
- 108010087914 epidermal growth factor receptor VIII Proteins 0.000 description 2
- GTTBEUCJPZQMDZ-UHFFFAOYSA-N erlotinib hydrochloride Chemical compound [H+].[Cl-].C=12C=C(OCCOC)C(OCCOC)=CC2=NC=NC=1NC1=CC=CC(C#C)=C1 GTTBEUCJPZQMDZ-UHFFFAOYSA-N 0.000 description 2
- 229960005073 erlotinib hydrochloride Drugs 0.000 description 2
- 210000003527 eukaryotic cell Anatomy 0.000 description 2
- 230000001747 exhibiting effect Effects 0.000 description 2
- 239000000284 extract Substances 0.000 description 2
- 230000001605 fetal effect Effects 0.000 description 2
- GNBHRKFJIUUOQI-UHFFFAOYSA-N fluorescein Chemical compound O1C(=O)C2=CC=CC=C2C21C1=CC=C(O)C=C1OC1=CC(O)=CC=C21 GNBHRKFJIUUOQI-UHFFFAOYSA-N 0.000 description 2
- 239000011724 folic acid Substances 0.000 description 2
- OVBPIULPVIDEAO-LBPRGKRZSA-N folic acid Chemical compound C=1N=C2NC(N)=NC(=O)C2=NC=1CNC1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 OVBPIULPVIDEAO-LBPRGKRZSA-N 0.000 description 2
- VVIAGPKUTFNRDU-ABLWVSNPSA-N folinic acid Chemical compound C1NC=2NC(N)=NC(=O)C=2N(C=O)C1CNC1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 VVIAGPKUTFNRDU-ABLWVSNPSA-N 0.000 description 2
- 235000008191 folinic acid Nutrition 0.000 description 2
- 239000011672 folinic acid Substances 0.000 description 2
- CHPZKNULDCNCBW-UHFFFAOYSA-N gallium nitrate Chemical compound [Ga+3].[O-][N+]([O-])=O.[O-][N+]([O-])=O.[O-][N+]([O-])=O CHPZKNULDCNCBW-UHFFFAOYSA-N 0.000 description 2
- 238000001502 gel electrophoresis Methods 0.000 description 2
- 229960005277 gemcitabine Drugs 0.000 description 2
- 238000007429 general method Methods 0.000 description 2
- PCHJSUWPFVWCPO-UHFFFAOYSA-N gold Chemical compound [Au] PCHJSUWPFVWCPO-UHFFFAOYSA-N 0.000 description 2
- 239000010931 gold Substances 0.000 description 2
- 229910052737 gold Inorganic materials 0.000 description 2
- 230000012010 growth Effects 0.000 description 2
- 239000001963 growth medium Substances 0.000 description 2
- 230000003394 haemopoietic effect Effects 0.000 description 2
- 150000004820 halides Chemical class 0.000 description 2
- 239000000833 heterodimer Substances 0.000 description 2
- BXWNKGSJHAJOGX-UHFFFAOYSA-N hexadecan-1-ol Chemical compound CCCCCCCCCCCCCCCCO BXWNKGSJHAJOGX-UHFFFAOYSA-N 0.000 description 2
- 210000005260 human cell Anatomy 0.000 description 2
- 125000002887 hydroxy group Chemical group [H]O* 0.000 description 2
- 229960001101 ifosfamide Drugs 0.000 description 2
- HOMGKSMUEGBAAB-UHFFFAOYSA-N ifosfamide Chemical compound ClCCNP1(=O)OCCCN1CCCl HOMGKSMUEGBAAB-UHFFFAOYSA-N 0.000 description 2
- 230000002519 immonomodulatory effect Effects 0.000 description 2
- 239000012642 immune effector Substances 0.000 description 2
- 238000002649 immunization Methods 0.000 description 2
- 230000005847 immunogenicity Effects 0.000 description 2
- 238000009169 immunotherapy Methods 0.000 description 2
- 230000006872 improvement Effects 0.000 description 2
- 208000015181 infectious disease Diseases 0.000 description 2
- 229940047124 interferons Drugs 0.000 description 2
- 108010074108 interleukin-21 Proteins 0.000 description 2
- 229940047122 interleukins Drugs 0.000 description 2
- 229960005386 ipilimumab Drugs 0.000 description 2
- 229960004768 irinotecan Drugs 0.000 description 2
- 238000002372 labelling Methods 0.000 description 2
- 150000002605 large molecules Chemical class 0.000 description 2
- 229960001691 leucovorin Drugs 0.000 description 2
- GFIJNRVAKGFPGQ-LIJARHBVSA-N leuprolide Chemical compound CCNC(=O)[C@@H]1CCCN1C(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](CC(C)C)NC(=O)[C@@H](NC(=O)[C@H](CO)NC(=O)[C@H](CC=1C2=CC=CC=C2NC=1)NC(=O)[C@H](CC=1N=CNC=1)NC(=O)[C@H]1NC(=O)CC1)CC1=CC=C(O)C=C1 GFIJNRVAKGFPGQ-LIJARHBVSA-N 0.000 description 2
- 229960004338 leuprorelin Drugs 0.000 description 2
- 150000002632 lipids Chemical class 0.000 description 2
- 239000012669 liquid formulation Substances 0.000 description 2
- 210000004698 lymphocyte Anatomy 0.000 description 2
- 125000003588 lysine group Chemical group [H]N([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])(N([H])[H])C(*)=O 0.000 description 2
- RLSSMJSEOOYNOY-UHFFFAOYSA-N m-cresol Chemical compound CC1=CC=CC(O)=C1 RLSSMJSEOOYNOY-UHFFFAOYSA-N 0.000 description 2
- 229940124302 mTOR inhibitor Drugs 0.000 description 2
- 229920002521 macromolecule Polymers 0.000 description 2
- HQKMJHAJHXVSDF-UHFFFAOYSA-L magnesium stearate Chemical compound [Mg+2].CCCCCCCCCCCCCCCCCC([O-])=O.CCCCCCCCCCCCCCCCCC([O-])=O HQKMJHAJHXVSDF-UHFFFAOYSA-L 0.000 description 2
- 210000004962 mammalian cell Anatomy 0.000 description 2
- 239000003628 mammalian target of rapamycin inhibitor Substances 0.000 description 2
- 239000000594 mannitol Substances 0.000 description 2
- 235000010355 mannitol Nutrition 0.000 description 2
- WKPWGQKGSOKKOO-RSFHAFMBSA-N maytansine Chemical compound CO[C@@H]([C@@]1(O)C[C@](OC(=O)N1)([C@H]([C@@H]1O[C@@]1(C)[C@@H](OC(=O)[C@H](C)N(C)C(C)=O)CC(=O)N1C)C)[H])\C=C\C=C(C)\CC2=CC(OC)=C(Cl)C1=C2 WKPWGQKGSOKKOO-RSFHAFMBSA-N 0.000 description 2
- 238000005259 measurement Methods 0.000 description 2
- 230000007246 mechanism Effects 0.000 description 2
- 239000012528 membrane Substances 0.000 description 2
- 210000004379 membrane Anatomy 0.000 description 2
- GLVAUDGFNGKCSF-UHFFFAOYSA-N mercaptopurine Chemical compound S=C1NC=NC2=C1NC=N2 GLVAUDGFNGKCSF-UHFFFAOYSA-N 0.000 description 2
- 108020004999 messenger RNA Proteins 0.000 description 2
- 150000002739 metals Chemical class 0.000 description 2
- 244000005700 microbiome Species 0.000 description 2
- 210000000274 microglia Anatomy 0.000 description 2
- 239000004005 microsphere Substances 0.000 description 2
- 235000013336 milk Nutrition 0.000 description 2
- 239000008267 milk Substances 0.000 description 2
- 210000004080 milk Anatomy 0.000 description 2
- 229960001156 mitoxantrone Drugs 0.000 description 2
- KKZJGLLVHKMTCM-UHFFFAOYSA-N mitoxantrone Chemical compound O=C1C2=C(O)C=CC(O)=C2C(=O)C2=C1C(NCCNCCO)=CC=C2NCCNCCO KKZJGLLVHKMTCM-UHFFFAOYSA-N 0.000 description 2
- 238000002156 mixing Methods 0.000 description 2
- 239000003607 modifier Substances 0.000 description 2
- 238000012544 monitoring process Methods 0.000 description 2
- 239000013642 negative control Substances 0.000 description 2
- 229960001420 nimustine Drugs 0.000 description 2
- VFEDRRNHLBGPNN-UHFFFAOYSA-N nimustine Chemical compound CC1=NC=C(CNC(=O)N(CCCl)N=O)C(N)=N1 VFEDRRNHLBGPNN-UHFFFAOYSA-N 0.000 description 2
- 231100000252 nontoxic Toxicity 0.000 description 2
- 230000003000 nontoxic effect Effects 0.000 description 2
- 238000003199 nucleic acid amplification method Methods 0.000 description 2
- 229960001756 oxaliplatin Drugs 0.000 description 2
- DWAFYCQODLXJNR-BNTLRKBRSA-L oxaliplatin Chemical compound O1C(=O)C(=O)O[Pt]11N[C@@H]2CCCC[C@H]2N1 DWAFYCQODLXJNR-BNTLRKBRSA-L 0.000 description 2
- 230000001590 oxidative effect Effects 0.000 description 2
- 238000004806 packaging method and process Methods 0.000 description 2
- 229960003330 pentetic acid Drugs 0.000 description 2
- 230000008782 phagocytosis Effects 0.000 description 2
- 239000012071 phase Substances 0.000 description 2
- NBIIXXVUZAFLBC-UHFFFAOYSA-K phosphate Chemical compound [O-]P([O-])([O-])=O NBIIXXVUZAFLBC-UHFFFAOYSA-K 0.000 description 2
- 239000010452 phosphate Substances 0.000 description 2
- 230000026731 phosphorylation Effects 0.000 description 2
- 238000006366 phosphorylation reaction Methods 0.000 description 2
- 210000004180 plasmocyte Anatomy 0.000 description 2
- BASFCYQUMIYNBI-UHFFFAOYSA-N platinum Chemical compound [Pt] BASFCYQUMIYNBI-UHFFFAOYSA-N 0.000 description 2
- 229920001481 poly(stearyl methacrylate) Polymers 0.000 description 2
- 238000003752 polymerase chain reaction Methods 0.000 description 2
- 229920001155 polypropylene Polymers 0.000 description 2
- 229920002223 polystyrene Polymers 0.000 description 2
- 229920000036 polyvinylpyrrolidone Polymers 0.000 description 2
- 239000001267 polyvinylpyrrolidone Substances 0.000 description 2
- 235000013855 polyvinylpyrrolidone Nutrition 0.000 description 2
- 239000002243 precursor Substances 0.000 description 2
- 125000002924 primary amino group Chemical group [H]N([H])* 0.000 description 2
- QELSKZZBTMNZEB-UHFFFAOYSA-N propylparaben Chemical compound CCCOC(=O)C1=CC=C(O)C=C1 QELSKZZBTMNZEB-UHFFFAOYSA-N 0.000 description 2
- 125000006239 protecting group Chemical group 0.000 description 2
- 238000002818 protein evolution Methods 0.000 description 2
- ZCCUUQDIBDJBTK-UHFFFAOYSA-N psoralen Chemical compound C1=C2OC(=O)C=CC2=CC2=C1OC=C2 ZCCUUQDIBDJBTK-UHFFFAOYSA-N 0.000 description 2
- 230000005180 public health Effects 0.000 description 2
- 150000003212 purines Chemical class 0.000 description 2
- 229950010131 puromycin Drugs 0.000 description 2
- 150000003230 pyrimidines Chemical class 0.000 description 2
- 238000011002 quantification Methods 0.000 description 2
- 238000001959 radiotherapy Methods 0.000 description 2
- 229960004622 raloxifene Drugs 0.000 description 2
- GZUITABIAKMVPG-UHFFFAOYSA-N raloxifene Chemical compound C1=CC(O)=CC=C1C1=C(C(=O)C=2C=CC(OCCN3CCCCC3)=CC=2)C2=CC=C(O)C=C2S1 GZUITABIAKMVPG-UHFFFAOYSA-N 0.000 description 2
- 229960003876 ranibizumab Drugs 0.000 description 2
- 230000001105 regulatory effect Effects 0.000 description 2
- 230000010076 replication Effects 0.000 description 2
- 238000011160 research Methods 0.000 description 2
- GHMLBKRAJCXXBS-UHFFFAOYSA-N resorcinol Chemical compound OC1=CC=CC(O)=C1 GHMLBKRAJCXXBS-UHFFFAOYSA-N 0.000 description 2
- 230000004044 response Effects 0.000 description 2
- FGDZQCVHDSGLHJ-UHFFFAOYSA-M rubidium chloride Chemical compound [Cl-].[Rb+] FGDZQCVHDSGLHJ-UHFFFAOYSA-M 0.000 description 2
- HXCHCVDVKSCDHU-PJKCJEBCSA-N s-[(2r,3s,4s,6s)-6-[[(2r,3s,4s,5r,6r)-5-[(2s,4s,5s)-5-(ethylamino)-4-methoxyoxan-2-yl]oxy-4-hydroxy-6-[[(2s,5z,9r,13e)-9-hydroxy-12-(methoxycarbonylamino)-13-[2-(methyltrisulfanyl)ethylidene]-11-oxo-2-bicyclo[7.3.1]trideca-1(12),5-dien-3,7-diynyl]oxy]-2-m Chemical compound C1[C@H](OC)[C@@H](NCC)CO[C@H]1O[C@H]1[C@H](O[C@@H]2C\3=C(NC(=O)OC)C(=O)C[C@@](C/3=C/CSSSC)(O)C#C\C=C/C#C2)O[C@H](C)[C@@H](NO[C@@H]2O[C@H](C)[C@@H](SC(=O)C=3C(=C(OC)C(O[C@H]4[C@@H]([C@H](OC)[C@@H](O)[C@H](C)O4)O)=C(I)C=3C)OC)[C@@H](O)C2)[C@@H]1O HXCHCVDVKSCDHU-PJKCJEBCSA-N 0.000 description 2
- 229940095743 selective estrogen receptor modulator Drugs 0.000 description 2
- 239000000333 selective estrogen receptor modulator Substances 0.000 description 2
- 238000002741 site-directed mutagenesis Methods 0.000 description 2
- 229910052708 sodium Inorganic materials 0.000 description 2
- 239000001632 sodium acetate Substances 0.000 description 2
- 235000017281 sodium acetate Nutrition 0.000 description 2
- 239000008247 solid mixture Substances 0.000 description 2
- 239000000600 sorbitol Substances 0.000 description 2
- 235000010356 sorbitol Nutrition 0.000 description 2
- 239000003549 soybean oil Substances 0.000 description 2
- 235000012424 soybean oil Nutrition 0.000 description 2
- 230000009870 specific binding Effects 0.000 description 2
- 238000012409 standard PCR amplification Methods 0.000 description 2
- 230000000638 stimulation Effects 0.000 description 2
- 239000011550 stock solution Substances 0.000 description 2
- 238000003860 storage Methods 0.000 description 2
- 238000007920 subcutaneous administration Methods 0.000 description 2
- 239000005720 sucrose Substances 0.000 description 2
- 229960001796 sunitinib Drugs 0.000 description 2
- WINHZLLDWRZWRT-ATVHPVEESA-N sunitinib Chemical compound CCN(CC)CCNC(=O)C1=C(C)NC(\C=C/2C3=CC(F)=CC=C3NC\2=O)=C1C WINHZLLDWRZWRT-ATVHPVEESA-N 0.000 description 2
- 230000001629 suppression Effects 0.000 description 2
- 230000009885 systemic effect Effects 0.000 description 2
- 229960001196 thiotepa Drugs 0.000 description 2
- QQHMKNYGKVVGCZ-UHFFFAOYSA-N tipiracil Chemical compound N1C(=O)NC(=O)C(Cl)=C1CN1C(=N)CCC1 QQHMKNYGKVVGCZ-UHFFFAOYSA-N 0.000 description 2
- 229960002952 tipiracil Drugs 0.000 description 2
- 210000001519 tissue Anatomy 0.000 description 2
- 229960000940 tivozanib Drugs 0.000 description 2
- 238000011200 topical administration Methods 0.000 description 2
- XFCLJVABOIYOMF-QPLCGJKRSA-N toremifene Chemical compound C1=CC(OCCN(C)C)=CC=C1C(\C=1C=CC=CC=1)=C(\CCCl)C1=CC=CC=C1 XFCLJVABOIYOMF-QPLCGJKRSA-N 0.000 description 2
- 239000003053 toxin Substances 0.000 description 2
- 231100000765 toxin Toxicity 0.000 description 2
- 230000009261 transgenic effect Effects 0.000 description 2
- 238000011269 treatment regimen Methods 0.000 description 2
- 229930013292 trichothecene Natural products 0.000 description 2
- 150000003327 trichothecene derivatives Chemical class 0.000 description 2
- VSQQQLOSPVPRAZ-RRKCRQDMSA-N trifluridine Chemical compound C1[C@H](O)[C@@H](CO)O[C@H]1N1C(=O)NC(=O)C(C(F)(F)F)=C1 VSQQQLOSPVPRAZ-RRKCRQDMSA-N 0.000 description 2
- 229960003962 trifluridine Drugs 0.000 description 2
- 210000003171 tumor-infiltrating lymphocyte Anatomy 0.000 description 2
- 229940121358 tyrosine kinase inhibitor Drugs 0.000 description 2
- 239000005483 tyrosine kinase inhibitor Substances 0.000 description 2
- 241001430294 unidentified retrovirus Species 0.000 description 2
- 229960005486 vaccine Drugs 0.000 description 2
- 239000013603 viral vector Substances 0.000 description 2
- 238000005406 washing Methods 0.000 description 2
- 239000000080 wetting agent Substances 0.000 description 2
- DGVVWUTYPXICAM-UHFFFAOYSA-N β‐Mercaptoethanol Chemical compound OCCS DGVVWUTYPXICAM-UHFFFAOYSA-N 0.000 description 2
- HDTRYLNUVZCQOY-UHFFFAOYSA-N α-D-glucopyranosyl-α-D-glucopyranoside Natural products OC1C(O)C(O)C(CO)OC1OC1C(O)C(O)C(O)C(CO)O1 HDTRYLNUVZCQOY-UHFFFAOYSA-N 0.000 description 1
- KQODQNJLJQHFQV-UHFFFAOYSA-N (-)-hemiasterlin Natural products C1=CC=C2C(C(C)(C)C(C(=O)NC(C(=O)N(C)C(C=C(C)C(O)=O)C(C)C)C(C)(C)C)NC)=CN(C)C2=C1 KQODQNJLJQHFQV-UHFFFAOYSA-N 0.000 description 1
- ORFNVPGICPYLJV-YTVPMEHESA-N (2s)-2-[[(2r,3r)-3-[(2s)-1-[(3r,4s,5s)-4-[[(2s)-2-[[(2s)-2-[6-(2,5-dioxopyrrol-1-yl)hexanoyl-methylamino]-3-methylbutanoyl]amino]-3-methylbutanoyl]-methylamino]-3-methoxy-5-methylheptanoyl]pyrrolidin-2-yl]-3-methoxy-2-methylpropanoyl]amino]-3-phenylpropan Chemical compound C([C@H](NC(=O)[C@H](C)[C@@H](OC)[C@@H]1CCCN1C(=O)C[C@H]([C@H]([C@@H](C)CC)N(C)C(=O)[C@@H](NC(=O)[C@H](C(C)C)N(C)C(=O)CCCCCN1C(C=CC1=O)=O)C(C)C)OC)C(O)=O)C1=CC=CC=C1 ORFNVPGICPYLJV-YTVPMEHESA-N 0.000 description 1
- FLWWDYNPWOSLEO-HQVZTVAUSA-N (2s)-2-[[4-[1-(2-amino-4-oxo-1h-pteridin-6-yl)ethyl-methylamino]benzoyl]amino]pentanedioic acid Chemical compound C=1N=C2NC(N)=NC(=O)C2=NC=1C(C)N(C)C1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 FLWWDYNPWOSLEO-HQVZTVAUSA-N 0.000 description 1
- XMQUEQJCYRFIQS-YFKPBYRVSA-N (2s)-2-amino-5-ethoxy-5-oxopentanoic acid Chemical compound CCOC(=O)CC[C@H](N)C(O)=O XMQUEQJCYRFIQS-YFKPBYRVSA-N 0.000 description 1
- KYBXNPIASYUWLN-WUCPZUCCSA-N (2s)-5-hydroxypyrrolidine-2-carboxylic acid Chemical compound OC1CC[C@@H](C(O)=O)N1 KYBXNPIASYUWLN-WUCPZUCCSA-N 0.000 description 1
- FYGDTMLNYKFZSV-URKRLVJHSA-N (2s,3r,4s,5s,6r)-2-[(2r,4r,5r,6s)-4,5-dihydroxy-2-(hydroxymethyl)-6-[(2r,4r,5r,6s)-4,5,6-trihydroxy-2-(hydroxymethyl)oxan-3-yl]oxyoxan-3-yl]oxy-6-(hydroxymethyl)oxane-3,4,5-triol Chemical compound O[C@@H]1[C@@H](O)[C@H](O)[C@@H](CO)O[C@H]1OC1[C@@H](CO)O[C@@H](OC2[C@H](O[C@H](O)[C@H](O)[C@H]2O)CO)[C@H](O)[C@H]1O FYGDTMLNYKFZSV-URKRLVJHSA-N 0.000 description 1
- DLKUYSQUHXBYPB-NSSHGSRYSA-N (2s,4r)-4-[[2-[(1r,3r)-1-acetyloxy-4-methyl-3-[3-methylbutanoyloxymethyl-[(2s,3s)-3-methyl-2-[[(2r)-1-methylpiperidine-2-carbonyl]amino]pentanoyl]amino]pentyl]-1,3-thiazole-4-carbonyl]amino]-2-methyl-5-(4-methylphenyl)pentanoic acid Chemical compound N([C@@H]([C@@H](C)CC)C(=O)N(COC(=O)CC(C)C)[C@H](C[C@@H](OC(C)=O)C=1SC=C(N=1)C(=O)N[C@H](C[C@H](C)C(O)=O)CC=1C=CC(C)=CC=1)C(C)C)C(=O)[C@H]1CCCCN1C DLKUYSQUHXBYPB-NSSHGSRYSA-N 0.000 description 1
- CGMTUJFWROPELF-YPAAEMCBSA-N (3E,5S)-5-[(2S)-butan-2-yl]-3-(1-hydroxyethylidene)pyrrolidine-2,4-dione Chemical compound CC[C@H](C)[C@@H]1NC(=O)\C(=C(/C)O)C1=O CGMTUJFWROPELF-YPAAEMCBSA-N 0.000 description 1
- TVIRNGFXQVMMGB-OFWIHYRESA-N (3s,6r,10r,13e,16s)-16-[(2r,3r,4s)-4-chloro-3-hydroxy-4-phenylbutan-2-yl]-10-[(3-chloro-4-methoxyphenyl)methyl]-6-methyl-3-(2-methylpropyl)-1,4-dioxa-8,11-diazacyclohexadec-13-ene-2,5,9,12-tetrone Chemical compound C1=C(Cl)C(OC)=CC=C1C[C@@H]1C(=O)NC[C@@H](C)C(=O)O[C@@H](CC(C)C)C(=O)O[C@H]([C@H](C)[C@@H](O)[C@@H](Cl)C=2C=CC=CC=2)C/C=C/C(=O)N1 TVIRNGFXQVMMGB-OFWIHYRESA-N 0.000 description 1
- AESVUZLWRXEGEX-DKCAWCKPSA-N (7S,9R)-7-[(2S,4R,5R,6R)-4-amino-5-hydroxy-6-methyloxan-2-yl]oxy-6,9,11-trihydroxy-9-(2-hydroxyacetyl)-4-methoxy-8,10-dihydro-7H-tetracene-5,12-dione iron(3+) Chemical compound [Fe+3].COc1cccc2C(=O)c3c(O)c4C[C@@](O)(C[C@H](O[C@@H]5C[C@@H](N)[C@@H](O)[C@@H](C)O5)c4c(O)c3C(=O)c12)C(=O)CO AESVUZLWRXEGEX-DKCAWCKPSA-N 0.000 description 1
- JXVAMODRWBNUSF-KZQKBALLSA-N (7s,9r,10r)-7-[(2r,4s,5s,6s)-5-[[(2s,4as,5as,7s,9s,9ar,10ar)-2,9-dimethyl-3-oxo-4,4a,5a,6,7,9,9a,10a-octahydrodipyrano[4,2-a:4',3'-e][1,4]dioxin-7-yl]oxy]-4-(dimethylamino)-6-methyloxan-2-yl]oxy-10-[(2s,4s,5s,6s)-4-(dimethylamino)-5-hydroxy-6-methyloxan-2 Chemical compound O([C@@H]1C2=C(O)C=3C(=O)C4=CC=CC(O)=C4C(=O)C=3C(O)=C2[C@@H](O[C@@H]2O[C@@H](C)[C@@H](O[C@@H]3O[C@@H](C)[C@H]4O[C@@H]5O[C@@H](C)C(=O)C[C@@H]5O[C@H]4C3)[C@H](C2)N(C)C)C[C@]1(O)CC)[C@H]1C[C@H](N(C)C)[C@H](O)[C@H](C)O1 JXVAMODRWBNUSF-KZQKBALLSA-N 0.000 description 1
- INAUWOVKEZHHDM-PEDBPRJASA-N (7s,9s)-6,9,11-trihydroxy-9-(2-hydroxyacetyl)-7-[(2r,4s,5s,6s)-5-hydroxy-6-methyl-4-morpholin-4-yloxan-2-yl]oxy-4-methoxy-8,10-dihydro-7h-tetracene-5,12-dione;hydrochloride Chemical compound Cl.N1([C@H]2C[C@@H](O[C@@H](C)[C@H]2O)O[C@H]2C[C@@](O)(CC=3C(O)=C4C(=O)C=5C=CC=C(C=5C(=O)C4=C(O)C=32)OC)C(=O)CO)CCOCC1 INAUWOVKEZHHDM-PEDBPRJASA-N 0.000 description 1
- RCFNNLSZHVHCEK-IMHLAKCZSA-N (7s,9s)-7-(4-amino-6-methyloxan-2-yl)oxy-6,9,11-trihydroxy-9-(2-hydroxyacetyl)-4-methoxy-8,10-dihydro-7h-tetracene-5,12-dione;hydrochloride Chemical compound [Cl-].O([C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(=O)CO)C1CC([NH3+])CC(C)O1 RCFNNLSZHVHCEK-IMHLAKCZSA-N 0.000 description 1
- FPVKHBSQESCIEP-UHFFFAOYSA-N (8S)-3-(2-deoxy-beta-D-erythro-pentofuranosyl)-3,6,7,8-tetrahydroimidazo[4,5-d][1,3]diazepin-8-ol Natural products C1C(O)C(CO)OC1N1C(NC=NCC2O)=C2N=C1 FPVKHBSQESCIEP-UHFFFAOYSA-N 0.000 description 1
- IEXUMDBQLIVNHZ-YOUGDJEHSA-N (8s,11r,13r,14s,17s)-11-[4-(dimethylamino)phenyl]-17-hydroxy-17-(3-hydroxypropyl)-13-methyl-1,2,6,7,8,11,12,14,15,16-decahydrocyclopenta[a]phenanthren-3-one Chemical compound C1=CC(N(C)C)=CC=C1[C@@H]1C2=C3CCC(=O)C=C3CC[C@H]2[C@H](CC[C@]2(O)CCCO)[C@@]2(C)C1 IEXUMDBQLIVNHZ-YOUGDJEHSA-N 0.000 description 1
- FDKXTQMXEQVLRF-ZHACJKMWSA-N (E)-dacarbazine Chemical compound CN(C)\N=N\c1[nH]cnc1C(N)=O FDKXTQMXEQVLRF-ZHACJKMWSA-N 0.000 description 1
- LKJPYSCBVHEWIU-KRWDZBQOSA-N (R)-bicalutamide Chemical compound C([C@@](O)(C)C(=O)NC=1C=C(C(C#N)=CC=1)C(F)(F)F)S(=O)(=O)C1=CC=C(F)C=C1 LKJPYSCBVHEWIU-KRWDZBQOSA-N 0.000 description 1
- AGNGYMCLFWQVGX-AGFFZDDWSA-N (e)-1-[(2s)-2-amino-2-carboxyethoxy]-2-diazonioethenolate Chemical compound OC(=O)[C@@H](N)CO\C([O-])=C\[N+]#N AGNGYMCLFWQVGX-AGFFZDDWSA-N 0.000 description 1
- KQODQNJLJQHFQV-MKWZWQCGSA-N (e,4s)-4-[[(2s)-3,3-dimethyl-2-[[(2s)-3-methyl-2-(methylamino)-3-(1-methylindol-3-yl)butanoyl]amino]butanoyl]-methylamino]-2,5-dimethylhex-2-enoic acid Chemical compound C1=CC=C2C(C(C)(C)[C@@H](C(=O)N[C@H](C(=O)N(C)[C@H](\C=C(/C)C(O)=O)C(C)C)C(C)(C)C)NC)=CN(C)C2=C1 KQODQNJLJQHFQV-MKWZWQCGSA-N 0.000 description 1
- FONKWHRXTPJODV-DNQXCXABSA-N 1,3-bis[2-[(8s)-8-(chloromethyl)-4-hydroxy-1-methyl-7,8-dihydro-3h-pyrrolo[3,2-e]indole-6-carbonyl]-1h-indol-5-yl]urea Chemical compound C1([C@H](CCl)CN2C(=O)C=3NC4=CC=C(C=C4C=3)NC(=O)NC=3C=C4C=C(NC4=CC=3)C(=O)N3C4=CC(O)=C5NC=C(C5=C4[C@H](CCl)C3)C)=C2C=C(O)C2=C1C(C)=CN2 FONKWHRXTPJODV-DNQXCXABSA-N 0.000 description 1
- ITWBWJFEJCHKSN-UHFFFAOYSA-N 1,4,7-triazonane Chemical compound C1CNCCNCCN1 ITWBWJFEJCHKSN-UHFFFAOYSA-N 0.000 description 1
- DWZAEMINVBZMHQ-UHFFFAOYSA-N 1-[4-[4-(dimethylamino)piperidine-1-carbonyl]phenyl]-3-[4-(4,6-dimorpholin-4-yl-1,3,5-triazin-2-yl)phenyl]urea Chemical compound C1CC(N(C)C)CCN1C(=O)C(C=C1)=CC=C1NC(=O)NC1=CC=C(C=2N=C(N=C(N=2)N2CCOCC2)N2CCOCC2)C=C1 DWZAEMINVBZMHQ-UHFFFAOYSA-N 0.000 description 1
- PZNPLUBHRSSFHT-RRHRGVEJSA-N 1-hexadecanoyl-2-octadecanoyl-sn-glycero-3-phosphocholine Chemical compound CCCCCCCCCCCCCCCCCC(=O)O[C@@H](COP([O-])(=O)OCC[N+](C)(C)C)COC(=O)CCCCCCCCCCCCCCC PZNPLUBHRSSFHT-RRHRGVEJSA-N 0.000 description 1
- BTOTXLJHDSNXMW-POYBYMJQSA-N 2,3-dideoxyuridine Chemical compound O1[C@H](CO)CC[C@@H]1N1C(=O)NC(=O)C=C1 BTOTXLJHDSNXMW-POYBYMJQSA-N 0.000 description 1
- BOMZMNZEXMAQQW-UHFFFAOYSA-N 2,5,11-trimethyl-6h-pyrido[4,3-b]carbazol-2-ium-9-ol;acetate Chemical compound CC([O-])=O.C[N+]1=CC=C2C(C)=C(NC=3C4=CC(O)=CC=3)C4=C(C)C2=C1 BOMZMNZEXMAQQW-UHFFFAOYSA-N 0.000 description 1
- GVJXGCIPWAVXJP-UHFFFAOYSA-N 2,5-dioxo-1-oxoniopyrrolidine-3-sulfonate Chemical compound ON1C(=O)CC(S(O)(=O)=O)C1=O GVJXGCIPWAVXJP-UHFFFAOYSA-N 0.000 description 1
- FALRKNHUBBKYCC-UHFFFAOYSA-N 2-(chloromethyl)pyridine-3-carbonitrile Chemical compound ClCC1=NC=CC=C1C#N FALRKNHUBBKYCC-UHFFFAOYSA-N 0.000 description 1
- RTQWWZBSTRGEAV-PKHIMPSTSA-N 2-[[(2s)-2-[bis(carboxymethyl)amino]-3-[4-(methylcarbamoylamino)phenyl]propyl]-[2-[bis(carboxymethyl)amino]propyl]amino]acetic acid Chemical compound CNC(=O)NC1=CC=C(C[C@@H](CN(CC(C)N(CC(O)=O)CC(O)=O)CC(O)=O)N(CC(O)=O)CC(O)=O)C=C1 RTQWWZBSTRGEAV-PKHIMPSTSA-N 0.000 description 1
- QCXJFISCRQIYID-IAEPZHFASA-N 2-amino-1-n-[(3s,6s,7r,10s,16s)-3-[(2s)-butan-2-yl]-7,11,14-trimethyl-2,5,9,12,15-pentaoxo-10-propan-2-yl-8-oxa-1,4,11,14-tetrazabicyclo[14.3.0]nonadecan-6-yl]-4,6-dimethyl-3-oxo-9-n-[(3s,6s,7r,10s,16s)-7,11,14-trimethyl-2,5,9,12,15-pentaoxo-3,10-di(propa Chemical compound C[C@H]1OC(=O)[C@H](C(C)C)N(C)C(=O)CN(C)C(=O)[C@@H]2CCCN2C(=O)[C@H](C(C)C)NC(=O)[C@H]1NC(=O)C1=C(N=C2C(C(=O)N[C@@H]3C(=O)N[C@H](C(N4CCC[C@H]4C(=O)N(C)CC(=O)N(C)[C@@H](C(C)C)C(=O)O[C@@H]3C)=O)[C@@H](C)CC)=C(N)C(=O)C(C)=C2O2)C2=C(C)C=C1 QCXJFISCRQIYID-IAEPZHFASA-N 0.000 description 1
- 125000000979 2-amino-2-oxoethyl group Chemical group [H]C([*])([H])C(=O)N([H])[H] 0.000 description 1
- KGTRXRJMKPFFHY-UHFFFAOYSA-N 2-amino-3,7-dihydropurine-6-thione;3,7-dihydropurine-6-thione Chemical compound S=C1N=CNC2=C1NC=N2.S=C1NC(N)=NC2=C1NC=N2 KGTRXRJMKPFFHY-UHFFFAOYSA-N 0.000 description 1
- FDAYLTPAFBGXAB-UHFFFAOYSA-N 2-chloro-n,n-bis(2-chloroethyl)ethanamine Chemical compound ClCCN(CCCl)CCCl FDAYLTPAFBGXAB-UHFFFAOYSA-N 0.000 description 1
- YIMDLWDNDGKDTJ-QLKYHASDSA-N 3'-deamino-3'-(3-cyanomorpholin-4-yl)doxorubicin Chemical compound N1([C@H]2C[C@@H](O[C@@H](C)[C@H]2O)O[C@H]2C[C@@](O)(CC=3C(O)=C4C(=O)C=5C=CC=C(C=5C(=O)C4=C(O)C=32)OC)C(=O)CO)CCOCC1C#N YIMDLWDNDGKDTJ-QLKYHASDSA-N 0.000 description 1
- UAIUNKRWKOVEES-UHFFFAOYSA-N 3,3',5,5'-tetramethylbenzidine Chemical compound CC1=C(N)C(C)=CC(C=2C=C(C)C(N)=C(C)C=2)=C1 UAIUNKRWKOVEES-UHFFFAOYSA-N 0.000 description 1
- NDMPLJNOPCLANR-UHFFFAOYSA-N 3,4-dihydroxy-15-(4-hydroxy-18-methoxycarbonyl-5,18-seco-ibogamin-18-yl)-16-methoxy-1-methyl-6,7-didehydro-aspidospermidine-3-carboxylic acid methyl ester Natural products C1C(CC)(O)CC(CC2(C(=O)OC)C=3C(=CC4=C(C56C(C(C(O)C7(CC)C=CCN(C67)CC5)(O)C(=O)OC)N4C)C=3)OC)CN1CCC1=C2NC2=CC=CC=C12 NDMPLJNOPCLANR-UHFFFAOYSA-N 0.000 description 1
- PWMYMKOUNYTVQN-UHFFFAOYSA-N 3-(8,8-diethyl-2-aza-8-germaspiro[4.5]decan-2-yl)-n,n-dimethylpropan-1-amine Chemical compound C1C[Ge](CC)(CC)CCC11CN(CCCN(C)C)CC1 PWMYMKOUNYTVQN-UHFFFAOYSA-N 0.000 description 1
- VXGRJERITKFWPL-UHFFFAOYSA-N 4',5'-Dihydropsoralen Natural products C1=C2OC(=O)C=CC2=CC2=C1OCC2 VXGRJERITKFWPL-UHFFFAOYSA-N 0.000 description 1
- AOJJSUZBOXZQNB-VTZDEGQISA-N 4'-epidoxorubicin Chemical compound O([C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(=O)CO)[C@H]1C[C@H](N)[C@@H](O)[C@H](C)O1 AOJJSUZBOXZQNB-VTZDEGQISA-N 0.000 description 1
- CLPFFLWZZBQMAO-UHFFFAOYSA-N 4-(5,6,7,8-tetrahydroimidazo[1,5-a]pyridin-5-yl)benzonitrile Chemical compound C1=CC(C#N)=CC=C1C1N2C=NC=C2CCC1 CLPFFLWZZBQMAO-UHFFFAOYSA-N 0.000 description 1
- DODQJNMQWMSYGS-QPLCGJKRSA-N 4-[(z)-1-[4-[2-(dimethylamino)ethoxy]phenyl]-1-phenylbut-1-en-2-yl]phenol Chemical compound C=1C=C(O)C=CC=1C(/CC)=C(C=1C=CC(OCCN(C)C)=CC=1)/C1=CC=CC=C1 DODQJNMQWMSYGS-QPLCGJKRSA-N 0.000 description 1
- FWMNVWWHGCHHJJ-SKKKGAJSSA-N 4-amino-1-[(2r)-6-amino-2-[[(2r)-2-[[(2r)-2-[[(2r)-2-amino-3-phenylpropanoyl]amino]-3-phenylpropanoyl]amino]-4-methylpentanoyl]amino]hexanoyl]piperidine-4-carboxylic acid Chemical compound C([C@H](C(=O)N[C@H](CC(C)C)C(=O)N[C@H](CCCCN)C(=O)N1CCC(N)(CC1)C(O)=O)NC(=O)[C@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 FWMNVWWHGCHHJJ-SKKKGAJSSA-N 0.000 description 1
- TVZGACDUOSZQKY-LBPRGKRZSA-N 4-aminofolic acid Chemical compound C1=NC2=NC(N)=NC(N)=C2N=C1CNC1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 TVZGACDUOSZQKY-LBPRGKRZSA-N 0.000 description 1
- 150000005007 4-aminopyrimidines Chemical class 0.000 description 1
- IDPUKCWIGUEADI-UHFFFAOYSA-N 5-[bis(2-chloroethyl)amino]uracil Chemical compound ClCCN(CCCl)C1=CNC(=O)NC1=O IDPUKCWIGUEADI-UHFFFAOYSA-N 0.000 description 1
- NMUSYJAQQFHJEW-KVTDHHQDSA-N 5-azacytidine Chemical compound O=C1N=C(N)N=CN1[C@H]1[C@H](O)[C@H](O)[C@@H](CO)O1 NMUSYJAQQFHJEW-KVTDHHQDSA-N 0.000 description 1
- NJYVEMPWNAYQQN-UHFFFAOYSA-N 5-carboxyfluorescein Chemical compound C12=CC=C(O)C=C2OC2=CC(O)=CC=C2C21OC(=O)C1=CC(C(=O)O)=CC=C21 NJYVEMPWNAYQQN-UHFFFAOYSA-N 0.000 description 1
- YMZMTOFQCVHHFB-UHFFFAOYSA-N 5-carboxytetramethylrhodamine Chemical compound C=12C=CC(N(C)C)=CC2=[O+]C2=CC(N(C)C)=CC=C2C=1C1=CC=C(C(O)=O)C=C1C([O-])=O YMZMTOFQCVHHFB-UHFFFAOYSA-N 0.000 description 1
- 229940117976 5-hydroxylysine Drugs 0.000 description 1
- WYWHKKSPHMUBEB-UHFFFAOYSA-N 6-Mercaptoguanine Natural products N1C(N)=NC(=S)C2=C1N=CN2 WYWHKKSPHMUBEB-UHFFFAOYSA-N 0.000 description 1
- WYXSYVWAUAUWLD-SHUUEZRQSA-N 6-azauridine Chemical compound O[C@@H]1[C@H](O)[C@@H](CO)O[C@H]1N1C(=O)NC(=O)C=N1 WYXSYVWAUAUWLD-SHUUEZRQSA-N 0.000 description 1
- BZTDTCNHAFUJOG-UHFFFAOYSA-N 6-carboxyfluorescein Chemical compound C12=CC=C(O)C=C2OC2=CC(O)=CC=C2C11OC(=O)C2=CC=C(C(=O)O)C=C21 BZTDTCNHAFUJOG-UHFFFAOYSA-N 0.000 description 1
- 229960005538 6-diazo-5-oxo-L-norleucine Drugs 0.000 description 1
- YCWQAMGASJSUIP-YFKPBYRVSA-N 6-diazo-5-oxo-L-norleucine Chemical compound OC(=O)[C@@H](N)CCC(=O)C=[N+]=[N-] YCWQAMGASJSUIP-YFKPBYRVSA-N 0.000 description 1
- YXHLJMWYDTXDHS-IRFLANFNSA-N 7-aminoactinomycin D Chemical compound C[C@H]1OC(=O)[C@H](C(C)C)N(C)C(=O)CN(C)C(=O)[C@@H]2CCCN2C(=O)[C@@H](C(C)C)NC(=O)[C@H]1NC(=O)C1=C(N)C(=O)C(C)=C2OC(C(C)=C(N)C=C3C(=O)N[C@@H]4C(=O)N[C@@H](C(N5CCC[C@H]5C(=O)N(C)CC(=O)N(C)[C@@H](C(C)C)C(=O)O[C@@H]4C)=O)C(C)C)=C3N=C21 YXHLJMWYDTXDHS-IRFLANFNSA-N 0.000 description 1
- 108700012813 7-aminoactinomycin D Proteins 0.000 description 1
- ZGXJTSGNIOSYLO-UHFFFAOYSA-N 88755TAZ87 Chemical compound NCC(=O)CCC(O)=O ZGXJTSGNIOSYLO-UHFFFAOYSA-N 0.000 description 1
- 102100031585 ADP-ribosyl cyclase/cyclic ADP-ribose hydrolase 1 Human genes 0.000 description 1
- 108060000255 AIM2 Proteins 0.000 description 1
- 102100032814 ATP-dependent zinc metalloprotease YME1L1 Human genes 0.000 description 1
- 208000035657 Abasia Diseases 0.000 description 1
- 208000026872 Addison Disease Diseases 0.000 description 1
- 206010067484 Adverse reaction Diseases 0.000 description 1
- 208000008190 Agammaglobulinemia Diseases 0.000 description 1
- 229920000936 Agarose Polymers 0.000 description 1
- NHLAEBFGWPXFGI-WHFBIAKZSA-N Ala-Gly-Asn Chemical compound C[C@@H](C(=O)NCC(=O)N[C@@H](CC(=O)N)C(=O)O)N NHLAEBFGWPXFGI-WHFBIAKZSA-N 0.000 description 1
- 102000009027 Albumins Human genes 0.000 description 1
- 108010088751 Albumins Proteins 0.000 description 1
- 241000545417 Aleurites Species 0.000 description 1
- 239000012099 Alexa Fluor family Substances 0.000 description 1
- 235000019489 Almond oil Nutrition 0.000 description 1
- GUBGYTABKSRVRQ-XLOQQCSPSA-N Alpha-Lactose Chemical compound O[C@@H]1[C@@H](O)[C@@H](O)[C@@H](CO)O[C@H]1O[C@@H]1[C@@H](CO)O[C@H](O)[C@H](O)[C@H]1O GUBGYTABKSRVRQ-XLOQQCSPSA-N 0.000 description 1
- 241000710929 Alphavirus Species 0.000 description 1
- CEIZFXOZIQNICU-UHFFFAOYSA-N Alternaria alternata Crofton-weed toxin Natural products CCC(C)C1NC(=O)C(C(C)=O)=C1O CEIZFXOZIQNICU-UHFFFAOYSA-N 0.000 description 1
- 102000013142 Amylases Human genes 0.000 description 1
- 108010065511 Amylases Proteins 0.000 description 1
- 206010002556 Ankylosing Spondylitis Diseases 0.000 description 1
- 208000003343 Antiphospholipid Syndrome Diseases 0.000 description 1
- 208000001839 Antisynthetase syndrome Diseases 0.000 description 1
- 101100099626 Arabidopsis thaliana TIK gene Proteins 0.000 description 1
- 239000004475 Arginine Substances 0.000 description 1
- BFYIZQONLCFLEV-DAELLWKTSA-N Aromasine Chemical compound O=C1C=C[C@]2(C)[C@H]3CC[C@](C)(C(CC4)=O)[C@@H]4[C@@H]3CC(=C)C2=C1 BFYIZQONLCFLEV-DAELLWKTSA-N 0.000 description 1
- 108010078554 Aromatase Proteins 0.000 description 1
- 206010003267 Arthritis reactive Diseases 0.000 description 1
- DCXYFEDJOCDNAF-UHFFFAOYSA-N Asparagine Natural products OC(=O)C(N)CC(N)=O DCXYFEDJOCDNAF-UHFFFAOYSA-N 0.000 description 1
- 206010003645 Atopy Diseases 0.000 description 1
- 101710192393 Attachment protein G3P Proteins 0.000 description 1
- 241000972773 Aulopiformes Species 0.000 description 1
- 206010003827 Autoimmune hepatitis Diseases 0.000 description 1
- 208000000659 Autoimmune lymphoproliferative syndrome Diseases 0.000 description 1
- 206010069002 Autoimmune pancreatitis Diseases 0.000 description 1
- 108090001008 Avidin Proteins 0.000 description 1
- NOWKCMXCCJGMRR-UHFFFAOYSA-N Aziridine Chemical class C1CN1 NOWKCMXCCJGMRR-UHFFFAOYSA-N 0.000 description 1
- 102100029822 B- and T-lymphocyte attenuator Human genes 0.000 description 1
- 108010012919 B-Cell Antigen Receptors Proteins 0.000 description 1
- 102000019260 B-Cell Antigen Receptors Human genes 0.000 description 1
- 108010074708 B7-H1 Antigen Proteins 0.000 description 1
- 229940123944 B7-H3 antagonist Drugs 0.000 description 1
- 229940116375 B7-H4 antagonist Drugs 0.000 description 1
- FTEDXVNDVHYDQW-UHFFFAOYSA-N BAPTA Chemical compound OC(=O)CN(CC(O)=O)C1=CC=CC=C1OCCOC1=CC=CC=C1N(CC(O)=O)CC(O)=O FTEDXVNDVHYDQW-UHFFFAOYSA-N 0.000 description 1
- 229940125565 BMS-986016 Drugs 0.000 description 1
- 235000014469 Bacillus subtilis Nutrition 0.000 description 1
- 102100021676 Baculoviral IAP repeat-containing protein 1 Human genes 0.000 description 1
- 208000023328 Basedow disease Diseases 0.000 description 1
- 208000027496 Behcet disease Diseases 0.000 description 1
- VGGGPCQERPFHOB-MCIONIFRSA-N Bestatin Chemical compound CC(C)C[C@H](C(O)=O)NC(=O)[C@@H](O)[C@H](N)CC1=CC=CC=C1 VGGGPCQERPFHOB-MCIONIFRSA-N 0.000 description 1
- 229920002498 Beta-glucan Polymers 0.000 description 1
- 208000008439 Biliary Liver Cirrhosis Diseases 0.000 description 1
- 208000033222 Biliary cirrhosis primary Diseases 0.000 description 1
- 229940122361 Bisphosphonate Drugs 0.000 description 1
- 108010006654 Bleomycin Proteins 0.000 description 1
- 229920002799 BoPET Polymers 0.000 description 1
- 206010005949 Bone cancer Diseases 0.000 description 1
- 208000018084 Bone neoplasm Diseases 0.000 description 1
- ZOXJGFHDIHLPTG-UHFFFAOYSA-N Boron Chemical compound [B] ZOXJGFHDIHLPTG-UHFFFAOYSA-N 0.000 description 1
- 241000283690 Bos taurus Species 0.000 description 1
- 208000003174 Brain Neoplasms Diseases 0.000 description 1
- MBABCNBNDNGODA-LTGLSHGVSA-N Bullatacin Natural products O=C1C(C[C@H](O)CCCCCCCCCC[C@@H](O)[C@@H]2O[C@@H]([C@@H]3O[C@H]([C@@H](O)CCCCCCCCCC)CC3)CC2)=C[C@H](C)O1 MBABCNBNDNGODA-LTGLSHGVSA-N 0.000 description 1
- KGGVWMAPBXIMEM-ZRTAFWODSA-N Bullatacinone Chemical compound O1[C@@H]([C@@H](O)CCCCCCCCCC)CC[C@@H]1[C@@H]1O[C@@H]([C@H](O)CCCCCCCCCC[C@H]2OC(=O)[C@H](CC(C)=O)C2)CC1 KGGVWMAPBXIMEM-ZRTAFWODSA-N 0.000 description 1
- KGGVWMAPBXIMEM-JQFCFGFHSA-N Bullatacinone Natural products O=C(C[C@H]1C(=O)O[C@H](CCCCCCCCCC[C@H](O)[C@@H]2O[C@@H]([C@@H]3O[C@@H]([C@@H](O)CCCCCCCCCC)CC3)CC2)C1)C KGGVWMAPBXIMEM-JQFCFGFHSA-N 0.000 description 1
- COVZYZSDYWQREU-UHFFFAOYSA-N Busulfan Chemical compound CS(=O)(=O)OCCCCOS(C)(=O)=O COVZYZSDYWQREU-UHFFFAOYSA-N 0.000 description 1
- 102100027140 Butyrophilin subfamily 1 member A1 Human genes 0.000 description 1
- 102100028989 C-X-C chemokine receptor type 2 Human genes 0.000 description 1
- 101710183446 C-type lectin domain family 4 member E Proteins 0.000 description 1
- 102100040839 C-type lectin domain family 6 member A Human genes 0.000 description 1
- 101710125370 C-type lectin domain family 6 member A Proteins 0.000 description 1
- 102100040840 C-type lectin domain family 7 member A Human genes 0.000 description 1
- 102100039521 C-type lectin domain family 9 member A Human genes 0.000 description 1
- 108700012439 CA9 Proteins 0.000 description 1
- 102100024263 CD160 antigen Human genes 0.000 description 1
- 102100038077 CD226 antigen Human genes 0.000 description 1
- 102100027207 CD27 antigen Human genes 0.000 description 1
- 229940123205 CD28 agonist Drugs 0.000 description 1
- 108010029697 CD40 Ligand Proteins 0.000 description 1
- 102100032937 CD40 ligand Human genes 0.000 description 1
- 108010038940 CD48 Antigen Proteins 0.000 description 1
- 102100036008 CD48 antigen Human genes 0.000 description 1
- 108010062802 CD66 antigens Proteins 0.000 description 1
- 102100025221 CD70 antigen Human genes 0.000 description 1
- 102100024152 Cadherin-17 Human genes 0.000 description 1
- OYPRJOBELJOOCE-UHFFFAOYSA-N Calcium Chemical compound [Ca] OYPRJOBELJOOCE-UHFFFAOYSA-N 0.000 description 1
- UXVMQQNJUSDDNG-UHFFFAOYSA-L Calcium chloride Chemical compound [Cl-].[Cl-].[Ca+2] UXVMQQNJUSDDNG-UHFFFAOYSA-L 0.000 description 1
- 241000282465 Canis Species 0.000 description 1
- 101710158575 Cap-specific mRNA (nucleoside-2'-O-)-methyltransferase Proteins 0.000 description 1
- 101710169873 Capsid protein G8P Proteins 0.000 description 1
- 102100024423 Carbonic anhydrase 9 Human genes 0.000 description 1
- SHHKQEUPHAENFK-UHFFFAOYSA-N Carboquone Chemical compound O=C1C(C)=C(N2CC2)C(=O)C(C(COC(N)=O)OC)=C1N1CC1 SHHKQEUPHAENFK-UHFFFAOYSA-N 0.000 description 1
- 102100024533 Carcinoembryonic antigen-related cell adhesion molecule 1 Human genes 0.000 description 1
- 102100025466 Carcinoembryonic antigen-related cell adhesion molecule 3 Human genes 0.000 description 1
- 102100025472 Carcinoembryonic antigen-related cell adhesion molecule 4 Human genes 0.000 description 1
- 102100025475 Carcinoembryonic antigen-related cell adhesion molecule 5 Human genes 0.000 description 1
- 102100025473 Carcinoembryonic antigen-related cell adhesion molecule 6 Human genes 0.000 description 1
- 102100025470 Carcinoembryonic antigen-related cell adhesion molecule 8 Human genes 0.000 description 1
- DLGOEMSEDOSKAD-UHFFFAOYSA-N Carmustine Chemical compound ClCCNC(=O)N(N=O)CCCl DLGOEMSEDOSKAD-UHFFFAOYSA-N 0.000 description 1
- 208000005024 Castleman disease Diseases 0.000 description 1
- 231100000023 Cell-mediated cytotoxicity Toxicity 0.000 description 1
- 206010057250 Cell-mediated cytotoxicity Diseases 0.000 description 1
- 206010008342 Cervix carcinoma Diseases 0.000 description 1
- 108091007741 Chimeric antigen receptor T cells Proteins 0.000 description 1
- JWBOIMRXGHLCPP-UHFFFAOYSA-N Chloditan Chemical compound C=1C=CC=C(Cl)C=1C(C(Cl)Cl)C1=CC=C(Cl)C=C1 JWBOIMRXGHLCPP-UHFFFAOYSA-N 0.000 description 1
- XCDXSSFOJZZGQC-UHFFFAOYSA-N Chlornaphazine Chemical compound C1=CC=CC2=CC(N(CCCl)CCCl)=CC=C21 XCDXSSFOJZZGQC-UHFFFAOYSA-N 0.000 description 1
- MKQWTWSXVILIKJ-LXGUWJNJSA-N Chlorozotocin Chemical compound OC[C@@H](O)[C@@H](O)[C@H](O)[C@H](C=O)NC(=O)N(N=O)CCCl MKQWTWSXVILIKJ-LXGUWJNJSA-N 0.000 description 1
- 241000251730 Chondrichthyes Species 0.000 description 1
- 208000006332 Choriocarcinoma Diseases 0.000 description 1
- KRKNYBCHXYNGOX-UHFFFAOYSA-K Citrate Chemical compound [O-]C(=O)CC(O)(CC([O-])=O)C([O-])=O KRKNYBCHXYNGOX-UHFFFAOYSA-K 0.000 description 1
- 108700010070 Codon Usage Proteins 0.000 description 1
- 208000015943 Coeliac disease Diseases 0.000 description 1
- 208000011038 Cold agglutinin disease Diseases 0.000 description 1
- 206010009868 Cold type haemolytic anaemia Diseases 0.000 description 1
- 206010009900 Colitis ulcerative Diseases 0.000 description 1
- 206010009944 Colon cancer Diseases 0.000 description 1
- 102000007644 Colony-Stimulating Factors Human genes 0.000 description 1
- 108010071942 Colony-Stimulating Factors Proteins 0.000 description 1
- 208000035473 Communicable disease Diseases 0.000 description 1
- 108020004635 Complementary DNA Proteins 0.000 description 1
- 108091035707 Consensus sequence Proteins 0.000 description 1
- 229920002261 Corn starch Polymers 0.000 description 1
- 241000699802 Cricetulus griseus Species 0.000 description 1
- 208000011231 Crohn disease Diseases 0.000 description 1
- 108700032819 Croton tiglium crotin II Proteins 0.000 description 1
- 229930188224 Cryptophycin Natural products 0.000 description 1
- PMATZTZNYRCHOR-CGLBZJNRSA-N Cyclosporin A Chemical compound CC[C@@H]1NC(=O)[C@H]([C@H](O)[C@H](C)C\C=C\C)N(C)C(=O)[C@H](C(C)C)N(C)C(=O)[C@H](CC(C)C)N(C)C(=O)[C@H](CC(C)C)N(C)C(=O)[C@@H](C)NC(=O)[C@H](C)NC(=O)[C@H](CC(C)C)N(C)C(=O)[C@H](C(C)C)NC(=O)[C@H](CC(C)C)N(C)C(=O)CN(C)C1=O PMATZTZNYRCHOR-CGLBZJNRSA-N 0.000 description 1
- 229930105110 Cyclosporin A Natural products 0.000 description 1
- 108010036949 Cyclosporine Proteins 0.000 description 1
- HAIWUXASLYEWLM-UHFFFAOYSA-N D-manno-Heptulose Natural products OCC1OC(O)(CO)C(O)C(O)C1O HAIWUXASLYEWLM-UHFFFAOYSA-N 0.000 description 1
- WQZGKKKJIJFFOK-QTVWNMPRSA-N D-mannopyranose Chemical compound OC[C@H]1OC(O)[C@@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-QTVWNMPRSA-N 0.000 description 1
- HMFHBZSHGGEWLO-SOOFDHNKSA-N D-ribofuranose Chemical compound OC[C@H]1OC(O)[C@H](O)[C@@H]1O HMFHBZSHGGEWLO-SOOFDHNKSA-N 0.000 description 1
- 108010037897 DC-specific ICAM-3 grabbing nonintegrin Proteins 0.000 description 1
- 102000016928 DNA-directed DNA polymerase Human genes 0.000 description 1
- 108010014303 DNA-directed DNA polymerase Proteins 0.000 description 1
- 108090000626 DNA-directed RNA polymerases Proteins 0.000 description 1
- 102000004163 DNA-directed RNA polymerases Human genes 0.000 description 1
- WEAHRLBPCANXCN-UHFFFAOYSA-N Daunomycin Natural products CCC1(O)CC(OC2CC(N)C(O)C(C)O2)c3cc4C(=O)c5c(OC)cccc5C(=O)c4c(O)c3C1 WEAHRLBPCANXCN-UHFFFAOYSA-N 0.000 description 1
- 102100036466 Delta-like protein 3 Human genes 0.000 description 1
- 102100033553 Delta-like protein 4 Human genes 0.000 description 1
- 108010008532 Deoxyribonuclease I Proteins 0.000 description 1
- 102100030012 Deoxyribonuclease-1 Human genes 0.000 description 1
- 108010002156 Depsipeptides Proteins 0.000 description 1
- 206010012438 Dermatitis atopic Diseases 0.000 description 1
- 229920001353 Dextrin Polymers 0.000 description 1
- 239000004375 Dextrin Substances 0.000 description 1
- AUGQEEXBDZWUJY-ZLJUKNTDSA-N Diacetoxyscirpenol Chemical compound C([C@]12[C@]3(C)[C@H](OC(C)=O)[C@@H](O)[C@H]1O[C@@H]1C=C(C)CC[C@@]13COC(=O)C)O2 AUGQEEXBDZWUJY-ZLJUKNTDSA-N 0.000 description 1
- AUGQEEXBDZWUJY-UHFFFAOYSA-N Diacetoxyscirpenol Natural products CC(=O)OCC12CCC(C)=CC1OC1C(O)C(OC(C)=O)C2(C)C11CO1 AUGQEEXBDZWUJY-UHFFFAOYSA-N 0.000 description 1
- 235000019739 Dicalciumphosphate Nutrition 0.000 description 1
- 108010053187 Diphtheria Toxin Proteins 0.000 description 1
- 102000016607 Diphtheria Toxin Human genes 0.000 description 1
- SNRUBQQJIBEYMU-UHFFFAOYSA-N Dodecane Natural products CCCCCCCCCCCC SNRUBQQJIBEYMU-UHFFFAOYSA-N 0.000 description 1
- ZQZFYGIXNQKOAV-OCEACIFDSA-N Droloxifene Chemical compound C=1C=CC=CC=1C(/CC)=C(C=1C=C(O)C=CC=1)\C1=CC=C(OCCN(C)C)C=C1 ZQZFYGIXNQKOAV-OCEACIFDSA-N 0.000 description 1
- 238000012286 ELISA Assay Methods 0.000 description 1
- 101000895909 Elizabethkingia meningoseptica Endo-beta-N-acetylglucosaminidase F1 Proteins 0.000 description 1
- 101000895912 Elizabethkingia meningoseptica Endo-beta-N-acetylglucosaminidase F2 Proteins 0.000 description 1
- 101000895922 Elizabethkingia meningoseptica Endo-beta-N-acetylglucosaminidase F3 Proteins 0.000 description 1
- 102100038083 Endosialin Human genes 0.000 description 1
- 101710144543 Endosialin Proteins 0.000 description 1
- SAMRUMKYXPVKPA-VFKOLLTISA-N Enocitabine Chemical compound O=C1N=C(NC(=O)CCCCCCCCCCCCCCCCCCCCC)C=CN1[C@H]1[C@@H](O)[C@H](O)[C@@H](CO)O1 SAMRUMKYXPVKPA-VFKOLLTISA-N 0.000 description 1
- 206010014954 Eosinophilic fasciitis Diseases 0.000 description 1
- 102100033942 Ephrin-A4 Human genes 0.000 description 1
- 206010066919 Epidemic polyarthritis Diseases 0.000 description 1
- HTIJFSOGRVMCQR-UHFFFAOYSA-N Epirubicin Natural products COc1cccc2C(=O)c3c(O)c4CC(O)(CC(OC5CC(N)C(=O)C(C)O5)c4c(O)c3C(=O)c12)C(=O)CO HTIJFSOGRVMCQR-UHFFFAOYSA-N 0.000 description 1
- OBMLHUPNRURLOK-XGRAFVIBSA-N Epitiostanol Chemical compound C1[C@@H]2S[C@@H]2C[C@]2(C)[C@H]3CC[C@](C)([C@H](CC4)O)[C@@H]4[C@@H]3CC[C@H]21 OBMLHUPNRURLOK-XGRAFVIBSA-N 0.000 description 1
- 102000003951 Erythropoietin Human genes 0.000 description 1
- 108090000394 Erythropoietin Proteins 0.000 description 1
- 208000000461 Esophageal Neoplasms Diseases 0.000 description 1
- 229930189413 Esperamicin Natural products 0.000 description 1
- 108010008165 Etanercept Proteins 0.000 description 1
- JOYRKODLDBILNP-UHFFFAOYSA-N Ethyl urethane Chemical compound CCOC(N)=O JOYRKODLDBILNP-UHFFFAOYSA-N 0.000 description 1
- 108010021468 Fc gamma receptor IIA Proteins 0.000 description 1
- 229920001917 Ficoll Polymers 0.000 description 1
- 241000724791 Filamentous phage Species 0.000 description 1
- 208000003098 Ganglion Cysts Diseases 0.000 description 1
- 108010010803 Gelatin Proteins 0.000 description 1
- JRZJKWGQFNTSRN-UHFFFAOYSA-N Geldanamycin Natural products C1C(C)CC(OC)C(O)C(C)C=C(C)C(OC(N)=O)C(OC)CCC=C(C)C(=O)NC2=CC(=O)C(OC)=C1C2=O JRZJKWGQFNTSRN-UHFFFAOYSA-N 0.000 description 1
- 108700004714 Gelonium multiflorum GEL Proteins 0.000 description 1
- 208000007465 Giant cell arteritis Diseases 0.000 description 1
- 208000032612 Glial tumor Diseases 0.000 description 1
- 206010018338 Glioma Diseases 0.000 description 1
- 229920001503 Glucan Polymers 0.000 description 1
- WHUUTDBJXJRKMK-UHFFFAOYSA-N Glutamic acid Natural products OC(=O)C(N)CCC(O)=O WHUUTDBJXJRKMK-UHFFFAOYSA-N 0.000 description 1
- SXRSQZLOMIGNAQ-UHFFFAOYSA-N Glutaraldehyde Chemical compound O=CCCCC=O SXRSQZLOMIGNAQ-UHFFFAOYSA-N 0.000 description 1
- JZNWSCPGTDBMEW-UHFFFAOYSA-N Glycerophosphorylethanolamin Natural products NCCOP(O)(=O)OCC(O)CO JZNWSCPGTDBMEW-UHFFFAOYSA-N 0.000 description 1
- 244000068988 Glycine max Species 0.000 description 1
- 102000051366 Glycosyltransferases Human genes 0.000 description 1
- 108700023372 Glycosyltransferases Proteins 0.000 description 1
- 208000024869 Goodpasture syndrome Diseases 0.000 description 1
- 108010069236 Goserelin Proteins 0.000 description 1
- BLCLNMBMMGCOAS-URPVMXJPSA-N Goserelin Chemical compound C([C@@H](C(=O)N[C@H](COC(C)(C)C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N1[C@@H](CCC1)C(=O)NNC(N)=O)NC(=O)[C@H](CO)NC(=O)[C@H](CC=1C2=CC=CC=C2NC=1)NC(=O)[C@H](CC=1NC=NC=1)NC(=O)[C@H]1NC(=O)CC1)C1=CC=C(O)C=C1 BLCLNMBMMGCOAS-URPVMXJPSA-N 0.000 description 1
- 208000009329 Graft vs Host Disease Diseases 0.000 description 1
- 206010072579 Granulomatosis with polyangiitis Diseases 0.000 description 1
- 208000015023 Graves' disease Diseases 0.000 description 1
- 240000001080 Grifola frondosa Species 0.000 description 1
- 235000007710 Grifola frondosa Nutrition 0.000 description 1
- 102000009465 Growth Factor Receptors Human genes 0.000 description 1
- 108010009202 Growth Factor Receptors Proteins 0.000 description 1
- 102100022662 Guanylyl cyclase C Human genes 0.000 description 1
- 208000035895 Guillain-Barré syndrome Diseases 0.000 description 1
- 208000031886 HIV Infections Diseases 0.000 description 1
- 208000037357 HIV infectious disease Diseases 0.000 description 1
- 208000016905 Hashimoto encephalopathy Diseases 0.000 description 1
- 208000030836 Hashimoto thyroiditis Diseases 0.000 description 1
- 108090000031 Hedgehog Proteins Proteins 0.000 description 1
- 102000003693 Hedgehog Proteins Human genes 0.000 description 1
- 102100034459 Hepatitis A virus cellular receptor 1 Human genes 0.000 description 1
- 241000238631 Hexapoda Species 0.000 description 1
- 102100026122 High affinity immunoglobulin gamma Fc receptor I Human genes 0.000 description 1
- CUEQQFOGARVNHU-VGDYDELISA-N His-Ser-Ile Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O CUEQQFOGARVNHU-VGDYDELISA-N 0.000 description 1
- 102100038970 Histone-lysine N-methyltransferase EZH2 Human genes 0.000 description 1
- 101000777636 Homo sapiens ADP-ribosyl cyclase/cyclic ADP-ribose hydrolase 1 Proteins 0.000 description 1
- 101000864344 Homo sapiens B- and T-lymphocyte attenuator Proteins 0.000 description 1
- 101000984929 Homo sapiens Butyrophilin subfamily 1 member A1 Proteins 0.000 description 1
- 101000888548 Homo sapiens C-type lectin domain family 9 member A Proteins 0.000 description 1
- 101000761938 Homo sapiens CD160 antigen Proteins 0.000 description 1
- 101000914511 Homo sapiens CD27 antigen Proteins 0.000 description 1
- 101000934356 Homo sapiens CD70 antigen Proteins 0.000 description 1
- 101000762247 Homo sapiens Cadherin-17 Proteins 0.000 description 1
- 101000914337 Homo sapiens Carcinoembryonic antigen-related cell adhesion molecule 3 Proteins 0.000 description 1
- 101000914325 Homo sapiens Carcinoembryonic antigen-related cell adhesion molecule 4 Proteins 0.000 description 1
- 101000914326 Homo sapiens Carcinoembryonic antigen-related cell adhesion molecule 6 Proteins 0.000 description 1
- 101000914320 Homo sapiens Carcinoembryonic antigen-related cell adhesion molecule 8 Proteins 0.000 description 1
- 101000928513 Homo sapiens Delta-like protein 3 Proteins 0.000 description 1
- 101000872077 Homo sapiens Delta-like protein 4 Proteins 0.000 description 1
- 101000925259 Homo sapiens Ephrin-A4 Proteins 0.000 description 1
- 101000899808 Homo sapiens Guanylyl cyclase C Proteins 0.000 description 1
- 101001068136 Homo sapiens Hepatitis A virus cellular receptor 1 Proteins 0.000 description 1
- 101000913074 Homo sapiens High affinity immunoglobulin gamma Fc receptor I Proteins 0.000 description 1
- 101000882127 Homo sapiens Histone-lysine N-methyltransferase EZH2 Proteins 0.000 description 1
- 101000878602 Homo sapiens Immunoglobulin alpha Fc receptor Proteins 0.000 description 1
- 101000606465 Homo sapiens Inactive tyrosine-protein kinase 7 Proteins 0.000 description 1
- 101000998146 Homo sapiens Interleukin-17A Proteins 0.000 description 1
- 101001138062 Homo sapiens Leukocyte-associated immunoglobulin-like receptor 1 Proteins 0.000 description 1
- 101000917858 Homo sapiens Low affinity immunoglobulin gamma Fc region receptor III-A Proteins 0.000 description 1
- 101000917839 Homo sapiens Low affinity immunoglobulin gamma Fc region receptor III-B Proteins 0.000 description 1
- 101001063392 Homo sapiens Lymphocyte function-associated antigen 3 Proteins 0.000 description 1
- 101000577126 Homo sapiens Monocarboxylate transporter 4 Proteins 0.000 description 1
- 101000577129 Homo sapiens Monocarboxylate transporter 5 Proteins 0.000 description 1
- 101001133056 Homo sapiens Mucin-1 Proteins 0.000 description 1
- 101001109501 Homo sapiens NKG2-D type II integral membrane protein Proteins 0.000 description 1
- 101000979572 Homo sapiens NLR family CARD domain-containing protein 4 Proteins 0.000 description 1
- 101001125032 Homo sapiens Nucleotide-binding oligomerization domain-containing protein 1 Proteins 0.000 description 1
- 101001126417 Homo sapiens Platelet-derived growth factor receptor alpha Proteins 0.000 description 1
- 101000617725 Homo sapiens Pregnancy-specific beta-1-glycoprotein 2 Proteins 0.000 description 1
- 101000831286 Homo sapiens Protein timeless homolog Proteins 0.000 description 1
- 101001134801 Homo sapiens Protocadherin beta-2 Proteins 0.000 description 1
- 101000932478 Homo sapiens Receptor-type tyrosine-protein kinase FLT3 Proteins 0.000 description 1
- 101000752245 Homo sapiens Rho guanine nucleotide exchange factor 5 Proteins 0.000 description 1
- 101000633778 Homo sapiens SLAM family member 5 Proteins 0.000 description 1
- 101000633792 Homo sapiens SLAM family member 9 Proteins 0.000 description 1
- 101000984753 Homo sapiens Serine/threonine-protein kinase B-raf Proteins 0.000 description 1
- 101000669511 Homo sapiens T-cell immunoglobulin and mucin domain-containing protein 4 Proteins 0.000 description 1
- 101100207070 Homo sapiens TNFSF8 gene Proteins 0.000 description 1
- 101000847107 Homo sapiens Tetraspanin-8 Proteins 0.000 description 1
- 101000831567 Homo sapiens Toll-like receptor 2 Proteins 0.000 description 1
- 101000669447 Homo sapiens Toll-like receptor 4 Proteins 0.000 description 1
- 101000669460 Homo sapiens Toll-like receptor 5 Proteins 0.000 description 1
- 101000669406 Homo sapiens Toll-like receptor 6 Proteins 0.000 description 1
- 101000800479 Homo sapiens Toll-like receptor 9 Proteins 0.000 description 1
- 101000798700 Homo sapiens Transmembrane protease serine 3 Proteins 0.000 description 1
- 101000798702 Homo sapiens Transmembrane protease serine 4 Proteins 0.000 description 1
- 101000679903 Homo sapiens Tumor necrosis factor receptor superfamily member 25 Proteins 0.000 description 1
- 101000864342 Homo sapiens Tyrosine-protein kinase BTK Proteins 0.000 description 1
- 101000851018 Homo sapiens Vascular endothelial growth factor receptor 1 Proteins 0.000 description 1
- 101000851007 Homo sapiens Vascular endothelial growth factor receptor 2 Proteins 0.000 description 1
- 108010001336 Horseradish Peroxidase Proteins 0.000 description 1
- 238000012450 HuMAb Mouse Methods 0.000 description 1
- 108091006905 Human Serum Albumin Proteins 0.000 description 1
- 102000008100 Human Serum Albumin Human genes 0.000 description 1
- 241000700588 Human alphaherpesvirus 1 Species 0.000 description 1
- VSNHCAURESNICA-UHFFFAOYSA-N Hydroxyurea Chemical compound NC(=O)NO VSNHCAURESNICA-UHFFFAOYSA-N 0.000 description 1
- 206010020983 Hypogammaglobulinaemia Diseases 0.000 description 1
- 102100034980 ICOS ligand Human genes 0.000 description 1
- 229940043367 IDO1 inhibitor Drugs 0.000 description 1
- MPBVHIBUJCELCL-UHFFFAOYSA-N Ibandronate Chemical compound CCCCCN(C)CCC(O)(P(O)(O)=O)P(O)(O)=O MPBVHIBUJCELCL-UHFFFAOYSA-N 0.000 description 1
- XDXDZDZNSLXDNA-TZNDIEGXSA-N Idarubicin Chemical compound C1[C@H](N)[C@H](O)[C@H](C)O[C@H]1O[C@@H]1C2=C(O)C(C(=O)C3=CC=CC=C3C3=O)=C3C(O)=C2C[C@@](O)(C(C)=O)C1 XDXDZDZNSLXDNA-TZNDIEGXSA-N 0.000 description 1
- XDXDZDZNSLXDNA-UHFFFAOYSA-N Idarubicin Natural products C1C(N)C(O)C(C)OC1OC1C2=C(O)C(C(=O)C3=CC=CC=C3C3=O)=C3C(O)=C2CC(O)(C(C)=O)C1 XDXDZDZNSLXDNA-UHFFFAOYSA-N 0.000 description 1
- 206010021245 Idiopathic thrombocytopenic purpura Diseases 0.000 description 1
- LPFBXFILACZHIB-LAEOZQHASA-N Ile-Gly-Glu Chemical compound CC[C@H](C)[C@@H](C(=O)NCC(=O)N[C@@H](CCC(=O)O)C(=O)O)N LPFBXFILACZHIB-LAEOZQHASA-N 0.000 description 1
- DGAQECJNVWCQMB-PUAWFVPOSA-M Ilexoside XXIX Chemical class C[C@@H]1CC[C@@]2(CC[C@@]3(C(=CC[C@H]4[C@]3(CC[C@@H]5[C@@]4(CC[C@@H](C5(C)C)OS(=O)(=O)[O-])C)C)[C@@H]2[C@]1(C)O)C)C(=O)O[C@H]6[C@@H]([C@H]([C@@H]([C@H](O6)CO)O)O)O.[Na+] DGAQECJNVWCQMB-PUAWFVPOSA-M 0.000 description 1
- 229940123309 Immune checkpoint modulator Drugs 0.000 description 1
- 102000001706 Immunoglobulin Fab Fragments Human genes 0.000 description 1
- 108700005091 Immunoglobulin Genes Proteins 0.000 description 1
- 102100038005 Immunoglobulin alpha Fc receptor Human genes 0.000 description 1
- 102100039813 Inactive tyrosine-protein kinase 7 Human genes 0.000 description 1
- 238000012695 Interfacial polymerization Methods 0.000 description 1
- 102000003996 Interferon-beta Human genes 0.000 description 1
- 108090000467 Interferon-beta Proteins 0.000 description 1
- 102000008070 Interferon-gamma Human genes 0.000 description 1
- 102100024064 Interferon-inducible protein AIM2 Human genes 0.000 description 1
- 102000003815 Interleukin-11 Human genes 0.000 description 1
- 102100033461 Interleukin-17A Human genes 0.000 description 1
- 108010002386 Interleukin-3 Proteins 0.000 description 1
- 102000000646 Interleukin-3 Human genes 0.000 description 1
- 102100021592 Interleukin-7 Human genes 0.000 description 1
- 108010002586 Interleukin-7 Proteins 0.000 description 1
- 108010018951 Interleukin-8B Receptors Proteins 0.000 description 1
- 229940122245 Janus kinase inhibitor Drugs 0.000 description 1
- 102000002698 KIR Receptors Human genes 0.000 description 1
- 108010043610 KIR Receptors Proteins 0.000 description 1
- 101150069255 KLRC1 gene Proteins 0.000 description 1
- 229940124785 KRAS inhibitor Drugs 0.000 description 1
- 208000008839 Kidney Neoplasms Diseases 0.000 description 1
- QNAYBMKLOCPYGJ-REOHCLBHSA-N L-alanine Chemical compound C[C@H](N)C(O)=O QNAYBMKLOCPYGJ-REOHCLBHSA-N 0.000 description 1
- ODKSFYDXXFIFQN-BYPYZUCNSA-P L-argininium(2+) Chemical compound NC(=[NH2+])NCCC[C@H]([NH3+])C(O)=O ODKSFYDXXFIFQN-BYPYZUCNSA-P 0.000 description 1
- LEVWYRKDKASIDU-IMJSIDKUSA-N L-cystine Chemical compound [O-]C(=O)[C@@H]([NH3+])CSSC[C@H]([NH3+])C([O-])=O LEVWYRKDKASIDU-IMJSIDKUSA-N 0.000 description 1
- HSNZZMHEPUFJNZ-UHFFFAOYSA-N L-galacto-2-Heptulose Natural products OCC(O)C(O)C(O)C(O)C(=O)CO HSNZZMHEPUFJNZ-UHFFFAOYSA-N 0.000 description 1
- HNDVDQJCIGZPNO-YFKPBYRVSA-N L-histidine Chemical compound OC(=O)[C@@H](N)CC1=CN=CN1 HNDVDQJCIGZPNO-YFKPBYRVSA-N 0.000 description 1
- FFEARJCKVFRZRR-BYPYZUCNSA-N L-methionine Chemical compound CSCC[C@H](N)C(O)=O FFEARJCKVFRZRR-BYPYZUCNSA-N 0.000 description 1
- LRQKBLKVPFOOQJ-YFKPBYRVSA-N L-norleucine Chemical compound CCCC[C@H]([NH3+])C([O-])=O LRQKBLKVPFOOQJ-YFKPBYRVSA-N 0.000 description 1
- OUYCCCASQSFEME-QMMMGPOBSA-N L-tyrosine Chemical compound OC(=O)[C@@H](N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-QMMMGPOBSA-N 0.000 description 1
- 239000002145 L01XE14 - Bosutinib Substances 0.000 description 1
- 239000002146 L01XE16 - Crizotinib Substances 0.000 description 1
- 239000002138 L01XE21 - Regorafenib Substances 0.000 description 1
- JLERVPBPJHKRBJ-UHFFFAOYSA-N LY 117018 Chemical compound C1=CC(O)=CC=C1C1=C(C(=O)C=2C=CC(OCCN3CCCC3)=CC=2)C2=CC=C(O)C=C2S1 JLERVPBPJHKRBJ-UHFFFAOYSA-N 0.000 description 1
- GUBGYTABKSRVRQ-QKKXKWKRSA-N Lactose Natural products OC[C@H]1O[C@@H](O[C@H]2[C@H](O)[C@@H](O)C(O)O[C@@H]2CO)[C@H](O)[C@@H](O)[C@H]1O GUBGYTABKSRVRQ-QKKXKWKRSA-N 0.000 description 1
- 229920001491 Lentinan Polymers 0.000 description 1
- 102100020943 Leukocyte-associated immunoglobulin-like receptor 1 Human genes 0.000 description 1
- GQYIWUVLTXOXAJ-UHFFFAOYSA-N Lomustine Chemical compound ClCCN(N=O)C(=O)NC1CCCCC1 GQYIWUVLTXOXAJ-UHFFFAOYSA-N 0.000 description 1
- 102100029204 Low affinity immunoglobulin gamma Fc region receptor II-a Human genes 0.000 description 1
- 206010058467 Lung neoplasm malignant Diseases 0.000 description 1
- 101710157884 Lymphocyte antigen 75 Proteins 0.000 description 1
- 102100030984 Lymphocyte function-associated antigen 3 Human genes 0.000 description 1
- 206010025323 Lymphomas Diseases 0.000 description 1
- 241000282567 Macaca fascicularis Species 0.000 description 1
- 101100404845 Macaca mulatta NKG2A gene Proteins 0.000 description 1
- 239000004907 Macro-emulsion Substances 0.000 description 1
- FYYHWMGAXLPEAU-UHFFFAOYSA-N Magnesium Chemical compound [Mg] FYYHWMGAXLPEAU-UHFFFAOYSA-N 0.000 description 1
- 101710125418 Major capsid protein Proteins 0.000 description 1
- 101710156564 Major tail protein Gp23 Proteins 0.000 description 1
- VJRAUFKOOPNFIQ-UHFFFAOYSA-N Marcellomycin Natural products C12=C(O)C=3C(=O)C4=C(O)C=CC(O)=C4C(=O)C=3C=C2C(C(=O)OC)C(CC)(O)CC1OC(OC1C)CC(N(C)C)C1OC(OC1C)CC(O)C1OC1CC(O)C(O)C(C)O1 VJRAUFKOOPNFIQ-UHFFFAOYSA-N 0.000 description 1
- 108010061593 Member 14 Tumor Necrosis Factor Receptors Proteins 0.000 description 1
- IVDYZAAPOLNZKG-KWHRADDSSA-N Mepitiostane Chemical compound O([C@@H]1[C@]2(CC[C@@H]3[C@@]4(C)C[C@H]5S[C@H]5C[C@@H]4CC[C@H]3[C@@H]2CC1)C)C1(OC)CCCC1 IVDYZAAPOLNZKG-KWHRADDSSA-N 0.000 description 1
- 206010049567 Miller Fisher syndrome Diseases 0.000 description 1
- VFKZTMPDYBFSTM-KVTDHHQDSA-N Mitobronitol Chemical compound BrC[C@@H](O)[C@@H](O)[C@H](O)[C@H](O)CBr VFKZTMPDYBFSTM-KVTDHHQDSA-N 0.000 description 1
- 229930192392 Mitomycin Natural products 0.000 description 1
- 244000302512 Momordica charantia Species 0.000 description 1
- 235000009811 Momordica charantia Nutrition 0.000 description 1
- 102100025276 Monocarboxylate transporter 4 Human genes 0.000 description 1
- 208000003445 Mouth Neoplasms Diseases 0.000 description 1
- 108010008707 Mucin-1 Proteins 0.000 description 1
- 108010063954 Mucins Proteins 0.000 description 1
- 101100490437 Mus musculus Acvrl1 gene Proteins 0.000 description 1
- 101100207071 Mus musculus Tnfsf8 gene Proteins 0.000 description 1
- 101000597780 Mus musculus Tumor necrosis factor ligand superfamily member 18 Proteins 0.000 description 1
- 101100540667 Mus musculus Vtcn1 gene Proteins 0.000 description 1
- 241000187918 Mycobacterium obuense Species 0.000 description 1
- 239000005041 Mylar™ Substances 0.000 description 1
- OVRNDRQMDRJTHS-CBQIKETKSA-N N-Acetyl-D-Galactosamine Chemical compound CC(=O)N[C@H]1[C@@H](O)O[C@H](CO)[C@H](O)[C@@H]1O OVRNDRQMDRJTHS-CBQIKETKSA-N 0.000 description 1
- NQTADLQHYWFPDB-UHFFFAOYSA-N N-Hydroxysuccinimide Chemical compound ON1C(=O)CCC1=O NQTADLQHYWFPDB-UHFFFAOYSA-N 0.000 description 1
- OVBPIULPVIDEAO-UHFFFAOYSA-N N-Pteroyl-L-glutaminsaeure Natural products C=1N=C2NC(N)=NC(=O)C2=NC=1CNC1=CC=C(C(=O)NC(CCC(O)=O)C(O)=O)C=C1 OVBPIULPVIDEAO-UHFFFAOYSA-N 0.000 description 1
- OVRNDRQMDRJTHS-UHFFFAOYSA-N N-acelyl-D-glucosamine Natural products CC(=O)NC1C(O)OC(CO)C(O)C1O OVRNDRQMDRJTHS-UHFFFAOYSA-N 0.000 description 1
- MBLBDJOUHNCFQT-UHFFFAOYSA-N N-acetyl-D-galactosamine Natural products CC(=O)NC(C=O)C(O)C(O)C(O)CO MBLBDJOUHNCFQT-UHFFFAOYSA-N 0.000 description 1
- OVRNDRQMDRJTHS-RTRLPJTCSA-N N-acetyl-D-glucosamine Chemical compound CC(=O)N[C@H]1C(O)O[C@H](CO)[C@@H](O)[C@@H]1O OVRNDRQMDRJTHS-RTRLPJTCSA-N 0.000 description 1
- MBLBDJOUHNCFQT-LXGUWJNJSA-N N-acetylglucosamine Natural products CC(=O)N[C@@H](C=O)[C@@H](O)[C@H](O)[C@H](O)CO MBLBDJOUHNCFQT-LXGUWJNJSA-N 0.000 description 1
- UBQYURCVBFRUQT-UHFFFAOYSA-N N-benzoyl-Ferrioxamine B Chemical compound CC(=O)N(O)CCCCCNC(=O)CCC(=O)N(O)CCCCCNC(=O)CCC(=O)N(O)CCCCCN UBQYURCVBFRUQT-UHFFFAOYSA-N 0.000 description 1
- ZDZOTLJHXYCWBA-VCVYQWHSSA-N N-debenzoyl-N-(tert-butoxycarbonyl)-10-deacetyltaxol Chemical compound O([C@H]1[C@H]2[C@@](C([C@H](O)C3=C(C)[C@@H](OC(=O)[C@H](O)[C@@H](NC(=O)OC(C)(C)C)C=4C=CC=CC=4)C[C@]1(O)C3(C)C)=O)(C)[C@@H](O)C[C@H]1OC[C@]12OC(=O)C)C(=O)C1=CC=CC=C1 ZDZOTLJHXYCWBA-VCVYQWHSSA-N 0.000 description 1
- 102100022691 NACHT, LRR and PYD domains-containing protein 3 Human genes 0.000 description 1
- 102100022682 NKG2-A/NKG2-B type II integral membrane protein Human genes 0.000 description 1
- 102100022680 NKG2-D type II integral membrane protein Human genes 0.000 description 1
- 102100023435 NLR family CARD domain-containing protein 4 Human genes 0.000 description 1
- 102100029527 Natural cytotoxicity triggering receptor 3 ligand 1 Human genes 0.000 description 1
- 101710141230 Natural killer cell receptor 2B4 Proteins 0.000 description 1
- 102100035488 Nectin-2 Human genes 0.000 description 1
- 102100035486 Nectin-4 Human genes 0.000 description 1
- 101710043865 Nectin-4 Proteins 0.000 description 1
- 108700019961 Neoplasm Genes Proteins 0.000 description 1
- 102000048850 Neoplasm Genes Human genes 0.000 description 1
- 206010061309 Neoplasm progression Diseases 0.000 description 1
- 208000012902 Nervous system disease Diseases 0.000 description 1
- 108010006696 Neuronal Apoptosis-Inhibitory Protein Proteins 0.000 description 1
- 244000061176 Nicotiana tabacum Species 0.000 description 1
- 235000002637 Nicotiana tabacum Nutrition 0.000 description 1
- SYNHCENRCUAUNM-UHFFFAOYSA-N Nitrogen mustard N-oxide hydrochloride Chemical compound Cl.ClCC[N+]([O-])(C)CCCl SYNHCENRCUAUNM-UHFFFAOYSA-N 0.000 description 1
- KGTDRFCXGRULNK-UHFFFAOYSA-N Nogalamycin Natural products COC1C(OC)(C)C(OC)C(C)OC1OC1C2=C(O)C(C(=O)C3=C(O)C=C4C5(C)OC(C(C(C5O)N(C)C)O)OC4=C3C3=O)=C3C=C2C(C(=O)OC)C(C)(O)C1 KGTDRFCXGRULNK-UHFFFAOYSA-N 0.000 description 1
- 101710163270 Nuclease Proteins 0.000 description 1
- 102100029424 Nucleotide-binding oligomerization domain-containing protein 1 Human genes 0.000 description 1
- 239000004677 Nylon Substances 0.000 description 1
- KUIFHYPNNRVEKZ-VIJRYAKMSA-N O-(N-acetyl-alpha-D-galactosaminyl)-L-threonine Chemical compound OC(=O)[C@@H](N)[C@@H](C)O[C@H]1O[C@H](CO)[C@H](O)[C@H](O)[C@H]1NC(C)=O KUIFHYPNNRVEKZ-VIJRYAKMSA-N 0.000 description 1
- 108010042215 OX40 Ligand Proteins 0.000 description 1
- 206010030155 Oesophageal carcinoma Diseases 0.000 description 1
- 108020005187 Oligonucleotide Probes Proteins 0.000 description 1
- 108010038807 Oligopeptides Proteins 0.000 description 1
- 102000015636 Oligopeptides Human genes 0.000 description 1
- 241000283973 Oryctolagus cuniculus Species 0.000 description 1
- 239000012661 PARP inhibitor Substances 0.000 description 1
- 229930012538 Paclitaxel Natural products 0.000 description 1
- VREZDOWOLGNDPW-ALTGWBOUSA-N Pancratistatin Chemical compound C1=C2[C@H]3[C@@H](O)[C@H](O)[C@@H](O)[C@@H](O)[C@@H]3NC(=O)C2=C(O)C2=C1OCO2 VREZDOWOLGNDPW-ALTGWBOUSA-N 0.000 description 1
- VREZDOWOLGNDPW-MYVCAWNPSA-N Pancratistatin Natural products O=C1N[C@H]2[C@H](O)[C@H](O)[C@H](O)[C@H](O)[C@@H]2c2c1c(O)c1OCOc1c2 VREZDOWOLGNDPW-MYVCAWNPSA-N 0.000 description 1
- 206010061902 Pancreatic neoplasm Diseases 0.000 description 1
- 208000030852 Parasitic disease Diseases 0.000 description 1
- 206010034277 Pemphigoid Diseases 0.000 description 1
- 241000721454 Pemphigus Species 0.000 description 1
- 108010057150 Peplomycin Proteins 0.000 description 1
- 102000007079 Peptide Fragments Human genes 0.000 description 1
- 108010033276 Peptide Fragments Proteins 0.000 description 1
- 102100038551 Peptide-N(4)-(N-acetyl-beta-glucosaminyl)asparagine amidase Human genes 0.000 description 1
- 102000000447 Peptide-N4-(N-acetyl-beta-glucosaminyl) Asparagine Amidase Human genes 0.000 description 1
- 108010055817 Peptide-N4-(N-acetyl-beta-glucosaminyl) Asparagine Amidase Proteins 0.000 description 1
- HGNGAMWHGGANAU-WHOFXGATSA-N Phe-Gly-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CC1=CC=CC=C1 HGNGAMWHGGANAU-WHOFXGATSA-N 0.000 description 1
- ABLZXFCXXLZCGV-UHFFFAOYSA-N Phosphorous acid Chemical group OP(O)=O ABLZXFCXXLZCGV-UHFFFAOYSA-N 0.000 description 1
- 101100413173 Phytolacca americana PAP2 gene Proteins 0.000 description 1
- KMSKQZKKOZQFFG-HSUXVGOQSA-N Pirarubicin Chemical compound O([C@H]1[C@@H](N)C[C@@H](O[C@H]1C)O[C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(=O)CO)[C@H]1CCCCO1 KMSKQZKKOZQFFG-HSUXVGOQSA-N 0.000 description 1
- 102100030485 Platelet-derived growth factor receptor alpha Human genes 0.000 description 1
- 102100029740 Poliovirus receptor Human genes 0.000 description 1
- 241000276498 Pollachius virens Species 0.000 description 1
- 229940121906 Poly ADP ribose polymerase inhibitor Drugs 0.000 description 1
- 206010065159 Polychondritis Diseases 0.000 description 1
- 229920002562 Polyethylene Glycol 3350 Polymers 0.000 description 1
- 108091036414 Polyinosinic:polycytidylic acid Proteins 0.000 description 1
- 229920001213 Polysorbate 20 Polymers 0.000 description 1
- 229920001214 Polysorbate 60 Polymers 0.000 description 1
- 208000012654 Primary biliary cholangitis Diseases 0.000 description 1
- 101800000795 Proadrenomedullin N-20 terminal peptide Proteins 0.000 description 1
- 102100024216 Programmed cell death 1 ligand 1 Human genes 0.000 description 1
- ONIBWKKTOPOVIA-UHFFFAOYSA-N Proline Natural products OC(=O)C1CCCN1 ONIBWKKTOPOVIA-UHFFFAOYSA-N 0.000 description 1
- 206010060862 Prostate cancer Diseases 0.000 description 1
- 208000000236 Prostatic Neoplasms Diseases 0.000 description 1
- 108010029485 Protein Isoforms Proteins 0.000 description 1
- 102000001708 Protein Isoforms Human genes 0.000 description 1
- 102100034607 Protein arginine N-methyltransferase 5 Human genes 0.000 description 1
- 101710084427 Protein arginine N-methyltransferase 5 Proteins 0.000 description 1
- 102100033437 Protocadherin beta-2 Human genes 0.000 description 1
- 101000762949 Pseudomonas aeruginosa (strain ATCC 15692 / DSM 22644 / CIP 104116 / JCM 14847 / LMG 12228 / 1C / PRS 101 / PAO1) Exotoxin A Proteins 0.000 description 1
- 108010001946 Pyrin Domain-Containing 3 Protein NLR Family Proteins 0.000 description 1
- 229940044606 RIG-I agonist Drugs 0.000 description 1
- AHHFEZNOXOZZQA-ZEBDFXRSSA-N Ranimustine Chemical compound CO[C@H]1O[C@H](CNC(=O)N(CCCl)N=O)[C@@H](O)[C@H](O)[C@H]1O AHHFEZNOXOZZQA-ZEBDFXRSSA-N 0.000 description 1
- 101710100969 Receptor tyrosine-protein kinase erbB-3 Proteins 0.000 description 1
- 102100029986 Receptor tyrosine-protein kinase erbB-3 Human genes 0.000 description 1
- 102100029981 Receptor tyrosine-protein kinase erbB-4 Human genes 0.000 description 1
- 101710100963 Receptor tyrosine-protein kinase erbB-4 Proteins 0.000 description 1
- 102100020718 Receptor-type tyrosine-protein kinase FLT3 Human genes 0.000 description 1
- 206010038389 Renal cancer Diseases 0.000 description 1
- 108091028664 Ribonucleotide Proteins 0.000 description 1
- PYMYPHUHKUWMLA-LMVFSUKVSA-N Ribose Natural products OC[C@@H](O)[C@@H](O)[C@@H](O)C=O PYMYPHUHKUWMLA-LMVFSUKVSA-N 0.000 description 1
- 241000710942 Ross River virus Species 0.000 description 1
- 239000006146 Roswell Park Memorial Institute medium Substances 0.000 description 1
- 101150036449 SIRPA gene Proteins 0.000 description 1
- 102100029216 SLAM family member 5 Human genes 0.000 description 1
- 102100029196 SLAM family member 9 Human genes 0.000 description 1
- 235000019485 Safflower oil Nutrition 0.000 description 1
- 206010039491 Sarcoma Diseases 0.000 description 1
- HAIWUXASLYEWLM-AZEWMMITSA-N Sedoheptulose Natural products OC[C@H]1[C@H](O)[C@H](O)[C@H](O)[C@@](O)(CO)O1 HAIWUXASLYEWLM-AZEWMMITSA-N 0.000 description 1
- 241000710961 Semliki Forest virus Species 0.000 description 1
- AEGUWTFAQQWVLC-BQBZGAKWSA-N Ser-Gly-Arg Chemical compound [H]N[C@@H](CO)C(=O)NCC(=O)N[C@@H](CCCNC(N)=N)C(O)=O AEGUWTFAQQWVLC-BQBZGAKWSA-N 0.000 description 1
- 102100027103 Serine/threonine-protein kinase B-raf Human genes 0.000 description 1
- 108010071390 Serum Albumin Proteins 0.000 description 1
- 102000007562 Serum Albumin Human genes 0.000 description 1
- 208000032384 Severe immune-mediated enteropathy Diseases 0.000 description 1
- 229920001800 Shellac Polymers 0.000 description 1
- 241000710960 Sindbis virus Species 0.000 description 1
- 108010003723 Single-Domain Antibodies Proteins 0.000 description 1
- 108020004682 Single-Stranded DNA Proteins 0.000 description 1
- 208000021386 Sjogren Syndrome Diseases 0.000 description 1
- 208000000453 Skin Neoplasms Diseases 0.000 description 1
- 241000191940 Staphylococcus Species 0.000 description 1
- 235000021355 Stearic acid Nutrition 0.000 description 1
- 208000005718 Stomach Neoplasms Diseases 0.000 description 1
- 101000895926 Streptomyces plicatus Endo-beta-N-acetylglucosaminidase H Proteins 0.000 description 1
- 108091027544 Subgenomic mRNA Proteins 0.000 description 1
- 208000005400 Synovial Cyst Diseases 0.000 description 1
- 230000006044 T cell activation Effects 0.000 description 1
- 229940126530 T cell activator Drugs 0.000 description 1
- 230000010782 T cell mediated cytotoxicity Effects 0.000 description 1
- 230000006052 T cell proliferation Effects 0.000 description 1
- 230000005867 T cell response Effects 0.000 description 1
- BXFOFFBJRFZBQZ-QYWOHJEZSA-N T-2 toxin Chemical compound C([C@@]12[C@]3(C)[C@H](OC(C)=O)[C@@H](O)[C@H]1O[C@H]1[C@]3(COC(C)=O)C[C@@H](C(=C1)C)OC(=O)CC(C)C)O2 BXFOFFBJRFZBQZ-QYWOHJEZSA-N 0.000 description 1
- 102100039367 T-cell immunoglobulin and mucin domain-containing protein 4 Human genes 0.000 description 1
- 102100033447 T-lymphocyte surface antigen Ly-9 Human genes 0.000 description 1
- 101710114141 T-lymphocyte surface antigen Ly-9 Proteins 0.000 description 1
- 229940123803 TIM3 antagonist Drugs 0.000 description 1
- 108091021474 TMEM173 Proteins 0.000 description 1
- QJJXYPPXXYFBGM-LFZNUXCKSA-N Tacrolimus Chemical compound C1C[C@@H](O)[C@H](OC)C[C@@H]1\C=C(/C)[C@@H]1[C@H](C)[C@@H](O)CC(=O)[C@H](CC=C)/C=C(C)/C[C@H](C)C[C@H](OC)[C@H]([C@H](C[C@H]2C)OC)O[C@@]2(O)C(=O)C(=O)N2CCCC[C@H]2C(=O)O1 QJJXYPPXXYFBGM-LFZNUXCKSA-N 0.000 description 1
- 229940123237 Taxane Drugs 0.000 description 1
- CBPNZQVSJQDFBE-FUXHJELOSA-N Temsirolimus Chemical compound C1C[C@@H](OC(=O)C(C)(CO)CO)[C@H](OC)C[C@@H]1C[C@@H](C)[C@H]1OC(=O)[C@@H]2CCCCN2C(=O)C(=O)[C@](O)(O2)[C@H](C)CC[C@H]2C[C@H](OC)/C(C)=C/C=C/C=C/[C@@H](C)C[C@@H](C)C(=O)[C@H](OC)[C@H](O)/C(C)=C/[C@@H](C)C(=O)C1 CBPNZQVSJQDFBE-FUXHJELOSA-N 0.000 description 1
- 102100028644 Tenascin-R Human genes 0.000 description 1
- CGMTUJFWROPELF-UHFFFAOYSA-N Tenuazonic acid Natural products CCC(C)C1NC(=O)C(=C(C)/O)C1=O CGMTUJFWROPELF-UHFFFAOYSA-N 0.000 description 1
- 239000004098 Tetracycline Substances 0.000 description 1
- 102100032802 Tetraspanin-8 Human genes 0.000 description 1
- RYYWUUFWQRZTIU-UHFFFAOYSA-N Thiophosphoric acid Chemical class OP(O)(S)=O RYYWUUFWQRZTIU-UHFFFAOYSA-N 0.000 description 1
- OGOYMQWIWHGTGH-KZVJFYERSA-N Thr-Val-Ala Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C)C(O)=O OGOYMQWIWHGTGH-KZVJFYERSA-N 0.000 description 1
- KZTLZZQTJMCGIP-ZJDVBMNYSA-N Thr-Val-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O KZTLZZQTJMCGIP-ZJDVBMNYSA-N 0.000 description 1
- AYFVYJQAPQTCCC-UHFFFAOYSA-N Threonine Natural products CC(O)C(N)C(O)=O AYFVYJQAPQTCCC-UHFFFAOYSA-N 0.000 description 1
- 208000000728 Thymus Neoplasms Diseases 0.000 description 1
- 108010034949 Thyroglobulin Proteins 0.000 description 1
- 102000009843 Thyroglobulin Human genes 0.000 description 1
- 208000024770 Thyroid neoplasm Diseases 0.000 description 1
- 102100024333 Toll-like receptor 2 Human genes 0.000 description 1
- 102100039360 Toll-like receptor 4 Human genes 0.000 description 1
- 102100039357 Toll-like receptor 5 Human genes 0.000 description 1
- 102100039387 Toll-like receptor 6 Human genes 0.000 description 1
- 102000004887 Transforming Growth Factor beta Human genes 0.000 description 1
- 108090001012 Transforming Growth Factor beta Proteins 0.000 description 1
- 108060008539 Transglutaminase Proteins 0.000 description 1
- 102100032454 Transmembrane protease serine 3 Human genes 0.000 description 1
- HDTRYLNUVZCQOY-WSWWMNSNSA-N Trehalose Natural products O[C@@H]1[C@@H](O)[C@@H](O)[C@@H](CO)O[C@@H]1O[C@@H]1[C@H](O)[C@@H](O)[C@@H](O)[C@@H](CO)O1 HDTRYLNUVZCQOY-WSWWMNSNSA-N 0.000 description 1
- 239000007983 Tris buffer Substances 0.000 description 1
- FYAMXEPQQLNQDM-UHFFFAOYSA-N Tris(1-aziridinyl)phosphine oxide Chemical compound C1CN1P(N1CC1)(=O)N1CC1 FYAMXEPQQLNQDM-UHFFFAOYSA-N 0.000 description 1
- 101710162629 Trypsin inhibitor Proteins 0.000 description 1
- 229940122618 Trypsin inhibitor Drugs 0.000 description 1
- 102100040653 Tryptophan 2,3-dioxygenase Human genes 0.000 description 1
- 101710136122 Tryptophan 2,3-dioxygenase Proteins 0.000 description 1
- 102100024587 Tumor necrosis factor ligand superfamily member 15 Human genes 0.000 description 1
- 108090000138 Tumor necrosis factor ligand superfamily member 15 Proteins 0.000 description 1
- 102100035283 Tumor necrosis factor ligand superfamily member 18 Human genes 0.000 description 1
- 102100026890 Tumor necrosis factor ligand superfamily member 4 Human genes 0.000 description 1
- 102100032100 Tumor necrosis factor ligand superfamily member 8 Human genes 0.000 description 1
- 102100028785 Tumor necrosis factor receptor superfamily member 14 Human genes 0.000 description 1
- 102100022203 Tumor necrosis factor receptor superfamily member 25 Human genes 0.000 description 1
- 108091005906 Type I transmembrane proteins Proteins 0.000 description 1
- 206010053613 Type IV hypersensitivity reaction Diseases 0.000 description 1
- 201000006704 Ulcerative Colitis Diseases 0.000 description 1
- 208000025851 Undifferentiated connective tissue disease Diseases 0.000 description 1
- 208000017379 Undifferentiated connective tissue syndrome Diseases 0.000 description 1
- 208000006105 Uterine Cervical Neoplasms Diseases 0.000 description 1
- 206010046851 Uveitis Diseases 0.000 description 1
- 101150117115 V gene Proteins 0.000 description 1
- 108091008605 VEGF receptors Proteins 0.000 description 1
- 241000700618 Vaccinia virus Species 0.000 description 1
- 102100033178 Vascular endothelial growth factor receptor 1 Human genes 0.000 description 1
- 206010047115 Vasculitis Diseases 0.000 description 1
- 241000710959 Venezuelan equine encephalitis virus Species 0.000 description 1
- JXLYSJRDGCGARV-WWYNWVTFSA-N Vinblastine Natural products O=C(O[C@H]1[C@](O)(C(=O)OC)[C@@H]2N(C)c3c(cc(c(OC)c3)[C@]3(C(=O)OC)c4[nH]c5c(c4CCN4C[C@](O)(CC)C[C@H](C3)C4)cccc5)[C@@]32[C@H]2[C@@]1(CC)C=CCN2CC3)C JXLYSJRDGCGARV-WWYNWVTFSA-N 0.000 description 1
- 229940122803 Vinca alkaloid Drugs 0.000 description 1
- 208000036142 Viral infection Diseases 0.000 description 1
- 102100040310 Z-DNA-binding protein 1 Human genes 0.000 description 1
- 101710181770 Z-DNA-binding protein 1 Proteins 0.000 description 1
- IFJUINDAXYAPTO-UUBSBJJBSA-N [(8r,9s,13s,14s,17s)-17-[2-[4-[4-[bis(2-chloroethyl)amino]phenyl]butanoyloxy]acetyl]oxy-13-methyl-6,7,8,9,11,12,14,15,16,17-decahydrocyclopenta[a]phenanthren-3-yl] benzoate Chemical compound C([C@@H]1[C@@H](C2=CC=3)CC[C@]4([C@H]1CC[C@@H]4OC(=O)COC(=O)CCCC=1C=CC(=CC=1)N(CCCl)CCCl)C)CC2=CC=3OC(=O)C1=CC=CC=C1 IFJUINDAXYAPTO-UUBSBJJBSA-N 0.000 description 1
- IHGLINDYFMDHJG-UHFFFAOYSA-N [2-(4-methoxyphenyl)-3,4-dihydronaphthalen-1-yl]-[4-(2-pyrrolidin-1-ylethoxy)phenyl]methanone Chemical compound C1=CC(OC)=CC=C1C(CCC1=CC=CC=C11)=C1C(=O)C(C=C1)=CC=C1OCCN1CCCC1 IHGLINDYFMDHJG-UHFFFAOYSA-N 0.000 description 1
- XZSRRNFBEIOBDA-CFNBKWCHSA-N [2-[(2s,4s)-4-[(2r,4s,5s,6s)-4-amino-5-hydroxy-6-methyloxan-2-yl]oxy-2,5,12-trihydroxy-7-methoxy-6,11-dioxo-3,4-dihydro-1h-tetracen-2-yl]-2-oxoethyl] 2,2-diethoxyacetate Chemical compound O([C@H]1C[C@](CC2=C(O)C=3C(=O)C4=CC=CC(OC)=C4C(=O)C=3C(O)=C21)(O)C(=O)COC(=O)C(OCC)OCC)[C@H]1C[C@H](N)[C@H](O)[C@H](C)O1 XZSRRNFBEIOBDA-CFNBKWCHSA-N 0.000 description 1
- IEDXPSOJFSVCKU-HOKPPMCLSA-N [4-[[(2S)-5-(carbamoylamino)-2-[[(2S)-2-[6-(2,5-dioxopyrrolidin-1-yl)hexanoylamino]-3-methylbutanoyl]amino]pentanoyl]amino]phenyl]methyl N-[(2S)-1-[[(2S)-1-[[(3R,4S,5S)-1-[(2S)-2-[(1R,2R)-3-[[(1S,2R)-1-hydroxy-1-phenylpropan-2-yl]amino]-1-methoxy-2-methyl-3-oxopropyl]pyrrolidin-1-yl]-3-methoxy-5-methyl-1-oxoheptan-4-yl]-methylamino]-3-methyl-1-oxobutan-2-yl]amino]-3-methyl-1-oxobutan-2-yl]-N-methylcarbamate Chemical compound CC[C@H](C)[C@@H]([C@@H](CC(=O)N1CCC[C@H]1[C@H](OC)[C@@H](C)C(=O)N[C@H](C)[C@@H](O)c1ccccc1)OC)N(C)C(=O)[C@@H](NC(=O)[C@H](C(C)C)N(C)C(=O)OCc1ccc(NC(=O)[C@H](CCCNC(N)=O)NC(=O)[C@@H](NC(=O)CCCCCN2C(=O)CCC2=O)C(C)C)cc1)C(C)C IEDXPSOJFSVCKU-HOKPPMCLSA-N 0.000 description 1
- 230000001594 aberrant effect Effects 0.000 description 1
- 238000010521 absorption reaction Methods 0.000 description 1
- 238000009825 accumulation Methods 0.000 description 1
- ZOZKYEHVNDEUCO-XUTVFYLZSA-N aceglatone Chemical compound O1C(=O)[C@H](OC(C)=O)[C@@H]2OC(=O)[C@@H](OC(=O)C)[C@@H]21 ZOZKYEHVNDEUCO-XUTVFYLZSA-N 0.000 description 1
- 229950002684 aceglatone Drugs 0.000 description 1
- QTBSBXVTEAMEQO-UHFFFAOYSA-N acetic acid Substances CC(O)=O QTBSBXVTEAMEQO-UHFFFAOYSA-N 0.000 description 1
- 229940081735 acetylcellulose Drugs 0.000 description 1
- 230000002378 acidificating effect Effects 0.000 description 1
- 229930183665 actinomycin Natural products 0.000 description 1
- RJURFGZVJUQBHK-IIXSONLDSA-N actinomycin D Chemical compound C[C@H]1OC(=O)[C@H](C(C)C)N(C)C(=O)CN(C)C(=O)[C@@H]2CCCN2C(=O)[C@@H](C(C)C)NC(=O)[C@H]1NC(=O)C1=C(N)C(=O)C(C)=C2OC(C(C)=CC=C3C(=O)N[C@@H]4C(=O)N[C@@H](C(N5CCC[C@H]5C(=O)N(C)CC(=O)N(C)[C@@H](C(C)C)C(=O)O[C@@H]4C)=O)C(C)C)=C3N=C21 RJURFGZVJUQBHK-IIXSONLDSA-N 0.000 description 1
- 230000009471 action Effects 0.000 description 1
- 230000004913 activation Effects 0.000 description 1
- 230000013564 activation of immune response Effects 0.000 description 1
- 208000002552 acute disseminated encephalomyelitis Diseases 0.000 description 1
- 125000002015 acyclic group Chemical group 0.000 description 1
- 230000033289 adaptive immune response Effects 0.000 description 1
- 108091005764 adaptor proteins Proteins 0.000 description 1
- 102000035181 adaptor proteins Human genes 0.000 description 1
- 229950004955 adozelesin Drugs 0.000 description 1
- BYRVKDUQDLJUBX-JJCDCTGGSA-N adozelesin Chemical compound C1=CC=C2OC(C(=O)NC=3C=C4C=C(NC4=CC=3)C(=O)N3C[C@H]4C[C@]44C5=C(C(C=C43)=O)NC=C5C)=CC2=C1 BYRVKDUQDLJUBX-JJCDCTGGSA-N 0.000 description 1
- 210000004100 adrenal gland Anatomy 0.000 description 1
- 239000003463 adsorbent Substances 0.000 description 1
- 230000002411 adverse Effects 0.000 description 1
- 230000006838 adverse reaction Effects 0.000 description 1
- 239000000443 aerosol Substances 0.000 description 1
- 238000001042 affinity chromatography Methods 0.000 description 1
- 235000004279 alanine Nutrition 0.000 description 1
- 238000012867 alanine scanning Methods 0.000 description 1
- 229960000548 alemtuzumab Drugs 0.000 description 1
- 125000003342 alkenyl group Chemical group 0.000 description 1
- 229940045714 alkyl sulfonate alkylating agent Drugs 0.000 description 1
- 150000008052 alkyl sulfonates Chemical class 0.000 description 1
- SHGAZHPCJJPHSC-YCNIQYBTSA-N all-trans-retinoic acid Chemical compound OC(=O)\C=C(/C)\C=C\C=C(/C)\C=C\C1=C(C)CCCC1(C)C SHGAZHPCJJPHSC-YCNIQYBTSA-N 0.000 description 1
- 208000026935 allergic disease Diseases 0.000 description 1
- 230000007815 allergy Effects 0.000 description 1
- 239000008168 almond oil Substances 0.000 description 1
- HDTRYLNUVZCQOY-LIZSDCNHSA-N alpha,alpha-trehalose Chemical compound O[C@@H]1[C@@H](O)[C@H](O)[C@@H](CO)O[C@@H]1O[C@@H]1[C@H](O)[C@@H](O)[C@H](O)[C@@H](CO)O1 HDTRYLNUVZCQOY-LIZSDCNHSA-N 0.000 description 1
- HMFHBZSHGGEWLO-UHFFFAOYSA-N alpha-D-Furanose-Ribose Natural products OCC1OC(O)C(O)C1O HMFHBZSHGGEWLO-UHFFFAOYSA-N 0.000 description 1
- WQZGKKKJIJFFOK-PHYPRBDBSA-N alpha-D-galactose Chemical compound OC[C@H]1O[C@H](O)[C@H](O)[C@@H](O)[C@H]1O WQZGKKKJIJFFOK-PHYPRBDBSA-N 0.000 description 1
- SRBFZHDQGSBBOR-STGXQOJASA-N alpha-D-lyxopyranose Chemical compound O[C@@H]1CO[C@H](O)[C@@H](O)[C@H]1O SRBFZHDQGSBBOR-STGXQOJASA-N 0.000 description 1
- 229960000473 altretamine Drugs 0.000 description 1
- 229940059260 amidate Drugs 0.000 description 1
- 125000004103 aminoalkyl group Chemical group 0.000 description 1
- 229960002749 aminolevulinic acid Drugs 0.000 description 1
- 229960003896 aminopterin Drugs 0.000 description 1
- 238000012870 ammonium sulfate precipitation Methods 0.000 description 1
- 229960001220 amsacrine Drugs 0.000 description 1
- XCPGHVQEEXUHNC-UHFFFAOYSA-N amsacrine Chemical compound COC1=CC(NS(C)(=O)=O)=CC=C1NC1=C(C=CC=C2)C2=NC2=CC=CC=C12 XCPGHVQEEXUHNC-UHFFFAOYSA-N 0.000 description 1
- 235000019418 amylase Nutrition 0.000 description 1
- 229940025131 amylases Drugs 0.000 description 1
- 206010002026 amyotrophic lateral sclerosis Diseases 0.000 description 1
- 238000012436 analytical size exclusion chromatography Methods 0.000 description 1
- 229960002932 anastrozole Drugs 0.000 description 1
- YBBLVLTVTVSKRW-UHFFFAOYSA-N anastrozole Chemical compound N#CC(C)(C)C1=CC(C(C)(C#N)C)=CC(CN2N=CN=C2)=C1 YBBLVLTVTVSKRW-UHFFFAOYSA-N 0.000 description 1
- 238000004873 anchoring Methods 0.000 description 1
- BBDAGFIXKZCXAH-CCXZUQQUSA-N ancitabine Chemical compound N=C1C=CN2[C@@H]3O[C@H](CO)[C@@H](O)[C@@H]3OC2=N1 BBDAGFIXKZCXAH-CCXZUQQUSA-N 0.000 description 1
- 229950000242 ancitabine Drugs 0.000 description 1
- 239000003098 androgen Substances 0.000 description 1
- 229940030486 androgens Drugs 0.000 description 1
- 230000033115 angiogenesis Effects 0.000 description 1
- 239000004037 angiogenesis inhibitor Substances 0.000 description 1
- 229940121369 angiogenesis inhibitor Drugs 0.000 description 1
- 150000008064 anhydrides Chemical class 0.000 description 1
- 210000004102 animal cell Anatomy 0.000 description 1
- 238000010171 animal model Methods 0.000 description 1
- 229940045799 anthracyclines and related substance Drugs 0.000 description 1
- 230000002280 anti-androgenic effect Effects 0.000 description 1
- 229940046836 anti-estrogen Drugs 0.000 description 1
- 230000001833 anti-estrogenic effect Effects 0.000 description 1
- 230000000340 anti-metabolite Effects 0.000 description 1
- 230000000692 anti-sense effect Effects 0.000 description 1
- 230000000259 anti-tumor effect Effects 0.000 description 1
- 230000000840 anti-viral effect Effects 0.000 description 1
- 239000000051 antiandrogen Substances 0.000 description 1
- 229940030495 antiandrogen sex hormone and modulator of the genital system Drugs 0.000 description 1
- 230000009830 antibody antigen interaction Effects 0.000 description 1
- 239000000611 antibody drug conjugate Substances 0.000 description 1
- 239000013059 antihormonal agent Substances 0.000 description 1
- 229940100197 antimetabolite Drugs 0.000 description 1
- 239000002256 antimetabolite Substances 0.000 description 1
- 229940045687 antimetabolites folic acid analogs Drugs 0.000 description 1
- 229940058303 antinematodal benzimidazole derivative Drugs 0.000 description 1
- 229940045719 antineoplastic alkylating agent nitrosoureas Drugs 0.000 description 1
- 239000003963 antioxidant agent Substances 0.000 description 1
- 235000006708 antioxidants Nutrition 0.000 description 1
- 239000000074 antisense oligonucleotide Substances 0.000 description 1
- 238000012230 antisense oligonucleotides Methods 0.000 description 1
- 239000007864 aqueous solution Substances 0.000 description 1
- 239000003125 aqueous solvent Substances 0.000 description 1
- PYMYPHUHKUWMLA-WDCZJNDASA-N arabinose Chemical compound OC[C@@H](O)[C@@H](O)[C@H](O)C=O PYMYPHUHKUWMLA-WDCZJNDASA-N 0.000 description 1
- 150000008209 arabinosides Chemical class 0.000 description 1
- ODKSFYDXXFIFQN-UHFFFAOYSA-N arginine Natural products OC(=O)C(N)CCCNC(N)=N ODKSFYDXXFIFQN-UHFFFAOYSA-N 0.000 description 1
- 239000003886 aromatase inhibitor Substances 0.000 description 1
- 229940046844 aromatase inhibitors Drugs 0.000 description 1
- 229960005070 ascorbic acid Drugs 0.000 description 1
- 235000010323 ascorbic acid Nutrition 0.000 description 1
- 239000011668 ascorbic acid Substances 0.000 description 1
- 229960001230 asparagine Drugs 0.000 description 1
- 235000009582 asparagine Nutrition 0.000 description 1
- 125000000613 asparagine group Chemical group N[C@@H](CC(N)=O)C(=O)* 0.000 description 1
- 229960003852 atezolizumab Drugs 0.000 description 1
- 201000008937 atopic dermatitis Diseases 0.000 description 1
- 230000001363 autoimmune Effects 0.000 description 1
- 208000001974 autoimmune enteropathy Diseases 0.000 description 1
- 201000000448 autoimmune hemolytic anemia Diseases 0.000 description 1
- 208000027625 autoimmune inner ear disease Diseases 0.000 description 1
- 201000004339 autoimmune neuropathy Diseases 0.000 description 1
- 201000005011 autoimmune peripheral neuropathy Diseases 0.000 description 1
- 201000011385 autoimmune polyendocrine syndrome Diseases 0.000 description 1
- 206010071572 autoimmune progesterone dermatitis Diseases 0.000 description 1
- 208000029407 autoimmune urticaria Diseases 0.000 description 1
- 229960003005 axitinib Drugs 0.000 description 1
- RITAVMQDGBJQJZ-FMIVXFBMSA-N axitinib Chemical compound CNC(=O)C1=CC=CC=C1SC1=CC=C(C(\C=C\C=2N=CC=CC=2)=NN2)C2=C1 RITAVMQDGBJQJZ-FMIVXFBMSA-N 0.000 description 1
- 229960002756 azacitidine Drugs 0.000 description 1
- VSRXQHXAPYXROS-UHFFFAOYSA-N azanide;cyclobutane-1,1-dicarboxylic acid;platinum(2+) Chemical compound [NH2-].[NH2-].[Pt+2].OC(=O)C1(C(O)=O)CCC1 VSRXQHXAPYXROS-UHFFFAOYSA-N 0.000 description 1
- 229960002170 azathioprine Drugs 0.000 description 1
- LMEKQMALGUDUQG-UHFFFAOYSA-N azathioprine Chemical compound CN1C=NC([N+]([O-])=O)=C1SC1=NC=NC2=C1NC=N2 LMEKQMALGUDUQG-UHFFFAOYSA-N 0.000 description 1
- 150000001541 aziridines Chemical class 0.000 description 1
- WZSDNEJJUSYNSG-UHFFFAOYSA-N azocan-1-yl-(3,4,5-trimethoxyphenyl)methanone Chemical compound COC1=C(OC)C(OC)=CC(C(=O)N2CCCCCCC2)=C1 WZSDNEJJUSYNSG-UHFFFAOYSA-N 0.000 description 1
- 230000001580 bacterial effect Effects 0.000 description 1
- 239000011324 bead Substances 0.000 description 1
- 208000013404 behavioral symptom Diseases 0.000 description 1
- 229960000686 benzalkonium chloride Drugs 0.000 description 1
- 229960001950 benzethonium chloride Drugs 0.000 description 1
- UREZNYTWGJKWBI-UHFFFAOYSA-M benzethonium chloride Chemical compound [Cl-].C1=CC(C(C)(C)CC(C)(C)C)=CC=C1OCCOCC[N+](C)(C)CC1=CC=CC=C1 UREZNYTWGJKWBI-UHFFFAOYSA-M 0.000 description 1
- 125000003785 benzimidazolyl group Chemical class N1=C(NC2=C1C=CC=C2)* 0.000 description 1
- 229940049706 benzodiazepine Drugs 0.000 description 1
- 235000019445 benzyl alcohol Nutrition 0.000 description 1
- CADWTSSKOVRVJC-UHFFFAOYSA-N benzyl(dimethyl)azanium;chloride Chemical compound [Cl-].C[NH+](C)CC1=CC=CC=C1 CADWTSSKOVRVJC-UHFFFAOYSA-N 0.000 description 1
- DRTQHJPVMGBUCF-PSQAKQOGSA-N beta-L-uridine Natural products O[C@H]1[C@@H](O)[C@H](CO)O[C@@H]1N1C(=O)NC(=O)C=C1 DRTQHJPVMGBUCF-PSQAKQOGSA-N 0.000 description 1
- 229960000997 bicalutamide Drugs 0.000 description 1
- 230000001588 bifunctional effect Effects 0.000 description 1
- 238000013357 binding ELISA Methods 0.000 description 1
- 230000003115 biocidal effect Effects 0.000 description 1
- 239000012620 biological material Substances 0.000 description 1
- 230000033228 biological regulation Effects 0.000 description 1
- 229920001222 biopolymer Polymers 0.000 description 1
- 229960002685 biotin Drugs 0.000 description 1
- 235000020958 biotin Nutrition 0.000 description 1
- 239000011616 biotin Substances 0.000 description 1
- HUTDDBSSHVOYJR-UHFFFAOYSA-H bis[(2-oxo-1,3,2$l^{5},4$l^{2}-dioxaphosphaplumbetan-2-yl)oxy]lead Chemical compound [Pb+2].[Pb+2].[Pb+2].[O-]P([O-])([O-])=O.[O-]P([O-])([O-])=O HUTDDBSSHVOYJR-UHFFFAOYSA-H 0.000 description 1
- 229950008548 bisantrene Drugs 0.000 description 1
- 150000004663 bisphosphonates Chemical class 0.000 description 1
- 229950006844 bizelesin Drugs 0.000 description 1
- 229960001561 bleomycin Drugs 0.000 description 1
- OYVAGSVQBOHSSS-UAPAGMARSA-O bleomycin A2 Chemical compound N([C@H](C(=O)N[C@H](C)[C@@H](O)[C@H](C)C(=O)N[C@@H]([C@H](O)C)C(=O)NCCC=1SC=C(N=1)C=1SC=C(N=1)C(=O)NCCC[S+](C)C)[C@@H](O[C@H]1[C@H]([C@@H](O)[C@H](O)[C@H](CO)O1)O[C@@H]1[C@H]([C@@H](OC(N)=O)[C@H](O)[C@@H](CO)O1)O)C=1N=CNC=1)C(=O)C1=NC([C@H](CC(N)=O)NC[C@H](N)C(N)=O)=NC(N)=C1C OYVAGSVQBOHSSS-UAPAGMARSA-O 0.000 description 1
- 230000000903 blocking effect Effects 0.000 description 1
- 210000004369 blood Anatomy 0.000 description 1
- 239000008280 blood Substances 0.000 description 1
- 210000001124 body fluid Anatomy 0.000 description 1
- 239000010839 body fluid Substances 0.000 description 1
- 238000006664 bond formation reaction Methods 0.000 description 1
- 229910052796 boron Inorganic materials 0.000 description 1
- UBPYILGKFZZVDX-UHFFFAOYSA-N bosutinib Chemical compound C1=C(Cl)C(OC)=CC(NC=2C3=CC(OC)=C(OCCCN4CCN(C)CC4)C=C3N=CC=2C#N)=C1Cl UBPYILGKFZZVDX-UHFFFAOYSA-N 0.000 description 1
- 229960003736 bosutinib Drugs 0.000 description 1
- 229960000455 brentuximab vedotin Drugs 0.000 description 1
- 229950000025 brolucizumab Drugs 0.000 description 1
- 229960005520 bryostatin Drugs 0.000 description 1
- MJQUEDHRCUIRLF-TVIXENOKSA-N bryostatin 1 Chemical compound C([C@@H]1CC(/[C@@H]([C@@](C(C)(C)/C=C/2)(O)O1)OC(=O)/C=C/C=C/CCC)=C\C(=O)OC)[C@H]([C@@H](C)O)OC(=O)C[C@H](O)C[C@@H](O1)C[C@H](OC(C)=O)C(C)(C)[C@]1(O)C[C@@H]1C\C(=C\C(=O)OC)C[C@H]\2O1 MJQUEDHRCUIRLF-TVIXENOKSA-N 0.000 description 1
- MUIWQCKLQMOUAT-AKUNNTHJSA-N bryostatin 20 Natural products COC(=O)C=C1C[C@@]2(C)C[C@]3(O)O[C@](C)(C[C@@H](O)CC(=O)O[C@](C)(C[C@@]4(C)O[C@](O)(CC5=CC(=O)O[C@]45C)C(C)(C)C=C[C@@](C)(C1)O2)[C@@H](C)O)C[C@H](OC(=O)C(C)(C)C)C3(C)C MUIWQCKLQMOUAT-AKUNNTHJSA-N 0.000 description 1
- 239000006172 buffering agent Substances 0.000 description 1
- MBABCNBNDNGODA-LUVUIASKSA-N bullatacin Chemical compound O1[C@@H]([C@@H](O)CCCCCCCCCC)CC[C@@H]1[C@@H]1O[C@@H]([C@H](O)CCCCCCCCCC[C@@H](O)CC=2C(O[C@@H](C)C=2)=O)CC1 MBABCNBNDNGODA-LUVUIASKSA-N 0.000 description 1
- 229960002092 busulfan Drugs 0.000 description 1
- DQXBYHZEEUGOBF-UHFFFAOYSA-N but-3-enoic acid;ethene Chemical compound C=C.OC(=O)CC=C DQXBYHZEEUGOBF-UHFFFAOYSA-N 0.000 description 1
- LRHPLDYGYMQRHN-UHFFFAOYSA-N butyl alcohol Substances CCCCO LRHPLDYGYMQRHN-UHFFFAOYSA-N 0.000 description 1
- 125000000484 butyl group Chemical group [H]C([*])([H])C([H])([H])C([H])([H])C([H])([H])[H] 0.000 description 1
- PKFDLKSEZWEFGL-MHARETSRSA-N c-di-GMP Chemical compound C([C@H]1O2)OP(O)(=O)O[C@H]3[C@@H](O)[C@H](N4C5=C(C(NC(N)=N5)=O)N=C4)O[C@@H]3COP(O)(=O)O[C@H]1[C@@H](O)[C@@H]2N1C(N=C(NC2=O)N)=C2N=C1 PKFDLKSEZWEFGL-MHARETSRSA-N 0.000 description 1
- 108700002839 cactinomycin Proteins 0.000 description 1
- 229950009908 cactinomycin Drugs 0.000 description 1
- 239000011575 calcium Substances 0.000 description 1
- 229910052791 calcium Inorganic materials 0.000 description 1
- 239000001110 calcium chloride Substances 0.000 description 1
- 229910001628 calcium chloride Inorganic materials 0.000 description 1
- 229910000389 calcium phosphate Inorganic materials 0.000 description 1
- 235000011010 calcium phosphates Nutrition 0.000 description 1
- 229950007712 camrelizumab Drugs 0.000 description 1
- 150000004657 carbamic acid derivatives Chemical class 0.000 description 1
- 125000002837 carbocyclic group Chemical group 0.000 description 1
- 125000004432 carbon atom Chemical group C* 0.000 description 1
- 125000002915 carbonyl group Chemical group [*:2]C([*:1])=O 0.000 description 1
- 229960004562 carboplatin Drugs 0.000 description 1
- 229960002115 carboquone Drugs 0.000 description 1
- 229960005243 carmustine Drugs 0.000 description 1
- BBZDXMBRAFTCAA-AREMUKBSSA-N carzelesin Chemical compound C1=2NC=C(C)C=2C([C@H](CCl)CN2C(=O)C=3NC4=CC=C(C=C4C=3)NC(=O)C3=CC4=CC=C(C=C4O3)N(CC)CC)=C2C=C1OC(=O)NC1=CC=CC=C1 BBZDXMBRAFTCAA-AREMUKBSSA-N 0.000 description 1
- 229950007509 carzelesin Drugs 0.000 description 1
- 108010047060 carzinophilin Proteins 0.000 description 1
- 230000015556 catabolic process Effects 0.000 description 1
- 238000005341 cation exchange Methods 0.000 description 1
- 125000002091 cationic group Chemical group 0.000 description 1
- 238000000423 cell based assay Methods 0.000 description 1
- 238000010370 cell cloning Methods 0.000 description 1
- 230000005779 cell damage Effects 0.000 description 1
- 230000030833 cell death Effects 0.000 description 1
- 230000007910 cell fusion Effects 0.000 description 1
- 208000037887 cell injury Diseases 0.000 description 1
- 230000006037 cell lysis Effects 0.000 description 1
- 210000000170 cell membrane Anatomy 0.000 description 1
- 230000005890 cell-mediated cytotoxicity Effects 0.000 description 1
- 230000001413 cellular effect Effects 0.000 description 1
- 229920002678 cellulose Polymers 0.000 description 1
- 235000010980 cellulose Nutrition 0.000 description 1
- 229920002301 cellulose acetate Polymers 0.000 description 1
- 201000010881 cervical cancer Diseases 0.000 description 1
- 229960000541 cetyl alcohol Drugs 0.000 description 1
- 230000005591 charge neutralization Effects 0.000 description 1
- 230000009920 chelation Effects 0.000 description 1
- 238000007385 chemical modification Methods 0.000 description 1
- 238000002512 chemotherapy Methods 0.000 description 1
- 229950008249 chlornaphazine Drugs 0.000 description 1
- 229960001480 chlorozotocin Drugs 0.000 description 1
- 235000012000 cholesterol Nutrition 0.000 description 1
- 238000004587 chromatography analysis Methods 0.000 description 1
- ZYVSOIYQKUDENJ-WKSBCEQHSA-N chromomycin A3 Chemical compound O([C@@H]1C[C@@H](O[C@H](C)[C@@H]1OC(C)=O)OC=1C=C2C=C3C[C@H]([C@@H](C(=O)C3=C(O)C2=C(O)C=1C)O[C@@H]1O[C@H](C)[C@@H](O)[C@H](O[C@@H]2O[C@H](C)[C@@H](O)[C@H](O[C@@H]3O[C@@H](C)[C@H](OC(C)=O)[C@@](C)(O)C3)C2)C1)[C@H](OC)C(=O)[C@@H](O)[C@@H](C)O)[C@@H]1C[C@@H](O)[C@@H](OC)[C@@H](C)O1 ZYVSOIYQKUDENJ-WKSBCEQHSA-N 0.000 description 1
- 239000013611 chromosomal DNA Substances 0.000 description 1
- 230000001684 chronic effect Effects 0.000 description 1
- 208000025302 chronic primary adrenal insufficiency Diseases 0.000 description 1
- 208000024376 chronic urticaria Diseases 0.000 description 1
- 229960001265 ciclosporin Drugs 0.000 description 1
- ACSIXWWBWUQEHA-UHFFFAOYSA-N clodronic acid Chemical compound OP(O)(=O)C(Cl)(Cl)P(O)(O)=O ACSIXWWBWUQEHA-UHFFFAOYSA-N 0.000 description 1
- 229960002286 clodronic acid Drugs 0.000 description 1
- 239000013599 cloning vector Substances 0.000 description 1
- 230000004186 co-expression Effects 0.000 description 1
- 238000005354 coacervation Methods 0.000 description 1
- 239000011248 coating agent Substances 0.000 description 1
- 229950009660 cofetuzumab pelidotin Drugs 0.000 description 1
- 208000029742 colonic neoplasm Diseases 0.000 description 1
- 229940047120 colony stimulating factors Drugs 0.000 description 1
- 230000002301 combined effect Effects 0.000 description 1
- 150000004814 combretastatins Chemical class 0.000 description 1
- 238000012875 competitive assay Methods 0.000 description 1
- 230000002860 competitive effect Effects 0.000 description 1
- 230000004154 complement system Effects 0.000 description 1
- 238000012790 confirmation Methods 0.000 description 1
- 230000001268 conjugating effect Effects 0.000 description 1
- 239000000356 contaminant Substances 0.000 description 1
- 235000005687 corn oil Nutrition 0.000 description 1
- 239000002285 corn oil Substances 0.000 description 1
- 239000008120 corn starch Substances 0.000 description 1
- 210000004351 coronary vessel Anatomy 0.000 description 1
- 230000000139 costimulatory effect Effects 0.000 description 1
- 235000012343 cottonseed oil Nutrition 0.000 description 1
- 239000002385 cottonseed oil Substances 0.000 description 1
- 229960005061 crizotinib Drugs 0.000 description 1
- KTEIFNKAUNYNJU-GFCCVEGCSA-N crizotinib Chemical compound O([C@H](C)C=1C(=C(F)C=CC=1Cl)Cl)C(C(=NC=1)N)=CC=1C(=C1)C=NN1C1CCNCC1 KTEIFNKAUNYNJU-GFCCVEGCSA-N 0.000 description 1
- 230000009260 cross reactivity Effects 0.000 description 1
- 108010089438 cryptophycin 1 Proteins 0.000 description 1
- PSNOPSMXOBPNNV-VVCTWANISA-N cryptophycin 1 Chemical compound C1=C(Cl)C(OC)=CC=C1C[C@@H]1C(=O)NC[C@@H](C)C(=O)O[C@@H](CC(C)C)C(=O)O[C@H]([C@H](C)[C@@H]2[C@H](O2)C=2C=CC=CC=2)C/C=C/C(=O)N1 PSNOPSMXOBPNNV-VVCTWANISA-N 0.000 description 1
- 108010090203 cryptophycin 8 Proteins 0.000 description 1
- PSNOPSMXOBPNNV-UHFFFAOYSA-N cryptophycin-327 Natural products C1=C(Cl)C(OC)=CC=C1CC1C(=O)NCC(C)C(=O)OC(CC(C)C)C(=O)OC(C(C)C2C(O2)C=2C=CC=CC=2)CC=CC(=O)N1 PSNOPSMXOBPNNV-UHFFFAOYSA-N 0.000 description 1
- 238000012866 crystallographic experiment Methods 0.000 description 1
- 238000012258 culturing Methods 0.000 description 1
- 125000004122 cyclic group Chemical group 0.000 description 1
- 239000002875 cyclin dependent kinase inhibitor Substances 0.000 description 1
- 229940043378 cyclin-dependent kinase inhibitor Drugs 0.000 description 1
- 125000000392 cycloalkenyl group Chemical group 0.000 description 1
- 125000000753 cycloalkyl group Chemical group 0.000 description 1
- DAKAHRYFTUOCIF-UHFFFAOYSA-N cyclohexanol;pentan-3-ol Chemical compound CCC(O)CC.OC1CCCCC1 DAKAHRYFTUOCIF-UHFFFAOYSA-N 0.000 description 1
- 229930182912 cyclosporin Natural products 0.000 description 1
- 229960003067 cystine Drugs 0.000 description 1
- 229960000684 cytarabine Drugs 0.000 description 1
- 231100000433 cytotoxic Toxicity 0.000 description 1
- 230000001472 cytotoxic effect Effects 0.000 description 1
- 230000003013 cytotoxicity Effects 0.000 description 1
- 231100000135 cytotoxicity Toxicity 0.000 description 1
- 238000002784 cytotoxicity assay Methods 0.000 description 1
- 231100000263 cytotoxicity test Toxicity 0.000 description 1
- 229960003901 dacarbazine Drugs 0.000 description 1
- LVXJQMNHJWSHET-AATRIKPKSA-N dacomitinib Chemical compound C=12C=C(NC(=O)\C=C\CN3CCCCC3)C(OC)=CC2=NC=NC=1NC1=CC=C(F)C(Cl)=C1 LVXJQMNHJWSHET-AATRIKPKSA-N 0.000 description 1
- 229950002205 dacomitinib Drugs 0.000 description 1
- 229960000640 dactinomycin Drugs 0.000 description 1
- 229960002204 daratumumab Drugs 0.000 description 1
- 229960000975 daunorubicin Drugs 0.000 description 1
- 230000006240 deamidation Effects 0.000 description 1
- 230000003247 decreasing effect Effects 0.000 description 1
- 108010025838 dectin 1 Proteins 0.000 description 1
- 229960000958 deferoxamine Drugs 0.000 description 1
- 238000006731 degradation reaction Methods 0.000 description 1
- 239000003405 delayed action preparation Substances 0.000 description 1
- YSMODUONRAFBET-UHFFFAOYSA-N delta-DL-hydroxylysine Natural products NCC(O)CCC(N)C(O)=O YSMODUONRAFBET-UHFFFAOYSA-N 0.000 description 1
- 229940127276 delta-like ligand 3 Drugs 0.000 description 1
- 239000003398 denaturant Substances 0.000 description 1
- 239000005547 deoxyribonucleotide Substances 0.000 description 1
- 125000002637 deoxyribonucleotide group Chemical group 0.000 description 1
- 238000013461 design Methods 0.000 description 1
- 229950003913 detorubicin Drugs 0.000 description 1
- 238000011161 development Methods 0.000 description 1
- 230000018109 developmental process Effects 0.000 description 1
- 229960000633 dextran sulfate Drugs 0.000 description 1
- 235000019425 dextrin Nutrition 0.000 description 1
- 206010012601 diabetes mellitus Diseases 0.000 description 1
- 238000000502 dialysis Methods 0.000 description 1
- WVYXNIXAMZOZFK-UHFFFAOYSA-N diaziquone Chemical compound O=C1C(NC(=O)OCC)=C(N2CC2)C(=O)C(NC(=O)OCC)=C1N1CC1 WVYXNIXAMZOZFK-UHFFFAOYSA-N 0.000 description 1
- 229950002389 diaziquone Drugs 0.000 description 1
- NEFBYIFKOOEVPA-UHFFFAOYSA-K dicalcium phosphate Chemical compound [Ca+2].[Ca+2].[O-]P([O-])([O-])=O NEFBYIFKOOEVPA-UHFFFAOYSA-K 0.000 description 1
- 229910000390 dicalcium phosphate Inorganic materials 0.000 description 1
- 229940038472 dicalcium phosphate Drugs 0.000 description 1
- 239000003085 diluting agent Substances 0.000 description 1
- 239000000539 dimer Substances 0.000 description 1
- 229960004497 dinutuximab Drugs 0.000 description 1
- 150000002016 disaccharides Chemical class 0.000 description 1
- 125000002228 disulfide group Chemical group 0.000 description 1
- NAGJZTKCGNOGPW-UHFFFAOYSA-N dithiophosphoric acid Chemical class OP(O)(S)=S NAGJZTKCGNOGPW-UHFFFAOYSA-N 0.000 description 1
- 239000003534 dna topoisomerase inhibitor Substances 0.000 description 1
- 229960003668 docetaxel Drugs 0.000 description 1
- AMRJKAQTDDKMCE-UHFFFAOYSA-N dolastatin Chemical compound CC(C)C(N(C)C)C(=O)NC(C(C)C)C(=O)N(C)C(C(C)C)C(OC)CC(=O)N1CCCC1C(OC)C(C)C(=O)NC(C=1SC=CN=1)CC1=CC=CC=C1 AMRJKAQTDDKMCE-UHFFFAOYSA-N 0.000 description 1
- 231100000673 dose–response relationship Toxicity 0.000 description 1
- 229950004203 droloxifene Drugs 0.000 description 1
- NOTIQUSPUUHHEH-UXOVVSIBSA-N dromostanolone propionate Chemical compound C([C@@H]1CC2)C(=O)[C@H](C)C[C@]1(C)[C@@H]1[C@@H]2[C@@H]2CC[C@H](OC(=O)CC)[C@@]2(C)CC1 NOTIQUSPUUHHEH-UXOVVSIBSA-N 0.000 description 1
- 229950004683 drostanolone propionate Drugs 0.000 description 1
- 238000009509 drug development Methods 0.000 description 1
- 230000009977 dual effect Effects 0.000 description 1
- VQNATVDKACXKTF-XELLLNAOSA-N duocarmycin Chemical compound COC1=C(OC)C(OC)=C2NC(C(=O)N3C4=CC(=O)C5=C([C@@]64C[C@@H]6C3)C=C(N5)C(=O)OC)=CC2=C1 VQNATVDKACXKTF-XELLLNAOSA-N 0.000 description 1
- 210000001198 duodenum Anatomy 0.000 description 1
- 229950009791 durvalumab Drugs 0.000 description 1
- FSIRXIHZBIXHKT-MHTVFEQDSA-N edatrexate Chemical compound C=1N=C2N=C(N)N=C(N)C2=NC=1CC(CC)C1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 FSIRXIHZBIXHKT-MHTVFEQDSA-N 0.000 description 1
- 229950006700 edatrexate Drugs 0.000 description 1
- VLCYCQAOQCDTCN-UHFFFAOYSA-N eflornithine Chemical compound NCCCC(N)(C(F)F)C(O)=O VLCYCQAOQCDTCN-UHFFFAOYSA-N 0.000 description 1
- 229950000549 elliptinium acetate Drugs 0.000 description 1
- 229960004137 elotuzumab Drugs 0.000 description 1
- 239000003480 eluent Substances 0.000 description 1
- 239000012149 elution buffer Substances 0.000 description 1
- 210000002257 embryonic structure Anatomy 0.000 description 1
- 239000003995 emulsifying agent Substances 0.000 description 1
- 239000008393 encapsulating agent Substances 0.000 description 1
- 230000012202 endocytosis Effects 0.000 description 1
- 239000002158 endotoxin Substances 0.000 description 1
- 230000002708 enhancing effect Effects 0.000 description 1
- JOZGNYDSEBIJDH-UHFFFAOYSA-N eniluracil Chemical compound O=C1NC=C(C#C)C(=O)N1 JOZGNYDSEBIJDH-UHFFFAOYSA-N 0.000 description 1
- 229950010213 eniluracil Drugs 0.000 description 1
- 229950011487 enocitabine Drugs 0.000 description 1
- 108010028531 enomycin Proteins 0.000 description 1
- 239000002702 enteric coating Substances 0.000 description 1
- 230000002255 enzymatic effect Effects 0.000 description 1
- YQGOJNYOYNNSMM-UHFFFAOYSA-N eosin Chemical compound [Na+].OC(=O)C1=CC=CC=C1C1=C2C=C(Br)C(=O)C(Br)=C2OC2=C(Br)C(O)=C(Br)C=C21 YQGOJNYOYNNSMM-UHFFFAOYSA-N 0.000 description 1
- 230000001973 epigenetic effect Effects 0.000 description 1
- 229960001904 epirubicin Drugs 0.000 description 1
- 229950002973 epitiostanol Drugs 0.000 description 1
- 229930013356 epothilone Natural products 0.000 description 1
- 150000003883 epothilone derivatives Chemical class 0.000 description 1
- YSMODUONRAFBET-UHNVWZDZSA-N erythro-5-hydroxy-L-lysine Chemical compound NC[C@H](O)CC[C@H](N)C(O)=O YSMODUONRAFBET-UHNVWZDZSA-N 0.000 description 1
- 210000003743 erythrocyte Anatomy 0.000 description 1
- 229940105423 erythropoietin Drugs 0.000 description 1
- IINNWAYUJNWZRM-UHFFFAOYSA-L erythrosin B Chemical compound [Na+].[Na+].[O-]C(=O)C1=CC=CC=C1C1=C2C=C(I)C(=O)C(I)=C2OC2=C(I)C([O-])=C(I)C=C21 IINNWAYUJNWZRM-UHFFFAOYSA-L 0.000 description 1
- 229940011411 erythrosine Drugs 0.000 description 1
- 235000012732 erythrosine Nutrition 0.000 description 1
- 239000004174 erythrosine Substances 0.000 description 1
- 201000004101 esophageal cancer Diseases 0.000 description 1
- 229950002017 esorubicin Drugs 0.000 description 1
- ITSGNOIFAJAQHJ-BMFNZSJVSA-N esorubicin Chemical compound O([C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(=O)CO)[C@H]1C[C@H](N)C[C@H](C)O1 ITSGNOIFAJAQHJ-BMFNZSJVSA-N 0.000 description 1
- LJQQFQHBKUKHIS-WJHRIEJJSA-N esperamicin Chemical compound O1CC(NC(C)C)C(OC)CC1OC1C(O)C(NOC2OC(C)C(SC)C(O)C2)C(C)OC1OC1C(\C2=C/CSSSC)=C(NC(=O)OC)C(=O)C(OC3OC(C)C(O)C(OC(=O)C=4C(=CC(OC)=C(OC)C=4)NC(=O)C(=C)OC)C3)C2(O)C#C\C=C/C#C1 LJQQFQHBKUKHIS-WJHRIEJJSA-N 0.000 description 1
- 150000002148 esters Chemical class 0.000 description 1
- 229960001842 estramustine Drugs 0.000 description 1
- FRPJXPJMRWBBIH-RBRWEJTLSA-N estramustine Chemical compound ClCCN(CCCl)C(=O)OC1=CC=C2[C@H]3CC[C@](C)([C@H](CC4)O)[C@@H]4[C@@H]3CCC2=C1 FRPJXPJMRWBBIH-RBRWEJTLSA-N 0.000 description 1
- 229940011871 estrogen Drugs 0.000 description 1
- 239000000262 estrogen Substances 0.000 description 1
- 239000000328 estrogen antagonist Substances 0.000 description 1
- 229960000403 etanercept Drugs 0.000 description 1
- 229940031098 ethanolamine Drugs 0.000 description 1
- QSRLNKCNOLVZIR-KRWDZBQOSA-N ethyl (2s)-2-[[2-[4-[bis(2-chloroethyl)amino]phenyl]acetyl]amino]-4-methylsulfanylbutanoate Chemical compound CCOC(=O)[C@H](CCSC)NC(=O)CC1=CC=C(N(CCCl)CCCl)C=C1 QSRLNKCNOLVZIR-KRWDZBQOSA-N 0.000 description 1
- 239000005038 ethylene vinyl acetate Substances 0.000 description 1
- NPUKDXXFDDZOKR-LLVKDONJSA-N etomidate Chemical compound CCOC(=O)C1=CN=CN1[C@H](C)C1=CC=CC=C1 NPUKDXXFDDZOKR-LLVKDONJSA-N 0.000 description 1
- VJJPUSNTGOMMGY-MRVIYFEKSA-N etoposide Chemical compound COC1=C(O)C(OC)=CC([C@@H]2C3=CC=4OCOC=4C=C3[C@@H](O[C@H]3[C@@H]([C@@H](O)[C@@H]4O[C@H](C)OC[C@H]4O3)O)[C@@H]3[C@@H]2C(OC3)=O)=C1 VJJPUSNTGOMMGY-MRVIYFEKSA-N 0.000 description 1
- 238000001704 evaporation Methods 0.000 description 1
- 230000007717 exclusion Effects 0.000 description 1
- 229960000255 exemestane Drugs 0.000 description 1
- 208000024519 eye neoplasm Diseases 0.000 description 1
- 229950011548 fadrozole Drugs 0.000 description 1
- 210000003754 fetus Anatomy 0.000 description 1
- 210000002950 fibroblast Anatomy 0.000 description 1
- 238000009459 flexible packaging Methods 0.000 description 1
- 238000000684 flow cytometry Methods 0.000 description 1
- 229960000961 floxuridine Drugs 0.000 description 1
- ODKNJVUHOIMIIZ-RRKCRQDMSA-N floxuridine Chemical compound C1[C@H](O)[C@@H](CO)O[C@H]1N1C(=O)NC(=O)C(F)=C1 ODKNJVUHOIMIIZ-RRKCRQDMSA-N 0.000 description 1
- 229960000390 fludarabine Drugs 0.000 description 1
- GIUYCYHIANZCFB-FJFJXFQQSA-N fludarabine phosphate Chemical compound C1=NC=2C(N)=NC(F)=NC=2N1[C@@H]1O[C@H](COP(O)(O)=O)[C@@H](O)[C@@H]1O GIUYCYHIANZCFB-FJFJXFQQSA-N 0.000 description 1
- NBVXSUQYWXRMNV-UHFFFAOYSA-N fluoromethane Chemical compound FC NBVXSUQYWXRMNV-UHFFFAOYSA-N 0.000 description 1
- IJJVMEJXYNJXOJ-UHFFFAOYSA-N fluquinconazole Chemical compound C=1C=C(Cl)C=C(Cl)C=1N1C(=O)C2=CC(F)=CC=C2N=C1N1C=NC=N1 IJJVMEJXYNJXOJ-UHFFFAOYSA-N 0.000 description 1
- 229960002074 flutamide Drugs 0.000 description 1
- MKXKFYHWDHIYRV-UHFFFAOYSA-N flutamide Chemical compound CC(C)C(=O)NC1=CC=C([N+]([O-])=O)C(C(F)(F)F)=C1 MKXKFYHWDHIYRV-UHFFFAOYSA-N 0.000 description 1
- 229940014144 folate Drugs 0.000 description 1
- 235000019152 folic acid Nutrition 0.000 description 1
- 229960000304 folic acid Drugs 0.000 description 1
- 150000002224 folic acids Chemical class 0.000 description 1
- 229960004421 formestane Drugs 0.000 description 1
- OSVMTWJCGUFAOD-KZQROQTASA-N formestane Chemical compound O=C1CC[C@]2(C)[C@H]3CC[C@](C)(C(CC4)=O)[C@@H]4[C@@H]3CCC2=C1O OSVMTWJCGUFAOD-KZQROQTASA-N 0.000 description 1
- 229960004783 fotemustine Drugs 0.000 description 1
- YAKWPXVTIGTRJH-UHFFFAOYSA-N fotemustine Chemical compound CCOP(=O)(OCC)C(C)NC(=O)N(CCCl)N=O YAKWPXVTIGTRJH-UHFFFAOYSA-N 0.000 description 1
- 125000002446 fucosyl group Chemical group C1([C@@H](O)[C@H](O)[C@H](O)[C@@H](O1)C)* 0.000 description 1
- 230000005714 functional activity Effects 0.000 description 1
- 229930182830 galactose Natural products 0.000 description 1
- 229940044658 gallium nitrate Drugs 0.000 description 1
- 229960002963 ganciclovir Drugs 0.000 description 1
- IRSCQMHQWWYFCW-UHFFFAOYSA-N ganciclovir Chemical compound O=C1NC(N)=NC2=C1N=CN2COC(CO)CO IRSCQMHQWWYFCW-UHFFFAOYSA-N 0.000 description 1
- 150000002270 gangliosides Chemical class 0.000 description 1
- 239000007789 gas Substances 0.000 description 1
- 206010017758 gastric cancer Diseases 0.000 description 1
- 230000002496 gastric effect Effects 0.000 description 1
- 229950008209 gedatolisib Drugs 0.000 description 1
- 229920000159 gelatin Polymers 0.000 description 1
- 239000008273 gelatin Substances 0.000 description 1
- 235000019322 gelatine Nutrition 0.000 description 1
- 235000011852 gelatine desserts Nutrition 0.000 description 1
- QTQAWLPCGQOSGP-GBTDJJJQSA-N geldanamycin Chemical compound N1C(=O)\C(C)=C/C=C\[C@@H](OC)[C@H](OC(N)=O)\C(C)=C/[C@@H](C)[C@@H](O)[C@H](OC)C[C@@H](C)CC2=C(OC)C(=O)C=C1C2=O QTQAWLPCGQOSGP-GBTDJJJQSA-N 0.000 description 1
- 229960005144 gemcitabine hydrochloride Drugs 0.000 description 1
- 229960003297 gemtuzumab ozogamicin Drugs 0.000 description 1
- 230000002068 genetic effect Effects 0.000 description 1
- 238000010353 genetic engineering Methods 0.000 description 1
- 230000035784 germination Effects 0.000 description 1
- SFNSLLSYNZWZQG-VQIMIIECSA-N glasdegib Chemical compound N([C@@H]1CCN([C@H](C1)C=1NC2=CC=CC=C2N=1)C)C(=O)NC1=CC=C(C#N)C=C1 SFNSLLSYNZWZQG-VQIMIIECSA-N 0.000 description 1
- 229950003566 glasdegib Drugs 0.000 description 1
- 239000011521 glass Substances 0.000 description 1
- 208000005017 glioblastoma Diseases 0.000 description 1
- 239000003862 glucocorticoid Substances 0.000 description 1
- 150000008271 glucosaminides Chemical class 0.000 description 1
- 229960002989 glutamic acid Drugs 0.000 description 1
- 150000004676 glycans Chemical class 0.000 description 1
- 229930182470 glycoside Natural products 0.000 description 1
- 229960002913 goserelin Drugs 0.000 description 1
- 208000024908 graft versus host disease Diseases 0.000 description 1
- 239000008187 granular material Substances 0.000 description 1
- 229940093915 gynecological organic acid Drugs 0.000 description 1
- 238000003306 harvesting Methods 0.000 description 1
- 201000010536 head and neck cancer Diseases 0.000 description 1
- 208000014829 head and neck neoplasm Diseases 0.000 description 1
- 210000002216 heart Anatomy 0.000 description 1
- 210000002837 heart atrium Anatomy 0.000 description 1
- 210000003709 heart valve Anatomy 0.000 description 1
- 230000002489 hematologic effect Effects 0.000 description 1
- 108010057806 hemiasterlin Proteins 0.000 description 1
- 229930187626 hemiasterlin Natural products 0.000 description 1
- 125000000623 heterocyclic group Chemical group 0.000 description 1
- 238000005734 heterodimerization reaction Methods 0.000 description 1
- UUVWYPNAQBNQJQ-UHFFFAOYSA-N hexamethylmelamine Chemical compound CN(C)C1=NC(N(C)C)=NC(N(C)C)=N1 UUVWYPNAQBNQJQ-UHFFFAOYSA-N 0.000 description 1
- 238000004128 high performance liquid chromatography Methods 0.000 description 1
- HNDVDQJCIGZPNO-UHFFFAOYSA-N histidine Natural products OC(=O)C(N)CC1=CN=CN1 HNDVDQJCIGZPNO-UHFFFAOYSA-N 0.000 description 1
- 239000008240 homogeneous mixture Substances 0.000 description 1
- 238000000265 homogenisation Methods 0.000 description 1
- 230000003054 hormonal effect Effects 0.000 description 1
- 229940088597 hormone Drugs 0.000 description 1
- 239000005556 hormone Substances 0.000 description 1
- 238000001794 hormone therapy Methods 0.000 description 1
- 102000050022 human STING1 Human genes 0.000 description 1
- 102000045710 human TLR9 Human genes 0.000 description 1
- 208000033519 human immunodeficiency virus infectious disease Diseases 0.000 description 1
- 239000000017 hydrogel Substances 0.000 description 1
- 229920001477 hydrophilic polymer Polymers 0.000 description 1
- 229920001600 hydrophobic polymer Polymers 0.000 description 1
- 125000002349 hydroxyamino group Chemical group [H]ON([H])[*] 0.000 description 1
- 229960001330 hydroxycarbamide Drugs 0.000 description 1
- 229920003063 hydroxymethyl cellulose Polymers 0.000 description 1
- 229940031574 hydroxymethyl cellulose Drugs 0.000 description 1
- 229940015872 ibandronate Drugs 0.000 description 1
- 229960001001 ibritumomab tiuxetan Drugs 0.000 description 1
- 229960000908 idarubicin Drugs 0.000 description 1
- RAXXELZNTBOGNW-UHFFFAOYSA-N imidazole Substances C1=CNC=N1 RAXXELZNTBOGNW-UHFFFAOYSA-N 0.000 description 1
- 125000004857 imidazopyridinyl group Chemical class N1C(=NC2=C1C=CC=N2)* 0.000 description 1
- 229940124669 imidazoquinoline Drugs 0.000 description 1
- 208000026278 immune system disease Diseases 0.000 description 1
- 230000036039 immunity Effects 0.000 description 1
- 239000002955 immunomodulating agent Substances 0.000 description 1
- 238000001114 immunoprecipitation Methods 0.000 description 1
- 230000001506 immunosuppresive effect Effects 0.000 description 1
- 230000002637 immunotoxin Effects 0.000 description 1
- 229940051026 immunotoxin Drugs 0.000 description 1
- 239000002596 immunotoxin Substances 0.000 description 1
- 231100000608 immunotoxin Toxicity 0.000 description 1
- DBIGHPPNXATHOF-UHFFFAOYSA-N improsulfan Chemical compound CS(=O)(=O)OCCCNCCCOS(C)(=O)=O DBIGHPPNXATHOF-UHFFFAOYSA-N 0.000 description 1
- 229950008097 improsulfan Drugs 0.000 description 1
- 238000011503 in vivo imaging Methods 0.000 description 1
- 238000011065 in-situ storage Methods 0.000 description 1
- 238000010348 incorporation Methods 0.000 description 1
- 229910052738 indium Inorganic materials 0.000 description 1
- 239000012678 infectious agent Substances 0.000 description 1
- 208000027866 inflammatory disease Diseases 0.000 description 1
- 230000002757 inflammatory effect Effects 0.000 description 1
- 238000011081 inoculation Methods 0.000 description 1
- 229950004101 inotuzumab ozogamicin Drugs 0.000 description 1
- 239000000138 intercalating agent Substances 0.000 description 1
- 229940079322 interferon Drugs 0.000 description 1
- 230000004068 intracellular signaling Effects 0.000 description 1
- 230000008863 intramolecular interaction Effects 0.000 description 1
- 238000007919 intrasynovial administration Methods 0.000 description 1
- 238000007913 intrathecal administration Methods 0.000 description 1
- SZVJSHCCFOBDDC-UHFFFAOYSA-N iron(II,III) oxide Inorganic materials O=[Fe]O[Fe]O[Fe]=O SZVJSHCCFOBDDC-UHFFFAOYSA-N 0.000 description 1
- 229950007752 isatuximab Drugs 0.000 description 1
- 238000002955 isolation Methods 0.000 description 1
- 108010045069 keyhole-limpet hemocyanin Proteins 0.000 description 1
- 201000010982 kidney cancer Diseases 0.000 description 1
- 239000008101 lactose Substances 0.000 description 1
- 229910052747 lanthanoid Inorganic materials 0.000 description 1
- 150000002602 lanthanoids Chemical class 0.000 description 1
- 229940115286 lentinan Drugs 0.000 description 1
- 229940121292 leronlimab Drugs 0.000 description 1
- 229960003881 letrozole Drugs 0.000 description 1
- HPJKCIUCZWXJDR-UHFFFAOYSA-N letrozole Chemical compound C1=CC(C#N)=CC=C1C(N1N=CN=C1)C1=CC=C(C#N)C=C1 HPJKCIUCZWXJDR-UHFFFAOYSA-N 0.000 description 1
- 208000032839 leukemia Diseases 0.000 description 1
- RGLRXNKKBLIBQS-XNHQSDQCSA-N leuprolide acetate Chemical compound CC(O)=O.CCNC(=O)[C@@H]1CCCN1C(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](CC(C)C)NC(=O)[C@@H](NC(=O)[C@H](CO)NC(=O)[C@H](CC=1C2=CC=CC=C2NC=1)NC(=O)[C@H](CC=1N=CNC=1)NC(=O)[C@H]1NC(=O)CC1)CC1=CC=C(O)C=C1 RGLRXNKKBLIBQS-XNHQSDQCSA-N 0.000 description 1
- 230000000670 limiting effect Effects 0.000 description 1
- 208000012987 lip and oral cavity carcinoma Diseases 0.000 description 1
- 239000002960 lipid emulsion Substances 0.000 description 1
- 230000029226 lipidation Effects 0.000 description 1
- 238000001638 lipofection Methods 0.000 description 1
- INHCSSUBVCNVSK-UHFFFAOYSA-L lithium sulfate Inorganic materials [Li+].[Li+].[O-]S([O-])(=O)=O INHCSSUBVCNVSK-UHFFFAOYSA-L 0.000 description 1
- 201000007270 liver cancer Diseases 0.000 description 1
- 208000014018 liver neoplasm Diseases 0.000 description 1
- 229960002247 lomustine Drugs 0.000 description 1
- 229950001290 lorlatinib Drugs 0.000 description 1
- IIXWYSCJSQVBQM-LLVKDONJSA-N lorlatinib Chemical compound N=1N(C)C(C#N)=C2C=1CN(C)C(=O)C1=CC=C(F)C=C1[C@@H](C)OC1=CC2=CN=C1N IIXWYSCJSQVBQM-LLVKDONJSA-N 0.000 description 1
- 238000003670 luciferase enzyme activity assay Methods 0.000 description 1
- 210000004072 lung Anatomy 0.000 description 1
- 201000005202 lung cancer Diseases 0.000 description 1
- 208000020816 lung neoplasm Diseases 0.000 description 1
- 229940087857 lupron Drugs 0.000 description 1
- 239000008176 lyophilized powder Substances 0.000 description 1
- 210000002540 macrophage Anatomy 0.000 description 1
- 239000011777 magnesium Substances 0.000 description 1
- 229910052749 magnesium Inorganic materials 0.000 description 1
- 229910001629 magnesium chloride Inorganic materials 0.000 description 1
- 235000019359 magnesium stearate Nutrition 0.000 description 1
- 230000036210 malignancy Effects 0.000 description 1
- 208000015486 malignant pancreatic neoplasm Diseases 0.000 description 1
- 238000007726 management method Methods 0.000 description 1
- MQXVYODZCMMZEM-ZYUZMQFOSA-N mannomustine Chemical compound ClCCNC[C@@H](O)[C@@H](O)[C@H](O)[C@H](O)CNCCCl MQXVYODZCMMZEM-ZYUZMQFOSA-N 0.000 description 1
- 229950008612 mannomustine Drugs 0.000 description 1
- 229950003135 margetuximab Drugs 0.000 description 1
- 230000008774 maternal effect Effects 0.000 description 1
- 229960004961 mechlorethamine Drugs 0.000 description 1
- HAWPXGHAZFHHAD-UHFFFAOYSA-N mechlorethamine Chemical compound ClCCN(C)CCCl HAWPXGHAZFHHAD-UHFFFAOYSA-N 0.000 description 1
- 229960004296 megestrol acetate Drugs 0.000 description 1
- RQZAXGRLVPAYTJ-GQFGMJRRSA-N megestrol acetate Chemical compound C1=C(C)C2=CC(=O)CC[C@]2(C)[C@@H]2[C@@H]1[C@@H]1CC[C@@](C(C)=O)(OC(=O)C)[C@@]1(C)CC2 RQZAXGRLVPAYTJ-GQFGMJRRSA-N 0.000 description 1
- 201000001441 melanoma Diseases 0.000 description 1
- 229960001924 melphalan Drugs 0.000 description 1
- SGDBTWWWUNNDEQ-LBPRGKRZSA-N melphalan Chemical compound OC(=O)[C@@H](N)CC1=CC=C(N(CCCl)CCCl)C=C1 SGDBTWWWUNNDEQ-LBPRGKRZSA-N 0.000 description 1
- 229950009246 mepitiostane Drugs 0.000 description 1
- 229960001428 mercaptopurine Drugs 0.000 description 1
- 230000037353 metabolic pathway Effects 0.000 description 1
- 229910044991 metal oxide Inorganic materials 0.000 description 1
- 150000004706 metal oxides Chemical class 0.000 description 1
- 230000001394 metastastic effect Effects 0.000 description 1
- 206010061289 metastatic neoplasm Diseases 0.000 description 1
- 229940071648 metered dose inhaler Drugs 0.000 description 1
- 229930182817 methionine Natural products 0.000 description 1
- 125000001360 methionine group Chemical group N[C@@H](CCSC)C(=O)* 0.000 description 1
- VJRAUFKOOPNFIQ-TVEKBUMESA-N methyl (1r,2r,4s)-4-[(2r,4s,5s,6s)-5-[(2s,4s,5s,6s)-5-[(2s,4s,5s,6s)-4,5-dihydroxy-6-methyloxan-2-yl]oxy-4-hydroxy-6-methyloxan-2-yl]oxy-4-(dimethylamino)-6-methyloxan-2-yl]oxy-2-ethyl-2,5,7,10-tetrahydroxy-6,11-dioxo-3,4-dihydro-1h-tetracene-1-carboxylat Chemical compound O([C@H]1[C@@H](O)C[C@@H](O[C@H]1C)O[C@H]1[C@H](C[C@@H](O[C@H]1C)O[C@H]1C[C@]([C@@H](C2=CC=3C(=O)C4=C(O)C=CC(O)=C4C(=O)C=3C(O)=C21)C(=O)OC)(O)CC)N(C)C)[C@H]1C[C@H](O)[C@H](O)[C@H](C)O1 VJRAUFKOOPNFIQ-TVEKBUMESA-N 0.000 description 1
- DFTAZNAEBRBBKP-UHFFFAOYSA-N methyl 4-sulfanylbutanimidate Chemical compound COC(=N)CCCS DFTAZNAEBRBBKP-UHFFFAOYSA-N 0.000 description 1
- 239000004292 methyl p-hydroxybenzoate Substances 0.000 description 1
- 235000010270 methyl p-hydroxybenzoate Nutrition 0.000 description 1
- 229960002216 methylparaben Drugs 0.000 description 1
- YACKEPLHDIMKIO-UHFFFAOYSA-N methylphosphonic acid Chemical compound CP(O)(O)=O YACKEPLHDIMKIO-UHFFFAOYSA-N 0.000 description 1
- HPNSFSBZBAHARI-UHFFFAOYSA-N micophenolic acid Natural products OC1=C(CC=C(C)CCC(O)=O)C(OC)=C(C)C2=C1C(=O)OC2 HPNSFSBZBAHARI-UHFFFAOYSA-N 0.000 description 1
- 239000004530 micro-emulsion Substances 0.000 description 1
- 229960005225 mifamurtide Drugs 0.000 description 1
- 108700007621 mifamurtide Proteins 0.000 description 1
- 230000003278 mimic effect Effects 0.000 description 1
- 229960005485 mitobronitol Drugs 0.000 description 1
- 229960003539 mitoguazone Drugs 0.000 description 1
- MXWHMTNPTTVWDM-NXOFHUPFSA-N mitoguazone Chemical compound NC(N)=N\N=C(/C)\C=N\N=C(N)N MXWHMTNPTTVWDM-NXOFHUPFSA-N 0.000 description 1
- VFKZTMPDYBFSTM-GUCUJZIJSA-N mitolactol Chemical compound BrC[C@H](O)[C@@H](O)[C@@H](O)[C@H](O)CBr VFKZTMPDYBFSTM-GUCUJZIJSA-N 0.000 description 1
- 229950010913 mitolactol Drugs 0.000 description 1
- 229960004857 mitomycin Drugs 0.000 description 1
- 229960000350 mitotane Drugs 0.000 description 1
- ZAHQPTJLOCWVPG-UHFFFAOYSA-N mitoxantrone dihydrochloride Chemical compound Cl.Cl.O=C1C2=C(O)C=CC(O)=C2C(=O)C2=C1C(NCCNCCO)=CC=C2NCCNCCO ZAHQPTJLOCWVPG-UHFFFAOYSA-N 0.000 description 1
- 229950007699 mogamulizumab Drugs 0.000 description 1
- 238000001823 molecular biology technique Methods 0.000 description 1
- 238000010369 molecular cloning Methods 0.000 description 1
- 150000002772 monosaccharides Chemical class 0.000 description 1
- 201000006417 multiple sclerosis Diseases 0.000 description 1
- 125000001446 muramyl group Chemical group N[C@@H](C=O)[C@@H](O[C@@H](C(=O)*)C)[C@H](O)[C@H](O)CO 0.000 description 1
- 206010028417 myasthenia gravis Diseases 0.000 description 1
- 229960004866 mycophenolate mofetil Drugs 0.000 description 1
- RTGDFNSFWBGLEC-SYZQJQIISA-N mycophenolate mofetil Chemical compound COC1=C(C)C=2COC(=O)C=2C(O)=C1C\C=C(/C)CCC(=O)OCCN1CCOCC1 RTGDFNSFWBGLEC-SYZQJQIISA-N 0.000 description 1
- 229960000951 mycophenolic acid Drugs 0.000 description 1
- HPNSFSBZBAHARI-RUDMXATFSA-N mycophenolic acid Chemical compound OC1=C(C\C=C(/C)CCC(O)=O)C(OC)=C(C)C2=C1C(=O)OC2 HPNSFSBZBAHARI-RUDMXATFSA-N 0.000 description 1
- NJSMWLQOCQIOPE-OCHFTUDZSA-N n-[(e)-[10-[(e)-(4,5-dihydro-1h-imidazol-2-ylhydrazinylidene)methyl]anthracen-9-yl]methylideneamino]-4,5-dihydro-1h-imidazol-2-amine Chemical compound N1CCN=C1N\N=C\C(C1=CC=CC=C11)=C(C=CC=C2)C2=C1\C=N\NC1=NCCN1 NJSMWLQOCQIOPE-OCHFTUDZSA-N 0.000 description 1
- OHDXDNUPVVYWOV-UHFFFAOYSA-N n-methyl-1-(2-naphthalen-1-ylsulfanylphenyl)methanamine Chemical compound CNCC1=CC=CC=C1SC1=CC=CC2=CC=CC=C12 OHDXDNUPVVYWOV-UHFFFAOYSA-N 0.000 description 1
- 239000002088 nanocapsule Substances 0.000 description 1
- 201000003631 narcolepsy Diseases 0.000 description 1
- 210000000822 natural killer cell Anatomy 0.000 description 1
- 229960000513 necitumumab Drugs 0.000 description 1
- QZGIWPZCWHMVQL-UIYAJPBUSA-N neocarzinostatin chromophore Chemical compound O1[C@H](C)[C@H](O)[C@H](O)[C@@H](NC)[C@H]1O[C@@H]1C/2=C/C#C[C@H]3O[C@@]3([C@@H]3OC(=O)OC3)C#CC\2=C[C@H]1OC(=O)C1=C(O)C=CC2=C(C)C=C(OC)C=C12 QZGIWPZCWHMVQL-UIYAJPBUSA-N 0.000 description 1
- 210000005170 neoplastic cell Anatomy 0.000 description 1
- 230000001613 neoplastic effect Effects 0.000 description 1
- 230000004770 neurodegeneration Effects 0.000 description 1
- 208000015122 neurodegenerative disease Diseases 0.000 description 1
- 210000000440 neutrophil Anatomy 0.000 description 1
- 229960002653 nilutamide Drugs 0.000 description 1
- XWXYUMMDTVBTOU-UHFFFAOYSA-N nilutamide Chemical compound O=C1C(C)(C)NC(=O)N1C1=CC=C([N+]([O-])=O)C(C(F)(F)F)=C1 XWXYUMMDTVBTOU-UHFFFAOYSA-N 0.000 description 1
- YMVWGSQGCWCDGW-UHFFFAOYSA-N nitracrine Chemical compound C1=CC([N+]([O-])=O)=C2C(NCCCN(C)C)=C(C=CC=C3)C3=NC2=C1 YMVWGSQGCWCDGW-UHFFFAOYSA-N 0.000 description 1
- 229950008607 nitracrine Drugs 0.000 description 1
- QJGQUHMNIGDVPM-UHFFFAOYSA-N nitrogen group Chemical group [N] QJGQUHMNIGDVPM-UHFFFAOYSA-N 0.000 description 1
- 229960003301 nivolumab Drugs 0.000 description 1
- 229950009266 nogalamycin Drugs 0.000 description 1
- KGTDRFCXGRULNK-JYOBTZKQSA-N nogalamycin Chemical compound CO[C@@H]1[C@@](OC)(C)[C@@H](OC)[C@H](C)O[C@H]1O[C@@H]1C2=C(O)C(C(=O)C3=C(O)C=C4[C@@]5(C)O[C@H]([C@H]([C@@H]([C@H]5O)N(C)C)O)OC4=C3C3=O)=C3C=C2[C@@H](C(=O)OC)[C@@](C)(O)C1 KGTDRFCXGRULNK-JYOBTZKQSA-N 0.000 description 1
- 230000036963 noncompetitive effect Effects 0.000 description 1
- 239000002736 nonionic surfactant Substances 0.000 description 1
- 230000000269 nucleophilic effect Effects 0.000 description 1
- 239000002777 nucleoside Substances 0.000 description 1
- 150000003833 nucleoside derivatives Chemical class 0.000 description 1
- 229920001778 nylon Polymers 0.000 description 1
- 229960003347 obinutuzumab Drugs 0.000 description 1
- QIQXTHQIDYTFRH-UHFFFAOYSA-N octadecanoic acid Chemical compound CCCCCCCCCCCCCCCCCC(O)=O QIQXTHQIDYTFRH-UHFFFAOYSA-N 0.000 description 1
- OQCDKBAXFALNLD-UHFFFAOYSA-N octadecanoic acid Natural products CCCCCCCC(C)CCCCCCCCC(O)=O OQCDKBAXFALNLD-UHFFFAOYSA-N 0.000 description 1
- 201000008106 ocular cancer Diseases 0.000 description 1
- 229960002450 ofatumumab Drugs 0.000 description 1
- 238000006384 oligomerization reaction Methods 0.000 description 1
- 239000002751 oligonucleotide probe Substances 0.000 description 1
- 238000002515 oligonucleotide synthesis Methods 0.000 description 1
- 229940121476 omburtamab Drugs 0.000 description 1
- 229950011093 onapristone Drugs 0.000 description 1
- 238000011275 oncology therapy Methods 0.000 description 1
- 230000003287 optical effect Effects 0.000 description 1
- 150000007524 organic acids Chemical class 0.000 description 1
- 235000005985 organic acids Nutrition 0.000 description 1
- 239000003960 organic solvent Substances 0.000 description 1
- 230000002611 ovarian Effects 0.000 description 1
- 210000001672 ovary Anatomy 0.000 description 1
- 230000002018 overexpression Effects 0.000 description 1
- 238000006213 oxygenation reaction Methods 0.000 description 1
- LXCFILQKKLGQFO-UHFFFAOYSA-N p-hydroxybenzoic acid methyl ester Natural products COC(=O)C1=CC=C(O)C=C1 LXCFILQKKLGQFO-UHFFFAOYSA-N 0.000 description 1
- 239000006174 pH buffer Substances 0.000 description 1
- 229960001592 paclitaxel Drugs 0.000 description 1
- PIRWNASAJNPKHT-SHZATDIYSA-N pamp Chemical compound C([C@@H](C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(N)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CO)NC(=O)[C@H](C)NC(=O)[C@@H](NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](C)N)C(C)C)C1=CC=CC=C1 PIRWNASAJNPKHT-SHZATDIYSA-N 0.000 description 1
- VREZDOWOLGNDPW-UHFFFAOYSA-N pancratistatine Natural products C1=C2C3C(O)C(O)C(O)C(O)C3NC(=O)C2=C(O)C2=C1OCO2 VREZDOWOLGNDPW-UHFFFAOYSA-N 0.000 description 1
- 201000002528 pancreatic cancer Diseases 0.000 description 1
- 208000008443 pancreatic carcinoma Diseases 0.000 description 1
- 238000007911 parenteral administration Methods 0.000 description 1
- 230000001575 pathological effect Effects 0.000 description 1
- 229940046159 pegylated liposomal doxorubicin Drugs 0.000 description 1
- 229960002621 pembrolizumab Drugs 0.000 description 1
- 230000035515 penetration Effects 0.000 description 1
- 229960002340 pentostatin Drugs 0.000 description 1
- FPVKHBSQESCIEP-JQCXWYLXSA-N pentostatin Chemical compound C1[C@H](O)[C@@H](CO)O[C@H]1N1C(N=CNC[C@H]2O)=C2N=C1 FPVKHBSQESCIEP-JQCXWYLXSA-N 0.000 description 1
- QIMGFXOHTOXMQP-GFAGFCTOSA-N peplomycin Chemical compound N([C@H](C(=O)N[C@H](C)[C@@H](O)[C@H](C)C(=O)N[C@@H]([C@H](O)C)C(=O)NCCC=1SC=C(N=1)C=1SC=C(N=1)C(=O)NCCCN[C@@H](C)C=1C=CC=CC=1)[C@@H](O[C@H]1[C@H]([C@@H](O)[C@H](O)[C@H](CO)O1)O[C@@H]1[C@H]([C@@H](OC(N)=O)[C@H](O)[C@@H](CO)O1)O)C=1NC=NC=1)C(=O)C1=NC([C@H](CC(N)=O)NC[C@H](N)C(N)=O)=NC(N)=C1C QIMGFXOHTOXMQP-GFAGFCTOSA-N 0.000 description 1
- 229950003180 peplomycin Drugs 0.000 description 1
- 108040002068 peptide-N4-(N-acetyl-beta-glucosaminyl)asparagine amidase activity proteins Proteins 0.000 description 1
- 210000003516 pericardium Anatomy 0.000 description 1
- 229940083251 peripheral vasodilators purine derivative Drugs 0.000 description 1
- 229960002087 pertuzumab Drugs 0.000 description 1
- 239000008024 pharmaceutical diluent Substances 0.000 description 1
- 108010076042 phenomycin Proteins 0.000 description 1
- 125000002467 phosphate group Chemical group [H]OP(=O)(O[H])O[*] 0.000 description 1
- WTJKGGKOPKCXLL-RRHRGVEJSA-N phosphatidylcholine Chemical compound CCCCCCCCCCCCCCCC(=O)OC[C@H](COP([O-])(=O)OCC[N+](C)(C)C)OC(=O)CCCCCCCC=CCCCCCCCC WTJKGGKOPKCXLL-RRHRGVEJSA-N 0.000 description 1
- 150000008104 phosphatidylethanolamines Chemical class 0.000 description 1
- 150000004713 phosphodiesters Chemical class 0.000 description 1
- 150000008298 phosphoramidates Chemical class 0.000 description 1
- 235000011007 phosphoric acid Nutrition 0.000 description 1
- 150000003013 phosphoric acid derivatives Chemical group 0.000 description 1
- 229950004354 phosphorylcholine Drugs 0.000 description 1
- PYJNAPOPMIJKJZ-UHFFFAOYSA-N phosphorylcholine chloride Chemical compound [Cl-].C[N+](C)(C)CCOP(O)(O)=O PYJNAPOPMIJKJZ-UHFFFAOYSA-N 0.000 description 1
- 230000004962 physiological condition Effects 0.000 description 1
- 230000035479 physiological effects, processes and functions Effects 0.000 description 1
- 229960000952 pipobroman Drugs 0.000 description 1
- NJBFOOCLYDNZJN-UHFFFAOYSA-N pipobroman Chemical compound BrCCC(=O)N1CCN(C(=O)CCBr)CC1 NJBFOOCLYDNZJN-UHFFFAOYSA-N 0.000 description 1
- NUKCGLDCWQXYOQ-UHFFFAOYSA-N piposulfan Chemical compound CS(=O)(=O)OCCC(=O)N1CCN(C(=O)CCOS(C)(=O)=O)CC1 NUKCGLDCWQXYOQ-UHFFFAOYSA-N 0.000 description 1
- 229950001100 piposulfan Drugs 0.000 description 1
- 229960001221 pirarubicin Drugs 0.000 description 1
- 229920003023 plastic Polymers 0.000 description 1
- 239000004033 plastic Substances 0.000 description 1
- 229910052697 platinum Inorganic materials 0.000 description 1
- 150000003057 platinum Chemical class 0.000 description 1
- 229950009416 polatuzumab vedotin Drugs 0.000 description 1
- 229920000729 poly(L-lysine) polymer Polymers 0.000 description 1
- 229920001200 poly(ethylene-vinyl acetate) Polymers 0.000 description 1
- 229920000747 poly(lactic acid) Polymers 0.000 description 1
- 229920003229 poly(methyl methacrylate) Polymers 0.000 description 1
- 229920002401 polyacrylamide Polymers 0.000 description 1
- 229920000728 polyester Polymers 0.000 description 1
- 229920000573 polyethylene Polymers 0.000 description 1
- 239000005020 polyethylene terephthalate Substances 0.000 description 1
- 229920000139 polyethylene terephthalate Polymers 0.000 description 1
- 229920002338 polyhydroxyethylmethacrylate Polymers 0.000 description 1
- 229940115272 polyinosinic:polycytidylic acid Drugs 0.000 description 1
- 229920000642 polymer Polymers 0.000 description 1
- 238000006116 polymerization reaction Methods 0.000 description 1
- 239000004926 polymethyl methacrylate Substances 0.000 description 1
- 208000005987 polymyositis Diseases 0.000 description 1
- 239000000256 polyoxyethylene sorbitan monolaurate Substances 0.000 description 1
- 235000010486 polyoxyethylene sorbitan monolaurate Nutrition 0.000 description 1
- 229920001282 polysaccharide Polymers 0.000 description 1
- 239000005017 polysaccharide Substances 0.000 description 1
- 229920002451 polyvinyl alcohol Polymers 0.000 description 1
- 239000011148 porous material Substances 0.000 description 1
- 230000004481 post-translational protein modification Effects 0.000 description 1
- 229910052700 potassium Inorganic materials 0.000 description 1
- OXCMYAYHXIHQOA-UHFFFAOYSA-N potassium;[2-butyl-5-chloro-3-[[4-[2-(1,2,4-triaza-3-azanidacyclopenta-1,4-dien-5-yl)phenyl]phenyl]methyl]imidazol-4-yl]methanol Chemical compound [K+].CCCCC1=NC(Cl)=C(CO)N1CC1=CC=C(C=2C(=CC=CC=2)C2=N[N-]N=N2)C=C1 OXCMYAYHXIHQOA-UHFFFAOYSA-N 0.000 description 1
- 239000003755 preservative agent Substances 0.000 description 1
- CPTBDICYNRMXFX-UHFFFAOYSA-N procarbazine Chemical compound CNNCC1=CC=C(C(=O)NC(C)C)C=C1 CPTBDICYNRMXFX-UHFFFAOYSA-N 0.000 description 1
- 229960000624 procarbazine Drugs 0.000 description 1
- 238000012545 processing Methods 0.000 description 1
- 230000002062 proliferating effect Effects 0.000 description 1
- 230000035755 proliferation Effects 0.000 description 1
- 230000002035 prolonged effect Effects 0.000 description 1
- 230000001737 promoting effect Effects 0.000 description 1
- 229960003415 propylparaben Drugs 0.000 description 1
- 239000012562 protein A resin Substances 0.000 description 1
- 230000004853 protein function Effects 0.000 description 1
- 238000001742 protein purification Methods 0.000 description 1
- WOLQREOUPKZMEX-UHFFFAOYSA-N pteroyltriglutamic acid Chemical compound C=1N=C2NC(N)=NC(=O)C2=NC=1CNC1=CC=C(C(=O)NC(CCC(=O)NC(CCC(=O)NC(CCC(O)=O)C(O)=O)C(O)=O)C(O)=O)C=C1 WOLQREOUPKZMEX-UHFFFAOYSA-N 0.000 description 1
- 229940083082 pyrimidine derivative acting on arteriolar smooth muscle Drugs 0.000 description 1
- YUOCYTRGANSSRY-UHFFFAOYSA-N pyrrolo[2,3-i][1,2]benzodiazepine Chemical class C1=CN=NC2=C3C=CN=C3C=CC2=C1 YUOCYTRGANSSRY-UHFFFAOYSA-N 0.000 description 1
- 238000010791 quenching Methods 0.000 description 1
- 230000000171 quenching effect Effects 0.000 description 1
- 238000003127 radioimmunoassay Methods 0.000 description 1
- 229960002633 ramucirumab Drugs 0.000 description 1
- 229960002185 ranimustine Drugs 0.000 description 1
- 208000002574 reactive arthritis Diseases 0.000 description 1
- 230000009257 reactivity Effects 0.000 description 1
- 229960004836 regorafenib Drugs 0.000 description 1
- FNHKPVJBJVTLMP-UHFFFAOYSA-N regorafenib Chemical compound C1=NC(C(=O)NC)=CC(OC=2C=C(F)C(NC(=O)NC=3C=C(C(Cl)=CC=3)C(F)(F)F)=CC=2)=C1 FNHKPVJBJVTLMP-UHFFFAOYSA-N 0.000 description 1
- 230000022532 regulation of transcription, DNA-dependent Effects 0.000 description 1
- 208000009169 relapsing polychondritis Diseases 0.000 description 1
- 229940121484 relatlimab Drugs 0.000 description 1
- 239000011347 resin Substances 0.000 description 1
- 229920005989 resin Polymers 0.000 description 1
- 230000000241 respiratory effect Effects 0.000 description 1
- 230000029058 respiratory gaseous exchange Effects 0.000 description 1
- 108091008146 restriction endonucleases Proteins 0.000 description 1
- 229930002330 retinoic acid Natural products 0.000 description 1
- 230000002441 reversible effect Effects 0.000 description 1
- 201000003068 rheumatic fever Diseases 0.000 description 1
- 206010039073 rheumatoid arthritis Diseases 0.000 description 1
- PYWVYCXTNDRMGF-UHFFFAOYSA-N rhodamine B Chemical compound [Cl-].C=12C=CC(=[N+](CC)CC)C=C2OC2=CC(N(CC)CC)=CC=C2C=1C1=CC=CC=C1C(O)=O PYWVYCXTNDRMGF-UHFFFAOYSA-N 0.000 description 1
- 239000002336 ribonucleotide Substances 0.000 description 1
- 125000002652 ribonucleotide group Chemical group 0.000 description 1
- 238000002702 ribosome display Methods 0.000 description 1
- 229960004641 rituximab Drugs 0.000 description 1
- 229950004892 rodorubicin Drugs 0.000 description 1
- MBABCNBNDNGODA-WPZDJQSSSA-N rolliniastatin 1 Natural products O1[C@@H]([C@@H](O)CCCCCCCCCC)CC[C@H]1[C@H]1O[C@@H]([C@H](O)CCCCCCCCCC[C@@H](O)CC=2C(O[C@@H](C)C=2)=O)CC1 MBABCNBNDNGODA-WPZDJQSSSA-N 0.000 description 1
- 102200048955 rs121434569 Human genes 0.000 description 1
- 229940102127 rubidium chloride Drugs 0.000 description 1
- VHXNKPBCCMUMSW-FQEVSTJZSA-N rubitecan Chemical compound C1=CC([N+]([O-])=O)=C2C=C(CN3C4=CC5=C(C3=O)COC(=O)[C@]5(O)CC)C4=NC2=C1 VHXNKPBCCMUMSW-FQEVSTJZSA-N 0.000 description 1
- 229950001460 sacituzumab Drugs 0.000 description 1
- 235000005713 safflower oil Nutrition 0.000 description 1
- 239000003813 safflower oil Substances 0.000 description 1
- 235000019515 salmon Nutrition 0.000 description 1
- 229930182947 sarcodictyin Natural products 0.000 description 1
- 229940018073 sasanlimab Drugs 0.000 description 1
- 238000009738 saturating Methods 0.000 description 1
- 238000002821 scintillation proximity assay Methods 0.000 description 1
- 230000003248 secreting effect Effects 0.000 description 1
- HSNZZMHEPUFJNZ-SHUUEZRQSA-N sedoheptulose Chemical compound OC[C@@H](O)[C@@H](O)[C@@H](O)[C@H](O)C(=O)CO HSNZZMHEPUFJNZ-SHUUEZRQSA-N 0.000 description 1
- 238000010187 selection method Methods 0.000 description 1
- 238000000926 separation method Methods 0.000 description 1
- 238000012163 sequencing technique Methods 0.000 description 1
- 239000008159 sesame oil Substances 0.000 description 1
- 235000011803 sesame oil Nutrition 0.000 description 1
- 239000004208 shellac Substances 0.000 description 1
- 229940113147 shellac Drugs 0.000 description 1
- ZLGIYFNHBLSMPS-ATJNOEHPSA-N shellac Chemical compound OCCCCCC(O)C(O)CCCCCCCC(O)=O.C1C23[C@H](C(O)=O)CCC2[C@](C)(CO)[C@@H]1C(C(O)=O)=C[C@@H]3O ZLGIYFNHBLSMPS-ATJNOEHPSA-N 0.000 description 1
- 235000013874 shellac Nutrition 0.000 description 1
- 238000004904 shortening Methods 0.000 description 1
- 239000013605 shuttle vector Substances 0.000 description 1
- 108091006024 signal transducing proteins Proteins 0.000 description 1
- 102000034285 signal transducing proteins Human genes 0.000 description 1
- 230000011664 signaling Effects 0.000 description 1
- 238000002603 single-photon emission computed tomography Methods 0.000 description 1
- 229960000714 sipuleucel-t Drugs 0.000 description 1
- 201000000849 skin cancer Diseases 0.000 description 1
- NGIYLSFJGRLEMI-MHTUOZSYSA-M sodium 2-[[(2S)-2-[[(4R)-4-[[(2S)-2-[[(2R)-2-[(2R,3R,4R,5R)-2-acetamido-4,5,6-trihydroxy-1-oxohexan-3-yl]oxypropanoyl]amino]propanoyl]amino]-5-amino-5-oxopentanoyl]amino]propanoyl]amino]ethyl [(2R)-2,3-di(hexadecanoyloxy)propyl] phosphate hydrate Chemical compound O.[Na+].CCCCCCCCCCCCCCCC(=O)OC[C@H](COP([O-])(=O)OCCNC(=O)[C@H](C)NC(=O)CC[C@@H](NC(=O)[C@H](C)NC(=O)[C@@H](C)O[C@@H]([C@H](O)[C@H](O)CO)[C@@H](NC(C)=O)C=O)C(N)=O)OC(=O)CCCCCCCCCCCCCCC NGIYLSFJGRLEMI-MHTUOZSYSA-M 0.000 description 1
- FQENQNTWSFEDLI-UHFFFAOYSA-J sodium diphosphate Chemical compound [Na+].[Na+].[Na+].[Na+].[O-]P([O-])(=O)OP([O-])([O-])=O FQENQNTWSFEDLI-UHFFFAOYSA-J 0.000 description 1
- 239000001488 sodium phosphate Substances 0.000 description 1
- 229910000162 sodium phosphate Inorganic materials 0.000 description 1
- 239000012064 sodium phosphate buffer Substances 0.000 description 1
- 229940048086 sodium pyrophosphate Drugs 0.000 description 1
- 239000007790 solid phase Substances 0.000 description 1
- 238000010532 solid phase synthesis reaction Methods 0.000 description 1
- 239000002904 solvent Substances 0.000 description 1
- 210000001082 somatic cell Anatomy 0.000 description 1
- 230000000392 somatic effect Effects 0.000 description 1
- XNZLMZRIGGHITK-VKXBZTRUSA-N soravtansine Chemical compound CO[C@@H]([C@@]1(O)C[C@H](OC(=O)N1)[C@@H](C)[C@@H]1O[C@@]1(C)[C@@H](OC(=O)[C@H](C)N(C)C(=O)CCC(C)(C)SSCC[C@@H](C(O)=O)S(O)(=O)=O)CC(=O)N1C)\C=C\C=C(C)\CC2=CC(OC)=C(Cl)C1=C2.CO[C@@H]([C@@]1(O)C[C@H](OC(=O)N1)[C@@H](C)[C@@H]1O[C@@]1(C)[C@@H](OC(=O)[C@H](C)N(C)C(=O)CCC(C)(C)SSCC[C@H](C(O)=O)S(O)(=O)=O)CC(=O)N1C)\C=C\C=C(C)\CC2=CC(OC)=C(Cl)C1=C2 XNZLMZRIGGHITK-VKXBZTRUSA-N 0.000 description 1
- 239000008347 soybean phospholipid Substances 0.000 description 1
- 229950007213 spartalizumab Drugs 0.000 description 1
- 238000004611 spectroscopical analysis Methods 0.000 description 1
- 229950006315 spirogermanium Drugs 0.000 description 1
- ICXJVZHDZFXYQC-UHFFFAOYSA-N spongistatin 1 Natural products OC1C(O2)(O)CC(O)C(C)C2CCCC=CC(O2)CC(O)CC2(O2)CC(OC)CC2CC(=O)C(C)C(OC(C)=O)C(C)C(=C)CC(O2)CC(C)(O)CC2(O2)CC(OC(C)=O)CC2CC(=O)OC2C(O)C(CC(=C)CC(O)C=CC(Cl)=C)OC1C2C ICXJVZHDZFXYQC-UHFFFAOYSA-N 0.000 description 1
- 230000007480 spreading Effects 0.000 description 1
- 238000003892 spreading Methods 0.000 description 1
- 230000000087 stabilizing effect Effects 0.000 description 1
- 230000010473 stable expression Effects 0.000 description 1
- 239000012128 staining reagent Substances 0.000 description 1
- 239000012192 staining solution Substances 0.000 description 1
- 238000012289 standard assay Methods 0.000 description 1
- SFVFIFLLYFPGHH-UHFFFAOYSA-M stearalkonium chloride Chemical compound [Cl-].CCCCCCCCCCCCCCCCCC[N+](C)(C)CC1=CC=CC=C1 SFVFIFLLYFPGHH-UHFFFAOYSA-M 0.000 description 1
- 239000008117 stearic acid Substances 0.000 description 1
- 238000011146 sterile filtration Methods 0.000 description 1
- 210000002784 stomach Anatomy 0.000 description 1
- 201000011549 stomach cancer Diseases 0.000 description 1
- 229960001052 streptozocin Drugs 0.000 description 1
- ZSJLQEPLLKMAKR-GKHCUFPYSA-N streptozocin Chemical compound O=NN(C)C(=O)N[C@H]1[C@@H](O)O[C@H](CO)[C@@H](O)[C@@H]1O ZSJLQEPLLKMAKR-GKHCUFPYSA-N 0.000 description 1
- 125000001424 substituent group Chemical group 0.000 description 1
- 229940014800 succinic anhydride Drugs 0.000 description 1
- 239000001797 sucrose acetate isobutyrate Substances 0.000 description 1
- 235000010983 sucrose acetate isobutyrate Nutrition 0.000 description 1
- UVGUPMLLGBCFEJ-SWTLDUCYSA-N sucrose acetate isobutyrate Chemical compound CC(C)C(=O)O[C@H]1[C@H](OC(=O)C(C)C)[C@@H](COC(=O)C(C)C)O[C@@]1(COC(C)=O)O[C@@H]1[C@H](OC(=O)C(C)C)[C@@H](OC(=O)C(C)C)[C@H](OC(=O)C(C)C)[C@@H](COC(C)=O)O1 UVGUPMLLGBCFEJ-SWTLDUCYSA-N 0.000 description 1
- 239000006228 supernatant Substances 0.000 description 1
- 239000013589 supplement Substances 0.000 description 1
- 230000009469 supplementation Effects 0.000 description 1
- 239000000829 suppository Substances 0.000 description 1
- 238000001356 surgical procedure Methods 0.000 description 1
- 230000004083 survival effect Effects 0.000 description 1
- 230000002459 sustained effect Effects 0.000 description 1
- 230000002889 sympathetic effect Effects 0.000 description 1
- 230000009897 systematic effect Effects 0.000 description 1
- 238000007910 systemic administration Methods 0.000 description 1
- 229940037128 systemic glucocorticoids Drugs 0.000 description 1
- 201000000596 systemic lupus erythematosus Diseases 0.000 description 1
- 229960001967 tacrolimus Drugs 0.000 description 1
- QJJXYPPXXYFBGM-SHYZHZOCSA-N tacrolimus Natural products CO[C@H]1C[C@H](CC[C@@H]1O)C=C(C)[C@H]2OC(=O)[C@H]3CCCCN3C(=O)C(=O)[C@@]4(O)O[C@@H]([C@H](C[C@H]4C)OC)[C@@H](C[C@H](C)CC(=C[C@@H](CC=C)C(=O)C[C@H](O)[C@H]2C)C)OC QJJXYPPXXYFBGM-SHYZHZOCSA-N 0.000 description 1
- 101150047061 tag-72 gene Proteins 0.000 description 1
- 239000000454 talc Substances 0.000 description 1
- 229910052623 talc Inorganic materials 0.000 description 1
- 235000012222 talc Nutrition 0.000 description 1
- 229960001603 tamoxifen Drugs 0.000 description 1
- 238000002626 targeted therapy Methods 0.000 description 1
- RCINICONZNJXQF-MZXODVADSA-N taxol Chemical compound O([C@@H]1[C@@]2(C[C@@H](C(C)=C(C2(C)C)[C@H](C([C@]2(C)[C@@H](O)C[C@H]3OC[C@]3([C@H]21)OC(C)=O)=O)OC(=O)C)OC(=O)[C@H](O)[C@@H](NC(=O)C=1C=CC=CC=1)C=1C=CC=CC=1)O)C(=O)C1=CC=CC=C1 RCINICONZNJXQF-MZXODVADSA-N 0.000 description 1
- 206010043207 temporal arteritis Diseases 0.000 description 1
- 229960000235 temsirolimus Drugs 0.000 description 1
- QFJCIRLUMZQUOT-UHFFFAOYSA-N temsirolimus Natural products C1CC(O)C(OC)CC1CC(C)C1OC(=O)C2CCCCN2C(=O)C(=O)C(O)(O2)C(C)CCC2CC(OC)C(C)=CC=CC=CC(C)CC(C)C(=O)C(OC)C(O)C(C)=CC(C)C(=O)C1 QFJCIRLUMZQUOT-UHFFFAOYSA-N 0.000 description 1
- 108010020387 tenascin R Proteins 0.000 description 1
- RBTVSNLYYIMMKS-UHFFFAOYSA-N tert-butyl 3-aminoazetidine-1-carboxylate;hydrochloride Chemical compound Cl.CC(C)(C)OC(=O)N1CC(N)C1 RBTVSNLYYIMMKS-UHFFFAOYSA-N 0.000 description 1
- 229960005353 testolactone Drugs 0.000 description 1
- BPEWUONYVDABNZ-DZBHQSCQSA-N testolactone Chemical compound O=C1C=C[C@]2(C)[C@H]3CC[C@](C)(OC(=O)CC4)[C@@H]4[C@@H]3CCC2=C1 BPEWUONYVDABNZ-DZBHQSCQSA-N 0.000 description 1
- 229930101283 tetracycline Natural products 0.000 description 1
- 229960002180 tetracycline Drugs 0.000 description 1
- 235000019364 tetracycline Nutrition 0.000 description 1
- 150000003522 tetracyclines Chemical class 0.000 description 1
- 235000019818 tetrasodium diphosphate Nutrition 0.000 description 1
- 239000001577 tetrasodium phosphonato phosphate Substances 0.000 description 1
- ZRKFYGHZFMAOKI-QMGMOQQFSA-N tgfbeta Chemical compound C([C@H](NC(=O)[C@H](C(C)C)NC(=O)CNC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@H](CC(C)C)NC(=O)CNC(=O)[C@H](C)NC(=O)[C@H](CO)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](NC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)[C@@H](NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CCSC)C(C)C)[C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](C)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)N1[C@@H](CCC1)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O)C1=CC=C(O)C=C1 ZRKFYGHZFMAOKI-QMGMOQQFSA-N 0.000 description 1
- 238000010257 thawing Methods 0.000 description 1
- 125000003396 thiol group Chemical group [H]S* 0.000 description 1
- 125000000341 threoninyl group Chemical group [H]OC([H])(C([H])([H])[H])C([H])(N([H])[H])C(*)=O 0.000 description 1
- 229940104230 thymidine Drugs 0.000 description 1
- 201000009377 thymus cancer Diseases 0.000 description 1
- 229960002175 thyroglobulin Drugs 0.000 description 1
- 201000002510 thyroid cancer Diseases 0.000 description 1
- YFTWHEBLORWGNI-UHFFFAOYSA-N tiamiprine Chemical compound CN1C=NC([N+]([O-])=O)=C1SC1=NC(N)=NC2=C1NC=N2 YFTWHEBLORWGNI-UHFFFAOYSA-N 0.000 description 1
- 229950011457 tiamiprine Drugs 0.000 description 1
- 229960003087 tioguanine Drugs 0.000 description 1
- MNRILEROXIRVNJ-UHFFFAOYSA-N tioguanine Chemical compound N1C(N)=NC(=S)C2=NC=N[C]21 MNRILEROXIRVNJ-UHFFFAOYSA-N 0.000 description 1
- 230000000699 topical effect Effects 0.000 description 1
- 229940044693 topoisomerase inhibitor Drugs 0.000 description 1
- 229960000303 topotecan Drugs 0.000 description 1
- UCFGDBYHRUNTLO-QHCPKHFHSA-N topotecan Chemical compound C1=C(O)C(CN(C)C)=C2C=C(CN3C4=CC5=C(C3=O)COC(=O)[C@]5(O)CC)C4=NC2=C1 UCFGDBYHRUNTLO-QHCPKHFHSA-N 0.000 description 1
- 229960005026 toremifene Drugs 0.000 description 1
- 238000013518 transcription Methods 0.000 description 1
- 230000035897 transcription Effects 0.000 description 1
- 102000003601 transglutaminase Human genes 0.000 description 1
- 230000001052 transient effect Effects 0.000 description 1
- 230000010474 transient expression Effects 0.000 description 1
- 230000007704 transition Effects 0.000 description 1
- 238000013519 translation Methods 0.000 description 1
- 230000014621 translational initiation Effects 0.000 description 1
- 208000009174 transverse myelitis Diseases 0.000 description 1
- 229960000575 trastuzumab Drugs 0.000 description 1
- 229950009027 trastuzumab duocarmazine Drugs 0.000 description 1
- 229960001612 trastuzumab emtansine Drugs 0.000 description 1
- 229950007217 tremelimumab Drugs 0.000 description 1
- 229950001353 tretamine Drugs 0.000 description 1
- IUCJMVBFZDHPDX-UHFFFAOYSA-N tretamine Chemical compound C1CN1C1=NC(N2CC2)=NC(N2CC2)=N1 IUCJMVBFZDHPDX-UHFFFAOYSA-N 0.000 description 1
- 229960001727 tretinoin Drugs 0.000 description 1
- PXSOHRWMIRDKMP-UHFFFAOYSA-N triaziquone Chemical compound O=C1C(N2CC2)=C(N2CC2)C(=O)C=C1N1CC1 PXSOHRWMIRDKMP-UHFFFAOYSA-N 0.000 description 1
- 229960004560 triaziquone Drugs 0.000 description 1
- QORWJWZARLRLPR-UHFFFAOYSA-H tricalcium bis(phosphate) Chemical compound [Ca+2].[Ca+2].[Ca+2].[O-]P([O-])([O-])=O.[O-]P([O-])([O-])=O QORWJWZARLRLPR-UHFFFAOYSA-H 0.000 description 1
- 229960001670 trilostane Drugs 0.000 description 1
- KVJXBPDAXMEYOA-CXANFOAXSA-N trilostane Chemical compound OC1=C(C#N)C[C@]2(C)[C@H]3CC[C@](C)([C@H](CC4)O)[C@@H]4[C@@H]3CC[C@@]32O[C@@H]31 KVJXBPDAXMEYOA-CXANFOAXSA-N 0.000 description 1
- NOYPYLRCIDNJJB-UHFFFAOYSA-N trimetrexate Chemical compound COC1=C(OC)C(OC)=CC(NCC=2C(=C3C(N)=NC(N)=NC3=CC=2)C)=C1 NOYPYLRCIDNJJB-UHFFFAOYSA-N 0.000 description 1
- 229960001099 trimetrexate Drugs 0.000 description 1
- 229950000212 trioxifene Drugs 0.000 description 1
- 239000001226 triphosphate Substances 0.000 description 1
- 235000011178 triphosphate Nutrition 0.000 description 1
- 125000002264 triphosphate group Chemical class [H]OP(=O)(O[H])OP(=O)(O[H])OP(=O)(O[H])O* 0.000 description 1
- LENZDBCJOHFCAS-UHFFFAOYSA-N tris Chemical compound OCC(N)(CO)CO LENZDBCJOHFCAS-UHFFFAOYSA-N 0.000 description 1
- RYFMWSXOAZQYPI-UHFFFAOYSA-K trisodium phosphate Chemical compound [Na+].[Na+].[Na+].[O-]P([O-])([O-])=O RYFMWSXOAZQYPI-UHFFFAOYSA-K 0.000 description 1
- 229960000875 trofosfamide Drugs 0.000 description 1
- UMKFEPPTGMDVMI-UHFFFAOYSA-N trofosfamide Chemical compound ClCCN(CCCl)P1(=O)OCCCN1CCCl UMKFEPPTGMDVMI-UHFFFAOYSA-N 0.000 description 1
- 239000002753 trypsin inhibitor Substances 0.000 description 1
- 229930184737 tubulysin Natural products 0.000 description 1
- 230000005909 tumor killing Effects 0.000 description 1
- 229950009811 ubenimex Drugs 0.000 description 1
- 229950004593 ublituximab Drugs 0.000 description 1
- 229940125117 ulevostinag Drugs 0.000 description 1
- 238000000108 ultra-filtration Methods 0.000 description 1
- DRTQHJPVMGBUCF-UHFFFAOYSA-N uracil arabinoside Natural products OC1C(O)C(CO)OC1N1C(=O)NC(=O)C=C1 DRTQHJPVMGBUCF-UHFFFAOYSA-N 0.000 description 1
- 229960001055 uracil mustard Drugs 0.000 description 1
- 229940045145 uridine Drugs 0.000 description 1
- 229950003520 utomilumab Drugs 0.000 description 1
- 229960003048 vinblastine Drugs 0.000 description 1
- JXLYSJRDGCGARV-XQKSVPLYSA-N vincaleukoblastine Chemical compound C([C@@H](C[C@]1(C(=O)OC)C=2C(=CC3=C([C@]45[C@H]([C@@]([C@H](OC(C)=O)[C@]6(CC)C=CCN([C@H]56)CC4)(O)C(=O)OC)N3C)C=2)OC)C[C@@](C2)(O)CC)N2CCC2=C1NC1=CC=CC=C21 JXLYSJRDGCGARV-XQKSVPLYSA-N 0.000 description 1
- 229960004528 vincristine Drugs 0.000 description 1
- OGWKCGZFUXNPDA-XQKSVPLYSA-N vincristine Chemical compound C([N@]1C[C@@H](C[C@]2(C(=O)OC)C=3C(=CC4=C([C@]56[C@H]([C@@]([C@H](OC(C)=O)[C@]7(CC)C=CCN([C@H]67)CC5)(O)C(=O)OC)N4C=O)C=3)OC)C[C@@](C1)(O)CC)CC1=C2NC2=CC=CC=C12 OGWKCGZFUXNPDA-XQKSVPLYSA-N 0.000 description 1
- OGWKCGZFUXNPDA-UHFFFAOYSA-N vincristine Natural products C1C(CC)(O)CC(CC2(C(=O)OC)C=3C(=CC4=C(C56C(C(C(OC(C)=O)C7(CC)C=CCN(C67)CC5)(O)C(=O)OC)N4C=O)C=3)OC)CN1CCC1=C2NC2=CC=CC=C12 OGWKCGZFUXNPDA-UHFFFAOYSA-N 0.000 description 1
- 229960004355 vindesine Drugs 0.000 description 1
- UGGWPQSBPIFKDZ-KOTLKJBCSA-N vindesine Chemical compound C([C@@H](C[C@]1(C(=O)OC)C=2C(=CC3=C([C@]45[C@H]([C@@]([C@H](O)[C@]6(CC)C=CCN([C@H]56)CC4)(O)C(N)=O)N3C)C=2)OC)C[C@@](C2)(O)CC)N2CCC2=C1N=C1[C]2C=CC=C1 UGGWPQSBPIFKDZ-KOTLKJBCSA-N 0.000 description 1
- GBABOYUKABKIAF-GHYRFKGUSA-N vinorelbine Chemical compound C1N(CC=2C3=CC=CC=C3NC=22)CC(CC)=C[C@H]1C[C@]2(C(=O)OC)C1=CC([C@]23[C@H]([C@]([C@H](OC(C)=O)[C@]4(CC)C=CCN([C@H]34)CC2)(O)C(=O)OC)N2C)=C2C=C1OC GBABOYUKABKIAF-GHYRFKGUSA-N 0.000 description 1
- 229960002066 vinorelbine Drugs 0.000 description 1
- 230000009385 viral infection Effects 0.000 description 1
- 229960005289 voclosporin Drugs 0.000 description 1
- BICRTLVBTLFLRD-PTWUADNWSA-N voclosporin Chemical compound CC[C@@H]1NC(=O)[C@H]([C@H](O)[C@H](C)C\C=C\C=C)N(C)C(=O)[C@H](C(C)C)N(C)C(=O)[C@H](CC(C)C)N(C)C(=O)[C@H](CC(C)C)N(C)C(=O)[C@@H](C)NC(=O)[C@H](C)NC(=O)[C@H](CC(C)C)N(C)C(=O)[C@H](C(C)C)NC(=O)[C@H](CC(C)C)N(C)C(=O)CN(C)C1=O BICRTLVBTLFLRD-PTWUADNWSA-N 0.000 description 1
- 108010057559 voclosporin Proteins 0.000 description 1
- 229960001771 vorozole Drugs 0.000 description 1
- XLMPPFTZALNBFS-INIZCTEOSA-N vorozole Chemical compound C1([C@@H](C2=CC=C3N=NN(C3=C2)C)N2N=CN=C2)=CC=C(Cl)C=C1 XLMPPFTZALNBFS-INIZCTEOSA-N 0.000 description 1
- 239000011534 wash buffer Substances 0.000 description 1
- 229920003169 water-soluble polymer Polymers 0.000 description 1
- 238000009736 wetting Methods 0.000 description 1
- 229940053867 xeloda Drugs 0.000 description 1
- 229960000641 zorubicin Drugs 0.000 description 1
- FBTUMDXHSRTGRV-ALTNURHMSA-N zorubicin Chemical compound O([C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(\C)=N\NC(=O)C=1C=CC=CC=1)[C@H]1C[C@H](N)[C@H](O)[C@H](C)O1 FBTUMDXHSRTGRV-ALTNURHMSA-N 0.000 description 1
Images



