ES2926369T3 - Molécula de ácido nucleico monocatenario que tiene función de suministro y capacidad de control de la expresión génica - Google Patents
Molécula de ácido nucleico monocatenario que tiene función de suministro y capacidad de control de la expresión génica Download PDFInfo
- Publication number
- ES2926369T3 ES2926369T3 ES16772690T ES16772690T ES2926369T3 ES 2926369 T3 ES2926369 T3 ES 2926369T3 ES 16772690 T ES16772690 T ES 16772690T ES 16772690 T ES16772690 T ES 16772690T ES 2926369 T3 ES2926369 T3 ES 2926369T3
- Authority
- ES
- Spain
- Prior art keywords
- nucleic acid
- aforementioned
- region
- expression
- acid molecule
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
- C12N15/113—Non-coding nucleic acids modulating the expression of genes, e.g. antisense oligonucleotides; Antisense DNA or RNA; Triplex- forming oligonucleotides; Catalytic nucleic acids, e.g. ribozymes; Nucleic acids used in co-suppression or gene silencing
- C12N15/1136—Non-coding nucleic acids modulating the expression of genes, e.g. antisense oligonucleotides; Antisense DNA or RNA; Triplex- forming oligonucleotides; Catalytic nucleic acids, e.g. ribozymes; Nucleic acids used in co-suppression or gene silencing against growth factors, growth regulators, cytokines, lymphokines or hormones
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K31/00—Medicinal preparations containing organic active ingredients
- A61K31/70—Carbohydrates; Sugars; Derivatives thereof
- A61K31/7088—Compounds having three or more nucleosides or nucleotides
- A61K31/7125—Nucleic acids or oligonucleotides having modified internucleoside linkage, i.e. other than 3'-5' phosphodiesters
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K48/00—Medicinal preparations containing genetic material which is inserted into cells of the living body to treat genetic diseases; Gene therapy
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P29/00—Non-central analgesic, antipyretic or antiinflammatory agents, e.g. antirheumatic agents; Non-steroidal antiinflammatory drugs [NSAID]
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
- C12N15/113—Non-coding nucleic acids modulating the expression of genes, e.g. antisense oligonucleotides; Antisense DNA or RNA; Triplex- forming oligonucleotides; Catalytic nucleic acids, e.g. ribozymes; Nucleic acids used in co-suppression or gene silencing
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/10—Type of nucleic acid
- C12N2310/14—Type of nucleic acid interfering N.A.
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/10—Type of nucleic acid
- C12N2310/14—Type of nucleic acid interfering N.A.
- C12N2310/141—MicroRNAs, miRNAs
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/30—Chemical structure
- C12N2310/35—Nature of the modification
- C12N2310/351—Conjugate
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/30—Chemical structure
- C12N2310/35—Nature of the modification
- C12N2310/351—Conjugate
- C12N2310/3513—Protein; Peptide
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/30—Chemical structure
- C12N2310/35—Nature of the modification
- C12N2310/351—Conjugate
- C12N2310/3515—Lipophilic moiety, e.g. cholesterol
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/50—Physical structure
- C12N2310/53—Physical structure partially self-complementary or closed
- C12N2310/531—Stem-loop; Hairpin
Landscapes
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Engineering & Computer Science (AREA)
- Genetics & Genomics (AREA)
- Chemical & Material Sciences (AREA)
- Molecular Biology (AREA)
- Biomedical Technology (AREA)
- General Health & Medical Sciences (AREA)
- Organic Chemistry (AREA)
- Biotechnology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Wood Science & Technology (AREA)
- General Engineering & Computer Science (AREA)
- Zoology (AREA)
- Animal Behavior & Ethology (AREA)
- Veterinary Medicine (AREA)
- Public Health (AREA)
- Pharmacology & Pharmacy (AREA)
- Medicinal Chemistry (AREA)
- Biochemistry (AREA)
- Epidemiology (AREA)
- Physics & Mathematics (AREA)
- Biophysics (AREA)
- Plant Pathology (AREA)
- Microbiology (AREA)
- Pain & Pain Management (AREA)
- Rheumatology (AREA)
- Chemical Kinetics & Catalysis (AREA)
- General Chemical & Material Sciences (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- Endocrinology (AREA)
- Pharmaceuticals Containing Other Organic And Inorganic Compounds (AREA)
- Medicines That Contain Protein Lipid Enzymes And Other Medicines (AREA)
- Medicinal Preparation (AREA)
- Micro-Organisms Or Cultivation Processes Thereof (AREA)
Abstract
La presente invención proporciona una molécula de ácido nucleico monocatenario que tiene una función de liberación y es capaz de inhibir la expresión de un gen diana. La molécula de ácido nucleico monocatenario de la presente invención es una molécula de ácido nucleico monocatenario compuesta por una región (Xc), una región enlazadora (Lx) y una región (X), en donde dicha región (Xc) es complementaria a dicha región (X), al menos una de dicha región (X) y dicha región (Xc) contiene una secuencia inhibidora de la expresión que inhibe la expresión del gen diana, y una sustancia biorelacionada que tiene una función de entrega está unida a al menos una seleccionada del grupo que consiste en el extremo 5', el extremo 3' y dicha región conectora (Lx). (Traducción automática con Google Translate, sin valor legal)
Description
DESCRIPCIÓN
Molécula de ácido nucleico monocatenario que tiene función de suministro y capacidad de control de la expresión génica Campo técnico
La presente invención se refiere a una molécula de ácido nucleico monocatenario que tiene una función de suministro y capacidad de regulación de la expresión génica, una composición que la contiene y su uso.
Antecedentes de la técnica
Como técnica para inhibir la expresión génica, por ejemplo, se conoce la interferencia de ARN (ARNi) (documento no de patente 1). La inhibición de la expresión génica por interferencia de ARN generalmente se lleva a cabo, por ejemplo, administrando una molécula corta de ARN bicatenaria a una célula o similar. La molécula de ARN bicatenaria antes mencionada se denomina generalmente ARNip (ARN de interferencia pequeño). Se ha descrito que la expresión génica también se puede inhibir mediante una molécula de ARN circular que tiene una cadena doble formada parcialmente en ella mediante reasociación intramolecular (documento de patente 1). Sin embargo, en estas técnicas, las moléculas de ARN para inducir la inhibición de la expresión génica tienen los siguientes problemas.
Primero, para producir el ARNip antes mencionado, es necesario sintetizar una cadena paralela y una cadena antiparalela por separado e hibridar estas cadenas al final del procedimiento. Por lo tanto, existe un problema de baja eficiencia de fabricación. Además, cuando se administra el ARNip mencionado anteriormente a una célula, es necesario administrar el ARNip a la célula a la vez que se reprime la disociación a los ARN monocatenarios, lo que requiere una laboriosa tarea de establecer las condiciones para manipular el ARNip. La molécula de ARN circular tiene el problema de que su síntesis es difícil. Para hacer frente a la situación, los autores de la presente invención construyeron una nueva molécula de ácido nucleico monocatenario que resuelve el problema (documentos de patente 2, 3).
El documento de patente 4 describe la modificación química de ARN de horquilla pequeños para inhibir la expresión génica.
El documento de patente 5 describe moléculas de ácido nucleico monocatenario que tienen una cadena principal de aminoácidos.
Lista de documentos
Documentos de patente
documento de patente 1: JP-A-2008-278784
documento de patente 2: WO 2012/017919
documento de patente 3: WO 2013/180038
documento de patente 4: WO 2011/0087305
documento de patente 5: EP 2801617
Documento no de patente
documento no de patente 1: Fire, et al., Nature, vol. 391, págs. 806-811, 1998
Sumario de la invención
Problemas para resolver por la invención
Además, se requiere que dicha nueva molécula de ácido nucleico monocatenario realice además una función superior de suministro al tejido o célula diana.
Por lo tanto, la presente invención tiene como objetivo proporcionar un ácido nucleico monocatenario que tenga una función de suministro y que sea capaz de inhibir la expresión de un gen diana.
Medios para resolver los problemas
Para lograr el objeto antes mencionado, la molécula de ácido nucleico monocatenario de la presente invención es una molécula de ácido nucleico monocatenario para inhibir la expresión de un gen diana, que consiste en una región (X), una región conectora (Lx) y una región (Xc), en donde
la región (X) antes mencionada es complementaria de la región (Xc) antes mencionada,
al menos una de la región (X) mencionada anteriormente y la región (Xc) mencionada anteriormente comprende
una secuencia inhibidora de la expresión que inhibe la expresión del gen diana, dicha región conectora (Lx) comprende la siguiente fórmula (I-4):

(en donde n es un número entero en el intervalo de 0 a 30 y m es un número entero en el intervalo de 0 a 30), una sustancia biorrelacionada que tiene una función de suministro se une a dicha región conectora (Lx) de la molécula de ácido nucleico monocatenario para inhibir la expresión de un gen diana, y dicha sustancia biorrelacionada es el ácido esteárico.
También se proporcionan:
una composición para inhibir la expresión de un gen diana, que comprende la molécula de ácido nucleico monocatenario según la invención;
una composición farmacéutica que comprende la molécula de ácido nucleico monocatenario según la invención; una composición farmacéutica según la invención para usar en un método para tratar la inflamación;
un método in vitro para inhibir la expresión de un gen diana, que comprende usar la molécula de ácido nucleico monocatenario según la invención;
uso del ácido nucleico según la invención en un método in vitro para inhibir la expresión de un gen diana; y una molécula de ácido nucleico para usar en el tratamiento de una enfermedad, en donde dicha molécula de ácido nucleico es la molécula de ácido nucleico monocatenario según la invención, y dicha molécula de ácido nucleico monocatenario comprende, como dicha secuencia inhibidora de la expresión, una secuencia que inhibe la expresión de un gen que causa dicha enfermedad.
Efecto de la invención
La molécula de ácido nucleico monocatenario de la presente invención puede realizar una función superior de suministro a un tejido o célula diana sin requerir esencialmente, por ejemplo, un vehículo para el suministro. Por lo tanto, por ejemplo, no es necesario considerar la toxicidad del vehículo, y puede obviarse un estudio para establecer diferentes condiciones relacionadas con la formación de un complejo de una molécula de ácido nucleico y un vehículo. En consecuencia, por ejemplo, se puede reducir el trabajo y el coste en términos de producción y uso.
Breve descripción de los dibujos
La figura 1 muestra vistas esquemáticas que ilustran un ejemplo de la molécula de ácido nucleico monocatenario de la presente invención.
La figura 2 es un gráfico de HPLC de una molécula de ácido nucleico monocatenario conjugado con C18 después de purificación en un ejemplo de la presente invención.
La figura 3 es un gráfico de HPLC de una molécula de ácido nucleico monocatenario conjugada con DOPE después de purificación en un ejemplo de la presente invención.
La figura 4 es un gráfico de HPLC de una molécula de ácido nucleico monocatenario conjugado con lactosa después de purificación en un ejemplo de la presente invención.
La figura 5 es un gráfico de HPLC de una molécula de ácido nucleico monocatenario conjugada con GE11 después de purificación en un ejemplo de la presente invención.
La figura 6 es un gráfico de HPLC de una molécula de ácido nucleico monocatenario conjugada con GE11(7) después de purificación en un ejemplo de la presente invención.
La figura 7 es un gráfico de HPLC de una molécula de ácido nucleico monocatenario conjugada con GE11(5)
después de purificación en un ejemplo de la presente invención.
La figura 8 es un gráfico de HPLC de una molécula de ácido nucleico monocatenario conjugada con GE11 después de purificación en un ejemplo de la presente invención.
La figura 9 es un gráfico de HPLC de una molécula de ácido nucleico monocatenario conjugada con GE11(7) después de purificación en un ejemplo de la presente invención.
La figura 10 es un gráfico de HPLC de una molécula de ácido nucleico monocatenario conjugada con GE11 (5) después de purificación en un ejemplo de la presente invención.
La figura 11 es un gráfico que muestra los valores relativos del nivel de expresión del gen de TGF-01 en un ejemplo de la presente invención.
La figura 12 es un gráfico que muestra los valores relativos del nivel de expresión del gen de TGF-01 en un ejemplo de la presente invención.
La figura 13 es un gráfico que muestra los valores relativos del nivel de expresión del gen de TGF-01 en un ejemplo de la presente invención.
La figura 14 es un gráfico que muestra los valores relativos del nivel de expresión del gen de TGF-01 en un ejemplo de la presente invención.
La figura 15 muestra los resultados de la electroforesis que muestra la reactividad con la proteína Dicer en un ejemplo de la presente invención.
La figura 16 muestra los resultados de la electroforesis que muestra la reactividad con la proteína Dicer en un ejemplo de la presente invención.
La figura 17 muestra los resultados de la electroforesis mostrando estabilidad en un ejemplo de la presente invención.
Descripción de realizaciones
A menos que se especifique lo contrario, los términos utilizados en la presente memoria descriptiva significan lo que generalmente se entiende por ellos en la técnica.
1. Molécula ssNc
La molécula de ácido nucleico monocatenario de la presente invención es, como se mencionó anteriormente, una molécula de ácido nucleico monocatenario para inhibir la expresión de un gen diana, que consiste en una región (X), una región conectora (Lx) y una región (Xc), y se caracteriza por que
la región (X) antes mencionada es complementaria de la región (Xc) antes mencionada,
al menos una de la región (X) mencionada anteriormente y la región (Xc) mencionada anteriormente comprende una secuencia inhibidora de la expresión que inhibe la expresión del gen diana, dicha región conectora (Lx) comprende la siguiente fórmula (I-4):

