RU2274643C2 - Выделенный оболочечный белок hcv, способ его получения и лекарство, вакцина, фармацевтическая композиция (варианты) его содержащие - Google Patents
Выделенный оболочечный белок hcv, способ его получения и лекарство, вакцина, фармацевтическая композиция (варианты) его содержащие Download PDFInfo
- Publication number
- RU2274643C2 RU2274643C2 RU2003130955/13A RU2003130955A RU2274643C2 RU 2274643 C2 RU2274643 C2 RU 2274643C2 RU 2003130955/13 A RU2003130955/13 A RU 2003130955/13A RU 2003130955 A RU2003130955 A RU 2003130955A RU 2274643 C2 RU2274643 C2 RU 2274643C2
- Authority
- RU
- Russia
- Prior art keywords
- hcv
- protein
- fragment
- envelope protein
- seq
- Prior art date
Links
- 108090000623 proteins and genes Proteins 0.000 title claims abstract description 273
- 102000004169 proteins and genes Human genes 0.000 title claims abstract description 265
- 238000000034 method Methods 0.000 title claims abstract description 60
- 229960005486 vaccine Drugs 0.000 title claims abstract description 28
- 239000003814 drug Substances 0.000 title claims abstract description 20
- 239000008194 pharmaceutical composition Substances 0.000 title claims abstract description 20
- 229940079593 drug Drugs 0.000 title claims abstract description 7
- -1 vaccine Substances 0.000 title description 19
- 241000711549 Hepacivirus C Species 0.000 claims abstract description 291
- 238000011282 treatment Methods 0.000 claims abstract description 23
- 208000015181 infectious disease Diseases 0.000 claims abstract description 17
- 230000001225 therapeutic effect Effects 0.000 claims abstract description 15
- 230000000069 prophylactic effect Effects 0.000 claims abstract description 11
- 235000018102 proteins Nutrition 0.000 claims description 249
- 101710091045 Envelope protein Proteins 0.000 claims description 151
- 101710188315 Protein X Proteins 0.000 claims description 151
- WQZGKKKJIJFFOK-QTVWNMPRSA-N D-mannopyranose Chemical compound OC[C@H]1OC(O)[C@@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-QTVWNMPRSA-N 0.000 claims description 118
- 239000012634 fragment Substances 0.000 claims description 105
- 210000004027 cell Anatomy 0.000 claims description 86
- 239000000203 mixture Substances 0.000 claims description 80
- 239000013598 vector Substances 0.000 claims description 68
- 108090000765 processed proteins & peptides Proteins 0.000 claims description 67
- 230000004988 N-glycosylation Effects 0.000 claims description 60
- 108010076504 Protein Sorting Signals Proteins 0.000 claims description 57
- 239000002245 particle Substances 0.000 claims description 57
- 241000235648 Pichia Species 0.000 claims description 56
- 241000282414 Homo sapiens Species 0.000 claims description 54
- 102000004196 processed proteins & peptides Human genes 0.000 claims description 50
- 238000012545 processing Methods 0.000 claims description 35
- 241000124008 Mammalia Species 0.000 claims description 34
- 230000015572 biosynthetic process Effects 0.000 claims description 25
- 239000002671 adjuvant Substances 0.000 claims description 23
- 150000007523 nucleic acids Chemical class 0.000 claims description 22
- 241000271566 Aves Species 0.000 claims description 20
- 108010014251 Muramidase Proteins 0.000 claims description 19
- 108010062010 N-Acetylmuramoyl-L-alanine Amidase Proteins 0.000 claims description 19
- 229960000274 lysozyme Drugs 0.000 claims description 19
- 239000004325 lysozyme Substances 0.000 claims description 19
- 235000010335 lysozyme Nutrition 0.000 claims description 19
- 102000039446 nucleic acids Human genes 0.000 claims description 19
- 108020004707 nucleic acids Proteins 0.000 claims description 19
- 239000007787 solid Substances 0.000 claims description 19
- 125000003275 alpha amino acid group Chemical group 0.000 claims description 18
- 230000006698 induction Effects 0.000 claims description 15
- 210000003527 eukaryotic cell Anatomy 0.000 claims description 13
- 238000004519 manufacturing process Methods 0.000 claims description 12
- DJQYYYCQOZMCRC-UHFFFAOYSA-N 2-aminopropane-1,3-dithiol Chemical group SCC(N)CS DJQYYYCQOZMCRC-UHFFFAOYSA-N 0.000 claims description 11
- 210000001744 T-lymphocyte Anatomy 0.000 claims description 11
- 230000028993 immune response Effects 0.000 claims description 11
- 230000001939 inductive effect Effects 0.000 claims description 11
- 230000000890 antigenic effect Effects 0.000 claims description 10
- 210000005253 yeast cell Anatomy 0.000 claims description 10
- 230000002163 immunogen Effects 0.000 claims description 9
- 238000002360 preparation method Methods 0.000 claims description 9
- 230000002860 competitive effect Effects 0.000 claims description 8
- 239000000178 monomer Substances 0.000 claims description 8
- 239000000758 substrate Substances 0.000 claims description 8
- 238000009007 Diagnostic Kit Methods 0.000 claims description 5
- 108700026244 Open Reading Frames Proteins 0.000 claims description 4
- 239000003937 drug carrier Substances 0.000 claims description 4
- 230000002265 prevention Effects 0.000 claims description 4
- 239000000539 dimer Substances 0.000 claims description 3
- OMLWNBVRVJYMBQ-YUMQZZPRSA-N Arg-Arg Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O OMLWNBVRVJYMBQ-YUMQZZPRSA-N 0.000 claims description 2
- JQFZHHSQMKZLRU-IUCAKERBSA-N Arg-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H](N)CCCN=C(N)N JQFZHHSQMKZLRU-IUCAKERBSA-N 0.000 claims description 2
- NPBGTPKLVJEOBE-IUCAKERBSA-N Lys-Arg Chemical compound NCCCC[C@H](N)C(=O)N[C@H](C(O)=O)CCCNC(N)=N NPBGTPKLVJEOBE-IUCAKERBSA-N 0.000 claims description 2
- NVGBPTNZLWRQSY-UWVGGRQHSA-N Lys-Lys Chemical compound NCCCC[C@H](N)C(=O)N[C@H](C(O)=O)CCCCN NVGBPTNZLWRQSY-UWVGGRQHSA-N 0.000 claims description 2
- 108010068380 arginylarginine Proteins 0.000 claims description 2
- 108010062796 arginyllysine Proteins 0.000 claims description 2
- 108010054155 lysyllysine Proteins 0.000 claims description 2
- 230000001131 transforming effect Effects 0.000 claims description 2
- 102100021696 Syncytin-1 Human genes 0.000 claims 25
- 102000016943 Muramidase Human genes 0.000 claims 3
- 239000000126 substance Substances 0.000 abstract description 21
- 230000000694 effects Effects 0.000 abstract description 8
- 238000003745 diagnosis Methods 0.000 abstract description 4
- 230000001976 improved effect Effects 0.000 abstract description 4
- 230000007721 medicinal effect Effects 0.000 abstract 1
- 238000011321 prophylaxis Methods 0.000 abstract 1
- 102100038132 Endogenous retrovirus group K member 6 Pro protein Human genes 0.000 description 126
- 235000001014 amino acid Nutrition 0.000 description 91
- 229940024606 amino acid Drugs 0.000 description 88
- 229920001542 oligosaccharide Polymers 0.000 description 85
- 150000001413 amino acids Chemical class 0.000 description 83
- 239000000047 product Substances 0.000 description 80
- 150000002482 oligosaccharides Chemical class 0.000 description 70
- 108700008783 Hepatitis C virus E1 Proteins 0.000 description 67
- 239000013612 plasmid Substances 0.000 description 64
- 238000003752 polymerase chain reaction Methods 0.000 description 62
- 238000011534 incubation Methods 0.000 description 56
- 239000000523 sample Substances 0.000 description 56
- 241000320412 Ogataea angusta Species 0.000 description 54
- 238000003776 cleavage reaction Methods 0.000 description 54
- 230000007017 scission Effects 0.000 description 54
- 238000006206 glycosylation reaction Methods 0.000 description 52
- 108020004414 DNA Proteins 0.000 description 50
- 230000013595 glycosylation Effects 0.000 description 50
- 102000053602 DNA Human genes 0.000 description 49
- 210000004962 mammalian cell Anatomy 0.000 description 45
- 125000000311 mannosyl group Chemical group C1([C@@H](O)[C@@H](O)[C@H](O)[C@H](O1)CO)* 0.000 description 43
- 238000010828 elution Methods 0.000 description 39
- RAXXELZNTBOGNW-UHFFFAOYSA-N imidazole Natural products C1=CNC=N1 RAXXELZNTBOGNW-UHFFFAOYSA-N 0.000 description 39
- 101710185720 Putative ethidium bromide resistance protein Proteins 0.000 description 38
- PXBFMLJZNCDSMP-UHFFFAOYSA-N 2-Aminobenzamide Chemical compound NC(=O)C1=CC=CC=C1N PXBFMLJZNCDSMP-UHFFFAOYSA-N 0.000 description 36
- LFQSCWFLJHTTHZ-UHFFFAOYSA-N Ethanol Chemical compound CCO LFQSCWFLJHTTHZ-UHFFFAOYSA-N 0.000 description 32
- 240000004808 Saccharomyces cerevisiae Species 0.000 description 32
- 235000014680 Saccharomyces cerevisiae Nutrition 0.000 description 32
- 238000006243 chemical reaction Methods 0.000 description 32
- QTBSBXVTEAMEQO-UHFFFAOYSA-N Acetic acid Chemical compound CC(O)=O QTBSBXVTEAMEQO-UHFFFAOYSA-N 0.000 description 31
- 241000700618 Vaccinia virus Species 0.000 description 31
- 239000000427 antigen Substances 0.000 description 31
- 108091007433 antigens Proteins 0.000 description 31
- 102000036639 antigens Human genes 0.000 description 31
- 108020004705 Codon Proteins 0.000 description 30
- 108010012864 alpha-Mannosidase Proteins 0.000 description 29
- 102000019199 alpha-Mannosidase Human genes 0.000 description 29
- 238000004458 analytical method Methods 0.000 description 28
- 239000000872 buffer Substances 0.000 description 28
- 238000000746 purification Methods 0.000 description 28
- 230000009257 reactivity Effects 0.000 description 28
- 238000002965 ELISA Methods 0.000 description 27
- LOKCTEFSRHRXRJ-UHFFFAOYSA-I dipotassium trisodium dihydrogen phosphate hydrogen phosphate dichloride Chemical compound P(=O)(O)(O)[O-].[K+].P(=O)(O)([O-])[O-].[Na+].[Na+].[Cl-].[K+].[Cl-].[Na+] LOKCTEFSRHRXRJ-UHFFFAOYSA-I 0.000 description 27
- 239000002953 phosphate buffered saline Substances 0.000 description 27
- 241000588724 Escherichia coli Species 0.000 description 25
- 238000001962 electrophoresis Methods 0.000 description 25
- 238000001262 western blot Methods 0.000 description 25
- DINOPBPYOCMGGD-VEDJBHDQSA-N Man(a1-2)Man(a1-2)Man(a1-3)[Man(a1-2)Man(a1-3)[Man(a1-2)Man(a1-6)]Man(a1-6)]Man(b1-4)GlcNAc(b1-4)GlcNAc Chemical compound O[C@@H]1[C@@H](NC(=O)C)C(O)O[C@H](CO)[C@H]1O[C@H]1[C@H](NC(C)=O)[C@@H](O)[C@H](O[C@H]2[C@H]([C@@H](O[C@@H]3[C@H]([C@@H](O)[C@H](O)[C@@H](CO)O3)O[C@@H]3[C@H]([C@@H](O)[C@H](O)[C@@H](CO)O3)O[C@@H]3[C@H]([C@@H](O)[C@H](O)[C@@H](CO)O3)O)[C@H](O)[C@@H](CO[C@@H]3[C@H]([C@@H](O[C@@H]4[C@H]([C@@H](O)[C@H](O)[C@@H](CO)O4)O[C@@H]4[C@H]([C@@H](O)[C@H](O)[C@@H](CO)O4)O)[C@H](O)[C@@H](CO[C@@H]4[C@H]([C@@H](O)[C@H](O)[C@@H](CO)O4)O[C@@H]4[C@H]([C@@H](O)[C@H](O)[C@@H](CO)O4)O)O3)O)O2)O)[C@@H](CO)O1 DINOPBPYOCMGGD-VEDJBHDQSA-N 0.000 description 24
- 241000235070 Saccharomyces Species 0.000 description 23
- 230000002441 reversible effect Effects 0.000 description 22
- 210000002966 serum Anatomy 0.000 description 22
- 239000003795 chemical substances by application Substances 0.000 description 21
- 150000002772 monosaccharides Chemical class 0.000 description 21
- PEDCQBHIVMGVHV-UHFFFAOYSA-N Glycerine Chemical compound OCC(O)CO PEDCQBHIVMGVHV-UHFFFAOYSA-N 0.000 description 20
- 239000002904 solvent Substances 0.000 description 20
- 241000235058 Komagataella pastoris Species 0.000 description 19
- OVRNDRQMDRJTHS-UHFFFAOYSA-N N-acelyl-D-glucosamine Natural products CC(=O)NC1C(O)OC(CO)C(O)C1O OVRNDRQMDRJTHS-UHFFFAOYSA-N 0.000 description 19
- MBLBDJOUHNCFQT-LXGUWJNJSA-N N-acetylglucosamine Natural products CC(=O)N[C@@H](C=O)[C@@H](O)[C@H](O)[C@H](O)CO MBLBDJOUHNCFQT-LXGUWJNJSA-N 0.000 description 19
- 239000000499 gel Substances 0.000 description 19
- 239000000463 material Substances 0.000 description 19
- 238000002264 polyacrylamide gel electrophoresis Methods 0.000 description 19
- 108091008146 restriction endonucleases Proteins 0.000 description 19
- 102000004190 Enzymes Human genes 0.000 description 18
- 108090000790 Enzymes Proteins 0.000 description 18
- OKKJLVBELUTLKV-UHFFFAOYSA-N Methanol Chemical compound OC OKKJLVBELUTLKV-UHFFFAOYSA-N 0.000 description 18
- 108010055059 beta-Mannosidase Proteins 0.000 description 18
- 229940088598 enzyme Drugs 0.000 description 18
- 238000002474 experimental method Methods 0.000 description 18
- 238000000855 fermentation Methods 0.000 description 18
- 230000004151 fermentation Effects 0.000 description 18
- 102100032487 Beta-mannosidase Human genes 0.000 description 17
- KWIUHFFTVRNATP-UHFFFAOYSA-N Betaine Natural products C[N+](C)(C)CC([O-])=O KWIUHFFTVRNATP-UHFFFAOYSA-N 0.000 description 17
- WQZGKKKJIJFFOK-GASJEMHNSA-N Glucose Natural products OC[C@H]1OC(O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-GASJEMHNSA-N 0.000 description 17
- 102100033468 Lysozyme C Human genes 0.000 description 17
- KWIUHFFTVRNATP-UHFFFAOYSA-O N,N,N-trimethylglycinium Chemical compound C[N+](C)(C)CC(O)=O KWIUHFFTVRNATP-UHFFFAOYSA-O 0.000 description 17
- 229960003237 betaine Drugs 0.000 description 17
- 150000001720 carbohydrates Chemical class 0.000 description 16
- 235000014633 carbohydrates Nutrition 0.000 description 16
- 125000000151 cysteine group Chemical class N[C@@H](CS)C(=O)* 0.000 description 16
- 238000004925 denaturation Methods 0.000 description 16
- 230000036425 denaturation Effects 0.000 description 16
- PGLTVOMIXTUURA-UHFFFAOYSA-N iodoacetamide Chemical compound NC(=O)CI PGLTVOMIXTUURA-UHFFFAOYSA-N 0.000 description 16
- ITFSNTMIZQUALH-BYBYOKTNSA-N n-[(2r,3r,4s,5r)-6-[(2s,3s,4s,5s,6r)-4,5-dihydroxy-6-(hydroxymethyl)-3-[(2r,3s,4s,5s,6r)-3,4,5-trihydroxy-6-(hydroxymethyl)oxan-2-yl]oxyoxan-2-yl]oxy-3,4-bis[[(2r,3s,4s,5r,6r)-5-hydroxy-6-(hydroxymethyl)-3,4-bis[[(2r,3s,4s,5s,6r)-3,4,5-trihydroxy-6-(hydro Chemical compound O([C@H]1[C@H](O)[C@@H](CO)O[C@H]([C@H]1O[C@@H]1[C@H]([C@@H](O)[C@H](O)[C@@H](CO)O1)O)O[C@H]([C@H](C=O)NC(=O)C)[C@H](O[C@@H]1[C@H]([C@@H](O[C@@H]2[C@H]([C@@H](O)[C@H](O)[C@@H](CO)O2)O)[C@H](O)[C@@H](CO)O1)O[C@@H]1[C@H]([C@@H](O)[C@H](O)[C@@H](CO)O1)O)[C@@H](CO[C@@H]1[C@H]([C@@H](O)[C@H](O)[C@@H](CO)O1)O[C@@H]1[C@H]([C@@H](O)[C@H](O)[C@@H](CO)O1)O)O[C@@H]1[C@H]([C@@H](O)[C@H](O)[C@@H](CO)O1)O)[C@H]1O[C@H](CO)[C@@H](O)[C@H](O)[C@@H]1O ITFSNTMIZQUALH-BYBYOKTNSA-N 0.000 description 16
- 229920001184 polypeptide Polymers 0.000 description 16
- 239000013605 shuttle vector Substances 0.000 description 16
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 16
- WEVYAHXRMPXWCK-UHFFFAOYSA-N Acetonitrile Chemical compound CC#N WEVYAHXRMPXWCK-UHFFFAOYSA-N 0.000 description 15
- 102000005744 Glycoside Hydrolases Human genes 0.000 description 15
- 108010031186 Glycoside Hydrolases Proteins 0.000 description 15
- OSKIPPQETUTOMW-YHLOVPAPSA-N N-[(2R,3R,4R,5S,6R)-5-[(2S,3R,4R,5S,6R)-3-Acetamido-5-[(2R,3S,4S,5R,6R)-4-[(2R,3S,4S,5S,6R)-3-[(2S,3S,4S,5S,6R)-4,5-dihydroxy-6-(hydroxymethyl)-3-[(2R,3S,4S,5S,6R)-3,4,5-trihydroxy-6-(hydroxymethyl)oxan-2-yl]oxyoxan-2-yl]oxy-4,5-dihydroxy-6-(hydroxymethyl)oxan-2-yl]oxy-6-[[(2S,3S,4S,5R,6R)-6-[[(2S,3S,4S,5S,6R)-4,5-dihydroxy-6-(hydroxymethyl)-3-[(2R,3S,4S,5S,6R)-3,4,5-trihydroxy-6-(hydroxymethyl)oxan-2-yl]oxyoxan-2-yl]oxymethyl]-3,5-dihydroxy-4-[(2R,3S,4S,5S,6R)-3,4,5-trihydroxy-6-(hydroxymethyl)oxan-2-yl]oxyoxan-2-yl]oxymethyl]-3,5-dihydroxyoxan-2-yl]oxy-4-hydroxy-6-(hydroxymethyl)oxan-2-yl]oxy-2,4-dihydroxy-6-(hydroxymethyl)oxan-3-yl]acetamide Chemical compound O[C@@H]1[C@@H](NC(=O)C)[C@H](O)O[C@H](CO)[C@H]1O[C@H]1[C@H](NC(C)=O)[C@@H](O)[C@H](O[C@@H]2[C@H]([C@@H](O[C@@H]3[C@H]([C@@H](O)[C@H](O)[C@@H](CO)O3)O[C@@H]3[C@H]([C@@H](O)[C@H](O)[C@@H](CO)O3)O[C@@H]3[C@H]([C@@H](O)[C@H](O)[C@@H](CO)O3)O)[C@H](O)[C@@H](CO[C@@H]3[C@H]([C@@H](O[C@@H]4[C@H]([C@@H](O)[C@H](O)[C@@H](CO)O4)O)[C@H](O)[C@@H](CO[C@@H]4[C@H]([C@@H](O)[C@H](O)[C@@H](CO)O4)O[C@@H]4[C@H]([C@@H](O)[C@H](O)[C@@H](CO)O4)O)O3)O)O2)O)[C@@H](CO)O1 OSKIPPQETUTOMW-YHLOVPAPSA-N 0.000 description 15
- OVRNDRQMDRJTHS-RTRLPJTCSA-N N-acetyl-D-glucosamine Chemical compound CC(=O)N[C@H]1C(O)O[C@H](CO)[C@@H](O)[C@@H]1O OVRNDRQMDRJTHS-RTRLPJTCSA-N 0.000 description 15
- ZMANZCXQSJIPKH-UHFFFAOYSA-N Triethylamine Chemical compound CCN(CC)CC ZMANZCXQSJIPKH-UHFFFAOYSA-N 0.000 description 15
- 150000001875 compounds Chemical class 0.000 description 15
- 239000011541 reaction mixture Substances 0.000 description 15
- 238000001542 size-exclusion chromatography Methods 0.000 description 15
- 102100021935 C-C motif chemokine 26 Human genes 0.000 description 14
- 101000897493 Homo sapiens C-C motif chemokine 26 Proteins 0.000 description 14
- AVKUERGKIZMTKX-NJBDSQKTSA-N ampicillin Chemical compound C1([C@@H](N)C(=O)N[C@H]2[C@H]3SC([C@@H](N3C2=O)C(O)=O)(C)C)=CC=CC=C1 AVKUERGKIZMTKX-NJBDSQKTSA-N 0.000 description 14
- 229960000723 ampicillin Drugs 0.000 description 14
- VHJLVAABSRFDPM-QWWZWVQMSA-N dithiothreitol Chemical compound SC[C@@H](O)[C@H](O)CS VHJLVAABSRFDPM-QWWZWVQMSA-N 0.000 description 14
- 239000002773 nucleotide Substances 0.000 description 14
- 125000003729 nucleotide group Chemical group 0.000 description 14
- 235000000346 sugar Nutrition 0.000 description 14
- 150000003573 thiols Chemical class 0.000 description 14
- 230000029936 alkylation Effects 0.000 description 13
- 238000005804 alkylation reaction Methods 0.000 description 13
- 230000004048 modification Effects 0.000 description 13
- 238000012986 modification Methods 0.000 description 13
- 238000012163 sequencing technique Methods 0.000 description 13
- 108700039791 Hepatitis C virus nucleocapsid Proteins 0.000 description 12
- 238000010521 absorption reaction Methods 0.000 description 12
- 230000002255 enzymatic effect Effects 0.000 description 12
- HNDVDQJCIGZPNO-UHFFFAOYSA-N histidine Natural products OC(=O)C(N)CC1=CN=CN1 HNDVDQJCIGZPNO-UHFFFAOYSA-N 0.000 description 12
- DVEKCXOJTLDBFE-UHFFFAOYSA-N n-dodecyl-n,n-dimethylglycinate Chemical compound CCCCCCCCCCCC[N+](C)(C)CC([O-])=O DVEKCXOJTLDBFE-UHFFFAOYSA-N 0.000 description 12
- 238000000926 separation method Methods 0.000 description 12
- 238000006277 sulfonation reaction Methods 0.000 description 12
- 238000010276 construction Methods 0.000 description 11
- 239000008103 glucose Substances 0.000 description 11
- SHFKGANKURXVMY-LCWPZEQJSA-N hcv e2 protein Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H](CCC(N)=O)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@@H](NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CO)NC(=O)[C@H](C)NC(=O)[C@H](CC=1C=CC=CC=1)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](NC(=O)[C@@H](NC(=O)[C@H](CC=1NC=NC=1)NC(=O)[C@H](C)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](C)NC(=O)CNC(=O)CNC(=O)[C@@H](NC(=O)[C@@H](NC(=O)[C@@H](NC(=O)[C@@H](NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)CNC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](NC(=O)CNC(=O)[C@H](C)NC(=O)[C@H](CC=1C=CC=CC=1)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CCSC)C(C)C)[C@@H](C)O)[C@@H](C)O)C(C)C)[C@@H](C)O)[C@@H](C)O)[C@@H](C)O)CC1=CC=CC=C1 SHFKGANKURXVMY-LCWPZEQJSA-N 0.000 description 11
- 238000004128 high performance liquid chromatography Methods 0.000 description 11
- 238000000338 in vitro Methods 0.000 description 11
- 239000002609 medium Substances 0.000 description 11
- 239000008188 pellet Substances 0.000 description 11
- 102000040430 polynucleotide Human genes 0.000 description 11
- 108091033319 polynucleotide Proteins 0.000 description 11
- 239000000243 solution Substances 0.000 description 11
- HTTJABKRGRZYRN-UHFFFAOYSA-N Heparin Chemical compound OC1C(NC(=O)C)C(O)OC(COS(O)(=O)=O)C1OC1C(OS(O)(=O)=O)C(O)C(OC2C(C(OS(O)(=O)=O)C(OC3C(C(O)C(O)C(O3)C(O)=O)OS(O)(=O)=O)C(CO)O2)NS(O)(=O)=O)C(C(O)=O)O1 HTTJABKRGRZYRN-UHFFFAOYSA-N 0.000 description 10
- 101710125507 Integrase/recombinase Proteins 0.000 description 10
- 102000003960 Ligases Human genes 0.000 description 10
- 108090000364 Ligases Proteins 0.000 description 10
- 229910019142 PO4 Inorganic materials 0.000 description 10
- 108010055817 Peptide-N4-(N-acetyl-beta-glucosaminyl) Asparagine Amidase Proteins 0.000 description 10
- 102000000447 Peptide-N4-(N-acetyl-beta-glucosaminyl) Asparagine Amidase Human genes 0.000 description 10
- 239000000969 carrier Substances 0.000 description 10
- 230000001684 chronic effect Effects 0.000 description 10
- 238000010367 cloning Methods 0.000 description 10
- 229960002897 heparin Drugs 0.000 description 10
- 229920000669 heparin Polymers 0.000 description 10
- 230000014759 maintenance of location Effects 0.000 description 10
- 239000012528 membrane Substances 0.000 description 10
- 230000009467 reduction Effects 0.000 description 10
- 230000009466 transformation Effects 0.000 description 10
- 238000002255 vaccination Methods 0.000 description 10
- 108091026890 Coding region Proteins 0.000 description 9
- 241000699670 Mus sp. Species 0.000 description 9
- 102000035195 Peptidases Human genes 0.000 description 9
- 108091005804 Peptidases Proteins 0.000 description 9
- 108010003533 Viral Envelope Proteins Proteins 0.000 description 9
- 239000011543 agarose gel Substances 0.000 description 9
- 239000007795 chemical reaction product Substances 0.000 description 9
- 238000004587 chromatography analysis Methods 0.000 description 9
- 238000002955 isolation Methods 0.000 description 9
- 229910052760 oxygen Inorganic materials 0.000 description 9
- 239000001301 oxygen Substances 0.000 description 9
- 239000002157 polynucleotide Substances 0.000 description 9
- 102000012410 DNA Ligases Human genes 0.000 description 8
- 108010061982 DNA Ligases Proteins 0.000 description 8
- 101710144111 Non-structural protein 3 Proteins 0.000 description 8
- 108091028043 Nucleic acid sequence Proteins 0.000 description 8
- 239000012505 Superdex™ Substances 0.000 description 8
- 238000000137 annealing Methods 0.000 description 8
- 238000003556 assay Methods 0.000 description 8
- QVGXLLKOCUKJST-UHFFFAOYSA-N atomic oxygen Chemical compound [O] QVGXLLKOCUKJST-UHFFFAOYSA-N 0.000 description 8
- 125000000837 carbohydrate group Chemical group 0.000 description 8
- 238000004113 cell culture Methods 0.000 description 8
- 230000000295 complement effect Effects 0.000 description 8
- 235000018417 cysteine Nutrition 0.000 description 8
- 238000010790 dilution Methods 0.000 description 8
- 239000012895 dilution Substances 0.000 description 8
- 238000002296 dynamic light scattering Methods 0.000 description 8
- 210000002472 endoplasmic reticulum Anatomy 0.000 description 8
- 230000002427 irreversible effect Effects 0.000 description 8
- 210000004379 membrane Anatomy 0.000 description 8
- 238000002703 mutagenesis Methods 0.000 description 8
- 231100000350 mutagenesis Toxicity 0.000 description 8
- 230000002829 reductive effect Effects 0.000 description 8
- 229920002477 rna polymer Polymers 0.000 description 8
- 108010041986 DNA Vaccines Proteins 0.000 description 7
- 229940021995 DNA vaccine Drugs 0.000 description 7
- 229920000057 Mannan Polymers 0.000 description 7
- HDFGOPSGAURCEO-UHFFFAOYSA-N N-ethylmaleimide Chemical compound CCN1C(=O)C=CC1=O HDFGOPSGAURCEO-UHFFFAOYSA-N 0.000 description 7
- 108091034117 Oligonucleotide Proteins 0.000 description 7
- 241000282579 Pan Species 0.000 description 7
- 241000700605 Viruses Species 0.000 description 7
- 125000000539 amino acid group Chemical group 0.000 description 7
- 210000004369 blood Anatomy 0.000 description 7
- 239000008280 blood Substances 0.000 description 7
- 239000005018 casein Substances 0.000 description 7
- BECPQYXYKAMYBN-UHFFFAOYSA-N casein, tech. Chemical compound NCCCCC(C(O)=O)N=C(O)C(CC(O)=O)N=C(O)C(CCC(O)=N)N=C(O)C(CC(C)C)N=C(O)C(CCC(O)=O)N=C(O)C(CC(O)=O)N=C(O)C(CCC(O)=O)N=C(O)C(C(C)O)N=C(O)C(CCC(O)=N)N=C(O)C(CCC(O)=N)N=C(O)C(CCC(O)=N)N=C(O)C(CCC(O)=O)N=C(O)C(CCC(O)=O)N=C(O)C(COP(O)(O)=O)N=C(O)C(CCC(O)=N)N=C(O)C(N)CC1=CC=CC=C1 BECPQYXYKAMYBN-UHFFFAOYSA-N 0.000 description 7
- 235000021240 caseins Nutrition 0.000 description 7
- 201000010099 disease Diseases 0.000 description 7
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 description 7
- 238000000605 extraction Methods 0.000 description 7
- 235000011187 glycerol Nutrition 0.000 description 7
- 230000003053 immunization Effects 0.000 description 7
- 238000003018 immunoassay Methods 0.000 description 7
- 238000013508 migration Methods 0.000 description 7
- 230000005012 migration Effects 0.000 description 7
- 230000003287 optical effect Effects 0.000 description 7
- NBIIXXVUZAFLBC-UHFFFAOYSA-K phosphate Chemical compound [O-]P([O-])([O-])=O NBIIXXVUZAFLBC-UHFFFAOYSA-K 0.000 description 7
- 239000010452 phosphate Substances 0.000 description 7
- 230000004044 response Effects 0.000 description 7
- YBJHBAHKTGYVGT-ZKWXMUAHSA-N (+)-Biotin Chemical compound N1C(=O)N[C@@H]2[C@H](CCCCC(=O)O)SC[C@@H]21 YBJHBAHKTGYVGT-ZKWXMUAHSA-N 0.000 description 6
- CSCPPACGZOOCGX-UHFFFAOYSA-N Acetone Chemical compound CC(C)=O CSCPPACGZOOCGX-UHFFFAOYSA-N 0.000 description 6
- 108010074860 Factor Xa Proteins 0.000 description 6
- KDXKERNSBIXSRK-YFKPBYRVSA-N L-lysine Chemical compound NCCCC[C@H](N)C(O)=O KDXKERNSBIXSRK-YFKPBYRVSA-N 0.000 description 6
- KDXKERNSBIXSRK-UHFFFAOYSA-N Lysine Natural products NCCCCC(N)C(O)=O KDXKERNSBIXSRK-UHFFFAOYSA-N 0.000 description 6
- 108010038049 Mating Factor Proteins 0.000 description 6
- GHAZCVNUKKZTLG-UHFFFAOYSA-N N-ethyl-succinimide Natural products CCN1C(=O)CCC1=O GHAZCVNUKKZTLG-UHFFFAOYSA-N 0.000 description 6
- 108010021757 Polynucleotide 5'-Hydroxyl-Kinase Proteins 0.000 description 6
- 102000008422 Polynucleotide 5'-hydroxyl-kinase Human genes 0.000 description 6
- 239000004365 Protease Substances 0.000 description 6
- HEMHJVSKTPXQMS-UHFFFAOYSA-M Sodium hydroxide Chemical compound [OH-].[Na+] HEMHJVSKTPXQMS-UHFFFAOYSA-M 0.000 description 6
- 230000009471 action Effects 0.000 description 6
- 238000001042 affinity chromatography Methods 0.000 description 6
- 108090000637 alpha-Amylases Proteins 0.000 description 6
- 102000004139 alpha-Amylases Human genes 0.000 description 6
- 229940024171 alpha-amylase Drugs 0.000 description 6
- 230000003698 anagen phase Effects 0.000 description 6
- 238000005119 centrifugation Methods 0.000 description 6
- 239000003153 chemical reaction reagent Substances 0.000 description 6
- 150000002019 disulfides Chemical class 0.000 description 6
- 238000001976 enzyme digestion Methods 0.000 description 6
- 238000002649 immunization Methods 0.000 description 6
- 230000003834 intracellular effect Effects 0.000 description 6
- 125000005647 linker group Chemical group 0.000 description 6
- 239000002502 liposome Substances 0.000 description 6
- 238000012216 screening Methods 0.000 description 6
- 238000010186 staining Methods 0.000 description 6
- 238000004448 titration Methods 0.000 description 6
- SBKVPJHMSUXZTA-MEJXFZFPSA-N (2S)-2-[[(2S)-2-[[(2S)-1-[(2S)-5-amino-2-[[2-[[(2S)-1-[(2S)-6-amino-2-[[(2S)-2-[[(2S)-5-amino-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-amino-3-(1H-indol-3-yl)propanoyl]amino]-3-(1H-imidazol-4-yl)propanoyl]amino]-3-(1H-indol-3-yl)propanoyl]amino]-4-methylpentanoyl]amino]-5-oxopentanoyl]amino]-4-methylpentanoyl]amino]hexanoyl]pyrrolidine-2-carbonyl]amino]acetyl]amino]-5-oxopentanoyl]pyrrolidine-2-carbonyl]amino]-4-methylsulfanylbutanoyl]amino]-3-(4-hydroxyphenyl)propanoic acid Chemical compound C([C@@H](C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N1CCC[C@H]1C(=O)NCC(=O)N[C@@H](CCC(N)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)NC(=O)[C@@H](N)CC=1C2=CC=CC=C2NC=1)C1=CNC=N1 SBKVPJHMSUXZTA-MEJXFZFPSA-N 0.000 description 5
- 108090001008 Avidin Proteins 0.000 description 5
- 244000062995 Cassia occidentalis Species 0.000 description 5
- 108010058643 Fungal Proteins Proteins 0.000 description 5
- DCXYFEDJOCDNAF-REOHCLBHSA-N L-asparagine Chemical compound OC(=O)[C@@H](N)CC(N)=O DCXYFEDJOCDNAF-REOHCLBHSA-N 0.000 description 5
- OVRNDRQMDRJTHS-FMDGEEDCSA-N N-acetyl-beta-D-glucosamine Chemical compound CC(=O)N[C@H]1[C@H](O)O[C@H](CO)[C@@H](O)[C@@H]1O OVRNDRQMDRJTHS-FMDGEEDCSA-N 0.000 description 5
- 239000002033 PVDF binder Substances 0.000 description 5
- 108010076039 Polyproteins Proteins 0.000 description 5
- 229920002684 Sepharose Polymers 0.000 description 5
- BQCADISMDOOEFD-UHFFFAOYSA-N Silver Chemical compound [Ag] BQCADISMDOOEFD-UHFFFAOYSA-N 0.000 description 5
- 229930006000 Sucrose Natural products 0.000 description 5
- CZMRCDWAGMRECN-UGDNZRGBSA-N Sucrose Chemical compound O[C@H]1[C@H](O)[C@@H](CO)O[C@@]1(CO)O[C@@H]1[C@H](O)[C@@H](O)[C@H](O)[C@@H](CO)O1 CZMRCDWAGMRECN-UGDNZRGBSA-N 0.000 description 5
- 108090000631 Trypsin Proteins 0.000 description 5
- 102000004142 Trypsin Human genes 0.000 description 5
- 238000002835 absorbance Methods 0.000 description 5
- 210000004899 c-terminal region Anatomy 0.000 description 5
- 210000001151 cytotoxic T lymphocyte Anatomy 0.000 description 5
- 239000007857 degradation product Substances 0.000 description 5
- 230000029087 digestion Effects 0.000 description 5
- 125000002791 glucosyl group Chemical group C1([C@H](O)[C@@H](O)[C@H](O)[C@H](O1)CO)* 0.000 description 5
- 238000001727 in vivo Methods 0.000 description 5
- 239000011159 matrix material Substances 0.000 description 5
- 210000000056 organ Anatomy 0.000 description 5
- 229920002981 polyvinylidene fluoride Polymers 0.000 description 5
- 239000002244 precipitate Substances 0.000 description 5
- 230000008569 process Effects 0.000 description 5
- 230000005664 protein glycosylation in endoplasmic reticulum Effects 0.000 description 5
- 229910052709 silver Inorganic materials 0.000 description 5
- 239000004332 silver Substances 0.000 description 5
- 230000004936 stimulating effect Effects 0.000 description 5
- 238000003756 stirring Methods 0.000 description 5
- 238000006467 substitution reaction Methods 0.000 description 5
- 239000005720 sucrose Substances 0.000 description 5
- 229910052717 sulfur Inorganic materials 0.000 description 5
- 238000012360 testing method Methods 0.000 description 5
- 210000001519 tissue Anatomy 0.000 description 5
- 239000012588 trypsin Substances 0.000 description 5
- 239000003643 water by type Substances 0.000 description 5
- 101710095342 Apolipoprotein B Proteins 0.000 description 4
- 102100040202 Apolipoprotein B-100 Human genes 0.000 description 4
- 102000007592 Apolipoproteins Human genes 0.000 description 4
- 108010071619 Apolipoproteins Proteins 0.000 description 4
- 102000016928 DNA-directed DNA polymerase Human genes 0.000 description 4
- 108010014303 DNA-directed DNA polymerase Proteins 0.000 description 4
- IAZDPXIOMUYVGZ-UHFFFAOYSA-N Dimethylsulphoxide Chemical compound CS(C)=O IAZDPXIOMUYVGZ-UHFFFAOYSA-N 0.000 description 4
- WHUUTDBJXJRKMK-UHFFFAOYSA-N Glutamic acid Natural products OC(=O)C(N)CCC(O)=O WHUUTDBJXJRKMK-UHFFFAOYSA-N 0.000 description 4
- WHUUTDBJXJRKMK-VKHMYHEASA-N L-glutamic acid Chemical compound OC(=O)[C@@H](N)CCC(O)=O WHUUTDBJXJRKMK-VKHMYHEASA-N 0.000 description 4
- ZDXPYRJPNDTMRX-VKHMYHEASA-N L-glutamine Chemical compound OC(=O)[C@@H](N)CCC(N)=O ZDXPYRJPNDTMRX-VKHMYHEASA-N 0.000 description 4
- 102000007330 LDL Lipoproteins Human genes 0.000 description 4
- 108010007622 LDL Lipoproteins Proteins 0.000 description 4
- 101001018085 Lysobacter enzymogenes Lysyl endopeptidase Proteins 0.000 description 4
- 241001529936 Murinae Species 0.000 description 4
- 125000001429 N-terminal alpha-amino-acid group Chemical group 0.000 description 4
- 239000000020 Nitrocellulose Substances 0.000 description 4
- 101800001020 Non-structural protein 4A Proteins 0.000 description 4
- 101800001019 Non-structural protein 4B Proteins 0.000 description 4
- 101800001014 Non-structural protein 5A Proteins 0.000 description 4
- 241000283973 Oryctolagus cuniculus Species 0.000 description 4
- 108091000080 Phosphotransferase Proteins 0.000 description 4
- 101800001554 RNA-directed RNA polymerase Proteins 0.000 description 4
- 108010090804 Streptavidin Proteins 0.000 description 4
- ISAKRJDGNUQOIC-UHFFFAOYSA-N Uracil Chemical compound O=C1C=CNC(=O)N1 ISAKRJDGNUQOIC-UHFFFAOYSA-N 0.000 description 4
- 238000005273 aeration Methods 0.000 description 4
- 230000000692 anti-sense effect Effects 0.000 description 4
- 230000000903 blocking effect Effects 0.000 description 4
- 229910052799 carbon Inorganic materials 0.000 description 4
- 239000003638 chemical reducing agent Substances 0.000 description 4
- XUJNEKJLAYXESH-UHFFFAOYSA-N cysteine Natural products SCC(N)C(O)=O XUJNEKJLAYXESH-UHFFFAOYSA-N 0.000 description 4
- 230000022811 deglycosylation Effects 0.000 description 4
- 239000003599 detergent Substances 0.000 description 4
- 238000002086 displacement chromatography Methods 0.000 description 4
- 239000012990 dithiocarbamate Substances 0.000 description 4
- 239000000975 dye Substances 0.000 description 4
- 239000012156 elution solvent Substances 0.000 description 4
- 230000005284 excitation Effects 0.000 description 4
- 238000009472 formulation Methods 0.000 description 4
- 150000004676 glycans Chemical class 0.000 description 4
- 239000001963 growth medium Substances 0.000 description 4
- 229910052736 halogen Inorganic materials 0.000 description 4
- 150000002367 halogens Chemical class 0.000 description 4
- 230000005847 immunogenicity Effects 0.000 description 4
- 238000011081 inoculation Methods 0.000 description 4
- 150000002632 lipids Chemical class 0.000 description 4
- 238000012544 monitoring process Methods 0.000 description 4
- 229950006780 n-acetylglucosamine Drugs 0.000 description 4
- 229920001220 nitrocellulos Polymers 0.000 description 4
- 229910052757 nitrogen Inorganic materials 0.000 description 4
- VIKNJXKGJWUCNN-XGXHKTLJSA-N norethisterone Chemical compound O=C1CC[C@@H]2[C@H]3CC[C@](C)([C@](CC4)(O)C#C)[C@@H]4[C@@H]3CCC2=C1 VIKNJXKGJWUCNN-XGXHKTLJSA-N 0.000 description 4
- 102000020233 phosphotransferase Human genes 0.000 description 4
- 229920001223 polyethylene glycol Polymers 0.000 description 4
- 239000002243 precursor Substances 0.000 description 4
- 235000019419 proteases Nutrition 0.000 description 4
- 230000002797 proteolythic effect Effects 0.000 description 4
- 239000012264 purified product Substances 0.000 description 4
- 230000002285 radioactive effect Effects 0.000 description 4
- 238000011160 research Methods 0.000 description 4
- GEHJYWRUCIMESM-UHFFFAOYSA-L sodium sulfite Chemical compound [Na+].[Na+].[O-]S([O-])=O GEHJYWRUCIMESM-UHFFFAOYSA-L 0.000 description 4
- 230000006641 stabilisation Effects 0.000 description 4
- 238000011105 stabilization Methods 0.000 description 4
- 230000008685 targeting Effects 0.000 description 4
- 230000014616 translation Effects 0.000 description 4
- 238000005406 washing Methods 0.000 description 4
- UMCMPZBLKLEWAF-BCTGSCMUSA-N 3-[(3-cholamidopropyl)dimethylammonio]propane-1-sulfonate Chemical compound C([C@H]1C[C@H]2O)[C@H](O)CC[C@]1(C)[C@@H]1[C@@H]2[C@@H]2CC[C@H]([C@@H](CCC(=O)NCCC[N+](C)(C)CCCS([O-])(=O)=O)C)[C@@]2(C)[C@@H](O)C1 UMCMPZBLKLEWAF-BCTGSCMUSA-N 0.000 description 3
- NGYHUCPPLJOZIX-XLPZGREQSA-N 5-methyl-dCTP Chemical compound O=C1N=C(N)C(C)=CN1[C@@H]1O[C@H](COP(O)(=O)OP(O)(=O)OP(O)(O)=O)[C@@H](O)C1 NGYHUCPPLJOZIX-XLPZGREQSA-N 0.000 description 3
- 108700016155 Acyl transferases Proteins 0.000 description 3
- 102000057234 Acyl transferases Human genes 0.000 description 3
- 229920001817 Agar Polymers 0.000 description 3
- NOWKCMXCCJGMRR-UHFFFAOYSA-N Aziridine Chemical compound C1CN1 NOWKCMXCCJGMRR-UHFFFAOYSA-N 0.000 description 3
- OKTJSMMVPCPJKN-UHFFFAOYSA-N Carbon Chemical compound [C] OKTJSMMVPCPJKN-UHFFFAOYSA-N 0.000 description 3
- BWGNESOTFCXPMA-UHFFFAOYSA-N Dihydrogen disulfide Chemical compound SS BWGNESOTFCXPMA-UHFFFAOYSA-N 0.000 description 3
- 108090000288 Glycoproteins Proteins 0.000 description 3
- 102000003886 Glycoproteins Human genes 0.000 description 3
- CKLJMWTZIZZHCS-REOHCLBHSA-N L-aspartic acid Chemical compound OC(=O)[C@@H](N)CC(O)=O CKLJMWTZIZZHCS-REOHCLBHSA-N 0.000 description 3
- FFEARJCKVFRZRR-BYPYZUCNSA-N L-methionine Chemical compound CSCC[C@H](N)C(O)=O FFEARJCKVFRZRR-BYPYZUCNSA-N 0.000 description 3
- 101710144128 Non-structural protein 2 Proteins 0.000 description 3
- 101710199667 Nuclear export protein Proteins 0.000 description 3
- 241000282577 Pan troglodytes Species 0.000 description 3
- 239000001888 Peptone Substances 0.000 description 3
- 108010080698 Peptones Proteins 0.000 description 3
- 102000003992 Peroxidases Human genes 0.000 description 3
- 239000002202 Polyethylene glycol Substances 0.000 description 3
- 239000004793 Polystyrene Substances 0.000 description 3
- 108010008281 Recombinant Fusion Proteins Proteins 0.000 description 3
- 102000007056 Recombinant Fusion Proteins Human genes 0.000 description 3
- NINIDFKCEFEMDL-UHFFFAOYSA-N Sulfur Chemical compound [S] NINIDFKCEFEMDL-UHFFFAOYSA-N 0.000 description 3
- PZBFGYYEXUXCOF-UHFFFAOYSA-N TCEP Chemical compound OC(=O)CCP(CCC(O)=O)CCC(O)=O PZBFGYYEXUXCOF-UHFFFAOYSA-N 0.000 description 3
- 102000002933 Thioredoxin Human genes 0.000 description 3
- 241000700647 Variola virus Species 0.000 description 3
- 230000001154 acute effect Effects 0.000 description 3
- 239000008272 agar Substances 0.000 description 3
- 239000002168 alkylating agent Substances 0.000 description 3
- 229940100198 alkylating agent Drugs 0.000 description 3
- 230000003321 amplification Effects 0.000 description 3
- 239000011324 bead Substances 0.000 description 3
- 239000012472 biological sample Substances 0.000 description 3
- 229960002685 biotin Drugs 0.000 description 3
- 235000020958 biotin Nutrition 0.000 description 3
- 239000011616 biotin Substances 0.000 description 3
- 210000000481 breast Anatomy 0.000 description 3
- 229940041514 candida albicans extract Drugs 0.000 description 3
- DKVNPHBNOWQYFE-UHFFFAOYSA-N carbamodithioic acid Chemical compound NC(S)=S DKVNPHBNOWQYFE-UHFFFAOYSA-N 0.000 description 3
- 230000015556 catabolic process Effects 0.000 description 3
- 239000013592 cell lysate Substances 0.000 description 3
- 239000006285 cell suspension Substances 0.000 description 3
- 238000004140 cleaning Methods 0.000 description 3
- 238000012258 culturing Methods 0.000 description 3
- SUYVUBYJARFZHO-RRKCRQDMSA-N dATP Chemical compound C1=NC=2C(N)=NC=NC=2N1[C@H]1C[C@H](O)[C@@H](COP(O)(=O)OP(O)(=O)OP(O)(O)=O)O1 SUYVUBYJARFZHO-RRKCRQDMSA-N 0.000 description 3
- SUYVUBYJARFZHO-UHFFFAOYSA-N dATP Natural products C1=NC=2C(N)=NC=NC=2N1C1CC(O)C(COP(O)(=O)OP(O)(=O)OP(O)(O)=O)O1 SUYVUBYJARFZHO-UHFFFAOYSA-N 0.000 description 3
- HAAZLUGHYHWQIW-KVQBGUIXSA-N dGTP Chemical compound C1=NC=2C(=O)NC(N)=NC=2N1[C@H]1C[C@H](O)[C@@H](COP(O)(=O)OP(O)(=O)OP(O)(O)=O)O1 HAAZLUGHYHWQIW-KVQBGUIXSA-N 0.000 description 3
- NHVNXKFIZYSCEB-XLPZGREQSA-N dTTP Chemical compound O=C1NC(=O)C(C)=CN1[C@@H]1O[C@H](COP(O)(=O)OP(O)(=O)OP(O)(O)=O)[C@@H](O)C1 NHVNXKFIZYSCEB-XLPZGREQSA-N 0.000 description 3
- 230000002950 deficient Effects 0.000 description 3
- 238000006731 degradation reaction Methods 0.000 description 3
- 238000013461 design Methods 0.000 description 3
- 238000011161 development Methods 0.000 description 3
- 230000018109 developmental process Effects 0.000 description 3
- 238000006073 displacement reaction Methods 0.000 description 3
- 238000010494 dissociation reaction Methods 0.000 description 3
- 230000005593 dissociations Effects 0.000 description 3
- VHJLVAABSRFDPM-ZXZARUISSA-N dithioerythritol Chemical compound SC[C@H](O)[C@H](O)CS VHJLVAABSRFDPM-ZXZARUISSA-N 0.000 description 3
- 238000005886 esterification reaction Methods 0.000 description 3
- 239000013613 expression plasmid Substances 0.000 description 3
- 125000000524 functional group Chemical group 0.000 description 3
- 238000001502 gel electrophoresis Methods 0.000 description 3
- 108091005608 glycosylated proteins Proteins 0.000 description 3
- 102000035122 glycosylated proteins Human genes 0.000 description 3
- 210000002288 golgi apparatus Anatomy 0.000 description 3
- 230000012010 growth Effects 0.000 description 3
- PJJJBBJSCAKJQF-UHFFFAOYSA-N guanidinium chloride Chemical compound [Cl-].NC(N)=[NH2+] PJJJBBJSCAKJQF-UHFFFAOYSA-N 0.000 description 3
- 230000001900 immune effect Effects 0.000 description 3
- 230000036039 immunity Effects 0.000 description 3
- 230000002458 infectious effect Effects 0.000 description 3
- 239000007924 injection Substances 0.000 description 3
- 238000002347 injection Methods 0.000 description 3
- 239000002054 inoculum Substances 0.000 description 3
- 239000000543 intermediate Substances 0.000 description 3
- 238000004949 mass spectrometry Methods 0.000 description 3
- 230000001404 mediated effect Effects 0.000 description 3
- 229930182817 methionine Natural products 0.000 description 3
- 229940035032 monophosphoryl lipid a Drugs 0.000 description 3
- 230000035772 mutation Effects 0.000 description 3
- 238000003199 nucleic acid amplification method Methods 0.000 description 3
- 235000019319 peptone Nutrition 0.000 description 3
- 108040007629 peroxidase activity proteins Proteins 0.000 description 3
- 239000013600 plasmid vector Substances 0.000 description 3
- 238000005498 polishing Methods 0.000 description 3
- 229920002401 polyacrylamide Polymers 0.000 description 3
- 235000021251 pulses Nutrition 0.000 description 3
- 238000011218 seed culture Methods 0.000 description 3
- 238000002741 site-directed mutagenesis Methods 0.000 description 3
- 239000012279 sodium borohydride Substances 0.000 description 3
- 229910000033 sodium borohydride Inorganic materials 0.000 description 3
- HAEPBEMBOAIUPN-UHFFFAOYSA-L sodium tetrathionate Chemical compound O.O.[Na+].[Na+].[O-]S(=O)(=O)SSS([O-])(=O)=O HAEPBEMBOAIUPN-UHFFFAOYSA-L 0.000 description 3
- 238000005063 solubilization Methods 0.000 description 3
- 230000007928 solubilization Effects 0.000 description 3
- 230000000087 stabilizing effect Effects 0.000 description 3
- 239000011593 sulfur Substances 0.000 description 3
- 239000006228 supernatant Substances 0.000 description 3
- 239000000725 suspension Substances 0.000 description 3
- 108060008226 thioredoxin Proteins 0.000 description 3
- 229940094937 thioredoxin Drugs 0.000 description 3
- 238000013519 translation Methods 0.000 description 3
- 238000000108 ultra-filtration Methods 0.000 description 3
- 210000003501 vero cell Anatomy 0.000 description 3
- 239000012138 yeast extract Substances 0.000 description 3
- 239000007222 ypd medium Substances 0.000 description 3
- DGVVWUTYPXICAM-UHFFFAOYSA-N β‐Mercaptoethanol Chemical compound OCCS DGVVWUTYPXICAM-UHFFFAOYSA-N 0.000 description 3
- DRHZYJAUECRAJM-DWSYSWFDSA-N (2s,3s,4s,5r,6r)-6-[[(3s,4s,4ar,6ar,6bs,8r,8ar,12as,14ar,14br)-8a-[(2s,3r,4s,5r,6r)-3-[(2s,3r,4s,5r,6s)-5-[(2s,3r,4s,5r)-4-[(2s,3r,4r)-3,4-dihydroxy-4-(hydroxymethyl)oxolan-2-yl]oxy-3,5-dihydroxyoxan-2-yl]oxy-3,4-dihydroxy-6-methyloxan-2-yl]oxy-5-[(3s,5s, Chemical compound O([C@H]1[C@H](O)[C@H](O[C@H]([C@@H]1O[C@H]1[C@@H]([C@@H](O)[C@@H](O)[C@@H](CO)O1)O)O[C@H]1CC[C@]2(C)[C@H]3CC=C4[C@@H]5CC(C)(C)CC[C@@]5([C@@H](C[C@@]4(C)[C@]3(C)CC[C@H]2[C@@]1(C=O)C)O)C(=O)O[C@@H]1O[C@H](C)[C@@H]([C@@H]([C@H]1O[C@H]1[C@@H]([C@H](O)[C@@H](O[C@H]2[C@@H]([C@@H](O[C@H]3[C@@H]([C@@](O)(CO)CO3)O)[C@H](O)CO2)O)[C@H](C)O1)O)O)OC(=O)C[C@@H](O)C[C@H](OC(=O)C[C@@H](O)C[C@@H]([C@@H](C)CC)O[C@H]1[C@@H]([C@@H](O)[C@H](CO)O1)O)[C@@H](C)CC)C(O)=O)[C@@H]1OC[C@@H](O)[C@H](O)[C@H]1O DRHZYJAUECRAJM-DWSYSWFDSA-N 0.000 description 2
- QFRHEHPVTSCSIH-UHFFFAOYSA-N 2,2,2-trifluoro-n-(2-iodoethyl)acetamide Chemical compound FC(F)(F)C(=O)NCCI QFRHEHPVTSCSIH-UHFFFAOYSA-N 0.000 description 2
- KIUMMUBSPKGMOY-UHFFFAOYSA-N 3,3'-Dithiobis(6-nitrobenzoic acid) Chemical compound C1=C([N+]([O-])=O)C(C(=O)O)=CC(SSC=2C=C(C(=CC=2)[N+]([O-])=O)C(O)=O)=C1 KIUMMUBSPKGMOY-UHFFFAOYSA-N 0.000 description 2
- HKJKONMZMPUGHJ-UHFFFAOYSA-N 4-amino-5-hydroxy-3-[(4-nitrophenyl)diazenyl]-6-phenyldiazenylnaphthalene-2,7-disulfonic acid Chemical compound OS(=O)(=O)C1=CC2=CC(S(O)(=O)=O)=C(N=NC=3C=CC=CC=3)C(O)=C2C(N)=C1N=NC1=CC=C([N+]([O-])=O)C=C1 HKJKONMZMPUGHJ-UHFFFAOYSA-N 0.000 description 2
- 208000002109 Argyria Diseases 0.000 description 2
- CIWBSHSKHKDKBQ-JLAZNSOCSA-N Ascorbic acid Chemical compound OC[C@H](O)[C@H]1OC(=O)C(O)=C1O CIWBSHSKHKDKBQ-JLAZNSOCSA-N 0.000 description 2
- DCXYFEDJOCDNAF-UHFFFAOYSA-N Asparagine Natural products OC(=O)C(N)CC(N)=O DCXYFEDJOCDNAF-UHFFFAOYSA-N 0.000 description 2
- 241000894006 Bacteria Species 0.000 description 2
- 241000283690 Bos taurus Species 0.000 description 2
- 230000005653 Brownian motion process Effects 0.000 description 2
- BIBOEMPSFOZZEM-UFLZEWODSA-N C(C)N1C(C=CC1=O)=O.OC(=O)CCCC[C@@H]1SC[C@@H]2NC(=O)N[C@H]12 Chemical compound C(C)N1C(C=CC1=O)=O.OC(=O)CCCC[C@@H]1SC[C@@H]2NC(=O)N[C@H]12 BIBOEMPSFOZZEM-UFLZEWODSA-N 0.000 description 2
- 125000001433 C-terminal amino-acid group Chemical group 0.000 description 2
- 241000238154 Carcinus maenas Species 0.000 description 2
- 102000003902 Cathepsin C Human genes 0.000 description 2
- 108090000267 Cathepsin C Proteins 0.000 description 2
- 101100223032 Emericella nidulans (strain FGSC A4 / ATCC 38163 / CBS 112.46 / NRRL 194 / M139) dapB gene Proteins 0.000 description 2
- QUSNBJAOOMFDIB-UHFFFAOYSA-N Ethylamine Chemical compound CCN QUSNBJAOOMFDIB-UHFFFAOYSA-N 0.000 description 2
- LYCAIKOWRPUZTN-UHFFFAOYSA-N Ethylene glycol Chemical compound OCCO LYCAIKOWRPUZTN-UHFFFAOYSA-N 0.000 description 2
- 241000206602 Eukaryota Species 0.000 description 2
- 102000017278 Glutaredoxin Human genes 0.000 description 2
- 108050005205 Glutaredoxin Proteins 0.000 description 2
- 229940121672 Glycosylation inhibitor Drugs 0.000 description 2
- 102000004269 Granulocyte Colony-Stimulating Factor Human genes 0.000 description 2
- 108010017080 Granulocyte Colony-Stimulating Factor Proteins 0.000 description 2
- 241000700721 Hepatitis B virus Species 0.000 description 2