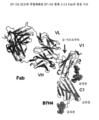
Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2803—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily
- C07K16/2827—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily against B7 molecules, e.g. CD80, CD86
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P37/00—Drugs for immunological or allergic disorders
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2803—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily
- C07K16/2809—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily against the T-cell receptor (TcR)-CD3 complex
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/505—Medicinal preparations containing antigens or antibodies comprising antibodies
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/30—Immunoglobulins specific features characterized by aspects of specificity or valency
- C07K2317/31—Immunoglobulins specific features characterized by aspects of specificity or valency multispecific
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/30—Immunoglobulins specific features characterized by aspects of specificity or valency
- C07K2317/33—Crossreactivity, e.g. for species or epitope, or lack of said crossreactivity
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/30—Immunoglobulins specific features characterized by aspects of specificity or valency
- C07K2317/34—Identification of a linear epitope shorter than 20 amino acid residues or of a conformational epitope defined by amino acid residues
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/52—Constant or Fc region; Isotype
- C07K2317/524—CH2 domain
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/52—Constant or Fc region; Isotype
- C07K2317/526—CH3 domain
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/73—Inducing cell death, e.g. apoptosis, necrosis or inhibition of cell proliferation
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/90—Immunoglobulins specific features characterized by (pharmaco)kinetic aspects or by stability of the immunoglobulin
- C07K2317/92—Affinity (KD), association rate (Ka), dissociation rate (Kd) or EC50 value
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/90—Immunoglobulins specific features characterized by (pharmaco)kinetic aspects or by stability of the immunoglobulin
- C07K2317/94—Stability, e.g. half-life, pH, temperature or enzyme-resistance
Landscapes
- Health & Medical Sciences (AREA)
- Immunology (AREA)
- Chemical & Material Sciences (AREA)
- Organic Chemistry (AREA)
- Life Sciences & Earth Sciences (AREA)
- General Health & Medical Sciences (AREA)
- Medicinal Chemistry (AREA)
- Biochemistry (AREA)
- Biophysics (AREA)
- Genetics & Genomics (AREA)
- Molecular Biology (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Chemical Kinetics & Catalysis (AREA)
- General Chemical & Material Sciences (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- Pharmacology & Pharmacy (AREA)
- Animal Behavior & Ethology (AREA)
- Public Health (AREA)
- Veterinary Medicine (AREA)
- Engineering & Computer Science (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Peptides Or Proteins (AREA)
- Micro-Organisms Or Cultivation Processes Thereof (AREA)
- Medicines Containing Antibodies Or Antigens For Use As Internal Diagnostic Agents (AREA)
- Pharmaceuticals Containing Other Organic And Inorganic Compounds (AREA)
- Preparation Of Compounds By Using Micro-Organisms (AREA)
- Medicines That Contain Protein Lipid Enzymes And Other Medicines (AREA)
Abstract
본 발명은 B7-H4 (B7 상동성 4, 유전자 VTCN1에 의해 코딩됨)에 특이적으로 결합하는 항체 및 B7-H4 및 CD3 (분화 클러스터 3) 둘 다에 특이적으로 결합하는 이중특이적 항체, 및 폴리뉴클레오티드, 제약 조성물 및 그의 방법 및 용도에 관한 것이다.
Description
본 발명은 B7-H4 (B7 상동성 4)에 특이적으로 결합하는 항체, B7-H4 항체를 포함하는 조성물, 및 그의 방법 및 용도에 관한 것이다. 본 발명은 또한 B7-H4 및 CD3 (분화 클러스터 3)에 특이적으로 결합하는 이중특이적 항체, 이중특이적 B7-H4 항체를 포함하는 조성물, 및 B7-H4를 발현하는 세포와 연관된 상태 (예를 들어, 암 또는 자가면역 질환)를 치료하기 위해 이중특이적 B7-H4 항체를 사용하는 방법에 관한 것이다. 이러한 이중특이적 항체의 생산 및 정제 방법, 및 진단 및 치료에서의 그의 용도가 또한 제공된다.
B7x, B7S1 또는 VTCN1로도 공지된 B7-H4 (B7 상동성 4, 유전자 VTCN1에 의해 코딩됨)는 유형 I 막횡단 단백질이고, B7 패밀리 단백질의 구성원이다. B7-H4는 15년 더 전에 처음 확인되었다 (Sica GL, et al. Immunity. 2003; 18:849-861). 그 이후로, B7-H4는 유방암 및 난소암 (Salceda S, et al., Exp Cell Res. 2005; 306:128-141) 및 많은 다른 암 세포에서 과다발현되는 것으로 밝혀졌다. 또한, 종양 내에서의 B7-H4 단백질 발현은 보다 짧은 기대 수명 및 질환 중증도와 관련된다는 것이 밝혀졌다 (Podojil, J.R., Miller, S.D., Immunological Reviews 2017; 276:40-51). B7-H4는 B7 패밀리 분자이지만, 이는 공지된 B7-패밀리 수용체, 즉 CTLA-4, ICOS, PD-1 또는 CD28 중 어떤 것에도 결합하지 않는다. B7-H4 특이적 수용체를 확인하기 위한 노력은 이러한 수용체가 활성화된 T 세포 상에서 발현된다는 것을 밝혀냈고, B7-H4 융합 단백질이 T 세포 상의 그의 추정 수용체에 결합하는 것은 T 세포 증식 및 시토카인 (IL-2, IFN-감마 및 IL17) 생산을 유의하게 억제하는 것으로 밝혀졌다. (Podojil, J.R., Miller, S.D., Immunological Reviews 2017; 276:40-51).
유방, 난소 및 다른 유형의 암 세포를 특이적으로 표적화하고 이에 특이적으로 결합할 수 있는 분자 및/또는 조성물에 대한 필요가 남아있다. 암을 앓고 있는 것으로 의심되는 개체를 치료하는 개선된 방법에 대한 필요가 존재한다.
B7-H4에 특이적으로 결합하는 항체 및 B7-H4 및 CD3 둘 다에 특이적으로 결합하는 이중특이적 항체 (이하 "B7-H4xCD3 이중특이적 항체")가 제공된다. 이중특이적 항체를 포함한 본원에 개시된 항체 중 일부는 암을 예방 및/또는 치료하는 생체내 효능을 갖는 것으로 입증된다.
한 측면에서, 본 발명은 (a) 서열식별번호(SEQ ID NO): 23, 서열식별번호: 155, 서열식별번호: 156, 서열식별번호: 157, 서열식별번호: 159, 서열식별번호: 161, 서열식별번호: 163, 서열식별번호: 165, 서열식별번호: 169, 서열식별번호: 171, 서열식별번호: 172, 서열식별번호: 173, 서열식별번호: 174, 서열식별번호: 175 및 서열식별번호: 176으로 이루어진 군으로부터 선택된 아미노산 서열을 갖는 중쇄 가변 영역 (VH)의 VH 상보성 결정 영역 (CDR) 1 (CDR1), VH CDR2 및 VH CDR3; 및 (B) 서열식별번호: 27, 서열식별번호: 139, 서열식별번호: 141, 서열식별번호: 167, 서열식별번호: 168, 서열식별번호: 169 및 서열식별번호: 170으로 이루어진 군으로부터 선택된 아미노산 서열을 갖는 경쇄 가변 영역 (VL)의 VL 상보성 결정 영역 1 (CDR1), VL CDR2 및 VL CDR3을 포함하는, B7-H4에 특이적으로 결합하는 단리된 항체를 제공한다.
일부 실시양태에서, 항체는 (a) 서열식별번호: 161의 아미노산 서열을 갖는 VH; 및 서열식별번호: 167의 아미노산 서열을 갖는 VL; (b) 서열식별번호: 172의 아미노산 서열을 갖는 VH; 및 서열식별번호: 139의 아미노산 서열을 갖는 VL; (c) 서열식별번호: 155의 아미노산 서열을 갖는 VH; 및 서열식별번호: 139의 아미노산 서열을 갖는 VL; (d) 서열식별번호: 156의 아미노산 서열을 갖는 VH; 및 서열식별번호: 139의 아미노산 서열을 갖는 VL; (e) 서열식별번호: 157의 아미노산 서열을 갖는 VH; 및 서열식별번호: 141의 아미노산 서열을 갖는 VL; (f) 서열식별번호: 155의 아미노산 서열을 갖는 VH; 및 서열식별번호: 141의 아미노산 서열을 갖는 VL; (g) 서열식별번호: 156의 아미노산 서열을 갖는 VH; 및 서열식별번호: 141의 아미노산 서열을 갖는 VL; (h) 서열식별번호: 159의 아미노산 서열을 갖는 VH; 및 서열식별번호: 27의 아미노산 서열을 갖는 VL; (i) 서열식별번호: 161의 아미노산 서열을 갖는 VH; 및 서열식별번호: 27의 아미노산 서열을 갖는 VL; (j) 서열식별번호: 163의 아미노산 서열을 갖는 VH; 및 서열식별번호: 27의 아미노산 서열을 갖는 VL; (k) 서열식별번호: 165의 아미노산 서열을 갖는 VH; 및 서열식별번호: 27의 아미노산 서열을 갖는 VL; (l) 서열식별번호: 23의 아미노산 서열을 갖는 VH; 및 서열식별번호: 167의 아미노산 서열을 갖는 VL; (m) 서열식별번호: 171의 아미노산 서열을 갖는 VH; 및 서열식별번호: 141의 아미노산 서열을 갖는 VL; (n) 서열식별번호: 172의 아미노산 서열을 갖는 VH; 및 서열식별번호: 141의 아미노산 서열을 갖는 VL; (o) 서열식별번호: 171의 아미노산 서열을 갖는 VH; 및 서열식별번호: 139의 아미노산 서열을 갖는 VL; (p) 서열식별번호: 173의 아미노산 서열을 갖는 VH; 및 서열식별번호: 139의 아미노산 서열을 갖는 VL; (q) 서열식별번호: 174의 아미노산 서열을 갖는 VH; 및 서열식별번호: 139의 아미노산 서열을 갖는 VL; (r) 서열식별번호: 175의 아미노산 서열을 갖는 VH; 및 서열식별번호: 139의 아미노산 서열을 갖는 VL; (s) 서열식별번호: 161의 아미노산 서열을 갖는 VH; 및 서열식별번호: 168의 아미노산 서열을 갖는 VL; (t) 서열식별번호: 161의 아미노산 서열을 갖는 VH; 및 서열식별번호: 169의 아미노산 서열을 갖는 VL; (u) 서열식별번호: 161의 아미노산 서열을 갖는 VH; 및 서열식별번호: 170의 아미노산 서열을 갖는 VL; 또는 (v) 서열식별번호: 172의 아미노산 서열을 갖는 VH; 및 서열식별번호: 139의 아미노산 서열을 갖는 VL을 포함한다.
일부 실시양태에서, 항체는 (a) 서열식별번호: 20의 아미노산 서열을 갖는 VH CDR1, 서열식별번호: 21의 아미노산 서열을 갖는 VH CDR2, 서열식별번호: 160의 아미노산 서열을 갖는 VH CDR3, 서열식별번호: 166의 아미노산 서열을 갖는 VL CDR1, 서열식별번호: 25의 아미노산 서열을 갖는 VL CDR2 및 서열식별번호: 153의 아미노산 서열을 갖는 VL CDR3; (b) 서열식별번호: 205의 아미노산 서열을 갖는 VH CDR1, 서열식별번호: 21의 아미노산 서열을 갖는 VH CDR2, 서열식별번호: 160의 아미노산 서열을 갖는 VH CDR3, 서열식별번호: 166의 아미노산 서열을 갖는 VL CDR1, 서열식별번호: 25의 아미노산 서열을 갖는 VL CDR2 및 서열식별번호: 153의 아미노산 서열을 갖는 VL CDR3; (c) 서열식별번호: 206의 아미노산 서열을 갖는 VH CDR1, 서열식별번호: 207의 아미노산 서열을 갖는 VH CDR2, 서열식별번호: 160의 아미노산 서열을 갖는 VH CDR3, 서열식별번호: 166의 아미노산 서열을 갖는 VL CDR1, 서열식별번호: 25의 아미노산 서열을 갖는 VL CDR2 및 서열식별번호: 153의 아미노산 서열을 갖는 VL CDR3; (d) 서열식별번호: 5의 아미노산 서열을 갖는 VH CDR1, 서열식별번호: 6의 아미노산 서열을 갖는 VH CDR2, 서열식별번호: 7의 아미노산 서열을 갖는 VH CDR3, 서열식별번호: 9의 아미노산 서열을 갖는 VL CDR1, 서열식별번호: 10의 아미노산 서열을 갖는 VL CDR2 및 서열식별번호: 138의 아미노산 서열을 갖는 VL CDR3; (e) 서열식별번호: 199의 아미노산 서열을 갖는 VH CDR1, 서열식별번호: 6의 아미노산 서열을 갖는 VH CDR2, 서열식별번호: 7의 아미노산 서열을 갖는 VH CDR3, 서열식별번호: 9의 아미노산 서열을 갖는 VL CDR1, 서열식별번호: 10의 아미노산 서열을 갖는 VL CDR2 및 서열식별번호: 138의 아미노산 서열을 갖는 VL CDR3; (f) 서열식별번호: 200의 아미노산 서열을 갖는 VH CDR1, 서열식별번호: 201의 아미노산 서열을 갖는 VH CDR2, 서열식별번호: 7의 아미노산 서열을 갖는 VH CDR3, 서열식별번호: 9의 아미노산 서열을 갖는 VL CDR1, 서열식별번호: 10의 아미노산 서열을 갖는 VL CDR2 및 서열식별번호: 138의 아미노산 서열을 갖는 VL CDR3; (g) 서열식별번호: 20의 아미노산 서열을 갖는 VH CDR1, 서열식별번호: 21의 아미노산 서열을 갖는 VH CDR2, 서열식별번호: 160의 아미노산 서열을 갖는 VH CDR3, 서열식별번호: 152의 아미노산 서열을 갖는 VL CDR1, 서열식별번호: 41의 아미노산 서열을 갖는 VL CDR2 및 서열식별번호: 153의 아미노산 서열을 갖는 VL CDR3; (h) 서열식별번호: 5의 아미노산 서열을 갖는 VH CDR1, 서열식별번호: 6의 아미노산 서열을 갖는 VH CDR2, 서열식별번호: 7의 아미노산 서열을 갖는 VH CDR3, 서열식별번호: 9의 아미노산 서열을 갖는 VL CDR1, 서열식별번호: 10의 아미노산 서열을 갖는 VL CDR2 및 서열식별번호: 138의 아미노산 서열을 갖는 VL CDR3; 또는 (i) 서열식별번호: 5의 아미노산 서열을 갖는 VH CDR1, 서열식별번호: 130의 아미노산 서열을 갖는 VH CDR2, 서열식별번호: 7의 아미노산 서열을 갖는 VH CDR3, 서열식별번호: 9의 아미노산 서열을 갖는 VL CDR1, 서열식별번호: 10의 아미노산 서열을 갖는 VL CDR2 및 서열식별번호: 138의 아미노산 서열을 갖는 VL CDR3을 포함한다.
한 측면에서, 본 발명은 서열식별번호: 20의 아미노산 서열을 갖는 VH CDR1, 서열식별번호: 21의 아미노산 서열을 갖는 VH CDR2, 서열식별번호: 160의 아미노산 서열을 갖는 VH CDR3, 서열식별번호: 166의 아미노산 서열을 갖는 VL CDR1, 서열식별번호: 25의 아미노산 서열을 갖는 VL CDR2 및 서열식별번호: 153의 아미노산 서열을 갖는 VL CDR3을 포함하는, B7-H4에 특이적으로 결합하는 단리된 항체를 제공한다.
일부 실시양태에서, 항체는 (a) 서열식별번호: 161의 아미노산 서열을 갖는 VH; 및 서열식별번호: 167의 아미노산 서열을 갖는 VL; (b) 서열식별번호: 172의 아미노산 서열을 갖는 VH; 및 서열식별번호: 139의 아미노산 서열을 갖는 VL; (c) 서열식별번호: 155의 아미노산 서열을 갖는 VH; 및 서열식별번호: 139의 아미노산 서열을 갖는 VL; (d) 서열식별번호: 156의 아미노산 서열을 갖는 VH; 및 서열식별번호: 139의 아미노산 서열을 갖는 VL; (e) 서열식별번호: 157의 아미노산 서열을 갖는 VH; 및 서열식별번호: 141의 아미노산 서열을 갖는 VL; (f) 서열식별번호: 155의 아미노산 서열을 갖는 VH; 서열식별번호: 141의 아미노산 서열을 갖는 VL; (g) 서열식별번호: 156의 아미노산 서열을 갖는 VH; 및 서열식별번호: 141의 아미노산 서열을 갖는 VL; (h) 서열식별번호: 159의 아미노산 서열을 갖는 VH; 및 서열식별번호: 27의 아미노산 서열을 갖는 VL; (i) 서열식별번호: 161의 아미노산 서열을 갖는 VH; 및 서열식별번호: 27의 아미노산 서열을 갖는 VL; (j) 서열식별번호: 163의 아미노산 서열을 갖는 VH; 및 서열식별번호: 27의 아미노산 서열을 갖는 VL; (k) 서열식별번호: 165의 아미노산 서열을 갖는 VH; 및 서열식별번호: 27의 아미노산 서열을 갖는 VL; (l) 서열식별번호: 23의 아미노산 서열을 갖는 VH; 및 서열식별번호: 167의 아미노산 서열을 갖는 VL; (m) 서열식별번호: 171의 아미노산 서열을 갖는 VH; 및 서열식별번호: 141의 아미노산 서열을 갖는 VL; (n) 서열식별번호: 172의 아미노산 서열을 갖는 VH; 및 서열식별번호: 141의 아미노산 서열을 갖는 VL; (o) 서열식별번호: 171의 아미노산 서열을 갖는 VH; 및 서열식별번호: 139의 아미노산 서열을 갖는 VL; (p) 서열식별번호: 173의 아미노산 서열을 갖는 VH; 및 서열식별번호: 139의 아미노산 서열을 갖는 VL; (q) 서열식별번호: 174의 아미노산 서열을 갖는 VH; 및 서열식별번호: 139의 아미노산 서열을 갖는 VL; (r) 서열식별번호: 175의 아미노산 서열을 갖는 VH; 및 서열식별번호: 139의 아미노산 서열을 갖는 VL; (s) 서열식별번호: 161의 아미노산 서열을 갖는 VH; 및 서열식별번호: 168의 아미노산 서열을 갖는 VL; (t) 서열식별번호: 161의 아미노산 서열을 갖는 VH; 및 서열식별번호: 169의 아미노산 서열을 갖는 VL; (u) 서열식별번호: 161의 아미노산 서열을 갖는 VH; 및 서열식별번호: 170의 아미노산 서열을 갖는 VL; 또는 (v) 서열식별번호: 172의 아미노산 서열을 갖는 VH; 및 서열식별번호: 139의 아미노산 서열을 갖는 VL을 포함한다.
한 측면에서, 본 발명은 서열식별번호: 161의 아미노산 서열을 갖는 VH; 및 서열식별번호: 167의 아미노산 서열을 갖는 VL을 포함하는, B7-H4에 특이적으로 결합하는 단리된 항체를 제공한다.
한 측면에서, 본 발명은 서열식별번호: 172의 아미노산 서열을 갖는 VH; 및 서열식별번호: 139의 아미노산 서열을 갖는 VL을 포함하는, B7-H4에 특이적으로 결합하는 단리된 항체를 제공한다.
일부 실시양태에서, 항체는 불변 영역을 추가로 포함한다. 일부 실시양태에서, 불변 영역은 IgG1 또는 IgG2의 이소형이다. 일부 실시양태에서, 항체는 A330S, P331S, D265A, C223E, P228E, L368E, C223R, E225R, P228R 및 K409R로 이루어진 군으로부터 선택된 1개 이상의 치환을 포함하는 인간 IgG2이며, 여기서 넘버링은 인간 IgG2 야생형 및 EU 넘버링 스킴에 따르고, 도 1에 제시된 바와 같다. 일부 실시양태에서, 항체는 치환 C223E, P228E 및 L368E를 포함한다.
한 측면에서, 본 발명은 서열식별번호: 190의 아미노산 서열을 갖는 중쇄 및 서열식별번호: 191의 아미노산 서열을 갖는 경쇄를 포함하는, B7-H4에 특이적으로 결합하는 단리된 항체를 제공한다.
한 측면에서, 본 발명은 서열식별번호: 186의 아미노산 서열을 갖는 중쇄 및 서열식별번호: 187의 아미노산 서열을 갖는 경쇄를 포함하는, B7-H4에 특이적으로 결합하는 단리된 항체를 제공한다.
일부 실시양태에서, 본 발명은 ATCC 수탁 번호 PTA-126779 하에 기탁된 폴리뉴클레오티드의 오픈 리딩 프레임 (ORF)에 의해 코딩된 전장 폴리펩티드의 아미노산 서열을 포함하는 중쇄 및 ATCC 수탁 번호 PTA-126781 하에 기탁된 폴리뉴클레오티드의 오픈 리딩 프레임 (ORF)에 의해 코딩된 전장 폴리펩티드의 아미노산 서열을 포함하는 경쇄를 포함하는, B7-H4에 특이적으로 결합하는 단리된 항체를 제공한다.
일부 실시양태에서, 각각의 VH CDR1, VH CDR2, VH CDR3, VL CDR1, VL CDR2 및 VL CDR3은 카바트 정의, 코티아 정의, AbM 정의 또는 CDR의 접촉 정의에 따라 정의된다.
한 측면에서, 본 발명은 (a) 서열식별번호: 8의 아미노산 서열을 갖는 VH 및 서열식별번호: 13의 아미노산 서열을 갖는 VL; (b) 서열식별번호: 8의 아미노산 서열을 갖는 VH 및 서열식별번호: 13의 아미노산 서열을 갖는 VL; (c) 서열식별번호: 39의 아미노산 서열을 갖는 VH 및 서열식별번호: 43의 아미노산 서열을 갖는 VL; (d) 서열식별번호: 46의 아미노산 서열을 갖는 VH 및 서열식별번호: 49의 아미노산 서열을 갖는 VL; (e) 서열식별번호: 52의 아미노산 서열을 갖는 VH 및 서열식별번호: 54의 아미노산 서열을 갖는 VL; (f) 서열식별번호: 57의 아미노산 서열을 갖는 VH 및 서열식별번호: 60의 아미노산 서열을 갖는 VL; (g) 서열식별번호: 16의 아미노산 서열을 갖는 VH 및 서열식별번호: 19의 아미노산 서열을 갖는 VL; (h) 서열식별번호: 64의 아미노산 서열을 갖는 VH 및 서열식별번호: 67의 아미노산 서열을 갖는 VL; (i) 서열식별번호: 69의 아미노산 서열을 갖는 VH 및 서열식별번호: 70의 아미노산 서열을 갖는 VL; (j) 서열식별번호: 74의 아미노산 서열을 갖는 VH 및 서열식별번호: 77의 아미노산 서열을 갖는 VL; (k) 서열식별번호: 80의 아미노산 서열을 갖는 VH 및 서열식별번호: 84의 아미노산 서열을 갖는 VL; (l) 서열식별번호: 87의 아미노산 서열을 갖는 VH 및 서열식별번호: 90의 아미노산 서열을 갖는 VL; (m) 서열식별번호: 23의 아미노산 서열을 갖는 VH 및 서열식별번호: 27의 아미노산 서열을 갖는 VL; (n) 서열식별번호: 94의 아미노산 서열을 갖는 VH 및 서열식별번호: 96의 아미노산 서열을 갖는 VL; (o) 서열식별번호: 100의 아미노산 서열을 갖는 VH 및 서열식별번호: 77의 아미노산 서열을 갖는 VL; 또는 (p) 서열식별번호: 104의 아미노산 서열을 갖는 VH 및 서열식별번호: 67의 아미노산 서열을 갖는 VL을 포함하는 제2 항체와 B7-H4에의 결합에 대해 경쟁하는, B7-H4에 특이적으로 결합하는 단리된 제1 항체이며; 인간 B7-H4에 대한 KD가 약 1 마이크로몰 내지 0.1 나노몰인 제1 항체를 제공한다. 일부 실시양태에서, 제1 항체 및 제2 항체는 각각 전장 IgG1 불변 영역을 포함한다. 일부 실시양태에서, 제1 항체 및 제2 항체는 둘 다 F(ab')2 단편 항체이다.
또 다른 측면에서, 본 발명은 서열식별번호: 1의 아미노산 서열을 갖는 B7-H4 세포외 도메인의 L44, K45, E46, G47, V48, L49, G50, L51, E64, D66, M68, T99 및 K101로 이루어진 군으로부터 선택된 적어도 2개, 적어도 3개, 적어도 4개, 적어도 5개, 적어도 6개, 적어도 7개, 적어도 8개, 적어도 9개, 적어도 10개, 적어도 11개 또는 적어도 12개의 아미노산 잔기를 포함하는 인간 B7-H4 상의 에피토프에 결합하는, B7-H4에 특이적으로 결합하는 단리된 항체를 제공한다. 일부 실시양태에서, 에피토프는 L44, K45, E46, G47, V48, L49, G50 및 L51로 이루어진 군으로부터 선택된 적어도 1개, 적어도 2개, 적어도 3개, 적어도 4개, 적어도 5개, 적어도 6 또는 적어도 7개의 아미노산 잔기 및 E64, D66, M68, T99 및 K101로 이루어진 군으로부터 선택된 적어도 1개, 적어도 2개, 적어도 3개 또는 적어도 4개의 아미노산 잔기를 포함한다. 일부 실시양태에서, 에피토프는 L44, K45, E46, G47, V48, L49, G50, L51, E64, D66, M68, T99 및 K101의 아미노산 잔기를 포함하거나 또는 그로 이루어진다.
또 다른 측면에서, 본 발명은 서열식별번호: 1의 아미노산 서열을 갖는 B7-H4 세포외 도메인의 V129, Y131, N132, S134, S135, E136, L138, V189, I191, V212, E214, S215, E216 및 I217로 이루어진 군으로부터 선택된 적어도 2개, 적어도 3개, 적어도 4개, 적어도 5개, 적어도 6개, 적어도 7개, 적어도 8개, 적어도 9개, 적어도 10개, 적어도 11개, 적어도 12개 또는 적어도 13개의 아미노산 잔기를 포함하는 인간 B7-H4 상의 에피토프에 결합하는, B7-H4에 특이적으로 결합하는 단리된 항체를 제공한다. 일부 실시양태에서, 에피토프는 V129, Y131, N132, S134, S135, E136 및 L138로 이루어진 군으로부터 선택된 적어도 1개, 적어도 2개, 적어도 3개, 적어도 4개, 적어도 5 또는 적어도 6개의 아미노산 잔기 및 V189, I191, V212, E214, S215, E216 및 I217로 이루어진 군으로부터의 적어도 1개, 적어도 2개, 적어도 3개, 적어도 4개, 적어도 5개, 적어도 6 또는 적어도 7개의 아미노산 잔기를 포함한다. 일부 실시양태에서, 에피토프는 아미노산 잔기 V129, Y131, N132, S134, S135, E136, L138, V189, I191, V212, E214, S215, E216 및 I217을 포함하거나 또는 그로 이루어진다.
또 다른 측면에서, 본 발명은 치료 유효량의 본 발명의 B7-H4 항체 또는 그의 항원 결합 단편 및 제약상 허용되는 담체를 포함하는 제약 조성물을 제공한다.
또 다른 측면에서, 본 발명은 본 발명의 B7-H4 항체를 코딩하는 단리된 폴리뉴클레오티드를 제공한다.
또 다른 측면에서, 본 발명은 (i) 본 발명의 B7-H4 항체의 중쇄 가변 영역 또는 (ii) 본 발명의 임의의 B7-H4 항체의 경쇄 가변 영역을 코딩하는 단리된 폴리뉴클레오티드를 제공한다.
또 다른 측면에서, 본 발명은 (i) 본 발명의 B7-H4 항체의 중쇄 또는 (ii) 본 발명의 임의의 B7-H4 항체의 경쇄를 코딩하는 단리된 폴리뉴클레오티드를 제공한다.
또 다른 측면에서, 본 발명은 본 발명의 임의의 폴리뉴클레오티드를 포함하는 벡터를 제공한다.
또 다른 측면에서, 본 발명은 본 발명의 항체를 재조합적으로 생산하는 단리된 숙주 세포를 제공한다.
또 다른 측면에서, 본 발명은 본 발명의 숙주 세포를 본 발명의 B7-H4 항체가 생산되도록 하는 조건 하에 배양하고, 숙주 세포 또는 배양물로부터 항체를 단리하는 것을 포함하는, 본 발명의 B7-H4 항체를 생산하는 방법을 제공한다.
또 다른 측면에서, 본 발명은 B7-H4를 발현하는 세포와 연관된 상태의 치료를 필요로 하는 대상체에게 유효량의 본 발명의 제약 조성물을 투여하는 것을 포함하는, 대상체에서 B7-H4를 발현하는 세포와 연관된 상태를 치료하는 방법을 제공한다. 일부 실시양태에서, 상태는 암이다. 일부 실시양태에서, 암은 유방암, 난소암, 방광암, 자궁암 또는 담관암이다.
또 다른 측면에서, 본 발명은 종양 성장 또는 진행의 억제를 필요로 하는, B7-H4를 발현하는 악성 세포를 갖는 대상체에게 유효량의 본 발명의 제약 조성물을 투여하는 것을 포함하는, 상기 대상체에서 종양 성장 또는 진행을 억제하는 방법을 제공한다.
또 다른 측면에서, 본 발명은 B7-H4를 발현하는 악성 세포의 전이의 억제를 필요로 하는 대상체에게 유효량의 본 발명의 제약 조성물을 투여하는 것을 포함하는, 대상체에서 B7-H4를 발현하는 악성 세포의 전이를 억제하는 방법을 제공한다.
또 다른 측면에서, 본 발명은 종양 퇴행의 유도를 필요로 하는, B7-H4를 발현하는 악성 세포를 갖는 대상체에게 유효량의 본 발명의 제약 조성물을 투여하는 것을 포함하는, 상기 대상체에서 종양 퇴행을 유도하는 방법을 제공한다.
또 다른 측면에서, 본 발명은 제1 중쇄 및 제1 경쇄 및 제2 중쇄 및 제2 경쇄를 포함하며, 여기서 제1 중쇄 및 제1 경쇄는 B7-H4에 결합하는 제1 항원 결합 도메인을 포함하는 제1 아암을 형성하고, 제2 중쇄 및 제2 경쇄는 CD3에 결합하는 제2 항원 결합 도메인을 포함하는 제2 아암을 형성하고, 여기서 (a) 제1 중쇄는 서열식별번호: 20의 아미노산 서열을 갖는 VH CDR1, 서열식별번호: 21의 아미노산 서열을 갖는 VH CDR2, 서열식별번호: 160의 아미노산 서열을 갖는 VH CDR3을 포함하고, 제1 경쇄는 서열식별번호: 166의 아미노산 서열을 갖는 VL CDR1, 서열식별번호: 25의 아미노산 서열을 갖는 VL CDR2 및 서열식별번호: 153의 아미노산 서열을 갖는 VL CDR3을 포함하거나; (b) 제1 중쇄는 서열식별번호: 205의 아미노산 서열을 갖는 VH CDR1, 서열식별번호: 21의 아미노산 서열을 갖는 VH CDR2, 서열식별번호: 160의 아미노산 서열을 갖는 VH CDR3을 포함하고, 제1 경쇄는 서열식별번호: 166의 아미노산 서열을 갖는 VL CDR1, 서열식별번호: 25의 아미노산 서열을 갖는 VL CDR2 및 서열식별번호: 153의 아미노산 서열을 갖는 VL CDR3을 포함하거나; (c) 제1 중쇄는 서열식별번호: 206의 아미노산 서열을 갖는 VH CDR1, 서열식별번호: 207의 아미노산 서열을 갖는 VH CDR2, 서열식별번호: 160의 아미노산 서열을 갖는 VH CDR3을 포함하고, 제1 경쇄는 서열식별번호: 166의 아미노산 서열을 갖는 VL CDR1, 서열식별번호: 25의 아미노산 서열을 갖는 VL CDR2 및 서열식별번호: 153의 아미노산 서열을 갖는 VL CDR3을 포함하거나; (d) 제1 중쇄는 서열식별번호: 5의 아미노산 서열을 갖는 VH CDR1, 서열식별번호: 6의 아미노산 서열을 갖는 VH CDR2, 서열식별번호: 7의 아미노산 서열을 갖는 VH CDR3을 포함하고, 제1 경쇄는 서열식별번호: 9의 아미노산 서열을 갖는 VL CDR1, 서열식별번호: 10의 아미노산 서열을 갖는 VL CDR2 및 서열식별번호: 138의 아미노산 서열을 갖는 VL CDR3을 포함하거나; (e) 제1 중쇄는 서열식별번호: 200의 아미노산 서열을 갖는 VH CDR1, 서열식별번호: 201의 아미노산 서열을 갖는 VH CDR2, 서열식별번호: 7의 아미노산 서열을 갖는 VH CDR3을 포함하고, 제1 경쇄는 서열식별번호: 9의 아미노산 서열을 갖는 VL CDR1, 서열식별번호: 10의 아미노산 서열을 갖는 VL CDR2 및 서열식별번호: 138의 아미노산 서열을 갖는 VL CDR3을 포함하거나; (f) 제1 중쇄는 서열식별번호: 199의 아미노산 서열을 갖는 VH CDR1, 서열식별번호: 6의 아미노산 서열을 갖는 VH CDR2, 서열식별번호: 7의 아미노산 서열을 갖는 VH CDR3을 포함하고, 제1 경쇄는 서열식별번호: 9의 아미노산 서열을 갖는 VL CDR1, 서열식별번호: 10의 아미노산 서열을 갖는 VL CDR2 및 서열식별번호: 138의 아미노산 서열을 갖는 VL CDR3을 포함하거나; (g) 제1 중쇄는 서열식별번호: 20의 아미노산 서열을 갖는 VH CDR1, 서열식별번호: 21의 아미노산 서열을 갖는 VH CDR2, 서열식별번호: 160의 아미노산 서열을 갖는 VH CDR3을 포함하고, 제1 경쇄는 서열식별번호: 152의 아미노산 서열을 갖는 VL CDR1, 서열식별번호: 41의 아미노산 서열을 갖는 VL CDR2 및 서열식별번호: 153의 아미노산 서열을 갖는 VL CDR3을 포함하거나; (h) 제1 중쇄는 서열식별번호: 5의 아미노산 서열을 갖는 VH CDR1, 서열식별번호: 6의 아미노산 서열을 갖는 VH CDR2, 서열식별번호: 7의 아미노산 서열을 갖는 VH CDR3을 포함하고, 제1 경쇄는 서열식별번호: 9의 아미노산 서열을 갖는 VL CDR1, 서열식별번호: 10의 아미노산 서열을 갖는 VL CDR2 및 서열식별번호: 138의 아미노산 서열을 갖는 VL CDR3을 포함하거나; 또는 (i) 제1 중쇄는 서열식별번호: 5의 아미노산 서열을 갖는 VH CDR1, 서열식별번호: 130의 아미노산 서열을 갖는 VH CDR2, 서열식별번호: 7의 아미노산 서열을 갖는 VH CDR3을 포함하고, 제1 경쇄는 서열식별번호: 9의 아미노산 서열을 갖는 VL CDR1, 서열식별번호: 10의 아미노산 서열을 갖는 VL CDR2 및 서열식별번호: 138의 아미노산 서열을 갖는 VL CDR3을 포함하는 것인, B7-H4 및 CD3 둘 다에 특이적으로 결합하는 이중특이적 항체를 제공한다.
이중특이적 항체의 일부 실시양태에서, (a) 제1 중쇄는 서열식별번호: 161의 아미노산 서열을 갖는 VH를 포함하고, 제1 경쇄는 서열식별번호: 167의 아미노산 서열을 갖는 VL을 포함하거나; (b) 제1 중쇄는 서열식별번호: 172의 아미노산 서열을 갖는 VH를 포함하고, 제1 경쇄는 서열식별번호: 139의 아미노산 서열을 갖는 VL을 포함하거나; (c) 제1 중쇄는 서열식별번호: 155의 아미노산 서열을 갖는 VH를 포함하고; 제1 경쇄는 서열식별번호: 139의 아미노산 서열을 갖는 VL을 포함하거나; (d) 제1 중쇄는 서열식별번호: 156의 아미노산 서열을 갖는 VH를 포함하고; 제1 경쇄는 서열식별번호: 139의 아미노산 서열을 갖는 VL을 포함하거나; (e) 제1 중쇄는 서열식별번호: 157의 아미노산 서열을 갖는 VH를 포함하고; 제1 경쇄는 서열식별번호: 141의 아미노산 서열을 갖는 VL을 포함하거나; (f) 제1 중쇄는 서열식별번호: 155의 아미노산 서열을 갖는 VH를 포함하고; 제1 경쇄는 서열식별번호: 141의 아미노산 서열을 갖는 VL을 포함하거나; (g) 제1 중쇄는 서열식별번호: 156의 아미노산 서열을 갖는 VH를 포함하고; 제1 경쇄는 서열식별번호: 141의 아미노산 서열을 갖는 VL을 포함하거나; (h) 제1 중쇄는 서열식별번호: 159의 아미노산 서열을 갖는 VH를 포함하고; 제1 경쇄는 서열식별번호: 27의 아미노산 서열을 갖는 VL을 포함하거나; (i) 제1 중쇄는 서열식별번호: 161의 아미노산 서열을 갖는 VH를 포함하고; 제1 경쇄는 서열식별번호: 27의 아미노산 서열을 갖는 VL을 포함하거나; (j) 제1 중쇄는 서열식별번호: 163의 아미노산 서열을 갖는 VH를 포함하고; 제1 경쇄는 서열식별번호: 27의 아미노산 서열을 갖는 VL을 포함하거나; (k) 제1 중쇄는 서열식별번호: 165의 아미노산 서열을 갖는 VH를 포함하고; 제1 경쇄는 서열식별번호: 27의 아미노산 서열을 갖는 VL을 포함하거나; (l) 제1 중쇄는 서열식별번호: 23의 아미노산 서열을 갖는 VH를 포함하고; 제1 경쇄는 서열식별번호: 167의 아미노산 서열을 갖는 VL을 포함하거나; (m) 제1 중쇄는 서열식별번호: 171의 아미노산 서열을 갖는 VH를 포함하고; 제1 경쇄는 서열식별번호: 141의 아미노산 서열을 갖는 VL을 포함하거나; (n) 제1 중쇄는 서열식별번호: 172의 아미노산 서열을 갖는 VH를 포함하고; 제1 경쇄는 서열식별번호: 141의 아미노산 서열을 갖는 VL을 포함하거나; (o) 제1 중쇄는 서열식별번호: 171의 아미노산 서열을 갖는 VH를 포함하고; 제1 경쇄는 서열식별번호: 139의 아미노산 서열을 갖는 VL을 포함하거나; (p) 제1 중쇄는 서열식별번호: 173의 아미노산 서열을 갖는 VH를 포함하고; 제1 경쇄는 서열식별번호: 139의 아미노산 서열을 갖는 VL을 포함하거나; (q) 제1 중쇄는 서열식별번호: 174의 아미노산 서열을 갖는 VH를 포함하고; 제1 경쇄는 서열식별번호: 139의 아미노산 서열을 갖는 VL을 포함하거나; (r) 제1 중쇄는 서열식별번호: 175의 아미노산 서열을 갖는 VH를 포함하고; 제1 경쇄는 서열식별번호: 139의 아미노산 서열을 갖는 VL을 포함하거나; (s) 제1 중쇄는 서열식별번호: 161의 아미노산 서열을 갖는 VH; 및 서열식별번호: 168의 아미노산 서열을 갖는 VL을 포함하거나; (t) 제1 중쇄는 서열식별번호: 161의 아미노산 서열을 갖는 VH를 포함하고; 제1 경쇄는 서열식별번호: 169의 아미노산 서열을 갖는 VL을 포함하거나; (u) 제1 중쇄는 서열식별번호: 161의 아미노산 서열을 갖는 VH를 포함하고; 제1 경쇄는 서열식별번호: 170의 아미노산 서열을 갖는 VL을 포함하거나; 또는 (v) 제1 중쇄는 서열식별번호: 172의 아미노산 서열을 갖는 VH를 포함하고; 제1 경쇄는 서열식별번호: 139의 아미노산 서열을 갖는 VL을 포함한다.
이중특이적 항체의 일부 실시양태에서, (a) 제2 중쇄는 서열식별번호: 28의 아미노산 서열을 갖는 VH CDR1, 서열식별번호: 105의 아미노산 서열을 갖는 VH CDR2, 서열식별번호: 30의 아미노산 서열을 갖는 VH CDR3을 포함하고, 제2 경쇄는 서열식별번호: 107의 아미노산 서열을 갖는 VL CDR1, 서열식별번호: 33의 아미노산 서열을 갖는 VL CDR2 및 서열식별번호: 34의 아미노산 서열을 갖는 VL CDR3을 포함하거나; (b) 제2 중쇄는 서열식별번호: 202의 아미노산 서열을 갖는 VH CDR1, 서열식별번호: 105의 아미노산 서열을 갖는 VH CDR2, 서열식별번호: 30의 아미노산 서열을 갖는 VH CDR3을 포함하고, 제2 경쇄는 서열식별번호: 107의 아미노산 서열을 갖는 VL CDR1, 서열식별번호: 33의 아미노산 서열을 갖는 VL CDR2 및 서열식별번호: 34의 아미노산 서열을 갖는 VL CDR3을 포함하거나; (c) 제2 중쇄는 서열식별번호: 203의 아미노산 서열을 갖는 VH CDR1, 서열식별번호: 204의 아미노산 서열을 갖는 VH CDR2, 서열식별번호: 30의 아미노산 서열을 갖는 VH CDR3을 포함하고, 제2 경쇄는 서열식별번호: 107의 아미노산 서열을 갖는 VL CDR1, 서열식별번호: 33의 아미노산 서열을 갖는 VL CDR2 및 서열식별번호: 34의 아미노산 서열을 갖는 VL CDR3을 포함하거나; (d) 제2 중쇄는 서열식별번호: 28의 아미노산 서열을 갖는 VH CDR1, 서열식별번호: 105의 아미노산 서열을 갖는 VH CDR2, 서열식별번호: 30의 아미노산 서열을 갖는 VH CDR3을 포함하고, 제2 경쇄는 서열식별번호: 107의 아미노산 서열을 갖는 VL CDR1, 서열식별번호: 33의 아미노산 서열을 갖는 VL CDR2 및 서열식별번호: 116의 아미노산 서열을 갖는 VL CDR3을 포함하거나; (e) 제2 중쇄는 서열식별번호: 28의 아미노산 서열을 갖는 VH CDR1, 서열식별번호: 109의 아미노산 서열을 갖는 VH CDR2, 서열식별번호: 30의 아미노산 서열을 갖는 VH CDR3을 포함하고, 제2 경쇄는 서열식별번호: 111의 아미노산 서열을 갖는 VL CDR1, 서열식별번호: 112의 아미노산 서열을 갖는 VL CDR2 및 서열식별번호: 34의 아미노산 서열을 갖는 VL CDR3을 포함하거나; 또는 (f) 제2 중쇄는 서열식별번호: 28의 아미노산 서열을 갖는 VH CDR1, 서열식별번호: 29의 아미노산 서열을 갖는 VH CDR2, 서열식별번호: 30의 아미노산 서열을 갖는 VH CDR3을 포함하고, 제2 경쇄는 서열식별번호: 32의 아미노산 서열을 갖는 VL CDR1, 서열식별번호: 33의 아미노산 서열을 갖는 VL CDR2 및 서열식별번호: 34의 아미노산 서열을 갖는 VL CDR3을 포함한다.
이중특이적 항체의 일부 실시양태에서, (a) 제2 중쇄는 서열식별번호: 106의 아미노산 서열을 갖는 VH를 포함하고, 제2 경쇄는 서열식별번호: 108의 아미노산 서열을 갖는 VL을 포함하거나; (b) 제2 중쇄는 서열식별번호: 115의 아미노산 서열을 갖는 VH를 포함하고, 제2 경쇄는 서열식별번호: 117의 아미노산 서열을 갖는 VL을 포함하거나; (c) 제2 중쇄는 서열식별번호: 110의 아미노산 서열을 갖는 VH를 포함하고, 제2 경쇄는 서열식별번호: 113의 아미노산 서열을 갖는 VL을 포함하거나; 또는 (d) 제2 중쇄는 서열식별번호: 31의 아미노산 서열을 갖는 VH를 포함하고, 제2 경쇄는 서열식별번호: 35의 아미노산 서열을 갖는 VL을 포함한다.
이중특이적 항체의 일부 실시양태에서, (a) 제1 중쇄는 서열식별번호: 20의 아미노산 서열을 갖는 VH CDR1, 서열식별번호: 21의 아미노산 서열을 갖는 VH CDR2, 서열식별번호: 160의 아미노산 서열을 갖는 VH CDR3을 포함하고, 제1 경쇄는 서열식별번호: 166의 아미노산 서열을 갖는 VL CDR1, 서열식별번호: 25의 아미노산 서열을 갖는 VL CDR2 및 서열식별번호: 153의 아미노산 서열을 갖는 VL CDR3을 포함하고; (b) 제2 중쇄는 서열식별번호: 28의 아미노산 서열을 갖는 VH CDR1, 서열식별번호: 105의 아미노산 서열을 갖는 VH CDR2, 서열식별번호: 30의 아미노산 서열을 갖는 VH CDR3을 포함하고, 제2 경쇄는 서열식별번호: 107의 아미노산 서열을 갖는 VL CDR1, 서열식별번호: 33의 아미노산 서열을 갖는 VL CDR2 및 서열식별번호: 34의 아미노산 서열을 갖는 VL CDR3을 포함한다.
이중특이적 항체의 일부 실시양태에서, (a) 제1 중쇄는 서열식별번호: 5의 아미노산 서열을 갖는 VH CDR1, 서열식별번호: 6의 아미노산 서열을 갖는 VH CDR2, 서열식별번호: 7의 아미노산 서열을 갖는 VH CDR3을 포함하고, 제1 경쇄는 서열식별번호: 9의 아미노산 서열을 갖는 VL CDR1, 서열식별번호: 10의 아미노산 서열을 갖는 VL CDR2 및 서열식별번호: 138의 아미노산 서열을 갖는 VL CDR3을 포함하고; (b) 제2 중쇄는 서열식별번호: 28의 아미노산 서열을 갖는 VH CDR1, 서열식별번호: 105의 아미노산 서열을 갖는 VH CDR2, 서열식별번호: 30의 아미노산 서열을 갖는 VH CDR3을 포함하고, 제2 경쇄는 서열식별번호: 107의 아미노산 서열을 갖는 VL CDR1, 서열식별번호: 33의 아미노산 서열을 갖는 VL CDR2 및 서열식별번호: 34의 아미노산 서열을 갖는 VL CDR3을 포함한다.
이중특이적 항체의 일부 실시양태에서, (a) 제1 중쇄는 서열식별번호: 161의 아미노산 서열을 갖는 VH를 포함하고, 제1 경쇄는 서열식별번호: 167의 아미노산 서열을 갖는 VL을 포함하고; (b) 제2 중쇄는 서열식별번호: 106의 아미노산 서열을 갖는 VH를 포함하고, 제2 경쇄는 서열식별번호: 108의 아미노산 서열을 갖는 VL을 포함한다.
이중특이적 항체의 일부 실시양태에서, (a) 제1 중쇄는 서열식별번호: 172의 아미노산 서열을 갖는 VH를 포함하고, 제1 경쇄는 서열식별번호: 139의 아미노산 서열을 갖는 VL을 포함하고; (b) 제2 중쇄는 서열식별번호: 106의 아미노산 서열을 갖는 VH를 포함하고, 제2 경쇄는 서열식별번호: 108의 아미노산 서열을 갖는 VL을 포함한다.
일부 실시양태에서, 이중특이적 항체는 불변 영역을 추가로 포함한다. 일부 실시양태에서, 불변 영역은 IgG1이다. 일부 실시양태에서, 불변 영역은 A330S, P331S, D265A, C223E, P228E, L368E, C223R, E225R, P228R 및 K409R로 이루어진 군으로부터 선택된 1개 이상의 치환을 포함하는 인간 IgG2이며, 여기서 넘버링은 인간 IgG2 야생형 및 EU 넘버링 스킴에 따르고, 도 1에 제시된 바와 같다.
이중특이적 항체의 일부 실시양태에서, 제1 아암은 치환 D265A, C223E, P228E 및 L368E를 갖는 hIgG2ΔA 불변 영역의 불변 영역을 추가로 포함하고, 제2 아암은 치환 D265A, C223R, E225R, P228R 및 K409R을 갖는 인간 IgG2ΔA 불변 영역을 추가로 포함하며, 여기서 넘버링은 인간 야생형 IgG2 및 EU 넘버링 스킴에 따르고, 도 1에 제시된 바와 같다.
한 측면에서, 본 발명은 제1 중쇄 및 제1 경쇄 및 제2 중쇄 및 제2 경쇄를 포함하며, 여기서 제1 중쇄 및 제1 경쇄는 B7-H4에 결합하는 제1 항원 결합 도메인을 포함하는 제1 항체 아암을 형성하고, 제2 중쇄 및 제2 경쇄는 CD3에 결합하는 제2 항원 결합 도메인을 형성하고, 여기서 (a) 제1 중쇄는 서열식별번호: 190의 아미노산 서열을 갖고; 제1 경쇄는 서열식별번호: 191의 아미노산 서열을 갖고; (b) 제2 중쇄는 서열식별번호: 188의 아미노산 서열을 갖고; 제2 경쇄는 189의 아미노산 서열을 갖는 것인, B7-H4 및 CD3 둘 다에 특이적으로 결합하는 이중특이적 항체를 제공한다.
또 다른 측면에서, 본 발명은 제1 중쇄 및 제1 경쇄 및 제2 중쇄 및 제2 경쇄를 포함하며, 여기서 제1 중쇄 및 제1 경쇄는 B7-H4에 결합하는 제1 항원 결합 도메인을 포함하는 제1 항체 아암을 형성하고, 제2 중쇄 및 제2 경쇄는 CD3에 결합하는 제2 항원 결합 도메인을 형성하고, 여기서 (a) 제1 중쇄는 서열식별번호: 186의 아미노산 서열을 갖고; 제1 경쇄는 서열식별번호: 187의 아미노산 서열을 갖고; (b) 제2 중쇄는 서열식별번호: 188의 아미노산 서열을 갖고; 제2 경쇄는 서열식별번호: 189의 아미노산 서열을 갖는 것인, B7-H4 및 CD3 둘 다에 특이적으로 결합하는 이중특이적 항체를 제공한다.
또 다른 측면에서, 본 발명은 제1 중쇄 및 제1 경쇄 및 제2 중쇄 및 제2 경쇄를 포함하며, 여기서 제1 중쇄 및 제1 경쇄는 B7-H4에 결합하는 제1 항원 결합 도메인을 포함하는 제1 항체 아암을 형성하고, 제2 중쇄 및 제2 경쇄는 CD3에 결합하는 제2 항원 결합 도메인을 형성하고, 여기서 (a) 제1 중쇄는 ATCC 수탁 번호 PTA-126779 하에 기탁된 오픈 리딩 프레임 (ORF)에 의해 코딩된 전장 폴리펩티드의 아미노산 서열을 포함하고, 제1 경쇄는 ATCC 수탁 번호 PTA-126781 하에 기탁된 오픈 리딩 프레임 (ORF)에 의해 코딩된 전장 폴리펩티드의 아미노산 서열을 포함하고; (b) 제2 중쇄는 ATCC 수탁 번호 PTA-126780 하에 기탁된 오픈 리딩 프레임 (ORF)에 의해 코딩된 전장 폴리펩티드의 아미노산 서열을 포함하고, 제2 경쇄는 ATCC 수탁 번호 PTA-126782 하에 기탁된 오픈 리딩 프레임 (ORF)에 의해 코딩된 전장 폴리펩티드의 아미노산 서열을 포함하는 것인, B7-H4 및 CD3에 특이적으로 결합하는 이중특이적 항체를 제공한다.
또 다른 측면에서, 본 발명은 서열식별번호: 1의 B7-H4 아미노산 서열의 L44, K45, E46, G47, V48, L49, G50, L51, S63, E64, D66, M68, T99 및 K101로 이루어진 군으로부터의 적어도 2개, 적어도 3개, 적어도 4개, 적어도 5개, 적어도 6개, 적어도 7개, 적어도 8개, 적어도 9개, 적어도 10개, 적어도 11개, 적어도 12개 또는 적어도 13개의 아미노산 잔기를 포함하는 인간 B7-H4 상의 에피토프에 결합하는, B7-H4 및 CD3 둘 다에 특이적으로 결합하는 이중특이적 항체를 제공한다. 일부 실시양태에서, 에피토프는 L44, K45, E46, G47, V48, L49, G50 및 L51로 이루어진 군으로부터의 적어도 1개, 적어도 2개, 적어도 3개, 적어도 4개, 적어도 5개, 적어도 6 또는 적어도 7개의 아미노산 잔기 및 S63, E64, D66, M68, T99 및 K101로 이루어진 군으로부터의 적어도 1개의 아미노산, 적어도 2개, 적어도 3개, 적어도 4 또는 적어도 5개의 아미노산 잔기를 포함한다. 일부 실시양태에서, 에피토프는 L44, K45, E46, G47, V48, L49, G50, L51, S63, E64, D66, M68, T99 및 K101의 아미노산 잔기를 포함하거나 또는 그로 이루어진다.
또 다른 측면에서, 본 발명은 서열식별번호: 1의 B7-H4 아미노산 서열의 V129, Y131, N132, S134, S135, E136, L138, V189, I191, V212, E214, S215, E216 및 I217로 이루어진 군으로부터의 적어도 2개, 적어도 3개, 적어도 4개, 적어도 5개, 적어도 6개, 적어도 7개, 적어도 8개, 적어도 9개, 적어도 10개, 적어도 11개, 적어도 12개 또는 적어도 13개의 아미노산 잔기를 포함하는 인간 B7-H4 상의 에피토프에 결합하는, B7-H4 및 CD3 둘 다에 특이적으로 결합하는 이중특이적 항체를 제공한다. 일부 실시양태에서, 에피토프는 V129, Y131, N132, S134, S135, E136 및 L138로 이루어진 군으로부터의 적어도 1개, 적어도 2개, 적어도 3개, 적어도 4개, 적어도 5 또는 적어도 6개의 아미노산 잔기 및 V189, I191, V212, E214, S215, E216 및 I217로 이루어진 군으로부터의 적어도 1개, 적어도 2개, 적어도 3개, 적어도 4개, 적어도 5 또는 적어도 6개의 아미노산 잔기를 포함한다. 일부 실시양태에서, 에피토프는 V129, Y131, N132, S134, S135, E136, L138, V189, I191, V212, E214, S215, E216 및 I217의 아미노산 잔기를 포함하거나 또는 그로 이루어진다.
또 다른 측면에서, 본 발명은 본 발명의 이중특이적 항체를 코딩하는 폴리뉴클레오티드를 제공한다.
또 다른 측면에서, 본 발명은 (i) 본 발명의 이중특이적 항체의 중쇄 또는 (ii) 본 발명의 이중특이적 항체의 경쇄를 코딩하는 폴리뉴클레오티드를 제공한다.
또 다른 측면에서, 본 발명은 본 발명의 폴리뉴클레오티드를 포함하는 벡터를 제공한다.
또 다른 측면에서, 본 발명은 본원에 개시된 폴리뉴클레오티드 또는 본원에 개시된 벡터를 포함하는 숙주 세포를 제공한다.
또 다른 측면에서, 본 발명은 의약으로서 사용하기 위한 본원에 개시된 이중특이적 항체를 제공한다. 일부 실시양태에서, 의약은 암의 치료를 위한 것일 수 있다.
또 다른 측면에서, 본 발명은 암의 치료를 필요로 하는 대상체에게 본원에 개시된 이중특이적 항체를 투여하는 것을 포함하는, 상기 대상체에서 암을 치료하는 방법을 제공한다.
또 다른 측면에서, 본 발명은 본원에 개시된 이중특이적 항체를 포함하는 제약 조성물을 제공한다.
또 다른 측면에서, 본 발명은 B7-H4를 발현하는 악성 세포와 연관된 상태의 치료를 필요로 하는 대상체에게 치료 유효량의 본원에 개시된 제약 조성물을 투여하는 것을 포함하는, 대상체에서 B7-H4를 발현하는 악성 세포와 연관된 상태를 치료하는 방법을 제공한다.
또 다른 측면에서, 본 발명은 의약으로서 사용하기 위한 본원에 개시된 바와 같은 B7-H4 항체, 이중특이적 항체, 제약 조성물, 폴리뉴클레오티드, 벡터 또는 숙주 세포를 제공한다.
또 다른 측면에서, 본 발명은 의약의 제조에서의 본원에 개시된 바와 같은 B7-H4 항체, 이중특이적 항체, 제약 조성물, 폴리뉴클레오티드, 벡터 또는 숙주 세포의 용도를 제공한다.
일부 실시양태에서, 상태는 암이다. 일부 실시양태에서, 암은 유방암, 난소암, 자궁암, 방광암 또는 담관암이다. 일부 실시양태에서, 방법 또는 용도는 유효량의 제2 치료제를 투여하는 것을 추가로 포함할 수 있다. 일부 실시양태에서, 제2 치료제는 항-PD-1 또는 항-PD-L1 항체 또는 팔보시클립이다. 일부 실시양태에서, 항-PD-1 항체는 RN888이다.
또 다른 측면에서, 본 발명은 종양 성장 또는 진행의 억제를 필요로 하는, B7-H4를 발현하는 악성 세포를 갖는 대상체에게 치료 유효량의 본원에 개시된 제약 조성물을 투여하는 것을 포함하는, 상기 대상체에서 종양 성장 또는 진행을 억제하는 방법을 제공한다.
또 다른 측면에서, 본 발명은 B7-H4를 발현하는 악성 세포를 갖는 대상체에서 종양 성장 또는 진행을 억제하는데 사용하기 위한 본원에 개시된 바와 같은 B7-H4 항체, 이중특이적 항체, 제약 조성물, 폴리뉴클레오티드, 벡터 또는 숙주 세포를 제공한다.
또 다른 측면에서, 본 발명은 B7-H4를 발현하는 악성 세포를 갖는 대상체에서 종양 성장 또는 진행을 억제하기 위한 의약의 제조에서의 본원에 개시된 바와 같은 B7-H4 항체, 이중특이적 항체, 제약 조성물, 폴리뉴클레오티드, 벡터 또는 숙주 세포의 용도를 제공한다.
일부 실시양태에서, 방법 또는 용도는 유효량의 제2 치료제를 투여하는 것을 추가로 포함할 수 있다. 일부 실시양태에서, 제2 치료제는 항-PD-1 또는 항-PD-L1 항체 또는 팔보시클립이다. 일부 실시양태에서, 항-PD-1 항체는 RN888이다.
또 다른 측면에서, 본 발명은 종양 퇴행의 유도를 필요로 하는, B7-H4를 발현하는 악성 세포를 갖는 대상체에게 유효량의 본원에 개시된 제약 조성물을 투여하는 것을 포함하는, 상기 대상체에서 종양 퇴행을 유도하는 방법을 제공한다.
또 다른 측면에서, 본 발명은 B7-H4를 발현하는 악성 세포를 갖는 대상체에서 종양 퇴행을 유도하는데 사용하기 위한 본원에 개시된 바와 같은 B7-H4 항체, 이중특이적 항체, 제약 조성물, 폴리뉴클레오티드, 벡터 또는 숙주 세포를 제공한다.
또 다른 측면에서, 본 발명은 B7-H4를 발현하는 악성 세포를 갖는 대상체에서 종양 퇴행을 유도하기 위한 의약의 제조에서의 본원에 개시된 바와 같은 B7-H4 항체, 제약 조성물, 폴리뉴클레오티드, 벡터 또는 숙주 세포의 용도를 제공한다.
일부 실시양태에서, 방법 또는 용도는 유효량의 제2 치료제를 투여하는 것을 추가로 포함할 수 있다. 일부 실시양태에서, 제2 치료제는 항-PD-1 또는 항-PD-L1 항체 또는 팔보시클립이다. 일부 실시양태에서, 항-PD-1 항체는 RN888이다.
일부 실시양태에서, 본 발명의 항체 또는 이중특이적 항체는 증가된 B7-H4 수용체 밀도 수준의 존재 하에 보다 낮은 EC50 값을 나타낸다. 바람직하게는, EC50 값은 0.0001nM 내지 100nM, 0.0001nM 내지 10nM, 0.0001nM 내지 1nM, 0.0001nM 내지 0.1nM, 0.0001nM 내지 0.0010nM, 0.001nM 내지 100nM, 0.01nM 내지 100nM, 0.1nM 내지 100nM, 0.001nM 내지 10nM, 0.001nM 내지 1nM, 0.01nM 내지 1nM, 또는 0.001nM 내지 0.1nM이다. 바람직하게는, EC50 값은 10nM 미만, 1nM 미만, 0.5nM 미만, 0.1nM 미만, 0.01nM 미만 또는 0.001nM 미만이다.
일부 실시양태에서, 본 발명의 항체 또는 이중특이적 항체는 세포용해 T 세포 반응을 활성화시킬 수 있다.
도 1은 인간 IgG2 야생형 서열에 따라 EU 넘버링 스킴을 사용하여 넘버링된, 불변 영역 내 다양한 위치에서 변형을 갖는 본원에 제공된 이중특이적 항체의 예시적인 IgG2 불변 영역의 아미노산 서열을 도시한다. 인간 IgG1 및 IgG4 야생형 서열 및 넘버링이 또한 도 1에 제공된다.
도 2a는 B7-H4 항체 0052 scFv 및 인간 B7-H4 세포외 도메인의 공-결정 구조를 도시한다.
도 2b는 B7-H4 항체 0058 Fab 및 인간 B7-H4 세포외 도메인의 공-결정 구조를 도시한다.
도 2c는 B7-H4 항체 1114 Fab 및 인간 B7-H4 세포외 도메인의 공-결정 구조를 도시한다.
도 2a는 B7-H4 항체 0052 scFv 및 인간 B7-H4 세포외 도메인의 공-결정 구조를 도시한다.
도 2b는 B7-H4 항체 0058 Fab 및 인간 B7-H4 세포외 도메인의 공-결정 구조를 도시한다.
도 2c는 B7-H4 항체 1114 Fab 및 인간 B7-H4 세포외 도메인의 공-결정 구조를 도시한다.
B7-H4 및 CD3에 특이적으로 결합하는 이중특이적 항체 ("B7-H4xCD3 이중특이적 항체")를 비롯한, B7-H4에 특이적으로 결합하는 항체, 이러한 항체를 제조하는 방법, 및 종양 진행을 억제하고 암을 치료 및/또는 예방하는 방법을 비롯한, 이러한 항체를 사용하는 방법이 본원에 개시된다.
일반적 기술
본 발명의 실시는, 달리 나타내지 않는 한, 관련 기술분야의 기술 내에 있는 분자 생물학 (재조합 기술 포함), 미생물학, 세포 생물학, 생화학 및 면역학의 통상적인 기술을 사용할 것이다. 이러한 기술은 다음과 같은 문헌에 상세하게 설명되어 있다: 문헌 [Molecular Cloning: A Laboratory Manual, second edition (Sambrook et al., 1989) Cold Spring Harbor Press; Oligonucleotide Synthesis (M.J. Gait, ed., 1984); Methods in Molecular Biology, Humana Press; Cell Biology: A Laboratory Notebook (J.E. Cellis, ed., 1998) Academic Press; Animal Cell Culture (R.I. Freshney, ed., 1987); Introduction to Cell and Tissue Culture (J.P. Mather and P.E. Roberts, 1998) Plenum Press; Cell and Tissue Culture: Laboratory Procedures (A. Doyle, J.B. Griffiths, and D.G. Newell, eds., 1993-1998) J. Wiley and Sons; Methods in Enzymology (Academic Press, Inc.); Handbook of Experimental Immunology (D.M. Weir and C.C. Blackwell, eds.); Gene Transfer Vectors for Mammalian Cells (J.M. Miller and M.P. Calos, eds., 1987); Current Protocols in Molecular Biology (F.M. Ausubel et al., eds., 1987); PCR: The Polymerase Chain Reaction, (Mullis et al., eds., 1994); Current Protocols in Immunology (J.E. Coligan et al., eds., 1991); Short Protocols in Molecular Biology (Wiley and Sons, 1999); Immunobiology (C.A. Janeway and P. Travers, 1997); Antibodies (P. Finch, 1997); Antibodies: a practical approach (D. Catty., ed., IRL Press, 1988-1989); Monoclonal antibodies: a practical approach (P. Shepherd and C. Dean, eds., Oxford University Press, 2000); Using antibodies: a laboratory manual (E. Harlow and D. Lane (Cold Spring Harbor Laboratory Press, 1999); The Antibodies (M. Zanetti and J.D. Capra, eds., Harwood Academic Publishers, 1995)].
정의
"항체"는 이뮤노글로불린 분자의 가변 영역 내에 위치하는 적어도 1개의 항원 인식 부위를 통해 표적, 예컨대 탄수화물, 폴리뉴클레오티드, 지질, 폴리펩티드 등에 특이적으로 결합할 수 있는 이뮤노글로불린 분자이다. 본원에 사용된 용어는 무손상 폴리클로날 또는 모노클로날 항체뿐만 아니라, 그의 항원 결합 단편, 예컨대, 예를 들어 Fab, Fab', F(ab')2, Fv, 단일 쇄 (ScFv) 및 도메인 항체 (예를 들어, 상어 및 낙타류 항체 포함), 항체를 포함하는 융합 단백질 (예를 들어, 비제한적으로 키메라 항원 수용체 (CAR) 또는 항체-시토카인 융합 단백질 포함), 및 항원 인식 부위를 포함하는 이뮤노글로불린 분자의 임의의 다른 변형된 형상을 포괄한다. 항체는 임의의 부류, 예컨대 IgG, IgA 또는 IgM (또는 그의 하위부류)의 항체를 포함하고, 항체는 임의의 특정한 부류일 필요는 없다. 항체의 중쇄의 불변 영역의 아미노산 서열에 따라, 이뮤노글로불린은 상이한 부류로 배정될 수 있다. 5가지 주요 부류의 이뮤노글로불린: IgA, IgD, IgE, IgG 및 IgM이 존재하고, 이들 중 몇몇은 하위부류 (이소형), 예를 들어 IgG1, IgG2, IgG3, IgG4, IgA1 및 IgA2로 추가로 나뉠 수 있다. 상이한 부류의 이뮤노글로불린에 상응하는 중쇄 불변 영역은 각각 알파, 델타, 엡실론, 감마 및 뮤로 불린다. 상이한 부류의 이뮤노글로불린의 서브유닛 구조 및 3차원 형상은 널리 공지되어 있다.
"단리된 항체"는 다른 단백질 및 세포 물질이 실질적으로 없는 항체를 지칭한다.
본원에 사용된 용어 항체의 "항원 결합 단편" 또는 "항원 결합 부분"은 주어진 항원 (예를 들어, B7-H4 또는 CD3)에 특이적으로 결합하는 능력을 보유하는 무손상 항체의 1개 이상의 단편을 지칭한다. 항체의 항원 결합 기능은 무손상 항체의 단편에 의해 수행될 수 있다. 용어 항체의 "항원 결합 단편" 내에 포괄되는 결합 단편의 예는 비제한적으로 Fab; Fab'; F(ab')2; VH 및 CH1 도메인으로 이루어진 Fd 단편; 항체의 단일 아암의 VL 및 VH 도메인으로 이루어진 Fv 단편; 단일 도메인 항체 (dAb) 단편 (Ward et al., Nature 341:544-546, 1989), 및 단리된 상보성 결정 영역 (CDR)을 포함한다.
표적 (예를 들어, B7-H4 단백질 또는 CD3 단백질)에 "우선적으로 결합" 또는 "특이적으로 결합" (본원에서 상호교환가능하게 사용됨)하는 항체, 항체 접합체 또는 폴리펩티드는 관련 기술분야에서 널리 이해되는 용어이고, 이러한 특이적 또는 우선적 결합을 결정하는 방법 또한 관련 기술분야에 널리 공지되어 있다. 분자는 그것이 대안적 세포 또는 물질보다 특정한 세포 또는 물질과 더 빈번하게, 더 신속하게, 더 긴 지속기간으로 및/또는 더 큰 친화도로 반응하거나 회합하는 경우에 "특이적 결합" 또는 "우선적 결합"을 나타내는 것으로 언급된다. 항체는 다른 물질에 결합하는 것보다 더 큰 친화도, 결합력으로, 더 용이하게 및/또는 더 긴 지속기간으로 결합하는 경우에 표적에 "특이적으로 결합"하거나 "우선적으로 결합"한다. 예를 들어, B7-H4 에피토프 또는 CD3 에피토프에 특이적으로 또는 우선적으로 결합하는 항체는 다른 B7-H4 에피토프, 비-B7-H4 에피토프, 다른 CD3 에피토프 또는 비-CD3 에피토프에 결합하는 것보다 더 큰 친화도, 결합력으로, 더 용이하게 및/또는 더 긴 지속기간으로 이러한 에피토프에 결합하는 항체이다. 또한, 이러한 정의를 읽음으로써, 예를 들어 제1 표적에 특이적으로 또는 우선적으로 결합하는 항체 (또는 모이어티 또는 에피토프)는 제2 표적에 특이적으로 또는 우선적으로 결합할 수 있거나 또는 결합하지 않을 수 있는 것으로 이해된다. 따라서, "특이적 결합" 또는 "우선적 결합"은 배타적 결합을 (포함할 수 있지만) 반드시 필요로 하는 것은 아니다. 일반적으로, 반드시는 아니지만, 결합에 대한 언급은 우선적 결합을 의미한다.
항체의 "가변 영역"은 항체 경쇄의 가변 영역 또는 항체 중쇄의 가변 영역을 단독으로 또는 조합하여 지칭한다. 관련 기술분야에 공지된 바와 같이, 중쇄 및 경쇄의 가변 영역은 각각 초가변 영역으로도 공지된 3개의 상보성 결정 영역 (CDR)에 의해 연결된 4개의 프레임워크 영역 (FR)으로 이루어진다. 각각의 쇄 내의 CDR은 FR에 의해 매우 근접하게 함께 유지되고, 다른 쇄로부터의 CDR과 함께 항체의 항원 결합 부위의 형성에 기여한다. CDR을 결정하기 위한 적어도 2가지 기술이 존재한다: (1) 교차-종 서열 가변성에 기초한 접근법 (즉, 문헌 [Kabat et al. Sequences of Proteins of Immunological Interest, (5th ed., 1991, National Institutes of Health, Bethesda MD)]); 및 (2) 항원-항체 복합체의 결정학적 연구에 기초한 접근법 (문헌 [Al-lazikani et al., 1997, J. Molec. Biol. 273:927-948]). 본원에 사용된 CDR은 어느 하나의 접근법에 의해 또는 둘 다의 접근법의 조합에 의해 정의된 CDR을 지칭할 수 있다.
가변 도메인의 "CDR"은 카바트, 코티아의 정의, 카바트 및 코티아 둘 다의 축적, AbM, 접촉 및/또는 입체형태적 정의 또는 관련 기술분야에 널리 공지된 임의의 CDR 결정 방법에 따라 확인되는 가변 영역 내의 아미노산 잔기이다. 항체 CDR은 카바트 등에 의해 처음 정의된 초가변 영역으로서 확인될 수 있다. 예를 들어, 문헌 [Kabat et al., 1992, Sequences of Proteins of Immunological Interest, 5th ed., Public Health Service, NIH, Washington D.C.]을 참조한다. CDR의 위치는 또한 코티아 등에 의해 처음 기재된 구조적 루프 구조로서 확인될 수 있다. 예를 들어, 문헌 [Chothia et al., Nature 342:877-883, 1989]을 참조한다. CDR 확인에 대한 다른 접근법은 카바트와 코티아 사이의 절충안이고 옥스포드 몰레큘라(Oxford Molecular)의 AbM 항체 모델링 소프트웨어 (현재 엑셀리스(Accelrys)®)를 사용하여 유래된 "AbM 정의", 또는 문헌 [MacCallum et al., J. Mol. Biol., 262:732-745, 1996]에 제시된, 관찰된 항원 접촉에 기초한 CDR의 "접촉 정의"를 포함한다. 본원에서 CDR의 "입체형태적 정의"로 지칭되는 또 다른 접근법에서, CDR의 위치는 항원 결합에 엔탈피 기여를 하는 잔기로서 확인될 수 있다. 예를 들어, 문헌 [Makabe et al., Journal of Biological Chemistry, 283:1156-1166, 2008]을 참조한다. 또 다른 CDR 경계 정의가 상기 접근법들 중 하나를 엄격하게 따르지 않을 수 있지만, 그럼에도 불구하고 카바트 CDR의 적어도 한 부분과 중첩될 것이며, 이들은 특정한 잔기 또는 잔기의 군 또는 심지어 전체 CDR이 항원 결합에 유의하게 영향을 미치지 않는다는 예측 또는 실험적 발견에 비추어 단축되거나 연장될 수 있다. 본원에 사용된 CDR은 관련 기술분야에 공지된 임의의 접근법 (접근법들의 조합 포함)에 의해 정의된 CDR을 지칭할 수 있다. 본원에 사용된 방법은 임의의 이들 접근법에 따라 정의된 CDR을 이용할 수 있다. 1개 초과의 CDR을 함유하는 임의의 주어진 실시양태에 대해, CDR은 카바트, 코티아, 연장, AbM, 접촉 및/또는 입체형태적 정의 중 어느 것에 따라 정의될 수 있다.
본원에 사용된 "모노클로날 항체"는 실질적으로 동종인 항체 집단으로부터 수득된 항체를 지칭하며, 즉 집단을 구성하는 개별 항체는 미량으로 존재할 수 있는 가능한 자연 발생 돌연변이를 제외하고는 동일하다. 모노클로날 항체는 고도로 특이적이고, 단일 항원 부위에 대해 지시된다. 추가로, 전형적으로 상이한 결정기 (에피토프)에 대해 지시된 상이한 항체를 포함하는 폴리클로날 항체 제제와 대조적으로, 각각의 모노클로날 항체는 항원 상의 단일 결정기에 대해 지시된다. 수식어 "모노클로날"은 실질적으로 동종인 항체 집단으로부터 수득되는 바와 같은 항체의 특징을 나타내고, 임의의 특정한 방법에 의한 항체의 생산을 요구하는 것으로 해석되어서는 안된다. 예를 들어, 본 발명에 따라 사용되는 모노클로날 항체는 문헌 [Kohler and Milstein, Nature 256:495, 1975]에 최초로 기재된 하이브리도마 방법에 의해 제조될 수 있거나, 또는 미국 특허 번호 4,816,567에 기재된 바와 같은 재조합 DNA 방법에 의해 제조될 수 있다. 모노클로날 항체는 또한, 예를 들어 문헌 [McCafferty et al., Nature 348:552-554, 1990]에 기재된 기술을 사용하여 생성된 파지 라이브러리로부터 단리될 수 있다.
본원에 사용된 "인간화" 항체는 비-인간 이뮤노글로불린으로부터 유래된 최소 서열을 함유하는 키메라 이뮤노글로불린, 이뮤노글로불린 쇄 또는 그의 단편 (예컨대 Fv, Fab, Fab', F(ab')2 또는 항체의 다른 항원 결합 하위서열)인 비-인간 (예를 들어 뮤린) 항체의 형태를 지칭한다. 바람직하게는, 인간화 항체는 수용자의 상보성 결정 영역 (CDR)으로부터의 잔기가 목적하는 특이성, 친화도 및 능력을 갖는 비-인간 종 (공여자 항체), 예컨대 마우스, 래트 또는 토끼의 CDR로부터의 잔기로 대체된 인간 이뮤노글로불린 (수용자 항체)이다. 일부 경우에, 인간 이뮤노글로불린의 Fv 프레임워크 영역 (FR) 잔기는 상응하는 비-인간 잔기에 의해 대체된다. 추가로, 인간화 항체는 수용자 항체 또는 도입된 CDR 또는 프레임워크 서열에서는 발견되지 않지만 항체 성능을 추가로 정밀화하고 최적화하기 위해 포함되는 잔기를 포함할 수 있다. 일반적으로, 인간화 항체는 적어도 1개, 전형적으로 2개의 가변 도메인을 실질적으로 모두 포함할 것이며, 여기서 모든 또는 실질적으로 모든 CDR 영역은 비-인간 이뮤노글로불린의 것에 상응하고, 모든 또는 실질적으로 모든 FR 영역은 인간 이뮤노글로불린 컨센서스 서열의 것이다. 인간화 항체는 최적으로는 이뮤노글로불린 불변 영역 또는 도메인 (Fc)의 적어도 한 부분, 전형적으로는 인간 이뮤노글로불린의 것을 또한 포함할 것이다. WO 99/58572에 기재된 바와 같이 변형된 Fc 영역을 갖는 항체가 바람직하다. 다른 형태의 인간화 항체는 원래 항체와 관련하여 변경된 1개 이상의 CDR (CDR L1, CDR L2, CDR L3, CDR H1, CDR H2 또는 CDR H3)을 가지며, 이는 또한 원래 항체로부터의 1개 이상의 CDR"로부터 유래된" 1개 이상의 CDR로 지칭된다.
본원에 사용된 "인간 항체"는 인간에 의해 생산되고/거나 관련 기술분야의 통상의 기술자에게 공지되거나 본원에 개시된 인간 항체를 제조하기 위한 임의의 기술을 사용하여 제조된 항체의 아미노산 서열에 상응하는 아미노산 서열을 갖는 항체를 의미한다. 인간 항체의 이러한 정의는 적어도 1개의 인간 중쇄 폴리펩티드 또는 적어도 1개의 인간 경쇄 폴리펩티드를 포함하는 항체를 포함한다. 하나의 이러한 예는 뮤린 경쇄 및 인간 중쇄 폴리펩티드를 포함하는 항체이다. 인간 항체는 관련 기술분야에 공지된 다양한 기술을 사용하여 생산될 수 있다. 한 실시양태에서, 인간 항체는 인간 항체를 발현하는 파지 라이브러리로부터 선택된다 (Vaughan et al., Nature Biotechnology, 14:309-314, 1996; Sheets et al., Proc. Natl. Acad. Sci. (USA) 95:6157-6162, 1998; Hoogenboom and Winter, J. Mol. Biol., 227:381, 1991; Marks et al., J. Mol. Biol., 222:581, 1991). 인간 항체는 또한 인간 이뮤노글로불린 유전자좌가 내인성 유전자좌 대신에 트랜스제닉 도입된 동물, 예를 들어 내인성 이뮤노글로불린 유전자가 부분적으로 또는 완전히 불활성화된 마우스의 면역화에 의해 제조될 수 있다. 이러한 접근법은 미국 특허 번호 5,545,807; 5,545,806; 5,569,825; 5,625,126; 5,633,425; 및 5,661,016에 기재되어 있다. 대안적으로, 인간 항체는 표적 항원에 대해 지시된 항체를 생산하는 인간 B 림프구를 불멸화시킴으로써 제조될 수 있다 (이러한 B 림프구는 개체로부터 또는 cDNA의 단일 세포 클로닝으로부터 회수될 수 있거나 또는 시험관내에서 면역화될 수 있음). 예를 들어, 문헌 [Cole et al. Monoclonal Antibodies and Cancer Therapy, Alan R. Liss, p. 77, 1985; Boerner et al., J. Immunol., 147 (1):86-95, 1991]; 및 미국 특허 번호 5,750,373을 참조한다.
용어 "키메라 항체"는 가변 영역 서열이 한 종으로부터 유래되고 불변 영역 서열이 또 다른 종으로부터 유래된 항체, 예컨대 가변 영역 서열이 마우스 항체로부터 유래되고 불변 영역 서열이 인간 항체로부터 유래된 항체를 지칭한다.
용어 "B7-H4"는 명사로서 그 자체로 사용되는 경우에, 유전자 VTCN1에 의해 코딩된 임의의 형태의 B7 상동성 4 단백질 및 B7 상동성 4 단백질의 활성의 적어도 일부를 보유하는 그의 변이체를 지칭한다. 하나의 예시적인 인간 B7-H4 서열은 유니프롯 식별자 Q7Z7D3-1 하에 제공된다. Q7Z7D3-1로 디스플레이된 서열은 성숙 형태로 추가로 프로세싱된다.
용어 "B7-H4 항체"는 B7-H4에 특이적으로 결합하는 항체를 지칭한다.
용어 "폴리펩티드", "올리고펩티드", "펩티드" 및 "단백질"은 임의의 길이, 바람직하게는 비교적 짧은 (예를 들어, 10-100개 아미노산) 아미노산의 쇄를 지칭하는 것으로 본원에서 상호교환가능하게 사용된다. 쇄는 선형 또는 분지형일 수 있고/거나, 변형된 아미노산을 포함할 수 있고/거나, 비-아미노산이 개재될 수 있다. 상기 용어는 또한 자연적으로 또는 개입에 의해; 예를 들어, 디술피드 결합 형성, 글리코실화, 지질화, 아세틸화, 인산화 또는 임의의 다른 조작 또는 변형, 예컨대 표지 성분과의 접합에 의해 변형된 아미노산 쇄를 포괄한다. 또한, 예를 들어 아미노산의 1개 이상의 유사체 (예를 들어, 비천연 아미노산 등 포함), 뿐만 아니라 관련 기술분야에 공지된 다른 변형을 함유하는 폴리펩티드가 상기 정의 내에 포함된다. 폴리펩티드는 단일 쇄 또는 회합된 쇄로서 발생할 수 있는 것으로 이해된다.
"1가 항체"는 분자당 1개의 항원 결합 부위를 포함한다 (예를 들어, IgG 또는 Fab). 일부 경우에, 1가 항체는 1개 초과의 항원 결합 부위를 가질 수 있지만, 결합 부위는 상이한 항원으로부터의 것이다.
"단일특이적 항체"는 2개의 결합 부위가 항원 상의 동일한 에피토프에 결합하도록 분자당 2개의 동일한 항원 결합 부위를 포함한다 (예를 들어 IgG). 따라서, 이들은 1개의 항원 분자에의 결합에 대해 서로 경쟁한다. 자연에서 발견되는 대부분의 항체는 단일특이적이다. 일부 경우에, 단일특이적 항체는 또한 1가 항체일 수 있다 (예를 들어 Fab).
"2가 항체"는 분자당 2개의 항원 결합 부위를 포함한다 (예를 들어, IgG). 일부 경우에, 2개의 결합 부위는 동일한 항원 특이성을 갖는다. 그러나, 2가 항체는 이중특이적일 수 있다.
본원에 사용된 용어 "이중특이적 항체" 또는 "이중-특이적 항체"는 상이한 항원에 대한 특이성을 갖는 2개의 항원 결합 부위를 생성하는 2개의 상이한 결합 특이성, 예를 들어 2개의 상이한 중쇄/경쇄 쌍을 갖는 하이브리드 항체를 지칭한다.
본원에 사용된 "힌지 영역", "힌지 서열" 및 그의 변이는, 예를 들어 문헌 [Janeway et al., ImmunoBiology: the immune system in health and disease, (Elsevier Science Ltd., NY) (4th ed., 1999); Bloom et al., Protein Science (1997), 6:407-415; Humphreys et al., J. Immunol. Methods (1997), 209:193-202]에 예시된, 관련 기술분야에 공지된 의미를 포함한다.
본원에 사용된 "이뮤노글로불린-유사 힌지 영역", "이뮤노글로불린-유사 힌지 서열" 및 그의 변이는 이뮤노글로불린-유사 또는 항체-유사 분자 (예를 들어, 이뮤노어드헤신)의 힌지 영역 및 힌지 서열을 지칭한다. 일부 실시양태에서, 이뮤노글로불린-유사 힌지 영역은 그의 키메라 형태, 예를 들어 키메라 IgG1/2 힌지 영역을 포함하여, 임의의 IgG1, IgG2, IgG3 또는 IgG4 하위유형으로부터 또는 IgA, IgE, IgD 또는 IgM으로부터 형성되거나 또는 그로부터 유래될 수 있다.
본원에 사용된 용어 "면역 이펙터 세포" 또는 "이펙터 세포"는 표적 세포의 생존율에 영향을 미치도록 활성화될 수 있는 인간 면역계 내의 세포의 천연 레퍼토리 내의 세포를 지칭한다. 표적 세포의 생존율은 세포 생존, 증식 및/또는 다른 세포와 상호작용하는 능력을 포함할 수 있다.
관련 기술분야에 공지된 바와 같이, 본원에서 상호교환가능하게 사용되는 "폴리뉴클레오티드" 또는 "핵산"은 임의의 길이의 뉴클레오티드의 쇄를 지칭하고, DNA 및 RNA를 포함한다. 뉴클레오티드는 데옥시리보뉴클레오티드, 리보뉴클레오티드, 변형된 뉴클레오티드 또는 염기 및/또는 그의 유사체, 또는 DNA 또는 RNA 폴리머라제에 의해 쇄 내로 혼입될 수 있는 임의의 기질일 수 있다. 폴리뉴클레오티드는 변형된 뉴클레오티드, 예컨대 메틸화 뉴클레오티드 및 그의 유사체를 포함할 수 있다. 존재하는 경우에, 뉴클레오티드 구조에 대한 변형은 쇄의 조립 전 또는 후에 부여될 수 있다. 뉴클레오티드의 서열에는 비-뉴클레오티드 성분이 개재될 수 있다. 폴리뉴클레오티드는 중합 후에, 예컨대 표지 성분과의 접합에 의해 추가로 변형될 수 있다. 다른 유형의 변형은, 예를 들어 "캡", 자연 발생 뉴클레오티드 중 1개 이상의 유사체로의 치환, 뉴클레오티드간 변형, 예컨대, 예를 들어 비하전된 연결 (예를 들어, 메틸 포스포네이트, 포스포트리에스테르, 포스포아미데이트, 카르바메이트 등) 및 하전된 연결 (예를 들어, 포스포로티오에이트, 포스포로디티오에이트 등)을 갖는 것, 펜던트 모이어티, 예컨대, 예를 들어 단백질 (예를 들어, 뉴클레아제, 독소, 항체, 신호 펩티드, 폴리-L-리신 등)을 함유하는 것, 삽입제 (예를 들어, 아크리딘, 프소랄렌 등)를 갖는 것, 킬레이트화제 (예를 들어, 금속, 방사성 금속, 붕소, 산화 금속 등)를 함유하는 것, 알킬화제를 함유하는 것, 변형된 연결 (예를 들어, 알파 아노머 핵산 등)을 갖는 것, 뿐만 아니라 폴리뉴클레오티드(들)의 비변형된 형태를 포함한다. 추가로, 당에 통상적으로 존재하는 임의의 히드록실 기는, 예를 들어 포스포네이트 기, 포스페이트 기에 의해 대체될 수 있거나, 표준 보호기에 의해 보호될 수 있거나, 또는 추가의 뉴클레오티드에 대한 추가의 연결을 제조하기 위해 활성화될 수 있거나, 또는 고체 지지체에 접합될 수 있다. 5' 및 3' 말단 OH는 인산화되거나 또는 아민 또는 1 내지 20개의 탄소 원자의 유기 캡핑 기 모이어티로 치환될 수 있다. 다른 히드록실이 또한 표준 보호 기로 유도체화될 수 있다. 폴리뉴클레오티드는 또한, 예를 들어 2'-O-메틸-, 2'-O-알릴, 2'-플루오로- 또는 2'-아지도-리보스, 카르보시클릭 당 유사체, 알파- 또는 베타-아노머 당, 에피머 당, 예컨대 아라비노스, 크실로스 또는 릭소스, 피라노스 당, 푸라노스 당, 세도헵툴로스, 비-시클릭 유사체 및 무염기성 뉴클레오시드 유사체, 예컨대 메틸 리보시드를 포함한, 일반적으로 관련 기술분야에 공지된 리보스 또는 데옥시리보스 당의 유사한 형태를 함유할 수 있다. 1개 이상의 포스포디에스테르 연결은 대안적 연결기에 의해 대체될 수 있다. 이들 대안적 연결 기는 포스페이트가 P(O)S ("티오에이트"), P(S)S ("디티오에이트"), (O)NR2 ("아미데이트"), P(O)R, P(O)OR', CO 또는 CH2 ("포름아세탈")에 의해 대체된 실시양태를 포함하나 이에 제한되지는 않으며, 여기서 각각의 R 또는 R'는 독립적으로 H 또는 임의로 에테르 (-O-) 연결을 함유하는 치환 또는 비치환된 알킬 (1-20 C), 아릴, 알케닐, 시클로알킬, 시클로알케닐 또는 아르알딜이다. 폴리뉴클레오티드 내의 모든 연결이 동일할 필요는 없다. 상기 설명은 RNA 및 DNA를 포함한, 본원에 언급된 모든 폴리뉴클레오티드에 적용된다.
관련 기술분야에 공지된 바와 같이, 항체의 "불변 영역"은 항체 경쇄의 불변 영역 또는 항체 중쇄의 불변 영역을 단독으로 또는 조합하여 지칭한다.
본원에 사용된 "실질적으로 순수한"은 적어도 50% 순수한 (즉, 오염물이 없는), 보다 바람직하게는 적어도 90% 순수한, 보다 바람직하게는 적어도 95% 순수한, 보다 더 바람직하게는 적어도 98% 순수한, 가장 바람직하게는 적어도 99% 순수한 물질을 지칭한다.
"숙주 세포"는 폴리뉴클레오티드 삽입물의 혼입을 위한 벡터(들)에 대한 수용자일 수 있거나 수용자였던 개별 세포 또는 세포 배양물을 포함한다. 숙주 세포는 단일 숙주 세포의 자손을 포함하고, 자손은 자연적, 우발적 또는 고의적 돌연변이로 인해 원래 모 세포와 (형태 또는 게놈 DNA 상보체 면에서) 반드시 완전히 동일하지는 않을 수 있다. 숙주 세포는 본 발명의 폴리뉴클레오티드(들)로 생체내 형질감염된 세포를 포함한다.
관련 기술분야에 공지된 바와 같이, 용어 "Fc 영역"은 이뮤노글로불린 중쇄의 C-말단 영역을 정의하는데 사용된다. "Fc 영역"은 천연 서열 Fc 영역 또는 변이체 Fc 영역일 수 있다. 이뮤노글로불린 중쇄의 Fc 영역의 경계는 달라질 수 있지만, 인간 IgG 중쇄 Fc 영역은 통상적으로 위치 Cys226에서의 아미노산 잔기로부터 또는 Pro230으로부터 그의 카르복실-말단까지의 스트레치로 정의된다. Fc 영역 내의 잔기의 넘버링은 카바트에서와 같은 EU 인덱스의 넘버링이다. 문헌 [Kabat et al., Sequences of Proteins of Immunological Interest, 5th Ed. Public Health Service, National Institutes of Health, Bethesda, Md., 1991]. 이뮤노글로불린의 Fc 영역은 일반적으로 2개의 불변 영역 CH2 및 CH3을 포함한다.
관련 기술분야에 사용된 "Fc 수용체" 및 "FcR"은 항체의 Fc 영역에 결합하는 수용체를 기재한다. 바람직한 FcR은 천연 서열 인간 FcR이다. 더욱이, 바람직한 FcR은 IgG 항체 (감마 수용체)에 결합하고, FcγRI, FcγRII 및 FcγRIII 하위부류의 수용체 (이들 수용체의 대립유전자 변이체 및 대안적으로 스플라이싱된 형태 포함)를 포함하는 것이다. FcγRII 수용체는 FcγRIIA ("활성화 수용체") 및 FcγRIIB ("억제 수용체")를 포함하며, 이들은 주로 세포질 도메인에서 상이한 유사한 아미노산 서열을 갖는다. FcR은 문헌 [Ravetch and Kinet, Ann. Rev. Immunol., 9:457-92, 1991; Capel et al., Immunomethods, 4:25-34, 1994; 및 de Haas et al., J. Lab. Clin. Med., 126:330-41, 1995]에서 검토된다. "FcR"은 또한 모체 IgG의 태아로의 전달을 담당하는 신생아 수용체 FcRn을 포함한다 (문헌 [Guyer et al., J. Immunol., 117:587, 1976; 및 Kim et al., J. Immunol., 24:249, 1994]).
항체와 관련하여 본원에 사용된 용어 "경쟁하다"는 제1 항체 또는 그의 항원 결합 단편 (또는 부분)이 제2 항체 또는 그의 항원 결합 부분의 결합과 충분히 유사한 방식으로 에피토프에 결합하여, 제1 항체와 그의 동족 에피토프의 결합의 결과가 제2 항체의 부재 하의 제1 항체의 결합과 비교하여 제2 항체의 존재 하에 검출가능하게 감소되는 것을 의미한다. 제2 항체의 그의 에피토프에 대한 결합이 또한 제1 항체의 존재 하에 검출가능하게 감소되는 대안도 이 경우에 해당될 수 있지만 반드시 그러할 필요는 없다. 즉, 제2 항체가 제1 항체의 그의 각각의 에피토프에 대한 결합을 억제하지 않으면서 제1 항체가 제2 항체의 그의 에피토프에 대한 결합을 억제할 수 있다. 그러나, 각각의 항체가 다른 항체와 그의 동족 에피토프 또는 리간드의 결합을 동일한 정도이든, 더 큰 정도이든 또는 더 적은 정도이든 검출가능하게 억제하는 경우에, 항체는 그의 각각의 에피토프(들)의 결합에 대해 서로 "교차-경쟁"하는 것으로 언급된다. 경쟁 및 교차-경쟁 항체 둘 다가 본 발명에 포괄된다. 이러한 경쟁 또는 교차-경쟁이 일어나는 메카니즘 (예를 들어, 입체 장애, 입체형태적 변화 또는 공통 에피토프 또는 그의 부분에 대한 결합)에 상관없이, 통상의 기술자는 본원에 제공된 교시에 기초하여, 이러한 경쟁 및/또는 교차-경쟁 항체가 포괄되고 본원에 개시된 방법에 유용할 수 있음을 인지할 것이다.
"기능적 Fc 영역"은 천연 서열 Fc 영역의 적어도 1개의 이펙터 기능을 보유한다. 예시적인 "이펙터 기능"은 C1q 결합; 보체 의존성 세포독성; Fc 수용체 결합; 항체-의존성 세포-매개 세포독성; 식세포작용; 세포 표면 수용체 (예를 들어, B 세포 수용체)의 하향-조절 등을 포함한다. 이러한 이펙터 기능은 일반적으로 Fc 영역이 결합 도메인 (예를 들어, 항체 가변 도메인)과 조합될 것을 요구하고, 이러한 항체 이펙터 기능을 평가하기 위해 관련 기술분야에 공지된 다양한 검정을 사용하여 평가될 수 있다.
"천연 서열 Fc 영역"은 자연에서 발견되는 Fc 영역의 아미노산 서열과 동일한 아미노산 서열을 포함한다. "변이체 Fc 영역"은 적어도 1개의 아미노산 변형에 의해 천연 서열 Fc 영역의 것과 상이하지만 천연 서열 Fc 영역의 적어도 1개의 이펙터 기능을 보유하는 아미노산 서열을 포함한다. 일부 실시양태에서, 변이체 Fc 영역은 천연 서열 Fc 영역 또는 모 폴리펩티드의 Fc 영역과 비교하여 적어도 1개의 아미노산 치환, 예를 들어 천연 서열 Fc 영역 또는 모 폴리펩티드의 Fc 영역에서 약 1 내지 약 10개의 아미노산 치환, 바람직하게는 약 1 내지 약 5개의 아미노산 치환을 갖는다. 본원에서 변이체 Fc 영역은 바람직하게는 천연 서열 Fc 영역 및/또는 모 폴리펩티드의 Fc 영역과 적어도 약 80% 서열 동일성, 가장 바람직하게는 적어도 약 90% 서열 동일성, 보다 바람직하게는 적어도 약 95%, 적어도 약 96%, 적어도 약 97%, 적어도 약 98%, 적어도 약 99% 서열 동일성을 가질 것이다.
용어 "이펙터 기능"은 항체의 Fc 영역에 기인하는 생물학적 활성을 지칭한다. 항체 이펙터 기능의 예는 항체-의존성 세포-매개 세포독성 (ADCC), Fc 수용체 결합, 보체 의존성 세포독성 (CDC), 식세포작용, C1q 결합 및 세포 표면 수용체 (예를 들어, B 세포 수용체; BCR)의 하향 조절을 포함하나 이에 제한되지는 않는다. 예를 들어, 미국 특허 번호 6,737,056을 참조한다. 이러한 이펙터 기능은 일반적으로 Fc 영역이 결합 도메인 (예를 들어, 항체 가변 도메인)과 조합될 것을 요구하고, 이러한 항체 이펙터 기능을 평가하기 위해 관련 기술분야에 공지된 다양한 검정을 사용하여 평가될 수 있다. 이펙터 기능의 예시적인 측정은 Fcγ3 및/또는 C1q 결합을 통한 것이다.
본원에 사용된 "항체-의존성 세포-매개 세포독성" 또는 "ADCC"는 Fc 수용체 (FcR)를 발현하는 비특이적 세포독성 세포 (예를 들어, 자연 킬러 (NK) 세포, 호중구 및 대식세포)가 표적 세포 상의 결합된 항체를 인식하고 후속적으로 표적 세포의 용해를 유발하는 세포-매개 반응을 지칭한다. 관심 분자의 ADCC 활성은 시험관내 ADCC 검정, 예컨대 미국 특허 번호 5,500,362 또는 5,821,337에 기재된 것을 사용하여 평가될 수 있다. 이러한 검정에 유용한 이펙터 세포는 말초 혈액 단핵 세포 (PBMC) 및 NK 세포를 포함한다. 대안적으로 또는 추가적으로, 관심 분자의 ADCC 활성은 생체내에서, 예를 들어 문헌 [Clynes et al., 1998, PNAS (USA), 95:652-656]에 개시된 바와 같은 동물 모델에서 평가될 수 있다.
"보체 의존성 세포독성" 또는 "CDC"는 보체의 존재 하에 표적을 용해시키는 것을 지칭한다. 보체 활성화 경로는 보체계의 제1 성분 (C1q)이 동족 항원과 복합체화된 분자 (예를 들어, 항체)에 결합함으로써 개시된다. 보체 활성화를 평가하기 위하여, 예를 들어 문헌 [Gazzano-Santoro et al., J. Immunol. Methods, 202: 163 (1996)]에 기재된 바와 같은 CDC 검정이 수행될 수 있다.
본원에 사용된 "치료"는 유익하거나 목적하는 임상 결과를 수득하기 위한 접근법이다. 본 발명의 목적상, 유익하거나 목적하는 임상 결과는 하기 중 1개 이상을 포함하나 이에 제한되지는 않는다: 신생물성 또는 암성 세포의 증식의 감소 (또는 파괴), 신생물성 세포의 전이의 억제, B7-H4 연관 질환 (예를 들어, 암 또는 자가면역 질환)의 완화, B7-H4 연관 질환 (예를 들어, 암 또는 자가면역 질환)으로 인한 증상의 감소, B7-H4 연관 질환 (예를 들어, 암 또는 자가면역 질환)을 앓고 있는 자의 삶의 질의 증가, B7-H4 연관 질환 (예를 들어, 암 또는 자가면역 질환)을 치료하는데 요구되는 다른 의약의 용량의 감소, B7-H4 연관 질환 (예를 들어, 암 또는 자가면역 질환)의 진행의 지연, B7-H4 연관 질환 (예를 들어, 암 또는 자가면역 질환)의 치유 및/또는 B7-H4 연관 질환 (예를 들어, 암 또는 자가면역 질환)을 갖는 환자의 생존 연장.
"호전"은 B7-H4 항체 또는 B7-H4 항체 접합체를 투여하지 않는 것과 비교하여 1종 이상의 증상의 경감 또는 개선을 의미한다. "호전"은 또한 증상의 지속기간의 단축 또는 감소를 포함한다.
본원에 사용된 바와 같은, 약물, 화합물 또는 제약 조성물의 "유효 투여량" 또는 "유효량"은 임의의 1개 이상의 유익하거나 목적하는 결과를 가져오기에 충분한 양이다. 예방적 사용의 경우에, 유익하거나 목적하는 결과는 질환의 생화학적, 조직학적 및/또는 행동 증상, 그의 합병증 및 질환의 발생 동안 나타나는 중간 병리학적 표현형을 포함한 질환의 위험을 제거 또는 감소시키거나, 그의 중증도를 경감시키거나 또는 그의 발병을 지연시키는 것을 포함한다. 치료적 사용의 경우에, 유익하거나 목적하는 결과는 다양한 B7-H4-연관 질환 또는 상태 (예컨대 암)의 1종 이상의 증상의 발생률 감소 또는 호전, 질환을 치료하는데 요구되는 다른 의약의 용량 감소, 또 다른 의약의 효과 증진 및/또는 환자의 B7-H4-연관 질환의 진행 지연과 같은 임상 결과를 포함한다. 유효 투여량은 1회 이상의 투여로 투여될 수 있다. 본 발명의 목적상, 약물, 화합물 또는 제약 조성물의 유효 투여량은 예방적 또는 치유적 치료를 직접적으로 또는 간접적으로 달성하기에 충분한 양이다. 임상 상황에서 이해되는 바와 같이, 약물, 화합물 또는 제약 조성물의 유효 투여량은 또 다른 약물, 화합물 또는 제약 조성물과 함께 달성될 수 있거나 그렇지 않을 수 있다. 따라서, "유효 투여량"은 1종 이상의 치료제의 투여와 관련하여 고려될 수 있고, 단일 작용제는 1종 이상의 다른 작용제와 함께 바람직한 결과가 달성될 수 있거나 달성되는 경우에 유효량으로 주어지는 것으로 간주될 수 있다.
"개체" 또는 "대상체"는 포유동물, 보다 바람직하게는 인간이다. 포유동물은 또한 농장 동물, 스포츠 동물, 애완동물, 영장류, 말, 개, 고양이, 마우스 및 래트를 포함하나 이에 제한되지는 않는다.
본원에 사용된 "벡터"는 숙주 세포에 1개 이상의 관심 유전자(들) 또는 서열(들)을 전달할 수 있는, 바람직하게는 이를 발현시킬 수 있는 구축물을 의미한다. 벡터의 예는 바이러스 벡터, 네이키드 DNA 또는 RNA 발현 벡터, 플라스미드, 코스미드 또는 파지 벡터, 양이온성 축합제와 회합된 DNA 또는 RNA 발현 벡터, 리포솜에 캡슐화된 DNA 또는 RNA 발현 벡터, 및 특정 진핵 세포, 예컨대 생산자 세포를 포함하나 이에 제한되지는 않는다.
본원에 사용된 "발현 제어 서열"은 핵산의 전사를 지시하는 핵산 서열을 의미한다. 발현 제어 서열은 프로모터, 예컨대 구성적 또는 유도성 프로모터, 또는 인핸서일 수 있다. 발현 제어 서열은 전사될 핵산 서열에 작동가능하게 연결된다.
본원에 사용된 "제약상 허용되는 담체" 또는 "제약상 허용되는 부형제"는 활성 성분과 조합되는 경우에 성분이 생물학적 활성을 보유하도록 하고 대상체의 면역계와 비-반응성인 임의의 물질을 포함한다. 예는 임의의 표준 제약 담체, 예컨대 포스페이트 완충 염수 용액, 물, 에멀젼, 예컨대 오일/물 에멀젼 및 다양한 유형의 습윤제를 포함하나 이에 제한되지는 않는다. 에어로졸 또는 비경구 투여를 위한 바람직한 희석제는 포스페이트 완충 염수 (PBS) 또는 생리 (0.9%) 염수이다. 이러한 담체를 포함하는 조성물은 널리 공지된 통상적인 방법에 의해 제제화된다 (예를 들어, 문헌 [Remington's Pharmaceutical Sciences, 18th edition, A. Gennaro, ed., Mack Publishing Co., Easton, PA, 1990; 및 Remington, The Science and Practice of Pharmacy 21st Ed. Mack Publishing, 2005] 참조).
본원에 사용된 용어 "kon" 또는 "ka"는 항원에의 항체 회합에 대한 속도 상수를 지칭한다. 구체적으로, 속도 상수 (kon/ka 및 koff/kd) 및 평형 해리 상수는 전체 항체 (즉, 2가) 및 단량체 B7-H4 단백질을 사용하여 측정된다.
본원에 사용된 용어 "koff" 또는 "kd"는 항체/항원 복합체로부터의 항체 해리에 대한 속도 상수를 지칭한다.
본원에 사용된 용어 "KD"는 항체-항원 상호작용의 평형 해리 상수를 지칭한다.
본원에서 "약" 값 또는 파라미터에 대한 언급은 그 값 또는 파라미터 자체에 관한 실시양태를 포함 (및 기재)한다. 예를 들어, "약 X"를 언급하는 기재는 "X"의 기재를 포함한다. 수치 범위는 범위를 정의하는 숫자를 포함한다.
실시양태가 본원에서 용어 "포함하는"으로 기재되는 모든 경우에, "로 이루어진" 및/또는 "로 본질적으로 이루어진"의 용어로 기재된 다른 유사한 실시양태가 또한 제공되는 것으로 이해된다.
본 발명의 측면 또는 실시양태가 마쿠쉬 군 또는 다른 대안적 군의 면에서 기재되는 경우에, 본 발명은 전체로서 열거된 전체 군, 뿐만 아니라 개별적으로 군의 각각의 구성원 및 주요 군의 모든 가능한 하위군, 뿐만 아니라 군 구성원 중 하나 이상이 부재하는 주요 군을 포괄한다. 본 발명은 또한 청구된 발명에서 임의의 군 구성원 중 하나 이상의 명백한 배제를 고려한다.
달리 정의되지 않는 한, 본원에 사용된 모든 기술 과학 용어는 본 발명이 속하는 관련 기술분야의 통상의 기술자에 의해 통상적으로 이해되는 바와 동일한 의미를 갖는다. 상충되는 경우에, 정의를 포함한 본 명세서가 우선할 것이다. 본 명세서 및 청구범위 전반에 걸쳐, 단어 "포함하다", 또는 "포함한다" 또는 "포함하는"과 같은 변형은 언급된 정수 또는 정수의 군을 포함하지만 임의의 다른 정수 또는 정수의 군을 배제하지 않는다는 것을 암시하는 것으로 이해될 것이다. 문맥상 달리 요구되지 않는 한, 단수 용어는 복수를 포함할 것이고, 복수 용어는 단수를 포함할 것이다.
예시적인 방법 및 물질이 본원에 기재되지만, 본원에 기재된 것과 유사하거나 동등한 방법 및 물질이 또한 본 발명의 실시 또는 시험에 사용될 수 있다. 물질, 방법 및 예는 단지 예시적이며, 제한적인 것으로 의도되지 않는다.
항체의 일반적 제조 방법
표적 항원, 예를 들어 본 발명에서 B7-H4에 특이적으로 결합하는 인간 및 마우스 항체의 생산을 위한 일반적 기술은 관련 기술분야에 공지되어 있고/거나 본원에 기재되어 있다.
파지 디스플레이:
일부 실시양태에서, 항체는 파지 디스플레이 기술에 의해 제조 및 선택될 수 있다. 예를 들어, 미국 특허 번호 5,565,332; 5,580,717; 5,733,743; 및 6,265,150; 및 문헌 [Winter et al., Annu. Rev. Immunol. 12:433-455, 1994]을 참조한다. 대안적으로, 파지 디스플레이 기술 (McCafferty et al., Nature 348:552-553, 1990)을 사용하여 비면역화된 공여자의 이뮤노글로불린 가변 (V) 도메인 유전자 레퍼토리로부터 인간 항체 및 항체 단편을 시험관내 생산할 수 있다. 이러한 기술에 따라, 항체 V 도메인 유전자를 사상 박테리오파지, 예컨대 M13 또는 fd의 주요 또는 부차적 코트 단백질 유전자 내로 인-프레임으로 클로닝하고, 파지 입자의 표면 상에 기능적 항체 단편으로서 디스플레이한다. 사상 입자는 파지 게놈의 단일-가닥 DNA 카피를 함유하기 때문에, 항체의 기능적 특성에 기초한 선택은 또한 이들 특성을 나타내는 항체를 코딩하는 유전자의 선택을 가져온다. 따라서, 파지는 B 세포의 특성의 일부를 모방한다. 파지 디스플레이는 다양한 포맷으로 수행될 수 있으며; 검토를 위해, 예를 들어 문헌 [Johnson, Kevin S. and Chiswell, David J., Current Opinion in Structural Biology 3:564-571, 1993]을 참조한다. V-유전자 절편의 여러 공급원이 파지 디스플레이에 사용될 수 있다. 문헌 [Clackson et al., Nature 352:624-628, 1991]은 면역화된 마우스의 비장으로부터 유래된 V 유전자의 소형 무작위 조합 라이브러리로부터 다양한 어레이의 항-옥사졸론 항체를 단리하였다. 인간 공여자로부터의 V 유전자의 레퍼토리가 구축될 수 있고, 다양한 어레이의 항원 (자기-항원 포함)에 대한 항체는 본질적으로 문헌 [Mark et al., J. Mol. Biol. 222:581-597, 1991, 또는 Griffith et al., EMBO J. 12:725-734, 1993]에 기재된 기술에 따라 단리될 수 있다. 자연 면역 반응에서, 항체 유전자는 돌연변이를 높은 비율로 축적한다 (체세포 과다돌연변이). 도입된 변화 중 일부는 보다 높은 친화도를 부여할 것이고, 고친화도 표면 이뮤노글로불린을 디스플레이하는 B 세포는 후속 항원 챌린지 동안 우선적으로 복제 및 분화된다. 이러한 자연 과정은 "쇄 셔플링"으로 공지된 기술을 사용함으로써 모방될 수 있다 (Marks et al., Bio/Technol. 10:779-783, 1992). 이 방법에서, 파지 디스플레이에 의해 수득된 "1차" 인간 항체의 친화도는 중쇄 및 경쇄 V 영역 유전자를 비면역화된 공여자로부터 수득된 V 도메인 유전자의 자연 발생 변이체의 레퍼토리 (레퍼토리)로 순차적으로 대체함으로써 개선될 수 있다. 이러한 기술은 pM-nM 범위의 친화도를 갖는 항체 및 항체 단편의 생산을 가능하게 한다. 매우 큰 파지 항체 레퍼토리 ("모든 라이브러리의 모체"로도 공지됨)를 제조하기 위한 전략은 문헌 [Waterhouse et al., Nucl. Acids Res. 21:2265-2266, 1993]에 기재되어 있다. 유전자 셔플링은 또한 설치류 항체로부터 인간 항체를 유도하는데 사용될 수 있으며, 여기서 인간 항체는 출발 설치류 항체와 유사한 친화도 및 특이성을 갖는다. "에피토프 각인"으로도 지칭되는 이 방법에 따라, 파지 디스플레이 기술에 의해 수득된 설치류 항체의 중쇄 또는 경쇄 V 도메인 유전자를 인간 V 도메인 유전자의 레퍼토리로 대체하여 설치류-인간 키메라를 생성한다. 항원에 대한 선택은 기능적 항원-결합 부위를 회복시킬 수 있는 인간 가변 영역의 단리를 가져오며, 즉 에피토프가 파트너의 선택을 좌우 (각인)한다. 나머지 설치류 V 도메인을 대체하기 위해 과정을 반복하는 경우에, 인간 항체가 수득된다 (PCT 공개 번호 WO 93/06213 참조). CDR 그라프팅에 의한 설치류 항체의 전통적인 인간화와는 달리, 이 기술은 설치류 기원의 프레임워크 또는 CDR 잔기를 갖지 않는 완전 인간 항체를 제공한다.
하이브리도마 기술:
일부 실시양태에서, 항체는 하이브리도마 기술을 사용하여 제조될 수 있다. 인간을 포함한 임의의 포유동물 대상체 또는 그로부터의 항체 생산 세포는 인간을 포함한 포유동물 하이브리도마 세포주의 생산을 위한 기초로서의 역할을 하도록 조작될 수 있는 것으로 고려된다. 숙주 동물의 면역화 경로 및 스케줄은 일반적으로 본원에 추가로 기재된 바와 같은 항체 자극 및 생산을 위한 확립된 통상적인 기술에 따른다. 전형적으로, 숙주 동물에게 소정 양의 본원에 기재된 바와 같은 것을 포함한 면역원을 복강내로, 근육내로, 경구로, 피하로, 족저내로 및/또는 피내로 접종한다.
하이브리도마는 문헌 [Kohler, B. and Milstein, C., 1975, Nature 256:495-497]의 일반적 체세포 혼성화 기술을 사용하여 또는 문헌 [Buck, D. W., et al., In Vitro, 18:377-381, 1982]에 의해 변형된 바와 같이 림프구 및 불멸화 골수종 세포로부터 제조될 수 있다. X63-Ag8.653 및 솔크 인스티튜트, 셀 디스트리뷰션 센터(Salk Institute, Cell Distribution Center) (미국 캘리포니아주 샌디에고)로부터의 것을 포함하나 이에 제한되지는 않는 이용가능한 골수종 세포주가 혼성화에 사용될 수 있다. 일반적으로, 상기 기술은 폴리에틸렌 글리콜과 같은 푸소겐을 사용하여 또는 관련 기술분야의 통상의 기술자에게 널리 공지된 전기적 수단에 의해 골수종 세포와 림프성 세포를 융합시키는 것을 수반한다. 융합 후, 세포를 융합 배지로부터 분리하고, 선택적 성장 배지, 예컨대 하이포크산틴-아미노프테린-티미딘 (HAT) 배지에서 성장시켜 비혼성화된 모 세포를 제거한다. 혈청이 보충되거나 보충되지 않은 본원에 기재된 임의의 배지가 모노클로날 항체를 분비하는 하이브리도마를 배양하는데 사용될 수 있다. 세포 융합 기술에 대한 또 다른 대안으로서, EBV 불멸화 B 세포가 본 발명의 B7-H4 모노클로날 항체를 생산하는데 사용될 수 있다. 하이브리도마 또는 다른 불멸화 B-세포는 원하는 경우에 확장 및 서브클로닝되고, 상청액은 통상적인 면역검정 절차 (예를 들어, 방사선면역검정, 효소 면역검정 또는 형광 면역검정)에 의해 항-면역원 활성에 대해 검정된다.
항체의 공급원으로서 사용될 수 있는 하이브리도마는 표적 항원, 예를 들어 B7-H4 또는 그의 부분에 특이적인 모노클로날 항체를 생산하는 모 하이브리도마의 모든 유도체, 자손 세포를 포괄한다.
이러한 항체를 생산하는 하이브리도마는 공지된 절차를 사용하여 시험관내 또는 생체내에서 성장시킬 수 있다. 모노클로날 항체는 원하는 경우에 통상적인 이뮤노글로불린 정제 절차, 예컨대 황산암모늄 침전, 겔 전기영동, 투석, 크로마토그래피 및 한외여과에 의해 배양 배지 또는 체액으로부터 단리될 수 있다. 목적하지 않는 활성은, 존재하는 경우에, 예를 들어 고체 상에 부착된 면역원으로 제조된 흡착제 상에 제제를 전개시키고, 목적하는 항체를 면역원으로부터 용리 또는 방출시킴으로써 제거될 수 있다. 이관능성 작용제 또는 유도체화제, 예를 들어 말레이미도벤조일 술포숙신이미드 에스테르 (시스테인 잔기를 통한 접합), N-히드록시숙신이미드 (리신 잔기를 통함), 글루타르알데히드, 숙신산 무수물, SOCl2 또는 R1N=C=NR (여기서 R 및 R1은 상이한 알킬 기임)을 사용하여, 면역화될 종에서 면역원성인 단백질, 예를 들어 키홀 림펫 헤모시아닌, 혈청 알부민, 소 티로글로불린 또는 대두 트립신 억제제에 접합된 표적 아미노산 서열을 함유하는 항원, 예를 들어 B7-H4 폴리펩티드 또는 단편으로 숙주 동물을 면역화시켜 항체 (예를 들어, 모노클로날 항체)의 집단을 생성할 수 있다.
재조합 항체
원하는 경우에, 관심 항체 (모노클로날 또는 폴리클로날), 예를 들어 하이브리도마 기술 하에 생성된 항체는 서열분석될 수 있고, 이어서 폴리뉴클레오티드 서열이 발현 또는 증식을 위해 벡터 내로 클로닝될 수 있다. 관심 항체를 코딩하는 서열은 숙주 세포에서 벡터 내에 유지될 수 있고, 이어서 숙주 세포가 향후 사용을 위해 확장 및 동결될 수 있다. 세포 배양물에서의 재조합 모노클로날 항체의 생산은 관련 기술분야에 공지된 수단에 의해 B 세포로부터 항체 유전자를 클로닝함으로써 수행될 수 있다. 예를 들어, 문헌 [Tiller et al., 2008, J. Immunol. Methods 329, 112]; 미국 특허 번호 7,314,622를 참조한다.
일부 실시양태에서, 폴리뉴클레오티드 서열은 항체를 "인간화"시키거나 또는 항체의 친화도 또는 다른 특징을 개선시키기 위한 유전자 조작에 사용될 수 있다. 항체는 또한, 예를 들어 개, 고양이, 영장류, 말 및 소에서 사용하기 위해 맞춤화될 수 있다.
일부 실시양태에서, 완전 인간 항체는 특이적 인간 이뮤노글로불린 단백질을 발현하도록 조작된 상업적으로 입수가능한 마우스를 사용함으로써 수득될 수 있다. 보다 바람직한 (예를 들어, 완전 인간 항체) 또는 보다 강건한 면역 반응을 생성하도록 설계된 트랜스제닉 동물이 또한 인간화 또는 인간 항체의 생성을 위해 사용될 수 있다. 이러한 기술의 예는 아브게닉스, 인크.(Abgenix, Inc.) (캘리포니아주 프리몬트)로부터의 제노마우스(Xenomouse)™ 및 메다렉스, 인크.(Medarex, Inc.) (뉴저지주 프린스턴)로부터의 HuMAb-마우스(HuMAb-Mouse)® 및 TC 마우스(TC Mouse)™이다.
먼저 숙주 동물로부터 항체 및 항체 생산 세포를 단리하고, 유전자 서열을 수득하고, 유전자 서열을 사용하여 숙주 세포 (예를 들어, CHO 세포)에서 항체를 재조합적으로 발현시킴으로써 항체가 재조합적으로 제조될 수 있다. 사용될 수 있는 또 다른 방법은 식물 (예를 들어, 담배) 또는 트랜스제닉 밀크에서 항체 서열을 발현시키는 것이다. 식물 또는 밀크에서 항체를 재조합적으로 발현시키는 방법이 개시되어 있다. 예를 들어, 문헌 [Peeters, et al. Vaccine 19:2756, 2001; Lonberg, N. and D. Huszar Int. Rev. Immunol 13:65, 1995; 및 Pollock, et al., J Immunol Methods 231:147, 1999]을 참조한다. 항체의 유도체, 예를 들어 도메인, 단일 쇄 등을 제조하는 방법은 관련 기술분야에 공지되어 있다.
면역검정 및 유동 세포측정법 분류 기술, 예컨대 형광 활성화 세포 분류 (FACS)가 또한 표적 항원, 예를 들어 B7-H4에 특이적인 항체를 단리하는데 사용될 수 있다.
모노클로날 항체를 코딩하는 DNA는 통상적인 절차를 사용하여 (예를 들어, 모노클로날 항체의 중쇄 및 경쇄를 코딩하는 유전자에 특이적으로 결합할 수 있는 올리고뉴클레오티드 프로브를 사용함으로써) 용이하게 단리되고 서열분석된다. 하이브리도마 세포는 이러한 DNA의 바람직한 공급원으로서의 역할을 한다. 단리되면, DNA는 발현 벡터 (예컨대 PCT 공개 번호 WO 87/04462에 개시된 발현 벡터) 내로 배치될 수 있고, 이어서 달리 이뮤노글로불린 단백질을 생산하지 않는 숙주 세포, 예컨대 이. 콜라이 세포, 원숭이 COS 세포, 차이니즈 햄스터 난소 (CHO) 세포 또는 골수종 세포 내로 형질감염되어, 재조합 숙주 세포에서의 모노클로날 항체의 합성이 얻어진다. 예를 들어, PCT 공개 번호 WO 87/04462를 참조한다. DNA는 또한, 예를 들어 코딩 서열을 상동 뮤린 서열 대신 인간 중쇄 및 경쇄 불변 도메인으로 치환시키거나 (Morrison et al., Proc. Nat. Acad. Sci. 81:6851, 1984), 또는 이뮤노글로불린 코딩 서열에 비-이뮤노글로불린 폴리펩티드에 대한 코딩 서열의 모두 또는 일부를 공유 연결함으로써 변형될 수 있다. 이러한 방식으로, 표적 항원, 예를 들어 B7-H4에 대한 결합 특이성을 갖는 "키메라" 또는 "하이브리드" 항체가 제조된다.
항체 단편은 항체의 단백질분해 또는 다른 분해에 의해, 상기 기재된 바와 같은 재조합 방법 (즉, 단일 또는 융합 폴리펩티드)에 의해 또는 화학적 합성에 의해 생산될 수 있다. 항체의 폴리펩티드, 특히 최대 약 50개 아미노산의 보다 짧은 폴리펩티드가 화학적 합성에 의해 편리하게 제조된다. 화학적 합성 방법은 관련 기술분야에 공지되어 있고, 상업적으로 입수가능하다. 예를 들어, 항체는 고체 상 방법을 사용하여 자동화 폴리펩티드 합성기에 의해 생산될 수 있다. 또한, 미국 특허 번호 5,807,715; 4,816,567; 및 6,331,415를 참조한다.
재조합 항체 - 친화도 성숙
항체는 일반적으로 친화도 성숙으로 공지된 방법에 의해 변형될 수 있다. 예를 들어, 친화도 성숙 항체는 관련 기술분야에 공지된 절차에 의해 생산될 수 있다 (Marks et al., 1992, Bio/Technology, 10:779-783; Barbas et al., 1994, Proc Nat. Acad. Sci, USA 91:3809-3813; Schier et al., 1995, Gene, 169:147-155; Yelton et al., 1995, J. Immunol., 155:1994-2004; Jackson et al., 1995, J. Immunol., 154(7):3310-9; Hawkins et al., 1992, J. Mol. Biol., 226:889-896; 및 PCT 공개 번호 WO2004/058184).
항체의 친화도를 조정하고 CDR을 특징화하기 위해 하기 방법이 사용될 수 있다. 항체의 CDR을 특징화하고/거나 폴리펩티드, 예컨대 항체의 결합 친화도를 변경 (예컨대 개선)시키는 한 방식은 "라이브러리 스캐닝 돌연변이유발"로 지칭된다. 일반적으로, 라이브러리 스캐닝 돌연변이유발은 하기와 같이 수행된다. 관련 기술분야에 인식된 방법을 사용하여 CDR 내의 1개 이상의 아미노산 위치를 2개 이상 (예컨대 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19 또는 20개)의 아미노산으로 대체한다. 이는 클론의 소형 라이브러리 (일부 실시양태에서, 분석되는 모든 아미노산 위치에 대해 하나)를 생성하며, (모든 위치에서 2개 이상의 아미노산이 치환되는 경우) 각각은 2개 이상의 구성원의 복잡성을 갖는다. 일반적으로, 라이브러리는 또한 천연 (비치환된) 아미노산을 포함하는 클론을 포함한다. 각각의 라이브러리로부터의 소수의 클론, 예를 들어 약 20-80개의 클론 (라이브러리의 복잡성에 좌우됨)을 표적 폴리펩티드 (또는 다른 결합 표적)에의 결합 친화도에 대해 스크리닝하고, 결합이 증가되거나, 동일하거나, 감소되거나 또는 전혀 없는 후보를 확인한다. 결합 친화도를 결정하는 방법은 관련 기술분야에 널리 공지되어 있다. 결합 친화도는, 예를 들어 약 2배 이상의 결합 친화도의 차이를 검출하는 비아코어(Biacore)™ 표면 플라즈몬 공명 분석, 키넥사(Kinexa)® 바이오센서, 섬광 근접 검정, ELISA, 오리겐(ORIGEN)® 면역검정, 형광 켄칭, 형광 전달 및/또는 효모 디스플레이를 사용하여 결정될 수 있다. 결합 친화도는 또한 적합한 생물검정을 사용하여 스크리닝될 수 있다. 비아코어™는 출발 항체가 이미 비교적 높은 친화도, 예를 들어 약 10 nM 이하의 KD로 결합하는 경우에 특히 유용하다.
일부 실시양태에서, CDR 내의 모든 아미노산 위치는 관련 기술분야에 인식된 돌연변이유발 방법 (이들 중 일부는 본원에 기재됨)을 사용하여 모든 20개의 천연 아미노산으로 대체된다 (일부 실시양태에서, 한 번에 하나씩). 이는 클론의 소형 라이브러리 (일부 실시양태에서, 분석되는 모든 아미노산 위치에 대해 하나)를 생성하며, (모든 위치에서 모든 20개의 아미노산이 치환되는 경우) 각각은 20개의 구성원의 복잡성을 갖는다.
일부 실시양태에서, 스크리닝될 라이브러리는 동일한 CDR 또는 2개 이상의 CDR에 있을 수 있는 2개 이상의 위치에서의 치환을 포함한다. 따라서, 라이브러리는 1개의 CDR 내의 2개 이상의 위치에서의 치환을 포함할 수 있다. 라이브러리는 2개 이상의 CDR 내의 2개 이상의 위치에서의 치환을 포함할 수 있다. 라이브러리는 3, 4, 5개 또는 그 초과의 위치에서의 치환을 포함할 수 있으며, 상기 위치는 2, 3, 4, 5 또는 6개의 CDR에서 발견된다. 치환은 낮은 중복 코돈을 사용하여 제조될 수 있다. 예를 들어, 문헌 [Balint et al., 1993, Gene 137 (1):109-18]의 표 2를 참조한다.
CDR은 중쇄 가변 영역 (VH) CDR3 및/또는 경쇄 가변 영역 (VL) CDR3일 수 있다. CDR은 VH CDR1, VH CDR2, VH CDR3, VL CDR1, VL CDR2 및/또는 VL CDR3 중 1개 이상일 수 있다. CDR은 카바트 CDR, 코티아 CDR, 연장된 CDR, AbM CDR, 접촉 CDR 또는 입체형태적 CDR일 수 있다.
개선된 결합을 갖는 후보를 서열분석함으로써, 개선된 친화도를 생성하는 CDR 치환 돌연변이체 ("개선된" 치환으로도 지칭됨)를 확인할 수 있다. 결합하는 후보를 또한 서열분석함으로써, 결합을 보유하는 CDR 치환을 확인할 수 있다.
다수 라운드의 스크리닝이 수행될 수 있다. 예를 들어, 개선된 결합을 갖는 후보 (각각 1개 이상의 CDR의 1개 이상의 위치에서 아미노산 치환을 포함함)는 또한 각각의 개선된 CDR 위치 (즉, 치환 돌연변이체가 개선된 결합을 나타내는 CDR 내의 아미노산 위치)에서 적어도 원래 아미노산 및 치환된 아미노산을 함유하는 제2 라이브러리의 설계에 유용하다. 이러한 라이브러리의 제조 및 스크리닝 또는 선택은 하기에 추가로 논의된다.
라이브러리 스캐닝 돌연변이유발은 또한, 개선된 결합, 동일한 결합 또는 감소된 결합을 나타내거나 결합을 전혀 나타내지 않는 클론의 빈도가 또한 항체-항원 복합체의 안정성에 대한 각각의 아미노산 위치의 중요성에 관한 정보를 제공하는 한, CDR을 특징화하기 위한 수단을 제공한다. 예를 들어, CDR의 위치가 모든 20개의 아미노산으로 변화된 경우에 결합을 보유한다면, 그 위치는 항원 결합에 요구될 가능성이 없는 위치로 확인된다. 반대로, CDR의 위치가 단지 적은 백분율의 치환에서만 결합을 보유하는 경우에, 그 위치는 CDR 기능에 중요한 위치로서 확인된다. 따라서, 라이브러리 스캐닝 돌연변이유발 방법은 많은 상이한 아미노산 (모든 20개의 아미노산 포함)으로 변화될 수 있는 CDR 내의 위치 및 변화될 수 없거나 단지 소수의 아미노산으로만 변화될 수 있는 CDR 내의 위치에 관한 정보를 생성한다.
개선된 친화도를 갖는 후보는 개선된 아미노산, 그 위치에서 원래 아미노산을 포함하는 제2 라이브러리에서 조합될 수 있고, 목적하는 스크리닝 또는 선택 방법을 사용하여 목적하는 또는 허용되는 라이브러리의 복잡성에 따라 그 위치에서 추가의 치환을 추가로 포함할 수 있다. 추가로, 원하는 경우에, 인접한 아미노산 위치는 적어도 2개 이상의 아미노산으로 무작위화될 수 있다. 인접한 아미노산의 무작위화는 돌연변이체 CDR에서 추가의 입체형태적 유연성을 허용할 수 있으며, 이는 다시, 보다 많은 수의 개선 돌연변이의 도입을 허용하거나 용이하게 할 수 있다. 라이브러리는 또한 제1 라운드의 스크리닝에서 개선된 친화도를 나타내지 않는 위치에서 치환을 포함할 수 있다.
제2 라이브러리는, 키넥사™ 바이오센서 분석을 사용한 스크리닝, 및 선택을 위한 관련 기술분야에 공지된 임의의 방법 (파지 디스플레이, 효모 디스플레이 및 리보솜 디스플레이 포함)을 사용한 선택을 포함한, 관련 기술분야에 공지된 임의의 방법을 사용하여 개선되고/거나 변경된 결합 친화도를 갖는 라이브러리 구성원에 대해 스크리닝 또는 선택된다.
본 발명의 항체를 발현시키기 위해, VH 및 VL 영역을 코딩하는 DNA 단편이 먼저 상기 기재된 임의의 방법을 사용하여 수득될 수 있다. 다양한 변형, 예를 들어 돌연변이, 결실 및/또는 부가가 또한 관련 기술분야의 통상의 기술자에게 공지된 표준 방법을 사용하여 DNA 서열 내로 도입될 수 있다. 예를 들어, 돌연변이유발은 표준 방법, 예컨대 PCR-매개 돌연변이유발을 사용하여 수행될 수 있으며, 여기서 돌연변이된 뉴클레오티드는 PCR 프라이머 내로 혼입되어 PCR 생성물이 목적하는 돌연변이 또는 부위-지정 돌연변이유발을 함유하도록 한다.
항체의 아미노산 서열은 항체의 특성에 유의하게 영향을 미치지 않는 기능적으로 동등한 가변 영역 및/또는 CDR뿐만 아니라 증진 또는 감소된 활성 및/또는 친화도를 갖는 변이체를 포함하도록 변형될 수 있다. 이러한 변형의 예는 항체의 기능적 활성을 유의하게 유해하게 변화시키지 않거나 또는 항체의 그의 표적 항원에 대한 친화도를 성숙 (증진)시키는 아미노산 잔기의 보존적 치환, 아미노산의 1개 이상의 결실 또는 부가를 포함한다.
아미노산 서열 삽입은 길이 범위가 1개의 잔기 내지 100개 이상의 잔기를 함유하는 폴리펩티드에 이르는 아미노- 및/또는 카르복실-말단 융합, 뿐만 아니라 단일 또는 다수 아미노산 잔기의 서열내 삽입을 포함한다. 말단 삽입물의 예는 N-말단 메티오닐 잔기를 갖는 항체 또는 에피토프 태그에 융합된 항체를 포함한다. 항체 분자의 다른 삽입 변이체는 혈액 순환시 항체의 반감기를 증가시키는 폴리펩티드 또는 효소가 항체의 N- 또는 C-말단에 융합된 것을 포함한다.
치환 변이체는 항체 분자 내의 적어도 1개의 아미노산 잔기가 그 자리에서 제거되고 상이한 잔기가 삽입된 것이다. 치환 돌연변이유발을 위한 가장 큰 관심 부위는 초가변 영역을 포함하지만, 프레임워크 변경이 또한 고려된다. 보존적 치환은 표 1에 "보존적 치환"의 제목 하에 제시된다. 이러한 치환이 생물학적 활성의 변화를 유발한다면, 표 1에서 "예시적인 치환"으로 명명된 또는 아미노산 부류와 관련하여 하기 추가로 기재된 바와 같은 보다 실질적인 변화가 도입될 수 있고, 생성물이 스크리닝될 수 있다.
표 1: 아미노산 치환