(en donde n es un número entero en el intervalo de 0 a 30 y m es un número entero en el intervalo de 0 a 30), una sustancia biorrelacionada que tiene una función de suministro se une a dicha región conectora (Lx) de la molécula de ácido nucleico monocatenario para inhibir la expresión de un gen diana, y dicha sustancia biorrelacionada es el ácido esteárico.
En la presente invención, "inhibición de la expresión de un gen diana" significa, por ejemplo, inhibir la expresión del gen diana antes mencionado. El mecanismo mediante el cual se logra la inhibición antes mencionada no está
particularmente limitado y puede ser, por ejemplo, regulación por disminución o silenciamiento. La inhibición de la expresión del gen diana antes mencionada puede verificarse, por ejemplo, por una disminución en la cantidad de un producto de transcripción derivado del gen diana; una disminución de la actividad del producto de transcripción mencionado; una disminución de la cantidad de un producto de traducción generado a partir del gen diana antes mencionado; una disminución de la actividad del producto de traducción antes mencionado; o similar. El producto de traducción antes mencionado puede ser, por ejemplo, proteínas maduras, proteínas precursoras antes de ser sometidas a procesamiento o modificación postraduccional.
La molécula de ácido nucleico monocatenario de la presente invención en lo sucesivo también puede denominarse la "molécula ssNc" de la presente invención. La molécula ssNc de la presente invención se puede utilizar para inhibir, por ejemplo, la expresión de un gen diana in vivo o in vitro y también puede denominarse "molécula ssNc para inhibir la expresión de un gen diana" o "inhibidor de la expresión de un gen diana". Además, la molécula ssNc de la presente invención puede inhibir la expresión del gen diana antes mencionado mediante, por ejemplo, interferencia de ARN, y también puede denominarse "molécula ssNc para interferencia de ARN", "molécula para inducir interferencia de ARN", "agente de interferencia de ARN" o "agente inductor de interferencia de ARN". La molécula ssNc de la presente invención también puede inhibir, por ejemplo, un efecto secundario como la inducción de interferón.
En la molécula ssNc de la presente invención, el extremo 5' y el extremo 3' no están unidos entre sí. Por lo tanto, también puede denominarse una molécula de ácido nucleico monocatenario lineal.
En la molécula ssNc de la presente invención, la región (Xc) antes mencionada es complementaria de la región (X) antes mencionada, la región (Xc) antes mencionada se pliega hacia atrás hacia la región (X) antes mencionada, y la región (Xc) antes mencionada y la región (X) antes mencionada pueden formar una cadena doble por auto-reasociación.
En la molécula ssNc de la presente invención, la secuencia inhibidora de la expresión antes mencionada es una secuencia que presenta, por ejemplo, una actividad de inhibición de la expresión antes mencionada de un gen diana cuando la molécula ssNc de la presente invención se introduce en una célula in vivo o in vitro. La secuencia inhibidora de la expresión antes mencionada no está particularmente limitada y puede establecerse según corresponda dependiendo del tipo de gen diana. Como la secuencia inhibidora de la expresión mencionada anteriormente, por ejemplo, se puede usar una secuencia implicada en la interferencia de ARN producida por ARNip según corresponda. En general, la interferencia de ARN es un fenómeno en el que Dicer escinde un ARN bicatenario largo (ARNbc) en una célula para producir un ARN bicatenario (ARNip: ARN de interferencia pequeño) compuesto de aproximadamente 19 a 21 pares de bases y que tiene un extremo 3' saliente, y uno de los ARN monocatenarios se une a un ARNm diana para degradar el ARNm antes mencionado, de modo que se inhibe la traducción del ARNm. Como la secuencia de ARN monocatenario del ARNip mencionado anteriormente que se une al ARNm diana mencionado anteriormente, por ejemplo, se han descrito varios tipos de secuencias para varios tipos de genes diana. En la presente invención, por ejemplo, la secuencia de ARN monocatenario del ARNip antes mencionado se puede usar como la secuencia inhibidora de la expresión antes mencionada. En la presente invención no solo se pueden utilizar las secuencias del ARN monocatenario del ARNip conocidas en el momento de la presentación de la presente solicitud sino también secuencias que serían identificadas en el futuro, por ejemplo, como la secuencia inhibidora de la expresión antes mencionada.
La secuencia inhibidora de la expresión antes mencionada es, por ejemplo, preferiblemente al menos 90% complementaria, más preferiblemente 95% complementaria, aún más preferiblemente 98% complementaria y particularmente preferiblemente 100% complementaria de una región predeterminada del gen diana mencionado anteriormente. Cuando se satisface tal complementariedad, por ejemplo, se puede reducir suficientemente un efecto fuera del objetivo.
Se especula que la inhibición de la expresión antes mencionada de un gen diana por la molécula ssNc de la presente invención se logra, por ejemplo, por interferencia de ARN o un fenómeno similar a la interferencia de ARN (fenómeno como la interferencia de ARN), que es causado por una estructura que configura la secuencia inhibidora de la expresión mencionada anteriormente, en al menos una de la región (X) antes mencionada y la región (Xc) antes mencionada. Debe señalarse, sin embargo, que la presente invención no está limitada en modo alguno por este mecanismo. A diferencia del denominado ARNip, por ejemplo, la molécula ssNc de la presente invención no se introduce en una célula o similar en forma de ARNbc compuesto por dos cadenas de ARN monocatenarios, y no siempre es necesario escindir la secuencia inhibidora de la expresión antes mencionada en la célula. Así, se puede decir, por ejemplo, que la molécula ssNc de la presente invención presenta una función similar a la interferencia del ARN.
En la molécula ssNc de la presente invención, la secuencia inhibidora de la expresión mencionada anteriormente está incluida en al menos una de la región (X) mencionada anteriormente y la región (Xc) mencionada anteriormente, como se ha descrito antes. La molécula ssNc de la presente invención puede incluir, por ejemplo, una secuencia inhibidora de la expresión o dos o más secuencias inhibidoras de la expresión mencionadas anteriormente.
En el último caso, la molécula ssNc de la presente invención puede incluir, por ejemplo: dos o más secuencias inhibidoras de la expresión idénticas para el mismo gen diana; dos o más secuencias inhibidoras de la expresión diferentes para el mismo gen diana; o dos o más secuencias inhibidoras de la expresión diferentes para genes diana diferentes. Cuando la molécula ssNc de la presente invención incluye dos o más secuencias inhibidoras de la expresión mencionadas anteriormente, las posiciones de las respectivas secuencias inhibidoras de la expresión no están
particularmente limitadas, y pueden estar en una región o regiones diferentes seleccionadas de la región (X) mencionada anteriormente y la región (Xc) mencionada anteriormente. Cuando la molécula ssNc de la presente invención incluye dos o más secuencias inhibidoras de la expresión mencionadas anteriormente para diferentes genes diana, por ejemplo, la molécula ssNc de la presente invención puede inhibir las expresiones de dos o más tipos de genes diana diferentes.
En la molécula ssNc de la presente invención, la secuencia inhibidora de la expresión antes mencionada solo necesita tener, por ejemplo, una actividad inhibidora de la expresión y también puede ser una secuencia de miARN madura. El proceso de generación del miARN y el proceso de inhibición de la expresión de proteínas por el miARN en el cuerpo se describen a continuación. En primer lugar, se expresa en el núcleo un transcrito de miARN monocatenario (PrimiARN) que tiene una estructura casquete en el extremo 5' y una estructura poli A en el extremo 3'. El Pri-miRNA mencionado anteriormente tiene una estructura de horquilla. El Pri-miRNA antes mencionado es escindido por RNasa (Drosha) para producir un precursor monocatenario (Pre-miRNA). El Pre-miARN antes mencionado tiene una estructura de horquilla que tiene una región de tallo y una región de bucle. El pre-miARN antes mencionado es transportado al citoplasma, escindido por la RNasa (Dicer) y, a partir de la estructura de tallo del mismo, se produce un miARN bicatenario que tiene un saliente de varias bases (p. ej., 1 - 4 bases) en el extremo 3'. Un miARN maduro monocatenario del miARN bicatenario se une a un complejo similar al RISC (complejo de silenciamiento inducido por ARN) y el complejo miARN/RISC maduro se une a un ARNm particular, por lo que se suprime la traducción de la proteína del ARNm antes mencionado. En la presente invención, la secuencia del miARN maduro antes mencionado puede usarse como la secuencia inhibidora de la expresión antes mencionada.
Cabe señalar que el objetivo de la presente invención no es la información de secuencia de la secuencia inhibidora de la expresión antes mencionada para el gen diana antes mencionado, sino, por ejemplo, la estructura de una molécula de ácido nucleico que permite la función de la actividad inhibidora de la expresión del gen diana antes mencionado debida a la secuencia inhibidora de la expresión antes mencionada en una célula. Por lo tanto, en la presente invención, pueden utilizarse no solo las secuencias del miARN maduro monocatenario de los miARN conocidas en el momento de la presentación de la presente solicitud, sino también las secuencias que se identificarían en el futuro, por ejemplo, como la secuencia inhibidora de la expresión antes mencionada.
Como se mencionó anteriormente, en el cuerpo, el pre-miARN antes mencionado es escindido y la secuencia de miARN maduro antes mencionada se produce a partir de una de las cadenas (también denominada cadena guía) de la estructura del tallo. En este caso, se produce una secuencia de miARN* menor (también denominada cadena pasajera) a partir de la otra cadena de la estructura de tallo antes mencionada. La secuencia de miARN* minoritaria mencionada anteriormente es generalmente una cadena complementaria que tiene un apareamiento erróneo en una o varias bases cuando se alinea con el Pre-miARN mencionado anteriormente. La molécula ssNc de la presente invención puede tener además, por ejemplo, la secuencia de miARN* menor antes mencionada.
La secuencia de miARN maduro mencionada anteriormente y la secuencia de miARN* menor mencionada anteriormente pueden tener una base que se vuelve no complementaria cuando ambas están alineadas. El miARN* menor antes mencionado tiene, por ejemplo, una complementariedad de, por ejemplo, 60 - 100% con la secuencia de miARN maduro antes mencionada. La secuencia de miARN maduro mencionada anteriormente y el miARN* menor mencionado anteriormente pueden tener cada uno, en su interior, la base mencionada anteriormente (p. ej., una o varias bases) que se vuelve no complementaria. El número de bases antes mencionadas es, por ejemplo, 2 - 15 bases. Las bases no complementarias antes mencionadas pueden ser, por ejemplo, continuas o no continuas.
La longitud de la secuencia de miARN* menor antes mencionada no está particularmente limitada y es diferente de la longitud de la secuencia de miARN maduro antes mencionada en, por ejemplo, 0 - 10 bases, preferiblemente 0 - 7 bases, más preferiblemente 0 - 5 bases. La secuencia de miARN* menor antes mencionada y la secuencia de miARN maduro antes mencionada pueden tener, por ejemplo, la misma longitud o la primera puede ser más larga o la última puede ser más larga.
En la molécula ssNc de la presente invención, la región (Xc) antes mencionada es complementaria de la región (X) antes mencionada. Solo es necesario que la región (Xc) antes mencionada tenga una secuencia complementaria de toda la región o parte de la región (X) antes mencionada. En concreto, por ejemplo, preferiblemente, la región (Xc) antes mencionada incluye o está compuesta por una secuencia complementaria de toda o parte de la región (X) antes mencionada. La región (Xc) antes mencionada puede ser, por ejemplo, perfectamente complementaria de toda la región o parte de la región (X) antes mencionada, o una o algunas bases en la región (Xc) antes mencionada pueden ser no complementarias de la misma.
La molécula ssNc de la presente invención está configurada de manera que tiene una región conectora (Lx) entre la región (Xc) antes mencionada y la región (X) antes mencionada y las regiones (Xc) y (X) antes mencionadas están unidas a través de la región conectora (Lx) antes mencionada.
La región conectora (Lx) antes mencionada tiene preferiblemente una estructura libre de auto-reasociación dentro de la misma región.
En la molécula ssNc de la presente invención, la sustancia biorrelacionada mencionada anteriormente es una
sustancia que muestra afinidad por los organismos vivos y también puede denominarse sustancia biocompatible. La molécula ssNc de la presente invención puede mejorar, por ejemplo, la eficiencia de suministro e introducción en una célula diana y/o la resistencia a la degradación enzimática al tener un lípido. Se supone que esto es atribuible, por ejemplo, al siguiente mecanismo. Es decir, la molécula ssNc de la presente invención tiene permeabilidad mejorada de la membrana celular y resistencia mejorada a la degradación enzimática al formar una estructura de micela como un todo con la región lipídica mencionada anteriormente y otras regiones de ácido nucleico. Además, se entiende que la molécula ssNc de la presente invención tiene una movilidad más mejorada en organismos vivos ya que la región lipídica mencionada anteriormente y otras regiones de ácido nucleico forman un complejo similar a un exosoma como un todo. La presente invención no se limita a dichos mecanismos.
La sustancia biorrelacionada antes mencionada es el ácido esteárico.
En la molécula ssNc de la presente invención, la sustancia biorrelacionada se une a dicha región conectora (Lx) de la molécula de ácido nucleico antes mencionada. También se describen sitios de unión de la sustancia biorrelacionada antes mencionada en el extremo 5' y el extremo 3' de la molécula de ácido nucleico antes mencionada.
En la molécula ssNc de la presente invención, la sustancia biorrelacionada antes mencionada puede unirse en un sitio o no menos de dos sitios.
En la molécula ssNc de la presente invención, la sustancia biorrelacionada antes mencionada se puede unir, por ejemplo, directa o indirectamente a la molécula de ácido nucleico antes mencionada, preferiblemente indirectamente. Cuando se une indirectamente, por ejemplo, es preferible la unión a través de un conector de unión. La estructura del conector de unión antes mencionado no está particularmente limitada y, por ejemplo, se puede mencionar el conector GMBS, conector etilenglicol o la estructura de la siguiente fórmula. En la siguiente fórmula, n' es un número entero positivo, Y es, por ejemplo, NH, S, O, CO y similares.
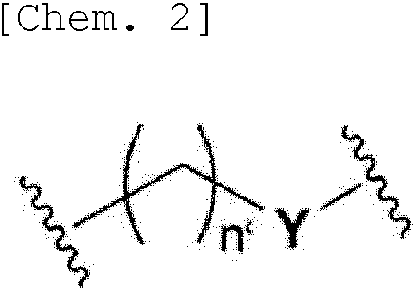
La vista esquemática de la Fig. 1 muestra una realización de la estructura de ácido nucleico de la molécula ssNc de la presente invención. Como una realización, la Fig. 1A es una vista esquemática que muestra el orden de las regiones respectivas en la molécula ssNc mencionada anteriormente. La Fig. 1B es una vista esquemática que muestra el estado donde se forman cadenas dobles en la molécula ssNc mencionada anteriormente. Como se muestra en la Fig. 1B, en la molécula ssNc mencionada anteriormente, se forma una doble cadena entre la región (Xc) antes mencionada y la región (X) antes mencionada, la región Lx antes mencionada forma una estructura de bucle de acuerdo con la longitud de la misma. Las vistas esquemáticas que se muestran en la Fig. 1 simplemente ilustran el orden en que están conectadas las regiones antes mencionadas y la relación de posición de las respectivas regiones que forman la doble cadena, y no limitan, por ejemplo, las longitudes de las respectivas regiones, la forma de la región conectora (Lx) antes mencionada, y similares.
En la molécula ssNc de la presente invención, la sustancia biorrelacionada antes mencionada se une, como se mencionó anteriormente, a la región conectora (Lx) en la Fig. 1.
En la molécula ssNc de la presente invención, el número de bases de la región (Xc) mencionada anteriormente y la región (X) mencionada anteriormente no está particularmente limitado y es, por ejemplo, como se describe a continuación. En la presente invención, "el número de bases" significa la "longitud", por ejemplo, y también puede denominarse "longitud de bases".
Como se ha descrito anteriormente, por ejemplo, la región (Xc) mencionada anteriormente puede ser complementaria de la región entera de la región (X) mencionada anteriormente. En este caso, es preferible que, por ejemplo, la región (Xc) mencionada anteriormente tenga la misma longitud de bases que la región (X) mencionada anteriormente, y esté compuesta por una secuencia de bases complementaria de la región entera del extremo 5' al extremo 3' de la región (X) antes mencionada. Es más preferible que la región (Xc) antes mencionada tenga la misma longitud de bases que la región (X) antes mencionada y todas las bases en la región (Xc) antes mencionada sean complementarias de todas las bases en la región (X) antes mencionada, es decir, por ejemplo, preferiblemente, la región (Xc) es perfectamente complementaria de la región (X). Debe indicarse, sin embargo, que la configuración de la región (Xc) no se limita a ella, y una o unas pocas bases en la región (Xc) pueden no ser complementarias de las bases correspondientes en la región (X), por ejemplo, como se describió anteriormente.
Además, como se ha descrito anteriormente, la región (Xc) antes mencionada puede ser complementaria, por ejemplo, de una parte de dicha región (X). En este caso, es preferible que, por ejemplo, la región (Xc) antes mencionada tenga la misma longitud de bases que la parte de la región (X) antes mencionada, es decir, la región (Xc) antes mencionada
esté compuesta por una secuencia de bases cuya longitud de bases es más corta que la longitud de bases de la región (X) mencionada anteriormente en una o más bases. Es más preferible que la región (Xc) antes mencionada tenga la misma longitud de bases que la parte de la región (X) antes mencionada y todas las bases en la región (Xc) antes mencionada sean complementarias de todas las bases en la parte de dicha región (X), es decir, por ejemplo, preferiblemente la región (Xc) es perfectamente complementaria de la parte de la región (X) antes mencionada. La parte de la región (X) mencionada anteriormente es preferiblemente una región (segmento) que tiene una secuencia de bases compuesta, por ejemplo, de bases sucesivas que comienzan desde la base en el extremo 5' (la 1a base) en la región (X) mencionada anteriormente.
En la molécula ssNc de la presente invención, la relación entre el número de bases (X) de la región (X) antes mencionada y el número de bases (Xc) de la región (Xc) antes mencionada cumple, por ejemplo, las condiciones de las siguientes expresiones (1) o (2). En el primer caso, cumple específicamente, por ejemplo, la siguiente condición (3).
X>Xc ■ ■ ■(1)
X - Xc = 1 - 10, preferiblemente 1,2 o 3,
más preferiblemente 1 o 2... (3)
X=Xc ■■■(2)
Aunque la longitud de cada región de la molécula ssNc de la presente invención se muestra a continuación, la presente invención no se limita a ella. En la presente invención, por ejemplo, el intervalo numérico del número de bases describe todos los números enteros positivos que caen dentro del intervalo y, por ejemplo, "1 - 4 bases" significa todas de "1, 2, 3, 4 bases" (en lo sucesivo lo mismo).
El número de bases en la región (X) mencionada anteriormente es, por ejemplo, 19 o más. El límite inferior del número de las bases es, por ejemplo, 19, preferiblemente 20 y más preferiblemente 21. El límite superior del número de bases antes mencionado es, por ejemplo, 50, preferiblemente 40 y más preferiblemente 30.
Cuando la región (X) mencionada anteriormente incluye la secuencia inhibidora de la expresión mencionada anteriormente, la región (X) mencionada anteriormente puede ser, por ejemplo, una región compuesta únicamente por la secuencia inhibidora de la expresión mencionada anteriormente o una región que incluye la secuencia inhibidora de la expresión mencionada anteriormente. El número de bases de la secuencia inhibidora de la expresión mencionada anteriormente es, por ejemplo, de 19 a 30, preferiblemente 19, 20 o 21. Cuando la región (X) mencionada anteriormente incluye la secuencia inhibidora de la expresión mencionada anteriormente, la secuencia inhibidora de la expresión mencionada anteriormente puede tener además una secuencia adicional en su lado 5' y/o 3'. El número de bases en la secuencia adicional antes mencionada es, por ejemplo, de 1 a 31, preferiblemente de 1 a 21, más preferiblemente de 1 a 11 y aún más preferiblemente de 1 a 7.
Cuando la región (Xc) mencionada anteriormente incluye la secuencia inhibidora de la expresión mencionada anteriormente, la región (Xc) mencionada anteriormente puede ser, por ejemplo, una región compuesta únicamente por la secuencia inhibidora de la expresión mencionada anteriormente o una región que incluye la secuencia inhibidora de la expresión mencionada anteriormente. Por ejemplo, la longitud de la secuencia inhibidora de la expresión mencionada anteriormente es como se ha descrito antes. Cuando la región (Xc) mencionada anteriormente incluye la secuencia inhibidora de la expresión mencionada anteriormente, la secuencia inhibidora de la expresión mencionada anteriormente puede tener además una secuencia adicional en su lado 5' y/o en su lado 3'. El número de bases en la secuencia adicional antes mencionada es, por ejemplo, de 1 a 11, preferiblemente de 1 a 7.
En la molécula ssNc de la presente invención, la longitud de la región conectora (Lx) mencionada anteriormente no está particularmente limitada. La región conectora mencionada anteriormente (Lx) tiene preferiblemente una longitud que permite, por ejemplo, que la región (X) mencionada anteriormente y la región (Xc) mencionada anteriormente formen una cadena doble.
La longitud completa de la molécula ssNc de la presente invención no está particularmente limitada. En la molécula ssNc de la presente invención, el límite inferior del número total de bases (el número de bases en toda su longitud) es, por ejemplo, 38, preferiblemente 42, más preferiblemente 50, aún más preferiblemente 51, y particularmente preferiblemente 52, y el límite superior de la misma es, por ejemplo, 300, preferiblemente 200, más preferiblemente 150, aún más preferiblemente 100, y particularmente preferiblemente 80. En la molécula ssNc de la presente invención, el límite inferior del número total de bases excluyendo las de la región conectora (Lx) mencionada anteriormente es, por ejemplo, 38, preferiblemente 42, más preferiblemente 50, aún más preferiblemente 51, y particularmente preferiblemente 52, y el límite superior de la misma es, por ejemplo, 300, preferiblemente 200, más preferiblemente 150, aún más preferiblemente 100 y particularmente preferiblemente 80.
En la molécula ssNc de la presente invención, las unidades constitucionales no están particularmente limitadas. Los ejemplos de las mismas incluyen restos de nucleótidos. Los ejemplos de los restos de nucleótidos mencionados anteriormente incluyen un resto de ribonucleótido y un resto de desoxirribonucleótido. El resto de nucleótido mencionado anteriormente puede ser, por ejemplo, el que no está modificado (resto de nucleótido no modificado) o el
que ha sido modificado (resto de nucleótido modificado). Al configurar la molécula ssNc de la presente invención para incluir el resto de nucleótido modificado mencionado anteriormente, por ejemplo, se puede mejorar la resistencia de la molécula ssNc a la nucleasa, permitiendo así mejorar la estabilidad de la molécula ssNc. Además, la molécula ssNc de la presente invención puede incluir además, por ejemplo, un resto no nucleotídico además del resto de nucleótido mencionado anteriormente. El detalle del resto de nucleótido mencionado anteriormente y el resto no nucleotídico mencionado anteriormente se describe más adelante.
En la molécula ssNc de la presente invención, la unidad constitucional de cada una de la región (X) mencionada anteriormente y la región (Xc) mencionada anteriormente es preferiblemente el resto de nucleótido mencionado anteriormente. Cada una de las regiones antes mencionadas está compuesta por, por ejemplo, cualquiera de los siguientes restos (1) a (3):
(1) un resto(s) de nucleótido(s) no modificado(s)
(2) un resto(s) de nucleótido(s) modificado(s)
(3) un resto(s) de nucleótido(s) no modificado(s) y un resto(s) de nucleótido(s) modificado(s).
Los ejemplos de la molécula ssNc de la presente invención son moléculas que incluyen el(los) resto(s) no nucleótido(s) mencionado(s) anteriormente además de los restos de nucleótidos mencionados anteriormente. En la molécula ssNc de la presente invención, por ejemplo, los restos de nucleótidos mencionados anteriormente pueden ser únicamente los restos de nucleótidos no modificados mencionados anteriormente; únicamente los restos de nucleótidos modificados anteriormente mencionados; o tanto el(los) resto(s) de nucleótido(s) no modificado(s) mencionado(s) como el(los) resto(s) de nucleótido(s) modificado(s) mencionado(s) anteriormente, como se ha descrito antes. Cuando la molécula ssNc antes mencionada incluye tanto el(los) resto(s) de nucleótido(s) no modificado(s) antes mencionado(s) como el(los) resto(s) de nucleótido(s) modificado(s) antes mencionado(s), el número de los restos de nucleótidos modificados antes mencionados no está particularmente limitado y es, por ejemplo, "de uno a varios", específicamente, por ejemplo, de 1 a 5, preferiblemente de 1 a 4, más preferiblemente de 1 a 3, y lo más preferiblemente 1 o 2. El número de los restos no nucleotídicos mencionados anteriormente no está particularmente limitado y es, por ejemplo, "de uno a varios", en concreto, por ejemplo, de 1 a 8, de 1 a 6, de 1 a 4, 1,2 o 3.
En la molécula ssNc de la presente invención, por ejemplo, el resto de nucleótido antes mencionado es preferiblemente un resto de ribonucleótido. En este caso, por ejemplo, la molécula ssNc de la presente invención también se denomina "molécula de ARN" o "molécula de ARNmc". Los ejemplos de la molécula de ARNmc antes mencionada incluyen moléculas compuestas únicamente por los restos de ribonucleótido antes mencionados; y una molécula que incluye el(los) resto(s) no nucleotídico(s) antes mencionado(s) además de los restos de ribonucleótidos mencionados anteriormente. Como se ha descrito antes, como los restos de ribonucleótidos mencionados anteriormente, por ejemplo, la molécula de ARNmc mencionada anteriormente puede incluir: los restos de ribonucleótidos no modificados mencionados anteriormente únicamente; los restos de ribonucleótidos modificados anteriormente mencionados únicamente; o tanto el(los) resto(s) de ribonucleótido(s) no modificado(s) antes mencionado(s) como el(los) resto(s) de ribonucleótido modificado(s) antes mencionado(s).
Cuando la molécula de ARNmc mencionada anteriormente incluye, por ejemplo, el(los) resto(s) de ribonucleótido(s) modificado(s) mencionado(s) anteriormente además de los restos de ribonucleótidos no modificados mencionados anteriormente, el número de restos de ribonucleótidos modificados mencionados anteriormente no está particularmente limitado y es, por ejemplo, " de uno a varios", específicamente, por ejemplo, de 1 a 5, preferiblemente de 1 a 4, más preferiblemente de 1 a 3, y lo más preferiblemente 1 o 2. El resto de ribonucleótido modificado mencionado anteriormente en contraste con el resto de ribonucleótido no modificado mencionado anteriormente puede ser, por ejemplo, el resto de desoxirribonucleótido antes mencionado obtenido mediante la sustitución de un resto de ribosa por un resto de desoxirribosa. Cuando la molécula de ARNmc mencionada anteriormente incluye, por ejemplo, el(los) resto(s) de desoxirribonucleótido(s) mencionado(s) anteriormente además del (de los) resto(s) de ribonucleótido(s) no modificado(s) mencionado(s) anteriormente, el número del (de los) resto(s) de desoxirribonucleótido(s) mencionado(s) anteriormente no está particularmente limitado y es, por ejemplo, "de uno a varios", específicamente, por ejemplo, de 1 a 5, preferiblemente de 1 a 4, más preferiblemente de 1 a 3 y lo más preferiblemente 1 o 2.
En la molécula ssNc de la presente invención, la región conectora (Lx) antes mencionada comprende un resto no nucleotídico representado por la siguiente fórmula (I-4):
[Chem. 1-4]

En la fórmula (I-4) mencionada anteriormente,
m es un número entero en el intervalo de 0 a 30; y
n es un número entero en el intervalo de 0 a 30.
Un ejemplo específico es la fórmula (I-4) mencionada anteriormente en donde n = 5 y m = 4. Su estructura se muestra mediante la siguiente fórmula (I-4a).

La molécula ssNc de la presente invención puede incluir, por ejemplo, una sustancia marcadora y se puede marcar con la sustancia marcadora mencionada anteriormente. La sustancia marcadora mencionada anteriormente no está particularmente limitada y puede ser, por ejemplo, una sustancia fluorescente, un colorante, un isótopo o similar. Los ejemplos de la sustancia marcadora mencionada anteriormente incluyen: fluoróforos tales como pireno, TAMRA, fluoresceína, un colorante Cy3 y un colorante Cy5. Los ejemplos del colorante mencionado anteriormente incluyen colorantes Alexa tales como Alexa 488. Los ejemplos del isótopo mencionado anteriormente incluyen isótopos estables y radioisótopos. Entre ellos, son preferibles los isótopos estables. Por ejemplo, los isótopos estables antes mencionados tienen un bajo riesgo de exposición a radiación y no requieren instalaciones especializadas. Por lo tanto, los isótopos estables tienen una excelente manejabilidad y pueden contribuir a la reducción de costes. Además, por ejemplo, el isótopo estable mencionado anteriormente no cambia las propiedades físicas de un compuesto marcado con el mismo y, por lo tanto, tiene una propiedad excelente como trazador. El isótopo estable mencionado anteriormente no está particularmente limitado, y los ejemplos del mismo incluyen 2H, 13C, 15N, 17O, 18O, 33S, 34S y 36S.
Como se ha descrito antes, la molécula ssNc de la presente invención puede inhibir la expresión antes mencionada de un gen diana. Así, la molécula ssNc de la presente invención se puede utilizar, por ejemplo, como un agente terapéutico para tratar una enfermedad causada por un gen. Cuando la molécula ssNc de la presente invención incluye, por ejemplo, como la secuencia inhibidora de la expresión antes mencionada, una secuencia que inhibe la expresión de un gen que causa la enfermedad antes mencionada, por ejemplo, es posible tratar la enfermedad antes mencionada inhibiendo la expresión del gen diana antes mencionado. En la presente invención, el término "tratamiento" abarca: la prevención de las enfermedades antes mencionadas; mejora de las enfermedades; y mejora del pronóstico, por ejemplo, y puede significar cualquiera de ellos.
El método de uso de la molécula ssNc de la presente invención no está particularmente limitado. Por ejemplo, la molécula ssNc mencionada anteriormente se puede administrar a un sujeto que tiene el gen diana mencionado anteriormente.
Los ejemplos del sujeto mencionado anteriormente al que se administra la molécula ssNc de la presente invención incluyen células, tejidos, órganos y similares. Los ejemplos del tema mencionado anteriormente también incluyen seres humanos, animales no humanos y similares, tales como mamíferos no humanos, es decir, mamíferos excluyendo seres humanos. La administración antes mencionada se puede llevar a cabo, por ejemplo, in vivo o in vitro. Las células antes mencionadas no están particularmente limitadas, y los ejemplos de las mismas incluyen: varias células cultivadas tales como células HeLa, células 293, células NIH3T3 y células COS; células madre tales como células ES y células madre hematopoyéticas; y células aisladas de organismos vivos, tales como células primarias cultivadas.
En la presente invención, el gen diana antes mencionado cuya expresión se va a inhibir no está particularmente limitado, y cualquier gen deseado se puede ajustar al gen diana. Además, como se mencionó anteriormente, la
secuencia inhibidora de la expresión mencionada anteriormente puede diseñarse según corresponda dependiendo del tipo del gen diana mencionado anteriormente.
En cuanto al uso de la molécula ssNc de la presente invención, se puede hacer referencia a la siguiente descripción en relación con la composición, el método de inhibición de la expresión in vitro, el ácido nucleico para usar en el tratamiento de una enfermedad, y similares de acuerdo con la presente invención que se describirá a continuación.
Dado que la molécula ssNc de la presente invención puede inhibir la expresión de un gen diana como se ha descrito antes, por ejemplo, es útil como producto farmacéutico, agente de diagnóstico, producto químico agrícola y una herramienta para llevar a cabo investigaciones sobre el producto químico agrícola, ciencias médicas, ciencias de la vida, y similares.
2. Resto de nucleótido
El resto de nucleótido mencionado anteriormente incluye, por ejemplo, un azúcar, una base y un fosfato como sus componentes. El resto de nucleótido mencionado anteriormente puede ser, por ejemplo, un resto de ribonucleótido o un resto de desoxirribonucleótido, como se ha descrito antes. El resto de ribonucleótido mencionado anteriormente tiene, por ejemplo, un resto de ribosa como azúcar; y adenina (A), guanina (G), citosina (C) o uracilo (U) como base. El resto de desoxirribosa antes mencionado tiene, por ejemplo, un resto de desoxirribosa como azúcar; y adenina (A), guanina (G), citosina (C) o timina (T) como base.
El resto de nucleótido mencionado anteriormente puede ser, por ejemplo, un resto de nucleótido no modificado o un resto de nucleótido modificado. Los componentes antes mencionados del resto de nucleótido no modificado antes mencionado son los mismos o sustancialmente los mismos que, por ejemplo, los componentes de un resto de nucleótido de origen natural. Preferiblemente, los componentes son los mismos o sustancialmente los mismos que los componentes de un resto de nucleótido que se produce naturalmente en el cuerpo humano.
El resto de nucleótido modificado mencionado anteriormente es, por ejemplo, un resto de nucleótido obtenido modificando el resto de nucleótido no modificado mencionado anteriormente. Por ejemplo, el resto de nucleótido modificado mencionado anteriormente puede ser tal que cualquiera de los componentes del resto de nucleótido no modificado mencionado anteriormente esté modificado. En la presente invención, "modificación" significa, por ejemplo, sustitución, adición y/o eliminación de cualquiera de los componentes antes mencionados; y sustitución, adición y/o deleción de un átomo(s) y/o un grupo(s) funcional(es) en el(los) componente(s) mencionado(s). También se puede denominar "modificación". Los ejemplos de los restos de nucleótidos modificados mencionados anteriormente incluyen restos de nucleótidos naturales y restos de nucleótidos modificados artificialmente. Con respecto a los restos de nucleótidos modificados naturales antes mencionados se puede hacer referencia, por ejemplo, a Limbach et al. (Limbach et al., 1994, “Summary: the modified nucleosides of RNA”, Nucleic Acids Res. 22: págs. 2183 a 2196). El resto de nucleótido modificado mencionado anteriormente puede ser, por ejemplo, un resto de una alternativa del nucleótido mencionado anteriormente.
Los ejemplos de la modificación del resto de nucleótido mencionado anteriormente incluyen la modificación de una cadena principal de ribosa-fosfato (en lo sucesivo, denominado "cadena principal de ribofosfato").
En la cadena principal de ribofosfato antes mencionada, por ejemplo, se puede modificar un resto de ribosa. En el resto de ribosa antes mencionado, por ejemplo, se puede modificar el carbono de la posición 2'. Específicamente, un grupo hidroxilo unido a, por ejemplo, el carbono en la posición 2' se puede sustituir por hidrógeno o halógeno tal como flúor. Sustituyendo el grupo hidroxilo unido al carbono en la posición 2' mencionado anteriormente por hidrógeno, es posible sustituir el resto de ribosa por desoxirribosa. El resto de ribosa mencionado anteriormente puede sustituirse por su estereoisómero, por ejemplo, y puede sustituirse, por ejemplo, por un resto de arabinosa.
La cadena principal de ribofosfato antes mencionada se puede sustituir, por ejemplo, por una cadena principal que no es de ribofosfato que tiene un resto no ribosa y/o no fosfato. La cadena principal que no es de ribofosfato mencionada anteriormente puede ser, por ejemplo, la cadena principal de ribofosfato mencionada anteriormente modificada para que no tenga carga. Los ejemplos de una alternativa obtenida mediante la sustitución de la cadena principal de ribofosfato por la cadena principal que no es de ribofosfato mencionada anteriormente en el nucleótido mencionado anteriormente incluyen morfolino, ciclobutilo y pirrolidina. Otros ejemplos de la alternativa antes mencionada incluyen restos de monómero de ácido nucleico artificial. Los ejemplos específicos de los mismos incluyen PNA (ácido nucleico peptídico), LNA (ácido nucleico bloqueado) y ENA (ácidos nucleicos con puente de 2'-O,4'-C-etileno). Entre ellos, es preferible el PNA.
En la cadena principal de ribofosfato antes mencionada, por ejemplo, se puede modificar un grupo fosfato. En la cadena principal de ribofosfato antes mencionada, un grupo fosfato lo más cercano al resto de azúcar se denomina "grupo a-fosfato". El grupo a-fosfato antes mencionado tiene carga negativa y las cargas eléctricas se distribuyen uniformemente entre dos átomos de oxígeno que no están unidos al resto de azúcar. Entre los cuatro átomos de oxígeno en el grupo a-fosfato mencionado anteriormente, los dos átomos de oxígeno no unidos al resto de azúcar en el enlace fosfodiéster entre los restos de nucleótidos se denominan en lo sucesivo "oxígenos no enlazantes". Por otro lado, dos átomos de oxígeno que están unidos al resto de azúcar en el enlace fosfodiéster entre los restos de nucleótidos antes mencionados se denominan en lo sucesivo "oxígenos enlazantes". Por ejemplo, el grupo a-fosfato
mencionado anteriormente se modifica preferiblemente para que no tenga carga, o para hacer que la distribución de cargas entre los oxígenos no enlazantes mencionados anteriormente sea asimétrica.
En el grupo fosfato mencionado anteriormente, por ejemplo, se puede(n) sustituir el(los) oxígeno(s) no enlazante(s) mencionado(s) anteriormente. El(los) oxígeno(s) antes mencionado(s) puede(n) sustituirse, por ejemplo, por cualquier átomo seleccionado de S (azufre), Se (selenio), B (boro), C (carbono), H (hidrógeno), N (nitrógeno) y OR (R es un grupo alquilo o un grupo arilo) y es preferible la sustitución por S. Es preferible que uno de los oxígenos no enlazantes se sustituya por S, por ejemplo, y es más preferible que se sustituyan ambos oxígenos no enlazantes mencionados anteriormente. Los ejemplos del grupo fosfato modificado antes mencionado incluyen fosforotioatos, fosforoditioatos, fosforoselenatos, boranofosfatos, ésteres de boranofosfato, hidrogenofosfonatos, fosforoamidatos, alquil o arilfosfonatos y fosfotriésteres. En particular, es preferible el fosforoditioato en el que los dos oxígenos no enlazantes mencionados anteriormente son sustituidos por S.
En el grupo fosfato mencionado anteriormente, por ejemplo, se pueden sustituir el(los) oxígeno(s) enlazante(s) mencionado(s) anteriormente. El(los) oxígeno(s) antes mencionado(s) puede(n) sustituirse, por ejemplo, por cualquier átomo seleccionado de S (azufre), C (carbono) y N (nitrógeno). Los ejemplos del grupo fosfato modificado mencionado anteriormente incluyen: fosforoamidatos con puente resultantes de la sustitución por N; fosforotioatos con puente resultantes de la sustitución por S; y metilenfosfonatos con puente resultantes de la sustitución por C. Preferiblemente, la sustitución del(de los) oxígeno(s) enlazante(s) antes mencionado(s) se lleva a cabo en, por ejemplo, al menos uno del resto de nucleótido del extremo 5' y el resto de nucleótido del extremo 3' de la molécula ssNc de la presente invención. Cuando la sustitución se lleva a cabo en el lado 5', es preferible la sustitución por C. Cuando la sustitución se lleva a cabo en el lado 3', es preferible la sustitución por N.
El grupo fosfato mencionado anteriormente se puede sustituir, por ejemplo, por el conector sin fosfato mencionado anteriormente. El conector mencionado anteriormente puede contener siloxano, carbonato, carboximetilo, carbamato, amida, tioéter, conector de óxido de etileno, sulfonato, sulfonamida, tioformacetal, formacetal, oxima, metilenimino, metilenmetilimino, metilenhidrazo, metilendimetilhidrazo, metilenoximetilimino o similares. Preferiblemente, el conector puede contener un grupo metilencarbonilamino y un grupo metilenmetilimino.
En la molécula ssNc de la presente invención, por ejemplo, se puede modificar al menos uno de un resto de nucleótido en el extremo 3' y un resto de nucleótido en el extremo 5'. Por ejemplo, se puede modificar el resto de nucleótido en uno cualquiera del extremo 3' y extremo 5', o se pueden modificar los restos de nucleótidos tanto en el extremo 3' como en el extremo 5'. La modificación antes mencionada puede ser, por ejemplo, como se ha descrito antes, y es preferible modificar un grupo(s) fosfato(s) en el(los) extremo(s). Por ejemplo, se puede modificar el grupo fosfato entero mencionado anteriormente, o se pueden modificar uno o más átomos en el grupo fosfato mencionado anteriormente. En el primer caso, por ejemplo, se puede sustituir o eliminar el grupo fosfato entero.
La modificación del(los) resto(s) de nucleótido(s) mencionado(s) anteriormente en el(los) extremo(s) puede ser, por ejemplo, la adición de cualquier otra molécula. Los ejemplos de la otra molécula antes mencionada incluyen moléculas funcionales tales como sustancias marcadoras y grupos protectores como se ha descrito antes. Los ejemplos de los grupos protectores antes mencionados incluyen S (azufre), Si (silicio), B (boro) y grupos que contienen éster. Las moléculas funcionales tales como las sustancias marcadoras antes mencionadas pueden usarse, por ejemplo, en la detección y similares de la molécula ssNc de la presente invención.
La otra molécula antes mencionada puede añadirse, por ejemplo, al grupo fosfato del resto de nucleótido mencionado anteriormente o puede añadirse al grupo fosfato mencionado anteriormente o al resto de azúcar mencionado anteriormente a través de un espaciador. Por ejemplo, el átomo terminal del espaciador antes mencionado se puede añadir a o sustituir a uno de los oxígenos enlazantes antes mencionados del grupo fosfato antes mencionado, o al O, N, S o C del resto de azúcar. El sitio de unión en el resto de azúcar antes mencionado es preferiblemente, por ejemplo, C en la posición 3', C en la posición 5' o cualquier átomo unido al mismo. Por ejemplo, el espaciador mencionado anteriormente también puede añadirse a o sustituir a un átomo terminal de la alternativa de nucleótido mencionada anteriormente, tal como PNA.
El espaciador antes mencionado no está particularmente limitado, y los ejemplos del mismo incluyen -(CH2)n-, -(CH2)nN-, -(CH2)nO- ,-(CH2)nS-, -O(CH2CH2O)nCH2CH2OH, azúcares abásicos, amida, carboxi, amina, oxiamina, oxiimina, tioéter, disulfuro, tiourea, sulfonamida y morfolino, y también reactivos de biotina y reactivos de fluoresceína. En las fórmulas antes mencionadas, n es un número entero positivo, y es preferible n = 3 o 6.
Otros ejemplos de la molécula antes mencionada para añadir al final incluyen colorantes, agentes intercalantes (p. ej., acridinas), agentes de reticulación (p. ej., psoraleno, mitomicina C), porfirinas (TPPC4, texafirina, safirina), hidrocarburos aromáticos policíclicos (p. ej., fenazina, dihidrofenazina), endonucleasas artificiales (p. ej., EDTA), transportadores lipófilos (p. ej., colesterol, ácido cólico, ácido adamantanoacético, ácido 1-pirenobutírico, dihidrotestosterona, 1,3-bis-O(hexadecil)glicerol, un grupo geraniloxihexilo, hexadecilglicerol, borneol, mentol, 1,3-propanodiol, un grupo heptadecilo, ácido palmítico, ácido mirístico, ácido O3-(oleoil)litocólico, ácido O3-(oleoil)cólico, dimetoxitritilo o fenoxatiina), complejos peptídicos (p. ej., péptido Antennapedia, péptido Tat), agentes alquilantes, fosfato, amino, mercapto, PEG (p. ej., PEG-40K), MPEG, [MPEG]2, poliamino, alquilo, alquilo sustituido, marcadores radiomarcados, enzimas, haptenos (p. ej., biotina), facilitadores del transporte/de la absorción (p. ej., aspirina, vitamina
E, ácido fólico) y ribonucleasas sintéticas (p. ej., imidazol, bisimidazol, histamina, grupos de imidazoles, complejos de acridina-imidazol, complejos de Eu3+ de tetraazamacrociclos).
En la molécula ssNc de la presente invención, por ejemplo, el extremo 5' mencionado anteriormente puede modificarse con un grupo fosfato o un análogo del grupo fosfato. Los ejemplos del grupo fosfato antes mencionado incluyen:
5'-monofosfato ((HO)2(O)P-O-5');
5'-difosfato ((HO)2(O)P-O-P(HO)(O)-O-5');
5'-trifosfato ((HO)2(O)P-O-(HO)(O)P-O-P(HO)(O)-O-5');
5'-casquete de guanosina (7-metilada o no metilada, 7 m-G-O-5'-(HO)(O)P-O-(HO)(O)P-O-P(HO)(O)-O-5'); 5'-casquete de adenosina (Appp);
cualquier estructura de casquete de nucleótido modificada o no modificada (N-O-5'-(HO)(O)P-O-(HO)(O)P-O-P(HO)(O)-O-5');
5'-monotiofosfato (fosforotioato: (HO)2(S)P-O-5');
5'-monoditiofosfato (fosforoditioato: (HO)(HS)(S)P-O-5');
5'-fosforotiolato ((HO)2(O)P-S-5');
monofosfato, difosfato y trifosfatos sustituidos con azufre (p. ej., 5'-a-tiotrifosfato, 5'-Y-tiotrifosfato y similares); 5'-fosforamidatos ((HO)2(O)P-NH-5', (HO)(NH2)(O)P-O-5');
5'-alquilfosfonatos (p. ej., RP(OH)(O)-O-5', (OH)2(O)P-5'-CH2, donde R es alquilo (p. ej., metilo, etilo, isopropilo, propilo o similares)); y
5'-alquileterfosfonatos (p. ej., RP(OH)(O)-O-5', donde R es alquiléter (p. ej., metoximetilo, etoximetilo o similares)). En el resto de nucleótido mencionado anteriormente, la base mencionada anteriormente no está particularmente limitada. La base antes mencionada puede ser, por ejemplo, una base natural o una base no natural. La base antes mencionada puede ser, por ejemplo, una base de origen natural o una base sintética. Como base mencionada anteriormente, se puede usar, por ejemplo, una base común, un análogo modificado de la misma y similares.
Los ejemplos de la base antes mencionada incluyen: bases de purina tales como adenina y guanina; y bases de pirimidina tales como citosina, uracilo y timina. Otros ejemplos de la base antes mencionada incluyen inosina, xantina, hipoxantina, nubularina, isoguanisina y tubercidina. Los ejemplos de la base antes mencionada también incluyen: 2-aminoadenina, derivados de alquilo tales como purina 6-metilada; derivados de alquilo tales como purina 2-propilada; 5-halouracilo y 5-halocitosina; 5-propiniluracilo y 5-propinilcitosina; 6-azouracilo, 6-azocitosina y 6-azotimina; 5-uracilo (pseudouracilo), 4-tiouracilo, 5-halouracilo, 5-(2-aminopropil)uracilo, 5-aminoaliluracilo; purinas 8-halogenadas, aminadas, tioladas, tioalquiladas, hidroxiladas y otras 8-sustituidas; pirimidinas 5-trifluorometiladas y otras 5-sustituidas; 7-metilguanina; pirimidinas 5-sustituidas; 6-azapirimidinas; purinas N-2, N-6 y O-6 sustituidas (incluyendo 2-aminopropiladenina); 5-propiniluracilo y 5-propinilcitosina; dihidrouracilo; 3-desaza-5-azacitosina; 2-aminopurina; 5-alquiluracilo; 7-alquilguanina; 5-alquilcitosina; 7-desazaadenina; N6,N6-dimetiladenina; 2,6-diaminopurina; 5-aminoalil-uracilo; N3-metiluracilo; 1,2,4-triazoles sustituidos; 2-piridinona; 5-nitroindol; 3-nitropirrol; 5-metoxiuracilo; ácido uracil-5-oxiacético; 5-metoxicarbonilmetiluracilo; 5-metil-2-tiouracilo; 5-metoxicarbonilmetil-2-tiouracilo; 5-metilaminometil-2-tiouracilo; 3-(3-amino-3-carboxipropil)uracilo; 3-metilcitosina; 5-metilcitosina; N4-acetilcitosina; 2-tiocitosina; N6-metiladenina; N6-isopentiladenina; 2-metiltio-N6-isopenteniladenina; N-metilguanina; y bases O alquiladas. Los ejemplos de las purinas y pirimidinas incluyen las descritas en la patente de EE.UU. N° 3,687,808, "Concise Encyclopedia of Polymer Science and Engineering", págs. 858 a 859, editado por Kroschwitz J. I, John Wiley & Sons, 1990, y Englisch et al, Angewandte Chemie, Edición internacional, 1991, vol. 30, pág. 613.
Otros ejemplos del resto de nucleótido modificado mencionado anteriormente incluyen aquellos que no tienen base, es decir, aquellos que tienen un esqueleto de ribofosfato abásico. Además, como el resto de nucleótido modificado mencionado anteriormente se pueden usar, por ejemplo, los descritos en la solicitud internacional WO 2004/080406 (fecha de presentación: 8 de marzo, 2004).
3. Resto no nucleotídico
El resto no nucleotídico mencionado anteriormente está presente en la región conectora (Lx) mencionada anteriormente. En la molécula de ácido nucleico monocatenario de la presente invención, un método para modificar la región conectora (Lx) mencionada anteriormente con la sustancia biorrelacionada mencionada anteriormente no está particularmente limitado.
Como una primera realización del método de modificación, por ejemplo, se muestra un ejemplo del método de modificación del extremo 5' de la molécula de ácido nucleico antes mencionada, por ejemplo, en el siguiente esquema 1.

Como una segunda realización del método de modificación, por ejemplo, a continuación se muestra un ejemplo del método de modificación de una región conectora que tiene un resto de aminoácido o un resto de péptido.
En primer lugar, se sintetiza una amidita mediante el método de síntesis del siguiente esquema 2. El siguiente esquema 2 es un ejemplo y el método no se limita al mismo. Por ejemplo, en el siguiente esquema 2 se usa Fmoc como grupo protector del grupo amino de la cadena lateral de Lys. Sin embargo, por ejemplo, se puede usar Tfa como en el esquema 6 en el ejemplo mencionado a continuación, o también se puede usar otro grupo protector.

Luego, usando la amidita mencionada anteriormente que tiene el conector de unión mencionado anteriormente, y mediante el método del siguiente esquema 3, se sintetiza una molécula de ácido nucleico, y la sustancia biorrelacionada mencionada anteriormente se une al conector de unión mencionado anteriormente en la molécula de ácido nucleico mencionada anteriormente.
[Chem. S3]

acoplamiento 
[ 
esquema 3
Cuando se introduce un conector tiol como el conector de unión mencionado anteriormente, la molécula de ácido nucleico mencionada anteriormente se sintetiza mediante el método de síntesis del siguiente esquema 4.

Luego, como se muestra en el siguiente esquema 5, la sustancia biorrelacionada mencionada anteriormente se une al conector tiol mencionado anteriormente en la molécula de ácido nucleico mencionada anteriormente a través de un enlace S-S.
[Chem . S5]
conector tiol
j Oligonucléotido 
 Oligonucleotido
Oligonucleotido 

esquema 5
Estos métodos son ejemplos y la presente invención no está limitada en absoluto por estas realizaciones.
4. Composición
La composición inhibidora de la expresión según la presente invención es, como se ha descrito anteriormente, una composición para inhibir la expresión de un gen diana, que contiene la molécula ssNc de la presente invención mencionada anteriormente. La composición de la presente invención se caracteriza por que contiene la molécula ssNc de la presente invención mencionada anteriormente, y otras configuraciones no están limitadas en modo alguno. La composición inhibidora de la expresión de la presente invención también puede denominarse, por ejemplo, reactivo inhibidor de la expresión.
De acuerdo con la presente invención, por ejemplo, mediante la administración a un sujeto en el que está presente el gen diana mencionado anteriormente, es posible inhibir la expresión del gen diana mencionado anteriormente.
Además, como se ha descrito anteriormente, la composición farmacéutica según la presente invención contiene la molécula ssNc de la presente invención mencionada anteriormente. La composición de la presente invención se caracteriza por que contiene la molécula ssNc de la presente invención mencionada anteriormente, y otras configuraciones no están limitadas en modo alguno. La composición farmacéutica de la presente invención también puede denominarse, por ejemplo, producto farmacéutico.
De acuerdo con la presente invención, por ejemplo, la administración a un paciente con una enfermedad causada por un gen puede inhibir la expresión del gen antes mencionado, tratando así la enfermedad antes mencionada. En la presente invención, el término "tratamiento" engloba, como se mencionó anteriormente, la prevención de las enfermedades antes mencionadas; mejora de las enfermedades; y mejora del pronóstico, por ejemplo, y puede significar cualquiera de ellos.
En la presente invención, una enfermedad para tratar no está particularmente limitada, y los ejemplos de la misma incluyen enfermedades causadas por la expresión de genes. Dependiendo del tipo de la enfermedad mencionada anteriormente, un gen que causa la enfermedad se puede determinar como el gen diana mencionado anteriormente y, además, dependiendo del gen diana mencionado anteriormente, se puede determinar según corresponda la secuencia inhibidora de la expresión mencionada anteriormente.
Un ejemplo específico es el siguiente. Determinando el gen de TGF-p1 mencionado anteriormente como el gen diana mencionado anteriormente e incorporando una secuencia inhibidora de la expresión para el gen mencionado anteriormente en la molécula ssNc mencionada anteriormente, la molécula ssNc puede usarse para el tratamiento de, por ejemplo, enfermedades inflamatorias, específicamente, lesión pulmonar aguda y similares.
El método de uso de la composición inhibidora de la expresión y la composición farmacéutica según la presente invención (en lo sucesivo, ambas composiciones se denominarán simplemente "las composiciones") no están particularmente limitadon, y los ejemplos de los mismos incluyen administrar la molécula ssNc mencionada anteriormente a un sujeto que tiene el gen diana antes mencionado.
Los ejemplos del sujeto mencionado anteriormente al que se administra la molécula ssNc de la presente invención incluyen células, tejidos y órganos. Los ejemplos del sujeto mencionado anteriormente también incluyen seres humanos, animales no humanos tales como mamíferos no humanos, es decir, mamíferos excluyendo seres humanos. La administración antes mencionada se puede realizar, por ejemplo, in vivo o in vitro. Las células antes mencionadas no están particularmente limitadas, y los ejemplos de las mismas incluyen: diversas células cultivadas tales como células HeLa, células 293, células NIH3T3 y células COS; células madre tales como células ES y células madre hematopoyéticas; y células aisladas de organismos vivos, tales como células cultivadas primarias.
El método de administración antes mencionado no está particularmente limitado y puede determinarse, por ejemplo, como apropiado dependiendo del sujeto. Cuando el sujeto mencionado anteriormente es una célula cultivada, el método de administración puede ser, por ejemplo, un método que usa un reactivo de transfección, un método de electroporación o similares.
Por ejemplo, cada una de las composiciones de la presente invención puede contener solo la molécula ssNc de la presente invención o además puede contener un aditivo(s) además de la molécula ssNc. El aditivo antes mencionado no está particularmente limitado y es preferiblemente, por ejemplo, un aditivo farmacéuticamente aceptable. El tipo del aditivo antes mencionado no está particularmente limitado y puede seleccionarse según corresponda dependiendo, por ejemplo, del tipo de sujeto.
5. Método de inhibición de la expresión in vitro
El método de inhibición de la expresión in vitro según la presente invención es, como se ha descrito anteriormente, un método para inhibir la expresión de un gen diana, en el que se usa la molécula ssNc de la presente invención antes mencionada. El método de inhibición de la expresión in vitro de la presente invención se caracteriza por que se usa en este la molécula ssNc de la presente invención mencionada anteriormente, y otras etapas y condiciones no están limitadas en modo alguno.
En el método de inhibición de la expresión in vitro de la presente invención, el mecanismo por el cual se inhibe la expresión del gen antes mencionado no está particularmente limitado, y los ejemplos del mismo incluyen la inhibición de la expresión por interferencia de ARN o un fenómeno similar a la interferencia de ARN. El método de inhibición de la expresión in vitro de la presente invención es, por ejemplo, un método para inducir la interferencia de ARN que inhibe la expresión antes mencionada de un gen diana, y también puede referirse a un método para inducir la expresión que se caracteriza por que se usa en este la molécula ssNc antes mencionada de la presente invención.
El método de inhibición de la expresión in vitro de la presente invención incluye, por ejemplo, la etapa de administrar la molécula ssNc mencionada anteriormente a un sujeto en el que está presente el gen diana mencionado anteriormente. Mediante la etapa de administración antes mencionada, por ejemplo, la molécula ssNc antes mencionada se pone en contacto con el sujeto antes mencionado al que se administra la molécula ssNc. Los ejemplos del sujeto antes mencionado al que se administra la molécula ssNc de la presente invención incluyen células, tejidos y órganos.
En el método de inhibición de la expresión in vitro de la presente invención, por ejemplo, la molécula ssNc mencionada anteriormente se puede administrar sola, o se puede administrar la composición mencionada anteriormente de la presente invención que contiene la molécula ssNc mencionada anteriormente. El método de administración antes mencionado no está particularmente limitado y, por ejemplo, puede seleccionarse como apropiado dependiendo del tipo de sujeto.
6. Método de tratamiento
Como se describió anteriormente, la invención proporciona la molécula ssNc antes mencionada para usar en un método para tratar una enfermedad. El método para tratar una enfermedad incluye la etapa de administrar la molécula ssNc antes mencionada de la presente invención a un paciente, y la molécula ssNc antes mencionada incluye, como la secuencia inhibidora de la expresión antes mencionada, una secuencia que inhibe la expresión de un gen que causa la enfermedad antes mencionada.
La descripción relativa al método de inhibición de la expresión mencionado anteriormente de la presente invención también se aplica, por ejemplo, al método de tratamiento. El método de administración antes mencionado no está particularmente limitado y puede ser cualquiera de, por ejemplo, administración oral y administración parenteral.
Ejemplos
A continuación se explican los ejemplos de la presente invención. Sin embargo, la presente invención no se limita a los siguientes ejemplos.
Ejemplo A1: Síntesis de una molécula de ácido nucleico monocatenario conjugada
(1) Síntesis de la molécula de ácido nucleico monocatenario
Las moléculas de ácido nucleico monocatenario que se muestran a continuación se sintetizaron mediante un sintetizador de ácidos nucleicos (nombre comercial: ABI Expedite (marca registrada) 8909 Nucleic Acid Synthesis System, Applied Biosystems) basado en el método de la fosforamidita. En la síntesis antes mencionada, se usó EMM amidita (documento Wo 2013/027843) como ARN amidita (en lo sucesivo la misma). La amidita antes mencionada se desprotegió por un método convencional. La molécula de ácido nucleico monocatenario sintetizada se purificó por HPLC. Se liofilizó cada una de las moléculas de ácido nucleico monocatenario después de la purificación. En las siguientes moléculas de ácido nucleico monocatenario, las partes subrayadas en KH-0001, NH-0005, PH-0009 son secuencias inhibidoras de la expresión del gen de TGF-p1 humano, y la parte subrayada en KH-0010 es una secuencia inhibidora de la expresión del gen de la luciferasa.
KH-0001 (SEQ ID NO: 29 (una secuencia que comprende una secuencia inhibidora de la expresión que inhibe la expresión del gen diana) y 37 (una secuencia que es complementaria de la SEQ ID NO: 29))
5'-GCAGAGUACACACAGCAUAUACC-Lx-GGUAUAUGCUGUGUGUACUCUGCUU-3' NH-0005 (SEQ ID NO: 30) 5'-GCAGAGUACACACAGCAUAUACCCCACACCGGUAUAUGCUGUGUGUACUCUGCUU-3'
PH-0009 (SEQ ID NO: 29 (una secuencia que comprende una secuencia inhibidora de la expresión que inhibe la expresión del gen diana) y 37 (una secuencia que es complementaria de la SEQ ID NO: 29))
5'-GCAGAGUACACACAGCAUAUACC-Lx-GGUAUAUGCUGUGUGUACUCUGCUU-3'
KH-0010 (SEQ ID NO: 31 (una secuencia que comprende una secuencia inhibidora de la expresión que inhibe la expresión del gen diana) y 38 (una secuencia que es complementaria de la SEQ ID NO: 31)
5'-CUUACGCUGAGUACUUCGAUUCC-Lx-GGAAUCGAAGUACUCAGCGUAAGUU-3'
KH-0030 (SEQ ID NO: 29 (una secuencia que comprende una secuencia inhibidora de la expresión que inhibe la expresión del gen diana) y 37 (una secuencia que es complementaria de la SEQ ID NO: 29))
5'-GCAGAGUACACACAGCAUAUACC-Lx-GGUAUAUGCUGUGUGUACUCUGCUU-3'
PH-0000 (SEQ ID NO: 32 (cadena del lado 3') y 39 (cadena del lado 5'))
5'-UACUAUUCGACACGCGAAGUUCC-Lx-GGAACUUCGCGGUUCGAAUAGUAUU-3'
KH-0001, que es la molécula de ácido nucleico monocatenario de la presente invención, es una molécula de ácido nucleico monocatenario que utiliza la siguiente lisina-amidita como región conectora (Lx).