- 241000725303 Human immunodeficiency virus Species 0.000 description 2
- OAKJQQAXSVQMHS-UHFFFAOYSA-N Hydrazine Chemical compound NN OAKJQQAXSVQMHS-UHFFFAOYSA-N 0.000 description 2
- QIGBRXMKCJKVMJ-UHFFFAOYSA-N Hydroquinone Chemical compound OC1=CC=C(O)C=C1 QIGBRXMKCJKVMJ-UHFFFAOYSA-N 0.000 description 2
- AVXURJPOCDRRFD-UHFFFAOYSA-N Hydroxylamine Chemical compound ON AVXURJPOCDRRFD-UHFFFAOYSA-N 0.000 description 2
- 241000257303 Hymenoptera Species 0.000 description 2
- 108050008546 Hyperglycemic hormone Proteins 0.000 description 2
- 108060003951 Immunoglobulin Proteins 0.000 description 2
- 101150045458 KEX2 gene Proteins 0.000 description 2
- PWKSKIMOESPYIA-BYPYZUCNSA-N L-N-acetyl-Cysteine Chemical compound CC(=O)N[C@@H](CS)C(O)=O PWKSKIMOESPYIA-BYPYZUCNSA-N 0.000 description 2
- 206010067125 Liver injury Diseases 0.000 description 2
- 239000004472 Lysine Substances 0.000 description 2
- 108050000633 Lysozyme C Proteins 0.000 description 2
- 102000001696 Mannosidases Human genes 0.000 description 2
- 108010054377 Mannosidases Proteins 0.000 description 2
- 241001465754 Metazoa Species 0.000 description 2
- 241000699666 Mus <mouse, genus> Species 0.000 description 2
- 101710132593 Protein E2 Proteins 0.000 description 2
- 108091028664 Ribonucleotide Proteins 0.000 description 2
- 101150028158 STE13 gene Proteins 0.000 description 2
- 241000311088 Schwanniomyces Species 0.000 description 2
- 108091081024 Start codon Proteins 0.000 description 2
- 101710172711 Structural protein Proteins 0.000 description 2
- 230000005867 T cell response Effects 0.000 description 2
- 102000005488 Thioesterase Human genes 0.000 description 2
- IQFYYKKMVGJFEH-XLPZGREQSA-N Thymidine Chemical compound O=C1NC(=O)C(C)=CN1[C@@H]1O[C@H](CO)[C@@H](O)C1 IQFYYKKMVGJFEH-XLPZGREQSA-N 0.000 description 2
- 108700029229 Transcriptional Regulatory Elements Proteins 0.000 description 2
- YJQCOFNZVFGCAF-UHFFFAOYSA-N Tunicamycin II Natural products O1C(CC(O)C2C(C(O)C(O2)N2C(NC(=O)C=C2)=O)O)C(O)C(O)C(NC(=O)C=CCCCCCCCCC(C)C)C1OC1OC(CO)C(O)C(O)C1NC(C)=O YJQCOFNZVFGCAF-UHFFFAOYSA-N 0.000 description 2
- XSQUKJJJFZCRTK-UHFFFAOYSA-N Urea Chemical compound NC(N)=O XSQUKJJJFZCRTK-UHFFFAOYSA-N 0.000 description 2
- 206010046865 Vaccinia virus infection Diseases 0.000 description 2
- 241000251539 Vertebrata <Metazoa> Species 0.000 description 2
- 108010067390 Viral Proteins Proteins 0.000 description 2
- IXKSXJFAGXLQOQ-XISFHERQSA-N WHWLQLKPGQPMY Chemical compound C([C@@H](C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N1CCC[C@H]1C(=O)NCC(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)NC(=O)[C@@H](N)CC=1C2=CC=CC=C2NC=1)C1=CNC=N1 IXKSXJFAGXLQOQ-XISFHERQSA-N 0.000 description 2
- 108010084455 Zeocin Proteins 0.000 description 2
- JLCPHMBAVCMARE-UHFFFAOYSA-N [3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-hydroxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methyl [5-(6-aminopurin-9-yl)-2-(hydroxymethyl)oxolan-3-yl] hydrogen phosphate Polymers Cc1cn(C2CC(OP(O)(=O)OCC3OC(CC3OP(O)(=O)OCC3OC(CC3O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c3nc(N)[nH]c4=O)C(COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3CO)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cc(C)c(=O)[nH]c3=O)n3cc(C)c(=O)[nH]c3=O)n3ccc(N)nc3=O)n3cc(C)c(=O)[nH]c3=O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)O2)c(=O)[nH]c1=O JLCPHMBAVCMARE-UHFFFAOYSA-N 0.000 description 2
- 239000013543 active substance Substances 0.000 description 2
- 108700014220 acyltransferase activity proteins Proteins 0.000 description 2
- 108091005764 adaptor proteins Proteins 0.000 description 2
- 102000035181 adaptor proteins Human genes 0.000 description 2
- HAXFWIACAGNFHA-UHFFFAOYSA-N aldrithiol Chemical compound C=1C=CC=NC=1SSC1=CC=CC=N1 HAXFWIACAGNFHA-UHFFFAOYSA-N 0.000 description 2
- 229940037003 alum Drugs 0.000 description 2
- 239000003963 antioxidant agent Substances 0.000 description 2
- 235000006708 antioxidants Nutrition 0.000 description 2
- 235000009582 asparagine Nutrition 0.000 description 2
- 229960001230 asparagine Drugs 0.000 description 2
- 238000002820 assay format Methods 0.000 description 2
- DKXNBNKWCZZMJT-VOXHDCLVSA-N beta-D-glucosyl-(1->4)-aldehydo-D-mannose Chemical compound O=C[C@@H](O)[C@@H](O)[C@@H]([C@H](O)CO)O[C@@H]1O[C@H](CO)[C@@H](O)[C@H](O)[C@H]1O DKXNBNKWCZZMJT-VOXHDCLVSA-N 0.000 description 2
- 230000003115 biocidal effect Effects 0.000 description 2
- 230000004071 biological effect Effects 0.000 description 2
- 238000005537 brownian motion Methods 0.000 description 2
- 239000006227 byproduct Substances 0.000 description 2
- 229940044199 carnosine Drugs 0.000 description 2
- 239000003054 catalyst Substances 0.000 description 2
- 230000007969 cellular immunity Effects 0.000 description 2
- 230000008859 change Effects 0.000 description 2
- 238000007385 chemical modification Methods 0.000 description 2
- 230000035071 co-translational protein modification Effects 0.000 description 2
- NKLPQNGYXWVELD-UHFFFAOYSA-M coomassie brilliant blue Chemical compound [Na+].C1=CC(OCC)=CC=C1NC1=CC=C(C(=C2C=CC(C=C2)=[N+](CC)CC=2C=C(C=CC=2)S([O-])(=O)=O)C=2C=CC(=CC=2)N(CC)CC=2C=C(C=CC=2)S([O-])(=O)=O)C=C1 NKLPQNGYXWVELD-UHFFFAOYSA-M 0.000 description 2
- 239000002577 cryoprotective agent Substances 0.000 description 2
- 239000013530 defoamer Substances 0.000 description 2
- 239000008367 deionised water Substances 0.000 description 2
- 229910021641 deionized water Inorganic materials 0.000 description 2
- 238000012217 deletion Methods 0.000 description 2
- 230000037430 deletion Effects 0.000 description 2
- 239000005547 deoxyribonucleotide Chemical class 0.000 description 2
- 125000002637 deoxyribonucleotide group Chemical class 0.000 description 2
- VLYUGYAKYZETRF-UHFFFAOYSA-N dihydrolipoamide Chemical compound NC(=O)CCCCC(S)CCS VLYUGYAKYZETRF-UHFFFAOYSA-N 0.000 description 2
- 239000003085 diluting agent Substances 0.000 description 2
- 239000003623 enhancer Substances 0.000 description 2
- 238000011156 evaluation Methods 0.000 description 2
- 230000000367 exoproteolytic effect Effects 0.000 description 2
- 238000010195 expression analysis Methods 0.000 description 2
- 238000001914 filtration Methods 0.000 description 2
- 239000012530 fluid Substances 0.000 description 2
- 238000005194 fractionation Methods 0.000 description 2
- 235000013922 glutamic acid Nutrition 0.000 description 2
- 239000004220 glutamic acid Substances 0.000 description 2
- ZDXPYRJPNDTMRX-UHFFFAOYSA-N glutamine Natural products OC(=O)C(N)CCC(N)=O ZDXPYRJPNDTMRX-UHFFFAOYSA-N 0.000 description 2
- RWSXRVCMGQZWBV-WDSKDSINSA-N glutathione Chemical compound OC(=O)[C@@H](N)CCC(=O)N[C@@H](CS)C(=O)NCC(O)=O RWSXRVCMGQZWBV-WDSKDSINSA-N 0.000 description 2
- 210000002443 helper t lymphocyte Anatomy 0.000 description 2
- 231100000234 hepatic damage Toxicity 0.000 description 2
- 208000006454 hepatitis Diseases 0.000 description 2
- 125000000487 histidyl group Chemical group [H]N([H])C(C(=O)O*)C([H])([H])C1=C([H])N([H])C([H])=N1 0.000 description 2
- 238000009396 hybridization Methods 0.000 description 2
- 229910052739 hydrogen Inorganic materials 0.000 description 2
- 239000001257 hydrogen Substances 0.000 description 2
- 230000002209 hydrophobic effect Effects 0.000 description 2
- 102000018358 immunoglobulin Human genes 0.000 description 2
- 229940072221 immunoglobulins Drugs 0.000 description 2
- 238000001114 immunoprecipitation Methods 0.000 description 2
- 230000001965 increasing effect Effects 0.000 description 2
- 238000003780 insertion Methods 0.000 description 2
- 230000037431 insertion Effects 0.000 description 2
- 239000007927 intramuscular injection Substances 0.000 description 2
- 238000010255 intramuscular injection Methods 0.000 description 2
- JDNTWHVOXJZDSN-UHFFFAOYSA-N iodoacetic acid Chemical compound OC(=O)CI JDNTWHVOXJZDSN-UHFFFAOYSA-N 0.000 description 2
- INQOMBQAUSQDDS-UHFFFAOYSA-N iodomethane Chemical compound IC INQOMBQAUSQDDS-UHFFFAOYSA-N 0.000 description 2
- 239000003446 ligand Substances 0.000 description 2
- 239000007788 liquid Substances 0.000 description 2
- 238000009630 liquid culture Methods 0.000 description 2
- 230000008818 liver damage Effects 0.000 description 2
- 230000001589 lymphoproliferative effect Effects 0.000 description 2
- 239000006166 lysate Substances 0.000 description 2
- 230000002934 lysing effect Effects 0.000 description 2
- 229920002521 macromolecule Polymers 0.000 description 2
- 150000008146 mannosides Chemical class 0.000 description 2
- 238000001906 matrix-assisted laser desorption--ionisation mass spectrometry Methods 0.000 description 2
- 229910021645 metal ion Inorganic materials 0.000 description 2
- 235000013336 milk Nutrition 0.000 description 2
- 210000004080 milk Anatomy 0.000 description 2
- 239000008267 milk Substances 0.000 description 2
- 230000003278 mimic effect Effects 0.000 description 2
- 239000003068 molecular probe Substances 0.000 description 2
- 231100000252 nontoxic Toxicity 0.000 description 2
- 230000003000 nontoxic effect Effects 0.000 description 2
- 108010091748 peptide A Proteins 0.000 description 2
- 210000003819 peripheral blood mononuclear cell Anatomy 0.000 description 2
- 239000000546 pharmaceutical excipient Substances 0.000 description 2
- XEBWQGVWTUSTLN-UHFFFAOYSA-M phenylmercury acetate Chemical compound CC(=O)O[Hg]C1=CC=CC=C1 XEBWQGVWTUSTLN-UHFFFAOYSA-M 0.000 description 2
- CWCMIVBLVUHDHK-ZSNHEYEWSA-N phleomycin D1 Chemical compound N([C@H](C(=O)N[C@H](C)[C@@H](O)[C@H](C)C(=O)N[C@@H]([C@H](O)C)C(=O)NCCC=1SC[C@@H](N=1)C=1SC=C(N=1)C(=O)NCCCCNC(N)=N)[C@@H](O[C@H]1[C@H]([C@@H](O)[C@H](O)[C@H](CO)O1)O[C@@H]1[C@H]([C@@H](OC(N)=O)[C@H](O)[C@@H](CO)O1)O)C=1N=CNC=1)C(=O)C1=NC([C@H](CC(N)=O)NC[C@H](N)C(N)=O)=NC(N)=C1C CWCMIVBLVUHDHK-ZSNHEYEWSA-N 0.000 description 2
- 230000026731 phosphorylation Effects 0.000 description 2
- 238000006366 phosphorylation reaction Methods 0.000 description 2
- 229920000642 polymer Polymers 0.000 description 2
- 230000004481 post-translational protein modification Effects 0.000 description 2
- 229940021993 prophylactic vaccine Drugs 0.000 description 2
- 230000006337 proteolytic cleavage Effects 0.000 description 2
- 239000008213 purified water Substances 0.000 description 2
- 238000003127 radioimmunoassay Methods 0.000 description 2
- 230000000717 retained effect Effects 0.000 description 2
- 238000012552 review Methods 0.000 description 2
- 239000002336 ribonucleotide Substances 0.000 description 2
- 125000002652 ribonucleotide group Chemical class 0.000 description 2
- 210000003935 rough endoplasmic reticulum Anatomy 0.000 description 2
- 239000011734 sodium Substances 0.000 description 2
- 235000010265 sodium sulphite Nutrition 0.000 description 2
- 230000003595 spectral effect Effects 0.000 description 2
- 239000007929 subcutaneous injection Substances 0.000 description 2
- 238000010254 subcutaneous injection Methods 0.000 description 2
- 150000008163 sugars Chemical class 0.000 description 2
- 229940124597 therapeutic agent Drugs 0.000 description 2
- 238000002560 therapeutic procedure Methods 0.000 description 2
- 108020002982 thioesterase Proteins 0.000 description 2
- 125000003396 thiol group Chemical group [H]S* 0.000 description 2
- RWQNBRDOKXIBIV-UHFFFAOYSA-N thymine Chemical compound CC1=CNC(=O)NC1=O RWQNBRDOKXIBIV-UHFFFAOYSA-N 0.000 description 2
- 239000013638 trimer Substances 0.000 description 2
- ZHSGGJXRNHWHRS-VIDYELAYSA-N tunicamycin Chemical compound O([C@H]1[C@@H]([C@H]([C@@H](O)[C@@H](CC(O)[C@@H]2[C@H]([C@@H](O)[C@@H](O2)N2C(NC(=O)C=C2)=O)O)O1)O)NC(=O)/C=C/CC(C)C)[C@H]1O[C@H](CO)[C@@H](O)[C@H](O)[C@H]1NC(C)=O ZHSGGJXRNHWHRS-VIDYELAYSA-N 0.000 description 2
- MEYZYGMYMLNUHJ-UHFFFAOYSA-N tunicamycin Natural products CC(C)CCCCCCCCCC=CC(=O)NC1C(O)C(O)C(CC(O)C2OC(C(O)C2O)N3C=CC(=O)NC3=O)OC1OC4OC(CO)C(O)C(O)C4NC(=O)C MEYZYGMYMLNUHJ-UHFFFAOYSA-N 0.000 description 2
- 229940035893 uracil Drugs 0.000 description 2
- 208000007089 vaccinia Diseases 0.000 description 2
- YHQZWWDVLJPRIF-JLHRHDQISA-N (4R)-4-[[(2S,3R)-2-[acetyl-[(3R,4R,5S,6R)-3-amino-4-[(1R)-1-carboxyethoxy]-5-hydroxy-6-(hydroxymethyl)oxan-2-yl]amino]-3-hydroxybutanoyl]amino]-5-amino-5-oxopentanoic acid Chemical compound C(C)(=O)N([C@@H]([C@H](O)C)C(=O)N[C@H](CCC(=O)O)C(N)=O)C1[C@H](N)[C@@H](O[C@@H](C(=O)O)C)[C@H](O)[C@H](O1)CO YHQZWWDVLJPRIF-JLHRHDQISA-N 0.000 description 1
- YYGNTYWPHWGJRM-UHFFFAOYSA-N (6E,10E,14E,18E)-2,6,10,15,19,23-hexamethyltetracosa-2,6,10,14,18,22-hexaene Chemical compound CC(C)=CCCC(C)=CCCC(C)=CCCC=C(C)CCC=C(C)CCC=C(C)C YYGNTYWPHWGJRM-UHFFFAOYSA-N 0.000 description 1
- GZCWLCBFPRFLKL-UHFFFAOYSA-N 1-prop-2-ynoxypropan-2-ol Chemical compound CC(O)COCC#C GZCWLCBFPRFLKL-UHFFFAOYSA-N 0.000 description 1
- PIINGYXNCHTJTF-UHFFFAOYSA-N 2-(2-azaniumylethylamino)acetate Chemical group NCCNCC(O)=O PIINGYXNCHTJTF-UHFFFAOYSA-N 0.000 description 1
- YWXCBLUCVBSYNJ-UHFFFAOYSA-N 2-(2-sulfanylethylsulfonyl)ethanethiol Chemical compound SCCS(=O)(=O)CCS YWXCBLUCVBSYNJ-UHFFFAOYSA-N 0.000 description 1
- WFIYPADYPQQLNN-UHFFFAOYSA-N 2-[2-(4-bromopyrazol-1-yl)ethyl]isoindole-1,3-dione Chemical compound C1=C(Br)C=NN1CCN1C(=O)C2=CC=CC=C2C1=O WFIYPADYPQQLNN-UHFFFAOYSA-N 0.000 description 1
- IZQAUUVBKYXMET-UHFFFAOYSA-N 2-bromoethanamine Chemical compound NCCBr IZQAUUVBKYXMET-UHFFFAOYSA-N 0.000 description 1
- CYWHLOXWVAWMFO-UHFFFAOYSA-N 3-sulfanyl-1h-pyridine-2-thione Chemical compound SC1=CC=CN=C1S CYWHLOXWVAWMFO-UHFFFAOYSA-N 0.000 description 1
- FWMNVWWHGCHHJJ-SKKKGAJSSA-N 4-amino-1-[(2r)-6-amino-2-[[(2r)-2-[[(2r)-2-[[(2r)-2-amino-3-phenylpropanoyl]amino]-3-phenylpropanoyl]amino]-4-methylpentanoyl]amino]hexanoyl]piperidine-4-carboxylic acid Chemical compound C([C@H](C(=O)N[C@H](CC(C)C)C(=O)N[C@H](CCCCN)C(=O)N1CCC(N)(CC1)C(O)=O)NC(=O)[C@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 FWMNVWWHGCHHJJ-SKKKGAJSSA-N 0.000 description 1
- 108010011619 6-Phytase Proteins 0.000 description 1
- ZVHHSBAWAOBBSE-UHFFFAOYSA-N 6-amino-1-(4-aminophenyl)arsanylhexan-1-one Chemical compound NCCCCCC(=O)[AsH]C1=CC=C(N)C=C1 ZVHHSBAWAOBBSE-UHFFFAOYSA-N 0.000 description 1
- 108010051457 Acid Phosphatase Proteins 0.000 description 1
- 102000013563 Acid Phosphatase Human genes 0.000 description 1
- 229920000936 Agarose Polymers 0.000 description 1
- 108020004774 Alkaline Phosphatase Proteins 0.000 description 1
- 102000002260 Alkaline Phosphatase Human genes 0.000 description 1
- 108091093088 Amplicon Proteins 0.000 description 1
- 239000004382 Amylase Substances 0.000 description 1
- 108010065511 Amylases Proteins 0.000 description 1
- 102000013142 Amylases Human genes 0.000 description 1
- 239000004475 Arginine Substances 0.000 description 1
- 108010002913 Asialoglycoproteins Proteins 0.000 description 1
- 241000228212 Aspergillus Species 0.000 description 1
- 241000228245 Aspergillus niger Species 0.000 description 1
- 241000228251 Aspergillus phoenicis Species 0.000 description 1
- WVDDGKGOMKODPV-UHFFFAOYSA-N Benzyl alcohol Chemical compound OCC1=CC=CC=C1 WVDDGKGOMKODPV-UHFFFAOYSA-N 0.000 description 1
- DWRXFEITVBNRMK-UHFFFAOYSA-N Beta-D-1-Arabinofuranosylthymine Natural products O=C1NC(=O)C(C)=CN1C1C(O)C(O)C(CO)O1 DWRXFEITVBNRMK-UHFFFAOYSA-N 0.000 description 1
- 239000002028 Biomass Substances 0.000 description 1
- 101100083253 Caenorhabditis elegans pho-1 gene Proteins 0.000 description 1
- 101710132601 Capsid protein Proteins 0.000 description 1
- QRYRORQUOLYVBU-VBKZILBWSA-N Carnosic acid Natural products CC([C@@H]1CC2)(C)CCC[C@]1(C(O)=O)C1=C2C=C(C(C)C)C(O)=C1O QRYRORQUOLYVBU-VBKZILBWSA-N 0.000 description 1
- 108010087806 Carnosine Proteins 0.000 description 1
- 108010039939 Cell Wall Skeleton Proteins 0.000 description 1
- 241001227713 Chiron Species 0.000 description 1
- 206010008909 Chronic Hepatitis Diseases 0.000 description 1
- FBPFZTCFMRRESA-KVTDHHQDSA-N D-Mannitol Chemical compound OC[C@@H](O)[C@@H](O)[C@H](O)[C@H](O)CO FBPFZTCFMRRESA-KVTDHHQDSA-N 0.000 description 1
- SHZGCJCMOBCMKK-UHFFFAOYSA-N D-mannomethylose Natural products CC1OC(O)C(O)C(O)C1O SHZGCJCMOBCMKK-UHFFFAOYSA-N 0.000 description 1
- 239000003298 DNA probe Substances 0.000 description 1
- 238000001712 DNA sequencing Methods 0.000 description 1
- 101710118188 DNA-binding protein HU-alpha Proteins 0.000 description 1
- 241000725619 Dengue virus Species 0.000 description 1
- 101100108820 Drosophila ananassae Amy35 gene Proteins 0.000 description 1
- 102100031636 Dynein axonemal heavy chain 9 Human genes 0.000 description 1
- 238000012286 ELISA Assay Methods 0.000 description 1
- 241000589566 Elizabethkingia meningoseptica Species 0.000 description 1
- 101710204837 Envelope small membrane protein Proteins 0.000 description 1
- 241001131785 Escherichia coli HB101 Species 0.000 description 1
- 108010091443 Exopeptidases Proteins 0.000 description 1
- 102000018389 Exopeptidases Human genes 0.000 description 1
- KRHYYFGTRYWZRS-UHFFFAOYSA-M Fluoride anion Chemical compound [F-] KRHYYFGTRYWZRS-UHFFFAOYSA-M 0.000 description 1
- 101000893906 Fowl adenovirus A serotype 1 (strain CELO / Phelps) Protein GAM-1 Proteins 0.000 description 1
- PNNNRSAQSRJVSB-SLPGGIOYSA-N Fucose Natural products C[C@H](O)[C@@H](O)[C@H](O)[C@H](O)C=O PNNNRSAQSRJVSB-SLPGGIOYSA-N 0.000 description 1
- 210000000712 G cell Anatomy 0.000 description 1
- 241000287828 Gallus gallus Species 0.000 description 1
- 101000930822 Giardia intestinalis Dipeptidyl-peptidase 4 Proteins 0.000 description 1
- 108010073178 Glucan 1,4-alpha-Glucosidase Proteins 0.000 description 1
- 102100022624 Glucoamylase Human genes 0.000 description 1
- 108010024636 Glutathione Proteins 0.000 description 1
- 229910004373 HOAc Inorganic materials 0.000 description 1
- 101000575170 Halobacterium salinarum (strain ATCC 700922 / JCM 11081 / NRC-1) 50S ribosomal protein L12 Proteins 0.000 description 1
- 241000237369 Helix pomatia Species 0.000 description 1
- 241000238631 Hexapoda Species 0.000 description 1
- 108010093488 His-His-His-His-His-His Proteins 0.000 description 1
- 241000282412 Homo Species 0.000 description 1
- 101000866325 Homo sapiens Dynein axonemal heavy chain 9 Proteins 0.000 description 1
- 101000957351 Homo sapiens Myc-associated zinc finger protein Proteins 0.000 description 1
- 108010001336 Horseradish Peroxidase Proteins 0.000 description 1
- UFHFLCQGNIYNRP-UHFFFAOYSA-N Hydrogen Chemical compound [H][H] UFHFLCQGNIYNRP-UHFFFAOYSA-N 0.000 description 1
- 206010020751 Hypersensitivity Diseases 0.000 description 1
- 206010069803 Injury associated with device Diseases 0.000 description 1
- 229930010555 Inosine Natural products 0.000 description 1
- UGQMRVRMYYASKQ-KQYNXXCUSA-N Inosine Chemical compound O[C@@H]1[C@H](O)[C@@H](CO)O[C@H]1N1C2=NC=NC(O)=C2N=C1 UGQMRVRMYYASKQ-KQYNXXCUSA-N 0.000 description 1
- 108010050904 Interferons Proteins 0.000 description 1
- 102000014150 Interferons Human genes 0.000 description 1
- 229920001202 Inulin Polymers 0.000 description 1
- 241001138401 Kluyveromyces lactis Species 0.000 description 1
- SHZGCJCMOBCMKK-DHVFOXMCSA-N L-fucopyranose Chemical compound C[C@@H]1OC(O)[C@@H](O)[C@H](O)[C@@H]1O SHZGCJCMOBCMKK-DHVFOXMCSA-N 0.000 description 1
- 241000235087 Lachancea kluyveri Species 0.000 description 1
- 108090001090 Lectins Proteins 0.000 description 1
- 102000004856 Lectins Human genes 0.000 description 1
- 208000035752 Live birth Diseases 0.000 description 1
- 101710145006 Lysis protein Proteins 0.000 description 1
- 102000008791 Lysozyme C Human genes 0.000 description 1
- 229930195725 Mannitol Natural products 0.000 description 1
- 102100038750 Myc-associated zinc finger protein Human genes 0.000 description 1
- CQOVPNPJLQNMDC-UHFFFAOYSA-N N-beta-alanyl-L-histidine Natural products NCCC(=O)NC(C(O)=O)CC1=CN=CN1 CQOVPNPJLQNMDC-UHFFFAOYSA-N 0.000 description 1
- 206010028980 Neoplasm Diseases 0.000 description 1
- 241000221960 Neurospora Species 0.000 description 1
- 241000221961 Neurospora crassa Species 0.000 description 1
- 239000004677 Nylon Substances 0.000 description 1
- 241000551283 Ogataea polymorpha RB11 Species 0.000 description 1
- 108010038807 Oligopeptides Proteins 0.000 description 1
- 102000015636 Oligopeptides Human genes 0.000 description 1
- 108091093037 Peptide nucleic acid Proteins 0.000 description 1
- 102100038551 Peptide-N(4)-(N-acetyl-beta-glucosaminyl)asparagine amidase Human genes 0.000 description 1
- 108010030544 Peptidyl-Lys metalloendopeptidase Proteins 0.000 description 1
- 208000037581 Persistent Infection Diseases 0.000 description 1
- 241000276498 Pollachius virens Species 0.000 description 1
- 229920000954 Polyglycolide Polymers 0.000 description 1
- 229920001213 Polysorbate 20 Polymers 0.000 description 1
- 241000288906 Primates Species 0.000 description 1
- 229940096437 Protein S Drugs 0.000 description 1
- 108010066124 Protein S Proteins 0.000 description 1
- 102000029301 Protein S Human genes 0.000 description 1
- 108090000919 Pyroglutamyl-Peptidase I Proteins 0.000 description 1
- 238000001069 Raman spectroscopy Methods 0.000 description 1
- 108020004511 Recombinant DNA Proteins 0.000 description 1
- IWUCXVSUMQZMFG-AFCXAGJDSA-N Ribavirin Chemical compound N1=C(C(=O)N)N=CN1[C@H]1[C@H](O)[C@H](O)[C@@H](CO)O1 IWUCXVSUMQZMFG-AFCXAGJDSA-N 0.000 description 1
- 101001007682 Saccharomyces cerevisiae (strain ATCC 204508 / S288c) Kexin Proteins 0.000 description 1
- 241000582914 Saccharomyces uvarum Species 0.000 description 1
- 241000235346 Schizosaccharomyces Species 0.000 description 1
- 241000235347 Schizosaccharomyces pombe Species 0.000 description 1
- 241001123650 Schwanniomyces occidentalis Species 0.000 description 1
- 241000287219 Serinus canaria Species 0.000 description 1
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 1
- DBMJMQXJHONAFJ-UHFFFAOYSA-M Sodium laurylsulphate Chemical compound [Na+].CCCCCCCCCCCCOS([O-])(=O)=O DBMJMQXJHONAFJ-UHFFFAOYSA-M 0.000 description 1
- 230000024932 T cell mediated immunity Effects 0.000 description 1
- BHEOSNUKNHRBNM-UHFFFAOYSA-N Tetramethylsqualene Natural products CC(=C)C(C)CCC(=C)C(C)CCC(C)=CCCC=C(C)CCC(C)C(=C)CCC(C)C(C)=C BHEOSNUKNHRBNM-UHFFFAOYSA-N 0.000 description 1
- AYFVYJQAPQTCCC-UHFFFAOYSA-N Threonine Natural products CC(O)C(N)C(O)=O AYFVYJQAPQTCCC-UHFFFAOYSA-N 0.000 description 1
- 239000004473 Threonine Substances 0.000 description 1
- 229920004898 Triton X-705 Polymers 0.000 description 1
- LUEWUZLMQUOBSB-UHFFFAOYSA-N UNPD55895 Natural products OC1C(O)C(O)C(CO)OC1OC1C(CO)OC(OC2C(OC(OC3C(OC(O)C(O)C3O)CO)C(O)C2O)CO)C(O)C1O LUEWUZLMQUOBSB-UHFFFAOYSA-N 0.000 description 1
- UZQJVUCHXGYFLQ-AYDHOLPZSA-N [(2s,3r,4s,5r,6r)-4-[(2s,3r,4s,5r,6r)-4-[(2r,3r,4s,5r,6r)-4-[(2s,3r,4s,5r,6r)-3,5-dihydroxy-6-(hydroxymethyl)-4-[(2s,3r,4s,5s,6r)-3,4,5-trihydroxy-6-(hydroxymethyl)oxan-2-yl]oxyoxan-2-yl]oxy-3,5-dihydroxy-6-(hydroxymethyl)oxan-2-yl]oxy-3,5-dihydroxy-6-(hy Chemical compound O([C@H]1[C@H](O)[C@@H](CO)O[C@H]([C@@H]1O)O[C@H]1[C@H](O)[C@@H](CO)O[C@H]([C@@H]1O)O[C@H]1CC[C@]2(C)[C@H]3CC=C4[C@@]([C@@]3(CC[C@H]2[C@@]1(C=O)C)C)(C)CC(O)[C@]1(CCC(CC14)(C)C)C(=O)O[C@H]1[C@@H]([C@@H](O[C@H]2[C@@H]([C@@H](O[C@H]3[C@@H]([C@@H](O[C@H]4[C@@H]([C@@H](O[C@H]5[C@@H]([C@@H](O)[C@H](O)[C@@H](CO)O5)O)[C@H](O)[C@@H](CO)O4)O)[C@H](O)[C@@H](CO)O3)O)[C@H](O)[C@@H](CO)O2)O)[C@H](O)[C@@H](CO)O1)O)[C@@H]1O[C@H](CO)[C@@H](O)[C@H](O)[C@H]1O UZQJVUCHXGYFLQ-AYDHOLPZSA-N 0.000 description 1
- 230000021736 acetylation Effects 0.000 description 1
- 238000006640 acetylation reaction Methods 0.000 description 1
- 229960004308 acetylcysteine Drugs 0.000 description 1
- 239000002253 acid Substances 0.000 description 1
- 150000007513 acids Chemical class 0.000 description 1
- 230000006978 adaptation Effects 0.000 description 1
- 230000000240 adjuvant effect Effects 0.000 description 1
- 239000000443 aerosol Substances 0.000 description 1
- 238000000246 agarose gel electrophoresis Methods 0.000 description 1
- 230000004520 agglutination Effects 0.000 description 1
- 230000002776 aggregation Effects 0.000 description 1
- 238000004220 aggregation Methods 0.000 description 1
- 230000002009 allergenic effect Effects 0.000 description 1
- 208000026935 allergic disease Diseases 0.000 description 1
- WQZGKKKJIJFFOK-PHYPRBDBSA-N alpha-D-galactose Chemical compound OC[C@H]1O[C@H](O)[C@H](O)[C@@H](O)[C@H]1O WQZGKKKJIJFFOK-PHYPRBDBSA-N 0.000 description 1
- 102000005840 alpha-Galactosidase Human genes 0.000 description 1
- 108010030291 alpha-Galactosidase Proteins 0.000 description 1
- 229910052782 aluminium Inorganic materials 0.000 description 1
- XAGFODPZIPBFFR-UHFFFAOYSA-N aluminium Chemical compound [Al] XAGFODPZIPBFFR-UHFFFAOYSA-N 0.000 description 1
- WNROFYMDJYEPJX-UHFFFAOYSA-K aluminium hydroxide Chemical compound [OH-].[OH-].[OH-].[Al+3] WNROFYMDJYEPJX-UHFFFAOYSA-K 0.000 description 1
- ILRRQNADMUWWFW-UHFFFAOYSA-K aluminium phosphate Chemical compound O1[Al]2OP1(=O)O2 ILRRQNADMUWWFW-UHFFFAOYSA-K 0.000 description 1
- 239000003708 ampul Substances 0.000 description 1
- 235000019418 amylase Nutrition 0.000 description 1
- 230000003078 antioxidant effect Effects 0.000 description 1
- 239000007864 aqueous solution Substances 0.000 description 1
- 239000007900 aqueous suspension Substances 0.000 description 1
- ODKSFYDXXFIFQN-UHFFFAOYSA-N arginine Natural products OC(=O)C(N)CCCNC(N)=N ODKSFYDXXFIFQN-UHFFFAOYSA-N 0.000 description 1
- 238000000149 argon plasma sintering Methods 0.000 description 1
- 229940072107 ascorbate Drugs 0.000 description 1
- 235000010323 ascorbic acid Nutrition 0.000 description 1
- 239000011668 ascorbic acid Substances 0.000 description 1
- 235000003704 aspartic acid Nutrition 0.000 description 1
- 238000005311 autocorrelation function Methods 0.000 description 1
- 229960004217 benzyl alcohol Drugs 0.000 description 1
- WQZGKKKJIJFFOK-VFUOTHLCSA-N beta-D-glucose Chemical compound OC[C@H]1O[C@@H](O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-VFUOTHLCSA-N 0.000 description 1
- 108010051210 beta-Fructofuranosidase Proteins 0.000 description 1
- 102000005936 beta-Galactosidase Human genes 0.000 description 1
- 108010005774 beta-Galactosidase Proteins 0.000 description 1
- IQFYYKKMVGJFEH-UHFFFAOYSA-N beta-L-thymidine Natural products O=C1NC(=O)C(C)=CN1C1OC(CO)C(O)C1 IQFYYKKMVGJFEH-UHFFFAOYSA-N 0.000 description 1
- SQVRNKJHWKZAKO-UHFFFAOYSA-N beta-N-Acetyl-D-neuraminic acid Natural products CC(=O)NC1C(O)CC(O)(C(O)=O)OC1C(O)C(O)CO SQVRNKJHWKZAKO-UHFFFAOYSA-N 0.000 description 1
- OQFSQFPPLPISGP-UHFFFAOYSA-N beta-carboxyaspartic acid Natural products OC(=O)C(N)C(C(O)=O)C(O)=O OQFSQFPPLPISGP-UHFFFAOYSA-N 0.000 description 1
- 229920001400 block copolymer Polymers 0.000 description 1
- 239000010836 blood and blood product Substances 0.000 description 1
- 229940125691 blood product Drugs 0.000 description 1
- 239000001045 blue dye Substances 0.000 description 1
- 229910052794 bromium Inorganic materials 0.000 description 1
- 239000007853 buffer solution Substances 0.000 description 1
- 239000004202 carbamide Substances 0.000 description 1
- 125000006297 carbonyl amino group Chemical group [H]N([*:2])C([*:1])=O 0.000 description 1
- CQOVPNPJLQNMDC-ZETCQYMHSA-N carnosine Chemical compound [NH3+]CCC(=O)N[C@H](C([O-])=O)CC1=CNC=N1 CQOVPNPJLQNMDC-ZETCQYMHSA-N 0.000 description 1
- 238000006555 catalytic reaction Methods 0.000 description 1
- 210000004520 cell wall skeleton Anatomy 0.000 description 1
- 230000007248 cellular mechanism Effects 0.000 description 1
- 230000036755 cellular response Effects 0.000 description 1
- 229920002301 cellulose acetate Polymers 0.000 description 1
- 210000001175 cerebrospinal fluid Anatomy 0.000 description 1
- 238000012512 characterization method Methods 0.000 description 1
- 239000013043 chemical agent Substances 0.000 description 1
- 210000004978 chinese hamster ovary cell Anatomy 0.000 description 1
- 229910052801 chlorine Inorganic materials 0.000 description 1
- 238000011210 chromatographic step Methods 0.000 description 1
- 238000011097 chromatography purification Methods 0.000 description 1
- 239000012539 chromatography resin Substances 0.000 description 1
- 210000000349 chromosome Anatomy 0.000 description 1
- 230000001427 coherent effect Effects 0.000 description 1
- 238000010668 complexation reaction Methods 0.000 description 1
- 230000021615 conjugation Effects 0.000 description 1
- 229920001577 copolymer Polymers 0.000 description 1
- 201000003740 cowpox Diseases 0.000 description 1
- 239000012531 culture fluid Substances 0.000 description 1
- 239000012228 culture supernatant Substances 0.000 description 1
- 210000004748 cultured cell Anatomy 0.000 description 1
- UFULAYFCSOUIOV-UHFFFAOYSA-N cysteamine Chemical compound NCCS UFULAYFCSOUIOV-UHFFFAOYSA-N 0.000 description 1
- 150000001944 cysteine derivatives Chemical class 0.000 description 1
- 230000009089 cytolysis Effects 0.000 description 1
- 231100000433 cytotoxic Toxicity 0.000 description 1
- 230000001472 cytotoxic effect Effects 0.000 description 1
- 238000007405 data analysis Methods 0.000 description 1
- 230000003247 decreasing effect Effects 0.000 description 1
- 230000007547 defect Effects 0.000 description 1
- 230000007123 defense Effects 0.000 description 1
- 230000001419 dependent effect Effects 0.000 description 1
- 230000030609 dephosphorylation Effects 0.000 description 1
- 238000006209 dephosphorylation reaction Methods 0.000 description 1
- 230000006326 desulfonation Effects 0.000 description 1
- 238000005869 desulfonation reaction Methods 0.000 description 1
- 238000001514 detection method Methods 0.000 description 1
- 238000002405 diagnostic procedure Methods 0.000 description 1
- 229910003460 diamond Inorganic materials 0.000 description 1
- 239000010432 diamond Substances 0.000 description 1
- 239000013024 dilution buffer Substances 0.000 description 1
- 238000004090 dissolution Methods 0.000 description 1
- 125000002228 disulfide group Chemical group 0.000 description 1
- 150000004659 dithiocarbamates Chemical class 0.000 description 1
- 150000004662 dithiols Chemical class 0.000 description 1
- GRWZHXKQBITJKP-UHFFFAOYSA-L dithionite(2-) Chemical compound [O-]S(=O)S([O-])=O GRWZHXKQBITJKP-UHFFFAOYSA-L 0.000 description 1
- PRAKJMSDJKAYCZ-UHFFFAOYSA-N dodecahydrosqualene Natural products CC(C)CCCC(C)CCCC(C)CCCCC(C)CCCC(C)CCCC(C)C PRAKJMSDJKAYCZ-UHFFFAOYSA-N 0.000 description 1
- 239000006196 drop Substances 0.000 description 1
- 238000004520 electroporation Methods 0.000 description 1
- 230000008030 elimination Effects 0.000 description 1
- 238000003379 elimination reaction Methods 0.000 description 1
- 239000003995 emulsifying agent Substances 0.000 description 1
- 239000000839 emulsion Substances 0.000 description 1
- 230000003241 endoproteolytic effect Effects 0.000 description 1
- 239000002158 endotoxin Substances 0.000 description 1
- 239000013604 expression vector Substances 0.000 description 1
- 239000000284 extract Substances 0.000 description 1
- 230000002349 favourable effect Effects 0.000 description 1
- 230000002538 fungal effect Effects 0.000 description 1
- 230000004927 fusion Effects 0.000 description 1
- 229930182830 galactose Natural products 0.000 description 1
- 238000003205 genotyping method Methods 0.000 description 1
- 239000011521 glass Substances 0.000 description 1
- 239000006481 glucose medium Substances 0.000 description 1
- 102000003642 glutaminyl-peptide cyclotransferase Human genes 0.000 description 1
- 108010081484 glutaminyl-peptide cyclotransferase Proteins 0.000 description 1
- 229960003180 glutathione Drugs 0.000 description 1
- 230000001279 glycosylating effect Effects 0.000 description 1
- 239000010931 gold Substances 0.000 description 1
- 229910052737 gold Inorganic materials 0.000 description 1
- LHGVFZTZFXWLCP-UHFFFAOYSA-N guaiacol Chemical compound COC1=CC=CC=C1O LHGVFZTZFXWLCP-UHFFFAOYSA-N 0.000 description 1
- 150000004820 halides Chemical group 0.000 description 1
- 230000036541 health Effects 0.000 description 1
- 230000005802 health problem Effects 0.000 description 1
- 229910001385 heavy metal Inorganic materials 0.000 description 1
- 231100000283 hepatitis Toxicity 0.000 description 1
- 206010073071 hepatocellular carcinoma Diseases 0.000 description 1
- 231100000844 hepatocellular carcinoma Toxicity 0.000 description 1
- 229940006607 hirudin Drugs 0.000 description 1
- 230000028996 humoral immune response Effects 0.000 description 1
- 210000004408 hybridoma Anatomy 0.000 description 1
- 230000007062 hydrolysis Effects 0.000 description 1
- 238000006460 hydrolysis reaction Methods 0.000 description 1
- WGCNASOHLSPBMP-UHFFFAOYSA-N hydroxyacetaldehyde Natural products OCC=O WGCNASOHLSPBMP-UHFFFAOYSA-N 0.000 description 1
- 230000009610 hypersensitivity Effects 0.000 description 1
- 210000000987 immune system Anatomy 0.000 description 1
- 230000004957 immunoregulator effect Effects 0.000 description 1
- 230000003308 immunostimulating effect Effects 0.000 description 1
- 238000002513 implantation Methods 0.000 description 1
- 239000012535 impurity Substances 0.000 description 1
- 206010022000 influenza Diseases 0.000 description 1
- 229960003786 inosine Drugs 0.000 description 1
- 238000009434 installation Methods 0.000 description 1
- 230000003993 interaction Effects 0.000 description 1
- 229940079322 interferon Drugs 0.000 description 1
- 230000000968 intestinal effect Effects 0.000 description 1
- 210000002011 intestinal secretion Anatomy 0.000 description 1
- 238000007918 intramuscular administration Methods 0.000 description 1
- 238000007912 intraperitoneal administration Methods 0.000 description 1
- 238000007913 intrathecal administration Methods 0.000 description 1
- 238000001990 intravenous administration Methods 0.000 description 1
- 229940029339 inulin Drugs 0.000 description 1
- JYJIGFIDKWBXDU-MNNPPOADSA-N inulin Chemical compound O[C@H]1[C@H](O)[C@@H](CO)O[C@@]1(CO)OC[C@]1(OC[C@]2(OC[C@]3(OC[C@]4(OC[C@]5(OC[C@]6(OC[C@]7(OC[C@]8(OC[C@]9(OC[C@]%10(OC[C@]%11(OC[C@]%12(OC[C@]%13(OC[C@]%14(OC[C@]%15(OC[C@]%16(OC[C@]%17(OC[C@]%18(OC[C@]%19(OC[C@]%20(OC[C@]%21(OC[C@]%22(OC[C@]%23(OC[C@]%24(OC[C@]%25(OC[C@]%26(OC[C@]%27(OC[C@]%28(OC[C@]%29(OC[C@]%30(OC[C@]%31(OC[C@]%32(OC[C@]%33(OC[C@]%34(OC[C@]%35(OC[C@]%36(O[C@@H]%37[C@@H]([C@@H](O)[C@H](O)[C@@H](CO)O%37)O)[C@H]([C@H](O)[C@@H](CO)O%36)O)[C@H]([C@H](O)[C@@H](CO)O%35)O)[C@H]([C@H](O)[C@@H](CO)O%34)O)[C@H]([C@H](O)[C@@H](CO)O%33)O)[C@H]([C@H](O)[C@@H](CO)O%32)O)[C@H]([C@H](O)[C@@H](CO)O%31)O)[C@H]([C@H](O)[C@@H](CO)O%30)O)[C@H]([C@H](O)[C@@H](CO)O%29)O)[C@H]([C@H](O)[C@@H](CO)O%28)O)[C@H]([C@H](O)[C@@H](CO)O%27)O)[C@H]([C@H](O)[C@@H](CO)O%26)O)[C@H]([C@H](O)[C@@H](CO)O%25)O)[C@H]([C@H](O)[C@@H](CO)O%24)O)[C@H]([C@H](O)[C@@H](CO)O%23)O)[C@H]([C@H](O)[C@@H](CO)O%22)O)[C@H]([C@H](O)[C@@H](CO)O%21)O)[C@H]([C@H](O)[C@@H](CO)O%20)O)[C@H]([C@H](O)[C@@H](CO)O%19)O)[C@H]([C@H](O)[C@@H](CO)O%18)O)[C@H]([C@H](O)[C@@H](CO)O%17)O)[C@H]([C@H](O)[C@@H](CO)O%16)O)[C@H]([C@H](O)[C@@H](CO)O%15)O)[C@H]([C@H](O)[C@@H](CO)O%14)O)[C@H]([C@H](O)[C@@H](CO)O%13)O)[C@H]([C@H](O)[C@@H](CO)O%12)O)[C@H]([C@H](O)[C@@H](CO)O%11)O)[C@H]([C@H](O)[C@@H](CO)O%10)O)[C@H]([C@H](O)[C@@H](CO)O9)O)[C@H]([C@H](O)[C@@H](CO)O8)O)[C@H]([C@H](O)[C@@H](CO)O7)O)[C@H]([C@H](O)[C@@H](CO)O6)O)[C@H]([C@H](O)[C@@H](CO)O5)O)[C@H]([C@H](O)[C@@H](CO)O4)O)[C@H]([C@H](O)[C@@H](CO)O3)O)[C@H]([C@H](O)[C@@H](CO)O2)O)[C@@H](O)[C@H](O)[C@@H](CO)O1 JYJIGFIDKWBXDU-MNNPPOADSA-N 0.000 description 1
- 239000001573 invertase Substances 0.000 description 1
- 235000011073 invertase Nutrition 0.000 description 1
- 229910052740 iodine Inorganic materials 0.000 description 1
- BWHLPLXXIDYSNW-UHFFFAOYSA-N ketorolac tromethamine Chemical compound OCC(N)(CO)CO.OC(=O)C1CCN2C1=CC=C2C(=O)C1=CC=CC=C1 BWHLPLXXIDYSNW-UHFFFAOYSA-N 0.000 description 1
- 238000002372 labelling Methods 0.000 description 1
- 238000011031 large-scale manufacturing process Methods 0.000 description 1
- 239000004816 latex Substances 0.000 description 1
- 229920000126 latex Polymers 0.000 description 1
- 239000002523 lectin Substances 0.000 description 1
- XIXADJRWDQXREU-UHFFFAOYSA-M lithium acetate Chemical compound [Li+].CC([O-])=O XIXADJRWDQXREU-UHFFFAOYSA-M 0.000 description 1
- 229940071257 lithium acetate Drugs 0.000 description 1
- 210000004185 liver Anatomy 0.000 description 1
- 238000012317 liver biopsy Methods 0.000 description 1
- 230000007774 longterm Effects 0.000 description 1
- 230000001926 lymphatic effect Effects 0.000 description 1
- 230000002101 lytic effect Effects 0.000 description 1
- UYQJCPNSAVWAFU-UHFFFAOYSA-N malto-tetraose Natural products OC1C(O)C(OC(C(O)CO)C(O)C(O)C=O)OC(CO)C1OC1C(O)C(O)C(OC2C(C(O)C(O)C(CO)O2)O)C(CO)O1 UYQJCPNSAVWAFU-UHFFFAOYSA-N 0.000 description 1
- LUEWUZLMQUOBSB-OUBHKODOSA-N maltotetraose Chemical compound O[C@H]1[C@H](O)[C@@H](O)[C@H](CO)O[C@H]1O[C@@H]1[C@H](CO)O[C@@H](O[C@@H]2[C@@H](O[C@@H](O[C@@H]3[C@@H](O[C@@H](O)[C@H](O)[C@H]3O)CO)[C@H](O)[C@H]2O)CO)[C@H](O)[C@H]1O LUEWUZLMQUOBSB-OUBHKODOSA-N 0.000 description 1
- 210000005075 mammary gland Anatomy 0.000 description 1
- 239000000594 mannitol Substances 0.000 description 1
- 235000010355 mannitol Nutrition 0.000 description 1
- 239000003550 marker Substances 0.000 description 1
- 230000013011 mating Effects 0.000 description 1
- SKEFKEOTNIPLCQ-LWIQTABASA-N mating hormone Chemical compound C([C@@H](C(=O)NC(CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N1[C@@H](CCC1)C(=O)NCC(=O)N[C@@H](CCC(N)=O)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CCS(C)=O)C(=O)NC(CC=1C=CC(O)=CC=1)C(O)=O)NC(=O)[C@@H](N)CC=1C2=CC=CC=C2NC=1)C1=CN=CN1 SKEFKEOTNIPLCQ-LWIQTABASA-N 0.000 description 1
- 230000035800 maturation Effects 0.000 description 1
- 238000005259 measurement Methods 0.000 description 1
- 229960003151 mercaptamine Drugs 0.000 description 1
- 230000004060 metabolic process Effects 0.000 description 1
- 229910052751 metal Inorganic materials 0.000 description 1
- 239000002184 metal Substances 0.000 description 1
- 230000011987 methylation Effects 0.000 description 1
- 238000007069 methylation reaction Methods 0.000 description 1
- 239000011859 microparticle Substances 0.000 description 1
- 238000002156 mixing Methods 0.000 description 1
- 125000000896 monocarboxylic acid group Chemical group 0.000 description 1
- 210000003097 mucus Anatomy 0.000 description 1
- IFVGFQAONSKBCR-UHFFFAOYSA-N n-[bis(aziridin-1-yl)phosphoryl]pyrimidin-2-amine Chemical compound C1CN1P(N1CC1)(=O)NC1=NC=CC=N1 IFVGFQAONSKBCR-UHFFFAOYSA-N 0.000 description 1
- 239000007923 nasal drop Substances 0.000 description 1
- 239000007922 nasal spray Substances 0.000 description 1
- 230000007935 neutral effect Effects 0.000 description 1
- 229920001778 nylon Polymers 0.000 description 1
- 238000006384 oligomerization reaction Methods 0.000 description 1
- 210000000287 oocyte Anatomy 0.000 description 1
- 238000005457 optimization Methods 0.000 description 1
- 230000036542 oxidative stress Effects 0.000 description 1
- 239000006179 pH buffering agent Substances 0.000 description 1
- 125000001312 palmitoyl group Chemical group O=C([*])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])[H] 0.000 description 1
- 230000036961 partial effect Effects 0.000 description 1
- 244000052769 pathogen Species 0.000 description 1
- 230000001717 pathogenic effect Effects 0.000 description 1
- 239000012071 phase Substances 0.000 description 1
- 125000001997 phenyl group Chemical group [H]C1=C([H])C([H])=C(*)C([H])=C1[H] 0.000 description 1
- 230000000704 physical effect Effects 0.000 description 1
- 229940085127 phytase Drugs 0.000 description 1
- 229920000747 poly(lactic acid) Polymers 0.000 description 1
- 238000006116 polymerization reaction Methods 0.000 description 1
- 239000000256 polyoxyethylene sorbitan monolaurate Substances 0.000 description 1
- 235000010486 polyoxyethylene sorbitan monolaurate Nutrition 0.000 description 1
- 235000010482 polyoxyethylene sorbitan monooleate Nutrition 0.000 description 1
- 229920001282 polysaccharide Polymers 0.000 description 1
- 239000005017 polysaccharide Substances 0.000 description 1
- 229920000053 polysorbate 80 Polymers 0.000 description 1
- 229920002223 polystyrene Polymers 0.000 description 1
- 239000004800 polyvinyl chloride Substances 0.000 description 1
- 229920000915 polyvinyl chloride Polymers 0.000 description 1
- 238000011533 pre-incubation Methods 0.000 description 1
- 239000003755 preservative agent Substances 0.000 description 1
- 230000003449 preventive effect Effects 0.000 description 1
- 125000002924 primary amino group Chemical group [H]N([H])* 0.000 description 1
- 230000035755 proliferation Effects 0.000 description 1
- 229940043274 prophylactic drug Drugs 0.000 description 1
- 235000019833 protease Nutrition 0.000 description 1
- 230000001681 protective effect Effects 0.000 description 1
- 230000012846 protein folding Effects 0.000 description 1
- 230000020978 protein processing Effects 0.000 description 1
- 239000012460 protein solution Substances 0.000 description 1
- 239000013014 purified material Substances 0.000 description 1
- 239000011535 reaction buffer Substances 0.000 description 1
- 238000010188 recombinant method Methods 0.000 description 1
- 238000011084 recovery Methods 0.000 description 1
- 230000006697 redox regulation Effects 0.000 description 1
- 230000022532 regulation of transcription, DNA-dependent Effects 0.000 description 1
- 230000001105 regulatory effect Effects 0.000 description 1
- 230000010076 replication Effects 0.000 description 1
- 230000000241 respiratory effect Effects 0.000 description 1
- 238000004366 reverse phase liquid chromatography Methods 0.000 description 1
- 229960000329 ribavirin Drugs 0.000 description 1
- HZCAHMRRMINHDJ-DBRKOABJSA-N ribavirin Natural products O[C@@H]1[C@H](O)[C@@H](CO)O[C@H]1N1N=CN=C1 HZCAHMRRMINHDJ-DBRKOABJSA-N 0.000 description 1
- 125000000548 ribosyl group Chemical group C1([C@H](O)[C@H](O)[C@H](O1)CO)* 0.000 description 1
- 238000007363 ring formation reaction Methods 0.000 description 1
- 238000002390 rotary evaporation Methods 0.000 description 1
- 238000009666 routine test Methods 0.000 description 1
- CQRYARSYNCAZFO-UHFFFAOYSA-N salicyl alcohol Chemical compound OCC1=CC=CC=C1O CQRYARSYNCAZFO-UHFFFAOYSA-N 0.000 description 1
- 210000003296 saliva Anatomy 0.000 description 1
- 239000012723 sample buffer Substances 0.000 description 1
- 229930182490 saponin Natural products 0.000 description 1
- 150000007949 saponins Chemical class 0.000 description 1
- 235000017709 saponins Nutrition 0.000 description 1
- 229920006395 saturated elastomer Polymers 0.000 description 1
- 239000006152 selective media Substances 0.000 description 1
- 150000003958 selenols Chemical class 0.000 description 1
- SQVRNKJHWKZAKO-OQPLDHBCSA-N sialic acid Chemical compound CC(=O)N[C@@H]1[C@@H](O)C[C@@](O)(C(O)=O)OC1[C@H](O)[C@H](O)CO SQVRNKJHWKZAKO-OQPLDHBCSA-N 0.000 description 1
- 210000000813 small intestine Anatomy 0.000 description 1
- 239000011780 sodium chloride Substances 0.000 description 1
- 238000002415 sodium dodecyl sulfate polyacrylamide gel electrophoresis Methods 0.000 description 1
- 239000007790 solid phase Substances 0.000 description 1
- 238000009331 sowing Methods 0.000 description 1
- 239000012798 spherical particle Substances 0.000 description 1
- 230000002269 spontaneous effect Effects 0.000 description 1
- 229940031439 squalene Drugs 0.000 description 1
- TUHBEKDERLKLEC-UHFFFAOYSA-N squalene Natural products CC(=CCCC(=CCCC(=CCCC=C(/C)CCC=C(/C)CC=C(C)C)C)C)C TUHBEKDERLKLEC-UHFFFAOYSA-N 0.000 description 1
- 230000000638 stimulation Effects 0.000 description 1
- 238000007920 subcutaneous administration Methods 0.000 description 1
- 239000000829 suppository Substances 0.000 description 1
- 238000003786 synthesis reaction Methods 0.000 description 1
- 210000001138 tear Anatomy 0.000 description 1
- 229940021747 therapeutic vaccine Drugs 0.000 description 1
- 150000003558 thiocarbamic acid derivatives Chemical class 0.000 description 1
- 229940104230 thymidine Drugs 0.000 description 1
- 229940113082 thymine Drugs 0.000 description 1
- HPGGPRDJHPYFRM-UHFFFAOYSA-J tin(iv) chloride Chemical compound Cl[Sn](Cl)(Cl)Cl HPGGPRDJHPYFRM-UHFFFAOYSA-J 0.000 description 1
- 230000002103 transcriptional effect Effects 0.000 description 1
- 238000012546 transfer Methods 0.000 description 1
- 238000002054 transplantation Methods 0.000 description 1
- 230000032258 transport Effects 0.000 description 1
- 230000001960 triggered effect Effects 0.000 description 1
- 108010087967 type I signal peptidase Proteins 0.000 description 1
- 241000701161 unidentified adenovirus Species 0.000 description 1
- 238000011144 upstream manufacturing Methods 0.000 description 1
- 210000002700 urine Anatomy 0.000 description 1
- 229930188461 vaccinine Natural products 0.000 description 1
- LSGOVYNHVSXFFJ-UHFFFAOYSA-N vanadate(3-) Chemical compound [O-][V]([O-])([O-])=O LSGOVYNHVSXFFJ-UHFFFAOYSA-N 0.000 description 1
- 238000012795 verification Methods 0.000 description 1
- 229920002554 vinyl polymer Polymers 0.000 description 1
- 210000002845 virion Anatomy 0.000 description 1
- 230000003612 virological effect Effects 0.000 description 1
- 239000011782 vitamin Substances 0.000 description 1
- 235000013343 vitamin Nutrition 0.000 description 1
- 229940088594 vitamin Drugs 0.000 description 1
- 229930003231 vitamin Natural products 0.000 description 1
- 238000009736 wetting Methods 0.000 description 1
- 239000000080 wetting agent Substances 0.000 description 1
Images