항체의 생물학적 특성에서의 실질적인 변형은 (a) 예를 들어 β-시트 또는 나선 입체형태로서의 치환 영역 내 폴리펩티드 백본의 구조, (b) 표적 부위에서 분자의 전하 또는 소수성, 또는 (c) 측쇄의 벌크를 유지하는 것에 대한 효과가 유의하게 상이한 치환을 선택함으로써 달성된다. 자연 발생 잔기는 공통적인 측쇄 특성에 기초하여 하기 군으로 나뉜다:
(1) 비-극성: 노르류신, Met, Ala, Val, Leu, Ile;
(2) 비하전된 극성: Cys, Ser, Thr, Asn, Gln;
(3) 산성 (음으로 하전됨): Asp, Glu;
(4) 염기성 (양으로 하전됨): Lys, Arg;
(5) 쇄 배향에 영향을 미치는 잔기: Gly, Pro; 및
(6) 방향족: Trp, Tyr, Phe, His.
비-보존적 치환은 이들 부류 중 하나의 구성원을 또 다른 부류로 교환함으로써 이루어진다.
예를 들어, 이루어질 수 있는 한 유형의 치환은 화학적으로 반응성일 수 있는 항체 내 1개 이상의 시스테인을 또 다른 잔기, 예컨대 비제한적으로 알라닌 또는 세린으로 변화시키는 것이다. 예를 들어, 비-정규 시스테인의 치환이 있을 수 있다. 치환은 가변 도메인의 CDR 또는 프레임워크 영역에서 또는 항체의 불변 영역에서 이루어질 수 있다. 일부 실시양태에서, 시스테인은 정규 시스테인이다. 항체의 적절한 입체형태를 유지하는데 수반되지 않는 임의의 시스테인 잔기는 일반적으로 세린으로 치환되어 분자의 산화 안정성을 개선시키고 이상 가교를 방지할 수 있다. 반대로, 특히 항체가 항체 단편, 예컨대 Fv 단편인 경우에, 시스테인 결합(들)이 항체에 부가되어 그의 안정성을 개선시킬 수 있다.
항체는 또한, 예를 들어 항체의 결합 특성을 변경시키기 위해, 예를 들어 중쇄 및/또는 경쇄의 가변 도메인에서 변형될 수 있다. 가변 영역에서의 변화는 결합 친화도 및/또는 특이성을 변경시킬 수 있다. 일부 실시양태에서, 1개 내지 5개 이하의 보존적 아미노산 치환이 CDR 도메인 내에서 이루어진다. 다른 실시양태에서, 1개 내지 3개 이하의 보존적 아미노산 치환이 CDR 도메인 내에서 이루어진다. 예를 들어, 돌연변이는 B7-H4에 대한 항체의 KD를 증가 또는 감소시키거나, koff를 증가 또는 감소시키거나, 또는 항체의 결합 특이성을 변경시키기 위해 CDR 영역 중 1개 이상에서 이루어질 수 있다. 부위-지정 돌연변이유발의 기술은 관련 기술분야에 널리 공지되어 있다. 예를 들어, 상기 문헌 [Sambrook et al.] 및 [Ausubel et al.]을 참조한다.
B7-H4 항체의 반감기를 증가시키기 위해 프레임워크 영역 또는 불변 영역에서 변형 또는 돌연변이가 또한 이루어질 수 있다. 예를 들어, PCT 공개 번호 WO 00/09560을 참조한다. 프레임워크 영역 또는 불변 영역에서의 돌연변이는 또한 항체의 면역원성을 변경시키거나, 또 다른 분자에 대한 공유 또는 비-공유 결합을 위한 부위를 제공하거나, 또는 보체 고정, FcR 결합 및 항체-의존성 세포-매개 세포독성과 같은 특성을 변경시키도록 이루어질 수 있다. 일부 실시양태에서, 1개 내지 5개 이하의 보존적 아미노산 치환이 프레임워크 영역 또는 불변 영역 내에서 이루어진다. 다른 실시양태에서, 1개 내지 3개 이하의 보존적 아미노산 치환이 프레임워크 영역 또는 불변 영역 내에서 이루어진다. 본 발명에 따르면, 단일 항체는 가변 도메인의 CDR 또는 프레임워크 영역 중 어느 1개 이상에서 또는 불변 영역에서 돌연변이를 가질 수 있다.
재조합 항체 - 글리코실화 변형:
본원에 제공된 항체의 변형은 또한 글리코실화 및 비글리코실화 폴리펩티드, 뿐만 아니라 다른 번역후 변형, 예컨대, 예를 들어 상이한 당에 의한 글리코실화, 아세틸화 및 인산화를 갖는 폴리펩티드를 포함한다. 항체는 그의 불변 영역 내의 보존된 위치에서 글리코실화된다 (Jefferis and Lund, 1997, Chem. Immunol. 65:111-128; Wright and Morrison, 1997, TibTECH 15:26-32). 이뮤노글로불린의 올리고사카라이드 측쇄는 단백질의 기능에 영향을 미치고 (Boyd et al., 1996, Mol. Immunol. 32:1311-1318; Wittwe and Howard, 1990, Biochem. 29:4175-4180), 당단백질의 부분들 사이의 분자내 상호작용은 당단백질의 입체형태 및 제시된 3차원 표면에 영향을 미칠 수 있다 (상기 문헌 [Jefferis and Lund]; [Wyss and Wagner, 1996, Current Opin. Biotech. 7:409-416]). 올리고사카라이드는 또한 특이적 인식 구조에 기초하여 주어진 당단백질을 특정 분자에 표적화하는 역할을 할 수 있다. 항체의 글리코실화는 또한 항체-의존성 세포성 세포독성 (ADCC)에 영향을 미치는 것으로 보고되었다. 특히, 양분성 GlcNAc의 형성을 촉매하는 글리코실트랜스퍼라제인 β(1,4)-N-아세틸글루코사미닐트랜스퍼라제 III (GnTIII)의 테트라시클린-조절된 발현을 갖는 CHO 세포에 의해 생산된 항체는 개선된 ADCC 활성을 갖는 것으로 보고되었다 (Umana et al., 1999, Nature Biotech. 17:176-180).
항체의 글리코실화는 전형적으로 N-연결 또는 O-연결된다. N-연결은 탄수화물 모이어티가 아스파라긴 잔기의 측쇄에 부착되는 것을 지칭한다. 트리펩티드 서열 아스파라긴-X-세린, 아스파라긴-X-트레오닌 및 아스파라긴-X-시스테인 (여기서 X는 프롤린을 제외한 임의의 아미노산임)은 탄수화물 모이어티를 아스파라긴 측쇄에 효소적으로 부착시키기 위한 인식 서열이다. 따라서, 폴리펩티드 내 이들 트리펩티드 서열 중 어느 하나의 존재는 잠재적인 글리코실화 부위를 생성한다. O-연결된 글리코실화는 히드록시아미노산, 가장 통상적으로는 세린 또는 트레오닌 (5-히드록시프롤린 또는 5-히드록시리신도 사용될 수 있지만)에 대한 당 N-아세틸갈락토사민, 갈락토스 또는 크실로스 중 하나의 부착을 지칭한다.
항체에 대한 글리코실화 부위의 부가는 (N-연결된 글리코실화 부위의 경우) 상기 기재된 트리펩티드 서열 중 1개 이상을 함유하도록 아미노산 서열을 변경시킴으로써 편리하게 달성된다. 변경은 또한 (O-연결된 글리코실화 부위의 경우) 원래 항체의 서열에 대한 1개 이상의 세린 또는 트레오닌 잔기의 부가 또는 그에 의한 치환에 의해 이루어질 수 있다.
항체의 글리코실화 패턴은 또한 기저 뉴클레오티드 서열의 변경 없이 변경될 수 있다. 글리코실화는 항체를 발현시키는데 사용된 숙주 세포에 크게 좌우된다. 잠재적 치료제로서의 재조합 당단백질, 예를 들어 항체의 발현에 사용되는 세포 유형은 거의 천연 세포가 아니기 때문에, 항체의 글리코실화 패턴의 변이가 예상될 수 있다 (예를 들어, 문헌 [Hse et al., 1997, J. Biol. Chem. 272:9062-9070] 참조).
숙주 세포의 선택에 추가로, 항체의 재조합 생산 동안 글리코실화에 영향을 미치는 인자는 성장 방식, 배지 제제, 배양 밀도, 산소화, pH, 정제 계획 등을 포함한다. 올리고사카라이드 생산에 관여하는 특정 효소의 도입 또는 과다발현을 포함한, 특정한 숙주 유기체에서 달성되는 글리코실화 패턴을 변경시키기 위한 다양한 방법이 제안되었다 (미국 특허 번호 5,047,335; 5,510,261 및 5,278,299). 글리코실화 또는 특정 유형의 글리코실화는, 예를 들어 엔도글리코시다제 H (엔도 H), N-글리코시다제 F, 엔도글리코시다제 F1, 엔도글리코시다제 F2, 엔도글리코시다제 F3을 사용하여 당단백질로부터 효소적으로 제거될 수 있다. 추가로, 재조합 숙주 세포는 특정 유형의 폴리사카라이드를 프로세싱하는데 결함이 있도록 유전자 조작될 수 있다. 이들 및 유사한 기술은 관련 기술분야에 널리 공지되어 있다.
다른 변형 방법은 효소적 수단, 산화적 치환 및 킬레이트화를 포함하나 이에 제한되지는 않는, 관련 기술분야에 공지된 커플링 기술을 사용하는 것을 포함한다. 변형은, 예를 들어 면역검정을 위한 표지의 부착을 위해 사용될 수 있다. 변형된 폴리펩티드는 관련 기술분야에 확립된 절차를 사용하여 제조되고, 관련 기술분야에 공지된 표준 검정을 사용하여 스크리닝될 수 있으며, 이들 중 일부는 하기 및 실시예에 기재된다.
재조합 항체 - 배선화:
"배선화"로 공지된 과정에서, VH 및 VL 서열 내의 특정 아미노산이 배선 VH 및 VL 서열에서 자연적으로 발견되는 것과 매칭되도록 돌연변이될 수 있다. 특히, VH 및 VL 서열 내의 프레임워크 영역의 아미노산 서열은 항체가 투여되는 경우에 면역원성의 위험을 감소시키기 위해 배선 서열과 매칭되도록 돌연변이될 수 있다. 인간 VH 및 VL 유전자에 대한 배선 DNA 서열은 관련 기술분야에 공지되어 있다 (예를 들어, "Vbase" 인간 배선 서열 데이터베이스 참조; 또한 문헌 [Kabat, E. A., et al., 1991, Sequences of Proteins of Immunological Interest, Fifth Edition, U.S. Department of Health and Human Services, NIH Publication No. 91-3242; Tomlinson et al., 1992, J. Mol. Biol. 227:776-798; 및 Cox et al., 1994, Eur. J. Immunol. 24:827-836] 참조).
재조합 항체 - 문제 부위 제거:
이루어질 수 있는 또 다른 유형의 아미노산 치환은 항체 내의 잠재적 단백질분해 부위를 제거하는 것이다. 이러한 부위는 가변 도메인의 CDR 또는 프레임워크 영역에서 또는 항체의 불변 영역에서 발생할 수 있다. 시스테인 잔기의 치환 및 단백질분해 부위의 제거는 항체 생성물에서 불균질성의 위험을 감소시키고, 따라서 그의 균질성을 증가시킬 수 있다. 또 다른 유형의 아미노산 치환은 잠재적 탈아미드화 부위를 형성하는 아스파라긴-글리신 쌍을 그 잔기 중 하나 또는 둘 다를 변경시킴으로써 제거하는 것이다. 또 다른 예에서, 본 발명의 항체의 중쇄의 C-말단 리신은 절단될 수 있다. 본 발명의 다양한 실시양태에서, 항체의 중쇄 및 경쇄는 임의로 신호 서열을 포함할 수 있다.
재조합 항체 - 다양한 형태:
본 발명의 VH 및 VL 절편을 코딩하는 DNA 단편이 수득되면, 이들 DNA 단편은 표준 재조합 DNA 기술에 의해 추가로 조작되어, 예를 들어 가변 영역 유전자를 전장 항체 쇄 유전자, Fab 단편 유전자 또는 scFv 유전자로 전환시킬 수 있다. 이들 조작에서, VL- 또는 VH-코딩 DNA 단편은 또 다른 단백질, 예컨대 항체 불변 영역 또는 가요성 링커를 코딩하는 또 다른 DNA 단편에 작동가능하게 연결된다. 이와 관련하여 사용된 용어 "작동가능하게 연결된"은 2개의 DNA 단편에 의해 코딩된 아미노산 서열이 인-프레임으로 유지되도록 2개의 DNA 단편이 연결됨을 의미하는 것으로 의도된다.
VH 영역을 코딩하는 단리된 DNA는 VH-코딩 DNA를 중쇄 불변 영역 (CH1, CH2 및 CH3)을 코딩하는 또 다른 DNA 분자에 작동가능하게 연결시킴으로써 전장 중쇄 유전자로 전환될 수 있다. 인간 중쇄 불변 영역 유전자의 서열은 관련 기술분야에 공지되어 있고 (예를 들어, 문헌 [Kabat, E. A., et al., 1991, Sequences of Proteins of Immunological Interest, Fifth Edition, U.S. Department of Health and Human Services, NIH Publication No. 91-3242] 참조), 이들 영역을 포괄하는 DNA 단편은 표준 PCR 증폭에 의해 수득될 수 있다. 중쇄 불변 영역은 IgG1, IgG2, IgG3, IgG4, IgA, IgE, IgM 또는 IgD 불변 영역일 수 있지만, 가장 바람직하게는 IgG1 또는 IgG2 불변 영역이다. IgG 불변 영역 서열은 상이한 개체 사이에서 발생하는 것으로 공지된 임의의 다양한 대립유전자 또는 동종이형, 예컨대 Gm(1), Gm(2), Gm(3) 및 Gm(17)일 수 있다. 이들 동종이형은 IgG1 불변 영역에서의 자연 발생 아미노산 치환을 나타낸다. Fab 단편 중쇄 유전자의 경우, VH-코딩 DNA는 중쇄 CH1 불변 영역만을 코딩하는 또 다른 DNA 분자에 작동가능하게 연결될 수 있다. CH1 중쇄 불변 영역은 임의의 중쇄 유전자로부터 유래될 수 있다.
VL 영역을 코딩하는 단리된 DNA는 VL-코딩 DNA를 경쇄 불변 영역 CL을 코딩하는 또 다른 DNA 분자에 작동가능하게 연결시킴으로써 전장 경쇄 유전자 (뿐만 아니라 Fab 경쇄 유전자)로 전환될 수 있다. 인간 경쇄 불변 영역 유전자의 서열은 관련 기술분야에 공지되어 있고 (예를 들어, 문헌 [Kabat, E. A., et al., 1991, Sequences of Proteins of Immunological Interest, Fifth Edition, U.S. Department of Health and Human Services, NIH Publication No. 91-3242] 참조), 이들 영역을 포괄하는 DNA 단편은 표준 PCR 증폭에 의해 수득될 수 있다. 경쇄 불변 영역은 카파 또는 람다 불변 영역일 수 있다. 카파 불변 영역은 상이한 개체 사이에서 발생하는 것으로 공지된 임의의 다양한 대립유전자, 예컨대 Inv(1), Inv(2) 및 Inv(3)일 수 있다. 람다 불변 영역은 3개의 람다 유전자 중 어느 것으로부터 유래될 수 있다.
scFv 유전자를 생성하기 위해, VH- 및 VL-코딩 DNA 단편을 가요성 링커를 코딩하는 또 다른 단편에 작동가능하게 연결시켜, VH 및 VL 서열이 인접 단일-쇄 단백질로서 발현되고 이때 VL 및 VH 영역이 가요성 링커에 의해 연결되어 있도록 할 수 있다 (예를 들어, 문헌 [Bird et al., 1988, Science 242:423-426; Huston et al., 1988, Proc. Natl. Acad. Sci. USA 85:5879-5883; McCafferty et al., 1990, Nature 348:552-554] 참조). 연결 펩티드의 예는 (GGGGS)3이며, 이는 하나의 가변 영역의 카르복시 말단과 다른 가변 영역의 아미노 말단 사이의 대략 3.5 nm를 가교한다. 다른 서열의 링커가 설계되고 사용되었다 (상기 문헌 [Bird et al., 1988]). 링커는 다시 추가의 기능, 예컨대 약물의 부착 또는 고체 지지체에 대한 부착을 위해 변형될 수 있다. 단일 쇄 항체는 단지 단일 VH 및 VL이 사용되는 경우에 1가, 2개의 VH 및 VL이 사용되는 경우에 2가, 또는 2개 초과의 VH 및 VL이 사용되는 경우에 다가일 수 있다. 표적 항원, 예를 들어 B7-H4 및 또 다른 분자에 특이적으로 결합하는 이중특이적 또는 다가 항체가 생성될 수 있다. 단일 쇄 변이체는 재조합적으로 또는 합성적으로 생산될 수 있다. scFv의 합성 생산을 위해, 자동화 합성기가 사용될 수 있다. scFv의 재조합 생산을 위해, scFv를 코딩하는 폴리뉴클레오티드를 함유하는 적합한 플라스미드가 적합한 숙주 세포, 진핵, 예컨대 효모, 식물, 곤충 또는 포유동물 세포, 또는 원핵, 예컨대 이. 콜라이 내로 도입될 수 있다. 관심 scFv를 코딩하는 폴리뉴클레오티드는 상용 조작, 예컨대 폴리뉴클레오티드의 라이게이션에 의해 제조될 수 있다. 생성된 scFv는 관련 기술분야에 공지된 표준 단백질 정제 기술을 사용하여 단리될 수 있다.
다른 형태의 단일 쇄 항체, 예컨대 디아바디가 또한 포괄된다. 디아바디는 VH 및 VL이 단일 폴리펩티드 쇄 상에서 발현되지만, 동일한 쇄 상의 2개의 도메인 사이에 쌍형성을 허용하기에는 너무 짧은 링커를 사용함으로써, 도메인이 또 다른 쇄의 상보적 도메인과 쌍형성하도록 강제하여 2개의 항원 결합 부위를 생성하는 2가의 이중특이적 항체이다 (예를 들어, 문헌 [Holliger, P., et al., 1993, Proc. Natl. Acad Sci. USA 90:6444-6448; Poljak, R. J., et al., 1994, Structure 2:1121-1123] 참조).
2개의 공유 연결된 항체를 포함하는 이종접합체 항체가 또한 본 발명의 범주 내에 있다. 이러한 항체는 원치않는 세포에 대한 면역계 세포의 표적화 (미국 특허 번호 4,676,980) 및 HIV 감염의 치료 (PCT 공개 번호 WO 91/00360 및 WO 92/200373; EP 03089)에 사용되었다. 이종접합체 항체는 임의의 편리한 가교 방법을 사용하여 제조될 수 있다. 적합한 가교제 및 기술은 관련 기술분야에 널리 공지되어 있고, 미국 특허 번호 4,676,980에 기재되어 있다.
키메라 또는 하이브리드 항체는 또한 가교제를 수반하는 것을 포함한, 합성 단백질 화학의 공지된 방법을 사용하여 시험관내에서 제조될 수 있다. 예를 들어, 면역독소는 디술피드 교환 반응을 사용하여 또는 티오에테르 결합을 형성함으로써 구축될 수 있다. 이러한 목적에 적합한 시약의 예는 이미노티올레이트 및 메틸-4-메르캅토부티르이미데이트를 포함한다.
또 다른 폴리펩티드에 연결된 모노클로날 항체의 모두 또는 부분을 포함하는 융합 항체가 제조될 수 있다. 일부 실시양태에서, 단지 항체의 가변 도메인만이 다른 폴리펩티드에 연결된다. 또 다른 실시양태에서, 항체의 VH 도메인은 제1 폴리펩티드에 연결되고, 항체의 VL 도메인은 VH 및 VL 도메인이 서로 상호작용하여 항원 결합 부위를 형성할 수 있는 방식으로 제1 폴리펩티드와 회합하는 제2 폴리펩티드에 연결된다. 또 다른 바람직한 실시양태에서, VH 도메인은 VH 및 VL 도메인이 서로 상호작용할 수 있도록 링커에 의해 VL 도메인으로부터 분리된다. 이어서, VH-링커-VL 항체는 다른 관심 폴리펩티드에 연결된다. 추가로, 2개 (또는 그 초과)의 단일-쇄 항체가 서로 연결된 융합 항체가 생성될 수 있다. 이는 단일 폴리펩티드 쇄 상에 2가 또는 다가 항체를 생성하길 원하는 경우 또는 이중특이적 항체를 생성하길 원하는 경우에 유용하다.
융합 항체는 관련 기술분야에 공지된 방법에 의해, 예를 들어 합성적으로 또는 재조합적으로 생성될 수 있다. 전형적으로, 융합 항체는 본원에 기재된 재조합 방법을 사용하여 이들을 코딩하는 폴리뉴클레오티드를 제조하고 발현시킴으로써 제조되지만, 이들은 또한, 예를 들어 화학적 합성을 포함한 관련 기술분야에 공지된 다른 수단에 의해 제조될 수도 있다.
다른 실시양태에서, 다른 변형된 항체는 항체 코딩 핵산 분자를 사용하여 제조될 수 있다. 예를 들어, "카파 바디" (Ill et al., 1997, Protein Eng. 10:949-57), "미니바디" (Martin et al., 1994, EMBO J. 13:5303-9), "디아바디" (상기 문헌 [Holliger et al.]), 또는 "야누신" (Traunecker et al., 1991, EMBO J. 10:3655-3659 및 Traunecker et al., 1992, Int. J. Cancer (Suppl.) 7:51-52)은 본 명세서의 교시에 따라 표준 분자 생물학적 기술을 사용하여 제조될 수 있다.
이중특이적 항체
이중특이적 항체를 제조하는 방법은 관련 기술분야에 공지되어 있다 (예를 들어, 문헌 [Suresh et al., 1986, Methods in Enzymology 121:210] 참조). 예를 들어, 이중특이적 항체 또는 항원-결합 단편은 하이브리도마의 융합 또는 Fab' 단편의 연결에 의해 생산될 수 있다. 예를 들어, 문헌 [Songsivilai & Lachmann, 1990, Clin. Exp. Immunol. 79:315-321, Kostelny et al., 1992, J. Immunol. 148:1547-1553]을 참조한다. 전통적으로, 이중특이적 항체의 재조합 생산은 2개의 이뮤노글로불린 중쇄-경쇄 쌍의 공동발현에 기초하였으며, 이때 2개의 중쇄는 상이한 특이성을 갖는다 (Millstein and Cuello, 1983, Nature 305, 537-539). 추가로, 이중특이적 항체는 "디아바디" 또는 "야누신"으로서 형성될 수 있다.
이중특이적 항체를 제조하기 위한 하나의 접근법에 따르면, 목적하는 결합 특이성 (항체-항원 결합 부위)을 갖는 항체 가변 도메인이 이뮤노글로불린 불변 영역 서열에 융합된다. 융합체는 바람직하게는 힌지, CH2 및 CH3 영역의 적어도 일부를 포함하는 이뮤노글로불린 중쇄 불변 영역을 갖는다. 경쇄 결합에 필요한 부위를 함유하는 제1 중쇄 불변 영역 (CH1)이 융합체 중 적어도 하나에 존재하는 것이 바람직하다. 이뮤노글로불린 중쇄 융합체 및 원하는 경우에 이뮤노글로불린 경쇄를 코딩하는 DNA가 개별 발현 벡터 내로 삽입되고, 적합한 숙주 유기체 내로 공동형질감염된다. 이는 구축에 사용된 동일하지 않은 비의 3개의 폴리펩티드 쇄가 최적의 수율을 제공하는 경우인 실시양태에서 3개의 폴리펩티드 단편의 상호 비율을 조정하는데 큰 유연성을 제공한다. 그러나, 동일한 비의 적어도 2개의 폴리펩티드 쇄의 발현이 고수율을 생성하는 경우 또는 비가 특정한 유의성을 갖지 않는 경우에, 2개 또는 모든 3개의 폴리펩티드 쇄에 대한 코딩 서열을 1개의 발현 벡터에 삽입하는 것이 가능하다.
하나의 접근법에서, 이중특이적 항체는 하나의 아암에 제1 결합 특이성을 갖는 하이브리드 이뮤노글로불린 중쇄 및 다른 아암에 하이브리드 이뮤노글로불린 중쇄-경쇄 쌍 (제2 결합 특이성을 제공함)으로 구성된다. 이중특이적 분자의 한쪽 절반에만 이뮤노글로불린 경쇄가 있는 이러한 비대칭 구조는 원치않는 이뮤노글로불린 쇄 조합물로부터 목적하는 이중특이적 화합물의 분리를 용이하게 한다. 이러한 접근법은 PCT 공개 번호 WO 94/04690에 기재되어 있다.
고체 지지체에 커플링시키기 위한 작용제에 접합된 항체
본 발명은 또한 고체 지지체 (예컨대 비오틴 또는 아비딘)에 대한 커플링을 용이하게 하는 작용제에 접합된 (예를 들어, 연결된) 항체를 포함하는 조성물을 제공한다. 단순성을 위해, 이들 방법이 본원에 기재된 임의의 항체 실시양태에 적용된다는 이해 하에 일반적으로 항체를 참조할 것이다. 접합은 일반적으로 본원에 기재된 바와 같은 이들 성분을 연결하는 것을 지칭한다. 연결 (일반적으로 이들 성분을 적어도 투여를 위해 근접하게 회합하여 고정시킴)은 임의의 수의 방식으로 달성될 수 있다. 예를 들어, 작용제와 항체 사이의 직접 반응은 각각이 다른 것과 반응할 수 있는 치환기를 보유하는 경우에 가능하다. 예를 들어, 한쪽의 친핵성 기, 예컨대 아미노 또는 술프히드릴 기는 다른 쪽의 카르보닐-함유 기, 예컨대 무수물 또는 산 할라이드 또는 양호한 이탈기 (예를 들어, 할라이드)를 함유하는 알킬 기와 반응할 수 있다.
항체는 많은 상이한 담체에 결합될 수 있다. 담체는 활성 및/또는 불활성일 수 있다. 널리 공지된 담체의 예는 폴리프로필렌, 폴리스티렌, 폴리에틸렌, 덱스트란, 나일론, 아밀라제, 유리, 천연 및 변형된 셀룰로스, 폴리아크릴아미드, 아가로스 및 마그네타이트를 포함한다. 담체의 성질은 본 발명의 목적상 가용성 또는 불용성일 수 있다. 관련 기술분야의 통상의 기술자는 항체에 결합하는 다른 적합한 담체를 알 것이거나 또는 상용 실험을 사용하여 이를 확인할 수 있을 것이다. 일부 실시양태에서, 담체는 폐, 심장 또는 심장 판막을 표적화하는 모이어티를 포함한다.
본 발명의 항체 또는 폴리펩티드는 표지제, 예컨대 형광 분자, 방사성 분자 또는 관련 기술분야에 공지된 임의의 다른 표지에 연결될 수 있다. 일반적으로 신호를 (직접적으로 또는 간접적으로) 제공하는 표지가 관련 기술분야에 공지되어 있다.
B7-H4 항체
본 발명은 B7-H4에 특이적으로 결합하는 항체 ("B7-H4 항체")를 제공한다. 본 발명의 B7-H4 항체는 하기 특징 중 어느 하나를 나타내야 한다: (a) ELISA 검정에서 플레이트 결합된 B7-H4에 결합함; (b) 세포 기반 검정에서 B7-H4 발현 종양 세포에 결합함; (c) 종양 세포가 B7-H4를 발현하는 것인 T 세포 매개 종양 세포 사멸에서 활성을 나타냄; (d) B7-H4를 발현하는 악성 종양을 갖는 대상체에서 종양 성장 또는 진행을 억제함; (e) 대상체에서 B7-H4를 발현하는 악성 세포와 연관된 상태의 1종 이상의 증상을 치료, 예방, 호전시킴.
B7-H4 항체는 관련 기술분야에 공지된 임의의 방법에 의해 제조될 수 있다. 표 2는 본 발명의 예시적인 B7-H4 항체를 기재한다. 표 2에 열거된 각각의 VH CDR1 (중쇄 가변 영역 CDR1)은 AbM CDR 정의에 따른다. 표 2에 열거된 각각의 VH CDR2 (중쇄 가변 영역 CDR2), VH CDR3 (중쇄 가변 영역 CDR3), VL CDR1 (경쇄 가변 영역 CDR1), VL CDR2 (경쇄 가변 영역 CDR2), VL CDR3 (경쇄 가변 영역 CDR3) 서열은 카바트 CDR 정의에 따른다.
따라서, 일부 실시양태에서, 본 발명은 표 2에 기재된 B7-H4 항체 중 어느 하나를 제공한다.
일부 실시양태에서, 본 발명은 B7-H4 항체 또는 B7-H4에 결합하는 그의 변이체 또는 B7-H4에 결합하는 그의 항원 결합 단편을 제공하며, 여기서 B7-H4 항체는 표 2에 기재된 항체의 VH 및 VL과 동일한 아미노산 서열을 갖는 VH 및 VL을 포함한다.
일부 실시양태에서, 본 발명은 B7-H4 항체 또는 B7-H4에 결합하는 그의 변이체 또는 B7-H4에 결합하는 그의 항원 결합 단편을 제공하며, 여기서 B7-H4 항체는
(i) 6개의 CDR 각각이 표 2에 기재된 항체의 VH 및 VL의 상응하는 CDR과 동일한 아미노산 서열을 갖는 것인 VH CDR1, VH CDR2, VH CDR3, VL CDR1, VL CDR2 및 VL CDR3,
(ii) 표 2에 기재된 임의의 항체의 VH의 3개의 CDR, 또는
(iii) 표 2에 기재된 임의의 항체의 VL의 3개의 CDR
을 포함하며, 여기서 CDR은 카바트 정의, 코티아 정의, AbM 정의 또는 카바트와 코티아 CDR의 조합 ("조합된 CDR" 또는 "연장된 CDR"로도 지칭됨)에 따라 정의된다.
일부 실시양태에서, 본 발명은 B7-H4 항체 또는 B7-H4에 결합하는 그의 변이체 또는 B7-H4에 결합하는 그의 항원 결합 단편을 제공하며, 여기서 B7-H4 항체는 VH CDR1, VH CDR2, VH CDR3, VL CDR1, VL CDR2 및 VL CDR3을 포함하고, 이들 각각은 표 2에 기재된 임의의 항체의 표 2에 열거된 상응하는 CDR과 동일한 아미노산 서열을 갖는다.
일부 실시양태에서, 본 발명은 표 2에 기재된 항체 중 어느 하나와 B7-H4에의 결합에 대해 경쟁하는 B7-H4 항체를 제공한다.
표 2. 예시적인 B7-H4 항체의 서열식별번호



