CN112996805A - 多链嵌合多肽和其用途 - Google Patents
多链嵌合多肽和其用途 Download PDFInfo
- Publication number
- CN112996805A CN112996805A CN201980070927.3A CN201980070927A CN112996805A CN 112996805 A CN112996805 A CN 112996805A CN 201980070927 A CN201980070927 A CN 201980070927A CN 112996805 A CN112996805 A CN 112996805A
- Authority
- CN
- China
- Prior art keywords
- amino acids
- chimeric polypeptide
- domain
- soluble
- cells
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
- 108090000765 processed proteins & peptides Proteins 0.000 title claims abstract description 203
- 229920001184 polypeptide Polymers 0.000 title claims abstract description 199
- 102000004196 processed proteins & peptides Human genes 0.000 title claims abstract description 199
- 230000027455 binding Effects 0.000 claims abstract description 207
- 108010000499 Thromboplastin Proteins 0.000 claims abstract description 125
- 238000000034 method Methods 0.000 claims abstract description 90
- 102000039446 nucleic acids Human genes 0.000 claims abstract description 18
- 108020004707 nucleic acids Proteins 0.000 claims abstract description 18
- 150000007523 nucleic acids Chemical class 0.000 claims abstract description 18
- 102100030859 Tissue factor Human genes 0.000 claims description 125
- 210000004027 cell Anatomy 0.000 claims description 57
- 108090000172 Interleukin-15 Proteins 0.000 claims description 56
- 102000003812 Interleukin-15 Human genes 0.000 claims description 56
- 101000635804 Homo sapiens Tissue factor Proteins 0.000 claims description 49
- 210000002865 immune cell Anatomy 0.000 claims description 47
- 239000000427 antigen Substances 0.000 claims description 42
- 108091007433 antigens Proteins 0.000 claims description 42
- 102000036639 antigens Human genes 0.000 claims description 42
- 239000003446 ligand Substances 0.000 claims description 35
- 210000000822 natural killer cell Anatomy 0.000 claims description 31
- 206010028980 Neoplasm Diseases 0.000 claims description 30
- 102000004169 proteins and genes Human genes 0.000 claims description 28
- 108090000623 proteins and genes Proteins 0.000 claims description 28
- 210000001519 tissue Anatomy 0.000 claims description 25
- 102100030704 Interleukin-21 Human genes 0.000 claims description 23
- 108010074108 interleukin-21 Proteins 0.000 claims description 23
- 239000000203 mixture Substances 0.000 claims description 22
- 102000000704 Interleukin-7 Human genes 0.000 claims description 21
- 108010002586 Interleukin-7 Proteins 0.000 claims description 21
- 210000001744 T-lymphocyte Anatomy 0.000 claims description 19
- 230000003993 interaction Effects 0.000 claims description 19
- 108010065805 Interleukin-12 Proteins 0.000 claims description 17
- 102000013462 Interleukin-12 Human genes 0.000 claims description 17
- 102000003810 Interleukin-18 Human genes 0.000 claims description 17
- 108090000171 Interleukin-18 Proteins 0.000 claims description 17
- 102000015696 Interleukins Human genes 0.000 claims description 17
- 108010063738 Interleukins Proteins 0.000 claims description 17
- 201000011510 cancer Diseases 0.000 claims description 17
- 108091005735 TGF-beta receptors Proteins 0.000 claims description 15
- 102000016715 Transforming Growth Factor beta Receptors Human genes 0.000 claims description 15
- -1 ULBP 3 Proteins 0.000 claims description 15
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 claims description 15
- 208000015181 infectious disease Diseases 0.000 claims description 15
- 208000024893 Acute lymphoblastic leukemia Diseases 0.000 claims description 12
- 208000014697 Acute lymphocytic leukaemia Diseases 0.000 claims description 12
- 201000009794 Idiopathic Pulmonary Fibrosis Diseases 0.000 claims description 12
- 201000003793 Myelodysplastic syndrome Diseases 0.000 claims description 12
- 208000006664 Precursor Cell Lymphoblastic Leukemia-Lymphoma Diseases 0.000 claims description 12
- 208000005718 Stomach Neoplasms Diseases 0.000 claims description 12
- 208000019425 cirrhosis of liver Diseases 0.000 claims description 12
- 201000010099 disease Diseases 0.000 claims description 12
- 206010017758 gastric cancer Diseases 0.000 claims description 12
- 208000036971 interstitial lung disease 2 Diseases 0.000 claims description 12
- 208000002780 macular degeneration Diseases 0.000 claims description 12
- 201000008482 osteoarthritis Diseases 0.000 claims description 12
- 201000008968 osteosarcoma Diseases 0.000 claims description 12
- 201000011549 stomach cancer Diseases 0.000 claims description 12
- 208000031261 Acute myeloid leukaemia Diseases 0.000 claims description 11
- 102000004127 Cytokines Human genes 0.000 claims description 11
- 108090000695 Cytokines Proteins 0.000 claims description 11
- 208000035473 Communicable disease Diseases 0.000 claims description 10
- 208000033776 Myeloid Acute Leukemia Diseases 0.000 claims description 10
- 230000015271 coagulation Effects 0.000 claims description 10
- 238000005345 coagulation Methods 0.000 claims description 10
- 102000003814 Interleukin-10 Human genes 0.000 claims description 9
- 108090000174 Interleukin-10 Proteins 0.000 claims description 9
- 102000004890 Interleukin-8 Human genes 0.000 claims description 9
- 108090001007 Interleukin-8 Proteins 0.000 claims description 9
- 108050005493 CD3 protein, epsilon/gamma/delta subunit Proteins 0.000 claims description 8
- 102000017420 CD3 protein, epsilon/gamma/delta subunit Human genes 0.000 claims description 8
- 208000006265 Renal cell carcinoma Diseases 0.000 claims description 8
- 230000001965 increasing effect Effects 0.000 claims description 8
- 208000032791 BCR-ABL1 positive chronic myelogenous leukemia Diseases 0.000 claims description 7
- 108010019670 Chimeric Antigen Receptors Proteins 0.000 claims description 7
- 206010029260 Neuroblastoma Diseases 0.000 claims description 7
- 206010061902 Pancreatic neoplasm Diseases 0.000 claims description 7
- 108091008874 T cell receptors Proteins 0.000 claims description 7
- 102000016266 T-Cell Antigen Receptors Human genes 0.000 claims description 7
- 102000003675 cytokine receptors Human genes 0.000 claims description 7
- 108010057085 cytokine receptors Proteins 0.000 claims description 7
- 238000001727 in vivo Methods 0.000 claims description 7
- 208000015486 malignant pancreatic neoplasm Diseases 0.000 claims description 7
- 201000001441 melanoma Diseases 0.000 claims description 7
- 201000002528 pancreatic cancer Diseases 0.000 claims description 7
- 208000008443 pancreatic carcinoma Diseases 0.000 claims description 7
- 102000005962 receptors Human genes 0.000 claims description 7
- 108020003175 receptors Proteins 0.000 claims description 7
- 201000004384 Alopecia Diseases 0.000 claims description 6
- 208000024827 Alzheimer disease Diseases 0.000 claims description 6
- 206010002329 Aneurysm Diseases 0.000 claims description 6
- 102000014461 Ataxins Human genes 0.000 claims description 6
- 108010078286 Ataxins Proteins 0.000 claims description 6
- 201000001320 Atherosclerosis Diseases 0.000 claims description 6
- 208000010839 B-cell chronic lymphocytic leukemia Diseases 0.000 claims description 6
- 208000003950 B-cell lymphoma Diseases 0.000 claims description 6
- 208000028564 B-cell non-Hodgkin lymphoma Diseases 0.000 claims description 6
- 206010006187 Breast cancer Diseases 0.000 claims description 6
- 208000026310 Breast neoplasm Diseases 0.000 claims description 6
- 206010006895 Cachexia Diseases 0.000 claims description 6
- 208000002177 Cataract Diseases 0.000 claims description 6
- 206010008025 Cerebellar ataxia Diseases 0.000 claims description 6
- 208000006545 Chronic Obstructive Pulmonary Disease Diseases 0.000 claims description 6
- 206010009944 Colon cancer Diseases 0.000 claims description 6
- 208000001333 Colorectal Neoplasms Diseases 0.000 claims description 6
- 201000003883 Cystic fibrosis Diseases 0.000 claims description 6
- 206010014733 Endometrial cancer Diseases 0.000 claims description 6
- 206010014759 Endometrial neoplasm Diseases 0.000 claims description 6
- 208000000461 Esophageal Neoplasms Diseases 0.000 claims description 6
- 208000006168 Ewing Sarcoma Diseases 0.000 claims description 6
- 206010016654 Fibrosis Diseases 0.000 claims description 6
- 208000010412 Glaucoma Diseases 0.000 claims description 6
- 101000991061 Homo sapiens MHC class I polypeptide-related sequence B Proteins 0.000 claims description 6
- 208000023105 Huntington disease Diseases 0.000 claims description 6
- 206010020772 Hypertension Diseases 0.000 claims description 6
- 206010020880 Hypertrophy Diseases 0.000 claims description 6
- 208000022559 Inflammatory bowel disease Diseases 0.000 claims description 6
- 102000000589 Interleukin-1 Human genes 0.000 claims description 6
- 108010002352 Interleukin-1 Proteins 0.000 claims description 6
- 108050003558 Interleukin-17 Proteins 0.000 claims description 6
- 102000013691 Interleukin-17 Human genes 0.000 claims description 6
- 108010002350 Interleukin-2 Proteins 0.000 claims description 6
- 102000000588 Interleukin-2 Human genes 0.000 claims description 6
- 108010002386 Interleukin-3 Proteins 0.000 claims description 6
- 102000000646 Interleukin-3 Human genes 0.000 claims description 6
- 206010061246 Intervertebral disc degeneration Diseases 0.000 claims description 6
- 206010024604 Lipoatrophy Diseases 0.000 claims description 6
- 206010049287 Lipodystrophy acquired Diseases 0.000 claims description 6
- 206010058467 Lung neoplasm malignant Diseases 0.000 claims description 6
- 102100030301 MHC class I polypeptide-related sequence A Human genes 0.000 claims description 6
- 102100030300 MHC class I polypeptide-related sequence B Human genes 0.000 claims description 6
- 208000034578 Multiple myelomas Diseases 0.000 claims description 6
- 206010030155 Oesophageal carcinoma Diseases 0.000 claims description 6
- 208000001132 Osteoporosis Diseases 0.000 claims description 6
- 206010033128 Ovarian cancer Diseases 0.000 claims description 6
- 206010061535 Ovarian neoplasm Diseases 0.000 claims description 6
- 206010033645 Pancreatitis Diseases 0.000 claims description 6
- 208000018737 Parkinson disease Diseases 0.000 claims description 6
- 206010035226 Plasma cell myeloma Diseases 0.000 claims description 6
- 206010060862 Prostate cancer Diseases 0.000 claims description 6
- 208000000236 Prostatic Neoplasms Diseases 0.000 claims description 6
- 208000001647 Renal Insufficiency Diseases 0.000 claims description 6
- 201000000582 Retinoblastoma Diseases 0.000 claims description 6
- 206010039491 Sarcoma Diseases 0.000 claims description 6
- 208000009415 Spinocerebellar Ataxias Diseases 0.000 claims description 6
- 208000031673 T-Cell Cutaneous Lymphoma Diseases 0.000 claims description 6
- 206010060872 Transplant failure Diseases 0.000 claims description 6
- 230000032683 aging Effects 0.000 claims description 6
- 206010002026 amyotrophic lateral sclerosis Diseases 0.000 claims description 6
- 201000004562 autosomal dominant cerebellar ataxia Diseases 0.000 claims description 6
- 210000003719 b-lymphocyte Anatomy 0.000 claims description 6
- 210000000988 bone and bone Anatomy 0.000 claims description 6
- 210000004413 cardiac myocyte Anatomy 0.000 claims description 6
- 201000007241 cutaneous T cell lymphoma Diseases 0.000 claims description 6
- 201000004101 esophageal cancer Diseases 0.000 claims description 6
- 230000004761 fibrosis Effects 0.000 claims description 6
- 239000012634 fragment Substances 0.000 claims description 6
- 208000005017 glioblastoma Diseases 0.000 claims description 6
- 206010061989 glomerulosclerosis Diseases 0.000 claims description 6
- 208000024963 hair loss Diseases 0.000 claims description 6
- 230000003676 hair loss Effects 0.000 claims description 6
- 201000010536 head and neck cancer Diseases 0.000 claims description 6
- 208000014829 head and neck neoplasm Diseases 0.000 claims description 6
- 201000005787 hematologic cancer Diseases 0.000 claims description 6
- 206010073071 hepatocellular carcinoma Diseases 0.000 claims description 6
- 231100000844 hepatocellular carcinoma Toxicity 0.000 claims description 6
- 210000003734 kidney Anatomy 0.000 claims description 6
- 201000006370 kidney failure Diseases 0.000 claims description 6
- 208000006132 lipodystrophy Diseases 0.000 claims description 6
- 201000007270 liver cancer Diseases 0.000 claims description 6
- 208000014018 liver neoplasm Diseases 0.000 claims description 6
- 210000004072 lung Anatomy 0.000 claims description 6
- 201000005202 lung cancer Diseases 0.000 claims description 6
- 208000020816 lung neoplasm Diseases 0.000 claims description 6
- 239000010445 mica Substances 0.000 claims description 6
- 229910052618 mica group Inorganic materials 0.000 claims description 6
- 201000006417 multiple sclerosis Diseases 0.000 claims description 6
- 201000005962 mycosis fungoides Diseases 0.000 claims description 6
- 208000010125 myocardial infarction Diseases 0.000 claims description 6
- 208000008338 non-alcoholic fatty liver disease Diseases 0.000 claims description 6
- 208000002154 non-small cell lung carcinoma Diseases 0.000 claims description 6
- 208000025638 primary cutaneous T-cell non-Hodgkin lymphoma Diseases 0.000 claims description 6
- 201000009410 rhabdomyosarcoma Diseases 0.000 claims description 6
- 208000001076 sarcopenia Diseases 0.000 claims description 6
- 206010041823 squamous cell carcinoma Diseases 0.000 claims description 6
- 206010044412 transitional cell carcinoma Diseases 0.000 claims description 6
- 208000029729 tumor suppressor gene on chromosome 11 Diseases 0.000 claims description 6
- 208000001072 type 2 diabetes mellitus Diseases 0.000 claims description 6
- 239000013598 vector Substances 0.000 claims description 6
- 230000029663 wound healing Effects 0.000 claims description 6
- 241000711573 Coronaviridae Species 0.000 claims description 5
- 241000701022 Cytomegalovirus Species 0.000 claims description 5
- 241000709661 Enterovirus Species 0.000 claims description 5
- 241000700721 Hepatitis B virus Species 0.000 claims description 5
- 241000709721 Hepatovirus A Species 0.000 claims description 5
- 101000917858 Homo sapiens Low affinity immunoglobulin gamma Fc region receptor III-A Proteins 0.000 claims description 5
- 241000725303 Human immunodeficiency virus Species 0.000 claims description 5
- 108020003285 Isocitrate lyase Proteins 0.000 claims description 5
- 241001631646 Papillomaviridae Species 0.000 claims description 5
- 241000702670 Rotavirus Species 0.000 claims description 5
- 241000700584 Simplexvirus Species 0.000 claims description 5
- 241000700647 Variola virus Species 0.000 claims description 5
- 210000003979 eosinophil Anatomy 0.000 claims description 5
- 210000002540 macrophage Anatomy 0.000 claims description 5
- 210000000440 neutrophil Anatomy 0.000 claims description 5
- 210000002784 stomach Anatomy 0.000 claims description 5
- 241000701161 unidentified adenovirus Species 0.000 claims description 5
- 241000712461 unidentified influenza virus Species 0.000 claims description 5
- 241000193830 Bacillus <bacterium> Species 0.000 claims description 4
- 210000001266 CD8-positive T-lymphocyte Anatomy 0.000 claims description 4
- 241000711549 Hepacivirus C Species 0.000 claims description 4
- 101000914514 Homo sapiens T-cell-specific surface glycoprotein CD28 Proteins 0.000 claims description 4
- 108010076504 Protein Sorting Signals Proteins 0.000 claims description 4
- 108050009621 Synapsin Proteins 0.000 claims description 4
- 102000001435 Synapsin Human genes 0.000 claims description 4
- 102100027213 T-cell-specific surface glycoprotein CD28 Human genes 0.000 claims description 4
- 210000000068 Th17 cell Anatomy 0.000 claims description 4
- 210000002203 alpha-beta t lymphocyte Anatomy 0.000 claims description 4
- 210000003651 basophil Anatomy 0.000 claims description 4
- 210000004443 dendritic cell Anatomy 0.000 claims description 4
- 210000004475 gamma-delta t lymphocyte Anatomy 0.000 claims description 4
- 239000001963 growth medium Substances 0.000 claims description 4
- 210000003630 histaminocyte Anatomy 0.000 claims description 4
- 238000000338 in vitro Methods 0.000 claims description 4
- 230000001939 inductive effect Effects 0.000 claims description 4
- 210000003738 lymphoid progenitor cell Anatomy 0.000 claims description 4
- 210000000581 natural killer T-cell Anatomy 0.000 claims description 4
- 210000005105 peripheral blood lymphocyte Anatomy 0.000 claims description 4
- 239000002243 precursor Substances 0.000 claims description 4
- 210000003289 regulatory T cell Anatomy 0.000 claims description 4
- 230000004936 stimulating effect Effects 0.000 claims description 4
- 210000003171 tumor-infiltrating lymphocyte Anatomy 0.000 claims description 4
- BGFTWECWAICPDG-UHFFFAOYSA-N 2-[bis(4-chlorophenyl)methyl]-4-n-[3-[bis(4-chlorophenyl)methyl]-4-(dimethylamino)phenyl]-1-n,1-n-dimethylbenzene-1,4-diamine Chemical compound C1=C(C(C=2C=CC(Cl)=CC=2)C=2C=CC(Cl)=CC=2)C(N(C)C)=CC=C1NC(C=1)=CC=C(N(C)C)C=1C(C=1C=CC(Cl)=CC=1)C1=CC=C(Cl)C=C1 BGFTWECWAICPDG-UHFFFAOYSA-N 0.000 claims description 3
- 102100023990 60S ribosomal protein L17 Human genes 0.000 claims description 3
- 108010008014 B-Cell Maturation Antigen Proteins 0.000 claims description 3
- 102000006942 B-Cell Maturation Antigen Human genes 0.000 claims description 3
- 102100038080 B-cell receptor CD22 Human genes 0.000 claims description 3
- 102100024222 B-lymphocyte antigen CD19 Human genes 0.000 claims description 3
- 102100038077 CD226 antigen Human genes 0.000 claims description 3
- 102000000905 Cadherin Human genes 0.000 claims description 3
- 108050007957 Cadherin Proteins 0.000 claims description 3
- 101100463133 Caenorhabditis elegans pdl-1 gene Proteins 0.000 claims description 3
- 102100025012 Dipeptidyl peptidase 4 Human genes 0.000 claims description 3
- 102100020715 Fms-related tyrosine kinase 3 ligand protein Human genes 0.000 claims description 3
- 101710162577 Fms-related tyrosine kinase 3 ligand protein Proteins 0.000 claims description 3
- 102100041003 Glutamate carboxypeptidase 2 Human genes 0.000 claims description 3
- 102000006354 HLA-DR Antigens Human genes 0.000 claims description 3
- 108010058597 HLA-DR Antigens Proteins 0.000 claims description 3
- 102100034458 Hepatitis A virus cellular receptor 2 Human genes 0.000 claims description 3
- 101000884305 Homo sapiens B-cell receptor CD22 Proteins 0.000 claims description 3
- 101000980825 Homo sapiens B-lymphocyte antigen CD19 Proteins 0.000 claims description 3
- 101000884298 Homo sapiens CD226 antigen Proteins 0.000 claims description 3
- 101000908391 Homo sapiens Dipeptidyl peptidase 4 Proteins 0.000 claims description 3
- 101000892862 Homo sapiens Glutamate carboxypeptidase 2 Proteins 0.000 claims description 3
- 101001068133 Homo sapiens Hepatitis A virus cellular receptor 2 Proteins 0.000 claims description 3
- 101000998120 Homo sapiens Interleukin-3 receptor subunit alpha Proteins 0.000 claims description 3
- 101000972282 Homo sapiens Mucin-5AC Proteins 0.000 claims description 3
- 101000972276 Homo sapiens Mucin-5B Proteins 0.000 claims description 3
- 101000934338 Homo sapiens Myeloid cell surface antigen CD33 Proteins 0.000 claims description 3
- 101001109501 Homo sapiens NKG2-D type II integral membrane protein Proteins 0.000 claims description 3
- 101000589305 Homo sapiens Natural cytotoxicity triggering receptor 2 Proteins 0.000 claims description 3
- 101000831007 Homo sapiens T-cell immunoreceptor with Ig and ITIM domains Proteins 0.000 claims description 3
- 101000611183 Homo sapiens Tumor necrosis factor Proteins 0.000 claims description 3
- 101001052849 Homo sapiens Tyrosine-protein kinase Fer Proteins 0.000 claims description 3
- 108090000723 Insulin-Like Growth Factor I Proteins 0.000 claims description 3
- 102000004218 Insulin-Like Growth Factor I Human genes 0.000 claims description 3
- 102100033493 Interleukin-3 receptor subunit alpha Human genes 0.000 claims description 3
- 108090000978 Interleukin-4 Proteins 0.000 claims description 3
- 102000004388 Interleukin-4 Human genes 0.000 claims description 3
- 102000004889 Interleukin-6 Human genes 0.000 claims description 3
- 108090001005 Interleukin-6 Proteins 0.000 claims description 3
- 102100037792 Interleukin-6 receptor subunit alpha Human genes 0.000 claims description 3
- 102100029193 Low affinity immunoglobulin gamma Fc region receptor III-A Human genes 0.000 claims description 3
- 101100069392 Mus musculus Gzma gene Proteins 0.000 claims description 3
- 102100025243 Myeloid cell surface antigen CD33 Human genes 0.000 claims description 3
- 102100022680 NKG2-D type II integral membrane protein Human genes 0.000 claims description 3
- 108010004217 Natural Cytotoxicity Triggering Receptor 1 Proteins 0.000 claims description 3
- 108010004222 Natural Cytotoxicity Triggering Receptor 3 Proteins 0.000 claims description 3
- 102100032870 Natural cytotoxicity triggering receptor 1 Human genes 0.000 claims description 3
- 102100032851 Natural cytotoxicity triggering receptor 2 Human genes 0.000 claims description 3
- 102100032852 Natural cytotoxicity triggering receptor 3 Human genes 0.000 claims description 3
- 102000018967 Platelet-Derived Growth Factor beta Receptor Human genes 0.000 claims description 3
- 108010051742 Platelet-Derived Growth Factor beta Receptor Proteins 0.000 claims description 3
- 101710089372 Programmed cell death protein 1 Proteins 0.000 claims description 3
- 101710100969 Receptor tyrosine-protein kinase erbB-3 Proteins 0.000 claims description 3
- 102100029986 Receptor tyrosine-protein kinase erbB-3 Human genes 0.000 claims description 3
- 102100024834 T-cell immunoreceptor with Ig and ITIM domains Human genes 0.000 claims description 3
- 102100024537 Tyrosine-protein kinase Fer Human genes 0.000 claims description 3
- 102000005789 Vascular Endothelial Growth Factors Human genes 0.000 claims description 3
- 108010019530 Vascular Endothelial Growth Factors Proteins 0.000 claims description 3
- 108091008324 binding proteins Proteins 0.000 claims description 3
- 230000004663 cell proliferation Effects 0.000 claims description 3
- 102000052116 epidermal growth factor receptor activity proteins Human genes 0.000 claims description 3
- 108700015053 epidermal growth factor receptor activity proteins Proteins 0.000 claims description 3
- 108040006732 interleukin-1 receptor activity proteins Proteins 0.000 claims description 3
- 102000014909 interleukin-1 receptor activity proteins Human genes 0.000 claims description 3
- 108040006858 interleukin-6 receptor activity proteins Proteins 0.000 claims description 3
- 238000004519 manufacturing process Methods 0.000 claims description 3
- YOHYSYJDKVYCJI-UHFFFAOYSA-N n-[3-[[6-[3-(trifluoromethyl)anilino]pyrimidin-4-yl]amino]phenyl]cyclopropanecarboxamide Chemical compound FC(F)(F)C1=CC=CC(NC=2N=CN=C(NC=3C=C(NC(=O)C4CC4)C=CC=3)C=2)=C1 YOHYSYJDKVYCJI-UHFFFAOYSA-N 0.000 claims description 3
- 229920001481 poly(stearyl methacrylate) Polymers 0.000 claims description 3
- 210000000130 stem cell Anatomy 0.000 claims description 3
- 101150044980 Akap1 gene Proteins 0.000 claims description 2
- 101001055157 Homo sapiens Interleukin-15 Proteins 0.000 claims description 2
- 102000000583 SNARE Proteins Human genes 0.000 claims description 2
- 108010041948 SNARE Proteins Proteins 0.000 claims description 2
- 102000004183 Synaptosomal-Associated Protein 25 Human genes 0.000 claims description 2
- 108010057722 Synaptosomal-Associated Protein 25 Proteins 0.000 claims description 2
- 238000012258 culturing Methods 0.000 claims description 2
- 230000004069 differentiation Effects 0.000 claims description 2
- 102000056003 human IL15 Human genes 0.000 claims description 2
- 230000002147 killing effect Effects 0.000 claims description 2
- 238000003032 molecular docking Methods 0.000 claims description 2
- 239000008194 pharmaceutical composition Substances 0.000 claims description 2
- 239000003161 ribonuclease inhibitor Substances 0.000 claims description 2
- 102100022005 B-lymphocyte antigen CD20 Human genes 0.000 claims 1
- 101000897405 Homo sapiens B-lymphocyte antigen CD20 Proteins 0.000 claims 1
- 102100022494 Mucin-5B Human genes 0.000 claims 1
- 102000023732 binding proteins Human genes 0.000 claims 1
- 102000003137 synaptotagmin Human genes 0.000 claims 1
- 108060008004 synaptotagmin Proteins 0.000 claims 1
- 102000002262 Thromboplastin Human genes 0.000 abstract 1
- 235000001014 amino acid Nutrition 0.000 description 1714
- 229940024606 amino acid Drugs 0.000 description 1670
- 150000001413 amino acids Chemical class 0.000 description 1670
- 125000003275 alpha amino acid group Chemical group 0.000 description 50
- 229940012414 factor viia Drugs 0.000 description 37
- 235000018102 proteins Nutrition 0.000 description 27
- 230000000875 corresponding effect Effects 0.000 description 25
- 238000001514 detection method Methods 0.000 description 19
- 241000699670 Mus sp. Species 0.000 description 16
- 108010014173 Factor X Proteins 0.000 description 13
- KDXKERNSBIXSRK-UHFFFAOYSA-N Lysine Natural products NCCCCC(N)C(O)=O KDXKERNSBIXSRK-UHFFFAOYSA-N 0.000 description 13
- 239000000758 substrate Substances 0.000 description 13
- 238000002965 ELISA Methods 0.000 description 12
- 230000004913 activation Effects 0.000 description 12
- 230000014509 gene expression Effects 0.000 description 12
- 239000012528 membrane Substances 0.000 description 11
- 238000010828 elution Methods 0.000 description 10
- UHBYWPGGCSDKFX-VKHMYHEASA-N gamma-carboxy-L-glutamic acid Chemical group OC(=O)[C@@H](N)CC(C(O)=O)C(O)=O UHBYWPGGCSDKFX-VKHMYHEASA-N 0.000 description 10
- 238000011282 treatment Methods 0.000 description 10
- 230000000694 effects Effects 0.000 description 9
- 230000003834 intracellular effect Effects 0.000 description 9
- 238000003118 sandwich ELISA Methods 0.000 description 9
- CKLJMWTZIZZHCS-REOHCLBHSA-N L-aspartic acid Chemical compound OC(=O)[C@@H](N)CC(O)=O CKLJMWTZIZZHCS-REOHCLBHSA-N 0.000 description 8
- 238000004113 cell culture Methods 0.000 description 8
- 239000012228 culture supernatant Substances 0.000 description 8
- 230000000638 stimulation Effects 0.000 description 8
- 230000035602 clotting Effects 0.000 description 7
- 230000003013 cytotoxicity Effects 0.000 description 7
- 231100000135 cytotoxicity Toxicity 0.000 description 7
- 239000002953 phosphate buffered saline Substances 0.000 description 7
- 238000002415 sodium dodecyl sulfate polyacrylamide gel electrophoresis Methods 0.000 description 7
- 210000000952 spleen Anatomy 0.000 description 7
- 238000011740 C57BL/6 mouse Methods 0.000 description 6
- 206010053567 Coagulopathies Diseases 0.000 description 6
- 108010074860 Factor Xa Proteins 0.000 description 6
- 210000000227 basophil cell of anterior lobe of hypophysis Anatomy 0.000 description 6
- 238000001516 cell proliferation assay Methods 0.000 description 6
- 230000002797 proteolythic effect Effects 0.000 description 6
- 238000001542 size-exclusion chromatography Methods 0.000 description 6
- 238000006467 substitution reaction Methods 0.000 description 6
- AGPKZVBTJJNPAG-WHFBIAKZSA-N L-isoleucine Chemical compound CC[C@H](C)[C@H](N)C(O)=O AGPKZVBTJJNPAG-WHFBIAKZSA-N 0.000 description 5
- COLNVLDHVKWLRT-QMMMGPOBSA-N L-phenylalanine Chemical compound OC(=O)[C@@H](N)CC1=CC=CC=C1 COLNVLDHVKWLRT-QMMMGPOBSA-N 0.000 description 5
- 230000015572 biosynthetic process Effects 0.000 description 5
- 230000001419 dependent effect Effects 0.000 description 5
- 230000035772 mutation Effects 0.000 description 5
- 230000035755 proliferation Effects 0.000 description 5
- 239000011347 resin Substances 0.000 description 5
- 229920005989 resin Polymers 0.000 description 5
- TZCPCKNHXULUIY-RGULYWFUSA-N 1,2-distearoyl-sn-glycero-3-phosphoserine Chemical compound CCCCCCCCCCCCCCCCCC(=O)OC[C@H](COP(O)(=O)OC[C@H](N)C(O)=O)OC(=O)CCCCCCCCCCCCCCCCC TZCPCKNHXULUIY-RGULYWFUSA-N 0.000 description 4
- 108020004414 DNA Proteins 0.000 description 4
- ZWZWYGMENQVNFU-UHFFFAOYSA-N Glycerophosphorylserin Natural products OC(=O)C(N)COP(O)(=O)OCC(O)CO ZWZWYGMENQVNFU-UHFFFAOYSA-N 0.000 description 4
- 241000124008 Mammalia Species 0.000 description 4
- 108010094028 Prothrombin Proteins 0.000 description 4
- 102100027378 Prothrombin Human genes 0.000 description 4
- 108090000190 Thrombin Proteins 0.000 description 4
- 235000004279 alanine Nutrition 0.000 description 4
- 125000000539 amino acid group Chemical group 0.000 description 4
- 238000003556 assay Methods 0.000 description 4
- 210000004899 c-terminal region Anatomy 0.000 description 4
- 210000004978 chinese hamster ovary cell Anatomy 0.000 description 4
- 238000003776 cleavage reaction Methods 0.000 description 4
- 230000001086 cytosolic effect Effects 0.000 description 4
- 238000000684 flow cytometry Methods 0.000 description 4
- 108020001507 fusion proteins Proteins 0.000 description 4
- 102000037865 fusion proteins Human genes 0.000 description 4
- 102000002467 interleukin receptors Human genes 0.000 description 4
- 108010093036 interleukin receptors Proteins 0.000 description 4
- 229940039716 prothrombin Drugs 0.000 description 4
- 230000007017 scission Effects 0.000 description 4
- 210000004988 splenocyte Anatomy 0.000 description 4
- 229960004072 thrombin Drugs 0.000 description 4
- 230000003827 upregulation Effects 0.000 description 4
- 239000004475 Arginine Substances 0.000 description 3
- 206010008342 Cervix carcinoma Diseases 0.000 description 3
- 102100025137 Early activation antigen CD69 Human genes 0.000 description 3
- 102100037642 Elongation factor G, mitochondrial Human genes 0.000 description 3
- 102000001398 Granzyme Human genes 0.000 description 3
- 108060005986 Granzyme Proteins 0.000 description 3
- 101000934374 Homo sapiens Early activation antigen CD69 Proteins 0.000 description 3
- 101000880344 Homo sapiens Elongation factor G, mitochondrial Proteins 0.000 description 3
- 101001057504 Homo sapiens Interferon-stimulated gene 20 kDa protein Proteins 0.000 description 3
- 101001055144 Homo sapiens Interleukin-2 receptor subunit alpha Proteins 0.000 description 3
- 101000917839 Homo sapiens Low affinity immunoglobulin gamma Fc region receptor III-B Proteins 0.000 description 3
- 102100027268 Interferon-stimulated gene 20 kDa protein Human genes 0.000 description 3
- 108010053727 Interleukin-15 Receptor alpha Subunit Proteins 0.000 description 3
- ZDXPYRJPNDTMRX-VKHMYHEASA-N L-glutamine Chemical compound OC(=O)[C@@H](N)CCC(N)=O ZDXPYRJPNDTMRX-VKHMYHEASA-N 0.000 description 3
- QIVBCDIJIAJPQS-VIFPVBQESA-N L-tryptophane Chemical compound C1=CC=C2C(C[C@H](N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-VIFPVBQESA-N 0.000 description 3
- OUYCCCASQSFEME-QMMMGPOBSA-N L-tyrosine Chemical compound OC(=O)[C@@H](N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-QMMMGPOBSA-N 0.000 description 3
- 102100029185 Low affinity immunoglobulin gamma Fc region receptor III-B Human genes 0.000 description 3
- 239000004472 Lysine Substances 0.000 description 3
- 101000635833 Mus musculus Tissue factor Proteins 0.000 description 3
- 101000635831 Rattus norvegicus Tissue factor Proteins 0.000 description 3
- 102000012479 Serine Proteases Human genes 0.000 description 3
- 108010022999 Serine Proteases Proteins 0.000 description 3
- QIVBCDIJIAJPQS-UHFFFAOYSA-N Tryptophan Natural products C1=CC=C2C(CC(N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-UHFFFAOYSA-N 0.000 description 3
- 208000006105 Uterine Cervical Neoplasms Diseases 0.000 description 3
- 235000021068 Western diet Nutrition 0.000 description 3
- 230000003024 amidolytic effect Effects 0.000 description 3
- 238000004458 analytical method Methods 0.000 description 3
- ODKSFYDXXFIFQN-UHFFFAOYSA-N arginine Natural products OC(=O)C(N)CCCNC(N)=N ODKSFYDXXFIFQN-UHFFFAOYSA-N 0.000 description 3
- 125000003118 aryl group Chemical group 0.000 description 3
- 235000003704 aspartic acid Nutrition 0.000 description 3
- OQFSQFPPLPISGP-UHFFFAOYSA-N beta-carboxyaspartic acid Natural products OC(=O)C(N)C(C(O)=O)C(O)=O OQFSQFPPLPISGP-UHFFFAOYSA-N 0.000 description 3
- 230000004071 biological effect Effects 0.000 description 3
- 210000004369 blood Anatomy 0.000 description 3
- 239000008280 blood Substances 0.000 description 3
- 239000011575 calcium Substances 0.000 description 3
- 230000003197 catalytic effect Effects 0.000 description 3
- 201000010881 cervical cancer Diseases 0.000 description 3
- 238000002512 chemotherapy Methods 0.000 description 3
- 230000022811 deglycosylation Effects 0.000 description 3
- 238000010586 diagram Methods 0.000 description 3
- 208000035475 disorder Diseases 0.000 description 3
- 239000012642 immune effector Substances 0.000 description 3
- 229940121354 immunomodulator Drugs 0.000 description 3
- 230000005764 inhibitory process Effects 0.000 description 3
- 229960000310 isoleucine Drugs 0.000 description 3
- AGPKZVBTJJNPAG-UHFFFAOYSA-N isoleucine Natural products CCC(C)C(N)C(O)=O AGPKZVBTJJNPAG-UHFFFAOYSA-N 0.000 description 3
- 239000000463 material Substances 0.000 description 3
- 230000001404 mediated effect Effects 0.000 description 3
- 210000003071 memory t lymphocyte Anatomy 0.000 description 3
- COLNVLDHVKWLRT-UHFFFAOYSA-N phenylalanine Natural products OC(=O)C(N)CC1=CC=CC=C1 COLNVLDHVKWLRT-UHFFFAOYSA-N 0.000 description 3
- 239000013641 positive control Substances 0.000 description 3
- 230000009467 reduction Effects 0.000 description 3
- 230000002829 reductive effect Effects 0.000 description 3
- 239000002904 solvent Substances 0.000 description 3
- 241000894007 species Species 0.000 description 3
- 208000024891 symptom Diseases 0.000 description 3
- ZRKFYGHZFMAOKI-QMGMOQQFSA-N tgfbeta Chemical compound C([C@H](NC(=O)[C@H](C(C)C)NC(=O)CNC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@H](CC(C)C)NC(=O)CNC(=O)[C@H](C)NC(=O)[C@H](CO)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](NC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)[C@@H](NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CCSC)C(C)C)[C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](C)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)N1[C@@H](CCC1)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O)C1=CC=C(O)C=C1 ZRKFYGHZFMAOKI-QMGMOQQFSA-N 0.000 description 3
- OUYCCCASQSFEME-UHFFFAOYSA-N tyrosine Natural products OC(=O)C(N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-UHFFFAOYSA-N 0.000 description 3
- 102000013918 Apolipoproteins E Human genes 0.000 description 2
- 108010025628 Apolipoproteins E Proteins 0.000 description 2
- 206010005003 Bladder cancer Diseases 0.000 description 2
- 102000014914 Carrier Proteins Human genes 0.000 description 2
- 208000010833 Chronic myeloid leukaemia Diseases 0.000 description 2
- 102000004190 Enzymes Human genes 0.000 description 2
- 108090000790 Enzymes Proteins 0.000 description 2
- 102000002090 Fibronectin type III Human genes 0.000 description 2
- 108050009401 Fibronectin type III Proteins 0.000 description 2
- DHMQDGOQFOQNFH-UHFFFAOYSA-N Glycine Chemical compound NCC(O)=O DHMQDGOQFOQNFH-UHFFFAOYSA-N 0.000 description 2
- 102000003839 Human Proteins Human genes 0.000 description 2
- 108090000144 Human Proteins Proteins 0.000 description 2
- 108060003951 Immunoglobulin Proteins 0.000 description 2
- 108010090444 Innovin Proteins 0.000 description 2
- 108010074328 Interferon-gamma Proteins 0.000 description 2
- 102000008070 Interferon-gamma Human genes 0.000 description 2
- 102000004556 Interleukin-15 Receptors Human genes 0.000 description 2
- 108010017535 Interleukin-15 Receptors Proteins 0.000 description 2
- QNAYBMKLOCPYGJ-REOHCLBHSA-N L-alanine Chemical compound C[C@H](N)C(O)=O QNAYBMKLOCPYGJ-REOHCLBHSA-N 0.000 description 2
- 102100022496 Mucin-5AC Human genes 0.000 description 2
- 208000033761 Myelogenous Chronic BCR-ABL Positive Leukemia Diseases 0.000 description 2
- 102000035195 Peptidases Human genes 0.000 description 2
- 108091005804 Peptidases Proteins 0.000 description 2
- 239000004365 Protease Substances 0.000 description 2
- 102100040247 Tumor necrosis factor Human genes 0.000 description 2
- 208000007097 Urinary Bladder Neoplasms Diseases 0.000 description 2
- 125000003295 alanine group Chemical group N[C@@H](C)C(=O)* 0.000 description 2
- 239000013078 crystal Substances 0.000 description 2
- LOKCTEFSRHRXRJ-UHFFFAOYSA-I dipotassium trisodium dihydrogen phosphate hydrogen phosphate dichloride Chemical compound P(=O)(O)(O)[O-].[K+].P(=O)(O)([O-])[O-].[Na+].[Na+].[Cl-].[K+].[Cl-].[Na+] LOKCTEFSRHRXRJ-UHFFFAOYSA-I 0.000 description 2
- 238000010494 dissociation reaction Methods 0.000 description 2
- 230000005593 dissociations Effects 0.000 description 2
- 229940088598 enzyme Drugs 0.000 description 2
- 230000007717 exclusion Effects 0.000 description 2
- 102000018358 immunoglobulin Human genes 0.000 description 2
- 229960003130 interferon gamma Drugs 0.000 description 2
- 230000004807 localization Effects 0.000 description 2
- 230000007246 mechanism Effects 0.000 description 2
- 238000010172 mouse model Methods 0.000 description 2
- 239000013642 negative control Substances 0.000 description 2
- 229910052760 oxygen Inorganic materials 0.000 description 2
- 239000001301 oxygen Substances 0.000 description 2
- 150000003904 phospholipids Chemical class 0.000 description 2
- 230000004962 physiological condition Effects 0.000 description 2
- 239000011148 porous material Substances 0.000 description 2
- 230000003389 potentiating effect Effects 0.000 description 2
- 235000019419 proteases Nutrition 0.000 description 2
- 108020001580 protein domains Proteins 0.000 description 2
- 238000002198 surface plasmon resonance spectroscopy Methods 0.000 description 2
- 201000005112 urinary bladder cancer Diseases 0.000 description 2
- MTCFGRXMJLQNBG-REOHCLBHSA-N (2S)-2-Amino-3-hydroxypropansäure Chemical compound OC[C@H](N)C(O)=O MTCFGRXMJLQNBG-REOHCLBHSA-N 0.000 description 1
- 108010016529 Bacillus amyloliquefaciens ribonuclease Proteins 0.000 description 1
- 102100032912 CD44 antigen Human genes 0.000 description 1
- OYPRJOBELJOOCE-UHFFFAOYSA-N Calcium Chemical compound [Ca] OYPRJOBELJOOCE-UHFFFAOYSA-N 0.000 description 1
- 102000000844 Cell Surface Receptors Human genes 0.000 description 1
- 108010001857 Cell Surface Receptors Proteins 0.000 description 1
- 102100026735 Coagulation factor VIII Human genes 0.000 description 1
- 108010062466 Enzyme Precursors Proteins 0.000 description 1
- 102000010911 Enzyme Precursors Human genes 0.000 description 1
- 108050001049 Extracellular proteins Proteins 0.000 description 1
- 108010054265 Factor VIIa Proteins 0.000 description 1
- 102100037362 Fibronectin Human genes 0.000 description 1
- 108010067306 Fibronectins Proteins 0.000 description 1
- 239000004471 Glycine Substances 0.000 description 1
- 241000711557 Hepacivirus Species 0.000 description 1
- 206010019799 Hepatitis viral Diseases 0.000 description 1
- 208000017604 Hodgkin disease Diseases 0.000 description 1
- 208000021519 Hodgkin lymphoma Diseases 0.000 description 1
- 208000010747 Hodgkins lymphoma Diseases 0.000 description 1
- 101000868273 Homo sapiens CD44 antigen Proteins 0.000 description 1
- 101000911390 Homo sapiens Coagulation factor VIII Proteins 0.000 description 1
- 101100334524 Homo sapiens FCGR3B gene Proteins 0.000 description 1
- 101001003140 Homo sapiens Interleukin-15 receptor subunit alpha Proteins 0.000 description 1
- 101000719024 Homo sapiens Ribosome-releasing factor 2, mitochondrial Proteins 0.000 description 1
- 101000638251 Homo sapiens Tumor necrosis factor ligand superfamily member 9 Proteins 0.000 description 1
- 101000851370 Homo sapiens Tumor necrosis factor receptor superfamily member 9 Proteins 0.000 description 1
- 108010021625 Immunoglobulin Fragments Proteins 0.000 description 1
- 102000008394 Immunoglobulin Fragments Human genes 0.000 description 1
- 102000012750 Membrane Glycoproteins Human genes 0.000 description 1
- 108010090054 Membrane Glycoproteins Proteins 0.000 description 1
- 241000699666 Mus <mouse, genus> Species 0.000 description 1
- 230000006051 NK cell activation Effects 0.000 description 1
- 208000007256 Nevus Diseases 0.000 description 1
- 208000015914 Non-Hodgkin lymphomas Diseases 0.000 description 1
- 108010076039 Polyproteins Proteins 0.000 description 1
- 102000002020 Protease-activated receptors Human genes 0.000 description 1
- 108050009310 Protease-activated receptors Proteins 0.000 description 1
- 206010038389 Renal cancer Diseases 0.000 description 1
- 108010083644 Ribonucleases Proteins 0.000 description 1
- 102000006382 Ribonucleases Human genes 0.000 description 1
- 102100025784 Ribosome-releasing factor 2, mitochondrial Human genes 0.000 description 1
- 102000005886 STAT4 Transcription Factor Human genes 0.000 description 1
- 108010019992 STAT4 Transcription Factor Proteins 0.000 description 1
- 102000001712 STAT5 Transcription Factor Human genes 0.000 description 1
- 108010029477 STAT5 Transcription Factor Proteins 0.000 description 1
- 108010003723 Single-Domain Antibodies Proteins 0.000 description 1
- 101100226845 Strongylocentrotus purpuratus EGF2 gene Proteins 0.000 description 1
- 102100032101 Tumor necrosis factor ligand superfamily member 9 Human genes 0.000 description 1
- 208000024248 Vascular System injury Diseases 0.000 description 1
- 208000012339 Vascular injury Diseases 0.000 description 1
- 230000002159 abnormal effect Effects 0.000 description 1
- 230000009471 action Effects 0.000 description 1
- 230000003213 activating effect Effects 0.000 description 1
- 238000012867 alanine scanning Methods 0.000 description 1
- 230000003281 allosteric effect Effects 0.000 description 1
- 230000008841 allosteric interaction Effects 0.000 description 1
- 230000003321 amplification Effects 0.000 description 1
- 230000000259 anti-tumor effect Effects 0.000 description 1
- 230000010056 antibody-dependent cellular cytotoxicity Effects 0.000 description 1
- 230000008901 benefit Effects 0.000 description 1
- 238000012575 bio-layer interferometry Methods 0.000 description 1
- 239000000872 buffer Substances 0.000 description 1
- 229910052791 calcium Inorganic materials 0.000 description 1
- 108090001015 cancer procoagulant Proteins 0.000 description 1
- 230000020411 cell activation Effects 0.000 description 1
- 230000005779 cell damage Effects 0.000 description 1
- 230000030833 cell death Effects 0.000 description 1
- 230000024245 cell differentiation Effects 0.000 description 1
- 208000037887 cell injury Diseases 0.000 description 1
- 210000000170 cell membrane Anatomy 0.000 description 1
- 239000000470 constituent Substances 0.000 description 1
- 230000009089 cytolysis Effects 0.000 description 1
- 210000005220 cytoplasmic tail Anatomy 0.000 description 1
- 210000001151 cytotoxic T lymphocyte Anatomy 0.000 description 1
- 230000001472 cytotoxic effect Effects 0.000 description 1
- 230000007423 decrease Effects 0.000 description 1
- 208000018180 degenerative disc disease Diseases 0.000 description 1
- 238000012217 deletion Methods 0.000 description 1
- 230000037430 deletion Effects 0.000 description 1
- 239000000539 dimer Substances 0.000 description 1
- 229940042399 direct acting antivirals protease inhibitors Drugs 0.000 description 1
- 230000002255 enzymatic effect Effects 0.000 description 1
- 238000002474 experimental method Methods 0.000 description 1
- 239000013604 expression vector Substances 0.000 description 1
- 230000006624 extrinsic pathway Effects 0.000 description 1
- 229960000301 factor viii Drugs 0.000 description 1
- 230000006870 function Effects 0.000 description 1
- 230000002496 gastric effect Effects 0.000 description 1
- 125000003712 glycosamine group Chemical group 0.000 description 1
- 125000003630 glycyl group Chemical group [H]N([H])C([H])([H])C(*)=O 0.000 description 1
- 230000010005 growth-factor like effect Effects 0.000 description 1
- 210000002443 helper t lymphocyte Anatomy 0.000 description 1
- 208000024200 hematopoietic and lymphoid system neoplasm Diseases 0.000 description 1
- 102000053350 human FCGR3B Human genes 0.000 description 1
- 230000007062 hydrolysis Effects 0.000 description 1
- 238000006460 hydrolysis reaction Methods 0.000 description 1
- 230000002209 hydrophobic effect Effects 0.000 description 1
- 201000001421 hyperglycemia Diseases 0.000 description 1
- 210000000987 immune system Anatomy 0.000 description 1
- 229940072221 immunoglobulins Drugs 0.000 description 1
- 230000006698 induction Effects 0.000 description 1
- 239000003999 initiator Substances 0.000 description 1
- 208000021600 intervertebral disc degenerative disease Diseases 0.000 description 1
- 230000006623 intrinsic pathway Effects 0.000 description 1
- 150000002500 ions Chemical class 0.000 description 1
- 230000000670 limiting effect Effects 0.000 description 1
- 210000004698 lymphocyte Anatomy 0.000 description 1
- 239000003550 marker Substances 0.000 description 1
- 210000001616 monocyte Anatomy 0.000 description 1
- 230000000869 mutational effect Effects 0.000 description 1
- 238000003199 nucleic acid amplification method Methods 0.000 description 1
- 230000036284 oxygen consumption Effects 0.000 description 1
- 230000036961 partial effect Effects 0.000 description 1
- 230000001717 pathogenic effect Effects 0.000 description 1
- 230000037361 pathway Effects 0.000 description 1
- 239000000137 peptide hydrolase inhibitor Substances 0.000 description 1
- 125000001151 peptidyl group Chemical group 0.000 description 1
- 210000003819 peripheral blood mononuclear cell Anatomy 0.000 description 1
- 230000026731 phosphorylation Effects 0.000 description 1
- 238000006366 phosphorylation reaction Methods 0.000 description 1
- 230000010118 platelet activation Effects 0.000 description 1
- 125000002924 primary amino group Chemical group [H]N([H])* 0.000 description 1
- 230000037452 priming Effects 0.000 description 1
- 230000008569 process Effects 0.000 description 1
- 230000001737 promoting effect Effects 0.000 description 1
- 230000017854 proteolysis Effects 0.000 description 1
- 230000006337 proteolytic cleavage Effects 0.000 description 1
- 238000000746 purification Methods 0.000 description 1
- 230000008707 rearrangement Effects 0.000 description 1
- 230000001105 regulatory effect Effects 0.000 description 1
- 201000010174 renal carcinoma Diseases 0.000 description 1
- 230000004044 response Effects 0.000 description 1
- 230000028327 secretion Effects 0.000 description 1
- 229960001153 serine Drugs 0.000 description 1
- 230000011664 signaling Effects 0.000 description 1
- 238000010186 staining Methods 0.000 description 1
- 235000000346 sugar Nutrition 0.000 description 1
- 230000014616 translation Effects 0.000 description 1
- 238000013519 translation Methods 0.000 description 1
- 102000035160 transmembrane proteins Human genes 0.000 description 1
- 108091005703 transmembrane proteins Proteins 0.000 description 1
- 210000004881 tumor cell Anatomy 0.000 description 1
Images

















































































































































































Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2803—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily
- C07K16/283—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily against Fc-receptors, e.g. CD16, CD32, CD64
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K38/00—Medicinal preparations containing peptides
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P25/00—Drugs for disorders of the nervous system
- A61P25/28—Drugs for disorders of the nervous system for treating neurodegenerative disorders of the central nervous system, e.g. nootropic agents, cognition enhancers, drugs for treating Alzheimer's disease or other forms of dementia
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P31/00—Antiinfectives, i.e. antibiotics, antiseptics, chemotherapeutics
- A61P31/12—Antivirals
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/52—Cytokines; Lymphokines; Interferons
- C07K14/54—Interleukins [IL]
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/52—Cytokines; Lymphokines; Interferons
- C07K14/54—Interleukins [IL]
- C07K14/5418—IL-7
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/52—Cytokines; Lymphokines; Interferons
- C07K14/54—Interleukins [IL]
- C07K14/5434—IL-12
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/52—Cytokines; Lymphokines; Interferons
- C07K14/54—Interleukins [IL]
- C07K14/5443—IL-15
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/705—Receptors; Cell surface antigens; Cell surface determinants
- C07K14/71—Receptors; Cell surface antigens; Cell surface determinants for growth factors; for growth regulators
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/705—Receptors; Cell surface antigens; Cell surface determinants
- C07K14/715—Receptors; Cell surface antigens; Cell surface determinants for cytokines; for lymphokines; for interferons
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/705—Receptors; Cell surface antigens; Cell surface determinants
- C07K14/715—Receptors; Cell surface antigens; Cell surface determinants for cytokines; for lymphokines; for interferons
- C07K14/7155—Receptors; Cell surface antigens; Cell surface determinants for cytokines; for lymphokines; for interferons for interleukins [IL]
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/745—Blood coagulation or fibrinolysis factors
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
- C12N15/62—DNA sequences coding for fusion proteins
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/60—Immunoglobulins specific features characterized by non-natural combinations of immunoglobulin fragments
- C07K2317/62—Immunoglobulins specific features characterized by non-natural combinations of immunoglobulin fragments comprising only variable region components
- C07K2317/622—Single chain antibody (scFv)
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/01—Fusion polypeptide containing a localisation/targetting motif
- C07K2319/02—Fusion polypeptide containing a localisation/targetting motif containing a signal sequence
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/01—Fusion polypeptide containing a localisation/targetting motif
- C07K2319/03—Fusion polypeptide containing a localisation/targetting motif containing a transmembrane segment
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/30—Non-immunoglobulin-derived peptide or protein having an immunoglobulin constant or Fc region, or a fragment thereof, attached thereto
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/32—Fusion polypeptide fusions with soluble part of a cell surface receptor, "decoy receptors"
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/70—Fusion polypeptide containing domain for protein-protein interaction
- C07K2319/74—Fusion polypeptide containing domain for protein-protein interaction containing a fusion for binding to a cell surface receptor
-
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y02—TECHNOLOGIES OR APPLICATIONS FOR MITIGATION OR ADAPTATION AGAINST CLIMATE CHANGE
- Y02A—TECHNOLOGIES FOR ADAPTATION TO CLIMATE CHANGE
- Y02A50/00—TECHNOLOGIES FOR ADAPTATION TO CLIMATE CHANGE in human health protection, e.g. against extreme weather
- Y02A50/30—Against vector-borne diseases, e.g. mosquito-borne, fly-borne, tick-borne or waterborne diseases whose impact is exacerbated by climate change
Abstract
本文提供多链嵌合多肽,其包括:(a)第一嵌合多肽,其包括第一靶标结合结构域、可溶性组织因子结构域和一对亲和结构域中的第一结构域;和(b)第二嵌合多肽,其包括一对亲和结构域中的第二结构域和第二靶标结合结构域,其中所述第一嵌合多肽和所述第二嵌合多肽通过所述一对亲和结构域中的所述第一结构域和所述第二结构域的结合而缔合。本文还提供使用这些多链嵌合多肽的方法和编码这些多链嵌合多肽的核酸。
Description
相关申请的交叉引用
本申请要求以下的优先权:2018年8月30日提交的美国专利申请第62/724,969号的优先权;2019年3月12日提交的美国专利申请第62/817,230号;2018年8月30日提交的美国专利申请第62/725,043号;2018年8月30日提交的美国专利申请第62/725,010号;2018年10月22日提交的美国专利申请第62/749,007号;2018年10月17日提交的美国专利申请第62/746,832号;2018年10月23日提交的美国专利申请第62/749,506号;2019年3月12日提交的美国专利申请第62/817,241号;2019年3月11日提交的美国专利申请第62/816,683号;和2019年7月31日提交的美国专利申请第62/881,088号,其中每一个均通过引用整体并入本文中。
技术领域
本公开涉及生物技术领域,更具体地,涉及抗原结合分子。
背景技术
组织因子(TF)是263个氨基酸的整体膜糖蛋白,分子量为约46kDa,并且是外源性凝血路径的触发蛋白,是体内凝血的主要引发子。通常不与循环血液接触的组织因子在暴露于循环凝血丝氨酸蛋白酶因子时引发凝血级联反应。血管损伤暴露了表达组织因子的内皮下细胞,从而引起与先前存在的血浆因子VIIa(FVIIa)形成钙依赖性高亲和性复合物。丝氨酸蛋白酶FVIIa与组织因子的结合促进FX快速裂解为FXa和FIX快速裂解为FIXa。然后,所得FXa和活性膜表面的蛋白水解活性低效地将少量凝血酶原转化为凝血酶。Fxa生成的凝血酶引发血小板激活,并且将微量原辅助因子V(FV)和因子VIII(FVIII)激活成为活性辅助因子Va(FVa)和因子VIIIa(FVIIIa)。FIXa与血小板表面上的FVIIIa复合形成内源性X酶(tenase)复合物,从而引起FXa的快速生成。FXa与FVa形成复合物,在激活的血小板表面形成凝血酶原复合物,从而引起凝血酶原快速裂解为凝血酶。
除了组织因子-FVIIa复合物外,最近的一项研究表明,组织因子-FVIIa-FXa复合物可激活FVIII,这将在引发阶段提供另外水平的FVIIIa。外源性路径通过有限量的凝血酶的激活来引发凝血至关重要,而内源性路径通过初始信号的急剧放大来维持凝血。
细胞表面上表达的许多组织因子被“加密”,为了完全参与凝血,其必须被“解密”。目前,细胞表面组织因子“解密”的机制尚不清楚,但是,阴离子磷脂的暴露在这一过程中起重要作用。健康细胞会主动将阴离子磷脂(如磷脂酰丝氨酸(PS))隔离到质膜的内叶。在细胞损伤、激活或胞质Ca2+水平提高之后,这种双层不对称性消失,引起外叶上PS暴露增加,从而增加了细胞表面组织因子-FVIIa复合物的比活性。已知PS暴露会降低组织因子-FVIIa复合物激活FIX和FX的表观Km,但另外的机制可包括组织因子或组织因子-FVIIa的构象重排以及随后的底物结合位点暴露。
发明内容
本发明基于以下发现:可溶性组织因子可用作包括抗原结合结构域的嵌合多肽的支架。基于这一发现,本文提供多链嵌合多肽,其包括:(a)第一嵌合多肽,其包括:(i)第一靶标结合结构域;(ii)可溶性组织因子结构域;和(iii)一对亲和结构域中的第一结构域;以及(b)第二嵌合多肽,其包括:(i)一对亲和结构域中的第二结构域;和(ii)第二靶标结合结构域,其中第一嵌合多肽和第二嵌合多肽通过所述一对亲和结构域中的第一结构域和第二结构域的结合而缔合。本文还提供组合物,其包括本文所描述的多链嵌合多肽中的任一种、编码本文所描述的多链嵌合多肽中的任一种的核酸和包括编码本文所描述的多链嵌合多肽中的任一种的核酸中的任一种的细胞。本文还提供刺激免疫细胞的方法和治疗有需要的受试者的方法,所述方法包括使用本文所描述的多链嵌合多肽中的任一种。本文还提供产生本文所描述的多链嵌合多肽中的任一种的方法。
因此,本文提供一种多链嵌合多肽,其包含:
(a)第一嵌合多肽,其包含:
(i)第一靶标结合结构域;
(ii)可溶性组织因子结构域;和
(iii)一对亲和结构域中的第一结构域;
(b)第二嵌合多肽,其包含:
(i)一对亲和结构域中的第二结构域;和
(ii)第二靶标结合结构域,
其中所述第一嵌合多肽和所述第二嵌合多肽通过所述一对亲和结构域中的所述第一结构域和所述第二结构域的结合而缔合。在一些实施例中,第一靶标结合结构域和可溶性组织因子结构域在第一嵌合多肽中彼此直接邻接。在一些实施例中,第一嵌合多肽进一步包含第一嵌合多肽中的第一靶标结合结构域与可溶性组织因子结构域之间的接头序列。在一些实施例中,可溶性组织因子结构域和一对亲和结构域中的第一结构域在第一嵌合多肽中彼此直接邻接。在一些实施例中,第一嵌合多肽进一步包含第一嵌合多肽中的可溶性组织因子结构域与一对亲和结构域中的第一结构域之间的接头序列。在一些实施例中,一对亲和结构域中的第二结构域和第二靶标结合结构域在第二嵌合多肽中彼此直接邻接。在一些实施例中,第二嵌合多肽进一步包含第二嵌合多肽中的一对亲和结构域中的第二结构域与第二靶标结合结构域之间的接头序列。在一些实施例中,第一靶标结合结构域和第二靶标结合结构域特异性结合到相同的抗原。在一些实施例中,第一靶标结合结构域和第二靶标结合结构域特异性结合到相同的表位。在一些实施例中,第一靶标结合结构域和第二靶标结合结构域包含相同的氨基酸序列。在一些实施例中,第一靶标结合结构域和第二靶标结合结构域特异性结合到不同的抗原。在一些实施例中,第一靶标结合结构域和第二靶标结合结构域中的一个或两个是抗原结合结构域。在一些实施例中,第一靶标结合结构域和第二靶标结合结构域各自是抗原结合结构域。在一些实施例中,抗原结合结构域包含scFv或单结构域抗体。在一些实施例中,第一靶标结合结构域和第二靶标结合结构域中的一个或两个特异性结合到选自以下组成的组的靶标:CD16a、CD28、CD3、CD33、CD20、CD19、CD22、CD123、IL-1R、IL-1、VEGF、IL-6R、IL-4、IL-10、PDL-1、TIGIT、PD-1、TIM3、CTLA4、MICA、MICB、IL-6、IL-8、TNFα、CD26a、CD36、ULBP2、CD30、CD200、IGF-1R、MUC4AC、MUC5AC、Trop-2、CMET、EGFR、HER1、HER2、HER3、PSMA、CEA、B7H3、EPCAM、BCMA、P-钙黏着蛋白、CEACAM5、UL16结合蛋白、HLA-DR、DLL4、TYRO3、AXL、MER、CD122、CD155、PDGF-DD、TGF-β受体II(TGF-βRII)的配体、TGF-βRIII的配体、DNAM-1的配体、NKp46的配体、NKp44的配体、NKG2D的配体、NKp30的配体、scMHCI的配体、scMHCII的配体、scTCR的配体、IL-1的受体、IL-2的受体、IL-3的受体、IL-7的受体、IL-8的受体、IL-10的受体、IL-12的受体、IL-15的受体、IL-17的受体、IL-18的受体、IL-21的受体、PDGF-DD的受体、干细胞因子(SCF)的受体、干细胞样酪氨酸激酶3配体(FLT3L)的受体、MICA的受体、MICB的受体、ULP16结合蛋白的受体、CD155的受体、CD122的受体和CD28的受体。在一些实施例中,第一靶标结合结构域和第二靶标结合结构域中的一个或两个是可溶性白介素、可溶性细胞因子蛋白或配体蛋白。在一些实施例中,可溶性白介素、可溶性细胞因子或配体蛋白选自以下组成的组:IL-1、IL-2、IL-3、IL-7、IL-8、IL-10、IL-12、IL-15、IL-17、IL-18、IL-21、PDGF-DD、SCF和FLT3L。在一些实施例中,第一靶标结合结构域和第二靶标结合结构域中的一个或两个是可溶性白介素、细胞因子受体或可溶性细胞表面受体。在一些实施例中,可溶性受体是可溶性TGF-β受体II(TGF-βRII)、可溶性TGF-βRIII、可溶性NKG2D、可溶性NKp30、可溶性NKp44、可溶性NKp46、可溶性DNAM-1、scMHCI、scMHCII、scTCR、可溶性CD155或可溶性CD28。在一些实施例中,第一嵌合多肽进一步包含一个或多个另外的靶标结合结构域,其中一个或多个另外的抗原结合结构域中的至少一个位于可溶性组织因子结构域与一对亲和结构域中的第一结构域之间。在一些实施例中,第一嵌合多肽进一步包含在可溶性组织因子结构域与一个或多个另外的抗原结合结构域中的至少一个之间的接头序列,和/或在一个或多个另外的抗原结合结构域中的至少一个与一对亲和结构域中的第一结构域之间的接头序列。在一些实施例中,第一嵌合多肽在第一嵌合多肽的N端和/或C端进一步包含一个或多个另外的靶标结合结构域。在一些实施例中,在第一嵌合多肽中,一个或多个另外的靶标结合结构域中的至少一个直接邻接一对亲和结构域中的第一结构域。在一些实施例中,第一嵌合多肽进一步包含一个或多个另外的靶标结合结构域中的至少一个与一对亲和结构域中的第一结构域之间的接头序列。在一些实施例中,在第一嵌合多肽中,一个或多个另外的靶标结合结构域中的至少一个直接邻接第一靶标结合结构域。在一些实施例中,第一嵌合多肽进一步包含一个或多个另外的靶标结合结构域中的至少一个与第一靶标结合结构域之间的接头序列。在一些实施例中,一个或多个另外的靶标结合结构域中的至少一个安置于第一嵌合多肽的N和/或C端,并且一个或多个另外的靶标结合结构域中的至少一个位于第一嵌合多肽中的可溶性组织因子结构域与一对亲和结构域中的第一结构域之间。在一些实施例中,在第一嵌合多肽中,安置于N端的一个或多个另外的靶标结合结构域中的至少一个另外的靶标结合结构域直接邻接第一靶标结合结构域或一对亲和结构域中的第一结构域。在一些实施例中,第一嵌合多肽进一步包含安置于第一嵌合多肽中的至少一个另外的靶标结合结构域与第一靶标结合结构域或一对亲和结构域中的第一结构域之间的接头序列。在一些实施例中,在第一嵌合多肽中,安置于C端的一个或多个另外的靶标结合结构域中的至少一个另外的靶标结合结构域直接邻接第一靶标结合结构域或一对亲和结构域中的第一结构域。在一些实施例中,第一嵌合多肽进一步包含安置于第一嵌合多肽中的至少一个另外的靶标结合结构域与第一靶标结合结构域或一对亲和结构域中的第一结构域之间的接头序列。在一些实施例中,位于可溶性组织因子结构域与一对亲和结构域中的第一结构域之间的一个或多个另外的靶标结合结构域中的至少一个,直接邻接可溶性组织因子结构域和/或一对亲和结构域中的第一结构域。在一些实施例中,第一嵌合多肽进一步包含安置于以下的接头序列:(i)可溶性组织因子结构域与一个或多个另外的靶标结合结构域中的至少一个之间,所述一个或多个另外的靶标结合结构域中的至少一个位于可溶性组织因子结构域与一对亲和结构域中的第一结构域之间,和/或(ii)一对亲和结构域中的第一结构域与一个或多个另外的靶标结合结构域中的至少一个之间,所述一个或多个另外的靶标结合结构域中的至少一个位于可溶性组织因子结构域与一对亲和结构域中的第一结构域之间。在一些实施例中,第二嵌合多肽在第二嵌合多肽的N端或C端进一步包含一个或多个另外的靶标结合结构域。在一些实施例中,在第二嵌合多肽中,一个或多个另外的靶标结合结构域中的至少一个直接邻接一对亲和结构域中的第二结构域。在一些实施例中,第二嵌合多肽进一步包含第二嵌合多肽中的一个或多个另外的靶标结合结构域中的至少一个与一对亲和结构域中的第二结构域之间的接头序列。在一些实施例中,在第二嵌合多肽中,一个或多个另外的靶标结合结构域中的至少一个直接邻接第二靶标结合结构域。在一些实施例中,第二嵌合多肽进一步包含第二嵌合多肽中一个或多个另外的靶标结合结构域中的至少一个与第二靶标结合结构域之间的接头序列。在一些实施例中,第一靶标结合结构域、第二靶标结合结构域和一个或多个另外的靶标结合结构域中的两个或更多个特异性结合到相同的抗原。在一些实施例中,第一靶标结合结构域、第二靶标结合结构域和一个或多个另外的靶标结合结构域中的两个或更多个特异性结合到相同的表位。在一些实施例中,第一靶标结合结构域、第二靶标结合结构域和一个或多个另外的靶标结合结构域中的两个或更多个包含相同的氨基酸序列。在一些实施例中,第一靶标结合结构域、第二靶标结合结构域和一个或多个另外的靶标结合结构域各自特异性结合到相同的抗原。在一些实施例中,第一靶标结合结构域、第二靶标结合结构域和一个或多个另外的靶标结合结构域各自特异性结合到相同的表位。在一些实施例中,第一靶标结合结构域、第二靶标结合结构域和一个或多个另外的靶标结合结构域各自包含相同的氨基酸序列。在一些实施例中,第一靶标结合结构域、第二靶标结合结构域和一个或多个另外的靶标结合结构域特异性结合到不同的抗原。在一些实施例中,第一靶标结合结构域、第二靶标结合结构域和一个或多个靶标结合结构域中的一个或多个是抗原结合结构域。在一些实施例中,第一靶标结合结构域、第二靶标结合结构域和一个或多个另外的靶标结合结构域各自是抗原结合结构域。在一些实施例中,抗原结合结构域包含scFv。在一些实施例中,第一靶标结合结构域、第二靶标结合结构域和一个或多个靶标结合结构域中的一个或多个特异性结合到选自以下组成的组的靶标:CD16a、CD28、CD3、CD33、CD20、CD19、CD22、CD123、IL-1R、IL-1、VEGF、IL-6R、IL-4、IL-10、PDL-1、TIGIT、PD-1、TIM3、CTLA4、MICA、MICB、IL-6、IL-8、TNFα、CD26a、CD36、ULBP2、CD30、CD200、IGF-1R、MUC4AC、MUC5AC、Trop-2、CMET、EGFR、HER1、HER2、HER3、PSMA、CEA、B7H3、EPCAM、BCMA、P-钙黏着蛋白、CEACAM5、UL16结合蛋白、HLA-DR、DLL4、TYRO3、AXL、MER、CD122、CD155、PDGF-DD、TGF-β受体II(TGF-βRII)的配体、TGF-βRIII的配体、DNAM-1的配体、NKp46的配体、NKp44的配体、NKG2D的配体、NKp30的配体、scMHCI的配体、scMHCII的配体、scTCR的配体、IL-1的受体、IL-2的受体、IL-3的受体、IL-7的受体、IL-8的受体、IL-10的受体、IL-12的受体、IL-15的受体、IL-17的受体、IL-18的受体、IL-21的受体、PDGF-DD的受体、干细胞因子(SCF)的受体、干细胞样酪氨酸激酶3配体(FLT3L)的受体、MICA的受体、MICB的受体、ULP16结合蛋白的受体、CD155的受体、CD122的受体和CD3的受体以及CD28的受体。在一些实施例中,第一靶标结合结构域、第二靶标结合结构域和一个或多个另外的靶标结合结构域中的一个或多个是可溶性白介素、可溶性细胞因子蛋白或配体蛋白。在一些实施例中,可溶性白介素、可溶性细胞因子或配体蛋白选自以下组成的组:IL-1、IL-2、IL-3、IL-7、IL-8、IL-10、IL-12、IL-15、IL-17、IL-18、IL-21、PDGF-DD、SCF和FLT3L。在一些实施例中,第一靶标结合结构域、第二靶标结合结构域和一个或多个另外的靶标结合结构域中的一个或多个是可溶性白介素或细胞因子受体。在一些实施例中,可溶性受体是可溶性TGF-β受体II(TGF-βRII)、可溶性TGF-βRIII、可溶性NKG2D、可溶性NKp30、可溶性NKp44、可溶性NKp46、可溶性DNAM-1、scMHCI、scMHCII、scTCR、可溶性CD155、可溶性CD122、可溶性CD3或可溶性CD28。在一些实施例中,第一嵌合多肽进一步包含在第一嵌合多肽的N端或C端的肽标签。在一些实施例中,第二嵌合多肽进一步包含在第二嵌合多肽的N端或C端的肽标签。在一些实施例中,可溶性组织因子结构域是可溶性人组织因子结构域。在一些实施例中,可溶性人组织因子结构域包含与SEQ ID NO:1至少80%相同的序列。在一些实施例中,可溶性人组织因子结构域包含与SEQ ID NO:1至少90%相同的序列。在一些实施例中,可溶性人组织因子结构域包含与SEQ ID NO:1至少95%相同的序列。在一些实施例中,可溶性人组织因子结构域不包含以下中的一个或多个:在对应于成熟野生型人组织因子蛋白的氨基酸位置20的氨基酸位置处的赖氨酸;在对应于成熟野生型人组织因子蛋白的氨基酸位置22的氨基酸位置处的异亮氨酸;在对应于成熟野生型人组织因子蛋白的氨基酸位置45的氨基酸位置处的色氨酸;在对应于成熟野生型人组织因子蛋白的氨基酸位置58的氨基酸位置处的天冬氨酸;在对应于成熟野生型人组织因子蛋白的氨基酸位置94的氨基酸位置处的酪氨酸;在对应于成熟野生型人组织因子蛋白的氨基酸位置135的氨基酸位置处的精氨酸;和在对应于成熟野生型人组织因子蛋白的氨基酸位置140的氨基酸位置处的苯丙氨酸。在一些实施例中,可溶性人组织因子结构域不包含以下中的任一种:在对应于成熟野生型人组织因子蛋白的氨基酸位置20的氨基酸位置处的赖氨酸;在对应于成熟野生型人组织因子蛋白的氨基酸位置22的氨基酸位置处的异亮氨酸;在对应于成熟野生型人组织因子蛋白的氨基酸位置45的氨基酸位置处的色氨酸;在对应于成熟野生型人组织因子蛋白的氨基酸位置58的氨基酸位置处的天冬氨酸;在对应于成熟野生型人组织因子蛋白的氨基酸位置94的氨基酸位置处的酪氨酸;在对应于成熟野生型人组织因子蛋白的氨基酸位置135的氨基酸位置处的精氨酸;和在对应于成熟野生型人组织因子蛋白的氨基酸位置140的氨基酸位置处的苯丙氨酸。在一些实施例中,可溶性组织因子结构域不能结合到因子VIIa。在一些实施例中,可溶性组织因子结构域不将非活性因子X转化为因子Xa。在一些实施例中,多链嵌合多肽不刺激哺乳动物的凝血。在本文提供的任何单链嵌合多肽的一些实施例中,人可溶性组织因子结构域不引发凝血。在本文提供的任何单链嵌合多肽的一些实施例中,可溶性组织因子结构域包含可溶性野生型人组织因子或由可溶性野生型人组织因子组成。
在一些实施例中,所述一对亲和结构域是来自人IL-15受体的α链(IL15Rα)的寿司结构域(sushi domain)和可溶性IL-15。在一些实施例中,可溶性IL15具有D8N或D8A氨基酸取代。在一些实施例中,人IL15Rα是成熟全长IL15Rα。在一些实施例中,所述一对亲和结构域选自以下组成的组:芽胞杆菌RNA酶(barnase)和芽胞杆菌RNA酶抑制子(barnstar)、PKA和AKAP、基于突变核糖核酸酶I片段的衔接子/对接标签模块以及基于蛋白质突触蛋白、突触结合蛋白、突触泡蛋白和SNAP25的相互作用的SNARE模块。在一些实施例中,第一嵌合多肽和/或第二嵌合多肽在其N端进一步包含信号序列。
在一些实施例中,多链嵌合多肽构成组合物。在一些实施例中,组合物是药物组合物。在一些实施例中,组合物包含至少一个剂量的多链嵌合多肽。在一些实施例中,试剂盒包含至少一个剂量的组合物。
在一些实施例中,本文提供一种刺激免疫细胞的方法,所述方法包含:使免疫细胞与有效量的上述多链嵌合多肽或组合物中的任一种接触。在一些实施例中,所述方法包含体外接触免疫细胞。在一些实施例中,所述方法包含从受试者获得免疫细胞。在一些实施例中,所述方法包含在接触步骤之前从受试者获得免疫细胞。在一些实施例中,所述方法包含体内接触免疫细胞。在一些实施例中,所述方法包含从以下组成的组选择免疫细胞:未成熟胸腺细胞、外周血淋巴细胞、初始T细胞、多能Th细胞前体、淋巴祖细胞、Treg细胞、记忆T细胞、Th17细胞、Th22细胞、Th9细胞、Th2细胞、Th1细胞、Th3细胞、γδT细胞、αβT细胞、肿瘤浸润性T细胞、CD8+T细胞、CD4+T细胞、自然杀伤T细胞、肥大细胞、巨噬细胞、嗜中性粒细胞、树突状细胞、嗜碱性粒细胞、嗜酸性粒细胞和自然杀伤细胞。在一些实施例中,所述方法包含基因修饰免疫细胞以表达嵌合抗原受体或重组T细胞受体。在一些实施例中,所述方法包含在接触步骤之后将编码嵌合抗原受体或重组T细胞受体的核酸引入到免疫细胞中。在一些实施例中,所述方法包含向有需要的受试者施用免疫细胞。在一些实施例中,所述方法包含将所述受试者患有鉴别或诊断为患有与年龄相关的疾病或病况。在一些实施例中,与年龄相关的疾病或病况选自以下组成的组:阿尔茨海默氏病(Alzheimer's disease)、动脉瘤、囊性纤维化、胰腺炎纤维化、青光眼、高血压、特发性肺纤维化、炎性肠病、椎间盘退变、黄斑变性、骨关节炎、2型糖尿病、脂肪萎缩、脂肪营养不良、动脉粥样硬化、白内障、COPD、特发性肺纤维化、肾移植失败、肝纤维化、骨量损失、心肌梗死、肌肉减少症、伤口愈合、脱发、心肌细胞肥大、骨关节炎、帕金森氏病(arkinson's disease)、与年龄相关的肺组织弹性丧失、黄斑变性、恶病质、肾小球硬化、肝硬化、NAFLD、骨质疏松症、肌萎缩性侧索硬化症、亨廷顿氏病(Huntington's disease)、脊髓小脑共济失调、多发性硬化症和肾功能不全。在一些实施例中,所述方法包含将受试者鉴别或诊断为患有癌症。在一些实施例中,癌症选自以下组成的组:实体肿瘤、血液肿瘤、肉瘤、骨肉瘤、成胶质细胞瘤、成神经细胞瘤、黑色素瘤、横纹肌肉瘤、尤文氏肉瘤(Ewing sarcoma)、骨肉瘤、B细胞瘤、多发性骨髓瘤、B细胞淋巴瘤、B细胞非霍奇金氏淋巴瘤(non-Hodgkin's lymphoma)、霍奇金氏淋巴瘤、慢性淋巴细胞性白血病(CLL)、急性骨髓性白血病(AML)、慢性骨髓性白血病(CML)、急性淋巴细胞性白血病(ALL)、骨髓增生异常综合症(MDS)、皮肤T细胞淋巴瘤、成视网膜细胞瘤、胃癌、尿路上皮癌、肺癌、肾细胞癌、胃和食管癌、胰腺癌、前列腺癌、乳腺癌、结直肠癌、卵巢癌、非小细胞肺癌、鳞状细胞头颈癌、子宫内膜癌、宫颈癌、肝癌和肝细胞癌。在一些实施例中,所述方法包含将受试者诊断或鉴别为患有感染性疾病。在一些实施例中,感染性疾病是感染人免疫缺陷病毒、巨细胞病毒、腺病毒、冠状病毒、鼻病毒、轮状病毒、天花、单纯疱疹病毒、乙型肝炎病毒、甲型肝炎病毒和丙型肝炎病毒、乳头瘤病毒和流感病毒。
本文还提供诱导或增加免疫细胞增殖的方法,所述方法包含:使免疫细胞与有效量的上述多链嵌合多肽或组合物中的任一种接触。在一些实施例中,所述方法包含体外接触免疫细胞。在一些实施例中,所述方法包含从受试者获得免疫细胞。在一些实施例中,所述方法包含在接触步骤之前从受试者获得免疫细胞。在一些实施例中,所述方法包含体内接触免疫细胞。在一些实施例中,所述方法包含从以下组成的组选择免疫细胞:未成熟胸腺细胞、外周血淋巴细胞、初始T细胞、多能Th细胞前体、淋巴祖细胞、Treg细胞、记忆T细胞、Th17细胞、Th22细胞、Th9细胞、Th2细胞、Th1细胞、Th3细胞、γδT细胞、αβT细胞、肿瘤浸润性T细胞、CD8+T细胞、CD4+T细胞、自然杀伤T细胞、肥大细胞、巨噬细胞、嗜中性粒细胞、树突状细胞、嗜碱性粒细胞、嗜酸性粒细胞和自然杀伤细胞。在一些实施例中,所述方法包含修饰免疫细胞以表达嵌合抗原受体或重组T细胞受体。在一些实施例中,所述方法进一步包含在接触步骤之后将编码嵌合抗原受体或重组T细胞受体的核酸引入到免疫细胞中。在一些实施例中,所述方法进一步包含向有需要的受试者施用免疫细胞。在一些实施例中,所述方法包含将所述受试者患有鉴别或诊断为患有与年龄相关的疾病或病况。在一些实施例中,与年龄相关的疾病或病况选自以下组成的组:阿尔茨海默氏病、动脉瘤、囊性纤维化、胰腺炎纤维化、青光眼、高血压、特发性肺纤维化、炎性肠病、椎间盘退变、黄斑变性、骨关节炎、2型糖尿病、脂肪萎缩、脂肪营养不良、动脉粥样硬化、白内障、COPD、特发性肺纤维化、肾移植失败、肝纤维化、骨量损失、心肌梗死、肌肉减少症、伤口愈合、脱发、心肌细胞肥大、骨关节炎、帕金森氏病、与年龄相关的肺组织弹性丧失、黄斑变性、恶病质、肾小球硬化、肝硬化、NAFLD、骨质疏松症、肌萎缩性侧索硬化症、亨廷顿氏病、脊髓小脑共济失调、多发性硬化症和肾功能不全。在一些实施例中,所述方法包含将受试者鉴别或诊断为患有癌症。在一些实施例中,癌症选自以下组成的组:实体肿瘤、血液肿瘤、肉瘤、骨肉瘤、成胶质细胞瘤、成神经细胞瘤、黑色素瘤、横纹肌肉瘤、尤文氏肉瘤、骨肉瘤、B细胞瘤、多发性骨髓瘤、B细胞淋巴瘤、B细胞非霍奇金氏淋巴瘤、霍奇金氏淋巴瘤、慢性淋巴细胞性白血病(CLL)、急性骨髓性白血病(AML)、慢性骨髓性白血病(CML)、急性淋巴细胞性白血病(ALL)、骨髓增生异常综合症(MDS)、皮肤T细胞淋巴瘤、成视网膜细胞瘤、胃癌、尿路上皮癌、肺癌、肾细胞癌、胃和食管癌、胰腺癌、前列腺癌、乳腺癌、结直肠癌、卵巢癌、非小细胞肺癌、鳞状细胞头颈癌、子宫内膜癌、宫颈癌、肝癌和肝细胞癌。在一些实施例中,所述方法包含将受试者诊断或鉴别为患有感染性疾病。在一些实施例中,感染性疾病是感染人免疫缺陷病毒、巨细胞病毒、腺病毒、冠状病毒、鼻病毒、轮状病毒、天花、单纯疱疹病毒、乙型肝炎病毒、甲型肝炎病毒和丙型肝炎病毒、乳头瘤病毒和流感病毒。
本文还提供诱导免疫细胞分化成记忆或记忆样免疫细胞的方法,所述方法包含:使免疫细胞与有效量的以上论述的多链嵌合多肽或组合物中的任一种接触。在一些实施例中,所述方法包含体外接触免疫细胞。在一些实施例中,所述方法包含从受试者获得免疫细胞。在一些实施例中,所述方法进一步包含在接触步骤之前从受试者获得免疫细胞。在一些实施例中,所述方法包含体内接触免疫细胞。在一些实施例中,免疫细胞选自以下组成的组:未成熟胸腺细胞、外周血淋巴细胞、初始T细胞、多能Th细胞前体、淋巴祖细胞、Treg细胞、Th17细胞、Th22细胞、Th9细胞、Th2细胞,Th1细胞、Th3细胞、γδT细胞、αβT细胞、肿瘤浸润性T细胞,CD8+T细胞、CD4+T细胞、自然杀伤T细胞、肥大细胞、巨噬细胞、嗜中性粒细胞、树突状细胞、嗜碱性粒细胞、嗜酸性粒细胞和自然杀伤细胞。在一些实施例中,免疫细胞先前已经过基因修饰以表达嵌合抗原受体或重组T细胞受体。在一些实施例中,所述方法进一步包含在接触步骤之后将编码嵌合抗原受体或重组T细胞受体的核酸引入到免疫细胞中。在一些实施例中,所述方法进一步包含向有需要的受试者施用免疫细胞。在一些实施例中,所述方法包含将所述受试者患有鉴别或诊断为患有与年龄相关的疾病或病况。在一些实施例中,与年龄相关的疾病或病况选自以下组成的组:阿尔茨海默氏病、动脉瘤、囊性纤维化、胰腺炎纤维化、青光眼、高血压、特发性肺纤维化、炎性肠病、椎间盘退变、黄斑变性、骨关节炎、2型糖尿病、脂肪萎缩、脂肪营养不良、动脉粥样硬化、白内障、COPD、特发性肺纤维化、肾移植失败、肝纤维化、骨量损失、心肌梗死、肌肉减少症、伤口愈合、脱发、心肌细胞肥大、骨关节炎、帕金森氏病、与年龄相关的肺组织弹性丧失、黄斑变性、恶病质、肾小球硬化、肝硬化、NAFLD、骨质疏松症、肌萎缩性侧索硬化症、亨廷顿氏病、脊髓小脑共济失调、多发性硬化症和肾功能不全。在一些实施例中,所述方法包含将受试者鉴别或诊断为患有癌症。在一些实施例中,癌症选自以下组成的组:实体肿瘤、血液肿瘤、肉瘤、骨肉瘤、成胶质细胞瘤、成神经细胞瘤、黑色素瘤、横纹肌肉瘤、尤文氏肉瘤、骨肉瘤、B细胞瘤、多发性骨髓瘤、B细胞淋巴瘤、B细胞非霍奇金氏淋巴瘤、霍奇金氏淋巴瘤、慢性淋巴细胞性白血病(CLL)、急性骨髓性白血病(AML)、慢性骨髓性白血病(CML)、急性淋巴细胞性白血病(ALL)、骨髓增生异常综合症(MDS)、皮肤T细胞淋巴瘤、成视网膜细胞瘤、胃癌、尿路上皮癌、肺癌、肾细胞癌、胃和食管癌、胰腺癌、前列腺癌、乳腺癌、结直肠癌、卵巢癌、非小细胞肺癌、鳞状细胞头颈癌、子宫内膜癌、宫颈癌、肝癌和肝细胞癌。在一些实施例中,所述方法包含将受试者诊断或鉴别为患有感染性疾病。在一些实施例中,感染性疾病是感染人免疫缺陷病毒、巨细胞病毒、腺病毒、冠状病毒、鼻病毒、轮状病毒、天花、单纯疱疹病毒、乙型肝炎病毒、甲型肝炎病毒和丙型肝炎病毒、乳头瘤病毒和流感病毒。
本文还提供在有需要的受试者中杀死癌细胞、受感染细胞或衰老细胞的方法,所述方法包含向受试者施用治疗有效量的以上论述的多链嵌合多肽或组合物中的任一种。在一些实施例中,所述方法包含将受试者鉴别或诊断为患有癌症。在一些实施例中,癌症选自以下组成的组:实体肿瘤、血液肿瘤、肉瘤、骨肉瘤、成胶质细胞瘤、成神经细胞瘤、黑色素瘤、横纹肌肉瘤、尤文氏肉瘤、骨肉瘤、B细胞瘤、多发性骨髓瘤、B细胞淋巴瘤、B细胞非霍奇金氏淋巴瘤、霍奇金氏淋巴瘤、慢性淋巴细胞性白血病(CLL)、急性骨髓性白血病(AML)、慢性骨髓性白血病(CML)、急性淋巴细胞性白血病(ALL)、骨髓增生异常综合症(MDS)、皮肤T细胞淋巴瘤、成视网膜细胞瘤、胃癌、尿路上皮癌、肺癌、肾细胞癌、胃和食管癌、胰腺癌、前列腺癌、乳腺癌、结直肠癌、卵巢癌、非小细胞肺癌、鳞状细胞头颈癌、子宫内膜癌、宫颈癌、肝癌和肝细胞癌。在一些实施例中,所述方法包含将所述受试者患有鉴别或诊断为患有与老化相关的疾病或病况。在一些实施例中,与老化相关的疾病或病况选自以下组成的组:阿尔茨海默氏病、动脉瘤、囊性纤维化、胰腺炎纤维化、青光眼、高血压、特发性肺纤维化、炎性肠病、椎间盘退变、黄斑变性、骨关节炎、2型糖尿病、脂肪萎缩、脂肪营养不良、动脉粥样硬化、白内障、COPD、特发性肺纤维化、肾移植失败、肝纤维化、骨量损失、心肌梗死、肌肉减少症、伤口愈合、脱发、心肌细胞肥大、骨关节炎、帕金森氏病、与年龄相关的肺组织弹性丧失、黄斑变性、恶病质、肾小球硬化、肝硬化、NAFLD、骨质疏松症、肌萎缩性侧索硬化症、亨廷顿氏病、脊髓小脑共济失调、多发性硬化症和肾功能不全。在一些实施例中,所述方法包含向受试者施用治疗有效量的以上论述的多链嵌合多肽或组合物中的任一种。在一些实施例中,所述方法包含将受试者鉴别或诊断为患有癌症。在一些实施例中,癌症选自以下组成的组:实体肿瘤、血液肿瘤、肉瘤、骨肉瘤、成胶质细胞瘤、成神经细胞瘤、黑色素瘤、横纹肌肉瘤、尤文氏肉瘤、骨肉瘤、B细胞瘤、多发性骨髓瘤、B细胞淋巴瘤、B细胞非霍奇金氏淋巴瘤、霍奇金氏淋巴瘤、慢性淋巴细胞性白血病(CLL)、急性骨髓性白血病(AML)、慢性骨髓性白血病(CML)、急性淋巴细胞性白血病(ALL)、骨髓增生异常综合症(MDS)、皮肤T细胞淋巴瘤、成视网膜细胞瘤、胃癌、尿路上皮癌、肺癌、肾细胞癌、胃和食管癌、胰腺癌、前列腺癌、乳腺癌、结直肠癌、卵巢癌、非小细胞肺癌、鳞状细胞头颈癌、子宫内膜癌、宫颈癌、肝癌和肝细胞癌。在一些实施例中,所述方法包含将所述受试者患有鉴别或诊断为患有与老化相关的疾病或病况。在一些实施例中,与老化相关的疾病或病况选自以下组成的组:阿尔茨海默氏病、动脉瘤、囊性纤维化、胰腺炎纤维化、青光眼、高血压、特发性肺纤维化、炎性肠病、椎间盘退变、黄斑变性、骨关节炎、2型糖尿病、脂肪萎缩、脂肪营养不良、动脉粥样硬化、白内障、COPD、特发性肺纤维化、肾移植失败、肝纤维化、骨量损失、心肌梗死、肌肉减少症、伤口愈合、脱发、心肌细胞肥大、骨关节炎、帕金森氏病、与年龄相关的肺组织弹性丧失、黄斑变性、恶病质、肾小球硬化、肝硬化、NAFLD、骨质疏松症、肌萎缩性侧索硬化症、亨廷顿氏病、脊髓小脑共济失调、多发性硬化症和肾功能不全。在一些实施例中,所述方法包含将受试者诊断或鉴别为患有感染性疾病。在一些实施例中,感染性疾病是感染人免疫缺陷病毒、巨细胞病毒、腺病毒、冠状病毒、鼻病毒、轮状病毒、天花、单纯疱疹病毒、乙型肝炎病毒、甲型肝炎病毒和丙型肝炎病毒、乳头瘤病毒和流感病毒。
本文还提供编码以上论述的多链嵌合多肽中的任一种的核酸。一些实施例包含含有以上论述的核酸中的任一种的载体。在一些实施例中,载体是表达载体。一些实施例包含含有以上论述的核酸中的任一种的细胞。
本文还提供产生多链嵌合多肽的方法,所述方法包含:在足以引起产生多链嵌合多肽的条件下在培养基中培养以上论述的细胞;和从细胞和/或培养基中回收多链嵌合多肽。在一些实施例中,所述方法包含通过以上论述的方法产生多链嵌合多肽。
在一些实施例中,突变可溶性人组织因子结构域包含与SEQ ID NO:3至少80%相同的序列。在一些实施例中,可溶性人组织因子结构域包含与SEQ ID NO:3至少90%相同的序列。在一些实施例中,可溶性人组织因子结构域包含与SEQ ID NO:3至少95%相同的序列。在一些实施例中,根据权利要求140所述的多链嵌合多肽,其中所述可溶性人组织因子结构域包含与SEQ ID NO:3100%相同的序列。在一些实施例中,可溶性人组织因子结构域包含与SEQ ID NO:4至少80%相同的序列。在一些实施例中,可溶性人组织因子结构域包含与SEQ ID NO:4至少90%相同的序列。在一些实施例中,可溶性人组织因子结构域包含与SEQ ID NO:4至少95%相同的序列。在一些实施例中,可溶性人组织因子结构域包含与SEQID NO:4 100%相同的序列。
如本文所用,术语“嵌合”是指包括最初衍生自两个不同来源(例如,两个不同的天然存在的蛋白质,例如,来自相同或不同物种)的氨基酸序列(例如,结构域)的多肽。例如,嵌合多肽可包括来自至少两种不同的天然存在的人蛋白质的结构域。在一些实例中,嵌合多肽可包括作为合成序列的结构域(例如,scFv)和衍生自天然存在的蛋白质(例如,天然存在的人蛋白质)的结构域。在一些实施例中,嵌合多肽可包括至少两个不同的结构域,其为合成序列(例如,两个不同的scFv)。
“抗原结合结构域”是能够与一种或多种不同抗原特异性结合的一个或多个蛋白质结构域(例如,由来自单个多肽的氨基酸形成或由来自两个或更多个多肽(例如,相同或不同的多肽)的氨基酸形成)。在一些实例中,抗原结合结构域可以与天然存在的抗体相似的特异性和亲和力结合到抗原或表位。在一些实施例中,抗原结合结构域可为抗体或其片段。在一些实施例中,抗原结合结构域可包括替代支架。抗原结合结构域的非限制性实例在本文中描述。抗原结合结构域的另外实例是本领域已知的。
“可溶性组织因子结构域”是指与缺少跨膜结构域和细胞内结构域的野生型哺乳动物组织因子蛋白(例如,野生型人组织因子蛋白)的段具有至少70%同一性(例如,至少75%同一性、至少80%同一性、至少85%同一性、至少90%同一性、至少95%同一性、至少99%同一性或100%相同)的多肽。本文描述可溶性组织因子结构域的非限制性实例。
术语“可溶性白介素蛋白”在本文中用于指成熟并且分泌的白介素蛋白或其生物活性片段。在一些实例中,可溶性白介素蛋白可包括与野生型成熟并且分泌的哺乳动物白介素蛋白(例如,野生型人白介素蛋白)至少70%相同、至少75%相同、至少80%相同、至少85%相同、至少90%相同、至少95%相同、至少99%相同或100%相同的序列,并且保留其生物活性。可溶性白介素蛋白的非限制性实例在本文中描述。
术语“可溶性细胞因子蛋白”在本文中用于指成熟并且分泌的细胞因子蛋白或其生物活性片段。在一些实例中,可溶性细胞因子蛋白可包括与野生型成熟并且分泌的哺乳动物白介素蛋白(例如,野生型人白介素蛋白)至少70%相同、至少75%相同、至少80%相同、至少85%相同、至少90%相同、至少95%相同、至少99%相同或100%相同的序列,并且保留其生物活性。可溶性细胞因子蛋白的非限制性实例在本文中描述。
术语“可溶性白介素受体”在本文中以最广义使用,指能够结合一个或多个其天然配体(例如,在生理条件下,例如,在室温下于磷酸盐缓冲盐水中),缺少跨膜结构域(和任选的细胞内结构域)的多肽。例如,可溶性白介素受体可包括与野生型白介素受体的细胞外结构域至少70%相同(例如,至少75%相同、至少80%相同、至少85%相同、至少90%相同、至少95%相同、至少99%相同或100%相同)的序列,并且保留其特异性结合到一个或多个其天然配体的能力,但缺少其跨膜结构域(并且任选地,还缺少其细胞内结构域)。本文描述可溶性白介素受体的非限制性实例。
术语“可溶性细胞因子受体”在本文中以最广义使用,指能够结合一个或多个其天然配体(例如,在生理条件下,例如,在室温下于磷酸盐缓冲盐水中),缺少跨膜结构域(和任选的细胞内结构域)的多肽。例如,可溶性细胞因子受体可包括与野生型细胞因子受体的细胞外结构域至少70%相同(例如,至少75%相同、至少80%相同、至少85%相同、至少90%相同、至少95%相同、至少99%相同或100%相同)的序列,并且保留其特异性结合到一个或多个其天然配体的能力,但缺少其跨膜结构域(并且任选地,还缺少其细胞内结构域)。本文描述可溶性细胞因子受体的非限制性实例。
术语“抗体”在本文中以其最广义使用,并且包括某些类型的免疫球蛋白分子,其包括一个或多个特异性结合到抗原或表位的抗原结合结构域。抗体具体包括例如完整抗体(例如,完整免疫球蛋白)、抗体片段和多特异性抗体。抗原结合结构域的一个实例是由VH-VL二聚体形成的抗原结合结构域。本文描述抗体的另外实例。抗体的另外实例是本领域已知的。
“亲和力”是指抗原结合位点与其结合伴侣(例如,抗原或表位)之间的非共价相互作用的总和的强度。除非另外说明,否则如本文所用,“亲和力”是指固有结合亲和力,其反映抗原结合结构域与抗原或表位的成员之间的1:1相互作用。分子X与其伴侣Y的亲和力可通过解离平衡常数(KD)表示。贡献于解离平衡常数的动力学组分在下文中更详细地描述。亲和力可通过本领域已知的常见方法来测量,包括本文所描述的方法。亲和力可例如使用表面等离振子体共振(SPR)技术(例如, )或生物层干涉术(例如,
)或生物层干涉术(例如, )来确定。确定对抗原结合结构域和其对应抗原或表位的亲和力的另外方法是本领域已知的。
)来确定。确定对抗原结合结构域和其对应抗原或表位的亲和力的另外方法是本领域已知的。
如本文所用,“多链多肽”是指包含两个或更多个(例如,三个、四个、五个、六个、七个、八个、九个或十个)蛋白链(例如,至少第一嵌合多肽和第二多肽)的多肽,其中两个或更多个蛋白链通过非共价键缔合形成四级结构。
术语“一对亲和结构域”是以小于小于1×10-7M(例如,小于1×10-8M、小于1×10- 9M、小于1×10-10M或小于1×10-11M)的KD彼此特异性结合的两个不同的蛋白质结构域。在一些实例中,一对亲和结构域可为一对天然存在的蛋白质。在一些实施例中,一对亲和结构域可为一对合成蛋白质。亲和结构域对的非限制性实例在本文中描述。
术语“表位”是指与抗原结合结构域特异性结合的抗原的一部分。表位可例如由表面可接近的氨基酸残基和/或糖侧链组成,并且可具有特定的三维结构特征以及特定的电荷特征。构象和非构象表位的区别在于,在存在变性溶剂的情况下,与前者的结合而非与后者的结合可能会丢失。表位可包含直接参与结合的氨基酸残基和不直接参与结合的其它氨基酸残基。鉴别与抗原结合结构域结合的表位的方法是本领域已知的。
“免疫效应细胞”是指哺乳动物的免疫系统的细胞,其能够直接或间接地识别哺乳动物中的病原性细胞(例如,癌细胞)和/或引起所述细胞的细胞停滞或细胞死亡。免疫效应细胞的非限制性实例包括巨噬细胞、T淋巴细胞(例如,细胞毒性T淋巴细胞和T辅助细胞)、自然杀伤细胞、嗜中性粒细胞、单核细胞和嗜酸性粒细胞。免疫效应细胞的另外实例是本领域已知的。
术语“治疗”是指改善病症的至少一种症状。在一些实例中,所治疗的病症是癌症,并且改善癌症的至少一种症状包括减少异常增殖、基因表达、信号传导、翻译和/或因子的分泌。一般来说,治疗方法包括向需要或已确定为需要这种治疗的受试者施用治疗有效量的组合物,所述组合物减少病症的至少一种症状。
除非另外定义,否则本文中使用的所有技术术语和科学术语的含义与本发明所属领域的普通技术人员通常理解的含义相同。本文描述用于本发明的方法和材料;还可使用其它在本领域已知的合适的方法和材料。材料、方法和实例仅是说明性的并且不旨在是限制性的。本文所提及的所有出版物、专利申请、专利、序列、数据库条目和其它参考文献通过引用以其整体并入。在发生冲突的情况下,应以本说明书(包括定义)为准。
本发明的其它特征和优点将通过以下详细描述和附图以及通过权利要求变得显而易见。
附图说明
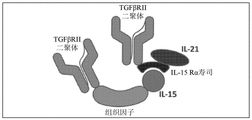
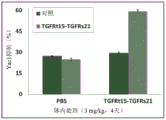
图1显示多链嵌合多肽的示例图:(i)第一嵌合多肽,其包括第一靶标结合结构域(A)、可溶性组织因子结构域、结构域亲和对中的第一结构域(可溶性白介素IL-15),和另外的靶标结合结构域(B);和(ii)第二嵌合多肽,其包括结构域亲和对中的第二结构域(IL-15受体α寿司结构域)、第二靶标结合结构域(C)和另外的抗原结合结构域(D)。顶部草图描绘第一和第二嵌合多肽通过一对亲和结构域的缔合。底部示意图显示第一和第二嵌合多肽中结构域的顺序。
图2显示多链嵌合多肽的示例图:(i)第一嵌合多肽,其包括第一靶标结合结构域(A)、包括五个氨基酸取代以便去除可溶性组织因子与FVIIa的结合的可溶性组织因子结构域、结构域亲和对中的第一结构域(包括D8N或D8A氨基酸取代的可溶性白介素IL-15)和另外的靶标结合结构域(B);和(ii)第二嵌合多肽,其包括结构域亲和对中的第二结构域(IL-15受体α寿司结构域)、第二靶标结合结构域(C)和另外的抗原结合结构域(D)。顶部草图描绘第一和第二嵌合多肽通过一对亲和结构域的缔合。底部示意图显示第一和第二嵌合多肽中结构域的顺序。在本文所描述的多链嵌合多肽中的任一种的其它实施例中,可溶性组织因子结构域可包含可溶性野生型人组织因子结构域或由可溶性野生型人组织因子结构域组成(包含野生型人组织因子内的连续序列或由野生型人组织因子内的连续序列组成)。
图3显示示例性IL-12/IL-15RαSu DNA构建体的示意图。
图4显示示例性IL-18/TF/IL-15DNA构建体的示意图。
图5显示示例性IL-12/IL-15RαSu与IL-18/TF/IL-15DNA构建体之间的相互作用的示意图。
图6显示产生IL-18/TF/IL-15:IL-12/IL-15RαSu复合物(18t15-12s)的示例性IL-12/IL-15RαSu与IL-18/TF/IL-15融合蛋白之间的相互作用的示意图。
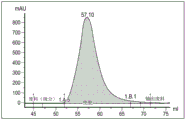
图7显示来自抗TF抗体亲和柱的18t15-12s纯化洗脱的色谱图。
图8显示在分析尺寸排阻柱上洗脱后,抗TF Ab/SEC纯化的18t15-12s蛋白的示例性色谱图,证明单体多蛋白18t15-12s复合物与蛋白质聚集体分离。
图9显示二硫键还原后18t15-12s复合物的4-12%SDS-PAGE的实例。泳道1:SeeBlue Plus2标记;泳道2:抗组织因子抗体亲和柱纯化的18t15-12s(0.5μg);泳道3:抗组织因子抗体亲和柱纯化的18t15-12s(1μg)。
图10显示去糖基化和未去糖基化18t15-12s的SDS PAGE分析。泳道1:抗组织因子抗体亲和柱纯化的18t15-12s(0.5μg),未去糖基化;泳道2:抗TF Ab纯化的18t15-12s(1μg),未去糖基化;泳道3:18t15-12s(1μg),去糖基化,泳道4:Mark12未染色的制造商。
图11显示用于18t15-12s复合物的夹心ELISA,其包含抗人组织因子捕获抗体和生物素化抗人IL-12检测抗体(BAF 219)。
图12显示用于18t15-12s复合物的夹心ELISA,其包含抗人组织因子捕获抗体和生物素化抗人IL-15检测抗体(BAM 247)。
图13显示用于18t15-12s复合物的夹心ELISA,其包含抗人组织因子捕获抗体和生物素化抗人IL-18检测抗体(D045-6)。
图14显示用于18t15-12s复合物的夹心ELISA,其包含抗人组织因子(I43)捕获抗体和抗人组织因子检测抗体。
图15显示由18t15-12s复合物(空心方块)和重组IL-15(黑色方块)介导的IL-15依赖性32Dβ细胞的增殖。
图16显示18t15-12s复合物(空心正方形)内IL-18的生物活性,其中重组IL-18(黑色正方形)和重组IL-12(黑色圆)分别用作阳性和阴性对照。
图17显示18t15-12s复合物(空心正方形)内IL-12的生物活性,其中重组IL-12(黑色圆)和重组IL-18(空心正方形)分别用作阳性和阴性对照。
图18A和18B显示由18t15-12s复合物诱导的NK细胞上CD25的细胞表面表达和由18t15-12s复合物诱导的NK细胞的细胞表面CD69表达。
图19显示由18t15-12s复合物诱导的NK细胞的细胞内干扰素γ表达的流式细胞术图。
图20显示18t15-12s诱导的人NK细胞对K562细胞的细胞毒性。
图21显示示例性IL-12/IL-15RαSu/αCD16 DNA构建体的示意图。
图22显示示例性IL-18/TF/IL-15DNA构建体的示意图。
图23显示示例性IL-12/IL-15RαSu/αCD16scFv与IL-18/TF/IL-15DNA构建体之间的相互作用的示意图。
图24显示示例性的18t15-12s/αCD16蛋白复合物的示意图。
图25显示用于18t15-12s16复合物的夹心ELISA,其包含抗人组织因子捕获抗体和生物素化抗人IL-12或IL-18检测抗体。
图26显示示例性TGFβRII/IL-15RαSu DNA构建体的示意图。
图27显示示例性IL-21/TF/IL-15构建体的示意图。
图28显示示例性IL-IL-21/TF/IL-15与TGFβRII/IL-15RαSu构建体之间的相互作用的示意图。
图29显示产生IL-21/TF/IL-15/TGFβRII/IL-15RαSu复合物(21t15-TGFRs)的示例性TGFβRII/IL-15RαSu与IL-21/TF/IL-15融合蛋白之间的相互作用的示意图。
图30显示来自抗TF抗体亲和柱的21t15-TGFRs纯化洗脱的色谱图。
图31显示示例性的21t15-TGFRs尺寸排阻色谱图,显示主要蛋白质峰和高分子量峰。
图32显示二硫键还原后21t15-TGFRs复合物的4-12%SDS-PAGE的实例。泳道1:Mark12未染色的标记(左侧的数字指示以kDa为单位的分子量);泳道2:21t15-TGFRs(0.5μg);泳道3:21t15-TGFRs(1μg);泳道4:21t15-TGFRs,去糖基化(1μg),其中MW是53kDa和39.08kDa的预期大小。
图33显示用于21t15-TGFRs复合物的夹心ELISA,其包含抗人组织因子捕获抗体和生物素化抗人IL-21检测抗体(13-7218-81,BioLegend)。
图34显示用于21t15-TGFRs复合物的夹心ELISA,其包含抗人组织因子捕获抗体和生物素化抗人IL-15检测抗体(BAM 247,安迪生物公司(R&D Systems))。
图35显示用于21t15-TGFRs复合物的夹心ELISA,其包含抗人组织因子捕获抗体和生物素化抗人TGFβRII检测抗体(BAF241,安迪生物公司)。
图36显示用于21t15-TGFRs复合物的夹心ELISA,其包含抗人组织因子(I43)捕获抗体和抗人组织因子检测抗体。
图37显示与IL-15(黑色方块)相比,由21t15-TGFRs复合物(空心方块)介导的IL-15依赖性32Dβ细胞增殖。
图38显示21t15-TGFRs复合物(空心正方形)内TGFβRII结构域的生物活性。TGFβRII/Fc(黑色方块)充当阳性对照。
图39A显示由21t15-TGFRs复合物诱导的NK细胞的细胞表面CD25表达的流式细胞术图。
图40显示由21t15-TGFRs复合物诱导的NK细胞的细胞表面CD69表达的流式细胞术图。
图41显示由21t15-TGFRs复合物诱导的NK细胞的细胞内干扰素γ表达的流式细胞术图。
图42显示21t15-TGFRs诱导的人NK细胞对K562细胞的细胞毒性。
图43显示示例性IL-7/IL-15RαSu DNA构建体的示意图。
图44显示示例性IL-21/TF/IL-15DNA构建体的示意图。
图45显示示例性IL-7/IL-15RαSu与IL-21/TF/IL-15DNA构建体之间的相互作用的示意图。
图46显示产生IL-21/TF/IL-15:IL-7/IL-15RαSu复合物(21t15-7s)的示例性IL-7/IL-15RαSu与IL-21/TF/IL-15融合蛋白之间的相互作用的示意图。
图47显示通过用21t15-7s+抗TF IgG1抗体刺激引起的原代自然杀伤(NK)细胞的扩增。
图48显示使用CD25 MFI和CD69 MFI作为NK细胞激活的标记,扩增的原代NK细胞的激活。
图49显示扩增的NK细胞对K562人肿瘤细胞的细胞毒活性,其中用21t15-7s+抗TFIgG1抗体刺激的NK细胞展现比未用21t15-7s+抗TF IgG1抗体刺激的NK细胞更大的K562细胞特异性溶解。
图50显示示例性IL-21/IL-15RαSu DNA构建体的示意图。
图51显示示例性IL-7/TF/IL-15DNA构建体的示意图。
图52显示示例性IL-21/IL-15RαSu与IL-7/TF/IL-15DNA构建体之间的相互作用的示意图。
图53显示产生IL-7/TF/IL-15:IL-21/IL-15RαSU复合物(7t15-21s)的示例性IL-21/IL-15RαSu与IL-7/TF/IL-15融合蛋白之间的相互作用的示意图。
图54以图解形式显示通过用21t15-TGFRs+抗TF IgG1抗体刺激引起的原代自然杀伤(NK)细胞的激活和扩增。
图55显示抗TF IgG1抗体、7t15-21s和含有等量抗TF IgG1抗体和7t15-21s的复合物的尺寸排阻色谱(SEC)图。
图56显示从两个不同供体的血液中分离的人NK细胞(2×106个细胞/毫升)的耗氧率(OCR),单位为皮摩尔/分钟。
图57显示从两个不同供体的血液中分离的人NK细胞(2×106个细胞/毫升)的细胞外酸化率(ECAR),单位为mpH/min。
图58显示7t15-16s21构建体的示意图。
图59显示7t15-16s21构建体的另一示意图。
图60A和60B显示与对照蛋白相比,7t15-16s21与表达人CD16b的CHO细胞的结合。
图61A-61C是来自使用针对IL-15、IL-21和IL-7的抗体检测7t15-16s21的ELISA实验的结果。
图62显示用7t15-16s21或重组IL-15进行32Dβ细胞增殖分析的结果。
图63显示在抗TF抗体树脂上结合和洗脱后,含7t15-16s21蛋白的细胞培养上清液的色谱图。
图64显示7t15-16s21的分析SEC图。
图65显示TGFRt15-16s21构建体的示意图。
图66显示TGFRt15-16s21构建体的另一示意图。
图67A和67B显示TGFRt15-16S21和7t15-21s与表达人CD16b的CHO细胞的结合亲和力。图67A显示TGFRt15-16S21与表达人CD16b的CHO细胞的结合亲和力。图67B显示7t15-21s与表达人CD16b的CHO细胞的结合亲和力。
图68显示由TGFRt15-16s21和TGFR-Fc引起的TGFβ1抑制的结果。
图69显示用TGFRt15-16s21或重组IL-15进行的32Dβ细胞增殖分析的结果。
图70A-70C显示使用ELISA用对应抗体检测TGFRt15-16s21中的IL-15、IL-21和TGFβRII的结果。
图71显示在抗TF抗体树脂上结合和洗脱后,含TGFRt15-16s21蛋白的细胞培养上清液的色谱图。
图72显示TGFRt15-16s21的还原SDS-PAGE分析的结果。
图73显示7t15-7s构建体的示意图。
图74显示7t15-7s构建体的另一示意图。
图75显示在抗TF抗体树脂上结合和洗脱后,含7t15-7s蛋白的细胞培养上清液的色谱图。
图76显示使用ELISA进行的对7t15-7s中的TF、IL-15和IL-7的检测。
图77显示TGFRt15-TGFRs构建体的示意图。
图78显示TGFRt15-TGFRs构建体的另一示意图。
图79显示由TGFRt15-TGFRs和TGFR-Fc引起的TGFβ1抑制的结果。
图80显示用TGFRt15-TGFRs或重组IL-15进行32Dβ细胞增殖分析的结果。
图81A和81B显示使用ELISA用对应抗体检测TGFRt15-TGFR中的IL-15和TGFβRII的结果。
图82是显示在抗TF抗体树脂上结合和洗脱后,含TGFRt15-TGFRs蛋白的细胞培养上清液的色谱图的线图。
图83显示TGFRt15-TGFRs的分析SEC图。
图84显示如通过还原SDS-PAGE分析的去糖基化前后的TGFRt15-TGFR。
图85A和85B显示经TGFRt15-TGFRs处理和对照处理的小鼠的脾脏重量和免疫细胞类型的百分比。图85A显示与PBS对照相比,用TGFRt15-TGFRs处理的小鼠的脾脏重量。图85B显示与PBS对照相比,用TGFRt15-TGFRs处理的小鼠中CD4+T细胞、CD8+T细胞和NK细胞的百分比。
图86A和86B显示用TGFRt15-TGFRs处理的小鼠中92小时内的脾脏重量和免疫刺激。图86A显示在处理后16、24、48、72和92小时用TGFRt15-TGFRs处理的小鼠的脾脏重量。图86B显示在处理后16、24、48、72和92小时用TGFRt15-TGFRs处理的小鼠中免疫细胞的百分比。
图87A和87B显示在一段时间内用TGFRt15-TGFRs处理的小鼠中Ki67和颗粒酶B的表达。
图88显示在C57BL/6小鼠中,TGFRt15-TGFRs增强脾细胞的细胞毒性。
图89显示在胰腺癌小鼠模型中,响应于PBS处理、单独的化疗、单独的TGFRt15-TGFRs或化疗与TGFRt15-TGFRs组合的肿瘤尺寸变化。
图90显示从用TGFRt15-TGFRs处理的小鼠分离的NK细胞的细胞毒性。
图91显示7t15-21s137L(长版)构建体的示意图。
图92显示7t15-21s137L(长版)构建体的另一示意图。
图93是显示在抗TF抗体树脂上结合和洗脱后,含7t15-21s137L(长版)蛋白质的细胞培养上清液的色谱图的线图。
图94显示7t15-21s137L(长版)的分析SEC图。
图95显示7t15-21s137L(短版)与CD137L(4.1BBL)的结合。
图96A-96C显示用ELISA进行的对7t15-21s137L(短版)中IL15、IL21和IL7的检测。图96A显示用ELISA进行的对7t15-21s137L(短版)中IL15的检测。图96B显示用ELISA进行的对7t15-21s137L(短版)中IL21的检测。图96C显示用ELISA进行的对7t15-21s137L(短版)中IL7的检测。
图97显示来自CTLL-2细胞增殖分析的结果。
图98显示7t15-1s137L(短版)在促进含IL21R的B9细胞增殖中的活性。
图99显示7t15-TGFRs构建体的示意图。
图100显示7t15-TGFRs构建体的另一示意图。
图101显示由7t15-TGFR和TGFR-Fc引起的TGFβ1抑制的结果。
图102A-102C显示用ELISA进行的对7t15-TGFRs中IL-15、TGFβRII和IL-7的检测。
图103显示用7t15-TGFRs或重组IL-15进行的32Dβ细胞增殖分析的结果。
图104是显示在抗TF抗体亲和柱上结合和洗脱后,含有7t15-TGFRs蛋白的细胞培养上清液的色谱图的线图。
图105显示如使用还原SDS-PAGE分析的去糖基化前后的7t15-TGFRs。
图106显示7t15-TGFRs蛋白中IL-7、IL-15和TGFβRII的ELISA检测。
图107A和107B显示经7t15-TGFRs处理和对照处理的小鼠的脾脏重量和免疫细胞类型的百分比。图107A显示与PBS对照相比,用各种剂量的7t15-TGFRs处理的小鼠的脾脏重量。图107B显示与PBS对照相比,在用不同剂量的7t15-TGFRs处理的小鼠中,CD4+T细胞、CD8+T细胞和NK细胞的百分比。
图108A和108B显示在C57BL/6小鼠中,7t15-TGFRs对CD4+和CD8+T细胞的CD44表达的上调。
图109A和109B显示在C57BL/6小鼠中,7t15-TGFRs对CD8+T细胞和NK细胞的Ki67表达和颗粒酶B表达的上调。
图110显示在C57BL/6小鼠中,7t15-TGFRs增强脾细胞的细胞毒性。
图111显示TGFRt15-21s137L构建体的示意图。
图112显示TGFRt15-21s137L构建体的另一示意图。
图113是显示在抗TF抗体亲和柱上结合和洗脱后,含TGFRt15-21s137L蛋白的细胞培养上清液的色谱图的线图。
图114显示TGFRt15-TGFRs21构建体的示意图。
图115显示TGFRt15-TGFRs21构建体的另一示意图。
图116是显示在抗TF抗体亲和柱上结合和洗脱后,含TGFRt15-TGFRs21蛋白的细胞培养上清液的色谱图的线图。
图117显示通过还原SDS-PAGE分析的去糖基化前后的TGFRt15-TGFRs21。
图118A和118B显示使用ELISA进行的TGFRt15-TGFRs21组分的检测。
图119A和119B显示在对照处理和TGFRt15-TGFRs21处理的小鼠的脾脏中存在的CD4+T细胞、CD8+T细胞和自然杀伤(NK)细胞的百分比和增殖。
图120显示用TGFRt15-TGFRs21处理的小鼠中脾细胞的颗粒酶B表达的上调。
图121显示在C57BL/6小鼠中,TGFRt15-TGFRs21增强脾细胞的细胞毒性。
图122显示TGFRt15-TGFRs16构建体的示意图。
图123显示TGFRt15-TGFRs16构建体的另一示意图。
图124显示TGFRt15-TGFRs137L构建体的示意图。
图125显示TGFRt15-TGFRs137L构建体的另一示意图。
图126显示用18t15-12s、18t15-12s16和7t15-21s刺激后淋巴细胞群体的表面表型的变化。
图127显示用18t15-12s刺激后NK细胞中磷酸化STAT4和磷酸化STAT5水平的提高。
图128A-128C显示用西方饮食喂养并用TGFRt15-TGFRs处理的ApoE-/-小鼠中Treg、NK细胞和CD8+T细胞的体内刺激。
图129A-129C显示用TGFRt15-TGFRs处理后C57BL/6小鼠的免疫刺激。
图130A和130B显示用西方饮食喂养并用TGFRt15-TGFRs处理的ApoE-/-小鼠中NK细胞和CD8+T细胞的增殖的体内诱导。
图131A和131B显示用TGFRt15-TGFRs处理NK细胞后,NK细胞的细胞毒性增强。
图132A和132B显示用TGFRt15-TGFRs处理NK细胞后,NK细胞的ADCC活性增强。
图133A-133H显示在黑色素瘤小鼠模型中,TGFRt15-TGFRs加抗TRP1抗体(TA99)与化疗组合的抗肿瘤活性。
图134A-134C显示TGFRt15-TGFRs改善了ApoE-/-小鼠中西方饮食引起的高血糖。
图135显示细胞表面染色,概述用18t15-12s刺激并在rhIL15中培养后,NK细胞分化成细胞因子诱导记忆样NK细胞(CIML-NK细胞)。
图136显示上调,显示用TGFRt15-TGFRs处理后CD44hi记忆T细胞上调。
图137显示用单链或多链嵌合多肽处理后因子X(FX)激活的图。
图138显示凝血酶原时间(PT)测试中含有变化浓度的因诺维(Innovin)的缓冲液的凝结时间。
图139显示PT分析中多链嵌合多肽的凝结时间。
图140显示当与32DB细胞混合时,PT分析中多链嵌合多肽的凝结时间。
图141显示当与人PBMC混合时,PT分析中多链嵌合多肽的凝结时间。
图142显示7t15-21s137L(长版)和7t15-21s137L(短版)与CD137(4.1BB)的结合。
图143A-143D显示使用ELISA通过相应抗体在7t15-21s137L(长版)中检测IL7、IL21、IL15和4.1BBL。
图144显示如通过含IL2RαβγCTLL2细胞增殖分析评估的7t15-21s137L(长版)和7t15-21s137L(短版)的IL-15活性。
具体实施方式
本文提供多链嵌合多肽,其包括:(a)第一嵌合多肽,其包括:(i)第一靶标结合结构域;(ii)可溶性组织因子结构域;(iii)一对亲和结构域中的第一结构域;和(b)第二嵌合多肽,其包括:(i)一对亲和结构域中的第二结构域;(ii)第二靶标结合结构域,其中所述第一嵌合多肽和所述第二嵌合多肽通过所述一对亲和结构域中的第一结构域和第二结构域的结合而缔合。本文还提供组合物,其包括本文所描述的多链嵌合多肽中的任一种、编码本文所描述的多链嵌合多肽中的任一种的核酸和包括编码本文所描述的多链嵌合多肽中的任一种的核酸中的任一种的细胞。本文还提供刺激免疫细胞的方法和治疗有需要的受试者的方法,所述方法包括使用本文所描述的多链嵌合多肽中的任一种。本文还提供产生本文所描述的多链嵌合多肽中的任一种的方法。
在本文所描述的多链嵌合多肽中的任一种的一些实例中,第一嵌合多肽和/或第二嵌合多肽的总长度可各自独立地为约50个氨基酸至约3000个氨基酸,约50个氨基酸至约2500个氨基酸,约50个氨基酸至约2000个氨基酸,约50个氨基酸至约1500个氨基酸,约50个氨基酸至约1000个氨基酸,约50个氨基酸至约950个氨基酸,约50个氨基酸至约900个氨基酸,约50个氨基酸至约850个氨基酸,约50个氨基酸至约800个氨基酸,约50个氨基酸至约750个氨基酸,约50个氨基酸至约700个氨基酸,约50个氨基酸至约650个氨基酸,约50个氨基酸至约600个氨基酸,约50个氨基酸至约550个氨基酸,约50个氨基酸至约500个氨基酸,约50个氨基酸至约480个氨基酸,约50个氨基酸至约460个氨基酸,约50个氨基酸至约440个氨基酸,约50个氨基酸至约420个氨基酸,约50个氨基酸至约400个氨基酸,约50个氨基酸至约380个氨基酸,约50个氨基酸至约360个氨基酸,约50个氨基酸至约340个氨基酸,约50个氨基酸至约320个氨基酸,约50个氨基酸至约300个氨基酸,约50个氨基酸至约280个氨基酸,约50个氨基酸至约260个氨基酸,约50个氨基酸至约240个氨基酸,约50个氨基酸至约220个氨基酸,约50个氨基酸至约200个氨基酸,约50个氨基酸至约150个氨基酸,约50个氨基酸至约100个氨基酸,约100个氨基酸至约3000个氨基酸,约100个氨基酸至约2500个氨基酸,约100个氨基酸至约2000个氨基酸,约100个氨基酸至约1500个氨基酸,约100个氨基酸至约1000个氨基酸,约100个氨基酸至约950个氨基酸,约100个氨基酸至约900个氨基酸,约100个氨基酸至约850个氨基酸,约100个氨基酸至约800个氨基酸,约100个氨基酸至约750个氨基酸,约100个氨基酸至约700个氨基酸,约100个氨基酸至约650个氨基酸,约100个氨基酸至约600个氨基酸,约100个氨基酸至约550个氨基酸,约100个氨基酸至约500个氨基酸,约100个氨基酸至约480个氨基酸,约100个氨基酸至约460个氨基酸,约100个氨基酸至约440个氨基酸,约100个氨基酸至约420个氨基酸,约100个氨基酸至约400个氨基酸,约100个氨基酸至约380个氨基酸,约100个氨基酸至约360个氨基酸,约100个氨基酸至约340个氨基酸,约100个氨基酸至约320个氨基酸,约100个氨基酸至约300个氨基酸,约100个氨基酸至约280个氨基酸,约100个氨基酸至约260个氨基酸,约100个氨基酸至约240个氨基酸,约100个氨基酸至约220个氨基酸,约100个氨基酸至约200个氨基酸,约100个氨基酸至约150个氨基酸,约150个氨基酸至约3000个氨基酸,约150个氨基酸至约2500个氨基酸,约150个氨基酸至约2000个氨基酸,约150个氨基酸至约1500个氨基酸,约150个氨基酸至约1000个氨基酸,约150个氨基酸至约950个氨基酸,约150个氨基酸至约900个氨基酸,约150个氨基酸至约850个氨基酸,约150个氨基酸至约800个氨基酸,约150个氨基酸至约750个氨基酸,约150个氨基酸至约700个氨基酸,约150个氨基酸至约650个氨基酸,约150个氨基酸至约600个氨基酸,约150个氨基酸至约550个氨基酸,约150个氨基酸至约500个氨基酸,约150个氨基酸至约480个氨基酸,约150个氨基酸至约460个氨基酸,约150个氨基酸至约440个氨基酸,约150个氨基酸至约420个氨基酸,约150个氨基酸至约400个氨基酸,约150个氨基酸至约380个氨基酸,约150个氨基酸至约360个氨基酸,约150个氨基酸至约340个氨基酸,约150个氨基酸至约320个氨基酸,约150个氨基酸至约300个氨基酸,约150个氨基酸至约280个氨基酸,约150个氨基酸至约260个氨基酸,约150个氨基酸至约240个氨基酸,约150个氨基酸至约220个氨基酸,约150个氨基酸至约200个氨基酸,约200个氨基酸至约3000个氨基酸,约200个氨基酸至约2500个氨基酸,约200个氨基酸至约2000个氨基酸,约200个氨基酸至约1500个氨基酸,约200个氨基酸至约1000个氨基酸,约200个氨基酸至约950个氨基酸,约200个氨基酸至约900个氨基酸,约200个氨基酸至约850个氨基酸,约200个氨基酸至约800个氨基酸,约200个氨基酸至约750个氨基酸,约200个氨基酸至约700个氨基酸,约200个氨基酸至约650个氨基酸,约200个氨基酸至约600个氨基酸,约200个氨基酸至约550个氨基酸,约200个氨基酸至约500个氨基酸,约200个氨基酸至约480个氨基酸,约200个氨基酸至约460个氨基酸,约200个氨基酸至约440个氨基酸,约200个氨基酸至约420个氨基酸,约200个氨基酸至约400个氨基酸,约200个氨基酸至约380个氨基酸,约200个氨基酸至约360个氨基酸,约200个氨基酸至约340个氨基酸,约200个氨基酸至约320个氨基酸,约200个氨基酸至约300个氨基酸,约200个氨基酸至约280个氨基酸,约200个氨基酸至约260个氨基酸,约200个氨基酸至约240个氨基酸,约200个氨基酸至约220个氨基酸,约220个氨基酸至约3000个氨基酸,约220个氨基酸至约2500个氨基酸,约220个氨基酸至约2000个氨基酸,约220个氨基酸至约1500个氨基酸,约220个氨基酸至约1000个氨基酸,约220个氨基酸至约950个氨基酸,约220个氨基酸至约900个氨基酸,约220个氨基酸至约850个氨基酸,约220个氨基酸至约800个氨基酸,约220个氨基酸至约750个氨基酸,约220个氨基酸至约700个氨基酸,约220个氨基酸至约650个氨基酸,约220个氨基酸至约600个氨基酸,约220个氨基酸至约550个氨基酸,约220个氨基酸至约500个氨基酸,约220个氨基酸至约480个氨基酸,约220个氨基酸至约460个氨基酸,约220个氨基酸至约440个氨基酸,约220个氨基酸至约420个氨基酸,约220个氨基酸至约400个氨基酸,约220个氨基酸至约380个氨基酸,约220个氨基酸至约360个氨基酸,约220个氨基酸至约340个氨基酸,约220个氨基酸至约320个氨基酸,约220个氨基酸至约300个氨基酸,约220个氨基酸至约280个氨基酸,约220个氨基酸至约260个氨基酸,约220个氨基酸至约240个氨基酸,约240个氨基酸至约3000个氨基酸,约240个氨基酸至约2500个氨基酸,约240个氨基酸至约2000个氨基酸,约240个氨基酸至约1500个氨基酸,约240个氨基酸至约1000个氨基酸,约240个氨基酸至约950个氨基酸,约240个氨基酸至约900个氨基酸,约240个氨基酸至约850个氨基酸,约240个氨基酸至约800个氨基酸,约240个氨基酸至约750个氨基酸,约240个氨基酸至约700个氨基酸,约240个氨基酸至约650个氨基酸,约240个氨基酸至约600个氨基酸,约240个氨基酸至约550个氨基酸,约240个氨基酸至约500个氨基酸,约240个氨基酸至约480个氨基酸,约240个氨基酸至约460个氨基酸,约240个氨基酸至约440个氨基酸,约240个氨基酸至约420个氨基酸,约240个氨基酸至约400个氨基酸,约240个氨基酸至约380个氨基酸,约240个氨基酸至约360个氨基酸,约240个氨基酸至约340个氨基酸,约240个氨基酸至约320个氨基酸,约240个氨基酸至约300个氨基酸,约240个氨基酸至约280个氨基酸,约240个氨基酸至约260个氨基酸,约260个氨基酸至约3000个氨基酸,约260个氨基酸至约2500个氨基酸,约260个氨基酸至约2000个氨基酸,约260个氨基酸至约1500个氨基酸,约260个氨基酸至约1000个氨基酸,约260个氨基酸至约950个氨基酸,约260个氨基酸至约900个氨基酸,约260个氨基酸至约850个氨基酸,约260个氨基酸至约800个氨基酸,约260个氨基酸至约750个氨基酸,约260个氨基酸至约700个氨基酸,约260个氨基酸至约650个氨基酸,约260个氨基酸至约600个氨基酸,约260个氨基酸至约550个氨基酸,约260个氨基酸至约500个氨基酸,约260个氨基酸至约480个氨基酸,约260个氨基酸至约460个氨基酸,约260个氨基酸至约440个氨基酸,约260个氨基酸至约420个氨基酸,约260个氨基酸至约400个氨基酸,约260个氨基酸至约380个氨基酸,约260个氨基酸至约360个氨基酸,约260个氨基酸至约340个氨基酸,约260个氨基酸至约320个氨基酸,约260个氨基酸至约300个氨基酸,约260个氨基酸至约280个氨基酸,约280个氨基酸至约3000个氨基酸,约280个氨基酸至约2500个氨基酸,约280个氨基酸至约2000个氨基酸,约280个氨基酸至约1500个氨基酸,约280个氨基酸至约1000个氨基酸,约280个氨基酸至约950个氨基酸,约280个氨基酸至约900个氨基酸,约280个氨基酸至约850个氨基酸,约280个氨基酸至约800个氨基酸,约280个氨基酸至约750个氨基酸,约280个氨基酸至约700个氨基酸,约280个氨基酸至约650个氨基酸,约280个氨基酸至约600个氨基酸,约280个氨基酸至约550个氨基酸,约280个氨基酸至约500个氨基酸,约280个氨基酸至约480个氨基酸,约280个氨基酸至约460个氨基酸,约280个氨基酸至约440个氨基酸,约280个氨基酸至约420个氨基酸,约280个氨基酸至约400个氨基酸,约280个氨基酸至约380个氨基酸,约280个氨基酸至约360个氨基酸,约280个氨基酸至约340个氨基酸,约280个氨基酸至约320个氨基酸,约280个氨基酸至约300个氨基酸,约300个氨基酸至约3000个氨基酸,约300个氨基酸至约2500个氨基酸,约300个氨基酸至约2000个氨基酸,约300个氨基酸至约1500个氨基酸,约300个氨基酸至约1000个氨基酸,约300个氨基酸至约950个氨基酸,约300个氨基酸至约900个氨基酸,约300个氨基酸至约850个氨基酸,约300个氨基酸至约800个氨基酸,约300个氨基酸至约750个氨基酸,约300个氨基酸至约700个氨基酸,约300个氨基酸至约650个氨基酸,约300个氨基酸至约600个氨基酸,约300个氨基酸至约550个氨基酸,约300个氨基酸至约500个氨基酸,约300个氨基酸至约480个氨基酸,约300个氨基酸至约460个氨基酸,约300个氨基酸至约440个氨基酸,约300个氨基酸至约420个氨基酸,约300个氨基酸至约400个氨基酸,约300个氨基酸至约380个氨基酸,约300个氨基酸至约360个氨基酸,约300个氨基酸至约340个氨基酸,约300个氨基酸至约320个氨基酸,约320个氨基酸至约3000个氨基酸,约320个氨基酸至约2500个氨基酸,约320个氨基酸至约2000个氨基酸,约320个氨基酸至约1500个氨基酸,约320个氨基酸至约1000个氨基酸,约320个氨基酸至约950个氨基酸,约320个氨基酸至约900个氨基酸,约320个氨基酸至约850个氨基酸,约320个氨基酸至约800个氨基酸,约320个氨基酸至约750个氨基酸,约320个氨基酸至约700个氨基酸,约320个氨基酸至约650个氨基酸,约320个氨基酸至约600个氨基酸,约320个氨基酸至约550个氨基酸,约320个氨基酸至约500个氨基酸,约320个氨基酸至约480个氨基酸,约320个氨基酸至约460个氨基酸,约320个氨基酸至约440个氨基酸,约320个氨基酸至约420个氨基酸,约320个氨基酸至约400个氨基酸,约320个氨基酸至约380个氨基酸,约320个氨基酸至约360个氨基酸,约320个氨基酸至约340个氨基酸,约340个氨基酸至约3000个氨基酸,约340个氨基酸至约2500个氨基酸,约340个氨基酸至约2000个氨基酸,约340个氨基酸至约1500个氨基酸,约340个氨基酸至约1000个氨基酸,约340个氨基酸至约950个氨基酸,约340个氨基酸至约900个氨基酸,约340个氨基酸至约850个氨基酸,约340个氨基酸至约800个氨基酸,约340个氨基酸至约750个氨基酸,约340个氨基酸至约700个氨基酸,约340个氨基酸至约650个氨基酸,约340个氨基酸至约600个氨基酸,约340个氨基酸至约550个氨基酸,约340个氨基酸至约500个氨基酸,约340个氨基酸至约480个氨基酸,约340个氨基酸至约460个氨基酸,约340个氨基酸至约440个氨基酸,约340个氨基酸至约420个氨基酸,约340个氨基酸至约400个氨基酸,约340个氨基酸至约380个氨基酸,约340个氨基酸至约360个氨基酸,约360个氨基酸至约3000个氨基酸,约360个氨基酸至约2500个氨基酸,约360个氨基酸至约2000个氨基酸,约360个氨基酸至约1500个氨基酸,约360个氨基酸至约1000个氨基酸,约360个氨基酸至约950个氨基酸,约360个氨基酸至约900个氨基酸,约360个氨基酸至约850个氨基酸,约360个氨基酸至约800个氨基酸,约360个氨基酸至约750个氨基酸,约360个氨基酸至约700个氨基酸,约360个氨基酸至约650个氨基酸,约360个氨基酸至约600个氨基酸,约360个氨基酸至约550个氨基酸,约360个氨基酸至约500个氨基酸,约360个氨基酸至约480个氨基酸,约360个氨基酸至约460个氨基酸,约360个氨基酸至约440个氨基酸,约360个氨基酸至约420个氨基酸,约360个氨基酸至约400个氨基酸,约360个氨基酸至约380个氨基酸,约380个氨基酸至约3000个氨基酸,约380个氨基酸至约2500个氨基酸,约380个氨基酸至约2000个氨基酸,约380个氨基酸至约1500个氨基酸,约380个氨基酸至约1000个氨基酸,约380个氨基酸至约950个氨基酸,约380个氨基酸至约900个氨基酸,约380个氨基酸至约850个氨基酸,约380个氨基酸至约800个氨基酸,约380个氨基酸至约750个氨基酸,约380个氨基酸至约700个氨基酸,约380个氨基酸至约650个氨基酸,约380个氨基酸至约600个氨基酸,约380个氨基酸至约550个氨基酸,约380个氨基酸至约500个氨基酸,约380个氨基酸至约480个氨基酸,约380个氨基酸至约460个氨基酸,约380个氨基酸至约440个氨基酸,约380个氨基酸至约420个氨基酸,约380个氨基酸至约400个氨基酸,约400个氨基酸至约3000个氨基酸,约400个氨基酸至约2500个氨基酸,约400个氨基酸至约2000个氨基酸,约400个氨基酸至约1500个氨基酸,约400个氨基酸至约1000个氨基酸,约400个氨基酸至约950个氨基酸,约400个氨基酸至约900个氨基酸,约400个氨基酸至约850个氨基酸,约400个氨基酸至约800个氨基酸,约400个氨基酸至约750个氨基酸,约400个氨基酸至约700个氨基酸,约400个氨基酸至约650个氨基酸,约400个氨基酸至约600个氨基酸,约400个氨基酸至约550个氨基酸,约400个氨基酸至约500个氨基酸,约400个氨基酸至约480个氨基酸,约400个氨基酸至约460个氨基酸,约400个氨基酸至约440个氨基酸,约400个氨基酸至约420个氨基酸,约420个氨基酸至约3000个氨基酸,约420个氨基酸至约2500个氨基酸,约420个氨基酸至约2000个氨基酸,约420个氨基酸至约1500个氨基酸,约420个氨基酸至约1000个氨基酸,约420个氨基酸至约950个氨基酸,约420个氨基酸至约900个氨基酸,约420个氨基酸至约850个氨基酸,约420个氨基酸至约800个氨基酸,约420个氨基酸至约750个氨基酸,约420个氨基酸至约700个氨基酸,约420个氨基酸至约650个氨基酸,约420个氨基酸至约600个氨基酸,约420个氨基酸至约550个氨基酸,约420个氨基酸至约500个氨基酸,约420个氨基酸至约480个氨基酸,约420个氨基酸至约460个氨基酸,约420个氨基酸至约440个氨基酸,约440个氨基酸至约3000个氨基酸,约440个氨基酸至约2500个氨基酸,约440个氨基酸至约2000个氨基酸,约440个氨基酸至约1500个氨基酸,约440个氨基酸至约1000个氨基酸,约440个氨基酸至约950个氨基酸,约440个氨基酸至约900个氨基酸,约440个氨基酸至约850个氨基酸,约440个氨基酸至约800个氨基酸,约440个氨基酸至约750个氨基酸,约440个氨基酸至约700个氨基酸,约440个氨基酸至约650个氨基酸,约440个氨基酸至约600个氨基酸,约440个氨基酸至约550个氨基酸,约440个氨基酸至约500个氨基酸,约440个氨基酸至约480个氨基酸,约440个氨基酸至约460个氨基酸,约460个氨基酸至约3000个氨基酸,约460个氨基酸至约2500个氨基酸,约460个氨基酸至约2000个氨基酸,约460个氨基酸至约1500个氨基酸,约460个氨基酸至约1000个氨基酸,约460个氨基酸至约950个氨基酸,约460个氨基酸至约900个氨基酸,约460个氨基酸至约850个氨基酸,约460个氨基酸至约800个氨基酸,约460个氨基酸至约750个氨基酸,约460个氨基酸至约700个氨基酸,约460个氨基酸至约650个氨基酸,约460个氨基酸至约600个氨基酸,约460个氨基酸至约550个氨基酸,约460个氨基酸至约500个氨基酸,约460个氨基酸至约480个氨基酸,约480个氨基酸至约3000个氨基酸,约480个氨基酸至约2500个氨基酸,约480个氨基酸至约2000个氨基酸,约480个氨基酸至约1500个氨基酸,约480个氨基酸至约1000个氨基酸,约480个氨基酸至约950个氨基酸,约480个氨基酸至约900个氨基酸,约480个氨基酸至约850个氨基酸,约480个氨基酸至约800个氨基酸,约480个氨基酸至约750个氨基酸,约480个氨基酸至约700个氨基酸,约480个氨基酸至约650个氨基酸,约480个氨基酸至约600个氨基酸,约480个氨基酸至约550个氨基酸,约480个氨基酸至约500个氨基酸,约500个氨基酸至约3000个氨基酸,约500个氨基酸至约2500个氨基酸,约500个氨基酸至约2000个氨基酸,约500个氨基酸至约1500个氨基酸,约500个氨基酸至约1000个氨基酸,约500个氨基酸至约950个氨基酸,约500个氨基酸至约900个氨基酸,约500个氨基酸至约850个氨基酸,约500个氨基酸至约800个氨基酸,约500个氨基酸至约750个氨基酸,约500个氨基酸至约700个氨基酸,约500个氨基酸至约650个氨基酸,约500个氨基酸至约600个氨基酸,约500个氨基酸至约550个氨基酸,约550个氨基酸至约3000个氨基酸,约550个氨基酸至约2500个氨基酸,约550个氨基酸至约2000个氨基酸,约550个氨基酸至约1500个氨基酸,约550个氨基酸至约1000个氨基酸,约550个氨基酸至约950个氨基酸,约550个氨基酸至约900个氨基酸,约550个氨基酸至约850个氨基酸,约550个氨基酸至约800个氨基酸,约550个氨基酸至约750个氨基酸,约550个氨基酸至约700个氨基酸,约550个氨基酸至约650个氨基酸,约550个氨基酸至约600个氨基酸,约600个氨基酸至约3000个氨基酸,约600个氨基酸至约2500个氨基酸,约600个氨基酸至约2000个氨基酸,约600个氨基酸至约1500个氨基酸,约600个氨基酸至约1000个氨基酸,约600个氨基酸至约950个氨基酸,约600个氨基酸至约900个氨基酸,约600个氨基酸至约850个氨基酸,约600个氨基酸至约800个氨基酸,约600个氨基酸至约750个氨基酸,约600个氨基酸至约700个氨基酸,约600个氨基酸至约650个氨基酸,约650个氨基酸至约3000个氨基酸,约650个氨基酸至约2500个氨基酸,约650个氨基酸至约2000个氨基酸,约650个氨基酸至约1500个氨基酸,约650个氨基酸至约1000个氨基酸,约650个氨基酸至约950个氨基酸,约650个氨基酸至约900个氨基酸,约650个氨基酸至约850个氨基酸,约650个氨基酸至约800个氨基酸,约650个氨基酸至约750个氨基酸,约650个氨基酸至约700个氨基酸,约700个氨基酸至约3000个氨基酸,约700个氨基酸至约2500个氨基酸,约700个氨基酸至约2000个氨基酸,约700个氨基酸至约1500个氨基酸,约700个氨基酸至约1000个氨基酸,约700个氨基酸至约950个氨基酸,约700个氨基酸至约900个氨基酸,约700个氨基酸至约850个氨基酸,约700个氨基酸至约800个氨基酸,约700个氨基酸至约750个氨基酸,约750个氨基酸至约3000个氨基酸,约750个氨基酸至约2500个氨基酸,约750个氨基酸至约2000个氨基酸,约750个氨基酸至约1500个氨基酸,约750个氨基酸至约1000个氨基酸,约750个氨基酸至约950个氨基酸,约750个氨基酸至约900个氨基酸,约750个氨基酸至约850个氨基酸,约750个氨基酸至约800个氨基酸,约800个氨基酸至约3000个氨基酸,约800个氨基酸至约2500个氨基酸,约800个氨基酸至约2000个氨基酸,约800个氨基酸至约1500个氨基酸,约800个氨基酸至约1000个氨基酸,约800个氨基酸至约950个氨基酸,约800个氨基酸至约900个氨基酸,约800个氨基酸至约850个氨基酸,约850个氨基酸至约3000个氨基酸,约850个氨基酸至约2500个氨基酸,约850个氨基酸至约2000个氨基酸,约850个氨基酸至约1500个氨基酸,约850个氨基酸至约1000个氨基酸,约850个氨基酸至约950个氨基酸,约850个氨基酸至约900个氨基酸,约900个氨基酸至约3000个氨基酸,约900个氨基酸至约2500个氨基酸,约900个氨基酸至约2000个氨基酸,约900个氨基酸至约1500个氨基酸,约900个氨基酸至约1000个氨基酸,约900个氨基酸至约950个氨基酸,约950个氨基酸至约3000个氨基酸,约950个氨基酸至约2500个氨基酸,约950个氨基酸至约2000个氨基酸,约950个氨基酸至约1500个氨基酸,约950个氨基酸至约1000个氨基酸,约1000个氨基酸至约3000个氨基酸,约1000个氨基酸至约2500个氨基酸,约1000个氨基酸至约2000个氨基酸,约1000个氨基酸至约1500个氨基酸,约1500个氨基酸至约3000个氨基酸,约1500个氨基酸至约2500个氨基酸,约1500个氨基酸至约2000个氨基酸,约2000个氨基酸至约3000个氨基酸,约2000个氨基酸至约2500个氨基酸,或约2500个氨基酸至约3000个氨基酸。图1和图2描绘本文提供的示例性多链嵌合多肽的图。
在本文所描述的多链嵌合多肽中的任一种的一些实施例中,第一靶标结合结构域(例如,本文所描述的第一靶标结合结构域中的任一种)和可溶性组织因子结构域(例如,本文所描述的示例性可溶性组织因子结构域中的任一种)在第一嵌合多肽中彼此直接邻接。在本文所描述的多链嵌合多肽中的任一种的一些实施例中,第一嵌合多肽进一步包含在第一嵌合多肽中的第一靶标结合结构域(例如,本文所描述的示例性第一靶标结合结构域中的任一种)与可溶性组织因子结构域(例如,本文所描述的示例性可溶性组织因子结构域中的任一种)之间的接头序列(例如,本文所描述或本领域已知的示例性接头序列中的任一种)。
在本文所描述的多链嵌合多肽中的任一种的一些实施例中,可溶性组织因子结构域(例如,本文所描述的示例性可溶性组织因子结构域中的任一种)与一对亲和结构域中的第一结构域(例如,本文所描述的示例性亲和结构域对中的任一种的示例性第一结构域中的任一种)在第一嵌合多肽中彼此直接邻接。在本文所描述的多链嵌合多肽中的任一种的一些实施例中,第一嵌合多肽进一步包含在第一嵌合多肽中的可溶性组织因子结构域(例如,本文所描述的示例性可溶性组织因子结构域中的任一种)与一对亲和结构域中的第一结构域(例如,本文所描述的示例性亲和结构域对中的任一种的示例性第一结构域中的任一种)之间的接头序列(例如,本文所描述或本领域已知的示例性接头序列中的任一种)。
在本文所描述的多链嵌合多肽中的任一种的一些实施例中,一对亲和结构域中的第二结构域(例如,本文所描述的示例性亲和结构域对中的任一种的示例性第二结构域中的任一种)与第二靶标结合结构域(例如,本文所描述的示例性第二靶标结合结构域中的任一种)在第二嵌合多肽中彼此直接邻接。在本文所描述的多链嵌合多肽中的任一种的一些实施例中,第二嵌合多肽进一步包含在第二嵌合多肽中的一对亲和结构域中的第二结构域(例如,本文所描述的示例性亲和结构域对中的任一种的示例性第二结构域中的任一种)与第二靶标结合结构域(例如,本文所描述的示例性第二靶标结合结构域中的任一种)之间的接头序列(例如,本文所描述或本领域已知的示例性接头序列中的任一种)。
这些嵌合多肽、核酸、载体、细胞和方法的非限制性方面在下文描述,并且可在无限制的情况下以任何组合使用。这些嵌合多肽、核酸、载体、细胞和方法的另外方面是本领域已知的。
组织因子
人组织因子是263个氨基酸的跨膜蛋白,其含有三个结构域:(1)219个氨基酸的N端细胞外结构域(残基1-219);(2)22个氨基酸的跨膜结构域(残基220-242);和(3)21个氨基酸的胞质C端尾(残基242-263)((UniProtKB标识符编号:P13726)。胞质尾在Ser253和Ser258处含有两个磷酸化位点,在Cys245处含有一个S-棕榈酰化位点。没有发现胞质结构域的缺失或突变影响组织因子凝血活性。组织因子在蛋白质细胞内结构域中Cys245处具有一个S-棕榈酰化位点。Cys245位于细胞内结构域的氨基酸端,并且靠近膜表面。组织因子跨膜结构域由单跨度的α-螺旋构成。
由两个纤连蛋白III型结构域构成的组织因子的细胞外结构域通过六氨基酸接头与跨膜结构域连接。这一接头提供构象灵活性,以使组织因子细胞外结构域与其跨膜结构域和胞质结构域解偶联。每个组织因子纤连蛋白III型模块均由两个重叠的β折叠构成,其中顶层折叠结构域含有三个反平行的β链,而底层折叠含有四个β链。β链通过β环在链βA和βB、βC和βD以及βE和βF之间连接,其在两个模块中均构象保守。有三个短的α螺旋段连接β链。组织因子的独特特征是链β10与链β11之间的17个氨基酸的β-发夹,这不是纤连蛋白超家族的常见成分。N端结构域还在β6F与β7G之间包含一个12个氨基酸的环,所述环不存在于C端结构域,并且是组织因子特有的。这种纤连蛋白III型结构域结构是免疫球蛋白样家族蛋白质折叠的特征,并且在广泛多种细胞外蛋白中是保守的。
一旦酶原FVII与组织结合形成活性组织因子-FVIIa复合物,就可通过有限的蛋白水解将其迅速转化为FVIIa。FVIIa以大约0.1nM(血浆FVII的1%)的浓度作为酶循环,也可直接结合到组织因子。组织因子与FVIIa在组织因子-FVIIa复合物上的变构相互作用极大地提高了FVIIa的酶促活性:小的发色肽基底物的水解速率提高约20到100倍,并且天然大分子底物FIX和FX的激活速率提高接近一百万倍。与结合到组织因子时FVIIa活性位点的变构激活相一致,磷脂双层上组织因子-FVIIa复合物的形成(即,当磷脂酰-L-丝氨酸暴露在膜表面时)以Ca2+依赖的方式提高FIX或FX激活的速率1000倍。相对于游离FVIIa,组织因子-FVIIa-磷脂复合物对FX激活的大约百万倍总体增加是凝血级联反应的关键调节点。
FVII是约50kDa的单链多肽,由406个氨基酸残基组成,具有N端富含γ-羧基谷氨酸(GLA)的结构域,两个表皮生长因子样结构域(EGF1和EFG2)和C端丝氨酸蛋白酶结构域。FVII通过在EGF2与蛋白酶结构域之间的短接头区中Ile-154-Arg152键的特异性蛋白水解裂解而被激活为FVIIa。这种裂解引起轻链和重链通过Cys135和Cys262的单个二硫键固定在一起。FVIIa通过其N端GLA结构域以Ca2+依赖性方式结合磷脂膜。GLA结构域的C端紧邻芳香族堆叠和两个EGF结构域。芳香族堆叠将GLA连接到结合单个Ca2+离子的EGF1结构域。占用这一Ca2+结合位点会增加FVIIa酰胺分解活性和组织因子缔合。催化三联体由His193、Asp242和Ser344组成,并且FVIIa蛋白酶域内单个Ca2+离子的结合对其催化活性至关重要。FVII对FVIIa的蛋白水解激活释放了Ile153处新形成的氨基端,使其向后折叠并且插入激活袋中,与Asp343的羧酸盐形成盐桥,以生成氧阴离子孔。这一盐桥的形成对于FVIIa活性至关重要。但是,在蛋白水解激活后,游离的FVIIa中不会发生氧阴离子孔的形成。结果,FVIIa以酶原样状态循环,血浆蛋白酶抑制剂不能很好识别所述状态,使其以大约90分钟的半衰期循环。
FVIIa活性位点在膜表面上方的组织因子介导的定位对于FVIIa朝向同源底物很重要。游离FVIIa在结合到膜上时采用稳定扩展结构,其活性位点定位在膜表面上方约 FVIIa与组织因子结合后,FVa活性位点将重新定位为更靠近膜约
FVIIa与组织因子结合后,FVa活性位点将重新定位为更靠近膜约 这种调节可帮助FVIIa催化三联体与靶标底物裂解位点正确对齐。使用无GLA结构域的FVIIa,已显示活性位点仍位于膜上方相似的距离,证明即使在没有FVIIa-膜相互作用的情况下,组织因子也能够完全支持FVIIa活性位点定位。另外的数据显示,只要组织因子细胞外结构域以某种方式系栓到膜表面,组织因子就支持完全FVIIa蛋白水解活性。但是,将FVIIa的活性位点提高到膜表面上方大于
这种调节可帮助FVIIa催化三联体与靶标底物裂解位点正确对齐。使用无GLA结构域的FVIIa,已显示活性位点仍位于膜上方相似的距离,证明即使在没有FVIIa-膜相互作用的情况下,组织因子也能够完全支持FVIIa活性位点定位。另外的数据显示,只要组织因子细胞外结构域以某种方式系栓到膜表面,组织因子就支持完全FVIIa蛋白水解活性。但是,将FVIIa的活性位点提高到膜表面上方大于 会大大降低组织因子-FVIIa复合物激活FX的能力,但不会降低组织因子-FVIIa的酰胺分解活性。
会大大降低组织因子-FVIIa复合物激活FX的能力,但不会降低组织因子-FVIIa的酰胺分解活性。
丙氨酸扫描诱变已用于评定组织因子细胞外结构域中特定氨基酸侧链对与FVIIa相互作用的作用(Gibbs等人,《生物化学(Biochemistry)》33(47):14003-14010,1994;Schullek等人,《生物化学杂志(J Biol Chem)》269(30):19399-19403,1994)。丙氨酸取代鉴别出有限数量的残基位置,在这些位置处,丙氨酸置换引起对FVIIa结合的亲和力降低5到10倍。发现这些残基侧链中的大多数在晶体结构中充分暴露于溶剂,与大分子配体相互作用一致。FVIIa配体结合位点位于两个模块之间边界处的宽广区上。在C模块中,位于突出的B-C环上的残基Arg135和Phe140提供与FVIIa的独立接触。Leu133位于手指状结构的基底部,并且挤入两个模块之间的裂缝中。这提供由Lys20、Thr60、Asp58和Ile22组成的重要结合残基的主要簇的连续性。Thr60仅部分暴露于溶剂,并且可能起局部结构作用,而不是与配体显著接触。结合位点延伸到模块间角的凹面,其涉及Glu24和Gln110,并且可能涉及更远的残基Val207。结合区从Asp58延伸到由Lys48、Lys46、Gln37、Asp44和Trp45形成的凸表面区。Trp45和Asp44不会独立地与FVIIa相互作用,表明Trp45位置处的突变效应可能反映这一侧链对邻近Asp44和Gln37侧链的局部堆积的结构重要性。相互作用区进一步包括两个表面暴露的芳香族残基Phe76和Tyr78,其在N模块中形成疏水簇的一部分。
组织因子-FVIIa的已知生理底物是FVII、FIX和FX以及某些蛋白酶激活的受体。突变分析已鉴别出许多残基,当突变时,所述残基支持对小肽基底物的完全FVIIa酰胺分解活性,但缺少支持大分子底物(即,FVII、FIX和FX)激活的能力(Ruf等人,《生物化学杂志》267(31):22206-22210,1992;Ruf等人,《生物化学杂志》267(9):6375-6381,1992;Huang等人,《生物化学杂志》271(36):21752-21757,1996;Kirchhofer等人,《生物化学》39(25):7380-7387,2000)。已显示在残基159-165处的组织因子环区和在这一柔性环中或附近的残基对于组织因子-FVIIa复合物的蛋白水解活性至关重要。这定义了提出的组织因子的底物结合位点外区,所述区与FVIIa活性位点相距甚远。甘氨酸残基被稍大的残基丙氨酸取代会大大损害组织因子-FVIIa的蛋白水解活性。这表明甘氨酸提供的柔性对于用于组织因子大分子底物识别的残基159-165的环至关重要。
还证明了残基Lys165和Lys166对于底物识别和结合很重要。这些残基中的任何一个突变为丙氨酸均会引起组织因子辅助因子功能的显著降低。在大多数组织因子-FVIIa结构中,Lys165和Lys166彼此背对,Lys165指向的FVIIa,而Lys166指向晶体结构中的底物结合位点外区。FVIIa的Lys165和Gla35之间的推定盐桥形成将支持组织因子与FVIIa的GLA结构域相互作用调节底物识别的观点。这些结果表明,组织因子胞外结构域的C端部分直接与FIX和FX的GLA结构域、可能的邻近EGF1结构域相互作用,并且FVIIa GLA结构域的存在可直接或间接调节这些相互作用。
可溶性组织因子结构域
在本文所描述的任何多肽、组合物或方法的一些实施例中,可溶性组织因子结构域可为缺少信号序列、跨膜结构域和细胞内结构域的野生型组织因子多肽。在一些实例中,可溶性组织因子结构域可为组织因子突变体,其中野生型组织因子多肽缺少信号序列、跨膜结构域和细胞内结构域,并且已在所选择的氨基酸处被进一步修饰。在一些实例中,可溶性组织因子结构域可为可溶性人组织因子结构域。在一些实例中,可溶性组织因子结构域可为可溶性小鼠组织因子结构域。在一些实例中,可溶性组织因子结构域可为可溶性大鼠组织因子结构域。可溶性人组织因子结构域、小鼠可溶性组织因子结构域、大鼠可溶性组织因子结构域和突变可溶性组织因子结构域的非限制性实例在以下显示。
示例性可溶性人组织因子结构域(SEQ ID NO:1)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
编码可溶性人组织因子结构域的示例性核酸(SEQ ID NO:2)
AGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAG
示例性突变可溶性人组织因子结构域(SEQ ID NO:3)
SGTTNTVAAYNLTWKSTNFATALEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECALTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVARNNTALSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
示例性突变可溶性人组织因子结构域(SEQ ID NO:4)
SGTTNTVAAYNLTWKSTNFATALEWEPKPVNQVYTVQISTKSGDAKSKCFYTTDTECALTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLAENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVARNNTALSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
示例性可溶性小鼠组织因子结构域(SEQ ID NO:5)
agipekafnltwistdfktilewqpkptnytytvqisdrsrnwknkcfsttdtecdltdeivkdvtwayeakvlsvprrnsvhgdgdqlvihgeeppftnapkflpyrdtnlgqpviqqfeqdgrklnvvvkdsltlvrkngtfltlrqvfgkdlgyiityrkgsstgkktnitntnefsidveegvsycffvqamifsrktnqnspgsstvcteqwksflge
示例性可溶性大鼠组织因子结构域(SEQ ID NO:6)
Agtppgkafnltwistdfktilewqpkptnytytvqisdrsrnwkykctgttdtecdltdeivkdvnwtyearvlsvpwrnsthgketlfgthgeeppftnarkflpyrdtkigqpviqkyeqggtklkvtvkdsftlvrkngtfltlrqvfgndlgyiltyrkdsstgrktntthtneflidvekgvsycffaqavifsrktnhkspesitkcteqwksvlge
在一些实施例中,可溶性组织因子结构域可包括与SEQ ID NO:1、3、4、5或6至少70%相同、至少72%相同、至少74%相同、至少76%相同、至少78%相同、至少80%相同、至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同的序列。在一些实施例中,可溶性组织因子结构域可包括SEQ ID NO:1、3、4、5或6的序列,其中一到二十个氨基酸(例如,2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19或20个氨基酸)从其N端去除和/或一到二十个氨基酸(例如,2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19或20个氨基酸)从其C端去除。
如本领域中可了解,本领域技术人员将理解,在不同哺乳动物物种之间保守的氨基酸的突变更可能降低蛋白质的活性和/或结构稳定性,而在不同哺乳动物物种之间不保守的蛋白质的突变不太可能降低蛋白质的活性和/或结构稳定性。
在本文所描述的多链嵌合多肽中的任一种的一些实例中,可溶性组织因子结构域不能结合到因子VIIa。在本文所描述的多链嵌合多肽中的任一种的一些实例中,可溶性组织因子结构域不将非活性因子X转化为因子Xa。在本文所描述的多链嵌合多肽中的任一种的一些实施例中,多链嵌合多肽不刺激哺乳动物的凝血。
在一些实例中,可溶性组织因子结构域可为可溶性人组织因子结构域。在一些实施例中,可溶性组织因子结构域可为可溶性小鼠组织因子结构域。在一些实施例中,可溶性组织因子结构域可为可溶性大鼠组织因子结构域。
在一些实例中,可溶性组织因子结构域不包括以下中的一个或多个(例如,两个、三个、四个、五个、六个或七个):在对应于成熟野生型人组织因子蛋白的氨基酸位置20的氨基酸位置处的赖氨酸;在对应于成熟野生型人组织因子蛋白的氨基酸位置22的氨基酸位置处的异亮氨酸;在对应于成熟野生型人组织因子蛋白的氨基酸位置45的氨基酸位置处的色氨酸;在对应于成熟野生型人组织因子蛋白的氨基酸位置58的氨基酸位置处的天冬氨酸;在对应于成熟野生型人组织因子蛋白的氨基酸位置94的氨基酸位置处的酪氨酸;在对应于成熟野生型人组织因子蛋白的氨基酸位置135的氨基酸位置处的精氨酸;和在对应于成熟野生型人组织因子蛋白的氨基酸位置140的氨基酸位置处的苯丙氨酸。在一些实施例中,突变可溶性组织因子具有SEQ ID NO:3或SEQ ID NO:4的氨基酸序列。
在一些实例中,可溶性组织因子结构域可由包括与SEQ ID NO:2至少70%相同、至少72%相同、至少74%相同、至少76%相同、至少78%相同、至少80%相同、至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同的序列的核酸编码。
在一些实施例中,可溶性组织因子结构域可具有的总长度为约20个氨基酸至约220个氨基酸,约20个氨基酸至约215个氨基酸,约20个氨基酸至约210个氨基酸,约20个氨基酸至约205个氨基酸,约20个氨基酸至约200个氨基酸,约20个氨基酸至约195个氨基酸,约20个氨基酸至约190个氨基酸,约20个氨基酸至约185个氨基酸,约20个氨基酸至约180个氨基酸,约20个氨基酸至约175个氨基酸,约20个氨基酸至约170个氨基酸,约20个氨基酸至约165个氨基酸,约20个氨基酸至约160个氨基酸,约20个氨基酸至约155个氨基酸,约20个氨基酸至约150个氨基酸,约20个氨基酸至约145个氨基酸,约20个氨基酸至约140个氨基酸,约20个氨基酸至约135个氨基酸,约20个氨基酸至约130个氨基酸,约20个氨基酸至约125个氨基酸,约20个氨基酸至约120个氨基酸,约20个氨基酸至约115个氨基酸,约20个氨基酸至约110个氨基酸,约20个氨基酸至约105个氨基酸,约20个氨基酸至约100个氨基酸,约20个氨基酸至约95个氨基酸,约20个氨基酸至约90个氨基酸,约20个氨基酸至约85个氨基酸,约20个氨基酸至约80个氨基酸,约20个氨基酸至约75个氨基酸,约20个氨基酸至约70个氨基酸,约20个氨基酸至约60个氨基酸,约20个氨基酸至约50个氨基酸,约20个氨基酸至约40个氨基酸,约20个氨基酸至约30个氨基酸,约30个氨基酸至约220个氨基酸,约30个氨基酸至约215个氨基酸,约30个氨基酸至约210个氨基酸,约30个氨基酸至约205个氨基酸,约30个氨基酸至约200个氨基酸,约30个氨基酸至约195个氨基酸,约30个氨基酸至约190个氨基酸,约30个氨基酸至约185个氨基酸,约30个氨基酸至约180个氨基酸,约30个氨基酸至约175个氨基酸,约30个氨基酸至约170个氨基酸,约30个氨基酸至约165个氨基酸,约30个氨基酸至约160个氨基酸,约30个氨基酸至约155个氨基酸,约30个氨基酸至约150个氨基酸,约30个氨基酸至约145个氨基酸,约30个氨基酸至约140个氨基酸,约30个氨基酸至约135个氨基酸,约30个氨基酸至约130个氨基酸,约30个氨基酸至约125个氨基酸,约30个氨基酸至约120个氨基酸,约30个氨基酸至约115个氨基酸,约30个氨基酸至约110个氨基酸,约30个氨基酸至约105个氨基酸,约30个氨基酸至约100个氨基酸,约30个氨基酸至约95个氨基酸,约30个氨基酸至约90个氨基酸,约30个氨基酸至约85个氨基酸,约30个氨基酸至约80个氨基酸,约30个氨基酸至约75个氨基酸,约30个氨基酸至约70个氨基酸,约30个氨基酸至约60个氨基酸,约30个氨基酸至约50个氨基酸,约30个氨基酸至约40个氨基酸,约40个氨基酸至约220个氨基酸,约40个氨基酸至约215个氨基酸,约40个氨基酸至约210个氨基酸,约40个氨基酸至约205个氨基酸,约40个氨基酸至约200个氨基酸,约40个氨基酸至约195个氨基酸,约40个氨基酸至约190个氨基酸,约40个氨基酸至约185个氨基酸,约40个氨基酸至约180个氨基酸,约40个氨基酸至约175个氨基酸,约40个氨基酸至约170个氨基酸,约40个氨基酸至约165个氨基酸,约40个氨基酸至约160个氨基酸,约40个氨基酸至约155个氨基酸,约40个氨基酸至约150个氨基酸,约40个氨基酸至约145个氨基酸,约40个氨基酸至约140个氨基酸,约40个氨基酸至约135个氨基酸,约40个氨基酸至约130个氨基酸,约40个氨基酸至约125个氨基酸,约40个氨基酸至约120个氨基酸,约40个氨基酸至约115个氨基酸,约40个氨基酸至约110个氨基酸,约40个氨基酸至约105个氨基酸,约40个氨基酸至约100个氨基酸,约40个氨基酸至约95个氨基酸,约40个氨基酸至约90个氨基酸,约40个氨基酸至约85个氨基酸,约40个氨基酸至约80个氨基酸,约40个氨基酸至约75个氨基酸,约40个氨基酸至约70个氨基酸,约40个氨基酸至约60个氨基酸,约40个氨基酸至约50个氨基酸,约50个氨基酸至约220个氨基酸,约50个氨基酸至约215个氨基酸,约50个氨基酸至约210个氨基酸,约50个氨基酸至约205个氨基酸,约50个氨基酸至约200个氨基酸,约50个氨基酸至约195个氨基酸,约50个氨基酸至约190个氨基酸,约50个氨基酸至约185个氨基酸,约50个氨基酸至约180个氨基酸,约50个氨基酸至约175个氨基酸,约50个氨基酸至约170个氨基酸,约50个氨基酸至约165个氨基酸,约50个氨基酸至约160个氨基酸,约50个氨基酸至约155个氨基酸,约50个氨基酸至约150个氨基酸,约50个氨基酸至约145个氨基酸,约50个氨基酸至约140个氨基酸,约50个氨基酸至约135个氨基酸,约50个氨基酸至约130个氨基酸,约50个氨基酸至约125个氨基酸,约50个氨基酸至约120个氨基酸,约50个氨基酸至约115个氨基酸,约50个氨基酸至约110个氨基酸,约50个氨基酸至约105个氨基酸,约50个氨基酸至约100个氨基酸,约50个氨基酸至约95个氨基酸,约50个氨基酸至约90个氨基酸,约50个氨基酸至约85个氨基酸,约50个氨基酸至约80个氨基酸,约50个氨基酸至约75个氨基酸,约50个氨基酸至约70个氨基酸,约50个氨基酸至约60个氨基酸,约60个氨基酸至约220个氨基酸,约60个氨基酸至约215个氨基酸,约60个氨基酸至约210个氨基酸,约60个氨基酸至约205个氨基酸,约60个氨基酸至约200个氨基酸,约60个氨基酸至约195个氨基酸,约60个氨基酸至约190个氨基酸,约60个氨基酸至约185个氨基酸,约60个氨基酸至约180个氨基酸,约60个氨基酸至约175个氨基酸,约60个氨基酸至约170个氨基酸,约60个氨基酸至约165个氨基酸,约60个氨基酸至约160个氨基酸,约60个氨基酸至约155个氨基酸,约60个氨基酸至约150个氨基酸,约60个氨基酸至约145个氨基酸,约60个氨基酸至约140个氨基酸,约60个氨基酸至约135个氨基酸,约60个氨基酸至约130个氨基酸,约60个氨基酸至约125个氨基酸,约60个氨基酸至约120个氨基酸,约60个氨基酸至约115个氨基酸,约60个氨基酸至约110个氨基酸,约60个氨基酸至约105个氨基酸,约60个氨基酸至约100个氨基酸,约60个氨基酸至约95个氨基酸,约60个氨基酸至约90个氨基酸,约60个氨基酸至约85个氨基酸,约60个氨基酸至约80个氨基酸,约60个氨基酸至约75个氨基酸,约60个氨基酸至约70个氨基酸,约70个氨基酸至约220个氨基酸,约70个氨基酸至约215个氨基酸,约70个氨基酸至约210个氨基酸,约70个氨基酸至约205个氨基酸,约70个氨基酸至约200个氨基酸,约70个氨基酸至约195个氨基酸,约70个氨基酸至约190个氨基酸,约70个氨基酸至约185个氨基酸,约70个氨基酸至约180个氨基酸,约70个氨基酸至约175个氨基酸,约70个氨基酸至约170个氨基酸,约70个氨基酸至约165个氨基酸,约70个氨基酸至约160个氨基酸,约70个氨基酸至约155个氨基酸,约70个氨基酸至约150个氨基酸,约70个氨基酸至约145个氨基酸,约70个氨基酸至约140个氨基酸,约70个氨基酸至约135个氨基酸,约70个氨基酸至约130个氨基酸,约70个氨基酸至约125个氨基酸,约70个氨基酸至约120个氨基酸,约70个氨基酸至约115个氨基酸,约70个氨基酸至约110个氨基酸,约70个氨基酸至约105个氨基酸,约70个氨基酸至约100个氨基酸,约70个氨基酸至约95个氨基酸,约70个氨基酸至约90个氨基酸,约70个氨基酸至约85个氨基酸,约70个氨基酸至约80个氨基酸,约80个氨基酸至约220个氨基酸,约80个氨基酸至约215个氨基酸,约80个氨基酸至约210个氨基酸,约80个氨基酸至约205个氨基酸,约80个氨基酸至约200个氨基酸,约80个氨基酸至约195个氨基酸,约80个氨基酸至约190个氨基酸,约80个氨基酸至约185个氨基酸,约80个氨基酸至约180个氨基酸,约80个氨基酸至约175个氨基酸,约80个氨基酸至约170个氨基酸,约80个氨基酸至约165个氨基酸,约80个氨基酸至约160个氨基酸,约80个氨基酸至约155个氨基酸,约80个氨基酸至约150个氨基酸,约80个氨基酸至约145个氨基酸,约80个氨基酸至约140个氨基酸,约80个氨基酸至约135个氨基酸,约80个氨基酸至约130个氨基酸,约80个氨基酸至约125个氨基酸,约80个氨基酸至约120个氨基酸,约80个氨基酸至约115个氨基酸,约80个氨基酸至约110个氨基酸,约80个氨基酸至约105个氨基酸,约80个氨基酸至约100个氨基酸,约80个氨基酸至约95个氨基酸,约80个氨基酸至约90个氨基酸,约90个氨基酸至约220个氨基酸,约90个氨基酸至约215个氨基酸,约90个氨基酸至约210个氨基酸,约90个氨基酸至约205个氨基酸,约90个氨基酸至约200个氨基酸,约90个氨基酸至约195个氨基酸,约90个氨基酸至约190个氨基酸,约90个氨基酸至约185个氨基酸,约90个氨基酸至约180个氨基酸,约90个氨基酸至约175个氨基酸,约90个氨基酸至约170个氨基酸,约90个氨基酸至约165个氨基酸,约90个氨基酸至约160个氨基酸,约90个氨基酸至约155个氨基酸,约90个氨基酸至约150个氨基酸,约90个氨基酸至约145个氨基酸,约90个氨基酸至约140个氨基酸,约90个氨基酸至约135个氨基酸,约90个氨基酸至约130个氨基酸,约90个氨基酸至约125个氨基酸,约90个氨基酸至约120个氨基酸,约90个氨基酸至约115个氨基酸,约90个氨基酸至约110个氨基酸,约90个氨基酸至约105个氨基酸,约90个氨基酸至约100个氨基酸,约100个氨基酸至约220个氨基酸,约100个氨基酸至约215个氨基酸,约100个氨基酸至约210个氨基酸,约100个氨基酸至约205个氨基酸,约100个氨基酸至约200个氨基酸,约100个氨基酸至约195个氨基酸,约100个氨基酸至约190个氨基酸,约100个氨基酸至约185个氨基酸,约100个氨基酸至约180个氨基酸,约100个氨基酸至约175个氨基酸,约100个氨基酸至约170个氨基酸,约100个氨基酸至约165个氨基酸,约100个氨基酸至约160个氨基酸,约100个氨基酸至约155个氨基酸,约100个氨基酸至约150个氨基酸,约100个氨基酸至约145个氨基酸,约100个氨基酸至约140个氨基酸,约100个氨基酸至约135个氨基酸,约100个氨基酸至约130个氨基酸,约100个氨基酸至约125个氨基酸,约100个氨基酸至约120个氨基酸,约100个氨基酸至约115个氨基酸,约100个氨基酸至约110个氨基酸,约110个氨基酸至约220个氨基酸,约110个氨基酸至约215个氨基酸,约110个氨基酸至约210个氨基酸,约110个氨基酸至约205个氨基酸,约110个氨基酸至约200个氨基酸,约110个氨基酸至约195个氨基酸,约110个氨基酸至约190个氨基酸,约110个氨基酸至约185个氨基酸,约110个氨基酸至约180个氨基酸,约110个氨基酸至约175个氨基酸,约110个氨基酸至约170个氨基酸,约110个氨基酸至约165个氨基酸,约110个氨基酸至约160个氨基酸,约110个氨基酸至约155个氨基酸,约110个氨基酸至约150个氨基酸,约110个氨基酸至约145个氨基酸,约110个氨基酸至约140个氨基酸,约110个氨基酸至约135个氨基酸,约110个氨基酸至约130个氨基酸,约110个氨基酸至约125个氨基酸,约110个氨基酸至约120个氨基酸,约110个氨基酸至约115个氨基酸,约115个氨基酸至约220个氨基酸,约115个氨基酸至约215个氨基酸,约115个氨基酸至约210个氨基酸,约115个氨基酸至约205个氨基酸,约115个氨基酸至约200个氨基酸,约115个氨基酸至约195个氨基酸,约115个氨基酸至约190个氨基酸,约115个氨基酸至约185个氨基酸,约115个氨基酸至约180个氨基酸,约115个氨基酸至约175个氨基酸,约115个氨基酸至约170个氨基酸,约115个氨基酸至约165个氨基酸,约115个氨基酸至约160个氨基酸,约115个氨基酸至约155个氨基酸,约115个氨基酸至约150个氨基酸,约115个氨基酸至约145个氨基酸,约115个氨基酸至约140个氨基酸,约115个氨基酸至约135个氨基酸,约115个氨基酸至约130个氨基酸,约115个氨基酸至约125个氨基酸,约115个氨基酸至约120个氨基酸,约120个氨基酸至约220个氨基酸,约120个氨基酸至约215个氨基酸,约120个氨基酸至约210个氨基酸,约120个氨基酸至约205个氨基酸,约120个氨基酸至约200个氨基酸,约120个氨基酸至约195个氨基酸,约120个氨基酸至约190个氨基酸,约120个氨基酸至约185个氨基酸,约120个氨基酸至约180个氨基酸,约120个氨基酸至约175个氨基酸,约120个氨基酸至约170个氨基酸,约120个氨基酸至约165个氨基酸,约120个氨基酸至约160个氨基酸,约120个氨基酸至约155个氨基酸,约120个氨基酸至约150个氨基酸,约120个氨基酸至约145个氨基酸,约120个氨基酸至约140个氨基酸,约120个氨基酸至约135个氨基酸,约120个氨基酸至约130个氨基酸,约120个氨基酸至约125个氨基酸,约125个氨基酸至约220个氨基酸,约125个氨基酸至约215个氨基酸,约125个氨基酸至约210个氨基酸,约125个氨基酸至约205个氨基酸,约125个氨基酸至约200个氨基酸,约125个氨基酸至约195个氨基酸,约125个氨基酸至约190个氨基酸,约125个氨基酸至约185个氨基酸,约125个氨基酸至约180个氨基酸,约125个氨基酸至约175个氨基酸,约125个氨基酸至约170个氨基酸,约125个氨基酸至约165个氨基酸,约125个氨基酸至约160个氨基酸,约125个氨基酸至约155个氨基酸,约125个氨基酸至约150个氨基酸,约125个氨基酸至约145个氨基酸,约125个氨基酸至约140个氨基酸,约125个氨基酸至约135个氨基酸,约125个氨基酸至约130个氨基酸,约130个氨基酸至约220个氨基酸,约130个氨基酸至约215个氨基酸,约130个氨基酸至约210个氨基酸,约130个氨基酸至约205个氨基酸,约130个氨基酸至约200个氨基酸,约130个氨基酸至约195个氨基酸,约130个氨基酸至约190个氨基酸,约130个氨基酸至约185个氨基酸,约130个氨基酸至约180个氨基酸,约130个氨基酸至约175个氨基酸,约130个氨基酸至约170个氨基酸,约130个氨基酸至约165个氨基酸,约130个氨基酸至约160个氨基酸,约130个氨基酸至约155个氨基酸,约130个氨基酸至约150个氨基酸,约130个氨基酸至约145个氨基酸,约130个氨基酸至约140个氨基酸,约130个氨基酸至约135个氨基酸,约135个氨基酸至约220个氨基酸,约135个氨基酸至约215个氨基酸,约135个氨基酸至约210个氨基酸,约135个氨基酸至约205个氨基酸,约135个氨基酸至约200个氨基酸,约135个氨基酸至约195个氨基酸,约135个氨基酸至约190个氨基酸,约135个氨基酸至约185个氨基酸,约135个氨基酸至约180个氨基酸,约135个氨基酸至约175个氨基酸,约135个氨基酸至约170个氨基酸,约135个氨基酸至约165个氨基酸,约135个氨基酸至约160个氨基酸,约135个氨基酸至约155个氨基酸,约135个氨基酸至约150个氨基酸,约135个氨基酸至约145个氨基酸,约135个氨基酸至约140个氨基酸,约140个氨基酸至约220个氨基酸,约140个氨基酸至约215个氨基酸,约140个氨基酸至约210个氨基酸,约140个氨基酸至约205个氨基酸,约140个氨基酸至约200个氨基酸,约140个氨基酸至约195个氨基酸,约140个氨基酸至约190个氨基酸,约140个氨基酸至约185个氨基酸,约140个氨基酸至约180个氨基酸,约140个氨基酸至约175个氨基酸,约140个氨基酸至约170个氨基酸,约140个氨基酸至约165个氨基酸,约140个氨基酸至约160个氨基酸,约140个氨基酸至约155个氨基酸,约140个氨基酸至约150个氨基酸,约140个氨基酸至约145个氨基酸,约145个氨基酸至约220个氨基酸,约145个氨基酸至约215个氨基酸,约145个氨基酸至约210个氨基酸,约145个氨基酸至约205个氨基酸,约145个氨基酸至约200个氨基酸,约145个氨基酸至约195个氨基酸,约145个氨基酸至约190个氨基酸,约145个氨基酸至约185个氨基酸,约145个氨基酸至约180个氨基酸,约145个氨基酸至约175个氨基酸,约145个氨基酸至约170个氨基酸,约145个氨基酸至约165个氨基酸,约145个氨基酸至约160个氨基酸,约145个氨基酸至约155个氨基酸,约145个氨基酸至约150个氨基酸,约150个氨基酸至约220个氨基酸,约150个氨基酸至约215个氨基酸,约150个氨基酸至约210个氨基酸,约150个氨基酸至约205个氨基酸,约150个氨基酸至约200个氨基酸,约150个氨基酸至约195个氨基酸,约150个氨基酸至约190个氨基酸,约150个氨基酸至约185个氨基酸,约150个氨基酸至约180个氨基酸,约150个氨基酸至约175个氨基酸,约150个氨基酸至约170个氨基酸,约150个氨基酸至约165个氨基酸,约150个氨基酸至约160个氨基酸,约150个氨基酸至约155个氨基酸,约155个氨基酸至约220个氨基酸,约155个氨基酸至约215个氨基酸,约155个氨基酸至约210个氨基酸,约155个氨基酸至约205个氨基酸,约155个氨基酸至约200个氨基酸,约155个氨基酸至约195个氨基酸,约155个氨基酸至约190个氨基酸,约155个氨基酸至约185个氨基酸,约155个氨基酸至约180个氨基酸,约155个氨基酸至约175个氨基酸,约155个氨基酸至约170个氨基酸,约155个氨基酸至约165个氨基酸,约155个氨基酸至约160个氨基酸,约160个氨基酸至约220个氨基酸,约160个氨基酸至约215个氨基酸,约160个氨基酸至约210个氨基酸,约160个氨基酸至约205个氨基酸,约160个氨基酸至约200个氨基酸,约160个氨基酸至约195个氨基酸,约160个氨基酸至约190个氨基酸,约160个氨基酸至约185个氨基酸,约160个氨基酸至约180个氨基酸,约160个氨基酸至约175个氨基酸,约160个氨基酸至约170个氨基酸,约160个氨基酸至约165个氨基酸,约165个氨基酸至约220个氨基酸,约165个氨基酸至约215个氨基酸,约165个氨基酸至约210个氨基酸,约165个氨基酸至约205个氨基酸,约165个氨基酸至约200个氨基酸,约165个氨基酸至约195个氨基酸,约165个氨基酸至约190个氨基酸,约165个氨基酸至约185个氨基酸,约165个氨基酸至约180个氨基酸,约165个氨基酸至约175个氨基酸,约165个氨基酸至约170个氨基酸,约170个氨基酸至约220个氨基酸,约170个氨基酸至约215个氨基酸,约170个氨基酸至约210个氨基酸,约170个氨基酸至约205个氨基酸,约170个氨基酸至约200个氨基酸,约170个氨基酸至约195个氨基酸,约170个氨基酸至约190个氨基酸,约170个氨基酸至约185个氨基酸,约170个氨基酸至约180个氨基酸,约170个氨基酸至约175个氨基酸,约175个氨基酸至约220个氨基酸,约175个氨基酸至约215个氨基酸,约175个氨基酸至约210个氨基酸,约175个氨基酸至约205个氨基酸,约175个氨基酸至约200个氨基酸,约175个氨基酸至约195个氨基酸,约175个氨基酸至约190个氨基酸,约175个氨基酸至约185个氨基酸,约175个氨基酸至约180个氨基酸,约180个氨基酸至约220个氨基酸,约180个氨基酸至约215个氨基酸,约180个氨基酸至约210个氨基酸,约180个氨基酸至约205个氨基酸,约180个氨基酸至约200个氨基酸,约180个氨基酸至约195个氨基酸,约180个氨基酸至约190个氨基酸,约180个氨基酸至约185个氨基酸,约185个氨基酸至约220个氨基酸,约185个氨基酸至约215个氨基酸,约185个氨基酸至约210个氨基酸,约185个氨基酸至约205个氨基酸,约185个氨基酸至约200个氨基酸,约185个氨基酸至约195个氨基酸,约185个氨基酸至约190个氨基酸,约190个氨基酸至约220个氨基酸,约190个氨基酸至约215个氨基酸,约190个氨基酸至约210个氨基酸,约190个氨基酸至约205个氨基酸,约190个氨基酸至约200个氨基酸,约190个氨基酸至约195个氨基酸,约195个氨基酸至约220个氨基酸,约195个氨基酸至约215个氨基酸,约195个氨基酸至约210个氨基酸,约195个氨基酸至约205个氨基酸,约195个氨基酸至约200个氨基酸,约200个氨基酸至约220个氨基酸,约200个氨基酸至约215个氨基酸,约200个氨基酸至约210个氨基酸,约200个氨基酸至约205个氨基酸,约205个氨基酸至约220个氨基酸,约205个氨基酸至约215个氨基酸,约205个氨基酸至约210个氨基酸,约210个氨基酸至约220个氨基酸,约210个氨基酸至约215个氨基酸,或约215个氨基酸至约220个氨基酸。
接头序列
在一些实施例中,接头序列可为柔性接头序列。可使用的接头序列的非限制性实例描述于Klein等人,《蛋白质工程、设计和选择(Protein Engineering,Design&Selection)》27(10):325–330,2014;Priyanka等人,《蛋白质科学(Protein Sci.)》22(2):153–167,2013中。在一些实例中,接头序列是合成接头序列。
在本文所描述的多链嵌合多肽中的任一种的一些实施例中,第一嵌合多肽可包括一个、两个、三个、四个、五个、六个、七个、八个、九个或十个接头序列(例如,相同或不同的接头序列,例如本文所描述或本领域已知的示例性接头序列中的任一种)。在本文所描述的多链嵌合多肽中的任一种的一些实施例中,第二嵌合多肽可包括一个、两个、三个、四个、五个、六个、七个、八个、九个或十个接头序列(例如,相同或不同的接头序列,例如本文所描述或本领域已知的示例性接头序列中的任一种)。
在一些实施例中,接头序列可具有的总长度为1个氨基酸至约100个氨基酸,1个氨基酸至约90个氨基酸,1个氨基酸至约80个氨基酸,1个氨基酸至约70个氨基酸,1个氨基酸至约60个氨基酸,1个氨基酸至约50个氨基酸,1个氨基酸至约45个氨基酸,1个氨基酸至约40个氨基酸,1个氨基酸至约35个氨基酸,1个氨基酸至约30个氨基酸,1个氨基酸至约25个氨基酸,1个氨基酸至约24个氨基酸,1个氨基酸至约22个氨基酸,1个氨基酸至约20个氨基酸,1个氨基酸至约18个氨基酸,1个氨基酸至约16个氨基酸,1个氨基酸至约14个氨基酸,1个氨基酸至约12个氨基酸,1个氨基酸至约10个氨基酸,1个氨基酸至约8个氨基酸,1个氨基酸至约6个氨基酸,1个氨基酸至约4个氨基酸,约2个氨基酸至约100个氨基酸,约2个氨基酸至约90个氨基酸,约2个氨基酸至约80个氨基酸,约2个氨基酸至约70个氨基酸,约2个氨基酸至约60个氨基酸,约2个氨基酸至约50个氨基酸,约2个氨基酸至约45个氨基酸,约2个氨基酸至约40个氨基酸,约2个氨基酸至约35个氨基酸,约2个氨基酸至约30个氨基酸,约2个氨基酸至约25个氨基酸,约2个氨基酸至约24个氨基酸,约2个氨基酸至约22个氨基酸,约2个氨基酸至约20个氨基酸,约2个氨基酸至约18个氨基酸,约2个氨基酸至约16个氨基酸,约2个氨基酸至约14个氨基酸,约2个氨基酸至约12个氨基酸,约2个氨基酸至约10个氨基酸,约2个氨基酸至约8个氨基酸,约2个氨基酸至约6个氨基酸,约2个氨基酸至约4个氨基酸,约4个氨基酸至约100个氨基酸,约4个氨基酸至约90个氨基酸,约4个氨基酸至约80个氨基酸,约4个氨基酸至约70个氨基酸,约4个氨基酸至约60个氨基酸,约4个氨基酸至约50个氨基酸,约4个氨基酸至约45个氨基酸,约4个氨基酸至约40个氨基酸,约4个氨基酸至约35个氨基酸,约4个氨基酸至约30个氨基酸,约4个氨基酸至约25个氨基酸,约4个氨基酸至约24个氨基酸,约4个氨基酸至约22个氨基酸,约4个氨基酸至约20个氨基酸,约4个氨基酸至约18个氨基酸,约4个氨基酸至约16个氨基酸,约4个氨基酸至约14个氨基酸,约4个氨基酸至约12个氨基酸,约4个氨基酸至约10个氨基酸,约4个氨基酸至约8个氨基酸,约4个氨基酸至约6个氨基酸,约6个氨基酸至约100个氨基酸,约6个氨基酸至约90个氨基酸,约6个氨基酸至约80个氨基酸,约6个氨基酸至约70个氨基酸,约6个氨基酸至约60个氨基酸,约6个氨基酸至约50个氨基酸,约6个氨基酸至约45个氨基酸,约6个氨基酸至约40个氨基酸,约6个氨基酸至约35个氨基酸,约6个氨基酸至约30个氨基酸,约6个氨基酸至约25个氨基酸,约6个氨基酸至约24个氨基酸,约6个氨基酸至约22个氨基酸,约6个氨基酸至约20个氨基酸,约6个氨基酸至约18个氨基酸,约6个氨基酸至约16个氨基酸,约6个氨基酸至约14个氨基酸,约6个氨基酸至约12个氨基酸,约6个氨基酸至约10个氨基酸,约6个氨基酸至约8个氨基酸,约8个氨基酸至约100个氨基酸,约8个氨基酸至约90个氨基酸,约8个氨基酸至约80个氨基酸,约8个氨基酸至约70个氨基酸,约8个氨基酸至约60个氨基酸,约8个氨基酸至约50个氨基酸,约8个氨基酸至约45个氨基酸,约8个氨基酸至约40个氨基酸,约8个氨基酸至约35个氨基酸,约8个氨基酸至约30个氨基酸,约8个氨基酸至约25个氨基酸,约8个氨基酸至约24个氨基酸,约8个氨基酸至约22个氨基酸,约8个氨基酸至约20个氨基酸,约8个氨基酸至约18个氨基酸,约8个氨基酸至约16个氨基酸,约8个氨基酸至约14个氨基酸,约8个氨基酸至约12个氨基酸,约8个氨基酸至约10个氨基酸,约10个氨基酸至约100个氨基酸,约10个氨基酸至约90个氨基酸,约10个氨基酸至约80个氨基酸,约10个氨基酸至约70个氨基酸,约10个氨基酸至约60个氨基酸,约10个氨基酸至约50个氨基酸,约10个氨基酸至约45个氨基酸,约10个氨基酸至约40个氨基酸,约10个氨基酸至约35个氨基酸,约10个氨基酸至约30个氨基酸,约10个氨基酸至约25个氨基酸,约10个氨基酸至约24个氨基酸,约10个氨基酸至约22个氨基酸,约10个氨基酸至约20个氨基酸,约10个氨基酸至约18个氨基酸,约10个氨基酸至约16个氨基酸,约10个氨基酸至约14个氨基酸,约10个氨基酸至约12个氨基酸,约12个氨基酸至约100个氨基酸,约12个氨基酸至约90个氨基酸,约12个氨基酸至约80个氨基酸,约12个氨基酸至约70个氨基酸,约12个氨基酸至约60个氨基酸,约12个氨基酸至约50个氨基酸,约12个氨基酸至约45个氨基酸,约12个氨基酸至约40个氨基酸,约12个氨基酸至约35个氨基酸,约12个氨基酸至约30个氨基酸,约12个氨基酸至约25个氨基酸,约12个氨基酸至约24个氨基酸,约12个氨基酸至约22个氨基酸,约12个氨基酸至约20个氨基酸,约12个氨基酸至约18个氨基酸,约12个氨基酸至约16个氨基酸,约12个氨基酸至约14个氨基酸,约14个氨基酸至约100个氨基酸,约14个氨基酸至约90个氨基酸,约14个氨基酸至约80个氨基酸,约14个氨基酸至约70个氨基酸,约14个氨基酸至约60个氨基酸,约14个氨基酸至约50个氨基酸,约14个氨基酸至约45个氨基酸,约14个氨基酸至约40个氨基酸,约14个氨基酸至约35个氨基酸,约14个氨基酸至约30个氨基酸,约14个氨基酸至约25个氨基酸,约14个氨基酸至约24个氨基酸,约14个氨基酸至约22个氨基酸,约14个氨基酸至约20个氨基酸,约14个氨基酸至约18个氨基酸,约14个氨基酸至约16个氨基酸,约16个氨基酸至约100个氨基酸,约16个氨基酸至约90个氨基酸,约16个氨基酸至约80个氨基酸,约16个氨基酸至约70个氨基酸,约16个氨基酸至约60个氨基酸,约16个氨基酸至约50个氨基酸,约16个氨基酸至约45个氨基酸,约16个氨基酸至约40个氨基酸,约16个氨基酸至约35个氨基酸,约16个氨基酸至约30个氨基酸,约16个氨基酸至约25个氨基酸,约16个氨基酸至约24个氨基酸,约16个氨基酸至约22个氨基酸,约16个氨基酸至约20个氨基酸,约16个氨基酸至约18个氨基酸,约18个氨基酸至约100个氨基酸,约18个氨基酸至约90个氨基酸,约18个氨基酸至约80个氨基酸,约18个氨基酸至约70个氨基酸,约18个氨基酸至约60个氨基酸,约18个氨基酸至约50个氨基酸,约18个氨基酸至约45个氨基酸,约18个氨基酸至约40个氨基酸,约18个氨基酸至约35个氨基酸,约18个氨基酸至约30个氨基酸,约18个氨基酸至约25个氨基酸,约18个氨基酸至约24个氨基酸,约18个氨基酸至约22个氨基酸,约18个氨基酸至约20个氨基酸,约20个氨基酸至约100个氨基酸,约20个氨基酸至约90个氨基酸,约20个氨基酸至约80个氨基酸,约20个氨基酸至约70个氨基酸,约20个氨基酸至约60个氨基酸,约20个氨基酸至约50个氨基酸,约20个氨基酸至约45个氨基酸,约20个氨基酸至约40个氨基酸,约20个氨基酸至约35个氨基酸,约20个氨基酸至约30个氨基酸,约20个氨基酸至约25个氨基酸,约20个氨基酸至约24个氨基酸,约20个氨基酸至约22个氨基酸,约22个氨基酸至约100个氨基酸,约22个氨基酸至约90个氨基酸,约22个氨基酸至约80个氨基酸,约22个氨基酸至约70个氨基酸,约22个氨基酸至约60个氨基酸,约22个氨基酸至约50个氨基酸,约22个氨基酸至约45个氨基酸,约22个氨基酸至约40个氨基酸,约22个氨基酸至约35个氨基酸,约22个氨基酸至约30个氨基酸,约22个氨基酸至约25个氨基酸,约22个氨基酸至约24个氨基酸,约25个氨基酸至约100个氨基酸,约25个氨基酸至约90个氨基酸,约25个氨基酸至约80个氨基酸,约25个氨基酸至约70个氨基酸,约25个氨基酸至约60个氨基酸,约25个氨基酸至约50个氨基酸,约25个氨基酸至约45个氨基酸,约25个氨基酸至约40个氨基酸,约25个氨基酸至约35个氨基酸,约25个氨基酸至约30个氨基酸,约30个氨基酸至约100个氨基酸,约30个氨基酸至约90个氨基酸,约30个氨基酸至约80个氨基酸,约30个氨基酸至约70个氨基酸,约30个氨基酸至约60个氨基酸,约30个氨基酸至约50个氨基酸,约30个氨基酸至约45个氨基酸,约30个氨基酸至约40个氨基酸,约30个氨基酸至约35个氨基酸,约35个氨基酸至约100个氨基酸,约35个氨基酸至约90个氨基酸,约35个氨基酸至约80个氨基酸,约35个氨基酸至约70个氨基酸,约35个氨基酸至约60个氨基酸,约35个氨基酸至约50个氨基酸,约35个氨基酸至约45个氨基酸,约35个氨基酸至约40个氨基酸,约40个氨基酸至约100个氨基酸,约40个氨基酸至约90个氨基酸,约40个氨基酸至约80个氨基酸,约40个氨基酸至约70个氨基酸,约40个氨基酸至约60个氨基酸,约40个氨基酸至约50个氨基酸,约40个氨基酸至约45个氨基酸,约45个氨基酸至约100个氨基酸,约45个氨基酸至约90个氨基酸,约45个氨基酸至约80个氨基酸,约45个氨基酸至约70个氨基酸,约45个氨基酸至约60个氨基酸,约45个氨基酸至约50个氨基酸,约50个氨基酸至约100个氨基酸,约50个氨基酸至约90个氨基酸,约50个氨基酸至约80个氨基酸,约50个氨基酸至约70个氨基酸,约50个氨基酸至约60个氨基酸,约60个氨基酸至约100个氨基酸,约60个氨基酸至约90个氨基酸,约60个氨基酸至约80个氨基酸,约60个氨基酸至约70个氨基酸,约70个氨基酸至约100个氨基酸,约70个氨基酸至约90个氨基酸,约70个氨基酸至约80个氨基酸,约80个氨基酸至约100个氨基酸,约80个氨基酸至约90个氨基酸,或约90个氨基酸至约100个氨基酸。
在一些实施例中,接头富含甘氨酸(Gly或G)残基。在一些实施例中,接头富含丝氨酸(Ser或S)残基。在一些实施例中,接头富含甘氨酸和丝氨酸残基。在一些实施例中,接头具有一个或多个甘氨酸-丝氨酸残基对(GS),例如1、2、3、4、5、6、7、8、9或10个或更多个GS对。在一些实施例中,接头具有一个或多个Gly-Gly-Gly-Ser(GGGS)序列,例如1、2、3、4、5、6、7、8、9或10个或更多个GGGS序列。在一些实施例中,接头具有一个或多个Gly-Gly-Gly-Gly-Ser(GGGGS)序列,例如1、2、3、4、5、6、7、8、9或10个或更多个GGGGS序列。在一些实施例中,接头具有一个或多个Gly-Gly-Ser-Gly(GGSG)序列,例如1、2、3、4、5、6、7、8、9或10个或更多个GGSG序列。
在一些实施例中,接头序列可包含以下或由以下组成:GGGGSGGGGSGGGGS(SEQ IDNO:7)。在一些实施例中,接头序列可由包含以下或由以下组成的核酸编码:GGCGGTGGAGGATCCGGAGGAGGTGGCTCCGGCGGCGGAGGATCT(SEQ ID NO:8)。在一些实施例中,接头序列可包含以下或由以下组成:GGGSGGGS(SEQ ID NO:9)。
靶标结合结构域
在本文所描述的多链嵌合多肽中的任一种的一些实施例中,第一靶标结合结构域、第二靶标结合结构域和/或另外的一个或多个靶标结合结构域可为抗原结合结构域(例如,本文所描述或本领域已知的示例性抗原结合结构域中的任一种)、可溶性白介素或细胞因子蛋白(例如,本文所描述的示例性可溶性白介素蛋白或可溶性细胞因子蛋白中的任一种)和可溶性白介素或细胞因子受体(例如,本文所描述的示例性可溶性白介素受体或可溶性细胞因子受体中的任一种)。
在本文所描述的多链嵌合多肽中的任一种的一些实施例中,一个或多个第一靶标结合结构域(例如,本文所描述或本领域已知的示例性第一靶标结合结构域中的任一种)、第二靶标结合结构域(例如,本文所描述或本领域已知的示例性第二靶标结合结构域中的任一种)和一个或多个另外的靶标结合结构域可各自独立地特异性结合到选自以下的组的靶标:特异性结合到选自以下组成的组的靶标:CD16a、CD28、CD3(例如,CD3α、CD3β、CD3δ、CD3ε和CD3γ中的一种或多种)、CD33、CD20、CD19、CD22、CD123、IL-1R、IL-1、VEGF、IL-6R、IL-4、IL-10、PDL-1、TIGIT、PD-1、TIM3、CTLA4、MICA、MICB、IL-6、IL-8、TNFα、CD26a、CD36、ULBP2、CD30、CD200、IGF-1R、MUC4AC、MUC5AC、Trop-2、CMET、EGFR、HER1、HER2、HER3、PSMA、CEA、B7H3、EPCAM、BCMA、P-钙黏着蛋白、CEACAM5、UL16结合蛋白(例如ULBP1、ULBP2、ULBP3、ULBP4、ULBP5和ULBP6)、HLA-DR、DLL4、TYRO3、AXL、MER、CD122、CD155、PDGF-DD、TGF-β受体II(TGF-βRII)的配体、TGF-βRIII的配体、DNAM-1的配体,NKp46的配体、NKp44的配体、NKG2D的配体、NKP30的配体、scMHCI的配体、scMHCII的配体、scTCR的配体、IL-1的受体、IL-2的受体、IL-3的受体、IL-7的受体、IL-8的受体、IL-10的受体、IL-12的受体、IL-15的受体、IL-17的受体、IL-18的受体、IL-21的受体、PDGF-DD的受体、干细胞因子(SCF)的受体、干细胞样酪氨酸激酶3配体(FLT3L)的受体、MICA的受体、MICB的受体、ULP16结合蛋白的受体、CD155的受体、CD122的受体和CD28的受体。
在本文所描述的多链嵌合多肽中的任一种的一些实施例中,第一靶标结合结构域、第二靶标结合结构域和/或一个或多个另外的靶标结合结构域的氨基酸总数可各自独立地为约5个氨基酸至约1000个氨基酸,约5个氨基酸至约950个氨基酸,约5个氨基酸至约900个氨基酸,约5个氨基酸至约850个氨基酸,约5个氨基酸至约800个氨基酸,约5个氨基酸至约750个氨基酸,约5个氨基酸至约700个氨基酸,约5个氨基酸至约650个氨基酸,约5个氨基酸至约600个氨基酸,约5个氨基酸至约550个氨基酸,约5个氨基酸至约500个氨基酸,约5个氨基酸至约450个氨基酸,约5个氨基酸至约400个氨基酸,约5个氨基酸至约350个氨基酸,约5个氨基酸至约300个氨基酸,约5个氨基酸至约280个氨基酸,约5个氨基酸至约260个氨基酸,约5个氨基酸至约240个氨基酸,约5个氨基酸至约220个氨基酸,约5个氨基酸至约200个氨基酸,约5个氨基酸至约195个氨基酸,约5个氨基酸至约190个氨基酸,约5个氨基酸至约185个氨基酸,约5个氨基酸至约180个氨基酸,约5个氨基酸至约175个氨基酸,约5个氨基酸至约170个氨基酸,约5个氨基酸至约165个氨基酸,约5个氨基酸至约160个氨基酸,约5个氨基酸至约155个氨基酸,约5个氨基酸至约150个氨基酸,约5个氨基酸至约145个氨基酸,约5个氨基酸至约140个氨基酸,约5个氨基酸至约135个氨基酸,约5个氨基酸至约130个氨基酸,约5个氨基酸至约125个氨基酸,约5个氨基酸至约120个氨基酸,约5个氨基酸至约115个氨基酸,约5个氨基酸至约110个氨基酸,约5个氨基酸至约105个氨基酸,约5个氨基酸至约100个氨基酸,约5个氨基酸至约95个氨基酸,约5个氨基酸至约90个氨基酸,约5个氨基酸至约85个氨基酸,约5个氨基酸至约80个氨基酸,约5个氨基酸至约75个氨基酸,约5个氨基酸至约70个氨基酸,约5个氨基酸至约65个氨基酸,约5个氨基酸至约60个氨基酸,约5个氨基酸至约55个氨基酸,约5个氨基酸至约50个氨基酸,约5个氨基酸至约45个氨基酸,约5个氨基酸至约40个氨基酸,约5个氨基酸至约35个氨基酸,约5个氨基酸至约30个氨基酸,约5个氨基酸至约25个氨基酸,约5个氨基酸至约20个氨基酸,约5个氨基酸至约15个氨基酸,约5个氨基酸至约10个氨基酸,约10个氨基酸至约1000个氨基酸,约10个氨基酸至约950个氨基酸,约10个氨基酸至约900个氨基酸,约10个氨基酸至约850个氨基酸,约10个氨基酸至约800个氨基酸,约10个氨基酸至约750个氨基酸,约10个氨基酸至约700个氨基酸,约10个氨基酸至约650个氨基酸,约10个氨基酸至约600个氨基酸,约10个氨基酸至约550个氨基酸,约10个氨基酸至约500个氨基酸,约10个氨基酸至约450个氨基酸,约10个氨基酸至约400个氨基酸,约10个氨基酸至约350个氨基酸,约10个氨基酸至约300个氨基酸,约10个氨基酸至约280个氨基酸,约10个氨基酸至约260个氨基酸,约10个氨基酸至约240个氨基酸,约10个氨基酸至约220个氨基酸,约10个氨基酸至约200个氨基酸,约10个氨基酸至约195个氨基酸,约10个氨基酸至约190个氨基酸,约10个氨基酸至约185个氨基酸,约10个氨基酸至约180个氨基酸,约10个氨基酸至约175个氨基酸,约10个氨基酸至约170个氨基酸,约10个氨基酸至约165个氨基酸,约10个氨基酸至约160个氨基酸,约10个氨基酸至约155个氨基酸,约10个氨基酸至约150个氨基酸,约10个氨基酸至约145个氨基酸,约10个氨基酸至约140个氨基酸,约10个氨基酸至约135个氨基酸,约10个氨基酸至约130个氨基酸,约10个氨基酸至约125个氨基酸,约10个氨基酸至约120个氨基酸,约10个氨基酸至约115个氨基酸,约10个氨基酸至约110个氨基酸,约10个氨基酸至约105个氨基酸,约10个氨基酸至约100个氨基酸,约10个氨基酸至约95个氨基酸,约10个氨基酸至约90个氨基酸,约10个氨基酸至约85个氨基酸,约10个氨基酸至约80个氨基酸,约10个氨基酸至约75个氨基酸,约10个氨基酸至约70个氨基酸,约10个氨基酸至约65个氨基酸,约10个氨基酸至约60个氨基酸,约10个氨基酸至约55个氨基酸,约10个氨基酸至约50个氨基酸,约10个氨基酸至约45个氨基酸,约10个氨基酸至约40个氨基酸,约10个氨基酸至约35个氨基酸,约10个氨基酸至约30个氨基酸,约10个氨基酸至约25个氨基酸,约10个氨基酸至约20个氨基酸,约10个氨基酸至约15个氨基酸,约15个氨基酸至约1000个氨基酸,约15个氨基酸至约950个氨基酸,约15个氨基酸至约900个氨基酸,约15个氨基酸至约850个氨基酸,约15个氨基酸至约800个氨基酸,约15个氨基酸至约750个氨基酸,约15个氨基酸至约700个氨基酸,约15个氨基酸至约650个氨基酸,约15个氨基酸至约600个氨基酸,约15个氨基酸至约550个氨基酸,约15个氨基酸至约500个氨基酸,约15个氨基酸至约450个氨基酸,约15个氨基酸至约400个氨基酸,约15个氨基酸至约350个氨基酸,约15个氨基酸至约300个氨基酸,约15个氨基酸至约280个氨基酸,约15个氨基酸至约260个氨基酸,约15个氨基酸至约240个氨基酸,约15个氨基酸至约220个氨基酸,约15个氨基酸至约200个氨基酸,约15个氨基酸至约195个氨基酸,约15个氨基酸至约190个氨基酸,约15个氨基酸至约185个氨基酸,约15个氨基酸至约180个氨基酸,约15个氨基酸至约175个氨基酸,约15个氨基酸至约170个氨基酸,约15个氨基酸至约165个氨基酸,约15个氨基酸至约160个氨基酸,约15个氨基酸至约155个氨基酸,约15个氨基酸至约150个氨基酸,约15个氨基酸至约145个氨基酸,约15个氨基酸至约140个氨基酸,约15个氨基酸至约135个氨基酸,约15个氨基酸至约130个氨基酸,约15个氨基酸至约125个氨基酸,约15个氨基酸至约120个氨基酸,约15个氨基酸至约115个氨基酸,约15个氨基酸至约110个氨基酸,约15个氨基酸至约105个氨基酸,约15个氨基酸至约100个氨基酸,约15个氨基酸至约95个氨基酸,约15个氨基酸至约90个氨基酸,约15个氨基酸至约85个氨基酸,约15个氨基酸至约80个氨基酸,约15个氨基酸至约75个氨基酸,约15个氨基酸至约70个氨基酸,约15个氨基酸至约65个氨基酸,约15个氨基酸至约60个氨基酸,约15个氨基酸至约55个氨基酸,约15个氨基酸至约50个氨基酸,约15个氨基酸至约45个氨基酸,约15个氨基酸至约40个氨基酸,约15个氨基酸至约35个氨基酸,约15个氨基酸至约30个氨基酸,约15个氨基酸至约25个氨基酸,约15个氨基酸至约20个氨基酸,约20个氨基酸至约1000个氨基酸,约20个氨基酸至约950个氨基酸,约20个氨基酸至约900个氨基酸,约20个氨基酸至约850个氨基酸,约20个氨基酸至约800个氨基酸,约20个氨基酸至约750个氨基酸,约20个氨基酸至约700个氨基酸,约20个氨基酸至约650个氨基酸,约20个氨基酸至约600个氨基酸,约20个氨基酸至约550个氨基酸,约20个氨基酸至约500个氨基酸,约20个氨基酸至约450个氨基酸,约20个氨基酸至约400个氨基酸,约20个氨基酸至约350个氨基酸,约20个氨基酸至约300个氨基酸,约20个氨基酸至约280个氨基酸,约20个氨基酸至约260个氨基酸,约20个氨基酸至约240个氨基酸,约20个氨基酸至约220个氨基酸,约20个氨基酸至约200个氨基酸,约20个氨基酸至约195个氨基酸,约20个氨基酸至约190个氨基酸,约20个氨基酸至约185个氨基酸,约20个氨基酸至约180个氨基酸,约20个氨基酸至约175个氨基酸,约20个氨基酸至约170个氨基酸,约20个氨基酸至约165个氨基酸,约20个氨基酸至约160个氨基酸,约20个氨基酸至约155个氨基酸,约20个氨基酸至约150个氨基酸,约20个氨基酸至约145个氨基酸,约20个氨基酸至约140个氨基酸,约20个氨基酸至约135个氨基酸,约20个氨基酸至约130个氨基酸,约20个氨基酸至约125个氨基酸,约20个氨基酸至约120个氨基酸,约20个氨基酸至约115个氨基酸,约20个氨基酸至约110个氨基酸,约20个氨基酸至约105个氨基酸,约20个氨基酸至约100个氨基酸,约20个氨基酸至约95个氨基酸,约20个氨基酸至约90个氨基酸,约20个氨基酸至约85个氨基酸,约20个氨基酸至约80个氨基酸,约20个氨基酸至约75个氨基酸,约20个氨基酸至约70个氨基酸,约20个氨基酸至约65个氨基酸,约20个氨基酸至约60个氨基酸,约20个氨基酸至约55个氨基酸,约20个氨基酸至约50个氨基酸,约20个氨基酸至约45个氨基酸,约20个氨基酸至约40个氨基酸,约20个氨基酸至约35个氨基酸,约20个氨基酸至约30个氨基酸,约20个氨基酸至约25个氨基酸,约25个氨基酸至约1000个氨基酸,约25个氨基酸至约950个氨基酸,约25个氨基酸至约900个氨基酸,约25个氨基酸至约850个氨基酸,约25个氨基酸至约800个氨基酸,约25个氨基酸至约750个氨基酸,约25个氨基酸至约700个氨基酸,约25个氨基酸至约650个氨基酸,约25个氨基酸至约600个氨基酸,约25个氨基酸至约550个氨基酸,约25个氨基酸至约500个氨基酸,约25个氨基酸至约450个氨基酸,约25个氨基酸至约400个氨基酸,约25个氨基酸至约350个氨基酸,约25个氨基酸至约300个氨基酸,约25个氨基酸至约280个氨基酸,约25个氨基酸至约260个氨基酸,约25个氨基酸至约240个氨基酸,约25个氨基酸至约220个氨基酸,约25个氨基酸至约200个氨基酸,约25个氨基酸至约195个氨基酸,约25个氨基酸至约190个氨基酸,约25个氨基酸至约185个氨基酸,约25个氨基酸至约180个氨基酸,约25个氨基酸至约175个氨基酸,约25个氨基酸至约170个氨基酸,约25个氨基酸至约165个氨基酸,约25个氨基酸至约160个氨基酸,约25个氨基酸至约155个氨基酸,约25个氨基酸至约150个氨基酸,约25个氨基酸至约145个氨基酸,约25个氨基酸至约140个氨基酸,约25个氨基酸至约135个氨基酸,约25个氨基酸至约130个氨基酸,约25个氨基酸至约125个氨基酸,约25个氨基酸至约120个氨基酸,约25个氨基酸至约115个氨基酸,约25个氨基酸至约110个氨基酸,约25个氨基酸至约105个氨基酸,约25个氨基酸至约100个氨基酸,约25个氨基酸至约95个氨基酸,约25个氨基酸至约90个氨基酸,约25个氨基酸至约85个氨基酸,约25个氨基酸至约80个氨基酸,约25个氨基酸至约75个氨基酸,约25个氨基酸至约70个氨基酸,约25个氨基酸至约65个氨基酸,约25个氨基酸至约60个氨基酸,约25个氨基酸至约55个氨基酸,约25个氨基酸至约50个氨基酸,约25个氨基酸至约45个氨基酸,约25个氨基酸至约40个氨基酸,约25个氨基酸至约35个氨基酸,约25个氨基酸至约30个氨基酸,约30个氨基酸至约1000个氨基酸,约30个氨基酸至约950个氨基酸,约30个氨基酸至约900个氨基酸,约30个氨基酸至约850个氨基酸,约30个氨基酸至约800个氨基酸,约30个氨基酸至约750个氨基酸,约30个氨基酸至约700个氨基酸,约30个氨基酸至约650个氨基酸,约30个氨基酸至约600个氨基酸,约30个氨基酸至约550个氨基酸,约30个氨基酸至约500个氨基酸,约30个氨基酸至约450个氨基酸,约30个氨基酸至约400个氨基酸,约30个氨基酸至约350个氨基酸,约30个氨基酸至约300个氨基酸,约30个氨基酸至约280个氨基酸,约30个氨基酸至约260个氨基酸,约30个氨基酸至约240个氨基酸,约30个氨基酸至约220个氨基酸,约30个氨基酸至约200个氨基酸,约30个氨基酸至约195个氨基酸,约30个氨基酸至约190个氨基酸,约30个氨基酸至约185个氨基酸,约30个氨基酸至约180个氨基酸,约30个氨基酸至约175个氨基酸,约30个氨基酸至约170个氨基酸,约30个氨基酸至约165个氨基酸,约30个氨基酸至约160个氨基酸,约30个氨基酸至约155个氨基酸,约30个氨基酸至约150个氨基酸,约30个氨基酸至约145个氨基酸,约30个氨基酸至约140个氨基酸,约30个氨基酸至约135个氨基酸,约30个氨基酸至约130个氨基酸,约30个氨基酸至约125个氨基酸,约30个氨基酸至约120个氨基酸,约30个氨基酸至约115个氨基酸,约30个氨基酸至约110个氨基酸,约30个氨基酸至约105个氨基酸,约30个氨基酸至约100个氨基酸,约30个氨基酸至约95个氨基酸,约30个氨基酸至约90个氨基酸,约30个氨基酸至约85个氨基酸,约30个氨基酸至约80个氨基酸,约30个氨基酸至约75个氨基酸,约30个氨基酸至约70个氨基酸,约30个氨基酸至约65个氨基酸,约30个氨基酸至约60个氨基酸,约30个氨基酸至约55个氨基酸,约30个氨基酸至约50个氨基酸,约30个氨基酸至约45个氨基酸,约30个氨基酸至约40个氨基酸,约30个氨基酸至约35个氨基酸,约35个氨基酸至约1000个氨基酸,约35个氨基酸至约950个氨基酸,约35个氨基酸至约900个氨基酸,约35个氨基酸至约850个氨基酸,约35个氨基酸至约800个氨基酸,约35个氨基酸至约750个氨基酸,约35个氨基酸至约700个氨基酸,约35个氨基酸至约650个氨基酸,约35个氨基酸至约600个氨基酸,约35个氨基酸至约550个氨基酸,约35个氨基酸至约500个氨基酸,约35个氨基酸至约450个氨基酸,约35个氨基酸至约400个氨基酸,约35个氨基酸至约350个氨基酸,约35个氨基酸至约300个氨基酸,约35个氨基酸至约280个氨基酸,约35个氨基酸至约260个氨基酸,约35个氨基酸至约240个氨基酸,约35个氨基酸至约220个氨基酸,约35个氨基酸至约200个氨基酸,约35个氨基酸至约195个氨基酸,约35个氨基酸至约190个氨基酸,约35个氨基酸至约185个氨基酸,约35个氨基酸至约180个氨基酸,约35个氨基酸至约175个氨基酸,约35个氨基酸至约170个氨基酸,约35个氨基酸至约165个氨基酸,约35个氨基酸至约160个氨基酸,约35个氨基酸至约155个氨基酸,约35个氨基酸至约150个氨基酸,约35个氨基酸至约145个氨基酸,约35个氨基酸至约140个氨基酸,约35个氨基酸至约135个氨基酸,约35个氨基酸至约130个氨基酸,约35个氨基酸至约125个氨基酸,约35个氨基酸至约120个氨基酸,约35个氨基酸至约115个氨基酸,约35个氨基酸至约110个氨基酸,约35个氨基酸至约105个氨基酸,约35个氨基酸至约100个氨基酸,约35个氨基酸至约95个氨基酸,约35个氨基酸至约90个氨基酸,约35个氨基酸至约85个氨基酸,约35个氨基酸至约80个氨基酸,约35个氨基酸至约75个氨基酸,约35个氨基酸至约70个氨基酸,约35个氨基酸至约65个氨基酸,约35个氨基酸至约60个氨基酸,约35个氨基酸至约55个氨基酸,约35个氨基酸至约50个氨基酸,约35个氨基酸至约45个氨基酸,约35个氨基酸至约40个氨基酸,约40个氨基酸至约1000个氨基酸,约40个氨基酸至约950个氨基酸,约40个氨基酸至约900个氨基酸,约40个氨基酸至约850个氨基酸,约40个氨基酸至约800个氨基酸,约40个氨基酸至约750个氨基酸,约40个氨基酸至约700个氨基酸,约40个氨基酸至约650个氨基酸,约40个氨基酸至约600个氨基酸,约40个氨基酸至约550个氨基酸,约40个氨基酸至约500个氨基酸,约40个氨基酸至约450个氨基酸,约40个氨基酸至约400个氨基酸,约40个氨基酸至约350个氨基酸,约40个氨基酸至约300个氨基酸,约40个氨基酸至约280个氨基酸,约40个氨基酸至约260个氨基酸,约40个氨基酸至约240个氨基酸,约40个氨基酸至约220个氨基酸,约40个氨基酸至约200个氨基酸,约40个氨基酸至约195个氨基酸,约40个氨基酸至约190个氨基酸,约40个氨基酸至约185个氨基酸,约40个氨基酸至约180个氨基酸,约40个氨基酸至约175个氨基酸,约40个氨基酸至约170个氨基酸,约40个氨基酸至约165个氨基酸,约40个氨基酸至约160个氨基酸,约40个氨基酸至约155个氨基酸,约40个氨基酸至约150个氨基酸,约40个氨基酸至约145个氨基酸,约40个氨基酸至约140个氨基酸,约40个氨基酸至约135个氨基酸,约40个氨基酸至约130个氨基酸,约40个氨基酸至约125个氨基酸,约40个氨基酸至约120个氨基酸,约40个氨基酸至约115个氨基酸,约40个氨基酸至约110个氨基酸,约40个氨基酸至约105个氨基酸,约40个氨基酸至约100个氨基酸,约40个氨基酸至约95个氨基酸,约40个氨基酸至约90个氨基酸,约40个氨基酸至约85个氨基酸,约40个氨基酸至约80个氨基酸,约40个氨基酸至约75个氨基酸,约40个氨基酸至约70个氨基酸,约40个氨基酸至约65个氨基酸,约40个氨基酸至约60个氨基酸,约40个氨基酸至约55个氨基酸,约40个氨基酸至约50个氨基酸,约40个氨基酸至约45个氨基酸,约45个氨基酸至约1000个氨基酸,约45个氨基酸至约950个氨基酸,约45个氨基酸至约900个氨基酸,约45个氨基酸至约850个氨基酸,约45个氨基酸至约800个氨基酸,约45个氨基酸至约750个氨基酸,约45个氨基酸至约700个氨基酸,约45个氨基酸至约650个氨基酸,约45个氨基酸至约600个氨基酸,约45个氨基酸至约550个氨基酸,约45个氨基酸至约500个氨基酸,约45个氨基酸至约450个氨基酸,约45个氨基酸至约400个氨基酸,约45个氨基酸至约350个氨基酸,约45个氨基酸至约300个氨基酸,约45个氨基酸至约280个氨基酸,约45个氨基酸至约260个氨基酸,约45个氨基酸至约240个氨基酸,约45个氨基酸至约220个氨基酸,约45个氨基酸至约200个氨基酸,约45个氨基酸至约195个氨基酸,约45个氨基酸至约190个氨基酸,约45个氨基酸至约185个氨基酸,约45个氨基酸至约180个氨基酸,约45个氨基酸至约175个氨基酸,约45个氨基酸至约170个氨基酸,约45个氨基酸至约165个氨基酸,约45个氨基酸至约160个氨基酸,约45个氨基酸至约155个氨基酸,约45个氨基酸至约150个氨基酸,约45个氨基酸至约145个氨基酸,约45个氨基酸至约140个氨基酸,约45个氨基酸至约135个氨基酸,约45个氨基酸至约130个氨基酸,约45个氨基酸至约125个氨基酸,约45个氨基酸至约120个氨基酸,约45个氨基酸至约115个氨基酸,约45个氨基酸至约110个氨基酸,约45个氨基酸至约105个氨基酸,约45个氨基酸至约100个氨基酸,约45个氨基酸至约95个氨基酸,约45个氨基酸至约90个氨基酸,约45个氨基酸至约85个氨基酸,约45个氨基酸至约80个氨基酸,约45个氨基酸至约75个氨基酸,约45个氨基酸至约70个氨基酸,约45个氨基酸至约65个氨基酸,约45个氨基酸至约60个氨基酸,约45个氨基酸至约55个氨基酸,约45个氨基酸至约50个氨基酸,约50个氨基酸至约1000个氨基酸,约50个氨基酸至约950个氨基酸,约50个氨基酸至约900个氨基酸,约50个氨基酸至约850个氨基酸,约50个氨基酸至约800个氨基酸,约50个氨基酸至约750个氨基酸,约50个氨基酸至约700个氨基酸,约50个氨基酸至约650个氨基酸,约50个氨基酸至约600个氨基酸,约50个氨基酸至约550个氨基酸,约50个氨基酸至约500个氨基酸,约50个氨基酸至约450个氨基酸,约50个氨基酸至约400个氨基酸,约50个氨基酸至约350个氨基酸,约50个氨基酸至约300个氨基酸,约50个氨基酸至约280个氨基酸,约50个氨基酸至约260个氨基酸,约50个氨基酸至约240个氨基酸,约50个氨基酸至约220个氨基酸,约50个氨基酸至约200个氨基酸,约50个氨基酸至约195个氨基酸,约50个氨基酸至约190个氨基酸,约50个氨基酸至约185个氨基酸,约50个氨基酸至约180个氨基酸,约50个氨基酸至约175个氨基酸,约50个氨基酸至约170个氨基酸,约50个氨基酸至约165个氨基酸,约50个氨基酸至约160个氨基酸,约50个氨基酸至约155个氨基酸,约50个氨基酸至约150个氨基酸,约50个氨基酸至约145个氨基酸,约50个氨基酸至约140个氨基酸,约50个氨基酸至约135个氨基酸,约50个氨基酸至约130个氨基酸,约50个氨基酸至约125个氨基酸,约50个氨基酸至约120个氨基酸,约50个氨基酸至约115个氨基酸,约50个氨基酸至约110个氨基酸,约50个氨基酸至约105个氨基酸,约50个氨基酸至约100个氨基酸,约50个氨基酸至约95个氨基酸,约50个氨基酸至约90个氨基酸,约50个氨基酸至约85个氨基酸,约50个氨基酸至约80个氨基酸,约50个氨基酸至约75个氨基酸,约50个氨基酸至约70个氨基酸,约50个氨基酸至约65个氨基酸,约50个氨基酸至约60个氨基酸,约50个氨基酸至约55个氨基酸,约55个氨基酸至约1000个氨基酸,约55个氨基酸至约950个氨基酸,约55个氨基酸至约900个氨基酸,约55个氨基酸至约850个氨基酸,约55个氨基酸至约800个氨基酸,约55个氨基酸至约750个氨基酸,约55个氨基酸至约700个氨基酸,约55个氨基酸至约650个氨基酸,约55个氨基酸至约600个氨基酸,约55个氨基酸至约550个氨基酸,约55个氨基酸至约500个氨基酸,约55个氨基酸至约450个氨基酸,约55个氨基酸至约400个氨基酸,约55个氨基酸至约350个氨基酸,约55个氨基酸至约300个氨基酸,约55个氨基酸至约280个氨基酸,约55个氨基酸至约260个氨基酸,约55个氨基酸至约240个氨基酸,约55个氨基酸至约220个氨基酸,约55个氨基酸至约200个氨基酸,约55个氨基酸至约195个氨基酸,约55个氨基酸至约190个氨基酸,约55个氨基酸至约185个氨基酸,约55个氨基酸至约180个氨基酸,约55个氨基酸至约175个氨基酸,约55个氨基酸至约170个氨基酸,约55个氨基酸至约165个氨基酸,约55个氨基酸至约160个氨基酸,约55个氨基酸至约155个氨基酸,约55个氨基酸至约150个氨基酸,约55个氨基酸至约145个氨基酸,约55个氨基酸至约140个氨基酸,约55个氨基酸至约135个氨基酸,约55个氨基酸至约130个氨基酸,约55个氨基酸至约125个氨基酸,约55个氨基酸至约120个氨基酸,约55个氨基酸至约115个氨基酸,约55个氨基酸至约110个氨基酸,约55个氨基酸至约105个氨基酸,约55个氨基酸至约100个氨基酸,约55个氨基酸至约95个氨基酸,约55个氨基酸至约90个氨基酸,约55个氨基酸至约85个氨基酸,约55个氨基酸至约80个氨基酸,约55个氨基酸至约75个氨基酸,约55个氨基酸至约70个氨基酸,约55个氨基酸至约65个氨基酸,约55个氨基酸至约60个氨基酸,约60个氨基酸至约1000个氨基酸,约60个氨基酸至约950个氨基酸,约60个氨基酸至约900个氨基酸,约60个氨基酸至约850个氨基酸,约60个氨基酸至约800个氨基酸,约60个氨基酸至约750个氨基酸,约60个氨基酸至约700个氨基酸,约60个氨基酸至约650个氨基酸,约60个氨基酸至约600个氨基酸,约60个氨基酸至约550个氨基酸,约60个氨基酸至约500个氨基酸,约60个氨基酸至约450个氨基酸,约60个氨基酸至约400个氨基酸,约60个氨基酸至约350个氨基酸,约60个氨基酸至约300个氨基酸,约60个氨基酸至约280个氨基酸,约60个氨基酸至约260个氨基酸,约60个氨基酸至约240个氨基酸,约60个氨基酸至约220个氨基酸,约60个氨基酸至约200个氨基酸,约60个氨基酸至约195个氨基酸,约60个氨基酸至约190个氨基酸,约60个氨基酸至约185个氨基酸,约60个氨基酸至约180个氨基酸,约60个氨基酸至约175个氨基酸,约60个氨基酸至约170个氨基酸,约60个氨基酸至约165个氨基酸,约60个氨基酸至约160个氨基酸,约60个氨基酸至约155个氨基酸,约60个氨基酸至约150个氨基酸,约60个氨基酸至约145个氨基酸,约60个氨基酸至约140个氨基酸,约60个氨基酸至约135个氨基酸,约60个氨基酸至约130个氨基酸,约60个氨基酸至约125个氨基酸,约60个氨基酸至约120个氨基酸,约60个氨基酸至约115个氨基酸,约60个氨基酸至约110个氨基酸,约60个氨基酸至约105个氨基酸,约60个氨基酸至约100个氨基酸,约60个氨基酸至约95个氨基酸,约60个氨基酸至约90个氨基酸,约60个氨基酸至约85个氨基酸,约60个氨基酸至约80个氨基酸,约60个氨基酸至约75个氨基酸,约60个氨基酸至约70个氨基酸,约60个氨基酸至约65个氨基酸,约65个氨基酸至约1000个氨基酸,约65个氨基酸至约950个氨基酸,约65个氨基酸至约900个氨基酸,约65个氨基酸至约850个氨基酸,约65个氨基酸至约800个氨基酸,约65个氨基酸至约750个氨基酸,约65个氨基酸至约700个氨基酸,约65个氨基酸至约650个氨基酸,约65个氨基酸至约600个氨基酸,约65个氨基酸至约550个氨基酸,约65个氨基酸至约500个氨基酸,约65个氨基酸至约450个氨基酸,约65个氨基酸至约400个氨基酸,约65个氨基酸至约350个氨基酸,约65个氨基酸至约300个氨基酸,约65个氨基酸至约280个氨基酸,约65个氨基酸至约260个氨基酸,约65个氨基酸至约240个氨基酸,约65个氨基酸至约220个氨基酸,约65个氨基酸至约200个氨基酸,约65个氨基酸至约195个氨基酸,约65个氨基酸至约190个氨基酸,约65个氨基酸至约185个氨基酸,约65个氨基酸至约180个氨基酸,约65个氨基酸至约175个氨基酸,约65个氨基酸至约170个氨基酸,约65个氨基酸至约165个氨基酸,约65个氨基酸至约160个氨基酸,约65个氨基酸至约155个氨基酸,约65个氨基酸至约150个氨基酸,约65个氨基酸至约145个氨基酸,约65个氨基酸至约140个氨基酸,约65个氨基酸至约135个氨基酸,约65个氨基酸至约130个氨基酸,约65个氨基酸至约125个氨基酸,约65个氨基酸至约120个氨基酸,约65个氨基酸至约115个氨基酸,约65个氨基酸至约110个氨基酸,约65个氨基酸至约105个氨基酸,约65个氨基酸至约100个氨基酸,约65个氨基酸至约95个氨基酸,约65个氨基酸至约90个氨基酸,约65个氨基酸至约85个氨基酸,约65个氨基酸至约80个氨基酸,约65个氨基酸至约75个氨基酸,约65个氨基酸至约70个氨基酸,约70个氨基酸至约1000个氨基酸,约70个氨基酸至约950个氨基酸,约70个氨基酸至约900个氨基酸,约70个氨基酸至约850个氨基酸,约70个氨基酸至约800个氨基酸,约70个氨基酸至约750个氨基酸,约70个氨基酸至约700个氨基酸,约70个氨基酸至约650个氨基酸,约70个氨基酸至约600个氨基酸,约70个氨基酸至约550个氨基酸,约70个氨基酸至约500个氨基酸,约70个氨基酸至约450个氨基酸,约70个氨基酸至约400个氨基酸,约70个氨基酸至约350个氨基酸,约70个氨基酸至约300个氨基酸,约70个氨基酸至约280个氨基酸,约70个氨基酸至约260个氨基酸,约70个氨基酸至约240个氨基酸,约70个氨基酸至约220个氨基酸,约70个氨基酸至约200个氨基酸,约70个氨基酸至约195个氨基酸,约70个氨基酸至约190个氨基酸,约70个氨基酸至约185个氨基酸,约70个氨基酸至约180个氨基酸,约70个氨基酸至约175个氨基酸,约70个氨基酸至约170个氨基酸,约70个氨基酸至约165个氨基酸,约70个氨基酸至约160个氨基酸,约70个氨基酸至约155个氨基酸,约70个氨基酸至约150个氨基酸,约70个氨基酸至约145个氨基酸,约70个氨基酸至约140个氨基酸,约70个氨基酸至约135个氨基酸,约70个氨基酸至约130个氨基酸,约70个氨基酸至约125个氨基酸,约70个氨基酸至约120个氨基酸,约70个氨基酸至约115个氨基酸,约70个氨基酸至约110个氨基酸,约70个氨基酸至约105个氨基酸,约70个氨基酸至约100个氨基酸,约70个氨基酸至约95个氨基酸,约70个氨基酸至约90个氨基酸,约70个氨基酸至约85个氨基酸,约70个氨基酸至约80个氨基酸,约70个氨基酸至约75个氨基酸,约75个氨基酸至约1000个氨基酸,约75个氨基酸至约950个氨基酸,约75个氨基酸至约900个氨基酸,约75个氨基酸至约850个氨基酸,约75个氨基酸至约800个氨基酸,约75个氨基酸至约750个氨基酸,约75个氨基酸至约700个氨基酸,约75个氨基酸至约650个氨基酸,约75个氨基酸至约600个氨基酸,约75个氨基酸至约550个氨基酸,约75个氨基酸至约500个氨基酸,约75个氨基酸至约450个氨基酸,约75个氨基酸至约400个氨基酸,约75个氨基酸至约350个氨基酸,约75个氨基酸至约300个氨基酸,约75个氨基酸至约280个氨基酸,约75个氨基酸至约260个氨基酸,约75个氨基酸至约240个氨基酸,约75个氨基酸至约220个氨基酸,约75个氨基酸至约200个氨基酸,约75个氨基酸至约195个氨基酸,约75个氨基酸至约190个氨基酸,约75个氨基酸至约185个氨基酸,约75个氨基酸至约180个氨基酸,约75个氨基酸至约175个氨基酸,约75个氨基酸至约170个氨基酸,约75个氨基酸至约165个氨基酸,约75个氨基酸至约160个氨基酸,约75个氨基酸至约155个氨基酸,约75个氨基酸至约150个氨基酸,约75个氨基酸至约145个氨基酸,约75个氨基酸至约140个氨基酸,约75个氨基酸至约135个氨基酸,约75个氨基酸至约130个氨基酸,约75个氨基酸至约125个氨基酸,约75个氨基酸至约120个氨基酸,约75个氨基酸至约115个氨基酸,约75个氨基酸至约110个氨基酸,约75个氨基酸至约105个氨基酸,约75个氨基酸至约100个氨基酸,约75个氨基酸至约95个氨基酸,约75个氨基酸至约90个氨基酸,约75个氨基酸至约85个氨基酸,约75个氨基酸至约80个氨基酸,约80个氨基酸至约1000个氨基酸,约80个氨基酸至约950个氨基酸,约80个氨基酸至约900个氨基酸,约80个氨基酸至约850个氨基酸,约80个氨基酸至约800个氨基酸,约80个氨基酸至约750个氨基酸,约80个氨基酸至约700个氨基酸,约80个氨基酸至约650个氨基酸,约80个氨基酸至约600个氨基酸,约80个氨基酸至约550个氨基酸,约80个氨基酸至约500个氨基酸,约80个氨基酸至约450个氨基酸,约80个氨基酸至约400个氨基酸,约80个氨基酸至约350个氨基酸,约80个氨基酸至约300个氨基酸,约80个氨基酸至约280个氨基酸,约80个氨基酸至约260个氨基酸,约80个氨基酸至约240个氨基酸,约80个氨基酸至约220个氨基酸,约80个氨基酸至约200个氨基酸,约80个氨基酸至约195个氨基酸,约80个氨基酸至约190个氨基酸,约80个氨基酸至约185个氨基酸,约80个氨基酸至约180个氨基酸,约80个氨基酸至约175个氨基酸,约80个氨基酸至约170个氨基酸,约80个氨基酸至约165个氨基酸,约80个氨基酸至约160个氨基酸,约80个氨基酸至约155个氨基酸,约80个氨基酸至约150个氨基酸,约80个氨基酸至约145个氨基酸,约80个氨基酸至约140个氨基酸,约80个氨基酸至约135个氨基酸,约80个氨基酸至约130个氨基酸,约80个氨基酸至约125个氨基酸,约80个氨基酸至约120个氨基酸,约80个氨基酸至约115个氨基酸,约80个氨基酸至约110个氨基酸,约80个氨基酸至约105个氨基酸,约80个氨基酸至约100个氨基酸,约80个氨基酸至约95个氨基酸,约80个氨基酸至约90个氨基酸,约80个氨基酸至约85个氨基酸,约85个氨基酸至约1000个氨基酸,约85个氨基酸至约950个氨基酸,约85个氨基酸至约900个氨基酸,约85个氨基酸至约850个氨基酸,约85个氨基酸至约800个氨基酸,约85个氨基酸至约750个氨基酸,约85个氨基酸至约700个氨基酸,约85个氨基酸至约650个氨基酸,约85个氨基酸至约600个氨基酸,约85个氨基酸至约550个氨基酸,约85个氨基酸至约500个氨基酸,约85个氨基酸至约450个氨基酸,约85个氨基酸至约400个氨基酸,约85个氨基酸至约350个氨基酸,约85个氨基酸至约300个氨基酸,约85个氨基酸至约280个氨基酸,约85个氨基酸至约260个氨基酸,约85个氨基酸至约240个氨基酸,约85个氨基酸至约220个氨基酸,约85个氨基酸至约200个氨基酸,约85个氨基酸至约195个氨基酸,约85个氨基酸至约190个氨基酸,约85个氨基酸至约185个氨基酸,约85个氨基酸至约180个氨基酸,约85个氨基酸至约175个氨基酸,约85个氨基酸至约170个氨基酸,约85个氨基酸至约165个氨基酸,约85个氨基酸至约160个氨基酸,约85个氨基酸至约155个氨基酸,约85个氨基酸至约150个氨基酸,约85个氨基酸至约145个氨基酸,约85个氨基酸至约140个氨基酸,约85个氨基酸至约135个氨基酸,约85个氨基酸至约130个氨基酸,约85个氨基酸至约125个氨基酸,约85个氨基酸至约120个氨基酸,约85个氨基酸至约115个氨基酸,约85个氨基酸至约110个氨基酸,约85个氨基酸至约105个氨基酸,约85个氨基酸至约100个氨基酸,约85个氨基酸至约95个氨基酸,约85个氨基酸至约90个氨基酸,约90个氨基酸至约1000个氨基酸,约90个氨基酸至约950个氨基酸,约90个氨基酸至约900个氨基酸,约90个氨基酸至约850个氨基酸,约90个氨基酸至约800个氨基酸,约90个氨基酸至约750个氨基酸,约90个氨基酸至约700个氨基酸,约90个氨基酸至约650个氨基酸,约90个氨基酸至约600个氨基酸,约90个氨基酸至约550个氨基酸,约90个氨基酸至约500个氨基酸,约90个氨基酸至约450个氨基酸,约90个氨基酸至约400个氨基酸,约90个氨基酸至约350个氨基酸,约90个氨基酸至约300个氨基酸,约90个氨基酸至约280个氨基酸,约90个氨基酸至约260个氨基酸,约90个氨基酸至约240个氨基酸,约90个氨基酸至约220个氨基酸,约90个氨基酸至约200个氨基酸,约90个氨基酸至约195个氨基酸,约90个氨基酸至约190个氨基酸,约90个氨基酸至约185个氨基酸,约90个氨基酸至约180个氨基酸,约90个氨基酸至约175个氨基酸,约90个氨基酸至约170个氨基酸,约90个氨基酸至约165个氨基酸,约90个氨基酸至约160个氨基酸,约90个氨基酸至约155个氨基酸,约90个氨基酸至约150个氨基酸,约90个氨基酸至约145个氨基酸,约90个氨基酸至约140个氨基酸,约90个氨基酸至约135个氨基酸,约90个氨基酸至约130个氨基酸,约90个氨基酸至约125个氨基酸,约90个氨基酸至约120个氨基酸,约90个氨基酸至约115个氨基酸,约90个氨基酸至约110个氨基酸,约90个氨基酸至约105个氨基酸,约90个氨基酸至约100个氨基酸,约90个氨基酸至约95个氨基酸,约95个氨基酸至约1000个氨基酸,约95个氨基酸至约950个氨基酸,约95个氨基酸至约900个氨基酸,约95个氨基酸至约850个氨基酸,约95个氨基酸至约800个氨基酸,约95个氨基酸至约750个氨基酸,约95个氨基酸至约700个氨基酸,约95个氨基酸至约650个氨基酸,约95个氨基酸至约600个氨基酸,约95个氨基酸至约550个氨基酸,约95个氨基酸至约500个氨基酸,约95个氨基酸至约450个氨基酸,约95个氨基酸至约400个氨基酸,约95个氨基酸至约350个氨基酸,约95个氨基酸至约300个氨基酸,约95个氨基酸至约280个氨基酸,约95个氨基酸至约260个氨基酸,约95个氨基酸至约240个氨基酸,约95个氨基酸至约220个氨基酸,约95个氨基酸至约200个氨基酸,约95个氨基酸至约195个氨基酸,约95个氨基酸至约190个氨基酸,约95个氨基酸至约185个氨基酸,约95个氨基酸至约180个氨基酸,约95个氨基酸至约175个氨基酸,约95个氨基酸至约170个氨基酸,约95个氨基酸至约165个氨基酸,约95个氨基酸至约160个氨基酸,约95个氨基酸至约155个氨基酸,约95个氨基酸至约150个氨基酸,约95个氨基酸至约145个氨基酸,约95个氨基酸至约140个氨基酸,约95个氨基酸至约135个氨基酸,约95个氨基酸至约130个氨基酸,约95个氨基酸至约125个氨基酸,约95个氨基酸至约120个氨基酸,约95个氨基酸至约115个氨基酸,约95个氨基酸至约110个氨基酸,约95个氨基酸至约105个氨基酸,约95个氨基酸至约100个氨基酸,约100个氨基酸至约1000个氨基酸,约100个氨基酸至约950个氨基酸,约100个氨基酸至约900个氨基酸,约100个氨基酸至约850个氨基酸,约100个氨基酸至约800个氨基酸,约100个氨基酸至约750个氨基酸,约100个氨基酸至约700个氨基酸,约100个氨基酸至约650个氨基酸,约100个氨基酸至约600个氨基酸,约100个氨基酸至约550个氨基酸,约100个氨基酸至约500个氨基酸,约100个氨基酸至约450个氨基酸,约100个氨基酸至约400个氨基酸,约100个氨基酸至约350个氨基酸,约100个氨基酸至约300个氨基酸,约100个氨基酸至约280个氨基酸,约100个氨基酸至约260个氨基酸,约100个氨基酸至约240个氨基酸,约100个氨基酸至约220个氨基酸,约100个氨基酸至约200个氨基酸,约100个氨基酸至约195个氨基酸,约100个氨基酸至约190个氨基酸,约100个氨基酸至约185个氨基酸,约100个氨基酸至约180个氨基酸,约100个氨基酸至约175个氨基酸,约100个氨基酸至约170个氨基酸,约100个氨基酸至约165个氨基酸,约100个氨基酸至约160个氨基酸,约100个氨基酸至约155个氨基酸,约100个氨基酸至约150个氨基酸,约100个氨基酸至约145个氨基酸,约100个氨基酸至约140个氨基酸,约100个氨基酸至约135个氨基酸,约100个氨基酸至约130个氨基酸,约100个氨基酸至约125个氨基酸,约100个氨基酸至约120个氨基酸,约100个氨基酸至约115个氨基酸,约100个氨基酸至约110个氨基酸,约100个氨基酸至约105个氨基酸,约105个氨基酸至约1000个氨基酸,约105个氨基酸至约950个氨基酸,约105个氨基酸至约900个氨基酸,约105个氨基酸至约850个氨基酸,约105个氨基酸至约800个氨基酸,约105个氨基酸至约750个氨基酸,约105个氨基酸至约700个氨基酸,约105个氨基酸至约650个氨基酸,约105个氨基酸至约600个氨基酸,约105个氨基酸至约550个氨基酸,约105个氨基酸至约500个氨基酸,约105个氨基酸至约450个氨基酸,约105个氨基酸至约400个氨基酸,约105个氨基酸至约350个氨基酸,约105个氨基酸至约300个氨基酸,约105个氨基酸至约280个氨基酸,约105个氨基酸至约260个氨基酸,约105个氨基酸至约240个氨基酸,约105个氨基酸至约220个氨基酸,约105个氨基酸至约200个氨基酸,约105个氨基酸至约195个氨基酸,约105个氨基酸至约190个氨基酸,约105个氨基酸至约185个氨基酸,约105个氨基酸至约180个氨基酸,约105个氨基酸至约175个氨基酸,约105个氨基酸至约170个氨基酸,约105个氨基酸至约165个氨基酸,约105个氨基酸至约160个氨基酸,约105个氨基酸至约155个氨基酸,约105个氨基酸至约150个氨基酸,约105个氨基酸至约145个氨基酸,约105个氨基酸至约140个氨基酸,约105个氨基酸至约135个氨基酸,约105个氨基酸至约130个氨基酸,约105个氨基酸至约125个氨基酸,约105个氨基酸至约120个氨基酸,约105个氨基酸至约115个氨基酸,约105个氨基酸至约110个氨基酸,约110个氨基酸至约1000个氨基酸,约110个氨基酸至约950个氨基酸,约110个氨基酸至约900个氨基酸,约110个氨基酸至约850个氨基酸,约110个氨基酸至约800个氨基酸,约110个氨基酸至约750个氨基酸,约110个氨基酸至约700个氨基酸,约110个氨基酸至约650个氨基酸,约110个氨基酸至约600个氨基酸,约110个氨基酸至约550个氨基酸,约110个氨基酸至约500个氨基酸,约110个氨基酸至约450个氨基酸,约110个氨基酸至约400个氨基酸,约110个氨基酸至约350个氨基酸,约110个氨基酸至约300个氨基酸,约110个氨基酸至约280个氨基酸,约110个氨基酸至约260个氨基酸,约110个氨基酸至约240个氨基酸,约110个氨基酸至约220个氨基酸,约110个氨基酸至约200个氨基酸,约110个氨基酸至约195个氨基酸,约110个氨基酸至约190个氨基酸,约110个氨基酸至约185个氨基酸,约110个氨基酸至约180个氨基酸,约110个氨基酸至约175个氨基酸,约110个氨基酸至约170个氨基酸,约110个氨基酸至约165个氨基酸,约110个氨基酸至约160个氨基酸,约110个氨基酸至约155个氨基酸,约110个氨基酸至约150个氨基酸,约110个氨基酸至约145个氨基酸,约110个氨基酸至约140个氨基酸,约110个氨基酸至约135个氨基酸,约110个氨基酸至约130个氨基酸,约110个氨基酸至约125个氨基酸,约110个氨基酸至约120个氨基酸,约110个氨基酸至约115个氨基酸,约115个氨基酸至约1000个氨基酸,约115个氨基酸至约950个氨基酸,约115个氨基酸至约900个氨基酸,约115个氨基酸至约850个氨基酸,约115个氨基酸至约800个氨基酸,约115个氨基酸至约750个氨基酸,约115个氨基酸至约700个氨基酸,约115个氨基酸至约650个氨基酸,约115个氨基酸至约600个氨基酸,约115个氨基酸至约550个氨基酸,约115个氨基酸至约500个氨基酸,约115个氨基酸至约450个氨基酸,约115个氨基酸至约400个氨基酸,约115个氨基酸至约350个氨基酸,约115个氨基酸至约300个氨基酸,约115个氨基酸至约280个氨基酸,约115个氨基酸至约260个氨基酸,约115个氨基酸至约240个氨基酸,约115个氨基酸至约220个氨基酸,约115个氨基酸至约200个氨基酸,约115个氨基酸至约195个氨基酸,约115个氨基酸至约190个氨基酸,约115个氨基酸至约185个氨基酸,约115个氨基酸至约180个氨基酸,约115个氨基酸至约175个氨基酸,约115个氨基酸至约170个氨基酸,约115个氨基酸至约165个氨基酸,约115个氨基酸至约160个氨基酸,约115个氨基酸至约155个氨基酸,约115个氨基酸至约150个氨基酸,约115个氨基酸至约145个氨基酸,约115个氨基酸至约140个氨基酸,约115个氨基酸至约135个氨基酸,约115个氨基酸至约130个氨基酸,约115个氨基酸至约125个氨基酸,约115个氨基酸至约120个氨基酸,约120个氨基酸至约1000个氨基酸,约120个氨基酸至约950个氨基酸,约120个氨基酸至约900个氨基酸,约120个氨基酸至约850个氨基酸,约120个氨基酸至约800个氨基酸,约120个氨基酸至约750个氨基酸,约120个氨基酸至约700个氨基酸,约120个氨基酸至约650个氨基酸,约120个氨基酸至约600个氨基酸,约120个氨基酸至约550个氨基酸,约120个氨基酸至约500个氨基酸,约120个氨基酸至约450个氨基酸,约120个氨基酸至约400个氨基酸,约120个氨基酸至约350个氨基酸,约120个氨基酸至约300个氨基酸,约120个氨基酸至约280个氨基酸,约120个氨基酸至约260个氨基酸,约120个氨基酸至约240个氨基酸,约120个氨基酸至约220个氨基酸,约120个氨基酸至约200个氨基酸,约120个氨基酸至约195个氨基酸,约120个氨基酸至约190个氨基酸,约120个氨基酸至约185个氨基酸,约120个氨基酸至约180个氨基酸,约120个氨基酸至约175个氨基酸,约120个氨基酸至约170个氨基酸,约120个氨基酸至约165个氨基酸,约120个氨基酸至约160个氨基酸,约120个氨基酸至约155个氨基酸,约120个氨基酸至约150个氨基酸,约120个氨基酸至约145个氨基酸,约120个氨基酸至约140个氨基酸,约120个氨基酸至约135个氨基酸,约120个氨基酸至约130个氨基酸,约120个氨基酸至约125个氨基酸,约125个氨基酸至约1000个氨基酸,约125个氨基酸至约950个氨基酸,约125个氨基酸至约900个氨基酸,约125个氨基酸至约850个氨基酸,约125个氨基酸至约800个氨基酸,约125个氨基酸至约750个氨基酸,约125个氨基酸至约700个氨基酸,约125个氨基酸至约650个氨基酸,约125个氨基酸至约600个氨基酸,约125个氨基酸至约550个氨基酸,约125个氨基酸至约500个氨基酸,约125个氨基酸至约450个氨基酸,约125个氨基酸至约400个氨基酸,约125个氨基酸至约350个氨基酸,约125个氨基酸至约300个氨基酸,约125个氨基酸至约280个氨基酸,约125个氨基酸至约260个氨基酸,约125个氨基酸至约240个氨基酸,约125个氨基酸至约220个氨基酸,约125个氨基酸至约200个氨基酸,约125个氨基酸至约195个氨基酸,约125个氨基酸至约190个氨基酸,约125个氨基酸至约185个氨基酸,约125个氨基酸至约180个氨基酸,约125个氨基酸至约175个氨基酸,约125个氨基酸至约170个氨基酸,约125个氨基酸至约165个氨基酸,约125个氨基酸至约160个氨基酸,约125个氨基酸至约155个氨基酸,约125个氨基酸至约150个氨基酸,约125个氨基酸至约145个氨基酸,约125个氨基酸至约140个氨基酸,约125个氨基酸至约135个氨基酸,约125个氨基酸至约130个氨基酸,约130个氨基酸至约1000个氨基酸,约130个氨基酸至约950个氨基酸,约130个氨基酸至约900个氨基酸,约130个氨基酸至约850个氨基酸,约130个氨基酸至约800个氨基酸,约130个氨基酸至约750个氨基酸,约130个氨基酸至约700个氨基酸,约130个氨基酸至约650个氨基酸,约130个氨基酸至约600个氨基酸,约130个氨基酸至约550个氨基酸,约130个氨基酸至约500个氨基酸,约130个氨基酸至约450个氨基酸,约130个氨基酸至约400个氨基酸,约130个氨基酸至约350个氨基酸,约130个氨基酸至约300个氨基酸,约130个氨基酸至约280个氨基酸,约130个氨基酸至约260个氨基酸,约130个氨基酸至约240个氨基酸,约130个氨基酸至约220个氨基酸,约130个氨基酸至约200个氨基酸,约130个氨基酸至约195个氨基酸,约130个氨基酸至约190个氨基酸,约130个氨基酸至约185个氨基酸,约130个氨基酸至约180个氨基酸,约130个氨基酸至约175个氨基酸,约130个氨基酸至约170个氨基酸,约130个氨基酸至约165个氨基酸,约130个氨基酸至约160个氨基酸,约130个氨基酸至约155个氨基酸,约130个氨基酸至约150个氨基酸,约130个氨基酸至约145个氨基酸,约130个氨基酸至约140个氨基酸,约130个氨基酸至约135个氨基酸,约135个氨基酸至约1000个氨基酸,约135个氨基酸至约950个氨基酸,约135个氨基酸至约900个氨基酸,约135个氨基酸至约850个氨基酸,约135个氨基酸至约800个氨基酸,约135个氨基酸至约750个氨基酸,约135个氨基酸至约700个氨基酸,约135个氨基酸至约650个氨基酸,约135个氨基酸至约600个氨基酸,约135个氨基酸至约550个氨基酸,约135个氨基酸至约500个氨基酸,约135个氨基酸至约450个氨基酸,约135个氨基酸至约400个氨基酸,约135个氨基酸至约350个氨基酸,约135个氨基酸至约300个氨基酸,约135个氨基酸至约280个氨基酸,约135个氨基酸至约260个氨基酸,约135个氨基酸至约240个氨基酸,约135个氨基酸至约220个氨基酸,约135个氨基酸至约200个氨基酸,约135个氨基酸至约195个氨基酸,约135个氨基酸至约190个氨基酸,约135个氨基酸至约185个氨基酸,约135个氨基酸至约180个氨基酸,约135个氨基酸至约175个氨基酸,约135个氨基酸至约170个氨基酸,约135个氨基酸至约165个氨基酸,约135个氨基酸至约160个氨基酸,约135个氨基酸至约155个氨基酸,约135个氨基酸至约150个氨基酸,约135个氨基酸至约145个氨基酸,约135个氨基酸至约140个氨基酸,约140个氨基酸至约1000个氨基酸,约140个氨基酸至约950个氨基酸,约140个氨基酸至约900个氨基酸,约140个氨基酸至约850个氨基酸,约140个氨基酸至约800个氨基酸,约140个氨基酸至约750个氨基酸,约140个氨基酸至约700个氨基酸,约140个氨基酸至约650个氨基酸,约140个氨基酸至约600个氨基酸,约140个氨基酸至约550个氨基酸,约140个氨基酸至约500个氨基酸,约140个氨基酸至约450个氨基酸,约140个氨基酸至约400个氨基酸,约140个氨基酸至约350个氨基酸,约140个氨基酸至约300个氨基酸,约140个氨基酸至约280个氨基酸,约140个氨基酸至约260个氨基酸,约140个氨基酸至约240个氨基酸,约140个氨基酸至约220个氨基酸,约140个氨基酸至约200个氨基酸,约140个氨基酸至约195个氨基酸,约140个氨基酸至约190个氨基酸,约140个氨基酸至约185个氨基酸,约140个氨基酸至约180个氨基酸,约140个氨基酸至约175个氨基酸,约140个氨基酸至约170个氨基酸,约140个氨基酸至约165个氨基酸,约140个氨基酸至约160个氨基酸,约140个氨基酸至约155个氨基酸,约140个氨基酸至约150个氨基酸,约140个氨基酸至约145个氨基酸,约145个氨基酸至约1000个氨基酸,约145个氨基酸至约950个氨基酸,约145个氨基酸至约900个氨基酸,约145个氨基酸至约850个氨基酸,约145个氨基酸至约800个氨基酸,约145个氨基酸至约750个氨基酸,约145个氨基酸至约700个氨基酸,约145个氨基酸至约650个氨基酸,约145个氨基酸至约600个氨基酸,约145个氨基酸至约550个氨基酸,约145个氨基酸至约500个氨基酸,约145个氨基酸至约450个氨基酸,约145个氨基酸至约400个氨基酸,约145个氨基酸至约350个氨基酸,约145个氨基酸至约300个氨基酸,约145个氨基酸至约280个氨基酸,约145个氨基酸至约260个氨基酸,约145个氨基酸至约240个氨基酸,约145个氨基酸至约220个氨基酸,约145个氨基酸至约200个氨基酸,约145个氨基酸至约195个氨基酸,约145个氨基酸至约190个氨基酸,约145个氨基酸至约185个氨基酸,约145个氨基酸至约180个氨基酸,约145个氨基酸至约175个氨基酸,约145个氨基酸至约170个氨基酸,约145个氨基酸至约165个氨基酸,约145个氨基酸至约160个氨基酸,约145个氨基酸至约155个氨基酸,约145个氨基酸至约150个氨基酸,约150个氨基酸至约1000个氨基酸,约150个氨基酸至约950个氨基酸,约150个氨基酸至约900个氨基酸,约150个氨基酸至约850个氨基酸,约150个氨基酸至约800个氨基酸,约150个氨基酸至约750个氨基酸,约150个氨基酸至约700个氨基酸,约150个氨基酸至约650个氨基酸,约150个氨基酸至约600个氨基酸,约150个氨基酸至约550个氨基酸,约150个氨基酸至约500个氨基酸,约150个氨基酸至约450个氨基酸,约150个氨基酸至约400个氨基酸,约150个氨基酸至约350个氨基酸,约150个氨基酸至约300个氨基酸,约150个氨基酸至约280个氨基酸,约150个氨基酸至约260个氨基酸,约150个氨基酸至约240个氨基酸,约150个氨基酸至约220个氨基酸,约150个氨基酸至约200个氨基酸,约150个氨基酸至约195个氨基酸,约150个氨基酸至约190个氨基酸,约150个氨基酸至约185个氨基酸,约150个氨基酸至约180个氨基酸,约150个氨基酸至约175个氨基酸,约150个氨基酸至约170个氨基酸,约150个氨基酸至约165个氨基酸,约150个氨基酸至约160个氨基酸,约150个氨基酸至约155个氨基酸,约155个氨基酸至约1000个氨基酸,约155个氨基酸至约950个氨基酸,约155个氨基酸至约900个氨基酸,约155个氨基酸至约850个氨基酸,约155个氨基酸至约800个氨基酸,约155个氨基酸至约750个氨基酸,约155个氨基酸至约700个氨基酸,约155个氨基酸至约650个氨基酸,约155个氨基酸至约600个氨基酸,约155个氨基酸至约550个氨基酸,约155个氨基酸至约500个氨基酸,约155个氨基酸至约450个氨基酸,约155个氨基酸至约400个氨基酸,约155个氨基酸至约350个氨基酸,约155个氨基酸至约300个氨基酸,约155个氨基酸至约280个氨基酸,约155个氨基酸至约260个氨基酸,约155个氨基酸至约240个氨基酸,约155个氨基酸至约220个氨基酸,约155个氨基酸至约200个氨基酸,约155个氨基酸至约195个氨基酸,约155个氨基酸至约190个氨基酸,约155个氨基酸至约185个氨基酸,约155个氨基酸至约180个氨基酸,约155个氨基酸至约175个氨基酸,约155个氨基酸至约170个氨基酸,约155个氨基酸至约165个氨基酸,约155个氨基酸至约160个氨基酸,约160个氨基酸至约1000个氨基酸,约160个氨基酸至约950个氨基酸,约160个氨基酸至约900个氨基酸,约160个氨基酸至约850个氨基酸,约160个氨基酸至约800个氨基酸,约160个氨基酸至约750个氨基酸,约160个氨基酸至约700个氨基酸,约160个氨基酸至约650个氨基酸,约160个氨基酸至约600个氨基酸,约160个氨基酸至约550个氨基酸,约160个氨基酸至约500个氨基酸,约160个氨基酸至约450个氨基酸,约160个氨基酸至约400个氨基酸,约160个氨基酸至约350个氨基酸,约160个氨基酸至约300个氨基酸,约160个氨基酸至约280个氨基酸,约160个氨基酸至约260个氨基酸,约160个氨基酸至约240个氨基酸,约160个氨基酸至约220个氨基酸,约160个氨基酸至约200个氨基酸,约160个氨基酸至约195个氨基酸,约160个氨基酸至约190个氨基酸,约160个氨基酸至约185个氨基酸,约160个氨基酸至约180个氨基酸,约160个氨基酸至约175个氨基酸,约160个氨基酸至约170个氨基酸,约160个氨基酸至约165个氨基酸,约165个氨基酸至约1000个氨基酸,约165个氨基酸至约950个氨基酸,约165个氨基酸至约900个氨基酸,约165个氨基酸至约850个氨基酸,约165个氨基酸至约800个氨基酸,约165个氨基酸至约750个氨基酸,约165个氨基酸至约700个氨基酸,约165个氨基酸至约650个氨基酸,约165个氨基酸至约600个氨基酸,约165个氨基酸至约550个氨基酸,约165个氨基酸至约500个氨基酸,约165个氨基酸至约450个氨基酸,约165个氨基酸至约400个氨基酸,约165个氨基酸至约350个氨基酸,约165个氨基酸至约300个氨基酸,约165个氨基酸至约280个氨基酸,约165个氨基酸至约260个氨基酸,约165个氨基酸至约240个氨基酸,约165个氨基酸至约220个氨基酸,约165个氨基酸至约200个氨基酸,约165个氨基酸至约195个氨基酸,约165个氨基酸至约190个氨基酸,约165个氨基酸至约185个氨基酸,约165个氨基酸至约180个氨基酸,约165个氨基酸至约175个氨基酸,约165个氨基酸至约170个氨基酸,约170个氨基酸至约1000个氨基酸,约170个氨基酸至约950个氨基酸,约170个氨基酸至约900个氨基酸,约170个氨基酸至约850个氨基酸,约170个氨基酸至约800个氨基酸,约170个氨基酸至约750个氨基酸,约170个氨基酸至约700个氨基酸,约170个氨基酸至约650个氨基酸,约170个氨基酸至约600个氨基酸,约170个氨基酸至约550个氨基酸,约170个氨基酸至约500个氨基酸,约170个氨基酸至约450个氨基酸,约170个氨基酸至约400个氨基酸,约170个氨基酸至约350个氨基酸,约170个氨基酸至约300个氨基酸,约170个氨基酸至约280个氨基酸,约170个氨基酸至约260个氨基酸,约170个氨基酸至约240个氨基酸,约170个氨基酸至约220个氨基酸,约170个氨基酸至约200个氨基酸,约170个氨基酸至约195个氨基酸,约170个氨基酸至约190个氨基酸,约170个氨基酸至约185个氨基酸,约170个氨基酸至约180个氨基酸,约170个氨基酸至约175个氨基酸,约175个氨基酸至约1000个氨基酸,约175个氨基酸至约950个氨基酸,约175个氨基酸至约900个氨基酸,约175个氨基酸至约850个氨基酸,约175个氨基酸至约800个氨基酸,约175个氨基酸至约750个氨基酸,约175个氨基酸至约700个氨基酸,约175个氨基酸至约650个氨基酸,约175个氨基酸至约600个氨基酸,约175个氨基酸至约550个氨基酸,约175个氨基酸至约500个氨基酸,约175个氨基酸至约450个氨基酸,约175个氨基酸至约400个氨基酸,约175个氨基酸至约350个氨基酸,约175个氨基酸至约300个氨基酸,约175个氨基酸至约280个氨基酸,约175个氨基酸至约260个氨基酸,约175个氨基酸至约240个氨基酸,约175个氨基酸至约220个氨基酸,约175个氨基酸至约200个氨基酸,约175个氨基酸至约195个氨基酸,约175个氨基酸至约190个氨基酸,约175个氨基酸至约185个氨基酸,约175个氨基酸至约180个氨基酸,约180个氨基酸至约1000个氨基酸,约180个氨基酸至约950个氨基酸,约180个氨基酸至约900个氨基酸,约180个氨基酸至约850个氨基酸,约180个氨基酸至约800个氨基酸,约180个氨基酸至约750个氨基酸,约180个氨基酸至约700个氨基酸,约180个氨基酸至约650个氨基酸,约180个氨基酸至约600个氨基酸,约180个氨基酸至约550个氨基酸,约180个氨基酸至约500个氨基酸,约180个氨基酸至约450个氨基酸,约180个氨基酸至约400个氨基酸,约180个氨基酸至约350个氨基酸,约180个氨基酸至约300个氨基酸,约180个氨基酸至约280个氨基酸,约180个氨基酸至约260个氨基酸,约180个氨基酸至约240个氨基酸,约180个氨基酸至约220个氨基酸,约180个氨基酸至约200个氨基酸,约180个氨基酸至约195个氨基酸,约180个氨基酸至约190个氨基酸,约180个氨基酸至约185个氨基酸,约185个氨基酸至约1000个氨基酸,约185个氨基酸至约950个氨基酸,约185个氨基酸至约900个氨基酸,约185个氨基酸至约850个氨基酸,约185个氨基酸至约800个氨基酸,约185个氨基酸至约750个氨基酸,约185个氨基酸至约700个氨基酸,约185个氨基酸至约650个氨基酸,约185个氨基酸至约600个氨基酸,约185个氨基酸至约550个氨基酸,约185个氨基酸至约500个氨基酸,约185个氨基酸至约450个氨基酸,约185个氨基酸至约400个氨基酸,约185个氨基酸至约350个氨基酸,约185个氨基酸至约300个氨基酸,约185个氨基酸至约280个氨基酸,约185个氨基酸至约260个氨基酸,约185个氨基酸至约240个氨基酸,约185个氨基酸至约220个氨基酸,约185个氨基酸至约200个氨基酸,约185个氨基酸至约195个氨基酸,约185个氨基酸至约190个氨基酸,约190个氨基酸至约1000个氨基酸,约190个氨基酸至约950个氨基酸,约190个氨基酸至约900个氨基酸,约190个氨基酸至约850个氨基酸,约190个氨基酸至约800个氨基酸,约190个氨基酸至约750个氨基酸,约190个氨基酸至约700个氨基酸,约190个氨基酸至约650个氨基酸,约190个氨基酸至约600个氨基酸,约190个氨基酸至约550个氨基酸,约190个氨基酸至约500个氨基酸,约190个氨基酸至约450个氨基酸,约190个氨基酸至约400个氨基酸,约190个氨基酸至约350个氨基酸,约190个氨基酸至约300个氨基酸,约190个氨基酸至约280个氨基酸,约190个氨基酸至约260个氨基酸,约190个氨基酸至约240个氨基酸,约190个氨基酸至约220个氨基酸,约190个氨基酸至约200个氨基酸,约190个氨基酸至约195个氨基酸,约195个氨基酸至约1000个氨基酸,约195个氨基酸至约950个氨基酸,约195个氨基酸至约900个氨基酸,约195个氨基酸至约850个氨基酸,约195个氨基酸至约800个氨基酸,约195个氨基酸至约750个氨基酸,约195个氨基酸至约700个氨基酸,约195个氨基酸至约650个氨基酸,约195个氨基酸至约600个氨基酸,约195个氨基酸至约550个氨基酸,约195个氨基酸至约500个氨基酸,约195个氨基酸至约450个氨基酸,约195个氨基酸至约400个氨基酸,约195个氨基酸至约350个氨基酸,约195个氨基酸至约300个氨基酸,约195个氨基酸至约280个氨基酸,约195个氨基酸至约260个氨基酸,约195个氨基酸至约240个氨基酸,约195个氨基酸至约220个氨基酸,约195个氨基酸至约200个氨基酸,约200个氨基酸至约1000个氨基酸,约200个氨基酸至约950个氨基酸,约200个氨基酸至约900个氨基酸,约200个氨基酸至约850个氨基酸,约200个氨基酸至约800个氨基酸,约200个氨基酸至约750个氨基酸,约200个氨基酸至约700个氨基酸,约200个氨基酸至约650个氨基酸,约200个氨基酸至约600个氨基酸,约200个氨基酸至约550个氨基酸,约200个氨基酸至约500个氨基酸,约200个氨基酸至约450个氨基酸,约200个氨基酸至约400个氨基酸,约200个氨基酸至约350个氨基酸,约200个氨基酸至约300个氨基酸,约200个氨基酸至约280个氨基酸,约200个氨基酸至约260个氨基酸,约200个氨基酸至约240个氨基酸,约200个氨基酸至约220个氨基酸,约220个氨基酸至约1000个氨基酸,约220个氨基酸至约950个氨基酸,约220个氨基酸至约900个氨基酸,约220个氨基酸至约850个氨基酸,约220个氨基酸至约800个氨基酸,约220个氨基酸至约750个氨基酸,约220个氨基酸至约700个氨基酸,约220个氨基酸至约650个氨基酸,约220个氨基酸至约600个氨基酸,约220个氨基酸至约550个氨基酸,约220个氨基酸至约500个氨基酸,约220个氨基酸至约450个氨基酸,约220个氨基酸至约400个氨基酸,约220个氨基酸至约350个氨基酸,约220个氨基酸至约300个氨基酸,约220个氨基酸至约280个氨基酸,约220个氨基酸至约260个氨基酸,约220个氨基酸至约240个氨基酸,约240个氨基酸至约1000个氨基酸,约240个氨基酸至约950个氨基酸,约240个氨基酸至约900个氨基酸,约240个氨基酸至约850个氨基酸,约240个氨基酸至约800个氨基酸,约240个氨基酸至约750个氨基酸,约240个氨基酸至约700个氨基酸,约240个氨基酸至约650个氨基酸,约240个氨基酸至约600个氨基酸,约240个氨基酸至约550个氨基酸,约240个氨基酸至约500个氨基酸,约240个氨基酸至约450个氨基酸,约240个氨基酸至约400个氨基酸,约240个氨基酸至约350个氨基酸,约240个氨基酸至约300个氨基酸,约240个氨基酸至约280个氨基酸,约240个氨基酸至约260个氨基酸,约260个氨基酸至约1000个氨基酸,约260个氨基酸至约950个氨基酸,约260个氨基酸至约900个氨基酸,约260个氨基酸至约850个氨基酸,约260个氨基酸至约800个氨基酸,约260个氨基酸至约750个氨基酸,约260个氨基酸至约700个氨基酸,约260个氨基酸至约650个氨基酸,约260个氨基酸至约600个氨基酸,约260个氨基酸至约550个氨基酸,约260个氨基酸至约500个氨基酸,约260个氨基酸至约450个氨基酸,约260个氨基酸至约400个氨基酸,约260个氨基酸至约350个氨基酸,约260个氨基酸至约300个氨基酸,约260个氨基酸至约280个氨基酸,约280个氨基酸至约1000个氨基酸,约280个氨基酸至约950个氨基酸,约280个氨基酸至约900个氨基酸,约280个氨基酸至约850个氨基酸,约280个氨基酸至约800个氨基酸,约280个氨基酸至约750个氨基酸,约280个氨基酸至约700个氨基酸,约280个氨基酸至约650个氨基酸,约280个氨基酸至约600个氨基酸,约280个氨基酸至约550个氨基酸,约280个氨基酸至约500个氨基酸,约280个氨基酸至约450个氨基酸,约280个氨基酸至约400个氨基酸,约280个氨基酸至约350个氨基酸,约280个氨基酸至约300个氨基酸,约300个氨基酸至约1000个氨基酸,约300个氨基酸至约950个氨基酸,约300个氨基酸至约900个氨基酸,约300个氨基酸至约850个氨基酸,约300个氨基酸至约800个氨基酸,约300个氨基酸至约750个氨基酸,约300个氨基酸至约700个氨基酸,约300个氨基酸至约650个氨基酸,约300个氨基酸至约600个氨基酸,约300个氨基酸至约550个氨基酸,约300个氨基酸至约500个氨基酸,约300个氨基酸至约450个氨基酸,约300个氨基酸至约400个氨基酸,约300个氨基酸至约350个氨基酸,约350个氨基酸至约1000个氨基酸,约350个氨基酸至约950个氨基酸,约350个氨基酸至约900个氨基酸,约350个氨基酸至约850个氨基酸,约350个氨基酸至约800个氨基酸,约350个氨基酸至约750个氨基酸,约350个氨基酸至约700个氨基酸,约350个氨基酸至约650个氨基酸,约350个氨基酸至约600个氨基酸,约350个氨基酸至约550个氨基酸,约350个氨基酸至约500个氨基酸,约350个氨基酸至约450个氨基酸,约350个氨基酸至约400个氨基酸,约400个氨基酸至约1000个氨基酸,约400个氨基酸至约950个氨基酸,约400个氨基酸至约900个氨基酸,约400个氨基酸至约850个氨基酸,约400个氨基酸至约800个氨基酸,约400个氨基酸至约750个氨基酸,约400个氨基酸至约700个氨基酸,约400个氨基酸至约650个氨基酸,约400个氨基酸至约600个氨基酸,约400个氨基酸至约550个氨基酸,约400个氨基酸至约500个氨基酸,约400个氨基酸至约450个氨基酸,约450个氨基酸至约1000个氨基酸,约450个氨基酸至约950个氨基酸,约450个氨基酸至约900个氨基酸,约450个氨基酸至约850个氨基酸,约450个氨基酸至约800个氨基酸,约450个氨基酸至约750个氨基酸,约450个氨基酸至约700个氨基酸,约450个氨基酸至约650个氨基酸,约450个氨基酸至约600个氨基酸,约450个氨基酸至约550个氨基酸,约450个氨基酸至约500个氨基酸,约500个氨基酸至约1000个氨基酸,约500个氨基酸至约950个氨基酸,约500个氨基酸至约900个氨基酸,约500个氨基酸至约850个氨基酸,约500个氨基酸至约800个氨基酸,约500个氨基酸至约750个氨基酸,约500个氨基酸至约700个氨基酸,约500个氨基酸至约650个氨基酸,约500个氨基酸至约600个氨基酸,约500个氨基酸至约550个氨基酸,约550个氨基酸至约1000个氨基酸,约550个氨基酸至约950个氨基酸,约550个氨基酸至约900个氨基酸,约550个氨基酸至约850个氨基酸,约550个氨基酸至约800个氨基酸,约550个氨基酸至约750个氨基酸,约550个氨基酸至约700个氨基酸,约550个氨基酸至约650个氨基酸,约550个氨基酸至约600个氨基酸,约600个氨基酸至约1000个氨基酸,约600个氨基酸至约950个氨基酸,约600个氨基酸至约900个氨基酸,约600个氨基酸至约850个氨基酸,约600个氨基酸至约800个氨基酸,约600个氨基酸至约750个氨基酸,约600个氨基酸至约700个氨基酸,约600个氨基酸至约650个氨基酸,约650个氨基酸至约1000个氨基酸,约650个氨基酸至约950个氨基酸,约650个氨基酸至约900个氨基酸,约650个氨基酸至约850个氨基酸,约650个氨基酸至约800个氨基酸,约650个氨基酸至约750个氨基酸,约650个氨基酸至约700个氨基酸,约700个氨基酸至约1000个氨基酸,约700个氨基酸至约950个氨基酸,约700个氨基酸至约900个氨基酸,约700个氨基酸至约850个氨基酸,约700个氨基酸至约800个氨基酸,约700个氨基酸至约750个氨基酸,约750个氨基酸至约1000个氨基酸,约750个氨基酸至约950个氨基酸,约750个氨基酸至约900个氨基酸,约750个氨基酸至约850个氨基酸,约750个氨基酸至约800个氨基酸,约800个氨基酸至约1000个氨基酸,约800个氨基酸至约950个氨基酸,约800个氨基酸至约900个氨基酸,约800个氨基酸至约850个氨基酸,约850个氨基酸至约1000个氨基酸,约850个氨基酸至约950个氨基酸,约850个氨基酸至约900个氨基酸,约900个氨基酸至约1000个氨基酸,约900个氨基酸至约950个氨基酸,或约950个氨基酸至约1000个氨基酸。
本文所描述的靶标结合结构域中的任一种均可以小于1×10-7M、小于1×10-8M、小于1×10-9M、小于1×10-10M、小于1×10-11M、小于1×10-12M或小于1×10-13M的解离平衡常数(KD)与其靶标结合。在一些实施例中,本文提供的抗原结合蛋白构建体可以约1×10-3M至约1×10-5M、约1×10-4M至约1×10-6M、约1×10-5M至约1×10-7M、约1×10-6M至约1×10-8M、约1×10-7M至约1×10-9M、约1×10-8M至约1×10-10M或约1×10-9M至约1×10-11M(包括端点)的KD结合到识别抗原。
本文所描述的靶标结合结构域中的任一种均可结合到其靶标,其中KD为约1pM至约30nM之间(例如,约1pM至约25nM,约1pM至约20nM,约1pM至约15nM,约1pM至约10nM,约1pM至约5nM,约1pM至约2nM,约1pM至约1nM,约1pM至约950pM,约1pM至约900pM,约1pM至约850pM,约1pM至约800pM,约1pM至约750pM,约1pM至约700pM,约1pM至约650pM,约1pM至约600pM,约1pM至约550pM,约1pM至约500pM,约1pM至约450pM,约1pM至约400pM,约1pM至约350pM,约1pM至约300pM,约1pM至约250pM,约1pM至约200pM,约1pM至约150pM,约1pM至约100pM,约1pM至约90pM,约1pM至约80pM,约1pM至约70pM,约1pM至约60pM,约1pM至约50pM,约1pM至约40pM,约1pM至约30pM,约1pM至约20pM,约1pM至约10pM,约1pM至约5pM,约1pM至约4pM,约1pM至约3pM,约1pM至约2pM,约2pM至约30nM,约2pM至约25nM,约2pM至约20nM,约2pM至约15nM,约2pM至约10nM,约2pM至约5nM,约2pM至约2nM,约2pM至约1nM,约2pM至约950pM,约2pM至约900pM,约2pM至约850pM,约2pM至约800pM,约2pM至约750pM,约2pM至约700pM,约2pM至约650pM,约2pM至约600pM,约2pM至约550pM,约2pM至约500pM,约2pM至约450pM,约2pM至约400pM,约2pM至约350pM,约2pM至约300pM,约2pM至约250pM,约2pM至约200pM,约2pM至约150pM,约2pM至约100pM,约2pM至约90pM,约2pM至约80pM,约2pM至约70pM,约2pM至约60pM,约2pM至约50pM,约2pM至约40pM,约2pM至约30pM,约2pM至约20pM,约2pM至约10pM,约2pM至约5pM,约2pM至约4pM,约2pM至约3pM,约5pM至约30nM,约5pM至约25nM,约5pM至约20nM,约5pM至约15nM,约5pM至约10nM,约5pM至约5nM,约5pM至约2nM,约5pM至约1nM,约5pM至约950pM,约5pM至约900pM,约5pM至约850pM,约5pM至约800pM,约5pM至约750pM,约5pM至约700pM,约5pM至约650pM,约5pM至约600pM,约5pM至约550pM,约5pM至约500pM,约5pM至约450pM,约5pM至约400pM,约5pM至约350pM,约5pM至约300pM,约5pM至约250pM,约5pM至约200pM,约5pM至约150pM,约5pM至约100pM,约5pM至约90pM,约5pM至约80pM,约5pM至约70pM,约5pM至约60pM,约5pM至约50pM,约5pM至约40pM,约5pM至约30pM,约5pM至约20pM,约5pM至约10pM,约10pM至约30nM,约10pM至约25nM,约10pM至约20nM,约10pM至约15nM,约10pM至约10nM,约10pM至约5nM,约10pM至约2nM,约10pM至约1nM,约10pM至约950pM,约10pM至约900pM,约10pM至约850pM,约10pM至约800pM,约10pM至约750pM,约10pM至约700pM,约10pM至约650pM,约10pM至约600pM,约10pM至约550pM,约10pM至约500pM,约10pM至约450pM,约10pM至约400pM,约10pM至约350pM,约10pM至约300pM,约10pM至约250pM,约10pM至约200pM,约10pM至约150pM,约10pM至约100pM,约10pM至约90pM,约10pM至约80pM,约10pM至约70pM,约10pM至约60pM,约10pM至约50pM,约10pM至约40pM,约10pM至约30pM,约10pM至约20pM,约15pM至约30nM,约15pM至约25nM,约15pM至约20nM,约15pM至约15nM,约15pM至约10nM,约15pM至约5nM,约15pM至约2nM,约15pM至约1nM,约15pM至约950pM,约15pM至约900pM,约15pM至约850pM,约15pM至约800pM,约15pM至约750pM,约15pM至约700pM,约15pM至约650pM,约15pM至约600pM,约15pM至约550pM,约15pM至约500pM,约15pM至约450pM,约15pM至约400pM,约15pM至约350pM,约15pM至约300pM,约15pM至约250pM,约15pM至约200pM,约15pM至约150pM,约15pM至约100pM,约15pM至约90pM,约15pM至约80pM,约15pM至约70pM,约15pM至约60pM,约15pM至约50pM,约15pM至约40pM,约15pM至约30pM,约15pM至约20pM,约20pM至约30nM,约20pM至约25nM,约20pM至约20nM,约20pM至约15nM,约20pM至约10nM,约20pM至约5nM,约20pM至约2nM,约20pM至约1nM,约20pM至约950pM,约20pM至约900pM,约20pM至约850pM,约20pM至约800pM,约20pM至约750pM,约20pM至约700pM,约20pM至约650pM,约20pM至约600pM,约20pM至约550pM,约20pM至约500pM,约20pM至约450pM,约20pM至约400pM,约20pM至约350pM,约20pM至约300pM,约20pM至约250pM,约20pM至约20pM,约200pM至约150pM,约20pM至约100pM,约20pM至约90pM,约20pM至约80pM,约20pM至约70pM,约20pM至约60pM,约20pM至约50pM,约20pM至约40pM,约20pM至约30pM,约30pM至约30nM,约30pM至约25nM,约30pM至约30nM,约30pM至约15nM,约30pM至约10nM,约30pM至约5nM,约30pM至约2nM,约30pM至约1nM,约30pM至约950pM,约30pM至约900pM,约30pM至约850pM,约30pM至约800pM,约30pM至约750pM,约30pM至约700pM,约30pM至约650pM,约30pM至约600pM,约30pM至约550pM,约30pM至约500pM,约30pM至约450pM,约30pM至约400pM,约30pM至约350pM,约30pM至约300pM,约30pM至约250pM,约30pM至约200pM,约30pM至约150pM,约30pM至约100pM,约30pM至约90pM,约30pM至约80pM,约30pM至约70pM,约30pM至约60pM,约30pM至约50pM,约30pM至约40pM,约40pM至约30nM,约40pM至约25nM,约40pM至约30nM,约40pM至约15nM,约40pM至约10nM,约40pM至约5nM,约40pM至约2nM,约40pM至约1nM,约40pM至约950pM,约40pM至约900pM,约40pM至约850pM,约40pM至约800pM,约40pM至约750pM,约40pM至约700pM,约40pM至约650pM,约40pM至约600pM,约40pM至约550pM,约40pM至约500pM,约40pM至约450pM,约40pM至约400pM,约40pM至约350pM,约40pM至约300pM,约40pM至约250pM,约40pM至约200pM,约40pM至约150pM,约40pM至约100pM,约40pM至约90pM,约40pM至约80pM,约40pM至约70pM,约40pM至约60pM,约40pM至约50pM,约50pM至约30nM,约50pM至约25nM,约50pM至约30nM,约50pM至约15nM,约50pM至约10nM,约50pM至约5nM,约50pM至约2nM,约50pM至约1nM,约50pM至约950pM,约50pM至约900pM,约50pM至约850pM,约50pM至约800pM,约50pM至约750pM,约50pM至约700pM,约50pM至约650pM,约50pM至约600pM,约50pM至约550pM,约50pM至约500pM,约50pM至约450pM,约50pM至约400pM,约50pM至约350pM,约50pM至约300pM,约50pM至约250pM,约50pM至约200pM,约50pM至约150pM,约50pM至约100pM,约50pM至约90pM,约50pM至约80pM,约50pM至约70pM,约50pM至约60pM,约60pM至约30nM,约60pM至约25nM,约60pM至约30nM,约60pM至约15nM,约60pM至约10nM,约60pM至约5nM,约60pM至约2nM,约60pM至约1nM,约60pM至约950pM,约60pM至约900pM,约60pM至约850pM,约60pM至约800pM,约60pM至约750pM,约60pM至约700pM,约60pM至约650pM,约60pM至约600pM,约60pM至约550pM,约60pM至约500pM,约60pM至约450pM,约60pM至约400pM,约60pM至约350pM,约60pM至约300pM,约60pM至约250pM,约60pM至约200pM,约60pM至约150pM,约60pM至约100pM,约60pM至约90pM,约60pM至约80pM,约60pM至约70pM,约70pM至约30nM,约70pM至约25nM,约70pM至约30nM,约70pM至约15nM,约70pM至约10nM,约70pM至约5nM,约70pM至约2nM,约70pM至约1nM,约70pM至约950pM,约70pM至约900pM,约70pM至约850pM,约70pM至约800pM,约70pM至约750pM,约70pM至约700pM,约70pM至约650pM,约70pM至约600pM,约70pM至约550pM,约70pM至约500pM,约70pM至约450pM,约70pM至约400pM,约70pM至约350pM,约70pM至约300pM,约70pM至约250pM,约70pM至约200pM,约70pM至约150pM,约70pM至约100pM,约70pM至约90pM,约70pM至约80pM,约80pM至约30nM,约80pM至约25nM,约80pM至约30nM,约80pM至约15nM,约80pM至约10nM,约80pM至约5nM,约80pM至约2nM,约80pM至约1nM,约80pM至约950pM,约80pM至约900pM,约80pM至约850pM,约80pM至约800pM,约80pM至约750pM,约80pM至约700pM,约80pM至约650pM,约80pM至约600pM,约80pM至约550pM,约80pM至约500pM,约80pM至约450pM,约80pM至约400pM,约80pM至约350pM,约80pM至约300pM,约80pM至约250pM,约80pM至约200pM,约80pM至约150pM,约80pM至约100pM,约80pM至约90pM,约90pM至约30nM,约90pM至约25nM,约90pM至约30nM,约90pM至约15nM,约90pM至约10nM,约90pM至约5nM,约90pM至约2nM,约90pM至约1nM,约90pM至约950pM,约90pM至约900pM,约90pM至约850pM,约90pM至约800pM,约90pM至约750pM,约90pM至约700pM,约90pM至约650pM,约90pM至约600pM,约90pM至约550pM,约90pM至约500pM,约90pM至约450pM,约90pM至约400pM,约90pM至约350pM,约90pM至约300pM,约90pM至约250pM,约90pM至约200pM,约90pM至约150pM,约90pM至约100pM,约100pM至约30nM,约100pM至约25nM,约100pM至约30nM,约100pM至约15nM,约100pM至约10nM,约100pM至约5nM,约100pM至约2nM,约100pM至约1nM,约100pM至约950pM,约100pM至约900pM,约100pM至约850pM,约100pM至约800pM,约100pM至约750pM,约100pM至约700pM,约100pM至约650pM,约100pM至约600pM,约100pM至约550pM,约100pM至约500pM,约100pM至约450pM,约100pM至约400pM,约100pM至约350pM,约100pM至约300pM,约100pM至约250pM,约100pM至约200pM,约100pM至约150pM,约150pM至约30nM,约150pM至约25nM,约150pM至约30nM,约150pM至约15nM,约150pM至约10nM,约150pM至约5nM,约150pM至约2nM,约150pM至约1nM,约150pM至约950pM,约150pM至约900pM,约150pM至约850pM,约150pM至约800pM,约150pM至约750pM,约150pM至约700pM,约150pM至约650pM,约150pM至约600pM,约150pM至约550pM,约150pM至约500pM,约150pM至约450pM,约150pM至约400pM,约150pM至约350pM,约150pM至约300pM,约150pM至约250pM,约150pM至约200pM,约200pM至约30nM,约200pM至约25nM,约200pM至约30nM,约200pM至约15nM,约200pM至约10nM,约200pM至约5nM,约200pM至约2nM,约200pM至约1nM,约200pM至约950pM,约200pM至约900pM,约200pM至约850pM,约200pM至约800pM,约200pM至约750pM,约200pM至约700pM,约200pM至约650pM,约200pM至约600pM,约200pM至约550pM,约200pM至约500pM,约200pM至约450pM,约200pM至约400pM,约200pM至约350pM,约200pM至约300pM,约200pM至约250pM,约300pM至约30nM,约300pM至约25nM,约300pM至约30nM,约300pM至约15nM,约300pM至约10nM,约300pM至约5nM,约300pM至约2nM,约300pM至约1nM,约300pM至约950pM,约300pM至约900pM,约300pM至约850pM,约300pM至约800pM,约300pM至约750pM,约300pM至约700pM,约300pM至约650pM,约300pM至约600pM,约300pM至约550pM,约300pM至约500pM,约300pM至约450pM,约300pM至约400pM,约300pM至约350pM,约400pM至约30nM,约400pM至约25nM,约400pM至约30nM,约400pM至约15nM,约400pM至约10nM,约400pM至约5nM,约400pM至约2nM,约400pM至约1nM,约400pM至约950pM,约400pM至约900pM,约400pM至约850pM,约400pM至约800pM,约400pM至约750pM,约400pM至约700pM,约400pM至约650pM,约400pM至约600pM,约400pM至约550pM,约400pM至约500pM,约500pM至约30nM,约500pM至约25nM,约500pM至约30nM,约500pM至约15nM,约500pM至约10nM,约500pM至约5nM,约500pM至约2nM,约500pM至约1nM,约500pM至约950pM,约500pM至约900pM,约500pM至约850pM,约500pM至约800pM,约500pM至约750pM,约500pM至约700pM,约500pM至约650pM,约500pM至约600pM,约500pM至约550pM,约600pM至约30nM,约600pM至约25nM,约600pM至约30nM,约600pM至约15nM,约600pM至约10nM,约600pM至约5nM,约600pM至约2nM,约600pM至约1nM,约600pM至约950pM,约600pM至约900pM,约600pM至约850pM,约600pM至约800pM,约600pM至约750pM,约600pM至约700pM,约600pM至约650pM,约700pM至约30nM,约700pM至约25nM,约700pM至约30nM,约700pM至约15nM,约700pM至约10nM,约700pM至约5nM,约700pM至约2nM,约700pM至约1nM,约700pM至约950pM,约700pM至约900pM,约700pM至约850pM,约700pM至约800pM,约700pM至约750pM,约800pM至约30nM,约800pM至约25nM,约800pM至约30nM,约800pM至约15nM,约800pM至约10nM,约800pM至约5nM,约800pM至约2nM,约800pM至约1nM,约800pM至约950pM,约800pM至约900pM,约800pM至约850pM,约900pM至约30nM,约900pM至约25nM,约900pM至约30nM,约900pM至约15nM,约900pM至约10nM,约900pM至约5nM,约900pM至约2nM,约900pM至约1nM,约900pM至约950pM,约1nM至约30nM,约1nM至约25nM,约1nM至约20nM,约1nM至约15nM,约1nM至约10nM,约1nM至约5nM,约2nM至约30nM,约2nM至约25nM,约2nM至约20nM,约2nM至约15nM,约2nM至约10nM,约2nM至约5nM,约4nM至约30nM,约4nM至约25nM,约4nM至约20nM,约4nM至约15nM,约4nM至约10nM,约4nM至约5nM,约5nM至约30nM,约5nM至约25nM,约5nM至约20nM,约5nM至约15nM,约5nM至约10nM,约10nM至约30nM,约10nM至约25nM,约10nM至约20nM,约10nM至约15nM,约15nM至约30nM,约15nM至约25nM,约15nM至约20nM,约20nM至约30nM,和约20nM至约25nM)。
本文所描述的靶标结合结构域中的任一种均可结合到其靶标,其中KD为约1nM至约10nM之间(例如,约1nM至约9nM,约1nM至约8nM,约1nM至约7nM,约1nM至约6nM,约1nM至约5nM,约1nM至约4nM,约1nM至约3nM,约1nM至约2nM,约2nM至约10nM,约2nM至约9nM,约2nM至约8nM,约2nM至约7nM,约2nM至约6nM,约2nM至约5nM,约2nM至约4nM,约2nM至约3nM,约3nM至约10nM,约3nM至约9nM,约3nM至约8nM,约3nM至约7nM,约3nM至约6nM,约3nM至约5nM,约3nM至约4nM,约4nM至约10nM,约4nM至约9nM,约4nM至约8nM,约4nM至约7nM,约4nM至约6nM,约4nM至约5nM,约5nM至约10nM,约5nM至约9nM,约5nM至约8nM,约5nM至约7nM,约5nM至约6nM,约6nM至约10nM,约6nM至约9nM,约6nM至约8nM,约6nM至约7nM,约7nM至约10nM,约7nM至约9nM,约7nM至约8nM,约8nM至约10nM,约8nM至约9nM,和约9nM至约10nM)。
可使用本领域中已知的多种不同方法来确定本文所描述的抗原结合蛋白构建体中的任一种的KD值(例如,电泳迁移率迁移分析、滤膜结合分析、表面等离振子体共振和生物分子结合动力学分析等)。
抗原结合结构域
在本文所描述的多链嵌合多肽中的任一种的一些实施例中,第一靶标结合结构域和第二靶标结合结构域特异性结合到相同的抗原。在这些多链嵌合多肽的一些实施例中,第一靶标结合结构域和第二靶标结合结构域特异性结合到相同的表位。在这些多链嵌合多肽的一些实施例中,第一靶标结合结构域和第二靶标结合结构域包括相同的氨基酸序列。
在本文所描述的多链嵌合多肽中的任一种的一些实施例中,第一靶标结合结构域和第二靶标结合结构域特异性结合到不同的抗原。
在本文所描述的多链嵌合多肽中的任一种的一些实施例中,第一靶标结合结构域和第二靶标结合结构域中的一个或两个是抗原结合结构域。在本文所描述的多链嵌合多肽中的任一种的一些实施例中,第一靶标结合结构域和第二靶标结合结构域各自是抗原结合结构域。
在本文所描述的多链嵌合多肽中的任一种的一些实施例中,抗原结合结构域包括或为scFv或单结构域抗体(例如,VHH或VNAR结构域)。
在一些实例中,抗原结合结构域(例如,本文所描述的抗原结合结构域中的任一种)可特异性结合到以下中的任一种:CD16a(参见例如美国专利第9,035,026号中所描述的那些)、CD28(参见例如美国专利第7,723,482号中所描述的那些)、CD3(参见例如美国专利第9,226,962号中所描述的那些)、CD33(参见例如美国专利第8,759,494号中所描述的那些)、CD20(参见例如WO 2014/026054中所描述的那些)、CD19(参见例如美国专利第9,701,758号中所描述的那些)、CD22(参见例如WO 2003/104425中所描述的那些),CD123(参见例如WO 2014/130635中所描述的那些)、IL-1R(参见例如美国专利第8,741,604号中所描述的那些)、IL-1(参见例如WO 2014/095808中所描述的那些)、VEGF(参见例如美国专利第9,090,684号中所描述的那些)、IL-6R(参见例如美国专利第7,482,436号中所描述的那些)、IL-4(参见例如美国专利申请公开第2012/0171197号中所描述的那些)、IL-10(参见例如美国专利申请公开第2016/0340413号中所描述的那些)、PDL-1(参见例如Drees等人,《蛋白质表达和纯化(Protein Express.Purif.)》94:60-66,2014中所描述的那些)、TIGIT(参见例如美国专利申请公开第2017/0198042号中所描述的那些)、PD-1(参见例如美国专利第7,488,802号中所描述的那些)、TIM3(参见例如美国专利第8,552,156号中所描述的那些、CTLA4(参见例如WO 2012/120125中所描述的那些)、MICA(参见例如WO 2016/154585中所描述的那些)、MICB(参见例如美国专利第8,753,640号中所描述的那些)、IL-6(参见例如Gejima等人,《人抗体(Human Antibodies)》11(4):121-129,2002中所描述的那些)、IL-8(参见例如美国专利第6,117,980号中所描述的那些)、TNFα(参见例如Geng等人,《免疫学研究(Immunol.Res.)》62(3):377-385,2015中所描述的那些)、CD26a(参见例如WO 2017/189526中所描述的那些)、CD36(参见例如美国专利申请公开第2015/0259429号中所描述的那些)、ULBP2(参见例如美国专利第9,273,136号中所描述的那些)、CD30(参见例如Homach等人,《斯堪的纳维亚免疫学杂志(Scand.J.Immunol.)》48(5):497-501,1998中所描述的那些)、CD200(参见例如美国专利第9,085,623号中所描述的那些)、IGF-1R(参见例如美国专利申请公开第2017/0051063号中所描述的那些)、MUC4AC(参见例如WO 2012/170470中所描述的那些)、MUC5AC(参见例如美国专利第9,238,084号中所描述的那些)、Trop-2(参见例如WO 2013/068946中所描述的那些)、CMET(参见例如Edwardraja等人,《生物技术与生物工程(Biotechnol.Bioeng.)》106(3):367-375,2010中所描述的那些)、EGFR(参见例如Akbari等人,《蛋白质表达和纯化》127:8-15,2016中所描述的那些)、HER1(参见例如美国专利申请公开第2013/0274446号中所描述的那些)、HER2(参见例如Cao等人,《生物技术快报(Biotechnol.Lett.)》37(7):1347-1354,2015中所描述的那些)、HER3(参见例如美国专利第9,505,843号中所描述的那些)、PSMA(参见例如Parker等人,《蛋白质表达和纯化》89(2):136-145,2013中所描述的那些)、CEA(参见例如WO 1995/015341中所描述的那些)、B7H3(参见例如美国专利第9,371,395号中所描述的那些)、EPCAM(参见例如WO 2014/159531中描述的那些)、BCMA(参见例如Smith等人,《分子疗法(Mol.Ther.)》26(6):1447-1456,2018中所描述的那些)、P-钙粘着蛋白(参见例如美国专利第7,452,537号中所描述的那些)、CEACAM5(参见例如美国专利第9,617,345号中所描述的那些)、UL16结合蛋白(参见例如WO 2017/083612中所述)、HLA-DR(参见例如Pistillo等人,《实验和临床免疫遗传学(Exp.Clin.Immunogenet.)》14(2):123-130,1997中所描述的那些)、DLL4(参见例如WO2014/007513中所描述的那些)、TYRO3(参见例如WO 2016/166348中所描述的那些)、AXL(参见例如WO 2012/175692中所描述的那些)、MER(参见例如WO 2016/106221中所描述的那些)、CD122(参见例如美国专利申请公开第2016/0367664号中所描述的那些)、CD155(参见例如WO 2017/149538中所描述的那些)或PDGF-DD(参见例如美国专利第9,441,034号中所描述的那些)。
存在于本文所描述的多链嵌合多肽中的任一种中的抗原结合结构域各自独立地选自以下组成的组:VHH结构域、VNAR结构域和scFv。在一些实施例中,本文所描述的抗原结合结构域中的任一种是BiTe、(scFv)2、纳米抗体(nanobody)、纳米抗体-HAS、DART、TandAb、单链双功能抗体(scDiabody)、单链双功能抗体-CH3、scFv-CH-CL-scFv、HSAbody、单链双功能抗体-HAS或串联scFv。可用于多链嵌合多肽中的任一种的抗原结合结构域的另外实例是本领域已知的。
VHH结构域是可在骆驼科动物中发现的单个单体可变抗体结构域。VNAR结构域是可在软骨鱼中发现的单个单体可变抗体结构域。VHH结构域和VNAR结构域的非限制性方面描述于例如Cromie等人,《医药化学当前话题(Curr.Top.Med.Chem.)》15:2543-2557,2016;DeGenst等人,《发育与比较免疫学(Dev.Comp.Immunol.)》30:187-198,2006;De Meyer等人,《生物技术趋势(Trends Biotechnol.)》32:263-270,2014;Kijanka等人,《纳米医学(Nanomedicine)》10:161-174,2015;Kovaleva等人,《生物疗法专家观点(Expert.Opin.Biol.Ther.)》14:1527-1539,2014;Krah等人,《免疫药理学和免疫毒理学(Immunopharmacol.Immunotoxicol.)》38:21-28,2016;Mujic-Delic等人,《药理科学趋势(Trends Pharmacol.Sci.)》35:247-255,2014;Muyldermans,《生物技术杂志(J.Biotechnol.)》74:277-302,2001;Muyldermans等人,《生物化学科学趋势(TrendsBiochem.Sci.)》26:230-235,2001;Muyldermans,《生物化学年鉴(Ann.Rev.Biochem.)》82:775-797,2013;Rahbarizadeh等人,《免疫学研究(Immunol.Invest.)》40:299-338,2011;Van Audenhove等人,《E生物医学(EBioMedicine)》8:40-48,2016;Van Bockstaele等人,《研究药物当前观点(Curr.Opin.Investig.Drugs)》10:1212-1224,2009;Vincke等人,《分子生物学方法(Methods Mol.Biol.)》911:15-26,2012;和Wesolowski等人,《医学微生物学和免疫学(Med.Microbiol.Immunol.)》198:157-174,2009。
在一些实施例中,本文所描述的多链嵌合多肽中的每个抗原结合结构域均为VHH结构域,或至少一个抗原结合结构域为VHH结构域。在一些实施例中,本文所描述的多链嵌合多肽中的每个抗原结合结构域均为VNAR结构域,或至少一个抗原结合结构域为VNAR结构域。在一些实施例中,本文所描述的多链嵌合多肽中的每个抗原结合结构域均为scFv结构域,或至少一个抗原结合结构域为scFv结构域。
在一些实施例中,存在于多链嵌合多肽中的两个或更多个多肽可组装(例如,非共价组装)以形成本文所描述的抗原结合结构域中的任一种,例如抗体的抗原结合片段(例如,本文所描述抗体的抗原结合片段中的任一种)、VHH-scAb、VHH-Fab、双scFab、F(ab')2、双功能抗体、crossMab、DAF(二合一)、DAF(四合一)、DutaMab、DT-IgG、隆突-孔(knobs-in-holes)共同轻链、隆突-孔组合件、电荷对、Fab臂交换、SEEDbody、LUZ-Y、Fcab、κλ体、正交Fab、DVD-IgG、IgG(H)-scFv、scFv-(H)IgG、IgG(L)-scFv、scFv-(L)IgG、IgG(L,H)-Fv、IgG(H)-V、V(H)-IgG、IgG(L)-V、V(L)-IgG、KIH IgG-scFab、2scFv-IgG、IgG-2scFv、scFv4-Ig、Zybody、DVI-IgG、双功能抗体-CH3、三体、微型抗体(miniantibody)、微抗体(minibody)、TriBi微抗体、scFv-CH3 KIH、Fab-scFv、F(ab')2-scFv2、scFv-KIH、Fab-scFv-Fc、四价HCAb、单链双功能抗体-Fc、双功能抗体-Fc、串联scFv-Fc、内抗体(Intrabody)、对接和锁定(dock and lock)、lmmTAC、IgG-IgG缀合物、Cov-X体和scFv1-PEG-scFv2。参见例如Spiess等人,《分子免疫学(Mol.Immunol.)》67:95-106,2015,其在此全文并入,以便描述这些元件。抗体的抗原结合片段的非限制性实例包括Fv片段、Fab片段、F(ab')2片段和Fab'片段。抗体的抗原结合片段的另外实例是IgG的抗原结合片段(例如,IgG1、IgG2、IgG3或IgG4的抗原结合片段)(例如,人或人源化IgG,例如人或人源化IgG1、IgG2、IgG3或IgG4的抗原结合片段);IgA的抗原结合片段(例如,IgA1或IgA2的抗原结合片段)(例如,人或人源化IgA,例如人或人源化IgA1或IgA2的抗原结合片段);IgD的抗原结合片段(例如,人或人源化IgD的抗原结合片段);IgE的抗原结合片段(例如,人或人源化IgE的抗原结合片段);或IgM的抗原结合片段(例如,人或人源化IgM的抗原结合片段)。
“Fv”片段包括一个重链可变结构域和一个轻链可变结构域的非共价连接的二聚体。
“Fab”片段包括除Fv片段的重链和轻链可变结构域外,轻链的恒定结构域和重链的第一恒定结构域(CH1)。
“F(ab')2”片段包括在铰链区附近通过二硫键接合的两个Fab片段。
“双可变结构域免疫球蛋白”或“DVD-Ig”是指多价且多特异性结合蛋白,如例如DiGiammarino等人,《分子生物学方法》899:145-156,2012;Jakob等人,《单抗(MABs)》5:358-363,2013;和美国专利第7,612,181号;第8,258,268号;第8,586,714号;第8,716,450号;第8,722,855号;第8,735,546号;和第8,822,645号中所描述,其中的每一个均通过引用整体并入。
DART描述于例如Garber,《自然综述:药物发现(Nature Reviews DrugDiscovery)》13:799-801,2014中。
在本文所描述的抗原结合结构域中的任一种的一些实施例中,可结合到选自以下组成的组的抗原:蛋白质、碳水化合物、脂质和其组合。
抗原结合结构域的另外实例和方面是本领域已知的。
可溶性白介素或细胞因子蛋白
在本文所描述的多链嵌合多肽中的任一种的一些实施例中,第一靶标结合结构域和第二靶标结合结构域中的一个或两个可为可溶性白介素蛋白或可溶性细胞因子蛋白。在一些实施例中,可溶性白介素或可溶性细胞因子蛋白选自以下组成的组:IL-2、IL-3、IL-7、IL-8、IL-10、IL-12、IL-15、IL-17、IL-18、IL-21、PDGF-DD、SCF和FLT3L。可溶性IL-2、IL-3、IL-7、IL-8、IL-10、IL-15、IL-17、IL-18、IL-21、PDGF-DD、SCF和FLT3L的非限制性实例在以下提供。
人可溶性IL-2(SEQ ID NO:9)