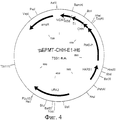
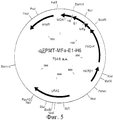















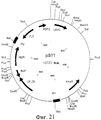





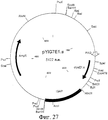

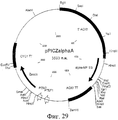
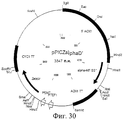
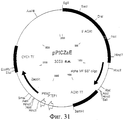


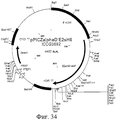

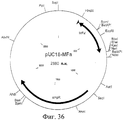



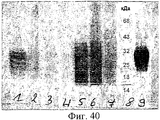




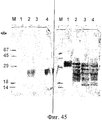










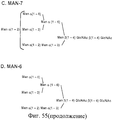
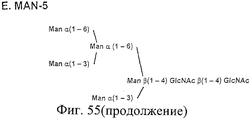


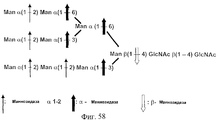

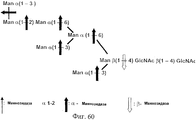

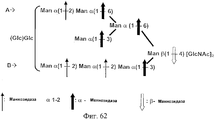






Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/005—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from viruses
- C07K14/08—RNA viruses
- C07K14/18—Togaviridae; Flaviviridae
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/005—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from viruses
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P31/00—Antiinfectives, i.e. antibiotics, antiseptics, chemotherapeutics
- A61P31/12—Antivirals
- A61P31/14—Antivirals for RNA viruses
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N7/00—Viruses; Bacteriophages; Compositions thereof; Preparation or purification thereof
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/51—Medicinal preparations containing antigens or antibodies comprising whole cells, viruses or DNA/RNA
- A61K2039/525—Virus
- A61K2039/5258—Virus-like particles
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K38/00—Medicinal preparations containing peptides
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/01—Fusion polypeptide containing a localisation/targetting motif
- C07K2319/02—Fusion polypeptide containing a localisation/targetting motif containing a signal sequence
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/50—Fusion polypeptide containing protease site
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2770/00—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA ssRNA viruses positive-sense
- C12N2770/00011—Details
- C12N2770/24011—Flaviviridae
- C12N2770/24211—Hepacivirus, e.g. hepatitis C virus, hepatitis G virus
- C12N2770/24222—New viral proteins or individual genes, new structural or functional aspects of known viral proteins or genes
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2770/00—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA ssRNA viruses positive-sense
- C12N2770/00011—Details
- C12N2770/24011—Flaviviridae
- C12N2770/24211—Hepacivirus, e.g. hepatitis C virus, hepatitis G virus
- C12N2770/24223—Virus like particles [VLP]
Landscapes
- Life Sciences & Earth Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Health & Medical Sciences (AREA)
- Organic Chemistry (AREA)
- Virology (AREA)
- Genetics & Genomics (AREA)
- Medicinal Chemistry (AREA)
- General Health & Medical Sciences (AREA)
- Biochemistry (AREA)
- Molecular Biology (AREA)
- Engineering & Computer Science (AREA)
- Zoology (AREA)
- Wood Science & Technology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Gastroenterology & Hepatology (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Biophysics (AREA)
- Microbiology (AREA)
- Biotechnology (AREA)
- General Engineering & Computer Science (AREA)
- Biomedical Technology (AREA)
- Immunology (AREA)
- Oncology (AREA)
- Animal Behavior & Ethology (AREA)
- General Chemical & Material Sciences (AREA)
- Public Health (AREA)
- Pharmacology & Pharmacy (AREA)
- Chemical Kinetics & Catalysis (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- Communicable Diseases (AREA)
- Veterinary Medicine (AREA)
- Peptides Or Proteins (AREA)
- Medicines Containing Antibodies Or Antigens For Use As Internal Diagnostic Agents (AREA)
- Micro-Organisms Or Cultivation Processes Thereof (AREA)
- Preparation Of Compounds By Using Micro-Organisms (AREA)
- Medicines That Contain Protein Lipid Enzymes And Other Medicines (AREA)
- Measuring Or Testing Involving Enzymes Or Micro-Organisms (AREA)
Abstract
Изобретение относится к области вирусологии и биотехнологии. Предложен оболочечный белок HCV (вирус гепатита С). Белок характеризуется тем, что 80% его сайтов гликозилирования являются кор-гликозилированными. Такой белок является более предпочтительным для его диагностического, профилактического и терапевтического применения. Предложен также способ получения такого белка, а также лекарство, вакцина и различные фармацевтические композиции, содержащие такой белок. Предложенная группа изобретения может быть использована в медицине для диагностики, лечения и профилактики HCV инфекции, а также к прогнозированию клинической эффективности лечения. 12 н. и 25 з.п. ф-лы, 68 ил., 16 табл.
Description
ОБЛАСТЬ ИЗОБРЕТЕНИЯ
Настоящее изобретение относится к общей области экспрессии рекомбинантных белков, к диагностике HCV (вирус гепатита С) инфекции, к лечению или профилактике HCV инфекции и к прогнозированию/мониторингу клинической эффективности лечения индивида с хроническим гепатитом или прогнозированию/мониторингу естественной болезни.
Более конкретно настоящее изобретение относится к экспрессии оболочечных белков вируса гепатита С в дрожжах, штаммам дрожжей для экспрессии кор-гликозилированных оболочечных вирусных белков HCV и к применению оболочечных белков HCV по настоящему изобретению в диагностике, профилактике или лечении.
ПРЕДШЕСТВУЮЩИЙ УРОВЕНЬ ТЕХНИКИ
Инфекция вирусом гепатита С (HCV) является серьезной проблемой для здоровья как в развитых, так и развивающихся странах. Установлено, что примерно от 1 до 5% мирового населения поражено этим вирусом. HCV инфекция оказывается самой главной причиной гепатита, связанного с переливанием крови, и часто прогрессирует в хроническое повреждение печени. Более того, существуют свидетельства участия HCV в индукции гепатоцеллюлярной карциномы. Следовательно, потребность в надежных диагностических методах и эффективных терапевтических агентах высока. Кроме того, нужны чувствительные и специфичные способы скрининга кровепродуктов, зараженных HCV, и улучшенные способы культивирования HCV.
HCV представляет собой вирус, содержащий положительную цепь РНК размером приблизительно 9600 оснований, которая кодирует единственный полипротеин-предшественник, состоящий примерно из 3000 аминокислот. Показано, что протеолитическое расщепление этого предшественника, сопряженное с ко- и пост-трансляционными модификациями, приводит по меньшей мере к трем структурным и шести неструктурным белкам. На основании гомологии последовательностей структурные белки можно в функциональном отношении определить как один коровый белок и два оболочечных гликопротеина: Е1 и Е2. Белок Е1 состоит из 192 аминокислот и содержит от 4 до 5 сайтов N-гликозилирования, в зависимости от генотипа HCV. Белок Е2 состоит из 363-370 аминокислот и содержит от 9 до 11 сайтов N-гликозилирования, в зависимости от генотипа HCV (обзоры см. в: Major and Feinstone, 1997; Maertens and Stuyver, 1997). Белок Е1 содержит различные вариабельные домены (Maertens and Stuyver, 1997). Белок Е2 содержит три сверхвариабельных домена, из которых главный домен локализован на N-конце этого белка (Maertens and Stuyver, 1997). Гликопротеины HCV локализуются главным образом в ЭР, где они модифицируются и собираются в олигомерные комплексы.
У эукариотов остатки сахара обычно присоединены к четырем разным аминокислотным остаткам. Эти аминокислотные остатки классифицируются как O-связанные (серии, треонин и гидроксилизин) и N-связанные (аспарагин). O-связанные сахара синтезируются в аппарате Гольджи или шероховатом эндоплазматическом ретикулюме (ЭР) из нуклеотидных сахаров. N-связанные сахара синтезируются из общего предшественника и затем подвергаются процессингу. Считают, что оболочечные белки HCV N-гликозилированы. Из уровня техники известно, что добавление N-связанных углеводных цепей важно для стабилизации складчатых интермедиатов и, таким образом, для эффективной укладки, предотвращения неправильной укладки и деградации в эндоплазматическом ретикулюме, олигомеризации, биологической активности и транспорта гликопротеинов (см. обзоры Rose et al., 1988; Doms et al., 1993; Helenius, 1994). Консенсусными сайтами для присоединения N-связанных олигосахаридов являются трипептидные последовательности Asn-X-Ser и Asn-X-Thr (где Х может быть любой аминокислотой) в составе полипептидов. После добавления N-связанного олигосахарида к полипептиду этот олигосахарид подвергается дальнейшему процессингу в сложный тип (содержащий N-ацетилглюкозамин, маннозу, фукозу, галактозу и сиаловую кислоту) или высокоманнозный тип (содержащий N-ацетилглюкозамин и маннозу). Считается, что оболочечные белки HCV относятся к высокоманнозному типу. Процессинг N-связанных олигосахаридов в дрожжах сильно отличается от процессинга в аппарате Гольджи млекопитающих. В дрожжах олигосахаридные цепи удлиняются в аппарате Гольджи поэтапным добавлением маннозы, что приводит к сложным высокоманнозным структурам и называется гипергликозилированием. В отличие от этого белки, экспрессируемые в прокариотах, никогда не гликозилируются.
Типы гликозилирования белков или пептидов высокоманнозного типа определены для множества разных эукариотических клеток. В клетках млекопитающих в среднем от 5 до 9 маннозных единиц связаны с двумя N-ацетилглюкозаминовыми группировками в олигосахариде с гликозилированием корового типа (структура кратко представлена как Man(5-9)GlcNAc(2)). Kop-гликозилирование относится к структуре, похожей на структуры, обведенные рамками на Фиг.3 в Herscovics and Orleans (1993).
Имеются сообщения, что метилотрофные дрожжи Pichia pastoris присоединяют в среднем от 8 до 14 маннозных единиц, то есть Man(8-14)GlcNAc(2), на каждый сайт гликозилирования (Tschopp в ЕР 0256421), и что приблизительно 85% N-связанных олигосахаридов находятся в диапазоне размеров Man(8-14)GlcNAc(2) (Grinna and Tschopp 1989). Другие исследователи опубликовали несколько отличные олигосахаридные структуры, присоединенные к гетерологичным белкам, экспрессируемым в Р.pastoris: Man(8-9)GlcNAc(2) (Montesino et al. 1989), Man(9-14)GlcNAc(2) или Man(9-15)GlcNAc(2) (Kalidas et al. 2001) и Man(8-18)GlcNAc(2) с преобладанием Man(9-12)GlcNAc(2), причем основным олисахаридом в целом является Man(10)GlcNAc(2) (Miele et al. 1998). Trimble et al. (1991) сообщили, что примерно в 75% N-связанных олигосахаридов имеется примерно поровну Man(8)GlcNAc(2) и Man(9)GlcNAc(2), причем дополнительно 17% сайтов гликозилирования занимает Man(10)GlcNAc(2), а остальные 8% сайтов - Man(11)GtcNAc(2). О гипергликозилировании белков, экспрессируемых в Р.pastoris, сообщают редко (Scorer et al. 1993).
Aspergillus niger добавляет к сайтам гликозилирования Man(5-10)GlcNAc(2) (Panchal and Wodzinski 1998).
Дефектный по гликозилированию мутант mnn9 Saccharomyces cerevisiae отличается от S.cerevisiae дикого типа тем, что клетки mnn9 продуцируют гликозилированные белки с модифицированным олигосахаридом, состоящим из Man(9-13)GlcNAc(2), вместо гипергликозилированных белков (Mackay et al., в US 5135854 и Kniskern et al. в WO 94/01132). О другом мутанте S.cerevisiae, och1mnn9, сообщали, что к сайтам гликозилирования в белках он добавляет Man(8)GlcNAc(2) (Yoshifumi et al., JP 06277086).
Для коровых олигосахаридов S.cerevisiae (дикий тип и мутант mnn9) характерно присутствие концевых α1,3-связанных маннозных остатков (Montesino et al., 1998). Олигосахариды, присоединенные к сайтам гликозилирования белков, экспрессируемых в Р.pastoris или в S.cerevisiae och1mnn1, лишены таких концевых α1,3-связанных манноз (Gellissen et al. 2000). Концевые α1,3-связанные маннозы считаются аллергенными (Jenkins et al. 1996). Поэтому белки, несущие на своих олигосахаридах концевые остатки α1,3-связанной маннозы, не пригодны для диагностических или терапевтических целей.
Тип гликозилирования белков, экспрессируемых в метилотрофных дрожжах Hansenula polymorpha, несмотря на использование этих дрожжей для продуцирования значительного числа гетерологичных белков (см. Табл.3 в Gellisen et al. 2000), не был исследован в деталях. Эксперименты Janowicz et al. (1991) и Diminskiy et al. (1997) создают впечатление, что Н.polymorpha не гликозилирует или очень слабо гликозилирует большой или малый поверхностный антиген вируса гепатита В (HBsAg). Наиболее вероятно это происходит из-за того, что HBsAg экспрессировался без сигнального пептида, что предотвращало поступление продуцированного HBsAg в просвет эндоплазматического ретикулюма (ЭР) и гликозилирование. Есть сообщение об ограниченном добавлении моно- и дигексоз к G-CSF (гранулоцитарный колониестимулирующий фактор), продуцируемому в Н.polymorpha (Fischer et al. в WO 00/40727). С другой стороны, наблюдали гипергликозилирование гетерологичной α-галактозидазы, экспрессируемой в клетках Н.polymorpha (Fellinger et al. 1991).
В настоящее время доказано, что вакцинация против болезни является одним из самых экономически эффективных и действенных способов контроля болезней. Однако, несмотря на многообещающие результаты, усилия по разработке эффективной вакцины против HVC были спряжены с трудностями. Непременным условием для вакцин является индукция иммунного ответа у пациентов. Следовательно, надо идентифицировать антигенные детерминанты HVC и в надлежащих условиях вводить их пациентам. Антигенные детерминанты можно разделить по меньшей мере на две формы, а именно, линейные и конформационные эпитопы. Конформационные эпитопы являются результатом складывания молекулы в трехмерном пространстве, что включает в себя ко- и пост-трансляционные модификации, такие как гликозилирование. В общем, считают, что реализацией самых эффективных вакцин будут конформационные эпитопы, поскольку они представляют собой эпитопы, которые напоминают подобные нативным эпитопы HVC и которые могут быть сохранены лучше, чем действительные линейные аминокислотные последовательности. Следовательно, первоочередную важность для генерирования анигенных детерминант HVC, подобных нативным, имеет окончательная степень гликозилирования оболочечных белков HVC. Однако есть кажущиеся непреодолимыми проблемы с культивированием HVC, которые приводят ко всего лишь ничтожным количествам вирионов. Кроме того, имеются обширные проблемы с экспрессией и очисткой рекомбинантных белков, приводящие как к малым количествам белков, так и к гипергликозилированным белкам или белкам, которые не гликозилированы.
Оболочечные белки HCV были получены рекомбинантными методами в Escherichia coli, клетках насекомых, клетках дрожжей и клетках млекопитающих. Однако у высших эукариот экспрессия характеризуется трудностями в получении больших количеств антигенов для получения, в конечном счете, вакцины. Результатом экспрессия в прокариотах, таких как Е.coli, являются оболочечные белки HCV, которые не гликозилированы. Результатом экспрессии оболочечных белков HCV в дрожжах является гипергликозилирование. Как уже продемонстрировали Maertens et al. в WO 96/04385, экспрессия оболочечного белка Е2 HCV в Saccharomyces cerevisiae приводит к белкам, которые сильно гликозилированы. Это гипергликозилирование приводит к экранированию эпитопов белка. Хотя Mustilli et al. (1999) утверждают, что результатом экспрессии белка Е2 HCV в S.cerevisiae является кор-гликозилирование, результаты внутриклеточной экспрессии этого материала показывают, что по меньшей мере его часть гипергликозилирована, тогда как корректный процессинг остальной части этого материала не продемонстрирован. Более того, гипергликозилирование, которое наблюдали Mustilli et al. (1999), могло быть предотвращено только присутствием туникамицина, инигибитора гликозилирования, и это, таким образом, не отражает гликозилирование, происходящее в нормальных, естественных условиях роста. Потребность в оболочечных белках HCV, происходящих из внутриклеточного источника, вполне признана (Maertens et al. в WO 96/04385, Heile et al., 2000). Еще одним примером этой потребности является плохая реакционная способность секретируемого Е2, происходящего из дрожжей, с сыворотками шимпанзе, иммунизированных белком Е2, происходящим из культуры клеток млекопитающего, как засвидетельствовано на Фиг.5 в Mustilli et al (1999). Это далее документируют Rosa et al. (1996), которые показывают, что иммунизация оболочечными белками HCV дрожжевого происхождения не может защитить от контрольного инфицирования.
Следовательно, существует потребность в эффективных системах экспрессии, результатом которых являются большие и экономически эффективные количества белков, имеющих в то же время тип гликозилирования, подобный нативному, с отсутствием концевой α1,3-связанной маннозы. В частности, такие системы необходимы для продукции оболочечных белков HCV.
КРАТКОЕ ИЗЛОЖЕНИЕ СУЩНОСТИ ИЗОБРЕТЕНИЯ
Первый аспект настоящего изобретения относится к выделенному оболочечному белку HCV или его фрагменту, содержащему по меньшей мере один сайт N-гликозилирования, отличающемуся тем, что он является продуктом экспрессии в эукариотической клетке, и дополнительно отличающемуся тем, что в среднем вплоть до 80% сайтов N-гликозилирования кор-гликозилированы. В частности, более 70% указанных кор-гликозилированных сайтов гликозилированы олигоманнозой со структурой, определяемой как Man(8-10)-GlcNAc(2). Более того, соотношение олигоманнозы, имеющей структуру Man(7)-GlcNAc(2) и олигоманнозы, имеющей структуру Man(8)-GlcNAc(2), меньше или равно 0,45. Более конкретно, указанные олигоманнозы содержат менее 10% концевой α1,3-маннозы. Эукариотической клеткой, экспрессирующей указанный выделенный оболочечный белок HCV или его часть, может быть дрожжевая клетка, такая как клетка Hansenula.
Еще один аспект настоящего изобретения относится к выделенному оболочечному белку HCV или его части согласно изобретению, который(ая) получен(а) из белка, содержащего лидерный пептид птичьего лизоцима или его функциональный вариант, присоединенный к указанному оболочечному белку HCV или его фрагменту. Более конкретно, указанный выделенный оболочечный белок HCV или его часть получен(а) из белка, характеризуемого структурой
CL-[(A1)a-(PS1)b-(A2)c]-HCVENV-[(A3)d-(PS2)e-(A4)f]
где:
CL является лидерным пептидом птичьего лизоцима или его функциональным эквивалентом,
А1, А2, A3 и А4 являются адаптерными пептидами, которые могут быть одинаковыми или разными,
PS1 и PS2 являются сайтами процессинга, которые могут быть одинаковыми или разными,
HCVENV является оболочечным белком HCV или его частью,
а, b, с, d, e и f равны 0 или 1, и
где, возможно, А1 и/или А2 представляют собой часть PS1, и/или где A3 и/или А4 представляют собой часть PS2.
Другой аспект этого изобретения охватывает выделенный оболочечный белок HCV или его фрагмент согласно изобретению, который содержится в структуре, выбранной из группы, состоящей из мономеров, гомодимеров, гетеродимеров, гомо-олигомеров и гетеро-олигомеров. Альтернативно указанный выделенный оболочечный белок HCV или его фрагмент согласно изобретению содержится в вирусоподобной частице. Более конкретно, любой выделенный оболочечный белок HCV или его фрагмент согласно изобретению может содержать цистеины, у которых цистеиновые тиольные группы модифицированы химическим путем.
Конкретные аспекты этого изобретения относятся к выделенным оболочечным белкам HCV или их фрагменту согласно изобретению, которые являются антигенными или иммуногенными и/или которые содержат эпитоп, стимулирующий Т-клетки.
Дальнейший аспект относится к композиции, содержащей выделенный оболочечный белок HCV или его фрагмент согласно изобретению. Указанная композиция может дополнительно содержать фармацевтически приемлемый носитель и может быть лекарством или вакциной.
Это изобретение также относится к способу получения выделенного оболочечного белка HCV или его фрагмента согласно изобретению.
Другой способ по этому изобретению представляет собой способ обнаружения присутствия анти-HCV антител в образце, подозреваемом в том, что он содержит анти-HCV антитела, при котором:
1) оболочечный белок HCV или его часть по любому из пп.1-15 формулы изобретения приводят в контакт с указанным образцом в условиях, допускающих образование комплекса указанного оболочечного белка HCV или его части с указанными анти-HCV антителами,
2) выявляют комплекс, образованный на стадии (1),
3) на основании результатов стадии (2) делают вывод о присутствии указанных анти-HCV антител в указанном образце.
Более конкретно, указанный способ может включать в себя стадию (1), на которой указанное приведение в контакт происходит к конкурентных условиях. В частности, в указанных способах может быть использована твердая подложка, к которой присоединен указанный оболочечный белок HCV или его часть.
Далее это изобретение относится к диагностическому набору для обнаружения присутствия анти-HCV антител в образце, подозреваемом в том, что он содержит анти-HCV антитела, содержащему оболочечный белок HCV или его часть согласно изобретению. Более конкретно, указанный набор содержит указанный оболочечный белок HCV или его часть, присоединенный(ую) к твердой подложке.
Это изобретение также относится к лекарству или вакцине, которые содержат оболочечный белок HCV или его часть согласно изобретению.
Также это изобретение охватывает фармацевтическую композицию для индукции у млекопитающего HCV-специфичного иммунного ответа, содержащую эффективное количество оболочечного белка HCV или его части согласно изобретению и, возможно, фармацевтически приемлемый адъювант. Указанная фармацевтическая композиция может альтернативно быть способна индуцировать у млекопитающего HCV-специфичные антитела и/или индуцировать у млекопитающего Т-клеточную функцию. Более того, указанная фармацевтическая комсайт может быть профилактической композицией или терапевтической композицией. В частности, указанное млекопитающее является человеком.
ПОЯСНЕНИЯ К ФИГУРАМ ГРАФИЧЕСКИХ МАТЕРИАЛОВ
Фиг.1. Схематическая карта вектора pGEMT-E1sH6RB, который имеет последовательность, определенную в SEQ ID NO:6.
Фиг.2. Схематическая карта вектора pCHH-Hir, который имеет последовательность, определенную в SEQ ID NO:9.
Фиг.3. Схематическая карта вектора pFPMT121, который имеет последовательность, определенную в SEQ ID NO:12.
Фиг.4. Схематическая карта вектора pFPMT-CHH-Е1-Н6, который имеет последовательность, определенную в SEQ ID NO:13.
Фиг.5. Схематическая карта вектора pFPMT-MFa-E1-H6, который имеет последовательность, определенную в SEQ ID NO:16.
Фиг.6. Схематическая карта вектора pUC18-FMD-MFa-E1-H6, который имеет последовательность, определенную в SEQ ID NO:17.
Фиг.7. Схематическая карта вектора pUC18-FMD-CL-E1-H6, который имеет последовательность, определенную в SEQ ID NO:20.
Фиг.8. Схематическая карта вектора pFPMT-CL-E1-Н6, который имеет последовательность, определенную в SEQ ID NO:21.
Фиг.9. Схематическая карта вектора pSР72Е2Н6, который имеет последовательность, определенную в SEQ ID NO:22.
Фиг.10. Схематическая карта вектора рМРТ121, который имеет последовательность, определенную в SEQ ID NO:23.
Фиг.11. Схематическая карта вектора pFPMT-MFa-E2-H6, который имеет последовательность, определенную в SEQ ID NO:24.
Фиг.12. Схематическая карта вектора pMPT-MFa-E2-H6, который имеет последовательность, определенную в SEQ ID NO:25.
Фиг.13. Схематическая карта вектора pMF30, который имеет последовательность, определенную в SEQ ID NO:28.
Фиг.14. Схематическая карта вектора pFPMT-CL-E2-H6, который имеет последовательность, определенную в SEQ ID NO:32.
Фиг.15. Схематическая карта вектора pUC18-FMD-CL-E1, который имеет последовательность, определенную в SEQ ID NO:35.
Фиг.16. Схематическая карта вектора pFPMT-CL-E1, который имеет последовательность, определенную в SEQ ID NO:36.
Фиг.17. Схематическая карта вектора pUC18-FMD-CL-H6-E1-K-H6, который имеет последовательность, определенную в SEQ ID NO:39.
Фиг.18. Схематическая карта вектора pFPMT-CL-H6-K-E1, который имеет последовательность, определенную в SEQ ID NO:40.
Фиг.19. Схематическая карта вектора pYIG5, который имеет последовательность, определенную в SEQ ID NO:41.
Фиг.20. Схематическая карта вектора pYIG5E1H6, который имеет последовательность, определенную в SEQ ID NO:42.
Фиг.21. Схематическая карта вектора pSY1, который имеет последовательность, определенную в SEQ ID NO:43.
Фиг.22. Схематическая карта вектора pSY1aMFE1sH6a, который имеет последовательность, определенную в SEQ ID NO:44.
Фиг.23. Схематическая карта вектора pBSK-E2sH6, который имеет последовательность, определенную в SEQ ID NO:45.
Фиг.24. Схематическая карта вектора pYIG5HCCL-22aH6, который имеет последовательность, определенную в SEQ ID NO:46.
Фиг.25. Схематическая карта вектора pYYIGSE2H6, который имеет последовательность, определенную в SEQ ID NO:47.
Фиг.26. Схематическая карта вектора pYIG7, который имеет последовательность, определенную в SEQ ID NO:48.
Фиг.27. Схематическая карта вектора pYIG7E1, который имеет последовательность, определенную в SEQ ID NO:49.
Фиг.28. Схематическая карта вектора pSY1YIG7E1s, который имеет последовательность, определенную в SEQ ID NO:50.
Фиг.29. Схематическая карта вектора pPICZalphaA, который имеет последовательность, определенную в SEQ ID NO:51.
Фиг.30. Схематическая карта вектора pPICZalphaD', который имеет последовательность, определенную в SEQ ID NO:52.
Фиг.31. Схематическая карта вектора pPICZalphaE', который имеет последовательность, определенную в SEQ ID NO:53.
Фиг.32. Схематическая карта вектора pPICZalphaD'E1sH6, который имеет последовательность, определенную в SEQ ID NO:58.
Фиг.33. Схематическая карта вектора pPICZalphaE'E1sH6, который имеет последовательность, определенную в SEQ ID NO:59.
Фиг.34. Схематическая карта вектора pPICZalphaD'E2sH6, который имеет последовательность, определенную в SEQ ID NO:60.
Фиг.35. Схематическая карта вектора pPICZalphaE'E2sH6, который имеет последовательность, определенную в SEQ ID NO:61.
Фиг.36. Схематическая карта вектора pUC18MFa, который имеет последовательность, определенную в SEQ ID NO:62.
Фиг.37. Профиль элюции хроматографии с вытеснением по размеру частиц белка Е2-Н6, очищенного с помощью IMAC, экспрессированного в MFa-Е2-Н6-экспрессирующей Hansenula polymorpha (см. Пример 15). На оси Х показан объем элюции (в мл). Вертикальные линии через профиль элюции показывают собранные фракции. "Р1"=объединенные фракции 4-9, "Р2"=объединенные фракции 30-35, "Р3"=объединенные фракции 37-44. Ось Y показывает спектральную поглощательную способность, приведенную в мЕА (милли единицы абсорбции). На оси Х показан объем элюции в мл.
Фиг.38. Различные пулы и фракции, собранные после хроматографии с вытеснением по размеру частиц (см. Фиг.37), были проанализированы с помощью электрофореза в полиакриламидном геле с додецилсульфатом натрия в невосстанавливающих условиях (Na-ДДС-ПААГ электрофорез) с последующим окрашиванием полиакриламидного геля серебром. Проанализированные пулы ("Р1", "Р2" и "Р3") и фракции (с 16 по 26) указаны в верхней части изображения геля, окрашенного серебром. Слева (дорожка "М") указаны размеры маркеров молекулярной массы.
Фиг.39. Фракции 17-23 после стадии хроматографии с вытеснением по размеру частиц как показано на Фиг.37, были объединены и проалкилированы. После этого белковый материал был подвергнут обработке посредством Endo H для дегликозилирования. Необработанный и обработанный посредством Endo H материал был разделен на Na-ДДС-ПААГ геле и подвергнут блоттингу на мембране PVDF (поливинилдифторид). Блот был окрашен красителем амидо черный.
Дорожка 1: алкилированный Е2-Н2 до обработки посредством Endo H.
Дорожка 2: алкилированный Е2-Н2 после обработки посредством Endo H.
Фиг.40. Вестерн-блот-анализ клеточных лизатов Е1, экспрессированного в Saccharomyces cerevisiae.
Вестерн-блот обрабатывали с использованием El-специфичного моноклонального антитела IGH 201.
Дорожки 1-4: продукт экспрессии после 2, 3, 5 или 7 дней экспрессии, соответственно, в клоне Saccharomyces, трансформированном pSY1Y1G7E1s (SEQ ID NO:50, Фиг.28), содержащей нуклеотидную последовательность, которая кодирует лидерный пептид куриного лизоцима, присоединенный к Е1-Н6.
Дорожки 5-7: продукт экспрессии через 2, 3 или 5 дней экспрессии, соответственно, в клоне Saccharomyces, трансформированном pSY1aMFE1sH6aYIG1 (SEQ ID NO:44, Фиг.22), содержащей нуклеотидную последовательность, которая кодирует лидерный пептид α-фактора спаривания, присоединенный к Е1-Н6.
Дорожка 8: маркеры молекулярной массы, как указано.
Дорожка 9: очищенный E1s, продуцируемый клетками млекопитающего, инфицированными HCV-рекомбинантным вирусом коровьей оспы.
Фиг.41. Анализ белка Е2-Е6, экспрессированного и процессированного из CL-E2-H6 до Е2-Н6 в Н.polymorpha, который был очищен афинной хроматографией с иммобилизованными ионами металлов (IMAC) (см. Пример 17). Белки из разных промывочных фракций (дорожки 2-4) и элюированных фракций (дорожки 5-7) были проанализированы с помощью Na-ДДС-ПААГ электрофореза в восстанавливающих условиях с последующим окрашиванием геля серебром (А, верхнее изображение) или посредством вестерн-блоттинга с использованием специфического моноклонального антитела, направленного против Е2 (В, нижнее изображение). Размеры маркеров молекулярной массы указаны слева.
Фиг.42. Профиль элюции первого этапа IMAC-хроматографии на колонке Ni-IDA (хелатирующая Sepharose FF, нагруженная Ni2+, Pharmacia) для очистки сульфонированного белка Н6-К-Е1, продуцированного Н.polymorpha (см. Пример 18). Колонку уравновешивали буфером А (50 мМ фосфат, 6М GuHCl, 1% Empigen ВВ (об./об.), рН 7,2), обогащенным 20 мМ имидазола. После нанесения образца колонку последовательно промывали буфером А, содержащим 20 мМ и 50 мМ имидазола, соответственно (как показано на хроматограмме). Следующий этап промывки и элюции His-меченых продуктов выполнялся последовательным нанесением буфера В (забуференный фосфатами физиологический раствор (PBS), 1% empigen ВВ, рН 7,2), обогащенного 50 мМ имидазола и 200 мМ имидазола, соответственно (как указано на хроматограмме). Были объединены следующие фракции: пул промывки 1 (фракции 8-11, промывка с 50 мМ имидазола). Элюированный материал собирали отдельными фракциями от 63-й до 72-й или объединяли в пул элюции (фракции 63-69). На оси Y показано поглощение в мЕА (милли единицы абсорбции). На оси Х показан объем элюции в мл.
Фиг.43. Анализ очищенного посредством IMAC белка Н6-К-Е1 (см. Фиг.42), экспрессированного и процессированного из CL-H6-K-E1 до Н6-К-Е1 в Н.polymorpha. Белки в пуле промывки 1 (дорожка 12) и фракциях элюции от 63 до 72 (дорожки 2-11) были проанализированы посредством Na-ДДС-ПААГ электрофореза в восстанавливающих условиях с последующим окрашиванием геля серебром (А, верхнее изображение). Белки, присутствовавшие в образце перед IMAC (дорожка 2), в проходном пуле (дорожка 4), в промывочном пуле 1 (дорожка 5) и в пуле элюции (дорожка 6), были проанализированы вестерн-блоттингом с использованием специфического моноклонального антитела, направленного против Е1 (В, нижнее изображение, на дорожку 3 образец не наносили). Размеры маркеров молекулярной массы (дорожка М) указаны слева.
Фиг.44. Профиль элюции второго этапа IMAC-хроматографии на колонке Ni-IDA (хелатирующая Sepharose PF, нагруженная Mi2+, Pharmacia) для очистки Е1, являющегося результатом процессинга Н6-К-Е1 in vitro (очистка: см. Фиг.42) посредством Endo Lys-C. Поток собирали в разные фракции (1-40), которые были подвергнуты скринингу на присутствие Els-продуктов. Фракции (7-28), содержавшие интактный Е1, процессированный из Н6-К-Е1, объединяли. На оси Y показана спектральная поглощательная способность, приведенная в мЕА (миллиединицы абсорбции). На оси Х показан объем элюции в мл.
Фиг.45. Вестерн-блот-анализ, демонстрирующий специфические полосы белка E1s, прореагировавшие с биотинилированным гепарином (см. также Пример 19). Были проанализированы препараты E1s, очищенные из культуры клеток млекопитающего, инфицированных HCV-рекомбинантным вирусом коровьей оспы, или экспрессируемые Н.polymorpha. Панель справа от вертикальной линии показывает вестерн-блот, проявленный моноклональным биотинилированным E1-специфичным IGH 200. Панель слева от вертикальной линии показывает вестерн-блот, проявленный биотинилированным гепарином. Из этих результатов сделан вывод, что высокую аффинность к гепарину имеет главным образом E1s с низким уровнем гликозилирования.
Дорожки М: маркер молекулярной массы (молекулярные массы указаны слева).
Дорожки 1: E1s из клеток млекопитающего, алкилированный в ходе выделения.
Дорожки 2: E1s-H6, экспрессируемый Н.polymorpha и сульфонированный в ходе выделения.
Дорожки 3: E1s-H6, экспрессируемый Н.polymorpha и алкилированный в ходе выделения.
Дорожки 4: тот же материал, что был загружен на дорожку 2, но обработанный дитиортреитолом для превращения сульфонированных Cys-тиольных группы в Cys-тиольные.
Фиг.46. Профиль хроматографии с вытеснением по размеру частиц (SEC, size exclusion chromatography) очищенного белка Е2-Н6, экспрессированного в Н.polymorpha, в его сульфонированной форме, который прогнали в PBS, 3% бетаина для того, чтобы вызвать образование вирусоподобных частиц (VLP) заменой Empigen BB на бетаин. Объединенные фракции, содержащие VLPs, которые были использованы в дальнейшем исследовании, указаны знаком "↔". Ось Y показывает абсорбцию, приведенную в мЕА (миллиединицы абсорбции). На оси Х показан объем элюции в мл. См. также Пример 20.
Фиг.47. Профиль хроматографии с вытеснением по размеру частиц (SEC, size exclusion chromatography) очищенного белка Е2-Н6, экспрессированного в Н.polymorpha, в его алкилированной форме, который прогнали в PBS, 3% бетаина для того, чтобы вызвать образование вирусоподобных частиц (VLP) заменой Empigen BB на бетаин. Объединенные фракции, содержащие VLPs, указаны знаком "↔". Ось Y показывает абсорбцию, приведенную в мЕА (миллиединицы абсорбции). На оси Х показан объем элюции в мл. См. также Пример 20.
Фиг.48. Профиль хроматографии с вытеснением по размеру частиц (SEC, size exclusion chromatography) очищенного белка Е1, экспрессированного в Н.polymorpha, в его сульфонированной форме, который прогнали в PBS, 3% бетаина для того, чтобы вызвать образование вирусоподобных частиц (VLP) заменой Empigen BB на бетаин. Объединенные фракции, содержащие VLPs, указаны знаком "↔". Ось Y показывает абсорбцию, приведенную в мЕА (миллиединицы абсорбции). На оси Х показан объем элюции в мл. См. также Пример 20.
Фиг.49. Профиль хроматографии с вытеснением по размеру частиц (SEC, size exclusion chromatography) очищенного белка Е1, экспрессированного в Н.polymorpha, в его алкилированной форме, который прогнали в PBS, 3% бетаина для того, чтобы вызвать образование вирусоподобных частиц (VLP) заменой Empigen BB на бетаин. Объединенные фракции, содержащие VLPs, указаны знаком "↔". Ось Y показывает абсорбцию, приведенную в мЕА (миллиединицы абсорбции). На оси Х показан объем элюции в мл. См. также Пример 20.
Фиг.50. Na-ДДС-ПААГ (в восстанавливающих условиях) и анализ вестерн-блоттингом вирусоподобных частиц, выделенных после хроматографии с вытеснением по размеру частиц, как описано для Фиг.48 и 49. Левая панель: окрашенный серебром Na-ДДС-ПААГ гель. Правая панель: вестерн-блот с использованием специфических моноклональных антител против белка Е1 (IGH201). Дорожки 1: маркеры молекулярной массы (молекулярные массы указаны слева); дорожки 2: пул VLPs, содержащих сульфонированный Е1 (Фиг.48); дорожки 3: пул VLPs, содержащих алкилированный Е1 (Фиг.49). См. также Пример 20.
Фиг.51. Е1, продуцированный в клетках млекопитающего ("М"), или Е1, продуцируемый в Hansenula ("H"), были нанесены на твердую подложку для твердофазного иммуноферментного анализа (ELISA), чтобы определить конечную точку титрования антител, присутствующих в сыворотках после вакцинации мышей белком Е1, продуцированным в клетках млекопитающего (верхняя панель), или после вакцинации мышей белком Е1, продуцируемым в Hansenula (нижняя панель). Горизонтальная полоса представляет средний титр антител. Конечные титры (кратности разведения) указаны на оси Y. См. также Пример 22.
Фиг.52. Е1, продуцированный в Hansenula, был алкилирован ("А") или сульфонирован ("S") и нанесен на твердую подложку для твердофазного иммуноферментного анализа (ELISA), чтобы определить конечную точку титрования антител, присутствующих в сыворотках после вакцинации мышей белком Е1, продуцируемым в Hansenula, который был алкилирован (верхняя панель) или после вакцинации мышей белком Е1, продуцируемым в Hansenuta, который был сульфонирован (нижняя панель). Горизонтальная полоса представляет средний титр антител. Конечные титры (кратности разведения) указаны на оси Y. См. также Пример 23.
Фиг.53. HCV E1, продуцированный клетками млекопитающего, которые были инфицированы HCV-рекомбинантным вирусом коровьей оспы, и HCV E1, продуцированный Н.polymorpha, были нанесены непосредственно на планшеты для ELISA. Были определены титры в конечных точках для антител в сыворотках от шимпанзе, вакцинированных белком E1, который был продуцирован клетками млекопитающего (верхняя панель), или мышиных моноклональных антител, наработанных против белка E1, продуцированного клетками млекопитающего (нижняя панель). Шимпанзе Yoran и Marti получили профилактические вакцинации. Шимпанзе Ton, Phil, Marcel, Peggy и Femma получили терапевтические вакцинации. Черные сплошные столбики: планшет для ELISA, покрытый белком E1, продуцированным клетками млекопитающих. Незакрашенные столбики: планшет для ELISA, покрытый белком E1, продуцированным Hansenula. Титры в конечных точках (кратности разведения) указаны на оси Y. См. также Пример 24.
Фиг.54. Проведенный с применением флуорофоров углеводный гель-электрофорез олигосахаридов, высвобождаемых из белка E1, продуцированного клетками млекопитающего, которые были инфицированы HCV-рекомбинантным вирусом коровьей оспы, и из белка Е1-Н6, продуцированного Hansenula.
Дорожка 1: Многоступенчатый глюкозный стандарт, слева указано количество моносахаридов (от 3 до 10, обозначенные как G3-G10).
Дорожка 2: 25 мкг N-связанных олигосахаридов, высвобожденных из (алкилированного) белка E1, продуцированного клетками млекопитающего.
Дорожка 3: 25 мкг N-связанных олигосахаридов, высвобожденных из (алкилированного) белка E1, продуцированного Hansenula.
Дорожка 4: 100 пмоль мальтотетраозы.
См. также Пример 25.
Фиг.55. На данном рисунке представлены упрощенные структуры эталонных олигоманноз Man-9 (Фиг.55.А), Man-8 (Фиг.55.В), Man-7 (Фиг.55.С), Man-6 (Фиг.55.D) и Man-5 (Фиг.55.Е). "Man"=манноза; "GlcNAc"=N-ацетилглюкозамин; "α"=α-связь между двумя маннозами; "β"=β-связь между двумя маннозами; "(1-3)", "(1-4)" и "(1-6)"=связи (1-3), (1-4) и (1-6), соответственно, между двумя маннозами. Скобки на Фиг.55.В и 55.С показывают, что 2 и 1, соответственно, маннозных остатка слева от скобок связаны связью α(1-2) с 2 и 1, соответственно, из 3 маннозных остатков справа от скобок. См. также Пример 26.
Фиг.56. На этом рисунке представлена высшая олигоманноза, состоящая из 10 маннозных группировок, присоединенных к хитобиозе. Каждый концевой маннозный остаток связан α(1-3)-связью с неконцевым маннозным остатком. Тонкая направленная вверх указательная стрелка показывает связи олигосахарида, которые подвержены расщеплению α(1-2)-маннозидазой (таковых в данной олигоманнозе нет), толстая направленная вверх или влево указательная стрелка показывает связи олигосахарида, которые подвержены расщеплению α-маннозидазой после удаления α(1-2)-связанных манноз (не применимо к данной олигоманнозе), а незакрашенная направленная вниз указательная стрелка показывает связи олигосахарида, которые подвержены расщеплению β-маннозидазой после удаления α-связанных манноз. См. также Пример 26.
Фиг.57. На этом рисунке представлена высшая олигоманноза, состоящая из 9 маннозных группировок, присоединенных к хитобиозе. В этой олигоманнозе один концевой маннозный остаток связан α(1-2)-связью с неконцевым маннозным остатком. Тонкая направленная вверх указательная стрелка показывает связи олигосахарида, которые подвержены расщеплению α(1-2)-маннозидазой, толстая направленная вверх или влево указательная стрелка показывает связи олигосахарида, которые подвержены расщеплению α-маннозидазой после удаления α(1-2)-связанных манноз, а незакрашенная направленная вниз указательная стрелка показывает связи олигосахарида, которые подвержены расщеплению β-маннозидазой после удаления α-связанных манноз. См. также Пример 26.
Фиг.58. На этом рисунке представлена эталонная высшая олигоманноза Man-9, состоящую из 9 маннозных группировок, присоединенных к хитобиозе. В этой олигоманнозе все концевые маннозные остатки связаны α(1-2)-связью с неконцевым маннозным остатком. Тонкая направленная вверх указательная стрелка показывает связи олигосахарида, которые подвержены расщеплению α(1-2)-маннозидазой, толстая направленная вверх или влево указательная стрелка показывает связи олигосахарида, которые подвержены расщеплению α-маннозидазой после удаления α(1-2)-связанных манноз, а незакрашенная направленная вниз указательная стрелка показывает связи олигосахарида, которые подвержены расщеплению β-маннозидазой после удаления α-связанных манноз. См. также Пример 26.
Фиг.59. На этом рисунке представлена высшая олигоманноза Man-8, состоящая из 8 маннозных группировок, присоединенных к хитобиозе. В этой олигоманнозе все концевые маннозные остатки связаны α(1-3)-связью или α(1-6)-связью с неконцевым маннозным остатком, что делает эту структуру полностью устойчивой к расщеплению α(1-2)-маннозидазой. Толстая направленная вверх указательная стрелка показывает связи олигосахарида, которые подвержены расщеплению α-маннозидазой, а незакрашенная направленная вниз указательная стрелка показывает связи олигосахарида, которые подвержены расщеплению β-маннозидазой после удаления α-связанных манноз. См. также Пример 26.
Фиг.60. На этом рисунке представлена высшая олигоманноза Man-7, состоящая из 7 маннозных группировок, присоединенных к хитобиозе. В этой олигоманнозе все концевые маннозные остатки связаны α(1-3)-связью с неконцевым маннозным остатком, что делает эту структуру полностью устойчивой к расщеплению α(1-2)-маннозидазой. Толстая направленная вверх указательная стрелка показывает связи олигосахарида, которые подвержены расщеплению α-маннозидазой, а незакрашенная направленная вниз указательная стрелка показывает связи олигосахарида, которые подвержены расщеплению β-маннозидазой после удаления α-связанных манноз. См. также Пример 26.
Фиг.61. На этом рисунке представлена высшая олигоманноза, состоящая из 9 маннозных группировок, присоединенных к хитобиозе. В этой олигоманнозе один концевой маннозный остаток связан α(1-2)-связью с неконцевым маннозным остатком. Тонкая направленная вверх указательная стрелка показывает связи олигосахарида, которые подвержены расщеплению α(1-2)-маннозидазой, толстая направленная вверх или влево указательная стрелка показывает связи олигосахарида, которые подвержены расщеплению α-маннозидазой после удаления α(1-2)-связанных манноз, а незакрашенная направленная вниз указательная стрелка показывает связи олигосахарида, которые подвержены расщеплению β-маннозидазой после удаления α-связанных манноз. См. также Пример 26.
Фиг.62. На этом рисунке представлен предполагаемый содержащий глюкозу олигосахарид, состоящий из одной или двух глюкозных группировок и восьми маннозных группировок, присоединенных к хитобиозе. В этом олигосахариде каждый из концевых α(1-2)-связанных маннозных остатков А- или В-ветви ("А→" и "В→" на рисунке) несет один или два глюкозных остатка, как указано обозначением (Glc)Glc слева от скобки. Тонкая направленная вверх указательная стрелка показывает связи олигосахарида, которые подвержены расщеплению α(1-2)-маннозидазой при условии, что к концевому маннозному остатку не присоединена глюкоза. Толстая направленная вверх или влево указательная стрелка показывает связи олигосахарида, которые подвержены расщеплению α-маннозидазой после удаления α(1-2)-связанных манноз, а незакрашенная направленная вниз указательная стрелка показывает связи олигосахарида, которые подвержены расщеплению β-маннозидазой после удаления α-связанных манноз. Общий обзор возможных продуктов реакций содержится в Таблице 10 Примера 26.
Фиг.63. Реакционные продукты Man-9 после инкубации в течение ночи с экзогликозидазами или без них были разделены на колонке TSK gel-Amide-80 (0,46×25 см, Tosoh Biosep), присоединенной к установке ВЭЖХ Waters Alliance. Разделение олигосахаридов проводили при температуре окружающей среды при 1,0 мл/мин. Растворитель А состоял из 0,1% уксусной кислоты в ацетонитриле, а растворитель В состоял из 0,2% уксусной кислоты и 0,2% триэтиламина в воде. Разделение меченных 2-аминобензамидом (2-АВ) олигосахаридов проводили с использованием 28% В, изократического для 5 объемов колонки, с последующи линейным возрастанием до 45% В еще для 15 объемов колонки. Состав растворителя для элюции указан на правой оси Y как % растворителя В в растворителе А (об./об.). Время элюции указано в минутах на оси X. Левая ось Y показывает флуоресценцию элюируемых меченых 2-аминобензамидом (2-АВ) олигосахаридов. Длина волны возбуждения 2-аминобензамида равна 330 нм, а длина волны испускания равна 420 нм.
Кривая 1 ("1") хроматограммы показывает элюцию Man-9, инкубированного в течение ночи без экзогликозидазы. Кривая 2 ("2") показывает элюцию смеси Man-5 и Man-6 после инкубации Man-9 в течение ночи с α(1-2)-маннозидазой. Кривые 3 и 4 ("3" и "4") показывают элюцию 4'-β-маннозилхитобиозы после инкубации Man-9 с α-маннозидазой в течение 1 часа и в течение ночи, соответственно. Кривая 5 ("5") показывает элюцию хитобиозы после инкубации Man-9 с α- и β-маннозидазой в течение ночи. Кривые 1-5 представлены как наложенные друг на друга, и у них, как у таковых, не все соответствующие базовые линии находятся на нулевом уровне. Кривая 6 ("6") показывает использованный градиент растворителей.
Пики, если они есть, указанные латинскими буквами от А до К в верхней части рисунка, представляют собой: А, хитобоза; В, 4'-β-маннозилхитобиоза; С, Man-2; D, Man-3; Е, Man-4; F, Man-5; G, Man-6; Н, Man-7; I, Man-7; J, Man-8; К, Man-10. См. также Пример 26.
Фиг.64. Реакционные продукты олигосахаридов, полученных из E1s, продуцируемого Saccharomyces, после инкубации в течение ночи с экзогликозидазами или без них были разделены на колонке TSK gel-Amide-80 (0,46×25 см, Tosoh Biosep), присоединенной к установке ВЭЖХ Waters Alliance. Разделение олигосахаридов проводили при температуре окружающей среды при 1,0 мл/мин. Растворитель А состоял из 0,1% уксусной кислоты в ацетонитриле, а растворитель В состоял из 0,2% уксусной кислоты и 0,2% триэтиламина в воде. Разделение меченых 2-аминобензамидом олигосахаридов проводили с использованием 28% В, изократического для 5 объемов колонки, с последующим линейным возрастанием до 45% В еще для 15 объемов колонки. Состав растворителя для элюции указан на правой оси Y как % растворителя В в растворе А (об./об.). Время элюции указано в минутах на оси X. Левая ось Y показывает флуоресценцию элюируемых меченных 2-аминобензамидом олигосахаридов. Длина волны возбуждения 2-аминобензамида равна 330 нм, а длина волны испускания равна 420 нм.
Кривая 1 ("1") хроматограммы показывает элюцию олигосахаридов, полученных из E1s, продуцируемого Saccharomyces, после инкубации в течение ночи без экзогликозидаз. Кривая 2 ("2") показывает элюцию олигосахаридов, полученных из E1s, продуцируемого Saccharomyces, после инкубации Man-9 в течение ночи с α(1-2)-маннозидазой. Кривые 3 и 4 ("3" и "4") показывают элюцию олигосахаридов, полученных из E1s, продуцируемого Saccharomyces, после инкубации с α-маннозидазой в течение 1 часа и в течение ночи, соответственно. Кривая 5 "5" показывает элюцию олигосахаридов, полученных из E1s, продуцируемого Saccharomyces, после инкубации с α- и β-маннозидазой в течение ночи. Кривые 1-5 представлены как наложенные друг на друга, и у них, как у таковых, не все соответствующие базовые линии находятся на нулевом уровне. Кривая 6 ("6") показывает использованный градиент растворителей.
Пики, если они есть, указанные латинскими буквами от А до К в верхней части рисунка, представляют собой: А, хитобоза; В, 4'-β-маннозилхитобиоза; С, Man-2; D, Man-3; Е, Man-4; F, Man-5; G, Man-6; H, Man-7; I, Man-7; J, Man-8; К, Man-10. См. также Пример 26.
Фиг.65. Реакционные продукты олигосахаридов, полученных из E1s, продуцируемого клетками млекопитающего, трансфицированными вирусом коровьей оспы, после инкубации в течение ночи с экзогликозидазами или без них были разделены на колонке TSK gel-Amide-80 (0,46×25 см, Tosoh Biosep), присоединенной к установке ВЭЖХ Waters Alliance. Разделение олигосахаридов проводили при температуре окружающей среды при 1,0 мл/мин. Растворитель А состоял из 0,1% уксусной кислоты в ацетонитриле, а растворитель В состоял из 0,2% уксусной кислоты и 0,2% триэтиламина в воде. Разделение меченых 2-аминобензамидом олигосахаридов проводили с использованием 28% В, изократического для 5 объемов колонки, с последующим линейным возрастанием до 45% В еще для 15 объемов колонки. Состав растворителя для элюции указан на правой оси Y как % растворителя В в растворе А (об./об.). Время элюции указано в минутах на оси X. Левая ось Y показывает флуоресценцию элюируемых меченных 2-аминобензамидом олигосахаридов. Длина волны возбуждения 2-аминобензамида равна 330 нм, а длина волны испускания равна 420 нм.
Кривая 1 ("1") хроматограммы показывает элюцию олигосахаридов, полученных из E1s, продуцируемого клетками млекопитающего, трансфицированными вирусом коровьей оспы, после инкубации в течение ночи без экзогликозидаз. Кривая 2 ("2") показывает элюцию олигосахаридов, полученных из E1s, продуцируемого клетками млекопитающего, трансфицированными вирусом коровьей оспы, после инкубации Man-9 в течение ночи с α(1-2)-маннозидазой. Кривые 3 и 4 ("3" и "4") показывают элюцию олигосахаридов, полученных из E1s, продуцируемого клетками млекопитающего, трансфицированными вирусом коровьей оспы, после инкубации с α-маннозидазой в течение 1 часа и в течение ночи, соответственно. Кривая 5 "5" показывает элюцию олигосахаридов, полученных из E1s, продуцируемого клетками млекопитающего, трансфицированными вирусом коровьей оспы, после инкубации с α- и β-маннозидазой в течение ночи. Кривые 1-5 представлены как наложенные друг на друга, и у них, как у таковых, не все соответствующие базовые линии находятся на нулевом уровне. Кривая 6 ("6") показывает использованный градиент растворителей.
Пики, если они есть, указанные латинскими буквами от А до К в верхней части рисунка, представляют собой: А, хитобоза; В, 4'-β-маннозилхитобиоза; С, Man-2; D, Man-3; Е, Man-4; F, Man-5; G, Man-6; H, Man-7; I, Man-7; J, Man-8; К, Man-10. См. также Пример 26.
Фиг.66. Реакционные продукты олигосахаридов, полученных из E1s, продуцируемого Hansenula, после инкубации в течение ночи с экзогликозидазами или без них были разделены на колонке TSK gel-Amide-80 (0,46×25 см, Tosoh Biosep), присоединенной к установке ВЭЖХ Waters Alliance. Разделение олигосахаридов проводили при температуре окружающей среды при 1,0 мл/мин. Растворитель А состоял из 0,1% уксусной кислоты в ацетонитриле, а растворитель В состоял из 0,2% уксусной кислоты и 0,2% триэтиламина в воде. Разделение меченых 2-аминобензамидом олигосахаридов проводили с использованием 28% В, изократического для 5 объемов колонки, с последующим линейным возрастанием до 45% В еще для 15 объемов колонки. Состав растворителя для элюции указан на правой оси Y как % растворителя В в растворе А (об./об.). Время элюции указано в минутах на оси X. Левая ось Y показывает флуоресценцию элюируемых меченных 2-аминобензамидом олигосахаридов. Длина волны возбуждения 2-аминобензамида равна 330 нм, а длина волны испускания равна 420 нм.
Кривая 1 ("1") хроматограммы показывает элюцию олигосахаридов, полученных из E1s, продуцируемого Hansenula, после инкубации в течение ночи без экзогликозидаз. Кривая 2 ("2") показывает элюцию олигосахаридов, полученных из E1s, продуцируемого Hansenula, после инкубации Man-9 в течение ночи с α(1-2)-маннозидазой. Кривые 3 и 4 ("3" и "4") показывают элюцию олигосахаридов, полученных из E1s, продуцируемого Hansenula, после инкубации с α-маннозидазой в течение ночи. Кривая 5 "5" показывает элюцию олигосахаридов, полученных из E1s, продуцируемого Hansenula, после инкубации с α- и β-маннозидазой в течение ночи. Кривые 1-5 представлены как наложенные друг на друга, и у них, как у таковых, не все соответствующие базовые линии находятся на нулевом уровне. Кривая 6 ("6") показывает использованный градиент растворителей.
Пики, если они есть, указанные латинскими буквами от А до К в верхней части рисунка, представляют собой: А, хитобоза; В, 4'-β-маннозилхитобиоза; С, Man-2; D, Man-3; Е, Man-4; F, Man-5; G, Man-6; H, Man-7; I, Man-7; J, Man-8; К, Man-10. См. также Пример 26.
Фиг.67. Анализ белков Е1, продуцируемых Hansenula и клетками млекопитающего, инфицированными HCV-рекомбинантным вирусом коровьей оспы, посредством Na-ДДС-ПААГ и окрашивания Кумасси бриллиантовым синим.
Дорожка 1: маркеры молекулярной массы с молекулярными массами, указанными слева; дорожка 2: алкилированный E1s, продуцируемый Hansenula polymorpha (10 мкг); дорожка 3: алкилированный E1s, продуцируемый Hansenula polymorpha (5 мкг); дорожка 4: алкилированный E1s, продуцируемый Hansenula polymorpha (2,5 мкг); дорожка 5: алкилированный E1s, продуцируемый клетками vero, инфицированными HCV-рекомбинантным вирусом коровьей оспы (10 мкг); дорожка 6: алкилированный E1s, продуцируемый клетками vero, инфицированными HCV-рекомбинантным вирусом коровьей оспы (5 мкг); дорожка 7: алкилированный E1s, продуцируемый клетками vero, инфицированными HCV-рекомбинантным вирусом коровьей оспы (2,5 мкг). См. также Пример 27.
Фиг.68. Последовательность белка HCV E2-H6 (SEQ ID NO:5) с указанием трипсиновых фрагментов (последовательности в прямоугольных рамках) дегликозилированного белка. Гликозилированные Asn-остатки превращены в Asp-остатки ферментом PNGase F и указаны знаком "*" под последовательностью. Asn-остатки подвержены протеолитическому расщеплению Asp-N-эндопептидазой. Возможными сайтами N-гликозилирования в E2-H6 (SEC ID NO:5) являются N417, N423, N430, N448, N478, N532, N540, N556, N576, N623 и N645 согласно нумерации в полипротеине HCV; на данном рисунке эти сайты пронумерованы как N34, N40, N47, N65, N95, N149, N157, N173, N193, N240 и N262. См. также Пример 28.
ПОДРОБНОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
В работе, которая привела к этому изобретению, было замечено, что экспрессия гликозилированных оболочечных белков HCV в Saccharomyces cerevisiae, Pichia pastoris и Hansenula polymorpha была возможна путем экспрессии указанных оболочечных белков HCV в виде белков, содержащих сигнальную пептидную последовательность, присоединенную к указанным оболочечным белкам HCV. Однако типы гликозилирования оболочечных белков HCV, экспрессировавшихся в этих трех видах дрожжей, были очень разными (см. Примеры 6, 10, 13 и 25). Более конкретно, оболочечные белки HCV из S.cerevisiae (мутант с дефектом гликозилирования) и Н.polymorpha были гликозилированы до некоторой степени схожим с кор-гликозилированием образом. Оболочечные белки HCV, экспрессировавшиеся в Pichia pastoris, были гипергликозилированы, несмотря на ранние сообщения о том, что белки, экспрессируемые в этих дрожжах, обычно не являются гипергликозилированными (Gellisen et al. 2000, Surgue et al. 1997).
При дальнейшем анализе типов гликозилирования белков HCV, продуцированных S.cerevisiae (штамм с дефектом гликозилирования), Н.polymorpha и клетками млекопитающего, инфицированными HCV-рекомбинантным вирусом коровьей оспы, было неожиданно обнаружено, что оболочечные белки HCV, продуцируемые Hansenula, демонстрировали тип гликозилирования, который весьма благоприятен для диагностических, профилактических и терапевтических применений этих оболочечных белков HCV (см. Примеры 21-24 и 26-29). Это неожиданное открытие отражено в разных аспектах и воплощениях настоящего изобретения, как это представлено ниже.
Первый аспект этого изобретения относится к выделенному оболочечному белку HCV или его фрагменту, содержащему по меньшей мере один сайт N-гликозилирования, отличающемуся тем, что он представляет собой продукт экспрессии в эукариотической клетке, и дополнительно отличающемуся тем, что в среднем до 50%, 51%, 52%, 53%, 54%, 55%, 56%, 57%, 58%, 59%, 60%, 61%, 62%, 63%, 64%, 65%, 66%, 67%, 68%, 69%, 70%, 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79% и 80% N-гликозилированных сайтов являются кор-гликозилированными. Более конкретно, более чем 60%, 61%, 62%, 63%, 64%, 65%, 66%, 67%, 68%, 69%, 70%, 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94% и 95% этих N-гликозилированных сайтов гликозилированы олигоманнозой со структурой, определяемой как Man(8-10)-GlcNAc(2). Более конкретно для любой из вышеуказанных особенностей N-гликозилирования, соотношение сайтов, кор-гликозилированных олигоманнозой, имеющей структуру Man(7)-GlcNAc(2), и сайтов, кор-гликозилированных олигоманнозой, имеющей структуру Man(8)-GlcNAc(2), меньше или равно 0,15; 0,2; 0,25; 0,30; 0,35; 0,40; 0,44; 0,45 или 0,50. Еще более конкретно для любой из вышеуказанных особенностей N-гликозилирования, указанные олигоманнозы содержат менее 20%, 19%, 18%, 17%, 16%, 15%, 14%, 13%, 12%, 11%, 10%, 9%, 8%, 7%, 6% или 5% концевой α1,3-маннозы.
Выражение "N-гликозилированные сайты, гликозилированные олигоманнозой, имеющей структуру, определяемую как Man(8-10)-GlcNAc(2)" означает, что указанные N-гликозилированные сайты гликозилированы любой из Man(8)-GlcNAc(2), Man(9)-GlcNAc(2) или Man(10)-GlcNAc(2).
Должно быть ясно, что один и тот же сайт N-гликозилирования в двух белках может быть занят разными олигоманнозами.
Термин "белок" относится к полимеру аминокислот и не касается конкретной длины этого продукта; таким образом, в это определение белка включены пептиды, олигопептиды и полипептиды. Также этот термин не касается пост-экспрессионных модификаций белка, например, гликозилирований, ацетилирований, фосфорилирований и тому подобного, и не исключает их. В это определение включены, например, полипептиды, содержащие один или более чем один аналог аминокислоты (включая, например, неприродные аминокислоты, PNA и так далее), полипептиды с замещенными связями, а также другие модификации, известные в данной области, как встречающиеся, так и не встречающиеся в природе.
Под "пре-про-белком" или "пре-белком" при использовании здесь подразумевается, соответственно, белок, содержащий пре-про-последовательность, присоединенную к белку, представляющему интерес, или белок, содержащий про-последовательность, присоединенную к белку, представляющему интерес. В качестве альтернатив "пре-последовательности" используют термины " сигнальная последовательность", "сигнальный пептид", "лидерный пептид" или "лидерная поледовательность"; все они относятся к аминокислотной последовательности, которая направляет пре-белок в шероховатый эндоплазматический ретикулюм (ЭР), что является предпосылкой N-гликозилирования. "Сигнальная последовательность", "сигнальный пептид", "лидерный пептид" или "лидерная последовательность" отщепляется, то есть «отделяется» от белка, содержащего эту сигнальную последовательность, присоединенную к белку, представляющему интерес, в просветном участке этого ЭР специфическими протеазами хозяина, именуемым сигнальными пептидазами. Аналогично, пре-про-белок превращается в про-белок при перемещении в просвет ЭР. В зависимости от природы "про"-аминокислотной последовательности, она может или не может быть удалена клеткой-хозяином, экспрессирующей пре-про-белок. Хорошо известной пре-про-аминокислотной последовательностью является пре-про-последовательность α-фактора спаривания у α-фактора спаривания S.cerevisiae.
Под "оболочечным белком HCV" подразумевается оболочечный белок Е1 HCV или Е2 HCV или его часть, посредством которой указанные белки могут быть получены из штамма HCV любого генотипа. Более конкретно, HCVENV выбирают из группы аминокислотных последовательностей, состоящей из аминокислотных последовательностей SEQ ID NOs:85-98, из аминокислотных последовательностей, которые по меньшей мере на 90% идентичны аминокислотным последовательностям SEQ ID NOs:85-98, и из фрагментов любой из них. "Идентичными" аминокислотами считаются группы консервативных аминокислот, как описано выше, а именно, группа, состоящая из Met, Ile, Ley и Val; группа, состоящая из Arg, Lys и His; группа, состоящая из Phe, Trp и Tyr; группа, состоящая из Asp и Glu; группа, состоящая из Asn и Gln; группа, состоящая из Cys, Ser и Thr; и группа, состоящая из Ala и Gly.
Более конкретно, термин "оболочечные белки HCV" относится к полипептиду или его аналогу (например, мимотопам), содержащему аминокислотную последовательность (и/или аналоги аминокислот), определяющую по меньшей мере один эпитоп HCV из области Е1 или Е2 в дополнение к сайту гликозилирования. Эти оболочечные белки могут быть как мономерными, гетеро-олигомерными, так и гомо-олигомерными формами рекомбинантно экспрессируемых оболочечных белков. В типичных случаях последовательности, определяющие эпитоп, соответствуют аминокислотным последовательностям либо участка Е1, либо участка Е2 из HCV (идентично либо посредством замен аналогами нативного аминокислотного остатка, которые не нарушают эпитоп).
Должно быть понятно, что эпитоп HCV может быть локализован совместно с сайтом гликозилирования.
В общем последовательность, определяющая эпитоп, должна быть длиной в 3 или 4 аминокислоты, более типично длиной в 5, 6 или 7 аминокислот, более типично длиной в 8 или 9 аминокислот и еще более типично длиной в 10 или более чем 10 аминокислот. Что касается конформационных эпитопов, то длина последовательности, определяющей эпитоп, может быть подвержена большим вариациям, поскольку считают, что эти эпитопы формируются трехмерной структурой антигена (например, укладкой). Так, аминокислоты, определяющие эпитоп, могут быть относительно немногочисленными, но широко разбросанными по длине молекулы и приводимыми в правильную конформацию эпитопа путем укладки. Участки антигена между остатками, определяющими эпитоп, могут не быть критичными для конформационной структуры эпитопа. Например, делеция или замена этих промежуточных последовательностей может не влиять на конформационный эпитоп при условии, что сохраняются последовательности, которые критичны для эпитопа (например, цистеины, вовлеченные в образование дисульфидных связей, сайты гликозилирования и так далее). Конформационный эпитоп может быть также образован двумя или более чем двумя существенными участками субъединиц гомо-олигомера или гетеро-олигомера.
Эпитоп определенного полипептида при использовании здесь обозначает эпитопы, у которых аминокислотная последовательность такая же, как у эпитопа этого определенного полипептида, и их иммунологические эквиваленты. Такие эквиваленты также включают в себя варианты, специфичные для штамма, субтипа (=генотипа) или типа (группы), например для известных в настоящее время последовательностей или штаммов, относящихся к генотипам 1а, 1b, 1с, 1d, 1e, 1f, 2a, 2b, 2c, 2d, 2e, 2f, 2g, 2h, 2i, 3а, 3b, 3с, 3d, 3е, 3f, 3g, 4а, 4b, 4c, 4d, 4e, 4f, 4g, 4h, 4i, 4j, 4k, 4l, 5a, 5b, 6a, 6b, 6с, 7a, 7b, 8a, 8b, 9a, 9b, 10a, 11 (и его субтипам), 12 (и его субтипам) или 13 (и его подтипам), или любым другим вновь определенным (суб)типам HCV. Следует понимать, что аминокислоты, составляющие эпитоп, не обязательно должны быть частью линейной последовательности, но могут быть разделены любым количеством аминокислот, тем самым образуя конформационный эпитоп.
Антигены HCV по настоящему изобретению включают в себя эпитопы из (оболочечных) доменов Е1 и/или Е2 из HCV. Домен Е1, который считают соответствующим вирусному оболочечному белку, по современным оценкам простирается в промежутке аминокислот 192-383 полипротеина HCV (Hijikata et al., 1991). Считают, что при экспрессии в системе млекопитающего (будучи гликозилированным) он имеет молекулярную массу около 35 кДа при определении посредством Na-ДДС-ПААГ электрофореза. Считают, что белок Е2, который прежде называли NS1, простирается в промежутке аминокислот 384-809 или 384-746 (Grakoui et al., 1993) полипротеина HCV и также является оболочечным белком. Считают, что при экспрессии в системе вируса коровьей оспы (будучи гликозилированным) он имеет кажущуюся по определению в геле молекулярную массу около 72 кДа. Понятно, что эти конечные параметры белка являются приблизительными (например, карбокси-терминальный конец Е2 может находиться где-то в районе аминокислот 730-820, например, оканчиваться аминокислотой 730, 735, 740, 742, 745, предпочтительно 746, 747, 748, 750, 760, 770, 780, 790, 800, 809, 810, 820). Белок Е2 может также экспрессироваться вместе с белком Е1 и/или кором (аминокислоты 1-191), и/или Р7 (аминокислоты 747-809), и/или NS2 (аминокислоты 810-1026), и/или NS3 (аминокислоты 1027-1657), и/или NS4A (аминокислоты 1658-1711), и/или NS4B (аминокислоты 1712-1972), и/или NS5A (аминокислоты 1973-2420), и/или NS5B (аминокислоты 2421-3011), и/или любой частью этих белков HCV, отличных от Е2. Аналогично, белок Е1 может также экспрессироваться вместе с Е2, и/или кором (аминокислотами 1-191), и/или Р7 (аминокислоты 747-809), и/или NS2 (аминокислоты 810-1026), и/или NS3 (аминокислоты 1027-1657), и/или NS4A (аминокислоты 1658-1711), и/или NS4B (аминокислоты 1712-1972), и/или NS5A (аминокислоты 1973-2420), и/или NS5B (аминокислоты 2421-3011), и/или любой частью этих HCV белков, отличных от Е1. Экспрессия вместе с этими другими белками HCV может быть важной для достижения правильной укладки белка.
Термин "Е1" при использовании здесь также включает в себя аналоги и усеченные формы, которые являются иммунологически перекрестно-реактивными с природным Е1 и включают в себя белки Е1 генотипов 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12 или 13 или любого другого вновь идентифицированного типа или субтипа HCV. Термин "Е2" при использовании здесь также включает в себя аналоги и усеченные формы, которые являются иммунологически перекрестно-реактивными с природным Е2 и включают в себя белки Е2 генотипов 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12 или 13 или любого другого вновь идентифицированного типа или субтипа HCV. Например, Kato et al. (1992) сообщают о вставках множественных кодонов между кодоном 383 и кодоном 384, а также о делециях аминокислот 384-387. Таким образом, понятно также, что изоляты, использованные в разделе примеров настоящего изобретения, не предназначены для того, чтобы ограничить объем этого изобретения, и что любой изолят HCV, относящийся к типу 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12 или 13 или любому новому генотипу HCV, является подходящим источником последовательности Е1 и/или Е2 для практики по настоящему изобретению. Аналогично, как описано выше, белки HCV, которые экспрессируются совместно с оболочечными белками HCV по настоящему изобретению, могут быть получены из HCV любого типа, также из того же типа, что и оболочечные белки HCV по настоящему изобретению.
"Е1/Е2" при использовании здесь относится к олигомерной форме оболочечных белков, содержащих по меньшей мере один Е1 компонент и по меньшей мере один Е2 компонент.
Термин "специфические олигомерные" оболочечные белки Е1 и/или Е2, и/или Е1/Е2 относится ко всем возможным олигомерным формам рекомбинантно экспрессируемых оболочечных белков Е1 и/или Е2, которые не являются агрегатами. Специфические олигомерные оболочечные белки Е1 и/или Е2 также называются гомо-олигомерными оболочечными белками Е1 или Е2 (см. ниже). Термин "единичные или специфические олигомерные" оболочечные белки Е1 и/или Е2, и/или Е1/Е2 относится к отдельным мономерным белкам Е1 или Е2 (отдельным в строгом смысле этого слова), а также к рекомбинантно экспрессируемым специфическим олигомерным белкам Е1 и/или Е2, и/или Е1/Е2. Эти отдельные или специфические олигомерные оболочечные белки по настоящему изобретению можно далее определить следующей формулой: (Е1)х(Е2)у, где х может быть числом между 0 и 100, а у может быть числом между 0 и 100, при условии, что х и у оба не равны 0. При х=1 и у=0 указанные оболочечные белки включают в себя мономерный Е1.
Термин "гомо-олигомер" при использовании здесь относится к комплексу Е1 или Е2, содержащему более чем один мономер Е1 или Е2, например, димеры Е1/Е1, тримеры Е1/Е1/Е1 или тетрамеры Е1/Е1/Е1/Е1 и димеры Е2/Е2, тримеры Е2/Е2/Е2 или тетрамеры Е2/Е2/Е2/Е2, Е1 пентамеры и гексамеры, Е2 пентамеры и гексамеры, или любые гомо-олигомеры Е1 или Е2 высшего порядка, - все они в объеме этого определения являются "гомо-олигомерами". Эти олигомеры могут содержать один, два или несколько разных мономеров Е1 или Е2, полученных из разных типов или субтипов вируса гепатита С, включая, например, те, что описали Maertens et al. в WO94/25601 и WO96/13590, в обоих случаях настоящих заявителей. Такие смешанные олигомеры все равно в объеме этого изобретения являются гомо-олигомерами и могут обеспечить возможность более универсальной диагностики, профилактики или лечения HCV.
Антигены Е1 и Е2, использованные в настоящем изобретении, могут быть полноразмерными вирусными белками, их по существу полноразмерными версиями или их функциональными фрагментами (например, фрагментами, содержащими по меньшей мере один эпитоп и/или сайт гликозилирования). Более того, антигены HCV по настоящему изобретению могут также включать в себя другие последовательности, которые не блокируют или не предотвращают образование конформационного эпитопа, представляющего интерес. Наличие или отсутствие конформационного эпитопа можно легко определить путем скрининга антигена, представляющего интерес, с помощью антитела (поликлональной или моноклональной сыворотки к конформационному эпитопу) и сравнением его реактивности с реактивностью денатурированной версии этого антигена, которая сохраняет только линейные эпитопы (если они есть). В таком скрининге с использованием поликлональных антител может быть полезно сначала адсорбировать поликлональную сыворотку денатурированным антигеном и посмотреть, сохранит ли она антитела к антигену, представляющему интерес.
Белки HCV по настоящему изобретению могут быть гликозилированы. Под гликозилированными белками подразумевают белки, которые содержат одну или более чем одну углеводную группу, в частности группы сахаров. В общем, все эукариотические клетки способны гликозилировать белки. После выравнивания последовательностей оболочечных белков разных генотипов HCV можно сделать вывод, что для правильной укладки и реактивности требуются не все 6 сайтов гликозилирования в белке Е1 HCV. Далее известно, что сайт гликозилирования в положении 325 не модифицируется путем N-гликозилирования (Fournillier-Jacob et al. 1996, Meunier et al. 1999). Более того, белок Е1 субтипа 1b HCV содержит 6 сайтов гликозилирования, но некоторые из этих сайтов гликозилирования у определенных (суб)типов отсутствуют. Четвертый углеводный мотив (на Asn250), имеющийся у типов 1b, 6а, 7, 8 и 9, отсутствует у всех остальных типов, известных на данное время. Этот мотив присоединения сахара может быть мутирован с образованием белка Е1 типа 1b с улучшенной реактивностью. Кроме того, последовательности типа 2b демонстрируют сайт экстра-гликозилирования в области V5 (на Asn299). У изолята S83, относящегося к генотипу 2с, первый углеводный мотив в области V1 (на Asn) даже отсутствует, тогда как он имеется у всех остальных изолятов (Stuyver et al., 1994). Однако даже у полностью консервативных мотивов присоединения сахаров присутствие углевода может не требоваться для укладки, но может играть определенную роль в ускользании от иммунологического надзора. Таким образом, идентификацию роли гликозилирования можно проверить далее мутагенезом мотивов гликозилирования. Мутагенез мотива гликозилирования (последовательностей NXS или NXT) может быть осуществлен либо мутированием кодонов для N, S или Т таким образом, чтобы эти кодоны кодировали аминокислоты, отличные от N в случае N, и/или аминокислоты, отличные от S или Т в случае S или в случае Т. Альтернативно, позицию Х можно мутировать в Р, поскольку известно, что NPS или NPT не часто модифицируются углеводами. После установления того, какие мотивы присоединения сахаров требуются для укладки и/или реактивности, а какие не требуются, можно производить комбинации таких мутаций. Такие эксперименты подробно описали Maertens et al. в Примере 8 из WO96/04385, которая конкретно включена сюда путем ссылки.
Термин «гликозилирование» при использовании в настоящем изобретении относится к N-гликозилированию, если не оговорено иначе.
В частности, настоящее изобретение относится к оболочечным белкам HCV или их частям, которые являются кор-гликозилированными. В этом отношении термин "кор-гликозилирование" относится к структуре, "сходной" со структурой, которая представлена обведенной рамкой структурой на Фиг.3 в Herscovics and Orlean (1993). Таким образом, указанная углеводная структура содержит 10-11 моносахаридов. Важно, что указанное описание включено сюда ссылкой на него. Термин "сходный" подразумевает, что к этой структуре добавлено не более четырех дополнительных моносахаридов или что не более трех моносахаридов удалено из этой структуры. Следовательно, углеводная структура кор-гликозилирования, о которой идет речь в настоящем изобретении, состоит минимум из 7 и максимум из 15 моносахаридов и может состоять из 8, 9, 10, 11, 12, 13 или 14 моносахаридов. Подразумеваемые моносахариды предпочтительно представляют собой глюкозу, маннозу или N-ацетилглюкозамин.
Альтернативный аспект настоящего изобретения относится к выделенному оболочечному белку HCV или его фрагменту, содержащему по меньшей мере один сайт N-гликозилирования, отличающемуся тем, что он является продуктом экспрессии в эукариотической клетке, и дополнительно отличающемуся тем, что более чем 60%, 61%, 62%, 63%, 64%, 65%, 66%, 67%, 68%, 69%, 70%, 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94% или 95% сайтов N-гликозилирования гликозилированы олигоманнозой со структурой, определяемой как Man(8-10)-GlcNAc(2). Более конкретно для вышеприведенной характеристики N-гликозилирования, соотношение сайтов, кор-гликозилированных олигоманнозой, имеющей структуру Man(7)-GlcNAc(2), и сайтов, кор-гликозилированных олигоманнозой, имеющей структуру Man(8)-GlcNAc(2), меньше или равно 0,15; 0,2; 0,25; 0,30; 0,35; 0,40; 0,44; 0,45 или 0,50. Еще более конкретно для любой из вышеуказанных характеристик N-гликозилирования, указанные олигоманнозы содержат менее 20%, 19%, 18%, 17%, 16%, 15%, 14%, 13%, 12%, 11%, 10%, 9%, 8%, 7%, 6% или 5% концевой α1,3-маннозы.
Еще один альтернативный аспект настоящего изобретения относится к выделенному оболочечному белку HCV или его фрагменту, содержащему по меньшей мере один сайт N-гликозилирования, отличающемуся тем, что он является продуктом экспрессии в эукариотической клетке, и дополнительно отличающемуся тем, что сайты N-гликозилирования заняты олигоманнозами, причем соотношение олигоманноз со структурой Man(7)-GlcNAc(2) и олигоманноз со структурой Man(8)-GlcNAc(2) меньше или равно 0,15; 0,2; 0,25; 0,30; 0,35; 0,40; 0,44; 0,45 или 0,50. Еще более конкретно для вышеуказанных характеристик N-гликозилирования, указанные олигоманнозы содержат менее чем 20%, 19%, 18%, 17%, 16%, 15%, 14%, 13%, 12%, 11%, 10%, 9%, 8%, 7%, 6% или 5% концевой α1,3-маннозы.
Другой альтернативный аспект настоящего изобретения охватывает выделенный оболочечный белок HCV или его фрагмент, содержащий по меньшей мере один сайт N-гликозилирования, отличающийся тем, что он является продуктом экспрессии в эукариотической клетке не-млекопитающего, и дополнительно отличающийся тем, что число сайтов N-гликозилирования по меньшей мере на 5%, 6%, 7%, 8%, 9%, 10%, 11%, 12%, 13% или 15% меньше, чем число сайтов N-гликозилирования у того же белка или его фрагмента, экспрессируемого из вируса коровьей оспы в эукариотической клетке, подверженной инфицированию или инфицированной указанным вирусом коровьей оспы. Более конкретно в отношении вышеприведенной характеристики N-гликозилирования, вплоть до 50%, 51%, 52%, 53%, 54%, 55%, 56%, 57%, 58%, 59%, 60%, 61%, 62%, 63%, 64%, 65%, 66%, 67%, 68%, 69%, 70%, 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79% и 80% сайтов N-гликозилирования являются кор-гликозилированными. Более конкретно, более чем 60%, 61%, 62%, 63%, 64%, 65%, 66%, 67%, 68%, 69%, 70%, 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94% и 95% сайтов N-гликозилирования гликозилированы олигоманнозой со структурой, определяемой как Man(8-10)-GlcNAc(2). Более конкретно в отношении любой из вышеуказанных характеристик N-гликозилирования, соотношение сайтов, кор-гликозилированных олигоманнозой, имеющей структуру Man(7)-GlcNAc(2), и сайтов, кор-гликозилированных олигоманнозой, имеющей структуру Man(8)-GlcNAc(2), меньше или равно 0,15; 0,2; 0,25; 0,30; 0,35; 0,40; 0,44; 0,45 или 0,50. Еще более конкретно в отношении любой из вышеуказанных характеристик N-гликозилирования, указанные олигоманнозы содержат менее 20%, 19%, 18%, 17%, 16%, 15%, 14%, 13%, 12%, 11%, 10%, 9%, 8%, 7%, 6% или 5% концевой α1,3-маннозы.
В другом аспекте этого изобретения выделенный оболочечный белок HCV или его часть согласно изобретению является продуктом экспрессии в дрожжевой клетке. Более конкретно, выделенный оболочечный белок HCV или его часть согласно изобретению является продуктом экспрессии в клетке штаммов Saccharomyces, таких как Saccharomyces cerevisiae, Saccharomyces kluyveri или Saccharomyces uvarum, Schizosaccharomyces, таких как Schizosaccharomyces pombe, Kluyveromyces, таких как Kluyveromyces lactis, Yarrowia, таких как Yarrowia lipolytica, Hansenula, таких как Hansenula polymorpha, Pichia, таких как Pichia pastoris, видов Aspergillus species, Neurospora, таких как Neurospora crassa, или Schwanniomyces, таких как Schwanniomyces occidentalis, или в мутантных клетках, полученных из любых из них. Более конкретно, выделенный оболочечный белок HCV или его часть согласно изобретению является продуктом экспрессии в клетке Hansenula. Еще более конкретно, выделенный оболочечный белок HCV или его часть согласно изобретению является продуктом экспрессии в дрожжевой клетке, например клетке Hansenula, в отсутствие ингибиторов гликозилирования, таких как туникамицин.
В другом аспекте этого изобретения выделенный оболочечный белок HCV или его часть по изобретению получены из белка, содержащего лидерный пептид птичьего лизоцима или его функциональный вариант, присоединенный к указанному оболочечному белку HCV или его фрагменту. Более конкретно, выделенный оболочечный белок HCV или его часть согласно изобретению получены из белка, который характеризуется следующей структурой
CL-[(A1)a-(PS1)b-(A2)c]-HCVENV-[(A3)d-(PS2)e-(А4)f]
где:
CL является лидерным пептидом птичьего лизоцима или его функциональным эквивалентом,
А1, А2, A3 и А4 являются адаптерными пептидами, которые могут быть одинаковыми или разными,
PS1 и PS2 являются сайтами процессинга, которые могут быть одинаковыми или разными,
HCVENV является оболочечным белком HCV или его частью,
а, b, с, d, e и f равны 0 или 1, и
где, возможно, А1 и/или А2 представляют собой часть PS1, и/или где A3 и/или А4 представляют собой часть PS2.
Под "лидерным пептидом птичьего лизоцима или его функциональным эквивалентом, присоединенным к оболочечному белку HCV или его части" подразумевается, что С-концевая аминокислота указанного лидерного пептида ковалентно связана пептидной связью с N-концевой аминокислотой указанного оболочечного белка HCV или его части. Альтернативно, С-концевая аминокислота указанного лидерного пептида отделена от N-концевой аминокислоты указанного оболочечного белка HCV или его части пептидом или белком. Указанный пептид или белок может иметь структуру [(А1)а-(PS1)b-(А2)с] как определено выше.
Образование представляющего интерес оболочечного белка HCV из белка, содержащего лидерный пептид птичьего лизоцима или его функциональный эквивалент, который присоединен к оболочечному белку HCV или его части, или из белка, характеризующегося структурой CL-[(A1)a-(PS1)b-(A2)c]-HCVENV-[(A3)d-(PS2)e-(A4)f], можно осуществить in vivo посредством протеолитических комплексов клеток, в которых экспрессируется этот пре-белок. Более конкретно, стадию, заключающуюся в удалении птичьего лидерного пептида, предпочтительно осуществляют in vivo протеолитическими комплексами клеток, в которых экспрессируется этот пре-белок. Образование можно, однако, осуществлять исключительно in vitro после и/или во время выделения и/или очистки пре-белка и/или белка из клеток, экспрессирующих этот пре-белок, и/или из культуральной жидкости, в которой выращивают клетки, экспрессирующие этот пре-белок. Альтернативно указанное образование in vivo осуществляют в комбинации с указанным образованием in vitro. Образование этого представляющего интерес белка HCV из рекомбинантно экспрессируемого пре-белка может дополнительно включать в себя применение протеолитического(их) фермента(ов) на стадии «полирования», когда все примесные белки, присутствующие вместе с белком, представляющим интерес, или их большая часть подвергается разложению, и когда белок, представляющий интерес, является устойчивым к «полирующему(щим)» протеолитическим(ому) ферментам(у). Образование и «полировка» не являются взаимно исключающими процессами и могут быть осуществлены применением одного и того же отдельного протеолитического фермента. В качестве примера здесь приведен белок E1s HCV генотипа 1b (SEC ID NO:2), который лишен Lys-остатков. При расщеплении белкового экстракта, содержащего указанные белки Е1 из HCV, эндопротеиназой Lys-C (endo-lys С) белки Е1 расщепляться не будут, тогда как загрязняющие белки, содержащие одни или более чем один Lys-остаток, разлагаются. Такой процесс может значительно упростить или улучшить выделение и/или очистку белков Е1 HCV. Более того, включением дополнительного Lys-остатка в пре-белок, например, между лидерным пептидом и белком Е1 HCV, можно получить дополнительную полезную возможность корректировать in vitro отделение лидерного пептида от пре-белка Е1 HCV. Другие белки Е1 HCV могут содержать Lys-остаток по одному или более чем одному из положений 4, 40, 42, 44, 61, 65 или 179 (причем положение 1 является первой N-концевой природной аминокислотой белка Е1, то есть положением 192 полипротеина HCV). Для того, чтобы сделать возможным применение endo-lys С как описано выше, указанные Lys-остатки можно мутировать в другой аминокислотный остаток, предпочтительно в Arg-остаток.
Под "корректно удаленным" лидерным пептидом подразумевается, что указанный лидерный пептид удаляют из белка, содержащего эту сигнальную последовательность, присоединенную к белку, представляющему интерес, с высокой эффективностью, то есть большое число пре-(про-)белков превращают в (про-)белки, и с высокой точностью, то есть удаляют только пре-аминокислотную последовательность, но не какие-либо аминокислоты белка, представляющего интерес, присоединенного к указанной пре-аминокислотной последовательности. Под "удалением лидерного пептида с высокой эффективностью" подразумевается, что по меньшей мере около 40%, но более предпочтительно около 50%, 55%, 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%, 96%, 97%, 98% или даже 99% пре-белков превращают в белок, из которого удалена эта пре-последовательность. Альтернативно, если существенная часть экспрессируемых пре-белков не превращена в белок, из которого удалена пре-последовательность, эти пре-белки все равно можно очистить или удалить во время очистки.
Под "функциональным эквивалентом лидерного пептида птичьего лизоцима (CL)" подразумевается лидерный пептид CL, в котором одна или более чем одна аминокислота заменена другой аминокислотой, причем указанная замена является консервативной аминокислотной заменой. Под "консервативной аминокислотной заменой" подразумевается замена аминокислоты, принадлежащей к группе консервативных аминокислот, другой аминокислотой, принадлежащей к той же группе консервативных аминокислот. В качестве групп консервативных аминокислот рассматривают: группу, состоящую из Met, Ile, Leu и Val; группу, состоящую из Arg, Lys и His; группу, состоящую из Phe, Trp и Tyr; группу, состоящую из Asp и Glu; группу, состоящую из Asn и Gln; группу, состоящую из Cys, Ser и Thr; и группу, состоящую из Ala и Gly. Примером консервативной аминокислотной замены в лидерном пептиде CL является природная вариация в положении 6, причем аминокислота в этом положении представляет собой либо Val, либо Ile; другая вариация случается в положении 17, причем аминокислота в этом положении представляет собой, среди прочего, Leu или Pro (см. SEQ ID NO:1). Получающиеся лидерные пептиды CL следует, таким образом, считать функциональными эквивалентами. Другие функциональные эквиваленты лидерных пепитидов CL включают в себя те лидерные пептиды, которые воспроизводят те же технические аспекты лидерных пептидов CL, что описаны во всем настоящем изобретении, в том числе варианты с делениями и варианты со вставками.
Под "А" или "адаптерным пептидом" подразумевается пептид (например, от 1 до 30 аминокислот) или белок, который может служить линкером между, например, лидерным пептидом и сайтом процессинга (PS), лидерным пептидом и белком, представляющим интерес, PS и белком, представляющим интерес, и/или белком, представляющим интерес и PS; и/или может служить линкером N- и С-конца, например, лидерного пептида, PS или белка, представляющего интерес. Адаптерный пептид "А" может иметь определенную трехмерную структуру, например, α-спиральную или β-складчатую или их комбинацию. Или же трехмерная структура А не является хорошо определенной, например, структура, представляющая собой свернутый клубок. Адаптер А может быть частью, например, пре-последовательности, про-последовательности, последовательности белка, представляющего интерес, или сайта процессинга. Адаптер А может служить меткой, улучшающей или делающей возможным обнаружение и/или очистку, и/или процессинг белка, частью которого является А. Одним из примеров пептида А является пептид Hn, представляющий собой гистидиновую метку (НННННН; SEQ ID NO:63), причем n обычно равно шести, но может быть 7, 8, 9, 10, 11 или 12. Другие примеры А-пептидов включают в себя пептиды EEGEPK (Kjeldsen et al. в WO98/28429; SEQ ID NO:64) или EEAEPK (Kjeldsen et al. в WO97/22706; SEQ ID NO:65), о которых сообщают, что они, когда присутствуют на N-конце белка, представляющего интерес, усиливают выход ферментации, а также защищают N-конец белка, представляющего интерес, от процессинга дипептидиламинопептидазой, что имеет результатом гомогенность N-конца полипептида. В то же время, созревание белка, представляющего интерес, in vitro, то есть, удаление указанных пептидов EEGEPK (SEQ ID NO:64) и EEAEPK (SEQ ID NO:65) из белка, представляющего интерес, может быть осуществлено применением, например, endo-lys С, которая отщепляет С-конец Lys-остатка указанных пептидов. Указанные пептиды, таким образом, выполняют функцию адаптерного пептида (А), а также сайта процессинга (см. ниже). Адаптерные пептиды приведены в SEQ ID NOs:63-65, 70-72 и 74-82. Другим примером адаптерного белка является иммуно-молчащий линкер G4S. Другие примеры адаптерных белков перечислены в Табл.2 в Stevens (Stevens et al. 2000).
Под "PS" или «сайтом процессинга» подразумевается специфический сайт процессинга белка или процессируемый сайт. Указанный процессинг может происходить ферментативным или химическим путем. Примеры сайтов процессинга, предрасположенных к специфическому ферментативному процессингу, включают в себя IEGR↓X (SEQ ID NO:66), IDGR↓X (SEQ ID NO:67), AEGR↓X (SEQ ID NO:68), все из которых распознаются и расщепляются между остатками Arg и Xaa (любая аминокислота), как указано знаком "↓", протеазой, представляющей собой бычий фактор Ха (Nagai, R. and Thogersen, H.C. 1984). Другим примером сайта PS является двухосновный сайт, например Arg-Arg, Lys-Lys, Arg-Lys или Lys-Arg, расщепляемый дрожжевой протеазой Кех2 (Julius, D. et al. 1984). Сайт PS может быть также одноосновным Lys-сайтом. Указанный одноосновный Lys-PS-сайт может также быть включен в С-конец пептида А. Примерами адаптерных пептидов А, содержащих С-концевой одноосновный Lys-PS-сайт, являются пептиды, представленные SEQ ID NOs:64-65 и 74-76. Экзопротеолитическое удаление гистидиновой метки (His-tag) (HHHHHH, SEQ ID NO:63) возможно применением дипептидиламинопептидазы I (DAPазы) в отдельности или в комбинации с глутаминциклотрансферазой (Q-циклазой) и пироглутаматаминопептидазой (pGAPазой) (Pedersen, J. et al. 1999). Указанные экзопептидазы, содержащие рекомбинантную His-tag (позволяющую удалить пептидазу из реакционной смеси аффинной хроматографией с использованием иммобилизованного металла, IMAC), имеются в продаже, например, TAGZyme System от Unizyme Laboratories (Hørsholm, DK). Таким образом, под "процессингом" в общем подразумевается любой способ или процедура, посредством которой белок специфически расщепляется или может быть расщеплен по меньшей мере в одном сайте процессинга, когда указанный сайт процессинга присутствует в указанном белке. PS может быть предрасположен к эндопротеолитическому расщеплению или может быть предрасположен к экзопротеолитическому расщеплению, в любом случае это расщепление является специфичным, то есть не распространяется на сайты, отличные от сайтов, распознаваемых протеолитическим ферментом процессинга. Множество сайтов PS приведено в SEQ ID NOs:66-68 и 83-84.
Универсальность структуры [(A1/3)a/d-(PS1/2)b/e-(A2/4)c/f)], как отмечено выше, демонстрируют некоторые примеры. В первом примере указанная структура присутствует на С-терминальном конце белка, представляющего интерес, содержащегося в пре-белке, причем A3 является пептидом "VIEGR" (SEQ ID NO:69), который перекрывается с сайтом фактора Ха "IEGRX" (SEQ ID NO:66), а Х=А4 является гистидиновой меткой (SEQ ID NO:63) (таким образом, d, е, и f, d в этом случае все равны 1). Белок HCV, представляющий интерес, может быть (возможно) очищен посредством IMAC. После процессинга фактором Ха этот (возможно очищенный) белок HCV, представляющий интерес, должен иметь на своем С-конце процессированный сайт PS, который представляет собой "IEGR" (SEQ ID NO:70). Вариантом процессированного фактором Ха сайта процессинга может быть IDGR (SEQ ID NO:71) или AEGR (SEQ ID NO:72). В еще одном примере структура [(A1/3)a/d-(PS1/2)b/e-(A2/4)c/f)] присутствует на N-конце представляющего интерес белка HCV. Более того, А1 является гистидиновой меткой (SEQ ID NO:63), PS является сайтом распознавания фактором Ха (любая из SEQ ID NOs:66-68), причем Х является белком, представляющим интерес, а=b=1 и с=0. При корректном удалении лидерного пептида, например, клеткой-хозяином, получающийся белок HCV, представляющий интерес, может быть (возможно) очищен посредством IMAC. После процессинга фактором Ха этот белок, представляющий интерес, будет лишен структуры [(А1)а-(PS1)b-(А2)с)].
Далее должно быть ясно, что любой из А1, А2, A3, А4, PS1 и PS2, если он присутствует, может присутствовать в повторяющейся структуре. Такую повторяющуюся структуру, если она присутствует, в этом контексте все равно считают за 1, то есть, а, с, d, d, e или f равны 1, даже если, например, А1 имеется, например, как два повтора (А1-А1).
Еще один аспект настоящего изобретения относится к любому выделенному оболочечному белку HCV или его фрагменту по этому изобретению, в котором тиольные группы цистеина модифицированы химическим путем.
Еще один аспект настоящего изобретения относится к любому выделенному оболочечному белку HCV или его фрагменту по этому изобретению, который является антигенным.
Еще один аспект настоящего изобретения относится к любому выделенному оболочечному белку HCV или его фрагменту по этому изобретению, который является иммуногенным.
Еще один аспект настоящего изобретения относится к любому выделенному оболочечному белку HCV или его фрагменту по этому изобретению, который содержит эпитоп, стимулирующий Т-клетки.
Другой аспект настоящего изобретения относится к любому выделенному оболочечному белку HCV или его фрагменту по этому изобретению, который содержится в структуре, выбранной из группы, состоящей из мономеров, гомодимеров, гетеродимеров, гомо-олигомеров и гетеро-олигомеров.
Еще один аспект настоящего изобретения относится к любому выделенному оболочечному белку HCV или его фрагменту по этому изобретению, который содержится в вирусоподобной частице.
В описанных здесь оболочечных белках HCV или их частях, содержащих по меньшей мере один остаток цистеина, но предпочтительно 2 или более чем два остатка цистеина, цистеиновые тиольные группы можно необратимо защитить химическими или ферментативными средствами. В частности, "необратимая защита" или "необратимое блокирование" химическими средствами относится к алкилированию, предпочтительно алкилированию оболочечных белков HCV алкилирующими агентами, такими как, например, активные галогены, этиленимин или N-(йодэтил)-трифторацетамид. В этом отношении следует понимать, что алкилирование цистеиновых тиольных групп относится к замене тиольного водорода структурой (CH2)nR, где n означает 0, 1, 2, 3 или 4, a R=Н, СООН, NH2, CONH2, фенил или любое их производное. Алкилирование можно проводить любым способом, известным в данной области, например, активными галогенами X(CH2)nR, где Х представляет собой галоген, такой как I, Br, Cl, или F. Примерами активных галогенов являются метилйодид, йодоуксусная кислота, йодацетамид и 2-бромэтиламин. В других способах алкилирования применяют NEM (N-этилмалеимид) или биотин-NEM, их смесь или этиленимин или N-(йодоэтил)-трифторацетамид, причем оба приводят к замене Н- на -CH2-CH2-NH2 (Hermanson, G.Т. 1996). Термин "алкилирующие агенты" при использовании здесь относится к соединениям, которые способны производить алкилирование, как здесь описано. Результатом таких алкилирований в конечном счете является модифицированный цистеин, который может имитировать другие аминокислоты. Результатом алкилирования этиленимином является структура, похожая на лизин таким образом, что вводит новые сайты расщепления для трипсина (Hermanson, G.Т. 1996). Сходным образом, результатом применения метилйодида является аминокислота, схожая с метионином, тогда как результатом применения йодацетата и йодацетамида являются аминокислоты, схожие с глутаминовой кислотой и глутамином, соответственно. По аналогии, эти аминокислоты предпочтительно применяют в прямом мутировании цистеина. Поэтому настоящее изобретение касается описанных здесь оболочечных белков HCV, у которых по меньшей мере один цистеиновый остаток описанного здесь оболочечного белка HCV мутирован в природную аминокислоту, предпочтительно в метионин, глутаминовую кислоту, глутамин или лизин. Термин "мутирован" относится к сайт-направленному мутагенезу нуклеиновых кислот, кодирующих эти аминокислоты, то есть к способам, хорошо известным в данной области, таким как, например, сайт-направленный мутагенез посредством ПЦР или опосредованный олигонуклеотидами мутаганез, как описано в (Samrock, J. et al. 1989). Следует понимать, что в разделе «Примеры» настоящего изобретения алкилирование относится к применению йодацетамида в качестве алкилирующего агента, если не указано иначе.
Следует также понимать, что в процедуре очистки цистеиновые тиольные группы белков HCV или их частей по настоящему изобретению можно защищать обратимо. Цель обратимой защиты состоит в том, чтобы стабилизировать белок HCV или его часть. В частности, серусодержащая функциональная группа (например, тиолы и дисульфиды) остается после проведения обратимой защиты в нереактивном состоянии. Таким образом, серусодержащая функциональная группа не способна реагировать с другими соединениями, например, теряет склонность образовывать или обменивать дисульфидные связи, как например,
| R1-SH+R2-SH | -Х→ | R1-S-S-R2; |
| R1-S-S-R2+R3-SH | -Х→ | R1-S-S-R3+R2-SH; |
| R1-S-S-R2+R3-S-S-R4 | -Х→ | R1-S-S-R3+R2-S-S-R4. |
Описанные реакции между тиольными и/или дисульфидными остатками не ограничены межмолекулярными процессами, но могут происходить внутримолекулярным образом.
Термин "обратимая защита" или "обратимое блокирование" при использовании здесь подразумевает ковалентное связывание модифицирующих агентов с цистеиновыми тиольными группами, а также такое манипулирование окружением белка HCV, при котором окислительно-восстановительное состояние цистеиновых тиольных групп остается незатронутым в ходе последующих стадий процедуры очистки (экранирование). Обратимую защиту цистеиновых тиольных групп можно осуществлять химическими или ферментативными средствами.
Термин "обратимая защита ферментативными средствами" при использовании здесь подразумевает обратимую защиту, опосредованную ферментами, такими как, например, ацил-трансферазы, в частности ацил-трансферазы, которые вовлечены в катализирование тио-этерификации, такие как пальмитоилацилтрансфераза (см. ниже).
Термин "обратимая защита химическими средствами" при использовании здесь подразумевает обратимую защиту:
1. Модифицирующими агентами, которые обратимо модифицируют цистеинилы, как например сульфонирование и тио-этерификация.
Сульфонирование является реакцией, в которой тиол или цистеины, участвующие в дисульфидных мостиках, модифицируются в S-сульфонат: RSH→RS-SO3 - (Darbre, A. 1986) или RS-SR→2RS-SO3 - (сульфитолизис; (Kumar, N. et al. 1986)). Реактивами для сульфонирования являются, например, Na2SO3 или тетратионат натрия. Применяют указанные реактивы для сульфонирования в концентрации 10-200 мМ, более предпочтительно в концентрации 50-200 мМ. Сульфонирование возможно может быть проведено в присутствии катализатора, такого как, например, Cu2+ (100 мкС - 1 мМ) или цистеин (1-10 мМ).
Эту реакцию можно проводить в условиях, которые денатурируют белок, так же как в условиях, которые оставляют белок нативным (Kumar, N. et al. 1985, Kumar, N. et al. 1986).
Образование тиоэфирной связи или тио-этерификация описывается реакцией:
RSH+R'COX→RS-COR',
где Х в соединении R'CO-X предпочтительно является галогенидом.
2. Модифицирующими агентами, которые обратимо модифицируют цистеинилы настоящего изобретения, такими как, например, тяжелые металлы, в частности Zn2+, Cd2+, моно-, дитио- и дисульфид-соединениями (например, арил- и алкил-метантиосульфонат, дитиопиридин, дитиоморфолин, дигидролипоамид, реагент Элмана, aldrothiol™ (Aldrich) (Rein, A. et al. 1996), дитиокарбаматы), или тиолирующими агентами (например, глутатион, N-ацетилцистеин, цистеинамин). Дитиокарбамат включает в себя обширный класс молекул, имеющих функциональную группу R1R2NC(S)SR3, которая придает им способность реагировать с сульфгидрильными группами. Используют тиол-содержащие соединения предпочтительно в концентрации 0,1-50 мМ, более предпочтительно в концентрации 1-50 мМ и даже еще более предпочтительно в концентрации 10-50 мМ.
3. В присутствии модифицирующих агентов, которые сохраняют (стабилизируют) состояние тиола, в частности антиоксидантов, таких как, например, дитиотреитол (DTT), дигидроаскорбат, витамины и производные, маннит, аминокислоты, пептиды и производные (например, гистидин, эрготионеин, карнозин, метионин), галлаты, гидроксианизол, гидрокситолуол, гидрохинон, гидроксиметилфенол и их производные, в диапазоне концентраций 10 мкм - 10 мМ, более предпочтительно в концентрации 1-10 мМ.
4. Использованием условий, стабилизирующих тиол, таких как, например, (1) кофакторы, такие как ионы металлов (Zn2+, Mg2+), АТФ, (2) контроль рН (например, для белков в большинстве случаев рН≈5, либо рН предпочтительно соответствует тиольному рКа-2, например, для пептидов, очищенных хроматографией с обращенной фазой при рН≈2).
Результатом комбинаций обратимой защиты, описанной в (1), (2), (3) и 4, могут быть сходным образом чистые и претерпевшие повторную укладку белки HCV. Поэтому можно использовать соединения, представляющие собой комбинации, например Z103 (Zn-карнозин), предпочтительно в концентрации 1-10 мМ. Должно быть ясно, что обратимая защита также относится, помимо вышеописанной модификации групп или экранирования, к любому способу защиты цистеинила, который может быть обращен ферментативно или химически без разрушения пептидного скелета. В этом отношении настоящее изобретение конкретно относится к пептидам, полученным классическим химическим синтезом (см. выше), в котором, например, тиоэфирные связи расщепляются тиоэстеразой, щелочными буферными условиями (Beckman, N.J. et al., 1997) или обработкой гидроксиламином (Vingerhoeds, M.H. et al., 1996).
Тиол-содержащие белки HCV можно очистить, например, на смолах для афинной хроматографии, которые содержат (1) отщепляемое соединительное звено, содержащее дисульфидную связь (например, иммобилизованная 5,5'-дитиобис(2-нитробензойная кислота) (Jayabaskaran, С. et al. 1987) и ковалентной хроматографией на активированной тиол-сефарозе 4В (Pharmacia) или (2) аминогексаноил-4-аминофениларсин в качестве иммобилизованного лиганда. Последнюю аффинную матрицу применяли для очистки белков, которые подвержены окислительно-восстановительному регулированию, и дитиольных белков, которые являются мишенями окислительного стресса (Kalef, E. et al. 1993).
Обратимую защиту можно также применять для увеличения солюбилизации и экстракции пептидов (Pomroy, N.C. and Deber, C.N. 1998).
Соединения для обратимой защиты и стабилизации тиолов могут иметь мономерную, полимерную и липосомную форму.
Снятие состояния обратимой защиты цистеиновых остатков можно осуществлять химическими или ферментативными средствами, например:
- восстановителем, в частности, дитиотреитолом, DTE, 2-меркаптоэтанолом, дитионитом, SnCl2, боргидридом натрия, гидроксиламином, ТСЕР, в частности в концентрации 1-200 мМ, более предпочтительно в концентрации 50-200 мМ;
- удалением условий или агентов, стабилизирующих тиол, например, повышением рН;
- ферментами, в частности тиоэстеразами, глутаредоксином, тиоредоксином, в частности, в концентрации 0,01-5 мкМ, еще более предпочтительно в диапазоне концентраций 0,1-5 мкМ;
- комбинациями вышеописанных химических и/или ферментативных условий.
Снятие состояния обратимой защиты цистеиновых остатков можно осуществлять in vitro или in vivo, например в клетке или в индивиде.
Должно быть понятно, что в процедуре очистки цистеиновые остатки можно подвергать или не подвергать необратимому блокированию или замещению с помощью любого агента обратимой модификации из перечисленных выше.
Восстановителем по настоящему изобретению является любой агент, который достигает восстановления серы в цистеиновых остатках, например, дисульфидных "S-S"-мостиков, десульфонирования цистеинового остатка (RS-SO3 -→RSH). Антиоксидантом является любой реагент, который сохраняет состояние тиола и/или минимизирует образование или обмена "S-S". Восстановление дисульфидных мостиков "S-S" представляет собой химическую реакцию, посредством которой дисульфиды восстанавливаются до тиола (-SH). Тем самым в настоящее описание включены ссылкой на них агенты и способы разрушения дисульфидрых мостиков, которые описали Maertens et al. в WO 96/04385. Восстановления "S-S" можно достичь (1) последовательностями ферментативных каскадов или (2) восстанавливающими соединениями. Известно, что ферменты, подобные тиоредоксину, глутаредоксину, вовлечены в восстановлении дисульфидов in vivo, и показано, что они эффективны в восстановлении "S-S"-мостиков in vitro. Дисульфидные связи быстро расщепляются восстановленным тиоредоксином при рН 7,0 с кажущейся скоростью второго порядка, которая примерно в 104 раз больше, чем соответствующая константа скорости для реакции с дитиотреитолом. Кинетику восстановления можно сильно улучшить предварительной инкубацией раствора белка с 1 мМ дитиотреитола или дигидролипоамида (Holmgren, A. 1979). Тиольными соединениями, способными восстанавливать дисульфидные мостики белков, являются, например, дитиотреитол (DTT), дитиоэритритол (DTE), β-меркаптоэтанол, тиокарбаматы, бис(2-меркаптоэтил)сульфон и N,N'-бис(меркаптоацетил)гидразин и дитионит натрия. Восстанавливающие агенты без тиольных групп, например, аскорбат или хлорид олова (SnCl2), для которых показано, что они очень полезны в восстановлении дисульфидных мостиков в моноклональных антителах (Thakur, M.L. et al. 1991), можно также применять для восстановления белков HCV. Кроме того, на окислительно-восстановительный статус белков HCV могут влиять изменения значений рН. Было показано, что обработка борогидридом натрия эффективна для восстановления дисульфидных мостиков в пептидах (Gailit, J. 1993). Трис-(2-карбоксиэтил)фосфин (ТСЕР) способен восстанавливать дисульфиды при низких рН (Burns, J. et al. 1991). Селенол катализирует восстановление дисульфидов до тиолов, когда в качестве восстановителя применяют DTT или борогидрид натрия. В качестве предшественника этого катализатора применяли имеющийся в продаже диселенид селеноцистеамин (Singh, R. and Kats.L. 1995).
Термин "иммуногенный" относится к способности белка или вещества вызывать иммунный ответ. Иммунный ответ представляет собой тотальный ответ организма на введение антигена и включает в себя образование антител, клеточный иммунитет, гиперчувствительность или иммунологическую толерантность. Клеточный иммунитет относится к ответу Т-хелперных клеток или CTL-клеток.
Термин «антигенный» относится к способности белка или вещества вызывать образование антитела или элисировать клеточный ответ.
Выражение "эпитоп, стимулирующий Т-клетки" согласно настоящему изобретению относится к эпитопу, способному стимулировать Т-клетки или CTL-клетки, соответственно. Эпитоп, стимулирующий Т-хелперные клетки, можно выбрать мониторингом лимфопролиферативного ответа на полипептиды, содержащие в своих аминокислотных последовательностях (предполагаемый) эпитоп, стимулирующий Т-клетки. Указанный лимфопролиферативный ответ можно измерять либо Т-хелперным анализом, при котором стимулируют in vitro мононуклеарные клетки периферической крови (PMBCs, peripheral blood mononuclear cells) из сывороток пациентов варьирующими концентрациями пептидов, подлежащих тестированию на активность, стимулирующую Т-клетки, и подсчитывают количество поглощения меченого радиоактивной меткой тимидина. Эпитоп, стимулирующий CTL, можно выбрать посредством анализа цитотоксичеких Т-кпеток (CTL), измеряющего литическую активность цитотоксических клеток с использованием высвобождения 51Cr. Пролиферацию считают положительной, когда индекс стимуляции (среднее значение числа импульсов в минуту в культурах, стимулированных антигеном/среднее значение числа импульсов в минуту в контрольных культурах) превышает 1, предпочтительно превышает 2, наиболее предпочтительно превышает 3.
Другой аспект этого изобретения относится к композиции, содержащей выделенный оболочечный белок HCV или его фрагмент по настоящему изобретению. Указанная композиция может дополнительно содержать фармацевтически приемлемый носитель и может представлять собой лекарство или вакцину.
Еще один аспект этого изобретения охватывает лекарство или вакцину, содержащие выделенный оболочечный белок HCV или его фрагмент по настоящему изобретению.
Еще один аспект этого изобретения включает в себя фармацевтическую композицию для индуцирования HCV-специфичного иммунного ответа у млекопитающего, содержащую эффективное количество оболочечного белка HCV или его части по изобретению и, возможно, фармацевтически приемлемый адъювант. Указанная фармацевтическая композиция, содержащая эффективное количество оболочечного белка HCV или его части согласно изобретению, может также быть способна индуцировать HCV-специфичные антитела у млекопитающего или может быть способна индуцировать Т-клеточную функцию у млекопитающего. Указанная фармацевтическая композиция, содержащая эффективное количество оболочечного белка HCV или его части согласно изобретению, может быть профилактической композицией или терапевтической композицией. В специфическом воплощении указанное млекопитающее является человеком.
"Млекопитающее" следует понимать как любого члена класса Mammalia высших позвоночных, включая людей, который характеризуется живорождением, волосяным покровом, млечными железами у самок, вырабатывающими молоко для вскармливания детенышей. Таким образом, млекопитающие включают в себя приматов, не являющихся людьми, и мышей trimera (Zauberman et al. 1999).
"Вакцина" или "лекарство" представляет собой композицию, способную элисировать защиту против заболевания, причем защита может быть частичной либо полной, а заболевание может быть либо в острой фазе, либо хронической, и в этом случае вакцина или лекарство являются профилактическими вакциной или лекарством. Вакцина или лекарство могут быть пригодны для лечения уже больного индивида, и в этом случае они называются терапевтическими вакциной или лекарством. Подобным же образом фармацевтическую композицию можно применять для целей как профилактических, так и/или терапевтических, и в этих случаях это будет профилактическая и/или терапевтическая композиция, соответственно.
Оболочечные белки HCV по настоящему изобретению можно применять как таковые, в биотинилированной форме (как раскрыто в WO 93/18054) и/или в виде комплекса с Neutralite Avidin (Molecular Probes Inc., Eugene, OR, USA), авидином или стрептавидином. Следует отметить, что "вакцина" или "лекарство" могут содержать в дополнение к активному началу "фармацевтически приемлемый носитель" или "фармацевтически приемлемый адъювант", который может быть подходящим эксципиентом, разбавителем, носителем или адъювантом, которые, сами по себе, не индуцируют продукцию антител, вредных для индивида, получающего эту композицию, а также не элисируют защиту. Типичные носители обычно представляют собой крупные медленно метаболизируемые макромолекулы, такие как белки, полисахариды, полимолочные кислоты, полигликолевые кислоты, полимерные аминокислоты, сополимеры аминокислот и неактивные вирусные частицы. Такие носители хорошо известны специалистам. Предпочтительные адъюванты для усиления эффективности композиции включают в себя следующие: гидроксид алюминия, алюминий в комбинации с 3-O-деацилированным монофосфориллипидом А, как описано в WO 93/19780, фосфат алюминия, как описано в WO 93/24148, N-ацетил-мурамил-L-треонил-D-изоглутамин, как описано в патенте США №4606918, N-ацетил-нормурамил-L-аланил-D-изоглутамин, N-ацетилмурамил-L-аланил-D-изоглутамил-L-аланин-2-(1',2'-дипальмитоил-sn-глицеро-3-гидроксифосфорилокси)-этиламин, RIBI (ImmunoChem Research Inc., Hamilton, MT, USA), который содержит монофосфориллипид А, дезинтоксицированный эндотоксин, трегалоза-6,6-димиколат и скелет клеточной стенки (MPL+TDM+CWS) в 2%-ной эмульсии сквален/твин 80. Любой из этих трех компонентов, MPL, TDM или CWS, можно также применять по-отдельности или в комбинации 2 на 2. MPL можно также заменить его синтетическим аналогом, который обозначают как RC-529. Кроме того, можно применять такие адъюванты, как Stimulon (Cambridge Bioscience, Worcester, MA, USA), SAF-1 (Syntex) или бактериальные адъюванты на основе ДНК, такие как ISS (Dynavax) или CpG (Coley Pharmaceuticals), а также такие адъюванты, как комбинации между QS21 и 3-дез-O-ацетилированным монофосфориллипидом А (WO 94/001153) или MF-59 (Chiron), или адъюванты на основе поли[ди(карбоксилатофенокси)фосфазин]а (Virus Research Institute), или адъюванты на основе блок-сополимеров, такие как Optivax (Vaxcel, Cythx), или адъюванты на основе инулина, такие как Algammulin и Gammalnulin (Anutech), неполный адъювант Фрейнда (IFA) или препараты Gerbu (Gerbu Biotechnik), но не ограничиваются ими. Надо понимать, что полный адъювант Фрейнда (CFA) можно использовать для применений на субъектах, не являющихся людьми, а также для исследовательских целей. "Вакцинная композиция" может дополнительно содержать эксципиенты и разбавители, которые по своей сути являются нетоксичными и не терапевтическими, такие как вода, физиологический раствор, глицерин, этанол, увлажняющие и эмульгирующие агенты, вещества, забуферивающие рН, консерванты и тому подобное. В типичном случае вакцинную композицию готовят как инъецируемую в виде водного раствора или суспензии. Инъекция может быть подкожной, внутримышечной, внутривенной, внутрибрюшинной, внутриоболочечной, внутрикожной. Другие типы введения включают в себя имплантацию, суппозитории, пероральный прием внутрь, введение в тонкий кишечник, ингаляцию, аэрозоли или назальные спреи или капли. Также могут быть приготовлены твердые формы, пригодные для растворения или суспендирования в жидких носителях перед инъекцией. Эти препараты можно также эмульгировать или инкапсулировать в липосомы для усиления адъювантного эффекта. Полипептиды можно также включать в иммуностимулирующие комплексы вместе с сапонинами, например Quil A (ISCOMS). Вакцинные композиции содержат эффективное количество активного вещества, а также любой из вышеупомянутых компонентов. "Эффективное количество" активного вещества означает, что введение этого количества индивиду, как в виде разовой дозы, так и частью серии, эффективно для предотвращения или лечения заболевания или для индукции желаемого эффекта. Это количество варьирует в зависимости от здоровья и физического состояния индивида, подлежащего лечению, таксономической группы индивида, подлежащего лечению (например, человек, примат кроме человека, примат и т.д.), способности иммунной системы индивида давать эффективный иммунный ответ, желаемой степени защиты, препарата вакцины, оценки лечащим врачом, штамма инфекционного патогена и других уместных факторов. Предполагается, что это количество должно попасть в относительно широкий диапазон, который можно определить обычными испытаниями. Обычно это количество варьирует от 0,01 до 1000 мкг/дозу, более конкретно от 0,1 до 100 мкг/дозу. Режим дозирования может представлять собой схему разовых доз или схему множественных доз. Вакцину можно вводить в сочетании с другими иммунорегуляторными агентами.
Другой аспект данного изобретения относится к способу получения выделенного оболочечного белка HCV или его фрагмента согласно изобретению.
Указанный способ получения выделенного оболочечного белка HCV или его части включает в себя, например, трансформацию клетки-хозяина рекомбинантной нуклеиновой кислотой или вектором, содержащими открытую рамку считывания, которая кодирует указанный оболочечный белок HCV или часть этого белка, причем указанная клетка-хозяин способна экспрессировать указанный оболочечный белок HCV или его часть. Указанный способ может дополнительно включать в себя культивирование указанных клеток-хозяев в подходящей среде для того, чтобы осуществить экспрессию указанного белка и выделить экспрессируемый белок из культуры указанных клеток-хозяев или из указанных клеток-хозяев. Указанное выделение может включать в себя одно или более чем одно из следующего: (1) лизис указанных клеток-хозяев в присутствии агента, вызывающего диссоциацию комплексов, (2) химическая модификация цистеиновых тиольных групп в выделенных белках, причем указанная химическая модификация может быть обратимой или необратимой, и (3) аффинная хроматография с использованием гепарина.
Примерами "агентов, вызывающих диссоциацию комплексов" являются хлорид гуанидиния и мочевина. В общем, агент, вызывающий диссоциацию комплексов, представляет собой химический продукт, который может разрушать структуру водородных связей воды. В концентрированных растворах они могут денатурировать белки, поскольку они снижают гидрофобный эффект.
Под "рекомбинантной нуклеиновой кислотой" подразумевается нуклеиновая кислота природного или синтетического происхождения, которая была подвергнута по меньшей мере одной манипуляции техники рекомбинантных ДНК, такой как расщепление ферментом рестрикции, ПЦР (полимеразная цепная реакция), лигирование, дефосфорилирование, фосфорилирование, мутагенез, адаптация кодонов для экспрессии в гетерологичной клетке и т.д. В общем, рекомбинантная нуклеиновая кислота представляет собой фрагмент природной нуклеиновой кислоты или содержит по меньшей мере два фрагмента нуклеиновой кислоты, которые не связаны между собой в природе, или является полностью синтетической нуклеиновой кислотой.
Термины "полинуклеотид", "полинуклеиновая кислота", "последовательность нуклеиновой кислоты" "нуклеотидная последовательность", "молекула нуклеиновой кислоты", "олигонуклеотид", "зонд" или "праймер" при использовании здесь относятся к нуклеотидам, как рибонуклетидам, так и дезоксирибонуклеотидам, пептидным нуклеотидам или замкнутым нуклеотидам, или к их комбинации, в полимерной форме любой длины или любой формы (например, разветвленная ДНК). Указанные термины дополнительно включают в себя двунитевые (ds) и однонитевые (ss) полинуклеотиды, а также трехнитевые полинуклеотиды. Указанные термины также включают в себя известные модификации нуклеотидов, такие как метилирование, циклизация, и "кэпы", а также замены одного или более чем одного природного нуклеотида аналогом, таким как инозин, или неамплифицируемыми мономерами, таким как HEG (гексетиленгликоль). Рибонуклеотиды обозначаются как NTPs, дезоксирибонуклеотиды - как dNTPs, а дидезоксирибонуклеотиды - как ddNTPs.
Нуклеотиды, как правило, можно метить радиоактивными метками, хемилюминесцентным способом, флуоресцентным способом, фосфоресцентным способом или инфракрасными красителями, либо меткой усиленного поверхностью комбинационного рассеяния или плазмено-резонансной частицей (PRP, plasmon resonant particle).
Указанные термины "полинуклеотид", "полинуклеиновая кислота", "последовательность нуклеиновой кислоты", "нуклеотидная последовательность", "молекула нуклеиновой кислоты", "олигонуклеотид", "зонд" или "праймер" также охватывают пептидонуклеиновые кислоты (PNAs, peptide nucleic acids), которые представляют собой аналог ДНК, в котором скелет представляет собой псевдопептид, состоящий из N-(2-аминоэтил)-глициновых единиц вместо сахара. PNAs имитируют поведение ДНК и связывают комплиментарные нити нуклеиновой кислоты. Результатом нейтрального скелета PNA является более сильное связывание и более высокая специфичность, чем достигаемая нормальным путем. Кроме того, уникальные химические, физические и биологические свойства PNA были использованы для того, чтобы получать мощные биомолекулярные инструменты, антисмысловые и антигенные агенты, молекулярные зонды и биосенсоры. PNA-зонды обычно могут быть более короткими, чем ДНК-зонды и обычно имеют от 6 до 20 оснований в длину или, более оптимально, от 12 до 18 оснований в длину (Nielsen, P.E. 2001). Указанные термины далее охватывают замкнутые нуклеиновые кислоты (LNAs, locked nucleic acids), которые представляют собой производные РНК, в которых рибозное кольцо скреплено метиленовой связью между 2'-кислородом и 4'-углеродом. LNAs проявляют беспрецедентное сродство связывания с целевыми последовательностями ДНК или РНК. LNA нуклеотиды могут быть олигомеризованы и могут быть включены в химерные или миксомерные молекулы LNA/ДНК или LNA/PHK. Похоже, что LNA нетоксичны для культивируемых клеток (Orum, H. and Wengel, J. 2001, Wahlenstedt, С. et al., 2000). В общем, принимают в рассмотрение химеры или миксомеры любой ДНК, РНК, PNA или LNA, а также любые из них, в которых тимин заменен на урацил.
Из вышесказанного ясно, что настоящее изобретение также относится к применению кор-гликозилированных оболочечных белков HCV согласно изобретению или композиции согласно изобретению в изготовлении вакцинной HCV композиции. В частности, настоящее изобретение относится к применению кор-гликозилированного оболочечного белка HCV согласно изобретению для индукции иммунитета против HCV у хронических носителей HCV. Более конкретно, настоящее изобретение относится к применению определенного здесь кор-гликозилированного оболочечного белка HCV для индукции иммунитета против HCV у хронических носителей HCV до, одновременно или после любой другой терапии, такой как, например, хорошо известная интерфероновая терапия одна или в сочетании с введением малых лекарств для лечения HCV-инфекции, таких как, например, рибавирин. Такую композицию можно также применять до или после трансплантации печени или после предполагаемого инфицирования, такого как, например, травма иглой.
Другой аспект этого изобретения относится к способу обнаружения присутствия анти-HCV антител в образце, подозреваемом в том, что он содержит анти-HCV антитела, при котором:
(1) оболочечный белок HCV или его часть согласно изобретению приводят в контакт с указанным образцом в условиях, допускающих образование комплекса указанного оболочечного белка HCV или его части с указанными анти-HCV антителами,
(2) выявляют комплекс, образованный на стадии (1),
(3) из результатов стадии (2) делают вывод о присутствии указанных анти-HCV антител в указанном образце.
В конкретном воплощении стадия приведения в контакт (1) указанного способа осуществляется к конкурентных условиях. В другом конкретном воплощении указанного способа указанный оболочечный белок HCV или его часть присоединены к твердой подложке. В дополнительном воплощении указанный образец, подозреваемый в том, что он содержит анти-HCV антитела, является биологическим образцом.
Другой аспект этого изобретения относится к диагностическому набору для обнаружения присутствия анти-HCV антител в образце, подозреваемом в том, что он содержит анти-HCV антитела, содержащему оболочечный белок HCV или его часть согласно изобретению. В конкретном воплощении указанный оболочечный белок HCV или его часть присоединены к твердой подложке. В дополнительном воплощении указанный образец, подозреваемый в том, что он содержит анти-HCV антитела, является биологическим образцом.
Термин "биологический образец" при использовании здесь относится к образцу ткани или жидкости, выделенной из индивида, включая, например, сыворотку, плазму, лимфатическую жидкость, наружные отделы кожи, респираторный, кишечный или мочеполовой тракт, ооциты, слезы, слюну, молоко, клетки крови, опухоли, органы, продукты кишечной секреции, слизь, спинно-мозговую жидкость, наружные секреты, такие как, например, экскременты, моча, сперма и тому подобное, но не ограничиваясь ими.
Оболочечные белки HCV по настоящему изобретению или их части особенно подходят для включения в такие способы, как способы иммунного анализа, для обнаружения HCV и/или генотипирования HCV, для прогнозирования/мониторинга HCV заболевания, либо в качестве терапевтического агента.
Эти способы, такие как способы иммунного анализа, по настоящему изобретению задействуют оболочечные белки HCV по настоящему изобретению, которые сохраняют линейные (в случае пептидов) и конформационные эпитопы, распознаваемые антителами в сыворотках от HCV-инфицированных индивидов. Антигены Е1 и Е2 из HCV по настоящему изобретению можно применять практически в любом формате анализа, который использует известный антиген для обнаружения антител. Конечно, следует избегать или адаптировать формат, который денатурирует конформационный эпитоп HCV. Общим свойством всех этих анализов является то, что антиген приводят в контакт с компонентом организма, подозреваемым в том, что он содержит HCV антитела, в условиях, которые позволяют антигену связаться с любым таким антителом, присутствующим в этом компоненте. Такими условиями в типичном случае являются физиологическая температура, рН и ионная сила при использовании избытка антигена. За инкубацией этого антигена с пробой следует выявление иммунных комплексов, содержащих этот антиген.
Схемы иммунных анализов допускают широкое варьирование, и в данной области известно много форматов. Протоколы могут, например, использовать твердые подложки или иммунопреципитацию. Большинство анализов предусматривает применение меченого антитела или полипептида, причем метки могут быть, например, ферментными, флуоресцентными, хемилюминесцентными, радиоактивными, или представлять собой молекулы красителей. Известны также анализы, которые усиливают сигналы от иммунного комплекса, примерами каковых могут быть анализы, которые используют биотин и авидин или стрептавидин, и иммунные анализы с ферментами в качестве меток или медиаторов, такие как твердофазный иммуноферментный анализ (ELISA) и радиоиммуноанализ (RIA).
Иммунный анализ может быть, без ограничений, в гетерогенном или гомогенном формате и стандартного или конкурентного типа. В гетерогенном формате полипептид в типичном случае связан с твердой матрицей или подложкой для того, чтобы способствовать отделению образца от полипептида после инкубации. Примерами твердых подложек, которые можно применять, являются нитроцеллюлоза (например, в форме мембраны или лунки для микротитрования), поливинилхлорид (например, в форме листов или лунок для микротитрования), полистирольный латекс (например, в форме шариков или планшетов для микротитрования), поливинилидинфторид (известный как Immunolon™), диазотированная бумага, нейлоновые мембраны, активированные шарики и гранулы белка A (Protein А). Например, в гетерогенном формате можно применять планшеты для микротитрования Dynatech Immunolon™ 1 или Immunolon™ 2. Твердую подожку, содержащую антигенные полипептиды, в типичном случае промывают после отделения ее от анализируемого образца и перед выявлением связанных антител. В данной области известны как стандартный, так и конкурентный формат.
В гомогенном формате анализируемый образец инкубируют с комбинацией антигенов в растворе. Например, это может происходить в условиях, при которых будут преципитировать любые образовавшиеся комплексы антиген-антитело. В данной области известны как стандартный, так и конкурентный формат.
В стандартном формате количество антител, таких как анти-HCV-антитела, в комплексах антиген-антитело определяют прямым путем. Это можно осуществить путем определения того, будут ли меченые анти-ксеногенные (например, анти-человеческие) антитела, которые распознают эпитоп на указанных антителах, таких как анти-HCV антитела, связываться благодаря образованию комплекса. В конкурентном формате вывод о количестве указанных антител, таких как анти-HCV антитела, в образце делают на основании определения конкурентного эффекта в отношении связывания известного количества (меченого) антитела (или другого конкурирующего лиганда) или антигена в комплексе.
Комплексы антиген-антитело можно выявлять с помощью любой методики из числа известных в зависимости от формата. Например, немеченые антитела, такие как анти-HCV антитела, можно выявлять с использованием конъюгата анти-ксеногенного lg в комплексе с меткой (например, меткой, которая представляет собой фермент).
В формате анализа, представляющем собой иммунопреципитацию или агглютинацию, реакция между антигеном и антителом образует белковый кластер, который преципитирует из раствора или суспензии и образует видимый слой или пленку преципитата. Если в анализируемой пробе или образце нет антитела, преципитат не образуется.
Оболочечные белки HCV или их специфические части по настоящему изобретению, состоящие из конформационных эпитопов, в типичном случае должны быть упакованы в форме набора для применения в этих иммунных анализах. Этот набор в норме должен содержать в отдельных контейнерах нативный антиген HCV, препараты для контроля антител (позитивные и/или негативные), меченое антитело, когда этого требует формат анализа, реагенты, генерирующие сигнал (например, ферментный субстрат), если метка не генерирует сигнал непосредственно. Нативный антиген HCV может быть уже связан с твердой матрицей или отделен вместе с реагентами для его связывания с этой матрицей. В набор должны быть включены инструкции (например, письменные, на магнитофонной ленте, на CD-ROM и т.д.) по проведению анализа.
Выбранная твердая фаза может включать в себя полимерные или стеклянные шарики, нитроцеллюлозу, микрочастицы, микролунки реакционного планшета, пробирки для анализа или магнитные шарики. Вещество, генерирующее сигнал, может включать в себя фермент, люминесцентное соединение, хромоген, радиоактивный элемент и хемилюминесцентное соединение. Примеры ферментов включают в себя щелочные фосфатазы, пероксидазу хрена и бета-галактозидазу. Примеры соединений-усилителей включают в себя биотин, антибиотин и авидин. Примеры компонентов, связывающих соединения-усилители, включают в себя биотин, антибиотин и авидин. Для того чтобы блокировать эффекты субстанций, подобных ревматоидным факторам, анализируемый образец помещают в условия, обеспечивающие блокирование эффектов субстанций, подобных ревматоидным факторам. Эти условия включают в себя приведение анализируемого образца в контакт с некоторым количеством античеловеческого IgG для образования смеси и инкубацию этой смеси в течение некоторого времени в условиях, достаточных для образования продукта реакционной смеси, существенно свободного от субстанций, подобных ревматоидным факторам.
В частности, настоящее изобретение относится к применению оболочечного белка HCV или его части по настоящему изобретению для изготовления диагностического набора.
Поскольку кор-гликозилированные оболочечные белки HCV по настоящему изобретению высоко иммуногенны и стимулируют как гуморальный, так и клеточный иммунный ответ, то настоящее изобретение далее относится к набору для обнаружения связанного с HCV Т-клеточного ответа, содержащему олигомерные частицы или отдельный очищенный оболочечный белок HCV по данному изобретению. Т-клеточный ответ на HCV можно измерять, например, так, как описано Leroux-Roels et al. в WO 95/12677.
Дальнейший аспект этого изобретения относится к способу индуцирования HCV-специфичного иммунного ответа у млекопитающего, при котором указанному млекопитающему вводят эффективное количество оболочечного белка HCV или его части согласно изобретению, возможно содержащего фармацевтически приемлемый адъювант. Указанный способ, при котором указанному млекопитающему вводят эффективное количество оболочечного белка HCV или его части согласно изобретению, можно также применять для индукции HCV-специфичных антител у млекопитающего или для индукции специфичной Т-клеточной функции у млекопитающего. В указанных способах указанное введение может осуществляться для профилактических целей, то есть являться профилактическим введением, или для терапевтических целей, то есть являться терапевтическим введением.
Еще один аспект этого изобретения относится к способу иммунизации млекопитающего, при котором указанному млекопитающему вводят эффективное количество оболочечного белка HCV или его части согласно изобретению, возможно содержащего фармацевтически приемлемый адъювант.
Настоящее изобретение также относится к способу лечения млекопитающего, инфицированного HCV, при котором указанному млекопитающему вводят эффективное количество оболочечного белка HCV или его части согласно изобретению, возможно содержащего фармацевтически приемлемый адъювант.
Любые из вышеописанных аспектов этого изобретения или воплощений, специфичных для указанных аспектов, также применимы вообще к белкам, представляющим интерес, которые представляют собой продукт экспрессии в эукариотических клетках и которые дополнительно характеризуются теми же свойствами гликозилирования, какие описаны выше для двух разных оболочечных белков HCV.
Таким образом, более конкретно это изобретение относится к выделенному белку, представляющему интерес, или его фрагменту, содержащему по меньшей мере один сайт N-гликозилирования, отличающемуся тем, что он является продуктом экспрессии в эукариотической клетке, и дополнительно отличающемуся тем, что в среднем до 50%, 51%, 52%, 53%, 54%, 55%, 56%, 57%, 58%, 59%, 60%, 61%, 62%, 63%, 64%, 65%, 66%, 67%, 68%, 69%, 70%, 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79% и 80% сайтов N-гликозилирования являются кор-гликозилированными. Более конкретно, более чем 60%, 61%, 62%, 63%, 64%, 65%, 66%, 67%, 68%, 69%, 70%, 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94% и 95% сайтов N-гликозилирования гликозилированы олигоманнозой со структурой, определяемой как Man(8-10)-GlcNAc(2). Более конкретно для любой из вышеуказанных особенностей N-гликозилирования, соотношение сайтов, кор-гликозилированных олигоманнозой, имеющей структуру Man(7)-GlcNAc(2), и сайтов, кор-гликозилированных олигоманнозой, имеющей структуру Man(8)-GlcNAc(2), меньше или равно 0,15; 0,2; 0,25; 0,30; 0,35; 0,40; 0,44; 0,45 или 0,50. Еще более конкретно для любой из вышеуказанных особенностей N-гликозилирования, указанные олигоманнозы содержат менее чем 20%, 19%, 18%, 17%, 16%, 15%, 14%, 13%, 12%, 11%, 10%, 9%, 8%, 7%, 6% или 5% концевой α1,3-маннозы.
Другой альтернативный аспект этого изобретения относится к выделенному белку, представляющему интерес, или его фрагменту, содержащему по меньшей мере один сайт N-гликозилирования, отличающемуся тем, что он является продуктом экспрессии в эукариотической клетке, и дополнительно отличающемуся тем, что сайты N-гликозилирования заняты олигоманнозами, причем соотношение олигоманноз, имеющих структуру Man(7)-GlcNAc(2), и олигоманноз, имеющих структуру Man(8)-GlcNAc(2), меньше или равно 0,15; 0,2; 0,25; 0,30; 0,35; 0,40; 0,44; 0,45 или 0,50. Еще более конкретно для любой из вышеуказанных особенностей N-гликозилирования, указанные олигоманнозы содержат менее 20%, 19%, 18%, 17%, 16%, 15%, 14%, 13%, 12%, 11%, 10%, 9%, 8%, 7%, 6% или 5% концевой α1,3-маннозы.
В частности, указанный выделенный белок, представляющий интерес, или его фрагмент является продуктом эспрессии в дрожжевой клетке, такой как клетка Hansenula. Указанный выделенный белок, представляющий интерес, или его фрагмент может быть, например, вирусным оболочечным белком или его фрагментом, таким как оболочечный белок HCV или оболочечный белок HBV (вирус гепатита В), или их фрагмент. Другие служащие примерами вирусные оболочечные белки включают в себя оболочечный белок gp120 из HIV (вирус иммунодефицита человека) и вирусный оболочечный белок вируса, принадлежащего к Flavirideae. В общем, указанным выделенным белком, представляющим интерес, или его фрагментом может быть любой белок, требующий особенностей N-гликозилирования по настоящему изобретению.
Под "HCV-рекомбинантным вирусом коровьей оспы" подразумевается вирус коровьей оспы, содержащий последовательность нуклеиновой кислоты, кодирующую белок HCV или его часть.
Термины "частицы, подобные вирусу HCV, образованные оболочечным белком HCV" и "олигомерные частицы, образованные оболочечными белками HCV" определены здесь как структуры специфической природы и формы, содержащие несколько основных единиц оболочечных белков Е1 и/или Е2 из HCV, которые сами по себе считаются состоящими из одного или двух мономеров Е1 и/или Е2, соответственно. Должно быть ясно, что частицы по настоящему изобретению определены как лишенные инфекционных РНКовых геномов HCV. Частицы по настоящему изобретению могут быть частицами высшего порядка сферической природы, которые могут быть пустыми, состоящими из остова из оболочечных белков, в которые можно инкорпорировать липиды, детергенты, коровый белок HCV или молекулы адъюванта. Эти частицы могут быть также инкапсулированы липосомами или аполипопротеинами, таким как, например, аполипопротеин В или липопротеины низкой плотности, или любыми другими средствами нацеливания указанных частиц на конкретный орган или ткань. В этом случае такие пустые сферические частицы часто называют "вирусоподобными частицами" или VLPs (virus-like particles). Альтернативно, эти частицы высшего порядка могут быть твердыми сферическими структурами, в которых вся сфера, состоит из олигомеров оболочечных белков Е1 и Е2 из HCV, в которые можно дополнительно инкорпорировать липиды, детергенты, коровый белок HCV или молекулы адъюванта и которые в свою очередь сами могут быть инкапсулированы липосомами и/или аполипопротеинами, такими как, например, аполипопротеин В или липопротеины низкой плотности, или любыми другими средствами нацеливания указанных частиц на конкретный орган или ткань, например, асиалогликопротеинами. Эти частицы могут также состоять из более мелких структур (в сравнении с вышеуказанными пустыми или твердыми сферическими структурами), обычно круглой (см. дальше) формы, которые обычно не содержат более одного слоя оболочечных белков HCV. Типичным примером таких более мелких частиц являются розеткоподобные структуры, которые состоят из меньшего числа оболочечных белков HCV, обычно от 4 до 16. Специфический пример последних включает в себя более мелкие частицы, получаемые из белка Е1 в 0,2%-ном CHAPS как показано здесь в примере, которые, судя по всему, содержат 8-10 мономеров E1s. Такие розеткоподобные структуры обычно организованы в плоскости и имеют округлую форму, то есть, форму колеса. Опять же можно дополнительно инкорпорировать липиды, детергенты, коровый белок HCV или молекулы адъювантов, или же эти более мелкие частицы могут быть инкапсулированы липосомами или аполипопротеинами, такими как, например, аполипопротеин В или липопротеины низкой плотности, или любыми другими средствами нацеливания указанных частиц на конкретный орган или ткань. Более мелкие частицы могут также формировать мелкие сферические или глобулярные структуры, состоящие из сходного меньшего числа оболочечных белков Е1 или Е2 из HCV, в которые можно дополнительно инкорпорировать липиды, детергенты, коровый белок HCV или молекулы адъювантов, или же эти более мелкие частицы могут быть в свою очередь инкапсулированы липосомами или аполипопротеинами, такими как, например, аполипопротеин В или липопротеины низкой плотности, или любыми другими средствами нацеливания указанных частиц на конкретный орган или ткань. Размер (то есть диаметр) определенных выше частиц при измерении хорошо известной в данной области методикой динамического светорассеяния (см. дальше в. разделе Примеры) обычно составляет от 1 до 100 нм, более предпочтительно от 2 до 70 нм, даже еще более предпочтительно от 2 до 40 нм, от 3 до 20 нм, от 5 до 16 нм, от 7 до 14 нм или от 8 до 12 нм.
В частности, настоящее изобретение относится к способу очистки кор-гликозилированных оболочечных белков вируса гепатита С (HCV) или любой их части, подходящей для применения в иммуноанализе или вакцине, при котором:
(1) выращивают неспособные к гликозилированию штаммы Hansenula или Saccharomyces, трансформированные оболочечным геном, кодирующим белок HCV E1 и/или HCV E2 или любую их часть, в подходящей культуральной среде;
(2) вызывают экспрессию указанного гена, кодирующего HCV E1 и/или HCV E2 или любую их часть, и
(3) очищают указанный кор-гликозилированный белок HCV E1 и/или HCV E2 или любую их часть из указанной культуры клеток.
Это изобретение далее относится к способу очистки кор-гликозилированных оболочечных белков вируса гепатита С (HCV) или любой их части, подходящей для применения в иммуноанализе или вакцине, при котором:
(1) выращивают неспособные к гликозилированию штаммы Hansenula или Saccharomyces, трансформированные оболочечным геном, кодирующим белок HCV E1 и/или HCV E2 или любую их часть, в подходящей культуральной среде;
(2) вызывают экспрессию указанного гена, кодирующего HCV E1 и/или HCV E2 или любую их часть, и
(3) очищают указанный экспрессируемый внутриклеточно кор-гликозилированный белок HCV E1 и/или HCV E2 или любую их часть при лизировании трансформированной клетки-хозяина.
Это изобретение далее относится к способу очистки кор-гликозилированных оболочечных белков вируса гепатита С (HCV) или любой их части, подходящих для применения в иммуноанализе или вакцине, при котором:
(1) выращивают неспособные к гликозилированию штаммы Hansenula или Saccharomyces, трансформированные оболочечным геном, кодирующим белок HCV E1 и/или HCV E2 или любую их часть, в подходящей культуральной среде, причем указанный белок HCV E1 и/или HCV E2 или любая их часть содержит по меньшей мере две Cys-аминокислоты;
(2) вызывают экспрессию указанного гена, кодирующего HCV E1 и/или HCV E2 или любую их часть, и
(3) очищают указанный кор-гликозилированный белок HCV E1 и/или HCV E2 или любую их часть, в которых указанные Cys-аминокислоты обратимо защищены химическими и/или ферментативными средствами, из указанной культуры.
Это изобретение далее относится к способу очистки кор-гликозилированных оболочечных белков вируса гепатита С (HCV) или любой их части, подходящей для применения в иммуноанализе или вакцине, при котором:
(1) выращивают неспособные к гликозилированию штаммы Hansenuta или Saccharomyces, трансформированные оболочечным геном, кодирующим белок HCV E1 и/или HCV E2 или любую их часть, в подходящей культуральной среде, причем указанный белок HCV E1 и/или HCV Е2 или любая их часть содержит по меньшей мере две Cys-аминокислоты;
(2) вызывают экспрессию указанного гена, кодирующего HCV E1 и/или HCV E2 или любую их часть, и
(3) очищают указанный экспрессируемый внутриклеточно кор-гликозилированный белок HCV E1 и/или HCV E2 или любую их часть при лизировании трансфомированной клетки-хозяина, причем указанные Cys-аминокислоты обратимо защищены химическими и/или ферментативными средствами.
Настоящее изобретение специфически относится к способу очистки рекомбинантных кор-гликозилированных дрожжевых белков HCV или любой их части, как описано здесь, при котором указанная очистка включает в себя аффинную хроматографию с гепарином.
Следовательно, настоящее изобретение относится к способу очистки рекомбинантных кор-гликозилированных дрожжевых белков HCV или любой их части, как описано здесь, при котором указанным химическим средством является сульфонирование.
Следовательно, настоящее изобретение также относится к способу очистки рекомбинантных кор-гликозилированных дрожжевых белков HCV или любой их части, как описано здесь, при котором указанную обратимую защиту Cys-аминокислот заменяют на необратимую защиту химическими и/или ферментативными средствами.
Следовательно, настоящее изобретение также относится к способу очистки рекомбинантных кор-гликозилированных дрожжевых белков HCV или любой их части, как описано здесь, при котором указанная защита химическим средством представляет собой йодацетамид.
Следовательно, настоящее изобретение относится также к способу очистки рекомбинантных кор-гликозилированных дрожжевых белков HCV или любой их части, как описано здесь, при котором указанная необратимая защита химическими средствами представляет собой NEM или биотин-NEM или их смесь.
Настоящее изобретение относится также к композиции, как определено выше, которая также содержит HCV кор, Е1, Е2, Р7, NS2, NS3, NS4A, NS4B, NS5A и/или NS5B белок или их части. Кор-гликозилированные белки Е1, Е2 и/или Е1/Е2 по настоящему изобретению можно, например, комбинировать с другими антигенами HCV, такими как, например, кор, Р7, NS3, NS4A, NS4B, NS5A и/или NS5B. Очистка этих белков NS3 должна предпочтительно включать в себя обратимую модификацию цистеиновых остатков и даже более предпочтительно сульфонирование цистеинов. Способы осуществления такой обратимой модификации, включая сульфонирование, были описаны для белков NS3 в Maertens et al. (PCT/EP99/02547). Следует подчеркнуть, что все содержание последнего документа, включающее в себя все определения, включено в настоящую заявку ссылкой.
Также настоящее изобретение относится к применению описанного здесь кор-гликозилированного оболочечного белка для индуции иммунитета против вируса HCV, отличающемуся тем, что указанный кор-гликозилированный оболочечный белок применяют как часть серии времени и соединений. В этом отношении следует понимать, что термин "серия времени и соединений" относится к введению индивиду соединений, которые применяют для элисирования иммунного ответа, через определенные интервалы времени. Эти соединения могут включать в себя любой из следующих компонентов: кор-гликозилированный оболочечный белок, HCV ДНК вакцинную композицию, полипептиды HCV. В этом смысле серия включает в себя любое введение из числа следующих:
(1) антиген HCV, такой как, например, кор-гликозилированный оболочечный белок, через определенные интервалы времени;
(2) антиген HCV, такой как, например, кор-гликозилированный оболочечный белок, в комбинации с HCV ДНК вакцинной композицией, причем указанные олигомерные частицы кор-гликозилированного оболочечного белка и указанную HCV ДНК вакцинную композицию можно водить одновременно или через разные интервалы времени, в том числе переменные интервалы времени; или
(3) (1) или (2), возможно в комбинации с другими HCV пептидами, через определенные интервалы времени.
В этом отношении должно быть ясно, что HCV ДНК вакцинная композиция содержит нуклеиновые кислоты, кодирующие оболочечный пептид HCV, включая пептиды Е1, Е2, Е1/Е2, пептид NS3, другие пептиды HCV или части указанных пептидов. Более того, надо понимать, что указанные пептиды HCV включают в себя оболочечные пептиды HCV, в том числе пептиды Е1, Е2, Е1/Е2, другие пептиды HCV или их части. Термин "другие пептиды HCV" относится к любому пептиду HCV или его фрагменту. В пункте (1) вышеприведенной схемы HCV ДНК вакцинная композиция содержит предпочтительно нуклеиновые кислоты, кодирующие оболочечные пептиды HCV. В пункте (2) вышеприведенной схемы HCV ДНК вакцинная композиция состоит еще более предпочтительно из нуклеиновых кислот, кодирующих оболочечные пептиды HCV, возможно в комбинации с HCV NS3 ДНК вакцинной композицией. В этом отношении должно быть ясно, что HCV ДНК вакцинная композиция содержит плазмидный вектор, содержащий полинуклеотидную последовательность, кодирующую пептид HCV, как описано выше, функциональным образом соединенную с элементами регуляции транскрипции. При использовании здесь "плазмидный вектор" относится к молекуле нуклеиновой кислоты, способной транспортировать другую нуклеиновую кислоту, с которой она соединена. Предпочтительными векторами являются те, которые способны к автономной репликации и/или экспрессии нуклеиновых кислот, с которыми они соединены. В целом плазмидные векторы представляют собой кольцевые двунитевые ДНК-вые петли, которые в их векторной форме не связаны с хромосомой, но не ограничиваются этим. При использовании здесь "полинукпеотидная последовательность" относится к полинуклеотидам, таким как дезоксирибонуклеиновая кислота (ДНК) и, если уместно, рибонуклеиновая кислота (РНК). Этот термин следует понимать как включающий в себя в качестве эквивалентов аналоги РНК или ДНК, полученные из аналогов нуклеотидов, и одно-(смысловые и антисмысловые) и двунитевые полинуклеотиды. При использовании здесь термин "элемент регуляции транскрипции" относится к нуклеотидной последовательности, которая содержит необходимые регуляторные элементы так, что при введении в живую клетку позвоночного способны направлять клеточные механизмы на продуцирование продуктов трансляции, кодируемых этим полинуклеотидом. Термин "функциональным образом" относится к непосредственному соединению, где все компоненты сконфигурированы так, чтобы выполнять их обычную функцию. Таким образом, элементы регуляции транскрипции, функциональным образом присоединенные к нукпеотидной последовательности, способны запускать экспрессию указанной нуклеотидной последовательности.
Специалисты могут понять, что с успехом можно применять разные транскрипционные промоторы, терминаторы, векторы-носители или специфические генные последовательности.
Альтернативно ДНК вакцину можно доставлять с помощью живого вектора, такого как аденовирус, поксвирус канареек, MVA и тому подобное.
Настоящее изобретение проиллюстрировано Примерами, изложенными ниже. Эти примеры являются всего лишь иллюстративными, и нельзя считать, что они как-либо ограничивают или лимитируют это изобретение.
ПРИМЕРЫ
ПРИМЕР 1
КОНСТРУИРОВАНИЕ ЧЕЛНОЧНОГО ВЕКТОРА pFPMT-MFα-E1-Н6
Конструировали плазмиды для трансформации Hasenula polymorpha следующим образом. Челночный вектор pFPMT-MFα-E1-H6 конструировали в многостадийной процедуре. Исходно клонировали последовательность нуклеиновой кислоты, кодирующую белок HCV E1s (SEQ ID NO:2) вслед за лидерной последовательностью СНН (СНН=гипергликемический гормон из Carcinus maenas), которую затем заменяли на лидерную последовательность MFα (MFα=α-фактор спаривания Saccharomyces cerevisiae).
Сначала методом «бесшовного» клонирования (Pargett, K.A. and Sorge, J.A. 1996) конструировали производное плазмиды pUC18, несущее блок СНН-Е1-Н6 в виде EcoR1/BamH1-фрагмента. Для этого посредством ПЦР как описано ниже получали фрагмент ДНК, кодирующий E1s-H6, и акцепторную плазмиду, производную от плазмиды pCHH-Hir.
Получение фрагмента ДНК, кодирующего E1s-H6
Фрагмент ДНК, кодирующий Е1-Н6 (кодирующий белок E1s из HCV типа 1b, состоящий из аминокислот 192-326 из E1s и удлиненный шестью His-остатками; SEQ ID NO:5) выделяли способом ПЦР из плазмиды pGEMTE1sH6 (SEQ ID NO:6, Фиг.1). Для этого использовали следующие праймеры:
-CHHE1-F:
(SEQ ID NO:7);
Eam1104I сайт подчеркнут, точка означает сайт расщепления. Основания, напечатанные жирным шрифтом, комплементарны основаниям праймера CHH-links. Неотмеченные основания гибридизуются в пределах стартового участка Е1 (192-326) в смысловом направлении; и
- CHHE1-R:
(SEQ ID NO:8);
Eam1104I сайт подчеркнут, точка означает сайт расщепления. Основания, напечатанные жирным шрифтом, комплементарны основаниям праймера MF30-rechts. Основания, образующие BаmН1 сайт, полезный для последующей процедуры клонирования, выделены курсивом. Неотмеченные основания гибридизуются в антисмысловом направлении в пределах конца блока Е1-Н6, который включат в себя стоп-кодон и три дополнительных основания между стоп-кодоном и SamH1 сайтом.
Реакционную смесь составляли следующим образом: общий объем 50 мкл, содержащий 20 нг Eco31I-линеаризованной pGEMTE1sH6, по 0,2 мкМ каждого из праймеров CHHE1-F и CHHE1-R, по 0,2 мкМ каждого из dNTP's, однократный буфер 2 (Expand Long Template PCR System, Boehringer, Cat No 1681 834), 2,5 ед. полимеразной смеси (Expand Long Template PCR System, Boehringer, Cat No 1681 834).
Использовали программу 1, причем указанная программа состоит из следующих этапов:
1. денатурация: 5 мин при 95°С;
2. 10 циклов по 30 сек денатурации при 95°С, 30 сек отжига при 65°С и 130 сек элонгации при 68°С;
3. терминация при 4°С.
Затем к образцу, полученному в программе 1, добавляли 5 мл 10× буфера 2 (Expand Long Template PCR System, Boehringer, Cat No 1681 834), 40 мкл H2O и 5 мкл [dATP, dGTP и dTTP (по 2 мМ каждого); 10 мМ 5-метил-dCTP] и проводили дальнейшую амплификацию по программе 2, состоящей из следующих этапов:
1. денатурация: 5 мин при 95°С;
2. 5 циклов по 45 сек денатурации при 95°С, 30 сек отжига при 65°С и 130 сек при 68°С;
3. терминация при 4°С.
Получение акцепторной плазмиды, производной от pCHH-Hir
Акцепторный фрагмент был получен посредством ПЦР из плазмиды pCHH-Hir (SEQ ID NO:9; Фиг.2) и состоял почти полностью из плазмиды pCHH-Hir за исключением того, что в этом продукте ПЦР не присутствует последовательность, кодирующая Hir. Для этой ПЦР использовали следующие праймеры:
1. CHH-links:
(SEQ ID NO:10)
Eam1104I сайт подчеркнут, точка обозначает сайт расщепления. Основания, напечатанные жирным шрифтом, комплементарны основаниям праймера CHHE1-F. Неотмеченные основания гибридизуются в пределах конца последовательности СНН в антисмысловом направлении; и
2. MF30-rechts:
(SEQ ID NO:11)
Eam1104I сайт подчеркнут, точка обозначает сайт расщепления. Основания, напечатанные жирным шрифтом, комплементарны основаниям праймера CHHE1-R. Неотмеченные основания гибридизуются в пределах последовательностей pUC18 за клонированной CHH-Hirudin HL20 плазмиды pCHH-Hir в направлении от вставки.
Реакционную смесь составляли следующим образом: общий объем 50 мкл, содержащий 20 нг Asр718I-линеаризованной pCHH-Hir, по 0,2 мкМ каждого из праймеров, CHH-links и MF30-rechts, по 0,2 мкМ каждого из dNTP's, 1× буфер 2 (Expand Long Template PCR System, Boehringer, Cat No 1681 834), 2,5 ед. полимеразной смеси (Expand Long Template PCR System, Boehringer, Cat No 1681 834).
Использовали программу 1, как описано выше.
Затем к образцу, полученному в программе 1, добавляли 5 мкл 10× буфера 2 (Expand Long Template PCR System, Boehringer, Cat No 1681 834), 40 мкл Н2O и 5 мкл [dATP, dGTP и dTTP (no 2 мМ каждого); 10 мМ 5-метил-dCTP] и проводили дальнейшую амплификацию по программе 2, как описано выше.
Получение вектора рСННЕ1
Фрагмент ДНК, кодирующий E1s-H6, и акцепторную плазмиду, полученную из pCHH-Hir способом ПЦР как описано выше, очищали с использованием набора для очистки продуктов ПЦР (Qiagen) в соответствии со спецификациями поставщика. Затем расщепляли очищенные фрагменты по отдельности рестриктазой Еаm1104I. Затем фрагмент ДНК E1s-H6 лигировали в акцепторную плазмиду, полученную из pCHH-Hir, используя лигазу Т4 (Boehringer) в соответствии со спецификациями поставщика.
Смесью, полученной после лигирования, трансформировали клетки Е.coli XL-Gold и анализировали плазмидную ДНК нескольких устойчивых к ампициллину колоний путем обработки рестриктазами EcoR1 и BamH1. Выбирали позитивный клон и обозначали его как рСННЕ1.
Получение вектора pFPMT-CHH-E1H6
EcoR1/BamH1-фрагмент из рСННЕ1 лигировали с вектором pFPMT121 (SEQ ID NO:12; Фиг.3), обработанным рестриктазами EcoR1 и BamH1. Использовали лигазу Т4 (Boehringer) в соответствии с инструкциями поставщика. Смесь, полученную после лигирования, использовали для трансформации клеток Е.coli DH5αF'. Анализировали несколько трансформантов по рестрикционному паттерну плазмидной ДНК и оставляли позитивный клон, который обозначали как pFPMT-CHH-E1H6 (SEQ ID NO:13; Фиг.4).
Получение pFPMT-MFα-E1-H6
Наконец, получали челночный вектор pFPMT-MFα-E1-H6 лигированием трех фрагментов, представлявших собой:
1. 6,961 т.н. фрагмент pFPMT121, обработанный EcoR1/BamH1 (SEQ ID NO:12; Фиг.3),
2. 0,245 т.н. EcoR1/HindIII-фрагмент pUC18-MFa (SEQ ID NO:62; Фиг.36) и
3. 0,442 т.н. HindIII/BamH1-фрагмент 0,454 т.н. продукта ПЦР, полученный из pFPMT-CHH-E1H6.
0,454 т.н. продукт ПЦР, дающий фрагмент №3, получали посредством ПЦР, используя следующие праймеры:
1. праймер MFα-E1 f-Hi:
5'-aggggtaagcttggataaaaggtatgaggtgcgcaacgtgtccgggatgt-3'
(SEQ ID NO:14)
2. праймер Е1 back-Bam:
5'-agttacggatccttaatggtgatggtggtggtgccagttcat-3'
(SEQ ID NO:15).
Реакционную смесь составляли следующим образом: объем реакционной смеси 50 мкл, pFPMT-CHH-E1-H6 (EcoR1-линеаризованная; 15 нг/мкл), 0,5 мкл; праймер MFa-E1 f-Hi (50 мкМ), 0,25 мкл; праймер Е1 back-Barn (50 мкМ), 0,25 мкл; dNTP's (все по 2 мМ), 5 мкл; ДМСО (диметилсульфоксид), 5 мкл; Н2O, 33,5 мкл; Буфер 2 (сконцентрированный 10×) набора Expand Long Template PCR System (Boehringer Mannheim; Cat. No 1681 834), 5 мкл; полимеразная смесь Expand Long Template PCR System (1 ед./мкл), 0,5 мкл.
Применяли программу ПЦР, состоящую из следующих этапов:
1. денатурация: 5 мин при 95°С,
2. 29 циклов по 45 сек денатурации при 95°С, 45 сек отжига при 55°С и 40 сек элонгации при 68°С,
3. терминация при 4°С,
На основании использованных праймеров, полученный 0,454 т.н. продукт ПЦР, содержал кодоны Е1 (192-326), за которыми следовали шесть кодонов гистидина и стоп-кодон "taa", фланкированные «вверх по течению» 22 3'-терминальными парами оснований пре-про-последовательности MFα (включая существенный для клонирования HindIII сайт плюс избыточные шесть пар оснований) и фланкированные «вниз по течению» (существенный для клонирования) BamHI сайтом и избыточными шестью парами оснований.
Для реакции лигирования применяли ДНК-лигазу Т4 (Boehringer Mannheim) в соответствии с условиями поставщика (объем образца 20 мкл).
Смесью, полученной после лигирования, трансформировали клетки Е.coli HB101 и оставляли позитивные клоны после рестрикционного анализа плазмид, выделенных из нескольких трансформантов. Отбирали позитивную плазмиду и обозначали как pFPMT-MFα-E1-E6 (SEQ ID NO:16; Фиг.5).
ПРИМЕР 2
КОНСТРУИРОВАНИЕ ЧЕЛНОЧНОГО ВЕКТОРА pFPMT-CL-E1-H6
Плазмиды для трансформации Hansesula polymorpha конструировали следующим образом. Челночный вектор pFPMT-CL-E1-H6 конструировали в три этапа, начиная с pFPMT-MFα-E1-H6 (SEQ ID NO:16; Фиг.5).
На первом этапе рамку считывания MFα-E1-H6 плазмиды pFPMT-MFα-E1-Н6 субклонировали в вектор pUC18. Для этого 1,798 т.н. Sa/I/BamH1 фрагмент плазмиды pFPMT-MFα-E1-H6 (содержащий промотор FMD плюс MFα-E1-H6) лигировали с Sa/I/BamH1 векторным фрагментом плазмиды pUC18 с помощью лигазы Т4 (Boehringer) в соответствии со спецификациями поставщика. Результатом этого была плазмида, которая изображена на Фиг.6 (SEQ ID NO:17) и далее обозначена как рМа12-1 (pUC18-FMD-MFα-E1-H6). Смесь, полученную при лигировании, использовали для трансформации клеток Е.coli DH5αF'. Отбирали несколько устойчивых к ампициллину колоний и анализировали расщеплением плазмидной ДНК, выделенной из отобранных клонов, ферментами рестрикции. Позитивный клон анализировали далее определением последовательности ДНК в последовательности, кодирующей MFα-E1-H6. Корректный клон использовали для ПЦР направленного мутагенеза для замены пре-про-последовательности MFα кодонами пре-последовательности птичьего лизоцима ("CL", что соответствует аминокислотам 1-18 птичьего лизоцима; SEQ ID NO:1). Принцип примененного ПЦР-направленного мутагенеза основан на амплификации всей плазмиды с желательными изменениями, локализованными на 5'-концах праймеров. На последующих этапах модифицируют концы линейного ПЦР продукта перед самолигированием, приводящим к желаемой измененной плазмиде.
Для реакции ПЦР использовали следующие праймеры:
1. праймер CL hin:
(SEQ ID NO:18);
2. праймер CL her neu:
(SEQ ID NO:19).
Подчеркнутые 5'-участки праймеров содержат кодоны, соответствующие приблизительно половине пре-последовательности птичьего лизоцима. Праймер CL her neu включает в себя рестрикционный сайт для SpeI (курсив). Неподчеркнутые участки праймеров гибридизуются с кодонами для аминокислотных остатков 192-199 из Е1 (CL hin) или со стартовым кодоном "atg" над EcoR1 сайтом вплоть до положения -19 (считая от EcoR1 сайта) промотора FMD. Эти праймеры предназначены для амплификации полной рМа12-1, посредством чего заменяют кодоны пре-про-последовательности MFα кодонами пре-последовательности птичьего лизоцима.
Реакционную смесь составляли следующим образом: pUC18-FMD-Mfα-Е1-Н6 (рМа12-1; 1,3 нг/мкл), 1 мкл; праймер CL hin (100 мкМ), 2 мкл; праймер CL her neu (100 мкМ), 2 мкл; dNTP's (все по 2,5 мМ), 8 мкл; H2O, 76 мкл; буфер 2 (сконцентрированный 10×) Expand Long Template PCR System (Boehringer; Cat. No 1681834), 10 мкл; полимеразная смесь Expand Long Template PCR System (1 ед./мкл), 0,75 мкл.
Применяли программу ПЦР, состоящую из следующих этапов:
1. денатурация: 15 мин при 95°С
2. 35 циклов по 30 сек денатурации при 95°С, 1 мин отжига при 60°С и 1 мин элонгации при 72°С
3. терминация при 4°С.
Полученный ПЦР продукт проверяли на правильность размера электрофорезом в агарозном геле (3,5 тысяч нуклеотидов (т.н.)). После этого из продукта ПЦР удаляли 3'-А избыточности Т4-полимеразной реакцией, приводящей к тупым концам с 3'- и 5'-ОН-группами. Для этого ПЦР продукт обрабатывали полимеразой Т4 (Boehringer; 1 ед./мкл): к оставшимся 95 мкл реакционной смеси ПЦР добавляли 1 мкл полимеразы Т4 и 4 мкл dNTP's (все по 2,5 мМ). Образец инкубировали в течение 20 мин при 37°С. Затем ДНК осаждали этанолом и собирали в 16 мкл Н2O.
Затем киназной реакцией к ПЦР продукту с тупыми концами добавляли 5'-фосфаты. Для этого к 16 мкл ПЦР продукта с тупыми концами добавляли 1 мкл полинуклеотидкиназы Т4 (Boehringer, 1 ед./мкл), 2 мкл концентрированного в 10 раз буфера для Т4-полинукпеотидкиназной реакции (Boehringer) и 1 мкл АТР (10 мМ). Образец инкубировали в течение 30 мин при 37°С.
Затем ДНК наносили на 1%-ный агарозный гель и выделяли полосу корректного продукта с помощью набора для гелевой экстракции (Qiagen) в соответствии с условиями поставщика. Затем пятьдесят (50) нг очищенного продукта подвергали самолигированию с применением лигазы Т4 (Boehringer) в соответствии с условиями поставщика. После 72 ч инкубации при 16°С ДНК в смеси для лигирования осаждали этанолом и растворяли в 20 мкл воды.
Затем трансформировали клетки Е.coli DH5α-F' десятью микролитрами образца после лигирования. Плазмидную ДНК нескольких клонов, устойчивых к ампициллину, проверяли путем расщепления ферментами рестрикции. Отбирали позитивный клон и обозначали его как p27d-3 (pUC18-FMD-CL-E1-H6, SEQ ID NO:20, Фиг.7). Затем проверяли рамку считывания CL-E1-H6 секвенированием ДНК.
На последнем этапе конструировали челночный вектор pFPMT-CL-E1-H6 как описано ниже. 0,486 т.н. EcoR1/BamH1-фрагмент плазмиды p27d-3 (содержащий CL-E1(192-326)-H6) лигировали с EcoRI/fiamHt-обработанной плазмидой pFPMT121 (SEQ ID NO:12, Фиг.3). Для этой реакции использовали лигазу Т4 (Boehringer) в соответствии с рекомендациями поставщика. ДНК в образце для лигирования осаждали этанолом и растворяли в 10 мкл Н2O. Трансформировали клетки Е.coli DH5αF' десятью микролитрами образца после лигирования и анализировали ДНК нескольких клонов, устойчивых к ампициллину, обраработкой рестриктазами EcoR1 и ВаmН1. Плазмидный клон р37-5 (pFPMT-CL-E1-H6; SEQ ID NO:21, Фиг.8) демонстрировал желаемые размеры фрагментов, а именно, 0,486 т.н. и 6,961 т.н. Корректную последовательность CL-E1-H6 из р37-5 подтверждали секвенированием.
ПРИМЕР 3
КОНСТРУИРОВАНИЕ ЧЕЛНОЧНЫХ ВЕКТОРОВ
pFPMT-MFα-E2-H6 и pMPT-MFα-E2-H6
Плазмиды для трансформации Hansenula polymorpha конструировали следующим образом. Последовательность ДНК, кодирующую MFα-E2s (аминокислоты 384-673 HCV E2)-VIEGR-His6 (SEQ ID NO:5), выделяли в виде 1,331 т.н. EcoR1/Bg/II-фрагмента из плазмиды pSP72E2H6 (SEQ ID NO:22; Фиг.9). Этот фрагмент лигировали с подвергнутыми рестрикции посредством EcoR1/Bg/II векторами pFPMT121 (SEQ ID NO:12, Фиг.С+2) или рМРТ121 (SEQ ID NO:23; Фиг.10), используя ДНК-лигазу Т4 (Boehringer Mannheim) в соответствии с рекомендациями поставщика. После трансформации Е.coli и проверки плазмидной ДНК, выделенной из разных трансформантов, путем обработки ферментами рестрикции сохраняли позитивные клоны и обозначали полученные челночные векторы как pFPMT-MFα-Н6 (SEQ ID NO:22, Фиг.11) и pMPT-MFα-E2-H6 (SEQ ID NO:23, Фиг.12), соответственно.
ПРИМЕР 4
КОНСТРУИРОВАНИЕ ЧЕЛНОЧНОГО ВЕКТОРА pFPMT-CL-E2-H6
Челночный вектор pFPMT-CL-E2-H6 собирали в трехэтапной процедуре. Готовили промежуточный конструкт, в котором последовательность, кодирующую белок Е2, клонировали вслед за сигнальной последовательностью α-амилазы из Schwanniomyces accidentalis. Это осуществляли способом «бесшовного» клонирования (Padgett, K.A. and Sorge, J.A. 1996).
Получение фрагмента ДНК, кодирующего E2s-H6
Сначала амплифицировали последовательность ДНК, кодирующую Е2-Н6 (аминокислоты 384-673 из HCV E2, удлиненные линкерным пептидом "VEIGR" и шестью остатками His, SEQ ID NO:5) из плазмиды pSP72E2H6 (SEQ ID NO:24, Фиг.11) посредством ПЦР. Использованные праймеры обозначены как MF30E2/F и MF30E2/R и имеют следующие последовательности:
- праймер MF30E2/F:
(SEQ ID NO:26);
сайт Eam1104I подчеркнут, точка обозначает сайт расщепления этим ферементом, последний кодон сигнальной последовательности из S.occidentalis напечатан жирным шрифтом, непомеченные основания гибридизуются с кодонами Е2 (аминокислоты 384-390 HCV E2);
- праймер MF30E2/R:
(SEQ ID NO:27);
сайт Eam1104I подчеркнут; точка обозначает сайт расщепления этим ферментом; основания, напечатанные жирным шрифтом, комплементарны основаниям праймера MF30-Rrechts (см. ниже), напечатанным жирным шрифтом; сайт BamHI, подлежащая введению в конструкт, напечатана курсивом; непомеченная последовательность гибридизуется со стоп-кодоном и шестью концевыми His кодонами E2 (384-673)-VIEGR-H6 (SEQ ID NO:5).
Реакционную смесь составляли следующим образом: общий объем 50 мкл, содержащий 20 нг 1,33 т.н. EcoR1/Bg/II-фрагмента из pSP72E2H6, по 2 мкМ праймеров MF30E2/F и MF30E2/R, dNTP's (каждого по 2 мкМ), 1× буфер 2 (Expand Long Template PCR System, Boehringer, Cat. No 1681834), 2,5 ед. полимеразной смеси (Expand Long Template PCR System, Boehringer, Cat. No 1681834)
Для ПЦР применяли программу 3, состоящую из следующих этапов:
1. денатурация: 5 мин при 95°С;
2. 10 циклов по 30 сек денатурации при 95°С, 30 сек отжига при 65°С и 1 мин элонгации при 68°С
3. терминация при 4°С.
Затем к образцу, произведенному в программе 3 для ПЦР, добавляли 10 мкл 10× буфера 2 (Expand Long Template PCR System, Boehringer, Cat. No 1681834), 40 мкл Н2O и 5 мкл [dATP, dGTP и dTTP (каждого по 2 мМ), 10 мМ 5-метил-dCTP], и продолжали по программе 4 для ПЦР, состоящей из следующих этапов:
1. денатурация 5 мин при 95°С
2. 5 циклов по 45 сек денатурации при 95°С, 30 сек отжига при 65°С и 1 мин элонгации при 68°С.
3. терминация при 4°С.
Получение акцепторной плазмиды, производной от pMF30
Второй фрагмент происходил из плазмиды pMF30 (SEQ ID NO:28, Фиг.13); ампликон почти полностью представлял собой плазмиду pMF30 за исключением кодонов зрелой α-амилазы из S.occidentalis; модификации, нужные для клонирования, были введены путем соответствующих праймеров. Применяли следующие наборы праймеров:
- праймер MF30-Links:
(SEQ ID NO:29; сайт Eam1104I подчеркнут; точка обозначает сайт расщепления этим ферментом; "cct", напечатанные жирным шрифтом, комплементарны напечатанным жирным шрифтом "agg" праймера MF30E2/F (см. выше); непомеченные основания и напечатанные жирным шрифтом гибридизуются с 26-ю концевыми основаниями кодонов α-амилазы из S.accidentalis в pMF30);
- праймер MF30-Rechts:
(SEQ ID NO:11; сайт Eam1104I подчеркнут; точка обозначает сайт расщепления этим ферментом; "ctg", напечатанные жирным шрифтом, комплементарны напечатанным жирным шрифтом "cag" праймера MF30E2/R (см. выше); непомеченные основания гибридизуются с последовательностями плазмиды pUC18 «вниз по течению» от стоп-кодона α-амилазы из S.occidentalis в pMF30).
Реакционную смесь составляли следующим образом: общий объем 50 мкл, содержащий 20 нг Bg/II-линеаризованной pMF30, по 0,2 мкМ каждого из праймеров MF30-Links и MF30-Rechts, dNTP's (по 0,2 мкМ каждого), 1× буфер 1 (Expand Long Template PCR System, Boehringer, Cat. No 1681834), 2,5 ед. полимеразной смеси (Expand Long Template PCR System, Boehringer, Cat. No 1681834). Применяли те же программы ПЦР (программы 3 и 4), какие были описаны выше, за исключением того, что в обеих программах периоды элонгации были продлены от 1 мин до 4 мин.
Получение вектора pAMY-E2
Фрагмент ДНК, кодирующий белок E2s-H6, и акцепторную-плазмиду, производную от pMF30, которую получали способом ПЦР, контролировали по их соответствующим размерам электрофорезом в 1%-ном агарозном геле. ПЦР продукты очищали с помощью набора для очистки ПЦР продуктов (Quigen) в соответствии с инструкциями поставщика. Затем обрабатывали очищенные фрагменты по отдельности рестриктазой Еаm11004I. Лигирование этого фрагмента E2s-H6 с акцепторной плазмидой, производной от pMF30, выполняли с использованием лигазы Т4 (Boehringer) в соответствии с рекомендациями поставщика. Смесь, полученную лигированием, применяли для трансформации клеток Е.coli DH5αF', и плазмидные ДНК нескольких клонов анализировали путем рестрикции EcoRI/BamHI. Выбирали позитивный клон, далее обозначали его плазмиду как pAMY-E2 и использовали ее для дальнейшей модификации как описано ниже.
Получение вектора pUC18-CL-E2-H6
pAMY-E2 подвергали ПЦР-направляемому мутагенезу для того, чтобы заменить кодоны сигнальной последовательности α-амилазы кодонами пре-последовательности птичьего лизоцима. Далее он обозначен как "CL" в соответствии с первыми 18-ю аминокислотами ORF (открытая рамка считывания) птичьего лизоцима (SEQ ID NO:1). Для этого мутаганеза применяли следующие праймеры:
- праймер CL2 hin:
(SEQ ID NO:30) и
- праймер CL2 her:
(SEQ ID NO:31).
Подчеркнутые 5'-участки праймеров содержат последовательности ДНК, соответствующие примерно половине пре-последовательности птичьего лизоцима. Праймер CL2 her включает в себя сайты рестрикции SpeI (курсив) и EcoRI (дважды подчеркнутый курсив). Неподчеркнутые участки праймеров гибридизуются с кодонами аминокислотных остатков 384-392 из Е2 (CL2 hin) или со стартовым кодоном "atg" около EcoRI сайта вплоть до положения -19 (при отсчете от сайта EcoRI) промотора FMD. Эти праймеры предназначены для амплификации полного вектора pAMY-E2, посредством чего происходит замена кодонов сигнальной последовательности α-амилазы кодонами пре-последовательности птичьего лизоцима.
Реакцию ПЦР проводили в соответствии со следующей программой:
1. денатурация: 15 мин при 95°С
2. 35 циклов по 30 сек денатурации при 95°С, 1 мин отжига при 60°С и 1 мин элонгации при 72°С
3. терминация при 4°С.
Использовали следующую реакционную смесь: pAMY-E2 (1 нг/мкл), 1 мкл; праймер CL2 hin (100 мкМ), 2 мкл; праймер CL2 her (100 мкМ), 2 мкл; dNTP's (no 2,5 мМ каждого), 8 мкл; H2O, 76 мкл; 10× буфер 2 набора Expand Long Template PCR System (Boehringer, Cat. No 1681834), 10 мкл, полимеразная смесь набора Expand Long Template PCR System (1 ед./мкл), 0,75 мкл.
Получившийся ПЦР продукт проверяли гель-электрофорезом в 1%-ном агарозном геле. ПЦР фрагмент перед лигированием модифицировали следующим образом. 3'-А концевые избыточности удаляли полимеразой Т4, результатом чего были тупые концы с 3'- и 5'-ОН-группами. Для этого к оставшимся 95 мкл реакционной смеси ПЦР добавляли 1 мкл полимеразы Т4 (Boehringer, 1 ед./мкл) вместе с 4 мкл dNTP's (по 2,5 мМ каждого). Образец инкубировали в течение 20 мин при 37°С. Затем ДНК осаждали этанолом и растворяли в 16 мкл деионизированной воды. За этим следовала обработка киназой для добавления 5'-фосфатов к ПЦР продукту с тупыми концами. К 16 мкл растворенного ПЦР продукта с тупыми концами добавляли 1 мкл полинуклеотидкиназы Т4 (Boehringer, 1 ед./мкл), 2 мкл концентрированного в 10 раз буфера для Т4-полинуклеотидкиназной реакции (Boehringer) и 1 мкл АТР (10 мМ). Образец инкубировали в течение 30 мин при 37°С.
Затем обработанный киназой образец разделяли в 1%-ном агарозном геле. Полосу продукта отделяли. ДНК экстрагировали из фрагмента агарозы с помощью набора для гелевой экстракции (Gel Extraction kit, Qiagen) в соответствии с рекомендациями поставщика. Затем пятьдесят (50) нг очищенного продукта подвергали самолигированию с помощью лигазы Т4 (Boehringer) в соответствии с инструкциями поставщика. После 16 часов инкубации при 16°С ДНК в смеси для лигирования осаждали этанолом и растворяли в 20 мкл H2O (образец после лигирования).
Клетки Е.coli DH5αF' трансформировали 10 мкл образца после лигирования. Далее несколько клонов, устойчивых к ампициллину, характеризовали рестрикционным анализом выделенной плазмидной ДНК. Позитивный клон обозначали как pUC18-CL-E2-H6 и использовали для дальнейших модификаций как описано ниже.
Получение челночного вектора pFPMT-CL-E2-H6
EcoRI/BamHI-фрагмент длиной 0,966 т.н. выделяли из pUC18-CL-E2-H6 (содержащей CL-E2(384-673)-VIEGR-H6) и лигировали в подвергнутую EcoRI/BamHI-рестрикциН pFPMT121 (SEQ ID NO:12, Фиг.3). Для этой реакции использовали лигазу Т (Boehringer) в соответствии с условиями поставщика. Образец лигирования осаждали этанолом и растворяли в 10 мкл воды и использовали для трансформации клеток Е.coli DH5αF'. После рестрикционного анализа отбирали позитивный клон и соответствующую плазмиду обозначали как pFPMT-CL-E2-H6 (SEQ ID NO:32, Фиг.14).
ПРИМЕР 5
КОНСТРУИРОВАНИЕ ЧЕЛНОЧНОГО ВЕКТОРА pFPMT-CL-K-H6-E1
Конструирование этого челночного вектора состояло из двух этапов.
На первом этапе посредством сайт-направленного мутагенеза создавали конструкт pUC18-FMD-CL-H6-K-E1-H6. В качестве матрицы использовали pUC18-FMD-CL-E1 (SEQ ID NO:20, Фиг.7). Применяли следующие праймеры:
- Праймер Н6К hin neu:
(SEQ ID NO:37).
- Праймер H6KRK her neu:
(SEQ ID NO:38).
(Основания, обеспечивающие дополнительные кодоны, подчеркнуты).
Реакционную смесь для ПЦР составляли следующим образом: pUC18-FMD-CL-E1-H6 (2 нг/мкл), 1 мкп; праймер Н6К hin neu (100 мкМ), 2 мкл; праймер H6KRK her neu (100 мкМ), 2 мкл; dNTP's (по 2,5 мМ каждого), 8 мкл; H2O, 76 мкл; концентрированный в 10 раз буфер 2 набора Expand Long Template PCR System (Boehringer, Cat. No 1681834), 10 мкл; полимеразная смесь набора Expand Long Template PCR System (1 ед./мкл), 0,75 мкл.
Примененная программа ПЦР состояла из следующих этапов:
- этап денатурации: 15 мин при 95°С
- 35 циклов по 30 сек денатурации при 95°С, 1 мин отжига при 60°С и 5 мин элонгации при 72°С
- терминация при 4°С.
Аликвоту образца ПЦР анализировали в 1%-ном агарозном геле для проверки ее размера, который был корректным (примерно 4,2 т.н.).
После этого у ПЦР продукта удаляли 3'-А концевые избыточности полимеразой Т4, результатом чего были тупые концы с 3'- и 5'-ОН-группами. Для этого к оставшимся 95 мкл реакционной смеси ПЦР добавляли 1 мкл полимеразы Т4 (Boeringer, 1 ед./мл) и 4 мкл dNTP's (по 2,5 мМ каждого). Образец инкубировали в течение 20 мин при 37°С. Затем ДНК в образце осаждали этанолом и растворяли в 16 мкл воды.
Затем к ПЦР продукту с тупыми концами добавляли 5'-фосфаты киназной реакцией. Для этого к 16 мкл растворенного ПЦР продукта с тупыми концами добавляли 1 мкл полинуклеотидкиназы Т4 (Boehringer, 1 ед./мкл), 2 мкл сконцентрированного в 10 раз буфера для Т4-полинуклеотидкиназной реакции (Boehringer) и 1 мкл АТР (10 мМ). Образец инкубировали в течение 30 мин при 37°С.
Затем образец наносили на 1%-ный агарозный гель и выделяли полосу соответствующего продукта с помощью набора для гелевой экстракции (Qiagen) в соответствии с условиями поставщика. Затем пятьдесят (50) нг очищенного продукта подвергали самолигированию лигазой Т4 (Boehringer) в соответствии с рекомендациями поставщика. После 72 ч инкубации при 16°С ДНК в смеси для лигирования осаждали этанолом и растворяли в 10 мкл воды.
Затем 5 мкл образца лигирования трансформировали клетки Е.coli DH5αF'. Плазмидную ДНК нескольких клонов, устойчивых к ампициллину, анализировали обработкой ферментами рестрикции, отбирали позитивный клон и обозначали соответствующую плазмиду как pUC18-FMD-CL-H6-E1-K-H6 (SEQ ID NO:39, Фиг.17).
На втором этапе конструировали вектор переноса лигированием двух фрагментов. В нижеследующем конструировании участвовали фрагменты с Bc/I-липкими концами. Поскольку Bc/I может расщеплять свой сайт только по неметилированной ДНК, применяемыми плазмидами pUC18-FMD-CL-H6-K-E1-Н6 (SEQ ID NO:39, Фиг.17) и pFPMT-CL-EI (SEQ ID NO:36, Фиг.16) трансформировали штамм Е.coli dam-. После каждой трансформации отбирали колонию, устойчивую к ампициллину, выращивали в жидкой культуре и для последующего применения получали неметилированную плазмидную ДНК. Получали 1,273 т.н. Bc/I/HindIII-фрагмент неметилированной плазмиды pUC18-FMD-CL-H6-K-E1-H6 (содержащий промотор FMD, кодоны блока CL-H6-К и начало Е1) и 6,075 т.н. Bc/I/HindIII-фрагмент плазмиды pFPMT-CL-E1 (содержащий недостающую часть рамки считывания Е1, начиная с сайта Bc/I, без С-концевой гистидиновой метки, а также элементы, локализованные в pFPMT121, за исключением промотора FMD) и лигировали вместе в течение 72 часов при 16°С с использованием лигазы Т4 (Boehringer) в общем объеме 20 мкл в соответствии со спецификациями поставщика. Затем для обессоливания смеси лигирования ее помещали на кусок нитроцеллюлозной мембраны, плавающий на стерильной деионизированной воде (инкубация в течение 30 мин при комнатной температуре). Способом электропорации трасформировали клетки Е.coli TOP10 пятью микролитрами обессоленного образца. Плазмидную ДНК нескольких полученных колоний, устойчивых к ампициллину, анализировали обработкой рестрикционными ферментами. Позитивный клон отбирали и обозначали как pFPMT-CL-H6-K-E1 (SEQ ID NO:40, Фиг.18).
ПРИМЕР 6
ТРАНСФОРМАЦИЯ HANSENULA POLYMORPHA И СЕЛЕКЦИЯ ТРАНСФОРМАНТОВ
Штамм RB11 Н.polymorpha трансформировали (протокол PEG(полиэтиленгликоль)-опосредованного захвата ДНК по существу как описано Klebe, J.R. et al. 1983 с модификацией по Roggenkamp, R. et al. 1986) разными исходными челночными векторами как описано в Примерах 1-5. Для каждой трансформации отбирали 72 колоний, прототрофных по урацилу, и использовали для получения штаммов в нижеследующей процедуре. Каждой колонией инокулировали 2 мл жидкой культуры и выращивали в опытных пробирках в течение 48 часов (37°С, 160 об/мин, угол 45°) в селективной среде (YNB/глюкоза, Difco). Этот этап определен как этап первого пассажа. Аликвоту 150 мкл культур этапа первого пассажа использовали для инокуляции 2 мл свежей среды YNB/глюкоза. Инкубировали культуры снова как описано выше (этап второго пассажа). В целом проводили восемь таких этапов пассирования. Аликвоты культур после этапов третьего и восьмого пассажа использовали для инокуляции 2 мл неселективной среды YPD (Difco). После 48 часов инкубации при 37°С(160 об/мин, угол 45°, так называемый первый этап стабилизации) аликвоты по 150 мкл этих YPD-культур использовали для инокуляции свежих 2 мл YPD-культур, которые инкубировали как описано выше (второй этап стабилизации). Аликвоты культур второго этапа стабилизации высевали штрихом на чашки, содержащие селективный YNB/агар. Инкубировали эти чашки в течение четырех дней, пока не становились видимыми макроскопические колонии. Хорошо определяемую отдельную колонию каждой сепарации определяли как штамм и использовали для дальнейшего анализа экспрессии.
Анализ экспрессии проводили в культурах в малых качалочных колбах. Из вышеупомянутой чашки с YNB/агаром отбирали колонию и инокулировали в 2 мл YPD и инкубировали в течение 48 часов как упомянуто выше. Эту аликвоту объемом 2 мл использовали как посевную культуру для культуры в качалочной колбе на 20 мл. В качестве среды использовали YP-глицерин (1%), а качалочную колбу инкубировали на роторном шейкере (200 об/мин, 37°С). После 48 часов роста в культуру добавляли 1% МеОН для индукции экспрессионной кассеты. Через разные интервалы времени собирали осадок клеток из аликвот по 1 мл и хранили при -20°С до дальнейшего анализа. Экспрессию специфических белков анализировали с помощью комбинации электрофореза в Na-ДДС ПААГ и вестерн-блоттинга. Для этого солюбилизировали осадки клеток в буфере для образцов (Трис-HCl-Ма-ДДС) и инкубировали более 15 минут при 95°С. Разделяли белки в 15%-ном полиакриламидном геле и проводили блоттинг (влажный блот, бикарбонатный буфер) на нитроцеллюлозных мембранах. Проявляли блоты с использованием специфических мышиных анти-Е1 (IGH 201) или мышиных анти-Е2 (IGH 216, описаны Maertens et al. в WO 96/04385) в качестве первых антител, а в качестве второго антитела использовали кроличий антимышиный АР. Окрашивание проводили посредством NBT-BCIP. Для дальнейшего анализа отбирали позитивные штаммы.
Пять из этих позитивных клонов использовали для эксперимента по экспрессии в качалочной колбе. Из чашки с YNB отбирали колонию соответствующего штамма и использовали ее для инокуляции 2 мл YPD. Инкубировали эти культуры как описано выше. Эту клеточную суспензию использовали для инокуляции второй посевной культуры в 100 мл среды YPD в качалочной колбе на 500 мл. Эту качалочную колбу инкубировали на роторном шейкере в течение 48 часов при 37°С и 200 об/мин. Аликвоту этой посевной культуры объемом 25 мл использовали для инокуляции 250 миллилитров среды YP-глицерин (1%) и инкубировали в качалочной колбе с отбойными перегородками на 2 л в вышеописанных условиях. Через 48 часов после инокуляции добавляли 1% МеОН (индукция промотора) и качалочные колбы инкубировали дальше в вышеописанных условиях. Через 24 часа после индукции останавливали эксперимент и собирали осадки клеток центрифугированием. Уровень экспрессии пяти разных клонов анализировали комбинацией Na-ДДС-ПААГ-электрофореза и вестерн-блоттинга (условия как и выше). На гель наносили титрационную серию каждого клона и отбирали самый продуктивный штамм для дальнейших испытаний ферментацией и очисткой.
Неожиданно оказалось, что Н.polymorpha, представляющая собой дрожжевой штамм, близкородственный Pichia pastoris (Gellissen, G. 2000), способна экспрессировать белки HCV по существу без гипергликозилирования и, таким образом, с группировками сахаров, которые сравнимы по размеру с оболочечными белками HCV, экспрессируемыми клетками млекопитающего, которые инфицированы HCV-рекомбинантным вирусом коровьей оспы.
Штамм RB11 Hansenula polymorpha был депонирован 19 апреля 2002 года в соответствии с условиями Будапештского договора в Mycotheque de I'UCL (MUCL), Universite Catholique de Louvain, Laboratoire de mycologie, Place Croix du Sud 3 bte 6, B-1348 Louvain-la-Neuve, Belgium) и имеет MUCL депозитарный номер MUCL43805.
ПРИМЕР 7
КОНСТРУИРОВАНИЕ ВЕКТОРА pSY1aMFE1sH6a
Экспрессионную плазмиду для S.cerevisiae конструировали следующим образом. Последовательность, кодирующую Е1, выделяли как Ns/1/Eco52I-фрагмент из pGEMT-E1sH6 (SEQ ID NO:6, Фиг.1), у которой делали тупые концы (с помощью ДНК-полимеразы Т4), и клонировали в вектор pYIG5 (SEQ ID NO:41, Фиг.19) с использованием ДНК-лигазы Т4 (Boehringer) в соответствии со спецификациями поставщика. Кпонирование было таким, что фрагмент, кодирующий E1s-H6, был присоединен прямым образом и в рамке с последовательностью, кодирующей αMF. Смесью лигирования трансформировали клетки Е.coli DH5αF'. Затем анализировали плазмидную ДНК нескольких клонов, устойчивых к ампициллину, рестрикционным расщеплением, отбирали позитивный клон и обозначали его как pYIG5E1H6 (ICCG3470; SEQ ID NO:42, Фиг.20).
Экспрессионную кассету (содержащую αMF-последовательность и E1s-кодирующий участок с гистидиновой меткой) переносили в виде BamHI-фрагмента(2790 п.н.) плазмиды pYIG6E1H6 в челночный вектор pSY1 для E.coli/S.cerevisiae (SEQ ID NO:21, Фиг.43), расщепленный рестриктазой BamHI. Лигирование осуществляли ДНК-лигазой Т4 (Boehringer) в соответствии с условиями поставщика. Трансфомировали смесью лигирования клетки Е.coli DH5αF' и анализировали плазмидную ДНК нескольких колоний, устойчивых к ампициллину, расщеплением рестрикционными ферментами. Позитивный клон отбирали и обозначали как pSY1aMFE1sH6a (ICCG3479; SEQ ID NO:44, Фиг.22).
ПРИМЕР 8
КОНСТРУИРОВАНИЕ ВЕКТОРА pSYYIGSE2H6
Экспрессионную плазмиду pSYYIGSE2H6 для S.cerevisiae конструировали следующим образом. Последовательность, кодирующую Е2, выделяли как Sa/I/KpnI-фрагмент из плазмиды pBSK-E2sH6 (SEQ ID NO:45, Фиг.23) с тупыми концами (с помощью ДНК-полимеразы Е4) и затем клонировали в вектор pYIG5 (SEQ ID NO:41, Фиг.19) с использованием ДНК-лигазы Т4 (Boehringer) в соответствии со спецификациями поставщика. Клонирование было таким, что фрагмент, кодирующий Е2-Н6, был присоединен прямым образом и в рамке последовательности, кодирующей αMF. Трансформировали смесью лигирования клетки Е.coli DH5αF', анализировали плазмидную ДНК нескольких клонов, устойчивых к ампициллину, рестрикционным расщеплением, отбирали позитивный клон и обозначали его как pYIG5HCCL-22аН6 (ICCG2424; SEQ ID NO:46, Фиг.24).
Экспрессионную кассету (содержащую αMF-последовательность и Е2(384-673)-кодирующий участок с гистидиновой меткой) переносили в виде BamHI-фрагмента (3281 п.н.) плазмиды pYIG5HCCL-22aH6 в челночный вектор pSY1 для Е.coli/S.cerevisiae (SEQ ID NO:43, Фиг.21), раскрытый рестриктазой ВаmН1. Лигирование осуществляли ДНК-лигазой Т4 (Boehringer) в соответствии с условиями поставщика. Трансформировали смесью лигирования клетки Е.coli DH5αF' и анализировали плазмидную ДНК нескольких колоний, устойчивых к ампициллину, расщеплением рестрикционными ферментами. Позитивный по рестрикции клон отбирали и обозначали как pSYYIGSE2H6 (ICCG2466; SEQ ID NO:47, Фиг.25).
ПРИМЕР 9
КОНСТРУИРОВАНИЕ ВЕКТОРА pSY1YIG7E1s
Экспрессионную плазмиду pSY1YIG7E1s для S.cerevisiae конструировали следующим образом. Последовательность, кодирующую Е1, выделяли как NS/1/Есо52I-фрагмент из плазмиды pGEMT-E1s (SEQ ID NO:6, Фиг.1) с тупыми концами и клонировали в вектор pYIG7 (SEQ ID NO:48, Фиг.26) с использованием ДНК-лигазы Т4 (Boehringer) в соответствии со спецификациями поставщика. Кпонирование было таким, что фрагмент, кодирующий Е1, был присоединен прямым образом и в рамке с последовательностью, кодирующей αMF. Трансформировали смесью лигирования клетки Е.coli DH5αF', анализировали плазмидную ДНК нескольких клонов, устойчивых к ампициллину, рестрикционным расщеплением, отбирали позитивный клон и обозначали его как pYIG7E1 (SEQ ID NO:49, Фиг.27).
Экспрессионную кассету (содержащую лидерную последовательность CL и Е1(192-326)-кодирующий участок) переносили в виде BamHI-фрагмента (2790 п.н.) плазмиды pYIG7E1 в BamHI-расщепленный челночный вектор pSY1 для Е.coli/S.cerevisiae (SEQ ID NO:43, Фиг.21). Лигирование осуществляли ДНК-лигазой Т4 (Boehringer) в соответствии с условиями поставщика. Трансформировали смесью лигирования клетки Е.coli DH5αF' и анализировали плазмидную ДНК нескольких колоний, устойчивых к ампициллину, расщеплением рестрикционными ферментами. Позитивный клон отбирали и обозначали как pSY1YIG7E1s (SEQ ID NO:50, Фиг.28).
ПРИМЕР 10
ТРАНСФОРМАЦИЯ SACCHAROMYCES CEREVISIAE И СЕЛЕКЦИЯ ТРАНСФОРМАНТОВ
Для преодоления проблем гипергликозилирования, о которых часто сообщают в случае белков, сверхэкспрессируемых в Saccharomyces cerevisiae, осуществили скрининг мутантов. Этот скрининг был основан на методе Баллу (Ballou, L. et al. 1991), и с его помощью были отобраны спонтанные рецессивные мутанты, устойчивые к ортованадату. Исходную селекцию штаммов выполняли на основании типа гликозилирования инвертазы, наблюдаемого после нативного гель-электрофореза. Штамм со сниженной способностью к гликозилированию отобрали для последующих экспериментов по экспрессии рекомбинантных белков и обозначили как штамм IYCC155. Природу мутации далее не исследовали.
Указанный дефектный по гликозилированию штамм IYCC155 трансформировали плазмидами как описано в Примерах 7-9 по существу литий-ацетатным способом, как описано Elble, R. 1992. Несколько Ura-дополненных штаммов отобрали с селективной чашки YNB+2%-ный агар (Difco) и использовали для инокуляции 2 мл среды YNB+2% глюкозы. Инкубировали эти культуры в течение 72 часов при 37°С и 200 об/мин на орбитальном шейкере и анализирвали супернатант культур и внутриклеточные фракции на экспрессию Е1 вестерн-блоттингом с проявкой E1-специфичным мышиным моноклональным антителом (IGH 201). Высокопродуцирующий клон был отобран для дальнейших экспериментов.
В использованном здесь дефектном по гликозилированию мутанте S.cerevisiae экспрессии белков препятствуют субоптимальные характеристики роста таких штаммов, что ведет к более низкому выходу биомассы и, таким образом, более низкому выходу желаемых белков в сравнении со штаммами S.cerevisiae дикого типа. Выход желаемых белков был все равно значительно выше, чем в клетках млекопитающего.
ПРИМЕР 11
КОНСТРУИРОВАНИЕ ВЕКТОРОВ pPICZalphaD'E1sH6 и pPICZalphaE'E1sH6
Челночный вектор pPICZalphaE'E1sH6 конструировали, начиная с вектора pPICZalphaA (Invitrogen; SEQ ID NO:51, Фиг.29). На первом этапе указанный вектор адаптировали, чтобы сделать возможным клонирование E1-кодирующей последовательности непосредственно за сайтом расщепления протеазами процессинга КЕХ2 или STE13, соответственно. Для этого расщепляли pPICZalphaA рестриктазами Xhol и Notl. Продукт расщепления разделяли на 1%-ном агарозном геле и фрагмент длиной 3519 т.н. (основная часть вектора) выделяли и очищали с помощью набора для гелевой экстракции (Qiagen). Затем этот фрагмент лигировали с использованием полимеразы Т4 (Boeringer) в соответствии с условиями поставщика в присутствии специфических олигонуклеотидов с получением pPICZalphaD' (SEQ ID NO:52, Фиг.30) или pPICZalphaE' (SEQ ID NO:53, Фиг.31).
Использовали следующие олигонуклеотиды:
- для конструирования pPICZalphaD':
8822: 5'-TCGAGAAAAGGGGCCCGAATTCGCATGC-3' (SEQ ID NO:54) и
8823: 5'-GGCCGCATGCGAATTCGGGCCCCTTTTC-3' (SEQ ID NO:55),
которые дают после гибридизации линкерный олигонуклеотид:
TCGAGAAAAGGGGCCCGAATTCGCATGC (SEQ ID NO:54)
CTTTTCCCCGGGCTTAAGCGTACGCCGG (SEQ ID NO:55)
- для конструирования pPICZalphaE':
8649: 5'-TCGAGAAAAGAGAGGCTGAAGCCTGCAGCATATGC-3' (SEQ ID NO:56)
8650: 5'-GGCCGCATATGCTGCAGGCTTCAGCCTCTCTTTTC-3' (SEQ ID NO:57)
которые дают после гибридизации линкерный олигонуклеотид:
TCGAGAAAAGAGAGGCTGAAGCCTGCAGCATATGC (SEQ ID NO:56)
CTTTTCTCTCCGACTTCGGACGTCGTATACGCCGG (SEQ ID NO:57)
Эти челночные векторы pPICZalphaD' и pPICZalphaE' имеют нововведенные сайты клонирования непосредственно за сайтом расщепления соответствующих протеаз процессинга, КЕХ2 и STE13.
Последовательность, кодирующую Е1-Н6, выделяли в виде Ns/1/Eco52I-фрагмента из pGEMT-E1sH6 (SEQ ID NO:6, Фиг.1). Этот фрагмент очищали с использованием набора для гелевой экстракции (Qiagen) после разделения перевара в 1%-ном агарозном геле. Концы полученнного фрагмента делали тупыми (с использованием ДНК-полимеразы Т4) и лигировали либо в pPICZalphaD', либо в pPICZalphaE' прямо за соответствующим сайтом расщепления протеазы процессинга.
Трансформировали смесями лигирования клетки Е.coli TOP10F' и анализировали плазмидные ДНК нескольких колоний, устойчивых к зеоцину, расщеплением ферментами рестрикции. Отбирали позитивные клоны и обозначали их как pPICZalphaD'E1sH6 (ICCG3694; SEQ ID NO:58, Фиг.32) и pPICZalphaE'E1sH6 (ICCG3475; SEQ ID NO:59, Фиг.33), соответственно.
ПРИМЕР 12
КОНСТРУИРОВАНИЕ ВЕКТОРОВ pPICZalphaD'E2sH6 и pPICZalphaE'E2sH6
Конструировали челночные векторы pPICZalphaD' и pPICZalphaE' как описано в Примере 11.
Последовательность, кодирующую Е2-Н6, выделяли как Sa/I/KpnI-фрагмент из pBSK-E2sH6 (SEQ ID NO:45, Фиг.23). Этот фрагмент очищали с помощью набора для гелевой экстракции (Qiagen) после разделения перевара в 1%-ном агарозном геле. Концы полученного фрагмента делали тупыми (с использованием ДНК-полимеразы Т4) и лигировали либо в pPICZaIphaD', либо в pPICZalphaE' прямо за соответствующим сайтом расщепления протеазой процессинга.
Трансформировали смесью лигирования клетки Е.coli TOP10F' и анализировали плазмидные ДНК нескольких колоний, устойчивых к зеоцину, расщеплением ферментами рестрикции. Отбирали позитивные клоны и обозначали их как pPICZalphaD'E2sH6 (ICCG3692; SEQ ID NO:60, Фиг.34) и pPICZalphaE'E2sH6 (ICGG3476; SEQ ID NO:61, Фиг.35), соответственно.
ПРИМЕР 13
ТРАНСФОРМАЦИЯ PICHIA PASTORIS И СЕЛЕКЦИЯ ТРАНСФОРМАНТОВ
Векторными плазмидами Р.pastoris, как описано в Примерах 11 и 12, трансформировали клетки Р.pastoris в соответствии с условиями поставщика (Invitrogen). Отбирали линии, продуцирующие Е1 и Е2, для дальнейшей характеристики.
Экспрессировали оболочечные белки HCV в Р.pastoris, штамме дрожжей, хорошо известному благодаря тому факту, что гипергликозилирование у него в норме отсутствует (Gellissen, G. 2000), и ранее использовавшемуся для экспрессии белка Е вируса денге в GST-слитом виде (Sugrue, R.G. et al. 1997). Примечательно, что результирующие экспрессируемые в Р.pastoris оболочечные белки HCV проявляли гликозилирование, сходное с тем, которое наблюдают в штаммах Saccharomyces дикого типа. Более конкретно, оболочечные белки HCV, продуцируемые Р.pastoris, гипергликозилированы (на основании молекулярной массы продуктов экспрессии, выявляемых в вестерн-блотах белков, выделенных из трансформированных клеток Р.pastoris).
ПРИМЕР 14
УСЛОВИЯ КУЛЬТИВИРОВАНИЯ ДЛЯ SACCHAROMYCES CEREVISIAE, HANSENULA POLYMORPHA И PICHIA PASTORIS
Saccharomyces cerevisiae
Создание банка клеток
Из выбранного рекомбинантного клона готовили основной банк клеток и рабочий банк клеток.
Из культуры в середине экспоненциальной фазы роста в качалочной колбе (условия инкубации как для ферментационных посевных культур) готовили крио-ампулы. В качестве криопротектора добавляли глицерин (конечная концентрация 50%).
Ферментация
Начинали посевные культуры с крио-сохраняемой ампулы рабочего банка клеток и выращивали в 500 мл среды (YBN, обогащенная 2% сахарозы, Difco) в качалочных колбах Эрленмейера на 2 л при 37°С и 200 об/мин в течение 48 часов.
Ферментацию в типичных случаях проводили в ферментаторах Biostat С с рабочим объемом 15 л (В.Braun Int., Melsungen, Germany). Ферментационная среда содержала 1% дрожжевого экстракта, 2% пептона и 2% сахарозы в качестве источника углерода. В качестве пеногасителя применяли полиэтиленгликоль.
В типичных случаях во время ферментации контролировали температуру, рН и растворенный кислород, применимые установки этих параметров суммированы в Табл.1. Растворенный кислород контролировали каскадным способом путем перемешивания/аэрации. рН контролировали добавлением NaOH (0,5 М) или Н3РО4 (8,5%).
| Табл.1. Типичные установки параметров для ферментации S.cerevisia |
|
| Параметр | Установка параметра |
| Температура | 33-37°С |
| рН | 4,2-5,0 |
| DO (растворенный кислород, фаза роста) | 10-40% насыщения воздухом |
| DO (индукция) | 0-5% |
| Аэрация | 0,5-1,8 vvm* |
| перемешивание | 150-900 об/мин |
| * замена объема в минуту | |
Ферментацию начинали добавлением 10% посевной культуры. Во время фазы роста концентрацию сахарозы независимо отслеживали с помощью ВЭЖХ (высокоэффективная жидкостная хроматография) анализа (колонка Polysphere OAKC Merck).
Во время фазы роста растворенный кислород контролировали каскадным контролем (перемешивание/аэрация). После полного метаболизирования сахарозы продукцию гетерологичных белков запускал эндогенно продуцируемый этанол, причем для удержания его концентрации около 0,5% (независимый ВЭЖХ анализ, колонка Polysphere OAKC) по порциям добавляли EtOH. Во время этой фазы индукции растворенный кислород поддерживали ниже 5% насыщения воздухом подгонкой тока воздуха и скорости перемешивания вручную.
В типичном случае ферментацию завершали через 48-72 часа после индукции, концентрируя клетки фильтрацией в тангенциальном потоке с последующим центрифугированием концентрированной суспензии клеток с получением осадка клеток. Если не выполняли анализ немедленно, хранили осадки клеток при -70°С.
Hansenula polymorpha
Создание банка клеток
Из выбранного рекомбинантного клона готовили основной банк клеток и рабочий банк клеток.
Из культуры в середине экспоненциальной фазы роста в качалочной колбе (условия инкубации как для ферментационных посевных культур) готовили криоампулы. В качестве криопротектора добавляли глицерин (конечная концентрация 50%).
Ферментация
Начинали посевные культуры с криосохраняемой (-70°С) ампулы рабочего банка клеток и выращивали в 500 мл среды (YBN, Difco) в качалочных колбах Эрленмейера на 2 л при 37°С и 200 об/мин в течение 48 часов.
В типичных случаях проводили ферментации в ферментаторах Biostat С с рабочим объемом 15 л (В.Braun Int., Melsungen, Germany). Ферментационная среда содержала 1% дрожжевого экстракта, 2% пептона и 1% глицерина в качестве источника углерода. В качестве пеногасителя применяли полиэтиленгликоль.
В типичных случаях во время ферментации контролировали температуру, рН и растворенный кислород, применимые установки этих параметров суммированы в Табл.2. Растворенный кислород контролировали путем перемешивания. рН контролировали добавлением раствора NaOH (0,5 М) или Н3РО4 (8,5%).
| Табл.2. Типичные установки для параметров ферментации Н.polymorpha |
|
| Параметр | Установка параметра |
| Температура | 30-40°С |
| рН | 4,2-5,0 |
| DO (растворенный кислород) | 10-40% насыщения воздухом |
| Аэрация | 0,5-1,8 vvm* |
| перемешивание | 150-900 об/мин |
| * замена объема в минуту | |
Ферментацию начинали добавлением 10% посевной культуры. Во время фазы роста концентрацию глицерина отслеживали независимо с помощью ВЭЖХ анализа (колонка Polysphere OAKC Merck) и через 24 часа после полного потребления глицерина добавляли 1% метанола для того, чтобы индуцировать экспрессию гетерологичных белков. Ферментацию завершали через 24 часа после индукции, концентрируя клетки фильтрацией в тангенциальном потоке с последующим центрифугированием концентрированной суспензии клеток с получением осадка клеток. Если не выполняли анализ немедленно, хранили осадки клеток при -70°С.
Pichia pastoris
Эксперименты по мелкомасштабному продуцированию белков рекомбинантным Pichia pastoris были поставлены на культурах в качалочных колбах. Выращивали посевные культуры в течение ночи в среде YPD (Difco). Исходный рН среды корректировали до 4,5. Инкубировали качалочные колбы на роторном шейкере при 200-250 об/мин и 37°С.
Мелкомасштабное продуцирование в типичных случаях осуществляли в объеме 500 мл в качалочных колбах на 500 мл и начинали 10%-ной инокуляцией в экспрессионную среду, содержащую 1% дрожжевого экстракта, 2% пептона (оба продукта от Difco) и 2% глицерина в качестве источника углерода. Условия инкубации были такими же, как для посевной культуры. Примерно через 72 часа после инокуляции начинали индукцию добавлением 1% МеОН. Через 24 часа после индукции собирали клетки центрифугированием. Если не выполняли анализ немедленно, хранили осадки клеток при -70°С.
ПРИМЕР 15
УДАЛЕНИЕ ЛИДЕРНОГО ПЕПТИДА ИЗ БЕЛКОВ MFα-E1-H6 И MFα-E2-H6, ЭКСПРЕССИРУЕМЫХ В ВЫБРАННЫХ ДРОЖЖЕВЫХ КЛЕТКАХ
Далее анализировали продукты экспрессии белковых конструктов Е1 и Е2 HCV с лидерной последовательностью α-фактора спаривания дрожжей (αMF) S.cerevisiae в Hansenula polymorpha и в штамме Saccharomyces cerevisia, дефектном по гликозилированию. Поскольку оба генотипа 1b HCV E1s (аминокислоты 192-326) и HCV E2s (аминокислоты 383-637, удлиненные последовательностью VIEGR (SEQ ID NO:69)) экспрессировались как белки с С-концевой гистидиновой меткой (Н6, НННННН, SEQ ID NO:63, далее в этом примере указанные белки HCV обозначены как αMF-E1-H6 И αMF-E2-H6), быструю и эффективную очистку экспрессируемых продуктов после солюбилизации клеток дрожжей хлоридом гуанидиния (GuHCl) осуществляли на Ni-IDA (Ni-иминодиуксусная кислота). Вкратце, ресуспензировали клеточные осадки в среде, состоящей из 50 мМ фосфата, 6 М GuHCl, рН 7,4 (9 объемов на 1 г клеток). Сульфонировали белки в течение ночи при комнатной температуре (КТ) в присутствии 320 мМ (4% масс./об.) сульфита натрия и 65 мМ (2% масс./об.) тетратионата натрия. Осветляли лизат после цикла замораживания-оттаивания центрифугированием (10000 g, 30 мин, 4°С) и добавляли к супернатанту Empigen (Albright & Wilson, UK) и имидазол до конечной концентрации 1% (масс./об.) и 20 мМ, соответственно. Образец фильтровали (0,22 мкМ) и наносили на колонку с Ni-IDA Sepharose FF, которую уравновешивали 50 мМ фосфатом, 6М GuHCl, 1% Empigen (буфер А), обогащенным 20 мМ имидазола. Колонку промывали последовательно буфером А, содержащим 20 мМ и 50 мМ имидазола, соответственно, до тех пор, пока поглощение при 280 нм не достигало базового уровня. Элюировали продукты с гистидиновой меткой нанесением буфера D, 50 мМ фосфат, 6 М GuHCl, 0,2% (для Е1) или 1% (для Е2) Empigen, 200 мМ имидазол. Анализировали элюированный материал Na-ДДС-ППАГ-электрофорезом и вестерн-блоттингом с использованием специфических моноклональных антител против Е1 (IGH201) или Е2 (IGH212).
Немедленно анализировали E1-продукты расщеплением по Эдману.
Поскольку на этой стадии Na-ДДС-ПААГ-электрофорез уже выявлял очень сложную картину белковых полос для HCV E2, проводили дальнейшую фракционализацию вытеснительной хроматографией. Ni-IDA элюат концентрировали ультрафильтрацией (MWCO 10 kDa, centriplus, Amicon, Millipore) и наносили на Superdex G200 (10/30 или 16/60, Pharmacia) в PBS (забуференный фосфатом физиологический раствор), 1% Empigen или PBS, 3% Empigen. Собирали и алкилировали (инкубация с 10 мМ DTT (дитиотрейтол) в течение 3 часов при комнатной температуре с последующей инкубацией с 3 мМ йодоацетамида в течение 3 часов при КГ) элюированные фракции, содержащие Е2-продукты с молекулярной массой между примерно 80 кДа и примерно 45 кДа, то есть фракции 17-23 профиля элюции на Фиг.37 на основании миграции при Na-ДДС-ПААГ электрофорезе (Фиг.38). Образцы для амино-терминального секвенирования обрабатывали Endo H (Roche Biochemical) или оставляли их необработанными. Для амино-концевого секвенирования гликозилированные или дегликозилированные Е2-продукты подвергали блоттингу на PVDF-мембранах. Блот гликозилированного и дегликозилированного Е2, окрашенный красителем амидо черным, показан на Фиг.39.
Секвенирование очищенных продуктов Е1 и Е2 приводит к разочаровывающему наблюдению, состоящему в том, что удаление сигнальной последовательности из оболочечных белков HCV происходит только частично (см. Таблицу 3). Кроме того, большинство побочных продуктов (продукты деградации и продукты, все еще содержащие лидерную последовательность или ее часть) гликозилировано. Это гликозилирование отчасти свойственно даже нерасщепленному фрагменту сигнальной последовательности, который содержит еще и сайт N-гликозилирования. Эти сайты можно мутировать, чтобы добиться меньшего гликозилирования побочных продуктов. Однако даже еще более проблематично то наблюдение, что некоторые альтернативно расщепленные продукты при сравнении с желаемым интактным оболочечным белком имеют отличие только в 1-4 аминокислоты. Следовательно, очистка корректно процессированного продукта практически невозможна из-за отсутствия биохимических характеристик, в достаточной степени дифференцирующих различные продукты экспрессии. Несколько продуктов деградации могут быть результатом Кех-2-подобного расщепления (например, расщепление, наблюдаемое после аминокислоты 196 из Е1, которое является расщеплением после аргинина), которое требуется также для отщепления лидера α-фактора спаривания и которое, таким образом, нельзя блокировать без нарушения этого необходимого процесса.
Клон с высокой продукцией Е1, полученный трансформацией S.cerevisiae IYCC155 плазмидой pSY1YIGE1s (SEQ ID NO:50, Фиг.28), сравнили с высокопродуктивным клоном, полученным трансформацией S.cerevisiae IYCC155 плазмидой pSY1aMFE1sH6aYIG1E1s (SEQ ID NO:44, Фиг.22). Внутриклеточную экспрессию белка Е1 оценивали спустя 2-7 дней после индукции посредством вестерн-блоттинга с использованием моноклональных антител, специфичных к Е1 (IGH 201). Как можно судить по Фиг.40, максимальную экспрессию у обоих штаммов наблюдали через 2 дня, но паттерны экспрессии у обоих штаммов совершенно разные. Экспрессия с лидером α-фактора спаривания приводит к очень сложной картине полос, что является следствием того факта, что процессинг лидера неэффективен. Это приводит к нескольким продуктам экспрессии с разными амино-концами, среди которых некоторые модифицированы 1-5 N-гликозилированиями. Однако для Е1, экспрессируемого с лидером CL, видно ограниченное число отдельных полос, что отражает высокий уровень корректного удаления лидера CL и тот факт, что только этот корректно процессированный материал может быть модифицирован N-гликозилированием (от 1 до 5 цепей), как видно в случае белка Е1, полученного из Hansenula и экспрессируемого с тем же лидером CL (см. Пример 16).
Гибридомная клеточная линия, продуцирующая монокональное антитело, направленное против Е1 (IGH201), было депонировано 12 марта 1998 г. согласно условиям Будапештского договора в Европейской коллекции клеточных культур, Center for Applied Microbiology & Research, Salisbury, Wiltshire SP4 0JG, UK, и получила депозитарный номер ЕСАСС 98031216. Maertens et al. в WO 96/04385 описали моноклональное антитело, направленное против Е2 (IGH212) как антитело 12D11F2 в примере 7.4.

ПРИМЕР 16
ЭКСПРЕССИЯ Е1 КОНСТРУКТА В ДРОЖЖАХ, ПРИГОДНЫХ ДЛЯ КРУПНОМАСШТАБНОГО ПРОДУЦИРОВАНИЯ И ОЧИСТКИ
Для замены лидерного пептида белка αMF S.cerevisiae использовали несколько других лидерных последовательностей, включая СНН (лидерная последовательность гипергликемического гормона из Carcinus maenas), Amy1 (лидерная последовательность амилазы из S.occidentalis), Gam1 (лидерная последовательность глюкоамилазы из S.occidentalis), Phy5 (лидерная последовательность грибковой фитазы), pho1 (лидерная последовательность кислой фосфатазы из Pichia pastoris) и CL (лидерная последовательность птичьего лизоцима С, 1,4-бета-N-ацетилмурамидазы С) и соединяли с Е1-Н6 (то есть с С-концевой гистидиновой меткой). Экспрессировали все конструкты в Hansenula polymorpha и подвергали каждый из получавшихся клеточных лизатов анализу вестерн-блоттингом. Это сразу позволило сделать вывод, что степень удаления лидерной или сигнальной последовательности или пептида была очень низкой, за исключением случая, когда в качестве лидерного пептида в конструкте использован CL. Это было подтверждено для конструкта СНН-Е1-Н6 расщеплением по Эдману материала, очищенного на Ni-IDA: корректно расщепленный продукт не был выявлен, хотя было получено несколько разных последовательностей (см. Таблицу 4).
| Таблица 4. Идентификация N-концов белков СНН-Е1-Н6, экспрессируемых в Н.polymorpha, на основании секвенирования N-концевых аминокислот разных белковых полос после разделения Na-ДДС-ПААГ электрофорезом и блоттинга на PVDF-мембране |
|
| Молекулярная масса | Идентифицированные N-концы |
| 45 кДа | начинается с аминокислоты 27 лидера СНН=отщеплена только пре-последовательность, про-последовательность все еще прикреплена |
| 26 кДа | - частично начинается с аминокислоты 1 лидера СНН=пре-про-последовательность не удалена - частично начинается с аминокислоты 9 лидера СНН=продукт альтернативной трансляции, начинающейся со второго колона AUG |
| 24 кДа | - частично начинается с аминокислоты 1 лидера СНН=пре-про-последовательность не удалена - частично начинается с аминокислоты 9 лидера СНН=продукт альтернативной трансляции, начиная со второго колона AUG |
Как уже отмечено, вестерн-блоты клеточных лизатов выявили паттерн белковых полос, специфических для Е1, который указывает на более высокий уровень корректного удаления лидерного пептида CL. Это удивительно, поскольку этот лидер не происходит из дрожжей. Секвенирование аминокислот расщеплением по Эдману материала, солюбилизированного гидрохлоридом гуанидиния и очищенного на Ni-IDA, действительно подтвердило, что 84% белков Е1 расщеплено корректно и этот материал по существу свободен от продуктов деградации. Все же 16% непроцессированного материала присутствует, но, поскольку этот материал не гликозилирован, его можно легко удалить из смеси, что позволяет провести специфическое обогащение корректно отщепленного и гликозилированного Е1. Таким способом обогащения может быть аффинная хроматография на лектинах, в Примере 19 даны и другие альтернативы. Альтернативно, более высокогидрофобный характер негликозилированного материала можно использовать для выбора и оптимизации других процедур обогащения. Корректное удаление лидерного пептида CL из белка CL-E1-H6 было далее подтверждено масс-спектрометрией, которая также подтвердила то, что занятыми могут быть до 4 из 5 сайтов гликозилирования генотипа 1b E1s, вследствие чего последовательность NNSS (аминокислоты 233-236; SEQ ID NO:73) считают единственным сайтом N-гликозилирования.
ПРИМЕР 17
ОЧИСТКА И БИОХИМИЧЕСКАЯ ХАРАКТЕРИСТИКА БЕЛКА HCV E2, ЭКСПРЕССИРУЕМОГО В HANSENULA POLYMORPHA ИЗ КОНСТРУКТА, КОДИРУЮЩЕГО CL-E2-H6
Анализировали эффективность удаления лидерного пептида CL из белка CL-E2-VIEGR-H6 (далее в этом Примере обозначаемого как "CL-E2-H6"), экспрессируемого в Hansenula polymorpha. Поскольку HCV E2s (аминокислоты 383-673) экспрессировался как белок с гистидиновой меткой, быструю и эффективную очистку экспрессируемого белка после GuHCI-солюбилизации собранных клеток осуществляли на NI-IDA. Вкратце, ресуспензировали клеточные осадки в 30 мМ фосфата, 6 М GuHCl, pH 7,2 (9 мл буфера/г клеток). Белок сульфонировали в течение ночи при комнатной температуре (КТ) в присутствии 320 мМ (4% масс./об.) сульфита натрия и 65 мМ (2% масс./об.) тетратионата натрия. Осветляли лизат после цикла замораживания-оттаивания центрифугированием (10000 g, 30 мин, 4°С). Добавляли Empigen BB (Albright & Wilson) и имидазол до конечной концентрации 1% (масс./об.) и 20 мМ, соответственно. Выполняли все дальнейшие хроматографические этапы на установке Åkta FPLC (быстрая жидкостная хроматография белков) (Pharmacia). Образец фильтровали через мембрану (ацетат целлюлозы) с порами размером 0,22 мкм и наносили на Ni-IDA-колонку (хелатирующая Sepharose FF, нагруженная Ni2+, Pharmacia), которую уравновешивали 50 мМ фосфата, 6М GuHCl, 1% Empigen BB, pH 7,2 (буфер А), обогащенным 20 мМ имидазола. Колонку промывали последовательно буфером А, содержащим 20 мМ и 50 мМ имидазола, соответственно, до тех пор, пока поглощение при 280 нм не достигало базового уровня. Элюировали продукты с гистидиновой меткой нанесением буфера D, 50 мМ фосфата, 6 М GuHCl, 0,2% Empigen BB (pH 7,2), 200 мМ имидазола. Очищенный материал анализировали Na-ДДС-ПААГ-электрофорезоми и вестерн-блоттингом с использованием специфического моноклонального антитела против E2 (IGH212) (Фиг.41). Очищенный с помощью IMAC белок Е2-Н6 подвергали также N-концевому секвенированию расщеплением по Эдману. С этой целью обрабатывали белки N-гликозидазой F (Roche) (0,2 ед./мкг Е2, инкубация в течение 1 часа при 37°С в забуференном фосфатами физиологическом растворе с 3% Empigen BB) или оставляли их необработанными. Гликозилированные и негликозилированные белки Е2-Н6 подвергали Na-ДДС-ПААГ электрофорезу и проводили блоттинг на PVDF-мембране для секвенирования аминокислот (анализ проводили на секвенаторе белков PROCISE™ 492, Applied Biosystems). Поскольку на этой стадии Na-ДДС-ПААГ выявлял некоторые продукты деградации, выполняли дальнейшее фракционирование вытеснительной хроматографией. Для этого Ni-IDA элюат концентрировали ультрафильтрацией (MWCO 10 кДа, centriplus, Amicon, Millipore) и наносили на Superdex G200 (Pharmacia) в PBS, 1% Empigen BB. Объединяли элюированные фракции, содержащие главным образом продукты, относящиеся к интактному Е2, с относительной молекулярной массой между примерно 30 кДа и примерно 70 кДа на основании миграции в Na-ДДС-ПААГ и в конце концов алкилировали их (инкубация с 5 мМ DTT в течение 30 мин при 37°С с последующей инкубацией с 20 мМ йодоацетамида в течение 30 мин при 37°С). Возможное присутствие продуктов деградации после IMAC-очистки можно, таким образом, устранить дальнейшим фракционированием интактного продукта вытеснительной хроматографией. Был получен неожиданно хороший результат. На основании N-концевого секвенирования можно оценить количество Е2 продукта, у которого удален лидерный пептид CL. Общее количество белковых продуктов рассчитывают в пмолях белка на основании интенсивности пиков, получаемых при расщеплении по Эдману. Затем для каждого конкретного белка (то есть, для каждого "выявленного N-конца") оценивают мольн.% относительно общего количества. В данном эксперименте выявляли только правильный N-конец Е2-Н6, а другие варианты Е2-Н6, не имеющие аминокислот белка Е2 или содержащие N-концевые аминокислоты, не содержащиеся в белке Е2, отсутствовали. Следовательно, белок Е2-Н6, экспрессируемый Н.polymorpha как белок CL-E2-H6, был выделен без какого-либо дальнейшего процессирования in vitro как белок, более чем на 95% расщепленный правильно. Это резко контрастирует с точностью удаления лидерного пептида у Н.polymorpha для белка αMF-E2-H6 с образованием белка Е2-Н6, оцениваемым как происходящее у 25% выделенных белков (см. Таблицу 3).
ПРИМЕР 18
ОЧИСТКА И БИОХИМИЧЕСКАЯ ХАРАКТЕРИСТИКА БЕЛКА HCV E1, ЭКСПРЕССИРУЕМОГО В HANSENULA POLYMORPHA ИЗ КОНСТРУКТА, КОДИРУЮЩЕГО CL-H6-K-E1, И ПРОЦЕССИНГ Н6-СОДЕРЖАЩИХ БЕЛКОВ IN VITRO
Анализировали эффективность удаления лидерного пептида CL из белка CL-H6-K-E1, экспрессируемого в Н.polymorpha, а также эффективность последующего процессинга in vitro с целью удаления адаптерного пептида Н6 с гистидиновой меткой (Н6 (his-tag)), а также Endo Lys-C сайта процессинга. Поскольку HCV E1s (аминокислоты 192-326) экспрессировался как белок CL-H6-K-E1 с N-концевой His-K-меткой, быструю и эффективную очистку можно осуществить так, как описано в Примере 17. Профиль элюции IMAC-хроматографической очистки белков Н6-К-Е1 (и возможно остаточного CL-H6-K-E1) показан на Фиг.42. После Na-ДДС-ПААГ электрофореза с окрашиванием геля серебром и анализа вестерн-блоттингом с использованием специфического моноклонального антитела, направленного против E1 (IGH201) (Фиг.43), объединяли в пул элюированные фракции 63-69, содержащие рекомбинантные E1s продукты («IMAC-пул») и подвергали их обработке эндопротеиназой Lyc-C (Roche) в течение ночи (соотношение фермент/субстрат 1/50 (масс./масс.), 37°С) для удаления Н6-К-слитого хвоста. Удаление непроцессированного слитого продукта осуществляли на этапе негативной IMAC-хроматографии на Ni-IDA-колонке, в результате чего собирали Endo-Lys-C-процессированные белки в проходящей фракции. Для этого образец белка, расщепленного эндопротеиназой Lys-C, после 10-кратного разведения смесью 10 мМ NaH2PO4·3H2O, 1% (об./об.) Empigen В, рН 7,2 (буфер В), наносили на Ni-IDA-колонку с последующим промыванием буфером В до тех пор, пока поглощение при 280 нм не достигало базового уровня. Проходящий поток собирали в разные фракции (1-40), которые подвергали скринингу на присутствие E1s-продуктов (Фиг.44). Объединяли фракции 7-28, содержащие интактный Е1, у которого N-концевой Н6-К (и возможно остаточный CL-H6-K) хвост был удален (с относительной молекулярной массой между примерно 15 кДа и примерно 30 кДа на основании миграции в Na-ДДС-ПААГ с последующим окрашиванием серебром или анализа вестерн-блоттингом с использованием специфического моноклонального антитела, направленного против Е1 (IGH201)) и в конце концов алкилировали их (инкубация с 5 мМ DTT в течение 30 мин при 37°С с последующей инкубацией с 20 мМ йодоацетамида в течение 30 мин при 37С).
Этот материал подвергали N-концевому секвенированию (расщепление по Эдману). С этой целью обрабатывали образцы белков N-гликозидазой F (Roche) (0,2 ед./мкг Е2, инкубация в течение 1 часа при 37°С в PBS/3% Empigen ВВ) или оставляли их необработанными. Гликозилированные и негликозилированные белки Е1 разделяли Na-ДДС-электрофорезом в ПААГ и проводили блоттинг на PVDF-мембране для дальнейшего анализа расщеплением по Эдману (анализ проводили на секвенаторе белков PROCISE™ 492, Applied Biosystems). На основании N-концевого секвенирования можно оценить количество правильно процессированного Е1 продукта (процессинг включает в себя правильное отщепление Н6-К-последовательонсти). Общее количество белковых продуктов рассчитывают в пмолях белка на основании интенсивности пиков, получаемых при расщеплении по Эдману. Затем для каждого конкретного белка (то есть для каждого "выявленного N-конца") оценивают мольн.% относительно общего количества. В данном эксперименте выявили только правильный N-конец белка Е1, yj не N-концы других процессированных вариантов Н6-К-Е1. На этом основании было установлено, что in vitro процессинг эндопротеиназой Lys-C (Endo Lys-C) белка Е1, представляющего собой Н6-К-Е1 (и возможно остаточного CL-H6-K-E1) до белка Е1 происходит с точностью более 95%.
ПРИМЕР 19
СПЕЦИФИЧЕСКОЕ УДАЛЕНИЕ НИЗКОГЛИКОЗИЛИРОВАННЫХ ФОРМ HCV E1 ГЕПАРИНОМ
Для выявления специфических этапов очистки для оболочечных белков HCV из дрожжевых клеток оценили связывание с гепарином. Известно, что гепарин связывается с несколькими вирусами и, соответственно, уже было высказано предположение о связывании с оболочкой HCV (Garson, J. A. et al. 1999). Для того, чтобы проанализировать это потенциальное связывание, биотилировали гепарин и анализировали взаимодействие с HCV E1 в титрационных микропланшетах, покрытых либо сульфонированным HCV E1 из Н.polymorpha, либо алкилированным HCV E1 из Н.polymorpha (оба получены как описано в Примере 16), либо алкилированным HCV E1 из культуры клеток млекопитающего, трансфицированных вектором экспрессии на основе вируса коровьей оспы. Неожиданно наблюдали сильное связывание только с сульфонированным HCV E1 из Н.polymorpha, тогда как связывание с HCV E1 из культуры клеток млекопитающего полностью отсутствовало. Посредством вестерн-блоттинга авторам удалось показать, что это связывание было специфичным для полос смеси белка HCV E1 с низкой молекулярной массой (Фиг.45), соответствующих низкогликозилированным зрелым HCV E1s. Из фиг.45 также видно, что сульфонирование не является необходимым для связывания гепарина, поскольку при ликвидации такого сульфонирования связывание по прежнему наблюдается для E1, имеющего низкую молекулярную массу (дорожка 4). Алкилирование, напротив, существенно снижает это связывание, однако это может быть вызвано специфическим агентом алкилирования (йодоацетамидом), использованным в этом примере. Это связывание продемонстрировало еще и промышленную применимость CL-HVC-оболочечных экспрессионных кассет для дрожжей, поскольку можно специфически обогатить препараты HCV E1 для получения препарата с белками HCV E1, имеющими более высокую степень гликозилирования (то есть, у них оккупировано больше сайтов гликозилирования).
ПРИМЕР 20
ФОРМИРОВАНИЕ И АНАЛИЗ ВИРУСОПОДОБНЫХ ЧАСТИЦ (VLPS)
Превращение оболочечных белков HCV E1 и Е2, экспрессируемых в Н.polymorpha (Примеры 16-18) в VLPs, осуществляли по существу так, как описано Depla et al. в WO 99/67285 и Bosman et al. в WO 01/30815. Вкратце, после культивирования трансформированных клеток Н.polymorpha, во время которого экспрессировались оболочечные белки HCV, собирали клетки, лизировали их в GuHCl и сульфонировали как описано в Примере 17. Затем очищали содержащие гистидиновую метку белки IMAC-хроматографией и концентрировали ультрафильтрацией как описано в Примере 17.
ФОРМИРОВАНИЕ VLP ИЗ ОБОЛОЧЕЧНЫХ БЕЛКОВ HCV С СУЛЬФОНИРОВАННЫМИ CYS-ТИОЛЬНЫМИ ГРУППАМИ
Концентрированные оболочечные белки HCV, сульфонированные во время процедуры выделения, не подвергали восстанавливающей обработке и наносили их на колонку для хроматографии с вытеснением по размеру частиц (Superdex G200, Pharmacia), уравновешенную PBS, 1% (об./об.) Empigen. Анализировали элюированные фракции Na-ДДС-ПААГ электрофорезом и вестерн-блоттингом. Объединяли фракции с относительной молекулярной массой от примерно 29 до примерно 15 кДа (на основании миграции на Na-ДДС-ПААГ), концентрировали их и наносили на Superdex G200, уравновешенную PBS, 3% (масс./об.) бетаина, для того, чтобы вызвать образование вирусоподобных частиц (VLP). Объединяли фракции, концентрировали и обессоливали до PBS, 0,5% (масс./об.) бетаина.
ФОРМИРОВАНИЕ VLP ИЗ ОБОЛОЧЕЧНЫХ БЕЛКОВ HCV С НЕОБРАТИМО МОДИФИЦИРОВАННЫМИ CYS-ТИОЛЬНЫМИ ГРУППАМИ
Для того, чтобы превратить сульфонированные Cys-тиольные группы в свободные Cys-тиольные группы, концентрированные оболочечные белки HCV, сульфонированные во время процедуры выделения, подвергали восстанавливающей обработке (инкубация в присутствии 5 мМ DTT в PBS). Необратимую модификацию Cys-тиольных групп осуществляли (1) инкубацией в течение 30 мин в присутствии 20 мМ йодацетамида, или (2) инкубацией в течение 30 мин в присутствии 5 мМ N-этилмалеимида (NEM) и 15 мМ биотин-N-этилмалеимида. Затем наносили белки на колонку для хроматографии с вытеснением по размеру частиц (Superdex G200, Pharmacia), уравновешенную PBS, 1% (об./об.) Empigen в случае блокирования йодоацетамидом, или PBS, 0,2% CHAPS в случае блокирования посредством NEM и биотин-NEM. Анализировали элюированные фракции Na-ДДС-ПААГ-электрофорезом и вестерн-блоттингом. Объединяли фракции с относительной молекулярной массой от примерно 29 до примерно 15 кДа (на основании миграции в Na-ДДС-ПААГ), концентрировали их и наносили на колонку Superdex G200, уравновешенную PBS, 3% (масс./об.) бетаина, для того, чтобы вызвать образование вирусоподобных частиц. Фракции объединяли, концентрировали и обессоливали до PBS, 0,5% (масс./об.) бетаина в случае блокирования йодоацетамидом, или PBS, 0,05% CHAPS в случае блокирования с помощью NEM и биотин-NEM.
ФОРМИРОВАНИЕ VLP ИЗ ОБОЛОЧЕЧНЫХ БЕЛКОВ HCV С ОБРАТИМО МОДИФИЦИРОВАННЫМИ CYS-ТИОЛЬНЫМИ ГРУППАМИ
Для того, чтобы превратить сульфонированные Cys-тиольные группы в свободные Cys-тиольные группы, сконцентрированные оболочечные белки HCV, сульфонированные во время процедуры выделения, подвергали восстанавливающей обработке (инкубация в присутствии 5 мМ DTT в PBS). Необратимую модификацию Cys-тиольных групп осуществляли инкубацией в течение 30 мин в присутствии дитиодипиридина (DTDP), дитиокарбамата (DTC) или цистеина. Затем наносили белки на колонку для хроматографии с вытеснением по размеру частиц (Superdex G200, Pharmacia), уравновешенную PBS, 1% (об./об.) Empigen. Элюированные фракции анализировали Na-ДДС-ПААГ-электрофорезом и вестерн-блоттингом. Объединяли фракции с относительной молекулярной массой от примерно 29 до примерно 15 кДа (на основании миграции в Na-ДДС-ПААГ), концентрировали их и наносили на Superdex G200, уравновешенный PBS, 3% (масс./об.) бетаина, для того, чтобы вызвать образование вирусоподобных частиц (VLP). Объединяли фракции, концентрировали и обессаливали до PBS, 0,5% (масс./об.) бетаина.
Профили элюции хроматографии с вытеснением по размерам частиц в PBS, 3% (масс./об.) бетаина для получения VLPs из Е2-Н6, экспрессированного в Н. polymorpha, показаны на Фиг.46 (сульфонированный) и Фиг.47 (алкилированный йодоацетамидом).
Профили элюции хроматографии с вытеснением по размерам частиц в PBS, 3% (масс./об.) бетаина для получения VLPs из Е1, экспрессированного в Н.polymorpha, показаны на Фиг.48 (сульфонированный) и Фиг.49 (алкилированный йодоацетамидом). Полученные VLPs были проанализированы Na-ДДС-ПААГ-электрофорезом и вестерн-блоттингом как показано на Фиг.50.
АНАЛИЗ РАЗМЕРОВ VLPS, ОБРАЗОВАННЫХ ОБОЛОЧЕЧНЫМИ БЕЛКАМИ HCV, ЭКСПРЕССИРОВАННЫМИ В Н.polymorpha
Размер частиц VLP определяли динамическим светорассеяньем. Для экспериментов по светорассеянью применяли анализатор размеров частиц (Model Zetasizer 100 HS, Malvern Instruments Ltd., Malvern, Worcester, UK), который управлялся с помощью программного обеспечения для фотоно-корреляционной спектроскопии (PCS). Фотоно-корреляционная спектроскопия или динамическое светорассеянье (DLS) представляет собой оптический способ измерения броуновского движения и его соотнесения с размером частиц. Свет от непрерывного видимого лазерного луча направляют через совокупность макромолекул или частиц в суспензии, движущихся в результате броуновского движения. Некоторая часть лазерного света рассеивается частицами, и этот рассеянный свет измеряют фотоумножителем. Флуктуации интенсивности рассеянного света превращают в электрические импульсы и подают их на коррелятор. Это генерирует функцию автокорреляции, направляемую в компьютер, который производит соответствующий анализ данных. Использованным лазером был монохроматический когерентный He-Ne лазер мощностью 10 мВт с фиксированной длиной волны 633 нм. Для каждого образца делали 6 последовательных измерений. Результаты этих экспериментов суммированы в Таблице 5.
| Таблица 5. Результаты анализа динамического светорассеяния указанных VLP-композиций оболочечных белков HCV, экспрессированных в Н.polymorpha. Размеры VLP частиц приведены как их средний диаметр. |
|||
| Cys-тиольная модификация | Е1-Н6 | E2-VIEGR-H6 | Е1 |
| сульфонирование | 25-45 нм | 20 нм | 20-26 нм |
| алкилирование (йодоацетамид) | 23-56 нм | 20-56 нм | 21-25 нм |
То наблюдение, что сульфонированный HCV E1, полученный из Н.polymorpha, образует частицы с размерами в том же диапазоне, что и алкилированный HCV E1 из Hansenula, является удивительным. Такого эффекта не ожидали, поскольку сильное (до 8 Cys-тиольных групп может быть модифицировано на HCV E1) общее увеличение отрицательных зарядов вследствие сульфонирования должно вызвать ионное отталкивание между субъединицами. Другие протестированные агенты, обратимо модифицирующие цистеин, также делали возможным формирование частиц, однако получаемые таким путем HCV E1 оказались менее стабильными, чем сульфонированный материал, приводящий к агрегации HCV E1 на основе дисульфидов. Для применения этих других обратимых блокаторов нужна дальнейшая оптимизация условий.
ПРИМЕР 21
АНТИГЕННАЯ ЭКВИВАЛЕНТНОСТЬ ПРОДУЦИРУЕМОГО HANSENULA HCV Е1-Н6 И HCV E1, ПРОДУЦИРУЕМОГО КЛЕТКАМИ МЛЕКОПИТАЮЩЕГО, ИНФИЦИРОВАННЫМИ ВИРУСОМ КОРОВЬЕЙ ОСПЫ
Реактивность продуцируемого Hansenula HCV E1-H6 с сыворотками от хронических носителей HCV сравнили с реактивностью HCV E1, продуцируемого клетками млекопитающего, инфицированными HCV-рекомбинантным вирусом коровьей оспы, как описано Depla et al. в WO 99/67285. Оба протестированных препарата HCV-E1 состояли из VLP's, в которых белки HCV E1 были алкилированы N-этилмалеимидом и биотин-N-этилмалеимидом. Реактивности обоих VLP-препаратов HCV E1 с сыворотками от хронических носителей HCV определяли твердофазным иммуноферментным анализом (ELISA). Результаты суммированы в Таблице 6. Как можно заключить из Таблицы 6, между HCV E1, экспрессированным в клетках млекопитающего, инфицированных HCV-рекомбинантным вирусом коровьей оспы, и HCV E1, экспрессированным в Н.polymorpha, не было различий по реактивности.
| Таблица 6. Антигенность Е1, продуцируемого в культуре клеток млекопитающего или продуцируемого в Н.polymorpha оценивали на панели сывороток от людей, являющихся хроническими носителями HCV. Для этой цели биотинилированный Е1 связывали с планшетами для ELISA, покрытыми стрептавидином. После этого добавляли человеческие сыворотки в разведении 1/20 и связанные иммуноглобулины из сывороток, связавшихся с Е1, выявляли с помощью специфичного вторичного кроличьего антитела против IgG-Fc человека, меченного пероксидазой. Результаты выражены как значения оптической плотности (ОП). Усредненные значения являются средними значениями оптических плотностей всех тестированных образцов сыворотки. |
|||||
| Сыворотка | Hansenula | млекопитающее | Сыворотка | Hansenula | млекопитающее |
| 17766 | 1,218 | 1,159 | 55337 | 1,591 | 1,416 |
| 17767 | 1,513 | 1,363 | 55348 | 1,392 | 1,261 |
| 17777 | 0,806 | 0,626 | 55340 | 1,202 | 0,959 |
| 17784 | 1,592 | 1,527 | 55342 | 1,599 | 1,477 |
| 17785 | 1,508 | 1,439 | 55345 | 1,266 | 1,428 |
| 17794 | 1,724 | 1,597 | 55349 | 1,329 | 1,137 |
| 17798 | 1,132 | 0,989 | 55350 | 1,486 | 1,422 |
| 17801 | 1,636 | 1,504 | 55352 | 0,722 | 1,329 |
| 17805 | 1,053 | 0,944 | 55353 | 1,065 | 1,157 |
| 17810 | 1,134 | 0,999 | 55354 | 1,118 | 1,092 |
| 17819 | 1,404 | 1,24 | 55355 | 0,754 | 0,677 |
| 17820 | 1,308 | 1,4 | 55362 | 1,43 | 1,349 |
| 17826 | 1,163 | 1,009 | 55365 | 1,612 | 1,608 |
| 17827 | 1,668 | 1,652 | 55368 | 0,972 | 0,959 |
| 17849 | 1,595 | 1,317 | 55369 | 1,506 | 1,377 |
| 55333 | 1,217 | 1,168 | среднее | 1,313 | 1,245 |
ПРИМЕР 22
ИММУНОГЕННАЯ ЭКВИВАЛЕНТНОСТЬ HCV E1-H6, ПРОДУЦИРУЕМОГО HANSENULA, И HCV Е1, ПРОДУЦИРУЕМОГО КЛЕТКАМИ МЛЕКОПИТАЮЩЕГО, ИНФИЦИРОВАННЫМИ ВИРУСОМ КОРОВЬЕЙ ОСПЫ
Иммуногенность HCV E1-H6, продуцируемого Hansenula, сравнивали с иммуногенностью HCV E1, продуцируемого клетками млекопитающего, инфицированными HCV-рекомбинантным вирусом коровьей оспы, как описано Depla et al. в WO 99/67285. Оба протестированных препарата HCV E1 состояли из VLP's, в которых белки HCV E1 были алкилированы иодоацетоамидом. В состав обоих препаратов VLP вводили квасцы и инъецировали оба препарата мышам Balb/c (3 внутримышечной/подкожной инъекции с интервалом в 3 недели, причем каждая инъекция состояла из 5 мкг E1 в 125 мкл, содержащих 0,13% Alhydrogel, Superfos, Дания). У мышей брали кровь через десять дней после третьей иммунизации.
Результаты этих экспериментов показаны на Фиг.51. Для верхней части Фиг.51 определяли антитела, выработанные после иммунизации VLPs из E1, продуцированного в клетках млекопитающего. Титры антител определяли способом ELISA (см. Пример 21), при котором E1, продуцированным в клетках, млекопитающего (М), или E1, продуцированным в Hansenula (H), покрывали непосредственно ELISA твердую подложку, после чего блокировали планшеты для ELISA казеином. Для нижней части Фиг.51 определяли антитела, выработанные после иммунизации VLPs из E1, продуцированного в Hansenula. Титры антител определяли способом ELISA (см. Пример 21), при котором E1, продуцированным в клетках млекопитающего (М), или E1, продуцированным в Hansenula (H), покрывали непосредственно ELISA твердую подложку, после чего блокировали планшеты для ELISA казеином.
Определяемые титры антител были титрами, представляющими собой конечные точки. Титр, представляющий собой конечную точку, определяют как разведение сыворотки, приводящее к оптической плотности (определяемой способом ELISA), равное двукратному среднему базовому уровню в данном анализе.
Фиг.51 показывает, что между иммуногенными свойствами обоих E1-композиций не было существенных различий и что определяемые титры антител не зависят от антигена, использованного в ELISA для титрования до конечной точки.
HCV E1 дрожжевого происхождения при вакцинации индуцировал защитный ответ, сходный с защитным ответом, полученным при вакцинации аликилированым HCV E1, полученным из культуры клеток млекопитающего. Этот последний ответ был способен предотвращать хроническое развитие HCV после острой инфекции.
ПРИМЕР 23
АНТИГЕННЫЙ И ИММУНОГЕННЫЙ ПРОФИЛЬ ПРОДУЦИРУЕМОГО HANSENULA HCV E1-H6, КОТОРЫЙ ЯВЛЯЕТСЯ СУЛЬФОНИРОВАННЫМ
Реактивность продуцируемого Hansenula HCV E1-H6 с сыворотками от хронических носителей HCV сравнивали с реактивностью HCV E1, продуцируемого клетками млекопитающего, инфицированными HCV-рекомбинантным вирусом коровьей оспы, как описано Depla et al. в WO 99/67285. Оба протестированных препарата HCV-E1 состояли из VLP's, в которых продуцированные Hansenula белки HCV E1 были сульфонированы, а продуцированные клетками млекопитающего HCV E1 были алкилированы. Результаты даны в Таблице 7. Хотя общая (средняя) реактивность была идентичной, в индивидуальных сыворотках были замечены некоторые значительные. различия. Это значит, что сульфонированный материал представляет по меньшей мере некоторые из своих эпитопов способом, отличным от алкилированных HCV E1.
Иммуногенность продуцируемого Hansenula HCV E1-H6, который был сульфонирован, сравнивали с иммуногенностью продуцируемого Hansenula HCV E1-H6, который был алкилирован. Оба тестированных препарата HCV-E1 состояли из VLP's. Оба VLP препарата были составлены с квасцами и инъецированы мышам Balb/c (3 внутримышечные/подкожные инъекции с трехнедельными интервалами между каждыми, причем каждая состояла из 5 мкг E1 в 125 мкл, содержащих 0,13% Alhydrogel, Superfos, Denmark). У мышей брали кровь через 10 дней после третьей иммунизации.
Определяли титры антител подобно тому, что описано в Примере 22. Неожиданно оказалось, что иммунизация сульфонированным материалом приводила к более высоким титрам антител, независимо от антигена, использованного в ELISA для оценки этих титров (Фиг.51, верхняя панель: титрование антител, вырабатываемых против алкилированного E1; нижняя панель: титрование антител, вырабатываемых против сульфонированного E1; "А": алкилированный E1, нанесенный на планшет для ELISA; "S": сульфонированный Е1, нанесенный на планшет для ELISA). Однако в этом эксперименте индивидуальные титры различны в зависимости от антигена, использованного для анализа, что подтверждает наблюдение, отмеченное с сыворотками HCV пациентов. Следовательно, HCV E1, у которого цистеиновые тиольные группы модифицированы обратимым образом, может быть более иммуногенным и, таким образом, иметь более высокую активность в качестве вакцины, защищающей от HCV (хронической инфекции). В добавление к этому, менее вероятна индукция ответа на нео-эпитопы, индуцированные необратимым блокированием.
| Таблица 7. Антигенность алкилированного Е1 (продуцируемого в культуре клеток млекопитающего) или сульфонированного Е1-Н6 (продуцируемого в Н.polymorpha) оценивали на панели сывороток от людей, являющихся хроническими носителями HCV («сыворотки пациентов») и на панели контрольных сывороток («сыворотки доноров крови»). Для этой цели связывали Е1 с планшетами для ELISA, после чего планшеты далее насыщали казеином. Добавляли человеческие сыворотки в разведении 1/20 и выявляли связанные иммуноглобулины с помощью вторичных специфических кроличьих антител против человеческого IgG-Fc, меченных пероксидазой. Результаты выражены как значения оптической плотности (ОП). Усредненные значения являются средними значениями оптических плотностей всех тестированных проб сыворотки. |
||||||
| сыворотки пациентов | сыворотки доноров крови | |||||
| № сыворотки | Hansenula | млекопитающее | № Сыворотки | Hansenula | млекопитающее | |
| 17766 | 0,646 | 0,333 | F500 | 0,055 | 0,054 | |
| 17777 | 0,46 | 0,447 | F504 | 0,05 | 0,05 | |
| 17785 | 0,74 | 0,417 | F508 | 0,05 | 0,054 | |
| 17794 | 1,446 | 1,487 | F510 | 0,05 | 0,058 | |
| 17801 | 0,71 | 0,902 | F511 | 0,05 | 0,051 | |
| 17819 | 0,312 | 0,539 | F512 | 0,051 | 0,057 | |
| 17827 | 1,596 | 1,576 | F513 | 0,051 | 0,052 | |
| 17849 | 0,586 | 0,964 | F527 | 0,057 | 0,054 | |
| 55333 | 0,69 | 0,534 | Среднее | 0,052 | 0,054 | |
| 55338 | 0,461 | 0,233 | ||||
| 55340 | 0,106 | 0,084 | ||||
| 55345 | 1,474 | 1,258 | ||||
| 55352 | 1,008 | 0,668 | ||||
| 55355 | 0,453 | 0,444 | ||||
| 55362 | 0,362 | 0,717 | ||||
| 55369 | 0,24 | 0,452 | ||||
| Среднее | 0,706 | 0,691 | ||||
ПРИМЕР 24
ИДЕНТИЧНЫЕ АНТИГЕННЫЕ РЕАКТИВНОСТИ HCV E1-H6, ПРОДУЦИРУЕМОГО HANSENULA, И HCV E1, ПРОДУЦИРУЕМОГО КЛЕТКАМИ МЛЕКОПИТАЮЩЕГО, ИНФИЦИРОВАННЫМИ ВИРУСОМ КОРОВЬЕЙ ОСПЫ, С СЫВОРОТКАМИ ОТ ВАКЦИНИРОВАННЫХ ШИМПАНЗЕ
Сравнивали реактивности E1, продуцируемого клетками млекопитающего, инфицированными HCV-рекомбинантным вирусом коровьей оспы, и E1-H6, продуцируемого Hansenula (оба алкилированы), с сыворотками от вакцинированных шимпанзе и с моноклональными антителами. Для этого наносили указанные белки E1 прямо на планшеты для ELISA с последующим насыщением этих планшетов казеином. Определяли конечные титры антител, связывающих белки E1, нанесенные на планшеты для ELISA, для сывороток шимпанзе и для специфичных мышиных моноклональных антител, которые были получены от животных, иммунизированных белком E1, продуцируемым клетками млекопитающего. Определение конечного титра выполняли так, как описано в Примере 22. Использованными мышиными моноклональными антителами были IGH201 (см. Пример 15), IGH198 (IGH198=23С12 в Maertens et al. в WO 96/04385), IGH203 (IGH203=15G6 в Maertens et al. в WO 96/04385) и IGH202 (IGH202=3F3 в Maertens et al. в WO 99/50301).
Как можно заключить из Фиг.53, при тестировании белка E1, продуцированного как Hansenula, так и клеткам млекопитающего, реактивности семи разных шимпанзе идентичны. Реактивности моноклональных антител против белка HCV E1 также почти равны. Два из шимпанзе (Yoran и Marti) были включены в исследовании профилактической вакцины и были способны избежать острой инфекции при инфицировании, тогда как контрольное животное не избежало этой инфекции. Пять других шимпанзе (Ton, Phil, Marcel, Femma) были включены в исследования терапевтической вакцинации и при иммунизациях HCV E1 продемонстрировали уменьшение поражения печени согласно результатам определения ALT (аланинаминотрансфераза) в сыворотке и/или гистологическому индексу активности при биопсии печени.
Результаты, полученные в этом эксперименте, явно отличаются от того, что было обнаружено Mustilli и соавторы (Mustili, A.C. et al. 1999), которые экспрессировали белок HCV E2 как в Saccharomyces cerevisiae, так и в Kluyveromyces lactis. Очищенный белок E2, продуцируемый дрожжами, отличался от HCV E2, продуцированного клетками млекопитающего (СНО, клетки яичника китайского хомячка) в том, что с сыворотками от шимпанзе, иммунизированных HCV E2, продуцированным клетками млекопитающего, наблюдали более низкую активность, тогда как реактивность с моноклональными антителами была более высокой для продуцируемого дрожжами белка HCV E2.
ПРИМЕР 25
ГЛИКОПРОФИЛИРОВАНИЕ HCV E1 УГЛЕВОДНЫМ ЭЛЕКТРОФОРЕЗОМ С ИСПОЛЬЗОВАНИЕМ ФЛУОРОФОРА (FACE)
Сравнивали профили гликозилирования HCV E1, продуцируемого Hansenula, и HCV E1, продуцируемого клетками млекопитающего, инфицированными HCV-рекомбинантным вирусом коровьей оспы, как описано Depla et al. в WO 99/67285. Это осушествляли углеводным электрофорезом с использованием флуорофора (FACE). Для этого из E1s, продуцированного клетками млекопитающего или Hansenula, с помощью пептид-N-гликозидазы (PNGase F) высвобождали олигосахариды и метили ANTS (перед обработкой пептид-N-гликозидазой белки E1 алкилировали йодоацетамидом). Разделяли ANTS-меченые олигосахариды электрофорезом в ПААГ в 21%-ном полиакриламидном геле при силе тока 15 мА при 4°С в течение 2-3 часов. Из Фиг.54 сделали вывод, что олигосахариды на белке E1, продуцированном клетками млекопитающего, и на белке Е1-Н6, продуцированном Hansenula, мигрируют подобно олигомальтозе со степенью полимеризации от 7 до 11 моносахиридов. Это свидетельствует о том, что экспрессионная система Hansenula удивительным образом приводит к белку E1, который не гипергликозилирован и имеет цепи сахаров с длиной, сходной с цепями сахаров, добавляемых к белкам E1, продуцируемым в клетках млекопитающего.
ПРИМЕР 26
СЕКВЕНИРОВАНИЕ N-СВЯЗАННОГО ОЛИГОСАХАРИДА, ПОЛУЧЕННОГО ИЗ E1s, ПРОДУЦИРУЕМОГО SACCHAROMYCES И HANSENULA, И ИЗ E1s, ПРОДУЦИРУЕМОГО КЛЕТКАМИ МЛЕКОПИТАЮЩЕГО, ИНФИЦИРОВАННЫМИ HCV-РЕКОМБИНАНТНЫМ ВИРУСОМ КОРОВЬЕЙ ОСПЫ
Белок E1s (225 мкг), очищенный из культуры Saccharomyces или Hansenula (см. Примеры 15-16) или из культуры клеток RK13, инфицированных HCV-рекомбинантным вирусом коровьей оспы (см. Maertens et at. в WO 96/04385) и представленный в PBS, 0,5% бетаина, разбавляли инкубационным буфером для дегликозилирования (50 мМ Na2HPO4, 0,75% Nonidet P-40) до конечной концентрации 140 мкг/мл. Концентрированной Н3РО4 доводили рН этого раствора до рН 5,5. К этому раствору добавляли 2 ед. PNGase F (пептид-N4-ацетил-бета-глюкозаминил)-аспарагинамидаза из Flavobacterium meningosepticum; EC 3.5.1.52, получена от Roche) и инкубировали этот образец в течение ночи при 37°С. После инкубации в течение ночи доводили рН этого раствора до рН 5,5 концентрированной Н3РО4. Затем осаждали белки и олигосахариды добавлением 4-х объемов ацетона (при -20°С) и инкубировали эти смеси при -20°С в течение 15 мин. Центрифугировали образцы при 4°С в течение 5 мин при 13000 об/мин. Отбрасывали ацетоновый супернатант и после добавления 150 мкл ледяного 60%-ного метанола инкубировали осадок при -20°С в течение 1 часа. Собирали этот метанольный супернатант, содержащий высвобожденные олигосахариды, и сушили роторным выпариванием (SpeedVac).
Растворяли высушенные гликаны белка E1s, а также эталонные олигосахариды (все от Glyco, Bicester, UK; см. Фиг.55) Man-9 (11 моносахаридных единиц), Man-8 (10 моносахаридных единиц), Man-7 (9 моносахаридных единиц), Man-6 (8 моносахаридных единиц) и Man-5 (7 моносахаридных единиц) в 5 мкл 2-аминобензамидного (2-АВ) метящего реагента (±0,35М 2-АВ + ±1М NaCNBH3 в 30% НОАс/70% DMSO) с получением конечной концентрации гликанов между 5 и 100 мкМ. Затем инкубировали этот раствор гликанов в течение 2 часов при 65°С. Через 30 мин перемешивали образцы на вортексе. Избыток 2-аминобензамида после конъюгации удаляли следующим образом. Образец разводили в 16 мкл очищенной воды (MilliQ) и наносили на колонку с Sephadex G-10 (диаметр 1 см, высота 1,2 см, Amersham Biosciences, присоединена к системе VacElut, Varian) после того, как колонку продували досуха.
Элюировали меченые олигосахариды нанесением двух порций по 100 мкл очищенной воды (MilliQ) на колонку. Высушивали элюаты эталонных углеводов (Man-9, Man-8, Man-7 и Man-6) и хранили их при -70°С до анализа способом ВЭЖХ. Распределяли элюаты образцов белка E1s, а также эталонного гликана Man-9 по 4-м пронумерованным пробиркам для ПЦР и высушивали. Проводили реакции, как указано в Табл.8, причем всем реакциям давали проходить в течение ночи при 37°С, кроме реакции в пробирке 3, которую останавливали через 1 час. Конечными концентрациями использованных экзогликозидазных ферментов (все получены от Glyko, Bicester, UK) были: для α1-2-маннозидазы (из Aspergillus saitoi) - 2 миллиединицы/мл; для α-маннозидазы (Jack Bean) - 50 ед./мл; для β-маннозидазы (Helix pomatia) - 4 ед./мл.
| Таблица 8. Сводка по реакционным смесям для секвенирования олигосахаридов |
|||||
| Номер пробирки | 1 | 2 | 3 | 4 | 5 |
| E1s (пмоль) | 400 | 400 | 400 | 400 | 400 |
| α-1-2-маннозидаза (мкл) | - | 4 | - | - | - |
| α-маннозидаза (мкл) | - | - | 5 | 5 | 5 |
| β-маннозидиза (мкл) | - | - | - | - | 4 |
| инкубационный буфер 4× (мкл) | 5 | 5 | 5 | 5 | 5 |
| H2O качества MilliQ (мкл) | 15 | 11 | 10 | 10 | 6 |
На Фиг.56 показана высшая олигоманноза, состоящая из 10 маннозных группировок, присоединенных к хитобиозе. Каждый терминальный маннозный остаток связан α(1-3)-связью с неконцевым маннозным остатком. Олигоманноза на Фиг.56 полностью устойчива к расщеплению экзогликозидазой α-(1-2)-маннозидазой. Длительная (в течение ночи) инкубация олигоманнозы по Фиг.56 с экзогликозидазой α-маннозидазой приводит к расщеплению всех α-связей, а именно, α-(1-2), α-(1-3), α-(1-6), но не β-связей. Получившимся олигосахаридом, таким образом, должна быть 4'-β-маннозилхитобиоза. Эту 4'-β-маннозилхитобиозную группировку можно превратить в маннозу и хитобиозу действием экзогликозидазы β-маннозидазы. В соответствии со спецификациями поставщика (Glyko), α-маннозидаза полностью превращает эталонный олигосахарид Man-6 (см. Фиг.55 D) в 4'-маннозилхитобиозу, и сообщается, что ее дальнейшее превращение в маннозу и хитобиозу тоже является полным.
На Фиг.57 показана высшая олигоманноза, состоящая из 9 маннозных группировок, присоединенных к хитобиозе. В этой олигоманнозе один концевой маннозный остаток связан α(1-2)-связью с неконцевым маннозным остатком. При действии экзогликозидазы α-(1-2)-маннозидазы указанная α-(1-2)-связанная манноза удаляется. При последующем действии α-маннозидазы и β-маннозидазы получаются продукты реакции, описанные для олигоманнозы согласно Фиг.56. В соответствии со спецификациями поставщика (Glyko), α-(1-2)-маннозидаза способна превращать эталонные олигосахариды Man-9 и Man-6 в Man-5 (см. Фиг.55) с эффективностью более 90%.
На Фиг.58 показана эталонная высшая олигоманноза Man-9, состоящая из 9 маннозных группировок, присоединенных к хитобиозе. В этой олигоманозе концевой маннозный остаток связан α(1-2)-связью с неконцевым маннозным остатком. При действии экзогликозидазы α-(1-2)-маннозидазы Man-9 превратится, таким образом, в Man-5, в соответствии со спецификацией поставщика, более чем на 90%. Последующее расщепление α-маннозидазой превращает Man-5 в 4'-β-маннозилхитобиозу.
Содержимое разных реакционных пробирок, как указано в Табл.8, высушивали на центрифужном вакуумном испарителе или в лиофилизаторе и хранили при -70°С до анализа способом ВЭЖХ. Перед нанесением на колонку каждый образец (белок E1s и эталон) растворяли в 25 мкл воды и наносили на колонку TSK gel-Amide-80 (0,46×25 см, Tosoh Biosep), подсоединенную к установке ВЭЖХ Waters Alliance.
Разделение олигосохаридов осуществляли при температуре окружающей среды при 1,0 мл/мин. Растворитель А состоял из 0,1% уксусной кислоты в ацетонитриле, растворитель В состоял из 0,2% уксусной кислоты и 0,2% триэтиламина в воде. Разделение олигосахаридов, меченных 2-аминобинзамидом, осуществляли с использованием 28% В, изократического для 5 объемов колонки, за которым следовало линейное увеличение до 45% В для пятнадцати объемов колонки.
Эталонный олигосахарид Man-6 элюируется при 53±1 мин, Man-7 элюируется при 59±1 мин, Man-8 при 67±2 мин, а Man-9 при 70±1 мин; 4'-β-маннозилхитобиоза элюируется при 10±1 мин, а хитобиоза при 6±1 мин (не показано). Пример приведен для реакционного продукта Man-9 после инкубации в течение ночи без экзогликозидаз (кривая 1 хроматограммы на Фиг.63; только Man-9), после инкубации в течение ночи с α-(1-2)-маннозидазой (кривая 2 хроматограммы на Фиг.63; смесь Man-5 и Man-6), после инкубации с α-маннозидазой в течение 1 часа или ночи (кривые 3 и 4, соответственно, хроматограммы на Фиг.63; только 4'-β-маннозилхитобиоза) и после инкубации в течение ночи с α-и β-маннозидазой (кривая 5 хроматограммы на Фиг.63; только хитобиоза). Кривая 6 хроматограммы на Фиг.63 показывает примененный градиент растворителя.
Продуктами реакции олигосахаридов белка E1s, продуцируемого Saccharomyces (получено после обработки PNGaseF), без экзогликозидаз были главным образом четыре присутствующих углевода, элюируемые при 59±1 мин (15%), 67±1 мин (45%), 70±1 мин (25%) и 75±1 мин (15%). Общее содержание Man(8)-GlcNAc(2) и Man(9)-GlcNAc(2) в белке E1s, продуцируемом Saccharomyces, составляло около 65%. В реакции с α-1-2-маннозидазой исчезли только углеводы со временем удерживания 70±1 мин. Интенсивность углевода со временем удерживания 75±1 мин осталась той же, а интенсивность углевода со временем удерживания 67±1 мин увеличилась. Это значит, что не все концевые маннозные единицы имеют α-(1-2)-конфигурацию. После инкубации в течение ночи с α-маннозидазой все углеводные цепи были восстановлены до 4'-β-маннозилхитобиозной группировки. Это значит, что углевод является высшей маннозой и все маннозные остатки, кроме одного, имеют α-конфигурацию. Восстановление этой 4'-β-маннозилхитобиозной группировки до хитобиозы обнаружилось после инкубации в течение ночи с β-маннозидазой. Полученные хроматограммы изображены на Фиг.64 и были получены при тех же условиях, что описаны для хроматограммы на Фиг.63. Результаты суммированы в Табл.9.
Неожиданно такие же эксперименты, повторенные с E1s, продуцированным клетками, инфицированными вирусом коровьей оспы, показали совершено другую картину. В реакционной смеси без ферментов присутствовала сложная смесь углеводов (см. Фиг.65 и Таблицу 9). Общее содержание моносахарид(8)-GlcNAc(2) и моносахарид(9)-GlcNAc(2) составляло 37%. После реакции с α-1-2-маннозидазой исчезли углеводы с величинами времени удерживания 70±1 мин и 59±1 мин. После инкубации в течение ночи с α-маннозидазой осталось значительное количество моносахарид(6)-GlcNAc(2) в дополнение к продукту, представляющему собой 4'-β-маннозилхитобиозу. Это указывает на то, что одна из олигосахаридных цепей устойчива к разложению α-маннозидазой. Это можно объяснить присутствием одного или двух глюкозных остатков, присоединенных к Manα(1-2)-терминированной цепи N-связанного олигосахарида. Предполагаемая структура такого олигосахарида, содержащего глюкозу, представлена на Фиг.62. Возможные реакционные продукты олигосахаридов, содержащих глюкозу, приведены в Таблице 10. Поскольку после α-1-2-маннозидазной реакции не остаются Man-7-эквивалентные олигосахариды (то есть олигосахариды, состоящие из 9 моносахаридов), эти глюкозные остатки скорее всего связаны с В-цепью олигосахаридной структуры, приведенной на Фиг.62. Однако нельзя исключить, что обе цепи, А и В, олигосахарида на Фиг.62 частично терминированы глюкозой.
Восстановление этой 4'-β-маннозилхитобиозной группировки до хитобиозы обнаружилось после инкубации в течение ночи с β-маннозидазой. Полученные хроматограммы изображены на Фиг.65 и были получены при тех же условиях, что описаны для хроматограмм на Фиг.63-64. Полученные результаты суммированы в Табл.9.
Такие же эксперименты были повторены с белком E1s, продуцированым Hasenula, и неожиданно они показали совершенно другую картину. В реакции без ферментов присутствовали главным образом два углевода с временем удерживания 67±2 мин и 70±1 мин, что соответствует Man-8 и Man-9, соответственно. Общее содержание Man(8)-GlcNAc(2) и Man(9)-GlcNAc(2) в белке E1s, который продуцирован Hasenula, составляло около 90%. После реакции с α-(1-2)-маннозидазой углеводы были восстановлены главным образом до Man-5 со временем удерживания 45±1 мин и Man-6 со временем удерживания 53±1 мин. После инкубации в течение ночи с α-маннозидазой все углеводные цепи были восстановлены до 4'-β-маннозилхитобиозной группировки. Это значит, что углевод является высокоманнозным и все маннозные остатки, кроме одного, имеют α-конфигурацию. Восстановление этой 4'-β-маннозилхитобиозной группировки до хитобиозы стало очевидным после инкубации в течение ночи с β-маннозидазой. Полученные хроматограммы изображены на Фиг.66 и они были получены при тех же условиях, что описаны для хроматограмм на Фиг.63-65.
Полученные результаты суммированы в Табл.9.
| Таблица 9. Олигоманнозы, получающиеся при расщеплении олигоманноз, полученных из E1s, продуцируемых Saccharomyces ("Sc") и Hansenula ("Hp"), a также из E1s, продуцируемого клетками млекопитающего, инфицированными HCV-рекомбинантным вирусом коровьей оспы ("Vac"). Указаны разные олигоманнозы и значения их хроматографического времени удерживания ("Rt" в минутах), а процентное содержание данной олигоманнозы относительно общего содержания олигоманноз (верхний ряд), а также наиболее вероятная структура для каждой наблюдаемой олигоманнозы указаны с отсылкой к любому из Фиг.55-62. Олигоманнозы с концевыми α-(1-3)-маннозами отмечены зонком "°". Олигоманнозы с концевыми глюкозами отмечены знаком "*", для некоторых сделана отсылка "из 62*", означающая, что данную структуру можно получить из структуры, приведенной на Фиг.62. "1" означает реакцию без экзогликозидаз, "2" означает реакцию с α-(1-2)-маннозидазой. Олигоманноза со временем удерживания 45±1 мин предположительно является олигоманнозой, содержащей 5 маннозных остатков, связанных с хитобиозой. Олигоманноза со временем удерживания 75±1 мин предположительно является олигоманнозой, содержащей 10 маннозных остатков, связанных с хитобиозой. |
||||||
| (Man-5) Rt: 45±1 | Man-6 Rt: 53±1 | Man-7 Rt:59±1 | Man-8 Rt: 67±1 | Man-9 Rt:70±1 | (Man-10) Rt:75±1 | |
| Sc1 структура | / | 1% 55.D |
14% 55.С | 42% 59° |
23% 57° 61° |
18% 56° |
| Sс2 структура | 17% 55.Е |
/ | 8% 60° |
50% 59° |
6% 57° 61° |
16% 56° |
| Vac1 структура | 3% 55.Е |
32% из 62* и Табл.10 | 20% 55.С | 23% из 62* и Табл.10 | 14% из 62* и Табл.10 | 14% из 62* и Табл.10 |
| Vac1 структура | 74% 55.Е |
2% из 62* и Табл.10 | / | 20% из 62* и Табл.10 | 4% из 62* и Табл. 10 | / из 62* и Табл.10 |
| Нр1 структура | / | 2% 55.D |
7% 55.С |
54% 55.В |
36% 58 | / |
| Нр21 структура | 80% 55.Е |
20% 55.D |
/ | / | / | / |
| Таблица 10. Продукты, содержащие глюкозу N-связанных олигосахаридов после реакции с α-(1-2)-маннозидазой или α-(1-2)-маннозидазой и α-маннозидазой |
|||
| Man-эквивалент | Продукт α-(1-2)-маннозидазы (1) | продукт α-маннозидазы (после (1)) | |
| Ветвь А+2 Glc | Man-10 | Man-8 | Man-6 |
| Ветвь А+1 Glc | Man-9 | Man-7 | Man-6 |
| Ветвь А без Glc | Man-8 | Man-5 | 4'-β-маннозилхитобиоза |
| Ветвь В+2 Glc | Man-10 | Man-9 | Man-6 |
| Ветвь В+1 Glc | Man-9 | Man-8 | Man-6 |
| Ветвь В без Glc | Man-8 | Man-5 | 4'-β-маннозилхитобиоза |
ПРИМЕР 27
ОККУПАЦИЯ САЙТОВ N-ГЛИКОЗИЛИРОВАНИЯ В РЕКОМБИНАНТНОМ HCV E1
В зависимости от количества оккупированных сайтов N-гликозилирования, E1s демонстрирует разное миграционное поведение при анализе посредством Na-ДДС-ПААГ-электрофореза. На основании этого свойства можно оценить среднее количество оккупированных сайтов N-гликозилирования в E1 продукте. Для этого образцы очищенного E1-продукта подвергали Na-ДДС-электрофорезу в ПААГ и окрашиванию красителем кумасси бриллиантовым синим (Coomassie Brilliant Blue) (Фиг.67) и анализировали далее с помощью пакета программного обеспечения ImageMaster 1D Prime (Pharmacia). Вкратце, сканировали гель и для каждого конкретного белка оценивали полосу и % присутствия (ее интенсивность относительно суммарной интенсивности разных полос, вследствие чего сумма всех полос составляет 100%) (Табл.11). Следует отметить, что каждая конкретная полоса белка представляет E1s-молекулы с одним и тем же числом оккупированных сайтов N-гликозилирования.
Полученные результаты показали, что основная часть (>90%) E1-продукта, продуцируемого Hansenula, имеет число оккупированных сайтов N-гликозилирования, которое на один или более чем один сайт меньше, чем имеет белок E1s, полученный из экспрессионной системы на основе вируса коровьей оспы (как описали Maertens et al. в WO 96/04385). Если допустить, что в E1 продукте, полученном из вируса коровьей оспы, оккупированы все сайты N-гликозилирования (в которых последовательность "NNSS" (SEQ ID NO:73) в положении 233-236 в Е1 рассматривается как один сайт N-гликозилирования), вполне можно заключить, что среднее число оккупированных сайтов N-гликозилирования в белке Е1, экспрессируемом Hansenuta, не превосходит 80% от всех доступных сайтов N-гликозилирования.
| Табл.11. Оценка среднего числа оккупированных сайтов N-гликозилирования в белках Е1, полученных из Hansenula polymorpha и экспрессионных систем коровья оспа/vero, Na-ДДС-электрофорезом в ПААГ и анализом интенсивности окрашивания красителем Кумасси бриллиантовый синий. Белковые полосы указаны по молекулярной массе. См. Фиг.67. |
||
| Алкилированный E1s | % присутствия (относительная интенсивность) | |
| Hansenula polymorpha | Эксперимент 1 | Эксперимент 2 |
| молекулярная масса 29 | 9 | 8 |
| молекулярная масса 25 | 25 | 27 |
| молекулярная масса 21 | 38 | 42 |
| молекулярная масса 18 | 27 | 22 |
| молекулярная масса 14-15 | не определено количественно | не определено количественно |
| Коровья оспа/vero | ||
| молекулярная масса 29 | 100 | 100 |
ПРИМЕР 28
ОККУПАЦИЯ САЙТОВ N-ГЛИКОЗИЛИРОВАНИЯ В РЕКОМБИНАНТНОМ HCV E2
Дегликозилировали ферментом PNGase F двести (200) мкг белка Е2-Н6, продуцированного Hansenula. Дегликозилированный E2s-H6 наносили на мини-гель (10 мкг/дорожка). Полосы белка обрабатывали трипсином и endoAsp-N. Определяли массы получившихся белков масс-спектрометрией Maldi-MS (метод высушенной капли и тонкого слоя).
Этот метод можно использовать для определения степени N-гликозилирования: во время дегликозилирования фермент PNGase F отщепляет полную цепь сахара и в то же время аспарагин (N) гидролизуется до аспарагиновой кислоты (D). Разница по массе между этими двумя аминокислотами составляет 1 Да, что можно определить масс-спектрометрией. Кроме того, гидролиз N до D создает новые сайта расщепления для фермента Asp-N.
Возможными сайтами гликозилирования в E2s являются N417, N423, N430, N448, N532, N540, N556, N576, N623 и N645 (см. Фиг.68). Анализ Maldi-MS показал для каждого из этих сайтов гликозилирования, что N-гликозилирование не полное, потому что после дегликозилирования посредством PNGase F были найдены пептиды либо с N, либо с D в сайте гликозилирования (разница по массе составляет 1 Да). Отношение числа D-остатков к числу N-остатков дает показатель средней оккупации одной сайта N-гликозилирования цепью сахара по всем белкам E2, экспрессируемым Hansenula и присутствующим в анализируемом образце. Эти результаты суммированы в Табл.12-14.
Из этих результатов рассчитали, что в среднем каждый сайт гликозилирования был гликозилирован примерно на 54%.
| Таблица 12. Процент гликозилирования, определенный по пептидам, являющимся продуктами действия трипсина, содержащими один сайт N-гликозилирования |
||||||||
| Сайт N-гликозилирования | Гликозилировано | Не гликозилировано | ||||||
| N430 | 60% | 40% | ||||||
| N448 | 50% | 50% | ||||||
| N556 | 80% | 20% | ||||||
| N576 | 90% | 10% | ||||||
| N623 | 20% | 80% | ||||||
| N645 | 10% | 90% | ||||||
| Таблица 13. Процент гликозилирования, определенный по пептидам, являющимся продуктами действия трипсина, содержащими два сайта N-гликозилирования |
||||||||
| Сайт N-гликозилирования | Оба сайта гликозилированы | 1 из двух сайтов гликозилирован | Ни один из сайтов не гликозилирован | Рассчитано для одного N | ||||
| N417 и N423 | 70% | 25% | 5% | 85% | ||||
| N532 и N540 | 0% | 80% | 20% | 40% | ||||
| Таблица 14. Процент гликозилирования, определенный для N478, в переваре Asp-N |
||||||||
| Сайт N-гликозилирования | Гликозилировано | Не гликозилировано | ||||||
| N478 | 35% | 65% | ||||||
ПРИМЕР 29
РЕАКТИВНОСТЬ СЫВОРОТОК ОТ ДОНОРОВ КРОВИ С HCV Е1, ПРОДУЦИРУЕМЫМ SACCHAROMYCES ИЛИ HANSENULA
Оба белка, E1s-H6, продуцируемый Saccharomyces (эспрессируемый с α-MF лидером), и E1s-H6, продуцируемый Hansenula (экспрессируемый с CL лидером), очищали, как описано в Примерах 15 и 16 и в заключении подвергали их алкилированию и процедуре образования VLP как описано в Примере 20. Адсорбировали оба белка прямо на титрационный микропланшет при 0,5 мкг/мл (1 час, 37°С) и после блокирования планшета (PBS-0,1% казеин, 1 час, 37°С) инкубировали сыворотки от прошедших скрининг на HCV негативных доноров крови в разведении 1/20 (PBS-0,5% казеин, 10% (масс//об/) сахароза, 0,2% (об//об.) Тритон Х-705, 1 час, 37°С). В заключении определяли связывание, используя вторичную кроличью анти-человеческий IgG-Fc специфическую антисыворотку, конъюгированную с пероксидазой (Dako, Denmark) в разведении 1/50000 (PBS-0,1% казеин, 1 час, комнатная температура), с последующим развитием окраски. Между всеми этапами трижды промывали планшеты PBS-0,05% (масс//об.) Твин-20. Для сравнения также анализировали эти сыворотки идентичным образом на E1s, полученном из клеток млекопитающего и продуцированном и очищенном как описали Depla et al. в WO 99/67285.
Уровень отсечки для этого анализа способом ELISA установили в двукратное среднее фона (то есть реактивность всех сывороток в тех же самых условиях, но со стрептавидином, адсорбированном на лунках).
По Табл.15 можно судить, что реактивность выше указанного уровня отсечки с Saccharomyces-продуцированным Е1 проявили многие (75%) сыворотки, тогда как некоторую реактивность выше указанного уровня отсечки с Hansenula-продуцированным Е1 проявили только немногие сыворотки (6%). Эту разницу в реактивности приписали присутствию концевых α(1-3)-манноз, связанных с α(1-2)-маннозами Saccharomyces-продуцированного Е1, как свидетельствует Пример 26. Young и соавторы (1998) ранее уже показали, что этот тип манноз также ответственен за реактивность человеческих сывороток с маннаном из Saccharomyces. Для дальнейшего подтверждения того, что реактивность с Saccharomyces-продуцированным Е1 можно приписать этому типу маннозных остатков, повторили ELISA с Saccharomyces-продуцированным Е1, причем разведенные сыворотки доноров крови предварительно инкубировали (1 час при 37°С) с 1 или 5 мг/мл маннана (Sigma), добавленным к буферу для разведения. Как можно судить по Табл.16, предварительная инкубация с маннаном снижала реактивность этого белка Е1 с сыворотками доноров крови зависимым от концентрации образом до фоновых уровней у всех анализированных сывороток, кроме одной (F556). (Средняя оптическая плотность снижалась от 0,24 без конкуренции со стороны маннана до 0,06 с использованием 5 мг маннана/мл.)

| Табл.16. Реактивность белка Е1, продуцируемого в клетках Saccharomyces, как в Табл.15, но в присутствии 5 мг маннана/ мл. Реактивности выше уровня отсечки указаны в черных ячейках |
|||
| № сыворотки | Концентрация маннана | ||
| 0 мг/мл | 1 мг/мл | 5 мг/мл | |
| F552 | 0,207 | 0,128 | 0,103 |
| F553 | 0,487 | 0,098 | 0,050 |
| F555 | 0,066 | 0,044 | 0,041 |
| F556 | 0,769 | 0,540 | 0,372 |
| F557 | 0,158 | 0,094 | 0,088 |
| F558 | 0,250 | 0,076 | 0,046 |
| F559 | 0,300 | 0,077 | 0,066 |
| F560 | 0,356 | 0,088 | 0,044 |
| F562 | 0,122 | 0,106 | 0,089 |
| F563 | 0,164 | 0,091 | 0,049 |
| F570 | 0,110 | 0,043 | 0,040 |
| F571 | 0,212 | 0,057 | 0,042 |
| F572 | 0,464 | 0,087 | 0,043 |
| F575 | 0,095 | 0,081 | 0,062 |
| F576 | 0,138 | 0,042 | 0,043 |
| F577 | 0,216 | 0,042 | 0,041 |
| F578 | 0,125 | 0,100 | 0,093 |
| F581 | 0,083 | 0,064 | 0,042 |
| F594 | 0,102 | 0,044 | 0,041 |
| F595 | 0,520 | 0,088 | 0,044 |
| F598 | 0,340 | 0,054 | 0,042 |
| F450 | 0,053 | 0,060 | 0,053 |
| F453 | 0,116 | 0,049 | 0,044 |
| F456 | 0,112 | 0,050 | 0,043 |
| F458 | 0,086 | 0,051 | 0,042 |
| F459 | 0,054 | 0,044 | 0,042 |
| F463 | 0,078 | 0,043 | 0,041 |
| F466 | 0,172 | 0,111 | 0,085 |
| F467 | 0,420 | 0,117 | 0,049 |
| F469 | 0,053 | 0,043 | 0,041 |
| F470 | 0,220 | 0,070 | 0,061 |
| F473 | 0,924 | 0,183 | 0,063 |
| F479 | 0,059 | 0,049 | 0,043 |
| F480 | 0,281 | 0,155 | 0,054 |
| F481 | 0,355 | 0,042 | 0,046 |
| F488 | 0,474 | 0"090 | 0,046 |
| среднее | 0,243 | 0,089 | 0,062 |
Источники информации








































































































































































Claims (37)
1. Выделенный оболочечный белок HCV (вирус гепатита С) или его фрагмент, индуцирующий HCV-специфичный иммунный ответ и содержащий по меньшей мере один сайт N-гликозилирования, отличающийся тем, что он является продуктом экспрессии в эукариотической клетке и дополнительно отличающийся тем, что в среднем до 80% сайтов N-гликозилирования являются кор-гликозилированными.
2. Выделенный оболочечный белок HCV или его фрагмент по п.1, где более 70% указанных кор-гликозилированных сайтов гликозилированы олигоманнозой, содержащей от 8 до 10 манноз.
3. Выделенный оболочечный белок HCV или его фрагмент по п.1, где соотношение сайтов, кор-гликозилированных олигоманнозой со структурой, определяемой как Man(7)-GlcNAc(2), и сайтов, кор-гликозилированных олигоманнозой со структурой, определяемой как Man(8)-GlcNAc(2), меньше или равно 0,45.
4. Выделенный оболочечный белок HCV или его фрагмент по п.2, где указанные олигоманнозы содержат менее 10% концевой α1,3-маннозы.
5. Выделенный оболочечный белок HCV или его часть по п.1, который является продуктом экспрессии в дрожжевой клетке.
6. Выделенный оболочечный белок HCV или его часть по п.5, где указанная дрожжевая клетка является клеткой Hansenula.
7. Выделенный оболочечный белок HCV или его часть по п.1, который получен из белка, содержащего лидерный пептид птичьего лизоцима или его функциональный вариант, присоединенный к указанному оболочечному белку HCV или его фрагменту.
8. Выделенный оболочечный белок HCV или его часть по п.7, который получен из белка, характеризуемого следующей структурой:
CL-[(Al)a-(PS1)b-(A2)c]-HCVENV-[(A3)d-(PS2)e-(A4)f],
где CL представляет собой лидерный пептид птичьего лизоцима или его функциональный эквивалент;
А1, А2, A3 и А4 являются адаптерными пептидами, которые могут быть одинаковыми или разными;
PS1 и PS2 являются сайтами процессинга, которые могут быть одинаковыми или разными;
HCVENV представляет собой оболочечный белок HCV или его часть;
а, b, с, d, e и f обозначают 0 или 1, и
где, возможно, A1 и/или А2 являются частью PS1, и/или A3 и/или А4 являются частью PS2.
9. Выделенный оболочечный белок HCV или его фрагмент по п.8, где указанный лидерный пептид птичьего лизоцима CL имеет аминокислотную последовательность, определяемую как SEQ ID NO:1.
10. Выделенный оболочечный белок HCV или его фрагмент по п.8, где А имеет аминокислотную последовательность, выбранную из SEQ ID NOs:63-65, 70-72 и 74-82, где PS имеет аминокислотную последовательность, выбранную из SEQ ID NOs:66-68 и 83-84, либо где PS является двухосновным сайтом, таким как Lys-Lys, Arg-Arg, Lys-Arg и Arg-Lys, или одноосновным сайтом, таким как Lys, и где HCVENV выбран из SEQ ID NOs:85-98 и их фрагментов.
11. Мономер, димер или олигомер, содержащий выделенный оболочечный белок HCV или его фрагмент по п.1.
12. Вирусоподобная частица, содержащая выделенный оболочечный белок HCV или его фрагмент по п.1.
13. Выделенный оболочечный белок HCV или его фрагмент по п.1, в котором цистеиновые тиольные группы модифицированы химическим путем.
14. Выделенный оболочечный белок HCV или его фрагмент по п.1, который является антигенным.
15. Выделенный оболочечный белок HCV или его фрагмент по п.1, который является иммуногенным.
16. Выделенный оболочечный белок HCV или его фрагмент по п.1, который содержит Т-клеточный эпитоп.
17. Композиция для индукции HCV-специфичного иммунного ответа, содержащая выделенный оболочечный белок HCV или его фрагмент по любому из пп.1-16 и, возможно, фармацевтически приемлемый носитель.
18. Способ получения выделенного оболочечного белка HCV или его фрагмента по любому из пп.1-16, включающий трансформацию клетки-хозяина рекомбинантной нуклеиновой кислотой или вектором, содержащими открытую рамку считывания, которая кодирует указанный оболочечный белок HCV или его фрагмент, причем указанная клетка-хозяин способна экспрессировать указанный оболочечный белок HCV или его фрагмент.
19. Способ обнаружения присутствия анти-HCV антител в образце, подозреваемом в том, что он содержит анти-HCV антитела, при котором:
1) оболочечный белок HCV или его часть по любому из пп.1-16 приводят в контакт с указанным образцом в условиях, допускающих образование комплекса указанного оболочечного белка HCV или его части с указанными анти-HCV антителами,
2) выявляют комплекс, образовавшийся на стадии (1), и
3) из результатов стадии (2) делают вывод о присутствии указанных анти-HCV антител в указанном образце.
20. Способ по п.19, где указанное приведение в контакт на стадии (1) происходит в конкурентных условиях.
21. Способ по п.19, где указанный оболочечный белок HCV или его часть присоединены к твердой подложке.
22. Диагностический набор для обнаружения присутствия анти-HCV антител в образце, подозреваемом в том, что он содержит анти-HCV антитела, содержащий оболочечный белок HCV или его часть по любому из пп.1-16 и препараты для контроля антител.
23. Диагностический набор по п.22, где указанный оболочечный белок HCV или его часть присоединены к твердой подложке.
24. Лекарство для лечения HCV инфекции, содержащее оболочечный белок HCV или его часть по любому из пп.1-16.
25. Вакцина для профилактики HCV инфекции, содержащая оболочечный белок HCV или его часть по любому из пп.1-16.
26. Фармацевтическая композиция для индукции HCV-специфичного иммунного ответа у млекопитающего, содержащая эффективное количество оболочечного белка HCV или его части по любому из пп.1-16 и, возможно, фармацевтически приемлемый адъювант.
27. Фармацевтическая композиция по п.26, которая является профилактической композицией.
28. Фармацевтическая композиция по п.26, которая является терапевтической композицией.
29. Фармацевтическая композиция по п.26, где указанное млекопитающее является человеком.
30. Фармацевтическая композиция для индукции HCV-специфичных антител у млекопитающего, содержащая эффективное количество оболочечного белка HCV или его части по любому из пп.1-16 и, возможно, фармацевтически приемлемый адъювант.
31. Фармацевтическая композиция по п.30, которая является профилактической композицией.
32. Фармацевтическая композиция по п.30, которая является терапевтической композицией.
33. Фармацевтическая композиция по п.30, где указанное млекопитающее является человеком.
34. Фармацевтическая композиция для индукции Т-клеточной функции у млекопитающего, содержащая эффективное количество оболочечного белка HCV или его части по любому из пп.1-16 и, возможно, фармацевтически приемлемый адъювант.
35. Фармацевтическая композиция по п.34, которая является профилактической композицией.
36. Фармацевтическая композиция по п.34, которая является терапевтической композицией.
37. Фармацевтическая композиция по п.34, где указанное млекопитающее является человеком.
Applications Claiming Priority (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP01870088 | 2001-04-24 | ||
| EP01870088.0 | 2001-04-24 | ||
| US30560401P | 2001-07-17 | 2001-07-17 | |
| US60/305,604 | 2001-07-17 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| RU2003130955A RU2003130955A (ru) | 2005-04-20 |
| RU2274643C2 true RU2274643C2 (ru) | 2006-04-20 |
Family
ID=34072546
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| RU2003130955/13A RU2274643C2 (ru) | 2001-04-24 | 2002-04-24 | Выделенный оболочечный белок hcv, способ его получения и лекарство, вакцина, фармацевтическая композиция (варианты) его содержащие |
Country Status (20)
| Country | Link |
|---|---|
| US (3) | US7238356B2 (ru) |
| EP (3) | EP1414942A2 (ru) |
| JP (2) | JP4261195B2 (ru) |
| KR (1) | KR100950104B1 (ru) |
| CN (1) | CN1636050A (ru) |
| AR (3) | AR035867A1 (ru) |
| AU (3) | AU2002252856A1 (ru) |
| BR (2) | BR0209034A (ru) |
| CA (3) | CA2443781A1 (ru) |
| CZ (1) | CZ20032853A3 (ru) |
| HU (1) | HUP0303924A2 (ru) |
| MX (2) | MXPA03009626A (ru) |
| NZ (2) | NZ529019A (ru) |
| OA (1) | OA13092A (ru) |
| PL (1) | PL366621A1 (ru) |
| RU (1) | RU2274643C2 (ru) |
| SK (1) | SK13142003A3 (ru) |
| WO (3) | WO2002086101A2 (ru) |
| YU (1) | YU84103A (ru) |
| ZA (3) | ZA200308272B (ru) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| RU2741347C2 (ru) * | 2015-11-13 | 2021-01-25 | Тарлан МАММЕДОВ | Получение in vivo n-дегликозилированных рекомбинантных белков посредством совместной экспрессии с endo h |
Families Citing this family (28)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20040185061A1 (en) * | 1994-07-29 | 2004-09-23 | Innogenetics N.V. | Redox reversible HCV proteins with native-like conformation |
| US7238356B2 (en) * | 2001-04-24 | 2007-07-03 | Innogenetics N.V. | Core-glycosylated HCV envelope proteins |
| DE10143490C2 (de) * | 2001-09-05 | 2003-12-11 | Gsf Forschungszentrum Umwelt | Rekombinantes MVA mit der Fähigkeit zur Expression von HCV Struktur-Antigenen |
| EP1558283A2 (en) * | 2002-11-08 | 2005-08-03 | Innogenetics N.V. | Hcv vaccine compositions comprising e1 and ns3 peptides |
| US7439042B2 (en) * | 2002-12-16 | 2008-10-21 | Globeimmune, Inc. | Yeast-based therapeutic for chronic hepatitis C infection |
| JP4371739B2 (ja) * | 2003-09-02 | 2009-11-25 | 株式会社東芝 | シリアルataインタフェースを持つ電子機器及びシリアルataバスのパワーセーブ方法 |
| EP1602664A1 (en) * | 2004-03-08 | 2005-12-07 | Innogenetics N.V. | HCV E1 comprising specific disulfide bridges |
| EP1574517A1 (en) * | 2004-03-09 | 2005-09-14 | Innogenetics N.V. | HCV E1 comprising specific disulfide bridges |
| JP4885476B2 (ja) * | 2004-05-21 | 2012-02-29 | 株式会社日本触媒 | タンパク質及び/又はペプチドの細胞内導入方法 |
| KR20070068460A (ko) * | 2004-10-18 | 2007-06-29 | 글로브이뮨 | 만성 c형 간염에 대한 효모계 치료 |
| AU2011254055B2 (en) * | 2004-10-18 | 2012-12-20 | Globeimmune, Inc. | Yeast-based therapeutic for chronic hepatitis C infection |
| US20060234360A1 (en) * | 2005-04-13 | 2006-10-19 | Paola Branduardi | Ascorbic acid production from D-glucose in yeast |
| US7951384B2 (en) * | 2005-08-05 | 2011-05-31 | University Of Massachusetts | Virus-like particles as vaccines for paramyxovirus |
| US9216212B2 (en) | 2005-08-05 | 2015-12-22 | University Of Massachusetts | Virus-like particles as vaccines for paramyxovirus |
| AR058140A1 (es) * | 2005-10-24 | 2008-01-23 | Wyeth Corp | Metodo de produccion proteica utilizando compuestos anti-senescencia |
| CA2651456A1 (en) * | 2006-05-19 | 2007-11-29 | Glycofi, Inc. | Recombinant vectors |
| AU2015234338C1 (en) * | 2006-07-28 | 2017-07-20 | The Trustees Of The University Of Pennsylvania | Improved vaccines and methods for using the same |
| AU2007288129B2 (en) * | 2006-08-25 | 2013-03-07 | The Macfarlane Burnet Institute For Medical Research And Public Health Limited | Recombinant HCV E2 glycoprotein |
| WO2010033841A1 (en) | 2008-09-19 | 2010-03-25 | Globeimmune, Inc. | Immunotherapy for chronic hepatitis c virus infection |
| WO2010039224A2 (en) | 2008-09-30 | 2010-04-08 | University Of Massachusetts Medical School | Respiratory syncytial virus (rsv) sequences for protein expression and vaccines |
| US20100104555A1 (en) * | 2008-10-24 | 2010-04-29 | The Scripps Research Institute | HCV neutralizing epitopes |
| DE102009044224A1 (de) * | 2009-10-09 | 2011-04-28 | PomBio Tech GmbH Starterzentrum der Universität des Saarlandes Campus Geb. A1-1 | Methode zur Produktion von HCV Virus-ähnlichen Partikeln |
| MY167159A (en) | 2010-12-22 | 2018-08-13 | Bayer Ip Gmbh | Enhanced immune response in bovine species |
| US20140155469A1 (en) | 2011-04-19 | 2014-06-05 | The Research Foundation Of State University Of New York | Adeno-associated-virus rep sequences, vectors and viruses |
| EP3590950A1 (en) | 2011-05-09 | 2020-01-08 | Ablynx NV | Method for the production of immunoglobulin single varible domains |
| CA2940794C (en) * | 2014-02-28 | 2022-05-31 | Bayer Animal Health Gmbh | Immunostimulatory plasmids |
| DK3184642T3 (da) * | 2015-12-22 | 2019-08-12 | Bisy E U | Gærcelle |
| AU2017332854A1 (en) | 2016-09-21 | 2019-04-11 | The Governors Of The University Of Alberta | Hepatitis C virus immunogenic compositions and methods of use thereof |
Family Cites Families (28)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US4395395A (en) * | 1979-05-21 | 1983-07-26 | The United States Of America As Represented By The Department Of Health And Human Services | Detection of non-A, non-B hepatitis associated antigen |
| EP0288198A3 (en) | 1987-04-20 | 1989-03-29 | Takeda Chemical Industries, Ltd. | Production of peptide |
| US5135854A (en) * | 1987-10-29 | 1992-08-04 | Zymogenetics, Inc. | Methods of regulating protein glycosylation |
| US5698390A (en) * | 1987-11-18 | 1997-12-16 | Chiron Corporation | Hepatitis C immunoassays |
| US5350671A (en) * | 1987-11-18 | 1994-09-27 | Chiron Corporation | HCV immunoassays employing C domain antigens |
| US5683864A (en) * | 1987-11-18 | 1997-11-04 | Chiron Corporation | Combinations of hepatitis C virus (HCV) antigens for use in immunoassays for anti-HCV antibodies |
| JP2791418B2 (ja) * | 1987-12-02 | 1998-08-27 | 株式会社ミドリ十字 | 異種蛋白質の製造方法、組換えdna、形質転換体 |
| NO177065C (no) * | 1988-09-26 | 1995-07-12 | Labofina Sa | Framgangsmåte for framstilling av enzymatisk aktivt humant lysozym |
| US5747239A (en) * | 1990-02-16 | 1998-05-05 | United Biomedical, Inc. | Synthetic peptides specific for the detection of antibodies to HCV, diagnosis of HCV infection and preventions thereof as vaccines |
| US5712087A (en) * | 1990-04-04 | 1998-01-27 | Chiron Corporation | Immunoassays for anti-HCV antibodies employing combinations of hepatitis C virus (HCV) antigens |
| WO1992001800A1 (en) * | 1990-07-20 | 1992-02-06 | Chiron Corporation | Method for integrative transformation of yeast using dispersed repetitive elements |
| CA2047792C (en) | 1990-07-26 | 2002-07-02 | Chang Y. Wang | Synthetic peptides specific for the detection of antibodies to hcv, diagnosis of hcv infection and prevention thereof as vaccines |
| RO117329B1 (ro) | 1991-06-24 | 2002-01-30 | Chiron Corp Emeryville | Polipeptide care contin o secventa a virusului hepatitei c |
| AU4659993A (en) | 1992-07-07 | 1994-01-31 | Merck & Co., Inc. | Vaccine comprising mixed pres1+pres2+s and core particle |
| DK0992580T3 (da) * | 1993-11-04 | 2005-07-11 | Innogenetics Nv | Epitoper på human T-celler, som er immundominante for hepatitis C-virus |
| EP1845108A3 (en) * | 1994-07-29 | 2007-10-24 | Innogenetics N.V. | Monoclonal antibodies to purified hepatitis c virus envelope proteins for diagnostic and therapeutic use |
| ZA9610456B (en) * | 1995-12-20 | 1997-06-20 | Novo Nordisk As | N-terminally extended proteins expressed in yeast |
| US5935824A (en) * | 1996-01-31 | 1999-08-10 | Technologene, Inc. | Protein expression system |
| WO1998028429A1 (en) * | 1996-12-20 | 1998-07-02 | Novo Nordisk A/S | N-terminally extended proteins expressed in yeast |
| WO1999024466A2 (en) | 1997-11-06 | 1999-05-20 | Innogenetics N.V. | Multi-mer peptides derived from hepatitis c virus envelope proteins for diagnostic use and vaccination purposes |
| KR20010034305A (ko) * | 1998-01-23 | 2001-04-25 | 한센 핀 베네드 | 효모에서 원하는 폴리펩티드를 만드는 방법 |
| DE69920895T3 (de) | 1998-04-17 | 2009-09-03 | N.V. Innogenetics S.A. | Verbessertes immundiagnostische tests durch verwendung von reduzierende agenzien |
| DK1090033T4 (da) * | 1998-06-24 | 2008-03-31 | Innogenetics Nv | Partikler af HCV-kappeproteiner: Anvendelse til vaccination |
| NZ518095A (en) * | 1999-10-27 | 2003-09-26 | Innogenetics N | Redox reversible HCV proteins with native-like conformation |
| CZ20032164A3 (cs) | 2001-01-11 | 2003-10-15 | Innogenetics N. V. | Purifikované obalové proteiny viru hepatitidy C pro diagnostické a terapeutické použití |
| US7238356B2 (en) * | 2001-04-24 | 2007-07-03 | Innogenetics N.V. | Core-glycosylated HCV envelope proteins |
| WO2003051912A2 (en) | 2001-12-18 | 2003-06-26 | Innogenetics N.V. | Purified hepatitis c virus envelope proteins for diagnostic and therapeutic use |
| EP1558283A2 (en) * | 2002-11-08 | 2005-08-03 | Innogenetics N.V. | Hcv vaccine compositions comprising e1 and ns3 peptides |
-
2002
- 2002-04-24 US US10/128,590 patent/US7238356B2/en not_active Expired - Fee Related
- 2002-04-24 US US10/128,578 patent/US7048930B2/en not_active Expired - Fee Related
- 2002-04-24 JP JP2002583615A patent/JP4261195B2/ja not_active Expired - Fee Related
- 2002-04-24 NZ NZ529019A patent/NZ529019A/en unknown
- 2002-04-24 SK SK1314-2003A patent/SK13142003A3/sk unknown
- 2002-04-24 RU RU2003130955/13A patent/RU2274643C2/ru not_active IP Right Cessation
- 2002-04-24 WO PCT/BE2002/000064 patent/WO2002086101A2/en active IP Right Grant
- 2002-04-24 NZ NZ529324A patent/NZ529324A/en unknown
- 2002-04-24 AR ARP020101493A patent/AR035867A1/es unknown
- 2002-04-24 CN CNA028126076A patent/CN1636050A/zh active Pending
- 2002-04-24 EP EP02721875A patent/EP1414942A2/en not_active Withdrawn
- 2002-04-24 MX MXPA03009626A patent/MXPA03009626A/es not_active Application Discontinuation
- 2002-04-24 MX MXPA03009632A patent/MXPA03009632A/es not_active Application Discontinuation
- 2002-04-24 WO PCT/BE2002/000062 patent/WO2002085932A2/en active IP Right Grant
- 2002-04-24 JP JP2002583616A patent/JP4173741B2/ja not_active Expired - Fee Related
- 2002-04-24 PL PL02366621A patent/PL366621A1/xx not_active Application Discontinuation
- 2002-04-24 AR ARP020101494A patent/AR035868A1/es unknown
- 2002-04-24 EP EP02764023A patent/EP1381671A2/en not_active Withdrawn
- 2002-04-24 HU HU0303924A patent/HUP0303924A2/hu unknown
- 2002-04-24 BR BR0209034-1A patent/BR0209034A/pt not_active IP Right Cessation
- 2002-04-24 AR ARP020101495A patent/AR035869A1/es unknown
- 2002-04-24 CA CA002443781A patent/CA2443781A1/en not_active Abandoned
- 2002-04-24 AU AU2002252856A patent/AU2002252856A1/en not_active Abandoned
- 2002-04-24 BR BR0209033-3A patent/BR0209033A/pt not_active IP Right Cessation
- 2002-04-24 EP EP02727059A patent/EP1417298A2/en not_active Withdrawn
- 2002-04-24 CZ CZ20032853A patent/CZ20032853A3/cs unknown
- 2002-04-24 YU YU84103A patent/YU84103A/sh unknown
- 2002-04-24 CA CA002443740A patent/CA2443740A1/en not_active Abandoned
- 2002-04-24 US US10/128,587 patent/US7314925B2/en not_active Expired - Fee Related
- 2002-04-24 KR KR1020037013778A patent/KR100950104B1/ko not_active IP Right Cessation
- 2002-04-24 AU AU2002308449A patent/AU2002308449B2/en not_active Ceased
- 2002-04-24 CA CA002444006A patent/CA2444006A1/en not_active Abandoned
- 2002-04-24 WO PCT/BE2002/000063 patent/WO2002086100A2/en active Application Filing
- 2002-04-24 OA OA1200500194A patent/OA13092A/en unknown
- 2002-04-24 AU AU2002257392A patent/AU2002257392B2/en not_active Ceased
-
2003
- 2003-10-23 ZA ZA200308272A patent/ZA200308272B/en unknown
- 2003-10-23 ZA ZA200308274A patent/ZA200308274B/en unknown
- 2003-10-23 ZA ZA200308277A patent/ZA200308277B/en unknown
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| RU2741347C2 (ru) * | 2015-11-13 | 2021-01-25 | Тарлан МАММЕДОВ | Получение in vivo n-дегликозилированных рекомбинантных белков посредством совместной экспрессии с endo h |
Also Published As
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| RU2274643C2 (ru) | Выделенный оболочечный белок hcv, способ его получения и лекарство, вакцина, фармацевтическая композиция (варианты) его содержащие | |
| AU2002257392A1 (en) | Core-glycosylated hcv envelope proteins | |
| Nemchinov et al. | Development of a plant-derived subunit vaccine candidate against hepatitis C virus | |
| KR100559096B1 (ko) | Hcv 피막 단백질 입자 및 그의 백신접종용 용도 | |
| AU2002308449A1 (en) | Constructs and methods for expression of recombinant HCV envelope proteins | |
| JP2001511459A (ja) | フラビウイルス感染に対抗する組換え二量体エンベロープワクチン | |
| JP2018533934A (ja) | C型肝炎ウイルスe1/e2ヘテロダイマー及びそれを生成する方法 | |
| JP2001508457A (ja) | デング熱ウイルスのプレm/mエピトープ、合成ペプチド、キメラタンパク質およびその用途 | |
| US20080274144A1 (en) | Hcv e1 comprising specific disulfide bridges | |
| US20190284230A1 (en) | Assembled glycoproteins | |
| US20080124763A1 (en) | Constructs and methods for expression of recombinant proteins in methylotrophic yeast cells | |
| BG108373A (bg) | Гликосилирани в сърцевина протеини, обвиващи вируса на хепатит с | |
| JP2004536582A (ja) | 組換え型hcvエンベロープタンパク質の発現のための構築物及び方法 | |
| JP2007289204A (ja) | 組換え型hcvエンベロープタンパク質の発現のための構築物及び方法 | |
| EP1602664A1 (en) | HCV E1 comprising specific disulfide bridges | |
| SABLON et al. | Patent 2443740 Summary |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| MM4A | The patent is invalid due to non-payment of fees |
Effective date: 20080425 |