표 3은 표 2에 열거된 B7-H4 항체, 표 4에 열거된 CD3 항체 및 표 5에 열거된 B7-H4xCD3 이중특이적 항체를 포함한 본 발명의 예시적인 항체의 상응하는 서열 식별자를 갖는 서열, 및 본 발명의 항체를 생성하거나 시험하기 위해 사용된 B7-H4 세포외 도메인의 서열을 보여준다. 여러 VH 및 VL 서열, 즉 서열식별번호: 106, 108, 139, 161, 167 및 172의 카바트 CDR은 밑줄친 아미노산 서열로 표시되고, 코티아 CDR은 볼드체 아미노산 서열로 표시된다. 표 2, 표 4 및 표 5에 기재된 서열 이외에, 하기는 표 3에 포함된 일부 추가의 서열의 설명이다.
서열식별번호: 1은 인간 B7-H4 단백질의 세포외 도메인의 아미노산 서열이다.
서열식별번호: 2는 시노 B7-H4 단백질의 세포외 도메인의 아미노산 서열이다.
서열식별번호: 3은 마우스 B7-H4 단백질의 세포외 도메인의 아미노산 서열이다.
서열식별번호: 4는 래트 B7-H4 단백질의 세포외 도메인의 아미노산 서열이다.
항체 1156 및 항체 1167은 B7-H4xCD3 이중특이적 항체이고; 둘 다는 표 5에 기재된다.
서열식별번호: 186 및 187은 각각 이중특이적 항체 1156의 제1 아암 (B7-H4 아암)의 전장 중쇄 및 전장 경쇄의 아미노산 서열이다.
서열식별번호: 188 및 189는 각각 이중특이적 항체 1156 및 이중특이적 항체 1167의 제2 아암 (CD3 아암)의 전장 중쇄 및 전장 경쇄 각각의 아미노산 서열이다.
서열식별번호: 190 및 191은 각각 이중특이적 항체 1167의 제1 아암 (B7-H4 아암)의 전장 중쇄 및 전장 경쇄 각각의 아미노산 서열이다.
서열식별번호: 192는 이중특이적 항체 1156의 제1 아암 (B7-H4 아암)의 전장 중쇄를 코딩하는 뉴클레오티드 서열이다.
서열식별번호: 193은 이중특이적 항체 1156의 제1 아암 (B7-H4 아암)의 전장 경쇄를 코딩하는 뉴클레오티드 서열이다.
서열식별번호: 194는 이중특이적 항체 1156 및 1167의 제2 아암 (CD3 아암)의 전장 중쇄를 코딩하는 뉴클레오티드 서열이다.
서열식별번호: 195는 이중특이적 항체 1156 및 1167의 제2 아암 (CD3 아암)의 전장 경쇄를 코딩하는 뉴클레오티드 서열이다.
서열식별번호: 196은 이중특이적 항체 1167의 제1 아암 (B7-H4 아암)의 전장 중쇄를 코딩하는 뉴클레오티드 서열이다.
서열식별번호: 197은 이중특이적 항체 1167의 제1 아암 (B7-H4 아암)의 전장 경쇄를 코딩하는 뉴클레오티드 서열이다.
서열식별번호: 198은 본원의 항체의 일반적 제조 방법에 기재된 (GGGGS)3 펩티드 링커의 아미노산 서열이다.
서열식별번호: 199는 이중특이적 항체 1156의 제1 아암 (B7-H4 아암)의 카바트 VH CDR1의 서열이다.
서열식별번호: 200은 이중특이적 항체 1156의 제1 아암 (B7-H4 아암)의 코티아 VH CDR1의 서열이다.
서열식별번호: 201은 이중특이적 항체 1156의 제1 아암 (B7-H4 아암)의 코티아 VH CDR2의 서열이다.
서열식별번호: 202는 이중특이적 항체 1156 및 이중특이적 항체 1167의 제2 아암 (CD3 아암)의 카바트 VH CDR1의 서열이다.
서열식별번호: 203은 이중특이적 항체 1156 및 이중특이적 항체 1167의 제2 아암 (CD3 아암)의 코티아 VH CDR1의 서열이다.
서열식별번호: 204는 이중특이적 항체 1156 및 이중특이적 항체 1167의 제2 아암 (CD3 아암)의 코티아 VH CDR2의 서열이다.
서열식별번호: 205는 이중특이적 항체 1167의 제1 아암 (B7-H4 아암)의 카바트 VH CDR1의 서열이다.
서열식별번호: 206은 이중특이적 항체 1167의 제1 아암 (B7-H4 아암)의 코티아 VH CDR1의 서열이다.
서열식별번호: 207은 이중특이적 항체 1167의 제1 아암 (B7-H4 아암)의 코티아 VH CDR2의 서열이다.
서열식별번호: 208은 인간 IgG2 야생형 IGHG2*01의 불변 영역 1 (CH1), 힌지, CH2 및 CH3 영역의 아미노산 서열이다.
서열식별번호: 209는 인간 IgG1 야생형 IGHG1*01의 CH1, 힌지, CH2 및 CH3 영역의 아미노산 서열이다.
서열식별번호: 210은 인간 IgG4 야생형 IGHG4*01의 CH1, 힌지, CH2 및 CH3 영역의 아미노산 서열이다.
IGHG2*01, IGHG1*01 및 IGHG4*01은 IMGT/진(Gene)-DB의 인간 IGHC 군에 따른다 (Giudicelli, V. et al. Nucleic Acids Res., 33: D256 - D261 (2005)).
표 3. 서열식별번호 서열