人可溶性IL-3(SEQ ID NO:10)


人可溶性IL-7(SEQ ID NO:11)

人可溶性IL-8(SEQ ID NO:12)

人可溶性IL-10(SEQ ID NO:13)

人可溶性IL-15(SEQ ID NO:14)

人可溶性IL-17(SEQ ID NO:15)

人可溶性IL-18(SEQ ID NO:16)

人可溶性PDGF-DD(SEQ ID NO:17)


人可溶性SCF(SEQ ID NO:18)

人可溶性FLT3L(SEQ ID NO:19)

以下提供可溶性MICA、MICB、ULBP1、ULBP2、ULBP3、ULBP4、ULBP5和ULBP6的非限制性实例。
人可溶性MICA(SEQ ID NO:20)

人可溶性MICB(SEQ ID NO:21)

人可溶性ULBP1(SEQ ID NO:22)

人可溶性ULBP2(SEQ ID NO:23)

人可溶性ULBP3(SEQ ID NO:24)

人可溶性ULBP4(SEQ ID NO:25)

人可溶性ULBP5(SEQ ID NO:26)

人可溶性ULBP6(SEQ ID NO:27)

可溶性白介素蛋白和可溶性细胞因子蛋白的另外实例是本领域已知的。
可溶性受体
在本文所描述的多链嵌合多肽中的任一种的一些实施例中,第一靶标结合结构域和第二靶标结合结构域中的一个或两个是可溶性白介素受体、可溶性细胞因子受体或配体受体。在一些实施例中,可溶性受体是可溶性TGF-β受体II(TGF-βRII)(参见例如Yung等人,《美国呼吸与重症医学杂志(Am.J.Resp.Crit.Care Med.)》194(9):1140-1151,2016中所描述的那些)、可溶性TGF-βRIII(参见例如Heng等人,《胎盘(Placenta)》57:320,2017中所描述的那些)、可溶性NKG2D(参见例如Cosman等人,《免疫(Immunity)》14(2):123-133,2001;Costa等人,《免疫学前沿(Front.Immunol.)》,第9卷,第1150条,2018年5月29日;doi:10.3389/fimmu.2018.01150)、可溶性NKp30(参见例如Costa等人,《免疫学前沿》,第9卷,第1150条,2018年5月29日;doi:10.3389/fimmu.2018.01150)、可溶性NKp44(参见例如Costa等人,《免疫学前沿》,第9卷,第1150条,2018年5月29日;doi:10.3389/fimmu.2018.01150中所描述的那些)、可溶性NKp46(参见例如Mandelboim等人,《自然(Nature)》409:1055-1060,2001;Costa等人,《免疫学前沿》,第9卷,第1150条,2018年5月29日;doi:10.3389/fimmu.2018.01150中所描述的那些)、可溶性DNAM-1(参见例如Costa等人,《免疫学前沿》,第9卷,第1150条,2018年5月29日;doi:10.3389/fimmu.2018.01150中所描述的那些)、scMHCI(参见例如Washburn等人,《公共科学图书馆·综合(PLoS One)》6(3):e18439,2011中所描述的那些)、scMHCII(参见例如Bishwajit等人,《细胞免疫学(Cellular Immunol.)》170(1):25-33,1996中所描述的那些)、scTCR(参见例如Weber等人,《自然》356(6372):793-796,1992中所描述的那些)、可溶性CD155(参见例如Tahara-Hanaoka等人,《国际免疫学(Int.Immunol.)》16(4):533-538,2004中所描述的那些)或可溶性CD28(参见例如Hebbar等人,《临床与实验免疫学(Clin.Exp.Immunol.)》136:388-392,2004)。
可溶性白介素受体和可溶性细胞因子受体的另外实例是本领域已知的。
另外的抗原结合结构域
在多链嵌合多肽中的任一种的一些实施例中,第一嵌合多肽进一步包括一个或多个(例如,两个、三个、四个、五个、六个、七个、八个、九个或十个)另外的靶标结合结构域(例如,本文所描述或本领域已知的示例性靶标结合结构域中的任一种),其中一个或多个另外的抗原结合结构域中的至少一个位于可溶性组织因子结构域(例如,本文所描述或本领域已知的示例性可溶性组织因子结构域中的任一种)与一对亲和结构域中的第一结构域(例如,本文所描述的示例性亲和结构域对中的任一种的示例性第一结构域中的任一种)之间。在一些实施例中,第一嵌合多肽可进一步包括在可溶性组织因子结构域(例如,本文所描述的示例性可溶性组织因子结构域中的任一种)与一个或多个另外的靶标结合结构域中的至少一个(例如,本文所描述或本领域已知的示例性靶标结合结构域中的任一种)之间的接头序列(例如,本文所描述或本领域已知的示例性接头序列中的任一种),和/或一个或多个另外的靶标结合结构域中的至少一个(例如,本文描述或本领域已知的示例性靶标结合结构域中的任一种)与一对亲和结构域中的第一结构域(例如,本文所描述的示例性亲和结构域对中的任一种的本文所描述的示例性第一结构域中的任一种)之间的本文所接头序列(例如,本文所描述或本领域已知的示例性接头序列中的任一种)。
在本文所描述的多链嵌合多肽中的任一种的一些实施例中,第一嵌合多肽在第一嵌合多肽的N端和/或C端进一步包括一个或多个(例如,两个、三个、四个、五个、六个、七个、八个、九个或十个)另外的靶标结合结构域。在一些实施例中,在第一嵌合多肽中,一个或多个另外的靶标结合结构域中的至少一个(例如,本文所描述或本领域已知的示例性靶标结合结构域中的任一种)直接邻接亲和结构域对中的第一结构域(例如,本文所描述的示例性亲和结构域对中的任一种的本文所描述的示例性第一结构域中的任一种)。在一些实施例中,第一嵌合多肽进一步包括在一个或多个另外的靶标结合结构域中的至少一个(例如,本文所描述或本领域已知的示例性靶标结合结构域中的任一种)与一对亲和结构域中的第一结构域(例如,本文所描述的示例性亲和结构域对中的任一种的本文所描述的示例性第一结构域中的任一种)之间的接头序列(例如,本文所描述或本领域已知的示例性接头序列中的任一种)。在一些实施例中,在第一嵌合多肽中,一个或多个另外的靶标结合结构域中的至少一个(例如,本文描述或本领域已知的示例性靶标结合结构域中的任一种)直接邻接第一靶标结合结构域(例如,本文所描述或本领域已知的示例性靶标结合结构域中的任一种)。在一些实施例中,第一嵌合多肽进一步包含在一个或多个另外的靶标结合结构域中的至少一个(例如,本文所描述或本领域已知的示例性靶标结合结构域中的任一种)与第一靶标结合结构域(例如,本文所描述或本领域已知的示例性靶标结合结构域中的任一种)之间的接头序列(例如,本文所描述或本领域已知的示例性接头序列中的任一种)。
在本文所描述的多链嵌合多肽中的任一种的一些实施例中,在第一嵌合多肽中,一个或多个另外的靶标结合结构域中的至少一个(例如,本文所描述或本领域已知的示例性靶标结合结构域中的任一种)安置于第一嵌合多肽的N和/或C端,并且一个或多个另外的靶标结合结构域中的至少一个(例如,本文所描述或本领域已知的示例性靶标结合结构域中的任一种)定位在可溶性组织因子结构域(例如,本文所描述或本领域已知的任何示例性可溶性组织因子结构域中的任一种)与一对亲和结构域中的第一结构域(例如,本文所描述的示例性亲和结构域对中的任一种的示例性第一结构域中的任一种)之间。在一些实施例中,在第一嵌合多肽中,安置于N端的一个或多个另外的靶标结合结构域中的至少一个另外的靶标结合结构域(例如,本文所描述或本领域已知的示例性靶标结合结构域中的任一种)直接邻接第一靶标结合结构域(例如,本文所描述或本领域已知的示例性靶标结合结构域中的任一种)或一对亲和结构域中的第一结构域(例如,本文所描述的示例性亲和结构域对中的任一种的示例性第一结构域中的任一种)。在一些实施例中,第一嵌合多肽进一步包含第一嵌合多肽中安置于至少一个另外的靶标结合结构域(例如,本文所描述或本领域已知的示例性靶标结合结构域中的任一种)与第一靶标结合结构域(例如,本文所描述或本领域已知的示例性靶标结合结构域中的任一种)或一对亲和结构域中的第一结构域(例如,本文所描述的示例性亲和结构域对中的任一种的示例性第一结构域中的任一种)之间的接头序列(例如,本文所描述或本领域已知的接头序列中的任一种)。在一些实施例中,在第一嵌合多肽中,安置于C端的一个或多个另外的靶标结合结构域中的至少一个另外的靶标结合结构域(例如,本文所描述或本领域已知的示例性靶标结合结构域中的任一种)直接邻接第一靶标结合结构域(例如,本文所描述或本领域已知的示例性靶标结合结构域中的任一种)或一对亲和结构域中的第一结构域(例如,本文所描述的示例性亲和结构域对中的任一种的示例性第一结构域中的任一种)。在一些实施例中,第一嵌合多肽进一步包括第一嵌合多肽中安置于至少一个另外的靶标结合结构域(例如,本文所描述或本领域已知的示例性靶标结合结构域中的任一种)与第一靶标结合结构域(例如,本文所描述或本领域已知的示例性靶标结合结构域中的任一种)或一对亲和结构域中的第一结构域(例如,本文所描述的示例性亲和结构域对中的任一种的示例性第一结构域中的任一种)之间的接头序列(例如,本文所描述或本领域已知的接头序列中的任一种)。在一些实施例中,位于可溶性组织因子结构域(例如,本文所描述的示例性可溶性组织因子结构域中的任一种)与一对亲和结构域中的第一结构域(例如,本文所描述的第一结构域中的任一种或本文所描述的示例性亲和结构域对中的任一种)之间的一个或多个另外的靶标结合结构域中的至少一个(例如,本文所描述或本领域已知的示例性靶标结合结构域中的任一种)直接邻接可溶性组织因子结构域和/或一对亲和结构域中的第一结构域。在一些实施例中,第一嵌合多肽进一步包含接头序列(例如,本文所描述或本领域已知的示例性接头序列中的任一种),所述接头序列安置于(i)可溶性组织因子结构域(例如,本文所描述的示例性可溶性组织因子中的任一种)与一个或多个另外的靶标结合结构域中的至少一个(例如,本文所描述或本领域已知的示例性靶标结合结构域中的任一种)之间,所述一个或多个另外的靶标结合结构域中的至少一个位于可溶性组织因子结构域(例如,本文所描述的示例性可溶性组织因子中的任一种)与一对亲和结构域中的第一结构域(例如,本文所描述的示例性亲和结构域对中的任一种的示例性第一结构域中的任一种)之间,和/或(ii)一对亲和结构域中的一个结构域与一个或多个另外的靶标结合结构域中的至少一个之间,所述一个或多个另外的靶标结合结构域中的至少一个位于可溶性组织因子结构域与一对亲和结构域中的第一结构域之间。
在本文所描述的多链嵌合多肽中的任一种的一些实施例中,第二嵌合多肽在第二嵌合多肽的N端和/或C端进一步包括一个或多个(例如,两个、三个、四个、五个、六个、七个、八个、九个或十个)另外的靶标结合结构域(例如,本文所描述或本领域已知的示例性靶标结合结构域中的任一种)。在一些实施例中,在第二嵌合多肽中,一个或多个另外的靶标结合结构域中的至少一个(例如,本文所描述或本领域已知的示例性靶标结合结构域中的任一种)直接邻接所述一对亲和结构域中的第二结构域(例如,本文所描述的示例性亲和结构域对中的任一种的示例性第二结构域中的任一种)。在一些实施例中,第二嵌合多肽进一步包括第二嵌合多肽中在一个或多个另外的靶标结合结构域中的至少一个(例如,本文所描述或本领域已知的示例性靶标结合结构域中的任一种)与一对亲和结构域中的第二结构域(例如,本文所描述的示例性亲和结构域对中的任一种的示例性第二结构域中的任一种)之间的接头序列(例如,本文所描述或本领域已知的示例性接头序列中的任一种)。在一些实施例中,在第二嵌合多肽中,一个或多个另外的靶标结合结构域中的至少一个(例如,本文所描述或本领域已知的示例性靶标结合结构域中的任一种)直接邻接第二靶标结合结构域(例如,本文所描述或本领域已知的靶标结合结构域中的任一种)。在一些实施例中,第二嵌合多肽进一步包括第二嵌合多肽中在一个或多个另外的靶标结合结构域中的至少一个(例如,本文所描述或本领域已知的示例性靶标结合结构域中的任一种)与第二靶标结合结构域(例如,本文所描述或本领域已知的示例性靶标结合结构域中的任一种)之间的接头序列(例如,本文所描述或本领域已知的示例性接头序列中的任一种)。
在本文所描述的多链嵌合多肽中的任一种的一些实施例中,第一靶标结合结构域、第二靶标结合结构域和一个或多个另外的靶标结合结构域中的两个或更多个(例如,三个或更多个、四个或更多个、五个或更多个、六个或更多个、七个或更多个、八个或更多个、九个或更多个或十个或更多个)特异性结合到相同的抗原。在一些实施例中,第一靶标结合结构域、第二靶标结合结构域和一个或多个另外的靶标结合结构域中的两个或更多个(例如,三个或更多个、四个或更多个、五个或更多个、六个或更多个、七个或更多个、八个或更多个、九个或更多个或十个或更多个)特异性结合到相同的表位。在一些实施例中,第一靶标结合结构域、第二靶标结合结构域和一个或多个另外的靶标结合结构域中的两个或更多个(例如,三个或更多个、四个或更多个、五个或更多个、六个或更多个、七个或更多个、八个或更多个、九个或更多个或十个或更多个)包括相同的氨基酸序列。在一些实施例中,第一靶标结合结构域、第二靶标结合结构域和一个或多个另外的靶标结合结构域各自特异性结合到相同的抗原。在一些实施例中,第一靶标结合结构域、第二靶标结合结构域和一个或多个另外的靶标结合结构域各自特异性结合到相同的表位。在一些实施例中,第一靶标结合结构域、第二靶标结合结构域和一个或多个另外的靶标结合结构域各自包括相同的氨基酸序列。
在本文所描述的多链嵌合多肽中的任一种的一些实施例中,第一靶标结合结构域、第二靶标结合结构域和一个或多个另外的靶标结合结构域特异性结合到不同的抗原。在本文所描述的多链嵌合多肽中的任一种的一些实施例中,第一靶标结合结构域、第二靶标结合结构域和一个或多个靶标结合结构域中的一个或多个(例如,两个或更多个、三个或更多个、四个或更多个、五个或更多个、六个或更多个、七个或更多个、八个或更多个、九个或更多个或十个或更多个)是抗原结合结构域。在一些实施例中,第一靶标结合结构域、第二靶标结合结构域和一个或多个另外的靶标结合结构域各自是抗原结合结构域(例如,scFv或单结构域抗体)。
亲和结构域对
在一些实施例中,多链嵌合多肽包括:1)包括一对亲和结构域中的第一结构域的第一嵌合多肽,和2)包括一对亲和结构域中的第二结构域的第二嵌合多肽,使得第一嵌合多肽和第二嵌合多肽通过一对亲和结构域中的第一结构域和第二结构域的结合而缔合。在一些实施例中,所述一对亲和结构域是来自人IL-15受体的α链(IL15Rα)的寿司结构域和可溶性IL-15。寿司结构域,也称为短共有重复序列或1型糖蛋白基序,是蛋白质-蛋白质相互作用中的常见基序。已在许多蛋白质结合分子,包括补体组分C1r、C1s、因子H和C2m以及非免疫分子因子XIII和β2-糖蛋白上鉴别了寿司结构域。典型的寿司结构域具有大约60个氨基酸残基,并且包含四个半胱氨酸(Ranganathan,《太平洋生物计算专题讨论会(Pac.SympBiocomput.)》2000:155-67)。第一半胱氨酸可与第三半胱氨酸形成二硫键,并且第二半胱氨酸可与第四半胱氨酸形成二硫桥键。在其中一对亲和结构域中的一个成员是可溶性IL-15的一些实施例中,可溶性IL15具有D8N或D8A氨基酸取代。在其中一对亲和结构域中的一个成员是人IL-15受体的α链(IL15Rα)的一些实施例中,人IL15Rα是成熟全长IL15Rα。在一些实施例中,所述一对亲和结构域是芽胞杆菌RNA酶和芽胞杆菌RNA酶抑制子。在一些实施例中,所述一对亲和结构域是PKA和AKAP。在一些实施例中,所述一对亲和结构域是基于突变核糖核酸酶I片段的衔接子/对接标签模块(Rossi,《美国国家科学院院刊(Proc NatlAcad Sci USA.)》103:6841-6846,2006;Sharkey等人,《癌症研究(Cancer Res.)》68:5282-5290,2008;Rossi等人,《药物科学趋势(Trends Pharmacol Sci.)》33:474-481,2012)或基于蛋白质突触蛋白、突触结合蛋白、突触泡蛋白和SNAP25相互作用的SNARE模块(Deyev等人,《自然·生物技术(Nat Biotechnol.)》1486-1492,2003)。
在一些实施例中,多链嵌合多肽的第一嵌合多肽包括一对亲和结构域中的第一结构域,并且多链嵌合多肽的第二嵌合多肽包括一对亲和结构域中的第二结构域,其中一对亲和结构域中的第一结构域和一对亲和结构域中的第二结构域以小于1×10-7M、小于1×10-8M、小于1×10-9M、小于1×10-10M、小于1×10-11M、小于1×10-12M或小于1×10-13M的解离平衡常数(KD)彼此结合。在一些实施例中,一对亲和结构域中的第一结构域与一对亲和结构域中的第二结构域彼此结合,其中KD为约1×10-4M至约1×10-6M、约1×10-5M至约1×10- 7M、约1×10-6M至约1×10-8M、约1×10-7M至约1×10-9M、约1×10-8M至约1×10-10M、约1×10- 9M至约1×10-11M、约1×10-10M至约1×10-12M、约1×10-11M至约1×10-13M、约1×10-4M至约1×10-5M、约1×10-5M至约1×10-6M、约1×10-6M至约1×10-7M、约1×10-7M至约1×10-8M、约1×10-8M至约1×10-9M、约1×10-9M至约1×10-10M、约1×10-10M至约1×10-11M、约1×10-11M至约1×10-12M或约1×10-12M至约1×10-13M(包括端点)。本领域已知的多种不同方法中的任一种均可用于确定一对亲和结构域中的第一结构域与一对亲和结构域中的第二结构域的结合的KD值(例如,电泳迁移变动分析、滤膜结合分析、表面等离子体共振和生物分子结合动力学分析等)。
在一些实施例中,多链嵌合多肽的第一嵌合多肽包括一对亲和结构域中的第一结构域,并且多链嵌合多肽的第二嵌合多肽包括一对亲和结构域中的第二结构域,其中一对亲和结构域中的第一结构域、一对亲和结构域中的第二结构域或两者为约10至100个氨基酸的长度。例如,一对亲和结构域中的第一结构域、一对亲和结构域中的第二结构域或两者可为约10至100个氨基酸的长度,约15至100个氨基酸的长度,约20至100个氨基酸的长度,约25至100个氨基酸的长度,约30至100个氨基酸的长度,约35至100个氨基酸的长度,约40至100个氨基酸的长度,约45至100个氨基酸的长度,约50至100个氨基酸的长度,约55至100个氨基酸的长度,约60至100个氨基酸的长度,约65至100个氨基酸的长度,约70至100个氨基酸的长度,约75至100个氨基酸的长度,约80至100个氨基酸的长度,约85至100个氨基酸的长度,约90至100个氨基酸的长度,约95至100个氨基酸的长度,约10至95个氨基酸的长度,约10至90个氨基酸的长度,约10至85个氨基酸的长度,约10至80个氨基酸的长度,约10至75个氨基酸的长度,约10至70个氨基酸的长度,约10至65个氨基酸的长度,约10至60个氨基酸的长度,约10至55个氨基酸的长度,约10至50个氨基酸的长度,约10至45个氨基酸的长度,约10至40个氨基酸的长度,约10至35个氨基酸的长度,约10至30个氨基酸的长度,约10至25个氨基酸的长度,约10至20个氨基酸的长度,约10至15个氨基酸的长度,约20至30个氨基酸的长度,约30至40个氨基酸的长度,约40至50个氨基酸的长度,约50至60个氨基酸的长度,约60至70个氨基酸的长度,约70至80个氨基酸的长度,约80至90个氨基酸的长度,约90至100个氨基酸的长度,约20至90个氨基酸的长度,约30至80个氨基酸的长度,约40至70个氨基酸的长度,约50至60个氨基酸的长度,或介于两者之间的任何范围。在一些实施例中,一对亲和结构域中的第一结构域、一对亲和结构域中的第二结构域或两者均为约1015、20、25、30、35、40、45、50、55、60、65、70、75、80、85、90、95或100个氨基酸的长度。
在一些实施例中,本文公开的一对亲和结构域中的第一和/或第二结构域中的任一种可在其N端和/或C端包括一个或多个另外的氨基酸(例如1、2、3、5、6、7、8、9、10个或更多个氨基酸),只要一对亲和结构域中第一个和/或第二结构域的功能保持完整即可。例如,来自人IL-15受体的α链(IL15Rα)的寿司结构域可在N端和/或C端包括一个或多个另外的氨基酸,同时仍保留与可溶性IL-15结合的能力。另外地或可替代地,可溶性IL-15可在N端和/或C端包括一个或多个另外的氨基酸,同时仍保留与来自人IL-15受体的α链(IL15Rα)的寿司结构域结合的能力。
来自IL-15受体α的α链(IL15Rα)的寿司结构域的非限制性实例可包括与ITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR(SEQ ID NO:28)至少70%相同、至少75%相同、至少80%相同、至少85%相同、至少90%相同、至少95%相同、至少99%相同或100%相同的序列。在一些实施例中,来自IL15Rα的α链的寿司结构域可由包括ATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG(SEQ ID NO:29)的核酸编码。
在一些实施例中,可溶性IL-15可包括与NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS(SEQ ID NO:14)至少70%相同、至少75%相同、至少80%相同、至少85%相同、至少90%相同、至少95%相同、至少99%相同或100%相同的序列。在一些实施例中,可溶性IL-15可由包括AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC(SEQ ID NO:30)的序列的核酸编码。
信号序列
在一些实施例中,多链嵌合多肽包括第一嵌合多肽,所述第一嵌合多肽在其N端包括信号序列。在一些实施例中,多链嵌合多肽包括第二嵌合多肽,所述第二嵌合多肽在其N端包括信号序列。在一些实施例中,多链嵌合多肽的第一嵌合多肽和多链嵌合多肽的第二嵌合多肽均包括信号序列。如本领域普通技术人员将理解,信号序列是存在于许多内源产生的蛋白质的N端的氨基酸序列,其将蛋白质引导到分泌路径(例如,蛋白质被引导以存在于某些细胞内细胞器中、存在于细胞膜中或从细胞中分泌)。信号序列是异质的,并且其一级氨基酸序列差异很大。但是,信号序列的长度典型地为16至30个氨基酸,并且包括亲水、通常带正电荷的N端区,中央疏水域和含有信号肽酶的裂解位点的C端区。
在一些实施例中,多链嵌合多肽的第一嵌合多肽、多链嵌合多肽的第二嵌合多肽或两者包括具有氨基酸序列MKWVTFISLLFLFSSAYS(SEQ ID NO:31)的信号序列。在一些实施例中,多链嵌合多肽的第一嵌合多肽、多链嵌合多肽的第二嵌合多肽或两者包括由核酸序列ATGAAATGGGTGACCTTTATTTCTTTACTGTTCCTCTTTAGCAGCGCCTACTCC(SEQ ID NO:32)、ATGAAGTGGGTCACATTTATCTCTTTACTGTTCCTCTTCTCCAGCGCCTACAGC(SEQ ID NO:33)或ATGAAATGGGTGACCTTTATTTCTTTACTGTTCCTCTTTAGCAGCGCCTACTCC(SEQ ID NO:34)编码的信号序列。
在一些实施例中,多链嵌合多肽的第一嵌合多肽、多链嵌合多肽的第二嵌合多肽或两者包括具有氨基酸序列MKCLLYLAFLFLGVNC(SEQ ID NO:35)的信号序列。在一些实施例中,多链嵌合多肽的第一嵌合多肽、多链嵌合多肽的第二嵌合多肽或两者包括具有氨基酸序列MGQIVTMFEALPHIIDEVINIVIIVLIIITSIKAVYNFATCGILALVSFLFLAGRSCG(SEQ ID NO:36)的信号序列。在一些实施例中,多链嵌合多肽的第一嵌合多肽、多链嵌合多肽的第二嵌合多肽或两者包括具有氨基酸序列MPNHQSGSPTGSSDLLLSGKKQRPHLALRRKRRREMRKINRKVRRMNLAPIKEKTAWQHLQALISEAEEVLKTSQTPQNSLTLFLALLSVLGPPVTG(SEQ ID NO:37)的信号序列。在一些实施例中,多链嵌合多肽的第一嵌合多肽、多链嵌合多肽的第二嵌合多肽或两者包括具有氨基酸序列MDSKGSSQKGSRLLLLLVVSNLLLCQGVVS(SEQ ID NO:38)的信号序列。本领域普通技术人员将知道用于本文所描述的多链嵌合多肽的第一嵌合多肽和/或第二嵌合多肽的其它合适的信号序列。
在一些实施例中,多链嵌合多肽的第一嵌合多肽、多链嵌合多肽的第二嵌合多肽或两者包括信号序列,其具有约10至100个氨基酸的长度。例如,信号序列可为约10至100个氨基酸的长度,约15至100个氨基酸的长度,约20至100个氨基酸的长度,约25至100个氨基酸的长度,约30至100个氨基酸的长度,约35至100个氨基酸的长度,约40至100个氨基酸的长度,约45至100个氨基酸的长度,约50至100个氨基酸的长度,约55至100个氨基酸的长度,约60至100个氨基酸的长度,约65至100个氨基酸的长度,约70至100个氨基酸的长度,约75至100个氨基酸的长度,约80至100个氨基酸的长度,约85至100个氨基酸的长度,约90至100个氨基酸的长度,约95至100个氨基酸的长度,约10至95个氨基酸的长度,约10至90个氨基酸的长度,约10至85个氨基酸的长度,约10至80个氨基酸的长度,约10至75个氨基酸的长度,约10至70个氨基酸的长度,约10至65个氨基酸的长度,约10至60个氨基酸的长度,约10至55个氨基酸的长度,约10至50个氨基酸的长度,约10至45个氨基酸的长度,约10至40个氨基酸的长度,约10至35个氨基酸的长度,约10至30个氨基酸的长度,约10至25个氨基酸的长度,约10至20个氨基酸的长度,约10至15个氨基酸的长度,约20至30个氨基酸的长度,约30至40个氨基酸的长度,约40至50个氨基酸的长度,约50至60个氨基酸的长度,约60至70个氨基酸的长度,约70至80个氨基酸的长度,约80至90个氨基酸的长度,约90至100个氨基酸的长度,约20至90个氨基酸的长度,约30至80个氨基酸的长度,约40至70个氨基酸的长度,约50至60个氨基酸的长度,或介于两者之间的任何范围。在一些实施例中,信号序列为约1015、20、25、30、35、40、45、50、55、60、65、70、75、80、85、90、95或100个氨基酸的长度。
在一些实施例中,本文公开的信号序列中的任一种可在其N端和/或C端包括一个或多个另外的氨基酸(例如,1、2、3、5、6、7、8、9、10个或更多个氨基酸),只要信号序列的功能保持完整即可。例如,具有氨基酸序列MKCLLYLAFLFLGVNC(SEQ ID NO:35)的信号序列可在N端或C端包括一个或多个另外的氨基酸,同时仍保留将多链嵌合多肽的第一嵌合多肽、多链嵌合多肽的第二嵌合多肽或两者引导到分泌路径的能力。
在一些实施例中,多链嵌合多肽的第一嵌合多肽、多链嵌合多肽的第二嵌合多肽或两者包括将多链嵌合多肽引导到细胞外空间中的信号序列。这类实施例可用于产生相对容易分离和/或纯化的多链嵌合多肽。
肽标签
在一些实施例中,多链嵌合多肽包括第一嵌合多肽,其包括肽标签(例如,在第一嵌合多肽的N端或C端)。在一些实施例中,多链嵌合多肽包括第二嵌合多肽,其包括肽标签(例如,在第二嵌合多肽的N端或C端)。在一些实施例中,多链嵌合多肽的第一嵌合多肽和多链嵌合多肽的第二嵌合多肽均包括肽标签。在一些实施例中,多链嵌合多肽的第一嵌合多肽、多链嵌合多肽的第二嵌合多肽或两者包括两个或更多个肽标签。
可包括在多链嵌合多肽的第一嵌合多肽、多链嵌合多肽的第二嵌合多肽或两者中的示例性肽标签包括但不限于AviTag(GLNDIFEAQKIEWHE;SEQ ID NO:39)、钙调蛋白标签(KRRWKKNFIAVSAANRFKKISSSGAL;SEQ ID NO:40)、聚谷氨酸标签(EEEEEE;SEQ ID NO:41)、E标签(GAPVPYPDPLEPR;SEQ ID NO:42)、FLAG标签(DYKDDDDK;SEQ ID NO:43)、HA标签、来自血凝素的肽(YPYDVPDYA;SEQ ID NO:44)、his标签(HHHHH(SEQ ID NO:45);HHHHHH(SEQ IDNO:46);HHHHHHH(SEQ ID NO:47);HHHHHHHH(SEQ ID NO:48);HHHHHHHHH(SEQ ID NO:49);或HHHHHHHHHH(SEQ ID NO:50))、myc标签(EQKLISEEDL;SEQ ID NO:51)、NE标签(TKENPRSNQEESYDDNES;SEQ ID NO:52)、S标签、(KETAAAKFERQHMDS;SEQ ID NO:53)、SBP标签(MDEKTTGWRGGHVVEGLAGELEQLRARLEHHPQGQREP;SEQ ID NO:54)、Softag 1(SLAELLNAGLGGS;SEQ ID NO:55)、Softag 3(TQDPSRVG;SEQ ID NO:56)、Spot标签(PDRVRAVSHWSS;SEQ ID NO:57)、Strep标签(WSHPQFEK;SEQ ID NO:58)、TC标签(CCPGCC;SEQ ID NO:59)、Ty标签(EVHTNQDPLD;SEQ ID NO:60)、V5标签(GKPIPNPLLGLDST;SEQ IDNO:61)、VSV标签(YTDIEMNRLGK;SEQ ID NO:62)和Xpress标签(DLYDDDDK;SEQ ID NO:63)。在一些实施例中,组织因子蛋白是肽标签。
可包括在多链嵌合多肽的第一嵌合多肽、多链嵌合多肽的第二嵌合多肽或两者中的肽标签可用于与多链嵌合多肽相关的多种应用中的任一种。例如,肽标签可用于纯化多链嵌合多肽。作为一个非限制性实例,多链嵌合多肽的第一嵌合多肽(例如,重组表达的第一嵌合多肽)、多链嵌合多肽的第二嵌合多肽(例如,重组表达的第二嵌合多肽)或两者可包括myc标签;可使用识别myc标签的抗体纯化包括加myc标签的第一嵌合多肽、加myc标签的第二嵌合多肽或两者的多链嵌合多肽。识别myc标签的抗体的一个非限制性实例是9E10,其可从非商业发展研究杂交瘤银行(Developmental Studies Hybridoma Bank)获得。作为另一非限制性实例,多链嵌合多肽的第一嵌合多肽(例如,重组表达的第一嵌合多肽)、多链嵌合多肽的第二嵌合多肽(例如,重组表达的第二嵌合多肽)或两者可包括组氨酸标签;可使用镍或钴螯合物纯化包括加组氨酸标签的第一嵌合多肽、加组氨酸标签的第二嵌合多肽或两者的多链嵌合多肽。本领域普通技术人员将知道其它合适的标签和结合这些标签的试剂以用于纯化多链嵌合多肽。在一些实施例中,纯化后从多链嵌合多肽的第一嵌合多肽和/或第二嵌合多肽中去除肽标签。在一些实施例中,纯化后未从多链嵌合多肽的第一嵌合多肽和/或第二嵌合多肽中去除肽标签。
可包括在多链嵌合多肽的第一嵌合多肽、多链嵌合多肽的第二嵌合多肽或两者中的肽标签可用于例如多链嵌合多肽的免疫沉淀、多链嵌合多肽的成像(例如,通过蛋白质印迹、ELISA、流式细胞术和/或免疫细胞化学)和/或多链嵌合多肽的增溶。
在一些实施例中,多链嵌合多肽的第一嵌合多肽、多链嵌合多肽的第二嵌合多肽或两者包括肽标签,其具有约10至100个氨基酸的长度。例如,肽标签可为约10至100个氨基酸的长度,约15至100个氨基酸的长度,约20至100个氨基酸的长度,约25至100个氨基酸的长度,约30至100个氨基酸的长度,约35至100个氨基酸的长度,约40至100个氨基酸的长度,约45至100个氨基酸的长度,约50至100个氨基酸的长度,约55至100个氨基酸的长度,约60至100个氨基酸的长度,约65至100个氨基酸的长度,约70至100个氨基酸的长度,约75至100个氨基酸的长度,约80至100个氨基酸的长度,约85至100个氨基酸的长度,约90至100个氨基酸的长度,约95至100个氨基酸的长度,约10至95个氨基酸的长度,约10至90个氨基酸的长度,约10至85个氨基酸的长度,约10至80个氨基酸的长度,约10至75个氨基酸的长度,约10至70个氨基酸的长度,约10至65个氨基酸的长度,约10至60个氨基酸的长度,约10至55个氨基酸的长度,约10至50个氨基酸的长度,约10至45个氨基酸的长度,约10至40个氨基酸的长度,约10至35个氨基酸的长度,约10至30个氨基酸的长度,约10至25个氨基酸的长度,约10至20个氨基酸的长度,约10至15个氨基酸的长度,约20至30个氨基酸的长度,约30至40个氨基酸的长度,约40至50个氨基酸的长度,约50至60个氨基酸的长度,约60至70个氨基酸的长度,约70至80个氨基酸的长度,约80至90个氨基酸的长度,约90至100个氨基酸的长度,约20至90个氨基酸的长度,约30至80个氨基酸的长度,约40至70个氨基酸的长度,约50至60个氨基酸的长度,或介于两者之间的任何范围。在一些实施例中,肽标签为约1015、20、25、30、35、40、45、50、55、60、65、70、75、80、85、90、95或100个氨基酸的长度。
多链嵌合多肽的第一嵌合多肽、多链嵌合多肽的第二嵌合多肽或两者中包括的肽标签可具有任何合适的长度。例如,肽标签的长度可为5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20或更多个氨基酸。在多链嵌合多肽包括两个或更多个肽标签的实施例中,两个或更多个肽标签可具有相同或不同的长度。在一些实施例中,本文公开的任何肽标签可在N端和/或C端包括一个或多个另外的氨基酸(例如,1、2、3、5、6、7、8、9、10个或更多个氨基酸),只要肽标签的功能保持完整即可。例如,具有氨基酸序列EQKLISEEDL(SEQ ID NO:64)的myc标签可包括一个或多个另外的氨基酸(例如,在肽标签的N端和/或C端),同时仍保留与抗体(例如,9E10)结合的能力。
示例性多链嵌合多肽-A型
在本文所描述的多链嵌合多肽中的任一种的一些实施例中,第一靶标结合结构域和第二靶标结合结构域各自独立地特异性结合到IL-18的受体或IL-12的受体。在这些多链嵌合多肽的一些实例中,第一靶标结合结构域和可溶性组织因子结构域在第一嵌合多肽中彼此直接邻接。在这些多链嵌合多肽的一些实例中,第一嵌合多肽进一步包含第一嵌合多肽中的第一靶标结合结构域与可溶性组织因子结构域之间的接头序列(例如,本文所描述的示例性接头中的任一种)。
在这些多链嵌合多肽的一些实施例中,一对亲和结构域中的第二结构域和第二靶标结合结构域在第二嵌合多肽中彼此直接邻接。在这些多链嵌合多肽的一些实施例中,第二嵌合多肽进一步包括第二嵌合多肽中的一对亲和结构域中的第二结构域与第二靶标结合结构域之间的接头序列(例如,本文所描述的示例性接头中的任一种)。
在这些多链嵌合多肽的一些实施例中,可溶性组织因子结构域可为本文所描述的示例性可溶性组织因子结构域中的任一种。在这些多链嵌合多肽的一些实施例中,所述一对亲和结构域可为本文所描述的示例性亲和结构域对中的任一种。
在这些多链嵌合多肽的一些实施例中,第一靶标结合结构域和第二靶标结合结构域中的一个或两个是激动性抗原结合结构域。在这些多链嵌合多肽的一些实施例中,第一靶标结合结构域和第二靶标结合结构域各自是激动性抗原结合结构域。在这些多链嵌合多肽的一些实施例中,抗原结合结构域包括scFv或单结构域抗体。
在这些多链嵌合多肽的一些实施例中,第一靶标结合结构域和第二靶标结合结构域中的一个或两个是可溶性IL-15或可溶性IL-18。在这些多链嵌合多肽的一些实施例中,第一靶标结合结构域和第二靶标结合结构域各自独立地为可溶性IL-15或可溶性IL-18。在这些多链嵌合多肽的一些实施例中,第一靶标结合结构域和第二靶标结合结构域均特异性结合到IL-18的受体或IL-12的受体。在这些多链嵌合多肽的一些实施例中,第一靶标结合结构域和第二靶标结合结构域特异性结合到相同的表位。在这些多链嵌合多肽的一些实施例中,第一靶标结合结构域和第二靶标结合结构域包括相同的氨基酸序列。
在这些多链嵌合多肽的一些实施例中,第一靶标结合结构域特异性结合到IL-12的受体,并且第二靶标结合结构域特异性结合到IL-18的受体。在这些多链嵌合多肽的一些实施例中,第一靶标结合结构域特异性结合到IL-18的受体,并且第二靶标结合结构域特异性结合到IL-12的受体。
在这些多链嵌合多肽的一些实施例中,第一靶标结合结构域包括可溶性IL-18(例如,可溶性人IL-18)。
在这些多链嵌合多肽的一些实施例中,可溶性人IL-18包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
YFGKLESKLSVIRNLNDQVLFIDQGNRPLFEDMTDSDCRDNAPRTIFIISMYKDSQPRGMAVTISVKCEKISTLSCENKIISFKEMNPPDNIKDTKSDIIFFQRSVPGHDNKMQFESSSYEGYFLACEKERDLFKLILKKEDELGDRSIMFTVQNED(SEQ ID NO:16)。
在这些多链嵌合多肽的一些实施例中,可溶性人IL-18由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
TACTTCGGCAAACTGGAATCCAAGCTGAGCGTGATCCGGAATTTAAACGACCAAGTTCTGTTTATCGATCAAGGTAACCGGCCTCTGTTCGAGGACATGACCGACTCCGATTGCCGGGACAATGCCCCCCGGACCATCTTCATTATCTCCATGTACAAGGACAGCCAGCCCCGGGGCATGGCTGTGACAATTAGCGTGAAGTGTGAGAAAATCAGCACTTTATCTTGTGAGAACAAGATCATCTCCTTTAAGGAAATGAACCCCCCCGATAACATCAAGGACACCAAGTCCGATATCATCTTCTTCCAGCGGTCCGTGCCCGGTCACGATAACAAGATGCAGTTCGAATCCTCCTCCTACGAGGGCTACTTTTTAGCTTGTGAAAAGGAGAGGGATTTATTCAAGCTGATCCTCAAGAAGGAGGACGAGCTGGGCGATCGTTCCATCATGTTCACCGTCCAAAACGAGGAT(SEQ ID NO:65)。
在这些多链嵌合多肽的一些实施例中,第二靶标结合结构域包括可溶性IL-12(例如,可溶性人IL-12)。在这些多链嵌合多肽的一些实施例中,可溶性人IL-15包括可溶性人IL-12β(p40)的序列和可溶性人IL-12α(p35)的序列。在这些多链嵌合多肽的一些实施例中,可溶性IL-15人IL-15进一步包括可溶性IL-12β(p40)的序列与可溶性人IL-12α(p35)的序列之间的接头序列(例如,本文所描述的示例性接头序列中的任一种)。在这些多链嵌合多肽的一些实例中,接头序列包含GGGGSGGGGSGGGGS(SEQ ID NO:7)。
在这些多链嵌合多肽的一些实施例中,可溶性人IL-12β(p40)的序列包含与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
IWELKKDVYVVELDWYPDAPGEMVVLTCDTPEEDGITWTLDQSSEVLGSGKTLTIQVKEFGDAGQYTCHKGGEVLSHSLLLLHKKEDGIWSTDILKDQKEPKNKTFLRCEAKNYSGRFTCWWLTTISTDLTFSVKSSRGSSDPQGVTCGAATLSAERVRGDNKEYEYSVECQEDSACPAAEESLPIEVMVDAVHKLKYENYTSSFFIRDIIKPDPPKNLQLKPLKNSRQVEVSWEYPDTWSTPHSYFSLTFCVQVQGKSKREKKDRVFTDKTSATVICRKNASISVRAQDRYYSSSWSEWASVPCS(SEQ ID NO:66)。
在这些多链嵌合多肽的一些实施例中,可溶性人IL-12β(p40)由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
ATTTGGGAACTGAAGAAGGACGTCTACGTGGTCGAACTGGACTGGTATCCCGATGCTCCCGGCGAAATGGTGGTGCTCACTTGTGACACCCCCGAAGAAGACGGCATCACTTGGACCCTCGATCAGAGCAGCGAGGTGCTGGGCTCCGGAAAGACCCTCACAATCCAAGTTAAGGAGTTCGGAGACGCTGGCCAATACACATGCCACAAGGGAGGCGAGGTGCTCAGCCATTCCTTATTATTATTACACAAGAAGGAAGACGGAATCTGGTCCACCGACATTTTAAAAGATCAGAAGGAGCCCAAGAATAAGACCTTTTTAAGGTGTGAGGCCAAAAACTACAGCGGTCGTTTCACTTGTTGGTGGCTGACCACCATTTCCACCGATTTAACCTTCTCCGTGAAAAGCAGCCGGGGAAGCTCCGACCCTCAAGGTGTGACATGTGGAGCCGCTACCCTCAGCGCTGAGAGGGTTCGTGGCGATAACAAGGAATACGAGTACAGCGTGGAGTGCCAAGAAGATAGCGCTTGTCCCGCTGCCGAAGAATCTTTACCCATTGAGGTGATGGTGGACGCCGTGCACAAACTCAAGTACGAGAACTACACCTCCTCCTTCTTTATCCGGGACATCATTAAGCCCGATCCTCCTAAGAATTTACAGCTGAAGCCTCTCAAAAATAGCCGGCAAGTTGAGGTCTCTTGGGAATATCCCGACACTTGGAGCACACCCCACAGCTACTTCTCTTTAACCTTTTGTGTGCAAGTTCAAGGTAAAAGCAAGCGGGAGAAGAAAGACCGGGTGTTTACCGACAAAACCAGCGCCACCGTCATCTGTCGGAAGAACGCCTCCATCAGCGTGAGGGCTCAAGATCGTTATTACTCCAGCAGCTGGTCCGAGTGGGCCAGCGTGCCTTGTTCC(SEQ ID NO:67)。
在这些多链嵌合多肽的一些实施例中,可溶性人IL-12α(p35)包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
RNLPVATPDPGMFPCLHHSQNLLRAVSNMLQKARQTLEFYPCTSEEIDHEDITKDKTSTVEACLPLELTKNESCLNSRETSFITNGSCLASRKTSFMMALCLSSIYEDLKMYQVEFKTMNAKLLMDPKRQIFLDQNMLAVIDELMQALNFNSETVPQKSSLEEPDFYKTKIKLCILLHAFRIRAVTIDRVMSYLNAS(SEQ ID NO:68)。
在这些多链嵌合多肽的一些实施例中,可溶性人IL-12α(p35)由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
CGTAACCTCCCCGTGGCTACCCCCGATCCCGGAATGTTCCCTTGTTTACACCACAGCCAGAATTTACTGAGGGCCGTGAGCAACATGCTGCAGAAAGCTAGGCAGACTTTAGAATTTTACCCTTGCACCAGCGAGGAGATCGACCATGAAGATATCACCAAGGACAAGACATCCACCGTGGAGGCTTGTTTACCTCTGGAGCTGACAAAGAACGAGTCTTGTCTCAACTCTCGTGAAACCAGCTTCATCACAAATGGCTCTTGTTTAGCTTCCCGGAAGACCTCCTTTATGATGGCTTTATGCCTCAGCTCCATCTACGAGGATTTAAAGATGTACCAAGTGGAGTTCAAGACCATGAACGCCAAGCTGCTCATGGACCCTAAACGGCAGATCTTTTTAGACCAGAACATGCTGGCTGTGATTGATGAGCTGATGCAAGCTTTAAACTTCAACTCCGAGACCGTCCCTCAGAAGTCCTCCCTCGAGGAGCCCGATTTTTACAAGACAAAGATCAAACTGTGCATTTTACTCCACGCCTTTAGGATCCGGGCCGTGACCATTGACCGGGTCATGAGCTATTTAAACGCCAGC(SEQ IDNO:69)。
在一些实施例中,第一嵌合多肽可包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
YFGKLESKLSVIRNLNDQVLFIDQGNRPLFEDMTDSDCRDNAPRTIFIISMYKDSQPRGMAVTISVKCEKISTLSCENKIISFKEMNPPDNIKDTKSDIIFFQRSVPGHDNKMQFESSSYEGYFLACEKERDLFKLILKKEDELGDRSIMFTVQNEDSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS(SEQ ID NO:70)。
在一些实施例中,第一嵌合多肽由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
TACTTCGGCAAACTGGAATCCAAGCTGAGCGTGATCCGGAATTTAAACGACCAAGTTCTGTTTATCGATCAAGGTAACCGGCCTCTGTTCGAGGACATGACCGACTCCGATTGCCGGGACAATGCCCCCCGGACCATCTTCATTATCTCCATGTACAAGGACAGCCAGCCCCGGGGCATGGCTGTGACAATTAGCGTGAAGTGTGAGAAAATCAGCACTTTATCTTGTGAGAACAAGATCATCTCCTTTAAGGAAATGAACCCCCCCGATAACATCAAGGACACCAAGTCCGATATCATCTTCTTCCAGCGGTCCGTGCCCGGTCACGATAACAAGATGCAGTTCGAATCCTCCTCCTACGAGGGCTACTTTTTAGCTTGTGAAAAGGAGAGGGATTTATTCAAGCTGATCCTCAAGAAGGAGGACGAGCTGGGCGATCGTTCCATCATGTTCACCGTCCAAAACGAGGATAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC(SEQ ID NO:71)。
在一些实施例中,第一嵌合多肽可包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
MKWVTFISLLFLFSSAYSYFGKLESKLSVIRNLNDQVLFIDQGNRPLFEDMTDSDCRDNAPRTIFIISMYKDSQPRGMAVTISVKCEKISTLSCENKIISFKEMNPPDNIKDTKSDIIFFQRSVPGHDNKMQFESSSYEGYFLACEKERDLFKLILKKEDELGDRSIMFTVQNEDSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS(SEQ ID NO:72)。
在一些实施例中,第一嵌合多肽由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
ATGAAGTGGGTCACATTTATCTCTTTACTGTTCCTCTTCTCCAGCGCCTACAGCTACTTCGGCAAACTGGAATCCAAGCTGAGCGTGATCCGGAATTTAAACGACCAAGTTCTGTTTATCGATCAAGGTAACCGGCCTCTGTTCGAGGACATGACCGACTCCGATTGCCGGGACAATGCCCCCCGGACCATCTTCATTATCTCCATGTACAAGGACAGCCAGCCCCGGGGCATGGCTGTGACAATTAGCGTGAAGTGTGAGAAAATCAGCACTTTATCTTGTGAGAACAAGATCATCTCCTTTAAGGAAATGAACCCCCCCGATAACATCAAGGACACCAAGTCCGATATCATCTTCTTCCAGCGGTCCGTGCCCGGTCACGATAACAAGATGCAGTTCGAATCCTCCTCCTACGAGGGCTACTTTTTAGCTTGTGAAAAGGAGAGGGATTTATTCAAGCTGATCCTCAAGAAGGAGGACGAGCTGGGCGATCGTTCCATCATGTTCACCGTCCAAAACGAGGATAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC(SEQ ID NO:73)。
在一些实施例中,第二嵌合多肽可包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
IWELKKDVYVVELDWYPDAPGEMVVLTCDTPEEDGITWTLDQSSEVLGSGKTLTIQVKEFGDAGQYTCHKGGEVLSHSLLLLHKKEDGIWSTDILKDQKEPKNKTFLRCEAKNYSGRFTCWWLTTISTDLTFSVKSSRGSSDPQGVTCGAATLSAERVRGDNKEYEYSVECQEDSACPAAEESLPIEVMVDAVHKLKYENYTSSFFIRDIIKPDPPKNLQLKPLKNSRQVEVSWEYPDTWSTPHSYFSLTFCVQVQGKSKREKKDRVFTDKTSATVICRKNASISVRAQDRYYSSSWSEWASVPCSGGGGSGGGGSGGGGSRNLPVATPDPGMFPCLHHSQNLLRAVSNMLQKARQTLEFYPCTSEEIDHEDITKDKTSTVEACLPLELTKNESCLNSRETSFITNGSCLASRKTSFMMALCLSSIYEDLKMYQVEFKTMNAKLLMDPKRQIFLDQNMLAVIDELMQALNFNSETVPQKSSLEEPDFYKTKIKLCILLHAFRIRAVTIDRVMSYLNASITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR(SEQ ID NO:74)。
在一些实施例中,第二嵌合多肽由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
ATTTGGGAACTGAAGAAGGACGTCTACGTGGTCGAACTGGACTGGTATCCCGATGCTCCCGGCGAAATGGTGGTGCTCACTTGTGACACCCCCGAAGAAGACGGCATCACTTGGACCCTCGATCAGAGCAGCGAGGTGCTGGGCTCCGGAAAGACCCTCACAATCCAAGTTAAGGAGTTCGGAGACGCTGGCCAATACACATGCCACAAGGGAGGCGAGGTGCTCAGCCATTCCTTATTATTATTACACAAGAAGGAAGACGGAATCTGGTCCACCGACATTTTAAAAGATCAGAAGGAGCCCAAGAATAAGACCTTTTTAAGGTGTGAGGCCAAAAACTACAGCGGTCGTTTCACTTGTTGGTGGCTGACCACCATTTCCACCGATTTAACCTTCTCCGTGAAAAGCAGCCGGGGAAGCTCCGACCCTCAAGGTGTGACATGTGGAGCCGCTACCCTCAGCGCTGAGAGGGTTCGTGGCGATAACAAGGAATACGAGTACAGCGTGGAGTGCCAAGAAGATAGCGCTTGTCCCGCTGCCGAAGAATCTTTACCCATTGAGGTGATGGTGGACGCCGTGCACAAACTCAAGTACGAGAACTACACCTCCTCCTTCTTTATCCGGGACATCATTAAGCCCGATCCTCCTAAGAATTTACAGCTGAAGCCTCTCAAAAATAGCCGGCAAGTTGAGGTCTCTTGGGAATATCCCGACACTTGGAGCACACCCCACAGCTACTTCTCTTTAACCTTTTGTGTGCAAGTTCAAGGTAAAAGCAAGCGGGAGAAGAAAGACCGGGTGTTTACCGACAAAACCAGCGCCACCGTCATCTGTCGGAAGAACGCCTCCATCAGCGTGAGGGCTCAAGATCGTTATTACTCCAGCAGCTGGTCCGAGTGGGCCAGCGTGCCTTGTTCCGGCGGTGGAGGATCCGGAGGAGGTGGCTCCGGCGGCGGAGGATCTCGTAACCTCCCCGTGGCTACCCCCGATCCCGGAATGTTCCCTTGTTTACACCACAGCCAGAATTTACTGAGGGCCGTGAGCAACATGCTGCAGAAAGCTAGGCAGACTTTAGAATTTTACCCTTGCACCAGCGAGGAGATCGACCATGAAGATATCACCAAGGACAAGACATCCACCGTGGAGGCTTGTTTACCTCTGGAGCTGACAAAGAACGAGTCTTGTCTCAACTCTCGTGAAACCAGCTTCATCACAAATGGCTCTTGTTTAGCTTCCCGGAAGACCTCCTTTATGATGGCTTTATGCCTCAGCTCCATCTACGAGGATTTAAAGATGTACCAAGTGGAGTTCAAGACCATGAACGCCAAGCTGCTCATGGACCCTAAACGGCAGATCTTTTTAGACCAGAACATGCTGGCTGTGATTGATGAGCTGATGCAAGCTTTAAACTTCAACTCCGAGACCGTCCCTCAGAAGTCCTCCCTCGAGGAGCCCGATTTTTACAAGACAAAGATCAAACTGTGCATTTTACTCCACGCCTTTAGGATCCGGGCCGTGACCATTGACCGGGTCATGAGCTATTTAAACGCCAGCATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG(SEQ ID NO:75)。
在一些实施例中,第二嵌合多肽可包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
MKWVTFISLLFLFSSAYSIWELKKDVYVVELDWYPDAPGEMVVLTCDTPEEDGITWTLDQSSEVLGSGKTLTIQVKEFGDAGQYTCHKGGEVLSHSLLLLHKKEDGIWSTDILKDQKEPKNKTFLRCEAKNYSGRFTCWWLTTISTDLTFSVKSSRGSSDPQGVTCGAATLSAERVRGDNKEYEYSVECQEDSACPAAEESLPIEVMVDAVHKLKYENYTSSFFIRDIIKPDPPKNLQLKPLKNSRQVEVSWEYPDTWSTPHSYFSLTFCVQVQGKSKREKKDRVFTDKTSATVICRKNASISVRAQDRYYSSSWSEWASVPCSGGGGSGGGGSGGGGSRNLPVATPDPGMFPCLHHSQNLLRAVSNMLQKARQTLEFYPCTSEEIDHEDITKDKTSTVEACLPLELTKNESCLNSRETSFITNGSCLASRKTSFMMALCLSSIYEDLKMYQVEFKTMNAKLLMDPKRQIFLDQNMLAVIDELMQALNFNSETVPQKSSLEEPDFYKTKIKLCILLHAFRIRAVTIDRVMSYLNASITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR(SEQ ID NO:76)。
在一些实施例中,第二嵌合多肽由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
ATGAAATGGGTGACCTTTATTTCTTTACTGTTCCTCTTTAGCAGCGCCTACTCCATTTGGGAACTGAAGAAGGACGTCTACGTGGTCGAACTGGACTGGTATCCCGATGCTCCCGGCGAAATGGTGGTGCTCACTTGTGACACCCCCGAAGAAGACGGCATCACTTGGACCCTCGATCAGAGCAGCGAGGTGCTGGGCTCCGGAAAGACCCTCACAATCCAAGTTAAGGAGTTCGGAGACGCTGGCCAATACACATGCCACAAGGGAGGCGAGGTGCTCAGCCATTCCTTATTATTATTACACAAGAAGGAAGACGGAATCTGGTCCACCGACATTTTAAAAGATCAGAAGGAGCCCAAGAATAAGACCTTTTTAAGGTGTGAGGCCAAAAACTACAGCGGTCGTTTCACTTGTTGGTGGCTGACCACCATTTCCACCGATTTAACCTTCTCCGTGAAAAGCAGCCGGGGAAGCTCCGACCCTCAAGGTGTGACATGTGGAGCCGCTACCCTCAGCGCTGAGAGGGTTCGTGGCGATAACAAGGAATACGAGTACAGCGTGGAGTGCCAAGAAGATAGCGCTTGTCCCGCTGCCGAAGAATCTTTACCCATTGAGGTGATGGTGGACGCCGTGCACAAACTCAAGTACGAGAACTACACCTCCTCCTTCTTTATCCGGGACATCATTAAGCCCGATCCTCCTAAGAATTTACAGCTGAAGCCTCTCAAAAATAGCCGGCAAGTTGAGGTCTCTTGGGAATATCCCGACACTTGGAGCACACCCCACAGCTACTTCTCTTTAACCTTTTGTGTGCAAGTTCAAGGTAAAAGCAAGCGGGAGAAGAAAGACCGGGTGTTTACCGACAAAACCAGCGCCACCGTCATCTGTCGGAAGAACGCCTCCATCAGCGTGAGGGCTCAAGATCGTTATTACTCCAGCAGCTGGTCCGAGTGGGCCAGCGTGCCTTGTTCCGGCGGTGGAGGATCCGGAGGAGGTGGCTCCGGCGGCGGAGGATCTCGTAACCTCCCCGTGGCTACCCCCGATCCCGGAATGTTCCCTTGTTTACACCACAGCCAGAATTTACTGAGGGCCGTGAGCAACATGCTGCAGAAAGCTAGGCAGACTTTAGAATTTTACCCTTGCACCAGCGAGGAGATCGACCATGAAGATATCACCAAGGACAAGACATCCACCGTGGAGGCTTGTTTACCTCTGGAGCTGACAAAGAACGAGTCTTGTCTCAACTCTCGTGAAACCAGCTTCATCACAAATGGCTCTTGTTTAGCTTCCCGGAAGACCTCCTTTATGATGGCTTTATGCCTCAGCTCCATCTACGAGGATTTAAAGATGTACCAAGTGGAGTTCAAGACCATGAACGCCAAGCTGCTCATGGACCCTAAACGGCAGATCTTTTTAGACCAGAACATGCTGGCTGTGATTGATGAGCTGATGCAAGCTTTAAACTTCAACTCCGAGACCGTCCCTCAGAAGTCCTCCCTCGAGGAGCCCGATTTTTACAAGACAAAGATCAAACTGTGCATTTTACTCCACGCCTTTAGGATCCGGGCCGTGACCATTGACCGGGTCATGAGCTATTTAAACGCCAGCATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG(SEQ ID NO:77)。
示例性多链嵌合多肽-B型
在本文所描述的多链嵌合多肽中的任一种的一些实施例中,第一靶标结合结构域和第二靶标结合结构域各自独立地特异性结合到IL-21的受体或TGF-β。在这些多链嵌合多肽的一些实例中,第一靶标结合结构域和可溶性组织因子结构域在第一嵌合多肽中彼此直接邻接。在这些多链嵌合多肽的一些实例中,第一嵌合多肽进一步包含第一嵌合多肽中的第一靶标结合结构域与可溶性组织因子结构域之间的接头序列(例如,本文所描述的示例性接头中的任一种)。
在这些多链嵌合多肽的一些实施例中,可溶性组织因子结构域和一对亲和结构域中的第一结构域在第一嵌合多肽中彼此直接邻接。在这些多链嵌合多肽的一些实施例中,第一嵌合多肽进一步包括第一嵌合多肽中的可溶性组织因子结构域与一对亲和结构域中的第一结构域之间的接头序列(例如,本文所描述的示例性接头中的任一种)。
在这些多链嵌合多肽的一些实施例中,一对亲和结构域中的第二结构域和第二靶标结合结构域在第二嵌合多肽中彼此直接邻接。在这些多链嵌合多肽的一些实施例中,第二嵌合多肽进一步包括第二嵌合多肽中的一对亲和结构域中的第二结构域与第二靶标结合结构域之间的接头序列(例如,本文所描述的示例性接头中的任一种)。
在这些多链嵌合多肽的一些实施例中,可溶性组织因子结构域可为本文所描述的示例性可溶性组织因子结构域中的任一种。在这些多链嵌合多肽的一些实施例中,所述一对亲和结构域可为本文所描述的示例性亲和结构域对中的任一种。
在这些多链嵌合多肽的一些实施例中,第一靶标结合结构域和第二靶标结合结构域中的一个或两个是可溶性IL-21(例如,可溶性人IL-21多肽)或可溶性TGF-β受体(例如,可溶性TGFRβRII受体)。在这些多链嵌合多肽的一些实施例中,第一靶标结合结构域和第二靶标结合结构域各自独立地为可溶性IL-21或可溶性TGF-β受体(例如,可溶性TGFRβRII受体)。在这些多链嵌合多肽的一些实施例中,第一靶标结合结构域和第二靶标结合结构域均特异性结合到IL-21的受体或TGF-β。在这些多链嵌合多肽的一些实施例中,第一靶标结合结构域和第二靶标结合结构域特异性结合到相同的表位。在这些多链嵌合多肽的一些实施例中,第一靶标结合结构域和第二靶标结合结构域包括相同的氨基酸序列。
在这些多链嵌合多肽的一些实施例中,第一靶标结合结构域特异性结合到IL-21的受体,并且第二靶标结合结构域特异性结合到TGF-β。在这些多链嵌合多肽的一些实施例中,第一靶标结合结构域特异性结合TGF-β,并且第二靶标结合结构域特异性结合到IL-21的受体。
在这些多链嵌合多肽的一些实施例中,第一靶标结合结构域包括可溶性IL-21(例如,可溶性人IL-21)。在这些多链嵌合多肽的一些实施例中,可溶性人IL-21包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS(SEQ ID NO:78)。
在这些多链嵌合多肽的一些实施例中,可溶性人IL-21由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC(SEQ ID NO:79)。
在这些多链嵌合多肽的一些实施例中,第二靶标结合结构域包括可溶性TGF-β受体(例如,可溶性TGFRβRII受体(例如,可溶性人TGFRβRII受体))。在这些多链嵌合多肽的一些实施例中,可溶性人TGFRβRII包括可溶性人TGFRβRII的第一序列和可溶性人TGFRβRII的第二序列。在这些多链嵌合多肽的一些实施例中,可溶性人TGFRβRII包括安置于可溶性人TGFRβRII的第一序列与可溶性人TGFRβRII的第二序列之间的接头。在这些多链嵌合多肽的一些实例中,接头包括序列GGGGSGGGGSGGGGS(SEQ ID NO:7)。
在这些多链嵌合多肽的一些实施例中,可溶性人TGFRβRII受体的第一序列包含与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD(SEQ IDNO:80)。
在这些多链嵌合多肽的一些实施例中,可溶性人TGFRβRII受体的第二序列包含与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD(SEQ IDNO:81)。
在这些多链嵌合多肽的一些实施例中,可溶性人TGFRβRII受体的第一序列由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCACGATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGAT(SEQ ID NO:82)。
在这些多链嵌合多肽的一些实施例中,可溶性人TGFRβRII受体的第二序列由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
ATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCACAATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC(SEQ ID NO:83)。
在这些多链嵌合多肽的一些实施例中,可溶性人TGFRβRII受体由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCACGATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCACAATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC(SEQ ID NO:84)。
在这些多链嵌合多肽的一些实施例中,人TGFβRII受体包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD(SEQ IDNO:85)。
在一些实施例中,第一嵌合多肽可包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDSSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS(SEQ ID NO:86)。
在一些实施例中,第一嵌合多肽由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCCTCCGGCACCACCAATACCGTGGCCGCTTATAACCTCACATGGAAGAGCACCAACTTCAAGACAATTCTGGAATGGGAACCCAAGCCCGTCAATCAAGTTTACACCGTGCAGATCTCCACCAAATCCGGAGACTGGAAGAGCAAGTGCTTCTACACAACAGACACCGAGTGTGATTTAACCGACGAAATCGTCAAGGACGTCAAGCAAACCTATCTGGCTCGGGTCTTTTCCTACCCCGCTGGCAATGTCGAGTCCACCGGCTCCGCTGGCGAGCCTCTCTACGAGAATTCCCCCGAATTCACCCCTTATTTAGAGACCAATTTAGGCCAGCCTACCATCCAGAGCTTCGAGCAAGTTGGCACCAAGGTGAACGTCACCGTCGAGGATGAAAGGACTTTAGTGCGGCGGAATAACACATTTTTATCCCTCCGGGATGTGTTCGGCAAAGACCTCATCTACACACTGTACTATTGGAAGTCCAGCTCCTCCGGCAAAAAGACCGCTAAGACCAACACCAACGAGTTTTTAATTGACGTGGACAAAGGCGAGAACTACTGCTTCAGCGTGCAAGCCGTGATCCCTTCTCGTACCGTCAACCGGAAGAGCACAGATTCCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC(SEQ ID NO:87)。
在一些实施例中,第一嵌合多肽可包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
MKWVTFISLLFLFSSAYSQGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDSSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS(SEQ ID NO:88)。
在一些实施例中,第一嵌合多肽由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCCAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCCTCCGGCACCACCAATACCGTGGCCGCTTATAACCTCACATGGAAGAGCACCAACTTCAAGACAATTCTGGAATGGGAACCCAAGCCCGTCAATCAAGTTTACACCGTGCAGATCTCCACCAAATCCGGAGACTGGAAGAGCAAGTGCTTCTACACAACAGACACCGAGTGTGATTTAACCGACGAAATCGTCAAGGACGTCAAGCAAACCTATCTGGCTCGGGTCTTTTCCTACCCCGCTGGCAATGTCGAGTCCACCGGCTCCGCTGGCGAGCCTCTCTACGAGAATTCCCCCGAATTCACCCCTTATTTAGAGACCAATTTAGGCCAGCCTACCATCCAGAGCTTCGAGCAAGTTGGCACCAAGGTGAACGTCACCGTCGAGGATGAAAGGACTTTAGTGCGGCGGAATAACACATTTTTATCCCTCCGGGATGTGTTCGGCAAAGACCTCATCTACACACTGTACTATTGGAAGTCCAGCTCCTCCGGCAAAAAGACCGCTAAGACCAACACCAACGAGTTTTTAATTGACGTGGACAAAGGCGAGAACTACTGCTTCAGCGTGCAAGCCGTGATCCCTTCTCGTACCGTCAACCGGAAGAGCACAGATTCCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC(SEQ ID NO:89)。
在一些实施例中,第二嵌合多肽可包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR(SEQ ID NO:90)。
在一些实施例中,第二嵌合多肽由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCACGATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCACAATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACATCACGTGTCCTCCTCCTATGTCCGTGGAACACGCAGACATCTGGGTCAAGAGCTACAGCTTGTACTCCAGGGAGCGGTACATTTGTAACTCTGGTTTCAAGCGTAAAGCCGGCACGTCCAGCCTGACGGAGTGCGTGTTGAACAAGGCCACGAATGTCGCCCACTGGACAACCCCCAGTCTCAAATGTATTAGA(SEQ ID NO:91)。
在一些实施例中,第二嵌合多肽可包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
MKWVTFISLLFLFSSAYSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR(SEQ ID NO:92)。
在一些实施例中,第二嵌合多肽由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCACGATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCACAATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACATCACGTGTCCTCCTCCTATGTCCGTGGAACACGCAGACATCTGGGTCAAGAGCTACAGCTTGTACTCCAGGGAGCGGTACATTTGTAACTCTGGTTTCAAGCGTAAAGCCGGCACGTCCAGCCTGACGGAGTGCGTGTTGAACAAGGCCACGAATGTCGCCCACTGGACAACCCCCAGTCTCAAATGTATTAGA(SEQ ID NO:93)。
示例性多链嵌合多肽-C型
在本文所描述的多链嵌合多肽中的任一种的一些实施例中,第一靶标结合结构域和第二靶标结合结构域各自独立地特异性结合到IL-7的受体或IL-21的受体。在这些多链嵌合多肽的一些实例中,第一靶标结合结构域和可溶性组织因子结构域在第一嵌合多肽中彼此直接邻接。在这些多链嵌合多肽的一些实例中,第一嵌合多肽进一步包含第一嵌合多肽中的第一靶标结合结构域与可溶性组织因子结构域之间的接头序列(例如,本文所描述的示例性接头中的任一种)。
在这些多链嵌合多肽的一些实施例中,可溶性组织因子结构域和一对亲和结构域中的第一结构域在第一嵌合多肽中彼此直接邻接。在这些多链嵌合多肽的一些实施例中,第一嵌合多肽进一步包括第一嵌合多肽中的可溶性组织因子结构域与一对亲和结构域中的第一结构域之间的接头序列(例如,本文所描述的示例性接头中的任一种)。
在这些多链嵌合多肽的一些实施例中,一对亲和结构域中的第二结构域和第二靶标结合结构域在第二嵌合多肽中彼此直接邻接。在这些多链嵌合多肽的一些实施例中,第二嵌合多肽进一步包括第二嵌合多肽中的一对亲和结构域中的第二结构域与第二靶标结合结构域之间的接头序列(例如,本文所描述的示例性接头中的任一种)。
在这些多链嵌合多肽的一些实施例中,可溶性组织因子结构域可为本文所描述的示例性可溶性组织因子结构域中的任一种。在这些多链嵌合多肽的一些实施例中,所述一对亲和结构域可为本文所描述的示例性亲和结构域对中的任一种。
在这些多链嵌合多肽的一些实施例中,第一靶标结合结构域和第二靶标结合结构域中的一个或两个是可溶性IL-21(例如,可溶性人IL-21多肽)或可溶性IL-7(例如,可溶性人IL-7多肽)。在这些多链嵌合多肽的一些实施例中,第一靶标结合结构域和第二靶标结合结构域各自独立地为可溶性IL-21或可溶性IL-7。在这些多链嵌合多肽的一些实施例中,第一靶标结合结构域和第二靶标结合结构域均特异性结合到IL-21的受体或IL-7的受体。在这些多链嵌合多肽的一些实施例中,第一靶标结合结构域和第二靶标结合结构域特异性结合到相同的表位。在这些多链嵌合多肽的一些实施例中,第一靶标结合结构域和第二靶标结合结构域包括相同的氨基酸序列。
在这些多链嵌合多肽的一些实施例中,第一靶标结合结构域特异性结合到IL-21的受体,并且第二靶标结合结构域特异性结合到IL-7的受体。在这些多链嵌合多肽的一些实施例中,第一靶标结合结构域特异性结合到IL-7的受体,并且第二靶标结合结构域特异性结合到IL-21的受体。
在这些多链嵌合多肽的一些实施例中,第一靶标结合结构域包括可溶性IL-21(例如,可溶性人IL-21)。
在这些多链嵌合多肽的一些实施例中,可溶性人IL-21包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS(SEQ ID NO:78)。
在这些多链嵌合多肽的一些实施例中,可溶性人IL-21由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
CAAGGTCAAGATCGCCACATGATTAGAATGCGTCAACTTATAGATATTGTTGATCAGCTGAAAAATTATGTGAATGACTTGGTCCCTGAATTTCTGCCAGCTCCAGAAGATGTAGAGACAAACTGTGAGTGGTCAGCTTTTTCCTGTTTTCAGAAGGCCCAACTAAAGTCAGCAAATACAGGAAACAATGAAAGGATAATCAATGTATCAATTAAAAAGCTGAAGAGGAAACCACCTTCCACAAATGCAGGGAGAAGACAGAAACACAGACTAACATGCCCTTCATGTGATTCTTATGAGAAAAAACCACCCAAAGAATTCCTAGAAAGATTCAAATCACTTCTCCAAAAGATGATTCATCAGCATCTGTCCTCTAGAACACACGGAAGTGAAGATTCC(SEQ ID NO:94)。
在这些多链嵌合多肽的一些实施例中,可溶性人IL-21由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC(SEQ ID NO:79)。
在这些多链嵌合多肽的一些实施例中,可溶性人IL-7的序列包含与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWNKILMGTKEH(SEQ ID NO:11)。
在这些多链嵌合多肽的一些实施例中,可溶性人IL-7由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
GATTGTGATATTGAAGGTAAAGATGGCAAACAATATGAGAGTGTTCTAATGGTCAGCATCGATCAATTATTGGACAGCATGAAAGAAATTGGTAGCAATTGCCTGAATAATGAATTTAACTTTTTTAAAAGACATATCTGTGATGCTAATAAGGAAGGTATGTTTTTATTCCGTGCTGCTCGCAAGTTGAGGCAATTTCTTAAAATGAATAGCACTGGTGATTTTGATCTCCACTTATTAAAAGTTTCAGAAGGCACAACAATACTGTTGAACTGCACTGGCCAGGTTAAAGGAAGAAAACCAGCTGCCCTGGGTGAAGCCCAACCAACAAAGAGTTTGGAAGAAAATAAATCTTTAAAGGAACAGAAAAAACTGAATGACTTGTGTTTCCTAAAGAGACTATTACAAGAGATAAAAACTTGTTGGAATAAAATTTTGATGGGCACTAAAGAACAC(SEQ ID NO:95)。
在一些实施例中,第一嵌合多肽可包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDSSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS(SEQ ID NO:96)。
在一些实施例中,第一嵌合多肽由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
CAAGGTCAAGATCGCCACATGATTAGAATGCGTCAACTTATAGATATTGTTGATCAGCTGAAAAATTATGTGAATGACTTGGTCCCTGAATTTCTGCCAGCTCCAGAAGATGTAGAGACAAACTGTGAGTGGTCAGCTTTTTCCTGTTTTCAGAAGGCCCAACTAAAGTCAGCAAATACAGGAAACAATGAAAGGATAATCAATGTATCAATTAAAAAGCTGAAGAGGAAACCACCTTCCACAAATGCAGGGAGAAGACAGAAACACAGACTAACATGCCCTTCATGTGATTCTTATGAGAAAAAACCACCCAAAGAATTCCTAGAAAGATTCAAATCACTTCTCCAAAAGATGATTCATCAGCATCTGTCCTCTAGAACACACGGAAGTGAAGATTCCTCAGGCACTACAAATACTGTGGCAGCATATAATTTAACTTGGAAATCAACTAATTTCAAGACAATTTTGGAGTGGGAACCCAAACCCGTCAATCAAGTCTACACTGTTCAAATAAGCACTAAGTCAGGAGATTGGAAAAGCAAATGCTTTTACACAACAGACACAGAGTGTGACCTCACCGACGAGATTGTGAAGGATGTGAAGCAGACGTACTTGGCACGGGTCTTCTCCTACCCGGCAGGGAATGTGGAGAGCACCGGTTCTGCTGGGGAGCCTCTGTATGAGAACTCCCCAGAGTTCACACCTTACCTGGAGACAAACCTCGGACAGCCAACAATTCAGAGTTTTGAACAGGTGGGAACAAAAGTGAATGTGACCGTAGAAGATGAACGGACTTTAGTCAGAAGGAACAACACTTTCCTAAGCCTCCGGGATGTTTTTGGCAAGGACTTAATTTATACACTTTATTATTGGAAATCTTCAAGTTCAGGAAAGAAAACAGCCAAAACAAACACTAATGAGTTTTTGATTGATGTGGATAAAGGAGAAAACTACTGTTTCAGTGTTCAAGCAGTGATTCCCTCCCGAACAGTTAACCGGAAGAGTACAGACAGCCCGGTAGAGTGTATGGGCCAGGAGAAAGGGGAATTCAGAGAAAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC(SEQ ID NO:97)。
在一些实施例中,第一嵌合多肽可包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
MGVKVLFALICIAVAEAQGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDSSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS(SEQ ID NO:98)。
在一些实施例中,第一嵌合多肽由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
ATGGGAGTGAAAGTTCTTTTTGCCCTTATTTGTATTGCTGTGGCCGAGGCCCAAGGTCAAGATCGCCACATGATTAGAATGCGTCAACTTATAGATATTGTTGATCAGCTGAAAAATTATGTGAATGACTTGGTCCCTGAATTTCTGCCAGCTCCAGAAGATGTAGAGACAAACTGTGAGTGGTCAGCTTTTTCCTGTTTTCAGAAGGCCCAACTAAAGTCAGCAAATACAGGAAACAATGAAAGGATAATCAATGTATCAATTAAAAAGCTGAAGAGGAAACCACCTTCCACAAATGCAGGGAGAAGACAGAAACACAGACTAACATGCCCTTCATGTGATTCTTATGAGAAAAAACCACCCAAAGAATTCCTAGAAAGATTCAAATCACTTCTCCAAAAGATGATTCATCAGCATCTGTCCTCTAGAACACACGGAAGTGAAGATTCCTCAGGCACTACAAATACTGTGGCAGCATATAATTTAACTTGGAAATCAACTAATTTCAAGACAATTTTGGAGTGGGAACCCAAACCCGTCAATCAAGTCTACACTGTTCAAATAAGCACTAAGTCAGGAGATTGGAAAAGCAAATGCTTTTACACAACAGACACAGAGTGTGACCTCACCGACGAGATTGTGAAGGATGTGAAGCAGACGTACTTGGCACGGGTCTTCTCCTACCCGGCAGGGAATGTGGAGAGCACCGGTTCTGCTGGGGAGCCTCTGTATGAGAACTCCCCAGAGTTCACACCTTACCTGGAGACAAACCTCGGACAGCCAACAATTCAGAGTTTTGAACAGGTGGGAACAAAAGTGAATGTGACCGTAGAAGATGAACGGACTTTAGTCAGAAGGAACAACACTTTCCTAAGCCTCCGGGATGTTTTTGGCAAGGACTTAATTTATACACTTTATTATTGGAAATCTTCAAGTTCAGGAAAGAAAACAGCCAAAACAAACACTAATGAGTTTTTGATTGATGTGGATAAAGGAGAAAACTACTGTTTCAGTGTTCAAGCAGTGATTCCCTCCCGAACAGTTAACCGGAAGAGTACAGACAGCCCGGTAGAGTGTATGGGCCAGGAGAAAGGGGAATTCAGAGAAAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC(SEQ ID NO:99)。
在一些实施例中,第二嵌合多肽可包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWNKILMGTKEHITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR(SEQID NO:100)。
在一些实施例中,第二嵌合多肽由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
GATTGTGATATTGAAGGTAAAGATGGCAAACAATATGAGAGTGTTCTAATGGTCAGCATCGATCAATTATTGGACAGCATGAAAGAAATTGGTAGCAATTGCCTGAATAATGAATTTAACTTTTTTAAAAGACATATCTGTGATGCTAATAAGGAAGGTATGTTTTTATTCCGTGCTGCTCGCAAGTTGAGGCAATTTCTTAAAATGAATAGCACTGGTGATTTTGATCTCCACTTATTAAAAGTTTCAGAAGGCACAACAATACTGTTGAACTGCACTGGCCAGGTTAAAGGAAGAAAACCAGCTGCCCTGGGTGAAGCCCAACCAACAAAGAGTTTGGAAGAAAATAAATCTTTAAAGGAACAGAAAAAACTGAATGACTTGTGTTTCCTAAAGAGACTATTACAAGAGATAAAAACTTGTTGGAATAAAATTTTGATGGGCACTAAAGAACACATCACGTGCCCTCCCCCCATGTCCGTGGAACACGCAGACATCTGGGTCAAGAGCTACAGCTTGTACTCCAGGGAGCGGTACATTTGTAACTCTGGTTTCAAGCGTAAAGCCGGCACGTCCAGCCTGACGGAGTGCGTGTTGAACAAGGCCACGAATGTCGCCCACTGGACAACCCCCAGTCTCAAATGCATTAGA(SEQ ID NO:101)。
在一些实施例中,第二嵌合多肽可包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
MGVKVLFALICIAVAEADCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWNKILMGTKEHITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR(SEQ ID NO:102)。
在一些实施例中,第二嵌合多肽由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
ATGGGAGTGAAAGTTCTTTTTGCCCTTATTTGTATTGCTGTGGCCGAGGCCGATTGTGATATTGAAGGTAAAGATGGCAAACAATATGAGAGTGTTCTAATGGTCAGCATCGATCAATTATTGGACAGCATGAAAGAAATTGGTAGCAATTGCCTGAATAATGAATTTAACTTTTTTAAAAGACATATCTGTGATGCTAATAAGGAAGGTATGTTTTTATTCCGTGCTGCTCGCAAGTTGAGGCAATTTCTTAAAATGAATAGCACTGGTGATTTTGATCTCCACTTATTAAAAGTTTCAGAAGGCACAACAATACTGTTGAACTGCACTGGCCAGGTTAAAGGAAGAAAACCAGCTGCCCTGGGTGAAGCCCAACCAACAAAGAGTTTGGAAGAAAATAAATCTTTAAAGGAACAGAAAAAACTGAATGACTTGTGTTTCCTAAAGAGACTATTACAAGAGATAAAAACTTGTTGGAATAAAATTTTGATGGGCACTAAAGAACACATCACGTGCCCTCCCCCCATGTCCGTGGAACACGCAGACATCTGGGTCAAGAGCTACAGCTTGTACTCCAGGGAGCGGTACATTTGTAACTCTGGTTTCAAGCGTAAAGCCGGCACGTCCAGCCTGACGGAGTGCGTGTTGAACAAGGCCACGAATGTCGCCCACTGGACAACCCCCAGTCTCAAATGCATTAGA(SEQ ID NO:103)。
示例性多链嵌合多肽-D型
在本文所描述的多链嵌合多肽中的任一种的一些实施例中,第一靶标结合结构域和第二靶标结合结构域各自独立地特异性结合到IL-7的受体或IL-21的受体。在这些多链嵌合多肽的一些实例中,第一靶标结合结构域和可溶性组织因子结构域在第一嵌合多肽中彼此直接邻接。在这些多链嵌合多肽的一些实例中,第一嵌合多肽进一步包含第一嵌合多肽中的第一靶标结合结构域与可溶性组织因子结构域之间的接头序列(例如,本文所描述的示例性接头中的任一种)。
在这些多链嵌合多肽的一些实施例中,可溶性组织因子结构域和一对亲和结构域中的第一结构域在第一嵌合多肽中彼此直接邻接。在这些多链嵌合多肽的一些实施例中,第一嵌合多肽进一步包括第一嵌合多肽中的可溶性组织因子结构域与一对亲和结构域中的第一结构域之间的接头序列(例如,本文所描述的示例性接头中的任一种)。
在这些多链嵌合多肽的一些实施例中,一对亲和结构域中的第二结构域和第二靶标结合结构域在第二嵌合多肽中彼此直接邻接。在这些多链嵌合多肽的一些实施例中,第二嵌合多肽进一步包括第二嵌合多肽中的一对亲和结构域中的第二结构域与第二靶标结合结构域之间的接头序列(例如,本文所描述的示例性接头中的任一种)。
在这些多链嵌合多肽的一些实施例中,可溶性组织因子结构域可为本文所描述的示例性可溶性组织因子结构域中的任一种。在这些多链嵌合多肽的一些实施例中,所述一对亲和结构域可为本文所描述的示例性亲和结构域对中的任一种。
在这些多链嵌合多肽的一些实施例中,第一靶标结合结构域和第二靶标结合结构域中的一个或两个是可溶性IL-21(例如,可溶性人IL-21多肽)或可溶性IL-7(例如,可溶性人IL-7多肽)。在这些多链嵌合多肽的一些实施例中,第一靶标结合结构域和第二靶标结合结构域各自独立地为可溶性IL-21或可溶性IL-7。在这些多链嵌合多肽的一些实施例中,第一靶标结合结构域和第二靶标结合结构域均特异性结合到IL-21的受体或IL-7的受体。在这些多链嵌合多肽的一些实施例中,第一靶标结合结构域和第二靶标结合结构域特异性结合到相同的表位。在这些多链嵌合多肽的一些实施例中,第一靶标结合结构域和第二靶标结合结构域包括相同的氨基酸序列。
在这些多链嵌合多肽的一些实施例中,第一靶标结合结构域特异性结合到IL-21的受体,并且第二靶标结合结构域特异性结合到IL-7的受体。在这些多链嵌合多肽的一些实施例中,第一靶标结合结构域特异性结合到IL-7的受体,并且第二靶标结合结构域特异性结合到IL-21的受体。
在这些多链嵌合多肽的一些实施例中,可溶性人IL-21包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS(SEQ ID NO:78)。
在这些多链嵌合多肽的一些实施例中,可溶性人IL-21由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
CAAGGTCAAGATCGCCACATGATTAGAATGCGTCAACTTATAGATATTGTTGATCAGCTGAAAAATTATGTGAATGACTTGGTCCCTGAATTTCTGCCAGCTCCAGAAGATGTAGAGACAAACTGTGAGTGGTCAGCTTTTTCCTGTTTTCAGAAGGCCCAACTAAAGTCAGCAAATACAGGAAACAATGAAAGGATAATCAATGTATCAATTAAAAAGCTGAAGAGGAAACCACCTTCCACAAATGCAGGGAGAAGACAGAAACACAGACTAACATGCCCTTCATGTGATTCTTATGAGAAAAAACCACCCAAAGAATTCCTAGAAAGATTCAAATCACTTCTCCAAAAGATGATTCATCAGCATCTGTCCTCTAGAACACACGGAAGTGAAGATTCC(SEQ ID NO:94)。
在这些多链嵌合多肽的一些实施例中,可溶性人IL-21由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC(SEQ ID NO:79)。
在这些多链嵌合多肽的一些实施例中,可溶性人IL-7的序列包含与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWNKILMGTKEH(SEQ ID NO:11)。
在这些多链嵌合多肽的一些实施例中,可溶性人IL-7由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
GATTGTGATATTGAAGGTAAAGATGGCAAACAATATGAGAGTGTTCTAATGGTCAGCATCGATCAATTATTGGACAGCATGAAAGAAATTGGTAGCAATTGCCTGAATAATGAATTTAACTTTTTTAAAAGACATATCTGTGATGCTAATAAGGAAGGTATGTTTTTATTCCGTGCTGCTCGCAAGTTGAGGCAATTTCTTAAAATGAATAGCACTGGTGATTTTGATCTCCACTTATTAAAAGTTTCAGAAGGCACAACAATACTGTTGAACTGCACTGGCCAGGTTAAAGGAAGAAAACCAGCTGCCCTGGGTGAAGCCCAACCAACAAAGAGTTTGGAAGAAAATAAATCTTTAAAGGAACAGAAAAAACTGAATGACTTGTGTTTCCTAAAGAGACTATTACAAGAGATAAAAACTTGTTGGAATAAAATTTTGATGGGCACTAAAGAACAC(SEQ ID NO:95)。
在一些实施例中,第一嵌合多肽可包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWNKILMGTKEHSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS(SEQ ID NO:104)。
在一些实施例中,第一嵌合多肽由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
GATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGTTCAACTTCTTCAAGCGGCACATCTGCGACGCCAACAAGGAGGGCATGTTCCTGTTCAGGGCCGCCAGGAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGGTGAAGGGCCGGAAACCTGCTGCTCTGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGAACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCATAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC(SEQ ID NO:105)。
在一些实施例中,第一嵌合多肽可包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
MKWVTFISLLFLFSSAYSDCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWNKILMGTKEHSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS(SEQ ID NO:106)。
在一些实施例中,第一嵌合多肽由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCGATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGTTCAACTTCTTCAAGCGGCACATCTGCGACGCCAACAAGGAGGGCATGTTCCTGTTCAGGGCCGCCAGGAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGGTGAAGGGCCGGAAACCTGCTGCTCTGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGAACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCATAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC(SEQID NO:107)。
在一些实施例中,第二嵌合多肽可包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDSITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR(SEQ ID NO:108)。
在一些实施例中,第二嵌合多肽由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCCATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG(SEQ IDNO:109)。
在一些实施例中,第二嵌合多肽可包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
MKWVTFISLLFLFSSAYSQGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDSITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR(SEQID NO:110)。
在一些实施例中,第二嵌合多肽由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCCAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCCATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG(SEQ ID NO:111)。
示例性多链嵌合多肽-E型
在本文所描述的多链嵌合多肽中的任一种的一些实施例中,第一靶标结合结构域和第二靶标结合结构域各自独立地特异性结合到IL-18(例如,可溶性人IL-18)的受体、IL-12(例如,可溶性人IL-12)的受体或CD16(例如,抗CD16 scFv)。在本文所描述的这些多链嵌合多肽的一些实施例中,第一嵌合多肽进一步包括另外的靶标结合结构域。在本文所描述的这些多链嵌合多肽的一些实施例中,第二嵌合多肽进一步包括另外的靶标结合结构域。在本文所描述的这些多链嵌合多肽的一些实施例中,另外的靶标结合结构域特异性结合到CD16或IL-12的受体。
在这些多链嵌合多肽的一些实例中,第一靶标结合结构域和可溶性组织因子结构域在第一嵌合多肽中彼此直接邻接。在这些多链嵌合多肽的一些实例中,第一嵌合多肽进一步包含第一嵌合多肽中的第一靶标结合结构域与可溶性组织因子结构域之间的接头序列(例如,本文所描述的示例性接头中的任一种)。
在这些多链嵌合多肽的一些实施例中,可溶性组织因子结构域和一对亲和结构域中的第一结构域在第一嵌合多肽中彼此直接邻接。在这些多链嵌合多肽的一些实施例中,第一嵌合多肽进一步包括第一嵌合多肽中的可溶性组织因子结构域与一对亲和结构域中的第一结构域之间的接头序列(例如,本文所描述的示例性接头中的任一种)。
在这些多链嵌合多肽的一些实施例中,一对亲和结构域中的第二结构域和第二靶标结合结构域在第二嵌合多肽中彼此直接邻接。在这些多链嵌合多肽的一些实施例中,第二嵌合多肽进一步包括第二嵌合多肽中的一对亲和结构域中的第二结构域与第二靶标结合结构域之间的接头序列(例如,本文所描述的示例性接头中的任一种)。
在一些实施例中,第二嵌合多肽在第二嵌合多肽的N端或C端进一步包含一个或多个另外的靶标结合结构域。
在这些多链嵌合多肽的一些实施例中,另外的靶标结合结构域和一对亲和结构域中的第二结构域在第二嵌合多肽中彼此直接邻接。在这些多链嵌合多肽的一些实施例中,第二嵌合多肽进一步包括第二嵌合多肽中的一对亲和结构域中的第二结构域与另外的靶标结合结构域之间的接头序列(例如,本文所描述的示例性接头中的任一种)。
在这些多链嵌合多肽的一些实施例中,另外的靶标结合结构域和第二靶标结合结构域在第二嵌合多肽中直接彼此邻接。在这些多链嵌合多肽的一些实施例中,第二嵌合多肽进一步包括第二嵌合多肽中的第二靶标结合结构域与另外的靶标结合结构域之间的接头序列(例如,本文所描述的示例性接头中的任一种)。
在这些多链嵌合多肽的一些实施例中,可溶性组织因子结构域可为本文所描述的示例性可溶性组织因子结构域中的任一种。在这些多链嵌合多肽的一些实施例中,所述一对亲和结构域可为本文所描述的示例性亲和结构域对中的任一种。
在这些多链嵌合多肽的一些实施例中,第一靶标结合结构域、第二靶标结合结构域和另外的抗原结合结构域中的一个或多个是激动性抗原结合结构域。在这些多链嵌合多肽的一些实施例中,第一靶标结合结构域、第二靶标结合结构域和另外的抗原结合结构域各自是激动性抗原结合结构域。在这些多链嵌合多肽的一些实施例中,抗原结合结构域包括scFv或单结构域抗体。
在这些多链嵌合多肽的一些实施例中,第一靶标结合结构域和第二靶标结合结构域中的一个或两个是可溶性IL-15或可溶性IL-18。在这些多链嵌合多肽的一些实施例中,第一靶标结合结构域和第二靶标结合结构域各自独立地为可溶性IL-15或可溶性IL-18。在这些多链嵌合多肽的一些实施例中,第一靶标结合结构域和第二靶标结合结构域均特异性结合到IL-18的受体或IL-12的受体。在这些多链嵌合多肽的一些实施例中,第一靶标结合结构域和第二靶标结合结构域特异性结合到相同的表位。在这些多链嵌合多肽的一些实施例中,第一靶标结合结构域和第二靶标结合结构域包括相同的氨基酸序列。
在这些多链嵌合多肽的一些实施例中,第一靶标结合结构域特异性结合到IL-12的受体,并且第二靶标结合结构域特异性结合到IL-18的受体。在这些多链嵌合多肽的一些实施例中,第一靶标结合结构域特异性结合到IL-18的受体,并且第二靶标结合结构域特异性结合到IL-12的受体。在这些多链嵌合多肽的一些实施例中,第一靶标结合结构域特异性结合到CD16,并且第二靶标结合结构域特异性结合到IL-18的受体。在这些多链嵌合多肽的一些实施例中,第一靶标结合结构域特异性结合到IL-18的受体,并且第二靶标结合结构域特异性结合到CD16。
在这些多链嵌合多肽的一些实施例中,第一靶标结合结构域、第二靶标结合结构域和一个或多个另外的靶标结合结构域中的两个或更多个特异性结合到相同的抗原。在一些实施例中,第一靶标结合结构域、第二靶标结合结构域和一个或多个另外的靶标结合结构域中的两个或更多个特异性结合到相同的表位。在一些实施例中,第一靶标结合结构域、第二靶标结合结构域和一个或多个另外的靶标结合结构域中的两个或更多个包含相同的氨基酸序列。
在这些多链嵌合多肽的一些实施例中,第一靶标结合结构域包括可溶性IL-18(例如,可溶性人IL-18)。
在这些多链嵌合多肽的一些实施例中,可溶性人IL-18包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
YFGKLESKLSVIRNLNDQVLFIDQGNRPLFEDMTDSDCRDNAPRTIFIISMYKDSQPRGMAVTISVKCEKISTLSCENKIISFKEMNPPDNIKDTKSDIIFFQRSVPGHDNKMQFESSSYEGYFLACEKERDLFKLILKKEDELGDRSIMFTVQNED(SEQ ID NO:16)。
在这些多链嵌合多肽的一些实施例中,可溶性人IL-18由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
TACTTCGGCAAACTGGAATCCAAGCTGAGCGTGATCCGGAATTTAAACGACCAAGTTCTGTTTATCGATCAAGGTAACCGGCCTCTGTTCGAGGACATGACCGACTCCGATTGCCGGGACAATGCCCCCCGGACCATCTTCATTATCTCCATGTACAAGGACAGCCAGCCCCGGGGCATGGCTGTGACAATTAGCGTGAAGTGTGAGAAAATCAGCACTTTATCTTGTGAGAACAAGATCATCTCCTTTAAGGAAATGAACCCCCCCGATAACATCAAGGACACCAAGTCCGATATCATCTTCTTCCAGCGGTCCGTGCCCGGTCACGATAACAAGATGCAGTTCGAATCCTCCTCCTACGAGGGCTACTTTTTAGCTTGTGAAAAGGAGAGGGATTTATTCAAGCTGATCCTCAAGAAGGAGGACGAGCTGGGCGATCGTTCCATCATGTTCACCGTCCAAAACGAGGAT(SEQ ID NO:65)。
在这些多链嵌合多肽的一些实施例中,第二靶标结合结构域包括可溶性IL-12(例如,可溶性人IL-12)。在这些多链嵌合多肽的一些实施例中,可溶性人IL-15包括可溶性人IL-12β(p40)的序列和可溶性人IL-12α(p35)的序列。在这些多链嵌合多肽的一些实施例中,可溶性IL-15(例如,可溶性人IL-15)进一步包括可溶性IL-12β(p40)的序列与可溶性人IL-12α(p35)的序列之间的接头序列(例如,本文所描述的示例性接头序列中的任一种)。在这些多链嵌合多肽的一些实例中,接头序列包含GGGGSGGGGSGGGGS(SEQ ID NO:7)。
在这些多链嵌合多肽的一些实施例中,可溶性人IL-12β(p40)的序列包含与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
IWELKKDVYVVELDWYPDAPGEMVVLTCDTPEEDGITWTLDQSSEVLGSGKTLTIQVKEFGDAGQYTCHKGGEVLSHSLLLLHKKEDGIWSTDILKDQKEPKNKTFLRCEAKNYSGRFTCWWLTTISTDLTFSVKSSRGSSDPQGVTCGAATLSAERVRGDNKEYEYSVECQEDSACPAAEESLPIEVMVDAVHKLKYENYTSSFFIRDIIKPDPPKNLQLKPLKNSRQVEVSWEYPDTWSTPHSYFSLTFCVQVQGKSKREKKDRVFTDKTSATVICRKNASISVRAQDRYYSSSWSEWASVPCS(SEQ ID NO:66)。
在这些多链嵌合多肽的一些实施例中,可溶性人IL-12β(p40)由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
ATTTGGGAACTGAAGAAGGACGTCTACGTGGTCGAACTGGACTGGTATCCCGATGCTCCCGGCGAAATGGTGGTGCTCACTTGTGACACCCCCGAAGAAGACGGCATCACTTGGACCCTCGATCAGAGCAGCGAGGTGCTGGGCTCCGGAAAGACCCTCACAATCCAAGTTAAGGAGTTCGGAGACGCTGGCCAATACACATGCCACAAGGGAGGCGAGGTGCTCAGCCATTCCTTATTATTATTACACAAGAAGGAAGACGGAATCTGGTCCACCGACATTTTAAAAGATCAGAAGGAGCCCAAGAATAAGACCTTTTTAAGGTGTGAGGCCAAAAACTACAGCGGTCGTTTCACTTGTTGGTGGCTGACCACCATTTCCACCGATTTAACCTTCTCCGTGAAAAGCAGCCGGGGAAGCTCCGACCCTCAAGGTGTGACATGTGGAGCCGCTACCCTCAGCGCTGAGAGGGTTCGTGGCGATAACAAGGAATACGAGTACAGCGTGGAGTGCCAAGAAGATAGCGCTTGTCCCGCTGCCGAAGAATCTTTACCCATTGAGGTGATGGTGGACGCCGTGCACAAACTCAAGTACGAGAACTACACCTCCTCCTTCTTTATCCGGGACATCATTAAGCCCGATCCTCCTAAGAATTTACAGCTGAAGCCTCTCAAAAATAGCCGGCAAGTTGAGGTCTCTTGGGAATATCCCGACACTTGGAGCACACCCCACAGCTACTTCTCTTTAACCTTTTGTGTGCAAGTTCAAGGTAAAAGCAAGCGGGAGAAGAAAGACCGGGTGTTTACCGACAAAACCAGCGCCACCGTCATCTGTCGGAAGAACGCCTCCATCAGCGTGAGGGCTCAAGATCGTTATTACTCCAGCAGCTGGTCCGAGTGGGCCAGCGTGCCTTGTTCC(SEQ ID NO:67)。
在这些多链嵌合多肽的一些实施例中,可溶性人IL-12α(p35)包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
RNLPVATPDPGMFPCLHHSQNLLRAVSNMLQKARQTLEFYPCTSEEIDHEDITKDKTSTVEACLPLELTKNESCLNSRETSFITNGSCLASRKTSFMMALCLSSIYEDLKMYQVEFKTMNAKLLMDPKRQIFLDQNMLAVIDELMQALNFNSETVPQKSSLEEPDFYKTKIKLCILLHAFRIRAVTIDRVMSYLNAS(SEQ ID NO:68)。
在这些多链嵌合多肽的一些实施例中,可溶性人IL-12α(p35)由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
CGTAACCTCCCCGTGGCTACCCCCGATCCCGGAATGTTCCCTTGTTTACACCACAGCCAGAATTTACTGAGGGCCGTGAGCAACATGCTGCAGAAAGCTAGGCAGACTTTAGAATTTTACCCTTGCACCAGCGAGGAGATCGACCATGAAGATATCACCAAGGACAAGACATCCACCGTGGAGGCTTGTTTACCTCTGGAGCTGACAAAGAACGAGTCTTGTCTCAACTCTCGTGAAACCAGCTTCATCACAAATGGCTCTTGTTTAGCTTCCCGGAAGACCTCCTTTATGATGGCTTTATGCCTCAGCTCCATCTACGAGGATTTAAAGATGTACCAAGTGGAGTTCAAGACCATGAACGCCAAGCTGCTCATGGACCCTAAACGGCAGATCTTTTTAGACCAGAACATGCTGGCTGTGATTGATGAGCTGATGCAAGCTTTAAACTTCAACTCCGAGACCGTCCCTCAGAAGTCCTCCCTCGAGGAGCCCGATTTTTACAAGACAAAGATCAAACTGTGCATTTTACTCCACGCCTTTAGGATCCGGGCCGTGACCATTGACCGGGTCATGAGCTATTTAAACGCCAGC(SEQ IDNO:69)。
在这些多链嵌合多肽的一些实施例中,另外的靶标结合结构域包括特异性结合到CD16的scFv(例如,抗CD16 scFv)。
在这些多链嵌合多肽的一些实施例中,特异性结合到CD16的scFv包括轻链可变结构域,所述轻链可变结构域包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
SELTQDPAVSVALGQTVRITCQGDSLRSYYASWYQQKPGQAPVLVIYGKNNRPSGIPDRFSGSSSGNTASLTITGAQAEDEADYYCNSRDSSGNHVVFGGGTKLTVGH(SEQ ID NO:112)。
在这些多链嵌合多肽的一些实施例中,特异性结合到CD16的scFv由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的轻链可变结构域序列编码:
TCCGAGCTGACCCAGGACCCTGCTGTGTCCGTGGCTCTGGGCCAGACCGTGAGGATCACCTGCCAGGGCGACTCCCTGAGGTCCTACTACGCCTCCTGGTACCAGCAGAAGCCCGGCCAGGCTCCTGTGCTGGTGATCTACGGCAAGAACAACAGGCCCTCCGGCATCCCTGACAGGTTCTCCGGATCCTCCTCCGGCAACACCGCCTCCCTGACCATCACAGGCGCTCAGGCCGAGGACGAGGCTGACTACTACTGCAACTCCAGGGACTCCTCCGGCAACCATGTGGTGTTCGGCGGCGGCACCAAGCTGACCGTGGGCCAT(SEQ ID NO:113)。
在这些多链嵌合多肽的一些实施例中,特异性结合到CD16的scFv包括重链可变结构域,所述重链可变结构域包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
EVQLVESGGGVVRPGGSLRLSCAASGFTFDDYGMSWVRQAPGKGLEWVSGINWNGGSTGYADSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARGRSLLFDYWGQGTLVTVSR(SEQ ID NO:114)。
在这些多链嵌合多肽的一些实施例中,特异性结合到CD16的scFv由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的重链可变结构域序列编码:
GAGGTGCAGCTGGTGGAGTCCGGAGGAGGAGTGGTGAGGCCTGGAGGCTCCCTGAGGCTGAGCTGTGCTGCCTCCGGCTTCACCTTCGACGACTACGGCATGTCCTGGGTGAGGCAGGCTCCTGGAAAGGGCCTGGAGTGGGTGTCCGGCATCAACTGGAACGGCGGATCCACCGGCTACGCCGATTCCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACTCCCTGTACCTGCAGATGAACTCCCTGAGGGCCGAGGACACCGCCGTGTACTACTGCGCCAGGGGCAGGTCCCTGCTGTTCGACTACTGGGGACAGGGCACCCTGGTGACCGTGTCCAGG(SEQ ID NO:115)。
在一些实施例中,第一嵌合多肽可包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
YFGKLESKLSVIRNLNDQVLFIDQGNRPLFEDMTDSDCRDNAPRTIFIISMYKDSQPRGMAVTISVKCEKISTLSCENKIISFKEMNPPDNIKDTKSDIIFFQRSVPGHDNKMQFESSSYEGYFLACEKERDLFKLILKKEDELGDRSIMFTVQNEDSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS(SEQ ID NO:116)。
在一些实施例中,第一嵌合多肽由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
TACTTCGGCAAACTGGAATCCAAGCTGAGCGTGATCCGGAATTTAAACGACCAAGTTCTGTTTATCGATCAAGGTAACCGGCCTCTGTTCGAGGACATGACCGACTCCGATTGCCGGGACAATGCCCCCCGGACCATCTTCATTATCTCCATGTACAAGGACAGCCAGCCCCGGGGCATGGCTGTGACAATTAGCGTGAAGTGTGAGAAAATCAGCACTTTATCTTGTGAGAACAAGATCATCTCCTTTAAGGAAATGAACCCCCCCGATAACATCAAGGACACCAAGTCCGATATCATCTTCTTCCAGCGGTCCGTGCCCGGTCACGATAACAAGATGCAGTTCGAATCCTCCTCCTACGAGGGCTACTTTTTAGCTTGTGAAAAGGAGAGGGATTTATTCAAGCTGATCCTCAAGAAGGAGGACGAGCTGGGCGATCGTTCCATCATGTTCACCGTCCAAAACGAGGATAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC(SEQ ID NO:117)。
在一些实施例中,第一嵌合多肽可包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
MKWVTFISLLFLFSSAYSYFGKLESKLSVIRNLNDQVLFIDQGNRPLFEDMTDSDCRDNAPRTIFIISMYKDSQPRGMAVTISVKCEKISTLSCENKIISFKEMNPPDNIKDTKSDIIFFQRSVPGHDNKMQFESSSYEGYFLACEKERDLFKLILKKEDELGDRSIMFTVQNEDSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS(SEQ ID NO:118)。
在一些实施例中,第一嵌合多肽由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
ATGAAGTGGGTCACATTTATCTCTTTACTGTTCCTCTTCTCCAGCGCCTACAGCTACTTCGGCAAACTGGAATCCAAGCTGAGCGTGATCCGGAATTTAAACGACCAAGTTCTGTTTATCGATCAAGGTAACCGGCCTCTGTTCGAGGACATGACCGACTCCGATTGCCGGGACAATGCCCCCCGGACCATCTTCATTATCTCCATGTACAAGGACAGCCAGCCCCGGGGCATGGCTGTGACAATTAGCGTGAAGTGTGAGAAAATCAGCACTTTATCTTGTGAGAACAAGATCATCTCCTTTAAGGAAATGAACCCCCCCGATAACATCAAGGACACCAAGTCCGATATCATCTTCTTCCAGCGGTCCGTGCCCGGTCACGATAACAAGATGCAGTTCGAATCCTCCTCCTACGAGGGCTACTTTTTAGCTTGTGAAAAGGAGAGGGATTTATTCAAGCTGATCCTCAAGAAGGAGGACGAGCTGGGCGATCGTTCCATCATGTTCACCGTCCAAAACGAGGATAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC(SEQ ID NO:119)。
在一些实施例中,第二嵌合多肽可包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
IWELKKDVYVVELDWYPDAPGEMVVLTCDTPEEDGITWTLDQSSEVLGSGKTLTIQVKEFGDAGQYTCHKGGEVLSHSLLLLHKKEDGIWSTDILKDQKEPKNKTFLRCEAKNYSGRFTCWWLTTISTDLTFSVKSSRGSSDPQGVTCGAATLSAERVRGDNKEYEYSVECQEDSACPAAEESLPIEVMVDAVHKLKYENYTSSFFIRDIIKPDPPKNLQLKPLKNSRQVEVSWEYPDTWSTPHSYFSLTFCVQVQGKSKREKKDRVFTDKTSATVICRKNASISVRAQDRYYSSSWSEWASVPCSGGGGSGGGGSGGGGSRNLPVATPDPGMFPCLHHSQNLLRAVSNMLQKARQTLEFYPCTSEEIDHEDITKDKTSTVEACLPLELTKNESCLNSRETSFITNGSCLASRKTSFMMALCLSSIYEDLKMYQVEFKTMNAKLLMDPKRQIFLDQNMLAVIDELMQALNFNSETVPQKSSLEEPDFYKTKIKLCILLHAFRIRAVTIDRVMSYLNASITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIRSELTQDPAVSVALGQTVRITCQGDSLRSYYASWYQQKPGQAPVLVIYGKNNRPSGIPDRFSGSSSGNTASLTITGAQAEDEADYYCNSRDSSGNHVVFGGGTKLTVGHGGGGSGGGGSGGGGSEVQLVESGGGVVRPGGSLRLSCAASGFTFDDYGMSWVRQAPGKGLEWVSGINWNGGSTGYADSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARGRSLLFDYWGQGTLVTVSR(SEQID NO:120)。
在一些实施例中,第二嵌合多肽由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
ATTTGGGAACTGAAGAAGGACGTCTACGTGGTCGAACTGGACTGGTATCCCGATGCTCCCGGCGAAATGGTGGTGCTCACTTGTGACACCCCCGAAGAAGACGGCATCACTTGGACCCTCGATCAGAGCAGCGAGGTGCTGGGCTCCGGAAAGACCCTCACAATCCAAGTTAAGGAGTTCGGAGACGCTGGCCAATACACATGCCACAAGGGAGGCGAGGTGCTCAGCCATTCCTTATTATTATTACACAAGAAGGAAGACGGAATCTGGTCCACCGACATTTTAAAAGATCAGAAGGAGCCCAAGAATAAGACCTTTTTAAGGTGTGAGGCCAAAAACTACAGCGGTCGTTTCACTTGTTGGTGGCTGACCACCATTTCCACCGATTTAACCTTCTCCGTGAAAAGCAGCCGGGGAAGCTCCGACCCTCAAGGTGTGACATGTGGAGCCGCTACCCTCAGCGCTGAGAGGGTTCGTGGCGATAACAAGGAATACGAGTACAGCGTGGAGTGCCAAGAAGATAGCGCTTGTCCCGCTGCCGAAGAATCTTTACCCATTGAGGTGATGGTGGACGCCGTGCACAAACTCAAGTACGAGAACTACACCTCCTCCTTCTTTATCCGGGACATCATTAAGCCCGATCCTCCTAAGAATTTACAGCTGAAGCCTCTCAAAAATAGCCGGCAAGTTGAGGTCTCTTGGGAATATCCCGACACTTGGAGCACACCCCACAGCTACTTCTCTTTAACCTTTTGTGTGCAAGTTCAAGGTAAAAGCAAGCGGGAGAAGAAAGACCGGGTGTTTACCGACAAAACCAGCGCCACCGTCATCTGTCGGAAGAACGCCTCCATCAGCGTGAGGGCTCAAGATCGTTATTACTCCAGCAGCTGGTCCGAGTGGGCCAGCGTGCCTTGTTCCGGCGGTGGAGGATCCGGAGGAGGTGGCTCCGGCGGCGGAGGATCTCGTAACCTCCCCGTGGCTACCCCCGATCCCGGAATGTTCCCTTGTTTACACCACAGCCAGAATTTACTGAGGGCCGTGAGCAACATGCTGCAGAAAGCTAGGCAGACTTTAGAATTTTACCCTTGCACCAGCGAGGAGATCGACCATGAAGATATCACCAAGGACAAGACATCCACCGTGGAGGCTTGTTTACCTCTGGAGCTGACAAAGAACGAGTCTTGTCTCAACTCTCGTGAAACCAGCTTCATCACAAATGGCTCTTGTTTAGCTTCCCGGAAGACCTCCTTTATGATGGCTTTATGCCTCAGCTCCATCTACGAGGATTTAAAGATGTACCAAGTGGAGTTCAAGACCATGAACGCCAAGCTGCTCATGGACCCTAAACGGCAGATCTTTTTAGACCAGAACATGCTGGCTGTGATTGATGAGCTGATGCAAGCTTTAAACTTCAACTCCGAGACCGTCCCTCAGAAGTCCTCCCTCGAGGAGCCCGATTTTTACAAGACAAAGATCAAACTGTGCATTTTACTCCACGCCTTTAGGATCCGGGCCGTGACCATTGACCGGGTCATGAGCTATTTAAACGCCAGCATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGGTCCGAGCTGACCCAGGACCCTGCTGTGTCCGTGGCTCTGGGCCAGACCGTGAGGATCACCTGCCAGGGCGACTCCCTGAGGTCCTACTACGCCTCCTGGTACCAGCAGAAGCCCGGCCAGGCTCCTGTGCTGGTGATCTACGGCAAGAACAACAGGCCCTCCGGCATCCCTGACAGGTTCTCCGGATCCTCCTCCGGCAACACCGCCTCCCTGACCATCACAGGCGCTCAGGCCGAGGACGAGGCTGACTACTACTGCAACTCCAGGGACTCCTCCGGCAACCATGTGGTGTTCGGCGGCGGCACCAAGCTGACCGTGGGCCATGGCGGCGGCGGCTCCGGAGGCGGCGGCAGCGGCGGAGGAGGATCCGAGGTGCAGCTGGTGGAGTCCGGAGGAGGAGTGGTGAGGCCTGGAGGCTCCCTGAGGCTGAGCTGTGCTGCCTCCGGCTTCACCTTCGACGACTACGGCATGTCCTGGGTGAGGCAGGCTCCTGGAAAGGGCCTGGAGTGGGTGTCCGGCATCAACTGGAACGGCGGATCCACCGGCTACGCCGATTCCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACTCCCTGTACCTGCAGATGAACTCCCTGAGGGCCGAGGACACCGCCGTGTACTACTGCGCCAGGGGCAGGTCCCTGCTGTTCGACTACTGGGGACAGGGCACCCTGGTGACCGTGTCCAGG(SEQ ID NO:121)。
在一些实施例中,第二嵌合多肽可包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
MKWVTFISLLFLFSSAYSIWELKKDVYVVELDWYPDAPGEMVVLTCDTPEEDGITWTLDQSSEVLGSGKTLTIQVKEFGDAGQYTCHKGGEVLSHSLLLLHKKEDGIWSTDILKDQKEPKNKTFLRCEAKNYSGRFTCWWLTTISTDLTFSVKSSRGSSDPQGVTCGAATLSAERVRGDNKEYEYSVECQEDSACPAAEESLPIEVMVDAVHKLKYENYTSSFFIRDIIKPDPPKNLQLKPLKNSRQVEVSWEYPDTWSTPHSYFSLTFCVQVQGKSKREKKDRVFTDKTSATVICRKNASISVRAQDRYYSSSWSEWASVPCSGGGGSGGGGSGGGGSRNLPVATPDPGMFPCLHHSQNLLRAVSNMLQKARQTLEFYPCTSEEIDHEDITKDKTSTVEACLPLELTKNESCLNSRETSFITNGSCLASRKTSFMMALCLSSIYEDLKMYQVEFKTMNAKLLMDPKRQIFLDQNMLAVIDELMQALNFNSETVPQKSSLEEPDFYKTKIKLCILLHAFRIRAVTIDRVMSYLNASITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIRSELTQDPAVSVALGQTVRITCQGDSLRSYYASWYQQKPGQAPVLVIYGKNNRPSGIPDRFSGSSSGNTASLTITGAQAEDEADYYCNSRDSSGNHVVFGGGTKLTVGHGGGGSGGGGSGGGGSEVQLVESGGGVVRPGGSLRLSCAASGFTFDDYGMSWVRQAPGKGLEWVSGINWNGGSTGYADSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARGRSLLFDYWGQGTLVTVSR(SEQ ID NO:122)。
在一些实施例中,第二嵌合多肽由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
ATGAAATGGGTGACCTTTATTTCTTTACTGTTCCTCTTTAGCAGCGCCTACTCCATTTGGGAACTGAAGAAGGACGTCTACGTGGTCGAACTGGACTGGTATCCCGATGCTCCCGGCGAAATGGTGGTGCTCACTTGTGACACCCCCGAAGAAGACGGCATCACTTGGACCCTCGATCAGAGCAGCGAGGTGCTGGGCTCCGGAAAGACCCTCACAATCCAAGTTAAGGAGTTCGGAGACGCTGGCCAATACACATGCCACAAGGGAGGCGAGGTGCTCAGCCATTCCTTATTATTATTACACAAGAAGGAAGACGGAATCTGGTCCACCGACATTTTAAAAGATCAGAAGGAGCCCAAGAATAAGACCTTTTTAAGGTGTGAGGCCAAAAACTACAGCGGTCGTTTCACTTGTTGGTGGCTGACCACCATTTCCACCGATTTAACCTTCTCCGTGAAAAGCAGCCGGGGAAGCTCCGACCCTCAAGGTGTGACATGTGGAGCCGCTACCCTCAGCGCTGAGAGGGTTCGTGGCGATAACAAGGAATACGAGTACAGCGTGGAGTGCCAAGAAGATAGCGCTTGTCCCGCTGCCGAAGAATCTTTACCCATTGAGGTGATGGTGGACGCCGTGCACAAACTCAAGTACGAGAACTACACCTCCTCCTTCTTTATCCGGGACATCATTAAGCCCGATCCTCCTAAGAATTTACAGCTGAAGCCTCTCAAAAATAGCCGGCAAGTTGAGGTCTCTTGGGAATATCCCGACACTTGGAGCACACCCCACAGCTACTTCTCTTTAACCTTTTGTGTGCAAGTTCAAGGTAAAAGCAAGCGGGAGAAGAAAGACCGGGTGTTTACCGACAAAACCAGCGCCACCGTCATCTGTCGGAAGAACGCCTCCATCAGCGTGAGGGCTCAAGATCGTTATTACTCCAGCAGCTGGTCCGAGTGGGCCAGCGTGCCTTGTTCCGGCGGTGGAGGATCCGGAGGAGGTGGCTCCGGCGGCGGAGGATCTCGTAACCTCCCCGTGGCTACCCCCGATCCCGGAATGTTCCCTTGTTTACACCACAGCCAGAATTTACTGAGGGCCGTGAGCAACATGCTGCAGAAAGCTAGGCAGACTTTAGAATTTTACCCTTGCACCAGCGAGGAGATCGACCATGAAGATATCACCAAGGACAAGACATCCACCGTGGAGGCTTGTTTACCTCTGGAGCTGACAAAGAACGAGTCTTGTCTCAACTCTCGTGAAACCAGCTTCATCACAAATGGCTCTTGTTTAGCTTCCCGGAAGACCTCCTTTATGATGGCTTTATGCCTCAGCTCCATCTACGAGGATTTAAAGATGTACCAAGTGGAGTTCAAGACCATGAACGCCAAGCTGCTCATGGACCCTAAACGGCAGATCTTTTTAGACCAGAACATGCTGGCTGTGATTGATGAGCTGATGCAAGCTTTAAACTTCAACTCCGAGACCGTCCCTCAGAAGTCCTCCCTCGAGGAGCCCGATTTTTACAAGACAAAGATCAAACTGTGCATTTTACTCCACGCCTTTAGGATCCGGGCCGTGACCATTGACCGGGTCATGAGCTATTTAAACGCCAGCATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGGTCCGAGCTGACCCAGGACCCTGCTGTGTCCGTGGCTCTGGGCCAGACCGTGAGGATCACCTGCCAGGGCGACTCCCTGAGGTCCTACTACGCCTCCTGGTACCAGCAGAAGCCCGGCCAGGCTCCTGTGCTGGTGATCTACGGCAAGAACAACAGGCCCTCCGGCATCCCTGACAGGTTCTCCGGATCCTCCTCCGGCAACACCGCCTCCCTGACCATCACAGGCGCTCAGGCCGAGGACGAGGCTGACTACTACTGCAACTCCAGGGACTCCTCCGGCAACCATGTGGTGTTCGGCGGCGGCACCAAGCTGACCGTGGGCCATGGCGGCGGCGGCTCCGGAGGCGGCGGCAGCGGCGGAGGAGGATCCGAGGTGCAGCTGGTGGAGTCCGGAGGAGGAGTGGTGAGGCCTGGAGGCTCCCTGAGGCTGAGCTGTGCTGCCTCCGGCTTCACCTTCGACGACTACGGCATGTCCTGGGTGAGGCAGGCTCCTGGAAAGGGCCTGGAGTGGGTGTCCGGCATCAACTGGAACGGCGGATCCACCGGCTACGCCGATTCCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACTCCCTGTACCTGCAGATGAACTCCCTGAGGGCCGAGGACACCGCCGTGTACTACTGCGCCAGGGGCAGGTCCCTGCTGTTCGACTACTGGGGACAGGGCACCCTGGTGACCGTGTCCAGG(SEQ ID NO:123)。
示例性多链嵌合多肽-F型
在本文所描述的多链嵌合多肽中的任一种的一些实施例中,第一靶标结合结构域和第二靶标结合结构域各自独立地特异性结合到IL-7(例如,可溶性人IL-7)的受体、CD16(例如,抗CD16 scFv)或IL-21(例如,可溶性人IL-21)的受体。在本文所描述的这些多链嵌合多肽的一些实施例中,第一嵌合多肽进一步包括另外的靶标结合结构域。在本文所描述的这些多链嵌合多肽的一些实施例中,第二嵌合多肽进一步包括另外的靶标结合结构域。在本文所描述的这些多链嵌合多肽的一些实施例中,另外的靶标结合结构域特异性结合到CD16或IL-21的受体。
在这些多链嵌合多肽的一些实例中,第一靶标结合结构域和可溶性组织因子结构域在第一嵌合多肽中彼此直接邻接。在这些多链嵌合多肽的一些实例中,第一嵌合多肽进一步包含第一嵌合多肽中的第一靶标结合结构域与可溶性组织因子结构域之间的接头序列(例如,本文所描述的示例性接头中的任一种)。
在这些多链嵌合多肽的一些实施例中,可溶性组织因子结构域和一对亲和结构域中的第一结构域在第一嵌合多肽中彼此直接邻接。在这些多链嵌合多肽的一些实施例中,第一嵌合多肽进一步包括第一嵌合多肽中的可溶性组织因子结构域与一对亲和结构域中的第一结构域之间的接头序列(例如,本文所描述的示例性接头中的任一种)。
在这些多链嵌合多肽的一些实施例中,一对亲和结构域中的第二结构域和第二靶标结合结构域在第二嵌合多肽中彼此直接邻接。在这些多链嵌合多肽的一些实施例中,第二嵌合多肽进一步包括第二嵌合多肽中的一对亲和结构域中的第二结构域与第二靶标结合结构域之间的接头序列(例如,本文所描述的示例性接头中的任一种)。
在一些实施例中,第二嵌合多肽在第二嵌合多肽的N端或C端进一步包含一个或多个另外的靶标结合结构域。
在这些多链嵌合多肽的一些实施例中,另外的靶标结合结构域和一对亲和结构域中的第二结构域在第二嵌合多肽中彼此直接邻接。在这些多链嵌合多肽的一些实施例中,第二嵌合多肽进一步包括第二嵌合多肽中的一对亲和结构域中的第二结构域与另外的靶标结合结构域之间的接头序列(例如,本文所描述的示例性接头中的任一种)。
在这些多链嵌合多肽的一些实施例中,另外的靶标结合结构域和第二靶标结合结构域在第二嵌合多肽中直接彼此邻接。在这些多链嵌合多肽的一些实施例中,第二嵌合多肽进一步包括第二嵌合多肽中的第二靶标结合结构域与另外的靶标结合结构域之间的接头序列(例如,本文所描述的示例性接头中的任一种)。
在这些多链嵌合多肽的一些实施例中,可溶性组织因子结构域可为本文所描述的示例性可溶性组织因子结构域中的任一种。在这些多链嵌合多肽的一些实施例中,所述一对亲和结构域可为本文所描述的示例性亲和结构域对中的任一种。
在这些多链嵌合多肽的一些实施例中,第一靶标结合结构域、第二靶标结合结构域和另外的抗原结合结构域中的一个或多个是激动性抗原结合结构域。在这些多链嵌合多肽的一些实施例中,第一靶标结合结构域、第二靶标结合结构域和另外的抗原结合结构域各自是激动性抗原结合结构域。在这些多链嵌合多肽的一些实施例中,抗原结合结构域包括scFv或单结构域抗体。
在本文所描述的多链嵌合多肽中的任一种的一些实施例中,第一靶标结合结构域特异性结合到受体IL-7,并且第二靶标结合结构域特异性结合到CD16或IL-21的受体。在本文所描述的多链嵌合多肽中的任一种的一些实施例中,第一靶标结合结构域包括可溶性IL-7蛋白。在本文所描述的多链嵌合多肽中的任一种的一些实施例中,可溶性IL-7蛋白是可溶性人IL-7。在本文所描述的多链嵌合多肽中的任一种的一些实施例中,第二抗原结合结构域包括特异性结合到CD16的靶标结合结构域。在本文所描述的多链嵌合多肽中的任一种的一些实施例中,第二靶标结合结构域包括特异性结合到CD16的scFv。在本文所描述的多链嵌合多肽中的任一种的一些实施例中,第二靶标结合结构域特异性结合到IL-21的受体。在本文所描述的多链嵌合多肽中的任一种的一些实施例中,第二靶标结合结构域包括可溶性IL-21。在本文所描述的多链嵌合多肽中的任一种的一些实施例中,可溶性IL-21是可溶性人IL-21。在本文所描述的多链嵌合多肽中的任一种的一些实施例中,第二嵌合多肽进一步包括特异性结合到IL-21的受体的另外的靶标结合结构域。在本文所描述的多链嵌合多肽中的任一种的一些实施例中,另外的靶标结合结构域包括可溶性IL-21。在本文所描述的多链嵌合多肽中的任一种的一些实施例中,可溶性IL-21是可溶性人IL-21。在本文所描述的多链嵌合多肽中的任一种的一些实施例中,第二嵌合多肽进一步包括特异性结合到CD16的另外的靶标结合结构域。
在这些多链嵌合多肽的一些实施例中,第一靶标结合结构域、第二靶标结合结构域和一个或多个另外的靶标结合结构域中的两个或更多个特异性结合到相同的抗原。在一些实施例中,第一靶标结合结构域、第二靶标结合结构域和一个或多个另外的靶标结合结构域中的两个或更多个特异性结合到相同的表位。在一些实施例中,第一靶标结合结构域、第二靶标结合结构域和一个或多个另外的靶标结合结构域中的两个或更多个包含相同的氨基酸序列。
在这些多链嵌合多肽的一些实施例中,第一靶标结合结构域包括可溶性IL-7(例如,可溶性人IL-7)。
在这些多链嵌合多肽的一些实施例中,可溶性人IL-7包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWNKILMGTKEH(SEQ ID NO:11)。
在这些多链嵌合多肽的一些实施例中,可溶性人IL-7由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
GATTGTGATATTGAAGGTAAAGATGGCAAACAATATGAGAGTGTTCTAATGGTCAGCATCGATCAATTATTGGACAGCATGAAAGAAATTGGTAGCAATTGCCTGAATAATGAATTTAACTTTTTTAAAAGACATATCTGTGATGCTAATAAGGAAGGTATGTTTTTATTCCGTGCTGCTCGCAAGTTGAGGCAATTTCTTAAAATGAATAGCACTGGTGATTTTGATCTCCACTTATTAAAAGTTTCAGAAGGCACAACAATACTGTTGAACTGCACTGGCCAGGTTAAAGGAAGAAAACCAGCTGCCCTGGGTGAAGCCCAACCAACAAAGAGTTTGGAAGAAAATAAATCTTTAAAGGAACAGAAAAAACTGAATGACTTGTGTTTCCTAAAGAGACTATTACAAGAGATAAAAACTTGTTGGAATAAAATTTTGATGGGCACTAAAGAACAC(SEQ ID NO:95)。
在这些多链嵌合多肽的一些实施例中,可溶性人IL-7由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
GATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGTTCAACTTCTTCAAGCGGCACATCTGCGACGCCAACAAGGAGGGCATGTTCCTGTTCAGGGCCGCCAGGAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGGTGAAGGGCCGGAAACCTGCTGCTCTGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGAACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCAT(SEQ ID NO:124)。
在这些多链嵌合多肽的一些实施例中,可溶性人IL-21的序列包含与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS(SEQ ID NO:78)。
在这些多链嵌合多肽的一些实施例中,可溶性人IL-21由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
CAAGGTCAAGATCGCCACATGATTAGAATGCGTCAACTTATAGATATTGTTGATCAGCTGAAAAATTATGTGAATGACTTGGTCCCTGAATTTCTGCCAGCTCCAGAAGATGTAGAGACAAACTGTGAGTGGTCAGCTTTTTCCTGTTTTCAGAAGGCCCAACTAAAGTCAGCAAATACAGGAAACAATGAAAGGATAATCAATGTATCAATTAAAAAGCTGAAGAGGAAACCACCTTCCACAAATGCAGGGAGAAGACAGAAACACAGACTAACATGCCCTTCATGTGATTCTTATGAGAAAAAACCACCCAAAGAATTCCTAGAAAGATTCAAATCACTTCTCCAAAAGATGATTCATCAGCATCTGTCCTCTAGAACACACGGAAGTGAAGATTCC(SEQ ID NO:94)。
在这些多链嵌合多肽的一些实施例中,可溶性人IL-21由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC(SEQ ID NO:79)。
在这些多链嵌合多肽的一些实施例中,另外的靶标结合结构域包括特异性结合到CD16的scFv(例如,抗CD16 scFv)。
在这些多链嵌合多肽的一些实施例中,特异性结合到CD16的scFv包括轻链可变结构域,所述轻链可变结构域包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
SELTQDPAVSVALGQTVRITCQGDSLRSYYASWYQQKPGQAPVLVIYGKNNRPSGIPDRFSGSSSGNTASLTITGAQAEDEADYYCNSRDSSGNHVVFGGGTKLTVGH(SEQ ID NO:112)。
在这些多链嵌合多肽的一些实施例中,特异性结合到CD16的scFv由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的轻链可变结构域序列编码:
TCCGAGCTGACCCAGGACCCTGCTGTGTCCGTGGCTCTGGGCCAGACCGTGAGGATCACCTGCCAGGGCGACTCCCTGAGGTCCTACTACGCCTCCTGGTACCAGCAGAAGCCCGGCCAGGCTCCTGTGCTGGTGATCTACGGCAAGAACAACAGGCCCTCCGGCATCCCTGACAGGTTCTCCGGATCCTCCTCCGGCAACACCGCCTCCCTGACCATCACAGGCGCTCAGGCCGAGGACGAGGCTGACTACTACTGCAACTCCAGGGACTCCTCCGGCAACCATGTGGTGTTCGGCGGCGGCACCAAGCTGACCGTGGGCCAT(SEQ ID NO:113)。
在这些多链嵌合多肽的一些实施例中,特异性结合到CD16的scFv包括重链可变结构域,所述重链可变结构域包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
EVQLVESGGGVVRPGGSLRLSCAASGFTFDDYGMSWVRQAPGKGLEWVSGINWNGGSTGYADSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARGRSLLFDYWGQGTLVTVSR(SEQ ID NO:114)。
在这些多链嵌合多肽的一些实施例中,特异性结合到CD16的scFv由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的重链可变结构域序列编码:
GAGGTGCAGCTGGTGGAGTCCGGAGGAGGAGTGGTGAGGCCTGGAGGCTCCCTGAGGCTGAGCTGTGCTGCCTCCGGCTTCACCTTCGACGACTACGGCATGTCCTGGGTGAGGCAGGCTCCTGGAAAGGGCCTGGAGTGGGTGTCCGGCATCAACTGGAACGGCGGATCCACCGGCTACGCCGATTCCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACTCCCTGTACCTGCAGATGAACTCCCTGAGGGCCGAGGACACCGCCGTGTACTACTGCGCCAGGGGCAGGTCCCTGCTGTTCGACTACTGGGGACAGGGCACCCTGGTGACCGTGTCCAGG(SEQ ID NO:115)。
在一些实施例中,第一嵌合多肽可包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWNKILMGTKEHSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS(SEQ ID NO:125)。
在一些实施例中,第一嵌合多肽由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
GATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGTTCAACTTCTTCAAGCGGCACATCTGCGACGCCAACAAGGAGGGCATGTTCCTGTTCAGGGCCGCCAGGAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGGTGAAGGGCCGGAAACCTGCTGCTCTGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGAACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCATAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC(SEQ ID NO:126)。
在一些实施例中,第一嵌合多肽可包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
MKWVTFISLLFLFSSAYSDCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWNKILMGTKEHSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS(SEQ ID NO:127)。
在一些实施例中,第一嵌合多肽由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCGATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGTTCAACTTCTTCAAGCGGCACATCTGCGACGCCAACAAGGAGGGCATGTTCCTGTTCAGGGCCGCCAGGAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGGTGAAGGGCCGGAAACCTGCTGCTCTGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGAACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCATAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC(SEQID NO:128)。
在一些实施例中,第二嵌合多肽可包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
SELTQDPAVSVALGQTVRITCQGDSLRSYYASWYQQKPGQAPVLVIYGKNNRPSGIPDRFSGSSSGNTASLTITGAQAEDEADYYCNSRDSSGNHVVFGGGTKLTVGHGGGGSGGGGSGGGGSEVQLVESGGGVVRPGGSLRLSCAASGFTFDDYGMSWVRQAPGKGLEWVSGINWNGGSTGYADSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARGRSLLFDYWGQGTLVTVSRITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIRQGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS(SEQ ID NO:129)。
在一些实施例中,第二嵌合多肽由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
TCCGAGCTGACCCAGGACCCTGCTGTGTCCGTGGCTCTGGGCCAGACCGTGAGGATCACCTGCCAGGGCGACTCCCTGAGGTCCTACTACGCCTCCTGGTACCAGCAGAAGCCCGGCCAGGCTCCTGTGCTGGTGATCTACGGCAAGAACAACAGGCCCTCCGGCATCCCTGACAGGTTCTCCGGATCCTCCTCCGGCAACACCGCCTCCCTGACCATCACAGGCGCTCAGGCCGAGGACGAGGCTGACTACTACTGCAACTCCAGGGACTCCTCCGGCAACCATGTGGTGTTCGGCGGCGGCACCAAGCTGACCGTGGGCCATGGCGGCGGCGGCTCCGGAGGCGGCGGCAGCGGCGGAGGAGGATCCGAGGTGCAGCTGGTGGAGTCCGGAGGAGGAGTGGTGAGGCCTGGAGGCTCCCTGAGGCTGAGCTGTGCTGCCTCCGGCTTCACCTTCGACGACTACGGCATGTCCTGGGTGAGGCAGGCTCCTGGAAAGGGCCTGGAGTGGGTGTCCGGCATCAACTGGAACGGCGGATCCACCGGCTACGCCGATTCCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACTCCCTGTACCTGCAGATGAACTCCCTGAGGGCCGAGGACACCGCCGTGTACTACTGCGCCAGGGGCAGGTCCCTGCTGTTCGACTACTGGGGACAGGGCACCCTGGTGACCGTGTCCAGGATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGGCAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC(SEQ ID NO:130)。
在一些实施例中,第二嵌合多肽可包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
MKWVTFISLLFLFSSAYSSELTQDPAVSVALGQTVRITCQGDSLRSYYASWYQQKPGQAPVLVIYGKNNRPSGIPDRFSGSSSGNTASLTITGAQAEDEADYYCNSRDSSGNHVVFGGGTKLTVGHGGGGSGGGGSGGGGSEVQLVESGGGVVRPGGSLRLSCAASGFTFDDYGMSWVRQAPGKGLEWVSGINWNGGSTGYADSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARGRSLLFDYWGQGTLVTVSRITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIRQGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS(SEQ ID NO:131)。
在一些实施例中,第二嵌合多肽由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCTCCGAGCTGACCCAGGACCCTGCTGTGTCCGTGGCTCTGGGCCAGACCGTGAGGATCACCTGCCAGGGCGACTCCCTGAGGTCCTACTACGCCTCCTGGTACCAGCAGAAGCCCGGCCAGGCTCCTGTGCTGGTGATCTACGGCAAGAACAACAGGCCCTCCGGCATCCCTGACAGGTTCTCCGGATCCTCCTCCGGCAACACCGCCTCCCTGACCATCACAGGCGCTCAGGCCGAGGACGAGGCTGACTACTACTGCAACTCCAGGGACTCCTCCGGCAACCATGTGGTGTTCGGCGGCGGCACCAAGCTGACCGTGGGCCATGGCGGCGGCGGCTCCGGAGGCGGCGGCAGCGGCGGAGGAGGATCCGAGGTGCAGCTGGTGGAGTCCGGAGGAGGAGTGGTGAGGCCTGGAGGCTCCCTGAGGCTGAGCTGTGCTGCCTCCGGCTTCACCTTCGACGACTACGGCATGTCCTGGGTGAGGCAGGCTCCTGGAAAGGGCCTGGAGTGGGTGTCCGGCATCAACTGGAACGGCGGATCCACCGGCTACGCCGATTCCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACTCCCTGTACCTGCAGATGAACTCCCTGAGGGCCGAGGACACCGCCGTGTACTACTGCGCCAGGGGCAGGTCCCTGCTGTTCGACTACTGGGGACAGGGCACCCTGGTGACCGTGTCCAGGATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGGCAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC(SEQ ID NO:132)。
示例性多链嵌合多肽-G型
在本文所描述的多链嵌合多肽中的任一种的一些实施例中,第一靶标结合结构域和第二靶标结合结构域各自独立地特异性结合到TGFβ(例如,人TGFβRII受体)、CD16(例如,抗CD16 scFv)或IL-21(例如,可溶性人IL-21)的受体。在本文所描述的这些多链嵌合多肽的一些实施例中,第一嵌合多肽进一步包括另外的靶标结合结构域。在本文所描述的这些多链嵌合多肽的一些实施例中,第二嵌合多肽进一步包括另外的靶标结合结构域。在本文所描述的这些多链嵌合多肽的一些实施例中,另外的靶标结合结构域特异性结合到CD16或IL-21的受体。
在这些多链嵌合多肽的一些实例中,第一靶标结合结构域和可溶性组织因子结构域在第一嵌合多肽中彼此直接邻接。在这些多链嵌合多肽的一些实例中,第一嵌合多肽进一步包含第一嵌合多肽中的第一靶标结合结构域与可溶性组织因子结构域之间的接头序列(例如,本文所描述的示例性接头中的任一种)。
在这些多链嵌合多肽的一些实施例中,可溶性组织因子结构域和一对亲和结构域中的第一结构域在第一嵌合多肽中彼此直接邻接。在这些多链嵌合多肽的一些实施例中,第一嵌合多肽进一步包括第一嵌合多肽中的可溶性组织因子结构域与一对亲和结构域中的第一结构域之间的接头序列(例如,本文所描述的示例性接头中的任一种)。
在这些多链嵌合多肽的一些实施例中,一对亲和结构域中的第二结构域和第二靶标结合结构域在第二嵌合多肽中彼此直接邻接。在这些多链嵌合多肽的一些实施例中,第二嵌合多肽进一步包括第二嵌合多肽中的一对亲和结构域中的第二结构域与第二靶标结合结构域之间的接头序列(例如,本文所描述的示例性接头中的任一种)。
在一些实施例中,第二嵌合多肽在第二嵌合多肽的N端或C端进一步包含一个或多个另外的靶标结合结构域。
在这些多链嵌合多肽的一些实施例中,另外的靶标结合结构域和一对亲和结构域中的第二结构域在第二嵌合多肽中彼此直接邻接。在这些多链嵌合多肽的一些实施例中,第二嵌合多肽进一步包括第二嵌合多肽中的一对亲和结构域中的第二结构域与另外的靶标结合结构域之间的接头序列(例如,本文所描述的示例性接头中的任一种)。
在这些多链嵌合多肽的一些实施例中,另外的靶标结合结构域和第二靶标结合结构域在第二嵌合多肽中直接彼此邻接。在这些多链嵌合多肽的一些实施例中,第二嵌合多肽进一步包括第二嵌合多肽中的第二靶标结合结构域与另外的靶标结合结构域之间的接头序列(例如,本文所描述的示例性接头中的任一种)。
在这些多链嵌合多肽的一些实施例中,可溶性组织因子结构域可为本文所描述的示例性可溶性组织因子结构域中的任一种。在这些多链嵌合多肽的一些实施例中,所述一对亲和结构域可为本文所描述的示例性亲和结构域对中的任一种。
在这些多链嵌合多肽的一些实施例中,第一靶标结合结构域、第二靶标结合结构域和另外的抗原结合结构域中的一个或多个是激动性抗原结合结构域。在这些多链嵌合多肽的一些实施例中,第一靶标结合结构域、第二靶标结合结构域和另外的抗原结合结构域各自是激动性抗原结合结构域。在这些多链嵌合多肽的一些实施例中,抗原结合结构域包括scFv或单结构域抗体。
在本文所描述的多链嵌合多肽中的任一种的一些实施例中,第一靶标结合结构域和第二靶标结合结构域各自独立地特异性结合到TGF-β、CD16或IL-21的受体。在本文所描述的多链嵌合多肽中的任一种的一些实施例中,第一靶标结合结构域特异性结合到TGF-β,并且第二靶标结合结构域特异性结合到CD16或IL-21的受体。在本文所描述的多链嵌合多肽中的任一种的一些实施例中,第一靶标结合结构域是可溶性TGF-β受体。在本文所描述的多链嵌合多肽中的任一种的一些实施例中,可溶性TGF-β受体是可溶性TGFβRII受体。在本文所描述的多链嵌合多肽中的任一种的一些实施例中,第二靶标结合结构域特异性结合到CD16。在本文所描述的多链嵌合多肽中的任一种的一些实施例中,第二抗原结合结构域包括特异性结合到CD16的抗原结合结构域。在本文所描述的多链嵌合多肽中的任一种的一些实施例中,第二抗原结合结构域包括特异性结合到CD16的scFv。在本文所描述的多链嵌合多肽中的任一种的一些实施例中,第二靶标结合结构域特异性结合到IL-21的受体。在本文所描述的多链嵌合多肽中的任一种的一些实施例中,第二靶标结合结构域包括可溶性IL-21。在本文所描述的多链嵌合多肽中的任一种的一些实施例中,第二靶标结合结构域包括可溶性人IL-21。在本文所描述的多链嵌合多肽中的任一种的一些实施例中,第二嵌合多肽进一步包括特异性结合到IL-21的受体的另外的靶标结合结构域。在本文所描述的多链嵌合多肽中的任一种的一些实施例中,另外的靶标结合结构域包括可溶性IL-21。在本文所描述的多链嵌合多肽中的任一种的一些实施例中,可溶性IL-21是可溶性人IL-21。在本文所描述的多链嵌合多肽中的任一种的一些实施例中,第二嵌合多肽进一步包括特异性结合到CD16的另外的靶标结合结构域。
在这些多链嵌合多肽的一些实施例中,第一靶标结合结构域、第二靶标结合结构域和一个或多个另外的靶标结合结构域中的两个或更多个特异性结合到相同的抗原。在一些实施例中,第一靶标结合结构域、第二靶标结合结构域和一个或多个另外的靶标结合结构域中的两个或更多个特异性结合到相同的表位。在一些实施例中,第一靶标结合结构域、第二靶标结合结构域和一个或多个另外的靶标结合结构域中的两个或更多个包含相同的氨基酸序列。
在这些多链嵌合多肽的一些实施例中,第一靶标结合结构域包括TGFβRII受体(例如,可溶性人TGFβRII受体)。在这些多链嵌合多肽的一些实施例中,可溶性人TGFRβRII包括可溶性人TGFRβRII的第一序列和可溶性人TGFRβRII的第二序列。在这些多链嵌合多肽的一些实施例中,可溶性人TGFRβRII包括安置于可溶性人TGFRβRII的第一序列与可溶性人TGFRβRII的第二序列之间的接头。在这些多链嵌合多肽的一些实例中,接头包括序列GGGGSGGGGSGGGGS(SEQ ID NO:7)。
在这些多链嵌合多肽的一些实施例中,可溶性人TGFRβRII受体的第一序列包含与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD(SEQ IDNO:80)。
在这些多链嵌合多肽的一些实施例中,可溶性人TGFRβRII受体的第二序列包含与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD(SEQ IDNO:81)。
在这些多链嵌合多肽的一些实施例中,可溶性人TGFRβRII受体的第一序列由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGAT(SEQ ID NO:82)。
在这些多链嵌合多肽的一些实施例中,可溶性人TGFRβRII受体的第二序列由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
ATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC(SEQ ID NO:83)。
在这些多链嵌合多肽的一些实施例中,可溶性TGF-β受体包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD(SEQ IDNO:85)。
在这些多链嵌合多肽的一些实施例中,可溶性人TGFβRII受体由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC(SEQ ID NO:84)。
在这些多链嵌合多肽的一些实施例中,可溶性人IL-21的序列包含与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS(SEQ ID NO:78)。
在这些多链嵌合多肽的一些实施例中,可溶性人IL-21由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
CAAGGTCAAGATCGCCACATGATTAGAATGCGTCAACTTATAGATATTGTTGATCAGCTGAAAAATTATGTGAATGACTTGGTCCCTGAATTTCTGCCAGCTCCAGAAGATGTAGAGACAAACTGTGAGTGGTCAGCTTTTTCCTGTTTTCAGAAGGCCCAACTAAAGTCAGCAAATACAGGAAACAATGAAAGGATAATCAATGTATCAATTAAAAAGCTGAAGAGGAAACCACCTTCCACAAATGCAGGGAGAAGACAGAAACACAGACTAACATGCCCTTCATGTGATTCTTATGAGAAAAAACCACCCAAAGAATTCCTAGAAAGATTCAAATCACTTCTCCAAAAGATGATTCATCAGCATCTGTCCTCTAGAACACACGGAAGTGAAGATTCC(SEQ ID NO:94)。
在这些多链嵌合多肽的一些实施例中,可溶性人IL-21由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC(SEQ ID NO:79)。
在这些多链嵌合多肽的一些实施例中,特异性结合到CD16的scFv包括轻链可变结构域,所述轻链可变结构域包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
SELTQDPAVSVALGQTVRITCQGDSLRSYYASWYQQKPGQAPVLVIYGKNNRPSGIPDRFSGSSSGNTASLTITGAQAEDEADYYCNSRDSSGNHVVFGGGTKLTVGH(SEQ ID NO:112)。
在这些多链嵌合多肽的一些实施例中,特异性结合到CD16的scFv由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的轻链可变结构域序列编码:
TCCGAGCTGACCCAGGACCCTGCTGTGTCCGTGGCTCTGGGCCAGACCGTGAGGATCACCTGCCAGGGCGACTCCCTGAGGTCCTACTACGCCTCCTGGTACCAGCAGAAGCCCGGCCAGGCTCCTGTGCTGGTGATCTACGGCAAGAACAACAGGCCCTCCGGCATCCCTGACAGGTTCTCCGGATCCTCCTCCGGCAACACCGCCTCCCTGACCATCACAGGCGCTCAGGCCGAGGACGAGGCTGACTACTACTGCAACTCCAGGGACTCCTCCGGCAACCATGTGGTGTTCGGCGGCGGCACCAAGCTGACCGTGGGCCAT(SEQ ID NO:113)。
在这些多链嵌合多肽的一些实施例中,特异性结合到CD16的scFv包括重链可变结构域,所述重链可变结构域包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
EVQLVESGGGVVRPGGSLRLSCAASGFTFDDYGMSWVRQAPGKGLEWVSGINWNGGSTGYADSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARGRSLLFDYWGQGTLVTVSR(SEQ ID NO:114)。
在这些多链嵌合多肽的一些实施例中,特异性结合到CD16的scFv由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的重链可变结构域序列编码:
GAGGTGCAGCTGGTGGAGTCCGGAGGAGGAGTGGTGAGGCCTGGAGGCTCCCTGAGGCTGAGCTGTGCTGCCTCCGGCTTCACCTTCGACGACTACGGCATGTCCTGGGTGAGGCAGGCTCCTGGAAAGGGCCTGGAGTGGGTGTCCGGCATCAACTGGAACGGCGGATCCACCGGCTACGCCGATTCCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACTCCCTGTACCTGCAGATGAACTCCCTGAGGGCCGAGGACACCGCCGTGTACTACTGCGCCAGGGGCAGGTCCCTGCTGTTCGACTACTGGGGACAGGGCACCCTGGTGACCGTGTCCAGG(SEQ ID NO:115)。
在一些实施例中,第一嵌合多肽可包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS(SEQ ID NO:133)。
在一些实施例中,第一嵌合多肽由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC(SEQ ID NO:134)。
在一些实施例中,第一嵌合多肽可包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
MKWVTFISLLFLFSSAYSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS(SEQ ID NO:135)。
在一些实施例中,第一嵌合多肽由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC(SEQ ID NO:136)。
在一些实施例中,第二嵌合多肽可包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
SELTQDPAVSVALGQTVRITCQGDSLRSYYASWYQQKPGQAPVLVIYGKNNRPSGIPDRFSGSSSGNTASLTITGAQAEDEADYYCNSRDSSGNHVVFGGGTKLTVGHGGGGSGGGGSGGGGSEVQLVESGGGVVRPGGSLRLSCAASGFTFDDYGMSWVRQAPGKGLEWVSGINWNGGSTGYADSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARGRSLLFDYWGQGTLVTVSRITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIRQGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS(SEQ ID NO:137)。
在一些实施例中,第二嵌合多肽由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
TCCGAGCTGACCCAGGACCCTGCTGTGTCCGTGGCTCTGGGCCAGACCGTGAGGATCACCTGCCAGGGCGACTCCCTGAGGTCCTACTACGCCTCCTGGTACCAGCAGAAGCCCGGCCAGGCTCCTGTGCTGGTGATCTACGGCAAGAACAACAGGCCCTCCGGCATCCCTGACAGGTTCTCCGGATCCTCCTCCGGCAACACCGCCTCCCTGACCATCACAGGCGCTCAGGCCGAGGACGAGGCTGACTACTACTGCAACTCCAGGGACTCCTCCGGCAACCATGTGGTGTTCGGCGGCGGCACCAAGCTGACCGTGGGCCATGGCGGCGGCGGCTCCGGAGGCGGCGGCAGCGGCGGAGGAGGATCCGAGGTGCAGCTGGTGGAGTCCGGAGGAGGAGTGGTGAGGCCTGGAGGCTCCCTGAGGCTGAGCTGTGCTGCCTCCGGCTTCACCTTCGACGACTACGGCATGTCCTGGGTGAGGCAGGCTCCTGGAAAGGGCCTGGAGTGGGTGTCCGGCATCAACTGGAACGGCGGATCCACCGGCTACGCCGATTCCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACTCCCTGTACCTGCAGATGAACTCCCTGAGGGCCGAGGACACCGCCGTGTACTACTGCGCCAGGGGCAGGTCCCTGCTGTTCGACTACTGGGGACAGGGCACCCTGGTGACCGTGTCCAGGATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGGCAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC(SEQ ID NO:138)。
在一些实施例中,第二嵌合多肽可包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
MKWVTFISLLFLFSSAYSSELTQDPAVSVALGQTVRITCQGDSLRSYYASWYQQKPGQAPVLVIYGKNNRPSGIPDRFSGSSSGNTASLTITGAQAEDEADYYCNSRDSSGNHVVFGGGTKLTVGHGGGGSGGGGSGGGGSEVQLVESGGGVVRPGGSLRLSCAASGFTFDDYGMSWVRQAPGKGLEWVSGINWNGGSTGYADSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARGRSLLFDYWGQGTLVTVSRITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIRQGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS(SEQ ID NO:139)。
在一些实施例中,第二嵌合多肽由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCTCCGAGCTGACCCAGGACCCTGCTGTGTCCGTGGCTCTGGGCCAGACCGTGAGGATCACCTGCCAGGGCGACTCCCTGAGGTCCTACTACGCCTCCTGGTACCAGCAGAAGCCCGGCCAGGCTCCTGTGCTGGTGATCTACGGCAAGAACAACAGGCCCTCCGGCATCCCTGACAGGTTCTCCGGATCCTCCTCCGGCAACACCGCCTCCCTGACCATCACAGGCGCTCAGGCCGAGGACGAGGCTGACTACTACTGCAACTCCAGGGACTCCTCCGGCAACCATGTGGTGTTCGGCGGCGGCACCAAGCTGACCGTGGGCCATGGCGGCGGCGGCTCCGGAGGCGGCGGCAGCGGCGGAGGAGGATCCGAGGTGCAGCTGGTGGAGTCCGGAGGAGGAGTGGTGAGGCCTGGAGGCTCCCTGAGGCTGAGCTGTGCTGCCTCCGGCTTCACCTTCGACGACTACGGCATGTCCTGGGTGAGGCAGGCTCCTGGAAAGGGCCTGGAGTGGGTGTCCGGCATCAACTGGAACGGCGGATCCACCGGCTACGCCGATTCCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACTCCCTGTACCTGCAGATGAACTCCCTGAGGGCCGAGGACACCGCCGTGTACTACTGCGCCAGGGGCAGGTCCCTGCTGTTCGACTACTGGGGACAGGGCACCCTGGTGACCGTGTCCAGGATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGGCAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC(SEQ ID NO:140)。
示例性多链嵌合多肽-H型
在本文所描述的多链嵌合多肽中的任一种的一些实施例中,第一靶标结合结构域和第二靶标结合结构域各自独立地特异性结合到IL-7的受体。在这些多链嵌合多肽的一些实例中,第一靶标结合结构域和可溶性组织因子结构域在第一嵌合多肽中彼此直接邻接。在这些多链嵌合多肽的一些实例中,第一嵌合多肽进一步包含第一嵌合多肽中的第一靶标结合结构域与可溶性组织因子结构域之间的接头序列(例如,本文所描述的示例性接头中的任一种)。
在这些多链嵌合多肽的一些实施例中,可溶性组织因子结构域和一对亲和结构域中的第一结构域在第一嵌合多肽中彼此直接邻接。在这些多链嵌合多肽的一些实施例中,第一嵌合多肽进一步包括第一嵌合多肽中的可溶性组织因子结构域与一对亲和结构域中的第一结构域之间的接头序列(例如,本文所描述的示例性接头中的任一种)。
在这些多链嵌合多肽的一些实施例中,一对亲和结构域中的第二结构域和第二靶标结合结构域在第二嵌合多肽中彼此直接邻接。在这些多链嵌合多肽的一些实施例中,第二嵌合多肽进一步包括第二嵌合多肽中的一对亲和结构域中的第二结构域与第二靶标结合结构域之间的接头序列(例如,本文所描述的示例性接头中的任一种)。
在这些多链嵌合多肽的一些实施例中,可溶性组织因子结构域可为本文所描述的示例性可溶性组织因子结构域中的任一种。在这些多链嵌合多肽的一些实施例中,所述一对亲和结构域可为本文所描述的示例性亲和结构域对中的任一种。
在这些多链嵌合多肽的一些实施例中,第一靶标结合结构域和第二靶标结合结构域各自独立地特异性结合到IL-7的受体。在这些多链嵌合多肽的一些实施例中,第一靶标结合结构域和第二靶标结合结构域特异性结合到相同的表位。在这些多链嵌合多肽的一些实施例中,第一靶标结合结构域和第二靶标结合结构域包括相同的氨基酸序列。
在这些多链嵌合多肽的一些实施例中,第一靶标结合结构域和第二靶标结合结构域包括可溶性IL-7(例如,可溶性人IL-7)。在这些多链嵌合多肽的一些实施例中,可溶性人IL-7包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWNKILMGTKEH(SEQ ID NO:11)。
在这些多链嵌合多肽的一些实施例中,可溶性人IL-7由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
GATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGTTCAACTTCTTCAAGCGGCACATCTGCGACGCCAACAAGGAGGGCATGTTCCTGTTCAGGGCCGCCAGGAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGGTGAAGGGCCGGAAACCTGCTGCTCTGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGAACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCAT(SEQ ID NO:95)。
在一些实施例中,第一嵌合多肽可包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWNKILMGTKEHSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS(SEQ ID NO:141)。
在一些实施例中,第一嵌合多肽由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
GATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGTTCAACTTCTTCAAGCGGCACATCTGCGACGCCAACAAGGAGGGCATGTTCCTGTTCAGGGCCGCCAGGAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGGTGAAGGGCCGGAAACCTGCTGCTCTGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGAACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCATAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC(SEQ ID NO:142)。
在一些实施例中,第一嵌合多肽可包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
MKWVTFISLLFLFSSAYSDCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWNKILMGTKEHSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS(SEQ ID NO:143)。
在一些实施例中,第一嵌合多肽由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCGATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGTTCAACTTCTTCAAGCGGCACATCTGCGACGCCAACAAGGAGGGCATGTTCCTGTTCAGGGCCGCCAGGAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGGTGAAGGGCCGGAAACCTGCTGCTCTGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGAACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCATAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC(SEQID NO:144)。
在一些实施例中,第二嵌合多肽可包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWNKILMGTKEHITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR(SEQID NO:145)。
在一些实施例中,第二嵌合多肽由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
GATTGTGATATTGAAGGTAAAGATGGCAAACAATATGAGAGTGTTCTAATGGTCAGCATCGATCAATTATTGGACAGCATGAAAGAAATTGGTAGCAATTGCCTGAATAATGAATTTAACTTTTTTAAAAGACATATCTGTGATGCTAATAAGGAAGGTATGTTTTTATTCCGTGCTGCTCGCAAGTTGAGGCAATTTCTTAAAATGAATAGCACTGGTGATTTTGATCTCCACTTATTAAAAGTTTCAGAAGGCACAACAATACTGTTGAACTGCACTGGCCAGGTTAAAGGAAGAAAACCAGCTGCCCTGGGTGAAGCCCAACCAACAAAGAGTTTGGAAGAAAATAAATCTTTAAAGGAACAGAAAAAACTGAATGACTTGTGTTTCCTAAAGAGACTATTACAAGAGATAAAAACTTGTTGGAATAAAATTTTGATGGGCACTAAAGAACACATCACGTGCCCTCCCCCCATGTCCGTGGAACACGCAGACATCTGGGTCAAGAGCTACAGCTTGTACTCCAGGGAGCGGTACATTTGTAACTCTGGTTTCAAGCGTAAAGCCGGCACGTCCAGCCTGACGGAGTGCGTGTTGAACAAGGCCACGAATGTCGCCCACTGGACAACCCCCAGTCTCAAATGCATTAGA(SEQ ID NO:146)。
在一些实施例中,第二嵌合多肽可包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
MKWVTFISLLFLFSSAYSDCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWNKILMGTKEHITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR(SEQ ID NO:147)。
在一些实施例中,第二嵌合多肽由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCGATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGTTCAACTTCTTCAAGCGGCACATCTGCGACGCCAACAAGGAGGGCATGTTCCTGTTCAGGGCCGCCAGGAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGGTGAAGGGCCGGAAACCTGCTGCTCTGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGAACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCATATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG(SEQ ID NO:148)。
示例性多链嵌合多肽-I型
在本文所描述的多链嵌合多肽中的任一种的一些实施例中,第一靶标结合结构域和第二靶标结合结构域各自独立地特异性结合到TGF-β。在这些多链嵌合多肽的一些实例中,第一靶标结合结构域和可溶性组织因子结构域在第一嵌合多肽中彼此直接邻接。在这些多链嵌合多肽的一些实例中,第一嵌合多肽进一步包含第一嵌合多肽中的第一靶标结合结构域与可溶性组织因子结构域之间的接头序列(例如,本文所描述的示例性接头中的任一种)。
在这些多链嵌合多肽的一些实施例中,可溶性组织因子结构域和一对亲和结构域中的第一结构域在第一嵌合多肽中彼此直接邻接。在这些多链嵌合多肽的一些实施例中,第一嵌合多肽进一步包括第一嵌合多肽中的可溶性组织因子结构域与一对亲和结构域中的第一结构域之间的接头序列(例如,本文所描述的示例性接头中的任一种)。
在这些多链嵌合多肽的一些实施例中,一对亲和结构域中的第二结构域和第二靶标结合结构域在第二嵌合多肽中彼此直接邻接。在这些多链嵌合多肽的一些实施例中,第二嵌合多肽进一步包括第二嵌合多肽中的一对亲和结构域中的第二结构域与第二靶标结合结构域之间的接头序列(例如,本文所描述的示例性接头中的任一种)。
在这些多链嵌合多肽的一些实施例中,可溶性组织因子结构域可为本文所描述的示例性可溶性组织因子结构域中的任一种。在这些多链嵌合多肽的一些实施例中,所述一对亲和结构域可为本文所描述的示例性亲和结构域对中的任一种。
在这些多链嵌合多肽的一些实施例中,第一靶标结合结构域和第二靶标结合结构域各自独立地特异性结合到TGF-β。在这些多链嵌合多肽的一些实施例中,第一靶标结合结构域和第二靶标结合结构域特异性结合到相同的表位。在这些多链嵌合多肽的一些实施例中,第一靶标结合结构域和第二靶标结合结构域包括相同的氨基酸序列。
在这些多链嵌合多肽的一些实施例中,第一靶标结合结构域和第二靶标结合结构域是可溶性TGF-β受体(例如,可溶性TGFβRII受体,例如可溶性人TGFβRII)。在这些多链嵌合多肽的一些实施例中,可溶性人TGFRβRII包括可溶性人TGFRβRII的第一序列和可溶性人TGFRβRII的第二序列。在这些多链嵌合多肽的一些实施例中,可溶性人TGFRβRII包括安置于可溶性人TGFRβRII的第一序列与可溶性人TGFRβRII的第二序列之间的接头。在这些多链嵌合多肽的一些实例中,接头包括序列GGGGSGGGGSGGGGS(SEQ ID NO:7)。
在这些多链嵌合多肽的一些实施例中,可溶性人TGFRβRII受体的第一序列包含与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD(SEQ IDNO:80)。
在这些多链嵌合多肽的一些实施例中,可溶性人TGFRβRII受体的第二序列包含与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
c(SEQ ID NO:81)。
在这些多链嵌合多肽的一些实施例中,可溶性人TGFRβRII受体的第一序列由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGAT(SEQ ID NO:82)。
在这些多链嵌合多肽的一些实施例中,可溶性人TGFRβRII受体的第二序列由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
ATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC(SEQ ID NO:83)。
在这些多链嵌合多肽的一些实施例中,可溶性TGF-β受体包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD(SEQ IDNO:85)。
在这些多链嵌合多肽的一些实施例中,可溶性TGF-β受体由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC(SEQ ID NO:84)。
在一些实施例中,第一嵌合多肽可包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS(SEQ ID NO:149)。
在一些实施例中,第一嵌合多肽由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC(SEQ ID NO:150)。
在一些实施例中,第一嵌合多肽可包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
MKWVTFISLLFLFSSAYSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS(SEQ ID NO:151)。
在一些实施例中,第一嵌合多肽由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC(SEQ ID NO:152)。
在一些实施例中,第二嵌合多肽可包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR(SEQ ID NO:153)。
在一些实施例中,第二嵌合多肽由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG(SEQ ID NO:154)。
在一些实施例中,第二嵌合多肽可包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
MKWVTFISLLFLFSSAYSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR(SEQ ID NO:155)。
在一些实施例中,第二嵌合多肽由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG(SEQ ID NO:156)。
示例性多链嵌合多肽-J型
在本文所描述的多链嵌合多肽中的任一种的一些实施例中,第一靶标结合结构域和第二靶标结合结构域各自独立地特异性结合到IL-7的受体、IL-21的受体或CD137L的受体。在本文所描述的这些多链嵌合多肽的一些实施例中,第二嵌合多肽进一步包括另外的靶标结合结构域。在本文所描述的这些多链嵌合多肽的一些实施例中,另外的靶标结合结构域特异性结合到IL-21(例如,可溶性IL-21,例如可溶性人IL-21)的受体或CD137L(例如,可溶性CD137L,例如可溶性人CD137L)的受体。
在这些多链嵌合多肽的一些实例中,第一靶标结合结构域和可溶性组织因子结构域在第一嵌合多肽中彼此直接邻接。在这些多链嵌合多肽的一些实例中,第一嵌合多肽进一步包含第一嵌合多肽中的第一靶标结合结构域与可溶性组织因子结构域之间的接头序列(例如,本文所描述的示例性接头中的任一种)。
在这些多链嵌合多肽的一些实施例中,可溶性组织因子结构域和一对亲和结构域中的第一结构域在第一嵌合多肽中彼此直接邻接。在这些多链嵌合多肽的一些实施例中,第一嵌合多肽进一步包括第一嵌合多肽中的可溶性组织因子结构域与一对亲和结构域中的第一结构域之间的接头序列(例如,本文所描述的示例性接头中的任一种)。
在这些多链嵌合多肽的一些实施例中,一对亲和结构域中的第二结构域和第二靶标结合结构域在第二嵌合多肽中彼此直接邻接。在这些多链嵌合多肽的一些实施例中,第二嵌合多肽进一步包括第二嵌合多肽中的一对亲和结构域中的第二结构域与第二靶标结合结构域之间的接头序列(例如,本文所描述的示例性接头中的任一种)。
在一些实施例中,第二嵌合多肽在第二嵌合多肽的N端或C端进一步包含一个或多个另外的靶标结合结构域。
在这些多链嵌合多肽的一些实施例中,另外的靶标结合结构域和一对亲和结构域中的第二结构域在第二嵌合多肽中彼此直接邻接。在这些多链嵌合多肽的一些实施例中,第二嵌合多肽进一步包括第二嵌合多肽中的一对亲和结构域中的第二结构域与另外的靶标结合结构域之间的接头序列(例如,本文所描述的示例性接头中的任一种)。
在这些多链嵌合多肽的一些实施例中,另外的靶标结合结构域和第二靶标结合结构域在第二嵌合多肽中直接彼此邻接。在这些多链嵌合多肽的一些实施例中,第二嵌合多肽进一步包括第二嵌合多肽中的第二靶标结合结构域与另外的靶标结合结构域之间的接头序列(例如,本文所描述的示例性接头中的任一种)。
在这些多链嵌合多肽的一些实施例中,可溶性组织因子结构域可为本文所描述的示例性可溶性组织因子结构域中的任一种。在这些多链嵌合多肽的一些实施例中,所述一对亲和结构域可为本文所描述的示例性亲和结构域对中的任一种。
在一些实施例中,第二嵌合多肽可包括另外的靶标结合结构域。在一些实施例中,另外的靶标结合结构域和
在这些多链嵌合多肽的一些实施例中,第一靶标结合结构域、第二靶标结合结构域和另外的靶标结合结构域中的一个或多个是激动性抗原结合结构域。在这些多链嵌合多肽的一些实施例中,第一靶标结合结构域、第二靶标结合结构域和另外的靶标结合结构域各自是激动性抗原结合结构域。在这些多链嵌合多肽的一些实施例中,抗原结合结构域包括scFv或单结构域抗体。
在这些多链嵌合多肽的一些实施例中,第一靶标结合结构域特异性结合到IL-7的受体,并且第二靶标结合结构域特异性结合到IL-21的受体或CD137L的受体。在一些实施例中,另外的靶标结合结构域特异性结合到IL-21的受体或CD137L的受体。
在这些多链嵌合多肽的一些实施例中,第一靶标结合结构域是可溶性IL-7(例如,可溶性人IL-7)。在这些多链嵌合多肽的一些实施例中,可溶性人IL-7包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWNKILMGTKEH(SEQ ID NO:11)。
在这些多链嵌合多肽的一些实施例中,可溶性人IL-7由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
GATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGTTCAACTTCTTCAAGCGGCACATCTGCGACGCCAACAAGGAGGGCATGTTCCTGTTCAGGGCCGCCAGGAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGGTGAAGGGCCGGAAACCTGCTGCTCTGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGAACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCAT(SEQ ID NO:124)。
在这些多链嵌合多肽的一些实施例中,第二靶标结合结构域或另外的靶标结合结构域特异性结合到IL-21的受体。在这些多链嵌合多肽的一些实施例中,第二靶标结合结构域或另外的靶标结合结构域是可溶性IL-21(例如,可溶性人IL-21)。
在这些多链嵌合多肽的一些实施例中,可溶性人IL-21包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS(SEQ ID NO:78)。
在这些多链嵌合多肽的一些实施例中,可溶性人IL-21由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC(SEQ ID NO:79)。
在这些多链嵌合多肽的一些实施例中,第二靶标结合结构域特异性结合到CD137L的受体。在这些多链嵌合多肽的一些实施例中,第二嵌合多肽进一步包含特异性结合到CD137L的受体的另外的靶标结合结构域。在这些多链嵌合多肽的一些实施例中,第二靶标结合结构域和/或另外的靶标结合结构域是可溶性CD137L(例如,可溶性人CD137L)。
在这些多链嵌合多肽的一些实施例中,可溶性人CD137L包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
REGPELSPDDPAGLLDLRQGMFAQLVAQNVLLIDGPLSWYSDPGLAGVSLTGGLSYKEDTKELVVAKAGVYYVFFQLELRRVVAGEGSGSVSLALHLQPLRSAAGAAALALTVDLPPASSEARNSAFGFQGRLLHLSAGQRLGVHLHTEARARHAWQLTQGATVLGLFRVTPEIPAGLPSPRSE(SEQ ID NO:157)。
在这些多链嵌合多肽的一些实施例中,可溶性人CD137L由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
CGCGAGGGTCCCGAGCTTTCGCCCGACGATCCCGCCGGCCTCTTGGACCTGCGGCAGGGCATGTTTGCGCAGCTGGTGGCCCAAAATGTTCTGCTGATCGATGGGCCCCTGAGCTGGTACAGTGACCCAGGCCTGGCAGGCGTGTCCCTGACGGGGGGCCTGAGCTACAAAGAGGACACGAAGGAGCTGGTGGTGGCCAAGGCTGGAGTCTACTATGTCTTCTTTCAACTAGAGCTGCGGCGCGTGGTGGCCGGCGAGGGCTCAGGCTCCGTTTCACTTGCGCTGCACCTGCAGCCACTGCGCTCTGCTGCTGGGGCCGCCGCCCTGGCTTTGACCGTGGACCTGCCACCCGCCTCCTCCGAGGCTCGGAACTCGGCCTTCGGTTTCCAGGGCCGCTTGCTGCACCTGAGTGCCGGCCAGCGCCTGGGCGTCCATCTTCACACTGAGGCCAGGGCACGCCATGCCTGGCAGCTTACCCAGGGCGCCACAGTCTTGGGACTCTTCCGGGTGACCCCCGAAATCCCAGCCGGACTCCCTTCACCGAGGTCGGAA(SEQ ID NO:158)。
在这些多链嵌合多肽的一些实施例中,可溶性人CD137L包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
DPAGLLDLRQGMFAQLVAQNVLLIDGPLSWYSDPGLAGVSLTGGLSYKEDTKELVVAKAGVYYVFFQLELRRVVAGEGSGSVSLALHLQPLRSAAGAAALALTVDLPPASSEARNSAFGFQGRLLHLSAGQRLGVHLHTEARARHAWQLTQGATVLGLFRVTPEI(SEQ ID NO:159)。
在这些多链嵌合多肽的一些实施例中,可溶性人CD137L由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
GATCCCGCCGGCCTCTTGGACCTGCGGCAGGGCATGTTTGCGCAGCTGGTGGCCCAAAATGTTCTGCTGATCGATGGGCCCCTGAGCTGGTACAGTGACCCAGGCCTGGCAGGCGTGTCCCTGACGGGGGGCCTGAGCTACAAAGAGGACACGAAGGAGCTGGTGGTGGCCAAGGCTGGAGTCTACTATGTCTTCTTTCAACTAGAGCTGCGGCGCGTGGTGGCCGGCGAGGGCTCAGGCTCCGTTTCACTTGCGCTGCACCTGCAGCCACTGCGCTCTGCTGCTGGGGCCGCCGCCCTGGCTTTGACCGTGGACCTGCCACCCGCCTCCTCCGAGGCTCGGAACTCGGCCTTCGGTTTCCAGGGCCGCTTGCTGCACCTGAGTGCCGGCCAGCGCCTGGGCGTCCATCTTCACACTGAGGCCAGGGCACGCCATGCCTGGCAGCTTACCCAGGGCGCCACAGTCTTGGGACTCTTCCGGGTGACCCCCGAAATC(SEQ ID NO:160)。
在一些实施例中,第一嵌合多肽可包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWNKILMGTKEHSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS(SEQ ID NO:161)。
在一些实施例中,第一嵌合多肽由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
GATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGTTCAACTTCTTCAAGCGGCACATCTGCGACGCCAACAAGGAGGGCATGTTCCTGTTCAGGGCCGCCAGGAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGGTGAAGGGCCGGAAACCTGCTGCTCTGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGAACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCATAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC(SEQ ID NO:162)。
在一些实施例中,第一嵌合多肽可包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
MKWVTFISLLFLFSSAYSDCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWNKILMGTKEHSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS(SEQ ID NO:163)。
在一些实施例中,第一嵌合多肽由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCGATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGTTCAACTTCTTCAAGCGGCACATCTGCGACGCCAACAAGGAGGGCATGTTCCTGTTCAGGGCCGCCAGGAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGGTGAAGGGCCGGAAACCTGCTGCTCTGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGAACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCATAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC(SEQID NO:164)。
在一些实施例中,第二嵌合多肽可包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDSITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIRGGGGSGGGGSGGGGSREGPELSPDDPAGLLDLRQGMFAQLVAQNVLLIDGPLSWYSDPGLAGVSLTGGLSYKEDTKELVVAKAGVYYVFFQLELRRVVAGEGSGSVSLALHLQPLRSAAGAAALALTVDLPPASSEARNSAFGFQGRLLHLSAGQRLGVHLHTEARARHAWQLTQGATVLGLFRVTPEIPAGLPSPRSE(SEQ ID NO:165)。
在一些实施例中,第二嵌合多肽由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCCATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGGGGCGGTGGAGGATCCGGAGGAGGTGGCTCCGGCGGCGGAGGATCTCGCGAGGGTCCCGAGCTTTCGCCCGACGATCCCGCCGGCCTCTTGGACCTGCGGCAGGGCATGTTTGCGCAGCTGGTGGCCCAAAATGTTCTGCTGATCGATGGGCCCCTGAGCTGGTACAGTGACCCAGGCCTGGCAGGCGTGTCCCTGACGGGGGGCCTGAGCTACAAAGAGGACACGAAGGAGCTGGTGGTGGCCAAGGCTGGAGTCTACTATGTCTTCTTTCAACTAGAGCTGCGGCGCGTGGTGGCCGGCGAGGGCTCAGGCTCCGTTTCACTTGCGCTGCACCTGCAGCCACTGCGCTCTGCTGCTGGGGCCGCCGCCCTGGCTTTGACCGTGGACCTGCCACCCGCCTCCTCCGAGGCTCGGAACTCGGCCTTCGGTTTCCAGGGCCGCTTGCTGCACCTGAGTGCCGGCCAGCGCCTGGGCGTCCATCTTCACACTGAGGCCAGGGCACGCCATGCCTGGCAGCTTACCCAGGGCGCCACAGTCTTGGGACTCTTCCGGGTGACCCCCGAAATCCCAGCCGGACTCCCTTCACCGAGGTCGGAA(SEQ ID NO:166)。
在一些实施例中,第二嵌合多肽可包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
MKWVTFISLLFLFSSAYSQGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDSITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIRGGGGSGGGGSGGGGSREGPELSPDDPAGLLDLRQGMFAQLVAQNVLLIDGPLSWYSDPGLAGVSLTGGLSYKEDTKELVVAKAGVYYVFFQLELRRVVAGEGSGSVSLALHLQPLRSAAGAAALALTVDLPPASSEARNSAFGFQGRLLHLSAGQRLGVHLHTEARARHAWQLTQGATVLGLFRVTPEIPAGLPSPRSE(SEQ ID NO:167)。
在一些实施例中,第二嵌合多肽由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCCAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCCATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGGGGCGGTGGAGGATCCGGAGGAGGTGGCTCCGGCGGCGGAGGATCTCGCGAGGGTCCCGAGCTTTCGCCCGACGATCCCGCCGGCCTCTTGGACCTGCGGCAGGGCATGTTTGCGCAGCTGGTGGCCCAAAATGTTCTGCTGATCGATGGGCCCCTGAGCTGGTACAGTGACCCAGGCCTGGCAGGCGTGTCCCTGACGGGGGGCCTGAGCTACAAAGAGGACACGAAGGAGCTGGTGGTGGCCAAGGCTGGAGTCTACTATGTCTTCTTTCAACTAGAGCTGCGGCGCGTGGTGGCCGGCGAGGGCTCAGGCTCCGTTTCACTTGCGCTGCACCTGCAGCCACTGCGCTCTGCTGCTGGGGCCGCCGCCCTGGCTTTGACCGTGGACCTGCCACCCGCCTCCTCCGAGGCTCGGAACTCGGCCTTCGGTTTCCAGGGCCGCTTGCTGCACCTGAGTGCCGGCCAGCGCCTGGGCGTCCATCTTCACACTGAGGCCAGGGCACGCCATGCCTGGCAGCTTACCCAGGGCGCCACAGTCTTGGGACTCTTCCGGGTGACCCCCGAAATCCCAGCCGGACTCCCTTCACCGAGGTCGGAA(SEQ ID NO:168)。
在一些实施例中,第二嵌合多肽可包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDSITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIRGGGGSGGGGSGGGGSDPAGLLDLRQGMFAQLVAQNVLLIDGPLSWYSDPGLAGVSLTGGLSYKEDTKELVVAKAGVYYVFFQLELRRVVAGEGSGSVSLALHLQPLRSAAGAAALALTVDLPPASSEARNSAFGFQGRLLHLSAGQRLGVHLHTEARARHAWQLTQGATVLGLFRVTPEI(SEQ ID NO:169)。
在一些实施例中,第二嵌合多肽由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCCATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGGGGCGGTGGAGGATCCGGAGGAGGTGGCTCCGGCGGCGGAGGATCTGATCCCGCCGGCCTCTTGGACCTGCGGCAGGGCATGTTTGCGCAGCTGGTGGCCCAAAATGTTCTGCTGATCGATGGGCCCCTGAGCTGGTACAGTGACCCAGGCCTGGCAGGCGTGTCCCTGACGGGGGGCCTGAGCTACAAAGAGGACACGAAGGAGCTGGTGGTGGCCAAGGCTGGAGTCTACTATGTCTTCTTTCAACTAGAGCTGCGGCGCGTGGTGGCCGGCGAGGGCTCAGGCTCCGTTTCACTTGCGCTGCACCTGCAGCCACTGCGCTCTGCTGCTGGGGCCGCCGCCCTGGCTTTGACCGTGGACCTGCCACCCGCCTCCTCCGAGGCTCGGAACTCGGCCTTCGGTTTCCAGGGCCGCTTGCTGCACCTGAGTGCCGGCCAGCGCCTGGGCGTCCATCTTCACACTGAGGCCAGGGCACGCCATGCCTGGCAGCTTACCCAGGGCGCCACAGTCTTGGGACTCTTCCGGGTGACCCCCGAAATC(SEQ ID NO:170)。
在一些实施例中,第二嵌合多肽可包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
MKWVTFISLLFLFSSAYSQGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDSITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIRGGGGSGGGGSGGGGSDPAGLLDLRQGMFAQLVAQNVLLIDGPLSWYSDPGLAGVSLTGGLSYKEDTKELVVAKAGVYYVFFQLELRRVVAGEGSGSVSLALHLQPLRSAAGAAALALTVDLPPASSEARNSAFGFQGRLLHLSAGQRLGVHLHTEARARHAWQLTQGATVLGLFRVTPEI(SEQ ID NO:171)。
在一些实施例中,第二嵌合多肽由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCCAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCCATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGGGGCGGTGGAGGATCCGGAGGAGGTGGCTCCGGCGGCGGAGGATCTGATCCCGCCGGCCTCTTGGACCTGCGGCAGGGCATGTTTGCGCAGCTGGTGGCCCAAAATGTTCTGCTGATCGATGGGCCCCTGAGCTGGTACAGTGACCCAGGCCTGGCAGGCGTGTCCCTGACGGGGGGCCTGAGCTACAAAGAGGACACGAAGGAGCTGGTGGTGGCCAAGGCTGGAGTCTACTATGTCTTCTTTCAACTAGAGCTGCGGCGCGTGGTGGCCGGCGAGGGCTCAGGCTCCGTTTCACTTGCGCTGCACCTGCAGCCACTGCGCTCTGCTGCTGGGGCCGCCGCCCTGGCTTTGACCGTGGACCTGCCACCCGCCTCCTCCGAGGCTCGGAACTCGGCCTTCGGTTTCCAGGGCCGCTTGCTGCACCTGAGTGCCGGCCAGCGCCTGGGCGTCCATCTTCACACTGAGGCCAGGGCACGCCATGCCTGGCAGCTTACCCAGGGCGCCACAGTCTTGGGACTCTTCCGGGTGACCCCCGAAATC(SEQ ID NO:172)。
示例性多链嵌合多肽-K型
在本文所描述的多链嵌合多肽中的任一种的一些实施例中,第一靶标结合结构域和第二靶标结合结构域各自独立地特异性结合到IL-7的受体或TGF-β。在这些多链嵌合多肽的一些实例中,第一靶标结合结构域和可溶性组织因子结构域在第一嵌合多肽中彼此直接邻接。在这些多链嵌合多肽的一些实例中,第一嵌合多肽进一步包含第一嵌合多肽中的第一靶标结合结构域与可溶性组织因子结构域之间的接头序列(例如,本文所描述的示例性接头中的任一种)。
在这些多链嵌合多肽的一些实施例中,可溶性组织因子结构域和一对亲和结构域中的第一结构域在第一嵌合多肽中彼此直接邻接。在这些多链嵌合多肽的一些实施例中,第一嵌合多肽进一步包括第一嵌合多肽中的可溶性组织因子结构域与一对亲和结构域中的第一结构域之间的接头序列(例如,本文所描述的示例性接头中的任一种)。
在这些多链嵌合多肽的一些实施例中,一对亲和结构域中的第二结构域和第二靶标结合结构域在第二嵌合多肽中彼此直接邻接。在这些多链嵌合多肽的一些实施例中,第二嵌合多肽进一步包括第二嵌合多肽中的一对亲和结构域中的第二结构域与第二靶标结合结构域之间的接头序列(例如,本文所描述的示例性接头中的任一种)。
在这些多链嵌合多肽的一些实施例中,可溶性组织因子结构域可为本文所描述的示例性可溶性组织因子结构域中的任一种。在这些多链嵌合多肽的一些实施例中,所述一对亲和结构域可为本文所描述的示例性亲和结构域对中的任一种。
在这些多链嵌合多肽的一些实施例中,第一靶标结合结构域特异性结合到IL-7的受体,并且第二靶标结合结构域特异性结合到TGF-β。在这些多链嵌合多肽的一些实施例中,第一靶标结合结构域特异性结合到TGF-β,并且第二靶标结合结构域特异性结合到IL-7的受体。
在这些多链嵌合多肽的一些实施例中,第一靶标结合结构域包括可溶性IL-7蛋白(例如,可溶性人IL-7蛋白)。在这些多链嵌合多肽的一些实施例中,可溶性人IL-7蛋白包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWNKILMGTKEH(SEQ ID NO:11)。
在这些多链嵌合多肽的一些实施例中,可溶性人IL-7由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
GATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGTTCAACTTCTTCAAGCGGCACATCTGCGACGCCAACAAGGAGGGCATGTTCCTGTTCAGGGCCGCCAGGAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGGTGAAGGGCCGGAAACCTGCTGCTCTGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGAACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCAT(SEQ ID NO:124)。
在这些多链嵌合多肽的一些实施例中,第二靶标结合结构域包含特异性结合到TGF-β的靶标结合结构域。在这些多链嵌合多肽的一些实施例中,第二靶标结合结构域是可溶性TGF-β受体(例如,可溶性TGFβRII受体,例如可溶性人TGFβRII受体)。在这些多链嵌合多肽的一些实施例中,可溶性人TGFRβRII包括可溶性人TGFRβRII的第一序列和可溶性人TGFRβRII的第二序列。在这些多链嵌合多肽的一些实施例中,可溶性人TGFRβRII包括安置于可溶性人TGFRβRII的第一序列与可溶性人TGFRβRII的第二序列之间的接头。在这些多链嵌合多肽的一些实例中,接头包括序列GGGGSGGGGSGGGGS(SEQ ID NO:7)。
在这些多链嵌合多肽的一些实施例中,可溶性人TGFRβRII受体的第一序列包含与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD(SEQ IDNO:80)。
在这些多链嵌合多肽的一些实施例中,可溶性人TGFRβRII受体的第二序列包含与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD(SEQ IDNO:81)。
在这些多链嵌合多肽的一些实施例中,可溶性人TGFRβRII受体的第一序列由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGAT(SEQ ID NO:82)。
在这些多链嵌合多肽的一些实施例中,可溶性人TGFRβRII受体的第二序列由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
ATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC(SEQ ID NO:83)。
在这些多链嵌合多肽的一些实施例中,可溶性TGF-β受体包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD(SEQ IDNO:85)。
在这些多链嵌合多肽的一些实施例中,可溶性TGF-β受体由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC(SEQ ID NO:84)。
在一些实施例中,第一嵌合多肽可包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWNKILMGTKEHSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS(SEQ ID NO:173)。
在一些实施例中,第一嵌合多肽由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
GATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGTTCAACTTCTTCAAGCGGCACATCTGCGACGCCAACAAGGAGGGCATGTTCCTGTTCAGGGCCGCCAGGAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGGTGAAGGGCCGGAAACCTGCTGCTCTGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGAACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCATAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC(SEQ ID NO:174)。
在一些实施例中,第一嵌合多肽可包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
MKWVTFISLLFLFSSAYSDCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWNKILMGTKEHSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS(SEQ ID NO:175)。
在一些实施例中,第一嵌合多肽由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCGATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGTTCAACTTCTTCAAGCGGCACATCTGCGACGCCAACAAGGAGGGCATGTTCCTGTTCAGGGCCGCCAGGAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGGTGAAGGGCCGGAAACCTGCTGCTCTGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGAACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCATAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC(SEQID NO:176)。
在一些实施例中,第二嵌合多肽可包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR(SEQ ID NO:177)。
在一些实施例中,第二嵌合多肽由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG(SEQ ID NO:178)。
在一些实施例中,第二嵌合多肽可包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
MKWVTFISLLFLFSSAYSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR(SEQ ID NO:179)。
在一些实施例中,第二嵌合多肽由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG(SEQ ID NO:180)。
示例性多链嵌合多肽-L型
在本文所描述的多链嵌合多肽中的任一种的一些实施例中,第一靶标结合结构域和第二靶标结合结构域各自独立地特异性结合到TGF-β、IL-21的受体或CD137L的受体。在本文所描述的这些多链嵌合多肽的一些实施例中,第二嵌合多肽进一步包括另外的靶标结合结构域。在本文所描述的这些多链嵌合多肽的一些实施例中,另外的靶标结合结构域特异性结合到IL-21(例如,可溶性IL-21,例如可溶性人IL-21)的受体或CD137L(例如,可溶性CD137L,例如可溶性人CD137L)的受体。
在这些多链嵌合多肽的一些实例中,第一靶标结合结构域和可溶性组织因子结构域在第一嵌合多肽中彼此直接邻接。在这些多链嵌合多肽的一些实例中,第一嵌合多肽进一步包含第一嵌合多肽中的第一靶标结合结构域与可溶性组织因子结构域之间的接头序列(例如,本文所描述的示例性接头中的任一种)。
在这些多链嵌合多肽的一些实施例中,可溶性组织因子结构域和一对亲和结构域中的第一结构域在第一嵌合多肽中彼此直接邻接。在这些多链嵌合多肽的一些实施例中,第一嵌合多肽进一步包括第一嵌合多肽中的可溶性组织因子结构域与一对亲和结构域中的第一结构域之间的接头序列(例如,本文所描述的示例性接头中的任一种)。
在这些多链嵌合多肽的一些实施例中,一对亲和结构域中的第二结构域和第二靶标结合结构域在第二嵌合多肽中彼此直接邻接。在这些多链嵌合多肽的一些实施例中,第二嵌合多肽进一步包括第二嵌合多肽中的一对亲和结构域中的第二结构域与第二靶标结合结构域之间的接头序列(例如,本文所描述的示例性接头中的任一种)。
在一些实施例中,第二嵌合多肽在第二嵌合多肽的N端或C端进一步包含一个或多个另外的靶标结合结构域。
在这些多链嵌合多肽的一些实施例中,另外的靶标结合结构域和一对亲和结构域中的第二结构域在第二嵌合多肽中彼此直接邻接。在这些多链嵌合多肽的一些实施例中,第二嵌合多肽进一步包括第二嵌合多肽中的一对亲和结构域中的第二结构域与另外的靶标结合结构域之间的接头序列(例如,本文所描述的示例性接头中的任一种)。
在这些多链嵌合多肽的一些实施例中,另外的靶标结合结构域和第二靶标结合结构域在第二嵌合多肽中直接彼此邻接。在这些多链嵌合多肽的一些实施例中,第二嵌合多肽进一步包括第二嵌合多肽中的第二靶标结合结构域与另外的靶标结合结构域之间的接头序列(例如,本文所描述的示例性接头中的任一种)。
在这些多链嵌合多肽的一些实施例中,可溶性组织因子结构域可为本文所描述的示例性可溶性组织因子结构域中的任一种。在这些多链嵌合多肽的一些实施例中,所述一对亲和结构域可为本文所描述的示例性亲和结构域对中的任一种。
在这些多链嵌合多肽的一些实施例中,第一靶标结合结构域、第二靶标结合结构域和另外的靶标结合结构域中的一个或多个是激动性抗原结合结构域。在这些多链嵌合多肽的一些实施例中,第一靶标结合结构域、第二靶标结合结构域和另外的靶标结合结构域各自是激动性抗原结合结构域。在这些多链嵌合多肽的一些实施例中,抗原结合结构域包括scFv或单结构域抗体。
在这些多链嵌合多肽的一些实施例中,第一靶标结合结构域特异性结合到TGF-β,并且第二靶标结合结构域特异性结合到IL-21的受体或CD137L的受体。
在这些多链嵌合多肽的一些实施例中,第一靶标结合结构域是可溶性TGF-β受体(例如,可溶性TGFβRII受体,例如可溶性人TGFβRII受体)。在这些多链嵌合多肽的一些实施例中,可溶性人TGFRβRII包括可溶性人TGFRβRII的第一序列和可溶性人TGFRβRII的第二序列。在这些多链嵌合多肽的一些实施例中,可溶性人TGFRβRII包括安置于可溶性人TGFRβRII的第一序列与可溶性人TGFRβRII的第二序列之间的接头。在这些多链嵌合多肽的一些实例中,接头包括序列GGGGSGGGGSGGGGS(SEQ ID NO:7)。
在这些多链嵌合多肽的一些实施例中,可溶性人TGFRβRII受体的第一序列包含与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD(SEQ IDNO:80)。
在这些多链嵌合多肽的一些实施例中,可溶性人TGFRβRII受体的第二序列包含与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD(SEQ IDNO:81)。
在这些多链嵌合多肽的一些实施例中,可溶性人TGFRβRII受体的第一序列由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGAT(SEQ ID NO:82)。
在这些多链嵌合多肽的一些实施例中,可溶性人TGFRβRII受体的第二序列由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
ATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC(SEQ ID NO:83)。
在这些多链嵌合多肽的一些实施例中,可溶性TGF-β受体包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD(SEQ IDNO:85)。
在这些多链嵌合多肽的一些实施例中,可溶性TGF-β受体由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC(SEQ ID NO:84)。
在这些多链嵌合多肽的一些实施例中,第二靶标结合结构域或另外的靶标结合结构域特异性结合到IL-21的受体。在这些多链嵌合多肽的一些实施例中,第二靶标结合结构域或另外的靶标结合结构域包括可溶性IL-21(例如,可溶性人IL-21)。
在这些多链嵌合多肽的一些实施例中,可溶性人IL-21包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS(SEQ ID NO:78)。
在这些多链嵌合多肽的一些实施例中,可溶性人IL-21由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC(SEQ ID NO:79)。
在这些多链嵌合多肽的一些实施例中,第二靶标结合结构域或另外的靶标结合结构域特异性结合到CD137L的受体。在这些多链嵌合多肽的一些实施例中,第二靶标结合结构域和/或另外的靶标结合结构域包括可溶性CD137L(例如,可溶性人CD137L)。
在这些多链嵌合多肽的一些实施例中,可溶性CD137L包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
REGPELSPDDPAGLLDLRQGMFAQLVAQNVLLIDGPLSWYSDPGLAGVSLTGGLSYKEDTKELVVAKAGVYYVFFQLELRRVVAGEGSGSVSLALHLQPLRSAAGAAALALTVDLPPASSEARNSAFGFQGRLLHLSAGQRLGVHLHTEARARHAWQLTQGATVLGLFRVTPEIPAGLPSPRSE(SEQ ID NO:157)。
在这些多链嵌合多肽的一些实施例中,可溶性CD137L由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
CGCGAGGGTCCCGAGCTTTCGCCCGACGATCCCGCCGGCCTCTTGGACCTGCGGCAGGGCATGTTTGCGCAGCTGGTGGCCCAAAATGTTCTGCTGATCGATGGGCCCCTGAGCTGGTACAGTGACCCAGGCCTGGCAGGCGTGTCCCTGACGGGGGGCCTGAGCTACAAAGAGGACACGAAGGAGCTGGTGGTGGCCAAGGCTGGAGTCTACTATGTCTTCTTTCAACTAGAGCTGCGGCGCGTGGTGGCCGGCGAGGGCTCAGGCTCCGTTTCACTTGCGCTGCACCTGCAGCCACTGCGCTCTGCTGCTGGGGCCGCCGCCCTGGCTTTGACCGTGGACCTGCCACCCGCCTCCTCCGAGGCTCGGAACTCGGCCTTCGGTTTCCAGGGCCGCTTGCTGCACCTGAGTGCCGGCCAGCGCCTGGGCGTCCATCTTCACACTGAGGCCAGGGCACGCCATGCCTGGCAGCTTACCCAGGGCGCCACAGTCTTGGGACTCTTCCGGGTGACCCCCGAAATCCCAGCCGGACTCCCTTCACCGAGGTCGGAA(SEQ ID NO:158)。
在这些多链嵌合多肽的一些实施例中,可溶性人CD137L包括与以下至少80%相同(例如,至少85%相同、至少90%相同、至少95%相同、至少96%相同、至少97%相同、至少98%相同、至少99%相同或100%相同)的序列:
DPAGLLDLRQGMFAQLVAQNVLLIDGPLSWYSDPGLAGVSLTGGLSYKEDTKELVVAKAGVYYVFFQLELRRVVAGEGSGSVSLALHLQPLRSAAGAAALALTVDLPPASSEARNSAFGFQGRLLHLSAGQRLGVHLHTEARARHAWQLTQGATVLGLFRVTPEI(SEQ ID NO:159)。
在这些多链嵌合多肽的一些实施例中,可溶性人CD137L由与以下至少80%相同(例如,至少85%相同、至少90%相同、至少95%相同、至少96%相同、至少97%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
GATCCCGCCGGCCTCTTGGACCTGCGGCAGGGCATGTTTGCGCAGCTGGTGGCCCAAAATGTTCTGCTGATCGATGGGCCCCTGAGCTGGTACAGTGACCCAGGCCTGGCAGGCGTGTCCCTGACGGGGGGCCTGAGCTACAAAGAGGACACGAAGGAGCTGGTGGTGGCCAAGGCTGGAGTCTACTATGTCTTCTTTCAACTAGAGCTGCGGCGCGTGGTGGCCGGCGAGGGCTCAGGCTCCGTTTCACTTGCGCTGCACCTGCAGCCACTGCGCTCTGCTGCTGGGGCCGCCGCCCTGGCTTTGACCGTGGACCTGCCACCCGCCTCCTCCGAGGCTCGGAACTCGGCCTTCGGTTTCCAGGGCCGCTTGCTGCACCTGAGTGCCGGCCAGCGCCTGGGCGTCCATCTTCACACTGAGGCCAGGGCACGCCATGCCTGGCAGCTTACCCAGGGCGCCACAGTCTTGGGACTCTTCCGGGTGACCCCCGAAATC(SEQ ID NO:160)。
在一些实施例中,第一嵌合多肽可包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS(SEQ ID NO:181)。
在一些实施例中,第一嵌合多肽由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC(SEQ ID NO:182)。
在一些实施例中,第一嵌合多肽可包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
MKWVTFISLLFLFSSAYSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS(SEQ ID NO:183)。
在一些实施例中,第一嵌合多肽由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC(SEQ ID NO:184)。
在一些实施例中,第二嵌合多肽可包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDSITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIRGGGGSGGGGSGGGGSREGPELSPDDPAGLLDLRQGMFAQLVAQNVLLIDGPLSWYSDPGLAGVSLTGGLSYKEDTKELVVAKAGVYYVFFQLELRRVVAGEGSGSVSLALHLQPLRSAAGAAALALTVDLPPASSEARNSAFGFQGRLLHLSAGQRLGVHLHTEARARHAWQLTQGATVLGLFRVTPEIPAGLPSPRSE(SEQ ID NO:185)。