Las NH-0005 y PH-0009 mencionadas anteriormente son moléculas de ácido nucleico monocatenario de ejemplos comparativos, NH-0005 es una molécula de ácido nucleico monocatenario que utiliza solo restos de nucleótidos como región conectora (Lx) y PH-0009 es una molécula de ácido nucleico monocatenario que utiliza la siguiente L-prolinadiamida-amidita como región conectora (Lx).

KH-0010, que es la molécula de ácido nucleico monocatenario de la presente invención, es una molécula de ácido nucleico monocatenario que utiliza la lisina-amidita mencionada anteriormente como región conectora (Lx).
KH-0030, que es la molécula de ácido nucleico monocatenario de la presente invención, es una molécula de ácido nucleico monocatenario que utiliza la siguiente lisina-colesterolamidita como región conectora (Lx).

La PH-0000 mencionada anteriormente es una molécula de ácido nucleico monocatenario como control negativo y es una molécula de ácido nucleico monocatenario que utiliza la L-prolinadiamida-amidita mencionada anteriormente como región conectora (Lx).
(2) Síntesis de una molécula de ácido nucleico monocatenario conjugada con lípidos
A continuación se muestra la estructura de KH-0001-C18, que es la molécula de ácido nucleico monocatenario conjugada con lípidos de la presente invención.
KH-0001 -C18 es una molécula de ácido nucleico monocatenario en la que el ácido esteárico (C18) como lípido de una cadena se une a la región conectora (Lx) de la KH-0001 mencionada anteriormente mediante el método mencionado a continuación.
KH-0001 -C18 (SEQ ID NO: 29 (una secuencia que comprende una secuencia inhibidora de la expresión que inhibe la expresión del gen diana) y 37 (una secuencia que es complementaria de la SEQ ID NO: 29))

Síntesis de KH-0001 -C18
Se mezclaron KH-0001 500 gmol/l (200 gl), solución de C18-NHS/DMF 50 mmol/l (80 gl), isopropanol (320 gl) y tampón de carbonato (400 gl) (pH 9.2, concentración final 100 mmol/l) y la mezcla se agitó a 40°C durante 3 horas. La mezcla de reacción se purificó por HPLC (columna: Develosil C8-UG-5, 5 gm, 10 x 50 mm; caudal: 4.7 ml/min; detección: UV 260 nm; horno de columna: 35°C; Tampón A: TEAA 50 mmol/l, CH3CN al 5%; Tampón B: CH3CN) para separar el pico del producto objeto. La fracción separada se sometió a precipitación con etanol y el precipitado resultante se disolvió en agua destilada para inyección (Otsuka Pharmaceutical Co., Ltd.). Se midió la absorbancia UV a 260 nm y se calculó el rendimiento para dar KH-0001-C18 (6.5 mg) con una pureza de 98.45%. Espectrometría de masas: 15989.34 (Calculado: 15989.06). En la Fig. 2 se muestra un gráfico de HPLC después de la purificación.
La estructura de KH-0001-DOPE, que es la molécula de ácido nucleico monocatenario conjugada con lípidos, se muestra a continuación.
KH-0001 -DOPE es una molécula de ácido nucleico monocatenario en la que DOPE como lípido de cadena doble se une a la región conectora (Lx) de la KH-0001 mencionada anteriormente mediante el método mencionado a continuación. KH-0001 -DOPE (SEQ ID NO: 29 (una secuencia que comprende una secuencia inhibidora de la expresión que inhibe la expresión del gen diana) y 37 (una secuencia que es complementaria de la SEQ ID NO: 29))

Síntesis de KH-0001-DOPE
Se mezclaron KH-0001 (1115 pM, 100 pl), solución de DOPE-NHS/etanol 10 mM (400 pl), etanol (200 pl), solución acuosa de trietilamina al 1 % (100 pl) y agua destilada para inyección (200 pl) y la mezcla se agitó a 40°C durante 3 h. La mezcla de reacción se purificó por HPLC (columna: Develosil C8-UG-5, 5 pm, 10 x 50 mm; caudal: 4.7 ml/min; detección: UV 260 nm; horno de columna: 35°C; Tampón A: TEAA 50 mM, CH3CN al 5%; Tampón B: CH3CN) y se separó el pico del producto objeto. La fracción separada se sometió a precipitación con etanol y el precipitado resultante se disolvió en agua destilada para inyección. Se midió la absorbancia a UV 260 nm y se calculó el rendimiento para dar KH-0001-DOPE (3.0 mg) que tenía una pureza de 98.64%. Espectrometría de masas: 16562.52 (Calculado: 16562.71). En la Fig. 3 se muestra un gráfico de HPLC después de la purificación.
La estructura de KH-0001 -Chol, que es la molécula de ácido nucleico monocatenario conjugada con lípido, se muestra a continuación.
KH-0001-Chol es una molécula de ácido nucleico monocatenario en la que el colesterol se une mediante un conector de etilenglicol a la región conectora (Lx) de la KH-0001 mencionada anteriormente mediante el método mencionado a continuación.
KH-0001-Chol (SEQ ID NO: 29 (una secuencia que comprende una secuencia inhibidora de la expresión que inhibe la expresión del gen diana) y 37 (una secuencia que es complementaria a la SEQ ID NO: 29))
[Chem. KHChol]
Colesterol
GCAGAGUACACACAGCAUAUAC c
UUGGUCUCAUGUGUGUCGUAUAUGG

Síntesis de KH-0001 -Chol
Se mezclaron KH-0001 500 pmol/l (200 pl), solución de éster de colesteril-EG-NHS/DMF 50 mmol/l (80 pl), isopropanol (320 pl) y tampón de carbonato (400 pl) (pH 9.2, concentración final 100 mmol/l) y la mezcla se agitó a 50°C durante la noche. La mezcla de reacción se purificó por HPLC (columna: Develosil C8-UG-5, 5 pm, 10 x 50 mm; caudal: 4.7 ml/min; detección: UV 260 nm; horno de columna: 35°C; Tampón A: TEAA 50 mmol/l, CH3CN al 5%; Tampón B: CH3CN) y se separó el pico del producto objeto. La fracción separada se sometió a precipitación con etanol y el precipitado resultante se disolvió en agua destilada para inyección (Otsuka Pharmaceutical Co., Ltd.). Se midió la absorbancia UV a 260 nm y se calculó el rendimiento para dar KH-0001-Chol (0.9 mg) con una pureza de 95.47%. Espectrometría de masas: 16382.13 (Calculado: 16382.55).
(3) Síntesis de la molécula de ácido nucleico monocatenario conjugada con carbohidrato
La estructura de KH-0001-Lac, que es la molécula de ácido nucleico monocatenario conjugada con carbohidrato, se muestra a continuación.
KH-0001-Lac es una molécula de ácido nucleico monocatenario en la que la lactosa como disacárido se une a la región conectora (Lx) de la KH-0001 mencionada anteriormente mediante el método mencionado a continuación. KH-0001 -Lac (SEQ ID NO: 29 (una secuencia que comprende una secuencia inhibidora de la expresión que inhibe la expresión del gen diana) y 37 (una secuencia que es complementaria de la SEQ ID NO: 29))

Síntesis de KH-0001 -Lac
Se mezclaron KH-0001 1 mmol/l (100 pl), lactosa 2 mol/l (50 pl), metanol (600 pl), tampón acetato (200 pl) (pH 3.8, concentración final 200 mmol/l) y solución de NaBH3CN/metanol 10 mol/l (50 pl) y la mezcla se agitó a 60°C durante 20 horas. La mezcla de reacción se purificó mediante Sephadex G-25 (PD-10; GE Healthcare) y la producción del producto objetivo se confirmó por espectrometría de masas. Espectrometría de masas: 16048.38 (Calculado: 16048.89). En la Fig. 4 se muestra un gráfico de HPLC después de la purificación.
La estructura de KH-0001 -GalNAc, que es la molécula de ácido nucleico monocatenario conjugada con carbohidrato, se muestra a continuación.
KH-0001-GalNAc es una molécula de ácido nucleico monocatenario en la que la N-acetilgalactosamina como monosacárido se une a la región conectora (Lx) de la KH-0001 antes mencionada mediante el método mencionado a continuación.
KH-0001 -GalNAc (SEQ ID NO: 29 (una secuencia que comprende una secuencia inhibidora de la expresión que inhibe la expresión del gen diana) y 37 (una secuencia que es complementaria de la SEQ ID NO: 29))
[Chem. KHGalNAc]

Síntesis de KH-0001 -GalNAc
Se mezclaron KH-0001 1 mmol/l (100 pl), N-acetilgalactosamina 2 mol/l (50 pl), metanol (600 pl), tampón de acetato (200 pl) (pH 3.8, concentración final 200 mmol/l) y solución de NaBH3CN/metanol 10 mol /l (50 pl) y la mezcla se agitó a 60°C durante la noche. La mezcla de reacción se purificó mediante Sephadex G-25 (PD-10; Ge Healthcare) y la producción del producto objetivo se confirmó por espectrometría de masas. Espectrometría de masas: 15927.54 (Calculado: 15927.81).
La estructura de KH-0001-GlcNAc, que es la molécula de ácido nucleico monocatenario conjugada con carbohidrato, se muestra a continuación.
KH-0001 -GlcNAc es una molécula de ácido nucleico monocatenario en la que la N-acetilglucosamina como monosacárido se une a la región conectora (Lx) de la KH-0001 antes mencionada mediante el método mencionado a continuación. KH-0001 -GlcNAc (SEQ ID NO: 29 (una secuencia que comprende una secuencia inhibidora de la expresión que inhibe la expresión del gen diana) y 37 (una secuencia que es complementaria de la SEQ ID NO: 29))

Síntesis de KH-0001 -GlcNAc
Se mezclaron KH-0001 1 mmol/l (100 pl), N-acetilglucosamina 2 mol/l (50 pl), metanol (600 pl), tampón de acetato (200 pl) (pH 3.8, concentración final 200 mmol/l) y solución de NaBH3CN/metanol 10 mol /l (50 pl) y la mezcla se agitó
a 60°C durante la noche. La mezcla de reacción se purificó mediante Sephadex G-25 (PD-10; GE Healthcare) y la producción del producto objetivo se confirmó por espectrometría de masas. Espectrometría de masas: 15927.85 (Calculado: 15927.81).
(4) Síntesis de la molécula de ácido nucleico monocatenario conjugada con péptido
La estructura de KH-0010-GE11, que es la molécula de ácido nucleico monocatenario conjugada con péptido, se muestra a continuación.
KH-0010-GE11 es una molécula de ácido nucleico monocatenario en la que GE11 como un péptido que se muestra en la SEQ ID NO: 12 mencionada anteriormente se une a través de un conector GMBS a la región conectora (Lx) de la KH-0010 mencionada anteriormente mediante el método mencionado a continuación.
KH-0010-GE11 (SEQ ID NO: 31 (una secuencia que comprende una secuencia inhibidora de la expresión que inhibe la expresión del gen diana) y 38 (una secuencia que es complementaria de la SEQ ID NO: 31))
[C h em . KHGE11]

Síntesis de KH-0010-GE11
Se mezclaron KH-0010 500 pmol/l (200 pl), solución de GMBS/DMF 4 mmol/l (500 pl) y tampón de fosfato (pH 7.0, concentración final 120 mmol/l), y la mezcla se agitó a temperatura ambiente durante 3 h. La mezcla de reacción se purificó mediante Sephadex G-25 (PD-10; GE Healthcare), se añadió 1 mg de péptido GE11 en tampón de fosfato 100 mmol/l (pH 7.0) y la mezcla se agitó a temperatura ambiente durante 1 h. La mezcla de reacción se purificó por HPLC (columna: Develosil C8-UG-5, 5 pm, 10 x 50 mm; caudal: 4.7 ml/min; detección: UV 260 nm; horno de columna: 35°C; Tampón A: TEAA 50 mmol/l, CH3CN al 5%; Tampón B: CH3CN), y se separó el pico del producto objeto. La fracción separada se sometió a precipitación con etanol y el precipitado resultante se disolvió en agua destilada para inyección (Otsuka Pharmaceutical Co., Ltd.). Se midió la absorbancia UV a 260 nm y se calculó el rendimiento para dar KH-0010-GE11 (0.7 mg) con una pureza de 95.97%. En la Fig.5 se muestra un gráfico de HPLC después de la purificación. A continuación se muestra la estructura de KH-0010-GE11(7), que es la molécula de ácido nucleico monocatenario conjugada con péptido.
KH-0010-GE11(7) es una molécula de ácido nucleico monocatenario en la que GE11(7) como un péptido mostrado por la SEQ ID NO: 13 antes mencionada se une, a través de un conector GMBS, a la región conectora (Lx) de la KH-0010 antes mencionada por el método mencionado a continuación.
KH-0010-GE11(7) (SEQ ID NO: 31 (una secuencia que comprende una secuencia inhibidora de la expresión que inhibe la expresión del gen diana) y 38 (una secuencia que es complementaria de la SEQ ID NO: 31))
[Chem. KHGE11(7)]

Síntesis de KH-0010-GE11 (7)
Se mezclaron KH-0010 500 pmol/l (200 pl), solución de GMBS/DMF 4 mmol/l (500 pl) y tampón de fosfato (pH 7.0, concentración final 120 mmol/l), y la mezcla se agitó a temperatura ambiente durante 3 h. La mezcla de reacción se purificó mediante Sephadex G-25 (PD-10; GE Healthcare), se añadió 1 mg del péptido GE11 (7) en tampón de fosfato
100 mmol/l (pH 7.0) y la mezcla se agitó a temperatura ambiente durante 1 h. La mezcla de reacción se purificó por HPLC (columna: Develosil C8-UG-5, 5 pm, 10 x 50 mm; caudal: 4.7 ml/min; detección: UV 260 nm; horno de columna: 35°C; Tampón A: TEAA 50 mmol/l, CH3CN al 5%; Tampón B: CH3CN) y se separó el pico del producto objeto. La fracción separada se sometió a precipitación con etanol y el precipitado resultante se disolvió en agua destilada para inyección (Otsuka Pharmaceutical Co., Ltd.). Se midió la absorbancia UV a 260 nm y se calculó el rendimiento para dar KH-0010-GE11(7) (0.3 mg) con una pureza de 95.12%. Espectrometría de masas: 16877.66 (Calculado: 16877.74). En la Fig. 6 se muestra un gráfico de HPLC después de la purificación.
A continuación se muestra la estructura de KH-0010-GE11(5), que es la molécula de ácido nucleico monocatenario conjugada con péptido.
KH-0010-GE11(5) es una molécula de ácido nucleico monocatenario en la que GE11(5) como un péptido que se muestra en la SEQ ID NO: 14 mencionada anteriormente se une, a través de un conector GMBS, a la región conectora (Lx) de la KH-0010 antes mencionada por el método mencionado a continuación.
KH-0010-GE11(5) (SEQ ID NO: 31 (una secuencia que comprende una secuencia inhibidora de la expresión que inhibe la expresión del gen diana) y 38 (una secuencia que es complementaria de la SEQ ID NO: 31))

Síntesis de KH-0010-GE11 (5)
Se mezclaron KH-0010 500 pmol/l (200 pl), solución de GMBS/DMF 4 mmol/l (500 pl) y tampón de fosfato (pH 7.0, concentración final 120 mmol/l), y la mezcla se agitó a temperatura ambiente durante 3 h. La mezcla de reacción se purificó mediante Sephadex G-25 (PD-10; GE Healthcare), se añadió 1 mg de péptido GE11(5) en tampón de fosfato 100 mmol/l (pH 7.0) y la mezcla se agitó a temperatura ambiente durante 1 h. La mezcla de reacción se purificó por HPLC (columna: Develosil C8-UG-5, 5 pm, 10 x 50 mm; caudal: 4.7 ml/min; detección: UV 260 nm; horno de columna: 35°C; Tampón A: TEAA 50 mmol/l, CH3CN al 5%; Tampón B: CH3CN) y se separó el pico del producto objeto. La fracción separada se sometió a precipitación con etanol y el precipitado resultante se disolvió en agua destilada para inyección (Otsuka Pharmaceutical Co., Ltd.). Se midió la absorbancia UV a 260 nm y se calculó el rendimiento para dar KH-0010-GE11(5) (0.6 mg) con una pureza de 92.12%. Espectrometría de masas: 16657.41 (Calculado: 16657.54). En la Fig. 7 se muestra un gráfico de HPLC después de la purificación.
A continuación se muestra la estructura de KH-0001-GE11, que es la molécula de ácido nucleico monocatenario conjugada con péptido.
KH-0001-GE11 es una molécula de ácido nucleico monocatenario en la que GE11 como un péptido mostrado por la SEQ ID NO: 12 mencionada anteriormente se une, a través de un conector GMBS, a la región conectora (Lx) de la KH-0001 mencionada anteriormente por el método mencionado a continuación.
KH-0001 -GE11 (SEQ ID NO: 29 (una secuencia que comprende una secuencia inhibidora de la expresión que inhibe la expresión del gen diana) y 37 (una secuencia que es complementaria de la SEQ ID NO: 29))
[C h em . K H 01G E 11]

Síntesis de KH-0001-GE11
Se mezclaron KH-0001 500 pmol/l (800 pl), solución de GMBS/DMF 4 mmol/l (2000 pl), tampón de fosfato 1 mol/l (pH 7.0) (480 pl) y agua destilada para inyección (720 pl), y la mezcla se agitó a temperatura ambiente durante 3 h. La mezcla de reacción se purificó mediante Sephadex G-25 (PD-10; GE Healthcare) y se usó una cantidad de 1/3 de la misma para la siguiente reacción. Se añadió 1 mg de péptido GE11 en tampón de fosfato 100 mmol/l (pH 7.0) y la mezcla se agitó a temperatura ambiente durante 1 h. La mezcla de reacción se purificó por HPLC (columna: Develosil C8-UG-5, 5 pm, 10 x 50 mm; caudal: 4.7 ml/min; detección: UV 260 nm; horno de columna: 35°C; Tampón A: TEAA 50 mmol/l, CH3CN al 5%; Tampón B: CH3CN) y se separó el pico del producto objeto. La fracción separada se sometió a precipitación con etanol y el precipitado resultante se disolvió en agua destilada para inyección (Otsuka Pharmaceutical Co., Ltd.). Se midió la absorbancia UV a 260 nm y se calculó el rendimiento para dar KH-0001 -GE11 (1.1 mg) con una pureza de 96.85%. Espectrometría de masas: 17530.41 (Calculado: 17530.61). En la Fig. 8 se muestra un gráfico de HPLC después de la purificación.
A continuación se muestra la estructura de KH-0001-GE11(7), que es la molécula de ácido nucleico monocatenario conjugada con péptido.
KH-0001-GE11(7) es una molécula de ácido nucleico monocatenario en la que GE11(7) como un péptido mostrado por la SEQ ID NO: 13 antes mencionada se une, a través de un conector GMBS, a la región conectora (Lx) de la KH-0001 antes mencionada por el método mencionado a continuación.
KH-0001-GE11(7) (SEQ ID NO: 29 (una secuencia que comprende una secuencia inhibidora de la expresión que inhibe la expresión del gen diana) y 37 (una secuencia que es complementaria de la SEQ ID NO: 29))

Síntesis de KH-0001 -GE11 (7)
Se mezclaron KH-0001 500 pmol/l (800 pl), solución de GMBS/DMF 4 mmol/l (2000 pl), tampón de fosfato 1 mol/l (pH 7.0) (480 pl) y agua destilada para inyección (720 pl), y la mezcla se agitó a temperatura ambiente durante 3 h. La mezcla de reacción se purificó mediante Sephadex G-25 (PD-10; GE Healthcare) y se usó una cantidad de 1/3 de la misma para la siguiente reacción. Se añadió 1 mg de péptido GE11 (7) en tampón de fosfato 100 mmol/l (pH 7.0) y la mezcla se agitó a temperatura ambiente durante 1 h. La mezcla de reacción se purificó por HPLC (columna: Develosil C8-UG-5, 5 pm, 10 x 50 mm; caudal: 4.7 ml/min; detección: UV 260 nm; horno de columna: 35°C; Tampón A: TEAA 50 mmol/l, CH3CN al 5%; Tampón B: CH3CN) y se separó el pico del producto objeto. La fracción separada se sometió a precipitación con etanol y el precipitado resultante se disolvió en agua destilada para inyección (Otsuka Pharmaceutical Co., Ltd.). Se midió la absorbancia a UV 260 nm y se calculó el rendimiento para dar KH-0001 -Ge 11 (7) (1.1 mg) con una pureza de 96.40%. Espectrometría de masas: 16877.65 (Calculado: 16877.74). En la Fig. 9 se muestra un gráfico de HPLC después de la purificación.
A continuación se muestra la estructura de KH-0001-GE11(5), que es la molécula de ácido nucleico monocatenario conjugada con péptido.
KH-0001-GE11(5) es una molécula de ácido nucleico monocatenario en la que GE11(5) como un péptido que se muestra en la Se Q ID NO: 14 mencionada anteriormente se une, a través de un conector GMBS, a la región conectora (Lx) de la KH-0001 antes mencionada por el método mencionado a continuación.
KH-0001-GE11(5) (SEQ ID NO: 29 (una secuencia que comprende una secuencia inhibidora de la expresión que inhibe la expresión del gen diana) y 37 (una secuencia que es complementaria de la SEQ ID NO: 29))

Síntesis de KH-0001-GE11(5)
Se mezclaron KH-0001 500 pmol/l (800 pl), solución de GMBS/DMF 4 mmol/l (2000 pl), tampón de fosfato 1 mol/l (pH 7.0) (480 pl) y agua destilada para inyección (720 pl), y la mezcla se agitó a temperatura ambiente durante 3 h. La mezcla de reacción se purificó mediante Sephadex G-25 (PD-10; GE Healthcare) y se usó una cantidad de 1/3 de la misma para la siguiente reacción. Se añadió 1 mg de péptido GE11 (5) en tampón de fosfato 100 mmol/l (pH 7.0) y la mezcla se agitó a temperatura ambiente durante 1 h. La mezcla de reacción se purificó por HPLC (columna: Develosil C8-UG-5, 5 pm, 10 x 50 mm; caudal: 4.7 ml/min; detección: UV 260 nm; horno de columna: 35°C; Tampón A: TEAA 50 mmol/l, CH3CN al 5%; Tampón B: CH3CN) y se separó el pico del producto objeto. La fracción separada se sometió a precipitación con etanol y el precipitado resultante se disolvió en agua destilada para inyección (Otsuka Pharmaceutical Co., Ltd.). Se midió la absorbancia UV a 260 nm y se calculó el rendimiento para dar KH-0001 -Ge 11 (5) (1.1 mg) con una pureza de 98.09%. Espectrometría de masas: 16657.49 (Calculado: 16657.54). En la Fig. 10 se muestra un gráfico de HPLC después de la purificación.
Ejemplo B1: Efecto inhibidor de la expresión génica de una molécula de ácido nucleico monocatenario conjugada con lípidos
Se examinó el efecto inhibidor de la expresión del gen de TGF-P1 de la molécula de ácido nucleico monocatenario conjugada con lípido KH-0001 -C18 que tiene una secuencia inhibidora de la expresión dirigida al gen de TGF-01, que se sintetiza en el Ejemplo A1 mencionado anteriormente, y la molécula de ácido nucleico monocatenario sin conjugado PH-0009 como ejemplo comparativo.
Cada una de las moléculas de ácido nucleico monocatenario mencionadas anteriormente se disolvió en agua destilada para inyección (Otsuka Pharmaceutical Co., Ltd.) para preparar una solución de molécula de ácido nucleico monocatenario.
Como células, se usaron células A549 (DS Pharma Biomedical Co., Ltd.). Como medio, se utilizó DMEM (Invitrogen) que contenía FBS al 10%. Las condiciones de cultivo fueron 37°C, 5% de CO2.
En primer lugar, las células se cultivaron en el medio antes mencionado y la solución de cultivo se dispensó en una placa de 24 pocillos de manera que cada pocillo contuviera 400 pl de la solución de cultivo para lograr una densidad de 4 x 104 células/pocillo. Las células en el pocillo mencionado anteriormente se transfectaron con la molécula de ácido nucleico monocatenario mencionada anteriormente usando un reactivo de transfección RNAiMAX (Invitrogen) según el protocolo del reactivo de transfección mencionado anteriormente. Específicamente, la transfección se llevó a cabo ajustando la composición por pocillo de la siguiente manera. En la siguiente composición, (A) es el reactivo de transfección mencionado anteriormente, (B) es Opti-MEM (Invitrogen), (C) es la solución de molécula de ácido nucleico monocatenario mencionada anteriormente y se añadieron 98.5 pl de (B) y (C) en combinación. En el pocillo mencionado anteriormente, la concentración final de la molécula de ácido nucleico monocatenario mencionada anteriormente fue de 0.01,0.1, 1 nmol/l.
Tabla 1
(composición por pocillo: pl)
solución de cultivo 400
(A) 1.5
(B) y (C) 98.5
total 500
Después de la transfección, las células en los pocillos antes mencionados se cultivaron durante 24 horas y luego se recogió el ARN utilizando un RNeasy Mini Kit (Qiagen, Países Bajos) de acuerdo con el protocolo suministrado con el mismo. Posteriormente, se sintetizó ADNc a partir del ARN antes mencionado utilizando una transcriptasa inversa (nombre comercial: SuperScript III, Invitrogen) de acuerdo con el protocolo suministrado con la misma. Luego, como se
muestra a continuación, se llevó a cabo la PCR usando el ADNc sintetizado mencionado anteriormente como molde, y se midió el nivel de expresión del gen de TGF-p1 y el del gen de p-actina como patrón interno. El nivel de expresión mencionado anteriormente del gen de TGF-p1 se normalizó con referencia al del gen de p-actina mencionado anteriormente.
La mencionada PCR se llevó a cabo utilizando un LightCycler FastStart DNA Master SYBR Green I (nombre comercial, Roche) como reactivo y un Light Cycler DX400 (nombre comercial, Roche) como instrumento (en lo sucesivo el mismo). El gen de TGF-p1 y el gen de p-actina mencionados anteriormente se amplificaron utilizando los siguientes conjuntos de cebadores, respectivamente.
Conjunto de cebadores de PCR para el gen de TGF-p1
(SEQ ID NO: 33) 5'-TTGTGCGGCAGTGGTTGAGCCG-3'
(SEQ ID NO: 34) 5'-GAAGCAGGAAAGGCCGGTTCATGC-3'
Conjunto de cebadores para el gen de p-actina
(SEQ ID NO: 35) 5'-GCCACGGCTGCTTCCAGCTCCTC-3'
(SEQ ID NO: 36) 5'-AGGTCTTTGCGGATGTCCACGTCAC-3'
Como control 1, con respecto a las células en la solución de cultivo antes mencionada a las que se añadieron 100 |ul de la solución (B) antes mencionada, también se midieron los niveles de expresión de los genes (-). Además, como control 2, con respecto a las células sometidas a los mismos procedimientos de transfección que en el anterior, excepto que no se añadió la solución de ARN antes mencionada y que se añadieron la (B) antes mencionada y 1.5 |ul de la (A) antes mencionada para que la cantidad total de (A) y (B) fuera de 100 |ul, también se midió el nivel de expresión del gen (testigo).
En cuanto al nivel de expresión normalizado del gen de TGF-p1, el valor relativo en la célula en la que se introdujo cada molécula de ácido nucleico monocatenario se determinó basado en el nivel de expresión en las células de control (-) fijado en 1.
Los resultados del mismo se muestran en la Fig. 11. La Fig. 11 es un gráfico que muestra el nivel de expresión relativo del gen de TGF-p1, y el eje vertical indica el nivel de expresión génica relativo. Como se muestra en la Fig. 11, se encontró que KH-0001 -C18 tenía una fuerte actividad inhibidora de la expresión génica del mismo nivel que PH-0009.
Ejemplo B2: Efecto inhibidor de la expresión génica en la molécula de ácido nucleico monocatenario conjugada con lípido, molécula de ácido nucleico monocatenario conjugada con carbohidrato y molécula de ácido nucleico monocatenario conjugada con péptido
Se estudió el efecto inhibidor de la expresión génica de TGF-p1 de las siguientes molécula de ácido nucleico monocatenario conjugada con lípido, molécula de ácido nucleico monocatenario conjugada con carbohidrato y molécula de ácido nucleico monocatenario conjugada con péptido sintetizadas en el Ejemplo A1 mencionado anteriormente y que tienen una secuencia inhibidora de la expresión dirigida al gen de TGF-p1. Como molécula de ácido nucleico monocatenario conjugada con lípidos, se usaron KH-0001-C18, KH-0001-DOPE, KH-0001-Chol y KH-0030, se usaron KH-0001 -Lac, KH-0001 -GalNAc y k H- 0001 -GlcNAc como molécula de ácido nucleico monocatenario conjugada con carbohidrato, y se usaron KH-0001 -GE11, KH-0001 -GE11 (7) y KH-0001 -GE11 (5) como la molécula de ácido nucleico monocatenaria conjugada con péptido. Como control negativo, se usó PH-0000, y se usaron KH-0001 y PH-0009, que son moléculas de ácido nucleico monocatenario sin conjugado, como ejemplo comparativo.
Al considerar el efecto inhibidor de la expresión génica de la molécula de ácido nucleico monocatenario conjugada con lípido y la molécula de ácido nucleico monocatenario conjugada con péptido, se utilizaron células A549 (DS Pharma Biomedical Co., Ltd.). Al considerar el efecto inhibidor de la expresión génica de la molécula de ácido nucleico monocatenario conjugada con carbohidrato, se usaron células HepG2 (DS Pharma Biomedical Co., Ltd.). Como medio, se utilizó DMEM (Invitrogen) que contenía FBS al 10%. Las condiciones de cultivo fueron 37°C, 5% de CO2.
Se midió el nivel de expresión génica mediante un método similar al del Ejemplo B1 excepto en los siguientes puntos. Como transcriptasa inversa, se utilizó Transcriptor First Strand cDNA Synthesis Kit (nombre comercial, Roche), LightCycler480 SYBR Green I Master (nombre comercial, Roche) como reactivo de PCR, y se usó Light Cycler480 Instrument II (nombre comercial, Roche) como instrumento para la PCR. La concentración final de la molécula de ácido nucleico monocatenario conjugada con carbohidrato y la molécula de ácido nucleico monocatenario conjugada con péptido se fijó en 0.1 y 1 nmol/l, respectivamente, y la concentración final de la molécula de ácido nucleico monocatenario conjugada con lípido se fijó en 1 nmol/l.
En cuanto al nivel de expresión del gen de TGF-p1 después de la modificación, el valor relativo del nivel de expresión en las células en las que se introdujo cada molécula de ácido nucleico monocatenario se determinó con el nivel de expresión de las células de control 2 (testigo) como 1.
Los resultados de la misma se muestran en las Figs. 12 - 14. Cada figura es un gráfico que muestra el valor relativo
del nivel de expresión del gen de TGF-p1, en donde el eje vertical muestra el nivel relativo de expresión del gen. La figura 12 muestra los resultados de la molécula de ácido nucleico monocatenario conjugada con carbohidrato, la figura 13 muestra los resultados de la molécula de ácido nucleico monocatenario conjugada con péptido y la figura 14 muestra los resultados de la molécula de ácido nucleico monocatenario conjugada con lípido. Como se muestra en la Fig. 12, todas las moléculas de ácido nucleico monocatenario conjugadas con carbohidratos mostraron una fuerte actividad inhibidora de la expresión génica del mismo nivel que la de KH-0001 y PH-0009. Como se muestra en la Fig. 13, todas las moléculas de ácido nucleico monocatenario conjugadas con péptido mostraron una fuerte actividad inhibidora de la expresión génica del mismo nivel que la de KH-0001 y PH-0009. Como se muestra en la Fig. 14, KH-0001 -C18 mostró una fuerte actividad inhibidora de la expresión génica del mismo nivel que la de KH-0001 y PH-0009. El nivel relativo de expresión génica de KH-0001-DOPE, KH-0001-Chol y KH-0030 fue de 0.1 - 0.35, mostrando así una actividad inhibidora de la expresión génica.
Ejemplo C1: Reactividad de la molécula de ácido nucleico monocatenario conjugada con lípido con la proteína Dicer
Se estudiaron la molécula de ácido nucleico monocatenario conjugada con lípido KH-0001-C18 sintetizada en el Ejemplo A1 mencionado anteriormente, y la molécula de ácido nucleico monocatenario sin conjugado PH-0009 y la molécula de ácido nucleico monocatenario NH-0005 en la que la región conectora Lx consiste solo en restos de nucleótidos, cada una de Ejemplo comparativo, para determinar la reactividad con la proteína Dicer.
Utilizando el Recombinant Human Dicer Enzyme Kit (nombre comercial, Genlantis) como reactivo, y de acuerdo con el protocolo adjunto, se preparó una mezcla de reacción que contenía la proteína Dicer antes mencionada y la molécula de ácido nucleico antes mencionada, y se incubó a 37°C. El tiempo de incubación se fijó en 0, 2, 6, 24, 48, 72 h. A la mezcla de reacción mencionada anteriormente, después de incubación durante un tiempo dado, se añadió un líquido de inactivación de la reacción del reactivo mencionado anteriormente, y la mezcla se sometió a electroforesis en gel de poliacrilamida al 20%-urea 7 M. Posteriormente, el gel de poliacrilamida antes mencionado se tiñó con SYBR Green II (nombre comercial, Lonza) y se analizó usando ChemiDoc (nombre comercial, Bio-Rad).
Los resultados del mismo se muestran en la Fig. 15. La Fig. 15(A) muestra los resultados de la electroforesis que muestra la reactividad de NH-0005 con la proteína Dicer, la Fig. 15(B) muestra los resultados de la electroforesis que muestra la reactividad de PH-0009 con la proteína Dicer, y la Fig. 15(C) muestra los resultados de la electroforesis que muestra la reactividad de KH-0001-C18 con la proteína Dicer. En cada figura, la hilera "M" es un marcador de peso molecular (20, 30, 40, 50 y 100 bases), (h) es el tiempo de incubación antes mencionado y R es una muestra sin tratar.
PH-0009 sin conjugado y NH-0005 en el que la región conectora consiste en un nucleótido natural, cada una de ejemplo comparativo, reaccionaron gradualmente con la proteína Dicer mencionada anteriormente y la reacción continuó hasta después de 6 h. Por el contrario, KH-0001-C18 que tenía un conjugado de lípido reaccionó rápidamente con la Dicer mencionada anteriormente y la reacción se completó 2 horas más tarde. Para examinar en detalle la reactividad de KH-0001-C18 con la proteína Dicer, el tiempo de incubación se fijó en 0, 5, 10, 30, 60, 90, 120 min y la reacción y el análisis se realizaron de la misma manera.
Los resultados del mismo se muestran en la Fig. 16. La hilera "M" es un marcador de peso molecular (20, 30, 40, 50 y 100 bases), (min) es el tiempo de incubación mencionado anteriormente (min), y R es una muestra sin tratar. Como se muestra en la Fig. 16, KH-0001-C18 reaccionó rápidamente con la proteína Dicer y la reacción se había completado 60 min más tarde.
A partir de los resultados anteriores, se encontró que la reactividad de la molécula de ácido nucleico monocatenario conjugada con lípido con la proteína Dicer mejoró notablemente. Es decir, cuando se considera junto con los resultados del efecto inhibidor de la expresión génica del Ejemplo B1 mencionado anteriormente, se considera que la molécula de ácido nucleico monocatenario conjugada con lípido tiene potencialmente la capacidad de ejercer rápidamente un efecto de interferencia de ARN después de ser introducida en la célula.
Ejemplo C2: Estabilidad de una molécula de ácido nucleico monocatenario conjugada con lípido en suero humano
Se estudió la estabilidad en el suero humano de la molécula de ácido nucleico monocatenario conjugada con lípido KH-0001 -C18 sintetizada en el Ejemplo A1 mencionado anteriormente, y la molécula de ácido nucleico monocatenario sin conjugado PH-0009 y la molécula de ácido nucleico monocatenario NH-0005 en la que la región conectora Lx consiste solo en restos de nucleótidos, cada una de ejemplo comparativo.
En primer lugar, se incubó una mezcla (30 pl) de la molécula de ácido nucleico monocatenario mencionada anteriormente y suero humano normal (MP Biomedicals) en 1x PBS a 37°C. En la mezcla mencionada anteriormente (30 pl), la cantidad de la molécula de ácido nucleico monocatenario mencionada anteriormente se fijó en 60 pmol, y la cantidad del suero humano normal mencionado anteriormente se fijó en una concentración final de 10%. A las 0 h, 1 h, 3 h, 5 h y 24 h después del comienzo de la incubación, la mezcla se trató térmicamente a 95°C durante 10 min y se enfrió rápidamente en hielo para interrumpir la reacción. Posteriormente, la fracción de ARN se extrajo según el método de Bligh y Dyer (http://biochem2.umin.jp/contents/Manuals/manual54.html). El extracto obtenido se sometió a electroforesis en gel de poliacrilamida 20/-urea 7 M, se tiñó con SYBR Green II (nombre comercial, Lonza) y se analizó usando ChemiDoc (nombre comercial, Bio-Rad).
Los resultados del mismo se muestran en la Fig. 17. En la Fig. 17, la hilera "M" es un marcador de peso molecular y (h) es un tiempo de incubación.
Como se muestra en la Fig. 17, se confirmó que la NH-0005 del ejemplo comparativo en el que la región conectora Lx consiste solo en restos de nucleótidos mostró un progreso rápido de una reacción de descomposición y se logró la descomposición completa 1 hora después de la incubación. Por el contrario, KH-0001-C18 de la presente invención mostró una descomposición tan ligera como PH-0009 del ejemplo comparativo y no mostró descomposición completa incluso 5 horas después de la reacción.
A partir de los resultados del Ejemplo B1 mencionado anteriormente, el Ejemplo B2 mencionado anteriormente, el Ejemplo C1 mencionado anteriormente y el Ejemplo C2 mencionado anteriormente, se considera que la molécula de ácido nucleico monocatenario conjugada con lípido tiene estabilidad en el cuerpo y potencialmente tiene la capacidad de ejercer un efecto de interferencia de ARN después de ser introducida en la célula.
Ejemplo de referencia 1: Síntesis de Lys-amidita
De acuerdo con el siguiente esquema 6, se sintetizó DMTr-Lys-amidita (7) que es una lisina (Lys)-amidita. En el siguiente esquema 6, "Tfa" es un grupo trifluoroacetilo.

(1) Síntesis del compuesto 2
A una solución en piridina (124 ml) de ácido 6-hidroxihexanoico (6 g, 15.1 mmol) se añadieron cloruro de 4,4'-dimetoxitritilo (20 g, 1.3 eq.) y dimetilaminopiridina (0.5 g, 0.1 eq.) y la mezcla se agitó a temperatura ambiente durante 20 horas. Una vez completada la reacción, se añadió metanol (10 ml), la mezcla se agitó durante 10 min y el disolvente se evaporó. El líquido de reacción se diluyó con acetato de etilo, se lavó tres veces con tampón de TEAA (pH 8-9) y se lavó una vez con salmuera saturada. La capa orgánica se secó sobre sulfato sódico y el disolvente se evaporó a presión reducida para dar el compuesto 2 (31 g, que contenía piridina) como un aceite de color amarillo pálido.
(2) Síntesis del compuesto 4
A una solución en acetonitrilo (45 ml) del compuesto 3 (2.7 g, 7.9 mmol), diciclohexilcarbodiimida (1.9 g, 1.2 eq.) y monohidrato de 1 -hidroxibenzotriazol (2.6 g, 2.4 eq.) se añadió una solución en acetonitrilo (5 ml) de 4-amino-1 -butanol (0.86 g, 1.2 eq.), y la mezcla se agitó a temperatura ambiente durante 16 horas. Una vez completada la reacción, el precipitado se recogió por filtración y el disolvente del filtrado se evaporó mediante un evaporador. Se añadió diclorometano al residuo obtenido y la mezcla se lavó tres veces con tampón de acetato (pH 4) y tres veces con solución acuosa saturada de bicarbonato de sodio. La capa orgánica se secó sobre sulfato de sodio y el disolvente se evaporó a presión reducida. El producto bruto obtenido se purificó por cromatografía en columna de gel de sílice (eluyente: diclorometano/metanol = 10/1) para dar el compuesto 4 (2.8 g, rendimiento de 85%) como un sólido blanco. Los valores analíticos instrumentales del compuesto 4 se muestran a continuación.
compuesto 4;
RMN-1H (400 MHz, CDCb) 5: 7.07 (br, 1H), 6.72 (t, J=5.6 Hz, 1H), 4.03 (m, 1H), 3.66 (d, J=4.9 Hz, 2H), 3.37 (dd, J=12.9, 6.3 Hz, 2H), 3,29 (dd, J=12,4, 6,3 Hz, 2H), 1,83 (s, 2H), 1,66-1,60 (m, 6H), 1,44 (s, 9H), 1,41-1,37 (m, 2H)
(3) Síntesis del compuesto 5
El compuesto 4 (2.5 g, 6.1 mmol) se agitó en solución de ácido clorhídrico/tetrahidrofurano (4 M, 45 ml) a temperatura ambiente durante 2 h. Una vez completada la reacción, el disolvente se evaporó a presión reducida. El residuo obtenido se disolvió en etanol y se destiló azeotrópicamente con tolueno. El disolvente se evaporó para dar el compuesto 5 (1.9 g) como un sólido blanco. Los valores analíticos instrumentales del compuesto 5 se muestran a continuación.
compuesto 5;
RMN-1H (400 MHz, CD3OD) 5: 3.85-3.81 (m, 1H), 3.59-3.56 (m, 2H), 3.32-3.20 (m, 2H), 1.94-1.80 (m, 2H), 1.66-1.58 (m, 6H), 1.46 -1.40 (m, 2H)
(4) Síntesis del compuesto 6
A una solución (150 ml) del compuesto 2 (que contenía piridina, 24 g, 35.5 mmol), diciclohexilcarbodiimida (8.8 g, 1.2 eq.), e 1-hidroxibenzotriazol monohidrato (7.2 g, 1.5 eq.) se añadió trietilamina (4.5 ml, 0.9 eq.), se añadió además una solución en N,N-dimetilformamida (30 ml) del compuesto 5 (10 g, 0.9 eq.) y la mezcla se agitó a temperatura ambiente durante 20 h. Una vez completada la reacción, el precipitado se recogió por filtración y el disolvente del filtrado se evaporó mediante un evaporador. Se añadió diclorometano al residuo obtenido y la mezcla se lavó tres veces con solución acuosa saturada de bicarbonato de sodio. La capa orgánica se secó sobre sulfato de sodio y el disolvente se evaporó a presión reducida. El producto bruto obtenido se purificó por cromatografía en columna de gel de sílice (eluyente: diclorometano/metanol = 20/1 piridina al 0.05%) para dar el compuesto 6 (16 g, rendimiento de 70%) como un sólido amarillo pálido. Los valores analíticos instrumentales del compuesto 6 se muestran a continuación.
compuesto 6;
RMN-1H (400 MHz, CDCla) 5: 7.43-7.40 (m, 2H), 7.32-7.26 (m, 6H), 7.21-7.17 (m, 1H), 6.81 (d, J=8.8 Hz, 4H), 4.39 4.37 (m, 1H), 3.78 (s, 6H), 3.64-3.61 (m, 2H), 3.33-3.22 (m, 4H), 3.03 (t, J=6.6 Hz, 2H), 2.19 (t, J=7.6 Hz, 2H), 1,79 1,54 (m, 12H), 1.40-1.34 (m, 4H)
(5) Síntesis del compuesto 7
A una solución en acetonitrilo anhidro (3.5 ml) del material de partida (1.26 g, 1.73 mmol), que se secó azeotrópicamente con acetonitrilo, se añadieron tetrazolida de diisopropilamonio (394 mg, 1.3 eq.) y 2-cianoetoxi-N,N,N’,N'-tetraisopropil-fosforodiamidita (700 mg, 1.3 eq.), y la mezcla se agitó a temperatura ambiente durante 2.5 horas. Se añadió diclorometano, la mezcla se lavó con solución acuosa saturada de bicarbonato sódico y salmuera saturada y se secó sobre sulfato sódico y el disolvente se evaporó. El producto bruto obtenido se purificó por cromatografía en columna de gel de sílice (aminosílice, eluyente: n-hexano/acetato de etilo = 2/3) para dar el compuesto 7 (1.3 g, rendimiento de 78%) como un sólido blanco. Los valores analíticos instrumentales del compuesto 7 se muestran a continuación.
compuesto 7;
RMN-1H (400 MHz, CDCI3) 5: 7.43-7.41 (m, 2H), 7.32-7.17(m, 7H), 6.81 (dt, J=9.3, 2.9 Hz, 4H), 4.42-4.37 (m, 1H), 3.78 (s, 6H), 3.88-3.54 (m, 6H), 3.32-3.20 (m, 4H), 3.03 (t, J=6.3 Hz, 2H), 2.19 (t, J=7.6 Hz, 2H), 1.83-1.53 (m, 12H), 1.42-1.31 (m, 4H), 1.28-1.24 (m, 2H), 1.18-1.16 (m, 12H)
RMN-31P (162 MHz, CDCla) 5: 146.9
Ejemplo de referencia 2: Síntesis de Gly-amidita
De acuerdo con el siguiente esquema 7, se sintetizó DMTr-Gly-amidita (compuesto 12) que es una glicina (Gly)-amidita.