일부 실시양태에서, 본 발명은 또한 CDR 접촉 영역에 기초한 B7-H4 항체의 CDR 부분을 제공한다. CDR 접촉 영역은 항체에 항원에 대한 특이성을 부여하는 항체의 영역이다. 일반적으로, CDR 접촉 영역은 CDR 및 버니어 구역 내의 잔기 위치를 포함하며, 이는 특이적 항원에 결합하는 항체에 대해 적절한 루프 구조를 유지하기 위해 제약된다. 예를 들어, 문헌 [Makabe et al., J. Biol. Chem., 283:1156-1166, 2007]을 참조한다. CDR 접촉 영역의 결정은 관련 기술분야의 기술 내에 있다.
B7-H4, 예컨대 hB7-H4의 세포외 도메인에 대한 본원에 기재된 바와 같은 B7-H4 항체의 결합 친화도 (KD)는 약 0.002 nM 내지 약 6500 nM일 수 있다. 일부 실시양태에서, 결합 친화도는 약 6500 nm, 6000 nm, 5986 nm, 5567 nm, 5500 nm, 4500 nm, 4000 nm, 3500 nm, 3000 nm, 2500 nm, 2134 nm, 2000 nm, 1500 nm, 1000 nm, 750 nm, 500 nm, 400 nm, 300 nm, 250 nm, 200 nM, 193 nM, 100 nM, 90 nM, 50 nM, 45 nM, 40 nM, 35 nM, 30 nM, 25 nM, 20 nM, 19 nm, 18 nm, 17 nm, 16 nm, 15 nM, 10 nM, 8 nM, 7.5 nM, 7 nM, 6.5 nM, 6 nM, 5.5 nM, 5 nM, 4 nM, 3 nM, 2 nM, 1 nM, 0.5 nM, 0.3 nM, 0.1 nM, 0.01 nM 또는 0.002 nM 중 어느 것이다. 일부 실시양태에서, 결합 친화도는 대략 약 6500 nm, 6000 nm, 5500 nm, 5000 nm, 4000 nm, 3000 nm, 2000 nm, 1000 nm, 900 nm, 800 nm, 250 nM, 200 nM, 100 nM, 50 nM, 30 nM, 20 nM, 10 nM, 7.5 nM, 7 nM, 6.5 nM, 6 nM, 5 nM, 4.5 nM, 4 nM, 3.5 nM, 3 nM, 2.5 nM, 2 nM, 1.5 nM, 1 nM 또는 0.5 nM 중 어느 것 미만이다.
일부 실시양태에서, 본 발명의 B7-H4 항체는 전장 인간 항체이다.
일부 실시양태에서, 본 발명의 B7-H4 항체는 단일 쇄 가변 영역 항체 (scFv)이다.
일부 실시양태에서, 본 발명의 B7-H4 항체는 디아바디 또는 미니바디이다.
일부 실시양태에서, 본 발명의 B7-H4 항체는 B7-H4에 결합하는 항원 결합 부분을 포함하는 융합 단백질이며, 여기서 항원 결합 부분은 VH CDR1, VH CDR2, VH CDR3, VL CDR1, VL CDR2 및 VL CDR3을 포함하고, 여기서 6개의 CDR은 각각 표 2에 기재된 항체의 상응하는 CDR과 동일한 아미노산 서열을 갖는다.
일부 실시양태에서, 본 발명은 B7-H4에 특이적으로 결합하는 세포외 도메인, 제1 막횡단 도메인 및 세포내 신호전달 도메인을 포함하는 키메라 항원 수용체 (CAR)를 제공한다. 일부 실시양태에서, 세포외 도메인은 VH CDR1, VH CDR2, VH CDR3, VL CDR1, VL CDR2 및 VL CDR3을 포함하는 단일 쇄 Fv 단편 (ScFv)을 포함하며, 여기서 6개의 CDR은 각각 표 2에 기재된 항체의 상응하는 CDR과 동일한 아미노산 서열을 갖는다.
본 발명은 또한 본원에 개시된 임의의 항체를 제조하는 방법을 제공한다. 본원에 제공된 항체는 관련 기술분야에 공지된 절차에 의해 제조될 수 있다.
B7-H4 항체 접합체
본 발명은 또한 본원에 기재된 바와 같은 B7-H4 항체 또는 그의 항원 결합 단편의 접합체 (또는 면역접합체)를 제공하며, 여기서 항체 또는 항원 결합 단편은 표적화된 면역요법을 위한 작용제 (예를 들어, 세포독성제)에 직접적으로 또는 링커를 통해 간접적으로 접합된다 (예를 들어, 항체-약물 접합체). 예를 들어, 세포독성제는 종양 (예를 들어, B7-H4 발현 종양)으로의 세포독성제 모이어티의 표적화된 국부 전달을 위해 본원에 기재된 바와 같은 B7-H4 항체 또는 그의 항원 결합 단편에 연결 또는 접합될 수 있다.
세포독성제 또는 다른 치료제를 항체에 접합시키는 방법은 다양한 공개물에 기재되어 있다. 예를 들어, 접합 반응이 일어나도록 쇄간 디술피드 결합을 환원시킴으로써 활성화되는 시스테인 술프히드릴 기를 통해 또는 리신 측쇄 아민을 통해 항체에서 화학적 변형이 이루어질 수 있다. 예를 들어, 문헌 [Tanaka et al., FEBS Letters 579:2092-2096, 2005 및 Gentle et al., Bioconjugate Chem. 15:658-663, 2004]을 참조한다. 정의된 화학량론을 갖는 특이적 약물 접합을 위해 항체의 특이적 부위에서 조작된 반응성 시스테인 잔기가 또한 기재되었다. 예를 들어, 문헌 [Junutula et al., Nature Biotechnology, 26:925-932, 2008]을 참조한다. 트랜스글루타미나제 및 아민 (예를 들어, 반응성 아민을 포함하거나 또는 그에 부착된 세포독성제)의 존재 하에 폴리펩티드 조작에 의해 반응성 (즉, 아실 공여자로서 공유 결합을 형성할 수 있음)으로 만든 아실 공여자 글루타민-함유 태그 또는 내인성 글루타민을 사용한 접합이 또한 국제 출원 WO2012/059882 및 WO2015015448에 기재되어 있다.
본 발명의 B7-H4 항체 또는 항원 결합 단편에 접합될 수 있는 작용제는 세포독성제, 면역조정제, 영상화제, 치료 단백질, 생체중합체 또는 올리고뉴클레오티드를 포함하나 이에 제한되지는 않는다.
B7-H4 항체 또는 그의 항원 결합 단편에 접합될 수 있는 세포독성제의 예는 안트라시클린, 아우리스타틴, 돌라스타틴, 콤브레타스타틴, 두오카르마이신, 피롤로벤조디아제핀 이량체, 인돌리노-벤조디아제핀 이량체, 에네디인, 겔다나마이신, 메이탄신, 퓨로마이신, 탁산, 빈카 알칼로이드, 캄프토테신, 튜부리신, 헤미아스텔린, 스플라이세오스타틴, 플라디에놀리드 및 그의 입체이성질체, 동배체, 유사체 또는 유도체를 포함하나 이에 제한되지는 않는다.
B7-H4 항체 또는 그의 항원 결합 단편에 접합될 수 있는 면역조정제의 예는 간시클로비르, 에타네르셉트, 타크롤리무스, 시롤리무스, 보클로스포린, 시클로스포린, 라파마이신, 시클로포스파미드, 아자티오프린, 미코페놀레이트 모페틸, 메토트렉세이트, 글루코코르티코이드 및 그의 유사체, 시토카인, 줄기 세포 성장 인자, 림프독소, 종양 괴사 인자 (TNF), 조혈 인자, 인터류킨 (예를 들어, 인터류킨-1 (IL-1), IL-2, IL-3, IL-6, IL-10, IL-12, IL-18 및 IL-21), 콜로니 자극 인자 (예를 들어, 과립구-콜로니 자극 인자 (G-CSF) 및 과립구 대식세포-콜로니 자극 인자 (GM-CSF)), 인터페론 (예를 들어, 인터페론-α, -β 및 -γ), "S 1 인자"로 지정된 줄기 세포 성장 인자, 에리트로포이에틴 및 트롬보포이에틴 또는 그의 조합을 포함하나 이에 제한되지는 않는다.
B7-H4 항체 또는 그의 항원 결합 단편에 접합될 수 있는 영상화제 (예를 들어, 형광단 또는 킬레이트화제)의 예는, 예컨대 플루오레세인, 로다민, 란타나이드 인광체 및 그의 유도체 또는 킬레이트화제에 결합된 방사성동위원소를 포함한다. 형광단의 예는 플루오레세인 이소티오시아네이트 (FITC) (예를 들어, 5-FITC), 플루오레세인 아미다이트 (FAM) (예를 들어, 5-FAM), 에오신, 카르복시플루오레세인, 에리트로신, 알렉사 플루오르(Alexa Fluor)® (예를 들어, 알렉사 350, 405, 430, 488, 500, 514, 532, 546, 555, 568, 594, 610, 633, 647, 660, 680, 700 또는 750), 카르복시테트라메틸로다민 (TAMRA) (예를 들어, 5-TAMRA), 테트라메틸로다민 (TMR) 및 술포로다민 (SR) (예를 들어, SR101)을 포함하나 이에 제한되지는 않는다. 킬레이트화제의 예는 1,4,7,10-테트라아자시클로도데칸-N,N',N",N"'-테트라아세트산 (DOTA), 1,4,7-트리아자시클로노난-1,4,7-트리아세트산 (NOTA), 1,4,7-트리아자시클로노난, 1-글루타르산-4,7-아세트산 (데페록사민), 디에틸렌트리아민펜타아세트산 (DTPA) 및 1,2-비스(o-아미노페녹시)에탄-N,N,N',N'-테트라아세트산) (BAPTA)을 포함하나 이에 제한되지는 않는다.
일부 실시양태에서, 작용제는 독소, 호르몬, 효소 및 성장 인자를 포함하나 이에 제한되지는 않는 치료 단백질이다.
독소 단백질 (또는 폴리펩티드)의 예는 디프테리아 (예를 들어, 디프테리아 A 쇄), 슈도모나스 외독소 및 내독소, 리신 (예를 들어, 리신 A 쇄), 아브린 (예를 들어, 아브린 A 쇄), 모데신 (예를 들어, 모데신 A 쇄), 알파-사르신, 알레우리테스 포르디이 단백질, 디안틴 단백질, 리보뉴클레아제 (RNase), DNase I, 스타필로코쿠스 장독소-A, 미국자리공 항바이러스 단백질, 겔로닌, 디프테리아 독소, 피토라카 아메리카나 단백질 (PAPI, PAPII 및 PAP-S), 모모르디카 카란티아 억제제, 쿠르신, 크로틴, 사파오나리아 오피시날리스 억제제, 미토겔린, 레스트릭토신, 페노마이신, 에노마이신, 트리코테센, 억제제 시스틴 노트 (ICK) 펩티드 (예를 들어, 세라토톡신) 및 코노톡신 (예를 들어, KIIIA 또는 SmIIIa)을 포함하나 이에 제한되지는 않는다.
일부 실시양태에서, 작용제는 생체적합성 중합체이다. 본원에 기재된 바와 같은 B7-H4 항체 또는 항원 결합 단편은 생체적합성 중합체에 접합되어 혈청 반감기 및 생물활성을 증가시키고/거나 생체내 반감기를 연장시킬 수 있다. 생체적합성 중합체의 예는 수용성 중합체, 예컨대 폴리에틸렌 글리콜 (PEG) 또는 그의 유도체 및 쯔비터이온-함유 생체적합성 중합체 (예를 들어, 포스포릴콜린 함유 중합체)를 포함한다.
일부 실시양태에서, 작용제는 올리고뉴클레오티드, 예컨대 안티센스 올리고뉴클레오티드이다.
CD3 항체
본 발명은 CD3 (예를 들어, 인간 CD3)에 결합하는 항체를 추가로 제공한다.
일부 실시양태에서, 본 발명은 CD3에 특이적으로 결합하는 단리된 항체를 제공하며, 여기서 항체는 다음을 포함한다:
a) 서열식별번호: 31의 아미노산 서열을 갖는 VH, 서열식별번호: 35의 아미노산 서열을 갖는 VL, 서열식별번호: 178의 아미노산 서열의 중쇄 불변 영역 (CH) 및 서열식별번호: 12의 아미노산 서열의 경쇄 불변 영역 (CL);
b) 서열식별번호: 110의 아미노산 서열을 갖는 VH, 서열식별번호: 113의 아미노산 서열을 갖는 VL, 서열식별번호: 180의 아미노산 서열의 CH 및 서열식별번호: 12의 아미노산 서열의 CL;
c) 서열식별번호: 115의 아미노산 서열을 갖는 VH, 서열식별번호: 117의 아미노산 서열을 갖는 VL, 서열식별번호: 180의 아미노산 서열의 CH 및 서열식별번호: 12의 아미노산 서열의 CL;
d) 서열식별번호: 106의 아미노산 서열을 갖는 VH, 서열식별번호: 108의 아미노산 서열을 갖는 VL, 서열식별번호: 182의 아미노산 서열의 CH 및 서열식별번호: 12의 아미노산 서열의 CL;
e) 서열식별번호: 106의 아미노산 서열을 갖는 VH, 서열식별번호: 108의 아미노산 서열을 갖는 VL, 서열식별번호: 184의 아미노산 서열의 CH 및 서열식별번호: 12의 아미노산 서열의 CL; 또는
f) 서열식별번호: 106의 아미노산 서열을 갖는 VH, 서열식별번호: 108의 아미노산 서열을 갖는 VL, 서열식별번호: 178의 아미노산 서열의 CH 및 서열식별번호: 12의 아미노산 서열의 CL.
또 다른 실시양태에서, 본 발명은 CD3에 특이적으로 결합하는 항체를 제공하며, 여기서 항체는 각각 표 4에 열거된 항체 중 어느 하나의 상응하는 CDR의 아미노산 서열과 동일한 아미노산 서열을 갖는 VH CDR1, VH CDR2, VH CDR3, VL CDR1, VL CDR2 및 VL CDR3을 포함한다.
또 다른 실시양태에서, 본 발명은 CD3에 특이적으로 결합하는 항체를 제공하며, 여기서 항체는 각각 표 4에 열거된 항체 중 어느 하나의 VH 및 VL의 아미노산 서열과 동일한 아미노산 서열을 갖는 VH 및 VL을 포함한다.
표 4는 본 발명의 예시적인 CD3 항체를 기재한다.
표 4. 예시적인 CD3 항체

B7-H4 이중특이적 항체
본 발명은 또한 B7-H4 및 제2 항원에 특이적으로 결합하는 이중특이적 항체를 제공한다.
제2 항원
일부 실시양태에서, 제2 항원은 인간 면역 이펙터 세포 상에 위치한 이펙터 항원이다. 인간 이펙터 세포 상의 이펙터 항원의 개념은 관련 기술분야에 널리 공지되어 있다. 예시적인 이펙터 항원은 CD3, CD16, NKG2D, NKp-46, CD2, CD28, CD25, CD64 및 CD89를 포함하나 이에 제한되지는 않는다.
일부 실시양태에서, 제2 항원은 CD3이다.
일부 실시양태에서, 제2 항원은 표적 세포 상의 표적 항원 (B7-H4 이외의 것)일 수 있으며, 여기서 표적 세포는 인간에 대해 천연 또는 외래인 세포일 수 있다. 천연 표적 세포에서, 세포는 악성 세포이거나 병리학적으로 변형되도록 형질전환되었을 수 있다 (예를 들어, 바이러스, 플라스모디움 또는 박테리아로 감염된 천연 표적 세포). 외래 표적 세포에서, 세포는 침입 병원체, 예컨대 박테리아, 플라스모디움 또는 바이러스이다.
표적 항원은 질환 상태 (예를 들어, 염증성 질환, 증식성 질환 (예를 들어, 암), 면역 장애, 신경계 질환, 신경변성 질환, 자가면역 질환, 감염성 질환 (예를 들어, 바이러스 감염 또는 기생충 감염), 알레르기 반응, 이식편-대-숙주 질환 또는 숙주-대-이식편 질환)의 표적 세포 상에서 발현된다. 표적 항원은 이펙터 항원이 아니다. 표적 항원의 예는 B7-H4, EpCAM (상피 세포 부착 분자), CCR5 (케모카인 수용체 유형 5), CD19, HER (인간 표피 성장 인자 수용체)-2/neu, HER-3, HER-4, EGFR (표피 성장 인자 수용체), PSMA, CEA, MUC-1 (뮤신), MUC2, MUC3, MUC4, MUC5AC, MUC5B, MUC7, CIhCG, 루이스-Y, CD20, CD33, CD30, 강글리오시드 GD3, 9-O-아세틸-GD3, GM2, 글로보 H, 푸코실 GM1, 폴리 SA, GD2, 카르보안히드라제 IX (MN/CA IX), CD44v6, Shh (소닉 헤지호그), Wue-1, 형질 세포 항원, (막-결합) IgE, MCSP (흑색종 콘드로이틴 술페이트 프로테오글리칸), CCR8, TNF-알파 전구체, STEAP, 메소텔린, A33 항원, PSCA (전립선 줄기 세포 항원), Ly-6; 데스모글레인 4, E-카드헤린 네오에피토프, 태아 아세틸콜린 수용체, CD25, CA19-9 마커, CA-125 마커 및 MIS (뮐러 억제 물질) 수용체 유형 II, sTn (시알릴화 Tn 항원; TAG-72), FAP (섬유모세포 활성화 항원), 엔도시알린, EGFRvIII, LG, SAS 및 CD63을 포함하나 이에 제한되지는 않는다.
B7-H4xCD3 이중특이적 항체
하기 표 5는 B7-H4 및 CD3 둘 다에 특이적으로 결합하는 본 발명의 예시적인 이중특이적 항체 ("B7-H4xCD3 이중특이적 항체")의 제1 아암 및 제2 아암 둘 다의 CDR, 불변 영역 및 가변 영역의 서열식별번호를 제공한다.
표 5. 예시적인 B7-H4xCD3 이중특이적 항체