在一些实施例中,第二嵌合多肽由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCCATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGGGGCGGTGGAGGATCCGGAGGAGGTGGCTCCGGCGGCGGAGGATCTCGCGAGGGTCCCGAGCTTTCGCCCGACGATCCCGCCGGCCTCTTGGACCTGCGGCAGGGCATGTTTGCGCAGCTGGTGGCCCAAAATGTTCTGCTGATCGATGGGCCCCTGAGCTGGTACAGTGACCCAGGCCTGGCAGGCGTGTCCCTGACGGGGGGCCTGAGCTACAAAGAGGACACGAAGGAGCTGGTGGTGGCCAAGGCTGGAGTCTACTATGTCTTCTTTCAACTAGAGCTGCGGCGCGTGGTGGCCGGCGAGGGCTCAGGCTCCGTTTCACTTGCGCTGCACCTGCAGCCACTGCGCTCTGCTGCTGGGGCCGCCGCCCTGGCTTTGACCGTGGACCTGCCACCCGCCTCCTCCGAGGCTCGGAACTCGGCCTTCGGTTTCCAGGGCCGCTTGCTGCACCTGAGTGCCGGCCAGCGCCTGGGCGTCCATCTTCACACTGAGGCCAGGGCACGCCATGCCTGGCAGCTTACCCAGGGCGCCACAGTCTTGGGACTCTTCCGGGTGACCCCCGAAATCCCAGCCGGACTCCCTTCACCGAGGTCGGAA(SEQ ID NO:186)。
在一些实施例中,第二嵌合多肽可包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
MKWVTFISLLFLFSSAYSQGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDSITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIRGGGGSGGGGSGGGGSREGPELSPDDPAGLLDLRQGMFAQLVAQNVLLIDGPLSWYSDPGLAGVSLTGGLSYKEDTKELVVAKAGVYYVFFQLELRRVVAGEGSGSVSLALHLQPLRSAAGAAALALTVDLPPASSEARNSAFGFQGRLLHLSAGQRLGVHLHTEARARHAWQLTQGATVLGLFRVTPEIPAGLPSPRSE(SEQ ID NO:187)。
在一些实施例中,第二嵌合多肽由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCCAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCCATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGGGGCGGTGGAGGATCCGGAGGAGGTGGCTCCGGCGGCGGAGGATCTCGCGAGGGTCCCGAGCTTTCGCCCGACGATCCCGCCGGCCTCTTGGACCTGCGGCAGGGCATGTTTGCGCAGCTGGTGGCCCAAAATGTTCTGCTGATCGATGGGCCCCTGAGCTGGTACAGTGACCCAGGCCTGGCAGGCGTGTCCCTGACGGGGGGCCTGAGCTACAAAGAGGACACGAAGGAGCTGGTGGTGGCCAAGGCTGGAGTCTACTATGTCTTCTTTCAACTAGAGCTGCGGCGCGTGGTGGCCGGCGAGGGCTCAGGCTCCGTTTCACTTGCGCTGCACCTGCAGCCACTGCGCTCTGCTGCTGGGGCCGCCGCCCTGGCTTTGACCGTGGACCTGCCACCCGCCTCCTCCGAGGCTCGGAACTCGGCCTTCGGTTTCCAGGGCCGCTTGCTGCACCTGAGTGCCGGCCAGCGCCTGGGCGTCCATCTTCACACTGAGGCCAGGGCACGCCATGCCTGGCAGCTTACCCAGGGCGCCACAGTCTTGGGACTCTTCCGGGTGACCCCCGAAATCCCAGCCGGACTCCCTTCACCGAGGTCGGAA(SEQ ID NO:188)。
在一些实施例中,第二嵌合多肽可包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDSITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIRGGGGSGGGGSGGGGSDPAGLLDLRQGMFAQLVAQNVLLIDGPLSWYSDPGLAGVSLTGGLSYKEDTKELVVAKAGVYYVFFQLELRRVVAGEGSGSVSLALHLQPLRSAAGAAALALTVDLPPASSEARNSAFGFQGRLLHLSAGQRLGVHLHTEARARHAWQLTQGATVLGLFRVTPEI(SEQ ID NO:189)。
在一些实施例中,第二嵌合多肽由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCCATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGGGGCGGTGGAGGATCCGGAGGAGGTGGCTCCGGCGGCGGAGGATCTGATCCCGCCGGCCTCTTGGACCTGCGGCAGGGCATGTTTGCGCAGCTGGTGGCCCAAAATGTTCTGCTGATCGATGGGCCCCTGAGCTGGTACAGTGACCCAGGCCTGGCAGGCGTGTCCCTGACGGGGGGCCTGAGCTACAAAGAGGACACGAAGGAGCTGGTGGTGGCCAAGGCTGGAGTCTACTATGTCTTCTTTCAACTAGAGCTGCGGCGCGTGGTGGCCGGCGAGGGCTCAGGCTCCGTTTCACTTGCGCTGCACCTGCAGCCACTGCGCTCTGCTGCTGGGGCCGCCGCCCTGGCTTTGACCGTGGACCTGCCACCCGCCTCCTCCGAGGCTCGGAACTCGGCCTTCGGTTTCCAGGGCCGCTTGCTGCACCTGAGTGCCGGCCAGCGCCTGGGCGTCCATCTTCACACTGAGGCCAGGGCACGCCATGCCTGGCAGCTTACCCAGGGCGCCACAGTCTTGGGACTCTTCCGGGTGACCCCCGAAATC(SEQ ID NO:190)。
在一些实施例中,第二嵌合多肽可包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
MKWVTFISLLFLFSSAYSQGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDSITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIRGGGGSGGGGSGGGGSDPAGLLDLRQGMFAQLVAQNVLLIDGPLSWYSDPGLAGVSLTGGLSYKEDTKELVVAKAGVYYVFFQLELRRVVAGEGSGSVSLALHLQPLRSAAGAAALALTVDLPPASSEARNSAFGFQGRLLHLSAGQRLGVHLHTEARARHAWQLTQGATVLGLFRVTPEI(SEQ ID NO:191)。
在一些实施例中,第二嵌合多肽由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCCAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCCATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGGGGCGGTGGAGGATCCGGAGGAGGTGGCTCCGGCGGCGGAGGATCTGATCCCGCCGGCCTCTTGGACCTGCGGCAGGGCATGTTTGCGCAGCTGGTGGCCCAAAATGTTCTGCTGATCGATGGGCCCCTGAGCTGGTACAGTGACCCAGGCCTGGCAGGCGTGTCCCTGACGGGGGGCCTGAGCTACAAAGAGGACACGAAGGAGCTGGTGGTGGCCAAGGCTGGAGTCTACTATGTCTTCTTTCAACTAGAGCTGCGGCGCGTGGTGGCCGGCGAGGGCTCAGGCTCCGTTTCACTTGCGCTGCACCTGCAGCCACTGCGCTCTGCTGCTGGGGCCGCCGCCCTGGCTTTGACCGTGGACCTGCCACCCGCCTCCTCCGAGGCTCGGAACTCGGCCTTCGGTTTCCAGGGCCGCTTGCTGCACCTGAGTGCCGGCCAGCGCCTGGGCGTCCATCTTCACACTGAGGCCAGGGCACGCCATGCCTGGCAGCTTACCCAGGGCGCCACAGTCTTGGGACTCTTCCGGGTGACCCCCGAAATC(SEQ ID NO:192)。
示例性多链嵌合多肽-M型
在本文所描述的多链嵌合多肽中的任一种的一些实施例中,第一靶标结合结构域和第二靶标结合结构域各自独立地特异性结合到TGF-β或IL-21的受体。在本文所描述的这些多链嵌合多肽的一些实施例中,第二嵌合多肽进一步包括另外的靶标结合结构域。在本文所描述的这些多链嵌合多肽的一些实施例中,另外的靶标结合结构域特异性结合到IL-21(例如,可溶性IL-21,例如可溶性人IL-21)的受体或TGF-β(例如,可溶性TGF-β受体,例如可溶性TGFβRII受体)。
在这些多链嵌合多肽的一些实例中,第一靶标结合结构域和可溶性组织因子结构域在第一嵌合多肽中彼此直接邻接。在这些多链嵌合多肽的一些实例中,第一嵌合多肽进一步包含第一嵌合多肽中的第一靶标结合结构域与可溶性组织因子结构域之间的接头序列(例如,本文所描述的示例性接头中的任一种)。
在这些多链嵌合多肽的一些实施例中,可溶性组织因子结构域和一对亲和结构域中的第一结构域在第一嵌合多肽中彼此直接邻接。在这些多链嵌合多肽的一些实施例中,第一嵌合多肽进一步包括第一嵌合多肽中的可溶性组织因子结构域与一对亲和结构域中的第一结构域之间的接头序列(例如,本文所描述的示例性接头中的任一种)。
在这些多链嵌合多肽的一些实施例中,一对亲和结构域中的第二结构域和第二靶标结合结构域在第二嵌合多肽中彼此直接邻接。在这些多链嵌合多肽的一些实施例中,第二嵌合多肽进一步包括第二嵌合多肽中的一对亲和结构域中的第二结构域与第二靶标结合结构域之间的接头序列(例如,本文所描述的示例性接头中的任一种)。
在一些实施例中,第二嵌合多肽在第二嵌合多肽的N端或C端进一步包含一个或多个另外的靶标结合结构域。
在这些多链嵌合多肽的一些实施例中,另外的靶标结合结构域和一对亲和结构域中的第二结构域在第二嵌合多肽中彼此直接邻接。在这些多链嵌合多肽的一些实施例中,第二嵌合多肽进一步包括第二嵌合多肽中的一对亲和结构域中的第二结构域与另外的靶标结合结构域之间的接头序列(例如,本文所描述的示例性接头中的任一种)。
在这些多链嵌合多肽的一些实施例中,另外的靶标结合结构域和第二靶标结合结构域在第二嵌合多肽中直接彼此邻接。在这些多链嵌合多肽的一些实施例中,第二嵌合多肽进一步包括第二嵌合多肽中的第二靶标结合结构域与另外的靶标结合结构域之间的接头序列(例如,本文所描述的示例性接头中的任一种)。
在这些多链嵌合多肽的一些实施例中,可溶性组织因子结构域可为本文所描述的示例性可溶性组织因子结构域中的任一种。在这些多链嵌合多肽的一些实施例中,所述一对亲和结构域可为本文所描述的示例性亲和结构域对中的任一种。
在这些多链嵌合多肽的一些实施例中,第一靶标结合结构域特异性结合到TGF-β,并且第二靶标结合结构域特异性结合到TGF-β或IL-21的受体。在这些多链嵌合多肽的一些实施例中,第一靶标结合结构域是可溶性TGF-β受体(例如,可溶性TGFβRII受体,例如可溶性人TGFβRII受体)。在这些多链嵌合多肽的一些实施例中,可溶性人TGFRβRII包括可溶性人TGFRβRII的第一序列和可溶性人TGFRβRII的第二序列。在这些多链嵌合多肽的一些实施例中,可溶性人TGFRβRII包括安置于可溶性人TGFRβRII的第一序列与可溶性人TGFRβRII的第二序列之间的接头。在这些多链嵌合多肽的一些实例中,接头包括序列GGGGSGGGGSGGGGS(SEQ ID NO:7)。
在这些多链嵌合多肽的一些实施例中,可溶性人TGFRβRII受体的第一序列包含与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD(SEQ IDNO:80)。
在这些多链嵌合多肽的一些实施例中,可溶性人TGFRβRII受体的第二序列包含与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD(SEQ IDNO:81)。
在这些多链嵌合多肽的一些实施例中,可溶性人TGFRβRII受体的第一序列由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGAT(SEQ ID NO:82)。
在这些多链嵌合多肽的一些实施例中,可溶性人TGFRβRII受体的第二序列由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
ATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC(SEQ ID NO:83)。
在这些多链嵌合多肽的一些实施例中,可溶性TGF-β受体包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD(SEQ IDNO:85)。
在这些多链嵌合多肽的一些实施例中,可溶性TGF-β受体由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC(SEQ ID NO:84)。
在这些多链嵌合多肽的一些实施例中,第二靶标结合结构域特异性结合到IL-21的受体。在这些多链嵌合多肽的一些实施例中,第二靶标结合结构域包括可溶性IL-21(例如,人可溶性IL-21)。在这些多链嵌合多肽的一些实施例中,可溶性IL-21包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS(SEQ ID NO:78)。
在这些多链嵌合多肽的一些实施例中,可溶性IL-21由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC(SEQ ID NO:79)。
在一些实施例中,第一嵌合多肽可包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS(SEQ ID NO:193)。
在一些实施例中,第一嵌合多肽由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC(SEQ ID NO:194)。
在一些实施例中,第一嵌合多肽可包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
MKWVTFISLLFLFSSAYSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS(SEQ ID NO:195)。
在一些实施例中,第一嵌合多肽由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC(SEQ ID NO:196)。
在一些实施例中,第二嵌合多肽可包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIRQGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS(SEQ ID NO:197)。
在一些实施例中,第二嵌合多肽由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGGCAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC(SEQ ID NO:198)。
在一些实施例中,第二嵌合多肽可包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
MKWVTFISLLFLFSSAYSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIRQGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS(SEQ ID NO:199)。
在一些实施例中,第二嵌合多肽由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGGCAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC(SEQID NO:200)。
示例性多链嵌合多肽-N型
在本文所描述的多链嵌合多肽中的任一种的一些实施例中,第一靶标结合结构域和第二靶标结合结构域各自独立地特异性结合到TGF-β或CD16。在本文所描述的这些多链嵌合多肽的一些实施例中,第二嵌合多肽进一步包括另外的靶标结合结构域。在本文所描述的这些多链嵌合多肽的一些实施例中,所述另外的靶标结合结构域特异性结合到CD16(例如,抗CD16 scFv)或TGF-β(例如,可溶性TGF-β受体,例如可溶性TGFβRII受体)。
在这些多链嵌合多肽的一些实例中,第一靶标结合结构域和可溶性组织因子结构域在第一嵌合多肽中彼此直接邻接。在这些多链嵌合多肽的一些实例中,第一嵌合多肽进一步包含第一嵌合多肽中的第一靶标结合结构域与可溶性组织因子结构域之间的接头序列(例如,本文所描述的示例性接头中的任一种)。
在这些多链嵌合多肽的一些实施例中,可溶性组织因子结构域和一对亲和结构域中的第一结构域在第一嵌合多肽中彼此直接邻接。在这些多链嵌合多肽的一些实施例中,第一嵌合多肽进一步包括第一嵌合多肽中的可溶性组织因子结构域与一对亲和结构域中的第一结构域之间的接头序列(例如,本文所描述的示例性接头中的任一种)。
在这些多链嵌合多肽的一些实施例中,一对亲和结构域中的第二结构域和第二靶标结合结构域在第二嵌合多肽中彼此直接邻接。在这些多链嵌合多肽的一些实施例中,第二嵌合多肽进一步包括第二嵌合多肽中的一对亲和结构域中的第二结构域与第二靶标结合结构域之间的接头序列(例如,本文所描述的示例性接头中的任一种)。
在一些实施例中,第二嵌合多肽在第二嵌合多肽的N端或C端进一步包含一个或多个另外的靶标结合结构域。
在这些多链嵌合多肽的一些实施例中,另外的靶标结合结构域和一对亲和结构域中的第二结构域在第二嵌合多肽中彼此直接邻接。在这些多链嵌合多肽的一些实施例中,第二嵌合多肽进一步包括第二嵌合多肽中的一对亲和结构域中的第二结构域与另外的靶标结合结构域之间的接头序列(例如,本文所描述的示例性接头中的任一种)。
在这些多链嵌合多肽的一些实施例中,另外的靶标结合结构域和第二靶标结合结构域在第二嵌合多肽中直接彼此邻接。在这些多链嵌合多肽的一些实施例中,第二嵌合多肽进一步包括第二嵌合多肽中的第二靶标结合结构域与另外的靶标结合结构域之间的接头序列(例如,本文所描述的示例性接头中的任一种)。
在这些多链嵌合多肽的一些实施例中,可溶性组织因子结构域可为本文所描述的示例性可溶性组织因子结构域中的任一种。在这些多链嵌合多肽的一些实施例中,所述一对亲和结构域可为本文所描述的示例性亲和结构域对中的任一种。
在这些多链嵌合多肽的一些实施例中,第一靶标结合结构域特异性结合到TGF-β,并且第二靶标结合结构域特异性结合到TGF-β或CD16。在这些多链嵌合多肽的一些实施例中,第一靶标结合结构域是可溶性TGF-β受体(例如,可溶性TGFβRII受体,例如可溶性人TGFβRII受体)。在这些多链嵌合多肽的一些实施例中,可溶性人TGFRβRII包括可溶性人TGFRβRII的第一序列和可溶性人TGFRβRII的第二序列。在这些多链嵌合多肽的一些实施例中,可溶性人TGFRβRII包括安置于可溶性人TGFRβRII的第一序列与可溶性人TGFRβRII的第二序列之间的接头。在这些多链嵌合多肽的一些实例中,接头包括序列GGGGSGGGGSGGGGS(SEQID NO:7)。
在这些多链嵌合多肽的一些实施例中,可溶性人TGFRβRII受体的第一序列包含与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD(SEQ IDNO:80)。
在这些多链嵌合多肽的一些实施例中,可溶性人TGFRβRII受体的第二序列包含与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD(SEQ IDNO:81)。
在这些多链嵌合多肽的一些实施例中,可溶性人TGFRβRII受体的第一序列由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGAT(SEQ ID NO:82)。
在这些多链嵌合多肽的一些实施例中,可溶性人TGFRβRII受体的第二序列由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
ATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC(SEQ ID NO:83)。
在这些多链嵌合多肽的一些实施例中,可溶性TGF-β受体包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD(SEQ IDNO:85)。
在这些多链嵌合多肽的一些实施例中,可溶性TGF-β受体由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC(SEQ ID NO:84)。
在这些多链嵌合多肽的一些实施例中,第二靶标结合结构域特异性结合到CD16。在这些多链嵌合多肽的一些实施例中,第二靶标结合结构域包括抗CD16 scFv。在这些多链嵌合多肽的一些实施例中,特异性结合到CD16的scFv包括轻链可变结构域,所述轻链可变结构域包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
SELTQDPAVSVALGQTVRITCQGDSLRSYYASWYQQKPGQAPVLVIYGKNNRPSGIPDRFSGSSSGNTASLTITGAQAEDEADYYCNSRDSSGNHVVFGGGTKLTVGH(SEQ ID NO:112)。
在这些多链嵌合多肽的一些实施例中,特异性结合到CD16的scFv由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的轻链可变结构域序列编码:
TCCGAGCTGACCCAGGACCCTGCTGTGTCCGTGGCTCTGGGCCAGACCGTGAGGATCACCTGCCAGGGCGACTCCCTGAGGTCCTACTACGCCTCCTGGTACCAGCAGAAGCCCGGCCAGGCTCCTGTGCTGGTGATCTACGGCAAGAACAACAGGCCCTCCGGCATCCCTGACAGGTTCTCCGGATCCTCCTCCGGCAACACCGCCTCCCTGACCATCACAGGCGCTCAGGCCGAGGACGAGGCTGACTACTACTGCAACTCCAGGGACTCCTCCGGCAACCATGTGGTGTTCGGCGGCGGCACCAAGCTGACCGTGGGCCAT(SEQ ID NO:113)。
在这些多链嵌合多肽的一些实施例中,特异性结合到CD16的scFv包括重链可变结构域,所述重链可变结构域包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
EVQLVESGGGVVRPGGSLRLSCAASGFTFDDYGMSWVRQAPGKGLEWVSGINWNGGSTGYADSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARGRSLLFDYWGQGTLVTVSR(SEQ ID NO:114)。
在这些多链嵌合多肽的一些实施例中,特异性结合到CD16的scFv由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的重链可变结构域序列编码:
GAGGTGCAGCTGGTGGAGTCCGGAGGAGGAGTGGTGAGGCCTGGAGGCTCCCTGAGGCTGAGCTGTGCTGCCTCCGGCTTCACCTTCGACGACTACGGCATGTCCTGGGTGAGGCAGGCTCCTGGAAAGGGCCTGGAGTGGGTGTCCGGCATCAACTGGAACGGCGGATCCACCGGCTACGCCGATTCCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACTCCCTGTACCTGCAGATGAACTCCCTGAGGGCCGAGGACACCGCCGTGTACTACTGCGCCAGGGGCAGGTCCCTGCTGTTCGACTACTGGGGACAGGGCACCCTGGTGACCGTGTCCAGG(SEQ ID NO:115)。
在一些实施例中,第一嵌合多肽可包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS(SEQ ID NO:201)。
在一些实施例中,第一嵌合多肽由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC(SEQ ID NO:202)。
在一些实施例中,第一嵌合多肽可包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
MKWVTFISLLFLFSSAYSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS(SEQ ID NO:203)。
在一些实施例中,第一嵌合多肽由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC(SEQ ID NO:204)。
在一些实施例中,第二嵌合多肽可包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIRSELTQDPAVSVALGQTVRITCQGDSLRSYYASWYQQKPGQAPVLVIYGKNNRPSGIPDRFSGSSSGNTASLTITGAQAEDEADYYCNSRDSSGNHVVFGGGTKLTVGHGGGGSGGGGSGGGGSEVQLVESGGGVVRPGGSLRLSCAASGFTFDDYGMSWVRQAPGKGLEWVSGINWNGGSTGYADSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARGRSLLFDYWGQGTLVTVSR(SEQ IDNO:205)。
在一些实施例中,第二嵌合多肽由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGGTCCGAGCTGACCCAGGACCCTGCTGTGTCCGTGGCTCTGGGCCAGACCGTGAGGATCACCTGCCAGGGCGACTCCCTGAGGTCCTACTACGCCTCCTGGTACCAGCAGAAGCCCGGCCAGGCTCCTGTGCTGGTGATCTACGGCAAGAACAACAGGCCCTCCGGCATCCCTGACAGGTTCTCCGGATCCTCCTCCGGCAACACCGCCTCCCTGACCATCACAGGCGCTCAGGCCGAGGACGAGGCTGACTACTACTGCAACTCCAGGGACTCCTCCGGCAACCATGTGGTGTTCGGCGGCGGCACCAAGCTGACCGTGGGCCATGGCGGCGGCGGCTCCGGAGGCGGCGGCAGCGGCGGAGGAGGATCCGAGGTGCAGCTGGTGGAGTCCGGAGGAGGAGTGGTGAGGCCTGGAGGCTCCCTGAGGCTGAGCTGTGCTGCCTCCGGCTTCACCTTCGACGACTACGGCATGTCCTGGGTGAGGCAGGCTCCTGGAAAGGGCCTGGAGTGGGTGTCCGGCATCAACTGGAACGGCGGATCCACCGGCTACGCCGATTCCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACTCCCTGTACCTGCAGATGAACTCCCTGAGGGCCGAGGACACCGCCGTGTACTACTGCGCCAGGGGCAGGTCCCTGCTGTTCGACTACTGGGGACAGGGCACCCTGGTGACCGTGTCCAGG(SEQ ID NO:206)。
在一些实施例中,第二嵌合多肽可包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
MKWVTFISLLFLFSSAYSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIRSELTQDPAVSVALGQTVRITCQGDSLRSYYASWYQQKPGQAPVLVIYGKNNRPSGIPDRFSGSSSGNTASLTITGAQAEDEADYYCNSRDSSGNHVVFGGGTKLTVGHGGGGSGGGGSGGGGSEVQLVESGGGVVRPGGSLRLSCAASGFTFDDYGMSWVRQAPGKGLEWVSGINWNGGSTGYADSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARGRSLLFDYWGQGTLVTVSR(SEQ ID NO:207)。
在一些实施例中,第二嵌合多肽由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGGTCCGAGCTGACCCAGGACCCTGCTGTGTCCGTGGCTCTGGGCCAGACCGTGAGGATCACCTGCCAGGGCGACTCCCTGAGGTCCTACTACGCCTCCTGGTACCAGCAGAAGCCCGGCCAGGCTCCTGTGCTGGTGATCTACGGCAAGAACAACAGGCCCTCCGGCATCCCTGACAGGTTCTCCGGATCCTCCTCCGGCAACACCGCCTCCCTGACCATCACAGGCGCTCAGGCCGAGGACGAGGCTGACTACTACTGCAACTCCAGGGACTCCTCCGGCAACCATGTGGTGTTCGGCGGCGGCACCAAGCTGACCGTGGGCCATGGCGGCGGCGGCTCCGGAGGCGGCGGCAGCGGCGGAGGAGGATCCGAGGTGCAGCTGGTGGAGTCCGGAGGAGGAGTGGTGAGGCCTGGAGGCTCCCTGAGGCTGAGCTGTGCTGCCTCCGGCTTCACCTTCGACGACTACGGCATGTCCTGGGTGAGGCAGGCTCCTGGAAAGGGCCTGGAGTGGGTGTCCGGCATCAACTGGAACGGCGGATCCACCGGCTACGCCGATTCCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACTCCCTGTACCTGCAGATGAACTCCCTGAGGGCCGAGGACACCGCCGTGTACTACTGCGCCAGGGGCAGGTCCCTGCTGTTCGACTACTGGGGACAGGGCACCCTGGTGACCGTGTCCAGG(SEQ ID NO:208)。
示例性多链嵌合多肽-O型
在本文所描述的多链嵌合多肽中的任一种的一些实施例中,第一靶标结合结构域和第二靶标结合结构域各自独立地特异性结合到TGF-β或CD137L的受体。在本文所描述的这些多链嵌合多肽的一些实施例中,第二嵌合多肽进一步包括另外的靶标结合结构域。在本文所描述的这些多链嵌合多肽的一些实施例中,所述另外的靶标结合结构域特异性结合到TGF-β的受体(例如,可溶性TGF-β受体,例如可溶性TGFβRII受体)或CD137L。
在这些多链嵌合多肽的一些实例中,第一靶标结合结构域和可溶性组织因子结构域在第一嵌合多肽中彼此直接邻接。在这些多链嵌合多肽的一些实例中,第一嵌合多肽进一步包含第一嵌合多肽中的第一靶标结合结构域与可溶性组织因子结构域之间的接头序列(例如,本文所描述的示例性接头中的任一种)。
在这些多链嵌合多肽的一些实施例中,可溶性组织因子结构域和一对亲和结构域中的第一结构域在第一嵌合多肽中彼此直接邻接。在这些多链嵌合多肽的一些实施例中,第一嵌合多肽进一步包括第一嵌合多肽中的可溶性组织因子结构域与一对亲和结构域中的第一结构域之间的接头序列(例如,本文所描述的示例性接头中的任一种)。
在这些多链嵌合多肽的一些实施例中,一对亲和结构域中的第二结构域和第二靶标结合结构域在第二嵌合多肽中彼此直接邻接。在这些多链嵌合多肽的一些实施例中,第二嵌合多肽进一步包括第二嵌合多肽中的一对亲和结构域中的第二结构域与第二靶标结合结构域之间的接头序列(例如,本文所描述的示例性接头中的任一种)。
在一些实施例中,第二嵌合多肽在第二嵌合多肽的N端或C端进一步包含一个或多个另外的靶标结合结构域。
在这些多链嵌合多肽的一些实施例中,另外的靶标结合结构域和一对亲和结构域中的第二结构域在第二嵌合多肽中彼此直接邻接。在这些多链嵌合多肽的一些实施例中,第二嵌合多肽进一步包括第二嵌合多肽中的一对亲和结构域中的第二结构域与另外的靶标结合结构域之间的接头序列(例如,本文所描述的示例性接头中的任一种)。
在这些多链嵌合多肽的一些实施例中,另外的靶标结合结构域和第二靶标结合结构域在第二嵌合多肽中直接彼此邻接。在这些多链嵌合多肽的一些实施例中,第二嵌合多肽进一步包括第二嵌合多肽中的第二靶标结合结构域与另外的靶标结合结构域之间的接头序列(例如,本文所描述的示例性接头中的任一种)。
在这些多链嵌合多肽的一些实施例中,可溶性组织因子结构域可为本文所描述的示例性可溶性组织因子结构域中的任一种。在这些多链嵌合多肽的一些实施例中,所述一对亲和结构域可为本文所描述的示例性亲和结构域对中的任一种。
在这些多链嵌合多肽的一些实施例中,第一靶标结合结构域特异性结合到TGF-β,并且第二靶标结合结构域特异性结合到CD137L。在这些多链嵌合多肽的一些实施例中,第一靶标结合结构域或另外的靶标结合结构域是可溶性TGF-β受体(例如,可溶性TGFβRII受体,例如可溶性人TGFβRII受体)。
在这些多链嵌合多肽的一些实施例中,可溶性人TGFRβRII包括可溶性人TGFRβRII的第一序列和可溶性人TGFRβRII的第二序列。在这些多链嵌合多肽的一些实施例中,可溶性人TGFRβRII包括安置于可溶性人TGFRβRII的第一序列与可溶性人TGFRβRII的第二序列之间的接头。在这些多链嵌合多肽的一些实例中,接头包括序列GGGGSGGGGSGGGGS(SEQ IDNO:7)。
在这些多链嵌合多肽的一些实施例中,可溶性人TGFRβRII受体的第一序列包含与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD(SEQ IDNO:80)。
在这些多链嵌合多肽的一些实施例中,可溶性人TGFRβRII受体的第二序列包含与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD(SEQ IDNO:81)。
在这些多链嵌合多肽的一些实施例中,可溶性人TGFRβRII受体的第一序列由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGAT(SEQ ID NO:82)。
在这些多链嵌合多肽的一些实施例中,可溶性人TGFRβRII受体的第二序列由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
ATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC(SEQ ID NO:83)。
在这些多链嵌合多肽的一些实施例中,可溶性TGF-β受体包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD(SEQ IDNO:85)。
在这些多链嵌合多肽的一些实施例中,可溶性TGF-β受体由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC(SEQ ID NO:84)。
在一些实施例中这些多链嵌合多肽,第二靶标结合结构域包括可溶性CD137L蛋白(例如,可溶性人CD137L蛋白)。在这些多链嵌合多肽的一些实施例中,可溶性人CD137L包括与以下至少80%相同(例如,至少85%相同、至少90%相同、至少95%相同、至少96%相同、至少97%相同、至少98%相同、至少99%相同或100%相同)的序列:
REGPELSPDDPAGLLDLRQGMFAQLVAQNVLLIDGPLSWYSDPGLAGVSLTGGLSYKEDTKELVVAKAGVYYVFFQLELRRVVAGEGSGSVSLALHLQPLRSAAGAAALALTVDLPPASSEARNSAFGFQGRLLHLSAGQRLGVHLHTEARARHAWQLTQGATVLGLFRVTPEIPAGLPSPRSE(SEQ ID NO:157)。
在这些多链嵌合多肽的一些实施例中,可溶性人CD137L由与以下至少80%相同(例如,至少85%相同、至少90%相同、至少95%相同、至少96%相同、至少97%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
CGCGAGGGTCCCGAGCTTTCGCCCGACGATCCCGCCGGCCTCTTGGACCTGCGGCAGGGCATGTTTGCGCAGCTGGTGGCCCAAAATGTTCTGCTGATCGATGGGCCCCTGAGCTGGTACAGTGACCCAGGCCTGGCAGGCGTGTCCCTGACGGGGGGCCTGAGCTACAAAGAGGACACGAAGGAGCTGGTGGTGGCCAAGGCTGGAGTCTACTATGTCTTCTTTCAACTAGAGCTGCGGCGCGTGGTGGCCGGCGAGGGCTCAGGCTCCGTTTCACTTGCGCTGCACCTGCAGCCACTGCGCTCTGCTGCTGGGGCCGCCGCCCTGGCTTTGACCGTGGACCTGCCACCCGCCTCCTCCGAGGCTCGGAACTCGGCCTTCGGTTTCCAGGGCCGCTTGCTGCACCTGAGTGCCGGCCAGCGCCTGGGCGTCCATCTTCACACTGAGGCCAGGGCACGCCATGCCTGGCAGCTTACCCAGGGCGCCACAGTCTTGGGACTCTTCCGGGTGACCCCCGAAATCCCAGCCGGACTCCCTTCACCGAGGTCGGAA(SEQ ID NO:158)。
在这些多链嵌合多肽的一些实施例中,可溶性人CD137L包括与以下至少80%相同(例如,至少85%相同、至少90%相同、至少95%相同、至少96%相同、至少97%相同、至少98%相同、至少99%相同或100%相同)的序列:
DPAGLLDLRQGMFAQLVAQNVLLIDGPLSWYSDPGLAGVSLTGGLSYKEDTKELVVAKAGVYYVFFQLELRRVVAGEGSGSVSLALHLQPLRSAAGAAALALTVDLPPASSEARNSAFGFQGRLLHLSAGQRLGVHLHTEARARHAWQLTQGATVLGLFRVTPEI(SEQ ID NO:159)。
在这些多链嵌合多肽的一些实施例中,可溶性人CD137L由与以下至少80%相同(例如,至少85%相同、至少90%相同、至少95%相同、至少96%相同、至少97%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
GATCCCGCCGGCCTCTTGGACCTGCGGCAGGGCATGTTTGCGCAGCTGGTGGCCCAAAATGTTCTGCTGATCGATGGGCCCCTGAGCTGGTACAGTGACCCAGGCCTGGCAGGCGTGTCCCTGACGGGGGGCCTGAGCTACAAAGAGGACACGAAGGAGCTGGTGGTGGCCAAGGCTGGAGTCTACTATGTCTTCTTTCAACTAGAGCTGCGGCGCGTGGTGGCCGGCGAGGGCTCAGGCTCCGTTTCACTTGCGCTGCACCTGCAGCCACTGCGCTCTGCTGCTGGGGCCGCCGCCCTGGCTTTGACCGTGGACCTGCCACCCGCCTCCTCCGAGGCTCGGAACTCGGCCTTCGGTTTCCAGGGCCGCTTGCTGCACCTGAGTGCCGGCCAGCGCCTGGGCGTCCATCTTCACACTGAGGCCAGGGCACGCCATGCCTGGCAGCTTACCCAGGGCGCCACAGTCTTGGGACTCTTCCGGGTGACCCCCGAAATC(SEQ ID NO:160)。
在一些实施例中,第一嵌合多肽可包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS(SEQ ID NO:209)。
在一些实施例中,第一嵌合多肽由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC(SEQ ID NO:210)。
在一些实施例中,第一嵌合多肽可包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
MKWVTFISLLFLFSSAYSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS(SEQ ID NO:211)。
在一些实施例中,第一嵌合多肽由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC(SEQ ID NO:212)。
在一些实施例中,第二嵌合多肽可包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIRGGGGSGGGGSGGGGSREGPELSPDDPAGLLDLRQGMFAQLVAQNVLLIDGPLSWYSDPGLAGVSLTGGLSYKEDTKELVVAKAGVYYVFFQLELRRVVAGEGSGSVSLALHLQPLRSAAGAAALALTVDLPPASSEARNSAFGFQGRLLHLSAGQRLGVHLHTEARARHAWQLTQGATVLGLFRVTPEIPAGLPSPRSE(SEQ ID NO:213)。
在一些实施例中,第二嵌合多肽由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGGGGCGGTGGAGGATCCGGAGGAGGTGGCTCCGGCGGCGGAGGATCTCGCGAGGGTCCCGAGCTTTCGCCCGACGATCCCGCCGGCCTCTTGGACCTGCGGCAGGGCATGTTTGCGCAGCTGGTGGCCCAAAATGTTCTGCTGATCGATGGGCCCCTGAGCTGGTACAGTGACCCAGGCCTGGCAGGCGTGTCCCTGACGGGGGGCCTGAGCTACAAAGAGGACACGAAGGAGCTGGTGGTGGCCAAGGCTGGAGTCTACTATGTCTTCTTTCAACTAGAGCTGCGGCGCGTGGTGGCCGGCGAGGGCTCAGGCTCCGTTTCACTTGCGCTGCACCTGCAGCCACTGCGCTCTGCTGCTGGGGCCGCCGCCCTGGCTTTGACCGTGGACCTGCCACCCGCCTCCTCCGAGGCTCGGAACTCGGCCTTCGGTTTCCAGGGCCGCTTGCTGCACCTGAGTGCCGGCCAGCGCCTGGGCGTCCATCTTCACACTGAGGCCAGGGCACGCCATGCCTGGCAGCTTACCCAGGGCGCCACAGTCTTGGGACTCTTCCGGGTGACCCCCGAAATCCCAGCCGGACTCCCTTCACCGAGGTCGGAA(SEQ ID NO:214)。
在一些实施例中,第二嵌合多肽可包括与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列:
MKWVTFISLLFLFSSAYSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIRGGGGSGGGGSGGGGSREGPELSPDDPAGLLDLRQGMFAQLVAQNVLLIDGPLSWYSDPGLAGVSLTGGLSYKEDTKELVVAKAGVYYVFFQLELRRVVAGEGSGSVSLALHLQPLRSAAGAAALALTVDLPPASSEARNSAFGFQGRLLHLSAGQRLGVHLHTEARARHAWQLTQGATVLGLFRVTPEIPAGLPSPRSE(SEQ ID NO:215)。
在一些实施例中,第二嵌合多肽由与以下至少80%相同(例如,至少82%相同、至少84%相同、至少86%相同、至少88%相同、至少90%相同、至少92%相同、至少94%相同、至少96%相同、至少98%相同、至少99%相同或100%相同)的序列编码:
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGGGGCGGTGGAGGATCCGGAGGAGGTGGCTCCGGCGGCGGAGGATCTCGCGAGGGTCCCGAGCTTTCGCCCGACGATCCCGCCGGCCTCTTGGACCTGCGGCAGGGCATGTTTGCGCAGCTGGTGGCCCAAAATGTTCTGCTGATCGATGGGCCCCTGAGCTGGTACAGTGACCCAGGCCTGGCAGGCGTGTCCCTGACGGGGGGCCTGAGCTACAAAGAGGACACGAAGGAGCTGGTGGTGGCCAAGGCTGGAGTCTACTATGTCTTCTTTCAACTAGAGCTGCGGCGCGTGGTGGCCGGCGAGGGCTCAGGCTCCGTTTCACTTGCGCTGCACCTGCAGCCACTGCGCTCTGCTGCTGGGGCCGCCGCCCTGGCTTTGACCGTGGACCTGCCACCCGCCTCCTCCGAGGCTCGGAACTCGGCCTTCGGTTTCCAGGGCCGCTTGCTGCACCTGAGTGCCGGCCAGCGCCTGGGCGTCCATCTTCACACTGAGGCCAGGGCACGCCATGCCTGGCAGCTTACCCAGGGCGCCACAGTCTTGGGACTCTTCCGGGTGACCCCCGAAATCCCAGCCGGACTCCCTTCACCGAGGTCGGAA(SEQ ID NO:216)。
组合物/试剂盒
本文还提供包括本文所描述的任何多链嵌合多肽、任何细胞或任何核酸中的至少一种的组合物(例如,药物组合物)。在一些实施例中,组合物包括本文所描述的任何多链嵌合多肽中的至少一种。在一些实施例中,组合物包括免疫细胞中的任一种(例如,本文所描述的免疫细胞中的任一种,例如使用本文所描述的方法中的任一种产生的免疫细胞中的任一种)。
在一些实施例中,将药物组合物配制成用于不同的给药途径(例如,静脉内、皮下)。在一些实施例中,药物组合物可包括药学上可接受的载体(例如,磷酸盐缓冲盐水)。
可将药物组合物的单次或多次施用给予有需要的受试者,例如取决于:受试者所需和耐受的剂量和频率。配制物应提供足够量的活性剂以有效治疗、预防或改善病况、疾病或症状。
本文还提供试剂盒,其包括本文所描述的多链嵌合多肽、组合物、核酸或细胞(例如,免疫细胞)中的任一种。在一些实施例中,试剂盒可包括用于进行本文所描述的方法中的任一种的说明书。在一些实施例中,试剂盒可包括至少一个剂量的本文所描述的药物组合物中的任一种。
核酸/载体
本文还提供编码本文所描述的多链嵌合多肽中的任一种的核酸。在一些实施例中,第一核酸可编码第一嵌合多肽,并且第二核酸可编码第二嵌合多肽。在一些实施例中,单个核酸可编码第一嵌合多肽和第二嵌合多肽两者。
本文还提供载体,其包括编码本文所描述的多链嵌合多肽中的任一种的核酸中的任一种。在一些实施例中,第一载体可包括编码第一嵌合多肽的核酸,并且第二载体可包括编码第二嵌合多肽的核酸。在一些实施例中,单个载体可包括编码第一嵌合多肽的第一核酸和编码第二嵌合多肽的第二核酸。
本文所描述的载体中的任一种可为表达载体。例如,表达载体可包括与编码第一嵌合多肽和第二嵌合多肽的序列可操作地连接的启动子序列。
载体的非限制性实例包括质粒、转座子、粘粒和病毒载体(例如,任何腺病毒载体(例如,pSV或pCMV载体)、腺相关病毒(AAV)载体、慢病毒载体和逆转录病毒载体)和任何 载体。载体可例如包括足够的用于表达的顺式作用元件;其它表达元件可由宿主哺乳动物细胞或在体外表达系统中提供。熟练从业人员将能够选择合适的载体和哺乳动物细胞以制备本文所描述的多链嵌合多肽中的任一种。
载体。载体可例如包括足够的用于表达的顺式作用元件;其它表达元件可由宿主哺乳动物细胞或在体外表达系统中提供。熟练从业人员将能够选择合适的载体和哺乳动物细胞以制备本文所描述的多链嵌合多肽中的任一种。
细胞
本文还提供细胞(例如,本文所描述或本领域已知的示例性细胞中的任一种),其包含编码本文所描述的多链嵌合多肽中的任一种(例如,编码第一和第二嵌合多肽两者)的本文所描述的核酸中的任一种。本文还提供细胞(例如,本文所描述或本领域已知的示例性细胞中的任一种),其包含编码本文所描述的第一嵌合多肽中的任一种的本文所描述的核酸中的任一种。还提供细胞(例如,本文所描述或本领域已知的示例性细胞中的任一种),其包含编码本文所描述的第二嵌合多肽中的任一种的本文所描述的核酸中的任一种。
本文还提供细胞(例如,本文所描述或本领域已知的示例性细胞中的任一种),其包括编码本文所描述的多链嵌合多肽中的任一种(例如,编码第一和第二嵌合多肽两者)的本文所描述的载体中的任一种。本文还提供细胞(例如,本文所描述或本领域已知的示例性细胞中的任一种),其包括编码本文所描述的第一嵌合多肽中的任一种的本文所描述的载体中的任一种。本文还提供细胞(例如,本文所描述或本领域已知的示例性细胞中的任一种),其包括编码本文所描述的第二嵌合多肽中的任一种的本文所描述的载体中的任一种。
在本文所描述的方法中的任一种的一些实施例中,细胞可为真核细胞。如本文所用,术语“真核细胞”是指具有明显的膜结合核的细胞。这类细胞可包括例如哺乳动物(例如,啮齿动物、非人灵长类动物或人)、昆虫、真菌或植物细胞。在一些实施例中,真核细胞是酵母细胞,如啤酒酵母。在一些实施例中,真核细胞是高级真核生物,如哺乳动物、禽类、植物或昆虫细胞。哺乳动物细胞的非限制性实例包括中国仓鼠卵巢细胞和人胚胎肾细胞(例如,HEK293细胞)。
将核酸和表达载体引入到细胞(例如,真核细胞)中的方法是本领域已知的。可用于将核酸引入到细胞中的方法的非限制性实例包括脂质转染、转染、电穿孔、显微注射、磷酸钙转染、基于树状大分子的转染、阳离子聚合物转染、细胞挤压、声致穿孔、光学转染、刺穿感染、流体动力学递送、磁转染、病毒转导(例如,腺病毒和慢病毒转导)和纳米颗粒转染。
产生多链嵌合多肽的方法
本文还提供产生本文所描述的多链嵌合多肽中的任一种的方法,其包括在足以引起产生多链嵌合多肽的条件下在培养基中培养本文所描述的细胞中的任一种;和从细胞和/或培养基中回收多链嵌合多肽。
本文还提供产生本文所描述的多链嵌合多肽中的任一种的方法,其包括:在足以引起产生第一嵌合多肽的条件下在第一培养基中培养本文所描述的细胞中的任一种;从细胞和/或第一培养基中回收第一嵌合多肽;在足以引起产生第二嵌合多肽的条件下,在第二培养基中培养本文所描述的细胞中的任一种;从细胞和/或第二培养基中回收第二嵌合多肽;将回收的第一嵌合多肽和回收的第二嵌合多肽组合(例如,混合)以形成多链嵌合多肽(例如,本文所描述的多链嵌合多肽中的任一种)。
可使用本领域众所周知的技术(例如,硫酸铵沉淀、聚乙二醇沉淀、离子交换色谱法(阴离子或阳离子)、基于疏水相互作用的色谱法、金属亲和色谱法、配体亲和色谱法和尺寸排阻色谱法)从细胞(例如,真核细胞)中回收多链嵌合多肽、第一嵌合多肽或第二嵌合多肽。
培养细胞的方法是本领域众所周知的。可将细胞在有利于增殖、分化和生长的条件下体外维持。简单来说,可通过使细胞(例如,任何细胞)与细胞培养基接触来培养细胞,所述细胞培养基包括必需的生长因子和补充剂以支持细胞活力和生长。
本文还提供通过本文所描述的方法中的任一种产生的多链嵌合多肽(例如,本文所描述的多链嵌合多肽中的任一种)、第一嵌合多肽(例如,第一嵌合多肽中的任一种)或第二嵌合多肽(例如,第二嵌合多肽中的任一种)。
刺激免疫细胞的方法
本文还提供刺激免疫细胞(例如,本文所描述或本领域已知的示例性免疫细胞中的任一种)的方法,其包括使免疫细胞与有效量的本文所描述的多链嵌合多肽中的任一种或本文所描述的组合物(例如,药物组合物)中的任一种接触。在一些实例中,免疫细胞在体外接触(例如,在足以引起对免疫细胞的刺激的条件下在合适的液体培养基中)。
在一些实例中,免疫细胞先前已获自受试者(例如,哺乳动物,例如人)。这些方法的一些实施例进一步包括在接触步骤之前从受试者获得免疫细胞。
在一些实例中,免疫细胞在体内接触。在这类实施例中,将多链嵌合多肽以足以引起对受试者中的免疫细胞的刺激的量施用于受试者(例如,哺乳动物,例如人)。
在本文所描述的任何方法的一些实例中,免疫细胞可为未成熟胸腺细胞、外周血淋巴细胞、初始T细胞、多能Th细胞前体、淋巴祖细胞、Treg细胞、记忆T细胞、Th17细胞、Th22细胞、Th9细胞、Th2细胞、Th1细胞、Th3细胞、γδT细胞、αβT细胞、肿瘤浸润性T细胞、CD8+T细胞、CD4+T细胞、自然杀伤T细胞、肥大细胞、巨噬细胞、嗜中性粒细胞、树突状细胞、嗜碱性粒细胞、嗜酸性粒细胞或自然杀伤细胞或其组合。
在一些实例中,免疫细胞先前已经过基因修饰以表达嵌合抗原受体或重组T细胞受体。在一些实例中,免疫细胞(例如,本文所描述的免疫细胞中的任一种)先前已经过基因修饰以表达共刺激分子(例如,CD28)。
这些方法的一些实施例可进一步包括在接触步骤之后,将编码嵌合抗原受体或重组T细胞受体的核酸引入到免疫细胞(例如,本文所描述的免疫细胞中的任一种)中。这些方法的一些实施例可进一步包括在接触步骤之后,将编码共刺激分子(例如,CD28)的核酸引入到免疫细胞(例如,本文所描述的免疫细胞中的任一种)中。
这些方法的一些实施例可进一步包括将治疗有效量的免疫细胞施用于有需要的受试者(例如,本文所描述的示例性受试者中的任一种)。
在一些实例中,受试者可为被鉴别或诊断为患有与年龄相关的疾病或病况的受试者。与年龄相关的疾病或病症的非限制性实例包括:阿尔茨海默氏病、动脉瘤、囊性纤维化、胰腺炎纤维化、青光眼、高血压、特发性肺纤维化、炎性肠病、椎间盘退变、黄斑变性、骨关节炎、2型糖尿病、脂肪萎缩、脂肪营养不良、动脉粥样硬化、白内障、COPD、特发性肺纤维化、肾移植失败、肝纤维化、骨量损失、心肌梗死、肌肉减少症、伤口愈合、脱发、心肌细胞肥大、骨关节炎、帕金森氏病、与年龄相关的肺组织弹性丧失、黄斑变性、恶病质、肾小球硬化、肝硬化、NAFLD、骨质疏松症、肌萎缩性侧索硬化症、亨廷顿氏病、脊髓小脑共济失调、多发性硬化症和肾功能不全。
在一些实例中,受试者可为已被鉴别或诊断为患有癌症的受试者。癌症的非限制性实例包括:实体肿瘤、血液肿瘤、肉瘤、骨肉瘤、成胶质细胞瘤、成神经细胞瘤、黑色素瘤、横纹肌肉瘤、尤文氏肉瘤、骨肉瘤、B细胞瘤、多发性骨髓瘤、B细胞淋巴瘤、B细胞非霍奇金氏淋巴瘤、霍奇金氏淋巴瘤、慢性淋巴细胞性白血病(CLL)、急性骨髓性白血病(AML)、慢性骨髓性白血病(CML)、急性淋巴细胞性白血病(ALL)、骨髓增生异常综合症(MDS)、皮肤T细胞淋巴瘤、成视网膜细胞瘤、胃癌、尿路上皮癌、肺癌、肾细胞癌、胃和食管癌、胰腺癌、前列腺癌、乳腺癌、结直肠癌、卵巢癌、非小细胞肺癌、鳞状细胞头颈癌、子宫内膜癌、宫颈癌、肝癌和肝细胞癌。
在一些实例中,受试者可为已被诊断或鉴别为患有感染性疾病的受试者。感染性疾病的非限制性实例包括感染人免疫缺陷病毒、巨细胞病毒、腺病毒、冠状病毒、鼻病毒、轮状病毒、天花、单纯疱疹病毒、乙型肝炎病毒、甲型肝炎病毒和丙型肝炎病毒、乳头瘤病毒或流感病毒。
可使用本领域已知的方法来确定免疫细胞的激活。例如,可通过检测在免疫细胞激活后分泌的细胞因子和趋化因子的水平或上调的细胞毒性颗粒和调节分子的水平来确定免疫细胞的激活。在免疫细胞激活后分泌或上调的细胞因子、趋化因子、细胞毒性颗粒和调节分子的非限制性实例包括:IL-2、IFN-γ、IL-1、IL-4、IL-5、IL-6、IL-7、IL-9、IL-10、IL-12、IL-13、IL-15、IL-17、IL-18、IL-22、IL-33、白三烯B4、CCL5、TNFα、颗粒酶、穿孔素、TGFβ、STAT3、STAT4、STAT5、RORγT、FOXP3、STAT6和GATA3。这些细胞因子、趋化因子、细胞毒性颗粒或调节分子的检测可使用免疫分析(例如,酶联免疫吸附分析)和定量PCR进行。例如,免疫细胞的激活可引起增加约1%至约800%(例如,约1%至约750%,约1%至约700%,约1%至约650%,约1%至约600%,约1%至约550%,约1%至约500%,约1%至约450%,约1%至约400%,约1%至约350%,约1%至约300%,约1%至约280%,约1%至约260%,约1%至约240%,约1%至约220%,约1%至约200%,约1%至约180%,约1%至约160%,约1%至约140%,约1%至约120%,约1%至约100%,约1%至约90%,约1%至约80%,约1%至约70%,约1%至约60%,约1%至约50%,约1%至约45%,约1%至约40%,约1%至约35%,约1%至约30%,约1%至约25%,约1%至约20%,约1%至约15%,约1%至约10%,约1%至约5%,约5%至约800%,约5%至约750%,约5%至约700%,约5%至约650%,约5%至约600%,约5%至约550%,约5%至约500%,约5%至约450%,约5%至约400%,约5%至约350%,约5%至约300%,约5%至约280%,约5%至约260%,约5%至约240%,约5%至约220%,约5%至约200%,约5%至约180%,约5%至约160%,约5%至约140%,约5%至约120%,约5%至约100%,约5%至约90%,约5%至约80%,约5%至约70%,约5%至约60%,约5%至约50%,约5%至约45%,约5%至约40%,约5%至约35%,约5%至约30%,约5%至约25%,约5%至约20%,约5%至约15%,约5%至约10%,约10%至约800%,约10%至约750%,约10%至约700%,约10%至约650%,约10%至约600%,约10%至约550%,约10%至约500%,约10%至约450%,约10%至约400%,约10%至约350%,约10%至约300%,约10%至约280%,约10%至约260%,约10%至约240%,约10%至约220%,约10%至约200%,约10%至约180%,约10%至约160%,约10%至约140%,约10%至约120%,约10%至约100%,约10%至约90%,约10%至约80%,约10%至约70%,约10%至约60%,约10%至约50%,约10%至约45%,约10%至约40%,约10%至约35%,约10%至约30%,约10%至约25%,约10%至约20%,约10%至约15%,约15%至约800%,约15%至约750%,约15%至约700%,约15%至约650%,约15%至约600%,约15%至约550%,约15%至约500%,约15%至约450%,约15%至约400%,约15%至约350%,约15%至约300%,约15%至约280%,约15%至约260%,约15%至约240%,约15%至约220%,约15%至约200%,约15%至约180%,约15%至约160%,约15%至约140%,约15%至约120%,约15%至约100%,约15%至约90%,约15%至约80%,约15%至约70%,约15%至约60%,约15%至约50%,约15%至约45%,约15%至约40%,约15%至约35%,约15%至约30%,约15%至约25%,约15%至约20%,约20%至约800%,约20%至约750%,约20%至约700%,约20%至约650%,约20%至约600%,约20%至约550%,约20%至约500%,约20%至约450%,约20%至约400%,约20%至约350%,约20%至约300%,约20%至约280%,约20%至约260%,约20%至约240%,约20%至约220%,约20%至约200%,约20%至约180%,约20%至约160%,约20%至约140%,约20%至约120%,约20%至约100%,约20%至约90%,约20%至约80%,约20%至约70%,约20%至约60%,约20%至约50%,约20%至约45%,约20%至约40%,约20%至约35%,约20%至约30%,约20%至约25%,约25%至约800%,约25%至约750%,约25%至约700%,约25%至约650%,约25%至约600%,约25%至约550%,约25%至约500%,约25%至约450%,约25%至约400%,约25%至约350%,约25%至约300%,约25%至约280%,约25%至约260%,约25%至约240%,约25%至约220%,约25%至约200%,约25%至约180%,约25%至约160%,约25%至约140%,约25%至约120%,约25%至约100%,约25%至约90%,约25%至约80%,约25%至约70%,约25%至约60%,约25%至约50%,约25%至约45%,约25%至约40%,约25%至约35%,约35%至约800%,约35%至约750%,约35%至约700%,约35%至约650%,约35%至约600%,约35%至约550%,约35%至约500%,约35%至约450%,约35%至约400%,约35%至约350%,约35%至约300%,约35%至约280%,约35%至约260%,约35%至约240%,约35%至约220%,约35%至约200%,约35%至约180%,约35%至约160%,约35%至约140%,约35%至约120%,约35%至约100%,约35%至约90%,约35%至约80%,约35%至约70%,约35%至约60%,约35%至约50%,约35%至约45%,约35%至约40%,约40%至约800%,约40%至约750%,约40%至约700%,约40%至约650%,约40%至约600%,约40%至约550%,约40%至约500%,约40%至约450%,约40%至约400%,约40%至约350%,约40%至约300%,约40%至约280%,约40%至约260%,约40%至约240%,约40%至约220%,约40%至约200%,约40%至约180%,约40%至约160%,约40%至约140%,约40%至约120%,约40%至约100%,约40%至约90%,约40%至约80%,约40%至约70%,约40%至约60%,约40%至约50%,约40%至约45%,约45%至约800%,约45%至约750%,约45%至约700%,约45%至约650%,约45%至约600%,约45%至约550%,约45%至约500%,约45%至约450%,约45%至约400%,约45%至约350%,约45%至约300%,约45%至约280%,约45%至约260%,约45%至约240%,约45%至约220%,约45%至约200%,约45%至约180%,约45%至约160%,约45%至约140%,约45%至约120%,约45%至约100%,约45%至约90%,约45%至约80%,约45%至约70%,约45%至约60%,约45%至约50%,约50%至约800%,约50%至约750%,约50%至约700%,约50%至约650%,约50%至约600%,约50%至约550%,约50%至约500%,约50%至约450%,约50%至约400%,约50%至约350%,约50%至约300%,约50%至约280%,约50%至约260%,约50%至约240%,约50%至约220%,约50%至约200%,约50%至约180%,约50%至约160%,约50%至约140%,约50%至约120%,约50%至约100%,约50%至约90%,约50%至约80%,约50%至约70%,约50%至约60%,约60%至约800%,约60%至约750%,约60%至约700%,约60%至约650%,约60%至约600%,约60%至约550%,约60%至约500%,约60%至约450%,约60%至约400%,约60%至约350%,约60%至约300%,约60%至约280%,约60%至约260%,约60%至约240%,约60%至约220%,约60%至约200%,约60%至约180%,约60%至约160%,约60%至约140%,约60%至约120%,约60%至约100%,约60%至约90%,约60%至约80%,约60%至约70%,约70%至约800%,约70%至约750%,约70%至约700%,约70%至约650%,约70%至约600%,约70%至约550%,约70%至约500%,约70%至约450%,约70%至约400%,约70%至约350%,约70%至约300%,约70%至约280%,约70%至约260%,约70%至约240%,约70%至约220%,约70%至约200%,约70%至约180%,约70%至约160%,约70%至约140%,约70%至约120%,约70%至约100%,约70%至约90%,约70%至约80%,约80%至约800%,约80%至约750%,约80%至约700%,约80%至约650%,约80%至约600%,约80%至约550%,约80%至约500%,约80%至约450%,约80%至约400%,约80%至约350%,约80%至约300%,约80%至约280%,约80%至约260%,约80%至约240%,约80%至约220%,约80%至约200%,约80%至约180%,约80%至约160%,约80%至约140%,约80%至约120%,约80%至约100%,约80%至约90%,约90%至约800%,约90%至约750%,约90%至约700%,约90%至约650%,约90%至约600%,约90%至约550%,约90%至约500%,约90%至约450%,约90%至约400%,约90%至约350%,约90%至约300%,约90%至约280%,约90%至约260%,约90%至约240%,约90%至约220%,约90%至约200%,约90%至约180%,约90%至约160%,约90%至约140%,约90%至约120%,约90%至约100%,约100%至约800%,约100%至约750%,约100%至约700%,约100%至约650%,约100%至约600%,约100%至约550%,约100%至约500%,约100%至约450%,约100%至约400%,约100%至约350%,约100%至约300%,约100%至约280%,约100%至约260%,约100%至约240%,约100%至约220%,约100%至约200%,约100%至约180%,约100%至约160%,约100%至约140%,约100%至约120%,约120%至约800%,约120%至约750%,约120%至约700%,约120%至约650%,约120%至约600%,约120%至约550%,约120%至约500%,约120%至约450%,约120%至约400%,约120%至约350%,约120%至约300%,约120%至约280%,约120%至约260%,约120%至约240%,约120%至约220%,约120%至约200%,约120%至约180%,约120%至约160%,约120%至约140%,约140%至约800%,约140%至约750%,约140%至约700%,约140%至约650%,约140%至约600%,约140%至约550%,约140%至约500%,约140%至约450%,约140%至约400%,约140%至约350%,约140%至约300%,约140%至约280%,约140%至约260%,约140%至约240%,约140%至约220%,约140%至约200%,约140%至约180%,约140%至约160%,约160%至约800%,约160%至约750%,约160%至约700%,约160%至约650%,约160%至约600%,约160%至约550%,约160%至约500%,约160%至约450%,约160%至约400%,约160%至约350%,约160%至约300%,约160%至约280%,约160%至约260%,约160%至约240%,约160%至约220%,约160%至约200%,约160%至约180%,约180%至约800%,约180%至约750%,约180%至约700%,约180%至约650%,约180%至约600%,约180%至约550%,约180%至约500%,约180%至约450%,约180%至约400%,约180%至约350%,约180%至约300%,约180%至约280%,约180%至约260%,约180%至约240%,约180%至约220%,约180%至约200%,约200%至约800%,约200%至约750%,约200%至约700%,约200%至约650%,约200%至约600%,约200%至约550%,约200%至约500%,约200%至约450%,约200%至约400%,约200%至约350%,约200%至约300%,约200%至约280%,约200%至约260%,约200%至约240%,约200%至约220%,约220%至约800%,约220%至约750%,约220%至约700%,约220%至约650%,约220%至约600%,约220%至约550%,约220%至约500%,约220%至约450%,约220%至约400%,约220%至约350%,约220%至约300%,约220%至约280%,约220%至约260%,约220%至约240%,约240%至约800%,约240%至约750%,约240%至约700%,约240%至约650%,约240%至约600%,约240%至约550%,约240%至约500%,约240%至约450%,约240%至约400%,约240%至约350%,约240%至约300%,约240%至约280%,约240%至约260%,约260%至约800%,约260%至约750%,约260%至约700%,约260%至约650%,约260%至约600%,约260%至约550%,约260%至约500%,约260%至约450%,约260%至约400%,约260%至约350%,约260%至约300%,约260%至约280%,约280%至约800%,约280%至约750%,约280%至约700%,约280%至约650%,约280%至约600%,约280%至约550%,约280%至约500%,约280%至约450%,约280%至约400%,约280%至约350%,约280%至约300%,约300%至约800%,约300%至约750%,约300%至约700%,约300%至约650%,约300%至约600%,约300%至约550%,约300%至约500%,约300%至约450%,约300%至约400%,约300%至约350%,约350%至约800%,约350%至约750%,约350%至约700%,约350%至约650%,约350%至约600%,约350%至约550%,约350%至约500%,约350%至约450%,约350%至约400%,约400%至约800%,约400%至约750%,约400%至约700%,约400%至约650%,约400%至约600%,约400%至约550%,约400%至约500%,约400%至约450%,约450%至约800%,约450%至约750%,约450%至约700%,约450%至约650%,约450%至约600%,约450%至约550%,约450%至约500%,约500%至约800%,约500%至约750%,约500%至约700%,约500%至约650%,约500%至约600%,约500%至约550%,约550%至约800%,约550%至约750%,约550%至约700%,约550%至约650%,约550%至约600%,约600%至约800%,约600%至约750%,约600%至约700%,约600%至约650%,约650%至约800%,约650%至约750%,约650%至约700%,约700%至约800%,约700%至约750%或约750%至约800%)本文所描述的任何细胞因子或趋化因子或细胞毒性颗粒或调节分子中的一种或多种(例如,IL-2、IFN-γ、IL-1、IL-4、IL-5、IL-6、IL-7、IL-9、IL-10、IL-12、IL-13、IL-15、IL-17、IL-18、IL-22、IL-33、白三烯B4、CCL5、TNFα、颗粒酶、穿孔素、TGFβ、STAT3、STAT4、STAT5、RORγT、FOXP3和GATA3)(例如,与未与本文所描述的多链嵌合多肽中的任一种接触的对照中的一种或多种细胞因子、趋化因子、细胞毒性颗粒和调节分子的水平相比)。
诱导或增加免疫细胞增殖的方法
本文还提供诱导或增加免疫细胞(例如,本文所描述或本领域已知的示例性免疫细胞中的任一种)增殖的方法,其包括使免疫细胞与有效量的本文所描述的多链嵌合多肽中的任一种或本文所描述的组合物(例如,药物组合物)中的任一种接触。在一些实例中,免疫细胞在体外接触(例如,在足以引起对免疫细胞的刺激的条件下在合适的液体培养基中)。
在一些实例中,免疫细胞先前已获自受试者(例如,哺乳动物,例如人)。这些方法的一些实施例进一步包括在接触步骤之前从受试者获得免疫细胞。
在一些实例中,免疫细胞在体内接触。在这类实施例中,将多链嵌合多肽以足以引起对受试者中的免疫细胞的刺激的量施用于受试者(例如,哺乳动物,例如人)。
在本文所描述的任何方法的一些实例中,免疫细胞可为未成熟胸腺细胞、外周血淋巴细胞、初始T细胞、多能Th细胞前体、淋巴祖细胞、Treg细胞、记忆T细胞、Th17细胞、Th22细胞、Th9细胞、Th2细胞、Th1细胞、Th3细胞、γδT细胞、αβT细胞、肿瘤浸润性T细胞、CD8+T细胞、CD4+T细胞、自然杀伤T细胞、肥大细胞、巨噬细胞、嗜中性粒细胞、树突状细胞、嗜碱性粒细胞、嗜酸性粒细胞或自然杀伤细胞或其组合。
在一些实例中,免疫细胞先前已经过基因修饰以表达嵌合抗原受体或重组T细胞受体。在一些实例中,免疫细胞(例如,本文所描述的免疫细胞中的任一种)先前已经过基因修饰以表达共刺激分子(例如,CD28)。
这些方法的一些实施例可进一步包括在接触步骤之后,将编码嵌合抗原受体或重组T细胞受体的核酸引入到免疫细胞(例如,本文所描述的免疫细胞中的任一种)中。这些方法的一些实施例可进一步包括在接触步骤之后,将编码共刺激分子(例如,CD28)的核酸引入到免疫细胞(例如,本文所描述的免疫细胞中的任一种)中。
这些方法的一些实施例可进一步包括将治疗有效量的免疫细胞施用于有需要的受试者(例如,本文所描述的示例性受试者中的任一种)。
在一些实例中,受试者可为被鉴别或诊断为患有与年龄相关的疾病或病况的受试者。与年龄相关的疾病或病症的非限制性实例包括:阿尔茨海默氏病、动脉瘤、囊性纤维化、胰腺炎纤维化、青光眼、高血压、特发性肺纤维化、炎性肠病、椎间盘退变、黄斑变性、骨关节炎、2型糖尿病、脂肪萎缩、脂肪营养不良、动脉粥样硬化、白内障、COPD、特发性肺纤维化、肾移植失败、肝纤维化、骨量损失、心肌梗死、肌肉减少症、伤口愈合、脱发、心肌细胞肥大、骨关节炎、帕金森氏病、与年龄相关的肺组织弹性丧失、黄斑变性、恶病质、肾小球硬化、肝硬化、NAFLD、骨质疏松症、肌萎缩性侧索硬化症、亨廷顿氏病、脊髓小脑共济失调、多发性硬化症和肾功能不全。
在一些实例中,受试者可为已被鉴别或诊断为患有癌症的受试者。癌症的非限制性实例包括:实体肿瘤、血液肿瘤、肉瘤、骨肉瘤、成胶质细胞瘤、成神经细胞瘤、黑色素瘤、横纹肌肉瘤、尤文氏肉瘤、骨肉瘤、B细胞瘤、多发性骨髓瘤、B细胞淋巴瘤、B细胞非霍奇金氏淋巴瘤、霍奇金氏淋巴瘤、慢性淋巴细胞性白血病(CLL)、急性骨髓性白血病(AML)、慢性骨髓性白血病(CML)、急性淋巴细胞性白血病(ALL)、骨髓增生异常综合症(MDS)、皮肤T细胞淋巴瘤、成视网膜细胞瘤、胃癌、尿路上皮癌、肺癌、肾细胞癌、胃和食管癌、胰腺癌、前列腺癌、乳腺癌、结直肠癌、卵巢癌、非小细胞肺癌、鳞状细胞头颈癌、子宫内膜癌、宫颈癌、肝癌和肝细胞癌。
在一些实例中,受试者可为已被诊断或鉴别为患有感染性疾病的受试者。感染性疾病的非限制性实例包括感染人免疫缺陷病毒、巨细胞病毒、腺病毒、冠状病毒、鼻病毒、轮状病毒、天花、单纯疱疹病毒、乙型肝炎病毒、甲型肝炎病毒和丙型肝炎病毒、乳头瘤病毒或流感病毒。
免疫细胞增殖的检测可使用本领域已知的方法进行,例如流式细胞术(例如,荧光辅助流式细胞术)、显微镜检查和免疫荧光显微镜检查,例如通过将未经多链嵌合多肽接触的样品中免疫细胞浓度的增加速率与经本文所描述的多链嵌合多肽中的任一种接触的相似样品中的免疫细胞浓度增加的速率进行比较来进行)。在其它实例中,免疫细胞的增殖可通过检测由增殖免疫细胞分泌或上调的一种或多种细胞因子或趋化因子或细胞毒性颗粒或调节性分子(例如,IL-2、IFN-γ、IL-1、IL-4、IL-5、IL-6、IL-7、IL-9、IL-10、IL-12、IL-13、IL-15、IL-17、IL-18、IL-22、IL-33、白三烯B4、CCL5、TNFα、颗粒酶、穿孔素、TGFβ、STAT3、STAT4、STAT5、RORγT、FOXP3和GATA3中的一种或多种)水平的提高(例如,与未与本文所描述的多链嵌合多肽中的任一种接触的对照中的一种或多种细胞因子、趋化因子、细胞毒性颗粒和调节分子的水平相比)而间接检测。
在一些实施例中,本文提供的方法可引起与不与本文所描述的多链嵌合多肽中的任一种接触的类似对照样品中免疫细胞浓度的增加速率相比,与本文所描述的多链嵌合多肽中的任一种接触的样品中免疫细胞浓度的增加速率增加(例如,约1%至约800%增加或本文所描述的这一范围的任何子范围)。
诱导免疫细胞分化的方法
本文还提供诱导免疫细胞(例如,本文所描述或本领域已知的示例性免疫细胞中的任一种)分化成记忆或记忆样免疫细胞的方法,其包括使免疫细胞与有效量的本文所描述的多链嵌合多肽中的任一种或本文所描述的组合物(例如,药物组合物)中的任一种接触。在一些实例中,免疫细胞在体外接触(例如,在足以引起对免疫细胞的刺激的条件下在合适的液体培养基中)。
在一些实例中,免疫细胞先前已获自受试者(例如,哺乳动物,例如人)。这些方法的一些实施例进一步包括在接触步骤之前从受试者获得免疫细胞。
在一些实例中,免疫细胞在体内接触。在这类实施例中,将多链嵌合多肽以足以引起对受试者中的免疫细胞的刺激的量施用于受试者(例如,哺乳动物,例如人)。
在本文所描述的任何方法的一些实例中,免疫细胞可为未成熟胸腺细胞、外周血淋巴细胞、初始T细胞、多能Th细胞前体、淋巴祖细胞、Treg细胞、Th17细胞、Th22细胞、Th9细胞、Th2细胞、Th1细胞、Th3细胞、γδT细胞、αβT细胞、肿瘤浸润性T细胞、CD8+T细胞、CD4+T细胞、自然杀伤T细胞、肥大细胞、巨噬细胞、嗜中性粒细胞、树突状细胞、嗜碱性粒细胞、嗜酸性粒细胞或自然杀伤细胞或其组合。
在一些实例中,免疫细胞先前已经过基因修饰以表达嵌合抗原受体或重组T细胞受体。在一些实例中,免疫细胞(例如,本文所描述的免疫细胞中的任一种)先前已经过基因修饰以表达共刺激分子(例如,CD28)。
在一些实例中,将有效量的本文所描述的多链嵌合多肽中的任一种或本文所描述的组合物(例如,药物组合物)中的任一种与抗TF IgG1抗体组合以产生记忆或记忆样免疫细胞。
这些方法的一些实施例可进一步包括在接触步骤之后,将编码嵌合抗原受体或重组T细胞受体的核酸引入到免疫细胞(例如,本文所描述的免疫细胞中的任一种)中。这些方法的一些实施例可进一步包括在接触步骤之后,将编码共刺激分子(例如,CD28)的核酸引入到免疫细胞(例如,本文所描述的免疫细胞中的任一种)中。
这些方法的一些实施例可进一步包括将治疗有效量的免疫细胞施用于有需要的受试者(例如,本文所描述的示例性受试者中的任一种)。
在一些实例中,受试者可为被鉴别或诊断为患有与年龄相关的疾病或病况的受试者。与年龄相关的疾病或病症的非限制性实例包括:阿尔茨海默氏病、动脉瘤、囊性纤维化、胰腺炎纤维化、青光眼、高血压、特发性肺纤维化、炎性肠病、椎间盘退变、黄斑变性、骨关节炎、2型糖尿病、脂肪萎缩、脂肪营养不良、动脉粥样硬化、白内障、COPD、特发性肺纤维化、肾移植失败、肝纤维化、骨量损失、心肌梗死、肌肉减少症、伤口愈合、脱发、心肌细胞肥大、骨关节炎、帕金森氏病、与年龄相关的肺组织弹性丧失、黄斑变性、恶病质、肾小球硬化、肝硬化、NAFLD、骨质疏松症、肌萎缩性侧索硬化症、亨廷顿氏病、脊髓小脑共济失调、多发性硬化症和肾功能不全。
在一些实例中,受试者可为已被鉴别或诊断为患有癌症的受试者。癌症的非限制性实例包括:实体肿瘤、血液肿瘤、肉瘤、骨肉瘤、成胶质细胞瘤、成神经细胞瘤、黑色素瘤、横纹肌肉瘤、尤文氏肉瘤、骨肉瘤、B细胞瘤、多发性骨髓瘤、B细胞淋巴瘤、B细胞非霍奇金氏淋巴瘤、霍奇金氏淋巴瘤、慢性淋巴细胞性白血病(CLL)、急性骨髓性白血病(AML)、慢性骨髓性白血病(CML)、急性淋巴细胞性白血病(ALL)、骨髓增生异常综合症(MDS)、皮肤T细胞淋巴瘤、成视网膜细胞瘤、胃癌、尿路上皮癌、肺癌、肾细胞癌、胃和食管癌、胰腺癌、前列腺癌、乳腺癌、结直肠癌、卵巢癌、非小细胞肺癌、鳞状细胞头颈癌、子宫内膜癌、宫颈癌、肝癌和肝细胞癌。
在一些实例中,受试者可为已被诊断或鉴别为患有感染性疾病的受试者。感染性疾病的非限制性实例包括感染人免疫缺陷病毒、巨细胞病毒、腺病毒、冠状病毒、鼻病毒、轮状病毒、天花、单纯疱疹病毒、乙型肝炎病毒、甲型肝炎病毒和丙型肝炎病毒、乳头瘤病毒或流感病毒。
在一些实例中,免疫细胞是NK细胞,并且记忆NK细胞的检测可包括例如检测IL-12、IL-18、IL-33、CD25、CD69、CD62L、STAT4、Zbtb32、DNAM-1、NKp30、NKp44、NKp46、BIM、Noxa、SOCS1、BNIP3、BNIP3L、IFN-γ、CXCL16、CXCR6、NKG2D、TRAIL、CD49、Ly49D、CD49b和Ly79H中的一种或多种的水平。O'Sullivan等人,《免疫》43:634-645,2015中描述对NK记忆细胞和其检测方法的描述。
在一些实例中,免疫细胞是T细胞,并且记忆T细胞的检测可包括例如检测CD45RO、CCR7、L-选择蛋白(CD62L)、CD44、CD45RA、整联蛋白αeβ7、CD43、CD27、CD28、IL-7Rα、CD95、IL-2Rβ、CXCR3和LFA-1中的一种或多种的表达水平。在一些实例中,免疫细胞是B细胞,并且记忆B细胞的检测可包括例如CD27表达水平的检测。记忆或记忆样免疫细胞的其它类型和标记是本领域已知的。
治疗方法
本文还提供治疗有需要的受试者(例如,本文所描述或本领域已知的示例性受试者中的任一种)的方法,其包括向受试者施用治疗有效量的本文所描述的多链嵌合多肽中的任一种或本文所描述的组合物(例如,药物组合物)中的任一种。
在这些方法的一些实施例中,受试者已被鉴别或诊断为患有癌症。癌症的非限制性实例包括:实体肿瘤、血液肿瘤、肉瘤、骨肉瘤、成胶质细胞瘤、成神经细胞瘤、黑色素瘤、横纹肌肉瘤、尤文氏肉瘤、骨肉瘤、B细胞瘤、多发性骨髓瘤、B细胞淋巴瘤、B细胞非霍奇金氏淋巴瘤、霍奇金氏淋巴瘤、慢性淋巴细胞性白血病(CLL)、急性骨髓性白血病(AML)、慢性骨髓性白血病(CML)、急性淋巴细胞性白血病(ALL)、骨髓增生异常综合症(MDS)、皮肤T细胞淋巴瘤、成视网膜细胞瘤、胃癌、尿路上皮癌、肺癌、肾细胞癌、胃和食管癌、胰腺癌、前列腺癌、乳腺癌、结直肠癌、卵巢癌、非小细胞肺癌、鳞状细胞头颈癌、子宫内膜癌、宫颈癌、肝癌和肝细胞癌。在一些实施例中,这些方法可引起受试者中癌症的一种或多种症状的数目、严重性或频率降低(例如,与治疗前受试者中癌症的一种或多种症状的数目、严重性或频率相比)。在一些实施例中,这些方法可引起受试者中一种或多种实体肿瘤的体积减少(例如,约1%减少至约99%减少,约1%减少至约95%减少,约1%减少至约90%减少,约1%减少至约85%减少,约1%减少至约80%减少,约1%减少至约75%减少,约1%减少至约70%减少,约1%减少至约65%减少,约1%减少至约60%减少,约1%减少至约55%减少,约1%减少至约50%减少,约1%减少至约45%减少,约1%减少至约40%减少,约1%减少至约35%减少,约1%减少至约30%减少,约1%减少至约25%减少,约1%减少至约20%减少,约1%减少至约15%减少,约1%减少至约10%减少,约1%减少至约5%减少,约5%减少至约99%减少,约5%减少至约95%减少,约5%减少至约90%减少,约5%减少至约85%减少,约5%减少至约80%减少,约5%减少至约75%减少,约5%减少至约70%减少,约5%减少至约65%减少,约5%减少至约60%减少,约5%减少至约55%减少,约5%减少至约50%减少,约5%减少至约45%减少,约5%减少至约40%减少,约5%减少至约35%减少,约5%减少至约30%减少,约5%减少至约25%减少,约5%减少至约20%减少,约5%减少至约15%减少,约5%减少至约10%减少,约10%减少至约99%减少,约10%减少至约95%减少,约10%减少至约90%减少,约10%减少至约85%减少,约10%减少至约80%减少,约10%减少至约75%减少,约10%减少至约70%减少,约10%减少至约65%减少,约10%减少至约60%减少,约10%减少至约55%减少,约10%减少至约50%减少,约10%减少至约45%减少,约10%减少至约40%减少,约10%减少至约35%减少,约10%减少至约30%减少,约10%减少至约25%减少,约10%减少至约20%减少,约10%减少至约15%减少,约15%减少至约99%减少,约15%减少至约95%减少,约15%减少至约90%减少,约15%减少至约85%减少,约15%减少至约80%减少,约15%减少至约75%减少,约15%减少至约70%减少,约15%减少至约65%减少,约15%减少至约60%减少,约15%减少至约55%减少,约15%减少至约50%减少,约15%减少至约45%减少,约15%减少至约40%减少,约15%减少至约35%减少,约15%减少至约30%减少,约15%减少至约25%减少,约15%减少至约20%减少,约20%减少至约99%减少,约20%减少至约95%减少,约20%减少至约90%减少,约20%减少至约85%减少,约20%减少至约80%减少,约20%减少至约75%减少,约20%减少至约70%减少,约20%减少至约65%减少,约20%减少至约60%减少,约20%减少至约55%减少,约20%减少至约50%减少,约20%减少至约45%减少,约20%减少至约40%减少,约20%减少至约35%减少,约20%减少至约30%减少,约20%减少至约25%减少,约25%减少至约99%减少,约25%减少至约95%减少,约25%减少至约90%减少,约25%减少至约85%减少,约25%减少至约80%减少,约25%减少至约75%减少,约25%减少至约70%减少,约25%减少至约65%减少,约25%减少至约60%减少,约25%减少至约55%减少,约25%减少至约50%减少,约25%减少至约45%减少,约25%减少至约40%减少,约25%减少至约35%减少,约25%减少至约30%减少,约30%减少至约99%减少,约30%减少至约95%减少,约30%减少至约90%减少,约30%减少至约85%减少,约30%减少至约80%减少,约30%减少至约75%减少,约30%减少至约70%减少,约30%减少至约65%减少,约30%减少至约60%减少,约30%减少至约55%减少,约30%减少至约50%减少,约30%减少至约45%减少,约30%减少至约40%减少,约30%减少至约35%减少,约35%减少至约99%减少,约35%减少至约95%减少,约35%减少至约90%减少,约35%减少至约85%减少,约35%减少至约80%减少,约35%减少至约75%减少,约35%减少至约70%减少,约35%减少至约65%减少,约35%减少至约60%减少,约35%减少至约55%减少,约35%减少至约50%减少,约35%减少至约45%减少,约35%减少至约40%减少,约40%减少至约99%减少,约40%减少至约95%减少,约40%减少至约90%减少,约40%减少至约85%减少,约40%减少至约80%减少,约40%减少至约75%减少,约40%减少至约70%减少,约40%减少至约65%减少,约40%减少至约60%减少,约40%减少至约55%减少,约40%减少至约50%减少,约40%减少至约45%减少,约45%减少至约99%减少,约45%减少至约95%减少,约45%减少至约90%减少,约45%减少至约85%减少,约45%减少至约80%减少,约45%减少至约75%减少,约45%减少至约70%减少,约45%减少至约65%减少,约45%减少至约60%减少,约45%减少至约55%减少,约45%减少至约50%减少,约50%减少至约99%减少,约50%减少至约95%减少,约50%减少至约90%减少,约50%减少至约85%减少,约50%减少至约80%减少,约50%减少至约75%减少,约50%减少至约70%减少,约50%减少至约65%减少,约50%减少至约60%减少,约50%减少至约55%减少,约55%减少至约99%减少,约55%减少至约95%减少,约55%减少至约90%减少,约55%减少至约85%减少,约55%减少至约80%减少,约55%减少至约75%减少,约55%减少至约70%减少,约55%减少至约65%减少,约55%减少至约60%减少,约60%减少至约99%减少,约60%减少至约95%减少,约60%减少至约90%减少,约60%减少至约85%减少,约60%减少至约80%减少,约60%减少至约75%减少,约60%减少至约70%减少,约60%减少至约65%减少,约65%减少至约99%减少,约65%减少至约95%减少,约65%减少至约90%减少,约65%减少至约85%减少,约65%减少至约80%减少,约65%减少至约75%减少,约65%减少至约70%减少,约70%减少至约99%减少,约70%减少至约95%减少,约70%减少至约90%减少,约70%减少至约85%减少,约70%减少至约80%减少,约70%减少至约75%减少,约75%减少至约99%减少,约75%减少至约95%减少,约75%减少至约90%减少,约75%减少至约85%减少,约75%减少至约80%减少,约80%减少至约99%减少,约80%减少至约95%减少,约80%减少至约90%减少,约80%减少至约85%减少,约85%减少至约99%减少,约85%减少至约95%减少,约85%减少至约90%减少,约90%减少至约99%减少,约90%减少至约95%减少或约95%减少至约99%减少)(例如,与治疗之前或治疗开始时一种或多种实体肿瘤的体积相比)。在一些实施例中,这些方法可减少(例如,约1%减少至约99%减少或本文所描述的这一范围的任何子范围)在受试者中发生转移或发生一种或多种另外的转移的风险(例如,与在治疗之前的受试者或施用不同治疗的相似受试者或受试者群体中发生转移或发生一种或多种另外的转移的风险相比)。
在这些方法的一些实例中,受试者已被鉴别或诊断为患有与老化相关的疾病或病况。与老化相关的疾病或病况的非限制性实例包括:阿尔茨海默氏病、动脉瘤、囊性纤维化、胰腺炎纤维化、青光眼、高血压、特发性肺纤维化、炎性肠病、椎间盘退变、黄斑变性、骨关节炎、2型糖尿病、脂肪萎缩、脂肪营养不良、动脉粥样硬化、白内障、COPD、特发性肺纤维化、肾移植失败、肝纤维化、骨量损失、心肌梗死、肌肉减少症、伤口愈合、脱发、心肌细胞肥大、骨关节炎、帕金森氏病、与年龄相关的肺组织弹性丧失、黄斑变性、恶病质、肾小球硬化、肝硬化、NAFLD、骨质疏松症、肌萎缩性侧索硬化症、亨廷顿氏病、脊髓小脑共济失调、多发性硬化症和肾功能不全。在一些实例中,这些方法可引起受试者中与老化相关的疾病或病况的一种或多种症状的数目、严重性或频率降低(例如,与治疗前受试者中与老化相关的疾病或病况的一种或多种症状的数目、严重性或频率相比)。在一些实例中,方法可引起例如与治疗前受试者中衰老细胞的数目相比,受试者中衰老细胞的数目降低(例如,受试者中与老化相关的疾病或病症中所涉及和/或牵涉的一种或多种特定组织中衰老细胞的数目降低)(例如,约1%降低至约99%降低,约1%降低至约95%降低,约1%降低至约90%降低,约1%降低至约85%降低,约1%降低至约80%降低,约1%降低至约75%降低,约1%降低至约70%降低,约1%降低至约65%降低,约1%降低至约60%降低,约1%降低至约55%降低,约1%降低至约50%降低,约1%降低至约45%降低,约1%降低至约40%降低,约1%降低至约35%降低,约1%降低至约30%降低,约1%降低至约25%降低,约1%降低至约20%降低,约1%降低至约15%降低,约1%降低至约10%降低,约1%降低至约5%降低,约5%降低至约99%降低,约5%降低至约95%降低,约5%降低至约90%降低,约5%降低至约85%降低,约5%降低至约80%降低,约5%降低至约75%降低,约5%降低至约70%降低,约5%降低至约65%降低,约5%降低至约60%降低,约5%降低至约55%降低,约5%降低至约50%降低,约5%降低至约45%降低,约5%降低至约40%降低,约5%降低至约35%降低,约5%降低至约30%降低,约5%降低至约25%降低,约5%降低至约20%降低,约5%降低至约15%降低,约5%降低至约10%降低,约10%降低至约99%降低,约10%降低至约95%降低,约10%降低至约90%降低,约10%降低至约85%降低,约10%降低至约80%降低,约10%降低至约75%降低,约10%降低至约70%降低,约10%降低至约65%降低,约10%降低至约60%降低,约10%降低至约55%降低,约10%降低至约50%降低,约10%降低至约45%降低,约10%降低至约40%降低,约10%降低至约35%降低,约10%降低至约30%降低,约10%降低至约25%降低,约10%降低至约20%降低,约10%降低至约15%降低,约15%降低至约99%降低,约15%降低至约95%降低,约15%降低至约90%降低,约15%降低至约85%降低,约15%降低至约80%降低,约15%降低至约75%降低,约15%降低至约70%降低,约15%降低至约65%降低,约15%降低至约60%降低,约15%降低至约55%降低,约15%降低至约50%降低,约15%降低至约45%降低,约15%降低至约40%降低,约15%降低至约35%降低,约15%降低至约30%降低,约15%降低至约25%降低,约15%降低至约20%降低,约20%降低至约99%降低,约20%降低至约95%降低,约20%降低至约90%降低,约20%降低至约85%降低,约20%降低至约80%降低,约20%降低至约75%降低,约20%降低至约70%降低,约20%降低至约65%降低,约20%降低至约60%降低,约20%降低至约55%降低,约20%降低至约50%降低,约20%降低至约45%降低,约20%降低至约40%降低,约20%降低至约35%降低,约20%降低至约30%降低,约20%降低至约25%降低,约25%降低至约99%降低,约25%降低至约95%降低,约25%降低至约90%降低,约25%降低至约85%降低,约25%降低至约80%降低,约25%降低至约75%降低,约25%降低至约70%降低,约25%降低至约65%降低,约25%降低至约60%降低,约25%降低至约55%降低,约25%降低至约50%降低,约25%降低至约45%降低,约25%降低至约40%降低,约25%降低至约35%降低,约25%降低至约30%降低,约30%降低至约99%降低,约30%降低至约95%降低,约30%降低至约90%降低,约30%降低至约85%降低,约30%降低至约80%降低,约30%降低至约75%降低,约30%降低至约70%降低,约30%降低至约65%降低,约30%降低至约60%降低,约30%降低至约55%降低,约30%降低至约50%降低,约30%降低至约45%降低,约30%降低至约40%降低,约30%降低至约35%降低,约35%降低至约99%降低,约35%降低至约95%降低,约35%降低至约90%降低,约35%降低至约85%降低,约35%降低至约80%降低,约35%降低至约75%降低,约35%降低至约70%降低,约35%降低至约65%降低,约35%降低至约60%降低,约35%降低至约55%降低,约35%降低至约50%降低,约35%降低至约45%降低,约35%降低至约40%降低,约40%降低至约99%降低,约40%降低至约95%降低,约40%降低至约90%降低,约40%降低至约85%降低,约40%降低至约80%降低,约40%降低至约75%降低,约40%降低至约70%降低,约40%降低至约65%降低,约40%降低至约60%降低,约40%降低至约55%降低,约40%降低至约50%降低,约40%降低至约45%降低,约45%降低至约99%降低,约45%降低至约95%降低,约45%降低至约90%降低,约45%降低至约85%降低,约45%降低至约80%降低,约45%降低至约75%降低,约45%降低至约70%降低,约45%降低至约65%降低,约45%降低至约60%降低,约45%降低至约55%降低,约45%降低至约50%降低,约50%降低至约99%降低,约50%降低至约95%降低,约50%降低至约90%降低,约50%降低至约85%降低,约50%降低至约80%降低,约50%降低至约75%降低,约50%降低至约70%降低,约50%降低至约65%降低,约50%降低至约60%降低,约50%降低至约55%降低,约55%降低至约99%降低,约55%降低至约95%降低,约55%降低至约90%降低,约55%降低至约85%降低,约55%降低至约80%降低,约55%降低至约75%降低,约55%降低至约70%降低,约55%降低至约65%降低,约55%降低至约60%降低,约60%降低至约99%降低,约60%降低至约95%降低,约60%降低至约90%降低,约60%降低至约85%降低,约60%降低至约80%降低,约60%降低至约75%降低,约60%降低至约70%降低,约60%降低至约65%降低,约65%降低至约99%降低,约65%降低至约95%降低,约65%降低至约90%降低,约65%降低至约85%降低,约65%降低至约80%降低,约65%降低至约75%降低,约65%降低至约70%降低,约70%降低至约99%降低,约70%降低至约95%降低,约70%降低至约90%降低,约70%降低至约85%降低,约70%降低至约80%降低,约70%降低至约75%降低,约75%降低至约99%降低,约75%降低至约95%降低,约75%降低至约90%降低,约75%降低至约85%降低,约75%降低至约80%降低,约80%降低至约99%降低,约80%降低至约95%降低,约80%降低至约90%降低,约80%降低至约85%降低,约85%降低至约99%降低,约85%降低至约95%降低,约85%降低至约90%降低,约90%降低至约99%降低,约90%降低至约95%降低或约95%降低至约99%降低)。
在这些方法的一些实例中,受试者已被诊断或鉴别为患有感染性疾病。感染性疾病的非限制性实例包括感染人免疫缺陷病毒、巨细胞病毒、腺病毒、冠状病毒、鼻病毒、轮状病毒、天花、单纯疱疹病毒、乙型肝炎病毒、甲型肝炎病毒和丙型肝炎病毒、乳头瘤病毒和流感病毒。在一些实施例中,这些方法可引起受试者中感染滴度(例如,病毒滴度)的降低(例如,与治疗前受试者中的感染滴度相比)。在一些实施例中,这些方法可引起受试者中感染性疾病(例如,病毒感染)的一种或多种症状的数目、严重性或频率降低(例如,与治疗之前受试者中感染性疾病的一种或多种症状的数目、严重性或频率相比)。
术语“受试者”是指任何哺乳动物。在一些实施例中,受试者或“需要治疗的受试者”可为犬科动物(例如,狗)、猫科动物(例如,猫)、马科动物(例如,马)、绵羊、牛、猪、山羊、灵长类动物,例如猿猴(例如,猴(例如狨猴、狒狒)或猿(例如,大猩猩、黑猩猩、猩猩或长臂猿)或人;或啮齿动物(例如,小鼠、豚鼠、仓鼠或大鼠)。在一些实施例中,受试者或“需要治疗的受试者”可为非人哺乳动物,尤其可使用常规用作证明在人中的治疗功效的模型的哺乳动物(例如,鼠、兔、猪、犬或灵长类动物)。
杀死癌细胞、受感染细胞或衰老细胞的方法
本文还提供杀死有需要的受试者(例如,本文所描述或本领域已知的示例性受试者中的任一种)的癌细胞(例如,本文所描述或本领域已知的示例性癌症类型中的任一种)、受感染细胞(例如,感染有本文所描述或本领域已知的示例性病毒中的任一种的细胞)、或衰老细胞(例如,衰老癌细胞、衰老成纤维细胞或衰老内皮细胞)的方法,所述方法包括向受试者施用治疗有效量的本文所描述的多链嵌合多肽中的任一种或本文所描述的组合物(例如,药物组合物)中的任一种。
在这些方法的一些实施例中,受试者已被鉴别或诊断为患有癌症。癌症的非限制性实例包括:实体肿瘤、血液肿瘤、肉瘤、骨肉瘤、成胶质细胞瘤、成神经细胞瘤、黑色素瘤、横纹肌肉瘤、尤文氏肉瘤、骨肉瘤、B细胞瘤、多发性骨髓瘤、B细胞淋巴瘤、B细胞非霍奇金氏淋巴瘤、霍奇金氏淋巴瘤、慢性淋巴细胞性白血病(CLL)、急性骨髓性白血病(AML)、慢性骨髓性白血病(CML)、急性淋巴细胞性白血病(ALL)、骨髓增生异常综合症(MDS)、皮肤T细胞淋巴瘤、成视网膜细胞瘤、胃癌、尿路上皮癌、肺癌、肾细胞癌、胃和食管癌、胰腺癌、前列腺癌、乳腺癌、结直肠癌、卵巢癌、非小细胞肺癌、鳞状细胞头颈癌、子宫内膜癌、宫颈癌、肝癌和肝细胞癌。
在这些方法的一些实例中,受试者已被鉴别或诊断为患有与老化相关的疾病或病况。与老化相关的疾病或病况的非限制性实例包括:阿尔茨海默氏病、动脉瘤、囊性纤维化、胰腺炎纤维化、青光眼、高血压、特发性肺纤维化、炎性肠病、椎间盘退变、黄斑变性、骨关节炎、2型糖尿病、脂肪萎缩、脂肪营养不良、动脉粥样硬化、白内障、COPD、特发性肺纤维化、肾移植失败、肝纤维化、骨量损失、心肌梗死、肌肉减少症、伤口愈合、脱发、心肌细胞肥大、骨关节炎、帕金森氏病、与年龄相关的肺组织弹性丧失、黄斑变性、恶病质、肾小球硬化、肝硬化、NAFLD、骨质疏松症、肌萎缩性侧索硬化症、亨廷顿氏病、脊髓小脑共济失调、多发性硬化症和肾功能不全。
在这些方法的一些实例中,受试者已被诊断或鉴别为患有感染性疾病。感染性疾病的非限制性实例包括感染人免疫缺陷病毒、巨细胞病毒、腺病毒、冠状病毒、鼻病毒、轮状病毒、天花、单纯疱疹病毒、乙型肝炎病毒、甲型肝炎病毒和丙型肝炎病毒、乳头瘤病毒和流感病毒。
衰老细胞
衰老是不可逆的生长停滞的一种形式,伴随着表型变化、对细胞凋亡的抗性和损伤感知信号传导路径的激活。细胞衰老最早在培养的人成纤维细胞中描述,所述细胞失去了增殖能力,在约50群体翻倍后到达永久停滞(称为海弗利克极限(Hayflick limit))。衰老被认为是可由广泛范围的内在和外在伤害,包括氧化和遗传毒性应激、DNA损伤、端粒损耗、致癌激活、线粒体功能障碍或化疗剂诱导的应激反应。
衰老细胞保持代谢活性,并且可通过其分泌表型影响组织止血、疾病和老化。衰老被认为是生理过程,并且对促进伤口愈合、组织稳态、再生和纤维化调节很重要。例如,在伤口愈合期间观察到衰老细胞的瞬时诱导,并且其有助于伤口愈合。衰老的最重要作用之一可能是其在肿瘤抑制中的作用。但是,衰老细胞的积累也驱动老化和与老化相关的疾病和病况。衰老表型还可触发慢性炎性反应,并且因此增强慢性炎症病况以促进肿瘤生长。衰老与老化之间的联系最初是基于衰老细胞在老化组织中积累的观察结果。转基因模型的使用已使得能够在许多年龄相关的病理中系统地检测衰老细胞。选择性消除衰老细胞的策略展现衰老细胞确实可在老化和相关病理中起因果作用。
衰老细胞显示重要且独特的特性,包括形态、染色质组织、基因表达和代谢的变化。存在与细胞衰老相关的几种生化和功能特性,如(i)细胞周期蛋白依赖性激酶的抑制子p16和p21的表达增加,(ii)存在衰老相关的β-半乳糖苷酶,即溶酶体活性的标记,(iii)出现衰老相关的异染色质灶和核纤层蛋白B1水平下调,(iv)对由抗凋亡BCL家族蛋白表达增加引起的凋亡的抗性,和(v)CD26(DPP4)、CD36(清道夫(Scavenger)受体)、叉头盒4(FOXO4)和分泌性载体膜蛋白4(SCAMP4)上调。衰老细胞还表达炎症特征,即所谓的衰老相关分泌表型(SASP)。通过SASP,衰老细胞产生广泛范围的炎性细胞因子(IL-6、IL-8)、生长因子(TGF-β)、趋化因子(CCL-2)和基质金属蛋白酶(MMP-3、MMP-9),其以细胞自主方式运作以增强衰老(自分泌作用),并且与微环境通信并改变微环境(旁分泌作用)。SASP因子可通过触发衰老监视,即免疫介导的衰老细胞清除来促进肿瘤抑制。但是,慢性炎症也是肿瘤发生的已知驱动因素,并且越来越多的证据表明,慢性SASP也可促进癌症和与老化相关的疾病。
衰老细胞的分泌概况取决于环境。例如,人成纤维细胞中不同的线粒体功能障碍诱导的线粒体功能障碍相关衰老(MiDAS)引起缺乏IL-1依赖性炎症因子的SASP出现。NAD+/NADH比率的降低激活AMPK信号传导,其通过激活p53诱导MiDAS。结果,p53抑制NF-κB信号传导,其为促炎性SASP的关键诱导因素。相反,由人细胞中持续性DNA损伤引起的细胞衰老诱导炎性SASP,其依赖于共济失调毛细血管扩张突变(ATM)激酶的激活,而不依赖于p53的激活。特别地,IL-6和IL-8的表达和分泌水平提高。还展现了由异位表达p16INK4a和p21CIP1引起的细胞衰老诱导人成纤维细胞的衰老表型,且不存在炎性SASP,表明生长停滞本身并不刺激SASP。
衰老的最主要特征之一是稳定生长停滞。这是通过两个重要路径,即p16/Rb和p53/p21实现的,这两个路径均为肿瘤抑制的关键。DNA损伤引起:(1)染色质中γH2Ax(组蛋白编码基因)和53BP1(DNA损伤反应中涉及)的高沉积:这引起激酶级联反应的激活,最终引起p53激活,和(2)p16INK4a和ARF(均由CDKN2A编码)和P15INK4b(由CDKN2B编码)的激活:p53诱导细胞周期蛋白依赖性激酶抑制子(p21)的转录,并且与p16INK4a和p15INK4b两者一起阻断细胞周期进展的基因(CDK4和CDK6)。这最终引起成视网膜细胞瘤蛋白(Rb)磷酸化不足,并且使细胞周期停滞在G1期。
在正常老化的情况下,选择性杀死衰老细胞已显示可显著改善小鼠的健康寿命,并且改善与年龄相关的疾病或癌症疗法的结果(Ovadya,《临床研究杂志(J ClinInvest.)》128(4):1247-1254,2018)。在自然界中,衰老细胞通常被先天免疫细胞去除。衰老的诱导不仅阻止了受损/改变的细胞的潜在增殖和转化,而且还通过产生SASP因子(主要起自然杀伤(NK)细胞的化学引诱物(如IL-15和CCL2)和巨噬细胞的化学引诱物(如CFS-1和CCL2)的作用)促进组织修复。这些先天免疫细胞介导消除应激细胞的免疫监视机制。衰老细胞通常上调NK细胞激活受体NKG2D和DNAM-1配体,其属于应激诱导性配体家族:抵抗感染性疾病和恶性肿瘤的一线免疫防御的重要组分。受体激活后,NK细胞可接着通过其溶细胞机构特异性诱导衰老细胞的死亡。已在肝纤维化(Sagiv,《致癌基因(Oncogene)》32(15):1971-1977,2013)、肝细胞癌(Iannello,《实验医学杂志(J Exp Med)》210(10):2057-2069,2013)、多发性骨髓瘤(Soriani,《血液(Blood)》113(15):3503-3511,2009)和由甲羟戊酸路径功能异常应激的神经胶质瘤细胞(Ciaglia,《国际癌症杂志(Int J Cancer)》142(1):176-190,2018)中指出了NK细胞在衰老细胞的免疫监视中的作用。子宫内膜细胞经历急性细胞衰老,并且不会分化成蜕膜细胞。分化的蜕膜细胞分泌IL-15,并且从而募集子宫NK细胞以靶向并消除未分化的衰老细胞,因此有助于重塑和年轻化子宫内膜(Brighton,《E生命(Elife)》6:e31274,2017)。以类似的机制,在肝纤维化过程中,表达p53的衰老肝卫星细胞使驻留库普弗(Kupfer)巨噬细胞和新浸润的巨噬细胞的极化偏向促炎性M1表型,其显示衰老活性。已显示F4/80+巨噬细胞在清除小鼠子宫衰老细胞以维持产后子宫功能中起关键作用。
衰老细胞主要通过上调NKG2D(在NK细胞上表达)的配体、趋化因子和其它SASP因子来募集NK细胞。肝纤维化的体内模型已显示激活的NK细胞有效清除衰老细胞(Krizhanovsky,《细胞(Cell)》134(4):657-667,2008)。研究已描述各种模型来研究衰老,包括肝纤维化(Krizhanovsky,《细胞》134(4):657-667,2008)、骨关节炎(Xu,《老年学杂志:A系列,生物科学与医学(J Gerontol A Biol Sci Med Sci)》72(6):780-785,2017)和帕金森氏病(Chinta,《细胞报告(Cell Rep)》22(4):930-940,2018)。用于研究衰老细胞的动物模型描述于:Krizhanovsky,《细胞》134(4):657-667,2008;Baker,《自然》479(7372):232-236,2011;Farr,《自然·医学(Nat Med)》23(9):1072-1079,2017;Bourgeois,《欧洲生物化学学会联合会快报(FEBS Lett)》592(12):2083-2097,2018;Xu,《自然·医学》24(8):1246-1256,2018)。
另外的治疗剂
本文所描述的方法中的任一种的一些实施例可进一步包括向受试者(例如,本文所描述的受试者中的任一种)施用治疗有效量的一种或多种另外的治疗剂。可与多链嵌合多肽(例如,本文所描述的多链嵌合多肽中的任一种)或免疫细胞(例如,以单一配制物或两种或更多种配制物的形式向受试者施用)大体同时向受试者施用一种或多种另外的治疗剂。在一些实施例中,可在施用多链嵌合多肽(例如,本文所描述的多链嵌合多肽中的任一种)或免疫细胞之前向受试者施用一种或多种另外的治疗剂。在一些实施例中,可在向受试者施用多链嵌合多肽(例如,本文所描述的多链嵌合多肽中的任一种)或免疫细胞后向受试者施用一种或多种另外的治疗剂。
另外的治疗剂的非限制性实例包括:抗癌药物、激活受体激动剂、免疫检查点抑制剂、用于阻断HLA特异性抑制受体的试剂、糖原合酶激酶(GSK)3抑制剂和抗体。
抗癌药的非限制性实例包括抗代谢药物(例如,5-氟尿嘧啶(5-FU)、6-巯基嘌呤(6-MP)、卡培他滨(capecitabine)、阿糖胞苷(cytarabine)、氟尿苷(floxuridine)、氟达拉滨(fludarabine)、吉西他滨(gemcitabine)、羟基脲、甲氨蝶呤(methotrexate)、6-硫鸟嘌呤、克拉屈滨(cladribine)、奈拉滨(nelarabine)、喷司他汀(pentostatin)或培美曲塞(pemetrexed))、植物碱(例如,长春碱(vinblastine)、长春新碱(vincristine)、长春地辛(vindesine)、喜树碱(camptothecin)、9-甲氧基喜树碱、狗牙花定碱(coronaridine)、紫杉醇(taxol)、乌檀根碱(naucleaoral)、二异戊二烯基化吲哚生物碱(diprenylated indolealkaloid)、山矢车菊碱(montamine)、希什金矢车菊碱(schischkiniin)、原小蘖碱(protoberberine)、小蘖碱(berberine)、血根碱(sanguinarine)、白屈菜红碱(chelerythrine)、白屈菜碱(chelidonine)、鹅掌楸碱(liriodenine)、山岗蠹吾碱(clivorine)、β-咔啉、脱甲氧基娃儿藤碱(antofine)、娃儿藤碱(tylophorine)、白叶藤碱(cryptolepine)、新白叶藤碱(neocryptolepine)、紫堇诺灵碱(corynoline)、依兰碱(sampangine)、咔唑、文珠兰碱(crinamine)、高山网球花碱(montanine)、玫瑰树碱(ellipticine)、太平洋紫杉醇(paclitaxel)、多西他赛(docetaxel)、依托泊苷(etoposide)、替尼泊苷(tenisopide)、伊立替康(irinotecan)、拓扑替康(topotecan)或吖啶酮生物碱)、蛋白酶体抑制剂(例如,乳胞素(lactacystin)、双硫仑(disulfiram)、表没食子儿茶素-3-没食子酸酯、马里佐米(marizomib)(盐孢菌素(salinosporamide)A)、奥普佐米(oprozomib)(ONX-0912)、地兰佐米(delanzomib)(CEP-18770)、环氧霉素(epoxomicin)、MG132、β-羟基β-甲基丁酸盐、硼替佐米(bortezomib)、卡非佐米(carfilzomib)或埃沙佐米(ixazomib))、抗肿瘤抗生素(例如,阿霉素(doxorubicin)、柔红霉素(daunorubicin)、表柔比星(epirubicin)、米托蒽醌(mitoxantrone)、伊达比星(idarubicin)、放线菌素(actinomycin)、普卡霉素(plicamycin)、丝裂霉素(mitomycin)或博来霉素(bleomycin))、组蛋白脱乙酰基酶抑制剂(例如,伏立诺他(vorinostat)、帕比诺他(panobinostat)、贝林司他(belinostat)、吉韦诺他(givinostat)、阿贝辛他(abexinostat)、缩肽(depsipeptide)、恩替诺特(entinostat)、苯基丁酸盐、丙戊酸、曲古抑菌素(trichostatin)A、达西司他(dacinostat)、莫西司他(mocetinostat)、普瑞司他(pracinostat)、烟酰胺(nicotinamide)、坎比诺尔(cambinol)、替诺文(tenovin)1、替诺文6、斯汀诺(sirtinol)、利可司他(ricolinostat)、替非司他(tefinostat)、凯维林(kevetrin)、奎西司他(quisinostat)、雷米诺他(resminostat)、泰克地那林(tacedinaline)、西达本胺(chidamide)或赛利司他(selisistat))、酪氨酸激酶抑制剂(例如,阿昔替尼(axitinib)、达沙替尼(dasatinib)、恩可非尼(encorafinib)、厄洛替尼(erlotinib)、伊马替尼(imatinib)、尼洛替尼(nilotinib)、帕唑帕尼(pazopanib)和舒尼替尼(sunitinib))和化疗剂(例如,全反式维甲酸、阿扎胞苷(azacitidine)、硫唑嘌呤(azathioprine)、去氧氟尿苷、埃博霉素(epothilone)、羟脲、伊马替尼、替尼泊苷、硫鸟嘌呤、戊柔比星(valrubicin)、维罗非尼(vemurafenib)和来那度胺(lenalidomide))。化疗剂的另外实例包括烷化剂,例如二氯甲二乙胺、环磷酰胺(cyclophosphamide)、苯丁酸氮芥(chlorambucil)、美法仑(melphalan)、异环磷酰胺(ifosfamide)、噻替派(thiotepa)、六甲三聚氰胺(hexamethylmelamine)、白消安(busulfan)、六甲蜜胺(altretamine)、丙卡巴肼(procarbazine)、达卡巴嗪(dacarbazine)、替莫唑胺(temozolomide)、卡莫司汀(carmustine)、罗莫司汀(lumustine)、链脲霉素(streptozocin)、卡铂(carboplatin)、顺铂(cisplatin)和奥沙利铂(oxaliplatin)。
激活受体激动剂的非限制性实例包括激活和增强NK细胞的细胞毒性的激活受体的任何激动剂,包括抗CD16抗体(例如,抗CD16/CD30双特异性单克隆抗体(BiMAb))和基于Fc的融合蛋白。检查点抑制剂的非限制性实例包括抗PD-1抗体(例如,MEDI0680)、抗PD-L1抗体(例如,BCD-135、BGB-A333、CBT-502、CK-301、CS1001、FAZ053、KN035、MDX-1105、MSB2311、SHR-1316、抗PD-L1/CTLA-4双特异性抗体KN046、抗PD-L1/TGFβRII融合蛋白M7824、抗PD-L1/TIM-3双特异性抗体LY3415244、阿特珠单抗(atezolizumab)或阿维鲁单抗(avelumab))、抗TIM3抗体(例如,TSR-022、Sym023或MBG453)和抗CTLA-4抗体(例如,AGEN1884、MK-1308或抗CTLA-4/OX40双特异性抗体ATOR-1015)。用于阻断HLA特异性抑制受体的试剂的非限制性实例包括莫那力单抗(monalizumab)(例如,抗HLA-ENKG2A抑制受体单克隆抗体)。GSK3抑制剂的非限制性实例包括替格鲁西布(tideglusib)或CHIR99021。可用作另外的治疗剂的抗体的非限制性实例包括抗CD26抗体(例如,YS110)、抗CD36抗体和可结合到NK细胞上的Fc受体(例如,CD16)并激活所述受体的任何其它抗体或抗体构建体。在一些实施例中,另外的治疗剂可为胰岛素或二甲双胍(metformin)。
实例
本发明在以下实例中进行了进一步描述,所述实例不限制权利要求中所描述的本发明的范围。
实例1.示例性多链嵌合多肽的构建和其特性评估
生成两个多链嵌合多肽并且评估其特性。两个多链嵌合多肽中的每一个均包括第一嵌合多肽,其包括与第一靶标结合结构域和结构域亲和对中的第一结构域共价连接的可溶性组织因子结构域。两个多链嵌合多肽中的每一个中的第二嵌合多肽包括结构域亲和对中的第二结构域和第二靶标结合结构域。
多链嵌合多肽的逻辑基础构建的描述
组织因子(TF)是一种稳定的跨膜蛋白,含有236个氨基酸残基。组织因子的截短的重组219个氨基酸的胞外域是可溶的,并且已知在细菌或哺乳动物细胞中以高水平表达。在不希望受特定理论束缚的情况下,申请人推测219-aa组织因子可用作产生独特多链嵌合多肽的连接接头。
由在发酵液中生长的CHO细胞以高水平产生包括可溶性组织因子结构域的第一嵌合多肽。通过在固体基质上偶联的抗组织因子单克隆抗体(mAb)纯化这些第一嵌合多肽。值得注意的是,组织因子含有FVIIa和FX的结合位点。当组织因子未锚定到磷脂双层时,组织因子-FVIIa复合物对FX的催化活性低约100万倍。因此,在不希望受特定理论束缚的情况下,申请人推测在第一嵌合多肽的构建中使用不跨膜的组织因子的219-aa胞外域可消除第一嵌合多肽中组织因子的促凝活性。为了进一步降低或消除219-aa组织因子的促凝活性,可在组织因子中进行选择突变,具体来说在已知有助于FVIIa结合位点结合能的七个氨基酸残基上。
所描述的嵌合多肽的结合相互作用的表征
为了确定第一和第二嵌合多肽是否彼此结合以形成多链嵌合多肽,进行体外结合分析。为了确定包含可溶性组织因子结构域的第一嵌合多肽是否由抗TF mAb识别并结合,进行体外结合分析。值得注意的是,数据表明突变组织因子蛋白仍由已知与组织因子上的FX结合位点结合的抗TF mAb识别并选择性结合。为了确定包含与scFv或细胞因子共价连接的可溶性组织因子结构域的第一嵌合多肽(参见图1和图2)是否具有功能性scFvs或细胞因子,进行体外结合分析。来自前述分析的数据与具有预期生物活性的纯化的第一嵌合多肽一致(例如,scFv选择性结合预期靶抗原或细胞因子选择性结合预期受体或结合蛋白)。
另外,使用包括彼此结合的第一和第二嵌合多肽的两个多链嵌合多肽进行的实验展现预期靶标结合活性(例如,多链嵌合多肽特异性结合到由第一靶标结合结构域特异性识别的靶标和由第二靶标结合结构域特异性识别的靶标)。
基于前述结果,申请人得出结论,可溶性组织因子连接接头提供或实现了编码scFv、白介素、细胞因子、白介素受体或细胞因子受体的多肽在三维空间中相对于可溶性组织因子结构域并且相对于彼此的适当呈现,使得各自保留预期生物特性和活性。
当第一和第二嵌合多肽两者被共表达时,异二聚复合物以高水平分泌到发酵液中。捕获复合物并且使用亲和色谱法通过缀合到固体基质的抗TF mAb容易地纯化。如通过体外结合分析所分析,这些多链嵌合多肽的第一和第二靶标结合结构域保留其预期生物活性。因此,多链嵌合多肽的组装提供适用于生物活性的结构域的空间呈现和折叠。重要的是,多链嵌合多肽的空间布置不干扰组织因子上的FX结合位点,这使得能够使用抗TF mAb进行亲和纯化。
所描述的嵌合多肽的稳定性的表征
两种纯化的多链嵌合多肽均为稳定的。这些多链嵌合多肽在人血清中在37℃下培育72小时时具有完整结构和完全生物活性。
所描述的嵌合多肽聚集倾向的表征
在4℃下在PBS中存储时,两种纯化的多链嵌合多肽均不形成聚集体。
所描述的嵌合多肽的粘度表征
当将多链嵌合多肽以高达50mg/mL的浓度在PBS中配制时,不存在粘度问题。
多链嵌合多肽平台的另外应用
来自这些研究的数据显示,本文所描述的平台技术可用于产生可以本文所描述的格式中的任一种与衍生自抗体的靶标结合结构域融合的分子,包括但不限于粘附分子、受体、细胞因子、配体和趋化因子。利用适当的靶标结合结构域,所得多链嵌合多肽可促进各种免疫效应细胞的缀合并介导靶细胞,包括癌细胞、受病毒感染的细胞或衰老细胞的破坏。多链嵌合多肽中的其它结构域刺激、激活并吸引免疫系统,以增强效应细胞对靶细胞的细胞毒性。
实例2:IL-12/IL-15RαSu
DNA构建体的产生
在非限制性实例中,产生IL-12/IL-15RαSu DNA构建体(图3)。人IL-12亚基序列、人IL-15RαSu序列、人IL-15序列、人组织因子219序列和人IL-18序列从UniProt网站获得,并且这些序列的DNA由金唯智(Genewiz)合成。制造DNA构建体,用GS(3)接头将IL-12亚基β(p40)连接到IL-12亚基α(p35)以生成IL-12的单链形式,并且然后直接将IL-12序列连接到IL-15RαSu序列。最终的IL-12/IL-15RαSu DNA构建体序列由金唯智合成。
IL12/IL-15RαSu构建体(包括信号肽序列)的核酸序列如下(SEQ ID NO:77):
(信号肽)
ATGAAATGGGTGACCTTTATTTCTTTACTGTTCCTCTTTAGCAGCGCCTACTCC
(人IL-12亚基β(p40))
ATTTGGGAACTGAAGAAGGACGTCTACGTGGTCGAACTGGACTGGTATCCCGATGCTCCCGGCGAAATGGTGGTGCTCACTTGTGACACCCCCGAAGAAGACGGCATCACTTGGACCCTCGATCAGAGCAGCGAGGTGCTGGGCTCCGGAAAGACCCTCACAATCCAAGTTAAGGAGTTCGGAGACGCTGGCCAATACACATGCCACAAGGGAGGCGAGGTGCTCAGCCATTCCTTATTATTATTACACAAGAAGGAAGACGGAATCTGGTCCACCGACATTTTAAAAGATCAGAAGGAGCCCAAGAATAAGACCTTTTTAAGGTGTGAGGCCAAAAACTACAGCGGTCGTTTCACTTGTTGGTGGCTGACCACCATTTCCACCGATTTAACCTTCTCCGTGAAAAGCAGCCGGGGAAGCTCCGACCCTCAAGGTGTGACATGTGGAGCCGCTACCCTCAGCGCTGAGAGGGTTCGTGGCGATAACAAGGAATACGAGTACAGCGTGGAGTGCCAAGAAGATAGCGCTTGTCCCGCTGCCGAAGAATCTTTACCCATTGAGGTGATGGTGGACGCCGTGCACAAACTCAAGTACGAGAACTACACCTCCTCCTTCTTTATCCGGGACATCATTAAGCCCGATCCTCCTAAGAATTTACAGCTGAAGCCTCTCAAAAATAGCCGGCAAGTTGAGGTCTCTTGGGAATATCCCGACACTTGGAGCACACCCCACAGCTACTTCTCTTTAACCTTTTGTGTGCAAGTTCAAGGTAAAAGCAAGCGGGAGAAGAAAGACCGGGTGTTTACCGACAAAACCAGCGCCACCGTCATCTGTCGGAAGAACGCCTCCATCAGCGTGAGGGCTCAAGATCGTTATTACTCCAGCAGCTGGTCCGAGTGGGCCAGCGTGCCTTGTTCC
(接头)
GGCGGTGGAGGATCCGGAGGAGGTGGCTCCGGCGGCGGAGGATCT
(人IL-12亚基α(p35))
CGTAACCTCCCCGTGGCTACCCCCGATCCCGGAATGTTCCCTTGTTTACACCACAGCCAGAATTTACTGAGGGCCGTGAGCAACATGCTGCAGAAAGCTAGGCAGACTTTAGAATTTTACCCTTGCACCAGCGAGGAGATCGACCATGAAGATATCACCAAGGACAAGACATCCACCGTGGAGGCTTGTTTACCTCTGGAGCTGACAAAGAACGAGTCTTGTCTCAACTCTCGTGAAACCAGCTTCATCACAAATGGCTCTTGTTTAGCTTCCCGGAAGACCTCCTTTATGATGGCTTTATGCCTCAGCTCCATCTACGAGGATTTAAAGATGTACCAAGTGGAGTTCAAGACCATGAACGCCAAGCTGCTCATGGACCCTAAACGGCAGATCTTTTTAGACCAGAACATGCTGGCTGTGATTGATGAGCTGATGCAAGCTTTAAACTTCAACTCCGAGACCGTCCCTCAGAAGTCCTCCCTCGAGGAGCCCGATTTTTACAAGACAAAGATCAAACTGTGCATTTTACTCCACGCCTTTAGGATCCGGGCCGTGACCATTGACCGGGTCATGAGCTATTTAAACGCCAGC
(人IL-15Rα寿司结构域)
ATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG
实例3:IL-18/TF/IL-15DNA构建体的产生
在非限制性实例中,制造IL-18/TF/IL-15构建体(图4),将IL-18序列连接到组织因子219的N端编码区,并且进一步将IL-18/TF构建体与IL-15的N端编码区连接。由金唯智合成的IL-18/TF/IL-15构建体(包括前导序列)的核酸序列如下(SEQ ID NO:73):
(信号肽)
ATGAAGTGGGTCACATTTATCTCTTTACTGTTCCTCTTCTCCAGCGCCTACAGC
(人IL-18)
TACTTCGGCAAACTGGAATCCAAGCTGAGCGTGATCCGGAATTTAAACGACCAAGTTCTGTTTATCGATCAAGGTAACCGGCCTCTGTTCGAGGACATGACCGACTCCGATTGCCGGGACAATGCCCCCCGGACCATCTTCATTATCTCCATGTACAAGGACAGCCAGCCCCGGGGCATGGCTGTGACAATTAGCGTGAAGTGTGAGAAAATCAGCACTTTATCTTGTGAGAACAAGATCATCTCCTTTAAGGAAATGAACCCCCCCGATAACATCAAGGACACCAAGTCCGATATCATCTTCTTCCAGCGGTCCGTGCCCGGTCACGATAACAAGATGCAGTTCGAATCCTCCTCCTACGAGGGCTACTTTTTAGCTTGTGAAAAGGAGAGGGATTTATTCAAGCTGATCCTCAAGAAGGAGGACGAGCTGGGCGATCGTTCCATCATGTTCACCGTCCAAAACGAGGAT
(人组织因子219)
AGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAG
(人IL-15)
AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC
实例4:IL-12/IL-15RαSu和IL-18/TF/IL-15融合蛋白的分泌
将IL-12/IL-15RαSu和IL-18/TF/IL-15DNA构建体克隆到pMSGV-1修饰的逆转录病毒表达载体(如Hughes,《人基因疗法(Hum Gene Ther)》16:457–72,2005,在此以引用的方式并入)中,并且将表达载体转染到CHO-K1细胞中。两种构建体在CHO-K1细胞中的共表达使得可形成和分泌可溶性IL-18/TF/IL-15:IL-12/IL-15RαSu蛋白复合物(称为18t15-12s;图5和图6)。使用抗TF抗体亲和色谱法和尺寸排阻色谱法从CHO-K1细胞培养上清液中纯化18t15-12s蛋白,得到由IL-12/IL-15RαSu和IL-18/TF/IL-15融合蛋白组成的可溶性(非聚集)蛋白复合物。
IL12/IL-15RαSu融合蛋白(包括信号肽序列)的氨基酸序列如下(SEQ ID NO:76):
(信号肽)
MKWVTFISLLFLFSSAYS
(人IL-12亚基β(p40))
IWELKKDVYVVELDWYPDAPGEMVVLTCDTPEEDGITWTLDQSSEVLGSGKTLTIQVKEFGDAGQYTCHKGGEVLSHSLLLLHKKEDGIWSTDILKDQKEPKNKTFLRCEAKNYSGRFTCWWLTTISTDLTFSVKSSRGSSDPQGVTCGAATLSAERVRGDNKEYEYSVECQEDSACPAAEESLPIEVMVDAVHKLKYENYTSSFFIRDIIKPDPPKNLQLKPLKNSRQVEVSWEYPDTWSTPHSYFSLTFCVQVQGKSKREKKDRVFTDKTSATVICRKNASISVRAQDRYYSSSWSEWASVPCS
(接头)
GGGGSGGGGSGGGGS
(人IL-12亚基α(p35))
RNLPVATPDPGMFPCLHHSQNLLRAVSNMLQKARQTLEFYPCTSEEIDHEDITKDKTSTVEACLPLELTKNESCLNSRETSFITNGSCLASRKTSFMMALCLSSIYEDLKMYQVEFKTMNAKLLMDPKRQIFLDQNMLAVIDELMQALNFNSETVPQKSSLEEPDFYKTKIKLCILLHAFRIRAVTIDRVMSYLNAS
(人IL-15Rα寿司结构域)
ITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR
IL-18/TF/IL-15融合蛋白(包括信号肽序列)的氨基酸序列如下(SEQ ID NO:72):
(信号肽)
MKWVTFISLLFLFSSAYS
(人IL-18)
YFGKLESKLSVIRNLNDQVLFIDQGNRPLFEDMTDSDCRDNAPRTIFIISMYKDSQPRGMAVTISVKCEKISTLSCENKIISFKEMNPPDNIKDTKSDIIFFQRSVPGHDNKMQFESSSYEGYFLACEKERDLFKLILKKEDELGDRSIMFTVQNED
(人组织因子219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(人IL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
在一些情况下,将前导(信号序列)肽从完整的多肽上裂解下来以生成可能可溶或分泌的成熟形式。
实例5:通过免疫亲和色谱法纯化18t15-12s
将抗TF抗体亲和柱连接到通用电气医疗集团(GE Healthcare)TMAKTAAvant蛋白纯化系统。除洗脱步骤外,所有步骤的流速均为4mL/min,洗脱步骤的流速为2mL/min。
18t15-12s的细胞培养物收获物用1M Tris碱调节到pH 7.4,并且加载到用5个柱体积的PBS平衡的抗TF抗体亲和柱上。加载样品后,用5个柱体积的PBS洗涤柱,接着用6个柱体积的0.1M乙酸,pH 2.9洗脱。收集280nm处的吸光度,并且然后通过添加1M Tris碱将样品中和到pH 7.5-8.0。然后使用具有30KDa分子量截断值的 离心过滤器将中和的样品缓冲液交换到PBS中。图7显示18t15-12s复合物结合抗TF抗体亲和柱,其中TF是18t15-12s结合伴侣。将缓冲液交换的蛋白质样品存储在2-8℃下,以用于进一步生化分析和生物活性测试。
离心过滤器将中和的样品缓冲液交换到PBS中。图7显示18t15-12s复合物结合抗TF抗体亲和柱,其中TF是18t15-12s结合伴侣。将缓冲液交换的蛋白质样品存储在2-8℃下,以用于进一步生化分析和生物活性测试。
每次洗脱后,接着使用6个柱体积的0.1M甘氨酸,pH 2.5剥离抗TF抗体亲和柱。然后使用10个柱体积的PBS、0.05%叠氮化钠中和所述柱,并且存储在2-8℃下。
实例6:18t15-12s的尺寸排阻色谱法
将通用电气医疗集团 200增加10/300GL凝胶过滤柱连接到通用电气医疗集团AKTATMAvant蛋白纯化系统。用2个柱体积的PBS平衡所述柱。流速为0.8mL/min。使用毛细管环将200μL 1mg/mL的18t15-12s复合物注入到色谱柱上。用1.25个柱体积的PBS追赶注射液。SEC色谱图如图8所示。有一个主要的18t15-12s蛋白峰以及一个较小的高分子量峰,可能是由于18t15-12s二聚体或聚集体的糖基化程度不同所致。
200增加10/300GL凝胶过滤柱连接到通用电气医疗集团AKTATMAvant蛋白纯化系统。用2个柱体积的PBS平衡所述柱。流速为0.8mL/min。使用毛细管环将200μL 1mg/mL的18t15-12s复合物注入到色谱柱上。用1.25个柱体积的PBS追赶注射液。SEC色谱图如图8所示。有一个主要的18t15-12s蛋白峰以及一个较小的高分子量峰,可能是由于18t15-12s二聚体或聚集体的糖基化程度不同所致。
实例7:18t15-12s的SDS-PAGE
为了确定纯度和蛋白质分子量,使用4-12%NuPage Bis-Tris蛋白质凝胶SDS-PAGE分析纯化的18t15-12s蛋白质样品。凝胶用InstantBlueTM染色约30min,接着在纯化水中脱色过夜。图9显示抗TF抗体亲和纯化的18t15-12s的示例SDS凝胶,其中条带在预期分子量(66kDa和56kDa)处。
实例8:CHO-K1细胞中18t15-12s的糖基化
根据制造商的说明书,使用蛋白质去糖基化混合物II试剂盒(新英格兰生物实验室(New England Biolabs))确认CHO-K1细胞中18t15-12s的糖基化。图10显示去糖基化和未去糖基化的18t15-12s的示例SDS PAGE。去糖基化降低18t15-12s的分子量,如图10泳道4所示。
实例9:18t15-12s复合物的重组蛋白定量
使用标准夹心ELISA方法检测并定量了18t15-12s复合物(图11-14)。抗人组织因子抗体充当捕获抗体,并且生物素化抗人IL-12、IL-15或IL-18抗体(BAF 219、BAM 247、D045-6,所有为安迪生物公司产品)充当检测抗体。还使用抗人组织因子捕获抗体(I43)和抗人组织因子抗体检测抗体检测纯化的18t15-12s蛋白复合物中的组织因子。将I43/抗TF抗体ELISA与相似浓度下的纯化组织因子进行比较。
实例10:18t15-12s复合物的免疫刺激能力
为了评定18t15-12s复合物的IL-15免疫刺激活性,向200μL IMDM:10%FBS培养基中32Dβ细胞(104个细胞/孔)中添加逐渐提高浓度的18t15-12s。将32Dβ细胞在37℃下培育3天。在第四天,添加WST-1增殖试剂(10μL/孔),并且在4小时后,在450nm处测量吸光度,以基于WST-1裂解为可溶性甲臜染料来确定细胞增殖。评定人重组IL-15的生物活性作为阳性对照。如图15所示,18t15-12s展现32Dβ细胞的IL-15依赖性细胞增殖。与人重组IL-15相比,18t15-12s复合物展现降低的活性,可能是由于IL-18和组织因子与IL-15结构域的连接所致。
为了评定18t15-12s复合物中IL-12和IL-18的个别活性,将18t15-12s添加到200μLIMDM:10%热灭活的FBS培养基中HEK-Blue IL-12和HEK-Blue IL-18报告细胞(5×104个细胞/孔;hkb-il12和hkb-hmil18,英伟杰(InvivoGen))中。将细胞在37℃下培育过夜。将20μl诱导的HEK-Blue IL-12和HEK-Blue IL-18报告细胞上清液添加180μl QUANTI-Blue(英伟杰)中,并且在37℃下培育1-3小时。通过测量620nm处的吸光度来评定IL-12或IL-18活性。将人重组IL-12或IL-18评定为阳性或阴性对照。如图16和图17所示,18t15-12s复合物的每个细胞因子结构域均保留特定生物活性。与人重组IL-18或IL-12相比,18t15-12s的活性降低,可能是由于IL-15和组织因子与IL-18结构域的连接以及IL-12与IL-15Rα寿司结构域的连接所致。
实例11:18t15-12s复合物诱导细胞因子诱导的记忆样NK细胞
在用饱和量的IL-12(10ng/mL)、IL-15(50ng/mL)和IL-18(50ng/mL)过夜刺激纯化的NK细胞后,可离体诱导细胞因子诱导的记忆样NK细胞。这些记忆样特性已通过IL-2受体ɑ(IL-2Rɑ、CD25)、CD69(和其它激活标记)的表达和增加的IFN-γ产生进行测量。为了评估18t15-12s复合物促进细胞因子诱导的记忆样NK细胞生成的能力,用0.01nM至10000nM的18t15-12s复合物或个别细胞因子(重组IL-12(10ng/mL)、IL-18(50ng/mL)和IL-15(50ng/mL))的组合刺激纯化的人NK细胞(>95%CD56+)14-18小时。通过抗体染色和流式细胞术评定细胞表面CD25和CD 69表达以及细胞内IFN-γ水平。
从血库获得新鲜的人白细胞,并且用RosetteSep/人NK细胞试剂(干细胞技术有限公司(StemCell Technologies))分离CD56+NK细胞。NK细胞的纯度>70%,并且通过用对CD56-BV421、CD16-BV510、CD25-PE、CD69-APCFire750具有特异性的抗体(BioLegend)染色得到证实。对细胞进行计数,并且将其以0.2×106个/mL在0.2mL完全培养基(RPMI 1640(吉毕科公司(Gibco),补充有2mM L-谷氨酰胺(Thermo Life Technologies)、青霉素(ThermoLife Technologies))、链霉素(Thermo Life Technologies)和10%FBS(Hyclone))的96孔平底板中重悬。在37℃,5%CO2下用细胞因子hIL-12(10ng/mL)(Biolegend)、hIL-18(50ng/mL)(安迪生物公司)和hIL-15(50ng/mL)(NCI)的混合物或用0.01nM至10000nM 18t15-12s刺激细胞14-18小时。然后收获细胞,并且用对CD56-BV421、CD16-BV510、CD25-PE、CD69-APCFire750具有特异性的抗体(BioLegend)表面染色30分钟。染色后,将细胞在FACS缓冲液(1×PBS(Hyclone),含0.5%BSA(EMD密理博(EMD Millipore))和0.001%叠氮化钠(西格玛(Sigma)))中洗涤(室温下1500RPM 5分钟)。洗涤两次后,使用BD FACSCelestaTM流式细胞仪分析细胞(绘制的数据-平均荧光强度;图18A和图18B)。
从血库获得新鲜的人白细胞,并且用RosetteSep/人NK细胞试剂(干细胞技术有限公司)分离CD56+NK细胞。NK细胞的纯度>70%,并且通过用CD56-BV421、CD16-BV510、CD25-PE、CD69-APCFire750特异性抗体(BioLegend)染色得到证实。对细胞进行计数,并且将其以0.2×106个/mL在0.2mL完全培养基(RPMI 1640(吉毕科公司),补充有2mM L-谷氨酰胺(Thermo Life Technologies)、青霉素(Thermo Life Technologies))、链霉素(ThermoLife Technologies)和10%FBS(Hyclone))的96孔平底板中重悬。在37℃,5%CO2下用hIL-12(10ng/mL)(Biolegend)、hIL-18(50ng/mL)(安迪(R&D))和hIL-15(50ng/mL)(NCI)的细胞因子混合物或0.01nM至10000nM 18t15-12s复合物刺激细胞14-18小时。然后将细胞用10μg/mL布雷菲德菌素(Brefeldin)A(西格玛)和1×莫能菌素(Monensin)(eBioscience)处理4小时,然后收集并用对CD56-BV421、CD16-BV510、CD25-PE、CD69-APCFire750具有特异性的抗体染色30分钟。染色后,将细胞在FACS缓冲液(1×PBS(Hyclone),含0.5%BSA(EMD密理博)和0.001%叠氮化钠(西格玛))中洗涤(室温下1500RPM 5分钟),并且在室温下固定10分钟。固定后,将细胞在1×透化缓冲液(eBioscience)中洗涤(室温下1500RPM 5分钟),并且在室温下用IFN-γ-PE Ab(Biolegend)染色30分钟。用1×透化的缓冲液再次洗涤细胞,然后用FACS缓冲液洗涤。将细胞沉淀重悬于300μl FACS缓冲液中,并且使用BD FACSCelestaTM流式细胞仪进行分析(绘制的IFN-γ阳性细胞百分比;图19)。
实例12:NK细胞对人肿瘤细胞的体外细胞毒性
在存在逐渐提高浓度的18t15-12s复合物或作为对照的细胞因子混合物的情况下,将人骨髓性白血病细胞K562(CellTrace紫罗兰标记)与纯化的人NK细胞一起培育。20小时后,收获培养物,用碘化丙啶(PI)染色,并且通过流式细胞术评定。如图20所示,18t15-12s复合物以与细胞因子混合物相似或更大的水平诱导人NK对K562的细胞毒性,其中18t15-12s复合物和细胞因子混合物均诱导比培养基对照更大的细胞毒性。
实例13:IL-12/IL-15RαSu/αCD16scFv和IL-18/TF/IL-15DNA构建体的产生
在非限制性实例中,产生IL-12/IL-15RαSu/αCD16scFv和IL-18/TF/IL-15DNA构建体(图21和图22)。人IL-12亚基序列、人IL-15RαSu序列、人IL-15序列、人组织因子219序列和人IL-18序列由金唯智合成。制造DNA构建体,用GS(3)接头将IL-12亚基β(p40)连接到IL-12亚基α(p35)以生成IL-12的单链形式,直接将IL-12序列连接到IL-15RαSu序列,并且直接将IL-12/IL-15RαSu构建体连接到αCD16scFv的N端编码区。
IL-12/IL-15RαSu/αCD16scFv构建体的核酸序列如下(SEQ ID NO:123):
(信号肽)
ATGAAATGGGTGACCTTTATTTCTTTACTGTTCCTCTTTAGCAGCGCCTACTCC
(人IL-12亚基β(p40))
ATTTGGGAACTGAAGAAGGACGTCTACGTGGTCGAACTGGACTGGTATCCCGATGCTCCCGGCGAAATGGTGGTGCTCACTTGTGACACCCCCGAAGAAGACGGCATCACTTGGACCCTCGATCAGAGCAGCGAGGTGCTGGGCTCCGGAAAGACCCTCACAATCCAAGTTAAGGAGTTCGGAGACGCTGGCCAATACACATGCCACAAGGGAGGCGAGGTGCTCAGCCATTCCTTATTATTATTACACAAGAAGGAAGACGGAATCTGGTCCACCGACATTTTAAAAGATCAGAAGGAGCCCAAGAATAAGACCTTTTTAAGGTGTGAGGCCAAAAACTACAGCGGTCGTTTCACTTGTTGGTGGCTGACCACCATTTCCACCGATTTAACCTTCTCCGTGAAAAGCAGCCGGGGAAGCTCCGACCCTCAAGGTGTGACATGTGGAGCCGCTACCCTCAGCGCTGAGAGGGTTCGTGGCGATAACAAGGAATACGAGTACAGCGTGGAGTGCCAAGAAGATAGCGCTTGTCCCGCTGCCGAAGAATCTTTACCCATTGAGGTGATGGTGGACGCCGTGCACAAACTCAAGTACGAGAACTACACCTCCTCCTTCTTTATCCGGGACATCATTAAGCCCGATCCTCCTAAGAATTTACAGCTGAAGCCTCTCAAAAATAGCCGGCAAGTTGAGGTCTCTTGGGAATATCCCGACACTTGGAGCACACCCCACAGCTACTTCTCTTTAACCTTTTGTGTGCAAGTTCAAGGTAAAAGCAAGCGGGAGAAGAAAGACCGGGTGTTTACCGACAAAACCAGCGCCACCGTCATCTGTCGGAAGAACGCCTCCATCAGCGTGAGGGCTCAAGATCGTTATTACTCCAGCAGCTGGTCCGAGTGGGCCAGCGTGCCTTGTTCC
(接头)
GGCGGTGGAGGATCCGGAGGAGGTGGCTCCGGCGGCGGAGGATCT
(人IL-12亚基α(p35))
CGTAACCTCCCCGTGGCTACCCCCGATCCCGGAATGTTCCCTTGTTTACACCACAGCCAGAATTTACTGAGGGCCGTGAGCAACATGCTGCAGAAAGCTAGGCAGACTTTAGAATTTTACCCTTGCACCAGCGAGGAGATCGACCATGAAGATATCACCAAGGACAAGACATCCACCGTGGAGGCTTGTTTACCTCTGGAGCTGACAAAGAACGAGTCTTGTCTCAACTCTCGTGAAACCAGCTTCATCACAAATGGCTCTTGTTTAGCTTCCCGGAAGACCTCCTTTATGATGGCTTTATGCCTCAGCTCCATCTACGAGGATTTAAAGATGTACCAAGTGGAGTTCAAGACCATGAACGCCAAGCTGCTCATGGACCCTAAACGGCAGATCTTTTTAGACCAGAACATGCTGGCTGTGATTGATGAGCTGATGCAAGCTTTAAACTTCAACTCCGAGACCGTCCCTCAGAAGTCCTCCCTCGAGGAGCCCGATTTTTACAAGACAAAGATCAAACTGTGCATTTTACTCCACGCCTTTAGGATCCGGGCCGTGACCATTGACCGGGTCATGAGCTATTTAAACGCCAGC
(人IL-15Rα寿司结构域)
ATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG
(抗人CD16轻链可变结构域)
TCCGAGCTGACCCAGGACCCTGCTGTGTCCGTGGCTCTGGGCCAGACCGTGAGGATCACCTGCCAGGGCGACTCCCTGAGGTCCTACTACGCCTCCTGGTACCAGCAGAAGCCCGGCCAGGCTCCTGTGCTGGTGATCTACGGCAAGAACAACAGGCCCTCCGGCATCCCTGACAGGTTCTCCGGATCCTCCTCCGGCAACACCGCCTCCCTGACCATCACAGGCGCTCAGGCCGAGGACGAGGCTGACTACTACTGCAACTCCAGGGACTCCTCCGGCAACCATGTGGTGTTCGGCGGCGGCACCAAGCTGACCGTGGGCCAT
(接头)
GGCGGCGGCGGCTCCGGAGGCGGCGGCAGCGGCGGAGGAGGATCC
(抗人CD16重链可变结构域)
GAGGTGCAGCTGGTGGAGTCCGGAGGAGGAGTGGTGAGGCCTGGAGGCTCCCTGAGGCTGAGCTGTGCTGCCTCCGGCTTCACCTTCGACGACTACGGCATGTCCTGGGTGAGGCAGGCTCCTGGAAAGGGCCTGGAGTGGGTGTCCGGCATCAACTGGAACGGCGGATCCACCGGCTACGCCGATTCCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACTCCCTGTACCTGCAGATGAACTCCCTGAGGGCCGAGGACACCGCCGTGTACTACTGCGCCAGGGGCAGGTCCCTGCTGTTCGACTACTGGGGACAGGGCACCCTGGTGACCGTGTCCAGG
还制造构建体,将IL-18序列连接到组织因子219的N端编码区,并且将IL-18/TF构建体与IL-15的N端编码区连接(图22)。IL-18/TF/IL-15构建体(包括前导序列)的核酸序列如下(SEQ ID NO:73):
(信号肽)
ATGAAGTGGGTCACATTTATCTCTTTACTGTTCCTCTTCTCCAGCGCCTACAGC
(人IL-18)
TACTTCGGCAAACTGGAATCCAAGCTGAGCGTGATCCGGAATTTAAACGACCAAGTTCTGTTTATCGATCAAGGTAACCGGCCTCTGTTCGAGGACATGACCGACTCCGATTGCCGGGACAATGCCCCCCGGACCATCTTCATTATCTCCATGTACAAGGACAGCCAGCCCCGGGGCATGGCTGTGACAATTAGCGTGAAGTGTGAGAAAATCAGCACTTTATCTTGTGAGAACAAGATCATCTCCTTTAAGGAAATGAACCCCCCCGATAACATCAAGGACACCAAGTCCGATATCATCTTCTTCCAGCGGTCCGTGCCCGGTCACGATAACAAGATGCAGTTCGAATCCTCCTCCTACGAGGGCTACTTTTTAGCTTGTGAAAAGGAGAGGGATTTATTCAAGCTGATCCTCAAGAAGGAGGACGAGCTGGGCGATCGTTCCATCATGTTCACCGTCCAAAACGAGGAT
(人组织因子219)
AGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAG
(人IL-15)
AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC
实例14:IL-12/IL-15RαSu/αCD16scFv和IL-18/TF/IL-15融合蛋白的分泌
将IL-12/IL-15RαSu/αCD16scFv和IL-18/TF/IL-15构建体克隆到pMSGV-1修饰的逆转录病毒表达载体(Hughes,《人基因疗法》16:457–72,2005,通过引用并入本文)中,然后将表达载体转染到CHO-K1细胞中。两种构建体在CHO-K1细胞中的共表达引起可溶性IL-18/TF/IL-15:IL-12/IL-15RαSu/αCD16scFv蛋白复合物(称为18t15-12s/αCD16;图23和24)的分泌。两种构建体在CHO-K1细胞中的共表达引起可溶性IL-18/TF/IL-15:IL-12/IL-15RαSu/αCD16scFv蛋白复合物(称为18t15-12s/αCD16;图23和图24)的分泌,所述复合物可通过抗TF Ab亲和力和其它色谱方法纯化。在一些情况下,将信号肽从完整多肽上裂解下来以生成成熟形式。
IL-12/IL-15RαSu/αCD16scFv融合蛋白(包括信号肽序列)的氨基酸序列如下(SEQID NO:122):
(信号肽)
MKWVTFISLLFLFSSAYS
(人IL-12亚基β(p40))
IWELKKDVYVVELDWYPDAPGEMVVLTCDTPEEDGITWTLDQSSEVLGSGKTLTIQVKEFGDAGQYTCHKGGEVLSHSLLLLHKKEDGIWSTDILKDQKEPKNKTFLRCEAKNYSGRFTCWWLTTISTDLTFSVKSSRGSSDPQGVTCGAATLSAERVRGDNKEYEYSVECQEDSACPAAEESLPIEVMVDAVHKLKYENYTSSFFIRDIIKPDPPKNLQLKPLKNSRQVEVSWEYPDTWSTPHSYFSLTFCVQVQGKSKREKKDRVFTDKTSATVICRKNASISVRAQDRYYSSSWSEWASVPCS
(接头)
GGGGSGGGGSGGGGS
(人IL-12亚基α(p35))
RNLPVATPDPGMFPCLHHSQNLLRAVSNMLQKARQTLEFYPCTSEEIDHEDITKDKTSTVEACLPLELTKNESCLNSRETSFITNGSCLASRKTSFMMALCLSSIYEDLKMYQVEFKTMNAKLLMDPKRQIFLDQNMLAVIDELMQALNFNSETVPQKSSLEEPDFYKTKIKLCILLHAFRIRAVTIDRVMSYLNAS
(人IL-15Rα寿司结构域)
ITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR
(抗人CD16轻链可变结构域)
SELTQDPAVSVALGQTVRITCQGDSLRSYYASWYQQKPGQAPVLVIYGKNNRPSGIPDRFSGSSSGNTASLTITGAQAEDEADYYCNSRDSSGNHVVFGGGTKLTVGH
(接头)
GGGGSGGGGSGGGGS
(抗人CD16重链可变结构域)
EVQLVESGGGVVRPGGSLRLSCAASGFTFDDYGMSWVRQAPGKGLEWVSGINWNGGSTGYADSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARGRSLLFDYWGQGTLVTVSR
IL-18/TF/IL-15融合蛋白(包括前导序列)的氨基酸序列如下(SEQ ID NO:72):
(信号肽)
MKWVTFISLLFLFSSAYS
(人IL-18)
YFGKLESKLSVIRNLNDQVLFIDQGNRPLFEDMTDSDCRDNAPRTIFIISMYKDSQPRGMAVTISVKCEKISTLSCENKIISFKEMNPPDNIKDTKSDIIFFQRSVPGHDNKMQFESSSYEGYFLACEKERDLFKLILKKEDELGDRSIMFTVQNED
(人组织因子219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(人IL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
实例15:IL-18/IL-15RαSu和IL-12/TF/IL-15DNA构建体的产生
在非限制性实例中,产生IL-18/IL-15RαSu和IL-12/TF/IL-15DNA构建体。人IL-18亚基序列、人IL-15RαSu序列、人IL-12序列、人组织因子219序列和人IL-15序列由金唯智合成。制造DNA构建体,将IL-18直接连接到IL-15RαSu。还制造另外的构建体,将IL-12序列连接到人组织因子219形式的N端编码区,并且进一步将IL-12/TF构建体连接到IL-15的N端编码区。如上所述,使用IL-12的单链形式(p40-接头-p35)。
IL-18/IL-15RαSu构建体(包括信号肽序列)的核酸序列如下(SEQ ID NO:217):
(信号肽)
ATGAAGTGGGTCACATTTATCTCTTTACTGTTCCTCTTCTCCAGCGCCTACAGC
(人IL-18)
TACTTCGGCAAACTGGAATCCAAGCTGAGCGTGATCCGGAATTTAAACGACCAAGTTCTGTTTATCGATCAAGGTAACCGGCCTCTGTTCGAGGACATGACCGACTCCGATTGCCGGGACAATGCCCCCCGGACCATCTTCATTATCTCCATGTACAAGGACAGCCAGCCCCGGGGCATGGCTGTGACAATTAGCGTGAAGTGTGAGAAAATCAGCACTTTATCTTGTGAGAACAAGATCATCTCCTTTAAGGAAATGAACCCCCCCGATAACATCAAGGACACCAAGTCCGATATCATCTTCTTCCAGCGGTCCGTGCCCGGTCACGATAACAAGATGCAGTTCGAATCCTCCTCCTACGAGGGCTACTTTTTAGCTTGTGAAAAGGAGAGGGATTTATTCAAGCTGATCCTCAAGAAGGAGGACGAGCTGGGCGATCGTTCCATCATGTTCACCGTCCAAAACGAGGAT
(人IL-15Rα寿司结构域)
ATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG
IL-12/TF/IL-15构建体(包括前导序列)的核酸序列如下(SEQ ID NO:218):
(信号肽)
ATGAAATGGGTGACCTTTATTTCTTTACTGTTCCTCTTTAGCAGCGCCTACTCC
(人IL-12亚基β(p40))
ATTTGGGAACTGAAGAAGGACGTCTACGTGGTCGAACTGGACTGGTATCCCGATGCTCCCGGCGAAATGGTGGTGCTCACTTGTGACACCCCCGAAGAAGACGGCATCACTTGGACCCTCGATCAGAGCAGCGAGGTGCTGGGCTCCGGAAAGACCCTCACAATCCAAGTTAAGGAGTTCGGAGACGCTGGCCAATACACATGCCACAAGGGAGGCGAGGTGCTCAGCCATTCCTTATTATTATTACACAAGAAGGAAGACGGAATCTGGTCCACCGACATTTTAAAAGATCAGAAGGAGCCCAAGAATAAGACCTTTTTAAGGTGTGAGGCCAAAAACTACAGCGGTCGTTTCACTTGTTGGTGGCTGACCACCATTTCCACCGATTTAACCTTCTCCGTGAAAAGCAGCCGGGGAAGCTCCGACCCTCAAGGTGTGACATGTGGAGCCGCTACCCTCAGCGCTGAGAGGGTTCGTGGCGATAACAAGGAATACGAGTACAGCGTGGAGTGCCAAGAAGATAGCGCTTGTCCCGCTGCCGAAGAATCTTTACCCATTGAGGTGATGGTGGACGCCGTGCACAAACTCAAGTACGAGAACTACACCTCCTCCTTCTTTATCCGGGACATCATTAAGCCCGATCCTCCTAAGAATTTACAGCTGAAGCCTCTCAAAAATAGCCGGCAAGTTGAGGTCTCTTGGGAATATCCCGACACTTGGAGCACACCCCACAGCTACTTCTCTTTAACCTTTTGTGTGCAAGTTCAAGGTAAAAGCAAGCGGGAGAAGAAAGACCGGGTGTTTACCGACAAAACCAGCGCCACCGTCATCTGTCGGAAGAACGCCTCCATCAGCGTGAGGGCTCAAGATCGTTATTACTCCAGCAGCTGGTCCGAGTGGGCCAGCGTGCCTTGTTCC
(接头)
GGCGGTGGAGGATCCGGAGGAGGTGGCTCCGGCGGCGGAGGATCT
(人IL-12亚基α(p35))
CGTAACCTCCCCGTGGCTACCCCCGATCCCGGAATGTTCCCTTGTTTACACCACAGCCAGAATTTACTGAGGGCCGTGAGCAACATGCTGCAGAAAGCTAGGCAGACTTTAGAATTTTACCCTTGCACCAGCGAGGAGATCGACCATGAAGATATCACCAAGGACAAGACATCCACCGTGGAGGCTTGTTTACCTCTGGAGCTGACAAAGAACGAGTCTTGTCTCAACTCTCGTGAAACCAGCTTCATCACAAATGGCTCTTGTTTAGCTTCCCGGAAGACCTCCTTTATGATGGCTTTATGCCTCAGCTCCATCTACGAGGATTTAAAGATGTACCAAGTGGAGTTCAAGACCATGAACGCCAAGCTGCTCATGGACCCTAAACGGCAGATCTTTTTAGACCAGAACATGCTGGCTGTGATTGATGAGCTGATGCAAGCTTTAAACTTCAACTCCGAGACCGTCCCTCAGAAGTCCTCCCTCGAGGAGCCCGATTTTTACAAGACAAAGATCAAACTGTGCATTTTACTCCACGCCTTTAGGATCCGGGCCGTGACCATTGACCGGGTCATGAGCTATTTAAACGCCAGC
(人组织因子219)
AGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAG
(人IL-15)
AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC
实例16:IL-18/IL-15RαSu和IL-12/TF/IL-15融合蛋白的分泌
将IL-18/IL-15RαSu和IL-12/TF/IL-15构建体克隆到pMSGV-1修饰的逆转录病毒表达载体(Hughes,《人基因疗法》16:457–72,2005,通过引用并入本文)中,并且将表达载体转染到CHO-K1细胞中。两种构建体在CHO-K1细胞中的共表达引起可溶性IL-12/TF/IL-15:IL-18/IL-15RαSu蛋白复合物(称为12t15/s18)的分泌,所述复合物可通过抗TF Ab亲和力和其它色谱方法纯化。
IL-18/IL-15RαSu融合蛋白(包括信号肽序列)的氨基酸序列如下(SEQ ID NO:219):
(信号肽)
MKWVTFISLLFLFSSAYS
(人IL-18)
YFGKLESKLSVIRNLNDQVLFIDQGNRPLFEDMTDSDCRDNAPRTIFIISMYKDSQPRGMAVTISVKCEKISTLSCENKIISFKEMNPPDNIKDTKSDIIFFQRSVPGHDNKMQFESSSYEGYFLACEKERDLFKLILKKEDELGDRSIMFTVQNED
(人IL-15Rα寿司结构域)
ITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR
IL-12/TF/IL-15融合蛋白(包括前导序列)的氨基酸序列如下(SEQ ID NO:220):
(信号肽)
MKWVTFISLLFLFSSAYS
(人IL-12亚基β(p40))
IWELKKDVYVVELDWYPDAPGEMVVLTCDTPEEDGITWTLDQSSEVLGSGKTLTIQVKEFGDAGQYTCHKGGEVLSHSLLLLHKKEDGIWSTDILKDQKEPKNKTFLRCEAKNYSGRFTCWWLTTISTDLTFSVKSSRGSSDPQGVTCGAATLSAERVRGDNKEYEYSVECQEDSACPAAEESLPIEVMVDAVHKLKYENYTSSFFIRDIIKPDPPKNLQLKPLKNSRQVEVSWEYPDTWSTPHSYFSLTFCVQVQGKSKREKKDRVFTDKTSATVICRKNASISVRAQDRYYSSSWSEWASVPCS
(接头)
GGGGSGGGGSGGGGS
(人IL-12亚基α(p35))
RNLPVATPDPGMFPCLHHSQNLLRAVSNMLQKARQTLEFYPCTSEEIDHEDITKDKTSTVEACLPLELTKNESCLNSRETSFITNGSCLASRKTSFMMALCLSSIYEDLKMYQVEFKTMNAKLLMDPKRQIFLDQNMLAVIDELMQALNFNSETVPQKSSLEEPDFYKTKIKLCILLHAFRIRAVTIDRVMSYLNAS
(人组织因子219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(人IL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
在一些情况下,将前导肽从完整多肽上裂解下来以生成可能可溶或分泌的成熟形式。
实例17:18t15-12s16复合物的重组蛋白定量
使用标准夹心ELISA方法检测并定量18t15-12s16复合物(包含IL-12/IL-15RαSu/αCD16scFv;IL-18/TF/IL-15)(图25)。抗人组织因子抗体/IL-2或抗TF Ab/IL-18充当捕获抗体,并且生物素化抗人IL-12或IL-18抗体(BAF 219、D045-6,均为安迪生物公司产品)充当检测抗体。还使用抗人组织因子抗体(I43)和抗人组织因子抗体检测抗体来检测组织因子。
实例18:TGFβRII/IL-15RαSu和IL-21/TF/IL-15构建体的产生
在非限制性实例中,产生TGFβRII/IL-15RαSu DNA构建体(图26)。人TGFβRII二聚体和人IL-21序列从UniProt网站获得,并且这些序列的DNA由金唯智合成。制造DNA构建体,用接头将TGFβRII连接到另一TGFβRII以生成TGFβRII的单链形式,并且然后直接将TGFβRII单链二聚体序列连接到IL-15RαSu的N端编码区。
TGFβRII/IL-15RαSu构建体(包括信号序列)的核酸序列如下(SEQ ID NO:93):
(信号肽)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(人TGFβRII-第1片段)
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCACGATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGAT
(接头)
GGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGT
(人TGFβRII-第2片段)
ATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCACAATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC
(人IL-15Rα寿司结构域)
ATCACGTGTCCTCCTCCTATGTCCGTGGAACACGCAGACATCTGGGTCAAGAGCTACAGCTTGTACTCCAGGGAGCGGTACATTTGTAACTCTGGTTTCAAGCGTAAAGCCGGCACGTCCAGCCTGACGGAGTGCGTGTTGAACAAGGCCACGAATGTCGCCCACTGGACAACCCCCAGTCTCAAATGTATTAGA
另外,制造IL-21/TF/IL-15构建体,将IL-21序列连接到组织因子219的N端编码区,并且进一步将IL-21/TF构建体连接到IL-15的N端编码区(图27)。IL-21/TF/IL-15构建体(包括前导序列)的核酸序列如下(SEQ ID NO:89):
(信号肽)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(人IL-21)
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC
(人组织因子219)
TCCGGCACCACCAATACCGTGGCCGCTTATAACCTCACATGGAAGAGCACCAACTTCAAGACAATTCTGGAATGGGAACCCAAGCCCGTCAATCAAGTTTACACCGTGCAGATCTCCACCAAATCCGGAGACTGGAAGAGCAAGTGCTTCTACACAACAGACACCGAGTGTGATTTAACCGACGAAATCGTCAAGGACGTCAAGCAAACCTATCTGGCTCGGGTCTTTTCCTACCCCGCTGGCAATGTCGAGTCCACCGGCTCCGCTGGCGAGCCTCTCTACGAGAATTCCCCCGAATTCACCCCTTATTTAGAGACCAATTTAGGCCAGCCTACCATCCAGAGCTTCGAGCAAGTTGGCACCAAGGTGAACGTCACCGTCGAGGATGAAAGGACTTTAGTGCGGCGGAATAACACATTTTTATCCCTCCGGGATGTGTTCGGCAAAGACCTCATCTACACACTGTACTATTGGAAGTCCAGCTCCTCCGGCAAAAAGACCGCTAAGACCAACACCAACGAGTTTTTAATTGACGTGGACAAAGGCGAGAACTACTGCTTCAGCGTGCAAGCCGTGATCCCTTCTCGTACCGTCAACCGGAAGAGCACAGATTCCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAG
(人IL-15)
AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC
实例19:TGFβRII/IL-15RαSu和IL-21/TF/IL-15融合蛋白的分泌
将TGFβRII/IL-15RαSu和IL-21/TF/IL-15DNA构建体克隆到pMSGV-1修饰的逆转录病毒表达载体(如Hughes,《人基因疗法》16:457–72,2005中所描述,其通过引用并入本文)中,并且将表达载体转染到CHO-K1细胞中。两种构建体在CHO-K1细胞中的共表达引起可溶性IL-21/TF/IL-15:TGFβRII/IL-15RαSu蛋白复合物(称为21t15-TGFRs;图28和图29)的分泌。使用抗TF抗体亲和色谱法和其它色谱方法从CHO-K1细胞培养上清液中纯化21t15-TGFRs复合物。
TGFβRII/IL-15RαSu构建体(包括信号肽序列)的氨基酸序列如下(SEQ ID NO:92):
(信号肽)
MKWVTFISLLFLFSSAYS
(人TGFβRII-第1片段)
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD
(接头)
GGGGSGGGGSGGGGS
(人TGFβRII-第2片段)
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD
(人IL-15Rα寿司结构域)
ITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR
成熟的IL-21/TF/IL-15融合蛋白(包括信号肽序列)的氨基酸序列如下(SEQ IDNO:88):
(信号肽)
MKWVTFISLLFLFSSAYS
(人IL-21)
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS
(人组织因子219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(人IL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
在一些情况下,将前导肽从完整多肽上裂解下来以生成可能可溶或分泌的成熟形式。
实例20:通过免疫亲和色谱法纯化21t15-TGFRs
将抗TF抗体亲和柱连接到通用电气医疗集团AKTATMAvant蛋白纯化系统。除洗脱步骤外,所有步骤的流速均为4mL/min,洗脱步骤的流速为2mL/min。
21t15-TGFRs的细胞培养收获物用1M Tris碱调节到pH 7.4,并且加载到用5个柱体积的PBS平衡的抗TF抗体亲和柱上。加载样品后,用5个柱体积的PBS洗涤柱,接着用6个柱体积的0.1M乙酸,pH 2.9洗脱。收集280nm处的吸光度,并且然后接着通过添加1M Tris碱将样品中和到pH 7.5-8.0。然后使用具有30KDa分子量截断值的 离心过滤器将中和的样品缓冲液交换到PBS中。图30显示21t15-TGFRs复合物结合抗TF抗体亲和柱,其中TF是21t15-TGFRs结合伴侣。将缓冲液交换的蛋白质样品存储在2-8℃下,以用于进一步生化分析和生物活性测试。
离心过滤器将中和的样品缓冲液交换到PBS中。图30显示21t15-TGFRs复合物结合抗TF抗体亲和柱,其中TF是21t15-TGFRs结合伴侣。将缓冲液交换的蛋白质样品存储在2-8℃下,以用于进一步生化分析和生物活性测试。
每次洗脱后,接着使用6个柱体积的0.1M甘氨酸,pH 2.5剥离抗TF抗体亲和柱。然后使用10个柱体积的PBS、0.05%叠氮化钠中和所述柱,并且存储在2-8℃下。
实例21:21t15-TGFRs的尺寸排阻色谱
将通用电气医疗集团 200增加10/300GL凝胶过滤柱连接到通用电气医疗集团AKTATMAvant蛋白纯化系统。用2个柱体积的PBS平衡所述柱。流速为0.8mL/min。使用毛细管环将200μL 1mg/mL的21t15-TGFRs复合物注入到色谱柱上。然后用1.25个柱体积的PBS追赶注射液。SEC色谱图如图31所示。有两个蛋白质峰,可能代表21t15-TGFRs的单体和二聚体形式。
200增加10/300GL凝胶过滤柱连接到通用电气医疗集团AKTATMAvant蛋白纯化系统。用2个柱体积的PBS平衡所述柱。流速为0.8mL/min。使用毛细管环将200μL 1mg/mL的21t15-TGFRs复合物注入到色谱柱上。然后用1.25个柱体积的PBS追赶注射液。SEC色谱图如图31所示。有两个蛋白质峰,可能代表21t15-TGFRs的单体和二聚体形式。
实例22:21t15-TGFRs的SDS-PAGE
为了确定纯度和蛋白质分子量,使用4-12%NuPage Bis-Tris蛋白质凝胶SDS-PAGE在还原条件下分析纯化的21t15-TGFRs复合蛋白质样品。凝胶用InstantBlueTM染色约30min,接着在纯化水中脱色过夜。图32显示抗TF抗体亲和纯化的21t15-TGFRs的示例SDS凝胶,其中条带在39.08kDa和53kDa处。
使用蛋白质去糖基化混合物II试剂盒(新英格兰生物实验室)和制造商的说明书,确认CHO细胞中21t15-TGFRs的糖基化。去糖基化降低21t15-TGFRs的分子量,如图32泳道4所示。
实例23:21t15-TGFRs复合物的重组蛋白定量
21t15-TGFRs复合物使用标准夹心ELISA方法检测并定量(图33-37)。抗人组织因子抗体充当捕获抗体并且生物素化抗人IL-21、IL-15或TGFβRII充当检测抗体。还使用抗人组织因子捕获抗体(I43)和抗人组织因子抗体检测抗体来检测组织因子。将I43/抗TF抗体ELISA与相似浓度下的纯化组织因子进行比较。
实例24:21t15-TGFRs复合物的免疫刺激能力
为了评定21t15-TGFRs复合物的IL-15免疫刺激活性,向200μL IMDM:10%FBS培养基中32Dβ细胞(104个细胞/孔)中添加逐渐提高浓度的21t15-TGFRs,并且将细胞在37℃下培育3天。在第四天,然后添加WST-1增殖试剂(10μL/孔),并且在4小时后,在450nm处测量吸光度,以基于WST-1裂解为可溶性甲臜染料来确定细胞增殖。评定人重组IL-15的生物活性作为阳性对照。如图37所示,21t15-TGFRs展现IL-15依赖性32Dβ细胞增殖。与人重组IL-15相比,21t15-TGFRs复合物减少了,这可能是由于IL-21和组织因子与IL-15结构域的连接所致。
另外,HEK-Blue TGFβ报告细胞(hkb-tgfb,英伟杰)用于测量21t15-TGFRs阻断TGFβ1活性的能力(图38)。将浓度逐渐提高的21t15-TGFRs与0.1nM TGFβ1混合并添加到200μLIMDM:10%热灭活FBS培养基中HEK-Blue TGFβ报告细胞(2.5×104个细胞/孔)中。将细胞在37℃下培育过夜。第二天,将20μl诱导的HEK-Blue TGFβ报告细胞上清液添加到180μlQUANTI-Blue(英伟杰)中,并且在37℃下培育1-3小时。通过测量620nm处的吸光度来评定21t15-TGFRs活性。评定人重组TGFβRII/Fc活性作为阳性对照。
这些结果展现21t15-TGFRs复合物的TGFβRII结构域保留其捕获TGFβ1的能力。与人重组TGFβRII/Fc相比,21t15-TGFRs阻断TGFβ1活性的能力降低,可能是由于TGFβRII连接到IL-15Rα寿司结构域所致。
实例25:21t15-TGFRs复合物诱导细胞因子诱导的记忆样NK细胞
在用饱和量的细胞因子过夜刺激纯化的NK细胞后,可离体诱导细胞因子诱导的记忆样NK细胞。这些记忆样特性可通过IL-2受体ɑ(IL-2Rɑ、CD25)、CD69(和其它激活标记)的表达,和增加的IFN-γ产生来测量。为了评估21t15-TGFRs复合物促进细胞因子诱导的记忆样NK细胞生成的能力,用1nM至100nM的21t15-TGFRs复合物刺激纯化的人NK细胞(>95%CD56+)14-18小时。通过抗体染色和流式细胞术评定细胞表面CD25和CD 69表达以及细胞内IFN-γ水平。
从血库获得新鲜的人白细胞,并且用RosetteSep/人NK细胞试剂(干细胞技术有限公司)分离CD56+NK细胞。NK细胞的纯度>70%,并且通过用CD56-BV421、CD16-BV510、CD25-PE、CD69-APCFire750特异性抗体(BioLegend)染色得到证实。对细胞进行计数,并且将其以0.2×106个/mL在0.2mL完全培养基(RPMI 1640(吉毕科公司),补充有2mM L-谷氨酰胺(Thermo Life Technologies)、青霉素(Thermo Life Technologies))、链霉素(ThermoLife Technologies)和10%FBS(Hyclone))的96孔平底板中重悬。在37℃,5%CO2下用hIL-21(50ng/mL)(Biolegend)和hIL-15(50ng/mL)(NCI)的混合细胞因子或用1nM、10nM或100nM21t15-TGFRs复合物刺激细胞过夜14-18小时。然后收获细胞,并且用CD56-BV421、CD16-BV510、CD25-PE、CD69-APCFire750特异性抗体表面染色30分钟。染色后,将细胞在FACS缓冲液(含0.5%BSA(EMD密理博)和0.001%叠氮化钠(西格玛)的1×PBS(Hyclone))中洗涤(室温下1500RPM 5分钟)。洗涤两次后,使用BD FACSCelestaTM流式细胞仪分析细胞。(绘制的数据-平均荧光强度;图39和图40)。
从血库获得新鲜的人白细胞,并且用RosetteSep/人NK细胞试剂(干细胞技术有限公司)分离CD56+NK细胞。NK细胞的纯度>70%,并且通过用CD56-BV421、CD16-BV510、CD25-PE、CD69-APCFire750特异性抗体(BioLegend)染色得到证实。对细胞进行计数,并且将其以0.2×106个/mL在0.2mL完全培养基(RPMI 1640(吉毕科公司),补充有2mM L-谷氨酰胺(Thermo Life Technologies)、青霉素(Thermo Life Technologies))、链霉素(ThermoLife Technologies)和10%FBS(Hyclone))的96孔平底板中重悬。在37℃,5%CO2下用hIL-21(50ng/mL)(Biolegend)和hIL-15(50ng/mL)(NCI)的混合细胞因子或1nM、10nM或100nM21t15-TGFRs复合物刺激细胞过夜14-18小时。然后将细胞用10μg/mL布雷菲德菌素A(西格玛)和1×莫能菌素(eBioscience)处理4小时。收获细胞,并且用CD56-BV421、CD16-BV510、CD25-PE、CD69-APCFire750特异性抗体表面染色30分钟。染色后,将细胞在FACS缓冲液(含0.5%BSA(EMD密理博)和0.001%叠氮化钠(西格玛)的1×PBS(Hyclone)中洗涤(室温下1500RPM 5分钟),并且在室温下固定10分钟。固定后,将细胞用1×透化缓冲液(eBioscience)洗涤(室温下1500RPM,持续5分钟),并且在室温下对细胞内IFN-γ-PE Ab(Biolegend)染色30分钟。用1×透化的缓冲液再次洗涤细胞,然后用FACS缓冲液洗涤。将细胞沉淀重悬于300μl FACS缓冲液中,并且使用BD FACSCelestaTM流式细胞仪进行分析。(绘制的IFN-γ阳性细胞百分比;图41)。
实例26:NK细胞对人肿瘤细胞的体外细胞毒性
在存在逐渐提高浓度的21t15-TGFRs复合物的情况下,将人骨髓性白血病细胞K562(CellTrace紫罗兰标记)与纯化的人NK细胞一起培育(使用StemCell人NK细胞纯化试剂盒(E:T比;2:1))。20小时后,收获培养物,用碘化丙啶(PI)染色,并且通过流式细胞术评定。如图42所示,与对照相比,21t15-TGFRs复合物诱导人NK对K562的细胞毒性。
实例27:IL-21/TF突变体/IL-15DNA构建体的产生和与TGFβRII/IL-15RαSuTGF的
所得融合蛋白复合物
在非限制性实例中,通过将IL-21直接连接到组织因子219突变体的N端编码区,并且进一步将IL-21/TF突变体连接到IL-15的N端编码区来制造IL-21/TF突变体/IL-15DNA构建体。
IL-21/TF突变体/IL-15构建体(包括信号肽序列)的核酸序列如下(SEQ ID NO:221,加阴影的核苷酸是突变体,并且突变密码子带有下划线):
(信号序列)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(人IL-21)
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC
(人组织因子219突变体)
TCCGGCACCACCAATACCGTGGCCGCTTATAACCTCACATGGAAGAGCACCAACTTCGCGACAGCTCTG GAATGGGAACCCAAGCCCGTCAATCAAGTTTACACCGTGCAGATCTCCACCAAATCCGGAGACTGGAAGAGCAAGTG CTTCTACACAACAGACACCGAGTGTGCTTTAACCGACGAAATCGTCAAGGACGTCAAGCAAACCTATCTGGCTCGGG TCTTTTCCTACCCCGCTGGCAATGTCGAGTCCACCGGCTCCGCTGGCGAGCCTCTCTACGAGAATTCCCCCGAATTC ACCCCTTATTTAGAGACCAATTTAGGCCAGCCTACCATCCAGAGCTTCGAGCAAGTTGGCACCAAGGTGAACGTCAC CGTCGAGGATGAAAGGACTTTAGTGGCGCGGAATAACACAGCTTTATCCCTCCGGGATGTGTTCGGCAAAGACCTCA TCTACACACTGTACTATTGGAAGTCCAGCTCCTCCGGCAAAAAGACCGCTAAGACCAACACCAACGAGTTTTTAATT GACGTGGACAAAGGCGAGAACTACTGCTTCAGCGTGCAAGCCGTGATCCCTTCTCGTACCGTCAACCGGAAGAGCAC AGATTCCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAG
(人IL-15)
AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC
IL-21/TF突变体/IL-15构建体(包括信号肽序列)的氨基酸序列如下(SEQ ID NO:222,取代的残基加阴影):
(信号肽)
MKWVTFISLLFLFSSAYS
(人IL-21)
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS
(人组织因子219)
SGTTNTVAAYNLTWKSTNFATALEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECALTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVARNNTALSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(人IL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
在一些情况下,将前导肽从完整多肽上裂解下来以生成可能可溶或分泌的成熟形式。
在一些实施例中,IL-21/TF突变体/IL-15DNA构建体可与TGFβRII/IL-15RαSu DNA构建体组合,使用如上所述的逆转录病毒载体转染到细胞中,并且表达为IL-21/TF突变体/IL-15和TGFβRII/IL-15RαSu融合蛋白。TGFβRII/IL-15RαSu融合蛋白的IL-15RαSu结构域结合到IL-21/TF突变体/IL-15融合蛋白的IL-15结构域,产生IL-21/TF突变体/IL-15:TGFβRII/IL-15RαSu复合物。
实例28:IL-21/IL-15RαSu和TGFβRII/TF/IL-15 DNA构建体和所得融合蛋白复合
物的产生
在非限制性实例中,通过将IL-21直接连接到IL-15RαSu亚基序列来制造IL-21/IL-15RαSu DNA构建体。IL-21/IL-15RαSu构建体(包括信号序列)的核酸序列如下(SEQ IDNO:111):
(信号序列)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(人IL-21)
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC
(人IL-15Rα寿司结构域)
ATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG
IL-21/IL-15RαSu构建体(包括信号肽序列)的氨基酸序列如下(SEQ ID NO:110):
(信号肽)
MKWVTFISLLFLFSSAYS
(人IL-21)
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS
(人IL-15Rα寿司结构域)
ITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR
在一些情况下,将前导肽从完整多肽上裂解下来以生成可能可溶或分泌的成熟形式。
在一些实施例中,IL-21/IL-15RαSu DNA构建体可与TGFβRII/TF/IL-15DNA构建体组合,转染到如上所述的逆转录病毒载体中,并且表达为IL-21/IL-15RαSu和TGFβRII/TF/IL-15融合蛋白。IL-21/IL-15RαSu融合蛋白的IL-15RαSu结构域结合到TGFβRII/TF/IL-15融合蛋白的IL-15结构域,产生TGFβRII/TF/IL-15:IL-21/IL-15RαSu复合物。
通过将TGFβRII序列连接到人组织因子219形式的N端编码区,并且然后将TGFβRII/TF构建体连接到IL-15的N端编码区,产生TGFβRII/TF/IL-15RαSu DNA构建体。如上所述,使用TGFβRII的单链形式(TGFβRII-接头-TGFβRII)。TGFβRII/TF/IL-15构建体(包括前导序列)的核酸序列如下(SEQ ID NO:136):
(信号肽)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(人TGFβRII-第1片段)
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCACGATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGAT
(接头)
GGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGT
(人TGFβRII-第2片段)
ATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCACAATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC
(人组织因子219)
TCCGGCACCACCAATACCGTGGCCGCTTATAACCTCACATGGAAGAGCACCAACTTCAAGACAATTCTGGAATGGGAACCCAAGCCCGTCAATCAAGTTTACACCGTGCAGATCTCCACCAAATCCGGAGACTGGAAGAGCAAGTGCTTCTACACAACAGACACCGAGTGTGATTTAACCGACGAAATCGTCAAGGACGTCAAGCAAACCTATCTGGCTCGGGTCTTTTCCTACCCCGCTGGCAATGTCGAGTCCACCGGCTCCGCTGGCGAGCCTCTCTACGAGAATTCCCCCGAATTCACCCCTTATTTAGAGACCAATTTAGGCCAGCCTACCATCCAGAGCTTCGAGCAAGTTGGCACCAAGGTGAACGTCACCGTCGAGGATGAAAGGACTTTAGTGCGGCGGAATAACACATTTTTATCCCTCCGGGATGTGTTCGGCAAAGACCTCATCTACACACTGTACTATTGGAAGTCCAGCTCCTCCGGCAAAAAGACCGCTAAGACCAACACCAACGAGTTTTTAATTGACGTGGACAAAGGCGAGAACTACTGCTTCAGCGTGCAAGCCGTGATCCCTTCTCGTACCGTCAACCGGAAGAGCACAGATTCCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAG
(人IL-15)
AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC
TGFβRII/TF/IL-15融合蛋白(包括信号肽)的氨基酸序列如下(SEQ ID NO:135):
(信号肽)
MKWVTFISLLFLFSSAYS
(人TGFβRII-第1片段)
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD
(接头)
GGGGSGGGGSGGGGS
(人TGFβRII-第2片段)
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD
(人组织因子219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(人IL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
实例29:IL-7/IL-15RαSu
DNA构建体的产生
在非限制性实例中,产生IL-7/IL-15RαSu DNA构建体(参见图43)。人IL-7序列、人IL-15RαSu序列、人IL-15序列和人组织因子219序列从UniProt网站获得,并且这些序列的DNA由金唯智合成。制造DNA构建体,将IL-7序列连接到IL-15RαSu序列。最终的IL-7/IL-15RαSu DNA构建体序列由金唯智合成。
编码IL-7/IL-15RαSu构建体的第二嵌合多肽(包括信号肽序列)的核酸序列如下(SEQ ID NO:103):
(信号肽)
ATGGGAGTGAAAGTTCTTTTTGCCCTTATTTGTATTGCTGTGGCCGAGGCC
(人IL-7)
GATTGTGATATTGAAGGTAAAGATGGCAAACAATATGAGAGTGTTCTAATGGTCAGCATCGATCAATTATTGGACAGCATGAAAGAAATTGGTAGCAATTGCCTGAATAATGAATTTAACTTTTTTAAAAGACATATCTGTGATGCTAATAAGGAAGGTATGTTTTTATTCCGTGCTGCTCGCAAGTTGAGGCAATTTCTTAAAATGAATAGCACTGGTGATTTTGATCTCCACTTATTAAAAGTTTCAGAAGGCACAACAATACTGTTGAACTGCACTGGCCAGGTTAAAGGAAGAAAACCAGCTGCCCTGGGTGAAGCCCAACCAACAAAGAGTTTGGAAGAAAATAAATCTTTAAAGGAACAGAAAAAACTGAATGACTTGTGTTTCCTAAAGAGACTATTACAAGAGATAAAAACTTGTTGGAATAAAATTTTGATGGGCACTAAAGAACAC
(人IL-15Rα寿司结构域)
ATCACGTGCCCTCCCCCCATGTCCGTGGAACACGCAGACATCTGGGTCAAGAGCTACAGCTTGTACTCCAGGGAGCGGTACATTTGTAACTCTGGTTTCAAGCGTAAAGCCGGCACGTCCAGCCTGACGGAGTGCGTGTTGAACAAGGCCACGAATGTCGCCCACTGGACAACCCCCAGTCTCAAATGCATTAGA
IL-7/IL-15RαSu构建体的第二嵌合多肽(包括信号肽序列)如下(SEQ ID NO:102):
(信号肽)
MKWVTFISLLFLFSSAYS
(人IL-7)
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWNKILMGTKEH
(人组织因子219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(人IL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
实例30:IL-21/TF/IL-15DNA构建体的产生
在非限制性实例中,通过将IL-21序列连接到组织因子219的N端编码区,并且进一步将IL-21/TF构建体与IL-15的N端编码区连接,制造IL-21/TF/IL-15构建体(图44)。
由金唯智合成的编码IL-21/TF/IL-15构建体的第一嵌合多肽(包括前导序列)的核酸序列如下(SEQ ID NO:89):
(信号肽)
ATGGGAGTGAAAGTTCTTTTTGCCCTTATTTGTATTGCTGTGGCCGAGGCC
(人IL-21片段)
CAAGGTCAAGATCGCCACATGATTAGAATGCGTCAACTTATAGATATTGTTGATCAGCTGAAAAATTATGTGAATGACTTGGTCCCTGAATTTCTGCCAGCTCCAGAAGATGTAGAGACAAACTGTGAGTGGTCAGCTTTTTCCTGTTTTCAGAAGGCCCAACTAAAGTCAGCAAATACAGGAAACAATGAAAGGATAATCAATGTATCAATTAAAAAGCTGAAGAGGAAACCACCTTCCACAAATGCAGGGAGAAGACAGAAACACAGACTAACATGCCCTTCATGTGATTCTTATGAGAAAAAACCACCCAAAGAATTCCTAGAAAGATTCAAATCACTTCTCCAAAAGATGATTCATCAGCATCTGTCCTCTAGAACACACGGAAGTGAAGATTCC
(人组织因子219)
TCAGGCACTACAAATACTGTGGCAGCATATAATTTAACTTGGAAATCAACTAATTTCAAGACAATTTTGGAGTGGGAACCCAAACCCGTCAATCAAGTCTACACTGTTCAAATAAGCACTAAGTCAGGAGATTGGAAAAGCAAATGCTTTTACACAACAGACACAGAGTGTGACCTCACCGACGAGATTGTGAAGGATGTGAAGCAGACGTACTTGGCACGGGTCTTCTCCTACCCGGCAGGGAATGTGGAGAGCACCGGTTCTGCTGGGGAGCCTCTGTATGAGAACTCCCCAGAGTTCACACCTTACCTGGAGACAAACCTCGGACAGCCAACAATTCAGAGTTTTGAACAGGTGGGAACAAAAGTGAATGTGACCGTAGAAGATGAACGGACTTTAGTCAGAAGGAACAACACTTTCCTAAGCCTCCGGGATGTTTTTGGCAAGGACTTAATTTATACACTTTATTATTGGAAATCTTCAAGTTCAGGAAAGAAAACAGCCAAAACAAACACTAATGAGTTTTTGATTGATGTGGATAAAGGAGAAAACTACTGTTTCAGTGTTCAAGCAGTGATTCCCTCCCGAACAGTTAACCGGAAGAGTACAGACAGCCCGGTAGAGTGTATGGGCCAGGAGAAAGGGGAATTCAGAGAA
(人IL-15)
AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC
包括前导序列的IL-21/TF/IL-15构建体的第一嵌合多肽是SEQ ID NO:88:
(信号肽)
MGVKVLFALICIAVAEA(SEQ ID NO:223)
(人IL-21)
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS
(人组织因子219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(人IL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
实例31:IL-7/IL-15RαSu和IL-21/TF/IL-15融合蛋白的分泌
将IL-7/IL-15RαSu和IL-21/TF/IL-15DNA构建体克隆到pMSGV-1修饰的逆转录病毒表达载体(Hughes,《人基因疗法》16:457–72,2005,通过引用并入本文)中,并且将表达载体转染到CHO-K1细胞中。两种构建体在CHO-K1细胞中的共表达使得可形成和分泌可溶性IL-21/TF/IL-15:IL-7/IL-15RαSu蛋白复合物(称为21t15-7s;图45和图46)。使用抗TF抗体亲和色谱法和尺寸排阻色谱法从CHO-K1细胞培养上清液中纯化21t15-7s蛋白,得到由IL-7/IL-15RαSu和IL-21/TF/IL-15融合蛋白组成的可溶性(非聚集)蛋白复合物。
在一些情况下,将前导(信号序列)肽从完整的多肽上裂解下来以生成可能可溶或分泌的成熟形式。
实例32:通过免疫亲和色谱法纯化21t15-7s
将抗TF抗体亲和柱连接到通用电气医疗集团TMAKTA Avant蛋白纯化系统。除洗脱步骤外,所有步骤的流速均为4mL/min,洗脱步骤的流速为2mL/min。
21t15-7s的细胞培养收获物用1M Tris碱调节到pH 7.4,并且加载到用5个柱体积的PBS平衡的抗TF抗体亲和柱上。加载样品后,用5个柱体积的PBS洗涤柱,接着用6个柱体积的0.1M乙酸,pH 2.9洗脱。收集280nm处的吸光度,并且然后通过添加1M Tris碱将样品中和到pH 7.5-8.0。然后使用具有30KDa分子量截断值的 离心过滤器将中和的样品缓冲液交换到PBS中。将缓冲液交换的蛋白质样品存储在2-8℃下以用于进一步生化分析和生物活性测试。
离心过滤器将中和的样品缓冲液交换到PBS中。将缓冲液交换的蛋白质样品存储在2-8℃下以用于进一步生化分析和生物活性测试。
每次洗脱后,接着使用6个柱体积的0.1M甘氨酸,pH 2.5剥离抗TF抗体亲和柱。然后使用10个柱体积的PBS、0.05%叠氮化钠中和所述柱,并且存储在2-8℃下。
实例33:尺寸排阻色谱
将通用电气医疗集团 200增加10/300GL凝胶过滤柱连接到通用电气医疗集团AKTATMAvant蛋白纯化系统。用2个柱体积的PBS平衡所述柱。流速为0.7mL/min。使用毛细管环将200μL 1mg/mL的7t15-21s复合物注入到色谱柱上。用1.25个柱体积的PBS追赶注射液。
200增加10/300GL凝胶过滤柱连接到通用电气医疗集团AKTATMAvant蛋白纯化系统。用2个柱体积的PBS平衡所述柱。流速为0.7mL/min。使用毛细管环将200μL 1mg/mL的7t15-21s复合物注入到色谱柱上。用1.25个柱体积的PBS追赶注射液。
实例34:21t15-7s和21t15-TGFRs的SDS-PAGE
为了确定纯度和蛋白质分子量,使用4-12%NuPage Bis-Tris蛋白质凝胶SDS-PAGE分析纯化的21t15-7s或21t15-TGFRs蛋白质样品。凝胶将用InstantBlueTM染色约30min,接着在纯化水中脱色过夜。
实例35:CHO-K1细胞中21t15-7s和21t15-TGFRs的糖基化
根据制造商的说明书,使用蛋白质去糖基化混合物II试剂盒(新英格兰生物实验室)确认CHO-K1细胞中21t15-7s的糖基化或CHO-K1细胞中21t15-TGFRs的糖基化。
实例36:21t15-7s和21t15-TGFRs复合物的重组蛋白定量
使用标准夹心ELISA方法检测并定量21t15-7s复合物或21t15-TGFRs复合物。抗人组织因子抗体(IgG1)充当捕获抗体,并且生物素化抗人IL-21、IL-15或IL-7抗体(21t15-7s)或生物素化抗人IL-21、IL-15或TGF-βRII抗体(21t15-TGFRs)充当检测抗体。使用抗人组织因子捕获抗体和抗人组织因子抗体(IgG1)检测抗体检测纯化的21t15-7s或21t15-TGFRs蛋白复合物中的组织因子。将抗TF抗体ELISA与相似浓度下的纯化的组织因子进行比较。
实例37:21t15-7s复合物+抗TFIgG1抗体或21t15-TGFRs复合物+抗TFIgG1抗体的
原代自然杀伤(NK)细胞的扩增能力
为了评定21t15-7s复合物扩增原代自然杀伤(NK)细胞的能力,将21t15-7s复合物和21t15-7s复合物+抗TF IgG1抗体添加到从新鲜人白细胞样品获得的NK细胞中。在37℃和5%CO2下,用50nM的21t15-7s复合物伴随或不伴随25nM的抗TF IgG1或抗TF IgG4抗体刺激细胞。通过每48-72小时计数,将细胞维持在0.5×106个/mL,不超过2.0×106个/mL的浓度下,并且用新鲜刺激物补充培养基。用21t15-7s复合物或抗TF IgG1抗体或抗TF IgG4抗体或抗TF IgG4+21t15-7s复合物刺激的细胞维持到第5天。图47显示与21t15-7s复合物+抗TFIgG1抗体一起培育后原代NK细胞的扩增。图54也显示结果的示意图。
实例38:21t15-7s复合物+抗TFIgG1抗体或21t15-TGFRs复合物+抗TFIgG1抗体激
活扩增的NK细胞
用21t15-7s复合物+抗TF IgG1抗体过夜刺激纯化的NK细胞后,可离体诱导原代NK细胞。从血库获得新鲜的人白细胞,并且用RosetteSep/人NK细胞试剂(干细胞技术有限公司)分离CD56+NK细胞。NK细胞的纯度>80%,并且通过用CD56-BV421和CD16-BV510特异性抗体(BioLegend)染色得到证实。对细胞进行计数,并且将其以1×106个/mL重悬于24孔平底板中的1mL完全培养基(RPMI 1640(吉毕科公司),补充有4mM L-谷氨酰胺(Thermo LifeTechnologies)、青霉素(Thermo Life Technologies)、链霉素(Thermo LifeTechnologies)、非必需氨基酸(Thermo Life Technologies)、丙酮酸钠(Thermo LifeTechnologies)和10%FBS(Hyclone))中。在37℃和5%CO2下,用50nM的21t15-7s伴随或不伴随25nM的抗TF IgG1抗体刺激细胞。每48-72小时对细胞进行计数,并且将其维持在0.5×106个/mL至2.0×106个/mL的浓度下直到第14天。定期用新鲜刺激物补充培养基。收获细胞并在第3天用CD56-BV421、CD16-BV510、CD25-PE、CD69-APCFire750特异性抗体(Biolegend并通过流式细胞术-Celeste-BD Bioscience进行分析)进行表面染色。图48显示激活标记CD25 MFI和CD69 MFI。激活标记CD25 MFI随21t15-7s复合物+抗TF IgG1抗体刺激而增加,但不随21t15-7s复合物刺激而增加。激活标记CD69 MFI随21t15-7s复合物+抗TF IgG1抗体和单独的21t15-7s复合物两者增加。
实例39:NK细胞对人肿瘤细胞的细胞毒性
从血库获得新鲜的人血白细胞层。使用RosetteSep/人NK细胞试剂(干细胞技术有限公司)通过阴性选择分离NK细胞。在37℃和5%CO2下,将NK细胞在含21t15-7s 100nM和50nM抗TF IgG1抗体的完全RPMI-1640培养基中培养长达11天。将激活的NK细胞与Celltrace紫罗兰标记的K562细胞以等于2:1的E:T比混合,并且在37℃下培育4小时。收获混合物,并且通过碘化丙啶染色和流式细胞术确定死亡的K562细胞的百分比。图49显示当与扩增的NK细胞一起培育时,K562细胞的特异性溶解增加。
实例40:IL-21/IL-15RαSu
DNA构建体的产生
在非限制性实例中,产生IL-21/IL-15RαSu DNA构建体。人IL-21序列和人IL-15RαSu序列从UniProt网站获得,并且这些序列的DNA由金唯智合成。制造DNA构建体,将IL-21序列连接到IL-15RαSu序列。最终的IL-21/IL-15RαSu DNA构建体序列由金唯智合成。参见图50。
实例41:IL-7/TF/IL-15DNA构建体的产生
在非限制性实例中,通过将IL-7序列连接到组织因子219的N端编码区,并且进一步将IL-7/TF构建体与IL-15的N端编码区连接来制造IL-7/TF/IL-15构建体。参见图51。
实例42:IL-21/IL-15Rα寿司DNA构建体的产生
在非限制性实例中,产生IL-21/IL-15RαSu的第二嵌合多肽。人IL-21和人IL-15Rα寿司序列从UniProt网站获得,并且这些序列的DNA由金唯智合成。制造DNA构建体,将IL-21序列连接到IL-15Rα寿司序列。最终的IL-21/IL-15RαSu DNA构建体序列由金唯智合成。
由金唯智合成的编码IL-21/IL-15RαSu结构域的第二嵌合多肽(包括前导序列)的核酸序列如下(SEQ ID NO:111):
(信号肽)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(人IL-21)
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC
(人IL-15Rα寿司结构域)
ATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG
IL-21/IL-15Rα寿司结构域的第二嵌合多肽(包括前导序列)如下(SEQ ID NO:110):
(信号序列)
MKWVTFISLLFLFSSAYS
(人IL-21)
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS
(人IL-15Rα寿司结构域)
ITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR
实例43:IL-7/TF/IL-15DNA构建体的产生
在非限制性实例中,通过将IL-7序列连接到组织因子219的N端编码区,并且进一步将IL-7/TF构建体与IL-15的N端编码区连接来制造IL-7/TF/IL-15的示例性第一嵌合多肽。由金唯智合成的编码IL-7/TF/IL-15的第一嵌合多肽(包括前导序列)的核酸序列如下(SEQ ID NO:107):
(信号肽)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(人IL-7片段)
GATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGTTCAACTTCTTCAAGCGGCACATCTGCGACGCCAACAAGGAGGGCATGTTCCTGTTCAGGGCCGCCAGGAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGGTGAAGGGCCGGAAACCTGCTGCTCTGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGAACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCAT
(人组织因子219)
AGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAG
(人IL-15)
AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC
IL-7/TF/IL-15的第一嵌合多肽(包括前导序列)如下(SEQ ID NO:106):
(信号肽)
MKWVTFISLLFLFSSAYS
(人IL-7)
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWNKILMGTKEH
(人组织因子219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(人IL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
实例44:IL-21/IL-15RαSu和IL-7/TF/IL-15融合蛋白的分泌
将IL-21/IL-15RαSu和IL-7/TF/IL-15DNA构建体克隆到pMSGV-1修饰的逆转录病毒表达载体(Hughes,《人基因疗法》16:457–72,2005,通过引用并入本文)中,并且将表达载体转染到CHO-K1细胞中。两种构建体在CHO-K1细胞中的共表达使得可形成和分泌可溶性IL-7/TF/IL-15:IL-21/IL-15RαSu蛋白复合物(称为7t15-21s)。使用抗TF抗体(IgG1)亲和色谱法和尺寸排阻色谱法从CHO-K1细胞培养上清液中纯化7t15-21s蛋白,得到由IL-21/IL-15RαSu和IL-7/TF/IL-15融合蛋白组成的可溶性(非聚集)蛋白复合物。参见图52和图53。
实例45:IL-21/IL-15RαSu和IL-7/TF/IL-15融合蛋白的分析尺寸排阻色谱法
(SEC)分析
为了确定抗组织因子单克隆抗体和7t15-21s是否可形成抗体-融合-分子复合物,进行分析尺寸排阻色谱法(SEC)。将Superdex 200增加10/300GL凝胶过滤柱(来自通用电气医疗集团)连接到AKTA Avant系统(来自通用电气医疗集团)。用2个柱体积的PBS平衡所述柱。流速为0.7mL/min。抗TF mAb(1mg/mL)、7t15-21s(1mg/mL)和以1:1比混合的混合物的样品,因此每种蛋白质的最终浓度为0.5mg/mL)处于PBS中。使用毛细管环将每个样品注入Superdex 200色谱柱,并且通过SEC分析所述样品。每个样品的SEC色谱图如图55所示。SEC结果表明7t15-21s有两个蛋白峰,可能代表7t15-21s二聚体(表观分子量为199.2kDa)和更高的低聚物,并且抗TF mAb有一个峰(表观分子量为206.8kDa)。但是,如所预期,在含有抗TF mAb和7t15-21s的混合物样品中形成了更高分子量的新蛋白质峰(表观分子量为576.9kDa),表明抗TF mAb和7t15-21s通过抗TF mAb与融合蛋白复合物中的TF结合形成抗体-抗原复合物。
实例46:7t15-21s复合物+抗TFIgG1抗体的原代自然杀伤(NK)细胞的扩增能力
为了评定7t15-21s复合物扩增原代自然杀伤(NK)细胞的能力,将7t15-21s复合物和7t15-21s复合物+抗TF IgG1抗体添加到从新鲜人白细胞样品获得的NK细胞中。在37℃和5%CO2下,用50nM的7t15-21s复合物伴随或不伴随25nM的抗TF IgG1或抗TF IgG4抗体刺激细胞。通过每48-72小时计数,将细胞维持在0.5×106个/mL,不超过2.0×106个/mL的浓度下,并且用新鲜刺激物补充培养基。将用7t15-21s复合物或抗TF IgG1抗体或抗TF IgG4抗体或抗TF IgG4+7t15-21s复合物刺激的细胞维持到第5天。观察到与21t15-7s复合物+抗TFIgG1抗体一起培育后原代NK细胞扩增。
实例47:7t15-21s复合物+抗TF IgG1抗体激活扩增的NK细胞
用7t15-21s复合物+抗TF IgG1抗体过夜刺激纯化的NK细胞后,离体诱导原代NK细胞。从血库获得新鲜的人白细胞,并且用RosetteSep/人NK细胞试剂(干细胞技术有限公司)分离CD56+NK细胞。NK细胞的纯度>80%,并且通过用CD56-BV421和CD16-BV510特异性抗体(BioLegend)染色得到证实。对细胞进行计数,并且将其以1×106个/mL重悬于24孔平底板中的1mL完全培养基(RPMI 1640(吉毕科公司),补充有4mM L-谷氨酰胺(Thermo LifeTechnologies)、青霉素(Thermo Life Technologies)、链霉素(Thermo LifeTechnologies)、非必需氨基酸(Thermo Life Technologies)、丙酮酸钠(Thermo LifeTechnologies)和10%FBS(Hyclone))中。在37℃和5%CO2下,用50nM的7t15-21s伴随或不伴随25nM的抗TF IgG1抗体刺激细胞。每48-72小时对细胞计数一次,并且将其维持在0.5×106个/mL至2.0×106个/mL的浓度下直到第14天。定期补充新鲜刺激物。在第3天,收集细胞并用CD56-BV421、CD16-BV510、CD25-PE、CD69-APCFire750特异性抗体(Biolegend)进行表面染色,并且通过流式细胞术-Celeste-BD Bioscience)进行分析。观察到激活标记CD25MFI随7t15-21s复合物+抗TF IgG1抗体刺激而增加,但不随7t15-21s复合物刺激而增加。观察到激活标记CD69MFI随7t15-21s复合物+抗TF IgG1抗体和单独的7t15-21s复合物两者增加。
实例48:使用18t15-12s增加NK细胞中的葡萄糖代谢
进行了一组实验以确定18t15-12s的构建体(图6)对从人血中纯化的NK细胞的耗氧率和细胞外酸化率(ECAR)的影响。
在这些实验中,从血库中两个不同的人供体获得新鲜的人白细胞,并且使用RosetteSep/人NK细胞试剂(干细胞技术有限公司)通过阴性选择分离NK细胞。NK细胞的纯度>80%,并且通过用CD56-BV421和CD16-BV510特异性Ab(BioLegend)染色得到证实。对细胞进行计数,并且将其以2×106个/mL重悬于24孔平底板中的1mL完全培养基(RPMI 1640(吉毕科公司),补充有4mM L-谷氨酰胺(Thermo Life Technologies)、青霉素(ThermoLife Technologies)、链霉素(Thermo Life Technologies)、非必需氨基酸(Thermo LifeTechnologies)、丙酮酸钠(Thermo Life Technologies)和10%FBS(Hyclone))中。在37℃和5%CO2下,用(1)单独的培养基,(2)100nM 18t15-12s或(3)单细胞因子重组人IL-12(0.25μg)、重组人IL-15(1.25μg)和重组人IL-18(1.25μg)的混合物刺激细胞过夜。第二天,收获细胞,并且使用XFp分析仪(Seahorse Bioscience)对扩增的NK细胞进行细胞外通量分析。将收获的细胞洗涤并铺板,2.0×105个细胞/孔,至少一式两份,以用于OCR(耗氧率)和ECAR(细胞外酸化率)的细胞外通量分析。在含有2mM谷氨酰胺的Seahorse培养基中进行糖酵解应激测试。在分析过程中使用以下物质:10mM葡萄糖;100nM寡霉素;和100mM 2-脱氧-D-葡萄糖(2DG)。
数据显示,与用重组人IL-12、重组人IL-15和重组人IL-18的组合激活的相同细胞相比,18t15-12s引起显著提高的耗氧率(图56)和细胞外酸化率(ECAR)(图57)。
实例49:7t15-16s21融合蛋白生成和表征
生成融合蛋白复合物,其包含抗CD16scFv/IL-15RαSu/IL-21和IL-7/TF/IL-15融合蛋白。人IL-7和IL-21序列从UniProt网站获得,并且这些序列的DNA由金唯智合成。具体来说,制造构建体,将IL-7序列连接到组织因子219的N端编码区,接着连接到IL-15的N端编码区。
以下显示包含IL-7连接到组织因子219的N端,后接IL-15的N端的构建体的核酸和蛋白质序列。
IL-7/TF/IL-15构建体(包括信号肽序列)的核酸序列如下:
(信号肽)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(人IL-7)
GATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGTTCAACTTCTTCAAGCGGCACATCTGCGACGCCAACAAGGAGGGCATGTTCCTGTTCAGGGCCGCCAGGAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGGTGAAGGGCCGGAAACCTGCTGCTCTGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGAACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCAT
(人组织因子219)
AGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAG
(人IL-15)
AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC
IL-7/TF/IL-15融合蛋白(包括前导序列)的氨基酸序列如下:
(信号肽)
MKWVTFISLLFLFSSAYS
(人IL-7)
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWNKILMGTKEH
(人组织因子219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(人IL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
还通过将人CD16scFv序列连接到IL-15RαSu链的N端编码区,接着连接到由金唯智合成的IL-21的N端编码区来制造构建体。以下显示包含抗CD16scFv连接到IL-15RαSu链的N端,后接IL-21的N端编码区的构建体的核酸和蛋白质序列。
抗CD16SscFv/IL-15RαSu/IL-21构建体(包括信号肽序列)的核酸序列如下:
(信号肽)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
((抗人CD16scFv)
TCCGAGCTGACCCAGGACCCTGCTGTGTCCGTGGCTCTGGGCCAGACCGTGAGGATCACCTGCCAGGGCGACTCCCTGAGGTCCTACTACGCCTCCTGGTACCAGCAGAAGCCCGGCCAGGCTCCTGTGCTGGTGATCTACGGCAAGAACAACAGGCCCTCCGGCATCCCTGACAGGTTCTCCGGATCCTCCTCCGGCAACACCGCCTCCCTGACCATCACAGGCGCTCAGGCCGAGGACGAGGCTGACTACTACTGCAACTCCAGGGACTCCTCCGGCAACCATGTGGTGTTCGGCGGCGGCACCAAGCTGACCGTGGGCCATGGCGGCGGCGGCTCCGGAGGCGGCGGCAGCGGCGGAGGAGGATCCGAGGTGCAGCTGGTGGAGTCCGGAGGAGGAGTGGTGAGGCCTGGAGGCTCCCTGAGGCTGAGCTGTGCTGCCTCCGGCTTCACCTTCGACGACTACGGCATGTCCTGGGTGAGGCAGGCTCCTGGAAAGGGCCTGGAGTGGGTGTCCGGCATCAACTGGAACGGCGGATCCACCGGCTACGCCGATTCCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACTCCCTGTACCTGCAGATGAACTCCCTGAGGGCCGAGGACACCGCCGTGTACTACTGCGCCAGGGGCAGGTCCCTGCTGTTCGACTACTGGGGACAGGGCACCCTGGTGACCGTGTCCAGG
(人IL-15Rα寿司结构域)
ATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG
(人IL-21)
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC
抗CD16scFv/IL-15RαSu/IL-21构建体(包括信号肽序列)的氨基酸序列如下:
(信号肽)
MKWVTFISLLFLFSSAYS
(抗人CD16scFv)
SELTQDPAVSVALGQTVRITCQGDSLRSYYASWYQQKPGQAPVLVIYGKNNRPSGIPDRFSGSSSGNTASLTITGAQAEDEADYYCNSRDSSGNHVVFGGGTKLTVGHGGGGSGGGGSGGGGSEVQLVESGGGVVRPGGSLRLSCAASGFTFDDYGMSWVRQAPGKGLEWVSGINWNGGSTGYADSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARGRSLLFDYWGQGTLVTVSR
(人IL-15Rα寿司结构域)
ITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR
(人IL-21)
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS
在一些情况下,将前导肽从完整多肽上裂解下来以生成可能可溶或分泌的成熟形式。
将抗CD16scFv/IL-15RαSu/IL-21和IL-7/TF/IL-15构建体克隆到修饰的逆转录病毒表达载体中,如前所述(Hughes MS,Yu YY,Dudley ME,Zheng Z,Robbins PF,Li Y等人.《衍生自具有明显抗肿瘤反应的患者的TCR基因的转移传送高度活性T细胞效应功能(Transfer of a TCR gene derived from a patient with a marked antitumorresponse conveys highly active T-cell effector functions)》.《人基因疗法》2005;16:457–72),并且将表达载体转染到CHO-K1细胞中。两种构建体在CHO-K1细胞中的共表达使得可形成和分泌可溶性IL-7/TF/IL-15:抗CD16scFv/IL-15RαSu/IL-21蛋白复合物(称为7t15-16s21;图58和图59),其可通过基于抗TF IgG1的亲和力和其它色谱方法纯化。
7t15-16s21与表达人CD16b的CHO细胞结合
用pMC质粒中的人CD16b转染CHO细胞,并且用10μg/mL杀稻瘟菌素选择10天。将稳定表达CD16b的CHO细胞用1.2μg/mL的含有抗人CD16 scFv的18t15-12s或作为阴性对照的不含抗人CD16 scFv的7t15-16s21进行染色,并且然后用生物素化抗人组织因子Ab和PE缀合的链霉亲和素染色。如图60A所示,仅有含有抗人CD16scFv的7t15-16s21使细胞染色。如图60B所示,18t15-12s没有染色表达人CD16b的CHO细胞。
使用ELISA检测7t15-16s21中的IL-15、IL-21和IL-7
将96孔板用R5(包被缓冲液)中的100μL(8μg/mL)抗TF IgG1包被,并且在室温(RT)下培育2小时。将板洗涤3次,并且用100μL 1%BSA的PBS溶液阻断。将7t15-16s21的连续稀释液(以1:3的比)添加到孔中,并且在RT下培育60min。洗涤3次后,将50ng/mL的生物素化抗IL15抗体(BAM247,安迪生物公司)、500ng/mL的生物素化抗IL-21抗体(13-7218-81,安迪生物公司)或500ng/mL的生物素化抗IL-7抗体(506602,安迪生物公司)添加到孔中并且在RT下培育60min。将板洗涤3次,并且与0.25μg/mL的HRP-SA(Jackson ImmunoResearch)以每孔100μL在RT下培育30min,接着洗涤4次并与100μl的ABTS在RT下培育2min。在405nm处读取吸光度。如图61A-61C所示,通过个别抗体检测7t15-16s21中的IL-15、IL-21和IL-7结构域。
7t15-16s21中的IL-15促进含IL-2Rβ和共同γ链的32Dβ细胞增殖
为了分析7t15-16s21中IL-15的活性,使用表达IL2Rβ和共同γ链的32Dβ细胞,将7t15-16s21的IL-15活性与重组IL-15进行比较,并且评估其对促进细胞增殖的作用。将IL-15依赖性32Dβ细胞用IMDM-10%FBS洗涤5次,并且以2×104个细胞/孔接种在孔中。将连续稀释的7t15-16s21或IL-15添加到细胞中(图62)。将细胞在CO2培养箱中在37℃下培育3天。通过在第3天向每个孔中添加10μl WST1并在CO2培养箱中在37℃下再培养3小时来检测细胞增殖。通过分析产生的甲臜染料的量来测量450nm处的吸光度。如图62所示,7t15-16s21和IL-15促进32Dβ细胞增殖,7t15-16s21和IL-15的EC50分别为172.2pM和16.63pM。
来自抗TF抗体亲和柱的7t15-16s21的纯化洗脱色谱。
将从细胞培养物中收获的7t15-16s21加载到用5个柱体积的PBS平衡的抗TF抗体亲和柱上。然后用5个柱体积的PBS洗涤所述柱,接着用6个柱体积的0.1M乙酸(pH 2.9)洗脱。收集A280洗脱峰,并且用1M Tris碱中和到pH 7.5-8.0。使用具有30KDa分子量截断值的Amicon离心过滤器将中和的样品缓冲液交换到PBS中。图63是显示在抗TF抗体树脂上结合和洗脱后,含有7t15-16s21蛋白的细胞培养上清液的色谱图的线图。如图63所示,抗TF抗体亲和柱结合含有TF的7t15-16s21。将缓冲液交换的蛋白质样品存储在2-8℃下,以用于进一步生化分析和生物活性测试。每次洗脱后,使用6个柱体积的0.1M甘氨酸(pH 2.5)剥离抗TF抗体亲和柱。然后使用5个柱体积的PBS和7个柱体积的20%乙醇中和所述柱,以进行存储。抗TF抗体亲和柱连接到通用电气医疗集团AKTA Avant系统。除洗脱步骤外,所有步骤的流速均为4mL/min,洗脱步骤的流速为2mL/min。
7t15-16s21的分析尺寸排阻色谱(SEC)分析
为了对7t15-16s21进行尺寸排阻色谱(SEC)分析,使用与AKTA Avant系统(通用电气医疗集团)连接的Superdex 200增加10/300GL凝胶过滤柱(通用电气医疗集团)。用2个柱体积的PBS平衡所述柱。流速为0.7mL/min。使用毛细管环将在PBS中含有7t15-16s21的样品注入Superdex 200色谱柱,并且通过SEC进行分析。如图64所示,SEC结果显示7t15-16s21有两个蛋白质峰。
实例50:TGFRt15-16s21融合蛋白的产生和表征
生成包含抗人CD16scFv/IL-15RαSu/IL21和TGFβ受体II/TF/IL-15融合蛋白的融合蛋白复合物(图65和66)。人TGFβ受体II(Ile24-Asp159)、组织因子219和IL-15序列从UniProt网站获得,并且这些序列的DNA由金唯智合成。具体来说,制造构建体,将两个TGFβ受体II序列与G4S(3)接头连接以生成TGFβ受体II的单链形式,并且然后直接连接到组织因子219的N端编码区,接着连接到IL-15的N端编码区。
以下显示包含两个TGFβ受体II连接到组织因子219的N端,后接IL-15的N端的构建体的核酸和蛋白质序列。
两个TGFβ受体II/TF/IL-15构建体(包括信号肽序列)的核酸序列如下:
(信号肽)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(两个人TGFβ受体II片段)
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC
(人组织因子219)
AGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAG
(人IL-15)
AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC
TGFβ受体II/TF/IL-15融合蛋白(包括前导序列)的氨基酸序列如下:
(信号肽)
MKWVTFISLLFLFSSAYS
(人TGFβ受体II)
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD
(人组织因子219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(人IL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
还通过将抗人CD16scFv序列连接到IL-15RαSu链的N端编码区,接着连接到由金唯智合成的IL-21的N端编码区来制造构建体。以下显示包含抗人CD16scFv连接到IL-15RαSu的N端,后接IL-21的N端编码区的构建体的核酸和蛋白质序列。
抗CD16scFv/IL-15RαSu/IL-21构建体(包括信号肽序列)的核酸序列如下:
(信号肽)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(抗人CD16scFv)
TCCGAGCTGACCCAGGACCCTGCTGTGTCCGTGGCTCTGGGCCAGACCGTGAGGATCACCTGCCAGGGCGACTCCCTGAGGTCCTACTACGCCTCCTGGTACCAGCAGAAGCCCGGCCAGGCTCCTGTGCTGGTGATCTACGGCAAGAACAACAGGCCCTCCGGCATCCCTGACAGGTTCTCCGGATCCTCCTCCGGCAACACCGCCTCCCTGACCATCACAGGCGCTCAGGCCGAGGACGAGGCTGACTACTACTGCAACTCCAGGGACTCCTCCGGCAACCATGTGGTGTTCGGCGGCGGCACCAAGCTGACCGTGGGCCATGGCGGCGGCGGCTCCGGAGGCGGCGGCAGCGGCGGAGGAGGATCCGAGGTGCAGCTGGTGGAGTCCGGAGGAGGAGTGGTGAGGCCTGGAGGCTCCCTGAGGCTGAGCTGTGCTGCCTCCGGCTTCACCTTCGACGACTACGGCATGTCCTGGGTGAGGCAGGCTCCTGGAAAGGGCCTGGAGTGGGTGTCCGGCATCAACTGGAACGGCGGATCCACCGGCTACGCCGATTCCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACTCCCTGTACCTGCAGATGAACTCCCTGAGGGCCGAGGACACCGCCGTGTACTACTGCGCCAGGGGCAGGTCCCTGCTGTTCGACTACTGGGGACAGGGCACCCTGGTGACCGTGTCCAGG
(人IL-15Rα寿司结构域)
ATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG
(人IL-21)
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC
抗CD16scFv/IL-15RαSu/IL-21构建体(包括信号肽序列)的氨基酸序列如下:
(信号肽)
MKWVTFISLLFLFSSAYS
(抗人CD16scFv)
SELTQDPAVSVALGQTVRITCQGDSLRSYYASWYQQKPGQAPVLVIYGKNNRPSGIPDRFSGSSSGNTASLTITGAQAEDEADYYCNSRDSSGNHVVFGGGTKLTVGHGGGGSGGGGSGGGGSEVQLVESGGGVVRPGGSLRLSCAASGFTFDDYGMSWVRQAPGKGLEWVSGINWNGGSTGYADSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARGRSLLFDYWGQGTLVTVSR
(人IL-15Rα寿司结构域)
ITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR
(人IL-21)
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS
在一些情况下,将前导肽从完整多肽上裂解下来以生成可能可溶或分泌的成熟形式。
将抗CD16scFv/IL-15RαSu/IL-21和TGFR/TF/IL-15构建体克隆到修饰的逆转录病毒表达载体中,如前所述(Hughes MS,Yu YY,Dudley ME,Zheng Z,Robbins PF,Li Y等人.《衍生自具有明显抗肿瘤反应的患者的TCR基因的转移传送高度活性T细胞效应功能》.《人基因疗法》2005;16:457–72),并且将表达载体转染到CHO-K1细胞中。两种构建体在CHO-K1细胞中的共表达使得可形成和分泌可溶性TGFR/TF/IL-15:CD16scFv/IL-15RαSu/IL-21蛋白复合物(称为TGFRt15-16s21),其可通过基于抗TF IgG1的亲和力和其它色谱方法纯化。
TGFRt15-16s21与表达人CD16b的CHO细胞之间的相互作用
用pMC质粒中的人CD16b转染CHO细胞,并且用10μg/mL杀稻瘟菌素选择10天。将稳定表达CD16b的细胞用1.2μg/mL含有抗人CD16 scFv的TGFRt15-16s21,或作为阴性对照的不含抗人CD16 scFv的7t15-21s,并且用生物素化抗人组织因子抗体染色和PE缀合链霉亲和素染色。如图67A和67B所示,含有抗人CD16scFv的TGFRt15-16s21显示正结合,而7t15-21s不显示结合。
TGFRt15-16s21对HEK-Blue TGFβ细胞中TGFβ1活性的影响。
为了评估TGFRt15-16s21中TGFβRII的活性,分析TGFRt15-16s21对HEK-Blue TGFβ细胞中TGFβ1活性的影响。将HEK-Blue TGFβ细胞(英伟杰)用预温热的PBS洗涤两次,并且以5×105个细胞/mL重悬于测试培养基(DMEM,10%热灭活的FCS,1×谷氨酰胺,1×抗生素-抗真菌剂和2×谷氨酰胺)中。在平底96孔板中,向每个孔中添加50μl细胞(2.5×104个细胞/孔),并且接着添加50μL 0.1nM TGFβ1(安迪生物公司)。然后将以1:3连续稀释制备的TGFRt15-16s21或TGFR-Fc(安迪生物公司)添加到板中,以达到200μL的总体积。在37℃下培育24小时后,将40μL诱导的HEK-Blue TGFβ细胞上清液添加到平底96孔板中的160μL预温热的QUANTI-Blue(英伟杰)中,并且在37℃下培育1-3小时。然后使用酶标仪(Multiscan Sky)在620-655nM下测定OD值。用GraphPad Prism 7.04计算每个蛋白质样品的IC50。TGFRt15-16s21和TGFR-Fc的IC50分别为9127pM和460.6pM。这些结果显示TGFRt15-16s21中的TGFβRII结构域能够阻断HEK-Blue TGFβ细胞中TGFβ-1的活性。
TGFRt15-16s21中的IL-15促进含IL-2Rβ和共同γ链的32Dβ细胞增殖
为了分析TGFRt15-16s21中IL-15的活性,使用表达IL2Rβ和共同γ链的32Dβ细胞将TGFRt15-16s21的IL-15活性与重组IL-15进行比较,并且评估其对促进细胞增殖的作用。将IL-15依赖性32Dβ细胞用IMDM-10%FBS洗涤5次,并且以2×104个细胞/孔接种在孔中。将连续稀释的TGFRt15-16s21或IL-15添加到细胞中(图68)。将细胞在CO2培养箱中在37℃下培育3天。通过在第3天向每个孔中添加10μL WST1并在CO2培养箱中在37℃下再培养3小时来检测细胞增殖。通过分析产生的甲臜染料的量来测量450nm处的吸光度。如图68所示,TGFRt15-16s21和IL-15促进32Dβ细胞增殖,TGFRt15-16s21和IL-15的EC50分别为51298pM和10.63pM。
使用ELISA检测TGFRt15-16s21中的IL-15、IL-21和TGFβRII
将96孔板用R5(包被缓冲液)中的100μL(8μg/mL)抗TF IgG1包被,并且在室温(RT)下培育2小时。将板洗涤3次,并且用100μL 1%BSA的PBS溶液阻断。添加以1:3的比连续稀释的TGFRt15-16s21,并且在RT下培育60min。洗涤三次后,每孔施加50ng/mL的生物素化抗IL-15抗体(BAM247,安迪生物公司)、500ng/mL的生物素化抗IL-21抗体(13-7218-81,安迪生物公司)或200ng/mL的生物素化抗TGFβRII抗体(BAF241,安迪生物公司),并且在RT下培育60min。洗涤三次后,进行与0.25μg/mL的HRP-SA(Jackson ImmunoResearch以每孔100μL在RT下培育30min,接着进行4次洗涤,并且与100μL的ABTS在RT下培育2min。在405nm处读取吸光度。数据如图69所示。如图70A-70C所示,TGFRt15-16s21中的IL-15、IL-21和TGFβRII结构域由对应的抗体检测。