(1) N-(4-hidroxibutil)-Na-Fmoc-glicinamida (compuesto 8)
A una solución en N,N-dimetilformamida anhidra (100 ml) de Fmoc-glicina (4.00 g, 13.45 mmol), diciclohexilcarbodiimida (3.33 g, 16.15 mmol) y 1-hidroxibenzotriazol monohidrato (4.94 g, 32.29 mmol) se le añadió una solución en N,N-dimetilformamida anhidra (30 ml) de 4-aminobutanol (1.44 g, 16.15 mmol) y la mezcla se agitó a temperatura ambiente durante la noche en una atmósfera de argón. El precipitado resultante se separó por filtración y el filtrado se concentró a presión reducida. Se añadió diclorometano (200 ml) al residuo obtenido y la mezcla se lavó tres veces con solución acuosa saturada de bicarbonato de sodio y se lavó adicionalmente con salmuera saturada. Después de secar sobre sulfato de sodio, el disolvente se evaporó a presión reducida. El residuo obtenido se sometió a cromatografía en columna de gel de sílice (eluyente: diclorometano-metanol (95:5) para dar la N-(4-hidroxibutil)-Na-Fmoc-glicinamida (8) (4.30 g, 87%). Los valores analíticos instrumentales de la N-(4-hidroxibutil)-Na-Fmoc-glicinamida (8) se muestran a continuación.
N-(4-hidroxibutil)-Na-Fmoc-glicinamida (8);
RMN-1H (400 MHz, CDCls): 5=7.78-7.76 (2H, d, J=7.3 Hz), 7.65-7.63 (2H, d, J=7.3 Hz), 7.42-7.41 (2H, t, J=7.6 Hz), 7.34-7.30 ( 2H, td, J=7.6, 1.1 Hz), 4.42-4.40 (2H, d, J=7.3 Hz), 4.25-4.22 (1H, t, J=6.8 Hz), 3.83 (2H, s), 3.60-3.55 (2H, m), 3,30-3,25 (2H, m), 1,61-1,55 (4H, m).
(2) N-(4-O-DMTr-hidroxibutil)-Na-Fmoc-glicinamida (compuesto 9)
El compuesto 8 (4.20 g, 11.40 mmol) se secó azeotrópicamente tres veces con piridina anhidra. Se añadieron al residuo por azeotropía cloruro de 4,4'-dimetoxitritilo (5.80 g, 17.10 mmol) y piridina anhidra (80 ml) y la mezcla se agitó a temperatura ambiente durante la noche. Se añadió metanol (20 ml) a la mezcla de reacción obtenida y la mezcla se agitó a temperatura ambiente durante 30 min y el disolvente se evaporó a presión reducida. A continuación, se añadió diclorometano (200 ml) y la mezcla se lavó tres veces con solución acuosa saturada de bicarbonato sódico y se lavó adicionalmente con salmuera saturada. Después de secar sobre sulfato de sodio, el disolvente se evaporó a presión reducida para dar la N-(4-O-DMTr-hidroxibutil)-Na-Fmoc-glicinamida (9) sin purificar (11.40 g).
(3) N-(4-O-DMTr-hidroxibutil)-glicinamida (compuesto 10)
Al compuesto 9 no purificado (11.40 g, 16.99 mmol) se le añadieron N,N-dimetilformamida (45 ml) y piperidina (11.7 ml) a temperatura ambiente y la mezcla se agitó a temperatura ambiente durante la noche. El disolvente de la mezcla de reacción se evaporó a presión reducida y el residuo obtenido se sometió a cromatografía en columna de gel de sílice (eluyente: diclorometano-metanol (9:1) piridina al 0.05%) para dar la glicina-4,4'-dimetoxitritiloxibutanamida (3) (4.90 g, 96%, 2 etapas). Los valores analíticos instrumentales de la N-(4-O-DMTr-hidroxibutil)-glicinamida (10) se muestran a continuación.
N-(4-O-DMTr-hidroxibutil)-glicinamida (10);
RMN-1H (400 MHz, CDCla): 5=7.44-7.42 (2H, m), 7.33-7.26 (6H, m), 7.21-7.20 (1H, m), 6.83-6.80 (4H, m), 3.79 (6H, s), 3.49 (2H, s), 3.30-3.28 (2H, t, J=6.3 Hz), 3.09-3.06 (2H, t, J=5.9 Hz), 1.61 -1.55 (4H, m).
(4) N-(4-O-DMTr-hidroxibutil)-Na-(6-hidroxihexanoil)-glicinamida (compuesto 11)
El compuesto 10 (4.80 g, 10.70 mmol) se secó azeotrópicamente tres veces con piridina anhidra, se añadieron ácido 6-hidroxihexanoico (1.70 g, 12.84 mmol), hidrocloruro de 1-etil-3-(3-dimetilaminopropil)carbodiimida (2.46 g, 12.84 mmol), 1-hidroxibenzotriazol monohidrato (3.93 g, 25.69 mmol) y diclorometano anhidro (60 ml) a temperatura ambiente en atmósfera de argón y la mezcla se agitó durante 10 min. Se añadió trietilamina (3.90 g, 38.53 mmol) a la mezcla así obtenida y la mezcla se agitó a temperatura ambiente durante la noche en atmósfera de argón. Se añadió diclorometano (200 ml) a la mezcla de reacción obtenida y la mezcla se lavó tres veces con solución acuosa saturada de bicarbonato de sodio y se lavó una vez más con salmuera saturada. La capa orgánica se separó y se secó sobre sulfato de sodio y el disolvente se evaporó a presión reducida. El residuo obtenido se sometió a cromatografía en columna de gel de sílice (eluyente: diclorometano-metanol (95:5) piridina al 0.05%) para dar la N-(4-O-DMTrhidroxibutil)-Na-(6-hidroxihexanoil)-glicinamida (11) (4.80 g, 80%). Los valores analíticos instrumentales de la N-(4-O-DMTr-hidroxibutil)-Na-(6-hidroxihexanoil)-glicinamida (11) se muestran a continuación.
N-(4-O-DMTr-hidroxibutil)-Na-(6-hidroxihexanoil)-glicinamida (11);
RMN-1H (400 MHz, CDCh): 5=7.43-7.40 (2H, m), 7.33-7.26 (6H, m), 7.22-7.20 (1H, m), 6.83-6.80 (4H, m), 3.85 (2H, s), 3.78 (6H ,s), 3.63-3.60 (2H, t, J=6.3 Hz), 3.26-3.23 (2H, t, J=6.1 Hz), 3.07-3.05 (2H, t, J=5.6 Hz), 2.26-2.22 (2H, t, J=7.3 Hz), 1.68-1.52 (8H, m), 1.41 -1.36 (2H, m).
(5) N-(4-O-DMTr-hidroxibutil)-Na-(6-O-(2-cianoetil-N,N-diisopropilfosfitil)-hidroxihexanoil)-glicinamida (compuesto 12)
El compuesto 11 (4.70 g, 8.35 mmol) se secó azeotrópicamente tres veces con piridina anhidra. Luego, se añadió tetrazolida de diisopropilamonio (1.72 g, 10.02 mmol), se extrajo el aire de la mezcla a presión reducida y se cargó con argón gaseoso y se añadió acetonitrilo anhidro (5 ml). Además, se añadió una solución (4 ml) de 2-cianoetoxi-N,N,N',N'-tetraisopropil-fosforodiamidita (3.02 g, 10.02 mmol) en una mezcla anhidra de acetonitrilo-diclorometano 1:1
y la mezcla se agitó a temperatura ambiente durante 4 h en atmósfera de argón. Se añadió diclorometano (150 ml) a la mezcla de reacción obtenida y la mezcla se lavó dos veces con solución acuosa saturada de bicarbonato de sodio y se lavó una vez más con salmuera saturada. La capa orgánica se separó y se secó sobre sulfato de sodio y el disolvente se evaporó a presión reducida. El residuo obtenido se sometió a cromatografía en columna utilizando aminosílice (eluyente: n-hexano-acetona (3:2) trietilamina al 0.1%) para dar la amida de ácido hidroxihexanoico de la glicina-4,4'-dimetoxitritiloxibutanamida-fosforamidita (12) (4.50 g, 71%, HPLC 98.2%). Los valores analíticos instrumentales de la N-(4-O-DMTr-hidroxibutil)-Na-(6-O-(2-cianoetil-N,N-diisopropilfosfitil)-hidroxihexanoil)-glicinamida (12) se muestran a continuación.
N-(4-O-DMTr-hidroxibutil)-Na-(6-O-(2-cianoetil-N,N-diisopropilfosfitil)-hidroxihexanoil)-glicinamida (12);
RMN-1H (400 MHz, CDCla): 5=7.43-7.40 (2H, m), 7.33-7.26 (6H, m), 7.22-7.20 (1H, m), 6.83-6.80 (4H, m), 3.85-3.81 (4H, s), 3.78 (6H, s), 3.63-3.61 (2H, t, J=6.3 Hz), 3.26-3.23 (2H, t, J=6.1 Hz), 3.05-2.97 (4H, m), 2.64-2.62 (2H, t ,J=6.4 Hz), 2.25-2.23 (2H, t, J=7.3 Hz), 1.68-1.52 (8H,m), 1.40-1.38 (2H,m), 1.13-1.20 (12H, m). RMN-31P (162 MHz, CDCla): 5=146.57.
Ejemplo de referencia 3: Síntesis de prolina-amidita
De acuerdo con el siguiente esquema 8, se sintetizó el compuesto 17, que es una amidita que contiene una cadena principal de prolina.

(1) N-(4-hidroxibutil)-Na-Fmoc-L-prolinamida (compuesto 14)
Se utilizó el compuesto 13 (Fmoc-L-prolina) como material de partida. Se mezclaron el compuesto 13 mencionado anteriormente (10.00 g, 29.64 mmol), 4-amino-1-butanol (3.18 g, 35.56 mmol) y 1-hidroxibenzotriazol (10.90 g, 70.72 mmol). Se extrajo el aire de la mezcla antes mencionada a presión reducida y se cargó con argón gaseoso. Se añadió acetonitrilo anhidro (140 ml) a la mezcla antes mencionada a temperatura ambiente y se añadió además una solución (70 ml) de diciclohexilcarbodiimida (7.34 g, 35.56 mmol) en acetonitrilo anhidro. A continuación, se agitó durante 15 horas a temperatura ambiente en atmósfera de argón. Una vez completada la reacción, el precipitado generado se separó por filtración y el disolvente del filtrado recogido se evaporó a presión reducida. Se añadió diclorometano (200 ml) al residuo obtenido y la mezcla se lavó con solución acuosa saturada de bicarbonato de sodio (200 ml). Luego, se recogió una capa orgánica y se secó sobre sulfato de magnesio. A continuación, se filtró la capa orgánica antes mencionada y se evaporó a presión reducida el disolvente del filtrado obtenido. Se añadió éter dietílico (200 ml) al residuo, convirtiendo así el residuo en polvo. El polvo así obtenido se recogió por filtración. Así, se obtuvo el compuesto 14 en forma de polvo incoloro (10.34 g, rendimiento 84%). Los valores analíticos instrumentales del compuesto 14 mencionado anteriormente se muestran a continuación.
compuesto 14:
RMN-1H (CDCls): 57.76-7.83 (m, 2H, Ar-H), 7.50-7.63 (m, 2H, Ar-H), 7.38-7.43 (m, 2H, Ar-H), 7.28-7.33 (m, 2H, Ar-H), 4.40-4.46 (m, 1H, CH), 4.15-4.31 (m, 2H, CH2), 3.67-3.73 (m, 2H, CH2), 3.35-3.52 (m, 2H, CH2), 3.18-3.30 (m, 2H, CH2), 2.20-2.50 (m, 4H), 1.81 -2.03 (m, 3H), 1.47-1.54 (m, 2H);
Ms (FAB+): m/z 409 (M+H+).
(2) N-(4-O-DMTr-hidroxibutil)-L-prolinamida (compuesto 15)
La N-(4-hidroxibutil)-Na-Fmoc-L-prolinamida (compuesto 14) (7.80 g, 19.09 mmol) se mezcló con piridina anhidra (5 ml) y la mezcla se secó por destilación azeotrópica a temperatura ambiente. Al residuo obtenido se le añadieron cloruro de 4,4'-dimetoxitritilo (8.20 g, 24.20 mmol), DMAP (23 mg, 0.19 mmol) y piridina anhidra (39 ml). La mezcla se agitó a temperatura ambiente durante 1 h, se añadió metanol (7.8 ml) y la mezcla se agitó a temperatura ambiente durante 30 min. La mezcla se diluyó con diclorometano (100 ml), se lavó con solución acuosa saturada de hidrogenocarbonato de sodio (150 ml) y se separó la capa orgánica. La capa orgánica antes mencionada se secó sobre sulfato de sodio y se filtró. El disolvente del filtrado obtenido se evaporó a presión reducida. Al residuo sin purificar obtenido se le añadieron dimetilformamida anhidra (39 ml) y piperidina (18.7 ml, 189 mmol) y la mezcla se agitó a temperatura ambiente durante 1 h. Una vez completada la reacción, el disolvente de la mezcla antes mencionada se evaporó a presión reducida a temperatura ambiente. El residuo obtenido se sometió a cromatografía en columna de gel de sílice (nombre comercial Wakogel C-300, eluyente CH2Cl2:CH3OH = 9:1, que contiene piridina al 0.05%) para dar el compuesto 15 como un aceite amarillo pálido (9.11 g, rendimiento del 98%). Los valores analíticos instrumentales del compuesto 15 antes mencionado se muestran a continuación.
compuesto 15:
RMN-1H (CDCla): 57.39-7.43 (m, 2H, Ar-H), 7.30 (d, J=8.8 Hz, 4H, Ar-H), 7,21 (tt, 1H, 4.9, 1.3 Hz, Ar-H), 6.81 (d, J=8.8 Hz, 4H, Ar-H), 3.78 (s, 6H, OCH3), 3,71 (dd, H, J=6.3 Hz, 5.4 Hz, CH), 3.21 (2H, 12.9, 6.3 Hz, 2H, CH2), 3.05 (t, J=6.3Hz, 2H, CH2), 2.85-2.91 (m, 2H, CH2), 2.08-2.17 (m, 1H, CH), 1.85-2.00 (m, 3H), 1.55-1.65 (m, 5H);
Ms (FAB+); m/z 489 (M+H+), 303 (DMTr+).
(3) N-(4-O-DMTr-hidroxibutil)-Na-(6-hidroxihexanoil)-L-prolinamida (compuesto 16)
Se mezcló una solución en diclorometano anhidro (120 ml) de la N-(4-O-DMTr-hidroxibutil)-L-prolinamida obtenida (compuesto 15) (6.01 g, 12.28 mmol), EDC (2.83 g, 14.74 mmol), 1-hidroxibenzotriazol (3.98 g, 29.47 mmol) y trietilamina (4.47 g, 44.21 mmol). A esta mezcla se le añadió además ácido 6-hidroxihexano (1.95 g, 14.47 mmol) a temperatura ambiente en atmósfera de argón y después la mezcla se agitó a temperatura ambiente durante 1 h en atmósfera de argón. La mezcla antes mencionada se diluyó con diclorometano (600 ml) y se lavó 3 veces con salmuera saturada (800 ml). La capa orgánica se recuperó, se secó sobre sulfato de sodio y se filtró. El disolvente del filtrado obtenido se evaporó a presión reducida, con lo que se obtuvo el compuesto 16 antes mencionado en forma de espuma de color amarillo pálido (6.29 g, rendimiento de 85%). Los valores analíticos instrumentales del compuesto 16 antes mencionado se muestran a continuación.
compuesto 16:
RMN-1H (CDCl3): 57.41-7.43 (m, 2H, Ar-H), 7.27-7.31 (m, 4H, Ar-H), 7.19-7.26 (m, 2H, Ar-H), 7.17-7.21 (m, 1H, Ar-H), 6.79-6.82 (m, 4H, Ar-H), 4.51-4.53 (m, 1H, CH), 3.79 (s, 6H, OCH)3), 3.61 (t, 2H, J=6.4 Hz, CH2), 3.50-3.5 (m, 1H, CH), 3.36-3.43 (m, 1H, CH), 3.15-3.24 (m, 2H, CH2), 3.04 (t, J=6.3 Hz, 2H, CH2), 2.38-2.45 (m, 1H, CH), 2.31 (t, 6.8 Hz, 2H, CH2), 2.05-2.20 (m, 1H, CH), 1.92-2.00 (m, 1H, CH), 1.75-1.83 (m, 1H, CH), 1.48-1.71 (m, 8H), 1.35-1.44 (m, 2H, CH2);
Ms (FAB+): m/z 602 (M+), 303 (DMTr+).
(4) N-(4-O-DMT r-hidroxibutil)-Na-(6-O-(2-cianoetil-N,N-diisopropilfosfitil)-hidroxihexanoil)-L-prolinamida (compuesto 17) La N-(4-O-DMTr-hidroxibutil)-Na-(6-hidroxihexanoil)-L-prolinamida (compuesto 16) (8.55 g, 14.18 mmol) antes mencionada obtenida se mezcló con acetonitrilo anhidro y la mezcla se secó por destilación azeotrópica 3 veces a temperatura ambiente. Al residuo obtenido se le añadió tetrazolida de diisopropilamonio (2.91 g, 17.02 mmol), y se extrajo el aire de la mezcla a presión reducida y se cargó con argón gaseoso. A la mezcla antes mencionada se añadió acetonitrilo anhidro (10 ml) y, además, se añadió una solución en acetonitrilo anhidro (7 ml) de 2-cianoetoxi-N,N,N',N'-tetraisopropilfosforodiamidita (5.13 g, 17.02 mmol). La mezcla se agitó a temperatura ambiente durante 2 h en atmósfera de argón, luego se diluyó con diclorometano, se lavó 3 veces con solución acuosa saturada de hidrogenocarbonato de sodio (200 ml) y se lavó con salmuera saturada (200 ml). La capa orgánica se recuperó, se secó sobre sulfato de sodio y se filtró. El disolvente del filtrado obtenido antes mencionado se evaporó a presión reducida. El residuo obtenido se sometió a cromatografía en columna usando gel de aminosílice como relleno (eluyente hexano:acetato de etilo = 1:3, que contenía piridina al 0.05%) para dar el compuesto 17 como un jarabe incoloro (10.25 g, pureza 92%, rendimiento 83%). Los valores analíticos instrumentales del compuesto 17 mencionado anteriormente se muestran a continuación. compuesto 17:
RMN-1H (CDCls) : 57.40-7.42 (m, 2H, Ar-H), 7.29-7.31 (m, 4H, Ar-H), 7.25-7.27 (m, 2H, Ar-H), 7.17-7.21 (m, 1H, Ar-H), 6.80-6.82 (m, 4H, Ar-H), 4.51-4.53 (m, 1H, CH), 3.75-3.93 (m,4H), 3.79 (s, 6H, OCHs), 3.45-3.60 (m, 4H), 3.35 3.45 (m, 1H, CH), 3.20-3.29 (m,1H), 3.04 (t, J=6.4 Hz, 2H, CH2), 2.62 (t, J=5.8 Hz, 2H, CH2), 2.40-2.44 (m, 1H, CH), 2.31 (t, 7.8 Hz, 2H, CH2), 2.03-2.19 (m, 1H, CH), 1.92-2.02 (m, 1H, CH), 1.70-1.83 (m, 1H, CH), 1.51-1.71 (m, 8H), 1.35-1.44 (m, 2H, CH2), 1.18 (d, J=6.8 Hz, 6H, CH3), 1.16 (d, J=6.8 Hz, 6H, CH3); RMN-31P (CDCh): 5147.17;
Ms (FAB+): m/z 802 (M+), 303 (DMTr+), 201 (C8H19N2OP+).
Ejemplo de referencia 4: Síntesis de lisina-colesterolamidita
El compuesto 11, que es la lisina-colesterolamidita, se produjo según el siguiente esquema.

(1) Síntesis de imidazol-1-carboxilato de (colest-5-eno-3p-ilo) (compuesto 2)
A una solución en piridina (200 ml) de colesterol (compuesto 1) (8.0 g, 20 mmol) se añadió N,N-carbonildiimidazol (6.6 g, 2.0 eq.) y la mezcla se agitó a temperatura ambiente durante 4 h. El disolvente se evaporó en un evaporador y la solución se diluyó con diclorometano. Esta solución se lavó con solución acuosa de dihidrogenofosfato de sodio al 5% y luego se lavó con salmuera saturada. La capa orgánica se secó sobre sulfato de sodio y el disolvente se evaporó. El residuo se secó a presión reducida para dar una sustancia sólida blanca (9.8 g, rendimiento de 98%). Los valores analíticos instrumentales del compuesto (2) se muestran a continuación.
RMN-1H (500 MHz, CDCh) 5: 8.13 (s, 1H), 7.42 (s, 1H), 7.06 (s, 1H), 5.40-5.45 (m, 1H), 4.75-4.85 (m, 1H), 2.45-2.54 (m, 2H), 1.58-2.06 (m, 7H), 0.90-1.58 (m, 19H), 1.06 (s, 3H), 0.92 (d, 3H, J=6.3 Hz), 0.87 (d, 6H, J=6.8 Hz), 0.69 (s, 3H).
(2) Síntesis de ácido 6-(4,4'-dimetoxitritil)hexanoico (compuesto 4)
A una solución en piridina (75 ml) de ácido 6-hidroxihexanoico (compuesto 3) (3.0 g, 23 mmol) secada por destilación azeotrópica y 4-dimetilaminopiridina (DMAP) (0.28 g, 0.1 eq.) se añadió cloruro de 4,4-dimetoxitritilo (DMTrCl) (7.8 g, 1.0 eq.) y la mezcla se agitó a temperatura ambiente durante 5 horas. Después de confirmar la desaparición del material de partida por TLC, se añadió metanol y la mezcla se agitó durante 30 min. El disolvente se evaporó mediante un evaporador y la solución se diluyó con diclorometano. Esta solución se lavó con solución acuosa saturada de hidrogenocarbonato de sodio y se lavó con salmuera saturada. La capa orgánica se secó sobre sulfato de sodio y el disolvente se evaporó. La mezcla se trituró con hexano y se secó a presión reducida para dar un aceite (7.8 g).
(3) Síntesis de (1 -((4-hidroxibutil)amino)-1 -oxo-6-(2,2,2-trifluoroacetamido)hexan-2-il)carbamato de t-butilo (compuesto 6)
A una solución en N,N-dimetilformamida (160 ml) de N-a-(t-butoxicarbonil)-N-s-trifluoroacetil-L-lisina (compuesto 5) (8.0 g, 24 mmol) se añadieron 4-amino-1-butanol (2.4 g, 1.2 eq.) y 1-hidroxibenzotriazol monohidrato (HOBt) (8.6 g, 2.4 eq.), y la mezcla se agitó a 0°C. Se añadió hidrocloruro de 1-etil-3-(3-dimetilaminopropil)carbodiimida (EDC) (5.4 g, 1.2 eq.) y la mezcla se agitó durante 30 min. La mezcla se agitó a temperatura ambiente durante la noche. El disolvente se evaporó de la solución de reacción mediante un evaporador. Al residuo obtenido se le añadió diclorometano y la mezcla se lavó con una solución acuosa saturada de hidrogenocarbonato de sodio y se lavó con salmuera saturada. La capa orgánica se secó sobre sulfato de sodio y el disolvente se evaporó a presión reducida. El residuo se lavó con hexano y el precipitado se recogió por filtración y se secó a presión reducida para dar una sustancia sólida (7.0 g, rendimiento de 73%). Los valores analíticos instrumentales del compuesto (6) se muestran a continuación.
RMN-1H (500 MHz, CDCla) 5: 7.16 (br, 1H), 6.77 (t, J= 5.4 Hz, 1H), 4.04 (m, 1H), 3.66 (d, J= 5.4 Hz, 2H), 3.37 (dd, J= 12.9, 6.3 Hz, 2H), 3.29 (dd, J= 12.4, 6.3 Hz, 2H), 1.84-1.79 (m, 2H), 1.66-1.56 (m, 6H), 1.44 (s, 9H), 1.41 -1.37 (m, 2H).
(4) Síntesis de (6-amino-1-((4-hidroxibutil)amino)-1-oxohexan-2-il)carbamato de t-butilo (compuesto 7)
A una solución en metanol (30 ml) del compuesto 6 (3.0 g, 7.2 mmol) se le añadió amoniaco acuoso (26.5 ml, 50 eq.) y la mezcla se agitó a temperatura ambiente durante un día. Además, se añadió amoniaco acuoso (26.5 ml, 50 eq.) y la mezcla se agitó a 40°C durante 7 horas. Una vez completada la reacción, el disolvente se evaporó a presión reducida. El residuo se secó a presión reducida para dar un aceite (2.3 g). Los valores analíticos instrumentales del compuesto (7) se muestran a continuación.
ESI-EM: m/z 318.25 [M+H]+
(5) Síntesis de (6-((4-hidroxibutil)amino)-6-oxohexano-1,5-diil)dicarbamato de t-butilo y (colest-5-eno-3p-ilo) (compuesto 8)
A una solución en piridina (100 ml) del compuesto 7 (2.3 g, 7.3 mmol) se añadieron el compuesto 2 (14 g, 4.0 eq.) y 4-dimetilaminopiridina (DMAP) (0.27 g, 0.3 eq.), y la mezcla se agitó a 40°C durante 5 días. El disolvente se evaporó mediante un evaporador y la solución se diluyó con diclorometano. Esta solución se lavó con solución acuosa saturada de hidrogenocarbonato de sodio y se lavó con salmuera saturada. La capa orgánica se secó sobre sulfato de sodio y el disolvente se evaporó. El residuo obtenido se purificó por cromatografía en columna de gel de sílice (eluyente diclorometano:metanol = 20:1) para dar una sustancia sólida (3.5 g, rendimiento 67%). Los valores analíticos instrumentales del compuesto (8) se muestran a continuación.
RMN-1H (500 MHz, CDCla) 5: 5.37 (s, 1H), 4.74 (m, 1H), 4.47 (m, 1H), 3.67 (m, 2H), 3.30 (m, 2H), 3.19-3.11 (m, 2H), 2.34 (d , 2H, J=6.3 Hz), 1.98 (m, 2H), 1.90-1.80 (m, 5H), 1.65-1.00 (m, 38H), 0.99 (s, 3H), 0.92 (d, 3H, J=6.3 Hz), 0.87 (d, 6H, J=6.8 Hz), 0.69 (s, 3H).
ESI-EM: m/z 730.59 [M+H]+, 752.57 [M+Na]+, 1460.19 [2 M+H]+, 1482.16 [2 M+Na]+
(6) Síntesis de (5-amino-6-((4-hidroxibutil)amino)-6-oxohexil)carbamato de colest-5-eno-3p-ilo (compuesto 9)
Se añadió el compuesto 8 (3.4 g, 4.7 mmol) a una solución de ácido clorhídrico/metanol 2 M (150 ml) y la mezcla se agitó a temperatura ambiente durante 3 h. Una vez completada la reacción, el disolvente se evaporó a presión reducida. El residuo se trituró con hexano y se secó a presión reducida para dar una sustancia sólida (2.7 g,
rendimiento de 93%). Los valores analíticos instrumentales del compuesto (9) se muestran a continuación.
ESI-EM: m/z 630.54 [M+H]+, 1460.07 [2 M+H]+
(7) Síntesis de (5-(6-(4,4'-dimetoxitritil)hexanamida)-6-((4-hidroxibutil)amino)-6-oxohexil)carbamato de colest-5-eno-3p-ilo (compuesto 10)
A una solución en N,N-dimetilformamida (90 ml) del compuesto 9 (2.5 g, 4.0 mmol) se le añadió el compuesto 4 (2.6 g, 1.5 eq.), 1 -hidroxibenzotriazol monohidrato (HOBt) (1.8 g, 3.0 eq.) y trietilamina (1.2 g, 3.0 eq.), y la mezcla se agitó a 0°C. Se añadió hidrocloruro de 1 -etil-3-(3-dimetilaminopropil)carbodiimida (EDC) (1.1 g, 1.5 eq.) y la mezcla se agitó durante 30 min. Luego, la mezcla se agitó a temperatura ambiente durante la noche. El disolvente se evaporó de la solución de reacción mediante un evaporador. Al residuo obtenido se le añadió diclorometano y la mezcla se lavó con una solución acuosa saturada de hidrogenocarbonato de sodio y se lavó con salmuera saturada. La capa orgánica se secó sobre sulfato de sodio y el disolvente se evaporó a presión reducida. El residuo obtenido se purificó por cromatografía en columna de gel de sílice (eluyente acetato de etilo piridina al 0.05% ^ acetato de etilo:metanol (30:1) piridina al 0.05%) para dar una sustancia sólida (2.0 g, rendimiento de 50%). Los valores analíticos instrumentales del compuesto (10) se muestran a continuación.
RMN-1H (500 MHz, CDCla) 5: 7.42-7.41 (m, 2H), 7.32-7.26 (m, 6H), 7.21-7.18 (m, 1H), 6.81 (d, J= 8.8 Hz, 4H), 5.37 (s, 1H), 4.79 (m, 1H), 4.32 (m, 1H), 3.78 (s, 6H), 3.64-3.61 (m, 2H), 3.29-3.25 (m, 2H), 3.18-3.09 (m, 2H), 3.02 (t , J= 6.6 Hz, 2H), 2.35-2.26 (m, 2H), 2.19 (t, J= 7.6 Hz, 2H), 2.06-1.58 (m, 9H), 1.58-0.90 (m, 33H), 0.99 (s, 3H), 0.92 (d, 3H, J=6.3 Hz), 0.87 (d, 6H, J=6.8 Hz), 0.69 (s, 3H).
ESI-EM: m/z 1068.72 [M+Na]+, 1084.71 [M+K]+
(8) Síntesis de (5-(6-(4,4'-dimetoxitritil)hexanamida)-6-((4-(((2-cianoetoxi)(diisopropilamino)fosfino)oxi)butilo)amino)-6-oxohexil)carbamato de colest-5-eno-3p-ilo (compuesto 11)
A una solución en diclorometano (8 ml) del compuesto 10 (2.3 g, 2.2 mmol) secada por destilación azeotrópica se añadió tetrazolida de diisopropilamonio (DIPAT) (0.45 g, 1.2 eq.). Se añadió una solución en diclorometano (2 ml) de 2-cianoetoxi-N,N,N',N'-tetraisopropil-fosforodiamidita (0.80 g, 1.2 eq.) y la mezcla se agitó a 40°C durante 3 horas. La mezcla se diluyó con diclorometano y se lavó con solución acuosa saturada de hidrogenocarbonato de sodio y salmuera saturada. La capa orgánica se secó sobre sulfato de sodio y el disolvente se evaporó. El residuo se sometió a cromatografía en columna (eluyente n-hexano:acetato de etilo (1:2) trietilamina al 0.1%) usando aminosílice para dar una sustancia sólida (2.2 g, rendimiento de 81%). Los valores analíticos instrumentales del compuesto (11) se muestran a continuación.
RMN-1H (500 MHz, CDCla) 5: 7.43-7.41 (m, 2H), 7.32-7.25 (m, 6H), 7.21-7.17 (m, 1H), 6.81 (d, J= 8.8 Hz, 4H), 5.36 (s, 1H), 4.78 (m, 1H), 4.34 (m, 1H), 3.78 (s, 6H), 3.70-3.55 (m, 6H), 3.28-3.23 (m, 2H), 3.13-3.09 (m, 2H), 3.02 (t , J= 6.6 Hz, 2H), 2.64 (t, J= 6.5 Hz, 2H), 2.19 (t, J= 7.6 Hz, 2H), 2.00-1.78 (m, 6H), 1.65-0.90 (m, 38H), 1.18-1.16 (m, 12H), 0.99 (s, 3H), 0.92 (d, 3H, J=6.3 Hz), 0.87 (d, 6H, J=6.8 Hz), 0.67 (s, 3H). RMN-31P (202 MHz, CDCta): 5=148.074, 147.913
ESI-EM: m/z 1268.85 [M+Na]+, 1284.82 [M+K]+
Ejemplo de referencia 5: Síntesis de la forma de éster activo de ácido graso
De acuerdo con el siguiente esquema 9, se sintetizó el éster de N-hidroxisuccinimida del ácido mirístico (C14-NHS), éster de N-hidroxisuccinimida del ácido palmítico (C16-NHS) o éster de N-hidroxisuccinimida del ácido esteárico (C18-NHS). Además, de acuerdo con el siguiente esquema 10, se sintetizó el éster de N-hidroxisuccinimida del ácido oleico (C 18:1 -NHS).
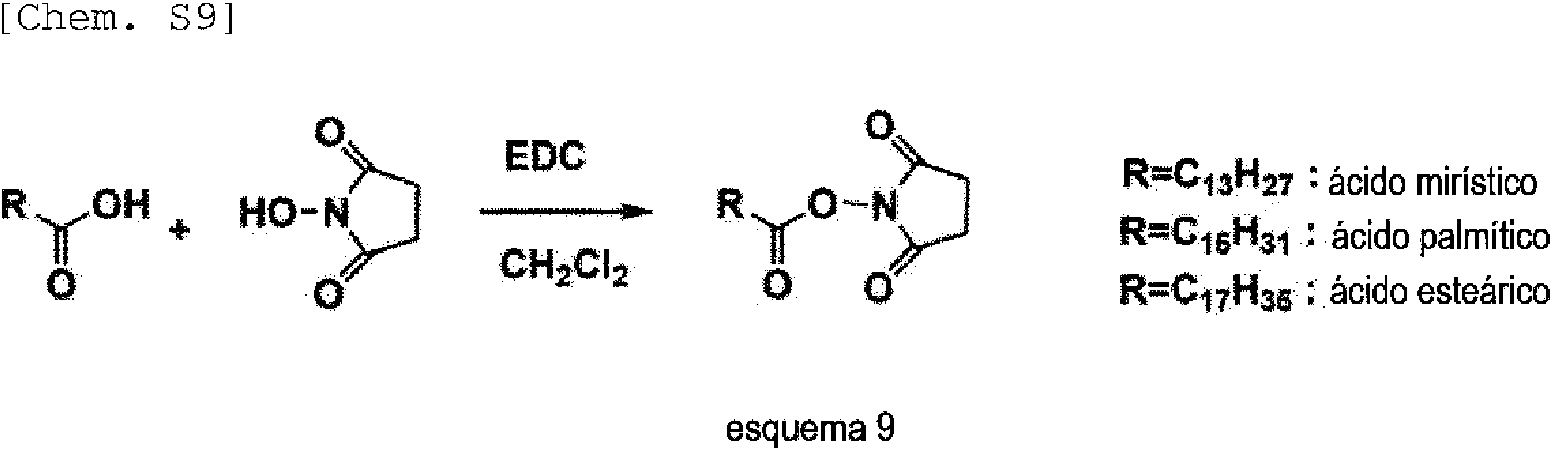

Síntesis del éster de N-hidroxisuccinimida del ácido mirístico (C14-NHS)
Se disolvió ácido mirístico (1.5 g, 6.6 mmol) en diclorometano (30 ml) y se agitó la mezcla. A esta solución se añadieron N-hidroxisuccinimida (0.91 g, 1.2 eq.) e hidrocloruro de 1-etil-3-(3-dimetilaminopropil)carbodiimida (EDC) (1.5 g, 1.2 eq.), y la mezcla se agitó durante la noche. Después de lavar dos veces con agua, la mezcla se lavó una vez con salmuera saturada, se secó sobre sulfato sódico y el disolvente se evaporó a presión reducida. El residuo obtenido se purificó por cromatografía en columna de gel de sílice (acetato de etilo/hexano = 1/3) para dar el producto objeto (1.4 g, rendimiento de 67%). Los resultados de la medición de RMN del éster de N-hidroxisuccinimida del ácido mirístico obtenido (C14-NHS) se muestran a continuación.
Éster de N-hidroxisuccinimida del ácido mirístico (C14-NHS): RMN 1H (CDCta) 5: 2.83 (4H, s), 2.60 (2H, t, J=7.6Hz), 1.74 (2H, q, J=7.6 Hz), 1.44 (2H, q, J=6.9 Hz), 1.48-1.22 (18H, m), 0.88 (3H, t, J=6.8 Hz).
Síntesis del éster de N-hidroxisuccinimida del ácido palmítico (C16-NHS)
Se disolvió ácido palmítico (6.0 g, 23 mmol) en diclorometano (110 ml) y se agitó la mezcla. A esta solución se añadieron N-hidroxisuccinimida (3.2 g, 1.2 eq.) e hidrocloruro de 1 -etil-3-(3-dimetilaminopropil)carbodiimida (EDC) (5.4 g, 1.2 eq.), y la mezcla se agitó durante la noche. Después de lavar dos veces con agua, la mezcla se lavó una vez con salmuera saturada, se secó sobre sulfato sódico y el disolvente se evaporó a presión reducida. El residuo obtenido se purificó por cromatografía en columna de gel de sílice (acetato de etilo/hexano = 1/2) para dar el producto objeto (7.8 g, rendimiento de 94%). Los resultados de la medición de RMN del éster de N-hidroxisuccinimida del ácido palmítico obtenido (C16-NHS) se muestran a continuación.
éster de N-hidroxisuccinimida del ácido palmítico (C16-NHS):
RMN-1H (CDCla) 5: 2.84 (4H, s), 2.60 (2H, t, J=7.6Hz), 1.74 (2H, q, J=7.6Hz), 1.38 (2H, q, J=6.9Hz), 1.43-1.20 (m, 22H), 0.88 (3H, t, J=6.8Hz).
Síntesis del éster de N-hidroxisuccinimida del ácido esteárico (C18-NHS)
Se disolvió ácido esteárico (3.0 g, 11 mmol) en diclorometano (100 ml) y se agitó la mezcla. A esta solución se añadieron N-hidroxisuccinimida (1.5 g, 1.2 eq.) e hidrocloruro de 1 -etil-3-(3-dimetilaminopropil)carbodiimida (EDC) (2.4 g, 1.2 eq.), y la mezcla se agitó durante 2 días. Después de lavar dos veces con agua, la mezcla se lavó una vez con salmuera saturada, se secó sobre sulfato sódico y el disolvente se evaporó a presión reducida. El residuo obtenido se purificó por cromatografía en columna de gel de sílice (acetato de etilo/hexano = 1/3) para dar el producto objeto (2.8 g, rendimiento de 70%). Los resultados de la medición de RMN del éster de N-hidroxisuccinimida del ácido esteárico obtenido (C18-NHS) se muestran a continuación.
Éster de N-hidroxisuccinimida del ácido esteárico (C18-NHS):
RMN-1H (CDCla) 5: 2.84 (4H, m), 2.60 (2H, t, J=7.6 Hz), 1.74 (2H, q, J=7.6 Hz), 1.38 (2H, q, J=6.9 Hz), 1.43-1.20 (m, 26H), 0.88 (3H, t, J=6.8 Hz).
Síntesis del éster de N-hidroxisuccinimida del ácido oleico (C18:1 -NHS)
Se disolvió ácido oleico (4.0 g, 14 mmol) en diclorometano (70 ml) y se agitó la mezcla. A esta solución se añadieron N-hidroxisuccinimida (2.0 g, 1.2 eq.) e hidrocloruro de 1-etil-3-(3-dimetilaminopropil)carbodiimida (EDC) (3.3 g, 1.2 eq.), y la mezcla se agitó durante la noche. Después de lavar dos veces con agua, la mezcla se lavó una vez con salmuera saturada, se secó sobre sulfato sódico y el disolvente se evaporó a presión reducida. El residuo obtenido se purificó por cromatografía en columna de gel de sílice (acetato de etilo/hexano = 1/3) para dar el producto objeto (5.2 g, rendimiento de 97%). Los resultados de la medición de RMN del éster de N-hidroxisuccinimida del ácido oleico obtenido (C18:1-NHS) se muestran a continuación.
éster de N-hidroxisuccinimida del ácido oleico (C18:1-NHS):
RMN-1H (CDCta) 5: 5.35 (2H, m), 2.83 (4H, s), 2.60 (2H, t, J=7.6 Hz), 2.01 (4H, m), 1.75 (2H, q, J=7.6 Hz), 1.41- 1.27 (20 H, m), 0.88 (3H, t, J = 6.8 Hz).
Claims (14)
1. Una molécula de ácido nucleico monocatenario para inhibir la expresión de un gen diana, que consiste en una región (X), una región conectora (Lx) y una región (Xc), en donde
dicha región (X) es complementaria de dicha región (Xc),
al menos una de dicha región (X) y dicha región (Xc) comprende una secuencia inhibidora de la expresión que inhibe la expresión del gen diana,
dicha región conectora (Lx) comprende la siguiente fórmula (I-4):

(en donde n es un número entero en el intervalo de 0 a 30 y m es un número entero en el intervalo de 0 a 30), una sustancia biorrelacionada que tiene una función de suministro se une a dicha región conectora (Lx) de la molécula de ácido nucleico monocatenario para inhibir la expresión de un gen diana, y
dicha sustancia biorrelacionada es ácido esteárico.
2. La molécula de ácido nucleico monocatenario según la reivindicación 1, en donde dicha fórmula (1 -4) es la siguiente fórmula (I-4a):

3. La molécula de ácido nucleico monocatenario según la reivindicación 1 o la reivindicación 2, en donde un número de bases (X) de dicha región (X) y un número de bases (Xc) de dicha región (Xc) satisfacen las siguientes condiciones de la fórmula (1) o la fórmula (2):
X>Xc ■ ■ ■(1)
X-Xc ■ ■ ■(2) , opcionalmente
(a) en donde el número de bases (X) de dicha región (X) y el número de bases (Xc) de dicha región (Xc) satisfacen la siguiente fórmula (3):
X-Xc=l, 2 o 3 — (3) ; y/0
(b) en donde el número de bases (Xc) de dicha región (Xc) es 19 - 30; y/o
(c) que es una molécula de ARN; y/o
(d) en donde el número total de bases de dicha molécula de ácido nucleico monocatenario no es inferior a 38.
4. La molécula de ácido nucleico monocatenario según una cualquiera de las reivindicaciones 1 a 3:
(a) que comprende al menos un resto modificado; y/o
(b) que comprende un isótopo estable.
5. La molécula de ácido nucleico monocatenario según una cualquiera de las reivindicaciones 1 a 4, en donde: (a) dicha secuencia inhibidora de la expresión es una secuencia de miARN madura; o
(b) dicha región (X) y dicha región (Xc) son respectivamente:
(1) SEQ ID NO: 29 y SEQ ID NO: 37, o
(2) SEQ ID NO: 31 y SEQ ID NO: 38.
6. Una composición para inhibir la expresión de un gen diana, que comprende la molécula de ácido nucleico monocatenario según una cualquiera de las reivindicaciones 1 a 5.
7. Una composición farmacéutica que comprende la molécula de ácido nucleico monocatenario según una cualquiera de las reivindicaciones 1 a 5.
8. La composición farmacéutica según la reivindicación 7, para usar en un método para tratar la inflamación.
9. Un método in vitro para inhibir la expresión de un gen diana, que comprende usar la molécula de ácido nucleico monocatenario según una cualquiera de las reivindicaciones 1 a 5.
10. El método in vitro según la reivindicación 9, en donde
(a) el método comprende una etapa de administrar dicha molécula de ácido nucleico monocatenario a una célula, tejido u órgano; y/o
(b) la expresión del gen es inhibida por interferencia de ARN.
11. Uso del ácido nucleico según una cualquiera de las reivindicaciones 1 a 5, en un método in vitro para inhibir la expresión de un gen diana.
12. El uso según la reivindicación 11, en donde
(a) el método comprende una etapa de administrar dicha molécula de ácido nucleico monocatenario a una célula, tejido u órgano; y/o
(b) la expresión del gen es inhibida por interferencia de ARN.
13. El método in vitro según la reivindicación 9, en donde la molécula de ácido nucleico monocatenario induce interferencia de ARN.
14. Una molécula de ácido nucleico para uso en el tratamiento de una enfermedad, en donde dicha molécula de ácido nucleico es la molécula de ácido nucleico monocatenario según una cualquiera de las reivindicaciones 1 a 5, y dicha molécula de ácido nucleico monocatenario comprende, como dicha secuencia inhibidora de la expresión, una secuencia que inhibe la expresión de un gen que causa dicha enfermedad.
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2015065770 | 2015-03-27 | ||
| PCT/JP2016/059779 WO2016158809A1 (ja) | 2015-03-27 | 2016-03-26 | デリバリー機能と遺伝子発現制御能を有する一本鎖核酸分子 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| ES2926369T3 true ES2926369T3 (es) | 2022-10-25 |
Family
ID=57005807
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| ES16772690T Active ES2926369T3 (es) | 2015-03-27 | 2016-03-26 | Molécula de ácido nucleico monocatenario que tiene función de suministro y capacidad de control de la expresión génica |
Country Status (7)
| Country | Link |
|---|---|
| US (1) | US11142769B2 (es) |
| EP (1) | EP3276003B1 (es) |
| JP (2) | JP6602847B2 (es) |
| CN (1) | CN108064289A (es) |
| ES (1) | ES2926369T3 (es) |
| HK (1) | HK1244031A1 (es) |
| WO (1) | WO2016158809A1 (es) |
Families Citing this family (10)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP3088524A4 (en) | 2013-12-26 | 2017-08-09 | Tokyo Medical University | Artificial mimic mirna for controlling gene expression, and use of same |
| MX2016008518A (es) | 2013-12-27 | 2017-01-26 | Bonac Corp | Micro-acido ribonucleico (micro-arn) concordante artificial para controlar la expresion genetica y uso del mismo. |
| RU2740032C2 (ru) | 2014-12-27 | 2020-12-30 | Бонак Корпорейшн | ВСТРЕЧАЮЩИЕСЯ В ПРИРОДЕ миРНК ДЛЯ КОНТРОЛИРОВАНИЯ ЭКСПРЕССИИ ГЕНОВ И ИХ ПРИМЕНЕНИЕ |
| SG11201913541QA (en) | 2017-07-28 | 2020-02-27 | Kyorin Pharmaceutical Co Ltd | Therapeutic agent for fibrosis |
| TWI830718B (zh) * | 2018-02-09 | 2024-02-01 | 日商住友化學股份有限公司 | 核酸分子之製造方法 |
| MX2021007271A (es) * | 2018-12-21 | 2021-07-15 | Onxeo | Nuevas moleculas de acido nucleico conjugado y sus usos. |
| KR20220143063A (ko) * | 2020-02-19 | 2022-10-24 | 남미 테라퓨틱스, 인크. | 암의 치료에 유용한 TGFβ 길항제 전구약물을 함유하는 제제화된 및/또는 공동-제제화된 리포솜 조성물 및 그의 방법 |
| JPWO2021193954A1 (es) * | 2020-03-27 | 2021-09-30 | ||
| CN113621003B (zh) * | 2021-09-10 | 2023-02-03 | 国科温州研究院(温州生物材料与工程研究所) | 一种制备有机分子共价修饰的功能化核酸材料的方法及其应用 |
| CN114249791A (zh) * | 2021-12-27 | 2022-03-29 | 北京工商大学 | 一种甾醇衍生的酰胺基寡肽型表面活性剂及其制备方法 |
Family Cites Families (107)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| DE873543C (de) | 1942-10-28 | 1953-04-16 | Basf Ag | Verfahren zur Herstellung von hydroxyl- bzw. sulfhydryl-gruppenhaltigen Dicarbaminsaeureestern |
| US3687808A (en) | 1969-08-14 | 1972-08-29 | Univ Leland Stanford Junior | Synthetic polynucleotides |
| US4550163A (en) | 1979-02-05 | 1985-10-29 | Abbott Laboratories | Ligand analog-irreversible enzyme inhibitor conjugates |
| US20030232355A1 (en) | 1992-05-22 | 2003-12-18 | Isis Pharmaceuticals, Inc. | Double-stranded peptide nucleic acids |
| US5631148A (en) | 1994-04-22 | 1997-05-20 | Chiron Corporation | Ribozymes with product ejection by strand displacement |
| GB9621367D0 (en) | 1996-10-14 | 1996-12-04 | Isis Innovation | Chiral peptide nucleic acids |
| US6197557B1 (en) | 1997-03-05 | 2001-03-06 | The Regents Of The University Of Michigan | Compositions and methods for analysis of nucleic acids |
| EP1013770A1 (en) | 1998-12-23 | 2000-06-28 | Université Louis Pasteur de Strasbourg | Non-viral transfection vector |
| FR2790757B1 (fr) | 1999-03-09 | 2003-08-01 | Bioalliance Pharma | Oligonucleotides contenant une sequence antisens stabilises par une structure secondaire et compositions pharmaceutiques les contenant. |
| US6852334B1 (en) | 1999-04-20 | 2005-02-08 | The University Of British Columbia | Cationic peg-lipids and methods of use |
| US7833992B2 (en) | 2001-05-18 | 2010-11-16 | Merck Sharpe & Dohme | Conjugates and compositions for cellular delivery |
| US6962906B2 (en) | 2000-03-14 | 2005-11-08 | Active Motif | Oligonucleotide analogues, methods of synthesis and methods of use |
| DK1412517T3 (da) | 2001-03-09 | 2007-03-05 | Boston Probes Inc | Fremgangsmåder, kits og sammensætninger af kombinationsoligomerer |
| EP1627061B1 (en) | 2001-05-18 | 2009-08-12 | Sirna Therapeutics, Inc. | RNA INTERFERENCE MEDIATED INHIBITION OF GENE EXPRESSION USING CHEMICALLY MODIFIED SHORT INTERFERING NUCLEIC ACID (siNA) |
| US6905827B2 (en) | 2001-06-08 | 2005-06-14 | Expression Diagnostics, Inc. | Methods and compositions for diagnosing or monitoring auto immune and chronic inflammatory diseases |
| CA2465129A1 (en) | 2001-10-29 | 2003-05-08 | Mcgill University | Acyclic linker-containing oligonucleotides and uses thereof |
| AU2003219900A1 (en) | 2002-02-22 | 2003-09-09 | James R. Eshleman | Antigene locks and therapeutic uses thereof |
| JP2005521393A (ja) | 2002-03-20 | 2005-07-21 | マサチューセッツ インスティテュート オブ テクノロジー | Hiv治療 |
| DK3222724T3 (en) | 2002-08-05 | 2018-12-03 | Silence Therapeutics Gmbh | ADDITIONALLY UNKNOWN FORMS OF INTERFERRING RNA MOLECULES |
| US20040058886A1 (en) | 2002-08-08 | 2004-03-25 | Dharmacon, Inc. | Short interfering RNAs having a hairpin structure containing a non-nucleotide loop |
| US6936651B2 (en) | 2002-12-17 | 2005-08-30 | E. I. Du Pont De Nemours And Company | Compatibility improvement in crystalline thermoplastics with mineral fillers |
| EP1608735A4 (en) | 2003-04-03 | 2008-11-05 | Alnylam Pharmaceuticals | RNAI CONJUGATES |
| JP2007516695A (ja) | 2003-06-12 | 2007-06-28 | アプレラ コーポレイション | ユニバーサル塩基アナログを含む組合せ核酸塩基オリゴマーならびにこれらを作製する方法および使用する方法 |
| US8106180B2 (en) | 2003-08-07 | 2012-01-31 | Whitehead Institute For Biomedical Research | Methods and products for expression of micro RNAs |
| EP1669450B1 (en) | 2003-09-30 | 2011-11-09 | AnGes MG, Inc. | Staple type oligonucleotide and drug comprising the same |
| EP1680439A2 (en) | 2003-10-14 | 2006-07-19 | Kernel Biopharma Inc. | Dual phase-pna conjugates for the delivery of pna through the blood brain barrier |
| US20050209141A1 (en) | 2003-10-17 | 2005-09-22 | Silver Randi B | Mast cell-derived renin |
| CA2572151A1 (en) | 2004-06-30 | 2006-08-24 | Alnylam Pharmaceuticals, Inc. | Oligonucleotides comprising a non-phosphate backbone linkage |
| AU2005276245C1 (en) | 2004-08-23 | 2015-02-26 | Sylentis S.A.U. | Treatment of eye disorders characterized by an elevated introacular pressure by siRNAs |
| JP5087924B2 (ja) | 2004-08-26 | 2012-12-05 | 日本新薬株式会社 | ガラクトース誘導体、薬物担体及び医薬組成物 |
| EP1789551A2 (en) | 2004-08-31 | 2007-05-30 | Sylentis S.A.U. | Methods and compositions to inhibit p2x7 receptor expression |
| BRPI0516874A (pt) | 2004-10-12 | 2008-09-23 | Univ Rockefeller | micrornas |
| ES2503765T3 (es) | 2004-11-12 | 2014-10-07 | Asuragen, Inc. | Procedimientos y composiciones que implican miARN y moléculas inhibidoras de miARN |
| BRPI0519690A2 (pt) | 2004-12-30 | 2009-03-03 | Todd M Hauser | composiÇÕes e mÉtodos para modular a expressço de genes usando oligonucleotÍdeos autoprotegidos |
| CA2638797A1 (en) | 2006-03-01 | 2007-09-07 | Nippon Shinyaku Co., Ltd. | Galactose derivative, drug carrier and medicinal composition |
| WO2007143315A2 (en) | 2006-05-05 | 2007-12-13 | Isis Pharmaceutical, Inc. | Compounds and methods for modulating expression of pcsk9 |
| CA2653941C (en) | 2006-05-31 | 2013-01-08 | The Regents Of The University Of California | Substituted amino purine derivatives and uses thereof |
| EP1890152A1 (en) | 2006-08-14 | 2008-02-20 | Charite Universitätsmedizin-Berlin | Determination of renin/prorenin receptor activity |
| JP2008220366A (ja) | 2007-02-16 | 2008-09-25 | National Institute Of Advanced Industrial & Technology | 修飾型pna/rna複合体 |
| JP5145557B2 (ja) | 2007-03-01 | 2013-02-20 | 財団法人ヒューマンサイエンス振興財団 | マイクロrnaを有効成分として含有する腫瘍増殖抑制剤、および癌治療用医薬組成物 |
| JP5759673B2 (ja) | 2007-03-21 | 2015-08-05 | ブルックヘブン サイエンス アソシエイツ,エルエルシー | 組み合わされたヘアピン−アンチセンス組成物および発現を調節するための方法 |
| CN101121934B (zh) | 2007-04-11 | 2011-12-07 | 哈尔滨医科大学 | 多靶点miRNA反义核苷酸的制备方法 |
| US8399248B2 (en) | 2007-05-03 | 2013-03-19 | Merck Sharp & Dohme Corp. | Methods of using MIR34 as a biomarker for TP53 functional status |
| JP5296328B2 (ja) | 2007-05-09 | 2013-09-25 | 独立行政法人理化学研究所 | 1本鎖環状rnaおよびその製造方法 |
| US20090123501A1 (en) * | 2007-05-17 | 2009-05-14 | Baylor College Of Medicine | Inhibition of the sh2-domain containing protein tyr-phosphatase, shp-1, to enhance vaccines |
| EP2155911B1 (en) | 2007-05-23 | 2013-08-28 | Dharmacon, Inc. | Micro-RNA scaffolds, non-naturally occurring micro-RNAs, and methods for optimizing non-naturally occurring micro-RNAs |
| DK2164967T3 (en) | 2007-05-31 | 2015-10-19 | Univ Iowa Res Found | Reduction of off-target rna interferenstoksicitet |
| US20110212075A1 (en) | 2007-06-25 | 2011-09-01 | Siemens Aktiengesellschaft | Screening method for polymorphic markers in htra1 gene in neurodegenerative disorders |
| US9328345B2 (en) | 2007-08-27 | 2016-05-03 | 1 Globe Health Institute Llc | Compositions of asymmetric interfering RNA and uses thereof |
| WO2009048932A2 (en) | 2007-10-09 | 2009-04-16 | Children's Medical Center Corporation | Methods to regulate mirna processing by targeting lin-28 |
| AU2008309520A1 (en) | 2007-10-12 | 2009-04-16 | The Provost, Fellows And Scholars Of The College Of The Holy And Undivided Trinity Of Queen Elizabeth, Near Dublin | Method for opening tight junctions |
| TW200927177A (en) | 2007-10-24 | 2009-07-01 | Nat Inst Of Advanced Ind Scien | Lipid-modified double-stranded RNA having potent RNA interference effect |
| US20090131358A1 (en) | 2007-11-15 | 2009-05-21 | Alcon Research, Ltd. | LOW DENSITY LIPOPROTEIN RECEPTOR-MEDIATED siRNA DELIVERY |
| WO2009074076A1 (fr) | 2007-11-29 | 2009-06-18 | Suzhou Ribo Life Science Co., Ltd | Molécule complexe interférant avec l'expression de gènes cibles, et ses méthodes de préparation |
| CA3043911A1 (en) | 2007-12-04 | 2009-07-02 | Arbutus Biopharma Corporation | Targeting lipids |
| US20110159586A1 (en) | 2007-12-07 | 2011-06-30 | Halo-Bio Rnai Therapeutics, Inc. | Compositions and methods for modulating gene expression using asymmetrically-active precursor polynucleotides |
| EP2256191A4 (en) | 2008-02-15 | 2011-07-06 | Riken | SINGLE-STRANDED CYCLIC NUCLEIC ACID COMPLEX AND METHOD FOR PRODUCING SAME |
| JP5906508B2 (ja) | 2008-03-31 | 2016-04-20 | 国立研究開発法人産業技術総合研究所 | Rna干渉効果が高い2本鎖脂質修飾rna |
| WO2009126563A1 (en) | 2008-04-11 | 2009-10-15 | The University Of North Carolina At Chapel Hill | Methods and compositions for the regulation of microrna processing |
| WO2009143619A1 (en) | 2008-05-27 | 2009-12-03 | Chum | Methods of treating or preventing obesity and obesity-related hypertension |
| WO2010056737A2 (en) | 2008-11-11 | 2010-05-20 | Mirna Therapeutics, Inc. | Methods and compositions involving mirnas in cancer stem cells |
| WO2010058824A1 (ja) | 2008-11-19 | 2010-05-27 | 国立大学法人岐阜大学 | 間葉系細胞の分化を調節するための薬剤及びその利用 |
| EP2411518A2 (en) * | 2009-03-27 | 2012-02-01 | Merck Sharp&Dohme Corp. | Rna interference mediated inhibition of the high affinity ige receptor alpha chain (fcerla) gene expression using short interfering nucleic acid (sina) |
| CN102575252B (zh) | 2009-06-01 | 2016-04-20 | 光环生物干扰疗法公司 | 用于多价rna干扰的多核苷酸、组合物及其使用方法 |
| US8871730B2 (en) * | 2009-07-13 | 2014-10-28 | Somagenics Inc. | Chemical modification of short small hairpin RNAs for inhibition of gene expression |
| JP2012533587A (ja) | 2009-07-22 | 2012-12-27 | セニックス バイオサイエンス ゲーエムベーハー | 自然に存在する細胞内輸送経路を介して化合物を送達するための送達システム及びコンジュゲート |
| US9096850B2 (en) | 2009-08-24 | 2015-08-04 | Sirna Therapeutics, Inc. | Segmented micro RNA mimetics |
| US20110052666A1 (en) | 2009-09-03 | 2011-03-03 | Medtronic, Inc. | Compositions, Methods, and Systems for SIRNA Delivery |
| EP2496268A4 (en) | 2009-11-06 | 2013-06-19 | Univ Chung Ang Ind | GENE DELIVERY SYSTEMS BASED ON NANOPARTICLES |
| AU2010330814B2 (en) * | 2009-12-18 | 2017-01-12 | Acuitas Therapeutics Inc. | Methods and compositions for delivery of nucleic acids |
| SG181823A1 (en) | 2009-12-23 | 2012-07-30 | Max Planck Gesellschaft | Influenza targets |
| BR112012015755B1 (pt) | 2009-12-23 | 2021-06-22 | Novartis Ag | Lipídeo furtivo, e composição |
| IL265674B2 (en) * | 2010-03-24 | 2024-05-01 | Phio Pharm Corp | Rana disorder in cutaneous and fibrotic symptoms |
| CN101845071B (zh) | 2010-03-25 | 2012-02-01 | 北京欧凯纳斯科技有限公司 | 一种2’或3’偶联氨基酸的核苷衍生物、其制备方法及应用 |
| JP5555940B2 (ja) | 2010-04-14 | 2014-07-23 | 国立大学法人佐賀大学 | 増殖糖尿病網膜症の検出方法および予防・治療剤のスクリーニング方法 |
| EP3358014B1 (en) | 2010-04-19 | 2020-12-23 | TAGCyx Biotechnologies Inc. | Method for stabilizing functional nucleic acids |
| PL2561078T3 (pl) | 2010-04-23 | 2019-02-28 | Cold Spring Harbor Laboratory | Nowe, strukturalnie zaprojektowane shRNA |
| CN102918158B (zh) | 2010-05-31 | 2014-05-28 | 山东大学 | 与多囊卵巢综合征相关的snp、包含snp的芯片及其应用 |
| ES2550487T3 (es) | 2010-07-08 | 2015-11-10 | Bonac Corporation | Molécula de ácido nucleico monocatenario para controlar la expresión génica |
| US8785121B2 (en) | 2010-07-08 | 2014-07-22 | Bonac Corporation | Single-stranded nucleic acid molecule for controlling gene expression |
| US8618073B2 (en) | 2010-07-22 | 2013-12-31 | The University Of North Carolina At Chapel Hill | Use of miR-29 for cell protection |
| EP2628801B1 (en) | 2010-08-03 | 2015-01-07 | Bonac Corporation | Single-stranded nucleic acid molecule having nitrogen-containing alicyclic skeleton |
| US8691782B2 (en) | 2010-08-03 | 2014-04-08 | Bonac Corporation | Single-stranded nucleic acid molecule having nitrogen-containing alicyclic skeleton |
| KR20130100278A (ko) * | 2010-08-31 | 2013-09-10 | 머크 샤프 앤드 돔 코포레이션 | 올리고뉴클레오티드의 전달을 위한 신규 단일 화학 존재물 및 방법 |
| EP2647713B1 (en) | 2010-12-02 | 2018-02-21 | Daiichi Sankyo Company, Limited | Modified single-strand polynucleotide |
| CN102559666B (zh) | 2010-12-18 | 2013-12-25 | 中国科学院上海生命科学研究院 | 抑制植物病毒的人工miRNA及其构建和用途 |
| JP2014506791A (ja) | 2011-02-03 | 2014-03-20 | マーナ セラピューティクス インコーポレイテッド | miR−34の合成模倣体 |
| CN102784398B (zh) | 2011-05-16 | 2014-06-18 | 南京大学 | 内皮抑素作为递送系统和化学合成的rna干扰分子组成的组合物及应用 |
| WO2012161124A1 (ja) | 2011-05-20 | 2012-11-29 | 国立大学法人愛媛大学 | マイクロrna又はその発現系を含む組成物 |
| EP2527440A1 (en) | 2011-05-27 | 2012-11-28 | Institut Curie | Cancer treatment by combining DNA molecules mimicking double strand breaks with hyperthermia |
| JP2013055913A (ja) | 2011-09-09 | 2013-03-28 | Bonac Corp | 遺伝子発現制御のための一本鎖rna分子 |
| WO2013077446A1 (ja) | 2011-11-26 | 2013-05-30 | 株式会社ボナック | 遺伝子発現制御のための一本鎖核酸分子 |
| CN110055247A (zh) | 2012-01-07 | 2019-07-26 | 株式会社博纳克 | 具有氨基酸骨架的单链核酸分子 |
| JP2013153736A (ja) * | 2012-01-07 | 2013-08-15 | Bonac Corp | ペプチド骨格を有する一本鎖核酸分子 |
| EP3254700B1 (en) | 2012-03-04 | 2019-10-23 | Bonac Corporation | Micro-rna inhibitor |
| AR090905A1 (es) * | 2012-05-02 | 2014-12-17 | Merck Sharp & Dohme | Conjugados que contienen tetragalnac y peptidos y procedimientos para la administracion de oligonucleotidos, composicion farmaceutica |
| JP6126088B2 (ja) * | 2012-05-26 | 2017-05-10 | 株式会社ボナック | デリバリー機能を有する遺伝子発現制御用の一本鎖核酸分子 |
| EP2975938A4 (en) | 2013-03-15 | 2017-02-15 | Ohio State Innovation Foundation | Inhibitors of prmt5 and methods of their use |
| CN110317810A (zh) | 2013-05-22 | 2019-10-11 | 阿尔尼拉姆医药品有限公司 | Tmprss6 irna组合物及其使用方法 |
| WO2015093495A1 (ja) | 2013-12-16 | 2015-06-25 | 株式会社ボナック | TGF-β1遺伝子発現制御のための一本鎖核酸分子 |
| EP3088524A4 (en) | 2013-12-26 | 2017-08-09 | Tokyo Medical University | Artificial mimic mirna for controlling gene expression, and use of same |
| WO2015099188A1 (ja) | 2013-12-27 | 2015-07-02 | 株式会社ボナック | 遺伝子発現制御のための人工マッチ型miRNAおよびその用途 |
| MX2016008518A (es) | 2013-12-27 | 2017-01-26 | Bonac Corp | Micro-acido ribonucleico (micro-arn) concordante artificial para controlar la expresion genetica y uso del mismo. |
| US10119140B2 (en) | 2014-04-18 | 2018-11-06 | Board Of Regents Of The Nevada System Of Higher Education On Behalf Of The University Of Nevada, Reno | Methods for enhancing or decreasing the levels of MIR124 and MIR29 in subjects with muscular dystrophy |
| EA201692370A1 (ru) | 2014-05-22 | 2017-03-31 | Элнилэм Фармасьютикалз, Инк. | КОМПОЗИЦИИ иРНК АНГИОТЕНЗИНОГЕНА (AGT) И СПОСОБЫ ИХ ИСПОЛЬЗОВАНИЯ |
| RU2740032C2 (ru) | 2014-12-27 | 2020-12-30 | Бонак Корпорейшн | ВСТРЕЧАЮЩИЕСЯ В ПРИРОДЕ миРНК ДЛЯ КОНТРОЛИРОВАНИЯ ЭКСПРЕССИИ ГЕНОВ И ИХ ПРИМЕНЕНИЕ |
| JP6634095B2 (ja) | 2015-12-29 | 2020-01-22 | 国立大学法人北海道大学 | プロレニン遺伝子またはプロレニン受容体遺伝子の発現を抑制する一本鎖核酸分子およびその用途 |
-
2016
- 2016-03-26 JP JP2017509942A patent/JP6602847B2/ja not_active Expired - Fee Related
- 2016-03-26 EP EP16772690.0A patent/EP3276003B1/en active Active
- 2016-03-26 WO PCT/JP2016/059779 patent/WO2016158809A1/ja active Application Filing
- 2016-03-26 US US15/562,231 patent/US11142769B2/en active Active
- 2016-03-26 ES ES16772690T patent/ES2926369T3/es active Active
- 2016-03-26 CN CN201680019154.2A patent/CN108064289A/zh active Pending
-
2018
- 2018-03-14 HK HK18103546.3A patent/HK1244031A1/zh unknown
-
2019
- 2019-10-09 JP JP2019185954A patent/JP6883349B2/ja active Active
Also Published As
| Publication number | Publication date |
|---|---|
| JP6883349B2 (ja) | 2021-06-09 |
| US20180119151A1 (en) | 2018-05-03 |
| EP3276003A4 (en) | 2019-02-20 |
| EP3276003A1 (en) | 2018-01-31 |
| JP6602847B2 (ja) | 2019-11-06 |
| JPWO2016158809A1 (ja) | 2017-11-16 |
| WO2016158809A1 (ja) | 2016-10-06 |
| JP2020022475A (ja) | 2020-02-13 |
| HK1244031A1 (zh) | 2018-07-27 |
| EP3276003B1 (en) | 2022-07-20 |
| CN108064289A (zh) | 2018-05-22 |
| US11142769B2 (en) | 2021-10-12 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| ES2926369T3 (es) | Molécula de ácido nucleico monocatenario que tiene función de suministro y capacidad de control de la expresión génica | |
| AU2018363840B2 (en) | Nucleic acids for inhibiting expression of LPA in a cell | |
| ES2550487T3 (es) | Molécula de ácido nucleico monocatenario para controlar la expresión génica | |
| US10238752B2 (en) | Single-stranded nucleic acid molecule for regulating expression of gene having delivering function | |
| ES2805026T3 (es) | Acido nucleico unido a un glucoconjugado trivalente | |
| KR101674778B1 (ko) | 아미노산 골격을 갖는 단일-가닥 핵산 분자 | |
| ES2932295T3 (es) | Acidos nucleicos para inhibir la expresión de LPA en una célula | |
| EP3696269A1 (en) | Single-stranded nucleic acid molecule, and production method therefor | |
| WO2015093495A1 (ja) | TGF-β1遺伝子発現制御のための一本鎖核酸分子 | |
| JP2017046596A (ja) | TGF−β1遺伝子発現制御のための一本鎖核酸分子 | |
| EP3385272A1 (en) | Further novel oligonucleotide-ligand conjugates | |
| EP3235906B1 (en) | Single-stranded nucleic acid molecule for inhibiting tgf- beta 1 expression | |
| RU2822093C1 (ru) | Нуклеиновые кислоты для ингибирования экспрессии lpa в клетке |