표 5의 각각의 이중특이적 항체는 2개의 아암: B7-H4에 결합하는 제1 아암 및 CD3에 결합하는 제2 아암을 포함한다. 제1 아암 및 제2 아암 둘 다의 중쇄 CDR (VH CDR), 경쇄 CDR (VL CDR), 중쇄 가변 영역 (VH), 경쇄 가변 영역 (VL), 중쇄 불변 영역 (CH) 및 경쇄 불변 영역 (CL) 각각의 아미노산 서열의 서열식별번호가 표 5에 제시된다. (표 5에 열거된 각각의 서열식별번호의 아미노산 서열은 본원의 이전 세션의 표 3에 기재되어 있다.) 표 5의 각각의 VH CDR1 서열은 AbM 정의에 따르고, 표 5에 열거된 각각의 VH CDR2, VH CDR3, VL CDR1, VL CDR2, VL CDR3 서열은 카바트 정의에 따른다.
일부 실시양태에서, 본 발명은 제1 경쇄 및 제1 중쇄 및 제2 경쇄 및 제2 중쇄를 포함하며, 여기서 제1 경쇄 및 제1 중쇄는 B7-H4에 결합하는 제1 항원 결합 도메인을 포함하는 제1 아암을 형성하고, 제2 경쇄 및 제2 중쇄는 CD3에 결합하는 제2 항원 결합 도메인을 포함하는 제2 아암을 형성하는 것인, B7-H4 및 CD3 둘 다에 특이적으로 결합하는 이중특이적 항체를 제공한다.
일부 실시양태에서, 제1 중쇄는 VH 및 CH를 포함하고, 제1 경쇄는 VL 및 CL을 포함하고, 제2 중쇄는 VH 및 CH를 포함하고, 제2 경쇄는 VL 및 CL을 포함하며, 여기서 제1 및 제2 중쇄 VH 및 CH 및 제1 및 제2 경쇄 VL 및 CL은 표 5에 열거된 임의의 이중특이적 항체의 아미노산 서열과 동일한 아미노산 서열을 포함한다.
일부 실시양태에서, 제1 경쇄는 VL을 포함하고, 제1 중쇄는 VH를 포함하고, 제2 경쇄는 VL을 포함하고, 제2 중쇄는 VH를 포함하며, 여기서 제1 및 제2 중쇄 및 제1 및 제2 경쇄의 각각의 VH 및 VL은 표 5에 열거된 이중특이적 항체 중 어느 하나의 아미노산 서열과 동일한 아미노산 서열을 갖는다.
일부 실시양태에서, 제1 경쇄는 VL CDR1, VL CDR2 및 VL CDR3을 포함하고, 제1 중쇄는 VH CDR1, VH CDR2 및 VH CDR3을 포함하고, 제2 경쇄는 VL CDR1, VL CDR2 및 VL CDR3을 포함하고, 제2 중쇄는 VH CDR1, VH CDR2 및 VH CDR3을 포함하며, 여기서 본 발명의 이중특이적 항체의 제1 아암 및 제2 아암의 각각의 VL CDR1, VL CDR2, VL CDR3, VH CDR1, VH CDR2 및 VH CDR3은 표 5에 기재된 이중특이적 항체 중 어느 하나의 제1 아암 및 제2 아암의 각각의 VL CDR1, VL CDR2, VL CDR3, VH CDR1, VH CDR2 및 VH CDR3의 아미노산 서열과 동일한 아미노산 서열을 갖는다. 일부 실시양태에서, CDR은 카바트 정의, 코티아 정의, AbM 정의 또는 카바트와 코티아 CDR의 조합 ("조합된 CDR" 또는 "연장된 CDR"로도 지칭됨)에 따라 정의된다.
B7-H4 항체, CD3 항체 및 B7-H4xCD3 이중특이적 항체의 불변 영역
일부 실시양태에서, 본원에 제공된 항체는 1개 이상의 불변 영역을 포함한다. 일부 실시양태에서, 항체는, 예를 들어 전장 인간 항체일 수 있다. 일부 실시양태에서, 전장 인간 항체는 IgG1, IgG2, IgG3 또는 IgG4 이소형을 갖는다. 일부 실시양태에서, 항체는 면역학적으로 불활성인 Fc 영역을 포함할 수 있다.
달리 명시되지 않는 한, 인간 IgG1, IgG2 및 IgG4의 불변 영역의 본원에서의 모든 넘버링은 EU 넘버링 스킴에 따르고, 각각 야생형 인간 IgG1, IgG2 및 IgG4를 참조한다. 인간 IgG1, IgG2 및 IgG4의 힌지-CH2 영역의 넘버링은 도 1에 기재되고 예시된 바와 같다. IgG2, IgG1 및 IgG4에 대해 도 1에서 사용된 서열은 IMGT/진-DB의 인간 IGHC 군으로부터의 IGHG2*01, IGHG1*01 및 IGHG4*01의 CH1, H, CH2 및 CH3 영역이다 (IMGT/GENE-DB: Giudicelli, V. et al. Nucleic Acids Res., 33: D256 - D261 (2005). PMID: 15608191).
일부 실시양태에서, Fc는 인간 IgG4 Fc이다. 일부 실시양태에서, 본원에 제공된 항체는 하기 돌연변이를 포함하는 IgG4의 불변 영역을 포함할 수 있다 (Armour et al., 2003, Molecular Immunology 40 585-593): E233F234L235에서 P233V234A235 (IgG4Δc). 또 다른 실시양태에서, Fc는 인간 IgG4 E233F234L235에서 결실 G236을 갖는 P233V234A235 (IgG4Δb)일 수 있다. 일부 실시양태에서, Fc는 S228에서 P228로의 힌지 안정화 돌연변이를 함유하는 임의의 인간 IgG4 Fc (IgG4, IgG4Δb 또는 IgG4Δc)일 수 있다 (Aalberse et al., 2002, Immunology 105, 9-19).
일부 실시양태에서, Fc는 인간 IgG2 Fc이다. 일부 실시양태에서, Fc는 A330P331에서 S330S331로의 돌연변이를 함유하는 인간 IgG2 (IgG2Δa)이며, 여기서 및 단락의 나머지에서 아미노산 잔기는 야생형 인간 IgG2 서열을 참조하고 EU 넘버링 스킴에 따라 넘버링된다 (Eur. J. Immunol., 1999, 29:2613-2624). 일부 실시양태에서, Fc는 D265A의 치환을 갖는 인간 IgG2Δa Fc이다. 일부 실시양태에서, 항체는 인간 IgG2의 힌지 영역 내의 위치 223, 225 및 228에서의 돌연변이 (예를 들어, (C223E 또는 C223R), (E225R) 및 (P228E 또는 P228R)) 및 Fc에서 CH3 영역 내의 위치 409 또는 368에서의 돌연변이 (예를 들어, K409R 또는 L368E)를 추가로 함유한다. 도 1은 EU 넘버링 스킴을 포함하는 본원에 사용된 인간 IgG2 불변 영역의 구체적 넘버링을 보여준다.
일부 실시양태에서, 본 발명의 항체는 인간 Fc 감마 수용체에 대해 증가 또는 감소된 결합 친화도를 갖거나, 면역학적으로 불활성 또는 부분적으로 불활성인, 예를 들어 보체 매개 용해를 촉발하지 않거나, 항체-의존성 세포 매개 세포독성 (ADCC)을 자극하지 않거나 또는 소교세포를 활성화시키지 않거나; 또는 하기: 보체 매개 용해를 촉발하는 것, ADCC를 자극하는 것 또는 소교세포를 활성화시키는 것 중 어느 1개 이상에서 (비변형된 항체와 비교하여) 감소된 활성을 갖는 변형된 불변 영역을 포함한다. 불변 영역의 상이한 변형을 사용하여 이펙터 기능의 최적 수준 및/또는 조합을 달성할 수 있다. 예를 들어, 문헌 [Morgan et al., Immunology 86:319-324, 1995; Lund et al., J. Immunology 157:4963-9 157:4963-4969, 1996; Idusogie et al., J. Immunology 164:4178-4184, 2000; Tao et al., J. Immunology 143: 2595-2601, 1989; 및 Jefferis et al., Immunological Reviews 163:59-76, 1998]을 참조한다. 일부 실시양태에서, 불변 영역은 문헌 [Eur. J. Immunol., 1999, 29:2613-2624]; PCT 공개 번호 WO99/058572에 기재된 바와 같이 변형된다.
일부 실시양태에서, 본 발명의 항체의 불변 영역은 Fc 감마 수용체 및 보체 및 면역계와의 상호작용을 피하도록 변형될 수 있다. 이러한 불변 영역을 갖는 항체의 제조 기술은 WO 99/58572에 기재되어 있다. 예를 들어, 불변 영역은 항체가 인간에서의 임상 시험 및 치료에 사용되는 경우에 면역 반응을 피하기 위해 인간 불변 영역과 보다 유사하도록 조작될 수 있다. 예를 들어, 미국 특허 번호 5,997,867 및 5,866,692를 참조한다.
일부 실시양태에서, 불변 영역은 N-연결된 글리코실화에 대해 비-글리코실화된다. 일부 실시양태에서, 불변 영역은 불변 영역 내의 N-글리코실화 인식 서열의 일부인 올리고사카라이드 부착 잔기 및/또는 플랭킹 잔기를 돌연변이시킴으로써 N-연결된 글리코실화에 대해 비-글리코실화된다. 예를 들어, N-글리코실화 부위 N297은, 예를 들어 A, Q, K 또는 H로 돌연변이될 수 있다. 문헌 [Tao et al., J. Immunology 143: 2595-2601, 1989; 및 Jefferis et al., Immunological Reviews 163:59-76, 1998]을 참조한다. 일부 실시양태에서, 불변 영역은 N-연결된 글리코실화에 대해 비-글리코실화된다. 불변 영역은 효소적으로 (예컨대 효소 PNGase에 의해 탄수화물을 제거함) 또는 글리코실화 결핍 숙주 세포에서의 발현에 의해 N-연결된 글리코실화에 대해 비-글리코실화될 수 있다.
일부 실시양태에서, 본 발명의 항체는 PCT 공개 번호 WO 99/58572에 기재된 바와 같은 불변 영역 변형을 포함한다. 이들 항체는, 표적 분자에 지시된 결합 도메인에 추가로, 인간 이뮤노글로불린 중쇄의 불변 영역의 모두 또는 일부에 대해 실질적으로 상동인 아미노산 서열을 갖는 이펙터 도메인을 포함한다. 이들 항체는 유의한 보체 의존성 용해 또는 세포-매개 표적 파괴를 촉발하지 않으면서 표적 분자에 결합할 수 있다. 일부 실시양태에서, 이펙터 도메인은 FcRn 및/또는 FcγRIIb에 특이적으로 결합할 수 있다. 이들은 전형적으로 2개 이상의 인간 이뮤노글로불린 중쇄 CH2 도메인으로부터 유래된 키메라 도메인을 기반으로 한다. 이러한 방식으로 변형된 항체는 통상적인 항체 요법에 대한 염증성 및 다른 유해 반응을 피하기 위해 만성 항체 요법에서 사용하기에 특히 적합하다.
일부 실시양태에서, 본 발명의 항체는 비변형된 항체와 비교하여 FcRn에 대한 증가된 결합 친화도 및/또는 증가된 혈청 반감기를 갖는 변형된 불변 영역을 포함한다.
일부 실시양태에서, 본 발명의 항체는 서열식별번호: 177, 서열식별번호: 178, 서열식별번호: 179, 서열식별번호: 180, 서열식별번호: 181, 서열식별번호: 182, 서열식별번호: 183, 서열식별번호: 184 및 서열식별번호: 185로 이루어진 군으로부터 선택된 아미노산 서열을 포함하는 중쇄 불변 영역을 포함한다.
일부 실시양태에서, 본 발명의 항체는 서열식별번호: 12 또는 서열식별번호: 121의 아미노산 서열을 포함하는 경쇄 불변 영역을 포함한다.
일부 실시양태에서, 본 발명의 B7-H4xCD3 이중특이적 항체는 제1 중쇄 및 제2 중쇄를 포함하고, 각각의 중쇄는 힌지 영역을 함유한다. 일부 실시양태에서, 중쇄 중 하나의 힌지 영역은 아미노산 변형을 함유하며, 여기서 치환 아미노산은 이중특이적 항체의 다른 중쇄의 힌지 영역 내의 상응하는 아미노산과 반대 전하를 갖는다. 이러한 접근법은 국제 특허 출원 번호 PCT/US2011/036419 (WO2011/143545)에 기재되어 있다.
일부 실시양태에서, 본 발명의 B7-H4xCD3 이중특이적 항체는 제1 및 제2 이뮤노글로불린-유사 Fc 영역을 포함하고, 이중특이적 항체는 제1 및 제2 이뮤노글로불린-유사 Fc 영역 (예를 들어, 힌지 영역 및/또는 CH3 영역) 사이의 계면을 변경 또는 조작함으로써 증진된다. 이러한 접근법에서, 이중특이적 항체는 CH3 영역으로 구성될 수 있으며, 여기서 CH3 영역은 함께 상호작용하여 CH3 계면을 형성하는 제1 CH3 폴리펩티드 및 제2 CH3 폴리펩티드를 포함하고, 여기서 CH3 계면 내의 1개 이상의 아미노산은 동종이량체 형성을 탈안정화시키고 동종이량체 형성에 정전기적으로 불리하지 않다. 이러한 접근법은 국제 특허 출원 번호 PCT/US2011/036419 (WO2011/143545)에 기재되어 있다.
일부 실시양태에서, 본 발명의 B7-H4xCD3 이중특이적 항체는 B7-H4에 대해 지시된 항체 아암에 대해 조작된 글루타민-함유 펩티드 태그 및 제2 항원에 대해 지시된 항체 아암에 대해 조작된 또 다른 펩티드 태그 (예를 들어, Lys-함유 펩티드 태그 또는 반응성 내인성 Lys)를 포함한다. 이러한 접근법은 국제 특허 출원 번호 PCT/IB2011/054899 (WO2012/059882)에 기재되어 있다.
일부 실시양태에서, 본 발명의 이중특이적 항체는 제1 경쇄 및 제1 중쇄 및 제2 경쇄 및 제2 중쇄를 포함하는 전장 인간 항체를 포함하며, 여기서 제1 경쇄 및 제1 중쇄는 B7-H4에 결합하는 제1 항원 결합 도메인을 포함하는 제1 항체 아암을 형성하고, 제2 경쇄 및 제2 중쇄는 CD3에 결합하는 제2 항원 결합 도메인을 형성하는 제2 항체 아암을 형성한다. 일부 실시양태에서, 이중특이적 항체는 전장 인간 IgG2이다. 일부 실시양태에서, 이중특이적 항체는 A330P331에서 S330S331로의 돌연변이를 함유하는 전장 IgG2이다 (IgG2Δa). 일부 실시양태에서, 이중특이적 항체는 D265A의 돌연변이를 추가로 포함하는 인간 IgG2Δa이다. 일부 실시양태에서, 제1 중쇄는 위치 223, 228 및/또는 368에서의 아미노산 변형을 포함한다. 일부 실시양태에서, 제1 중쇄의 위치 223, 228 및 368에서의 아미노산 변형은 C223E, P228E 및/또는 L368E이다. 일부 실시양태에서, 제2 중쇄는 위치 223, 225, 228 및/또는 409에서의 아미노산 변형을 포함한다. 일부 실시양태에서, 제2 중쇄의 위치 223, 225, 228 및 409에서의 아미노산 변형은 C223R, E225R, P228R 및/또는 K409R이다.
일부 실시양태에서, 이중특이적 항체는 전장 인간 IgG2Δa D265A이며, 여기서 제1 중쇄는 C223E, P228E 및 L368E의 아미노산 변형을 추가로 포함하고, 제2 중쇄는 C223R, E225R, P228R 및 K409R의 아미노산 변형을 추가로 포함한다. 본원에서의 모든 아미노산 넘버링은 인간 IgG2 야생형 및 EU 넘버링 스킴에 따르고 (Eur. J. Immunol., 1999, 29:2613-2624), 도 1에 제시된 바와 같다. 도 1은 제1 중쇄 불변 영역 (B7-H4 결합 아암, 상단), 제2 중쇄 불변 영역 (CD3 결합 아암, 중간) (둘 다 본 단락에 기재된 바와 같음) 및 인간 IgG2 야생형 불변 영역 (하단)의 아미노산 서열의 정렬을 도시한다.
일부 실시양태에서, 이중특이적 항체의 제1 중쇄는 서열식별번호: 181 또는 서열식별번호: 177의 아미노산 서열을 포함하는 불변 영역을 포함하고, 이중특이적 항체의 제2 중쇄는 서열식별번호: 178의 아미노산 서열을 포함하는 불변 영역을 포함한다.
일부 실시양태에서, 이중특이적 항체의 제1 중쇄 및 제2 중쇄는 인간 IgG1의 힌지 영역 내의 위치 221 및 228에서의 아미노산 변형 (예를 들어, (D221R 또는 D221E) 및 (P228R 또는 P228E)) 및 CH3 영역 내의 위치 409 또는 368에서의 아미노산 변형 (예를 들어, K409R 또는 L368E (EU 넘버링 스킴))을 포함한다.
일부 실시양태에서, 이중특이적 항체의 제1 중쇄 및 제2 중쇄는 인간 IgG4의 힌지 영역 내의 위치 228에서의 아미노산 변형 (예를 들어, (P228E 또는 P228R)) 및 CH3 영역 내의 위치 409 또는 368에서의 아미노산 변형 (예를 들어, R409 또는 L368E (EU 넘버링 스킴))을 포함한다.
B7-H4 항체, B7-H4xCD3 이중특이적 항체 및 B7-H4xCD3 이중특이적 항체를 포함한 본 발명의 항체는 모노클로날 항체, 폴리클로날 항체, 항체 단편 (예를 들어, Fab, Fab', F(ab')2, Fv, Fc 등), 키메라 항체, 단일 쇄 가변 영역 단편 (ScFv), 그의 돌연변이체, 항체 부분 (예를 들어, 도메인 항체)을 포함하는 융합 단백질, 인간화 항체, 및 항체의 글리코실화 변이체, 항체의 아미노산 서열 변이체 및 공유 변형된 항체를 포함한, 요구되는 특이성의 항원 인식 부위를 포함하는 임의의 다른 변형된 형상의 이뮤노글로불린 분자를 포괄한다. 항체는 뮤린, 래트, 인간 또는 임의의 다른 기원 (키메라 또는 인간화 항체 포함)일 수 있다.
폴리뉴클레오티드, 벡터 및 숙주 세포
폴리뉴클레오티드
본 발명은 또한 본 발명의 B7-H4xCD3 이중특이적 항체 및 CD3 항체를 비롯한 B7-H4 항체를 코딩하는 폴리뉴클레오티드 및 상기 폴리뉴클레오티드를 포함하는 벡터 및 숙주 세포를 제공한다.
본 발명은 또한 본 발명의 임의의 폴리뉴클레오티드를 포함하는 조성물, 예컨대 제약 조성물을 제공한다. 일부 실시양태에서, 조성물은 본원에 기재된 임의의 항체를 코딩하는 폴리뉴클레오티드를 포함하는 발현 벡터를 포함한다. 일부 실시양태에서, 조성물은 서열식별번호: 196 및 서열식별번호: 197에 제시된 폴리뉴클레오티드 중 어느 하나 또는 둘 다를 포함하는 발현 벡터를 포함한다. 일부 실시양태에서, 조성물은 서열식별번호: 192 및 서열식별번호: 193에 제시된 폴리뉴클레오티드 중 어느 하나 또는 둘 다를 포함한다. 일부 실시양태에서, 조성물은 서열식별번호: 194 및 서열식별번호: 195에 제시된 폴리뉴클레오티드 중 어느 하나 또는 둘 다를 포함한다.
임의의 이러한 서열에 대한 폴리뉴클레오티드 상보성이 또한 본 발명에 포괄된다. 폴리뉴클레오티드는 단일-가닥 (코딩 또는 안티센스) 또는 이중-가닥일 수 있고, DNA (게놈, cDNA 또는 합성) 또는 RNA 분자일 수 있다. RNA 분자는 인트론을 함유하고 DNA 분자에 1-대-1 방식으로 상응하는 HnRNA 분자 및 인트론을 함유하지 않는 mRNA 분자를 포함한다. 추가의 코딩 또는 비-코딩 서열이 본 발명의 폴리뉴클레오티드 내에 존재할 수 있지만 반드시 그러할 필요는 없고, 폴리뉴클레오티드는 다른 분자 및/또는 지지체 물질에 연결될 수 있지만 반드시 그러할 필요는 없다.
폴리뉴클레오티드는 천연 서열 (즉, 항체 또는 그의 부분을 코딩하는 내인성 서열)을 포함할 수 있거나 또는 이러한 서열의 변이체를 포함할 수 있다. 폴리뉴클레오티드 변이체는 코딩된 폴리펩티드의 면역반응성이 천연 면역반응성 분자에 비해 감소되지 않도록 하는 1개 이상의 치환, 부가, 결실 및/또는 삽입을 함유한다. 코딩된 폴리펩티드의 면역반응성에 대한 효과는 일반적으로 본원에 기재된 바와 같이 평가될 수 있다. 변이체는 바람직하게는 천연 항체 또는 그의 부분을 코딩하는 폴리뉴클레오티드 서열에 대해 적어도 약 70% 동일성, 보다 바람직하게는 적어도 약 80% 동일성, 보다 더 바람직하게는 적어도 약 90% 동일성, 가장 바람직하게는 적어도 약 95% 동일성을 나타낸다.
2개의 폴리뉴클레오티드 또는 폴리펩티드 서열은 2개의 서열 내의 뉴클레오티드 또는 아미노산의 서열이 하기 기재된 바와 같이 최대 상응도로 정렬되었을 때 동일한 경우에 "동일한" 것으로 언급된다. 2개의 서열 사이의 비교는 전형적으로 서열 유사성의 국부 영역을 확인하고 비교하기 위해 비교 윈도우에 걸쳐 서열을 비교함으로써 수행된다. 본원에 사용된 "비교 윈도우"는 적어도 약 20개의 인접 위치, 통상적으로 30 내지 약 75개 또는 40 내지 약 50개의 인접 위치의 절편을 지칭하며, 여기서 서열은 2개의 서열이 최적으로 정렬된 후에 동일한 수의 인접 위치의 참조 서열과 비교될 수 있다.
비교를 위한 서열의 최적 정렬은 디폴트 파라미터를 사용하여 생물정보학 소프트웨어의 레이저진 스위트 (디엔에이스타, 인크.(DNASTAR, Inc.), 위스콘신주 매디슨) 내의 메그얼라인 프로그램을 사용하여 수행될 수 있다. 이 프로그램은 하기 참고문헌에 기재된 여러 정렬 스킴을 구현한다: 문헌 [Dayhoff, M.O., 1978, A model of evolutionary change in proteins - Matrices for detecting distant relationships. In Dayhoff, M.O. (ed.) Atlas of Protein Sequence and Structure, National Biomedical Research Foundation, Washington DC Vol. 5, Suppl. 3, pp. 345-358; Hein J., 1990, Unified Approach to Alignment and Phylogenes pp. 626-645 Methods in Enzymology vol. 183, Academic Press, Inc., San Diego, CA; Higgins, D.G. and Sharp, P.M., 1989, CABIOS 5:151-153; Myers, E.W. and Muller W., 1988, CABIOS 4:11-17; Robinson, E.D., 1971, Comb. Theor. 11:105; Santou, N., Nes, M., 1987, Mol. Biol. Evol. 4:406-425; Sneath, P.H.A. and Sokal, R.R., 1973, Numerical Taxonomy the Principles and Practice of Numerical Taxonomy, Freeman Press, San Francisco, CA; Wilbur, W.J. and Lipman, D.J., 1983, Proc. Natl. Acad. Sci. USA 80:726-730].
바람직하게는, "서열 동일성의 백분율"은 2개의 최적으로 정렬된 서열을 적어도 20개의 위치의 비교 윈도우에 걸쳐 비교함으로써 결정되며, 여기서 비교 윈도우 내의 폴리뉴클레오티드 또는 폴리펩티드 서열의 부분은 2개의 서열의 최적 정렬을 위해 참조 서열 (부가 또는 결실을 포함하지 않음)과 비교하여 20 퍼센트 이하, 통상적으로 5 내지 15 퍼센트 또는 10 내지 12 퍼센트의 부가 또는 결실 (즉, 갭)을 포함할 수 있다. 백분율은 동일한 핵산 염기 또는 아미노산 잔기가 두 서열에서 발생하는 위치의 수를 결정하여 매칭되는 위치의 수를 산출하고, 매칭되는 위치의 수를 참조 서열 내의 위치의 총수 (즉, 윈도우 크기)로 나누고, 결과에 100을 곱하여 서열 동일성의 백분율을 산출함으로써 계산된다.
변이체는 또한 또는 대안적으로, 천연 유전자 또는 그의 부분 또는 상보체에 대해 실질적으로 상동일 수 있다. 이러한 폴리뉴클레오티드 변이체는 천연 항체를 코딩하는 자연 발생 DNA 서열 (또는 상보성 서열)에 중간 정도로 엄격한 조건 하에 혼성화할 수 있다.
적합한 "중간 정도로 엄격한 조건"은 5 X SSC, 0.5% SDS, 1.0 mM EDTA (pH 8.0)의 용액 중에서 사전세척하고; 50℃-65℃, 5 X SSC에서 밤새 혼성화하고; 이어서 0.1% SDS를 함유하는 각각의 2X, 0.5X 및 0.2X SSC로 65℃에서 20분 동안 2회 세척하는 것을 포함한다.
본원에 사용된 "고도로 엄격한 조건" 또는 "고 엄격도 조건"은 (1) 세척을 위해 낮은 이온 강도 및 높은 온도, 예를 들어 50℃에서 0.015 M 염화나트륨/0.0015 M 시트르산나트륨/0.1% 소듐 도데실 술페이트를 사용하거나; (2) 혼성화 동안 42℃에서 변성제, 예컨대 포름아미드, 예를 들어 50% (v/v) 포름아미드 + 0.1% 소 혈청 알부민/0.1% 피콜/0.1% 폴리비닐피롤리돈/50 mM 인산나트륨 완충제 (pH 6.5) + 750 mM 염화나트륨, 75 mM 시트르산나트륨을 사용하거나; 또는 (3) 42℃에서 50% 포름아미드, 5 x SSC (0.75 M NaCl, 0.075 M 시트르산나트륨), 50 mM 인산나트륨 (pH 6.8), 0.1% 피로인산나트륨, 5 x 덴하르트 용액, 초음파처리된 연어 정자 DNA (50 μg/ml), 0.1% SDS 및 10% 덱스트란 술페이트를 사용하고, 42℃에서 0.2 x SSC (염화나트륨/시트르산나트륨) 및 55℃에서 50% 포름아미드로 세척하고, 이어서 55℃에서 EDTA를 함유하는 0.1 x SSC로 이루어진 고-엄격도 세척을 수행하는 것이다. 관련 기술분야의 통상의 기술자는 프로브 길이 등과 같은 인자를 수용하기 위해 필요에 따라 온도, 이온 강도 등을 조정하는 방법을 인식할 것이다.
관련 기술분야의 통상의 기술자는 유전자 코드의 축중성의 결과로서, 본원에 기재된 바와 같은 폴리펩티드를 코딩하는 많은 뉴클레오티드 서열이 존재한다는 것을 인지할 것이다. 이들 폴리뉴클레오티드 중 일부는 임의의 천연 유전자의 뉴클레오티드 서열에 대해 최소의 상동성을 보유한다. 그럼에도 불구하고, 코돈 용법에서의 차이로 인해 달라지는 폴리뉴클레오티드가 본 발명에 의해 구체적으로 고려된다. 추가로, 본원에 제공된 폴리뉴클레오티드 서열을 포함하는 유전자의 대립유전자는 본 발명의 범주 내에 있다. 대립유전자는 뉴클레오티드의 1개 이상의 돌연변이, 예컨대 결실, 부가 및/또는 치환의 결과로서 변경된 내인성 유전자이다. 생성된 mRNA 및 단백질은 변경된 구조 또는 기능을 가질 수 있지만, 반드시 그러할 필요는 없다. 대립유전자는 표준 기술 (예컨대 혼성화, 증폭 및/또는 데이터베이스 서열 비교)을 사용하여 확인될 수 있다.
본 발명의 폴리뉴클레오티드는 화학적 합성, 재조합 방법 또는 PCR을 사용하여 수득될 수 있다. 화학적 폴리뉴클레오티드 합성 방법은 관련 기술분야에 널리 공지되어 있고, 본원에 상세히 기재될 필요는 없다. 관련 기술분야의 통상의 기술자는 본원에 제공된 서열 및 상업적 DNA 합성기를 사용하여 목적하는 DNA 서열을 생성할 수 있다.
재조합 방법을 사용하여 폴리뉴클레오티드를 제조하기 위해, 목적하는 서열을 포함하는 폴리뉴클레오티드가 적합한 벡터 내로 삽입될 수 있고, 벡터가 다시 본원에 추가로 논의된 바와 같이 복제 및 증폭을 위해 적합한 숙주 세포 내로 도입될 수 있다. 폴리뉴클레오티드는 관련 기술분야에 공지된 임의의 수단에 의해 숙주 세포 내로 삽입될 수 있다. 세포는 직접 흡수, 세포내이입, 형질감염, F-메이팅 또는 전기천공에 의해 외인성 폴리뉴클레오티드를 도입함으로써 형질전환된다. 도입되면, 외인성 폴리뉴클레오티드는 세포 내에서 비-통합된 벡터 (예컨대 플라스미드)로서 유지되거나 또는 숙주 세포 게놈 내로 통합될 수 있다. 이와 같이 증폭된 폴리뉴클레오티드는 관련 기술분야에 널리 공지된 방법에 의해 숙주 세포로부터 단리될 수 있다. 예를 들어, 문헌 [Sambrook et al., 1989]을 참조한다.
대안적으로, PCR은 DNA 서열의 재현을 가능하게 한다. PCR 기술은 관련 기술분야에 널리 공지되어 있고, 미국 특허 번호 4,683,195, 4,800,159, 4,754,065 및 4,683,202, 뿐만 아니라 문헌 [PCR: The Polymerase Chain Reaction, Mullis et al. eds., Birkauswer Press, Boston, 1994]에 기재되어 있다.
RNA는 적절한 벡터 내의 단리된 DNA를 사용하고 이를 적합한 숙주 세포 내로 삽입함으로써 수득될 수 있다. 세포가 복제되고 DNA가 RNA로 전사되는 경우에, RNA는 이어서, 예를 들어 상기 문헌 [Sambrook et al., 1989]에 제시된 바와 같이 관련 기술분야의 통상의 기술자에게 널리 공지된 방법을 사용하여 단리될 수 있다.
벡터
적합한 클로닝 벡터는 표준 기술에 따라 구축될 수 있거나 또는 관련 기술분야에서 이용가능한 다수의 클로닝 벡터로부터 선택될 수 있다. 선택된 클로닝 벡터는 사용하고자 의도되는 숙주 세포에 따라 달라질 수 있지만, 유용한 클로닝 벡터는 일반적으로 자기-복제 능력을 가질 것이고/거나, 특정한 제한 엔도뉴클레아제에 대한 단일 표적을 보유할 수 있고/거나, 벡터를 함유하는 클론을 선택하는데 사용될 수 있는 마커에 대한 유전자를 보유할 수 있다. 적합한 예는 플라스미드 및 박테리아 바이러스, 예를 들어 pUC18, pUC19, 블루스크립트 (예를 들어, pBS SK+) 및 그의 유도체, mp18, mp19, pBR322, pMB9, ColE1, pCR1, RP4, 파지 DNA 및 셔틀 벡터, 예컨대 pSA3 및 pAT28을 포함한다. 이들 및 많은 다른 클로닝 벡터는 상업적 판매업체, 예컨대 바이오라드(BioRad), 스트라테진(Strategene) 및 인비트로젠(Invitrogen)으로부터 입수가능하다.
발현 벡터는 일반적으로 본 발명에 따른 폴리뉴클레오티드를 함유하는 복제가능한 폴리뉴클레오티드 구축물이다. 이는 발현 벡터가 숙주 세포에서 에피솜으로서 또는 염색체 DNA의 필수 부분으로서 복제가능해야 한다는 것을 암시한다. 적합한 발현 벡터는 플라스미드, 바이러스 벡터, 예컨대 아데노바이러스, 아데노-연관 바이러스, 레트로바이러스, 코스미드 및 PCT 공개 번호 WO 87/04462에 개시된 발현 벡터(들)를 포함하나 이에 제한되지는 않는다. 벡터 성분은 일반적으로 하기 중 1종 이상을 포함할 수 있으나 이에 제한되지는 않는다: 신호 서열; 복제 기점; 1종 이상의 마커 유전자; 적합한 전사 제어 요소 (예컨대 프로모터, 인핸서 및 종결인자). 발현 (즉, 번역)을 위해, 1종 이상의 번역 제어 요소, 예컨대 리보솜 결합 부위, 번역 개시 부위 및 정지 코돈이 또한 통상적으로 요구된다.
관심 폴리뉴클레오티드를 함유하는 벡터는 전기천공, 염화칼슘, 염화루비듐, 인산칼슘, DEAE-덱스트란 또는 다른 물질을 사용한 형질감염; 미세발사체 충격; 리포펙션; 및 감염 (예를 들어, 벡터가 감염원, 예컨대 백시니아 바이러스인 경우)을 포함한 임의의 다수의 적절한 수단에 의해 숙주 세포 내로 도입될 수 있다. 도입 벡터 또는 폴리뉴클레오티드의 선택은 종종 숙주 세포의 특색에 좌우될 것이다.
숙주 세포
본 발명은 또한 본원에 기재된 임의의 폴리뉴클레오티드를 포함하는 숙주 세포를 제공한다. 이종 DNA를 과다발현할 수 있는 임의의 숙주 세포가 관심 항체, 폴리펩티드 또는 단백질을 코딩하는 유전자를 단리하기 위한 목적으로 사용될 수 있다. 포유동물 숙주 세포의 비제한적 예는 COS, HeLa 및 CHO 세포를 포함하나 이에 제한되지는 않는다. 또한, PCT 공개 번호 WO 87/04462를 참조한다. 적합한 비-포유동물 숙주 세포는 원핵생물 (예컨대 이. 콜라이(E. coli) 또는 비. 서브틸리스(B. subtillis)) 및 효모 (예컨대 에스. 세레비자에(S. cerevisae), 에스. 폼베(S. pombe); 또는 케이. 락티스(K. lactis))를 포함한다. 바람직하게는, 숙주 세포는 숙주 세포에 존재하는 경우에 상응하는 관심 내인성 항체 또는 단백질의 수준보다 약 5배 더 높은, 보다 바람직하게는 10배 더 높은, 보다 더 바람직하게는 20배 더 높은 수준으로 cDNA를 발현한다. 숙주 세포를 B7-H4 또는 B7-H4 도메인 (예를 들어, 도메인 1-4)에의 특이적 결합에 대해 스크리닝하는 것은 면역검정 또는 FACS에 의해 수행된다. 관심 항체 또는 단백질을 과다발현하는 세포가 확인될 수 있다.
단백질 발현 및/또는 전달
발현 벡터는 B7-H4, CD3 또는 다른 종양 항원 항체의 발현을 지시하는데 사용될 수 있다. 관련 기술분야의 통상의 기술자는 생체내에서 외인성 단백질의 발현을 얻기 위해 발현 벡터를 투여하는 것에 친숙하다. 예를 들어, 미국 특허 번호 6,436,908; 6,413,942; 및 6,376,471을 참조한다. 발현 벡터의 투여는 주사, 경구 투여, 입자 총 또는 카테터삽입 투여 및 국소 투여를 포함한, 국부 또는 전신 투여를 포함한다. 또 다른 실시양태에서, 발현 벡터는 교감신경 줄기 또는 신경절에 또는 관상 동맥, 심방, 심실 또는 심막 내로 직접 투여된다.
발현 벡터 또는 서브게놈 폴리뉴클레오티드를 함유하는 치료 조성물의 표적화된 전달이 또한 사용될 수 있다. 수용체-매개 DNA 전달 기술은, 예를 들어 문헌 [Findeis et al., Trends Biotechnol., 1993, 11:202; Chiou et al., Gene Therapeutics: Methods And Applications Of Direct Gene Transfer, J.A. Wolff, ed., 1994; Wu et al., J. Biol. Chem., 263:621, 1988; Wu et al., J. Biol. Chem., 269:542, 1994; Zenke et al., Proc. Natl. Acad. Sci. USA, 87:3655, 1990; 및 Wu et al., J. Biol. Chem., 266:338, 1991]에 기재되어 있다. 폴리뉴클레오티드를 함유하는 치료 조성물은 유전자 요법 프로토콜에서 국부 투여를 위해 약 100 ng 내지 약 200 mg 범위의 DNA로 투여된다. 또한, 약 500 ng 내지 약 50 mg, 약 1 μg 내지 약 2 mg, 약 5 μg 내지 약 500 μg 및 약 20 μg 내지 약 100 μg 농도 범위의 DNA가 유전자 요법 프로토콜 동안 사용될 수 있다. 치료 폴리뉴클레오티드 및 폴리펩티드는 유전자 전달 비히클을 사용하여 전달될 수 있다. 유전자 전달 비히클은 바이러스 또는 비-바이러스 기원일 수 있다 (일반적으로, 문헌 [Jolly, Cancer Gene Therapy,1:51, 1994; Kimura, Human Gene Therapy, 5:845, 1994; Connelly, Human Gene Therapy, 1995, 1:185; 및 Kaplitt, Nature Genetics, 6:148, 1994] 참조). 이러한 코딩 서열의 발현은 내인성 포유동물 또는 이종 프로모터를 사용하여 유도될 수 있다. 코딩 서열의 발현은 구성적이거나 또는 조절될 수 있다.
목적하는 폴리뉴클레오티드의 전달 및 목적하는 세포에서의 발현을 위한 바이러스-기반 벡터는 관련 기술분야에 널리 공지되어 있다. 예시적인 바이러스-기반 비히클은 재조합 레트로바이러스 (예를 들어, PCT 공개 번호 WO 90/07936; WO 94/03622; WO 93/25698; WO 93/25234; WO 93/11230; WO 93/10218; WO 91/02805; 미국 특허 번호 5,219,740 및 4,777,127; 영국 특허 번호 2,200,651; 및 유럽 특허 번호 0 345 242 참조), 알파바이러스-기반 벡터 (예를 들어, 신드비스 바이러스 벡터, 셈리키 포레스트 바이러스 (ATCC VR-67; ATCC VR-1247), 로스강 바이러스 (ATCC VR-373; ATCC VR-1246) 및 베네수엘라 말 뇌염 바이러스 (ATCC VR-923; ATCC VR-1250; ATCC VR 1249; ATCC VR-532)), 및 아데노-연관 바이러스 (AAV) 벡터 (예를 들어, PCT 공개 번호 WO 94/12649, WO 93/03769; WO 93/19191; WO 94/28938; WO 95/11984 및 WO 95/00655 참조)를 포함하나 이에 제한되지는 않는다. 문헌 [Curiel, Hum. Gene Ther., 1992, 3:147]에 기재된 바와 같은 사멸 아데노바이러스에 연결된 DNA의 투여가 또한 사용될 수 있다.
사멸 아데노바이러스 단독에 연결되거나 연결되지 않은 다가양이온성 축합 DNA (예를 들어, 문헌 [Curiel, Hum. Gene Ther., 3:147, 1992] 참조); 리간드-연결 DNA (예를 들어, 문헌 [Wu, J. Biol. Chem., 264:16985, 1989] 참조); 진핵 세포 전달 비히클 세포 (예를 들어, 미국 특허 번호 5,814,482; PCT 공개 번호 WO 95/07994; WO 96/17072; WO 95/30763; 및 WO 97/42338 참조) 및 핵 전하 중화 또는 세포막과의 융합을 포함하나 이에 제한되지는 않는 비-바이러스 전달 비히클 및 방법이 또한 사용될 수 있다. 네이키드 DNA가 또한 사용될 수 있다. 예시적인 네이키드 DNA 도입 방법은 PCT 공개 번호 WO 90/11092 및 미국 특허 번호 5,580,859에 기재되어 있다. 유전자 전달 비히클로서 작용할 수 있는 리포솜은 미국 특허 번호 5,422,120; PCT 공개 번호 WO 95/13796; WO 94/23697; WO 91/14445; 및 EP 0524968에 기재되어 있다. 추가의 접근법은 문헌 [Philip, Mol. Cell Biol., 14:2411, 1994 및 Woffendin, Proc. Natl. Acad. Sci., 91:1581, 1994]에 기재되어 있다.
ATCC 기탁
본 발명의 대표적인 물질은 2020년 6월 19일에 아메리칸 타입 컬쳐 콜렉션 (ATCC)에 기탁되었다. ATCC 수탁 번호 PTA-126779를 갖는 벡터는 이중특이적 항체 1167의 전장 제1 중쇄 (B7-H4 아암)를 코딩하는 폴리뉴클레오티드를 함유한다. ATCC 수탁 번호 PTA-126781을 갖는 벡터는 이중특이적 항체 1167의 전장 제1 경쇄 (B7-H4 아암)를 코딩하는 폴리뉴클레오티드를 함유한다. ATCC 수탁 번호 PTA-126780을 갖는 벡터는 이중특이적 항체 1167의 전장 제2 중쇄 (CD3 아암)를 코딩하는 폴리뉴클레오티드를 함유한다. ATCC 수탁 번호 PTA-126782를 갖는 벡터는 이중특이적 항체 1167의 전장 제2 경쇄 (CD3 아암)를 코딩하는 폴리뉴클레오티드를 함유한다.
기탁은 특허절차상 미생물 기탁의 국제적 승인에 관한 부다페스트 조약 및 그 하의 규정 (부다페스트 조약)의 조항 하에 이루어졌다. 이는 기탁일로부터 30년 동안 기탁물의 생존 배양물의 유지를 보장한다. 기탁물은 부다페스트 조약의 조항 하에 및 화이자, 인크.(Pfizer, Inc.)와 ATCC 사이의 협정에 따라 ATCC에 의해 입수가능할 것이며, 상기 협정은 관련 미국 특허의 허여시 또는 임의의 미국 또는 외국 특허 출원의 공개시 (어느 것이든지 먼저인 것), 기탁물의 배양물의 자손을 영구적이고 비제한적으로 공중이 입수할 수 있는 것을 보장하고, 35 U.S.C. 122항 및 이에 따른 미국 특허상표청장의 규칙 (886 OG 638에 대한 특정 참조와 함께 37 C.F.R. 1.14항 포함)에 따라 자격이 있는 것으로 특허상표청장에 의해 결정된 이가 자손을 입수할 수 있는 것을 보장한다.
본 출원의 수탁자는 기탁시의 상기 물질의 배양물이 적합한 조건 하에 배양될 경우에 사멸하거나 또는 분실되거나 또는 파괴되어야 한다면, 이 물질을 동일한 또 다른 것으로 즉시 대체하고 고지할 것에 동의하였다. 기탁된 물질의 입수가능성은 특허법에 따라 임의의 정부의 권한 하에 부여된 권리에 위반하여 본 발명을 실시할 수 있는 라이센스로서 해석되는 것은 아니다.
본 발명의 항체의 제조 방법.
본 발명의 항체는 관련 기술분야에 공지되고 본원에 기재된 바와 같은 임의의 방법에 의해 제조될 수 있다.
예를 들어, 본원에 기재된 B7-H4 항체는 B7-H4에 대한 결합을 검출 및/또는 측정하는 관련 기술분야에 공지된 방법을 사용하여 확인 또는 특징화될 수 있다. 일부 실시양태에서, B7-H4 항체는 후보 작용제와 B7-H4의 결합 검정을 수행함으로써 확인된다. 결합 검정은 정제된 B7-H4 폴리펩티드(들)로 또는 B7-H4 폴리펩티드(들)를 자연적으로 발현하거나 발현하도록 형질감염된 세포로 수행될 수 있다. 한 실시양태에서, 결합 검정은 공지된 B7-H4 항체와 B7-H4 결합에 대해 경쟁하는 후보 항체의 능력을 평가하는 경쟁적 결합 검정이다. 검정은 ELISA 포맷을 포함한 다양한 포맷으로 수행될 수 있다.
초기 확인 후에, 후보 B7-H4 항체의 활성은 표적화된 생물학적 활성을 시험하는 것으로 공지된 생물검정에 의해 추가로 확인되고 정밀화될 수 있다. 대안적으로, 생물검정은 후보를 직접 스크리닝하는데 사용될 수 있다. 항체를 확인하고 특징화하는 방법 중 일부는 실시예에 상세히 기재되어 있다.
B7-H4 항체는 관련 기술분야에 널리 공지된 방법을 사용하여 특징화될 수 있다. 예를 들어, 하나의 방법은 그것이 결합하는 에피토프를 확인하는 것 또는 "에피토프 맵핑"이다. 예를 들어 문헌 [Harlow and Lane, Using Antibodies, a Laboratory Manual, Cold Spring Harbor Laboratory Press, Cold Spring Harbor, New York, 1999]의 챕터 11에 기재된 바와 같은, 항체-항원 복합체의 결정 구조의 해석, 경쟁 검정, 유전자 단편 발현 검정 및 합성 펩티드-기반 검정을 포함한, 단백질 상의 에피토프의 위치를 맵핑하고 특징화하는 방법 다수가 관련 기술분야에 공지되어 있다. 추가의 예에서, 에피토프 맵핑은 항체가 결합하는 서열을 결정하는데 사용될 수 있다. 에피토프 맵핑은 다양한 공급원, 예를 들어 펩스캔 시스템즈(Pepscan Systems) (네덜란드 8219 PH 렐리스타트 에델헤르트베크 15)로부터 상업적으로 입수가능하다. 에피토프는 선형 에피토프, 즉 아미노산의 단일 스트레치에 함유된 에피토프일 수 있거나, 또는 반드시 단일 스트레치에 함유될 필요는 없을 수 있는 아미노산의 3차원 상호작용에 의해 형성된 입체형태적 에피토프일 수 있다. 다양한 길이 (예를 들어, 적어도 4-6개 아미노산 길이)의 펩티드가 단리 또는 합성되고 (예를 들어, 재조합적으로), B7-H4, CD3 또는 다른 종양 항원 항체와의 결합 검정에 사용될 수 있다. 또 다른 예에서, B7-H4, CD3 또는 다른 종양 항원 항체가 결합하는 에피토프는, B7-H4, CD3 또는 다른 종양 항원 서열로부터 유래된 중첩 펩티드를 사용하고 B7-H4, CD3 또는 다른 종양 항원 항체에 의한 결합을 결정함으로써 체계적인 스크리닝에서 결정될 수 있다. 유전자 단편 발현 검정에 따르면, B7-H4, CD3 또는 다른 종양 항원을 코딩하는 오픈 리딩 프레임이 무작위로 또는 특이적 유전자 구축에 의해 단편화되고, B7-H4, CD3 또는 다른 종양 항원의 발현된 단편과 시험될 항체의 반응성이 결정된다. 유전자 단편은, 예를 들어 PCR에 의해 생산된 다음, 방사성 아미노산의 존재 하에 시험관내에서 단백질로 전사 및 번역될 수 있다. 이어서, 방사성 표지된 B7-H4, CD3 또는 다른 종양 항원 단편에 대한 항체의 결합이 면역침전 및 겔 전기영동에 의해 결정된다. 또한, 파지 입자의 표면 상에 디스플레이된 무작위 펩티드 서열의 대형 라이브러리 (파지 라이브러리)를 사용함으로써 특정 에피토프가 확인될 수 있다. 대안적으로, 정의된 중첩 펩티드 단편의 라이브러리가 간단한 결합 검정에서 시험 항체에의 결합에 대해 시험될 수 있다. 추가의 예에서, 항원 결합 도메인의 돌연변이유발, 도메인 스와핑 실험 및 알라닌 스캐닝 돌연변이유발이 수행되어, 에피토프 결합에 요구되고/거나 충분하고/거나 필요한 잔기를 확인할 수 있다. 예를 들어, 도메인 스와핑 실험은 B7-H4, CD3 또는 다른 종양 항원 단백질의 다양한 단편이 또 다른 종 (예를 들어, 마우스)으로부터의 B7-H4 또는 밀접하게 관련되지만 항원적으로 구별되는 단백질 (예를 들어, B7-H3)로부터의 서열로 대체 (스와핑)된 돌연변이 B7-H4, CD3 또는 다른 종양 항원을 사용하여 수행될 수 있다. 돌연변이 B7-H4, CD3 또는 다른 종양 항원에 대한 항체의 결합을 평가함으로써, 항체 결합에 대한 특정한 B7-H4, CD3 또는 다른 종양 항원 단편의 중요성이 평가될 수 있다.
B7-H4, CD3 또는 다른 종양 항원 항체를 특징화하는데 사용될 수 있는 또 다른 방법은 동일한 항원, 즉 B7-H4, CD3 또는 다른 종양 항원 상의 다양한 단편에 결합하는 것으로 공지된 다른 항체와의 경쟁 검정을 사용하여, B7-H4, CD3 또는 다른 종양 항원 항체가 다른 항체와 동일한 에피토프에 결합하는지 여부를 결정하는 것이다. 경쟁 검정은 관련 기술분야의 통상의 기술자에게 널리 공지되어 있다.
제약 조성물 및 제제
본 발명은 유효량의 본 발명의 B7-H4 항체 또는 B7-H4xCD3 이중특이적 항체를 포함하는 제약 조성물을 제공한다. 제약 조성물은 다양한 제제로 존재할 수 있다.
본 발명의 B7-H4xCD3 이중특이적 항체를 비롯한 B7-H4 항체의 다양한 제제가 투여에 사용될 수 있다. 일부 실시양태에서, 항체는 순수하게 투여될 수 있다. 일부 실시양태에서, 항체 및 제약상 허용되는 부형제는 다양한 제제로 존재할 수 있다. 제약상 허용되는 부형제는 관련 기술분야에 공지되어 있다. 적합한 부형제는 안정화제, 습윤제 및 유화제, 다양한 오스몰농도를 위한 염, 캡슐화제, 완충제 및 피부 침투 증진제를 포함하나 이에 제한되지는 않는다. 부형제뿐만 아니라 비경구 및 비-비경구 약물 전달을 위한 제제는 문헌 [Remington, The Science and Practice of Pharmacy 21st Ed. Mack Publishing, 2005]에 제시되어 있다. 일부 실시양태에서, 이들 작용제 (부형제)는 주사 (예를 들어, 복강내로, 정맥내로, 피하로, 근육내로 등)에 의한 투여를 위해 제제화된다. 따라서, 이들 작용제는 제약상 허용되는 비히클, 예컨대 염수, 링거액, 덱스트로스 용액 등과 조합될 수 있다. 특정한 투여 요법, 즉 용량, 시기 및 반복은 특정한 개체 및 그 개체의 의료 병력에 좌우될 것이다.
본 발명의 방법에 따라 사용되는 본 발명의 B7-H4xCD3 이중특이적 항체를 비롯한 B7-H4 항체의 치료 제제는 목적하는 정도의 순도를 갖는 항체를 임의적인 제약상 허용되는 담체, 부형제 또는 안정화제 (Remington, The Science and Practice of Pharmacy 21st Ed. Mack Publishing, 2005)와 혼합하여 동결건조 제제 또는 수용액의 형태로 저장을 위해 제조된다. 허용되는 담체, 부형제 또는 안정화제는 사용되는 투여량 및 농도에서 수용자에게 비독성이고, 완충제, 예컨대 포스페이트, 시트레이트 및 다른 유기 산; 염, 예컨대 염화나트륨; 항산화제, 예를 들어 아스코르브산 및 메티오닌; 보존제 (예컨대 옥타데실디메틸벤질 암모늄 클로라이드; 헥사메토늄 클로라이드; 벤즈알코늄 클로라이드, 벤제토늄 클로라이드; 페놀, 부틸 또는 벤질 알콜; 알킬 파라벤, 예컨대 메틸 또는 프로필 파라벤; 카테콜; 레조르시놀; 시클로헥산올; 3-펜탄올; 및 m-크레졸); 저분자량 (약 10개 미만의 잔기) 폴리펩티드; 단백질, 예컨대 혈청 알부민, 젤라틴 또는 이뮤노글로불린; 친수성 중합체, 예컨대 폴리비닐피롤리돈; 아미노산, 예컨대 글리신, 글루타민, 아스파라긴, 히스티딘, 아르기닌 또는 리신; 모노사카라이드, 디사카라이드 및 다른 탄수화물, 예컨대 글루코스, 만노스 또는 덱스트린; 킬레이트화제, 예컨대 EDTA; 당, 예컨대 수크로스, 만니톨, 트레할로스 또는 소르비톨; 염-형성 반대-이온, 예컨대 나트륨; 금속 착물 (예를 들어, Zn-단백질 착물); 및/또는 비-이온성 계면활성제, 예컨대 트윈(TWEEN)™, 플루로닉스(PLURONICS)™ 또는 폴리에틸렌 글리콜 (PEG)을 포함할 수 있다.
본 발명의 B7-H4xCD3 이중특이적 항체를 비롯한 B7-H4 항체를 함유하는 리포솜은 관련 기술분야에 공지된 방법, 예컨대 문헌 [Epstein, et al., Proc. Natl. Acad. Sci. USA 82:3688, 1985; Hwang, et al., Proc. Natl Acad. Sci. USA 77:4030, 1980]; 및 미국 특허 번호 4,485,045 및 4,544,545에 기재된 방법에 의해 제조된다. 순환 시간이 증진된 리포솜은 미국 특허 번호 5,013,556에 개시되어 있다. 특히 유용한 리포솜은 포스파티딜콜린, 콜레스테롤 및 PEG-유도체화 포스파티딜에탄올아민 (PEG-PE)을 포함하는 지질 조성물을 사용한 역상 증발 방법에 의해 생성될 수 있다. 리포솜은 한정된 세공 크기의 필터를 통해 압출되어 목적하는 직경을 갖는 리포솜을 생성한다.
활성 성분은 또한, 예를 들어 코아세르베이션 기술에 의해 또는 계면 중합에 의해 제조된 마이크로캡슐, 예를 들어 각각 히드록시메틸셀룰로스 또는 젤라틴-마이크로캡슐 및 폴리-(메틸메타크릴레이트) 마이크로캡슐에, 콜로이드성 약물 전달 시스템 (예를 들어, 리포솜, 알부민 마이크로구체, 마이크로에멀젼, 나노입자 및 나노캡슐)에 또는 마크로에멀젼에 포획될 수 있다. 이러한 기술은 문헌 [Remington, The Science and Practice of Pharmacy 21st Ed. Mack Publishing, 2005]에 개시되어 있다.
지속-방출 제제가 제조될 수 있다. 지속-방출 제제의 적합한 예는 항체를 함유하는 고체 소수성 중합체의 반투과성 매트릭스를 포함하며, 이 매트릭스는 성형품, 예를 들어 필름 또는 마이크로캡슐의 형태이다. 지속-방출 매트릭스의 예는 폴리에스테르, 히드로겔 (예를 들어, 폴리(2-히드록시에틸-메타크릴레이트) 또는 폴리(비닐알콜)), 폴리락티드 (미국 특허 번호 3,773,919), L-글루탐산 및 7 에틸-L-글루타메이트의 공중합체, 비-분해성 에틸렌-비닐 아세테이트, 분해성 락트산-글리콜산 공중합체, 예컨대 루프론 데포(LUPRON DEPOT)™ (락트산-글리콜산 공중합체 및 류프롤리드 아세테이트로 구성된 주사가능한 마이크로구체), 수크로스 아세테이트 이소부티레이트 및 폴리-D-(-)-3-히드록시부티르산을 포함한다.
생체내 투여에 사용될 제제는 멸균되어야 한다. 이는, 예를 들어 멸균 여과 막을 통한 여과에 의해 용이하게 달성된다. 치료 항체, 예를 들어 본 발명의 조성물의 B7-H4xCD3 이중특이적 항체를 비롯한 B7-H4 항체는 일반적으로 멸균 접근 포트를 갖는 용기, 예를 들어 피하 주사 바늘로 뚫을 수 있는 마개를 갖는 정맥내 용액 백 또는 바이알 내에 배치된다.
본 발명에 따른 조성물은 경구, 비경구 또는 직장 투여 또는 흡입 또는 취입에 의한 투여를 위한 단위 투여 형태, 예컨대 정제, 환제, 캡슐, 분말, 과립, 용액 또는 현탁액 또는 좌제일 수 있다.
고체 조성물, 예컨대 정제를 제조하기 위해, 주요 활성 성분을 제약 담체, 예를 들어 통상적인 정제화 성분, 예컨대 옥수수 전분, 락토스, 수크로스, 소르비톨, 활석, 스테아르산, 스테아르산마그네슘, 인산이칼슘 또는 검 및 다른 제약 희석제, 예를 들어 물과 혼합하여, 본 발명의 화합물 또는 그의 비-독성 제약상 허용되는 염의 균질 혼합물을 함유하는 고체 예비제제 조성물을 형성한다. 이들 예비제제 조성물을 균질한 것으로 언급하는 경우, 이는 활성 성분이 조성물 전반에 걸쳐 고르게 분산되어 조성물이 동등하게 효과적인 단위 투여 형태, 예컨대 정제, 환제 및 캡슐로 용이하게 세분될 수 있음을 의미한다. 이어서, 이러한 고체 예비제제 조성물은 0.1 내지 약 500 mg의 본 발명의 활성 성분을 함유하는 상기 기재된 유형의 단위 투여 형태로 세분된다. 신규 조성물의 정제 또는 환제는 코팅되거나 또는 달리 배합되어 지속 작용의 이점을 제공하는 투여 형태를 제공할 수 있다. 예를 들어, 정제 또는 환제는 내부 투여 및 외부 투여 성분을 포함할 수 있으며, 후자는 전자 위의 외피의 형태이다. 2종의 성분은 위에서의 붕해에 저항하는 역할을 하고 내부 성분이 십이지장 내로 무손상 통과하거나 방출이 지연되도록 하는 장용 층에 의해 분리될 수 있다. 다양한 물질이 이러한 장용 층 또는 코팅에 사용될 수 있으며, 이러한 물질은 다수의 중합체 산 및 중합체 산과 쉘락, 세틸 알콜 및 셀룰로스 아세테이트와 같은 물질의 혼합물을 포함한다.
적합한 표면-활성제는, 특히 비-이온성 작용제, 예컨대 폴리옥시에틸렌소르비탄 (예를 들어, 트윈(Tween)™ 20, 40, 60, 80 또는 85) 및 다른 소르비탄 (예를 들어, 스팬(Span)™ 20, 40, 60, 80 또는 85)을 포함한다. 표면-활성제를 갖는 조성물은 편리하게는 0.05 내지 5%의 표면-활성제를 포함할 것이고, 0.1 내지 2.5%일 수 있다. 필요한 경우에, 다른 성분, 예를 들어 만니톨 또는 다른 제약상 허용되는 비히클이 첨가될 수 있는 것으로 인지될 것이다.
적합한 에멀젼은 상업적으로 입수가능한 지방 에멀젼, 예컨대 인트라리피드(Intralipid)™, 리포신(Liposyn)™, 인포누트롤(Infonutrol)™, 리포푼딘(Lipofundin)™ 및 리피피산(Lipiphysan)™을 사용하여 제조될 수 있다. 활성 성분은 사전-혼합된 에멀젼 조성물 중에 용해될 수 있거나 또는 대안적으로 오일 (예를 들어 대두 오일, 홍화 오일, 목화씨 오일, 참깨 오일, 옥수수 오일 또는 아몬드 오일) 중에 용해될 수 있고, 에멀젼은 인지질 (예를 들어 난 인지질, 대두 인지질 또는 대두 레시틴) 및 물과 혼합시 형성될 수 있다. 에멀젼의 장성을 조정하기 위해 다른 성분, 예를 들어 글리세롤 또는 글루코스가 첨가될 수 있다는 것이 인지될 것이다. 적합한 에멀젼은 전형적으로 20% 이하, 예를 들어 5 내지 20%의 오일을 함유할 것이다. 지방 에멀젼은 0.1 내지 1.0 μm, 특히 0.1 내지 0.5 μm의 지방 액적을 포함할 수 있고, 5.5 내지 8.0 범위의 pH를 가질 수 있다.
에멀젼 조성물은 본 발명의 B7-H4xCD3 이중특이적 항체를 비롯한 B7-H4 항체를 인트라리피드™ 또는 그의 성분 (대두 오일, 난 인지질, 글리세롤 및 물)과 혼합함으로써 제조된 것일 수 있다.
흡입 또는 취입을 위한 조성물은 제약상 허용되는 수성 또는 유기 용매 또는 그의 혼합물 중의 용액 및 현탁액 및 분말을 포함한다. 액체 또는 고체 조성물은 상기 제시된 바와 같은 적합한 제약상 허용되는 부형제를 함유할 수 있다. 일부 실시양태에서, 조성물은 국부 또는 전신 효과를 위해 구강 또는 비강 호흡 경로에 의해 투여된다. 바람직하게는 멸균된 제약상 허용되는 용매 중의 조성물은 기체의 사용에 의해 네뷸라이징될 수 있다. 네뷸라이징된 용액은 네뷸라이징 장치로부터 직접 호흡될 수 있거나 또는 네뷸라이징 장치가 페이스 마스크, 텐트 또는 간헐적 양압 호흡 기계에 부착될 수 있다. 용액, 현탁액 또는 분말 조성물은 제제를 적절한 방식으로 전달하는 장치로부터, 바람직하게는 경구로 또는 비강으로 투여될 수 있다.
본 발명의 항체의 사용 방법
본 발명의 항체는 치유적 치료 방법 및 진단적 치료 방법을 포함하나 이에 제한되지는 않는 다양한 적용에 유용하다.
치유적 치료:
한 측면에서, 본 발명은 대상체에서 B7-H4 발현과 연관된 상태를 치료하는 방법을 제공한다. 또 다른 측면에서, 본 발명은 대상체에서 B7-H4 발현과 연관된 상태를 치료하기 위한 본 발명의 B7-H4xCD3 이중특이적 항체를 비롯한 B7-H4 항체, 또는 B7-H4xCD3 이중특이적 항체를 비롯한 B7-H4 항체를 포함하는 제약 조성물을 제공한다. 일부 실시양태에서, 대상체에서 B7-H4 발현과 연관된 상태를 치료하는 방법은 그의 치료를 필요로 하는 대상체에게 본 발명의 B7-H4xCD3 이중특이적 항체를 비롯한 B7-H4 항체를 포함하는 제약 조성물의 유효량을 투여하는 것을 포함한다. 일부 실시양태에서, 상태는 암이다. 본원에 사용된 암은 방광암, 유방암, 자궁경부암, 융모막암종, 결장암, 식도암, 위암, 교모세포종, 신경교종, 뇌 종양, 두경부암, 신장암, 폐암, 구강암, 난소암, 췌장암, 전립선암, 간암, 자궁암, 골암, 백혈병, 림프종, 육종, 혈액암, 갑상선암, 흉선암, 안암 및 피부암을 포함하나 이에 제한되지는 않는다. 일부 실시양태에서, 암은 유방암, 방광암, 자궁암 또는 난소암이다.
일부 실시양태에서, (1) B7-H4를 발현하는 악성 세포를 갖는 대상체에서 종양 성장 또는 진행을 억제하거나, (2) 대상체에서 B7-H4를 발현하는 전이 세포를 억제하거나, 또는 (3) 악성 세포의 종양 퇴행의 유도를 필요로 하는 대상체에게 본원에 기재된 바와 같은 B7-H4xCD3 이중특이적 항체를 비롯한 B7-H4 항체를 포함하는 제약 조성물의 유효량을 투여하는 것을 포함하는, 대상체에서 악성 세포의 종양 퇴행을 유도하기 위한 방법 및 이를 위한 B7-H4xCD3 이중특이적 항체를 비롯한 B7-H4 항체 또는 제약 조성물이 제공된다.
일부 실시양태에서, 자가면역 장애의 치료를 필요로 하는 대상체에게 본원에 기재된 바와 같은 B7-H4xCD3 이중특이적 항체를 비롯한 B7-H4 항체를 포함하는 제약 조성물의 유효량을 투여하는 것을 포함하는, 대상체에서 자가면역 장애를 치료하기 위한 방법 및 이를 위한 B7-H4xCD3 이중특이적 항체를 비롯한 B7-H4 항체 또는 제약 조성물이 제공된다. 본원에 사용된 자가면역 장애는 전신 홍반성 루푸스, 류마티스 관절염, 당뇨병 (제I형), 다발성 경화증, 애디슨병, 복강 질환, 피부근염, 그레이브스병, 하시모토 갑상선염, 하시모토 뇌병증, 중증 근무력증, 악성 빈혈, 반응성 관절염, 쇼그렌 증후군, 급성 파종성 뇌척수염, 무감마글로불린혈증, 근위축성 측삭 경화증, 강직성 척추염, 항인지질 증후군, 항신테타제 증후군, 아토피성 알레르기, 아토피성 피부염, 자가면역 장병증, 자가면역 용혈성 빈혈, 자가면역 간염, 자가면역 내이 질환, 자가면역 림프증식성 증후군, 자가면역 말초 신경병증, 자가면역 췌장염, 자가면역 다발내분비 증후군, 자가면역 프로게스테론 피부염, 자가면역 혈소판감소성 자반증, 자가면역 두드러기, 자가면역 포도막염, 베체트병, 캐슬만병, 저온 응집소 질환, 크론병, 피부근염, 호산구성 근막염, 위장 유천포창, 굿패스쳐 증후군, 길랑-바레 증후군, 화농성 한선염, 특발성 혈소판감소성 자반증, 기면증, 심상성 천포창, 악성 빈혈, 다발근염, 원발성 담도 간경변증, 재발성 다발연골염, 류마티스성 열, 측두 동맥염, 횡단성 척수염, 궤양성 결장염, 미분화 결합 조직 질환, 혈관염 및 베게너 육아종증을 포함하나 이에 제한되지는 않는다.
진단적 치료:
또 다른 측면에서, B7-H4 발현과 연관된 상태를 검출, 진단 및/또는 모니터링하는 방법이 제공된다. 예를 들어, 본원에 기재된 B7-H4xCD3 이중특이적 항체를 비롯한 B7-H4 항체는 검출가능한 모이어티, 예컨대 영상화제 및 효소-기질 표지로 표지될 수 있다. 본원에 기재된 바와 같은 항체는 또한 생체내 진단 검정, 예컨대 생체내 영상화 (예를 들어, PET 또는 SPECT), 또는 염색 시약에 사용될 수 있다. 대안적으로, 방법은 시험관내 또는 생체외 진단 검정에 사용될 수 있다.
한 측면에서, 진단에 사용하기 위한, 바람직하게는 B7-H4 발현과 연관된 상태를 진단하는데 사용하기 위한 본원에 기재된 바와 같은 B7-H4xCD3 이중특이적 항체를 비롯한 B7-H4 항체가 제공된다.
전달 경로:
본 발명의 B7-H4xCD3 이중특이적 항체를 비롯한 B7-H4 항체는 임의의 적합한 경로를 통해 개체에게 투여될 수 있다. 따라서, 일부 실시양태에서, 항체는 공지된 방법에 따라, 예컨대 정맥내 투여, 예를 들어 볼루스로서 또는 일정 기간에 걸친 연속 주입에 의해, 근육내, 복강내, 뇌척수내, 두개내, 경피, 피하, 관절내, 설하, 활막내, 취입, 척수강내, 경구, 흡입 또는 국소 경로를 통해 개체에게 투여된다. 투여는 전신, 예를 들어 정맥내 투여 또는 국부 투여일 수 있다. 제트 네뷸라이저 및 초음파 네뷸라이저를 비롯한 액체 제제를 위한 상업적으로 입수가능한 네뷸라이저가 투여에 유용하다. 액체 제제는 직접 네뷸라이징될 수 있고, 동결건조된 분말은 재구성 후에 네뷸라이징될 수 있다. 대안적으로, 항체는 플루오로카본 제제 및 계량 용량 흡입기를 사용하여 에어로졸화될 수 있거나 또는 동결건조 및 밀링된 분말로서 흡입될 수 있다.
한 실시양태에서, 항체는 부위-특이적 또는 표적화된 국부 전달 기술을 통해 투여된다. 부위-특이적 또는 표적화된 국부 전달 기술의 예는 항체의 다양한 이식형 데포 공급원 또는 국부 전달 카테터, 예컨대 주입 카테터, 유치 카테터 또는 바늘 카테터, 합성 이식편, 외막 랩, 션트 및 스텐트 또는 다른 이식형 장치, 부위 특이적 담체, 직접 주사 또는 직접 적용을 포함한다. 예를 들어, PCT 공개 번호 WO 00/53211 및 미국 특허 번호 5,981,568을 참조한다.
투여량:
본 발명의 B7-H4xCD3 이중특이적 항체를 비롯한 B7-H4 항체는 주사 (예를 들어, 복강내로, 정맥내로, 피하로, 근육내로 등)에 의한 것을 포함한 임의의 적합한 방법을 사용하여 투여될 수 있다. 항체는 또한 본원에 기재된 바와 같이 흡입을 통해 투여될 수 있다. 일반적으로, 항체의 투여를 위한 초기 후보 투여량은 약 2 mg/kg일 수 있다. 본 발명의 목적상, 전형적인 1일 투여량은 상기 언급된 인자에 따라 약 3 μg/kg 내지 30 μg/kg, 내지 300 μg/kg, 내지 3 mg/kg, 내지 30 mg/kg, 내지 100 mg/kg 또는 그 초과 중 어느 하나의 범위일 수 있다. 예를 들어, 약 1 mg/kg, 약 2.5 mg/kg, 약 5 mg/kg, 약 10 mg/kg 및 약 25 mg/kg의 투여량이 사용될 수 있다. 수일 이상에 걸친 반복 투여의 경우에, 상태에 따라, 치료는 증상의 목적하는 억제가 발생할 때까지 또는 예를 들어 암 세포의 종양 성장/진행 또는 전이를 억제하거나 지연시키기에 충분한 치료 수준이 달성될 때까지 지속된다. 예시적인 투여 요법은 항체 약 2 mg/kg의 초기 용량, 이어서 약 1 mg/kg의 매주 유지 용량, 또는 이어서 약 1 mg/kg의 격주 유지 용량을 투여하는 것을 포함한다. 다른 예시적인 투여 요법은 증가하는 용량 (예를 들어, 1 mg/kg의 초기 용량 및 매주 또는 보다 긴 기간마다 1회 이상의 더 높은 용량으로의 점진적 증가)을 투여하는 것을 포함한다. 진료의가 달성하고자 하는 약동학적 붕괴 패턴에 따라 다른 투여 요법이 또한 유용할 수 있다. 예를 들어, 일부 실시양태에서, 1주 1 내지 4회의 투여가 고려된다. 다른 실시양태에서, 1개월 1회 또는 격월 또는 3개월마다 1회 투여하는 것이 고려된다. 이러한 요법의 진행은 통상적인 기술 및 검정에 의해 용이하게 모니터링된다. 항체의 투여 요법은 시간 경과에 따라 달라질 수 있다.
본 발명의 목적상, 본 발명의 B7-H4xCD3 이중특이적 항체를 비롯한 B7-H4 항체의 적절한 투여량은 치료될 증상의 유형 및 중증도, 작용제가 치료 목적으로 투여되는지의 여부, 선행 요법, 환자의 임상 병력 및 작용제에 대한 반응, 투여된 작용제에 대한 환자의 클리어런스율 및 담당 의사의 판단에 좌우될 것이다. 전형적으로, 임상의는 목적하는 결과를 달성하는 투여량에 도달할 때까지 항체를 투여할 것이다. 용량 및/또는 빈도는 치료 과정에 따라 달라질 수 있다. 실험적 고려사항, 예컨대 반감기는 일반적으로 투여량의 결정에 기여할 것이다. 예를 들어, 인간 면역계와 상용성인 항체, 예컨대 인간화 항체 또는 완전 인간 항체는 항체의 반감기를 연장시키고 항체가 숙주의 면역계에 의해 공격받는 것을 방지하는데 사용될 수 있다. 투여 빈도는 요법 과정에 걸쳐 결정 및 조정될 수 있고, 반드시는 아니지만 일반적으로 증상의 치료 및/또는 억제 및/또는 호전 및/또는 지연, 예를 들어 종양 성장 억제 또는 지연 등에 기초한다. 대안적으로, 항체의 지속 연속 방출 제제가 적절할 수 있다. 지속 방출을 달성하기 위한 다양한 제제 및 장치는 관련 기술분야에 공지되어 있다.
한 실시양태에서, 본 발명의 B7-H4xCD3 이중특이적 항체를 비롯한 B7-H4 항체에 대한 투여량은 항체의 1회 이상의 투여(들)가 제공된 개체에서 실험적으로 결정될 수 있다. 개체에게 항체의 증분 투여량을 제공할 수 있다. 효능을 평가하기 위해, 질환의 지표를 추적할 수 있다.
본 발명의 방법에 따른 본 발명의 B7-H4xCD3 이중특이적 항체를 비롯한 B7-H4 항체의 투여는, 예를 들어 수용자의 생리학적 상태, 투여의 목적이 치료적인지 예방적인지의 여부 및 숙련된 진료의에게 공지된 다른 인자에 따라 연속적 또는 간헐적일 수 있다. 항체의 투여는 미리 선택된 기간에 걸쳐 본질적으로 연속적일 수 있거나 또는 일련의 이격된 용량으로 이루어질 수 있다.
일부 실시양태에서, 본 발명의 B7-H4xCD3 이중특이적 항체를 비롯한 1종 초과의 B7-H4 항체가 존재할 수 있다. B7-H4xCD3 이중특이적 항체를 비롯한 적어도 1종, 적어도 2종, 적어도 3종, 적어도 4종, 적어도 5종 또는 그 초과의 상이한 B7-H4 항체가 존재할 수 있다. 일반적으로, 이들 항체는 서로 유해한 영향을 미치지 않는 상보적 활성을 가질 수 있다. 예를 들어, 하기 항체 중 1종 이상이 사용될 수 있다: B7-H4 또는 CD3 상의 하나의 에피토프에 대해 지시된 제1 B7-H4 또는 CD3 항체 및 B7-H4 또는 CD3 상의 상이한 에피토프에 대해 지시된 제2 B7-H4 또는 CD3 항체.
조합물
일부 실시양태에서, B7-H4xCD3 이중특이적 항체를 비롯한 본 발명의 B7-H4 항체는 1종 이상의 추가의 치료제의 투여와 조합되어 투여될 수 있다. 추가의 치료제는 생물요법제 및/또는 화학요법제, 예컨대 비제한적으로 백신, CAR-T 세포-기반 요법, 방사선요법, 시토카인 요법, CD3 이중특이적 항체, 다른 면역억제 경로의 억제제, 혈관신생의 억제제, T 세포 활성화제, 대사 경로의 억제제, mTOR 억제제, 아데노신 경로의 억제제, 티로신 키나제 억제제, 예컨대 비제한적으로 인리타, ALK 억제제 및 수니티닙, BRAF 억제제, 후성적 변형제, IDO1 억제제, JAK 억제제, STAT 억제제, 시클린-의존성 키나제 억제제, 생물요법제 (VEGF, VEGFR, EGFR, Her2/neu, 다른 성장 인자 수용체, CD40, CD-40L, CTLA-4, OX-40, 4-1BB, TIGIT 및 ICOS에 대한 항체를 포함하나 이에 제한되지는 않음), 면역원성 작용제 (예를 들어, 약독화된 암성 세포, 종양 항원, 항원 제시 세포, 예컨대 종양 유래 항원 또는 핵산으로 펄스된 수지상 세포, 면역 자극 시토카인 (예를 들어, IL-2, IFNα2, GM-CSF) 및 면역 자극 시토카인, 예컨대 비제한적으로 GM-CSF를 코딩하는 유전자로 형질감염된 세포)를 포함하나 이에 제한되지는 않는다.
생물요법제의 예는 치료 항체, 면역 조정제 및 치료 면역 세포를 포함한다.
치료 항체는 다양한 상이한 항원에 대한 특이성을 가질 수 있다. 예를 들어, 치료 항체는 종양 연관-항원에 대해 지시되어, 항원에 대한 항체의 결합이 항원을 발현하는 세포의 사멸을 촉진하도록 할 수 있다. 다른 예에서, 치료 항체는 면역 세포 상의 항원 (예를 들어 PD-1)에 대해 지시되어, 항체의 결합이 항원을 발현하는 세포의 활성의 하향조절을 방지하도록 (및 이에 의해 항원을 발현하는 세포의 활성을 촉진하도록) 할 수 있다. 일부 상황에서, 치료 항체는 다수의 상이한 메카니즘을 통해 기능할 수 있다 (예를 들어, 이는 i) 항원을 발현하는 세포의 사멸을 촉진하는 것 및 ii) 항원이 항원을 발현하는 세포와 접촉하는 면역 세포의 활성의 하향-조절을 유발하는 것을 방지하는 것 둘 다일 수 있음).
치료 항체는, 예를 들어 하기와 같이 열거된 항원에 대해 지시될 수 있다. 일부 항원에 대해, 항원에 대해 지시된 예시적인 항체가 또한 하기에 포함된다 (항원 뒤의 대괄호 / 소괄호 안에). 하기 항원은 또한 본원에서 "표적 항원" 등으로 지칭될 수 있다. 본원의 치료 항체에 대한 표적 항원은, 예를 들어: 4-1BB (예를 들어 우토밀루맙); 5T4; A33; 알파-폴레이트 수용체 1 (예를 들어 미르베툭시맙 소라브탄신); Alk-1; B7-H4 [예를 들어 PF-06863135 (US9969809 참조)]; BTN1A1 (예를 들어 WO2018222689 참조); CA-125 (예를 들어 아바고보맙); 카르보안히드라제 IX; CCR2; CCR4 (예를 들어 모가물리주맙); CCR5 (예를 들어 레론리맙); CCR8; CD3 [예를 들어 블리나투모맙 (CD3/CD19 이중특이적), PF-06671008 (CD3/P-카드헤린 이중특이적), PF-06863135 (CD3/B7-H4 이중특이적), CD19 (예를 들어 블리나투모맙, MOR208); CD20 (예를 들어 이브리투모맙 티욱세탄, 오비누투주맙, 오파투무맙, 리툭시맙, 우블리툭시맙); CD22 (이노투주맙 오조가미신, 목세투모맙 파수도톡스); CD25; CD28; CD30 (예를 들어 브렌툭시맙 베도틴); CD33 (예를 들어 겜투주맙 오조가미신); CD38 (예를 들어 다라투무맙, 이사툭시맙), CD40; CD-40L; CD44v6; CD47; CD52 (예를 들어 알렘투주맙); CD63; CD79 (예를 들어 폴라투주맙 베도틴); CD80; CD123; CD276 / B7-H3 (예를 들어 옴부르타맙); CDH17; CEA; ClhCG; CTLA-4 (예를 들어 이필리무맙, 트레멜리무맙), CXCR4; 데스모글레인 4; DLL3 (예를 들어 로발피투주맙 테시린); DLL4; E-카드헤린; EDA; EDB; EFNA4; EGFR (예를 들어 세툭시맙, 데파툭시주맙 마포도틴, 네시투무맙, 파니투무맙); EGFRvIII; 엔도시알린; EpCAM (예를 들어 오포르투주맙 모나톡스); FAP; 태아 아세틸콜린 수용체; FLT3 (예를 들어 WO2018/220584 참조); GD2 (예를 들어 디누툭시맙, 3F8); GD3; GITR; 글로보H; GM1; GM2; GUCY2C (예를 들어 PF-07062119); HER2/neu [예를 들어 마르게툭시맙, 페르투주맙, 트라스투주맙; 아도-트라스투주맙 엠탄신, 트라스투주맙 듀오카르마진, PF-06804103 (US8828401 참조)]; HER3; HER4; ICOS; IL-10; ITG-AvB6; LAG-3 (예를 들어 렐라틀리맙); 루이스-Y; LG; Ly-6; M-CSF [예를 들어 PD-0360324 (US7326414 참조)]; MCSP; 메소텔린; MUC1; MUC2; MUC3; MUC4; MUC5AC; MUC5B; MUC7; MUC16; Notch1; Notch3; 넥틴-4 (예를 들어 엔포르투맙 베도틴); OX40 [예를 들어 PF-04518600 (US7960515 참조)]; P-카드헤린 [예를 들어 PF-06671008 (WO2016/001810 참조)]; PCDHB2; PD-1 [예를 들어 BCD-100, 캄렐리주맙, 세미플리맙, 게놀림주맙 (CBT-501), MEDI0680, 니볼루맙, 펨브롤리주맙, 사산리맙 (WO2016/092419 참조), 신틸리맙, 스파르탈리주맙, STI-A1110, 티슬렐리주맙, TSR-042]; PD-L1 (예를 들어 아테졸리주맙, 두르발루맙, BMS-936559 (MDX-1105) 또는 LY3300054); PDGFRA (예를 들어 올라라투맙); 형질 세포 항원; PolySA; PSCA; PSMA; PTK7 [예를 들어 PF-06647020 (US9409995 참조)]; Ror1; SAS; SCRx6; SLAMF7 (예를 들어 엘로투주맙); SHH; SIRPa (예를 들어 ED9, Effi-DEM); STEAP; TGF-베타; TIGIT; TIM-3; TMPRSS3; TNF-알파 전구체; TROP-2 (예를 들어 사시투주맙 고비테칸); TSPAN8; VEGF (예를 들어 베바시주맙, 브롤루시주맙); VEGFR1 (예를 들어 라니비주맙); VEGFR2 (예를 들어 라무시루맙, 라니비주맙); Wue-1.
면역 조정제는 대상체에서 면역 반응을 자극할 수 있는 다양한 상이한 분자 유형, 예컨대 패턴 인식 수용체 (PRR) 효능제, 면역자극 시토카인 및 암 백신을 포함한다.
패턴 인식 수용체 (PRR)는 면역계의 세포에 의해 발현되고 병원체 및/또는 세포 손상 또는 사멸과 연관된 다양한 분자를 인식하는 수용체이다. PRR은 선천성 면역 반응 및 적응 면역 반응 둘 다에 관여한다. PRR 효능제는 대상체에서 면역 반응을 자극하는데 사용될 수 있다. 톨-유사 수용체 (TLR), RIG-I-유사 수용체 (RLR), 뉴클레오티드-결합 올리고머화 도메인 (NOD)-유사 수용체 (NLR), C-유형 렉틴 수용체 (CLR) 및 인터페론 유전자의 자극제 (STING) 단백질을 포함한 PRR 분자의 다수의 부류가 존재한다.
용어 "TLR" 및 "톨-유사 수용체"는 임의의 톨-유사 수용체를 지칭한다. 톨-유사 수용체는 면역 반응의 활성화에 관여하는 수용체이다. TLR은, 예를 들어 미생물에서 발현되는 병원체-연관 분자 패턴 (PAMP), 뿐만 아니라 사멸된 또는 사멸하는 세포로부터 방출되는 내인성 손상-연관 분자 패턴 (DAMP)을 인식한다.
TLR을 활성화시키는 (및 이에 의해 면역 반응을 활성화시키는) 분자는 본원에서 "TLR 효능제"로 지칭된다. TLR 효능제는, 예를 들어 소분자 (예를 들어 약 1000 달톤 미만의 분자량을 갖는 유기 분자), 뿐만 아니라 대분자 (예를 들어 올리고뉴클레오티드 및 단백질)를 포함할 수 있다. 일부 TLR 효능제는 단일 유형의 TLR (예를 들어 TLR3 또는 TLR9)에 특이적인 반면, 일부 TLR 효능제는 2종 이상의 유형의 TLR (예를 들어 TLR7 및 TLR8 둘 다)을 활성화시킨다.
본원에 제공된 예시적인 TLR 효능제는 TLR2, TLR3, TLR4, TLR5, TLR6, TLR7, TLR8 및 TLR9의 효능제를 포함한다.
예시적인 소분자 TLR 효능제는, 예를 들어 미국 특허 번호 4,689,338; 4,929,624; 5,266,575; 5,268,376; 5,346,905; 5,352,784; 5,389,640; 5,446,153; 5,482,936; 5,756,747; 6,110,929; 6,194,425; 6,331,539; 6,376,669; 6,451,810; 6,525,064; 6,541,485; 6,545,016; 6,545,017; 6,573,273; 6,656,938; 6,660,735; 6,660,747; 6,664,260; 6,664,264; 6,664,265; 6,667,312; 6,670,372; 6,677,347; 6,677,348; 6,677,349; 6,683,088; 6,756,382; 6,797,718; 6,818,650; 및 7,7091,214; 미국 특허 공개 번호 2004/0091491, 2004/0176367 및 2006/0100229; 및 국제 공개 번호 WO 2005/18551, WO 2005/18556, WO 2005/20999, WO 2005/032484, WO 2005/048933, WO 2005/048945, WO 2005/051317, WO 2005/051324, WO 2005/066169, WO 2005/066170, WO 2005/066172, WO 2005/076783, WO 2005/079195, WO 2005/094531, WO 2005/123079, WO 2005/123080, WO 2006/009826, WO 2006/009832, WO 2006/026760, WO 2006/028451, WO 2006/028545, WO 2006/028962, WO 2006/029115, WO 2006/038923, WO 2006/065280, WO 2006/074003, WO 2006/083440, WO 2006/086449, WO 2006/091394, WO 2006/086633, WO 2006/086634, WO 2006/091567, WO 2006/091568, WO 2006/091647, WO 2006/093514 및 WO 2006/098852에 개시된 것을 포함한다.
소분자 TLR 효능제의 추가의 예는 특정 퓨린 유도체 (예컨대 미국 특허 번호 6,376,501 및 6,028,076에 기재된 것), 특정 이미다조퀴놀린 아미드 유도체 (예컨대 미국 특허 번호 6,069,149에 기재된 것), 특정 이미다조피리딘 유도체 (예컨대 미국 특허 번호 6,518,265에 기재된 것), 특정 벤즈이미다졸 유도체 (예컨대 미국 특허 번호 6,387,938에 기재된 것), 5원 질소 함유 헤테로시클릭 고리에 융합된 4-아미노피리미딘의 특정 유도체 (예컨대 미국 특허 번호 6,376,501; 6,028,076 및 6,329,381; 및 WO 02/08905에 기재된 아데닌 유도체), 및 특정 3-.베타.-D-리보푸라노실티아졸로 [4,5-d]피리미딘 유도체 (예컨대 미국 공개 번호 2003/0199461에 기재된 것), 및 특정 소분자 면역-강화제 화합물, 예컨대, 예를 들어 미국 특허 공개 번호 2005/0136065에 기재된 것을 포함한다.
예시적인 대분자 TLR 효능제는 올리고뉴클레오티드 서열로서 포함된다. 일부 TLR 효능제 올리고뉴클레오티드 서열은 시토신-구아닌 디뉴클레오티드 (CpG)를 함유하고, 예를 들어 미국 특허 번호 6,194,388; 6,207,646; 6,239,116; 6,339,068; 및 6,406,705에 기재되어 있다. 일부 CpG-함유 올리고뉴클레오티드는 합성 면역조정 구조적 모티프, 예컨대, 예를 들어 미국 특허 번호 6,426,334 및 6,476,000에 기재된 것을 포함할 수 있다. 다른 TLR 효능제 뉴클레오티드 서열은 CpG 서열이 결여되어 있고, 예를 들어 국제 특허 공개 번호 WO 00/75304에 기재되어 있다. 또 다른 TLR 효능제 뉴클레오티드 서열은 구아노신- 및 우리딘-풍부 단일-가닥 RNA (ssRNA), 예컨대, 예를 들어 문헌 [Heil et ah, Science, vol. 303, pp. 1526-1529, Mar. 5, 2004]에 기재된 것을 포함한다.
다른 TLR 효능제는 생물학적 분자, 예컨대 아미노알킬 글루코사미니드 포스페이트 (AGP)를 포함하고, 예를 들어 미국 특허 번호 6,113,918; 6,303,347; 6,525,028; 및 6,649,172에 기재되어 있다.
TLR 효능제는 또한 다수의 상이한 유형의 TLR 수용체를 활성화시킬 수 있는 불활성화된 병원체 또는 그의 분획을 포함한다. 예시적인 병원체-유래 TLR 효능제는 BCG, 미코박테리움 오부엔세 추출물, 탈리모겐 라허파렙벡 (T-Vec) (HSV-1로부터 유래됨) 및 펙사-Vec (백시나 바이러스로부터 유래됨)을 포함한다.
일부 실시양태에서, TLR 효능제는 TLR에 특이적으로 결합하는 효능제 항체일 수 있다.
RLR은, 예를 들어 dsRNA를 검출하는 다양한 시토졸 PRR을 포함한다. RLR의 예는, 예를 들어 레티노산-유도성 유전자 I (RIG-I), 흑색종 분화-연관 유전자 5 (MDA-5) 및 유전학 및 생리학 실험실 2 (LGP2)를 포함한다.
본원에 사용된 "RLR 효능제"는 RLR에 결합시, (1) RLR을 자극 또는 활성화시키거나, (2) RLR의 활성, 기능 또는 존재를 증진, 증가, 촉진, 유도 또는 연장시키거나, 또는 (3) RLR의 발현을 증진, 증가, 촉진 또는 유도하는 임의의 분자를 의미한다. 본 발명의 임의의 치료 방법, 의약 및 용도에 유용한 RLR 효능제는, 예를 들어 RLR에 결합하는 핵산 및 그의 유도체 및 RLR에 특이적으로 결합하는 효능작용 모노클로날 항체 (mAb)를 포함한다.
본 발명의 치료 방법, 의약 및 용도에 유용한 RLR 효능제의 예는, 예를 들어 비캡핑된 5' 트리포스페이트를 갖는 짧은 이중-가닥 RNA (RIG-I 효능제); 폴리 I:C (MDA-5 효능제) 및 BO-112 (MDA-A 효능제)를 포함한다.
NLR은, 예를 들어 손상-연관 분자 패턴 (DAMP) 분자를 검출하는 다양한 PRR을 포함한다. NLR은 서브패밀리 NLRA-A, NLRB-B, NLRC-C 및 NLRP-P를 포함한다. NLR의 예는, 예를 들어 NOD1, NOD2, NAIP, NLRC4 및 NLRP3을 포함한다.
본원에 사용된 "NLR 효능제"는 NLR에 결합시, (1) NLR을 자극 또는 활성화시키거나, (2) NLR의 활성, 기능 또는 존재를 증진, 증가, 촉진, 유도 또는 연장시키거나, 또는 (3) NLR의 발현을 증진, 증가, 촉진 또는 유도하는 임의의 분자를 의미한다. 본 발명의 임의의 치료 방법, 의약 및 용도에 유용한 NLR 효능제는, 예를 들어 NLR에 결합하는 DAMP 및 그의 유도체 및 NLR에 특이적으로 결합하는 효능작용 모노클로날 항체 (mAb)를 포함한다.
본 발명의 치료 방법, 의약 및 용도에 유용한 NLR 효능제의 예는, 예를 들어 리포솜성 뮤라밀 트리펩티드 / 미파무르티드 (NOD2 효능제)를 포함한다.
CLR은, 예를 들어 탄수화물 및 당단백질을 검출하는 다양한 PRR을 포함한다. CLR은 막횡단 CLR 및 분비된 CLR 둘 다를 포함한다. CLR의 예는, 예를 들어 DEC-205 / CD205, 대식세포 만노스 수용체 (MMR), 덱틴-1, 덱틴-2, 민클, DC-SIGN, DNGR-1 및 만노스-결합 렉틴 (MBL)을 포함한다.
본원에 사용된 "CLR 효능제"는 CLR에 결합시, (1) CLR을 자극 또는 활성화시키거나, (2) CLR의 활성, 기능 또는 존재를 증진, 증가, 촉진, 유도 또는 연장시키거나, 또는 (3) CLR의 발현을 증진, 증가, 촉진 또는 유도하는 임의의 분자를 의미한다. 본 발명의 임의의 치료 방법, 의약 및 용도에 유용한 CLR 효능제는, 예를 들어 CLR에 결합하는 탄수화물 및 그의 유도체 및 CLR에 특이적으로 결합하는 효능작용 모노클로날 항체 (mAb)를 포함한다.
본 발명의 치료 방법, 의약 및 용도에 유용한 CLR 효능제의 예는, 예를 들어 MD-분획 (그리폴라 프론도사(Grifola frondosa)로부터의 정제된 가용성 베타-글루칸 추출물) 및 임프라임 PGG (효모로부터 유래된 베타 1,3/1,6-글루칸 PAMP)를 포함한다.
STING 단백질은 제1형 인터페론 신호전달에서 시토졸 DNA 센서 및 어댑터 단백질 둘 다로서 기능한다. 용어 "STING" 및 "인터페론 유전자의 자극제"는 STING 단백질의 임의의 형태, 뿐만 아니라 STING의 활성의 적어도 일부를 보유하는 변이체, 이소형 및 종 상동체를 지칭한다. 예컨대 인간 STING에 대한 구체적 언급에 의해 다르게 나타내지 않는 한, STING는 천연 서열 STING의 모든 포유동물 종, 예를 들어 인간, 원숭이 및 마우스를 포함한다. 하나의 예시적인 인간 TLR9는 유니프롯 등록 번호 Q86WV6 하에 제공된다. STING는 또한 TMEM173으로 공지되어 있다.
본원에 사용된 "STING 효능제"는 TLR9에 결합시, (1) STING를 자극 또는 활성화시키거나, (2) STING의 활성, 기능 또는 존재를 증진, 증가, 촉진, 유도 또는 연장시키거나, 또는 (3) STING의 발현을 증진, 증가, 촉진 또는 유도하는 임의의 분자를 의미한다. 본 발명의 임의의 치료 방법, 의약 및 용도에 유용한 STING 효능제는, 예를 들어 STING에 결합하는 핵산 리간드를 포함한다.
본 발명의 치료 방법, 의약 및 용도에 유용한 STING 효능제의 예는 다양한 면역자극 핵산, 예컨대 합성 이중 가닥 DNA, 시클릭 디-GMP, 시클릭-GMP-AMP (cGAMP), 합성 시클릭 디뉴클레오티드 (CDN), 예컨대 MK-1454 및 ADU-S100 (MIW815), 및 소분자, 예컨대 P0-424를 포함한다.
다른 PRR은, 예를 들어 IFN-조절 인자의 DNA-의존성 활성화제 (DAI) 및 흑색종 부재 2 (AIM2)를 포함한다.
면역자극 시토카인은 면역 반응을 자극하는 다양한 신호전달 단백질, 예컨대 인터페론, 인터류킨 및 조혈 성장 인자를 포함한다.
예시적인 면역자극 시토카인은 GM-CSF, G-CSF, IFN-알파, IFN-감마; IL-2 (예를 들어 데니류킨 디피톡스), IL-6, IL-7, IL-11, IL-12, IL-15, IL-18, IL-21 및 TNF-알파를 포함한다.
면역자극 시토카인은 임의의 적합한 포맷을 가질 수 있다. 일부 실시양태에서, 면역자극 시토카인은 야생형 시토카인의 재조합 버전일 수 있다. 일부 실시양태에서, 면역자극 시토카인은 상응하는 야생형 시토카인과 비교하여 1개 이상의 아미노산 변화를 갖는 뮤테인일 수 있다. 일부 실시양태에서, 면역자극 시토카인은 시토카인 및 적어도 1종의 다른 기능적 단백질 (예를 들어, 항체)을 함유하는 키메라 단백질 내로 혼입될 수 있다. 일부 실시양태에서, 면역자극 시토카인은 약물 / 작용제 (예를 들어 가능한 ADC 성분으로서 본원의 다른 곳에 기재된 바와 같은 임의의 약물 / 작용제)에 공유 연결될 수 있다.
암 백신은 종양 연관 항원을 함유하는 (또는 대상체에서 종양 연관 항원을 생성하는데 사용될 수 있는) 다양한 조성물을 포함하고, 따라서 종양 연관 항원을 함유하는 종양 세포에 대해 지시될 대상체에서의 면역 반응을 유발하는데 사용될 수 있다.
암 백신에 포함될 수 있는 예시적인 물질은 약독화된 암성 세포, 종양 항원, 항원 제시 세포, 예컨대 종양 유래 항원으로 펄스된 수지상 세포 또는 종양 연관 항원을 코딩하는 핵산을 포함한다. 일부 실시양태에서, 암 백신은 환자 자신의 암 세포로 제조될 수 있다. 일부 실시양태에서, 암 백신은 환자 자신의 암 세포로부터의 것이 아닌 생물학적 물질로 제조될 수 있다.
암 백신은, 예를 들어 시푸류셀-T 및 탈리모겐 라허파렙벡 (T-VEC)을 포함한다.
면역 세포 요법은 암 세포를 표적화할 수 있는 면역 세포로 환자를 치료하는 것을 수반한다. 면역 세포 요법은, 예를 들어 종양-침윤 림프구 (TIL) 및 키메라 항원 수용체 T 세포 (CAR-T 세포)를 포함한다.
화학요법제의 예는 알킬화제, 예컨대 티오테파 및 시클로포스파미드; 알킬 술포네이트, 예컨대 부술판, 임프로술판 및 피포술판; 아지리딘, 예컨대 벤조도파, 카르보쿠온, 메투레도파 및 우레도파; 에틸렌이민 및 메틸라멜라민, 예컨대 알트레타민, 트리에틸렌멜라민, 트리에틸렌포스포르아미드, 트리에틸렌티오포스포르아미드 및 트리메틸올로멜라민; 아세토게닌 (특히, 불라타신 및 불라타시논); 캄프토테신 (합성 유사체 토포테칸 포함); 브리오스타틴; 칼리스타틴; CC-1065 (그의 아도젤레신, 카르젤레신 및 비젤레신 합성 유사체 포함); 크립토피신 (특히, 크립토피신 1 및 크립토피신 8); 돌라스타틴; 두오카르마이신 (합성 유사체, KW-2189 및 CBI-TMI 포함); 엘레우테로빈; 판크라티스타틴; 사르코딕티인; 스폰지스타틴; 질소 머스타드, 예컨대 클로람부실, 클로르나파진, 콜로포스파미드, 에스트라무스틴, 이포스파미드, 메클로레타민, 메클로레타민 옥시드 히드로클로라이드, 멜팔란, 노벰비킨, 페네스테린, 프레드니무스틴, 트로포스파미드, 우라실 머스타드; 니트로소우레아, 예컨대 카르무스틴, 클로로조토신, 포테무스틴, 로무스틴, 니무스틴, 라니무스틴; 항생제, 예컨대 에네디인 항생제 (예를 들어, 칼리케아미신, 특히 칼리케아미신 감마1I 및 칼리케아미신 phiI1, 예를 들어 문헌 [Agnew, Chem. Intl. Ed. Engl., 33:183-186 (1994)] 참조); 디네미신 A를 포함한 디네미신; 비스포스포네이트, 예컨대 클로드로네이트; 에스페라미신; 뿐만 아니라 네오카르지노스타틴 발색단 및 관련 색소단백질 에네디인 항생제 발색단), 아클라시노마이신, 악티노마이신, 아우트라마이신, 아자세린, 블레오마이신, 칵티노마이신, 카라비신, 카미노마이신, 카르지노필린, 크로모마이신, 닥티노마이신, 다우노루비신, 데토루비신, 6-디아조-5-옥소-L-노르류신, 독소루비신 (모르폴리노-독소루비신, 시아노모르폴리노-독소루비신, 2-피롤리노-독소루비신 및 데옥시독소루비신 포함), PEG화 리포솜 독소루비신, 에피루비신, 에소루비신, 이다루비신, 마르셀로마이신, 미토마이신, 예컨대 미토마이신 C, 미코페놀산, 노갈라마이신, 올리보마이신, 페플로마이신, 포트피로마이신, 퓨로마이신, 쿠엘라마이신, 로도루비신, 스트렙토니그린, 스트렙토조신, 투베르시딘, 우베니멕스, 지노스타틴, 조루비신; 항대사물, 예컨대 메토트렉세이트 및 5-플루오로우라실 (5-FU); 폴산 유사체, 예컨대 데노프테린, 메토트렉세이트, 프테로프테린, 트리메트렉세이트; 퓨린 유사체, 예컨대 플루다라빈, 6-메르캅토퓨린, 티아미프린, 티오구아닌; 피리미딘 유사체, 예컨대 안시타빈, 아자시티딘, 6-아자우리딘, 카르모푸르, 시타라빈, 디데옥시우리딘, 독시플루리딘, 에노시타빈, 플록수리딘; 안드로겐, 예컨대 칼루스테론, 드로모스타놀론 프로피오네이트, 에피티오스타놀, 메피티오스탄, 테스토락톤; 항부신제, 예컨대 아미노글루테티미드, 미토탄, 트릴로스탄; 폴산 보충제, 예컨대 프롤린산; 아세글라톤; 알도포스파미드 글리코시드; 아미노레불린산; 에닐우라실; 암사크린; 베스트라부실; 비산트렌; 에다트락세이트; 데포파민; 데메콜신; 디아지쿠온; 엘포르미틴; 엘립티늄 아세테이트; 에포틸론; 에토글루시드; 질산갈륨; 히드록시우레아; 렌티난; 로니다민; 메이탄시노이드, 예컨대 메이탄신 및 안사미토신; 미토구아존; 미톡산트론; 모피다몰; 니트라크린; 펜토스타틴; 페나메트; 피라루비신; 로속산트론; 포도필린산; 2-에틸히드라지드; 프로카르바진; 라족산; 리족신; 시조푸란; 스피로게르마늄; 테누아존산; 트리아지쿠온; 2,2',2"-트리클로로트리에틸아민; 트리코테센 (특히 T-2 독소, 베라큐린 A, 로리딘 A 및 안구이딘); 우레탄; 빈데신; 다카르바진; 만노무스틴; 미토브로니톨; 미토락톨; 피포브로만; 가시토신; 아라비노시드 ("Ara-C"); 시클로포스파미드; 티오테파; 탁소이드, 예를 들어 파클리탁셀 및 도세탁셀; 클로람부실; 겜시타빈; 6-티오구아닌; 메르캅토퓨린; 메토트렉세이트; 백금 유사체, 예컨대 시스플라틴 및 카르보플라틴; 빈블라스틴; 백금; 에토포시드 (VP-16); 이포스파미드; 미톡산트론; 빈크리스틴; 비노렐빈; 노반트론; 테니포시드; 에다트렉세이트; 다우노마이신; 아미노프테린; 젤로다; 이반드로네이트; CPT-11; 토포이소머라제 억제제 RFS 2000; 디플루오로메틸오르니틴 (DMFO); 레티노이드, 예컨대 레티노산; 카페시타빈; 및 상기 중 어느 것의 제약상 허용되는 염, 산 또는 유도체를 포함한다. 종양에 대한 호르몬 작용을 조절 또는 억제하는 작용을 하는 항호르몬제, 예컨대 항에스트로겐 및 선택적 에스트로겐 수용체 조정제 (SERM), 예를 들어 타목시펜, 랄록시펜, 드롤록시펜, 4-히드록시타목시펜, 트리옥시펜, 케옥시펜, LY117018, 오나프리스톤 및 토레미펜 (파레스톤); 부신에서의 에스트로겐 생산을 조절하는 효소 아로마타제를 억제하는 아로마타제 억제제, 예를 들어 4(5)-이미다졸, 아미노글루테티미드, 메게스트롤 아세테이트, 엑세메스탄, 포르메스탄, 파드로졸, 보로졸, 레트로졸 및 아나스트로졸; 및 항안드로겐, 예컨대 플루타미드, 닐루타미드, 비칼루타미드, 류프롤리드 및 고세렐린; KRAS 억제제; MCT4 억제제; MAT2a 억제제; 티로신 키나제 억제제, 예컨대 수니티닙, 악시티닙; alk/c-Met/ROS 억제제, 예컨대 크리조티닙, 로를라티닙; mTOR 억제제, 예컨대 템시롤리무스, 게다톨리십; src/abl 억제제, 예컨대 보수티닙; 시클린-의존성 키나제 (CDK) 억제제, 예컨대 팔보시클립, PF-06873600; erb 억제제, 예컨대 다코미티닙; PARP 억제제, 예컨대 탈라조파립; SMO 억제제, 예컨대 글라스데깁, PF-5274857; EGFR T790M 억제제, 예컨대 PF-06747775; EZH2 억제제, 예컨대 PF-06821497; PRMT5 억제제, 예컨대 PF-06939999; TGFRβr1 억제제, 예컨대 PF-06952229; 및 상기 중 어느 것의 제약상 허용되는 염, 산 또는 유도체가 또한 포함된다. 구체적 실시양태에서, 이러한 추가의 치료제는 베바시주맙, 세툭시맙, 시롤리무스, 파니투무맙, 5-플루오로우라실 (5-FU), 카페시타빈, 티보자닙, 이리노테칸, 옥살리플라틴, 시스플라틴, 트리플루리딘, 티피라실, 류코보린, 겜시타빈, 레고라페닙 또는 에를로티닙 히드로클로라이드이다.
일부 실시양태에서, 본 발명의 B7-H4xCD3 이중특이적 항체를 비롯한 B7-H4 항체는 면역 체크포인트 조정제 또는 공동자극제를 표적화하는 1종 이상의 다른 치료제, 예컨대, 예를 들어 비제한적으로, CTLA-4, LAG-3, B7-H3, B7-H4, B7-DC (PD-L2), B7-H5, B7-H6, B7-H8, B7-H2, B7-1, B7-2, ICOS, ICOS-L, TIGIT, CD2, CD47, CD80, CD86, CD48, CD58, CD226, CD155, CD112, LAIR1, 2B4, BTLA, CD160, TIM1, TIM-3, TIM4, VISTA (PD-H1), OX40, OX40L, GITR, GITRL, CD70, CD27, 4-1BB, 4-BBL, DR3, TL1A, CD40, CD40L, CD30, CD30L, LIGHT, HVEM, SLAM (SLAMF1, CD150), SLAMF2 (CD48), SLAMF3 (CD229), SLAMF4 (2B4, CD244), SLAMF5 (CD84), SLAMF6 (NTB-A), SLAMCF7 (CS1), SLAMF8 (BLAME), SLAMF9 (CD2F), CD28, CEACAM1 (CD66a), CEACAM3, CEACAM4, CEACAM5, CEACAM6, CEACAM7, CEACAM8, CEACAM1-3AS CEACAM3C2, CEACAM1-15, PSG1-11, CEACAM1-4C1, CEACAM1-4S, CEACAM1-4L, IDO, TDO, CCR2, CD39-CD73-아데노신 경로 (A2AR), BTK, TIK, CXCR2, CXCR4, CCR4, CCR8, CCR5, CSF-1 또는 선천성 면역 반응 조정제를 표적화하는 작용제와 함께 사용된다.
일부 실시양태에서, 본 발명의 B7-H4xCD3 이중특이적 항체를 비롯한 B7-H4 항체는, 예를 들어 항-CTLA-4 길항제 항체, 예컨대, 예를 들어 이필리무맙; 항-LAG-3 길항제 항체, 예컨대 BMS-986016 및 IMP701; 항-TIM-3 길항제 항체; 항-B7-H3 길항제 항체, 예컨대, 예를 들어 MGA271; 항-VISTA 길항제 항체; 항-TIGIT 길항제 항체; 항체; 항-CD80 항체; 항-CD86 항체; 항-B7-H4 길항제 항체; 항-ICOS 효능제 항체; 항-CD28 효능제 항체; 선천성 면역 반응 조정제 (예를 들어, TLR, KIR, NKG2A) 및 IDO 억제제와 함께 사용된다.
일부 실시양태에서, B7-H4xCD3 이중특이적 항체를 비롯한 본 발명의 B7-H4 항체는 OX40 효능제, 예컨대, 예를 들어 항-OX-40 효능제 항체와 함께 사용된다. 일부 실시양태에서, 본 발명의 B7-H4xCD3 이중특이적 항체를 비롯한 B7-H4 항체는 GITR 효능제, 예컨대, 예를 들어 항-GITR 효능제 항체, 예컨대, 예를 들어 비제한적으로 TRX518과 함께 사용된다. 일부 실시양태에서, 본 발명의 B7-H4xCD3 이중특이적 항체를 비롯한 B7-H4 항체는 IDO 억제제와 함께 사용된다. 일부 실시양태에서, GUCY2c 항체 또는 CD3-GUCY2c 이중특이적 항체는 시토카인 요법, 예컨대, 예를 들어 비제한적으로 IL-15, CSF-1, MCSF-1 등과 함께 사용된다.
일부 실시양태에서, B7-H4xCD3 이중특이적 항체를 비롯한 본 발명의 B7-H4 항체는 1종 이상의 다른 치료 항체, 예컨대, 예를 들어 비제한적으로 CD19, CD22, CD40, CD52 또는 CCR4를 표적화하는 항체와 함께 사용된다.
특정 실시양태에서, 본 발명의 B7-H4xCD3 이중특이적 항체를 비롯한 B7-H4 항체의 조성물은 적어도 1종의 추가의 작용제, 예컨대 베바시주맙, 세툭시맙, 시롤리무스, 파니투무맙, 5-플루오로우라실 (5-FU), 카페시타빈, 티보자닙, 이리노테칸, 옥살리플라틴, 시스플라틴, 트리플루리딘, 티피라실, 류코보린, 겜시타빈 및 에를로티닙 히드로클로라이드를 포함한다.
일부 실시양태에서, 본 발명의 B7-H4xCD3 이중특이적 항체를 포함한 B7-H4 항체는 수분 내지 수주 범위의 간격으로 다른 작용제 치료 전 또는 후에 공-투여될 수 있거나 또는 순차적으로 투여될 수 있다. 다른 작용제 및/또는 단백질 또는 폴리뉴클레오티드가 개별적으로 투여되는 실시양태에서, 일반적으로 각각의 전달 사이에 상당한 기간이 소요되지 않았으므로, 본 발명의 작용제 및 조성물이 대상체에 대해 유리하게 조합된 효과를 여전히 발휘할 수 있도록 보장할 것이다. 이러한 경우에, 서로 약 12-24시간 내에, 보다 바람직하게는 서로 약 6-12시간 내에 양식 둘 다를 투여할 수 있는 것으로 고려된다. 그러나, 일부 상황에서, 각각의 투여 사이에 수일 (2, 3, 4, 5, 6 또는 7일) 내지 수주 (1, 2, 3, 4, 5, 6, 7 또는 8주)가 경과하는 경우, 투여 기간을 유의하게 연장시키는 것이 바람직할 수 있다.
일부 실시양태에서, 본 발명의 B7-H4xCD3 이중특이적 항체를 비롯한 B7-H4 항체의 치료 요법은 수술, 방사선 요법, 화학요법, 표적화 요법, 면역요법, 호르몬 요법, 혈관신생 억제 및 완화적 관리로 이루어진 군으로부터 선택된 전통적인 요법을 추가로 포함하는 치료 요법과 조합된다.
키트
본 발명은 또한 본 방법에 사용하기 위한 키트를 제공한다. 본 발명의 키트는 본 발명의 B7-H4xCD3 이중특이적 항체를 비롯한 B7-H4 항체 및 본원에 기재된 본 발명의 임의의 방법에 따른 사용에 대한 지침서를 포함하는 1개 이상의 용기를 포함한다. 일반적으로, 이들 지침서는 상기 기재된 치유적 치료를 위한 본 발명의 B7-H4xCD3 이중특이적 항체를 비롯한 B7-H4 항체의 투여에 대한 설명을 포함한다.
본원에 기재된 바와 같은 본 발명의 B7-H4xCD3 이중특이적 항체를 비롯한 B7-H4 항체의 사용에 관한 지침서는 일반적으로 의도된 치료를 위한 투여량, 투여 스케줄 및 투여 경로에 관한 정보를 포함한다. 용기는 단위 용량, 벌크 패키지 (예를 들어, 다중-용량 패키지) 또는 하위-단위 용량일 수 있다. 본 발명의 키트에 공급된 지침서는 전형적으로 라벨 또는 패키지 삽입물 상의 서면 지침서 (예를 들어, 키트에 포함된 종이 시트)이지만, 기계-판독가능한 지침서 (예를 들어, 자기 또는 광학 저장 디스크 상에 보유된 지침서)가 또한 허용된다.
본 발명의 키트는 적합한 패키징 내에 있다. 적합한 패키징은 바이알, 병, 단지, 가요성 패키징 (예를 들어, 밀봉된 마일라 또는 플라스틱 백) 등을 포함하나 이에 제한되지는 않는다. 특정 장치, 예컨대 흡입기, 비강 투여 장치 (예를 들어, 아토마이저) 또는 주입 장치, 예컨대 미니펌프와 조합하여 사용하기 위한 패키지가 또한 고려된다. 키트는 멸균 접근 포트를 가질 수 있다 (예를 들어, 용기는 피하 주사 바늘로 뚫을 수 있는 마개를 갖는 정맥내 용액 백 또는 바이알일 수 있음). 용기는 또한 멸균 접근 포트를 가질 수 있다 (예를 들어, 용기는 피하 주사 바늘로 뚫을 수 있는 마개를 갖는 정맥내 용액 백 또는 바이알일 수 있음). 조성물 내의 적어도 1종의 활성제는 본 발명의 B7-H4xCD3 이중특이적 항체를 비롯한 B7-H4 항체이다. 용기는 제2 제약 활성제를 추가로 포함할 수 있다.
키트는 임의로 추가의 성분, 예컨대 완충제 및 해석 정보를 제공할 수 있다. 통상적으로, 키트는 용기 및 용기 상에 있거나 용기와 회합된 라벨 또는 패키지 삽입물(들)을 포함한다.
하기 실시예는 단지 예시적 목적을 위해 제공되며, 어떠한 방식으로도 본 발명의 범주를 제한하는 것으로 의도되지 않는다. 실제로, 본원에 제시되고 기재된 것 이외의 본 발명의 다양한 변형이 상기 기재로부터 관련 기술분야의 통상의 기술자에게 명백해질 것이고, 이는 첨부된 청구범위의 범주 내에 속할 것이다.
실시예
실시예 1. B7-H4 항체 및 B7-H4xCD3 이중특이적 항체의 고처리량 발현 및 정제.
B7-H4 동종이량체 항체의 상보적 구축물 쌍 (12.5 μg의 각각의 중쇄 및 경쇄)을 엑스피펙타민(ExpiFectamine)™ 293 형질감염 키트 (라이프 테크놀로지스(Life Technologies))를 사용하여 1백만개 세포/ml의 HEK 293 세포를 함유하는 25 mL 대수기 배양물 내로 공동-형질감염시켰다. 형질감염 24시간 후에, 엑스피펙타민 형질감염 증진제를 첨가하고, 세포를 추가 4-5일 동안 성장시킨 후에 수거하였다. 이어서, 소모된 배양물을 수집하고, 원심분리하여 세포 파편을 제거한 다음, 20 μm 필터에 통과시켰다.
이어서, B7-H4 동종이량체를 함유하는 정화된 조건화 배지를 단백질 A 친화도 크로마토그래피를 사용하여 정제하였다. 액체 핸들러 (테칸(Tecan))를 사용하여 Mab셀렉트 슈어(MabSelect SuRe)™ 단백질 A 수지 (지이 헬스케어(GE Healthcare))로 사전-패킹된 0.45 mL 마이크로 칼럼 (레플리겐(Repligen)) 상에 샘플을 로딩하였다. 결합된 단백질을 PBS pH 7.2로 세척한 다음, 20 mM 시트르산, 150 mM 염화나트륨 pH 3.5로 용리시키고, 2M 트리스 pH 8.0으로 중화시켰다. 애질런트(Aglient) 1200 HPLC 상에서 Mab HTP 칼럼 (도소 바이오사이언스(Tosoh Bioscience))이 구비된 분석용 크기 배제 크로마토그래피를 제조업체의 프로토콜에 따라 사용하여 단백질을 순도에 대해 분석하였다. 마이크로 분광광도계 (트리네안(Trinean))를 사용하여 OD280 nm를 측정함으로써 농도를 결정하였다.
CD3 동종이량체 항체를 상기와 유사하게 제조하고, 실시예 2에 기재된 바와 같이 2 L의 배양물로부터 정제하였다. 간략하게, 2 L의 expi293 세포 (인비트로젠)를 제조업체의 프로토콜에 따라 0.5 μg/ml의 각각의 중쇄 및 경쇄로 형질감염시켰다. 조건화 배지를 제5일에 수거하고, MAB 셀렉트 슈어 LX 수지 (지이 헬스케어)에 의해 포획하였다.
등몰량의 B7-H4 동종이량체 및 CD3 동종이량체를 혼합하고, 이들을 1 mM GSH와 함께 37℃에서 24시간 동안 인큐베이션함으로써 이중특이적 항체를 형성하였다. 이어서, G25 세파덱스 드립 칼럼 (지이 헬스케어)을 제조업체의 방법에 따라 사용하여 샘플을 PBS pH 7.2 내로 탈염시켰다. 제어된 Fab 아암 교환 (이종이량체의 형성)의 효율을 WCX 칼럼 (지이 헬스케어)을 사용하여 얕은 염 구배 (20 mM MES pH 5.4, 0-1 M NaCl)로 분석하였다.
표 2의 B7-H4 항체 및 표 5의 B7-H4xCD3 이중특이적 항체를 본 발명의 방법에 따라 제조하였다.
실시예 2. B7-H4xCD3 이중특이적 항체 1167 및 1156의 생산.
B7-H4xCD3 이중특이적 항체 1167 항-B7-H4 아암 중쇄 (서열식별번호: 196), 항-B7-H4 경쇄 (서열식별번호: 197), B7-H4xCD3 이중특이적 항체 1156 항-B7-H4 아암 중쇄 (서열식별번호: 192), 항-B7-H4 경쇄 (서열식별번호: 193), 항-CD3 아암 중쇄 (서열식별번호: 194) 및 항-CD3 경쇄 (서열식별번호: 195)를 코딩하는 cDNA를 포유동물 발현 벡터 내로 클로닝하였다. C223E, P228E 및 L368E의 3개의 추가의 치환을 갖는 항-B7-H4 IgG2 dA D265A 중쇄 (집합적으로 "EEE") 및 4개의 추가의 치환 C223R, E225R, P228R, K409R을 갖는 항-CD3 IgG2 dA D265A (집합적으로 "RRR")를 상응하는 경쇄와 함께 형질감염시키고, 2 L의 expi293 세포 (인비트로젠)를 제조업체 프로토콜에 따라 사용하여 전체 "EEE" 및 "RRR" 아암을 개별적으로 발현시켰다. 형질감염을 위한 중쇄 및 경쇄의 DNA 비는 중량 기준으로 1:1이었다 (1 ug/ml의 배양물, 총 DNA). 두 동종이량체 (RRR 및 EEE)에 대한 조건화 배지를 제5일에 수거하고, MAB 셀렉트 슈어 LX 수지 (지이 헬스케어)에 의해 개별적으로 포획하였다. mAb 셀렉트 슈어 LX 수지로부터의 용리액을 사용하여 시험관내에서 이중특이적 분자의 이종이량체화를 수행하였다. 간략하게, RRR 및 EEE 동종이량체를 이중특이적 항체 1156 및 1167 각각에 대해 20배 및 10배 몰 과량의 시스테인의 존재 하에 1:1 몰비로 혼합하였다. 혼합물 용액을 실온 pH 8.0에서 18시간 동안 인큐베이션하였다. 산화환원-후(Post-RedOx)를 이중특이적 항체 1156 및 1167에 대해 각각 50 mM MES 완충제 pH 5.6으로 1:4 및 1:9로 희석한 다음, 실온에서 모노-S 칼럼 (CEX 정제, 지이 헬스케어 라이프 사이언시스(GE Healthcare Life Sciences)) 상에 전개시켰다. 양이온 교환 용리 완충제 (50mM MES, 1000mM NaCl, pH 5.6)를 구배 하에 사용하여 칼럼으로부터 단백질을 용리시켰다. AKTA 퓨어 앤드 아반트 (지이 헬스케어 라이프 사이언시스) 상에서 정제를 수행하였다. 세파덱스 G-25 파인 (지이 헬스케어 라이프 사이언시스)을 사용하여 PBS-CMF (포스페이트 완충 염수; 칼슘 및 마그네슘 무함유)로의 최종 완충제 교환을 수행하였다. 아미노산 서열로부터 계산된 몰 흡수 계수를 사용하여 280 nm에서의 흡광도를 측정함으로써 단백질 정량화를 달성하였다.
실시예 3. 플레이트 결합된 huB7-H4에 대한 IC50을 시험하기 위한 경쟁 ELISA
하기 표 7에 기재된 배선화 및 최적화 변이체의 결합 강도를 ELISA에서 모 B7-H4 항체 0052 또는 0058과의 경쟁에 의해 평가하였다. ELISA 플레이트 (써모 피셔(Thermo Fisher); 384-웰)를 PBS 완충제 중 B7-H4 세포외 도메인 ("ECD") (6xhis F29-A258) 1 μg/mL (25 ug/웰)로 4℃에서 밤새 부드럽게 진탕시키면서 코팅하였다. 코팅 용액을 버리고, 플레이트를 실온에서 1시간 동안 웰당 50 μL PBS-1% BSA로 차단하였다. 차단 용액을 버리고, 플레이트를 TBST로 4회 세척하였다. 분석된 mAb의 2배 연속 희석물을 제조하고, EC80에 상응하는 농도의 비오티닐화 B7-H4 항체 0052 (28D10 최적화 시리즈의 경우) 또는 B7-H4 항체 0058 (37D4 최적화 시리즈의 경우)과 혼합하였다. 희석된 시험 mAb 및 비오티닐화 모 mAb의 1:1 혼합물 25 ul를 플레이트에 2회 반복으로 첨가하였다. 플레이트를 천천히 진탕시켜 실온에서 2시간 동안 인큐베이션하였다. 플레이트를 웰당 100 μL의 세척 완충제 (TBST)로 4회 세척하고, PBS/BSA 완충제 중에 1:4000 희석된 20 μL의 스트렙타비딘-HRP 접합체와 함께 1시간 동안 인큐베이션하였다. 플레이트를 이전과 같이 7회 세척하고, 20 μL의 TNB 기질과 함께 10분 동안 인큐베이션하였다. 0.18 M 황산을 첨가하여 반응을 종결시켰다. 이어서, 엔비전(EnVision)® 플레이트 판독기 (엔비전® 멀티라벨 플레이트 판독기, 퍼킨 엘머(Perkin Elmer))를 제조업체의 프로토콜에 따라 사용하여 450 nm에서 흡광도를 측정하였다. 비오티닐화 0052 및 0058을 상기 기재된 바와 같이 제조된 인간 B7-H4 ECD로 코팅된 플레이트와 함께 실온에서 인큐베이션함으로써 모 항체 0052 및 0058의 EC80을 결정하였다. 항체의 2배 연속 희석물을 제조하고, 25 ul를 웰에 첨가하였다. 2시간 인큐베이션한 후, 플레이트를 세척하고, PBS/BSA 완충제 중에 1:4000 희석된 스트렙타비딘-HRP 접합체와 함께 인큐베이션하고, 이어서 상기 기재된 바와 같이 세척하고, TNB 기질을 첨가하였다. 반응을 0.18 M 황산으로 종결시킨 다음, 엔비전® 플레이트 판독기 (엔비전® 멀티라벨 플레이트 판독기, 퍼킨 엘머)를 사용하여 450 nm에서 흡광도를 측정하였다. 그래프패드 프리즘에서 4 파라미터 비-선형 회귀 분석을 사용하여 EC80 값을 계산하였다.
표 2 및 표 5의 선택된 항체를 이 방법에 따라 시험하였으며, 생성된 데이터는 표 7에 제시되어 있다.
실시예 4. 친화도 포획 자기-상호작용 나노입자 분광분석법 (AC-SINS)
항체 및 항체-유사 단백질은 특히 증가된 농도에서 그 자신과 상호작용하는 잠재력을 갖는다. 이러한 자기-상호작용은 약물 개발 동안 제제화와 연관된 점도 난제뿐만 아니라 증가된 클리어런스 위험으로 이어질 수 있다. (Avery et al. MAbs. 2018; 10(2): 244-255). AC-SINS 검정은 자기-상호작용을 측정하고, 높은 점도 및 불량한 약동학적 특성에 대한 잠재력을 예측하는 것을 돕는데 사용된다.
AC-SINS 검정을 퍼킨-엘머 야누스 액체 핸들링 로봇 상에서 384-웰 포맷으로 표준화하였다. 20 nm 금 나노입자 (테드 펠라, 인크.(Ted Pella, Inc.), #15705)를 80% 염소 항-인간 Fc (잭슨 이뮤노리서치 래보러토리즈, 인크.(Jackson ImmunoResearch Laboratories, Inc.) # 109-005-098) 및 20% 비-특이적 염소 폴리클로날 항체 (잭슨 이뮤노리서치 래보러토리즈, 인크. # 005-000-003)의 혼합물로 코팅하고, 이를 20 mM 아세트산나트륨 pH 4.3 중에 완충제 교환하고, 0.4 mg/ml로 희석하였다. 실온에서 1시간 인큐베이션한 후, 금 나노입자 상에 점유되지 않은 부위를 티올화 폴리에틸렌 글리콜 (2 kD)로 차단하였다. 이어서, 코팅된 나노입자를 시린지 필터를 사용하여 10배 농축시키고, 10 μl를 PBS pH 7.2 중 0.05 mg/ml의 mAb 100 μl에 첨가하였다. 코팅된 나노입자를 96-웰 폴리프로필렌 플레이트에서 2시간 동안 관심 항체와 함께 인큐베이션한 다음, 384-웰 폴리스티렌 플레이트로 옮기고, 테칸 M1000 분광광도계 상에서 판독하였다. 흡광도를 450-650 nm에서 2 nm 증분으로 판독하고, 마이크로소프트 엑셀 마크로를 사용하여 최대 흡광도를 확인하고, 데이터를 평활화하고, 2차 다항식을 사용하여 데이터를 피팅하였다. 평균 블랭크 (PBS 완충제 단독)의 평활화된 최대 흡광도를 항체 샘플의 평활화된 최대 흡광도로부터 차감하여 항체 AC-SINS 점수를 결정하였다.
표 2 및 표 5의 선택된 항체를 이 방법에 따라 시험하였으며, 생성된 데이터는 표 7에 제시되어 있다.
실시예 5. DNA 및 인슐린 다중특이성 ELISA
384-웰 ELISA 플레이트 (눈크 맥시소르프(Nunc Maxisorp))를 PBS pH 7.5 중 DNA (10 μg/ml) 및 인슐린 (5 μg/ml)으로 4℃에서 밤새 코팅하였다. 문헌 [Tiller et al., J. Immunol. Methods 329, 112, 2008]; 미국 특허 번호 7,314,622에 기재된 검정으로부터 적합화된 ELISA를 퍼킨엘머 야누스 액체 핸들링 로봇 상에서 수행하였다. 웰을 물로 세척하고, 50 μl의 다반응성 ELISA 완충제 (PEB; 0.5% 트윈-20, 1 mM EDTA를 함유하는 PBS)로 실온에서 1시간 동안 차단하고, 물로 3회 헹구었다. 25 μl 중 연속-희석된 mAb를 웰에 사중으로 첨가하고, 실온에서 1시간 동안 인큐베이션하였다. 플레이트를 물로 3회 세척하고, 양고추냉이 퍼옥시다제 (잭슨 이뮤노리서치)에 접합된 10 ng/ml 염소 항-인간 IgG (Fcγ 단편 특이적) 25 μl를 각각의 웰에 첨가하였다. 플레이트를 실온에서 1시간 동안 인큐베이션하고, 80 μl의 물로 3회 세척하고, 25 μl의 TMB 기질 (시그마 알드리치(Sigma Aldrich))을 각각의 웰에 첨가하였다. 각각의 웰에 25 μl의 0.18 M 오르토-인산을 첨가함으로써 6분 50초 후에 반응을 정지시키고, 450nm에서 흡광도를 판독하였다. 10 μg/ml의 항체의 ELISA 신호 대 완충제를 함유하는 웰의 신호의 비로서 DNA- 및 인슐린-결합 점수를 계산하였다. 표 2 및 표 5의 선택된 항체를 본원에 기재된 DNA 및 인슐린 결합 ELISA 절차에 따라 시험하여 그에 제시된 다중특이성 점수를 얻었으며, 데이터는 표 7에 제시되어 있다.
표 7. B7-H4 항체 및 B7-H4xCD3 이중특이적 항체의 경쟁 ELISA, AC-INS 결과



실시예 6. 시차 주사 열량측정 (DSC) 분석
포스페이트-완충 염수 (PBS) 용액 중에 항체를 400 μl의 부피 중 0.6 mg/ml로 희석하였다. 참조 셀에서 완충제 블랭크로서 PBS를 사용하였다. PBS는 137 mM NaCl, 2.7 mM KCl, 8.1 mM Na2HPO4 및 1.47 mM KH2PO4, pH 7.2를 함유하였다. 오토샘플러 (말번 인스트루먼츠 리미티드(Malvern Instruments Ltd), 영국 말번)가 구비된 마이크로칼 VP-모세관 DSC의 샘플 트레이 내로 샘플을 분배하였다. 샘플을 10℃에서 5분 동안 평형화시킨 다음, 시간당 100℃의 속도로 110℃까지 스캐닝하였다. 16초의 필터링 기간을 선택하였다. 미가공 데이터를 기준선 보정하고, 단백질 농도를 정규화하였다. 오리진 소프트웨어 7.0 (오리진랩 코포레이션(OriginLab Corporation), 매사추세츠주 노샘프턴)을 사용하여 데이터를 적절한 수의 전이로 MN2-스테이트 모델에 피팅하였다. IgG1 포맷의 최적화된 항-B7-H4 결합 도메인의 시차 주사 열량측정의 결과가 표 8에 제시되어 있다.
표 8. IgG1 mAb 포맷에서 DSC에 의한 최적화된 클론의 열 안정성.

실시예 7. B7-H4 IgG1 mAb의 표면 플라즈몬 공명 (SPR) 분석
하이브리도마로부터 수득한 항-B7-H4 클론을 IgG1 mAb 포맷으로, 비아코어™ 8K 기기 (지이 헬스케어)를 사용하여 표면 플라즈몬 공명에 의해 25℃에서 인간 B7-H4 ECD (세포외 도메인)에의 결합에 대해 평가하였다. 항-인간 Fc (GE BR-1008-39)를 먼저 제조업체의 프로토콜에 따라 CM5 센서 칩 상에 코팅하였다. 인간 항-B7-H4 IgG1 mAb를 행크 완충 염수 (HBS)-EP+ pH=7.4 중에서 0.75 ug/mL, 50 uL/분으로 20초 동안 칩 상에 전개시켰다. 이어서, (클론: 7H7, 33G4, 11F12, 33A4, 13F4, 37D4, 19D3, 27C12, 42E2, 28D10, 46E10 및 32F3의 경우) 900 nM로부터 시작하여 및 (클론: 29G6 및 47A1의 경우) 100 nM로부터 시작하여 3배 희석으로 5가지 상이한 농도의 인간 B7-H4 ECD를 50 uL/분으로 60초 동안 칩 상에 전개시켜 회합되도록 한 다음, 300초 동안 해리시켰다. 생성된 센소그램 데이터를 비아코어™ T200 평가 소프트웨어 버전 3.0 (지이 헬스케어)의 1:1 랭뮤어 모델에 피팅함으로써 결합 친화도 및 속도 상수를 결정하였다. 각각의 전개 사이에 3X 3 M MgCl2를 사용하여 칩을 재생시켰다. 결과가 표 9-A에 제시되어 있다.
표 9-A. 25℃에서 SPR에 의한 인간 B7-H4 ECD에 대한 IgG1 포맷의 하이브리도마 클론의 결합 동역학

IgG1 mAb 포맷의 최적화된 항-B7-H4 항체 및 상응하는 모 항체를 비아코어™ 8K 기기 (지이 헬스케어)를 사용하여 표면 플라즈몬 공명에 의해 37℃에서 인간 B7-H4 ECD에의 결합에 대해 시험하였다. 항-인간 Fc (GE BR-1008-39)를 먼저 제조업체의 프로토콜에 따라 CM5 센서 칩 상에 코팅하였다. 인간 항-B7-H4 IgG1 mAb를 행크 완충 염수 (HBS)-EP+ pH=7.4 중에서 0.75 ug/mL, 50 uL/분으로 30초 동안 칩 상에 전개시켰다. 이어서, 300 nM에서 시작하여 3배 희석으로 5가지 상이한 농도의 인간 B7-H4 ECD를 50 uL/분으로 65초 동안 칩 상에 전개시켜 회합되도록 한 다음, 600초 동안 해리시켰다. 생성된 센소그램 데이터를 비아코어™ T200 평가 소프트웨어 버전 3.0 (지이 헬스케어)의 1:1 랭뮤어 모델에 피팅함으로써 결합 친화도 및 속도 상수를 결정하였다. 각각의 전개 사이에 3X 3 M MgCl2를 사용하여 50 uL/분으로 30초 동안 칩을 재생시켰다. 결과가 표 9-B에 제시되어 있다.
표 9-B. 37℃에서 SPR에 의한 인간 B7-H4 ECD에 대한 IgG1 포맷의 모 및 최적화된 항체의 결합 동역학

IgG1 mAb 포맷의 최적화된 항-B7-H4 항체 및 상응하는 모 항체를 비아코어™ 8K 기기 (지이 헬스케어)를 사용하여 표면 플라즈몬 공명에 의해 37℃에서 시노 및 마우스 B7-H4 ECD에의 교차-반응성에 대해 시험하였다. 항-인간 Fc (GE BR-1008-39)를 먼저 제조업체의 프로토콜에 따라 CM5 센서 칩 상에 코팅하였다. 인간 항-B7-H4 IgG1 mAb를 행크 완충 염수 (HBS)-EP+ pH=7.4 중에서 0.75 ug/mL, 50 uL/분으로 30초 동안 칩 상에 전개시켰다. 이어서, 900 nM에서 시작하여 3배 희석으로 5가지 상이한 농도의 시노 및 마우스 B7-H4 ECD를 50 uL/분으로 65초 동안 칩 상에 전개시켜 회합되도록 한 다음, 600초 동안 해리시켰다. 생성된 센소그램 데이터를 비아코어™ T200 평가 소프트웨어 버전 3.0 (지이 헬스케어)의 1:1 랭뮤어 모델에 피팅함으로써 결합 친화도 및 속도 상수를 결정하였다. 각각의 전개 사이에 3X 3 M MgCl2를 사용하여 50 uL/분으로 30초 동안 칩을 재생시켰다. 결과가 표 9-C에 제시되어 있다.
표 9-C. 37℃에서 SPR에 의한 시노 및 마우스 B7-H4 ECD에 대한 IgG1 포맷의 모 및 최적화된 항체의 결합 동역학

실시예 8: B7-H4xCD3 이중특이적 항체의 표면 플라즈몬 공명 (SPR) 분석
인간, 시노 및 마우스 B7-H4 ECD에 대한 모 하이브리도마 클론의 B7-H4xCD3 이중특이적 항체의 결합 친화도를 비아코어™ T200 기기 (지이 헬스케어)를 사용하여 25℃ 또는 37℃에서 10 Hz의 수집 속도로 결정하였다. 항-인간 Fc (GE BR-1008-39)를 먼저 제조업체의 프로토콜에 따라 CM5 센서 칩 상에 코팅하였다. B7-H4-CD3 IgG2 EEE/RRR 이중특이적 항체를 행크 완충 염수 (HBS)-EP+ pH=7.4 중에서 0.5 ug/mL, 50 uL/분으로 20-25초 동안 칩 상에 전개시켰다. 인간, 시노 및 마우스 B7-H4 ECD를 50 uL/분으로 65초 동안 칩 상에 전개시켜 회합되도록 한 다음, 300초 동안 해리시켰다. 시노의 경우 400 nM에서 시작하여 및 인간 및 마우스 항원의 경우 900 nM에서 시작하여 3배 희석으로 5가지 상이한 농도의 항원을 사용하였다. 600초 동안 해리를 모니터링하고, 3 M MgCl2를 사용하여 50uL/분으로 30초 동안 표면을 3회 재생시켰다. 생성된 센소그램 데이터를 비아코어™ T200 평가 소프트웨어 버전 3.0 (지이 헬스케어)의 1:1 랭뮤어 모델에 피팅함으로써 결합 친화도 및 속도 상수를 결정하였다. 결과가 표 10-A에 제시되어 있다.
표 10-A. 25℃ 또는 37℃에서 SPR에 의한 인간, 시노 및 마우스 B7-H4 ECD에 대한 모 이중특이적 항체의 결합 동역학.

인간 및 시노 CD3에 대한 모 하이브리도마 클론의 B7-H4xCD3 이중특이적 항체의 결합 친화도를 비아코어™ T200 기기 (지이 헬스케어)를 사용하여 25℃에서 10 Hz의 수집 속도로 결정하였다. 항-His (GE 10260125)를 먼저 제조업체의 프로토콜에 따라 CM5 센서 칩 상에 코팅하였다. 인간 CD3 (델타/엡실론 이종이량체)을 행크 완충 염수 (HBS)-EP+ pH=7.4 중에서 0.50 ug/mL, 10 uL/분으로 30초 동안 칩 상에 전개시켰다. 150 nM 내지 5.6 nM 범위의 농도를 갖는 B7-H4xCD3 이중특이적 단백질의 3배 연속 희석물을 50 μl/분의 유량으로 72초 동안 센서 표면 상에 주입하였다. 300초 동안 해리를 모니터링하고, 10 mM 글리신 pH 1.5를 사용하여 50 uL/분으로 20초 동안 표면을 재생시켰다. 생성된 센소그램 데이터를 비아코어™ T200 평가 소프트웨어 버전 3.0 (지이 헬스케어)의 1:1 랭뮤어 모델에 피팅함으로써 결합 친화도 및 속도 상수를 결정하였다. 결과가 표 10-B에 제시되어 있다.
표 10-B. 25℃에서 SPR에 의한 인간 및 시노 CD3에 대한 모 하이브리도마 클론의 B7-H4xCD3 이중특이적 항체의 결합 동역학.

인간, 시노 및 뮤린 B7-H4 ECD에 대한 B7-H4xCD3 이중특이적 항체의 결합 친화도를 비아코어™ T200 기기 (지이 헬스케어)를 사용하여 37℃에서 10 Hz의 수집 속도로 결정하였다. 항-인간 Fc (GE BR-1008-39)를 먼저 제조업체의 프로토콜에 따라 CM5 센서 칩 상에 코팅하였다. B7-H4xCD3 IgG2 EEE/RRR 이중특이적 항체를 행크 완충 염수 (HBS)-EP+ pH=7.4 중에서 0.75 ug/mL, 50 uL/분으로 30초 동안 칩 상에 전개시켰다. 인간, 시노, 마우스 및 래트 B7-H4 ECD를 50 uL/분으로 60초 동안 칩 상에 전개시켜 회합되도록 한 다음, 300초 동안 해리시켰다. 인간 및 시노의 경우 270 nM에서 시작하여 및 래트 및 마우스 항원의 경우 2100 nM에서 시작하여 3배 희석으로 5가지 상이한 농도의 항원을 사용하였다. 600초 동안 해리를 모니터링하고, 3 M MgCl2를 사용하여 50uL/분으로 30초 동안 표면을 3회 재생시켰다. 생성된 센소그램 데이터를 비아코어™ T200 평가 소프트웨어 버전 3.0 (지이 헬스케어)의 1:1 랭뮤어 모델에 피팅함으로써 결합 친화도 및 속도 상수를 결정하였다. 결과가 표 10-C에 제시되어 있다.
표 10-C. 37℃에서 SPR에 의한 인간, 시노, 래트 및 마우스 B7-H4 ECD에 대한 모 및 최적화된 이중특이적 항체의 결합 동역학

인간 및 시노 CD3에 대한 B7-H4-CD3 이중특이적 항체의 결합 친화도를 비아코어™ T200 기기 (지이 헬스케어)를 사용하여 37℃에서 10 Hz의 수집 속도로 결정하였다. 항-His (GE 10260125)를 먼저 제조업체의 프로토콜에 따라 CM5 센서 칩 상에 코팅하였다. 인간 및 시노 CD3 (델타/엡실론 이종이량체)을 행크 완충 염수 (HBS)-EP+ pH=7.4 중에서 0.50 ug/mL, 10 uL/분으로 36초 동안 칩 상에 전개시켰다. 300 nM 내지 3.7 nM 범위의 농도를 갖는 B7-H4-CD3 이중특이적 단백질의 3배 연속 희석물을 50 μl/분의 유량으로 72초 동안 센서 표면 상에 주입하였다. 200초 동안 해리를 모니터링하고, 10 mM 글리신 pH 1.5를 사용하여 50 uL/분으로 20초 동안 표면을 재생시켰다. 생성된 센소그램 데이터를 비아코어™ T200 평가 소프트웨어 버전 3.0 (지이 헬스케어)의 1:1 랭뮤어 모델에 피팅함으로써 결합 친화도 및 속도 상수를 결정하였다. 결과가 표 10-D에 제시되어 있다.
표 10-D. 37℃에서 SPR에 의한 인간 및 시노 CD3에 대한 B7-H4-CD3 이중특이적 항체의 결합 동역학.

인간 B7-H4 및 CD3에 대한 CD3-B7-H4xCD3 이중특이적 항체가 일시적 expi293 또는 안정한 CHO 세포로부터 생산된 경우에 이러한 이중특이적 항체의 결합 친화도의 비교를 비아코어™ T200 기기 (지이 헬스케어)를 사용하여 37℃에서 10 Hz의 수집 속도로 수행하였다. B7-H4의 결합을 시험하기 위해, B7-H4-CD3 IgG2 EEE/RRR 이중특이적 항체를 0.5 ug/mL, 50 uL/분으로 36초 동안 칩 상에 전개시키고, 인간 B7-H4 ECD를 50 uL/분으로 72초 동안 칩 상에 전개시켜 회합되도록 한 다음, 200초 동안 해리시킨 것을 제외하고는, 상기 기재된 바와 같이 유사한 실험을 수행하였다. 동일한 농도 세트를 사용하였다. CD3의 결합을 시험하기 위해, 동일한 파라미터로 상기 기재된 바와 같이 유사한 실험을 수행하였다. 결과가 표 10-E에 제시되어 있다.
표 10-E. 37℃에서 SPR에 의해 시험된 expi293에서의 일시적 발현 또는 CHO에서의 안정한 발현으로부터 유래된 최적화된 이중특이적 항체의 결합 동역학.

다양한 CD3 변이체를 함유하는 이중특이적 항체 대비 인간 B7-H4 및 CD3에 대한 CD3-B7-H4xCD3 이중특이적 항체의 결합 친화도의 비교를 비아코어™ T200 기기 (지이 헬스케어)를 사용하여 37℃에서 10 Hz의 수집 속도로 수행하였다. CD3의 결합을 시험하기 위해, 하기 변화를 사용하여 상기 기재된 바와 같이 유사한 실험을 수행하였다. 900 nM 내지 3.7 nM 범위의 농도를 갖는 B7-H4-CD3 이중특이적 단백질의 3배 연속 희석물을 50 μl/분의 유량으로 60초 동안 센서 표면 상에 주입하였다. 생성된 센소그램 데이터를 비아코어™ T200 평가 소프트웨어 버전 3.0 (지이 헬스케어)의 1:1 랭뮤어 모델에 피팅함으로써 결합 친화도 및 속도 상수를 결정하였다. 결과가 표 10-F에 제시되어 있다.
표 10-F. 37℃에서 SPR에 의해 시험된 인간 CD3에 대한 상이한 CD3 변이체를 갖는 이중특이적 항체의 결합 동역학.

IgG2 또는 IgG1 EEE/RRR 스캐폴드에 기초한 이중특이적 항체 대비 인간 B7-H4 및 CD3에 대한 CD3-B7-H4xCD3 이중특이적 항체의 결합 친화도의 비교를 비아코어™ T200 기기 (지이 헬스케어)를 사용하여 37℃에서 10 Hz의 수집 속도로 수행하였다. B7-H4의 결합을 시험하기 위해, B7-H4-CD3 IgG2 EEE/RRR 이중특이적 항체를 0.75 ug/mL, 10 uL/분으로 40초 동안 칩 상에 전개시키고, 인간 B7-H4 ECD를 50 uL/분으로 65초 동안 칩 상에 전개시켜 회합되도록 한 다음, 600초 동안 해리시킨 것을 제외하고는, 상기 기재된 바와 같이 유사한 실험을 수행하였다. 300 nM 내지 11 nM 범위의 농도를 사용하였다. CD3의 결합을 시험하기 위해, 하기 변화를 사용하여 상기 기재된 바와 같이 유사한 실험을 수행하였다. 900 nM 내지 3.7 nM 범위의 농도를 갖는 B7-H4-CD3 이중특이적 단백질의 3배 연속 희석물을 50 μl/분의 유량으로 60초 동안 센서 표면 상에 주입하였다. 생성된 센소그램 데이터를 비아코어™ T200 평가 소프트웨어 버전 3.0 (지이 헬스케어)의 1:1 랭뮤어 모델에 피팅함으로써 결합 친화도 및 속도 상수를 결정하였다. 결과가 표 10-G에 제시되어 있다.
표 10-G. 37℃에서 SPR에 의해 시험된 이중특이적 항체의 결합 동역학.