使用抗TF抗体亲和柱的TGFRt15-16s21的纯化洗脱色谱
将从细胞培养物中收获的TGFRt15-16s21加载到用5个柱体积的PBS平衡的抗TF抗体亲和柱上。加载样品后,用5个柱体积的PBS洗涤色谱柱,接着用6个柱体积的0.1M乙酸(pH2.9)洗脱。收集A280洗脱峰,并且然后用1M Tris碱中和到pH 7.5-8.0。然后使用具有30KDa分子量截断值的Amicon离心过滤器将中和的样品缓冲液交换到PBS中。如图71所示,抗TF抗体亲和柱与TGFRt15-16s21结合,其含有组织因子作为融合伴侣。将缓冲液交换的蛋白质样品存储在2-8℃下,以用于进一步生化分析和生物活性测试。每次洗脱后,使用6个柱体积的0.1M甘氨酸(pH 2.5)剥离抗TF抗体亲和柱。然后使用5个柱体积的PBS和7个柱体积的20%乙醇中和所述柱,以进行存储。抗TF抗体亲和柱连接到通用电气医疗集团AKTA Avant系统。除洗脱步骤外,所有步骤的流速均为4mL/min,洗脱步骤的流速为2mL/min。
TGFRt15-16s21的还原SDS-PAGE
为了确定TGFRt15-16s21蛋白的纯度和分子量,在还原条件下通过十二烷基硫酸钠聚丙烯酰胺凝胶(4-12%NuPage Bis-Tris凝胶)电泳(SDS-PAGE)分析用抗TF抗体亲和柱纯化的蛋白质样品。电泳后,将凝胶用InstantBlue染色约30min,接着在纯化水中脱色过夜。
为了验证TGFRt15-16s21蛋白在CHO细胞中翻译后经历糖基化,根据制造商的说明书,使用来自新英格兰生物实验室的蛋白质去糖基化混合物II试剂盒进行去糖基化实验。图72显示未去糖基化(红色轮廓的泳道1)和去糖基化(黄色轮廓的泳道2)状态下样品的还原SDS-PAGE分析的结果。结果显示,当在CHO细胞中表达时,TGFRt15-16s21蛋白被糖基化。去糖基化后,纯化的样品在还原SDS凝胶中显示预期的分子量(69kDa和48kDa)。泳道M装有10μL SeeBlue Plus2预染标准液。
实例51:7t15-7s融合蛋白的生成和表征
生成包含IL-7/TF/IL-15和IL-7/IL-15RαSu融合蛋白的融合蛋白复合物(图73和图74)。人IL-7、组织因子219和IL-15序列从UniProt网站获得,并且这些序列的DNA由金唯智合成。具体来说,制造构建体,将IL-7序列连接到组织因子219的N端编码区,接着连接到IL-15的N端编码区。
以下显示包含IL-7连接到组织因子219的N端,后接IL-15的N端的构建体的核酸和蛋白质序列。
7t15构建体(包括信号肽序列)的核酸序列如下:
(信号肽)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(人IL7)
GATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGTTCAACTTCTTCAAGCGGCACATCTGCGACGCCAACAAGGAGGGCATGTTCCTGTTCAGGGCCGCCAGGAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGGTGAAGGGCCGGAAACCTGCTGCTCTGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGAACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCAT
(人组织因子219)
AGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAG
(人IL-15)
AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC
7t15融合蛋白(包括前导序列)的氨基酸序列如下:
(信号肽)
MKWVTFISLLFLFSSAYS
(人IL7)
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWNKILMGTKEH
(人组织因子219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(人IL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
还通过将IL-7序列连接到由金唯智合成的IL-15RαSu链的N端编码区来制造构建体。以下显示包含IL-7连接到IL-15RαSu链的N端的构建体的核酸和蛋白质序列。
7s构建体(包括信号肽序列)的核酸序列如下:
(信号肽)
ATGGGAGTGAAAGTTCTTTTTGCCCTTATTTGTATTGCTGTGGCCGAGGCC
(人IL7)
GATTGTGATATTGAAGGTAAAGATGGCAAACAATATGAGAGTGTTCTAATGGTCAGCATCGATCAATTATTGGACAGCATGAAAGAAATTGGTAGCAATTGCCTGAATAATGAATTTAACTTTTTTAAAAGACATATCTGTGATGCTAATAAGGAAGGTATGTTTTTATTCCGTGCTGCTCGCAAGTTGAGGCAATTTCTTAAAATGAATAGCACTGGTGATTTTGATCTCCACTTATTAAAAGTTTCAGAAGGCACAACAATACTGTTGAACTGCACTGGCCAGGTTAAAGGAAGAAAACCAGCTGCCCTGGGTGAAGCCCAACCAACAAAGAGTTTGGAAGAAAATAAATCTTTAAAGGAACAGAAAAAACTGAATGACTTGTGTTTCCTAAAGAGACTATTACAAGAGATAAAAACTTGTTGGAATAAAATTTTGATGGGCACTAAAGAACAC
(人IL-15Rα寿司结构域)
ATCACGTGCCCTCCCCCCATGTCCGTGGAACACGCAGACATCTGGGTCAAGAGCTACAGCTTGTACTCCAGGGAGCGGTACATTTGTAACTCTGGTTTCAAGCGTAAAGCCGGCACGTCCAGCCTGACGGAGTGCGTGTTGAACAAGGCCACGAATGTCGCCCACTGGACAACCCCCAGTCTCAAATGCATTAGA
7s融合蛋白(包括前导序列)的氨基酸序列如下:
(信号肽)
MGVKVLFALICIAVAEA
(人IL7)
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWNKILMGTKEH
(人IL-15Rα寿司结构域)
ITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR
将抗IL-7/TF/IL-15和IL-7/IL-15RαSu构建体克隆到修饰的逆转录病毒表达载体中,如前所述(Hughes MS,Yu YY,Dudley ME,Zheng Z,Robbins PF,Li Y等人.《衍生自具有明显抗肿瘤反应的患者的TCR基因的转移传送高度活性T细胞效应功能》.《人基因疗法》2005;16:457–72),并且将表达载体转染到CHO-K1细胞中。两种构建体在CHO-K1细胞中的共表达使得可形成和分泌称为7t15-7s的可溶性IL-7/TF/IL-15:IL-7/IL-15RαSu蛋白复合物,其可通过抗TF IgG1亲和力和其它色谱方法纯化。
使用抗TF抗体亲和柱纯化7t15-7s的洗脱色谱图
将从细胞培养物中收获的7t15-7s加载到用5个柱体积的PBS平衡的抗TF抗体亲和柱上。加载样品后,用5个柱体积的PBS洗涤色谱柱,接着用6个柱体积的0.1M乙酸(pH 2.9)洗脱。收集A280洗脱峰,并且然后用1M Tris碱中和到pH 7.5-8.0。然后使用具有30KDa分子量截断值的Amicon离心过滤器将中和的样品缓冲液交换到PBS中。如图75所示,抗TF抗体亲和柱与含有组织因子(TF)作为融合伴侣的7t15-7s结合。将缓冲液交换的蛋白质样品存储在2-8℃下,以用于进一步生化分析和生物活性测试。每次洗脱后,使用6个柱体积的0.1M甘氨酸(pH 2.5)剥离抗TF抗体亲和柱。然后使用5个柱体积的PBS和7个柱体积的20%乙醇中和所述柱,以进行存储。抗TF抗体亲和柱连接到通用电气医疗集团AKTA Avant系统。除洗脱步骤外,所有步骤的流速均为4mL/min,洗脱步骤的流速为2mL/min。
C57BL/6小鼠中7t15-7s的免疫刺激
7t15-7s是多链多肽(本文所描述的A型多链多肽),包括作为人IL-7、人组织因子219片段和人IL-15的可溶性融合物的第一多肽(7t15),和作为人IL-7和人IL-15受体α链的寿司结构域的可溶性融合物的第二多肽(7s)。
CHO细胞用IL7-TF-IL15(7t15)和IL7-IL15Ra寿司结构域(7s)载体共转染。从转染的CHO细胞培养上清液中纯化7t15-7s复合物。通过ELISA在复合物中展现IL-7、IL-15和组织因子(TF)组分,如图76所示。将人源化抗TF单克隆抗体(抗TF IgG1)用作捕获抗体来确定7t15-7s中的TF,并且将生物素化抗人IL-15抗体(安迪生物公司)和生物素化抗人IL-7抗体(安迪生物公司)用作检测抗体,分别检测7t15-7s中的IL-15和IL-7,后接过氧化物酶缀合的链霉亲和素(Jackson ImmunoResearch Lab)和ABTS底物(Surmodics IVD,Inc.)。
实例52:TGFRt15-TGFRs融合蛋白生成和表征
生成融合蛋白复合物,其包含TGFβ受体II/IL-15RαSu和TGFβ受体II/TF/IL-15融合蛋白(图77和图78)。人TGFβ受体II(Ile24-Asp159)、组织因子219和IL-15序列从UniProt网站获得,并且这些序列的DNA由金唯智合成。具体来说,制造构建体,将两个TGFβ受体II序列与G4S(3)接头连接以生成TGFβ受体II的单链形式,并且然后直接连接到组织因子219的N端编码区,接着连接到IL-15的N端编码区。
以下显示包含两个TGFβ受体II连接到组织因子219的N端,后接IL-15的N端的构建体的核酸和蛋白质序列。
两个TGFβ受体II/TF/IL-15构建体(包括信号肽序列)的核酸序列如下:
(信号肽)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(两个人TGFβ受体II片段)
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC
(人组织因子219)
AGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAG
(人IL-15)
AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC
TGFβ受体II/TF/IL-15融合蛋白(包括前导序列)的氨基酸序列如下:
(信号肽)
MKWVTFISLLFLFSSAYS
(人TGFβ受体II)
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD
(人组织因子219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(人IL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
还通过将两个TGFβ受体II直接连接到由金唯智合成的IL-15RαSu链来构建构建体。以下显示包含TGFβ受体II连接到IL-15RαSu的N端的构建体的核酸和蛋白质序列。
TGFβ受体II/IL-15RαSu构建体(包括信号肽序列)的核酸序列如下:
(信号肽)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(两个人TGFβ受体II片段)
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC
(人IL-15Rα寿司结构域)
ATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG
两个TGFβ受体II/IL-15RαSu构建体(包括信号肽序列)的氨基酸序列如下:
(信号肽)
MKWVTFISLLFLFSSAYS
(两个人TGFβ受体II细胞外结构域)
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD
(人IL-15Rα寿司结构域)
ITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR
在一些情况下,将前导肽从完整多肽上裂解下来以生成可能可溶或分泌的成熟形式。
将TGFβR/IL-15RαSu和TGFβR/TF/IL-15构建体克隆到修饰的逆转录病毒表达载体中,如前所述(Hughes MS,Yu YY,Dudley ME,Zheng Z,Robbins PF,Li Y等人.《衍生自具有明显抗肿瘤反应的患者的TCR基因的转移传送高度活性T细胞效应功能》.《人基因疗法》2005;16:457–72),并且将表达载体转染到CHO-K1细胞中。两种构建体在CHO-K1细胞中的共表达使得可形成和分泌可溶性TGFβR/TF/IL-15:TGFβR/IL-15RαSu蛋白复合物(称为TGFRt15-TGFRs),其可通过抗-TF IgG1亲和力和其它色谱方法纯化。
TGFRt15-TGFRs对HEK-Blue TGFβ细胞中TGFβ1活性的影响
为了评估TGFRt15-TGFRs中TGFβRII的活性,分析TGFRt15-TGFRs对HEK-Blue TGFβ细胞中TGFβ1活性的影响。将HEK-Blue TGFβ细胞(英伟杰)用预温热的PBS洗涤两次,并且以5×105个细胞/mL重悬于测试培养基(DMEM,10%热灭活的FCS,1×谷氨酰胺,1×抗生素-抗真菌剂和2×谷氨酰胺)中。在平底96孔板中,向每个孔中添加50μL细胞(2.5×104个细胞/孔),并且接着添加50μL 0.1nM TGFβ1(安迪生物公司)。然后将以1:3连续稀释制备的TGFRt15-TGFRs或TGFR-Fc(安迪生物公司)添加到板中,以达到200μL的总体积。在37℃下培育24小时后,将40μL诱导的HEK-Blue TGFβ细胞上清液添加到平底96孔板中的160μL预温热的QUANTI-Blue(英伟杰)中,并且在37℃下培育1-3小时。然后使用酶标仪(Multiscan Sky)在620-655nM下测定OD值。用GraphPad Prism 7.04计算每个蛋白质样品的IC50。TGFRt15-TGFRs和TGFR-Fc的IC50分别为216.9pM和460.6pM。这些结果显示TGFRt15-TGFRs中的TGFβRII结构域能够阻断HEK-Blue TGFβ细胞中TGFβ1的活性。
TGFRt15-TGFRs中的IL-15促进含IL-2Rβ和共同γ链的32Dβ细胞增殖
为了评估TGFRt15-TGFRs中IL-15的活性,使用表达IL2Rβ和共同γ链的32Dβ细胞将TGFRt15-TGFRs的IL-15活性与重组IL-15进行比较,并且评估其对促进细胞增殖的作用。将IL-15依赖性32Dβ细胞用IMDM-10%FBS洗涤5次,并且以2×104个细胞/孔接种在孔中。将连续稀释的TGFRt15-TGFRs或IL-15添加到细胞中(图79)。将细胞在CO2培养箱中在37℃下培育3天。通过在第3天向每个孔中添加10μL WST1并在CO2培养箱中在37℃下再培养3小时来检测细胞增殖。通过分析产生的甲臜染料的量来测量450nm处的吸光度。如图79所示,TGFRt15-TGFRs和IL-15促进了32Dβ细胞增殖,TGFRt15-TGFRs和IL-15的EC50分别为1901pM和10.63pM。
使用ELISA用对应抗体检测TGFRt15-TGFRs中的IL-15和TGFβRII结构域
将96孔板用R5(包被缓冲液)中的100μL(8μg/mL)抗TF IgG1包被,并且在室温(RT)下培育2小时。将板洗涤3次,并且用100μL 1%BSA的PBS溶液阻断。TGFRt15-TGFRs以1:3连续稀释添加,并且在RT下培育60min。洗涤3次后,将50ng/mL的生物素化抗IL-15抗体(BAM247,安迪生物公司)或200ng/mL的生物素化抗TGFβRII抗体(BAF241,安迪生物公司)添加到孔中并且在RT下培育60min。接着将板洗涤3次,并且以每孔100μL添加0.25μg/mL的HRP-SA(Jackson ImmunoResearch),并且在RT下培育30min,接着洗涤4次并与100μL的ABTS在RT下培育2min。读取405nm处的吸光度。如图81A和81B所示,由个别抗体检测TGFRt15-TGFRs中的IL-15和TGFβRII结构域。
来自抗TF抗体亲和柱的TGFRt15-TGFRs的纯化洗脱色谱
将从细胞培养物中收获的TGFRt15-TGFRs加载到用5个柱体积的PBS平衡的抗TF抗体亲和柱上。加载样品后,用5个柱体积的PBS洗涤色谱柱,接着用6个柱体积的0.1M乙酸(pH2.9)洗脱。收集A280洗脱峰,并且然后用1M Tris碱中和到pH 7.5-8.0。然后使用具有30KDa分子量截断值的Amicon离心过滤器将中和的样品缓冲液交换到PBS中。如图82所示,抗TF抗体亲和柱与含有TF作为融合伴侣的TGFRt15-TGFRs结合。将缓冲液交换的蛋白质样品存储在2-8℃下,以用于进一步生化分析和生物活性测试。每次洗脱后,使用6个柱体积的0.1M甘氨酸(pH 2.5)剥离抗TF抗体亲和柱。然后使用5个柱体积的PBS和7个柱体积的20%乙醇中和所述柱,以进行存储。抗TF抗体亲和柱连接到通用电气医疗集团AKTA Avant系统。除洗脱步骤外,所有步骤的流速均为4mL/min,洗脱步骤的流速为2mL/min。
TGFRt15-TGFRs的分析尺寸排阻色谱(SEC)分析
将Superdex 200增加10/300GL凝胶过滤柱(来自通用电气医疗集团)连接到AKTAAvant系统(来自通用电气医疗集团)。用2个柱体积的PBS平衡所述柱。流速为0.7mL/min。使用毛细管环将含有PBS中TGFRt15-TGFRs的样品注入Superdex 200色谱柱,并且通过SEC分析。样品的SEC色谱图如图83所示。SEC结果显示TGFRt15-TGFRs的四个蛋白质峰。
TGFRt15-TGFRs的还原SDS-PAGE分析
为了确定TGFRt15-TGFRs蛋白的纯度和分子量,在还原条件下通过十二烷基硫酸钠聚丙烯酰胺凝胶(4-12%NuPage Bis-Tris凝胶)电泳(SDS-PAGE)方法分析用抗TF抗体亲和柱纯化的蛋白质样品。电泳后,将凝胶用InstantBlue染色约30min,接着在纯化水中脱色过夜。
为了验证TGFRt15-TGFRs蛋白在CHO细胞中翻译后经历糖基化,使用来自新英格兰生物实验室的蛋白质去糖基化混合物II试剂盒和制造商的说明书进行去糖基化实验。图84显示未去糖基化(红色轮廓的泳道1)和去糖基化(黄色轮廓的泳道2)状态下样品的还原SDS-PAGE分析。结果显示,当在CHO细胞中表达时,TGFRt15-TGFRs蛋白被糖基化。去糖基化后,纯化的样品在还原SDS凝胶中显示预期的分子量(69kDa和39kDa)。泳道M上装有10ulSeeBlue Plus2预染标准液。
TGFRt15-TGFRs在C57BL/6小鼠中的免疫刺激活性
TGFRt15-TGFRs是多链多肽(本文所描述的A型多链多肽),其包括作为两个TGFβRII结构域、人组织因子219片段和人IL-15的可溶性融合物的第一多肽,和作为两个TGFβRII结构域和人IL-15受体α链的寿司结构域的可溶性融合物的第二多肽。
将野生型C57BL/6小鼠用对照溶液或0.3mg/kg、1mg/kg、3mg/kg或10mg/kgTGFRt15-TGFRs皮下处理。处理后四天,评估脾脏重量和脾脏中存在的各种免疫细胞类型的百分比。如图85A所示,用TGFRt15-TGFRs处理的小鼠的脾脏重量随TGFRt15-TGFRs剂量的增加而增加。此外,分别用1mg/kg、3mg/kg和10mg/kg TGFRt15-TGFRs处理的小鼠的脾脏重量分别比用对照溶液处理的小鼠高。另外,评估在对照处理和TGFRt15-TGFRs处理的小鼠的脾脏中存在的CD4+T细胞、CD8+T细胞、NK细胞和CD19+B细胞的百分比。如图85B所示,在用TGFRt15-TGFRs处理的小鼠的脾脏中,CD8+T细胞和NK细胞的百分比均随TGFRt15-TGFRs剂量的增加而增加。具体来说,与对照处理的小鼠相比,用0.3mg/kg、3mg/kg和10mg/kgTGFRt15-TGFRs处理的小鼠中CD8+T细胞的百分比更高,并且与对照处理的小鼠相比,用0.3mg/kg、1mg/kg、3mg/kg和10mg/kg TGFRt15-TGFRs处理的小鼠中NK细胞的百分比更高。这些结果证明TGFRt15-TGFRs能够刺激脾脏中的免疫细胞,尤其CD8+T细胞和NK细胞。
在野生型C57BL/6小鼠中评估TGFRt15-TGFRs分子的药代动力学。用3mg/kg剂量下的TGFRt15-TGFRs皮下处理小鼠。在各个时间点从尾静脉排出小鼠血液,并且制备血清。用ELISA测定小鼠血清中的TGFRt15-TGFRs浓度(捕获:抗人组织因子抗体;检测:生物素化抗人TGFβ受体抗体,后接过氧化物酶缀合的链霉亲和素和ABTS底物)。结果显示,TGFRt15-TGFRs在C57BL/6小鼠中的半衰期为12.66小时。
制备小鼠脾细胞以便评估随时间推移TGFRt15-TGFRs在小鼠中的免疫刺激活性。如图86A所示,用TGFRt15-TGFRs处理的小鼠的脾脏重量在处理后48小时增加,并且随时间持续增加。另外,评估在对照处理和TGFRt15-TGFRs处理的小鼠的脾脏中存在的CD4+T细胞、CD8+T细胞、NK细胞和CD19+B细胞的百分比。如图86B所示,在用TGFRt15-TGFRs处理的小鼠的脾脏中,在处理后48小时,CD8+T细胞和NK细胞的百分比均增加,并且在单剂量处理后随时间推移越来越高。这些结果进一步证明TGFRt15-TGFRs能够刺激脾脏中的免疫细胞,尤其CD8+T细胞和NK细胞。
此外,在单剂量(3mg/kg)TGFRt15-TGFRs后从小鼠分离的脾细胞中,评估基于脾细胞Ki67表达的免疫细胞的动态增殖和基于颗粒酶B表达的细胞毒性潜力。如图87A和87B所示,在用TGFRt15-TGFRs处理的小鼠的脾脏中,在处理后24小时NK细胞的Ki67和颗粒酶B的表达增加,并且CD8+T细胞和NK细胞的其表达在单剂量处理后48小时和后续时间点均增加。这些结果证明TGFRt15-TGFRs不仅增加CD8+T细胞和NK细胞的数目,而且增强这些细胞的细胞毒性。TGFRt15-TGFRs的单剂量处理引起CD8+T细胞和NK细胞增殖至少4天。
还评估来自用TGFRt15-TGFRs处理的小鼠的脾细胞对肿瘤细胞的细胞毒性。用CellTrace紫罗兰标记小莫洛尼(Moloney)白血病细胞(Yac-1),并且将其用作肿瘤靶细胞。在处理后的各个时间点,由TGFRt15-TGFRs(3mg/kg)处理的小鼠脾脏制备脾细胞,并且将其用作效应细胞。将靶细胞与效应细胞以E:T比=10:1混合,并且在37℃下培育20小时。通过使用流式细胞术分析碘化丙啶阳性、紫罗兰标记的Yac-1细胞来评定靶细胞活力。使用以下公式计算Yac-1肿瘤抑制的百分比:(1-[实验样品中的Yac-1活细胞数]/[不含脾细胞的样品中的Yac-1活细胞数])×100。如图88所示,来自TGFRt15-TGFRs处理的小鼠的脾细胞对Yac-1细胞的细胞毒性比对照小鼠脾细胞强。
响应于化疗和/或TGFRt15-TGFRs的肿瘤尺寸分析
将胰腺癌细胞(SW1990, CRL-2172)皮下(sc)注射到C57BL/6scid小鼠(杰克逊实验室(The Jackson Laboratory),001913,2×106个细胞/小鼠,在100μL HBSS中)中以建立胰腺癌小鼠模型。注射肿瘤细胞两周后,开始用阿布拉生(Abraxane)(新基医药(Celgene),68817-134,5mg/kg,i.p.)和吉西他滨(西格玛奥德里奇(Sigma Aldrich),G6423,40mg/kg,i.p.)的组合腹膜内化疗,接着在2天内用TGFRt15-TGFRs(3mg/kg,s.c.)进行免疫治疗。以上程序视为一个治疗周期,并且重复另外3个周期(1个周期/周)。对照组被设置为注射SW1990的小鼠,其单独接受PBS、化疗(吉西他滨和阿布拉生)或TGFRt15-TGFRs。伴随治疗周期,每隔一天测量并记录每只动物的肿瘤尺寸,直到注射SW1990细胞后2个月实验终止。按组分析肿瘤体积的测量,并且结果表明,与PBS组相比,接受化疗和TGFRt15-TGFRs组合的动物的肿瘤明显更小,而单独化疗和TGFRt15-TGFRs疗法均不能与组合一样充分作用(图89)。
CRL-2172)皮下(sc)注射到C57BL/6scid小鼠(杰克逊实验室(The Jackson Laboratory),001913,2×106个细胞/小鼠,在100μL HBSS中)中以建立胰腺癌小鼠模型。注射肿瘤细胞两周后,开始用阿布拉生(Abraxane)(新基医药(Celgene),68817-134,5mg/kg,i.p.)和吉西他滨(西格玛奥德里奇(Sigma Aldrich),G6423,40mg/kg,i.p.)的组合腹膜内化疗,接着在2天内用TGFRt15-TGFRs(3mg/kg,s.c.)进行免疫治疗。以上程序视为一个治疗周期,并且重复另外3个周期(1个周期/周)。对照组被设置为注射SW1990的小鼠,其单独接受PBS、化疗(吉西他滨和阿布拉生)或TGFRt15-TGFRs。伴随治疗周期,每隔一天测量并记录每只动物的肿瘤尺寸,直到注射SW1990细胞后2个月实验终止。按组分析肿瘤体积的测量,并且结果表明,与PBS组相比,接受化疗和TGFRt15-TGFRs组合的动物的肿瘤明显更小,而单独化疗和TGFRt15-TGFRs疗法均不能与组合一样充分作用(图89)。
体外衰老B16F10黑色素瘤模型
接下来,评估激活的小鼠NK细胞在体外杀死衰老的B16F10黑色素瘤细胞。用CellTrace紫罗兰标记B16F10衰老细胞(B16F10-SNC)细胞,并且与不同E:T比的体外2t2激活的小鼠NK细胞(从用TGFRt15-TGFRs10 mg/kg注射4天的C57BL/6的小鼠脾脏中分离)一起培育16小时。将细胞用胰蛋白酶消化,洗涤并重悬在含有碘化丙啶(PI)溶液的完全培养基中。通过流式细胞术评定细胞毒性(图90)。
实例53:7t15-21s137L(长版)融合蛋白生成和表征
产生包含IL-21/IL-15RαSu/CD137L和IL-7/TF/IL-15融合蛋白的融合蛋白复合物(图91和图92)。具体来说,制造构建体,将IL-7序列连接到组织因子219的N端编码区,接着连接到IL-15的N端编码区。以下显示包含IL-7连接到组织因子219的N端,后接IL-15的N端的构建体的核酸和蛋白质序列。
7t15构建体(包括信号肽序列)的核酸序列如下:
(信号肽)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(人IL7)
GATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGTTCAACTTCTTCAAGCGGCACATCTGCGACGCCAACAAGGAGGGCATGTTCCTGTTCAGGGCCGCCAGGAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGGTGAAGGGCCGGAAACCTGCTGCTCTGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGAACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCAT
(人组织因子219)
AGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAG
(人IL-15)
AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC
7t15融合蛋白(包括前导序列)的氨基酸序列如下:
(信号肽)
MKWVTFISLLFLFSSAYS
(人IL7)
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWNKILMGTKEH
(人组织因子219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(人IL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
以下显示21s137L的核酸和蛋白质序列。21s137L构建体(包括信号肽序列)的核酸序列如下:
(信号肽)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(人IL-21)
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC
(人IL-15Rα寿司结构域)
ATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG
((G4S)3接头)
GGCGGTGGAGGATCCGGAGGAGGTGGCTCCGGCGGCGGAGGATCT
(人CD137L)
CGCGAGGGTCCCGAGCTTTCGCCCGACGATCCCGCCGGCCTCTTGGACCTGCGGCAGGGCATGTTTGCGCAGCTGGTGGCCCAAAATGTTCTGCTGATCGATGGGCCCCTGAGCTGGTACAGTGACCCAGGCCTGGCAGGCGTGTCCCTGACGGGGGGCCTGAGCTACAAAGAGGACACGAAGGAGCTGGTGGTGGCCAAGGCTGGAGTCTACTATGTCTTCTTTCAACTAGAGCTGCGGCGCGTGGTGGCCGGCGAGGGCTCAGGCTCCGTTTCACTTGCGCTGCACCTGCAGCCACTGCGCTCTGCTGCTGGGGCCGCCGCCCTGGCTTTGACCGTGGACCTGCCACCCGCCTCCTCCGAGGCTCGGAACTCGGCCTTCGGTTTCCAGGGCCGCTTGCTGCACCTGAGTGCCGGCCAGCGCCTGGGCGTCCATCTTCACACTGAGGCCAGGGCACGCCATGCCTGGCAGCTTACCCAGGGCGCCACAGTCTTGGGACTCTTCCGGGTGACCCCCGAAATCCCAGCCGGACTCCCTTCACCGAGGTCGGAA
21s137L融合蛋白(包括前导序列)的氨基酸序列如下:
(信号肽)
MKWVTFISLLFLFSSAYS
(人IL-21)
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS
(人IL-15Rα寿司结构域)
ITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR
((G4S)3接头)
GGGGSGGGGSGGGGS
(人CD137L)
REGPELSPDDPAGLLDLRQGMFAQLVAQNVLLIDGPLSWYSDPGLAGVSLTGGLSYKEDTKELVVAKAGVYYVFFQLELRRVVAGEGSGSVSLALHLQPLRSAAGAAALALTVDLPPASSEARNSAFGFQGRLLHLSAGQRLGVHLHTEARARHAWQLTQGATVLGLFRVTPEIPAGLPSPRSE
在一些情况下,将前导肽从完整多肽上裂解下来以生成可能可溶或分泌的成熟形式。
将IL-21/IL-15RαSu/CD137L和IL-7/TF/IL-15构建体克隆到修饰的逆转录病毒表达载体中,如前所述(Hughes MS,Yu YY,Dudley ME,Zheng Z,Robbins PF,Li Y等人.《衍生自具有明显抗肿瘤反应的患者的TCR基因的转移传送高度活性T细胞效应功能》.《人基因疗法》2005;16:457–72),并且将表达载体转染到CHO-K1细胞中。两种构建体在CHO-K1细胞中的共表达使得可形成和分泌可溶性IL-7/TF/IL-15:IL-21/IL-15RαSu/CD137L蛋白复合物(称为7t15-21s137L),其可通过抗TF IgG1亲和力和其它色谱方法纯化。
使用抗TF抗体亲和柱的7t15-21s137L的纯化洗脱色谱
将从细胞培养物中收获的7t15-21s137L加载到用5个柱体积的PBS平衡的抗TF抗体亲和柱上。加载样品后,用5个柱体积的PBS洗涤色谱柱,接着用6个柱体积的0.1M乙酸(pH2.9)洗脱。收集A280洗脱峰,并且然后用1M Tris碱中和到pH 7.5-8.0。然后使用具有30KDa分子量截断值的Amicon离心过滤器将中和的样品缓冲液交换到PBS中。如图93所示,抗TF抗体亲和柱与含有TF作为融合伴侣的7t15-21s137L结合。将缓冲液交换的蛋白质样品存储在2-8℃下,以用于进一步生化分析和生物活性测试。每次洗脱后,使用6个柱体积的0.1M甘氨酸(pH 2.5)剥离抗TF抗体亲和柱。然后使用5个柱体积的PBS和7个柱体积的20%乙醇中和所述柱,以进行存储。抗TF抗体亲和柱连接到通用电气医疗集团AKTA Avant系统。除洗脱步骤外,所有步骤的流速均为4mL/min,洗脱步骤的流速为2mL/min。图94显示7t15-21s137L的分析SEC曲线。
实例54:7t15-21s137L(短版)融合蛋白生成和表征
生成包含IL-21/IL-15RαSu/CD137L和IL-7/TF/IL-15融合蛋白的融合蛋白复合物。具体来说,制造构建体,将IL-7序列连接到组织因子219的N端编码区,接着连接到IL-15的N端编码区。以下显示包含IL-7连接到组织因子219的N端,后接IL-15的N端的构建体的核酸和蛋白质序列。
7t15构建体(包括信号肽序列)的核酸序列如下:
(信号肽)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(人IL7)
GATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGTTCAACTTCTTCAAGCGGCACATCTGCGACGCCAACAAGGAGGGCATGTTCCTGTTCAGGGCCGCCAGGAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGGTGAAGGGCCGGAAACCTGCTGCTCTGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGAACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCAT
(人组织因子219)
AGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAG
(人IL-15)
AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC
7t15融合蛋白(包括前导序列)的氨基酸序列如下:
(信号肽)
MKWVTFISLLFLFSSAYS
(人IL7)
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWNKILMGTKEH
(人组织因子219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(人IL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
以下显示21s137L(短版)的核酸和蛋白质序列。21s137L(短版)构建体(包括信号肽序列)的核酸序列如下:
(信号肽)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(人IL-21)
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC
(人IL-15Rα寿司结构域)
ATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG
((G4S)3接头)
GGCGGTGGAGGATCCGGAGGAGGTGGCTCCGGCGGCGGAGGATCT
(人CD137配体短版)
GATCCCGCCGGCCTCTTGGACCTGCGGCAGGGCATGTTTGCGCAGCTGGTGGCCCAAAATGTTCTGCTGATCGATGGGCCCCTGAGCTGGTACAGTGACCCAGGCCTGGCAGGCGTGTCCCTGACGGGGGGCCTGAGCTACAAAGAGGACACGAAGGAGCTGGTGGTGGCCAAGGCTGGAGTCTACTATGTCTTCTTTCAACTAGAGCTGCGGCGCGTGGTGGCCGGCGAGGGCTCAGGCTCCGTTTCACTTGCGCTGCACCTGCAGCCACTGCGCTCTGCTGCTGGGGCCGCCGCCCTGGCTTTGACCGTGGACCTGCCACCCGCCTCCTCCGAGGCTCGGAACTCGGCCTTCGGTTTCCAGGGCCGCTTGCTGCACCTGAGTGCCGGCCAGCGCCTGGGCGTCCATCTTCACACTGAGGCCAGGGCACGCCATGCCTGGCAGCTTACCCAGGGCGCCACAGTCTTGGGACTCTTCCGGGTGACCCCCGAAATC
21s137L(短版)构建体(包括信号肽序列)的氨基酸序列如下:
(信号肽)
MKWVTFISLLFLFSSAYS
(人IL-21)
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS
(人IL-15Rα寿司结构域)
ITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR
((G4S)3接头)
GGGGSGGGGSGGGGS
(人CD137配体短版)
DPAGLLDLRQGMFAQLVAQNVLLIDGPLSWYSDPGLAGVSLTGGLSYKEDTKELVVAKAGVYYVFFQLELRRVVAGEGSGSVSLALHLQPLRSAAGAAALALTVDLPPASSEARNSAFGFQGRLLHLSAGQRLGVHLHTEARARHAWQLTQGATVLGLFRVTPEI
将IL-21/IL-15RαSu/CD137L(短版)和IL-7/TF/IL-15构建体克隆到修饰的逆转录病毒表达载体中,如前所述(Hughes MS,Yu YY,Dudley ME,Zheng Z,Robbins PF,Li Y等人.《衍生自具有明显抗肿瘤反应的患者的TCR基因的转移传送高度活性T细胞效应功能》.《人基因疗法》2005;16:457–72),并且将表达载体转染到CHO-K1细胞中。CHO-K1细胞中两种构建体的共表达使得可形成和分泌可溶性IL-7/TF/IL-15:IL-21/IL-15RαSu/CD137L蛋白复合物(称为7t15-21s137L(短版)),其可通过抗TF IgG1亲和力和其它色谱方法纯化。
7t15-21s137L(短版)与CD137(4.1BB)的结合
在第1天,将96孔板用R5(包被缓冲液)中的100μL(2.5μg/mL)的GAH IgG Fc(G-102-C,安迪生物公司)或仅R5包被,并且在4℃下培育过夜。在第2天,将板洗涤三次,并且在37℃下用300μL PBS中的1%BSA阻断2小时。以100μL/孔添加10ng/mL的4.1BB/Fc(838-4B,安迪生物公司),并且将其在RT下培育2小时。洗涤三次后,将7t15-21s137L或7t15-21s以1/3的比(从10nM开始)连续稀释,并且在4℃下培育过夜。在第3天,在3次洗涤后,将300ng/mL的生物素化抗hTF抗体(BAF2339,安迪生物公司)以每孔100μL添加,并且在RT下培育2小时。然后将板洗涤三次,并且与0.25μg/mL的HRP-SA(Jackson ImmuneResearch)以每孔100μL培育30min,接着洗涤3次并与100μL的ABTS在RT下培育2min。在405nm处读取吸光度。如图95所示,与7t15-21s相比,7t15-21s137L(短版)显示与4.1BB/Fc(蓝线)的显著相互作用。
用ELISA检测7t15-21s137L(短版)中的IL-15、IL-21和IL-7
将96孔板用R5(包被缓冲液)中的100μL(8μg/mL)抗TF IgG1包被,并且在室温下培育2小时。将板洗涤3次,并且用100μL的1%BSA的PBS溶液阻断。添加以1:3的比连续稀释的7t15-21s137L(短版),并且在RT下培育60min。洗涤三次后,将50ng/mL的生物素化抗IL15抗体(BAM247,安迪生物公司)、500ng/mL的生物素化抗IL21抗体(13-7218-81,安迪生物公司)或500ng/mL的生物素化抗IL7抗体(506602,安迪生物公司)添加到孔中,并且在RT下培育60min。洗涤三次并且与0.25μg/mL的HRP-SA(Jackson ImmunoResearch)以每孔100μL在RT下培育进行30min后,接着进行四次洗涤,并且与100μL的ABTS在RT下培育2min。在405nm处读取吸光度。如图96A-96C所示,通过对应的抗体检测到7t15-21s137L(短版)中的IL-15、IL-21和IL-7结构域。
7t15-1s137L(短版)中的IL-15促进含IL2Rαβγ的CTLL2细胞增殖
为了评估7t15-21s137L(短版)中IL-15的活性,将7t15-21s137L(短版)与重组IL15在促进表达IL2Rαβγ的CTLL2细胞增殖的方面进行比较。将IL-15依赖性CTLL2细胞用IMDM-10%FBS洗涤5次,并且以2×104个细胞/孔接种到孔中。将连续稀释的7t15-21s137L(短版)或IL-15添加到细胞中(图97)。将细胞在CO2培养箱中在37℃下培育3天。通过在第3天向每个孔中添加10μL WST1,并且在CO2培养箱中在37℃下再培养3小时来检测细胞增殖。通过测量在450nm处的吸光度来分析产生的甲臜染料的量。如图97所示,7t15-21s137L(短版)和IL-15促进CTLL2细胞增殖。7t15-21s137L(短版)和IL-15的EC50分别为55.91pM和6.22pM。
7t15-1s137L(短版)中的IL-21促进含IL21R的B9细胞增殖
为了评估7t15-21s137L(短版)的IL-21活性,将7t15-21s137L(短版)与重组IL-21在促进表达IL-21R的B9细胞增殖的方面进行比较。将含有IL-21R的B9细胞用RPMI-10%FBS洗涤5次,并且以1×104个细胞/孔接种到孔中。将连续稀释的7t15-21s137L(短版)或IL-21添加到细胞中(图98)。将细胞在CO2培养箱中在37℃下培育5天。通过在第5天向每个孔中添加10μL WST1,并且在CO2培养箱中在37℃下再培养4小时来检测细胞增殖。通过测量在450nm处的吸光度来分析产生的甲臜染料的量。如图98所示,7t15-21s137L(短版)和IL-21促进B9细胞增殖。7t15-21s137L(短版)和IL-21的EC50分别为104.1nM和72.55nM。
实例55:7t15-TGFRs融合蛋白生成和表征
生成包含TGFβ受体II/IL-15RαSu和IL-7/TF/IL-15融合蛋白的融合蛋白复合物(图99和图100)。人TGFβ受体II(Ile24-Asp159)、组织因子219、IL-15和IL-7序列从UniProt网站获得,并且这些序列的DNA由金唯智合成。具体来说,制造构建体,将IL-7序列连接到组织因子219的N端编码区,接着连接到IL-15的N端编码区。以下显示包含IL-7连接到组织因子219的N端,后接IL-15的N端的构建体的核酸和蛋白质序列。
7t15构建体(包括信号肽序列)的核酸序列如下:
(信号肽)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(人IL7)
GATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGTTCAACTTCTTCAAGCGGCACATCTGCGACGCCAACAAGGAGGGCATGTTCCTGTTCAGGGCCGCCAGGAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGGTGAAGGGCCGGAAACCTGCTGCTCTGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGAACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCAT
(人组织因子219)
AGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAG
(人IL-15)
AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC
7t15融合蛋白(包括前导序列)的氨基酸序列如下:
(信号肽)
MKWVTFISLLFLFSSAYS
(人IL7)
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWNKILMGTKEH
(人组织因子219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(人IL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
还通过将两个TGFβ受体II直接连接到由金唯智合成的IL-15RαSu链来制造构建体。以下显示包含TGFβ受体II连接到IL-15RαSu的N端的构建体的核酸和蛋白质序列。
TGFRs构建体(包括信号肽序列)的核酸序列如下:
(信号肽)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(人TGFβ受体II片段)
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC
(人IL-15Rα寿司结构域)
ATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG
TGFRs融合蛋白(包括前导序列)的氨基酸序列如下:
(信号肽)
MKWVTFISLLFLFSSAYS
(人TGFβ受体II)
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD
(人IL-15Rα寿司结构域)
ITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR
7t15-TGFRs对HEK-Blue TGFβ细胞中TGFβ1活性的影响
为了评估7t15-TGFRs中TGFβR的活性,分析7t15-TGFRs对HEK-Blue TGFβ细胞中TGFβ1活性的影响。将HEK-Blue TGFβ细胞(英伟杰)用预温热的PBS洗涤两次,并且以5×105个细胞/mL重悬于测试培养基(DMEM,10%热灭活的FCS,1×谷氨酰胺,1×抗生素-抗真菌剂和2×谷氨酰胺)中。在平底96孔板中,向每个孔中添加50μL细胞(2.5×104个细胞/孔),并且接着添加50μL 0.1nM TGFβ1(安迪生物公司)。然后将以1:3连续稀释制备的7t15-TGFRs或TGFR-Fc(安迪生物公司)添加到板中,以达到200μL的总体积。在37℃下培育24小时后,将40μL诱导的HEK-Blue TGFβ细胞上清液添加到平底96孔板中的160μL预温热的QUANTI-Blue(英伟杰)中,并且在37℃下培育1-3小时。然后使用酶标仪(Multiscan Sky)在620-655nM下测定OD值。用GraphPad Prism 7.04计算每个蛋白质样品的IC50。7t15-TGFRs和TGFR-Fc的IC50分别为1142pM和558.6pM。这些结果显示7t15-TGFRs中的TGFβR能够阻断HEK-Blue TGFβ细胞中TGFβ1的活性。
用ELISA检测7t15-TGFRs中的IL-15、TGFβRII和IL-7
将96孔板用R5(包被缓冲液)中的100μL(8μg/mL)抗TF IgG1包被,并且在室温(RT)下培育2小时。将板洗涤三次,并且用100μL 1%BSA的PBS溶液阻断。添加7t15-TGFRs的连续稀释液(1:3的比),并且在RT下培育60min。洗涤3次后,添加50ng/mL的生物素化抗IL-15抗体(BAM247,安迪生物公司)、200ng/mL的生物素化抗TGFbRII抗体(BAF241,安迪生物公司)或500ng/mL的生物素化抗IL-7抗体(506602,安迪生物公司)并在RT下培育60min。洗涤三次后,与0.25μg/mL的HRP-SA(Jackson ImmunoResearch)以每孔100μL在RT下培育进行30min,接着进行4次洗涤,并且与100μL ABTS在RT下培育2min。在405nm处读取吸光度。数据如图101所示。如图102A-102C所示,通过对应的抗体检测7t15-TGFRs中的IL-15、TGFR和IL-7。
7t15-TGFRs中的IL-15促进含IL-2Rβ和共同γ链的32Dβ细胞增殖
为了评估7t15-TGFRs中IL-15的活性,使用表达IL2Rβ和共同γ链的32Dβ细胞,将7t15-TGFRs与重组IL-15进行比较,并且评估其对促进细胞增殖的作用。将IL-15依赖性32Dβ细胞用IMDM-10%FBS洗涤5次,并且以2×104个细胞/孔接种在孔中。将连续稀释的7t15-TGFRs或IL-15添加到细胞中(图103)。将细胞在CO2培养箱中在37℃下培育3天。通过在第3天向每个孔中添加10μL WST1并在CO2培养箱中在37℃下再培养3小时来检测细胞增殖。通过测量在450nm处的吸光度来分析产生的甲臜染料的量。如图103所示,7t15-TGFRs和IL-15促进32Dβ细胞增殖,7t15-TGFRs和IL-15的EC50分别为126nM和16.63pM。
使用抗TF抗体亲和柱的7t15-TGFRs的纯化洗脱色谱
将从细胞培养物中收获的7t15-TGFRs加载到用5个柱体积的PBS平衡的抗TF抗体亲和柱上。加载样品后,用5个柱体积的PBS洗涤色谱柱,接着用6个柱体积的0.1M乙酸(pH2.9)洗脱。收集A280洗脱峰,并且然后用1M Tris碱中和到pH 7.5-8.0。然后使用具有30KDa分子量截断值的Amicon离心过滤器将中和的样品缓冲液交换到PBS中。如图104所示,抗TF抗体亲和柱可结合含有TF作为7t15-TGFRs的融合伴侣的7t15-TGFRs。将缓冲液交换的蛋白质样品存储在2-8℃下,以用于进一步生化分析和生物活性测试。每次洗脱后,使用6个柱体积的0.1M甘氨酸(pH 2.5)剥离抗TF抗体亲和柱。然后使用5个柱体积的PBS和7个柱体积的20%乙醇中和所述柱,以进行存储。抗TF抗体亲和柱连接到通用电气医疗集团AKTAAvant系统。除洗脱步骤外,所有步骤的流速均为4mL/min,洗脱步骤的流速为2mL/min。
减少7t15-TGFRs的SDS-PAGE分析
为了确定蛋白质的纯度和分子量,在还原条件下通过十二烷基硫酸钠聚丙烯酰胺凝胶(4-12%NuPage Bis-Tris凝胶)电泳(SDS-PAGE)方法分析用抗TF抗体亲和柱纯化的7t15-TGFRs蛋白样品。电泳后,将凝胶用InstantBlue染色约30min,接着在纯化水中脱色过夜。
为了验证7t15-TGFRs蛋白在CHO细胞中翻译后经历糖基化,使用来自新英格兰生物实验室的蛋白质去糖基化混合物II试剂盒和制造商的说明书进行去糖基化实验。图105显示未去糖基化(红色轮廓的泳道1)和去糖基化(黄色轮廓的泳道2)状态的样品的还原SDS-PAGE分析。这些结果显示所述蛋白在CHO细胞中表达时被糖基化。去糖基化后,纯化的样品在还原SDS凝胶中显示预期的分子量(55kDa和39kDa)。泳道M上装有10ul SeeBluePlus2预染标准液。
7t15-TGFRs的表征
7t15-TGFRs是多链多肽(本文所描述的A型多链多肽),其包括作为人IL-7、人组织因子219片段和人IL-15的可溶性融合物的第一多肽(7t15),和作为单链的两个TGFβRII结构域和人IL-15受体α链寿司结构域的可溶性融合物的第二多肽(TGFRs)。
CHO细胞用7t15和TGFRs载体共转染。从转染的CHO细胞培养上清液中纯化7t15-TGFRs复合物。如图106所示,通过ELISA证明复合物中的IL-7、IL-15、TGFβ受体和组织因子(TF)组分。使用人源化抗TF单克隆抗体(anti-TF IgG1)作为捕获抗体来确定7t15-TGFRs中的TF,并且使用针对人IL-15抗体(安迪生物公司)、人IL-7(Biolegend)、抗-TGFβ受体(安迪生物公司)的生物素化抗体作为检测抗体,以分别确定7t15-TGFRs中的IL-7、IL-15和TGFβ受体。然后使用过氧化物酶缀合的链霉亲和素(Jackson ImmunoResearch Lab)和ABTS底物(Surmodics IVD,Inc.)以检测结合的生物素化抗体。通过ELISA分析结果(图106)。
C57BL/6小鼠中7t15-TGFRs的体内表征
为了确定体内7t15-TGFRs的免疫刺激活性,将C57BL/6小鼠用对照溶液(PBS)或7t15-TGFRs以0.3、1、3和10mg/kg进行皮下处理。使经过处理的小鼠安乐死。在处理后第4天收集小鼠脾脏并称重。制备单个脾细胞悬浮液,并且用荧光染料缀合的抗CD4、抗CD8和抗NK1.1抗体染色,并且通过流式细胞术分析CD4+T细胞、CD8+T细胞和NK细胞的百分比。结果显示,基于脾脏重量,7t15-TGFRs尤其在1-10mg/kg下可有效扩增脾细胞(图107A)。在所有测试剂量下,与对照处理的小鼠相比,CD8+T细胞和NK细胞的百分比更高(图107B)。
CD4+和CD8+T细胞的CD44表达
已知IL-15诱导T细胞上的CD44表达和记忆T细胞的发育。评定在7t15-TGFRs处理的小鼠中CD4+和CD8+T细胞的CD44表达。用7t15-TGFRs皮下处理C57BL/6小鼠。用荧光染料缀合的抗CD4、抗CD8和抗CD44单克隆抗体针对免疫细胞亚群对脾细胞进行染色。通过流式细胞术分析总CD4+T细胞的CD4+CD44高T细胞的百分比和总CD8+T细胞的CD8+CD44高T细胞的百分比。如图108A和108B所示,7t15-TGFRs显著激活CD4+和CD8+T细胞分化成记忆T细胞。
此外,还评估在小鼠单剂量处理后,7t15-TGFRs诱导的脾细胞基于Ki67表达的免疫细胞的动态增殖,和脾细胞基于颗粒酶B表达的细胞毒性潜力。用7t15-TGFRs以3mg/kg皮下处理C57BL/6小鼠。使经过处理的小鼠安乐死并制备脾细胞。制备的脾细胞用荧光染料缀合的抗CD4、抗CD8和抗–NK1.1(NK)抗体针对免疫细胞亚群进行染色,并且然后用抗Ki67抗体针对细胞增殖进行细胞内染色,并且用抗颗粒酶B抗体针对细胞毒性标记进行细胞内染色。通过流式细胞术分析对应免疫细胞亚群的Ki67和颗粒酶B的平均荧光强度(MFI)。如图109A和109B所示,在用7t15-TGFRs处理的小鼠的脾脏中,与PBS对照处理相比,CD8+T细胞和NK细胞的Ki67和颗粒酶B的表达增加。这些结果证明7t15-TGFRs不仅增加CD8+T细胞和NK细胞的数目,而且增强这些细胞的潜在细胞毒性。
另外,还评估小鼠脾细胞对肿瘤细胞的细胞毒性。将小鼠Yac-1细胞用CellTrace紫罗兰标记,并且用作肿瘤靶细胞。从7t15-TGFRs处理的小鼠制备脾细胞,并且将其用作效应细胞。将靶细胞与效应细胞以E:T比=10:1在RPMI-10培养基中在具有或不具有100nM的7t15-TGFRs的情况下混合,并且在37℃下培育20小时。通过使用流式细胞术分析活的紫罗兰标记的Yac-1细胞来评定靶标Yac-1细胞抑制。使用以下公式计算Yac-1抑制的百分比:(1-实验样品中的Yac-1活细胞数/不含脾细胞的样品中的Yac-1活细胞数)×100。如图110所示,7t15-TGFRs处理的小鼠脾细胞对Yac-1细胞的细胞毒性强于对照小鼠脾细胞,并且在细胞毒性分析过程中添加7t15-TGFRs进一步增强脾细胞对Yac-1靶细胞的细胞毒性。
实例56:TGFRt15-21s137L融合蛋白生成和表征
生成包含IL-21/IL-15RαSu/CD137L和TGFβ受体II/TF/IL-15融合蛋白的融合蛋白复合物(图111和图112)。人TGFβ受体II(Ile24-Asp159)、组织因子219和IL-15序列从UniProt网站获得,并且这些序列的DNA由金唯智合成。具体来说,制造构建体,将两个TGFβ受体II序列连接到G4S(3)接头以生成TGFβ受体II的单链形式,并且然后直接连接到组织因子219的N端编码区,接着连接到IL-15的N端编码区。
TGFRt15构建体(包括信号肽序列)的核酸序列如下:
(信号肽)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(人TGFβ受体II片段)
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC
(人组织因子219)
AGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAG
(人IL-15)
AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC
TGFRt15融合蛋白(包括前导序列)的氨基酸序列如下:
(信号肽)
MKWVTFISLLFLFSSAYS
(人TGFβ受体II)
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD
(人组织因子219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(人IL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
以下显示21s137L的核酸和蛋白质序列。21s137L构建体(包括信号肽序列)的核酸序列如下:
(信号肽)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(人IL-21)
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC
(人IL-15Rα寿司结构域)
ATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG
((G4S)3接头)
GGCGGTGGAGGATCCGGAGGAGGTGGCTCCGGCGGCGGAGGATCT
(人CD137L)
CGCGAGGGTCCCGAGCTTTCGCCCGACGATCCCGCCGGCCTCTTGGACCTGCGGCAGGGCATGTTTGCGCAGCTGGTGGCCCAAAATGTTCTGCTGATCGATGGGCCCCTGAGCTGGTACAGTGACCCAGGCCTGGCAGGCGTGTCCCTGACGGGGGGCCTGAGCTACAAAGAGGACACGAAGGAGCTGGTGGTGGCCAAGGCTGGAGTCTACTATGTCTTCTTTCAACTAGAGCTGCGGCGCGTGGTGGCCGGCGAGGGCTCAGGCTCCGTTTCACTTGCGCTGCACCTGCAGCCACTGCGCTCTGCTGCTGGGGCCGCCGCCCTGGCTTTGACCGTGGACCTGCCACCCGCCTCCTCCGAGGCTCGGAACTCGGCCTTCGGTTTCCAGGGCCGCTTGCTGCACCTGAGTGCCGGCCAGCGCCTGGGCGTCCATCTTCACACTGAGGCCAGGGCACGCCATGCCTGGCAGCTTACCCAGGGCGCCACAGTCTTGGGACTCTTCCGGGTGACCCCCGAAATCCCAGCCGGACTCCCTTCACCGAGGTCGGAA
21s137L融合蛋白(包括前导序列)的氨基酸序列如下:
(信号肽)
MKWVTFISLLFLFSSAYS
(人IL-21)
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS
(人IL-15Rα寿司结构域)
ITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR
((G4S)3接头)
GGGGSGGGGSGGGGS
(人CD137L)
REGPELSPDDPAGLLDLRQGMFAQLVAQNVLLIDGPLSWYSDPGLAGVSLTGGLSYKEDTKELVVAKAGVYYVFFQLELRRVVAGEGSGSVSLALHLQPLRSAAGAAALALTVDLPPASSEARNSAFGFQGRLLHLSAGQRLGVHLHTEARARHAWQLTQGATVLGLFRVTPEIPAGLPSPRSE
在一些情况下,将前导肽从完整多肽上裂解下来以生成可能可溶或分泌的成熟形式。
将IL-21/IL-15RαSu/CD137L和TGFR/TF/IL-15构建体克隆到修饰的逆转录病毒表达载体中,如前所述(Hughes MS,Yu YY,Dudley ME,Zheng Z,Robbins PF,Li Y等人.《衍生自具有明显抗肿瘤反应的患者的TCR基因的转移传送高度活性T细胞效应功能》.《人基因疗法》2005;16:457–72),并且将表达载体转染到CHO-K1细胞中。两种构建体在CHO-K1细胞中的共表达使得可形成和分泌可溶性TGFR/TF/IL-15:IL-21/IL-15RαSu/CD137L蛋白复合物(称为TGFRt15-21s137L),其可通过抗TF IgG1亲和力和其它色谱方法纯化。
使用抗TF抗体亲和柱的TGFRt15-21s137L的纯化洗脱色谱
将从细胞培养物中收获的TGFRt15-21s137L加载到用5个柱体积的PBS平衡的抗TF抗体亲和柱上。加载样品后,用5个柱体积的PBS洗涤色谱柱,接着用6个柱体积的0.1M乙酸(pH 2.9)洗脱。收集A280洗脱峰,并且然后用1M Tris碱中和到pH 7.5-8.0。然后使用具有30KDa分子量截断值的Amicon离心过滤器将中和的样品缓冲液交换到PBS中。如图113所示,抗TF抗体亲和柱与含有TF作为TGFRt15-21s137L的融合伴侣的TGFRt15-21s137L结合。将缓冲液交换的蛋白质样品存储在2-8℃下,以用于进一步生化分析和生物活性测试。每次洗脱后,使用6个柱体积的0.1M甘氨酸(pH 2.5)剥离抗TF抗体亲和柱。然后使用5个柱体积的PBS和7个柱体积的20%乙醇中和所述柱,以进行存储。抗TF抗体亲和柱连接到通用电气医疗集团AKTA Avant系统。除洗脱步骤外,所有步骤的流速均为4mL/min,洗脱步骤的流速为2mL/min。
实例57:TGFRt15-TGFRs21融合蛋白生成和表征
生成包含TGFβ受体II/IL-15RαSu/IL-21和TGFβ受体II/TF/IL-15融合蛋白的融合蛋白复合物(图114和图115)。人TGFβ受体II(Ile24-Asp159)、组织因子219、IL-21和IL-15序列从UniProt网站获得,并且这些序列的DNA由金唯智合成。具体来说,制造构建体,将两个TGFβ受体II序列与G4S(3)接头连接以生成TGFβ受体II的单链形式,并且然后直接连接到组织因子219的N端编码区,接着连接到IL-15的N端编码区。
以下显示包含两个TGFβ受体II连接到组织因子219的N端,后接IL-15的N端的构建体的核酸和蛋白质序列。
TGFRt15构建体(包括信号肽序列)的核酸序列如下:
(信号肽)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(人TGFβ受体II片段)
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC
(人组织因子219)
AGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAG
(人IL-15)
AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC
TGFRt15融合蛋白(包括前导序列)的氨基酸序列如下:
(信号肽)
MKWVTFISLLFLFSSAYS
(人TGFβ受体II)
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD
(人组织因子219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(人IL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
还通过将两个TGFβ受体II直接连接到IL-15RαSu链,接着连接到由金唯智合成的IL-21的N端编码区来制造构建体。以下显示包含TGFβ受体II连接到IL-15RαSu的N端,后接IL-21的N端的构建体的核酸和蛋白质序列。
TGFRs21构建体(包括信号肽序列)的核酸序列如下:
(信号肽)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(人TGFβ受体II片段)
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC
(人IL-15Rα寿司结构域)
ATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG
(人IL-21)
CAAGGTCAAGATCGCCACATGATTAGAATGCGTCAACTTATAGATATTGTTGATCAGCTGAAAAATTATGTGAATGACTTGGTCCCTGAATTTCTGCCAGCTCCAGAAGATGTAGAGACAAACTGTGAGTGGTCAGCTTTTTCCTGTTTTCAGAAGGCCCAACTAAAGTCAGCAAATACAGGAAACAATGAAAGGATAATCAATGTATCAATTAAAAAGCTGAAGAGGAAACCACCTTCCACAAATGCAGGGAGAAGACAGAAACACAGACTAACATGCCCTTCATGTGATTCTTATGAGAAAAAACCACCCAAAGAATTCCTAGAAAGATTCAAATCACTTCTCCAAAAGATGATTCATCAGCATCTGTCCTCTAGAACACACGGAAGTGAAGATTCC
TGFRs21融合蛋白(包括前导序列)的氨基酸序列如下:
(信号肽)
MKWVTFISLLFLFSSAYS
(人TGFβ受体II)
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD
(人IL-15Rα寿司结构域)
ITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR
(人IL-21)
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS
在一些情况下,将前导肽从完整多肽上裂解下来以生成可能可溶或分泌的成熟形式。
将TGFR/IL-15RαSu/IL-21和TGFR/TF/IL-15构建体克隆到修饰的逆转录病毒表达载体中,如前所述(Hughes MS,Yu YY,Dudley ME,Zheng Z,Robbins PF,Li Y等人.《衍生自具有明显抗肿瘤反应的患者的TCR基因的转移传送高度活性T细胞效应功能》.《人基因疗法》2005;16:457–72),并且将表达载体转染到CHO-K1细胞中。两种构建体在CHO-K1细胞中的共表达使得可形成和分泌可溶性TGFR/TF/IL-15:TGFR/IL-15RαSu/IL-21蛋白复合物(称为TGFRt15-TGFRs21),其可通过抗TF抗体IgG1亲和力和其它色谱方法纯化。
使用抗TF抗体亲和柱的TGFRt15-TGFRs21的纯化洗脱色谱
从细胞培养物中收获的TGFRt15-TGFRs21被加载到用5个柱体积的PBS平衡的抗TF抗体亲和柱上。加载样品后,用5个柱体积的PBS洗涤色谱柱,接着用6个柱体积的0.1M乙酸(pH 2.9)洗脱。收集A280洗脱峰,并且然后用1M Tris碱中和到pH 7.5-8.0。然后使用具有30KDa分子量截断值的Amicon离心过滤器将中和的样品缓冲液交换到PBS中。如图116所示,抗TF抗体亲和柱与含有TF作为融合伴侣的TGFRt15-TGFRs21结合。将缓冲液交换的蛋白质样品存储在2-8℃下,以用于进一步生化分析和生物活性测试。每次洗脱后,使用6个柱体积的0.1M甘氨酸(pH 2.5)剥离抗TF抗体亲和柱。然后使用5个柱体积的PBS和7个柱体积的20%乙醇中和所述柱,以进行存储。抗TF抗体亲和柱连接到通用电气医疗集团AKTA Avant系统。除洗脱步骤外,所有步骤的流速均为4mL/min,洗脱步骤的流速为2mL/min。
TGFRt15-TGFRs21的还原SDS-PAGE分析
为了确定蛋白质的纯度和分子量,在还原条件下通过十二烷基硫酸钠聚丙烯酰胺凝胶(4-12%NuPage Bis-Tris凝胶)电泳(SDS-PAGE)方法分析用抗TF抗体亲和柱纯化的TGFRt15-TGFRs21蛋白样品。电泳后,将凝胶用InstantBlue染色约30min,接着在纯化水中脱色过夜。
为了验证TGFRt15-TGFRs21蛋白质在CHO细胞中翻译后经历糖基化,使用来自新英格兰生物实验室的蛋白质去糖基化混合物II试剂盒和制造商的说明书进行去糖基化实验。图117显示未去糖基化(红色轮廓的泳道1)和去糖基化(黄色轮廓的泳道2)状态的样品的还原SDS-PAGE分析。清楚的是,当蛋白质在CHO细胞中表达时,所述蛋白质被糖基化。去糖基化后,纯化的样品在还原SDS凝胶中显示预期的分子量(69kDa和55kDa)。泳道M装有10ulSeeBlue Plus2预染标准液。
TGFRt15-TGFRs21在C57BL/6小鼠中的免疫刺激
TGFRt15-TGFRs21是多链多肽(本文所描述的A型多链多肽),其包括作为单链的两个TGFβRII结构域、人组织因子219片段和人IL-15的可溶性融合物的第一多肽(TGFRt15),和作为单链的两个TGFβRII结构域、人IL-15受体α链的寿司结构域和人IL-21的可溶性融合物的第二多肽(TGFRs21)。
CHO细胞用TGFRt15和TGFRs21载体共转染。从转染的CHO细胞培养上清液中纯化TGFRt15-TGFRs21复合物。如图118A-B所示,通过ELISA在复合物中证明TGFβ受体、IL-15、IL-21和组织因子(TF)组分。使用人源化抗TF单克隆抗体(抗TF IgG1)作为捕获抗体以确定TGFRt15-TGFRs21中的TF,使用生物素化抗人IL-15抗体(安迪生物公司)、生物素化抗人TGFβ受体抗体(安迪生物公司)和生物素化抗人IL-21抗体(安迪生物公司)作为检测抗体以分别确定TGFRt15-TGFRs21中的IL-15、TGFβ受体和IL-21。为了检测,使用过氧化物酶缀合的链霉亲和素(Jackson ImmunoResearch Lab)和ABTS。
用对照溶液(PBS)或TGFRt15-TGFRs21以3mg/kg皮下处理野生型C57BL/6小鼠。处理后四天,评估脾脏重量和脾脏中存在的各种免疫细胞类型的百分比。如图119A所示,评估在对照处理和TGFRt15-TGFRs21处理的小鼠的脾脏中存在的CD4+T细胞、CD8+T细胞和NK细胞的百分比。还评估在TGFRt15-TGFRs21处理后基于Ki67表达的免疫细胞的动态增殖。将脾细胞用荧光染料缀合的抗CD4、抗CD8和抗–NK1.1(NK)抗体染色,并且然后用抗Ki67抗体细胞内染色。通过流式细胞术分析CD4+T细胞、CD8+T细胞和NK细胞的百分比以及对应免疫细胞亚群的Ki67的平均荧光强度(MFI)(图119A和119B)。此外,还评估小鼠单次剂量处理后由TGFRt15-TGFRs21诱导的脾细胞基于颗粒酶B表达的细胞毒性潜力。如图120所示,在用TGFRt15-TGFRs21处理的小鼠的脾脏中,NK细胞的颗粒酶B表达在处理后增加。将来自TGFRt15-TGFRs21处理的小鼠的脾细胞用荧光染料缀合的抗CD4、抗CD8和抗NK1.1(NK)抗体染色,并且然后用抗颗粒酶B抗体细胞内染色。通过流式细胞术分析对应免疫细胞亚群的颗粒酶B的平均荧光强度(MFI)(图120)。
如图119A所示,在用TGFRt15-TGFRs21处理的小鼠的脾脏中,在单次TGFRt15-TGFRs21处理后第4天,CD8+T细胞和NK细胞的百分比均增加。这些结果证明TGFRt15-TGFRs21能够诱导免疫细胞在小鼠脾脏中增殖,尤其CD8+T细胞和NK细胞。
另外,还评估小鼠脾细胞对肿瘤细胞的细胞毒性。将小鼠Yac-1细胞用CellTrace紫罗兰标记,并且用作肿瘤靶细胞。从TGFRt15-TGFRs21处理的小鼠制备脾细胞,并且将其用作效应细胞。将靶细胞与效应细胞以E:T比=10:1在RPMI-10培养基中在具有或不具有100nM的TGFRt15-TGFRs21的情况下混合,并且在37℃下培育24小时。通过使用流式细胞术分析活的紫罗兰标记的Yac-1细胞来评定靶标Yac-1细胞抑制。使用以下公式计算Yac-1抑制的百分比:(1-[实验样品中Yac-1活细胞数]/[不含脾细胞的样品中Yac-1活细胞数])×100。如图121所示,在细胞毒性分析期间,在存在TGFRt15-TGFRs21的情况下,TGFRt15-TGFRs21处理的小鼠脾细胞对Yac-1细胞的细胞毒性强于对照小鼠细胞(图121)。
实例58:TGFRt15-TGFRs16融合蛋白生成
生成包含TGFβ受体II/IL-15RαSu/抗CD16scFv和TGFβ受体II/TF/IL-15融合蛋白的融合蛋白复合物(图122和图123)。人TGFβ受体II(Ile24-Asp159)、组织因子219和IL-15序列从UniProt网站获得,并且这些序列的DNA由金唯智合成。具体来说,制造构建体,将两个TGFβ受体II序列与G4S(3)接头连接以生成TGFβ受体II的单链形式,并且然后直接连接到组织因子219的N端编码区,接着连接到IL-15的N端编码区。
以下显示包含两个TGFβ受体II连接到组织因子219的N端,后接IL-15的N端的构建体的核酸和蛋白质序列。
TGFRt15构建体(包括信号肽序列)的核酸序列如下:
(信号肽)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(人TGFβ受体II片段)
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC
(人组织因子219)
AGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAG
(人IL-15)
AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC
TGFRt15融合蛋白(包括前导序列)的氨基酸序列如下:
(信号肽)
MKWVTFISLLFLFSSAYS
(人TGFβ受体II)
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD
(人组织因子219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(人IL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
还通过将两个TGFβ受体II直接连接到IL-15RαSu链,接着连接到由金唯智合成的抗CD16scFv序列来制造构建体。以下显示包含TGFβ受体II连接到IL-15RαSu的N端,后接抗CD16scFv序列的构建体的核酸和蛋白质序列。
TGFRs16构建体(包括信号肽序列)的核酸序列如下:
(信号肽)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(人TGFβ受体II片段)
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC
(人IL-15Rα寿司结构域)
ATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG
(抗人CD16scFv)
TCCGAGCTGACCCAGGACCCTGCTGTGTCCGTGGCTCTGGGCCAGACCGTGAGGATCACCTGCCAGGGCGACTCCCTGAGGTCCTACTACGCCTCCTGGTACCAGCAGAAGCCCGGCCAGGCTCCTGTGCTGGTGATCTACGGCAAGAACAACAGGCCCTCCGGCATCCCTGACAGGTTCTCCGGATCCTCCTCCGGCAACACCGCCTCCCTGACCATCACAGGCGCTCAGGCCGAGGACGAGGCTGACTACTACTGCAACTCCAGGGACTCCTCCGGCAACCATGTGGTGTTCGGCGGCGGCACCAAGCTGACCGTGGGCCATGGCGGCGGCGGCTCCGGAGGCGGCGGCAGCGGCGGAGGAGGATCCGAGGTGCAGCTGGTGGAGTCCGGAGGAGGAGTGGTGAGGCCTGGAGGCTCCCTGAGGCTGAGCTGTGCTGCCTCCGGCTTCACCTTCGACGACTACGGCATGTCCTGGGTGAGGCAGGCTCCTGGAAAGGGCCTGGAGTGGGTGTCCGGCATCAACTGGAACGGCGGATCCACCGGCTACGCCGATTCCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACTCCCTGTACCTGCAGATGAACTCCCTGAGGGCCGAGGACACCGCCGTGTACTACTGCGCCAGGGGCAGGTCCCTGCTGTTCGACTACTGGGGACAGGGCACCCTGGTGACCGTGTCCAGG
TGFRs16融合蛋白(包括前导序列)的氨基酸序列如下:
(信号肽)
MKWVTFISLLFLFSSAYS
(人TGFβ受体II)
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD
(人IL-15Rα寿司结构域)
ITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR
(抗人CD16scFv)
SELTQDPAVSVALGQTVRITCQGDSLRSYYASWYQQKPGQAPVLVIYGKNNRPSGIPDRFSGSSSGNTASLTITGAQAEDEADYYCNSRDSSGNHVVFGGGTKLTVGHGGGGSGGGGSGGGGSEVQLVESGGGVVRPGGSLRLSCAASGFTFDDYGMSWVRQAPGKGLEWVSGINWNGGSTGYADSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARGRSLLFDYWGQGTLVTVSR
在一些情况下,将前导肽从完整多肽上裂解下来以生成可能可溶或分泌的成熟形式。
将TGFR/IL-15RαSu/抗CD16scFv和TGFR/TF/IL-15构建体克隆到修饰的逆转录病毒表达载体中,如前所述(Hughes MS,Yu YY,Dudley ME,Zheng Z,Robbins PF,Li Y等人.《衍生自具有明显抗肿瘤反应的患者的TCR基因的转移传送高度活性T细胞效应功能》.《人基因疗法》2005;16:457–72),并且将表达载体转染到CHO-K1细胞中。两种构建体在CHO-K1细胞中的共表达使得可形成和分泌可溶性TGFR/TF/IL-15:TGFR/IL-15RαSu/抗CD16scFv蛋白复合物(称为TGFRt15-TGFRs16),其通过抗TF IgG1亲和力和其它色谱方法纯化。
实例59:TGFRt15-TGFRs137L融合蛋白生成
生成包含TGFβ受体II/IL-15RαSu/CD137L和TGFβ受体II/TF/IL-15融合蛋白的融合蛋白复合物(图124和图125)。人TGFβ受体II(Ile24-Asp159)、组织因子219、CD137L和IL-15序列从UniProt网站获得,并且这些序列的DNA由金唯智合成。具体来说,制造构建体,将两个TGFβ受体II序列与G4S(3)接头连接以生成TGFβ受体II的单链形式,并且然后直接连接到组织因子219的N端编码区,接着连接到IL-15的N端编码区。
以下显示包含两个TGFβ受体II连接到组织因子219的N端,后接IL-15的N端的构建体的核酸和蛋白质序列。
TGFRt15构建体(包括信号肽序列)的核酸序列如下:
(信号肽)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(人TGFβ受体II片段)
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC
(人组织因子219)
AGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAG
(人IL-15)
AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC
TGFRt15融合蛋白(包括前导序列)的氨基酸序列如下:
(信号肽)
MKWVTFISLLFLFSSAYS
(人TGFβ受体II)
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD
(人组织因子219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(人IL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
还通过将两个TGFβ受体II直接连接到IL-15RαSu链,接着连接到(G4S)3接头和由金唯智合成的CD137L序列来制造构建体。以下显示包含TGFβ受体II连接到IL-15RαSu的N端,后接(G4S)3接头和CD137L序列的构建体的核酸和蛋白质序列。
TGFRs137L构建体(包括信号肽序列)的核酸序列如下:
(信号肽)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(人TGFβ受体II片段)
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC
(人IL-15Rα寿司结构域)
ATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG
((G4S)3接头)
GGCGGTGGAGGATCCGGAGGAGGTGGCTCCGGCGGCGGAGGATCT
(人CD137L)
CGCGAGGGTCCCGAGCTTTCGCCCGACGATCCCGCCGGCCTCTTGGACCTGCGGCAGGGCATGTTTGCGCAGCTGGTGGCCCAAAATGTTCTGCTGATCGATGGGCCCCTGAGCTGGTACAGTGACCCAGGCCTGGCAGGCGTGTCCCTGACGGGGGGCCTGAGCTACAAAGAGGACACGAAGGAGCTGGTGGTGGCCAAGGCTGGAGTCTACTATGTCTTCTTTCAACTAGAGCTGCGGCGCGTGGTGGCCGGCGAGGGCTCAGGCTCCGTTTCACTTGCGCTGCACCTGCAGCCACTGCGCTCTGCTGCTGGGGCCGCCGCCCTGGCTTTGACCGTGGACCTGCCACCCGCCTCCTCCGAGGCTCGGAACTCGGCCTTCGGTTTCCAGGGCCGCTTGCTGCACCTGAGTGCCGGCCAGCGCCTGGGCGTCCATCTTCACACTGAGGCCAGGGCACGCCATGCCTGGCAGCTTACCCAGGGCGCCACAGTCTTGGGACTCTTCCGGGTGACCCCCGAAATCCCAGCCGGACTCCCTTCACCGAGGTCGGAA
TGFRs137L融合蛋白(包括前导序列)的氨基酸序列如下:
(信号肽)
MKWVTFISLLFLFSSAYS
(人TGFβ受体II)
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD
(人IL-15Rα寿司结构域)
ITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR
((G4S)3接头)
GGGGSGGGGSGGGGS
(人CD137L)
REGPELSPDDPAGLLDLRQGMFAQLVAQNVLLIDGPLSWYSDPGLAGVSLTGGLSYKEDTKELVVAKAGVYYVFFQLELRRVVAGEGSGSVSLALHLQPLRSAAGAAALALTVDLPPASSEARNSAFGFQGRLLHLSAGQRLGVHLHTEARARHAWQLTQGATVLGLFRVTPEIPAGLPSPRSE
在一些情况下,将前导肽从完整多肽上裂解下来以生成可能可溶或分泌的成熟形式。
将TGFR/IL-15RαSu/CD137L和TGFR/TF/IL-15构建体克隆到修饰的逆转录病毒表达载体中,如前所述(Hughes MS,Yu YY,Dudley ME,Zheng Z,Robbins PF,Li Y等人.《衍生自具有明显抗肿瘤反应的患者的TCR基因的转移传送高度活性T细胞效应功能》.《人基因疗法》2005;16:457–72),并且将表达载体转染到CHO-K1细胞中。两种构建体在CHO-K1细胞中的共表达使得可形成和分泌可溶性TGFR/TF/IL-15:TGFR/IL-15RαSu/CD137L蛋白复合物(称为TGFRt15-TGFRs137L),其可通过抗TF IgG1亲和力和其它色谱方法纯化。
实例60:由多链嵌合多肽构建体体外刺激NK细胞
进行了一组实验,以评定用18t15-12s、18t15-12s16和7t15-21s刺激后淋巴细胞群体的表面表型的变化。在这些实验中,从血库获得新鲜的人白细胞。用Ficoll-PAQUEPlus(通用电气医疗集团)密度梯度培养基分离外周血淋巴细胞。对细胞进行计数并将其以0.2×106个/mL的浓度重悬于96孔平底板中0.2mL完全培养基(RPMI 1640(吉毕科公司),补充有2mM L-谷氨酰胺(Thermo Life Technologies)、青霉素(Thermo LifeTechnologies)、链霉素(Thermo Life Technologies)和10%FBS(Hyclone))中。在37℃和5%CO2下用以下物质刺激细胞16小时:18t15-12s(100nM)、18t15-12s16(100nM)、单细胞因子rhIL15(50ng/mL)(美天旎(Miltenyi))、rhIL18(50ng/mL)(英伟杰)和rhIL-12(10ng/mL)(派普泰克(Peprotech))的混合物;7t15-21s(100nM)+抗TF抗体(50nM);7t15-21s(100nM);或抗TF抗体(50nM)。第二天,收获细胞并用对CD4或CD8、CD62L和CD69具有特异性的抗体表面染色30分钟。表面染色后,将细胞在FACS缓冲液(含0.5%BSA(EMD密理博)和0.001%叠氮化钠(西格玛)的1×PBS(Hyclone)中洗涤(室温下1500RPM 5分钟)。两次洗涤后,通过流式细胞术(Celesta-BD Bioscience)分析细胞。图126显示纯化的淋巴细胞群体(CD4和CD8 T细胞)与18t15-12s、18t15-12s16或7t15-21s+抗TF抗体一起过夜培育引起表达CD69的CD8和CD4 T细胞的百分比增加。另外,与7t15-21s+抗TF抗体一起培育引起表达CD62L的CD8和CD4 T细胞的百分比增加(图126)。
进行一组实验以确定在用18t15-12s刺激后NK细胞中磷酸化STAT4和磷酸化STAT5水平的提高。在这些实验中,从血库获得新鲜的人白细胞,并且用RosetteSep/人NK细胞试剂(干细胞技术有限公司)分离CD56+NK细胞。NK细胞的纯度>70%,并且通过用CD56-BV421、CD16-BV510、CD25-PE和CD69-APCFire750特异性抗体(BioLegend)染色得到证实。对细胞进行计数并将其以0.05×106个/mL的浓度重悬于96孔平底板中0.1mL完全培养基(RPMI 1640(吉毕科公司),补充有2mM L-谷氨酰胺(Thermo Life Technologies)、青霉素(ThermoLife Technologies)、链霉素(Thermo Life Technologies)和10%FBS(Hyclone))中。在37℃和5%CO2下,用hIL-12(10ng/mL)(Biolegend)或hIL-15(50ng/mL)(NCI)(单细胞因子)或18t15-12s(100nM)刺激细胞90分钟。未刺激的NK细胞(US)用作对照。收获细胞并将其固定在多聚甲醛(西格玛)中到达1.6%的最终浓度。将板在黑暗中在室温下培育10分钟。添加FACS缓冲液(1×PBS(Hyclone),含0.5%BSA(EMD密理博)和0.001%叠氮化钠(西格玛))(100μL),并且将细胞转移到96孔“V”底板。将细胞在室温下以1500RPM洗涤5分钟。通过轻轻上下移吸,将细胞沉淀与100μL冷却甲醇混合,并且在4℃下培育细胞30分钟。将细胞与100mL FACS缓冲液混合,并且在室温下以1500RPM洗涤5分钟。将细胞沉淀与50mL含4mLpSTAT4(BD Bioscience)和pSTAT5抗体(BD Bioscience)的FACS缓冲液混合,接着在黑暗中在室温下培育30分钟。将细胞与100mL FACS缓冲液混合,并且在室温下以1500RPM洗涤5分钟。将细胞沉淀与50mL FACS缓冲液混合,并且通过流式细胞术(Celesta-BD Bioscience)分析细胞。图127显示NK细胞与18t15-12s一起培育诱导pSTAT4和pSTAT5的增加(绘制数据,归一化倍数变化)。
实例61:通过TGFRt15-TGFRs在体内刺激NK细胞
进行一组实验来确定TGFRt15-TGFRs构建体对以西方饮食喂养的ApoE-/-小鼠的免疫刺激的影响。在这些实验中,给6周龄雌性B6.129P2-ApoEtm1Unc/J小鼠(杰克逊实验室)喂食含有21%脂肪、0.15%胆固醇、34.1%蔗糖,19.5%酪蛋白和15%淀粉的西方饮食(TD88137,Envigo Laboratories)。西方饮食8周后,将小鼠用3mg/kg的TGFRt15-TGFRs皮下注射。处理后三天,将小鼠禁食16小时,并且然后通过眼眶后静脉丛穿刺收集血样。将血液与10μL 0.5M EDTA混合,并且抽取20μL血液用于淋巴细胞亚群分析。将红血细胞用ACK(0.15M NH4Cl,1.0mM KHCO3,0.1mM Na2EDTA,pH 7.4)溶解,并且将淋巴细胞在4℃下在FACS染色缓冲液(PBS中1%BSA)中用抗小鼠CD8a和抗小鼠NK1.1抗体染色30分钟。将细胞洗涤一次并用BD FACS Celesta分析。对于Treg染色,在4℃下在FACS染色缓冲液中,用抗小鼠CD4和抗小鼠CD25抗体将ACK处理的血液淋巴细胞染色30分钟。将细胞洗涤一次并重悬于固定/通透性工作溶液中,并且在室温下培育60分钟。将细胞洗涤一次并重悬于通透缓冲液中。将样品在室温下以300-400×g离心5分钟,并且然后弃去上清液。将细胞沉淀重悬于残余体积中,并且用1×通透缓冲液将体积调节到约100μL。将抗Foxp3抗体添加到细胞中,并且将细胞在室温下培育30分钟。将通透缓冲液(200μL)添加到细胞中,并且将细胞在室温下以300-400×g离心5分钟。将细胞重悬于在流式细胞术染色缓冲液中,并且在流式细胞仪上进行分析。图128A-128C显示,用TGFRt15-TGFRs处理增加用西方饮食喂养的ApoE-/-小鼠中NK细胞和CD8+T细胞的百分比。
实例62:体内免疫细胞增殖的诱导
进行一组实验以确定TGFRt15-TGFRs构建体对C57BL/6小鼠免疫刺激的作用。在这些实验中,用0.1、0.3、1、3和10mg/kg对照溶液(PBS)或TGFRt15-TGFRs皮下处理C57BL/6小鼠。在处理后4天使经过处理的小鼠安乐死。测量脾脏重量并制备脾细胞悬浮液。将脾细胞悬浮液用缀合的抗CD4、抗CD8和抗NK1.1(NK)抗体染色。另外针对增殖标记Ki67对细胞进行染色。图129A显示用TGFRt15-TGFRs处理的小鼠的脾脏重量随TGFRt15-TGFRs剂量的增加而增加。另外,与仅用对照溶液处理的小鼠相比,用1mg/kg、3mg/kg和10mg/kg TGFRt15-TGFRs处理的小鼠的脾脏重量更高。CD8+T细胞和NK细胞的百分比均随TGFRt15-TGFRs剂量的增加而增加(图129B)。最后,在所有测试的TGFRt15-TGFRs剂量下,TGFRt15-TGFRs显著上调CD8+T细胞和NK细胞两者中细胞增殖标记Ki67的表达(图129C)。这些结果证明,TGFRt15-TGFRs处理诱导C57BL/6小鼠中CD8+T细胞和NK细胞两者的增殖。
进行一组实验来确定TGFRt15-TGFRs构建体对以西方饮食喂养的ApoE-/-小鼠的免疫刺激的影响。在这些实验中,给6周龄雌性B6.129P2-ApoEtm1Unc/J小鼠(杰克逊实验室)喂食含有21%脂肪、0.15%胆固醇、34.1%蔗糖,19.5%酪蛋白和15%淀粉的西方饮食(TD88137,Envigo Laboratories)。西方饮食8周后,将小鼠用3mg/kg的TGFRt15-TGFRs皮下注射。处理后三天,将小鼠禁食16小时,并且然后通过眼眶后静脉丛穿刺收集血样。将血液与10μL 0.5M EDTA混合,并且抽取20μL血液用于淋巴细胞亚群分析。将红血细胞用ACK(0.15M NH4Cl,1.0mM KHCO3,0.1mM Na2EDTA,pH 7.4)溶解,并且将淋巴细胞在4℃下在FACS染色缓冲液(PBS中1%BSA)中用抗小鼠CD8a和抗小鼠NK1.1抗体染色30分钟。将细胞洗涤一次并在室温下重悬于固定缓冲液(BioLegend目录号420801)中20分钟。将细胞以350×g离心5分钟,将固定的细胞重悬于细胞内染色通透洗涤缓冲液(BioLegend目录号421002)中,并且然后以350×g离心5分钟。然后在RT下将细胞用抗Ki67抗体染色20分钟。将细胞用细胞内染色通透洗涤缓冲液洗涤两次,并且以350×g离心5分钟。然后将细胞重悬于FACS染色缓冲液中。用BD FACS Celesta分析淋巴细胞亚群。如图130A和130B中所描述,用TGFRt15-TGFRs处理ApoE-/-小鼠诱导NK和CD8+T细胞增殖(Ki67阳性染色)。
实例63:用多链构建体处理后NK介导的细胞毒性
进行一组实验以确定用TGFRt15-TGFRs处理NK细胞是否增强NK细胞的细胞毒性。在这些实验中,将人道迪(Daudi)B淋巴瘤细胞用CellTrace紫罗兰(CTV)标记,并且用作肿瘤靶细胞。3mg/kg的TGFRt15-TGFRs皮下处理后4天,对C57BL/6雌性小鼠脾脏使用磁性细胞分选方法(美天旎生物技术(Miltenyi Biotec)),用NK1.1阳性选择分离小鼠NK效应细胞。用RosetteSep/人NK细胞试剂(干细胞技术有限公司)从衍生自人血白细胞层的外周血单核细胞中分离人NK效应细胞。将靶细胞(人道迪B淋巴瘤细胞)与效应细胞(小鼠NK效应细胞或人NK效应细胞)在存在50nM TGFRt15-TGFRs或不存在TGFRt15-TGFRs(对照)的情况下混合,并且在37℃下对于小鼠NK细胞培育44小时,且对于人NK细胞培育20小时。通过使用流式细胞术分析碘化丙啶阳性、CTV标记的细胞来评定靶细胞(道迪)活力。使用公式(1-实验样品中活肿瘤细胞数/不含NK细胞的样品中的活肿瘤细胞数)×100计算道迪抑制的百分比。图131显示相比于不存在TGFRt15-TGFRs激活的情况,用TGFRt15-TGFRs激活NK细胞后,小鼠(图131A)和人(图131B)NK细胞对道迪B细胞的细胞毒性显著增强。
进行一组实验以确定用TGFRt15-TGFRs处理后的小鼠和人NK细胞的抗体依赖性细胞毒性(ADCC)。在这些实验中,将人道迪B淋巴瘤细胞用CellTrace紫罗兰(CTV)标记,并且用作肿瘤靶细胞。3mg/kg的TGFRt15-TGFRs皮下处理后4天,对C57BL/6雌性小鼠脾脏使用磁性细胞分选方法(美天旎生物技术),用NK1.1阳性选择分离小鼠NK效应细胞。用RosetteSep/人NK细胞试剂(干细胞技术有限公司)从衍生自人血白细胞层的外周血单核细胞中分离人NK效应细胞。将靶细胞(道迪B细胞)与效应细胞(小鼠NK效应细胞或人NK效应细胞)在存在抗CD20抗体(10nM利妥昔单抗(Rituximab),基因泰克(Genentech))并且存在50nM TGFRt15-TGFRs或不存在TGFRt15-TGFRs(对照)的情况下混合,并且在37℃下对于小鼠NK细胞培育44小时,且对于人NK细胞培育20小时。道迪B细胞表达抗CD20抗体的CD20靶标。培育后通过使用流式细胞术分析碘化丙啶阳性、CTV标记的靶细胞来评定靶细胞活力。使用公式(1-实验样品中活肿瘤细胞数/不含NK细胞的样品中的活肿瘤细胞数)×100计算道迪抑制的百分比。图132显示相比于不存在TGFRt15-TGFRs激活的情况,用TGFRt15-TGFRs激活NK细胞后,小鼠NK细胞(图132A)和人NK细胞(图132B)对道迪B细胞的ADCC活性更强。
实例64:癌症的治疗
进行一组实验,以评定在黑色素瘤小鼠模型中TGFRt15-TGFRs加抗TRP1抗体(TA99)与化疗组合的抗肿瘤活性。在这些实验中,将C57BL/6小鼠用0.5×106个B16F10黑色素瘤细胞皮下注射。在第1天、第4天和第7天用三个剂量的多西他赛(10mg/kg)(DTX)处理小鼠,接着在第9天用单剂量足组合免疫疗法TGFRt15-TGFRs(3mg/kg)+抗-TRP1抗体TA99(200μg)处理小鼠。图133A显示处理方案的示意图。通过卡尺测量监测肿瘤生长,并且使用公式V=(L×W2)/2来计算肿瘤体积,其中L是最大肿瘤直径,并且W是垂直肿瘤直径。图133B显示与盐水对照和DTX处理组相比,DTX+TGFRt15-TGFRs+TA99显著减少肿瘤生长(N=10,****p<0.001,多次t检验分析)。
为了评定B16F10肿瘤模型中的免疫细胞亚群,进行外周血分析。在这些实验中,将C57BL/6小鼠用B16F10细胞注射,并且用DTX、DTX+TGFRt15-TGFRs+TA99或盐水处理。对于DTX+TGFRt15-TGFRs+TA99组免疫疗法后第2、5、8天,并且对于DTX和盐水组肿瘤注射后第11天,从荷B16F10瘤小鼠的下颌下静脉采血。在ACK溶解缓冲液中溶解RBC,并且将淋巴细胞洗涤并用抗NK1.1、抗CD8和抗CD4抗体染色。通过流式细胞术(Celesta-BD Bioscience)分析细胞。图133C-133E显示与盐水和DTX处理组相比,DTX+TGFRt15-TGFRs+TA99处理诱导肿瘤中NK细胞和CD8+T细胞百分比的增加。
在第17天,使用Trizol从用盐水、DTX或DTX+TGFRt15-TGFRs+TA99处理的小鼠的肿瘤中提取总RNA。使用QuantiTect逆转录试剂盒(凯杰(Qiagen))将总RNA(1μg)用于cDNA合成。使用FAM标记的衰老细胞标记(F)p21(G)DPP4和(H)IL6预先设计的引物,用CFX96检测系统(伯乐(Bio-Rad))进行实时PCR。将管家基因18S核糖体RNA用作内部对照,以将表达水平的变异性归一化。相对于18S rRNA,每个靶标mRNA的表达基于Ct计算为2–Δ(ΔCt),其中ΔCt=Ct靶标–Ct18S。数据呈现为相比于盐水对照的变化倍数。图133F-133H显示DTX处理诱导衰老肿瘤细胞增加,所述细胞随后在用TGFRt15-TGFRs+TA99免疫疗法处理后减少。
进行一组实验以研究通过TGFRt15-TGFRs改善ApoE-/-小鼠中西方饮食诱导的高血糖症。在这些实验中,给6周龄雌性B6.129P2-ApoEtm1Unc/J小鼠(杰克逊实验室)喂食含有21%脂肪、0.15%胆固醇、34.1%蔗糖,19.5%酪蛋白和15%淀粉的西方饮食(TD88137,Envigo Laboratories)。西方饮食8周后,将小鼠用3mg/kg的TGFRt15-TGFRs皮下注射。处理后三天,将小鼠禁食16小时,并且然后通过眼眶后静脉丛穿刺收集血样。用血糖仪(OneTouch UltraMini)和GenUltimated测试条,使用一滴新鲜血液检测血糖。如图134A所示,TGFRt15-TGFRs处理减少由西方饮食诱导的高血糖症。用Eve Technologies的小鼠大鼠代谢阵列(Mouse Rat Metabolic Array)分析血浆胰岛素和抵抗素水平。使用以下公式计算HOMA-IR:稳态模型评定-胰岛素抵抗=血糖(mg/dL)*胰岛素(mU/mL)/405。如图134B所示,与未处理组相比,TGFRt15-TGFRs处理降低胰岛素抵抗。如图142C所示,与未处理组相比,TGFRt15-TGFRs(p<0.05)显著降低抵抗素水平,这可能与TGFRt15-TGFRs诱导的胰岛素抵抗降低相关(图134B)。
实例65:诱导NK细胞分化成细胞因子诱导的记忆样NK细胞
进行一组实验,以评定用18t15-12s刺激后NK细胞分化成细胞因子诱导的记忆样NK细胞(CIMK-NK细胞)。在这些实验中,从血库获得新鲜的人白细胞,并且用RosetteSep/人NK细胞试剂(干细胞技术有限公司)分离CD56+NK细胞。NK细胞的纯度>90%,并且通过用CD56-BV421、CD16-BV510,CD25-PE和CD69-APCFire750抗体(BioLegend)染色来确认。对细胞进行计数并且将其以2×106个/mL重悬于24孔平底板中的2mL完全培养基(RPMI1640(吉毕科公司),补充有2mM L-谷氨酰胺(Thermo Life Technologies)、青霉素(Thermo LifeTechnologies)、链霉素(Thermo Life Technologies)和10%FBS(Hyclone))中。细胞未刺激(“无添加”)或用18t15-12s(100nM)或包括rhIL15(50ng/mL)(美天旎)、rhIL18(50ng/mL)(英伟杰)和rhIL-12(10ng/mL)(派普泰克)的单一细胞因子的混合物(“单一细胞因子”)在37℃和5%CO2下刺激16小时。第二天,收获细胞,并且在室温下用温热完全培养基以1000RPM洗涤两次持续10分钟。将细胞以2×106个/mL重悬于24孔平底板中的2mL含rhIL15(1ng/mL)的完全培养基中。每2天后,将一半培养基替换为含有rhIL15的新鲜完全培养基。
为了评定第7天NK细胞记忆表型的变化,将细胞用针对细胞表面CD56、CD16、CD27、CD62L、NKp30和NKp44的抗体染色(BioLegend)。表面染色后,将细胞在含0.5%BSA(EMD密理博)和0.001%叠氮化钠(西格玛)的FACS缓冲液(1×PBS(Hyclone))中洗涤(室温下1500RPM5分钟)。两次洗涤后,通过流式细胞术(Celesta-BD Bioscience)分析细胞。图135显示将NK细胞与18t15-12s一起培育引起表达CD27、CD62L和NKp44的CD16+CD56+NK细胞百分比增加,并且CD16+CD56+NK细胞中NKp30水平(MFI)提高。
实例66:CD44记忆T细胞的上调
进行一组实验以评定用TGFRt15-TGFRs处理后CD44记忆T细胞的上调。在这些实验中,将C57BL/6小鼠用TGFRt15-TGFR皮下注射。使经过处理的小鼠安乐死并在处理后4天(TGFRt15-TGFRs)制备单个脾细胞悬浮液。将制备的脾细胞用荧光染料缀合的抗CD4、抗CD8和抗CD44抗体染色,并且通过流式细胞术分析CD4+T细胞或CD8+T细胞中CD44高T细胞的百分比。结果显示,TGFRt15-TGFRs上调记忆标记CD44在CD4+和CD8+T细胞上的表达(图136)。这些发现表明TGFRt15-TGFRs能够诱导小鼠T细胞分化成记忆T细胞。
实例67:用单链或多链嵌合多肽处理后的组织因子凝血分析
在用单链或多链嵌合多肽处理后,进行一组实验以评定凝血。为了引发凝血级联路径,组织因子(TF)与因子VIIa(FVIIa)结合以形成TF/FVIIa复合物。然后,TF/FVIIa复合物结合因子X(FX),并且将FX转化为FXa。
因子VIIa(FVIIa)活性分析
一种测量凝血的分析涉及测量因子VIIa(FVIIa)活性。这类分析需要组织因子和钙的存在。TF/FVIIa复合物活性可通过小的底物或天然蛋白质底物,例如因子X(FX)进行测量。当FX用作底物时,磷脂也是TF/FVIIa活性所需的。在这一分析中,用FVIIa特异性发色底物S-2288(Diapharma,俄亥俄州西切斯特(West Chester,OH))确定FVIIa活性。S-2288底物的颜色变化可通过分光光度法测量,并且与FVIIa(例如,TF/FVIIa复合物)的蛋白水解活性成比例。
在这些实验中,比较以下组的FVIIa活性:组织因子结构域的219个氨基酸的胞外域(TF219)、具有野生型组织因子结构域的多链嵌合多肽和具有突变组织因子结构域的多链嵌合多肽。含有突变组织因子分子的嵌合多肽用以下氨基酸位点处对TF结构域的突变构建:Lys20、Ile22、Asp58、Arg135和Phe140。
为了评定FVIIa的活性,将FVIIa和TF219或含TF219的多链嵌合多肽以等摩尔浓度(10nM)以70μL总体积在96孔ELISA板的所有孔中混合。在37℃下培育10分钟后,添加10μL8mM S-2288底物以开始反应。然后将培育在37℃下保持20分钟。最后,通过读取405nm处的吸光度来监测颜色变化。表1和表2中显示不同TF/VIIa复合物的OD值。表1显示TF219、21t15-21s野生型(WT)和21t15-21s突变体(Mut)的比较。表2显示TF219、21t15-TGFRs野生型(WT)和21t15-TGFRs突变体(Mut)的比较。这些数据显示,在发色S-2288用作底物时,含TF219的多链嵌合多肽(例如,21t15-21s-WT、21t15-21s-Mut、21t15-TGFRS-WT和21t15-TGFRS-Mut)的FVIIa活性比TF219低。值得注意的是,与含有野生型TF219的多链嵌合多肽相比,含有TF219突变的多链嵌合多肽显示低得多的FVIIa活性。
表1.FVIIa活性
| 分子 | 405nm处的OD值 |
| TF<sub>219</sub> | 0.307 |
| 21t15/21S-WT | 0.136 |
| 21t15/21S-Mut | 0.095 |
WT:野生型TF219,Mut:含有突变的TF219。
表2.FVIIa活性
| 分子 | 405nm处的OD值 |
| TF<sub>219</sub> | 0.345 |
| 21t15/TGFRS-WT | 0.227 |
| 21t15/TGFRS-Mut | 0.100 |
WT:野生型TF219,Mut:含有突变的TF219。
因子X(FX)激活分析
测量凝血的另一分析涉及测量因子X(FX)的激活。简单来说,在钙和磷脂的存在下,TF/VIIa将凝血因子X(FX)激活为因子Xa(FXa)。与不含跨膜结构域的TF219相比,含有TF的跨膜结构域的TF243将FX激活为FXa的活性更高。通过使用FXa特异性发色底物S-2765(Diapharma,俄亥俄州西切斯特)测量FXa活性来确定TF/VIIa依赖性的FX激活。S-2765的颜色变化可通过分光光度法进行监测,并且与FXa的蛋白水解活性成比例。
在这些实验中,将多链嵌合多肽(18t15-12s、小鼠(m)21t15、21t15-TGFRs和21t15-7s)的FX激活与阳性对照(因诺维)或TF219进行比较。将TF219(或含TF219的多链嵌合多肽)/FVIIa复合物以等摩尔浓度(每个0.1nM)在96孔ELISA板的圆底孔中以50μL的体积混合,之后添加10μL 180nM FX。在37℃下培育15分钟(在此期间FX转化为Fxa)后,向每个孔中添加8μL 0.5M EDTA(其螯合钙,并且从而终止由TF/VIIa进行FX激活)以停止FX激活。接下来,将10μL 3.2mM S-2765底物添加反应混合物中。紧接着,在405nm处测量板吸光度,并且记录为在0时间的吸光度。然后将板在37℃下培育10-20分钟。通过培育后读取405nm处的吸光度来监测颜色变化。使用发色底物S-2765通过FXa活性测量的FX激活结果如图137所示。在这一实验中,使用含有脂化重组人TF243的商业凝血酶原试剂因诺维作为FX激活的阳性对照。用纯化水将因诺维重构到约10nM TF243。接下来,通过将等体积的0.2nM FVIIa与0.2nM因诺维混合来制造0.1nM TF/VIIa复合物。因诺维展现非常强效的FX激活活性,而TF219和含TF219的多链嵌合多肽具有非常低的FX激活活性,从而证实TF219在TF/FVIIa复合物中对于体内激活天然底物FX不具有活性。
凝血酶原时间测试
测量凝血的第三种分析是凝血酶原时间(PT)测试,其测量凝血活性。此处,PT测试使用市售正常人血浆(Ci-Trol凝血对照,I级)进行。对于标准PT测试,在钙的存在下,通过添加脂化重组人TF243因诺维来引发凝血反应。由STart PT分析仪(Diagnostics Stago,新泽西州帕西帕尼(Parsippany,NJ))监测并报告凝血时间。通过将0.2mL在PT分析缓冲液(50mM Tris-HCl,pH 7.5,14.6mM CaCl2,0.1%BSA)中稀释的因诺维的各种稀释液注入含有0.1mL在37℃下预温热的正常人血浆的比色皿中,开始PT分析。在PT分析中,较短的PT时间(凝血时间)指示较高的TF依赖性凝血活性,而较长的PT(凝血时间)指示较低的TF依赖性凝血活性。
如图138所示,将不同量的因诺维(例如,用纯化水重构,等效于10nM脂化重组人TF243的因诺维视为100%因诺维)添加到PT分析中展现剂量反应关系,其中较低浓度的TF243引起较长的PT时间(较低的凝血活性)。例如,0.001%的因诺维的PT时间大于110秒,这几乎与单独的缓冲液相同。
在另一实验中,对TF219和多链嵌合多肽进行PT测试,所述多肽包括:18t15-12s、7t15-21s、21t15-TGFRs-WT和21t15-TGFRs-Mut。图139显示TF219和含TF219的多链嵌合多肽(浓度为100nM)具有延长的PT时间,表明凝血活性极低或无凝血活性。
还进行研究以评估在存在携带多链嵌合多肽(32Dβ或人PBMC)的细胞因子组分的受体的其它细胞存在下,培育多链嵌合多肽是否会影响PT分析中的凝血时间。为了检查表达IL-15受体的细胞(32Dβ细胞)或表达IL-15和IL-21受体的细胞(PBMC)是否会结合含IL-15的多链嵌合多肽以模拟天然TF作为细胞FVIIa受体,将含TF219的多链嵌合多肽(对于每个分子,在100nM浓度下)在PT分析缓冲液中稀释并与32Dβ细胞(在2×105个细胞/mL下)或PBMC(在1×105个细胞/mL下)在室温下一起预培育20-30分钟。然后如上所述进行PT分析。图140和141显示以100nM最终浓度与32Dβ细胞(图140)或PBMC(图141)混合的TF219和含TF219的多链嵌合多肽的PT时间延长,与0.001-0.01%因诺维相似(等效于0.1pM至1.0pM TF243)。以相对的TF243活性百分比表示,含TF219的多链嵌合多肽与因诺维相比,TF依赖性凝血活性低100,000至1,000,000倍。这证明即使在分子结合到完整的细胞膜表面,如32Dβ或PBMC时,含TF219的多链嵌合多肽也具有极低或不具有TF依赖性凝血活性。
实例68:7t15-21s137L(长版)的表征
7t15构建体(包括信号肽序列)的核酸序列如下(SEQ ID NO:107):
(信号肽)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(人IL7)
GATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGTTCAACTTCTTCAAGCGGCACATCTGCGACGCCAACAAGGAGGGCATGTTCCTGTTCAGGGCCGCCAGGAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGGTGAAGGGCCGGAAACCTGCTGCTCTGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGAACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCAT
(人组织因子219)
AGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAG
(人IL-15)
AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC
7t15融合蛋白(包括前导序列)的氨基酸序列如下(SEQ ID NO:106):
(信号肽)
MKWVTFISLLFLFSSAYS
(人IL7)
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWNKILMGTKEH
(人组织因子219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(人IL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIH
DTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
21s137L构建体(包括信号肽序列)的核酸序列如下(SEQ ID NO:225):
(信号肽)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(人IL-21)
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC
(人IL-15Rα寿司结构域)
ATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG
((G4S)3接头)
GGCGGTGGAGGATCCGGAGGAGGTGGCTCCGGCGGCGGAGGATCT
(人CD137L)
CGCGAGGGTCCCGAGCTTTCGCCCGACGATCCCGCCGGCCTCTTGGACCTGCGGCAGGGCATGTTTGCGCAGCTGGTGGCCCAAAATGTTCTGCTGATCGATGGGCCCCTGAGCTGGTACAGTGACCCAGGCCTGGCAGGCGTGTCCCTGACGGGGGGCCTGAGCTACAAAGAGGACACGAAGGAGCTGGTGGTGGCCAAGGCTGGAGTCTACTATGTCTTCTTTCAACTAGAGCTGCGGCGCGTGGTGGCCGGCGAGGGCTCAGGCTCCGTTTCACTTGCGCTGCACCTGCAGCCACTGCGCTCTGCTGCTGGGGCCGCCGCCCTGGCTTTGACCGTGGACCTGCCACCCGCCTCCTCCGAGGCTCGGAACTCGGCCTTCGGTTTCCAGGGCCGCTTGCTGCACCTGAGTGCCGGCCAGCGCCTGGGCGTCCATCTTCACACTGAGGCCAGGGCACGCCATGCCTGGCAGCTTACCCAGGGCGCCACAGTCTTGGGACTCTTCCGGGTGACCCCCGAAATCCCAGCCGGACTCCCTTCACCGAGGTCGGAA
21s137L融合蛋白(包括前导序列)的氨基酸序列如下(SEQ ID NO:226):
(信号肽)
MKWVTFISLLFLFSSAYS
(人IL-21)
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS
(人IL-15Rα寿司结构域)
ITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPS
LKCIR
((G4S)3接头)
GGGGSGGGGSGGGGS
(人CD137L)
REGPELSPDDPAGLLDLRQGMFAQLVAQNVLLIDGPLSWYSDPGLAGVSLTGGLSYKEDTKELVVAKAGVYYVFFQLELRRVVAGEGSGSVSLALHLQPLRSAAGAAALALTVDLPPASSEARNSAFGFQGRLLHLSAGQRLGVHLHTEARARHAWQLTQGATVLGLFRVTPEIPAGLPSPRSE
进行以下实验以评估7t15-21s137L中的CD137L部分是否完整以结合到CD137(4.1BB)。在第1天,将96孔板用的100μL(2.5μg/mL)R5(包被缓冲液)中GAH IgG Fc(G-102-C,安迪生物公司)包被过夜。在第2天,将板洗涤三次并用300μL PBS中的1%BSA 37℃下阻断2小时。以100μL的量添加10ng/mL的4.1BB/Fc(838-4B,安迪生物公司)在RT下培育2小时。洗涤三次后,以10nM开始添加7t15-21s137L(长版)或7t15-21s137Ls(短版),或以1/3稀释度从180ng/mL开始添加重组人4.1BBL,接着在4℃下培育过夜。在第3天,将板洗涤三次,并且以每孔100μL施加500ng/mL的生物素化山羊抗人4.1BBL(BAF2295,安迪生物公司),接着在RT下培育2小时。将板洗涤三次,并且与0.25μg/mL HRP-SA(杰克逊免疫研究)以每孔100μL培育30min。然后将板洗涤三次,并且与100μL ABTS在RT下培育2min。在405nm处读取结果。如图142所示,与重组人4.1BB配体(rhCD137L,浅灰色星)相比,7t15-21s137L(长版)和7t15-21s137L(短版)均可与4.1BB/Fc(深色菱形和灰色方块)相互作用。与7t15-21s137L(短版)(灰色方块)相比,7t15-21s137L(长版)(深色菱形)与4.1BB/Fc更好地相互作用。
进行以下实验以评估7t15-21s137L(长版)中的组分IL7、IL21、IL15和4.1BBL是否完整,以使用ELISA通过个别抗体检测。将96孔板用100μL(4μg/mL)R5(包被缓冲液)中的抗TF(人IgG1)包被,并且在RT下培育2小时。将板洗涤三次,并且用100μL PBS中的1%BSA阻断。以10nM起始并且以1/3稀释度添加纯化的7t15-21s137L(长版),接着在RT下培育60min。将板洗涤三次,并且每孔添加500ng/mL生物素化抗IL7(506602,安迪生物公司)、500ng/mL生物化抗IL21(13-7218-81,安迪生物公司)、50ng/mL生物素化抗IL15(BAM247,安迪生物公司)或500ng/ml生物素化山羊抗人4.1BBL(BAF2295,安迪生物公司)并在室温下培育60min。将板洗涤三次并在RT下与0.25μg/mL的HRP-SA(杰克逊免疫研究)以每孔100μL培育30min。将板洗涤四次,并且与100μL ABTS在室温下培育2min。在405nm处读取吸光度结果。如图143A-143D所示,通过个别抗体检测到7t15-21s137L(长版)中包括IL7、IL21、IL15和4.1BBL的组分。
进行以下实验以评估IL15在7t15-21s137L(长版)和7t15-21s137L(短版)中的活性。将7t15-21s137L(长版)和7t15-21s137L(短版)促进表达IL2Rαβγ的CTLL2细胞增殖的能力与重组IL15进行比较。将IL15依赖性CTLL2细胞用IMDM-10%FBS洗涤五次,并且以2×104个细胞/孔接种到孔中。将连续稀释的7t15-21s137L(长版)、7t15-21s137L(短版)或IL15添加到细胞中。将细胞在CO2培养箱中在37℃下培育3天。通过在第3天向每个孔中添加20μL PrestoBlue(A13261,赛默飞世尔(ThermoFisher)),并且在CO2培养箱中在37℃下再培养4小时来检测细胞增殖。在微量滴定板读取器中读取570-610nm处的原始吸光度。如图144所示,7t15-21s137L(长版)、7t15-21s137L(短版)和IL15均促进CTLL2细胞增殖。7t15-21s137L(长版)、7t15-21s137L(短版)和IL15的EC50是分别51.19pM、55.75pM和4.947pM。
其它实施例
应理解,虽然已结合其具体描述对本发明进行了描述,但前面的描述旨在说明而非限制本发明的范围,本发明的范围由所附权利要求书的范围限定。其它方面、优点以及修改均处于以下权利要求书的范围内。
示例性实施例
实施例A1.一种多链嵌合多肽,其包含:
(a)第一嵌合多肽,其包含:
(i)第一靶标结合结构域;
(ii)可溶性组织因子结构域;和
(iii)一对亲和结构域中的第一结构域;
(b)第二嵌合多肽,其包含:
(i)一对亲和结构域中的第二结构域;和
(ii)第二靶标结合结构域,
其中所述第一嵌合多肽和所述第二嵌合多肽通过所述一对亲和结构域中的所述第一结构域和所述第二结构域的结合而缔合。
实施例A2.根据实施例A1所述的多链嵌合多肽,其中所述第一靶标结合结构域和所述可溶性组织因子结构域在所述第一嵌合多肽中彼此直接邻接。
实施例A3.根据实施例A1所述的多链嵌合多肽,其中所述第一嵌合多肽进一步包含所述第一嵌合多肽中的所述第一靶标结合结构域与所述可溶性组织因子结构域之间的接头序列。
实施例A4.根据实施例A1至A3中任一项所述的多链嵌合多肽,其中所述可溶性组织因子结构域和所述一对亲和结构域中的所述第一结构域在所述第一嵌合多肽中彼此直接邻接。
实施例A5.根据实施例A1至A3中任一项所述的多链嵌合多肽,其中所述第一嵌合多肽进一步包含所述第一嵌合多肽中的所述可溶性组织因子结构域与所述一对亲和结构域中的所述第一结构域之间的接头序列。
实施例A6.根据实施例A1至A5中任一项所述的多链嵌合多肽,其中所述一对亲和结构域中的所述第二结构域和所述第二靶标结合结构域在所述第二嵌合多肽中彼此直接邻接。
实施例A7.根据实施例A1至A5中任一项所述的多链嵌合多肽,其中所述第二嵌合多肽进一步包含所述第二嵌合多肽中的所述一对亲和结构域中的所述第二结构域与所述第二靶标结合结构域之间的接头序列。
实施例A8.根据实施例A1至A7中任一项所述的多链嵌合多肽,其中所述第一靶标结合结构域和所述第二靶标结合结构域特异性结合到相同的抗原。
实施例A9.根据实施例A8所述的多链嵌合多肽,其中所述第一靶标结合结构域和所述第二靶标结合结构域特异性结合到相同的表位。
实施例A10.根据实施例A9所述的多链嵌合多肽,其中所述第一靶标结合结构域和所述第二靶标结合结构域包含相同的氨基酸序列。
实施例A11.根据实施例A1至A7中任一项所述的多链嵌合多肽,其中所述第一靶标结合结构域和所述第二靶标结合结构域特异性结合到不同的抗原。
实施例A12.根据实施例A1至A11中任一项所述的多链嵌合多肽,其中所述第一靶标结合结构域和所述第二靶标结合结构域中的一个或两个是抗原结合结构域。
实施例A13.根据实施例A12所述的多链嵌合多肽,其中所述第一靶标结合结构域和所述第二靶标结合结构域各自是抗原结合结构域。
实施例A14.根据实施例A12或A13所述的多链嵌合多肽,其中抗原结合结构域包含scFv或单结构域抗体。
实施例A15.根据实施例A1至A14中任一项所述的多链嵌合多肽,其中所述第一靶标结合结构域和所述第二靶标结合结构域中的一个或两个特异性结合到选自以下组成的组的靶标:CD16a、CD28、CD3、CD33、CD20、CD19、CD22、CD123、IL-1R、IL-1、VEGF、IL-6R、IL-4、IL-10、PDL-1、TIGIT、PD-1、TIM3、CTLA4、MICA、MICB、IL-6、IL-8、TNFα、CD26a、CD36、ULBP2、CD30、CD200、IGF-1R、MUC4AC、MUC5AC、Trop-2、CMET、EGFR、HER1、HER2、HER3、PSMA、CEA、B7H3、EPCAM、BCMA、P-钙黏着蛋白、CEACAM5、UL16结合蛋白、HLA-DR、DLL4、TYRO3、AXL、MER、CD122、CD155、PDGF-DD、TGF-β受体II(TGF-βRII)的配体、TGF-βRIII的配体、DNAM-1的配体、NKp46的配体、NKp44的配体、NKG2D的配体、NKP30的配体、scMHCI的配体、scMHCII的配体、scTCR的配体、IL-1的受体、IL-2的受体、IL-3的受体、IL-7的受体、IL-8的受体、IL-10的受体、IL-12的受体、IL-15的受体、IL-17的受体、IL-18的受体、IL-21的受体、PDGF-DD的受体、干细胞因子(SCF)的受体、干细胞样酪氨酸激酶3配体(FLT3L)的受体、MICA的受体、MICB的受体、ULP16结合蛋白的受体、CD155的受体、CD122的受体和CD28的受体。
实施例A16.根据实施例A1至A14中任一项所述的多链嵌合多肽,其中所述第一靶标结合结构域和所述第二靶标结合结构域中的一个或两个是可溶性白介素或细胞因子蛋白。
实施例A17.根据实施例A16所述的多链嵌合多肽,其中所述可溶性白介素、细胞因子或配体蛋白选自以下组成的组:IL-1、IL-2、IL-3、IL-7、IL-8、IL-10、IL-12、IL-15、IL-17、IL-18、IL-21、PDGF-DD、SCF和FLT3L。
实施例A18.根据实施例A1-A14中任一项所述的多链嵌合多肽,其中所述第一靶标结合结构域和所述第二靶标结合结构域中的一个或两个是可溶性白介素或细胞因子受体。
实施例A19.根据实施例A18所述的多链嵌合多肽,其中所述可溶性受体是可溶性TGF-β受体II(TGF-βRII)、可溶性TGF-βRIII、可溶性NKG2D、可溶性NKp30、可溶性NKp44、可溶性NKp46、可溶性DNAM-1、scMHCI、scMHCII、scTCR、可溶性CD155或可溶性CD28。
实施例A20.根据实施例A1至A19中任一项所述的多链嵌合多肽,其中所述第一嵌合多肽进一步包含一个或多个另外的靶标结合结构域,其中所述一个或多个另外的抗原结合结构域中的至少一个位于所述可溶性组织因子结构域与所述一对亲和结构域中的所述第一结构域之间。
实施例A21.根据实施例A20所述的多链嵌合多肽,其中所述第一嵌合多肽进一步包含在所述可溶性组织因子结构域与所述一个或多个另外的抗原结合结构域中的所述至少一个之间的接头序列,和/或在所述一个或多个另外的抗原结合结构域中的所述至少一个与所述一对亲和结构域中的所述第一结构域之间的接头序列。
实施例A22.根据实施例A1至A19中任一项所述的多链嵌合多肽,其中所述第一嵌合多肽在所述第一嵌合多肽的N端和/或C端进一步包含一个或多个另外的靶标结合结构域。
实施例A23.根据实施例A22所述的多链嵌合多肽,其中在所述第一嵌合多肽中,所述一个或多个另外的靶标结合结构域中的至少一个直接邻接所述一对亲和结构域中的所述第一结构域。
实施例A24.根据实施例A22所述的多链嵌合多肽,其中所述第一嵌合多肽进一步包含在所述一个或多个另外的靶标结合结构域中的所述至少一个与所述一对亲和结构域中的所述第一结构域之间的接头序列。
实施例A25.根据实施例A22所述的多链嵌合多肽,其中在所述第一嵌合多肽中,所述一个或多个另外的靶标结合结构域中的所述至少一个直接邻接所述第一靶标结合结构域。
实施例A26.根据实施例A22所述的多链嵌合多肽,其中所述第一嵌合多肽进一步包含在所述一个或多个另外的靶标结合结构域中的所述至少一个与所述第一靶标结合结构域之间的接头序列。
实施例A27.根据实施例A22所述的多链嵌合多肽,其中所述一个或多个另外的靶标结合结构域中的至少一个安置于所述第一嵌合多肽的N和/或C端,并且所述一个或多个另外的靶标结合结构域中的至少一个位于所述第一嵌合多肽中所述可溶性组织因子结构域与所述一对亲和结构域中的所述第一结构域之间。
实施例A28.根据实施例A27所述的多链嵌合多肽,其中在所述第一嵌合多肽中,安置于N端的所述一个或多个另外的靶标结合结构域中的至少一个另外的靶标结合结构域直接邻接所述第一靶标结合结构域或所述一对亲和结构域中的所述第一结构域。
实施例A29.根据实施例A27所述的多链嵌合多肽,其中所述第一嵌合多肽进一步包含安置于所述第一嵌合多肽中的所述至少一个另外的靶标结合结构域与所述第一靶标结合结构域或所述一对亲和结构域中的所述第一结构域之间的接头序列。
实施例A30.根据实施例A27所述的多链嵌合多肽,其中在所述第一嵌合多肽中,安置于C端的所述一个或多个另外的靶标结合结构域中的至少一个另外的靶标结合结构域直接邻接所述第一靶标结合结构域或所述一对亲和结构域中的所述第一结构域。
实施例A31.根据实施例A27所述的多链嵌合多肽,其中所述第一嵌合多肽进一步包含安置于所述第一嵌合多肽中的所述至少一个另外的靶标结合结构域与所述第一靶标结合结构域或所述一对亲和结构域中的所述第一结构域之间的接头序列。
实施例A32.根据实施例A27所述的多链嵌合多肽,其中位于所述可溶性组织因子结构域与所述一对亲和结构域中的所述第一结构域之间的所述一个或多个另外的靶标结合结构域中的所述至少一个,直接邻接所述可溶性组织因子结构域和/或所述一对亲和结构域中的所述第一结构域。
实施例A33.根据实施例A27所述的多链嵌合多肽,其中所述第一嵌合多肽进一步包含安置于以下的接头序列:(i)所述可溶性组织因子结构域与所述一个或多个另外的靶标结合结构域中的所述至少一个之间,所述一个或多个另外的靶标结合结构域中的所述至少一个位于所述可溶性组织因子结构域与所述一对亲和结构域中的所述第一结构域之间,和/或(ii)所述一对亲和结构域中的所述第一结构域与所述一个或多个另外的靶标结合结构域中的所述至少一个之间,所述一个或多个另外的靶标结合结构域中的所述至少一个位于所述可溶性组织因子结构域与所述一对亲和结构域中的所述第一结构域之间。
实施例A34.根据实施例A1至A33中任一项所述的多链嵌合多肽,其中所述第二嵌合多肽在所述第二嵌合多肽的N端或C端进一步包含一个或多个另外的靶标结合结构域。
实施例A35.根据实施例A34所述的多链嵌合多肽,其中在所述第二嵌合多肽中,所述一个或多个另外的靶标结合结构域中的至少一个直接邻接所述一对亲和结构域中的所述第二结构域。
实施例A36.根据实施例A34所述的多链嵌合多肽,其中所述第二嵌合多肽进一步包含所述第二嵌合多肽中的所述一个或多个另外的靶标结合结构域中的至少一个与所述一对亲和结构域中的所述第二结构域之间的接头序列。
实施例A37.根据实施例A34所述的多链嵌合多肽,其中在所述第二嵌合多肽中,所述一个或多个另外的靶标结合结构域中的至少一个直接邻接所述第二靶标结合结构域。
实施例A38.根据实施例A34所述的多链嵌合多肽,其中所述第二嵌合多肽进一步包含所述第二嵌合多肽中的所述一个或多个另外的靶标结合结构域中的至少一个与所述第二靶标结合结构域之间的接头序列。
实施例A39.根据实施例A20至A38中任一项所述的多链嵌合多肽,其中所述第一靶标结合结构域、所述第二靶标结合结构域和所述一个或多个另外的靶标结合结构域中的两个或更多个特异性结合到相同的抗原。
实施例A40.根据实施例A39所述的多链嵌合多肽,其中所述第一靶标结合结构域、所述第二靶标结合结构域和所述一个或多个另外的靶标结合结构域中的两个或更多个特异性结合到相同的表位。
实施例A41.根据实施例A40所述的多链嵌合多肽,其中所述第一靶标结合结构域、所述第二靶标结合结构域和所述一个或多个另外的靶标结合结构域中的两个或更多个包含相同的氨基酸序列。
实施例A42.根据实施例A39所述的多链嵌合多肽,其中所述第一靶标结合结构域、所述第二靶标结合结构域和所述一个或多个另外的靶标结合结构域各自特异性结合到相同的抗原。
实施例A43.根据实施例A42所述的多链嵌合多肽,其中所述第一靶标结合结构域、所述第二靶标结合结构域和所述一个或多个另外的靶标结合结构域各自特异性结合到相同的表位。
实施例A44.根据实施例A43所述的多链嵌合多肽,其中所述第一靶标结合结构域、所述第二靶标结合结构域和所述一个或多个另外的靶标结合结构域各自包含相同的氨基酸序列。
实施例A45.根据实施例A20至A38中任一项所述的多链嵌合多肽,其中所述第一靶标结合结构域、所述第二靶标结合结构域和所述一个或多个另外的靶标结合结构域特异性结合到不同的抗原。
实施例A46.根据实施例A20至A45中任一项所述的多链嵌合多肽,其中所述第一靶标结合结构域、所述第二靶标结合结构域和一个或多个靶标结合结构域中的一个或多个是抗原结合结构域。
实施例A47.根据实施例A46所述的多链嵌合多肽,其中所述第一靶标结合结构域、所述第二靶标结合结构域和所述一个或多个另外的靶标结合结构域各自是抗原结合结构域。
实施例A48.根据实施例A47所述的多链嵌合多肽,其中抗原结合结构域包含scFv。
实施例A49.根据实施例A20至A48中任一项所述的多链嵌合多肽,其中所述第一靶标结合结构域、所述第二靶标结合结构域和一个或多个靶标结合结构域中的一个或多个特异性结合到选自以下组成的组的靶标:CD16a、CD28、CD3、CD33、CD20、CD19、CD22、CD123、IL-1R、IL-1、VEGF、IL-6R、IL-4、IL-10、PDL-1、TIGIT、PD-1、TIM3、CTLA4、MICA、MICB、IL-6、IL-8、TNFα、CD26a、CD36、ULBP2、CD30、CD200、IGF-1R、MUC4AC、MUC5AC、Trop-2、CMET、EGFR、HER1、HER2、HER3、PSMA、CEA、B7H3、EPCAM、BCMA、P-钙黏着蛋白、CEACAM5、UL16结合蛋白、HLA-DR、DLL4、TYRO3、AXL、MER、CD122、CD155、PDGF-DD、TGF-β受体II(TGF-βRII)的配体、TGF-βRIII的配体、DNAM-1的配体、NKp46的配体、NKp44的配体、NKG2D的配体、NKP30的配体、scMHCI的配体、scMHCII的配体、scTCR的配体、IL-1的受体、IL-2的受体、IL-3的受体、IL-7的受体、IL-8的受体、IL-10的受体、IL-12的受体、IL-15的受体、IL-17的受体、IL-18的受体、IL-21的受体、PDGF-DD的受体、干细胞因子(SCF)的受体、干细胞样酪氨酸激酶3配体(FLT3L)的受体、MICA的受体、MICB的受体、ULP16结合蛋白的受体、CD155的受体、CD122的受体和CD3的受体以及CD28的受体。
实施例A50.根据实施例A20至A48中任一项所述的多链嵌合多肽,其中所述第一靶标结合结构域、所述第二靶标结合结构域和所述一个或多个另外的靶标结合结构域中的一个或多个是可溶性白介素或细胞因子蛋白。
实施例A51.根据实施例A50所述的多链嵌合多肽,其中所述可溶性白介素、细胞因子或配体蛋白选自以下组成的组:IL-1、IL-2、IL-3、IL-7、IL-8、IL-10、IL-12、IL-15、IL-17、IL-18、IL-21、PDGF-DD、SCF和FLT3L。
实施例A52.根据实施例A20至A48中任一项所述的多链嵌合多肽,其中所述第一靶标结合结构域、所述第二靶标结合结构域和所述一个或多个另外的靶标结合结构域中的一个或多个是可溶性白介素或细胞因子受体。
实施例A53.根据实施例A52所述的多链嵌合多肽,其中所述可溶性受体是可溶性TGF-β受体II(TGF-βRII)、可溶性TGF-βRIII、可溶性NKG2D、可溶性NKp30、可溶性NKp44、可溶性NKp46、可溶性DNAM-1、scMHCI、scMHCII、scTCR、可溶性CD155、可溶性CD122、可溶性CD3或可溶性CD28。
实施例A54.根据实施例A1至A53中任一项所述的多链嵌合多肽,其中所述第一嵌合多肽进一步包含在所述第一嵌合多肽的N端或C端的肽标签。
实施例A55.根据实施例A1至A53中任一项所述的多链嵌合多肽,其中所述第二嵌合多肽进一步包含在所述第二嵌合多肽的N端或C端的肽标签。
实施例A56.根据实施例A1至A55中任一项所述的多链嵌合多肽,其中所述可溶性组织因子结构域是可溶性人组织因子结构域。
实施例A57.根据实施例A56所述的多链嵌合多肽,其中所述可溶性人组织因子结构域包含与SEQ ID NO:1至少80%相同的序列。
实施例A58.根据实施例A57所述的多链嵌合多肽,其中所述可溶性人组织因子结构域包含与SEQ ID NO:1至少90%相同的序列。
实施例A59.根据实施例A58所述的多链嵌合多肽,其中所述可溶性人组织因子结构域包含与SEQ ID NO:1至少95%相同的序列。
实施例A60.根据实施例A56至A59中任一项所述的多链嵌合多肽,其中所述可溶性人组织因子结构域不包含以下中的一种或多种:
在对应于成熟野生型人组织因子蛋白的氨基酸位置20的氨基酸位置处的赖氨酸;
在对应于成熟野生型人组织因子蛋白的氨基酸位置22的氨基酸位置处的异亮氨酸;
在对应于成熟野生型人组织因子蛋白的氨基酸位置45的氨基酸位置处的色氨酸;
在对应于成熟野生型人组织因子蛋白的氨基酸位置58的氨基酸位置处的天冬氨酸;
在对应于成熟野生型人组织因子蛋白的氨基酸位置94的氨基酸位置处的酪氨酸;
在对应于成熟野生型人组织因子蛋白的氨基酸位置135的氨基酸位置处的精氨酸;和
在对应于成熟野生型人组织因子蛋白的氨基酸位置140的氨基酸位置处的苯丙氨酸。
实施例A61.根据实施例A60所述的多链嵌合多肽,其中所述可溶性人组织因子结构域不包含以下中的任一种:
在对应于成熟野生型人组织因子蛋白的氨基酸位置20的氨基酸位置处的赖氨酸;
在对应于成熟野生型人组织因子蛋白的氨基酸位置22的氨基酸位置处的异亮氨酸;
在对应于成熟野生型人组织因子蛋白的氨基酸位置45的氨基酸位置处的色氨酸;
在对应于成熟野生型人组织因子蛋白的氨基酸位置58的氨基酸位置处的天冬氨酸;
在对应于成熟野生型人组织因子蛋白的氨基酸位置94的氨基酸位置处的酪氨酸;
在对应于成熟野生型人组织因子蛋白的氨基酸位置135的氨基酸位置处的精氨酸;和
在对应于成熟野生型人组织因子蛋白的氨基酸位置140的氨基酸位置处的苯丙氨酸。
实施例A62.根据实施例A1至A61中任一项所述的多链嵌合多肽,其中所述可溶性组织因子结构域不能结合到因子VIIa。
实施例A63.根据实施例A1至A62中任一项所述的多链嵌合多肽,其中所述可溶性组织因子结构域不将非活性因子X转化为因子Xa。
实施例A64.根据实施例A1至A63中任一项所述的多链嵌合多肽,其中所述多链嵌合多肽不刺激哺乳动物的凝血。
实施例A65.根据实施例A1至A64中任一项所述的多链嵌合多肽,其中所述一对亲和结构域是来自人IL-15受体的α链(IL15Rα)的寿司结构域和可溶性IL-15。
实施例A66.根据实施例A65所述的多链嵌合多肽,其中所述可溶性IL15具有D8N或D8A氨基酸取代。
实施例A67.根据实施例A65或A66所述的多链嵌合多肽,其中所述人IL15Rα是成熟全长IL15Rα。
实施例A68.根据实施例A1至A64中任一项所述的多链嵌合多肽,其中所述一对亲和结构域选自以下组成的组:芽胞杆菌RNA酶和芽胞杆菌RNA酶抑制子、PKA和AKAP、基于突变核糖核酸酶I片段的衔接子/对接标签模块以及基于蛋白质突触蛋白、突触结合蛋白、突触泡蛋白和SNAP25的相互作用的SNARE模块。
实施例A69.根据实施例A1至A68中任一项所述的多链嵌合多肽,其中所述第一嵌合多肽和/或所述第二嵌合多肽在其N端进一步包含信号序列。
实施例A70.一种组合物,其包含根据实施例A1至A69所述的多链嵌合多肽中的任一种。
实施例A71.根据实施例A70所述的组合物,其中所述组合物是药物组合物。
实施例A72.一种试剂盒,其包含至少一个剂量的根据实施例A70或A71所述的组合物。
实施例A73.一种刺激免疫细胞的方法,所述方法包含:
使免疫细胞与有效量的根据实施例A1至A69所述的多链嵌合多肽中的任一种或根据实施例A70或A71所述的组合物接触。
实施例A74.根据实施例A73所述的方法,其中所述免疫细胞在体外接触。
实施例A75.根据实施例A74所述的方法,其中所述免疫细胞先前获自受试者。
实施例A76.根据实施例A75所述的方法,其中所述方法进一步包含在接触步骤之前从所述受试者获得所述免疫细胞。
实施例A77.根据实施例A73所述的方法,其中所述免疫细胞在体内接触。
实施例A78.根据实施例A73至A77中任一项所述的方法,其中所述免疫细胞选自以下组成的组:未成熟胸腺细胞、外周血淋巴细胞、初始T细胞、多能Th细胞前体、淋巴祖细胞、Treg细胞、记忆T细胞、Th17细胞、Th22细胞、Th9细胞、Th2细胞、Th1细胞、Th3细胞、γδT细胞、αβT细胞、肿瘤浸润性T细胞、CD8+T细胞、CD4+T细胞、自然杀伤T细胞、肥大细胞、巨噬细胞、嗜中性粒细胞、树突状细胞、嗜碱性粒细胞、嗜酸性粒细胞和自然杀伤细胞。
实施例A79.根据实施例A73至A78中任一项所述的方法,其中所述免疫细胞先前已经过基因修饰以表达嵌合抗原受体或重组T细胞受体。
实施例A80.根据实施例A73至A78中任一项所述的方法,其中所述方法进一步包含在接触步骤之后,将编码嵌合抗原受体或重组T细胞受体的核酸引入到所述免疫细胞中。
实施例A81.根据实施例A73至A80中任一项所述的方法,其中所述方法进一步包含向有需要的受试者施用所述免疫细胞。
实施例A82.根据实施例A81所述的方法,其中所述受试者已被鉴别或诊断为患有与年龄相关的疾病或病况。
实施例A83.根据实施例A82所述的方法,其中所述与年龄相关的疾病或病况选自以下组成的组:阿尔茨海默氏病、动脉瘤、囊性纤维化、胰腺炎纤维化、青光眼、高血压、特发性肺纤维化、炎性肠病、椎间盘退变、黄斑变性、骨关节炎、2型糖尿病、脂肪萎缩、脂肪营养不良、动脉粥样硬化、白内障、COPD、特发性肺纤维化、肾移植失败、肝纤维化、骨量损失、心肌梗死、肌肉减少症、伤口愈合、脱发、心肌细胞肥大、骨关节炎、帕金森氏病、与年龄相关的肺组织弹性丧失、黄斑变性、恶病质、肾小球硬化、肝硬化、NAFLD、骨质疏松症、肌萎缩性侧索硬化症、亨廷顿氏病、脊髓小脑共济失调、多发性硬化症和肾功能不全。
实施例A84.根据实施例A81所述的方法,其中所述受试者已被鉴别或诊断为患有癌症。
实施例A85.根据实施例A84所述的方法,其中所述癌症选自以下组成的组:实体肿瘤、血液肿瘤、肉瘤、骨肉瘤、成胶质细胞瘤、成神经细胞瘤、黑色素瘤、横纹肌肉瘤、尤文氏肉瘤、骨肉瘤、B细胞瘤、多发性骨髓瘤、B细胞淋巴瘤、B细胞非霍奇金氏淋巴瘤、霍奇金氏淋巴瘤、慢性淋巴细胞性白血病(CLL)、急性骨髓性白血病(AML)、慢性骨髓性白血病(CML)、急性淋巴细胞性白血病(ALL)、骨髓增生异常综合症(MDS)、皮肤T细胞淋巴瘤、成视网膜细胞瘤、胃癌、尿路上皮癌、肺癌、肾细胞癌、胃和食管癌、胰腺癌、前列腺癌、乳腺癌、结直肠癌、卵巢癌、非小细胞肺癌、鳞状细胞头颈癌、子宫内膜癌、宫颈癌、肝癌和肝细胞癌。
实施例A86.根据实施例A81所述的方法,其中所述受试者已被诊断或鉴别为患有感染性疾病。
实施例A87.根据实施例A86所述的方法,其中所述感染性疾病是感染人免疫缺陷病毒、巨细胞病毒、腺病毒、冠状病毒、鼻病毒、轮状病毒、天花、单纯疱疹病毒、乙型肝炎病毒、甲型肝炎病毒和丙型肝炎病毒、乳头瘤病毒和流感病毒。
实施例A88.一种诱导或增加免疫细胞增殖的方法,所述方法包含:
使免疫细胞与有效量的根据实施例A1至A69所述的多链嵌合多肽中的任一种或根据实施例A70或A71所述的组合物接触。
实施例A89.根据实施例A88所述的方法,其中所述免疫细胞在体外接触。
实施例A90.根据实施例A89所述的方法,其中所述免疫细胞先前获自受试者。
实施例A91.根据实施例A90所述的方法,其中所述方法进一步包含在接触步骤之前从所述受试者获得所述免疫细胞。
实施例A92.根据实施例A88所述的方法,其中所述免疫细胞在体内接触。
实施例A93.根据实施例A88至A92中任一项所述的方法,其中所述免疫细胞选自以下组成的组:未成熟胸腺细胞、外周血淋巴细胞、初始T细胞、多能Th细胞前体、淋巴祖细胞、Treg细胞、记忆T细胞、Th17细胞、Th22细胞、Th9细胞、Th2细胞、Th1细胞、Th3细胞、γδT细胞、αβT细胞、肿瘤浸润性T细胞、CD8+T细胞、CD4+T细胞、自然杀伤T细胞、肥大细胞、巨噬细胞、嗜中性粒细胞、树突状细胞、嗜碱性粒细胞、嗜酸性粒细胞和自然杀伤细胞。
实施例A94.根据实施例A88至A93中任一项所述的方法,其中所述免疫细胞先前已经过基因修饰以表达嵌合抗原受体或重组T细胞受体。
实施例A95.根据实施例A88至A93中任一项所述的方法,其中所述方法进一步包含在接触步骤之后,将编码嵌合抗原受体或重组T细胞受体的核酸引入到所述免疫细胞中。
实施例A96.根据实施例A88至A95中任一项所述的方法,其中所述方法进一步包含向有需要的受试者施用所述免疫细胞。
实施例A97.根据实施例A96所述的方法,其中所述受试者已被鉴别或诊断为患有与年龄相关的疾病或病况。
实施例A98.根据实施例A97所述的方法,其中所述与年龄相关的疾病或病况选自以下组成的组:阿尔茨海默氏病、动脉瘤、囊性纤维化、胰腺炎纤维化、青光眼、高血压、特发性肺纤维化、炎性肠病、椎间盘退变、黄斑变性、骨关节炎、2型糖尿病、脂肪萎缩、脂肪营养不良、动脉粥样硬化、白内障、COPD、特发性肺纤维化、肾移植失败、肝纤维化、骨量损失、心肌梗死、肌肉减少症、伤口愈合、脱发、心肌细胞肥大、骨关节炎、帕金森氏病、与年龄相关的肺组织弹性丧失、黄斑变性、恶病质、肾小球硬化、肝硬化、NAFLD、骨质疏松症、肌萎缩性侧索硬化症、亨廷顿氏病、脊髓小脑共济失调、多发性硬化症和肾功能不全。
实施例A99.根据实施例A96所述的方法,其中所述受试者已被鉴别或诊断为患有癌症。
实施例A100.根据实施例A99所述的方法,其中所述癌症选自以下组成的组:实体肿瘤、血液肿瘤、肉瘤、骨肉瘤、成胶质细胞瘤、成神经细胞瘤、黑色素瘤、横纹肌肉瘤、尤文氏肉瘤、骨肉瘤、B细胞瘤、多发性骨髓瘤、B细胞淋巴瘤、B细胞非霍奇金氏淋巴瘤、霍奇金氏淋巴瘤、慢性淋巴细胞性白血病(CLL)、急性骨髓性白血病(AML)、慢性骨髓性白血病(CML)、急性淋巴细胞性白血病(ALL)、骨髓增生异常综合症(MDS)、皮肤T细胞淋巴瘤、成视网膜细胞瘤、胃癌、尿路上皮癌、肺癌、肾细胞癌、胃和食管癌、胰腺癌、前列腺癌、乳腺癌、结直肠癌、卵巢癌、非小细胞肺癌、鳞状细胞头颈癌、子宫内膜癌、宫颈癌、肝癌和肝细胞癌。
实施例A101.根据实施例A96所述的方法,其中所述受试者已被诊断或鉴别为患有感染性疾病。
实施例A102.根据实施例A96所述的方法,其中所述感染性疾病是感染人免疫缺陷病毒、巨细胞病毒、腺病毒、冠状病毒、鼻病毒、轮状病毒、天花、单纯疱疹病毒、乙型肝炎病毒、甲型肝炎病毒和丙型肝炎病毒、乳头瘤病毒和流感病毒。
实施例A103.一种诱导免疫细胞分化成记忆或记忆样免疫细胞的方法,所述方法包含:
使免疫细胞与有效量的根据实施例A1至A69所述的多链嵌合多肽中的任一种或根据实施例A70或A71所述的组合物接触。
实施例A104.根据实施例A103所述的方法,其中所述免疫细胞在体外接触。
实施例A105.根据实施例A104所述的方法,其中所述免疫细胞先前获自受试者。
实施例A106.根据实施例A105所述的方法,其中所述方法进一步包含在接触步骤之前从所述受试者获得所述免疫细胞。
实施例A107.根据实施例A103所述的方法,其中所述免疫细胞在体内接触。
实施例A108.根据实施例A103至A107中任一项所述的方法,其中所述免疫细胞选自以下组成的组:未成熟胸腺细胞、外周血淋巴细胞、初始T细胞、多能Th细胞前体、淋巴祖细胞、Treg细胞、Th17细胞、Th22细胞、Th9细胞、Th2细胞、Th1细胞、Th3细胞、γδT细胞、αβT细胞、肿瘤浸润性T细胞、CD8+T细胞、CD4+T细胞、自然杀伤T细胞、肥大细胞、巨噬细胞、嗜中性粒细胞、树突状细胞、嗜碱性粒细胞、嗜酸性粒细胞和自然杀伤细胞。
实施例A109.根据实施例A103至A108中任一项所述的方法,其中所述免疫细胞先前已经过基因修饰以表达嵌合抗原受体或重组T细胞受体。
实施例A110.根据实施例A103至A108中任一项所述的方法,其中所述方法进一步包含在接触步骤之后,将编码嵌合抗原受体或重组T细胞受体的核酸引入到所述免疫细胞中。
实施例A111.根据实施例A103至A110中任一项所述的方法,其中所述方法进一步包含向有需要的受试者施用所述免疫细胞。
实施例A112.根据实施例A111所述的方法,其中所述受试者已被鉴别或诊断为患有与年龄相关的疾病或病况。
实施例A113.根据实施例A112所述的方法,其中所述与年龄相关的疾病或病况选自以下组成的组:阿尔茨海默氏病、动脉瘤、囊性纤维化、胰腺炎纤维化、青光眼、高血压、特发性肺纤维化、炎性肠病、椎间盘退变、黄斑变性、骨关节炎、2型糖尿病、脂肪萎缩、脂肪营养不良、动脉粥样硬化、白内障、COPD、特发性肺纤维化、肾移植失败、肝纤维化、骨量损失、心肌梗死、肌肉减少症、伤口愈合、脱发、心肌细胞肥大、骨关节炎、帕金森氏病、与年龄相关的肺组织弹性丧失、黄斑变性、恶病质、肾小球硬化、肝硬化、NAFLD、骨质疏松症、肌萎缩性侧索硬化症、亨廷顿氏病、脊髓小脑共济失调、多发性硬化症和肾功能不全。
实施例A114.根据实施例A111所述的方法,其中所述受试者已被鉴别或诊断为患有癌症。
实施例A115.根据实施例A114所述的方法,其中所述癌症选自以下组成的组:实体肿瘤、血液肿瘤、肉瘤、骨肉瘤、成胶质细胞瘤、成神经细胞瘤、黑色素瘤、横纹肌肉瘤、尤文氏肉瘤、骨肉瘤、B细胞瘤、多发性骨髓瘤、B细胞淋巴瘤、B细胞非霍奇金氏淋巴瘤、霍奇金氏淋巴瘤、慢性淋巴细胞性白血病(CLL)、急性骨髓性白血病(AML)、慢性骨髓性白血病(CML)、急性淋巴细胞性白血病(ALL)、骨髓增生异常综合症(MDS)、皮肤T细胞淋巴瘤、成视网膜细胞瘤、胃癌、尿路上皮癌、肺癌、肾细胞癌、胃和食管癌、胰腺癌、前列腺癌、乳腺癌、结直肠癌、卵巢癌、非小细胞肺癌、鳞状细胞头颈癌、子宫内膜癌、宫颈癌、肝癌和肝细胞癌。
实施例A116.根据实施例A111所述的方法,其中所述受试者已被诊断或鉴别为患有感染性疾病。
实施例A117.根据实施例A116所述的方法,其中所述感染性疾病是感染人免疫缺陷病毒、巨细胞病毒、腺病毒、冠状病毒、鼻病毒、轮状病毒、天花、单纯疱疹病毒、乙型肝炎病毒、甲型肝炎病毒和丙型肝炎病毒、乳头瘤病毒和流感病毒。
实施例A118.一种在有需要的受试者中杀死癌细胞、受感染细胞或衰老细胞的方法,所述方法包含向所述受试者施用治疗有效量的根据实施例A1至A69所述的多链嵌合多肽中的任一种或根据实施例A70或A71所述的组合物。
实施例A119.根据实施例A118所述的方法,其中所述受试者已被鉴别或诊断为患有癌症。
实施例A120.根据实施例A119所述的方法,其中所述癌症选自以下组成的组:实体肿瘤、血液肿瘤、肉瘤、骨肉瘤、成胶质细胞瘤、成神经细胞瘤、黑色素瘤、横纹肌肉瘤、尤文氏肉瘤、骨肉瘤、B细胞瘤、多发性骨髓瘤、B细胞淋巴瘤、B细胞非霍奇金氏淋巴瘤、霍奇金氏淋巴瘤、慢性淋巴细胞性白血病(CLL)、急性骨髓性白血病(AML)、慢性骨髓性白血病(CML)、急性淋巴细胞性白血病(ALL)、骨髓增生异常综合症(MDS)、皮肤T细胞淋巴瘤、成视网膜细胞瘤、胃癌、尿路上皮癌、肺癌、肾细胞癌、胃和食管癌、胰腺癌、前列腺癌、乳腺癌、结直肠癌、卵巢癌、非小细胞肺癌、鳞状细胞头颈癌、子宫内膜癌、宫颈癌、肝癌和肝细胞癌。
实施例A121.根据实施例A118所述的方法,其中所述受试者已被鉴别或诊断为患有与老化相关的疾病或病况。
实施例A122.根据实施例A121所述的方法,其中所述与老化相关的疾病或病况选自以下组成的组:阿尔茨海默氏病、动脉瘤、囊性纤维化、胰腺炎纤维化、青光眼、高血压、特发性肺纤维化、炎性肠病、椎间盘退变、黄斑变性、骨关节炎、2型糖尿病、脂肪萎缩、脂肪营养不良、动脉粥样硬化、白内障、COPD、特发性肺纤维化、肾移植失败、肝纤维化、骨量损失、心肌梗死、肌肉减少症、伤口愈合、脱发、心肌细胞肥大、骨关节炎、帕金森氏病、与年龄相关的肺组织弹性丧失、黄斑变性、恶病质、肾小球硬化、肝硬化、NAFLD、骨质疏松症、肌萎缩性侧索硬化症、亨廷顿氏病、脊髓小脑共济失调、多发性硬化症和肾功能不全。
实施例A123.一种治疗有需要的受试者的方法,所述方法包含向所述受试者施用治疗有效量的根据实施例A1至A69所述的多链嵌合多肽中的任一种或根据实施例A70或A71所述的组合物。
实施例A124.根据实施例A123所述的方法,其中所述受试者已被鉴别或诊断为患有癌症。
实施例A125.根据实施例A124所述的方法,其中所述癌症选自以下组成的组:实体肿瘤、血液肿瘤、肉瘤、骨肉瘤、成胶质细胞瘤、成神经细胞瘤、黑色素瘤、横纹肌肉瘤、尤文氏肉瘤、骨肉瘤、B细胞瘤、多发性骨髓瘤、B细胞淋巴瘤、B细胞非霍奇金氏淋巴瘤、霍奇金氏淋巴瘤、慢性淋巴细胞性白血病(CLL)、急性骨髓性白血病(AML)、慢性骨髓性白血病(CML)、急性淋巴细胞性白血病(ALL)、骨髓增生异常综合症(MDS)、皮肤T细胞淋巴瘤、成视网膜细胞瘤、胃癌、尿路上皮癌、肺癌、肾细胞癌、胃和食管癌、胰腺癌、前列腺癌、乳腺癌、结直肠癌、卵巢癌、非小细胞肺癌、鳞状细胞头颈癌、子宫内膜癌、宫颈癌、肝癌和肝细胞癌。
实施例A126.根据实施例A123所述的方法,其中所述受试者已被鉴别或诊断为患有与老化相关的疾病或病况。
实施例A127.根据实施例A126所述的方法,其中所述与老化相关的疾病或病况选自以下组成的组:阿尔茨海默氏病、动脉瘤、囊性纤维化、胰腺炎纤维化、青光眼、高血压、特发性肺纤维化、炎性肠病、椎间盘退变、黄斑变性、骨关节炎、2型糖尿病、脂肪萎缩、脂肪营养不良、动脉粥样硬化、白内障、COPD、特发性肺纤维化、肾移植失败、肝纤维化、骨量损失、心肌梗死、肌肉减少症、伤口愈合、脱发、心肌细胞肥大、骨关节炎、帕金森氏病、与年龄相关的肺组织弹性丧失、黄斑变性、恶病质、肾小球硬化、肝硬化、NAFLD、骨质疏松症、肌萎缩性侧索硬化症、亨廷顿氏病、脊髓小脑共济失调、多发性硬化症和肾功能不全。
实施例A128.根据实施例A123所述的方法,其中所述受试者已被诊断或鉴别为患有感染性疾病。
实施例A129.根据实施例A128所述的方法,其中所述感染性疾病是感染人免疫缺陷病毒、巨细胞病毒、腺病毒、冠状病毒、鼻病毒、轮状病毒、天花、单纯疱疹病毒、乙型肝炎病毒、甲型肝炎病毒和丙型肝炎病毒、乳头瘤病毒和流感病毒。
实施例A130.核酸,其编码根据实施例A1至A69中任一项所述的多链嵌合多肽中的任一种。
实施例A131.一种载体,其包含根据实施例A130所述的核酸。
实施例A132.根据实施例A131所述的载体,其中所述载体是表达载体。
实施例A133.一种细胞,其包含根据实施例A130所述的核酸或根据实施例A131或A132所述的载体。
实施例A134.一种产生多链嵌合多肽的方法,所述方法包含:
在足以引起产生所述多链嵌合多肽的条件下在培养基中培养根据实施例A133所述的细胞;和
从所述细胞和/或所述培养基中回收所述多链嵌合多肽。
实施例A135.一种多链嵌合多肽,其通过根据实施例A134所述的方法产生。
实施例A136.根据实施例A56所述的多链嵌合多肽,其中所述可溶性人组织因子结构域包含与SEQ ID NO:3至少80%相同的序列。
实施例A137.根据实施例A136所述的多链嵌合多肽,其中所述可溶性人组织因子结构域包含与SEQ ID NO:3至少90%相同的序列。
实施例A138.根据实施例A137所述的多链嵌合多肽,其中所述可溶性人组织因子结构域包含与SEQ ID NO:3至少95%相同的序列。
实施例A139.根据实施例A138所述的多链嵌合多肽,其中所述可溶性人组织因子结构域包含与SEQ ID NO:3100%相同的序列。
实施例A140.根据实施例A56所述的多链嵌合多肽,其中所述可溶性人组织因子结构域包含与SEQ ID NO:4至少80%相同的序列。
实施例A141.根据实施例A140所述的多链嵌合多肽,其中所述可溶性人组织因子结构域包含与SEQ ID NO:4至少90%相同的序列。
实施例A142.根据实施例A141所述的多链嵌合多肽,其中所述可溶性人组织因子结构域包含与SEQ ID NO:4至少95%相同的序列。
实施例A143.根据实施例A142所述的多链嵌合多肽,其中所述可溶性人组织因子结构域包含与SEQ ID NO:4100%相同的序列。
实施例A144.根据实施例56所述的多链嵌合多肽,其中人可溶性组织因子结构域不引发凝结。
实施例A145.根据权利要求1至59中任一项所述的多链嵌合多肽,其中所述可溶性组织因子结构域包含来自野生型可溶性人组织因子的序列或由来自野生型可溶性人组织因子的序列组成。
B.示例性实施例
实施例B1.一种多链嵌合多肽,其包含:
(a)第一嵌合多肽,其包含:
(i)第一靶标结合结构域;
(ii)可溶性组织因子结构域;和
(iii)一对亲和结构域中的第一结构域;
(b)第二嵌合多肽,其包含:
(i)一对亲和结构域中的第二结构域;和
(ii)第二靶标结合结构域,
其中:
所述第一嵌合多肽和所述第二嵌合多肽通过所述一对亲和结构域中的所述第一结构域和所述第二结构域的结合而缔合;
所述第一靶标结合结构域和所述第二靶标结合结构域各自独立地特异性结合到IL-18的受体或IL-12的受体。
实施例B2.根据实施例B1所述的多链嵌合多肽,其中所述第一靶标结合结构域和所述可溶性组织因子结构域在所述第一嵌合多肽中彼此直接邻接。
实施例B3.根据实施例B1所述的多链嵌合多肽,其中所述第一嵌合多肽进一步包含所述第一嵌合多肽中的所述第一靶标结合结构域与所述可溶性组织因子结构域之间的接头序列。
实施例B4.根据实施例B1至B3中任一项所述的多链嵌合多肽,其中所述可溶性组织因子结构域和所述一对亲和结构域中的所述第一结构域在所述第一嵌合多肽中彼此直接邻接。
实施例B5.根据实施例B1至B3中任一项所述的多链嵌合多肽,其中所述第一嵌合多肽进一步包含所述第一嵌合多肽中的所述可溶性组织因子结构域与所述一对亲和结构域中的所述第一结构域之间的接头序列。
实施例B6.根据实施例B1至B5中任一项所述的多链嵌合多肽,其中所述一对亲和结构域中的所述第二结构域和所述第二靶标结合结构域在所述第二嵌合多肽中彼此直接邻接。
实施例B7.根据实施例B1至B5中任一项所述的多链嵌合多肽,其中所述第二嵌合多肽进一步包含所述第二嵌合多肽中的所述一对亲和结构域中的所述第二结构域与所述第二靶标结合结构域之间的接头序列。
实施例B8.根据实施例B1至B7中任一项所述的多链嵌合多肽,其中所述可溶性组织因子结构域是可溶性人组织因子结构域。
实施例B9.根据实施例B8所述的多链嵌合多肽,其中所述可溶性人组织因子结构域包含与SEQ ID NO:1至少80%相同的序列。
实施例B10.根据实施例B9所述的多链嵌合多肽,其中所述可溶性人组织因子结构域包含与SEQ ID NO:1至少90%相同的序列。
实施例B11.根据实施例B10所述的多链嵌合多肽,其中所述可溶性人组织因子结构域包含与SEQ ID NO:1至少95%相同的序列。
实施例B12.根据实施例B8至B11中任一项所述的多链嵌合多肽,其中所述可溶性人组织因子结构域不包含以下中的一种或多种:
在对应于成熟野生型人组织因子蛋白的氨基酸位置20的氨基酸位置处的赖氨酸;
在对应于成熟野生型人组织因子蛋白的氨基酸位置22的氨基酸位置处的异亮氨酸;
在对应于成熟野生型人组织因子蛋白的氨基酸位置45的氨基酸位置处的色氨酸;
在对应于成熟野生型人组织因子蛋白的氨基酸位置58的氨基酸位置处的天冬氨酸;
在对应于成熟野生型人组织因子蛋白的氨基酸位置94的氨基酸位置处的酪氨酸;
在对应于成熟野生型人组织因子蛋白的氨基酸位置135的氨基酸位置处的精氨酸;和
在对应于成熟野生型人组织因子蛋白的氨基酸位置140的氨基酸位置处的苯丙氨酸。
实施例B13.根据实施例B12所述的多链嵌合多肽,其中所述可溶性人组织因子结构域不包含以下中的任一种:
在对应于成熟野生型人组织因子蛋白的氨基酸位置20的氨基酸位置处的赖氨酸;
在对应于成熟野生型人组织因子蛋白的氨基酸位置22的氨基酸位置处的异亮氨酸;
在对应于成熟野生型人组织因子蛋白的氨基酸位置45的氨基酸位置处的色氨酸;
在对应于成熟野生型人组织因子蛋白的氨基酸位置58的氨基酸位置处的天冬氨酸;
在对应于成熟野生型人组织因子蛋白的氨基酸位置94的氨基酸位置处的酪氨酸;
在对应于成熟野生型人组织因子蛋白的氨基酸位置135的氨基酸位置处的精氨酸;和
在对应于成熟野生型人组织因子蛋白的氨基酸位置140的氨基酸位置处的苯丙氨酸。
实施例B14.根据实施例B1至B13中任一项所述的多链嵌合多肽,其中所述可溶性组织因子结构域不能结合到因子VIIa。
实施例B15.根据实施例B1至B14中任一项所述的多链嵌合多肽,其中所述可溶性组织因子结构域不将非活性因子X转化为因子Xa。
实施例B16.根据实施例B1至B15中任一项所述的多链嵌合多肽,其中所述多链嵌合多肽不刺激哺乳动物中的凝结。
实施例B17.根据实施例B1至B16中任一项的所述多链嵌合多肽,其中所述第一嵌合多肽进一步包含在所述第一嵌合多肽的N端或C端的肽标签。
实施例B18.根据实施例B1至B17中任一项所述的多链嵌合多肽,其中所述第二嵌合多肽进一步包含在所述第二嵌合多肽的N端或C端的肽标签。
实施例B19.根据实施例B1至18中任一项所述的多链嵌合多肽,其中所述第一嵌合多肽和/或所述第二嵌合多肽在其N端进一步包含信号序列。
实施例B20.根据实施例B19所述的多链嵌合多肽,其中所述信号序列包含SEQ IDNO:31。
实施例B21.根据实施例B20所述的多链嵌合多肽,其中所述信号序列是SEQ IDNO:31。
实施例B22.根据实施例B1至B21中任一项所述的多链嵌合多肽,其中所述一对亲和结构域是来自人IL-15受体的α链(IL15Rα)的寿司结构域和可溶性IL-15。
实施例B23.根据实施例B22所述的多链嵌合多肽,其中所述可溶性IL-15具有D8N或D8A氨基酸取代。
实施例B24.根据实施例B22所述的多链嵌合多肽,其中所述可溶性IL-15包含与SEQ ID NO:14至少80%相同的序列。
实施例B25.根据实施例B24所述的多链嵌合多肽,其中所述可溶性IL-15包含与SEQ ID NO:14至少90%相同的序列。
实施例B26.根据实施例B25所述的多链嵌合多肽,其中所述可溶性IL-15包含与SEQ ID NO:14至少95%相同的序列。
实施例B27.根据实施例B26所述的多链嵌合多肽,其中所述可溶性IL-15包含SEQID NO:14。
实施例B28.根据实施例B22至B27中任一项所述的多链嵌合多肽,其中IL15Rα的寿司结构域包含来自人IL15Rα的寿司结构域。
实施例B29.根据实施例B28所述的多链嵌合多肽,其中来自人IL15Rα的所述寿司结构域包含与SEQ ID NO:28至少80%相同的序列。
实施例B30.根据实施例B29所述的多链嵌合多肽,其中来自人IL15Rα的所述寿司结构域包含与SEQ ID NO:28至少90%相同的序列。
实施例B31.根据实施例B30所述的多链嵌合多肽,其中来自人IL15Rα的所述寿司结构域包含与SEQ ID NO:28至少95%相同的序列。
实施例B32.根据实施例B31所述的多链嵌合多肽,其中来自人IL15Rα的所述寿司结构域包含SEQ ID NO:28。
实施例B33.根据实施例B28所述的多链嵌合多肽,其中来自人IL15Rα的所述寿司结构域是成熟全长IL15Rα。
实施例B34.根据实施例B1至B21中任一项所述的多链嵌合多肽,其中所述一对亲和结构域选自以下组成的组:芽胞杆菌RNA酶和芽胞杆菌RNA酶抑制子、PKA和AKAP、基于突变核糖核酸酶I片段的衔接子/对接标签模块以及基于蛋白质突触蛋白、突触结合蛋白、突触泡蛋白和SNAP25的相互作用的SNARE模块。
实施例B35.根据实施例B1至B34中任一项所述的多链嵌合多肽,其中所述第一靶标结合结构域和所述第二靶标结合结构域中的一个或两个是激动性抗原结合结构域。
实施例B36.根据实施例B35所述的多链嵌合多肽,其中所述第一靶标结合结构域和所述第二靶标结合结构域各自是激动性抗原结合结构域。
实施例B37.根据实施例B35或B36所述的多链嵌合多肽,其中抗原结合结构域包含scFv或单结构域抗体。
实施例B38.根据实施例B1至B34中任一项所述的多链嵌合多肽,其中所述第一靶标结合结构域和所述第二靶标结合结构域中的一个或两个是可溶性IL-15或可溶性IL-18。
实施例B39.根据实施例B38所述的多链嵌合多肽,其中所述第一靶标结合结构域和所述第二靶标结合结构域各自独立地为可溶性IL-15或可溶性IL-18。
实施例B40.根据实施例B1至B39中任一项所述的多链嵌合多肽,其中所述第一靶标结合结构域和所述第二靶标结合结构域均特异性结合到IL-18的受体或IL-12的受体。
实施例B41.根据实施例B40所述的多链嵌合多肽,其中所述第一靶标结合结构域和所述第二靶标结合结构域特异性结合到相同的表位。
实施例B42.根据实施例B41所述的多链嵌合多肽,其中所述第一靶标结合结构域和所述第二靶标结合结构域包含相同的氨基酸序列。
实施例B43.根据实施例B1至B39中任一项所述的多链嵌合多肽,其中所述第一靶标结合结构域特异性结合到IL-12的受体,并且所述第二靶标结合结构域特异性结合到IL-18的受体。
实施例B44.根据实施例B1至B39中任一项所述的多链嵌合多肽,其中所述第一靶标结合结构域特异性结合到IL-18的受体,并且所述第二靶标结合结构域特异性结合到IL-12的受体。
实施例B45.根据实施例B44所述的多链嵌合多肽,其中所述第一靶标结合结构域包含可溶性IL-18。
实施例B46.根据实施例B45所述的多链嵌合多肽,其中所述可溶性IL-18是可溶性人IL-18。
实施例B47.根据实施例B46所述的多链嵌合多肽,其中所述可溶性人IL-18包含与SEQ ID NO:16至少80%相同的序列。
实施例B48.根据实施例B47所述的多链嵌合多肽,其中所述可溶性人IL-18包含与SEQ ID NO:16至少90%相同的序列。
实施例B49.根据实施例B48所述的多链嵌合多肽,其中所述可溶性人IL-18包含与SEQ ID NO:16至少95%相同的序列。
实施例B50.根据实施例B49所述的多链嵌合多肽,其中所述可溶性人IL-18包含SEQ ID NO:16的序列。
实施例B51.根据实施例B44至B50中任一项所述的多链嵌合多肽,其中所述第二靶标结合结构域包含可溶性IL-12。
实施例B52.根据实施例B51所述的多链嵌合多肽,其中所述可溶性IL-18是可溶性人IL-12。
实施例B53.根据实施例B52所述的多链嵌合多肽,其中所述可溶性人IL-15包含可溶性人IL-12β(p40)的序列和可溶性人IL-12α(p35)的序列。
实施例B54.根据实施例B53所述的多链嵌合多肽,其中所述可溶性人IL-15进一步包含在所述可溶性IL-12β(p40)的序列与所述可溶性人IL-12α(p35)的序列之间的接头序列。
实施例B55.根据实施例B54所述的多链嵌合多肽,其中所述接头序列包含SEQ IDNO:7。
实施例B56.根据实施例B53至B55中任一项所述的多链嵌合多肽,其中所述可溶性人IL-12β(p40)的序列包含与SEQ ID NO:66至少80%相同的序列。
实施例B57.根据实施例B56所述的多链嵌合多肽,其中所述可溶性人IL-12β(p40)的序列包含与SEQ ID NO:66至少90%相同的序列。
实施例B58.根据实施例B57所述的多链嵌合多肽,其中所述可溶性人IL-12β(p40)的序列包含与SEQ ID NO:66至少95%相同的序列。
实施例B59.根据实施例B58所述的多链嵌合多肽,其中所述可溶性人IL-12β(p40)的序列包含SEQ ID NO:66。
实施例B60.根据实施例B53至B59中任一项所述的多链嵌合多肽,其中所述可溶性人IL-12α(p35)的序列包含与SEQ ID NO:68至少80%相同的序列。
实施例B61.根据实施例B60所述的多链嵌合多肽,其中所述可溶性人IL-12α(p35)的序列包含与SEQ ID NO:68至少90%相同的序列。
实施例B62.根据实施例B61所述的多链嵌合多肽,其中所述可溶性人IL-12α(p35)的序列包含与SEQ ID NO:68至少95%相同的序列。
实施例B63.根据实施例B62所述的多链嵌合多肽,其中所述可溶性人IL-12α(p35)的序列包含SEQ ID NO:68。
实施例B64.根据实施例B1所述的多链嵌合多肽,其中所述第一嵌合多肽包含与SEQ ID NO:70至少80%相同的序列。
实施例B65.根据实施例B64所述的多链嵌合多肽,其中所述第一嵌合多肽包含与SEQ ID NO:70至少90%相同的序列。
实施例B66.根据实施例B65所述的多链嵌合多肽,其中所述第一嵌合多肽包含与SEQ ID NO:70至少95%相同的序列。
实施例B67.根据实施例B66所述的多链嵌合多肽,其中所述第一嵌合多肽包含SEQID NO:70。
实施例B68.根据实施例B67所述的多链嵌合多肽,其中所述第一嵌合多肽包含SEQID NO:72。
实施例B69.根据实施例B1和B64至B68中任一项所述的多链嵌合多肽,其中所述第二嵌合多肽包含与SEQ ID NO:74至少80%相同的序列。
实施例B70.根据实施例B69所述的多链嵌合多肽,其中所述第二嵌合多肽包含与SEQ ID NO:74至少90%相同的序列。
实施例B71.根据实施例B70所述的多链嵌合多肽,其中所述第二嵌合多肽包含与SEQ ID NO:74至少95%相同的序列。
实施例B72.根据实施例B71所述的多链嵌合多肽,其中所述第二嵌合多肽包含SEQID NO:74。
实施例B73.根据实施例B72所述的多链嵌合多肽,其中所述第二嵌合多肽包含SEQID NO:74。
实施例B74.根据实施例B1至B63中任一项所述的多链嵌合多肽,其中所述第一嵌合多肽进一步包含一个或多个另外的靶标结合结构域,其中所述一个或多个另外的抗原结合结构域中的至少一个位于所述可溶性组织因子结构域与所述一对亲和结构域中的所述第一结构域之间。
实施例B75.根据实施例B74所述的多链嵌合多肽,其中所述第一嵌合多肽进一步包含在所述可溶性组织因子结构域与所述一个或多个另外的抗原结合结构域中的所述至少一个之间的接头序列,和/或在所述一个或多个另外的抗原结合结构域中的所述至少一个与所述一对亲和结构域中的所述第一结构域之间的接头序列。
实施例B76.根据实施例B1至B63中任一项所述的多链嵌合多肽,其中所述第一嵌合多肽在所述第一嵌合多肽的N端和/或C端进一步包含一个或多个另外的靶标结合结构域。
实施例B77.根据实施例B76所述的多链嵌合多肽,其中在所述第一嵌合多肽中,所述一个或多个另外的靶标结合结构域中的至少一个直接邻接所述一对亲和结构域中的所述第一结构域。
实施例B78.根据实施例B76所述的多链嵌合多肽,其中所述第一嵌合多肽进一步包含在所述一个或多个另外的靶标结合结构域中的所述至少一个与所述一对亲和结构域中的所述第一结构域之间的接头序列。
实施例B79.根据实施例B76所述的多链嵌合多肽,其中在所述第一嵌合多肽中,所述一个或多个另外的靶标结合结构域中的所述至少一个直接邻接所述第一靶标结合结构域。
实施例B80.根据实施例B76所述的多链嵌合多肽,其中所述第一嵌合多肽进一步包含在所述一个或多个另外的靶标结合结构域中的所述至少一个与所述第一靶标结合结构域之间的接头序列。
实施例B81.根据实施例B76所述的多链嵌合多肽,其中所述一个或多个另外的靶标结合结构域中的至少一个安置于所述第一嵌合多肽的N和/或C端,并且所述一个或多个另外的靶标结合结构域中的至少一个位于所述第一嵌合多肽中所述可溶性组织因子结构域与所述一对亲和结构域中的所述第一结构域之间。
实施例B82.根据实施例B81所述的多链嵌合多肽,其中在所述第一嵌合多肽中,安置于N端的所述一个或多个另外的靶标结合结构域中的至少一个另外的靶标结合结构域直接邻接所述第一靶标结合结构域或所述一对亲和结构域中的所述第一结构域。
实施例B83.根据实施例B81所述的多链嵌合多肽,其中所述第一嵌合多肽进一步包含安置于所述第一嵌合多肽中的所述至少一个另外的靶标结合结构域与所述第一靶标结合结构域或所述一对亲和结构域中的所述第一结构域之间的接头序列。
实施例B84.根据实施例B81所述的多链嵌合多肽,其中在所述第一嵌合多肽中,安置于C端的所述一个或多个另外的靶标结合结构域中的至少一个另外的靶标结合结构域直接邻接所述第一靶标结合结构域或所述一对亲和结构域中的所述第一结构域。
实施例B85.根据实施例B81所述的多链嵌合多肽,其中所述第一嵌合多肽进一步包含安置于所述第一嵌合多肽中的所述至少一个另外的靶标结合结构域与所述第一靶标结合结构域或所述一对亲和结构域中的所述第一结构域之间的接头序列。
实施例B86.根据实施例B81所述的多链嵌合多肽,其中位于所述可溶性组织因子结构域与所述一对亲和结构域中的所述第一结构域之间的所述一个或多个另外的靶标结合结构域中的所述至少一个,直接邻接所述可溶性组织因子结构域和/或所述一对亲和结构域中的所述第一结构域。
实施例B87.根据实施例B81所述的多链嵌合多肽,其中所述第一嵌合多肽进一步包含安置于以下的接头序列:(i)所述可溶性组织因子结构域与所述一个或多个另外的靶标结合结构域中的所述至少一个之间,所述一个或多个另外的靶标结合结构域中的所述至少一个位于所述可溶性组织因子结构域与所述一对亲和结构域中的所述第一结构域之间,和/或(ii)所述一对亲和结构域中的所述第一结构域与所述一个或多个另外的靶标结合结构域中的所述至少一个之间,所述一个或多个另外的靶标结合结构域中的所述至少一个位于所述可溶性组织因子结构域与所述一对亲和结构域中的所述第一结构域之间。
实施例B88.根据实施例B1至B63和B74至B87中任一项所述的多链嵌合多肽,其中所述第二嵌合多肽在所述第二嵌合多肽的N端或C端进一步包含一个或多个另外的靶标结合结构域。
实施例B89.根据实施例B88所述的多链嵌合多肽,其中在所述第二嵌合多肽中,所述一个或多个另外的靶标结合结构域中的至少一个直接邻接所述一对亲和结构域中的所述第二结构域。
实施例B90.根据实施例B88所述的多链嵌合多肽,其中所述第二嵌合多肽进一步包含所述第二嵌合多肽中的所述一个或多个另外的靶标结合结构域中的至少一个与所述一对亲和结构域中的所述第二结构域之间的接头序列。
实施例B91.根据实施例B88所述的多链嵌合多肽,其中在所述第二嵌合多肽中,所述一个或多个另外的靶标结合结构域中的至少一个直接邻接所述第二靶标结合结构域。
实施例B92.根据实施例B88所述的多链嵌合多肽,其中所述第二嵌合多肽进一步包含所述第二嵌合多肽中的所述一个或多个另外的靶标结合结构域中的至少一个与所述第二靶标结合结构域之间的接头序列。
实施例B93.根据实施例B74至B92中任一项所述的多链嵌合多肽,其中所述第一靶标结合结构域、所述第二靶标结合结构域和所述一个或多个另外的靶标结合结构域中的两个或更多个特异性结合到相同的抗原。
实施例B94.根据实施例B93所述的多链嵌合多肽,其中所述第一靶标结合结构域、所述第二靶标结合结构域和所述一个或多个另外的靶标结合结构域中的两个或更多个特异性结合到相同的表位。
实施例B95.根据实施例B94所述的多链嵌合多肽,其中所述第一靶标结合结构域、所述第二靶标结合结构域和所述一个或多个另外的靶标结合结构域中的两个或更多个包含相同的氨基酸序列。
实施例B96.根据实施例B74至B92中任一项所述的多链嵌合多肽,其中所述第一靶标结合结构域、所述第二靶标结合结构域和所述一个或多个另外的靶标结合结构域特异性结合到不同的抗原。
实施例B97.根据实施例B74至B96中任一项所述的多链嵌合多肽,其中所述一个或多个另外的抗原结合结构域特异性结合到选自以下组成的组的靶标:CD16a、CD28、CD3、CD33、CD20、CD19、CD22、CD123、IL-1R、IL-1、VEGF、IL-6R、IL-4、IL-10、PDL-1、TIGIT、PD-1、TIM3、CTLA4、MICA、MICB、IL-6、IL-8、TNFα、CD26a、CD36、ULBP2、CD30、CD200、IGF-1R、MUC4AC、MUC5AC、Trop-2、CMET、EGFR、HER1、HER2、HER3、PSMA、CEA、B7H3、EPCAM、BCMA、P-钙黏着蛋白、CEACAM5、UL16结合蛋白、HLA-DR、DLL4、TYRO3、AXL、MER、CD122、CD155、PDGF-DD、TGF-β受体II(TGF-βRII)的配体、TGF-βRIII的配体、DNAM-1的配体、NKp46的配体、NKp44的配体、NKG2D的配体、NKP30的配体、scMHCI的配体、scMHCII的配体、scTCR的配体、IL-1的受体、IL-2的受体、IL-3的受体、IL-7的受体、IL-8的受体、IL-10的受体、IL-12的受体、IL-15的受体、IL-17的受体、IL-18的受体、IL-21的受体、PDGF-DD的受体、干细胞因子(SCF)的受体、干细胞样酪氨酸激酶3配体(FLT3L)的受体、MICA的受体、MICB的受体、ULP16结合蛋白的受体、CD155的受体和CD28的受体。
实施例B98.根据实施例B74至B96中任一项所述的多链嵌合多肽,其中所述一个或多个另外的靶标结合结构域是可溶性白介素或细胞因子蛋白。
实施例B99.根据实施例B98所述的多链嵌合多肽,其中所述可溶性白介素、细胞因子或配体蛋白选自以下组成的组:IL-1、IL-2、IL-3、IL-7、IL-8、IL-10、IL-12、IL-15、IL-17、IL-18、IL-21、PDGF-DD、SCF和FLT3L。
实施例B100.根据实施例B74至B96中任一项所述的多链嵌合多肽,其中所述一个或多个另外的靶标结合结构域是可溶性白介素或细胞因子受体。
实施例B101.根据实施例B100所述的多链嵌合多肽,其中所述可溶性受体是可溶性TGF-β受体II(TGF-βRII)、可溶性TGF-βRIII、可溶性NKG2D、可溶性NKp30、可溶性NKp44、可溶性NKp46、可溶性DNAM-1、scMHCI、scMHCII、scTCR、可溶性CD155、可溶性CD122或可溶性CD28。
实施例B102.一种组合物,其包含根据实施例B1至B101所述的多链嵌合多肽中的任一种。
实施例B103.根据实施例B102所述的组合物,其中所述组合物是药物组合物。
实施例B104.一种试剂盒,其包含至少一个剂量的根据实施例B102或B103所述的组合物。
实施例B105.一种刺激免疫细胞的方法,所述方法包含:
使免疫细胞与有效量的根据实施例B1至B101所述的多链嵌合多肽中的任一种或根据实施例B102或B103所述的组合物接触。
实施例B106.根据实施例B105所述的方法,其中所述免疫细胞在体外接触。
实施例B107.根据实施例B106所述的方法,其中所述免疫细胞先前获自受试者。
实施例B108.根据实施例B107所述的方法,其中所述方法进一步包含在接触步骤之前从所述受试者获得所述免疫细胞。
实施例B109.根据实施例B105所述的方法,其中所述免疫细胞在体内接触。
实施例B110.根据实施例B105至B109中任一项所述的方法,其中所述免疫细胞选自以下组成的组:未成熟胸腺细胞、外周血淋巴细胞、初始T细胞、多能Th细胞前体、淋巴祖细胞、Treg细胞、记忆T细胞、Th17细胞、Th22细胞、Th9细胞、Th2细胞、Th1细胞、Th3细胞、γδT细胞、αβT细胞、肿瘤浸润性T细胞、CD8+T细胞、CD4+T细胞、自然杀伤T细胞、肥大细胞、巨噬细胞、嗜中性粒细胞、树突状细胞、嗜碱性粒细胞、嗜酸性粒细胞和自然杀伤细胞。
实施例B111.根据实施例B105至B110中任一项所述的方法,其中所述免疫细胞先前已经过基因修饰以表达嵌合抗原受体或重组T细胞受体。
实施例B112.根据实施例B105至B110中任一项所述的方法,其中所述方法进一步包含在接触步骤之后,将编码嵌合抗原受体或重组T细胞受体的核酸引入到所述免疫细胞中。
实施例B113.根据实施例B105至B112中任一项所述的方法,其中所述方法进一步包含向有需要的受试者施用所述免疫细胞。
实施例B114.根据实施例B113所述的方法,其中所述受试者已被鉴别或诊断为患有与年龄相关的疾病或病况。
实施例B115.根据实施例B114所述的方法,其中所述与年龄相关的疾病或病况选自以下组成的组:阿尔茨海默氏病、动脉瘤、囊性纤维化、胰腺炎纤维化、青光眼、高血压、特发性肺纤维化、炎性肠病、椎间盘退变、黄斑变性、骨关节炎、2型糖尿病、脂肪萎缩、脂肪营养不良、动脉粥样硬化、白内障、COPD、特发性肺纤维化、肾移植失败、肝纤维化、骨量损失、心肌梗死、肌肉减少症、伤口愈合、脱发、心肌细胞肥大、骨关节炎、帕金森氏病、与年龄相关的肺组织弹性丧失、黄斑变性、恶病质、肾小球硬化、肝硬化、NAFLD、骨质疏松症、肌萎缩性侧索硬化症、亨廷顿氏病、脊髓小脑共济失调、多发性硬化症和肾功能不全。
实施例B116.根据实施例B113所述的方法,其中所述受试者已被鉴别或诊断为患有癌症。
实施例B117.根据实施例B116所述的方法,其中所述癌症选自以下组成的组:实体肿瘤、血液肿瘤、肉瘤、骨肉瘤、成胶质细胞瘤、成神经细胞瘤、黑色素瘤、横纹肌肉瘤、尤文氏肉瘤、骨肉瘤、B细胞瘤、多发性骨髓瘤、B细胞淋巴瘤、B细胞非霍奇金氏淋巴瘤、霍奇金氏淋巴瘤、慢性淋巴细胞性白血病(CLL)、急性骨髓性白血病(AML)、慢性骨髓性白血病(CML)、急性淋巴细胞性白血病(ALL)、骨髓增生异常综合症(MDS)、皮肤T细胞淋巴瘤、成视网膜细胞瘤、胃癌、尿路上皮癌、肺癌、肾细胞癌、胃和食管癌、胰腺癌、前列腺癌、乳腺癌、结直肠癌、卵巢癌、非小细胞肺癌、鳞状细胞头颈癌、子宫内膜癌、宫颈癌、肝癌和肝细胞癌。
实施例B118.根据实施例B113所述的方法,其中所述受试者已被诊断或鉴别为患有感染性疾病。
实施例B119.根据实施例B118所述的方法,其中所述感染性疾病是感染人免疫缺陷病毒、巨细胞病毒、腺病毒、冠状病毒、鼻病毒、轮状病毒、天花、单纯疱疹病毒、乙型肝炎病毒、甲型肝炎病毒和丙型肝炎病毒、乳头瘤病毒和流感病毒。
实施例B120.一种诱导或增加免疫细胞增殖的方法,所述方法包含:
使免疫细胞与有效量的根据实施例B1至B101所述的多链嵌合多肽中的任一种或根据实施例B102或B103所述的组合物接触。
实施例B121.根据实施例B120所述的方法,其中所述免疫细胞在体外接触。
实施例B122.根据实施例B121所述的方法,其中所述免疫细胞先前获自受试者。
实施例B123.根据实施例B122所述的方法,其中所述方法进一步包含在接触步骤之前从所述受试者获得所述免疫细胞。
实施例B124.根据实施例B120所述的方法,其中所述免疫细胞在体内接触。
实施例B125.根据实施例B120至B124中任一项所述的方法,其中所述免疫细胞选自以下组成的组:未成熟胸腺细胞、外周血淋巴细胞、初始T细胞、多能Th细胞前体、淋巴祖细胞、Treg细胞、记忆T细胞、Th17细胞、Th22细胞、Th9细胞、Th2细胞、Th1细胞、Th3细胞、γδT细胞、αβT细胞、肿瘤浸润性T细胞、CD8+T细胞、CD4+T细胞、自然杀伤T细胞、肥大细胞、巨噬细胞、嗜中性粒细胞、树突状细胞、嗜碱性粒细胞、嗜酸性粒细胞和自然杀伤细胞。
实施例B126.根据实施例B120至B125中任一项所述的方法,其中所述免疫细胞先前已经过基因修饰以表达嵌合抗原受体或重组T细胞受体。
实施例B127.根据实施例B120至B125中任一项所述的方法,其中所述方法进一步包含在接触步骤之后,将编码嵌合抗原受体或重组T细胞受体的核酸引入到所述免疫细胞中。
实施例B128.根据实施例B120至B127中任一项所述的方法,其中所述方法进一步包含向有需要的受试者施用所述免疫细胞。
实施例B129.根据实施例B128所述的方法,其中所述受试者已被鉴别或诊断为患有与年龄相关的疾病或病况。
实施例B130.根据实施例B129所述的方法,其中所述与年龄相关的疾病或病况选自以下组成的组:阿尔茨海默氏病、动脉瘤、囊性纤维化、胰腺炎纤维化、青光眼、高血压、特发性肺纤维化、炎性肠病、椎间盘退变、黄斑变性、骨关节炎、2型糖尿病、脂肪萎缩、脂肪营养不良、动脉粥样硬化、白内障、COPD、特发性肺纤维化、肾移植失败、肝纤维化、骨量损失、心肌梗死、肌肉减少症、伤口愈合、脱发、心肌细胞肥大、骨关节炎、帕金森氏病、与年龄相关的肺组织弹性丧失、黄斑变性、恶病质、肾小球硬化、肝硬化、NAFLD、骨质疏松症、肌萎缩性侧索硬化症、亨廷顿氏病、脊髓小脑共济失调、多发性硬化症和肾功能不全。
实施例B131.根据实施例B128所述的方法,其中所述受试者已被鉴别或诊断为患有癌症。
实施例B132.根据实施例B131所述的方法,其中所述癌症选自以下组成的组:实体肿瘤、血液肿瘤、肉瘤、骨肉瘤、成胶质细胞瘤、成神经细胞瘤、黑色素瘤、横纹肌肉瘤、尤文氏肉瘤、骨肉瘤、B细胞瘤、多发性骨髓瘤、B细胞淋巴瘤、B细胞非霍奇金氏淋巴瘤、霍奇金氏淋巴瘤、慢性淋巴细胞性白血病(CLL)、急性骨髓性白血病(AML)、慢性骨髓性白血病(CML)、急性淋巴细胞性白血病(ALL)、骨髓增生异常综合症(MDS)、皮肤T细胞淋巴瘤、成视网膜细胞瘤、胃癌、尿路上皮癌、肺癌、肾细胞癌、胃和食管癌、胰腺癌、前列腺癌、乳腺癌、结直肠癌、卵巢癌、非小细胞肺癌、鳞状细胞头颈癌、子宫内膜癌、宫颈癌、肝癌和肝细胞癌。
实施例B133.根据实施例B128所述的方法,其中所述受试者已被诊断或鉴别为患有感染性疾病。
实施例B134.根据实施例B128所述的方法,其中所述感染性疾病是感染人免疫缺陷病毒、巨细胞病毒、腺病毒、冠状病毒、鼻病毒、轮状病毒、天花、单纯疱疹病毒、乙型肝炎病毒、甲型肝炎病毒和丙型肝炎病毒、乳头瘤病毒和流感病毒。
实施例B135.一种诱导免疫细胞分化成记忆或记忆样免疫细胞的方法,所述方法包含:
使免疫细胞与有效量的根据实施例B1至B101所述的多链嵌合多肽中的任一种或根据实施例B102或B103所述的组合物接触。
实施例B136.根据实施例B135所述的方法,其中所述免疫细胞在体外接触。
实施例B137.根据实施例B136所述的方法,其中所述免疫细胞先前获自受试者。
实施例B138.根据实施例B137所述的方法,其中所述方法进一步包含在接触步骤之前从所述受试者获得所述免疫细胞。
实施例B139.根据实施例B135所述的方法,其中所述免疫细胞在体内接触。
实施例B140.根据实施例B135至B139中任一项所述的方法,其中所述免疫细胞选自以下组成的组:未成熟胸腺细胞、外周血淋巴细胞、初始T细胞、多能Th细胞前体、淋巴祖细胞、Treg细胞、Th17细胞、Th22细胞、Th9细胞、Th2细胞、Th1细胞、Th3细胞、γδT细胞、αβT细胞、肿瘤浸润性T细胞、CD8+T细胞、CD4+T细胞、自然杀伤T细胞、肥大细胞、巨噬细胞、嗜中性粒细胞、树突状细胞、嗜碱性粒细胞、嗜酸性粒细胞和自然杀伤细胞。
实施例B141.根据实施例B135至B140中任一项所述的方法,其中所述免疫细胞先前已经过基因修饰以表达嵌合抗原受体或重组T细胞受体。
实施例B142.根据实施例B135至B140中任一项所述的方法,其中所述方法进一步包含在接触步骤之后,将编码嵌合抗原受体或重组T细胞受体的核酸引入到所述免疫细胞中。
实施例B143.根据实施例B135至B142中任一项所述的方法,其中所述方法进一步包含向有需要的受试者施用所述免疫细胞。
实施例B144.根据实施例B143所述的方法,其中所述受试者已被鉴别或诊断为患有与年龄相关的疾病或病况。
实施例B145.根据实施例B144所述的方法,其中所述与年龄相关的疾病或病况选自以下组成的组:阿尔茨海默氏病、动脉瘤、囊性纤维化、胰腺炎纤维化、青光眼、高血压、特发性肺纤维化、炎性肠病、椎间盘退变、黄斑变性、骨关节炎、2型糖尿病、脂肪萎缩、脂肪营养不良、动脉粥样硬化、白内障、COPD、特发性肺纤维化、肾移植失败、肝纤维化、骨量损失、心肌梗死、肌肉减少症、伤口愈合、脱发、心肌细胞肥大、骨关节炎、帕金森氏病、与年龄相关的肺组织弹性丧失、黄斑变性、恶病质、肾小球硬化、肝硬化、NAFLD、骨质疏松症、肌萎缩性侧索硬化症、亨廷顿氏病、脊髓小脑共济失调、多发性硬化症和肾功能不全。
实施例B146.根据实施例B143所述的方法,其中所述受试者已被鉴别或诊断为患有癌症。
实施例B147.根据实施例B146所述的方法,其中所述癌症选自以下组成的组:实体肿瘤、血液肿瘤、肉瘤、骨肉瘤、成胶质细胞瘤、成神经细胞瘤、黑色素瘤、横纹肌肉瘤、尤文氏肉瘤、骨肉瘤、B细胞瘤、多发性骨髓瘤、B细胞淋巴瘤、B细胞非霍奇金氏淋巴瘤、霍奇金氏淋巴瘤、慢性淋巴细胞性白血病(CLL)、急性骨髓性白血病(AML)、慢性骨髓性白血病(CML)、急性淋巴细胞性白血病(ALL)、骨髓增生异常综合症(MDS)、皮肤T细胞淋巴瘤、成视网膜细胞瘤、胃癌、尿路上皮癌、肺癌、肾细胞癌、胃和食管癌、胰腺癌、前列腺癌、乳腺癌、结直肠癌、卵巢癌、非小细胞肺癌、鳞状细胞头颈癌、子宫内膜癌、宫颈癌、肝癌和肝细胞癌。
实施例B148.根据实施例B143所述的方法,其中所述受试者已被诊断或鉴别为患有感染性疾病。
实施例B149.根据实施例B148所述的方法,其中所述感染性疾病是感染人免疫缺陷病毒、巨细胞病毒、腺病毒、冠状病毒、鼻病毒、轮状病毒、天花、单纯疱疹病毒、乙型肝炎病毒、甲型肝炎病毒和丙型肝炎病毒、乳头瘤病毒和流感病毒。
实施例B150.一种在有需要的受试者中杀死癌细胞、受感染细胞或衰老细胞的方法,所述方法包含向所述受试者施用治疗有效量的根据实施例B1至B101所述的多链嵌合多肽中的任一种或根据实施例B102或B103所述的组合物。
实施例B151.根据实施例B150所述的方法,其中所述受试者已被鉴别或诊断为患有癌症。
实施例B152.根据实施例B151所述的方法,其中所述癌症选自以下组成的组:实体肿瘤、血液肿瘤、肉瘤、骨肉瘤、成胶质细胞瘤、成神经细胞瘤、黑色素瘤、横纹肌肉瘤、尤文氏肉瘤、骨肉瘤、B细胞瘤、多发性骨髓瘤、B细胞淋巴瘤、B细胞非霍奇金氏淋巴瘤、霍奇金氏淋巴瘤、慢性淋巴细胞性白血病(CLL)、急性骨髓性白血病(AML)、慢性骨髓性白血病(CML)、急性淋巴细胞性白血病(ALL)、骨髓增生异常综合症(MDS)、皮肤T细胞淋巴瘤、成视网膜细胞瘤、胃癌、尿路上皮癌、肺癌、肾细胞癌、胃和食管癌、胰腺癌、前列腺癌、乳腺癌、结直肠癌、卵巢癌、非小细胞肺癌、鳞状细胞头颈癌、子宫内膜癌、宫颈癌、肝癌和肝细胞癌。
实施例B153.根据实施例B150所述的方法,其中所述受试者已被鉴别或诊断为患有与老化相关的疾病或病况。
实施例B154.根据实施例B153所述的方法,其中所述与老化相关的疾病或病况选自以下组成的组:阿尔茨海默氏病、动脉瘤、囊性纤维化、胰腺炎纤维化、青光眼、高血压、特发性肺纤维化、炎性肠病、椎间盘退变、黄斑变性、骨关节炎、2型糖尿病、脂肪萎缩、脂肪营养不良、动脉粥样硬化、白内障、COPD、特发性肺纤维化、肾移植失败、肝纤维化、骨量损失、心肌梗死、肌肉减少症、伤口愈合、脱发、心肌细胞肥大、骨关节炎、帕金森氏病、与年龄相关的肺组织弹性丧失、黄斑变性、恶病质、肾小球硬化、肝硬化、NAFLD、骨质疏松症、肌萎缩性侧索硬化症、亨廷顿氏病、脊髓小脑共济失调、多发性硬化症和肾功能不全。
实施例B155.一种治疗有需要的受试者的方法,所述方法包含向所述受试者施用治疗有效量的根据实施例B1至B101所述的多链嵌合多肽中的任一种或根据实施例B102或B103所述的组合物。
实施例B156.根据实施例B155所述的方法,其中所述受试者已被鉴别或诊断为患有癌症或感染性疾病。
实施例B157.根据实施例B156所述的方法,其中所述癌症选自以下组成的组:实体肿瘤、血液肿瘤、肉瘤、骨肉瘤、成胶质细胞瘤、成神经细胞瘤、黑色素瘤、横纹肌肉瘤、尤文氏肉瘤、骨肉瘤、B细胞瘤、多发性骨髓瘤、B细胞淋巴瘤、B细胞非霍奇金氏淋巴瘤、霍奇金氏淋巴瘤、慢性淋巴细胞性白血病(CLL)、急性骨髓性白血病(AML)、慢性骨髓性白血病(CML)、急性淋巴细胞性白血病(ALL)、骨髓增生异常综合症(MDS)、皮肤T细胞淋巴瘤、成视网膜细胞瘤、胃癌、尿路上皮癌、肺癌、肾细胞癌、胃和食管癌、胰腺癌、前列腺癌、乳腺癌、结直肠癌、卵巢癌、非小细胞肺癌、鳞状细胞头颈癌、子宫内膜癌、宫颈癌、肝癌和肝细胞癌。
实施例B158.根据实施例B155所述的方法,其中所述受试者已被鉴别或诊断为患有与年龄相关的疾病或病况。
实施例B159.根据实施例B158所述的方法,其中所述与年龄相关的疾病或病况选自以下组成的组:阿尔茨海默氏病、动脉瘤、囊性纤维化、胰腺炎纤维化、青光眼、高血压、特发性肺纤维化、炎性肠病、椎间盘退变、黄斑变性、骨关节炎、2型糖尿病、脂肪萎缩、脂肪营养不良、动脉粥样硬化、白内障、COPD、特发性肺纤维化、肾移植失败、肝纤维化、骨量损失、心肌梗死、肌肉减少症、伤口愈合、脱发、心肌细胞肥大、骨关节炎、帕金森氏病、与年龄相关的肺组织弹性丧失、黄斑变性、恶病质、肾小球硬化、肝硬化、NAFLD、骨质疏松症、肌萎缩性侧索硬化症、亨廷顿氏病、脊髓小脑共济失调、多发性硬化症和肾功能不全。
实施例B160.根据实施例B155所述的方法,其中所述受试者已被诊断或鉴别为患有感染性疾病。
实施例B161.根据实施例B160所述的方法,其中所述感染性疾病是感染人免疫缺陷病毒、巨细胞病毒、腺病毒、冠状病毒、鼻病毒、轮状病毒、天花、单纯疱疹病毒、乙型肝炎病毒、甲型肝炎病毒和丙型肝炎病毒、乳头瘤病毒和流感病毒。
实施例B162.核酸,其编码根据实施例B1至B101中任一项所述的多链嵌合多肽中的任一种。
实施例B163.一种载体,其包含根据实施例B162所述的核酸。
实施例B164.根据实施例B163所述的载体,其中所述载体是表达载体。
实施例B165.一种细胞,其包含根据实施例B162所述的核酸或根据实施例B163或B164所述的载体。
实施例B166.一种产生多链嵌合多肽的方法,所述方法包含:
在足以引起产生所述多链嵌合多肽的条件下在培养基中培养根据实施例B165所述的细胞;和
从所述细胞和/或所述培养基中回收所述多链嵌合多肽。
实施例B167.一种多链嵌合多肽,其通过根据实施例B166所述的方法产生。
实施例B168.根据实施例B8所述的多链嵌合多肽,其中所述可溶性人组织因子结构域包含与SEQ ID NO:3至少80%相同的序列。
实施例B169.根据实施例B168所述的多链嵌合多肽,其中所述可溶性人组织因子结构域包含与SEQ ID NO:3至少90%相同的序列。
实施例B170.根据实施例B169所述的多链嵌合多肽,其中所述可溶性人组织因子结构域包含与SEQ ID NO:3至少95%相同的序列。
实施例B171.根据实施例B170所述的多链嵌合多肽,其中所述可溶性人组织因子结构域包含与SEQ ID NO:3100%相同的序列。
实施例B172.根据实施例B8所述的多链嵌合多肽,其中所述可溶性人组织因子结构域包含与SEQ ID NO:4至少80%相同的序列。
实施例B173.根据实施例B172所述的多链嵌合多肽,其中所述可溶性人组织因子结构域包含与SEQ ID NO:4至少90%相同的序列。
实施例B174.根据实施例B173所述的多链嵌合多肽,其中所述可溶性人组织因子结构域包含与SEQ ID NO:4至少95%相同的序列。
实施例B175.根据实施例B174所述的多链嵌合多肽,其中所述可溶性人组织因子结构域包含与SEQ ID NO:4100%相同的序列。
C.示例性实施例
实施例C1.一种多链嵌合多肽,其包含:
(a)第一嵌合多肽,其包含:
(i)第一靶标结合结构域;
(ii)可溶性组织因子结构域;和
(iii)一对亲和结构域中的第一结构域;
(b)第二嵌合多肽,其包含:
(i)一对亲和结构域中的第二结构域;和
(ii)第二靶标结合结构域,
其中:
所述第一嵌合多肽和所述第二嵌合多肽通过所述一对亲和结构域中的所述第一结构域和所述第二结构域的结合而缔合;和
所述第一靶标结合结构域和所述第二靶标结合结构域各自独立地特异性结合到IL-21的受体或肿瘤生长因子受体βII(TGFβRII)的配体。
实施例C2.根据实施例C1所述的多链嵌合多肽,其中所述第一靶标结合结构域和所述可溶性组织因子结构域在所述第一嵌合多肽中彼此直接邻接。
实施例C3.根据实施例C1所述的多链嵌合多肽,其中所述第一嵌合多肽进一步包含所述第一嵌合多肽中的所述第一靶标结合结构域与所述可溶性组织因子结构域之间的接头序列。
实施例C4.根据实施例C1至C3中任一项所述的多链嵌合多肽,其中所述可溶性组织因子结构域和所述一对亲和结构域中的所述第一结构域在所述第一嵌合多肽中彼此直接邻接。
实施例C5.根据实施例C1至C3中任一项所述的多链嵌合多肽,其中所述第一嵌合多肽进一步包含所述第一嵌合多肽中的所述可溶性组织因子结构域与所述一对亲和结构域中的所述第一结构域之间的接头序列。
实施例C6.根据实施例C1至C5中任一项所述的多链嵌合多肽,其中所述一对亲和结构域中的所述第二结构域和所述第二靶标结合结构域在所述第二嵌合多肽中彼此直接邻接。
实施例C7.根据实施例C1至C5中任一项所述的多链嵌合多肽,其中所述第二嵌合多肽进一步包含所述第二嵌合多肽中的所述一对亲和结构域中的所述第二结构域与所述第二靶标结合结构域之间的接头序列。
实施例C8.根据实施例C1至C7中任一项所述的多链嵌合多肽,其中所述可溶性组织因子结构域是可溶性人组织因子结构域。
实施例C9.根据实施例C8所述的多链嵌合多肽,其中所述可溶性人组织因子结构域包含与SEQ ID NO:1至少80%相同的序列。
实施例C10.根据实施例C9所述的多链嵌合多肽,其中所述可溶性人组织因子结构域包含与SEQ ID NO:1至少90%相同的序列。
实施例C11.根据实施例C10所述的多链嵌合多肽,其中所述可溶性人组织因子结构域包含与SEQ ID NO:1至少95%相同的序列。
实施例C12.根据实施例C8至C11中任一项所述的多链嵌合多肽,其中所述可溶性人组织因子结构域不包含以下中的一种或多种:
在对应于成熟野生型人组织因子蛋白的氨基酸位置20的氨基酸位置处的赖氨酸;
在对应于成熟野生型人组织因子蛋白的氨基酸位置22的氨基酸位置处的异亮氨酸;
在对应于成熟野生型人组织因子蛋白的氨基酸位置45的氨基酸位置处的色氨酸;
在对应于成熟野生型人组织因子蛋白的氨基酸位置58的氨基酸位置处的天冬氨酸;
在对应于成熟野生型人组织因子蛋白的氨基酸位置94的氨基酸位置处的酪氨酸;
在对应于成熟野生型人组织因子蛋白的氨基酸位置135的氨基酸位置处的精氨酸;和
在对应于成熟野生型人组织因子蛋白的氨基酸位置140的氨基酸位置处的苯丙氨酸。
实施例C13.根据实施例C12所述的多链嵌合多肽,其中所述可溶性人组织因子结构域不包含以下中的任一种:
在对应于成熟野生型人组织因子蛋白的氨基酸位置20的氨基酸位置处的赖氨酸;
在对应于成熟野生型人组织因子蛋白的氨基酸位置22的氨基酸位置处的异亮氨酸;
在对应于成熟野生型人组织因子蛋白的氨基酸位置45的氨基酸位置处的色氨酸;
在对应于成熟野生型人组织因子蛋白的氨基酸位置58的氨基酸位置处的天冬氨酸;
在对应于成熟野生型人组织因子蛋白的氨基酸位置94的氨基酸位置处的酪氨酸;
在对应于成熟野生型人组织因子蛋白的氨基酸位置135的氨基酸位置处的精氨酸;和
在对应于成熟野生型人组织因子蛋白的氨基酸位置140的氨基酸位置处的苯丙氨酸。
实施例C14.根据实施例C1至C13中任一项所述的多链嵌合多肽,其中所述可溶性组织因子结构域不能结合到因子VIIa。
实施例C15.根据实施例C1至C14中任一项所述的多链嵌合多肽,其中所述可溶性组织因子结构域不将非活性因子X转化为因子Xa。
实施例C16.根据实施例C1至C15中任一项所述的多链嵌合多肽,其中所述多链嵌合多肽不刺激哺乳动物的凝血。
实施例C17.根据实施例C1至C16中任一项的所述多链嵌合多肽,其中所述第一嵌合多肽进一步包含在所述第一嵌合多肽的N端或C端的肽标签。
实施例C18.根据实施例C1至C17中任一项所述的多链嵌合多肽,其中所述第二嵌合多肽进一步包含在所述第二嵌合多肽的N端或C端的肽标签。
实施例C19.根据实施例C1至C18中任一项所述的多链嵌合多肽,其中所述第一嵌合多肽和/或所述第二嵌合多肽在其N端进一步包含信号序列。
实施例C20.根据实施例C19所述的多链嵌合多肽,其中所述信号序列包含SEQ IDNO:31。
实施例C21.根据实施例C20所述的多链嵌合多肽,其中所述信号序列是SEQ IDNO:31。
实施例C22.根据实施例C1至C21中任一项所述的多链嵌合多肽,其中所述一对亲和结构域是来自人IL-15受体的α链(IL15Rα的寿司结构域和可溶性IL-15。
实施例C23.根据实施例C22所述的多链嵌合多肽,其中所述可溶性IL-15具有D8N或D8A氨基酸取代。
实施例C24.根据实施例C22所述的多链嵌合多肽,其中所述可溶性IL-15包含与SEQ ID NO:14至少80%相同的序列。
实施例C25.根据实施例C24所述的多链嵌合多肽,其中所述可溶性IL-15包含与SEQ ID NO:14至少90%相同的序列。
实施例C26.根据实施例C25所述的多链嵌合多肽,其中所述可溶性IL-15包含与SEQ ID NO:14至少95%相同的序列。
实施例C27.根据实施例C26所述的多链嵌合多肽,其中所述可溶性IL-15包含SEQID NO:14。
实施例C28.根据实施例C22至C27中任一项所述的多链嵌合多肽,其中IL15Rα的寿司结构域包含来自人IL15Rα的寿司结构域。
实施例C29.根据实施例C28所述的多链嵌合多肽,其中来自人IL15Rα的所述寿司结构域包含与SEQ ID NO:28至少80%相同的序列。
实施例C30.根据实施例C29所述的多链嵌合多肽,其中来自人IL15Rα的所述寿司结构域包含与SEQ ID NO:28至少90%相同的序列。
实施例C31.根据实施例C30所述的多链嵌合多肽,其中来自人IL15Rα的所述寿司结构域包含与SEQ ID NO:28至少95%相同的序列。
实施例C32.根据实施例C31所述的多链嵌合多肽,其中来自人IL15Rα的所述寿司结构域包含SEQ ID NO:28。
实施例C33.根据实施例C28所述的多链嵌合多肽,其中来自人IL15Rα的所述寿司结构域是成熟全长IL15Rα。
实施例C34.根据实施例C1至C21中任一项所述的多链嵌合多肽,其中所述一对亲和结构域选自以下组成的组:芽胞杆菌RNA酶和芽胞杆菌RNA酶抑制子、PKA和AKAP、基于突变核糖核酸酶I片段的衔接子/对接标签模块以及基于蛋白质突触蛋白、突触结合蛋白、突触泡蛋白和SNAP25的相互作用的SNARE模块。
实施例C35.根据实施例C1至C34中任一项所述的多链嵌合多肽,其中所述第一靶标结合结构域和所述第二靶标结合结构域中的一个或两个是抗原结合结构域。
实施例C36.根据实施例C35所述的多链嵌合多肽,其中所述第一靶标结合结构域和所述第二靶标结合结构域是抗原结合结构域。
实施例C37.根据实施例C35或C36所述的多链嵌合多肽,其中抗原结合结构域包含scFv或单结构域抗体。
实施例C38.根据实施例C1至C34中任一项所述的多链嵌合多肽,其中所述第一靶标结合结构域和所述第二靶标结合结构域中的一个或两个是可溶性IL-21或可溶性TGFβRII。
实施例C39.根据实施例C1至C38中任一项所述的多链嵌合多肽,其中所述第一靶标结合结构域和所述第二靶标结合结构域均特异性结合到IL-21的受体或TGFβRII的配体。
实施例C40.根据实施例C39所述的多链嵌合多肽,其中所述第一靶标结合结构域和所述第二靶标结合结构域特异性结合到相同的表位。
实施例C41.根据实施例C40所述的多链嵌合多肽,其中所述第一靶标结合结构域和所述第二靶标结合结构域包含相同的氨基酸序列。
实施例C42.根据实施例C1至C38中任一项所述的多链嵌合多肽,其中所述第一靶标结合结构域特异性结合到TGFβRII的配体,并且所述第二靶标结合结构域特异性结合到IL-21的受体。
实施例C43.根据实施例C1至C38中任一项所述的多链嵌合多肽,其中所述第一靶标结合结构域特异性结合到IL-21的受体,并且所述第二靶标结合结构域特异性结合到TGFβRII的配体。
实施例C44.根据实施例C43所述的多链嵌合多肽,其中所述第一靶标结合结构域包含可溶性IL-21。
实施例C45.根据实施例C44所述的多链嵌合多肽,其中所述可溶性IL-21是可溶性人IL-21。
实施例C46.根据实施例C45所述的多链嵌合多肽,其中所述可溶性人IL-21包含与SEQ ID NO:78至少80%相同的序列。
实施例C47.根据实施例C46所述的多链嵌合多肽,其中所述可溶性人IL-21包含与SEQ ID NO:78至少90%相同的序列。
实施例C48.根据实施例C47所述的多链嵌合多肽,其中所述可溶性人IL-21包含与SEQ ID NO:78至少95%相同的序列。
实施例C49.根据实施例C48所述的多链嵌合多肽,其中所述可溶性人IL-21包含SEQ ID NO:78的序列。
实施例C50.根据实施例C43至C49中任一项所述的多链嵌合多肽,其中所述第二靶标结合结构域包含可溶性TGFβRII。
实施例C51.根据实施例C50所述的多链嵌合多肽,其中所述可溶性TGFβRII是可溶性人TGFβRII。
实施例C52.根据实施例C51所述的多链嵌合多肽,其中所述可溶性人TGFβRII包含可溶性人TGFβRII的第一序列和可溶性人TGFβRII的第二序列。
实施例C53.根据实施例C52所述的多链嵌合多肽,其中所述可溶性人TGFβRII进一步包含在可溶性人TGFβRII的所述第一序列与可溶性人TGFβRII的所述第二序列之间的接头序列。
实施例C54.根据实施例C53所述的多链嵌合多肽,其中所述接头序列包含SEQ IDNO:7。
实施例C55.根据实施例C52至C54中任一项所述的多链嵌合多肽,其中可溶性人TGFβRII的所述第一序列包含与SEQ ID NO:80至少80%相同的序列。
实施例C56.根据实施例C55所述的多链嵌合多肽,其中可溶性人TGFβRII的所述第一序列包含与SEQ ID NO:80至少90%相同的序列。
实施例C57.根据实施例C56所述的多链嵌合多肽,其中可溶性人TGFβRII的所述第一序列包含与SEQ ID NO:80至少95%相同的序列。
实施例C58.根据实施例C57所述的多链嵌合多肽,其中可溶性人TGFβRII的所述第一序列包含SEQ ID NO:80。
实施例C59.根据实施例C52至C58中任一项所述的多链嵌合多肽,其中可溶性人TGFβRII的所述第二序列包含与SEQ ID NO:81至少80%相同的序列。
实施例C60.根据实施例C59所述的多链嵌合多肽,其中所述可溶性人TGFβRII的第二序列包含与SEQ ID NO:81至少90%相同的序列。
实施例C61.根据实施例C60所述的多链嵌合多肽,其中可溶性人TGFβRII的所述第二序列包含与SEQ ID NO:81至少95%相同的序列。
实施例C62.根据实施例C61所述的多链嵌合多肽,其中可溶性人TGFβRII的所述第二序列包含SEQ ID NO:81。
实施例C63.根据实施例C1所述的多链嵌合多肽,其中所述第一嵌合多肽包含与SEQ ID NO:86至少80%相同的序列。
实施例C64.根据实施例C63所述的多链嵌合多肽,其中所述第一嵌合多肽包含与SEQ ID NO:86至少90%相同的序列。
实施例C65.根据实施例C64所述的多链嵌合多肽,其中所述第一嵌合多肽包含与SEQ ID NO:86至少95%相同的序列。
实施例C66.根据实施例C65所述的多链嵌合多肽,其中所述第一嵌合多肽包含SEQID NO:86。
实施例C67.根据实施例C66所述的多链嵌合多肽,其中所述第一嵌合多肽包含SEQID NO:88。
实施例C68.根据实施例C1和C63至C67中任一项所述的多链嵌合多肽,其中所述第二嵌合多肽包含与SEQ ID NO:90至少80%相同的序列。
实施例C69.根据实施例C68所述的多链嵌合多肽,其中所述第二嵌合多肽包含与SEQ ID NO:90至少90%相同的序列。
实施例C70.根据实施例C69所述的多链嵌合多肽,其中所述第二嵌合多肽包含与SEQ ID NO:90至少95%相同的序列。
实施例C71.根据实施例C70所述的多链嵌合多肽,其中所述第二嵌合多肽包含SEQID NO:90。
实施例C72.根据实施例C71所述的多链嵌合多肽,其中所述第二嵌合多肽包含SEQID NO:92。
实施例C73.根据实施例C1至C62中任一项所述的多链嵌合多肽,其中所述第一嵌合多肽进一步包含一个或多个另外的靶标结合结构域,其中所述一个或多个另外的抗原结合结构域中的至少一个位于所述可溶性组织因子结构域与所述一对亲和结构域中的所述第一结构域之间。
实施例C74.根据实施例C73所述的多链嵌合多肽,其中所述第一嵌合多肽进一步包含在所述可溶性组织因子结构域与所述一个或多个另外的抗原结合结构域中的所述至少一个之间的接头序列,和/或在所述一个或多个另外的抗原结合结构域中的所述至少一个与所述一对亲和结构域中的所述第一结构域之间的接头序列。
实施例C75.根据实施例C1至C62中任一项所述的多链嵌合多肽,其中所述第一嵌合多肽在所述第一嵌合多肽的N端和/或C端进一步包含一个或多个另外的靶标结合结构域。
实施例C76.根据实施例C75所述的多链嵌合多肽,其中在所述第一嵌合多肽中,所述一个或多个另外的靶标结合结构域中的至少一个直接邻接所述一对亲和结构域中的所述第一结构域。
实施例C77.根据实施例C75所述的多链嵌合多肽,其中所述第一嵌合多肽进一步包含在所述一个或多个另外的靶标结合结构域中的所述至少一个与所述一对亲和结构域中的所述第一结构域之间的接头序列。
实施例C78.根据实施例C75所述的多链嵌合多肽,其中在所述第一嵌合多肽中,所述一个或多个另外的靶标结合结构域中的所述至少一个直接邻接所述第一靶标结合结构域。
实施例C79.根据实施例C75所述的多链嵌合多肽,其中所述第一嵌合多肽进一步包含在所述一个或多个另外的靶标结合结构域中的所述至少一个与所述第一靶标结合结构域之间的接头序列。
实施例C80.根据实施例C75所述的多链嵌合多肽,其中所述一个或多个另外的靶标结合结构域中的至少一个安置于所述第一嵌合多肽的N和/或C端,并且所述一个或多个另外的靶标结合结构域中的至少一个位于所述第一嵌合多肽中所述可溶性组织因子结构域与所述一对亲和结构域中的所述第一结构域之间。
实施例C81.根据实施例C80所述的多链嵌合多肽,其中在所述第一嵌合多肽中,安置于N端的所述一个或多个另外的靶标结合结构域中的至少一个另外的靶标结合结构域直接邻接所述第一靶标结合结构域或所述一对亲和结构域中的所述第一结构域。
实施例C82.根据实施例C80所述的多链嵌合多肽,其中所述第一嵌合多肽进一步包含安置于所述第一嵌合多肽中的所述至少一个另外的靶标结合结构域与所述第一靶标结合结构域或所述一对亲和结构域中的所述第一结构域之间的接头序列。
实施例C83.根据实施例C80所述的多链嵌合多肽,其中在所述第一嵌合多肽中,安置于C端的所述一个或多个另外的靶标结合结构域中的至少一个另外的靶标结合结构域直接邻接所述第一靶标结合结构域或所述一对亲和结构域中的所述第一结构域。
实施例C84.根据实施例C80所述的多链嵌合多肽,其中所述第一嵌合多肽进一步包含安置于所述第一嵌合多肽中的所述至少一个另外的靶标结合结构域与所述第一靶标结合结构域或所述一对亲和结构域中的所述第一结构域之间的接头序列。
实施例C85.根据实施例C80所述的多链嵌合多肽,其中位于所述可溶性组织因子结构域与所述一对亲和结构域中的所述第一结构域之间的所述一个或多个另外的靶标结合结构域中的所述至少一个,直接邻接所述可溶性组织因子结构域和/或所述一对亲和结构域中的所述第一结构域。
实施例C86.根据实施例C80所述的多链嵌合多肽,其中所述第一嵌合多肽进一步包含安置于以下的接头序列:(i)所述可溶性组织因子结构域与所述一个或多个另外的靶标结合结构域中的所述至少一个之间,所述一个或多个另外的靶标结合结构域中的所述至少一个位于所述可溶性组织因子结构域与所述一对亲和结构域中的所述第一结构域之间,和/或(ii)所述一对亲和结构域中的所述第一结构域与所述一个或多个另外的靶标结合结构域中的所述至少一个之间,所述一个或多个另外的靶标结合结构域中的所述至少一个位于所述可溶性组织因子结构域与所述一对亲和结构域中的所述第一结构域之间。
实施例C87.根据实施例C1至C62和C73至C86中任一项所述的多链嵌合多肽,其中所述第二嵌合多肽在所述第二嵌合多肽的N端或C端进一步包含一个或多个另外的靶标结合结构域。
实施例C88.根据实施例C87所述的多链嵌合多肽,其中在所述第二嵌合多肽中,所述一个或多个另外的靶标结合结构域中的至少一个直接邻接所述一对亲和结构域中的所述第二结构域。
实施例C89.根据实施例C87所述的多链嵌合多肽,其中所述第二嵌合多肽进一步包含所述第二嵌合多肽中的所述一个或多个另外的靶标结合结构域中的至少一个与所述一对亲和结构域中的所述第二结构域之间的接头序列。
实施例C90.根据实施例C87所述的多链嵌合多肽,其中在所述第二嵌合多肽中,所述一个或多个另外的靶标结合结构域中的至少一个直接邻接所述第二靶标结合结构域。
实施例C91.根据实施例C87所述的多链嵌合多肽,其中所述第二嵌合多肽进一步包含所述第二嵌合多肽中的所述一个或多个另外的靶标结合结构域中的至少一个与所述第二靶标结合结构域之间的接头序列。
实施例C92.根据实施例C73至C91中任一项所述的多链嵌合多肽,其中所述第一靶标结合结构域、所述第二靶标结合结构域和所述一个或多个另外的靶标结合结构域中的两个或更多个特异性结合到相同的抗原。
实施例C93.根据实施例C92所述的多链嵌合多肽,其中所述第一靶标结合结构域、所述第二靶标结合结构域和所述一个或多个另外的靶标结合结构域中的两个或更多个特异性结合到相同的表位。
实施例C94.根据实施例C93所述的多链嵌合多肽,其中所述第一靶标结合结构域、所述第二靶标结合结构域和所述一个或多个另外的靶标结合结构域中的两个或更多个包含相同的氨基酸序列。
实施例C95.根据实施例C73至C91中任一项所述的多链嵌合多肽,其中所述第一靶标结合结构域、所述第二靶标结合结构域和所述一个或多个另外的靶标结合结构域特异性结合到不同的抗原。
实施例C96.根据实施例C73至C95中任一项所述的多链嵌合多肽,其中所述一个或多个另外的抗原结合结构域特异性结合到选自以下组成的组的靶标:CD16a、CD28、CD3、CD33、CD20、CD19、CD22、CD123、IL-1R、IL-1、VEGF、IL-6R、IL-4、IL-10、PDL-1、TIGIT、PD-1、TIM3、CTLA4、MICA、MICB、IL-6、IL-8、TNFα、CD26a、CD36、ULBP2、CD30、CD200、IGF-1R、MUC4AC、MUC5AC、Trop-2、CMET、EGFR、HER1、HER2、HER3、PSMA、CEA、B7H3、EPCAM、BCMA、P-钙黏着蛋白、CEACAM5、UL16结合蛋白、HLA-DR、DLL4、TYRO3、AXL、MER、CD122、CD155、PDGF-D、TGF-β受体II(TGF-RII)的配体、TGF-βRIII的配体、DNAM-1的配体、NKp46的配体、NKp44的配体、NKG2D的配体、NKp30的配体、scMHCI的配体、scMHCII的配体、scTCR的配体、IL-1的受体、IL-2的受体、IL-3的受体、IL-7的受体、IL-8的受体、IL-10的受体、IL-12的受体、IL-15的受体、IL-17的受体、IL-18的受体、IL-21的受体、PDGF-DD的受体、干细胞因子(SCF)的受体、干细胞样酪氨酸激酶3配体(FLT3L)的受体、MICA的受体、MICB的受体、ULP16结合蛋白的受体、CD155的受体和CD28的受体。
实施例C97.根据实施例C73至C95中任一项所述的多链嵌合多肽,其中所述一个或多个另外的靶标结合结构域是可溶性白介素或细胞因子蛋白。
实施例C98.根据实施例C97所述的多链嵌合多肽,其中所述可溶性白介素、细胞因子或配体蛋白选自以下组成的组:IL-1、IL-2、IL-3、IL-7、IL-8、IL-10、IL-12、IL-15、IL-17、IL-18、IL-21、PDGF-DD、SCF和FLT3L。
实施例C99.根据实施例C73至C95中任一项所述的多链嵌合多肽,其中所述一个或多个另外的靶标结合结构域是可溶性白介素或细胞因子受体。
实施例C100.根据实施例C99所述的多链嵌合多肽,其中所述可溶性受体是可溶性TGF-β受体II(TGF-βRII)、可溶性TGF-βRIII、可溶性NKG2D、可溶性NKp30、可溶性NKp44、可溶性NKp46、可溶性DNAM-1、scMHCI、scMHCII、scTCR、可溶性CD155或可溶性CD28。
实施例C101.一种组合物,其包含根据实施例C1至C100所述的多链嵌合多肽中的任一种。
实施例C102.根据实施例C101所述的组合物,其中所述组合物是药物组合物。
实施例C103.一种试剂盒,其包含至少一个剂量的根据实施例C101或C102所述的组合物。
实施例C104.一种刺激免疫细胞的方法,所述方法包含:
使免疫细胞与有效量的根据实施例C1至C100所述的多链嵌合多肽中的任一种或根据实施例C101或C102所述的组合物接触。
实施例C105.根据实施例C104所述的方法,其中所述免疫细胞在体外接触。
实施例C106.根据实施例C105所述的方法,其中所述免疫细胞先前获自受试者。
实施例C107.根据实施例C106所述的方法,其中所述方法进一步包含在接触步骤之前从所述受试者获得所述免疫细胞。
实施例C108.根据实施例C104所述的方法,其中所述免疫细胞在体内接触。
实施例C109.根据实施例C104至C108中任一项所述的方法,其中所述免疫细胞选自以下组成的组:未成熟胸腺细胞、外周血淋巴细胞、初始T细胞、多能Th细胞前体、淋巴祖细胞、Treg细胞、记忆T细胞、Th17细胞、Th22细胞、Th9细胞、Th2细胞、Th1细胞、Th3细胞、γδT细胞、αβT细胞、肿瘤浸润性T细胞、CD8+T细胞、CD4+T细胞、自然杀伤T细胞、肥大细胞、巨噬细胞、嗜中性粒细胞、树突状细胞、嗜碱性粒细胞、嗜酸性粒细胞和自然杀伤细胞。
实施例C110.根据实施例C104至C109中任一项所述的方法,其中所述免疫细胞先前已经过基因修饰以表达嵌合抗原受体或重组T细胞受体。
实施例C111.根据实施例C104至C109中任一项所述的方法,其中所述方法进一步包含在接触步骤之后,将编码嵌合抗原受体或重组T细胞受体的核酸引入到所述免疫细胞中。
实施例C112.根据实施例C104至C111中任一项所述的方法,其中所述方法进一步包含向有需要的受试者施用所述免疫细胞。
实施例C113.根据实施例C112所述的方法,其中所述受试者已被鉴别或诊断为患有与年龄相关的疾病或病况。
实施例C114.根据实施例C113所述的方法,其中所述与年龄相关的疾病或病况选自以下组成的组:阿尔茨海默氏病、动脉瘤、囊性纤维化、胰腺炎纤维化、青光眼、高血压、特发性肺纤维化、炎性肠病、椎间盘退变、黄斑变性、骨关节炎、2型糖尿病、脂肪萎缩、脂肪营养不良、动脉粥样硬化、白内障、COPD、特发性肺纤维化、肾移植失败、肝纤维化、骨量损失、心肌梗死、肌肉减少症、伤口愈合、脱发、心肌细胞肥大、骨关节炎、帕金森氏病、与年龄相关的肺组织弹性丧失、黄斑变性、恶病质、肾小球硬化、肝硬化、NAFLD、骨质疏松症、肌萎缩性侧索硬化症、亨廷顿氏病、脊髓小脑共济失调、多发性硬化症和肾功能不全。
实施例C115.根据实施例C112所述的方法,其中所述受试者已被鉴别或诊断为患有癌症。
实施例C116.根据实施例C115所述的方法,其中所述癌症选自以下组成的组:实体肿瘤、血液肿瘤、肉瘤、骨肉瘤、成胶质细胞瘤、成神经细胞瘤、黑色素瘤、横纹肌肉瘤、尤文氏肉瘤、骨肉瘤、B细胞瘤、多发性骨髓瘤、B细胞淋巴瘤、B细胞非霍奇金氏淋巴瘤、霍奇金氏淋巴瘤、慢性淋巴细胞性白血病(CLL)、急性骨髓性白血病(AML)、慢性骨髓性白血病(CML)、急性淋巴细胞性白血病(ALL)、骨髓增生异常综合症(MDS)、皮肤T细胞淋巴瘤、成视网膜细胞瘤、胃癌、尿路上皮癌、肺癌、肾细胞癌、胃和食管癌、胰腺癌、前列腺癌、乳腺癌、结直肠癌、卵巢癌、非小细胞肺癌、鳞状细胞头颈癌、子宫内膜癌、宫颈癌、肝癌和肝细胞癌。
实施例C117.根据实施例C112所述的方法,其中所述受试者已被诊断或鉴别为患有感染性疾病。
实施例C118.根据实施例C117所述的方法,其中所述感染性疾病是感染人免疫缺陷病毒、巨细胞病毒、腺病毒、冠状病毒、鼻病毒、轮状病毒、天花、单纯疱疹病毒、乙型肝炎病毒、甲型肝炎病毒和丙型肝炎病毒、乳头瘤病毒和流感病毒。
实施例C119.一种诱导或增加免疫细胞增殖的方法,所述方法包含:
使免疫细胞与有效量的根据实施例C1至C100所述的多链嵌合多肽中的任一种或根据实施例C101或C102所述的组合物接触。
实施例C120.根据实施例C119所述的方法,其中所述免疫细胞在体外接触。
实施例C121.根据实施例C120所述的方法,其中所述免疫细胞先前获自受试者。
实施例C122.根据实施例C121所述的方法,其中所述方法进一步包含在接触步骤之前从所述受试者获得所述免疫细胞。
实施例C123.根据实施例C119所述的方法,其中所述免疫细胞在体内接触。
实施例C124.根据实施例C119至C123中任一项所述的方法,其中所述免疫细胞选自以下组成的组:未成熟胸腺细胞、外周血淋巴细胞、初始T细胞、多能Th细胞前体、淋巴祖细胞、Treg细胞、记忆T细胞、Th17细胞、Th22细胞、Th9细胞、Th2细胞、Th1细胞、Th3细胞、γδT细胞、αβT细胞、肿瘤浸润性T细胞、CD8+T细胞、CD4+T细胞、自然杀伤T细胞、肥大细胞、巨噬细胞、嗜中性粒细胞、树突状细胞、嗜碱性粒细胞、嗜酸性粒细胞和自然杀伤细胞。
实施例C125.根据实施例C119至C124中任一项所述的方法,其中所述免疫细胞先前已经过基因修饰以表达嵌合抗原受体或重组T细胞受体。
实施例C126.根据实施例C119至C124中任一项所述的方法,其中所述方法进一步包含在接触步骤之后,将编码嵌合抗原受体或重组T细胞受体的核酸引入到所述免疫细胞中。
实施例C127.根据实施例C119至C126中任一项所述的方法,其中所述方法进一步包含向有需要的受试者施用所述免疫细胞。
实施例C128.根据实施例C127所述的方法,其中所述受试者已被鉴别或诊断为患有与年龄相关的疾病或病况。
实施例C129.根据实施例C128所述的方法,其中所述与年龄相关的疾病或病况选自以下组成的组:阿尔茨海默氏病、动脉瘤、囊性纤维化、胰腺炎纤维化、青光眼、高血压、特发性肺纤维化、炎性肠病、椎间盘退变、黄斑变性、骨关节炎、2型糖尿病、脂肪萎缩、脂肪营养不良、动脉粥样硬化、白内障、COPD、特发性肺纤维化、肾移植失败、肝纤维化、骨量损失、心肌梗死、肌肉减少症、伤口愈合、脱发、心肌细胞肥大、骨关节炎、帕金森氏病、与年龄相关的肺组织弹性丧失、黄斑变性、恶病质、肾小球硬化、肝硬化、NAFLD、骨质疏松症、肌萎缩性侧索硬化症、亨廷顿氏病、脊髓小脑共济失调、多发性硬化症和肾功能不全。
实施例C130.根据实施例C127所述的方法,其中所述受试者已被鉴别或诊断为患有癌症。
实施例C131.根据实施例C130所述的方法,其中所述癌症选自以下组成的组:实体肿瘤、血液肿瘤、肉瘤、骨肉瘤、成胶质细胞瘤、成神经细胞瘤、黑色素瘤、横纹肌肉瘤、尤文氏肉瘤、骨肉瘤、B细胞瘤、多发性骨髓瘤、B细胞淋巴瘤、B细胞非霍奇金氏淋巴瘤、霍奇金氏淋巴瘤、慢性淋巴细胞性白血病(CLL)、急性骨髓性白血病(AML)、慢性骨髓性白血病(CML)、急性淋巴细胞性白血病(ALL)、骨髓增生异常综合症(MDS)、皮肤T细胞淋巴瘤、成视网膜细胞瘤、胃癌、尿路上皮癌、肺癌、肾细胞癌、胃和食管癌、胰腺癌、前列腺癌、乳腺癌、结直肠癌、卵巢癌、非小细胞肺癌、鳞状细胞头颈癌、子宫内膜癌、宫颈癌、肝癌和肝细胞癌。
实施例C132.根据实施例C127所述的方法,其中所述受试者已被诊断或鉴别为患有感染性疾病。
实施例C133.根据实施例C127所述的方法,其中所述感染性疾病是感染人免疫缺陷病毒、巨细胞病毒、腺病毒、冠状病毒、鼻病毒、轮状病毒、天花、单纯疱疹病毒、乙型肝炎病毒、甲型肝炎病毒和丙型肝炎病毒、乳头瘤病毒和流感病毒。
实施例C134.一种诱导免疫细胞分化成记忆或记忆样免疫细胞的方法,所述方法包含:
使免疫细胞与有效量的根据实施例C1至C100所述的多链嵌合多肽中的任一种或根据实施例C101或C102所述的组合物接触。
实施例C135.根据实施例C134所述的方法,其中所述免疫细胞在体外接触。
实施例C136.根据实施例C135所述的方法,其中所述免疫细胞先前获自受试者。
实施例C137.根据实施例C136所述的方法,其中所述方法进一步包含在接触步骤之前从所述受试者获得所述免疫细胞。
实施例C138.根据实施例C134所述的方法,其中所述免疫细胞在体内接触。
实施例C139.根据实施例C134至C138中任一项所述的方法,其中所述免疫细胞选自以下组成的组:未成熟胸腺细胞、外周血淋巴细胞、初始T细胞、多能Th细胞前体、淋巴祖细胞、Treg细胞、Th17细胞、Th22细胞、Th9细胞、Th2细胞、Th1细胞、Th3细胞、γδT细胞、αβT细胞、肿瘤浸润性T细胞、CD8+T细胞、CD4+T细胞、自然杀伤T细胞、肥大细胞、巨噬细胞、嗜中性粒细胞、树突状细胞、嗜碱性粒细胞、嗜酸性粒细胞和自然杀伤细胞。
实施例C140.根据实施例C134至C139中任一项所述的方法,其中所述免疫细胞先前已经过基因修饰以表达嵌合抗原受体或重组T细胞受体。
实施例C141.根据实施例C134至C139中任一项所述的方法,其中所述方法进一步包含在接触步骤之后,将编码嵌合抗原受体或重组T细胞受体的核酸引入到所述免疫细胞中。
实施例C142.根据实施例C134至C141中任一项所述的方法,其中所述方法进一步包含向有需要的受试者施用所述免疫细胞。
实施例C143.根据实施例C142所述的方法,其中所述受试者已被鉴别或诊断为患有与年龄相关的疾病或病况。
实施例C144.根据实施例C143所述的方法,其中所述与年龄相关的疾病或病况选自以下组成的组:阿尔茨海默氏病、动脉瘤、囊性纤维化、胰腺炎纤维化、青光眼、高血压、特发性肺纤维化、炎性肠病、椎间盘退变、黄斑变性、骨关节炎、2型糖尿病、脂肪萎缩、脂肪营养不良、动脉粥样硬化、白内障、COPD、特发性肺纤维化、肾移植失败、肝纤维化、骨量损失、心肌梗死、肌肉减少症、伤口愈合、脱发、心肌细胞肥大、骨关节炎、帕金森氏病、与年龄相关的肺组织弹性丧失、黄斑变性、恶病质、肾小球硬化、肝硬化、NAFLD、骨质疏松症、肌萎缩性侧索硬化症、亨廷顿氏病、脊髓小脑共济失调、多发性硬化症和肾功能不全。
实施例C145.根据实施例C142所述的方法,其中所述受试者已被鉴别或诊断为患有癌症。
实施例C146.根据实施例C145所述的方法,其中所述癌症选自以下组成的组:实体肿瘤、血液肿瘤、肉瘤、骨肉瘤、成胶质细胞瘤、成神经细胞瘤、黑色素瘤、横纹肌肉瘤、尤文氏肉瘤、骨肉瘤、B细胞瘤、多发性骨髓瘤、B细胞淋巴瘤、B细胞非霍奇金氏淋巴瘤、霍奇金氏淋巴瘤、慢性淋巴细胞性白血病(CLL)、急性骨髓性白血病(AML)、慢性骨髓性白血病(CML)、急性淋巴细胞性白血病(ALL)、骨髓增生异常综合症(MDS)、皮肤T细胞淋巴瘤、成视网膜细胞瘤、胃癌、尿路上皮癌、肺癌、肾细胞癌、胃和食管癌、胰腺癌、前列腺癌、乳腺癌、结直肠癌、卵巢癌、非小细胞肺癌、鳞状细胞头颈癌、子宫内膜癌、宫颈癌、肝癌和肝细胞癌。
实施例C147.根据实施例C142所述的方法,其中所述受试者已被诊断或鉴别为患有感染性疾病。
实施例C148.根据实施例C147所述的方法,其中所述感染性疾病是感染人免疫缺陷病毒、巨细胞病毒、腺病毒、冠状病毒、鼻病毒、轮状病毒、天花、单纯疱疹病毒、乙型肝炎病毒、甲型肝炎病毒和丙型肝炎病毒、乳头瘤病毒和流感病毒。
实施例C149.一种在有需要的受试者中杀死癌细胞、受感染细胞或衰老细胞的方法,所述方法包含向所述受试者施用治疗有效量的根据实施例C1至C100所述的多链嵌合多肽中的任一种或根据实施例C101或C102所述的组合物。
实施例C150.根据实施例C149所述的方法,其中所述受试者已被鉴别或诊断为患有癌症。
实施例C151.根据实施例C150所述的方法,其中所述癌症选自以下组成的组:实体肿瘤、血液肿瘤、肉瘤、骨肉瘤、成胶质细胞瘤、成神经细胞瘤、黑色素瘤、横纹肌肉瘤、尤文氏肉瘤、骨肉瘤、B细胞瘤、多发性骨髓瘤、B细胞淋巴瘤、B细胞非霍奇金氏淋巴瘤、霍奇金氏淋巴瘤、慢性淋巴细胞性白血病(CLL)、急性骨髓性白血病(AML)、慢性骨髓性白血病(CML)、急性淋巴细胞性白血病(ALL)、骨髓增生异常综合症(MDS)、皮肤T细胞淋巴瘤、成视网膜细胞瘤、胃癌、尿路上皮癌、肺癌、肾细胞癌、胃和食管癌、胰腺癌、前列腺癌、乳腺癌、结直肠癌、卵巢癌、非小细胞肺癌、鳞状细胞头颈癌、子宫内膜癌、宫颈癌、肝癌和肝细胞癌。
实施例C152.根据实施例C149所述的方法,其中所述受试者已被鉴别或诊断为患有与老化相关的疾病或病况。
实施例C153.根据实施例C152所述的方法,其中所述与老化相关的疾病或病况选自以下组成的组:阿尔茨海默氏病、动脉瘤、囊性纤维化、胰腺炎纤维化、青光眼、高血压、特发性肺纤维化、炎性肠病、椎间盘退变、黄斑变性、骨关节炎、2型糖尿病、脂肪萎缩、脂肪营养不良、动脉粥样硬化、白内障、COPD、特发性肺纤维化、肾移植失败、肝纤维化、骨量损失、心肌梗死、肌肉减少症、伤口愈合、脱发、心肌细胞肥大、骨关节炎、帕金森氏病、与年龄相关的肺组织弹性丧失、黄斑变性、恶病质、肾小球硬化、肝硬化、NAFLD、骨质疏松症、肌萎缩性侧索硬化症、亨廷顿氏病、脊髓小脑共济失调、多发性硬化症和肾功能不全。
实施例C154.一种治疗有需要的受试者的方法,所述方法包含向所述受试者施用治疗有效量的根据实施例C1至C100所述的多链嵌合多肽中的任一种或根据实施例C101或C102所述的组合物。
实施例C155.根据实施例C154所述的方法,其中所述受试者已被鉴别或诊断为患有癌症或感染性疾病。
实施例C156.根据实施例C157所述的方法,其中所述癌症选自以下组成的组:实体肿瘤、血液肿瘤、肉瘤、骨肉瘤、成胶质细胞瘤、成神经细胞瘤、黑色素瘤、横纹肌肉瘤、尤文氏肉瘤、骨肉瘤、B细胞瘤、多发性骨髓瘤、B细胞淋巴瘤、B细胞非霍奇金氏淋巴瘤、霍奇金氏淋巴瘤、慢性淋巴细胞性白血病(CLL)、急性骨髓性白血病(AML)、慢性骨髓性白血病(CML)、急性淋巴细胞性白血病(ALL)、骨髓增生异常综合症(MDS)、皮肤T细胞淋巴瘤、成视网膜细胞瘤、胃癌、尿路上皮癌、肺癌、肾细胞癌、胃和食管癌、胰腺癌、前列腺癌、乳腺癌、结直肠癌、卵巢癌、非小细胞肺癌、鳞状细胞头颈癌、子宫内膜癌、宫颈癌、肝癌和肝细胞癌。
实施例C157.根据实施例C154所述的方法,其中所述受试者已被鉴别或诊断为患有与年龄相关的疾病或病况。
实施例C158.根据实施例C157所述的方法,其中所述与年龄相关的疾病或病况选自以下组成的组:阿尔茨海默氏病、动脉瘤、囊性纤维化、胰腺炎纤维化、青光眼、高血压、特发性肺纤维化、炎性肠病、椎间盘退变、黄斑变性、骨关节炎、2型糖尿病、脂肪萎缩、脂肪营养不良、动脉粥样硬化、白内障、COPD、特发性肺纤维化、肾移植失败、肝纤维化、骨量损失、心肌梗死、肌肉减少症、伤口愈合、脱发、心肌细胞肥大、骨关节炎、帕金森氏病、与年龄相关的肺组织弹性丧失、黄斑变性、恶病质、肾小球硬化、肝硬化、NAFLD、骨质疏松症、肌萎缩性侧索硬化症、亨廷顿氏病、脊髓小脑共济失调、多发性硬化症和肾功能不全。
实施例C159.根据实施例C154所述的方法,其中所述受试者已被诊断或鉴别为患有感染性疾病。
实施例C160.根据实施例C159所述的方法,其中所述感染性疾病是感染人免疫缺陷病毒、巨细胞病毒、腺病毒、冠状病毒、鼻病毒、轮状病毒、天花、单纯疱疹病毒、乙型肝炎病毒、甲型肝炎病毒和丙型肝炎病毒、乳头瘤病毒和流感病毒。
实施例C161.核酸,其编码根据实施例C1至C100中任一项所述的多链嵌合多肽中的任一种。
实施例C162.一种载体,其包含根据实施例C161所述的核酸。
实施例C163.根据实施例C162所述的载体,其中所述载体是表达载体。
实施例C164.一种细胞,其包含根据实施例C161所述的核酸或根据实施例C162或C163所述的载体。
实施例C165.一种产生多链嵌合多肽的方法,所述方法包含:
在足以引起产生所述多链嵌合多肽的条件下在培养基中培养根据实施例C164所述的细胞;和
从所述细胞和/或所述培养基中回收所述多链嵌合多肽。
实施例C166.一种多链嵌合多肽,其通过根据实施例C165所述的方法产生。
实施例C167.根据实施例C12所述的多链嵌合多肽,其中所述可溶性人组织因子结构域包含与SEQ ID NO:3至少80%相同的序列。
实施例C168.根据实施例C167所述的多链嵌合多肽,其中所述可溶性人组织因子结构域包含与SEQ ID NO:3至少90%相同的序列。
实施例C169.根据实施例C168所述的多链嵌合多肽,其中所述可溶性人组织因子结构域包含与SEQ ID NO:3至少95%相同的序列。
实施例C170.根据实施例C169所述的多链嵌合多肽,其中所述可溶性人组织因子结构域包含与SEQ ID NO:3100%相同的序列。
实施例C171.根据实施例C12所述的多链嵌合多肽,其中所述可溶性人组织因子结构域包含与SEQ ID NO:4至少80%相同的序列。
实施例C172.根据实施例C171所述的多链嵌合多肽,其中所述可溶性人组织因子结构域包含与SEQ ID NO:4至少90%相同的序列。
实施例C173.根据实施例C172所述的多链嵌合多肽,其中所述可溶性人组织因子结构域包含与SEQ ID NO:4至少95%相同的序列。
实施例C174.根据实施例C173所述的多链嵌合多肽,其中所述可溶性人组织因子结构域包含与SEQ ID NO:4100%相同的序列。
D.示例性实施例
实施例D1.一种多链嵌合多肽,其包含:
(c)第一嵌合多肽,其包含:
(i)第一靶标结合结构域;
(ii)可溶性组织因子结构域;和
(iii)一对亲和结构域中的第一结构域;
(d)第二嵌合多肽,其包含:
(i)一对亲和结构域中的第二结构域;和
(ii)第二靶标结合结构域,
其中:
所述第一嵌合多肽和所述第二嵌合多肽通过所述一对亲和结构域中的所述第一结构域和所述第二结构域的结合而缔合;
所述第一靶标结合结构域和所述第二靶标结合结构域各自独立地特异性结合到IL-21的受体或IL-7的受体。
实施例D2.根据实施例D1所述的多链嵌合多肽,其中所述第一靶标结合结构域和所述可溶性组织因子结构域在所述第一嵌合多肽中彼此直接邻接。
实施例D3.根据实施例D1所述的多链嵌合多肽,其中所述第一嵌合多肽进一步包含所述第一嵌合多肽中的所述第一靶标结合结构域与所述可溶性组织因子结构域之间的接头序列。
实施例D4.根据实施例D1至D3中任一项所述的多链嵌合多肽,其中所述可溶性组织因子结构域和所述一对亲和结构域中的所述第一结构域在所述第一嵌合多肽中彼此直接邻接。
实施例D5.根据实施例D1至D3中任一项所述的多链嵌合多肽,其中所述第一嵌合多肽进一步包含所述第一嵌合多肽中的所述可溶性组织因子结构域与所述一对亲和结构域中的所述第一结构域之间的接头序列。
实施例D6.根据实施例D1至D5中任一项所述的多链嵌合多肽,其中所述一对亲和结构域中的所述第二结构域和所述第二靶标结合结构域在所述第二嵌合多肽中彼此直接邻接。
实施例D7.根据实施例D1至D5中任一项所述的多链嵌合多肽,其中所述第二嵌合多肽进一步包含所述第二嵌合多肽中的所述一对亲和结构域中的所述第二结构域与所述第二靶标结合结构域之间的接头序列。
实施例D8.根据实施例D1至D7中任一项所述的多链嵌合多肽,其中所述可溶性组织因子结构域是可溶性人组织因子结构域。
实施例D9.根据实施例D8所述的多链嵌合多肽,其中所述可溶性人组织因子结构域包含与SEQ ID NO:1至少80%相同的序列。
实施例D10.根据实施例D9所述的多链嵌合多肽,其中所述可溶性人组织因子结构域包含与SEQ ID NO:1至少90%相同的序列。
实施例D11.根据实施例D10所述的多链嵌合多肽,其中所述可溶性人组织因子结构域包含与SEQ ID NO:1至少95%相同的序列。
实施例D12.根据实施例D11所述的多链嵌合多肽,其中所述可溶性人组织因子结构域包含SEQ ID NO:1。
实施例D13.根据实施例D8所述的多链嵌合多肽,其中所述可溶性人组织因子结构域包含与SEQ ID NO:3至少80%相同的序列。
实施例D14.根据实施例D13所述的多链嵌合多肽,其中所述可溶性人组织因子结构域包含与SEQ ID NO:3至少90%相同的序列。
实施例D15.根据实施例D14所述的多链嵌合多肽,其中所述可溶性人组织因子结构域包含与SEQ ID NO:3至少95%相同的序列。
实施例D16.根据实施例D15所述的多链嵌合多肽,其中所述可溶性人组织因子结构域包含SEQ ID NO:3。
实施例D17.根据实施例D8所述的多链嵌合多肽,其中所述可溶性人组织因子结构域包含与SEQ ID NO:4至少80%相同的序列。
实施例D18.根据实施例D17所述的多链嵌合多肽,其中所述可溶性人组织因子结构域包含与SEQ ID NO:4至少90%相同的序列。
实施例D19.根据实施例D18所述的多链嵌合多肽,其中所述可溶性人组织因子结构域包含与SEQ ID NO:4至少95%相同的序列。
实施例D20.根据实施例D19所述的多链嵌合多肽,其中所述可溶性人组织因子结构域包含SEQ ID NO:4。
实施例D21.根据实施例D8至D11、D13至D15和D17至D19中任一项所述的多链嵌合多肽,其中所述可溶性人组织因子结构域不包含以下中的一种或多种:
在对应于成熟野生型人组织因子蛋白的氨基酸位置20的氨基酸位置处的赖氨酸;
在对应于成熟野生型人组织因子蛋白的氨基酸位置22的氨基酸位置处的异亮氨酸;
在对应于成熟野生型人组织因子蛋白的氨基酸位置45的氨基酸位置处的色氨酸;
在对应于成熟野生型人组织因子蛋白的氨基酸位置58的氨基酸位置处的天冬氨酸;
在对应于成熟野生型人组织因子蛋白的氨基酸位置94的氨基酸位置处的酪氨酸;
在对应于成熟野生型人组织因子蛋白的氨基酸位置135的氨基酸位置处的精氨酸;和
在对应于成熟野生型人组织因子蛋白的氨基酸位置140的氨基酸位置处的苯丙氨酸。
实施例D22.根据实施例D21所述的多链嵌合多肽,其中所述可溶性人组织因子结构域不包含以下中的任一种:
在对应于成熟野生型人组织因子蛋白的氨基酸位置20的氨基酸位置处的赖氨酸;
在对应于成熟野生型人组织因子蛋白的氨基酸位置22的氨基酸位置处的异亮氨酸;
在对应于成熟野生型人组织因子蛋白的氨基酸位置45的氨基酸位置处的色氨酸;
在对应于成熟野生型人组织因子蛋白的氨基酸位置58的氨基酸位置处的天冬氨酸;
在对应于成熟野生型人组织因子蛋白的氨基酸位置94的氨基酸位置处的酪氨酸;
在对应于成熟野生型人组织因子蛋白的氨基酸位置135的氨基酸位置处的精氨酸;和
在对应于成熟野生型人组织因子蛋白的氨基酸位置140的氨基酸位置处的苯丙氨酸。
实施例D23.根据实施例D1至D22中任一项所述的多链嵌合多肽,其中所述可溶性组织因子结构域不能结合到因子VIIa。
实施例D24.根据实施例D1至D23中任一项所述的多链嵌合多肽,其中所述可溶性组织因子结构域不将非活性因子X转化为因子Xa。
实施例D25.根据实施例D1至D24中任一项所述的多链嵌合多肽,其中所述多链嵌合多肽不刺激哺乳动物中的凝结。
实施例D26.根据实施例D1至D25中任一项的所述多链嵌合多肽,其中所述第一嵌合多肽进一步包含在所述第一嵌合多肽的N端或C端的肽标签。
实施例D27.根据实施例D1至D26中任一项所述的多链嵌合多肽,其中所述第二嵌合多肽进一步包含在所述第二嵌合多肽的N端或C端的肽标签。
实施例D28.根据实施例D1至D27中任一项所述的多链嵌合多肽,其中所述第一嵌合多肽和/或所述第二嵌合多肽在其N端进一步包含信号序列。
实施例D29.根据实施例D28所述的多链嵌合多肽,其中所述信号序列包含SEQ IDNO:31。
实施例D30.根据实施例D28所述的多链嵌合多肽,其中所述信号序列是SEQ IDNO:223。
实施例D31.根据实施例D1至D30中任一项所述的多链嵌合多肽,其中所述一对亲和结构域是来自人IL-15受体的α链(IL15Rα)的寿司结构域和可溶性IL-15。
实施例D32.根据实施例D31所述的多链嵌合多肽,其中所述可溶性IL-15具有D8N或D8A氨基酸取代。
实施例D33.根据实施例D31所述的多链嵌合多肽,其中所述可溶性IL-15包含与SEQ ID NO:14至少80%相同的序列。
实施例D34.根据实施例D33所述的多链嵌合多肽,其中所述可溶性IL-15包含与SEQ ID NO:14至少90%相同的序列。
实施例D35.根据实施例D34所述的多链嵌合多肽,其中所述可溶性IL-15包含与SEQ ID NO:14至少95%相同的序列。
实施例D36.根据实施例D35所述的多链嵌合多肽,其中所述可溶性IL-15包含SEQID NO:14。
实施例D37.根据实施例D31至D36中任一项所述的多链嵌合多肽,其中IL15Rα的寿司结构域包含来自人IL15Rα的寿司结构域。
实施例D38.根据实施例D37所述的多链嵌合多肽,其中来自人IL15Rα的所述寿司结构域包含与SEQ ID NO:28至少80%相同的序列。
实施例D39.根据实施例D38所述的多链嵌合多肽,其中来自人IL15Rα的所述寿司结构域包含与SEQ ID NO:28至少90%相同的序列。
实施例D40.根据实施例D39所述的多链嵌合多肽,其中来自人IL15Rα的所述寿司结构域包含与SEQ ID NO:28至少95%相同的序列。
实施例D41.根据实施例D40所述的多链嵌合多肽,其中来自人IL15Rα的所述寿司结构域包含SEQ ID NO:28。
实施例D42.根据实施例D37所述的多链嵌合多肽,其中来自人IL15Rα的所述寿司结构域是成熟全长IL15Rα。
实施例D43.根据实施例D1至D30中任一项所述的多链嵌合多肽,其中所述一对亲和结构域选自以下组成的组:芽胞杆菌RNA酶和芽胞杆菌RNA酶抑制子、PKA和AKAP、基于突变核糖核酸酶I片段的衔接子/对接标签模块以及基于蛋白质突触蛋白、突触结合蛋白、突触泡蛋白和SNAP25的相互作用的SNARE模块。
实施例D44.根据实施例D1至D43中任一项所述的多链嵌合多肽,其中所述第一靶标结合结构域和所述第二靶标结合结构域中的一个或两个是激动性抗原结合结构域。
实施例D45.根据实施例D44所述的多链嵌合多肽,其中所述第一靶标结合结构域和所述第二靶标结合结构域各自是激动性抗原结合结构域。
实施例D46.根据实施例D44或D45所述的多链嵌合多肽,其中抗原结合结构域包含scFv或单结构域抗体。
实施例D47.根据实施例D1至D43中任一项所述的多链嵌合多肽,其中所述第一靶标结合结构域和所述第二靶标结合结构域中的一个或两个是可溶性IL-21或可溶性IL-7。
实施例D48.根据实施例D47所述的多链嵌合多肽,其中所述第一靶标结合结构域和所述第二靶标结合结构域各自独立地为可溶性IL-21或可溶性IL-7。
实施例D49.根据实施例D1至D48中任一项所述的多链嵌合多肽,其中所述第一靶标结合结构域和所述第二靶标结合结构域均特异性结合到IL-21的受体或IL-7的受体。
实施例D50.根据实施例D49所述的多链嵌合多肽,其中所述第一靶标结合结构域和所述第二靶标结合结构域特异性结合到相同的表位。
实施例D51.根据实施例D50所述的多链嵌合多肽,其中所述第一靶标结合结构域和所述第二靶标结合结构域包含相同的氨基酸序列。
实施例D52.根据实施例D1至D48中任一项所述的多链嵌合多肽,其中所述第一靶标结合结构域特异性结合到IL-21的受体,并且所述第二靶标结合结构域特异性结合到IL-7的受体。
实施例D53.根据实施例D1至D48中任一项所述的多链嵌合多肽,其中所述第一靶标结合结构域特异性结合到IL-7的受体,并且所述第二靶标结合结构域特异性结合到IL-21的受体。
实施例D54.根据实施例D53所述的多链嵌合多肽,其中所述第一靶标结合结构域包含可溶性IL-21。
实施例D55.根据实施例D54所述的多链嵌合多肽,其中所述可溶性IL-21是可溶性人IL-21。
实施例D56.根据实施例D55所述的多链嵌合多肽,其中所述可溶性人IL-21包含与SEQ ID NO:78至少80%相同的序列。
实施例D57.根据实施例D56所述的多链嵌合多肽,其中所述可溶性人IL-21包含与SEQ ID NO:78至少90%相同的序列。
实施例D58.根据实施例D57所述的多链嵌合多肽,其中所述可溶性人IL-21包含与SEQ ID NO:78至少95%相同的序列。
实施例D59.根据实施例D58所述的多链嵌合多肽,其中所述可溶性人IL-21包含SEQ ID NO:78的序列。
实施例D60.根据实施例D53至D59中任一项所述的多链嵌合多肽,其中所述第二靶标结合结构域包含可溶性IL-7。
实施例D61.根据实施例D60所述的多链嵌合多肽,其中所述可溶性IL-7是可溶性人IL-7。
实施例D62.根据实施例D61所述的多链嵌合多肽,其中所述可溶性人IL-7包含与SEQ ID NO:11至少80%相同的序列。
实施例D63.根据实施例D62所述的多链嵌合多肽,其中所述可溶性人IL-7包含与SEQ ID NO:11至少90%相同的序列。
实施例D64.根据实施例D63所述的多链嵌合多肽,其中所述可溶性人IL-7包含与SEQ ID NO:11至少95%相同的序列。
实施例D65.根据实施例D64所述的多链嵌合多肽,其中所述可溶性人IL-7包含SEQID NO:11的序列。
实施例D66.根据实施例D1所述的多链嵌合多肽,其中所述第一嵌合多肽包含与SEQ ID NO:104至少80%相同的序列。
实施例D67.根据实施例D66所述的多链嵌合多肽,其中所述第一嵌合多肽包含与SEQ ID NO:104至少90%相同的序列。
实施例D68.根据实施例D67所述的多链嵌合多肽,其中所述第一嵌合多肽包含与SEQ ID NO:104至少95%相同的序列。
实施例D69.根据实施例D68所述的多链嵌合多肽,其中所述第一嵌合多肽包含SEQID NO:104。
实施例D70.根据实施例D69所述的多链嵌合多肽,其中所述第一嵌合多肽包含SEQID NO:106。
实施例D71.根据实施例D1和D66至D70中任一项所述的多链嵌合多肽,其中所述第二嵌合多肽包含与SEQ ID NO:108至少80%相同的序列。
实施例D72.根据实施例D71所述的多链嵌合多肽,其中所述第二嵌合多肽包含与SEQ ID NO:108至少90%相同的序列。
实施例D73.根据实施例D72所述的多链嵌合多肽,其中所述第二嵌合多肽包含与SEQ ID NO:108至少95%相同的序列。
实施例D74.根据实施例D73所述的多链嵌合多肽,其中所述第二嵌合多肽包含SEQID NO:108。
实施例D75.根据实施例D74所述的多链嵌合多肽,其中所述第二嵌合多肽包含SEQID NO:110。
实施例D76.根据实施例D1所述的多链嵌合多肽,其中所述第一嵌合多肽包含与SEQ ID NO:96至少80%相同的序列。
实施例D77.根据实施例D76所述的多链嵌合多肽,其中所述第一嵌合多肽包含与SEQ ID NO:96至少90%相同的序列。
实施例D78.根据实施例D77所述的多链嵌合多肽,其中所述第一嵌合多肽包含与SEQ ID NO:96至少95%相同的序列。
实施例D79.根据实施例D68所述的多链嵌合多肽,其中所述第一嵌合多肽包含SEQID NO:96。
实施例D80.根据实施例D69所述的多链嵌合多肽,其中所述第一嵌合多肽包含SEQID NO:98。
实施例D81.根据实施例D1和D76至D80中任一项所述的多链嵌合多肽,其中所述第二嵌合多肽包含与SEQ ID NO:100至少80%相同的序列。
实施例D82.根据实施例D81所述的多链嵌合多肽,其中所述第二嵌合多肽包含与SEQ ID NO:100至少90%相同的序列。
实施例D83.根据实施例D82所述的多链嵌合多肽,其中所述第二嵌合多肽包含与SEQ ID NO:100至少95%相同的序列。
实施例D84.根据实施例D83所述的多链嵌合多肽,其中所述第二嵌合多肽包含SEQID NO:100。
实施例D85.根据实施例D84所述的多链嵌合多肽,其中所述第二嵌合多肽包含SEQID NO:106。
实施例D86.根据实施例D1至D65中任一项所述的多链嵌合多肽,其中所述第一嵌合多肽进一步包含一个或多个另外的靶标结合结构域,其中所述一个或多个另外的抗原结合结构域中的至少一个位于所述可溶性组织因子结构域与所述一对亲和结构域中的所述第一结构域之间。
实施例D87.根据实施例D86所述的多链嵌合多肽,其中所述第一嵌合多肽进一步包含在所述可溶性组织因子结构域与所述一个或多个另外的抗原结合结构域中的所述至少一个之间的接头序列,和/或在所述一个或多个另外的抗原结合结构域中的所述至少一个与所述一对亲和结构域中的所述第一结构域之间的接头序列。
实施例D88.根据实施例D1至D65中任一项所述的多链嵌合多肽,其中所述第一嵌合多肽在所述第一嵌合多肽的N端和/或C端进一步包含一个或多个另外的靶标结合结构域。
实施例D89.根据实施例D88所述的多链嵌合多肽,其中在所述第一嵌合多肽中,所述一个或多个另外的靶标结合结构域中的至少一个直接邻接所述一对亲和结构域中的所述第一结构域。
实施例D90.根据实施例D88所述的多链嵌合多肽,其中所述第一嵌合多肽进一步包含在所述一个或多个另外的靶标结合结构域中的所述至少一个与所述一对亲和结构域中的所述第一结构域之间的接头序列。
实施例D91.根据实施例D88所述的多链嵌合多肽,其中在所述第一嵌合多肽中,所述一个或多个另外的靶标结合结构域中的所述至少一个直接邻接所述第一靶标结合结构域。
实施例D92.根据实施例D88所述的多链嵌合多肽,其中所述第一嵌合多肽进一步包含在所述一个或多个另外的靶标结合结构域中的所述至少一个与所述第一靶标结合结构域之间的接头序列。
实施例D93.根据实施例D88所述的多链嵌合多肽,其中所述一个或多个另外的靶标结合结构域中的至少一个安置于所述第一嵌合多肽的N和/或C端,并且所述一个或多个另外的靶标结合结构域中的至少一个位于所述第一嵌合多肽中所述可溶性组织因子结构域与所述一对亲和结构域中的所述第一结构域之间。
实施例D94.根据实施例D93所述的多链嵌合多肽,其中在所述第一嵌合多肽中,安置于N端的所述一个或多个另外的靶标结合结构域中的至少一个另外的靶标结合结构域直接邻接所述第一靶标结合结构域或所述一对亲和结构域中的所述第一结构域。
实施例D95.根据实施例D93所述的多链嵌合多肽,其中所述第一嵌合多肽进一步包含安置于所述第一嵌合多肽中的所述至少一个另外的靶标结合结构域与所述第一靶标结合结构域或所述一对亲和结构域中的所述第一结构域之间的接头序列。
实施例D96.根据实施例D93所述的多链嵌合多肽,其中在所述第一嵌合多肽中,安置于C端的所述一个或多个另外的靶标结合结构域中的至少一个另外的靶标结合结构域直接邻接所述第一靶标结合结构域或所述一对亲和结构域中的所述第一结构域。
实施例D97.根据实施例D93所述的多链嵌合多肽,其中所述第一嵌合多肽进一步包含安置于所述第一嵌合多肽中的所述至少一个另外的靶标结合结构域与所述第一靶标结合结构域或所述一对亲和结构域中的所述第一结构域之间的接头序列。
实施例D98.根据实施例D93所述的多链嵌合多肽,其中位于所述可溶性组织因子结构域与所述一对亲和结构域中的所述第一结构域之间的所述一个或多个另外的靶标结合结构域中的所述至少一个,直接邻接所述可溶性组织因子结构域和/或所述一对亲和结构域中的所述第一结构域。
实施例D99.根据实施例D93所述的多链嵌合多肽,其中所述第一嵌合多肽进一步包含安置于以下的接头序列:(i)所述可溶性组织因子结构域与所述一个或多个另外的靶标结合结构域中的所述至少一个之间,所述一个或多个另外的靶标结合结构域中的所述至少一个位于所述可溶性组织因子结构域与所述一对亲和结构域中的所述第一结构域之间,和/或(ii)所述一对亲和结构域中的所述第一结构域与所述一个或多个另外的靶标结合结构域中的所述至少一个之间,所述一个或多个另外的靶标结合结构域中的所述至少一个位于所述可溶性组织因子结构域与所述一对亲和结构域中的所述第一结构域之间。
实施例D100.根据实施例D1至D65和D86至D99中任一项所述的多链嵌合多肽,其中所述第二嵌合多肽在所述第二嵌合多肽的N端或C端进一步包含一个或多个另外的靶标结合结构域。
实施例D101.根据实施例D100所述的多链嵌合多肽,其中在所述第二嵌合多肽中,所述一个或多个另外的靶标结合结构域中的至少一个直接邻接所述一对亲和结构域中的所述第二结构域。
实施例D102.根据实施例D100所述的多链嵌合多肽,其中所述第二嵌合多肽进一步包含所述第二嵌合多肽中的所述一个或多个另外的靶标结合结构域中的至少一个与所述一对亲和结构域中的所述第二结构域之间的接头序列。
实施例D103.根据实施例D100所述的多链嵌合多肽,其中在所述第二嵌合多肽中,所述一个或多个另外的靶标结合结构域中的至少一个直接邻接所述第二靶标结合结构域。
实施例D104.根据实施例D100所述的多链嵌合多肽,其中所述第二嵌合多肽进一步包含所述第二嵌合多肽中的所述一个或多个另外的靶标结合结构域中的至少一个与所述第二靶标结合结构域之间的接头序列。
实施例D105.根据实施例D86至D104中任一项所述的多链嵌合多肽,其中所述第一靶标结合结构域、所述第二靶标结合结构域和所述一个或多个另外的靶标结合结构域中的两个或更多个特异性结合到相同的抗原。
实施例D106.根据实施例D105所述的多链嵌合多肽,其中所述第一靶标结合结构域、所述第二靶标结合结构域和所述一个或多个另外的靶标结合结构域中的两个或更多个特异性结合到相同的表位。
实施例D107.根据实施例D106所述的多链嵌合多肽,其中所述第一靶标结合结构域、所述第二靶标结合结构域和所述一个或多个另外的靶标结合结构域中的两个或更多个包含相同的氨基酸序列。
实施例D108.根据实施例D86至D104中任一项所述的多链嵌合多肽,其中所述第一靶标结合结构域、所述第二靶标结合结构域和所述一个或多个另外的靶标结合结构域特异性结合到不同的抗原。
实施例D109.根据实施例D86至D108中任一项所述的多链嵌合多肽,其中所述一个或多个另外的抗原结合结构域特异性结合到选自以下组成的组的靶标:CD16a、CD28、CD3、CD33、CD20、CD19、CD22、CD123、IL-1R、IL-1、VEGF、IL-6R、IL-4、IL-10、PDL-1、TIGIT、PD-1、TIM3、CTLA4、MICA、MICB、IL-6、IL-8、TNFα、CD26a、CD36、ULBP2、CD30、CD200、IGF-1R、MUC4AC、MUC5AC、Trop-2、CMET、EGFR、HER1、HER2、HER3、PSMA、CEA、B7H3、EPCAM、BCMA、P-钙黏着蛋白、CEACAM5、UL16结合蛋白、HLA-DR、DLL4、TYRO3、AXL、MER、CD122、CD155、PDGF-DD、TGF-β受体II(TGF-βRII)的配体、TGF-βRIII的配体、DNAM-1的配体、NKp46的配体、NKp44的配体、NKG2D的配体、NKp30的配体、scMHCI的配体、scMHCII的配体、scTCR的配体、IL-1的受体、IL-2的受体、IL-3的受体、IL-7的受体、IL-8的受体、IL-10的受体、IL-12的受体、IL-15的受体、IL-17的受体、IL-18的受体、IL-21的受体、PDGF-DD的受体、干细胞因子(SCF)的受体、干细胞样酪氨酸激酶3配体(FLT3L)的受体、MICA的受体、MICB的受体、ULP16结合蛋白的受体、CD155的受体和CD28的受体。
实施例D110.根据实施例D86至D108中任一项所述的多链嵌合多肽,其中所述一个或多个另外的靶标结合结构域是可溶性白介素或细胞因子蛋白。
实施例D111.根据实施例D110所述的多链嵌合多肽,其中所述可溶性白介素、细胞因子或配体蛋白选自以下组成的组:IL-1、IL-2、IL-3、IL-7、IL-8、IL-10、IL-12、IL-15、IL-17、IL-18、IL-21、PDGF-DD、SCF和FLT3L。
实施例D112.根据实施例D86至D108中任一项所述的多链嵌合多肽,其中所述一个或多个另外的靶标结合结构域是可溶性白介素或细胞因子受体。
实施例D113.根据实施例D112所述的多链嵌合多肽,其中所述可溶性受体是可溶性TGF-β受体II(TGF-βRII)、可溶性TGF-βRIII、可溶性NKG2D、可溶性NKp30、可溶性NKp44、可溶性NKp46、可溶性DNAM-1、scMHCI、scMHCII、scTCR、可溶性CD155、可溶性CD122或可溶性CD28。
实施例D114.一种组合物,其包含根据实施例D1至D113所述的多链嵌合多肽中的任一种。
实施例D115.根据实施例D114所述的组合物,其中所述组合物是药物组合物。
实施例D116.一种试剂盒,其包含至少一个剂量的根据实施例D114或D115所述的组合物。
实施例D117.一种刺激免疫细胞的方法,所述方法包含:
使免疫细胞与有效量的根据实施例D1至D113所述的多链嵌合多肽中的任一种或根据实施例D114或D115所述的组合物接触。
实施例D118.根据实施例D117所述的方法,其中所述免疫细胞在体外接触。
实施例D119.根据实施例D118所述的方法,其中所述免疫细胞先前获自受试者。
实施例D120.根据实施例D119所述的方法,其中所述方法进一步包含在接触步骤之前从所述受试者获得所述免疫细胞。
实施例D121.根据实施例D117所述的方法,其中所述免疫细胞在体内接触。
实施例D122.根据实施例D117至D121中任一项所述的方法,其中所述免疫细胞选自以下组成的组:未成熟胸腺细胞、外周血淋巴细胞、初始T细胞、多能Th细胞前体、淋巴祖细胞、Treg细胞、记忆T细胞、Th17细胞、Th22细胞、Th9细胞、Th2细胞、Th1细胞、Th3细胞、γδT细胞、αβT细胞、肿瘤浸润性T细胞、CD8+T细胞、CD4+T细胞、自然杀伤T细胞、肥大细胞、巨噬细胞、嗜中性粒细胞、树突状细胞、嗜碱性粒细胞、嗜酸性粒细胞和自然杀伤细胞。
实施例D123.根据实施例D117至D122中任一项所述的方法,其中所述免疫细胞先前已经过基因修饰以表达嵌合抗原受体或重组T细胞受体。
实施例D124.根据实施例D117至D122中任一项所述的方法,其中所述方法进一步包含在接触步骤之后,将编码嵌合抗原受体或重组T细胞受体的核酸引入到所述免疫细胞中。
实施例D125.根据实施例D117至D124中任一项所述的方法,其中所述方法进一步包含向有需要的受试者施用所述免疫细胞。
实施例D126.根据实施例D125所述的方法,其中所述受试者已被鉴别或诊断为患有与年龄相关的疾病或病况。
实施例D127.根据实施例D126所述的方法,其中所述与年龄相关的疾病或病况选自以下组成的组:阿尔茨海默氏病、动脉瘤、囊性纤维化、胰腺炎纤维化、青光眼、高血压、特发性肺纤维化、炎性肠病、椎间盘退变、黄斑变性、骨关节炎、2型糖尿病、脂肪萎缩、脂肪营养不良、动脉粥样硬化、白内障、COPD、特发性肺纤维化、肾移植失败、肝纤维化、骨量损失、心肌梗死、肌肉减少症、伤口愈合、脱发、心肌细胞肥大、骨关节炎、帕金森氏病、与年龄相关的肺组织弹性丧失、黄斑变性、恶病质、肾小球硬化、肝硬化、NAFLD、骨质疏松症、肌萎缩性侧索硬化症、亨廷顿氏病、脊髓小脑共济失调、多发性硬化症和肾功能不全。
实施例D128.根据实施例D125所述的方法,其中所述受试者已被鉴别或诊断为患有癌症。
实施例D129.根据实施例D128所述的方法,其中所述癌症选自以下组成的组:实体肿瘤、血液肿瘤、肉瘤、骨肉瘤、成胶质细胞瘤、成神经细胞瘤、黑色素瘤、横纹肌肉瘤、尤文氏肉瘤、骨肉瘤、B细胞瘤、多发性骨髓瘤、B细胞淋巴瘤、B细胞非霍奇金氏淋巴瘤、霍奇金氏淋巴瘤、慢性淋巴细胞性白血病(CLL)、急性骨髓性白血病(AML)、慢性骨髓性白血病(CML)、急性淋巴细胞性白血病(ALL)、骨髓增生异常综合症(MDS)、皮肤T细胞淋巴瘤、成视网膜细胞瘤、胃癌、尿路上皮癌、肺癌、肾细胞癌、胃和食管癌、胰腺癌、前列腺癌、乳腺癌、结直肠癌、卵巢癌、非小细胞肺癌、鳞状细胞头颈癌、子宫内膜癌、宫颈癌、肝癌和肝细胞癌。
实施例D130.根据实施例D125所述的方法,其中所述受试者已被诊断或鉴别为患有感染性疾病。
实施例D131.根据实施例D130所述的方法,其中所述感染性疾病是感染人免疫缺陷病毒、巨细胞病毒、腺病毒、冠状病毒、鼻病毒、轮状病毒、天花、单纯疱疹病毒、乙型肝炎病毒、甲型肝炎病毒、丙型肝炎病毒、乳头瘤病毒或流感病毒。
实施例D132.一种诱导或增加免疫细胞增殖的方法,所述方法包含:
使免疫细胞与有效量的根据实施例D1至D113所述的多链嵌合多肽中的任一种或根据实施例D114或D115所述的组合物接触。
实施例D133.根据实施例D132所述的方法,其中所述免疫细胞在体外接触。
实施例D134.根据实施例D133所述的方法,其中所述免疫细胞先前获自受试者。
实施例D135.根据实施例D134所述的方法,其中所述方法进一步包含在接触步骤之前从所述受试者获得所述免疫细胞。
实施例D136.根据实施例D132所述的方法,其中所述免疫细胞在体内接触。
实施例D137.根据实施例D132至D136中任一项所述的方法,其中所述免疫细胞选自以下组成的组:未成熟胸腺细胞、外周血淋巴细胞、初始T细胞、多能Th细胞前体、淋巴祖细胞、Treg细胞、记忆T细胞、Th17细胞、Th22细胞、Th9细胞、Th2细胞、Th1细胞、Th3细胞、γδT细胞、αβT细胞、肿瘤浸润性T细胞、CD8+T细胞、CD4+T细胞、自然杀伤T细胞、肥大细胞、巨噬细胞、嗜中性粒细胞、树突状细胞、嗜碱性粒细胞、嗜酸性粒细胞和自然杀伤细胞。
实施例D138.根据实施例D132至D137中任一项所述的方法,其中所述免疫细胞先前已经过基因修饰以表达嵌合抗原受体或重组T细胞受体。
实施例D139.根据实施例D132至D137中任一项所述的方法,其中所述方法进一步包含在接触步骤之后,将编码嵌合抗原受体或重组T细胞受体的核酸引入到所述免疫细胞中。
实施例D140.根据实施例D132至D139中任一项所述的方法,其中所述方法进一步包含向有需要的受试者施用所述免疫细胞。
实施例D141.根据实施例D140所述的方法,其中所述受试者已被鉴别或诊断为患有与年龄相关的疾病或病况。
实施例D142.根据实施例D141所述的方法,其中所述与年龄相关的疾病或病况选自以下组成的组:阿尔茨海默氏病、动脉瘤、囊性纤维化、胰腺炎纤维化、青光眼、高血压、特发性肺纤维化、炎性肠病、椎间盘退变、黄斑变性、骨关节炎、2型糖尿病、脂肪萎缩、脂肪营养不良、动脉粥样硬化、白内障、COPD、特发性肺纤维化、肾移植失败、肝纤维化、骨量损失、心肌梗死、肌肉减少症、伤口愈合、脱发、心肌细胞肥大、骨关节炎、帕金森氏病、与年龄相关的肺组织弹性丧失、黄斑变性、恶病质、肾小球硬化、肝硬化、NAFLD、骨质疏松症、肌萎缩性侧索硬化症、亨廷顿氏病、脊髓小脑共济失调、多发性硬化症和肾功能不全。
实施例D143.根据实施例D140所述的方法,其中所述受试者已被鉴别或诊断为患有癌症。
实施例D144.根据实施例D143所述的方法,其中所述癌症选自以下组成的组:实体肿瘤、血液肿瘤、肉瘤、骨肉瘤、成胶质细胞瘤、成神经细胞瘤、黑色素瘤、横纹肌肉瘤、尤文氏肉瘤、骨肉瘤、B细胞瘤、多发性骨髓瘤、B细胞淋巴瘤、B细胞非霍奇金氏淋巴瘤、霍奇金氏淋巴瘤、慢性淋巴细胞性白血病(CLL)、急性骨髓性白血病(AML)、慢性骨髓性白血病(CML)、急性淋巴细胞性白血病(ALL)、骨髓增生异常综合症(MDS)、皮肤T细胞淋巴瘤、成视网膜细胞瘤、胃癌、尿路上皮癌、肺癌、肾细胞癌、胃和食管癌、胰腺癌、前列腺癌、乳腺癌、结直肠癌、卵巢癌、非小细胞肺癌、鳞状细胞头颈癌、子宫内膜癌、宫颈癌、肝癌和肝细胞癌。
实施例D145.根据实施例D140所述的方法,其中所述受试者已被诊断或鉴别为患有感染性疾病。
实施例D146.根据实施例D140所述的方法,其中所述感染性疾病是感染人免疫缺陷病毒、巨细胞病毒、腺病毒、冠状病毒、鼻病毒、轮状病毒、天花、单纯疱疹病毒、乙型肝炎病毒、甲型肝炎病毒、丙型肝炎病毒、乳头瘤病毒或流感病毒。
实施例D147.一种诱导免疫细胞分化成记忆或记忆样免疫细胞的方法,所述方法包含:
使免疫细胞与有效量的根据实施例D1至D113所述的多链嵌合多肽中的任一种或根据实施例D114或D115所述的组合物接触。
实施例D148.根据实施例D147所述的方法,其中所述免疫细胞在体外接触。
实施例D149.根据实施例D148所述的方法,其中所述免疫细胞先前获自受试者。
实施例D150.根据实施例D149所述的方法,其中所述方法进一步包含在接触步骤之前从所述受试者获得所述免疫细胞。
实施例D151.根据实施例D147所述的方法,其中所述免疫细胞在体内接触。
实施例D152.根据实施例D147至D151中任一项所述的方法,其中所述免疫细胞选自以下组成的组:未成熟胸腺细胞、外周血淋巴细胞、初始T细胞、多能Th细胞前体、淋巴祖细胞、Treg细胞、Th17细胞、Th22细胞、Th9细胞、Th2细胞、Th1细胞、Th3细胞、γδT细胞、αβT细胞、肿瘤浸润性T细胞、CD8+T细胞、CD4+T细胞、自然杀伤T细胞、肥大细胞、巨噬细胞、嗜中性粒细胞、树突状细胞、嗜碱性粒细胞、嗜酸性粒细胞和自然杀伤细胞。
实施例D153.根据实施例D147至D152中任一项所述的方法,其中所述免疫细胞先前已经过基因修饰以表达嵌合抗原受体或重组T细胞受体。
实施例D154.根据实施例D147至D152中任一项所述的方法,其中所述方法进一步包含在接触步骤之后,将编码嵌合抗原受体或重组T细胞受体的核酸引入到所述免疫细胞中。
实施例D155:根据实施例D147至D153中任一项所述的方法,其中使所述免疫细胞与抗TF IgG抗体接触以产生记忆或记忆样免疫细胞。
实施例D156.根据实施例D147至D155中任一项所述的方法,其中所述方法进一步包含向有需要的受试者施用所述免疫细胞。
实施例D157.根据实施例D156所述的方法,其中所述受试者已被鉴别或诊断为患有与年龄相关的疾病或病况。
实施例D158.根据实施例D156所述的方法,其中所述与年龄相关的疾病或病况选自以下组成的组:阿尔茨海默氏病、动脉瘤、囊性纤维化、胰腺炎纤维化、青光眼、高血压、特发性肺纤维化、炎性肠病、椎间盘退变、黄斑变性、骨关节炎、2型糖尿病、脂肪萎缩、脂肪营养不良、动脉粥样硬化、白内障、COPD、特发性肺纤维化、肾移植失败、肝纤维化、骨量损失、心肌梗死、肌肉减少症、伤口愈合、脱发、心肌细胞肥大、骨关节炎、帕金森氏病、与年龄相关的肺组织弹性丧失、黄斑变性、恶病质、肾小球硬化、肝硬化、NAFLD、骨质疏松症、肌萎缩性侧索硬化症、亨廷顿氏病、脊髓小脑共济失调、多发性硬化症和肾功能不全。
实施例D159.根据实施例D156所述的方法,其中所述受试者已被鉴别或诊断为患有癌症。
实施例D160.根据实施例D159所述的方法,其中所述癌症选自以下组成的组:实体肿瘤、血液肿瘤、肉瘤、骨肉瘤、成胶质细胞瘤、成神经细胞瘤、黑色素瘤、横纹肌肉瘤、尤文氏肉瘤、骨肉瘤、B细胞瘤、多发性骨髓瘤、B细胞淋巴瘤、B细胞非霍奇金氏淋巴瘤、霍奇金氏淋巴瘤、慢性淋巴细胞性白血病(CLL)、急性骨髓性白血病(AML)、慢性骨髓性白血病(CML)、急性淋巴细胞性白血病(ALL)、骨髓增生异常综合症(MDS)、皮肤T细胞淋巴瘤、成视网膜细胞瘤、胃癌、尿路上皮癌、肺癌、肾细胞癌、胃和食管癌、胰腺癌、前列腺癌、乳腺癌、结直肠癌、卵巢癌、非小细胞肺癌、鳞状细胞头颈癌、子宫内膜癌、宫颈癌、肝癌和肝细胞癌。
实施例D161.根据实施例D156所述的方法,其中所述受试者已被诊断或鉴别为患有感染性疾病。
实施例D162.根据实施例D161所述的方法,其中所述感染性疾病是感染人免疫缺陷病毒、巨细胞病毒、腺病毒、冠状病毒、鼻病毒、轮状病毒、天花、单纯疱疹病毒、乙型肝炎病毒、甲型肝炎病毒、丙型肝炎病毒、乳头瘤病毒或流感病毒。
实施例D163.一种在有需要的受试者中杀死癌细胞、受感染细胞或衰老细胞的方法,所述方法包含向所述受试者施用治疗有效量的根据实施例D1至D113所述的多链嵌合多肽中的任一种或根据实施例D114或D115所述的组合物。
实施例D164.根据实施例D163所述的方法,其中所述受试者已被鉴别或诊断为患有癌症。
实施例D165.根据实施例D164所述的方法,其中所述癌症选自以下组成的组:实体肿瘤、血液肿瘤、肉瘤、骨肉瘤、成胶质细胞瘤、成神经细胞瘤、黑色素瘤、横纹肌肉瘤、尤文氏肉瘤、骨肉瘤、B细胞瘤、多发性骨髓瘤、B细胞淋巴瘤、B细胞非霍奇金氏淋巴瘤、霍奇金氏淋巴瘤、慢性淋巴细胞性白血病(CLL)、急性骨髓性白血病(AML)、慢性骨髓性白血病(CML)、急性淋巴细胞性白血病(ALL)、骨髓增生异常综合症(MDS)、皮肤T细胞淋巴瘤、成视网膜细胞瘤、胃癌、尿路上皮癌、肺癌、肾细胞癌、胃和食管癌、胰腺癌、前列腺癌、乳腺癌、结直肠癌、卵巢癌、非小细胞肺癌、鳞状细胞头颈癌、子宫内膜癌、宫颈癌、肝癌和肝细胞癌。
实施例D166.根据实施例D163所述的方法,其中所述受试者已被鉴别或诊断为患有与老化相关的疾病或病况。
实施例D167.根据实施例D166所述的方法,其中所述与老化相关的疾病或病况选自以下组成的组:阿尔茨海默氏病、动脉瘤、囊性纤维化、胰腺炎纤维化、青光眼、高血压、特发性肺纤维化、炎性肠病、椎间盘退变、黄斑变性、骨关节炎、2型糖尿病、脂肪萎缩、脂肪营养不良、动脉粥样硬化、白内障、COPD、特发性肺纤维化、肾移植失败、肝纤维化、骨量损失、心肌梗死、肌肉减少症、伤口愈合、脱发、心肌细胞肥大、骨关节炎、帕金森氏病、与年龄相关的肺组织弹性丧失、黄斑变性、恶病质、肾小球硬化、肝硬化、NAFLD、骨质疏松症、肌萎缩性侧索硬化症、亨廷顿氏病、脊髓小脑共济失调、多发性硬化症和肾功能不全。
实施例D168.一种治疗有需要的受试者的方法,所述方法包含向所述受试者施用治疗有效量的根据实施例D1至D113所述的多链嵌合多肽中的任一种或根据实施例D114或D115所述的组合物。
实施例D169.根据实施例D168所述的方法,其中所述受试者已被鉴别或诊断为患有癌症或感染性疾病。
实施例D170.根据实施例D169所述的方法,其中所述癌症选自以下组成的组:实体肿瘤、血液肿瘤、肉瘤、骨肉瘤、成胶质细胞瘤、成神经细胞瘤、黑色素瘤、横纹肌肉瘤、尤文氏肉瘤、骨肉瘤、B细胞瘤、多发性骨髓瘤、B细胞淋巴瘤、B细胞非霍奇金氏淋巴瘤、霍奇金氏淋巴瘤、慢性淋巴细胞性白血病(CLL)、急性骨髓性白血病(AML)、慢性骨髓性白血病(CML)、急性淋巴细胞性白血病(ALL)、骨髓增生异常综合症(MDS)、皮肤T细胞淋巴瘤、成视网膜细胞瘤、胃癌、尿路上皮癌、肺癌、肾细胞癌、胃和食管癌、胰腺癌、前列腺癌、乳腺癌、结直肠癌、卵巢癌、非小细胞肺癌、鳞状细胞头颈癌、子宫内膜癌、宫颈癌、肝癌和肝细胞癌。
实施例D171.根据实施例D168所述的方法,其中所述受试者已被鉴别或诊断为患有与年龄相关的疾病或病况。
实施例D172.根据实施例D171所述的方法,其中所述与年龄相关的疾病或病况选自以下组成的组:阿尔茨海默氏病、动脉瘤、囊性纤维化、胰腺炎纤维化、青光眼、高血压、特发性肺纤维化、炎性肠病、椎间盘退变、黄斑变性、骨关节炎、2型糖尿病、脂肪萎缩、脂肪营养不良、动脉粥样硬化、白内障、COPD、特发性肺纤维化、肾移植失败、肝纤维化、骨量损失、心肌梗死、肌肉减少症、伤口愈合、脱发、心肌细胞肥大、骨关节炎、帕金森氏病、与年龄相关的肺组织弹性丧失、黄斑变性、恶病质、肾小球硬化、肝硬化、NAFLD、骨质疏松症、肌萎缩性侧索硬化症、亨廷顿氏病、脊髓小脑共济失调、多发性硬化症和肾功能不全。
实施例D173.根据实施例D168所述的方法,其中所述受试者已被诊断或鉴别为患有感染性疾病。
实施例D174.根据实施例D173所述的方法,其中所述感染性疾病是感染人免疫缺陷病毒、巨细胞病毒、腺病毒、冠状病毒、鼻病毒、轮状病毒、天花、单纯疱疹病毒、乙型肝炎病毒、甲型肝炎病毒、丙型肝炎病毒、乳头瘤病毒或流感病毒。
实施例D175.核酸,其编码根据实施例D1至D113中任一项所述的多链嵌合多肽中的任一种。
实施例D176.一种载体,其包含根据实施例D174所述的核酸。
实施例D177.根据实施例D176所述的载体,其中所述载体是表达载体。
实施例D178.一种细胞,其包含根据实施例D175所述的核酸或根据实施例D175或D176所述的载体。
实施例D179.一种产生多链嵌合多肽的方法,所述方法包含:
在足以引起产生所述多链嵌合多肽的条件下在培养基中培养根据实施例D177所述的细胞;和
从所述细胞和/或所述培养基中回收所述多链嵌合多肽。
实施例D180.一种多链嵌合多肽,其通过根据实施例D179所述的方法产生。
E.示例性实施例
实施例E1.一种多链嵌合多肽,其包含:
(e)第一嵌合多肽,其包含:
(i)第一靶标结合结构域;
(ii)可溶性组织因子结构域;和
(iii)一对亲和结构域中的第一结构域;
(f)第二嵌合多肽,其包含:
(i)一对亲和结构域中的第二结构域;和
(ii)第二靶标结合结构域,
其中:
所述第一嵌合多肽和所述第二嵌合多肽通过所述一对亲和结构域中的所述第一结构域和所述第二结构域的结合而缔合;和
所述第一靶标结合结构域和所述第二靶标结合结构域各自独立地特异性结合到:IL-7的受体、CD16、IL-21的受体、TGF-β或CD137L的受体。
实施例E2.根据实施例E1所述的多链嵌合多肽,其中所述第一靶标结合结构域和所述可溶性组织因子结构域在所述第一嵌合多肽中彼此直接邻接。
实施例E3.根据实施例E1所述的多链嵌合多肽,其中所述第一嵌合多肽进一步包含所述第一嵌合多肽中的所述第一靶标结合结构域与所述可溶性组织因子结构域之间的接头序列。
实施例E4.根据实施例E1至E3中任一项所述的多链嵌合多肽,其中所述可溶性组织因子结构域和所述一对亲和结构域中的所述第一结构域在所述第一嵌合多肽中彼此直接邻接。
实施例E5.根据实施例E1至E3中任一项所述的多链嵌合多肽,其中所述第一嵌合多肽进一步包含所述第一嵌合多肽中的所述可溶性组织因子结构域与所述一对亲和结构域中的所述第一结构域之间的接头序列。
实施例E6.根据实施例E1至E5中任一项所述的多链嵌合多肽,其中所述一对亲和结构域中的所述第二结构域和所述第二靶标结合结构域在所述第二嵌合多肽中彼此直接邻接。
实施例E7.根据实施例E1至E5中任一项所述的多链嵌合多肽,其中所述第二嵌合多肽进一步包含所述第二嵌合多肽中的所述一对亲和结构域中的所述第二结构域与所述第二靶标结合结构域之间的接头序列。
实施例E8.根据实施例E1至E7中任一项所述的多链嵌合多肽,其中所述可溶性组织因子结构域是可溶性人组织因子结构域。
实施例E9.根据实施例E8所述的多链嵌合多肽,其中所述可溶性人组织因子结构域包含与SEQ ID NO:1至少80%相同的序列。
实施例E10.根据实施例E9所述的多链嵌合多肽,其中所述可溶性人组织因子结构域包含与SEQ ID NO:1至少90%相同的序列。
实施例E11.根据实施例E10所述的多链嵌合多肽,其中所述可溶性人组织因子结构域包含与SEQ ID NO:1至少95%相同的序列。
实施例E12.根据实施例E8至E11中任一项所述的多链嵌合多肽,其中所述可溶性人组织因子结构域不包含以下中的一种或多种:
在对应于成熟野生型人组织因子蛋白的氨基酸位置20的氨基酸位置处的赖氨酸;
在对应于成熟野生型人组织因子蛋白的氨基酸位置22的氨基酸位置处的异亮氨酸;
在对应于成熟野生型人组织因子蛋白的氨基酸位置45的氨基酸位置处的色氨酸;
在对应于成熟野生型人组织因子蛋白的氨基酸位置58的氨基酸位置处的天冬氨酸;
在对应于成熟野生型人组织因子蛋白的氨基酸位置94的氨基酸位置处的酪氨酸;
在对应于成熟野生型人组织因子蛋白的氨基酸位置135的氨基酸位置处的精氨酸;和
在对应于成熟野生型人组织因子蛋白的氨基酸位置140的氨基酸位置处的苯丙氨酸。
实施例E13.根据实施例E12所述的多链嵌合多肽,其中所述可溶性人组织因子结构域不包含以下中的任一种:
在对应于成熟野生型人组织因子蛋白的氨基酸位置20的氨基酸位置处的赖氨酸;
在对应于成熟野生型人组织因子蛋白的氨基酸位置22的氨基酸位置处的异亮氨酸;
在对应于成熟野生型人组织因子蛋白的氨基酸位置45的氨基酸位置处的色氨酸;
在对应于成熟野生型人组织因子蛋白的氨基酸位置58的氨基酸位置处的天冬氨酸;
在对应于成熟野生型人组织因子蛋白的氨基酸位置94的氨基酸位置处的酪氨酸;
在对应于成熟野生型人组织因子蛋白的氨基酸位置135的氨基酸位置处的精氨酸;和
在对应于成熟野生型人组织因子蛋白的氨基酸位置140的氨基酸位置处的苯丙氨酸。
实施例E14.根据实施例E1至E13中任一项所述的多链嵌合多肽,其中所述可溶性组织因子结构域不能结合到因子VIIa。
实施例E15.根据实施例E1至E14中任一项所述的多链嵌合多肽,其中所述可溶性组织因子结构域不将非活性因子X转化为因子Xa。
实施例E16.根据实施例E1至E15中任一项所述的多链嵌合多肽,其中所述多链嵌合多肽不刺激哺乳动物中的凝结。
实施例E17.根据实施例E1至E16中任一项的所述多链嵌合多肽,其中所述第一嵌合多肽进一步包含在所述第一嵌合多肽的N端或C端的肽标签。
实施例E18.根据实施例E1至E17中任一项所述的多链嵌合多肽,其中所述第二嵌合多肽进一步包含在所述第二嵌合多肽的N端或C端的肽标签。
实施例E19.根据实施例E1至E18中任一项所述的多链嵌合多肽,其中所述第一嵌合多肽和/或所述第二嵌合多肽在其N端进一步包含信号序列。
实施例E20.根据实施例E19所述的多链嵌合多肽,其中所述信号序列包含SEQ IDNO:31。
实施例E21.根据实施例E20所述的多链嵌合多肽,其中所述信号序列是SEQ IDNO:31。
实施例E22.根据实施例E1-E21中任一项所述的多链嵌合多肽,其中所述一对亲和结构域是来自人IL-15受体的α链(IL15Rα)的寿司结构域和可溶性IL-15。
实施例E23.根据实施例E22所述的多链嵌合多肽,其中所述可溶性IL-15具有D8N或D8A氨基酸取代。
实施例E24.根据实施例E22所述的多链嵌合多肽,其中所述可溶性IL-15包含与SEQ ID NO:14至少80%相同的序列。
实施例E25.根据实施例E24所述的多链嵌合多肽,其中所述可溶性IL-15包含与SEQ ID NO:14至少90%相同的序列。
实施例E26.根据实施例E25所述的多链嵌合多肽,其中所述可溶性IL-15包含与SEQ ID NO:14至少95%相同的序列。
实施例E27.根据实施例E26所述的多链嵌合多肽,其中所述可溶性IL-15包含SEQID NO:14。
实施例E28.根据实施例E22至E27中任一项所述的多链嵌合多肽,其中IL15Rα的寿司结构域包含来自人IL15Rα的寿司结构域。
实施例E29.根据实施例E28所述的多链嵌合多肽,其中来自人IL15Rα的所述寿司结构域包含与SEQ ID NO:28至少80%相同的序列。
实施例E30.根据实施例E29所述的多链嵌合多肽,其中来自人IL15Rα的所述寿司结构域包含与SEQ ID NO:28至少90%相同的序列。
实施例E31.根据实施例E30所述的多链嵌合多肽,其中来自人IL15Rα的所述寿司结构域包含与SEQ ID NO:28至少95%相同的序列。
实施例E32.根据实施例E31所述的多链嵌合多肽,其中来自人IL15Rα的所述寿司结构域包含SEQ ID NO:28。
实施例E33.根据实施例E28所述的多链嵌合多肽,其中来自人IL15Rα的所述寿司结构域是成熟全长IL15Rα。
实施例E34.根据实施例E1至E21中任一项所述的多链嵌合多肽,其中所述一对亲和结构域选自以下组成的组:芽胞杆菌RNA酶和芽胞杆菌RNA酶抑制子、PKA和AKAP、基于突变核糖核酸酶I片段的衔接子/对接标签模块以及基于蛋白质突触蛋白、突触结合蛋白、突触泡蛋白和SNAP25的相互作用的SNARE模块。
实施例E35.根据实施例E1至E34中任一项所述的多链嵌合多肽,其中所述第一靶标结合结构域和所述第二靶标结合结构域各自独立地特异性结合到IL-7的受体、CD16或IL-21的受体。
实施例E36.根据实施例E35所述的多链嵌合多肽,其中所述第一靶标结合结构域特异性结合到受体IL-7,并且所述第二靶标结合结构域特异性结合到CD16或IL-21受体。
实施例E37.根据实施例E36所述的多链嵌合多肽,其中所述第一靶标结合结构域包含可溶性IL-7蛋白。
实施例E38.根据实施例E37所述的多链嵌合多肽,其中所述可溶性IL-7蛋白是可溶性人IL-7。
实施例E39.根据实施例E36至E38中任一项所述的多链嵌合多肽,其中所述第二抗原结合结构域包含特异性结合到CD16的抗原结合结构域。
实施例E40.根据实施例E39所述的多链嵌合多肽,其中所述第二抗原结合结构域包含特异性结合到CD16的scFv。
实施例E41.根据实施例E36至E38中任一项所述的多链嵌合多肽,其中所述第二抗原结合结构域特异性结合到IL-21的受体。
实施例E42.根据实施例E41所述的多链嵌合多肽,其中所述第二抗原结合结构域包含可溶性IL-21。
实施例E43.根据实施例E42所述的多链嵌合多肽,其中所述可溶性IL-21是可溶性人IL-21。
实施例E44.根据实施例E36至E40中任一项所述的多链嵌合多肽,其中所述第二嵌合多肽进一步包含特异性结合到IL-21的受体的另外的靶标结合结构域。
实施例E45.根据实施例E44所述的多链嵌合多肽,其中所述另外的靶标结合结构域包含可溶性IL-21。
实施例E46.根据实施例E45所述的多链嵌合多肽,其中所述可溶性IL-21是可溶性人IL-12。
实施例E47.根据实施例E1至E34中任一项所述的多链嵌合多肽,其中所述第一靶标结合结构域和所述第二靶标结合结构域各自独立地特异性结合到TGF-β、CD16或IL-21的受体。
实施例E48.根据实施例E47所述的多链嵌合多肽,其中所述第一靶标结合结构域特异性结合到TGF-β,并且所述第二靶标结合结构域特异性结合到CD16或IL-21的受体。
实施例E49.根据实施例E48的多特异性嵌合多肽,其中所述第一靶标结合结构域是可溶性TGF-β受体。
实施例E50.根据实施例E49所述的多特异性嵌合多肽,其中可溶性TGF-β受体是可溶性TGFβRII受体。
实施例E51.根据实施例E48至E50中任一项所述的多特异性嵌合多肽,其中所述第二靶标结合结构域特异性结合到CD16。
实施例E52.根据实施例E51所述的多特异性嵌合多肽,其中所述第二抗原结合结构域包含特异性结合到CD16的抗原结合结构域。
实施例E53.根据实施例E52所述的多链嵌合多肽,其中所述第二抗原结合结构域包含特异性结合到CD16的scFv。
实施例E54.根据实施例E48至E50中任一项所述的多链嵌合多肽,其中所述第二靶标结合结构域特异性结合到IL-21的受体。
实施例E55.根据实施例E54所述的多链嵌合多肽,其中所述第二靶标结合结构域包含可溶性IL-21。
实施例E56.根据实施例E55所述的多链嵌合多肽,其中所述第二靶标结合结构域包含可溶性人IL-21。
实施例E57.根据实施例E48至E53中任一项所述的多链嵌合多肽,其中所述第二嵌合多肽进一步包含特异性结合到IL-21的受体的另外的靶标结合结构域。
实施例E58.根据实施例E57所述的多链嵌合多肽,其中所述另外的靶标结合结构域包含可溶性IL-21。
实施例E59.根据实施例E58所述的多链嵌合多肽,其中所述可溶性IL-21是可溶性人IL-21。
实施例E60.根据实施例E1至E34中任一项所述的多链嵌合多肽,其中所述第一靶标结合结构域和所述第二靶标结合结构域各自独立地特异性结合到IL-7的受体。
实施例E61.根据实施例E60所述的多链嵌合多肽,其中所述第一靶标结合结构域和所述第二靶标结合结构域包括可溶性IL-7。
实施例E62.根据实施例E61所述的多链嵌合多肽,其中所述可溶性IL-7是可溶性人IL-7。
实施例E63.根据实施例E1至E34中任一项所述的多链嵌合多肽,其中所述第一靶标结合结构域和所述第二靶标结合结构域各自独立地特异性结合到TGF-β。
实施例E64.根据实施例E63的多特异性嵌合多肽,其中所述第一靶标结合结构域和所述第二靶标结合结构域是可溶性TGF-β受体。
实施例E65.根据实施例E64所述的多特异性嵌合多肽,其中所述可溶性TGF-β受体是可溶性TGFβRII受体。
实施例E66.根据实施例E1至E34中任一项所述的多特异性嵌合多肽,其中所述第一靶标结合结构域和所述第二靶标结合结构域各自独立地特异性结合到IL-7的受体、IL-21的受体或CD137L的受体。
实施例E67.根据实施例E66所述的多链嵌合多肽,其中所述第一靶标结合结构域特异性结合到IL-7的受体,并且所述第二靶标结合结构域特异性结合到IL-21的受体或CD137L的受体。
实施例E68.根据实施例E67的多特异性嵌合多肽,其中所述第一靶标结合结构域是可溶性IL-7。
实施例E69.根据实施例E68所述的多特异性嵌合多肽,其中所述可溶性IL-7是可溶性人IL-7。
实施例E70.根据实施例E67至E69中任一项所述的多链嵌合多肽,其中所述第二靶标结合结构域特异性结合到IL-21的受体。
实施例E71.根据实施例E70所述的多链嵌合多肽,其中所述第二靶标结合结构域是可溶性IL-21。
实施例E72.根据实施例E71所述的多链嵌合多肽,其中所述可溶性IL-21是可溶性人IL-21。
实施例E73.根据实施例E67至E69中任一项所述的多链嵌合多肽,其中所述第二抗原结合结构域特异性结合到CD137L的受体。
实施例E74.根据实施例E73所述的多链嵌合多肽,其中所述第二抗原结合结构域是可溶性CD137L。
实施例E75.根据实施例E74所述的多链嵌合多肽,其中所述可溶性CD137L是可溶性人CD137L。
实施例E76.根据实施例E67至E72中任一项所述的多链嵌合多肽,其中所述第二嵌合多肽进一步包含特异性结合到CD137L的受体的另外的靶标结合结构域。
实施例E77.根据实施例E76所述的多链嵌合多肽,其中所述另外的靶标结合结构域包含可溶性CD137L。
实施例E78.根据实施例E77所述的多链嵌合多肽,其中所述可溶性CD137L是可溶性人CD137L。
实施例E79.根据实施例E1至E34中任一项所述的多链嵌合多肽,其中所述第一靶标结合结构域和所述第二靶标结合结构域各自独立地特异性结合到IL-7的受体或TGF-β。
实施例E80.根据实施例E79所述的多链嵌合多肽,其中所述第一靶标结合结构域特异性结合到受体IL-7,并且所述第二靶标结合结构域特异性结合到TGF-β。
实施例E81.根据实施例E80所述的多链嵌合多肽,其中所述第一靶标结合结构域包含可溶性IL-7蛋白。
实施例E82.根据实施例E81所述的多链嵌合多肽,其中所述可溶性IL-7蛋白是可溶性人IL-7。
实施例E83.根据实施例E80至E82中任一项所述的多链嵌合多肽,其中所述第二抗原结合结构域包含特异性结合到TGF-β的抗原结合结构域。
实施例E84.根据实施例E83的多特异性嵌合多肽,其中所述第二靶标结合结构域是可溶性TGF-β受体。
实施例E85.根据实施例E84所述的多特异性嵌合多肽,其中所述可溶性TGF-β受体是可溶性TGFβRII受体。
实施例E86.根据实施例E1至E34中任一项所述的多链嵌合多肽,其中所述第一靶标结合结构域和所述第二靶向结合结构域各自独立地特异性结合到TGF-β、IL-21的受体或CD137L的受体。
实施例E87.根据实施例E86所述的多链嵌合多肽,其中所述第一靶标结合结构域特异性结合到TGF-β,并且所述第二靶标结合结构域特异性结合到IL-21的受体或CD137L的受体。
实施例E88.根据实施例E87的多特异性嵌合多肽,其中所述第一靶标结合结构域是可溶性TGF-β受体。
实施例E89.根据实施例E88所述的多特异性嵌合多肽,其中所述可溶性TGF-β受体是可溶性TGFβRII受体。
实施例E90.根据实施例E87至E89中任一项所述的多特异性嵌合多肽,其中所述第二靶标结合结构域特异性结合到IL-21的受体。
实施例E91.根据实施例E90所述的多链嵌合多肽,其中所述第二靶标结合结构域包含可溶性IL-21。
实施例E92.根据实施例E91所述的多链嵌合多肽,其中所述第二靶标结合结构域包含可溶性人IL-21。
实施例E93.根据实施例E87至E89中任一项所述的多特异性嵌合多肽,其中所述第二靶标结合结构域特异性结合到CD137L的受体。
实施例E94.根据实施例E93所述的多链嵌合多肽,其中所述第二靶标结合结构域包含可溶性CD137L。
实施例E95.根据实施例E94所述的多链嵌合多肽,其中所述第二靶标结合结构域包含可溶性人CD137L。
实施例E96.根据实施例E87至E92中任一项所述的多链嵌合多肽,其中所述第二嵌合多肽进一步包含特异性结合到CD137L的受体的另外的靶标结合结构域。
实施例E97.根据实施例E96所述的多链嵌合多肽,其中所述另外的靶标结合结构域包含可溶性CD137L。
实施例E98.根据实施例E97所述的多链嵌合多肽,其中所述可溶性CD137L是可溶性人CD137L。
实施例E99.根据实施例E1至E34中任一项所述的多链嵌合多肽,其中所述第一靶标结合结构域和所述第二靶标结合结构域各自独立地特异性结合到TGF-β或IL-21的受体。
实施例E100.根据实施例E99所述的多链嵌合多肽,其中所述第一靶标结合结构域特异性结合到TGF-β,并且所述第二靶标结合结构域特异性结合到TGF-β或IL-21的受体。
实施例E101.根据实施例E100的多特异性嵌合多肽,其中所述第一靶标结合结构域是可溶性TGF-β受体。
实施例E102.根据实施例E101所述的多特异性嵌合多肽,其中所述可溶性TGF-β受体是可溶性TGFβRII受体。
实施例E103.根据实施例E100至E102中任一项所述的多特异性嵌合多肽,其中所述第二靶标结合结构域特异性结合到IL-21的受体。
实施例E104.根据实施例E103所述的多链嵌合多肽,其中所述第二靶标结合结构域包含可溶性IL-21。
实施例E105.根据实施例E104所述的多链嵌合多肽,其中所述第二靶标结合结构域包含可溶性人IL-21。
实施例E106.根据实施例E100至E102中任一项所述的多特异性嵌合多肽,其中所述第二靶标结合结构域特异性结合到TGF-β。
实施例E107.根据实施例E106所述的多特异性嵌合多肽,其中所述第一靶标结合结构域是可溶性TGF-β受体。
实施例E108.根据实施例E107所述的多特异性嵌合多肽,其中所述可溶性TGF-β受体是可溶性TGFβRII受体。
实施例E109.根据实施例E100至E105中任一项所述的多特异性嵌合多肽,其中所述第二多肽进一步包含特异性结合到TGF-β的另外的靶标结合结构域。
实施例E110.根据实施例E109所述的多特异性嵌合多肽,其中所述第一靶标结合结构域是可溶性TGF-β受体。
实施例E111.根据实施例E110所述的多特异性嵌合多肽,其中所述可溶性TGF-β受体是可溶性TGFβRII受体。
实施例E112.根据实施例E1至E34中任一项所述的多链嵌合多肽,其中所述第一靶标结合结构域和所述第二靶向结合结构域各自独立地特异性结合到TGF-β或IL-16。
实施例E113.根据实施例E112所述的多链嵌合多肽,其中所述第一靶标结合结构域特异性结合到TGF-β,并且所述第二靶标结合结构域特异性结合到TGF-β或IL-16。
实施例E114.根据实施例E113的多特异性嵌合多肽,其中所述第一靶标结合结构域是可溶性TGF-β受体。
实施例E115.根据实施例E114所述的多特异性嵌合多肽,其中所述可溶性TGF-β受体是可溶性TGFβRII受体。
实施例E116.根据实施例E113至E115中任一项所述的多特异性嵌合多肽,其中所述第二靶标结合结构域特异性结合到IL-16。
实施例E117.根据实施例E116所述的多特异性嵌合多肽,其中所述第二抗原结合结构域包含特异性结合到CD16的抗原结合结构域。
实施例E118.根据实施例E117所述的多链嵌合多肽,其中所述第二抗原结合结构域包含特异性结合到CD16的scFv。
实施例E119.根据实施例E113至E115中任一项所述的多特异性嵌合多肽,其中所述第二靶标结合结构域特异性结合到TGF-β。
实施例E120.根据实施例E119所述的多特异性嵌合多肽,其中所述第一靶标结合结构域是可溶性TGF-β受体。
实施例E121.根据实施例E120所述的多特异性嵌合多肽,其中所述可溶性TGF-β受体是可溶性TGFβRII受体。
实施例E122.根据实施例E113至E118中任一项所述的多特异性嵌合多肽,其中所述第二嵌合多肽进一步包含特异性结合到TGF-β的另外的靶标结合结构域。
实施例E123.根据实施例E122所述的多特异性嵌合多肽,其中所述第一靶标结合结构域是可溶性TGF-β受体。
实施例E124.根据实施例E123所述的多特异性嵌合多肽,其中所述可溶性TGF-β受体是可溶性TGFβRII受体。
实施例E125.根据实施例E1至E34中任一项所述的多链嵌合多肽,其中所述第一靶标结合结构域和所述第二靶标结合结构域各自独立地特异性结合到TGF-β或CD137L的受体。
实施例E126.根据实施例E125所述的多链嵌合多肽,其中所述第一靶标结合结构域特异性结合到TGF-β,并且所述第二靶标结合结构域特异性结合到CD137L的受体。
实施例E127.根据实施例E126的多特异性嵌合多肽,其中所述第一靶标结合结构域是可溶性TGF-β受体。
实施例E128.根据实施例E127所述的多特异性嵌合多肽,其中所述可溶性TGF-β受体是可溶性TGFβRII受体。
实施例E129.根据实施例E128所述的多链嵌合多肽,其中所述第二靶标结合结构域包含可溶性CD137L蛋白。
实施例E130.根据实施例E129所述的多链嵌合多肽,其中所述可溶性CD137L蛋白是可溶性人CD137L。
实施例E131.根据实施例E126至E130中任一项所述的多链嵌合多肽,其中所述第二嵌合多肽进一步包含特异性结合到TGF-β的另外的靶标结合结构域。
实施例E132.根据实施例E131的多特异性嵌合多肽,其中所述另外的靶标结合结构域是可溶性TGF-β受体。
实施例E133.根据实施例E132所述的多特异性嵌合多肽,其中所述可溶性TGF-β受体是可溶性TGFβRII受体。
实施例E134.根据实施例E1所述的多链嵌合多肽,其中所述第一嵌合多肽包含与SEQ ID NO:104至少80%相同的序列。
实施例E135.根据实施例E134所述的多链嵌合多肽,其中所述第一嵌合多肽包含与SEQ ID NO:104至少90%相同的序列。
实施例E136.根据实施例E135所述的多链嵌合多肽,其中所述第一嵌合多肽包含与SEQ ID NO:104至少95%相同的序列。
实施例E137.根据实施例E136所述的多链嵌合多肽,其中所述第一嵌合多肽包含SEQ ID NO:104。
实施例E138.根据实施例E137所述的多链嵌合多肽,其中所述第一嵌合多肽包含SEQ ID NO:106。
实施例E139.根据实施例E1和E134至E138中任一项所述的多链嵌合多肽,其中所述第二嵌合多肽包含与SEQ ID NO:129至少80%相同的序列。
实施例E140.根据实施例E139所述的多链嵌合多肽,其中所述第二嵌合多肽包含与SEQ ID NO:129至少90%相同的序列。
实施例E141.根据实施例E140所述的多链嵌合多肽,其中所述第二嵌合多肽包含与SEQ ID NO:129至少95%相同的序列。
实施例E142.根据实施例E141所述的多链嵌合多肽,其中所述第二嵌合多肽包含SEQ ID NO:129。
实施例E143.根据实施例E142所述的多链嵌合多肽,其中所述第二嵌合多肽包含SEQ ID NO:131。
实施例E144.根据实施例E1所述的多链嵌合多肽,其中所述第一嵌合多肽包含与SEQ ID NO:133至少80%相同的序列。
实施例E145.根据实施例E144所述的多链嵌合多肽,其中所述第一嵌合多肽包含与SEQ ID NO:133至少90%相同的序列。
实施例E146.根据实施例E145所述的多链嵌合多肽,其中所述第一嵌合多肽包含与SEQ ID NO:133至少95%相同的序列。
实施例E147.根据实施例E146所述的多链嵌合多肽,其中所述第一嵌合多肽包含SEQ ID NO:133。
实施例E148.根据实施例E147所述的多链嵌合多肽,其中所述第一嵌合多肽包含SEQ ID NO:135。
实施例E149.根据实施例E1和E144至E148中任一项所述的多链嵌合多肽,其中所述第二嵌合多肽包含与SEQ ID NO:137至少80%相同的序列。
实施例E150.根据实施例E149所述的多链嵌合多肽,其中所述第二嵌合多肽包含与SEQ ID NO:137至少90%相同的序列。
实施例E151.根据实施例E150所述的多链嵌合多肽,其中所述第二嵌合多肽包含与SEQ ID NO:137至少95%相同的序列。
实施例E152.根据实施例E151所述的多链嵌合多肽,其中所述第二嵌合多肽包含SEQ ID NO:137。
实施例E153.根据实施例E152所述的多链嵌合多肽,其中所述第二嵌合多肽包含SEQ ID NO:139。
实施例E154.根据实施例E1所述的多链嵌合多肽,其中所述第一嵌合多肽包含与SEQ ID NO:141至少80%相同的序列。
实施例E155.根据实施例E154所述的多链嵌合多肽,其中所述第一嵌合多肽包含与SEQ ID NO:141至少90%相同的序列。
实施例E156.根据实施例E155所述的多链嵌合多肽,其中所述第一嵌合多肽包含与SEQ ID NO:141至少95%相同的序列。
实施例E157.根据实施例E156所述的多链嵌合多肽,其中所述第一嵌合多肽包含SEQ ID NO:141。
实施例E158.根据实施例E157所述的多链嵌合多肽,其中所述第一嵌合多肽包含SEQ ID NO:143。
实施例E159.根据实施例E1和E154至E158中任一项所述的多链嵌合多肽,其中所述第二嵌合多肽包含与SEQ ID NO:145至少80%相同的序列。
实施例E160.根据实施例E159所述的多链嵌合多肽,其中所述第二嵌合多肽包含与SEQ ID NO:145至少90%相同的序列。
实施例E161.根据实施例E160所述的多链嵌合多肽,其中所述第二嵌合多肽包含与SEQ ID NO:145至少95%相同的序列。
实施例E162.根据实施例E161所述的多链嵌合多肽,其中所述第二嵌合多肽包含SEQ ID NO:145。
实施例E163.根据实施例E162所述的多链嵌合多肽,其中所述第二嵌合多肽包含SEQ ID NO:147。
实施例E164.根据实施例E1所述的多链嵌合多肽,其中所述第一嵌合多肽包含与SEQ ID NO:149至少80%相同的序列。
实施例E165.根据实施例E164所述的多链嵌合多肽,其中所述第一嵌合多肽包含与SEQ ID NO:149至少90%相同的序列。
实施例E166.根据实施例E165所述的多链嵌合多肽,其中所述第一嵌合多肽包含与SEQ ID NO:149至少95%相同的序列。
实施例E167.根据实施例E166所述的多链嵌合多肽,其中所述第一嵌合多肽包含SEQ ID NO:149。
实施例E168.根据实施例E167所述的多链嵌合多肽,其中所述第一嵌合多肽包含SEQ ID NO:151。
实施例E169.根据实施例E1和E164至E168中任一项所述的多链嵌合多肽,其中所述第二嵌合多肽包含与SEQ ID NO:153至少80%相同的序列。
实施例E170.根据实施例E169所述的多链嵌合多肽,其中所述第二嵌合多肽包含与SEQ ID NO:153至少90%相同的序列。
实施例E171.根据实施例E170所述的多链嵌合多肽,其中所述第二嵌合多肽包含与SEQ ID NO:153至少95%相同的序列。
实施例E172.根据实施例E171所述的多链嵌合多肽,其中所述第二嵌合多肽包含SEQ ID NO:153。
实施例E173.根据实施例E172所述的多链嵌合多肽,其中所述第二嵌合多肽包含SEQ ID NO:155。
实施例E174.根据实施例E1所述的多链嵌合多肽,其中所述第一嵌合多肽包含与SEQ ID NO:161至少80%相同的序列。
实施例E175.根据实施例E174所述的多链嵌合多肽,其中所述第一嵌合多肽包含与SEQ ID NO:161至少90%相同的序列。
实施例E176.根据实施例E175所述的多链嵌合多肽,其中所述第一嵌合多肽包含与SEQ ID NO:161至少95%相同的序列。
实施例E177.根据实施例E176所述的多链嵌合多肽,其中所述第一嵌合多肽包含SEQ ID NO:161。
实施例E178.根据实施例E177所述的多链嵌合多肽,其中所述第一嵌合多肽包含SEQ ID NO:163。
实施例E179.根据实施例E1和E174至E178中任一项所述的多链嵌合多肽,其中所述第二嵌合多肽包含与SEQ ID NO:165至少80%相同的序列。
实施例E180.根据实施例E179所述的多链嵌合多肽,其中所述第二嵌合多肽包含与SEQ ID NO:165至少90%相同的序列。
实施例E181.根据实施例E180所述的多链嵌合多肽,其中所述第二嵌合多肽包含与SEQ ID NO:165至少95%相同的序列。
实施例E182.根据实施例E181所述的多链嵌合多肽,其中所述第二嵌合多肽包含SEQ ID NO:165。
实施例E183.根据实施例E182所述的多链嵌合多肽,其中所述第二嵌合多肽包含SEQ ID NO:167。
实施例E184.根据实施例E1所述的多链嵌合多肽,其中所述第一嵌合多肽包含与SEQ ID NO:173至少80%相同的序列。
实施例E185.根据实施例E184所述的多链嵌合多肽,其中所述第一嵌合多肽包含与SEQ ID NO:173至少90%相同的序列。
实施例E186.根据实施例E185所述的多链嵌合多肽,其中所述第一嵌合多肽包含与SEQ ID NO:173至少95%相同的序列。
实施例E187.根据实施例E186的多链嵌合多肽,其中所述第一嵌合多肽包含SEQID NO:173。
实施例E188.根据实施例E187的多链嵌合多肽,其中所述第一嵌合多肽包含SEQID NO:175。
实施例E189.根据实施例E1和E184-E188中任一项所述的多链嵌合多肽,其中所述第二嵌合多肽包含与SEQ ID NO:189至少80%相同的序列。
实施例E190.根据实施例E189所述的多链嵌合多肽,其中所述第二嵌合多肽包含与SEQ ID NO:189至少90%相同的序列。
实施例E191.根据实施例E190所述的多链嵌合多肽,其中所述第二嵌合多肽包含与SEQ ID NO:189至少95%相同的序列。
实施例E192.根据实施例E191所述的多链嵌合多肽,其中所述第二嵌合多肽包含SEQ ID NO:189。
实施例E193.根据实施例E192所述的多链嵌合多肽,其中所述第二嵌合多肽包含SEQ ID NO:191。
实施例E194.根据实施例E1所述的多链嵌合多肽,其中所述第一嵌合多肽包含与SEQ ID NO:173至少80%相同的序列。
实施例E195.根据实施例E194所述的多链嵌合多肽,其中所述第一嵌合多肽包含与SEQ ID NO:173至少90%相同的序列。
实施例E196.根据实施例E195所述的多链嵌合多肽,其中所述第一嵌合多肽包含与SEQ ID NO:173至少95%相同的序列。
实施例E197.根据实施例E196所述的多链嵌合多肽,其中所述第一嵌合多肽包含SEQ ID NO:173。
实施例E198.根据实施例E197所述的多链嵌合多肽,其中所述第一嵌合多肽包含SEQ ID NO:175。
实施例E199.根据实施例E1和E194至E198中任一项所述的多链嵌合多肽,其中所述第二嵌合多肽包含与SEQ ID NO:177至少80%相同的序列。
实施例E200.根据实施例E199所述的多链嵌合多肽,其中所述第二嵌合多肽包含与SEQ ID NO:177至少90%相同的序列。
实施例E201.根据实施例E200所述的多链嵌合多肽,其中所述第二嵌合多肽包含与SEQ ID NO:177至少95%相同的序列。
实施例E202.根据实施例E201所述的多链嵌合多肽,其中所述第二嵌合多肽包含SEQ ID NO:177。
实施例E203.根据实施例E202所述的多链嵌合多肽,其中所述第二嵌合多肽包含SEQ ID NO:179。
实施例E204.根据实施例E1所述的多链嵌合多肽,其中所述第一嵌合多肽包含与SEQ ID NO:181至少80%相同的序列。
实施例E205.根据实施例E204所述的多链嵌合多肽,其中所述第一嵌合多肽包含与SEQ ID NO:181至少90%相同的序列。
实施例E206.根据实施例E205所述的多链嵌合多肽,其中所述第一嵌合多肽包含与SEQ ID NO:181至少95%相同的序列。
实施例E207.根据实施例E206的多链嵌合多肽,其中所述第一嵌合多肽包含SEQID NO:181。
实施例E208.根据实施例E207的多链嵌合多肽,其中所述第一嵌合多肽包含SEQID NO:183。
实施例E209.根据实施例E1和E204至E208中任一项所述的多链嵌合多肽,其中所述第二嵌合多肽包含与SEQ ID NO:185至少80%相同的序列。
实施例E210.根据实施例E209所述的多链嵌合多肽,其中所述第二嵌合多肽包含与SEQ ID NO:185至少90%相同的序列。
实施例E211.根据实施例E210所述的多链嵌合多肽,其中所述第二嵌合多肽包含与SEQ ID NO:185至少95%相同的序列。
实施例E212.根据实施例E211所述的多链嵌合多肽,其中所述第二嵌合多肽包含SEQ ID NO:185。
实施例E213.根据实施例E212所述的多链嵌合多肽,其中所述第二嵌合多肽包含SEQ ID NO:187。
实施例E214.根据实施例E1所述的多链嵌合多肽,其中所述第一嵌合多肽包含与SEQ ID NO:193至少80%相同的序列。
实施例E215.根据实施例E214所述的多链嵌合多肽,其中所述第一嵌合多肽包含与SEQ ID NO:193至少90%相同的序列。
实施例E216.根据实施例E215所述的多链嵌合多肽,其中所述第一嵌合多肽包含与SEQ ID NO:193至少95%相同的序列。
实施例E217.根据实施例E216所述的多链嵌合多肽,其中所述第一嵌合多肽包含SEQ ID NO:193。
实施例E218.根据实施例E217所述的多链嵌合多肽,其中所述第一嵌合多肽包含SEQ ID NO:195。
实施例E219.根据实施例E1和E214至E218中任一项所述的多链嵌合多肽,其中所述第二嵌合多肽包含与SEQ ID NO:197至少80%相同的序列。
实施例E220.根据实施例E219所述的多链嵌合多肽,其中所述第二嵌合多肽包含与SEQ ID NO:197至少90%相同的序列。
实施例E221.根据实施例E220所述的多链嵌合多肽,其中所述第二嵌合多肽包含与SEQ ID NO:197至少95%相同的序列。
实施例E222.根据实施例E221所述的多链嵌合多肽,其中所述第二嵌合多肽包含SEQ ID NO:197。
实施例E223.根据实施例E222所述的多链嵌合多肽,其中所述第二嵌合多肽包含SEQ ID NO:199。
实施例E224.根据实施例E1所述的多链嵌合多肽,其中所述第一嵌合多肽包含与SEQ ID NO:201至少80%相同的序列。
实施例E225.根据实施例E224所述的多链嵌合多肽,其中所述第一嵌合多肽包含与SEQ ID NO:201至少90%相同的序列。
实施例E226.根据实施例E225所述的多链嵌合多肽,其中所述第一嵌合多肽包含与SEQ ID NO:201至少95%相同的序列。
实施例E227.根据实施例E226所述的多链嵌合多肽,其中所述第一嵌合多肽包含SEQ ID NO:201。
实施例E228.根据实施例E227所述的多链嵌合多肽,其中所述第一嵌合多肽包含SEQ ID NO:203。
实施例E229.根据实施例E1和E224至E228中任一项所述的多链嵌合多肽,其中所述第二嵌合多肽包含与SEQ ID NO:205至少80%相同的序列。
实施例E230.根据实施例E229所述的多链嵌合多肽,其中所述第二嵌合多肽包含与SEQ ID NO:205至少90%相同的序列。
实施例E231.根据实施例E230所述的多链嵌合多肽,其中所述第二嵌合多肽包含与SEQ ID NO:205至少95%相同的序列。
实施例E232.根据实施例E231所述的多链嵌合多肽,其中所述第二嵌合多肽包含SEQ ID NO:205。
实施例E233.根据实施例E232所述的多链嵌合多肽,其中所述第二嵌合多肽包含SEQ ID NO:207。
实施例E234.根据实施例E1所述的多链嵌合多肽,其中所述第一嵌合多肽包含与SEQ ID NO:209至少80%相同的序列。
实施例E235.根据实施例E234所述的多链嵌合多肽,其中所述第一嵌合多肽包含与SEQ ID NO:209至少90%相同的序列。
实施例E236.根据实施例E235所述的多链嵌合多肽,其中所述第一嵌合多肽包含与SEQ ID NO:209至少95%相同的序列。
实施例E237.根据实施例E236所述的多链嵌合多肽,其中所述第一嵌合多肽包含SEQ ID NO:209。
实施例E238.根据实施例E237所述的多链嵌合多肽,其中所述第一嵌合多肽包含SEQ ID NO:211。
实施例E239.根据实施例E1和E234-E238中任一项所述的多链嵌合多肽,其中所述第二嵌合多肽包含与SEQ ID NO:213至少80%相同的序列。
实施例E240.根据实施例E239所述的多链嵌合多肽,其中所述第二嵌合多肽包含与SEQ ID NO:213至少90%相同的序列。
实施例E241.根据实施例E240所述的多链嵌合多肽,其中所述第二嵌合多肽包含与SEQ ID NO:213至少95%相同的序列。
实施例E242.根据实施例E241所述的多链嵌合多肽,其中所述第二嵌合多肽包含SEQ ID NO:213。
实施例E243.根据实施例E242所述的多链嵌合多肽,其中所述第二嵌合多肽包含SEQ ID NO:215。
实施例E244.根据实施例E1至E133中任一项所述的多链嵌合多肽,其中所述第一嵌合多肽进一步包含一个或多个另外的靶标结合结构域,其中所述一个或多个另外的抗原结合结构域中的至少一个位于所述可溶性组织因子结构域与所述一对亲和结构域中的所述第一结构域之间。
实施例E245.根据实施例E244所述的多链嵌合多肽,其中所述第一嵌合多肽进一步包含在所述可溶性组织因子结构域与所述一个或多个另外的抗原结合结构域中的所述至少一个之间的接头序列,和/或在所述一个或多个另外的抗原结合结构域中的所述至少一个与所述一对亲和结构域中的所述第一结构域之间的接头序列。
实施例E246.根据实施例E1至E133中任一项所述的多链嵌合多肽,其中所述第一嵌合多肽在所述第一嵌合多肽的N端和/或C端进一步包含一个或多个另外的靶标结合结构域。
实施例E247.根据实施例E246所述的多链嵌合多肽,其中在所述第一嵌合多肽中,所述一个或多个另外的靶标结合结构域中的至少一个直接邻接所述一对亲和结构域中的所述第一结构域。
实施例E248.根据实施例E246所述的多链嵌合多肽,其中所述第一嵌合多肽进一步包含在所述一个或多个另外的靶标结合结构域中的所述至少一个与所述一对亲和结构域中的所述第一结构域之间的接头序列。
实施例E249.根据实施例E246的多链嵌合多肽,其中在所述第一嵌合多肽中,所述一个或多个另外的靶标结合结构域中的所述至少一个直接邻接所述第一靶标结合结构域。
实施例E250.根据实施例E246所述的多链嵌合多肽,其中所述第一嵌合多肽进一步包含在所述一个或多个另外的靶标结合结构域中的所述至少一个与所述第一靶标结合结构域之间的接头序列。
实施例E251.根据实施例E246所述的多链嵌合多肽,其中所述一个或多个另外的靶标结合结构域中的至少一个安置于所述第一嵌合多肽的N和/或C端,并且所述一个或多个另外的靶标结合结构域中的至少一个位于所述第一嵌合多肽中所述可溶性组织因子结构域与所述一对亲和结构域中的所述第一结构域之间。
实施例E252.根据实施例E251所述的多链嵌合多肽,其中在所述第一嵌合多肽中,安置于N端的所述一个或多个另外的靶标结合结构域中的至少一个另外的靶标结合结构域直接邻接所述第一靶标结合结构域或所述一对亲和结构域中的所述第一结构域。
实施例E253.根据实施例E251所述的多链嵌合多肽,其中所述第一嵌合多肽进一步包含安置于所述第一嵌合多肽中的所述至少一个另外的靶标结合结构域与所述第一靶标结合结构域或所述一对亲和结构域中的所述第一结构域之间的接头序列。
实施例E254.根据实施例E251所述的多链嵌合多肽,其中在所述第一嵌合多肽中,安置于C端的所述一个或多个另外的靶标结合结构域中的至少一个另外的靶标结合结构域直接邻接所述第一靶标结合结构域或所述一对亲和结构域中的所述第一结构域。
实施例E255.根据实施例E251所述的多链嵌合多肽,其中所述第一嵌合多肽进一步包含安置于所述第一嵌合多肽中的所述至少一个另外的靶标结合结构域与所述第一靶标结合结构域或所述一对亲和结构域中的所述第一结构域之间的接头序列。
实施例E256.根据实施例E251所述的多链嵌合多肽,其中位于所述可溶性组织因子结构域与所述一对亲和结构域中的所述第一结构域之间的所述一个或多个另外的靶标结合结构域中的所述至少一个,直接邻接所述可溶性组织因子结构域和/或所述一对亲和结构域中的所述第一结构域。
实施例E257.根据实施例E251所述的多链嵌合多肽,其中所述第一嵌合多肽进一步包含安置于以下的接头序列:(i)所述可溶性组织因子结构域与所述一个或多个另外的靶标结合结构域中的所述至少一个之间,所述一个或多个另外的靶标结合结构域中的所述至少一个位于所述可溶性组织因子结构域与所述一对亲和结构域中的所述第一结构域之间,和/或(ii)所述一对亲和结构域中的所述第一结构域与所述一个或多个另外的靶标结合结构域中的所述至少一个之间,所述一个或多个另外的靶标结合结构域中的所述至少一个位于所述可溶性组织因子结构域与所述一对亲和结构域中的所述第一结构域之间。
实施例E258.根据实施例E44至E46、E57至E59、E76至E78、E96至E98、E109至E111、E122至E124和E131至E133中任一项所述的多链嵌合多肽,其中所述第二嵌合多肽在所述第二嵌合多肽的N端或C端进一步包含所述另外的靶标结合结构域。
实施例E259.根据实施例E258所述的多链嵌合多肽,其中在所述第二嵌合多肽中,所述另外的靶标结合结构域直接邻接所述一对亲和结构域中的所述第二结构域。
实施例E260.根据实施例E258所述的多链嵌合多肽,其中所述第二嵌合多肽进一步包含所述第二嵌合多肽中的所述另外的靶标结合结构域与所述一对亲和结构域中的所述第二结构域之间的接头序列。
实施例E261.根据实施例E258所述的多链嵌合多肽,其中在所述第二嵌合多肽中,所述另外的靶标结合结构域直接邻接所述第二靶标结合结构域。
实施例E262.根据实施例E258所述的多链嵌合多肽,其中所述第二嵌合多肽进一步包含所述第二嵌合多肽中的所述另外的靶标结合结构域与另外靶标第二靶标结合结构域之间的接头序列。
实施例E263.一种组合物,其包含根据实施例E1至E262所述的多链嵌合多肽中的任一种。
实施例E264.根据实施例E263所述的组合物,其中所述组合物是药物组合物。
实施例E265.一种试剂盒,其包含至少一个剂量的根据实施例E263或E264所述的组合物。
实施例E266.一种刺激免疫细胞的方法,所述方法包含:
使免疫细胞与有效量的根据实施例E1至E262所述的多链嵌合多肽中的任一种或根据实施例E263或E264所述的组合物接触。
实施例E267.根据实施例E266所述的方法,其中所述免疫细胞在体外接触。
实施例E268.根据实施例E267所述的方法,其中所述免疫细胞先前获自受试者。
实施例E269.根据实施例E268所述的方法,其中所述方法进一步包含在接触步骤之前从所述受试者获得所述免疫细胞。
实施例E270.根据实施例E266所述的方法,其中所述免疫细胞在体内接触。
实施例E271.根据实施例E266至E270中任一项所述的方法,其中所述免疫细胞选自以下组成的组:未成熟胸腺细胞、外周血淋巴细胞、初始T细胞、多能Th细胞前体、淋巴祖细胞、Treg细胞、记忆T细胞、Th17细胞、Th22细胞、Th9细胞、Th2细胞、Th1细胞、Th3细胞、γδT细胞、αβT细胞、肿瘤浸润性T细胞、CD8+T细胞、CD4+T细胞、自然杀伤T细胞、肥大细胞、巨噬细胞、嗜中性粒细胞、树突状细胞、嗜碱性粒细胞、嗜酸性粒细胞和自然杀伤细胞。
实施例E272.根据实施例E266至E271中任一项所述的方法,其中所述免疫细胞先前已经过基因修饰以表达嵌合抗原受体或重组T细胞受体。
实施例E273.根据实施例E266至E271中任一项所述的方法,其中所述方法进一步包含在接触步骤之后,将编码嵌合抗原受体或重组T细胞受体的核酸引入到所述免疫细胞中。
实施例E274.根据实施例E266至E273中任一项所述的方法,其中所述方法进一步包含向有需要的受试者施用所述免疫细胞。
实施例E275.根据实施例E274所述的方法,其中所述受试者已被鉴别或诊断为患有与年龄相关的疾病或病况。
实施例E276.根据实施例E275所述的方法,其中所述与年龄相关的疾病或病况选自以下组成的组:阿尔茨海默氏病、动脉瘤、囊性纤维化、胰腺炎纤维化、青光眼、高血压、特发性肺纤维化、炎性肠病、椎间盘退变、黄斑变性、骨关节炎、2型糖尿病、脂肪萎缩、脂肪营养不良、动脉粥样硬化、白内障、COPD、特发性肺纤维化、肾移植失败、肝纤维化、骨量损失、心肌梗死、肌肉减少症、伤口愈合、脱发、心肌细胞肥大、骨关节炎、帕金森氏病、与年龄相关的肺组织弹性丧失、黄斑变性、恶病质、肾小球硬化、肝硬化、NAFLD、骨质疏松症、肌萎缩性侧索硬化症、亨廷顿氏病、脊髓小脑共济失调、多发性硬化症和肾功能不全。
实施例E277.根据实施例E274所述的方法,其中所述受试者已被鉴别或诊断为患有癌症。
实施例E278.根据实施例E277所述的方法,其中所述癌症选自以下组成的组:实体肿瘤、血液肿瘤、肉瘤、骨肉瘤、成胶质细胞瘤、成神经细胞瘤、黑色素瘤、横纹肌肉瘤、尤文氏肉瘤、骨肉瘤、B细胞瘤、多发性骨髓瘤、B细胞淋巴瘤、B细胞非霍奇金氏淋巴瘤、霍奇金氏淋巴瘤、慢性淋巴细胞性白血病(CLL)、急性骨髓性白血病(AML)、慢性骨髓性白血病(CML)、急性淋巴细胞性白血病(ALL)、骨髓增生异常综合症(MDS)、皮肤T细胞淋巴瘤、成视网膜细胞瘤、胃癌、尿路上皮癌、肺癌、肾细胞癌、胃和食管癌、胰腺癌、前列腺癌、乳腺癌、结直肠癌、卵巢癌、非小细胞肺癌、鳞状细胞头颈癌、子宫内膜癌、宫颈癌、肝癌和肝细胞癌。
实施例E279.根据实施例E274所述的方法,其中所述受试者已被诊断或鉴别为患有感染性疾病。
实施例E280.根据实施例E279所述的方法,其中所述感染性疾病是感染人免疫缺陷病毒、巨细胞病毒、腺病毒、冠状病毒、鼻病毒、轮状病毒、天花、单纯疱疹病毒、乙型肝炎病毒、甲型肝炎病毒和丙型肝炎病毒、乳头瘤病毒和流感病毒。
实施例E281.一种诱导或增加免疫细胞增殖的方法,所述方法包含:
使免疫细胞与有效量的根据实施例E1至E262所述的多链嵌合多肽中的任一种或根据实施例E263或E264所述的组合物接触。
实施例E282.根据实施例E281所述的方法,其中所述免疫细胞在体外接触。
实施例E283.根据实施例E282所述的方法,其中所述免疫细胞先前获自受试者。
实施例E284.根据实施例E283所述的方法,其中所述方法进一步包含在接触步骤之前从所述受试者获得所述免疫细胞。
实施例E285.根据实施例E281所述的方法,其中所述免疫细胞在体内接触。
实施例E286.根据实施例E281至E285中任一项所述的方法,其中所述免疫细胞选自以下组成的组:未成熟胸腺细胞、外周血淋巴细胞、初始T细胞、多能Th细胞前体、淋巴祖细胞、Treg细胞、记忆T细胞、Th17细胞、Th22细胞、Th9细胞、Th2细胞、Th1细胞、Th3细胞、γδT细胞、αβT细胞、肿瘤浸润性T细胞、CD8+T细胞、CD4+T细胞、自然杀伤T细胞、肥大细胞、巨噬细胞、嗜中性粒细胞、树突状细胞、嗜碱性粒细胞、嗜酸性粒细胞和自然杀伤细胞。
实施例E287.根据实施例E281至E286中任一项所述的方法,其中所述免疫细胞先前已经过基因修饰以表达嵌合抗原受体或重组T细胞受体。
实施例E288.根据实施例E281至E286中任一项所述的方法,其中所述方法进一步包含在接触步骤之后,将编码嵌合抗原受体或重组T细胞受体的核酸引入到所述免疫细胞中。
实施例E289.根据实施例E281至E288中任一项所述的方法,其中所述方法进一步包含向有需要的受试者施用所述免疫细胞。
实施例E290.根据实施例E289所述的方法,其中所述受试者已被鉴别或诊断为患有与年龄相关的疾病或病况。
实施例E291.根据实施例E290所述的方法,其中所述与年龄相关的疾病或病况选自以下组成的组:阿尔茨海默氏病、动脉瘤、囊性纤维化、胰腺炎纤维化、青光眼、高血压、特发性肺纤维化、炎性肠病、椎间盘退变、黄斑变性、骨关节炎、2型糖尿病、脂肪萎缩、脂肪营养不良、动脉粥样硬化、白内障、COPD、特发性肺纤维化、肾移植失败、肝纤维化、骨量损失、心肌梗死、肌肉减少症、伤口愈合、脱发、心肌细胞肥大、骨关节炎、帕金森氏病、与年龄相关的肺组织弹性丧失、黄斑变性、恶病质、肾小球硬化、肝硬化、NAFLD、骨质疏松症、肌萎缩性侧索硬化症、亨廷顿氏病、脊髓小脑共济失调、多发性硬化症和肾功能不全。
实施例E292.根据实施例E289所述的方法,其中所述受试者已被鉴别或诊断为患有癌症。
实施例E293.根据实施例E292所述的方法,其中所述癌症选自以下组成的组:实体肿瘤、血液肿瘤、肉瘤、骨肉瘤、成胶质细胞瘤、成神经细胞瘤、黑色素瘤、横纹肌肉瘤、尤文氏肉瘤、骨肉瘤、B细胞瘤、多发性骨髓瘤、B细胞淋巴瘤、B细胞非霍奇金氏淋巴瘤、霍奇金氏淋巴瘤、慢性淋巴细胞性白血病(CLL)、急性骨髓性白血病(AML)、慢性骨髓性白血病(CML)、急性淋巴细胞性白血病(ALL)、骨髓增生异常综合症(MDS)、皮肤T细胞淋巴瘤、成视网膜细胞瘤、胃癌、尿路上皮癌、肺癌、肾细胞癌、胃和食管癌、胰腺癌、前列腺癌、乳腺癌、结直肠癌、卵巢癌、非小细胞肺癌、鳞状细胞头颈癌、子宫内膜癌、宫颈癌、肝癌和肝细胞癌。
实施例E294.根据实施例E289所述的方法,其中所述受试者已被诊断或鉴别为患有感染性疾病。
实施例E295.根据实施例E289所述的方法,其中所述感染性疾病是感染人免疫缺陷病毒、巨细胞病毒、腺病毒、冠状病毒、鼻病毒、轮状病毒、天花、单纯疱疹病毒、乙型肝炎病毒、甲型肝炎病毒和丙型肝炎病毒、乳头瘤病毒和流感病毒。
实施例E296.一种诱导免疫细胞分化成记忆或记忆样免疫细胞的方法,所述方法包含:
使免疫细胞与有效量的根据实施例E1至E262所述的多链嵌合多肽中的任一种或根据实施例E263或E264所述的组合物接触。
实施例E297.根据实施例E296所述的方法,其中所述免疫细胞在体外接触。
实施例E298.根据实施例E297所述的方法,其中所述免疫细胞先前获自受试者。
实施例E299.根据实施例E298所述的方法,其中所述方法进一步包含在接触步骤之前从所述受试者获得所述免疫细胞。
实施例E300.根据实施例E296所述的方法,其中所述免疫细胞在体内接触。
实施例E301.根据实施例E296至E300中任一项所述的方法,其中所述免疫细胞选自以下组成的组:未成熟胸腺细胞、外周血淋巴细胞、初始T细胞、多能Th细胞前体、淋巴祖细胞、Treg细胞、Th17细胞、Th22细胞、Th9细胞、Th2细胞、Th1细胞、Th3细胞、γδT细胞、αβT细胞、肿瘤浸润性T细胞、CD8+T细胞、CD4+T细胞、自然杀伤T细胞、肥大细胞、巨噬细胞、嗜中性粒细胞、树突状细胞、嗜碱性粒细胞、嗜酸性粒细胞和自然杀伤细胞。
实施例E302.根据实施例E296至E301中任一项所述的方法,其中所述免疫细胞先前已经过基因修饰以表达嵌合抗原受体或重组T细胞受体。
实施例E303.根据实施例E296至E301中任一项所述的方法,其中所述方法进一步包含在接触步骤之后,将编码嵌合抗原受体或重组T细胞受体的核酸引入到所述免疫细胞中。
实施例E304.根据实施例E296至E303中任一项所述的方法,其中所述方法进一步包含向有需要的受试者施用所述免疫细胞。
实施例E305.根据实施例E304所述的方法,其中所述受试者已被鉴别或诊断为患有与年龄相关的疾病或病况。
实施例E306.根据实施例E305所述的方法,其中所述与年龄相关的疾病或病况选自以下组成的组:阿尔茨海默氏病、动脉瘤、囊性纤维化、胰腺炎纤维化、青光眼、高血压、特发性肺纤维化、炎性肠病、椎间盘退变、黄斑变性、骨关节炎、2型糖尿病、脂肪萎缩、脂肪营养不良、动脉粥样硬化、白内障、COPD、特发性肺纤维化、肾移植失败、肝纤维化、骨量损失、心肌梗死、肌肉减少症、伤口愈合、脱发、心肌细胞肥大、骨关节炎、帕金森氏病、与年龄相关的肺组织弹性丧失、黄斑变性、恶病质、肾小球硬化、肝硬化、NAFLD、骨质疏松症、肌萎缩性侧索硬化症、亨廷顿氏病、脊髓小脑共济失调、多发性硬化症和肾功能不全。
实施例E307.根据实施例E304所述的方法,其中所述受试者已被鉴别或诊断为患有癌症。
实施例E308.根据实施例E307所述的方法,其中所述癌症选自以下组成的组:实体肿瘤、血液肿瘤、肉瘤、骨肉瘤、成胶质细胞瘤、成神经细胞瘤、黑色素瘤、横纹肌肉瘤、尤文氏肉瘤、骨肉瘤、B细胞瘤、多发性骨髓瘤、B细胞淋巴瘤、B细胞非霍奇金氏淋巴瘤、霍奇金氏淋巴瘤、慢性淋巴细胞性白血病(CLL)、急性骨髓性白血病(AML)、慢性骨髓性白血病(CML)、急性淋巴细胞性白血病(ALL)、骨髓增生异常综合症(MDS)、皮肤T细胞淋巴瘤、成视网膜细胞瘤、胃癌、尿路上皮癌、肺癌、肾细胞癌、胃和食管癌、胰腺癌、前列腺癌、乳腺癌、结直肠癌、卵巢癌、非小细胞肺癌、鳞状细胞头颈癌、子宫内膜癌、宫颈癌、肝癌和肝细胞癌。
实施例E309.根据实施例E304所述的方法,其中所述受试者已被诊断或鉴别为患有感染性疾病。
实施例E310.根据实施例E309所述的方法,其中所述感染性疾病是感染人免疫缺陷病毒、巨细胞病毒、腺病毒、冠状病毒、鼻病毒、轮状病毒、天花、单纯疱疹病毒、乙型肝炎病毒、甲型肝炎病毒和丙型肝炎病毒、乳头瘤病毒和流感病毒。
实施例E311.一种在有需要的受试者中杀死癌细胞、受感染细胞或衰老细胞的方法,所述方法包含向所述受试者施用治疗有效量的根据实施例E1至E262所述的多链嵌合多肽中的任一种或根据实施例E263或E264所述的组合物。
实施例E312.根据实施例E311所述的方法,其中所述受试者已被鉴别或诊断为患有癌症。
实施例E313.根据实施例E312所述的方法,其中所述癌症选自以下组成的组:实体肿瘤、血液肿瘤、肉瘤、骨肉瘤、成胶质细胞瘤、成神经细胞瘤、黑色素瘤、横纹肌肉瘤、尤文氏肉瘤、骨肉瘤、B细胞瘤、多发性骨髓瘤、B细胞淋巴瘤、B细胞非霍奇金氏淋巴瘤、霍奇金氏淋巴瘤、慢性淋巴细胞性白血病(CLL)、急性骨髓性白血病(AML)、慢性骨髓性白血病(CML)、急性淋巴细胞性白血病(ALL)、骨髓增生异常综合症(MDS)、皮肤T细胞淋巴瘤、成视网膜细胞瘤、胃癌、尿路上皮癌、肺癌、肾细胞癌、胃和食管癌、胰腺癌、前列腺癌、乳腺癌、结直肠癌、卵巢癌、非小细胞肺癌、鳞状细胞头颈癌、子宫内膜癌、宫颈癌、肝癌和肝细胞癌。
实施例E314.根据实施例E311所述的方法,其中所述受试者已被鉴别或诊断为患有与老化相关的疾病或病况。
实施例E315.根据实施例E314所述的方法,其中所述与老化相关的疾病或病况选自以下组成的组:阿尔茨海默氏病、动脉瘤、囊性纤维化、胰腺炎纤维化、青光眼、高血压、特发性肺纤维化、炎性肠病、椎间盘退变、黄斑变性、骨关节炎、2型糖尿病、脂肪萎缩、脂肪营养不良、动脉粥样硬化、白内障、COPD、特发性肺纤维化、肾移植失败、肝纤维化、骨量损失、心肌梗死、肌肉减少症、伤口愈合、脱发、心肌细胞肥大、骨关节炎、帕金森氏病、与年龄相关的肺组织弹性丧失、黄斑变性、恶病质、肾小球硬化、肝硬化、NAFLD、骨质疏松症、肌萎缩性侧索硬化症、亨廷顿氏病、脊髓小脑共济失调、多发性硬化症和肾功能不全。
实施例E316.一种治疗有需要的受试者的方法,所述方法包含向所述受试者施用治疗有效量的根据实施例E1至E262所述的多链嵌合多肽中的任一种或根据实施例E263或E264所述的组合物。
实施例E317.根据实施例E316所述的方法,其中所述受试者已被鉴别或诊断为患有癌症或感染性疾病。
实施例E318.根据实施例E317所述的方法,其中所述癌症选自以下组成的组:实体肿瘤、血液肿瘤、肉瘤、骨肉瘤、成胶质细胞瘤、成神经细胞瘤、黑色素瘤、横纹肌肉瘤、尤文氏肉瘤、骨肉瘤、B细胞瘤、多发性骨髓瘤、B细胞淋巴瘤、B细胞非霍奇金氏淋巴瘤、霍奇金氏淋巴瘤、慢性淋巴细胞性白血病(CLL)、急性骨髓性白血病(AML)、慢性骨髓性白血病(CML)、急性淋巴细胞性白血病(ALL)、骨髓增生异常综合症(MDS)、皮肤T细胞淋巴瘤、成视网膜细胞瘤、胃癌、尿路上皮癌、肺癌、肾细胞癌、胃和食管癌、胰腺癌、前列腺癌、乳腺癌、结直肠癌、卵巢癌、非小细胞肺癌、鳞状细胞头颈癌、子宫内膜癌、宫颈癌、肝癌和肝细胞癌。
实施例E319.根据实施例E316所述的方法,其中所述受试者已被鉴别或诊断为患有与年龄相关的疾病或病况。
实施例E320.根据实施例E319所述的方法,其中所述与年龄相关的疾病或病况选自以下组成的组:阿尔茨海默氏病、动脉瘤、囊性纤维化、胰腺炎纤维化、青光眼、高血压、特发性肺纤维化、炎性肠病、椎间盘退变、黄斑变性、骨关节炎、2型糖尿病、脂肪萎缩、脂肪营养不良、动脉粥样硬化、白内障、COPD、特发性肺纤维化、肾移植失败、肝纤维化、骨量损失、心肌梗死、肌肉减少症、伤口愈合、脱发、心肌细胞肥大、骨关节炎、帕金森氏病、与年龄相关的肺组织弹性丧失、黄斑变性、恶病质、肾小球硬化、肝硬化、NAFLD、骨质疏松症、肌萎缩性侧索硬化症、亨廷顿氏病、脊髓小脑共济失调、多发性硬化症和肾功能不全。
实施例E321.根据实施例E316所述的方法,其中所述受试者已被诊断或鉴别为患有感染性疾病。
实施例E322.根据实施例E321所述的方法,其中所述感染性疾病是感染人免疫缺陷病毒、巨细胞病毒、腺病毒、冠状病毒、鼻病毒、轮状病毒、天花、单纯疱疹病毒、乙型肝炎病毒、甲型肝炎病毒和丙型肝炎病毒、乳头瘤病毒和流感病毒。
实施例E323.核酸,其编码根据实施例E1至E262中任一项所述的多链嵌合多肽中的任一种。
实施例E324.一种载体,其包含根据实施例E323所述的核酸。
实施例E325.根据实施例E324所述的载体,其中所述载体是表达载体。
实施例E326.一种细胞,其包含根据实施例E323所述的核酸或根据实施例E324或E325所述的载体。
实施例E327.一种产生多链嵌合多肽的方法,所述方法包含:
在足以引起产生所述多链嵌合多肽的条件下在培养基中培养根据实施例E326所述的细胞;和
从所述细胞和/或所述培养基中回收所述多链嵌合多肽。
实施例E328.一种多链嵌合多肽,其通过根据实施例E327所述的方法产生。
实施例E329.根据实施例E8所述的多链嵌合多肽,其中所述可溶性人组织因子结构域包含与SEQ ID NO:3至少80%相同的序列。
实施例E330.根据实施例E329所述的多链嵌合多肽,其中所述可溶性人组织因子结构域包含与SEQ ID NO:3至少90%相同的序列。
实施例E331.根据实施例E330所述的多链嵌合多肽,其中所述可溶性人组织因子结构域包含与SEQ ID NO:3至少95%相同的序列。
实施例E332.根据实施例E331所述的多链嵌合多肽,其中所述可溶性人组织因子结构域包含与SEQ ID NO:3100%相同的序列。
实施例E333.根据实施例E8所述的多链嵌合多肽,其中所述可溶性人组织因子结构域包含与SEQ ID NO:4至少80%相同的序列。
实施例E334.根据实施例E333所述的多链嵌合多肽,其中所述可溶性人组织因子结构域包含与SEQ ID NO:4至少90%相同的序列。
实施例E335.根据实施例E334所述的多链嵌合多肽,其中所述可溶性人组织因子结构域包含与SEQ ID NO:4至少95%相同的序列。
实施例E336.根据实施例E335所述的多链嵌合多肽,其中所述可溶性人组织因子结构域包含与SEQ ID NO:4 100%相同的序列。
F.示例性实施例
实施例F1.一种多链嵌合多肽,其包含:
(a)第一嵌合多肽,其包含:
(i)第一靶标结合结构域;
(ii)接头结构域;和
(iii)一对亲和结构域中的第一结构域;
(b)第二嵌合多肽,其包含:
(i)一对亲和结构域中的第二结构域;和
(ii)第二靶标结合结构域,
其中所述第一嵌合多肽和所述第二嵌合多肽通过所述一对亲和结构域中的所述第一结构域和所述第二结构域的结合而缔合。
实施例F2.根据实施例F1所述的多链嵌合多肽,其中所述第一靶标结合结构域和所述接头结构域在所述第一嵌合多肽中彼此直接邻接。
实施例F3.根据实施例F1所述的多链嵌合多肽,其中所述第一嵌合多肽进一步包含所述第一嵌合多肽中的所述第一靶标结合结构域与所述接头结构域之间的接头序列。
实施例F4.根据实施例F1至F3中任一项所述的多链嵌合多肽,其中所述第一嵌合多肽中的所述接头结构域和所述一对亲和结构域中的所述第一结构域直接直接邻接。
实施例F5.根据实施例F1至F3中任一项所述的多链嵌合多肽,其中所述第一嵌合多肽进一步包含所述第一嵌合多肽中的所述接头结构域与所述一对亲和结构域中的所述第一结构域之间的接头序列。
实施例F6.根据实施例F1至F5中任一项所述的多链嵌合多肽,其中所述一对亲和结构域中的所述第二结构域和所述第二靶标结合结构域在所述第二嵌合多肽中彼此直接邻接。
实施例F7.根据实施例F1至F5中任一项所述的多链嵌合多肽,其中所述第二嵌合多肽进一步包含所述第二嵌合多肽中的所述一对亲和结构域中的所述第二结构域与所述第二靶标结合结构域之间的接头序列。
实施例F8.根据实施例F1至F7中任一项所述的多链嵌合多肽,其中所述第一靶标结合结构域和所述第二靶标结合结构域特异性结合到相同的抗原。
实施例F9.根据实施例F8所述的多链嵌合多肽,其中所述第一靶标结合结构域和所述第二靶标结合结构域特异性结合到相同的表位。
实施例F10.根据实施例F9所述的多链嵌合多肽,其中所述第一靶标结合结构域和所述第二靶标结合结构域包含相同的氨基酸序列。
实施例F11.根据实施例F1至F7中任一项所述的多链嵌合多肽,其中所述第一靶标结合结构域和所述第二靶标结合结构域特异性结合到不同的抗原。
实施例F12.根据实施例F1至F11中任一项所述的多链嵌合多肽,其中所述第一靶标结合结构域和所述第二靶标结合结构域中的一个或两个是抗原结合结构域。
实施例F13.根据实施例F12所述的多链嵌合多肽,其中所述第一靶标结合结构域和所述第二靶标结合结构域各自是抗原结合结构域。
实施例F14.根据实施例F12或F13的多链嵌合多肽,其中所述抗原结合结构域包含scFv或单结构域抗体。
实施例F15.根据实施例F1至F14中任一项所述的多链嵌合多肽,其中所述第一靶标结合结构域和所述第二靶标结合结构域中的一个或两个特异性结合到选自以下组成的组的靶标:CD16a、CD28、CD3、CD33、CD20、CD19、CD22、CD123、IL-1R、IL-1、VEGF、IL-6R、IL-4、IL-10、PDL-1、TIGIT、PD-1、TIM3、CTLA4、MICA、MICB、IL-6、IL-8、TNFα、CD26a、CD36、ULBP2、CD30、CD200、CD80、CD86、PD-L2、B7-H4、HVEM、ILT3、ILT4、TIGIT、MHCII、LAG3、CD272、VISTA、CD137、CD40、CD47、CD70、OX40、IGF-1R、MUC4AC、MUC5AC、Trop-2、CMET、EGFR、HER1、HER2、HER3、PSMA、CEA、B7H3、EPCAM、BCMA、P-钙黏着蛋白、CEACAM5、UL16结合蛋白、HLA-DR、DLL4、TYRO3、AXL、MER、CD122、CD155、PDGF-DD、TGF-β受体II(TGF-βRII)的配体、TGF-βRIII的配体、DNAM-1的配体、NKp46的配体、NKp44的配体、NKG2D的配体、NKp30的配体、scMHCI的配体、scMHCII的配体、scTCR的配体、IL-1的受体、IL-2的受体、IL-3的受体、IL-7的受体、IL-8的受体、IL-10的受体、IL-12的受体、IL-15的受体、IL-17的受体、IL-18的受体、IL-21的受体、PDGF-DD的受体、干细胞因子(SCF)的受体、干细胞样酪氨酸激酶3配体(FLT3L)的受体、MICA的受体、MICB的受体、ULP16结合蛋白的受体、CD155的受体、CD122的受体和CD28的受体。
实施例F16.根据实施例F1至F14中任一项所述的多链嵌合多肽,其中所述第一靶标结合结构域和所述第二靶标结合结构域中的一个或两个是可溶性白介素或细胞因子蛋白。
实施例F17.根据实施例F16所述的多链嵌合多肽,其中所述可溶性白介素、细胞因子或配体蛋白选自以下组成的组:IL-1、IL-2、IL-3、IL-7、IL-8、IL-10、IL-12、IL-15、IL-17、IL-18、IL-21、PDGF-DD、SCF和FLT3L。
实施例F18.根据实施例F1至F14中任一项所述的多链嵌合多肽,其中所述第一靶标结合结构域和所述第二靶标结合结构域中的一个或两个是可溶性白介素或细胞因子受体。
实施例F19.根据实施例F18所述的多链嵌合多肽,其中所述可溶性受体是可溶性TGF-β受体II(TGF-βRII)、可溶性TGF-βRIII、可溶性NKG2D、可溶性NKp30、可溶性NKp44、可溶性NKp46、可溶性DNAM-1、scMHCI、scMHCII、scTCR、可溶性CD155或可溶性CD28。
实施例F20.根据实施例F1至F19中任一项所述的多链嵌合多肽,其中所述第一嵌合多肽进一步包含一个或多个另外的靶标结合结构域,其中一个或多个靶标结合结构域中的至少一个位于接头结构域与所述一对亲和结构域对中的所述第一结构域之间。
实施例F21.根据实施例F20所述的多链嵌合多肽,其中所述第一嵌合多肽进一步包含在所述接头结构域与一个或多个靶抗原结合结构域中的至少一个之间的接头序列,和/或在一个或多个靶抗原结合结构域中的至少一个与所述一对亲和结构域中的所述第一结构域之间的接头序列。
实施例F22.根据实施例F1至F19中任一项所述的多链嵌合多肽,其中所述第一嵌合多肽在所述第一嵌合多肽的N端和/或C端进一步包含一个或多个另外的靶标结合结构域。
实施例F23.根据实施例F22所述的多链嵌合多肽,其中在所述第一嵌合多肽中,所述一个或多个另外的靶标结合结构域中的至少一个直接邻接所述一对亲和结构域中的所述第一结构域。
实施例F24.根据实施例F22所述的多链嵌合多肽,其中所述第一嵌合多肽进一步包含在所述一个或多个另外的靶标结合结构域中的所述至少一个与所述一对亲和结构域中的所述第一结构域之间的接头序列。
实施例F25.根据实施例F22所述的多链嵌合多肽,其中在所述第一嵌合多肽中,所述一个或多个另外的靶标结合结构域中的所述至少一个直接邻接所述第一靶标结合结构域。
实施例F26.根据实施例F22所述的多链嵌合多肽,其中所述第一嵌合多肽进一步包含在所述一个或多个另外的靶标结合结构域中的所述至少一个与所述第一靶标结合结构域之间的接头序列。
实施例F27.根据实施例F22所述的多链嵌合多肽,其中所述一个或多个另外的靶标结合结构域中的至少一个安置于所述第一嵌合多肽的N和/或C端,并且所述一个或多个另外的靶标结合结构域中的至少一个位于所述第一嵌合多肽中所述接头结构域与所述一对亲和结构域中的所述第一结构域之间。
实施例F28.根据实施例F27所述的多链嵌合多肽,其中在所述第一嵌合多肽中,安置于N端的所述一个或多个另外的靶标结合结构域中的至少一个另外的靶标结合结构域直接邻接所述第一靶标结合结构域或所述一对亲和结构域中的所述第一结构域。
实施例F29.根据实施例F27所述的多链嵌合多肽,其中所述第一嵌合多肽进一步包含安置于所述第一嵌合多肽中的所述至少一个另外的靶标结合结构域与所述第一靶标结合结构域或所述一对亲和结构域中的所述第一结构域之间的接头序列。
实施例F30.根据实施例F27所述的多链嵌合多肽,其中在所述第一嵌合多肽中,安置于C端的所述一个或多个另外的靶标结合结构域中的至少一个另外的靶标结合结构域直接邻接所述第一靶标结合结构域或所述一对亲和结构域中的所述第一结构域。
实施例F31.根据实施例F27所述的多链嵌合多肽,其中所述第一嵌合多肽进一步包含安置于所述第一嵌合多肽中的所述至少一个另外的靶标结合结构域与所述第一靶标结合结构域或所述一对亲和结构域中的所述第一结构域之间的接头序列。
实施例F32.根据实施例F27所述的多链嵌合多肽,其中位于所述接头结构域与所述一对亲和结构域中的所述第一结构域之间的所述一个或多个另外的靶标结合结构域中的所述至少一个,直接邻接所述接头结构域和/或所述一对亲和结构域中的所述第一结构域。
实施例F33.根据实施例F27所述的多链嵌合多肽,其中所述第一嵌合多肽进一步包含安置于以下的接头序列:(i)所述接头结构域与所述一个或多个另外的靶标结合结构域中的所述至少一个之间,所述一个或多个另外的靶标结合结构域中的所述至少一个位于所述接头结构域与所述一对亲和结构域中的所述第一结构域之间,和/或(ii)所述一对亲和结构域中的所述第一结构域与所述一个或多个另外的靶标结合结构域中的所述至少一个之间,所述一个或多个另外的靶标结合结构域中的所述至少一个位于所述接头结构域与所述一对亲和结构域中的所述第一结构域之间。
实施例F34.根据实施例F1至F33中任一项所述的多链嵌合多肽,其中所述第二嵌合多肽在所述第二嵌合多肽的N端和/或C端进一步包含一个或多个另外的靶标结合结构域。
实施例F35.根据实施例F34所述的多链嵌合多肽,其中在所述第二嵌合多肽中,所述一个或多个另外的靶标结合结构域中的至少一个直接邻接所述一对亲和结构域中的所述第二结构域。
实施例F36.根据实施例F34所述的多链嵌合多肽,其中所述第二嵌合多肽进一步包含所述第二嵌合多肽中的所述一个或多个另外的靶标结合结构域中的至少一个与所述一对亲和结构域中的所述第二结构域之间的接头序列。
实施例F37.根据实施例F34所述的多链嵌合多肽,其中在所述第二嵌合多肽中,所述一个或多个另外的靶标结合结构域中的至少一个直接邻接所述第二靶标结合结构域。
实施例F38.根据实施例F34所述的多链嵌合多肽,其中所述第二嵌合多肽进一步包含所述第二嵌合多肽中的所述一个或多个另外的靶标结合结构域中的至少一个与所述第二靶标结合结构域之间的接头序列。
实施例F39.根据实施例F20至F38中任一项所述的多链嵌合多肽,其中所述第一靶标结合结构域、所述第二靶标结合结构域和所述一个或多个另外的靶标结合结构域中的两个或更多个特异性结合到相同的抗原。
实施例F40.根据实施例F39所述的多链嵌合多肽,其中所述第一靶标结合结构域、所述第二靶标结合结构域和所述一个或多个另外的靶标结合结构域中的两个或更多个特异性结合到相同的表位。
实施例F41.根据实施例F40所述的多链嵌合多肽,其中所述第一靶标结合结构域、所述第二靶标结合结构域和所述一个或多个另外的靶标结合结构域中的两个或更多个包含相同的氨基酸序列。
实施例F42.根据实施例F39所述的多链嵌合多肽,其中所述第一靶标结合结构域、所述第二靶标结合结构域和所述一个或多个另外的靶标结合结构域各自特异性结合到相同的抗原。
实施例F43.根据实施例F42所述的多链嵌合多肽,其中所述第一靶标结合结构域、所述第二靶标结合结构域和所述一个或多个另外的靶标结合结构域各自特异性结合到相同的表位。
实施例F44.根据实施例F43所述的多链嵌合多肽,其中所述第一靶标结合结构域、所述第二靶标结合结构域和所述一个或多个另外的靶标结合结构域各自包含相同的氨基酸序列。
实施例F45.根据实施例F20至F38中任一项所述的多链嵌合多肽,其中所述第一靶标结合结构域、所述第二靶标结合结构域和所述一个或多个另外的靶标结合结构域特异性结合到不同的抗原。
实施例F46.根据实施例F20至F45中任一项所述的多链嵌合多肽,其中所述第一靶标结合结构域、所述第二靶标结合结构域和一个或多个靶标结合结构域中的一个或多个是抗原结合结构域。
实施例F47.根据实施例F46所述的多链嵌合多肽,其中所述第一靶标结合结构域、所述第二靶标结合结构域和所述一个或多个另外的靶标结合结构域各自是抗原结合结构域。
实施例F48.根据实施例F46或F47的多链嵌合多肽,其中所述抗原结合结构域包含scFv。
实施例F49.根据实施例F20-F48中任一项所述的多链嵌合多肽,其中所述第一靶标结合结构域、所述第二靶标结合结构域和一个或多个靶标结合结构域中的一个或多个特异性结合到选自以下组成的组的靶标:CD16a、CD28、CD3、CD33、CD20、CD19、CD22、CD123、IL-1R、IL-1、VEGF、IL-6R、IL-4、IL-10、PDL-1、TIGIT、PD-1、TIM3、CTLA4、MICA、MICB、IL-6、IL-8、TNFα、CD26a、CD36、ULBP2、CD30、CD200、CD80、CD86、PD-L2、B7-H4、HVEM、ILT3、ILT4、TIGIT、MHCII、LAG3、CD272、VISTA、CD137、CD40、CD47、CD70、OX40、IGF-1R、MUC4AC、MUC5AC、Trop-2、CMET、EGFR、HER1、HER2、HER3、PSMA、CEA、B7H3、EPCAM、BCMA、P-钙黏着蛋白、CEACAM5、UL16结合蛋白、HLA-DR、DLL4、TYRO3、AXL、MER、CD122、CD155、PDGF-DD、TGF-β受体II(TGF-βRII)的配体、TGF-βRIII的配体、DNAM-1的配体、NKp46的配体、NKp44的配体、NKG2D的配体、NKp30的配体、scMHCI的配体、scMHCII的配体、scTCR的配体、IL-1的受体、IL-2的受体、IL-3的受体、IL-7的受体、IL-8的受体、IL-10的受体、IL-12的受体、IL-15的受体、IL-17的受体、IL-18的受体、IL-21的受体、PDGF-DD的受体、干细胞因子(SCF)的受体、干细胞样酪氨酸激酶3配体(FLT3L)的受体、MICA的受体、MICB的受体、ULP16结合蛋白的受体、CD155的受体、CD122的受体和CD3的受体以及CD28的受体。
实施例F50.根据实施例F20至F48中任一项所述的多链嵌合多肽,其中所述第一靶标结合结构域、所述第二靶标结合结构域和所述一个或多个另外的靶标结合结构域中的一个或多个是可溶性白介素或细胞因子蛋白。
实施例F52.根据实施例F20至F48中任一项所述的多链嵌合多肽,其中所述第一靶标结合结构域、所述第二靶标结合结构域和所述一个或多个另外的靶标结合结构域中的一个或多个是可溶性白介素或细胞因子受体。
实施例F53.根据实施例F52所述的多链嵌合多肽,其中所述可溶性受体是可溶性TGF-β受体II(TGF-βRII)、可溶性TGF-βRIII、可溶性NKG2D、可溶性NKp30、可溶性NKp44、可溶性NKp46、可溶性DNAM-1、scMHCI、scMHCII、scTCR、可溶性CD155、可溶性CD122、可溶性CD3或可溶性CD28。
实施例F54.根据实施例F1至F53中任一项的所述多链嵌合多肽,其中所述第一嵌合多肽进一步包含在所述第一嵌合多肽的N端或C端的肽标签。
实施例F55.根据实施例F1至F53中任一项所述的多链嵌合多肽,其中所述第二嵌合多肽进一步包含在所述第二嵌合多肽的N端或C端的肽标签。
实施例F56.根据实施例F1至F55中任一项所述的多链嵌合多肽,其中所述接头结构域是可溶性组织因子结构域。
实施例F57.根据实施例F56的多链嵌合多肽,其中所述可溶性组织因子结构域是可溶性人组织因子结构域。
实施例F58.根据实施例F57所述的多链嵌合多肽,其中所述可溶性人组织因子结构域包含与SEQ ID NO:1至少80%相同的序列。
实施例F59.根据实施例F58所述的多链嵌合多肽,其中所述可溶性人组织因子结构域包含与SEQ ID NO:1至少90%相同的序列。
实施例F60.根据实施例F59所述的多链嵌合多肽,其中所述可溶性人组织因子结构域包含与SEQ ID NO:1至少95%相同的序列。
实施例F61.根据实施例F57至F60中任一项所述的多链嵌合多肽,其中所述可溶性人组织因子结构域不包含以下中的一种或多种:
在对应于成熟野生型人组织因子蛋白的氨基酸位置20的氨基酸位置处的赖氨酸;
在对应于成熟野生型人组织因子蛋白的氨基酸位置22的氨基酸位置处的异亮氨酸;
在对应于成熟野生型人组织因子蛋白的氨基酸位置45的氨基酸位置处的色氨酸;
在对应于成熟野生型人组织因子蛋白的氨基酸位置58的氨基酸位置处的天冬氨酸;
在对应于成熟野生型人组织因子蛋白的氨基酸位置94的氨基酸位置处的酪氨酸;
在对应于成熟野生型人组织因子蛋白的氨基酸位置135的氨基酸位置处的精氨酸;和
在对应于成熟野生型人组织因子蛋白的氨基酸位置140的氨基酸位置处的苯丙氨酸。
实施例F62.根据实施例F61所述的多链嵌合多肽,其中所述可溶性人组织因子结构域不包含以下中的任一种:
在对应于成熟野生型人组织因子蛋白的氨基酸位置20的氨基酸位置处的赖氨酸;
在对应于成熟野生型人组织因子蛋白的氨基酸位置22的氨基酸位置处的异亮氨酸;
在对应于成熟野生型人组织因子蛋白的氨基酸位置45的氨基酸位置处的色氨酸;
在对应于成熟野生型人组织因子蛋白的氨基酸位置58的氨基酸位置处的天冬氨酸;
在对应于成熟野生型人组织因子蛋白的氨基酸位置94的氨基酸位置处的酪氨酸;
在对应于成熟野生型人组织因子蛋白的氨基酸位置135的氨基酸位置处的精氨酸;和
在对应于成熟野生型人组织因子蛋白的氨基酸位置140的氨基酸位置处的苯丙氨酸。
实施例F63.根据实施例F56至F62中任一项所述的多链嵌合多肽,其中所述可溶性组织因子结构域不能结合到因子VIIa。
实施例F64.根据实施例F56至F63中任一项所述的多链嵌合多肽,其中所述可溶性组织因子结构域不将非活性因子X转化为因子Xa。
实施例F65.根据实施例F56至F64中任一项所述的多链嵌合多肽,其中所述多链嵌合多肽不刺激哺乳动物的凝血。
实施例F66.根据实施例F1至F55中任一项所述的多链嵌合多肽,其中所述接头结构域选自以下组成的组:κ链和λ链。
实施例F67.根据实施例F1至F66中任一项所述的多链嵌合多肽,其中所述一对亲和结构域是来自人IL-15受体的α链(IL15Rα)的寿司结构域和可溶性IL-15。
实施例F68.根据实施例F67所述的多链嵌合多肽,其中所述可溶性IL15具有D8N或D8A氨基酸取代。
实施例F69.根据实施例F67或F68所述的多链嵌合多肽,其中所述人IL15Rα是成熟全长IL15Rα。
实施例F70.根据实施例F1至F66中任一项所述的多链嵌合多肽,其中所述一对亲和结构域选自以下组成的组:芽胞杆菌RNA酶和芽胞杆菌RNA酶抑制子、PKA和AKAP、基于突变核糖核酸酶I片段的衔接子/对接标签模块以及基于蛋白质突触蛋白、突触结合蛋白、突触泡蛋白和SNAP25的相互作用的SNARE模块。
实施例F71.根据实施例F1至F70中任一项所述的多链嵌合多肽,其中所述第一嵌合多肽和/或所述第二嵌合多肽在其N端进一步包含信号序列。
实施例F72.根据实施例F1至F70中任一项所述的多链嵌合多肽,其中所述第一嵌合多肽和/或所述第二嵌合多肽在其N端缺少信号序列。
实施例F73.一种组合物,其包含根据实施例F1至F72所述的多链嵌合多肽中的任一种。
实施例F74.根据实施例F73所述的组合物,其中所述组合物是药物组合物。
实施例F75.一种试剂盒,其包含至少一个剂量的根据实施例F73或F74所述的组合物。
实施例F76.核酸,其编码根据实施例F1至F72中任一项所述的多链嵌合多肽中的任一种。
实施例F77.一种载体,其包含根据实施例F76所述的核酸。
实施例F78.根据实施例F77所述的载体,其中所述载体是表达载体。
实施例F79.一种细胞,其包含根据实施例F76所述的核酸或根据实施例F77或F78所述的载体。
实施例F80.一种产生多链嵌合多肽的方法,所述方法包含:
在足以引起产生所述多链嵌合多肽的条件下在培养基中培养根据实施例F79所述的细胞;和
从所述细胞和/或所述培养基中回收所述多链嵌合多肽。
实施例F81.一种多链嵌合多肽,其通过根据实施例F80所述的方法产生。
序列表
<110> HCW生物制剂公司(HCW BIOLOGICS, INC.)
<120> 多链嵌合多肽和其用途
<130> 47039-0005WO1
<140>
<141>
<150> 62/881,088
<151> 2019-07-31
<150> 62/817,241
<151> 2019-03-12
<150> 62/817,230
<151> 2019-03-12
<150> 62/816,683
<151> 2019-03-11
<150> 62/749,506
<151> 2018-10-23
<150> 62/749,007
<151> 2018-10-22
<150> 62/746,832
<151> 2018-10-17
<150> 62/725,043
<151> 2018-08-30
<150> 62/725,010
<151> 2018-08-30
<150> 62/724,969
<151> 2018-08-30
<160> 226
<170> PatentIn 3.5版
<210> 1
<211> 219
<212> PRT
<213> 智人
<220>
<221> source
<223> /标注=“组织因子”
<400> 1
Ser Gly Thr Thr Asn Thr Val Ala Ala Tyr Asn Leu Thr Trp Lys Ser
1 5 10 15
Thr Asn Phe Lys Thr Ile Leu Glu Trp Glu Pro Lys Pro Val Asn Gln
20 25 30
Val Tyr Thr Val Gln Ile Ser Thr Lys Ser Gly Asp Trp Lys Ser Lys
35 40 45
Cys Phe Tyr Thr Thr Asp Thr Glu Cys Asp Leu Thr Asp Glu Ile Val
50 55 60
Lys Asp Val Lys Gln Thr Tyr Leu Ala Arg Val Phe Ser Tyr Pro Ala
65 70 75 80
Gly Asn Val Glu Ser Thr Gly Ser Ala Gly Glu Pro Leu Tyr Glu Asn
85 90 95
Ser Pro Glu Phe Thr Pro Tyr Leu Glu Thr Asn Leu Gly Gln Pro Thr
100 105 110
Ile Gln Ser Phe Glu Gln Val Gly Thr Lys Val Asn Val Thr Val Glu
115 120 125
Asp Glu Arg Thr Leu Val Arg Arg Asn Asn Thr Phe Leu Ser Leu Arg
130 135 140
Asp Val Phe Gly Lys Asp Leu Ile Tyr Thr Leu Tyr Tyr Trp Lys Ser
145 150 155 160
Ser Ser Ser Gly Lys Lys Thr Ala Lys Thr Asn Thr Asn Glu Phe Leu
165 170 175
Ile Asp Val Asp Lys Gly Glu Asn Tyr Cys Phe Ser Val Gln Ala Val
180 185 190
Ile Pro Ser Arg Thr Val Asn Arg Lys Ser Thr Asp Ser Pro Val Glu
195 200 205
Cys Met Gly Gln Glu Lys Gly Glu Phe Arg Glu
210 215
<210> 2
<211> 657
<212> DNA
<213> 智人
<220>
<221> source
<223> /标注=“组织因子”
<400> 2
agcggcacaa ccaacacagt cgctgcctat aacctcactt ggaagagcac caacttcaaa 60
accatcctcg aatgggaacc caaacccgtt aaccaagttt acaccgtgca gatcagcacc 120
aagtccggcg actggaagtc caaatgtttc tataccaccg acaccgagtg cgatctcacc 180
gatgagatcg tgaaagatgt gaaacagacc tacctcgccc gggtgtttag ctaccccgcc 240
ggcaatgtgg agagcactgg ttccgctggc gagcctttat acgagaacag ccccgaattt 300
accccttacc tcgagaccaa tttaggacag cccaccatcc aaagctttga gcaagttggc 360
acaaaggtga atgtgacagt ggaggacgag cggactttag tgcggcggaa caacaccttt 420
ctcagcctcc gggatgtgtt cggcaaagat ttaatctaca cactgtatta ctggaagtcc 480
tcttcctccg gcaagaagac agctaaaacc aacacaaacg agtttttaat cgacgtggat 540
aaaggcgaaa actactgttt cagcgtgcaa gctgtgatcc cctcccggac cgtgaatagg 600
aaaagcaccg atagccccgt tgagtgcatg ggccaagaaa agggcgagtt ccgggag 657
<210> 3
<211> 219
<212> PRT
<213> 智人
<220>
<221> source
<223> /标注=“组织因子”
<400> 3
Ser Gly Thr Thr Asn Thr Val Ala Ala Tyr Asn Leu Thr Trp Lys Ser
1 5 10 15
Thr Asn Phe Ala Thr Ala Leu Glu Trp Glu Pro Lys Pro Val Asn Gln
20 25 30
Val Tyr Thr Val Gln Ile Ser Thr Lys Ser Gly Asp Trp Lys Ser Lys
35 40 45
Cys Phe Tyr Thr Thr Asp Thr Glu Cys Ala Leu Thr Asp Glu Ile Val
50 55 60
Lys Asp Val Lys Gln Thr Tyr Leu Ala Arg Val Phe Ser Tyr Pro Ala
65 70 75 80
Gly Asn Val Glu Ser Thr Gly Ser Ala Gly Glu Pro Leu Tyr Glu Asn
85 90 95
Ser Pro Glu Phe Thr Pro Tyr Leu Glu Thr Asn Leu Gly Gln Pro Thr
100 105 110
Ile Gln Ser Phe Glu Gln Val Gly Thr Lys Val Asn Val Thr Val Glu
115 120 125
Asp Glu Arg Thr Leu Val Ala Arg Asn Asn Thr Ala Leu Ser Leu Arg
130 135 140
Asp Val Phe Gly Lys Asp Leu Ile Tyr Thr Leu Tyr Tyr Trp Lys Ser
145 150 155 160
Ser Ser Ser Gly Lys Lys Thr Ala Lys Thr Asn Thr Asn Glu Phe Leu
165 170 175
Ile Asp Val Asp Lys Gly Glu Asn Tyr Cys Phe Ser Val Gln Ala Val
180 185 190
Ile Pro Ser Arg Thr Val Asn Arg Lys Ser Thr Asp Ser Pro Val Glu
195 200 205
Cys Met Gly Gln Glu Lys Gly Glu Phe Arg Glu
210 215
<210> 4
<211> 219
<212> PRT
<213> 智人
<220>
<221> source
<223> /标注=“组织因子”
<400> 4
Ser Gly Thr Thr Asn Thr Val Ala Ala Tyr Asn Leu Thr Trp Lys Ser
1 5 10 15
Thr Asn Phe Ala Thr Ala Leu Glu Trp Glu Pro Lys Pro Val Asn Gln
20 25 30
Val Tyr Thr Val Gln Ile Ser Thr Lys Ser Gly Asp Ala Lys Ser Lys
35 40 45
Cys Phe Tyr Thr Thr Asp Thr Glu Cys Ala Leu Thr Asp Glu Ile Val
50 55 60
Lys Asp Val Lys Gln Thr Tyr Leu Ala Arg Val Phe Ser Tyr Pro Ala
65 70 75 80
Gly Asn Val Glu Ser Thr Gly Ser Ala Gly Glu Pro Leu Ala Glu Asn
85 90 95
Ser Pro Glu Phe Thr Pro Tyr Leu Glu Thr Asn Leu Gly Gln Pro Thr
100 105 110
Ile Gln Ser Phe Glu Gln Val Gly Thr Lys Val Asn Val Thr Val Glu
115 120 125
Asp Glu Arg Thr Leu Val Ala Arg Asn Asn Thr Ala Leu Ser Leu Arg
130 135 140
Asp Val Phe Gly Lys Asp Leu Ile Tyr Thr Leu Tyr Tyr Trp Lys Ser
145 150 155 160
Ser Ser Ser Gly Lys Lys Thr Ala Lys Thr Asn Thr Asn Glu Phe Leu
165 170 175
Ile Asp Val Asp Lys Gly Glu Asn Tyr Cys Phe Ser Val Gln Ala Val
180 185 190
Ile Pro Ser Arg Thr Val Asn Arg Lys Ser Thr Asp Ser Pro Val Glu
195 200 205
Cys Met Gly Gln Glu Lys Gly Glu Phe Arg Glu
210 215
<210> 5
<211> 223
<212> PRT
<213> 小鼠
<220>
<221> source
<223> /标注=“组织因子”
<400> 5
Ala Gly Ile Pro Glu Lys Ala Phe Asn Leu Thr Trp Ile Ser Thr Asp
1 5 10 15
Phe Lys Thr Ile Leu Glu Trp Gln Pro Lys Pro Thr Asn Tyr Thr Tyr
20 25 30
Thr Val Gln Ile Ser Asp Arg Ser Arg Asn Trp Lys Asn Lys Cys Phe
35 40 45
Ser Thr Thr Asp Thr Glu Cys Asp Leu Thr Asp Glu Ile Val Lys Asp
50 55 60
Val Thr Trp Ala Tyr Glu Ala Lys Val Leu Ser Val Pro Arg Arg Asn
65 70 75 80
Ser Val His Gly Asp Gly Asp Gln Leu Val Ile His Gly Glu Glu Pro
85 90 95
Pro Phe Thr Asn Ala Pro Lys Phe Leu Pro Tyr Arg Asp Thr Asn Leu
100 105 110
Gly Gln Pro Val Ile Gln Gln Phe Glu Gln Asp Gly Arg Lys Leu Asn
115 120 125
Val Val Val Lys Asp Ser Leu Thr Leu Val Arg Lys Asn Gly Thr Phe
130 135 140
Leu Thr Leu Arg Gln Val Phe Gly Lys Asp Leu Gly Tyr Ile Ile Thr
145 150 155 160
Tyr Arg Lys Gly Ser Ser Thr Gly Lys Lys Thr Asn Ile Thr Asn Thr
165 170 175
Asn Glu Phe Ser Ile Asp Val Glu Glu Gly Val Ser Tyr Cys Phe Phe
180 185 190
Val Gln Ala Met Ile Phe Ser Arg Lys Thr Asn Gln Asn Ser Pro Gly
195 200 205
Ser Ser Thr Val Cys Thr Glu Gln Trp Lys Ser Phe Leu Gly Glu
210 215 220
<210> 6
<211> 224
<212> PRT
<213> 大鼠
<220>
<221> source
<223> /标注=“组织因子”
<400> 6
Ala Gly Thr Pro Pro Gly Lys Ala Phe Asn Leu Thr Trp Ile Ser Thr
1 5 10 15
Asp Phe Lys Thr Ile Leu Glu Trp Gln Pro Lys Pro Thr Asn Tyr Thr
20 25 30
Tyr Thr Val Gln Ile Ser Asp Arg Ser Arg Asn Trp Lys Tyr Lys Cys
35 40 45
Thr Gly Thr Thr Asp Thr Glu Cys Asp Leu Thr Asp Glu Ile Val Lys
50 55 60
Asp Val Asn Trp Thr Tyr Glu Ala Arg Val Leu Ser Val Pro Trp Arg
65 70 75 80
Asn Ser Thr His Gly Lys Glu Thr Leu Phe Gly Thr His Gly Glu Glu
85 90 95
Pro Pro Phe Thr Asn Ala Arg Lys Phe Leu Pro Tyr Arg Asp Thr Lys
100 105 110
Ile Gly Gln Pro Val Ile Gln Lys Tyr Glu Gln Gly Gly Thr Lys Leu
115 120 125
Lys Val Thr Val Lys Asp Ser Phe Thr Leu Val Arg Lys Asn Gly Thr
130 135 140
Phe Leu Thr Leu Arg Gln Val Phe Gly Asn Asp Leu Gly Tyr Ile Leu
145 150 155 160
Thr Tyr Arg Lys Asp Ser Ser Thr Gly Arg Lys Thr Asn Thr Thr His
165 170 175
Thr Asn Glu Phe Leu Ile Asp Val Glu Lys Gly Val Ser Tyr Cys Phe
180 185 190
Phe Ala Gln Ala Val Ile Phe Ser Arg Lys Thr Asn His Lys Ser Pro
195 200 205
Glu Ser Ile Thr Lys Cys Thr Glu Gln Trp Lys Ser Val Leu Gly Glu
210 215 220
<210> 7
<211> 15
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成接头序列”
<400> 7
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
1 5 10 15
<210> 8
<211> 45
<212> DNA
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成接头序列”
<400> 8
ggcggtggag gatccggagg aggtggctcc ggcggcggag gatct 45
<210> 9
<211> 133
<212> PRT
<213> 智人
<220>
<221> source
<223> /标注=“IL-2”
<400> 9
Ala Pro Thr Ser Ser Ser Thr Lys Lys Thr Gln Leu Gln Leu Glu His
1 5 10 15
Leu Leu Leu Asp Leu Gln Met Ile Leu Asn Gly Ile Asn Asn Tyr Lys
20 25 30
Asn Pro Lys Leu Thr Arg Met Leu Thr Phe Lys Phe Tyr Met Pro Lys
35 40 45
Lys Ala Thr Glu Leu Lys His Leu Gln Cys Leu Glu Glu Glu Leu Lys
50 55 60
Pro Leu Glu Glu Val Leu Asn Leu Ala Gln Ser Lys Asn Phe His Leu
65 70 75 80
Arg Pro Arg Asp Leu Ile Ser Asn Ile Asn Val Ile Val Leu Glu Leu
85 90 95
Lys Gly Ser Glu Thr Thr Phe Met Cys Glu Tyr Ala Asp Glu Thr Ala
100 105 110
Thr Ile Val Glu Phe Leu Asn Arg Trp Ile Thr Phe Cys Gln Ser Ile
115 120 125
Ile Ser Thr Leu Thr
130
<210> 10
<211> 133
<212> PRT
<213> 智人
<220>
<221> source
<223> /标注=“IL-3”
<400> 10
Ala Pro Met Thr Gln Thr Thr Pro Leu Lys Thr Ser Trp Val Asn Cys
1 5 10 15
Ser Asn Met Ile Asp Glu Ile Ile Thr His Leu Lys Gln Pro Pro Leu
20 25 30
Pro Leu Leu Asp Phe Asn Asn Leu Asn Gly Glu Asp Gln Asp Ile Leu
35 40 45
Met Glu Asn Asn Leu Arg Arg Pro Asn Leu Glu Ala Phe Asn Arg Ala
50 55 60
Val Lys Ser Leu Gln Asn Ala Ser Ala Ile Glu Ser Ile Leu Lys Asn
65 70 75 80
Leu Leu Pro Cys Leu Pro Leu Ala Thr Ala Ala Pro Thr Arg His Pro
85 90 95
Ile His Ile Lys Asp Gly Asp Trp Asn Glu Phe Arg Arg Lys Leu Thr
100 105 110
Phe Tyr Leu Lys Thr Leu Glu Asn Ala Gln Ala Gln Gln Thr Thr Leu
115 120 125
Ser Leu Ala Ile Phe
130
<210> 11
<211> 152
<212> PRT
<213> 智人
<220>
<221> source
<223> /标注=“IL-7”
<400> 11
Asp Cys Asp Ile Glu Gly Lys Asp Gly Lys Gln Tyr Glu Ser Val Leu
1 5 10 15
Met Val Ser Ile Asp Gln Leu Leu Asp Ser Met Lys Glu Ile Gly Ser
20 25 30
Asn Cys Leu Asn Asn Glu Phe Asn Phe Phe Lys Arg His Ile Cys Asp
35 40 45
Ala Asn Lys Glu Gly Met Phe Leu Phe Arg Ala Ala Arg Lys Leu Arg
50 55 60
Gln Phe Leu Lys Met Asn Ser Thr Gly Asp Phe Asp Leu His Leu Leu
65 70 75 80
Lys Val Ser Glu Gly Thr Thr Ile Leu Leu Asn Cys Thr Gly Gln Val
85 90 95
Lys Gly Arg Lys Pro Ala Ala Leu Gly Glu Ala Gln Pro Thr Lys Ser
100 105 110
Leu Glu Glu Asn Lys Ser Leu Lys Glu Gln Lys Lys Leu Asn Asp Leu
115 120 125
Cys Phe Leu Lys Arg Leu Leu Gln Glu Ile Lys Thr Cys Trp Asn Lys
130 135 140
Ile Leu Met Gly Thr Lys Glu His
145 150
<210> 12
<211> 79
<212> PRT
<213> 智人
<220>
<221> source
<223> /标注=“IL-8”
<400> 12
Glu Gly Ala Val Leu Pro Arg Ser Ala Lys Glu Leu Arg Cys Gln Cys
1 5 10 15
Ile Lys Thr Tyr Ser Lys Pro Phe His Pro Lys Phe Ile Lys Glu Leu
20 25 30
Arg Val Ile Glu Ser Gly Pro His Cys Ala Asn Thr Glu Ile Ile Val
35 40 45
Lys Leu Ser Asp Gly Arg Glu Leu Cys Leu Asp Pro Lys Glu Asn Trp
50 55 60
Val Gln Arg Val Val Glu Lys Phe Leu Lys Arg Ala Glu Asn Ser
65 70 75
<210> 13
<211> 160
<212> PRT
<213> 智人
<220>
<221> source
<223> /标注=“IL-10”
<400> 13
Ser Pro Gly Gln Gly Thr Gln Ser Glu Asn Ser Cys Thr His Phe Pro
1 5 10 15
Gly Asn Leu Pro Asn Met Leu Arg Asp Leu Arg Asp Ala Phe Ser Arg
20 25 30
Val Lys Thr Phe Phe Gln Met Lys Asp Gln Leu Asp Asn Leu Leu Leu
35 40 45
Lys Glu Ser Leu Leu Glu Asp Phe Lys Gly Tyr Leu Gly Cys Gln Ala
50 55 60
Leu Ser Glu Met Ile Gln Phe Tyr Leu Glu Glu Val Met Pro Gln Ala
65 70 75 80
Glu Asn Gln Asp Pro Asp Ile Lys Ala His Val Asn Ser Leu Gly Glu
85 90 95
Asn Leu Lys Thr Leu Arg Leu Arg Leu Arg Arg Cys His Arg Phe Leu
100 105 110
Pro Cys Glu Asn Lys Ser Lys Ala Val Glu Gln Val Lys Asn Ala Phe
115 120 125
Asn Lys Leu Gln Glu Lys Gly Ile Tyr Lys Ala Met Ser Glu Phe Asp
130 135 140
Ile Phe Ile Asn Tyr Ile Glu Ala Tyr Met Thr Met Lys Ile Arg Asn
145 150 155 160
<210> 14
<211> 114
<212> PRT
<213> 智人
<220>
<221> source
<223> /标注=“IL-15”
<400> 14
Asn Trp Val Asn Val Ile Ser Asp Leu Lys Lys Ile Glu Asp Leu Ile
1 5 10 15
Gln Ser Met His Ile Asp Ala Thr Leu Tyr Thr Glu Ser Asp Val His
20 25 30
Pro Ser Cys Lys Val Thr Ala Met Lys Cys Phe Leu Leu Glu Leu Gln
35 40 45
Val Ile Ser Leu Glu Ser Gly Asp Ala Ser Ile His Asp Thr Val Glu
50 55 60
Asn Leu Ile Ile Leu Ala Asn Asn Ser Leu Ser Ser Asn Gly Asn Val
65 70 75 80
Thr Glu Ser Gly Cys Lys Glu Cys Glu Glu Leu Glu Glu Lys Asn Ile
85 90 95
Lys Glu Phe Leu Gln Ser Phe Val His Ile Val Gln Met Phe Ile Asn
100 105 110
Thr Ser
<210> 15
<211> 132
<212> PRT
<213> 智人
<220>
<221> source
<223> /标注=“IL-17”
<400> 15
Gly Ile Thr Ile Pro Arg Asn Pro Gly Cys Pro Asn Ser Glu Asp Lys
1 5 10 15
Asn Phe Pro Arg Thr Val Met Val Asn Leu Asn Ile His Asn Arg Asn
20 25 30
Thr Asn Thr Asn Pro Lys Arg Ser Ser Asp Tyr Tyr Asn Arg Ser Thr
35 40 45
Ser Pro Trp Asn Leu His Arg Asn Glu Asp Pro Glu Arg Tyr Pro Ser
50 55 60
Val Ile Trp Glu Ala Lys Cys Arg His Leu Gly Cys Ile Asn Ala Asp
65 70 75 80
Gly Asn Val Asp Tyr His Met Asn Ser Val Pro Ile Gln Gln Glu Ile
85 90 95
Leu Val Leu Arg Arg Glu Pro Pro His Cys Pro Asn Ser Phe Arg Leu
100 105 110
Glu Lys Ile Leu Val Ser Val Gly Cys Thr Cys Val Thr Pro Ile Val
115 120 125
His His Val Ala
130
<210> 16
<211> 157
<212> PRT
<213> 智人
<220>
<221> source
<223> /标注=“IL-18”
<400> 16
Tyr Phe Gly Lys Leu Glu Ser Lys Leu Ser Val Ile Arg Asn Leu Asn
1 5 10 15
Asp Gln Val Leu Phe Ile Asp Gln Gly Asn Arg Pro Leu Phe Glu Asp
20 25 30
Met Thr Asp Ser Asp Cys Arg Asp Asn Ala Pro Arg Thr Ile Phe Ile
35 40 45
Ile Ser Met Tyr Lys Asp Ser Gln Pro Arg Gly Met Ala Val Thr Ile
50 55 60
Ser Val Lys Cys Glu Lys Ile Ser Thr Leu Ser Cys Glu Asn Lys Ile
65 70 75 80
Ile Ser Phe Lys Glu Met Asn Pro Pro Asp Asn Ile Lys Asp Thr Lys
85 90 95
Ser Asp Ile Ile Phe Phe Gln Arg Ser Val Pro Gly His Asp Asn Lys
100 105 110
Met Gln Phe Glu Ser Ser Ser Tyr Glu Gly Tyr Phe Leu Ala Cys Glu
115 120 125
Lys Glu Arg Asp Leu Phe Lys Leu Ile Leu Lys Lys Glu Asp Glu Leu
130 135 140
Gly Asp Arg Ser Ile Met Phe Thr Val Gln Asn Glu Asp
145 150 155
<210> 17
<211> 352
<212> PRT
<213> 智人
<220>
<221> source
<223> /标注=“PDGF-DD”
<400> 17
Arg Asp Thr Ser Ala Thr Pro Gln Ser Ala Ser Ile Lys Ala Leu Arg
1 5 10 15
Asn Ala Asn Leu Arg Arg Asp Glu Ser Asn His Leu Thr Asp Leu Tyr
20 25 30
Arg Arg Asp Glu Thr Ile Gln Val Lys Gly Asn Gly Tyr Val Gln Ser
35 40 45
Pro Arg Phe Pro Asn Ser Tyr Pro Arg Asn Leu Leu Leu Thr Trp Arg
50 55 60
Leu His Ser Gln Glu Asn Thr Arg Ile Gln Leu Val Phe Asp Asn Gln
65 70 75 80
Phe Gly Leu Glu Glu Ala Glu Asn Asp Ile Cys Arg Tyr Asp Phe Val
85 90 95
Glu Val Glu Asp Ile Ser Glu Thr Ser Thr Ile Ile Arg Gly Arg Trp
100 105 110
Cys Gly His Lys Glu Val Pro Pro Arg Ile Lys Ser Arg Thr Asn Gln
115 120 125
Ile Lys Ile Thr Phe Lys Ser Asp Asp Tyr Phe Val Ala Lys Pro Gly
130 135 140
Phe Lys Ile Tyr Tyr Ser Leu Leu Glu Asp Phe Gln Pro Ala Ala Ala
145 150 155 160
Ser Glu Thr Asn Trp Glu Ser Val Thr Ser Ser Ile Ser Gly Val Ser
165 170 175
Tyr Asn Ser Pro Ser Val Thr Asp Pro Thr Leu Ile Ala Asp Ala Leu
180 185 190
Asp Lys Lys Ile Ala Glu Phe Asp Thr Val Glu Asp Leu Leu Lys Tyr
195 200 205
Phe Asn Pro Glu Ser Trp Gln Glu Asp Leu Glu Asn Met Tyr Leu Asp
210 215 220
Thr Pro Arg Tyr Arg Gly Arg Ser Tyr His Asp Arg Lys Ser Lys Val
225 230 235 240
Asp Leu Asp Arg Leu Asn Asp Asp Ala Lys Arg Tyr Ser Cys Thr Pro
245 250 255
Arg Asn Tyr Ser Val Asn Ile Arg Glu Glu Leu Lys Leu Ala Asn Val
260 265 270
Val Phe Phe Pro Arg Cys Leu Leu Val Gln Arg Cys Gly Gly Asn Cys
275 280 285
Gly Cys Gly Thr Val Asn Trp Arg Ser Cys Thr Cys Asn Ser Gly Lys
290 295 300
Thr Val Lys Lys Tyr His Glu Val Leu Gln Phe Glu Pro Gly His Ile
305 310 315 320
Lys Arg Arg Gly Arg Ala Lys Thr Met Ala Leu Val Asp Ile Gln Leu
325 330 335
Asp His His Glu Arg Cys Asp Cys Ile Cys Ser Ser Arg Pro Pro Arg
340 345 350
<210> 18
<211> 248
<212> PRT
<213> 智人
<220>
<221> source
<223> /标注=“SCF”
<400> 18
Glu Gly Ile Cys Arg Asn Arg Val Thr Asn Asn Val Lys Asp Val Thr
1 5 10 15
Lys Leu Val Ala Asn Leu Pro Lys Asp Tyr Met Ile Thr Leu Lys Tyr
20 25 30
Val Pro Gly Met Asp Val Leu Pro Ser His Cys Trp Ile Ser Glu Met
35 40 45
Val Val Gln Leu Ser Asp Ser Leu Thr Asp Leu Leu Asp Lys Phe Ser
50 55 60
Asn Ile Ser Glu Gly Leu Ser Asn Tyr Ser Ile Ile Asp Lys Leu Val
65 70 75 80
Asn Ile Val Asp Asp Leu Val Glu Cys Val Lys Glu Asn Ser Ser Lys
85 90 95
Asp Leu Lys Lys Ser Phe Lys Ser Pro Glu Pro Arg Leu Phe Thr Pro
100 105 110
Glu Glu Phe Phe Arg Ile Phe Asn Arg Ser Ile Asp Ala Phe Lys Asp
115 120 125
Phe Val Val Ala Ser Glu Thr Ser Asp Cys Val Val Ser Ser Thr Leu
130 135 140
Ser Pro Glu Lys Asp Ser Arg Val Ser Val Thr Lys Pro Phe Met Leu
145 150 155 160
Pro Pro Val Ala Ala Ser Ser Leu Arg Asn Asp Ser Ser Ser Ser Asn
165 170 175
Arg Lys Ala Lys Asn Pro Pro Gly Asp Ser Ser Leu His Trp Ala Ala
180 185 190
Met Ala Leu Pro Ala Leu Phe Ser Leu Ile Ile Gly Phe Ala Phe Gly
195 200 205
Ala Leu Tyr Trp Lys Lys Arg Gln Pro Ser Leu Thr Arg Ala Val Glu
210 215 220
Asn Ile Gln Ile Asn Glu Glu Asp Asn Glu Ile Ser Met Leu Gln Glu
225 230 235 240
Lys Glu Arg Glu Phe Gln Glu Val
245
<210> 19
<211> 209
<212> PRT
<213> 智人
<220>
<221> source
<223> /标注=“FLT3L”
<400> 19
Thr Gln Asp Cys Ser Phe Gln His Ser Pro Ile Ser Ser Asp Phe Ala
1 5 10 15
Val Lys Ile Arg Glu Leu Ser Asp Tyr Leu Leu Gln Asp Tyr Pro Val
20 25 30
Thr Val Ala Ser Asn Leu Gln Asp Glu Glu Leu Cys Gly Gly Leu Trp
35 40 45
Arg Leu Val Leu Ala Gln Arg Trp Met Glu Arg Leu Lys Thr Val Ala
50 55 60
Gly Ser Lys Met Gln Gly Leu Leu Glu Arg Val Asn Thr Glu Ile His
65 70 75 80
Phe Val Thr Lys Cys Ala Phe Gln Pro Pro Pro Ser Cys Leu Arg Phe
85 90 95
Val Gln Thr Asn Ile Ser Arg Leu Leu Gln Glu Thr Ser Glu Gln Leu
100 105 110
Val Ala Leu Lys Pro Trp Ile Thr Arg Gln Asn Phe Ser Arg Cys Leu
115 120 125
Glu Leu Gln Cys Gln Pro Asp Ser Ser Thr Leu Pro Pro Pro Trp Ser
130 135 140
Pro Arg Pro Leu Glu Ala Thr Ala Pro Thr Ala Pro Gln Pro Pro Leu
145 150 155 160
Leu Leu Leu Leu Leu Leu Pro Val Gly Leu Leu Leu Leu Ala Ala Ala
165 170 175
Trp Cys Leu His Trp Gln Arg Thr Arg Arg Arg Thr Pro Arg Pro Gly
180 185 190
Glu Gln Val Pro Pro Val Pro Ser Pro Gln Asp Leu Leu Leu Val Glu
195 200 205
His
<210> 20
<211> 360
<212> PRT
<213> 智人
<220>
<221> source
<223> /标注=“MICA”
<400> 20
Glu Pro His Ser Leu Arg Tyr Asn Leu Thr Val Leu Ser Trp Asp Gly
1 5 10 15
Ser Val Gln Ser Gly Phe Leu Thr Glu Val His Leu Asp Gly Gln Pro
20 25 30
Phe Leu Arg Cys Asp Arg Gln Lys Cys Arg Ala Lys Pro Gln Gly Gln
35 40 45
Trp Ala Glu Asp Val Leu Gly Asn Lys Thr Trp Asp Arg Glu Thr Arg
50 55 60
Asp Leu Thr Gly Asn Gly Lys Asp Leu Arg Met Thr Leu Ala His Ile
65 70 75 80
Lys Asp Gln Lys Glu Gly Leu His Ser Leu Gln Glu Ile Arg Val Cys
85 90 95
Glu Ile His Glu Asp Asn Ser Thr Arg Ser Ser Gln His Phe Tyr Tyr
100 105 110
Asp Gly Glu Leu Phe Leu Ser Gln Asn Leu Glu Thr Lys Glu Trp Thr
115 120 125
Met Pro Gln Ser Ser Arg Ala Gln Thr Leu Ala Met Asn Val Arg Asn
130 135 140
Phe Leu Lys Glu Asp Ala Met Lys Thr Lys Thr His Tyr His Ala Met
145 150 155 160
His Ala Asp Cys Leu Gln Glu Leu Arg Arg Tyr Leu Lys Ser Gly Val
165 170 175
Val Leu Arg Arg Thr Val Pro Pro Met Val Asn Val Thr Arg Ser Glu
180 185 190
Ala Ser Glu Gly Asn Ile Thr Val Thr Cys Arg Ala Ser Gly Phe Tyr
195 200 205
Pro Trp Asn Ile Thr Leu Ser Trp Arg Gln Asp Gly Val Ser Leu Ser
210 215 220
His Asp Thr Gln Gln Trp Gly Asp Val Leu Pro Asp Gly Asn Gly Thr
225 230 235 240
Tyr Gln Thr Trp Val Ala Thr Arg Ile Cys Gln Gly Glu Glu Gln Arg
245 250 255
Phe Thr Cys Tyr Met Glu His Ser Gly Asn His Ser Thr His Pro Val
260 265 270
Pro Ser Gly Lys Val Leu Val Leu Gln Ser His Trp Gln Thr Phe His
275 280 285
Val Ser Ala Val Ala Ala Ala Ala Ile Phe Val Ile Ile Ile Phe Tyr
290 295 300
Val Arg Cys Cys Lys Lys Lys Thr Ser Ala Ala Glu Gly Pro Glu Leu
305 310 315 320
Val Ser Leu Gln Val Leu Asp Gln His Pro Val Gly Thr Ser Asp His
325 330 335
Arg Asp Ala Thr Gln Leu Gly Phe Gln Pro Leu Met Ser Asp Leu Gly
340 345 350
Ser Thr Gly Ser Thr Glu Gly Ala
355 360
<210> 21
<211> 361
<212> PRT
<213> 智人
<220>
<221> source
<223> /标注=“MICB”
<400> 21
Ala Glu Pro His Ser Leu Arg Tyr Asn Leu Met Val Leu Ser Gln Asp
1 5 10 15
Glu Ser Val Gln Ser Gly Phe Leu Ala Glu Gly His Leu Asp Gly Gln
20 25 30
Pro Phe Leu Arg Tyr Asp Arg Gln Lys Arg Arg Ala Lys Pro Gln Gly
35 40 45
Gln Trp Ala Glu Asp Val Leu Gly Ala Lys Thr Trp Asp Thr Glu Thr
50 55 60
Glu Asp Leu Thr Glu Asn Gly Gln Asp Leu Arg Arg Thr Leu Thr His
65 70 75 80
Ile Lys Asp Gln Lys Gly Gly Leu His Ser Leu Gln Glu Ile Arg Val
85 90 95
Cys Glu Ile His Glu Asp Ser Ser Thr Arg Gly Ser Arg His Phe Tyr
100 105 110
Tyr Asp Gly Glu Leu Phe Leu Ser Gln Asn Leu Glu Thr Gln Glu Ser
115 120 125
Thr Val Pro Gln Ser Ser Arg Ala Gln Thr Leu Ala Met Asn Val Thr
130 135 140
Asn Phe Trp Lys Glu Asp Ala Met Lys Thr Lys Thr His Tyr Arg Ala
145 150 155 160
Met Gln Ala Asp Cys Leu Gln Lys Leu Gln Arg Tyr Leu Lys Ser Gly
165 170 175
Val Ala Ile Arg Arg Thr Val Pro Pro Met Val Asn Val Thr Cys Ser
180 185 190
Glu Val Ser Glu Gly Asn Ile Thr Val Thr Cys Arg Ala Ser Ser Phe
195 200 205
Tyr Pro Arg Asn Ile Thr Leu Thr Trp Arg Gln Asp Gly Val Ser Leu
210 215 220
Ser His Asn Thr Gln Gln Trp Gly Asp Val Leu Pro Asp Gly Asn Gly
225 230 235 240
Thr Tyr Gln Thr Trp Val Ala Thr Arg Ile Arg Gln Gly Glu Glu Gln
245 250 255
Arg Phe Thr Cys Tyr Met Glu His Ser Gly Asn His Gly Thr His Pro
260 265 270
Val Pro Ser Gly Lys Val Leu Val Leu Gln Ser Gln Arg Thr Asp Phe
275 280 285
Pro Tyr Val Ser Ala Ala Met Pro Cys Phe Val Ile Ile Ile Ile Leu
290 295 300
Cys Val Pro Cys Cys Lys Lys Lys Thr Ser Ala Ala Glu Gly Pro Glu
305 310 315 320
Leu Val Ser Leu Gln Val Leu Asp Gln His Pro Val Gly Thr Gly Asp
325 330 335
His Arg Asp Ala Ala Gln Leu Gly Phe Gln Pro Leu Met Ser Ala Thr
340 345 350
Gly Ser Thr Gly Ser Thr Glu Gly Ala
355 360
<210> 22
<211> 190
<212> PRT
<213> 智人
<220>
<221> source
<223> /标注=“ULBP1”
<400> 22
Trp Val Asp Thr His Cys Leu Cys Tyr Asp Phe Ile Ile Thr Pro Lys
1 5 10 15
Ser Arg Pro Glu Pro Gln Trp Cys Glu Val Gln Gly Leu Val Asp Glu
20 25 30
Arg Pro Phe Leu His Tyr Asp Cys Val Asn His Lys Ala Lys Ala Phe
35 40 45
Ala Ser Leu Gly Lys Lys Val Asn Val Thr Lys Thr Trp Glu Glu Gln
50 55 60
Thr Glu Thr Leu Arg Asp Val Val Asp Phe Leu Lys Gly Gln Leu Leu
65 70 75 80
Asp Ile Gln Val Glu Asn Leu Ile Pro Ile Glu Pro Leu Thr Leu Gln
85 90 95
Ala Arg Met Ser Cys Glu His Glu Ala His Gly His Gly Arg Gly Ser
100 105 110
Trp Gln Phe Leu Phe Asn Gly Gln Lys Phe Leu Leu Phe Asp Ser Asn
115 120 125
Asn Arg Lys Trp Thr Ala Leu His Pro Gly Ala Lys Lys Met Thr Glu
130 135 140
Lys Trp Glu Lys Asn Arg Asp Val Thr Met Phe Phe Gln Lys Ile Ser
145 150 155 160
Leu Gly Asp Cys Lys Met Trp Leu Glu Glu Phe Leu Met Tyr Trp Glu
165 170 175
Gln Met Leu Asp Pro Thr Lys Pro Pro Ser Leu Ala Pro Gly
180 185 190
<210> 23
<211> 191
<212> PRT
<213> 智人
<220>
<221> source
<223> /标注=“ULBP2”
<400> 23
Gly Arg Ala Asp Pro His Ser Leu Cys Tyr Asp Ile Thr Val Ile Pro
1 5 10 15
Lys Phe Arg Pro Gly Pro Arg Trp Cys Ala Val Gln Gly Gln Val Asp
20 25 30
Glu Lys Thr Phe Leu His Tyr Asp Cys Gly Asn Lys Thr Val Thr Pro
35 40 45
Val Ser Pro Leu Gly Lys Lys Leu Asn Val Thr Thr Ala Trp Lys Ala
50 55 60
Gln Asn Pro Val Leu Arg Glu Val Val Asp Ile Leu Thr Glu Gln Leu
65 70 75 80
Arg Asp Ile Gln Leu Glu Asn Tyr Thr Pro Lys Glu Pro Leu Thr Leu
85 90 95
Gln Ala Arg Met Ser Cys Glu Gln Lys Ala Glu Gly His Ser Ser Gly
100 105 110
Ser Trp Gln Phe Ser Phe Asp Gly Gln Ile Phe Leu Leu Phe Asp Ser
115 120 125
Glu Lys Arg Met Trp Thr Thr Val His Pro Gly Ala Arg Lys Met Lys
130 135 140
Glu Lys Trp Glu Asn Asp Lys Val Val Ala Met Ser Phe His Tyr Phe
145 150 155 160
Ser Met Gly Asp Cys Ile Gly Trp Leu Glu Asp Phe Leu Met Gly Met
165 170 175
Asp Ser Thr Leu Glu Pro Ser Ala Gly Ala Pro Leu Ala Met Ser
180 185 190
<210> 24
<211> 188
<212> PRT
<213> 智人
<220>
<221> source
<223> /标注=“ULBP3”
<400> 24
Asp Ala His Ser Leu Trp Tyr Asn Phe Thr Ile Ile His Leu Pro Arg
1 5 10 15
His Gly Gln Gln Trp Cys Glu Val Gln Ser Gln Val Asp Gln Lys Asn
20 25 30
Phe Leu Ser Tyr Asp Cys Gly Ser Asp Lys Val Leu Ser Met Gly His
35 40 45
Leu Glu Glu Gln Leu Tyr Ala Thr Asp Ala Trp Gly Lys Gln Leu Glu
50 55 60
Met Leu Arg Glu Val Gly Gln Arg Leu Arg Leu Glu Leu Ala Asp Thr
65 70 75 80
Glu Leu Glu Asp Phe Thr Pro Ser Gly Pro Leu Thr Leu Gln Val Arg
85 90 95
Met Ser Cys Glu Cys Glu Ala Asp Gly Tyr Ile Arg Gly Ser Trp Gln
100 105 110
Phe Ser Phe Asp Gly Arg Lys Phe Leu Leu Phe Asp Ser Asn Asn Arg
115 120 125
Lys Trp Thr Val Val His Ala Gly Ala Arg Arg Met Lys Glu Lys Trp
130 135 140
Glu Lys Asp Ser Gly Leu Thr Thr Phe Phe Lys Met Val Ser Met Arg
145 150 155 160
Asp Cys Lys Ser Trp Leu Arg Asp Phe Leu Met His Arg Lys Lys Arg
165 170 175
Leu Glu Pro Thr Ala Pro Pro Thr Met Ala Pro Gly
180 185
<210> 25
<211> 233
<212> PRT
<213> 智人
<220>
<221> source
<223> /标注=“ULBP4”
<400> 25
His Ser Leu Cys Phe Asn Phe Thr Ile Lys Ser Leu Ser Arg Pro Gly
1 5 10 15
Gln Pro Trp Cys Glu Ala Gln Val Phe Leu Asn Lys Asn Leu Phe Leu
20 25 30
Gln Tyr Asn Ser Asp Asn Asn Met Val Lys Pro Leu Gly Leu Leu Gly
35 40 45
Lys Lys Val Tyr Ala Thr Ser Thr Trp Gly Glu Leu Thr Gln Thr Leu
50 55 60
Gly Glu Val Gly Arg Asp Leu Arg Met Leu Leu Cys Asp Ile Lys Pro
65 70 75 80
Gln Ile Lys Thr Ser Asp Pro Ser Thr Leu Gln Val Glu Met Phe Cys
85 90 95
Gln Arg Glu Ala Glu Arg Cys Thr Gly Ala Ser Trp Gln Phe Ala Thr
100 105 110
Asn Gly Glu Lys Ser Leu Leu Phe Asp Ala Met Asn Met Thr Trp Thr
115 120 125
Val Ile Asn His Glu Ala Ser Lys Ile Lys Glu Thr Trp Lys Lys Asp
130 135 140
Arg Gly Leu Glu Lys Tyr Phe Arg Lys Leu Ser Lys Gly Asp Cys Asp
145 150 155 160
His Trp Leu Arg Glu Phe Leu Gly His Trp Glu Ala Met Pro Glu Pro
165 170 175
Thr Val Ser Pro Val Asn Ala Ser Asp Ile His Trp Ser Ser Ser Ser
180 185 190
Leu Pro Asp Arg Trp Ile Ile Leu Gly Ala Phe Ile Leu Leu Val Leu
195 200 205
Met Gly Ile Val Leu Ile Cys Val Trp Trp Gln Asn Gly Glu Trp Gln
210 215 220
Ala Gly Leu Trp Pro Leu Arg Thr Ser
225 230
<210> 26
<211> 193
<212> PRT
<213> 智人
<220>
<221> source
<223> /标注=“ULBP5”
<400> 26
Gly Leu Ala Asp Pro His Ser Leu Cys Tyr Asp Ile Thr Val Ile Pro
1 5 10 15
Lys Phe Arg Pro Gly Pro Arg Trp Cys Ala Val Gln Gly Gln Val Asp
20 25 30
Glu Lys Thr Phe Leu His Tyr Asp Cys Gly Ser Lys Thr Val Thr Pro
35 40 45
Val Ser Pro Leu Gly Lys Lys Leu Asn Val Thr Thr Ala Trp Lys Ala
50 55 60
Gln Asn Pro Val Leu Arg Glu Val Val Asp Ile Leu Thr Glu Gln Leu
65 70 75 80
Leu Asp Ile Gln Leu Glu Asn Tyr Ile Pro Lys Glu Pro Leu Thr Leu
85 90 95
Gln Ala Arg Met Ser Cys Glu Gln Lys Ala Glu Gly His Gly Ser Gly
100 105 110
Ser Trp Gln Leu Ser Phe Asp Gly Gln Ile Phe Leu Leu Phe Asp Ser
115 120 125
Glu Asn Arg Met Trp Thr Thr Val His Pro Gly Ala Arg Lys Met Lys
130 135 140
Glu Lys Trp Glu Asn Asp Lys Asp Met Thr Met Ser Phe His Tyr Ile
145 150 155 160
Ser Met Gly Asp Cys Thr Gly Trp Leu Glu Asp Phe Leu Met Gly Met
165 170 175
Asp Ser Thr Leu Glu Pro Ser Ala Gly Ala Pro Pro Thr Met Ser Ser
180 185 190
Gly
<210> 27
<211> 193
<212> PRT
<213> 智人
<220>
<221> source
<223> /标注=“ULBP6”
<400> 27
Arg Arg Asp Asp Pro His Ser Leu Cys Tyr Asp Ile Thr Val Ile Pro
1 5 10 15
Lys Phe Arg Pro Gly Pro Arg Trp Cys Ala Val Gln Gly Gln Val Asp
20 25 30
Glu Lys Thr Phe Leu His Tyr Asp Cys Gly Asn Lys Thr Val Thr Pro
35 40 45
Val Ser Pro Leu Gly Lys Lys Leu Asn Val Thr Met Ala Trp Lys Ala
50 55 60
Gln Asn Pro Val Leu Arg Glu Val Val Asp Ile Leu Thr Glu Gln Leu
65 70 75 80
Leu Asp Ile Gln Leu Glu Asn Tyr Thr Pro Lys Glu Pro Leu Thr Leu
85 90 95
Gln Ala Arg Met Ser Cys Glu Gln Lys Ala Glu Gly His Ser Ser Gly
100 105 110
Ser Trp Gln Phe Ser Ile Asp Gly Gln Thr Phe Leu Leu Phe Asp Ser
115 120 125
Glu Lys Arg Met Trp Thr Thr Val His Pro Gly Ala Arg Lys Met Lys
130 135 140
Glu Lys Trp Glu Asn Asp Lys Asp Val Ala Met Ser Phe His Tyr Ile
145 150 155 160
Ser Met Gly Asp Cys Ile Gly Trp Leu Glu Asp Phe Leu Met Gly Met
165 170 175
Asp Ser Thr Leu Glu Pro Ser Ala Gly Ala Pro Leu Ala Met Ser Ser
180 185 190
Gly
<210> 28
<211> 65
<212> PRT
<213> 智人
<220>
<221> source
<223> /标注=“IL15Rα”
<400> 28
Ile Thr Cys Pro Pro Pro Met Ser Val Glu His Ala Asp Ile Trp Val
1 5 10 15
Lys Ser Tyr Ser Leu Tyr Ser Arg Glu Arg Tyr Ile Cys Asn Ser Gly
20 25 30
Phe Lys Arg Lys Ala Gly Thr Ser Ser Leu Thr Glu Cys Val Leu Asn
35 40 45
Lys Ala Thr Asn Val Ala His Trp Thr Thr Pro Ser Leu Lys Cys Ile
50 55 60
Arg
65
<210> 29
<211> 195
<212> DNA
<213> 智人
<220>
<221> source
<223> /标注=“IL15Rα”
<400> 29
attacatgcc cccctcccat gagcgtggag cacgccgaca tctgggtgaa gagctatagc 60
ctctacagcc gggagaggta tatctgtaac agcggcttca agaggaaggc cggcaccagc 120
agcctcaccg agtgcgtgct gaataaggct accaacgtgg ctcactggac aacaccctct 180
ttaaagtgca tccgg 195
<210> 30
<211> 342
<212> DNA
<213> 智人
<220>
<221> source
<223> /标注=“IL-15”
<400> 30
aactgggtga acgtcatcag cgatttaaag aagatcgaag atttaattca gtccatgcat 60
atcgacgcca ctttatacac agaatccgac gtgcacccct cttgtaaggt gaccgccatg 120
aaatgttttt tactggagct gcaagttatc tctttagaga gcggagacgc tagcatccac 180
gacaccgtgg agaatttaat cattttagcc aataactctt tatccagcaa cggcaacgtg 240
acagagtccg gctgcaagga gtgcgaagag ctggaggaga agaacatcaa ggagtttctg 300
caatcctttg tgcacattgt ccagatgttc atcaatacct cc 342
<210> 31
<211> 18
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成肽”
<400> 31
Met Lys Trp Val Thr Phe Ile Ser Leu Leu Phe Leu Phe Ser Ser Ala
1 5 10 15
Tyr Ser
<210> 32
<211> 54
<212> DNA
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成寡核苷酸”
<400> 32
atgaaatggg tgacctttat ttctttactg ttcctcttta gcagcgccta ctcc 54
<210> 33
<211> 54
<212> DNA
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成寡核苷酸”
<400> 33
atgaagtggg tcacatttat ctctttactg ttcctcttct ccagcgccta cagc 54
<210> 34
<211> 54
<212> DNA
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成寡核苷酸”
<400> 34
atgaaatggg tgacctttat ttctttactg ttcctcttta gcagcgccta ctcc 54
<210> 35
<211> 16
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成肽”
<400> 35
Met Lys Cys Leu Leu Tyr Leu Ala Phe Leu Phe Leu Gly Val Asn Cys
1 5 10 15
<210> 36
<211> 58
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成多肽”
<400> 36
Met Gly Gln Ile Val Thr Met Phe Glu Ala Leu Pro His Ile Ile Asp
1 5 10 15
Glu Val Ile Asn Ile Val Ile Ile Val Leu Ile Ile Ile Thr Ser Ile
20 25 30
Lys Ala Val Tyr Asn Phe Ala Thr Cys Gly Ile Leu Ala Leu Val Ser
35 40 45
Phe Leu Phe Leu Ala Gly Arg Ser Cys Gly
50 55
<210> 37
<211> 97
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成多肽”
<400> 37
Met Pro Asn His Gln Ser Gly Ser Pro Thr Gly Ser Ser Asp Leu Leu
1 5 10 15
Leu Ser Gly Lys Lys Gln Arg Pro His Leu Ala Leu Arg Arg Lys Arg
20 25 30
Arg Arg Glu Met Arg Lys Ile Asn Arg Lys Val Arg Arg Met Asn Leu
35 40 45
Ala Pro Ile Lys Glu Lys Thr Ala Trp Gln His Leu Gln Ala Leu Ile
50 55 60
Ser Glu Ala Glu Glu Val Leu Lys Thr Ser Gln Thr Pro Gln Asn Ser
65 70 75 80
Leu Thr Leu Phe Leu Ala Leu Leu Ser Val Leu Gly Pro Pro Val Thr
85 90 95
Gly
<210> 38
<211> 30
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成多肽”
<400> 38
Met Asp Ser Lys Gly Ser Ser Gln Lys Gly Ser Arg Leu Leu Leu Leu
1 5 10 15
Leu Val Val Ser Asn Leu Leu Leu Cys Gln Gly Val Val Ser
20 25 30
<210> 39
<211> 15
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成AviTag序列”
<400> 39
Gly Leu Asn Asp Ile Phe Glu Ala Gln Lys Ile Glu Trp His Glu
1 5 10 15
<210> 40
<211> 26
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成标签序列”
<400> 40
Lys Arg Arg Trp Lys Lys Asn Phe Ile Ala Val Ser Ala Ala Asn Arg
1 5 10 15
Phe Lys Lys Ile Ser Ser Ser Gly Ala Leu
20 25
<210> 41
<211> 7
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成标签序列”
<400> 41
Glu Glu Glu Glu Glu Glu Thr
1 5
<210> 42
<211> 13
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成标签序列”
<400> 42
Gly Ala Pro Val Pro Tyr Pro Asp Pro Leu Glu Pro Arg
1 5 10
<210> 43
<211> 8
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成标签序列”
<400> 43
Asp Tyr Lys Asp Asp Asp Asp Lys
1 5
<210> 44
<211> 9
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成标签序列”
<400> 44
Tyr Pro Tyr Asp Val Pro Asp Tyr Ala
1 5
<210> 45
<211> 5
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成标签序列”
<400> 45
His His His His His
1 5
<210> 46
<211> 6
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成标签序列”
<400> 46
His His His His His His
1 5
<210> 47
<211> 7
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成标签序列”
<400> 47
His His His His His His His
1 5
<210> 48
<211> 8
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成标签序列”
<400> 48
His His His His His His His His
1 5
<210> 49
<211> 9
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成标签序列”
<400> 49
His His His His His His His His His
1 5
<210> 50
<211> 10
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成标签序列”
<400> 50
His His His His His His His His His His
1 5 10
<210> 51
<211> 10
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成标签序列”
<400> 51
Glu Gln Lys Leu Ile Ser Glu Glu Asp Leu
1 5 10
<210> 52
<211> 18
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成标签序列”
<400> 52
Thr Lys Glu Asn Pro Arg Ser Asn Gln Glu Glu Ser Tyr Asp Asp Asn
1 5 10 15
Glu Ser
<210> 53
<211> 15
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成标签序列”
<400> 53
Lys Glu Thr Ala Ala Ala Lys Phe Glu Arg Gln His Met Asp Ser
1 5 10 15
<210> 54
<211> 38
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成标签序列”
<400> 54
Met Asp Glu Lys Thr Thr Gly Trp Arg Gly Gly His Val Val Glu Gly
1 5 10 15
Leu Ala Gly Glu Leu Glu Gln Leu Arg Ala Arg Leu Glu His His Pro
20 25 30
Gln Gly Gln Arg Glu Pro
35
<210> 55
<211> 13
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成标签序列”
<400> 55
Ser Leu Ala Glu Leu Leu Asn Ala Gly Leu Gly Gly Ser
1 5 10
<210> 56
<211> 8
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成标签序列”
<400> 56
Thr Gln Asp Pro Ser Arg Val Gly
1 5
<210> 57
<211> 12
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成标签序列”
<400> 57
Pro Asp Arg Val Arg Ala Val Ser His Trp Ser Ser
1 5 10
<210> 58
<211> 8
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成标签序列”
<400> 58
Trp Ser His Pro Gln Phe Glu Lys
1 5
<210> 59
<211> 6
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成标签序列”
<400> 59
Cys Cys Pro Gly Cys Cys
1 5
<210> 60
<211> 10
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成标签序列”
<400> 60
Glu Val His Thr Asn Gln Asp Pro Leu Asp
1 5 10
<210> 61
<211> 14
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成标签序列”
<400> 61
Gly Lys Pro Ile Pro Asn Pro Leu Leu Gly Leu Asp Ser Thr
1 5 10
<210> 62
<211> 11
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成标签序列”
<400> 62
Tyr Thr Asp Ile Glu Met Asn Arg Leu Gly Lys
1 5 10
<210> 63
<211> 8
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成标签序列”
<400> 63
Asp Leu Tyr Asp Asp Asp Asp Lys
1 5
<210> 64
<211> 10
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成标签序列”
<400> 64
Glu Gln Lys Leu Ile Ser Glu Glu Asp Leu
1 5 10
<210> 65
<211> 471
<212> DNA
<213> 智人
<220>
<221> source
<223> /标注=“IL-18”
<400> 65
tacttcggca aactggaatc caagctgagc gtgatccgga atttaaacga ccaagttctg 60
tttatcgatc aaggtaaccg gcctctgttc gaggacatga ccgactccga ttgccgggac 120
aatgcccccc ggaccatctt cattatctcc atgtacaagg acagccagcc ccggggcatg 180
gctgtgacaa ttagcgtgaa gtgtgagaaa atcagcactt tatcttgtga gaacaagatc 240
atctccttta aggaaatgaa cccccccgat aacatcaagg acaccaagtc cgatatcatc 300
ttcttccagc ggtccgtgcc cggtcacgat aacaagatgc agttcgaatc ctcctcctac 360
gagggctact ttttagcttg tgaaaaggag agggatttat tcaagctgat cctcaagaag 420
gaggacgagc tgggcgatcg ttccatcatg ttcaccgtcc aaaacgagga t 471
<210> 66
<211> 306
<212> PRT
<213> 智人
<220>
<221> source
<223> /标注=“IL-12β”
<400> 66
Ile Trp Glu Leu Lys Lys Asp Val Tyr Val Val Glu Leu Asp Trp Tyr
1 5 10 15
Pro Asp Ala Pro Gly Glu Met Val Val Leu Thr Cys Asp Thr Pro Glu
20 25 30
Glu Asp Gly Ile Thr Trp Thr Leu Asp Gln Ser Ser Glu Val Leu Gly
35 40 45
Ser Gly Lys Thr Leu Thr Ile Gln Val Lys Glu Phe Gly Asp Ala Gly
50 55 60
Gln Tyr Thr Cys His Lys Gly Gly Glu Val Leu Ser His Ser Leu Leu
65 70 75 80
Leu Leu His Lys Lys Glu Asp Gly Ile Trp Ser Thr Asp Ile Leu Lys
85 90 95
Asp Gln Lys Glu Pro Lys Asn Lys Thr Phe Leu Arg Cys Glu Ala Lys
100 105 110
Asn Tyr Ser Gly Arg Phe Thr Cys Trp Trp Leu Thr Thr Ile Ser Thr
115 120 125
Asp Leu Thr Phe Ser Val Lys Ser Ser Arg Gly Ser Ser Asp Pro Gln
130 135 140
Gly Val Thr Cys Gly Ala Ala Thr Leu Ser Ala Glu Arg Val Arg Gly
145 150 155 160
Asp Asn Lys Glu Tyr Glu Tyr Ser Val Glu Cys Gln Glu Asp Ser Ala
165 170 175
Cys Pro Ala Ala Glu Glu Ser Leu Pro Ile Glu Val Met Val Asp Ala
180 185 190
Val His Lys Leu Lys Tyr Glu Asn Tyr Thr Ser Ser Phe Phe Ile Arg
195 200 205
Asp Ile Ile Lys Pro Asp Pro Pro Lys Asn Leu Gln Leu Lys Pro Leu
210 215 220
Lys Asn Ser Arg Gln Val Glu Val Ser Trp Glu Tyr Pro Asp Thr Trp
225 230 235 240
Ser Thr Pro His Ser Tyr Phe Ser Leu Thr Phe Cys Val Gln Val Gln
245 250 255
Gly Lys Ser Lys Arg Glu Lys Lys Asp Arg Val Phe Thr Asp Lys Thr
260 265 270
Ser Ala Thr Val Ile Cys Arg Lys Asn Ala Ser Ile Ser Val Arg Ala
275 280 285
Gln Asp Arg Tyr Tyr Ser Ser Ser Trp Ser Glu Trp Ala Ser Val Pro
290 295 300
Cys Ser
305
<210> 67
<211> 918
<212> DNA
<213> 智人
<220>
<221> source
<223> /标注=“IL-12β”
<400> 67
atttgggaac tgaagaagga cgtctacgtg gtcgaactgg actggtatcc cgatgctccc 60
ggcgaaatgg tggtgctcac ttgtgacacc cccgaagaag acggcatcac ttggaccctc 120
gatcagagca gcgaggtgct gggctccgga aagaccctca caatccaagt taaggagttc 180
ggagacgctg gccaatacac atgccacaag ggaggcgagg tgctcagcca ttccttatta 240
ttattacaca agaaggaaga cggaatctgg tccaccgaca ttttaaaaga tcagaaggag 300
cccaagaata agaccttttt aaggtgtgag gccaaaaact acagcggtcg tttcacttgt 360
tggtggctga ccaccatttc caccgattta accttctccg tgaaaagcag ccggggaagc 420
tccgaccctc aaggtgtgac atgtggagcc gctaccctca gcgctgagag ggttcgtggc 480
gataacaagg aatacgagta cagcgtggag tgccaagaag atagcgcttg tcccgctgcc 540
gaagaatctt tacccattga ggtgatggtg gacgccgtgc acaaactcaa gtacgagaac 600
tacacctcct ccttctttat ccgggacatc attaagcccg atcctcctaa gaatttacag 660
ctgaagcctc tcaaaaatag ccggcaagtt gaggtctctt gggaatatcc cgacacttgg 720
agcacacccc acagctactt ctctttaacc ttttgtgtgc aagttcaagg taaaagcaag 780
cgggagaaga aagaccgggt gtttaccgac aaaaccagcg ccaccgtcat ctgtcggaag 840
aacgcctcca tcagcgtgag ggctcaagat cgttattact ccagcagctg gtccgagtgg 900
gccagcgtgc cttgttcc 918
<210> 68
<211> 197
<212> PRT
<213> 智人
<220>
<221> source
<223> /标注=“IL-12α”
<400> 68
Arg Asn Leu Pro Val Ala Thr Pro Asp Pro Gly Met Phe Pro Cys Leu
1 5 10 15
His His Ser Gln Asn Leu Leu Arg Ala Val Ser Asn Met Leu Gln Lys
20 25 30
Ala Arg Gln Thr Leu Glu Phe Tyr Pro Cys Thr Ser Glu Glu Ile Asp
35 40 45
His Glu Asp Ile Thr Lys Asp Lys Thr Ser Thr Val Glu Ala Cys Leu
50 55 60
Pro Leu Glu Leu Thr Lys Asn Glu Ser Cys Leu Asn Ser Arg Glu Thr
65 70 75 80
Ser Phe Ile Thr Asn Gly Ser Cys Leu Ala Ser Arg Lys Thr Ser Phe
85 90 95
Met Met Ala Leu Cys Leu Ser Ser Ile Tyr Glu Asp Leu Lys Met Tyr
100 105 110
Gln Val Glu Phe Lys Thr Met Asn Ala Lys Leu Leu Met Asp Pro Lys
115 120 125
Arg Gln Ile Phe Leu Asp Gln Asn Met Leu Ala Val Ile Asp Glu Leu
130 135 140
Met Gln Ala Leu Asn Phe Asn Ser Glu Thr Val Pro Gln Lys Ser Ser
145 150 155 160
Leu Glu Glu Pro Asp Phe Tyr Lys Thr Lys Ile Lys Leu Cys Ile Leu
165 170 175
Leu His Ala Phe Arg Ile Arg Ala Val Thr Ile Asp Arg Val Met Ser
180 185 190
Tyr Leu Asn Ala Ser
195
<210> 69
<211> 591
<212> DNA
<213> 智人
<220>
<221> source
<223> /标注=“IL-12α”
<400> 69
cgtaacctcc ccgtggctac ccccgatccc ggaatgttcc cttgtttaca ccacagccag 60
aatttactga gggccgtgag caacatgctg cagaaagcta ggcagacttt agaattttac 120
ccttgcacca gcgaggagat cgaccatgaa gatatcacca aggacaagac atccaccgtg 180
gaggcttgtt tacctctgga gctgacaaag aacgagtctt gtctcaactc tcgtgaaacc 240
agcttcatca caaatggctc ttgtttagct tcccggaaga cctcctttat gatggcttta 300
tgcctcagct ccatctacga ggatttaaag atgtaccaag tggagttcaa gaccatgaac 360
gccaagctgc tcatggaccc taaacggcag atctttttag accagaacat gctggctgtg 420
attgatgagc tgatgcaagc tttaaacttc aactccgaga ccgtccctca gaagtcctcc 480
ctcgaggagc ccgattttta caagacaaag atcaaactgt gcattttact ccacgccttt 540
aggatccggg ccgtgaccat tgaccgggtc atgagctatt taaacgccag c 591
<210> 70
<211> 490
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成18t15-12s序列”
<400> 70
Tyr Phe Gly Lys Leu Glu Ser Lys Leu Ser Val Ile Arg Asn Leu Asn
1 5 10 15
Asp Gln Val Leu Phe Ile Asp Gln Gly Asn Arg Pro Leu Phe Glu Asp
20 25 30
Met Thr Asp Ser Asp Cys Arg Asp Asn Ala Pro Arg Thr Ile Phe Ile
35 40 45
Ile Ser Met Tyr Lys Asp Ser Gln Pro Arg Gly Met Ala Val Thr Ile
50 55 60
Ser Val Lys Cys Glu Lys Ile Ser Thr Leu Ser Cys Glu Asn Lys Ile
65 70 75 80
Ile Ser Phe Lys Glu Met Asn Pro Pro Asp Asn Ile Lys Asp Thr Lys
85 90 95
Ser Asp Ile Ile Phe Phe Gln Arg Ser Val Pro Gly His Asp Asn Lys
100 105 110
Met Gln Phe Glu Ser Ser Ser Tyr Glu Gly Tyr Phe Leu Ala Cys Glu
115 120 125
Lys Glu Arg Asp Leu Phe Lys Leu Ile Leu Lys Lys Glu Asp Glu Leu
130 135 140
Gly Asp Arg Ser Ile Met Phe Thr Val Gln Asn Glu Asp Ser Gly Thr
145 150 155 160
Thr Asn Thr Val Ala Ala Tyr Asn Leu Thr Trp Lys Ser Thr Asn Phe
165 170 175
Lys Thr Ile Leu Glu Trp Glu Pro Lys Pro Val Asn Gln Val Tyr Thr
180 185 190
Val Gln Ile Ser Thr Lys Ser Gly Asp Trp Lys Ser Lys Cys Phe Tyr
195 200 205
Thr Thr Asp Thr Glu Cys Asp Leu Thr Asp Glu Ile Val Lys Asp Val
210 215 220
Lys Gln Thr Tyr Leu Ala Arg Val Phe Ser Tyr Pro Ala Gly Asn Val
225 230 235 240
Glu Ser Thr Gly Ser Ala Gly Glu Pro Leu Tyr Glu Asn Ser Pro Glu
245 250 255
Phe Thr Pro Tyr Leu Glu Thr Asn Leu Gly Gln Pro Thr Ile Gln Ser
260 265 270
Phe Glu Gln Val Gly Thr Lys Val Asn Val Thr Val Glu Asp Glu Arg
275 280 285
Thr Leu Val Arg Arg Asn Asn Thr Phe Leu Ser Leu Arg Asp Val Phe
290 295 300
Gly Lys Asp Leu Ile Tyr Thr Leu Tyr Tyr Trp Lys Ser Ser Ser Ser
305 310 315 320
Gly Lys Lys Thr Ala Lys Thr Asn Thr Asn Glu Phe Leu Ile Asp Val
325 330 335
Asp Lys Gly Glu Asn Tyr Cys Phe Ser Val Gln Ala Val Ile Pro Ser
340 345 350
Arg Thr Val Asn Arg Lys Ser Thr Asp Ser Pro Val Glu Cys Met Gly
355 360 365
Gln Glu Lys Gly Glu Phe Arg Glu Asn Trp Val Asn Val Ile Ser Asp
370 375 380
Leu Lys Lys Ile Glu Asp Leu Ile Gln Ser Met His Ile Asp Ala Thr
385 390 395 400
Leu Tyr Thr Glu Ser Asp Val His Pro Ser Cys Lys Val Thr Ala Met
405 410 415
Lys Cys Phe Leu Leu Glu Leu Gln Val Ile Ser Leu Glu Ser Gly Asp
420 425 430
Ala Ser Ile His Asp Thr Val Glu Asn Leu Ile Ile Leu Ala Asn Asn
435 440 445
Ser Leu Ser Ser Asn Gly Asn Val Thr Glu Ser Gly Cys Lys Glu Cys
450 455 460
Glu Glu Leu Glu Glu Lys Asn Ile Lys Glu Phe Leu Gln Ser Phe Val
465 470 475 480
His Ile Val Gln Met Phe Ile Asn Thr Ser
485 490
<210> 71
<211> 1470
<212> DNA
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成18t15-12s序列”
<400> 71
tacttcggca aactggaatc caagctgagc gtgatccgga atttaaacga ccaagttctg 60
tttatcgatc aaggtaaccg gcctctgttc gaggacatga ccgactccga ttgccgggac 120
aatgcccccc ggaccatctt cattatctcc atgtacaagg acagccagcc ccggggcatg 180
gctgtgacaa ttagcgtgaa gtgtgagaaa atcagcactt tatcttgtga gaacaagatc 240
atctccttta aggaaatgaa cccccccgat aacatcaagg acaccaagtc cgatatcatc 300
ttcttccagc ggtccgtgcc cggtcacgat aacaagatgc agttcgaatc ctcctcctac 360
gagggctact ttttagcttg tgaaaaggag agggatttat tcaagctgat cctcaagaag 420
gaggacgagc tgggcgatcg ttccatcatg ttcaccgtcc aaaacgagga tagcggcaca 480
accaacacag tcgctgccta taacctcact tggaagagca ccaacttcaa aaccatcctc 540
gaatgggaac ccaaacccgt taaccaagtt tacaccgtgc agatcagcac caagtccggc 600
gactggaagt ccaaatgttt ctataccacc gacaccgagt gcgatctcac cgatgagatc 660
gtgaaagatg tgaaacagac ctacctcgcc cgggtgttta gctaccccgc cggcaatgtg 720
gagagcactg gttccgctgg cgagccttta tacgagaaca gccccgaatt taccccttac 780
ctcgagacca atttaggaca gcccaccatc caaagctttg agcaagttgg cacaaaggtg 840
aatgtgacag tggaggacga gcggacttta gtgcggcgga acaacacctt tctcagcctc 900
cgggatgtgt tcggcaaaga tttaatctac acactgtatt actggaagtc ctcttcctcc 960
ggcaagaaga cagctaaaac caacacaaac gagtttttaa tcgacgtgga taaaggcgaa 1020
aactactgtt tcagcgtgca agctgtgatc ccctcccgga ccgtgaatag gaaaagcacc 1080
gatagccccg ttgagtgcat gggccaagaa aagggcgagt tccgggagaa ctgggtgaac 1140
gtcatcagcg atttaaagaa gatcgaagat ttaattcagt ccatgcatat cgacgccact 1200
ttatacacag aatccgacgt gcacccctct tgtaaggtga ccgccatgaa atgtttttta 1260
ctggagctgc aagttatctc tttagagagc ggagacgcta gcatccacga caccgtggag 1320
aatttaatca ttttagccaa taactcttta tccagcaacg gcaacgtgac agagtccggc 1380
tgcaaggagt gcgaagagct ggaggagaag aacatcaagg agtttctgca atcctttgtg 1440
cacattgtcc agatgttcat caatacctcc 1470
<210> 72
<211> 508
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成18t15-12s序列”
<400> 72
Met Lys Trp Val Thr Phe Ile Ser Leu Leu Phe Leu Phe Ser Ser Ala
1 5 10 15
Tyr Ser Tyr Phe Gly Lys Leu Glu Ser Lys Leu Ser Val Ile Arg Asn
20 25 30
Leu Asn Asp Gln Val Leu Phe Ile Asp Gln Gly Asn Arg Pro Leu Phe
35 40 45
Glu Asp Met Thr Asp Ser Asp Cys Arg Asp Asn Ala Pro Arg Thr Ile
50 55 60
Phe Ile Ile Ser Met Tyr Lys Asp Ser Gln Pro Arg Gly Met Ala Val
65 70 75 80
Thr Ile Ser Val Lys Cys Glu Lys Ile Ser Thr Leu Ser Cys Glu Asn
85 90 95
Lys Ile Ile Ser Phe Lys Glu Met Asn Pro Pro Asp Asn Ile Lys Asp
100 105 110
Thr Lys Ser Asp Ile Ile Phe Phe Gln Arg Ser Val Pro Gly His Asp
115 120 125
Asn Lys Met Gln Phe Glu Ser Ser Ser Tyr Glu Gly Tyr Phe Leu Ala
130 135 140
Cys Glu Lys Glu Arg Asp Leu Phe Lys Leu Ile Leu Lys Lys Glu Asp
145 150 155 160
Glu Leu Gly Asp Arg Ser Ile Met Phe Thr Val Gln Asn Glu Asp Ser
165 170 175
Gly Thr Thr Asn Thr Val Ala Ala Tyr Asn Leu Thr Trp Lys Ser Thr
180 185 190
Asn Phe Lys Thr Ile Leu Glu Trp Glu Pro Lys Pro Val Asn Gln Val
195 200 205
Tyr Thr Val Gln Ile Ser Thr Lys Ser Gly Asp Trp Lys Ser Lys Cys
210 215 220
Phe Tyr Thr Thr Asp Thr Glu Cys Asp Leu Thr Asp Glu Ile Val Lys
225 230 235 240
Asp Val Lys Gln Thr Tyr Leu Ala Arg Val Phe Ser Tyr Pro Ala Gly
245 250 255
Asn Val Glu Ser Thr Gly Ser Ala Gly Glu Pro Leu Tyr Glu Asn Ser
260 265 270
Pro Glu Phe Thr Pro Tyr Leu Glu Thr Asn Leu Gly Gln Pro Thr Ile
275 280 285
Gln Ser Phe Glu Gln Val Gly Thr Lys Val Asn Val Thr Val Glu Asp
290 295 300
Glu Arg Thr Leu Val Arg Arg Asn Asn Thr Phe Leu Ser Leu Arg Asp
305 310 315 320
Val Phe Gly Lys Asp Leu Ile Tyr Thr Leu Tyr Tyr Trp Lys Ser Ser
325 330 335
Ser Ser Gly Lys Lys Thr Ala Lys Thr Asn Thr Asn Glu Phe Leu Ile
340 345 350
Asp Val Asp Lys Gly Glu Asn Tyr Cys Phe Ser Val Gln Ala Val Ile
355 360 365
Pro Ser Arg Thr Val Asn Arg Lys Ser Thr Asp Ser Pro Val Glu Cys
370 375 380
Met Gly Gln Glu Lys Gly Glu Phe Arg Glu Asn Trp Val Asn Val Ile
385 390 395 400
Ser Asp Leu Lys Lys Ile Glu Asp Leu Ile Gln Ser Met His Ile Asp
405 410 415
Ala Thr Leu Tyr Thr Glu Ser Asp Val His Pro Ser Cys Lys Val Thr
420 425 430
Ala Met Lys Cys Phe Leu Leu Glu Leu Gln Val Ile Ser Leu Glu Ser
435 440 445
Gly Asp Ala Ser Ile His Asp Thr Val Glu Asn Leu Ile Ile Leu Ala
450 455 460
Asn Asn Ser Leu Ser Ser Asn Gly Asn Val Thr Glu Ser Gly Cys Lys
465 470 475 480
Glu Cys Glu Glu Leu Glu Glu Lys Asn Ile Lys Glu Phe Leu Gln Ser
485 490 495
Phe Val His Ile Val Gln Met Phe Ile Asn Thr Ser
500 505
<210> 73
<211> 1524
<212> DNA
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成18t15-12s序列”
<400> 73
atgaagtggg tcacatttat ctctttactg ttcctcttct ccagcgccta cagctacttc 60
ggcaaactgg aatccaagct gagcgtgatc cggaatttaa acgaccaagt tctgtttatc 120
gatcaaggta accggcctct gttcgaggac atgaccgact ccgattgccg ggacaatgcc 180
ccccggacca tcttcattat ctccatgtac aaggacagcc agccccgggg catggctgtg 240
acaattagcg tgaagtgtga gaaaatcagc actttatctt gtgagaacaa gatcatctcc 300
tttaaggaaa tgaacccccc cgataacatc aaggacacca agtccgatat catcttcttc 360
cagcggtccg tgcccggtca cgataacaag atgcagttcg aatcctcctc ctacgagggc 420
tactttttag cttgtgaaaa ggagagggat ttattcaagc tgatcctcaa gaaggaggac 480
gagctgggcg atcgttccat catgttcacc gtccaaaacg aggatagcgg cacaaccaac 540
acagtcgctg cctataacct cacttggaag agcaccaact tcaaaaccat cctcgaatgg 600
gaacccaaac ccgttaacca agtttacacc gtgcagatca gcaccaagtc cggcgactgg 660
aagtccaaat gtttctatac caccgacacc gagtgcgatc tcaccgatga gatcgtgaaa 720
gatgtgaaac agacctacct cgcccgggtg tttagctacc ccgccggcaa tgtggagagc 780
actggttccg ctggcgagcc tttatacgag aacagccccg aatttacccc ttacctcgag 840
accaatttag gacagcccac catccaaagc tttgagcaag ttggcacaaa ggtgaatgtg 900
acagtggagg acgagcggac tttagtgcgg cggaacaaca cctttctcag cctccgggat 960
gtgttcggca aagatttaat ctacacactg tattactgga agtcctcttc ctccggcaag 1020
aagacagcta aaaccaacac aaacgagttt ttaatcgacg tggataaagg cgaaaactac 1080
tgtttcagcg tgcaagctgt gatcccctcc cggaccgtga ataggaaaag caccgatagc 1140
cccgttgagt gcatgggcca agaaaagggc gagttccggg agaactgggt gaacgtcatc 1200
agcgatttaa agaagatcga agatttaatt cagtccatgc atatcgacgc cactttatac 1260
acagaatccg acgtgcaccc ctcttgtaag gtgaccgcca tgaaatgttt tttactggag 1320
ctgcaagtta tctctttaga gagcggagac gctagcatcc acgacaccgt ggagaattta 1380
atcattttag ccaataactc tttatccagc aacggcaacg tgacagagtc cggctgcaag 1440
gagtgcgaag agctggagga gaagaacatc aaggagtttc tgcaatcctt tgtgcacatt 1500
gtccagatgt tcatcaatac ctcc 1524
<210> 74
<211> 583
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成18t15-12s序列”
<400> 74
Ile Trp Glu Leu Lys Lys Asp Val Tyr Val Val Glu Leu Asp Trp Tyr
1 5 10 15
Pro Asp Ala Pro Gly Glu Met Val Val Leu Thr Cys Asp Thr Pro Glu
20 25 30
Glu Asp Gly Ile Thr Trp Thr Leu Asp Gln Ser Ser Glu Val Leu Gly
35 40 45
Ser Gly Lys Thr Leu Thr Ile Gln Val Lys Glu Phe Gly Asp Ala Gly
50 55 60
Gln Tyr Thr Cys His Lys Gly Gly Glu Val Leu Ser His Ser Leu Leu
65 70 75 80
Leu Leu His Lys Lys Glu Asp Gly Ile Trp Ser Thr Asp Ile Leu Lys
85 90 95
Asp Gln Lys Glu Pro Lys Asn Lys Thr Phe Leu Arg Cys Glu Ala Lys
100 105 110
Asn Tyr Ser Gly Arg Phe Thr Cys Trp Trp Leu Thr Thr Ile Ser Thr
115 120 125
Asp Leu Thr Phe Ser Val Lys Ser Ser Arg Gly Ser Ser Asp Pro Gln
130 135 140
Gly Val Thr Cys Gly Ala Ala Thr Leu Ser Ala Glu Arg Val Arg Gly
145 150 155 160
Asp Asn Lys Glu Tyr Glu Tyr Ser Val Glu Cys Gln Glu Asp Ser Ala
165 170 175
Cys Pro Ala Ala Glu Glu Ser Leu Pro Ile Glu Val Met Val Asp Ala
180 185 190
Val His Lys Leu Lys Tyr Glu Asn Tyr Thr Ser Ser Phe Phe Ile Arg
195 200 205
Asp Ile Ile Lys Pro Asp Pro Pro Lys Asn Leu Gln Leu Lys Pro Leu
210 215 220
Lys Asn Ser Arg Gln Val Glu Val Ser Trp Glu Tyr Pro Asp Thr Trp
225 230 235 240
Ser Thr Pro His Ser Tyr Phe Ser Leu Thr Phe Cys Val Gln Val Gln
245 250 255
Gly Lys Ser Lys Arg Glu Lys Lys Asp Arg Val Phe Thr Asp Lys Thr
260 265 270
Ser Ala Thr Val Ile Cys Arg Lys Asn Ala Ser Ile Ser Val Arg Ala
275 280 285
Gln Asp Arg Tyr Tyr Ser Ser Ser Trp Ser Glu Trp Ala Ser Val Pro
290 295 300
Cys Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
305 310 315 320
Ser Arg Asn Leu Pro Val Ala Thr Pro Asp Pro Gly Met Phe Pro Cys
325 330 335
Leu His His Ser Gln Asn Leu Leu Arg Ala Val Ser Asn Met Leu Gln
340 345 350
Lys Ala Arg Gln Thr Leu Glu Phe Tyr Pro Cys Thr Ser Glu Glu Ile
355 360 365
Asp His Glu Asp Ile Thr Lys Asp Lys Thr Ser Thr Val Glu Ala Cys
370 375 380
Leu Pro Leu Glu Leu Thr Lys Asn Glu Ser Cys Leu Asn Ser Arg Glu
385 390 395 400
Thr Ser Phe Ile Thr Asn Gly Ser Cys Leu Ala Ser Arg Lys Thr Ser
405 410 415
Phe Met Met Ala Leu Cys Leu Ser Ser Ile Tyr Glu Asp Leu Lys Met
420 425 430
Tyr Gln Val Glu Phe Lys Thr Met Asn Ala Lys Leu Leu Met Asp Pro
435 440 445
Lys Arg Gln Ile Phe Leu Asp Gln Asn Met Leu Ala Val Ile Asp Glu
450 455 460
Leu Met Gln Ala Leu Asn Phe Asn Ser Glu Thr Val Pro Gln Lys Ser
465 470 475 480
Ser Leu Glu Glu Pro Asp Phe Tyr Lys Thr Lys Ile Lys Leu Cys Ile
485 490 495
Leu Leu His Ala Phe Arg Ile Arg Ala Val Thr Ile Asp Arg Val Met
500 505 510
Ser Tyr Leu Asn Ala Ser Ile Thr Cys Pro Pro Pro Met Ser Val Glu
515 520 525
His Ala Asp Ile Trp Val Lys Ser Tyr Ser Leu Tyr Ser Arg Glu Arg
530 535 540
Tyr Ile Cys Asn Ser Gly Phe Lys Arg Lys Ala Gly Thr Ser Ser Leu
545 550 555 560
Thr Glu Cys Val Leu Asn Lys Ala Thr Asn Val Ala His Trp Thr Thr
565 570 575
Pro Ser Leu Lys Cys Ile Arg
580
<210> 75
<211> 1749
<212> DNA
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成18t15-12s序列”
<400> 75
atttgggaac tgaagaagga cgtctacgtg gtcgaactgg actggtatcc cgatgctccc 60
ggcgaaatgg tggtgctcac ttgtgacacc cccgaagaag acggcatcac ttggaccctc 120
gatcagagca gcgaggtgct gggctccgga aagaccctca caatccaagt taaggagttc 180
ggagacgctg gccaatacac atgccacaag ggaggcgagg tgctcagcca ttccttatta 240
ttattacaca agaaggaaga cggaatctgg tccaccgaca ttttaaaaga tcagaaggag 300
cccaagaata agaccttttt aaggtgtgag gccaaaaact acagcggtcg tttcacttgt 360
tggtggctga ccaccatttc caccgattta accttctccg tgaaaagcag ccggggaagc 420
tccgaccctc aaggtgtgac atgtggagcc gctaccctca gcgctgagag ggttcgtggc 480
gataacaagg aatacgagta cagcgtggag tgccaagaag atagcgcttg tcccgctgcc 540
gaagaatctt tacccattga ggtgatggtg gacgccgtgc acaaactcaa gtacgagaac 600
tacacctcct ccttctttat ccgggacatc attaagcccg atcctcctaa gaatttacag 660
ctgaagcctc tcaaaaatag ccggcaagtt gaggtctctt gggaatatcc cgacacttgg 720
agcacacccc acagctactt ctctttaacc ttttgtgtgc aagttcaagg taaaagcaag 780
cgggagaaga aagaccgggt gtttaccgac aaaaccagcg ccaccgtcat ctgtcggaag 840
aacgcctcca tcagcgtgag ggctcaagat cgttattact ccagcagctg gtccgagtgg 900
gccagcgtgc cttgttccgg cggtggagga tccggaggag gtggctccgg cggcggagga 960
tctcgtaacc tccccgtggc tacccccgat cccggaatgt tcccttgttt acaccacagc 1020
cagaatttac tgagggccgt gagcaacatg ctgcagaaag ctaggcagac tttagaattt 1080
tacccttgca ccagcgagga gatcgaccat gaagatatca ccaaggacaa gacatccacc 1140
gtggaggctt gtttacctct ggagctgaca aagaacgagt cttgtctcaa ctctcgtgaa 1200
accagcttca tcacaaatgg ctcttgttta gcttcccgga agacctcctt tatgatggct 1260
ttatgcctca gctccatcta cgaggattta aagatgtacc aagtggagtt caagaccatg 1320
aacgccaagc tgctcatgga ccctaaacgg cagatctttt tagaccagaa catgctggct 1380
gtgattgatg agctgatgca agctttaaac ttcaactccg agaccgtccc tcagaagtcc 1440
tccctcgagg agcccgattt ttacaagaca aagatcaaac tgtgcatttt actccacgcc 1500
tttaggatcc gggccgtgac cattgaccgg gtcatgagct atttaaacgc cagcattaca 1560
tgcccccctc ccatgagcgt ggagcacgcc gacatctggg tgaagagcta tagcctctac 1620
agccgggaga ggtatatctg taacagcggc ttcaagagga aggccggcac cagcagcctc 1680
accgagtgcg tgctgaataa ggctaccaac gtggctcact ggacaacacc ctctttaaag 1740
tgcatccgg 1749
<210> 76
<211> 601
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成18t15-12s序列”
<400> 76
Met Lys Trp Val Thr Phe Ile Ser Leu Leu Phe Leu Phe Ser Ser Ala
1 5 10 15
Tyr Ser Ile Trp Glu Leu Lys Lys Asp Val Tyr Val Val Glu Leu Asp
20 25 30
Trp Tyr Pro Asp Ala Pro Gly Glu Met Val Val Leu Thr Cys Asp Thr
35 40 45
Pro Glu Glu Asp Gly Ile Thr Trp Thr Leu Asp Gln Ser Ser Glu Val
50 55 60
Leu Gly Ser Gly Lys Thr Leu Thr Ile Gln Val Lys Glu Phe Gly Asp
65 70 75 80
Ala Gly Gln Tyr Thr Cys His Lys Gly Gly Glu Val Leu Ser His Ser
85 90 95
Leu Leu Leu Leu His Lys Lys Glu Asp Gly Ile Trp Ser Thr Asp Ile
100 105 110
Leu Lys Asp Gln Lys Glu Pro Lys Asn Lys Thr Phe Leu Arg Cys Glu
115 120 125
Ala Lys Asn Tyr Ser Gly Arg Phe Thr Cys Trp Trp Leu Thr Thr Ile
130 135 140
Ser Thr Asp Leu Thr Phe Ser Val Lys Ser Ser Arg Gly Ser Ser Asp
145 150 155 160
Pro Gln Gly Val Thr Cys Gly Ala Ala Thr Leu Ser Ala Glu Arg Val
165 170 175
Arg Gly Asp Asn Lys Glu Tyr Glu Tyr Ser Val Glu Cys Gln Glu Asp
180 185 190
Ser Ala Cys Pro Ala Ala Glu Glu Ser Leu Pro Ile Glu Val Met Val
195 200 205
Asp Ala Val His Lys Leu Lys Tyr Glu Asn Tyr Thr Ser Ser Phe Phe
210 215 220
Ile Arg Asp Ile Ile Lys Pro Asp Pro Pro Lys Asn Leu Gln Leu Lys
225 230 235 240
Pro Leu Lys Asn Ser Arg Gln Val Glu Val Ser Trp Glu Tyr Pro Asp
245 250 255
Thr Trp Ser Thr Pro His Ser Tyr Phe Ser Leu Thr Phe Cys Val Gln
260 265 270
Val Gln Gly Lys Ser Lys Arg Glu Lys Lys Asp Arg Val Phe Thr Asp
275 280 285
Lys Thr Ser Ala Thr Val Ile Cys Arg Lys Asn Ala Ser Ile Ser Val
290 295 300
Arg Ala Gln Asp Arg Tyr Tyr Ser Ser Ser Trp Ser Glu Trp Ala Ser
305 310 315 320
Val Pro Cys Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
325 330 335
Gly Gly Ser Arg Asn Leu Pro Val Ala Thr Pro Asp Pro Gly Met Phe
340 345 350
Pro Cys Leu His His Ser Gln Asn Leu Leu Arg Ala Val Ser Asn Met
355 360 365
Leu Gln Lys Ala Arg Gln Thr Leu Glu Phe Tyr Pro Cys Thr Ser Glu
370 375 380
Glu Ile Asp His Glu Asp Ile Thr Lys Asp Lys Thr Ser Thr Val Glu
385 390 395 400
Ala Cys Leu Pro Leu Glu Leu Thr Lys Asn Glu Ser Cys Leu Asn Ser
405 410 415