실시예 9. B7-H4 및 CD3에 대한 항체의 세포-기반 결합.
B7-H4xCD3 이중특이적 분자에 대해 세포-기반 결합을 수행하였다. 700nM 농도의 B7-H4xCD3 이중특이적 분자로 시작한 12 단계 연속 희석물을 MX1, HCC1954-Luc, T47D 및 HEK293-huB7-H4를 포함한 다수의 인간 B7-H4 발현 세포주, 시노몰구스 B7-H4 발현 세포주 CHO-cyB7-H4 및 마우스 B7-H4 발현 세포주 HEK293-msB7-H4와 함께 인큐베이션하였다.
추가로, 건강한 공여자 PBMC로부터 단리된 CD3 발현 1차 인간 T 세포 및 시노몰구스 PBMC로부터 단리된 CD3 발현 세포, 뿐만 아니라 래트 비장 및 C57 및 BalbC 마우스 비장으로부터의 CD3 발현 세포로 결합을 수행하였다. T 세포 풍부화 키트 (스템셀 테크놀로지스(StemCell Technologies))를 사용하여 음성 선택에 의해 PBMC로부터 인간 범 T 세포를 단리하였다. 래트 및 마우스 비장을 기계적 균질화, 적혈구 용해 (로슈(Roche)) 및 여과 단계를 통해 처리하였다.
DPBS (깁코(Gibco)) 중 1% BSA (피셔 사이언티픽(Fisher Scientific)) 및 0.01% 아지드화나트륨 (리카 케미칼 캄파니(Ricca Chemical Company))을 함유하는 유동 완충제로 모든 세포를 2회 세척하고, 유동 완충제 중 웰당 100K 세포 밀도로 시딩하였다. 모든 원심분리 단계를 300g에서 5분 동안 수행하였다.
항체 내재화를 억제하는 기능을 하는 아지드화나트륨과 함께 37℃에서 2시간 동안 인큐베이션을 수행하였다. 비결합된 B7-H4xCD3 이중특이적 분자를 2 라운드의 37℃ 유동 완충제 세척/원심분리 단계로 세척하였다. 결합된 B7-H4xCD3 이중특이적 분자를 PE-표지된 염소 항-인간 Fcγ 2차 항체 (잭슨 이뮤노 리서치)로 검출하였다. 2차 항체 인큐베이션을 1:200 희석으로 37℃에서 30분 동안 수행하였다. 비결합된 2차 항체를 2 라운드의 37℃ 유동 완충제 세척/원심분리 단계로 세척하였다. 유동 완충제를 함유하는 7-AAD 생존능 염색 용액 (바이오 레전드(Bio Legend)) 중에 세포를 재현탁시키고, 유동 세포측정기 상에서 데이터를 획득하였다. 결합 포화의 EC50 측정치가 하기 표 11-A 및 표 11-B에 열거되어 있다. 세포 상에서, 이중특이적 항체 1167은 인간 CD3보다 더 높은 친화도로 인간 B7-H4에 결합하고, 인간 B7-H4와 대등한 친화도로 시노몰구스 B7-H4에 결합하고, 뮤린 또는 래트 B7-H4에는 결합하지 않는다.
HCC1806-Luc, HEK293 및 CHO 세포를 비롯한, B7-H4 (또는 CD3) 발현이 없는 음성 세포주는 결합을 나타내지 않았다.
표 11-A. B7-H4 발현 세포주에 결합하는 B7-H4xCD3 이중특이적 항체

표 11-B. CD3 발현 세포주에 대한 B7-H4xCD3 이중특이적 항체 결합

실시예 10. 최적화된 CD3-B7-H4xCD3 이중특이적 항체의 T 세포 매개 세포 사멸 활성
피콜 파크 (지이 헬스케어)를 사용하여 건강한 공여자 혈액으로부터 인간 PBMC를 단리하였다. 스템 셀 테크놀로지스로부터의 T 세포 풍부화 키트 (T 세포의 음성 선택)를 사용하여 PBMC로부터 범 T 세포를 단리하였다. 루시페라제 발현 구축물, HCC1954-Luc, OVCAR3-Luc 또는 HCT116-Luc로 형질감염된 B7-H4 발현 인간 종양 세포를 R10 배지 (RPMI, 10% FBS, 1% Penn/Strep, 3 ml의 45% 글루코스) 중에 재현탁시켰다. T 세포를 또한 R10 배지 중에 재현탁시키고, 이펙터 대 표적 비 (E:T 비) 5:1 또는 2.5:1로 종양 세포에 첨가하였다. 세포를 B7-H4xCD3 이중특이적 항체 또는 음성 대조군 CD3 이중특이적 항체의 연속 희석물로 처리하고, 250 x g에서 4분 동안 스핀 다운시켜 접촉을 개시하고, 37℃에서 48시간 동안 인큐베이션하였다.
루시페라제 검정을 위해, 빅터 (퍼킨 엘머)를 사용하여 네오라이트 시약 (퍼킨 엘머)을 사용하여 루시페라제 신호를 측정하였다. 그래프패드 프리즘에서 4 파라미터 비-선형 회귀 분석을 사용하여 EC50 값을 계산하였다.
락테이트 데히드로게나제 (LDH) 검정을 위해, 시토톡스 96 비-방사성 세포독성 검정 키트 (프로메가(Promega), G1780) 및 빅터 마이크로플레이트 판독기 (퍼킨 엘머)를 사용하여 손상된 표적 세포로부터 LDH를 방출시켰다. 그래프패드 프리즘에서 4 파라미터 비-선형 회귀 분석을 사용하여 EC50 값을 계산하였다.
결과가 표 12에 제시되어 있다. 이들 결과는 B7-H4xCD3 이중특이적 항체가 시험관내에서 인간 B7-H4를 발현하는 다양한 세포주의 세포독성 T 세포 사멸을 재지시하였음을 입증한다. 이들 세포주는 난소암 세포주에 추가로 HR+HER2-, HER2+ 및 TNBC 하위유형의 유방암 세포주를 포함한다. 추가로, 항체 1156 및 1167은 시노몰구스 원숭이에서도 교차 반응성인 것으로 나타났다.
표 12. 이중특이적 항체의 T 세포 매개 종양 세포 사멸 활성


실시예 11. B7-H4xCD3 이중특이적 항체 매개 활성의 생체내 평가-입양 전달 또는 PBMC 모델
인간 PBMC를 5% 인간 혈청 알부민 (제미니(Gemini) #100-318), 1% Penn/Strep, 무혈청 PBMC 해동 용액 (CTL # AA-005)으로 보충된 0.01 mM 2-메르캅토에탄올을 함유하는 배지 X-VIVO 15 (론자(Lonza)) 중에 대략 1천만개 세포/ml로 해동시켰다. 세포를 실온에서 5분 인큐베이션한 후에 스핀 다운시키고, 로보셉 완충제 (스템 셀 테크놀로지스) 중에 5천만개 세포/ml의 농도로 재현탁시켰다. 이지셉 인간 T 세포 풍부화 키트 (스템 셀 테크놀로지스)를 사용하여 T 세포를 단리하였다. 인간 T 세포 활성화/확장 키트 (밀테니(Miltenyi))를 사용하여 T 세포를 활성화 및 확장시켰다. 제2일에, 확장을 위해 T 세포를 지-렉스(G-Rex) 세포 배양 장치로 옮기고, IL-2 (스템 셀 테크놀로지스)를 배지에 첨가하고, 3일 후에 보충하였다. 활성화/확장 1주 후에 T 세포를 수거하였다. 수거 시점에, 비드를 자석으로 제거하고, 생체내 접종을 위해 세포를 DPBS 중에 1x107 또는 1.5x107개 세포/mL로 재현탁시켰다.
이종이식 연구를 위해, NSG 마우스에게 유방암 세포주 (MDA-MB468, HCC1954, MX1-Luc, ZR75-1 및 T47D) 또는 환자 유래 이종이식 (PDX-BRX-11380, PDX-BRX-12351, PDX-BRX-24301, PDX-BRX-24305, PDX-BRX-26302, PDX-BRX-26305, PDX-BRX-26360, PDX-OVX-24409) 단편을 옆구리에 피하로 접종하였다. 디지털 버니어 캘리퍼를 사용하여 종양 측정치를 수집하고, 변형된 타원체 식 1/2 x 길이 x 폭2를 사용하여 부피를 계산하였다. 마우스를 무작위화하고, 200-400 mm3의 종양 크기에서 병기결정하였다.
인간 PBMC 생착 실험 ("PMBC 모델")을 위해, 5백만개의 인간 PBMC를 제1 용량 6일 전에 정맥내로 주사하였다.
인간 T 세포 입양 전달 실험을 위해, 2백5십만개의 배양된 인간 T 세포를 제1 용량 1일 후에 접종하였다. 마우스에게 B7-H4xCD3 이중특이적 분자 또는 대조군을 0.2 mL 볼루스 주사로 매주 3회까지 투여하였다.
이식편 대 숙주 반응의 징후에 대한 연속 모니터링과 함께 종양 측정치를 매주 2회 수집하였다. 모든 B7-H4xCD3 이중특이적 분자는 세포주 이종이식 및 환자 유래된 이종이식 모델 둘 다에서 용량 의존성 T 세포 매개 항종양 활성을 나타냈다. 하기 표는 본원에서 수행된 다양한 실험의 용량, 종양 부피, SEM (평균의 표준 오차) 및 퍼센트 종양 성장 억제 (TGI)를 제시한다.
결과가 하기 표 13 A 내지 N에 기재되어 있다. 이들 결과는 B7-H4xCD3 이중특이적 항체가 생체내 유방암의 인간 세포주 이종이식 및 환자-유래된 이종이식 모델에서 정맥내 및 피하 투여 둘 다의 경우에 용량-의존적으로 종양사멸 활성을 유도하였음을 입증한다. 이들 모델은 HR+HER2-, HER2+ 및 TNBC 분자 하위유형의 유방암을 포함한다.
표 13-A. HCC1954 생착, 항체 1167 및 1156을 사용한 생체내 종양 억제 PMBC 모델

표 13-B. HCC1954 생착, 항체 0074, 0068 및 0087을 사용한 생체내 종양 억제 PMBC 모델

표 13-C. HCC1954 생착, 항체 0074, 0068 및 0077 및 0080을 사용한 생체내 종양 억제 입양 T 세포 전달 모델

표 13-D. MDA-MB-468 생착, 항체 0068, 0074, 0086, 1156 및 1167을 사용한 생체내 종양 억제 PMBC 모델

표 13-E. MDA-MB-468 생착, 항체 0068, 0074, 0087 및 0088을 사용한 생체내 종양 억제 PMBC 모델

표 13-F. MDA-MB-468 생착, 항체 0074, 0087 및 0088을 사용한 생체내 종양 억제 입양 T 세포 전달 모델

표 13-G. MDA-MB-468 생착, 항체 0074 및 0089를 사용한 생체내 종양 억제 입양 T 세포 전달 모델

표 13-H. MX1-Luc 생착, 항체 0068 및 1167을 사용한 생체내 종양 억제 입양 T 세포 전달 모델

표 13-I. MX1-Luc 생착, 항체 0068 및 0074를 사용한 생체내 종양 억제 입양 T 세포 전달 모델

표 13-J. T47D 생착, 항체 1167을 사용한 생체내 종양 억제 입양 T 세포 전달 모델

표 13-K. ZR75-1 생착, 항체 0068 및 0074를 사용한 생체내 종양 억제 PMBC 모델

표 13-L. PDX-BRX-11380 생착, 항체 0086 및 1167을 사용한 생체내 종양 억제 PMBC 모델

표 13-M. PDX-BRX-24301 생착, 항체 0086, 1156 및 1167을 사용한 생체내 종양 억제 PMBC 모델

표 13-N. PDX-BRX-26305 생착, 항체 0086 및 1167을 사용한 생체내 종양 억제 PMBC 모델

실시예 12: B7-H4에 대한 수용체 밀도 검정
B7-H4 발현 인간 종양 세포를 수거하고, 항체-PE 1:1 접합된 항 B7-H4 항체 및 음성 대조군 항체의 연속 희석물로 염색하였다. BD 퀀티브라이트(Quantibrite)™ 피코에리트린 (PE) 정량화 키트 (BD 바이오사이언시스(BD Biosciences), 카탈로그 번호 340495)와 함께 BD LSR포르테사 X-20을 사용하여 염색된 세포를 획득하였다. 퀀티브라이트 PE 키트로부터의 표준 곡선을 사용하여 항체의 포화 농도에서 세포당 B7-H4의 평균 수용체 밀도를 계산하였다.
결과가 표 14에 제시되어 있다. 결과는 시험관내 종양 세포의 재지시된 T 세포 사멸을 유도하는데 있어서 종양 세포 상의 B7-H4 밀도와 항체 1167의 시험관내 효력 사이에 강한 상관관계가 존재하며, B7-H4 밀도가 높을수록, 더 작은 EC50 값으로 나타난 바와 같이 효력이 더 높다는 것을 입증한다.
표 14. 시험관내 재지시된 T 세포 사멸을 유도하는데 있어서 인간 종양 세포주의 B7-H4 발현 밀도 및 항체 1167의 EC50

실시예 13: B7-H4 항체의 에피토프 비닝.
모노클로날 IgG1 형태의 B7-H4 항체를 옥텟레드(OctetRED) 384 (포르테바이오(ForteBio))에 의한 탠덤 비닝 검정을 사용하여 인간 B7-H4에 대한 경쟁적 및 비-경쟁적 결합에 대해 평가하였다. 옥텟 검정을 실온에서 수행하였다. 먼저, 아민 반응성 제2 세대 센서 (AR2G)를 EDC (1-에틸-3-[3-디메틸아미노프로필] 카르보디이미드 히드로클로라이드) 및 s-NHS (N-히드록시술포숙신이미드)로 300초 동안 활성화시켰다. 이어서, 사전활성화된 센서를 아세트산나트륨 pH 5.0 중에 희석된 제1 세트의 항-B7-H4 항체 (mAb 1)로 300초 동안 코팅한 다음, 에탄올 아민으로 추가로 300초 동안 켄칭하였다. 센서를 동역학 완충제 중에서 60초 동안 평형화시킨 후, 인간 B7-H4가 포획된 mAb 1에 300초 동안 결합하도록 하였다. 이어서, 센서를 동역학 완충제 중에 60초 동안 침지시키고, 이어서 제2 항체 (mAb 2)와 함께 300초 동안 인큐베이션하였다. 각각의 항체를 이러한 쌍별 조합 방식으로 시험하였다. 인간 B7-H4 ECD 상의 동일한 결합 영역에 대해 경쟁하는 mAb를 단일 빈으로 군분류하였다. 항-B7-H4 항체의 옥텟에 의한 에피토프 비닝은 B7-H4 항체에 의해 인식되는 2개의 고유한 에피토프 군을 입증한다 (표 15).
표 15. 인간 B7-H4 ECD를 사용한 하이브리도마 클론의 에피토프 비닝.

실시예 14: B7-H4 세포외 도메인 (ECD)과 복합체화된 항-B7-H4 항체 0052 scFv, 항-B7-H4 항체 0058 Fab 및 항체 1114 Fab의 결정화 및 구조 결정
항체 0052 scFv 및 B7-H4 ECD 공결정 구조: 결정화 시험을 위해, B7-H4 항체 0052 scFv와 B7-H4 ECD 사이의 복합체를 1:1.2 몰비로 형성하고, pH 7.5의 TBS를 함유하는 단백질 용액 중에 15.2 mg/ml로 농축시켰다. 100 mM HEPES pH 7.5, 200 mM 황산리튬, 25% PEG 3350을 함유하는 조건으로부터 행잉-드롭 증기-확산 방법에 의해 결정을 수득하였다. 결정은 셀 파라미터 a=59.33 Å; b=169.60 Å; c=213.98 Å을 갖는 사방정계 공간군 = P212121과 일치하는 대칭을 가졌고, 결정학적 비대칭 단위 내 B7-H4 항체 0052 scFv 및 B7-H4 ECD 복합체의 2개의 카피가 존재하였다. 결정을 액체 질소에서 급속 동결시켰다. 아르곤 국립 연구소 (APS)에서 IMCA 빔라인 17-ID에서 단일 동결 결정으로부터 2.6 Å 해상도로 설정된 데이터를 수집하였다. 데이터를 처리하고, 오토프록(autoPROC)을 사용하여 스케일링하였으며, 최종 데이터 세트는 60.3% 완전하였다.
PHASER를 사용한 분자 대체에 의해 구조를 해석하였다. COOT를 사용한 수동 조정 및 모델 재구축 및 오토부스터(autoBUSTER)를 사용한 결정학적 정밀화의 여러 반복 라운드는 결정학적 Rwork 22.2% 및 Rfree 25.0%인 항체 0052 scFv + B7-H4 ECD의 최종 모델을 산출하였으며, 여기서 Rwork= ||Fobs| - |Fcalc|| / |Fobs|이고, Rfree는 Rwork와 등가이지만 정밀화 과정으로부터 생략된 반사 중 무작위로 선택된 5%에 대해 계산되었다.
B7-H4 ECD와 복합체화된 B7-H4 항체 0052 scFV의 결정 구조가 도 2a에 제시되어 있다. 도 2a에 제시된 바와 같이, B7-H4 항체 0052는 B7-H4 ECD의 V2 도메인에 결합하고, B7-H4 V1 도메인의 전방 베타 시트로부터 떨어져 있다.
B7-H4 ECD 상의 에피토프 아미노산 잔기는 3.8 옹스트롬 이하의 항체 0052 아미노산 잔기와의 접촉을 갖는 아미노산 잔기로서 확인된다. 표 16-A는 항체 0052에 의해 인식되는 에피토프에 관여하는 B7-H4 ECD의 아미노산 잔기를 열거한다. 이들 중에서, (1) 상응하는 항체 아미노산 잔기와 수소 결합을 형성하거나 또는 (2) 표적-항체 상호작용시에 매립된 B7-H4 ECD 에피토프 아미노산 잔기가 표에 추가로 설명된다.
표 16-A. 항체 0052에 의한 B7-H4 세포외 도메인 에피토프 아미노산 잔기

항체 0058 Fab 및 B7-H4 ECD 공결정 구조: 유사하게, B7-H4 항체 0058 Fab와 B7-H4 ECD 사이의 복합체를 1:1.2 몰비로 형성하고, pH 7.5의 TBS를 함유하는 단백질 용액 중에 9.1 mg/ml로 농축시켰다. 100 mM HEPES pH 7.5, 100 mM 염화칼륨, 15% PEG 6000을 함유하는 조건으로부터 행잉-드롭 증기-확산 방법에 의해 결정을 수득하였다. 결정은 셀 파라미터 a=81.07 Å; b=96.99 Å; c=116.08 Å, α=90.00°; β=103.19°; γ=90.00°를 갖는 단사정계 공간군 = P21과 일치하는 대칭을 가졌고, 결정학적 비대칭 단위 내 B7-H4 항체 0058 Fab-B7-H4 복합체의 2개의 카피가 존재하였다. 결정을 20% 에틸렌 글리콜을 함유하는 저장 용액을 사용하여 동결-보호하고, 액체 질소 중에 급속 동결시켰다. 아르곤 국립 연구소 (APS)에서 IMCA 빔라인 17-ID에서 단일 동결 결정으로부터 2.2 Å 해상도로 설정된 데이터를 수집하였다. 데이터를 처리하고, 오토프록을 사용하여 스케일링하였으며, 최종 데이터 세트는 52.9% 완전하였다.
PHASER를 사용한 분자 대체에 의해 구조를 해석하였다. COOT를 사용한 수동 조정 및 모델 재구축 및 오토부스터를 사용한 결정학적 정밀화의 여러 반복 라운드는 결정학적 Rwork 21.6% 및 Rfree 23.7%인 B7-H4 항체 0058 Fab + B7-H4 ECD의 최종 모델을 산출하였으며, 여기서 Rwork= ||Fobs| - |Fcalc|| / |Fobs|이고, Rfree는 Rwork와 등가이지만 정밀화 과정으로부터 생략된 반사 중 무작위로 선택된 5%에 대해 계산되었다.
B7-H4 ECD와 복합체화된 B7-H4 항체 0058 Fab의 결정 구조가 도 2b에 제시되어 있다. 도 2b에 제시된 바와 같이, B7-H4 항체 0058은 B7-H4 ECD의 V1 도메인의 전방 베타 시트에서 및 그 주위에서 B7-H4 ECD에 결합한다.
B7-H4 ECD 상의 에피토프 아미노산 잔기는 3.8 옹스트롬 이하의 항체 0058 아미노산 잔기와의 접촉을 갖는 아미노산 잔기로서 확인된다. 표 16-B는 항체 0058에 의해 인식되는 에피토프에 관여하는 B7-H4 ECD의 아미노산 잔기를 열거한다. 이들 중에서, (1) 상응하는 항체 아미노산 잔기와 수소 결합을 형성하거나 또는 (2) 표적-항체 상호작용시에 매립된 B7-H4 ECD 에피토프 아미노산 잔기가 표에 추가로 설명된다.
항체 1114 Fab 및 B7-H4 ECD 공결정 구조: B7-H4 항체 1114 Fab와 B7-H4 ECD 사이의 복합체를 1:1 몰비로 형성하고, pH 7.5의 TBS를 함유하는 단백질 용액 중에 9.27 mg/ml로 농축시켰다. 100 mM HEPES pH 7.5, 100 mM 염화칼륨, 15% PEG 6000을 함유하는 조건으로부터 행잉-드롭 증기-확산 방법에 의해 결정을 수득하였다. 결정은 셀 파라미터 a=96.43 Å; b=78.19 Å; c=116.21, α=90.00; β=90.13.19; γ=90.00 Å을 갖는 단사정계 공간군 = P21과 일치하는 대칭을 가졌고, 결정학적 비대칭 단위 내 B7-H4 항체 1114 Fab 및 B7-H4 EDC 복합체의 2개의 카피가 존재하였다. 결정을 20% 글리세롤을 함유하는 저장 용액을 사용하여 동결-보호하고, 액체 질소에 급속 동결시켰다. 아르곤 국립 연구소 (APS)에서 IMCA 빔라인 17-ID에서 단일 동결 결정으로부터 2.32 Å 해상도로 설정된 데이터를 수집하였다. 데이터를 처리하고, 오토프록을 사용하여 스케일링하였으며, 최종 데이터 세트는 47.6% 완전하였다.
PHASER를 사용한 분자 대체에 의해 구조를 해석하였다. COOT를 사용한 수동 조정 및 모델 재구축 및 페닉스(Phenix)를 사용한 결정학적 정밀화의 여러 반복 라운드는 결정학적 Rwork 22.4% 및 Rfree 27.6%인 B7-H4 항체 1114 Fab + B7-H4 ECD의 최종 모델을 산출하였으며, 여기서 Rwork= ||Fobs| - |Fcalc|| / |Fobs|이고, Rfree는 Rwork와 등가이지만 정밀화 과정으로부터 생략된 반사 중 무작위로 선택된 5%에 대해 계산되었다.
B7-H4 ECD와 복합체화된 B7-H4 항체 1114 Fab의 결정 구조가 도 2c에 제시되어 있다. 도 2c에 제시된 바와 같이, B7-H4 항체 1114는 B7-H4 ECD의 V1 도메인의 전방 베타 시트에서 및 그 주위에서 B7-H4 ECD에 결합한다.
B7-H4 ECD 상의 에피토프 아미노산 잔기는 3.8 옹스트롬 이하의 항체 1114 아미노산 잔기와의 접촉을 갖는 아미노산 잔기로서 확인된다. 표 16-B는 항체 1114에 의해 인식되는 에피토프에 관여하는 B7-H4 ECD의 아미노산 잔기를 열거한다. 이들 중에서, (1) 상응하는 항체 아미노산 잔기와 수소 결합을 형성하거나 또는 (2) 표적-항체 상호작용시에 매립된 B7-H4 ECD 에피토프 아미노산 잔기가 표에 추가로 설명된다.
표 16-B. 항체 0058 및 항체 1114 둘 다에 의한 B7-H4 세포외 도메인 에피토프 아미노산 잔기

SEQUENCE LISTING
<110> PFIZER INC.
<120> THERAPEUTIC ANTIBODIES AND THEIR USES
<130> PC072604A
<150> US 63/053,243
<151> 2020-07-17
<160> 210
<170> PatentIn version 3.5
<210> 1
<211> 230
<212> PRT
<213> Homo sapiens
<400> 1
Phe Gly Ile Ser Gly Arg His Ser Ile Thr Val Thr Thr Val Ala Ser
1 5 10 15
Ala Gly Asn Ile Gly Glu Asp Gly Ile Leu Ser Cys Thr Phe Glu Pro
20 25 30
Asp Ile Lys Leu Ser Asp Ile Val Ile Gln Trp Leu Lys Glu Gly Val
35 40 45
Leu Gly Leu Val His Glu Phe Lys Glu Gly Lys Asp Glu Leu Ser Glu
50 55 60
Gln Asp Glu Met Phe Arg Gly Arg Thr Ala Val Phe Ala Asp Gln Val
65 70 75 80
Ile Val Gly Asn Ala Ser Leu Arg Leu Lys Asn Val Gln Leu Thr Asp
85 90 95
Ala Gly Thr Tyr Lys Cys Tyr Ile Ile Thr Ser Lys Gly Lys Gly Asn
100 105 110
Ala Asn Leu Glu Tyr Lys Thr Gly Ala Phe Ser Met Pro Glu Val Asn
115 120 125
Val Asp Tyr Asn Ala Ser Ser Glu Thr Leu Arg Cys Glu Ala Pro Arg
130 135 140
Trp Phe Pro Gln Pro Thr Val Val Trp Ala Ser Gln Val Asp Gln Gly
145 150 155 160
Ala Asn Phe Ser Glu Val Ser Asn Thr Ser Phe Glu Leu Asn Ser Glu
165 170 175
Asn Val Thr Met Lys Val Val Ser Val Leu Tyr Asn Val Thr Ile Asn
180 185 190
Asn Thr Tyr Ser Cys Met Ile Glu Asn Asp Ile Ala Lys Ala Thr Gly
195 200 205
Asp Ile Lys Val Thr Glu Ser Glu Ile Lys Arg Arg Ser His Leu Gln
210 215 220
Leu Leu Asn Ser Lys Ala
225 230
<210> 2
<211> 230
<212> PRT
<213> Macaca fascicularis
<400> 2
Phe Gly Ile Ser Gly Arg His Ser Ile Thr Val Thr Thr Val Ala Ser
1 5 10 15
Ala Gly Asn Ile Gly Glu Asp Gly Ile Leu Ser Cys Thr Phe Glu Pro
20 25 30
Asp Ile Lys Leu Ser Asp Ile Val Ile Gln Trp Leu Lys Glu Gly Val
35 40 45
Ile Gly Leu Val His Glu Phe Lys Glu Gly Lys Asp Glu Leu Ser Glu
50 55 60
Gln Asp Glu Met Phe Arg Gly Arg Thr Ala Val Phe Ala Asp Gln Val
65 70 75 80
Ile Val Gly Asn Ala Ser Leu Arg Leu Lys Asn Val Gln Leu Thr Asp
85 90 95
Ala Gly Thr Tyr Lys Cys Tyr Ile Ile Thr Ser Lys Gly Lys Gly Asn
100 105 110
Ala Asn Leu Glu Tyr Lys Thr Gly Ala Phe Ser Met Pro Glu Val Asn
115 120 125
Val Asp Tyr Asn Ala Ser Ser Glu Thr Leu Arg Cys Glu Ala Pro Arg
130 135 140
Trp Phe Pro Gln Pro Thr Val Val Trp Ala Ser Gln Val Asp Gln Gly
145 150 155 160
Ala Asn Phe Ser Glu Val Ser Asn Thr Ser Phe Glu Leu Asn Ser Glu
165 170 175
Asn Val Thr Met Lys Val Val Ser Val Leu Tyr Asn Val Thr Ile Asn
180 185 190
Asn Thr Tyr Ser Cys Met Ile Glu Asn Asp Ile Ala Lys Ala Thr Gly
195 200 205
Asp Ile Lys Val Thr Glu Ser Glu Ile Lys Arg Arg Ser His Leu Gln
210 215 220
Leu Leu Asn Ser Lys Ala
225 230
<210> 3
<211> 230
<212> PRT
<213> Mus musculus
<400> 3
Phe Gly Ile Ser Gly Lys His Phe Ile Thr Val Thr Thr Phe Thr Ser
1 5 10 15
Ala Gly Asn Ile Gly Glu Asp Gly Thr Leu Ser Cys Thr Phe Glu Pro
20 25 30
Asp Ile Lys Leu Asn Gly Ile Val Ile Gln Trp Leu Lys Glu Gly Ile
35 40 45
Lys Gly Leu Val His Glu Phe Lys Glu Gly Lys Asp Asp Leu Ser Gln
50 55 60
Gln His Glu Met Phe Arg Gly Arg Thr Ala Val Phe Ala Asp Gln Val
65 70 75 80
Val Val Gly Asn Ala Ser Leu Arg Leu Lys Asn Val Gln Leu Thr Asp
85 90 95
Ala Gly Thr Tyr Thr Cys Tyr Ile Arg Thr Ser Lys Gly Lys Gly Asn
100 105 110
Ala Asn Leu Glu Tyr Lys Thr Gly Ala Phe Ser Met Pro Glu Ile Asn
115 120 125
Val Asp Tyr Asn Ala Ser Ser Glu Ser Leu Arg Cys Glu Ala Pro Arg
130 135 140
Trp Phe Pro Gln Pro Thr Val Ala Trp Ala Ser Gln Val Asp Gln Gly
145 150 155 160
Ala Asn Phe Ser Glu Val Ser Asn Thr Ser Phe Glu Leu Asn Ser Glu
165 170 175
Asn Val Thr Met Lys Val Val Ser Val Leu Tyr Asn Val Thr Ile Asn
180 185 190
Asn Thr Tyr Ser Cys Met Ile Glu Asn Asp Ile Ala Lys Ala Thr Gly
195 200 205
Asp Ile Lys Val Thr Asp Ser Glu Val Lys Arg Arg Ser Gln Leu Gln
210 215 220
Leu Leu Asn Ser Gly Pro
225 230
<210> 4
<211> 229
<212> PRT
<213> Rattus norvegicus
<400> 4
Phe Gly Ile Ser Gly Lys His Phe Ile Thr Val Thr Thr Phe Thr Ser
1 5 10 15
Ala Gly Asn Ile Gly Glu Asp Gly Thr Leu Ser Cys Thr Phe Glu Pro
20 25 30
Asp Ile Lys Leu Asn Gly Ile Val Ile Gln Trp Leu Lys Glu Gly Ile
35 40 45
Lys Gly Leu Val His Glu Phe Lys Glu Gly Lys Asp Asp Leu Ser Gln
50 55 60
Gln His Glu Met Phe Arg Gly Arg Thr Ala Val Phe Ala Asp Gln Val
65 70 75 80
Val Val Gly Asn Ala Ser Leu Arg Leu Lys Asn Val Gln Leu Thr Asp
85 90 95
Ala Gly Thr Tyr Thr Cys Tyr Ile His Thr Ser Lys Gly Lys Gly Asn
100 105 110
Ala Asn Leu Glu Tyr Lys Thr Gly Ala Phe Ser Met Pro Glu Ile Asn
115 120 125
Val Asp Tyr Asn Ala Ser Ser Glu Ser Leu Arg Cys Glu Ala Pro Arg
130 135 140
Trp Phe Pro Gln Pro Thr Val Ala Trp Ala Ser Gln Val Asp Gln Gly
145 150 155 160
Ala Asn Phe Ser Glu Val Ser Asn Thr Ser Phe Glu Leu Asn Ser Glu
165 170 175
Asn Val Thr Met Lys Val Val Ser Val Leu Tyr Asn Val Thr Ile Asn
180 185 190
Asn Thr Tyr Ser Cys Met Ile Glu Asn Asp Ile Ala Lys Ala Thr Gly
195 200 205
Asp Ile Lys Val Thr Asp Ser Glu Val Lys Arg Arg Ser Gln Leu Glu
210 215 220
Leu Leu Asn Ser Gly
225
<210> 5
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 5
Gly Gly Ser Phe Ser Gly Tyr Tyr Trp Asn
1 5 10
<210> 6
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 6
Glu Ile Asn His Ser Gly Ser Ala Thr Tyr Asn Pro Ser Leu Lys Ser
1 5 10 15
<210> 7
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 7
Gly Leu Tyr Asn Trp Asn Val Asp His
1 5
<210> 8
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 8
Gln Val Gln Leu Gln Gln Trp Gly Ala Gly Leu Leu Lys Pro Ser Glu
1 5 10 15
Thr Leu Pro Leu Thr Cys Ala Val Tyr Gly Gly Ser Phe Ser Gly Tyr
20 25 30
Tyr Trp Asn Trp Ile Arg Gln Pro Pro Gly Lys Gly Leu Glu Trp Ile
35 40 45
Gly Glu Ile Asn His Ser Gly Ser Ala Thr Tyr Asn Pro Ser Leu Lys
50 55 60
Ser Arg Val Thr Ile Ser Val Asp Thr Ser Lys Asn His Phe Ser Leu
65 70 75 80
Lys Leu Ser Ser Val Thr Ala Ala Asp Thr Ala Val Tyr Phe Cys Ala
85 90 95
Arg Gly Leu Tyr Asn Trp Asn Val Asp His Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 9
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 9
Arg Ala Ser Gln Gly Ile Arg Asn Asp Leu Gly
1 5 10
<210> 10
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 10
Ala Ala Ser Ser Leu Gln Ser
1 5
<210> 11
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 11
Leu Gln His Asn Ser Tyr Pro Arg Thr
1 5
<210> 12
<211> 107
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 12
Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu
1 5 10 15
Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe
20 25 30
Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln
35 40 45
Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser
50 55 60
Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu
65 70 75 80
Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser
85 90 95
Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
100 105
<210> 13
<211> 107
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 13
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Gly Ile Arg Asn Asp
20 25 30
Leu Gly Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Arg Leu Ile
35 40 45
Tyr Ala Ala Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Glu Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln His Asn Ser Tyr Pro Arg
85 90 95
Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
100 105
<210> 14
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 14
Glu Ile Asn His Ser Gly Ser Thr Lys Tyr Asn Pro Ser Leu Lys Ser
1 5 10 15
<210> 15
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 15
Gly Leu Tyr Asn Trp Asn Val Asp Ser
1 5
<210> 16
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 16
Gln Val Gln Leu Gln Gln Trp Gly Ala Gly Leu Leu Lys Pro Ser Glu
1 5 10 15
Thr Leu Ser Leu Thr Cys Ala Val Tyr Gly Gly Ser Phe Ser Gly Tyr
20 25 30
Tyr Trp Asn Trp Ile Arg Gln Pro Pro Gly Lys Gly Leu Glu Trp Ile
35 40 45
Gly Glu Ile Asn His Ser Gly Ser Thr Lys Tyr Asn Pro Ser Leu Lys
50 55 60
Ser Arg Val Thr Ile Ser Gly Asp Thr Ser Lys Asn Gln Phe Ser Leu
65 70 75 80
Lys Leu Asn Ser Val Thr Ala Ala Asp Thr Ala Val Tyr Tyr Cys Val
85 90 95
Arg Gly Leu Tyr Asn Trp Asn Val Asp Ser Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 17
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 17
Val Ala Ser Ser Leu Gln Ser
1 5
<210> 18
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 18
Leu Gln His Asn Ser Tyr Pro Tyr Thr
1 5
<210> 19
<211> 107
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 19
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Gly Ile Arg Asn Asp
20 25 30
Leu Gly Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Arg Leu Ile
35 40 45
Tyr Val Ala Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Glu Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln His Asn Ser Tyr Pro Tyr
85 90 95
Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys
100 105
<210> 20
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 20
Gly Phe Thr Phe Ser Ser Tyr Ala Met Ser
1 5 10
<210> 21
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 21
Ala Ile Ser Gly Gly Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val Lys
1 5 10 15
Gly
<210> 22
<211> 13
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 22
Asp Ile Gln Trp Phe Gly Glu Ser Thr Leu Phe Asp Tyr
1 5 10
<210> 23
<211> 122
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 23
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ser Gly Gly Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Ile Gln Trp Phe Gly Glu Ser Thr Leu Phe Asp Tyr Trp
100 105 110
Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 24
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 24
Arg Ala Ser Gln Ser Ile Arg Ser Trp Leu Ala
1 5 10
<210> 25
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 25
Lys Ala Ser Ser Leu Glu Gly
1 5
<210> 26
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 26
Gln Gln Tyr Asn Ser Tyr Ser Arg Thr
1 5
<210> 27
<211> 107
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 27
Asp Ile Gln Leu Thr Gln Ser Pro Ser Thr Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Ser Ile Arg Ser Trp
20 25 30
Leu Ala Trp Phe Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Lys Ala Ser Ser Leu Glu Gly Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Glu Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Asp Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Tyr Asn Ser Tyr Ser Arg
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys
100 105
<210> 28
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 28
Gly Phe Thr Phe Ser Asp Tyr Tyr Met Thr
1 5 10
<210> 29
<211> 19
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 29
Phe Ile Arg Asn Arg Ala Arg Gly Tyr Thr Ser Asp His Asn Pro Ser
1 5 10 15
Val Lys Gly
<210> 30
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 30
Asp Arg Pro Ser Tyr Tyr Val Leu Asp Tyr
1 5 10
<210> 31
<211> 121
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 31
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Asp Tyr
20 25 30
Tyr Met Thr Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Phe Ile Arg Asn Arg Ala Arg Gly Tyr Thr Ser Asp His Asn Pro
50 55 60
Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser
65 70 75 80
Leu Tyr Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr
85 90 95
Tyr Cys Ala Arg Asp Arg Pro Ser Tyr Tyr Val Leu Asp Tyr Trp Gly
100 105 110
Gln Gly Thr Thr Val Thr Val Ser Ser
115 120
<210> 32
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 32
Lys Ser Ser Gln Ser Leu Phe Asn Val Arg Ser Arg Lys Asn Tyr Leu
1 5 10 15
Ala
<210> 33
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 33
Trp Ala Ser Thr Arg Glu Ser
1 5
<210> 34
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 34
Lys Gln Ser Tyr Asp Leu Phe Thr
1 5
<210> 35
<211> 112
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 35
Asp Ile Val Met Thr Gln Ser Pro Asp Ser Leu Ala Val Ser Leu Gly
1 5 10 15
Glu Arg Ala Thr Ile Asn Cys Lys Ser Ser Gln Ser Leu Phe Asn Val
20 25 30
Arg Ser Arg Lys Asn Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln
35 40 45
Pro Pro Lys Leu Leu Ile Ser Trp Ala Ser Thr Arg Glu Ser Gly Val
50 55 60
Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr
65 70 75 80
Ile Ser Ser Leu Gln Ala Glu Asp Val Ala Val Tyr Tyr Cys Lys Gln
85 90 95
Ser Tyr Asp Leu Phe Thr Phe Gly Ser Gly Thr Lys Leu Glu Ile Lys
100 105 110
<210> 36
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 36
Gly Phe Thr Phe Ser Ser Tyr Ala Met Lys
1 5 10
<210> 37
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 37
Thr Thr Ser Gly Ser Gly Gly Thr Thr Tyr Tyr Ala Asp Ser Val Lys
1 5 10 15
Gly
<210> 38
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 38
Ala Gly Trp Ala Ala Ala Phe Asp Tyr
1 5
<210> 39
<211> 118
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 39
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Lys Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Thr Thr Ser Gly Ser Gly Gly Thr Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Ala Gly Trp Ala Ala Ala Phe Asp Tyr Trp Gly Gln Gly Thr
100 105 110
Leu Val Thr Val Ser Ser
115
<210> 40
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 40
Arg Ala Ser Gln Ser Ile Ser Asp Trp Leu Ala
1 5 10
<210> 41
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 41
Lys Ala Ser Ser Leu Glu Ser
1 5
<210> 42
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 42
Gln Gln Cys Asn Ser Tyr Trp Thr
1 5
<210> 43
<211> 106
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 43
Asp Ile Gln Leu Thr Gln Phe Pro Ser Thr Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Ile Thr Ile Thr Cys Arg Ala Ser Gln Ser Ile Ser Asp Trp
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Lys Ala Ser Ser Leu Glu Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Glu Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Asp Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Cys Asn Ser Tyr Trp Thr
85 90 95
Phe Gly Gln Gly Thr Lys Val Glu Ile Lys
100 105
<210> 44
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 44
Ala Ile Ser Gly Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val Lys
1 5 10 15
Gly
<210> 45
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 45
Asp Ile Gln Trp Phe Gly Glu Ser Val Phe Asp Tyr
1 5 10
<210> 46
<211> 121
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 46
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ser Gly Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Phe
65 70 75 80
Leu His Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Ile Gln Trp Phe Gly Glu Ser Val Phe Asp Tyr Trp Gly
100 105 110
Gln Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 47
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 47
Arg Ala Ser Gln Ser Ile Ser Ser Trp Leu Ala
1 5 10
<210> 48
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 48
Gln Tyr Tyr Asn Ser Tyr Ser Arg Thr
1 5
<210> 49
<211> 107
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 49
Asp Ile Gln Met Thr Gln Ser Pro Ser Thr Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Ser Ile Ser Ser Trp
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Lys Ala Ser Ser Leu Glu Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Asn Gly Ser Gly Thr Glu Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Asp Asp Leu Ala Thr Tyr Tyr Cys Gln Tyr Tyr Asn Ser Tyr Ser Arg
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys
100 105
<210> 50
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 50
Glu Ile Asn His Ser Gly Ser Ala Asn Tyr Asn Pro Ser Leu Lys Ser
1 5 10 15
<210> 51
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 51
Gly Leu Tyr Asn Trp Asn Val Asp Arg
1 5
<210> 52
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 52
Gln Val Gln Leu Gln Gln Trp Gly Ala Gly Leu Leu Lys Pro Ser Glu
1 5 10 15
Thr Leu Ser Leu Thr Cys Ala Leu Tyr Gly Gly Ser Phe Ser Gly Tyr
20 25 30
Tyr Trp Asn Trp Ile Arg Gln Pro Pro Gly Lys Gly Leu Glu Trp Ile
35 40 45
Gly Glu Ile Asn His Ser Gly Ser Ala Asn Tyr Asn Pro Ser Leu Lys
50 55 60
Ser Arg Val Thr Ile Ser Val Asp Thr Ser Lys Asn Gln Phe Ser Leu
65 70 75 80
Arg Leu Ser Ser Val Thr Ala Ala Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Gly Leu Tyr Asn Trp Asn Val Asp Arg Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 53
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 53
Leu Gln His Asn Ser Tyr Pro Leu Thr
1 5
<210> 54
<211> 107
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 54
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Gly Ile Arg Asn Asp
20 25 30
Leu Gly Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Arg Leu Ile
35 40 45
Tyr Ala Ala Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Glu Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln His Asn Ser Tyr Pro Leu
85 90 95
Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
100 105
<210> 55
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 55
Ser Ile Ser Gly Asn Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val Lys
1 5 10 15
Gly
<210> 56
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 56
Val Gly Trp Arg Thr Gly Asp Tyr
1 5
<210> 57
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 57
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ser Ile Ser Gly Asn Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Ser
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Val Gly Trp Arg Thr Gly Asp Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 58
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 58
Lys Ala Ser Asp Leu Glu Ser
1 5
<210> 59
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 59
Gln Gln Tyr Asn Ser Tyr Ser Trp Thr
1 5
<210> 60
<211> 107
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 60
Asp Ile Gln Leu Thr Gln Ser Pro Ser Thr Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Ser Ile Ser Ser Trp
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Ala Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Lys Ala Ser Asp Leu Glu Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Ile Glu Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Asp Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Tyr Asn Ser Tyr Ser Trp
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys
100 105
<210> 61
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 61
Gly Gly Pro Phe Ser Gly Tyr Phe Trp Ser
1 5 10
<210> 62
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 62
Glu Ile Asn His Ser Gly Asn Thr Asn Tyr Asn Pro Ser Leu Lys Ser
1 5 10 15
<210> 63
<211> 15
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 63
Ala Gly Gly Asp Tyr Gly Phe Tyr Tyr Tyr Tyr Gly Met Asp Val
1 5 10 15
<210> 64
<211> 123
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 64
Gln Val Gln Leu Gln Gln Trp Gly Ala Gly Leu Leu Lys Pro Ser Glu
1 5 10 15
Thr Leu Ser Leu Thr Cys Ala Val Tyr Gly Gly Pro Phe Ser Gly Tyr
20 25 30
Phe Trp Ser Trp Ile Arg Gln Pro Pro Gly Lys Gly Leu Glu Trp Ile
35 40 45
Gly Glu Ile Asn His Ser Gly Asn Thr Asn Tyr Asn Pro Ser Leu Lys
50 55 60
Ser Arg Val Thr Ile Ser Val Asp Thr Ser Lys Asn Gln Phe Ser Leu
65 70 75 80
Lys Leu Ser Ser Val Thr Ala Ala Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Ala Gly Gly Asp Tyr Gly Phe Tyr Tyr Tyr Tyr Gly Met Asp Val
100 105 110
Trp Gly Gln Gly Thr Thr Val Thr Val Ser Ser
115 120
<210> 65
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 65
Lys Ala Ser Arg Leu Glu Ser
1 5
<210> 66
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 66
Gln Gln Tyr Asn Ser Tyr
1 5
<210> 67
<211> 104
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 67
Asp Ile Gln Leu Thr Gln Ser Pro Ser Thr Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Ser Ile Ser Ser Trp
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Glu Leu Leu Val
35 40 45
Tyr Lys Ala Ser Arg Leu Glu Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Glu Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Asp Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Tyr Asn Ser Tyr Phe Gly
85 90 95
Gly Gly Thr Lys Val Glu Ile Lys
100
<210> 68
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 68
Gly Leu Tyr Asn Trp Asn Val Asp Cys
1 5
<210> 69
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 69
Gln Val Gln Leu Gln Gln Trp Gly Ala Gly Leu Leu Lys Pro Ser Glu
1 5 10 15
Thr Leu Ser Leu Thr Cys Ala Val Tyr Gly Gly Ser Phe Ser Gly Tyr
20 25 30
Tyr Trp Asn Trp Ile Arg Gln Pro Pro Gly Lys Gly Leu Glu Trp Ile
35 40 45
Gly Glu Ile Asn His Ser Gly Ser Ala Thr Tyr Asn Pro Ser Leu Lys
50 55 60
Ser Arg Val Thr Ile Ser Val Asp Thr Ser Lys Asn His Phe Ser Leu
65 70 75 80
Lys Leu Asn Ser Val Thr Ala Ala Gly Thr Ala Val Tyr Phe Cys Ala
85 90 95
Arg Gly Leu Tyr Asn Trp Asn Val Asp Cys Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 70
<211> 107
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 70
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Gly Ile Arg Asn Asp
20 25 30
Leu Gly Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Arg Leu Ile
35 40 45
Tyr Ala Ala Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Glu Phe Ser Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln His Asn Ser Tyr Pro Arg
85 90 95
Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
100 105
<210> 71
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 71
Gly Gly Ser Ile Ser Ser Ser Ser Tyr Tyr Trp Gly
1 5 10
<210> 72
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 72
Thr Ile Tyr Phe Ser Gly Asn Thr Tyr Tyr Asn Pro Ser Leu Lys Ser
1 5 10 15
<210> 73
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 73
Leu Arg Val Thr Met Val Arg Gly Val Ile Ile Gly Val Phe Asp Tyr
1 5 10 15
<210> 74
<211> 126
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 74
Gln Val Gln Leu Gln Glu Ser Gly Pro Gly Leu Val Lys Pro Ser Glu
1 5 10 15
Thr Leu Ser Leu Thr Cys Thr Val Ser Gly Gly Ser Ile Ser Ser Ser
20 25 30
Ser Tyr Tyr Trp Gly Trp Ile Arg Gln Pro Pro Gly Lys Gly Leu Glu
35 40 45
Trp Ile Gly Thr Ile Tyr Phe Ser Gly Asn Thr Tyr Tyr Asn Pro Ser
50 55 60
Leu Lys Ser Arg Val Thr Ile Ser Val Asp Thr Ser Lys Ser Gln Leu
65 70 75 80
Ser Leu Lys Leu Asn Ser Val Thr Ala Ala Asp Thr Ala Val Tyr Tyr
85 90 95
Cys Ala Arg Leu Arg Val Thr Met Val Arg Gly Val Ile Ile Gly Val
100 105 110
Phe Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120 125
<210> 75
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 75
Lys Ser Ser Gln Ser Val Leu Tyr Ser Ser Asn Asn Lys Asn Tyr Leu
1 5 10 15
Ala
<210> 76
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 76
Gln Gln Tyr Tyr Ser Thr Pro Pro Thr
1 5
<210> 77
<211> 113
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 77
Asp Ile Val Met Thr Gln Ser Pro Asp Ser Leu Ala Val Ser Leu Gly
1 5 10 15
Glu Arg Ala Thr Ile Asn Cys Lys Ser Ser Gln Ser Val Leu Tyr Ser
20 25 30
Ser Asn Asn Lys Asn Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln
35 40 45
Pro Pro Lys Leu Leu Ile Tyr Trp Ala Ser Thr Arg Glu Ser Gly Val
50 55 60
Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr
65 70 75 80
Ile Ser Ser Leu Gln Ala Glu Asp Val Ala Val Tyr Tyr Cys Gln Gln
85 90 95
Tyr Tyr Ser Thr Pro Pro Thr Phe Gly Gln Gly Thr Lys Val Glu Ile
100 105 110
Lys
<210> 78
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 78
Gly Phe Thr Phe Ser Thr Tyr Ala Met Asn
1 5 10
<210> 79
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 79
Val Asp Val Val Ala Arg Tyr Tyr Gly Met Asp Val
1 5 10
<210> 80
<211> 121
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 80
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Thr Tyr
20 25 30
Ala Met Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Ala Trp Val
35 40 45
Ser Ala Ile Ser Gly Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asp Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Val Asp Val Val Ala Arg Tyr Tyr Gly Met Asp Val Trp Gly
100 105 110
Gln Gly Thr Thr Val Thr Val Ser Ser
115 120
<210> 81
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 81
Arg Ala Ser Gln Ser Ile Ser Gly Trp Leu Ala
1 5 10
<210> 82
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 82
Glu Ala Ser Ser Leu Glu Ser
1 5
<210> 83
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 83
Gln Gln Tyr Lys Ser Tyr Ser Trp Thr
1 5
<210> 84
<211> 107
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 84
Asp Ile Gln Met Thr Gln Ser Pro Ser Thr Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Ser Ile Ser Gly Trp
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Glu Ala Ser Ser Leu Glu Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Glu Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Asp Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Tyr Lys Ser Tyr Ser Trp
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys
100 105
<210> 85
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 85
Ala Ile Ser Gly Arg Gly Gly Ser Thr Tyr Tyr Thr Asp Ser Val Lys
1 5 10 15
Gly
<210> 86
<211> 13
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 86
Asp Leu Gln Trp Phe Gly Glu Ser Thr Leu Phe Asp Tyr
1 5 10
<210> 87
<211> 122
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 87
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ser Gly Arg Gly Gly Ser Thr Tyr Tyr Thr Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Arg Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ile Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Leu Gln Trp Phe Gly Glu Ser Thr Leu Phe Asp Tyr Trp
100 105 110
Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 88
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 88
Arg Ala Ser Gln Ser Ile Ser Ala Trp Leu Ala
1 5 10
<210> 89
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 89
Gln Gln Tyr Asn Ser Tyr Ser Arg Ser
1 5
<210> 90
<211> 107
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 90
Asp Ile Gln Leu Thr Gln Ser Pro Ser Thr Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Ser Ile Ser Ala Trp
20 25 30
Leu Ala Trp Phe Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Lys Ala Ser Ser Leu Glu Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Glu Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Asp Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Tyr Asn Ser Tyr Ser Arg
85 90 95
Ser Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys
100 105
<210> 91
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 91
Gly Phe Thr Phe Ser Ser Tyr Ala Leu Ser
1 5 10
<210> 92
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 92
Thr Ile Asn Val Gly Gly Val Asp Thr Asn Tyr Ala Gly Ser Val Lys
1 5 10 15
Gly
<210> 93
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 93
Ala Arg Ile Thr Met Val Arg Gly Val Ile Ile Pro Leu Phe Asp Tyr
1 5 10 15
<210> 94
<211> 125
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 94
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Leu Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Thr Ile Asn Val Gly Gly Val Asp Thr Asn Tyr Ala Gly Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Pro Lys Asn Thr Leu Cys
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr His Cys
85 90 95
Ala Lys Ala Arg Ile Thr Met Val Arg Gly Val Ile Ile Pro Leu Phe
100 105 110
Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ala Ser
115 120 125
<210> 95
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 95
Gln Gln Phe Tyr Ser Thr Pro Val Thr
1 5
<210> 96
<211> 113
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 96
Asp Ile Val Met Thr Gln Ser Pro Asp Ser Leu Ala Val Ser Leu Gly
1 5 10 15
Glu Arg Ala Thr Ile Asn Cys Lys Ser Ser Gln Ser Val Leu Tyr Ser
20 25 30
Ser Asn Asn Lys Asn Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln
35 40 45
Pro Pro Lys Leu Leu Ile Tyr Trp Ala Ser Thr Arg Glu Ser Gly Val
50 55 60
Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr
65 70 75 80
Ile Ser Ser Leu Gln Ala Glu Asp Val Ala Val Tyr Tyr Cys Gln Gln
85 90 95
Phe Tyr Ser Thr Pro Val Thr Phe Gly Gly Gly Thr Lys Val Glu Ile
100 105 110
Lys
<210> 97
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 97
Thr Gly Ser Ile Ser Ser Ser Ser Tyr Tyr Trp Gly
1 5 10
<210> 98
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 98
Thr Ile Tyr Phe Ser Gly Ser Thr Tyr Tyr Asn Pro Ser Leu Lys Ser
1 5 10 15
<210> 99
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 99
Leu Arg Val Thr Met Val Arg Gly Val Ile Ile Gly Val Phe Asp Phe
1 5 10 15
<210> 100
<211> 126
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 100
Gln Val Gln Leu Gln Glu Ser Gly Pro Gly Leu Val Lys Pro Ser Glu
1 5 10 15
Thr Leu Ser Leu Thr Cys Thr Val Ser Thr Gly Ser Ile Ser Ser Ser
20 25 30
Ser Tyr Tyr Trp Gly Trp Ile Arg Gln Pro Pro Gly Lys Gly Leu Glu
35 40 45
Trp Ile Gly Thr Ile Tyr Phe Ser Gly Ser Thr Tyr Tyr Asn Pro Ser
50 55 60
Leu Lys Ser Arg Val Thr Ile Ser Val Asp Thr Ser Lys Asn Gln Phe
65 70 75 80
Ser Leu Lys Leu Thr Ser Val Thr Ala Ala Asp Thr Ala Val Tyr Tyr
85 90 95
Cys Ala Arg Leu Arg Val Thr Met Val Arg Gly Val Ile Ile Gly Val
100 105 110
Phe Asp Phe Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120 125
<210> 101
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 101
Gly Gly Ser Phe Ser Gly Tyr Phe Trp Ser
1 5 10
<210> 102
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 102
Glu Phe Asn His Ser Gly Gly Thr Asn Ser Asn Pro Ser Leu Lys Ser
1 5 10 15
<210> 103
<211> 15
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 103
Ala Gly Gly Asp Tyr Gly Phe Tyr Tyr Tyr Tyr Gly Leu Asp Val
1 5 10 15
<210> 104
<211> 123
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 104
Gln Val Gln Leu Gln Gln Trp Gly Ala Gly Leu Leu Lys Pro Ser Glu
1 5 10 15
Thr Leu Ser Leu Thr Cys Ala Val Tyr Gly Gly Ser Phe Ser Gly Tyr
20 25 30
Phe Trp Ser Trp Ile Arg Gln Pro Pro Gly Lys Gly Leu Glu Trp Ile
35 40 45
Gly Glu Phe Asn His Ser Gly Gly Thr Asn Ser Asn Pro Ser Leu Lys
50 55 60
Ser Arg Val Thr Met Ser Val Asp Thr Ser Lys Asn Gln Phe Ser Leu
65 70 75 80
Lys Leu Ser Ser Val Thr Ala Ala Asp Thr Ala Val Tyr Phe Cys Ala
85 90 95
Arg Ala Gly Gly Asp Tyr Gly Phe Tyr Tyr Tyr Tyr Gly Leu Asp Val
100 105 110
Trp Gly Gln Gly Thr Thr Val Thr Val Ser Ser
115 120
<210> 105
<211> 19
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 105
Phe Ile Arg Asn Gln Ala Arg Gly Tyr Thr Ser Asp His Asn Pro Ser
1 5 10 15
Val Lys Gly
<210> 106
<211> 121
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 106
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Asp Tyr
20 25 30
Tyr Met Thr Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Phe Ile Arg Asn Gln Ala Arg Gly Tyr Thr Ser Asp His Asn Pro
50 55 60
Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser
65 70 75 80
Leu Tyr Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr
85 90 95
Tyr Cys Ala Arg Asp Arg Pro Ser Tyr Tyr Val Leu Asp Tyr Trp Gly
100 105 110
Gln Gly Thr Thr Val Thr Val Ser Ser
115 120
<210> 107
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 107
Thr Ser Ser Gln Ser Leu Phe Asn Val Arg Ser Gln Lys Asn Tyr Leu
1 5 10 15
Ala
<210> 108
<211> 112
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 108
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Thr Ser Ser Gln Ser Leu Phe Asn Val
20 25 30
Arg Ser Gln Lys Asn Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Lys
35 40 45
Ala Pro Lys Leu Leu Ile Tyr Trp Ala Ser Thr Arg Glu Ser Gly Val
50 55 60
Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr
65 70 75 80
Ile Ser Ser Leu Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Lys Gln
85 90 95
Ser Tyr Asp Leu Phe Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
100 105 110
<210> 109
<211> 19
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 109
Phe Ile Arg Asn Gln Asp Arg Gly Tyr Thr Ser Asp His Gln Pro Ser
1 5 10 15
Val Lys Gly
<210> 110
<211> 121
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 110
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Asp Tyr
20 25 30
Tyr Met Thr Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Phe Ile Arg Asn Gln Asp Arg Gly Tyr Thr Ser Asp His Gln Pro
50 55 60
Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser
65 70 75 80
Leu Tyr Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr
85 90 95
Tyr Cys Ala Arg Asp Arg Pro Ser Tyr Tyr Val Leu Asp Tyr Trp Gly
100 105 110
Gln Gly Thr Thr Val Thr Val Ser Ser
115 120
<210> 111
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 111
Thr Ser Asp Gln Ser Leu Phe Asn Val Arg Ser Gly Lys Asn Tyr Leu
1 5 10 15
Ala
<210> 112
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 112
Trp Ala Ser Asp Arg Glu Ser
1 5
<210> 113
<211> 112
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 113
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Thr Ser Asp Gln Ser Leu Phe Asn Val
20 25 30
Arg Ser Gly Lys Asn Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Lys
35 40 45
Ala Pro Lys Leu Leu Ile Tyr Trp Ala Ser Asp Arg Glu Ser Gly Val
50 55 60
Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr
65 70 75 80
Ile Ser Ser Leu Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Lys Gln
85 90 95
Ser Tyr Asp Leu Phe Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
100 105 110
<210> 114
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 114
Asp Arg His Ser Tyr Tyr Val Leu Asp Tyr
1 5 10
<210> 115
<211> 121
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 115
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Asp Tyr
20 25 30
Tyr Met Thr Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Phe Ile Arg Asn Gln Ala Arg Gly Tyr Thr Ser Asp His Asn Pro
50 55 60
Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser
65 70 75 80
Leu Tyr Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr
85 90 95
Tyr Cys Ala Arg Asp Arg His Ser Tyr Tyr Val Leu Asp Tyr Trp Gly
100 105 110
Gln Gly Thr Thr Val Thr Val Ser Ser
115 120
<210> 116
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 116
Lys Gln Ser Tyr Tyr Leu Phe Thr
1 5
<210> 117
<211> 112
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 117
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Thr Ser Ser Gln Ser Leu Phe Asn Val
20 25 30
Arg Ser Gln Lys Asn Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Lys
35 40 45
Ala Pro Lys Leu Leu Ile Tyr Trp Ala Ser Thr Arg Glu Ser Gly Val
50 55 60
Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr
65 70 75 80
Ile Ser Ser Leu Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Lys Gln
85 90 95
Ser Tyr Tyr Leu Phe Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
100 105 110
<210> 118
<211> 107
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 118
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Ser Ile Arg Ser Trp
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Lys Ala Ser Ser Leu Glu Gly Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Tyr Asn Ser Tyr Ser Arg
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys
100 105
<210> 119
<211> 107
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 119
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Gly Ile Arg Asn Asp
20 25 30
Leu Gly Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Val Ala Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln His Asn Ser Tyr Pro Tyr
85 90 95
Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys
100 105
<210> 120
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 120
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Ser Phe Ser Gly Tyr
20 25 30
Tyr Trp Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Ile
35 40 45
Gly Glu Ile Asn His Ser Gly Ser Thr Lys Tyr Asn Pro Ser Leu Lys
50 55 60
Ser Arg Phe Thr Ile Ser Gly Asp Asn Ala Lys Asn Ser Phe Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Val
85 90 95
Arg Gly Leu Tyr Asn Trp Asn Val Asp Ser Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 121
<211> 107
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 121
Arg Ala Asp Ala Ala Pro Thr Val Ser Ile Phe Pro Pro Ser Ser Glu
1 5 10 15
Gln Leu Thr Ser Gly Gly Ala Ser Val Val Cys Phe Leu Asn Asn Phe
20 25 30
Tyr Pro Lys Asp Ile Asn Val Lys Trp Lys Ile Asp Gly Ser Glu Arg
35 40 45
Gln Asn Gly Val Leu Asn Ser Trp Thr Asp Gln Asp Ser Lys Asp Ser
50 55 60
Thr Tyr Ser Met Ser Ser Thr Leu Thr Leu Thr Lys Asp Glu Tyr Glu
65 70 75 80
Arg His Asn Ser Tyr Thr Cys Glu Ala Thr His Lys Thr Ser Thr Ser
85 90 95
Pro Ile Val Lys Ser Phe Asn Arg Asn Glu Cys
100 105
<210> 122
<211> 107
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 122
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Gly Ile Arg Asn Asp
20 25 30
Leu Gly Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Arg Leu Ile
35 40 45
Tyr Val Ala Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln His Asn Ser Tyr Pro Tyr
85 90 95
Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys
100 105
<210> 123
<211> 107
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 123
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Ser Ile Arg Ser Trp
20 25 30
Leu Ala Trp Phe Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Lys Ala Ser Ser Leu Glu Gly Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Tyr Asn Ser Tyr Ser Arg
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys
100 105
<210> 124
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 124
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Ser Phe Ser Gly Tyr
20 25 30
Tyr Trp Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Glu Ile Asn His Ser Gly Ser Ala Thr Tyr Asn Pro Ser Leu Lys
50 55 60
Ser Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Gly Leu Tyr Asn Trp Asn Val Asp His Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 125
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 125
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Val Ser Gly Gly Ser Phe Ser Gly Tyr
20 25 30
Tyr Trp Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Ile
35 40 45
Gly Glu Ile Asn His Ser Gly Ser Ala Thr Tyr Asn Pro Ser Leu Lys
50 55 60
Ser Arg Phe Thr Ile Ser Val Asp Thr Ala Lys Asn Ser Phe Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Gly Leu Tyr Asn Trp Asn Val Asp His Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 126
<211> 107
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 126
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Gly Ile Arg Asn Asp
20 25 30
Leu Gly Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Arg Leu Ile
35 40 45
Tyr Ala Ala Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln His Asn Ser Tyr Pro Arg
85 90 95
Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
100 105
<210> 127
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 127
Gly Gly Ser Phe Ser Gly Tyr Tyr Trp Ser
1 5 10
<210> 128
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 128
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Val Ser Gly Gly Ser Phe Ser Gly Tyr
20 25 30
Tyr Trp Ser Trp Val Arg Gln Pro Pro Gly Lys Gly Leu Glu Trp Ile
35 40 45
Gly Glu Ile Asn His Ser Gly Ser Ala Thr Tyr Asn Pro Ser Leu Lys
50 55 60
Ser Arg Phe Thr Ile Ser Val Asp Thr Ala Lys Asn Ser Phe Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Gly Leu Tyr Asn Trp Asn Val Asp His Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 129
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 129
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Val Ser Gly Gly Ser Phe Ser Gly Tyr
20 25 30
Tyr Trp Asn Trp Ile Arg Gln Pro Pro Gly Lys Gly Leu Glu Trp Ile
35 40 45
Gly Glu Ile Asn His Ser Gly Ser Ala Thr Tyr Asn Pro Ser Leu Lys
50 55 60
Ser Arg Phe Thr Ile Ser Val Asp Thr Ala Lys Asn Ser Phe Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Gly Leu Tyr Asn Trp Asn Val Asp His Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 130
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 130
Glu Ile Asp His Gln Gly Ser Thr Lys Tyr Asn Pro Ser Leu Lys Ser
1 5 10 15
<210> 131
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 131
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Val Ser Gly Gly Ser Phe Ser Gly Tyr
20 25 30
Tyr Trp Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Ile
35 40 45
Gly Glu Ile Asp His Gln Gly Ser Thr Lys Tyr Asn Pro Ser Leu Lys
50 55 60
Ser Arg Phe Thr Ile Ser Val Asp Thr Ala Lys Asn Ser Phe Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Gly Leu Tyr Asn Trp Asn Val Asp His Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 132
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 132
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Val Ser Gly Gly Ser Phe Ser Gly Tyr
20 25 30
Tyr Trp Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Ile
35 40 45
Gly Glu Ile Asn His Ser Gly Ser Ala Thr Tyr Asn Pro Ser Leu Lys
50 55 60
Ser Arg Val Thr Ile Ser Val Asp Thr Ala Lys Asn Ser Phe Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Gly Leu Tyr Asn Trp Asn Val Asp His Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 133
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 133
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Ser Phe Ser Gly Tyr
20 25 30
Tyr Trp Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Glu Ile Asn His Ser Gly Ser Ala Thr Tyr Asn Pro Ser Leu Lys
50 55 60
Ser Arg Phe Thr Ile Ser Arg Asp Thr Ala Lys Asn Ser Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Gly Leu Tyr Asn Trp Asn Val Asp His Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 134
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 134
Glu Ile Asn His Ser Gly Ser Ala Thr Tyr Val Asp Ser Val Lys Gly
1 5 10 15
<210> 135
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 135
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Val Ser Gly Gly Ser Phe Ser Gly Tyr
20 25 30
Tyr Trp Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Ile
35 40 45
Gly Glu Ile Asn His Ser Gly Ser Ala Thr Tyr Val Asp Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Thr Ala Lys Asn Ser Phe Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Gly Leu Tyr Asn Trp Asn Val Asp His Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 136
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 136
Glu Leu Tyr Asn Trp Asn Val Asp His
1 5
<210> 137
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 137
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Val Ser Gly Gly Ser Phe Ser Gly Tyr
20 25 30
Tyr Trp Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Ile
35 40 45
Gly Glu Ile Asn His Ser Gly Ser Ala Thr Tyr Asn Pro Ser Leu Lys
50 55 60
Ser Arg Phe Thr Ile Ser Val Asp Thr Ala Lys Asn Ser Phe Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Glu Leu Tyr Asn Trp Asn Val Asp His Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 138
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 138
Leu Gln His Asn Ala Tyr Pro Arg Thr
1 5
<210> 139
<211> 107
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 139
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Gly Ile Arg Asn Asp
20 25 30
Leu Gly Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Arg Leu Ile
35 40 45
Tyr Ala Ala Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln His Asn Ala Tyr Pro Arg
85 90 95
Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
100 105
<210> 140
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 140
Leu Gln His Ser Ser Tyr Pro Arg Thr
1 5
<210> 141
<211> 107
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 141
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Gly Ile Arg Asn Asp
20 25 30
Leu Gly Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Arg Leu Ile
35 40 45
Tyr Ala Ala Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln His Ser Ser Tyr Pro Arg
85 90 95
Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
100 105
<210> 142
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 142
Leu Gln His Gln Ser Tyr Pro Arg Thr
1 5
<210> 143
<211> 107
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 143
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Gly Ile Arg Asn Asp
20 25 30
Leu Gly Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Arg Leu Ile
35 40 45
Tyr Ala Ala Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln His Gln Ser Tyr Pro Arg
85 90 95
Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
100 105
<210> 144
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 144
Leu Gln His Ala Ser Tyr Pro Arg Thr
1 5
<210> 145
<211> 107
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 145
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Gly Ile Arg Asn Asp
20 25 30
Leu Gly Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Arg Leu Ile
35 40 45
Tyr Ala Ala Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln His Ala Ser Tyr Pro Arg
85 90 95
Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
100 105
<210> 146
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 146
Leu Gln His Asn Ala Tyr Pro Tyr Thr
1 5
<210> 147
<211> 107
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 147
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Gly Ile Arg Asn Asp
20 25 30
Leu Gly Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Arg Leu Ile
35 40 45
Tyr Ala Ala Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln His Asn Ala Tyr Pro Tyr
85 90 95
Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys
100 105
<210> 148
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 148
Leu Gln His Gln Ser Tyr Pro Tyr Thr
1 5
<210> 149
<211> 107
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 149
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Gly Ile Arg Asn Asp
20 25 30
Leu Gly Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Arg Leu Ile
35 40 45
Tyr Ala Ala Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln His Gln Ser Tyr Pro Tyr
85 90 95
Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys
100 105
<210> 150
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 150
Leu Gln His Ala Ser Tyr Pro Tyr Thr
1 5
<210> 151
<211> 107
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 151
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Gly Ile Arg Asn Asp
20 25 30
Leu Gly Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Arg Leu Ile
35 40 45
Tyr Ala Ala Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln His Ala Ser Tyr Pro Tyr
85 90 95
Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys
100 105
<210> 152
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 152
Arg Ala Ser Gln Ser Thr Arg Ser Trp Leu Ala
1 5 10
<210> 153
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 153
Gln Gln Tyr Gly Ser Tyr Ser Arg Thr
1 5
<210> 154
<211> 107
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 154
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Ser Thr Arg Ser Trp
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Lys Ala Ser Ser Leu Glu Gly Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Tyr Gly Ser Tyr Ser Arg
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys
100 105
<210> 155
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 155
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Ser Phe Ser Gly Tyr
20 25 30
Tyr Trp Asn Trp Ile Arg Gln Pro Pro Gly Lys Gly Leu Glu Trp Ile
35 40 45
Gly Glu Ile Asp His Gln Gly Ser Thr Lys Tyr Asn Pro Ser Leu Lys
50 55 60
Ser Arg Val Thr Ile Ser Val Asp Thr Ala Lys Asn Ser Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Gly Leu Tyr Asn Trp Asn Val Asp His Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 156
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 156
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Val Ser Gly Gly Ser Phe Ser Gly Tyr
20 25 30
Tyr Trp Asn Trp Ile Arg Gln Pro Pro Gly Lys Gly Leu Glu Trp Ile
35 40 45
Gly Glu Ile Asp His Gln Gly Ser Thr Lys Tyr Asn Pro Ser Leu Lys
50 55 60
Ser Arg Val Thr Ile Ser Val Asp Thr Ala Lys Asn Ser Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Glu Leu Tyr Asn Trp Asn Val Asp His Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 157
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 157
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Ser Phe Ser Gly Tyr
20 25 30
Tyr Trp Asn Trp Ile Arg Gln Pro Pro Gly Lys Gly Leu Glu Trp Ile
35 40 45
Gly Glu Ile Asp His Gln Gly Ser Thr Lys Tyr Asn Pro Ser Leu Lys
50 55 60
Ser Arg Val Thr Ile Ser Val Asp Thr Ala Lys Asn Ser Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Glu Leu Tyr Asn Trp Asn Val Asp His Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 158
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 158
Ala Ile Ser Gly Gly Gly Gly Ser Thr Gln Tyr Ala Asp Ser Val Lys
1 5 10 15
Gly
<210> 159
<211> 122
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 159
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ser Gly Gly Gly Gly Ser Thr Gln Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Ile Gln Trp Phe Gly Glu Ser Thr Leu Phe Asp Tyr Trp
100 105 110
Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 160
<211> 13
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 160
Asp Ile Gln Trp Tyr Gly Glu Ser Thr Leu Phe Asp Tyr
1 5 10
<210> 161
<211> 122
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 161
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ser Gly Gly Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Ile Gln Trp Tyr Gly Glu Ser Thr Leu Phe Asp Tyr Trp
100 105 110
Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 162
<211> 13
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 162
Asp Ile Gln Trp His Gly Glu Ser Thr Leu Phe Asp Tyr
1 5 10
<210> 163
<211> 122
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 163
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ser Gly Gly Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Ile Gln Trp His Gly Glu Ser Thr Leu Phe Asp Tyr Trp
100 105 110
Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 164
<211> 13
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 164
Asp Ile Gln Trp Phe Gly Arg Ser Thr Leu Phe Asp Tyr
1 5 10
<210> 165
<211> 122
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 165
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ser Gly Gly Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Ile Gln Trp Phe Gly Arg Ser Thr Leu Phe Asp Tyr Trp
100 105 110
Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 166
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 166
Arg Ala Ser Gln Ser Thr Arg Ser His Leu Ala
1 5 10
<210> 167
<211> 107
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 167
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Ser Thr Arg Ser His
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Lys Ala Ser Ser Leu Glu Gly Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Tyr Gly Ser Tyr Ser Arg
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys
100 105
<210> 168
<211> 107
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 168
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Ser Thr Arg Ser Trp
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Lys Ala Ser Ser Leu Glu Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Tyr Gly Ser Tyr Ser Arg
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys
100 105
<210> 169
<211> 107
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 169
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Ser Thr Arg Ser Trp
20 25 30
Leu Ala Trp His Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Lys Ala Ser Ser Leu Glu Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Tyr Gly Ser Tyr Ser Arg
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys
100 105
<210> 170
<211> 107
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 170
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Ser Thr Arg Ser Trp
20 25 30
Leu Ala Trp Leu Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Lys Ala Ser Ser Leu Glu Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Tyr Gly Ser Tyr Ser Arg
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys
100 105
<210> 171
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 171
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Val Ser Gly Gly Ser Phe Ser Gly Tyr
20 25 30
Tyr Trp Asn Trp Ile Arg Gln Pro Pro Gly Lys Gly Leu Glu Trp Ile
35 40 45
Gly Glu Ile Asn His Ser Gly Ser Ala Thr Tyr Asn Pro Ser Leu Lys
50 55 60
Ser Arg Val Thr Ile Ser Val Asp Thr Ala Lys Asn Ser Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Gly Leu Tyr Asn Trp Asn Val Asp His Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 172
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 172
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Val Ser Gly Gly Ser Phe Ser Gly Tyr
20 25 30
Tyr Trp Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Ile
35 40 45
Gly Glu Ile Asn His Ser Gly Ser Ala Thr Tyr Asn Pro Ser Leu Lys
50 55 60
Ser Arg Val Thr Ile Ser Val Asp Thr Ala Lys Asn Ser Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Gly Leu Tyr Asn Trp Asn Val Asp His Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 173
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 173
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Val Ser Gly Gly Ser Phe Ser Gly Tyr
20 25 30
Tyr Trp Asn Trp Ile Arg Gln Pro Pro Gly Lys Gly Leu Glu Trp Ile
35 40 45
Gly Glu Ile Asp His Gln Gly Ser Thr Lys Tyr Asn Pro Ser Leu Lys
50 55 60
Ser Arg Val Thr Ile Ser Val Asp Thr Ala Lys Asn Ser Phe Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Gly Leu Tyr Asn Trp Asn Val Asp His Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 174
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 174
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Ser Phe Ser Gly Tyr
20 25 30
Tyr Trp Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Ile
35 40 45
Gly Glu Ile Asn His Ser Gly Ser Ala Thr Tyr Asn Pro Ser Leu Lys
50 55 60
Ser Arg Val Thr Ile Ser Val Asp Thr Ala Lys Asn Ser Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Gly Leu Tyr Asn Trp Asn Val Asp His Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 175
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 175
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Ser Phe Ser Gly Tyr
20 25 30
Tyr Trp Asn Trp Ile Arg Gln Pro Pro Gly Lys Gly Leu Glu Trp Ile
35 40 45
Gly Glu Ile Asn His Ser Gly Ser Ala Thr Tyr Asn Pro Ser Leu Lys
50 55 60
Ser Arg Val Thr Ile Ser Val Asp Thr Ala Lys Asn Ser Phe Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Gly Leu Tyr Asn Trp Asn Val Asp His Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 176
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 176
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Ser Phe Ser Gly Tyr
20 25 30
Tyr Trp Asn Trp Ile Arg Gln Pro Pro Gly Lys Gly Leu Glu Trp Ile
35 40 45
Gly Glu Ile Asn His Ser Gly Ser Ala Thr Tyr Asn Pro Ser Leu Lys
50 55 60
Ser Arg Val Thr Ile Ser Val Asp Thr Ala Lys Asn Ser Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Gly Leu Tyr Asn Trp Asn Val Asp His Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 177
<211> 326
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 177
Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Cys Ser Arg
1 5 10 15
Ser Thr Ser Glu Ser Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr
20 25 30
Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser
35 40 45
Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser
50 55 60
Leu Ser Ser Val Val Thr Val Pro Ser Ser Asn Phe Gly Thr Gln Thr
65 70 75 80
Tyr Thr Cys Asn Val Asp His Lys Pro Ser Asn Thr Lys Val Asp Lys
85 90 95
Thr Val Glu Arg Lys Cys Glu Val Glu Cys Pro Glu Cys Pro Ala Pro
100 105 110
Pro Val Ala Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp
115 120 125
Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Ala
130 135 140
Val Ser His Glu Asp Pro Glu Val Gln Phe Asn Trp Tyr Val Asp Gly
145 150 155 160
Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Phe Asn
165 170 175
Ser Thr Phe Arg Val Val Ser Val Leu Thr Val Val His Gln Asp Trp
180 185 190
Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Gly Leu Pro
195 200 205
Ser Ser Ile Glu Lys Thr Ile Ser Lys Thr Lys Gly Gln Pro Arg Glu
210 215 220
Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Glu Glu Met Thr Lys Asn
225 230 235 240
Gln Val Ser Leu Thr Cys Glu Val Lys Gly Phe Tyr Pro Ser Asp Ile
245 250 255
Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr
260 265 270
Thr Pro Pro Met Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys
275 280 285
Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys
290 295 300
Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu
305 310 315 320
Ser Leu Ser Pro Gly Lys
325
<210> 178
<211> 326
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 178
Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Cys Ser Arg
1 5 10 15
Ser Thr Ser Glu Ser Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr
20 25 30
Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser
35 40 45
Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser
50 55 60
Leu Ser Ser Val Val Thr Val Pro Ser Ser Asn Phe Gly Thr Gln Thr
65 70 75 80
Tyr Thr Cys Asn Val Asp His Lys Pro Ser Asn Thr Lys Val Asp Lys
85 90 95
Thr Val Glu Arg Lys Cys Arg Val Arg Cys Pro Arg Cys Pro Ala Pro
100 105 110
Pro Val Ala Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp
115 120 125
Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Ala
130 135 140
Val Ser His Glu Asp Pro Glu Val Gln Phe Asn Trp Tyr Val Asp Gly
145 150 155 160
Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Phe Asn
165 170 175
Ser Thr Phe Arg Val Val Ser Val Leu Thr Val Val His Gln Asp Trp
180 185 190
Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Gly Leu Pro
195 200 205
Ser Ser Ile Glu Lys Thr Ile Ser Lys Thr Lys Gly Gln Pro Arg Glu
210 215 220
Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Glu Glu Met Thr Lys Asn
225 230 235 240
Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile
245 250 255
Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr
260 265 270
Thr Pro Pro Met Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Arg
275 280 285
Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys
290 295 300
Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu
305 310 315 320
Ser Leu Ser Pro Gly Lys
325
<210> 179
<211> 329
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 179
Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys
1 5 10 15
Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr
20 25 30
Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser
35 40 45
Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser
50 55 60
Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr
65 70 75 80
Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys
85 90 95
Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys
100 105 110
Pro Ala Pro Glu Ala Ala Gly Ala Pro Ser Val Phe Leu Phe Pro Pro
115 120 125
Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys
130 135 140
Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp
145 150 155 160
Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu
165 170 175
Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu
180 185 190
His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn
195 200 205
Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly
210 215 220
Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Glu Glu
225 230 235 240
Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr
245 250 255
Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn
260 265 270
Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe
275 280 285
Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn
290 295 300
Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr
305 310 315 320
Gln Lys Ser Leu Ser Leu Ser Pro Gly
325
<210> 180
<211> 325
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 180
Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Cys Ser Arg
1 5 10 15
Ser Thr Ser Glu Ser Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr
20 25 30
Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser
35 40 45
Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser
50 55 60
Leu Ser Ser Val Val Thr Val Pro Ser Ser Asn Phe Gly Thr Gln Thr
65 70 75 80
Tyr Thr Cys Asn Val Asp His Lys Pro Ser Asn Thr Lys Val Asp Lys
85 90 95
Thr Val Glu Arg Lys Cys Arg Val Arg Cys Pro Arg Cys Pro Ala Pro
100 105 110
Pro Val Ala Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp
115 120 125
Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Ala
130 135 140
Val Ser His Glu Asp Pro Glu Val Gln Phe Asn Trp Tyr Val Asp Gly
145 150 155 160
Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Phe Asn
165 170 175
Ser Thr Phe Arg Val Val Ser Val Leu Thr Val Val His Gln Asp Trp
180 185 190
Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Gly Leu Pro
195 200 205
Ser Ser Ile Glu Lys Thr Ile Ser Lys Thr Lys Gly Gln Pro Arg Glu
210 215 220
Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Glu Glu Met Thr Lys Asn
225 230 235 240
Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile
245 250 255
Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr
260 265 270
Thr Pro Pro Met Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Arg
275 280 285
Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys
290 295 300
Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu
305 310 315 320
Ser Leu Ser Pro Gly
325
<210> 181
<211> 325
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 181
Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Cys Ser Arg
1 5 10 15
Ser Thr Ser Glu Ser Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr
20 25 30
Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser
35 40 45
Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser
50 55 60
Leu Ser Ser Val Val Thr Val Pro Ser Ser Asn Phe Gly Thr Gln Thr
65 70 75 80
Tyr Thr Cys Asn Val Asp His Lys Pro Ser Asn Thr Lys Val Asp Lys
85 90 95
Thr Val Glu Arg Lys Cys Glu Val Glu Cys Pro Glu Cys Pro Ala Pro
100 105 110
Pro Val Ala Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp
115 120 125
Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Ala
130 135 140
Val Ser His Glu Asp Pro Glu Val Gln Phe Asn Trp Tyr Val Asp Gly
145 150 155 160
Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Phe Asn
165 170 175
Ser Thr Phe Arg Val Val Ser Val Leu Thr Val Val His Gln Asp Trp
180 185 190
Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Gly Leu Pro
195 200 205
Ser Ser Ile Glu Lys Thr Ile Ser Lys Thr Lys Gly Gln Pro Arg Glu
210 215 220
Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Glu Glu Met Thr Lys Asn
225 230 235 240
Gln Val Ser Leu Thr Cys Glu Val Lys Gly Phe Tyr Pro Ser Asp Ile
245 250 255
Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr
260 265 270
Thr Pro Pro Met Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys
275 280 285
Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys
290 295 300
Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu
305 310 315 320
Ser Leu Ser Pro Gly
325
<210> 182
<211> 329
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 182
Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys
1 5 10 15
Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr
20 25 30
Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser
35 40 45
Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser
50 55 60
Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr
65 70 75 80
Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys
85 90 95
Lys Val Glu Pro Lys Ser Cys Arg Lys Thr His Thr Cys Pro Arg Cys
100 105 110
Pro Ala Pro Glu Ala Ala Gly Ala Pro Ser Val Phe Leu Phe Pro Pro
115 120 125
Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys
130 135 140
Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp
145 150 155 160
Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu
165 170 175
Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu
180 185 190
His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn
195 200 205
Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly
210 215 220
Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Glu Glu
225 230 235 240
Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr
245 250 255
Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn
260 265 270
Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe
275 280 285
Leu Tyr Ser Arg Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn
290 295 300
Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr
305 310 315 320
Gln Lys Ser Leu Ser Leu Ser Pro Gly
325
<210> 183
<211> 329
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 183
Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys
1 5 10 15
Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr
20 25 30
Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser
35 40 45
Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser
50 55 60
Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr
65 70 75 80
Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys
85 90 95
Lys Val Glu Pro Lys Ser Cys Glu Lys Thr His Thr Cys Pro Glu Cys
100 105 110
Pro Ala Pro Glu Ala Ala Gly Ala Pro Ser Val Phe Leu Phe Pro Pro
115 120 125
Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys
130 135 140
Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp
145 150 155 160
Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu
165 170 175
Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu
180 185 190
His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn
195 200 205
Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly
210 215 220
Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Glu Glu
225 230 235 240
Met Thr Lys Asn Gln Val Ser Leu Thr Cys Glu Val Lys Gly Phe Tyr
245 250 255
Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn
260 265 270
Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe
275 280 285
Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn
290 295 300
Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr
305 310 315 320
Gln Lys Ser Leu Ser Leu Ser Pro Gly
325
<210> 184
<211> 329
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 184
Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys
1 5 10 15
Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr
20 25 30
Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser
35 40 45
Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser
50 55 60
Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr
65 70 75 80
Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys
85 90 95
Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys
100 105 110
Pro Ala Pro Glu Ala Ala Gly Ala Pro Ser Val Phe Leu Phe Pro Pro
115 120 125
Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys
130 135 140
Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp
145 150 155 160
Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu
165 170 175
Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu
180 185 190
His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn
195 200 205
Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly
210 215 220
Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Glu Glu
225 230 235 240
Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr
245 250 255
Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn
260 265 270
Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe
275 280 285
Leu Tyr Ser Arg Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn
290 295 300
Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr
305 310 315 320
Gln Lys Ser Leu Ser Leu Ser Pro Gly
325
<210> 185
<211> 329
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 185
Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys
1 5 10 15
Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr
20 25 30
Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser
35 40 45
Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser
50 55 60
Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr
65 70 75 80
Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys
85 90 95
Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys
100 105 110
Pro Ala Pro Glu Ala Ala Gly Ala Pro Ser Val Phe Leu Phe Pro Pro
115 120 125
Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys
130 135 140
Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp
145 150 155 160
Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu
165 170 175
Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu
180 185 190
His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn
195 200 205
Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly
210 215 220
Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Glu Glu
225 230 235 240
Met Thr Lys Asn Gln Val Ser Leu Thr Cys Glu Val Lys Gly Phe Tyr
245 250 255
Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn
260 265 270
Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe
275 280 285
Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn
290 295 300
Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr
305 310 315 320
Gln Lys Ser Leu Ser Leu Ser Pro Gly
325
<210> 186
<211> 443
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 186
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Val Ser Gly Gly Ser Phe Ser Gly Tyr
20 25 30
Tyr Trp Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Ile
35 40 45
Gly Glu Ile Asn His Ser Gly Ser Ala Thr Tyr Asn Pro Ser Leu Lys
50 55 60
Ser Arg Val Thr Ile Ser Val Asp Thr Ala Lys Asn Ser Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Gly Leu Tyr Asn Trp Asn Val Asp His Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu
115 120 125
Ala Pro Cys Ser Arg Ser Thr Ser Glu Ser Thr Ala Ala Leu Gly Cys
130 135 140
Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser
145 150 155 160
Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser
165 170 175
Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Asn
180 185 190
Phe Gly Thr Gln Thr Tyr Thr Cys Asn Val Asp His Lys Pro Ser Asn
195 200 205
Thr Lys Val Asp Lys Thr Val Glu Arg Lys Cys Glu Val Glu Cys Pro
210 215 220
Glu Cys Pro Ala Pro Pro Val Ala Gly Pro Ser Val Phe Leu Phe Pro
225 230 235 240
Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr
245 250 255
Cys Val Val Val Ala Val Ser His Glu Asp Pro Glu Val Gln Phe Asn
260 265 270
Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg
275 280 285
Glu Glu Gln Phe Asn Ser Thr Phe Arg Val Val Ser Val Leu Thr Val
290 295 300
Val His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser
305 310 315 320
Asn Lys Gly Leu Pro Ser Ser Ile Glu Lys Thr Ile Ser Lys Thr Lys
325 330 335
Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Glu
340 345 350
Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys Glu Val Lys Gly Phe
355 360 365
Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu
370 375 380
Asn Asn Tyr Lys Thr Thr Pro Pro Met Leu Asp Ser Asp Gly Ser Phe
385 390 395 400
Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly
405 410 415
Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr
420 425 430
Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
435 440
<210> 187
<211> 214
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 187
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Gly Ile Arg Asn Asp
20 25 30
Leu Gly Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Arg Leu Ile
35 40 45
Tyr Ala Ala Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln His Asn Ala Tyr Pro Arg
85 90 95
Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 188
<211> 447
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 188
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Asp Tyr
20 25 30
Tyr Met Thr Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Phe Ile Arg Asn Gln Ala Arg Gly Tyr Thr Ser Asp His Asn Pro
50 55 60
Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser
65 70 75 80
Leu Tyr Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr
85 90 95
Tyr Cys Ala Arg Asp Arg Pro Ser Tyr Tyr Val Leu Asp Tyr Trp Gly
100 105 110
Gln Gly Thr Thr Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser
115 120 125
Val Phe Pro Leu Ala Pro Cys Ser Arg Ser Thr Ser Glu Ser Thr Ala
130 135 140
Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val
145 150 155 160
Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala
165 170 175
Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val
180 185 190
Pro Ser Ser Asn Phe Gly Thr Gln Thr Tyr Thr Cys Asn Val Asp His
195 200 205
Lys Pro Ser Asn Thr Lys Val Asp Lys Thr Val Glu Arg Lys Cys Arg
210 215 220
Val Arg Cys Pro Arg Cys Pro Ala Pro Pro Val Ala Gly Pro Ser Val
225 230 235 240
Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr
245 250 255
Pro Glu Val Thr Cys Val Val Val Ala Val Ser His Glu Asp Pro Glu
260 265 270
Val Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys
275 280 285
Thr Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr Phe Arg Val Val Ser
290 295 300
Val Leu Thr Val Val His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys
305 310 315 320
Cys Lys Val Ser Asn Lys Gly Leu Pro Ser Ser Ile Glu Lys Thr Ile
325 330 335
Ser Lys Thr Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro
340 345 350
Pro Ser Arg Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu
355 360 365
Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn
370 375 380
Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Met Leu Asp Ser
385 390 395 400
Asp Gly Ser Phe Phe Leu Tyr Ser Arg Leu Thr Val Asp Lys Ser Arg
405 410 415
Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu
420 425 430
His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
435 440 445
<210> 189
<211> 219
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 189
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Thr Ser Ser Gln Ser Leu Phe Asn Val
20 25 30
Arg Ser Gln Lys Asn Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Lys
35 40 45
Ala Pro Lys Leu Leu Ile Tyr Trp Ala Ser Thr Arg Glu Ser Gly Val
50 55 60
Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr
65 70 75 80
Ile Ser Ser Leu Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Lys Gln
85 90 95
Ser Tyr Asp Leu Phe Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
100 105 110
Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu
115 120 125
Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe
130 135 140
Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln
145 150 155 160
Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser
165 170 175
Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu
180 185 190
Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser
195 200 205
Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
210 215
<210> 190
<211> 448
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 190
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ser Gly Gly Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Ile Gln Trp Tyr Gly Glu Ser Thr Leu Phe Asp Tyr Trp
100 105 110
Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro
115 120 125
Ser Val Phe Pro Leu Ala Pro Cys Ser Arg Ser Thr Ser Glu Ser Thr
130 135 140
Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr
145 150 155 160
Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro
165 170 175
Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr
180 185 190
Val Pro Ser Ser Asn Phe Gly Thr Gln Thr Tyr Thr Cys Asn Val Asp
195 200 205
His Lys Pro Ser Asn Thr Lys Val Asp Lys Thr Val Glu Arg Lys Cys
210 215 220
Glu Val Glu Cys Pro Glu Cys Pro Ala Pro Pro Val Ala Gly Pro Ser
225 230 235 240
Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg
245 250 255
Thr Pro Glu Val Thr Cys Val Val Val Ala Val Ser His Glu Asp Pro
260 265 270
Glu Val Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala
275 280 285
Lys Thr Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr Phe Arg Val Val
290 295 300
Ser Val Leu Thr Val Val His Gln Asp Trp Leu Asn Gly Lys Glu Tyr
305 310 315 320
Lys Cys Lys Val Ser Asn Lys Gly Leu Pro Ser Ser Ile Glu Lys Thr
325 330 335
Ile Ser Lys Thr Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu
340 345 350
Pro Pro Ser Arg Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys
355 360 365
Glu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser
370 375 380
Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Met Leu Asp
385 390 395 400
Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser
405 410 415
Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala
420 425 430
Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
435 440 445
<210> 191
<211> 214
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 191
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Ser Thr Arg Ser His
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Lys Ala Ser Ser Leu Glu Gly Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Tyr Gly Ser Tyr Ser Arg
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 192
<211> 1329
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 192
gaggtgcagc tggtggagtc tgggggaggc ttggtccagc ctggggggtc cctgagactc 60
tcctgtgcag tgtctggagg gtcctttagt ggttattact ggaactgggt gcgccaggcc 120
ccagggaagg ggctggagtg gattggggaa ataaaccact ccggaagcgc cacctataac 180
ccgtctctca agagtcgagt gaccatctcc gtagacacgg ccaagaactc actgtatctg 240
caaatgaaca gcctgagagc cgaggacacg gctgtgtatt actgtgcgag aggcctttac 300
aactggaacg tggaccactg gggccagggc accctggtca ccgtctcctc agcgtcgacc 360
aagggcccat cggtcttccc cctggcgccc tgctccagga gcacctccga gagcacagcg 420
gccctgggct gcctggtcaa ggactacttc cccgaaccgg tgacggtgtc gtggaactca 480
ggcgctctga ccagcggcgt gcacaccttc ccggctgtcc tacagtcctc aggactctac 540
tccctcagca gcgtagtgac cgtgccctcc agcaacttcg gcacccagac ctacacctgc 600
aacgtagatc acaagcccag caacaccaag gtggacaaga cagttgagcg caaatgtgag 660
gtcgagtgcc cagagtgccc agcaccacct gtggcaggac cgtcagtctt cctcttcccc 720
ccaaaaccca aggacaccct catgatctcc cggacccctg aggtcacgtg cgtggtggtg 780
gccgtgagcc acgaagaccc cgaggtccag ttcaactggt acgtggacgg cgtggaggtg 840
cataatgcca agacaaagcc acgggaggag cagttcaaca gcacgttccg tgtggtcagc 900
gtcctcaccg tcgtgcacca ggactggctg aacggcaagg agtacaagtg caaggtctcc 960
aacaaaggcc tcccatcctc catcgagaaa accatctcca aaaccaaagg gcagccccga 1020
gaaccacagg tgtacaccct gcccccatcc cgggaggaga tgaccaagaa ccaggtcagc 1080
ctgacctgcg aggtcaaagg cttctacccc agcgacatcg ccgtggagtg ggagagcaat 1140
gggcagccgg agaacaacta caagaccaca cctcccatgc tggactccga cggctccttc 1200
ttcctctaca gcaagctcac cgtggacaag agcaggtggc agcaggggaa cgtcttctca 1260
tgctccgtga tgcatgaggc tctgcacaac cactacacac agaagagcct ctccctgtcc 1320
cccggaaaa 1329
<210> 193
<211> 642
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 193
gacatccaga tgacccagtc tccatcctcc ctgtctgcat ctgtaggaga cagagtcacc 60
atcacttgcc gggcaagtca gggcattaga aatgatttag gctggtatca gcagaaacca 120
gggaaagccc ctaagcgcct gatctatgct gcatccagtt tgcaaagtgg ggtcccatca 180
aggttcagtg gcagtggatc tgggacagat ttcactctca ccatcagcag tctgcaacct 240
gaagattttg caacttacta ctgtctacag cataatgcct accctcgcac tttcggcgga 300
gggaccaagg tggagatcaa acgtacggtg gctgcaccat ctgtcttcat cttcccgcca 360
tctgatgagc agttgaaatc tggaactgcc tctgttgtgt gcctgctgaa taacttctat 420
cccagagagg ccaaagtaca gtggaaggtg gataacgccc tccaatcggg taactcccag 480
gagagtgtca cagagcagga cagcaaggac agcacctaca gcctcagcag caccctgacg 540
ctgagcaaag cagactacga gaaacacaaa gtctacgcct gcgaagtcac ccatcagggc 600
ctgagctcgc ccgtcacaaa gagcttcaac aggggagagt gt 642
<210> 194
<211> 1341
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 194
gaagtgcagc ttgtggagtc cggtggcgga ctcgtgcagc cgggcggatc cctgagactg 60
tcgtgtgccg catcaggatt caccttttcc gactattaca tgacctgggt ccgccaagct 120
cccgggaagg gcctggaatg ggtggccttc atccgcaacc aggcccgggg ctacacttcc 180
gatcacaacc ctagcgtgaa gggaaggttc accatttcgc gggacaacgc gaagaattcc 240
ctgtacctcc aaatgaacag cctgcgggcc gaggacactg ccgtctacta ctgcgcccgc 300
gatagaccaa gctactacgt gttggactac tggggacagg ggaccacggt caccgtctcc 360
tcagcctcca ccaagggccc atcggtcttc cccctggcgc cctgctccag gagcacctcc 420
gagagcacag cggccctggg ctgcctggtc aaggactact tccccgaacc ggtgacggtg 480
tcgtggaact caggcgctct gaccagcggc gtgcacacct tcccggctgt cctacagtcc 540
tcaggactct actccctcag cagcgtagtg accgtgccct ccagcaactt cggcacccag 600
acctacacct gcaacgtaga tcacaagccc agcaacacca aggtggacaa gacagttgag 660
cgcaaatgtc gtgtcaggtg cccaaggtgc ccagcaccac ctgtggcagg accgtcagtc 720
ttcctcttcc ccccaaaacc caaggacacc ctcatgatct cccggacccc tgaggtcacg 780
tgcgtggtgg tggccgtgag ccacgaagac cccgaggtcc agttcaactg gtacgtggac 840
ggcgtggagg tgcataatgc caagacaaag ccacgggagg agcagttcaa cagcacgttc 900
cgtgtggtca gcgtcctcac cgtcgtgcac caggactggc tgaacggcaa ggagtacaag 960
tgcaaggtct ccaacaaagg cctcccatcc tccatcgaga aaaccatctc caaaaccaaa 1020
gggcagcccc gagaaccaca ggtgtacacc ctgcccccat cccgggagga gatgaccaag 1080
aaccaggtca gcctgacctg cctggtcaaa ggcttctacc ccagcgacat cgccgtggag 1140
tgggagagca atgggcagcc ggagaacaac tacaagacca cacctcccat gctggactcc 1200
gacggctcct tcttcctcta cagcaggctc accgtggaca agagcaggtg gcagcagggg 1260
aacgtcttct catgctccgt gatgcatgag gctctgcaca accactacac acagaagagc 1320
ctctccctgt ctccgggtaa a 1341
<210> 195
<211> 657
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 195
gacatccaaa tgacccagtc accgtcatcg ctctcggctt ccgtgggcga tagagtgacc 60
attacttgca cgagctccca gtccctgttc aacgtgcgca gccagaagaa ctacctcgcc 120
tggtaccagc agaagcctgg aaaagccccg aagcttctga tctactgggc ctcgacccgg 180
gagtctggtg tcccatcccg gttctccgga tccggctccg ggaccgactt cactctgacc 240
attagcagcc tgcagcccga agatttcgcg acctattact gcaagcaatc ctacgacttg 300
ttcacttttg gcgggggaac caaggtcgag atcaaacgaa ctgtggctgc accatctgtc 360
ttcatcttcc cgccatctga tgagcagttg aaatctggaa ctgcctctgt tgtgtgcctg 420
ctgaataact tctatcccag agaggccaaa gtacagtgga aggtggataa cgccctccaa 480
tcgggtaact cccaggagag tgtcacagag caggacagca aggacagcac ctacagcctc 540
agcagcaccc tgacgctgag caaagcagac tacgagaaac acaaagtcta cgcctgcgaa 600
gtcacccatc agggcctgag ctcgcccgtc acaaagagct tcaacagggg agagtgt 657
<210> 196
<211> 1344
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 196
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgagactc 60
tcctgtgcag cctctggatt cacctttagc agctatgcca tgagctgggt ccgccaggct 120
ccagggaagg ggctggaatg ggtctcagct attagtggtg gtggtggtag cacatactac 180
gcagactccg tgaagggccg gttcaccatc tccagagaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgag agccgaggac acggccgtat attactgtgc gagggacata 300
cagtggtacg gggagtcaac cctctttgac tactggggcc agggaaccct ggtcaccgtc 360
tcctcagcgt cgaccaaggg cccatcggtc ttccccctgg cgccctgctc caggagcacc 420
tccgagagca cagcggccct gggctgcctg gtcaaggact acttccccga accggtgacg 480
gtgtcgtgga actcaggcgc tctgaccagc ggcgtgcaca ccttcccggc tgtcctacag 540
tcctcaggac tctactccct cagcagcgta gtgaccgtgc cctccagcaa cttcggcacc 600
cagacctaca cctgcaacgt agatcacaag cccagcaaca ccaaggtgga caagacagtt 660
gagcgcaaat gtgaggtcga gtgcccagag tgcccagcac cacctgtggc aggaccgtca 720
gtcttcctct tccccccaaa acccaaggac accctcatga tctcccggac ccctgaggtc 780
acgtgcgtgg tggtggccgt gagccacgaa gaccccgagg tccagttcaa ctggtacgtg 840
gacggcgtgg aggtgcataa tgccaagaca aagccacggg aggagcagtt caacagcacg 900
ttccgtgtgg tcagcgtcct caccgtcgtg caccaggact ggctgaacgg caaggagtac 960
aagtgcaagg tctccaacaa aggcctccca tcctccatcg agaaaaccat ctccaaaacc 1020
aaagggcagc cccgagaacc acaggtgtac accctgcccc catcccggga ggagatgacc 1080
aagaaccagg tcagcctgac ctgcgaggtc aaaggcttct accccagcga catcgccgtg 1140
gagtgggaga gcaatgggca gccggagaac aactacaaga ccacacctcc catgctggac 1200
tccgacggct ccttcttcct ctacagcaag ctcaccgtgg acaagagcag gtggcagcag 1260
gggaacgtct tctcatgctc cgtgatgcat gaggctctgc acaaccacta cacacagaag 1320
agcctctccc tgtcccccgg aaaa 1344
<210> 197
<211> 642
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 197
gacatccaga tgacccagtc tccatcctcc ctgtctgcat ctgtaggaga cagagtcacc 60
atcacttgcc gggcaagtca gagcacccgt agccacttag cctggtatca gcagaaacca 120
gggaaagccc ctaagctcct gatctataag gcatccagtt tggaaggtgg ggtcccatca 180
aggttcagtg gcagtggatc tgggacagat ttcactctca ccatcagcag tctgcaacct 240
gaagattttg caacttacta ctgtcaacag tatggcagtt attctcggac gttcggccaa 300
gggaccaagg tggaaatcaa acgtacggtg gctgcaccat ctgtcttcat cttcccgcca 360
tctgatgagc agttgaaatc tggaactgcc tctgttgtgt gcctgctgaa taacttctat 420
cccagagagg ccaaagtaca gtggaaggtg gataacgccc tccaatcggg taactcccag 480
gagagtgtca cagagcagga cagcaaggac agcacctaca gcctcagcag caccctgacg 540
ctgagcaaag cagactacga gaaacacaaa gtctacgcct gcgaagtcac ccatcagggc 600
ctgagctcgc ccgtcacaaa gagcttcaac aggggagagt gt 642
<210> 198
<211> 15
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 198
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
1 5 10 15
<210> 199
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 199
Gly Tyr Tyr Trp Asn
1 5
<210> 200
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 200
Gly Gly Ser Phe Ser Gly Tyr
1 5
<210> 201
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 201
Asn His Ser Gly Ser
1 5
<210> 202
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 202
Asp Tyr Tyr Met Thr
1 5
<210> 203
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 203
Gly Phe Thr Phe Ser Asp Tyr
1 5
<210> 204
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 204
Arg Asn Gln Ala Arg Gly Tyr Thr
1 5
<210> 205
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 205
Ser Tyr Ala Met Ser
1 5
<210> 206
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 206
Gly Phe Thr Phe Ser Ser Tyr
1 5
<210> 207
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 207
Ser Gly Gly Gly Gly Ser
1 5
<210> 208
<211> 326
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 208
Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Cys Ser Arg
1 5 10 15
Ser Thr Ser Glu Ser Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr
20 25 30
Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser
35 40 45
Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser
50 55 60
Leu Ser Ser Val Val Thr Val Pro Ser Ser Asn Phe Gly Thr Gln Thr
65 70 75 80
Tyr Thr Cys Asn Val Asp His Lys Pro Ser Asn Thr Lys Val Asp Lys
85 90 95
Thr Val Glu Arg Lys Cys Cys Val Glu Cys Pro Pro Cys Pro Ala Pro
100 105 110
Pro Val Ala Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp
115 120 125
Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp
130 135 140
Val Ser His Glu Asp Pro Glu Val Gln Phe Asn Trp Tyr Val Asp Gly
145 150 155 160
Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Phe Asn
165 170 175
Ser Thr Phe Arg Val Val Ser Val Leu Thr Val Val His Gln Asp Trp
180 185 190
Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Gly Leu Pro
195 200 205
Ala Pro Ile Glu Lys Thr Ile Ser Lys Thr Lys Gly Gln Pro Arg Glu
210 215 220
Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Glu Glu Met Thr Lys Asn
225 230 235 240
Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile
245 250 255
Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr
260 265 270
Thr Pro Pro Met Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys
275 280 285
Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys
290 295 300
Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu
305 310 315 320
Ser Leu Ser Pro Gly Lys
325
<210> 209
<211> 330
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 209
Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys
1 5 10 15
Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr
20 25 30
Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser
35 40 45
Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser
50 55 60
Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr
65 70 75 80
Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys
85 90 95
Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys
100 105 110
Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro
115 120 125
Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys
130 135 140
Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp
145 150 155 160
Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu
165 170 175
Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu
180 185 190
His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn
195 200 205
Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly
210 215 220
Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu
225 230 235 240
Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr
245 250 255
Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn
260 265 270
Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe
275 280 285
Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn
290 295 300
Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr
305 310 315 320
Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
325 330
<210> 210
<211> 326
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 210
Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Cys Ser Arg
1 5 10 15
Ser Thr Ser Glu Ser Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr
20 25 30
Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser
35 40 45
Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser
50 55 60
Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Lys Thr
65 70 75 80
Tyr Thr Cys Asn Val Asp His Lys Pro Ser Asn Thr Lys Val Asp Lys
85 90 95
Arg Val Glu Ser Lys Tyr Gly Pro Pro Cys Ser Cys Pro Ala Pro Glu
100 105 110
Phe Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp
115 120 125
Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp
130 135 140
Val Ser Gln Glu Asp Pro Glu Val Gln Phe Asn Trp Tyr Val Asp Gly
145 150 155 160
Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Phe Asn
165 170 175
Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp
180 185 190
Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Gly Leu Pro
195 200 205
Ser Ser Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu
210 215 220
Pro Gln Val Tyr Thr Leu Pro Pro Ser Gln Glu Glu Met Thr Lys Asn
225 230 235 240
Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile
245 250 255
Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr
260 265 270
Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Arg
275 280 285
Leu Thr Val Asp Lys Ser Arg Trp Gln Glu Gly Asn Val Phe Ser Cys
290 295 300
Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu
305 310 315 320
Ser Leu Ser Leu Gly Lys
325
Claims (53)
- (a) 서열식별번호: 23, 서열식별번호: 155, 서열식별번호: 156, 서열식별번호: 157, 서열식별번호: 159, 서열식별번호: 161, 서열식별번호: 163, 서열식별번호: 165, 서열식별번호: 169, 서열식별번호: 171, 서열식별번호: 172, 서열식별번호: 173, 서열식별번호: 174, 서열식별번호: 175 및 서열식별번호: 176으로 이루어진 군으로부터 선택된 아미노산 서열을 갖는 중쇄 가변 영역 (VH)의 VH 상보성 결정 영역 (CDR) 1 (CDR1), VH CDR2 및 VH CDR3; 및
(b) 서열식별번호: 27, 서열식별번호: 139, 서열식별번호: 141, 서열식별번호: 167, 서열식별번호: 168, 서열식별번호: 169 및 서열식별번호: 170으로 이루어진 군으로부터 선택된 아미노산 서열을 갖는 경쇄 가변 영역 (VL)의 VL 상보성 결정 영역 1 (CDR1), VL CDR2 및 VL CDR3
을 포함하는, B7-H4에 특이적으로 결합하는 단리된 항체. - 제1항에 있어서,
(a) 서열식별번호: 161의 아미노산 서열을 갖는 VH; 및 서열식별번호: 167의 아미노산 서열을 갖는 VL;
(b) 서열식별번호: 172의 아미노산 서열을 갖는 VH; 및 서열식별번호: 139의 아미노산 서열을 갖는 VL;
(c) 서열식별번호: 155의 아미노산 서열을 갖는 VH; 및 서열식별번호: 139의 아미노산 서열을 갖는 VL;
(d) 서열식별번호: 156의 아미노산 서열을 갖는 VH; 및 서열식별번호: 139의 아미노산 서열을 갖는 VL;
(e) 서열식별번호: 157의 아미노산 서열을 갖는 VH; 및 서열식별번호: 141의 아미노산 서열을 갖는 VL;
(f) 서열식별번호: 155의 아미노산 서열을 갖는 VH; 및 서열식별번호: 141의 아미노산 서열을 갖는 VL;
(g) 서열식별번호: 156의 아미노산 서열을 갖는 VH; 및 서열식별번호: 141의 아미노산 서열을 갖는 VL;
(h) 서열식별번호: 159의 아미노산 서열을 갖는 VH; 및 서열식별번호: 27의 아미노산 서열을 갖는 VL;
(i) 서열식별번호: 161의 아미노산 서열을 갖는 VH; 및 서열식별번호: 27의 아미노산 서열을 갖는 VL;
(j) 서열식별번호: 163의 아미노산 서열을 갖는 VH; 및 서열식별번호: 27의 아미노산 서열을 갖는 VL;
(k) 서열식별번호: 165의 아미노산 서열을 갖는 VH; 및 서열식별번호: 27의 아미노산 서열을 갖는 VL;
(l) 서열식별번호: 23의 아미노산 서열을 갖는 VH; 및 서열식별번호: 167의 아미노산 서열을 갖는 VL;
(m) 서열식별번호: 171의 아미노산 서열을 갖는 VH; 및 서열식별번호: 141의 아미노산 서열을 갖는 VL;
(n) 서열식별번호: 172의 아미노산 서열을 갖는 VH; 및 서열식별번호: 141의 아미노산 서열을 갖는 VL;
(o) 서열식별번호: 171의 아미노산 서열을 갖는 VH; 및 서열식별번호: 139의 아미노산 서열을 갖는 VL;
(p) 서열식별번호: 173의 아미노산 서열을 갖는 VH; 및 서열식별번호: 139의 아미노산 서열을 갖는 VL;
(q) 서열식별번호: 174의 아미노산 서열을 갖는 VH; 및 서열식별번호: 139의 아미노산 서열을 갖는 VL;
(r) 서열식별번호: 175의 아미노산 서열을 갖는 VH; 및 서열식별번호: 139의 아미노산 서열을 갖는 VL;
(s) 서열식별번호: 161의 아미노산 서열을 갖는 VH; 및 서열식별번호: 168의 아미노산 서열을 갖는 VL;
(t) 서열식별번호: 161의 아미노산 서열을 갖는 VH; 및 서열식별번호: 169의 아미노산 서열을 갖는 VL;
(u) 서열식별번호: 161의 아미노산 서열을 갖는 VH; 및 서열식별번호: 170의 아미노산 서열을 갖는 VL; 또는
(v) 서열식별번호: 172의 아미노산 서열을 갖는 VH; 및 서열식별번호: 139의 아미노산 서열을 갖는 VL
을 포함하는 항체로부터의 VH CDR1, VH CDR2, VH CDR3, VL CDR1, VL CDR2 및 VL CDR3을 포함하는 항체. - 제1항에 있어서,
(a) 서열식별번호: 20의 아미노산 서열을 갖는 VH CDR1, 서열식별번호: 21의 아미노산 서열을 갖는 VH CDR2, 서열식별번호: 160의 아미노산 서열을 갖는 VH CDR3, 서열식별번호: 166의 아미노산 서열을 갖는 VL CDR1, 서열식별번호: 25의 아미노산 서열을 갖는 VL CDR2 및 서열식별번호: 153의 아미노산 서열을 갖는 VL CDR3;
(b) 서열식별번호: 205의 아미노산 서열을 갖는 VH CDR1, 서열식별번호: 21의 아미노산 서열을 갖는 VH CDR2, 서열식별번호: 160의 아미노산 서열을 갖는 VH CDR3, 서열식별번호: 166의 아미노산 서열을 갖는 VL CDR1, 서열식별번호: 25의 아미노산 서열을 갖는 VL CDR2 및 서열식별번호: 153의 아미노산 서열을 갖는 VL CDR3;
(c) 서열식별번호: 206의 아미노산 서열을 갖는 VH CDR1, 서열식별번호: 207의 아미노산 서열을 갖는 VH CDR2, 서열식별번호: 160의 아미노산 서열을 갖는 VH CDR3, 서열식별번호: 166의 아미노산 서열을 갖는 VL CDR1, 서열식별번호: 25의 아미노산 서열을 갖는 VL CDR2 및 서열식별번호: 153의 아미노산 서열을 갖는 VL CDR3;
(d) 서열식별번호: 5의 아미노산 서열을 갖는 VH CDR1, 서열식별번호: 6의 아미노산 서열을 갖는 VH CDR2, 서열식별번호: 7의 아미노산 서열을 갖는 VH CDR3, 서열식별번호: 9의 아미노산 서열을 갖는 VL CDR1, 서열식별번호: 10의 아미노산 서열을 갖는 VL CDR2 및 서열식별번호: 138의 아미노산 서열을 갖는 VL CDR3;
(e) 서열식별번호: 199의 아미노산 서열을 갖는 VH CDR1, 서열식별번호: 6의 아미노산 서열을 갖는 VH CDR2, 서열식별번호: 7의 아미노산 서열을 갖는 VH CDR3, 서열식별번호: 9의 아미노산 서열을 갖는 VL CDR1, 서열식별번호: 10의 아미노산 서열을 갖는 VL CDR2 및 서열식별번호: 138의 아미노산 서열을 갖는 VL CDR3;
(f) 서열식별번호: 200의 아미노산 서열을 갖는 VH CDR1, 서열식별번호: 201의 아미노산 서열을 갖는 VH CDR2, 서열식별번호: 7의 아미노산 서열을 갖는 VH CDR3, 서열식별번호: 9의 아미노산 서열을 갖는 VL CDR1, 서열식별번호: 10의 아미노산 서열을 갖는 VL CDR2 및 서열식별번호: 138의 아미노산 서열을 갖는 VL CDR3;
(g) 서열식별번호: 20의 아미노산 서열을 갖는 VH CDR1, 서열식별번호: 21의 아미노산 서열을 갖는 VH CDR2, 서열식별번호: 160의 아미노산 서열을 갖는 VH CDR3, 서열식별번호: 152의 아미노산 서열을 갖는 VL CDR1, 서열식별번호: 41의 아미노산 서열을 갖는 VL CDR2 및 서열식별번호: 153의 아미노산 서열을 갖는 VL CDR3;
(h) 서열식별번호: 5의 아미노산 서열을 갖는 VH CDR1, 서열식별번호: 6의 아미노산 서열을 갖는 VH CDR2, 서열식별번호: 7의 아미노산 서열을 갖는 VH CDR3, 서열식별번호: 9의 아미노산 서열을 갖는 VL CDR1, 서열식별번호: 10의 아미노산 서열을 갖는 VL CDR2 및 서열식별번호: 138의 아미노산 서열을 갖는 VL CDR3; 또는
(i) 서열식별번호: 5의 아미노산 서열을 갖는 VH CDR1, 서열식별번호: 130의 아미노산 서열을 갖는 VH CDR2, 서열식별번호: 7의 아미노산 서열을 갖는 VH CDR3, 서열식별번호: 9의 아미노산 서열을 갖는 VL CDR1, 서열식별번호: 10의 아미노산 서열을 갖는 VL CDR2 및 서열식별번호: 138의 아미노산 서열을 갖는 VL CDR3
을 포함하는 항체. - 서열식별번호: 20의 아미노산 서열을 갖는 VH CDR1, 서열식별번호: 21의 아미노산 서열을 갖는 VH CDR2, 서열식별번호: 160의 아미노산 서열을 갖는 VH CDR3, 서열식별번호: 166의 아미노산 서열을 갖는 VL CDR1, 서열식별번호: 25의 아미노산 서열을 갖는 VL CDR2 및 서열식별번호: 153의 아미노산 서열을 갖는 VL CDR3을 포함하는, B7-H4에 특이적으로 결합하는 단리된 항체.
- 제1항에 있어서,
(a) 서열식별번호: 161의 아미노산 서열을 갖는 VH; 및 서열식별번호: 167의 아미노산 서열을 갖는 VL;
(b) 서열식별번호: 172의 아미노산 서열을 갖는 VH; 및 서열식별번호: 139의 아미노산 서열을 갖는 VL;
(c) 서열식별번호: 155의 아미노산 서열을 갖는 VH; 및 서열식별번호: 139의 아미노산 서열을 갖는 VL;
(d) 서열식별번호: 156의 아미노산 서열을 갖는 VH; 및 서열식별번호: 139의 아미노산 서열을 갖는 VL;
(e) 서열식별번호: 157의 아미노산 서열을 갖는 VH; 및 서열식별번호: 141의 아미노산 서열을 갖는 VL;
(f) 서열식별번호: 155의 아미노산 서열을 갖는 VH; 서열식별번호: 141의 아미노산 서열을 갖는 VL;
(g) 서열식별번호: 156의 아미노산 서열을 갖는 VH; 및 서열식별번호: 141의 아미노산 서열을 갖는 VL;
(h) 서열식별번호: 159의 아미노산 서열을 갖는 VH; 및 서열식별번호: 27의 아미노산 서열을 갖는 VL;
(i) 서열식별번호: 161의 아미노산 서열을 갖는 VH; 및 서열식별번호: 27의 아미노산 서열을 갖는 VL;
(j) 서열식별번호: 163의 아미노산 서열을 갖는 VH; 및 서열식별번호: 27의 아미노산 서열을 갖는 VL;
(k) 서열식별번호: 165의 아미노산 서열을 갖는 VH; 및 서열식별번호: 27의 아미노산 서열을 갖는 VL;
(l) 서열식별번호: 23의 아미노산 서열을 갖는 VH; 및 서열식별번호: 167의 아미노산 서열을 갖는 VL;
(m) 서열식별번호: 171의 아미노산 서열을 갖는 VH; 및 서열식별번호: 141의 아미노산 서열을 갖는 VL;
(n) 서열식별번호: 172의 아미노산 서열을 갖는 VH; 및 서열식별번호: 141의 아미노산 서열을 갖는 VL;
(o) 서열식별번호: 171의 아미노산 서열을 갖는 VH; 및 서열식별번호: 139의 아미노산 서열을 갖는 VL;
(p) 서열식별번호: 173의 아미노산 서열을 갖는 VH; 및 서열식별번호: 139의 아미노산 서열을 갖는 VL;
(q) 서열식별번호: 174의 아미노산 서열을 갖는 VH; 및 서열식별번호: 139의 아미노산 서열을 갖는 VL;
(r) 서열식별번호: 175의 아미노산 서열을 갖는 VH; 및 서열식별번호: 139의 아미노산 서열을 갖는 VL;
(s) 서열식별번호: 161의 아미노산 서열을 갖는 VH; 및 서열식별번호: 168의 아미노산 서열을 갖는 VL;
(t) 서열식별번호: 161의 아미노산 서열을 갖는 VH; 및 서열식별번호: 169의 아미노산 서열을 갖는 VL;
(u) 서열식별번호: 161의 아미노산 서열을 갖는 VH; 및 서열식별번호: 170의 아미노산 서열을 갖는 VL; 또는
(v) 서열식별번호: 172의 아미노산 서열을 갖는 VH; 및 서열식별번호: 139의 아미노산 서열을 갖는 VL
을 포함하는 항체. - 서열식별번호: 161의 아미노산 서열을 갖는 VH 및 서열식별번호: 167의 아미노산 서열을 갖는 VL을 포함하는, B7-H4에 특이적으로 결합하는 단리된 항체.
- 서열식별번호: 172의 아미노산 서열을 갖는 VH 및 서열식별번호: 139의 아미노산 서열을 갖는 VL을 포함하는, B7-H4에 특이적으로 결합하는 단리된 항체.
- 제1항 내지 제7항 중 어느 한 항에 있어서, 불변 영역을 추가로 포함하는 항체.
- 제8항에 있어서, 불변 영역이 IgG1 또는 IgG2의 이소형인 항체.
- 제1항 내지 제9항 중 어느 한 항에 있어서, 항체가 A330S, P331S, D265A, C223E, P228E, L368E, C223R, E225R, P228R 및 K409R로 이루어진 군으로부터 선택된 1개 이상의 치환을 포함하는 인간 IgG2이며, 여기서 넘버링은 인간 IgG2 야생형 및 EU 넘버링 스킴에 따르고, 도 1에 제시된 바와 같은 것인 항체.
- 제10항에 있어서, 치환 C223E, P228E 및 L368E를 포함하는 항체.
- 제10항 또는 제11항에 있어서, 치환 A330S, P331S 및 D265A를 포함하는 항체.
- 서열식별번호: 190의 아미노산 서열을 갖는 중쇄 및 서열식별번호: 191의 아미노산 서열을 갖는 경쇄를 포함하는, B7-H4에 특이적으로 결합하는 단리된 항체.
- 서열식별번호: 186의 아미노산 서열을 갖는 중쇄 및 서열식별번호: 187의 아미노산 서열을 갖는 경쇄를 포함하는, B7-H4에 특이적으로 결합하는 단리된 항체.
- ATCC 수탁 번호 PTA-126779 하에 기탁된 폴리뉴클레오티드의 오픈 리딩 프레임 (ORF)에 의해 코딩된 전장 폴리펩티드의 아미노산 서열을 포함하는 중쇄 및 ATCC 수탁 번호 PTA-126781 하에 기탁된 폴리뉴클레오티드의 오픈 리딩 프레임 (ORF)에 의해 코딩된 전장 폴리펩티드의 아미노산 서열을 포함하는 경쇄를 포함하는, B7-H4에 특이적으로 결합하는 단리된 항체.
- 제1항 또는 제2항에 있어서, 각각의 VH CDR1, VH CDR2, VH CDR3, VL CDR1, VL CDR2 및 VL CDR3이 카바트 정의, 코티아 정의, AbM 정의 또는 CDR의 접촉 정의에 따라 정의되는 것인 항체.
- (a) 서열식별번호: 8의 아미노산 서열을 갖는 VH 및 서열식별번호: 13의 아미노산 서열을 갖는 VL;
(b) 서열식별번호: 8의 아미노산 서열을 갖는 VH 및 서열식별번호: 13의 아미노산 서열을 갖는 VL;
(c) 서열식별번호: 39의 아미노산 서열을 갖는 VH 및 서열식별번호: 43의 아미노산 서열을 갖는 VL;
(d) 서열식별번호: 46의 아미노산 서열을 갖는 VH 및 서열식별번호: 49의 아미노산 서열을 갖는 VL;
(e) 서열식별번호: 52의 아미노산 서열을 갖는 VH 및 서열식별번호: 54의 아미노산 서열을 갖는 VL;
(f) 서열식별번호: 57의 아미노산 서열을 갖는 VH 및 서열식별번호: 60의 아미노산 서열을 갖는 VL;
(g) 서열식별번호: 16의 아미노산 서열을 갖는 VH 및 서열식별번호: 19의 아미노산 서열을 갖는 VL;
(h) 서열식별번호: 64의 아미노산 서열을 갖는 VH 및 서열식별번호: 67의 아미노산 서열을 갖는 VL;
(i) 서열식별번호: 69의 아미노산 서열을 갖는 VH 및 서열식별번호: 70의 아미노산 서열을 갖는 VL;
(j) 서열식별번호: 74의 아미노산 서열을 갖는 VH 및 서열식별번호: 77의 아미노산 서열을 갖는 VL;
(k) 서열식별번호: 80의 아미노산 서열을 갖는 VH 및 서열식별번호: 84의 아미노산 서열을 갖는 VL;
(l) 서열식별번호: 87의 아미노산 서열을 갖는 VH 및 서열식별번호: 90의 아미노산 서열을 갖는 VL;
(m) 서열식별번호: 23의 아미노산 서열을 갖는 VH 및 서열식별번호: 27의 아미노산 서열을 갖는 VL;
(n) 서열식별번호: 94의 아미노산 서열을 갖는 VH 및 서열식별번호: 96의 아미노산 서열을 갖는 VL;
(o) 서열식별번호: 100의 아미노산 서열을 갖는 VH 및 서열식별번호: 77의 아미노산 서열을 갖는 VL; 또는
(p) 서열식별번호: 104의 아미노산 서열을 갖는 VH 및 서열식별번호: 67의 아미노산 서열을 갖는 VL
을 포함하는 제2 항체와 B7-H4에의 결합에 대해 경쟁하는, B7-H4에 특이적으로 결합하는 단리된 제1 항체로서,
여기서 제1 항체는 인간 B7-H4에 대한 KD가 약 1 마이크로몰 내지 0.1 나노몰인 단리된 제1 항체. - 서열식별번호: 1의 아미노산 서열을 갖는 B7-H4 세포외 도메인의 L44, K45, E46, G47, V48, L49, G50, L51, E64, D66, M68, T99 및 K101로 이루어진 군으로부터 선택된 적어도 2개의 아미노산 잔기를 포함하는 인간 B7-H4 상의 에피토프에 결합하는, B7-H4에 특이적으로 결합하는 단리된 항체.
- 제1항 내지 제18항 중 어느 한 항의 치료 유효량의 항체 또는 항원 결합 단편 및 제약상 허용되는 담체를 포함하는 제약 조성물.
- (i) 제1항 내지 제16항 중 어느 한 항의 항체의 중쇄; 또는 (ii) 제1항 내지 제16항 중 어느 한 항의 항체의 경쇄를 코딩하는 단리된 폴리뉴클레오티드.
- 제20항의 폴리뉴클레오티드를 포함하는 벡터.
- 제1항 내지 제16항 중 어느 한 항의 항체를 재조합적으로 생산하는 단리된 숙주 세포.
- B7-H4를 발현하는 세포와 연관된 상태의 치료를 필요로 하는 대상체에게 유효량의 제19항의 제약 조성물을 투여하는 것을 포함하는, 대상체에서 B7-H4를 발현하는 세포와 연관된 상태를 치료하는 방법.
- 제23항에 있어서, 상태가 암인 방법.
- 제24항에 있어서, 암이 유방암, 난소암, 방광암, 자궁암 또는 담관암인 방법.
- 제1 중쇄 및 제1 경쇄 및 제2 중쇄 및 제2 경쇄를 포함하며, 여기서 제1 중쇄 및 제1 경쇄는 B7-H4에 결합하는 제1 항원 결합 도메인을 포함하는 제1 아암을 형성하고, 제2 중쇄 및 제2 경쇄는 CD3에 결합하는 제2 항원 결합 도메인을 포함하는 제2 아암을 형성하고, 여기서
(a) 제1 중쇄는 서열식별번호: 20의 아미노산 서열을 갖는 VH CDR1, 서열식별번호: 21의 아미노산 서열을 갖는 VH CDR2, 서열식별번호: 160의 아미노산 서열을 갖는 VH CDR3을 포함하고, 제1 경쇄는 서열식별번호: 166의 아미노산 서열을 갖는 VL CDR1, 서열식별번호: 25의 아미노산 서열을 갖는 VL CDR2 및 서열식별번호: 153의 아미노산 서열을 갖는 VL CDR3을 포함하거나;
(b) 제1 중쇄는 서열식별번호: 205의 아미노산 서열을 갖는 VH CDR1, 서열식별번호: 21의 아미노산 서열을 갖는 VH CDR2, 서열식별번호: 160의 아미노산 서열을 갖는 VH CDR3을 포함하고, 제1 경쇄는 서열식별번호: 166의 아미노산 서열을 갖는 VL CDR1, 서열식별번호: 25의 아미노산 서열을 갖는 VL CDR2 및 서열식별번호: 153의 아미노산 서열을 갖는 VL CDR3을 포함하거나;
(c) 제1 중쇄는 서열식별번호: 206의 아미노산 서열을 갖는 VH CDR1, 서열식별번호: 207의 아미노산 서열을 갖는 VH CDR2, 서열식별번호: 160의 아미노산 서열을 갖는 VH CDR3을 포함하고, 제1 경쇄는 서열식별번호: 166의 아미노산 서열을 갖는 VL CDR1, 서열식별번호: 25의 아미노산 서열을 갖는 VL CDR2 및 서열식별번호: 153의 아미노산 서열을 갖는 VL CDR3을 포함하거나;
(d) 제1 중쇄는 서열식별번호: 5의 아미노산 서열을 갖는 VH CDR1, 서열식별번호: 6의 아미노산 서열을 갖는 VH CDR2, 서열식별번호: 7의 아미노산 서열을 갖는 VH CDR3을 포함하고, 제1 경쇄는 서열식별번호: 9의 아미노산 서열을 갖는 VL CDR1, 서열식별번호: 10의 아미노산 서열을 갖는 VL CDR2 및 서열식별번호: 138의 아미노산 서열을 갖는 VL CDR3을 포함하거나;
(e) 제1 중쇄는 서열식별번호: 200의 아미노산 서열을 갖는 VH CDR1, 서열식별번호: 201의 아미노산 서열을 갖는 VH CDR2, 서열식별번호: 7의 아미노산 서열을 갖는 VH CDR3을 포함하고, 제1 경쇄는 서열식별번호: 9의 아미노산 서열을 갖는 VL CDR1, 서열식별번호: 10의 아미노산 서열을 갖는 VL CDR2 및 서열식별번호: 138의 아미노산 서열을 갖는 VL CDR3을 포함하거나;
(f) 제1 중쇄는 서열식별번호: 199의 아미노산 서열을 갖는 VH CDR1, 서열식별번호: 6의 아미노산 서열을 갖는 VH CDR2, 서열식별번호: 7의 아미노산 서열을 갖는 VH CDR3을 포함하고, 제1 경쇄는 서열식별번호: 9의 아미노산 서열을 갖는 VL CDR1, 서열식별번호: 10의 아미노산 서열을 갖는 VL CDR2 및 서열식별번호: 138의 아미노산 서열을 갖는 VL CDR3을 포함하거나;
(g) 제1 중쇄는 서열식별번호: 20의 아미노산 서열을 갖는 VH CDR1, 서열식별번호: 21의 아미노산 서열을 갖는 VH CDR2, 서열식별번호: 160의 아미노산 서열을 갖는 VH CDR3을 포함하고, 제1 경쇄는 서열식별번호: 152의 아미노산 서열을 갖는 VL CDR1, 서열식별번호: 41의 아미노산 서열을 갖는 VL CDR2 및 서열식별번호: 153의 아미노산 서열을 갖는 VL CDR3을 포함하거나;
(h) 제1 중쇄는 서열식별번호: 5의 아미노산 서열을 갖는 VH CDR1, 서열식별번호: 6의 아미노산 서열을 갖는 VH CDR2, 서열식별번호: 7의 아미노산 서열을 갖는 VH CDR3을 포함하고, 제1 경쇄는 서열식별번호: 9의 아미노산 서열을 갖는 VL CDR1, 서열식별번호: 10의 아미노산 서열을 갖는 VL CDR2 및 서열식별번호: 138의 아미노산 서열을 갖는 VL CDR3을 포함하거나; 또는
(i) 제1 중쇄는 서열식별번호: 5의 아미노산 서열을 갖는 VH CDR1, 서열식별번호: 130의 아미노산 서열을 갖는 VH CDR2, 서열식별번호: 7의 아미노산 서열을 갖는 VH CDR3을 포함하고, 제1 경쇄는 서열식별번호: 9의 아미노산 서열을 갖는 VL CDR1, 서열식별번호: 10의 아미노산 서열을 갖는 VL CDR2 및 서열식별번호: 138의 아미노산 서열을 갖는 VL CDR3을 포함하는 것인,
B7-H4 및 CD3 둘 다에 특이적으로 결합하는 이중특이적 항체. - 제26항에 있어서,
(a) 제1 중쇄가 서열식별번호: 161의 아미노산 서열을 갖는 VH를 포함하고, 제1 경쇄가 서열식별번호: 167의 아미노산 서열을 갖는 VL을 포함하거나;
(b) 제1 중쇄가 서열식별번호: 172의 아미노산 서열을 갖는 VH를 포함하고, 제1 경쇄가 서열식별번호: 139의 아미노산 서열을 갖는 VL을 포함하거나;
(c) 제1 중쇄가 서열식별번호: 155의 아미노산 서열을 갖는 VH를 포함하고; 제1 경쇄가 서열식별번호: 139의 아미노산 서열을 갖는 VL을 포함하거나;
(d) 제1 중쇄가 서열식별번호: 156의 아미노산 서열을 갖는 VH를 포함하고; 제1 경쇄가 서열식별번호: 139의 아미노산 서열을 갖는 VL을 포함하거나;
(e) 제1 중쇄가 서열식별번호: 157의 아미노산 서열을 갖는 VH를 포함하고; 제1 경쇄가 서열식별번호: 141의 아미노산 서열을 갖는 VL을 포함하거나;
(f) 제1 중쇄가 서열식별번호: 155의 아미노산 서열을 갖는 VH를 포함하고; 제1 경쇄가 서열식별번호: 141의 아미노산 서열을 갖는 VL을 포함하거나;
(g) 제1 중쇄가 서열식별번호: 156의 아미노산 서열을 갖는 VH를 포함하고; 제1 경쇄가 서열식별번호: 141의 아미노산 서열을 갖는 VL을 포함하거나;
(h) 제1 중쇄가 서열식별번호: 159의 아미노산 서열을 갖는 VH를 포함하고; 제1 경쇄가 서열식별번호: 27의 아미노산 서열을 갖는 VL을 포함하거나;
(i) 제1 중쇄가 서열식별번호: 161의 아미노산 서열을 갖는 VH를 포함하고; 제1 경쇄가 서열식별번호: 27의 아미노산 서열을 갖는 VL을 포함하거나;
(j) 제1 중쇄가 서열식별번호: 163의 아미노산 서열을 갖는 VH를 포함하고; 제1 경쇄가 서열식별번호: 27의 아미노산 서열을 갖는 VL을 포함하거나;
(k) 제1 중쇄가 서열식별번호: 165의 아미노산 서열을 갖는 VH를 포함하고; 제1 경쇄가 서열식별번호: 27의 아미노산 서열을 갖는 VL을 포함하거나;
(l) 제1 중쇄가 서열식별번호: 23의 아미노산 서열을 갖는 VH를 포함하고; 제1 경쇄가 서열식별번호: 167의 아미노산 서열을 갖는 VL을 포함하거나;
(m) 제1 중쇄가 서열식별번호: 171의 아미노산 서열을 갖는 VH를 포함하고; 제1 경쇄가 서열식별번호: 141의 아미노산 서열을 갖는 VL을 포함하거나;
(n) 제1 중쇄가 서열식별번호: 172의 아미노산 서열을 갖는 VH를 포함하고; 제1 경쇄가 서열식별번호: 141의 아미노산 서열을 갖는 VL을 포함하거나;
(o) 제1 중쇄가 서열식별번호: 171의 아미노산 서열을 갖는 VH를 포함하고; 제1 경쇄가 서열식별번호: 139의 아미노산 서열을 갖는 VL을 포함하거나;
(p) 제1 중쇄가 서열식별번호: 173의 아미노산 서열을 갖는 VH를 포함하고; 제1 경쇄가 서열식별번호: 139의 아미노산 서열을 갖는 VL을 포함하거나;
(q) 제1 중쇄가 서열식별번호: 174의 아미노산 서열을 갖는 VH를 포함하고; 제1 경쇄가 서열식별번호: 139의 아미노산 서열을 갖는 VL을 포함하거나;
(r) 제1 중쇄가 서열식별번호: 175의 아미노산 서열을 갖는 VH를 포함하고; 제1 경쇄가 서열식별번호: 139의 아미노산 서열을 갖는 VL을 포함하거나;
(s) 제1 중쇄가 서열식별번호: 161의 아미노산 서열을 갖는 VH; 및 서열식별번호: 168의 아미노산 서열을 갖는 VL을 포함하거나;
(t) 제1 중쇄가 서열식별번호: 161의 아미노산 서열을 갖는 VH를 포함하고; 제1 경쇄가 서열식별번호: 169의 아미노산 서열을 갖는 VL을 포함하거나;
(u) 제1 중쇄가 서열식별번호: 161의 아미노산 서열을 갖는 VH를 포함하고; 제1 경쇄가 서열식별번호: 170의 아미노산 서열을 갖는 VL을 포함하거나; 또는
(v) 제1 중쇄가 서열식별번호: 172의 아미노산 서열을 갖는 VH를 포함하고; 제1 경쇄가 서열식별번호: 139의 아미노산 서열을 갖는 VL을 포함하는 것인
이중특이적 항체. - 제26항 또는 제27항에 있어서,
(a) 제2 중쇄가 서열식별번호: 28의 아미노산 서열을 갖는 VH CDR1, 서열식별번호: 105의 아미노산 서열을 갖는 VH CDR2, 서열식별번호: 30의 아미노산 서열을 갖는 VH CDR3을 포함하고, 제2 경쇄가 서열식별번호: 107의 아미노산 서열을 갖는 VL CDR1, 서열식별번호: 33의 아미노산 서열을 갖는 VL CDR2 및 서열식별번호: 34의 아미노산 서열을 갖는 VL CDR3을 포함하거나;
(b) 제2 중쇄가 서열식별번호: 202의 아미노산 서열을 갖는 VH CDR1, 서열식별번호: 105의 아미노산 서열을 갖는 VH CDR2, 서열식별번호: 30의 아미노산 서열을 갖는 VH CDR3을 포함하고, 제2 경쇄가 서열식별번호: 107의 아미노산 서열을 갖는 VL CDR1, 서열식별번호: 33의 아미노산 서열을 갖는 VL CDR2 및 서열식별번호: 34의 아미노산 서열을 갖는 VL CDR3을 포함하거나;
(c) 제2 중쇄가 서열식별번호: 203의 아미노산 서열을 갖는 VH CDR1, 서열식별번호: 204의 아미노산 서열을 갖는 VH CDR2, 서열식별번호: 30의 아미노산 서열을 갖는 VH CDR3을 포함하고, 제2 경쇄가 서열식별번호: 107의 아미노산 서열을 갖는 VL CDR1, 서열식별번호: 33의 아미노산 서열을 갖는 VL CDR2 및 서열식별번호: 34의 아미노산 서열을 갖는 VL CDR3을 포함하거나;
(d) 제2 중쇄가 서열식별번호: 28의 아미노산 서열을 갖는 VH CDR1, 서열식별번호: 105의 아미노산 서열을 갖는 VH CDR2, 서열식별번호: 30의 아미노산 서열을 갖는 VH CDR3을 포함하고, 제2 경쇄가 서열식별번호: 107의 아미노산 서열을 갖는 VL CDR1, 서열식별번호: 33의 아미노산 서열을 갖는 VL CDR2 및 서열식별번호: 116의 아미노산 서열을 갖는 VL CDR3을 포함하거나;
(e) 제2 중쇄가 서열식별번호: 28의 아미노산 서열을 갖는 VH CDR1, 서열식별번호: 109의 아미노산 서열을 갖는 VH CDR2, 서열식별번호: 30의 아미노산 서열을 갖는 VH CDR3을 포함하고, 제2 경쇄가 서열식별번호: 111의 아미노산 서열을 갖는 VL CDR1, 서열식별번호: 112의 아미노산 서열을 갖는 VL CDR2 및 서열식별번호: 34의 아미노산 서열을 갖는 VL CDR3을 포함하거나; 또는
(f) 제2 중쇄가 서열식별번호: 28의 아미노산 서열을 갖는 VH CDR1, 서열식별번호: 29의 아미노산 서열을 갖는 VH CDR2, 서열식별번호: 30의 아미노산 서열을 갖는 VH CDR3을 포함하고, 제2 경쇄가 서열식별번호: 32의 아미노산 서열을 갖는 VL CDR1, 서열식별번호: 33의 아미노산 서열을 갖는 VL CDR2 및 서열식별번호: 34의 아미노산 서열을 갖는 VL CDR3을 포함하는 것인
이중특이적 항체. - 제26항 또는 제27항에 있어서,
(a) 제2 중쇄가 서열식별번호: 106의 아미노산 서열을 갖는 VH를 포함하고, 제2 경쇄가 서열식별번호: 108의 아미노산 서열을 갖는 VL을 포함하거나;
(b) 제2 중쇄가 서열식별번호: 115의 아미노산 서열을 갖는 VH를 포함하고, 제2 경쇄가 서열식별번호: 117의 아미노산 서열을 갖는 VL을 포함하거나;
(c) 제2 중쇄가 서열식별번호: 110의 아미노산 서열을 갖는 VH를 포함하고, 제2 경쇄가 서열식별번호: 113의 아미노산 서열을 갖는 VL을 포함하거나; 또는
(d) 제2 중쇄가 서열식별번호: 31의 아미노산 서열을 갖는 VH를 포함하고, 제2 경쇄가 서열식별번호: 35의 아미노산 서열을 갖는 VL을 포함하는 것인
이중특이적 항체. - 제26항에 있어서,
(a) 제1 중쇄가 서열식별번호: 20의 아미노산 서열을 갖는 VH CDR1, 서열식별번호: 21의 아미노산 서열을 갖는 VH CDR2, 서열식별번호: 160의 아미노산 서열을 갖는 VH CDR3을 포함하고, 제1 경쇄가 서열식별번호: 166의 아미노산 서열을 갖는 VL CDR1, 서열식별번호: 25의 아미노산 서열을 갖는 VL CDR2 및 서열식별번호: 153의 아미노산 서열을 갖는 VL CDR3을 포함하고;
(b) 제2 중쇄가 서열식별번호: 28의 아미노산 서열을 갖는 VH CDR1, 서열식별번호: 105의 아미노산 서열을 갖는 VH CDR2, 서열식별번호: 30의 아미노산 서열을 갖는 VH CDR3을 포함하고, 제2 경쇄가 서열식별번호: 107의 아미노산 서열을 갖는 VL CDR1, 서열식별번호: 33의 아미노산 서열을 갖는 VL CDR2 및 서열식별번호: 34의 아미노산 서열을 갖는 VL CDR3을 포함하는 것인
이중특이적 항체. - 제26항에 있어서,
(a) 제1 중쇄가 서열식별번호: 5의 아미노산 서열을 갖는 VH CDR1, 서열식별번호: 6의 아미노산 서열을 갖는 VH CDR2, 서열식별번호: 7의 아미노산 서열을 갖는 VH CDR3을 포함하고, 제1 경쇄가 서열식별번호: 9의 아미노산 서열을 갖는 VL CDR1, 서열식별번호: 10의 아미노산 서열을 갖는 VL CDR2 및 서열식별번호: 138의 아미노산 서열을 갖는 VL CDR3을 포함하고;
(b) 제2 중쇄가 서열식별번호: 28의 아미노산 서열을 갖는 VH CDR1, 서열식별번호: 105의 아미노산 서열을 갖는 VH CDR2, 서열식별번호: 30의 아미노산 서열을 갖는 VH CDR3을 포함하고, 제2 경쇄가 서열식별번호: 107의 아미노산 서열을 갖는 VL CDR1, 서열식별번호: 33의 아미노산 서열을 갖는 VL CDR2 및 서열식별번호: 34의 아미노산 서열을 갖는 VL CDR3을 포함하는 것인
이중특이적 항체. - 제26항에 있어서,
(a) 제1 중쇄가 서열식별번호: 161의 아미노산 서열을 갖는 VH를 포함하고, 제1 경쇄가 서열식별번호: 167의 아미노산 서열을 갖는 VL을 포함하고;
(b) 제2 중쇄가 서열식별번호: 106의 아미노산 서열을 갖는 VH를 포함하고, 제2 경쇄가 서열식별번호: 108의 아미노산 서열을 갖는 VL을 포함하는 것인
이중특이적 항체. - 제26항에 있어서,
(c) 제1 중쇄가 서열식별번호: 172의 아미노산 서열을 갖는 VH를 포함하고, 제1 경쇄가 서열식별번호: 139의 아미노산 서열을 갖는 VL을 포함하고;
(d) 제2 중쇄가 서열식별번호: 106의 아미노산 서열을 갖는 VH를 포함하고, 제2 경쇄가 서열식별번호: 108의 아미노산 서열을 갖는 VL을 포함하는 것인
이중특이적 항체. - 제26항 내지 제33항 중 어느 한 항에 있어서, 불변 영역을 추가로 포함하는 이중특이적 항체.
- 제34항에 있어서, 불변 영역이 IgG1인 이중특이적 항체.
- 제34항에 있어서, 불변 영역이 A330S, P331S, D265A, C223E, P228E, L368E, C223R, E225R, P228R 및 K409R로 이루어진 군으로부터 선택된 1개 이상의 치환을 포함하는 인간 IgG2이며, 여기서 넘버링은 인간 IgG2 야생형 및 EU 넘버링 스킴에 따르고, 도 1에 제시된 바와 같은 것인 이중특이적 항체.
- 제26항 내지 제34항 및 제36항 중 어느 한 항에 있어서, 제1 아암이 치환 D265A, C223E, P228E 및 L368E를 갖는 인간 IgG2ΔA 불변 영역을 추가로 포함하고, 제2 아암이 치환 D265A, C223R, E225R, P228R 및 K409R을 갖는 인간 IgG2ΔA 불변 영역을 추가로 포함하며, 여기서 넘버링은 인간 야생형 IgG2 및 EU 넘버링 스킴에 따르고, 도 1에 제시된 바와 같은 것인 이중특이적 항체.
- 제1 중쇄 및 제1 경쇄 및 제2 중쇄 및 제2 경쇄를 포함하며, 여기서 제1 중쇄 및 제1 경쇄는 B7-H4에 결합하는 제1 항원 결합 도메인을 포함하는 제1 항체 아암을 형성하고, 제2 중쇄 및 제2 경쇄는 CD3에 결합하는 제2 항원 결합 도메인을 형성하고, 여기서
(a) 제1 중쇄는 서열식별번호: 190의 아미노산 서열을 갖고; 제1 경쇄는 서열식별번호: 191의 아미노산 서열을 갖고;
(b) 제2 중쇄는 서열식별번호: 188의 아미노산 서열을 갖고; 제2 경쇄는 서열식별번호: 189의 아미노산 서열을 갖는 것인,
B7-H4 및 CD3 둘 다에 특이적으로 결합하는 이중특이적 항체. - 제1 중쇄 및 제1 경쇄 및 제2 중쇄 및 제2 경쇄를 포함하며, 여기서 제1 중쇄 및 제1 경쇄는 B7-H4에 결합하는 제1 항원 결합 도메인을 포함하는 제1 항체 아암을 형성하고, 제2 중쇄 및 제2 경쇄는 CD3에 결합하는 제2 항원 결합 도메인을 형성하고, 여기서
(a) 제1 중쇄는 서열식별번호: 186의 아미노산 서열을 갖고; 제1 경쇄는 서열식별번호: 187의 아미노산 서열을 갖고;
(b) 제2 중쇄는 서열식별번호: 188의 아미노산 서열을 갖고; 제2 경쇄는 서열식별번호: 189의 아미노산 서열을 갖는 것인,
B7-H4 및 CD3 둘 다에 특이적으로 결합하는 이중특이적 항체. - 제1 중쇄 및 제1 경쇄 및 제2 중쇄 및 제2 경쇄를 포함하며, 여기서 제1 중쇄 및 제1 경쇄는 B7-H4에 결합하는 제1 항원 결합 도메인을 포함하는 제1 항체 아암을 형성하고, 제2 중쇄 및 제2 경쇄는 CD3에 결합하는 제2 항원 결합 도메인을 형성하고, 여기서
(a) 제1 중쇄는 ATCC 수탁 번호 PTA-126779 하에 기탁된 오픈 리딩 프레임 (ORF)에 의해 코딩된 전장 폴리펩티드의 아미노산 서열을 포함하고, 제1 경쇄는 ATCC 수탁 번호 PTA-126781 하에 기탁된 오픈 리딩 프레임 (ORF)에 의해 코딩된 전장 폴리펩티드의 아미노산 서열을 포함하고;
(b) 제2 중쇄는 ATCC 수탁 번호 PTA-126780 하에 기탁된 오픈 리딩 프레임 (ORF)에 의해 코딩된 전장 폴리펩티드의 아미노산 서열을 포함하고, 제2 경쇄는 ATCC 수탁 번호 PTA-126782 하에 기탁된 오픈 리딩 프레임 (ORF)에 의해 코딩된 전장 폴리펩티드의 아미노산 서열을 포함하는 것인,
B7-H4 및 CD3에 특이적으로 결합하는 이중특이적 항체. - 서열식별번호: 1의 B7-H4 아미노산 서열의 L44, K45, E46, G47, V48, L49, G50, L51, S63, E64, D66, M68, T99 및 K101로 이루어진 군으로부터의 적어도 2개의 아미노산 잔기를 포함하는 인간 B7-H4 상의 에피토프에 결합하는, B7-H4 및 CD3 둘 다에 특이적으로 결합하는 이중특이적 항체.
- (i) 제26항 내지 제40항 중 어느 한 항의 항체의 중쇄 또는 (i) 제26항 내지 제40항 중 어느 한 항의 항체의 경쇄를 코딩하는 단리된 폴리뉴클레오티드 분자.
- 제42항의 폴리뉴클레오티드 분자를 포함하는 벡터.
- 제42항의 폴리뉴클레오티드 분자 또는 제43항의 벡터를 포함하는 숙주 세포.
- 제26항 내지 제40항 중 어느 한 항에 있어서, 의약으로서 사용하기 위한 이중특이적 항체.
- 제45항에 있어서, 의약이 암의 치료에 사용하기 위한 것인 이중특이적 항체.
- 암의 치료를 필요로 하는 대상체에게 제26항 내지 제40항 중 어느 한 항의 이중특이적 항체를 투여하는 것을 포함하는, 암의 치료를 필요로 하는 대상체에서 암을 치료하는 방법.
- 제26항 내지 제40항 중 어느 한 항의 이중특이적 항체를 포함하는 제약 조성물.
- B7-H4를 발현하는 악성 세포와 연관된 상태의 치료를 필요로 하는 대상체에게 치료 유효량의 제48항의 제약 조성물을 투여하는 것을 포함하는, 대상체에서 B7-H4를 발현하는 악성 세포와 연관된 상태를 치료하는 방법.
- 제49항에 있어서, 상태가 암인 방법.
- 제50항에 있어서, 암이 유방암, 난소암, 자궁암, 방광암 또는 담관암인 방법.
- 종양 성장 또는 진행의 억제를 필요로 하는, B7-H4를 발현하는 악성 세포를 갖는 대상체에게 치료 유효량의 제48항의 제약 조성물을 투여하는 것을 포함하는, B7-H4를 발현하는 악성 세포를 갖는 대상체에서 종양 성장 또는 진행을 억제하는 방법.
- 종양 퇴행의 유도를 필요로 하는, B7-H4를 발현하는 악성 세포를 갖는 대상체에게 유효량의 제48항의 제약 조성물을 투여하는 것을 포함하는, B7-H4를 발현하는 악성 세포를 갖는 대상체에서 종양 퇴행을 유도하는 방법.
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US202063053243P | 2020-07-17 | 2020-07-17 | |
| US63/053,243 | 2020-07-17 | ||
| PCT/IB2021/056346 WO2022013775A1 (en) | 2020-07-17 | 2021-07-14 | Therapeutic antibodies and their uses |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20230022246A true KR20230022246A (ko) | 2023-02-14 |
Family
ID=76971944
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020237001331A KR20230022246A (ko) | 2020-07-17 | 2021-07-14 | 치료 항체 및 그의 용도 |
Country Status (15)
| Country | Link |
|---|---|
| US (2) | US11840572B2 (ko) |
| EP (1) | EP4182346A1 (ko) |
| JP (1) | JP2023533793A (ko) |
| KR (1) | KR20230022246A (ko) |
| CN (1) | CN116323668A (ko) |
| AR (1) | AR122998A1 (ko) |
| AU (1) | AU2021308586A1 (ko) |
| BR (1) | BR112023000701A2 (ko) |
| CA (1) | CA3189590A1 (ko) |
| CO (1) | CO2023000529A2 (ko) |
| IL (1) | IL299939A (ko) |
| MX (1) | MX2023000662A (ko) |
| PE (1) | PE20231565A1 (ko) |
| TW (1) | TW202216779A (ko) |
| WO (1) | WO2022013775A1 (ko) |
Families Citing this family (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CR20230146A (es) * | 2020-09-11 | 2023-06-07 | Medimmune Ltd | Moléculas de unión a b7-h4 terapéuticas |
| CN112023062A (zh) * | 2020-09-18 | 2020-12-04 | 北京基因安科技有限公司 | 一个用可溶性IgE受体抑制过敏反应的方法 |
Family Cites Families (186)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US3773919A (en) | 1969-10-23 | 1973-11-20 | Du Pont | Polylactide-drug mixtures |
| FR2413974A1 (fr) | 1978-01-06 | 1979-08-03 | David Bernard | Sechoir pour feuilles imprimees par serigraphie |
| US4485045A (en) | 1981-07-06 | 1984-11-27 | Research Corporation | Synthetic phosphatidyl cholines useful in forming liposomes |
| US4816567A (en) | 1983-04-08 | 1989-03-28 | Genentech, Inc. | Recombinant immunoglobin preparations |
| US4544545A (en) | 1983-06-20 | 1985-10-01 | Trustees University Of Massachusetts | Liposomes containing modified cholesterol for organ targeting |
| IL73534A (en) | 1983-11-18 | 1990-12-23 | Riker Laboratories Inc | 1h-imidazo(4,5-c)quinoline-4-amines,their preparation and pharmaceutical compositions containing certain such compounds |
| US5807715A (en) | 1984-08-27 | 1998-09-15 | The Board Of Trustees Of The Leland Stanford Junior University | Methods and transformed mammalian lymphocyte cells for producing functional antigen-binding protein including chimeric immunoglobulin |
| US4754065A (en) | 1984-12-18 | 1988-06-28 | Cetus Corporation | Precursor to nucleic acid probe |
| US4683202A (en) | 1985-03-28 | 1987-07-28 | Cetus Corporation | Process for amplifying nucleic acid sequences |
| US4683195A (en) | 1986-01-30 | 1987-07-28 | Cetus Corporation | Process for amplifying, detecting, and/or-cloning nucleic acid sequences |
| US4676980A (en) | 1985-09-23 | 1987-06-30 | The United States Of America As Represented By The Secretary Of The Department Of Health And Human Services | Target specific cross-linked heteroantibodies |
| US4777127A (en) | 1985-09-30 | 1988-10-11 | Labsystems Oy | Human retrovirus-related products and methods of diagnosing and treating conditions associated with said retrovirus |
| GB8601597D0 (en) | 1986-01-23 | 1986-02-26 | Wilson R H | Nucleotide sequences |
| US4800159A (en) | 1986-02-07 | 1989-01-24 | Cetus Corporation | Process for amplifying, detecting, and/or cloning nucleic acid sequences |
| IL85035A0 (en) | 1987-01-08 | 1988-06-30 | Int Genetic Eng | Polynucleotide molecule,a chimeric antibody with specificity for human b cell surface antigen,a process for the preparation and methods utilizing the same |
| GB8702816D0 (en) | 1987-02-07 | 1987-03-11 | Al Sumidaie A M K | Obtaining retrovirus-containing fraction |
| US5219740A (en) | 1987-02-13 | 1993-06-15 | Fred Hutchinson Cancer Research Center | Retroviral gene transfer into diploid fibroblasts for gene therapy |
| US5422120A (en) | 1988-05-30 | 1995-06-06 | Depotech Corporation | Heterovesicular liposomes |
| AP129A (en) | 1988-06-03 | 1991-04-17 | Smithkline Biologicals S A | Expression of retrovirus gag protein eukaryotic cells |
| GB8823869D0 (en) | 1988-10-12 | 1988-11-16 | Medical Res Council | Production of antibodies |
| US5047335A (en) | 1988-12-21 | 1991-09-10 | The Regents Of The University Of Calif. | Process for controlling intracellular glycosylation of proteins |
| WO1990007936A1 (en) | 1989-01-23 | 1990-07-26 | Chiron Corporation | Recombinant therapies for infection and hyperproliferative disorders |
| US5756747A (en) | 1989-02-27 | 1998-05-26 | Riker Laboratories, Inc. | 1H-imidazo 4,5-c!quinolin-4-amines |
| US5703055A (en) | 1989-03-21 | 1997-12-30 | Wisconsin Alumni Research Foundation | Generation of antibodies through lipid mediated DNA delivery |
| DE69034078T2 (de) | 1989-03-21 | 2004-04-01 | Vical, Inc., San Diego | Expression von exogenen Polynukleotidsequenzen in Wirbeltieren |
| US6673776B1 (en) | 1989-03-21 | 2004-01-06 | Vical Incorporated | Expression of exogenous polynucleotide sequences in a vertebrate, mammal, fish, bird or human |
| US4929624A (en) | 1989-03-23 | 1990-05-29 | Minnesota Mining And Manufacturing Company | Olefinic 1H-imidazo(4,5-c)quinolin-4-amines |
| DE69029036T2 (de) | 1989-06-29 | 1997-05-22 | Medarex Inc | Bispezifische reagenzien für die aids-therapie |
| EP1645635A3 (en) | 1989-08-18 | 2010-07-07 | Oxford Biomedica (UK) Limited | Replication defective recombinant retroviruses expressing a palliative |
| US5585362A (en) | 1989-08-22 | 1996-12-17 | The Regents Of The University Of Michigan | Adenovirus vectors for gene therapy |
| US5013556A (en) | 1989-10-20 | 1991-05-07 | Liposome Technology, Inc. | Liposomes with enhanced circulation time |
| NZ237464A (en) | 1990-03-21 | 1995-02-24 | Depotech Corp | Liposomes with at least two separate chambers encapsulating two separate biologically active substances |
| US5427908A (en) | 1990-05-01 | 1995-06-27 | Affymax Technologies N.V. | Recombinant library screening methods |
| CA2086417C (en) | 1990-06-29 | 1999-07-06 | Biosource Technologies, Inc. | Melanin production by transformed organisms |
| US5661016A (en) | 1990-08-29 | 1997-08-26 | Genpharm International Inc. | Transgenic non-human animals capable of producing heterologous antibodies of various isotypes |
| ATE158021T1 (de) | 1990-08-29 | 1997-09-15 | Genpharm Int | Produktion und nützung nicht-menschliche transgentiere zur produktion heterologe antikörper |
| US5633425A (en) | 1990-08-29 | 1997-05-27 | Genpharm International, Inc. | Transgenic non-human animals capable of producing heterologous antibodies |
| US5545806A (en) | 1990-08-29 | 1996-08-13 | Genpharm International, Inc. | Ransgenic non-human animals for producing heterologous antibodies |
| US5625126A (en) | 1990-08-29 | 1997-04-29 | Genpharm International, Inc. | Transgenic non-human animals for producing heterologous antibodies |
| DK0564531T3 (da) | 1990-12-03 | 1998-09-28 | Genentech Inc | Berigelsesfremgangsmåde for variantproteiner med ændrede bindingsegenskaber |
| US5389640A (en) | 1991-03-01 | 1995-02-14 | Minnesota Mining And Manufacturing Company | 1-substituted, 2-substituted 1H-imidazo[4,5-c]quinolin-4-amines |
| US5278299A (en) | 1991-03-18 | 1994-01-11 | Scripps Clinic And Research Foundation | Method and composition for synthesizing sialylated glycosyl compounds |
| WO1992022653A1 (en) | 1991-06-14 | 1992-12-23 | Genentech, Inc. | Method for making humanized antibodies |
| GB9115364D0 (en) | 1991-07-16 | 1991-08-28 | Wellcome Found | Antibody |
| DE69233013T2 (de) | 1991-08-20 | 2004-03-04 | The Government Of The United States Of America As Represented By The Secretary Of National Institute Of Health, Office Of Technology Transfer | Adenovirus vermittelter gentransfer in den gastrointestinaltrakt |
| US5268376A (en) | 1991-09-04 | 1993-12-07 | Minnesota Mining And Manufacturing Company | 1-substituted 1H-imidazo[4,5-c]quinolin-4-amines |
| CA2078539C (en) | 1991-09-18 | 2005-08-02 | Kenya Shitara | Process for producing humanized chimera antibody |
| WO1993006213A1 (en) | 1991-09-23 | 1993-04-01 | Medical Research Council | Production of chimeric antibodies - a combinatorial approach |
| ES2136092T3 (es) | 1991-09-23 | 1999-11-16 | Medical Res Council | Procedimientos para la produccion de anticuerpos humanizados. |
| US5266575A (en) | 1991-11-06 | 1993-11-30 | Minnesota Mining And Manufacturing Company | 2-ethyl 1H-imidazo[4,5-ciquinolin-4-amines |
| WO1993010218A1 (en) | 1991-11-14 | 1993-05-27 | The United States Government As Represented By The Secretary Of The Department Of Health And Human Services | Vectors including foreign genes and negative selective markers |
| WO1993010260A1 (en) | 1991-11-21 | 1993-05-27 | The Board Of Trustees Of The Leland Stanford Junior University | Controlling degradation of glycoprotein oligosaccharides by extracellular glycosisases |
| GB9125623D0 (en) | 1991-12-02 | 1992-01-29 | Dynal As | Cell modification |
| FR2688514A1 (fr) | 1992-03-16 | 1993-09-17 | Centre Nat Rech Scient | Adenovirus recombinants defectifs exprimant des cytokines et medicaments antitumoraux les contenant. |
| US5733743A (en) | 1992-03-24 | 1998-03-31 | Cambridge Antibody Technology Limited | Methods for producing members of specific binding pairs |
| JPH07507689A (ja) | 1992-06-08 | 1995-08-31 | ザ リージェンツ オブ ザ ユニバーシティ オブ カリフォルニア | 特定組織のターゲティング方法及び組成物 |
| EP0644946A4 (en) | 1992-06-10 | 1997-03-12 | Us Health | VECTOR PARTICLES RESISTANT TO HUMAN SERUM INACTIVATION. |
| GB2269175A (en) | 1992-07-31 | 1994-02-02 | Imperial College | Retroviral vectors |
| WO1994004690A1 (en) | 1992-08-17 | 1994-03-03 | Genentech, Inc. | Bispecific immunoadhesins |
| WO1994012649A2 (en) | 1992-12-03 | 1994-06-09 | Genzyme Corporation | Gene therapy for cystic fibrosis |
| US5981568A (en) | 1993-01-28 | 1999-11-09 | Neorx Corporation | Therapeutic inhibitor of vascular smooth muscle cells |
| DK0695169T3 (da) | 1993-04-22 | 2003-03-17 | Skyepharma Inc | Multivesikulære liposomer med indkapslet cyclodextrin og farmakologisk aktive forbindelser samt fremgangsmåder til anvendelse af disse |
| CA2166118C (en) | 1993-06-24 | 2007-04-17 | Frank L. Graham | Adenovirus vectors for gene therapy |
| JPH09500128A (ja) | 1993-07-15 | 1997-01-07 | ミネソタ マイニング アンド マニュファクチャリング カンパニー | イミダゾ〔4,5−c〕ピリジン−4−アミン |
| US5352784A (en) | 1993-07-15 | 1994-10-04 | Minnesota Mining And Manufacturing Company | Fused cycloalkylimidazopyridines |
| US6015686A (en) | 1993-09-15 | 2000-01-18 | Chiron Viagene, Inc. | Eukaryotic layered vector initiation systems |
| DE69435224D1 (de) | 1993-09-15 | 2009-09-10 | Novartis Vaccines & Diagnostic | Rekombinante Alphavirus-Vektoren |
| PT797676E (pt) | 1993-10-25 | 2006-05-31 | Canji Inc | Vector adenoviral recombinante e metodos de utilizacao |
| RU2160093C2 (ru) | 1993-11-16 | 2000-12-10 | Скайефарма Инк. | Везикулы с регулируемым высвобождением активных ингредиентов |
| US6436908B1 (en) | 1995-05-30 | 2002-08-20 | Duke University | Use of exogenous β-adrenergic receptor and β-adrenergic receptor kinase gene constructs to enhance myocardial function |
| CA2158977A1 (en) | 1994-05-09 | 1995-11-10 | James G. Respess | Retroviral vectors having a reduced recombination rate |
| US6207646B1 (en) | 1994-07-15 | 2001-03-27 | University Of Iowa Research Foundation | Immunostimulatory nucleic acid molecules |
| US6239116B1 (en) | 1994-07-15 | 2001-05-29 | University Of Iowa Research Foundation | Immunostimulatory nucleic acid molecules |
| EP1167377B2 (en) | 1994-07-15 | 2012-08-08 | University of Iowa Research Foundation | Immunomodulatory oligonucleotides |
| AU4594996A (en) | 1994-11-30 | 1996-06-19 | Chiron Viagene, Inc. | Recombinant alphavirus vectors |
| US5482936A (en) | 1995-01-12 | 1996-01-09 | Minnesota Mining And Manufacturing Company | Imidazo[4,5-C]quinoline amines |
| US6265150B1 (en) | 1995-06-07 | 2001-07-24 | Becton Dickinson & Company | Phage antibodies |
| WO1997042338A1 (en) | 1996-05-06 | 1997-11-13 | Chiron Corporation | Crossless retroviral vectors |
| WO1998001448A1 (fr) | 1996-07-03 | 1998-01-15 | Japan Energy Corporation | Nouveaux derives de purine |
| US6387938B1 (en) | 1996-07-05 | 2002-05-14 | Mochida Pharmaceutical Co., Ltd. | Benzimidazole derivatives |
| US6069149A (en) | 1997-01-09 | 2000-05-30 | Terumo Kabushiki Kaisha | Amide derivatives and intermediates for the synthesis thereof |
| US6406705B1 (en) | 1997-03-10 | 2002-06-18 | University Of Iowa Research Foundation | Use of nucleic acids containing unmethylated CpG dinucleotide as an adjuvant |
| US6426334B1 (en) | 1997-04-30 | 2002-07-30 | Hybridon, Inc. | Oligonucleotide mediated specific cytokine induction and reduction of tumor growth in a mammal |
| US6303347B1 (en) | 1997-05-08 | 2001-10-16 | Corixa Corporation | Aminoalkyl glucosaminide phosphate compounds and their use as adjuvants and immunoeffectors |
| US6113918A (en) | 1997-05-08 | 2000-09-05 | Ribi Immunochem Research, Inc. | Aminoalkyl glucosamine phosphate compounds and their use as adjuvants and immunoeffectors |
| DE69838294T2 (de) | 1997-05-20 | 2009-08-13 | Ottawa Health Research Institute, Ottawa | Verfahren zur Herstellung von Nukleinsäurekonstrukten |
| WO1999018792A1 (en) | 1997-10-10 | 1999-04-22 | Johns Hopkins University | Gene delivery compositions and methods |
| NZ504800A (en) | 1997-11-28 | 2001-10-26 | Sumitomo Pharma | 6-Amino-9-benzyl-8-hydroxy-purine derivatives and interferon inducers, antiviral agents, anticancer agents and therapeutic agents for immunologic diseases thereof |
| UA67760C2 (uk) | 1997-12-11 | 2004-07-15 | Міннесота Майнінг Енд Мануфакчурінг Компані | Імідазонафтиридин та тетрагідроімідазонафтиридин, фармацевтична композиція, спосіб індукування біосинтезу цитокінів та спосіб лікування вірусної інфекції, проміжні сполуки |
| TW572758B (en) | 1997-12-22 | 2004-01-21 | Sumitomo Pharma | Type 2 helper T cell-selective immune response inhibitors comprising purine derivatives |
| GB9809951D0 (en) | 1998-05-08 | 1998-07-08 | Univ Cambridge Tech | Binding molecules |
| US6110929A (en) | 1998-07-28 | 2000-08-29 | 3M Innovative Properties Company | Oxazolo, thiazolo and selenazolo [4,5-c]-quinolin-4-amines and analogs thereof |
| JP2000119271A (ja) | 1998-08-12 | 2000-04-25 | Hokuriku Seiyaku Co Ltd | 1h―イミダゾピリジン誘導体 |
| AU770555B2 (en) | 1998-08-17 | 2004-02-26 | Abgenix, Inc. | Generation of modified molecules with increased serum half-lives |
| US6737056B1 (en) | 1999-01-15 | 2004-05-18 | Genentech, Inc. | Polypeptide variants with altered effector function |
| AU3734900A (en) | 1999-03-09 | 2000-09-28 | University Of Southern California | Method of promoting myocyte proliferation and myocardial tissue repair |
| CA2376634A1 (en) | 1999-06-08 | 2000-12-14 | Aventis Pasteur | Immunostimulant oligonucleotide |
| US6541485B1 (en) | 1999-06-10 | 2003-04-01 | 3M Innovative Properties Company | Urea substituted imidazoquinolines |
| US6756382B2 (en) | 1999-06-10 | 2004-06-29 | 3M Innovative Properties Company | Amide substituted imidazoquinolines |
| US6331539B1 (en) | 1999-06-10 | 2001-12-18 | 3M Innovative Properties Company | Sulfonamide and sulfamide substituted imidazoquinolines |
| US6451810B1 (en) | 1999-06-10 | 2002-09-17 | 3M Innovative Properties Company | Amide substituted imidazoquinolines |
| US6573273B1 (en) | 1999-06-10 | 2003-06-03 | 3M Innovative Properties Company | Urea substituted imidazoquinolines |
| AU783745B2 (en) | 1999-08-13 | 2005-12-01 | Hybridon, Inc. | Modulation of oligonucleotide CpG-mediated immune stimulation by positional modification of nucleosides |
| US6376669B1 (en) | 1999-11-05 | 2002-04-23 | 3M Innovative Properties Company | Dye labeled imidazoquinoline compounds |
| AU2001245823A1 (en) | 2000-03-17 | 2001-10-03 | Corixa Corporation | Novel amphipathic aldehydes and their use as adjuvants and immunoeffectors |
| US6651132B1 (en) | 2000-07-17 | 2003-11-18 | Microsoft Corporation | System and method for emulating the operation of a translation look-aside buffer |
| US6664260B2 (en) | 2000-12-08 | 2003-12-16 | 3M Innovative Properties Company | Heterocyclic ether substituted imidazoquinolines |
| US6525064B1 (en) | 2000-12-08 | 2003-02-25 | 3M Innovative Properties Company | Sulfonamido substituted imidazopyridines |
| US6545016B1 (en) | 2000-12-08 | 2003-04-08 | 3M Innovative Properties Company | Amide substituted imidazopyridines |
| US6545017B1 (en) | 2000-12-08 | 2003-04-08 | 3M Innovative Properties Company | Urea substituted imidazopyridines |
| US6660735B2 (en) | 2000-12-08 | 2003-12-09 | 3M Innovative Properties Company | Urea substituted imidazoquinoline ethers |
| US6677348B2 (en) | 2000-12-08 | 2004-01-13 | 3M Innovative Properties Company | Aryl ether substituted imidazoquinolines |
| US6677347B2 (en) | 2000-12-08 | 2004-01-13 | 3M Innovative Properties Company | Sulfonamido ether substituted imidazoquinolines |
| US6664264B2 (en) | 2000-12-08 | 2003-12-16 | 3M Innovative Properties Company | Thioether substituted imidazoquinolines |
| UA74852C2 (en) | 2000-12-08 | 2006-02-15 | 3M Innovative Properties Co | Urea-substituted imidazoquinoline ethers |
| US6667312B2 (en) | 2000-12-08 | 2003-12-23 | 3M Innovative Properties Company | Thioether substituted imidazoquinolines |
| US6660747B2 (en) | 2000-12-08 | 2003-12-09 | 3M Innovative Properties Company | Amido ether substituted imidazoquinolines |
| US6664265B2 (en) | 2000-12-08 | 2003-12-16 | 3M Innovative Properties Company | Amido ether substituted imidazoquinolines |
| JP4493337B2 (ja) | 2001-11-27 | 2010-06-30 | アナディス ファーマシューティカルズ インク | 3−β−D−リボフラノシルチアゾロ[4,5−d]ピリミジンヌクレオシド及びその使用 |
| US6677349B1 (en) | 2001-12-21 | 2004-01-13 | 3M Innovative Properties Company | Sulfonamide and sulfamide substituted imidazoquinolines |
| US6525028B1 (en) | 2002-02-04 | 2003-02-25 | Corixa Corporation | Immunoeffector compounds |
| AU2003237386A1 (en) | 2002-06-07 | 2003-12-22 | 3M Innovative Properties Company | Ether substituted imidazopyridines |
| WO2004032829A2 (en) | 2002-08-15 | 2004-04-22 | 3M Innovative Properties Company | Immunostimulatory compositions and methods of stimulating an immune response |
| US6818650B2 (en) | 2002-09-26 | 2004-11-16 | 3M Innovative Properties Company | 1H-imidazo dimers |
| EP1590348A1 (en) | 2002-12-20 | 2005-11-02 | 3M Innovative Properties Company | Aryl / hetaryl substituted imidazoquinolines |
| EP1575517B1 (en) | 2002-12-24 | 2012-04-11 | Rinat Neuroscience Corp. | Anti-ngf antibodies and methods using same |
| CA2517655A1 (en) | 2003-03-07 | 2004-09-23 | 3M Innovative Properties Company | 1-amino 1h-imidazoquinolines |
| ES2423800T3 (es) | 2003-03-28 | 2013-09-24 | Novartis Vaccines And Diagnostics, Inc. | Uso de compuestos orgánicos para la inmunopotenciación |
| WO2005018556A2 (en) | 2003-08-12 | 2005-03-03 | 3M Innovative Properties Company | Hydroxylamine substituted imidazo-containing compounds |
| ES2406730T3 (es) | 2003-08-27 | 2013-06-07 | 3M Innovative Properties Company | Imidazoquinolinas sustituidas con ariloxi y arilalquilenoxi |
| AR045563A1 (es) | 2003-09-10 | 2005-11-02 | Warner Lambert Co | Anticuerpos dirigidos a m-csf |
| CA2540598C (en) | 2003-10-03 | 2013-09-24 | 3M Innovative Properties Company | Pyrazolopyridines and analogs thereof |
| US7544697B2 (en) | 2003-10-03 | 2009-06-09 | Coley Pharmaceutical Group, Inc. | Pyrazolopyridines and analogs thereof |
| CA2540541C (en) | 2003-10-03 | 2012-03-27 | 3M Innovative Properties Company | Alkoxy substituted imidazoquinolines |
| EP1685129A4 (en) | 2003-11-14 | 2008-10-22 | 3M Innovative Properties Co | OXIMSUBSTITUTED IMIDAZORING CONNECTIONS |
| WO2005048945A2 (en) | 2003-11-14 | 2005-06-02 | 3M Innovative Properties Company | Hydroxylamine substituted imidazo ring compounds |
| EP1686992A4 (en) | 2003-11-25 | 2009-11-04 | 3M Innovative Properties Co | HYDROXYLAMINE, AND IMIDAZOQUINOLEINS, AND IMIDAZOPYRIDINES AND IMIDAZONAPHTYRIDINE SUBSTITUTED WITH OXIME |
| JP4891088B2 (ja) | 2003-11-25 | 2012-03-07 | スリーエム イノベイティブ プロパティズ カンパニー | 置換されたイミダゾ環系および方法 |
| AR048289A1 (es) | 2003-12-04 | 2006-04-19 | 3M Innovative Properties Co | Eteres de anillos imidazo sulfona sustituidos. |
| WO2005066172A1 (en) | 2003-12-29 | 2005-07-21 | 3M Innovative Properties Company | Piperazine, [1,4]diazepane, [1,4]diazocane, and [1,5]diazocane fused imidazo ring compounds |
| JP2007517035A (ja) | 2003-12-29 | 2007-06-28 | スリーエム イノベイティブ プロパティズ カンパニー | アリールアルケニルおよびアリールアルキニル置換されたイミダゾキノリン |
| CA2551399A1 (en) | 2003-12-30 | 2005-07-21 | 3M Innovative Properties Company | Imidazoquinolinyl, imidazopyridinyl, and imidazonaphthyridinyl sulfonamides |
| CA2559863A1 (en) | 2004-03-24 | 2005-10-13 | 3M Innovative Properties Company | Amide substituted imidazopyridines, imidazoquinolines, and imidazonaphthyridines |
| US20080015184A1 (en) | 2004-06-14 | 2008-01-17 | 3M Innovative Properties Company | Urea Substituted Imidazopyridines, Imidazoquinolines, and Imidazonaphthyridines |
| US8017779B2 (en) | 2004-06-15 | 2011-09-13 | 3M Innovative Properties Company | Nitrogen containing heterocyclyl substituted imidazoquinolines and imidazonaphthyridines |
| WO2006009832A1 (en) | 2004-06-18 | 2006-01-26 | 3M Innovative Properties Company | Substituted imidazo ring systems and methods |
| US8026366B2 (en) | 2004-06-18 | 2011-09-27 | 3M Innovative Properties Company | Aryloxy and arylalkyleneoxy substituted thiazoloquinolines and thiazolonaphthyridines |
| JP5128940B2 (ja) | 2004-06-18 | 2013-01-23 | スリーエム イノベイティブ プロパティズ カンパニー | 置換イミダゾキノリン、イミダゾピリジン、およびイミダゾナフチリジン |
| US20070259907A1 (en) | 2004-06-18 | 2007-11-08 | Prince Ryan B | Aryl and arylalkylenyl substituted thiazoloquinolines and thiazolonaphthyridines |
| US7915281B2 (en) | 2004-06-18 | 2011-03-29 | 3M Innovative Properties Company | Isoxazole, dihydroisoxazole, and oxadiazole substituted imidazo ring compounds and method |
| WO2006038923A2 (en) | 2004-06-18 | 2006-04-13 | 3M Innovative Properties Company | Aryl substituted imidazonaphthyridines |
| WO2006026760A2 (en) | 2004-09-02 | 2006-03-09 | 3M Innovative Properties Company | 1-amino imidazo-containing compounds and methods |
| WO2006029115A2 (en) | 2004-09-02 | 2006-03-16 | 3M Innovative Properties Company | 2-amino 1h imidazo ring systems and methods |
| JP5209312B2 (ja) | 2004-09-02 | 2013-06-12 | スリーエム イノベイティブ プロパティズ カンパニー | 1−アルコキシ1h−イミダゾ環系および方法 |
| WO2006028451A1 (en) | 2004-09-03 | 2006-03-16 | 3M Innovative Properties Company | 1-amino 1-h-imidazoquinolines |
| AU2005326708C1 (en) | 2004-12-30 | 2012-08-30 | 3M Innovative Properties Company | Substituted chiral fused [1,2]imidazo[4,5-c] ring compounds |
| AU2005322898B2 (en) | 2004-12-30 | 2011-11-24 | 3M Innovative Properties Company | Chiral fused (1,2)imidazo(4,5-c) ring compounds |
| US20080318998A1 (en) | 2005-02-09 | 2008-12-25 | Coley Pharmaceutical Group, Inc. | Alkyloxy Substituted Thiazoloquinolines and Thiazolonaphthyridines |
| WO2006086634A2 (en) | 2005-02-11 | 2006-08-17 | Coley Pharmaceutical Group, Inc. | Oxime and hydroxylamine substituted imidazo[4,5-c] ring compounds and methods |
| US8093390B2 (en) | 2005-02-11 | 2012-01-10 | 3M Innovative Properties Company | Substituted fused [1,2]imidazo[4,5-C] ring compounds and methods |
| US8658666B2 (en) | 2005-02-11 | 2014-02-25 | 3M Innovative Properties Company | Substituted imidazoquinolines and imidazonaphthyridines |
| AU2006216798A1 (en) | 2005-02-23 | 2006-08-31 | Coley Pharmaceutical Group, Inc. | Hydroxyalkyl substituted imidazoquinoline compounds and methods |
| JP2008538203A (ja) | 2005-02-23 | 2008-10-16 | コーリー ファーマシューティカル グループ,インコーポレイテッド | インターフェロンの生合成を優先的に誘導する方法 |
| EP1851224A2 (en) | 2005-02-23 | 2007-11-07 | 3M Innovative Properties Company | Hydroxyalkyl substituted imidazoquinolines |
| CA2598639A1 (en) | 2005-02-23 | 2006-08-31 | Coley Pharmaceutical Group, Inc. | Hydroxyalkyl substituted imidazonaphthyridines |
| US7314622B2 (en) | 2005-04-15 | 2008-01-01 | Neogenix Oncology, Inc. | Recombinant monoclonal antibodies and corresponding antigens for colon and pancreatic cancers |
| JP5761997B2 (ja) | 2007-12-14 | 2015-08-12 | ブリストル−マイヤーズ・スクイブ・カンパニー | ヒトox40受容体に対する結合分子 |
| EP2955221A1 (en) | 2009-11-04 | 2015-12-16 | DSM IP Assets B.V. | Talaromyces transformants |
| JP6022444B2 (ja) | 2010-05-14 | 2016-11-09 | ライナット ニューロサイエンス コーポレイション | ヘテロ二量体タンパク質ならびにそれを生産および精製するための方法 |
| CA2813411C (en) | 2010-11-05 | 2016-08-02 | Rinat Neuroscience Corporation | Engineered polypeptide conjugates and methods for making thereof using transglutaminase |
| SA112330278B1 (ar) | 2011-02-18 | 2015-10-09 | ستيم سينتركس، انك. | مواد ضابطة جديدة وطرق للاستخدام |
| JP6192233B2 (ja) | 2011-11-17 | 2017-09-06 | ファイザー・インク | 細胞毒性ペプチドおよびその抗体薬物コンジュゲート |
| JP6436965B2 (ja) * | 2013-03-14 | 2018-12-12 | ジェネンテック, インコーポレイテッド | 抗b7−h4抗体及びイムノコンジュゲート |
| JP6521959B2 (ja) | 2013-07-31 | 2019-05-29 | ライナット ニューロサイエンス コーポレイション | 操作されたポリペプチドコンジュゲート |
| AU2015283704A1 (en) | 2014-07-01 | 2016-12-15 | Pfizer Inc. | Bispecific heterodimeric diabodies and uses thereof |
| EP3191518B1 (en) * | 2014-09-12 | 2020-01-15 | Genentech, Inc. | Anti-b7-h4 antibodies and immunoconjugates |
| TWI595006B (zh) | 2014-12-09 | 2017-08-11 | 禮納特神經系統科學公司 | 抗pd-1抗體類和使用彼等之方法 |
| PE20221262A1 (es) | 2015-04-13 | 2022-08-16 | Pfizer | Anticuerpos terapeuticos y sus usos |
| CN109563503B (zh) * | 2016-07-26 | 2023-09-29 | 静冈县 | 抗b7-h4抗体 |
| US11932694B2 (en) * | 2017-04-19 | 2024-03-19 | Bluefin Biomedicine, Inc. | Anti-VTCN1 antibodies and antibody drug conjugates |
| AU2018277838A1 (en) | 2017-05-31 | 2019-12-19 | Stcube & Co., Inc. | Antibodies and molecules that immunospecifically bind to BTN1A1 and the therapeutic uses thereof |
| JP7234142B2 (ja) | 2017-06-02 | 2023-03-07 | ファイザー・インク | Flt3に特異的な抗体およびその使用 |
| UA128472C2 (uk) * | 2017-08-25 | 2024-07-24 | Файв Прайм Терапеутікс Інк. | B7-h4 антитіла і методи їх використання |
| KR20200115596A (ko) * | 2018-02-01 | 2020-10-07 | 화이자 인코포레이티드 | Cd70에 특이적인 항체 및 이의 용도 |
| SG11202010580TA (en) * | 2018-05-23 | 2020-12-30 | Pfizer | Antibodies specific for cd3 and uses thereof |
| KR102584675B1 (ko) * | 2018-05-23 | 2023-10-05 | 화이자 인코포레이티드 | GUCY2c에 특이적인 항체 및 이의 용도 |
-
2021
- 2021-07-14 KR KR1020237001331A patent/KR20230022246A/ko not_active Application Discontinuation
- 2021-07-14 TW TW110125857A patent/TW202216779A/zh unknown
- 2021-07-14 AU AU2021308586A patent/AU2021308586A1/en active Pending
- 2021-07-14 MX MX2023000662A patent/MX2023000662A/es unknown
- 2021-07-14 CA CA3189590A patent/CA3189590A1/en active Pending
- 2021-07-14 EP EP21743260.8A patent/EP4182346A1/en active Pending
- 2021-07-14 CN CN202180060839.2A patent/CN116323668A/zh active Pending
- 2021-07-14 PE PE2023000089A patent/PE20231565A1/es unknown
- 2021-07-14 WO PCT/IB2021/056346 patent/WO2022013775A1/en active Application Filing
- 2021-07-14 IL IL299939A patent/IL299939A/en unknown
- 2021-07-14 JP JP2023502582A patent/JP2023533793A/ja active Pending
- 2021-07-14 BR BR112023000701A patent/BR112023000701A2/pt not_active Application Discontinuation
- 2021-07-16 US US17/378,377 patent/US11840572B2/en active Active
- 2021-07-16 AR ARP210102013A patent/AR122998A1/es unknown
-
2023
- 2023-01-17 CO CONC2023/0000529A patent/CO2023000529A2/es unknown
- 2023-08-15 US US18/449,867 patent/US20240018244A1/en not_active Abandoned
Also Published As
| Publication number | Publication date |
|---|---|
| AU2021308586A1 (en) | 2023-03-02 |
| US20240018244A1 (en) | 2024-01-18 |
| IL299939A (en) | 2023-03-01 |
| US11840572B2 (en) | 2023-12-12 |
| JP2023533793A (ja) | 2023-08-04 |
| MX2023000662A (es) | 2023-02-27 |
| CA3189590A1 (en) | 2022-01-20 |
| PE20231565A1 (es) | 2023-10-04 |
| BR112023000701A2 (pt) | 2023-02-07 |
| CN116323668A (zh) | 2023-06-23 |
| TW202216779A (zh) | 2022-05-01 |
| WO2022013775A1 (en) | 2022-01-20 |
| AR122998A1 (es) | 2022-10-19 |
| EP4182346A1 (en) | 2023-05-24 |
| CO2023000529A2 (es) | 2023-01-26 |
| US20220017622A1 (en) | 2022-01-20 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11525010B2 (en) | Antibodies specific for GUCY2c and uses thereof | |
| KR102493282B1 (ko) | Tim3에 대한 항체 및 그의 용도 | |
| US11434292B2 (en) | Antibodies specific for CD3 and uses thereof | |
| US20240018244A1 (en) | Therapeutic antibodies and their uses | |
| KR20200092976A (ko) | 항-cd137 항체 및 이의 용도 | |
| KR20200108870A (ko) | Tim3에 대한 항체 및 그의 용도 | |
| US20230192839A1 (en) | Antibodies having conditional affinity and methods of use thereof | |
| JP2024528682A (ja) | 薬物組成物及び用途 | |
| KR20230107478A (ko) | 치료 항체 및 그의 용도 | |
| RU2780537C2 (ru) | Cd3-специфические антитела и их применение | |
| JP2023100255A (ja) | 治療用抗体およびそれらの使用 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| WITB | Written withdrawal of application |