Arg Glu Thr Ser Phe Ile Thr Asn Gly Ser Cys Leu Ala Ser Arg Lys
420 425 430
Thr Ser Phe Met Met Ala Leu Cys Leu Ser Ser Ile Tyr Glu Asp Leu
435 440 445
Lys Met Tyr Gln Val Glu Phe Lys Thr Met Asn Ala Lys Leu Leu Met
450 455 460
Asp Pro Lys Arg Gln Ile Phe Leu Asp Gln Asn Met Leu Ala Val Ile
465 470 475 480
Asp Glu Leu Met Gln Ala Leu Asn Phe Asn Ser Glu Thr Val Pro Gln
485 490 495
Lys Ser Ser Leu Glu Glu Pro Asp Phe Tyr Lys Thr Lys Ile Lys Leu
500 505 510
Cys Ile Leu Leu His Ala Phe Arg Ile Arg Ala Val Thr Ile Asp Arg
515 520 525
Val Met Ser Tyr Leu Asn Ala Ser Ile Thr Cys Pro Pro Pro Met Ser
530 535 540
Val Glu His Ala Asp Ile Trp Val Lys Ser Tyr Ser Leu Tyr Ser Arg
545 550 555 560
Glu Arg Tyr Ile Cys Asn Ser Gly Phe Lys Arg Lys Ala Gly Thr Ser
565 570 575
Ser Leu Thr Glu Cys Val Leu Asn Lys Ala Thr Asn Val Ala His Trp
580 585 590
Thr Thr Pro Ser Leu Lys Cys Ile Arg
595 600
<210> 77
<211> 1803
<212> DNA
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成18t15-12s序列”
<400> 77
atgaaatggg tgacctttat ttctttactg ttcctcttta gcagcgccta ctccatttgg 60
gaactgaaga aggacgtcta cgtggtcgaa ctggactggt atcccgatgc tcccggcgaa 120
atggtggtgc tcacttgtga cacccccgaa gaagacggca tcacttggac cctcgatcag 180
agcagcgagg tgctgggctc cggaaagacc ctcacaatcc aagttaagga gttcggagac 240
gctggccaat acacatgcca caagggaggc gaggtgctca gccattcctt attattatta 300
cacaagaagg aagacggaat ctggtccacc gacattttaa aagatcagaa ggagcccaag 360
aataagacct ttttaaggtg tgaggccaaa aactacagcg gtcgtttcac ttgttggtgg 420
ctgaccacca tttccaccga tttaaccttc tccgtgaaaa gcagccgggg aagctccgac 480
cctcaaggtg tgacatgtgg agccgctacc ctcagcgctg agagggttcg tggcgataac 540
aaggaatacg agtacagcgt ggagtgccaa gaagatagcg cttgtcccgc tgccgaagaa 600
tctttaccca ttgaggtgat ggtggacgcc gtgcacaaac tcaagtacga gaactacacc 660
tcctccttct ttatccggga catcattaag cccgatcctc ctaagaattt acagctgaag 720
cctctcaaaa atagccggca agttgaggtc tcttgggaat atcccgacac ttggagcaca 780
ccccacagct acttctcttt aaccttttgt gtgcaagttc aaggtaaaag caagcgggag 840
aagaaagacc gggtgtttac cgacaaaacc agcgccaccg tcatctgtcg gaagaacgcc 900
tccatcagcg tgagggctca agatcgttat tactccagca gctggtccga gtgggccagc 960
gtgccttgtt ccggcggtgg aggatccgga ggaggtggct ccggcggcgg aggatctcgt 1020
aacctccccg tggctacccc cgatcccgga atgttccctt gtttacacca cagccagaat 1080
ttactgaggg ccgtgagcaa catgctgcag aaagctaggc agactttaga attttaccct 1140
tgcaccagcg aggagatcga ccatgaagat atcaccaagg acaagacatc caccgtggag 1200
gcttgtttac ctctggagct gacaaagaac gagtcttgtc tcaactctcg tgaaaccagc 1260
ttcatcacaa atggctcttg tttagcttcc cggaagacct cctttatgat ggctttatgc 1320
ctcagctcca tctacgagga tttaaagatg taccaagtgg agttcaagac catgaacgcc 1380
aagctgctca tggaccctaa acggcagatc tttttagacc agaacatgct ggctgtgatt 1440
gatgagctga tgcaagcttt aaacttcaac tccgagaccg tccctcagaa gtcctccctc 1500
gaggagcccg atttttacaa gacaaagatc aaactgtgca ttttactcca cgcctttagg 1560
atccgggccg tgaccattga ccgggtcatg agctatttaa acgccagcat tacatgcccc 1620
cctcccatga gcgtggagca cgccgacatc tgggtgaaga gctatagcct ctacagccgg 1680
gagaggtata tctgtaacag cggcttcaag aggaaggccg gcaccagcag cctcaccgag 1740
tgcgtgctga ataaggctac caacgtggct cactggacaa caccctcttt aaagtgcatc 1800
cgg 1803
<210> 78
<211> 133
<212> PRT
<213> 智人
<220>
<221> source
<223> /标注=“IL-21”
<400> 78
Gln Gly Gln Asp Arg His Met Ile Arg Met Arg Gln Leu Ile Asp Ile
1 5 10 15
Val Asp Gln Leu Lys Asn Tyr Val Asn Asp Leu Val Pro Glu Phe Leu
20 25 30
Pro Ala Pro Glu Asp Val Glu Thr Asn Cys Glu Trp Ser Ala Phe Ser
35 40 45
Cys Phe Gln Lys Ala Gln Leu Lys Ser Ala Asn Thr Gly Asn Asn Glu
50 55 60
Arg Ile Ile Asn Val Ser Ile Lys Lys Leu Lys Arg Lys Pro Pro Ser
65 70 75 80
Thr Asn Ala Gly Arg Arg Gln Lys His Arg Leu Thr Cys Pro Ser Cys
85 90 95
Asp Ser Tyr Glu Lys Lys Pro Pro Lys Glu Phe Leu Glu Arg Phe Lys
100 105 110
Ser Leu Leu Gln Lys Met Ile His Gln His Leu Ser Ser Arg Thr His
115 120 125
Gly Ser Glu Asp Ser
130
<210> 79
<211> 399
<212> DNA
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成IL7RA MCP插入序列”
<400> 79
cagggccagg acaggcacat gatccggatg aggcagctca tcgacatcgt cgaccagctg 60
aagaactacg tgaacgacct ggtgcccgag tttctgcctg cccccgagga cgtggagacc 120
aactgcgagt ggtccgcctt ctcctgcttt cagaaggccc agctgaagtc cgccaacacc 180
ggcaacaacg agcggatcat caacgtgagc atcaagaagc tgaagcggaa gcctccctcc 240
acaaacgccg gcaggaggca gaagcacagg ctgacctgcc ccagctgtga ctcctacgag 300
aagaagcccc ccaaggagtt cctggagagg ttcaagtccc tgctgcagaa gatgatccat 360
cagcacctgt cctccaggac ccacggctcc gaggactcc 399
<210> 80
<211> 136
<212> PRT
<213> 智人
<220>
<221> source
<223> /标注=“TGFRβRII”
<400> 80
Ile Pro Pro His Val Gln Lys Ser Val Asn Asn Asp Met Ile Val Thr
1 5 10 15
Asp Asn Asn Gly Ala Val Lys Phe Pro Gln Leu Cys Lys Phe Cys Asp
20 25 30
Val Arg Phe Ser Thr Cys Asp Asn Gln Lys Ser Cys Met Ser Asn Cys
35 40 45
Ser Ile Thr Ser Ile Cys Glu Lys Pro Gln Glu Val Cys Val Ala Val
50 55 60
Trp Arg Lys Asn Asp Glu Asn Ile Thr Leu Glu Thr Val Cys His Asp
65 70 75 80
Pro Lys Leu Pro Tyr His Asp Phe Ile Leu Glu Asp Ala Ala Ser Pro
85 90 95
Lys Cys Ile Met Lys Glu Lys Lys Lys Pro Gly Glu Thr Phe Phe Met
100 105 110
Cys Ser Cys Ser Ser Asp Glu Cys Asn Asp Asn Ile Ile Phe Ser Glu
115 120 125
Glu Tyr Asn Thr Ser Asn Pro Asp
130 135
<210> 81
<211> 136
<212> PRT
<213> 智人
<220>
<221> source
<223> /标注=“TGFRβRII”
<400> 81
Ile Pro Pro His Val Gln Lys Ser Val Asn Asn Asp Met Ile Val Thr
1 5 10 15
Asp Asn Asn Gly Ala Val Lys Phe Pro Gln Leu Cys Lys Phe Cys Asp
20 25 30
Val Arg Phe Ser Thr Cys Asp Asn Gln Lys Ser Cys Met Ser Asn Cys
35 40 45
Ser Ile Thr Ser Ile Cys Glu Lys Pro Gln Glu Val Cys Val Ala Val
50 55 60
Trp Arg Lys Asn Asp Glu Asn Ile Thr Leu Glu Thr Val Cys His Asp
65 70 75 80
Pro Lys Leu Pro Tyr His Asp Phe Ile Leu Glu Asp Ala Ala Ser Pro
85 90 95
Lys Cys Ile Met Lys Glu Lys Lys Lys Pro Gly Glu Thr Phe Phe Met
100 105 110
Cys Ser Cys Ser Ser Asp Glu Cys Asn Asp Asn Ile Ile Phe Ser Glu
115 120 125
Glu Tyr Asn Thr Ser Asn Pro Asp
130 135
<210> 82
<211> 408
<212> DNA
<213> 智人
<220>
<221> source
<223> /标注=“TGFRβRII”
<400> 82
atcccccccc atgtgcaaaa gagcgtgaac aacgatatga tcgtgaccga caacaacggc 60
gccgtgaagt ttccccagct ctgcaagttc tgcgatgtca ggttcagcac ctgcgataat 120
cagaagtcct gcatgtccaa ctgcacgatc acctccatct gcgagaagcc ccaagaagtg 180
tgcgtggccg tgtggcggaa aaatgacgag aacatcaccc tggagaccgt gtgtcacgac 240
cccaagctcc cttatcacga cttcattctg gaggacgctg cctcccccaa atgcatcatg 300
aaggagaaga agaagcccgg agagaccttc tttatgtgtt cctgtagcag cgacgagtgt 360
aacgacaaca tcatcttcag cgaagagtac aacaccagca accctgat 408
<210> 83
<211> 408
<212> DNA
<213> 智人
<220>
<221> source
<223> /标注=“TGFRβRII”
<400> 83
attcctcccc acgtgcagaa gagcgtgaat aatgacatga tcgtgaccga taacaatggc 60
gccgtgaaat ttccccagct gtgcaaattc tgcgatgtga ggttttccac ctgcgacaac 120
cagaagtcct gtatgagcaa ctgcacaatc acctccatct gtgagaagcc tcaggaggtg 180
tgcgtggctg tctggcggaa gaatgacgag aatatcaccc tggaaaccgt ctgccacgat 240
cccaagctgc cctaccacga tttcatcctg gaagacgccg ccagccctaa gtgcatcatg 300
aaagagaaaa agaagcctgg cgagaccttt ttcatgtgct cctgcagcag cgacgaatgc 360
aacgacaata tcatctttag cgaggaatac aataccagca accccgac 408
<210> 84
<211> 960
<212> DNA
<213> 智人
<220>
<221> source
<223> /标注=“TGFRβRII”
<400> 84
aactgggtga atgtgatcag cgacctgaag aagatcgagg atctgatcca gagcatgcac 60
attgatgcca ccctgtacac agaatctgat gtgcacccta tcccccccca tgtgcaaaag 120
agcgtgaaca acgatatgat cgtgaccgac aacaacggcg ccgtgaagtt tccccagctc 180
tgcaagttct gcgatgtcag gttcagcacc tgcgataatc agaagtcctg catgtccaac 240
tgcacgatca cctccatctg cgagaagccc caagaagtgt gcgtggccgt gtggcggaaa 300
aatgacgaga acatcaccct ggagaccgtg tgtcacgacc ccaagctccc ttatcacgac 360
ttcattctgg aggacgctgc ctcccccaaa tgcatcatga aggagaagaa gaagcccgga 420
gagaccttct ttatgtgttc ctgtagcagc gacgagtgta acgacaacat catcttcagc 480
gaagagtaca acaccagcaa ccctgatgga ggtggcggat ccggaggtgg aggttctggt 540
ggaggtggga gtattcctcc ccacgtgcag aagagcgtga ataatgacat gatcgtgacc 600
gataacaatg gcgccgtgaa atttccccag ctgtgcaaat tctgcgatgt gaggttttcc 660
acctgcgaca accagaagtc ctgtatgagc aactgcacaa tcacctccat ctgtgagaag 720
cctcaggagg tgtgcgtggc tgtctggcgg aagaatgacg agaatatcac cctggaaacc 780
gtctgccacg atcccaagct gccctaccac gatttcatcc tggaagacgc cgccagccct 840
aagtgcatca tgaaagagaa aaagaagcct ggcgagacct ttttcatgtg ctcctgcagc 900
agcgacgaat gcaacgacaa tatcatcttt agcgaggaat acaataccag caaccccgac 960
<210> 85
<211> 287
<212> PRT
<213> 智人
<220>
<221> source
<223> /标注=“TGFRβRII”
<400> 85
Ile Pro Pro His Val Gln Lys Ser Val Asn Asn Asp Met Ile Val Thr
1 5 10 15
Asp Asn Asn Gly Ala Val Lys Phe Pro Gln Leu Cys Lys Phe Cys Asp
20 25 30
Val Arg Phe Ser Thr Cys Asp Asn Gln Lys Ser Cys Met Ser Asn Cys
35 40 45
Ser Ile Thr Ser Ile Cys Glu Lys Pro Gln Glu Val Cys Val Ala Val
50 55 60
Trp Arg Lys Asn Asp Glu Asn Ile Thr Leu Glu Thr Val Cys His Asp
65 70 75 80
Pro Lys Leu Pro Tyr His Asp Phe Ile Leu Glu Asp Ala Ala Ser Pro
85 90 95
Lys Cys Ile Met Lys Glu Lys Lys Lys Pro Gly Glu Thr Phe Phe Met
100 105 110
Cys Ser Cys Ser Ser Asp Glu Cys Asn Asp Asn Ile Ile Phe Ser Glu
115 120 125
Glu Tyr Asn Thr Ser Asn Pro Asp Gly Gly Gly Gly Ser Gly Gly Gly
130 135 140
Gly Ser Gly Gly Gly Gly Ser Ile Pro Pro His Val Gln Lys Ser Val
145 150 155 160
Asn Asn Asp Met Ile Val Thr Asp Asn Asn Gly Ala Val Lys Phe Pro
165 170 175
Gln Leu Cys Lys Phe Cys Asp Val Arg Phe Ser Thr Cys Asp Asn Gln
180 185 190
Lys Ser Cys Met Ser Asn Cys Ser Ile Thr Ser Ile Cys Glu Lys Pro
195 200 205
Gln Glu Val Cys Val Ala Val Trp Arg Lys Asn Asp Glu Asn Ile Thr
210 215 220
Leu Glu Thr Val Cys His Asp Pro Lys Leu Pro Tyr His Asp Phe Ile
225 230 235 240
Leu Glu Asp Ala Ala Ser Pro Lys Cys Ile Met Lys Glu Lys Lys Lys
245 250 255
Pro Gly Glu Thr Phe Phe Met Cys Ser Cys Ser Ser Asp Glu Cys Asn
260 265 270
Asp Asn Ile Ile Phe Ser Glu Glu Tyr Asn Thr Ser Asn Pro Asp
275 280 285
<210> 86
<211> 466
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成21t15-TGFRs序列”
<400> 86
Gln Gly Gln Asp Arg His Met Ile Arg Met Arg Gln Leu Ile Asp Ile
1 5 10 15
Val Asp Gln Leu Lys Asn Tyr Val Asn Asp Leu Val Pro Glu Phe Leu
20 25 30
Pro Ala Pro Glu Asp Val Glu Thr Asn Cys Glu Trp Ser Ala Phe Ser
35 40 45
Cys Phe Gln Lys Ala Gln Leu Lys Ser Ala Asn Thr Gly Asn Asn Glu
50 55 60
Arg Ile Ile Asn Val Ser Ile Lys Lys Leu Lys Arg Lys Pro Pro Ser
65 70 75 80
Thr Asn Ala Gly Arg Arg Gln Lys His Arg Leu Thr Cys Pro Ser Cys
85 90 95
Asp Ser Tyr Glu Lys Lys Pro Pro Lys Glu Phe Leu Glu Arg Phe Lys
100 105 110
Ser Leu Leu Gln Lys Met Ile His Gln His Leu Ser Ser Arg Thr His
115 120 125
Gly Ser Glu Asp Ser Ser Gly Thr Thr Asn Thr Val Ala Ala Tyr Asn
130 135 140
Leu Thr Trp Lys Ser Thr Asn Phe Lys Thr Ile Leu Glu Trp Glu Pro
145 150 155 160
Lys Pro Val Asn Gln Val Tyr Thr Val Gln Ile Ser Thr Lys Ser Gly
165 170 175
Asp Trp Lys Ser Lys Cys Phe Tyr Thr Thr Asp Thr Glu Cys Asp Leu
180 185 190
Thr Asp Glu Ile Val Lys Asp Val Lys Gln Thr Tyr Leu Ala Arg Val
195 200 205
Phe Ser Tyr Pro Ala Gly Asn Val Glu Ser Thr Gly Ser Ala Gly Glu
210 215 220
Pro Leu Tyr Glu Asn Ser Pro Glu Phe Thr Pro Tyr Leu Glu Thr Asn
225 230 235 240
Leu Gly Gln Pro Thr Ile Gln Ser Phe Glu Gln Val Gly Thr Lys Val
245 250 255
Asn Val Thr Val Glu Asp Glu Arg Thr Leu Val Arg Arg Asn Asn Thr
260 265 270
Phe Leu Ser Leu Arg Asp Val Phe Gly Lys Asp Leu Ile Tyr Thr Leu
275 280 285
Tyr Tyr Trp Lys Ser Ser Ser Ser Gly Lys Lys Thr Ala Lys Thr Asn
290 295 300
Thr Asn Glu Phe Leu Ile Asp Val Asp Lys Gly Glu Asn Tyr Cys Phe
305 310 315 320
Ser Val Gln Ala Val Ile Pro Ser Arg Thr Val Asn Arg Lys Ser Thr
325 330 335
Asp Ser Pro Val Glu Cys Met Gly Gln Glu Lys Gly Glu Phe Arg Glu
340 345 350
Asn Trp Val Asn Val Ile Ser Asp Leu Lys Lys Ile Glu Asp Leu Ile
355 360 365
Gln Ser Met His Ile Asp Ala Thr Leu Tyr Thr Glu Ser Asp Val His
370 375 380
Pro Ser Cys Lys Val Thr Ala Met Lys Cys Phe Leu Leu Glu Leu Gln
385 390 395 400
Val Ile Ser Leu Glu Ser Gly Asp Ala Ser Ile His Asp Thr Val Glu
405 410 415
Asn Leu Ile Ile Leu Ala Asn Asn Ser Leu Ser Ser Asn Gly Asn Val
420 425 430
Thr Glu Ser Gly Cys Lys Glu Cys Glu Glu Leu Glu Glu Lys Asn Ile
435 440 445
Lys Glu Phe Leu Gln Ser Phe Val His Ile Val Gln Met Phe Ile Asn
450 455 460
Thr Ser
465
<210> 87
<211> 1398
<212> DNA
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成21t15-TGFRs序列”
<400> 87
cagggccagg acaggcacat gatccggatg aggcagctca tcgacatcgt cgaccagctg 60
aagaactacg tgaacgacct ggtgcccgag tttctgcctg cccccgagga cgtggagacc 120
aactgcgagt ggtccgcctt ctcctgcttt cagaaggccc agctgaagtc cgccaacacc 180
ggcaacaacg agcggatcat caacgtgagc atcaagaagc tgaagcggaa gcctccctcc 240
acaaacgccg gcaggaggca gaagcacagg ctgacctgcc ccagctgtga ctcctacgag 300
aagaagcccc ccaaggagtt cctggagagg ttcaagtccc tgctgcagaa gatgatccat 360
cagcacctgt cctccaggac ccacggctcc gaggactcct ccggcaccac caataccgtg 420
gccgcttata acctcacatg gaagagcacc aacttcaaga caattctgga atgggaaccc 480
aagcccgtca atcaagttta caccgtgcag atctccacca aatccggaga ctggaagagc 540
aagtgcttct acacaacaga caccgagtgt gatttaaccg acgaaatcgt caaggacgtc 600
aagcaaacct atctggctcg ggtcttttcc taccccgctg gcaatgtcga gtccaccggc 660
tccgctggcg agcctctcta cgagaattcc cccgaattca ccccttattt agagaccaat 720
ttaggccagc ctaccatcca gagcttcgag caagttggca ccaaggtgaa cgtcaccgtc 780
gaggatgaaa ggactttagt gcggcggaat aacacatttt tatccctccg ggatgtgttc 840
ggcaaagacc tcatctacac actgtactat tggaagtcca gctcctccgg caaaaagacc 900
gctaagacca acaccaacga gtttttaatt gacgtggaca aaggcgagaa ctactgcttc 960
agcgtgcaag ccgtgatccc ttctcgtacc gtcaaccgga agagcacaga ttcccccgtt 1020
gagtgcatgg gccaagaaaa gggcgagttc cgggagaact gggtgaacgt catcagcgat 1080
ttaaagaaga tcgaagattt aattcagtcc atgcatatcg acgccacttt atacacagaa 1140
tccgacgtgc acccctcttg taaggtgacc gccatgaaat gttttttact ggagctgcaa 1200
gttatctctt tagagagcgg agacgctagc atccacgaca ccgtggagaa tttaatcatt 1260
ttagccaata actctttatc cagcaacggc aacgtgacag agtccggctg caaggagtgc 1320
gaagagctgg aggagaagaa catcaaggag tttctgcaat cctttgtgca cattgtccag 1380
atgttcatca atacctcc 1398
<210> 88
<211> 484
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成21t15-TGFRs序列”
<400> 88
Met Lys Trp Val Thr Phe Ile Ser Leu Leu Phe Leu Phe Ser Ser Ala
1 5 10 15
Tyr Ser Gln Gly Gln Asp Arg His Met Ile Arg Met Arg Gln Leu Ile
20 25 30
Asp Ile Val Asp Gln Leu Lys Asn Tyr Val Asn Asp Leu Val Pro Glu
35 40 45
Phe Leu Pro Ala Pro Glu Asp Val Glu Thr Asn Cys Glu Trp Ser Ala
50 55 60
Phe Ser Cys Phe Gln Lys Ala Gln Leu Lys Ser Ala Asn Thr Gly Asn
65 70 75 80
Asn Glu Arg Ile Ile Asn Val Ser Ile Lys Lys Leu Lys Arg Lys Pro
85 90 95
Pro Ser Thr Asn Ala Gly Arg Arg Gln Lys His Arg Leu Thr Cys Pro
100 105 110
Ser Cys Asp Ser Tyr Glu Lys Lys Pro Pro Lys Glu Phe Leu Glu Arg
115 120 125
Phe Lys Ser Leu Leu Gln Lys Met Ile His Gln His Leu Ser Ser Arg
130 135 140
Thr His Gly Ser Glu Asp Ser Ser Gly Thr Thr Asn Thr Val Ala Ala
145 150 155 160
Tyr Asn Leu Thr Trp Lys Ser Thr Asn Phe Lys Thr Ile Leu Glu Trp
165 170 175
Glu Pro Lys Pro Val Asn Gln Val Tyr Thr Val Gln Ile Ser Thr Lys
180 185 190
Ser Gly Asp Trp Lys Ser Lys Cys Phe Tyr Thr Thr Asp Thr Glu Cys
195 200 205
Asp Leu Thr Asp Glu Ile Val Lys Asp Val Lys Gln Thr Tyr Leu Ala
210 215 220
Arg Val Phe Ser Tyr Pro Ala Gly Asn Val Glu Ser Thr Gly Ser Ala
225 230 235 240
Gly Glu Pro Leu Tyr Glu Asn Ser Pro Glu Phe Thr Pro Tyr Leu Glu
245 250 255
Thr Asn Leu Gly Gln Pro Thr Ile Gln Ser Phe Glu Gln Val Gly Thr
260 265 270
Lys Val Asn Val Thr Val Glu Asp Glu Arg Thr Leu Val Arg Arg Asn
275 280 285
Asn Thr Phe Leu Ser Leu Arg Asp Val Phe Gly Lys Asp Leu Ile Tyr
290 295 300
Thr Leu Tyr Tyr Trp Lys Ser Ser Ser Ser Gly Lys Lys Thr Ala Lys
305 310 315 320
Thr Asn Thr Asn Glu Phe Leu Ile Asp Val Asp Lys Gly Glu Asn Tyr
325 330 335
Cys Phe Ser Val Gln Ala Val Ile Pro Ser Arg Thr Val Asn Arg Lys
340 345 350
Ser Thr Asp Ser Pro Val Glu Cys Met Gly Gln Glu Lys Gly Glu Phe
355 360 365
Arg Glu Asn Trp Val Asn Val Ile Ser Asp Leu Lys Lys Ile Glu Asp
370 375 380
Leu Ile Gln Ser Met His Ile Asp Ala Thr Leu Tyr Thr Glu Ser Asp
385 390 395 400
Val His Pro Ser Cys Lys Val Thr Ala Met Lys Cys Phe Leu Leu Glu
405 410 415
Leu Gln Val Ile Ser Leu Glu Ser Gly Asp Ala Ser Ile His Asp Thr
420 425 430
Val Glu Asn Leu Ile Ile Leu Ala Asn Asn Ser Leu Ser Ser Asn Gly
435 440 445
Asn Val Thr Glu Ser Gly Cys Lys Glu Cys Glu Glu Leu Glu Glu Lys
450 455 460
Asn Ile Lys Glu Phe Leu Gln Ser Phe Val His Ile Val Gln Met Phe
465 470 475 480
Ile Asn Thr Ser
<210> 89
<211> 1452
<212> DNA
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成21t15-TGFRs序列”
<400> 89
atgaagtggg tgaccttcat cagcctgctg ttcctgttct ccagcgccta ctcccagggc 60
caggacaggc acatgatccg gatgaggcag ctcatcgaca tcgtcgacca gctgaagaac 120
tacgtgaacg acctggtgcc cgagtttctg cctgcccccg aggacgtgga gaccaactgc 180
gagtggtccg ccttctcctg ctttcagaag gcccagctga agtccgccaa caccggcaac 240
aacgagcgga tcatcaacgt gagcatcaag aagctgaagc ggaagcctcc ctccacaaac 300
gccggcagga ggcagaagca caggctgacc tgccccagct gtgactccta cgagaagaag 360
ccccccaagg agttcctgga gaggttcaag tccctgctgc agaagatgat ccatcagcac 420
ctgtcctcca ggacccacgg ctccgaggac tcctccggca ccaccaatac cgtggccgct 480
tataacctca catggaagag caccaacttc aagacaattc tggaatggga acccaagccc 540
gtcaatcaag tttacaccgt gcagatctcc accaaatccg gagactggaa gagcaagtgc 600
ttctacacaa cagacaccga gtgtgattta accgacgaaa tcgtcaagga cgtcaagcaa 660
acctatctgg ctcgggtctt ttcctacccc gctggcaatg tcgagtccac cggctccgct 720
ggcgagcctc tctacgagaa ttcccccgaa ttcacccctt atttagagac caatttaggc 780
cagcctacca tccagagctt cgagcaagtt ggcaccaagg tgaacgtcac cgtcgaggat 840
gaaaggactt tagtgcggcg gaataacaca tttttatccc tccgggatgt gttcggcaaa 900
gacctcatct acacactgta ctattggaag tccagctcct ccggcaaaaa gaccgctaag 960
accaacacca acgagttttt aattgacgtg gacaaaggcg agaactactg cttcagcgtg 1020
caagccgtga tcccttctcg taccgtcaac cggaagagca cagattcccc cgttgagtgc 1080
atgggccaag aaaagggcga gttccgggag aactgggtga acgtcatcag cgatttaaag 1140
aagatcgaag atttaattca gtccatgcat atcgacgcca ctttatacac agaatccgac 1200
gtgcacccct cttgtaaggt gaccgccatg aaatgttttt tactggagct gcaagttatc 1260
tctttagaga gcggagacgc tagcatccac gacaccgtgg agaatttaat cattttagcc 1320
aataactctt tatccagcaa cggcaacgtg acagagtccg gctgcaagga gtgcgaagag 1380
ctggaggaga agaacatcaa ggagtttctg caatcctttg tgcacattgt ccagatgttc 1440
atcaatacct cc 1452
<210> 90
<211> 352
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成21t15-TGFRs序列”
<400> 90
Ile Pro Pro His Val Gln Lys Ser Val Asn Asn Asp Met Ile Val Thr
1 5 10 15
Asp Asn Asn Gly Ala Val Lys Phe Pro Gln Leu Cys Lys Phe Cys Asp
20 25 30
Val Arg Phe Ser Thr Cys Asp Asn Gln Lys Ser Cys Met Ser Asn Cys
35 40 45
Ser Ile Thr Ser Ile Cys Glu Lys Pro Gln Glu Val Cys Val Ala Val
50 55 60
Trp Arg Lys Asn Asp Glu Asn Ile Thr Leu Glu Thr Val Cys His Asp
65 70 75 80
Pro Lys Leu Pro Tyr His Asp Phe Ile Leu Glu Asp Ala Ala Ser Pro
85 90 95
Lys Cys Ile Met Lys Glu Lys Lys Lys Pro Gly Glu Thr Phe Phe Met
100 105 110
Cys Ser Cys Ser Ser Asp Glu Cys Asn Asp Asn Ile Ile Phe Ser Glu
115 120 125
Glu Tyr Asn Thr Ser Asn Pro Asp Gly Gly Gly Gly Ser Gly Gly Gly
130 135 140
Gly Ser Gly Gly Gly Gly Ser Ile Pro Pro His Val Gln Lys Ser Val
145 150 155 160
Asn Asn Asp Met Ile Val Thr Asp Asn Asn Gly Ala Val Lys Phe Pro
165 170 175
Gln Leu Cys Lys Phe Cys Asp Val Arg Phe Ser Thr Cys Asp Asn Gln
180 185 190
Lys Ser Cys Met Ser Asn Cys Ser Ile Thr Ser Ile Cys Glu Lys Pro
195 200 205
Gln Glu Val Cys Val Ala Val Trp Arg Lys Asn Asp Glu Asn Ile Thr
210 215 220
Leu Glu Thr Val Cys His Asp Pro Lys Leu Pro Tyr His Asp Phe Ile
225 230 235 240
Leu Glu Asp Ala Ala Ser Pro Lys Cys Ile Met Lys Glu Lys Lys Lys
245 250 255
Pro Gly Glu Thr Phe Phe Met Cys Ser Cys Ser Ser Asp Glu Cys Asn
260 265 270
Asp Asn Ile Ile Phe Ser Glu Glu Tyr Asn Thr Ser Asn Pro Asp Ile
275 280 285
Thr Cys Pro Pro Pro Met Ser Val Glu His Ala Asp Ile Trp Val Lys
290 295 300
Ser Tyr Ser Leu Tyr Ser Arg Glu Arg Tyr Ile Cys Asn Ser Gly Phe
305 310 315 320
Lys Arg Lys Ala Gly Thr Ser Ser Leu Thr Glu Cys Val Leu Asn Lys
325 330 335
Ala Thr Asn Val Ala His Trp Thr Thr Pro Ser Leu Lys Cys Ile Arg
340 345 350
<210> 91
<211> 1056
<212> DNA
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成21t15-TGFRs序列”
<400> 91
atcccccccc atgtgcaaaa gagcgtgaac aacgatatga tcgtgaccga caacaacggc 60
gccgtgaagt ttccccagct ctgcaagttc tgcgatgtca ggttcagcac ctgcgataat 120
cagaagtcct gcatgtccaa ctgcacgatc acctccatct gcgagaagcc ccaagaagtg 180
tgcgtggccg tgtggcggaa aaatgacgag aacatcaccc tggagaccgt gtgtcacgac 240
cccaagctcc cttatcacga cttcattctg gaggacgctg cctcccccaa atgcatcatg 300
aaggagaaga agaagcccgg agagaccttc tttatgtgtt cctgtagcag cgacgagtgt 360
aacgacaaca tcatcttcag cgaagagtac aacaccagca accctgatgg aggtggcgga 420
tccggaggtg gaggttctgg tggaggtggg agtattcctc cccacgtgca gaagagcgtg 480
aataatgaca tgatcgtgac cgataacaat ggcgccgtga aatttcccca gctgtgcaaa 540
ttctgcgatg tgaggttttc cacctgcgac aaccagaagt cctgtatgag caactgcaca 600
atcacctcca tctgtgagaa gcctcaggag gtgtgcgtgg ctgtctggcg gaagaatgac 660
gagaatatca ccctggaaac cgtctgccac gatcccaagc tgccctacca cgatttcatc 720
ctggaagacg ccgccagccc taagtgcatc atgaaagaga aaaagaagcc tggcgagacc 780
tttttcatgt gctcctgcag cagcgacgaa tgcaacgaca atatcatctt tagcgaggaa 840
tacaatacca gcaaccccga catcacgtgt cctcctccta tgtccgtgga acacgcagac 900
atctgggtca agagctacag cttgtactcc agggagcggt acatttgtaa ctctggtttc 960
aagcgtaaag ccggcacgtc cagcctgacg gagtgcgtgt tgaacaaggc cacgaatgtc 1020
gcccactgga caacccccag tctcaaatgt attaga 1056
<210> 92
<211> 370
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成21t15-TGFRs序列”
<400> 92
Met Lys Trp Val Thr Phe Ile Ser Leu Leu Phe Leu Phe Ser Ser Ala
1 5 10 15
Tyr Ser Ile Pro Pro His Val Gln Lys Ser Val Asn Asn Asp Met Ile
20 25 30
Val Thr Asp Asn Asn Gly Ala Val Lys Phe Pro Gln Leu Cys Lys Phe
35 40 45
Cys Asp Val Arg Phe Ser Thr Cys Asp Asn Gln Lys Ser Cys Met Ser
50 55 60
Asn Cys Ser Ile Thr Ser Ile Cys Glu Lys Pro Gln Glu Val Cys Val
65 70 75 80
Ala Val Trp Arg Lys Asn Asp Glu Asn Ile Thr Leu Glu Thr Val Cys
85 90 95
His Asp Pro Lys Leu Pro Tyr His Asp Phe Ile Leu Glu Asp Ala Ala
100 105 110
Ser Pro Lys Cys Ile Met Lys Glu Lys Lys Lys Pro Gly Glu Thr Phe
115 120 125
Phe Met Cys Ser Cys Ser Ser Asp Glu Cys Asn Asp Asn Ile Ile Phe
130 135 140
Ser Glu Glu Tyr Asn Thr Ser Asn Pro Asp Gly Gly Gly Gly Ser Gly
145 150 155 160
Gly Gly Gly Ser Gly Gly Gly Gly Ser Ile Pro Pro His Val Gln Lys
165 170 175
Ser Val Asn Asn Asp Met Ile Val Thr Asp Asn Asn Gly Ala Val Lys
180 185 190
Phe Pro Gln Leu Cys Lys Phe Cys Asp Val Arg Phe Ser Thr Cys Asp
195 200 205
Asn Gln Lys Ser Cys Met Ser Asn Cys Ser Ile Thr Ser Ile Cys Glu
210 215 220
Lys Pro Gln Glu Val Cys Val Ala Val Trp Arg Lys Asn Asp Glu Asn
225 230 235 240
Ile Thr Leu Glu Thr Val Cys His Asp Pro Lys Leu Pro Tyr His Asp
245 250 255
Phe Ile Leu Glu Asp Ala Ala Ser Pro Lys Cys Ile Met Lys Glu Lys
260 265 270
Lys Lys Pro Gly Glu Thr Phe Phe Met Cys Ser Cys Ser Ser Asp Glu
275 280 285
Cys Asn Asp Asn Ile Ile Phe Ser Glu Glu Tyr Asn Thr Ser Asn Pro
290 295 300
Asp Ile Thr Cys Pro Pro Pro Met Ser Val Glu His Ala Asp Ile Trp
305 310 315 320
Val Lys Ser Tyr Ser Leu Tyr Ser Arg Glu Arg Tyr Ile Cys Asn Ser
325 330 335
Gly Phe Lys Arg Lys Ala Gly Thr Ser Ser Leu Thr Glu Cys Val Leu
340 345 350
Asn Lys Ala Thr Asn Val Ala His Trp Thr Thr Pro Ser Leu Lys Cys
355 360 365
Ile Arg
370
<210> 93
<211> 1110
<212> DNA
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成21t15-TGFRs序列”
<400> 93
atgaagtggg tgaccttcat cagcctgctg ttcctgttct ccagcgccta ctccatcccc 60
ccccatgtgc aaaagagcgt gaacaacgat atgatcgtga ccgacaacaa cggcgccgtg 120
aagtttcccc agctctgcaa gttctgcgat gtcaggttca gcacctgcga taatcagaag 180
tcctgcatgt ccaactgcac gatcacctcc atctgcgaga agccccaaga agtgtgcgtg 240
gccgtgtggc ggaaaaatga cgagaacatc accctggaga ccgtgtgtca cgaccccaag 300
ctcccttatc acgacttcat tctggaggac gctgcctccc ccaaatgcat catgaaggag 360
aagaagaagc ccggagagac cttctttatg tgttcctgta gcagcgacga gtgtaacgac 420
aacatcatct tcagcgaaga gtacaacacc agcaaccctg atggaggtgg cggatccgga 480
ggtggaggtt ctggtggagg tgggagtatt cctccccacg tgcagaagag cgtgaataat 540
gacatgatcg tgaccgataa caatggcgcc gtgaaatttc cccagctgtg caaattctgc 600
gatgtgaggt tttccacctg cgacaaccag aagtcctgta tgagcaactg cacaatcacc 660
tccatctgtg agaagcctca ggaggtgtgc gtggctgtct ggcggaagaa tgacgagaat 720
atcaccctgg aaaccgtctg ccacgatccc aagctgccct accacgattt catcctggaa 780
gacgccgcca gccctaagtg catcatgaaa gagaaaaaga agcctggcga gacctttttc 840
atgtgctcct gcagcagcga cgaatgcaac gacaatatca tctttagcga ggaatacaat 900
accagcaacc ccgacatcac gtgtcctcct cctatgtccg tggaacacgc agacatctgg 960
gtcaagagct acagcttgta ctccagggag cggtacattt gtaactctgg tttcaagcgt 1020
aaagccggca cgtccagcct gacggagtgc gtgttgaaca aggccacgaa tgtcgcccac 1080
tggacaaccc ccagtctcaa atgtattaga 1110
<210> 94
<211> 399
<212> DNA
<213> 智人
<220>
<221> source
<223> /标注=“IL-21”
<400> 94
caaggtcaag atcgccacat gattagaatg cgtcaactta tagatattgt tgatcagctg 60
aaaaattatg tgaatgactt ggtccctgaa tttctgccag ctccagaaga tgtagagaca 120
aactgtgagt ggtcagcttt ttcctgtttt cagaaggccc aactaaagtc agcaaataca 180
ggaaacaatg aaaggataat caatgtatca attaaaaagc tgaagaggaa accaccttcc 240
acaaatgcag ggagaagaca gaaacacaga ctaacatgcc cttcatgtga ttcttatgag 300
aaaaaaccac ccaaagaatt cctagaaaga ttcaaatcac ttctccaaaa gatgattcat 360
cagcatctgt cctctagaac acacggaagt gaagattcc 399
<210> 95
<211> 456
<212> DNA
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成IL-7序列”
<400> 95
gattgtgata ttgaaggtaa agatggcaaa caatatgaga gtgttctaat ggtcagcatc 60
gatcaattat tggacagcat gaaagaaatt ggtagcaatt gcctgaataa tgaatttaac 120
ttttttaaaa gacatatctg tgatgctaat aaggaaggta tgtttttatt ccgtgctgct 180
cgcaagttga ggcaatttct taaaatgaat agcactggtg attttgatct ccacttatta 240
aaagtttcag aaggcacaac aatactgttg aactgcactg gccaggttaa aggaagaaaa 300
ccagctgccc tgggtgaagc ccaaccaaca aagagtttgg aagaaaataa atctttaaag 360
gaacagaaaa aactgaatga cttgtgtttc ctaaagagac tattacaaga gataaaaact 420
tgttggaata aaattttgat gggcactaaa gaacac 456
<210> 96
<211> 466
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成多肽”
<400> 96
Gln Gly Gln Asp Arg His Met Ile Arg Met Arg Gln Leu Ile Asp Ile
1 5 10 15
Val Asp Gln Leu Lys Asn Tyr Val Asn Asp Leu Val Pro Glu Phe Leu
20 25 30
Pro Ala Pro Glu Asp Val Glu Thr Asn Cys Glu Trp Ser Ala Phe Ser
35 40 45
Cys Phe Gln Lys Ala Gln Leu Lys Ser Ala Asn Thr Gly Asn Asn Glu
50 55 60
Arg Ile Ile Asn Val Ser Ile Lys Lys Leu Lys Arg Lys Pro Pro Ser
65 70 75 80
Thr Asn Ala Gly Arg Arg Gln Lys His Arg Leu Thr Cys Pro Ser Cys
85 90 95
Asp Ser Tyr Glu Lys Lys Pro Pro Lys Glu Phe Leu Glu Arg Phe Lys
100 105 110
Ser Leu Leu Gln Lys Met Ile His Gln His Leu Ser Ser Arg Thr His
115 120 125
Gly Ser Glu Asp Ser Ser Gly Thr Thr Asn Thr Val Ala Ala Tyr Asn
130 135 140
Leu Thr Trp Lys Ser Thr Asn Phe Lys Thr Ile Leu Glu Trp Glu Pro
145 150 155 160
Lys Pro Val Asn Gln Val Tyr Thr Val Gln Ile Ser Thr Lys Ser Gly
165 170 175
Asp Trp Lys Ser Lys Cys Phe Tyr Thr Thr Asp Thr Glu Cys Asp Leu
180 185 190
Thr Asp Glu Ile Val Lys Asp Val Lys Gln Thr Tyr Leu Ala Arg Val
195 200 205
Phe Ser Tyr Pro Ala Gly Asn Val Glu Ser Thr Gly Ser Ala Gly Glu
210 215 220
Pro Leu Tyr Glu Asn Ser Pro Glu Phe Thr Pro Tyr Leu Glu Thr Asn
225 230 235 240
Leu Gly Gln Pro Thr Ile Gln Ser Phe Glu Gln Val Gly Thr Lys Val
245 250 255
Asn Val Thr Val Glu Asp Glu Arg Thr Leu Val Arg Arg Asn Asn Thr
260 265 270
Phe Leu Ser Leu Arg Asp Val Phe Gly Lys Asp Leu Ile Tyr Thr Leu
275 280 285
Tyr Tyr Trp Lys Ser Ser Ser Ser Gly Lys Lys Thr Ala Lys Thr Asn
290 295 300
Thr Asn Glu Phe Leu Ile Asp Val Asp Lys Gly Glu Asn Tyr Cys Phe
305 310 315 320
Ser Val Gln Ala Val Ile Pro Ser Arg Thr Val Asn Arg Lys Ser Thr
325 330 335
Asp Ser Pro Val Glu Cys Met Gly Gln Glu Lys Gly Glu Phe Arg Glu
340 345 350
Asn Trp Val Asn Val Ile Ser Asp Leu Lys Lys Ile Glu Asp Leu Ile
355 360 365
Gln Ser Met His Ile Asp Ala Thr Leu Tyr Thr Glu Ser Asp Val His
370 375 380
Pro Ser Cys Lys Val Thr Ala Met Lys Cys Phe Leu Leu Glu Leu Gln
385 390 395 400
Val Ile Ser Leu Glu Ser Gly Asp Ala Ser Ile His Asp Thr Val Glu
405 410 415
Asn Leu Ile Ile Leu Ala Asn Asn Ser Leu Ser Ser Asn Gly Asn Val
420 425 430
Thr Glu Ser Gly Cys Lys Glu Cys Glu Glu Leu Glu Glu Lys Asn Ile
435 440 445
Lys Glu Phe Leu Gln Ser Phe Val His Ile Val Gln Met Phe Ile Asn
450 455 460
Thr Ser
465
<210> 97
<211> 1398
<212> DNA
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成21t15-7s序列”
<400> 97
caaggtcaag atcgccacat gattagaatg cgtcaactta tagatattgt tgatcagctg 60
aaaaattatg tgaatgactt ggtccctgaa tttctgccag ctccagaaga tgtagagaca 120
aactgtgagt ggtcagcttt ttcctgtttt cagaaggccc aactaaagtc agcaaataca 180
ggaaacaatg aaaggataat caatgtatca attaaaaagc tgaagaggaa accaccttcc 240
acaaatgcag ggagaagaca gaaacacaga ctaacatgcc cttcatgtga ttcttatgag 300
aaaaaaccac ccaaagaatt cctagaaaga ttcaaatcac ttctccaaaa gatgattcat 360
cagcatctgt cctctagaac acacggaagt gaagattcct caggcactac aaatactgtg 420
gcagcatata atttaacttg gaaatcaact aatttcaaga caattttgga gtgggaaccc 480
aaacccgtca atcaagtcta cactgttcaa ataagcacta agtcaggaga ttggaaaagc 540
aaatgctttt acacaacaga cacagagtgt gacctcaccg acgagattgt gaaggatgtg 600
aagcagacgt acttggcacg ggtcttctcc tacccggcag ggaatgtgga gagcaccggt 660
tctgctgggg agcctctgta tgagaactcc ccagagttca caccttacct ggagacaaac 720
ctcggacagc caacaattca gagttttgaa caggtgggaa caaaagtgaa tgtgaccgta 780
gaagatgaac ggactttagt cagaaggaac aacactttcc taagcctccg ggatgttttt 840
ggcaaggact taatttatac actttattat tggaaatctt caagttcagg aaagaaaaca 900
gccaaaacaa acactaatga gtttttgatt gatgtggata aaggagaaaa ctactgtttc 960
agtgttcaag cagtgattcc ctcccgaaca gttaaccgga agagtacaga cagcccggta 1020
gagtgtatgg gccaggagaa aggggaattc agagaaaact gggtgaacgt catcagcgat 1080
ttaaagaaga tcgaagattt aattcagtcc atgcatatcg acgccacttt atacacagaa 1140
tccgacgtgc acccctcttg taaggtgacc gccatgaaat gttttttact ggagctgcaa 1200
gttatctctt tagagagcgg agacgctagc atccacgaca ccgtggagaa tttaatcatt 1260
ttagccaata actctttatc cagcaacggc aacgtgacag agtccggctg caaggagtgc 1320
gaagagctgg aggagaagaa catcaaggag tttctgcaat cctttgtgca cattgtccag 1380
atgttcatca atacctcc 1398
<210> 98
<211> 483
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成21t15-7s序列”
<400> 98
Met Gly Val Lys Val Leu Phe Ala Leu Ile Cys Ile Ala Val Ala Glu
1 5 10 15
Ala Gln Gly Gln Asp Arg His Met Ile Arg Met Arg Gln Leu Ile Asp
20 25 30
Ile Val Asp Gln Leu Lys Asn Tyr Val Asn Asp Leu Val Pro Glu Phe
35 40 45
Leu Pro Ala Pro Glu Asp Val Glu Thr Asn Cys Glu Trp Ser Ala Phe
50 55 60
Ser Cys Phe Gln Lys Ala Gln Leu Lys Ser Ala Asn Thr Gly Asn Asn
65 70 75 80
Glu Arg Ile Ile Asn Val Ser Ile Lys Lys Leu Lys Arg Lys Pro Pro
85 90 95
Ser Thr Asn Ala Gly Arg Arg Gln Lys His Arg Leu Thr Cys Pro Ser
100 105 110
Cys Asp Ser Tyr Glu Lys Lys Pro Pro Lys Glu Phe Leu Glu Arg Phe
115 120 125
Lys Ser Leu Leu Gln Lys Met Ile His Gln His Leu Ser Ser Arg Thr
130 135 140
His Gly Ser Glu Asp Ser Ser Gly Thr Thr Asn Thr Val Ala Ala Tyr
145 150 155 160
Asn Leu Thr Trp Lys Ser Thr Asn Phe Lys Thr Ile Leu Glu Trp Glu
165 170 175
Pro Lys Pro Val Asn Gln Val Tyr Thr Val Gln Ile Ser Thr Lys Ser
180 185 190
Gly Asp Trp Lys Ser Lys Cys Phe Tyr Thr Thr Asp Thr Glu Cys Asp
195 200 205
Leu Thr Asp Glu Ile Val Lys Asp Val Lys Gln Thr Tyr Leu Ala Arg
210 215 220
Val Phe Ser Tyr Pro Ala Gly Asn Val Glu Ser Thr Gly Ser Ala Gly
225 230 235 240
Glu Pro Leu Tyr Glu Asn Ser Pro Glu Phe Thr Pro Tyr Leu Glu Thr
245 250 255
Asn Leu Gly Gln Pro Thr Ile Gln Ser Phe Glu Gln Val Gly Thr Lys
260 265 270
Val Asn Val Thr Val Glu Asp Glu Arg Thr Leu Val Arg Arg Asn Asn
275 280 285
Thr Phe Leu Ser Leu Arg Asp Val Phe Gly Lys Asp Leu Ile Tyr Thr
290 295 300
Leu Tyr Tyr Trp Lys Ser Ser Ser Ser Gly Lys Lys Thr Ala Lys Thr
305 310 315 320
Asn Thr Asn Glu Phe Leu Ile Asp Val Asp Lys Gly Glu Asn Tyr Cys
325 330 335
Phe Ser Val Gln Ala Val Ile Pro Ser Arg Thr Val Asn Arg Lys Ser
340 345 350
Thr Asp Ser Pro Val Glu Cys Met Gly Gln Glu Lys Gly Glu Phe Arg
355 360 365
Glu Asn Trp Val Asn Val Ile Ser Asp Leu Lys Lys Ile Glu Asp Leu
370 375 380
Ile Gln Ser Met His Ile Asp Ala Thr Leu Tyr Thr Glu Ser Asp Val
385 390 395 400
His Pro Ser Cys Lys Val Thr Ala Met Lys Cys Phe Leu Leu Glu Leu
405 410 415
Gln Val Ile Ser Leu Glu Ser Gly Asp Ala Ser Ile His Asp Thr Val
420 425 430
Glu Asn Leu Ile Ile Leu Ala Asn Asn Ser Leu Ser Ser Asn Gly Asn
435 440 445
Val Thr Glu Ser Gly Cys Lys Glu Cys Glu Glu Leu Glu Glu Lys Asn
450 455 460
Ile Lys Glu Phe Leu Gln Ser Phe Val His Ile Val Gln Met Phe Ile
465 470 475 480
Asn Thr Ser
<210> 99
<211> 1449
<212> DNA
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成21t15-7s序列”
<400> 99
atgggagtga aagttctttt tgcccttatt tgtattgctg tggccgaggc ccaaggtcaa 60
gatcgccaca tgattagaat gcgtcaactt atagatattg ttgatcagct gaaaaattat 120
gtgaatgact tggtccctga atttctgcca gctccagaag atgtagagac aaactgtgag 180
tggtcagctt tttcctgttt tcagaaggcc caactaaagt cagcaaatac aggaaacaat 240
gaaaggataa tcaatgtatc aattaaaaag ctgaagagga aaccaccttc cacaaatgca 300
gggagaagac agaaacacag actaacatgc ccttcatgtg attcttatga gaaaaaacca 360
cccaaagaat tcctagaaag attcaaatca cttctccaaa agatgattca tcagcatctg 420
tcctctagaa cacacggaag tgaagattcc tcaggcacta caaatactgt ggcagcatat 480
aatttaactt ggaaatcaac taatttcaag acaattttgg agtgggaacc caaacccgtc 540
aatcaagtct acactgttca aataagcact aagtcaggag attggaaaag caaatgcttt 600
tacacaacag acacagagtg tgacctcacc gacgagattg tgaaggatgt gaagcagacg 660
tacttggcac gggtcttctc ctacccggca gggaatgtgg agagcaccgg ttctgctggg 720
gagcctctgt atgagaactc cccagagttc acaccttacc tggagacaaa cctcggacag 780
ccaacaattc agagttttga acaggtggga acaaaagtga atgtgaccgt agaagatgaa 840
cggactttag tcagaaggaa caacactttc ctaagcctcc gggatgtttt tggcaaggac 900
ttaatttata cactttatta ttggaaatct tcaagttcag gaaagaaaac agccaaaaca 960
aacactaatg agtttttgat tgatgtggat aaaggagaaa actactgttt cagtgttcaa 1020
gcagtgattc cctcccgaac agttaaccgg aagagtacag acagcccggt agagtgtatg 1080
ggccaggaga aaggggaatt cagagaaaac tgggtgaacg tcatcagcga tttaaagaag 1140
atcgaagatt taattcagtc catgcatatc gacgccactt tatacacaga atccgacgtg 1200
cacccctctt gtaaggtgac cgccatgaaa tgttttttac tggagctgca agttatctct 1260
ttagagagcg gagacgctag catccacgac accgtggaga atttaatcat tttagccaat 1320
aactctttat ccagcaacgg caacgtgaca gagtccggct gcaaggagtg cgaagagctg 1380
gaggagaaga acatcaagga gtttctgcaa tcctttgtgc acattgtcca gatgttcatc 1440
aatacctcc 1449
<210> 100
<211> 217
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成21t15-7s序列”
<400> 100
Asp Cys Asp Ile Glu Gly Lys Asp Gly Lys Gln Tyr Glu Ser Val Leu
1 5 10 15
Met Val Ser Ile Asp Gln Leu Leu Asp Ser Met Lys Glu Ile Gly Ser
20 25 30
Asn Cys Leu Asn Asn Glu Phe Asn Phe Phe Lys Arg His Ile Cys Asp
35 40 45
Ala Asn Lys Glu Gly Met Phe Leu Phe Arg Ala Ala Arg Lys Leu Arg
50 55 60
Gln Phe Leu Lys Met Asn Ser Thr Gly Asp Phe Asp Leu His Leu Leu
65 70 75 80
Lys Val Ser Glu Gly Thr Thr Ile Leu Leu Asn Cys Thr Gly Gln Val
85 90 95
Lys Gly Arg Lys Pro Ala Ala Leu Gly Glu Ala Gln Pro Thr Lys Ser
100 105 110
Leu Glu Glu Asn Lys Ser Leu Lys Glu Gln Lys Lys Leu Asn Asp Leu
115 120 125
Cys Phe Leu Lys Arg Leu Leu Gln Glu Ile Lys Thr Cys Trp Asn Lys
130 135 140
Ile Leu Met Gly Thr Lys Glu His Ile Thr Cys Pro Pro Pro Met Ser
145 150 155 160
Val Glu His Ala Asp Ile Trp Val Lys Ser Tyr Ser Leu Tyr Ser Arg
165 170 175
Glu Arg Tyr Ile Cys Asn Ser Gly Phe Lys Arg Lys Ala Gly Thr Ser
180 185 190
Ser Leu Thr Glu Cys Val Leu Asn Lys Ala Thr Asn Val Ala His Trp
195 200 205
Thr Thr Pro Ser Leu Lys Cys Ile Arg
210 215
<210> 101
<211> 651
<212> DNA
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成21t15-7s序列”
<400> 101
gattgtgata ttgaaggtaa agatggcaaa caatatgaga gtgttctaat ggtcagcatc 60
gatcaattat tggacagcat gaaagaaatt ggtagcaatt gcctgaataa tgaatttaac 120
ttttttaaaa gacatatctg tgatgctaat aaggaaggta tgtttttatt ccgtgctgct 180
cgcaagttga ggcaatttct taaaatgaat agcactggtg attttgatct ccacttatta 240
aaagtttcag aaggcacaac aatactgttg aactgcactg gccaggttaa aggaagaaaa 300
ccagctgccc tgggtgaagc ccaaccaaca aagagtttgg aagaaaataa atctttaaag 360
gaacagaaaa aactgaatga cttgtgtttc ctaaagagac tattacaaga gataaaaact 420
tgttggaata aaattttgat gggcactaaa gaacacatca cgtgccctcc ccccatgtcc 480
gtggaacacg cagacatctg ggtcaagagc tacagcttgt actccaggga gcggtacatt 540
tgtaactctg gtttcaagcg taaagccggc acgtccagcc tgacggagtg cgtgttgaac 600
aaggccacga atgtcgccca ctggacaacc cccagtctca aatgcattag a 651
<210> 102
<211> 234
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成21t15-7s序列”
<400> 102
Met Gly Val Lys Val Leu Phe Ala Leu Ile Cys Ile Ala Val Ala Glu
1 5 10 15
Ala Asp Cys Asp Ile Glu Gly Lys Asp Gly Lys Gln Tyr Glu Ser Val
20 25 30
Leu Met Val Ser Ile Asp Gln Leu Leu Asp Ser Met Lys Glu Ile Gly
35 40 45
Ser Asn Cys Leu Asn Asn Glu Phe Asn Phe Phe Lys Arg His Ile Cys
50 55 60
Asp Ala Asn Lys Glu Gly Met Phe Leu Phe Arg Ala Ala Arg Lys Leu
65 70 75 80
Arg Gln Phe Leu Lys Met Asn Ser Thr Gly Asp Phe Asp Leu His Leu
85 90 95
Leu Lys Val Ser Glu Gly Thr Thr Ile Leu Leu Asn Cys Thr Gly Gln
100 105 110
Val Lys Gly Arg Lys Pro Ala Ala Leu Gly Glu Ala Gln Pro Thr Lys
115 120 125
Ser Leu Glu Glu Asn Lys Ser Leu Lys Glu Gln Lys Lys Leu Asn Asp
130 135 140
Leu Cys Phe Leu Lys Arg Leu Leu Gln Glu Ile Lys Thr Cys Trp Asn
145 150 155 160
Lys Ile Leu Met Gly Thr Lys Glu His Ile Thr Cys Pro Pro Pro Met
165 170 175
Ser Val Glu His Ala Asp Ile Trp Val Lys Ser Tyr Ser Leu Tyr Ser
180 185 190
Arg Glu Arg Tyr Ile Cys Asn Ser Gly Phe Lys Arg Lys Ala Gly Thr
195 200 205
Ser Ser Leu Thr Glu Cys Val Leu Asn Lys Ala Thr Asn Val Ala His
210 215 220
Trp Thr Thr Pro Ser Leu Lys Cys Ile Arg
225 230
<210> 103
<211> 702
<212> DNA
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成21t15-7s序列”
<400> 103
atgggagtga aagttctttt tgcccttatt tgtattgctg tggccgaggc cgattgtgat 60
attgaaggta aagatggcaa acaatatgag agtgttctaa tggtcagcat cgatcaatta 120
ttggacagca tgaaagaaat tggtagcaat tgcctgaata atgaatttaa cttttttaaa 180
agacatatct gtgatgctaa taaggaaggt atgtttttat tccgtgctgc tcgcaagttg 240
aggcaatttc ttaaaatgaa tagcactggt gattttgatc tccacttatt aaaagtttca 300
gaaggcacaa caatactgtt gaactgcact ggccaggtta aaggaagaaa accagctgcc 360
ctgggtgaag cccaaccaac aaagagtttg gaagaaaata aatctttaaa ggaacagaaa 420
aaactgaatg acttgtgttt cctaaagaga ctattacaag agataaaaac ttgttggaat 480
aaaattttga tgggcactaa agaacacatc acgtgccctc cccccatgtc cgtggaacac 540
gcagacatct gggtcaagag ctacagcttg tactccaggg agcggtacat ttgtaactct 600
ggtttcaagc gtaaagccgg cacgtccagc ctgacggagt gcgtgttgaa caaggccacg 660
aatgtcgccc actggacaac ccccagtctc aaatgcatta ga 702
<210> 104
<211> 485
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成7t15-21s序列”
<400> 104
Asp Cys Asp Ile Glu Gly Lys Asp Gly Lys Gln Tyr Glu Ser Val Leu
1 5 10 15
Met Val Ser Ile Asp Gln Leu Leu Asp Ser Met Lys Glu Ile Gly Ser
20 25 30
Asn Cys Leu Asn Asn Glu Phe Asn Phe Phe Lys Arg His Ile Cys Asp
35 40 45
Ala Asn Lys Glu Gly Met Phe Leu Phe Arg Ala Ala Arg Lys Leu Arg
50 55 60
Gln Phe Leu Lys Met Asn Ser Thr Gly Asp Phe Asp Leu His Leu Leu
65 70 75 80
Lys Val Ser Glu Gly Thr Thr Ile Leu Leu Asn Cys Thr Gly Gln Val
85 90 95
Lys Gly Arg Lys Pro Ala Ala Leu Gly Glu Ala Gln Pro Thr Lys Ser
100 105 110
Leu Glu Glu Asn Lys Ser Leu Lys Glu Gln Lys Lys Leu Asn Asp Leu
115 120 125
Cys Phe Leu Lys Arg Leu Leu Gln Glu Ile Lys Thr Cys Trp Asn Lys
130 135 140
Ile Leu Met Gly Thr Lys Glu His Ser Gly Thr Thr Asn Thr Val Ala
145 150 155 160
Ala Tyr Asn Leu Thr Trp Lys Ser Thr Asn Phe Lys Thr Ile Leu Glu
165 170 175
Trp Glu Pro Lys Pro Val Asn Gln Val Tyr Thr Val Gln Ile Ser Thr
180 185 190
Lys Ser Gly Asp Trp Lys Ser Lys Cys Phe Tyr Thr Thr Asp Thr Glu
195 200 205
Cys Asp Leu Thr Asp Glu Ile Val Lys Asp Val Lys Gln Thr Tyr Leu
210 215 220
Ala Arg Val Phe Ser Tyr Pro Ala Gly Asn Val Glu Ser Thr Gly Ser
225 230 235 240
Ala Gly Glu Pro Leu Tyr Glu Asn Ser Pro Glu Phe Thr Pro Tyr Leu
245 250 255
Glu Thr Asn Leu Gly Gln Pro Thr Ile Gln Ser Phe Glu Gln Val Gly
260 265 270
Thr Lys Val Asn Val Thr Val Glu Asp Glu Arg Thr Leu Val Arg Arg
275 280 285
Asn Asn Thr Phe Leu Ser Leu Arg Asp Val Phe Gly Lys Asp Leu Ile
290 295 300
Tyr Thr Leu Tyr Tyr Trp Lys Ser Ser Ser Ser Gly Lys Lys Thr Ala
305 310 315 320
Lys Thr Asn Thr Asn Glu Phe Leu Ile Asp Val Asp Lys Gly Glu Asn
325 330 335
Tyr Cys Phe Ser Val Gln Ala Val Ile Pro Ser Arg Thr Val Asn Arg
340 345 350
Lys Ser Thr Asp Ser Pro Val Glu Cys Met Gly Gln Glu Lys Gly Glu
355 360 365
Phe Arg Glu Asn Trp Val Asn Val Ile Ser Asp Leu Lys Lys Ile Glu
370 375 380
Asp Leu Ile Gln Ser Met His Ile Asp Ala Thr Leu Tyr Thr Glu Ser
385 390 395 400
Asp Val His Pro Ser Cys Lys Val Thr Ala Met Lys Cys Phe Leu Leu
405 410 415
Glu Leu Gln Val Ile Ser Leu Glu Ser Gly Asp Ala Ser Ile His Asp
420 425 430
Thr Val Glu Asn Leu Ile Ile Leu Ala Asn Asn Ser Leu Ser Ser Asn
435 440 445
Gly Asn Val Thr Glu Ser Gly Cys Lys Glu Cys Glu Glu Leu Glu Glu
450 455 460
Lys Asn Ile Lys Glu Phe Leu Gln Ser Phe Val His Ile Val Gln Met
465 470 475 480
Phe Ile Asn Thr Ser
485
<210> 105
<211> 1455
<212> DNA
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成7t15-21s序列”
<400> 105
gattgcgaca tcgagggcaa ggacggcaag cagtacgaga gcgtgctgat ggtgtccatc 60
gaccagctgc tggacagcat gaaggagatc ggctccaact gcctcaacaa cgagttcaac 120
ttcttcaagc ggcacatctg cgacgccaac aaggagggca tgttcctgtt cagggccgcc 180
aggaaactgc ggcagttcct gaagatgaac tccaccggcg acttcgacct gcacctgctg 240
aaggtgtccg agggcaccac catcctgctg aactgcaccg gacaggtgaa gggccggaaa 300
cctgctgctc tgggagaggc ccaacccacc aagagcctgg aggagaacaa gtccctgaag 360
gagcagaaga agctgaacga cctgtgcttc ctgaagaggc tgctgcagga gatcaagacc 420
tgctggaaca agatcctgat gggcaccaag gagcatagcg gcacaaccaa cacagtcgct 480
gcctataacc tcacttggaa gagcaccaac ttcaaaacca tcctcgaatg ggaacccaaa 540
cccgttaacc aagtttacac cgtgcagatc agcaccaagt ccggcgactg gaagtccaaa 600
tgtttctata ccaccgacac cgagtgcgat ctcaccgatg agatcgtgaa agatgtgaaa 660
cagacctacc tcgcccgggt gtttagctac cccgccggca atgtggagag cactggttcc 720
gctggcgagc ctttatacga gaacagcccc gaatttaccc cttacctcga gaccaattta 780
ggacagccca ccatccaaag ctttgagcaa gttggcacaa aggtgaatgt gacagtggag 840
gacgagcgga ctttagtgcg gcggaacaac acctttctca gcctccggga tgtgttcggc 900
aaagatttaa tctacacact gtattactgg aagtcctctt cctccggcaa gaagacagct 960
aaaaccaaca caaacgagtt tttaatcgac gtggataaag gcgaaaacta ctgtttcagc 1020
gtgcaagctg tgatcccctc ccggaccgtg aataggaaaa gcaccgatag ccccgttgag 1080
tgcatgggcc aagaaaaggg cgagttccgg gagaactggg tgaacgtcat cagcgattta 1140
aagaagatcg aagatttaat tcagtccatg catatcgacg ccactttata cacagaatcc 1200
gacgtgcacc cctcttgtaa ggtgaccgcc atgaaatgtt ttttactgga gctgcaagtt 1260
atctctttag agagcggaga cgctagcatc cacgacaccg tggagaattt aatcatttta 1320
gccaataact ctttatccag caacggcaac gtgacagagt ccggctgcaa ggagtgcgaa 1380
gagctggagg agaagaacat caaggagttt ctgcaatcct ttgtgcacat tgtccagatg 1440
ttcatcaata cctcc 1455
<210> 106
<211> 503
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成7t15-21s序列”
<400> 106
Met Lys Trp Val Thr Phe Ile Ser Leu Leu Phe Leu Phe Ser Ser Ala
1 5 10 15
Tyr Ser Asp Cys Asp Ile Glu Gly Lys Asp Gly Lys Gln Tyr Glu Ser
20 25 30
Val Leu Met Val Ser Ile Asp Gln Leu Leu Asp Ser Met Lys Glu Ile
35 40 45
Gly Ser Asn Cys Leu Asn Asn Glu Phe Asn Phe Phe Lys Arg His Ile
50 55 60
Cys Asp Ala Asn Lys Glu Gly Met Phe Leu Phe Arg Ala Ala Arg Lys
65 70 75 80
Leu Arg Gln Phe Leu Lys Met Asn Ser Thr Gly Asp Phe Asp Leu His
85 90 95
Leu Leu Lys Val Ser Glu Gly Thr Thr Ile Leu Leu Asn Cys Thr Gly
100 105 110
Gln Val Lys Gly Arg Lys Pro Ala Ala Leu Gly Glu Ala Gln Pro Thr
115 120 125
Lys Ser Leu Glu Glu Asn Lys Ser Leu Lys Glu Gln Lys Lys Leu Asn
130 135 140
Asp Leu Cys Phe Leu Lys Arg Leu Leu Gln Glu Ile Lys Thr Cys Trp
145 150 155 160
Asn Lys Ile Leu Met Gly Thr Lys Glu His Ser Gly Thr Thr Asn Thr
165 170 175
Val Ala Ala Tyr Asn Leu Thr Trp Lys Ser Thr Asn Phe Lys Thr Ile
180 185 190
Leu Glu Trp Glu Pro Lys Pro Val Asn Gln Val Tyr Thr Val Gln Ile
195 200 205
Ser Thr Lys Ser Gly Asp Trp Lys Ser Lys Cys Phe Tyr Thr Thr Asp
210 215 220
Thr Glu Cys Asp Leu Thr Asp Glu Ile Val Lys Asp Val Lys Gln Thr
225 230 235 240
Tyr Leu Ala Arg Val Phe Ser Tyr Pro Ala Gly Asn Val Glu Ser Thr
245 250 255
Gly Ser Ala Gly Glu Pro Leu Tyr Glu Asn Ser Pro Glu Phe Thr Pro
260 265 270
Tyr Leu Glu Thr Asn Leu Gly Gln Pro Thr Ile Gln Ser Phe Glu Gln
275 280 285
Val Gly Thr Lys Val Asn Val Thr Val Glu Asp Glu Arg Thr Leu Val
290 295 300
Arg Arg Asn Asn Thr Phe Leu Ser Leu Arg Asp Val Phe Gly Lys Asp
305 310 315 320
Leu Ile Tyr Thr Leu Tyr Tyr Trp Lys Ser Ser Ser Ser Gly Lys Lys
325 330 335
Thr Ala Lys Thr Asn Thr Asn Glu Phe Leu Ile Asp Val Asp Lys Gly
340 345 350
Glu Asn Tyr Cys Phe Ser Val Gln Ala Val Ile Pro Ser Arg Thr Val
355 360 365
Asn Arg Lys Ser Thr Asp Ser Pro Val Glu Cys Met Gly Gln Glu Lys
370 375 380
Gly Glu Phe Arg Glu Asn Trp Val Asn Val Ile Ser Asp Leu Lys Lys
385 390 395 400
Ile Glu Asp Leu Ile Gln Ser Met His Ile Asp Ala Thr Leu Tyr Thr
405 410 415
Glu Ser Asp Val His Pro Ser Cys Lys Val Thr Ala Met Lys Cys Phe
420 425 430
Leu Leu Glu Leu Gln Val Ile Ser Leu Glu Ser Gly Asp Ala Ser Ile
435 440 445
His Asp Thr Val Glu Asn Leu Ile Ile Leu Ala Asn Asn Ser Leu Ser
450 455 460
Ser Asn Gly Asn Val Thr Glu Ser Gly Cys Lys Glu Cys Glu Glu Leu
465 470 475 480
Glu Glu Lys Asn Ile Lys Glu Phe Leu Gln Ser Phe Val His Ile Val
485 490 495
Gln Met Phe Ile Asn Thr Ser
500
<210> 107
<211> 1508
<212> DNA
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成7t15-21s序列”
<400> 107
atgaagtggg tgaccttcat cagcctgctg ttcctgttct ccagcgccta ctccgattgc 60
gacatcgagg gcaaggacgg caagcagtac gagagcgtgc tgatggtgtc catcgaccag 120
ctgctggaca gcatgaagga gatcggctcc aactgcctca acaacgagtt caacttcttc 180
aagcggcaca tctgcgacgc caacaaggag ggcatgttcc tgttcagggc cgccaggaaa 240
ctgcggcagt tcctgaagat gaactccacc ggcgacttcg acctgcacct gctgaaggtg 300
tccgagggca ccaccatcct gctgaactgc accggacagg tgaagggccg gaaacctgct 360
gctctgggag aggcccaacc caccaagagc ctggaggaga acaagtccct gaaggagcag 420
aagaagctga acgacctgtg cttcctgaag aggctgctgc aggagatcaa gacctgctgg 480
aacaagatcc tgatgggcac caaggagcat agcggcacaa ccaacacagt cgctgcctat 540
aacctcactt ggaagagcac caacttcaaa accatcctcg aatgggaacc caaacccgtt 600
aaccaagttt acaccgtgca gatcagcacc aagtccggcg actggaagtc caaatgtttc 660
tataccaccg acaccgagtg cgatctcacc gatgagatcg tgaaagatgt gaaacagacc 720
tacctcgccc gggtgtttag ctaccccgcc ggcaatgtgg agagcactgg ttccgctggc 780
gagcctttat acgagaacag ccccgaattt accccttacc tcgagaccaa tttaggacag 840
cccaccatcc aaagctttga gcaagttggc acaaaggtga atgtgacagt ggaggacgag 900
cggactttag tgcggcggaa caacaccttt ctcagcctcc gggatgtgtt cggcaaagat 960
ttaatctaca cactgtatta ctggaagtcc tcttcctccg gcaagaagac agctaaaacc 1020
aacacaaacg agtttttaat cgacgtggat aaaggcgaaa actactgttt cagcgtgcaa 1080
gctgtgatcc cctcccggac cgtgaatagg aaaagcaccg atagccccgt tgagtgcatg 1140
ggccaagaaa agggcgagtt ccgggagaac tgggtgaacg tcatcagcga tttaaagaag 1200
atcgaagatt taattcagtc catgcatatc gacgccactt tatacacaga atccgacgtg 1260
cacccctctt gtaaggtgac cgccatgaaa tgttttttac tggagctgca agttatctct 1320
ttagagagcg gagacgctag catccacgac accgtggaga atttaatcat tttagccaat 1380
aactctttat ccagcaacgg caacgtgaca gagtccggct gcaaggagtg cgaagagctg 1440
gaggagaaga acatcaagga gtttctgcaa tcctttgtgc acattgtcca gatgttcatc 1500
aatacctc 1508
<210> 108
<211> 198
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成7t15-21s序列”
<400> 108
Gln Gly Gln Asp Arg His Met Ile Arg Met Arg Gln Leu Ile Asp Ile
1 5 10 15
Val Asp Gln Leu Lys Asn Tyr Val Asn Asp Leu Val Pro Glu Phe Leu
20 25 30
Pro Ala Pro Glu Asp Val Glu Thr Asn Cys Glu Trp Ser Ala Phe Ser
35 40 45
Cys Phe Gln Lys Ala Gln Leu Lys Ser Ala Asn Thr Gly Asn Asn Glu
50 55 60
Arg Ile Ile Asn Val Ser Ile Lys Lys Leu Lys Arg Lys Pro Pro Ser
65 70 75 80
Thr Asn Ala Gly Arg Arg Gln Lys His Arg Leu Thr Cys Pro Ser Cys
85 90 95
Asp Ser Tyr Glu Lys Lys Pro Pro Lys Glu Phe Leu Glu Arg Phe Lys
100 105 110
Ser Leu Leu Gln Lys Met Ile His Gln His Leu Ser Ser Arg Thr His
115 120 125
Gly Ser Glu Asp Ser Ile Thr Cys Pro Pro Pro Met Ser Val Glu His
130 135 140
Ala Asp Ile Trp Val Lys Ser Tyr Ser Leu Tyr Ser Arg Glu Arg Tyr
145 150 155 160
Ile Cys Asn Ser Gly Phe Lys Arg Lys Ala Gly Thr Ser Ser Leu Thr
165 170 175
Glu Cys Val Leu Asn Lys Ala Thr Asn Val Ala His Trp Thr Thr Pro
180 185 190
Ser Leu Lys Cys Ile Arg
195
<210> 109
<211> 594
<212> DNA
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成7t15-21s序列”
<400> 109
cagggccagg acaggcacat gatccggatg aggcagctca tcgacatcgt cgaccagctg 60
aagaactacg tgaacgacct ggtgcccgag tttctgcctg cccccgagga cgtggagacc 120
aactgcgagt ggtccgcctt ctcctgcttt cagaaggccc agctgaagtc cgccaacacc 180
ggcaacaacg agcggatcat caacgtgagc atcaagaagc tgaagcggaa gcctccctcc 240
acaaacgccg gcaggaggca gaagcacagg ctgacctgcc ccagctgtga ctcctacgag 300
aagaagcccc ccaaggagtt cctggagagg ttcaagtccc tgctgcagaa gatgatccat 360
cagcacctgt cctccaggac ccacggctcc gaggactcca ttacatgccc ccctcccatg 420
agcgtggagc acgccgacat ctgggtgaag agctatagcc tctacagccg ggagaggtat 480
atctgtaaca gcggcttcaa gaggaaggcc ggcaccagca gcctcaccga gtgcgtgctg 540
aataaggcta ccaacgtggc tcactggaca acaccctctt taaagtgcat ccgg 594
<210> 110
<211> 216
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成7t15-21s序列”
<400> 110
Met Lys Trp Val Thr Phe Ile Ser Leu Leu Phe Leu Phe Ser Ser Ala
1 5 10 15
Tyr Ser Gln Gly Gln Asp Arg His Met Ile Arg Met Arg Gln Leu Ile
20 25 30
Asp Ile Val Asp Gln Leu Lys Asn Tyr Val Asn Asp Leu Val Pro Glu
35 40 45
Phe Leu Pro Ala Pro Glu Asp Val Glu Thr Asn Cys Glu Trp Ser Ala
50 55 60
Phe Ser Cys Phe Gln Lys Ala Gln Leu Lys Ser Ala Asn Thr Gly Asn
65 70 75 80
Asn Glu Arg Ile Ile Asn Val Ser Ile Lys Lys Leu Lys Arg Lys Pro
85 90 95
Pro Ser Thr Asn Ala Gly Arg Arg Gln Lys His Arg Leu Thr Cys Pro
100 105 110
Ser Cys Asp Ser Tyr Glu Lys Lys Pro Pro Lys Glu Phe Leu Glu Arg
115 120 125
Phe Lys Ser Leu Leu Gln Lys Met Ile His Gln His Leu Ser Ser Arg
130 135 140
Thr His Gly Ser Glu Asp Ser Ile Thr Cys Pro Pro Pro Met Ser Val
145 150 155 160
Glu His Ala Asp Ile Trp Val Lys Ser Tyr Ser Leu Tyr Ser Arg Glu
165 170 175
Arg Tyr Ile Cys Asn Ser Gly Phe Lys Arg Lys Ala Gly Thr Ser Ser
180 185 190
Leu Thr Glu Cys Val Leu Asn Lys Ala Thr Asn Val Ala His Trp Thr
195 200 205
Thr Pro Ser Leu Lys Cys Ile Arg
210 215
<210> 111
<211> 648
<212> DNA
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成7t15-21s序列”
<400> 111
atgaagtggg tgaccttcat cagcctgctg ttcctgttct ccagcgccta ctcccagggc 60
caggacaggc acatgatccg gatgaggcag ctcatcgaca tcgtcgacca gctgaagaac 120
tacgtgaacg acctggtgcc cgagtttctg cctgcccccg aggacgtgga gaccaactgc 180
gagtggtccg ccttctcctg ctttcagaag gcccagctga agtccgccaa caccggcaac 240
aacgagcgga tcatcaacgt gagcatcaag aagctgaagc ggaagcctcc ctccacaaac 300
gccggcagga ggcagaagca caggctgacc tgccccagct gtgactccta cgagaagaag 360
ccccccaagg agttcctgga gaggttcaag tccctgctgc agaagatgat ccatcagcac 420
ctgtcctcca ggacccacgg ctccgaggac tccattacat gcccccctcc catgagcgtg 480
gagcacgccg acatctgggt gaagagctat agcctctaca gccgggagag gtatatctgt 540
aacagcggct tcaagaggaa ggccggcacc agcagcctca ccgagtgcgt gctgaataag 600
gctaccaacg tggctcactg gacaacaccc tctttaaagt gcatccgg 648
<210> 112
<211> 108
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成CD16 LC序列”
<400> 112
Ser Glu Leu Thr Gln Asp Pro Ala Val Ser Val Ala Leu Gly Gln Thr
1 5 10 15
Val Arg Ile Thr Cys Gln Gly Asp Ser Leu Arg Ser Tyr Tyr Ala Ser
20 25 30
Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Val Leu Val Ile Tyr Gly
35 40 45
Lys Asn Asn Arg Pro Ser Gly Ile Pro Asp Arg Phe Ser Gly Ser Ser
50 55 60
Ser Gly Asn Thr Ala Ser Leu Thr Ile Thr Gly Ala Gln Ala Glu Asp
65 70 75 80
Glu Ala Asp Tyr Tyr Cys Asn Ser Arg Asp Ser Ser Gly Asn His Val
85 90 95
Val Phe Gly Gly Gly Thr Lys Leu Thr Val Gly His
100 105
<210> 113
<211> 324
<212> DNA
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成CD16 LC序列”
<400> 113
tccgagctga cccaggaccc tgctgtgtcc gtggctctgg gccagaccgt gaggatcacc 60
tgccagggcg actccctgag gtcctactac gcctcctggt accagcagaa gcccggccag 120
gctcctgtgc tggtgatcta cggcaagaac aacaggccct ccggcatccc tgacaggttc 180
tccggatcct cctccggcaa caccgcctcc ctgaccatca caggcgctca ggccgaggac 240
gaggctgact actactgcaa ctccagggac tcctccggca accatgtggt gttcggcggc 300
ggcaccaagc tgaccgtggg ccat 324
<210> 114
<211> 117
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成CD16 HC序列”
<400> 114
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Arg Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Asp Asp Tyr
20 25 30
Gly Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gly Ile Asn Trp Asn Gly Gly Ser Thr Gly Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Arg Ser Leu Leu Phe Asp Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Arg
115
<210> 115
<211> 351
<212> DNA
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成CD16 HC序列”
<400> 115
gaggtgcagc tggtggagtc cggaggagga gtggtgaggc ctggaggctc cctgaggctg 60
agctgtgctg cctccggctt caccttcgac gactacggca tgtcctgggt gaggcaggct 120
cctggaaagg gcctggagtg ggtgtccggc atcaactgga acggcggatc caccggctac 180
gccgattccg tgaagggcag gttcaccatc agcagggaca acgccaagaa ctccctgtac 240
ctgcagatga actccctgag ggccgaggac accgccgtgt actactgcgc caggggcagg 300
tccctgctgt tcgactactg gggacagggc accctggtga ccgtgtccag g 351
<210> 116
<211> 490
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成18t15-12s16序列”
<400> 116
Tyr Phe Gly Lys Leu Glu Ser Lys Leu Ser Val Ile Arg Asn Leu Asn
1 5 10 15
Asp Gln Val Leu Phe Ile Asp Gln Gly Asn Arg Pro Leu Phe Glu Asp
20 25 30
Met Thr Asp Ser Asp Cys Arg Asp Asn Ala Pro Arg Thr Ile Phe Ile
35 40 45
Ile Ser Met Tyr Lys Asp Ser Gln Pro Arg Gly Met Ala Val Thr Ile
50 55 60
Ser Val Lys Cys Glu Lys Ile Ser Thr Leu Ser Cys Glu Asn Lys Ile
65 70 75 80
Ile Ser Phe Lys Glu Met Asn Pro Pro Asp Asn Ile Lys Asp Thr Lys
85 90 95
Ser Asp Ile Ile Phe Phe Gln Arg Ser Val Pro Gly His Asp Asn Lys
100 105 110
Met Gln Phe Glu Ser Ser Ser Tyr Glu Gly Tyr Phe Leu Ala Cys Glu
115 120 125
Lys Glu Arg Asp Leu Phe Lys Leu Ile Leu Lys Lys Glu Asp Glu Leu
130 135 140
Gly Asp Arg Ser Ile Met Phe Thr Val Gln Asn Glu Asp Ser Gly Thr
145 150 155 160
Thr Asn Thr Val Ala Ala Tyr Asn Leu Thr Trp Lys Ser Thr Asn Phe
165 170 175
Lys Thr Ile Leu Glu Trp Glu Pro Lys Pro Val Asn Gln Val Tyr Thr
180 185 190
Val Gln Ile Ser Thr Lys Ser Gly Asp Trp Lys Ser Lys Cys Phe Tyr
195 200 205
Thr Thr Asp Thr Glu Cys Asp Leu Thr Asp Glu Ile Val Lys Asp Val
210 215 220
Lys Gln Thr Tyr Leu Ala Arg Val Phe Ser Tyr Pro Ala Gly Asn Val
225 230 235 240
Glu Ser Thr Gly Ser Ala Gly Glu Pro Leu Tyr Glu Asn Ser Pro Glu
245 250 255
Phe Thr Pro Tyr Leu Glu Thr Asn Leu Gly Gln Pro Thr Ile Gln Ser
260 265 270
Phe Glu Gln Val Gly Thr Lys Val Asn Val Thr Val Glu Asp Glu Arg
275 280 285
Thr Leu Val Arg Arg Asn Asn Thr Phe Leu Ser Leu Arg Asp Val Phe
290 295 300
Gly Lys Asp Leu Ile Tyr Thr Leu Tyr Tyr Trp Lys Ser Ser Ser Ser
305 310 315 320
Gly Lys Lys Thr Ala Lys Thr Asn Thr Asn Glu Phe Leu Ile Asp Val
325 330 335
Asp Lys Gly Glu Asn Tyr Cys Phe Ser Val Gln Ala Val Ile Pro Ser
340 345 350
Arg Thr Val Asn Arg Lys Ser Thr Asp Ser Pro Val Glu Cys Met Gly
355 360 365
Gln Glu Lys Gly Glu Phe Arg Glu Asn Trp Val Asn Val Ile Ser Asp
370 375 380
Leu Lys Lys Ile Glu Asp Leu Ile Gln Ser Met His Ile Asp Ala Thr
385 390 395 400
Leu Tyr Thr Glu Ser Asp Val His Pro Ser Cys Lys Val Thr Ala Met
405 410 415
Lys Cys Phe Leu Leu Glu Leu Gln Val Ile Ser Leu Glu Ser Gly Asp
420 425 430
Ala Ser Ile His Asp Thr Val Glu Asn Leu Ile Ile Leu Ala Asn Asn
435 440 445
Ser Leu Ser Ser Asn Gly Asn Val Thr Glu Ser Gly Cys Lys Glu Cys
450 455 460
Glu Glu Leu Glu Glu Lys Asn Ile Lys Glu Phe Leu Gln Ser Phe Val
465 470 475 480
His Ile Val Gln Met Phe Ile Asn Thr Ser
485 490
<210> 117
<211> 1470
<212> DNA
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成18t15-12s16序列”
<400> 117
tacttcggca aactggaatc caagctgagc gtgatccgga atttaaacga ccaagttctg 60
tttatcgatc aaggtaaccg gcctctgttc gaggacatga ccgactccga ttgccgggac 120
aatgcccccc ggaccatctt cattatctcc atgtacaagg acagccagcc ccggggcatg 180
gctgtgacaa ttagcgtgaa gtgtgagaaa atcagcactt tatcttgtga gaacaagatc 240
atctccttta aggaaatgaa cccccccgat aacatcaagg acaccaagtc cgatatcatc 300
ttcttccagc ggtccgtgcc cggtcacgat aacaagatgc agttcgaatc ctcctcctac 360
gagggctact ttttagcttg tgaaaaggag agggatttat tcaagctgat cctcaagaag 420
gaggacgagc tgggcgatcg ttccatcatg ttcaccgtcc aaaacgagga tagcggcaca 480
accaacacag tcgctgccta taacctcact tggaagagca ccaacttcaa aaccatcctc 540
gaatgggaac ccaaacccgt taaccaagtt tacaccgtgc agatcagcac caagtccggc 600
gactggaagt ccaaatgttt ctataccacc gacaccgagt gcgatctcac cgatgagatc 660
gtgaaagatg tgaaacagac ctacctcgcc cgggtgttta gctaccccgc cggcaatgtg 720
gagagcactg gttccgctgg cgagccttta tacgagaaca gccccgaatt taccccttac 780
ctcgagacca atttaggaca gcccaccatc caaagctttg agcaagttgg cacaaaggtg 840
aatgtgacag tggaggacga gcggacttta gtgcggcgga acaacacctt tctcagcctc 900
cgggatgtgt tcggcaaaga tttaatctac acactgtatt actggaagtc ctcttcctcc 960
ggcaagaaga cagctaaaac caacacaaac gagtttttaa tcgacgtgga taaaggcgaa 1020
aactactgtt tcagcgtgca agctgtgatc ccctcccgga ccgtgaatag gaaaagcacc 1080
gatagccccg ttgagtgcat gggccaagaa aagggcgagt tccgggagaa ctgggtgaac 1140
gtcatcagcg atttaaagaa gatcgaagat ttaattcagt ccatgcatat cgacgccact 1200
ttatacacag aatccgacgt gcacccctct tgtaaggtga ccgccatgaa atgtttttta 1260
ctggagctgc aagttatctc tttagagagc ggagacgcta gcatccacga caccgtggag 1320
aatttaatca ttttagccaa taactcttta tccagcaacg gcaacgtgac agagtccggc 1380
tgcaaggagt gcgaagagct ggaggagaag aacatcaagg agtttctgca atcctttgtg 1440
cacattgtcc agatgttcat caatacctcc 1470
<210> 118
<211> 508
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成18t15-12s16序列”
<400> 118
Met Lys Trp Val Thr Phe Ile Ser Leu Leu Phe Leu Phe Ser Ser Ala
1 5 10 15
Tyr Ser Tyr Phe Gly Lys Leu Glu Ser Lys Leu Ser Val Ile Arg Asn
20 25 30
Leu Asn Asp Gln Val Leu Phe Ile Asp Gln Gly Asn Arg Pro Leu Phe
35 40 45
Glu Asp Met Thr Asp Ser Asp Cys Arg Asp Asn Ala Pro Arg Thr Ile
50 55 60
Phe Ile Ile Ser Met Tyr Lys Asp Ser Gln Pro Arg Gly Met Ala Val
65 70 75 80
Thr Ile Ser Val Lys Cys Glu Lys Ile Ser Thr Leu Ser Cys Glu Asn
85 90 95
Lys Ile Ile Ser Phe Lys Glu Met Asn Pro Pro Asp Asn Ile Lys Asp
100 105 110
Thr Lys Ser Asp Ile Ile Phe Phe Gln Arg Ser Val Pro Gly His Asp
115 120 125
Asn Lys Met Gln Phe Glu Ser Ser Ser Tyr Glu Gly Tyr Phe Leu Ala
130 135 140
Cys Glu Lys Glu Arg Asp Leu Phe Lys Leu Ile Leu Lys Lys Glu Asp
145 150 155 160
Glu Leu Gly Asp Arg Ser Ile Met Phe Thr Val Gln Asn Glu Asp Ser
165 170 175
Gly Thr Thr Asn Thr Val Ala Ala Tyr Asn Leu Thr Trp Lys Ser Thr
180 185 190
Asn Phe Lys Thr Ile Leu Glu Trp Glu Pro Lys Pro Val Asn Gln Val
195 200 205
Tyr Thr Val Gln Ile Ser Thr Lys Ser Gly Asp Trp Lys Ser Lys Cys
210 215 220
Phe Tyr Thr Thr Asp Thr Glu Cys Asp Leu Thr Asp Glu Ile Val Lys
225 230 235 240
Asp Val Lys Gln Thr Tyr Leu Ala Arg Val Phe Ser Tyr Pro Ala Gly
245 250 255
Asn Val Glu Ser Thr Gly Ser Ala Gly Glu Pro Leu Tyr Glu Asn Ser
260 265 270
Pro Glu Phe Thr Pro Tyr Leu Glu Thr Asn Leu Gly Gln Pro Thr Ile
275 280 285
Gln Ser Phe Glu Gln Val Gly Thr Lys Val Asn Val Thr Val Glu Asp
290 295 300
Glu Arg Thr Leu Val Arg Arg Asn Asn Thr Phe Leu Ser Leu Arg Asp
305 310 315 320
Val Phe Gly Lys Asp Leu Ile Tyr Thr Leu Tyr Tyr Trp Lys Ser Ser
325 330 335
Ser Ser Gly Lys Lys Thr Ala Lys Thr Asn Thr Asn Glu Phe Leu Ile
340 345 350
Asp Val Asp Lys Gly Glu Asn Tyr Cys Phe Ser Val Gln Ala Val Ile
355 360 365
Pro Ser Arg Thr Val Asn Arg Lys Ser Thr Asp Ser Pro Val Glu Cys
370 375 380
Met Gly Gln Glu Lys Gly Glu Phe Arg Glu Asn Trp Val Asn Val Ile
385 390 395 400
Ser Asp Leu Lys Lys Ile Glu Asp Leu Ile Gln Ser Met His Ile Asp
405 410 415
Ala Thr Leu Tyr Thr Glu Ser Asp Val His Pro Ser Cys Lys Val Thr
420 425 430
Ala Met Lys Cys Phe Leu Leu Glu Leu Gln Val Ile Ser Leu Glu Ser
435 440 445
Gly Asp Ala Ser Ile His Asp Thr Val Glu Asn Leu Ile Ile Leu Ala
450 455 460
Asn Asn Ser Leu Ser Ser Asn Gly Asn Val Thr Glu Ser Gly Cys Lys
465 470 475 480
Glu Cys Glu Glu Leu Glu Glu Lys Asn Ile Lys Glu Phe Leu Gln Ser
485 490 495
Phe Val His Ile Val Gln Met Phe Ile Asn Thr Ser
500 505
<210> 119
<211> 1524
<212> DNA
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成18t15-12s16序列”
<400> 119
atgaagtggg tcacatttat ctctttactg ttcctcttct ccagcgccta cagctacttc 60
ggcaaactgg aatccaagct gagcgtgatc cggaatttaa acgaccaagt tctgtttatc 120
gatcaaggta accggcctct gttcgaggac atgaccgact ccgattgccg ggacaatgcc 180
ccccggacca tcttcattat ctccatgtac aaggacagcc agccccgggg catggctgtg 240
acaattagcg tgaagtgtga gaaaatcagc actttatctt gtgagaacaa gatcatctcc 300
tttaaggaaa tgaacccccc cgataacatc aaggacacca agtccgatat catcttcttc 360
cagcggtccg tgcccggtca cgataacaag atgcagttcg aatcctcctc ctacgagggc 420
tactttttag cttgtgaaaa ggagagggat ttattcaagc tgatcctcaa gaaggaggac 480
gagctgggcg atcgttccat catgttcacc gtccaaaacg aggatagcgg cacaaccaac 540
acagtcgctg cctataacct cacttggaag agcaccaact tcaaaaccat cctcgaatgg 600
gaacccaaac ccgttaacca agtttacacc gtgcagatca gcaccaagtc cggcgactgg 660
aagtccaaat gtttctatac caccgacacc gagtgcgatc tcaccgatga gatcgtgaaa 720
gatgtgaaac agacctacct cgcccgggtg tttagctacc ccgccggcaa tgtggagagc 780
actggttccg ctggcgagcc tttatacgag aacagccccg aatttacccc ttacctcgag 840
accaatttag gacagcccac catccaaagc tttgagcaag ttggcacaaa ggtgaatgtg 900
acagtggagg acgagcggac tttagtgcgg cggaacaaca cctttctcag cctccgggat 960
gtgttcggca aagatttaat ctacacactg tattactgga agtcctcttc ctccggcaag 1020
aagacagcta aaaccaacac aaacgagttt ttaatcgacg tggataaagg cgaaaactac 1080
tgtttcagcg tgcaagctgt gatcccctcc cggaccgtga ataggaaaag caccgatagc 1140
cccgttgagt gcatgggcca agaaaagggc gagttccggg agaactgggt gaacgtcatc 1200
agcgatttaa agaagatcga agatttaatt cagtccatgc atatcgacgc cactttatac 1260
acagaatccg acgtgcaccc ctcttgtaag gtgaccgcca tgaaatgttt tttactggag 1320
ctgcaagtta tctctttaga gagcggagac gctagcatcc acgacaccgt ggagaattta 1380
atcattttag ccaataactc tttatccagc aacggcaacg tgacagagtc cggctgcaag 1440
gagtgcgaag agctggagga gaagaacatc aaggagtttc tgcaatcctt tgtgcacatt 1500
gtccagatgt tcatcaatac ctcc 1524
<210> 120
<211> 823
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成18t15-12s16序列”
<400> 120
Ile Trp Glu Leu Lys Lys Asp Val Tyr Val Val Glu Leu Asp Trp Tyr
1 5 10 15
Pro Asp Ala Pro Gly Glu Met Val Val Leu Thr Cys Asp Thr Pro Glu
20 25 30
Glu Asp Gly Ile Thr Trp Thr Leu Asp Gln Ser Ser Glu Val Leu Gly
35 40 45
Ser Gly Lys Thr Leu Thr Ile Gln Val Lys Glu Phe Gly Asp Ala Gly
50 55 60
Gln Tyr Thr Cys His Lys Gly Gly Glu Val Leu Ser His Ser Leu Leu
65 70 75 80
Leu Leu His Lys Lys Glu Asp Gly Ile Trp Ser Thr Asp Ile Leu Lys
85 90 95
Asp Gln Lys Glu Pro Lys Asn Lys Thr Phe Leu Arg Cys Glu Ala Lys
100 105 110
Asn Tyr Ser Gly Arg Phe Thr Cys Trp Trp Leu Thr Thr Ile Ser Thr
115 120 125
Asp Leu Thr Phe Ser Val Lys Ser Ser Arg Gly Ser Ser Asp Pro Gln
130 135 140
Gly Val Thr Cys Gly Ala Ala Thr Leu Ser Ala Glu Arg Val Arg Gly
145 150 155 160
Asp Asn Lys Glu Tyr Glu Tyr Ser Val Glu Cys Gln Glu Asp Ser Ala
165 170 175
Cys Pro Ala Ala Glu Glu Ser Leu Pro Ile Glu Val Met Val Asp Ala
180 185 190
Val His Lys Leu Lys Tyr Glu Asn Tyr Thr Ser Ser Phe Phe Ile Arg
195 200 205
Asp Ile Ile Lys Pro Asp Pro Pro Lys Asn Leu Gln Leu Lys Pro Leu
210 215 220
Lys Asn Ser Arg Gln Val Glu Val Ser Trp Glu Tyr Pro Asp Thr Trp
225 230 235 240
Ser Thr Pro His Ser Tyr Phe Ser Leu Thr Phe Cys Val Gln Val Gln
245 250 255
Gly Lys Ser Lys Arg Glu Lys Lys Asp Arg Val Phe Thr Asp Lys Thr
260 265 270
Ser Ala Thr Val Ile Cys Arg Lys Asn Ala Ser Ile Ser Val Arg Ala
275 280 285
Gln Asp Arg Tyr Tyr Ser Ser Ser Trp Ser Glu Trp Ala Ser Val Pro
290 295 300
Cys Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
305 310 315 320
Ser Arg Asn Leu Pro Val Ala Thr Pro Asp Pro Gly Met Phe Pro Cys
325 330 335
Leu His His Ser Gln Asn Leu Leu Arg Ala Val Ser Asn Met Leu Gln
340 345 350
Lys Ala Arg Gln Thr Leu Glu Phe Tyr Pro Cys Thr Ser Glu Glu Ile
355 360 365
Asp His Glu Asp Ile Thr Lys Asp Lys Thr Ser Thr Val Glu Ala Cys
370 375 380
Leu Pro Leu Glu Leu Thr Lys Asn Glu Ser Cys Leu Asn Ser Arg Glu
385 390 395 400
Thr Ser Phe Ile Thr Asn Gly Ser Cys Leu Ala Ser Arg Lys Thr Ser
405 410 415
Phe Met Met Ala Leu Cys Leu Ser Ser Ile Tyr Glu Asp Leu Lys Met
420 425 430
Tyr Gln Val Glu Phe Lys Thr Met Asn Ala Lys Leu Leu Met Asp Pro
435 440 445
Lys Arg Gln Ile Phe Leu Asp Gln Asn Met Leu Ala Val Ile Asp Glu
450 455 460
Leu Met Gln Ala Leu Asn Phe Asn Ser Glu Thr Val Pro Gln Lys Ser
465 470 475 480
Ser Leu Glu Glu Pro Asp Phe Tyr Lys Thr Lys Ile Lys Leu Cys Ile
485 490 495
Leu Leu His Ala Phe Arg Ile Arg Ala Val Thr Ile Asp Arg Val Met
500 505 510
Ser Tyr Leu Asn Ala Ser Ile Thr Cys Pro Pro Pro Met Ser Val Glu
515 520 525
His Ala Asp Ile Trp Val Lys Ser Tyr Ser Leu Tyr Ser Arg Glu Arg
530 535 540
Tyr Ile Cys Asn Ser Gly Phe Lys Arg Lys Ala Gly Thr Ser Ser Leu
545 550 555 560
Thr Glu Cys Val Leu Asn Lys Ala Thr Asn Val Ala His Trp Thr Thr
565 570 575
Pro Ser Leu Lys Cys Ile Arg Ser Glu Leu Thr Gln Asp Pro Ala Val
580 585 590
Ser Val Ala Leu Gly Gln Thr Val Arg Ile Thr Cys Gln Gly Asp Ser
595 600 605
Leu Arg Ser Tyr Tyr Ala Ser Trp Tyr Gln Gln Lys Pro Gly Gln Ala
610 615 620
Pro Val Leu Val Ile Tyr Gly Lys Asn Asn Arg Pro Ser Gly Ile Pro
625 630 635 640
Asp Arg Phe Ser Gly Ser Ser Ser Gly Asn Thr Ala Ser Leu Thr Ile
645 650 655
Thr Gly Ala Gln Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Asn Ser Arg
660 665 670
Asp Ser Ser Gly Asn His Val Val Phe Gly Gly Gly Thr Lys Leu Thr
675 680 685
Val Gly His Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly
690 695 700
Gly Ser Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Arg Pro
705 710 715 720
Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Asp
725 730 735
Asp Tyr Gly Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu
740 745 750
Trp Val Ser Gly Ile Asn Trp Asn Gly Gly Ser Thr Gly Tyr Ala Asp
755 760 765
Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser
770 775 780
Leu Tyr Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr
785 790 795 800
Tyr Cys Ala Arg Gly Arg Ser Leu Leu Phe Asp Tyr Trp Gly Gln Gly
805 810 815
Thr Leu Val Thr Val Ser Arg
820
<210> 121
<211> 2469
<212> DNA
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成18t15-12s16序列”
<400> 121
atttgggaac tgaagaagga cgtctacgtg gtcgaactgg actggtatcc cgatgctccc 60
ggcgaaatgg tggtgctcac ttgtgacacc cccgaagaag acggcatcac ttggaccctc 120
gatcagagca gcgaggtgct gggctccgga aagaccctca caatccaagt taaggagttc 180
ggagacgctg gccaatacac atgccacaag ggaggcgagg tgctcagcca ttccttatta 240
ttattacaca agaaggaaga cggaatctgg tccaccgaca ttttaaaaga tcagaaggag 300
cccaagaata agaccttttt aaggtgtgag gccaaaaact acagcggtcg tttcacttgt 360
tggtggctga ccaccatttc caccgattta accttctccg tgaaaagcag ccggggaagc 420
tccgaccctc aaggtgtgac atgtggagcc gctaccctca gcgctgagag ggttcgtggc 480
gataacaagg aatacgagta cagcgtggag tgccaagaag atagcgcttg tcccgctgcc 540
gaagaatctt tacccattga ggtgatggtg gacgccgtgc acaaactcaa gtacgagaac 600
tacacctcct ccttctttat ccgggacatc attaagcccg atcctcctaa gaatttacag 660
ctgaagcctc tcaaaaatag ccggcaagtt gaggtctctt gggaatatcc cgacacttgg 720
agcacacccc acagctactt ctctttaacc ttttgtgtgc aagttcaagg taaaagcaag 780
cgggagaaga aagaccgggt gtttaccgac aaaaccagcg ccaccgtcat ctgtcggaag 840
aacgcctcca tcagcgtgag ggctcaagat cgttattact ccagcagctg gtccgagtgg 900
gccagcgtgc cttgttccgg cggtggagga tccggaggag gtggctccgg cggcggagga 960
tctcgtaacc tccccgtggc tacccccgat cccggaatgt tcccttgttt acaccacagc 1020
cagaatttac tgagggccgt gagcaacatg ctgcagaaag ctaggcagac tttagaattt 1080
tacccttgca ccagcgagga gatcgaccat gaagatatca ccaaggacaa gacatccacc 1140
gtggaggctt gtttacctct ggagctgaca aagaacgagt cttgtctcaa ctctcgtgaa 1200
accagcttca tcacaaatgg ctcttgttta gcttcccgga agacctcctt tatgatggct 1260
ttatgcctca gctccatcta cgaggattta aagatgtacc aagtggagtt caagaccatg 1320
aacgccaagc tgctcatgga ccctaaacgg cagatctttt tagaccagaa catgctggct 1380
gtgattgatg agctgatgca agctttaaac ttcaactccg agaccgtccc tcagaagtcc 1440
tccctcgagg agcccgattt ttacaagaca aagatcaaac tgtgcatttt actccacgcc 1500
tttaggatcc gggccgtgac cattgaccgg gtcatgagct atttaaacgc cagcattaca 1560
tgcccccctc ccatgagcgt ggagcacgcc gacatctggg tgaagagcta tagcctctac 1620
agccgggaga ggtatatctg taacagcggc ttcaagagga aggccggcac cagcagcctc 1680
accgagtgcg tgctgaataa ggctaccaac gtggctcact ggacaacacc ctctttaaag 1740
tgcatccggt ccgagctgac ccaggaccct gctgtgtccg tggctctggg ccagaccgtg 1800
aggatcacct gccagggcga ctccctgagg tcctactacg cctcctggta ccagcagaag 1860
cccggccagg ctcctgtgct ggtgatctac ggcaagaaca acaggccctc cggcatccct 1920
gacaggttct ccggatcctc ctccggcaac accgcctccc tgaccatcac aggcgctcag 1980
gccgaggacg aggctgacta ctactgcaac tccagggact cctccggcaa ccatgtggtg 2040
ttcggcggcg gcaccaagct gaccgtgggc catggcggcg gcggctccgg aggcggcggc 2100
agcggcggag gaggatccga ggtgcagctg gtggagtccg gaggaggagt ggtgaggcct 2160
ggaggctccc tgaggctgag ctgtgctgcc tccggcttca ccttcgacga ctacggcatg 2220
tcctgggtga ggcaggctcc tggaaagggc ctggagtggg tgtccggcat caactggaac 2280
ggcggatcca ccggctacgc cgattccgtg aagggcaggt tcaccatcag cagggacaac 2340
gccaagaact ccctgtacct gcagatgaac tccctgaggg ccgaggacac cgccgtgtac 2400
tactgcgcca ggggcaggtc cctgctgttc gactactggg gacagggcac cctggtgacc 2460
gtgtccagg 2469
<210> 122
<211> 841
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成18t15-12s16序列”
<400> 122
Met Lys Trp Val Thr Phe Ile Ser Leu Leu Phe Leu Phe Ser Ser Ala
1 5 10 15
Tyr Ser Ile Trp Glu Leu Lys Lys Asp Val Tyr Val Val Glu Leu Asp
20 25 30
Trp Tyr Pro Asp Ala Pro Gly Glu Met Val Val Leu Thr Cys Asp Thr
35 40 45
Pro Glu Glu Asp Gly Ile Thr Trp Thr Leu Asp Gln Ser Ser Glu Val
50 55 60
Leu Gly Ser Gly Lys Thr Leu Thr Ile Gln Val Lys Glu Phe Gly Asp
65 70 75 80
Ala Gly Gln Tyr Thr Cys His Lys Gly Gly Glu Val Leu Ser His Ser
85 90 95
Leu Leu Leu Leu His Lys Lys Glu Asp Gly Ile Trp Ser Thr Asp Ile
100 105 110
Leu Lys Asp Gln Lys Glu Pro Lys Asn Lys Thr Phe Leu Arg Cys Glu
115 120 125
Ala Lys Asn Tyr Ser Gly Arg Phe Thr Cys Trp Trp Leu Thr Thr Ile
130 135 140
Ser Thr Asp Leu Thr Phe Ser Val Lys Ser Ser Arg Gly Ser Ser Asp
145 150 155 160
Pro Gln Gly Val Thr Cys Gly Ala Ala Thr Leu Ser Ala Glu Arg Val
165 170 175
Arg Gly Asp Asn Lys Glu Tyr Glu Tyr Ser Val Glu Cys Gln Glu Asp
180 185 190
Ser Ala Cys Pro Ala Ala Glu Glu Ser Leu Pro Ile Glu Val Met Val
195 200 205
Asp Ala Val His Lys Leu Lys Tyr Glu Asn Tyr Thr Ser Ser Phe Phe
210 215 220
Ile Arg Asp Ile Ile Lys Pro Asp Pro Pro Lys Asn Leu Gln Leu Lys
225 230 235 240
Pro Leu Lys Asn Ser Arg Gln Val Glu Val Ser Trp Glu Tyr Pro Asp
245 250 255
Thr Trp Ser Thr Pro His Ser Tyr Phe Ser Leu Thr Phe Cys Val Gln
260 265 270
Val Gln Gly Lys Ser Lys Arg Glu Lys Lys Asp Arg Val Phe Thr Asp
275 280 285
Lys Thr Ser Ala Thr Val Ile Cys Arg Lys Asn Ala Ser Ile Ser Val
290 295 300
Arg Ala Gln Asp Arg Tyr Tyr Ser Ser Ser Trp Ser Glu Trp Ala Ser
305 310 315 320
Val Pro Cys Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
325 330 335
Gly Gly Ser Arg Asn Leu Pro Val Ala Thr Pro Asp Pro Gly Met Phe
340 345 350
Pro Cys Leu His His Ser Gln Asn Leu Leu Arg Ala Val Ser Asn Met
355 360 365
Leu Gln Lys Ala Arg Gln Thr Leu Glu Phe Tyr Pro Cys Thr Ser Glu
370 375 380
Glu Ile Asp His Glu Asp Ile Thr Lys Asp Lys Thr Ser Thr Val Glu
385 390 395 400
Ala Cys Leu Pro Leu Glu Leu Thr Lys Asn Glu Ser Cys Leu Asn Ser
405 410 415
Arg Glu Thr Ser Phe Ile Thr Asn Gly Ser Cys Leu Ala Ser Arg Lys
420 425 430
Thr Ser Phe Met Met Ala Leu Cys Leu Ser Ser Ile Tyr Glu Asp Leu
435 440 445
Lys Met Tyr Gln Val Glu Phe Lys Thr Met Asn Ala Lys Leu Leu Met
450 455 460
Asp Pro Lys Arg Gln Ile Phe Leu Asp Gln Asn Met Leu Ala Val Ile
465 470 475 480
Asp Glu Leu Met Gln Ala Leu Asn Phe Asn Ser Glu Thr Val Pro Gln
485 490 495
Lys Ser Ser Leu Glu Glu Pro Asp Phe Tyr Lys Thr Lys Ile Lys Leu
500 505 510
Cys Ile Leu Leu His Ala Phe Arg Ile Arg Ala Val Thr Ile Asp Arg
515 520 525
Val Met Ser Tyr Leu Asn Ala Ser Ile Thr Cys Pro Pro Pro Met Ser
530 535 540
Val Glu His Ala Asp Ile Trp Val Lys Ser Tyr Ser Leu Tyr Ser Arg
545 550 555 560
Glu Arg Tyr Ile Cys Asn Ser Gly Phe Lys Arg Lys Ala Gly Thr Ser
565 570 575
Ser Leu Thr Glu Cys Val Leu Asn Lys Ala Thr Asn Val Ala His Trp
580 585 590
Thr Thr Pro Ser Leu Lys Cys Ile Arg Ser Glu Leu Thr Gln Asp Pro
595 600 605
Ala Val Ser Val Ala Leu Gly Gln Thr Val Arg Ile Thr Cys Gln Gly
610 615 620
Asp Ser Leu Arg Ser Tyr Tyr Ala Ser Trp Tyr Gln Gln Lys Pro Gly
625 630 635 640
Gln Ala Pro Val Leu Val Ile Tyr Gly Lys Asn Asn Arg Pro Ser Gly
645 650 655
Ile Pro Asp Arg Phe Ser Gly Ser Ser Ser Gly Asn Thr Ala Ser Leu
660 665 670
Thr Ile Thr Gly Ala Gln Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Asn
675 680 685
Ser Arg Asp Ser Ser Gly Asn His Val Val Phe Gly Gly Gly Thr Lys
690 695 700
Leu Thr Val Gly His Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
705 710 715 720
Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val
725 730 735
Arg Pro Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr
740 745 750
Phe Asp Asp Tyr Gly Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly
755 760 765
Leu Glu Trp Val Ser Gly Ile Asn Trp Asn Gly Gly Ser Thr Gly Tyr
770 775 780
Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys
785 790 795 800
Asn Ser Leu Tyr Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala
805 810 815
Val Tyr Tyr Cys Ala Arg Gly Arg Ser Leu Leu Phe Asp Tyr Trp Gly
820 825 830
Gln Gly Thr Leu Val Thr Val Ser Arg
835 840
<210> 123
<211> 2523
<212> DNA
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成18t15-12s16序列”
<400> 123
atgaaatggg tgacctttat ttctttactg ttcctcttta gcagcgccta ctccatttgg 60
gaactgaaga aggacgtcta cgtggtcgaa ctggactggt atcccgatgc tcccggcgaa 120
atggtggtgc tcacttgtga cacccccgaa gaagacggca tcacttggac cctcgatcag 180
agcagcgagg tgctgggctc cggaaagacc ctcacaatcc aagttaagga gttcggagac 240
gctggccaat acacatgcca caagggaggc gaggtgctca gccattcctt attattatta 300
cacaagaagg aagacggaat ctggtccacc gacattttaa aagatcagaa ggagcccaag 360
aataagacct ttttaaggtg tgaggccaaa aactacagcg gtcgtttcac ttgttggtgg 420
ctgaccacca tttccaccga tttaaccttc tccgtgaaaa gcagccgggg aagctccgac 480
cctcaaggtg tgacatgtgg agccgctacc ctcagcgctg agagggttcg tggcgataac 540
aaggaatacg agtacagcgt ggagtgccaa gaagatagcg cttgtcccgc tgccgaagaa 600
tctttaccca ttgaggtgat ggtggacgcc gtgcacaaac tcaagtacga gaactacacc 660
tcctccttct ttatccggga catcattaag cccgatcctc ctaagaattt acagctgaag 720
cctctcaaaa atagccggca agttgaggtc tcttgggaat atcccgacac ttggagcaca 780
ccccacagct acttctcttt aaccttttgt gtgcaagttc aaggtaaaag caagcgggag 840
aagaaagacc gggtgtttac cgacaaaacc agcgccaccg tcatctgtcg gaagaacgcc 900
tccatcagcg tgagggctca agatcgttat tactccagca gctggtccga gtgggccagc 960
gtgccttgtt ccggcggtgg aggatccgga ggaggtggct ccggcggcgg aggatctcgt 1020
aacctccccg tggctacccc cgatcccgga atgttccctt gtttacacca cagccagaat 1080
ttactgaggg ccgtgagcaa catgctgcag aaagctaggc agactttaga attttaccct 1140
tgcaccagcg aggagatcga ccatgaagat atcaccaagg acaagacatc caccgtggag 1200
gcttgtttac ctctggagct gacaaagaac gagtcttgtc tcaactctcg tgaaaccagc 1260
ttcatcacaa atggctcttg tttagcttcc cggaagacct cctttatgat ggctttatgc 1320
ctcagctcca tctacgagga tttaaagatg taccaagtgg agttcaagac catgaacgcc 1380
aagctgctca tggaccctaa acggcagatc tttttagacc agaacatgct ggctgtgatt 1440
gatgagctga tgcaagcttt aaacttcaac tccgagaccg tccctcagaa gtcctccctc 1500
gaggagcccg atttttacaa gacaaagatc aaactgtgca ttttactcca cgcctttagg 1560
atccgggccg tgaccattga ccgggtcatg agctatttaa acgccagcat tacatgcccc 1620
cctcccatga gcgtggagca cgccgacatc tgggtgaaga gctatagcct ctacagccgg 1680
gagaggtata tctgtaacag cggcttcaag aggaaggccg gcaccagcag cctcaccgag 1740
tgcgtgctga ataaggctac caacgtggct cactggacaa caccctcttt aaagtgcatc 1800
cggtccgagc tgacccagga ccctgctgtg tccgtggctc tgggccagac cgtgaggatc 1860
acctgccagg gcgactccct gaggtcctac tacgcctcct ggtaccagca gaagcccggc 1920
caggctcctg tgctggtgat ctacggcaag aacaacaggc cctccggcat ccctgacagg 1980
ttctccggat cctcctccgg caacaccgcc tccctgacca tcacaggcgc tcaggccgag 2040
gacgaggctg actactactg caactccagg gactcctccg gcaaccatgt ggtgttcggc 2100
ggcggcacca agctgaccgt gggccatggc ggcggcggct ccggaggcgg cggcagcggc 2160
ggaggaggat ccgaggtgca gctggtggag tccggaggag gagtggtgag gcctggaggc 2220
tccctgaggc tgagctgtgc tgcctccggc ttcaccttcg acgactacgg catgtcctgg 2280
gtgaggcagg ctcctggaaa gggcctggag tgggtgtccg gcatcaactg gaacggcgga 2340
tccaccggct acgccgattc cgtgaagggc aggttcacca tcagcaggga caacgccaag 2400
aactccctgt acctgcagat gaactccctg agggccgagg acaccgccgt gtactactgc 2460
gccaggggca ggtccctgct gttcgactac tggggacagg gcaccctggt gaccgtgtcc 2520
agg 2523
<210> 124
<211> 456
<212> DNA
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成IL-7序列”
<400> 124
gattgcgaca tcgagggcaa ggacggcaag cagtacgaga gcgtgctgat ggtgtccatc 60
gaccagctgc tggacagcat gaaggagatc ggctccaact gcctcaacaa cgagttcaac 120
ttcttcaagc ggcacatctg cgacgccaac aaggagggca tgttcctgtt cagggccgcc 180
aggaaactgc ggcagttcct gaagatgaac tccaccggcg acttcgacct gcacctgctg 240
aaggtgtccg agggcaccac catcctgctg aactgcaccg gacaggtgaa gggccggaaa 300
cctgctgctc tgggagaggc ccaacccacc aagagcctgg aggagaacaa gtccctgaag 360
gagcagaaga agctgaacga cctgtgcttc ctgaagaggc tgctgcagga gatcaagacc 420
tgctggaaca agatcctgat gggcaccaag gagcat 456
<210> 125
<211> 485
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成7t15-16s21序列”
<400> 125
Asp Cys Asp Ile Glu Gly Lys Asp Gly Lys Gln Tyr Glu Ser Val Leu
1 5 10 15
Met Val Ser Ile Asp Gln Leu Leu Asp Ser Met Lys Glu Ile Gly Ser
20 25 30
Asn Cys Leu Asn Asn Glu Phe Asn Phe Phe Lys Arg His Ile Cys Asp
35 40 45
Ala Asn Lys Glu Gly Met Phe Leu Phe Arg Ala Ala Arg Lys Leu Arg
50 55 60
Gln Phe Leu Lys Met Asn Ser Thr Gly Asp Phe Asp Leu His Leu Leu
65 70 75 80
Lys Val Ser Glu Gly Thr Thr Ile Leu Leu Asn Cys Thr Gly Gln Val
85 90 95
Lys Gly Arg Lys Pro Ala Ala Leu Gly Glu Ala Gln Pro Thr Lys Ser
100 105 110
Leu Glu Glu Asn Lys Ser Leu Lys Glu Gln Lys Lys Leu Asn Asp Leu
115 120 125
Cys Phe Leu Lys Arg Leu Leu Gln Glu Ile Lys Thr Cys Trp Asn Lys
130 135 140
Ile Leu Met Gly Thr Lys Glu His Ser Gly Thr Thr Asn Thr Val Ala
145 150 155 160
Ala Tyr Asn Leu Thr Trp Lys Ser Thr Asn Phe Lys Thr Ile Leu Glu
165 170 175
Trp Glu Pro Lys Pro Val Asn Gln Val Tyr Thr Val Gln Ile Ser Thr
180 185 190
Lys Ser Gly Asp Trp Lys Ser Lys Cys Phe Tyr Thr Thr Asp Thr Glu
195 200 205
Cys Asp Leu Thr Asp Glu Ile Val Lys Asp Val Lys Gln Thr Tyr Leu
210 215 220
Ala Arg Val Phe Ser Tyr Pro Ala Gly Asn Val Glu Ser Thr Gly Ser
225 230 235 240
Ala Gly Glu Pro Leu Tyr Glu Asn Ser Pro Glu Phe Thr Pro Tyr Leu
245 250 255
Glu Thr Asn Leu Gly Gln Pro Thr Ile Gln Ser Phe Glu Gln Val Gly
260 265 270
Thr Lys Val Asn Val Thr Val Glu Asp Glu Arg Thr Leu Val Arg Arg
275 280 285
Asn Asn Thr Phe Leu Ser Leu Arg Asp Val Phe Gly Lys Asp Leu Ile
290 295 300
Tyr Thr Leu Tyr Tyr Trp Lys Ser Ser Ser Ser Gly Lys Lys Thr Ala
305 310 315 320
Lys Thr Asn Thr Asn Glu Phe Leu Ile Asp Val Asp Lys Gly Glu Asn
325 330 335
Tyr Cys Phe Ser Val Gln Ala Val Ile Pro Ser Arg Thr Val Asn Arg
340 345 350
Lys Ser Thr Asp Ser Pro Val Glu Cys Met Gly Gln Glu Lys Gly Glu
355 360 365
Phe Arg Glu Asn Trp Val Asn Val Ile Ser Asp Leu Lys Lys Ile Glu
370 375 380
Asp Leu Ile Gln Ser Met His Ile Asp Ala Thr Leu Tyr Thr Glu Ser
385 390 395 400
Asp Val His Pro Ser Cys Lys Val Thr Ala Met Lys Cys Phe Leu Leu
405 410 415
Glu Leu Gln Val Ile Ser Leu Glu Ser Gly Asp Ala Ser Ile His Asp
420 425 430
Thr Val Glu Asn Leu Ile Ile Leu Ala Asn Asn Ser Leu Ser Ser Asn
435 440 445
Gly Asn Val Thr Glu Ser Gly Cys Lys Glu Cys Glu Glu Leu Glu Glu
450 455 460
Lys Asn Ile Lys Glu Phe Leu Gln Ser Phe Val His Ile Val Gln Met
465 470 475 480
Phe Ile Asn Thr Ser
485
<210> 126
<211> 1455
<212> DNA
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成7t15-16s21序列”
<400> 126
gattgcgaca tcgagggcaa ggacggcaag cagtacgaga gcgtgctgat ggtgtccatc 60
gaccagctgc tggacagcat gaaggagatc ggctccaact gcctcaacaa cgagttcaac 120
ttcttcaagc ggcacatctg cgacgccaac aaggagggca tgttcctgtt cagggccgcc 180
aggaaactgc ggcagttcct gaagatgaac tccaccggcg acttcgacct gcacctgctg 240
aaggtgtccg agggcaccac catcctgctg aactgcaccg gacaggtgaa gggccggaaa 300
cctgctgctc tgggagaggc ccaacccacc aagagcctgg aggagaacaa gtccctgaag 360
gagcagaaga agctgaacga cctgtgcttc ctgaagaggc tgctgcagga gatcaagacc 420
tgctggaaca agatcctgat gggcaccaag gagcatagcg gcacaaccaa cacagtcgct 480
gcctataacc tcacttggaa gagcaccaac ttcaaaacca tcctcgaatg ggaacccaaa 540
cccgttaacc aagtttacac cgtgcagatc agcaccaagt ccggcgactg gaagtccaaa 600
tgtttctata ccaccgacac cgagtgcgat ctcaccgatg agatcgtgaa agatgtgaaa 660
cagacctacc tcgcccgggt gtttagctac cccgccggca atgtggagag cactggttcc 720
gctggcgagc ctttatacga gaacagcccc gaatttaccc cttacctcga gaccaattta 780
ggacagccca ccatccaaag ctttgagcaa gttggcacaa aggtgaatgt gacagtggag 840
gacgagcgga ctttagtgcg gcggaacaac acctttctca gcctccggga tgtgttcggc 900
aaagatttaa tctacacact gtattactgg aagtcctctt cctccggcaa gaagacagct 960
aaaaccaaca caaacgagtt tttaatcgac gtggataaag gcgaaaacta ctgtttcagc 1020
gtgcaagctg tgatcccctc ccggaccgtg aataggaaaa gcaccgatag ccccgttgag 1080
tgcatgggcc aagaaaaggg cgagttccgg gagaactggg tgaacgtcat cagcgattta 1140
aagaagatcg aagatttaat tcagtccatg catatcgacg ccactttata cacagaatcc 1200
gacgtgcacc cctcttgtaa ggtgaccgcc atgaaatgtt ttttactgga gctgcaagtt 1260
atctctttag agagcggaga cgctagcatc cacgacaccg tggagaattt aatcatttta 1320
gccaataact ctttatccag caacggcaac gtgacagagt ccggctgcaa ggagtgcgaa 1380
gagctggagg agaagaacat caaggagttt ctgcaatcct ttgtgcacat tgtccagatg 1440
ttcatcaata cctcc 1455
<210> 127
<211> 503
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成7t15-16s21序列”
<400> 127
Met Lys Trp Val Thr Phe Ile Ser Leu Leu Phe Leu Phe Ser Ser Ala
1 5 10 15
Tyr Ser Asp Cys Asp Ile Glu Gly Lys Asp Gly Lys Gln Tyr Glu Ser
20 25 30
Val Leu Met Val Ser Ile Asp Gln Leu Leu Asp Ser Met Lys Glu Ile
35 40 45
Gly Ser Asn Cys Leu Asn Asn Glu Phe Asn Phe Phe Lys Arg His Ile
50 55 60
Cys Asp Ala Asn Lys Glu Gly Met Phe Leu Phe Arg Ala Ala Arg Lys
65 70 75 80
Leu Arg Gln Phe Leu Lys Met Asn Ser Thr Gly Asp Phe Asp Leu His
85 90 95
Leu Leu Lys Val Ser Glu Gly Thr Thr Ile Leu Leu Asn Cys Thr Gly
100 105 110
Gln Val Lys Gly Arg Lys Pro Ala Ala Leu Gly Glu Ala Gln Pro Thr
115 120 125
Lys Ser Leu Glu Glu Asn Lys Ser Leu Lys Glu Gln Lys Lys Leu Asn
130 135 140
Asp Leu Cys Phe Leu Lys Arg Leu Leu Gln Glu Ile Lys Thr Cys Trp
145 150 155 160
Asn Lys Ile Leu Met Gly Thr Lys Glu His Ser Gly Thr Thr Asn Thr
165 170 175
Val Ala Ala Tyr Asn Leu Thr Trp Lys Ser Thr Asn Phe Lys Thr Ile
180 185 190
Leu Glu Trp Glu Pro Lys Pro Val Asn Gln Val Tyr Thr Val Gln Ile
195 200 205
Ser Thr Lys Ser Gly Asp Trp Lys Ser Lys Cys Phe Tyr Thr Thr Asp
210 215 220
Thr Glu Cys Asp Leu Thr Asp Glu Ile Val Lys Asp Val Lys Gln Thr
225 230 235 240
Tyr Leu Ala Arg Val Phe Ser Tyr Pro Ala Gly Asn Val Glu Ser Thr
245 250 255
Gly Ser Ala Gly Glu Pro Leu Tyr Glu Asn Ser Pro Glu Phe Thr Pro
260 265 270
Tyr Leu Glu Thr Asn Leu Gly Gln Pro Thr Ile Gln Ser Phe Glu Gln
275 280 285
Val Gly Thr Lys Val Asn Val Thr Val Glu Asp Glu Arg Thr Leu Val
290 295 300
Arg Arg Asn Asn Thr Phe Leu Ser Leu Arg Asp Val Phe Gly Lys Asp
305 310 315 320
Leu Ile Tyr Thr Leu Tyr Tyr Trp Lys Ser Ser Ser Ser Gly Lys Lys
325 330 335
Thr Ala Lys Thr Asn Thr Asn Glu Phe Leu Ile Asp Val Asp Lys Gly
340 345 350
Glu Asn Tyr Cys Phe Ser Val Gln Ala Val Ile Pro Ser Arg Thr Val
355 360 365
Asn Arg Lys Ser Thr Asp Ser Pro Val Glu Cys Met Gly Gln Glu Lys
370 375 380
Gly Glu Phe Arg Glu Asn Trp Val Asn Val Ile Ser Asp Leu Lys Lys
385 390 395 400
Ile Glu Asp Leu Ile Gln Ser Met His Ile Asp Ala Thr Leu Tyr Thr
405 410 415
Glu Ser Asp Val His Pro Ser Cys Lys Val Thr Ala Met Lys Cys Phe
420 425 430
Leu Leu Glu Leu Gln Val Ile Ser Leu Glu Ser Gly Asp Ala Ser Ile
435 440 445
His Asp Thr Val Glu Asn Leu Ile Ile Leu Ala Asn Asn Ser Leu Ser
450 455 460
Ser Asn Gly Asn Val Thr Glu Ser Gly Cys Lys Glu Cys Glu Glu Leu
465 470 475 480
Glu Glu Lys Asn Ile Lys Glu Phe Leu Gln Ser Phe Val His Ile Val
485 490 495
Gln Met Phe Ile Asn Thr Ser
500
<210> 128
<211> 1509
<212> DNA
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成7t15-16s21序列”
<400> 128
atgaagtggg tgaccttcat cagcctgctg ttcctgttct ccagcgccta ctccgattgc 60
gacatcgagg gcaaggacgg caagcagtac gagagcgtgc tgatggtgtc catcgaccag 120
ctgctggaca gcatgaagga gatcggctcc aactgcctca acaacgagtt caacttcttc 180
aagcggcaca tctgcgacgc caacaaggag ggcatgttcc tgttcagggc cgccaggaaa 240
ctgcggcagt tcctgaagat gaactccacc ggcgacttcg acctgcacct gctgaaggtg 300
tccgagggca ccaccatcct gctgaactgc accggacagg tgaagggccg gaaacctgct 360
gctctgggag aggcccaacc caccaagagc ctggaggaga acaagtccct gaaggagcag 420
aagaagctga acgacctgtg cttcctgaag aggctgctgc aggagatcaa gacctgctgg 480
aacaagatcc tgatgggcac caaggagcat agcggcacaa ccaacacagt cgctgcctat 540
aacctcactt ggaagagcac caacttcaaa accatcctcg aatgggaacc caaacccgtt 600
aaccaagttt acaccgtgca gatcagcacc aagtccggcg actggaagtc caaatgtttc 660
tataccaccg acaccgagtg cgatctcacc gatgagatcg tgaaagatgt gaaacagacc 720
tacctcgccc gggtgtttag ctaccccgcc ggcaatgtgg agagcactgg ttccgctggc 780
gagcctttat acgagaacag ccccgaattt accccttacc tcgagaccaa tttaggacag 840
cccaccatcc aaagctttga gcaagttggc acaaaggtga atgtgacagt ggaggacgag 900
cggactttag tgcggcggaa caacaccttt ctcagcctcc gggatgtgtt cggcaaagat 960
ttaatctaca cactgtatta ctggaagtcc tcttcctccg gcaagaagac agctaaaacc 1020
aacacaaacg agtttttaat cgacgtggat aaaggcgaaa actactgttt cagcgtgcaa 1080
gctgtgatcc cctcccggac cgtgaatagg aaaagcaccg atagccccgt tgagtgcatg 1140
ggccaagaaa agggcgagtt ccgggagaac tgggtgaacg tcatcagcga tttaaagaag 1200
atcgaagatt taattcagtc catgcatatc gacgccactt tatacacaga atccgacgtg 1260
cacccctctt gtaaggtgac cgccatgaaa tgttttttac tggagctgca agttatctct 1320
ttagagagcg gagacgctag catccacgac accgtggaga atttaatcat tttagccaat 1380
aactctttat ccagcaacgg caacgtgaca gagtccggct gcaaggagtg cgaagagctg 1440
gaggagaaga acatcaagga gtttctgcaa tcctttgtgc acattgtcca gatgttcatc 1500
aatacctcc 1509
<210> 129
<211> 438
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成7t15-16s21序列”
<400> 129
Ser Glu Leu Thr Gln Asp Pro Ala Val Ser Val Ala Leu Gly Gln Thr
1 5 10 15
Val Arg Ile Thr Cys Gln Gly Asp Ser Leu Arg Ser Tyr Tyr Ala Ser
20 25 30
Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Val Leu Val Ile Tyr Gly
35 40 45
Lys Asn Asn Arg Pro Ser Gly Ile Pro Asp Arg Phe Ser Gly Ser Ser
50 55 60
Ser Gly Asn Thr Ala Ser Leu Thr Ile Thr Gly Ala Gln Ala Glu Asp
65 70 75 80
Glu Ala Asp Tyr Tyr Cys Asn Ser Arg Asp Ser Ser Gly Asn His Val
85 90 95
Val Phe Gly Gly Gly Thr Lys Leu Thr Val Gly His Gly Gly Gly Gly
100 105 110
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val
115 120 125
Glu Ser Gly Gly Gly Val Val Arg Pro Gly Gly Ser Leu Arg Leu Ser
130 135 140
Cys Ala Ala Ser Gly Phe Thr Phe Asp Asp Tyr Gly Met Ser Trp Val
145 150 155 160
Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val Ser Gly Ile Asn Trp
165 170 175
Asn Gly Gly Ser Thr Gly Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr
180 185 190
Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr Leu Gln Met Asn Ser
195 200 205
Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala Arg Gly Arg Ser
210 215 220
Leu Leu Phe Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser Arg
225 230 235 240
Ile Thr Cys Pro Pro Pro Met Ser Val Glu His Ala Asp Ile Trp Val
245 250 255
Lys Ser Tyr Ser Leu Tyr Ser Arg Glu Arg Tyr Ile Cys Asn Ser Gly
260 265 270
Phe Lys Arg Lys Ala Gly Thr Ser Ser Leu Thr Glu Cys Val Leu Asn
275 280 285
Lys Ala Thr Asn Val Ala His Trp Thr Thr Pro Ser Leu Lys Cys Ile
290 295 300
Arg Gln Gly Gln Asp Arg His Met Ile Arg Met Arg Gln Leu Ile Asp
305 310 315 320
Ile Val Asp Gln Leu Lys Asn Tyr Val Asn Asp Leu Val Pro Glu Phe
325 330 335
Leu Pro Ala Pro Glu Asp Val Glu Thr Asn Cys Glu Trp Ser Ala Phe
340 345 350
Ser Cys Phe Gln Lys Ala Gln Leu Lys Ser Ala Asn Thr Gly Asn Asn
355 360 365
Glu Arg Ile Ile Asn Val Ser Ile Lys Lys Leu Lys Arg Lys Pro Pro
370 375 380
Ser Thr Asn Ala Gly Arg Arg Gln Lys His Arg Leu Thr Cys Pro Ser
385 390 395 400
Cys Asp Ser Tyr Glu Lys Lys Pro Pro Lys Glu Phe Leu Glu Arg Phe
405 410 415
Lys Ser Leu Leu Gln Lys Met Ile His Gln His Leu Ser Ser Arg Thr
420 425 430
His Gly Ser Glu Asp Ser
435
<210> 130
<211> 1314
<212> DNA
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成7t15-16s21序列”
<400> 130
tccgagctga cccaggaccc tgctgtgtcc gtggctctgg gccagaccgt gaggatcacc 60
tgccagggcg actccctgag gtcctactac gcctcctggt accagcagaa gcccggccag 120
gctcctgtgc tggtgatcta cggcaagaac aacaggccct ccggcatccc tgacaggttc 180
tccggatcct cctccggcaa caccgcctcc ctgaccatca caggcgctca ggccgaggac 240
gaggctgact actactgcaa ctccagggac tcctccggca accatgtggt gttcggcggc 300
ggcaccaagc tgaccgtggg ccatggcggc ggcggctccg gaggcggcgg cagcggcgga 360
ggaggatccg aggtgcagct ggtggagtcc ggaggaggag tggtgaggcc tggaggctcc 420
ctgaggctga gctgtgctgc ctccggcttc accttcgacg actacggcat gtcctgggtg 480
aggcaggctc ctggaaaggg cctggagtgg gtgtccggca tcaactggaa cggcggatcc 540
accggctacg ccgattccgt gaagggcagg ttcaccatca gcagggacaa cgccaagaac 600
tccctgtacc tgcagatgaa ctccctgagg gccgaggaca ccgccgtgta ctactgcgcc 660
aggggcaggt ccctgctgtt cgactactgg ggacagggca ccctggtgac cgtgtccagg 720
attacatgcc cccctcccat gagcgtggag cacgccgaca tctgggtgaa gagctatagc 780
ctctacagcc gggagaggta tatctgtaac agcggcttca agaggaaggc cggcaccagc 840
agcctcaccg agtgcgtgct gaataaggct accaacgtgg ctcactggac aacaccctct 900
ttaaagtgca tccggcaggg ccaggacagg cacatgatcc ggatgaggca gctcatcgac 960
atcgtcgacc agctgaagaa ctacgtgaac gacctggtgc ccgagtttct gcctgccccc 1020
gaggacgtgg agaccaactg cgagtggtcc gccttctcct gctttcagaa ggcccagctg 1080
aagtccgcca acaccggcaa caacgagcgg atcatcaacg tgagcatcaa gaagctgaag 1140
cggaagcctc cctccacaaa cgccggcagg aggcagaagc acaggctgac ctgccccagc 1200
tgtgactcct acgagaagaa gccccccaag gagttcctgg agaggttcaa gtccctgctg 1260
cagaagatga tccatcagca cctgtcctcc aggacccacg gctccgagga ctcc 1314
<210> 131
<211> 456
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成7t15-16s21序列”
<400> 131
Met Lys Trp Val Thr Phe Ile Ser Leu Leu Phe Leu Phe Ser Ser Ala
1 5 10 15
Tyr Ser Ser Glu Leu Thr Gln Asp Pro Ala Val Ser Val Ala Leu Gly
20 25 30
Gln Thr Val Arg Ile Thr Cys Gln Gly Asp Ser Leu Arg Ser Tyr Tyr
35 40 45
Ala Ser Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Val Leu Val Ile
50 55 60
Tyr Gly Lys Asn Asn Arg Pro Ser Gly Ile Pro Asp Arg Phe Ser Gly
65 70 75 80
Ser Ser Ser Gly Asn Thr Ala Ser Leu Thr Ile Thr Gly Ala Gln Ala
85 90 95
Glu Asp Glu Ala Asp Tyr Tyr Cys Asn Ser Arg Asp Ser Ser Gly Asn
100 105 110
His Val Val Phe Gly Gly Gly Thr Lys Leu Thr Val Gly His Gly Gly
115 120 125
Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln
130 135 140
Leu Val Glu Ser Gly Gly Gly Val Val Arg Pro Gly Gly Ser Leu Arg
145 150 155 160
Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Asp Asp Tyr Gly Met Ser
165 170 175
Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val Ser Gly Ile
180 185 190
Asn Trp Asn Gly Gly Ser Thr Gly Tyr Ala Asp Ser Val Lys Gly Arg
195 200 205
Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr Leu Gln Met
210 215 220
Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala Arg Gly
225 230 235 240
Arg Ser Leu Leu Phe Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val
245 250 255
Ser Arg Ile Thr Cys Pro Pro Pro Met Ser Val Glu His Ala Asp Ile
260 265 270
Trp Val Lys Ser Tyr Ser Leu Tyr Ser Arg Glu Arg Tyr Ile Cys Asn
275 280 285
Ser Gly Phe Lys Arg Lys Ala Gly Thr Ser Ser Leu Thr Glu Cys Val
290 295 300
Leu Asn Lys Ala Thr Asn Val Ala His Trp Thr Thr Pro Ser Leu Lys
305 310 315 320
Cys Ile Arg Gln Gly Gln Asp Arg His Met Ile Arg Met Arg Gln Leu
325 330 335
Ile Asp Ile Val Asp Gln Leu Lys Asn Tyr Val Asn Asp Leu Val Pro
340 345 350
Glu Phe Leu Pro Ala Pro Glu Asp Val Glu Thr Asn Cys Glu Trp Ser
355 360 365
Ala Phe Ser Cys Phe Gln Lys Ala Gln Leu Lys Ser Ala Asn Thr Gly
370 375 380
Asn Asn Glu Arg Ile Ile Asn Val Ser Ile Lys Lys Leu Lys Arg Lys
385 390 395 400
Pro Pro Ser Thr Asn Ala Gly Arg Arg Gln Lys His Arg Leu Thr Cys
405 410 415
Pro Ser Cys Asp Ser Tyr Glu Lys Lys Pro Pro Lys Glu Phe Leu Glu
420 425 430
Arg Phe Lys Ser Leu Leu Gln Lys Met Ile His Gln His Leu Ser Ser
435 440 445
Arg Thr His Gly Ser Glu Asp Ser
450 455
<210> 132
<211> 1368
<212> DNA
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成7t15-16s21序列”
<400> 132
atgaagtggg tgaccttcat cagcctgctg ttcctgttct ccagcgccta ctcctccgag 60
ctgacccagg accctgctgt gtccgtggct ctgggccaga ccgtgaggat cacctgccag 120
ggcgactccc tgaggtccta ctacgcctcc tggtaccagc agaagcccgg ccaggctcct 180
gtgctggtga tctacggcaa gaacaacagg ccctccggca tccctgacag gttctccgga 240
tcctcctccg gcaacaccgc ctccctgacc atcacaggcg ctcaggccga ggacgaggct 300
gactactact gcaactccag ggactcctcc ggcaaccatg tggtgttcgg cggcggcacc 360
aagctgaccg tgggccatgg cggcggcggc tccggaggcg gcggcagcgg cggaggagga 420
tccgaggtgc agctggtgga gtccggagga ggagtggtga ggcctggagg ctccctgagg 480
ctgagctgtg ctgcctccgg cttcaccttc gacgactacg gcatgtcctg ggtgaggcag 540
gctcctggaa agggcctgga gtgggtgtcc ggcatcaact ggaacggcgg atccaccggc 600
tacgccgatt ccgtgaaggg caggttcacc atcagcaggg acaacgccaa gaactccctg 660
tacctgcaga tgaactccct gagggccgag gacaccgccg tgtactactg cgccaggggc 720
aggtccctgc tgttcgacta ctggggacag ggcaccctgg tgaccgtgtc caggattaca 780
tgcccccctc ccatgagcgt ggagcacgcc gacatctggg tgaagagcta tagcctctac 840
agccgggaga ggtatatctg taacagcggc ttcaagagga aggccggcac cagcagcctc 900
accgagtgcg tgctgaataa ggctaccaac gtggctcact ggacaacacc ctctttaaag 960
tgcatccggc agggccagga caggcacatg atccggatga ggcagctcat cgacatcgtc 1020
gaccagctga agaactacgt gaacgacctg gtgcccgagt ttctgcctgc ccccgaggac 1080
gtggagacca actgcgagtg gtccgccttc tcctgctttc agaaggccca gctgaagtcc 1140
gccaacaccg gcaacaacga gcggatcatc aacgtgagca tcaagaagct gaagcggaag 1200
cctccctcca caaacgccgg caggaggcag aagcacaggc tgacctgccc cagctgtgac 1260
tcctacgaga agaagccccc caaggagttc ctggagaggt tcaagtccct gctgcagaag 1320
atgatccatc agcacctgtc ctccaggacc cacggctccg aggactcc 1368
<210> 133
<211> 620
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成TGFRt15-16s21序列”
<400> 133
Ile Pro Pro His Val Gln Lys Ser Val Asn Asn Asp Met Ile Val Thr
1 5 10 15
Asp Asn Asn Gly Ala Val Lys Phe Pro Gln Leu Cys Lys Phe Cys Asp
20 25 30
Val Arg Phe Ser Thr Cys Asp Asn Gln Lys Ser Cys Met Ser Asn Cys
35 40 45
Ser Ile Thr Ser Ile Cys Glu Lys Pro Gln Glu Val Cys Val Ala Val
50 55 60
Trp Arg Lys Asn Asp Glu Asn Ile Thr Leu Glu Thr Val Cys His Asp
65 70 75 80
Pro Lys Leu Pro Tyr His Asp Phe Ile Leu Glu Asp Ala Ala Ser Pro
85 90 95
Lys Cys Ile Met Lys Glu Lys Lys Lys Pro Gly Glu Thr Phe Phe Met
100 105 110
Cys Ser Cys Ser Ser Asp Glu Cys Asn Asp Asn Ile Ile Phe Ser Glu
115 120 125
Glu Tyr Asn Thr Ser Asn Pro Asp Gly Gly Gly Gly Ser Gly Gly Gly
130 135 140
Gly Ser Gly Gly Gly Gly Ser Ile Pro Pro His Val Gln Lys Ser Val
145 150 155 160
Asn Asn Asp Met Ile Val Thr Asp Asn Asn Gly Ala Val Lys Phe Pro
165 170 175
Gln Leu Cys Lys Phe Cys Asp Val Arg Phe Ser Thr Cys Asp Asn Gln
180 185 190
Lys Ser Cys Met Ser Asn Cys Ser Ile Thr Ser Ile Cys Glu Lys Pro
195 200 205
Gln Glu Val Cys Val Ala Val Trp Arg Lys Asn Asp Glu Asn Ile Thr
210 215 220
Leu Glu Thr Val Cys His Asp Pro Lys Leu Pro Tyr His Asp Phe Ile
225 230 235 240
Leu Glu Asp Ala Ala Ser Pro Lys Cys Ile Met Lys Glu Lys Lys Lys
245 250 255
Pro Gly Glu Thr Phe Phe Met Cys Ser Cys Ser Ser Asp Glu Cys Asn
260 265 270
Asp Asn Ile Ile Phe Ser Glu Glu Tyr Asn Thr Ser Asn Pro Asp Ser
275 280 285
Gly Thr Thr Asn Thr Val Ala Ala Tyr Asn Leu Thr Trp Lys Ser Thr
290 295 300
Asn Phe Lys Thr Ile Leu Glu Trp Glu Pro Lys Pro Val Asn Gln Val
305 310 315 320
Tyr Thr Val Gln Ile Ser Thr Lys Ser Gly Asp Trp Lys Ser Lys Cys
325 330 335
Phe Tyr Thr Thr Asp Thr Glu Cys Asp Leu Thr Asp Glu Ile Val Lys
340 345 350
Asp Val Lys Gln Thr Tyr Leu Ala Arg Val Phe Ser Tyr Pro Ala Gly
355 360 365
Asn Val Glu Ser Thr Gly Ser Ala Gly Glu Pro Leu Tyr Glu Asn Ser
370 375 380
Pro Glu Phe Thr Pro Tyr Leu Glu Thr Asn Leu Gly Gln Pro Thr Ile
385 390 395 400
Gln Ser Phe Glu Gln Val Gly Thr Lys Val Asn Val Thr Val Glu Asp
405 410 415
Glu Arg Thr Leu Val Arg Arg Asn Asn Thr Phe Leu Ser Leu Arg Asp
420 425 430
Val Phe Gly Lys Asp Leu Ile Tyr Thr Leu Tyr Tyr Trp Lys Ser Ser
435 440 445
Ser Ser Gly Lys Lys Thr Ala Lys Thr Asn Thr Asn Glu Phe Leu Ile
450 455 460
Asp Val Asp Lys Gly Glu Asn Tyr Cys Phe Ser Val Gln Ala Val Ile
465 470 475 480
Pro Ser Arg Thr Val Asn Arg Lys Ser Thr Asp Ser Pro Val Glu Cys
485 490 495
Met Gly Gln Glu Lys Gly Glu Phe Arg Glu Asn Trp Val Asn Val Ile
500 505 510
Ser Asp Leu Lys Lys Ile Glu Asp Leu Ile Gln Ser Met His Ile Asp
515 520 525
Ala Thr Leu Tyr Thr Glu Ser Asp Val His Pro Ser Cys Lys Val Thr
530 535 540
Ala Met Lys Cys Phe Leu Leu Glu Leu Gln Val Ile Ser Leu Glu Ser
545 550 555 560
Gly Asp Ala Ser Ile His Asp Thr Val Glu Asn Leu Ile Ile Leu Ala
565 570 575
Asn Asn Ser Leu Ser Ser Asn Gly Asn Val Thr Glu Ser Gly Cys Lys
580 585 590
Glu Cys Glu Glu Leu Glu Glu Lys Asn Ile Lys Glu Phe Leu Gln Ser
595 600 605
Phe Val His Ile Val Gln Met Phe Ile Asn Thr Ser
610 615 620
<210> 134
<211> 1860
<212> DNA
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成TGFRt15-16s21序列”
<400> 134
atcccccccc atgtgcaaaa gagcgtgaac aacgatatga tcgtgaccga caacaacggc 60
gccgtgaagt ttccccagct ctgcaagttc tgcgatgtca ggttcagcac ctgcgataat 120
cagaagtcct gcatgtccaa ctgcagcatc acctccatct gcgagaagcc ccaagaagtg 180
tgcgtggccg tgtggcggaa aaatgacgag aacatcaccc tggagaccgt gtgtcacgac 240
cccaagctcc cttatcacga cttcattctg gaggacgctg cctcccccaa atgcatcatg 300
aaggagaaga agaagcccgg agagaccttc tttatgtgtt cctgtagcag cgacgagtgt 360
aacgacaaca tcatcttcag cgaagagtac aacaccagca accctgatgg aggtggcgga 420
tccggaggtg gaggttctgg tggaggtggg agtattcctc cccacgtgca gaagagcgtg 480
aataatgaca tgatcgtgac cgataacaat ggcgccgtga aatttcccca gctgtgcaaa 540
ttctgcgatg tgaggttttc cacctgcgac aaccagaagt cctgtatgag caactgctcc 600
atcacctcca tctgtgagaa gcctcaggag gtgtgcgtgg ctgtctggcg gaagaatgac 660
gagaatatca ccctggaaac cgtctgccac gatcccaagc tgccctacca cgatttcatc 720
ctggaagacg ccgccagccc taagtgcatc atgaaagaga aaaagaagcc tggcgagacc 780
tttttcatgt gctcctgcag cagcgacgaa tgcaacgaca atatcatctt tagcgaggaa 840
tacaatacca gcaaccccga cagcggcaca accaacacag tcgctgccta taacctcact 900
tggaagagca ccaacttcaa aaccatcctc gaatgggaac ccaaacccgt taaccaagtt 960
tacaccgtgc agatcagcac caagtccggc gactggaagt ccaaatgttt ctataccacc 1020
gacaccgagt gcgatctcac cgatgagatc gtgaaagatg tgaaacagac ctacctcgcc 1080
cgggtgttta gctaccccgc cggcaatgtg gagagcactg gttccgctgg cgagccttta 1140
tacgagaaca gccccgaatt taccccttac ctcgagacca atttaggaca gcccaccatc 1200
caaagctttg agcaagttgg cacaaaggtg aatgtgacag tggaggacga gcggacttta 1260
gtgcggcgga acaacacctt tctcagcctc cgggatgtgt tcggcaaaga tttaatctac 1320
acactgtatt actggaagtc ctcttcctcc ggcaagaaga cagctaaaac caacacaaac 1380
gagtttttaa tcgacgtgga taaaggcgaa aactactgtt tcagcgtgca agctgtgatc 1440
ccctcccgga ccgtgaatag gaaaagcacc gatagccccg ttgagtgcat gggccaagaa 1500
aagggcgagt tccgggagaa ctgggtgaac gtcatcagcg atttaaagaa gatcgaagat 1560
ttaattcagt ccatgcatat cgacgccact ttatacacag aatccgacgt gcacccctct 1620
tgtaaggtga ccgccatgaa atgtttttta ctggagctgc aagttatctc tttagagagc 1680
ggagacgcta gcatccacga caccgtggag aatttaatca ttttagccaa taactcttta 1740
tccagcaacg gcaacgtgac agagtccggc tgcaaggagt gcgaagagct ggaggagaag 1800
aacatcaagg agtttctgca atcctttgtg cacattgtcc agatgttcat caatacctcc 1860
<210> 135
<211> 638
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成TGFRt15-16s21序列”
<400> 135
Met Lys Trp Val Thr Phe Ile Ser Leu Leu Phe Leu Phe Ser Ser Ala
1 5 10 15
Tyr Ser Ile Pro Pro His Val Gln Lys Ser Val Asn Asn Asp Met Ile
20 25 30
Val Thr Asp Asn Asn Gly Ala Val Lys Phe Pro Gln Leu Cys Lys Phe
35 40 45
Cys Asp Val Arg Phe Ser Thr Cys Asp Asn Gln Lys Ser Cys Met Ser
50 55 60
Asn Cys Ser Ile Thr Ser Ile Cys Glu Lys Pro Gln Glu Val Cys Val
65 70 75 80
Ala Val Trp Arg Lys Asn Asp Glu Asn Ile Thr Leu Glu Thr Val Cys
85 90 95
His Asp Pro Lys Leu Pro Tyr His Asp Phe Ile Leu Glu Asp Ala Ala
100 105 110
Ser Pro Lys Cys Ile Met Lys Glu Lys Lys Lys Pro Gly Glu Thr Phe
115 120 125
Phe Met Cys Ser Cys Ser Ser Asp Glu Cys Asn Asp Asn Ile Ile Phe
130 135 140
Ser Glu Glu Tyr Asn Thr Ser Asn Pro Asp Gly Gly Gly Gly Ser Gly
145 150 155 160
Gly Gly Gly Ser Gly Gly Gly Gly Ser Ile Pro Pro His Val Gln Lys
165 170 175
Ser Val Asn Asn Asp Met Ile Val Thr Asp Asn Asn Gly Ala Val Lys
180 185 190
Phe Pro Gln Leu Cys Lys Phe Cys Asp Val Arg Phe Ser Thr Cys Asp
195 200 205
Asn Gln Lys Ser Cys Met Ser Asn Cys Ser Ile Thr Ser Ile Cys Glu
210 215 220
Lys Pro Gln Glu Val Cys Val Ala Val Trp Arg Lys Asn Asp Glu Asn
225 230 235 240
Ile Thr Leu Glu Thr Val Cys His Asp Pro Lys Leu Pro Tyr His Asp
245 250 255
Phe Ile Leu Glu Asp Ala Ala Ser Pro Lys Cys Ile Met Lys Glu Lys
260 265 270
Lys Lys Pro Gly Glu Thr Phe Phe Met Cys Ser Cys Ser Ser Asp Glu
275 280 285
Cys Asn Asp Asn Ile Ile Phe Ser Glu Glu Tyr Asn Thr Ser Asn Pro
290 295 300
Asp Ser Gly Thr Thr Asn Thr Val Ala Ala Tyr Asn Leu Thr Trp Lys
305 310 315 320
Ser Thr Asn Phe Lys Thr Ile Leu Glu Trp Glu Pro Lys Pro Val Asn
325 330 335
Gln Val Tyr Thr Val Gln Ile Ser Thr Lys Ser Gly Asp Trp Lys Ser
340 345 350
Lys Cys Phe Tyr Thr Thr Asp Thr Glu Cys Asp Leu Thr Asp Glu Ile
355 360 365
Val Lys Asp Val Lys Gln Thr Tyr Leu Ala Arg Val Phe Ser Tyr Pro
370 375 380
Ala Gly Asn Val Glu Ser Thr Gly Ser Ala Gly Glu Pro Leu Tyr Glu
385 390 395 400
Asn Ser Pro Glu Phe Thr Pro Tyr Leu Glu Thr Asn Leu Gly Gln Pro
405 410 415
Thr Ile Gln Ser Phe Glu Gln Val Gly Thr Lys Val Asn Val Thr Val
420 425 430
Glu Asp Glu Arg Thr Leu Val Arg Arg Asn Asn Thr Phe Leu Ser Leu
435 440 445
Arg Asp Val Phe Gly Lys Asp Leu Ile Tyr Thr Leu Tyr Tyr Trp Lys
450 455 460
Ser Ser Ser Ser Gly Lys Lys Thr Ala Lys Thr Asn Thr Asn Glu Phe
465 470 475 480
Leu Ile Asp Val Asp Lys Gly Glu Asn Tyr Cys Phe Ser Val Gln Ala
485 490 495
Val Ile Pro Ser Arg Thr Val Asn Arg Lys Ser Thr Asp Ser Pro Val
500 505 510
Glu Cys Met Gly Gln Glu Lys Gly Glu Phe Arg Glu Asn Trp Val Asn
515 520 525
Val Ile Ser Asp Leu Lys Lys Ile Glu Asp Leu Ile Gln Ser Met His
530 535 540
Ile Asp Ala Thr Leu Tyr Thr Glu Ser Asp Val His Pro Ser Cys Lys
545 550 555 560
Val Thr Ala Met Lys Cys Phe Leu Leu Glu Leu Gln Val Ile Ser Leu
565 570 575
Glu Ser Gly Asp Ala Ser Ile His Asp Thr Val Glu Asn Leu Ile Ile
580 585 590
Leu Ala Asn Asn Ser Leu Ser Ser Asn Gly Asn Val Thr Glu Ser Gly
595 600 605
Cys Lys Glu Cys Glu Glu Leu Glu Glu Lys Asn Ile Lys Glu Phe Leu
610 615 620
Gln Ser Phe Val His Ile Val Gln Met Phe Ile Asn Thr Ser
625 630 635
<210> 136
<211> 1914
<212> DNA
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成TGFRt15-16s21序列”
<400> 136
atgaagtggg tgaccttcat cagcctgctg ttcctgttct ccagcgccta ctccatcccc 60
ccccatgtgc aaaagagcgt gaacaacgat atgatcgtga ccgacaacaa cggcgccgtg 120
aagtttcccc agctctgcaa gttctgcgat gtcaggttca gcacctgcga taatcagaag 180
tcctgcatgt ccaactgcag catcacctcc atctgcgaga agccccaaga agtgtgcgtg 240
gccgtgtggc ggaaaaatga cgagaacatc accctggaga ccgtgtgtca cgaccccaag 300
ctcccttatc acgacttcat tctggaggac gctgcctccc ccaaatgcat catgaaggag 360
aagaagaagc ccggagagac cttctttatg tgttcctgta gcagcgacga gtgtaacgac 420
aacatcatct tcagcgaaga gtacaacacc agcaaccctg atggaggtgg cggatccgga 480
ggtggaggtt ctggtggagg tgggagtatt cctccccacg tgcagaagag cgtgaataat 540
gacatgatcg tgaccgataa caatggcgcc gtgaaatttc cccagctgtg caaattctgc 600
gatgtgaggt tttccacctg cgacaaccag aagtcctgta tgagcaactg ctccatcacc 660
tccatctgtg agaagcctca ggaggtgtgc gtggctgtct ggcggaagaa tgacgagaat 720
atcaccctgg aaaccgtctg ccacgatccc aagctgccct accacgattt catcctggaa 780
gacgccgcca gccctaagtg catcatgaaa gagaaaaaga agcctggcga gacctttttc 840
atgtgctcct gcagcagcga cgaatgcaac gacaatatca tctttagcga ggaatacaat 900
accagcaacc ccgacagcgg cacaaccaac acagtcgctg cctataacct cacttggaag 960
agcaccaact tcaaaaccat cctcgaatgg gaacccaaac ccgttaacca agtttacacc 1020
gtgcagatca gcaccaagtc cggcgactgg aagtccaaat gtttctatac caccgacacc 1080
gagtgcgatc tcaccgatga gatcgtgaaa gatgtgaaac agacctacct cgcccgggtg 1140
tttagctacc ccgccggcaa tgtggagagc actggttccg ctggcgagcc tttatacgag 1200
aacagccccg aatttacccc ttacctcgag accaatttag gacagcccac catccaaagc 1260
tttgagcaag ttggcacaaa ggtgaatgtg acagtggagg acgagcggac tttagtgcgg 1320
cggaacaaca cctttctcag cctccgggat gtgttcggca aagatttaat ctacacactg 1380
tattactgga agtcctcttc ctccggcaag aagacagcta aaaccaacac aaacgagttt 1440
ttaatcgacg tggataaagg cgaaaactac tgtttcagcg tgcaagctgt gatcccctcc 1500
cggaccgtga ataggaaaag caccgatagc cccgttgagt gcatgggcca agaaaagggc 1560
gagttccggg agaactgggt gaacgtcatc agcgatttaa agaagatcga agatttaatt 1620
cagtccatgc atatcgacgc cactttatac acagaatccg acgtgcaccc ctcttgtaag 1680
gtgaccgcca tgaaatgttt tttactggag ctgcaagtta tctctttaga gagcggagac 1740
gctagcatcc acgacaccgt ggagaattta atcattttag ccaataactc tttatccagc 1800
aacggcaacg tgacagagtc cggctgcaag gagtgcgaag agctggagga gaagaacatc 1860
aaggagtttc tgcaatcctt tgtgcacatt gtccagatgt tcatcaatac ctcc 1914
<210> 137
<211> 438
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成TGFRt15-16s21序列”
<400> 137
Ser Glu Leu Thr Gln Asp Pro Ala Val Ser Val Ala Leu Gly Gln Thr
1 5 10 15
Val Arg Ile Thr Cys Gln Gly Asp Ser Leu Arg Ser Tyr Tyr Ala Ser
20 25 30
Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Val Leu Val Ile Tyr Gly
35 40 45
Lys Asn Asn Arg Pro Ser Gly Ile Pro Asp Arg Phe Ser Gly Ser Ser
50 55 60
Ser Gly Asn Thr Ala Ser Leu Thr Ile Thr Gly Ala Gln Ala Glu Asp
65 70 75 80
Glu Ala Asp Tyr Tyr Cys Asn Ser Arg Asp Ser Ser Gly Asn His Val
85 90 95
Val Phe Gly Gly Gly Thr Lys Leu Thr Val Gly His Gly Gly Gly Gly
100 105 110
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val
115 120 125
Glu Ser Gly Gly Gly Val Val Arg Pro Gly Gly Ser Leu Arg Leu Ser
130 135 140
Cys Ala Ala Ser Gly Phe Thr Phe Asp Asp Tyr Gly Met Ser Trp Val
145 150 155 160
Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val Ser Gly Ile Asn Trp
165 170 175
Asn Gly Gly Ser Thr Gly Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr
180 185 190
Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr Leu Gln Met Asn Ser
195 200 205
Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala Arg Gly Arg Ser
210 215 220
Leu Leu Phe Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser Arg
225 230 235 240
Ile Thr Cys Pro Pro Pro Met Ser Val Glu His Ala Asp Ile Trp Val
245 250 255
Lys Ser Tyr Ser Leu Tyr Ser Arg Glu Arg Tyr Ile Cys Asn Ser Gly
260 265 270
Phe Lys Arg Lys Ala Gly Thr Ser Ser Leu Thr Glu Cys Val Leu Asn
275 280 285
Lys Ala Thr Asn Val Ala His Trp Thr Thr Pro Ser Leu Lys Cys Ile
290 295 300
Arg Gln Gly Gln Asp Arg His Met Ile Arg Met Arg Gln Leu Ile Asp
305 310 315 320
Ile Val Asp Gln Leu Lys Asn Tyr Val Asn Asp Leu Val Pro Glu Phe
325 330 335
Leu Pro Ala Pro Glu Asp Val Glu Thr Asn Cys Glu Trp Ser Ala Phe
340 345 350
Ser Cys Phe Gln Lys Ala Gln Leu Lys Ser Ala Asn Thr Gly Asn Asn
355 360 365
Glu Arg Ile Ile Asn Val Ser Ile Lys Lys Leu Lys Arg Lys Pro Pro
370 375 380
Ser Thr Asn Ala Gly Arg Arg Gln Lys His Arg Leu Thr Cys Pro Ser
385 390 395 400
Cys Asp Ser Tyr Glu Lys Lys Pro Pro Lys Glu Phe Leu Glu Arg Phe
405 410 415
Lys Ser Leu Leu Gln Lys Met Ile His Gln His Leu Ser Ser Arg Thr
420 425 430
His Gly Ser Glu Asp Ser
435
<210> 138
<211> 1314
<212> DNA
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成TGFRt15-16s21序列”
<400> 138
tccgagctga cccaggaccc tgctgtgtcc gtggctctgg gccagaccgt gaggatcacc 60
tgccagggcg actccctgag gtcctactac gcctcctggt accagcagaa gcccggccag 120
gctcctgtgc tggtgatcta cggcaagaac aacaggccct ccggcatccc tgacaggttc 180
tccggatcct cctccggcaa caccgcctcc ctgaccatca caggcgctca ggccgaggac 240
gaggctgact actactgcaa ctccagggac tcctccggca accatgtggt gttcggcggc 300
ggcaccaagc tgaccgtggg ccatggcggc ggcggctccg gaggcggcgg cagcggcgga 360
ggaggatccg aggtgcagct ggtggagtcc ggaggaggag tggtgaggcc tggaggctcc 420
ctgaggctga gctgtgctgc ctccggcttc accttcgacg actacggcat gtcctgggtg 480
aggcaggctc ctggaaaggg cctggagtgg gtgtccggca tcaactggaa cggcggatcc 540
accggctacg ccgattccgt gaagggcagg ttcaccatca gcagggacaa cgccaagaac 600
tccctgtacc tgcagatgaa ctccctgagg gccgaggaca ccgccgtgta ctactgcgcc 660
aggggcaggt ccctgctgtt cgactactgg ggacagggca ccctggtgac cgtgtccagg 720
attacatgcc cccctcccat gagcgtggag cacgccgaca tctgggtgaa gagctatagc 780
ctctacagcc gggagaggta tatctgtaac agcggcttca agaggaaggc cggcaccagc 840
agcctcaccg agtgcgtgct gaataaggct accaacgtgg ctcactggac aacaccctct 900
ttaaagtgca tccggcaggg ccaggacagg cacatgatcc ggatgaggca gctcatcgac 960
atcgtcgacc agctgaagaa ctacgtgaac gacctggtgc ccgagtttct gcctgccccc 1020
gaggacgtgg agaccaactg cgagtggtcc gccttctcct gctttcagaa ggcccagctg 1080
aagtccgcca acaccggcaa caacgagcgg atcatcaacg tgagcatcaa gaagctgaag 1140
cggaagcctc cctccacaaa cgccggcagg aggcagaagc acaggctgac ctgccccagc 1200
tgtgactcct acgagaagaa gccccccaag gagttcctgg agaggttcaa gtccctgctg 1260
cagaagatga tccatcagca cctgtcctcc aggacccacg gctccgagga ctcc 1314
<210> 139
<211> 456
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成TGFRt15-16s21序列”
<400> 139
Met Lys Trp Val Thr Phe Ile Ser Leu Leu Phe Leu Phe Ser Ser Ala
1 5 10 15
Tyr Ser Ser Glu Leu Thr Gln Asp Pro Ala Val Ser Val Ala Leu Gly
20 25 30
Gln Thr Val Arg Ile Thr Cys Gln Gly Asp Ser Leu Arg Ser Tyr Tyr
35 40 45
Ala Ser Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Val Leu Val Ile
50 55 60
Tyr Gly Lys Asn Asn Arg Pro Ser Gly Ile Pro Asp Arg Phe Ser Gly
65 70 75 80
Ser Ser Ser Gly Asn Thr Ala Ser Leu Thr Ile Thr Gly Ala Gln Ala
85 90 95
Glu Asp Glu Ala Asp Tyr Tyr Cys Asn Ser Arg Asp Ser Ser Gly Asn
100 105 110
His Val Val Phe Gly Gly Gly Thr Lys Leu Thr Val Gly His Gly Gly
115 120 125
Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln
130 135 140
Leu Val Glu Ser Gly Gly Gly Val Val Arg Pro Gly Gly Ser Leu Arg
145 150 155 160
Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Asp Asp Tyr Gly Met Ser
165 170 175
Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val Ser Gly Ile
180 185 190
Asn Trp Asn Gly Gly Ser Thr Gly Tyr Ala Asp Ser Val Lys Gly Arg
195 200 205
Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr Leu Gln Met
210 215 220
Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala Arg Gly
225 230 235 240
Arg Ser Leu Leu Phe Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val
245 250 255
Ser Arg Ile Thr Cys Pro Pro Pro Met Ser Val Glu His Ala Asp Ile
260 265 270
Trp Val Lys Ser Tyr Ser Leu Tyr Ser Arg Glu Arg Tyr Ile Cys Asn
275 280 285
Ser Gly Phe Lys Arg Lys Ala Gly Thr Ser Ser Leu Thr Glu Cys Val
290 295 300
Leu Asn Lys Ala Thr Asn Val Ala His Trp Thr Thr Pro Ser Leu Lys
305 310 315 320
Cys Ile Arg Gln Gly Gln Asp Arg His Met Ile Arg Met Arg Gln Leu
325 330 335
Ile Asp Ile Val Asp Gln Leu Lys Asn Tyr Val Asn Asp Leu Val Pro
340 345 350
Glu Phe Leu Pro Ala Pro Glu Asp Val Glu Thr Asn Cys Glu Trp Ser
355 360 365
Ala Phe Ser Cys Phe Gln Lys Ala Gln Leu Lys Ser Ala Asn Thr Gly
370 375 380
Asn Asn Glu Arg Ile Ile Asn Val Ser Ile Lys Lys Leu Lys Arg Lys
385 390 395 400
Pro Pro Ser Thr Asn Ala Gly Arg Arg Gln Lys His Arg Leu Thr Cys
405 410 415
Pro Ser Cys Asp Ser Tyr Glu Lys Lys Pro Pro Lys Glu Phe Leu Glu
420 425 430
Arg Phe Lys Ser Leu Leu Gln Lys Met Ile His Gln His Leu Ser Ser
435 440 445
Arg Thr His Gly Ser Glu Asp Ser
450 455
<210> 140
<211> 1368
<212> DNA
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成TGFRt15-16s21序列”
<400> 140
atgaagtggg tgaccttcat cagcctgctg ttcctgttct ccagcgccta ctcctccgag 60
ctgacccagg accctgctgt gtccgtggct ctgggccaga ccgtgaggat cacctgccag 120
ggcgactccc tgaggtccta ctacgcctcc tggtaccagc agaagcccgg ccaggctcct 180
gtgctggtga tctacggcaa gaacaacagg ccctccggca tccctgacag gttctccgga 240
tcctcctccg gcaacaccgc ctccctgacc atcacaggcg ctcaggccga ggacgaggct 300
gactactact gcaactccag ggactcctcc ggcaaccatg tggtgttcgg cggcggcacc 360
aagctgaccg tgggccatgg cggcggcggc tccggaggcg gcggcagcgg cggaggagga 420
tccgaggtgc agctggtgga gtccggagga ggagtggtga ggcctggagg ctccctgagg 480
ctgagctgtg ctgcctccgg cttcaccttc gacgactacg gcatgtcctg ggtgaggcag 540
gctcctggaa agggcctgga gtgggtgtcc ggcatcaact ggaacggcgg atccaccggc 600
tacgccgatt ccgtgaaggg caggttcacc atcagcaggg acaacgccaa gaactccctg 660
tacctgcaga tgaactccct gagggccgag gacaccgccg tgtactactg cgccaggggc 720
aggtccctgc tgttcgacta ctggggacag ggcaccctgg tgaccgtgtc caggattaca 780
tgcccccctc ccatgagcgt ggagcacgcc gacatctggg tgaagagcta tagcctctac 840
agccgggaga ggtatatctg taacagcggc ttcaagagga aggccggcac cagcagcctc 900
accgagtgcg tgctgaataa ggctaccaac gtggctcact ggacaacacc ctctttaaag 960
tgcatccggc agggccagga caggcacatg atccggatga ggcagctcat cgacatcgtc 1020
gaccagctga agaactacgt gaacgacctg gtgcccgagt ttctgcctgc ccccgaggac 1080
gtggagacca actgcgagtg gtccgccttc tcctgctttc agaaggccca gctgaagtcc 1140
gccaacaccg gcaacaacga gcggatcatc aacgtgagca tcaagaagct gaagcggaag 1200
cctccctcca caaacgccgg caggaggcag aagcacaggc tgacctgccc cagctgtgac 1260
tcctacgaga agaagccccc caaggagttc ctggagaggt tcaagtccct gctgcagaag 1320
atgatccatc agcacctgtc ctccaggacc cacggctccg aggactcc 1368
<210> 141
<211> 485
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成7t15-7s序列”
<400> 141
Asp Cys Asp Ile Glu Gly Lys Asp Gly Lys Gln Tyr Glu Ser Val Leu
1 5 10 15
Met Val Ser Ile Asp Gln Leu Leu Asp Ser Met Lys Glu Ile Gly Ser
20 25 30
Asn Cys Leu Asn Asn Glu Phe Asn Phe Phe Lys Arg His Ile Cys Asp
35 40 45
Ala Asn Lys Glu Gly Met Phe Leu Phe Arg Ala Ala Arg Lys Leu Arg
50 55 60
Gln Phe Leu Lys Met Asn Ser Thr Gly Asp Phe Asp Leu His Leu Leu
65 70 75 80
Lys Val Ser Glu Gly Thr Thr Ile Leu Leu Asn Cys Thr Gly Gln Val
85 90 95
Lys Gly Arg Lys Pro Ala Ala Leu Gly Glu Ala Gln Pro Thr Lys Ser
100 105 110
Leu Glu Glu Asn Lys Ser Leu Lys Glu Gln Lys Lys Leu Asn Asp Leu
115 120 125
Cys Phe Leu Lys Arg Leu Leu Gln Glu Ile Lys Thr Cys Trp Asn Lys
130 135 140
Ile Leu Met Gly Thr Lys Glu His Ser Gly Thr Thr Asn Thr Val Ala
145 150 155 160
Ala Tyr Asn Leu Thr Trp Lys Ser Thr Asn Phe Lys Thr Ile Leu Glu
165 170 175
Trp Glu Pro Lys Pro Val Asn Gln Val Tyr Thr Val Gln Ile Ser Thr
180 185 190
Lys Ser Gly Asp Trp Lys Ser Lys Cys Phe Tyr Thr Thr Asp Thr Glu
195 200 205
Cys Asp Leu Thr Asp Glu Ile Val Lys Asp Val Lys Gln Thr Tyr Leu
210 215 220
Ala Arg Val Phe Ser Tyr Pro Ala Gly Asn Val Glu Ser Thr Gly Ser
225 230 235 240
Ala Gly Glu Pro Leu Tyr Glu Asn Ser Pro Glu Phe Thr Pro Tyr Leu
245 250 255
Glu Thr Asn Leu Gly Gln Pro Thr Ile Gln Ser Phe Glu Gln Val Gly
260 265 270
Thr Lys Val Asn Val Thr Val Glu Asp Glu Arg Thr Leu Val Arg Arg
275 280 285
Asn Asn Thr Phe Leu Ser Leu Arg Asp Val Phe Gly Lys Asp Leu Ile
290 295 300
Tyr Thr Leu Tyr Tyr Trp Lys Ser Ser Ser Ser Gly Lys Lys Thr Ala
305 310 315 320
Lys Thr Asn Thr Asn Glu Phe Leu Ile Asp Val Asp Lys Gly Glu Asn
325 330 335
Tyr Cys Phe Ser Val Gln Ala Val Ile Pro Ser Arg Thr Val Asn Arg
340 345 350
Lys Ser Thr Asp Ser Pro Val Glu Cys Met Gly Gln Glu Lys Gly Glu
355 360 365
Phe Arg Glu Asn Trp Val Asn Val Ile Ser Asp Leu Lys Lys Ile Glu
370 375 380
Asp Leu Ile Gln Ser Met His Ile Asp Ala Thr Leu Tyr Thr Glu Ser
385 390 395 400
Asp Val His Pro Ser Cys Lys Val Thr Ala Met Lys Cys Phe Leu Leu
405 410 415
Glu Leu Gln Val Ile Ser Leu Glu Ser Gly Asp Ala Ser Ile His Asp
420 425 430
Thr Val Glu Asn Leu Ile Ile Leu Ala Asn Asn Ser Leu Ser Ser Asn
435 440 445
Gly Asn Val Thr Glu Ser Gly Cys Lys Glu Cys Glu Glu Leu Glu Glu
450 455 460
Lys Asn Ile Lys Glu Phe Leu Gln Ser Phe Val His Ile Val Gln Met
465 470 475 480
Phe Ile Asn Thr Ser
485
<210> 142
<211> 1455
<212> DNA
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成7t15-7s序列”
<400> 142
gattgcgaca tcgagggcaa ggacggcaag cagtacgaga gcgtgctgat ggtgtccatc 60
gaccagctgc tggacagcat gaaggagatc ggctccaact gcctcaacaa cgagttcaac 120
ttcttcaagc ggcacatctg cgacgccaac aaggagggca tgttcctgtt cagggccgcc 180
aggaaactgc ggcagttcct gaagatgaac tccaccggcg acttcgacct gcacctgctg 240
aaggtgtccg agggcaccac catcctgctg aactgcaccg gacaggtgaa gggccggaaa 300
cctgctgctc tgggagaggc ccaacccacc aagagcctgg aggagaacaa gtccctgaag 360
gagcagaaga agctgaacga cctgtgcttc ctgaagaggc tgctgcagga gatcaagacc 420
tgctggaaca agatcctgat gggcaccaag gagcatagcg gcacaaccaa cacagtcgct 480
gcctataacc tcacttggaa gagcaccaac ttcaaaacca tcctcgaatg ggaacccaaa 540
cccgttaacc aagtttacac cgtgcagatc agcaccaagt ccggcgactg gaagtccaaa 600
tgtttctata ccaccgacac cgagtgcgat ctcaccgatg agatcgtgaa agatgtgaaa 660
cagacctacc tcgcccgggt gtttagctac cccgccggca atgtggagag cactggttcc 720
gctggcgagc ctttatacga gaacagcccc gaatttaccc cttacctcga gaccaattta 780
ggacagccca ccatccaaag ctttgagcaa gttggcacaa aggtgaatgt gacagtggag 840
gacgagcgga ctttagtgcg gcggaacaac acctttctca gcctccggga tgtgttcggc 900
aaagatttaa tctacacact gtattactgg aagtcctctt cctccggcaa gaagacagct 960
aaaaccaaca caaacgagtt tttaatcgac gtggataaag gcgaaaacta ctgtttcagc 1020
gtgcaagctg tgatcccctc ccggaccgtg aataggaaaa gcaccgatag ccccgttgag 1080
tgcatgggcc aagaaaaggg cgagttccgg gagaactggg tgaacgtcat cagcgattta 1140
aagaagatcg aagatttaat tcagtccatg catatcgacg ccactttata cacagaatcc 1200
gacgtgcacc cctcttgtaa ggtgaccgcc atgaaatgtt ttttactgga gctgcaagtt 1260
atctctttag agagcggaga cgctagcatc cacgacaccg tggagaattt aatcatttta 1320
gccaataact ctttatccag caacggcaac gtgacagagt ccggctgcaa ggagtgcgaa 1380
gagctggagg agaagaacat caaggagttt ctgcaatcct ttgtgcacat tgtccagatg 1440
ttcatcaata cctcc 1455
<210> 143
<211> 503
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成7t15-7s序列”
<400> 143
Met Lys Trp Val Thr Phe Ile Ser Leu Leu Phe Leu Phe Ser Ser Ala
1 5 10 15
Tyr Ser Asp Cys Asp Ile Glu Gly Lys Asp Gly Lys Gln Tyr Glu Ser
20 25 30
Val Leu Met Val Ser Ile Asp Gln Leu Leu Asp Ser Met Lys Glu Ile
35 40 45
Gly Ser Asn Cys Leu Asn Asn Glu Phe Asn Phe Phe Lys Arg His Ile
50 55 60
Cys Asp Ala Asn Lys Glu Gly Met Phe Leu Phe Arg Ala Ala Arg Lys
65 70 75 80
Leu Arg Gln Phe Leu Lys Met Asn Ser Thr Gly Asp Phe Asp Leu His
85 90 95
Leu Leu Lys Val Ser Glu Gly Thr Thr Ile Leu Leu Asn Cys Thr Gly
100 105 110
Gln Val Lys Gly Arg Lys Pro Ala Ala Leu Gly Glu Ala Gln Pro Thr
115 120 125
Lys Ser Leu Glu Glu Asn Lys Ser Leu Lys Glu Gln Lys Lys Leu Asn
130 135 140
Asp Leu Cys Phe Leu Lys Arg Leu Leu Gln Glu Ile Lys Thr Cys Trp
145 150 155 160
Asn Lys Ile Leu Met Gly Thr Lys Glu His Ser Gly Thr Thr Asn Thr
165 170 175
Val Ala Ala Tyr Asn Leu Thr Trp Lys Ser Thr Asn Phe Lys Thr Ile
180 185 190
Leu Glu Trp Glu Pro Lys Pro Val Asn Gln Val Tyr Thr Val Gln Ile
195 200 205
Ser Thr Lys Ser Gly Asp Trp Lys Ser Lys Cys Phe Tyr Thr Thr Asp
210 215 220
Thr Glu Cys Asp Leu Thr Asp Glu Ile Val Lys Asp Val Lys Gln Thr
225 230 235 240
Tyr Leu Ala Arg Val Phe Ser Tyr Pro Ala Gly Asn Val Glu Ser Thr
245 250 255
Gly Ser Ala Gly Glu Pro Leu Tyr Glu Asn Ser Pro Glu Phe Thr Pro
260 265 270
Tyr Leu Glu Thr Asn Leu Gly Gln Pro Thr Ile Gln Ser Phe Glu Gln
275 280 285
Val Gly Thr Lys Val Asn Val Thr Val Glu Asp Glu Arg Thr Leu Val
290 295 300
Arg Arg Asn Asn Thr Phe Leu Ser Leu Arg Asp Val Phe Gly Lys Asp
305 310 315 320
Leu Ile Tyr Thr Leu Tyr Tyr Trp Lys Ser Ser Ser Ser Gly Lys Lys
325 330 335
Thr Ala Lys Thr Asn Thr Asn Glu Phe Leu Ile Asp Val Asp Lys Gly
340 345 350
Glu Asn Tyr Cys Phe Ser Val Gln Ala Val Ile Pro Ser Arg Thr Val
355 360 365
Asn Arg Lys Ser Thr Asp Ser Pro Val Glu Cys Met Gly Gln Glu Lys
370 375 380
Gly Glu Phe Arg Glu Asn Trp Val Asn Val Ile Ser Asp Leu Lys Lys
385 390 395 400
Ile Glu Asp Leu Ile Gln Ser Met His Ile Asp Ala Thr Leu Tyr Thr
405 410 415
Glu Ser Asp Val His Pro Ser Cys Lys Val Thr Ala Met Lys Cys Phe
420 425 430
Leu Leu Glu Leu Gln Val Ile Ser Leu Glu Ser Gly Asp Ala Ser Ile
435 440 445
His Asp Thr Val Glu Asn Leu Ile Ile Leu Ala Asn Asn Ser Leu Ser
450 455 460
Ser Asn Gly Asn Val Thr Glu Ser Gly Cys Lys Glu Cys Glu Glu Leu
465 470 475 480
Glu Glu Lys Asn Ile Lys Glu Phe Leu Gln Ser Phe Val His Ile Val
485 490 495
Gln Met Phe Ile Asn Thr Ser
500
<210> 144
<211> 1509
<212> DNA
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成多核苷酸”
<400> 144
atgaagtggg tgaccttcat cagcctgctg ttcctgttct ccagcgccta ctccgattgc 60
gacatcgagg gcaaggacgg caagcagtac gagagcgtgc tgatggtgtc catcgaccag 120
ctgctggaca gcatgaagga gatcggctcc aactgcctca acaacgagtt caacttcttc 180
aagcggcaca tctgcgacgc caacaaggag ggcatgttcc tgttcagggc cgccaggaaa 240
ctgcggcagt tcctgaagat gaactccacc ggcgacttcg acctgcacct gctgaaggtg 300
tccgagggca ccaccatcct gctgaactgc accggacagg tgaagggccg gaaacctgct 360
gctctgggag aggcccaacc caccaagagc ctggaggaga acaagtccct gaaggagcag 420
aagaagctga acgacctgtg cttcctgaag aggctgctgc aggagatcaa gacctgctgg 480
aacaagatcc tgatgggcac caaggagcat agcggcacaa ccaacacagt cgctgcctat 540
aacctcactt ggaagagcac caacttcaaa accatcctcg aatgggaacc caaacccgtt 600
aaccaagttt acaccgtgca gatcagcacc aagtccggcg actggaagtc caaatgtttc 660
tataccaccg acaccgagtg cgatctcacc gatgagatcg tgaaagatgt gaaacagacc 720
tacctcgccc gggtgtttag ctaccccgcc ggcaatgtgg agagcactgg ttccgctggc 780
gagcctttat acgagaacag ccccgaattt accccttacc tcgagaccaa tttaggacag 840
cccaccatcc aaagctttga gcaagttggc acaaaggtga atgtgacagt ggaggacgag 900
cggactttag tgcggcggaa caacaccttt ctcagcctcc gggatgtgtt cggcaaagat 960
ttaatctaca cactgtatta ctggaagtcc tcttcctccg gcaagaagac agctaaaacc 1020
aacacaaacg agtttttaat cgacgtggat aaaggcgaaa actactgttt cagcgtgcaa 1080
gctgtgatcc cctcccggac cgtgaatagg aaaagcaccg atagccccgt tgagtgcatg 1140
ggccaagaaa agggcgagtt ccgggagaac tgggtgaacg tcatcagcga tttaaagaag 1200
atcgaagatt taattcagtc catgcatatc gacgccactt tatacacaga atccgacgtg 1260
cacccctctt gtaaggtgac cgccatgaaa tgttttttac tggagctgca agttatctct 1320
ttagagagcg gagacgctag catccacgac accgtggaga atttaatcat tttagccaat 1380
aactctttat ccagcaacgg caacgtgaca gagtccggct gcaaggagtg cgaagagctg 1440
gaggagaaga acatcaagga gtttctgcaa tcctttgtgc acattgtcca gatgttcatc 1500
aatacctcc 1509
<210> 145
<211> 217
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成7t15-7s序列”
<400> 145
Asp Cys Asp Ile Glu Gly Lys Asp Gly Lys Gln Tyr Glu Ser Val Leu
1 5 10 15
Met Val Ser Ile Asp Gln Leu Leu Asp Ser Met Lys Glu Ile Gly Ser
20 25 30
Asn Cys Leu Asn Asn Glu Phe Asn Phe Phe Lys Arg His Ile Cys Asp
35 40 45
Ala Asn Lys Glu Gly Met Phe Leu Phe Arg Ala Ala Arg Lys Leu Arg
50 55 60
Gln Phe Leu Lys Met Asn Ser Thr Gly Asp Phe Asp Leu His Leu Leu
65 70 75 80
Lys Val Ser Glu Gly Thr Thr Ile Leu Leu Asn Cys Thr Gly Gln Val
85 90 95
Lys Gly Arg Lys Pro Ala Ala Leu Gly Glu Ala Gln Pro Thr Lys Ser
100 105 110
Leu Glu Glu Asn Lys Ser Leu Lys Glu Gln Lys Lys Leu Asn Asp Leu
115 120 125
Cys Phe Leu Lys Arg Leu Leu Gln Glu Ile Lys Thr Cys Trp Asn Lys
130 135 140
Ile Leu Met Gly Thr Lys Glu His Ile Thr Cys Pro Pro Pro Met Ser
145 150 155 160
Val Glu His Ala Asp Ile Trp Val Lys Ser Tyr Ser Leu Tyr Ser Arg
165 170 175
Glu Arg Tyr Ile Cys Asn Ser Gly Phe Lys Arg Lys Ala Gly Thr Ser
180 185 190
Ser Leu Thr Glu Cys Val Leu Asn Lys Ala Thr Asn Val Ala His Trp
195 200 205
Thr Thr Pro Ser Leu Lys Cys Ile Arg
210 215
<210> 146
<211> 651
<212> DNA
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成7t15-7s序列”
<400> 146
gattgtgata ttgaaggtaa agatggcaaa caatatgaga gtgttctaat ggtcagcatc 60
gatcaattat tggacagcat gaaagaaatt ggtagcaatt gcctgaataa tgaatttaac 120
ttttttaaaa gacatatctg tgatgctaat aaggaaggta tgtttttatt ccgtgctgct 180
cgcaagttga ggcaatttct taaaatgaat agcactggtg attttgatct ccacttatta 240
aaagtttcag aaggcacaac aatactgttg aactgcactg gccaggttaa aggaagaaaa 300
ccagctgccc tgggtgaagc ccaaccaaca aagagtttgg aagaaaataa atctttaaag 360
gaacagaaaa aactgaatga cttgtgtttc ctaaagagac tattacaaga gataaaaact 420
tgttggaata aaattttgat gggcactaaa gaacacatca cgtgccctcc ccccatgtcc 480
gtggaacacg cagacatctg ggtcaagagc tacagcttgt actccaggga gcggtacatt 540
tgtaactctg gtttcaagcg taaagccggc acgtccagcc tgacggagtg cgtgttgaac 600
aaggccacga atgtcgccca ctggacaacc cccagtctca aatgcattag a 651
<210> 147
<211> 235
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成7t15-7s序列”
<400> 147
Met Lys Trp Val Thr Phe Ile Ser Leu Leu Phe Leu Phe Ser Ser Ala
1 5 10 15
Tyr Ser Asp Cys Asp Ile Glu Gly Lys Asp Gly Lys Gln Tyr Glu Ser
20 25 30
Val Leu Met Val Ser Ile Asp Gln Leu Leu Asp Ser Met Lys Glu Ile
35 40 45
Gly Ser Asn Cys Leu Asn Asn Glu Phe Asn Phe Phe Lys Arg His Ile
50 55 60
Cys Asp Ala Asn Lys Glu Gly Met Phe Leu Phe Arg Ala Ala Arg Lys
65 70 75 80
Leu Arg Gln Phe Leu Lys Met Asn Ser Thr Gly Asp Phe Asp Leu His
85 90 95
Leu Leu Lys Val Ser Glu Gly Thr Thr Ile Leu Leu Asn Cys Thr Gly
100 105 110
Gln Val Lys Gly Arg Lys Pro Ala Ala Leu Gly Glu Ala Gln Pro Thr
115 120 125
Lys Ser Leu Glu Glu Asn Lys Ser Leu Lys Glu Gln Lys Lys Leu Asn
130 135 140
Asp Leu Cys Phe Leu Lys Arg Leu Leu Gln Glu Ile Lys Thr Cys Trp
145 150 155 160
Asn Lys Ile Leu Met Gly Thr Lys Glu His Ile Thr Cys Pro Pro Pro
165 170 175
Met Ser Val Glu His Ala Asp Ile Trp Val Lys Ser Tyr Ser Leu Tyr
180 185 190
Ser Arg Glu Arg Tyr Ile Cys Asn Ser Gly Phe Lys Arg Lys Ala Gly
195 200 205
Thr Ser Ser Leu Thr Glu Cys Val Leu Asn Lys Ala Thr Asn Val Ala
210 215 220
His Trp Thr Thr Pro Ser Leu Lys Cys Ile Arg
225 230 235
<210> 148
<211> 705
<212> DNA
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成7t15-7s序列”
<400> 148
atgaagtggg tgaccttcat cagcctgctg ttcctgttct ccagcgccta ctccgattgc 60
gacatcgagg gcaaggacgg caagcagtac gagagcgtgc tgatggtgtc catcgaccag 120
ctgctggaca gcatgaagga gatcggctcc aactgcctca acaacgagtt caacttcttc 180
aagcggcaca tctgcgacgc caacaaggag ggcatgttcc tgttcagggc cgccaggaaa 240
ctgcggcagt tcctgaagat gaactccacc ggcgacttcg acctgcacct gctgaaggtg 300
tccgagggca ccaccatcct gctgaactgc accggacagg tgaagggccg gaaacctgct 360
gctctgggag aggcccaacc caccaagagc ctggaggaga acaagtccct gaaggagcag 420
aagaagctga acgacctgtg cttcctgaag aggctgctgc aggagatcaa gacctgctgg 480
aacaagatcc tgatgggcac caaggagcat attacatgcc cccctcccat gagcgtggag 540
cacgccgaca tctgggtgaa gagctatagc ctctacagcc gggagaggta tatctgtaac 600
agcggcttca agaggaaggc cggcaccagc agcctcaccg agtgcgtgct gaataaggct 660
accaacgtgg ctcactggac aacaccctct ttaaagtgca tccgg 705
<210> 149
<211> 620
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成TGFRt15-TGFR序列”
<400> 149
Ile Pro Pro His Val Gln Lys Ser Val Asn Asn Asp Met Ile Val Thr
1 5 10 15
Asp Asn Asn Gly Ala Val Lys Phe Pro Gln Leu Cys Lys Phe Cys Asp
20 25 30
Val Arg Phe Ser Thr Cys Asp Asn Gln Lys Ser Cys Met Ser Asn Cys
35 40 45
Ser Ile Thr Ser Ile Cys Glu Lys Pro Gln Glu Val Cys Val Ala Val
50 55 60
Trp Arg Lys Asn Asp Glu Asn Ile Thr Leu Glu Thr Val Cys His Asp
65 70 75 80
Pro Lys Leu Pro Tyr His Asp Phe Ile Leu Glu Asp Ala Ala Ser Pro
85 90 95
Lys Cys Ile Met Lys Glu Lys Lys Lys Pro Gly Glu Thr Phe Phe Met
100 105 110
Cys Ser Cys Ser Ser Asp Glu Cys Asn Asp Asn Ile Ile Phe Ser Glu
115 120 125
Glu Tyr Asn Thr Ser Asn Pro Asp Gly Gly Gly Gly Ser Gly Gly Gly
130 135 140
Gly Ser Gly Gly Gly Gly Ser Ile Pro Pro His Val Gln Lys Ser Val
145 150 155 160
Asn Asn Asp Met Ile Val Thr Asp Asn Asn Gly Ala Val Lys Phe Pro
165 170 175
Gln Leu Cys Lys Phe Cys Asp Val Arg Phe Ser Thr Cys Asp Asn Gln
180 185 190
Lys Ser Cys Met Ser Asn Cys Ser Ile Thr Ser Ile Cys Glu Lys Pro
195 200 205
Gln Glu Val Cys Val Ala Val Trp Arg Lys Asn Asp Glu Asn Ile Thr
210 215 220
Leu Glu Thr Val Cys His Asp Pro Lys Leu Pro Tyr His Asp Phe Ile
225 230 235 240
Leu Glu Asp Ala Ala Ser Pro Lys Cys Ile Met Lys Glu Lys Lys Lys
245 250 255
Pro Gly Glu Thr Phe Phe Met Cys Ser Cys Ser Ser Asp Glu Cys Asn
260 265 270
Asp Asn Ile Ile Phe Ser Glu Glu Tyr Asn Thr Ser Asn Pro Asp Ser
275 280 285
Gly Thr Thr Asn Thr Val Ala Ala Tyr Asn Leu Thr Trp Lys Ser Thr
290 295 300
Asn Phe Lys Thr Ile Leu Glu Trp Glu Pro Lys Pro Val Asn Gln Val
305 310 315 320
Tyr Thr Val Gln Ile Ser Thr Lys Ser Gly Asp Trp Lys Ser Lys Cys
325 330 335
Phe Tyr Thr Thr Asp Thr Glu Cys Asp Leu Thr Asp Glu Ile Val Lys
340 345 350
Asp Val Lys Gln Thr Tyr Leu Ala Arg Val Phe Ser Tyr Pro Ala Gly
355 360 365
Asn Val Glu Ser Thr Gly Ser Ala Gly Glu Pro Leu Tyr Glu Asn Ser
370 375 380
Pro Glu Phe Thr Pro Tyr Leu Glu Thr Asn Leu Gly Gln Pro Thr Ile
385 390 395 400
Gln Ser Phe Glu Gln Val Gly Thr Lys Val Asn Val Thr Val Glu Asp
405 410 415
Glu Arg Thr Leu Val Arg Arg Asn Asn Thr Phe Leu Ser Leu Arg Asp
420 425 430
Val Phe Gly Lys Asp Leu Ile Tyr Thr Leu Tyr Tyr Trp Lys Ser Ser
435 440 445
Ser Ser Gly Lys Lys Thr Ala Lys Thr Asn Thr Asn Glu Phe Leu Ile
450 455 460
Asp Val Asp Lys Gly Glu Asn Tyr Cys Phe Ser Val Gln Ala Val Ile
465 470 475 480
Pro Ser Arg Thr Val Asn Arg Lys Ser Thr Asp Ser Pro Val Glu Cys
485 490 495
Met Gly Gln Glu Lys Gly Glu Phe Arg Glu Asn Trp Val Asn Val Ile
500 505 510
Ser Asp Leu Lys Lys Ile Glu Asp Leu Ile Gln Ser Met His Ile Asp
515 520 525
Ala Thr Leu Tyr Thr Glu Ser Asp Val His Pro Ser Cys Lys Val Thr
530 535 540
Ala Met Lys Cys Phe Leu Leu Glu Leu Gln Val Ile Ser Leu Glu Ser
545 550 555 560
Gly Asp Ala Ser Ile His Asp Thr Val Glu Asn Leu Ile Ile Leu Ala
565 570 575
Asn Asn Ser Leu Ser Ser Asn Gly Asn Val Thr Glu Ser Gly Cys Lys
580 585 590
Glu Cys Glu Glu Leu Glu Glu Lys Asn Ile Lys Glu Phe Leu Gln Ser
595 600 605
Phe Val His Ile Val Gln Met Phe Ile Asn Thr Ser
610 615 620
<210> 150
<211> 1860
<212> DNA
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成TGFRt15-TGFR序列”
<400> 150
atcccccccc atgtgcaaaa gagcgtgaac aacgatatga tcgtgaccga caacaacggc 60
gccgtgaagt ttccccagct ctgcaagttc tgcgatgtca ggttcagcac ctgcgataat 120
cagaagtcct gcatgtccaa ctgcagcatc acctccatct gcgagaagcc ccaagaagtg 180
tgcgtggccg tgtggcggaa aaatgacgag aacatcaccc tggagaccgt gtgtcacgac 240
cccaagctcc cttatcacga cttcattctg gaggacgctg cctcccccaa atgcatcatg 300
aaggagaaga agaagcccgg agagaccttc tttatgtgtt cctgtagcag cgacgagtgt 360
aacgacaaca tcatcttcag cgaagagtac aacaccagca accctgatgg aggtggcgga 420
tccggaggtg gaggttctgg tggaggtggg agtattcctc cccacgtgca gaagagcgtg 480
aataatgaca tgatcgtgac cgataacaat ggcgccgtga aatttcccca gctgtgcaaa 540
ttctgcgatg tgaggttttc cacctgcgac aaccagaagt cctgtatgag caactgctcc 600
atcacctcca tctgtgagaa gcctcaggag gtgtgcgtgg ctgtctggcg gaagaatgac 660
gagaatatca ccctggaaac cgtctgccac gatcccaagc tgccctacca cgatttcatc 720
ctggaagacg ccgccagccc taagtgcatc atgaaagaga aaaagaagcc tggcgagacc 780
tttttcatgt gctcctgcag cagcgacgaa tgcaacgaca atatcatctt tagcgaggaa 840
tacaatacca gcaaccccga cagcggcaca accaacacag tcgctgccta taacctcact 900
tggaagagca ccaacttcaa aaccatcctc gaatgggaac ccaaacccgt taaccaagtt 960
tacaccgtgc agatcagcac caagtccggc gactggaagt ccaaatgttt ctataccacc 1020
gacaccgagt gcgatctcac cgatgagatc gtgaaagatg tgaaacagac ctacctcgcc 1080
cgggtgttta gctaccccgc cggcaatgtg gagagcactg gttccgctgg cgagccttta 1140
tacgagaaca gccccgaatt taccccttac ctcgagacca atttaggaca gcccaccatc 1200
caaagctttg agcaagttgg cacaaaggtg aatgtgacag tggaggacga gcggacttta 1260
gtgcggcgga acaacacctt tctcagcctc cgggatgtgt tcggcaaaga tttaatctac 1320
acactgtatt actggaagtc ctcttcctcc ggcaagaaga cagctaaaac caacacaaac 1380
gagtttttaa tcgacgtgga taaaggcgaa aactactgtt tcagcgtgca agctgtgatc 1440
ccctcccgga ccgtgaatag gaaaagcacc gatagccccg ttgagtgcat gggccaagaa 1500
aagggcgagt tccgggagaa ctgggtgaac gtcatcagcg atttaaagaa gatcgaagat 1560
ttaattcagt ccatgcatat cgacgccact ttatacacag aatccgacgt gcacccctct 1620
tgtaaggtga ccgccatgaa atgtttttta ctggagctgc aagttatctc tttagagagc 1680
ggagacgcta gcatccacga caccgtggag aatttaatca ttttagccaa taactcttta 1740
tccagcaacg gcaacgtgac agagtccggc tgcaaggagt gcgaagagct ggaggagaag 1800
aacatcaagg agtttctgca atcctttgtg cacattgtcc agatgttcat caatacctcc 1860
<210> 151
<211> 638
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成TGFRt15-TGFR序列”
<400> 151
Met Lys Trp Val Thr Phe Ile Ser Leu Leu Phe Leu Phe Ser Ser Ala
1 5 10 15
Tyr Ser Ile Pro Pro His Val Gln Lys Ser Val Asn Asn Asp Met Ile
20 25 30
Val Thr Asp Asn Asn Gly Ala Val Lys Phe Pro Gln Leu Cys Lys Phe
35 40 45
Cys Asp Val Arg Phe Ser Thr Cys Asp Asn Gln Lys Ser Cys Met Ser
50 55 60
Asn Cys Ser Ile Thr Ser Ile Cys Glu Lys Pro Gln Glu Val Cys Val
65 70 75 80
Ala Val Trp Arg Lys Asn Asp Glu Asn Ile Thr Leu Glu Thr Val Cys
85 90 95
His Asp Pro Lys Leu Pro Tyr His Asp Phe Ile Leu Glu Asp Ala Ala
100 105 110
Ser Pro Lys Cys Ile Met Lys Glu Lys Lys Lys Pro Gly Glu Thr Phe
115 120 125
Phe Met Cys Ser Cys Ser Ser Asp Glu Cys Asn Asp Asn Ile Ile Phe
130 135 140
Ser Glu Glu Tyr Asn Thr Ser Asn Pro Asp Gly Gly Gly Gly Ser Gly
145 150 155 160
Gly Gly Gly Ser Gly Gly Gly Gly Ser Ile Pro Pro His Val Gln Lys
165 170 175
Ser Val Asn Asn Asp Met Ile Val Thr Asp Asn Asn Gly Ala Val Lys
180 185 190
Phe Pro Gln Leu Cys Lys Phe Cys Asp Val Arg Phe Ser Thr Cys Asp
195 200 205
Asn Gln Lys Ser Cys Met Ser Asn Cys Ser Ile Thr Ser Ile Cys Glu
210 215 220
Lys Pro Gln Glu Val Cys Val Ala Val Trp Arg Lys Asn Asp Glu Asn
225 230 235 240
Ile Thr Leu Glu Thr Val Cys His Asp Pro Lys Leu Pro Tyr His Asp
245 250 255
Phe Ile Leu Glu Asp Ala Ala Ser Pro Lys Cys Ile Met Lys Glu Lys
260 265 270
Lys Lys Pro Gly Glu Thr Phe Phe Met Cys Ser Cys Ser Ser Asp Glu
275 280 285
Cys Asn Asp Asn Ile Ile Phe Ser Glu Glu Tyr Asn Thr Ser Asn Pro
290 295 300
Asp Ser Gly Thr Thr Asn Thr Val Ala Ala Tyr Asn Leu Thr Trp Lys
305 310 315 320
Ser Thr Asn Phe Lys Thr Ile Leu Glu Trp Glu Pro Lys Pro Val Asn
325 330 335
Gln Val Tyr Thr Val Gln Ile Ser Thr Lys Ser Gly Asp Trp Lys Ser
340 345 350
Lys Cys Phe Tyr Thr Thr Asp Thr Glu Cys Asp Leu Thr Asp Glu Ile
355 360 365
Val Lys Asp Val Lys Gln Thr Tyr Leu Ala Arg Val Phe Ser Tyr Pro
370 375 380
Ala Gly Asn Val Glu Ser Thr Gly Ser Ala Gly Glu Pro Leu Tyr Glu
385 390 395 400
Asn Ser Pro Glu Phe Thr Pro Tyr Leu Glu Thr Asn Leu Gly Gln Pro
405 410 415
Thr Ile Gln Ser Phe Glu Gln Val Gly Thr Lys Val Asn Val Thr Val
420 425 430
Glu Asp Glu Arg Thr Leu Val Arg Arg Asn Asn Thr Phe Leu Ser Leu
435 440 445
Arg Asp Val Phe Gly Lys Asp Leu Ile Tyr Thr Leu Tyr Tyr Trp Lys
450 455 460
Ser Ser Ser Ser Gly Lys Lys Thr Ala Lys Thr Asn Thr Asn Glu Phe
465 470 475 480
Leu Ile Asp Val Asp Lys Gly Glu Asn Tyr Cys Phe Ser Val Gln Ala
485 490 495
Val Ile Pro Ser Arg Thr Val Asn Arg Lys Ser Thr Asp Ser Pro Val
500 505 510
Glu Cys Met Gly Gln Glu Lys Gly Glu Phe Arg Glu Asn Trp Val Asn
515 520 525
Val Ile Ser Asp Leu Lys Lys Ile Glu Asp Leu Ile Gln Ser Met His
530 535 540
Ile Asp Ala Thr Leu Tyr Thr Glu Ser Asp Val His Pro Ser Cys Lys
545 550 555 560
Val Thr Ala Met Lys Cys Phe Leu Leu Glu Leu Gln Val Ile Ser Leu
565 570 575
Glu Ser Gly Asp Ala Ser Ile His Asp Thr Val Glu Asn Leu Ile Ile
580 585 590
Leu Ala Asn Asn Ser Leu Ser Ser Asn Gly Asn Val Thr Glu Ser Gly
595 600 605
Cys Lys Glu Cys Glu Glu Leu Glu Glu Lys Asn Ile Lys Glu Phe Leu
610 615 620
Gln Ser Phe Val His Ile Val Gln Met Phe Ile Asn Thr Ser
625 630 635
<210> 152
<211> 1914
<212> DNA
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成TGFRt15-TGFR序列”
<400> 152
atgaagtggg tgaccttcat cagcctgctg ttcctgttct ccagcgccta ctccatcccc 60
ccccatgtgc aaaagagcgt gaacaacgat atgatcgtga ccgacaacaa cggcgccgtg 120
aagtttcccc agctctgcaa gttctgcgat gtcaggttca gcacctgcga taatcagaag 180
tcctgcatgt ccaactgcag catcacctcc atctgcgaga agccccaaga agtgtgcgtg 240
gccgtgtggc ggaaaaatga cgagaacatc accctggaga ccgtgtgtca cgaccccaag 300
ctcccttatc acgacttcat tctggaggac gctgcctccc ccaaatgcat catgaaggag 360
aagaagaagc ccggagagac cttctttatg tgttcctgta gcagcgacga gtgtaacgac 420
aacatcatct tcagcgaaga gtacaacacc agcaaccctg atggaggtgg cggatccgga 480
ggtggaggtt ctggtggagg tgggagtatt cctccccacg tgcagaagag cgtgaataat 540
gacatgatcg tgaccgataa caatggcgcc gtgaaatttc cccagctgtg caaattctgc 600
gatgtgaggt tttccacctg cgacaaccag aagtcctgta tgagcaactg ctccatcacc 660
tccatctgtg agaagcctca ggaggtgtgc gtggctgtct ggcggaagaa tgacgagaat 720
atcaccctgg aaaccgtctg ccacgatccc aagctgccct accacgattt catcctggaa 780
gacgccgcca gccctaagtg catcatgaaa gagaaaaaga agcctggcga gacctttttc 840
atgtgctcct gcagcagcga cgaatgcaac gacaatatca tctttagcga ggaatacaat 900
accagcaacc ccgacagcgg cacaaccaac acagtcgctg cctataacct cacttggaag 960
agcaccaact tcaaaaccat cctcgaatgg gaacccaaac ccgttaacca agtttacacc 1020
gtgcagatca gcaccaagtc cggcgactgg aagtccaaat gtttctatac caccgacacc 1080
gagtgcgatc tcaccgatga gatcgtgaaa gatgtgaaac agacctacct cgcccgggtg 1140
tttagctacc ccgccggcaa tgtggagagc actggttccg ctggcgagcc tttatacgag 1200
aacagccccg aatttacccc ttacctcgag accaatttag gacagcccac catccaaagc 1260
tttgagcaag ttggcacaaa ggtgaatgtg acagtggagg acgagcggac tttagtgcgg 1320
cggaacaaca cctttctcag cctccgggat gtgttcggca aagatttaat ctacacactg 1380
tattactgga agtcctcttc ctccggcaag aagacagcta aaaccaacac aaacgagttt 1440
ttaatcgacg tggataaagg cgaaaactac tgtttcagcg tgcaagctgt gatcccctcc 1500
cggaccgtga ataggaaaag caccgatagc cccgttgagt gcatgggcca agaaaagggc 1560
gagttccggg agaactgggt gaacgtcatc agcgatttaa agaagatcga agatttaatt 1620
cagtccatgc atatcgacgc cactttatac acagaatccg acgtgcaccc ctcttgtaag 1680
gtgaccgcca tgaaatgttt tttactggag ctgcaagtta tctctttaga gagcggagac 1740
gctagcatcc acgacaccgt ggagaattta atcattttag ccaataactc tttatccagc 1800
aacggcaacg tgacagagtc cggctgcaag gagtgcgaag agctggagga gaagaacatc 1860
aaggagtttc tgcaatcctt tgtgcacatt gtccagatgt tcatcaatac ctcc 1914
<210> 153
<211> 352
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成TGFRt15-TGFR序列”
<400> 153
Ile Pro Pro His Val Gln Lys Ser Val Asn Asn Asp Met Ile Val Thr
1 5 10 15
Asp Asn Asn Gly Ala Val Lys Phe Pro Gln Leu Cys Lys Phe Cys Asp
20 25 30
Val Arg Phe Ser Thr Cys Asp Asn Gln Lys Ser Cys Met Ser Asn Cys
35 40 45
Ser Ile Thr Ser Ile Cys Glu Lys Pro Gln Glu Val Cys Val Ala Val
50 55 60
Trp Arg Lys Asn Asp Glu Asn Ile Thr Leu Glu Thr Val Cys His Asp
65 70 75 80
Pro Lys Leu Pro Tyr His Asp Phe Ile Leu Glu Asp Ala Ala Ser Pro
85 90 95
Lys Cys Ile Met Lys Glu Lys Lys Lys Pro Gly Glu Thr Phe Phe Met
100 105 110
Cys Ser Cys Ser Ser Asp Glu Cys Asn Asp Asn Ile Ile Phe Ser Glu
115 120 125
Glu Tyr Asn Thr Ser Asn Pro Asp Gly Gly Gly Gly Ser Gly Gly Gly
130 135 140
Gly Ser Gly Gly Gly Gly Ser Ile Pro Pro His Val Gln Lys Ser Val
145 150 155 160
Asn Asn Asp Met Ile Val Thr Asp Asn Asn Gly Ala Val Lys Phe Pro
165 170 175
Gln Leu Cys Lys Phe Cys Asp Val Arg Phe Ser Thr Cys Asp Asn Gln
180 185 190
Lys Ser Cys Met Ser Asn Cys Ser Ile Thr Ser Ile Cys Glu Lys Pro
195 200 205
Gln Glu Val Cys Val Ala Val Trp Arg Lys Asn Asp Glu Asn Ile Thr
210 215 220
Leu Glu Thr Val Cys His Asp Pro Lys Leu Pro Tyr His Asp Phe Ile
225 230 235 240
Leu Glu Asp Ala Ala Ser Pro Lys Cys Ile Met Lys Glu Lys Lys Lys
245 250 255
Pro Gly Glu Thr Phe Phe Met Cys Ser Cys Ser Ser Asp Glu Cys Asn
260 265 270
Asp Asn Ile Ile Phe Ser Glu Glu Tyr Asn Thr Ser Asn Pro Asp Ile
275 280 285
Thr Cys Pro Pro Pro Met Ser Val Glu His Ala Asp Ile Trp Val Lys
290 295 300
Ser Tyr Ser Leu Tyr Ser Arg Glu Arg Tyr Ile Cys Asn Ser Gly Phe
305 310 315 320
Lys Arg Lys Ala Gly Thr Ser Ser Leu Thr Glu Cys Val Leu Asn Lys
325 330 335
Ala Thr Asn Val Ala His Trp Thr Thr Pro Ser Leu Lys Cys Ile Arg
340 345 350
<210> 154
<211> 1056
<212> DNA
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成TGFRt15-TGFR序列”
<400> 154
atcccccccc atgtgcaaaa gagcgtgaac aacgatatga tcgtgaccga caacaacggc 60
gccgtgaagt ttccccagct ctgcaagttc tgcgatgtca ggttcagcac ctgcgataat 120
cagaagtcct gcatgtccaa ctgcagcatc acctccatct gcgagaagcc ccaagaagtg 180
tgcgtggccg tgtggcggaa aaatgacgag aacatcaccc tggagaccgt gtgtcacgac 240
cccaagctcc cttatcacga cttcattctg gaggacgctg cctcccccaa atgcatcatg 300
aaggagaaga agaagcccgg agagaccttc tttatgtgtt cctgtagcag cgacgagtgt 360
aacgacaaca tcatcttcag cgaagagtac aacaccagca accctgatgg aggtggcgga 420
tccggaggtg gaggttctgg tggaggtggg agtattcctc cccacgtgca gaagagcgtg 480
aataatgaca tgatcgtgac cgataacaat ggcgccgtga aatttcccca gctgtgcaaa 540
ttctgcgatg tgaggttttc cacctgcgac aaccagaagt cctgtatgag caactgctcc 600
atcacctcca tctgtgagaa gcctcaggag gtgtgcgtgg ctgtctggcg gaagaatgac 660
gagaatatca ccctggaaac cgtctgccac gatcccaagc tgccctacca cgatttcatc 720
ctggaagacg ccgccagccc taagtgcatc atgaaagaga aaaagaagcc tggcgagacc 780
tttttcatgt gctcctgcag cagcgacgaa tgcaacgaca atatcatctt tagcgaggaa 840
tacaatacca gcaaccccga cattacatgc ccccctccca tgagcgtgga gcacgccgac 900
atctgggtga agagctatag cctctacagc cgggagaggt atatctgtaa cagcggcttc 960
aagaggaagg ccggcaccag cagcctcacc gagtgcgtgc tgaataaggc taccaacgtg 1020
gctcactgga caacaccctc tttaaagtgc atccgg 1056
<210> 155
<211> 370
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成TGFRt15-TGFR序列”
<400> 155
Met Lys Trp Val Thr Phe Ile Ser Leu Leu Phe Leu Phe Ser Ser Ala
1 5 10 15
Tyr Ser Ile Pro Pro His Val Gln Lys Ser Val Asn Asn Asp Met Ile
20 25 30
Val Thr Asp Asn Asn Gly Ala Val Lys Phe Pro Gln Leu Cys Lys Phe
35 40 45
Cys Asp Val Arg Phe Ser Thr Cys Asp Asn Gln Lys Ser Cys Met Ser
50 55 60
Asn Cys Ser Ile Thr Ser Ile Cys Glu Lys Pro Gln Glu Val Cys Val
65 70 75 80
Ala Val Trp Arg Lys Asn Asp Glu Asn Ile Thr Leu Glu Thr Val Cys
85 90 95
His Asp Pro Lys Leu Pro Tyr His Asp Phe Ile Leu Glu Asp Ala Ala
100 105 110
Ser Pro Lys Cys Ile Met Lys Glu Lys Lys Lys Pro Gly Glu Thr Phe
115 120 125
Phe Met Cys Ser Cys Ser Ser Asp Glu Cys Asn Asp Asn Ile Ile Phe
130 135 140
Ser Glu Glu Tyr Asn Thr Ser Asn Pro Asp Gly Gly Gly Gly Ser Gly
145 150 155 160
Gly Gly Gly Ser Gly Gly Gly Gly Ser Ile Pro Pro His Val Gln Lys
165 170 175
Ser Val Asn Asn Asp Met Ile Val Thr Asp Asn Asn Gly Ala Val Lys
180 185 190
Phe Pro Gln Leu Cys Lys Phe Cys Asp Val Arg Phe Ser Thr Cys Asp
195 200 205
Asn Gln Lys Ser Cys Met Ser Asn Cys Ser Ile Thr Ser Ile Cys Glu
210 215 220
Lys Pro Gln Glu Val Cys Val Ala Val Trp Arg Lys Asn Asp Glu Asn
225 230 235 240
Ile Thr Leu Glu Thr Val Cys His Asp Pro Lys Leu Pro Tyr His Asp
245 250 255
Phe Ile Leu Glu Asp Ala Ala Ser Pro Lys Cys Ile Met Lys Glu Lys
260 265 270
Lys Lys Pro Gly Glu Thr Phe Phe Met Cys Ser Cys Ser Ser Asp Glu
275 280 285
Cys Asn Asp Asn Ile Ile Phe Ser Glu Glu Tyr Asn Thr Ser Asn Pro
290 295 300
Asp Ile Thr Cys Pro Pro Pro Met Ser Val Glu His Ala Asp Ile Trp
305 310 315 320
Val Lys Ser Tyr Ser Leu Tyr Ser Arg Glu Arg Tyr Ile Cys Asn Ser
325 330 335
Gly Phe Lys Arg Lys Ala Gly Thr Ser Ser Leu Thr Glu Cys Val Leu
340 345 350
Asn Lys Ala Thr Asn Val Ala His Trp Thr Thr Pro Ser Leu Lys Cys
355 360 365
Ile Arg
370
<210> 156
<211> 1110
<212> DNA
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成TGFRt15-TGFR序列”
<400> 156
atgaagtggg tgaccttcat cagcctgctg ttcctgttct ccagcgccta ctccatcccc 60
ccccatgtgc aaaagagcgt gaacaacgat atgatcgtga ccgacaacaa cggcgccgtg 120
aagtttcccc agctctgcaa gttctgcgat gtcaggttca gcacctgcga taatcagaag 180
tcctgcatgt ccaactgcag catcacctcc atctgcgaga agccccaaga agtgtgcgtg 240
gccgtgtggc ggaaaaatga cgagaacatc accctggaga ccgtgtgtca cgaccccaag 300
ctcccttatc acgacttcat tctggaggac gctgcctccc ccaaatgcat catgaaggag 360
aagaagaagc ccggagagac cttctttatg tgttcctgta gcagcgacga gtgtaacgac 420
aacatcatct tcagcgaaga gtacaacacc agcaaccctg atggaggtgg cggatccgga 480
ggtggaggtt ctggtggagg tgggagtatt cctccccacg tgcagaagag cgtgaataat 540
gacatgatcg tgaccgataa caatggcgcc gtgaaatttc cccagctgtg caaattctgc 600
gatgtgaggt tttccacctg cgacaaccag aagtcctgta tgagcaactg ctccatcacc 660
tccatctgtg agaagcctca ggaggtgtgc gtggctgtct ggcggaagaa tgacgagaat 720
atcaccctgg aaaccgtctg ccacgatccc aagctgccct accacgattt catcctggaa 780
gacgccgcca gccctaagtg catcatgaaa gagaaaaaga agcctggcga gacctttttc 840
atgtgctcct gcagcagcga cgaatgcaac gacaatatca tctttagcga ggaatacaat 900
accagcaacc ccgacattac atgcccccct cccatgagcg tggagcacgc cgacatctgg 960
gtgaagagct atagcctcta cagccgggag aggtatatct gtaacagcgg cttcaagagg 1020
aaggccggca ccagcagcct caccgagtgc gtgctgaata aggctaccaa cgtggctcac 1080
tggacaacac cctctttaaa gtgcatccgg 1110
<210> 157
<211> 184
<212> PRT
<213> 智人
<220>
<221> source
<223> /标注=“CD137L”
<400> 157
Arg Glu Gly Pro Glu Leu Ser Pro Asp Asp Pro Ala Gly Leu Leu Asp
1 5 10 15
Leu Arg Gln Gly Met Phe Ala Gln Leu Val Ala Gln Asn Val Leu Leu
20 25 30
Ile Asp Gly Pro Leu Ser Trp Tyr Ser Asp Pro Gly Leu Ala Gly Val
35 40 45
Ser Leu Thr Gly Gly Leu Ser Tyr Lys Glu Asp Thr Lys Glu Leu Val
50 55 60
Val Ala Lys Ala Gly Val Tyr Tyr Val Phe Phe Gln Leu Glu Leu Arg
65 70 75 80
Arg Val Val Ala Gly Glu Gly Ser Gly Ser Val Ser Leu Ala Leu His
85 90 95
Leu Gln Pro Leu Arg Ser Ala Ala Gly Ala Ala Ala Leu Ala Leu Thr
100 105 110
Val Asp Leu Pro Pro Ala Ser Ser Glu Ala Arg Asn Ser Ala Phe Gly
115 120 125
Phe Gln Gly Arg Leu Leu His Leu Ser Ala Gly Gln Arg Leu Gly Val
130 135 140
His Leu His Thr Glu Ala Arg Ala Arg His Ala Trp Gln Leu Thr Gln
145 150 155 160
Gly Ala Thr Val Leu Gly Leu Phe Arg Val Thr Pro Glu Ile Pro Ala
165 170 175
Gly Leu Pro Ser Pro Arg Ser Glu
180
<210> 158
<211> 552
<212> DNA
<213> 智人
<220>
<221> source
<223> /标注=“CD137L”
<400> 158
cgcgagggtc ccgagctttc gcccgacgat cccgccggcc tcttggacct gcggcagggc 60
atgtttgcgc agctggtggc ccaaaatgtt ctgctgatcg atgggcccct gagctggtac 120
agtgacccag gcctggcagg cgtgtccctg acggggggcc tgagctacaa agaggacacg 180
aaggagctgg tggtggccaa ggctggagtc tactatgtct tctttcaact agagctgcgg 240
cgcgtggtgg ccggcgaggg ctcaggctcc gtttcacttg cgctgcacct gcagccactg 300
cgctctgctg ctggggccgc cgccctggct ttgaccgtgg acctgccacc cgcctcctcc 360
gaggctcgga actcggcctt cggtttccag ggccgcttgc tgcacctgag tgccggccag 420
cgcctgggcg tccatcttca cactgaggcc agggcacgcc atgcctggca gcttacccag 480
ggcgccacag tcttgggact cttccgggtg acccccgaaa tcccagccgg actcccttca 540
ccgaggtcgg aa 552
<210> 159
<211> 165
<212> PRT
<213> 智人
<220>
<221> source
<223> /标注=“CD137L”
<400> 159
Asp Pro Ala Gly Leu Leu Asp Leu Arg Gln Gly Met Phe Ala Gln Leu
1 5 10 15
Val Ala Gln Asn Val Leu Leu Ile Asp Gly Pro Leu Ser Trp Tyr Ser
20 25 30
Asp Pro Gly Leu Ala Gly Val Ser Leu Thr Gly Gly Leu Ser Tyr Lys
35 40 45
Glu Asp Thr Lys Glu Leu Val Val Ala Lys Ala Gly Val Tyr Tyr Val
50 55 60
Phe Phe Gln Leu Glu Leu Arg Arg Val Val Ala Gly Glu Gly Ser Gly
65 70 75 80
Ser Val Ser Leu Ala Leu His Leu Gln Pro Leu Arg Ser Ala Ala Gly
85 90 95
Ala Ala Ala Leu Ala Leu Thr Val Asp Leu Pro Pro Ala Ser Ser Glu
100 105 110
Ala Arg Asn Ser Ala Phe Gly Phe Gln Gly Arg Leu Leu His Leu Ser
115 120 125
Ala Gly Gln Arg Leu Gly Val His Leu His Thr Glu Ala Arg Ala Arg
130 135 140
His Ala Trp Gln Leu Thr Gln Gly Ala Thr Val Leu Gly Leu Phe Arg
145 150 155 160
Val Thr Pro Glu Ile
165
<210> 160
<211> 495
<212> DNA
<213> 智人
<220>
<221> source
<223> /标注=“CD137L”
<400> 160
gatcccgccg gcctcttgga cctgcggcag ggcatgtttg cgcagctggt ggcccaaaat 60
gttctgctga tcgatgggcc cctgagctgg tacagtgacc caggcctggc aggcgtgtcc 120
ctgacggggg gcctgagcta caaagaggac acgaaggagc tggtggtggc caaggctgga 180
gtctactatg tcttctttca actagagctg cggcgcgtgg tggccggcga gggctcaggc 240
tccgtttcac ttgcgctgca cctgcagcca ctgcgctctg ctgctggggc cgccgccctg 300
gctttgaccg tggacctgcc acccgcctcc tccgaggctc ggaactcggc cttcggtttc 360
cagggccgct tgctgcacct gagtgccggc cagcgcctgg gcgtccatct tcacactgag 420
gccagggcac gccatgcctg gcagcttacc cagggcgcca cagtcttggg actcttccgg 480
gtgacccccg aaatc 495
<210> 161
<211> 485
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成7t15-21s137L序列”
<400> 161
Asp Cys Asp Ile Glu Gly Lys Asp Gly Lys Gln Tyr Glu Ser Val Leu
1 5 10 15
Met Val Ser Ile Asp Gln Leu Leu Asp Ser Met Lys Glu Ile Gly Ser
20 25 30
Asn Cys Leu Asn Asn Glu Phe Asn Phe Phe Lys Arg His Ile Cys Asp
35 40 45
Ala Asn Lys Glu Gly Met Phe Leu Phe Arg Ala Ala Arg Lys Leu Arg
50 55 60
Gln Phe Leu Lys Met Asn Ser Thr Gly Asp Phe Asp Leu His Leu Leu
65 70 75 80
Lys Val Ser Glu Gly Thr Thr Ile Leu Leu Asn Cys Thr Gly Gln Val
85 90 95
Lys Gly Arg Lys Pro Ala Ala Leu Gly Glu Ala Gln Pro Thr Lys Ser
100 105 110
Leu Glu Glu Asn Lys Ser Leu Lys Glu Gln Lys Lys Leu Asn Asp Leu
115 120 125
Cys Phe Leu Lys Arg Leu Leu Gln Glu Ile Lys Thr Cys Trp Asn Lys
130 135 140
Ile Leu Met Gly Thr Lys Glu His Ser Gly Thr Thr Asn Thr Val Ala
145 150 155 160
Ala Tyr Asn Leu Thr Trp Lys Ser Thr Asn Phe Lys Thr Ile Leu Glu
165 170 175
Trp Glu Pro Lys Pro Val Asn Gln Val Tyr Thr Val Gln Ile Ser Thr
180 185 190
Lys Ser Gly Asp Trp Lys Ser Lys Cys Phe Tyr Thr Thr Asp Thr Glu
195 200 205
Cys Asp Leu Thr Asp Glu Ile Val Lys Asp Val Lys Gln Thr Tyr Leu
210 215 220
Ala Arg Val Phe Ser Tyr Pro Ala Gly Asn Val Glu Ser Thr Gly Ser
225 230 235 240
Ala Gly Glu Pro Leu Tyr Glu Asn Ser Pro Glu Phe Thr Pro Tyr Leu
245 250 255
Glu Thr Asn Leu Gly Gln Pro Thr Ile Gln Ser Phe Glu Gln Val Gly
260 265 270
Thr Lys Val Asn Val Thr Val Glu Asp Glu Arg Thr Leu Val Arg Arg
275 280 285
Asn Asn Thr Phe Leu Ser Leu Arg Asp Val Phe Gly Lys Asp Leu Ile
290 295 300
Tyr Thr Leu Tyr Tyr Trp Lys Ser Ser Ser Ser Gly Lys Lys Thr Ala
305 310 315 320
Lys Thr Asn Thr Asn Glu Phe Leu Ile Asp Val Asp Lys Gly Glu Asn
325 330 335
Tyr Cys Phe Ser Val Gln Ala Val Ile Pro Ser Arg Thr Val Asn Arg
340 345 350
Lys Ser Thr Asp Ser Pro Val Glu Cys Met Gly Gln Glu Lys Gly Glu
355 360 365
Phe Arg Glu Asn Trp Val Asn Val Ile Ser Asp Leu Lys Lys Ile Glu
370 375 380
Asp Leu Ile Gln Ser Met His Ile Asp Ala Thr Leu Tyr Thr Glu Ser
385 390 395 400
Asp Val His Pro Ser Cys Lys Val Thr Ala Met Lys Cys Phe Leu Leu
405 410 415
Glu Leu Gln Val Ile Ser Leu Glu Ser Gly Asp Ala Ser Ile His Asp
420 425 430
Thr Val Glu Asn Leu Ile Ile Leu Ala Asn Asn Ser Leu Ser Ser Asn
435 440 445
Gly Asn Val Thr Glu Ser Gly Cys Lys Glu Cys Glu Glu Leu Glu Glu
450 455 460
Lys Asn Ile Lys Glu Phe Leu Gln Ser Phe Val His Ile Val Gln Met
465 470 475 480
Phe Ile Asn Thr Ser
485
<210> 162
<211> 1455
<212> DNA
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成7t15-21s137L序列”
<400> 162
gattgcgaca tcgagggcaa ggacggcaag cagtacgaga gcgtgctgat ggtgtccatc 60
gaccagctgc tggacagcat gaaggagatc ggctccaact gcctcaacaa cgagttcaac 120
ttcttcaagc ggcacatctg cgacgccaac aaggagggca tgttcctgtt cagggccgcc 180
aggaaactgc ggcagttcct gaagatgaac tccaccggcg acttcgacct gcacctgctg 240
aaggtgtccg agggcaccac catcctgctg aactgcaccg gacaggtgaa gggccggaaa 300
cctgctgctc tgggagaggc ccaacccacc aagagcctgg aggagaacaa gtccctgaag 360
gagcagaaga agctgaacga cctgtgcttc ctgaagaggc tgctgcagga gatcaagacc 420
tgctggaaca agatcctgat gggcaccaag gagcatagcg gcacaaccaa cacagtcgct 480
gcctataacc tcacttggaa gagcaccaac ttcaaaacca tcctcgaatg ggaacccaaa 540
cccgttaacc aagtttacac cgtgcagatc agcaccaagt ccggcgactg gaagtccaaa 600
tgtttctata ccaccgacac cgagtgcgat ctcaccgatg agatcgtgaa agatgtgaaa 660
cagacctacc tcgcccgggt gtttagctac cccgccggca atgtggagag cactggttcc 720
gctggcgagc ctttatacga gaacagcccc gaatttaccc cttacctcga gaccaattta 780
ggacagccca ccatccaaag ctttgagcaa gttggcacaa aggtgaatgt gacagtggag 840
gacgagcgga ctttagtgcg gcggaacaac acctttctca gcctccggga tgtgttcggc 900
aaagatttaa tctacacact gtattactgg aagtcctctt cctccggcaa gaagacagct 960
aaaaccaaca caaacgagtt tttaatcgac gtggataaag gcgaaaacta ctgtttcagc 1020
gtgcaagctg tgatcccctc ccggaccgtg aataggaaaa gcaccgatag ccccgttgag 1080
tgcatgggcc aagaaaaggg cgagttccgg gagaactggg tgaacgtcat cagcgattta 1140
aagaagatcg aagatttaat tcagtccatg catatcgacg ccactttata cacagaatcc 1200
gacgtgcacc cctcttgtaa ggtgaccgcc atgaaatgtt ttttactgga gctgcaagtt 1260
atctctttag agagcggaga cgctagcatc cacgacaccg tggagaattt aatcatttta 1320
gccaataact ctttatccag caacggcaac gtgacagagt ccggctgcaa ggagtgcgaa 1380
gagctggagg agaagaacat caaggagttt ctgcaatcct ttgtgcacat tgtccagatg 1440
ttcatcaata cctcc 1455
<210> 163
<211> 503
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成7t15-21s137L序列”
<400> 163
Met Lys Trp Val Thr Phe Ile Ser Leu Leu Phe Leu Phe Ser Ser Ala
1 5 10 15
Tyr Ser Asp Cys Asp Ile Glu Gly Lys Asp Gly Lys Gln Tyr Glu Ser
20 25 30
Val Leu Met Val Ser Ile Asp Gln Leu Leu Asp Ser Met Lys Glu Ile
35 40 45
Gly Ser Asn Cys Leu Asn Asn Glu Phe Asn Phe Phe Lys Arg His Ile
50 55 60
Cys Asp Ala Asn Lys Glu Gly Met Phe Leu Phe Arg Ala Ala Arg Lys
65 70 75 80
Leu Arg Gln Phe Leu Lys Met Asn Ser Thr Gly Asp Phe Asp Leu His
85 90 95
Leu Leu Lys Val Ser Glu Gly Thr Thr Ile Leu Leu Asn Cys Thr Gly
100 105 110
Gln Val Lys Gly Arg Lys Pro Ala Ala Leu Gly Glu Ala Gln Pro Thr
115 120 125
Lys Ser Leu Glu Glu Asn Lys Ser Leu Lys Glu Gln Lys Lys Leu Asn
130 135 140
Asp Leu Cys Phe Leu Lys Arg Leu Leu Gln Glu Ile Lys Thr Cys Trp
145 150 155 160
Asn Lys Ile Leu Met Gly Thr Lys Glu His Ser Gly Thr Thr Asn Thr
165 170 175
Val Ala Ala Tyr Asn Leu Thr Trp Lys Ser Thr Asn Phe Lys Thr Ile
180 185 190
Leu Glu Trp Glu Pro Lys Pro Val Asn Gln Val Tyr Thr Val Gln Ile
195 200 205
Ser Thr Lys Ser Gly Asp Trp Lys Ser Lys Cys Phe Tyr Thr Thr Asp
210 215 220
Thr Glu Cys Asp Leu Thr Asp Glu Ile Val Lys Asp Val Lys Gln Thr
225 230 235 240
Tyr Leu Ala Arg Val Phe Ser Tyr Pro Ala Gly Asn Val Glu Ser Thr
245 250 255
Gly Ser Ala Gly Glu Pro Leu Tyr Glu Asn Ser Pro Glu Phe Thr Pro
260 265 270
Tyr Leu Glu Thr Asn Leu Gly Gln Pro Thr Ile Gln Ser Phe Glu Gln
275 280 285
Val Gly Thr Lys Val Asn Val Thr Val Glu Asp Glu Arg Thr Leu Val
290 295 300
Arg Arg Asn Asn Thr Phe Leu Ser Leu Arg Asp Val Phe Gly Lys Asp
305 310 315 320
Leu Ile Tyr Thr Leu Tyr Tyr Trp Lys Ser Ser Ser Ser Gly Lys Lys
325 330 335
Thr Ala Lys Thr Asn Thr Asn Glu Phe Leu Ile Asp Val Asp Lys Gly
340 345 350
Glu Asn Tyr Cys Phe Ser Val Gln Ala Val Ile Pro Ser Arg Thr Val
355 360 365
Asn Arg Lys Ser Thr Asp Ser Pro Val Glu Cys Met Gly Gln Glu Lys
370 375 380
Gly Glu Phe Arg Glu Asn Trp Val Asn Val Ile Ser Asp Leu Lys Lys
385 390 395 400
Ile Glu Asp Leu Ile Gln Ser Met His Ile Asp Ala Thr Leu Tyr Thr
405 410 415
Glu Ser Asp Val His Pro Ser Cys Lys Val Thr Ala Met Lys Cys Phe
420 425 430
Leu Leu Glu Leu Gln Val Ile Ser Leu Glu Ser Gly Asp Ala Ser Ile
435 440 445
His Asp Thr Val Glu Asn Leu Ile Ile Leu Ala Asn Asn Ser Leu Ser
450 455 460
Ser Asn Gly Asn Val Thr Glu Ser Gly Cys Lys Glu Cys Glu Glu Leu
465 470 475 480
Glu Glu Lys Asn Ile Lys Glu Phe Leu Gln Ser Phe Val His Ile Val
485 490 495
Gln Met Phe Ile Asn Thr Ser
500
<210> 164
<211> 1509
<212> DNA
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成7t15-21s137L序列”
<400> 164
atgaagtggg tgaccttcat cagcctgctg ttcctgttct ccagcgccta ctccgattgc 60
gacatcgagg gcaaggacgg caagcagtac gagagcgtgc tgatggtgtc catcgaccag 120
ctgctggaca gcatgaagga gatcggctcc aactgcctca acaacgagtt caacttcttc 180
aagcggcaca tctgcgacgc caacaaggag ggcatgttcc tgttcagggc cgccaggaaa 240
ctgcggcagt tcctgaagat gaactccacc ggcgacttcg acctgcacct gctgaaggtg 300
tccgagggca ccaccatcct gctgaactgc accggacagg tgaagggccg gaaacctgct 360
gctctgggag aggcccaacc caccaagagc ctggaggaga acaagtccct gaaggagcag 420
aagaagctga acgacctgtg cttcctgaag aggctgctgc aggagatcaa gacctgctgg 480
aacaagatcc tgatgggcac caaggagcat agcggcacaa ccaacacagt cgctgcctat 540
aacctcactt ggaagagcac caacttcaaa accatcctcg aatgggaacc caaacccgtt 600
aaccaagttt acaccgtgca gatcagcacc aagtccggcg actggaagtc caaatgtttc 660
tataccaccg acaccgagtg cgatctcacc gatgagatcg tgaaagatgt gaaacagacc 720
tacctcgccc gggtgtttag ctaccccgcc ggcaatgtgg agagcactgg ttccgctggc 780
gagcctttat acgagaacag ccccgaattt accccttacc tcgagaccaa tttaggacag 840
cccaccatcc aaagctttga gcaagttggc acaaaggtga atgtgacagt ggaggacgag 900
cggactttag tgcggcggaa caacaccttt ctcagcctcc gggatgtgtt cggcaaagat 960
ttaatctaca cactgtatta ctggaagtcc tcttcctccg gcaagaagac agctaaaacc 1020
aacacaaacg agtttttaat cgacgtggat aaaggcgaaa actactgttt cagcgtgcaa 1080
gctgtgatcc cctcccggac cgtgaatagg aaaagcaccg atagccccgt tgagtgcatg 1140
ggccaagaaa agggcgagtt ccgggagaac tgggtgaacg tcatcagcga tttaaagaag 1200
atcgaagatt taattcagtc catgcatatc gacgccactt tatacacaga atccgacgtg 1260
cacccctctt gtaaggtgac cgccatgaaa tgttttttac tggagctgca agttatctct 1320
ttagagagcg gagacgctag catccacgac accgtggaga atttaatcat tttagccaat 1380
aactctttat ccagcaacgg caacgtgaca gagtccggct gcaaggagtg cgaagagctg 1440
gaggagaaga acatcaagga gtttctgcaa tcctttgtgc acattgtcca gatgttcatc 1500
aatacctcc 1509
<210> 165
<211> 397
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成7t15-21s137L序列”
<400> 165
Gln Gly Gln Asp Arg His Met Ile Arg Met Arg Gln Leu Ile Asp Ile
1 5 10 15
Val Asp Gln Leu Lys Asn Tyr Val Asn Asp Leu Val Pro Glu Phe Leu
20 25 30
Pro Ala Pro Glu Asp Val Glu Thr Asn Cys Glu Trp Ser Ala Phe Ser
35 40 45
Cys Phe Gln Lys Ala Gln Leu Lys Ser Ala Asn Thr Gly Asn Asn Glu
50 55 60
Arg Ile Ile Asn Val Ser Ile Lys Lys Leu Lys Arg Lys Pro Pro Ser
65 70 75 80
Thr Asn Ala Gly Arg Arg Gln Lys His Arg Leu Thr Cys Pro Ser Cys
85 90 95
Asp Ser Tyr Glu Lys Lys Pro Pro Lys Glu Phe Leu Glu Arg Phe Lys
100 105 110
Ser Leu Leu Gln Lys Met Ile His Gln His Leu Ser Ser Arg Thr His
115 120 125
Gly Ser Glu Asp Ser Ile Thr Cys Pro Pro Pro Met Ser Val Glu His
130 135 140
Ala Asp Ile Trp Val Lys Ser Tyr Ser Leu Tyr Ser Arg Glu Arg Tyr
145 150 155 160
Ile Cys Asn Ser Gly Phe Lys Arg Lys Ala Gly Thr Ser Ser Leu Thr
165 170 175
Glu Cys Val Leu Asn Lys Ala Thr Asn Val Ala His Trp Thr Thr Pro
180 185 190
Ser Leu Lys Cys Ile Arg Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
195 200 205
Gly Gly Gly Gly Ser Arg Glu Gly Pro Glu Leu Ser Pro Asp Asp Pro
210 215 220
Ala Gly Leu Leu Asp Leu Arg Gln Gly Met Phe Ala Gln Leu Val Ala
225 230 235 240
Gln Asn Val Leu Leu Ile Asp Gly Pro Leu Ser Trp Tyr Ser Asp Pro
245 250 255
Gly Leu Ala Gly Val Ser Leu Thr Gly Gly Leu Ser Tyr Lys Glu Asp
260 265 270
Thr Lys Glu Leu Val Val Ala Lys Ala Gly Val Tyr Tyr Val Phe Phe
275 280 285
Gln Leu Glu Leu Arg Arg Val Val Ala Gly Glu Gly Ser Gly Ser Val
290 295 300
Ser Leu Ala Leu His Leu Gln Pro Leu Arg Ser Ala Ala Gly Ala Ala
305 310 315 320
Ala Leu Ala Leu Thr Val Asp Leu Pro Pro Ala Ser Ser Glu Ala Arg
325 330 335
Asn Ser Ala Phe Gly Phe Gln Gly Arg Leu Leu His Leu Ser Ala Gly
340 345 350
Gln Arg Leu Gly Val His Leu His Thr Glu Ala Arg Ala Arg His Ala
355 360 365
Trp Gln Leu Thr Gln Gly Ala Thr Val Leu Gly Leu Phe Arg Val Thr
370 375 380
Pro Glu Ile Pro Ala Gly Leu Pro Ser Pro Arg Ser Glu
385 390 395
<210> 166
<211> 1191
<212> DNA
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成7t15-21s137L序列”
<400> 166
cagggccagg acaggcacat gatccggatg aggcagctca tcgacatcgt cgaccagctg 60
aagaactacg tgaacgacct ggtgcccgag tttctgcctg cccccgagga cgtggagacc 120
aactgcgagt ggtccgcctt ctcctgcttt cagaaggccc agctgaagtc cgccaacacc 180
ggcaacaacg agcggatcat caacgtgagc atcaagaagc tgaagcggaa gcctccctcc 240
acaaacgccg gcaggaggca gaagcacagg ctgacctgcc ccagctgtga ctcctacgag 300
aagaagcccc ccaaggagtt cctggagagg ttcaagtccc tgctgcagaa gatgatccat 360
cagcacctgt cctccaggac ccacggctcc gaggactcca ttacatgccc ccctcccatg 420
agcgtggagc acgccgacat ctgggtgaag agctatagcc tctacagccg ggagaggtat 480
atctgtaaca gcggcttcaa gaggaaggcc ggcaccagca gcctcaccga gtgcgtgctg 540
aataaggcta ccaacgtggc tcactggaca acaccctctt taaagtgcat ccggggcggt 600
ggaggatccg gaggaggtgg ctccggcggc ggaggatctc gcgagggtcc cgagctttcg 660
cccgacgatc ccgccggcct cttggacctg cggcagggca tgtttgcgca gctggtggcc 720
caaaatgttc tgctgatcga tgggcccctg agctggtaca gtgacccagg cctggcaggc 780
gtgtccctga cggggggcct gagctacaaa gaggacacga aggagctggt ggtggccaag 840
gctggagtct actatgtctt ctttcaacta gagctgcggc gcgtggtggc cggcgagggc 900
tcaggctccg tttcacttgc gctgcacctg cagccactgc gctctgctgc tggggccgcc 960
gccctggctt tgaccgtgga cctgccaccc gcctcctccg aggctcggaa ctcggccttc 1020
ggtttccagg gccgcttgct gcacctgagt gccggccagc gcctgggcgt ccatcttcac 1080
actgaggcca gggcacgcca tgcctggcag cttacccagg gcgccacagt cttgggactc 1140
ttccgggtga cccccgaaat cccagccgga ctcccttcac cgaggtcgga a 1191
<210> 167
<211> 415
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成7t15-21s137L序列”
<400> 167
Met Lys Trp Val Thr Phe Ile Ser Leu Leu Phe Leu Phe Ser Ser Ala
1 5 10 15
Tyr Ser Gln Gly Gln Asp Arg His Met Ile Arg Met Arg Gln Leu Ile
20 25 30
Asp Ile Val Asp Gln Leu Lys Asn Tyr Val Asn Asp Leu Val Pro Glu
35 40 45
Phe Leu Pro Ala Pro Glu Asp Val Glu Thr Asn Cys Glu Trp Ser Ala
50 55 60
Phe Ser Cys Phe Gln Lys Ala Gln Leu Lys Ser Ala Asn Thr Gly Asn
65 70 75 80
Asn Glu Arg Ile Ile Asn Val Ser Ile Lys Lys Leu Lys Arg Lys Pro
85 90 95
Pro Ser Thr Asn Ala Gly Arg Arg Gln Lys His Arg Leu Thr Cys Pro
100 105 110
Ser Cys Asp Ser Tyr Glu Lys Lys Pro Pro Lys Glu Phe Leu Glu Arg
115 120 125
Phe Lys Ser Leu Leu Gln Lys Met Ile His Gln His Leu Ser Ser Arg
130 135 140
Thr His Gly Ser Glu Asp Ser Ile Thr Cys Pro Pro Pro Met Ser Val
145 150 155 160
Glu His Ala Asp Ile Trp Val Lys Ser Tyr Ser Leu Tyr Ser Arg Glu
165 170 175
Arg Tyr Ile Cys Asn Ser Gly Phe Lys Arg Lys Ala Gly Thr Ser Ser
180 185 190
Leu Thr Glu Cys Val Leu Asn Lys Ala Thr Asn Val Ala His Trp Thr
195 200 205
Thr Pro Ser Leu Lys Cys Ile Arg Gly Gly Gly Gly Ser Gly Gly Gly
210 215 220
Gly Ser Gly Gly Gly Gly Ser Arg Glu Gly Pro Glu Leu Ser Pro Asp
225 230 235 240
Asp Pro Ala Gly Leu Leu Asp Leu Arg Gln Gly Met Phe Ala Gln Leu
245 250 255
Val Ala Gln Asn Val Leu Leu Ile Asp Gly Pro Leu Ser Trp Tyr Ser
260 265 270
Asp Pro Gly Leu Ala Gly Val Ser Leu Thr Gly Gly Leu Ser Tyr Lys
275 280 285
Glu Asp Thr Lys Glu Leu Val Val Ala Lys Ala Gly Val Tyr Tyr Val
290 295 300
Phe Phe Gln Leu Glu Leu Arg Arg Val Val Ala Gly Glu Gly Ser Gly
305 310 315 320
Ser Val Ser Leu Ala Leu His Leu Gln Pro Leu Arg Ser Ala Ala Gly
325 330 335
Ala Ala Ala Leu Ala Leu Thr Val Asp Leu Pro Pro Ala Ser Ser Glu
340 345 350
Ala Arg Asn Ser Ala Phe Gly Phe Gln Gly Arg Leu Leu His Leu Ser
355 360 365
Ala Gly Gln Arg Leu Gly Val His Leu His Thr Glu Ala Arg Ala Arg
370 375 380
His Ala Trp Gln Leu Thr Gln Gly Ala Thr Val Leu Gly Leu Phe Arg
385 390 395 400
Val Thr Pro Glu Ile Pro Ala Gly Leu Pro Ser Pro Arg Ser Glu
405 410 415
<210> 168
<211> 1245
<212> DNA
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成7t15-21s137L序列”
<400> 168
atgaagtggg tgaccttcat cagcctgctg ttcctgttct ccagcgccta ctcccagggc 60
caggacaggc acatgatccg gatgaggcag ctcatcgaca tcgtcgacca gctgaagaac 120
tacgtgaacg acctggtgcc cgagtttctg cctgcccccg aggacgtgga gaccaactgc 180
gagtggtccg ccttctcctg ctttcagaag gcccagctga agtccgccaa caccggcaac 240
aacgagcgga tcatcaacgt gagcatcaag aagctgaagc ggaagcctcc ctccacaaac 300
gccggcagga ggcagaagca caggctgacc tgccccagct gtgactccta cgagaagaag 360
ccccccaagg agttcctgga gaggttcaag tccctgctgc agaagatgat ccatcagcac 420
ctgtcctcca ggacccacgg ctccgaggac tccattacat gcccccctcc catgagcgtg 480
gagcacgccg acatctgggt gaagagctat agcctctaca gccgggagag gtatatctgt 540
aacagcggct tcaagaggaa ggccggcacc agcagcctca ccgagtgcgt gctgaataag 600
gctaccaacg tggctcactg gacaacaccc tctttaaagt gcatccgggg cggtggagga 660
tccggaggag gtggctccgg cggcggagga tctcgcgagg gtcccgagct ttcgcccgac 720
gatcccgccg gcctcttgga cctgcggcag ggcatgtttg cgcagctggt ggcccaaaat 780
gttctgctga tcgatgggcc cctgagctgg tacagtgacc caggcctggc aggcgtgtcc 840
ctgacggggg gcctgagcta caaagaggac acgaaggagc tggtggtggc caaggctgga 900
gtctactatg tcttctttca actagagctg cggcgcgtgg tggccggcga gggctcaggc 960
tccgtttcac ttgcgctgca cctgcagcca ctgcgctctg ctgctggggc cgccgccctg 1020
gctttgaccg tggacctgcc acccgcctcc tccgaggctc ggaactcggc cttcggtttc 1080
cagggccgct tgctgcacct gagtgccggc cagcgcctgg gcgtccatct tcacactgag 1140
gccagggcac gccatgcctg gcagcttacc cagggcgcca cagtcttggg actcttccgg 1200
gtgacccccg aaatcccagc cggactccct tcaccgaggt cggaa 1245
<210> 169
<211> 378
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成7t15-21s137L序列”
<400> 169
Gln Gly Gln Asp Arg His Met Ile Arg Met Arg Gln Leu Ile Asp Ile
1 5 10 15
Val Asp Gln Leu Lys Asn Tyr Val Asn Asp Leu Val Pro Glu Phe Leu
20 25 30
Pro Ala Pro Glu Asp Val Glu Thr Asn Cys Glu Trp Ser Ala Phe Ser
35 40 45
Cys Phe Gln Lys Ala Gln Leu Lys Ser Ala Asn Thr Gly Asn Asn Glu
50 55 60
Arg Ile Ile Asn Val Ser Ile Lys Lys Leu Lys Arg Lys Pro Pro Ser
65 70 75 80
Thr Asn Ala Gly Arg Arg Gln Lys His Arg Leu Thr Cys Pro Ser Cys
85 90 95
Asp Ser Tyr Glu Lys Lys Pro Pro Lys Glu Phe Leu Glu Arg Phe Lys
100 105 110
Ser Leu Leu Gln Lys Met Ile His Gln His Leu Ser Ser Arg Thr His
115 120 125
Gly Ser Glu Asp Ser Ile Thr Cys Pro Pro Pro Met Ser Val Glu His
130 135 140
Ala Asp Ile Trp Val Lys Ser Tyr Ser Leu Tyr Ser Arg Glu Arg Tyr
145 150 155 160
Ile Cys Asn Ser Gly Phe Lys Arg Lys Ala Gly Thr Ser Ser Leu Thr
165 170 175
Glu Cys Val Leu Asn Lys Ala Thr Asn Val Ala His Trp Thr Thr Pro
180 185 190
Ser Leu Lys Cys Ile Arg Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
195 200 205
Gly Gly Gly Gly Ser Asp Pro Ala Gly Leu Leu Asp Leu Arg Gln Gly
210 215 220
Met Phe Ala Gln Leu Val Ala Gln Asn Val Leu Leu Ile Asp Gly Pro
225 230 235 240
Leu Ser Trp Tyr Ser Asp Pro Gly Leu Ala Gly Val Ser Leu Thr Gly
245 250 255
Gly Leu Ser Tyr Lys Glu Asp Thr Lys Glu Leu Val Val Ala Lys Ala
260 265 270
Gly Val Tyr Tyr Val Phe Phe Gln Leu Glu Leu Arg Arg Val Val Ala
275 280 285
Gly Glu Gly Ser Gly Ser Val Ser Leu Ala Leu His Leu Gln Pro Leu
290 295 300
Arg Ser Ala Ala Gly Ala Ala Ala Leu Ala Leu Thr Val Asp Leu Pro
305 310 315 320
Pro Ala Ser Ser Glu Ala Arg Asn Ser Ala Phe Gly Phe Gln Gly Arg
325 330 335
Leu Leu His Leu Ser Ala Gly Gln Arg Leu Gly Val His Leu His Thr
340 345 350
Glu Ala Arg Ala Arg His Ala Trp Gln Leu Thr Gln Gly Ala Thr Val
355 360 365
Leu Gly Leu Phe Arg Val Thr Pro Glu Ile
370 375
<210> 170
<211> 1134
<212> DNA
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成7t15-21s137L序列”
<400> 170
cagggccagg acaggcacat gatccggatg aggcagctca tcgacatcgt cgaccagctg 60
aagaactacg tgaacgacct ggtgcccgag tttctgcctg cccccgagga cgtggagacc 120
aactgcgagt ggtccgcctt ctcctgcttt cagaaggccc agctgaagtc cgccaacacc 180
ggcaacaacg agcggatcat caacgtgagc atcaagaagc tgaagcggaa gcctccctcc 240
acaaacgccg gcaggaggca gaagcacagg ctgacctgcc ccagctgtga ctcctacgag 300
aagaagcccc ccaaggagtt cctggagagg ttcaagtccc tgctgcagaa gatgatccat 360
cagcacctgt cctccaggac ccacggctcc gaggactcca ttacatgccc ccctcccatg 420
agcgtggagc acgccgacat ctgggtgaag agctatagcc tctacagccg ggagaggtat 480
atctgtaaca gcggcttcaa gaggaaggcc ggcaccagca gcctcaccga gtgcgtgctg 540
aataaggcta ccaacgtggc tcactggaca acaccctctt taaagtgcat ccggggcggt 600
ggaggatccg gaggaggtgg ctccggcggc ggaggatctg atcccgccgg cctcttggac 660
ctgcggcagg gcatgtttgc gcagctggtg gcccaaaatg ttctgctgat cgatgggccc 720
ctgagctggt acagtgaccc aggcctggca ggcgtgtccc tgacgggggg cctgagctac 780
aaagaggaca cgaaggagct ggtggtggcc aaggctggag tctactatgt cttctttcaa 840
ctagagctgc ggcgcgtggt ggccggcgag ggctcaggct ccgtttcact tgcgctgcac 900
ctgcagccac tgcgctctgc tgctggggcc gccgccctgg ctttgaccgt ggacctgcca 960
cccgcctcct ccgaggctcg gaactcggcc ttcggtttcc agggccgctt gctgcacctg 1020
agtgccggcc agcgcctggg cgtccatctt cacactgagg ccagggcacg ccatgcctgg 1080
cagcttaccc agggcgccac agtcttggga ctcttccggg tgacccccga aatc 1134
<210> 171
<211> 396
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成7t15-21s137L序列”
<400> 171
Met Lys Trp Val Thr Phe Ile Ser Leu Leu Phe Leu Phe Ser Ser Ala
1 5 10 15
Tyr Ser Gln Gly Gln Asp Arg His Met Ile Arg Met Arg Gln Leu Ile
20 25 30
Asp Ile Val Asp Gln Leu Lys Asn Tyr Val Asn Asp Leu Val Pro Glu
35 40 45
Phe Leu Pro Ala Pro Glu Asp Val Glu Thr Asn Cys Glu Trp Ser Ala
50 55 60
Phe Ser Cys Phe Gln Lys Ala Gln Leu Lys Ser Ala Asn Thr Gly Asn
65 70 75 80
Asn Glu Arg Ile Ile Asn Val Ser Ile Lys Lys Leu Lys Arg Lys Pro
85 90 95
Pro Ser Thr Asn Ala Gly Arg Arg Gln Lys His Arg Leu Thr Cys Pro
100 105 110
Ser Cys Asp Ser Tyr Glu Lys Lys Pro Pro Lys Glu Phe Leu Glu Arg
115 120 125
Phe Lys Ser Leu Leu Gln Lys Met Ile His Gln His Leu Ser Ser Arg
130 135 140
Thr His Gly Ser Glu Asp Ser Ile Thr Cys Pro Pro Pro Met Ser Val
145 150 155 160
Glu His Ala Asp Ile Trp Val Lys Ser Tyr Ser Leu Tyr Ser Arg Glu
165 170 175
Arg Tyr Ile Cys Asn Ser Gly Phe Lys Arg Lys Ala Gly Thr Ser Ser
180 185 190
Leu Thr Glu Cys Val Leu Asn Lys Ala Thr Asn Val Ala His Trp Thr
195 200 205
Thr Pro Ser Leu Lys Cys Ile Arg Gly Gly Gly Gly Ser Gly Gly Gly
210 215 220
Gly Ser Gly Gly Gly Gly Ser Asp Pro Ala Gly Leu Leu Asp Leu Arg
225 230 235 240
Gln Gly Met Phe Ala Gln Leu Val Ala Gln Asn Val Leu Leu Ile Asp
245 250 255
Gly Pro Leu Ser Trp Tyr Ser Asp Pro Gly Leu Ala Gly Val Ser Leu
260 265 270
Thr Gly Gly Leu Ser Tyr Lys Glu Asp Thr Lys Glu Leu Val Val Ala
275 280 285
Lys Ala Gly Val Tyr Tyr Val Phe Phe Gln Leu Glu Leu Arg Arg Val
290 295 300
Val Ala Gly Glu Gly Ser Gly Ser Val Ser Leu Ala Leu His Leu Gln
305 310 315 320
Pro Leu Arg Ser Ala Ala Gly Ala Ala Ala Leu Ala Leu Thr Val Asp
325 330 335
Leu Pro Pro Ala Ser Ser Glu Ala Arg Asn Ser Ala Phe Gly Phe Gln
340 345 350
Gly Arg Leu Leu His Leu Ser Ala Gly Gln Arg Leu Gly Val His Leu
355 360 365
His Thr Glu Ala Arg Ala Arg His Ala Trp Gln Leu Thr Gln Gly Ala
370 375 380
Thr Val Leu Gly Leu Phe Arg Val Thr Pro Glu Ile
385 390 395
<210> 172
<211> 1188
<212> DNA
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成7t15-21s137L序列”
<400> 172
atgaagtggg tgaccttcat cagcctgctg ttcctgttct ccagcgccta ctcccagggc 60
caggacaggc acatgatccg gatgaggcag ctcatcgaca tcgtcgacca gctgaagaac 120
tacgtgaacg acctggtgcc cgagtttctg cctgcccccg aggacgtgga gaccaactgc 180
gagtggtccg ccttctcctg ctttcagaag gcccagctga agtccgccaa caccggcaac 240
aacgagcgga tcatcaacgt gagcatcaag aagctgaagc ggaagcctcc ctccacaaac 300
gccggcagga ggcagaagca caggctgacc tgccccagct gtgactccta cgagaagaag 360
ccccccaagg agttcctgga gaggttcaag tccctgctgc agaagatgat ccatcagcac 420
ctgtcctcca ggacccacgg ctccgaggac tccattacat gcccccctcc catgagcgtg 480
gagcacgccg acatctgggt gaagagctat agcctctaca gccgggagag gtatatctgt 540
aacagcggct tcaagaggaa ggccggcacc agcagcctca ccgagtgcgt gctgaataag 600
gctaccaacg tggctcactg gacaacaccc tctttaaagt gcatccgggg cggtggagga 660
tccggaggag gtggctccgg cggcggagga tctgatcccg ccggcctctt ggacctgcgg 720
cagggcatgt ttgcgcagct ggtggcccaa aatgttctgc tgatcgatgg gcccctgagc 780
tggtacagtg acccaggcct ggcaggcgtg tccctgacgg ggggcctgag ctacaaagag 840
gacacgaagg agctggtggt ggccaaggct ggagtctact atgtcttctt tcaactagag 900
ctgcggcgcg tggtggccgg cgagggctca ggctccgttt cacttgcgct gcacctgcag 960
ccactgcgct ctgctgctgg ggccgccgcc ctggctttga ccgtggacct gccacccgcc 1020
tcctccgagg ctcggaactc ggccttcggt ttccagggcc gcttgctgca cctgagtgcc 1080
ggccagcgcc tgggcgtcca tcttcacact gaggccaggg cacgccatgc ctggcagctt 1140
acccagggcg ccacagtctt gggactcttc cgggtgaccc ccgaaatc 1188
<210> 173
<211> 485
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成7t15-TGFRs序列”
<400> 173
Asp Cys Asp Ile Glu Gly Lys Asp Gly Lys Gln Tyr Glu Ser Val Leu
1 5 10 15
Met Val Ser Ile Asp Gln Leu Leu Asp Ser Met Lys Glu Ile Gly Ser
20 25 30
Asn Cys Leu Asn Asn Glu Phe Asn Phe Phe Lys Arg His Ile Cys Asp
35 40 45
Ala Asn Lys Glu Gly Met Phe Leu Phe Arg Ala Ala Arg Lys Leu Arg
50 55 60
Gln Phe Leu Lys Met Asn Ser Thr Gly Asp Phe Asp Leu His Leu Leu
65 70 75 80
Lys Val Ser Glu Gly Thr Thr Ile Leu Leu Asn Cys Thr Gly Gln Val
85 90 95
Lys Gly Arg Lys Pro Ala Ala Leu Gly Glu Ala Gln Pro Thr Lys Ser
100 105 110
Leu Glu Glu Asn Lys Ser Leu Lys Glu Gln Lys Lys Leu Asn Asp Leu
115 120 125
Cys Phe Leu Lys Arg Leu Leu Gln Glu Ile Lys Thr Cys Trp Asn Lys
130 135 140
Ile Leu Met Gly Thr Lys Glu His Ser Gly Thr Thr Asn Thr Val Ala
145 150 155 160
Ala Tyr Asn Leu Thr Trp Lys Ser Thr Asn Phe Lys Thr Ile Leu Glu
165 170 175
Trp Glu Pro Lys Pro Val Asn Gln Val Tyr Thr Val Gln Ile Ser Thr
180 185 190
Lys Ser Gly Asp Trp Lys Ser Lys Cys Phe Tyr Thr Thr Asp Thr Glu
195 200 205
Cys Asp Leu Thr Asp Glu Ile Val Lys Asp Val Lys Gln Thr Tyr Leu
210 215 220
Ala Arg Val Phe Ser Tyr Pro Ala Gly Asn Val Glu Ser Thr Gly Ser
225 230 235 240
Ala Gly Glu Pro Leu Tyr Glu Asn Ser Pro Glu Phe Thr Pro Tyr Leu
245 250 255
Glu Thr Asn Leu Gly Gln Pro Thr Ile Gln Ser Phe Glu Gln Val Gly
260 265 270
Thr Lys Val Asn Val Thr Val Glu Asp Glu Arg Thr Leu Val Arg Arg
275 280 285
Asn Asn Thr Phe Leu Ser Leu Arg Asp Val Phe Gly Lys Asp Leu Ile
290 295 300
Tyr Thr Leu Tyr Tyr Trp Lys Ser Ser Ser Ser Gly Lys Lys Thr Ala
305 310 315 320
Lys Thr Asn Thr Asn Glu Phe Leu Ile Asp Val Asp Lys Gly Glu Asn
325 330 335
Tyr Cys Phe Ser Val Gln Ala Val Ile Pro Ser Arg Thr Val Asn Arg
340 345 350
Lys Ser Thr Asp Ser Pro Val Glu Cys Met Gly Gln Glu Lys Gly Glu
355 360 365
Phe Arg Glu Asn Trp Val Asn Val Ile Ser Asp Leu Lys Lys Ile Glu
370 375 380
Asp Leu Ile Gln Ser Met His Ile Asp Ala Thr Leu Tyr Thr Glu Ser
385 390 395 400
Asp Val His Pro Ser Cys Lys Val Thr Ala Met Lys Cys Phe Leu Leu
405 410 415
Glu Leu Gln Val Ile Ser Leu Glu Ser Gly Asp Ala Ser Ile His Asp
420 425 430
Thr Val Glu Asn Leu Ile Ile Leu Ala Asn Asn Ser Leu Ser Ser Asn
435 440 445
Gly Asn Val Thr Glu Ser Gly Cys Lys Glu Cys Glu Glu Leu Glu Glu
450 455 460
Lys Asn Ile Lys Glu Phe Leu Gln Ser Phe Val His Ile Val Gln Met
465 470 475 480
Phe Ile Asn Thr Ser
485
<210> 174
<211> 1455
<212> DNA
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成7t15-TGFRs序列”
<400> 174
gattgcgaca tcgagggcaa ggacggcaag cagtacgaga gcgtgctgat ggtgtccatc 60
gaccagctgc tggacagcat gaaggagatc ggctccaact gcctcaacaa cgagttcaac 120
ttcttcaagc ggcacatctg cgacgccaac aaggagggca tgttcctgtt cagggccgcc 180
aggaaactgc ggcagttcct gaagatgaac tccaccggcg acttcgacct gcacctgctg 240
aaggtgtccg agggcaccac catcctgctg aactgcaccg gacaggtgaa gggccggaaa 300
cctgctgctc tgggagaggc ccaacccacc aagagcctgg aggagaacaa gtccctgaag 360
gagcagaaga agctgaacga cctgtgcttc ctgaagaggc tgctgcagga gatcaagacc 420
tgctggaaca agatcctgat gggcaccaag gagcatagcg gcacaaccaa cacagtcgct 480
gcctataacc tcacttggaa gagcaccaac ttcaaaacca tcctcgaatg ggaacccaaa 540
cccgttaacc aagtttacac cgtgcagatc agcaccaagt ccggcgactg gaagtccaaa 600
tgtttctata ccaccgacac cgagtgcgat ctcaccgatg agatcgtgaa agatgtgaaa 660
cagacctacc tcgcccgggt gtttagctac cccgccggca atgtggagag cactggttcc 720
gctggcgagc ctttatacga gaacagcccc gaatttaccc cttacctcga gaccaattta 780
ggacagccca ccatccaaag ctttgagcaa gttggcacaa aggtgaatgt gacagtggag 840
gacgagcgga ctttagtgcg gcggaacaac acctttctca gcctccggga tgtgttcggc 900
aaagatttaa tctacacact gtattactgg aagtcctctt cctccggcaa gaagacagct 960
aaaaccaaca caaacgagtt tttaatcgac gtggataaag gcgaaaacta ctgtttcagc 1020
gtgcaagctg tgatcccctc ccggaccgtg aataggaaaa gcaccgatag ccccgttgag 1080
tgcatgggcc aagaaaaggg cgagttccgg gagaactggg tgaacgtcat cagcgattta 1140
aagaagatcg aagatttaat tcagtccatg catatcgacg ccactttata cacagaatcc 1200
gacgtgcacc cctcttgtaa ggtgaccgcc atgaaatgtt ttttactgga gctgcaagtt 1260
atctctttag agagcggaga cgctagcatc cacgacaccg tggagaattt aatcatttta 1320
gccaataact ctttatccag caacggcaac gtgacagagt ccggctgcaa ggagtgcgaa 1380
gagctggagg agaagaacat caaggagttt ctgcaatcct ttgtgcacat tgtccagatg 1440
ttcatcaata cctcc 1455
<210> 175
<211> 502
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成7t15-TGFRs序列”
<400> 175
Met Lys Trp Val Thr Phe Ile Ser Leu Leu Phe Leu Phe Ser Ser Ala
1 5 10 15
Tyr Ser Asp Cys Asp Ile Glu Gly Lys Asp Gly Lys Gln Tyr Glu Ser
20 25 30
Val Leu Met Val Ser Ile Asp Gln Leu Leu Asp Ser Met Lys Glu Ile
35 40 45
Gly Ser Asn Cys Leu Asn Asn Glu Phe Asn Phe Phe Lys Arg His Ile
50 55 60
Cys Asp Ala Asn Lys Glu Gly Met Phe Leu Phe Arg Ala Ala Arg Lys
65 70 75 80
Leu Arg Gln Phe Leu Lys Met Asn Ser Thr Gly Asp Phe Asp Leu His
85 90 95
Leu Leu Lys Val Ser Glu Gly Thr Thr Ile Leu Leu Asn Cys Thr Gly
100 105 110
Gln Val Lys Gly Arg Lys Pro Ala Ala Leu Gly Glu Ala Gln Pro Thr
115 120 125
Lys Ser Leu Glu Glu Asn Lys Ser Leu Lys Glu Gln Lys Lys Leu Asn
130 135 140
Asp Leu Cys Phe Leu Lys Arg Leu Leu Gln Glu Ile Lys Thr Cys Trp
145 150 155 160
Asn Lys Ile Leu Met Gly Thr Lys Glu His Ser Gly Thr Thr Asn Thr
165 170 175
Val Ala Ala Tyr Asn Leu Thr Trp Lys Ser Thr Asn Phe Lys Thr Ile
180 185 190
Leu Glu Trp Glu Pro Lys Pro Val Asn Gln Val Tyr Thr Val Gln Ile
195 200 205
Ser Thr Lys Ser Gly Asp Trp Lys Ser Lys Cys Phe Tyr Thr Thr Asp
210 215 220
Thr Glu Cys Asp Leu Thr Asp Glu Ile Val Lys Asp Val Lys Gln Thr
225 230 235 240
Tyr Leu Ala Arg Val Phe Ser Tyr Pro Ala Gly Asn Val Glu Ser Thr
245 250 255
Gly Ser Ala Gly Glu Pro Leu Tyr Glu Asn Ser Pro Glu Phe Thr Pro
260 265 270
Tyr Leu Glu Thr Asn Leu Gly Gln Pro Thr Ile Gln Ser Phe Glu Gln
275 280 285
Val Gly Thr Lys Val Asn Val Thr Val Glu Asp Glu Arg Thr Leu Val
290 295 300
Arg Arg Asn Asn Thr Phe Leu Ser Leu Arg Asp Val Phe Gly Lys Asp
305 310 315 320
Leu Ile Tyr Thr Leu Tyr Tyr Trp Lys Ser Ser Ser Ser Gly Lys Lys
325 330 335
Thr Ala Lys Thr Asn Thr Asn Glu Phe Leu Ile Asp Val Asp Lys Gly
340 345 350
Glu Asn Tyr Cys Phe Ser Val Gln Ala Val Ile Pro Ser Arg Thr Val
355 360 365
Asn Arg Lys Ser Thr Asp Ser Pro Val Glu Cys Met Gly Gln Glu Lys
370 375 380
Gly Glu Phe Arg Glu Asn Trp Val Asn Val Ile Ser Asp Leu Lys Lys
385 390 395 400
Ile Glu Asp Leu Ile Gln Ser Met His Ile Asp Ala Thr Leu Tyr Thr
405 410 415
Glu Ser Asp Val His Pro Ser Cys Lys Val Thr Ala Met Lys Cys Phe
420 425 430
Leu Leu Glu Leu Gln Val Ile Ser Leu Glu Ser Gly Asp Ala Ser Ile
435 440 445
His Asp Thr Val Glu Asn Leu Ile Ile Leu Ala Asn Asn Ser Leu Ser
450 455 460
Ser Asn Gly Asn Val Thr Glu Ser Gly Cys Lys Glu Cys Glu Glu Leu
465 470 475 480
Glu Glu Lys Asn Ile Lys Glu Phe Leu Gln Ser Phe Val His Ile Val
485 490 495
Gln Met Phe Ile Asn Thr
500
<210> 176
<211> 1509
<212> DNA
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成7t15-TGFRs序列”
<400> 176
atgaagtggg tgaccttcat cagcctgctg ttcctgttct ccagcgccta ctccgattgc 60
gacatcgagg gcaaggacgg caagcagtac gagagcgtgc tgatggtgtc catcgaccag 120
ctgctggaca gcatgaagga gatcggctcc aactgcctca acaacgagtt caacttcttc 180
aagcggcaca tctgcgacgc caacaaggag ggcatgttcc tgttcagggc cgccaggaaa 240
ctgcggcagt tcctgaagat gaactccacc ggcgacttcg acctgcacct gctgaaggtg 300
tccgagggca ccaccatcct gctgaactgc accggacagg tgaagggccg gaaacctgct 360
gctctgggag aggcccaacc caccaagagc ctggaggaga acaagtccct gaaggagcag 420
aagaagctga acgacctgtg cttcctgaag aggctgctgc aggagatcaa gacctgctgg 480
aacaagatcc tgatgggcac caaggagcat agcggcacaa ccaacacagt cgctgcctat 540
aacctcactt ggaagagcac caacttcaaa accatcctcg aatgggaacc caaacccgtt 600
aaccaagttt acaccgtgca gatcagcacc aagtccggcg actggaagtc caaatgtttc 660
tataccaccg acaccgagtg cgatctcacc gatgagatcg tgaaagatgt gaaacagacc 720
tacctcgccc gggtgtttag ctaccccgcc ggcaatgtgg agagcactgg ttccgctggc 780
gagcctttat acgagaacag ccccgaattt accccttacc tcgagaccaa tttaggacag 840
cccaccatcc aaagctttga gcaagttggc acaaaggtga atgtgacagt ggaggacgag 900
cggactttag tgcggcggaa caacaccttt ctcagcctcc gggatgtgtt cggcaaagat 960
ttaatctaca cactgtatta ctggaagtcc tcttcctccg gcaagaagac agctaaaacc 1020
aacacaaacg agtttttaat cgacgtggat aaaggcgaaa actactgttt cagcgtgcaa 1080
gctgtgatcc cctcccggac cgtgaatagg aaaagcaccg atagccccgt tgagtgcatg 1140
ggccaagaaa agggcgagtt ccgggagaac tgggtgaacg tcatcagcga tttaaagaag 1200
atcgaagatt taattcagtc catgcatatc gacgccactt tatacacaga atccgacgtg 1260
cacccctctt gtaaggtgac cgccatgaaa tgttttttac tggagctgca agttatctct 1320
ttagagagcg gagacgctag catccacgac accgtggaga atttaatcat tttagccaat 1380
aactctttat ccagcaacgg caacgtgaca gagtccggct gcaaggagtg cgaagagctg 1440
gaggagaaga acatcaagga gtttctgcaa tcctttgtgc acattgtcca gatgttcatc 1500
aatacctcc 1509
<210> 177
<211> 352
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成7t15-TGFRs序列”
<400> 177
Ile Pro Pro His Val Gln Lys Ser Val Asn Asn Asp Met Ile Val Thr
1 5 10 15
Asp Asn Asn Gly Ala Val Lys Phe Pro Gln Leu Cys Lys Phe Cys Asp
20 25 30
Val Arg Phe Ser Thr Cys Asp Asn Gln Lys Ser Cys Met Ser Asn Cys
35 40 45
Ser Ile Thr Ser Ile Cys Glu Lys Pro Gln Glu Val Cys Val Ala Val
50 55 60
Trp Arg Lys Asn Asp Glu Asn Ile Thr Leu Glu Thr Val Cys His Asp
65 70 75 80
Pro Lys Leu Pro Tyr His Asp Phe Ile Leu Glu Asp Ala Ala Ser Pro
85 90 95
Lys Cys Ile Met Lys Glu Lys Lys Lys Pro Gly Glu Thr Phe Phe Met
100 105 110
Cys Ser Cys Ser Ser Asp Glu Cys Asn Asp Asn Ile Ile Phe Ser Glu
115 120 125
Glu Tyr Asn Thr Ser Asn Pro Asp Gly Gly Gly Gly Ser Gly Gly Gly
130 135 140
Gly Ser Gly Gly Gly Gly Ser Ile Pro Pro His Val Gln Lys Ser Val
145 150 155 160
Asn Asn Asp Met Ile Val Thr Asp Asn Asn Gly Ala Val Lys Phe Pro
165 170 175
Gln Leu Cys Lys Phe Cys Asp Val Arg Phe Ser Thr Cys Asp Asn Gln
180 185 190
Lys Ser Cys Met Ser Asn Cys Ser Ile Thr Ser Ile Cys Glu Lys Pro
195 200 205
Gln Glu Val Cys Val Ala Val Trp Arg Lys Asn Asp Glu Asn Ile Thr
210 215 220
Leu Glu Thr Val Cys His Asp Pro Lys Leu Pro Tyr His Asp Phe Ile
225 230 235 240
Leu Glu Asp Ala Ala Ser Pro Lys Cys Ile Met Lys Glu Lys Lys Lys
245 250 255
Pro Gly Glu Thr Phe Phe Met Cys Ser Cys Ser Ser Asp Glu Cys Asn
260 265 270
Asp Asn Ile Ile Phe Ser Glu Glu Tyr Asn Thr Ser Asn Pro Asp Ile
275 280 285
Thr Cys Pro Pro Pro Met Ser Val Glu His Ala Asp Ile Trp Val Lys
290 295 300
Ser Tyr Ser Leu Tyr Ser Arg Glu Arg Tyr Ile Cys Asn Ser Gly Phe
305 310 315 320
Lys Arg Lys Ala Gly Thr Ser Ser Leu Thr Glu Cys Val Leu Asn Lys
325 330 335
Ala Thr Asn Val Ala His Trp Thr Thr Pro Ser Leu Lys Cys Ile Arg
340 345 350
<210> 178
<211> 1056
<212> DNA
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成7t15-TGFRs序列”
<400> 178
atcccccccc atgtgcaaaa gagcgtgaac aacgatatga tcgtgaccga caacaacggc 60
gccgtgaagt ttccccagct ctgcaagttc tgcgatgtca ggttcagcac ctgcgataat 120
cagaagtcct gcatgtccaa ctgcagcatc acctccatct gcgagaagcc ccaagaagtg 180
tgcgtggccg tgtggcggaa aaatgacgag aacatcaccc tggagaccgt gtgtcacgac 240
cccaagctcc cttatcacga cttcattctg gaggacgctg cctcccccaa atgcatcatg 300
aaggagaaga agaagcccgg agagaccttc tttatgtgtt cctgtagcag cgacgagtgt 360
aacgacaaca tcatcttcag cgaagagtac aacaccagca accctgatgg aggtggcgga 420
tccggaggtg gaggttctgg tggaggtggg agtattcctc cccacgtgca gaagagcgtg 480
aataatgaca tgatcgtgac cgataacaat ggcgccgtga aatttcccca gctgtgcaaa 540
ttctgcgatg tgaggttttc cacctgcgac aaccagaagt cctgtatgag caactgctcc 600
atcacctcca tctgtgagaa gcctcaggag gtgtgcgtgg ctgtctggcg gaagaatgac 660
gagaatatca ccctggaaac cgtctgccac gatcccaagc tgccctacca cgatttcatc 720
ctggaagacg ccgccagccc taagtgcatc atgaaagaga aaaagaagcc tggcgagacc 780
tttttcatgt gctcctgcag cagcgacgaa tgcaacgaca atatcatctt tagcgaggaa 840
tacaatacca gcaaccccga cattacatgc ccccctccca tgagcgtgga gcacgccgac 900
atctgggtga agagctatag cctctacagc cgggagaggt atatctgtaa cagcggcttc 960
aagaggaagg ccggcaccag cagcctcacc gagtgcgtgc tgaataaggc taccaacgtg 1020
gctcactgga caacaccctc tttaaagtgc atccgg 1056
<210> 179
<211> 370
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成7t15-TGFRs序列”
<400> 179
Met Lys Trp Val Thr Phe Ile Ser Leu Leu Phe Leu Phe Ser Ser Ala
1 5 10 15
Tyr Ser Ile Pro Pro His Val Gln Lys Ser Val Asn Asn Asp Met Ile
20 25 30
Val Thr Asp Asn Asn Gly Ala Val Lys Phe Pro Gln Leu Cys Lys Phe
35 40 45
Cys Asp Val Arg Phe Ser Thr Cys Asp Asn Gln Lys Ser Cys Met Ser
50 55 60
Asn Cys Ser Ile Thr Ser Ile Cys Glu Lys Pro Gln Glu Val Cys Val
65 70 75 80
Ala Val Trp Arg Lys Asn Asp Glu Asn Ile Thr Leu Glu Thr Val Cys
85 90 95
His Asp Pro Lys Leu Pro Tyr His Asp Phe Ile Leu Glu Asp Ala Ala
100 105 110
Ser Pro Lys Cys Ile Met Lys Glu Lys Lys Lys Pro Gly Glu Thr Phe
115 120 125
Phe Met Cys Ser Cys Ser Ser Asp Glu Cys Asn Asp Asn Ile Ile Phe
130 135 140
Ser Glu Glu Tyr Asn Thr Ser Asn Pro Asp Gly Gly Gly Gly Ser Gly
145 150 155 160
Gly Gly Gly Ser Gly Gly Gly Gly Ser Ile Pro Pro His Val Gln Lys
165 170 175
Ser Val Asn Asn Asp Met Ile Val Thr Asp Asn Asn Gly Ala Val Lys
180 185 190
Phe Pro Gln Leu Cys Lys Phe Cys Asp Val Arg Phe Ser Thr Cys Asp
195 200 205
Asn Gln Lys Ser Cys Met Ser Asn Cys Ser Ile Thr Ser Ile Cys Glu
210 215 220
Lys Pro Gln Glu Val Cys Val Ala Val Trp Arg Lys Asn Asp Glu Asn
225 230 235 240
Ile Thr Leu Glu Thr Val Cys His Asp Pro Lys Leu Pro Tyr His Asp
245 250 255
Phe Ile Leu Glu Asp Ala Ala Ser Pro Lys Cys Ile Met Lys Glu Lys
260 265 270
Lys Lys Pro Gly Glu Thr Phe Phe Met Cys Ser Cys Ser Ser Asp Glu
275 280 285
Cys Asn Asp Asn Ile Ile Phe Ser Glu Glu Tyr Asn Thr Ser Asn Pro
290 295 300
Asp Ile Thr Cys Pro Pro Pro Met Ser Val Glu His Ala Asp Ile Trp
305 310 315 320
Val Lys Ser Tyr Ser Leu Tyr Ser Arg Glu Arg Tyr Ile Cys Asn Ser
325 330 335
Gly Phe Lys Arg Lys Ala Gly Thr Ser Ser Leu Thr Glu Cys Val Leu
340 345 350
Asn Lys Ala Thr Asn Val Ala His Trp Thr Thr Pro Ser Leu Lys Cys
355 360 365
Ile Arg
370
<210> 180
<211> 1110
<212> DNA
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成7t15-TGFRs序列”
<400> 180
atgaagtggg tgaccttcat cagcctgctg ttcctgttct ccagcgccta ctccatcccc 60
ccccatgtgc aaaagagcgt gaacaacgat atgatcgtga ccgacaacaa cggcgccgtg 120
aagtttcccc agctctgcaa gttctgcgat gtcaggttca gcacctgcga taatcagaag 180
tcctgcatgt ccaactgcag catcacctcc atctgcgaga agccccaaga agtgtgcgtg 240
gccgtgtggc ggaaaaatga cgagaacatc accctggaga ccgtgtgtca cgaccccaag 300
ctcccttatc acgacttcat tctggaggac gctgcctccc ccaaatgcat catgaaggag 360
aagaagaagc ccggagagac cttctttatg tgttcctgta gcagcgacga gtgtaacgac 420
aacatcatct tcagcgaaga gtacaacacc agcaaccctg atggaggtgg cggatccgga 480
ggtggaggtt ctggtggagg tgggagtatt cctccccacg tgcagaagag cgtgaataat 540
gacatgatcg tgaccgataa caatggcgcc gtgaaatttc cccagctgtg caaattctgc 600
gatgtgaggt tttccacctg cgacaaccag aagtcctgta tgagcaactg ctccatcacc 660
tccatctgtg agaagcctca ggaggtgtgc gtggctgtct ggcggaagaa tgacgagaat 720
atcaccctgg aaaccgtctg ccacgatccc aagctgccct accacgattt catcctggaa 780
gacgccgcca gccctaagtg catcatgaaa gagaaaaaga agcctggcga gacctttttc 840
atgtgctcct gcagcagcga cgaatgcaac gacaatatca tctttagcga ggaatacaat 900
accagcaacc ccgacattac atgcccccct cccatgagcg tggagcacgc cgacatctgg 960
gtgaagagct atagcctcta cagccgggag aggtatatct gtaacagcgg cttcaagagg 1020
aaggccggca ccagcagcct caccgagtgc gtgctgaata aggctaccaa cgtggctcac 1080
tggacaacac cctctttaaa gtgcatccgg 1110
<210> 181
<211> 620
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成TGFRt15-21s137L序列”
<400> 181
Ile Pro Pro His Val Gln Lys Ser Val Asn Asn Asp Met Ile Val Thr
1 5 10 15
Asp Asn Asn Gly Ala Val Lys Phe Pro Gln Leu Cys Lys Phe Cys Asp
20 25 30
Val Arg Phe Ser Thr Cys Asp Asn Gln Lys Ser Cys Met Ser Asn Cys
35 40 45
Ser Ile Thr Ser Ile Cys Glu Lys Pro Gln Glu Val Cys Val Ala Val
50 55 60
Trp Arg Lys Asn Asp Glu Asn Ile Thr Leu Glu Thr Val Cys His Asp
65 70 75 80
Pro Lys Leu Pro Tyr His Asp Phe Ile Leu Glu Asp Ala Ala Ser Pro
85 90 95
Lys Cys Ile Met Lys Glu Lys Lys Lys Pro Gly Glu Thr Phe Phe Met
100 105 110
Cys Ser Cys Ser Ser Asp Glu Cys Asn Asp Asn Ile Ile Phe Ser Glu
115 120 125
Glu Tyr Asn Thr Ser Asn Pro Asp Gly Gly Gly Gly Ser Gly Gly Gly
130 135 140
Gly Ser Gly Gly Gly Gly Ser Ile Pro Pro His Val Gln Lys Ser Val
145 150 155 160
Asn Asn Asp Met Ile Val Thr Asp Asn Asn Gly Ala Val Lys Phe Pro
165 170 175
Gln Leu Cys Lys Phe Cys Asp Val Arg Phe Ser Thr Cys Asp Asn Gln
180 185 190
Lys Ser Cys Met Ser Asn Cys Ser Ile Thr Ser Ile Cys Glu Lys Pro
195 200 205
Gln Glu Val Cys Val Ala Val Trp Arg Lys Asn Asp Glu Asn Ile Thr
210 215 220
Leu Glu Thr Val Cys His Asp Pro Lys Leu Pro Tyr His Asp Phe Ile
225 230 235 240
Leu Glu Asp Ala Ala Ser Pro Lys Cys Ile Met Lys Glu Lys Lys Lys
245 250 255
Pro Gly Glu Thr Phe Phe Met Cys Ser Cys Ser Ser Asp Glu Cys Asn
260 265 270
Asp Asn Ile Ile Phe Ser Glu Glu Tyr Asn Thr Ser Asn Pro Asp Ser
275 280 285
Gly Thr Thr Asn Thr Val Ala Ala Tyr Asn Leu Thr Trp Lys Ser Thr
290 295 300
Asn Phe Lys Thr Ile Leu Glu Trp Glu Pro Lys Pro Val Asn Gln Val
305 310 315 320
Tyr Thr Val Gln Ile Ser Thr Lys Ser Gly Asp Trp Lys Ser Lys Cys
325 330 335
Phe Tyr Thr Thr Asp Thr Glu Cys Asp Leu Thr Asp Glu Ile Val Lys
340 345 350
Asp Val Lys Gln Thr Tyr Leu Ala Arg Val Phe Ser Tyr Pro Ala Gly
355 360 365
Asn Val Glu Ser Thr Gly Ser Ala Gly Glu Pro Leu Tyr Glu Asn Ser
370 375 380
Pro Glu Phe Thr Pro Tyr Leu Glu Thr Asn Leu Gly Gln Pro Thr Ile
385 390 395 400
Gln Ser Phe Glu Gln Val Gly Thr Lys Val Asn Val Thr Val Glu Asp
405 410 415
Glu Arg Thr Leu Val Arg Arg Asn Asn Thr Phe Leu Ser Leu Arg Asp
420 425 430
Val Phe Gly Lys Asp Leu Ile Tyr Thr Leu Tyr Tyr Trp Lys Ser Ser
435 440 445
Ser Ser Gly Lys Lys Thr Ala Lys Thr Asn Thr Asn Glu Phe Leu Ile
450 455 460
Asp Val Asp Lys Gly Glu Asn Tyr Cys Phe Ser Val Gln Ala Val Ile
465 470 475 480
Pro Ser Arg Thr Val Asn Arg Lys Ser Thr Asp Ser Pro Val Glu Cys
485 490 495
Met Gly Gln Glu Lys Gly Glu Phe Arg Glu Asn Trp Val Asn Val Ile
500 505 510
Ser Asp Leu Lys Lys Ile Glu Asp Leu Ile Gln Ser Met His Ile Asp
515 520 525
Ala Thr Leu Tyr Thr Glu Ser Asp Val His Pro Ser Cys Lys Val Thr
530 535 540
Ala Met Lys Cys Phe Leu Leu Glu Leu Gln Val Ile Ser Leu Glu Ser
545 550 555 560
Gly Asp Ala Ser Ile His Asp Thr Val Glu Asn Leu Ile Ile Leu Ala
565 570 575
Asn Asn Ser Leu Ser Ser Asn Gly Asn Val Thr Glu Ser Gly Cys Lys
580 585 590
Glu Cys Glu Glu Leu Glu Glu Lys Asn Ile Lys Glu Phe Leu Gln Ser
595 600 605
Phe Val His Ile Val Gln Met Phe Ile Asn Thr Ser
610 615 620
<210> 182
<211> 1860
<212> DNA
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成TGFRt15-21s137L序列”
<400> 182
atcccccccc atgtgcaaaa gagcgtgaac aacgatatga tcgtgaccga caacaacggc 60
gccgtgaagt ttccccagct ctgcaagttc tgcgatgtca ggttcagcac ctgcgataat 120
cagaagtcct gcatgtccaa ctgcagcatc acctccatct gcgagaagcc ccaagaagtg 180
tgcgtggccg tgtggcggaa aaatgacgag aacatcaccc tggagaccgt gtgtcacgac 240
cccaagctcc cttatcacga cttcattctg gaggacgctg cctcccccaa atgcatcatg 300
aaggagaaga agaagcccgg agagaccttc tttatgtgtt cctgtagcag cgacgagtgt 360
aacgacaaca tcatcttcag cgaagagtac aacaccagca accctgatgg aggtggcgga 420
tccggaggtg gaggttctgg tggaggtggg agtattcctc cccacgtgca gaagagcgtg 480
aataatgaca tgatcgtgac cgataacaat ggcgccgtga aatttcccca gctgtgcaaa 540
ttctgcgatg tgaggttttc cacctgcgac aaccagaagt cctgtatgag caactgctcc 600
atcacctcca tctgtgagaa gcctcaggag gtgtgcgtgg ctgtctggcg gaagaatgac 660
gagaatatca ccctggaaac cgtctgccac gatcccaagc tgccctacca cgatttcatc 720
ctggaagacg ccgccagccc taagtgcatc atgaaagaga aaaagaagcc tggcgagacc 780
tttttcatgt gctcctgcag cagcgacgaa tgcaacgaca atatcatctt tagcgaggaa 840
tacaatacca gcaaccccga cagcggcaca accaacacag tcgctgccta taacctcact 900
tggaagagca ccaacttcaa aaccatcctc gaatgggaac ccaaacccgt taaccaagtt 960
tacaccgtgc agatcagcac caagtccggc gactggaagt ccaaatgttt ctataccacc 1020
gacaccgagt gcgatctcac cgatgagatc gtgaaagatg tgaaacagac ctacctcgcc 1080
cgggtgttta gctaccccgc cggcaatgtg gagagcactg gttccgctgg cgagccttta 1140
tacgagaaca gccccgaatt taccccttac ctcgagacca atttaggaca gcccaccatc 1200
caaagctttg agcaagttgg cacaaaggtg aatgtgacag tggaggacga gcggacttta 1260
gtgcggcgga acaacacctt tctcagcctc cgggatgtgt tcggcaaaga tttaatctac 1320
acactgtatt actggaagtc ctcttcctcc ggcaagaaga cagctaaaac caacacaaac 1380
gagtttttaa tcgacgtgga taaaggcgaa aactactgtt tcagcgtgca agctgtgatc 1440
ccctcccgga ccgtgaatag gaaaagcacc gatagccccg ttgagtgcat gggccaagaa 1500
aagggcgagt tccgggagaa ctgggtgaac gtcatcagcg atttaaagaa gatcgaagat 1560
ttaattcagt ccatgcatat cgacgccact ttatacacag aatccgacgt gcacccctct 1620
tgtaaggtga ccgccatgaa atgtttttta ctggagctgc aagttatctc tttagagagc 1680
ggagacgcta gcatccacga caccgtggag aatttaatca ttttagccaa taactcttta 1740
tccagcaacg gcaacgtgac agagtccggc tgcaaggagt gcgaagagct ggaggagaag 1800
aacatcaagg agtttctgca atcctttgtg cacattgtcc agatgttcat caatacctcc 1860
<210> 183
<211> 638
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成TGFRt15-21s137L序列”
<400> 183
Met Lys Trp Val Thr Phe Ile Ser Leu Leu Phe Leu Phe Ser Ser Ala
1 5 10 15
Tyr Ser Ile Pro Pro His Val Gln Lys Ser Val Asn Asn Asp Met Ile
20 25 30
Val Thr Asp Asn Asn Gly Ala Val Lys Phe Pro Gln Leu Cys Lys Phe
35 40 45
Cys Asp Val Arg Phe Ser Thr Cys Asp Asn Gln Lys Ser Cys Met Ser
50 55 60
Asn Cys Ser Ile Thr Ser Ile Cys Glu Lys Pro Gln Glu Val Cys Val
65 70 75 80
Ala Val Trp Arg Lys Asn Asp Glu Asn Ile Thr Leu Glu Thr Val Cys
85 90 95
His Asp Pro Lys Leu Pro Tyr His Asp Phe Ile Leu Glu Asp Ala Ala
100 105 110
Ser Pro Lys Cys Ile Met Lys Glu Lys Lys Lys Pro Gly Glu Thr Phe
115 120 125
Phe Met Cys Ser Cys Ser Ser Asp Glu Cys Asn Asp Asn Ile Ile Phe
130 135 140
Ser Glu Glu Tyr Asn Thr Ser Asn Pro Asp Gly Gly Gly Gly Ser Gly
145 150 155 160
Gly Gly Gly Ser Gly Gly Gly Gly Ser Ile Pro Pro His Val Gln Lys
165 170 175
Ser Val Asn Asn Asp Met Ile Val Thr Asp Asn Asn Gly Ala Val Lys
180 185 190
Phe Pro Gln Leu Cys Lys Phe Cys Asp Val Arg Phe Ser Thr Cys Asp
195 200 205
Asn Gln Lys Ser Cys Met Ser Asn Cys Ser Ile Thr Ser Ile Cys Glu
210 215 220
Lys Pro Gln Glu Val Cys Val Ala Val Trp Arg Lys Asn Asp Glu Asn
225 230 235 240
Ile Thr Leu Glu Thr Val Cys His Asp Pro Lys Leu Pro Tyr His Asp
245 250 255
Phe Ile Leu Glu Asp Ala Ala Ser Pro Lys Cys Ile Met Lys Glu Lys
260 265 270
Lys Lys Pro Gly Glu Thr Phe Phe Met Cys Ser Cys Ser Ser Asp Glu
275 280 285
Cys Asn Asp Asn Ile Ile Phe Ser Glu Glu Tyr Asn Thr Ser Asn Pro
290 295 300
Asp Ser Gly Thr Thr Asn Thr Val Ala Ala Tyr Asn Leu Thr Trp Lys
305 310 315 320
Ser Thr Asn Phe Lys Thr Ile Leu Glu Trp Glu Pro Lys Pro Val Asn
325 330 335
Gln Val Tyr Thr Val Gln Ile Ser Thr Lys Ser Gly Asp Trp Lys Ser
340 345 350
Lys Cys Phe Tyr Thr Thr Asp Thr Glu Cys Asp Leu Thr Asp Glu Ile
355 360 365
Val Lys Asp Val Lys Gln Thr Tyr Leu Ala Arg Val Phe Ser Tyr Pro
370 375 380
Ala Gly Asn Val Glu Ser Thr Gly Ser Ala Gly Glu Pro Leu Tyr Glu
385 390 395 400
Asn Ser Pro Glu Phe Thr Pro Tyr Leu Glu Thr Asn Leu Gly Gln Pro
405 410 415
Thr Ile Gln Ser Phe Glu Gln Val Gly Thr Lys Val Asn Val Thr Val
420 425 430
Glu Asp Glu Arg Thr Leu Val Arg Arg Asn Asn Thr Phe Leu Ser Leu
435 440 445
Arg Asp Val Phe Gly Lys Asp Leu Ile Tyr Thr Leu Tyr Tyr Trp Lys
450 455 460
Ser Ser Ser Ser Gly Lys Lys Thr Ala Lys Thr Asn Thr Asn Glu Phe
465 470 475 480
Leu Ile Asp Val Asp Lys Gly Glu Asn Tyr Cys Phe Ser Val Gln Ala
485 490 495
Val Ile Pro Ser Arg Thr Val Asn Arg Lys Ser Thr Asp Ser Pro Val
500 505 510
Glu Cys Met Gly Gln Glu Lys Gly Glu Phe Arg Glu Asn Trp Val Asn
515 520 525
Val Ile Ser Asp Leu Lys Lys Ile Glu Asp Leu Ile Gln Ser Met His
530 535 540
Ile Asp Ala Thr Leu Tyr Thr Glu Ser Asp Val His Pro Ser Cys Lys
545 550 555 560
Val Thr Ala Met Lys Cys Phe Leu Leu Glu Leu Gln Val Ile Ser Leu
565 570 575
Glu Ser Gly Asp Ala Ser Ile His Asp Thr Val Glu Asn Leu Ile Ile
580 585 590
Leu Ala Asn Asn Ser Leu Ser Ser Asn Gly Asn Val Thr Glu Ser Gly
595 600 605
Cys Lys Glu Cys Glu Glu Leu Glu Glu Lys Asn Ile Lys Glu Phe Leu
610 615 620
Gln Ser Phe Val His Ile Val Gln Met Phe Ile Asn Thr Ser
625 630 635
<210> 184
<211> 1914
<212> DNA
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成TGFRt15-21s137L序列”
<400> 184
atgaagtggg tgaccttcat cagcctgctg ttcctgttct ccagcgccta ctccatcccc 60
ccccatgtgc aaaagagcgt gaacaacgat atgatcgtga ccgacaacaa cggcgccgtg 120
aagtttcccc agctctgcaa gttctgcgat gtcaggttca gcacctgcga taatcagaag 180
tcctgcatgt ccaactgcag catcacctcc atctgcgaga agccccaaga agtgtgcgtg 240
gccgtgtggc ggaaaaatga cgagaacatc accctggaga ccgtgtgtca cgaccccaag 300
ctcccttatc acgacttcat tctggaggac gctgcctccc ccaaatgcat catgaaggag 360
aagaagaagc ccggagagac cttctttatg tgttcctgta gcagcgacga gtgtaacgac 420
aacatcatct tcagcgaaga gtacaacacc agcaaccctg atggaggtgg cggatccgga 480
ggtggaggtt ctggtggagg tgggagtatt cctccccacg tgcagaagag cgtgaataat 540
gacatgatcg tgaccgataa caatggcgcc gtgaaatttc cccagctgtg caaattctgc 600
gatgtgaggt tttccacctg cgacaaccag aagtcctgta tgagcaactg ctccatcacc 660
tccatctgtg agaagcctca ggaggtgtgc gtggctgtct ggcggaagaa tgacgagaat 720
atcaccctgg aaaccgtctg ccacgatccc aagctgccct accacgattt catcctggaa 780
gacgccgcca gccctaagtg catcatgaaa gagaaaaaga agcctggcga gacctttttc 840
atgtgctcct gcagcagcga cgaatgcaac gacaatatca tctttagcga ggaatacaat 900
accagcaacc ccgacagcgg cacaaccaac acagtcgctg cctataacct cacttggaag 960
agcaccaact tcaaaaccat cctcgaatgg gaacccaaac ccgttaacca agtttacacc 1020
gtgcagatca gcaccaagtc cggcgactgg aagtccaaat gtttctatac caccgacacc 1080
gagtgcgatc tcaccgatga gatcgtgaaa gatgtgaaac agacctacct cgcccgggtg 1140
tttagctacc ccgccggcaa tgtggagagc actggttccg ctggcgagcc tttatacgag 1200
aacagccccg aatttacccc ttacctcgag accaatttag gacagcccac catccaaagc 1260
tttgagcaag ttggcacaaa ggtgaatgtg acagtggagg acgagcggac tttagtgcgg 1320
cggaacaaca cctttctcag cctccgggat gtgttcggca aagatttaat ctacacactg 1380
tattactgga agtcctcttc ctccggcaag aagacagcta aaaccaacac aaacgagttt 1440
ttaatcgacg tggataaagg cgaaaactac tgtttcagcg tgcaagctgt gatcccctcc 1500
cggaccgtga ataggaaaag caccgatagc cccgttgagt gcatgggcca agaaaagggc 1560
gagttccggg agaactgggt gaacgtcatc agcgatttaa agaagatcga agatttaatt 1620
cagtccatgc atatcgacgc cactttatac acagaatccg acgtgcaccc ctcttgtaag 1680
gtgaccgcca tgaaatgttt tttactggag ctgcaagtta tctctttaga gagcggagac 1740
gctagcatcc acgacaccgt ggagaattta atcattttag ccaataactc tttatccagc 1800
aacggcaacg tgacagagtc cggctgcaag gagtgcgaag agctggagga gaagaacatc 1860
aaggagtttc tgcaatcctt tgtgcacatt gtccagatgt tcatcaatac ctcc 1914
<210> 185
<211> 397
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成TGFRt15-21s137L序列”
<400> 185
Gln Gly Gln Asp Arg His Met Ile Arg Met Arg Gln Leu Ile Asp Ile
1 5 10 15
Val Asp Gln Leu Lys Asn Tyr Val Asn Asp Leu Val Pro Glu Phe Leu
20 25 30
Pro Ala Pro Glu Asp Val Glu Thr Asn Cys Glu Trp Ser Ala Phe Ser
35 40 45
Cys Phe Gln Lys Ala Gln Leu Lys Ser Ala Asn Thr Gly Asn Asn Glu
50 55 60
Arg Ile Ile Asn Val Ser Ile Lys Lys Leu Lys Arg Lys Pro Pro Ser
65 70 75 80
Thr Asn Ala Gly Arg Arg Gln Lys His Arg Leu Thr Cys Pro Ser Cys
85 90 95
Asp Ser Tyr Glu Lys Lys Pro Pro Lys Glu Phe Leu Glu Arg Phe Lys
100 105 110
Ser Leu Leu Gln Lys Met Ile His Gln His Leu Ser Ser Arg Thr His
115 120 125
Gly Ser Glu Asp Ser Ile Thr Cys Pro Pro Pro Met Ser Val Glu His
130 135 140
Ala Asp Ile Trp Val Lys Ser Tyr Ser Leu Tyr Ser Arg Glu Arg Tyr
145 150 155 160
Ile Cys Asn Ser Gly Phe Lys Arg Lys Ala Gly Thr Ser Ser Leu Thr
165 170 175
Glu Cys Val Leu Asn Lys Ala Thr Asn Val Ala His Trp Thr Thr Pro
180 185 190
Ser Leu Lys Cys Ile Arg Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
195 200 205
Gly Gly Gly Gly Ser Arg Glu Gly Pro Glu Leu Ser Pro Asp Asp Pro
210 215 220
Ala Gly Leu Leu Asp Leu Arg Gln Gly Met Phe Ala Gln Leu Val Ala
225 230 235 240
Gln Asn Val Leu Leu Ile Asp Gly Pro Leu Ser Trp Tyr Ser Asp Pro
245 250 255
Gly Leu Ala Gly Val Ser Leu Thr Gly Gly Leu Ser Tyr Lys Glu Asp
260 265 270
Thr Lys Glu Leu Val Val Ala Lys Ala Gly Val Tyr Tyr Val Phe Phe
275 280 285
Gln Leu Glu Leu Arg Arg Val Val Ala Gly Glu Gly Ser Gly Ser Val
290 295 300
Ser Leu Ala Leu His Leu Gln Pro Leu Arg Ser Ala Ala Gly Ala Ala
305 310 315 320
Ala Leu Ala Leu Thr Val Asp Leu Pro Pro Ala Ser Ser Glu Ala Arg
325 330 335
Asn Ser Ala Phe Gly Phe Gln Gly Arg Leu Leu His Leu Ser Ala Gly
340 345 350
Gln Arg Leu Gly Val His Leu His Thr Glu Ala Arg Ala Arg His Ala
355 360 365
Trp Gln Leu Thr Gln Gly Ala Thr Val Leu Gly Leu Phe Arg Val Thr
370 375 380
Pro Glu Ile Pro Ala Gly Leu Pro Ser Pro Arg Ser Glu
385 390 395
<210> 186
<211> 1191
<212> DNA
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成TGFRt15-21s137L序列”
<400> 186
cagggccagg acaggcacat gatccggatg aggcagctca tcgacatcgt cgaccagctg 60
aagaactacg tgaacgacct ggtgcccgag tttctgcctg cccccgagga cgtggagacc 120
aactgcgagt ggtccgcctt ctcctgcttt cagaaggccc agctgaagtc cgccaacacc 180
ggcaacaacg agcggatcat caacgtgagc atcaagaagc tgaagcggaa gcctccctcc 240
acaaacgccg gcaggaggca gaagcacagg ctgacctgcc ccagctgtga ctcctacgag 300
aagaagcccc ccaaggagtt cctggagagg ttcaagtccc tgctgcagaa gatgatccat 360
cagcacctgt cctccaggac ccacggctcc gaggactcca ttacatgccc ccctcccatg 420
agcgtggagc acgccgacat ctgggtgaag agctatagcc tctacagccg ggagaggtat 480
atctgtaaca gcggcttcaa gaggaaggcc ggcaccagca gcctcaccga gtgcgtgctg 540
aataaggcta ccaacgtggc tcactggaca acaccctctt taaagtgcat ccggggcggt 600
ggaggatccg gaggaggtgg ctccggcggc ggaggatctc gcgagggtcc cgagctttcg 660
cccgacgatc ccgccggcct cttggacctg cggcagggca tgtttgcgca gctggtggcc 720
caaaatgttc tgctgatcga tgggcccctg agctggtaca gtgacccagg cctggcaggc 780
gtgtccctga cggggggcct gagctacaaa gaggacacga aggagctggt ggtggccaag 840
gctggagtct actatgtctt ctttcaacta gagctgcggc gcgtggtggc cggcgagggc 900
tcaggctccg tttcacttgc gctgcacctg cagccactgc gctctgctgc tggggccgcc 960
gccctggctt tgaccgtgga cctgccaccc gcctcctccg aggctcggaa ctcggccttc 1020
ggtttccagg gccgcttgct gcacctgagt gccggccagc gcctgggcgt ccatcttcac 1080
actgaggcca gggcacgcca tgcctggcag cttacccagg gcgccacagt cttgggactc 1140
ttccgggtga cccccgaaat cccagccgga ctcccttcac cgaggtcgga a 1191
<210> 187
<211> 415
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成TGFRt15-21s137L序列”
<400> 187
Met Lys Trp Val Thr Phe Ile Ser Leu Leu Phe Leu Phe Ser Ser Ala
1 5 10 15
Tyr Ser Gln Gly Gln Asp Arg His Met Ile Arg Met Arg Gln Leu Ile
20 25 30
Asp Ile Val Asp Gln Leu Lys Asn Tyr Val Asn Asp Leu Val Pro Glu
35 40 45
Phe Leu Pro Ala Pro Glu Asp Val Glu Thr Asn Cys Glu Trp Ser Ala
50 55 60
Phe Ser Cys Phe Gln Lys Ala Gln Leu Lys Ser Ala Asn Thr Gly Asn
65 70 75 80
Asn Glu Arg Ile Ile Asn Val Ser Ile Lys Lys Leu Lys Arg Lys Pro
85 90 95
Pro Ser Thr Asn Ala Gly Arg Arg Gln Lys His Arg Leu Thr Cys Pro
100 105 110
Ser Cys Asp Ser Tyr Glu Lys Lys Pro Pro Lys Glu Phe Leu Glu Arg
115 120 125
Phe Lys Ser Leu Leu Gln Lys Met Ile His Gln His Leu Ser Ser Arg
130 135 140
Thr His Gly Ser Glu Asp Ser Ile Thr Cys Pro Pro Pro Met Ser Val
145 150 155 160
Glu His Ala Asp Ile Trp Val Lys Ser Tyr Ser Leu Tyr Ser Arg Glu
165 170 175
Arg Tyr Ile Cys Asn Ser Gly Phe Lys Arg Lys Ala Gly Thr Ser Ser
180 185 190
Leu Thr Glu Cys Val Leu Asn Lys Ala Thr Asn Val Ala His Trp Thr
195 200 205
Thr Pro Ser Leu Lys Cys Ile Arg Gly Gly Gly Gly Ser Gly Gly Gly
210 215 220
Gly Ser Gly Gly Gly Gly Ser Arg Glu Gly Pro Glu Leu Ser Pro Asp
225 230 235 240
Asp Pro Ala Gly Leu Leu Asp Leu Arg Gln Gly Met Phe Ala Gln Leu
245 250 255
Val Ala Gln Asn Val Leu Leu Ile Asp Gly Pro Leu Ser Trp Tyr Ser
260 265 270
Asp Pro Gly Leu Ala Gly Val Ser Leu Thr Gly Gly Leu Ser Tyr Lys
275 280 285
Glu Asp Thr Lys Glu Leu Val Val Ala Lys Ala Gly Val Tyr Tyr Val
290 295 300
Phe Phe Gln Leu Glu Leu Arg Arg Val Val Ala Gly Glu Gly Ser Gly
305 310 315 320
Ser Val Ser Leu Ala Leu His Leu Gln Pro Leu Arg Ser Ala Ala Gly
325 330 335
Ala Ala Ala Leu Ala Leu Thr Val Asp Leu Pro Pro Ala Ser Ser Glu
340 345 350
Ala Arg Asn Ser Ala Phe Gly Phe Gln Gly Arg Leu Leu His Leu Ser
355 360 365
Ala Gly Gln Arg Leu Gly Val His Leu His Thr Glu Ala Arg Ala Arg
370 375 380
His Ala Trp Gln Leu Thr Gln Gly Ala Thr Val Leu Gly Leu Phe Arg
385 390 395 400
Val Thr Pro Glu Ile Pro Ala Gly Leu Pro Ser Pro Arg Ser Glu
405 410 415
<210> 188
<211> 1245
<212> DNA
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成TGFRt15-21s137L序列”
<400> 188
atgaagtggg tgaccttcat cagcctgctg ttcctgttct ccagcgccta ctcccagggc 60
caggacaggc acatgatccg gatgaggcag ctcatcgaca tcgtcgacca gctgaagaac 120
tacgtgaacg acctggtgcc cgagtttctg cctgcccccg aggacgtgga gaccaactgc 180
gagtggtccg ccttctcctg ctttcagaag gcccagctga agtccgccaa caccggcaac 240
aacgagcgga tcatcaacgt gagcatcaag aagctgaagc ggaagcctcc ctccacaaac 300
gccggcagga ggcagaagca caggctgacc tgccccagct gtgactccta cgagaagaag 360
ccccccaagg agttcctgga gaggttcaag tccctgctgc agaagatgat ccatcagcac 420
ctgtcctcca ggacccacgg ctccgaggac tccattacat gcccccctcc catgagcgtg 480
gagcacgccg acatctgggt gaagagctat agcctctaca gccgggagag gtatatctgt 540
aacagcggct tcaagaggaa ggccggcacc agcagcctca ccgagtgcgt gctgaataag 600
gctaccaacg tggctcactg gacaacaccc tctttaaagt gcatccgggg cggtggagga 660
tccggaggag gtggctccgg cggcggagga tctcgcgagg gtcccgagct ttcgcccgac 720
gatcccgccg gcctcttgga cctgcggcag ggcatgtttg cgcagctggt ggcccaaaat 780
gttctgctga tcgatgggcc cctgagctgg tacagtgacc caggcctggc aggcgtgtcc 840
ctgacggggg gcctgagcta caaagaggac acgaaggagc tggtggtggc caaggctgga 900
gtctactatg tcttctttca actagagctg cggcgcgtgg tggccggcga gggctcaggc 960
tccgtttcac ttgcgctgca cctgcagcca ctgcgctctg ctgctggggc cgccgccctg 1020
gctttgaccg tggacctgcc acccgcctcc tccgaggctc ggaactcggc cttcggtttc 1080
cagggccgct tgctgcacct gagtgccggc cagcgcctgg gcgtccatct tcacactgag 1140
gccagggcac gccatgcctg gcagcttacc cagggcgcca cagtcttggg actcttccgg 1200
gtgacccccg aaatcccagc cggactccct tcaccgaggt cggaa 1245
<210> 189
<211> 378
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成TGFRt15-21s137L序列”
<400> 189
Gln Gly Gln Asp Arg His Met Ile Arg Met Arg Gln Leu Ile Asp Ile
1 5 10 15
Val Asp Gln Leu Lys Asn Tyr Val Asn Asp Leu Val Pro Glu Phe Leu
20 25 30
Pro Ala Pro Glu Asp Val Glu Thr Asn Cys Glu Trp Ser Ala Phe Ser
35 40 45
Cys Phe Gln Lys Ala Gln Leu Lys Ser Ala Asn Thr Gly Asn Asn Glu
50 55 60
Arg Ile Ile Asn Val Ser Ile Lys Lys Leu Lys Arg Lys Pro Pro Ser
65 70 75 80
Thr Asn Ala Gly Arg Arg Gln Lys His Arg Leu Thr Cys Pro Ser Cys
85 90 95
Asp Ser Tyr Glu Lys Lys Pro Pro Lys Glu Phe Leu Glu Arg Phe Lys
100 105 110
Ser Leu Leu Gln Lys Met Ile His Gln His Leu Ser Ser Arg Thr His
115 120 125
Gly Ser Glu Asp Ser Ile Thr Cys Pro Pro Pro Met Ser Val Glu His
130 135 140
Ala Asp Ile Trp Val Lys Ser Tyr Ser Leu Tyr Ser Arg Glu Arg Tyr
145 150 155 160
Ile Cys Asn Ser Gly Phe Lys Arg Lys Ala Gly Thr Ser Ser Leu Thr
165 170 175
Glu Cys Val Leu Asn Lys Ala Thr Asn Val Ala His Trp Thr Thr Pro
180 185 190
Ser Leu Lys Cys Ile Arg Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
195 200 205
Gly Gly Gly Gly Ser Asp Pro Ala Gly Leu Leu Asp Leu Arg Gln Gly
210 215 220
Met Phe Ala Gln Leu Val Ala Gln Asn Val Leu Leu Ile Asp Gly Pro
225 230 235 240
Leu Ser Trp Tyr Ser Asp Pro Gly Leu Ala Gly Val Ser Leu Thr Gly
245 250 255
Gly Leu Ser Tyr Lys Glu Asp Thr Lys Glu Leu Val Val Ala Lys Ala
260 265 270
Gly Val Tyr Tyr Val Phe Phe Gln Leu Glu Leu Arg Arg Val Val Ala
275 280 285
Gly Glu Gly Ser Gly Ser Val Ser Leu Ala Leu His Leu Gln Pro Leu
290 295 300
Arg Ser Ala Ala Gly Ala Ala Ala Leu Ala Leu Thr Val Asp Leu Pro
305 310 315 320
Pro Ala Ser Ser Glu Ala Arg Asn Ser Ala Phe Gly Phe Gln Gly Arg
325 330 335
Leu Leu His Leu Ser Ala Gly Gln Arg Leu Gly Val His Leu His Thr
340 345 350
Glu Ala Arg Ala Arg His Ala Trp Gln Leu Thr Gln Gly Ala Thr Val
355 360 365
Leu Gly Leu Phe Arg Val Thr Pro Glu Ile
370 375
<210> 190
<211> 1134
<212> DNA
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成TGFRt15-21s137L序列”
<400> 190
cagggccagg acaggcacat gatccggatg aggcagctca tcgacatcgt cgaccagctg 60
aagaactacg tgaacgacct ggtgcccgag tttctgcctg cccccgagga cgtggagacc 120
aactgcgagt ggtccgcctt ctcctgcttt cagaaggccc agctgaagtc cgccaacacc 180
ggcaacaacg agcggatcat caacgtgagc atcaagaagc tgaagcggaa gcctccctcc 240
acaaacgccg gcaggaggca gaagcacagg ctgacctgcc ccagctgtga ctcctacgag 300
aagaagcccc ccaaggagtt cctggagagg ttcaagtccc tgctgcagaa gatgatccat 360
cagcacctgt cctccaggac ccacggctcc gaggactcca ttacatgccc ccctcccatg 420
agcgtggagc acgccgacat ctgggtgaag agctatagcc tctacagccg ggagaggtat 480
atctgtaaca gcggcttcaa gaggaaggcc ggcaccagca gcctcaccga gtgcgtgctg 540
aataaggcta ccaacgtggc tcactggaca acaccctctt taaagtgcat ccggggcggt 600
ggaggatccg gaggaggtgg ctccggcggc ggaggatctg atcccgccgg cctcttggac 660
ctgcggcagg gcatgtttgc gcagctggtg gcccaaaatg ttctgctgat cgatgggccc 720
ctgagctggt acagtgaccc aggcctggca ggcgtgtccc tgacgggggg cctgagctac 780
aaagaggaca cgaaggagct ggtggtggcc aaggctggag tctactatgt cttctttcaa 840
ctagagctgc ggcgcgtggt ggccggcgag ggctcaggct ccgtttcact tgcgctgcac 900
ctgcagccac tgcgctctgc tgctggggcc gccgccctgg ctttgaccgt ggacctgcca 960
cccgcctcct ccgaggctcg gaactcggcc ttcggtttcc agggccgctt gctgcacctg 1020
agtgccggcc agcgcctggg cgtccatctt cacactgagg ccagggcacg ccatgcctgg 1080
cagcttaccc agggcgccac agtcttggga ctcttccggg tgacccccga aatc 1134
<210> 191
<211> 396
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成TGFRt15-21s137L序列”
<400> 191
Met Lys Trp Val Thr Phe Ile Ser Leu Leu Phe Leu Phe Ser Ser Ala
1 5 10 15
Tyr Ser Gln Gly Gln Asp Arg His Met Ile Arg Met Arg Gln Leu Ile
20 25 30
Asp Ile Val Asp Gln Leu Lys Asn Tyr Val Asn Asp Leu Val Pro Glu
35 40 45
Phe Leu Pro Ala Pro Glu Asp Val Glu Thr Asn Cys Glu Trp Ser Ala
50 55 60
Phe Ser Cys Phe Gln Lys Ala Gln Leu Lys Ser Ala Asn Thr Gly Asn
65 70 75 80
Asn Glu Arg Ile Ile Asn Val Ser Ile Lys Lys Leu Lys Arg Lys Pro
85 90 95
Pro Ser Thr Asn Ala Gly Arg Arg Gln Lys His Arg Leu Thr Cys Pro
100 105 110
Ser Cys Asp Ser Tyr Glu Lys Lys Pro Pro Lys Glu Phe Leu Glu Arg
115 120 125
Phe Lys Ser Leu Leu Gln Lys Met Ile His Gln His Leu Ser Ser Arg
130 135 140
Thr His Gly Ser Glu Asp Ser Ile Thr Cys Pro Pro Pro Met Ser Val
145 150 155 160
Glu His Ala Asp Ile Trp Val Lys Ser Tyr Ser Leu Tyr Ser Arg Glu
165 170 175
Arg Tyr Ile Cys Asn Ser Gly Phe Lys Arg Lys Ala Gly Thr Ser Ser
180 185 190
Leu Thr Glu Cys Val Leu Asn Lys Ala Thr Asn Val Ala His Trp Thr
195 200 205
Thr Pro Ser Leu Lys Cys Ile Arg Gly Gly Gly Gly Ser Gly Gly Gly
210 215 220
Gly Ser Gly Gly Gly Gly Ser Asp Pro Ala Gly Leu Leu Asp Leu Arg
225 230 235 240
Gln Gly Met Phe Ala Gln Leu Val Ala Gln Asn Val Leu Leu Ile Asp
245 250 255
Gly Pro Leu Ser Trp Tyr Ser Asp Pro Gly Leu Ala Gly Val Ser Leu
260 265 270
Thr Gly Gly Leu Ser Tyr Lys Glu Asp Thr Lys Glu Leu Val Val Ala
275 280 285
Lys Ala Gly Val Tyr Tyr Val Phe Phe Gln Leu Glu Leu Arg Arg Val
290 295 300
Val Ala Gly Glu Gly Ser Gly Ser Val Ser Leu Ala Leu His Leu Gln
305 310 315 320
Pro Leu Arg Ser Ala Ala Gly Ala Ala Ala Leu Ala Leu Thr Val Asp
325 330 335
Leu Pro Pro Ala Ser Ser Glu Ala Arg Asn Ser Ala Phe Gly Phe Gln
340 345 350
Gly Arg Leu Leu His Leu Ser Ala Gly Gln Arg Leu Gly Val His Leu
355 360 365
His Thr Glu Ala Arg Ala Arg His Ala Trp Gln Leu Thr Gln Gly Ala
370 375 380
Thr Val Leu Gly Leu Phe Arg Val Thr Pro Glu Ile
385 390 395
<210> 192
<211> 1188
<212> DNA
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成TGFRt15-21s137L序列”
<400> 192
atgaagtggg tgaccttcat cagcctgctg ttcctgttct ccagcgccta ctcccagggc 60
caggacaggc acatgatccg gatgaggcag ctcatcgaca tcgtcgacca gctgaagaac 120
tacgtgaacg acctggtgcc cgagtttctg cctgcccccg aggacgtgga gaccaactgc 180
gagtggtccg ccttctcctg ctttcagaag gcccagctga agtccgccaa caccggcaac 240
aacgagcgga tcatcaacgt gagcatcaag aagctgaagc ggaagcctcc ctccacaaac 300
gccggcagga ggcagaagca caggctgacc tgccccagct gtgactccta cgagaagaag 360
ccccccaagg agttcctgga gaggttcaag tccctgctgc agaagatgat ccatcagcac 420
ctgtcctcca ggacccacgg ctccgaggac tccattacat gcccccctcc catgagcgtg 480
gagcacgccg acatctgggt gaagagctat agcctctaca gccgggagag gtatatctgt 540
aacagcggct tcaagaggaa ggccggcacc agcagcctca ccgagtgcgt gctgaataag 600
gctaccaacg tggctcactg gacaacaccc tctttaaagt gcatccgggg cggtggagga 660
tccggaggag gtggctccgg cggcggagga tctgatcccg ccggcctctt ggacctgcgg 720
cagggcatgt ttgcgcagct ggtggcccaa aatgttctgc tgatcgatgg gcccctgagc 780
tggtacagtg acccaggcct ggcaggcgtg tccctgacgg ggggcctgag ctacaaagag 840
gacacgaagg agctggtggt ggccaaggct ggagtctact atgtcttctt tcaactagag 900
ctgcggcgcg tggtggccgg cgagggctca ggctccgttt cacttgcgct gcacctgcag 960
ccactgcgct ctgctgctgg ggccgccgcc ctggctttga ccgtggacct gccacccgcc 1020
tcctccgagg ctcggaactc ggccttcggt ttccagggcc gcttgctgca cctgagtgcc 1080
ggccagcgcc tgggcgtcca tcttcacact gaggccaggg cacgccatgc ctggcagctt 1140
acccagggcg ccacagtctt gggactcttc cgggtgaccc ccgaaatc 1188
<210> 193
<211> 620
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成TGFRt15-TGFRs21序列”
<400> 193
Ile Pro Pro His Val Gln Lys Ser Val Asn Asn Asp Met Ile Val Thr
1 5 10 15
Asp Asn Asn Gly Ala Val Lys Phe Pro Gln Leu Cys Lys Phe Cys Asp
20 25 30
Val Arg Phe Ser Thr Cys Asp Asn Gln Lys Ser Cys Met Ser Asn Cys
35 40 45
Ser Ile Thr Ser Ile Cys Glu Lys Pro Gln Glu Val Cys Val Ala Val
50 55 60
Trp Arg Lys Asn Asp Glu Asn Ile Thr Leu Glu Thr Val Cys His Asp
65 70 75 80
Pro Lys Leu Pro Tyr His Asp Phe Ile Leu Glu Asp Ala Ala Ser Pro
85 90 95
Lys Cys Ile Met Lys Glu Lys Lys Lys Pro Gly Glu Thr Phe Phe Met
100 105 110
Cys Ser Cys Ser Ser Asp Glu Cys Asn Asp Asn Ile Ile Phe Ser Glu
115 120 125
Glu Tyr Asn Thr Ser Asn Pro Asp Gly Gly Gly Gly Ser Gly Gly Gly
130 135 140
Gly Ser Gly Gly Gly Gly Ser Ile Pro Pro His Val Gln Lys Ser Val
145 150 155 160
Asn Asn Asp Met Ile Val Thr Asp Asn Asn Gly Ala Val Lys Phe Pro
165 170 175
Gln Leu Cys Lys Phe Cys Asp Val Arg Phe Ser Thr Cys Asp Asn Gln
180 185 190
Lys Ser Cys Met Ser Asn Cys Ser Ile Thr Ser Ile Cys Glu Lys Pro
195 200 205
Gln Glu Val Cys Val Ala Val Trp Arg Lys Asn Asp Glu Asn Ile Thr
210 215 220
Leu Glu Thr Val Cys His Asp Pro Lys Leu Pro Tyr His Asp Phe Ile
225 230 235 240
Leu Glu Asp Ala Ala Ser Pro Lys Cys Ile Met Lys Glu Lys Lys Lys
245 250 255
Pro Gly Glu Thr Phe Phe Met Cys Ser Cys Ser Ser Asp Glu Cys Asn
260 265 270
Asp Asn Ile Ile Phe Ser Glu Glu Tyr Asn Thr Ser Asn Pro Asp Ser
275 280 285
Gly Thr Thr Asn Thr Val Ala Ala Tyr Asn Leu Thr Trp Lys Ser Thr
290 295 300
Asn Phe Lys Thr Ile Leu Glu Trp Glu Pro Lys Pro Val Asn Gln Val
305 310 315 320
Tyr Thr Val Gln Ile Ser Thr Lys Ser Gly Asp Trp Lys Ser Lys Cys
325 330 335
Phe Tyr Thr Thr Asp Thr Glu Cys Asp Leu Thr Asp Glu Ile Val Lys
340 345 350
Asp Val Lys Gln Thr Tyr Leu Ala Arg Val Phe Ser Tyr Pro Ala Gly
355 360 365
Asn Val Glu Ser Thr Gly Ser Ala Gly Glu Pro Leu Tyr Glu Asn Ser
370 375 380
Pro Glu Phe Thr Pro Tyr Leu Glu Thr Asn Leu Gly Gln Pro Thr Ile
385 390 395 400
Gln Ser Phe Glu Gln Val Gly Thr Lys Val Asn Val Thr Val Glu Asp
405 410 415
Glu Arg Thr Leu Val Arg Arg Asn Asn Thr Phe Leu Ser Leu Arg Asp
420 425 430
Val Phe Gly Lys Asp Leu Ile Tyr Thr Leu Tyr Tyr Trp Lys Ser Ser
435 440 445
Ser Ser Gly Lys Lys Thr Ala Lys Thr Asn Thr Asn Glu Phe Leu Ile
450 455 460
Asp Val Asp Lys Gly Glu Asn Tyr Cys Phe Ser Val Gln Ala Val Ile
465 470 475 480
Pro Ser Arg Thr Val Asn Arg Lys Ser Thr Asp Ser Pro Val Glu Cys
485 490 495
Met Gly Gln Glu Lys Gly Glu Phe Arg Glu Asn Trp Val Asn Val Ile
500 505 510
Ser Asp Leu Lys Lys Ile Glu Asp Leu Ile Gln Ser Met His Ile Asp
515 520 525
Ala Thr Leu Tyr Thr Glu Ser Asp Val His Pro Ser Cys Lys Val Thr
530 535 540
Ala Met Lys Cys Phe Leu Leu Glu Leu Gln Val Ile Ser Leu Glu Ser
545 550 555 560
Gly Asp Ala Ser Ile His Asp Thr Val Glu Asn Leu Ile Ile Leu Ala
565 570 575
Asn Asn Ser Leu Ser Ser Asn Gly Asn Val Thr Glu Ser Gly Cys Lys
580 585 590
Glu Cys Glu Glu Leu Glu Glu Lys Asn Ile Lys Glu Phe Leu Gln Ser
595 600 605
Phe Val His Ile Val Gln Met Phe Ile Asn Thr Ser
610 615 620
<210> 194
<211> 1860
<212> DNA
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成TGFRt15-TGFRs21序列”
<400> 194
atcccccccc atgtgcaaaa gagcgtgaac aacgatatga tcgtgaccga caacaacggc 60
gccgtgaagt ttccccagct ctgcaagttc tgcgatgtca ggttcagcac ctgcgataat 120
cagaagtcct gcatgtccaa ctgcagcatc acctccatct gcgagaagcc ccaagaagtg 180
tgcgtggccg tgtggcggaa aaatgacgag aacatcaccc tggagaccgt gtgtcacgac 240
cccaagctcc cttatcacga cttcattctg gaggacgctg cctcccccaa atgcatcatg 300
aaggagaaga agaagcccgg agagaccttc tttatgtgtt cctgtagcag cgacgagtgt 360
aacgacaaca tcatcttcag cgaagagtac aacaccagca accctgatgg aggtggcgga 420
tccggaggtg gaggttctgg tggaggtggg agtattcctc cccacgtgca gaagagcgtg 480
aataatgaca tgatcgtgac cgataacaat ggcgccgtga aatttcccca gctgtgcaaa 540
ttctgcgatg tgaggttttc cacctgcgac aaccagaagt cctgtatgag caactgctcc 600
atcacctcca tctgtgagaa gcctcaggag gtgtgcgtgg ctgtctggcg gaagaatgac 660
gagaatatca ccctggaaac cgtctgccac gatcccaagc tgccctacca cgatttcatc 720
ctggaagacg ccgccagccc taagtgcatc atgaaagaga aaaagaagcc tggcgagacc 780
tttttcatgt gctcctgcag cagcgacgaa tgcaacgaca atatcatctt tagcgaggaa 840
tacaatacca gcaaccccga cagcggcaca accaacacag tcgctgccta taacctcact 900
tggaagagca ccaacttcaa aaccatcctc gaatgggaac ccaaacccgt taaccaagtt 960
tacaccgtgc agatcagcac caagtccggc gactggaagt ccaaatgttt ctataccacc 1020
gacaccgagt gcgatctcac cgatgagatc gtgaaagatg tgaaacagac ctacctcgcc 1080
cgggtgttta gctaccccgc cggcaatgtg gagagcactg gttccgctgg cgagccttta 1140
tacgagaaca gccccgaatt taccccttac ctcgagacca atttaggaca gcccaccatc 1200
caaagctttg agcaagttgg cacaaaggtg aatgtgacag tggaggacga gcggacttta 1260
gtgcggcgga acaacacctt tctcagcctc cgggatgtgt tcggcaaaga tttaatctac 1320
acactgtatt actggaagtc ctcttcctcc ggcaagaaga cagctaaaac caacacaaac 1380
gagtttttaa tcgacgtgga taaaggcgaa aactactgtt tcagcgtgca agctgtgatc 1440
ccctcccgga ccgtgaatag gaaaagcacc gatagccccg ttgagtgcat gggccaagaa 1500
aagggcgagt tccgggagaa ctgggtgaac gtcatcagcg atttaaagaa gatcgaagat 1560
ttaattcagt ccatgcatat cgacgccact ttatacacag aatccgacgt gcacccctct 1620
tgtaaggtga ccgccatgaa atgtttttta ctggagctgc aagttatctc tttagagagc 1680
ggagacgcta gcatccacga caccgtggag aatttaatca ttttagccaa taactcttta 1740
tccagcaacg gcaacgtgac agagtccggc tgcaaggagt gcgaagagct ggaggagaag 1800
aacatcaagg agtttctgca atcctttgtg cacattgtcc agatgttcat caatacctcc 1860
<210> 195
<211> 638
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成TGFRt15-TGFRs21序列”
<400> 195
Met Lys Trp Val Thr Phe Ile Ser Leu Leu Phe Leu Phe Ser Ser Ala
1 5 10 15
Tyr Ser Ile Pro Pro His Val Gln Lys Ser Val Asn Asn Asp Met Ile
20 25 30
Val Thr Asp Asn Asn Gly Ala Val Lys Phe Pro Gln Leu Cys Lys Phe
35 40 45
Cys Asp Val Arg Phe Ser Thr Cys Asp Asn Gln Lys Ser Cys Met Ser
50 55 60
Asn Cys Ser Ile Thr Ser Ile Cys Glu Lys Pro Gln Glu Val Cys Val
65 70 75 80
Ala Val Trp Arg Lys Asn Asp Glu Asn Ile Thr Leu Glu Thr Val Cys
85 90 95
His Asp Pro Lys Leu Pro Tyr His Asp Phe Ile Leu Glu Asp Ala Ala
100 105 110
Ser Pro Lys Cys Ile Met Lys Glu Lys Lys Lys Pro Gly Glu Thr Phe
115 120 125
Phe Met Cys Ser Cys Ser Ser Asp Glu Cys Asn Asp Asn Ile Ile Phe
130 135 140
Ser Glu Glu Tyr Asn Thr Ser Asn Pro Asp Gly Gly Gly Gly Ser Gly
145 150 155 160
Gly Gly Gly Ser Gly Gly Gly Gly Ser Ile Pro Pro His Val Gln Lys
165 170 175
Ser Val Asn Asn Asp Met Ile Val Thr Asp Asn Asn Gly Ala Val Lys
180 185 190
Phe Pro Gln Leu Cys Lys Phe Cys Asp Val Arg Phe Ser Thr Cys Asp
195 200 205
Asn Gln Lys Ser Cys Met Ser Asn Cys Ser Ile Thr Ser Ile Cys Glu
210 215 220
Lys Pro Gln Glu Val Cys Val Ala Val Trp Arg Lys Asn Asp Glu Asn
225 230 235 240
Ile Thr Leu Glu Thr Val Cys His Asp Pro Lys Leu Pro Tyr His Asp
245 250 255
Phe Ile Leu Glu Asp Ala Ala Ser Pro Lys Cys Ile Met Lys Glu Lys
260 265 270
Lys Lys Pro Gly Glu Thr Phe Phe Met Cys Ser Cys Ser Ser Asp Glu
275 280 285
Cys Asn Asp Asn Ile Ile Phe Ser Glu Glu Tyr Asn Thr Ser Asn Pro
290 295 300
Asp Ser Gly Thr Thr Asn Thr Val Ala Ala Tyr Asn Leu Thr Trp Lys
305 310 315 320
Ser Thr Asn Phe Lys Thr Ile Leu Glu Trp Glu Pro Lys Pro Val Asn
325 330 335
Gln Val Tyr Thr Val Gln Ile Ser Thr Lys Ser Gly Asp Trp Lys Ser
340 345 350
Lys Cys Phe Tyr Thr Thr Asp Thr Glu Cys Asp Leu Thr Asp Glu Ile
355 360 365
Val Lys Asp Val Lys Gln Thr Tyr Leu Ala Arg Val Phe Ser Tyr Pro
370 375 380
Ala Gly Asn Val Glu Ser Thr Gly Ser Ala Gly Glu Pro Leu Tyr Glu
385 390 395 400
Asn Ser Pro Glu Phe Thr Pro Tyr Leu Glu Thr Asn Leu Gly Gln Pro
405 410 415
Thr Ile Gln Ser Phe Glu Gln Val Gly Thr Lys Val Asn Val Thr Val
420 425 430
Glu Asp Glu Arg Thr Leu Val Arg Arg Asn Asn Thr Phe Leu Ser Leu
435 440 445
Arg Asp Val Phe Gly Lys Asp Leu Ile Tyr Thr Leu Tyr Tyr Trp Lys
450 455 460
Ser Ser Ser Ser Gly Lys Lys Thr Ala Lys Thr Asn Thr Asn Glu Phe
465 470 475 480
Leu Ile Asp Val Asp Lys Gly Glu Asn Tyr Cys Phe Ser Val Gln Ala
485 490 495
Val Ile Pro Ser Arg Thr Val Asn Arg Lys Ser Thr Asp Ser Pro Val
500 505 510
Glu Cys Met Gly Gln Glu Lys Gly Glu Phe Arg Glu Asn Trp Val Asn
515 520 525
Val Ile Ser Asp Leu Lys Lys Ile Glu Asp Leu Ile Gln Ser Met His
530 535 540
Ile Asp Ala Thr Leu Tyr Thr Glu Ser Asp Val His Pro Ser Cys Lys
545 550 555 560
Val Thr Ala Met Lys Cys Phe Leu Leu Glu Leu Gln Val Ile Ser Leu
565 570 575
Glu Ser Gly Asp Ala Ser Ile His Asp Thr Val Glu Asn Leu Ile Ile
580 585 590
Leu Ala Asn Asn Ser Leu Ser Ser Asn Gly Asn Val Thr Glu Ser Gly
595 600 605
Cys Lys Glu Cys Glu Glu Leu Glu Glu Lys Asn Ile Lys Glu Phe Leu
610 615 620
Gln Ser Phe Val His Ile Val Gln Met Phe Ile Asn Thr Ser
625 630 635
<210> 196
<211> 1914
<212> DNA
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成TGFRt15-TGFRs21序列”
<400> 196
atgaagtggg tgaccttcat cagcctgctg ttcctgttct ccagcgccta ctccatcccc 60
ccccatgtgc aaaagagcgt gaacaacgat atgatcgtga ccgacaacaa cggcgccgtg 120
aagtttcccc agctctgcaa gttctgcgat gtcaggttca gcacctgcga taatcagaag 180
tcctgcatgt ccaactgcag catcacctcc atctgcgaga agccccaaga agtgtgcgtg 240
gccgtgtggc ggaaaaatga cgagaacatc accctggaga ccgtgtgtca cgaccccaag 300
ctcccttatc acgacttcat tctggaggac gctgcctccc ccaaatgcat catgaaggag 360
aagaagaagc ccggagagac cttctttatg tgttcctgta gcagcgacga gtgtaacgac 420
aacatcatct tcagcgaaga gtacaacacc agcaaccctg atggaggtgg cggatccgga 480
ggtggaggtt ctggtggagg tgggagtatt cctccccacg tgcagaagag cgtgaataat 540
gacatgatcg tgaccgataa caatggcgcc gtgaaatttc cccagctgtg caaattctgc 600
gatgtgaggt tttccacctg cgacaaccag aagtcctgta tgagcaactg ctccatcacc 660
tccatctgtg agaagcctca ggaggtgtgc gtggctgtct ggcggaagaa tgacgagaat 720
atcaccctgg aaaccgtctg ccacgatccc aagctgccct accacgattt catcctggaa 780
gacgccgcca gccctaagtg catcatgaaa gagaaaaaga agcctggcga gacctttttc 840
atgtgctcct gcagcagcga cgaatgcaac gacaatatca tctttagcga ggaatacaat 900
accagcaacc ccgacagcgg cacaaccaac acagtcgctg cctataacct cacttggaag 960
agcaccaact tcaaaaccat cctcgaatgg gaacccaaac ccgttaacca agtttacacc 1020
gtgcagatca gcaccaagtc cggcgactgg aagtccaaat gtttctatac caccgacacc 1080
gagtgcgatc tcaccgatga gatcgtgaaa gatgtgaaac agacctacct cgcccgggtg 1140
tttagctacc ccgccggcaa tgtggagagc actggttccg ctggcgagcc tttatacgag 1200
aacagccccg aatttacccc ttacctcgag accaatttag gacagcccac catccaaagc 1260
tttgagcaag ttggcacaaa ggtgaatgtg acagtggagg acgagcggac tttagtgcgg 1320
cggaacaaca cctttctcag cctccgggat gtgttcggca aagatttaat ctacacactg 1380
tattactgga agtcctcttc ctccggcaag aagacagcta aaaccaacac aaacgagttt 1440
ttaatcgacg tggataaagg cgaaaactac tgtttcagcg tgcaagctgt gatcccctcc 1500
cggaccgtga ataggaaaag caccgatagc cccgttgagt gcatgggcca agaaaagggc 1560
gagttccggg agaactgggt gaacgtcatc agcgatttaa agaagatcga agatttaatt 1620
cagtccatgc atatcgacgc cactttatac acagaatccg acgtgcaccc ctcttgtaag 1680
gtgaccgcca tgaaatgttt tttactggag ctgcaagtta tctctttaga gagcggagac 1740
gctagcatcc acgacaccgt ggagaattta atcattttag ccaataactc tttatccagc 1800
aacggcaacg tgacagagtc cggctgcaag gagtgcgaag agctggagga gaagaacatc 1860
aaggagtttc tgcaatcctt tgtgcacatt gtccagatgt tcatcaatac ctcc 1914
<210> 197
<211> 485
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成TGFRt15-TGFRs21序列”
<400> 197
Ile Pro Pro His Val Gln Lys Ser Val Asn Asn Asp Met Ile Val Thr
1 5 10 15
Asp Asn Asn Gly Ala Val Lys Phe Pro Gln Leu Cys Lys Phe Cys Asp
20 25 30
Val Arg Phe Ser Thr Cys Asp Asn Gln Lys Ser Cys Met Ser Asn Cys
35 40 45
Ser Ile Thr Ser Ile Cys Glu Lys Pro Gln Glu Val Cys Val Ala Val
50 55 60
Trp Arg Lys Asn Asp Glu Asn Ile Thr Leu Glu Thr Val Cys His Asp
65 70 75 80
Pro Lys Leu Pro Tyr His Asp Phe Ile Leu Glu Asp Ala Ala Ser Pro
85 90 95
Lys Cys Ile Met Lys Glu Lys Lys Lys Pro Gly Glu Thr Phe Phe Met
100 105 110
Cys Ser Cys Ser Ser Asp Glu Cys Asn Asp Asn Ile Ile Phe Ser Glu
115 120 125
Glu Tyr Asn Thr Ser Asn Pro Asp Gly Gly Gly Gly Ser Gly Gly Gly
130 135 140
Gly Ser Gly Gly Gly Gly Ser Ile Pro Pro His Val Gln Lys Ser Val
145 150 155 160
Asn Asn Asp Met Ile Val Thr Asp Asn Asn Gly Ala Val Lys Phe Pro
165 170 175
Gln Leu Cys Lys Phe Cys Asp Val Arg Phe Ser Thr Cys Asp Asn Gln
180 185 190
Lys Ser Cys Met Ser Asn Cys Ser Ile Thr Ser Ile Cys Glu Lys Pro
195 200 205
Gln Glu Val Cys Val Ala Val Trp Arg Lys Asn Asp Glu Asn Ile Thr
210 215 220
Leu Glu Thr Val Cys His Asp Pro Lys Leu Pro Tyr His Asp Phe Ile
225 230 235 240
Leu Glu Asp Ala Ala Ser Pro Lys Cys Ile Met Lys Glu Lys Lys Lys
245 250 255
Pro Gly Glu Thr Phe Phe Met Cys Ser Cys Ser Ser Asp Glu Cys Asn
260 265 270
Asp Asn Ile Ile Phe Ser Glu Glu Tyr Asn Thr Ser Asn Pro Asp Ile
275 280 285
Thr Cys Pro Pro Pro Met Ser Val Glu His Ala Asp Ile Trp Val Lys
290 295 300
Ser Tyr Ser Leu Tyr Ser Arg Glu Arg Tyr Ile Cys Asn Ser Gly Phe
305 310 315 320
Lys Arg Lys Ala Gly Thr Ser Ser Leu Thr Glu Cys Val Leu Asn Lys
325 330 335
Ala Thr Asn Val Ala His Trp Thr Thr Pro Ser Leu Lys Cys Ile Arg
340 345 350
Gln Gly Gln Asp Arg His Met Ile Arg Met Arg Gln Leu Ile Asp Ile
355 360 365
Val Asp Gln Leu Lys Asn Tyr Val Asn Asp Leu Val Pro Glu Phe Leu
370 375 380
Pro Ala Pro Glu Asp Val Glu Thr Asn Cys Glu Trp Ser Ala Phe Ser
385 390 395 400
Cys Phe Gln Lys Ala Gln Leu Lys Ser Ala Asn Thr Gly Asn Asn Glu
405 410 415
Arg Ile Ile Asn Val Ser Ile Lys Lys Leu Lys Arg Lys Pro Pro Ser
420 425 430
Thr Asn Ala Gly Arg Arg Gln Lys His Arg Leu Thr Cys Pro Ser Cys
435 440 445
Asp Ser Tyr Glu Lys Lys Pro Pro Lys Glu Phe Leu Glu Arg Phe Lys
450 455 460
Ser Leu Leu Gln Lys Met Ile His Gln His Leu Ser Ser Arg Thr His
465 470 475 480
Gly Ser Glu Asp Ser
485
<210> 198
<211> 1455
<212> DNA
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成TGFRt15-TGFRs21序列”
<400> 198
atcccccccc atgtgcaaaa gagcgtgaac aacgatatga tcgtgaccga caacaacggc 60
gccgtgaagt ttccccagct ctgcaagttc tgcgatgtca ggttcagcac ctgcgataat 120
cagaagtcct gcatgtccaa ctgcagcatc acctccatct gcgagaagcc ccaagaagtg 180
tgcgtggccg tgtggcggaa aaatgacgag aacatcaccc tggagaccgt gtgtcacgac 240
cccaagctcc cttatcacga cttcattctg gaggacgctg cctcccccaa atgcatcatg 300
aaggagaaga agaagcccgg agagaccttc tttatgtgtt cctgtagcag cgacgagtgt 360
aacgacaaca tcatcttcag cgaagagtac aacaccagca accctgatgg aggtggcgga 420
tccggaggtg gaggttctgg tggaggtggg agtattcctc cccacgtgca gaagagcgtg 480
aataatgaca tgatcgtgac cgataacaat ggcgccgtga aatttcccca gctgtgcaaa 540
ttctgcgatg tgaggttttc cacctgcgac aaccagaagt cctgtatgag caactgctcc 600
atcacctcca tctgtgagaa gcctcaggag gtgtgcgtgg ctgtctggcg gaagaatgac 660
gagaatatca ccctggaaac cgtctgccac gatcccaagc tgccctacca cgatttcatc 720
ctggaagacg ccgccagccc taagtgcatc atgaaagaga aaaagaagcc tggcgagacc 780
tttttcatgt gctcctgcag cagcgacgaa tgcaacgaca atatcatctt tagcgaggaa 840
tacaatacca gcaaccccga cattacatgc ccccctccca tgagcgtgga gcacgccgac 900
atctgggtga agagctatag cctctacagc cgggagaggt atatctgtaa cagcggcttc 960
aagaggaagg ccggcaccag cagcctcacc gagtgcgtgc tgaataaggc taccaacgtg 1020
gctcactgga caacaccctc tttaaagtgc atccggcagg gccaggacag gcacatgatc 1080
cggatgaggc agctcatcga catcgtcgac cagctgaaga actacgtgaa cgacctggtg 1140
cccgagtttc tgcctgcccc cgaggacgtg gagaccaact gcgagtggtc cgccttctcc 1200
tgctttcaga aggcccagct gaagtccgcc aacaccggca acaacgagcg gatcatcaac 1260
gtgagcatca agaagctgaa gcggaagcct ccctccacaa acgccggcag gaggcagaag 1320
cacaggctga cctgccccag ctgtgactcc tacgagaaga agccccccaa ggagttcctg 1380
gagaggttca agtccctgct gcagaagatg atccatcagc acctgtcctc caggacccac 1440
ggctccgagg actcc 1455
<210> 199
<211> 503
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成TGFRt15-TGFRs21序列”
<400> 199
Met Lys Trp Val Thr Phe Ile Ser Leu Leu Phe Leu Phe Ser Ser Ala
1 5 10 15
Tyr Ser Ile Pro Pro His Val Gln Lys Ser Val Asn Asn Asp Met Ile
20 25 30
Val Thr Asp Asn Asn Gly Ala Val Lys Phe Pro Gln Leu Cys Lys Phe
35 40 45
Cys Asp Val Arg Phe Ser Thr Cys Asp Asn Gln Lys Ser Cys Met Ser
50 55 60
Asn Cys Ser Ile Thr Ser Ile Cys Glu Lys Pro Gln Glu Val Cys Val
65 70 75 80
Ala Val Trp Arg Lys Asn Asp Glu Asn Ile Thr Leu Glu Thr Val Cys
85 90 95
His Asp Pro Lys Leu Pro Tyr His Asp Phe Ile Leu Glu Asp Ala Ala
100 105 110
Ser Pro Lys Cys Ile Met Lys Glu Lys Lys Lys Pro Gly Glu Thr Phe
115 120 125
Phe Met Cys Ser Cys Ser Ser Asp Glu Cys Asn Asp Asn Ile Ile Phe
130 135 140
Ser Glu Glu Tyr Asn Thr Ser Asn Pro Asp Gly Gly Gly Gly Ser Gly
145 150 155 160
Gly Gly Gly Ser Gly Gly Gly Gly Ser Ile Pro Pro His Val Gln Lys
165 170 175
Ser Val Asn Asn Asp Met Ile Val Thr Asp Asn Asn Gly Ala Val Lys
180 185 190
Phe Pro Gln Leu Cys Lys Phe Cys Asp Val Arg Phe Ser Thr Cys Asp
195 200 205
Asn Gln Lys Ser Cys Met Ser Asn Cys Ser Ile Thr Ser Ile Cys Glu
210 215 220
Lys Pro Gln Glu Val Cys Val Ala Val Trp Arg Lys Asn Asp Glu Asn
225 230 235 240
Ile Thr Leu Glu Thr Val Cys His Asp Pro Lys Leu Pro Tyr His Asp
245 250 255
Phe Ile Leu Glu Asp Ala Ala Ser Pro Lys Cys Ile Met Lys Glu Lys
260 265 270
Lys Lys Pro Gly Glu Thr Phe Phe Met Cys Ser Cys Ser Ser Asp Glu
275 280 285
Cys Asn Asp Asn Ile Ile Phe Ser Glu Glu Tyr Asn Thr Ser Asn Pro
290 295 300
Asp Ile Thr Cys Pro Pro Pro Met Ser Val Glu His Ala Asp Ile Trp
305 310 315 320
Val Lys Ser Tyr Ser Leu Tyr Ser Arg Glu Arg Tyr Ile Cys Asn Ser
325 330 335
Gly Phe Lys Arg Lys Ala Gly Thr Ser Ser Leu Thr Glu Cys Val Leu
340 345 350
Asn Lys Ala Thr Asn Val Ala His Trp Thr Thr Pro Ser Leu Lys Cys
355 360 365
Ile Arg Gln Gly Gln Asp Arg His Met Ile Arg Met Arg Gln Leu Ile
370 375 380
Asp Ile Val Asp Gln Leu Lys Asn Tyr Val Asn Asp Leu Val Pro Glu
385 390 395 400
Phe Leu Pro Ala Pro Glu Asp Val Glu Thr Asn Cys Glu Trp Ser Ala
405 410 415
Phe Ser Cys Phe Gln Lys Ala Gln Leu Lys Ser Ala Asn Thr Gly Asn
420 425 430
Asn Glu Arg Ile Ile Asn Val Ser Ile Lys Lys Leu Lys Arg Lys Pro
435 440 445
Pro Ser Thr Asn Ala Gly Arg Arg Gln Lys His Arg Leu Thr Cys Pro
450 455 460
Ser Cys Asp Ser Tyr Glu Lys Lys Pro Pro Lys Glu Phe Leu Glu Arg
465 470 475 480
Phe Lys Ser Leu Leu Gln Lys Met Ile His Gln His Leu Ser Ser Arg
485 490 495
Thr His Gly Ser Glu Asp Ser
500
<210> 200
<211> 1509
<212> DNA
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成TGFRt15-TGFRs21序列”
<400> 200
atgaagtggg tgaccttcat cagcctgctg ttcctgttct ccagcgccta ctccatcccc 60
ccccatgtgc aaaagagcgt gaacaacgat atgatcgtga ccgacaacaa cggcgccgtg 120
aagtttcccc agctctgcaa gttctgcgat gtcaggttca gcacctgcga taatcagaag 180
tcctgcatgt ccaactgcag catcacctcc atctgcgaga agccccaaga agtgtgcgtg 240
gccgtgtggc ggaaaaatga cgagaacatc accctggaga ccgtgtgtca cgaccccaag 300
ctcccttatc acgacttcat tctggaggac gctgcctccc ccaaatgcat catgaaggag 360
aagaagaagc ccggagagac cttctttatg tgttcctgta gcagcgacga gtgtaacgac 420
aacatcatct tcagcgaaga gtacaacacc agcaaccctg atggaggtgg cggatccgga 480
ggtggaggtt ctggtggagg tgggagtatt cctccccacg tgcagaagag cgtgaataat 540
gacatgatcg tgaccgataa caatggcgcc gtgaaatttc cccagctgtg caaattctgc 600
gatgtgaggt tttccacctg cgacaaccag aagtcctgta tgagcaactg ctccatcacc 660
tccatctgtg agaagcctca ggaggtgtgc gtggctgtct ggcggaagaa tgacgagaat 720
atcaccctgg aaaccgtctg ccacgatccc aagctgccct accacgattt catcctggaa 780
gacgccgcca gccctaagtg catcatgaaa gagaaaaaga agcctggcga gacctttttc 840
atgtgctcct gcagcagcga cgaatgcaac gacaatatca tctttagcga ggaatacaat 900
accagcaacc ccgacattac atgcccccct cccatgagcg tggagcacgc cgacatctgg 960
gtgaagagct atagcctcta cagccgggag aggtatatct gtaacagcgg cttcaagagg 1020
aaggccggca ccagcagcct caccgagtgc gtgctgaata aggctaccaa cgtggctcac 1080
tggacaacac cctctttaaa gtgcatccgg cagggccagg acaggcacat gatccggatg 1140
aggcagctca tcgacatcgt cgaccagctg aagaactacg tgaacgacct ggtgcccgag 1200
tttctgcctg cccccgagga cgtggagacc aactgcgagt ggtccgcctt ctcctgcttt 1260
cagaaggccc agctgaagtc cgccaacacc ggcaacaacg agcggatcat caacgtgagc 1320
atcaagaagc tgaagcggaa gcctccctcc acaaacgccg gcaggaggca gaagcacagg 1380
ctgacctgcc ccagctgtga ctcctacgag aagaagcccc ccaaggagtt cctggagagg 1440
ttcaagtccc tgctgcagaa gatgatccat cagcacctgt cctccaggac ccacggctcc 1500
gaggactcc 1509
<210> 201
<211> 620
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成TGFRt15-TGFRs16序列”
<400> 201
Ile Pro Pro His Val Gln Lys Ser Val Asn Asn Asp Met Ile Val Thr
1 5 10 15
Asp Asn Asn Gly Ala Val Lys Phe Pro Gln Leu Cys Lys Phe Cys Asp
20 25 30
Val Arg Phe Ser Thr Cys Asp Asn Gln Lys Ser Cys Met Ser Asn Cys
35 40 45
Ser Ile Thr Ser Ile Cys Glu Lys Pro Gln Glu Val Cys Val Ala Val
50 55 60
Trp Arg Lys Asn Asp Glu Asn Ile Thr Leu Glu Thr Val Cys His Asp
65 70 75 80
Pro Lys Leu Pro Tyr His Asp Phe Ile Leu Glu Asp Ala Ala Ser Pro
85 90 95
Lys Cys Ile Met Lys Glu Lys Lys Lys Pro Gly Glu Thr Phe Phe Met
100 105 110
Cys Ser Cys Ser Ser Asp Glu Cys Asn Asp Asn Ile Ile Phe Ser Glu
115 120 125
Glu Tyr Asn Thr Ser Asn Pro Asp Gly Gly Gly Gly Ser Gly Gly Gly
130 135 140
Gly Ser Gly Gly Gly Gly Ser Ile Pro Pro His Val Gln Lys Ser Val
145 150 155 160
Asn Asn Asp Met Ile Val Thr Asp Asn Asn Gly Ala Val Lys Phe Pro
165 170 175
Gln Leu Cys Lys Phe Cys Asp Val Arg Phe Ser Thr Cys Asp Asn Gln
180 185 190
Lys Ser Cys Met Ser Asn Cys Ser Ile Thr Ser Ile Cys Glu Lys Pro
195 200 205
Gln Glu Val Cys Val Ala Val Trp Arg Lys Asn Asp Glu Asn Ile Thr
210 215 220
Leu Glu Thr Val Cys His Asp Pro Lys Leu Pro Tyr His Asp Phe Ile
225 230 235 240
Leu Glu Asp Ala Ala Ser Pro Lys Cys Ile Met Lys Glu Lys Lys Lys
245 250 255
Pro Gly Glu Thr Phe Phe Met Cys Ser Cys Ser Ser Asp Glu Cys Asn
260 265 270
Asp Asn Ile Ile Phe Ser Glu Glu Tyr Asn Thr Ser Asn Pro Asp Ser
275 280 285
Gly Thr Thr Asn Thr Val Ala Ala Tyr Asn Leu Thr Trp Lys Ser Thr
290 295 300
Asn Phe Lys Thr Ile Leu Glu Trp Glu Pro Lys Pro Val Asn Gln Val
305 310 315 320
Tyr Thr Val Gln Ile Ser Thr Lys Ser Gly Asp Trp Lys Ser Lys Cys
325 330 335
Phe Tyr Thr Thr Asp Thr Glu Cys Asp Leu Thr Asp Glu Ile Val Lys
340 345 350
Asp Val Lys Gln Thr Tyr Leu Ala Arg Val Phe Ser Tyr Pro Ala Gly
355 360 365
Asn Val Glu Ser Thr Gly Ser Ala Gly Glu Pro Leu Tyr Glu Asn Ser
370 375 380
Pro Glu Phe Thr Pro Tyr Leu Glu Thr Asn Leu Gly Gln Pro Thr Ile
385 390 395 400
Gln Ser Phe Glu Gln Val Gly Thr Lys Val Asn Val Thr Val Glu Asp
405 410 415
Glu Arg Thr Leu Val Arg Arg Asn Asn Thr Phe Leu Ser Leu Arg Asp
420 425 430
Val Phe Gly Lys Asp Leu Ile Tyr Thr Leu Tyr Tyr Trp Lys Ser Ser
435 440 445
Ser Ser Gly Lys Lys Thr Ala Lys Thr Asn Thr Asn Glu Phe Leu Ile
450 455 460
Asp Val Asp Lys Gly Glu Asn Tyr Cys Phe Ser Val Gln Ala Val Ile
465 470 475 480
Pro Ser Arg Thr Val Asn Arg Lys Ser Thr Asp Ser Pro Val Glu Cys
485 490 495
Met Gly Gln Glu Lys Gly Glu Phe Arg Glu Asn Trp Val Asn Val Ile
500 505 510
Ser Asp Leu Lys Lys Ile Glu Asp Leu Ile Gln Ser Met His Ile Asp
515 520 525
Ala Thr Leu Tyr Thr Glu Ser Asp Val His Pro Ser Cys Lys Val Thr
530 535 540
Ala Met Lys Cys Phe Leu Leu Glu Leu Gln Val Ile Ser Leu Glu Ser
545 550 555 560
Gly Asp Ala Ser Ile His Asp Thr Val Glu Asn Leu Ile Ile Leu Ala
565 570 575
Asn Asn Ser Leu Ser Ser Asn Gly Asn Val Thr Glu Ser Gly Cys Lys
580 585 590
Glu Cys Glu Glu Leu Glu Glu Lys Asn Ile Lys Glu Phe Leu Gln Ser
595 600 605
Phe Val His Ile Val Gln Met Phe Ile Asn Thr Ser
610 615 620
<210> 202
<211> 1860
<212> DNA
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成TGFRt15-TGFRs16序列”
<400> 202
atcccccccc atgtgcaaaa gagcgtgaac aacgatatga tcgtgaccga caacaacggc 60
gccgtgaagt ttccccagct ctgcaagttc tgcgatgtca ggttcagcac ctgcgataat 120
cagaagtcct gcatgtccaa ctgcagcatc acctccatct gcgagaagcc ccaagaagtg 180
tgcgtggccg tgtggcggaa aaatgacgag aacatcaccc tggagaccgt gtgtcacgac 240
cccaagctcc cttatcacga cttcattctg gaggacgctg cctcccccaa atgcatcatg 300
aaggagaaga agaagcccgg agagaccttc tttatgtgtt cctgtagcag cgacgagtgt 360
aacgacaaca tcatcttcag cgaagagtac aacaccagca accctgatgg aggtggcgga 420
tccggaggtg gaggttctgg tggaggtggg agtattcctc cccacgtgca gaagagcgtg 480
aataatgaca tgatcgtgac cgataacaat ggcgccgtga aatttcccca gctgtgcaaa 540
ttctgcgatg tgaggttttc cacctgcgac aaccagaagt cctgtatgag caactgctcc 600
atcacctcca tctgtgagaa gcctcaggag gtgtgcgtgg ctgtctggcg gaagaatgac 660
gagaatatca ccctggaaac cgtctgccac gatcccaagc tgccctacca cgatttcatc 720
ctggaagacg ccgccagccc taagtgcatc atgaaagaga aaaagaagcc tggcgagacc 780
tttttcatgt gctcctgcag cagcgacgaa tgcaacgaca atatcatctt tagcgaggaa 840
tacaatacca gcaaccccga cagcggcaca accaacacag tcgctgccta taacctcact 900
tggaagagca ccaacttcaa aaccatcctc gaatgggaac ccaaacccgt taaccaagtt 960
tacaccgtgc agatcagcac caagtccggc gactggaagt ccaaatgttt ctataccacc 1020
gacaccgagt gcgatctcac cgatgagatc gtgaaagatg tgaaacagac ctacctcgcc 1080
cgggtgttta gctaccccgc cggcaatgtg gagagcactg gttccgctgg cgagccttta 1140
tacgagaaca gccccgaatt taccccttac ctcgagacca atttaggaca gcccaccatc 1200
caaagctttg agcaagttgg cacaaaggtg aatgtgacag tggaggacga gcggacttta 1260
gtgcggcgga acaacacctt tctcagcctc cgggatgtgt tcggcaaaga tttaatctac 1320
acactgtatt actggaagtc ctcttcctcc ggcaagaaga cagctaaaac caacacaaac 1380
gagtttttaa tcgacgtgga taaaggcgaa aactactgtt tcagcgtgca agctgtgatc 1440
ccctcccgga ccgtgaatag gaaaagcacc gatagccccg ttgagtgcat gggccaagaa 1500
aagggcgagt tccgggagaa ctgggtgaac gtcatcagcg atttaaagaa gatcgaagat 1560
ttaattcagt ccatgcatat cgacgccact ttatacacag aatccgacgt gcacccctct 1620
tgtaaggtga ccgccatgaa atgtttttta ctggagctgc aagttatctc tttagagagc 1680
ggagacgcta gcatccacga caccgtggag aatttaatca ttttagccaa taactcttta 1740
tccagcaacg gcaacgtgac agagtccggc tgcaaggagt gcgaagagct ggaggagaag 1800
aacatcaagg agtttctgca atcctttgtg cacattgtcc agatgttcat caatacctcc 1860
<210> 203
<211> 638
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成TGFRt15-TGFRs16序列”
<400> 203
Met Lys Trp Val Thr Phe Ile Ser Leu Leu Phe Leu Phe Ser Ser Ala
1 5 10 15
Tyr Ser Ile Pro Pro His Val Gln Lys Ser Val Asn Asn Asp Met Ile
20 25 30
Val Thr Asp Asn Asn Gly Ala Val Lys Phe Pro Gln Leu Cys Lys Phe
35 40 45
Cys Asp Val Arg Phe Ser Thr Cys Asp Asn Gln Lys Ser Cys Met Ser
50 55 60
Asn Cys Ser Ile Thr Ser Ile Cys Glu Lys Pro Gln Glu Val Cys Val
65 70 75 80
Ala Val Trp Arg Lys Asn Asp Glu Asn Ile Thr Leu Glu Thr Val Cys
85 90 95
His Asp Pro Lys Leu Pro Tyr His Asp Phe Ile Leu Glu Asp Ala Ala
100 105 110
Ser Pro Lys Cys Ile Met Lys Glu Lys Lys Lys Pro Gly Glu Thr Phe
115 120 125
Phe Met Cys Ser Cys Ser Ser Asp Glu Cys Asn Asp Asn Ile Ile Phe
130 135 140
Ser Glu Glu Tyr Asn Thr Ser Asn Pro Asp Gly Gly Gly Gly Ser Gly
145 150 155 160
Gly Gly Gly Ser Gly Gly Gly Gly Ser Ile Pro Pro His Val Gln Lys
165 170 175
Ser Val Asn Asn Asp Met Ile Val Thr Asp Asn Asn Gly Ala Val Lys
180 185 190
Phe Pro Gln Leu Cys Lys Phe Cys Asp Val Arg Phe Ser Thr Cys Asp
195 200 205
Asn Gln Lys Ser Cys Met Ser Asn Cys Ser Ile Thr Ser Ile Cys Glu
210 215 220
Lys Pro Gln Glu Val Cys Val Ala Val Trp Arg Lys Asn Asp Glu Asn
225 230 235 240
Ile Thr Leu Glu Thr Val Cys His Asp Pro Lys Leu Pro Tyr His Asp
245 250 255
Phe Ile Leu Glu Asp Ala Ala Ser Pro Lys Cys Ile Met Lys Glu Lys
260 265 270
Lys Lys Pro Gly Glu Thr Phe Phe Met Cys Ser Cys Ser Ser Asp Glu
275 280 285
Cys Asn Asp Asn Ile Ile Phe Ser Glu Glu Tyr Asn Thr Ser Asn Pro
290 295 300
Asp Ser Gly Thr Thr Asn Thr Val Ala Ala Tyr Asn Leu Thr Trp Lys
305 310 315 320
Ser Thr Asn Phe Lys Thr Ile Leu Glu Trp Glu Pro Lys Pro Val Asn
325 330 335
Gln Val Tyr Thr Val Gln Ile Ser Thr Lys Ser Gly Asp Trp Lys Ser
340 345 350
Lys Cys Phe Tyr Thr Thr Asp Thr Glu Cys Asp Leu Thr Asp Glu Ile
355 360 365
Val Lys Asp Val Lys Gln Thr Tyr Leu Ala Arg Val Phe Ser Tyr Pro
370 375 380
Ala Gly Asn Val Glu Ser Thr Gly Ser Ala Gly Glu Pro Leu Tyr Glu
385 390 395 400
Asn Ser Pro Glu Phe Thr Pro Tyr Leu Glu Thr Asn Leu Gly Gln Pro
405 410 415
Thr Ile Gln Ser Phe Glu Gln Val Gly Thr Lys Val Asn Val Thr Val
420 425 430
Glu Asp Glu Arg Thr Leu Val Arg Arg Asn Asn Thr Phe Leu Ser Leu
435 440 445
Arg Asp Val Phe Gly Lys Asp Leu Ile Tyr Thr Leu Tyr Tyr Trp Lys
450 455 460
Ser Ser Ser Ser Gly Lys Lys Thr Ala Lys Thr Asn Thr Asn Glu Phe
465 470 475 480
Leu Ile Asp Val Asp Lys Gly Glu Asn Tyr Cys Phe Ser Val Gln Ala
485 490 495
Val Ile Pro Ser Arg Thr Val Asn Arg Lys Ser Thr Asp Ser Pro Val
500 505 510
Glu Cys Met Gly Gln Glu Lys Gly Glu Phe Arg Glu Asn Trp Val Asn
515 520 525
Val Ile Ser Asp Leu Lys Lys Ile Glu Asp Leu Ile Gln Ser Met His
530 535 540
Ile Asp Ala Thr Leu Tyr Thr Glu Ser Asp Val His Pro Ser Cys Lys
545 550 555 560
Val Thr Ala Met Lys Cys Phe Leu Leu Glu Leu Gln Val Ile Ser Leu
565 570 575
Glu Ser Gly Asp Ala Ser Ile His Asp Thr Val Glu Asn Leu Ile Ile
580 585 590
Leu Ala Asn Asn Ser Leu Ser Ser Asn Gly Asn Val Thr Glu Ser Gly
595 600 605
Cys Lys Glu Cys Glu Glu Leu Glu Glu Lys Asn Ile Lys Glu Phe Leu
610 615 620
Gln Ser Phe Val His Ile Val Gln Met Phe Ile Asn Thr Ser
625 630 635
<210> 204
<211> 1914
<212> DNA
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成TGFRt15-TGFRs16序列”
<400> 204
atgaagtggg tgaccttcat cagcctgctg ttcctgttct ccagcgccta ctccatcccc 60
ccccatgtgc aaaagagcgt gaacaacgat atgatcgtga ccgacaacaa cggcgccgtg 120
aagtttcccc agctctgcaa gttctgcgat gtcaggttca gcacctgcga taatcagaag 180
tcctgcatgt ccaactgcag catcacctcc atctgcgaga agccccaaga agtgtgcgtg 240
gccgtgtggc ggaaaaatga cgagaacatc accctggaga ccgtgtgtca cgaccccaag 300
ctcccttatc acgacttcat tctggaggac gctgcctccc ccaaatgcat catgaaggag 360
aagaagaagc ccggagagac cttctttatg tgttcctgta gcagcgacga gtgtaacgac 420
aacatcatct tcagcgaaga gtacaacacc agcaaccctg atggaggtgg cggatccgga 480
ggtggaggtt ctggtggagg tgggagtatt cctccccacg tgcagaagag cgtgaataat 540
gacatgatcg tgaccgataa caatggcgcc gtgaaatttc cccagctgtg caaattctgc 600
gatgtgaggt tttccacctg cgacaaccag aagtcctgta tgagcaactg ctccatcacc 660
tccatctgtg agaagcctca ggaggtgtgc gtggctgtct ggcggaagaa tgacgagaat 720
atcaccctgg aaaccgtctg ccacgatccc aagctgccct accacgattt catcctggaa 780
gacgccgcca gccctaagtg catcatgaaa gagaaaaaga agcctggcga gacctttttc 840
atgtgctcct gcagcagcga cgaatgcaac gacaatatca tctttagcga ggaatacaat 900
accagcaacc ccgacagcgg cacaaccaac acagtcgctg cctataacct cacttggaag 960
agcaccaact tcaaaaccat cctcgaatgg gaacccaaac ccgttaacca agtttacacc 1020
gtgcagatca gcaccaagtc cggcgactgg aagtccaaat gtttctatac caccgacacc 1080
gagtgcgatc tcaccgatga gatcgtgaaa gatgtgaaac agacctacct cgcccgggtg 1140
tttagctacc ccgccggcaa tgtggagagc actggttccg ctggcgagcc tttatacgag 1200
aacagccccg aatttacccc ttacctcgag accaatttag gacagcccac catccaaagc 1260
tttgagcaag ttggcacaaa ggtgaatgtg acagtggagg acgagcggac tttagtgcgg 1320
cggaacaaca cctttctcag cctccgggat gtgttcggca aagatttaat ctacacactg 1380
tattactgga agtcctcttc ctccggcaag aagacagcta aaaccaacac aaacgagttt 1440
ttaatcgacg tggataaagg cgaaaactac tgtttcagcg tgcaagctgt gatcccctcc 1500
cggaccgtga ataggaaaag caccgatagc cccgttgagt gcatgggcca agaaaagggc 1560
gagttccggg agaactgggt gaacgtcatc agcgatttaa agaagatcga agatttaatt 1620
cagtccatgc atatcgacgc cactttatac acagaatccg acgtgcaccc ctcttgtaag 1680
gtgaccgcca tgaaatgttt tttactggag ctgcaagtta tctctttaga gagcggagac 1740
gctagcatcc acgacaccgt ggagaattta atcattttag ccaataactc tttatccagc 1800
aacggcaacg tgacagagtc cggctgcaag gagtgcgaag agctggagga gaagaacatc 1860
aaggagtttc tgcaatcctt tgtgcacatt gtccagatgt tcatcaatac ctcc 1914
<210> 205
<211> 592
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成TGFRt15-TGFRs16序列”
<400> 205
Ile Pro Pro His Val Gln Lys Ser Val Asn Asn Asp Met Ile Val Thr
1 5 10 15
Asp Asn Asn Gly Ala Val Lys Phe Pro Gln Leu Cys Lys Phe Cys Asp
20 25 30
Val Arg Phe Ser Thr Cys Asp Asn Gln Lys Ser Cys Met Ser Asn Cys
35 40 45
Ser Ile Thr Ser Ile Cys Glu Lys Pro Gln Glu Val Cys Val Ala Val
50 55 60
Trp Arg Lys Asn Asp Glu Asn Ile Thr Leu Glu Thr Val Cys His Asp
65 70 75 80
Pro Lys Leu Pro Tyr His Asp Phe Ile Leu Glu Asp Ala Ala Ser Pro
85 90 95
Lys Cys Ile Met Lys Glu Lys Lys Lys Pro Gly Glu Thr Phe Phe Met
100 105 110
Cys Ser Cys Ser Ser Asp Glu Cys Asn Asp Asn Ile Ile Phe Ser Glu
115 120 125
Glu Tyr Asn Thr Ser Asn Pro Asp Gly Gly Gly Gly Ser Gly Gly Gly
130 135 140
Gly Ser Gly Gly Gly Gly Ser Ile Pro Pro His Val Gln Lys Ser Val
145 150 155 160
Asn Asn Asp Met Ile Val Thr Asp Asn Asn Gly Ala Val Lys Phe Pro
165 170 175
Gln Leu Cys Lys Phe Cys Asp Val Arg Phe Ser Thr Cys Asp Asn Gln
180 185 190
Lys Ser Cys Met Ser Asn Cys Ser Ile Thr Ser Ile Cys Glu Lys Pro
195 200 205
Gln Glu Val Cys Val Ala Val Trp Arg Lys Asn Asp Glu Asn Ile Thr
210 215 220
Leu Glu Thr Val Cys His Asp Pro Lys Leu Pro Tyr His Asp Phe Ile
225 230 235 240
Leu Glu Asp Ala Ala Ser Pro Lys Cys Ile Met Lys Glu Lys Lys Lys
245 250 255
Pro Gly Glu Thr Phe Phe Met Cys Ser Cys Ser Ser Asp Glu Cys Asn
260 265 270
Asp Asn Ile Ile Phe Ser Glu Glu Tyr Asn Thr Ser Asn Pro Asp Ile
275 280 285
Thr Cys Pro Pro Pro Met Ser Val Glu His Ala Asp Ile Trp Val Lys
290 295 300
Ser Tyr Ser Leu Tyr Ser Arg Glu Arg Tyr Ile Cys Asn Ser Gly Phe
305 310 315 320
Lys Arg Lys Ala Gly Thr Ser Ser Leu Thr Glu Cys Val Leu Asn Lys
325 330 335
Ala Thr Asn Val Ala His Trp Thr Thr Pro Ser Leu Lys Cys Ile Arg
340 345 350
Ser Glu Leu Thr Gln Asp Pro Ala Val Ser Val Ala Leu Gly Gln Thr
355 360 365
Val Arg Ile Thr Cys Gln Gly Asp Ser Leu Arg Ser Tyr Tyr Ala Ser
370 375 380
Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Val Leu Val Ile Tyr Gly
385 390 395 400
Lys Asn Asn Arg Pro Ser Gly Ile Pro Asp Arg Phe Ser Gly Ser Ser
405 410 415
Ser Gly Asn Thr Ala Ser Leu Thr Ile Thr Gly Ala Gln Ala Glu Asp
420 425 430
Glu Ala Asp Tyr Tyr Cys Asn Ser Arg Asp Ser Ser Gly Asn His Val
435 440 445
Val Phe Gly Gly Gly Thr Lys Leu Thr Val Gly His Gly Gly Gly Gly
450 455 460
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val
465 470 475 480
Glu Ser Gly Gly Gly Val Val Arg Pro Gly Gly Ser Leu Arg Leu Ser
485 490 495
Cys Ala Ala Ser Gly Phe Thr Phe Asp Asp Tyr Gly Met Ser Trp Val
500 505 510
Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val Ser Gly Ile Asn Trp
515 520 525
Asn Gly Gly Ser Thr Gly Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr
530 535 540
Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr Leu Gln Met Asn Ser
545 550 555 560
Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala Arg Gly Arg Ser
565 570 575
Leu Leu Phe Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser Arg
580 585 590
<210> 206
<211> 1776
<212> DNA
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成TGFRt15-TGFRs16序列”
<400> 206
atcccccccc atgtgcaaaa gagcgtgaac aacgatatga tcgtgaccga caacaacggc 60
gccgtgaagt ttccccagct ctgcaagttc tgcgatgtca ggttcagcac ctgcgataat 120
cagaagtcct gcatgtccaa ctgcagcatc acctccatct gcgagaagcc ccaagaagtg 180
tgcgtggccg tgtggcggaa aaatgacgag aacatcaccc tggagaccgt gtgtcacgac 240
cccaagctcc cttatcacga cttcattctg gaggacgctg cctcccccaa atgcatcatg 300
aaggagaaga agaagcccgg agagaccttc tttatgtgtt cctgtagcag cgacgagtgt 360
aacgacaaca tcatcttcag cgaagagtac aacaccagca accctgatgg aggtggcgga 420
tccggaggtg gaggttctgg tggaggtggg agtattcctc cccacgtgca gaagagcgtg 480
aataatgaca tgatcgtgac cgataacaat ggcgccgtga aatttcccca gctgtgcaaa 540
ttctgcgatg tgaggttttc cacctgcgac aaccagaagt cctgtatgag caactgctcc 600
atcacctcca tctgtgagaa gcctcaggag gtgtgcgtgg ctgtctggcg gaagaatgac 660
gagaatatca ccctggaaac cgtctgccac gatcccaagc tgccctacca cgatttcatc 720
ctggaagacg ccgccagccc taagtgcatc atgaaagaga aaaagaagcc tggcgagacc 780
tttttcatgt gctcctgcag cagcgacgaa tgcaacgaca atatcatctt tagcgaggaa 840
tacaatacca gcaaccccga cattacatgc ccccctccca tgagcgtgga gcacgccgac 900
atctgggtga agagctatag cctctacagc cgggagaggt atatctgtaa cagcggcttc 960
aagaggaagg ccggcaccag cagcctcacc gagtgcgtgc tgaataaggc taccaacgtg 1020
gctcactgga caacaccctc tttaaagtgc atccggtccg agctgaccca ggaccctgct 1080
gtgtccgtgg ctctgggcca gaccgtgagg atcacctgcc agggcgactc cctgaggtcc 1140
tactacgcct cctggtacca gcagaagccc ggccaggctc ctgtgctggt gatctacggc 1200
aagaacaaca ggccctccgg catccctgac aggttctccg gatcctcctc cggcaacacc 1260
gcctccctga ccatcacagg cgctcaggcc gaggacgagg ctgactacta ctgcaactcc 1320
agggactcct ccggcaacca tgtggtgttc ggcggcggca ccaagctgac cgtgggccat 1380
ggcggcggcg gctccggagg cggcggcagc ggcggaggag gatccgaggt gcagctggtg 1440
gagtccggag gaggagtggt gaggcctgga ggctccctga ggctgagctg tgctgcctcc 1500
ggcttcacct tcgacgacta cggcatgtcc tgggtgaggc aggctcctgg aaagggcctg 1560
gagtgggtgt ccggcatcaa ctggaacggc ggatccaccg gctacgccga ttccgtgaag 1620
ggcaggttca ccatcagcag ggacaacgcc aagaactccc tgtacctgca gatgaactcc 1680
ctgagggccg aggacaccgc cgtgtactac tgcgccaggg gcaggtccct gctgttcgac 1740
tactggggac agggcaccct ggtgaccgtg tccagg 1776
<210> 207
<211> 610
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成TGFRt15-TGFRs16序列”
<400> 207
Met Lys Trp Val Thr Phe Ile Ser Leu Leu Phe Leu Phe Ser Ser Ala
1 5 10 15
Tyr Ser Ile Pro Pro His Val Gln Lys Ser Val Asn Asn Asp Met Ile
20 25 30
Val Thr Asp Asn Asn Gly Ala Val Lys Phe Pro Gln Leu Cys Lys Phe
35 40 45
Cys Asp Val Arg Phe Ser Thr Cys Asp Asn Gln Lys Ser Cys Met Ser
50 55 60
Asn Cys Ser Ile Thr Ser Ile Cys Glu Lys Pro Gln Glu Val Cys Val
65 70 75 80
Ala Val Trp Arg Lys Asn Asp Glu Asn Ile Thr Leu Glu Thr Val Cys
85 90 95
His Asp Pro Lys Leu Pro Tyr His Asp Phe Ile Leu Glu Asp Ala Ala
100 105 110
Ser Pro Lys Cys Ile Met Lys Glu Lys Lys Lys Pro Gly Glu Thr Phe
115 120 125
Phe Met Cys Ser Cys Ser Ser Asp Glu Cys Asn Asp Asn Ile Ile Phe
130 135 140
Ser Glu Glu Tyr Asn Thr Ser Asn Pro Asp Gly Gly Gly Gly Ser Gly
145 150 155 160
Gly Gly Gly Ser Gly Gly Gly Gly Ser Ile Pro Pro His Val Gln Lys
165 170 175
Ser Val Asn Asn Asp Met Ile Val Thr Asp Asn Asn Gly Ala Val Lys
180 185 190
Phe Pro Gln Leu Cys Lys Phe Cys Asp Val Arg Phe Ser Thr Cys Asp
195 200 205
Asn Gln Lys Ser Cys Met Ser Asn Cys Ser Ile Thr Ser Ile Cys Glu
210 215 220
Lys Pro Gln Glu Val Cys Val Ala Val Trp Arg Lys Asn Asp Glu Asn
225 230 235 240
Ile Thr Leu Glu Thr Val Cys His Asp Pro Lys Leu Pro Tyr His Asp
245 250 255
Phe Ile Leu Glu Asp Ala Ala Ser Pro Lys Cys Ile Met Lys Glu Lys
260 265 270
Lys Lys Pro Gly Glu Thr Phe Phe Met Cys Ser Cys Ser Ser Asp Glu
275 280 285
Cys Asn Asp Asn Ile Ile Phe Ser Glu Glu Tyr Asn Thr Ser Asn Pro
290 295 300
Asp Ile Thr Cys Pro Pro Pro Met Ser Val Glu His Ala Asp Ile Trp
305 310 315 320
Val Lys Ser Tyr Ser Leu Tyr Ser Arg Glu Arg Tyr Ile Cys Asn Ser
325 330 335
Gly Phe Lys Arg Lys Ala Gly Thr Ser Ser Leu Thr Glu Cys Val Leu
340 345 350
Asn Lys Ala Thr Asn Val Ala His Trp Thr Thr Pro Ser Leu Lys Cys
355 360 365
Ile Arg Ser Glu Leu Thr Gln Asp Pro Ala Val Ser Val Ala Leu Gly
370 375 380
Gln Thr Val Arg Ile Thr Cys Gln Gly Asp Ser Leu Arg Ser Tyr Tyr
385 390 395 400
Ala Ser Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Val Leu Val Ile
405 410 415
Tyr Gly Lys Asn Asn Arg Pro Ser Gly Ile Pro Asp Arg Phe Ser Gly
420 425 430
Ser Ser Ser Gly Asn Thr Ala Ser Leu Thr Ile Thr Gly Ala Gln Ala
435 440 445
Glu Asp Glu Ala Asp Tyr Tyr Cys Asn Ser Arg Asp Ser Ser Gly Asn
450 455 460
His Val Val Phe Gly Gly Gly Thr Lys Leu Thr Val Gly His Gly Gly
465 470 475 480
Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln
485 490 495
Leu Val Glu Ser Gly Gly Gly Val Val Arg Pro Gly Gly Ser Leu Arg
500 505 510
Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Asp Asp Tyr Gly Met Ser
515 520 525
Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val Ser Gly Ile
530 535 540
Asn Trp Asn Gly Gly Ser Thr Gly Tyr Ala Asp Ser Val Lys Gly Arg
545 550 555 560
Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr Leu Gln Met
565 570 575
Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala Arg Gly
580 585 590
Arg Ser Leu Leu Phe Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val
595 600 605
Ser Arg
610
<210> 208
<211> 1830
<212> DNA
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成TGFRt15-TGFRs16序列”
<400> 208
atgaagtggg tgaccttcat cagcctgctg ttcctgttct ccagcgccta ctccatcccc 60
ccccatgtgc aaaagagcgt gaacaacgat atgatcgtga ccgacaacaa cggcgccgtg 120
aagtttcccc agctctgcaa gttctgcgat gtcaggttca gcacctgcga taatcagaag 180
tcctgcatgt ccaactgcag catcacctcc atctgcgaga agccccaaga agtgtgcgtg 240
gccgtgtggc ggaaaaatga cgagaacatc accctggaga ccgtgtgtca cgaccccaag 300
ctcccttatc acgacttcat tctggaggac gctgcctccc ccaaatgcat catgaaggag 360
aagaagaagc ccggagagac cttctttatg tgttcctgta gcagcgacga gtgtaacgac 420
aacatcatct tcagcgaaga gtacaacacc agcaaccctg atggaggtgg cggatccgga 480
ggtggaggtt ctggtggagg tgggagtatt cctccccacg tgcagaagag cgtgaataat 540
gacatgatcg tgaccgataa caatggcgcc gtgaaatttc cccagctgtg caaattctgc 600
gatgtgaggt tttccacctg cgacaaccag aagtcctgta tgagcaactg ctccatcacc 660
tccatctgtg agaagcctca ggaggtgtgc gtggctgtct ggcggaagaa tgacgagaat 720
atcaccctgg aaaccgtctg ccacgatccc aagctgccct accacgattt catcctggaa 780
gacgccgcca gccctaagtg catcatgaaa gagaaaaaga agcctggcga gacctttttc 840
atgtgctcct gcagcagcga cgaatgcaac gacaatatca tctttagcga ggaatacaat 900
accagcaacc ccgacattac atgcccccct cccatgagcg tggagcacgc cgacatctgg 960
gtgaagagct atagcctcta cagccgggag aggtatatct gtaacagcgg cttcaagagg 1020
aaggccggca ccagcagcct caccgagtgc gtgctgaata aggctaccaa cgtggctcac 1080
tggacaacac cctctttaaa gtgcatccgg tccgagctga cccaggaccc tgctgtgtcc 1140
gtggctctgg gccagaccgt gaggatcacc tgccagggcg actccctgag gtcctactac 1200
gcctcctggt accagcagaa gcccggccag gctcctgtgc tggtgatcta cggcaagaac 1260
aacaggccct ccggcatccc tgacaggttc tccggatcct cctccggcaa caccgcctcc 1320
ctgaccatca caggcgctca ggccgaggac gaggctgact actactgcaa ctccagggac 1380
tcctccggca accatgtggt gttcggcggc ggcaccaagc tgaccgtggg ccatggcggc 1440
ggcggctccg gaggcggcgg cagcggcgga ggaggatccg aggtgcagct ggtggagtcc 1500
ggaggaggag tggtgaggcc tggaggctcc ctgaggctga gctgtgctgc ctccggcttc 1560
accttcgacg actacggcat gtcctgggtg aggcaggctc ctggaaaggg cctggagtgg 1620
gtgtccggca tcaactggaa cggcggatcc accggctacg ccgattccgt gaagggcagg 1680
ttcaccatca gcagggacaa cgccaagaac tccctgtacc tgcagatgaa ctccctgagg 1740
gccgaggaca ccgccgtgta ctactgcgcc aggggcaggt ccctgctgtt cgactactgg 1800
ggacagggca ccctggtgac cgtgtccagg 1830
<210> 209
<211> 620
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成TGFRt15-TGFRs137序列”
<400> 209
Ile Pro Pro His Val Gln Lys Ser Val Asn Asn Asp Met Ile Val Thr
1 5 10 15
Asp Asn Asn Gly Ala Val Lys Phe Pro Gln Leu Cys Lys Phe Cys Asp
20 25 30
Val Arg Phe Ser Thr Cys Asp Asn Gln Lys Ser Cys Met Ser Asn Cys
35 40 45
Ser Ile Thr Ser Ile Cys Glu Lys Pro Gln Glu Val Cys Val Ala Val
50 55 60
Trp Arg Lys Asn Asp Glu Asn Ile Thr Leu Glu Thr Val Cys His Asp
65 70 75 80
Pro Lys Leu Pro Tyr His Asp Phe Ile Leu Glu Asp Ala Ala Ser Pro
85 90 95
Lys Cys Ile Met Lys Glu Lys Lys Lys Pro Gly Glu Thr Phe Phe Met
100 105 110
Cys Ser Cys Ser Ser Asp Glu Cys Asn Asp Asn Ile Ile Phe Ser Glu
115 120 125
Glu Tyr Asn Thr Ser Asn Pro Asp Gly Gly Gly Gly Ser Gly Gly Gly
130 135 140
Gly Ser Gly Gly Gly Gly Ser Ile Pro Pro His Val Gln Lys Ser Val
145 150 155 160
Asn Asn Asp Met Ile Val Thr Asp Asn Asn Gly Ala Val Lys Phe Pro
165 170 175
Gln Leu Cys Lys Phe Cys Asp Val Arg Phe Ser Thr Cys Asp Asn Gln
180 185 190
Lys Ser Cys Met Ser Asn Cys Ser Ile Thr Ser Ile Cys Glu Lys Pro
195 200 205
Gln Glu Val Cys Val Ala Val Trp Arg Lys Asn Asp Glu Asn Ile Thr
210 215 220
Leu Glu Thr Val Cys His Asp Pro Lys Leu Pro Tyr His Asp Phe Ile
225 230 235 240
Leu Glu Asp Ala Ala Ser Pro Lys Cys Ile Met Lys Glu Lys Lys Lys
245 250 255
Pro Gly Glu Thr Phe Phe Met Cys Ser Cys Ser Ser Asp Glu Cys Asn
260 265 270
Asp Asn Ile Ile Phe Ser Glu Glu Tyr Asn Thr Ser Asn Pro Asp Ser
275 280 285
Gly Thr Thr Asn Thr Val Ala Ala Tyr Asn Leu Thr Trp Lys Ser Thr
290 295 300
Asn Phe Lys Thr Ile Leu Glu Trp Glu Pro Lys Pro Val Asn Gln Val
305 310 315 320
Tyr Thr Val Gln Ile Ser Thr Lys Ser Gly Asp Trp Lys Ser Lys Cys
325 330 335
Phe Tyr Thr Thr Asp Thr Glu Cys Asp Leu Thr Asp Glu Ile Val Lys
340 345 350
Asp Val Lys Gln Thr Tyr Leu Ala Arg Val Phe Ser Tyr Pro Ala Gly
355 360 365
Asn Val Glu Ser Thr Gly Ser Ala Gly Glu Pro Leu Tyr Glu Asn Ser
370 375 380
Pro Glu Phe Thr Pro Tyr Leu Glu Thr Asn Leu Gly Gln Pro Thr Ile
385 390 395 400
Gln Ser Phe Glu Gln Val Gly Thr Lys Val Asn Val Thr Val Glu Asp
405 410 415
Glu Arg Thr Leu Val Arg Arg Asn Asn Thr Phe Leu Ser Leu Arg Asp
420 425 430
Val Phe Gly Lys Asp Leu Ile Tyr Thr Leu Tyr Tyr Trp Lys Ser Ser
435 440 445
Ser Ser Gly Lys Lys Thr Ala Lys Thr Asn Thr Asn Glu Phe Leu Ile
450 455 460
Asp Val Asp Lys Gly Glu Asn Tyr Cys Phe Ser Val Gln Ala Val Ile
465 470 475 480
Pro Ser Arg Thr Val Asn Arg Lys Ser Thr Asp Ser Pro Val Glu Cys
485 490 495
Met Gly Gln Glu Lys Gly Glu Phe Arg Glu Asn Trp Val Asn Val Ile
500 505 510
Ser Asp Leu Lys Lys Ile Glu Asp Leu Ile Gln Ser Met His Ile Asp
515 520 525
Ala Thr Leu Tyr Thr Glu Ser Asp Val His Pro Ser Cys Lys Val Thr
530 535 540
Ala Met Lys Cys Phe Leu Leu Glu Leu Gln Val Ile Ser Leu Glu Ser
545 550 555 560
Gly Asp Ala Ser Ile His Asp Thr Val Glu Asn Leu Ile Ile Leu Ala
565 570 575
Asn Asn Ser Leu Ser Ser Asn Gly Asn Val Thr Glu Ser Gly Cys Lys
580 585 590
Glu Cys Glu Glu Leu Glu Glu Lys Asn Ile Lys Glu Phe Leu Gln Ser
595 600 605
Phe Val His Ile Val Gln Met Phe Ile Asn Thr Ser
610 615 620
<210> 210
<211> 1860
<212> DNA
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成TGFRt15-TGFRs137序列”
<400> 210
atcccccccc atgtgcaaaa gagcgtgaac aacgatatga tcgtgaccga caacaacggc 60
gccgtgaagt ttccccagct ctgcaagttc tgcgatgtca ggttcagcac ctgcgataat 120
cagaagtcct gcatgtccaa ctgcagcatc acctccatct gcgagaagcc ccaagaagtg 180
tgcgtggccg tgtggcggaa aaatgacgag aacatcaccc tggagaccgt gtgtcacgac 240
cccaagctcc cttatcacga cttcattctg gaggacgctg cctcccccaa atgcatcatg 300
aaggagaaga agaagcccgg agagaccttc tttatgtgtt cctgtagcag cgacgagtgt 360
aacgacaaca tcatcttcag cgaagagtac aacaccagca accctgatgg aggtggcgga 420
tccggaggtg gaggttctgg tggaggtggg agtattcctc cccacgtgca gaagagcgtg 480
aataatgaca tgatcgtgac cgataacaat ggcgccgtga aatttcccca gctgtgcaaa 540
ttctgcgatg tgaggttttc cacctgcgac aaccagaagt cctgtatgag caactgctcc 600
atcacctcca tctgtgagaa gcctcaggag gtgtgcgtgg ctgtctggcg gaagaatgac 660
gagaatatca ccctggaaac cgtctgccac gatcccaagc tgccctacca cgatttcatc 720
ctggaagacg ccgccagccc taagtgcatc atgaaagaga aaaagaagcc tggcgagacc 780
tttttcatgt gctcctgcag cagcgacgaa tgcaacgaca atatcatctt tagcgaggaa 840
tacaatacca gcaaccccga cagcggcaca accaacacag tcgctgccta taacctcact 900
tggaagagca ccaacttcaa aaccatcctc gaatgggaac ccaaacccgt taaccaagtt 960
tacaccgtgc agatcagcac caagtccggc gactggaagt ccaaatgttt ctataccacc 1020
gacaccgagt gcgatctcac cgatgagatc gtgaaagatg tgaaacagac ctacctcgcc 1080
cgggtgttta gctaccccgc cggcaatgtg gagagcactg gttccgctgg cgagccttta 1140
tacgagaaca gccccgaatt taccccttac ctcgagacca atttaggaca gcccaccatc 1200
caaagctttg agcaagttgg cacaaaggtg aatgtgacag tggaggacga gcggacttta 1260
gtgcggcgga acaacacctt tctcagcctc cgggatgtgt tcggcaaaga tttaatctac 1320
acactgtatt actggaagtc ctcttcctcc ggcaagaaga cagctaaaac caacacaaac 1380
gagtttttaa tcgacgtgga taaaggcgaa aactactgtt tcagcgtgca agctgtgatc 1440
ccctcccgga ccgtgaatag gaaaagcacc gatagccccg ttgagtgcat gggccaagaa 1500
aagggcgagt tccgggagaa ctgggtgaac gtcatcagcg atttaaagaa gatcgaagat 1560
ttaattcagt ccatgcatat cgacgccact ttatacacag aatccgacgt gcacccctct 1620
tgtaaggtga ccgccatgaa atgtttttta ctggagctgc aagttatctc tttagagagc 1680
ggagacgcta gcatccacga caccgtggag aatttaatca ttttagccaa taactcttta 1740
tccagcaacg gcaacgtgac agagtccggc tgcaaggagt gcgaagagct ggaggagaag 1800
aacatcaagg agtttctgca atcctttgtg cacattgtcc agatgttcat caatacctcc 1860
<210> 211
<211> 638
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成TGFRt15-TGFRs137序列”
<400> 211
Met Lys Trp Val Thr Phe Ile Ser Leu Leu Phe Leu Phe Ser Ser Ala
1 5 10 15
Tyr Ser Ile Pro Pro His Val Gln Lys Ser Val Asn Asn Asp Met Ile
20 25 30
Val Thr Asp Asn Asn Gly Ala Val Lys Phe Pro Gln Leu Cys Lys Phe
35 40 45
Cys Asp Val Arg Phe Ser Thr Cys Asp Asn Gln Lys Ser Cys Met Ser
50 55 60
Asn Cys Ser Ile Thr Ser Ile Cys Glu Lys Pro Gln Glu Val Cys Val
65 70 75 80
Ala Val Trp Arg Lys Asn Asp Glu Asn Ile Thr Leu Glu Thr Val Cys
85 90 95
His Asp Pro Lys Leu Pro Tyr His Asp Phe Ile Leu Glu Asp Ala Ala
100 105 110
Ser Pro Lys Cys Ile Met Lys Glu Lys Lys Lys Pro Gly Glu Thr Phe
115 120 125
Phe Met Cys Ser Cys Ser Ser Asp Glu Cys Asn Asp Asn Ile Ile Phe
130 135 140
Ser Glu Glu Tyr Asn Thr Ser Asn Pro Asp Gly Gly Gly Gly Ser Gly
145 150 155 160
Gly Gly Gly Ser Gly Gly Gly Gly Ser Ile Pro Pro His Val Gln Lys
165 170 175
Ser Val Asn Asn Asp Met Ile Val Thr Asp Asn Asn Gly Ala Val Lys
180 185 190
Phe Pro Gln Leu Cys Lys Phe Cys Asp Val Arg Phe Ser Thr Cys Asp
195 200 205
Asn Gln Lys Ser Cys Met Ser Asn Cys Ser Ile Thr Ser Ile Cys Glu
210 215 220
Lys Pro Gln Glu Val Cys Val Ala Val Trp Arg Lys Asn Asp Glu Asn
225 230 235 240
Ile Thr Leu Glu Thr Val Cys His Asp Pro Lys Leu Pro Tyr His Asp
245 250 255
Phe Ile Leu Glu Asp Ala Ala Ser Pro Lys Cys Ile Met Lys Glu Lys
260 265 270
Lys Lys Pro Gly Glu Thr Phe Phe Met Cys Ser Cys Ser Ser Asp Glu
275 280 285
Cys Asn Asp Asn Ile Ile Phe Ser Glu Glu Tyr Asn Thr Ser Asn Pro
290 295 300
Asp Ser Gly Thr Thr Asn Thr Val Ala Ala Tyr Asn Leu Thr Trp Lys
305 310 315 320
Ser Thr Asn Phe Lys Thr Ile Leu Glu Trp Glu Pro Lys Pro Val Asn
325 330 335
Gln Val Tyr Thr Val Gln Ile Ser Thr Lys Ser Gly Asp Trp Lys Ser
340 345 350
Lys Cys Phe Tyr Thr Thr Asp Thr Glu Cys Asp Leu Thr Asp Glu Ile
355 360 365
Val Lys Asp Val Lys Gln Thr Tyr Leu Ala Arg Val Phe Ser Tyr Pro
370 375 380
Ala Gly Asn Val Glu Ser Thr Gly Ser Ala Gly Glu Pro Leu Tyr Glu
385 390 395 400
Asn Ser Pro Glu Phe Thr Pro Tyr Leu Glu Thr Asn Leu Gly Gln Pro
405 410 415
Thr Ile Gln Ser Phe Glu Gln Val Gly Thr Lys Val Asn Val Thr Val
420 425 430
Glu Asp Glu Arg Thr Leu Val Arg Arg Asn Asn Thr Phe Leu Ser Leu
435 440 445
Arg Asp Val Phe Gly Lys Asp Leu Ile Tyr Thr Leu Tyr Tyr Trp Lys
450 455 460
Ser Ser Ser Ser Gly Lys Lys Thr Ala Lys Thr Asn Thr Asn Glu Phe
465 470 475 480
Leu Ile Asp Val Asp Lys Gly Glu Asn Tyr Cys Phe Ser Val Gln Ala
485 490 495
Val Ile Pro Ser Arg Thr Val Asn Arg Lys Ser Thr Asp Ser Pro Val
500 505 510
Glu Cys Met Gly Gln Glu Lys Gly Glu Phe Arg Glu Asn Trp Val Asn
515 520 525
Val Ile Ser Asp Leu Lys Lys Ile Glu Asp Leu Ile Gln Ser Met His
530 535 540
Ile Asp Ala Thr Leu Tyr Thr Glu Ser Asp Val His Pro Ser Cys Lys
545 550 555 560
Val Thr Ala Met Lys Cys Phe Leu Leu Glu Leu Gln Val Ile Ser Leu
565 570 575
Glu Ser Gly Asp Ala Ser Ile His Asp Thr Val Glu Asn Leu Ile Ile
580 585 590
Leu Ala Asn Asn Ser Leu Ser Ser Asn Gly Asn Val Thr Glu Ser Gly
595 600 605
Cys Lys Glu Cys Glu Glu Leu Glu Glu Lys Asn Ile Lys Glu Phe Leu
610 615 620
Gln Ser Phe Val His Ile Val Gln Met Phe Ile Asn Thr Ser
625 630 635
<210> 212
<211> 1914
<212> DNA
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成TGFRt15-TGFRs137序列”
<400> 212
atgaagtggg tgaccttcat cagcctgctg ttcctgttct ccagcgccta ctccatcccc 60
ccccatgtgc aaaagagcgt gaacaacgat atgatcgtga ccgacaacaa cggcgccgtg 120
aagtttcccc agctctgcaa gttctgcgat gtcaggttca gcacctgcga taatcagaag 180
tcctgcatgt ccaactgcag catcacctcc atctgcgaga agccccaaga agtgtgcgtg 240
gccgtgtggc ggaaaaatga cgagaacatc accctggaga ccgtgtgtca cgaccccaag 300
ctcccttatc acgacttcat tctggaggac gctgcctccc ccaaatgcat catgaaggag 360
aagaagaagc ccggagagac cttctttatg tgttcctgta gcagcgacga gtgtaacgac 420
aacatcatct tcagcgaaga gtacaacacc agcaaccctg atggaggtgg cggatccgga 480
ggtggaggtt ctggtggagg tgggagtatt cctccccacg tgcagaagag cgtgaataat 540
gacatgatcg tgaccgataa caatggcgcc gtgaaatttc cccagctgtg caaattctgc 600
gatgtgaggt tttccacctg cgacaaccag aagtcctgta tgagcaactg ctccatcacc 660
tccatctgtg agaagcctca ggaggtgtgc gtggctgtct ggcggaagaa tgacgagaat 720
atcaccctgg aaaccgtctg ccacgatccc aagctgccct accacgattt catcctggaa 780
gacgccgcca gccctaagtg catcatgaaa gagaaaaaga agcctggcga gacctttttc 840
atgtgctcct gcagcagcga cgaatgcaac gacaatatca tctttagcga ggaatacaat 900
accagcaacc ccgacagcgg cacaaccaac acagtcgctg cctataacct cacttggaag 960
agcaccaact tcaaaaccat cctcgaatgg gaacccaaac ccgttaacca agtttacacc 1020
gtgcagatca gcaccaagtc cggcgactgg aagtccaaat gtttctatac caccgacacc 1080
gagtgcgatc tcaccgatga gatcgtgaaa gatgtgaaac agacctacct cgcccgggtg 1140
tttagctacc ccgccggcaa tgtggagagc actggttccg ctggcgagcc tttatacgag 1200
aacagccccg aatttacccc ttacctcgag accaatttag gacagcccac catccaaagc 1260
tttgagcaag ttggcacaaa ggtgaatgtg acagtggagg acgagcggac tttagtgcgg 1320
cggaacaaca cctttctcag cctccgggat gtgttcggca aagatttaat ctacacactg 1380
tattactgga agtcctcttc ctccggcaag aagacagcta aaaccaacac aaacgagttt 1440
ttaatcgacg tggataaagg cgaaaactac tgtttcagcg tgcaagctgt gatcccctcc 1500
cggaccgtga ataggaaaag caccgatagc cccgttgagt gcatgggcca agaaaagggc 1560
gagttccggg agaactgggt gaacgtcatc agcgatttaa agaagatcga agatttaatt 1620
cagtccatgc atatcgacgc cactttatac acagaatccg acgtgcaccc ctcttgtaag 1680
gtgaccgcca tgaaatgttt tttactggag ctgcaagtta tctctttaga gagcggagac 1740
gctagcatcc acgacaccgt ggagaattta atcattttag ccaataactc tttatccagc 1800
aacggcaacg tgacagagtc cggctgcaag gagtgcgaag agctggagga gaagaacatc 1860
aaggagtttc tgcaatcctt tgtgcacatt gtccagatgt tcatcaatac ctcc 1914
<210> 213
<211> 551
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成TGFRt15-TGFRs137序列”
<400> 213
Ile Pro Pro His Val Gln Lys Ser Val Asn Asn Asp Met Ile Val Thr
1 5 10 15
Asp Asn Asn Gly Ala Val Lys Phe Pro Gln Leu Cys Lys Phe Cys Asp
20 25 30
Val Arg Phe Ser Thr Cys Asp Asn Gln Lys Ser Cys Met Ser Asn Cys
35 40 45
Ser Ile Thr Ser Ile Cys Glu Lys Pro Gln Glu Val Cys Val Ala Val
50 55 60
Trp Arg Lys Asn Asp Glu Asn Ile Thr Leu Glu Thr Val Cys His Asp
65 70 75 80
Pro Lys Leu Pro Tyr His Asp Phe Ile Leu Glu Asp Ala Ala Ser Pro
85 90 95
Lys Cys Ile Met Lys Glu Lys Lys Lys Pro Gly Glu Thr Phe Phe Met
100 105 110
Cys Ser Cys Ser Ser Asp Glu Cys Asn Asp Asn Ile Ile Phe Ser Glu
115 120 125
Glu Tyr Asn Thr Ser Asn Pro Asp Gly Gly Gly Gly Ser Gly Gly Gly
130 135 140
Gly Ser Gly Gly Gly Gly Ser Ile Pro Pro His Val Gln Lys Ser Val
145 150 155 160
Asn Asn Asp Met Ile Val Thr Asp Asn Asn Gly Ala Val Lys Phe Pro
165 170 175
Gln Leu Cys Lys Phe Cys Asp Val Arg Phe Ser Thr Cys Asp Asn Gln
180 185 190
Lys Ser Cys Met Ser Asn Cys Ser Ile Thr Ser Ile Cys Glu Lys Pro
195 200 205
Gln Glu Val Cys Val Ala Val Trp Arg Lys Asn Asp Glu Asn Ile Thr
210 215 220
Leu Glu Thr Val Cys His Asp Pro Lys Leu Pro Tyr His Asp Phe Ile
225 230 235 240
Leu Glu Asp Ala Ala Ser Pro Lys Cys Ile Met Lys Glu Lys Lys Lys
245 250 255
Pro Gly Glu Thr Phe Phe Met Cys Ser Cys Ser Ser Asp Glu Cys Asn
260 265 270
Asp Asn Ile Ile Phe Ser Glu Glu Tyr Asn Thr Ser Asn Pro Asp Ile
275 280 285
Thr Cys Pro Pro Pro Met Ser Val Glu His Ala Asp Ile Trp Val Lys
290 295 300
Ser Tyr Ser Leu Tyr Ser Arg Glu Arg Tyr Ile Cys Asn Ser Gly Phe
305 310 315 320
Lys Arg Lys Ala Gly Thr Ser Ser Leu Thr Glu Cys Val Leu Asn Lys
325 330 335
Ala Thr Asn Val Ala His Trp Thr Thr Pro Ser Leu Lys Cys Ile Arg
340 345 350
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Arg
355 360 365
Glu Gly Pro Glu Leu Ser Pro Asp Asp Pro Ala Gly Leu Leu Asp Leu
370 375 380
Arg Gln Gly Met Phe Ala Gln Leu Val Ala Gln Asn Val Leu Leu Ile
385 390 395 400
Asp Gly Pro Leu Ser Trp Tyr Ser Asp Pro Gly Leu Ala Gly Val Ser
405 410 415
Leu Thr Gly Gly Leu Ser Tyr Lys Glu Asp Thr Lys Glu Leu Val Val
420 425 430
Ala Lys Ala Gly Val Tyr Tyr Val Phe Phe Gln Leu Glu Leu Arg Arg
435 440 445
Val Val Ala Gly Glu Gly Ser Gly Ser Val Ser Leu Ala Leu His Leu
450 455 460
Gln Pro Leu Arg Ser Ala Ala Gly Ala Ala Ala Leu Ala Leu Thr Val
465 470 475 480
Asp Leu Pro Pro Ala Ser Ser Glu Ala Arg Asn Ser Ala Phe Gly Phe
485 490 495
Gln Gly Arg Leu Leu His Leu Ser Ala Gly Gln Arg Leu Gly Val His
500 505 510
Leu His Thr Glu Ala Arg Ala Arg His Ala Trp Gln Leu Thr Gln Gly
515 520 525
Ala Thr Val Leu Gly Leu Phe Arg Val Thr Pro Glu Ile Pro Ala Gly
530 535 540
Leu Pro Ser Pro Arg Ser Glu
545 550
<210> 214
<211> 1653
<212> DNA
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成TGFRt15-TGFRs137序列”
<400> 214
atcccccccc atgtgcaaaa gagcgtgaac aacgatatga tcgtgaccga caacaacggc 60
gccgtgaagt ttccccagct ctgcaagttc tgcgatgtca ggttcagcac ctgcgataat 120
cagaagtcct gcatgtccaa ctgcagcatc acctccatct gcgagaagcc ccaagaagtg 180
tgcgtggccg tgtggcggaa aaatgacgag aacatcaccc tggagaccgt gtgtcacgac 240
cccaagctcc cttatcacga cttcattctg gaggacgctg cctcccccaa atgcatcatg 300
aaggagaaga agaagcccgg agagaccttc tttatgtgtt cctgtagcag cgacgagtgt 360
aacgacaaca tcatcttcag cgaagagtac aacaccagca accctgatgg aggtggcgga 420
tccggaggtg gaggttctgg tggaggtggg agtattcctc cccacgtgca gaagagcgtg 480
aataatgaca tgatcgtgac cgataacaat ggcgccgtga aatttcccca gctgtgcaaa 540
ttctgcgatg tgaggttttc cacctgcgac aaccagaagt cctgtatgag caactgctcc 600
atcacctcca tctgtgagaa gcctcaggag gtgtgcgtgg ctgtctggcg gaagaatgac 660
gagaatatca ccctggaaac cgtctgccac gatcccaagc tgccctacca cgatttcatc 720
ctggaagacg ccgccagccc taagtgcatc atgaaagaga aaaagaagcc tggcgagacc 780
tttttcatgt gctcctgcag cagcgacgaa tgcaacgaca atatcatctt tagcgaggaa 840
tacaatacca gcaaccccga cattacatgc ccccctccca tgagcgtgga gcacgccgac 900
atctgggtga agagctatag cctctacagc cgggagaggt atatctgtaa cagcggcttc 960
aagaggaagg ccggcaccag cagcctcacc gagtgcgtgc tgaataaggc taccaacgtg 1020
gctcactgga caacaccctc tttaaagtgc atccggggcg gtggaggatc cggaggaggt 1080
ggctccggcg gcggaggatc tcgcgagggt cccgagcttt cgcccgacga tcccgccggc 1140
ctcttggacc tgcggcaggg catgtttgcg cagctggtgg cccaaaatgt tctgctgatc 1200
gatgggcccc tgagctggta cagtgaccca ggcctggcag gcgtgtccct gacggggggc 1260
ctgagctaca aagaggacac gaaggagctg gtggtggcca aggctggagt ctactatgtc 1320
ttctttcaac tagagctgcg gcgcgtggtg gccggcgagg gctcaggctc cgtttcactt 1380
gcgctgcacc tgcagccact gcgctctgct gctggggccg ccgccctggc tttgaccgtg 1440
gacctgccac ccgcctcctc cgaggctcgg aactcggcct tcggtttcca gggccgcttg 1500
ctgcacctga gtgccggcca gcgcctgggc gtccatcttc acactgaggc cagggcacgc 1560
catgcctggc agcttaccca gggcgccaca gtcttgggac tcttccgggt gacccccgaa 1620
atcccagccg gactcccttc accgaggtcg gaa 1653
<210> 215
<211> 569
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成TGFRt15-TGFRs137序列”
<400> 215
Met Lys Trp Val Thr Phe Ile Ser Leu Leu Phe Leu Phe Ser Ser Ala
1 5 10 15
Tyr Ser Ile Pro Pro His Val Gln Lys Ser Val Asn Asn Asp Met Ile
20 25 30
Val Thr Asp Asn Asn Gly Ala Val Lys Phe Pro Gln Leu Cys Lys Phe
35 40 45
Cys Asp Val Arg Phe Ser Thr Cys Asp Asn Gln Lys Ser Cys Met Ser
50 55 60
Asn Cys Ser Ile Thr Ser Ile Cys Glu Lys Pro Gln Glu Val Cys Val
65 70 75 80
Ala Val Trp Arg Lys Asn Asp Glu Asn Ile Thr Leu Glu Thr Val Cys
85 90 95
His Asp Pro Lys Leu Pro Tyr His Asp Phe Ile Leu Glu Asp Ala Ala
100 105 110
Ser Pro Lys Cys Ile Met Lys Glu Lys Lys Lys Pro Gly Glu Thr Phe
115 120 125
Phe Met Cys Ser Cys Ser Ser Asp Glu Cys Asn Asp Asn Ile Ile Phe
130 135 140
Ser Glu Glu Tyr Asn Thr Ser Asn Pro Asp Gly Gly Gly Gly Ser Gly
145 150 155 160
Gly Gly Gly Ser Gly Gly Gly Gly Ser Ile Pro Pro His Val Gln Lys
165 170 175
Ser Val Asn Asn Asp Met Ile Val Thr Asp Asn Asn Gly Ala Val Lys
180 185 190
Phe Pro Gln Leu Cys Lys Phe Cys Asp Val Arg Phe Ser Thr Cys Asp
195 200 205
Asn Gln Lys Ser Cys Met Ser Asn Cys Ser Ile Thr Ser Ile Cys Glu
210 215 220
Lys Pro Gln Glu Val Cys Val Ala Val Trp Arg Lys Asn Asp Glu Asn
225 230 235 240
Ile Thr Leu Glu Thr Val Cys His Asp Pro Lys Leu Pro Tyr His Asp
245 250 255
Phe Ile Leu Glu Asp Ala Ala Ser Pro Lys Cys Ile Met Lys Glu Lys
260 265 270
Lys Lys Pro Gly Glu Thr Phe Phe Met Cys Ser Cys Ser Ser Asp Glu
275 280 285
Cys Asn Asp Asn Ile Ile Phe Ser Glu Glu Tyr Asn Thr Ser Asn Pro
290 295 300
Asp Ile Thr Cys Pro Pro Pro Met Ser Val Glu His Ala Asp Ile Trp
305 310 315 320
Val Lys Ser Tyr Ser Leu Tyr Ser Arg Glu Arg Tyr Ile Cys Asn Ser
325 330 335
Gly Phe Lys Arg Lys Ala Gly Thr Ser Ser Leu Thr Glu Cys Val Leu
340 345 350
Asn Lys Ala Thr Asn Val Ala His Trp Thr Thr Pro Ser Leu Lys Cys
355 360 365
Ile Arg Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
370 375 380
Ser Arg Glu Gly Pro Glu Leu Ser Pro Asp Asp Pro Ala Gly Leu Leu
385 390 395 400
Asp Leu Arg Gln Gly Met Phe Ala Gln Leu Val Ala Gln Asn Val Leu
405 410 415
Leu Ile Asp Gly Pro Leu Ser Trp Tyr Ser Asp Pro Gly Leu Ala Gly
420 425 430
Val Ser Leu Thr Gly Gly Leu Ser Tyr Lys Glu Asp Thr Lys Glu Leu
435 440 445
Val Val Ala Lys Ala Gly Val Tyr Tyr Val Phe Phe Gln Leu Glu Leu
450 455 460
Arg Arg Val Val Ala Gly Glu Gly Ser Gly Ser Val Ser Leu Ala Leu
465 470 475 480
His Leu Gln Pro Leu Arg Ser Ala Ala Gly Ala Ala Ala Leu Ala Leu
485 490 495
Thr Val Asp Leu Pro Pro Ala Ser Ser Glu Ala Arg Asn Ser Ala Phe
500 505 510
Gly Phe Gln Gly Arg Leu Leu His Leu Ser Ala Gly Gln Arg Leu Gly
515 520 525
Val His Leu His Thr Glu Ala Arg Ala Arg His Ala Trp Gln Leu Thr
530 535 540
Gln Gly Ala Thr Val Leu Gly Leu Phe Arg Val Thr Pro Glu Ile Pro
545 550 555 560
Ala Gly Leu Pro Ser Pro Arg Ser Glu
565
<210> 216
<211> 1707
<212> DNA
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成TGFRt15-TGFRs137序列”
<400> 216
atgaagtggg tgaccttcat cagcctgctg ttcctgttct ccagcgccta ctccatcccc 60
ccccatgtgc aaaagagcgt gaacaacgat atgatcgtga ccgacaacaa cggcgccgtg 120
aagtttcccc agctctgcaa gttctgcgat gtcaggttca gcacctgcga taatcagaag 180
tcctgcatgt ccaactgcag catcacctcc atctgcgaga agccccaaga agtgtgcgtg 240
gccgtgtggc ggaaaaatga cgagaacatc accctggaga ccgtgtgtca cgaccccaag 300
ctcccttatc acgacttcat tctggaggac gctgcctccc ccaaatgcat catgaaggag 360
aagaagaagc ccggagagac cttctttatg tgttcctgta gcagcgacga gtgtaacgac 420
aacatcatct tcagcgaaga gtacaacacc agcaaccctg atggaggtgg cggatccgga 480
ggtggaggtt ctggtggagg tgggagtatt cctccccacg tgcagaagag cgtgaataat 540
gacatgatcg tgaccgataa caatggcgcc gtgaaatttc cccagctgtg caaattctgc 600
gatgtgaggt tttccacctg cgacaaccag aagtcctgta tgagcaactg ctccatcacc 660
tccatctgtg agaagcctca ggaggtgtgc gtggctgtct ggcggaagaa tgacgagaat 720
atcaccctgg aaaccgtctg ccacgatccc aagctgccct accacgattt catcctggaa 780
gacgccgcca gccctaagtg catcatgaaa gagaaaaaga agcctggcga gacctttttc 840
atgtgctcct gcagcagcga cgaatgcaac gacaatatca tctttagcga ggaatacaat 900
accagcaacc ccgacattac atgcccccct cccatgagcg tggagcacgc cgacatctgg 960
gtgaagagct atagcctcta cagccgggag aggtatatct gtaacagcgg cttcaagagg 1020
aaggccggca ccagcagcct caccgagtgc gtgctgaata aggctaccaa cgtggctcac 1080
tggacaacac cctctttaaa gtgcatccgg ggcggtggag gatccggagg aggtggctcc 1140
ggcggcggag gatctcgcga gggtcccgag ctttcgcccg acgatcccgc cggcctcttg 1200
gacctgcggc agggcatgtt tgcgcagctg gtggcccaaa atgttctgct gatcgatggg 1260
cccctgagct ggtacagtga cccaggcctg gcaggcgtgt ccctgacggg gggcctgagc 1320
tacaaagagg acacgaagga gctggtggtg gccaaggctg gagtctacta tgtcttcttt 1380
caactagagc tgcggcgcgt ggtggccggc gagggctcag gctccgtttc acttgcgctg 1440
cacctgcagc cactgcgctc tgctgctggg gccgccgccc tggctttgac cgtggacctg 1500
ccacccgcct cctccgaggc tcggaactcg gccttcggtt tccagggccg cttgctgcac 1560
ctgagtgccg gccagcgcct gggcgtccat cttcacactg aggccagggc acgccatgcc 1620
tggcagctta cccagggcgc cacagtcttg ggactcttcc gggtgacccc cgaaatccca 1680
gccggactcc cttcaccgag gtcggaa 1707
<210> 217
<211> 720
<212> DNA
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成IL-18/IL-15RαSu序列”
<400> 217
atgaagtggg tcacatttat ctctttactg ttcctcttct ccagcgccta cagctacttc 60
ggcaaactgg aatccaagct gagcgtgatc cggaatttaa acgaccaagt tctgtttatc 120
gatcaaggta accggcctct gttcgaggac atgaccgact ccgattgccg ggacaatgcc 180
ccccggacca tcttcattat ctccatgtac aaggacagcc agccccgggg catggctgtg 240
acaattagcg tgaagtgtga gaaaatcagc actttatctt gtgagaacaa gatcatctcc 300
tttaaggaaa tgaacccccc cgataacatc aaggacacca agtccgatat catcttcttc 360
cagcggtccg tgcccggtca cgataacaag atgcagttcg aatcctcctc ctacgagggc 420
tactttttag cttgtgaaaa ggagagggat ttattcaagc tgatcctcaa gaaggaggac 480
gagctgggcg atcgttccat catgttcacc gtccaaaacg aggatattac atgcccccct 540
cccatgagcg tggagcacgc cgacatctgg gtgaagagct atagcctcta cagccgggag 600
aggtatatct gtaacagcgg cttcaagagg aaggccggca ccagcagcct caccgagtgc 660
gtgctgaata aggctaccaa cgtggctcac tggacaacac cctctttaaa gtgcatccgg 720
<210> 218
<211> 2607
<212> DNA
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成IL-12/TF/IL-15序列”
<400> 218
atgaaatggg tgacctttat ttctttactg ttcctcttta gcagcgccta ctccatttgg 60
gaactgaaga aggacgtcta cgtggtcgaa ctggactggt atcccgatgc tcccggcgaa 120
atggtggtgc tcacttgtga cacccccgaa gaagacggca tcacttggac cctcgatcag 180
agcagcgagg tgctgggctc cggaaagacc ctcacaatcc aagttaagga gttcggagac 240
gctggccaat acacatgcca caagggaggc gaggtgctca gccattcctt attattatta 300
cacaagaagg aagacggaat ctggtccacc gacattttaa aagatcagaa ggagcccaag 360
aataagacct ttttaaggtg tgaggccaaa aactacagcg gtcgtttcac ttgttggtgg 420
ctgaccacca tttccaccga tttaaccttc tccgtgaaaa gcagccgggg aagctccgac 480
cctcaaggtg tgacatgtgg agccgctacc ctcagcgctg agagggttcg tggcgataac 540
aaggaatacg agtacagcgt ggagtgccaa gaagatagcg cttgtcccgc tgccgaagaa 600
tctttaccca ttgaggtgat ggtggacgcc gtgcacaaac tcaagtacga gaactacacc 660
tcctccttct ttatccggga catcattaag cccgatcctc ctaagaattt acagctgaag 720
cctctcaaaa atagccggca agttgaggtc tcttgggaat atcccgacac ttggagcaca 780
ccccacagct acttctcttt aaccttttgt gtgcaagttc aaggtaaaag caagcgggag 840
aagaaagacc gggtgtttac cgacaaaacc agcgccaccg tcatctgtcg gaagaacgcc 900
tccatcagcg tgagggctca agatcgttat tactccagca gctggtccga gtgggccagc 960
gtgccttgtt ccggcggtgg aggatccgga ggaggtggct ccggcggcgg aggatctcgt 1020
aacctccccg tggctacccc cgatcccgga atgttccctt gtttacacca cagccagaat 1080
ttactgaggg ccgtgagcaa catgctgcag aaagctaggc agactttaga attttaccct 1140
tgcaccagcg aggagatcga ccatgaagat atcaccaagg acaagacatc caccgtggag 1200
gcttgtttac ctctggagct gacaaagaac gagtcttgtc tcaactctcg tgaaaccagc 1260
ttcatcacaa atggctcttg tttagcttcc cggaagacct cctttatgat ggctttatgc 1320
ctcagctcca tctacgagga tttaaagatg taccaagtgg agttcaagac catgaacgcc 1380
aagctgctca tggaccctaa acggcagatc tttttagacc agaacatgct ggctgtgatt 1440
gatgagctga tgcaagcttt aaacttcaac tccgagaccg tccctcagaa gtcctccctc 1500
gaggagcccg atttttacaa gacaaagatc aaactgtgca ttttactcca cgcctttagg 1560
atccgggccg tgaccattga ccgggtcatg agctatttaa acgccagcag cggcacaacc 1620
aacacagtcg ctgcctataa cctcacttgg aagagcacca acttcaaaac catcctcgaa 1680
tgggaaccca aacccgttaa ccaagtttac accgtgcaga tcagcaccaa gtccggcgac 1740
tggaagtcca aatgtttcta taccaccgac accgagtgcg atctcaccga tgagatcgtg 1800
aaagatgtga aacagaccta cctcgcccgg gtgtttagct accccgccgg caatgtggag 1860
agcactggtt ccgctggcga gcctttatac gagaacagcc ccgaatttac cccttacctc 1920
gagaccaatt taggacagcc caccatccaa agctttgagc aagttggcac aaaggtgaat 1980
gtgacagtgg aggacgagcg gactttagtg cggcggaaca acacctttct cagcctccgg 2040
gatgtgttcg gcaaagattt aatctacaca ctgtattact ggaagtcctc ttcctccggc 2100
aagaagacag ctaaaaccaa cacaaacgag tttttaatcg acgtggataa aggcgaaaac 2160
tactgtttca gcgtgcaagc tgtgatcccc tcccggaccg tgaataggaa aagcaccgat 2220
agccccgttg agtgcatggg ccaagaaaag ggcgagttcc gggagaactg ggtgaacgtc 2280
atcagcgatt taaagaagat cgaagattta attcagtcca tgcatatcga cgccacttta 2340
tacacagaat ccgacgtgca cccctcttgt aaggtgaccg ccatgaaatg ttttttactg 2400
gagctgcaag ttatctcttt agagagcgga gacgctagca tccacgacac cgtggagaat 2460
ttaatcattt tagccaataa ctctttatcc agcaacggca acgtgacaga gtccggctgc 2520
aaggagtgcg aagagctgga ggagaagaac atcaaggagt ttctgcaatc ctttgtgcac 2580
attgtccaga tgttcatcaa tacctcc 2607
<210> 219
<211> 240
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成IL-18/IL-15RαSu序列”
<400> 219
Met Lys Trp Val Thr Phe Ile Ser Leu Leu Phe Leu Phe Ser Ser Ala
1 5 10 15
Tyr Ser Tyr Phe Gly Lys Leu Glu Ser Lys Leu Ser Val Ile Arg Asn
20 25 30
Leu Asn Asp Gln Val Leu Phe Ile Asp Gln Gly Asn Arg Pro Leu Phe
35 40 45
Glu Asp Met Thr Asp Ser Asp Cys Arg Asp Asn Ala Pro Arg Thr Ile
50 55 60
Phe Ile Ile Ser Met Tyr Lys Asp Ser Gln Pro Arg Gly Met Ala Val
65 70 75 80
Thr Ile Ser Val Lys Cys Glu Lys Ile Ser Thr Leu Ser Cys Glu Asn
85 90 95
Lys Ile Ile Ser Phe Lys Glu Met Asn Pro Pro Asp Asn Ile Lys Asp
100 105 110
Thr Lys Ser Asp Ile Ile Phe Phe Gln Arg Ser Val Pro Gly His Asp
115 120 125
Asn Lys Met Gln Phe Glu Ser Ser Ser Tyr Glu Gly Tyr Phe Leu Ala
130 135 140
Cys Glu Lys Glu Arg Asp Leu Phe Lys Leu Ile Leu Lys Lys Glu Asp
145 150 155 160
Glu Leu Gly Asp Arg Ser Ile Met Phe Thr Val Gln Asn Glu Asp Ile
165 170 175
Thr Cys Pro Pro Pro Met Ser Val Glu His Ala Asp Ile Trp Val Lys
180 185 190
Ser Tyr Ser Leu Tyr Ser Arg Glu Arg Tyr Ile Cys Asn Ser Gly Phe
195 200 205
Lys Arg Lys Ala Gly Thr Ser Ser Leu Thr Glu Cys Val Leu Asn Lys
210 215 220
Ala Thr Asn Val Ala His Trp Thr Thr Pro Ser Leu Lys Cys Ile Arg
225 230 235 240
<210> 220
<211> 869
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成IL-12/TF/IL-15序列”
<400> 220
Met Lys Trp Val Thr Phe Ile Ser Leu Leu Phe Leu Phe Ser Ser Ala
1 5 10 15
Tyr Ser Ile Trp Glu Leu Lys Lys Asp Val Tyr Val Val Glu Leu Asp
20 25 30
Trp Tyr Pro Asp Ala Pro Gly Glu Met Val Val Leu Thr Cys Asp Thr
35 40 45
Pro Glu Glu Asp Gly Ile Thr Trp Thr Leu Asp Gln Ser Ser Glu Val
50 55 60
Leu Gly Ser Gly Lys Thr Leu Thr Ile Gln Val Lys Glu Phe Gly Asp
65 70 75 80
Ala Gly Gln Tyr Thr Cys His Lys Gly Gly Glu Val Leu Ser His Ser
85 90 95
Leu Leu Leu Leu His Lys Lys Glu Asp Gly Ile Trp Ser Thr Asp Ile
100 105 110
Leu Lys Asp Gln Lys Glu Pro Lys Asn Lys Thr Phe Leu Arg Cys Glu
115 120 125
Ala Lys Asn Tyr Ser Gly Arg Phe Thr Cys Trp Trp Leu Thr Thr Ile
130 135 140
Ser Thr Asp Leu Thr Phe Ser Val Lys Ser Ser Arg Gly Ser Ser Asp
145 150 155 160
Pro Gln Gly Val Thr Cys Gly Ala Ala Thr Leu Ser Ala Glu Arg Val
165 170 175
Arg Gly Asp Asn Lys Glu Tyr Glu Tyr Ser Val Glu Cys Gln Glu Asp
180 185 190
Ser Ala Cys Pro Ala Ala Glu Glu Ser Leu Pro Ile Glu Val Met Val
195 200 205
Asp Ala Val His Lys Leu Lys Tyr Glu Asn Tyr Thr Ser Ser Phe Phe
210 215 220
Ile Arg Asp Ile Ile Lys Pro Asp Pro Pro Lys Asn Leu Gln Leu Lys
225 230 235 240
Pro Leu Lys Asn Ser Arg Gln Val Glu Val Ser Trp Glu Tyr Pro Asp
245 250 255
Thr Trp Ser Thr Pro His Ser Tyr Phe Ser Leu Thr Phe Cys Val Gln
260 265 270
Val Gln Gly Lys Ser Lys Arg Glu Lys Lys Asp Arg Val Phe Thr Asp
275 280 285
Lys Thr Ser Ala Thr Val Ile Cys Arg Lys Asn Ala Ser Ile Ser Val
290 295 300
Arg Ala Gln Asp Arg Tyr Tyr Ser Ser Ser Trp Ser Glu Trp Ala Ser
305 310 315 320
Val Pro Cys Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
325 330 335
Gly Gly Ser Arg Asn Leu Pro Val Ala Thr Pro Asp Pro Gly Met Phe
340 345 350
Pro Cys Leu His His Ser Gln Asn Leu Leu Arg Ala Val Ser Asn Met
355 360 365
Leu Gln Lys Ala Arg Gln Thr Leu Glu Phe Tyr Pro Cys Thr Ser Glu
370 375 380
Glu Ile Asp His Glu Asp Ile Thr Lys Asp Lys Thr Ser Thr Val Glu
385 390 395 400
Ala Cys Leu Pro Leu Glu Leu Thr Lys Asn Glu Ser Cys Leu Asn Ser
405 410 415
Arg Glu Thr Ser Phe Ile Thr Asn Gly Ser Cys Leu Ala Ser Arg Lys
420 425 430
Thr Ser Phe Met Met Ala Leu Cys Leu Ser Ser Ile Tyr Glu Asp Leu
435 440 445
Lys Met Tyr Gln Val Glu Phe Lys Thr Met Asn Ala Lys Leu Leu Met
450 455 460
Asp Pro Lys Arg Gln Ile Phe Leu Asp Gln Asn Met Leu Ala Val Ile
465 470 475 480
Asp Glu Leu Met Gln Ala Leu Asn Phe Asn Ser Glu Thr Val Pro Gln
485 490 495
Lys Ser Ser Leu Glu Glu Pro Asp Phe Tyr Lys Thr Lys Ile Lys Leu
500 505 510
Cys Ile Leu Leu His Ala Phe Arg Ile Arg Ala Val Thr Ile Asp Arg
515 520 525
Val Met Ser Tyr Leu Asn Ala Ser Ser Gly Thr Thr Asn Thr Val Ala
530 535 540
Ala Tyr Asn Leu Thr Trp Lys Ser Thr Asn Phe Lys Thr Ile Leu Glu
545 550 555 560
Trp Glu Pro Lys Pro Val Asn Gln Val Tyr Thr Val Gln Ile Ser Thr
565 570 575
Lys Ser Gly Asp Trp Lys Ser Lys Cys Phe Tyr Thr Thr Asp Thr Glu
580 585 590
Cys Asp Leu Thr Asp Glu Ile Val Lys Asp Val Lys Gln Thr Tyr Leu
595 600 605
Ala Arg Val Phe Ser Tyr Pro Ala Gly Asn Val Glu Ser Thr Gly Ser
610 615 620
Ala Gly Glu Pro Leu Tyr Glu Asn Ser Pro Glu Phe Thr Pro Tyr Leu
625 630 635 640
Glu Thr Asn Leu Gly Gln Pro Thr Ile Gln Ser Phe Glu Gln Val Gly
645 650 655
Thr Lys Val Asn Val Thr Val Glu Asp Glu Arg Thr Leu Val Arg Arg
660 665 670
Asn Asn Thr Phe Leu Ser Leu Arg Asp Val Phe Gly Lys Asp Leu Ile
675 680 685
Tyr Thr Leu Tyr Tyr Trp Lys Ser Ser Ser Ser Gly Lys Lys Thr Ala
690 695 700
Lys Thr Asn Thr Asn Glu Phe Leu Ile Asp Val Asp Lys Gly Glu Asn
705 710 715 720
Tyr Cys Phe Ser Val Gln Ala Val Ile Pro Ser Arg Thr Val Asn Arg
725 730 735
Lys Ser Thr Asp Ser Pro Val Glu Cys Met Gly Gln Glu Lys Gly Glu
740 745 750
Phe Arg Glu Asn Trp Val Asn Val Ile Ser Asp Leu Lys Lys Ile Glu
755 760 765
Asp Leu Ile Gln Ser Met His Ile Asp Ala Thr Leu Tyr Thr Glu Ser
770 775 780
Asp Val His Pro Ser Cys Lys Val Thr Ala Met Lys Cys Phe Leu Leu
785 790 795 800
Glu Leu Gln Val Ile Ser Leu Glu Ser Gly Asp Ala Ser Ile His Asp
805 810 815
Thr Val Glu Asn Leu Ile Ile Leu Ala Asn Asn Ser Leu Ser Ser Asn
820 825 830
Gly Asn Val Thr Glu Ser Gly Cys Lys Glu Cys Glu Glu Leu Glu Glu
835 840 845
Lys Asn Ile Lys Glu Phe Leu Gln Ser Phe Val His Ile Val Gln Met
850 855 860
Phe Ile Asn Thr Ser
865
<210> 221
<211> 1452
<212> DNA
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成IL-21/TF突变体/IL-15序列”
<400> 221
atgaagtggg tgaccttcat cagcctgctg ttcctgttct ccagcgccta ctcccagggc 60
caggacaggc acatgatccg gatgaggcag ctcatcgaca tcgtcgacca gctgaagaac 120
tacgtgaacg acctggtgcc cgagtttctg cctgcccccg aggacgtgga gaccaactgc 180
gagtggtccg ccttctcctg ctttcagaag gcccagctga agtccgccaa caccggcaac 240
aacgagcgga tcatcaacgt gagcatcaag aagctgaagc ggaagcctcc ctccacaaac 300
gccggcagga ggcagaagca caggctgacc tgccccagct gtgactccta cgagaagaag 360
ccccccaagg agttcctgga gaggttcaag tccctgctgc agaagatgat ccatcagcac 420
ctgtcctcca ggacccacgg ctccgaggac tcctccggca ccaccaatac cgtggccgct 480
tataacctca catggaagag caccaacttc gcgacagctc tggaatggga acccaagccc 540
gtcaatcaag tttacaccgt gcagatctcc accaaatccg gagactggaa gagcaagtgc 600
ttctacacaa cagacaccga gtgtgcttta accgacgaaa tcgtcaagga cgtcaagcaa 660
acctatctgg ctcgggtctt ttcctacccc gctggcaatg tcgagtccac cggctccgct 720
ggcgagcctc tctacgagaa ttcccccgaa ttcacccctt atttagagac caatttaggc 780
cagcctacca tccagagctt cgagcaagtt ggcaccaagg tgaacgtcac cgtcgaggat 840
gaaaggactt tagtggcgcg gaataacaca gctttatccc tccgggatgt gttcggcaaa 900
gacctcatct acacactgta ctattggaag tccagctcct ccggcaaaaa gaccgctaag 960
accaacacca acgagttttt aattgacgtg gacaaaggcg agaactactg cttcagcgtg 1020
caagccgtga tcccttctcg taccgtcaac cggaagagca cagattcccc cgttgagtgc 1080
atgggccaag aaaagggcga gttccgggag aactgggtga acgtcatcag cgatttaaag 1140
aagatcgaag atttaattca gtccatgcat atcgacgcca ctttatacac agaatccgac 1200
gtgcacccct cttgtaaggt gaccgccatg aaatgttttt tactggagct gcaagttatc 1260
tctttagaga gcggagacgc tagcatccac gacaccgtgg agaatttaat cattttagcc 1320
aataactctt tatccagcaa cggcaacgtg acagagtccg gctgcaagga gtgcgaagag 1380
ctggaggaga agaacatcaa ggagtttctg caatcctttg tgcacattgt ccagatgttc 1440
atcaatacct cc 1452
<210> 222
<211> 483
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成IL-21/TF突变体/IL-15序列”
<400> 222
Lys Trp Val Thr Phe Ile Ser Leu Leu Phe Leu Phe Ser Ser Ala Tyr
1 5 10 15
Ser Gln Gly Gln Asp Arg His Met Ile Arg Met Arg Gln Leu Ile Asp
20 25 30
Ile Val Asp Gln Leu Lys Asn Tyr Val Asn Asp Leu Val Pro Glu Phe
35 40 45
Leu Pro Ala Pro Glu Asp Val Glu Thr Asn Cys Glu Trp Ser Ala Phe
50 55 60
Ser Cys Phe Gln Lys Ala Gln Leu Lys Ser Ala Asn Thr Gly Asn Asn
65 70 75 80
Glu Arg Ile Ile Asn Val Ser Ile Lys Lys Leu Lys Arg Lys Pro Pro
85 90 95
Ser Thr Asn Ala Gly Arg Arg Gln Lys His Arg Leu Thr Cys Pro Ser
100 105 110
Cys Asp Ser Tyr Glu Lys Lys Pro Pro Lys Glu Phe Leu Glu Arg Phe
115 120 125
Lys Ser Leu Leu Gln Lys Met Ile His Gln His Leu Ser Ser Arg Thr
130 135 140
His Gly Ser Glu Asp Ser Ser Gly Thr Thr Asn Thr Val Ala Ala Tyr
145 150 155 160
Asn Leu Thr Trp Lys Ser Thr Asn Phe Ala Thr Ala Leu Glu Trp Glu
165 170 175
Pro Lys Pro Val Asn Gln Val Tyr Thr Val Gln Ile Ser Thr Lys Ser
180 185 190
Gly Asp Trp Lys Ser Lys Cys Phe Tyr Thr Thr Asp Thr Glu Cys Ala
195 200 205
Leu Thr Asp Glu Ile Val Lys Asp Val Lys Gln Thr Tyr Leu Ala Arg
210 215 220
Val Phe Ser Tyr Pro Ala Gly Asn Val Glu Ser Thr Gly Ser Ala Gly
225 230 235 240
Glu Pro Leu Tyr Glu Asn Ser Pro Glu Phe Thr Pro Tyr Leu Glu Thr
245 250 255
Asn Leu Gly Gln Pro Thr Ile Gln Ser Phe Glu Gln Val Gly Thr Lys
260 265 270
Val Asn Val Thr Val Glu Asp Glu Arg Thr Leu Val Ala Arg Asn Asn
275 280 285
Thr Ala Leu Ser Leu Arg Asp Val Phe Gly Lys Asp Leu Ile Tyr Thr
290 295 300
Leu Tyr Tyr Trp Lys Ser Ser Ser Ser Gly Lys Lys Thr Ala Lys Thr
305 310 315 320
Asn Thr Asn Glu Phe Leu Ile Asp Val Asp Lys Gly Glu Asn Tyr Cys
325 330 335
Phe Ser Val Gln Ala Val Ile Pro Ser Arg Thr Val Asn Arg Lys Ser
340 345 350
Thr Asp Ser Pro Val Glu Cys Met Gly Gln Glu Lys Gly Glu Phe Arg
355 360 365
Glu Asn Trp Val Asn Val Ile Ser Asp Leu Lys Lys Ile Glu Asp Leu
370 375 380
Ile Gln Ser Met His Ile Asp Ala Thr Leu Tyr Thr Glu Ser Asp Val
385 390 395 400
His Pro Ser Cys Lys Val Thr Ala Met Lys Cys Phe Leu Leu Glu Leu
405 410 415
Gln Val Ile Ser Leu Glu Ser Gly Asp Ala Ser Ile His Asp Thr Val
420 425 430
Glu Asn Leu Ile Ile Leu Ala Asn Asn Ser Leu Ser Ser Asn Gly Asn
435 440 445
Val Thr Glu Ser Gly Cys Lys Glu Cys Glu Glu Leu Glu Glu Lys Asn
450 455 460
Ile Lys Glu Phe Leu Gln Ser Phe Val His Ile Val Gln Met Phe Ile
465 470 475 480
Asn Thr Ser
<210> 223
<211> 17
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成信号序列”
<400> 223
Met Gly Val Lys Val Leu Phe Ala Leu Ile Cys Ile Ala Val Ala Glu
1 5 10 15
Ala
<210> 224
<211> 8
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成接头序列”
<400> 224
Gly Gly Gly Ser Gly Gly Gly Ser
1 5
<210> 225
<211> 1245
<212> DNA
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成21s137L序列”
<400> 225
atgaagtggg tgaccttcat cagcctgctg ttcctgttct ccagcgccta ctcccagggc 60
caggacaggc acatgatccg gatgaggcag ctcatcgaca tcgtcgacca gctgaagaac 120
tacgtgaacg acctggtgcc cgagtttctg cctgcccccg aggacgtgga gaccaactgc 180
gagtggtccg ccttctcctg ctttcagaag gcccagctga agtccgccaa caccggcaac 240
aacgagcgga tcatcaacgt gagcatcaag aagctgaagc ggaagcctcc ctccacaaac 300
gccggcagga ggcagaagca caggctgacc tgccccagct gtgactccta cgagaagaag 360
ccccccaagg agttcctgga gaggttcaag tccctgctgc agaagatgat ccatcagcac 420
ctgtcctcca ggacccacgg ctccgaggac tccattacat gcccccctcc catgagcgtg 480
gagcacgccg acatctgggt gaagagctat agcctctaca gccgggagag gtatatctgt 540
aacagcggct tcaagaggaa ggccggcacc agcagcctca ccgagtgcgt gctgaataag 600
gctaccaacg tggctcactg gacaacaccc tctttaaagt gcatccgggg cggtggagga 660
tccggaggag gtggctccgg cggcggagga tctcgcgagg gtcccgagct ttcgcccgac 720
gatcccgccg gcctcttgga cctgcggcag ggcatgtttg cgcagctggt ggcccaaaat 780
gttctgctga tcgatgggcc cctgagctgg tacagtgacc caggcctggc aggcgtgtcc 840
ctgacggggg gcctgagcta caaagaggac acgaaggagc tggtggtggc caaggctgga 900
gtctactatg tcttctttca actagagctg cggcgcgtgg tggccggcga gggctcaggc 960
tccgtttcac ttgcgctgca cctgcagcca ctgcgctctg ctgctggggc cgccgccctg 1020
gctttgaccg tggacctgcc acccgcctcc tccgaggctc ggaactcggc cttcggtttc 1080
cagggccgct tgctgcacct gagtgccggc cagcgcctgg gcgtccatct tcacactgag 1140
gccagggcac gccatgcctg gcagcttacc cagggcgcca cagtcttggg actcttccgg 1200
gtgacccccg aaatcccagc cggactccct tcaccgaggt cggaa 1245
<210> 226
<211> 415
<212> PRT
<213> 人工序列
<220>
<221> source
<223> /标注=“人工序列的描述:合成21s137L序列”
<400> 226
Met Lys Trp Val Thr Phe Ile Ser Leu Leu Phe Leu Phe Ser Ser Ala
1 5 10 15
Tyr Ser Gln Gly Gln Asp Arg His Met Ile Arg Met Arg Gln Leu Ile
20 25 30
Asp Ile Val Asp Gln Leu Lys Asn Tyr Val Asn Asp Leu Val Pro Glu
35 40 45
Phe Leu Pro Ala Pro Glu Asp Val Glu Thr Asn Cys Glu Trp Ser Ala
50 55 60
Phe Ser Cys Phe Gln Lys Ala Gln Leu Lys Ser Ala Asn Thr Gly Asn
65 70 75 80
Asn Glu Arg Ile Ile Asn Val Ser Ile Lys Lys Leu Lys Arg Lys Pro
85 90 95
Pro Ser Thr Asn Ala Gly Arg Arg Gln Lys His Arg Leu Thr Cys Pro
100 105 110
Ser Cys Asp Ser Tyr Glu Lys Lys Pro Pro Lys Glu Phe Leu Glu Arg
115 120 125
Phe Lys Ser Leu Leu Gln Lys Met Ile His Gln His Leu Ser Ser Arg
130 135 140
Thr His Gly Ser Glu Asp Ser Ile Thr Cys Pro Pro Pro Met Ser Val
145 150 155 160
Glu His Ala Asp Ile Trp Val Lys Ser Tyr Ser Leu Tyr Ser Arg Glu
165 170 175
Arg Tyr Ile Cys Asn Ser Gly Phe Lys Arg Lys Ala Gly Thr Ser Ser
180 185 190
Leu Thr Glu Cys Val Leu Asn Lys Ala Thr Asn Val Ala His Trp Thr
195 200 205
Thr Pro Ser Leu Lys Cys Ile Arg Gly Gly Gly Gly Ser Gly Gly Gly
210 215 220
Gly Ser Gly Gly Gly Gly Ser Arg Glu Gly Pro Glu Leu Ser Pro Asp
225 230 235 240
Asp Pro Ala Gly Leu Leu Asp Leu Arg Gln Gly Met Phe Ala Gln Leu
245 250 255
Val Ala Gln Asn Val Leu Leu Ile Asp Gly Pro Leu Ser Trp Tyr Ser
260 265 270
Asp Pro Gly Leu Ala Gly Val Ser Leu Thr Gly Gly Leu Ser Tyr Lys
275 280 285
Glu Asp Thr Lys Glu Leu Val Val Ala Lys Ala Gly Val Tyr Tyr Val
290 295 300
Phe Phe Gln Leu Glu Leu Arg Arg Val Val Ala Gly Glu Gly Ser Gly
305 310 315 320
Ser Val Ser Leu Ala Leu His Leu Gln Pro Leu Arg Ser Ala Ala Gly
325 330 335
Ala Ala Ala Leu Ala Leu Thr Val Asp Leu Pro Pro Ala Ser Ser Glu
340 345 350
Ala Arg Asn Ser Ala Phe Gly Phe Gln Gly Arg Leu Leu His Leu Ser
355 360 365
Ala Gly Gln Arg Leu Gly Val His Leu His Thr Glu Ala Arg Ala Arg
370 375 380
His Ala Trp Gln Leu Thr Gln Gly Ala Thr Val Leu Gly Leu Phe Arg
385 390 395 400
Val Thr Pro Glu Ile Pro Ala Gly Leu Pro Ser Pro Arg Ser Glu
405 410 415
Claims (45)
1.一种多链嵌合多肽,其包含:
(a)第一嵌合多肽,其包含:
(i)第一靶标结合结构域;
(ii)可溶性组织因子结构域;和
(iii)一对亲和结构域中的第一结构域;
(b)第二嵌合多肽,其包含:
(i)一对亲和结构域中的第二结构域;和
(ii)第二靶标结合结构域,
其中所述第一嵌合多肽和所述第二嵌合多肽通过所述一对亲和结构域中的所述第一结构域和所述第二结构域的结合而缔合。
2.根据权利要求1所述的多链嵌合多肽,其中所述第一靶标结合结构域和所述可溶性组织因子结构域在所述第一嵌合多肽中彼此直接邻接。
3.根据权利要求1所述的多链嵌合多肽,其中所述第一嵌合多肽进一步包含所述第一嵌合多肽中的所述第一靶标结合结构域与所述可溶性组织因子结构域之间的接头序列。
4.根据权利要求1至3中任一项所述的多链嵌合多肽,其中所述可溶性组织因子结构域和所述一对亲和结构域中的所述第一结构域在所述第一嵌合多肽中彼此直接邻接。
5.根据权利要求1至3中任一项所述的多链嵌合多肽,其中所述第一嵌合多肽进一步包含所述第一嵌合多肽中的所述可溶性组织因子结构域与所述一对亲和结构域中的所述第一结构域之间的接头序列。
6.根据权利要求1至5中任一项所述的多链嵌合多肽,其中所述一对亲和结构域中的所述第二结构域和所述第二靶标结合结构域在所述第二嵌合多肽中彼此直接邻接。
7.根据权利要求1至5中任一项所述的多链嵌合多肽,其中所述第二嵌合多肽进一步包含所述第二嵌合多肽中的所述一对亲和结构域中的所述第二结构域与所述第二靶标结合结构域之间的接头序列。
8.根据权利要求1至7中任一项所述的多链嵌合多肽,其中所述第一靶标结合结构域和所述第二靶标结合结构域特异性结合到相同的抗原。
9.根据权利要求1至7中任一项所述的多链嵌合多肽,其中所述第一靶标结合结构域和所述第二靶标结合结构域特异性结合到不同的抗原。
10.根据权利要求1至9中任一项所述的多链嵌合多肽,其中所述第一靶标结合结构域和所述第二靶标结合结构域中的一个或两个是抗原结合结构域。
11.根据权利要求1至10中任一项所述的多链嵌合多肽,其中所述第一靶标结合结构域和所述第二靶标结合结构域中的一个或两个特异性结合到选自以下组成的组的靶标:CD16a、CD28、CD3、CD33、CD20、CD19、CD22、CD123、IL-1R、IL-1、VEGF、IL-6R、IL-4、IL-10、PDL-1、TIGIT、PD-1、TIM3、CTLA4、MICA、MICB、IL-6、IL-8、TNFα、CD26a、CD36、ULBP2、CD30、CD200、IGF-1R、MUC4AC、MUC5AC、Trop-2、CMET、EGFR、HER1、HER2、HER3、PSMA、CEA、B7H3、EPCAM、BCMA、P-钙黏着蛋白、CEACAM5、UL16结合蛋白、HLA-DR、DLL4、TYRO3、AXL、MER、CD122、CD155、PDGF-DD、TGF-β受体II(TGF-βRII)的配体、TGF-βRIII的配体、DNAM-1的配体、NKp46的配体、NKp44的配体、NKG2D的配体、NKp30的配体、scMHCI的配体、scMHCII的配体、scTCR的配体、IL-1的受体、IL-2的受体、IL-3的受体、IL-7的受体、IL-8的受体、IL-10的受体、IL-12的受体、IL-15的受体、IL-17的受体、IL-18的受体、IL-21的受体、PDGF-DD的受体、干细胞因子(SCF)的受体、干细胞样酪氨酸激酶3配体(FLT3L)的受体、MICA的受体、MICB的受体、ULP16结合蛋白的受体、CD155的受体、CD122的受体和CD28的受体。
12.根据权利要求1至10中任一项所述的多链嵌合多肽,其中所述第一靶标结合结构域和所述第二靶标结合结构域中的一个或两个是可溶性白介素或细胞因子蛋白。
13.根据权利要求12所述的多链嵌合多肽,其中所述可溶性白介素、细胞因子或配体蛋白选自以下组成的组:IL-1、IL-2、IL-3、IL-7、IL-8、IL-10、IL-12、IL-15、IL-17、IL-18、IL-21、PDGF-DD、SCF和FLT3L。
14.根据权利要求1至10中任一项所述的多链嵌合多肽,其中所述第一靶标结合结构域和所述第二靶标结合结构域中的一个或两个是可溶性白介素或细胞因子受体。
15.根据权利要求14所述的多链嵌合多肽,其中所述可溶性受体是可溶性TGF-β受体II(TGF-βRII)、可溶性TGF-βRIII、可溶性NKG2D、可溶性NKp30、可溶性NKp44、可溶性NKp46、可溶性DNAM-1、scMHCI、scMHCII、scTCR、可溶性CD155或可溶性CD28。
16.根据权利要求1至15中任一项所述的多链嵌合多肽,其中所述第一嵌合多肽进一步包含一个或多个另外的靶标结合结构域。
17.根据权利要求1至16中任一项所述的多链嵌合多肽,其中所述第二嵌合多肽进一步包含一个或多个另外的靶标结合结构域。
18.根据权利要求1至17中任一项所述的多链嵌合多肽,其中所述可溶性组织因子结构域是可溶性人组织因子结构域。
19.根据权利要求18所述的多链嵌合多肽,其中所述可溶性人组织因子结构域包含与SEQ ID NO:1至少80%相同的序列。
20.根据权利要求1至19中任一项所述的多链嵌合多肽,其中所述一对亲和结构域是来自人IL-15受体的α链(IL15Rα)的寿司结构域和可溶性IL-15。
21.根据权利要求1至19中任一项所述的多链嵌合多肽,其中所述一对亲和结构域选自以下组成的组:芽胞杆菌RNA酶和芽胞杆菌RNA酶抑制子、PKA和AKAP、基于突变核糖核酸酶I片段的衔接子/对接标签模块以及基于蛋白质突触蛋白、突触结合蛋白、突触泡蛋白和SNAP25的相互作用的SNARE模块。
22.根据权利要求1至21中任一项所述的多链嵌合多肽,其中所述第一嵌合多肽和/或所述第二嵌合多肽在其N端进一步包含信号序列。
23.一种组合物,其包含根据权利要求1至22所述的多链嵌合多肽中的任一种。
24.根据权利要求23所述的组合物,其中所述组合物是药物组合物。
25.一种试剂盒,其包含至少一个剂量的根据权利要求23或24所述的组合物。
26.一种刺激免疫细胞的方法,所述方法包含:
使免疫细胞与有效量的根据权利要求1至22所述的多链嵌合多肽中的任一种或根据权利要求23或24所述的组合物接触。
27.一种诱导或增加免疫细胞增殖的方法,所述方法包含:
使免疫细胞与有效量的根据权利要求1至22所述的多链嵌合多肽中的任一种或根据权利要求23或24所述的组合物接触。
28.一种诱导免疫细胞分化成记忆或记忆样免疫细胞的方法,所述方法包含:
使免疫细胞与有效量的根据权利要求1至22所述的多链嵌合多肽中的任一种或根据权利要求23或24所述的组合物接触。
29.根据权利要求26至28中任一项所述的方法,其中所述免疫细胞在体外接触。
30.根据权利要求26至28中任一项所述的方法,其中所述免疫细胞在体内接触。
31.根据权利要求26至30中任一项所述的方法,其中所述免疫细胞选自以下组成的组:未成熟胸腺细胞、外周血淋巴细胞、初始T细胞、多能Th细胞前体、淋巴祖细胞、Treg细胞、Th17细胞、Th22细胞、Th9细胞、Th2细胞、Th1细胞、Th3细胞、γδT细胞、αβT细胞、肿瘤浸润性T细胞、CD8+T细胞、CD4+T细胞、自然杀伤T细胞、肥大细胞、巨噬细胞、嗜中性粒细胞、树突状细胞、嗜碱性粒细胞、嗜酸性粒细胞和自然杀伤细胞。
32.根据权利要求26至31中任一项所述的方法,其中所述免疫细胞先前已经过基因修饰以表达嵌合抗原受体或重组T细胞受体。
33.一种在有需要的受试者中杀死癌细胞、受感染细胞或衰老细胞的方法,所述方法包含向所述受试者施用治疗有效量的根据权利要求1至22所述的多链嵌合多肽中的任一种或根据权利要求23或24所述的组合物。
34.一种治疗有需要的受试者的方法,所述方法包含向所述受试者施用治疗有效量的根据权利要求1至22所述的多链嵌合多肽中的任一种或根据权利要求23或24所述的组合物。
35.根据权利要求33或34所述的方法,其中所述受试者已被鉴别或诊断为患有癌症、与老化相关的疾病或病况或感染性疾病。
36.根据权利要求35所述的方法,其中所述癌症选自以下组成的组:实体肿瘤、血液肿瘤、肉瘤、骨肉瘤、成胶质细胞瘤、成神经细胞瘤、黑色素瘤、横纹肌肉瘤、尤文氏肉瘤、骨肉瘤、B细胞瘤、多发性骨髓瘤、B细胞淋巴瘤、B细胞非霍奇金氏淋巴瘤、霍奇金氏淋巴瘤、慢性淋巴细胞性白血病(CLL)、急性骨髓性白血病(AML)、慢性骨髓性白血病(CML)、急性淋巴细胞性白血病(ALL)、骨髓增生异常综合症(MDS)、皮肤T细胞淋巴瘤、成视网膜细胞瘤、胃癌、尿路上皮癌、肺癌、肾细胞癌、胃和食管癌、胰腺癌、前列腺癌、乳腺癌、结直肠癌、卵巢癌、非小细胞肺癌、鳞状细胞头颈癌、子宫内膜癌、宫颈癌、肝癌和肝细胞癌。
37.根据权利要求35所述的方法,其中所述与老化相关的疾病或病况选自以下组成的组:阿尔茨海默氏病、动脉瘤、囊性纤维化、胰腺炎纤维化、青光眼、高血压、特发性肺纤维化、炎性肠病、椎间盘退变、黄斑变性、骨关节炎、2型糖尿病、脂肪萎缩、脂肪营养不良、动脉粥样硬化、白内障、COPD、特发性肺纤维化、肾移植失败、肝纤维化、骨量损失、心肌梗死、肌肉减少症、伤口愈合、脱发、心肌细胞肥大、骨关节炎、帕金森氏病、与年龄相关的肺组织弹性丧失、黄斑变性、恶病质、肾小球硬化、肝硬化、NAFLD、骨质疏松症、肌萎缩性侧索硬化症、亨廷顿氏病、脊髓小脑共济失调、多发性硬化症和肾功能不全。
38.根据权利要求35所述的方法,其中所述感染性疾病是感染人免疫缺陷病毒、巨细胞病毒、腺病毒、冠状病毒、鼻病毒、轮状病毒、天花、单纯疱疹病毒、乙型肝炎病毒、甲型肝炎病毒和丙型肝炎病毒、乳头瘤病毒和流感病毒。
39.一种核酸,其编码根据权利要求1至22中任一项所述的多链嵌合多肽中的任一种。
40.一种载体,其包含根据权利要求39所述的核酸。
41.一种细胞,其包含根据权利要求39所述的核酸或根据权利要求40所述的载体。
42.一种产生多链嵌合多肽的方法,所述方法包含:
在足以引起产生所述多链嵌合多肽的条件下在培养基中培养根据权利要求41所述的细胞;和
从所述细胞和/或所述培养基中回收所述多链嵌合多肽。
43.一种多链嵌合多肽,其通过根据权利要求42所述的方法产生。
44.根据权利要求18所述的多链嵌合多肽,其中人可溶性组织因子结构域不引发凝血。
45.根据权利要求1至22中任一项所述的多链嵌合多肽,其中所述可溶性组织因子结构域包含来自野生型可溶性人组织因子的序列或由来自野生型可溶性人组织因子的序列组成。
Applications Claiming Priority (21)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201862724969P | 2018-08-30 | 2018-08-30 | |
| US201862725043P | 2018-08-30 | 2018-08-30 | |
| US201862725010P | 2018-08-30 | 2018-08-30 | |
| US62/725,010 | 2018-08-30 | ||
| US62/724,969 | 2018-08-30 | ||
| US62/725,043 | 2018-08-30 | ||
| US201862746832P | 2018-10-17 | 2018-10-17 | |
| US62/746,832 | 2018-10-17 | ||
| US201862749007P | 2018-10-22 | 2018-10-22 | |
| US62/749,007 | 2018-10-22 | ||
| US201862749506P | 2018-10-23 | 2018-10-23 | |
| US62/749,506 | 2018-10-23 | ||
| US201962816683P | 2019-03-11 | 2019-03-11 | |
| US62/816,683 | 2019-03-11 | ||
| US201962817230P | 2019-03-12 | 2019-03-12 | |
| US201962817241P | 2019-03-12 | 2019-03-12 | |
| US62/817,230 | 2019-03-12 | ||
| US62/817,241 | 2019-03-12 | ||
| US201962881088P | 2019-07-31 | 2019-07-31 | |
| US62/881,088 | 2019-07-31 | ||
| PCT/US2019/048881 WO2020047299A1 (en) | 2018-08-30 | 2019-08-29 | Multi-chain chimeric polypeptides and uses thereof |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN112996805A true CN112996805A (zh) | 2021-06-18 |
Family
ID=67928938
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201980070927.3A Pending CN112996805A (zh) | 2018-08-30 | 2019-08-29 | 多链嵌合多肽和其用途 |
Country Status (11)
| Country | Link |
|---|---|
| US (7) | US11518792B2 (zh) |
| EP (1) | EP3844181A1 (zh) |
| JP (2) | JP7397874B2 (zh) |
| KR (1) | KR20210070287A (zh) |
| CN (1) | CN112996805A (zh) |
| AU (1) | AU2019328290A1 (zh) |
| CA (1) | CA3108949A1 (zh) |
| IL (1) | IL280918A (zh) |
| SG (1) | SG11202101779RA (zh) |
| TW (1) | TW202122416A (zh) |
| WO (1) | WO2020047299A1 (zh) |
Families Citing this family (14)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US11401324B2 (en) | 2018-08-30 | 2022-08-02 | HCW Biologics, Inc. | Single-chain chimeric polypeptides and uses thereof |
| CN113015744A (zh) | 2018-08-30 | 2021-06-22 | Hcw生物科技公司 | 单链嵌合多肽和多链嵌合多肽以及其用途 |
| KR20210070287A (ko) | 2018-08-30 | 2021-06-14 | 에이치씨더블유 바이올로직스, 인크. | 다중-사슬 키메라 폴리펩타이드 및 이의 용도 |
| EP4321530A2 (en) | 2018-09-27 | 2024-02-14 | Xilio Development, Inc. | Masked cytokine polypeptides |
| JP2022537054A (ja) * | 2019-06-21 | 2022-08-23 | エイチシーダブリュー バイオロジックス インコーポレイテッド | 多鎖キメラポリペプチドおよびその使用 |
| CN115362169A (zh) * | 2020-02-11 | 2022-11-18 | Hcw生物科技公司 | 色谱树脂以及其用途 |
| WO2021247003A1 (en) * | 2020-06-01 | 2021-12-09 | HCW Biologics, Inc. | Methods of treating aging-related disorders |
| EP4157460A1 (en) * | 2020-06-01 | 2023-04-05 | HCW Biologics, Inc. | Methods of treating aging-related disorders |
| USD986799S1 (en) * | 2020-09-11 | 2023-05-23 | Wind Craft Aviation Inc. | Aircraft |
| CN114042154A (zh) * | 2021-12-14 | 2022-02-15 | 澳门大学 | 一种药物组合在制备抗肿瘤的联合治疗药物中的应用 |
| WO2023134716A1 (zh) * | 2022-01-14 | 2023-07-20 | 盛禾(中国)生物制药有限公司 | 一种结合b7h3和nkp30的双特异性抗体及其应用 |
| WO2023168363A1 (en) * | 2022-03-02 | 2023-09-07 | HCW Biologics, Inc. | Method of treating pancreatic cancer |
| US20240075141A1 (en) | 2022-03-18 | 2024-03-07 | WUGEN, Inc. | Chimeric receptor constructs for nk cells |
| WO2023183853A1 (en) | 2022-03-22 | 2023-09-28 | WUGEN, Inc. | Hybrid promoters, vectors containing same and methods of use |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20030219441A1 (en) * | 1992-03-05 | 2003-11-27 | Board Of Regents, The University Of Texas System | Combined methods and compositions for coagulation and tumor treatment |
| CN101653603A (zh) * | 2002-07-15 | 2010-02-24 | 得克萨斯大学体系董事会 | 与阴离子磷脂和氨基磷脂结合的抗体和肽及其治病用途 |
Family Cites Families (100)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| GB9324807D0 (en) | 1993-12-03 | 1994-01-19 | Cancer Res Campaign Tech | Tumour antibody |
| BR9508402A (pt) | 1994-07-11 | 1997-10-21 | Univ Texas | Ligante de união construção de fator de tecido composição farmacêutica kit e uso de um ligante de união |
| US6117980A (en) | 1997-02-21 | 2000-09-12 | Genentech, Inc. | Humanized anti-IL-8 monoclonal antibodies |
| US20060235209A9 (en) | 1997-03-10 | 2006-10-19 | Jin-An Jiao | Use of anti-tissue factor antibodies for treating thromboses |
| US20030109680A1 (en) | 2001-11-21 | 2003-06-12 | Sunol Molecular Corporation | Antibodies for inhibiting blood coagulation and methods of use thereof |
| JP2001206899A (ja) | 1999-11-18 | 2001-07-31 | Japan Tobacco Inc | TGF−βII型受容体に対するヒトモノクローナル抗体及びその医薬用途 |
| WO2001045636A1 (en) | 1999-12-20 | 2001-06-28 | Merck & Co., Inc. | Pharmaceutical kit |
| AU2001259215A1 (en) | 2000-04-28 | 2001-11-12 | La Jolla Institute For Allergy And Immunology | Human anti-cd40 antibodies and methods of making and using same |
| EP1355919B1 (en) | 2000-12-12 | 2010-11-24 | MedImmune, LLC | Molecules with extended half-lives, compositions and uses thereof |
| PT1345969E (pt) | 2000-12-26 | 2010-11-17 | Inst Nat Sante Rech Med | Anticorpos anti-cd28 |
| US20040204481A1 (en) | 2001-04-12 | 2004-10-14 | Pnina Fishman | Activation of natural killer cells by adenosine A3 receptor agonists |
| AU2002355955A1 (en) | 2001-08-13 | 2003-03-03 | University Of Southern California | Interleukin-2 mutants with reduced toxicity |
| TWI338009B (en) | 2001-10-29 | 2011-03-01 | Genentech Inc | Antibodies for inhibiting blood coagulation and methods of use thereof |
| AU2003239197A1 (en) | 2002-06-07 | 2003-12-22 | The Government Of The United States Of America, As Represented By The Secretary Of The Department Of | Novel stable anti-cd22 antibodies |
| US9321832B2 (en) | 2002-06-28 | 2016-04-26 | Domantis Limited | Ligand |
| AU2003261787B2 (en) | 2002-08-30 | 2008-11-06 | Juridical Foundation The Chemo-Sero-Therapeutic Research Institute | Human antihuman interleukin-6 antibody and fragment of the antibody |
| EP1400534B1 (en) | 2002-09-10 | 2015-10-28 | Affimed GmbH | Human CD3-specific antibody with immunosuppressive properties |
| CN101899114A (zh) | 2002-12-23 | 2010-12-01 | 惠氏公司 | 抗pd-1抗体及其用途 |
| WO2004076488A1 (en) | 2003-02-27 | 2004-09-10 | Theravision Gmbh | A molecule which binds cd80 and cd86 |
| JP2006523682A (ja) | 2003-03-21 | 2006-10-19 | ワイス | インターロイキン−21/インターロイキン−21受容体のアゴニストを用いた免疫学的障害の治療 |
| NZ543654A (en) | 2003-05-23 | 2009-05-31 | Wyeth Corp | GITR ligand and GITR ligand-related molecules and antibodies and uses thereof |
| US9005613B2 (en) | 2003-06-16 | 2015-04-14 | Immunomedics, Inc. | Anti-mucin antibodies for early detection and treatment of pancreatic cancer |
| NZ549040A (en) | 2004-02-17 | 2009-07-31 | Schering Corp | Use for interleukin-33 (IL33) and the IL-33 receptor complex |
| WO2005095460A2 (en) | 2004-03-30 | 2005-10-13 | Yissum Research Development Company Of The Hebrew University Of Jerusalem | Bi-specific antibodies for targeting cells involved in allergic-type reactions, compositions and uses thereof |
| US7393833B2 (en) * | 2005-03-09 | 2008-07-01 | The Board Of Regents Of The University Of Oklahoma | Chimeric proteins with phosphatidylserine binding domains |
| CN101203241B (zh) | 2005-04-19 | 2012-02-22 | 西雅图基因公司 | 人源化抗-cd70结合物和其应用 |
| WO2006114704A2 (en) | 2005-04-26 | 2006-11-02 | Pfizer Inc. | P-cadherin antibodies |
| ATE459648T1 (de) | 2005-05-11 | 2010-03-15 | Philogen Spa | Fusionsprotein von antikörper l19 gegen fibronectin ed-b und interleukin 12 |
| GB0510790D0 (en) | 2005-05-26 | 2005-06-29 | Syngenta Crop Protection Ag | Anti-CD16 binding molecules |
| US7612181B2 (en) | 2005-08-19 | 2009-11-03 | Abbott Laboratories | Dual variable domain immunoglobulin and uses thereof |
| US8092804B2 (en) | 2007-12-21 | 2012-01-10 | Medimmune Limited | Binding members for interleukin-4 receptor alpha (IL-4Rα)-173 |
| SI2274008T1 (sl) | 2008-03-27 | 2014-08-29 | Zymogenetics, Inc. | Sestavki in metode za zaviranje PDGFRBETA in VEGF-A |
| KR101817284B1 (ko) | 2008-06-25 | 2018-01-11 | 에스바테크 - 어 노바티스 컴파니 엘엘씨 | Vegf를 억제하는 안정하고 가용성인 항체 |
| MX2010014574A (es) | 2008-07-08 | 2011-04-27 | Abbott Lab | Inmunoglobulinas de dominio variable dual para prostaglandina e2 y usos de las mismas. |
| US9273136B2 (en) | 2008-08-04 | 2016-03-01 | The United States Of America, As Represented By The Secretary, Department Of Health And Human Services | Fully human anti-human NKG2D monoclonal antibodies |
| US8298533B2 (en) | 2008-11-07 | 2012-10-30 | Medimmune Limited | Antibodies to IL-1R1 |
| CN114835812A (zh) | 2008-12-09 | 2022-08-02 | 霍夫曼-拉罗奇有限公司 | 抗-pd-l1抗体及它们用于增强t细胞功能的用途 |
| RU2012112550A (ru) | 2009-09-01 | 2013-10-10 | Эбботт Лэборетриз | Иммуноглобулины с двумя вариабельными доменами и их применение |
| DE102009045006A1 (de) | 2009-09-25 | 2011-04-14 | Technische Universität Dresden | Anti-CD33 Antikörper und ihre Anwendung zum Immunotargeting bei der Behandlung von CD33-assoziierten Erkrankungen |
| BR112012008833A2 (pt) | 2009-10-15 | 2015-09-08 | Abbott Lab | imunoglobulinas de dominio variavel duplo e usos das mesmas |
| UY32979A (es) | 2009-10-28 | 2011-02-28 | Abbott Lab | Inmunoglobulinas con dominio variable dual y usos de las mismas |
| SG182823A1 (en) | 2010-02-11 | 2012-09-27 | Alexion Pharma Inc | Therapeutic methods using an ti-cd200 antibodies |
| CA2795279C (en) | 2010-04-08 | 2020-05-05 | Jn Biosciences Llc | Antibodies to cd122 |
| CN103079644B (zh) | 2010-06-11 | 2017-02-15 | 协和发酵麒麟株式会社 | 抗tim‑3抗体 |
| JP2013537415A (ja) | 2010-08-03 | 2013-10-03 | アッヴィ・インコーポレイテッド | 二重可変ドメイン免疫グロブリンおよびその使用 |
| JP2012034668A (ja) | 2010-08-12 | 2012-02-23 | Tohoku Univ | ヒト型化抗egfr抗体リジン置換可変領域断片及びその利用 |
| DK2918607T3 (en) * | 2010-09-21 | 2018-01-08 | Altor Bioscience Corp | MULTIMERIC IL-15 SOLUBLE MUSCLE MOLECULES AND PROCEDURES FOR PRODUCING AND USING THEREOF |
| BR112013008738B1 (pt) | 2010-10-11 | 2017-12-19 | Abbvie Bahamas Ltd. | Method for purification of a protein |
| CN102153653B (zh) | 2010-12-30 | 2012-08-15 | 厦门大学 | 肿瘤血管靶向多肽与组织因子的融合蛋白及其制备方法 |
| GB201103955D0 (en) | 2011-03-09 | 2011-04-20 | Antitope Ltd | Antibodies |
| WO2012145507A2 (en) | 2011-04-19 | 2012-10-26 | Merrimack Pharmaceuticals, Inc. | Monospecific and bispecific anti-igf-1r and anti-erbb3 antibodies |
| RS57279B1 (sr) | 2011-04-25 | 2018-08-31 | Daiichi Sankyo Co Ltd | Anti-b7-h3 antitelo |
| AU2012260601B2 (en) | 2011-05-25 | 2018-02-01 | Innate Pharma, S.A. | Anti-KIR antibodies for the treatment of inflammatory disorders |
| US8753640B2 (en) | 2011-05-31 | 2014-06-17 | University Of Washington Through Its Center For Commercialization | MIC-binding antibodies and methods of use thereof |
| WO2012170470A1 (en) | 2011-06-06 | 2012-12-13 | Board Of Regents Of The University Of Nebraska | Compositions and methods for detection and treatment of cancer |
| EP2723377B1 (en) | 2011-06-22 | 2018-06-13 | INSERM (Institut National de la Santé et de la Recherche Médicale) | Anti-axl antibodies and uses thereof |
| EP2537933A1 (en) | 2011-06-24 | 2012-12-26 | Institut National de la Santé et de la Recherche Médicale (INSERM) | An IL-15 and IL-15Ralpha sushi domain based immunocytokines |
| TWI495644B (zh) | 2011-11-11 | 2015-08-11 | Rinat Neuroscience Corp | 營養層細胞表面抗原(Trop-2)之專一性抗體類及彼等之用途 |
| GB2513793B (en) | 2012-01-26 | 2016-11-02 | Nugen Tech Inc | Compositions and methods for targeted nucleic acid sequence enrichment and high efficiency library generation |
| KR101535341B1 (ko) | 2012-07-02 | 2015-07-13 | 한화케미칼 주식회사 | Dll4에 특이적으로 결합하는 신규한 단일클론항체 및 이의 용도 |
| US9346872B2 (en) | 2012-08-08 | 2016-05-24 | Roche Glycart Ag | Interleukin-10 fusion proteins |
| WO2014026054A2 (en) | 2012-08-10 | 2014-02-13 | University Of Southern California | CD20 scFv-ELPs METHODS AND THERAPEUTICS |
| WO2014033130A1 (en) | 2012-08-28 | 2014-03-06 | Institut Curie | Cluster of differentiation 36 (cd36) as a therapeutic target for hiv infection |
| MX358321B (es) | 2012-11-20 | 2018-08-14 | Sanofi Sa | Anticuerpos anti-ceacam5 y usos de los mismos. |
| ES2895848T3 (es) | 2012-12-17 | 2022-02-22 | Cell Medica Inc | Anticuerpos contra IL-1 beta |
| EP2948475A2 (en) | 2013-01-23 | 2015-12-02 | AbbVie Inc. | Methods and compositions for modulating an immune response |
| TW201446794A (zh) | 2013-02-20 | 2014-12-16 | Novartis Ag | 利用抗-cd123嵌合抗原受體工程化t細胞之初級人類白血病有效靶向 |
| WO2014159531A1 (en) | 2013-03-14 | 2014-10-02 | The Board Of Regents Of The University Of Texas System | Monoclonal antibodies targeting epcam for detection of prostate cancer lymph node metastases |
| US9701758B2 (en) | 2013-05-24 | 2017-07-11 | Board Of Regents, The University Of Texas System | Anti-CD19 scFv (FMC63) polypeptide |
| JP2015030666A (ja) | 2013-07-31 | 2015-02-16 | 学校法人順天堂 | 抗ヒトcd26モノクローナル抗体又はその抗原結合性断片 |
| CN103709251B (zh) | 2013-12-19 | 2016-04-13 | 江苏众红生物工程创药研究院有限公司 | 全人源抗cd26抗体及其应用 |
| KR102127408B1 (ko) | 2014-01-29 | 2020-06-29 | 삼성전자주식회사 | 항 Her3 scFv 단편 및 이를 포함하는 항 c-Met/항 Her3 이중 특이 항체 |
| JOP20200096A1 (ar) | 2014-01-31 | 2017-06-16 | Children’S Medical Center Corp | جزيئات جسم مضاد لـ tim-3 واستخداماتها |
| FR3021970B1 (fr) | 2014-06-06 | 2018-01-26 | Universite Sciences Technologies Lille | Anticorps dirige contre la galectine 9 et inhibiteur de l'activite suppressive des lymphocytes t regulateurs |
| JO3664B1 (ar) | 2014-08-19 | 2020-08-27 | Merck Sharp & Dohme | أجسام مضادة لـ tigit |
| BR112016030670A2 (pt) | 2014-08-29 | 2017-10-31 | Hoffmann La Roche | "imunocitoquina" |
| CA2972048C (en) | 2014-12-22 | 2023-03-07 | The Rockefeller University | Anti-mertk agonistic antibodies and uses thereof |
| EP3270937A4 (en) | 2015-03-26 | 2018-09-12 | The Trustees Of Dartmouth College | Anti-mica antigen binding fragments, fusion molecules, cells which express and methods of using |
| EP3283523A1 (en) | 2015-04-17 | 2018-02-21 | Elsalys Biotech | Anti-tyro3 antibodies and uses thereof |
| KR101778439B1 (ko) | 2015-04-27 | 2017-09-14 | 울산대학교 산학협력단 | 자연살해세포 활성화제를 유효성분으로 함유하는 면역증강 및 항암활성증진용 조성물 |
| CN115925939A (zh) | 2015-08-06 | 2023-04-07 | 新加坡科技研究局 | IL2Rβ/通用γ链抗体 |
| WO2017043613A1 (ja) | 2015-09-11 | 2017-03-16 | ワイズエーシー株式会社 | 抗cd26抗体と他の抗癌剤とを組み合わせた癌治療用組成物 |
| CN113912724A (zh) | 2015-09-25 | 2022-01-11 | 豪夫迈·罗氏有限公司 | 抗tigit抗体和使用方法 |
| EP3373970A4 (en) | 2015-11-13 | 2019-07-10 | Dana Farber Cancer Institute, Inc. | NKG2D IG FUSION PROTEIN FOR CANCER IMMUNOTHERAPY |
| KR20180133399A (ko) | 2016-03-01 | 2018-12-14 | 이섬 리서치 디벨러프먼트 컴파니 오브 더 히브루 유니버시티 오브 예루살렘 엘티디. | 인간 폴리오바이러스 수용체(pvr)에 특이적인 항체 |
| WO2017189526A1 (en) | 2016-04-25 | 2017-11-02 | Musc Foundation For Research Development | Activated cd26-high immune cells and cd26-negative immune cells and uses thereof |
| AU2017345791B2 (en) | 2016-10-21 | 2020-10-22 | Altor Bioscience Corporation | Multimeric IL-15-based molecules |
| EP3565846A4 (en) | 2017-01-03 | 2020-01-22 | Bioatla, LLC | PROTEIN THERAPEUTIC AGENTS FOR THE TREATMENT OF SENESCENT CELLS |
| BR112019017869A2 (pt) | 2017-02-28 | 2020-05-12 | Affimed Gmbh | Combinação de um anticorpo anti-cd16a com uma citocina |
| WO2018165208A1 (en) | 2017-03-06 | 2018-09-13 | Altor Bioscience Corporation | Il-15-based fusions to il-12 and il-18 |
| KR20190126182A (ko) | 2017-03-27 | 2019-11-08 | 난트셀, 인크. | aNK 및 IL-12 조성물 및 방법 (ANK AND IL-12 COMPOSITIONS AND METHODS) |
| KR20200090742A (ko) | 2017-08-28 | 2020-07-29 | 알토 바이오사이언스 엘엘씨 | Il-7 및 il-21에의 il-15 기반 융합 |
| US11401324B2 (en) | 2018-08-30 | 2022-08-02 | HCW Biologics, Inc. | Single-chain chimeric polypeptides and uses thereof |
| CN113015744A (zh) | 2018-08-30 | 2021-06-22 | Hcw生物科技公司 | 单链嵌合多肽和多链嵌合多肽以及其用途 |
| KR20210070287A (ko) | 2018-08-30 | 2021-06-14 | 에이치씨더블유 바이올로직스, 인크. | 다중-사슬 키메라 폴리펩타이드 및 이의 용도 |
| JP2022537054A (ja) | 2019-06-21 | 2022-08-23 | エイチシーダブリュー バイオロジックス インコーポレイテッド | 多鎖キメラポリペプチドおよびその使用 |
| WO2021163298A1 (en) | 2020-02-11 | 2021-08-19 | HCW Biologics, Inc. | Methods of activating regulatory t cells |
| EP4103601A2 (en) | 2020-02-11 | 2022-12-21 | HCW Biologics, Inc. | Methods of treating age-related and inflammatory diseases |
| CN115362169A (zh) | 2020-02-11 | 2022-11-18 | Hcw生物科技公司 | 色谱树脂以及其用途 |
| US20220073578A1 (en) | 2020-06-01 | 2022-03-10 | HCW Biologics, Inc. | Methods of treating aging-related disorders |
-
2019
- 2019-08-29 KR KR1020217009434A patent/KR20210070287A/ko unknown
- 2019-08-29 CN CN201980070927.3A patent/CN112996805A/zh active Pending
- 2019-08-29 AU AU2019328290A patent/AU2019328290A1/en active Pending
- 2019-08-29 WO PCT/US2019/048881 patent/WO2020047299A1/en unknown
- 2019-08-29 CA CA3108949A patent/CA3108949A1/en active Pending
- 2019-08-29 SG SG11202101779RA patent/SG11202101779RA/en unknown
- 2019-08-29 JP JP2021535496A patent/JP7397874B2/ja active Active
- 2019-08-29 EP EP19766444.4A patent/EP3844181A1/en active Pending
- 2019-08-29 US US16/555,689 patent/US11518792B2/en active Active
- 2019-08-30 TW TW108131442A patent/TW202122416A/zh unknown
-
2020
- 2020-11-19 US US16/952,848 patent/US20210070825A1/en active Pending
- 2020-11-19 US US16/952,861 patent/US11884712B2/en active Active
-
2021
- 2021-02-16 IL IL280918A patent/IL280918A/en unknown
-
2022
- 2022-10-19 US US18/047,751 patent/US20230128292A1/en active Pending
- 2022-10-19 US US18/047,754 patent/US20230272027A1/en active Pending
-
2023
- 2023-10-30 US US18/497,083 patent/US20240124543A1/en active Pending
- 2023-10-30 US US18/497,169 patent/US20240124544A1/en active Pending
- 2023-12-01 JP JP2023203880A patent/JP2024026248A/ja active Pending
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20030219441A1 (en) * | 1992-03-05 | 2003-11-27 | Board Of Regents, The University Of Texas System | Combined methods and compositions for coagulation and tumor treatment |
| CN101653603A (zh) * | 2002-07-15 | 2010-02-24 | 得克萨斯大学体系董事会 | 与阴离子磷脂和氨基磷脂结合的抗体和肽及其治病用途 |
Also Published As
| Publication number | Publication date |
|---|---|
| US11884712B2 (en) | 2024-01-30 |
| US20210070825A1 (en) | 2021-03-11 |
| US20240124543A1 (en) | 2024-04-18 |
| SG11202101779RA (en) | 2021-03-30 |
| JP2021534828A (ja) | 2021-12-16 |
| WO2020047299A1 (en) | 2020-03-05 |
| EP3844181A1 (en) | 2021-07-07 |
| CA3108949A1 (en) | 2020-03-05 |
| TW202122416A (zh) | 2021-06-16 |
| KR20210070287A (ko) | 2021-06-14 |
| JP7397874B2 (ja) | 2023-12-13 |
| US20230128292A1 (en) | 2023-04-27 |
| JP2024026248A (ja) | 2024-02-28 |
| IL280918A (en) | 2021-04-29 |
| US20230272027A1 (en) | 2023-08-31 |
| AU2019328290A1 (en) | 2021-02-25 |
| US20200071374A1 (en) | 2020-03-05 |
| US20210070826A1 (en) | 2021-03-11 |
| US11518792B2 (en) | 2022-12-06 |
| US20240124544A1 (en) | 2024-04-18 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP7397874B2 (ja) | 多鎖キメラポリペプチドおよびその使用 | |
| JP6644678B2 (ja) | Ctla−4およびcd40の両方に特異的に結合可能である二重特異性分子 | |
| CN105873607B (zh) | 能够结合cd123和cd3的双特异性单价双抗体及其用途 | |
| JP2022062040A (ja) | プロm2マクロファージ分子の阻害剤と組み合わせてキメラ抗原受容体を用いる癌の処置 | |
| US20200385488A1 (en) | Multispecific proteins | |
| JP7407822B2 (ja) | 単鎖キメラポリペプチドおよびその使用 | |
| US11618776B2 (en) | Targeted heterodimeric Fc fusion proteins containing IL-15/IL-15RA and NKG2D antigen binding domains | |
| KR20160058767A (ko) | T 세포 수용체 | |
| CN113646335A (zh) | 使用对b细胞成熟抗原具有特异性的嵌合抗原受体的治疗的方法 | |
| CN114269903A (zh) | 多链嵌合多肽和其用途 | |
| JP2021504413A (ja) | 組み合わせ治療のための二重特異性抗体及びil−15の使用 | |
| US20240132561A1 (en) | Multi-chain chimeric polypeptides and uses thereof | |
| AU2021342487A1 (en) | Clinical dosing of sirp1a chimeric protein | |
| JP2022524994A (ja) | T細胞受容体及びその使用方法 | |
| KR20240058149A (ko) | Vista 항원-결합 분자를 사용한 암의 치료 및 예방 | |
| JP2024500065A (ja) | Tigitベースのキメラタンパク質及びlightベースのキメラタンパク質を使用してがんを処置する方法 | |
| TW202328196A (zh) | 使用vista抗原結合分子的癌症之治療及預防 | |
| CN116847866A (zh) | 使用基于tigit和基于light的嵌合蛋白治疗癌症的方法 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination |