KR20210113655A - 전립선 신생항원 및 이의 용도 - Google Patents
전립선 신생항원 및 이의 용도 Download PDFInfo
- Publication number
- KR20210113655A KR20210113655A KR1020217025212A KR20217025212A KR20210113655A KR 20210113655 A KR20210113655 A KR 20210113655A KR 1020217025212 A KR1020217025212 A KR 1020217025212A KR 20217025212 A KR20217025212 A KR 20217025212A KR 20210113655 A KR20210113655 A KR 20210113655A
- Authority
- KR
- South Korea
- Prior art keywords
- seq
- fragment
- polypeptide
- isolated
- present
- Prior art date
Links
- 210000002307 prostate Anatomy 0.000 title abstract description 17
- 102000040430 polynucleotide Human genes 0.000 claims abstract description 753
- 108091033319 polynucleotide Proteins 0.000 claims abstract description 753
- 239000002157 polynucleotide Substances 0.000 claims abstract description 753
- 229960005486 vaccine Drugs 0.000 claims abstract description 106
- 238000000034 method Methods 0.000 claims abstract description 93
- 239000013598 vector Substances 0.000 claims abstract description 93
- 239000012634 fragment Substances 0.000 claims description 1358
- 108090000765 processed proteins & peptides Proteins 0.000 claims description 1073
- 102000004196 processed proteins & peptides Human genes 0.000 claims description 1062
- 229920001184 polypeptide Polymers 0.000 claims description 1052
- 125000003275 alpha amino acid group Chemical group 0.000 claims description 329
- 150000001413 amino acids Chemical class 0.000 claims description 84
- 108090000623 proteins and genes Proteins 0.000 claims description 58
- 210000001744 T-lymphocyte Anatomy 0.000 claims description 56
- 206010060862 Prostate cancer Diseases 0.000 claims description 47
- 208000000236 Prostatic Neoplasms Diseases 0.000 claims description 47
- 210000004027 cell Anatomy 0.000 claims description 39
- 241000700605 Viruses Species 0.000 claims description 36
- 102000004169 proteins and genes Human genes 0.000 claims description 33
- 108091008874 T cell receptors Proteins 0.000 claims description 30
- 102000016266 T-Cell Antigen Receptors Human genes 0.000 claims description 26
- 239000000427 antigen Substances 0.000 claims description 25
- 108091007433 antigens Proteins 0.000 claims description 25
- 102000036639 antigens Human genes 0.000 claims description 25
- 102100034922 T-cell surface glycoprotein CD8 alpha chain Human genes 0.000 claims description 22
- 230000028993 immune response Effects 0.000 claims description 20
- 230000027455 binding Effects 0.000 claims description 18
- 238000011282 treatment Methods 0.000 claims description 18
- 108010019670 Chimeric Antigen Receptors Proteins 0.000 claims description 16
- 239000013603 viral vector Substances 0.000 claims description 16
- -1 IFNγ Proteins 0.000 claims description 14
- 238000007385 chemical modification Methods 0.000 claims description 13
- 229940124597 therapeutic agent Drugs 0.000 claims description 12
- 108060008682 Tumor Necrosis Factor Proteins 0.000 claims description 11
- 102000000852 Tumor Necrosis Factor-alpha Human genes 0.000 claims description 11
- 239000013604 expression vector Substances 0.000 claims description 10
- 230000002441 reversible effect Effects 0.000 claims description 10
- 241000700618 Vaccinia virus Species 0.000 claims description 9
- 230000001939 inductive effect Effects 0.000 claims description 9
- 108091032973 (ribonucleotides)n+m Proteins 0.000 claims description 8
- 108020004705 Codon Proteins 0.000 claims description 8
- 206010046865 Vaccinia virus infection Diseases 0.000 claims description 8
- 238000002560 therapeutic procedure Methods 0.000 claims description 8
- 208000007089 vaccinia Diseases 0.000 claims description 8
- 230000024932 T cell mediated immunity Effects 0.000 claims description 7
- 241000701161 unidentified adenovirus Species 0.000 claims description 7
- 241000598171 Human adenovirus sp. Species 0.000 claims description 6
- 229940125581 ImmunityBio COVID-19 vaccine Drugs 0.000 claims description 6
- 230000004913 activation Effects 0.000 claims description 6
- 239000008194 pharmaceutical composition Substances 0.000 claims description 6
- 230000008488 polyadenylation Effects 0.000 claims description 6
- 229940023860 canarypox virus HIV vaccine Drugs 0.000 claims description 5
- 230000001965 increasing effect Effects 0.000 claims description 5
- 230000035772 mutation Effects 0.000 claims description 5
- 238000002512 chemotherapy Methods 0.000 claims description 4
- 239000003623 enhancer Substances 0.000 claims description 4
- 239000003446 ligand Substances 0.000 claims description 4
- 241000990167 unclassified Simian adenoviruses Species 0.000 claims description 4
- 102000003812 Interleukin-15 Human genes 0.000 claims description 3
- 108090000172 Interleukin-15 Proteins 0.000 claims description 3
- 108010002350 Interleukin-2 Proteins 0.000 claims description 3
- 208000010658 metastatic prostate carcinoma Diseases 0.000 claims description 3
- 238000001356 surgical procedure Methods 0.000 claims description 3
- 241000702421 Dependoparvovirus Species 0.000 claims description 2
- 241000287828 Gallus gallus Species 0.000 claims description 2
- 239000002671 adjuvant Substances 0.000 claims description 2
- 239000003937 drug carrier Substances 0.000 claims description 2
- 239000000556 agonist Substances 0.000 claims 6
- 239000012830 cancer therapeutic Substances 0.000 claims 6
- 239000003112 inhibitor Substances 0.000 claims 6
- 229940076838 Immune checkpoint inhibitor Drugs 0.000 claims 4
- 238000009167 androgen deprivation therapy Methods 0.000 claims 4
- 230000002238 attenuated effect Effects 0.000 claims 4
- 239000012274 immune-checkpoint protein inhibitor Substances 0.000 claims 4
- 241001430294 unidentified retrovirus Species 0.000 claims 4
- 102000007066 Prostate-Specific Antigen Human genes 0.000 claims 3
- 108010072866 Prostate-Specific Antigen Proteins 0.000 claims 3
- 238000004519 manufacturing process Methods 0.000 claims 3
- UJZDIKVQFMCLBE-UHFFFAOYSA-N 1-(4-ethylphenyl)-3-(1h-indol-3-yl)urea Chemical compound C1=CC(CC)=CC=C1NC(=O)NC1=CNC2=CC=CC=C12 UJZDIKVQFMCLBE-UHFFFAOYSA-N 0.000 claims 2
- VSNHCAURESNICA-NJFSPNSNSA-N 1-oxidanylurea Chemical compound N[14C](=O)NO VSNHCAURESNICA-NJFSPNSNSA-N 0.000 claims 2
- BGFTWECWAICPDG-UHFFFAOYSA-N 2-[bis(4-chlorophenyl)methyl]-4-n-[3-[bis(4-chlorophenyl)methyl]-4-(dimethylamino)phenyl]-1-n,1-n-dimethylbenzene-1,4-diamine Chemical compound C1=C(C(C=2C=CC(Cl)=CC=2)C=2C=CC(Cl)=CC=2)C(N(C)C)=CC=C1NC(C=1)=CC=C(N(C)C)C=1C(C=1C=CC(Cl)=CC=1)C1=CC=C(Cl)C=C1 BGFTWECWAICPDG-UHFFFAOYSA-N 0.000 claims 2
- 102100031585 ADP-ribosyl cyclase/cyclic ADP-ribose hydrolase 1 Human genes 0.000 claims 2
- 102100037435 Antiviral innate immune response receptor RIG-I Human genes 0.000 claims 2
- 101710127675 Antiviral innate immune response receptor RIG-I Proteins 0.000 claims 2
- 108010008014 B-Cell Maturation Antigen Proteins 0.000 claims 2
- 102000006942 B-Cell Maturation Antigen Human genes 0.000 claims 2
- 102000008096 B7-H1 Antigen Human genes 0.000 claims 2
- 108010074708 B7-H1 Antigen Proteins 0.000 claims 2
- 229940124291 BTK inhibitor Drugs 0.000 claims 2
- 102100027207 CD27 antigen Human genes 0.000 claims 2
- 229940123205 CD28 agonist Drugs 0.000 claims 2
- 108050005493 CD3 protein, epsilon/gamma/delta subunit Proteins 0.000 claims 2
- 229940123189 CD40 agonist Drugs 0.000 claims 2
- 102100025221 CD70 antigen Human genes 0.000 claims 2
- 108010021064 CTLA-4 Antigen Proteins 0.000 claims 2
- 102000008203 CTLA-4 Antigen Human genes 0.000 claims 2
- 229940045513 CTLA4 antagonist Drugs 0.000 claims 2
- 102100039498 Cytotoxic T-lymphocyte protein 4 Human genes 0.000 claims 2
- 102100021197 G-protein coupled receptor family C group 5 member D Human genes 0.000 claims 2
- 108010017213 Granulocyte-Macrophage Colony-Stimulating Factor Proteins 0.000 claims 2
- 102100039620 Granulocyte-macrophage colony-stimulating factor Human genes 0.000 claims 2
- 101000777636 Homo sapiens ADP-ribosyl cyclase/cyclic ADP-ribose hydrolase 1 Proteins 0.000 claims 2
- 101000914511 Homo sapiens CD27 antigen Proteins 0.000 claims 2
- 101000934356 Homo sapiens CD70 antigen Proteins 0.000 claims 2
- 101000889276 Homo sapiens Cytotoxic T-lymphocyte protein 4 Proteins 0.000 claims 2
- 101001040713 Homo sapiens G-protein coupled receptor family C group 5 member D Proteins 0.000 claims 2
- 101001057504 Homo sapiens Interferon-stimulated gene 20 kDa protein Proteins 0.000 claims 2
- 101001055144 Homo sapiens Interleukin-2 receptor subunit alpha Proteins 0.000 claims 2
- 101000777628 Homo sapiens Leukocyte antigen CD37 Proteins 0.000 claims 2
- 101000934338 Homo sapiens Myeloid cell surface antigen CD33 Proteins 0.000 claims 2
- 102100027268 Interferon-stimulated gene 20 kDa protein Human genes 0.000 claims 2
- 108010002586 Interleukin-7 Proteins 0.000 claims 2
- 239000002144 L01XE18 - Ruxolitinib Substances 0.000 claims 2
- 102100031586 Leukocyte antigen CD37 Human genes 0.000 claims 2
- 102100025243 Myeloid cell surface antigen CD33 Human genes 0.000 claims 2
- 229940122113 STING antagonist Drugs 0.000 claims 2
- 101710165473 Tumor necrosis factor receptor superfamily member 4 Proteins 0.000 claims 2
- 102100022153 Tumor necrosis factor receptor superfamily member 4 Human genes 0.000 claims 2
- 102000005789 Vascular Endothelial Growth Factors Human genes 0.000 claims 2
- 108010019530 Vascular Endothelial Growth Factors Proteins 0.000 claims 2
- DIZPMCHEQGEION-UHFFFAOYSA-H aluminium sulfate (anhydrous) Chemical compound [Al+3].[Al+3].[O-]S([O-])(=O)=O.[O-]S([O-])(=O)=O.[O-]S([O-])(=O)=O DIZPMCHEQGEION-UHFFFAOYSA-H 0.000 claims 2
- 239000005557 antagonist Substances 0.000 claims 2
- 229960003852 atezolizumab Drugs 0.000 claims 2
- 229950002916 avelumab Drugs 0.000 claims 2
- 229940121418 budigalimab Drugs 0.000 claims 2
- 229950007712 camrelizumab Drugs 0.000 claims 2
- 239000002875 cyclin dependent kinase inhibitor Substances 0.000 claims 2
- 229940043378 cyclin-dependent kinase inhibitor Drugs 0.000 claims 2
- 229940127089 cytotoxic agent Drugs 0.000 claims 2
- 239000002254 cytotoxic agent Substances 0.000 claims 2
- 231100000599 cytotoxic agent Toxicity 0.000 claims 2
- 229950009791 durvalumab Drugs 0.000 claims 2
- 108700014844 flt3 ligand Proteins 0.000 claims 2
- 229960005386 ipilimumab Drugs 0.000 claims 2
- 108020004999 messenger RNA Proteins 0.000 claims 2
- 229960003301 nivolumab Drugs 0.000 claims 2
- 229960002621 pembrolizumab Drugs 0.000 claims 2
- 229940121482 prolgolimab Drugs 0.000 claims 2
- 230000005855 radiation Effects 0.000 claims 2
- HFNKQEVNSGCOJV-OAHLLOKOSA-N ruxolitinib Chemical compound C1([C@@H](CC#N)N2N=CC(=C2)C=2C=3C=CNC=3N=CN=2)CCCC1 HFNKQEVNSGCOJV-OAHLLOKOSA-N 0.000 claims 2
- 229960000215 ruxolitinib Drugs 0.000 claims 2
- 229950007213 spartalizumab Drugs 0.000 claims 2
- 238000002626 targeted therapy Methods 0.000 claims 2
- 229950007123 tislelizumab Drugs 0.000 claims 2
- 239000013607 AAV vector Substances 0.000 claims 1
- 101150014742 AGE1 gene Proteins 0.000 claims 1
- 101100447571 Caenorhabditis elegans gad-3 gene Proteins 0.000 claims 1
- 108010041986 DNA Vaccines Proteins 0.000 claims 1
- 229940021995 DNA vaccine Drugs 0.000 claims 1
- JOOXLOJCABQBSG-UHFFFAOYSA-N N-tert-butyl-3-[[5-methyl-2-[4-[2-(1-pyrrolidinyl)ethoxy]anilino]-4-pyrimidinyl]amino]benzenesulfonamide Chemical compound N1=C(NC=2C=C(C=CC=2)S(=O)(=O)NC(C)(C)C)C(C)=CN=C1NC(C=C1)=CC=C1OCCN1CCCC1 JOOXLOJCABQBSG-UHFFFAOYSA-N 0.000 claims 1
- 229940022005 RNA vaccine Drugs 0.000 claims 1
- 229940121530 balstilimab Drugs 0.000 claims 1
- 108010006025 bovine growth hormone Proteins 0.000 claims 1
- 229940067219 cetrelimab Drugs 0.000 claims 1
- 238000012258 culturing Methods 0.000 claims 1
- 229940121556 envafolimab Drugs 0.000 claims 1
- 210000003527 eukaryotic cell Anatomy 0.000 claims 1
- 229950003487 fedratinib Drugs 0.000 claims 1
- 210000002950 fibroblast Anatomy 0.000 claims 1
- 108700021021 mRNA Vaccine Proteins 0.000 claims 1
- 210000001161 mammalian embryo Anatomy 0.000 claims 1
- 210000001236 prokaryotic cell Anatomy 0.000 claims 1
- 229940018073 sasanlimab Drugs 0.000 claims 1
- 229940121497 sintilimab Drugs 0.000 claims 1
- 229940121514 toripalimab Drugs 0.000 claims 1
- 230000003612 virological effect Effects 0.000 abstract description 4
- 239000002245 particle Substances 0.000 abstract description 3
- 229940024606 amino acid Drugs 0.000 description 78
- 235000001014 amino acid Nutrition 0.000 description 78
- 239000002773 nucleotide Substances 0.000 description 61
- 125000003729 nucleotide group Chemical group 0.000 description 61
- 241000282414 Homo sapiens Species 0.000 description 34
- 235000018102 proteins Nutrition 0.000 description 20
- 238000006467 substitution reaction Methods 0.000 description 19
- 108060003951 Immunoglobulin Proteins 0.000 description 16
- 102000018358 immunoglobulin Human genes 0.000 description 16
- 108010047041 Complementarity Determining Regions Proteins 0.000 description 15
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 description 15
- 230000004048 modification Effects 0.000 description 12
- 238000012986 modification Methods 0.000 description 12
- 210000001151 cytotoxic T lymphocyte Anatomy 0.000 description 9
- 208000035475 disorder Diseases 0.000 description 9
- 210000003819 peripheral blood mononuclear cell Anatomy 0.000 description 9
- 230000015572 biosynthetic process Effects 0.000 description 8
- 239000003814 drug Substances 0.000 description 8
- 230000014509 gene expression Effects 0.000 description 8
- 230000002163 immunogen Effects 0.000 description 8
- 238000003786 synthesis reaction Methods 0.000 description 8
- KDXKERNSBIXSRK-UHFFFAOYSA-N Lysine Natural products NCCCCC(N)C(O)=O KDXKERNSBIXSRK-UHFFFAOYSA-N 0.000 description 6
- 238000012217 deletion Methods 0.000 description 6
- 230000037430 deletion Effects 0.000 description 6
- 201000010099 disease Diseases 0.000 description 6
- 238000003780 insertion Methods 0.000 description 6
- 230000037431 insertion Effects 0.000 description 6
- 230000010076 replication Effects 0.000 description 6
- 239000004472 Lysine Substances 0.000 description 5
- 206010028980 Neoplasm Diseases 0.000 description 5
- 230000004075 alteration Effects 0.000 description 5
- 125000000539 amino acid group Chemical group 0.000 description 5
- 239000003153 chemical reaction reagent Substances 0.000 description 5
- 239000003795 chemical substances by application Substances 0.000 description 5
- 238000010367 cloning Methods 0.000 description 5
- 238000000684 flow cytometry Methods 0.000 description 5
- 230000006870 function Effects 0.000 description 5
- 230000005847 immunogenicity Effects 0.000 description 5
- 239000000463 material Substances 0.000 description 5
- 230000004044 response Effects 0.000 description 5
- 230000000638 stimulation Effects 0.000 description 5
- 108020004414 DNA Proteins 0.000 description 4
- 108700005091 Immunoglobulin Genes Proteins 0.000 description 4
- DCXYFEDJOCDNAF-REOHCLBHSA-N L-asparagine Chemical compound OC(=O)[C@@H](N)CC(N)=O DCXYFEDJOCDNAF-REOHCLBHSA-N 0.000 description 4
- 230000002159 abnormal effect Effects 0.000 description 4
- 210000004899 c-terminal region Anatomy 0.000 description 4
- 238000006243 chemical reaction Methods 0.000 description 4
- 235000018417 cysteine Nutrition 0.000 description 4
- 210000002443 helper t lymphocyte Anatomy 0.000 description 4
- HNDVDQJCIGZPNO-UHFFFAOYSA-N histidine Natural products OC(=O)C(N)CC1=CN=CN1 HNDVDQJCIGZPNO-UHFFFAOYSA-N 0.000 description 4
- 230000002998 immunogenetic effect Effects 0.000 description 4
- 230000001976 improved effect Effects 0.000 description 4
- 239000000203 mixture Substances 0.000 description 4
- 210000000581 natural killer T-cell Anatomy 0.000 description 4
- 125000002924 primary amino group Chemical group [H]N([H])* 0.000 description 4
- 210000003289 regulatory T cell Anatomy 0.000 description 4
- 230000009258 tissue cross reactivity Effects 0.000 description 4
- NHJVRSWLHSJWIN-UHFFFAOYSA-N 2,4,6-trinitrobenzenesulfonic acid Chemical compound OS(=O)(=O)C1=C([N+]([O-])=O)C=C([N+]([O-])=O)C=C1[N+]([O-])=O NHJVRSWLHSJWIN-UHFFFAOYSA-N 0.000 description 3
- DCXYFEDJOCDNAF-UHFFFAOYSA-N Asparagine Natural products OC(=O)C(N)CC(N)=O DCXYFEDJOCDNAF-UHFFFAOYSA-N 0.000 description 3
- 102000004127 Cytokines Human genes 0.000 description 3
- 108090000695 Cytokines Proteins 0.000 description 3
- IAZDPXIOMUYVGZ-UHFFFAOYSA-N Dimethylsulphoxide Chemical compound CS(C)=O IAZDPXIOMUYVGZ-UHFFFAOYSA-N 0.000 description 3
- WSFSSNUMVMOOMR-UHFFFAOYSA-N Formaldehyde Chemical compound O=C WSFSSNUMVMOOMR-UHFFFAOYSA-N 0.000 description 3
- XUJNEKJLAYXESH-REOHCLBHSA-N L-Cysteine Chemical compound SC[C@H](N)C(O)=O XUJNEKJLAYXESH-REOHCLBHSA-N 0.000 description 3
- ZDXPYRJPNDTMRX-VKHMYHEASA-N L-glutamine Chemical compound OC(=O)[C@@H](N)CCC(N)=O ZDXPYRJPNDTMRX-VKHMYHEASA-N 0.000 description 3
- 241000124008 Mammalia Species 0.000 description 3
- 108091028043 Nucleic acid sequence Proteins 0.000 description 3
- 230000005867 T cell response Effects 0.000 description 3
- 241000251539 Vertebrata <Metazoa> Species 0.000 description 3
- 235000009582 asparagine Nutrition 0.000 description 3
- 229960001230 asparagine Drugs 0.000 description 3
- 201000011510 cancer Diseases 0.000 description 3
- 238000003776 cleavage reaction Methods 0.000 description 3
- 238000004132 cross linking Methods 0.000 description 3
- XUJNEKJLAYXESH-UHFFFAOYSA-N cysteine Natural products SCC(N)C(O)=O XUJNEKJLAYXESH-UHFFFAOYSA-N 0.000 description 3
- 230000004927 fusion Effects 0.000 description 3
- 210000004602 germ cell Anatomy 0.000 description 3
- ZDXPYRJPNDTMRX-UHFFFAOYSA-N glutamine Natural products OC(=O)C(N)CCC(N)=O ZDXPYRJPNDTMRX-UHFFFAOYSA-N 0.000 description 3
- 230000000670 limiting effect Effects 0.000 description 3
- 125000003588 lysine group Chemical group [H]N([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])(N([H])[H])C(*)=O 0.000 description 3
- 239000003550 marker Substances 0.000 description 3
- 210000003071 memory t lymphocyte Anatomy 0.000 description 3
- 206010061289 metastatic neoplasm Diseases 0.000 description 3
- 210000000822 natural killer cell Anatomy 0.000 description 3
- 239000012071 phase Substances 0.000 description 3
- 229920001223 polyethylene glycol Polymers 0.000 description 3
- 230000037452 priming Effects 0.000 description 3
- 238000003259 recombinant expression Methods 0.000 description 3
- 230000003362 replicative effect Effects 0.000 description 3
- 230000007017 scission Effects 0.000 description 3
- 239000007790 solid phase Substances 0.000 description 3
- 239000000126 substance Substances 0.000 description 3
- 208000024891 symptom Diseases 0.000 description 3
- 238000012360 testing method Methods 0.000 description 3
- 210000004881 tumor cell Anatomy 0.000 description 3
- NFGXHKASABOEEW-UHFFFAOYSA-N 1-methylethyl 11-methoxy-3,7,11-trimethyl-2,4-dodecadienoate Chemical compound COC(C)(C)CCCC(C)CC=CC(C)=CC(=O)OC(C)C NFGXHKASABOEEW-UHFFFAOYSA-N 0.000 description 2
- FWMNVWWHGCHHJJ-SKKKGAJSSA-N 4-amino-1-[(2r)-6-amino-2-[[(2r)-2-[[(2r)-2-[[(2r)-2-amino-3-phenylpropanoyl]amino]-3-phenylpropanoyl]amino]-4-methylpentanoyl]amino]hexanoyl]piperidine-4-carboxylic acid Chemical compound C([C@H](C(=O)N[C@H](CC(C)C)C(=O)N[C@H](CCCCN)C(=O)N1CCC(N)(CC1)C(O)=O)NC(=O)[C@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 FWMNVWWHGCHHJJ-SKKKGAJSSA-N 0.000 description 2
- JVJFIQYAHPMBBX-UHFFFAOYSA-N 4-hydroxynonenal Chemical compound CCCCCC(O)C=CC=O JVJFIQYAHPMBBX-UHFFFAOYSA-N 0.000 description 2
- 102100032187 Androgen receptor Human genes 0.000 description 2
- 241000283690 Bos taurus Species 0.000 description 2
- QSJXEFYPDANLFS-UHFFFAOYSA-N Diacetyl Chemical compound CC(=O)C(C)=O QSJXEFYPDANLFS-UHFFFAOYSA-N 0.000 description 2
- YQYJSBFKSSDGFO-UHFFFAOYSA-N Epihygromycin Natural products OC1C(O)C(C(=O)C)OC1OC(C(=C1)O)=CC=C1C=C(C)C(=O)NC1C(O)C(O)C2OCOC2C1O YQYJSBFKSSDGFO-UHFFFAOYSA-N 0.000 description 2
- WHUUTDBJXJRKMK-UHFFFAOYSA-N Glutamic acid Natural products OC(=O)C(N)CCC(O)=O WHUUTDBJXJRKMK-UHFFFAOYSA-N 0.000 description 2
- 241000282575 Gorilla Species 0.000 description 2
- 102000008949 Histocompatibility Antigens Class I Human genes 0.000 description 2
- 108010088652 Histocompatibility Antigens Class I Proteins 0.000 description 2
- 108010027412 Histocompatibility Antigens Class II Proteins 0.000 description 2
- 102000018713 Histocompatibility Antigens Class II Human genes 0.000 description 2
- 241001272567 Hominoidea Species 0.000 description 2
- MHAJPDPJQMAIIY-UHFFFAOYSA-N Hydrogen peroxide Chemical compound OO MHAJPDPJQMAIIY-UHFFFAOYSA-N 0.000 description 2
- ZQISRDCJNBUVMM-UHFFFAOYSA-N L-Histidinol Natural products OCC(N)CC1=CN=CN1 ZQISRDCJNBUVMM-UHFFFAOYSA-N 0.000 description 2
- CKLJMWTZIZZHCS-REOHCLBHSA-N L-aspartic acid Chemical compound OC(=O)[C@@H](N)CC(O)=O CKLJMWTZIZZHCS-REOHCLBHSA-N 0.000 description 2
- WHUUTDBJXJRKMK-VKHMYHEASA-N L-glutamic acid Chemical compound OC(=O)[C@@H](N)CCC(O)=O WHUUTDBJXJRKMK-VKHMYHEASA-N 0.000 description 2
- ZQISRDCJNBUVMM-YFKPBYRVSA-N L-histidinol Chemical compound OC[C@@H](N)CC1=CNC=N1 ZQISRDCJNBUVMM-YFKPBYRVSA-N 0.000 description 2
- OUYCCCASQSFEME-QMMMGPOBSA-N L-tyrosine Chemical compound OC(=O)[C@@H](N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-QMMMGPOBSA-N 0.000 description 2
- 241000712899 Lymphocytic choriomeningitis mammarenavirus Species 0.000 description 2
- 241000218605 Macacine betaherpesvirus 3 Species 0.000 description 2
- 241001465754 Metazoa Species 0.000 description 2
- AIJULSRZWUXGPQ-UHFFFAOYSA-N Methylglyoxal Chemical compound CC(=O)C=O AIJULSRZWUXGPQ-UHFFFAOYSA-N 0.000 description 2
- PCLIMKBDDGJMGD-UHFFFAOYSA-N N-bromosuccinimide Chemical compound BrN1C(=O)CCC1=O PCLIMKBDDGJMGD-UHFFFAOYSA-N 0.000 description 2
- 229930193140 Neomycin Natural products 0.000 description 2
- 241000282576 Pan paniscus Species 0.000 description 2
- 241000282577 Pan troglodytes Species 0.000 description 2
- ISWSIDIOOBJBQZ-UHFFFAOYSA-N Phenol Chemical compound OC1=CC=CC=C1 ISWSIDIOOBJBQZ-UHFFFAOYSA-N 0.000 description 2
- 101710101148 Probable 6-oxopurine nucleoside phosphorylase Proteins 0.000 description 2
- 108020005067 RNA Splice Sites Proteins 0.000 description 2
- 241000710961 Semliki Forest virus Species 0.000 description 2
- 241000700584 Simplexvirus Species 0.000 description 2
- 241000710960 Sindbis virus Species 0.000 description 2
- MUMGGOZAMZWBJJ-DYKIIFRCSA-N Testostosterone Chemical compound O=C1CC[C@]2(C)[C@H]3CC[C@](C)([C@H](CC4)O)[C@@H]4[C@@H]3CCC2=C1 MUMGGOZAMZWBJJ-DYKIIFRCSA-N 0.000 description 2
- 239000004098 Tetracycline Substances 0.000 description 2
- 102000006601 Thymidine Kinase Human genes 0.000 description 2
- 108020004440 Thymidine kinase Proteins 0.000 description 2
- 102000040945 Transcription factor Human genes 0.000 description 2
- 108091023040 Transcription factor Proteins 0.000 description 2
- DTQVDTLACAAQTR-UHFFFAOYSA-N Trifluoroacetic acid Chemical compound OC(=O)C(F)(F)F DTQVDTLACAAQTR-UHFFFAOYSA-N 0.000 description 2
- 241000710959 Venezuelan equine encephalitis virus Species 0.000 description 2
- 125000001931 aliphatic group Chemical group 0.000 description 2
- 230000009435 amidation Effects 0.000 description 2
- 238000007112 amidation reaction Methods 0.000 description 2
- 125000003368 amide group Chemical group 0.000 description 2
- 150000001408 amides Chemical class 0.000 description 2
- 108010080146 androgen receptors Proteins 0.000 description 2
- RDOXTESZEPMUJZ-UHFFFAOYSA-N anisole Chemical compound COC1=CC=CC=C1 RDOXTESZEPMUJZ-UHFFFAOYSA-N 0.000 description 2
- 210000000612 antigen-presenting cell Anatomy 0.000 description 2
- 230000000890 antigenic effect Effects 0.000 description 2
- 125000000637 arginyl group Chemical group N[C@@H](CCCNC(N)=N)C(=O)* 0.000 description 2
- 210000003719 b-lymphocyte Anatomy 0.000 description 2
- 230000001580 bacterial effect Effects 0.000 description 2
- 230000003115 biocidal effect Effects 0.000 description 2
- 230000021235 carbamoylation Effects 0.000 description 2
- 230000008878 coupling Effects 0.000 description 2
- 238000005859 coupling reaction Methods 0.000 description 2
- XVOYSCVBGLVSOL-UHFFFAOYSA-N cysteic acid Chemical compound OC(=O)C(N)CS(O)(=O)=O XVOYSCVBGLVSOL-UHFFFAOYSA-N 0.000 description 2
- 125000001295 dansyl group Chemical group [H]C1=C([H])C(N(C([H])([H])[H])C([H])([H])[H])=C2C([H])=C([H])C([H])=C(C2=C1[H])S(*)(=O)=O 0.000 description 2
- OQALFHMKVSJFRR-UHFFFAOYSA-N dityrosine Chemical compound OC(=O)C(N)CC1=CC=C(O)C(C=2C(=CC=C(CC(N)C(O)=O)C=2)O)=C1 OQALFHMKVSJFRR-UHFFFAOYSA-N 0.000 description 2
- WXCXUHSOUPDCQV-UHFFFAOYSA-N enzalutamide Chemical compound C1=C(F)C(C(=O)NC)=CC=C1N1C(C)(C)C(=O)N(C=2C=C(C(C#N)=CC=2)C(F)(F)F)C1=S WXCXUHSOUPDCQV-UHFFFAOYSA-N 0.000 description 2
- 230000002255 enzymatic effect Effects 0.000 description 2
- 230000037433 frameshift Effects 0.000 description 2
- 125000000524 functional group Chemical group 0.000 description 2
- 125000000291 glutamic acid group Chemical group N[C@@H](CCC(O)=O)C(=O)* 0.000 description 2
- 230000013595 glycosylation Effects 0.000 description 2
- 238000006206 glycosylation reaction Methods 0.000 description 2
- 125000001165 hydrophobic group Chemical group 0.000 description 2
- 230000006058 immune tolerance Effects 0.000 description 2
- 230000036039 immunity Effects 0.000 description 2
- 238000009169 immunotherapy Methods 0.000 description 2
- 238000000338 in vitro Methods 0.000 description 2
- 230000006698 induction Effects 0.000 description 2
- 230000003993 interaction Effects 0.000 description 2
- 230000003834 intracellular effect Effects 0.000 description 2
- 229960000318 kanamycin Drugs 0.000 description 2
- 229930027917 kanamycin Natural products 0.000 description 2
- SBUJHOSQTJFQJX-NOAMYHISSA-N kanamycin Chemical compound O[C@@H]1[C@@H](O)[C@H](O)[C@@H](CN)O[C@@H]1O[C@H]1[C@H](O)[C@@H](O[C@@H]2[C@@H]([C@@H](N)[C@H](O)[C@@H](CO)O2)O)[C@H](N)C[C@@H]1N SBUJHOSQTJFQJX-NOAMYHISSA-N 0.000 description 2
- 229930182823 kanamycin A Natural products 0.000 description 2
- 230000003211 malignant effect Effects 0.000 description 2
- 239000011159 matrix material Substances 0.000 description 2
- 230000001394 metastastic effect Effects 0.000 description 2
- 239000000178 monomer Substances 0.000 description 2
- 229960004927 neomycin Drugs 0.000 description 2
- 150000007523 nucleic acids Chemical group 0.000 description 2
- 230000003647 oxidation Effects 0.000 description 2
- 238000007254 oxidation reaction Methods 0.000 description 2
- 239000000816 peptidomimetic Substances 0.000 description 2
- OJUGVDODNPJEEC-UHFFFAOYSA-N phenylglyoxal Chemical compound O=CC(=O)C1=CC=CC=C1 OJUGVDODNPJEEC-UHFFFAOYSA-N 0.000 description 2
- 239000013612 plasmid Substances 0.000 description 2
- BASFCYQUMIYNBI-UHFFFAOYSA-N platinum Chemical compound [Pt] BASFCYQUMIYNBI-UHFFFAOYSA-N 0.000 description 2
- 230000004481 post-translational protein modification Effects 0.000 description 2
- 125000006239 protecting group Chemical group 0.000 description 2
- 230000009145 protein modification Effects 0.000 description 2
- 230000009257 reactivity Effects 0.000 description 2
- 208000037922 refractory disease Diseases 0.000 description 2
- 239000011347 resin Substances 0.000 description 2
- 229920005989 resin Polymers 0.000 description 2
- 230000009870 specific binding Effects 0.000 description 2
- 229960002180 tetracycline Drugs 0.000 description 2
- 229930101283 tetracycline Natural products 0.000 description 2
- 235000019364 tetracycline Nutrition 0.000 description 2
- 150000003522 tetracyclines Chemical class 0.000 description 2
- 230000001225 therapeutic effect Effects 0.000 description 2
- 210000001519 tissue Anatomy 0.000 description 2
- YUXKOWPNKJSTPQ-AXWWPMSFSA-N (2s,3r)-2-amino-3-hydroxybutanoic acid;(2s)-2-amino-3-hydroxypropanoic acid Chemical compound OC[C@H](N)C(O)=O.C[C@@H](O)[C@H](N)C(O)=O YUXKOWPNKJSTPQ-AXWWPMSFSA-N 0.000 description 1
- DHBXNPKRAUYBTH-UHFFFAOYSA-N 1,1-ethanedithiol Chemical compound CC(S)S DHBXNPKRAUYBTH-UHFFFAOYSA-N 0.000 description 1
- ASOKPJOREAFHNY-UHFFFAOYSA-N 1-Hydroxybenzotriazole Chemical compound C1=CC=C2N(O)N=NC2=C1 ASOKPJOREAFHNY-UHFFFAOYSA-N 0.000 description 1
- DURPTKYDGMDSBL-UHFFFAOYSA-N 1-butoxybutane Chemical class CCCCOCCCC DURPTKYDGMDSBL-UHFFFAOYSA-N 0.000 description 1
- LMDZBCPBFSXMTL-UHFFFAOYSA-N 1-ethyl-3-(3-dimethylaminopropyl)carbodiimide Chemical compound CCN=C=NCCCN(C)C LMDZBCPBFSXMTL-UHFFFAOYSA-N 0.000 description 1
- KFDPCYZHENQOBV-UHFFFAOYSA-N 2-(bromomethyl)-4-nitrophenol Chemical compound OC1=CC=C([N+]([O-])=O)C=C1CBr KFDPCYZHENQOBV-UHFFFAOYSA-N 0.000 description 1
- VUCNQOPCYRJCGQ-UHFFFAOYSA-N 2-[4-(hydroxymethyl)phenoxy]acetic acid Chemical class OCC1=CC=C(OCC(O)=O)C=C1 VUCNQOPCYRJCGQ-UHFFFAOYSA-N 0.000 description 1
- IZQAUUVBKYXMET-UHFFFAOYSA-N 2-bromoethanamine Chemical compound NCCBr IZQAUUVBKYXMET-UHFFFAOYSA-N 0.000 description 1
- JQPFYXFVUKHERX-UHFFFAOYSA-N 2-hydroxy-2-cyclohexen-1-one Natural products OC1=CCCCC1=O JQPFYXFVUKHERX-UHFFFAOYSA-N 0.000 description 1
- LJGHYPLBDBRCRZ-UHFFFAOYSA-N 3-(3-aminophenyl)sulfonylaniline Chemical compound NC1=CC=CC(S(=O)(=O)C=2C=C(N)C=CC=2)=C1 LJGHYPLBDBRCRZ-UHFFFAOYSA-N 0.000 description 1
- HVCOBJNICQPDBP-UHFFFAOYSA-N 3-[3-[3,5-dihydroxy-6-methyl-4-(3,4,5-trihydroxy-6-methyloxan-2-yl)oxyoxan-2-yl]oxydecanoyloxy]decanoic acid;hydrate Chemical compound O.OC1C(OC(CC(=O)OC(CCCCCCC)CC(O)=O)CCCCCCC)OC(C)C(O)C1OC1C(O)C(O)C(O)C(C)O1 HVCOBJNICQPDBP-UHFFFAOYSA-N 0.000 description 1
- WHNPOQXWAMXPTA-UHFFFAOYSA-N 3-methylbut-2-enamide Chemical compound CC(C)=CC(N)=O WHNPOQXWAMXPTA-UHFFFAOYSA-N 0.000 description 1
- SYMHUEFSSMBHJA-UHFFFAOYSA-N 6-methylpurine Chemical compound CC1=NC=NC2=C1NC=N2 SYMHUEFSSMBHJA-UHFFFAOYSA-N 0.000 description 1
- 101150101112 7 gene Proteins 0.000 description 1
- 206010069754 Acquired gene mutation Diseases 0.000 description 1
- 241000712891 Arenavirus Species 0.000 description 1
- 239000004475 Arginine Substances 0.000 description 1
- 244000186140 Asperula odorata Species 0.000 description 1
- BXTVQNYQYUTQAZ-UHFFFAOYSA-N BNPS-skatole Chemical compound N=1C2=CC=CC=C2C(C)(Br)C=1SC1=CC=CC=C1[N+]([O-])=O BXTVQNYQYUTQAZ-UHFFFAOYSA-N 0.000 description 1
- 241000894006 Bacteria Species 0.000 description 1
- 241000701106 Bovine adenovirus 3 Species 0.000 description 1
- 241000701822 Bovine papillomavirus Species 0.000 description 1
- 125000001433 C-terminal amino-acid group Chemical group 0.000 description 1
- 101100126625 Caenorhabditis elegans itr-1 gene Proteins 0.000 description 1
- 241000701157 Canine mastadenovirus A Species 0.000 description 1
- 241000282472 Canis lupus familiaris Species 0.000 description 1
- 241001217856 Chimpanzee adenovirus Species 0.000 description 1
- 241000938605 Crocodylia Species 0.000 description 1
- JPVYNHNXODAKFH-UHFFFAOYSA-N Cu2+ Chemical compound [Cu+2] JPVYNHNXODAKFH-UHFFFAOYSA-N 0.000 description 1
- 102000000311 Cytosine Deaminase Human genes 0.000 description 1
- 108010080611 Cytosine Deaminase Proteins 0.000 description 1
- 150000008574 D-amino acids Chemical class 0.000 description 1
- QOSSAOTZNIDXMA-UHFFFAOYSA-N Dicylcohexylcarbodiimide Chemical compound C1CCCCC1N=C=NC1CCCCC1 QOSSAOTZNIDXMA-UHFFFAOYSA-N 0.000 description 1
- 241000196324 Embryophyta Species 0.000 description 1
- 102000004190 Enzymes Human genes 0.000 description 1
- 108090000790 Enzymes Proteins 0.000 description 1
- 241000283086 Equidae Species 0.000 description 1
- 108700024394 Exon Proteins 0.000 description 1
- 108010008177 Fd immunoglobulins Proteins 0.000 description 1
- 241000282326 Felis catus Species 0.000 description 1
- 208000000666 Fowlpox Diseases 0.000 description 1
- 102100021260 Galactosylgalactosylxylosylprotein 3-beta-glucuronosyltransferase 1 Human genes 0.000 description 1
- 235000008526 Galium odoratum Nutrition 0.000 description 1
- SXRSQZLOMIGNAQ-UHFFFAOYSA-N Glutaraldehyde Chemical compound O=CCCCC=O SXRSQZLOMIGNAQ-UHFFFAOYSA-N 0.000 description 1
- 229930186217 Glycolipid Natural products 0.000 description 1
- 102000003886 Glycoproteins Human genes 0.000 description 1
- 108090000288 Glycoproteins Proteins 0.000 description 1
- 101000894906 Homo sapiens Galactosylgalactosylxylosylprotein 3-beta-glucuronosyltransferase 1 Proteins 0.000 description 1
- 101000581981 Homo sapiens Neural cell adhesion molecule 1 Proteins 0.000 description 1
- 101001074571 Homo sapiens PIN2/TERF1-interacting telomerase inhibitor 1 Proteins 0.000 description 1
- 101001073025 Homo sapiens Peroxisomal targeting signal 1 receptor Proteins 0.000 description 1
- 101000946860 Homo sapiens T-cell surface glycoprotein CD3 epsilon chain Proteins 0.000 description 1
- 241001135569 Human adenovirus 5 Species 0.000 description 1
- 108010067060 Immunoglobulin Variable Region Proteins 0.000 description 1
- 102000017727 Immunoglobulin Variable Region Human genes 0.000 description 1
- 206010061218 Inflammation Diseases 0.000 description 1
- 102000013691 Interleukin-17 Human genes 0.000 description 1
- 108050003558 Interleukin-17 Proteins 0.000 description 1
- 102000000588 Interleukin-2 Human genes 0.000 description 1
- 108091092195 Intron Proteins 0.000 description 1
- QNAYBMKLOCPYGJ-REOHCLBHSA-N L-alanine Chemical compound C[C@H](N)C(O)=O QNAYBMKLOCPYGJ-REOHCLBHSA-N 0.000 description 1
- 150000008575 L-amino acids Chemical class 0.000 description 1
- FFEARJCKVFRZRR-BYPYZUCNSA-N L-methionine Chemical compound CSCC[C@H](N)C(O)=O FFEARJCKVFRZRR-BYPYZUCNSA-N 0.000 description 1
- QIVBCDIJIAJPQS-VIFPVBQESA-N L-tryptophane Chemical compound C1=CC=C2C(C[C@H](N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-VIFPVBQESA-N 0.000 description 1
- 241000713666 Lentivirus Species 0.000 description 1
- PEEHTFAAVSWFBL-UHFFFAOYSA-N Maleimide Chemical compound O=C1NC(=O)C=C1 PEEHTFAAVSWFBL-UHFFFAOYSA-N 0.000 description 1
- 241000712079 Measles morbillivirus Species 0.000 description 1
- 241001183012 Modified Vaccinia Ankara virus Species 0.000 description 1
- 241001529936 Murinae Species 0.000 description 1
- 241000699670 Mus sp. Species 0.000 description 1
- VIHYIVKEECZGOU-UHFFFAOYSA-N N-acetylimidazole Chemical compound CC(=O)N1C=CN=C1 VIHYIVKEECZGOU-UHFFFAOYSA-N 0.000 description 1
- ZDZOTLJHXYCWBA-VCVYQWHSSA-N N-debenzoyl-N-(tert-butoxycarbonyl)-10-deacetyltaxol Chemical compound O([C@H]1[C@H]2[C@@](C([C@H](O)C3=C(C)[C@@H](OC(=O)[C@H](O)[C@@H](NC(=O)OC(C)(C)C)C=4C=CC=CC=4)C[C@]1(O)C3(C)C)=O)(C)[C@@H](O)C[C@H]1OC[C@]12OC(=O)C)C(=O)C1=CC=CC=C1 ZDZOTLJHXYCWBA-VCVYQWHSSA-N 0.000 description 1
- 102100027347 Neural cell adhesion molecule 1 Human genes 0.000 description 1
- 102000004459 Nitroreductase Human genes 0.000 description 1
- 240000007019 Oxalis corniculata Species 0.000 description 1
- 102100036257 PIN2/TERF1-interacting telomerase inhibitor 1 Human genes 0.000 description 1
- 102100026450 POU domain, class 3, transcription factor 4 Human genes 0.000 description 1
- 101710133389 POU domain, class 3, transcription factor 4 Proteins 0.000 description 1
- 241000282579 Pan Species 0.000 description 1
- 241001494479 Pecora Species 0.000 description 1
- 229930182555 Penicillin Natural products 0.000 description 1
- JGSARLDLIJGVTE-MBNYWOFBSA-N Penicillin G Chemical compound N([C@H]1[C@H]2SC([C@@H](N2C1=O)C(O)=O)(C)C)C(=O)CC1=CC=CC=C1 JGSARLDLIJGVTE-MBNYWOFBSA-N 0.000 description 1
- 239000004952 Polyamide Substances 0.000 description 1
- 239000002202 Polyethylene glycol Substances 0.000 description 1
- 241000282569 Pongo Species 0.000 description 1
- 241000282405 Pongo abelii Species 0.000 description 1
- 241000188845 Porcine adenovirus Species 0.000 description 1
- 108010029485 Protein Isoforms Proteins 0.000 description 1
- 102000001708 Protein Isoforms Human genes 0.000 description 1
- 102000030764 Purine-nucleoside phosphorylase Human genes 0.000 description 1
- 241000700159 Rattus Species 0.000 description 1
- 240000004808 Saccharomyces cerevisiae Species 0.000 description 1
- 230000006044 T cell activation Effects 0.000 description 1
- 102100035794 T-cell surface glycoprotein CD3 epsilon chain Human genes 0.000 description 1
- NYTOUQBROMCLBJ-UHFFFAOYSA-N Tetranitromethane Chemical compound [O-][N+](=O)C([N+]([O-])=O)([N+]([O-])=O)[N+]([O-])=O NYTOUQBROMCLBJ-UHFFFAOYSA-N 0.000 description 1
- QIVBCDIJIAJPQS-UHFFFAOYSA-N Tryptophan Natural products C1=CC=C2C(CC(N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-UHFFFAOYSA-N 0.000 description 1
- ZVQOOHYFBIDMTQ-UHFFFAOYSA-N [methyl(oxido){1-[6-(trifluoromethyl)pyridin-3-yl]ethyl}-lambda(6)-sulfanylidene]cyanamide Chemical compound N#CN=S(C)(=O)C(C)C1=CC=C(C(F)(F)F)N=C1 ZVQOOHYFBIDMTQ-UHFFFAOYSA-N 0.000 description 1
- 230000001594 aberrant effect Effects 0.000 description 1
- GZOSMCIZMLWJML-VJLLXTKPSA-N abiraterone Chemical compound C([C@H]1[C@H]2[C@@H]([C@]3(CC[C@H](O)CC3=CC2)C)CC[C@@]11C)C=C1C1=CC=CN=C1 GZOSMCIZMLWJML-VJLLXTKPSA-N 0.000 description 1
- 229960004103 abiraterone acetate Drugs 0.000 description 1
- UVIQSJCZCSLXRZ-UBUQANBQSA-N abiraterone acetate Chemical compound C([C@@H]1[C@]2(C)CC[C@@H]3[C@@]4(C)CC[C@@H](CC4=CC[C@H]31)OC(=O)C)C=C2C1=CC=CN=C1 UVIQSJCZCSLXRZ-UBUQANBQSA-N 0.000 description 1
- 125000002777 acetyl group Chemical group [H]C([H])([H])C(*)=O 0.000 description 1
- 239000002253 acid Substances 0.000 description 1
- 230000002378 acidificating effect Effects 0.000 description 1
- 230000003213 activating effect Effects 0.000 description 1
- 230000010933 acylation Effects 0.000 description 1
- 238000005917 acylation reaction Methods 0.000 description 1
- 239000000654 additive Substances 0.000 description 1
- 230000000996 additive effect Effects 0.000 description 1
- 235000004279 alanine Nutrition 0.000 description 1
- 239000013566 allergen Substances 0.000 description 1
- 150000003862 amino acid derivatives Chemical class 0.000 description 1
- 125000003277 amino group Chemical group 0.000 description 1
- 229960000723 ampicillin Drugs 0.000 description 1
- AVKUERGKIZMTKX-NJBDSQKTSA-N ampicillin Chemical compound C1([C@@H](N)C(=O)N[C@H]2[C@H]3SC([C@@H](N3C2=O)C(O)=O)(C)C)=CC=CC=C1 AVKUERGKIZMTKX-NJBDSQKTSA-N 0.000 description 1
- 238000004458 analytical method Methods 0.000 description 1
- 239000003098 androgen Substances 0.000 description 1
- 229940030486 androgens Drugs 0.000 description 1
- 150000008064 anhydrides Chemical class 0.000 description 1
- 239000003242 anti bacterial agent Substances 0.000 description 1
- 229940088710 antibiotic agent Drugs 0.000 description 1
- 230000005875 antibody response Effects 0.000 description 1
- 238000013459 approach Methods 0.000 description 1
- ODKSFYDXXFIFQN-UHFFFAOYSA-N arginine Natural products OC(=O)C(N)CCCNC(N)=N ODKSFYDXXFIFQN-UHFFFAOYSA-N 0.000 description 1
- 210000004507 artificial chromosome Anatomy 0.000 description 1
- 125000003118 aryl group Chemical group 0.000 description 1
- 235000003704 aspartic acid Nutrition 0.000 description 1
- 238000003556 assay Methods 0.000 description 1
- 210000004666 bacterial spore Anatomy 0.000 description 1
- OQFSQFPPLPISGP-UHFFFAOYSA-N beta-carboxyaspartic acid Natural products OC(=O)C(N)C(C(O)=O)C(O)=O OQFSQFPPLPISGP-UHFFFAOYSA-N 0.000 description 1
- 239000003139 biocide Substances 0.000 description 1
- 229960000074 biopharmaceutical Drugs 0.000 description 1
- 125000000484 butyl group Chemical group [H]C([*])([H])C([H])([H])C([H])([H])C([H])([H])[H] 0.000 description 1
- 125000004744 butyloxycarbonyl group Chemical group 0.000 description 1
- 125000003178 carboxy group Chemical group [H]OC(*)=O 0.000 description 1
- 231100000504 carcinogenesis Toxicity 0.000 description 1
- 239000005018 casein Substances 0.000 description 1
- BECPQYXYKAMYBN-UHFFFAOYSA-N casein, tech. Chemical compound NCCCCC(C(O)=O)N=C(O)C(CC(O)=O)N=C(O)C(CCC(O)=N)N=C(O)C(CC(C)C)N=C(O)C(CCC(O)=O)N=C(O)C(CC(O)=O)N=C(O)C(CCC(O)=O)N=C(O)C(C(C)O)N=C(O)C(CCC(O)=N)N=C(O)C(CCC(O)=N)N=C(O)C(CCC(O)=N)N=C(O)C(CCC(O)=O)N=C(O)C(CCC(O)=O)N=C(O)C(COP(O)(O)=O)N=C(O)C(CCC(O)=N)N=C(O)C(N)CC1=CC=CC=C1 BECPQYXYKAMYBN-UHFFFAOYSA-N 0.000 description 1
- 235000021240 caseins Nutrition 0.000 description 1
- 210000000170 cell membrane Anatomy 0.000 description 1
- 230000004663 cell proliferation Effects 0.000 description 1
- 230000001413 cellular effect Effects 0.000 description 1
- 230000036755 cellular response Effects 0.000 description 1
- 230000008859 change Effects 0.000 description 1
- 125000003636 chemical group Chemical group 0.000 description 1
- 235000013330 chicken meat Nutrition 0.000 description 1
- VDQQXEISLMTGAB-UHFFFAOYSA-N chloramine T Chemical compound [Na+].CC1=CC=C(S(=O)(=O)[N-]Cl)C=C1 VDQQXEISLMTGAB-UHFFFAOYSA-N 0.000 description 1
- 239000013611 chromosomal DNA Substances 0.000 description 1
- 230000002759 chromosomal effect Effects 0.000 description 1
- 239000002299 complementary DNA Substances 0.000 description 1
- 239000000470 constituent Substances 0.000 description 1
- 229910001431 copper ion Inorganic materials 0.000 description 1
- 238000010168 coupling process Methods 0.000 description 1
- 239000003431 cross linking reagent Substances 0.000 description 1
- XLJMAIOERFSOGZ-UHFFFAOYSA-M cyanate Chemical compound [O-]C#N XLJMAIOERFSOGZ-UHFFFAOYSA-M 0.000 description 1
- OILAIQUEIWYQPH-UHFFFAOYSA-N cyclohexane-1,2-dione Chemical compound O=C1CCCCC1=O OILAIQUEIWYQPH-UHFFFAOYSA-N 0.000 description 1
- 150000001945 cysteines Chemical class 0.000 description 1
- 230000001461 cytolytic effect Effects 0.000 description 1
- 210000005220 cytoplasmic tail Anatomy 0.000 description 1
- 230000009849 deactivation Effects 0.000 description 1
- 230000006240 deamidation Effects 0.000 description 1
- 230000034994 death Effects 0.000 description 1
- 230000002939 deleterious effect Effects 0.000 description 1
- 238000010511 deprotection reaction Methods 0.000 description 1
- 238000013461 design Methods 0.000 description 1
- 238000001514 detection method Methods 0.000 description 1
- 125000004386 diacrylate group Chemical group 0.000 description 1
- 150000004985 diamines Chemical class 0.000 description 1
- 125000004989 dicarbonyl group Chemical group 0.000 description 1
- FFYPMLJYZAEMQB-UHFFFAOYSA-N diethyl pyrocarbonate Chemical compound CCOC(=O)OC(=O)OCC FFYPMLJYZAEMQB-UHFFFAOYSA-N 0.000 description 1
- 238000010494 dissociation reaction Methods 0.000 description 1
- 230000005593 dissociations Effects 0.000 description 1
- 150000002019 disulfides Chemical class 0.000 description 1
- 229960003668 docetaxel Drugs 0.000 description 1
- 229940079593 drug Drugs 0.000 description 1
- 239000012636 effector Substances 0.000 description 1
- 229960004671 enzalutamide Drugs 0.000 description 1
- 230000005713 exacerbation Effects 0.000 description 1
- 230000002550 fecal effect Effects 0.000 description 1
- 210000004475 gamma-delta t lymphocyte Anatomy 0.000 description 1
- 229960002963 ganciclovir Drugs 0.000 description 1
- IRSCQMHQWWYFCW-UHFFFAOYSA-N ganciclovir Chemical compound O=C1NC(N)=NC2=C1N=CN2COC(CO)CO IRSCQMHQWWYFCW-UHFFFAOYSA-N 0.000 description 1
- 235000013922 glutamic acid Nutrition 0.000 description 1
- 239000004220 glutamic acid Substances 0.000 description 1
- 108020002326 glutamine synthetase Proteins 0.000 description 1
- 230000036541 health Effects 0.000 description 1
- 238000010438 heat treatment Methods 0.000 description 1
- 229910001385 heavy metal Inorganic materials 0.000 description 1
- 239000000833 heterodimer Substances 0.000 description 1
- 125000000487 histidyl group Chemical group [H]N([H])C(C(=O)O*)C([H])([H])C1=C([H])N([H])C([H])=N1 0.000 description 1
- 229940088597 hormone Drugs 0.000 description 1
- 239000005556 hormone Substances 0.000 description 1
- 230000004727 humoral immunity Effects 0.000 description 1
- 239000000017 hydrogel Substances 0.000 description 1
- 230000001900 immune effect Effects 0.000 description 1
- 210000000987 immune system Anatomy 0.000 description 1
- 230000003053 immunization Effects 0.000 description 1
- 238000002649 immunization Methods 0.000 description 1
- 229940072221 immunoglobulins Drugs 0.000 description 1
- 230000007365 immunoregulation Effects 0.000 description 1
- 238000010348 incorporation Methods 0.000 description 1
- 208000015181 infectious disease Diseases 0.000 description 1
- 230000002458 infectious effect Effects 0.000 description 1
- 230000004054 inflammatory process Effects 0.000 description 1
- 239000004615 ingredient Substances 0.000 description 1
- 230000002401 inhibitory effect Effects 0.000 description 1
- 230000000977 initiatory effect Effects 0.000 description 1
- PGLTVOMIXTUURA-UHFFFAOYSA-N iodoacetamide Chemical compound NC(=O)CI PGLTVOMIXTUURA-UHFFFAOYSA-N 0.000 description 1
- JDNTWHVOXJZDSN-UHFFFAOYSA-N iodoacetic acid Chemical compound OC(=O)CI JDNTWHVOXJZDSN-UHFFFAOYSA-N 0.000 description 1
- JXDYKVIHCLTXOP-UHFFFAOYSA-N isatin Chemical compound C1=CC=C2C(=O)C(=O)NC2=C1 JXDYKVIHCLTXOP-UHFFFAOYSA-N 0.000 description 1
- 238000002955 isolation Methods 0.000 description 1
- 125000000741 isoleucyl group Chemical group [H]N([H])C(C(C([H])([H])[H])C([H])([H])C([H])([H])[H])C(=O)O* 0.000 description 1
- 238000006317 isomerization reaction Methods 0.000 description 1
- 210000004698 lymphocyte Anatomy 0.000 description 1
- 229920002521 macromolecule Polymers 0.000 description 1
- 238000012423 maintenance Methods 0.000 description 1
- 230000036210 malignancy Effects 0.000 description 1
- 238000005259 measurement Methods 0.000 description 1
- 230000001404 mediated effect Effects 0.000 description 1
- 150000002730 mercury Chemical class 0.000 description 1
- 229930182817 methionine Natural products 0.000 description 1
- 125000001360 methionine group Chemical group N[C@@H](CCSC)C(=O)* 0.000 description 1
- UZKWTJUDCOPSNM-UHFFFAOYSA-N methoxybenzene Substances CCCCOC=C UZKWTJUDCOPSNM-UHFFFAOYSA-N 0.000 description 1
- ZCQGVFNHUATAJY-UHFFFAOYSA-N methyl 2-[methyl(prop-2-enoyl)amino]acetate Chemical compound COC(=O)CN(C)C(=O)C=C ZCQGVFNHUATAJY-UHFFFAOYSA-N 0.000 description 1
- 238000001823 molecular biology technique Methods 0.000 description 1
- CMWYAOXYQATXSI-UHFFFAOYSA-N n,n-dimethylformamide;piperidine Chemical compound CN(C)C=O.C1CCNCC1 CMWYAOXYQATXSI-UHFFFAOYSA-N 0.000 description 1
- 230000016864 negative regulation of biological process Effects 0.000 description 1
- FEMOMIGRRWSMCU-UHFFFAOYSA-N ninhydrin Chemical compound C1=CC=C2C(=O)C(O)(O)C(=O)C2=C1 FEMOMIGRRWSMCU-UHFFFAOYSA-N 0.000 description 1
- 108020001162 nitroreductase Proteins 0.000 description 1
- 230000000269 nucleophilic effect Effects 0.000 description 1
- 238000005457 optimization Methods 0.000 description 1
- 229940049954 penicillin Drugs 0.000 description 1
- 238000010647 peptide synthesis reaction Methods 0.000 description 1
- 229910052697 platinum Inorganic materials 0.000 description 1
- 229920002401 polyacrylamide Polymers 0.000 description 1
- 229920002647 polyamide Polymers 0.000 description 1
- 230000016919 positive regulation of biological process Effects 0.000 description 1
- GKKCIDNWFBPDBW-UHFFFAOYSA-M potassium cyanate Chemical compound [K]OC#N GKKCIDNWFBPDBW-UHFFFAOYSA-M 0.000 description 1
- 230000003389 potentiating effect Effects 0.000 description 1
- 239000002243 precursor Substances 0.000 description 1
- XOFYZVNMUHMLCC-ZPOLXVRWSA-N prednisone Chemical compound O=C1C=C[C@]2(C)[C@H]3C(=O)C[C@](C)([C@@](CC4)(O)C(=O)CO)[C@@H]4[C@@H]3CCC2=C1 XOFYZVNMUHMLCC-ZPOLXVRWSA-N 0.000 description 1
- 229960004618 prednisone Drugs 0.000 description 1
- 238000002360 preparation method Methods 0.000 description 1
- 230000002265 prevention Effects 0.000 description 1
- 238000012545 processing Methods 0.000 description 1
- 230000035755 proliferation Effects 0.000 description 1
- 230000009696 proliferative response Effects 0.000 description 1
- 230000000069 prophylactic effect Effects 0.000 description 1
- 208000023958 prostate neoplasm Diseases 0.000 description 1
- 230000001681 protective effect Effects 0.000 description 1
- 230000017854 proteolysis Effects 0.000 description 1
- 230000005180 public health Effects 0.000 description 1
- 238000000746 purification Methods 0.000 description 1
- 239000002516 radical scavenger Substances 0.000 description 1
- 238000001959 radiotherapy Methods 0.000 description 1
- 230000008707 rearrangement Effects 0.000 description 1
- 102000005962 receptors Human genes 0.000 description 1
- 108020003175 receptors Proteins 0.000 description 1
- 230000000306 recurrent effect Effects 0.000 description 1
- 230000009467 reduction Effects 0.000 description 1
- 238000006722 reduction reaction Methods 0.000 description 1
- 238000005932 reductive alkylation reaction Methods 0.000 description 1
- 230000001105 regulatory effect Effects 0.000 description 1
- 230000000284 resting effect Effects 0.000 description 1
- 230000000717 retained effect Effects 0.000 description 1
- 230000001177 retroviral effect Effects 0.000 description 1
- 230000035945 sensitivity Effects 0.000 description 1
- 238000012163 sequencing technique Methods 0.000 description 1
- 230000011664 signaling Effects 0.000 description 1
- 229940074386 skatole Drugs 0.000 description 1
- 239000007787 solid Substances 0.000 description 1
- 239000006104 solid solution Substances 0.000 description 1
- 230000037439 somatic mutation Effects 0.000 description 1
- 241000894007 species Species 0.000 description 1
- 230000010473 stable expression Effects 0.000 description 1
- 238000010561 standard procedure Methods 0.000 description 1
- 208000003265 stomatitis Diseases 0.000 description 1
- 230000002195 synergetic effect Effects 0.000 description 1
- 238000001308 synthesis method Methods 0.000 description 1
- 230000009885 systemic effect Effects 0.000 description 1
- 230000008685 targeting Effects 0.000 description 1
- 238000010998 test method Methods 0.000 description 1
- 229960003604 testosterone Drugs 0.000 description 1
- 230000000699 topical effect Effects 0.000 description 1
- 230000001988 toxicity Effects 0.000 description 1
- 231100000419 toxicity Toxicity 0.000 description 1
- 238000013518 transcription Methods 0.000 description 1
- 230000035897 transcription Effects 0.000 description 1
- 230000002103 transcriptional effect Effects 0.000 description 1
- 230000009466 transformation Effects 0.000 description 1
- 230000009261 transgenic effect Effects 0.000 description 1
- 230000010474 transient expression Effects 0.000 description 1
- 230000014616 translation Effects 0.000 description 1
- 238000013519 translation Methods 0.000 description 1
- 230000005945 translocation Effects 0.000 description 1
- 125000002221 trityl group Chemical group [H]C1=C([H])C([H])=C([H])C([H])=C1C([*])(C1=C(C(=C(C(=C1[H])[H])[H])[H])[H])C1=C([H])C([H])=C([H])C([H])=C1[H] 0.000 description 1
- OUYCCCASQSFEME-UHFFFAOYSA-N tyrosine Natural products OC(=O)C(N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-UHFFFAOYSA-N 0.000 description 1
- 125000001493 tyrosinyl group Chemical group [H]OC1=C([H])C([H])=C(C([H])=C1[H])C([H])([H])C([H])(N([H])[H])C(*)=O 0.000 description 1
- 241000701447 unidentified baculovirus Species 0.000 description 1
- 241001529453 unidentified herpesvirus Species 0.000 description 1
- 238000011144 upstream manufacturing Methods 0.000 description 1
- 230000029812 viral genome replication Effects 0.000 description 1
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 1
- 230000036642 wellbeing Effects 0.000 description 1
- 229940085728 xtandi Drugs 0.000 description 1
- 229940051084 zytiga Drugs 0.000 description 1
Images



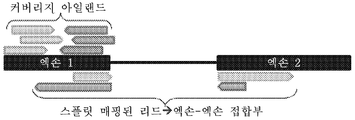

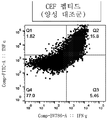






Classifications
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K35/00—Medicinal preparations containing materials or reaction products thereof with undetermined constitution
- A61K35/66—Microorganisms or materials therefrom
- A61K35/76—Viruses; Subviral particles; Bacteriophages
- A61K35/761—Adenovirus
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/0005—Vertebrate antigens
- A61K39/0011—Cancer antigens
- A61K39/001193—Prostate associated antigens e.g. Prostate stem cell antigen [PSCA]; Prostate carcinoma tumor antigen [PCTA]; PAP or PSGR
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/0005—Vertebrate antigens
- A61K39/0011—Cancer antigens
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/0005—Vertebrate antigens
- A61K39/0011—Cancer antigens
- A61K39/001193—Prostate associated antigens e.g. Prostate stem cell antigen [PSCA]; Prostate carcinoma tumor antigen [PCTA]; PAP or PSGR
- A61K39/001194—Prostate specific antigen [PSA]
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/0005—Vertebrate antigens
- A61K39/0011—Cancer antigens
- A61K39/001193—Prostate associated antigens e.g. Prostate stem cell antigen [PSCA]; Prostate carcinoma tumor antigen [PCTA]; PAP or PSGR
- A61K39/001195—Prostate specific membrane antigen [PSMA]
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/46—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans from vertebrates
- C07K14/47—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans from vertebrates from mammals
- C07K14/4701—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans from vertebrates from mammals not used
- C07K14/4748—Tumour specific antigens; Tumour rejection antigen precursors [TRAP], e.g. MAGE
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/30—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants from tumour cells
- C07K16/3069—Reproductive system, e.g. ovaria, uterus, testes, prostate
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/51—Medicinal preparations containing antigens or antibodies comprising whole cells, viruses or DNA/RNA
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/51—Medicinal preparations containing antigens or antibodies comprising whole cells, viruses or DNA/RNA
- A61K2039/525—Virus
- A61K2039/5256—Virus expressing foreign proteins
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/51—Medicinal preparations containing antigens or antibodies comprising whole cells, viruses or DNA/RNA
- A61K2039/53—DNA (RNA) vaccination
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/545—Medicinal preparations containing antigens or antibodies characterised by the dose, timing or administration schedule
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/57—Medicinal preparations containing antigens or antibodies characterised by the type of response, e.g. Th1, Th2
- A61K2039/572—Medicinal preparations containing antigens or antibodies characterised by the type of response, e.g. Th1, Th2 cytotoxic response
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/70—Multivalent vaccine
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/80—Vaccine for a specifically defined cancer
- A61K2039/884—Vaccine for a specifically defined cancer prostate
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K45/00—Medicinal preparations containing active ingredients not provided for in groups A61K31/00 - A61K41/00
- A61K45/06—Mixtures of active ingredients without chemical characterisation, e.g. antiphlogistics and cardiaca
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2710/00—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA dsDNA viruses
- C12N2710/00011—Details
- C12N2710/10011—Adenoviridae
- C12N2710/10311—Mastadenovirus, e.g. human or simian adenoviruses
- C12N2710/10341—Use of virus, viral particle or viral elements as a vector
- C12N2710/10343—Use of virus, viral particle or viral elements as a vector viral genome or elements thereof as genetic vector
Landscapes
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Chemical & Material Sciences (AREA)
- General Health & Medical Sciences (AREA)
- Medicinal Chemistry (AREA)
- Immunology (AREA)
- Veterinary Medicine (AREA)
- Pharmacology & Pharmacy (AREA)
- Animal Behavior & Ethology (AREA)
- Public Health (AREA)
- Epidemiology (AREA)
- Microbiology (AREA)
- Mycology (AREA)
- Oncology (AREA)
- Cell Biology (AREA)
- Organic Chemistry (AREA)
- Developmental Biology & Embryology (AREA)
- Molecular Biology (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Biochemistry (AREA)
- Biophysics (AREA)
- Genetics & Genomics (AREA)
- Virology (AREA)
- Zoology (AREA)
- Chemical Kinetics & Catalysis (AREA)
- Toxicology (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- Gastroenterology & Hepatology (AREA)
- General Chemical & Material Sciences (AREA)
- Pregnancy & Childbirth (AREA)
- Reproductive Health (AREA)
- Gynecology & Obstetrics (AREA)
- Micro-Organisms Or Cultivation Processes Thereof (AREA)
- Medicines Containing Antibodies Or Antigens For Use As Internal Diagnostic Agents (AREA)
- Peptides Or Proteins (AREA)
- Medicines That Contain Protein Lipid Enzymes And Other Medicines (AREA)
- Medicinal Preparation (AREA)
- Pharmaceuticals Containing Other Organic And Inorganic Compounds (AREA)
Abstract
본 발명은 전립선 신생항원, 이를 인코딩하는 폴리뉴클레오티드, 벡터, 숙주 세포, 재조합 바이러스 입자, 신생항원을 포함하는 백신, 전립선 신생항원에 결합하는 단백질성 분자, 및 이들의 제조 및 사용 방법에 관한 것이다.
Description
관련 출원의 상호 참조
본 출원은 2019년 10월 11일자로 출원된 미국 가출원 제62/913,969호, 2019년 8월 7일자로 출원된 미국 가출원 제62/883,786호, 2019년 5월 22일자로 출원된 미국 가출원 제62/851,273호 및 2019년 1월 10일자로 출원된 미국 가출원 제62/790,673호의 이익을 주장하며, 상술한 출원의 전체 내용은 전체적으로 본 명세서에 참고로 포함된다.
서열 목록
본 출원은 EFS-웹(EFS-Web)을 통해 제출된 서열 목록을 포함하며, 그 전체 내용이 전체적으로 본 명세서에 참고로 포함된다. 2019년 12월 16일자로 작성된 ASCII 텍스트 파일은 파일명이 JBI6160WOPCT2_ST25.txt이며, 크기가 554 킬로바이트이다.
전립선암은 남성에게서 가장 흔한 비피부 악성종양이며, 서구 사회에서 남성의 암으로 인한 두 번째로 높은 사망 원인이다. 전립선암은 전립선에서의 비정상 세포의 제어되지 않은 세포 증식으로 인해 발생된다. 전립선암 종양이 발생되면, 안드로겐, 예컨대 테스토스테론이 전립선암 증식을 촉진한다. 초기 단계에서, 국한성 전립선암은, 예를 들어 전립선의 외과적 제거 및 방사선요법을 포함하는 국소 요법으로 종종 치유가능하다. 그러나, 남성의 1/3 이하에 해당되는 바와 같이, 국소 요법으로 전립선암을 치료하지 못하면, 상기 질환은 불치의 전이성 질환으로 진행된다.
수년 동안, 악성 거세저항성 전립선암(mCRPC)을 가진 남성에 대해 확립된 표준 치료는 도세탁셀 화학요법이었다. 보다 최근에는, 프레드니손과 병용된 아비라테론 아세테이트(자이티가(ZYTIGA)®)가 전이성 거세저항성 전립선암을 치료하는 데 승인되었다. 엔잘루타미드(엑스탄디(XTANDI)®)와 같은 안드로겐 수용체(AR) 표적 약제도 전이성 거세저항성 전립선암을 치료하기 위한 시장에 뛰어들었다. 백금을 이용한 화학 요법은 제한된 결과 및 상당한 독성을 동반하면서, 분자적으로 선택되지 않은 전립선암 환자에서 다수의 임상 연구에서 시험되어 왔다. 그러나, 이들 치료에 대해 초기에 반응하지 않거나, 불응성(또는 저항성)이 되는 환자의 서브세트가 남아 있다. 그러한 환자에 대해서는 승인된 치료 옵션이 이용가능하지 않다.
그러나, 호르몬 감수성 전립선암, 호르몬 미실시(hormone  ) 고위험 전립선암 및 거세저항성 전립선암을 포함한 전립선암에 대한 치료가 여전히 필요하다.
) 고위험 전립선암 및 거세저항성 전립선암을 포함한 전립선암에 대한 치료가 여전히 필요하다.
본 발명은 서열 번호 1, 3, 5, 7, 9, 11, 13, 15, 17, 19, 21, 23, 25, 27, 29, 31, 33, 35, 37, 39, 41, 43, 45, 47, 49, 51, 53, 55, 57, 59, 61, 63, 65, 67, 69, 71, 73, 75, 77, 79, 81, 83, 85, 87, 89, 91, 93, 95, 97, 99, 101, 103, 105, 107, 109, 111, 113, 115, 117, 119, 121, 123, 125, 127, 129, 131, 133, 135, 137, 139, 141, 143, 145, 147, 149, 151, 153, 155, 157, 159, 161, 163, 165, 167, 169, 171, 173, 175, 177, 179, 181, 183, 185, 187, 189, 191, 193, 195, 197, 199, 201, 203, 205, 207, 209, 211, 213, 215, 217, 219, 221, 223, 225, 227, 229, 231, 233, 235, 237, 239, 241, 243, 245, 247, 249, 251, 253, 255, 257, 259, 261, 263, 265, 267, 269, 271, 273, 275, 277, 279, 281, 283, 285, 287, 289, 291, 293, 295, 297, 299, 301, 303, 305, 307, 309, 311, 313, 315, 317, 319, 321, 323, 325, 327, 329, 331, 333, 335, 337, 339, 341, 343, 345, 347, 349, 351, 353, 355, 357, 359, 361, 363, 365, 367, 369, 371, 373, 375, 379, 381, 383, 385, 387, 388, 389, 390, 391, 392, 393, 394, 395, 396, 397, 398, 399, 400, 401, 402, 403, 404, 405, 406, 407, 408, 426, 427, 428, 429, 430, 431, 432, 433, 434, 435, 436, 437, 438, 439, 440, 441, 442, 443, 444, 445, 446 또는 447의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다.
본 발명은 또한 서열 번호 2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26, 28, 30, 32, 34, 36, 38, 40, 42, 44, 46, 48, 50, 52, 54, 56, 58, 60, 62, 64, 66, 68, 70, 72, 74, 76, 78, 80, 82, 84, 86, 88, 90, 92, 94, 96, 98, 100, 102, 104, 106, 108, 110, 112, 114, 116, 118, 120, 122, 124, 126, 128, 130, 132, 134, 136, 138, 140, 142, 144, 146, 148, 150, 152, 154, 156, 158, 160, 162, 164, 166, 168, 170, 172, 174, 176, 178, 180, 182, 184, 186, 188, 190, 192, 194, 196, 198, 200, 202, 204, 206, 208, 210, 212, 214, 216, 218, 220, 222, 224, 226, 228, 230, 232, 234, 236, 238, 240, 242, 244, 246, 248, 250, 252, 254, 256, 258, 260, 262, 264, 266, 268, 270, 272, 274, 276, 278, 280, 282, 284, 286, 288, 290, 292, 294, 296, 298, 300, 302, 304, 306, 308, 310, 312, 314, 316, 318, 320, 322, 324, 326, 328, 330, 332, 334, 336, 338, 340, 342, 344, 346, 348, 350, 352, 354, 356, 358, 360, 362, 364, 366, 368, 370, 372, 374, 376, 380, 382, 384, 386, 448, 449, 450, 451, 452, 453, 454, 455, 456, 457, 458, 459, 460, 461, 462, 463, 464, 465, 466, 467, 468, 469, 470, 471, 472, 473, 474, 475, 476, 477, 478, 479, 480, 481, 482, 483, 484, 485, 486, 487, 488, 489, 490, 491, 492, 493, 494, 495, 496, 497, 498, 499, 500, 501, 503, 504, 505, 506, 507, 508, 509, 510, 511, 512, 513, 514, 515, 516, 517, 519, 520, 521, 522, 523, 524, 525, 528, 529, 530, 531, 532, 533, 534, 535, 536, 537, 538, 539 또는 540의 폴리뉴클레오티드 서열 또는 이의 단편을 포함하는 단리된 폴리뉴클레오티드를 제공한다.
본 발명은 또한 서열 번호 2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26, 28, 30, 32, 34, 36, 38, 40, 42, 44, 46, 48, 50, 52, 54, 56, 58, 60, 62, 64, 66, 68, 70, 72, 74, 76, 78, 80, 82, 84, 86, 88, 90, 92, 94, 96, 98, 100, 102, 104, 106, 108, 110, 112, 114, 116, 118, 120, 122, 124, 126, 128, 130, 132, 134, 136, 138, 140, 142, 144, 146, 148, 150, 152, 154, 156, 158, 160, 162, 164, 166, 168, 170, 172, 174, 176, 178, 180, 182, 184, 186, 188, 190, 192, 194, 196, 198, 200, 202, 204, 206, 208, 210, 212, 214, 216, 218, 220, 222, 224, 226, 228, 230, 232, 234, 236, 238, 240, 242, 244, 246, 248, 250, 252, 254, 256, 258, 260, 262, 264, 266, 268, 270, 272, 274, 276, 278, 280, 282, 284, 286, 288, 290, 292, 294, 296, 298, 300, 302, 304, 306, 308, 310, 312, 314, 316, 318, 320, 322, 324, 326, 328, 330, 332, 334, 336, 338, 340, 342, 344, 346, 348, 350, 352, 354, 356, 358, 360, 362, 364, 366, 368, 370, 372, 374, 376, 380, 382, 384, 386, 448, 449, 450, 451, 452, 453, 454, 455, 456, 457 및 458로 이루어진 군으로부터 선택되는 2개 이상의 폴리뉴클레오티드 및 이들의 단편을 포함하는 단리된 이종 폴리뉴클레오티드를 제공한다.
본 발명은 또한 서열 번호 1, 3, 5, 7, 9, 11, 13, 15, 17, 19, 21, 23, 25, 27, 29, 31, 33, 35, 37, 39, 41, 43, 45, 47, 49, 51, 53, 55, 57, 59, 61, 63, 65, 67, 69, 71, 73, 75, 77, 79, 81, 83, 85, 87, 89, 91, 93, 95, 97, 99, 101, 103, 105, 107, 109, 111, 113, 115, 117, 119, 121, 123, 125, 127, 129, 131, 133, 135, 137, 139, 141, 143, 145, 147, 149, 151, 153, 155, 157, 159, 161, 163, 165, 167, 169, 171, 173, 175, 177, 179, 181, 183, 185, 187, 189, 191, 193, 195, 197, 199, 201, 203, 205, 207, 209, 211, 213, 215, 217, 219, 221, 223, 225, 227, 229, 231, 233, 235, 237, 239, 241, 243, 245, 247, 249, 251, 253, 255, 257, 259, 261, 263, 265, 267, 269, 271, 273, 275, 277, 279, 281, 283, 285, 287, 289, 291, 293, 295, 297, 299, 301, 303, 305, 307, 309, 311, 313, 315, 317, 319, 321, 323, 325, 327, 329, 331, 333, 335, 337, 339, 341, 343, 345, 347, 349, 351, 353, 355, 357, 359, 361, 363, 365, 367, 369, 371, 373, 375, 379, 381, 383, 385, 387, 388, 389, 390, 391, 392, 393, 394, 395, 396, 397, 398, 399, 400, 401, 402, 403, 404, 405, 406, 407, 408, 426, 427, 428, 429, 430, 431, 432, 433, 434, 435, 436, 437, 438, 439, 440, 441, 442, 443, 444, 445, 446 및 447로 이루어진 군으로부터 선택되는 2개 이상의 폴리펩티드 및 이들의 단편을 포함하는 이종 폴리펩티드를 인코딩하는 단리된 이종 폴리뉴클레오티드를 제공한다.
본 발명은 또한 서열 번호 1, 3, 5, 7, 9, 11, 13, 15, 17, 19, 21, 23, 25, 27, 29, 31, 33, 35, 37, 39, 41, 43, 45, 47, 49, 51, 53, 55, 57, 59, 61, 63, 65, 67, 69, 71, 73, 75, 77, 79, 81, 83, 85, 87, 89, 91, 93, 95, 97, 99, 101, 103, 105, 107, 109, 111, 113, 115, 117, 119, 121, 123, 125, 127, 129, 131, 133, 135, 137, 139, 141, 143, 145, 147, 149, 151, 153, 155, 157, 159, 161, 163, 165, 167, 169, 171, 173, 175, 177, 179, 181, 183, 185, 187, 189, 191, 193, 195, 197, 199, 201, 203, 205, 207, 209, 211, 213, 215, 217, 219, 221, 223, 225, 227, 229, 231, 233, 235, 237, 239, 241, 243, 245, 247, 249, 251, 253, 255, 257, 259, 261, 263, 265, 267, 269, 271, 273, 275, 277, 279, 281, 283, 285, 287, 289, 291, 293, 295, 297, 299, 301, 303, 305, 307, 309, 311, 313, 315, 317, 319, 321, 323, 325, 327, 329, 331, 333, 335, 337, 339, 341, 343, 345, 347, 349, 351, 353, 355, 357, 359, 361, 363, 365, 367, 369, 371, 373, 375, 379, 381, 383, 385, 387, 388, 389, 390, 391, 392, 393, 394, 395, 396, 397, 398, 399, 400, 401, 402, 403, 404, 405, 406, 407, 408, 426, 427, 428, 429, 430, 431, 432, 433, 434, 435, 436, 437, 438, 439, 440, 441, 442, 443, 444, 445, 446 또는 447의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 제공한다.
본 발명은 또한 서열 번호 1, 3, 5, 7, 9, 11, 13, 15, 17, 19, 21, 23, 25, 27, 29, 31, 33, 35, 37, 39, 41, 43, 45, 47, 49, 51, 53, 55, 57, 59, 61, 63, 65, 67, 69, 71, 73, 75, 77, 79, 81, 83, 85, 87, 89, 91, 93, 95, 97, 99, 101, 103, 105, 107, 109, 111, 113, 115, 117, 119, 121, 123, 125, 127, 129, 131, 133, 135, 137, 139, 141, 143, 145, 147, 149, 151, 153, 155, 157, 159, 161, 163, 165, 167, 169, 171, 173, 175, 177, 179, 181, 183, 185, 187, 189, 191, 193, 195, 197, 199, 201, 203, 205, 207, 209, 211, 213, 215, 217, 219, 221, 223, 225, 227, 229, 231, 233, 235, 237, 239, 241, 243, 245, 247, 249, 251, 253, 255, 257, 259, 261, 263, 265, 267, 269, 271, 273, 275, 277, 279, 281, 283, 285, 287, 289, 291, 293, 295, 297, 299, 301, 303, 305, 307, 309, 311, 313, 315, 317, 319, 321, 323, 325, 327, 329, 331, 333, 335, 337, 339, 341, 343, 345, 347, 349, 351, 353, 355, 357, 359, 361, 363, 365, 367, 369, 371, 373, 375, 379, 381, 383, 385, 387, 388, 389, 390, 391, 392, 393, 394, 395, 396, 397, 398, 399, 400, 401, 402, 403, 404, 405, 406, 407, 408, 426, 427, 428, 429, 430, 431, 432, 433, 434, 435, 436, 437, 438, 439, 440, 441, 442, 443, 444, 445, 446 및 447로 이루어진 군으로부터 선택되는 2개 이상의 폴리펩티드 및 이들의 단편을 포함하는 단리된 이종 폴리펩티드를 제공한다.
본 발명은 또한,
서열 번호 1, 3, 5, 7, 9, 11, 13, 15, 17, 19, 21, 23, 25, 27, 29, 31, 33, 35, 37, 39, 41, 43, 45, 47, 49, 51, 53, 55, 57, 59, 61, 63, 65, 67, 69, 71, 73, 75, 77, 79, 81, 83, 85, 87, 89, 91, 93, 95, 97, 99, 101, 103, 105, 107, 109, 111, 113, 115, 117, 119, 121, 123, 125, 127, 129, 131, 133, 135, 137, 139, 141, 143, 145, 147, 149, 151, 153, 155, 157, 159, 161, 163, 165, 167, 169, 171, 173, 175, 177, 179, 181, 183, 185, 187, 189, 191, 193, 195, 197, 199, 201, 203, 205, 207, 209, 211, 213, 215, 217, 219, 221, 223, 225, 227, 229, 231, 233, 235, 237, 239, 241, 243, 245, 247, 249, 251, 253, 255, 257, 259, 261, 263, 265, 267, 269, 271, 273, 275, 277, 279, 281, 283, 285, 287, 289, 291, 293, 295, 297, 299, 301, 303, 305, 307, 309, 311, 313, 315, 317, 319, 321, 323, 325, 327, 329, 331, 333, 335, 337, 339, 341, 343, 345, 347, 349, 351, 353, 355, 357, 359, 361, 363, 365, 367, 369, 371, 373, 375, 379, 381, 383, 385, 387, 388, 389, 390, 391, 392, 393, 394, 395, 396, 397, 398, 399, 400, 401, 402, 403, 404, 405, 406, 407, 408, 426, 427, 428, 429, 430, 431, 432, 433, 434, 435, 436, 437, 438, 439, 440, 441, 442, 443, 444, 445, 446 또는 447 중 하나 이상의 폴리펩티드 또는 이들의 단편을 인코딩하는 폴리뉴클레오티드;
서열 번호 2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26, 28, 30, 32, 34, 36, 38, 40, 42, 44, 46, 48, 50, 52, 54, 56, 58, 60, 62, 64, 66, 68, 70, 72, 74, 76, 78, 80, 82, 84, 86, 88, 90, 92, 94, 96, 98, 100, 102, 104, 106, 108, 110, 112, 114, 116, 118, 120, 122, 124, 126, 128, 130, 132, 134, 136, 138, 140, 142, 144, 146, 148, 150, 152, 154, 156, 158, 160, 162, 164, 166, 168, 170, 172, 174, 176, 178, 180, 182, 184, 186, 188, 190, 192, 194, 196, 198, 200, 202, 204, 206, 208, 210, 212, 214, 216, 218, 220, 222, 224, 226, 228, 230, 232, 234, 236, 238, 240, 242, 244, 246, 248, 250, 252, 254, 256, 258, 260, 262, 264, 266, 268, 270, 272, 274, 276, 278, 280, 282, 284, 286, 288, 290, 292, 294, 296, 298, 300, 302, 304, 306, 308, 310, 312, 314, 316, 318, 320, 322, 324, 326, 328, 330, 332, 334, 336, 338, 340, 342, 344, 346, 348, 350, 352, 354, 356, 358, 360, 362, 364, 366, 368, 370, 372, 374, 376, 380, 382, 384, 386, 448, 449, 450, 451, 452, 453, 454, 455, 456, 457 또는 458 중 하나 이상의 폴리뉴클레오티드 또는 이들의 단편;
서열 번호 1, 3, 5, 7, 9, 11, 13, 15, 17, 19, 21, 23, 25, 27, 29, 31, 33, 35, 37, 39, 41, 43, 45, 47, 49, 51, 53, 55, 57, 59, 61, 63, 65, 67, 69, 71, 73, 75, 77, 79, 81, 83, 85, 87, 89, 91, 93, 95, 97, 99, 101, 103, 105, 107, 109, 111, 113, 115, 117, 119, 121, 123, 125, 127, 129, 131, 133, 135, 137, 139, 141, 143, 145, 147, 149, 151, 153, 155, 157, 159, 161, 163, 165, 167, 169, 171, 173, 175, 177, 179, 181, 183, 185, 187, 189, 191, 193, 195, 197, 199, 201, 203, 205, 207, 209, 211, 213, 215, 217, 219, 221, 223, 225, 227, 229, 231, 233, 235, 237, 239, 241, 243, 245, 247, 249, 251, 253, 255, 257, 259, 261, 263, 265, 267, 269, 271, 273, 275, 277, 279, 281, 283, 285, 287, 289, 291, 293, 295, 297, 299, 301, 303, 305, 307, 309, 311, 313, 315, 317, 319, 321, 323, 325, 327, 329, 331, 333, 335, 337, 339, 341, 343, 345, 347, 349, 351, 353, 355, 357, 359, 361, 363, 365, 367, 369, 371, 373, 375, 379, 381, 383, 385, 387, 388, 389, 390, 391, 392, 393, 394, 395, 396, 397, 398, 399, 400, 401, 402, 403, 404, 405, 406, 407, 408, 426, 427, 428, 429, 430, 431, 432, 433, 434, 435, 436, 437, 438, 439, 440, 441, 442, 443, 444, 445, 446 및 447로 이루어진 군으로부터 선택되는 2개 이상의 폴리펩티드 및 이들의 단편을 포함하는 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드; 또는
서열 번호 2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26, 28, 30, 32, 34, 36, 38, 40, 42, 44, 46, 48, 50, 52, 54, 56, 58, 60, 62, 64, 66, 68, 70, 72, 74, 76, 78, 80, 82, 84, 86, 88, 90, 92, 94, 96, 98, 100, 102, 104, 106, 108, 110, 112, 114, 116, 118, 120, 122, 124, 126, 128, 130, 132, 134, 136, 138, 140, 142, 144, 146, 148, 150, 152, 154, 156, 158, 160, 162, 164, 166, 168, 170, 172, 174, 176, 178, 180, 182, 184, 186, 188, 190, 192, 194, 196, 198, 200, 202, 204, 206, 208, 210, 212, 214, 216, 218, 220, 222, 224, 226, 228, 230, 232, 234, 236, 238, 240, 242, 244, 246, 248, 250, 252, 254, 256, 258, 260, 262, 264, 266, 268, 270, 272, 274, 276, 278, 280, 282, 284, 286, 288, 290, 292, 294, 296, 298, 300, 302, 304, 306, 308, 310, 312, 314, 316, 318, 320, 322, 324, 326, 328, 330, 332, 334, 336, 338, 340, 342, 344, 346, 348, 350, 352, 354, 356, 358, 360, 362, 364, 366, 368, 370, 372, 374, 376, 380, 382, 384, 386, 448, 449, 450, 451, 452, 453, 454, 455, 456, 457 및 458로 이루어진 군으로부터 선택되는 2개 이상의 폴리뉴클레오티드 및 이들의 단편을 포함하는 이종 폴리뉴클레오티드를 포함하는 벡터를 제공한다.
본 발명은 또한 본 발명의 벡터를 포함하는 재조합 인간 아데노바이러스(rAd)를 제공한다.
본 발명은 또한 본 발명의 벡터를 포함하는 재조합 변형된 백시니아 앙카라(recombinant modified vaccinia Ankara; rMVA)를 제공한다.
본 발명은 또한 본 발명의 벡터를 포함하는 재조합 유인원 아데노바이러스(rGAd)를 제공한다.
본 발명은 또한 본 발명의 벡터 또는 본 발명의 재조합 바이러스를 포함하거나 이로 형질도입된 세포를 제공한다.
본 발명은 또한 본 발명의 폴리뉴클레오티드를 포함하는 백신을 제공한다.
본 발명은 또한 본 발명의 이종 폴리뉴클레오티드를 포함하는 백신을 제공한다.
본 발명은 또한 본 발명의 폴리펩티드를 포함하는 백신을 제공한다.
본 발명은 또한 본 발명의 이종 폴리펩티드를 포함하는 백신을 제공한다.
본 발명은 또한 본 발명의 벡터를 포함하는 백신을 제공한다.
본 발명은 또한 본 발명의 rAd를 포함하는 백신을 제공한다.
본 발명은 또한 본 발명의 rMVA를 포함하는 백신을 제공한다.
본 발명은 또한 본 발명의 rGAd를 포함하는 백신을 제공한다.
본 발명은 또한 본 발명의 세포를 포함하는 백신을 제공한다.
본 발명은 또한 본 발명의 백신 및 약제학적으로 허용가능한 담체 또는 애주번트를 포함하는 약제학적 조성물을 제공한다.
본 발명은 또한 하나 이상의 본 발명의 백신 또는 본 발명의 약제학적 조성물을 포함하는 키트를 제공한다.
본 발명은 또한 하나 이상의 본 발명의 백신 또는 하나 이상의 본 발명의 약제학적 조성물의 치료적 유효량을 대상에게 투여하는 단계를 포함하는, 대상에서 전립선암을 예방하거나 치료하는 방법을 제공한다.
본 발명은 또한 대상에서 서열 번호 1, 3, 5, 7, 9, 11, 13, 15, 17, 19, 21, 23, 25, 27, 29, 31, 33, 35, 37, 39, 41, 43, 45, 47, 49, 51, 53, 55, 57, 59, 61, 63, 65, 67, 69, 71, 73, 75, 77, 79, 81, 83, 85, 87, 89, 91, 93, 95, 97, 99, 101, 103, 105, 107, 109, 111, 113, 115, 117, 119, 121, 123, 125, 127, 129, 131, 133, 135, 137, 139, 141, 143, 145, 147, 149, 151, 153, 155, 157, 159, 161, 163, 165, 167, 169, 171, 173, 175, 177, 179, 181, 183, 185, 187, 189, 191, 193, 195, 197, 199, 201, 203, 205, 207, 209, 211, 213, 215, 217, 219, 221, 223, 225, 227, 229, 231, 233, 235, 237, 239, 241, 243, 245, 247, 249, 251, 253, 255, 257, 259, 261, 263, 265, 267, 269, 271, 273, 275, 277, 279, 281, 283, 285, 287, 289, 291, 293, 295, 297, 299, 301, 303, 305, 307, 309, 311, 313, 315, 317, 319, 321, 323, 325, 327, 329, 331, 333, 335, 337, 339, 341, 343, 345, 347, 349, 351, 353, 355, 357, 359, 361, 363, 365, 367, 369, 371, 373, 375, 379, 381, 383, 385, 387, 388, 389, 390, 391, 392, 393, 394, 395, 396, 397, 398, 399, 400, 401, 402, 403, 404, 405, 406, 407, 408, 426, 427, 428, 429, 430, 431, 432, 433, 434, 435, 436, 437, 438, 439, 440, 441, 442, 443, 444, 445, 446 또는 447 중 하나 이상의 폴리펩티드 또는 이의 단편에 대한 면역반응을 유도하는 방법으로서, 하나 이상의 본 발명의 백신을 대상에게 투여하는 단계를 포함하는 방법을 제공한다.
본 발명은 또한 서열 번호 275, 381, 333, 337, 269, 253, 309, 325, 271, 305, 251, 245, 261, 265, 317, 255, 277, 297, 285, 437, 439, 442, 444, 379, 343, 211, 349, 213, 215, 221, 219, 225, 345, 353, 235, 223, 167, 171, 19, 23 및 177로 이루어진 군으로부터 선택되는 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40 또는 41개의 폴리펩티드 및 이들의 단편을 인코딩하는 단리된 이종 폴리뉴클레오티드를 제공한다.
본 발명은 또한 서열 번호 275, 381, 333, 337, 269, 253, 309, 325, 271, 305, 251, 245, 261, 265, 317, 255, 277, 297, 285, 437, 439, 442, 444, 379, 343, 211, 349, 213, 215, 221, 219, 225, 345, 353, 235, 223, 167, 171, 19, 23 및 177로 이루어진 군으로부터 선택되는 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40 또는 41개의 폴리펩티드 및 이들의 단편을 포함하는 단리된 이종 폴리펩티드를 제공한다.
본 발명은 또한,
서열 번호 275, 381, 333, 337, 269, 253, 309, 325, 271, 305, 251, 245, 261, 265, 317, 255, 277, 297, 285, 437, 439, 442, 444, 379, 343, 211, 349, 213, 215, 221, 219, 225, 345, 353, 235, 223, 167, 171, 19, 23 및 177로 이루어진 군으로부터 선택되는 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40 또는 41개의 폴리펩티드 및 이들의 단편을 포함하는 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드;
서열 번호 276, 382, 334, 338, 270, 254, 310, 326, 272, 306, 252, 246, 262, 266, 318, 256, 278, 298, 286, 448, 450, 453, 455, 380, 344, 212, 350, 214, 216, 222, 220, 226, 346, 354, 236, 224, 168, 172, 20, 24, 178, 459, 460, 461, 462, 463, 464, 465, 466, 467, 468, 469, 470, 471, 472, 473, 474, 475, 476, 477, 478, 479, 480, 481, 482, 483, 484, 485, 486, 487, 488, 489, 490, 491, 492, 493, 494, 495, 496, 497, 498, 499, 500, 501, 503, 504, 505, 506, 507, 508, 509, 510, 511, 512, 513, 514, 515, 516, 517, 519, 520, 521, 522, 523, 524, 525, 528, 529, 530, 531, 532, 533, 534, 535, 536, 537, 538, 539 및 540으로 이루어진 군으로부터 선택되는 2개 이상의 폴리뉴클레오티드 및 이들의 단편을 포함하는 이종 폴리뉴클레오티드;
서열 번호 459, 460, 461, 462, 463, 464, 465, 466, 467, 468, 469, 470, 471, 472, 473, 474, 475, 476, 477, 478, 479, 480, 481, 482, 483, 484, 485, 486, 487, 488, 489, 490, 491, 492, 493, 494, 495, 496, 497, 498 및 499로 이루어진 군으로부터 선택되는 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40 또는 41개의 폴리뉴클레오티드 및 이들의 단편을 포함하는 이종 폴리뉴클레오티드;
서열 번호 500, 501, 461, 503, 504, 505, 506, 507, 508, 509, 510, 511, 512, 513, 514, 515, 516, 517, 477, 519, 520, 521, 522, 523, 524, 525, 485, 486, 528, 529, 530, 531, 532, 533, 534, 535, 536, 537, 538, 539 및 540으로 이루어진 군으로부터 선택되는 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40 또는 41개의 폴리뉴클레오티드 및 이들의 단편을 포함하는 이종 폴리뉴클레오티드;
서열 번호 541, 550, 554, 555, 556, 623 또는 624의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드;
서열 번호 543, 552, 557, 558, 559, 625 또는 626의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드;
서열 번호 542 또는 서열 번호 551의 폴리뉴클레오티드 서열을 포함하는 이종 폴리뉴클레오티드; 또는
서열 번호 544 또는 서열 번호 553의 폴리뉴클레오티드 서열을 포함하는 이종 폴리뉴클레오티드를 포함하는 벡터를 제공한다.
본 발명은 또한,
서열 번호 275, 381, 333, 337, 269, 253, 309, 325, 271, 305, 251, 245, 261, 265, 317, 255, 277, 297, 285, 437, 439, 442, 444, 379, 343, 211, 349, 213, 215, 221, 219, 225, 345, 353, 235, 223, 167, 171, 19, 23 및 177로 이루어진 군으로부터 선택되는 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40 또는 41개의 폴리펩티드 및 이들의 단편을 포함하는 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드;
서열 번호 276, 382, 334, 338, 270, 254, 310, 326, 272, 306, 252, 246, 262, 266, 318, 256, 278, 298, 286, 448, 450, 453, 455, 380, 344, 212, 350, 214, 216, 222, 220, 226, 346, 354, 236, 224, 168, 172, 20, 24 및 178로 이루어진 군으로부터 선택되는 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40 또는 41개의 폴리뉴클레오티드 및 이들의 단편을 포함하는 이종 폴리뉴클레오티드;
서열 번호 459, 460, 461, 462, 463, 464, 465, 466, 467, 468, 469, 470, 471, 472, 473, 474, 475, 476, 477, 478, 479, 480, 481, 482, 483, 484, 485, 486, 487, 488, 489, 490, 491, 492, 493, 494, 495, 496, 497, 498 및 499로 이루어진 군으로부터 선택되는 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40 또는 41개의 폴리뉴클레오티드 및 이들의 단편을 포함하는 이종 폴리뉴클레오티드; 또는
서열 번호 500, 501, 461, 503, 504, 505, 506, 507, 508, 509, 510, 511, 512, 513, 514, 515, 516, 517, 477, 519, 520, 521, 522, 523, 524, 525, 485, 486, 528, 529, 530, 531, 532, 533, 534, 535, 536, 537, 538, 539 및 540으로 이루어진 군으로부터 선택되는 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40 또는 41개의 폴리뉴클레오티드 및 이들의 단편을 포함하는 이종 폴리뉴클레오티드를 포함하는 재조합 인간 아데노바이러스(rAd)를 제공한다.
본 발명은 또한,
서열 번호 275, 381, 333, 337, 269, 253, 309, 325, 271, 305, 251, 245, 261, 265, 317, 255, 277, 297, 285, 437, 439, 442, 444, 379, 343, 211, 349, 213, 215, 221, 219, 225, 345, 353, 235, 223, 167, 171, 19, 23 및 177로 이루어진 군으로부터 선택되는 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40 또는 41개의 폴리펩티드 및 이들의 단편을 포함하는 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드;
서열 번호 276, 382, 334, 338, 270, 254, 310, 326, 272, 306, 252, 246, 262, 266, 318, 256, 278, 298, 286, 448, 450, 453, 455, 380, 344, 212, 350, 214, 216, 222, 220, 226, 346, 354, 236, 224, 168, 172, 20, 24 및 178로 이루어진 군으로부터 선택되는 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40 또는 41개의 폴리뉴클레오티드 및 이들의 단편을 포함하는 이종 폴리뉴클레오티드;
서열 번호 459, 460, 461, 462, 463, 464, 465, 466, 467, 468, 469, 470, 471, 472, 473, 474, 475, 476, 477, 478, 479, 480, 481, 482, 483, 484, 485, 486, 487, 488, 489, 490, 491, 492, 493, 494, 495, 496, 497, 498 및 499로 이루어진 군으로부터 선택되는 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40 또는 41개의 폴리뉴클레오티드 및 이들의 단편을 포함하는 이종 폴리뉴클레오티드; 또는
서열 번호 500, 501, 461, 503, 504, 505, 506, 507, 508, 509, 510, 511, 512, 513, 514, 515, 516, 517, 477, 519, 520, 521, 522, 523, 524, 525, 485, 486, 528, 529, 530, 531, 532, 533, 534, 535, 536, 537, 538, 539 및 540으로 이루어진 군으로부터 선택되는 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40 또는 41개의 폴리뉴클레오티드 및 이들의 단편을 포함하는 이종 폴리뉴클레오티드를 포함하는 재조합 유인원 아데노바이러스(rGAd)를 제공한다.
본 발명은 또한,
서열 번호 275, 381, 333, 337, 269, 253, 309, 325, 271, 305, 251, 245, 261, 265, 317, 255, 277, 297, 285, 437, 439, 442, 444, 379, 343, 211, 349, 213, 215, 221, 219, 225, 345, 353, 235, 223, 167, 171, 19, 23 및 177로 이루어진 군으로부터 선택되는 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40 또는 41개의 폴리펩티드 및 이들의 단편을 포함하는 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드;
서열 번호 276, 382, 334, 338, 270, 254, 310, 326, 272, 306, 252, 246, 262, 266, 318, 256, 278, 298, 286, 448, 450, 453, 455, 380, 344, 212, 350, 214, 216, 222, 220, 226, 346, 354, 236, 224, 168, 172, 20, 24 및 178로 이루어진 군으로부터 선택되는 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40 또는 41개의 폴리뉴클레오티드 및 이들의 단편을 포함하는 이종 폴리뉴클레오티드;
서열 번호 459, 460, 461, 462, 463, 464, 465, 466, 467, 468, 469, 470, 471, 472, 473, 474, 475, 476, 477, 478, 479, 480, 481, 482, 483, 484, 485, 486, 487, 488, 489, 490, 491, 492, 493, 494, 495, 496, 497, 498 및 499로 이루어진 군으로부터 선택되는 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40 또는 41개의 폴리뉴클레오티드 및 이들의 단편을 포함하는 이종 폴리뉴클레오티드; 또는
서열 번호 500, 501, 461, 503, 504, 505, 506, 507, 508, 509, 510, 511, 512, 513, 514, 515, 516, 517, 477, 519, 520, 521, 522, 523, 524, 525, 485, 486, 528, 529, 530, 531, 532, 533, 534, 535, 536, 537, 538, 539 및 540으로 이루어진 군으로부터 선택되는 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40 또는 41개의 폴리뉴클레오티드 및 이들의 단편을 포함하는 이종 폴리뉴클레오티드를 포함하는 재조합 변형된 백시니아 앙카라(rMVA)를 제공한다.
본 발명은 또한,
서열 번호 275, 381, 333, 337, 269, 253, 309, 325, 271, 305, 251, 245, 261, 265, 317, 255, 277, 297, 285, 437, 439, 442, 444, 379, 343, 211, 349, 213, 215, 221, 219, 225, 345, 353, 235, 223, 167, 171, 19, 23 및 177로 이루어진 군으로부터 선택되는 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40 또는 41개의 폴리펩티드 및 이들의 단편을 포함하는 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드;
서열 번호 276, 382, 334, 338, 270, 254, 310, 326, 272, 306, 252, 246, 262, 266, 318, 256, 278, 298, 286, 448, 450, 453, 455, 380, 344, 212, 350, 214, 216, 222, 220, 226, 346, 354, 236, 224, 168, 172, 20, 24 및 178로 이루어진 군으로부터 선택되는 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40 또는 41개의 폴리뉴클레오티드 및 이들의 단편을 포함하는 이종 폴리뉴클레오티드;
서열 번호 459, 460, 461, 462, 463, 464, 465, 466, 467, 468, 469, 470, 471, 472, 473, 474, 475, 476, 477, 478, 479, 480, 481, 482, 483, 484, 485, 486, 487, 488, 489, 490, 491, 492, 493, 494, 495, 496, 497, 498 및 499로 이루어진 군으로부터 선택되는 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40 또는 41개의 폴리뉴클레오티드 및 이들의 단편을 포함하는 이종 폴리뉴클레오티드; 또는
서열 번호 500, 501, 461, 503, 504, 505, 506, 507, 508, 509, 510, 511, 512, 513, 514, 515, 516, 517, 477, 519, 520, 521, 522, 523, 524, 525, 485, 486, 528, 529, 530, 531, 532, 533, 534, 535, 536, 537, 538, 539 및 540으로 이루어진 군으로부터 선택되는 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40 또는 41개의 폴리뉴클레오티드 및 이들의 단편을 포함하는 이종 폴리뉴클레오티드를 포함하는, rAd를 포함하는 백신을 제공한다.
본 발명은 또한,
서열 번호 275, 381, 333, 337, 269, 253, 309, 325, 271, 305, 251, 245, 261, 265, 317, 255, 277, 297, 285, 437, 439, 442, 444, 379, 343, 211, 349, 213, 215, 221, 219, 225, 345, 353, 235, 223, 167, 171, 19, 23 및 177로 이루어진 군으로부터 선택되는 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40 또는 41개의 폴리펩티드 및 이들의 단편을 포함하는 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드;
서열 번호 276, 382, 334, 338, 270, 254, 310, 326, 272, 306, 252, 246, 262, 266, 318, 256, 278, 298, 286, 448, 450, 453, 455, 380, 344, 212, 350, 214, 216, 222, 220, 226, 346, 354, 236, 224, 168, 172, 20, 24 및 178로 이루어진 군으로부터 선택되는 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40 또는 41개의 폴리뉴클레오티드 및 이들의 단편을 포함하는 이종 폴리뉴클레오티드;
서열 번호 459, 460, 461, 462, 463, 464, 465, 466, 467, 468, 469, 470, 471, 472, 473, 474, 475, 476, 477, 478, 479, 480, 481, 482, 483, 484, 485, 486, 487, 488, 489, 490, 491, 492, 493, 494, 495, 496, 497, 498 및 499로 이루어진 군으로부터 선택되는 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40 또는 41개의 폴리뉴클레오티드 및 이들의 단편을 포함하는 이종 폴리뉴클레오티드; 또는
서열 번호 500, 501, 461, 503, 504, 505, 506, 507, 508, 509, 510, 511, 512, 513, 514, 515, 516, 517, 477, 519, 520, 521, 522, 523, 524, 525, 485, 486, 528, 529, 530, 531, 532, 533, 534, 535, 536, 537, 538, 539 및 540으로 이루어진 군으로부터 선택되는 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40 또는 41개의 폴리뉴클레오티드 및 이들의 단편을 포함하는 이종 폴리뉴클레오티드를 포함하는, rGAd20를 포함하는 백신을 제공한다.
본 발명은 또한,
서열 번호 275, 381, 333, 337, 269, 253, 309, 325, 271, 305, 251, 245, 261, 265, 317, 255, 277, 297, 285, 437, 439, 442, 444, 379, 343, 211, 349, 213, 215, 221, 219, 225, 345, 353, 235, 223, 167, 171, 19, 23 및 177로 이루어진 군으로부터 선택되는 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40 또는 41개의 폴리펩티드 및 이들의 단편을 포함하는 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드;
서열 번호 276, 382, 334, 338, 270, 254, 310, 326, 272, 306, 252, 246, 262, 266, 318, 256, 278, 298, 286, 448, 450, 453, 455, 380, 344, 212, 350, 214, 216, 222, 220, 226, 346, 354, 236, 224, 168, 172, 20, 24 및 178로 이루어진 군으로부터 선택되는 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40 또는 41개의 폴리뉴클레오티드 및 이들의 단편을 포함하는 이종 폴리뉴클레오티드;
서열 번호 459, 460, 461, 462, 463, 464, 465, 466, 467, 468, 469, 470, 471, 472, 473, 474, 475, 476, 477, 478, 479, 480, 481, 482, 483, 484, 485, 486, 487, 488, 489, 490, 491, 492, 493, 494, 495, 496, 497, 498 및 499로 이루어진 군으로부터 선택되는 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40 또는 41개의 폴리뉴클레오티드 및 이들의 단편을 포함하는 이종 폴리뉴클레오티드; 또는
서열 번호 500, 501, 461, 503, 504, 505, 506, 507, 508, 509, 510, 511, 512, 513, 514, 515, 516, 517, 477, 519, 520, 521, 522, 523, 524, 525, 485, 486, 528, 529, 530, 531, 532, 533, 534, 535, 536, 537, 538, 539 및 540으로 이루어진 군으로부터 선택되는 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40 또는 41개의 폴리뉴클레오티드 및 이들의 단편을 포함하는 이종 폴리뉴클레오티드를 포함하는, rMVA를 포함하는 백신을 제공한다.
본 발명은 또한 서열 번호 275, 381, 333, 337, 269, 253, 309, 325, 271, 305, 251, 245, 261, 265, 317, 255, 277, 297, 285, 437, 439, 442, 444, 379, 343, 211, 349, 213, 215, 221, 219, 225, 345, 353, 235, 223, 167, 171, 19, 23 및 177로 이루어진 군으로부터 선택되는 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40 또는 41개의 폴리펩티드 및 이들의 단편을 포함하는 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 백신을 제공한다.
본 발명은 또한,
서열 번호 275, 381, 333, 337, 269, 253, 309, 325, 271, 305, 251, 245, 261, 265, 317, 255, 277, 297, 285, 437, 439, 442, 444, 379, 343, 211, 349, 213, 215, 221, 219, 225, 345, 353, 235, 223, 167, 171, 19, 23 및 177로 이루어진 군으로부터 선택되는 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40 또는 41개의 폴리펩티드 및 이들의 단편을 포함하는 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 백신의 치료적 유효량을 프라임(prime)으로서 대상에게 투여하는 단계; 및
서열 번호 275, 381, 333, 337, 269, 253, 309, 325, 271, 305, 251, 245, 261, 265, 317, 255, 277, 297, 285, 437, 439, 442, 444, 379, 343, 211, 349, 213, 215, 221, 219, 225, 345, 353, 235, 223, 167, 171, 19, 23 및 177로 이루어진 군으로부터 선택되는 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40 또는 41개의 폴리펩티드 및 이들의 단편을 포함하는 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 백신의 치료적 유효량을 부스트(boost)로서 대상에게 투여하여; 대상에서 전립선암을 치료하거나 예방하는 단계를 포함하는, 대상에서 전립선암을 치료하거나 예방하는 방법을 제공한다.
본 발명은 또한 서열 번호 541, 550, 554, 555, 556, 623 또는 624의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 백신을 제공한다.
본 발명은 또한 서열 번호 543, 552, 557, 558, 559, 625 또는 626의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 백신을 제공한다.
본 발명은 또한,
서열 번호 275, 381, 333, 337, 269, 253, 309, 325, 271, 305, 251, 245, 261, 265, 317, 255, 277, 297, 285, 437, 439, 442, 444, 379, 343, 211, 349, 213, 215, 221, 219, 225, 345, 353, 235, 223, 167, 171, 19, 23 및 177로 이루어진 군으로부터 선택되는 2개 이상의 폴리펩티드를 포함하는 제1 이종 폴리펩티드를 인코딩하는 제1 이종 폴리뉴클레오티드를 포함하는 제1 백신; 및
서열 번호 275, 381, 333, 337, 269, 253, 309, 325, 271, 305, 251, 245, 261, 265, 317, 255, 277, 297, 285, 437, 439, 442, 444, 379, 343, 211, 349, 213, 215, 221, 219, 225, 345, 353, 235, 223, 167, 171, 19, 23 및 177로 이루어진 군으로부터 선택되는 2개 이상의 폴리펩티드를 포함하는 제2 이종 폴리펩티드를 인코딩하는 제2 이종 폴리뉴클레오티드를 포함하는 제2 백신 - 상기 제1 이종 폴리펩티드 및 제2 이종 폴리펩티드는 별개의 아미노산 서열을 가짐 - 을 대상에게 투여하는 단계를 포함하는, 대상에서 전립선암을 치료하거나 예방하는 방법을 제공한다.
본 발명은 또한,
서열 번호 275, 381, 333, 337, 269, 253, 309, 325, 271, 305, 251, 245, 261, 265, 317, 255, 277, 297, 285, 437, 439, 442, 444, 379, 343, 211, 349, 213, 215, 221, 219, 225, 345, 353, 235, 223, 167, 171, 19, 23 및 177로 이루어진 군으로부터 선택되는 2개 이상의 폴리펩티드를 포함하는 제1 이종 폴리펩티드를 인코딩하는 제1 이종 폴리뉴클레오티드를 포함하는 제1 백신; 및
서열 번호 275, 381, 333, 337, 269, 253, 309, 325, 271, 305, 251, 245, 261, 265, 317, 255, 277, 297, 285, 437, 439, 442, 444, 379, 343, 211, 349, 213, 215, 221, 219, 225, 345, 353, 235, 223, 167, 171, 19, 23 및 177로 이루어진 군으로부터 선택되는 2개 이상의 폴리펩티드를 포함하는 제2 이종 폴리펩티드를 인코딩하는 제2 이종 폴리뉴클레오티드를 포함하는 제2 백신 - 상기 제1 이종 폴리펩티드 및 제2 이종 폴리펩티드는 별개의 아미노산 서열을 가짐 - 을 대상에게 투여하는 단계를 포함하는, 대상에서 면역반응을 유도하는 방법을 제공한다.
본 발명은 또한 본 발명의 폴리펩티드에 특이적으로 결합하는 단리된 단백질성 분자를 제공한다.
본 발명은 또한 본 발명의 단백질성 분자를 대상에게 투여하는 단계를 포함하는, 대상에서 전립선암을 예방하거나 치료하는 방법을 제공한다.
본 발명의 상기 실시 형태는 구체적으로 언급된 폴리펩티드 및 이의 단편 이외에, 구체적으로 언급된 폴리펩티드와 상이한 하나 이상의 폴리펩티드를 포함하여, 추가의 폴리펩티드 서열도 포함하는 폴리펩티드를 포함하는 것으로 이해되어야 한다. 유사하게, 본 발명의 상기 실시 형태는 또한 구체적으로 언급된 폴리뉴클레오티드 및 이의 단편 이외에, 구체적으로 언급된 폴리뉴클레오티드와 상이한 하나 이상의 폴리뉴클레오티드를 포함하여, 추가의 폴리뉴클레오티드 서열도 포함하는 폴리뉴클레오티드를 포함한다.
도 1은 유전자 A와 유전자 B 사이의 키메라 리드-스루 융합(chimeric read-through fusion)의 카툰(cartoon)을 도시한다. 신생항원 펩티드 서열은 절단 접합부에서 발생한다.
도 2는 DNA 전좌와 같은 염색체 변화로 인한 유전자 융합의 카툰을 도시한다.
도 3은 대체 5' 또는 3' 스플라이스 부위, 보유된 인트론, 배제된 엑손 또는 대체 종결 또는 삽입을 갖는 스플라이스 변이체의 카툰을 도시한다.
도 4는 스플라이스 변이체를 확인하는 방법에 대한 카툰을 도시한다.
도 5a는 비자극(DMSO) 후에 PBMC 샘플에서의 TNFα+IFNγ+CD8+ T 세포 빈도를 나타내는 유세포 분석 도트 플롯을 도시한다.
도 5b는 CEF 펩티드에 의한 자극 후에 PBMC 샘플에서의 TNFα+IFNγ+CD8+ T 세포 빈도를 나타내는 유세포 분석 도트 플롯을 도시한다.
도 5c는 P16에 의한 자극 후에 PBMC 샘플에서의 TNFα+IFNγ+CD8+ T 세포 빈도를 나타내는 유세포 분석 도트 플롯을 도시한다.
도 5d는 P98에 의한 자극 후에 PBMC 샘플에서의 TNFα+IFNγ+CD8+ T 세포 빈도를 나타내는 유세포 분석 도트 플롯을 도시한다.
도 5e는 P3 자기 항원에 의한 자극 후에 PBMC 샘플에서의 TNFα+IFNγ+CD8+ T 세포 빈도를 나타내는 유세포 분석 도트 플롯을 도시한다.
도 6은 PBMC 샘플이 특정 신생항원에 대해 양성 면역반응을 나타내는 전립선암 환자의 수를 도시한다. P3, P6, P7, P9 및 P92는 자기 항원을 나타낸다.
도 7은 PBMC 샘플이 특정 신생항원에 대해 양성 CD4+ 면역반응을 나타내는 전립선암 환자의 수를 도시한다.
도 8은 PBMC 샘플이 특정 신생항원에 대해 양성 CD8+ 면역반응을 나타내는 전립선암 환자의 수를 도시한다.
도 2는 DNA 전좌와 같은 염색체 변화로 인한 유전자 융합의 카툰을 도시한다.
도 3은 대체 5' 또는 3' 스플라이스 부위, 보유된 인트론, 배제된 엑손 또는 대체 종결 또는 삽입을 갖는 스플라이스 변이체의 카툰을 도시한다.
도 4는 스플라이스 변이체를 확인하는 방법에 대한 카툰을 도시한다.
도 5a는 비자극(DMSO) 후에 PBMC 샘플에서의 TNFα+IFNγ+CD8+ T 세포 빈도를 나타내는 유세포 분석 도트 플롯을 도시한다.
도 5b는 CEF 펩티드에 의한 자극 후에 PBMC 샘플에서의 TNFα+IFNγ+CD8+ T 세포 빈도를 나타내는 유세포 분석 도트 플롯을 도시한다.
도 5c는 P16에 의한 자극 후에 PBMC 샘플에서의 TNFα+IFNγ+CD8+ T 세포 빈도를 나타내는 유세포 분석 도트 플롯을 도시한다.
도 5d는 P98에 의한 자극 후에 PBMC 샘플에서의 TNFα+IFNγ+CD8+ T 세포 빈도를 나타내는 유세포 분석 도트 플롯을 도시한다.
도 5e는 P3 자기 항원에 의한 자극 후에 PBMC 샘플에서의 TNFα+IFNγ+CD8+ T 세포 빈도를 나타내는 유세포 분석 도트 플롯을 도시한다.
도 6은 PBMC 샘플이 특정 신생항원에 대해 양성 면역반응을 나타내는 전립선암 환자의 수를 도시한다. P3, P6, P7, P9 및 P92는 자기 항원을 나타낸다.
도 7은 PBMC 샘플이 특정 신생항원에 대해 양성 CD4+ 면역반응을 나타내는 전립선암 환자의 수를 도시한다.
도 8은 PBMC 샘플이 특정 신생항원에 대해 양성 CD8+ 면역반응을 나타내는 전립선암 환자의 수를 도시한다.
정의
본 명세서에 인용된, 특허 및 특허 출원을 포함하지만 이에 한정되지 않는 모든 간행물은 마치 완전히 기재된 것처럼 본 명세서에 참고로 포함된다.
본 명세서에서 사용되는 용어는 단지 특정 실시 형태들을 설명하기 위한 것이며, 한정하는 것으로 의도되지 않음을 이해해야 한다. 달리 정의되지 않는 한, 본 명세서에서 사용되는 모든 기술 용어 및 과학 용어는 당업자가 일반적으로 이해하는 것과 동일한 의미를 갖는다.
본 명세서에 기재된 것과 유사하거나 또는 동등한 임의의 방법 및 재료가 본 발명의 시험 실시에 사용될 수 있지만, 예시적인 방법 및 재료가 본 명세서에 기재되어 있다. 본 발명의 상세한 설명 및 청구범위에서, 하기 용어가 사용될 것이다.
본 명세서 및 첨부된 청구범위에서 사용되는 단수형("a", "an" 및 "the")은 그 내용이 명확하게 달리 지시하지 않으면, 복수형 지시 대상을 포함한다. 따라서, 예를 들어, "세포"에 대한 언급은 2개 이상의 세포의 조합 등을 포함한다.
이행 용어 "포함하는", "기본적으로 ~로 이루어진" 및 "~로 이루어진"은 특허 용어에서 그들의 일반적으로 허용되는 의미를 함축하는 것으로 의도되며; 즉, (i) "포함하는(including)", "함유하는" 또는 "특징으로 하는"과 동의어인 "포함하는(comprising)"은 포괄적 또는 개방형(open-ended)이며, 추가의 언급되지 않은 요소 또는 방법 단계를 배제하지 않고; (ii) "~로 이루어진"은 청구항에 명시되지 않은 임의의 요소, 단계 또는 성분을 배제하며; (iii) "기본적으로 ~로 이루어진"은 청구범위를 명시된 재료 또는 단계 및 청구된 발명의 기본적이고 신규 특성(들)에 실질적으로 영향을 주지 않는 재료 또는 단계로 제한한다. 어구 "포함하는"(또는 이의 등가적 표현)의 관점에서 기재된 실시 형태는 또한 "~로 이루어진" 및 "기본적으로 ~로 이루어진"의 관점에서 독립적으로 기재된 것들을 실시 형태로서 제공한다.
본 명세서 및 첨부된 청구범위에 사용되는 어구 "및 이들의 단편"은 목록에 첨부될 때 관련 목록의 하나 이상의 구성원의 단편을 포함한다. 목록은 일례로서, 어구 "펩티드 A, B 및 C, 및 이들의 단편으로 이루어진 군"이 A, B, C, A의 단편, B의 단편 및/또는 C의 단편을 포함하는 마쿠쉬(Markush) 그룹을 명시하거나 열거하도록 마쿠쉬 그룹을 포함할 수 있다.
"단리된"은 분자가 생성되는 시스템, 예컨대 재조합 세포의 다른 성분으로부터 실질적으로 분리되고/되거나 정제된 분자(예컨대, 합성 폴리뉴클레오티드 또는 합성 폴리펩티드)의 상동 집단뿐만 아니라, 적어도 하나의 정제 또는 단리 단계를 거친 단백질을 지칭한다. "단리된"은 다른 세포 물질 및/또는 화학물질이 실질적으로 없는 분자를 지칭하며, 더 높은 순도로, 예컨대 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 100% 순도로 단리된 분자를 포함한다.
"폴리뉴클레오티드"는 당-포스페이트 골격 또는 다른 동등한 공유결합적 화학 특성에 의해 공유결합된 뉴클레오티드 쇄를 포함하는 합성 분자를 지칭한다. cDNA는 폴리뉴클레오티드의 전형적인 예이다.
"폴리펩티드" 또는 "단백질"은 폴리펩티드를 형성하도록 펩티드 결합으로 결합된 적어도 2개의 아미노산 잔기를 포함하는 분자를 지칭한다. 50개 미만의 아미노산의 작은 폴리펩티드는 "펩티드"로 지칭될 수 있다.
"면역원성 단편"은 단편이 MHC 클래스 I 또는 MHC 클래스 II 분자와 복합체를 형성할 때 세포독성 T 림프구, 헬퍼 T 림프구 또는 B 세포에 의해 인식되는 폴리펩티드를 지칭한다.
"인프레임(in-frame)"은 이종 폴리뉴클레오티드를 형성하기 위해 결합되는 제2 폴리뉴클레오티드의 코돈의 리딩 프레임과 동일한 제1 폴리뉴클레오티드의 코돈의 리딩 프레임을 지칭한다. 인프레임 이종 폴리뉴클레오티드는 제1 폴리뉴클레오티드 및 제2 폴리뉴클레오티드 둘 다에 의해 인코딩되는 이종 폴리펩티드를 인코딩한다.
"면역원성"은 하나 이상의 면역원성 단편을 포함하는 폴리펩티드를 지칭한다.
"이종"은 자연계에서 서로 동일한 관계에서 발견되지 않는 2개 이상의 폴리뉴클레오티드 또는 2개 이상의 폴리펩티드를 지칭한다.
"이종 폴리뉴클레오티드"는 본 명세서에 기재된 바와 같은 2개 이상의 신생항원을 인코딩하는 비자연적으로 발생하는 폴리뉴클레오티드를 지칭한다.
"이종 폴리펩티드"는 본 명세서에 기재된 바와 같은 2개 이상의 신생항원 폴리펩티드를 포함하는 비자연적으로 발생하는 폴리펩티드를 지칭한다.
"비자연적으로 발생하는"은 자연계에 존재하지 않는 분자를 지칭한다.
"벡터"는 생물계 내에서 복제가 가능하거나, 이러한 생물계 사이에서 이동할 수 있는 폴리뉴클레오티드를 지칭한다. 벡터 폴리뉴클레오티드는 전형적으로 생물계에서 이러한 폴리뉴클레오티드의 복제 또는 유지를 용이하게 하는 기능을 하는 복제 기점, 폴리아데닐화 신호 또는 선택 마커와 같은 요소를 포함한다. 그러한 생물계의 예에는 벡터를 복제할 수 있는 생물학적 요소를 이용하는 세포계, 바이러스 시스템, 동물계, 식물계 및 재구성된 생물계가 포함될 수 있다. 벡터를 포함하는 폴리뉴클레오티드는 DNA 또는 RNA 분자 또는 이들의 혼성체일 수 있다.
"발현 벡터"는 발현 벡터에 존재하는 폴리뉴클레오티드 서열에 의해 인코딩되는 폴리펩티드의 번역을 유도하기 위해 생물계 또는 재구성된 생물계에서 이용될 수 있는 벡터를 지칭한다.
"바이러스 벡터"는 바이러스 기원의 적어도 하나의 폴리뉴클레오티드 요소를 포함하고 바이러스 벡터 입자로 패키징되는 능력을 갖는 벡터 구축물을 지칭한다.
"신생항원"은 예를 들어, 종양 세포의 돌연변이 또는 종양 세포에 특이적인 번역 후 변형을 통해, 비악성 조직에 존재하는 상응하는 야생형 폴리펩티드와 구별되게 하는 적어도 하나의 변경을 갖는 전립선 종양 조직에 존재하는 폴리펩티드를 지칭한다. 돌연변이는 프레임시프트 또는 비프레임시프트 삽입 또는 결실, 미스센스 또는 넌센스 치환, 스플라이스 부위 변경, 비정상적인 스플라이스 변이체, 게놈 재배열 또는 유전자 융합, 또는 신생항원을 발생시키는 임의의 게놈 또는 발현 변화를 포함할 수 있다.
"유병률"은 전립선 신생항원을 보유하는 것으로 조사된 집단의 비율을 지칭한다.
"재조합"은 재조합 수단에 의해 제조, 발현, 생성 또는 단리된 폴리뉴클레오티드, 폴리펩티드, 벡터, 바이러스 및 기타 거대분자를 말한다.
"백신"은 접종자(예를 들어, 대상)에서 획득 면역을 유도하기 위해 의도적으로 투여되는 하나 이상의 면역원성 폴리펩티드, 면역원성 폴리뉴클레오티드 또는 단편, 또는 이들의 임의의 조합을 포함하는 조성물을 지칭한다.
암과 같은 질환 또는 장애의 "치료하다", "치료하는" 또는 "치료"는 다음 중 하나 이상을 달성하는 것을 말한다: 장애의 중증도 및/또는 지속기간을 감소시키는 것, 치료되는 장애의 특징적인 증상의 악화를 억제하는 것, 이전에 장애가 있었던 대상에서 장애의 재발을 제한하거나 예방하는 것, 또는 장애에 대해 이전에 증상이 있었던 대상에서 증상의 재발을 제한하거나 예방하는 것.
질환 또는 장애의 "예방하다", "예방하는", "예방" 또는 "예방법"은 장애가 대상에서 발생하는 것을 저지하는 것을 의미한다.
"치료적 유효량"은 필요한 용량에서 그리고 필요한 시간 동안 원하는 치료 결과를 달성하는 데 유효한 양을 지칭한다. 치료적 유효량은 개체의 질환 상태, 연령, 성별 및 체중, 그리고 치료제 또는 치료제들의 병용물이 개체에서 원하는 반응을 유도하는 능력과 같은 인자들에 따라 변동될 수 있다. 효과적인 치료제 또는 치료제들의 병용물의 예시적인 지표는, 예를 들어 환자의 개선된 웰빙(well-being)을 포함한다.
"재발성(relapsed)"은 치료제에 의한 전치료(prior treatment) 후의 개선 기간 후에 질환 또는 질환의 징후나 증상의 재발을 지칭한다.
"불응성(refractory)"은 치료에 반응하지 않는 질환을 지칭한다. 불응성 질환은 치료 전 또는 치료 개시 시에 치료에 대해 저항성이 있을 수 있거나, 불응성 질환은 치료 중에 저항성을 갖게 될 수 있다.
"대상"은 임의의 인간 또는 비인간 동물을 포함한다. "비인간 동물"은 모든 척추동물, 예를 들어 포유동물 및 비포유동물, 예컨대 비인간 영장류, 양, 개, 고양이, 말, 소, 닭, 양서류, 파충류 등을 포함한다. 용어 "대상" 및 "환자"는 본 명세서에서 상호 교환적으로 사용될 수 있다.
"와 병용하여"는 둘 이상의 치료제가 대상에게 혼합물 상태로 함께 투여되거나, 단제(single agent)로서 동시에 투여되거나, 단제로서 임의의 순서로 순차적으로 투여됨을 의미한다.
면역반응과 관련하여 "향상시키다" 또는 "유도하다"는 면역반응의 스케일 및/또는 효율을 증가시키거나 면역반응의 지속기간을 연장시키는 것을 지칭한다. 이 용어들은 "증강시키다"와 상호 교환적으로 사용된다.
"면역반응"은 척추동물 대상의 면역계에 의한 면역원성 폴리펩티드 또는 폴리뉴클레오티드 또는 단편에 대한 임의의 반응을 지칭한다. 예시적인 면역반응은 CD8+ CTL의 항원 특이적 유도를 포함하는 세포독성 T 림프구(CTL) 반응, T 세포 증식 반응 및 사이토카인 방출을 포함하는 헬퍼 T 세포 반응, 및 항체 반응을 포함하는 B 세포 반응과 같은, 체액성 면역 뿐만 아니라 국소 및 전신 세포성 면역반응을 포함한다.
"특이적으로 결합하다", "특이적 결합", "특이적으로 결합하는" 또는 "결합하다"는 항원 또는 항원 내의 에피토프(예를 들어, 전립선 신생항원)에 대해 다른 항원에 대한 친화성보다 더 큰 친화성으로 결합하는 단백질성 분자를 지칭한다. 전형적으로, 단백질성 분자는 약 1x10-7 M 이하, 예를 들어 약 5x10-8 M 이하, 약 1x10-8 M 이하, 약 1x10-9 M 이하, 약 1x10-10 M 이하, 약 1x10-11 M 이하 또는 약 1x10-12 M 이하의 평형 해리 상수(KD)로 항원 또는 항원 내의 에피토프에 결합하며, 이때 전형적으로 KD는 비특이적 항원(예를 들어, BSA, 카세인)에 결합하기 위한 이의 KD보다 적어도 100배 더 적다. 본 명세서에 기재된 전립선 신생항원과 관련하여, "특이적 결합"은 야생형 단백질에 대한 검출가능한 결합 없이 전립선 신생항원에 대한 단백질성 분자의 결합을 말하며, 신생항원은 그 변이체이다.
"변이체", "돌연변이체" 또는 "변경된"은 하나 이상의 변형, 예를 들어 하나 이상의 치환, 삽입 또는 결실에 의해 참조 폴리펩티드 또는 참조 폴리뉴클레오티드와 상이한 폴리펩티드 또는 폴리뉴클레오티드를 지칭한다.
"항체"는 뮤린, 인간, 인간화 및 키메라 단일클론 항체를 포함한 단일클론 항체, 항원 결합 단편, 이중특이성 또는 다중특이성 항체, 이량체성, 사량체성 또는 다량체성 항체, 단일쇄 항체, 도메인 항체를 포함하는 면역글로불린 분자, 및 필요한 특이성의 항원 결합 부위를 포함하는 임의의 다른 변형된 형태의 면역글로불린 분자를 지칭한다.
"전장 항체"는 다이설파이드 결합에 의해 상호 연결된 2개의 중쇄(HC) 및 2개의 경쇄(LC)뿐만 아니라 이의 다량체(예를 들어, IgM)로 구성된다. 각각의 중쇄는 중쇄 가변 도메인(VH) 및 중쇄 불변 도메인으로 구성되며, 중쇄 불변 도메인은 서브도메인 CH1, 힌지, CH2 및 CH3로 구성된다. 각각의 경쇄는 경쇄 가변 도메인(VL) 및 경쇄 불변 도메인(CL)으로 구성된다. VH 및 VL은 프레임워크 영역(FR)이 산재된, 상보성 결정 영역(CDR)으로 불리는 초가변성 영역으로 추가로 세분될 수 있다. 각각의 VH 및 VL은 3개의 CDR 및 4개의 FR 세그먼트로 구성되며, 아미노 말단부터 카르복시 말단까지 하기 순서대로 배열된다: FR1, CDR1, FR2, CDR2, FR3, CDR3 및 FR4.
"상보성 결정 영역( CDR )"은 항원에 결합하는 항체 영역이다. VH에 3개의 CDR(HCDR1, HCDR2, HCDR3)이 존재하고, VL에 3개의 CDR(LCDR1, LCDR2, LCDR3)이 존재한다. CDR은 카바트(Kabat)(문헌[Wu et al. (1970) J Exp Med 132: 211-50]; 문헌[Kabat et al., Sequences of Proteins of Immunological Interest, 5th Ed. Public Health Service, National Institutes of Health, Bethesda, Md., 1991]), 초티아(Chothia) (문헌[Chothia et al. (1987) J Mol Biol 196: 901-17]), IMGT(문헌[Lefranc et al. (2003) Dev Comp Immunol 27: 55-77]) 및 AbM(문헌[Martin and Thornton J Bmol Biol 263: 800-15, 1996])과 같은 다양한 설명을 사용하여 정의될 수 있다. 다양한 개요 설명과 가변 영역 넘버링 사이의 대응 관계가 기재되어 있다(예를 들어, 문헌[Lefranc et al. (2003) Dev Comp Immunol 27: 55-77]; 문헌[Honegger and Pluckthun, J Mol Biol (2001) 309:657-70]; International ImMunoGeneTics(IMGT) database; Web resources, http://www_imgt_org 참조). UCL Business PLC의 abYsis와 같은 이용가능한 프로그램을 사용하여 CDR을 상세하게 설명할 수 있다. 본 명세서에 사용되는 용어 "CDR", "HCDR1", "HCDR2", "HCDR3", "LCDR1", "LCDR2" 및 "LCDR3"는 본 명세서에 달리 명시적으로 기재되어 있지 않는 한, 상기에 기재된 방법들인 카바트, 초티아, IMGT 또는 AbM 중 임의의 것에 의해 정의된 CDR을 포함한다.
면역글로불린은 중쇄 불변 영역 아미노산 서열에 따라, 5개의 주요 분류, IgA, IgD, IgE, IgG 및 IgM으로 배정될 수 있다. IgA 및 IgG는 아이소타입(isotype) IgA1, IgA2, IgG1, IgG2, IgG3 및 IgG4로 추가로 하위 분류된다. 임의의 척추동물 종의 항체 경쇄는 그의 불변 도메인의 아미노산 서열에 기초하여, 명확하게 별개인 2개의 유형, 즉 카파(κ) 및 람다(λ) 중 하나로 배정될 수 있다.
"항원 결합 단편"은 모(parental) 전장 항체의 항원 결합 특성을 보유하는 면역글로불린 분자의 일부를 지칭한다. 예시적인 항원 결합 단편은 중쇄 상보성 결정 영역(HCDR) 1, 2 및/또는 3, 경쇄 상보성 결정 영역(LCDR) 1, 2 및/또는 3, VH, VL, VH 및 VL, Fab, F(ab')2, Fd 및 Fv 단편뿐만 아니라 하나의 VH 도메인 또는 하나의 VL 도메인으로 이루어진 도메인 항체(dAb)이다. VH 및 VL 도메인은 합성 링커를 통해 결합되어 다양한 유형의 단일쇄 항체 디자인을 형성할 수 있으며, 여기서 VH/VL 도메인은 VH 및 VL 도메인이 별개의 쇄에 의해 발현되는 경우에 분자내에서 또는 분자간에 쌍을 이루어서, 1가 항원 결합 부위, 예컨대 단일쇄 Fv(scFv) 또는 디아바디(diabody)를 형성하며, 이는 예를 들어 국제 특허 출원 공개 제WO1998/44001호, 국제 특허 출원 공개 제WO1988/01649호, 국제 특허 출원 공개 제WO1994/13804호 또는 국제 특허 출원 공개 제WO1992/01047호에 기재되어 있다.
"단일클론 항체"는 실질적으로 균질한 항체 분자 집단으로부터 얻어진 항체를 지칭하는데, 즉, 집단을 구성하는 개별 항체는 항체 중쇄로부터 C 말단 라이신의 제거와 같은 가능한 잘 알려진 변경, 또는 아미노산 이성질화 또는 탈아미드화, 메티오닌 산화 또는 아스파라긴 또는 글루타민 탈아미드화와 같은 번역 후 변형을 제외하고는 동일하다. 단일클론 항체는 전형적으로 1개의 항원 에피토프에 결합한다. 이중특이성 단일클론 항체는 2개의 별개의 항원 에피토프에 결합한다. 단일클론 항체는 항체 집단 내에 불균질한 글리코실화를 가질 수 있다. 단일클론 항체는 단일특이성 또는 다중특이성, 예컨대 이중특이성 1가, 2가 또는 다가일 수 있다.
"인간화 항체"는 하나 이상의 CDR이 비인간 종으로부터 유래되고, 하나 이상의 프레임워크가 인간 면역글로불린 서열로부터 유래되는 항체를 지칭한다. 인간화 항체는 프레임워크에 치환을 포함할 수 있으므로, 프레임워크는 발현된 인간 면역글로불린 또는 인간 면역글로불린 생식세포계열 유전자 서열의 정확한 카피가 아닐 수 있다.
"인간 항체"는 인간 대상에게 투여될 때 최소한의 면역반응을 갖도록 최적화된 항체를 지칭한다. 인간 항체의 가변 영역은 인간 면역글로불린 서열로부터 유래된다. 인간 항체가 불변 영역 또는 불변 영역의 일부를 포함하는 경우, 불변 영역은 또한 인간 면역글로불린 서열로부터 유래된다. 인간 항체는 인간 항체의 가변 영역이 인간 생식세포계열 면역글로불린 또는 재배열된 면역글로불린 유전자를 사용하는 시스템으로부터 얻어지는 경우, 인간 유래의 서열"로부터 유래되는" 중쇄 및 경쇄 가변 영역을 포함한다. 이러한 예시적인 시스템은 파지에 디스플레이된 인간 면역글로불린 유전자 라이브러리, 및 인간 면역글로불린 유전자좌를 보유하는 트랜스제닉 비인간 동물, 예컨대 마우스 또는 래트이다. "인간 항체"는 전형적으로, 인간 항체 및 인간 면역글로불린 유전자좌를 얻는 데 사용되는 시스템간의 차이, 체세포 돌연변이의 도입 또는 프레임워크 또는 CDR로의 치환의 의도적인 도입, 또는 둘 다로 인해 인간에서 발현된 면역글로불린과 비교하여 아미노산 차이를 포함한다. 전형적으로, "인간 항체"는 인간 생식세포계열 면역글로불린 또는 재배열된 면역글로불린 유전자에 의해 인코딩된 아미노산 서열과 아미노산 서열이 적어도 약 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% 또는 99% 동일하다. 일부 경우에, "인간 항체"는, 예를 들어 문헌[Knappik et al., (2000) J Mol Biol 296:57-86]에 기재된 바와 같이 인간 프레임워크 서열 분석으로부터 유래되는 공통 프레임워크 서열 또는 예를 들어, 문헌[Shi et al., (2010) J Mol Biol 397:385-96] 및 국제 특허 출원 공개 WO2009/085462호에 기재된 바와 같이 파지에 디스플레이된 인간 면역글로불린 유전자 라이브러리에 도입된 합성 HCDR3를 포함할 수 있다. 적어도 하나의 CDR이 비인간 종으로부터 유래되는 항체는 "인간 항체"의 정의에 포함되지 않는다.
"대체 스캐폴드"는 높은 입체형태 공차(conformational tolerance)의 가변 도메인과 관련된 구조화된 코어를 포함하는 단일쇄 단백질 프레임워크를 의미한다. 가변 도메인은 스캐폴드 완전성(integrity)을 손상시키지 않고서 도입되는 변이에 견디므로, 가변 도메인은 특이적 항원에 결합하도록 조작 및 선택될 수 있다.
"키메라 항원 수용체" 또는 "CAR"은 T 세포(예를 들어, 미감작 T 세포, 중추 기억 T 세포, 이펙터 기억 T 세포 또는 이들의 조합) 상에 리간드 또는 항원 특이성을 이식하는 조작된 T 세포 수용체를 지칭한다. CAR은 인공 T 세포 수용체, 키메라 T 세포 수용체 또는 키메라 면역수용체로도 알려져 있다. CAR은 항원에 결합할 수 있는 세포외 도메인, 막관통 도메인 및 적어도 하나의 세포내 도메인을 포함한다. CAR 세포내 도메인은 신호를 전달하여 세포에서 생물학적 과정의 활성화 또는 억제를 일으키는 도메인으로서 기능하는 것으로 알려진 폴리펩티드를 포함한다. 막관통 도메인은 세포막에 걸쳐 있는 것으로 알려져 있고 세포외 도메인과 신호전달 도메인을 연결하는 기능을 할 수 있는 임의의 펩티드 또는 폴리펩티드를 포함한다. 키메라 항원 수용체는 임의로, 세포외 도메인과 막관통 도메인 사이에서 링커로서의 역할을 하는 힌지 도메인을 포함할 수 있다.
"T 세포 수용체" 또는 "TCR"은 MHC 분자에 의해 제시될 때 펩티드를 인식할 수 있는 분자를 지칭한다. 자연 발생 TCR 이종이량체는 T 세포의 약 95%에서 알파(α) 및 베타(β) 사슬로 이루어지는 반면에, T 세포의 약 5%는 감마(γ) 및 델타(δ) 사슬로 이루어진 TCR을 갖는다. 천연 TCR의 각각의 사슬은 면역글로불린 슈퍼패밀리의 구성원이며, 하나의 N-말단 면역글로불린(Ig) 가변(V) 도메인, 하나의 Ig 불변(C)도메인, 막관통/세포 막관통 영역, 및 C 말단의 짧은 세포질 테일을 갖는다. TCRα 사슬 및 β 사슬 둘 다의 가변 도메인은 3개의 초가변 또는 상보성 결정 영역(CDR), CDR1, CDR2 및 CDR3를 가지며, 이는 MHC 상에 제시된 처리 항원을 인식하는 역할을 한다.
TCR은 전장 α/β 또는 γ/δ 이종이량체 또는 펩티드/MHC 복합체의 결합을 유지하는 TCR의 세포외 도메인의 일부를 포함하는 가용성 분자일 수 있다. TCR은 단일쇄 TCR로 조작될 수 있다.
"T 세포 수용체 복합체" 또는 "TCR 복합체"는 TCRα 및 TCRβ 사슬, CD3ε, CD3γ, CD3δ 및 CD3ζ 분자를 포함하는 공지의 TCR 복합체를 지칭한다. 일부 경우에, TCRα 및 TCRβ 사슬은 TCRγ 및 TCRδ 사슬로 치환된다. TCR 복합체를 형성하는 다양한 단백질의 아미노산 서열은 잘 알려져 있다.
"T 세포" 및 "T 림프구"는 상호 교환가능하며, 본 명세서에서 동의어로 사용된다. T 세포는 흉선세포, 미감작 T 림프구, 기억 T 세포, 미성숙 T 림프구, 성숙 T 림프구, 휴지지 T 림프구 또는 활성화 T 림프구를 포함한다. T 세포는 T 헬퍼(Th) 세포, 예를 들어 T 헬퍼 1(Th1) 또는 T 헬퍼 2(Th2) 세포일 수 있다. T 세포는 헬퍼 T 세포(HTL; CD4+ T 세포) CD4+ T 세포, 세포독성 T 세포(CTL; CD8+ T 세포), 종양 침윤 세포독성 T 세포(TIL; CD8+ T 세포), CD4+CD8+ T 세포 또는 T 세포의 임의의 다른 서브세트일 수 있다. 반불변(semi-invariant) αβ T 세포 수용체를 발현하지만, NK1.1과 같은 NK 세포와 전형적으로 관련된 다양한 분자 마커도 발현하는 특수화된 T 세포 집단을 지칭하는 "NKT 세포"도 포함된다. NKT 세포에는 CD4+, CD4-, CD8+ 및 CD8- 세포뿐만 아니라, NK1.1+ 및 NK1.1-도 포함된다. NKT 세포의 TCR은 MHC I 유사 분자 CD Id가 제시하는 당지질 항원을 인식한다는 점에서 독특하다. NKT 세포는 염증 또는 면역 관용을 촉진하는 사이토카인을 생성하는 능력으로 인해 보호 또는 유해 효과를 나타낼 수 있다. 또한, "감마-델타 T 세포(γδ T 세포)"가 포함되며, 이는 표면에 별개의 TCR을 갖는 T 세포의 작은 서브세트에 대한 특수화된 집단을 말하며, TCR이 α- 및 β-TCR 사슬로 지정된 2개의 당단백질 사슬로 구성되는 대부분의 T 세포와는 달리, γδ T 세포의 TCR은 γ 사슬 및 δ 사슬로 구성된다. γδ T 세포는 면역감시 및 면역조절에 관여할 수 있고, IL-17의 중요한 공급원이며 강력한 CD8+ 세포독성 T 세포 반응을 유도하는 것으로 밝혀졌다. 비정상적이거나 과도한 면역반응을 억제하고 면역 관용에 관여하는 T 세포를 지칭하는 "조절성 T 세포" 또는 "Treg"도 포함된다. Treg는 전형적으로 전사 인자 Foxp3 양성 CD4+T 세포이며, 또한 IL-10 생성 CD4+T 세포인 전사 인자 Foxp3 음성 조절성 T 세포를 포함할 수 있다.
"자연 살해 세포" 또는 "NK 세포"는 CD 16+ CD56+ 및/또는 CD57+ TCR - 표현형을 갖는 분화된 림프구를 지칭한다. NK는 특정 세포용해 효소의 활성화에 의해 "자기" MHC/HLA 항원을 발현하지 못하는 세포에 결합하여 이를 사멸시키는 이의 능력, NK 활성화 수용체에 대한 리간드를 발현하는 종양 세포 또는 다른 이상 세포(diseased cell)를 사멸시키는 능력 및 면역반응을 자극하거나 억제하는 사이토카인이라고 불리는 단백질 분자를 방출하는 능력을 특징으로 한다.
"약"은 당업자에 의해 결정된 바와 같은 특정 값이 허용되는 오차 범위 내에 있음을 의미하며, 이는 어떻게 그 값이 측정 또는 결정되는지, 즉 측정 시스템의 제한사항에 부분적으로 좌우될 것이다. 특정 분석, 결과 또는 실시 형태와 관련하여 실시예에서 또는 명세서에서의 다른 곳에서 달리 명시적으로 언급되지 않는 한, "약"은 당업계의 관행에 따른 1 표준 편차, 또는 최대 5%의 범위 어느 쪽이든 더 큰 값 이내에 있음을 의미한다.
"항원 제시 세포(APC)"는 주요 조직적합성 유전자 복합체 분자(MHC 클래스 I 또는 MHC 클래스 II 분자 또는 둘 다)와 관련하여 항원을 표면에 제시하는 임의의 세포를 지칭한다.
"프라임 - 부스트" 또는 "프라임 - 부스트 요법"은 제1 백신으로 T 세포 반응을 프라이밍한 후, 제2 백신에 의한 면역반응을 부스팅하는 것을 수반하는 대상를 치료하는 방법을 지칭한다. 제1 백신과 제2 백신은 전형적으로 구별된다. 이러한 프라임-부스트 면역화는 동일한 백신으로 프라이밍 및 부스팅에 의해 달성될 수 있는 것보다 더 큰 높이와 폭의 면역반응을 유도한다. 프라이밍 단계는 기억 세포를 개시하고, 부스트 단계는 기억 반응을 확장시킨다. 부스팅은 1회 또는 다수회 일어날 수 있다.
"촉진자 요소(facilitator element)"는 폴리뉴클레오티드 또는 폴리펩티드에 작동 가능하게 연결된 임의의 폴리뉴클레오티드 또는 폴리펩티드 요소를 말하며, 프로모터, 인핸서, 폴리아데닐화 신호, 정지 코돈, 단백질 태그, 예를 들어 히스티딘 태그 등을 포함한다. 본 명세서에서의 촉진자 요소는 조절 요소를 포함한다.
폴리펩티드 또는 폴리뉴클레오티드 서열과 관련하여 "별개의"는 동일하지 않은 폴리펩티드 또는 폴리뉴클레오티드 서열을 지칭한다.
조성물
본 발명은 전립선 신생항원, 이를 인코딩하는 폴리뉴클레오티드, 벡터, 숙주 세포, 신생항원 또는 신생항원을 인코딩하는 폴리뉴클레오티드를 포함하는 백신, 전립선 신생항원에 결합하는 단백질성 분자, 및 이들의 제조 및 사용 방법에 관한 것이다. 본 발명은 또한 전립선암 환자의 집단에 만연한 본 발명의 전립선 신생항원을 포함하는 백신을 제공하며, 이에 의해 국소성 또는 전이성 전립선암과 같은 각종 전립선암의 병기로 진단받은 광범위한 환자 집단을 치료하는데 유용할 수 있는 범용 백신(pan-vaccine)을 제공한다.
암세포는 게놈 변화 및 비정상적인 전사 프로그램으로 인해 발생하는 신생항원을 생성한다. 환자에서의 신생항원 부하(neoantigen burden)는 면역요법에 대한 반응과 관련되어 있다(문헌[Snyder et al., N Engl J Med. 2014 Dec 4;371(23):2189-2199. doi: 10.1056/NEJMoa1406498. Epub 2014 Nov 19]; 문헌[Le et al., N Engl J Med. 2015 Jun 25;372(26):2509-20. doi: 10.1056/NEJMoa1500596. Epub 2015 May 30]; 문헌[Rizvi et al., Science. 2015 Apr 3;348(6230):124-8. doi: 10.1126/science.aaa1348. Epub 2015 Mar 12]; 문헌[Van Allen et al., Science. 2015 Oct 9;350(6257):207-211. doi: 10.1126/science.aad0095. Epub 2015 Sep 10]). 본 발명은 전립선암 환자에서 일반적인 전립선 신생항원을 동정하는 것에 적어도 부분적으로 기초하며, 따라서 다양한 전립선암 환자의 치료에 적합한 요법을 개발하는 데 이용될 수 있다. 하나 이상의 본 발명의 신생항원 또는 신생항원을 인코딩하는 폴리뉴클레오티드는 또한 진단 또는 예후 목적을 위해 사용될 수 있다.
본 발명의 폴리펩티드 및 폴리뉴클레오티드
본 발명은 서열 번호 1, 3, 5, 7, 9, 11, 13, 15, 17, 19, 21, 23, 25, 27, 29, 31, 33, 35, 37, 39, 41, 43, 45, 47, 49, 51, 53, 55, 57, 59, 61, 63, 65, 67, 69, 71, 73, 75, 77, 79, 81, 83, 85, 87, 89, 91, 93, 95, 97, 99, 101, 103, 105, 107, 109, 111, 113, 115, 117, 119, 121, 123, 125, 127, 129, 131, 133, 135, 137, 139, 141, 143, 145, 147, 149, 151, 153, 155, 157, 159, 161, 163, 165, 167, 169, 171, 173, 175, 177, 179, 181, 183, 185, 187, 189, 191, 193, 195, 197, 199, 201, 203, 205, 207, 209, 211, 213, 215, 217, 219, 221, 223, 225, 227, 229, 231, 233, 235, 237, 239, 241, 243, 245, 247, 249, 251, 253, 255, 257, 259, 261, 263, 265, 267, 269, 271, 273, 275, 277, 279, 281, 283, 285, 287, 289, 291, 293, 295, 297, 299, 301, 303, 305, 307, 309, 311, 313, 315, 317, 319, 321, 323, 325, 327, 329, 331, 333, 335, 337, 339, 341, 343, 345, 347, 349, 351, 353, 355, 357, 359, 361, 363, 365, 367, 369, 371, 373, 375, 379, 381, 383, 385, 387, 388, 389, 390, 391, 392, 393, 394, 395, 396, 397, 398, 399, 400, 401, 402, 403, 404, 405, 406, 407, 408, 426, 427, 428, 429, 430, 431, 432, 433, 434, 435, 436, 437, 438, 439, 440, 441, 442, 443, 444, 445, 446 또는 447의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다.
본 발명은 또한 서열 번호 2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26, 28, 30, 32, 34, 36, 38, 40, 42, 44, 46, 48, 50, 52, 54, 56, 58, 60, 62, 64, 66, 68, 70, 72, 74, 76, 78, 80, 82, 84, 86, 88, 90, 92, 94, 96, 98, 100, 102, 104, 106, 108, 110, 112, 114, 116, 118, 120, 122, 124, 126, 128, 130, 132, 134, 136, 138, 140, 142, 144, 146, 148, 150, 152, 154, 156, 158, 160, 162, 164, 166, 168, 170, 172, 174, 176, 178, 180, 182, 184, 186, 188, 190, 192, 194, 196, 198, 200, 202, 204, 206, 208, 210, 212, 214, 216, 218, 220, 222, 224, 226, 228, 230, 232, 234, 236, 238, 240, 242, 244, 246, 248, 250, 252, 254, 256, 258, 260, 262, 264, 266, 268, 270, 272, 274, 276, 278, 280, 282, 284, 286, 288, 290, 292, 294, 296, 298, 300, 302, 304, 306, 308, 310, 312, 314, 316, 318, 320, 322, 324, 326, 328, 330, 332, 334, 336, 338, 340, 342, 344, 346, 348, 350, 352, 354, 356, 358, 360, 362, 364, 366, 368, 370, 372, 374, 376, 380, 382, 384, 386, 448, 449, 450, 451, 452, 453, 454, 455, 456, 457 또는 458의 폴리뉴클레오티드 서열 또는 이의 단편을 포함하는 단리된 폴리뉴클레오티드를 제공한다.
본 발명은 또한 서열 번호 459, 460, 461, 462, 463, 464, 465, 466, 467, 468, 469, 470, 471, 472, 473, 474, 475, 476, 477, 478, 479, 480, 481, 482, 483, 484, 485, 486, 487, 488, 489, 490, 491, 492, 493, 494, 495, 496, 497, 498, 499, 500, 501, 461, 503, 504, 505, 506, 507, 508, 509, 510, 511, 512, 513, 514, 515, 516, 517, 477, 519, 520, 521, 522, 523, 524, 525, 485, 486, 528, 529, 530, 531, 532, 533, 534, 535, 536, 537, 538, 539 또는 540의 폴리뉴클레오티드 서열 또는 이의 단편을 포함하는 단리된 폴리뉴클레오티드를 제공한다.
일부 실시 형태에서, 단편은 18개 이상의 뉴클레오티드를 포함한다. 일부 실시 형태에서, 단편은 21개 이상의 뉴클레오티드를 포함한다. 일부 실시 형태에서, 단편은 24개 이상의 뉴클레오티드를 포함한다. 일부 실시 형태에서, 단편은 27개 이상의 뉴클레오티드를 포함한다. 일부 실시 형태에서, 단편은 30개 이상의 뉴클레오티드를 포함한다. 일부 실시 형태에서, 단편은 33개 이상의 뉴클레오티드를 포함한다. 일부 실시 형태에서, 단편은 36개 이상의 뉴클레오티드를 포함한다. 일부 실시 형태에서, 단편은 39개 이상의 뉴클레오티드를 포함한다. 일부 실시 형태에서, 단편은 42개 이상의 뉴클레오티드를 포함한다. 일부 실시 형태에서, 단편은 45개 이상의 뉴클레오티드를 포함한다. 일부 실시 형태에서, 단편은 48개 이상의 뉴클레오티드를 포함한다. 일부 실시 형태에서, 단편은 51개 이상의 뉴클레오티드를 포함한다. 일부 실시 형태에서, 단편은 54개 이상의 뉴클레오티드를 포함한다. 일부 실시 형태에서, 단편은 57개 이상의 뉴클레오티드를 포함한다. 일부 실시 형태에서, 단편은 60개 이상의 뉴클레오티드를 포함한다. 일부 실시 형태에서, 단편은 63개 이상의 뉴클레오티드를 포함한다. 일부 실시 형태에서, 단편은 66개 이상의 뉴클레오티드를 포함한다. 일부 실시 형태에서, 단편은 69개 이상의 뉴클레오티드를 포함한다. 일부 실시 형태에서, 단편은 72개 이상의 뉴클레오티드를 포함한다. 일부 실시 형태에서, 단편은 75개 이상의 뉴클레오티드를 포함한다. 일부 실시 형태에서, 단편은 약 18개의 뉴클레오티드를 포함한다. 일부 실시 형태에서, 단편은 약 21개의 뉴클레오티드를 포함한다. 일부 실시 형태에서, 단편은 약 24개의 뉴클레오티드를 포함한다. 일부 실시 형태에서, 단편은 약 27개의 뉴클레오티드를 포함한다. 일부 실시 형태에서, 단편은 약 30개의 뉴클레오티드를 포함한다. 일부 실시 형태에서, 단편은 약 33개의 뉴클레오티드를 포함한다. 일부 실시 형태에서, 단편은 약 36개의 뉴클레오티드를 포함한다. 일부 실시 형태에서, 단편은 약 39개의 뉴클레오티드를 포함한다. 일부 실시 형태에서, 단편은 약 42개의 뉴클레오티드를 포함한다. 일부 실시 형태에서, 단편은 약 45개의 뉴클레오티드를 포함한다. 일부 실시 형태에서, 단편은 약 48개의 뉴클레오티드를 포함한다. 일부 실시 형태에서, 단편은 약 51개의 뉴클레오티드를 포함한다. 일부 실시 형태에서, 단편은 약 54개의 뉴클레오티드를 포함한다. 일부 실시 형태에서, 단편은 약 57개의 뉴클레오티드를 포함한다. 일부 실시 형태에서, 단편은 약 60개의 뉴클레오티드를 포함한다. 일부 실시 형태에서, 단편은 약 63개의 뉴클레오티드를 포함한다. 일부 실시 형태에서, 단편은 약 66개의 뉴클레오티드를 포함한다. 일부 실시 형태에서, 단편은 약 69개의 뉴클레오티드를 포함한다. 일부 실시 형태에서, 단편은 약 72개의 뉴클레오티드를 포함한다. 일부 실시 형태에서, 단편은 약 75개의 뉴클레오티드를 포함한다. 일부 실시 형태에서, 단편은 약 18 내지 75개의 뉴클레오티드를 포함한다. 일부 실시 형태에서, 단편은 약 21 내지 75개의 뉴클레오티드를 포함한다. 일부 실시 형태에서, 단편은 약 24 내지 75개의 뉴클레오티드를 포함한다. 일부 실시 형태에서, 단편은 약 24 내지 72개의 뉴클레오티드를 포함한다. 일부 실시 형태에서, 단편은 약 24 내지 69개의 뉴클레오티드를 포함한다. 일부 실시 형태에서, 단편은 약 24 내지 66개의 뉴클레오티드를 포함한다. 일부 실시 형태에서, 단편은 약 24 내지 63개의 뉴클레오티드를 포함한다. 일부 실시 형태에서, 단편은 약 24 내지 60개의 뉴클레오티드를 포함한다. 일부 실시 형태에서, 단편은 약 24 내지 57개의 뉴클레오티드를 포함한다. 일부 실시 형태에서, 단편은 약 24 내지 54개의 뉴클레오티드를 포함한다. 일부 실시 형태에서, 단편은 약 24 내지 51개의 뉴클레오티드를 포함한다. 일부 실시 형태에서, 단편은 약 24 내지 48개의 뉴클레오티드를 포함한다. 일부 실시 형태에서, 단편은 약 24 내지 45개의 뉴클레오티드를 포함한다. 일부 실시 형태에서, 단편은 약 24 내지 42개의 뉴클레오티드를 포함한다. 일부 실시 형태에서, 단편은 약 27 내지 42개의 뉴클레오티드를 포함한다. 일부 실시 형태에서, 단편은 약 27 내지 39개의 뉴클레오티드를 포함한다. 일부 실시 형태에서, 단편은 약 27 내지 36개의 뉴클레오티드를 포함한다. 일부 실시 형태에서, 단편은 약 27 내지 33개의 뉴클레오티드를 포함한다. 일부 실시 형태에서, 단편은 약 27 내지 30개의 뉴클레오티드를 포함한다.
본 발명의 폴리뉴클레오티드 및 이종 폴리뉴클레오티드는 전립선 신생항원, 및 본 명세서에 기재된 2개 이상의 전립선 신생항원을 포함하는 이종 폴리펩티드를 인코딩한다. 본 발명의 폴리뉴클레오티드 및 이종 폴리뉴클레오티드는 본 발명의 폴리펩티드, 이종 폴리펩티드, 벡터, 재조합 바이러스, 세포 및 백신을 생성하는데 유용하다. 본 발명의 폴리뉴클레오티드 및 이종 폴리뉴클레오티드는 본 명세서에 기재된 바와 같은 바이러스 벡터 또는 본 명세서에 또한 기재된 바와 같은 다른 전달 기술을 포함한 다양한 기술을 사용하여 전립선암을 앓고 있는 대상에게 이들을 전달함으로써 치료제로서 이용될 수 있다.
본 발명은 또한 서열 번호 1의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 1의 폴리펩티드 또는 이의 단편은 서열 번호 2의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 3의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 3의 폴리펩티드 또는 이의 단편은 서열 번호 4의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 5의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 5의 폴리펩티드 또는 이의 단편은 서열 번호 6의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 7의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 7의 폴리펩티드 또는 이의 단편은 서열 번호 8의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 9의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 9의 폴리펩티드 또는 이의 단편은 서열 번호 10의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 11의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 11의 폴리펩티드 또는 이의 단편은 서열 번호 12의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 13의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 13의 폴리펩티드 또는 이의 단편은 서열 번호 14의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 15의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 15의 폴리펩티드 또는 이의 단편은 서열 번호 16의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 17의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 17의 폴리펩티드 또는 이의 단편은 서열 번호 18의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 19의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 19의 폴리펩티드 또는 이의 단편은 서열 번호 20의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다. 일부 실시 형태에서, 서열 번호 19의 폴리펩티드 또는 이의 단편은 서열 번호 497의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다. 일부 실시 형태에서, 서열 번호 19의 폴리펩티드 또는 이의 단편은 서열 번호 538의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 21의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 21의 폴리펩티드 또는 이의 단편은 서열 번호 22의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 23의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 23의 폴리펩티드 또는 이의 단편은 서열 번호 24의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다. 일부 실시 형태에서, 서열 번호 23의 폴리펩티드 또는 이의 단편은 서열 번호 498의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다. 일부 실시 형태에서, 서열 번호 23의 폴리펩티드 또는 이의 단편은 서열 번호 539의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 25의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 25의 폴리펩티드 또는 이의 단편은 서열 번호 26의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 27의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 27의 폴리펩티드 또는 이의 단편은 서열 번호 28의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 29의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 29의 폴리펩티드 또는 이의 단편은 서열 번호 30의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 31의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 31의 폴리펩티드 또는 이의 단편은 서열 번호 32의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 33의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 33의 폴리펩티드 또는 이의 단편은 서열 번호 34의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 35의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 35의 폴리펩티드 또는 이의 단편은 서열 번호 36의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 37의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 37의 폴리펩티드 또는 이의 단편은 서열 번호 38의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 39의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 39의 폴리펩티드 또는 이의 단편은 서열 번호 40의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 41의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 41의 폴리펩티드 또는 이의 단편은 서열 번호 42의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 43의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 43의 폴리펩티드 또는 이의 단편은 서열 번호 44의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 45의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 45의 폴리펩티드 또는 이의 단편은 서열 번호 46의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 47의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 47의 폴리펩티드 또는 이의 단편은 서열 번호 48의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 49의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 49의 폴리펩티드 또는 이의 단편은 서열 번호 50의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 51의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 51의 폴리펩티드 또는 이의 단편은 서열 번호 52의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 53의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 53의 폴리펩티드 또는 이의 단편은 서열 번호 54의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 55의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 55의 폴리펩티드 또는 이의 단편은 서열 번호 56의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 57의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 57의 폴리펩티드 또는 이의 단편은 서열 번호 58의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 59의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 59의 폴리펩티드 또는 이의 단편은 서열 번호 60의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 61의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 61의 폴리펩티드 또는 이의 단편은 서열 번호 62의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 63의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 63의 폴리펩티드 또는 이의 단편은 서열 번호 64의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 65의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 65의 폴리펩티드 또는 이의 단편은 서열 번호 66의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 67의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 67의 폴리펩티드 또는 이의 단편은 서열 번호 68의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 69의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 69의 폴리펩티드 또는 이의 단편은 서열 번호 70의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 71의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 71의 폴리펩티드 또는 이의 단편은 서열 번호 72의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 73의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 73의 폴리펩티드 또는 이의 단편은 서열 번호 74의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 75의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 75의 폴리펩티드 또는 이의 단편은 서열 번호 76의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 77의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 77의 폴리펩티드 또는 이의 단편은 서열 번호 78의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 79의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 79의 폴리펩티드 또는 이의 단편은 서열 번호 80의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 81의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 81의 폴리펩티드 또는 이의 단편은 서열 번호 82의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 83의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 83의 폴리펩티드 또는 이의 단편은 서열 번호 84의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 85의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 85의 폴리펩티드 또는 이의 단편은 서열 번호 86의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 87의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 87의 폴리펩티드 또는 이의 단편은 서열 번호 88의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 89의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 89의 폴리펩티드 또는 이의 단편은 서열 번호 90의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 91의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 91의 폴리펩티드 또는 이의 단편은 서열 번호 92의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 93의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 93의 폴리펩티드 또는 이의 단편은 서열 번호 94의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 95의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 95의 폴리펩티드 또는 이의 단편은 서열 번호 96의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 97의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 97의 폴리펩티드 또는 이의 단편은 서열 번호 98의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 99의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 99의 폴리펩티드 또는 이의 단편은 서열 번호 100의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 101의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 101의 폴리펩티드 또는 이의 단편은 서열 번호 102의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 103의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 103의 폴리펩티드 또는 이의 단편은 서열 번호 104의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 105의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 105의 폴리펩티드 또는 이의 단편은 서열 번호 106의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 107의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 107의 폴리펩티드 또는 이의 단편은 서열 번호 108의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 109의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 109의 폴리펩티드 또는 이의 단편은 서열 번호 110의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 111의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 111의 폴리펩티드 또는 이의 단편은 서열 번호 112의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 113의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 113의 폴리펩티드 또는 이의 단편은 서열 번호 114의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 115의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 115의 폴리펩티드 또는 이의 단편은 서열 번호 116의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 117의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 117의 폴리펩티드 또는 이의 단편은 서열 번호 118의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 119의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 119의 폴리펩티드 또는 이의 단편은 서열 번호 120의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 121의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 121의 폴리펩티드 또는 이의 단편은 서열 번호 122의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 123의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 123의 폴리펩티드 또는 이의 단편은 서열 번호 124의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 125의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 125의 폴리펩티드 또는 이의 단편은 서열 번호 126의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 127의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 127의 폴리펩티드 또는 이의 단편은 서열 번호 128의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 129의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 129의 폴리펩티드 또는 이의 단편은 서열 번호 130의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 131의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 131의 폴리펩티드 또는 이의 단편은 서열 번호 132의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 133의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 133의 폴리펩티드 또는 이의 단편은 서열 번호 134의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 135의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 135의 폴리펩티드 또는 이의 단편은 서열 번호 136의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 137의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 137의 폴리펩티드 또는 이의 단편은 서열 번호 138의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 139의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 139의 폴리펩티드 또는 이의 단편은 서열 번호 140의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 141의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 141의 폴리펩티드 또는 이의 단편은 서열 번호 142의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 143의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 143의 폴리펩티드 또는 이의 단편은 서열 번호 144의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 145의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 145의 폴리펩티드 또는 이의 단편은 서열 번호 146의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 147의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 147의 폴리펩티드 또는 이의 단편은 서열 번호 148의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 149의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 149의 폴리펩티드 또는 이의 단편은 서열 번호 150의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 151의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 151의 폴리펩티드 또는 이의 단편은 서열 번호 152의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 153의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 153의 폴리펩티드 또는 이의 단편은 서열 번호 154의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 155의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 155의 폴리펩티드 또는 이의 단편은 서열 번호 156의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 157의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 157의 폴리펩티드 또는 이의 단편은 서열 번호 158의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 159의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 159의 폴리펩티드 또는 이의 단편은 서열 번호 160의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 161의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 161의 폴리펩티드 또는 이의 단편은 서열 번호 162의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 163의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 163의 폴리펩티드 또는 이의 단편은 서열 번호 164의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 165의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 165의 폴리펩티드 또는 이의 단편은 서열 번호 166의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 167의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 167의 폴리펩티드 또는 이의 단편은 서열 번호 168의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다. 일부 실시 형태에서, 서열 번호 167의 폴리펩티드 또는 이의 단편은 서열 번호 495의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다. 일부 실시 형태에서, 서열 번호 167의 폴리펩티드 또는 이의 단편은 서열 번호 536의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 169의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 169의 폴리펩티드 또는 이의 단편은 서열 번호 170의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 171의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 171의 폴리펩티드 또는 이의 단편은 서열 번호 172의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다. 일부 실시 형태에서, 서열 번호 171의 폴리펩티드 또는 이의 단편은 서열 번호 496의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다. 일부 실시 형태에서, 서열 번호 171의 폴리펩티드 또는 이의 단편은 서열 번호 537의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 173의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 173의 폴리펩티드 또는 이의 단편은 서열 번호 174의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 175의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 175의 폴리펩티드 또는 이의 단편은 서열 번호 176의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 177의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 177의 폴리펩티드 또는 이의 단편은 서열 번호 178의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다. 일부 실시 형태에서, 서열 번호 177의 폴리펩티드 또는 이의 단편은 서열 번호 499의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다. 일부 실시 형태에서, 서열 번호 177의 폴리펩티드 또는 이의 단편은 서열 번호 540의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 179의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 179의 폴리펩티드 또는 이의 단편은 서열 번호 180의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 181의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 181의 폴리펩티드 또는 이의 단편은 서열 번호 182의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 183의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 183의 폴리펩티드 또는 이의 단편은 서열 번호 184의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 185의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 185의 폴리펩티드 또는 이의 단편은 서열 번호 186의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 187의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 187의 폴리펩티드 또는 이의 단편은 서열 번호 188의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 189의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 189의 폴리펩티드 또는 이의 단편은 서열 번호 190의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 191의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 191의 폴리펩티드 또는 이의 단편은 서열 번호 192의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 193의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 193의 폴리펩티드 또는 이의 단편은 서열 번호 194의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 195의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 195의 폴리펩티드 또는 이의 단편은 서열 번호 196의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 197의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 197의 폴리펩티드 또는 이의 단편은 서열 번호 198의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 199의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 199의 폴리펩티드 또는 이의 단편은 서열 번호 200의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 201의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 201의 폴리펩티드 또는 이의 단편은 서열 번호 202의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 203의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 203의 폴리펩티드 또는 이의 단편은 서열 번호 204의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 205의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 205의 폴리펩티드 또는 이의 단편은 서열 번호 206의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 207의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 207의 폴리펩티드 또는 이의 단편은 서열 번호 208의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 209의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 209의 폴리펩티드 또는 이의 단편은 서열 번호 210의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 211의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 211의 폴리펩티드 또는 이의 단편은 서열 번호 212의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다. 일부 실시 형태에서, 서열 번호 211의 폴리펩티드 또는 이의 단편은 서열 번호 484의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다. 일부 실시 형태에서, 서열 번호 211의 폴리펩티드 또는 이의 단편은 서열 번호 525의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 213의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 213의 폴리펩티드 또는 이의 단편은 서열 번호 214의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다. 일부 실시 형태에서, 서열 번호 213의 폴리펩티드 또는 이의 단편은 서열 번호 486의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 215의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 215의 폴리펩티드 또는 이의 단편은 서열 번호 216의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다. 일부 실시 형태에서, 서열 번호 215의 폴리펩티드 또는 이의 단편은 서열 번호 487의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다. 일부 실시 형태에서, 서열 번호 215의 폴리펩티드 또는 이의 단편은 서열 번호 528의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 217의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 217의 폴리펩티드 또는 이의 단편은 서열 번호 218의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 219의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 219의 폴리펩티드 또는 이의 단편은 서열 번호 220의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다. 일부 실시 형태에서, 서열 번호 219의 폴리펩티드 또는 이의 단편은 서열 번호 489의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다. 일부 실시 형태에서, 서열 번호 219의 폴리펩티드 또는 이의 단편은 서열 번호 530의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 221의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 221의 폴리펩티드 또는 이의 단편은 서열 번호 222의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다. 일부 실시 형태에서, 서열 번호 221의 폴리펩티드 또는 이의 단편은 서열 번호 488의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다. 일부 실시 형태에서, 서열 번호 221의 폴리펩티드 또는 이의 단편은 서열 번호 529의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 223의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 223의 폴리펩티드 또는 이의 단편은 서열 번호 224의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다. 일부 실시 형태에서, 서열 번호 223의 폴리펩티드 또는 이의 단편은 서열 번호 494의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다. 일부 실시 형태에서, 서열 번호 223의 폴리펩티드 또는 이의 단편은 서열 번호 535의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 225의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 225의 폴리펩티드 또는 이의 단편은 서열 번호 226의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다. 일부 실시 형태에서, 서열 번호 225의 폴리펩티드 또는 이의 단편은 서열 번호 490의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다. 일부 실시 형태에서, 서열 번호 225의 폴리펩티드 또는 이의 단편은 서열 번호 531의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 227의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 227의 폴리펩티드 또는 이의 단편은 서열 번호 228의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 229의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 229의 폴리펩티드 또는 이의 단편은 서열 번호 230의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 231의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 231의 폴리펩티드 또는 이의 단편은 서열 번호 232의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 233의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 233의 폴리펩티드 또는 이의 단편은 서열 번호 234의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 235의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 235의 폴리펩티드 또는 이의 단편은 서열 번호 236의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다. 일부 실시 형태에서, 서열 번호 235의 폴리펩티드 또는 이의 단편은 서열 번호 493의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다. 일부 실시 형태에서, 서열 번호 235의 폴리펩티드 또는 이의 단편은 서열 번호 534의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 237의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 237의 폴리펩티드 또는 이의 단편은 서열 번호 238의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 239의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 239의 폴리펩티드 또는 이의 단편은 서열 번호 240의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 241의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 241의 폴리펩티드 또는 이의 단편은 서열 번호 242의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 243의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 243의 폴리펩티드 또는 이의 단편은 서열 번호 244의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 245의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 245의 폴리펩티드 또는 이의 단편은 서열 번호 246의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다. 일부 실시 형태에서, 서열 번호 245의 폴리펩티드 또는 이의 단편은 서열 번호 470의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다. 일부 실시 형태에서, 서열 번호 245의 폴리펩티드 또는 이의 단편은 서열 번호 511의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 247의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 247의 폴리펩티드 또는 이의 단편은 서열 번호 248의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 249의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 249의 폴리펩티드 또는 이의 단편은 서열 번호 250의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 251의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 251의 폴리펩티드 또는 이의 단편은 서열 번호 252의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다. 일부 실시 형태에서, 서열 번호 251의 폴리펩티드 또는 이의 단편은 서열 번호 469의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다. 일부 실시 형태에서, 서열 번호 251의 폴리펩티드 또는 이의 단편은 서열 번호 510의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 253의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 253의 폴리펩티드 또는 이의 단편은 서열 번호 254의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다. 일부 실시 형태에서, 서열 번호 253의 폴리펩티드 또는 이의 단편은 서열 번호 464의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다. 일부 실시 형태에서, 서열 번호 253의 폴리펩티드 또는 이의 단편은 서열 번호 505의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 255의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 255의 폴리펩티드 또는 이의 단편은 서열 번호 256의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다. 일부 실시 형태에서, 서열 번호 255의 폴리펩티드 또는 이의 단편은 서열 번호 474의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다. 일부 실시 형태에서, 서열 번호 255의 폴리펩티드 또는 이의 단편은 서열 번호 515의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 257의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 257의 폴리펩티드 또는 이의 단편은 서열 번호 258의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 259의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 259의 폴리펩티드 또는 이의 단편은 서열 번호 260의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 261의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 261의 폴리펩티드 또는 이의 단편은 서열 번호 262의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다. 일부 실시 형태에서, 서열 번호 261의 폴리펩티드 또는 이의 단편은 서열 번호 471의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다. 일부 실시 형태에서, 서열 번호 261의 폴리펩티드 또는 이의 단편은 서열 번호 512의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 263의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 263의 폴리펩티드 또는 이의 단편은 서열 번호 264의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 265의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 265의 폴리펩티드 또는 이의 단편은 서열 번호 266의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다. 일부 실시 형태에서, 서열 번호 265의 폴리펩티드 또는 이의 단편은 서열 번호 472의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다. 일부 실시 형태에서, 서열 번호 265의 폴리펩티드 또는 이의 단편은 서열 번호 513의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 267의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 267의 폴리펩티드 또는 이의 단편은 서열 번호 268의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 269의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 269의 폴리펩티드 또는 이의 단편은 서열 번호 270의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다. 일부 실시 형태에서, 서열 번호 269의 폴리펩티드 또는 이의 단편은 서열 번호 463의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다. 일부 실시 형태에서, 서열 번호 269의 폴리펩티드 또는 이의 단편은 서열 번호 504의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 271의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 271의 폴리펩티드 또는 이의 단편은 서열 번호 272의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다. 일부 실시 형태에서, 서열 번호 271의 폴리펩티드 또는 이의 단편은 서열 번호 465의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다. 일부 실시 형태에서, 서열 번호 271의 폴리펩티드 또는 이의 단편은 서열 번호 508의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 273의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 273의 폴리펩티드 또는 이의 단편은 서열 번호 274의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 275의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 275의 폴리펩티드 또는 이의 단편은 서열 번호 276의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다. 일부 실시 형태에서, 서열 번호 275의 폴리펩티드 또는 이의 단편은 서열 번호 459의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다. 일부 실시 형태에서, 서열 번호 275의 폴리펩티드 또는 이의 단편은 서열 번호 500의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 277의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 277의 폴리펩티드 또는 이의 단편은 서열 번호 278의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다. 일부 실시 형태에서, 서열 번호 277의 폴리펩티드 또는 이의 단편은 서열 번호 475의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다. 일부 실시 형태에서, 서열 번호 277의 폴리펩티드 또는 이의 단편은 서열 번호 516의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 279의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 279의 폴리펩티드 또는 이의 단편은 서열 번호 280의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 281의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 281의 폴리펩티드 또는 이의 단편은 서열 번호 282의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 283의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 283의 폴리펩티드 또는 이의 단편은 서열 번호 284의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 285의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 285의 폴리펩티드 또는 이의 단편은 서열 번호 286의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다. 일부 실시 형태에서, 서열 번호 285의 폴리펩티드 또는 이의 단편은 서열 번호 477의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 287의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 287의 폴리펩티드 또는 이의 단편은 서열 번호 288의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 289의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 289의 폴리펩티드 또는 이의 단편은 서열 번호 290의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 291의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 291의 폴리펩티드 또는 이의 단편은 서열 번호 292의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 293의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 293의 폴리펩티드 또는 이의 단편은 서열 번호 294의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 295의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 295의 폴리펩티드 또는 이의 단편은 서열 번호 296의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 297의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 297의 폴리펩티드 또는 이의 단편은 서열 번호 298의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다. 일부 실시 형태에서, 서열 번호 297의 폴리펩티드 또는 이의 단편은 서열 번호 476의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다. 일부 실시 형태에서, 서열 번호 297의 폴리펩티드 또는 이의 단편은 서열 번호 517의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 299의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 299의 폴리펩티드 또는 이의 단편은 서열 번호 300의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 301의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 301의 폴리펩티드 또는 이의 단편은 서열 번호 302의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 303의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 303의 폴리펩티드 또는 이의 단편은 서열 번호 304의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 305의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 305의 폴리펩티드 또는 이의 단편은 서열 번호 306의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다. 일부 실시 형태에서, 서열 번호 305의 폴리펩티드 또는 이의 단편은 서열 번호 468의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다. 일부 실시 형태에서, 서열 번호 305의 폴리펩티드 또는 이의 단편은 서열 번호 509의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 307의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 307의 폴리펩티드 또는 이의 단편은 서열 번호 308의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 309의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 309의 폴리펩티드 또는 이의 단편은 서열 번호 310의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다. 일부 실시 형태에서, 서열 번호 309의 폴리펩티드 또는 이의 단편은 서열 번호 465의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다. 일부 실시 형태에서, 서열 번호 309의 폴리펩티드 또는 이의 단편은 서열 번호 506의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 311의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 311의 폴리펩티드 또는 이의 단편은 서열 번호 312의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 313의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 313의 폴리펩티드 또는 이의 단편은 서열 번호 314의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 315의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 315의 폴리펩티드 또는 이의 단편은 서열 번호 316의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 317의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 317의 폴리펩티드 또는 이의 단편은 서열 번호 318의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다. 일부 실시 형태에서, 서열 번호 317의 폴리펩티드 또는 이의 단편은 서열 번호 473의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다. 일부 실시 형태에서, 서열 번호 317의 폴리펩티드 또는 이의 단편은 서열 번호 514의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 319의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 319의 폴리펩티드 또는 이의 단편은 서열 번호 320의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 321의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 321의 폴리펩티드 또는 이의 단편은 서열 번호 322의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 323의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 323의 폴리펩티드 또는 이의 단편은 서열 번호 324의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 325의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 325의 폴리펩티드 또는 이의 단편은 서열 번호 326의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다. 일부 실시 형태에서, 서열 번호 325의 폴리펩티드 또는 이의 단편은 서열 번호 466의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다. 일부 실시 형태에서, 서열 번호 325의 폴리펩티드 또는 이의 단편은 서열 번호 507의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 327의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 327의 폴리펩티드 또는 이의 단편은 서열 번호 328의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 329의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 329의 폴리펩티드 또는 이의 단편은 서열 번호 330의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 331의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 331의 폴리펩티드 또는 이의 단편은 서열 번호 332의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 333의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 333의 폴리펩티드 또는 이의 단편은 서열 번호 334의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다. 일부 실시 형태에서, 서열 번호 333의 폴리펩티드 또는 이의 단편은 서열 번호 461의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 335의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 335의 폴리펩티드 또는 이의 단편은 서열 번호 336의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 337의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 337의 폴리펩티드 또는 이의 단편은 서열 번호 338의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다. 일부 실시 형태에서, 서열 번호 337의 폴리펩티드 또는 이의 단편은 서열 번호 462의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다. 일부 실시 형태에서, 서열 번호 337의 폴리펩티드 또는 이의 단편은 서열 번호 503의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 339의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 339의 폴리펩티드 또는 이의 단편은 서열 번호 340의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 341의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 341의 폴리펩티드 또는 이의 단편은 서열 번호 342의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 343의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 343의 폴리펩티드 또는 이의 단편은 서열 번호 344의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다. 일부 실시 형태에서, 서열 번호 343의 폴리펩티드 또는 이의 단편은 서열 번호 483의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다. 일부 실시 형태에서, 서열 번호 343의 폴리펩티드 또는 이의 단편은 서열 번호 524의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 345의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 345의 폴리펩티드 또는 이의 단편은 서열 번호 346의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다. 일부 실시 형태에서, 서열 번호 345의 폴리펩티드 또는 이의 단편은 서열 번호 491의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다. 일부 실시 형태에서, 서열 번호 345의 폴리펩티드 또는 이의 단편은 서열 번호 532의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 347의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 347의 폴리펩티드 또는 이의 단편은 서열 번호 348의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 349의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 349의 폴리펩티드 또는 이의 단편은 서열 번호 350의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다. 일부 실시 형태에서, 서열 번호 349의 폴리펩티드 또는 이의 단편은 서열 번호 485의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 351의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 351의 폴리펩티드 또는 이의 단편은 서열 번호 352의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 353의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 353의 폴리펩티드 또는 이의 단편은 서열 번호 354의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다. 일부 실시 형태에서, 서열 번호 353의 폴리펩티드 또는 이의 단편은 서열 번호 492의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다. 일부 실시 형태에서, 서열 번호 353의 폴리펩티드 또는 이의 단편은 서열 번호 533의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 355의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 355의 폴리펩티드 또는 이의 단편은 서열 번호 356의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 357의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 357의 폴리펩티드 또는 이의 단편은 서열 번호 358의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 359의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 359의 폴리펩티드 또는 이의 단편은 서열 번호 360의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 361의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 361의 폴리펩티드 또는 이의 단편은 서열 번호 362의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 363의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 363의 폴리펩티드 또는 이의 단편은 서열 번호 364의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 365의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 365의 폴리펩티드 또는 이의 단편은 서열 번호 366의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 367의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 367의 폴리펩티드 또는 이의 단편은 서열 번호 368의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 369의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 369의 폴리펩티드 또는 이의 단편은 서열 번호 370의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 371의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 371의 폴리펩티드 또는 이의 단편은 서열 번호 372의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 373의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 373의 폴리펩티드 또는 이의 단편은 서열 번호 374의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 375의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 375의 폴리펩티드 또는 이의 단편은 서열 번호 376의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 379의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 379의 폴리펩티드 또는 이의 단편은 서열 번호 380의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다. 일부 실시 형태에서, 서열 번호 379의 폴리펩티드 또는 이의 단편은 서열 번호 482의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다. 일부 실시 형태에서, 서열 번호 379의 폴리펩티드 또는 이의 단편은 서열 번호 523의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 381의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 381의 폴리펩티드 또는 이의 단편은 서열 번호 382의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다. 일부 실시 형태에서, 서열 번호 381의 폴리펩티드 또는 이의 단편은 서열 번호 460의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다. 일부 실시 형태에서, 서열 번호 381의 폴리펩티드 또는 이의 단편은 서열 번호 501의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 383의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 383의 폴리펩티드 또는 이의 단편은 서열 번호 384의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 385의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 385의 폴리펩티드 또는 이의 단편은 서열 번호 386의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 387의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다.
본 발명은 또한 서열 번호 388의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다.
본 발명은 또한 서열 번호 389의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다.
본 발명은 또한 서열 번호 390의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다.
본 발명은 또한 서열 번호 391의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다.
본 발명은 또한 서열 번호 392의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다.
본 발명은 또한 서열 번호 393의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다.
본 발명은 또한 서열 번호 394의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다.
본 발명은 또한 서열 번호 395의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다.
본 발명은 또한 서열 번호 396의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다.
본 발명은 또한 서열 번호 397의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다.
본 발명은 또한 서열 번호 398의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다.
본 발명은 또한 서열 번호 399의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다.
본 발명은 또한 서열 번호 400의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다.
본 발명은 또한 서열 번호 401의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다.
본 발명은 또한 서열 번호 402의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다.
본 발명은 또한 서열 번호 403의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다.
본 발명은 또한 서열 번호 404의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다.
본 발명은 또한 서열 번호 405의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다.
본 발명은 또한 서열 번호 406의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다.
본 발명은 또한 서열 번호 407의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다.
본 발명은 또한 서열 번호 408의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다.
본 발명은 또한 서열 번호 426의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다.
본 발명은 또한 서열 번호 427의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다.
본 발명은 또한 서열 번호 428의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다.
본 발명은 또한 서열 번호 429의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다.
본 발명은 또한 서열 번호 430의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다.
본 발명은 또한 서열 번호 431의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다.
본 발명은 또한 서열 번호 432의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다.
본 발명은 또한 서열 번호 433의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다.
본 발명은 또한 서열 번호 434의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다.
본 발명은 또한 서열 번호 435의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다.
본 발명은 또한 서열 번호 436의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다.
본 발명은 또한 서열 번호 437의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 437의 폴리펩티드 또는 이의 단편은 서열 번호 448의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다. 일부 실시 형태에서, 서열 번호 437의 폴리펩티드 또는 이의 단편은 서열 번호 478의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다. 일부 실시 형태에서, 서열 번호 437의 폴리펩티드 또는 이의 단편은 서열 번호 519의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 438의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 438의 폴리펩티드 또는 이의 단편은 서열 번호 449의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 439의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 439의 폴리펩티드 또는 이의 단편은 서열 번호 450의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다. 일부 실시 형태에서, 서열 번호 439의 폴리펩티드 또는 이의 단편은 서열 번호 479의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다. 일부 실시 형태에서, 서열 번호 439의 폴리펩티드 또는 이의 단편은 서열 번호 520의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 440의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 440의 폴리펩티드 또는 이의 단편은 서열 번호 451의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 441의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 441의 폴리펩티드 또는 이의 단편은 서열 번호 452의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 442의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 442의 폴리펩티드 또는 이의 단편은 서열 번호 453의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다. 일부 실시 형태에서, 서열 번호 442의 폴리펩티드 또는 이의 단편은 서열 번호 480의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다. 일부 실시 형태에서, 서열 번호 442의 폴리펩티드 또는 이의 단편은 서열 번호 521의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 443의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 443의 폴리펩티드 또는 이의 단편은 서열 번호 454의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 444의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 444의 폴리펩티드 또는 이의 단편은 서열 번호 455의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다. 일부 실시 형태에서, 서열 번호 444의 폴리펩티드 또는 이의 단편은 서열 번호 481의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다. 일부 실시 형태에서, 서열 번호 444의 폴리펩티드 또는 이의 단편은 서열 번호 522의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 445의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 445의 폴리펩티드 또는 이의 단편은 서열 번호 456의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 446의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 446의 폴리펩티드 또는 이의 단편은 서열 번호 457의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
본 발명은 또한 서열 번호 447의 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드를 제공한다. 일부 실시 형태에서, 서열 번호 447의 폴리펩티드 또는 이의 단편은 서열 번호 458의 폴리뉴클레오티드 또는 이의 단편에 의해 인코딩된다.
일부 실시 형태에서, 이종 폴리뉴클레오티드는 인프레임 이종 폴리뉴클레오티드이다.
본 발명은 또한 서열 번호 1, 3, 5, 7, 9, 11, 13, 15, 17, 19, 21, 23, 25, 27, 29, 31, 33, 35, 37, 39, 41, 43, 45, 47, 49, 51, 53, 55, 57, 59, 61, 63, 65, 67, 69, 71, 73, 75, 77, 79, 81, 83, 85, 87, 89, 91, 93, 95, 97, 99, 101, 103, 105, 107, 109, 111, 113, 115, 117, 119, 121, 123, 125, 127, 129, 131, 133, 135, 137, 139, 141, 143, 145, 147, 149, 151, 153, 155, 157, 159, 161, 163, 165, 167, 169, 171, 173, 175, 177, 179, 181, 183, 185, 187, 189, 191, 193, 195, 197, 199, 201, 203, 205, 207, 209, 211, 213, 215, 217, 219, 221, 223, 225, 227, 229, 231, 233, 235, 237, 239, 241, 243, 245, 247, 249, 251, 253, 255, 257, 259, 261, 263, 265, 267, 269, 271, 273, 275, 277, 279, 281, 283, 285, 287, 289, 291, 293, 295, 297, 299, 301, 303, 305, 307, 309, 311, 313, 315, 317, 319, 321, 323, 325, 327, 329, 331, 333, 335, 337, 339, 341, 343, 345, 347, 349, 351, 353, 355, 357, 359, 361, 363, 365, 367, 369, 371, 373, 375, 379, 381, 383, 385, 387, 388, 389, 390, 391, 392, 393, 394, 395, 396, 397, 398, 399, 400, 401, 402, 403, 404, 405, 406, 407, 408, 426, 427, 428, 429, 430, 431, 432, 433, 434, 435, 436, 437, 438, 439, 440, 441, 442, 443, 444, 445, 446 및 447로 이루어진 군으로부터 선택되는 2개 이상의 폴리펩티드 및 이들의 단편을 포함하는 이종 폴리펩티드를 인코딩하는 단리된 이종 폴리뉴클레오티드를 제공한다.
본 발명은 또한 서열 번호 275, 381, 333, 337, 269, 253, 309, 325, 271, 305, 251, 245, 261, 265, 317, 255, 277, 297, 285, 437, 439, 442, 444, 379, 343, 211, 349, 213, 215, 221, 219, 225, 345, 353, 235, 223, 167, 171, 19, 23 및 177로 이루어진 군으로부터 선택되는 2개 이상의 폴리펩티드 및 이들의 단편을 포함하는 이종 폴리펩티드를 인코딩하는 단리된 이종 폴리뉴클레오티드를 제공한다.
본 발명은 또한 서열 번호 2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26, 28, 30, 32, 34, 36, 38, 40, 42, 44, 46, 48, 50, 52, 54, 56, 58, 60, 62, 64, 66, 68, 70, 72, 74, 76, 78, 80, 82, 84, 86, 88, 90, 92, 94, 96, 98, 100, 102, 104, 106, 108, 110, 112, 114, 116, 118, 120, 122, 124, 126, 128, 130, 132, 134, 136, 138, 140, 142, 144, 146, 148, 150, 152, 154, 156, 158, 160, 162, 164, 166, 168, 170, 172, 174, 176, 178, 180, 182, 184, 186, 188, 190, 192, 194, 196, 198, 200, 202, 204, 206, 208, 210, 212, 214, 216, 218, 220, 222, 224, 226, 228, 230, 232, 234, 236, 238, 240, 242, 244, 246, 248, 250, 252, 254, 256, 258, 260, 262, 264, 266, 268, 270, 272, 274, 276, 278, 280, 282, 284, 286, 288, 290, 292, 294, 296, 298, 300, 302, 304, 306, 308, 310, 312, 314, 316, 318, 320, 322, 324, 326, 328, 330, 332, 334, 336, 338, 340, 342, 344, 346, 348, 350, 352, 354, 356, 358, 360, 362, 364, 366, 368, 370, 372, 374, 376, 380, 382, 384, 386, 448, 449, 450, 451, 452, 453, 454, 455, 456, 457 및 458로 이루어진 군으로부터 선택되는 2개 이상의 폴리뉴클레오티드 및 이들의 단편을 포함하는 단리된 이종 폴리뉴클레오티드를 제공한다.
본 발명은 또한 서열 번호 276, 382, 334, 338, 270, 254, 310, 326, 272, 306, 252, 246, 262, 266, 318, 256, 278, 298, 286, 448, 450, 453, 455, 380, 344, 212, 350, 214, 216, 222, 220, 226, 346, 354, 236, 224, 168, 172, 20, 24 및 178로 이루어진 군으로부터 선택되는 2개 이상의 폴리뉴클레오티드 및 이들의 단편을 포함하는 단리된 이종 폴리뉴클레오티드를 제공한다.
다양한 숙주에서의 발현을 위해, 폴리뉴클레오티드는 공지된 방법을 이용하여 코돈 최적화될 수 있다. 예를 들어, 아데노바이러스 발현을 위해, 서열 번호 459, 460, 461, 462, 463, 464, 465, 466, 467, 468, 469, 470, 471, 472, 473, 474, 475, 476, 477, 478, 479, 480, 481, 482, 483, 484, 485, 486, 487, 488, 489, 490, 491, 492, 493, 494, 495, 496, 497, 498 또는 499의 폴리뉴클레오티드 중 적어도 하나를 포함하는 이종 폴리뉴클레오티드가 사용될 수 있다. 변형된 백시니아 앙카라(MVA)에서의 발현을 위해, 서열 번호 500, 501, 461, 503, 504, 505, 506, 507, 508, 509, 510, 511, 512, 513, 514, 515, 516, 517, 477, 519, 520, 521, 522, 523, 524, 525, 485, 486, 528, 529, 530, 531, 532, 533, 534, 535, 536, 537, 538, 539 또는 540의 폴리뉴클레오티드 중 적어도 하나를 포함하는 이종 폴리뉴클레오티드가 사용될 수 있다.
본 발명은 또한 서열 번호 459, 460, 461, 462, 463, 464, 465, 466, 467, 468, 469, 470, 471, 472, 473, 474, 475, 476, 477, 478, 479, 480, 481, 482, 483, 484, 485, 486, 487, 488, 489, 490, 491, 492, 493, 494, 495, 496, 497, 498 및 499로 이루어진 군으로부터 선택되는 2개 이상의 폴리뉴클레오티드 및 이들의 단편을 포함하는 단리된 이종 폴리뉴클레오티드를 제공한다.
본 발명은 또한 서열 번호 500, 501, 461, 503, 504, 505, 506, 507, 508, 509, 510, 511, 512, 513, 514, 515, 516, 517, 477, 519, 520, 521, 522, 523, 524, 525, 485, 486, 528, 529, 530, 531, 532, 533, 534, 535, 536, 537, 538, 539 및 540으로 이루어진 군으로부터 선택되는 2개 이상의 폴리뉴클레오티드 및 이들의 단편을 포함하는 단리된 이종 폴리뉴클레오티드를 제공한다.
일부 실시 형태에서, 단리된 이종 폴리뉴클레오티드는 인프레임 이종 폴리뉴클레오티드이다.
일부 실시 형태에서, 단편은 길이가 약 6 내지 24개의 아미노산을 포함한다.
일부 실시 형태에서, 단편은 6개 이상의 아미노산을 포함한다. 일부 실시 형태에서, 단편은 7개 이상의 아미노산을 포함한다. 일부 실시 형태에서, 단편은 8개 이상의 아미노산을 포함한다. 일부 실시 형태에서, 단편은 9개 이상의 아미노산을 포함한다. 일부 실시 형태에서, 단편은 10개 이상의 아미노산을 포함한다. 일부 실시 형태에서, 단편은 11개 이상의 아미노산을 포함한다. 일부 실시 형태에서, 단편은 12개 이상의 아미노산을 포함한다. 일부 실시 형태에서, 단편은 13개 이상의 아미노산을 포함한다. 일부 실시 형태에서, 단편은 14개 이상의 아미노산을 포함한다. 일부 실시 형태에서, 단편은 15개 이상의 아미노산을 포함한다. 일부 실시 형태에서, 단편은 16개 이상의 아미노산을 포함한다. 일부 실시 형태에서, 단편은 17개 이상의 아미노산을 포함한다. 일부 실시 형태에서, 단편은 18개 이상의 아미노산을 포함한다. 일부 실시 형태에서, 단편은 19개 이상의 아미노산을 포함한다. 일부 실시 형태에서, 단편은 20개 이상의 아미노산을 포함한다. 일부 실시 형태에서, 단편은 21개 이상의 아미노산을 포함한다. 일부 실시 형태에서, 단편은 22개 이상의 아미노산을 포함한다. 일부 실시 형태에서, 단편은 23개 이상의 아미노산을 포함한다. 일부 실시 형태에서, 단편은 24개 이상의 아미노산을 포함한다. 일부 실시 형태에서, 단편은 25개 이상의 아미노산을 포함한다. 일부 실시 형태에서, 단편은 약 6개의 아미노산을 포함한다. 일부 실시 형태에서, 단편은 약 7개의 아미노산을 포함한다. 일부 실시 형태에서, 단편은 약 8개의 아미노산을 포함한다. 일부 실시 형태에서, 단편은 약 9개의 아미노산을 포함한다. 일부 실시 형태에서, 단편은 약 10개의 아미노산을 포함한다. 일부 실시 형태에서, 단편은 약 11개의 아미노산을 포함한다. 일부 실시 형태에서, 단편은 약 12개의 아미노산을 포함한다. 일부 실시 형태에서, 단편은 약 13개의 아미노산을 포함한다. 일부 실시 형태에서, 단편은 약 14개의 아미노산을 포함한다. 일부 실시 형태에서, 단편은 약 15개의 아미노산을 포함한다. 일부 실시 형태에서, 단편은 약 16개의 아미노산을 포함한다. 일부 실시 형태에서, 단편은 약 17개의 아미노산을 포함한다. 일부 실시 형태에서, 단편은 약 18개의 아미노산을 포함한다. 일부 실시 형태에서, 단편은 약 19개의 아미노산을 포함한다. 일부 실시 형태에서, 단편은 약 20개의 아미노산을 포함한다. 일부 실시 형태에서, 단편은 약 21개의 아미노산을 포함한다. 일부 실시 형태에서, 단편은 약 22개의 아미노산을 포함한다. 일부 실시 형태에서, 단편은 약 23개의 아미노산을 포함한다. 일부 실시 형태에서, 단편은 약 24개의 아미노산을 포함한다. 일부 실시 형태에서, 단편은 약 25개의 아미노산을 포함한다. 일부 실시 형태에서, 단편은 약 6 내지 25개의 아미노산을 포함한다. 일부 실시 형태에서, 단편은 약 7 내지 25개의 아미노산을 포함한다. 일부 실시 형태에서, 단편은 약 8 내지 25개의 아미노산을 포함한다. 일부 실시 형태에서, 단편은 약 8 내지 24개의 아미노산을 포함한다. 일부 실시 형태에서, 단편은 약 8 내지 23개의 아미노산을 포함한다. 일부 실시 형태에서, 단편은 약 8 내지 22개의 아미노산을 포함한다. 일부 실시 형태에서, 단편은 약 8 내지 21개의 아미노산을 포함한다. 일부 실시 형태에서, 단편은 약 8 내지 20개의 아미노산을 포함한다. 일부 실시 형태에서, 단편은 약 8 내지 19개의 아미노산을 포함한다. 일부 실시 형태에서, 단편은 약 8 내지 18개의 아미노산을 포함한다. 일부 실시 형태에서, 단편은 약 8 내지 17개의 아미노산을 포함한다. 일부 실시 형태에서, 단편은 약 8 내지 16개의 아미노산을 포함한다. 일부 실시 형태에서, 단편은 약 8 내지 15개의 아미노산을 포함한다. 일부 실시 형태에서, 단편은 약 8 내지 14개의 아미노산을 포함한다. 일부 실시 형태에서, 단편은 약 9 내지 14개의 아미노산을 포함한다. 일부 실시 형태에서, 단편은 약 9 내지 13개의 아미노산을 포함한다. 일부 실시 형태에서, 단편은 약 9 내지 12개의 아미노산을 포함한다. 일부 실시 형태에서, 단편은 약 9 내지 11개의 아미노산을 포함한다. 일부 실시 형태에서, 단편은 약 9 내지 10개의 아미노산을 포함한다.
일부 실시 형태에서, 단편은 서열 번호 387, 388, 389, 390, 391, 392, 393, 394, 395, 396, 397, 398, 399, 400, 401, 402, 403, 404, 405, 406, 407, 408, 560, 561, 562, 563, 564, 565, 566, 567, 568, 569, 570, 571, 572, 573, 574, 575, 576, 577, 578, 579, 580, 581, 582, 583, 584, 585, 586, 587, 588, 589, 590, 591, 592, 593, 594, 595, 596, 597, 598, 599, 600, 601, 602, 603, 604, 605, 606, 607, 608, 609, 610, 611, 612, 613, 614, 615, 616, 617, 618, 619, 620 또는 621을 포함한다.
일부 실시 형태에서, 단편은 서열 번호 377, 378, 415, 417, 418, 420, 502, 518, 526, 527, 714, 715, 716, 717, 718, 719, 720, 721, 722, 723, 724, 725, 726, 727, 728, 729, 730, 731, 732, 733, 734, 735, 736, 737, 738, 739, 740, 741, 742, 743, 744, 745, 746, 747, 748, 749, 750, 751, 752, 753, 74, 755, 756, 757, 758, 759, 760, 761, 762, 763, 764, 765, 766, 767, 768, 769, 770, 771, 772, 773, 774, 775, 776, 777, 778, 779, 780, 781, 782, 783, 784, 785, 786, 787, 788, 789, 790, 791, 792, 793, 794, 795, 796, 797, 798, 799, 800, 801, 802, 803, 804, 805, 806, 807, 808, 809, 810, 811, 812, 813, 814, 815, 816, 817, 818, 819, 820, 821, 822, 823, 824, 825, 826, 827, 828, 829, 830, 831, 832, 833, 834, 835, 836, 837, 838, 839, 840, 841, 842, 843, 844, 845, 846, 487, 848, 849, 850, 851, 852, 853, 854, 855, 856, 857, 858, 859, 860, 861, 862, 863, 864, 865, 866, 867, 868, 869, 870, 871, 872, 873, 874, 875, 876, 877, 878, 879, 880, 881, 882, 883, 884, 885, 886, 887, 888, 889, 890, 891, 892, 893, 894, 895, 896, 897, 898, 899, 900, 901, 902, 903, 904, 905, 906, 907, 908, 909, 910, 911, 912, 913, 914, 915, 916, 917, 918, 919, 920, 921, 922, 923, 924, 925, 926, 927, 928, 929, 930, 931, 932, 933, 934, 935, 936, 937, 938, 939, 940, 941, 942, 943, 944, 945, 946, 947, 948, 949, 950, 951, 952, 953, 954, 955, 956, 957, 958, 959, 960, 961, 962, 963, 964, 965, 966, 967, 968, 969, 970, 971, 972, 973, 974, 975, 976, 977, 978, 979, 980 또는 548을 포함한다.
일부 실시 형태에서, 단편은 면역원성 단편이다.
면역원성 단편은 일반적으로 T 세포를 활성화시키는 펩티드, 예를 들어 MHC에 제시될 때 세포독성 T 세포를 유도하는 펩티드이다. T 세포의 활성화 및/또는 세포독성 T 림프구의 유도를 평가하는 방법은 잘 알려져 있다. 예시적인 분석에서, 전립선암 환자로부터 단리된 PBMC는 시험 신생항원 또는 이의 단편 및 IL-25의 존재 하에 시험관내에서 배양된다. 배양물을 IL-15 및 IL-2로 주기적으로 보충하여, 추가로 12일간 배양할 수 있다. 12일째에, 배양물을 시험 신생항원 또는 이의 단편으로 재자극하고, 그 다음날 T 세포 활성화를 대조군 배양물과 비교하여 IFNγ+TNAα+ CD8+ 세포의 비율을 측정함으로써 평가할 수 있다.
본 발명은 또한 서열 번호 1, 3, 5, 7, 9, 11, 13, 15, 17, 19, 21, 23, 25, 27, 29, 31, 33, 35, 37, 39, 41, 43, 45, 47, 49, 51, 53, 55, 57, 59, 61, 63, 65, 67, 69, 71, 73, 75, 77, 79, 81, 83, 85, 87, 89, 91, 93, 95, 97, 99, 101, 103, 105, 107, 109, 111, 113, 115, 117, 119, 121, 123, 125, 127, 129, 131, 133, 135, 137, 139, 141, 143, 145, 147, 149, 151, 153, 155, 157, 159, 161, 163, 165, 167, 169, 171, 173, 175, 177, 179, 181, 183, 185, 187, 189, 191, 193, 195, 197, 199, 201, 203, 205, 207, 209, 211, 213, 215, 217, 219, 221, 223, 225, 227, 229, 231, 233, 235, 237, 239, 241, 243, 245, 247, 249, 251, 253, 255, 257, 259, 261, 263, 265, 267, 269, 271, 273, 275, 277, 279, 281, 283, 285, 287, 289, 291, 293, 295, 297, 299, 301, 303, 305, 307, 309, 311, 313, 315, 317, 319, 321, 323, 325, 327, 329, 331, 333, 335, 337, 339, 341, 343, 345, 347, 349, 351, 353, 355, 357, 359, 361, 363, 365, 367, 369, 371, 373, 375, 379, 381, 383, 385, 387, 388, 389, 390, 391, 392, 393, 394, 395, 396, 397, 398, 399, 400, 401, 402, 403, 404, 405, 406, 407, 408, 426, 427, 428, 429, 430, 431, 432, 433, 434, 435, 436, 437, 438, 439, 440, 441, 442, 443, 444, 445, 446 또는 447의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 제공한다.
일부 실시 형태에서, 폴리펩티드는 서열 번호 2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26, 28, 30, 32, 34, 36, 38, 40, 42, 44, 46, 48, 50, 52, 54, 56, 58, 60, 62, 64, 66, 68, 70, 72, 74, 76, 78, 80, 82, 84, 86, 88, 90, 92, 94, 96, 98, 100, 102, 104, 106, 108, 110, 112, 114, 116, 118, 120, 122, 124, 126, 128, 130, 132, 134, 136, 138, 140, 142, 144, 146, 148, 150, 152, 154, 156, 158, 160, 162, 164, 166, 168, 170, 172, 174, 176, 178, 180, 182, 184, 186, 188, 190, 192, 194, 196, 198, 200, 202, 204, 206, 208, 210, 212, 214, 216, 218, 220, 222, 224, 226, 228, 230, 232, 234, 236, 238, 240, 242, 244, 246, 248, 250, 252, 254, 256, 258, 260, 262, 264, 266, 268, 270, 272, 274, 276, 278, 280, 282, 284, 286, 288, 290, 292, 294, 296, 298, 300, 302, 304, 306, 308, 310, 312, 314, 316, 318, 320, 322, 324, 326, 328, 330, 332, 334, 336, 338, 340, 342, 344, 346, 348, 350, 352, 354, 356, 358, 360, 362, 364, 366, 368, 370, 372, 374, 376, 380, 382, 384, 386, 448, 449, 450, 451, 452, 453, 454, 455, 456, 457 또는 458의 폴리뉴클레오티드 서열 또는 이의 단편에 의해 인코딩된다.
일부 실시 형태에서, 폴리펩티드는 서열 번호 459, 460, 461, 462, 463, 464, 465, 466, 467, 468, 469, 470, 471, 472, 473, 474, 475, 476, 477, 478, 479, 480, 481, 482, 483, 484, 485, 486, 487, 488, 489, 490, 491, 492, 493, 494, 495, 496, 497, 498 또는 499의 폴리뉴클레오티드 서열 또는 이의 단편에 의해 인코딩된다.
일부 실시 형태에서, 폴리펩티드는 서열 번호 500, 501, 461, 503, 504, 505, 506, 507, 508, 509, 510, 511, 512, 513, 514, 515, 516, 517, 477, 519, 520, 521, 522, 523, 524, 525, 485, 486, 528, 529, 530, 531, 532, 533, 534, 535, 536, 537, 538, 539 또는 540의 폴리뉴클레오티드 서열 또는 이의 단편에 의해 인코딩된다.
본 발명의 폴리펩티드 및 이종 폴리펩티드는 본 명세서에 기재된 하나 이상의 전립선 신생항원을 포함한다. 본 발명의 폴리펩티드 및 이종 폴리펩티드는 본 발명의 재조합 바이러스, 세포 및 백신, 및 하나 이상의 본 발명의 전립선 신생항원에 특이적으로 결합하는 단백질성 분자를 생성하는데 유용하거나, 다양한 기술을 사용하여 전립선암을 앓고 있는 대상에게 이들을 전달함으로써 치료제로서 직접 사용될 수 있다. 2개 이상의 신생항원(예를 들어, 폴리펩티드)은 표준 클로닝 방법을 사용하여 임의의 순서로 백신에 혼입될 수 있다.
본 발명은 또한 서열 번호 1의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 3의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 5의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 7의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 9의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 11의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 13의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 15의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 17의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 19의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 21의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 23의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 25의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 27의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 29의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 31의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 33의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 35의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 37의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 39의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 41의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 43의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 45의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 47의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 49의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 51의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 53의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 55의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 57의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 59의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 61의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 63의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 65의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 67의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 69의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 71의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 73의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 75의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 77의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 79의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 81의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 83의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 85의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 87의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 89의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 91의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 93의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 95의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 97의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 99의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 101의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 103의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 105의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 107의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 109의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 111의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 113의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 115의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 117의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 119의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 121의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 123의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 125의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 127의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 129의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 131의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 133의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 135의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 137의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 139의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 141의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 143의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 145의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 147의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 149의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 151의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 153의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 155의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 157의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 159의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 161의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 163의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 165의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 167의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 169의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 171의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 173의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 175의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 177의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 179의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 181의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 183의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 185의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 187의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 189의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 191의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 193의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 195의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 197의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 199의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 201의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 203의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 205의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 207의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 209의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 211의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 213의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 215의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 217의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 219의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 221의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 223의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 225의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 227의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 229의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 231의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 233의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 235의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 237의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 239의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 241의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 243의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 245의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 247의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 249의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 251의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 253의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 255의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 257의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 259의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 261의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 263의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 265의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 267의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 269의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 271의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 273의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 275의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 277의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 279의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 281의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 283의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 285의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 287의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 289의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 291의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 293의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 295의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 297의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 299의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 301의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 303의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 305의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 307의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 309의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 311의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 313의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 315의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 317의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 319의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 321의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 323의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 325의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 327의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 329의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 331의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 333의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 335의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 337의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 339의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 341의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 343의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 345의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 347의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 349의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 351의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 353의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 355의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 357의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 359의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 361의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 363의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 365의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 367의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 369의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 371의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 373의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 375의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 379의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 381의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 383의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 385의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 387의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 388의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 389의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 390의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 391의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 392의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 393의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 394의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 395의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 396의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 397의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 398의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 399의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 400의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 401의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 402의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 403의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 404의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 405의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 406의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 407의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 408의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 426의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 427의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 428의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 429의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 430의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 431의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 432의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 433의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 434의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 435의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 436의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 437의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 438의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 439의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 440의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 441의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 442의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 443의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 444의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 445의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 446의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 447의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 560의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 561의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 562의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 563의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 564의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 565의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 566의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 567의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 568의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 569의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 570의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 571의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 572의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 573의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 574의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 575의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 576의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 577의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 578의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 579의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 580의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 581의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 582의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 583의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 584의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 585의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 586의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 587의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 588의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 589의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 590의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 591의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 592의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 593의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 594의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 595의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 596의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 597의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 598의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 599의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 600의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 601의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 602의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 603의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 604의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 605의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 606의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 607의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 608의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 609의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 610의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 611의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 612의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 613의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 614의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 615의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 616의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 617의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 618의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 619의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 620의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 621의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 1, 3, 5, 7, 9, 11, 13, 15, 17, 19, 21, 23, 25, 27, 29, 31, 33, 35, 37, 39, 41, 43, 45, 47, 49, 51, 53, 55, 57, 59, 61, 63, 65, 67, 69, 71, 73, 75, 77, 79, 81, 83, 85, 87, 89, 91, 93, 95, 97, 99, 101, 103, 105, 107, 109, 111, 113, 115, 117, 119, 121, 123, 125, 127, 129, 131, 133, 135, 137, 139, 141, 143, 145, 147, 149, 151, 153, 155, 157, 159, 161, 163, 165, 167, 169, 171, 173, 175, 177, 179, 181, 183, 185, 187, 189, 191, 193, 195, 197, 199, 201, 203, 205, 207, 209, 211, 213, 215, 217, 219, 221, 223, 225, 227, 229, 231, 233, 235, 237, 239, 241, 243, 245, 247, 249, 251, 253, 255, 257, 259, 261, 263, 265, 267, 269, 271, 273, 275, 277, 279, 281, 283, 285, 287, 289, 291, 293, 295, 297, 299, 301, 303, 305, 307, 309, 311, 313, 315, 317, 319, 321, 323, 325, 327, 329, 331, 333, 335, 337, 339, 341, 343, 345, 347, 349, 351, 353, 355, 357, 359, 361, 363, 365, 367, 369, 371, 373, 375, 379, 381, 383, 385, 387, 388, 389, 390, 391, 392, 393, 394, 395, 396, 397, 398, 399, 400, 401, 402, 403, 404, 405, 406, 407, 408, 426, 427, 428, 429, 430, 431, 432, 433, 434, 435, 436, 437, 438, 439, 440, 441, 442, 443, 444, 445, 446 및 447로 이루어진 군으로부터 선택되는 2개 이상의 폴리펩티드 및 이들의 단편을 포함하는 단리된 이종 폴리펩티드를 제공한다.
일부 실시 형태에서, 이종 폴리펩티드는 서열 번호 2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26, 28, 30, 32, 34, 36, 38, 40, 42, 44, 46, 48, 50, 52, 54, 56, 58, 60, 62, 64, 66, 68, 70, 72, 74, 76, 78, 80, 82, 84, 86, 88, 90, 92, 94, 96, 98, 100, 102, 104, 106, 108, 110, 112, 114, 116, 118, 120, 122, 124, 126, 128, 130, 132, 134, 136, 138, 140, 142, 144, 146, 148, 150, 152, 154, 156, 158, 160, 162, 164, 166, 168, 170, 172, 174, 176, 178, 180, 182, 184, 186, 188, 190, 192, 194, 196, 198, 200, 202, 204, 206, 208, 210, 212, 214, 216, 218, 220, 222, 224, 226, 228, 230, 232, 234, 236, 238, 240, 242, 244, 246, 248, 250, 252, 254, 256, 258, 260, 262, 264, 266, 268, 270, 272, 274, 276, 278, 280, 282, 284, 286, 288, 290, 292, 294, 296, 298, 300, 302, 304, 306, 308, 310, 312, 314, 316, 318, 320, 322, 324, 326, 328, 330, 332, 334, 336, 338, 340, 342, 344, 346, 348, 350, 352, 354, 356, 358, 360, 362, 364, 366, 368, 370, 372, 374, 376, 380, 382, 384, 386, 448, 449, 450, 451, 452, 453, 454, 455, 456, 457 및 458로 이루어진 군으로부터 선택되는 2개 이상의 폴리뉴클레오티드 및 이들의 단편에 의해 인코딩된다.
일부 실시 형태에서, 단편은 길이가 약 6 내지 25개의 아미노산, 예컨대 약 8 내지 25개의 아미노산이다.
일부 실시 형태에서, 단편은 서열 번호 387, 388, 389, 390, 391, 392, 393, 394, 395, 396, 397, 398, 399, 400, 401, 402, 403, 404, 405, 406, 407, 408, 560, 561, 562, 563, 564, 565, 566, 567, 568, 569, 570, 571, 572, 573, 574, 575, 576, 577, 578, 579, 580, 581, 582, 583, 584, 585, 586, 587, 588, 589, 590, 591, 592, 593, 594, 595, 596, 597, 598, 599, 600, 601, 602, 603, 604, 605, 606, 607, 608, 609, 610, 611, 612, 613, 614, 615, 616, 617, 618, 619, 620 또는 621의 폴리펩티드를 포함한다.
일부 실시 형태에서, 단편은 서열 번호 377, 378, 415, 417, 418, 420, 502, 518, 526, 527, 714, 715, 716, 717, 718, 719, 720, 721, 722, 723, 724, 725, 726, 727, 728, 729, 730, 731, 732, 733, 734, 735, 736, 737, 738, 739, 740, 741, 742, 743, 744, 745, 746, 747, 748, 749, 750, 751, 752, 753, 74, 755, 756, 757, 758, 759, 760, 761, 762, 763, 764, 765, 766, 767, 768, 769, 770, 771, 772, 773, 774, 775, 776, 777, 778, 779, 780, 781, 782, 783, 784, 785, 786, 787, 788, 789, 790, 791, 792, 793, 794, 795, 796, 797, 798, 799, 800, 801, 802, 803, 804, 805, 806, 807, 808, 809, 810, 811, 812, 813, 814, 815, 816, 817, 818, 819, 820, 821, 822, 823, 824, 825, 826, 827, 828, 829, 830, 831, 832, 833, 834, 835, 836, 837, 838, 839, 840, 841, 842, 843, 844, 845, 846, 487, 848, 849, 850, 851, 852, 853, 854, 855, 856, 857, 858, 859, 860, 861, 862, 863, 864, 865, 866, 867, 868, 869, 870, 871, 872, 873, 874, 875, 876, 877, 878, 879, 880, 881, 882, 883, 884, 885, 886, 887, 888, 889, 890, 891, 892, 893, 894, 895, 896, 897, 898, 899, 900, 901, 902, 903, 904, 905, 906, 907, 908, 909, 910, 911, 912, 913, 914, 915, 916, 917, 918, 919, 920, 921, 922, 923, 924, 925, 926, 927, 928, 929, 930, 931, 932, 933, 934, 935, 936, 937, 938, 939, 940, 941, 942, 943, 944, 945, 946, 947, 948, 949, 950, 951, 952, 953, 954, 955, 956, 957, 958, 959, 960, 961, 962, 963, 964, 965, 966, 967, 968, 969, 970, 971, 972, 973, 974, 975, 976, 977, 978, 979, 980 또는 548의 폴리펩티드를 포함한다.
본 발명은 또한 서열 번호 275, 381, 333, 337, 269, 253, 309, 325, 271, 305, 251, 245, 261, 265, 317, 255, 277, 297, 285, 437, 439, 442, 444, 379, 343, 211, 349, 213, 215, 221, 219, 225, 345, 353, 235, 223, 167, 171, 19, 23 및 177로 이루어진 군으로부터 선택되는 2개 이상의 폴리펩티드 및 이들의 단편을 포함하는 단리된 이종 폴리펩티드를 제공한다.
일부 실시 형태에서, 이종 폴리펩티드는 서열 번호 276, 382, 334, 338, 270, 254, 310, 326, 272, 306, 252, 246, 262, 266, 318, 256, 278, 298, 286, 448, 450, 453, 455, 380, 344, 212, 350, 214, 216, 222, 220, 226, 346, 354, 236, 224, 168, 172, 20, 24 및 178로 이루어진 군으로부터 선택되는 2개 이상의 폴리뉴클레오티드 및 이들의 단편을 포함하는 이종 폴리뉴클레오티드에 의해 인코딩된다.
일부 실시 형태에서, 이종 폴리펩티드는 서열 번호 459, 460, 461, 462, 463, 464, 465, 466, 467, 468, 469, 470, 471, 472, 473, 474, 475, 476, 477, 478, 479, 480, 481, 482, 483, 484, 485, 486, 487, 488, 489, 490, 491, 492, 493, 494, 495, 496, 497, 498 및 499로 이루어진 군으로부터 선택되는 2개 이상의 폴리뉴클레오티드 및 이들의 단편을 포함하는 이종 폴리뉴클레오티드에 의해 인코딩된다.
일부 실시 형태에서, 이종 폴리펩티드는 서열 번호 500, 501, 461, 503, 504, 505, 506, 507, 508, 509, 510, 511, 512, 513, 514, 515, 516, 517, 477, 519, 520, 521, 522, 523, 524, 525, 485, 486, 528, 529, 530, 531, 532, 533, 534, 535, 536, 537, 538, 539 및 540으로 이루어진 군으로부터 선택되는 2개 이상의 폴리뉴클레오티드 및 이들의 단편을 포함하는 이종 폴리뉴클레오티드에 의해 인코딩된다.
본 발명의 조작된 폴리뉴클레오티드, 폴리펩티드, 이종 폴리뉴클레오티드 및 이종 폴리펩티드의 변이체
폴리뉴클레오티드, 폴리펩티드, 이종 폴리뉴클레오티드 및 이종 폴리펩티드 또는 이들의 단편의 변이체가 본 발명의 범위 내에 있다. 예를 들어, 변이체는 변이체가 모체와 비교하여, 개선된 특성(예컨대, 면역원성 또는 안정성)을 보유하거나 갖는 한 하나 이상의 치환, 결실 또는 삽입을 포함할 수 있다. 일부 실시 형태에서, 서열 동일성은 모체와 변이체 간에 약 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% 또는 99%일 수 있다. 일부 실시 형태에서, 변이체는 보존적 치환에 의해 생성된다.
일부 실시 형태에서, 서열 동일성은 약 80%이다. 일부 실시 형태에서, 서열 동일성은 약 85%이다. 일부 실시 형태에서, 서열 동일성은 약 90%이다. 일부 실시 형태에서, 서열 동일성은 약 91%이다. 일부 실시 형태에서, 서열 동일성은 약 91%이다. 일부 실시 형태에서, 서열 동일성은 약 92%이다. 일부 실시 형태에서, 서열 동일성은 약 93%이다. 일부 실시 형태에서, 서열 동일성은 약 94%이다. 일부 실시 형태에서, 서열 동일성은 94%이다. 일부 실시 형태에서, 서열 동일성은 약 95%이다. 일부 실시 형태에서, 서열 동일성은 약 96%이다. 일부 실시 형태에서, 서열 동일성은 약 97%이다. 일부 실시 형태에서, 서열 동일성은 약 98%이다. 일부 실시 형태에서, 서열 동일성은 약 99%이다.
일부 실시 형태에서, 변이체는 변이체가 모체와 비교하여, 개선된 특성(예컨대, 면역원성 또는 안정성)을 보유하거나 갖는 한 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19 또는 20개의 치환, 결실 또는 삽입을 포함할 수 있다.
2개의 서열 간의 % 동일성은 서열들에 의해 공유되는 동일한 위치의 수의 함수(즉, % 동일성 = 동일한 위치의 수/위치의 총수 x 100)이며, 이때 2개의 서열의 최적의 정렬을 위해 도입되어야 할 필요가 있는 갭(gap)의 수, 및 각각의 갭의 길이를 고려한다. 두 아미노산 서열 사이의 % 동일성은, PAM120 가중치 잔기(weight residue) 표, 12의 갭 길이 페널티 및 4의 갭 페널티를 사용하여, ALIGN 프로그램(버전 2.0)에 통합된 이. 메이어스(E. Meyers) 및 더블유. 밀러(W. Miller)의 알고리즘(문헌[Comput. Appl. Biosci., 4:11-17 (1988)])을 사용하여 결정될 수 있다. 또한, 두 아미노산 서열 사이의 % 동일성은, 블로섬(Blossum) 62 매트릭스 또는 PAM250 매트릭스, 및 16, 14, 12, 10, 8, 6 또는 4의 갭 가중치 및 1, 2, 3, 4, 5 또는 6의 길이 가중치(length weight)를 사용하여, (http://_www_gcg_com에서 입수가능한) GCG 소프트웨어 패키지의 GAP 프로그램에 통합된 니들만(Needleman) 및 분쉬(Wunsch)의 알고리즘(문헌[J. Mol. Biol. 48:444-453 (1970)])을 사용하여 측정될 수 있다.
하나의 아미노산 변경을 포함하는 폴리펩티드 또는 이종 폴리펩티드 또는 이들의 단편의 변이체는 일반적으로 모체에 비해 유사한 3차 구조 및 항원성을 보유한다. 일부 경우에, 변이체는 또한 변이체가 증가된 항원성, TCR 또는 항체에 대한 증가된 결합 친화성 또는 이들 둘 다를 갖게 하는 적어도 하나의 아미노산 변경을 포함할 수 있다. 폴리펩티드 또는 이종 폴리펩티드의 변이체는 또한 HLA 분자에 결합하는 개선된 능력을 가질 수 있다.
본 발명의 변이체는 보존적 치환을 포함하도록 조작될 수 있다. 보존적 치환은 하기의 5개의 그룹 중 하나 내의 교환으로 정의된다: 그룹 1-작은 지방족, 비극성 또는 약간 극성인 잔기(Ala, Ser, Thr, Pro, Gly); 그룹 2-극성의 음전하를 띤 잔기 및 이의 아미드(Asp, Asn, Glu, Gin); 그룹 3-극성의 양전하를 띤 잔기(His, Arg, Lys); 그룹 4-큰 지방족 비극성 잔기(Met, Leu, lie, Val, Cys); 및 그룹 5-큰 방향족 잔기(Phe, Tyr, Trp).
본 발명의 변이체는 하나의 아미노산을 유사한 특성을 갖지만 크기가 다소 상이한 다른 아미노산으로 치환하는 것과 같은 덜한 보존적 치환, 예컨대 알라닌의 아이소류신 잔기로의 치환을 포함하도록 조작될 수 있다. 본 발명의 변이체는 또한 산성 아미노산을 극성인 것 또는 심지어 특성이 염기성인 것으로 치환하는 것을 수반할 수 있는 고도로 비보존적 치환을 포함하도록 조작될 수 있다.
본 발명의 변이체를 생성하기 위해 이루어질 수 있는 추가의 치환은 공통 L-아미노산 이외의 구조를 수반할 수 있는 치환을 포함한다. 따라서, D-아미노산 및 비표준 아미노산(즉, 일반적인 자연 발생 단백질성 아미노산 이외)은 또한 모체와 비교하여 면역원성이 향상된 변이체를 생성하기 위해 치환 목적으로 사용될 수 있다.
하나 이상의 위치에서 치환이 실질적으로 동등하거나 더 큰 면역원성을 갖는 폴리펩티드 또는 이종 폴리펩티드를 생성하는 것으로 밝혀지면, 이러한 치환 조합은 치환 조합이 변이체의 면역원성에 대한 상가 또는 상승 효과를 가져오는지를 확인하도록 시험될 수 있다.
TCR과의 상호작용에 실질적으로 기여하지 않는 아미노산 잔기는 혼입이 T 세포 반응성에 실질적으로 영향을 미치지 않고 관련 MHC에 대한 결합을 제거하지 않는 다른 아미노산으로 치환함으로써 변형될 수 있다. TCR과의 상호작용에 실질적으로 기여하지 않는 아미노산 잔기는 결실이 T 세포 반응성에 실질적으로 영향을 미치지 않고 관련 MHC에 대한 결합을 제거하지 않는 한 또한 결실될 수 있다.
또한, 폴리펩티드 또는 이종 폴리펩티드 또는 이의 단편, 또는 변이체는 더욱 강한 면역반응을 유도하기 위해 MHC 분자에 대한 안정성 및/또는 결합을 개선하도록 추가로 변형될 수 있다. 펩티드 서열의 이러한 최적화를 위한 방법은 당업계에 잘 알려져 있으며, 예를 들어 역 펩티드 결합 또는 비펩티드 결합의 도입을 포함한다. 역 펩티드 결합에서, 아미노산 잔기는 펩티드(-CO-NH-) 결합에 의해 결합되지 않지만, 펩티드 결합은 그 반대이다. 이러한 레트로-인버소 펩티드모방체(retro-inverso peptidomimetic)는 당업계에 공지된 방법을 사용하여 제조될 수 있다. 이러한 접근법은 측쇄의 방향이 아닌, 골격을 수반한 변화를 포함하는 슈도펩티드를 제조하는 것을 포함한다. CO-NH 펩티드 결합 대신에 NH-CO 결합을 포함하는 레트로-인버스 펩티드는 단백질 분해에 대하여 훨씬 더 저항성을 나타낸다. 사용될 수 있는 추가의 비펩티드 결합은 예를 들어, -CH2-NH, -CH2S-, -CH2CH2-, -CH=CH-, -COCH2-, -CH(OH)CH2- 및 -CH2SO-이다.
본 발명의 폴리펩티드 또는 이종 폴리펩티드 또는 이의 단편, 또는 변이체는 펩티드의 안정성, 생체이용률 및/또는 친화성을 향상시키기 위해, 이들의 아미노 및/또는 카르복시 말단에 존재하는 추가의 화학기로 합성될 수 있다. 예를 들어, 카르벤족실, 단실 또는 t-부틸옥시카르보닐기와 같은 소수성 기가 아미노 말단에 부가될 수 있다. 마찬가지로, 아세틸기 또는 9-플루오레닐메톡시-카르보닐기가 아미노 말단에 위치할 수 있다. 또한, 소수성 기, t-부틸옥시카르보닐기 또는 아미도기가 카르복시 말단에 부가될 수 있다.
또한, 본 발명의 폴리펩티드 또는 이종 폴리펩티드 또는 이의 단편, 또는 변이체는 이들의 입체 형태를 변경하도록 합성될 수 있다. 예를 들어, 펩티드의 하나 이상의 아미노산 잔기의 D 이성질체는 통상의 L 이성질체 대신에 사용될 수 있다.
유사하게, 본 발명의 폴리펩티드 또는 이종 폴리펩티드 또는 이의 단편, 또는 변이체는 본 발명의 폴리펩티드 또는 이종 폴리펩티드 또는 이의 단편, 또는 변이체의 합성 전후에 특정 아미노산을 반응시킴으로써 화학적으로 변형될 수 있다. 이러한 변형에 대한 예가 당업계에 잘 알려져 있으며, 예를 들어 문헌[R. Lundblad, Chemical Reagents for Protein Modification, 3rd ed. CRC Press, 2004 (Lundblad, 2004)]에 요약되어 있다. 아미노산의 화학적 변형은 아실화, 아미드화, 라이신의 피리독실화, 환원적 알킬화, 2,4,6-트라이니트로벤젠 설폰산(TNBS)에 의한 아미노기의 트라이니트로벤질화, 카르복실기의 아미드 변형 및 시스테인의 시스테산으로의 과포름산 산화에 의한 설프히드릴 변형, 수은 유도체의 형성, 다른 티올 화합물에 의한 혼합 다이설파이드의 형성, 말레이미드와의 반응, 요오도아세트산 또는 요오도아세트아미드에 의한 카르복시메틸화 및 알칼리성 pH에서의 시아네이트에 의한 카르바모일화에 의한 변형을 포함하지만, 이에 한정되지 않는다. 이와 관련하여 당업자는 단백질의 화학적 변형과 관련된 보다 광범위한 방법에 대하여 문헌[Chapter 15 of Current Protocols In Protein Science, Eds. Coligan et al. (John Wiley and Sons NY 1995-2000) (Coligan et a l., 1995)]을 참조한다.
간단히 말하면, 예를 들어 단백질의 아르기닐 잔기의 변형은 종종 페닐글리옥살, 2,3-부탄다이온 및 1,2-사이클로헥산다이온과 같은 인접 다이카르보닐 화합물의 반응에 기초하여 부가물을 형성한다. 다른 예는 메틸글리옥살과 아르기닌 잔기의 반응이다. 시스테인은 라이신 및 히스티딘과 같은 다른 친핵성 부위의 수반되는 변형 없이 변형될 수 있다. 결과적으로, 다수의 시약이 시스테인의 변형에 사용가능하다. 시그마-알드리치와 같은 회사의 웹사이트(Sigma-Aldrich; http_://www_ sigma-aldrich. com)는 특정 시약에 대한 정보를 제공한다. 단백질의 다이설파이드 결합의 선택적 환원이 또한 일반적이다. 다이설파이드 결합이 바이오의약품의 열처리 중에 형성되어 산화될 수 있다. 우드워드(Woodward)의 시약 K를 사용하여 특정 글루탐산 잔기를 변형시킬 수 있다. N-(3-(다이메틸아미노)프로필)-N'-에틸카르보다이이미드는 라이신 잔기와 글루탐산 잔기 사이에 분자내 가교를 형성하는 데 사용될 수 있다. 예를 들어, 다이에틸피로카르보네이트는 단백질의 히스티딜 잔기의 변형을 위한 시약이다. 히스티딘은 또한 4-하이드록시-2-노네날을 사용하여 변형될 수 있다. 라이신 잔기 및 다른 α-아미노기의 반응은 예를 들어, 표면에 대한 펩티드의 결합 또는 단백질/펩티드의 가교결합에 유용하다. 라이신은 폴리(에틸렌)글리콜의 부착 부위 및 단백질의 글리코실화에 있어서의 주요 변형 부위이다. 단백질의 메티오닌 잔기는 예를 들어, 요오도아세트아미드, 브로모에틸아민 및 클로라민 T를 사용하여 변형될 수 있다. 테트라니트로메탄 및 N-아세틸이미다졸은 티로실 잔기의 변형에 사용될 수 있다. 다이티로신의 형성을 통한 가교결합은 과산화수소/구리 이온으로 달성될 수 있다. 트립토판 변형에 대한 최근 연구에서는 N-브로모석신이미드, 2-하이드록시-5-니트로벤질 브로마이드 또는 3-브로모-3-메틸-2-(2-니트로페닐메르캅토)-3H-인돌(BPNS-스카톨(skatole))을 사용하였다. PEG를 사용한 치료용 단백질 및 펩티드의 성공적인 변형은 종종 순환 반감기의 연장과 관련이 있으며, 단백질과 글루타르알데히드, 폴리에틸렌 글리콜 다이아크릴레이트 및 포름알데히드의 가교는 하이드로젤의 제조에 사용된다. 면역요법을 위한 알레르겐의 화학적 변형은 종종 시안산칼륨을 사용한 카르바밀화에 의해 달성된다.
본 발명은 서열 번호 1, 3, 5, 7, 9, 11, 13, 15, 17, 19, 21, 23, 25, 27, 29, 31, 33, 35, 37, 39, 41, 43, 45, 47, 49, 51, 53, 55, 57, 59, 61, 63, 65, 67, 69, 71, 73, 75, 77, 79, 81, 83, 85, 87, 89, 91, 93, 95, 97, 99, 101, 103, 105, 107, 109, 111, 113, 115, 117, 119, 121, 123, 125, 127, 129, 131, 133, 135, 137, 139, 141, 143, 145, 147, 149, 151, 153, 155, 157, 159, 161, 163, 165, 167, 169, 171, 173, 175, 177, 179, 181, 183, 185, 187, 189, 191, 193, 195, 197, 199, 201, 203, 205, 207, 209, 211, 213, 215, 217, 219, 221, 223, 225, 227, 229, 231, 233, 235, 237, 239, 241, 243, 245, 247, 249, 251, 253, 255, 257, 259, 261, 263, 265, 267, 269, 271, 273, 275, 277, 279, 281, 283, 285, 287, 289, 291, 293, 295, 297, 299, 301, 303, 305, 307, 309, 311, 313, 315, 317, 319, 321, 323, 325, 327, 329, 331, 333, 335, 337, 339, 341, 343, 345, 347, 349, 351, 353, 355, 357, 359, 361, 363, 365, 367, 369, 371, 373, 375, 379, 381, 383, 385, 387, 388, 389, 390, 391, 392, 393, 394, 395, 396, 397, 398, 399, 400, 401, 402, 403, 404, 405, 406, 407, 408, 426, 427, 428, 429, 430, 431, 432, 433, 434, 435, 436, 437, 438, 439, 440, 441, 442, 443, 444, 445, 446 또는 447의 폴리펩티드와 약 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% 또는 99% 동일한 단리된 폴리펩티드를 제공한다.
본 발명은 또한 서열 번호 1, 3, 5, 7, 9, 11, 13, 15, 17, 19, 21, 23, 25, 27, 29, 31, 33, 35, 37, 39, 41, 43, 45, 47, 49, 51, 53, 55, 57, 59, 61, 63, 65, 67, 69, 71, 73, 75, 77, 79, 81, 83, 85, 87, 89, 91, 93, 95, 97, 99, 101, 103, 105, 107, 109, 111, 113, 115, 117, 119, 121, 123, 125, 127, 129, 131, 133, 135, 137, 139, 141, 143, 145, 147, 149, 151, 153, 155, 157, 159, 161, 163, 165, 167, 169, 171, 173, 175, 177, 179, 181, 183, 185, 187, 189, 191, 193, 195, 197, 199, 201, 203, 205, 207, 209, 211, 213, 215, 217, 219, 221, 223, 225, 227, 229, 231, 233, 235, 237, 239, 241, 243, 245, 247, 249, 251, 253, 255, 257, 259, 261, 263, 265, 267, 269, 271, 273, 275, 277, 279, 281, 283, 285, 287, 289, 291, 293, 295, 297, 299, 301, 303, 305, 307, 309, 311, 313, 315, 317, 319, 321, 323, 325, 327, 329, 331, 333, 335, 337, 339, 341, 343, 345, 347, 349, 351, 353, 355, 357, 359, 361, 363, 365, 367, 369, 371, 373, 375, 379, 381, 383, 385, 387, 388, 389, 390, 391, 392, 393, 394, 395, 396, 397, 398, 399, 400, 401, 402, 403, 404, 405, 406, 407, 408, 426, 427, 428, 429, 430, 431, 432, 433, 434, 435, 436, 437, 438, 439, 440, 441, 442, 443, 444, 445, 446 또는 447의 폴리펩티드와 비교하여, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19 또는 20개의 치환, 결실 또는 삽입을 갖는 폴리펩티드 서열을 포함하는 단리된 폴리펩티드를 제공한다.
본 발명은 또한 서열 번호 2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26, 28, 30, 32, 34, 36, 38, 40, 42, 44, 46, 48, 50, 52, 54, 56, 58, 60, 62, 64, 66, 68, 70, 72, 74, 76, 78, 80, 82, 84, 86, 88, 90, 92, 94, 96, 98, 100, 102, 104, 106, 108, 110, 112, 114, 116, 118, 120, 122, 124, 126, 128, 130, 132, 134, 136, 138, 140, 142, 144, 146, 148, 150, 152, 154, 156, 158, 160, 162, 164, 166, 168, 170, 172, 174, 176, 178, 180, 182, 184, 186, 188, 190, 192, 194, 196, 198, 200, 202, 204, 206, 208, 210, 212, 214, 216, 218, 220, 222, 224, 226, 228, 230, 232, 234, 236, 238, 240, 242, 244, 246, 248, 250, 252, 254, 256, 258, 260, 262, 264, 266, 268, 270, 272, 274, 276, 278, 280, 282, 284, 286, 288, 290, 292, 294, 296, 298, 300, 302, 304, 306, 308, 310, 312, 314, 316, 318, 320, 322, 324, 326, 328, 330, 332, 334, 336, 338, 340, 342, 344, 346, 348, 350, 352, 354, 356, 358, 360, 362, 364, 366, 368, 370, 372, 374, 376, 380, 382, 384, 386, 448, 449, 450, 451, 452, 453, 454, 455, 456, 457 또는 458의 폴리뉴클레오티드와 약 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% 또는 99% 동일한 단리된 폴리뉴클레오티드를 제공한다.
본 발명은 또한 서열 번호 387, 388, 389, 390, 391, 392, 393, 394, 395, 396, 397, 398, 399, 400, 401, 402, 403, 404, 405, 406, 407, 408, 560, 561, 562, 563, 564, 565, 566, 567, 568, 569, 570, 571, 572, 573, 574, 575, 576, 577, 578, 579, 580, 581, 582, 583, 584, 585, 586, 587, 588, 589, 590, 591, 592, 593, 594, 595, 596, 597, 598, 599, 600, 601, 602, 603, 604, 605, 606, 607, 608, 609, 610, 611, 612, 613, 614, 615, 616, 617, 618, 619, 620 또는 621의 폴리펩티드와 약 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% 또는 99% 동일한 단리된 폴리펩티드를 제공한다.
본 발명은 또한 서열 번호 377, 378, 415, 417, 418, 420, 502, 518, 526, 527, 714, 715, 716, 717, 718, 719, 720, 721, 722, 723, 724, 725, 726, 727, 728, 729, 730, 731, 732, 733, 734, 735, 736, 737, 738, 739, 740, 741, 742, 743, 744, 745, 746, 747, 748, 749, 750, 751, 752, 753, 74, 755, 756, 757, 758, 759, 760, 761, 762, 763, 764, 765, 766, 767, 768, 769, 770, 771, 772, 773, 774, 775, 776, 777, 778, 779, 780, 781, 782, 783, 784, 785, 786, 787, 788, 789, 790, 791, 792, 793, 794, 795, 796, 797, 798, 799, 800, 801, 802, 803, 804, 805, 806, 807, 808, 809, 810, 811, 812, 813, 814, 815, 816, 817, 818, 819, 820, 821, 822, 823, 824, 825, 826, 827, 828, 829, 830, 831, 832, 833, 834, 835, 836, 837, 838, 839, 840, 841, 842, 843, 844, 845, 846, 487, 848, 849, 850, 851, 852, 853, 854, 855, 856, 857, 858, 859, 860, 861, 862, 863, 864, 865, 866, 867, 868, 869, 870, 871, 872, 873, 874, 875, 876, 877, 878, 879, 880, 881, 882, 883, 884, 885, 886, 887, 888, 889, 890, 891, 892, 893, 894, 895, 896, 897, 898, 899, 900, 901, 902, 903, 904, 905, 906, 907, 908, 909, 910, 911, 912, 913, 914, 915, 916, 917, 918, 919, 920, 921, 922, 923, 924, 925, 926, 927, 928, 929, 930, 931, 932, 933, 934, 935, 936, 937, 938, 939, 940, 941, 942, 943, 944, 945, 946, 947, 948, 949, 950, 951, 952, 953, 954, 955, 956, 957, 958, 959, 960, 961, 962, 963, 964, 965, 966, 967, 968, 969, 970, 971, 972, 973, 974, 975, 976, 977, 978, 979, 980 또는 548의 폴리펩티드와 약 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% 또는 99% 동일한 단리된 폴리펩티드를 제공한다.
본 발명은 또한 서열 번호 541, 550, 554, 555, 556, 623 또는 624의 폴리펩티드와 약 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% 또는 99% 동일한 단리된 폴리펩티드를 제공한다.
본 발명은 또한 서열 번호 542 또는 서열 번호 551의 폴리펩티드와 약 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% 또는 99% 동일한 단리된 폴리뉴클레오티드를 제공한다.
본 발명은 또한 서열 번호 543, 552, 557, 558, 559, 625 또는 626의 폴리펩티드와 약 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% 또는 99% 동일한 단리된 폴리펩티드를 제공한다.
본 발명은 또한 서열 번호 544 또는 서열 번호 553의 폴리펩티드와 약 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% 또는 99% 동일한 단리된 폴리뉴클레오티드를 제공한다.
본 발명은 또한 서열 번호 1, 3, 5, 7, 9, 11, 13, 15, 17, 19, 21, 23, 25, 27, 29, 31, 33, 35, 37, 39, 41, 43, 45, 47, 49, 51, 53, 55, 57, 59, 61, 63, 65, 67, 69, 71, 73, 75, 77, 79, 81, 83, 85, 87, 89, 91, 93, 95, 97, 99, 101, 103, 105, 107, 109, 111, 113, 115, 117, 119, 121, 123, 125, 127, 129, 131, 133, 135, 137, 139, 141, 143, 145, 147, 149, 151, 153, 155, 157, 159, 161, 163, 165, 167, 169, 171, 173, 175, 177, 179, 181, 183, 185, 187, 189, 191, 193, 195, 197, 199, 201, 203, 205, 207, 209, 211, 213, 215, 217, 219, 221, 223, 225, 227, 229, 231, 233, 235, 237, 239, 241, 243, 245, 247, 249, 251, 253, 255, 257, 259, 261, 263, 265, 267, 269, 271, 273, 275, 277, 279, 281, 283, 285, 287, 289, 291, 293, 295, 297, 299, 301, 303, 305, 307, 309, 311, 313, 315, 317, 319, 321, 323, 325, 327, 329, 331, 333, 335, 337, 339, 341, 343, 345, 347, 349, 351, 353, 355, 357, 359, 361, 363, 365, 367, 369, 371, 373, 375, 379, 381, 383, 385, 387, 388, 389, 390, 391, 392, 393, 394, 395, 396, 397, 398, 399, 400, 401, 402, 403, 404, 405, 406, 407, 408, 426, 427, 428, 429, 430, 431, 432, 433, 434, 435, 436, 437, 438, 439, 440, 441, 442, 443, 444, 445, 446 및 447의 아미노산 서열 및 이들의 단편을 포함하는 단리된 폴리펩티드로서, 상기 폴리펩티드는 하나 이상의 역 펩티드 결합을 포함하는 단리된 폴리펩티드를 제공한다.
본 발명은 또한 서열 번호 387, 388, 389, 390, 391, 392, 393, 394, 395, 396, 397, 398, 399, 400, 401, 402, 403, 404, 405, 406, 407, 408, 560, 561, 562, 563, 564, 565, 566, 567, 568, 569, 570, 571, 572, 573, 574, 575, 576, 577, 578, 579, 580, 581, 582, 583, 584, 585, 586, 587, 588, 589, 590, 591, 592, 593, 594, 595, 596, 597, 598, 599, 600, 601, 602, 603, 604, 605, 606, 607, 608, 609, 610, 611, 612, 613, 614, 615, 616, 617, 618, 619, 620 또는 621의 아미노산 서열을 포함하는 단리된 폴리펩티드로서, 상기 폴리펩티드는 하나 이상의 역 펩티드 결합을 포함하는 단리된 폴리펩티드를 제공한다.
본 발명은 또한 서열 번호 377, 378, 415, 417, 418, 420, 502, 518, 526, 527, 714, 715, 716, 717, 718, 719, 720, 721, 722, 723, 724, 725, 726, 727, 728, 729, 730, 731, 732, 733, 734, 735, 736, 737, 738, 739, 740, 741, 742, 743, 744, 745, 746, 747, 748, 749, 750, 751, 752, 753, 74, 755, 756, 757, 758, 759, 760, 761, 762, 763, 764, 765, 766, 767, 768, 769, 770, 771, 772, 773, 774, 775, 776, 777, 778, 779, 780, 781, 782, 783, 784, 785, 786, 787, 788, 789, 790, 791, 792, 793, 794, 795, 796, 797, 798, 799, 800, 801, 802, 803, 804, 805, 806, 807, 808, 809, 810, 811, 812, 813, 814, 815, 816, 817, 818, 819, 820, 821, 822, 823, 824, 825, 826, 827, 828, 829, 830, 831, 832, 833, 834, 835, 836, 837, 838, 839, 840, 841, 842, 843, 844, 845, 846, 487, 848, 849, 850, 851, 852, 853, 854, 855, 856, 857, 858, 859, 860, 861, 862, 863, 864, 865, 866, 867, 868, 869, 870, 871, 872, 873, 874, 875, 876, 877, 878, 879, 880, 881, 882, 883, 884, 885, 886, 887, 888, 889, 890, 891, 892, 893, 894, 895, 896, 897, 898, 899, 900, 901, 902, 903, 904, 905, 906, 907, 908, 909, 910, 911, 912, 913, 914, 915, 916, 917, 918, 919, 920, 921, 922, 923, 924, 925, 926, 927, 928, 929, 930, 931, 932, 933, 934, 935, 936, 937, 938, 939, 940, 941, 942, 943, 944, 945, 946, 947, 948, 949, 950, 951, 952, 953, 954, 955, 956, 957, 958, 959, 960, 961, 962, 963, 964, 965, 966, 967, 968, 969, 970, 971, 972, 973, 974, 975, 976, 977, 978, 979, 980 또는 548의 아미노산 서열을 포함하는 단리된 폴리펩티드로서, 상기 폴리펩티드는 하나 이상의 역 펩티드 결합을 포함하는 단리된 폴리펩티드를 제공한다.
본 발명은 또한 서열 번호 541, 550, 554, 555, 556, 623 또는 624의 아미노산 서열을 포함하는 단리된 이종 폴리펩티드로서, 상기 이종 폴리펩티드는 하나 이상의 역 펩티드 결합을 포함하는 단리된 이종 폴리펩티드를 제공한다.
본 발명은 또한 서열 번호 543, 552, 557, 558, 559, 625 또는 626의 아미노산 서열을 포함하는 단리된 이종 폴리펩티드로서, 상기 이종 폴리펩티드는 하나 이상의 역 펩티드 결합을 포함하는 단리된 이종 폴리펩티드를 제공한다.
일부 실시 형태에서, 역 펩티드 결합은 NH-CO 결합을 포함한다.
일부 실시 형태에서, 역 펩티드 결합은 CH2-NH, -CH2S-, -CH2CH2-, -CH=CH-, -COCH2-, -CH(OH)CH2- 또는 -CH2SO- 결합을 포함한다.
본 발명은 또한 서열 번호 1, 3, 5, 7, 9, 11, 13, 15, 17, 19, 21, 23, 25, 27, 29, 31, 33, 35, 37, 39, 41, 43, 45, 47, 49, 51, 53, 55, 57, 59, 61, 63, 65, 67, 69, 71, 73, 75, 77, 79, 81, 83, 85, 87, 89, 91, 93, 95, 97, 99, 101, 103, 105, 107, 109, 111, 113, 115, 117, 119, 121, 123, 125, 127, 129, 131, 133, 135, 137, 139, 141, 143, 145, 147, 149, 151, 153, 155, 157, 159, 161, 163, 165, 167, 169, 171, 173, 175, 177, 179, 181, 183, 185, 187, 189, 191, 193, 195, 197, 199, 201, 203, 205, 207, 209, 211, 213, 215, 217, 219, 221, 223, 225, 227, 229, 231, 233, 235, 237, 239, 241, 243, 245, 247, 249, 251, 253, 255, 257, 259, 261, 263, 265, 267, 269, 271, 273, 275, 277, 279, 281, 283, 285, 287, 289, 291, 293, 295, 297, 299, 301, 303, 305, 307, 309, 311, 313, 315, 317, 319, 321, 323, 325, 327, 329, 331, 333, 335, 337, 339, 341, 343, 345, 347, 349, 351, 353, 355, 357, 359, 361, 363, 365, 367, 369, 371, 373, 375, 379, 381, 383, 385, 387, 388, 389, 390, 391, 392, 393, 394, 395, 396, 397, 398, 399, 400, 401, 402, 403, 404, 405, 406, 407, 408, 426, 427, 428, 429, 430, 431, 432, 433, 434, 435, 436, 437, 438, 439, 440, 441, 442, 443, 444, 445, 446 및 447의 아미노산 서열 및 이들의 단편을 포함하는 단리된 폴리펩티드로서, 상기 폴리펩티드는 하나 이상의 화학적 변형을 포함하는 단리된 폴리펩티드를 제공한다.
본 발명은 또한 서열 번호 387, 388, 389, 390, 391, 392, 393, 394, 395, 396, 397, 398, 399, 400, 401, 402, 403, 404, 405, 406, 407, 408, 560, 561, 562, 563, 564, 565, 566, 567, 568, 569, 570, 571, 572, 573, 574, 575, 576, 577, 578, 579, 580, 581, 582, 583, 584, 585, 586, 587, 588, 589, 590, 591, 592, 593, 594, 595, 596, 597, 598, 599, 600, 601, 602, 603, 604, 605, 606, 607, 608, 609, 610, 611, 612, 613, 614, 615, 616, 617, 618, 619, 620 또는 621의 아미노산 서열을 포함하는 단리된 폴리펩티드로서, 상기 폴리펩티드는 하나 이상의 화학적 변형을 포함하는 단리된 폴리펩티드를 제공한다.
본 발명은 또한 서열 번호 377, 378, 415, 417, 418, 420, 502, 518, 526, 527, 714, 715, 716, 717, 718, 719, 720, 721, 722, 723, 724, 725, 726, 727, 728, 729, 730, 731, 732, 733, 734, 735, 736, 737, 738, 739, 740, 741, 742, 743, 744, 745, 746, 747, 748, 749, 750, 751, 752, 753, 74, 755, 756, 757, 758, 759, 760, 761, 762, 763, 764, 765, 766, 767, 768, 769, 770, 771, 772, 773, 774, 775, 776, 777, 778, 779, 780, 781, 782, 783, 784, 785, 786, 787, 788, 789, 790, 791, 792, 793, 794, 795, 796, 797, 798, 799, 800, 801, 802, 803, 804, 805, 806, 807, 808, 809, 810, 811, 812, 813, 814, 815, 816, 817, 818, 819, 820, 821, 822, 823, 824, 825, 826, 827, 828, 829, 830, 831, 832, 833, 834, 835, 836, 837, 838, 839, 840, 841, 842, 843, 844, 845, 846, 487, 848, 849, 850, 851, 852, 853, 854, 855, 856, 857, 858, 859, 860, 861, 862, 863, 864, 865, 866, 867, 868, 869, 870, 871, 872, 873, 874, 875, 876, 877, 878, 879, 880, 881, 882, 883, 884, 885, 886, 887, 888, 889, 890, 891, 892, 893, 894, 895, 896, 897, 898, 899, 900, 901, 902, 903, 904, 905, 906, 907, 908, 909, 910, 911, 912, 913, 914, 915, 916, 917, 918, 919, 920, 921, 922, 923, 924, 925, 926, 927, 928, 929, 930, 931, 932, 933, 934, 935, 936, 937, 938, 939, 940, 941, 942, 943, 944, 945, 946, 947, 948, 949, 950, 951, 952, 953, 954, 955, 956, 957, 958, 959, 960, 961, 962, 963, 964, 965, 966, 967, 968, 969, 970, 971, 972, 973, 974, 975, 976, 977, 978, 979, 980 또는 548의 아미노산 서열을 포함하는 단리된 폴리펩티드로서, 상기 폴리펩티드는 하나 이상의 화학적 변형을 포함하는 단리된 폴리펩티드를 제공한다.
본 발명은 또한 서열 번호 541, 550, 554, 555, 556, 623 또는 624의 아미노산 서열을 포함하는 단리된 이종 폴리펩티드로서, 상기 이종 폴리펩티드는 하나 이상의 화학적 변형을 포함하는 단리된 이종 폴리펩티드를 제공한다.
본 발명은 또한 서열 번호 543, 552, 557, 558, 559, 625 또는 626의 아미노산 서열을 포함하는 단리된 이종 폴리펩티드로서, 상기 이종 폴리펩티드는 하나 이상의 화학적 변형을 포함하는 단리된 이종 폴리펩티드를 제공한다.
일부 실시 형태에서, 하나 이상의 화학적 변형은 아미노산의 카르보벤족실, 단실, t-부틸옥시카르보닐, 9-플루오레닐메톡시-카르보닐 또는 D 이성질체에 의한 변형을 포함한다.
본 발명의 폴리뉴클레오티드 및 폴리펩티드의 제조 방법
본 발명의 폴리뉴클레오티드 또는 변이체는 클로닝에 의해 얻어지거나 합성에 의해 생성되는 DNA 형태 또는 RNA 형태일 수 있다. DNA는 이중 가닥 또는 단일 가닥일 수 있다.
본 발명의 폴리뉴클레오티드 및 이종 폴리뉴클레오티드 또는 변이체를 생성하는 방법은 당업계에 공지되어 있으며, 화학적 합성, 효소적 합성(예를 들어, 인비트로 전사), 더 긴 전구체의 효소적 또는 화학적 절단, 폴리뉴클레오티드의 더 작은 단편의 화학 합성 후에 단편의 라이게이션 또는 공지된 PCR 방법을 포함한다. 합성될 폴리뉴클레오티드 서열은 원하는 아미노산 서열에 대해 적절한 코돈으로 설계될 수 있다. 일반적으로, 서열이 발현에 사용될 의도된 숙주에 대해 바람직한 코돈이 선택될 수 있다.
본 발명의 폴리펩티드 및 이종 폴리펩티드의 제조 방법은 당업계에 공지되어 있으며, 폴리펩티드의 클로닝 및 발현 및 폴리펩티드의 화학적 합성을 위한 표준 분자 생물학 기술을 포함한다.
펩티드는 루카스(Lukas) 등의 문헌[Lukas et al., 1981] 및 상기 문헌에 인용된 참고문헌에 의해 개시된 고상 펩티드 합성의 Fmoc-폴리아미드 모드에 의해 합성될 수 있다. 일시적 N-아미노기 보호는 9-플루오레닐메틸옥시카르보닐(Fmoc)기에 의해 제공된다. 이러한 고도로 염기 불안정한 보호기의 반복적 절단은 N,N-다이메틸포름아미드 중의 20% 피페리딘을 사용하여 행해진다. 측쇄 작용기는 이의 부틸 에테르(세린 트레오닌 및 타이로신의 경우), 부틸 에스테르(글루탐산 및 아스파르트산의 경우), 부틸옥시카르보닐 유도체(라이신 및 히스티딘의 경우), 트라이틸 유도체(시스테인의 경우) 및 4-메톡시-2,3,6-트라이메틸벤젠설포닐 유도체(아르기닌의 경우)로 보호될 수 있다. 글루타민 또는 아스파라긴이 C 말단 잔기인 경우, 측쇄 아미도 작용기의 보호를 위해 4,4'-다이메톡시벤즈하이드릴기가 사용된다. 고상 지지체는 다이메틸아크릴아미드(골격 단량체), 비스아크릴로일에틸렌 다이아민(가교제) 및 아크릴로일사르코신 메틸 에스테르(작용화제)의 세 가지 단량체로 구성된 폴리다이메틸-아크릴아미드 중합체를 기제로 한다. 사용되는 펩티드-수지 절단가능한 연결제는 산에 불안정한 4-하이드록시메틸-페녹시아세트산 유도체이다. 모든 아미노산 유도체는 역 N,N-다이사이클로헥실-카르보다이이미드/1-하이드록시벤조트라이아졸 매개 커플링 절차를 사용하여 첨가되는 아스파라긴 및 글루타민을 제외하고, 미리 형성된 대칭 무수물 유도체로서 첨가된다. 모든 커플링 및 탈보호 반응은 닌하이드린, 트라이니트로벤젠 설폰산 또는 아이소주석 시험 절차를 사용하여 모니터링된다. 합성 완료 시에, 50% 스캐빈저 믹스를 함유하는 95% 트라이플루오로아세트산으로 처리하여 측쇄 보호기를 동시에 제거하면서 펩티드를 수지 지지체로부터 절단한다. 일반적으로 사용되는 스캐빈저는 에탄다이티올, 페놀, 아니솔 및 물을 포함하며, 정확한 선택은 합성되는 펩티드의 구성 아미노산에 따라 달라진다. 또한, 펩티드의 합성을 위한 고체상 방법과 용액상 방법의 조합이 가능하다(예를 들어, 문헌[Bruckdorfer et al., 2004] 및 상기 문헌에 인용된 참고문헌 참조).
미국 특허 제4,897,445호는 표준 절차에 의해 합성된 폴리펩티드, 및 NaCNBH3의 존재 하에서 아미노 알데히드와 아미노산을 반응시켜 합성된 비펩티드 결합을 포함하는 폴리펩티드 사슬의 비펩티드 결합(-CH2-NH)의 고상 합성 방법을 제공한다.
본 발명의 벡터 및 재조합 바이러스
본 발명은 또한 본 발명의 폴리뉴클레오티드 또는 이종 폴리뉴클레오티드, 또는 이들의 단편 또는 변이체를 포함하는 벡터를 제공한다.
일부 실시 형태에서, 벡터는 발현 벡터이다. 일부 실시 형태에서, 벡터는 바이러스 벡터이다. 본 발명의 벡터는 본 발명의 벡터를 포함하는 재조합 바이러스를 생성하거나, 본 발명의 폴리펩티드를 발현하는데 이용될 수 있다.
본 발명은 또한 서열 번호 1, 3, 5, 7, 9, 11, 13, 15, 17, 19, 21, 23, 25, 27, 29, 31, 33, 35, 37, 39, 41, 43, 45, 47, 49, 51, 53, 55, 57, 59, 61, 63, 65, 67, 69, 71, 73, 75, 77, 79, 81, 83, 85, 87, 89, 91, 93, 95, 97, 99, 101, 103, 105, 107, 109, 111, 113, 115, 117, 119, 121, 123, 125, 127, 129, 131, 133, 135, 137, 139, 141, 143, 145, 147, 149, 151, 153, 155, 157, 159, 161, 163, 165, 167, 169, 171, 173, 175, 177, 179, 181, 183, 185, 187, 189, 191, 193, 195, 197, 199, 201, 203, 205, 207, 209, 211, 213, 215, 217, 219, 221, 223, 225, 227, 229, 231, 233, 235, 237, 239, 241, 243, 245, 247, 249, 251, 253, 255, 257, 259, 261, 263, 265, 267, 269, 271, 273, 275, 277, 279, 281, 283, 285, 287, 289, 291, 293, 295, 297, 299, 301, 303, 305, 307, 309, 311, 313, 315, 317, 319, 321, 323, 325, 327, 329, 331, 333, 335, 337, 339, 341, 343, 345, 347, 349, 351, 353, 355, 357, 359, 361, 363, 365, 367, 369, 371, 373, 375, 379, 381, 383, 385, 387, 388, 389, 390, 391, 392, 393, 394, 395, 396, 397, 398, 399, 400, 401, 402, 403, 404, 405, 406, 407, 408, 426, 427, 428, 429, 430, 431, 432, 433, 434, 435, 436, 437, 438, 439, 440, 441, 442, 443, 444, 445, 446 또는 447 중 하나 이상의 폴리펩티드 또는 이의 단편을 인코딩하는 폴리뉴클레오티드를 포함하는 벡터를 제공한다.
본 발명은 또한 서열 번호 1, 3, 5, 7, 9, 11, 13, 15, 17, 19, 21, 23, 25, 27, 29, 31, 33, 35, 37, 39, 41, 43, 45, 47, 49, 51, 53, 55, 57, 59, 61, 63, 65, 67, 69, 71, 73, 75, 77, 79, 81, 83, 85, 87, 89, 91, 93, 95, 97, 99, 101, 103, 105, 107, 109, 111, 113, 115, 117, 119, 121, 123, 125, 127, 129, 131, 133, 135, 137, 139, 141, 143, 145, 147, 149, 151, 153, 155, 157, 159, 161, 163, 165, 167, 169, 171, 173, 175, 177, 179, 181, 183, 185, 187, 189, 191, 193, 195, 197, 199, 201, 203, 205, 207, 209, 211, 213, 215, 217, 219, 221, 223, 225, 227, 229, 231, 233, 235, 237, 239, 241, 243, 245, 247, 249, 251, 253, 255, 257, 259, 261, 263, 265, 267, 269, 271, 273, 275, 277, 279, 281, 283, 285, 287, 289, 291, 293, 295, 297, 299, 301, 303, 305, 307, 309, 311, 313, 315, 317, 319, 321, 323, 325, 327, 329, 331, 333, 335, 337, 339, 341, 343, 345, 347, 349, 351, 353, 355, 357, 359, 361, 363, 365, 367, 369, 371, 373, 375, 379, 381, 383, 385, 387, 388, 389, 390, 391, 392, 393, 394, 395, 396, 397, 398, 399, 400, 401, 402, 403, 404, 405, 406, 407, 408, 426, 427, 428, 429, 430, 431, 432, 433, 434, 435, 436, 437, 438, 439, 440, 441, 442, 443, 444, 445, 446 또는 447의 폴리펩티드와 약 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% 또는 99% 동일한 폴리펩티드 또는 이의 단편을 인코딩하는 폴리뉴클레오티드를 포함하는 벡터를 제공한다.
본 발명은 또한 서열 번호 2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26, 28, 30, 32, 34, 36, 38, 40, 42, 44, 46, 48, 50, 52, 54, 56, 58, 60, 62, 64, 66, 68, 70, 72, 74, 76, 78, 80, 82, 84, 86, 88, 90, 92, 94, 96, 98, 100, 102, 104, 106, 108, 110, 112, 114, 116, 118, 120, 122, 124, 126, 128, 130, 132, 134, 136, 138, 140, 142, 144, 146, 148, 150, 152, 154, 156, 158, 160, 162, 164, 166, 168, 170, 172, 174, 176, 178, 180, 182, 184, 186, 188, 190, 192, 194, 196, 198, 200, 202, 204, 206, 208, 210, 212, 214, 216, 218, 220, 222, 224, 226, 228, 230, 232, 234, 236, 238, 240, 242, 244, 246, 248, 250, 252, 254, 256, 258, 260, 262, 264, 266, 268, 270, 272, 274, 276, 278, 280, 282, 284, 286, 288, 290, 292, 294, 296, 298, 300, 302, 304, 306, 308, 310, 312, 314, 316, 318, 320, 322, 324, 326, 328, 330, 332, 334, 336, 338, 340, 342, 344, 346, 348, 350, 352, 354, 356, 358, 360, 362, 364, 366, 368, 370, 372, 374, 376, 380, 382, 384, 386, 448, 449, 450, 451, 452, 453, 454, 455, 456, 457 또는 458 중 하나 이상의 폴리뉴클레오티드 또는 이의 단편을 포함하는 벡터를 제공한다.
본 발명은 또한 서열 번호 2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26, 28, 30, 32, 34, 36, 38, 40, 42, 44, 46, 48, 50, 52, 54, 56, 58, 60, 62, 64, 66, 68, 70, 72, 74, 76, 78, 80, 82, 84, 86, 88, 90, 92, 94, 96, 98, 100, 102, 104, 106, 108, 110, 112, 114, 116, 118, 120, 122, 124, 126, 128, 130, 132, 134, 136, 138, 140, 142, 144, 146, 148, 150, 152, 154, 156, 158, 160, 162, 164, 166, 168, 170, 172, 174, 176, 178, 180, 182, 184, 186, 188, 190, 192, 194, 196, 198, 200, 202, 204, 206, 208, 210, 212, 214, 216, 218, 220, 222, 224, 226, 228, 230, 232, 234, 236, 238, 240, 242, 244, 246, 248, 250, 252, 254, 256, 258, 260, 262, 264, 266, 268, 270, 272, 274, 276, 278, 280, 282, 284, 286, 288, 290, 292, 294, 296, 298, 300, 302, 304, 306, 308, 310, 312, 314, 316, 318, 320, 322, 324, 326, 328, 330, 332, 334, 336, 338, 340, 342, 344, 346, 348, 350, 352, 354, 356, 358, 360, 362, 364, 366, 368, 370, 372, 374, 376, 380, 382, 384, 386, 448, 449, 450, 451, 452, 453, 454, 455, 456, 457 또는 458의 폴리뉴클레오티드와 약 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% 또는 99% 동일한 폴리뉴클레오티드 또는 이의 단편을 포함하는 벡터를 제공한다.
본 발명은 또한 서열 번호 1, 3, 5, 7, 9, 11, 13, 15, 17, 19, 21, 23, 25, 27, 29, 31, 33, 35, 37, 39, 41, 43, 45, 47, 49, 51, 53, 55, 57, 59, 61, 63, 65, 67, 69, 71, 73, 75, 77, 79, 81, 83, 85, 87, 89, 91, 93, 95, 97, 99, 101, 103, 105, 107, 109, 111, 113, 115, 117, 119, 121, 123, 125, 127, 129, 131, 133, 135, 137, 139, 141, 143, 145, 147, 149, 151, 153, 155, 157, 159, 161, 163, 165, 167, 169, 171, 173, 175, 177, 179, 181, 183, 185, 187, 189, 191, 193, 195, 197, 199, 201, 203, 205, 207, 209, 211, 213, 215, 217, 219, 221, 223, 225, 227, 229, 231, 233, 235, 237, 239, 241, 243, 245, 247, 249, 251, 253, 255, 257, 259, 261, 263, 265, 267, 269, 271, 273, 275, 277, 279, 281, 283, 285, 287, 289, 291, 293, 295, 297, 299, 301, 303, 305, 307, 309, 311, 313, 315, 317, 319, 321, 323, 325, 327, 329, 331, 333, 335, 337, 339, 341, 343, 345, 347, 349, 351, 353, 355, 357, 359, 361, 363, 365, 367, 369, 371, 373, 375, 379, 381, 383, 385, 387, 388, 389, 390, 391, 392, 393, 394, 395, 396, 397, 398, 399, 400, 401, 402, 403, 404, 405, 406, 407, 408, 426, 427, 428, 429, 430, 431, 432, 433, 434, 435, 436, 437, 438, 439, 440, 441, 442, 443, 444, 445, 446 및 447로 이루어진 군으로부터 선택되는 2개 이상의 폴리펩티드 및 이들의 단편을 포함하는 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 벡터를 제공한다.
본 발명은 또한 서열 번호 2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26, 28, 30, 32, 34, 36, 38, 40, 42, 44, 46, 48, 50, 52, 54, 56, 58, 60, 62, 64, 66, 68, 70, 72, 74, 76, 78, 80, 82, 84, 86, 88, 90, 92, 94, 96, 98, 100, 102, 104, 106, 108, 110, 112, 114, 116, 118, 120, 122, 124, 126, 128, 130, 132, 134, 136, 138, 140, 142, 144, 146, 148, 150, 152, 154, 156, 158, 160, 162, 164, 166, 168, 170, 172, 174, 176, 178, 180, 182, 184, 186, 188, 190, 192, 194, 196, 198, 200, 202, 204, 206, 208, 210, 212, 214, 216, 218, 220, 222, 224, 226, 228, 230, 232, 234, 236, 238, 240, 242, 244, 246, 248, 250, 252, 254, 256, 258, 260, 262, 264, 266, 268, 270, 272, 274, 276, 278, 280, 282, 284, 286, 288, 290, 292, 294, 296, 298, 300, 302, 304, 306, 308, 310, 312, 314, 316, 318, 320, 322, 324, 326, 328, 330, 332, 334, 336, 338, 340, 342, 344, 346, 348, 350, 352, 354, 356, 358, 360, 362, 364, 366, 368, 370, 372, 374, 376, 380, 382, 384, 386, 448, 449, 450, 451, 452, 453, 454, 455, 456, 457 및 458로 이루어진 군으로부터 선택되는 2개 이상의 폴리뉴클레오티드 및 이들의 단편을 포함하는 이종 폴리뉴클레오티드를 포함하는 벡터를 제공한다.
본 발명은 또한 서열 번호 275, 381, 333, 337, 269, 253, 309, 325, 271, 305, 251, 245, 261, 265, 317, 255, 277, 297, 285, 437, 439, 442, 444, 379, 343, 211, 349, 213, 215, 221, 219, 225, 345, 353, 235, 223, 167, 171, 19, 23 및 177로 이루어진 군으로부터 선택되는 2개 이상의 폴리펩티드 및 이들의 단편을 포함하는 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 벡터를 제공한다.
본 발명은 또한 서열 번호 459, 460, 461, 462, 463, 464, 465, 466, 467, 468, 469, 470, 471, 472, 473, 474, 475, 476, 477, 478, 479, 480, 481, 482, 483, 484, 485, 486, 487, 488, 489, 490, 491, 492, 493, 494, 495, 496, 497, 498 및 499로 이루어진 군으로부터 선택되는 2개 이상의 폴리뉴클레오티드 및 이들의 단편을 포함하는 이종 폴리뉴클레오티드를 포함하는 벡터를 제공한다.
본 발명은 또한 서열 번호 500, 501, 461, 503, 504, 505, 506, 507, 508, 509, 510, 511, 512, 513, 514, 515, 516, 517, 477, 519, 520, 521, 522, 523, 524, 525, 485, 486, 528, 529, 530, 531, 532, 533, 534, 535, 536, 537, 538, 539 및 540으로 이루어진 군으로부터 선택되는 2개 이상의 폴리뉴클레오티드 및 이들의 단편을 포함하는 이종 폴리뉴클레오티드를 포함하는 벡터를 제공한다.
본 발명은 또한 본 발명의 벡터를 포함하는 재조합 바이러스를 제공한다. 본 발명은 또한 본 발명의 벡터를 포함하는 재조합 아데노바이러스를 제공한다.
본 발명은 또한 본 발명의 벡터를 포함하는 재조합 인간 아데노바이러스(rAd)를 제공한다.
본 발명은 또한 본 발명의 벡터를 포함하는 혈청형 26(rAd26)으로부터 유래된 재조합 인간 아데노바이러스를 제공한다.
본 발명은 또한 본 발명의 벡터를 포함하는 재조합 유인원 아데노바이러스(rGAd)를 제공한다.
일부 실시 형태에서, rGAd는 GAd20로부터 유래된다. 일부 실시 형태에서, rGAd는 GAd19으로부터 유래된다. 일부 실시 형태에서, rGAd는 GAd21으로부터 유래된다. 일부 실시 형태에서, rGAd는 GAd25로부터 유래된다. 일부 실시 형태에서, rGAd는 GAd26로부터 유래된다. 일부 실시 형태에서, rGAd는 GAd27으로부터 유래된다. 일부 실시 형태에서, rGAd는 GAd28으로부터 유래된다. 일부 실시 형태에서, rGAd는 GAd29으로부터 유래된다. 일부 실시 형태에서, rGAd는 GAd30로부터 유래된다. 일부 실시 형태에서, rGAd는 GAd31으로부터 유래된다. GAd19-21 및 GAd25-31은 국제 특허 공개 제WO2019/008111호에 기재되어 있으며, 일반 인간 집단에서 면역원성이 높고 기존의 면역이 없는 균주를 나타낸다 GAd20 게놈의 폴리뉴클레오티드 서열은 국제 특허 공개 제WO2019/008111호에 개시된 바와 같이 서열 번호 622로 나타나 있다.
서열 번호 622
CATCATCAATAATATACCTTATTTTGGATTGAGGCCAATATGATAATGAGGTGGGCGGGGCGAGGCGGGGCGGGTGACGTAGGACGCGCGAGTAGGGTTGGGAGGTGTGGCGGAAGTGTGGCATTTGCAAGTGGGAGGAGCTGACATGCAATCTTCCGTCGCGGAAAATGTGACGTTTTTGATGAGCGCCGCCTACCTCCGGAAGTGCCAATTTTCGCGCGCTTTTCACCGGATATCGTAGTAATTTTGGGCGGGACCATGTAAGATTTGGCCATTTTCGCGCGAAAAGTGAAACGGGGAAGTGAAAACTGAATAATAGGGCGTTAGTCATAGCGCGTAATATTTACCGAGGGCCGAGGGACTTTGACCGATTACGTGGAGGACTCGCCCAGGTGTTTTTTACGTGAATTTCCGCGTTCCGGGTCAAAGTCTCCGTTTTTATTGTCGCCGTCATCTGACGCGGAGGGTATTTAAACCCGCTGCGCTCCTAAAGAGGCCACTCTTGAGTGCCAGCGAGAAGAGTTTTCTCCTCCGCTCCGTTTCGGCGATCGAAAAATGAGACATTTAGCCTGCACTCCGGGTCTTTTGTCCGGCCGGGCGGCGTCCGAGCTTTTGGACGCTTTGCTCAATGAGGTTCTGAGCGATGATTTTCCGTCTACTACCCACTTTAGCCCACCTACTCTTCACGAACTGTACGATCTGGATGTACTGGTGGATGTGAACGATCCCAACGAGGAGGCGGTTTCTACGTTTTTTCCCGAGTCTGCGCTTTTGGCTGCCCAGGAGGGATTTGACCTACACACTCCGCCGCTGCCTATTTTAGAGTCTCCGCTGCCGGAGCCCAGTGGTATACCTTATATGCCTGAACTGCTTCCCGAAGTGGTAGACCTGACCTGCCACGAGCCGGGCTTTCCGCCCAGCGACGATGAGGGTGAGCCTTTTGCTTTAGACTATGCTGAGATACCTGGGCTCGGTTGCAGGTCTTGTGCATATCATCAGAGGGTTACCGGAGACCCCGAGGTTAAGTGTTCGCTGTGCTATATGAGGCTGACCTCTTCCTTTATCTACAGTAAGTTTTTTTGTGTAGGTGGGCTTTTTGGGTAGGTGGGTTTTGTGGCAGGACAGGTGTAAATGTTGCTTGTGTTTTTTGTACCTGCAGGTCCGGTGTCCGAGCCAGACCCGGAGCCCGACCGCGATCCCGAGCCGGATCCCGAGCCTCCTCGCAGGCCAAGGAAATTACCTTCCATTTTGTGCAAGCCTAAGACACCTGTGAGGACCAGCGAGGCGGACAGCACTGACTCTGGCACTTCTACCTCTCCTCCTGAAATTCACCCAGTGGTTCCTCTGGGTATACATAGACCTGTTGCTGTTAGAGTTTGCGGGCGACGCCCTGCAGTAGAGTGCATTGAGGACTTGCTTAACGATCCCGAGGGACCTTTGGACTTGAGCATTAAACGCCCTAGGCAATAAACCCCACCTAAGTAATAAACCCCACCTAAGTAATAAACTTTACCGCCCTTGGTTATTGAGATGACGCCCAATGTTTGCTTTTGAATGACTTCATGTGTATAATAAAAGTGAGTGTGGTCATAGGTCTCTTGTTTGTCTGGGCGGGGTTTAAGGGTATATAAGTTTCTCGGGGCTAAACTTGGTTACACTTGACCCCAATGGAGGCGTGGGGGTGCTTGGAGGAGTTTGCGGACGTGCGCCGTTTGCTGGACGAGAGCTCTAGCAATACCTATAGTATTTGGAGGTATCTGTGGGGCTCTACTCAGGCCAAGTTGGTCTTCAGAATTAAGCAGGATTACAAGTGCGATTTTGAAGAGCTTTTTAGTTCCTGTGGTGAGCTTTTGCAATCCTTGAATCTGGGCCACCAGGCTATCTTCCAGGAAAAGGTTCTCTCGACTTTGGATTTTTCCACTCCCGGGCGCACCGCCGCTTGTGTGGCTTTTGTGTCTTTTGTGCAAGATAAATGGAGCGGGGAGACCCACCTGAGTCACGGCTACGTGCTGGATTTCATGGCGATGGCTCTTTGGAGGGCTTACAACAAATGGAAGATTCAGAAGGAACTGTACGGTTCCGCCCTACGTCGTCCACTTCTGCAGCGGCAGGGGCTGATGTTTCCCGACCATCGCCAGCATCAGAATCTGGAAGACGAGCGAGCGGAGAAGATCAGCTTGAGAGCCGGCCTGGACCCTCCTCAGGAGGAATGAATCTCCCGCAGGTGGTTGAGCTGTTTCCCGAACTGAGACGGGTCCTGACTATCAGGGAGGATGGTCAGTTTGTGAAGAAGCTGAAGAGGGATCGGGGTGAGGGAGATGATGAGGCGGCTAGCAATTTAGCTTTTAGTCTGATAACTCGCCACCGACCGGAATGTATTACCTATCAGCAGATTAAGGAGAGTTGTGCCAACGAGCTGGATCTTTTGGGTCAGAAGTATAGCATAGAACAGCTTACCACTTACTGGCTTCAGCCCGGGGATGATTGGGAAGAGGCGATTAGGGTGTATGCAAAGGTGGCCCTGCGGCCCGATTGCAAGTATAAGATTACTAAGTTGGTTAATATTAGAAACTGCTGCTATATTTCTGGAAACGGGGCCGAAGTGGAGATAGATACTGAGGACAGGGTGGCTATTAGGTGTTGCATGATAAACATGTGGCCCGGGATACTGGGGATGGATGGGGTGATATTTATGAATGTGAGGTTCACGGGCCCCAACTTTAATGGTACGGTGTTCATGGGCAACACCAACTTGCTCCTGCATGGTGCGAGTTTCTATGGGTTTAACAACACCTGTATAGAGGCCTGGACCGATGTAAAGGTTCGAGGTTGTTCCTTTTATAGCTGTTGGAAGGCGGTGGTGTGTCGCCCTAAAAGCAGGGGTTCTGTGAAGAAATGCTTGTTTGAAAGGTGCACCCTAGGTATCCTTTCTGAGGGCAACTCCAGGGTGCGCCATAATGTGGCTTCGAACTGCGGTTGCTTCATGCAAGTGAAGGGGGTGAGCGTTATCAAGCATAACTCGGTCTGTGGAAACTGCGAGGATCGCGCCTCTCAGATGCTGACCTGCTTTGATGGCAACTGTCACCTGTTGAAGACCATTCATATAAGCAGTCACCCCAGAAAGGCCTGGCCCGTGTTTGAGCATAACATTCTGACCCGCTGTTCCTTGCATCTGGGGGTCAGGAGGGGTATGTTCCTGCCTTACCAGTGTAACTTTAGCCACACTAAAATCCTGCTGGAACCCGAGTGCATGACTAAGGTCAGCCTGAATGGTGTGTTTGATGTGAGTCTGAAGATTTGGAAGGTGCTGAGGTATGATGAGACCAGGACCAGGTGCCGACCCTGCGAGTGCGGCGGCAAGCACATGAGAAATCAGCCTGTGATGTTGGATGTGACCGAGGAGCTTAGGCCTGACCATCTGGTGCTGGCCTGCACCAGGGCCGAGTTTGGGTCTAGCGATGAGGATACCGATTGAGGTGGGTAAGGTGGGCGTGGCTAGCAGGGTGGGCGTGTATAAATTGGGGGTCTAAGGGGTCTCTCTGTTTGTCTTGCAACAGCCGCCGCCATGAGCGACACCGGCAACAGCTTTGATGGAAGCATCTTTAGTCCCTATCTGACAGTGCGCATGCCTCACTGGGCCGGAGTGCGTCAGAATGTGATGGGTTCCAACGTGGATGGACGTCCCGTTCTGCCTTCAAATTCGTCTACTATGGCCTACGCGACCGTGGGAGGAACTCCGCTGGACGCCGCGACCTCCGCCGCCGCCTCCGCCGCCGCCGCGACCGCGCGCAGCATGGCTACGGACCTTTACAGCTCTTTGGTGGCGAGCAGCGCGGCCTCTCGCGCGTCTGCTCGGGATGAGAAACTGACTGCTCTGCTGCTTAAACTGGAAGACTTGACCCGGGAGCTGGGTCAACTGACCCAGCAGGTTTCCAGCTTGCGTGAGAGCAGCCTTGCCTCCCCCTAATGGCCCATAATATAAATAAAAGCCAGTCTGTTTGGATTAAGCAAGTGTATGTTCTTTATTTAACTCTCCGCGCGCGGTAAGCCCGGGACCAGCGGTCTCGGTCGTTTAGGGTGCGGTGGATTTTTTCCAACACGTGGTACAGGTGGCTCTGGATGTTTAGATACATGGGCATGAGTCCATCCCTGGGGTGGAGGTAGCACCACTGCAGAGCTTCGTGCTCGGGGGTGGTGTTGTATATGATCCAGTCGTAGCAGGAGCGCTGGGCGTGGTGCTGAAAAATGTCCTTAAGCAAGAGGCTTATAGCTAGGGGGAGGCCCTTGGTGTAAGTGTTTACAAATCTGCTTAGCTGGGAGGGGTGCATCCGGGGGGATATGATGTGCATCTTGGACTGGATTTTTAGGTTGGCTATGTTCCCGCCCAGATCCCTTCTGGGATTCATGTTGTGCAGGACCACCAGCACGGTATATCCAGTGCACTTGGGAAATTTATCGTGGAGCTTAGACGGGAATGCATGGAAGAACTTGGAGACGCCCTTGTGGCCTCCCAGATTTTCCATACATTCGTCCATGATGATGGCAATGGGCCCGTGGGAAGCTGCCTGAGCAAAAACGTTTCTGGCATCGCTCACATCGTAGTTATGTTCCAGGGTGAGGTCATCATAGGACATCTTTACGAATCGGGGGCGAAGGGTCCCGGACTGGGGGATGATGGTACCCTCGGGCCCCGGGGCGTAGTTCCCCTCACAGATCTGCATCTCCCAGGCTTTCATTTCAGAGGGAGGGATCATATCCACCTGCGGGGCGATGAAAAAGACAGTTTCTGGCGCAGGGGAGATTAACTGGGATGAGAGCAGGTTTCTGAGCAGCTGTGACTTTCCACAGCCGGTGGGCCCATATATCACGCCTATCACCGGCTGCAGCTGGTAGTTAAGAGAGCTGCAGCTGCCGTCCTCCCGGAGCAGGGGGGCCACCTCGTTGAGCATATCCCTGACGTGGATGTTCTCCCTGACCAGTTCCGCCAGAAGGCGCTCGCCGCCCAGCGAAAGCAGCTCTTGCAAGGAAGCAAAATTTTTCAGCGGTTTCAGGCCATCGGCCGTGGGCATGTTTTTCAGCGTCTGGGTCAGCAGCTCCAGCCTGTCCCAGAGCTCGGTGATGTGCTCTACGGCATCTCGATCCAGCAGATCTCCTCGTTTCGCGGGTTGGGGCGGCTTTCGCTGTAGGGCACCAGCCGATGGGCGTCCAGCGGGGCCAGAGTCATGTCCTTCCATGGGCGCAGGGTCCTCGTCAGGGTGGTCTGGGTCACGGTGAAGGGGTGCGCTCCGGGTTGGGCACTGGCCAGGGTGCGCTTGAGGCTGGTTCTGCTGGTGCTGAATCGCTGCCGCTCTTCGCCCTGCGCGTCGGCCAGGTAGCATTTGACCATGGTCTCGTAGTCGAGACCCTCGGCGGCGTGCCCCTTGGCGCGGAGCTTTCCCTTGGAGGTGGCGCCGCACGAGGGGCACTGCAGGCTCTTCAGGGCGTAGAGCTTGGGAGCGAGAAACACGGACTCTGGGGAGTAGGCGTCCGCGCCGCAGGCCGAGCAGACCGTCTCGCATTCCACCAGCCAAGTGAGTTCCGGGCGGTCAGGGTCAAAAACCAGGTTGCCCCCATGCTTTTTGATGCGTTTCTTACCTTGGCTCTCCATGAGGCGGTGTCCCTTCTCGGTGACGAAGAGGCTGTCCGTGTCCCCGTAGACCGACTTCAGGGGCCTGTCTTCCAGCGGAGTGCCTCTGTCCTCCTCGTAGAGAAACTCTGACCACTCTGAGACGAAGGCCCGCGTCCAGGCCAGGACGAAGGAGGCCACGTGGGAGGGGTAGCGGTCGTTGTCCACTAGCGGGTCCACCTTCTCCAGGGTGTGCAGGCACATGTCCCCCTCCTCCGCGTCCAGAAAAGTGATTGGCTTGTAGGTGTAGGACACGTGACCGGGGGTTCCCAACGGGGGGGTATAAAAGGGGGTGGGTGCCCTTTCATCTTCACTCTCTTCCGCATCGCTGTCTGCGAGAGCCAGCTGCTGGGGTAAGTATTCCCTCTCGAAGGCGGGCATGACCTCAGCGCTCAGGTTGTCAGTTTCTAAAAATGAGGAGGATTTGATGTTCACCTGTCCGGAGGTGATACCTTTGAGGGTACCTGGGTCCATCTGGTCAGAAAACACTATTTTTTTGTTATCAAGCTTGGTGGCGAATGACCCGTAGAGGGCGTTGGAGAGCAGCTTGGCGATGGAGCGCAGGGTCTGGTTTTTGTCGCGGTCGGCTCGCTCCTTGGCCGCGATGTTGAGTTGCACGTACTCGCGGGCCACGCACTTCCACTCGGGGAACACGGTGGTGCGCTCGTCTGGGATCAGGCGCACCCTCCAGCCGCGGTTGTGCAGGGTGACCATGTCGACGCTGGTGGCGACCTCACCGCGCAGACGCTCGTTGGTCCAGCAGAGGCGGCCGCCCTTGCGCGAGCAGAAGGGGGGTAGGGGGTCCAGCTGGTCCTCGTTTGGGGGGTCCGCGTCGATGGTAAAGACCCCGGGGAGCAGGCGCGGGTCAAAGTAGTCGATCTTGCAAGCTTGCATGTCCAGAGCCCGCTGCCATTCGCGGGCGGCGAGCGCGCGCTCGTAGGGGTTGAGGGGCGGGCCCCAGGGCATGGGGTGGGTGAGCGCGGAGGCGTACATGCCGCAGATGTCATACACGTACAGGGGTTCCCTGAGGATACCGAGGTAGGTGGGGTAGCAGCGCCCCCCGCGGATGCTGGCGCGCACGTAGTCATAGAGCTCGTGGGAGGGGGCCAGCATGTTGGGCCCGAGGTTGGTGCGCTGGGGGCGCTCGGCGCGGAAGACGATCTGCCTGAAGATGGCGTGGGAGTTGGAGGAGATGGTGGGCCGCTGGAAGACGTTGAAGCTTGCTTCTTGCAAGCCCACGGAGTCCCTGACGAAGGAGGCGTAGGACTCGCGCAGCTTGTGCACCAGCTCGGCGGTGACCTGGACGTCGAGCGCACAGTAGTCGAGGGTCTCGCGGATGATGTCATACCTATCCTCCCCCTTCTTTTTCCACAGCTCGCGGTTGAGGACGAACTCTTCGCGGTCTTTCCAGTACTCTTGGAGGGGAAACCCGTCCGTGTCCGAACGGTAAGAGCCTAGCATGTAGAACTGGTTGACGGCCTGGTAGGGGCAGCAGCCCTTCTCCACGGGCAGCGCGTAGGCCTGCGCCGCCTTGCGGAGGGAGGTGTGGGTGAGGGCGAAAGTGTCCCTGACCATGACTTTGAGGTATTGATGTCTGAAGTCTGTGTCATCGCAGCCGCCCTGTTCCCACAGGGTGTAGTCCGTGCGCTTTTTGGAGCGCGGGTTGGGCAGGGAGAAGGTGAGGTCATTGAAGAGGATCTTCCCCGCTCGAGGCATGAAGTTTCTGGTGATGCGAAAGGGCCCTGGGACCGAGGAGCGGTTGTTGATGACCTGGGCGGCCAGGACGATCTCGTCAAAGCCGTTTATGTTGTGTCCCACGATGTAGAGCTCCAGGAAGCGGGGCTGGCCCTTGATGGAGGGGAGCTTTTTAAGTTCCTCGTAGGTAAGCTCCTCGGGCGATTCCAGGCCGTGCTCCTCCAGGGCCCAGTCTTGCAAGTGAGGGTTGGCCGCCAGGAAGGATCGCCAGAGGTCGCGGGCCATGAGGGTCTGCAGGCGGTCGCGGAAGGTTCTGAACTGCCGCCCCACGGCCATTTTTTCGGGGGTGATGCAGTAGAAGGTGAGGGGGTCTTTCTCCCAGGGGTCCCATCTGAGCTCTCGGGCGAGGTCGCGCGCGGCAGCGACCAGAGCCTCGTCGCCCCCCAGTTTCATGACCAGCATGAAGGGCACGAGTTGCTTGCCAAAGGCTCCCATCCAAGTGTAGGTTTCTACATCGTAGGTGACAAAGAGGCGCTCCGTGCGAGGATGAGAGCCGATTGGGAAGAACTGGATCTCCCGCCACCAGTTGGAGGATTGGCTGTTGATGTGGTGAAAGTAGAAGTCCCGTCTGCGGGCCGAGCACTCGTGCTGGCTTTTGTAAAAGCGACCGCAGTACTGGCAGCGCTGCACGGGTTGTATATCTTGCACGAGGTGAACCTGGCGACCTCTGACGAGGAAGCGCAGCGGGAATCTAAGTCCCCCGCCTGGGGTCCCGTGTGGCTGGTGGTCTTTTACTTTGGTTGTCTGGCCGCCAGCATCTGTCTCCTGGAGGGCGATGGTGGAACAGACCACCACGCCGCGAGAGCCGCAGGTCCAGATCTCGGCGCTCGGCGGGCGGAGTTTGATGACGACATCGCGCACATTGGAGCTGTCCATGGTCTCCAGCTCCCGCGGCGGCAGGTCAGCCGGGAGTTCCTGGAGGTTCACCTCGCAGAGACGGGTCAAGGCGCGGACAGTGTTGAGATGGTATCTGATTTCAAGGGGCATGTTGGAGGCGGAGTCGATGGCTTGCAGGAGGCCGCAGCCCCGGGGGGCCACGATGGTTCCCCGCGGGGCGCGAGGGGAGGCGGAAGCTGGGGGTGTGTTCAGAAGCGGTGACGCGGGCGGGCCCCCGGAGGTAGGGGGGGTTCCGGCCCCACAGGCATGGGCGGCAGGGGCACGTCTTCGCCGCGCGCGGGCAGGGGCTGGTGCTGGCTCCGAAGAGCGCTTGCGTGCGCGACGACGCGACGGTTGGTGTCCTGTATCTGGCGCCTCTGAGTGAAGACCACGGGTCCCGTGACCTTGAACCTGAAAGAGAGTTCGACAGAATCAATCTCGGCATCGTTGACAGCGGCCTGGCGCAGGATCTCCTGCACGTCGCCCGAGTTGTCCTGGTAGGCGATTTCTGCCATGAACTGCTCGATCTCTTCCTCCTGGAGATCTCCTCGTCCGGCGCGCTCCACGGTGGCCGCCAGGTCGTTGGAGATGCGACCCATGAGCTGCGAGAAGGCGTTGAGTCCGCCCTCGTTCCAGACCCGGCTGTAGACCACGCCCCCCTCGGCGTCGCGGGCGCGCATGACCACCTGGGCCAGGTTGAGCTCCACGTGTCGCGTGAAGACGGCGTAGTTGCGCAGGCGCTGGAAAAGGTAGTTCAGGGTGGTGGCGGTGTGCTCGGCGACGAAGAAGTACATGACCCAGCGCCGCAACGTGGATTCATTGATGTCCCCCAAGGCCTCCAGGCGCTCCATGGCCTCGTAGAAGTCCACGGCGAAGTTGAAAAACTGGGAGTTGCGAGCGGACACGGTCAACTCCTCCTCCAGAAGACGGATGAGCTCGGCGACAGTGTCGCGCACCTCGCGCTCGAAGGCCACGGGGGGCGCTTCTTCCTCTTCCACCTCTTCTTCCATGATTGCTTCTTCTTCTTCCTCAGCCGGGACGGGAGGGGGCGGCGGCGGGGGAGGGGCGCGGCGGCGGCGGCGGCGCACCGGGAGGCGGTCGATGAAGCGCTCGATCATCTCCCCCCGCATGCGGCGCATGGTCTCGGTGACGGCGCGGCCGTTCTCCCGGGGGCGCAGCTCGAAGACGCCGCCTCTCATTTCGCCGCGGGGCGGGCGGCCGTGAGGTAGCGAGACGGCGCTGACTATGCATCTTAACAATTGCTGTGTAGGTACGCCGCCAAGGGACCTGATTGAGTCCAGATCCACCGGATCCGAAAACCTTTGGAGGAAAGCGTCTATCCAGTCGCAGTCGCAAGGTAGGCTGAGCACCGTGGCGGGCGGGGGCGGGTCGGGAGAGTTCCTGGCGGAGATGCTGCTGATGATGTAATTAAAGTAGGCGGTCTTGAGAAGGCGGATGGTGGACAGGAGCACCATGTCTTTGGGTCCGGCCTGTTGGATGCGGAGGCGGTCGGCCATGCCCCAGGCCTCGTTCTGACACCGGCGCAGGTCTTTGTAGTAATCTTGCATGAGTCTTTCCACCGGCACTTCTTCTCCTTCCTCTTCTTCATCTCGCCGGTGGTTTCTCGCGCCGCCCATGCGCGTGACCCCAAAGCCCCTGAGCGGCTGCAGCAGGGCCAGGTCGGCGACCACGCGCTCGGCCAAGATGGCCTGCTGTACCTGAGTGAGGGTCCTCTCGAAGTCATCCATGTCCACGAAGCGGTGGTAGGCACCCGTGTTGATGGTGTAGGTGCAGTTGGCCATGACGGACCAGTTGACGGTCTGGTGTCCCGGCTGCGAGAGCTCCGTGTACCGCAGGCGCGAGAAGGCGCGGGAATCGAACACGTAGTCGTTGCAAGTCCGCACCAGATACTGGTAGCCCACCAGGAAGTGCGGCGGAGGTTGGCGATAGAGGGGCCAGCGCTGGGTGGCGGGGGCGCCGGGCGCCAGGTCTTCCAGCATGAGGCGGTGGTATCCGTAGATGTACCTGGACATCCAGGTGATGCCTGCGGCGGTGGTGGTGGCGCGCGCGTAGTCGCGGACCCGGTTCCAGATGTTTCGCAGGGGCGAGAAGTGTTCCATGGTCGGCACGCTCTGGCCGGTGAGGCGCGCGCAGTCGTTGACGCTCTATACACACACAAAAACGAAAGCGTTTACAGGGCTTTCGTTCTGTAGCCTGGAGGAAAGTAAATGGGTTGGGTTGCGGTGTGCCCCGGTTCGAGACCAAGCTGAGCTCAGCCGGCTGAAGCCGCAGCTAACGTGGTATTGGCAGTCCCGTCTCGACCCAGGCCCTGTATCCTCCAGGATACGGTCGAGAGCCCTTTTGCTTTCTTGGCCAAGCGCCCGTGGCGCGATCTGGGATAGATGGTCGCGATGAGAGGACAAAAGCGGCTCGCTTCCGTAGTCTGGAGAAACAATCGCCAGGGTTGCGTTGCGGCGTACCCCGGTTCGAGCCCCTATGGCGGCTTGGATCGGCCGGAACCGCGGCTAACGTGGGCTGTGGCAGCCCCGTCCTCAGGACCCCGCCAGCCGACTTCTCCAGTTACGGGAGCGAGCCCCTTTTGTTTTTTTATTTTTTAGATGCATCCCGTGCTGCGGCAGATGCGCCCCTCGCCCCGGCCCGATCAGCAGCAGCAACAGCAGGCATGCAGACCCCCCTCTCCTCTCCCCGCCCCGGTCACCACGGCCGCGGCGGCCGTGTCCGGTGCGGGGGGCGCGCTGGAGTCAGATGAGCCACCGCGGCGGCGACCTAGGCAGTATCTGGACTTGGAAGAGGGCGAGGGACTGGCGCGGCTGGGGGCGAGCTCTCCAGAGCGCCACCCGCGGGTGCAGTTGAAAAGGGACGCGCGTGAGGCGTACCTGCCGCGGCAAAACCTGTTTCGCGACCGCGGGGGCGAGGAGCCCGAGGAGATGCGGGACTGCAGGTTCCAAGCGGGGCGCGAGCTGCGCCGCGGCTTGGACAGACAGCGCCTGCTGCGCGAGGAGGACTTTGAGCCCGACACGCAGACGGGCATCAGCCCCGCGCGCGCGCACGTGGCCGCGGCCGACCTGGTGACCGCCTACGAGCAGACGGTGAACCAGGAGCGCAACTTCCAAAAAAGCTTCAACAACCACGTGCGCACGCTGGTGGCGCGCGAGGAGGTGACCCTGGGTCTCATGCATCTGTGGGACCTGGTGGAGGCGATCGTGCAGAACCCCAGCAGCAAGCCCCTGACCGCGCAGCTGTTCCTGGTGGTGCAGCACAGCAGGGACAACGAGGCCTTCAGGGAGGCGCTGCTGAACATCACCGAGCCGGAGGGGCGCTGGCTCCTGGACCTGATAAACATCCTGCAGAGCATAGTGGTGCAGGAGCGCAGCCTGAGCCTGGCCGAGAAGGTGGCGGCCATTAACTATTCTATGCTGAGCCTGGGCAAGTTCTACGCTCGCAAGATCTACAAGACCCCCTACGTGCCCATAGACAAGGAGGTGAAGATAGACAGCTTCTACATGCGCATGGCGCTGAAGGTGCTAACCCTGAGCGACGACCTGGGAGTGTACCGCAACGAGCGCATCCACAAGGCCGTGAGCGCCAGCCGGCGGCGCGAGCTGAGCGACCGCGAACTGATGCACAGTCTGCAGCGCGCGCTGACCGGCGCGGGCGAGGGCGACAGGGAGGTCGAGTCCTACTTTGACATGGGGGCCGACCTGCACTGGCAGCCGAGCCGCCGCGCCCTGGAAGCGGCGGGGGCGTACGGCGGCCCCCTGGCGGCCGATGACGAGGAAGAGGAGGACTATGAGCTAGAGGAGGGCGAGTACCTGGAGGACTGACCTGGCTGGTGGTGTTTTGGTATAGATGCAAGATCCGAACGTGGCGGACCCGGCGGTCCGGGCGGCGCTGCAGAGCCAGCCGTCCGGCATTAACTCCTCTGACGACTGGGCCGCGGCCATGGGTCGCATCATGGCCCTGACCGCGCGCAACCCCGAGGCCTTCAGGCAGCAGCCTCAGGCTAACCGGCTGGCGGCCATCTTGGAAGCGGTAGTGCCCGCGCGCTCCAACCCCACCCACGAGAAGGTGCTGGCCATAGTCAACGCGCTGGCGGAGAGCAGGGCCATCCGGGCAGACGAGGCCGGACTGGTGTACGATGCGCTGCTGCAGCGGGTGGCGCGGTACAACAGCGGCAACGTGCAGACCAACCTGGACCGCCTGGTGACGGACGTGCGCGAGGCCGTGGCGCAGCGCGAGCGCTTGCATCAGGACGGCAACCTGGGCTCGCTGGTGGCGCTAAACGCCTTCCTTAGCACCCAGCCGGCCAACGTACCGCGGGGGCAGGAGGACTACACCAACTTCTTGAGCGCGCTGCGGCTGATGGTGACCGAGGTCCCTCAGAGCGAGGTGTACCAGTCGGGGCCCGACTACTTCTTCCAGACCAGCAGACAGGGCTTGCAAACCGTGAACCTGAGCCAGGCTTTCAAGAACCTGCGGGGGCTGTGGGGAGTGAAGGCGCCCACCGGCGACCGGGCTACGGTGTCCAGCCTGCTAACCCCCAACTCGCGCCTGCTGCTGCTGCTGATCGCGCCCTTCACGGACAGCGGGAGCGTCTCGCGGGAGACCTATCTGGGCCACCTGCTGACGCTGTACCGCGAGGCCATCGGGCAGGCGCAGGTGGACGAGCACACCTTCCAGGAGATCACCAGCGTGAGCCACGCGCTGGGGCAGGAGGACACGGGCAGCCTGCAGGCGACCCTGAACTACCTGCTGACCAACAGGCGGCAGAAGATTCCCACGCTGCACAGCCTGACCCAGGAGGAGGAGCGCATCTTGCGCTACGTGCAGCAGAGCGTGAGCCTGAACCTGATGCGCGACGGCGTGACGCCCAGCGTGGCGCTGGACATGACCGCGCGCAACATGGAACCGGGCATGTACGCTTCCCAGCGGCCGTTCATCAACCGCCTGATGGACTACTTGCATCGGGCGGCGGCCGTGAACCCCGAGTACTTCACCAATGCCATTCTGAATCCCCACTGGATGCCCCCTCCGGGTTTCTACAACGGGGACTTCGAGGTGCCTGAGGTCAACGATGGGTTCCTCTGGGATGACATGGATGACAGTGTGTTCTCCCCCAACCCGCTGCGCGCCGCGTCTCTGCGATTGAAGGAGGGCTCTGACAGGGAAGGACCAAGGAGTCTGGCCTCCTCCCTGGCTCTGGGGGCGGTGGGCGCCACGGGCGCGGCGGCGCGGGGCAGCAGCCCCTTCCCCAGCCTGGCGGACTCTCTGAATAGCGGGCGGGTGAGCAGGCCCCGCTTGCTAGGCGAGGAGGAGTATCTGAACAACTCCCTGCTGCAGCCCGTGAGGGACAAAAACGCTCAGCGGCAGCAGTTTCCCAACAATGGGATAGAGAGCCTGGTGGACAAGATGTCCAGATGGAAGACGTATGCGCAGGAGTACAAGGAGTGGGAGGACCGCCAGCCGCGGCCCCTGCCGCCCCCTAGACAGCGCTGGCAGCGGCGCGCGTCCAACCGCCGCTGGAGGCAGGGGCCCGAGGACGATGATGACTCTGCAGATGACAGCAGCGTGTTGGACCTGGGCGGGAGCGGGAACCCCTTTTCGCACCTGCGCCCACGCCTGGGCAAGATGTTTTAAAAGAGAAAAATAAAAACTCACCAAGGCCATGGCGACGAGCGTTGGTTTTTTGTTCCCTTCCTTAGTATGCGGCGCGCGGCGATGTTCGAGGAGGGGCCTCCCCCCTCTTACGAGAGCGCGATGGGAATTTCTCCTGCGGCGCCCCTGCAGCCTCCCTACGTGCCTCCTCGGTACCTGCAACCTACAGGGGGGAGAAATAGCATCTGTTACTCTGAGCTGCAGCCCCTGTACGATACCACCAGACTGTACCTGGTGGACAACAAGTCCGCGGACGTGGCCTCCCTGAACTACCAGAACGACCACAGCGATTTTTTGACCACGGTGATCCAAAACAACGACTTCACCCCAACCGAGGCCAGTACCCAGACCATAAACCTGGACAACAGGTCGAACTGGGGCGGCGACCTGAAGACTATCCTGCACACCAATATGCCCAACGTGAACGAGTTCATGTTCACCAACTCTTTTAAGGCGCGGGTGATGGTGGCGCGCGAGCAGGGGGAGGCGAAGTACGAGTGGGTGGACTTCACGCTGCCCGAGGGCAACTACTCAGAGACCATGACTCTCGACCTGATGAACAATGCGATCGTGGAACACTATCTGAAAGTGGGCAGGCAGAACGGGGTGAAGGAGAGCGATATCGGGGTCAAGTTTGACACCAGAAACTTCCGTCTGGGCTGGGACCCTGTGACCGGGCTGGTCATGCCGGGGGTCTACACCAACGAGGCCTTTCATCCCGATATAGTGCTCCTGCCCGGCTGTGGGGTGGACTTCACCCAGAGCCGGCTGAGCAACCTGCTGGGCGTTCGCAAGCGGCAACCTTTCCAGGAGGGTTTCAAGATCACCTATGAGGATCTGGAGGGGGGCAACATTCCCGCGCTCCTTGATCTGGACGCCTACGAGGAGAGCTTGAAACCCGAGGAGAGCGCTGGCGACAGCGGCGAGAGTGGCGAGGAGCAAGCCGGCGGCGGCGGCAGCGCGTCGGTAGAAAACGAAAGTACTCCCGCAGTGGCGGCGGACGCTGCGGAGGTCGAGCCGGAGGCCATGCAGCAGGACGCAGAGGAGGGCGCGCAGGAGGACATGAACAATGGGGAGATCAGGGGCGACACTTTCGCCACCCGGGGCGAAGAAAAAGAGGCAGAGGCGGCGGCGGCGACGGCGGAAGCCGAAACCGAGGCAGAGGCAGAGCCCGAGACCGAAGTTATGGAAGACATGAATGATGGAGAACGTAGGGGTGACACGTTTGCCACCCGGGGCGAAGAGAAGGCGGCGGAGGCAGAAGCCGCGGCTGAGGAGGCGGCTGCGGCTGCGGCCAAGGCTGAGGCTGCGGCTGAGGCTAAGGTCGAAGCCGATGTTGCGGTTGAGGCTCAGGCTGAGGAGGAGGCGGCGGCTGAAGCAGTTAAGGAAAAGGCCCAGGCAGAGCAGGAAGAGAAAAAACCTGTCATTCAACCTCTAAAAGAAGATAGCAAAAAGCGCAGTTACAACGTCATTGAGGGCAGCACCTTTACCCAATACCGCAGCTGGTACCTGGCTTACAACTACGGCGACCCGGTCAAGGGGGTGCGCTCGTGGACCCTGCTCTGCACGCCGGACGTCACCTGCGGCTCCGAGCAGATGTACTGGTCGCTGCCAAACATGATGCAAGACCCGGTGACCTTCCGTTCCACGCGGCAGGTTAGCAACTTTCCGGTGGTGGGCGCCGAACTGCTGCCAGTACACTCCAAGAGTTTTTACAACGAGCAGGCCGTCTACTCCCAGCTGATCCGCCAGGCCACCTCTCTGACCCACGTGTTCAATCGCTTTCCCGAGAACCAGATTTTGGCGCGCCCGCCGGCCCCCACCATCACCACCGTCAGTGAAAACGTTCCTGCCCTCACAGATCACGGGACGCTACCGCTGCGCAACAGCATCTCAGGAGTCCAGCGAGTGACCATTACTGACGCCAGACGCCGGACCTGCCCCTACGTTTACAAGGCCTTGGGCATAGTCTCGCCGCGCGTCCTCTCCAGTCGCACTTTTTAAAACACATCCACCCACACGCTCCAAAATCATGTCCGTACTCATCTCGCCCAGCAACAACACCGGCTGGGGGCTGCGCGCACCCAGCAAGATGTTTGGAGGGGCAAGGAAGCGCTCCGACCAGCACCCCGTGCGCGTGCGCGGCCACTACCGCGCGCCCTGGGGTGCGCACAAGCGCGGGCGCACAGGGCGCACCACTGTGGATGATGTCATTGACTCCGTAGTGGAGCAGGCGCGCCACTACACACCCGGCGCGCCGACCGCCTCCGCCGTGTCCACCGTGGACCAGGCGATCGAAAGCGTGGTACAGGGGGCGCGGCACTATGCCAACCTTAAAAGTCGCCGCCGCCGCGTGGCGCGCCGCCATCGCCGGAGACCCCGGGCTACTGCCGCCGCGCGCCTTACCAAGGCTCTGCTCAAGCGCGCCAGGCGAACTGGCCACCGGGCCGCCATGAGGGCCGCACGGCGGGCTGCCGCTGCCGCGAGCGCCGTGGCCCCGCGGGCACGAAGGCGCGCGGCCGCTGCCGCCGCCGCCGCCATTTCCAGCTTGGCCTCGACGCGGCGCGGTAACATATACTGGGTGCGCGACTCGGTGAGCGGCACACGTGTGCCCGTGCGCTTTCGCCCCCCACGGAATTAGCACAAGACAACATACACACTGAGTCTCCTGCTGTTGTGTATCCCAGCGGCGACCGTCAGCAGCGGCGACATGTCCAAGCGCAAAATTAAAGAAGAGATGCTCCAGGTCATCGCGCCGGAGATCTATGGGCCCCCGAAGAAGGAGGAGGAGGATTACAAGCCCCGCAAGCTAAAGCGGGTCAAAAAGAAAAAGAAAGATGATGACGTTGACGAGGCGGTGGAGTTTGTCCGCCGCATGGCGCCCAGGCGCCCTGTGCAGTGGAAGGGTCGGCGCGTGCAGCGAGTCCTGCGCCCCGGCACCGCGGTGGTCTTTACGCCCGGCGAGCGTTCCACGCGCACTTTCAAGCGGGTGTACGATGAGGTGTACGGCGACGAGGATCTGTTGGAGCAGGCCAACCATCGATTTGGGGAGTTTGCATATGGGAAACGGCCTCGCGAGAGTCTAAAAGAGGACCTGCTGGCGCTACCGCTGGACGAGGGCAATCCCACCCCGAGTCTGAAGCCGGTGACCCTGCAACAGGTGCTGCCTTTGAGCGCGCCCAGCGAGCAGAAGCGAGGGTTAAAGCGCGAGGGCGGGGACCTGGCACCCACCGTGCAGTTGATGGTGCCCAAGCGGCAGAAGCTGGAGGACGTGCTGGAGAAAATGAAAGTAGAGCCCGGGATCCAGCCCGAGATCAAGGTCCGCCCTATCAAGCAGGTGGCGCCCGGCGTGGGAGTCCAGACCGTGGACGTTAGGATTCCCACGGAGGAGATGGAAACCCAAACCGCCACTCCCTCTTCGGCAGCAAGCGCCACCACCGGCGCCGCTTCGGTAGAGGTGCAGACGGACCCCTGGCTACCCGCCGCCACTATCGCCGTCGCCGCCGCCCCCCGTTCGCGCGGACGCAAGAGAAATTATCCAGCGGCCAGCGCGCTTATGCCCCAGTATGCGCTGCATCCATCCATCGCGCCCACCCCCGGCTACCGCGGGTACTCGTACCGCCCGCGCAGATCAGCCGGCACTCGCGGCCGCCGCCGCCGTGCGACCACAACCAGCCGCCGCCGTCGCCGCCGCCGCCAGCCAGTGCTGACCCCCGTGTCTGTAAGGAAGGTGGCTCGCTCGGGGAGCACGCTGGTGGTGCCCAGAGCGCGCTACCACCCCAGCATCGTTTAAAGCCGGTCTCTGTATGGTTCTTGCAGATATGGCCCTCACTTGTCGCCTTCGCTTCCCGGTGCCGGGATACCGAGGAAGAACTCACCGCCGCAGGGGCATGGCGGGCAGCGGTCTCCGCGGCGGCCGTCGCCATCGCCGGCGCGCAAAGAGCAGGCGCATGCGCGGCGGTGTGTTGCCCCTGCTGGTCCCGCTACTCGCCGCGGCGATCGGCGCCGTGCCCGGGATCGCCTCCGTGGCCCTGCAGGCGTCCCAGAAACATTGACTCTTGCAACCTTGCAAGCTTGCATTTTTGGAGGAAAAAATAAAAAAGTCTAGACTCTCACGCTCGCTTGGTCCTGTGACTATTTTGTAGAAAAAAGATGGAAGACATCAACTTTGCGTCGCTGGCCCCGCGTCACGGCTCGCGCCCGTTCATGGGAGACTGGACAGATATCGGCACCAGCAATATGAGCGGTGGCGCCTTCAGCTGGGGCAGTCTGTGGAGCGGCCTTAAAAATTTTGGTTCCACCATTAAGAACTATGGCAACAAAGCGTGGAACAGCAGCACGGGTCAGATGCTGAGAGACAAGTTGAAAGAGCAGAACTTCCAGGAGAAGGTGGCGCAGGGCCTGGCCTCTGGCATCAGCGGGGTGGTGGACATAGCTAACCAGGCCGTGCAGAAAAAGATAAACAGTCATCTGGACCCCCGCCCTCAGGTGGAGGAAACGCCTCCAGCCATGGAGACGGTGTCTCCCGAGGGCAAAGGCGAAAAGCGCCCGCGGCCCGACAGGGAAGAGACCCTGGTGTCACACACCGAGGAGCCGCCCTCTTACGAGGAGGCAGTCAAGGCCGGCCTGCCCACCACTCGCCCCATAGCTCCCATGGCCACCGGTGTGGTGGGTCACAGGCAACACACCCCCGCAACACTAGATCTGCCCCCGCCGTCCGAGCCGACTCGCCAGCCAAAGGCGGTGACGGTGTCCGCTCCCTCCACTTCCGCCGCCAACAGAGTGCCTCTGCGCCGCGCTGCGAGCGGCCCCCGGGCCTCGCGAGTCAGCGGCAACTGGCAGAGCACACTGAACAGCATCGTGGGCCTGGGAGTGAGGAGTGTGAAGCGCCGCCGTTGCTACTGAATGAGCAAGCTAGCTAACGTGTTGTATGTGTGTATGCGTCCTATGTCGCCGCCAGAGGAGCTGTTGAGCCGCCGGCGCCGTCTGCACTCCAGCGAATTTCAAGATGGCGACCCCATCGATGATGCCTCAGTGGTCGTACATGCACATCTCGGGCCAGGACGCTTCGGAGTACCTGAGCCCCGGGCTGGTGCAGTTCGCCCGCGCCACAGACACCTACTTCAACATGAGTAACAAGTTCAGGAACCCCACTGTGGCGCCCACCCACGATGTGACCACGGACCGGTCGCAGCGCCTGACGCTGCGGTTCATCCCCGTGGATCGGGAGGACACCGCTTACTCTTACAAGGCGCGGTTCACGCTGGCCGTGGGCGACAACCGCGTGCTGGACATGGCCTCCACTTACTTTGACATCCGGGGGGTGCTGGACAGGGGCCCCACTTTTAAGCCCTACTCGGGCACTGCCTACAACCCCCTGGCCCCCAAGGGCGCCCCCAATTCTTGTGAGTGGGAACAAGAGGAAAATCAGGTGGTCGCTGCAGATGATGAACTTGAAGATGAAGAAGCGCAAGCACAAGAGGAAGCCCCTGTGAAAAAAATTCATGTATATGCTCAGGCGCCTCTTTCTGGCGAAAAGATTTCCAAGGATGGTATCCAAATAGGTACTGAAGTCGTAGGAGATACATCTAAGGACACTTTTGCAGATAAAACATTCCAACCCGAACCTCAGATAGGCGAGTCTCAGTGGAACGAGGCTGATGCCACAGCAGCAGGAGGTAGAGTTTTGAAAAAGACTACCCCTATGAGACCTTGCTATGGATCCTATGCCAGGCCTACCAATGCCAACGGGGGTCAAGGAATTATGGTTGCCAATGAACAAGGAGTGTTGGAGTCTAAAGTAGAAATGCAATTTTTCTCTAACACCACAACCCTTAATGCGCGGGATGGAACCGGCAATCCCGAACCAAAGGTGGTGTTGTACAGCGAAGATGTCCACTTGGAATCTCCCGATACTCATCTGTCTTACAAGCCCAAAAAGGATGATGTTAATGCCAAAATCATGTTGGGTCAGCAAGCCATGCCCAACAGACCCAACCTCATTGGATTTAGAGATAATTTCATTGGGCTTATGTTTTACAACAGCACCGGTAACATGGGAGTGCTGGCGGGTCAGGCCTCTCAGTTGAATGCTGTGGTGGACTTGCAGGATAGAAACACAGAACTGTCATATCAGCTTCTGCTTGATTCAATTGGGGATAGAACCAGATACTTCTCCATGTGGAACCAGGCAGTGGATAGCTATGATCCAGATGTCAGAATTATTGAAAACCATGGGACTGAGGATGAACTGCCCAACTACTGCTTCCCTTTGGGCGGCATAGGAGTTACTGATACTTATCAAGGGATAAAAAATACCAATGGCAATGGTCAGTGGACCAAAGATGATCAGTTCGCGGACCGCAACGAAATAGGGGTGGGAAACAACTTCGCCATGGAGATCAACATCCAGGCCAACCTTTGGAGAAACTTCCTCTATGCAAACGTGGGGCTCTACCTGCCAGACAAGCTCAAGTACAACCCCACCAACGTGGACATCTCTGACAACCCCAACACCTATGACTACATGAACAAGCGGGTGGTGGCCCCTGGCCTGGTGGACTGCTTTGTCAATGTGGGAGCCAGGTGGTCCCTGGACTACATGGACAACGTCAACCCCTTCAACCACCACCGCAATGCGGGTCTGCGCTACCGCTCCATGATCCTGGGCAACGGGCGCTATGTGCCCTTTCACATCCAGGTACCCCAGAAGTTCTTTGCCATCAAGAACCTCCTGCTCCTGCCCGGCTCCTACACCTACGAGTGGAACTTCAGGAAGGATGTGAACATGGTCCTACAGAGCTCTCTGGGCAATGACCTTAGGGTGGATGGGGCCAGCATCAAGTTTGACAGCATCACCCTCTATGCTACATTTTTCCCCATGGCCCACAACACCGCCTCCACGCTTGAGGCCATGCTGAGAAACGACACCAACGACCAGTCCTTTAATGACTACCTCTCTGGGGCCAACATGCTCTACCCAATCCCAGCCAAGGCCACCAACGTGCCCATCTCCATCCCCTCTCGCAACTGGGCCGCCTTTAGAGGCTGGGCCTTTACCCGCCTTAAGACCAAGGAGACCCCCTCCCTGGGCTCGGGTTTTGATCCCTACTTTGTTTACTCGGGATCCATCCCCTACCTGGATGGCACCTTCTACCTCAACCACACTTTCAAGAAGATATCCATCATGTATGACTCCTCCGTCAGCTGGCCGGGCAACGACCGCTTGCTCACCCCCAATGAGTTCGAGGTCAAGCGCGCCGTGGACGGCGAGGGCTACAACGTGGCCCAGTGCAACATGACCAAGGACTGGTTCCTGGTGCAGATGCTGGCCAACTACAACATAGGCTACCAGGGCTTTTACATCCCAGAGAGCTACAAGGACAGGATGTACTCCTTCTTCAGAAATTTCCAACCCATGAGCCGACAGGTGGTGGACGAGACCAATTACAAGGACTATCAAGCCATTGGCATCACCCACCAGCACAACAACTCGGGTTTCGTGGGCTACCTGGCGCCCACCATGCGCGAGGGTCAGGCCTACCCCGCCAACTTCCCCTACCCCTTGATAGGCAAGACCGCGGTCGACAGCGTCACCCAGAAAAAGTTCCTCTGCGACCGCACCCTCTGGCGCATCCCCTTCTCTAGCAACTTCATGTCCATGGGTGCGCTCACGGACCTGGGCCAAAACCTGCTTTATGCCAACTCTGCCCATGCGCTGGACATGACTTTTGAGGTGGACCCCATGGACGAGCCCACCCTTCTCTATATTGTGTTTGAAGTGTTCGACGTGGTCAGAGTGCACCAGCCGCACCGCGGTGTCATCGAGACCGTGTACCTGCGTACGCCCTTCTCAGCCGGCAACGCCACCACCTAAGGAGACAGCGCCGCCGCCGCCTGCATGACGGGTTCCACCGAGCAAGAGCTCAGGGCCATTGCCAGAGACCTGGGATGCGGACCCTATTTTTTGGGCACCTATGACAAACGCTTCCCGGGCTTTATCTCCCGAGACAAGCTCGCCTGCGCCATTGTCAACACGGCCGCGCGCGAGACCGGGGGCGTGCACTGGCTGGCCTTTGGCTGGGACCCGCGCTCCAAAACTTGCTACCTCTTTGACCCCTTTGGCTTCTCCGATCAGCGCCTCAGGCAGATTTATGAGTTTGAGTACGAGGGGCTGCTGCGCCGCAGCGCGCTCGCCTCCTCGCCCGACCGCTGCATCACCCTTGAGAAGTCCACCGAAACCGTGCAGGGGCCCCACTCGGCCGCCTGCGGTCTCTTCTGTTGCATGTTTTTGCACGCCTTTGTGCACTGGCCTCAGAGTCCCATGGATTGCAACCCCACCATGAACTTGCTAAAGGGAGTGCCCAACGCCATGCTCCAGAGCCCCCAGGTCCAGCCCACCCTGCGCCGCAACCAGGAACAGCTTTACCGCTTCCTGGAGCGCCACTCCCCCTACTTCCGCAGCCACAGCGCGCGCATCCGGGGGGCCACCTCTTTTTGCCACTTGCAAGAAAACATGCAAGACGGAAAATGATGTACAGCATGCTTTTAATAAATGTAAAGACTGTGCACTTTAATTATACACGGGCTCTTTCTGGTTATTTATTCAACACCGCCGTCGCCATTTAGAAATCGAAAGGGTTCTGCCGTGCGTCGCCGTGCGCCACGGGCAGAGACACGTTGCGATACTGGAAGCGGCTCGCCCACTTGAACTCGGGCACCACCATGCGGGGCAGTGGTTCCTCGGGGAAGTTCTCGCTCCACAGGGTGCGGGTCAGCTGCAGCGCGCTCAGGAGGTCGGGAGCCGAGATCTTGAAGTCGCAGTTGGGGCCGGAACCCTGCGCGCGCGAGTTGCGGTACACGGGGTTGCAGCACTGGAACACCAGCAGGGCCGGATTATTCACGCTGGCCAGCAGGCTCTCGTCGCTGATCATGTCGCTGTCCAGATCCTCCGCGTTGCTCAGGGCGAATGGGGTCATCTTGCAGACCTGCCTGCCCAGGAAAGGCGGGAGCCCAGGCTTGCCGTTGCAGTCGCAGCGCAGGGGCATTAGCAGGTGCCCACGGCCCGACTGCGCCTGCGGGTACAACGCGCGCATGAAGGCTTCGATCTGCCTAAAAGCCACCTGGGTCTTGGCTCCCTCCGAAAAGAACATCCCACAGGACTTGCTGGAGAACTGGTTCGCGGGACAGCTGGCATCGTGCAGGCAGCAGCGCGCGTCAGTGTTGGCAATCTGCACCACGTTGCGACCCCACCGGTTTTTCACTATCTTGGCCTTGGAAGCCTGCTCCTTTAGCGCGCGCTGGCCGTTCTCGCTGGTCACATCCATCTCTATCACCTGTTCCTTGTTGATCATGTTTGTCCCGTGCAGACACTTTAGGTCGCCCTCCGTCTGGGTGCAGCGGTGCTCCCACAGCGCGCAACCGGTGGGCTCCCAATTCTTGTGGGTCACCCCCGCGTAGGCCTGCAGGTAGGCCTGCAGGAAGCGCCCCATCATGGTCATAAAGGTCTTCTGGCTCGTAAAGGTCAGCTGCAGGCCGCGATGCTCTTCGTTCAGCCAGGTCTTGCAGATGGCGGCCAGCGCCTCGGTCTGCTCGGGCAGCATCTTAAAATTTGTCTTCAGGTCGTTATCCACGTGGTACTTGTCCATCATGGCACGCGCCGCCTCCATGCCCTTCTCCCAGGCGGACACCATGGGCAGGCTTAGGGGGTTTATCACTTCCAGCGGCGAGGACACCGTACTTTCGATTTCTTCTTCCTCCCCCTCTTCCCGGCGCGCGCCCCCGCTGTTGCGCGCTCTTACCGCCTGCACCAAGGGGTCGTCTTCAGGCAAGCGCCGCACCGAGCGCTTGCCGCCCTTGACCTGCTTGATCAGTACCGGCGGGTTGCTGAAGCCCACCATGGTCAGCGCCGCCTGCTCTTCTTCGTCTTCGCTGTCTACCACTATTTCTGGGGAGGGGCTTCTCCGCTCTGCGGCAAAGGCGGCGGATCGCTTCTTTTTTTTCTTGGGAGCCGCCGCGATGGAGTCCGCCACGGCGACCGAGGTCGAGGGCGTGGGGCTGGGGGTGCGCGGTACCAGGGCCTCGTCGCCCTCGGACTCTTCCTCTGACTCCAGGCGGCGGCGGAGTCGCTTCTTTGGGGGCGCGCGCGTCAGCGGCGGCGGAGACGGGGACGGGGACGGGGACGGGACGCCCTCCACAGGGGGTGGTCTTCGCGCAGACCCGCGGCCGCGCTCGGGGGTCTTCTCGCGCTGGTCTTGGTCCCGACTGGCCATTGTATCCTCCTCCTCCTAGGCAGAGAGACATAAGGAGTCTATCATGCAAGTCGAGAAGGAGGAGAGCTTAACCACCCCCTCAGAGACCGCCGATGCGCCCGCCGTCGCCGTCGCCCCCGCTACCGCCGACGCGCCCGCCACACCGAGCGACACCCCCACGGACCCCCCCGCCGACGCACCCCTGTTCGAGGAAGCGGCCGTGGAGCAGGACCCGGGCTTTGTCTCGGCAGAGGAGGATTTGCAAGAGGAGGAGAATAAGGAGGAGAAGCCCTCAGTGCCAAAAGATCATAAAGAGCAAGACGAGCACGACGCAGACGCACACCAGGGTGAAGTCGGGCGGGGGGACGGAGGGCATGGCGGCGCCGACTACCTAGACGAAGGAAACGACGTGCTCTTGAAGCACCTGCATCGTCAGTGCGCCATCGTCTGCGACGCTCTGCAGGAGCGCAGCGAGGTGCCCCTCAGCGTGGCGGAGGTCAGCCGCGCCTACGAGCTCAGCCTCTTTTCCCCCCGGGTGCCCCCCCGCCGCCGCGAAAACGGCACATGCGAGCCCAACCCGCGCCTCAACTTCTACCCCGCCTTTGTGGTGCCCGAGGTCCTGGCCACCTATCACATCTTCTTTCAAAATTGCAAGATCCCCATCTCGTGCCGCGCCAACCGTAGCCGCGCCGATAAGATGCTGGCCCTGCGCCAGGGCGACCACATACCTGATATCGCCGCTTTGGAAGATGTGCCAAAGATCTTCGAGGGTCTGGGGCGCAACGAGAAGCGGGCAGCAAACTCTCTGCAACAGGAAAACAGCGAAAATGAGAGTCACACTGGAGCGCTGGTGGAGCTGGAGGGCGACAACGCCCGCCTGGCGGTGCTCAAGCGCAGCATCGAGGTCACCCACTTTGCCTACCCCGCGCTCAACCTGCCCCCCAAAGTCATGAACGCGGTCATGGACGGGCTGATCATGCGCCGCGGCCGGCCCCTCGCTCCAGATGCAAACTTGCATGAGGAGACCGAGGACGGTCAGCCCGTGGTCAGCGACGAGCAGCTGACGCGCTGGCTGGAGAGCGCGGACCCCGCCGAACTGGAGGAGCGGCGCAAGATGATGATGGCCGCGGTGCTGGTCACCGTAGAGCTGGAGTGTCTGCAGCGCTTCTTCGGTGACCCCGAGATGCAGAGAAAGGTCGAGGAGACCCTACACTACACCTTCCGCCAGGGCTACGTGCGCCAGGCTTGCAAGATCTCCAACGTGGAGCTCAGCAACCTGGTGTCCTACCTGGGCATCTTGCATGAAAACCGCCTTGGGCAGAGCGTGCTACACTCCACCCTGCGCGGGGAGGCGCGCCGCGACTACGTGCGCGACTGCGTTTACCTCTTCCTCTGCTACACCTGGCAGACGGCCATGGGGGTCTGGCAGCAGTGCCTGGAGGAGCGCAACCTCAAGGAGCTGGAGAAGCTTCTGCAGCGCGCGCTCAAAGACCTCTGGACGGGCTTCAACGAGCGCTCGGTGGCCGCCGCGCTAGCCGACCTCATCTTCCCCGAGCGCCTGCTCAAAACCCTCCAGCAGGGGCTGCCCGACTTCACCAGCCAAAGCATGTTGCAAAATTTTAGGAACTTTATCCTGGAGCGTTCTGGCATCCTACCCGCCACCTGCTGCGCCCTGCCCAGCGACTTTGTCCCCCTCGTGTACCGCGAGTGCCCCCCGCCGCTGTGGGGCCACTGCTACCTGTTCCAACTGGCCAACTACCTGTCCTACCACGCGGACCTCATGGAGGACTCCAGCGGCGAGGGGCTCATGGAGTGCCACTGCCGCTGCAACCTCTGCACGCCCCACCGCTCCCTGGTCTGCAACACCCAACTGCTCAGCGAGAGTCAGATTATCGGTACCTTCGAGCTACAGGGTCCGTCCTCCTCAGACGAGAAGTCCGCGGCTCCGGGGCTAAAACTCACTCCGGGGCTGTGGACTTCCGCCTACCTGCGCAAATTTGTACCTGAAGACTACCACGCCCACGAAATCAGGTTTTACGAGGACCAATCCCGCCCGCCCAAGGCGGAGCTGACCGCCTGCGTCATCACCCAGGGCGAGATCCTAGGCCAATTGCAAGCCATCCAAAAAGCCCGCCAAGAGTTTTTGCTGAAGAGGGGTCGGGGGGTGTATCTGGACCCCCAGTCGGGTGAGGAGCTCAACCCGGTTCCCCCGCTGCCACCGCCGCGGGACCTTGCTTCCCAGGATAAGCATCGCCATGGCTCCCAGAAAGAAGCAGCAGCGGCCGCCGCTGCCGCCGCCCCACATGCTGGAGGAAGAGGAGGAATACTGGGACAGTCAGGCAGAGGAGGTTTCGGACGAGGAGGAGCCGGAGACGGAGATGGAAGAGTGGGAGGAGGACAGCTTAGACGAGGAGGCTTCCGAAGCCGAAGAGGCAGGCGCAACACCGTCACCCTCGGCCGCAGCCCCCTCGCAGGCGCCCCCGAAGTCCGCTCCCAGCATCAGCAGCAACAGCAGCGCTATAACCTCCGCTCCTCCACCGCCGCGACCCACGGCCGACCGCAGACCCAACCGTAGATGGGACACCACCGGAACCGGGGCCGGTAAGTCCTCCGGGAGAGGCAAGCAAGCGCAGCGCCAAGGCTACCGCTCGTGGCGCGCTCACAAGAACGCCATAGTCGCTTGCTTGCAAGACTGCGGGGGGAACATCTCCTTCGCCCGCCGCTTCCTGCTCTTCCACCACGGTGTGGCCTTCCCCCGTAACGTCCTGCATTACTACCGTCATCTCTACAGCCCCTACTGCGGCGGCAGTGAGCCAGAGGCGGCCAGCGGCGGCGGCGCCCGTTTCGGTGCCTAGGAAGACCCAGGGCAAGACTTCAGCCAAGAAACTCGCGGCGACCGCGGCGAACGCGGTCGCGGGGGCCCTGCGCCTGACGGTGAACGAACCCCTGTCGACCCGCGAACTGAGGAACCGAATCTTCCCCACTCTCTATGCCATCTTCCAGCAGAGCAGAGGGCAGGATCAGGAACTGAAAGTAAAAAACAGGTCTCTGCGCTCCCTCACCCGCAGCTGTCTGTATCACAAGAGCGAAGACCAGCTTCGGCGCACGCTGGAGGACGCTGAGGCACTCTTCAGCAAATACTGCGCGCTCACTCTTAAGGACTAGCTCCGCGCCCTTCTCGAATTTAGGCGGGAACGCCTACGTCATCGCAGCGCCGCCGTCATGAGCAAGGACATTCCCACGCCATACATGTGGAGCTATCAGCCGCAGATGGGACTCGCGGCGGGCGCCTCCCAAGACTACTCCACCCGCATGAACTGGCTCAGTGCCGGCCCACACATGATCTCACAGGTTAATGACATCCGCACCCATCGAAACCAAATATTGGTGAAGCAGGCGGCAATTACCACCACGCCCCGCAATAATCCCAACCCCAGGGAGTGGCCCGCGTCCCTGGTGTATCAGGAAATTCCCGGCCCCACCACCGTACTACTTCCGCGTGATTCCCAGGCCGAAGTCCAAATGACTAACTCAGGGGCACAGCTCGCGGGCGGCTGTCGTCACAGGGTGCGGCCTCCTCGCCAGGGTATAACTCACCTGGAGATCCGAGGCAGAGGTATTCAGCTCAACGACGAGTCGGTGAGCTCCTCGCTCGGTCTCAGACCTGACGGGACCTTCCAGATAGCCGGAGCCGGCCGATCTTCCTTCACGCCCCGCCAGGCGTACCTGACTCTGCAGAGCTCGTCCTCGGCGCCGCGCTCGGGCGGCATCGGGACTCTCCAGTTCGTGCAGGAGTTTGTGCCCTCGGTCTACTTCAACCCCTTCTCGGGCTCTCCCGGTCGCTACCCGGACCAGTTTATCCCGAACTTTGACGCCGCGAGGGACTCGGTGGACGGCTACGACTGAATGTCGGGTGGACCCGGTGCAGAGCAACTTCGCCTGAAGCACCTTGACCACTGCCGCCGCCCTCAGTGCTTTGCCCGCTGTCAGACCGGTGAGTTCCAGTACTTTTCCCTGCCCGACTCGCACCCGGACGGCCCGGCGCACGGGGTGCGCTTTTTCATCCCGAGTCAGGTCCGCTCTACCCTAATCAGGGAGTTCACCGCCCGTCCCCTACTGGCGGAGTTGGAAAAGGGGCCTTCTATCCTAACCATTGCCTGCATTTGCTCTAACCCTGGATTACACCAAGATCTTTGCTGTCATTTGTGTGCTGAGTATAATAAAGGCTGAGATCAGAATCTACTCGGGCTCCTGTCGCCATCCTGTCAACGCCACCGTCCAAGCCCGGCCCGATCAGCCCGAGGTGAACCTCACCTGTGGTCTGCACCGGCGCCTGAGGAAATACCTAGCTTGGTACTACAACAGCACTCCCTTTGTGGTTTACAACAGCTTTGACCAGGACGGGGTCTCACTGAGGGATAACCTCTCGAACCTGAGCTACTCCATCAGGAAGAACAACACCCTCGAGCTACTTCCTCCTTACCTGCCCGGGACTTACCAGTGTGTCACCGGCCCCTGCACCCACACCCACCTGTTGATCGTAAACGACTCTCTTCCGAGAACAGACCTCAATAACTCCTCTCCGCAGTTCCCCAGAACAGGAGGTGAGCTCAGGAAACCCCGGGTAAAGAAGGGTGGACAAGAGTTAACACTTGTGGGGTTTCTGGTATATGTGACGCTGGTGGTGGCTCTTTTGATTAAGGCTTTTCCTTCCATGTCTGAACTATCCCTCTTCTTTTATGAACAACTCGACTAGTGCTAACGGGACCCTACCCAACGAATCGGGATTGAATATCGGTAACCAGGTTGCAGTTTCACTTTTGATTACCTTCATAGTCCTCTTCCTGCTAGTGCTGTCGCTTCTGTGCCTGCGGATCGGGGGCTGCTGCATCCACGTTTATATCTGGTGCTGGCTGTTTAGAAGGTTCGGAGACCACCGCAGGTAGAATAATGCTGCTTACCCTCTTTGTCCTGGCGCTGGCTGCCAGCTGCCAAGCCTTTTCCGAGGCTGACTTCATAGAGCCCCAGTGCAATATCACTTATAAATCTGAACGTGCCATCTGTACTATTCTAATCAAATGTGTTACTCAACACGATAAGGTGACTGTTAAATACAAAGATCAATTAAAAAAAGACGCACTTTACAGCAGCTGGCAACCAGGAGATGATCAAAAATACAATGTAACCGTCTTCCAGGGCAAACTCTCCAAAACTTACAATTACAATTTCCCATTTGAGCAGATGTGTGACTTTGTCATGTACATGGAAAAGCAGTACAAGCTGTGGCCTCCAACTCCCCAGGGCTGTGTGGAAAATCCAGGCTCTTTCTGTATGATCTCTCTCTGTGTAACTGTGCTGGCACTAATACTCACGCTTCTGTATCTCAGATTTAAATCAAGGCAAAGCTTCATTGATGAAAAGAAAATGCCATAATCGCTCAACGCTTGATTGCTAACACCGGGTTTTTATCCGCAGAATGATTGGAATCACCCTACTAATCACCTCCCTCCTTGCGATTGCCCATGGGTTGGAACGAATCGAAGTCCCTGTGGGGGCCAATGTTACCCTGGTGGGGCCTGTCGGCAATGCTACATTAATGTGGGAAAAATATACTAAAAATCAATGGGTTTCTTACTGCACTAACAAAAACAGCCACAAGCCCAGAGCCATCTGCGATGGGCAAAATCTAACCTTGATTGATGTTCAATTGCTGGATGCGGGCTACTATTATGGGCAGCTGGGTACAATGATTAATTACTGGAGACCCCACAGAGATTACATGCTTCACGTAGTAAAGGGTCCCATTAGCAGCCCAACCACCACCTCTACCACACCCACTACCACCACTACTCCCACCACCAGCACTGCCGCCCAGCCTCCTCATAGCAGAACAACCACTTTTATCAATTCCAAGTCCCACTCCCCCCACATTGCCGGCGGGCCCTCCGCCTCAGACTCCGAGACCACCGAGATCTGCTTCTGCAAATGCTCTGACGCCATTGCCCAGGATTTGGAAGATCACGAGGAAGATGAGCATGACTACGCAGATGCATGCCAGGCATCAGAGGCAGAAGCGCTACCGGTGGCCCTAAAACAGTATGCAGACTCCCACACCACCCCCAACCTTCCTCCACCTTCCCAGAAGCCAAGTTTCCTGGGGGAAAATGAAACTCTGCCTCTTTCCATACTAGCTCTGACATCTGTTGCTATTTTGGCCGCTCTGCTGGTGCTTCTATGCTCTATATGCTACCTGATCTGCTGCAGAAAGAAAAAATCTCACGGCCATGCTCACCAGCCCCTCATGCACTTCCCTTACCCTCCAGAGCTGGGCGACCACAAACTTTAAGTCTGCAGTAGCTATCTGCCCATCCCTTGTCAGTCGACAGCGATGAGCCCCACTAATCTAACAGCCTCTGGACTTACAACATTGTCTCTTAATGAGACCACCGCTCCTCAAGACCTGTACGATGGTGTCTCCGCGCTGGTTAACCAGTGGGATCACCTGGGCATATGGTGGCTCCTCATAGGAGCAGTGACCCTGTGCCTAATCCTGGTCTGGATCATCTGCTGCATCAAAAGCAGAAGACCCAGGCGGCGGCCCATCTACAGGCCCTTCGTCATCACACCTGAAGATAATGATGATGATGACACCACCTCCAGGCTGCAGAGCCTAAAGCAGCTACTCTTCTCTTTTACAGCATGGTAAATTGAATCATGCCCCGCATTTTCATCTACTTGCTTCTCCTTCCACTTTTTCTGGGCTCCTCTACATTGGCCACTGTGTCCCACATCGAGGTAGACTGCCTCACGCCCTTCACAGTCTACCTGCTTTTCGGCTTTGTCATCTGCACCTTTGTCTGCAGCGTTATCACTGTAGTGATCTGCTTCATACAGTGCATCGACTACATCTGTGTGCGGGTGGCCTACTTTAGACACCACCCCCAGTATCGCAACAGGGACATAGCGGCTCTCCTAAGACTTGTTTAAATCATGGCCAAATTACCTGTGATTGGTCTTCTGATTATCTGCTGCGTCCTAGCCGCGATTGGGACTCAACCTAATACCACCACCAGCGCTCCCAGAAAGAGACATGTATCCTGCAGCTTCAAGCGTCCCTGGAATATACCCCAATGCTTTACTGATGAACCTGAAATCTCTTTGGCTTGGTACTTCAGCGTCACCGCCCTTCTCATCTTCTGCAGTACGGTTATTGCTCTTGCCATCTACCCTTCCCTTAACCTGGGCTGGAATGCTGTCAACTCTATGGAATATCCCACCTTCCCAGAACCAGACCTGCCAGACCTGGTTGTTCTAAACGCGTTTCCTCCTCCTCCAGTTCAAAATCAGTTTCGCCCTCCGTCCCCTACGCCCACTGAGGTCAGCTACTTTAATCTAACAGGCGGAGATGACTGAAAACCTAGACCTAGAAATGGACGGTCTCTGCAGCGAGCAACGCACACTAGAGAGGCGCCGGCAAAAAGCAGAGCTCGAGCGTCTTAAACAAGAGCTCCAAGACGCCGTGGCCATACACCAGTGCAAAAAAGGGCTCTTCTGTCTGGTAAAACAGGCCACGCTCACCTATGAAAAAACAGGTGACACCCACCGCCTAGGATACAAGCTGCCCACACAGCGCCAAAAGTTTGCCCTTATGATAGGTGAACAACCCATCACCGTCACCCAGCACTCCGTGGAGACAGAAGGCTGCATTCATGCTCCCTGCAGGGGCGCTGACTGCCTCTACACCTTGATCAAAACCCTCTGCGGTCTCAGAGACCTTATCCCTTTCAATTGATCATAACTGTAATCAATAAAAAATCACTTACTTGAAATCTGATAGCAAGACTCTGTCCAATTTTTTCAGCAACACTTCCTTCCCCTCCTCCCAACTCTGGTACTCTAGGCGCCTCCTAGCTGCAAACTTCCTCCACAGTCTGAAGGGAATGTCAGATTCCTCCTCCTGTCCCTCCGCACCCACGATCTTCATGTTGTTACAGATGAAACGCGCGAGATCGTCTGACGAGACCTTCAACCCCGTGTACCCCTACGATACCGAGATCGCTCCGACTTCTGTCCCTTTCCTTACCCCTCCCTTTGTATCATCCGCAGGAATGCAAGAAAATCCAGCTGGGGTGCTGTCCCTGCACCTGTCAGAGCCCCTTACCACCCACAATGGGGCCCTGACTCTAAAAATGGGGGGCGGCCTGACCCTGGACAAGGAAGGGAATCTCACTTCCCAAAACATCACCAGTGTCGATCCCCCTCTCAAAAAAAGCAAGAACAACATCAGCCTTCAGACCGCCGCACCCCTCGCCGTCAGCTCCGGGGCCCTAACCCTTTTTGCCACTCCCCCCCTAGCGGTCAGTGGCGACAACCTTACTGTGCAGTCTCAGGCCCCTCTTACTTTGGAAGACTCAAAACTAACTCTGGCCACCAAAGGACCCCTAACTGTGTCCGAAGGCAAACTTGTCCTAGAAACAGAGCCTCCCCTGCATGCAAGTGACAGCAGTAGCCTGGGCCTTAGCGTCACGGCCCCACTTAGCATTAACAATGACAGCCTAGGACTAGACATGCAAGCGCCCATCAGCTCTCGAGATGGAAAACTGGCTCTAACAGTGGCGGCCCCCCTAACTGTGGCCGAGGGTATCAATGCTTTGGCAGTAGCCACAGGTAATGGTATTGGACTAAATGAAACCAACACACACCTGCAGGCAAAACTGGTCGCGCCCCTAGGCTTTGATACCAACGGCAACATTAAGCTAAGCGTCGCAGGAGGCATGAGGCTAAACAATAACACACTGATACTAGATGTAAACTACCCATTTGAGGCTCAAGGCCAACTGAGCCTAAGAGTGGGCTCGGGCCCACTATATGTAGATTCTAGTAGTCATAACCTAACCATTAGATGCCTTAGGGGATTGTATGTAACATCTTCTAACAACCAAAACGGTCTAGAGGCCAACATTAAACTAACAAAAGGCCTTGTGTATGACGGAAATGCCATAGCAGTTAATGTTGGCAAAGGGCTGGAATACAGCCCTACTGGCACAACAGAAAAACCTATACAGACTAAAATAGGTCTAGGCATGGAGTATGACACTGAGGGAGCCATGATGACAAAACTAGGCTCTGGACTAAGCTTTGACAATTCAGGAGCCATTGTGGTGGGAAACAAAAATGATGACAGGCTTACTTTGTGGACCACACCGGACCCATCGCCCAACTGTCAGATTTACTCTGAAAAAGATGCTAAACTAACCTTGGTACTGACTAAATGTGGCAGTCAGGTTGTAGGCACAGTATCTATTGCCGCTCTTAAAGGTAGCCTTGTGCCAATCACTAGTGCAATCAGTGTGGTTCAGATATACCTAAGGTTTGATGAAAATGGGGTGCTGATGAGTAACTCTTCACTTAATGGCGAATACTGGAATTTTAGAAACGGAGACTCAACTAATGGCACACCATATACAAACGCAGTGGGTTTTATGCCTAATCTACTGGCCTATCCTAAAGGTCAAACTACAACTGCAAAAAGTAACATTGTCAGCCAGGTCTACATGAACGGGGACGATACTAAACCCATGACATTTACAATCAACTTCAATGGCCTTAGTGAAACAGGGGATACCCCTGTCAGTAAATATTCCATGACATTCTCATGGAGGTGGCCAAATGGAAGCTACATAGGGCACAATTTTGTAACAAACTCCTTTACTTTCTCCTACATCGCCCAAGAATAAAGAAAGCACAGAGATGCTTGTTTTTGATTTCAAAATTGTGTGCTTTTATTTATTTTCAAGCTTACAGTATTTCCAGTAGTCATTAGAATAGAGCTTAATTAAACTGCATGAGAACCCTTCCACATAGCTTAAATTATCACCAGTGCAAATGGAAAAAAATCAACATACCTTTTTATCCAGATATCAAAGAACTCTAGTGGTCAGTTTTCCCCCACCCTCCCAGCTCACAGAATACACAGTCCTTTCCCCCCGGCTGGCTTTAAACAACACTATCTCATTGGTAACAGACATATTTTTAGGTGTAATAATCCACACGGTCTCTTGGCGGGCCAAACGCTGGTCTGTGATGTTAATAAACTCCCCAGGCAGCTCTTTCAAGTTCACGTCGCTGTCCAACTGCTGAAGCGCTCGCGGCTCCGACTGCGCCTCTAGCGGAGGCAACGGCAGCACCCGATCCTTGATCTATAAAGGAGTAGAGTCATAATCCCCCATAAGAATAGGGCGGTGATGCAGCAACAAGGCGCGCAGCAACTCCTGCCGCCGCCTCTCCGTACGACAGGAATGCAACGGGGTGGTGGTCTCCTCCGCGATAATCCGCACCGCTCGCAGCATCAGCATCCTCGTCCTCCGGGCACAGCAGCGCATCCTGATCTCACTGAGATCGGCGCAGTAAGTGCAGCACAACACCAAGATGTTATTTAAGATCCCACAGTGCAAAGCACTGTACCCAAAGCTCATGGCGGGAAGGACAGCCCCCACGTGACCATCGTACCAGATCCTCAGGTAAATCAAATGACGACCTCTCATAAACACGCTGGACATATACATCACCTCCTTGGGCATGAGCTGATTCACCACCTCTCGATACCACAGGCATCGCTGATTAATTAAAGACCCCTCGAGCACCATCCTGAACCAGGAAGCCAGCACCTGACCCCCCGCCAGGCACTGCAGGGACCCCGGTGAATCGCAGTGGCAGTGAAGACTCCAGCGCTCGTAGCCGTGAACCATAGAGCTGGTCATTATATCCACATTGGCACAACACAGACACACTTTCATACACTTTTTCATGATTAGCAGCTCCTCTCTAGTCAAGACCATATCCCAAGGAATCACCCACTCTTGAATCAAGGTAAATCCCACACAGCAGGGCAGGCCTCTCACATAACTCACGTTATGCATAGTGAGCGTGTCGCAATCTGGAAATACCGGATGATCTTCCATCACCGAAGCCCGGGTCTCCGTCTCAAAGGGAGGTAAACGGTCCCTCGTGTAGGGACAGTGGCGGGATAATCGAGATCGTGTTGAACGTAGAGTCATGCCAAAGGGAACAGCGGACGTACTCATATTTCCTCCAGCAGAACCAAGTGCGCGCGTGGCAGCTATCCCTGCGTCTTCTGTCTCGCCGCCTGCCCCGCTCGGTGTAGTAGTTGTAATACAGCCACTCCCTCAGACCGTCAAGGCGCTCCCTGGCGTCCGGATCTATAACAACACCGTCCTGCAGCGCCGCCCTGATGACATCCACCACCGTAGAGTATGCCAAGCCCAGCCACGAAATGCACTCACTTTGACAGCGAGAGATAGGAGGAGCGGGAAGAGATGGAAGAACCATGATAGTAAAAGAACTTTTATTCCAATCGATCCTCTACAATGTCAAAGTGTAGATCTATCAGATGGCACTGGTCTCCTCCGCTGAGTCGATCAAAAATAACAGCTAAACCACAAACAACACGATTGGTCAAATGCTGCACAAGGGCTTGCAGCATAAAATCGCCTCGAAAGTCCACCGCAAGCATAACATCAAAGCCACCGCCCCTATCATGATCTATGATAAAAACCCCACAGCTATCCACCAGACCCATATAGTTTTCATCTCTCCATCGTGAAAAAATATTTACAAGCTCCTCCTTTAAATCACCTCCAACCAATTCAAAAAGTTGAGCCAGACCGCCCTCCACCTTCATTTTCAGCATGCGCATCATGATTGCAAAAATTCAGGCTCCTCAGACACCTGTATAAGATTGAGAAGCGGAACGTTAACATCAATGTTTCGCTCGCGAAGATCGCGCCTCAGTGCAAGCATGATATAATCCCACAGGTCGGAGCGGATCAGCGAGGACATCTCCCCGCCAGGAACCAACTCAACGGAGCCTATGCTGATTATAATACGCATATTCGGGGCTATGCTAACCAGCACGGCCCCCAAATAGGCGTACTGCATAGGCGGCGACAAAAAGTGAACAGTTTGGGTTAAAAAATCAGGCAAACACTCGCGCAAAAAAGCAAGAACATCATAACCATGCTCATGCAAATAGATGCAAGTAAGCTCAGGAACGACCACAGAAAAATGCACAATTTTTCTCTCAAACATGACTGCGAGCCCTGCAAAAAATAAAAAAGAAACATTACACAAGAGTAGCCTGTCTTACAATGGGATAGACTACTCTAACCAACATAAGACGGGCCACGACATCGCCCGCGTGGCCATAAAAAAAATTATCCGTGTGATTAAAAAGAAGCACAGATAGCTGGCCAGTCATATCCGGAGTCATCACGTGCGAACCCGTGTAGACCCCCGGGTTGGACACATCGGCCAAACAAAGAAAGCGGCCAATGTATCCCGGAGGAATGATAACACTAAGACGAAGATACAACAGAATAACCCCATGGGGGGGAATAACAAAGTTAGTAGGTGAATAAAAACGATAAACACCCGAAACTCCCTCCTGCGTAGGCAAAATAGCGCCCTCCCCTTCCAAAACAACATACAGCGCTTCCACAGCAGCCATGACAAAAGACTCAAAACACTCAAAAGACTCAGTCTTACCAGGAAAATAAAAGCACTCTCACAGCACCAGCACTAATCAGAGTGTGAAGAGGGCCAAGTGCCGAACGAGTATATATAGGAATTAAAAATGACGTAAATGTGTAAAGGTCAAAAAACGCCCAGAAAAATACACAGACCAACGCCCGAAACGAAAACCCGCGAAAAAATACCCAGAAGTTCCTCAACAACCGCCACTTCCGCTTTCCCACGATACGTCACTTCCTCAAAAATAGCAAACTACATTTCCCACATGTACAAAACCAAAACCCCTCCCCTTGTCACCGCCCACAACTTACATAATCACAAACGTCAAAGCCTACGTCACCCGCCCCGCCTCGCCCCGCCCACCTCATTATCATATTGGCCTCAATCCAAAATAAGGTATATTATTGATGATG
본 발명은 또한 본 발명의 벡터를 포함하는 혈청형 20(rChAd20)으로부터 유래된 재조합 침팬지 아데노바이러스를 제공한다.
본 발명은 또한 본 발명의 벡터를 포함하는 재조합 변형된 백시니아 앙카라(rMVA)를 제공한다.
벡터는 임의의 숙주, 예컨대 박테리아, 효모 또는 포유동물에서의 본 발명의 폴리뉴클레오티드 또는 이종 폴리뉴클레오티드의 발현을 위한 벡터일 수 있다. 적절한 발현 벡터는 전형적으로 숙주 유기체 내에서 에피솜으로서 또는 숙주 염색체 DNA의 필수 부분으로서 복제가능하다. 통상적으로, 발현 벡터는 암피실린 내성, 하이그로마이신 내성, 테트라사이클린 내성, 카나마이신 내성 또는 네오마이신 내성과 같은 선택 마커를 포함하여, 원하는 DNA 서열로 형질전환되거나 형질도입된 세포의 검출을 가능하게 한다. 예시적인 벡터는 플라스미드, 코스미드, 파지, 바이러스 벡터, 트랜스포존 또는 인공 염색체이다.
본 발명의 벡터는 원형 또는 선형일 수 있다. 이들은 원핵생물 또는 진핵생물 숙주 세포에서 기능하는 복제계를 포함하도록 제조될 수 있다. 복제계는 예를 들어, ColE1, SV40, 2μ 플라스미드, λ, 소 유두종 바이러스 등으로부터 유래될 수 있다.
재조합 발현 벡터는 일시적 발현, 안정적 발현 또는 둘 다를 위해 설계될 수 있다. 또한, 재조합 발현 벡터는 구성적 발현 또는 유도성 발현을 위해 만들어질 수 있다.
또한, 재조합 발현 벡터는 자살 유전자를 포함하도록 만들어질 수 있다. "자살 유전자"는 자살 유전자를 발현하는 세포를 사멸시키는 유전자를 말한다. 자살 유전자는 유전자가 발현되는 세포에 제제, 예를 들어 약물에 대한 감수성을 부여하고, 세포가 제제와 접촉되거나 이에 노출될 때 세포를 사멸시키는 유전자일 수 있다. 자살 유전자는 당업계에 공지되어 있으며, 예를 들어 단순 헤르페스 바이러스(HSV), 티미딘 키나제(TK) 유전자, 시토신 데아미나제, 푸린 뉴클레오시드 포스포릴라제 및 니트로환원효소를 포함한다.
벡터는 또한 당업계에 잘 알려진 선택 마커를 포함할 수 있다. 선택 마커는 양성 및 음성 선택 마커를 포함한다. 마커 유전자는 살생물제 내성, 예를 들어 항생물질, 중금속 등에 대한 내성, 영양요구성 숙주에서 원영양성을 제공하기 위한 상보성 등을 포함한다. 예시적인 마커 유전자는 항생물질 내성 유전자(예를 들어, 네오마이신 내성 유전자, 하이그로마이신 내성 유전자, 카나마이신 내성 유전자, 테트라사이클린 내성 유전자, 페니실린 내성 유전자, 히스티디놀 내성 유전자, 히스티디놀 x 내성 유전자), 글루타민 합성효소 유전자, HSV-TK, 간시클로비르 선택을 위한 HSV-TK 유도체 또는 6-메틸푸린 선택을 위한 세균성 푸린 뉴클레오시드 포스포릴라제 유전자를 포함한다(문헌[Gadi et al., 7 Gene Ther. 1738-1743 (2000)]). 선택 마커 또는 클로닝 부위를 인코딩하는 핵산 서열은 관심 폴리펩티드 또는 클로닝 부위를 인코딩하는 핵산 서열의 상류 또는 하류에 있을 수 있다.
적절한 벡터가 알려져 있으며, 재조합 구축물을 생성하기 위해 많은 것이 시판되고 있다. 하기 벡터가 예로서 제공된다. 세균 벡터: pBs, 파지스크립트, PsiX174, pBluescript SK, pBs KS, pNH8a, pNH16a, pNH18a, pNH46a (미국 캘리포니아주 라호이아 소재의 스트라타진(Stratagene)); pTrc99A, pKK223-3, pKK233-3, pDR540 및 pRIT5(스웨덴 웁살라 소재의 파마시아(Pharmacia)). 진핵세포 벡터: pWLneo, pSV2cat, pOG44, PXR1, pSG(스트라타진), pSVK3, pBPV, pMSG 및 pSVL(파마시아). 트랜스포존 벡터: 슬리핑 뷰티(Sleeping Beauty) 트랜스포존 및 PiggyBac 트랜스포존.
일부 실시 형태에서, 벡터는 바이러스 벡터이다. 바이러스 벡터는 전형적으로 복제능력이 없도록, 예를 들어 복제하지 않도록 변형된 자연 발생 바이러스 게놈으로부터 유래된다. 복제하지 않는 바이러스는 복제를 위해 트랜스형 단백질을 제공해야 한다. 전형적으로, 이러한 단백질은 바이러스 생산 세포주에서 안정적으로 또는 일시적으로 발현되어, 바이러스 복제가 가능하다. 따라서 바이러스 벡터는 전형적으로 감염성이고 복제하지 않는다. 바이러스 벡터는 아데노바이러스 벡터, 아데노 관련 바이러스(AAV) 벡터(예를 들어, AAV 타입 5 및 타입 2), 알파바이러스 벡터(예를 들어, 베네수엘라 말 뇌염 바이러스(Venezuelan equine encephalitis virus, VEE), 신드비스 바이러스(Sindbis virus, SIN), 셈리키 삼림열 바이러스(Semliki forest virus, SFV) 및 VEE-SIN 키메라), 헤르페스 바이러스 벡터(예를 들어, 레서스 사이토메갈로바이러스(rhesus cytomegalovirus, RhCMV)와 같은 사이토메갈로바이러스로부터 유래된 벡터), 아레나바이러스 벡터(예를 들어, 림프구성 맥락수막염 바이러스(LCMV) 벡터), 홍역 바이러스 벡터, 폭스 바이러스 벡터(예를 들어, 백시니아 바이러스, 변형된 백시니아 바이러스 앙카라(MVA), NYVAC(코펜하겐 백시니아 균주로부터 유래됨), 및 아비폭스 벡터: 카나리아폭스(canarypox) (ALVAC) 및 조류폭스(fowlpox) (FPV) 벡터), 수포성 구내염 바이러스 벡터, 레트로바이러스 벡터, 렌티바이러스 벡터, 바이러스 유사 입자, 바큘로바이러스 벡터 및 세균 포자일 수 있다.
아데노바이러스 벡터
아데노바이러스 벡터는 인간 아데노바이러스(Ad)로부터 유래될 수 있지만, 또한 소 아데노바이러스(예를 들어, 소 아데노바이러스 3, BAdV3), 개 아데노바이러스(예를 들어, CAdV2), 돼지 아데노바이러스(예를 들어, PAdV3 또는 5) 또는 유인원, 예컨대 침팬지(Pan), 고릴라(Gorilla), 오랑우탄(Pongo), 보노보(Bonobo) (Pan paniscus) 및 커먼 침팬지(Pan troglodytes)와 같은 다른 종을 감염시키는 아데노바이러스로부터도 유래될 수 있다. 전형적으로, 자연 발생 유인원 아데노바이러스는 각각의 유인원의 대변 샘플로부터 분리된다.
인간 아데노바이러스 벡터는 다양한 아데노바이러스 혈청형, 예를 들어 인간 아데노바이러스 혈청형 hAd5, hAd7, hAd11, hAd26, hAd34, hAd35, hAd48, hAd49 또는 hAd50(혈청형은 Ad5, Ad7, Ad11, Ad26, Ad34, Ad35, Ad48, Ad49 또는 Ad50로도 지칭됨)로부터 유래될 수 있다.
유인원 아데노바이러스 벡터는 다양한 아데노바이러스 혈청형, 예를 들어 유인원 아데노바이러스 혈청형 GAd20, GAd19, GAd21, GAd25, GAd26, GAd27, GAd28, GAd29, GAd30, GAd31, ChAd3, ChAd4, ChAd5, ChAd6, ChAd7, ChAd8, ChAd9, ChAd10, ChAd11, ChAd16, ChAdI7, ChAd19, ChAd20, ChAd22, ChAd24, ChAd26, ChAd30, ChAd31, ChAd37, ChAd38, ChAd44, ChAd55, ChAd63, ChAd73, ChAd82, ChAd83, ChAd146, ChAd147, PanAd1, PanAd2 또는 PanAd3로부터 유래될 수 있다.
아데노바이러스 벡터는 당업계에 공지되어 있다. 대부분의 인간 및 비인간 아데노바이러스의 서열은 알려져 있으며, 다른 것들은 일상적인 절차를 사용하여 얻을 수 있다. Ad26의 예시적인 게놈 서열은 젠뱅크(GenBank) 수탁 번호 EF153474 및 국제 특허 공개 제WO2007/104792호의 서열 번호 1에서 발견된다. Ad35의 예시적인 게놈 서열은 국제 특허 공개 제WO2000/70071호의 도 6에서 발견된다. Ad26를 기반으로 한 벡터는 예를 들어, 국제 특허 공개 제WO2007/104792호에 기재되어 있다. Ad35를 기반으로 한 벡터는 예를 들어, 미국 특허 제7,270,811호 및 국제 특허 공개 제WO2000/70071호에 기재되어 있다. ChAd3, ChAd4, ChAd5, ChAd6, ChAd7, ChAd8, ChAd9, ChAd10, ChAd11, ChAd16, ChAd17, ChAd19, ChAd20, ChAd22, ChAd24, ChAd26, ChAd30, ChAd31, ChAd37, ChAd38, ChAd44, ChAd63 및 ChAd82에 기초한 벡터는 국제 특허 공개 제WO2005/071093호에 기재되어 있다. PanAd1, PanAd2, PanAd3, ChAd55, ChAd73, ChAd83, ChAd146 및 ChAd147에 기초한 벡터는 국제 특허 공개 제WO2010/086189호에 기재되어 있다.
아데노바이러스 벡터는 아데노바이러스 영역 E1, E2 및 E4 중 하나 이상과 같은, 바이러스 복제에 필수적인 유전자 산물의 하나 이상의 기능적 결실 또는 완전한 제거를 포함하도록 조작되어, 아데노바이러스가 복제할 수 없도록 만든다. E1 영역의 결실은 EIA, EIB 55K 또는 EIB 21K, 또는 이들의 임의의 조합의 결실을 포함할 수 있다. 복제 결손성 아데노바이러스는 헬퍼 플라스미드를 이용하여 생산 세포에 의해 트랜스형으로 결실 영역(들)에 의해 인코딩된 단백질을 제공하거나, 필요한 단백질을 발현하도록 생산 세포를 조작함으로써 증식된다. 아데노바이러스 벡터는 또한 복제에 불필요한 E3 영역에 결실이 있을 수 있으므로, 이러한 결실은 보완될 필요는 없다. 본 발명의 아데노바이러스 벡터는 E1 영역 및 E3 영역의 적어도 일부의 기능적 결실 또는 완전한 제거를 포함할 수 있다. 본 발명의 아데노바이러스 벡터는 E4 영역 및/또는 E2 영역의 기능적 결실 또는 완전한 제거를 추가로 포함할 수 있다. 이용될 수 있는 적절한 생산 세포는 El, 예를 들어 911 또는 PER.C6 세포(예를 들어, 미국 특허 제5,994,128호 참조), E1 형질전환된 양수 세포(예를 들어, EP 1230354 참조), E1 형질전환된 A549 세포(예를 들어, 국제 특허 공개 제WO1998/39411호, 미국 특허 제5,891,690호 참조)에 의해 불멸화된 인간 망막 세포이다. 사용될 수 있는 예시적인 벡터는 바이러스 복제에 충분한 기능적 E1 코딩 영역, E3 코딩 영역 내의 결실 및 E4 코딩 영역 내의 결실을 포함하되, 단, E4 오픈 리딩 프레임 6/7이 결실되지 않는 Ad26이다(예를 들어, 미국 특허 제9,750,801호 참조).
일부 실시 형태에서, 아데노바이러스 벡터는 인간 아데노바이러스(Ad) 벡터이다. 일부 실시 형태에서, Ad 벡터는 Ad5로부터 유래된다. 일부 실시 형태에서, Ad 벡터는 Ad11으로부터 유래된다. 일부 실시 형태에서, Ad 벡터는 Ad26로부터 유래된다. 일부 실시 형태에서, Ad 벡터는 Ad34로부터 유래된다. 일부 실시 형태에서, Ad 벡터는 Ad35로부터 유래된다. 일부 실시 형태에서, Ad 벡터는 Ad48으로부터 유래된다. 일부 실시 형태에서, Ad 벡터는 Ad49으로부터 유래된다. 일부 실시 형태에서, Ad 벡터는 Ad50로부터 유래된다.
일부 실시 형태에서, 아데노바이러스 벡터는 유인원 아데노바이러스(GAd) 벡터이다. 일부 실시 형태에서, GAd 벡터는 GAd20로부터 유래된다. 일부 실시 형태에서, GAd 벡터는 GAd19으로부터 유래된다. 일부 실시 형태에서, GAd 벡터는 GAd21으로부터 유래된다. 일부 실시 형태에서, GAd 벡터는 GAd25로부터 유래된다. 일부 실시 형태에서, GAd 벡터는 GAd26로부터 유래된다. 일부 실시 형태에서, GAd 벡터는 GAd27으로부터 유래된다. 일부 실시 형태에서, GAd 벡터는 GAd28으로부터 유래된다. 일부 실시 형태에서, GAd 벡터는 GAd29으로부터 유래된다. 일부 실시 형태에서, GAd 벡터는 GAd30로부터 유래된다. 일부 실시 형태에서, GAd 벡터는 GAd31으로부터 유래된다. 일부 실시 형태에서, GAd 벡터는 ChAd4로부터 유래된다. 일부 실시 형태에서, GAd 벡터는 ChAd5로부터 유래된다. 일부 실시 형태에서, GAd 벡터는 ChAd6로부터 유래된다. 일부 실시 형태에서, GAd 벡터는 ChAd7으로부터 유래된다. 일부 실시 형태에서, GAd 벡터는 ChAd8으로부터 유래된다. 일부 실시 형태에서, GAd 벡터는 ChAd9으로부터 유래된다. 일부 실시 형태에서, GAd 벡터는 ChAd20로부터 유래된다. 일부 실시 형태에서, GAd 벡터는 ChAd22로부터 유래된다. 일부 실시 형태에서, GAd 벡터는 ChAd24로부터 유래된다. 일부 실시 형태에서, GAd 벡터는 ChAd26로부터 유래된다. 일부 실시 형태에서, GAd 벡터는 ChAd30로부터 유래된다. 일부 실시 형태에서, GAd 벡터는 ChAd31으로부터 유래된다. 일부 실시 형태에서, GAd 벡터는 ChAd32로부터 유래된다. 일부 실시 형태에서, GAd 벡터는 ChAd33로부터 유래된다. 일부 실시 형태에서, GAd 벡터는 ChAd37으로부터 유래된다. 일부 실시 형태에서, GAd 벡터는 ChAd38으로부터 유래된다. 일부 실시 형태에서, GAd 벡터는 ChAd44로부터 유래된다. 일부 실시 형태에서, GAd 벡터는 ChAd55로부터 유래된다. 일부 실시 형태에서, GAd 벡터는 ChAd63로부터 유래된다. 일부 실시 형태에서, GAd 벡터는 ChAd68으로부터 유래된다. 일부 실시 형태에서, GAd 벡터는 ChAd73로부터 유래된다. 일부 실시 형태에서, GAd 벡터는 ChAd82로부터 유래된다. 일부 실시 형태에서, GAd 벡터는 ChAd83로부터 유래된다.
본 발명의 폴리펩티드 또는 이종 폴리펩티드는 얻어진 재조합 바이러스의 바이러스 생존력에 영향을 미치지 않는 벡터의 부위 또는 영역(삽입 영역)에 삽입될 수 있다. 본 발명의 폴리펩티드 또는 이종 폴리펩티드는 평행(5'에서 3'으로 전사됨) 또는 역평행(벡터 골격에 대해 3'에서 5' 방향으로 전사됨) 배향으로 결실 E1 영역에 삽입될 수 있다. 또한, 벡터가 사용을 위해 제조되는 포유류 숙주 세포에서 본 발명의 폴리펩티드 또는 이종 폴리펩티드의 발현을 유도할 수 있는 적절한 전사조절요소는 본 발명의 폴리펩티드 또는 이종 폴리펩티드에 작동가능하게 연결될 수 있다. "작동가능하게 연결된" 서열은 이들이 조절하는 핵산 서열과 인접한 발현 제어 서열 및 조절된 핵산 서열을 제어하기 위해 트랜스로 또는 좀 떨어져서 작용하는 조절 서열 둘 다를 포함한다.
재조합 아데노바이러스 입자는 바이러스 복제에 필요한 결손 바이러스 유전자를 트랜스형으로 공급하는 상보성 세포주 또는 헬퍼 바이러스를 사용하여 당해 기술 분야의 임의의 통상적인 기술(예를 들어, 국제 특허 공개 제WO1996/17070호)에 따라 제조 및 증식될 수 있다. 세포주 293(문헌[Graham et al., 1977, J. Gen. Virol. 36: 59-72]), PER.C6(예를 들어, 미국 특허 제5,994,128호 참조), E1 A549 및 911은 E1 결실을 보완하기 위해 통상 사용된다. 다른 세포주는 결손 벡터를 보완하도록 조작되었다(문헌[Yeh, et al., 1996, J. Virol. 70: 559-565]; 문헌[Kroughak and Graham, 1995, Human Gene Ther. 6: 1575-1586]; 문헌[Wang, et al., 1995, Gene Ther. 2: 775-783]; 문헌[Lusky, et al., 1998, J. Virol. 72: 2022-203]; EP 919627 및 국제 특허 공개 제WO1997/04119호). 아데노바이러스 입자는 배양 상청액으로부터 회수될 수 있지만, 용해 후 세포로부터도 회수될 수 있고, 임의로 표준 기술(예를 들어, 국제 특허 공개 제WO1996/27677호, 국제 특허 공개 제WO1998/00524호, 국제 특허 공개 제WO1998/26048호 및 국제 특허 공개 제WO2000/50573호에 기재된 크로마토그래피, 초원심분리법)에 따라 추가로 정제될 수 있다. 아데노바이러스 벡터를 증식시키기 위한 구성 및 방법은 또한, 예를 들어 미국 특허 제5,559,099호, 제5,837,511호, 제5,846,782호, 제5,851,806호, 제5,994,106호, 제5,994,128호, 제5,965,541호, 제5,981,225호, 제6,040,174호, 제6,020,191호 및 제6,113,913호에 기재되어 있다.
폭스바이러스 벡터
폭스바이러스(폭스바이러스과(Poxviridae)) 벡터는 천연두 바이러스(variola), 백시니아 바이러스, 우두 바이러스 또는 원숭이 폭스바이러스로부터 유래될 수 있다. 예시적인 백시니아 바이러스는 코펜하겐 백시니아 바이러스(Copenhagen vaccinia virus; W), 뉴욕 약독화 백시니아 바이러스(New York Attenuated Vaccinia Virus; NYVAC), ALVAC, TROVAC 및 변형된 백시니아 앙카라(MVA)이다.
MVA는 터키 앙카라의 백신 연구소(Vaccination Institute)에서 수년 동안 유지되어 인간 백신 접종의 기초로 사용된 진피 백시니아 균주 앙카라(CVA(Chorioallantois vaccinia Ankara) 바이러스)에서 유래한다. 그러나, 백시니아 바이러스(VACV)와 관련된 종종 중증의 백신 접종 후 합병증으로 인해, 더욱 약독화되고 더욱 안전한 천연두 백신을 생성하려는 여러 시도가 있었다.
MVA는 CVA 바이러스의 닭 배아 섬유아세포에 대한 516개의 연속 계대에 의해 생성되었다(문헌[Meyer et al., J. Gen. Virol., 72: 1031-1038 (1991)] 및 미국 특허 제10,035,832호). 이러한 장기 계대의 결과로서 생성된 MVA 바이러스는 게놈 서열의 약 31 킬로베이스를 결실하였고, 따라서 조류 세포에 고도로 제한된 숙주 세포로 기재되었다(문헌[Meyer, H. et al., Mapping of deletions in the genome of the highly attenuated vaccinia virus MVA and their influence on virulence, J. Gen. Virol. 72, 1031-1038, 199]; 문헌[Meisinger-Henschel et al., Genomic sequence of chorioallantois vaccinia virus Ankara, the ancestor of modified vaccinia virus Ankara, J. Gen. Virol. 88, 3249-3259, 2007]). MVA 게놈을 모체인 CVA와 비교하였더니, 게놈 DNA의 6개의 주요 결실(결실 I, II, III, IV, V 및 VI)이 나타나, 총 31,000개의 염기쌍에 달하였다(문헌[Meyer et al., J. Gen. Virol. 72:1031-8 (1991)]). 각종 동물 모델에서 생성된 MVA가 병원성이 유의하게 낮은 것으로 나타났다(문헌[Mayr, A. & Danner, K. Vaccination against pox diseases under immunosuppressive conditions, Dev. Biol. Stand. 41: 225-34, 1978]). MVA를 약독화시키기 위해 많은 계대가 사용되었기 때문에, CEF 세포의 계대 수에 따라 MVA 476 MG/14/78, MVA-571, MVA-572, MVA-574, MVA-575 및 MVA-BN과 같은 다양한 균주 또는 분리주가 존재한다. MVA 476 MG/14/78은 예를 들어, 국제 특허 공개 제WO2019/115816A1호에 기재되어 있다. MVA-572 균주는 1994년 1월 27일자로 기탁 번호 ECACC 94012707 하에, European Collection of Animal Cell Cultures("ECACC"), Health Protection Agency, Microbiology Services(영국("UK") SP4 0JG 솔즈베리 포튼 다운 소재)에 기탁되었다. MVA-575 균주는 2000년 12월 7일자로 기탁 번호 ECACC 00120707 하에 ECACC에 기탁되고; MVA-바바리안 노르딕(Bavarian Nordic)("MVA-BN") 균주는 2000년 8월 30일자로 기탁 번호 V00080038 하에 ECACC에 기탁되었다. MVA-BN 및 MVA-572의 게놈 서열은 젠뱅크(각각, 수탁 번호 DQ983238 및 DQ983237)에서 입수할 수 있다. 다른 MVA 균주의 게놈 서열은 표준 시퀀싱 방법을 사용하여 얻을 수 있다.
본 발명의 벡터 및 바이러스는 임의의 MVA 균주 또는 추가로 MVA 균주의 유도체로부터 유래될 수 있다. 추가의 예시적인 MVA 균주는 미국 20108 버지니아주 머내서스 소재의 아메리칸 타입 컬쳐 컬렉션(American Type Culture collection, ATCC)에 기탁된 기탁물 VR-1508이다.
MVA의 "유도체"는 모 MVA와 본질적으로 동일한 특성을 나타내지만, 이들의 게놈의 하나 이상의 부분에서 차이를 나타내는 바이러스를 말한다.
일부 실시 형태에서, MVA 벡터는 MVA 476 MG/14/78으로부터 유래된다. 일부 실시 형태에서, MVA 벡터는 MVA-571으로부터 유래된다. 일부 실시 형태에서, MVA 벡터는 MVA-572로부터 유래된다. 일부 실시 형태에서, MVA 벡터는 MVA-574로부터 유래된다. 일부 실시 형태에서, MVA 벡터는 MVA-575로부터 유래된다. 일부 실시 형태에서, MVA 벡터는 MVA-BN으로부터 유래된다.
본 발명의 폴리뉴클레오티드 또는 이종 폴리뉴클레오티드는 얻어진 재조합 바이러스의 바이러스 생존력에 영향을 미치지 않는 MVA 벡터의 부위 또는 영역(삽입 영역)에 삽입될 수 있다. 이러한 영역은 재조합 바이러스의 바이러스 생존력에 심각한 영향을 미치지 않으면서 재조합 형성을 가능하게 하는 영역에 대해 바이러스 DNA 단편을 테스트함으로써 용이하게 확인될 수 있다. 티미딘 키나제(TK) 유전자는 사용될 수 있는 삽입 영역이며, 모든 조사된 폭스바이러스 게놈과 같은 많은 바이러스에 존재한다. 또한, MVA는 6개의 자연 결실 부위를 포함하며, 각각은 삽입 부위로 사용될 수 있다(예를 들어, 결실 I, II, III, IV, V 및 VI; 예를 들어, 미국 특허 제5,185,146호 및 미국 특허 제6.440,442호 참조). MVA의 하나 이상의 유전자간 영역(IGR)은 또한 IGR IGR07/08, IGR 44/45, IGR 64/65, IGR 88/89, IGR 136/137 및 IGR 148/149과 같은 삽입 부위로 사용될 수 있다(예를 들어, 미국 특허 공개 제2018/0064803호 참조). 추가의 적절한 삽입 부위가 국제 특허 공개 제WO2005/048957호에 기재되어 있다.
rMVA와 같은 재조합 폭스바이러스 입자는 당해 기술분야에 기재된 바와 같이 제조된다(문헌[Piccini, et al., 1987, Methods of Enzymology 153: 545-563]; 미국 특허 제4,769,330호; 미국 특허 제4,772,848호; 미국 특허 제4,603,112호; 미국 특허 제5,100,587호 및 미국 특허 제5,179,993호). 예시적인 방법에서, 바이러스에 삽입될 DNA 서열은 MVA의 DNA 섹션에 상동성인 DNA가 삽입된 대장균(E. coli) 플라스미드 구축물에 배치될 수 있다. 별도로, 삽입되는 DNA 서열은 프로모터에 라이게이션될 수 있다. 프로모터-유전자 결합은 프로모터-유전자 결합이 비필수 유전자좌를 포함하는 MVA DNA의 영역에 플랭킹(flanking)하는 DNA 서열에 상동성인 DNA에 의해 양 말단에 플랭킹되도록 플라스미드 구축물에 위치될 수 있다. 얻어진 플라스미드 구축물은 대장균 내에서 증식에 의해 증폭되고 분리될 수 있다. 삽입될 DNA 유전자 서열을 포함하는 분리된 플라스미드는 예를 들어, 닭 배아 섬유아세포(CEF)의 세포 배양물에 트랜스펙션될 수 있으며, 동시에 상기 배양물은 MVA로 감염된다. 플라스미드의 상동성 MVA DNA와 바이러스 게놈 사이의 재조합은 각각, 외래 DNA 서열의 존재에 의해 변형된 MVA를 생성할 수 있다. rMVA 입자는 용해 단계(예를 들어, 화학적 용해, 동결/해동, 삼투압 충격, 초음파 처리 등) 후에 배양 상청액으로부터 또는 배양된 세포로부터 회수될 수 있다. 플라크 정제의 연속 라운드를 사용하여 오염 야생형 바이러스를 제거할 수 있다. 그 다음에, 바이러스 입자는 당업계에 공지된 기술(예를 들어, 크로마토그래프법 또는 염화세슘 또는 수크로스 구배 초원심분리법)을 사용하여 정제될 수 있다.
다른 바이러스 벡터 및 재조합 바이러스
다른 바이러스 벡터는 인간 아데노 관련 바이러스, 예컨대 AAV-2(아데노 관련 바이러스형 2)로부터 유래된 벡터를 포함한다. AAV 벡터의 매력적인 특징은 이들이 어떠한 바이러스 유전자도 발현하지 않는다는 것이다. AAV 벡터에 포함된 유일한 바이러스 DNA 서열은 145 bp 역방향 말단 반복체(ITR)이다. 따라서, 벌거벗은(naked) DNA로 면역화할 때와 같이, 발현되는 유일한 유전자는 항원 또는 항원 키메라의 유전자이다. 추가로, AAV 벡터는 인간 말초혈액 단핵구 유래 수지상 세포와 같은 분열 및 비분열 세포 둘 다를 지속적인 도입 유전자 발현과 점막 면역 생성을 위한 경구 및 비강내 전달 가능성으로 형질도입하는 것으로 알려져 있다. 더욱이, 필요한 DNA의 양은 50 ㎍ 또는 약 1015개의 카피의 벌거벗은 DNA 용량과 대조적으로 1010 내지 1011개의 입자 또는 DNA 카피의 용량에서의 최대 반응과 함께, 몇 자릿수로 훨씬 더 적은 것으로 보인다. AAV 벡터는 AAV ITR 키메라 단백질 인코딩 구축물 및 ITR이 없는 AAV 코딩 영역(AAV rep 및 cap 유전자)을 포함하는 AAV 헬퍼 플라스미드 ACG2에 함유된 DNA로 적절한 세포주(예를 들어, 인간 293 세포)의 공트랜스펙션에 의해 패키징된다. 세포는 이후에 아데노바이러스 Ad5로 감염된다. 벡터는 당업계에 공지된 방법(예를 들어, 염화세슘 밀도 구배 초원심분리법)을 사용하여 세포 용해물로부터 정제될 수 있으며, 검출 가능한 복제 가능 AAV 또는 아데노바이러스가 없는지 확인하기 위해 검증된다(예를 들어, 세포변성 효과 생물학적 검정에 의해).
레트로바이러스 벡터가 또한 사용될 수 있다. 레트로바이러스는 바이러스에 인코딩된 역전사효소를 사용하여 복제하는 통합 바이러스 부류로, 바이러스 RNA 게놈을 감염 세포(예를 들어, 표적 세포)의 염색체 DNA에 통합되는 이중 가닥 DNA로 복제한다. 이러한 벡터는 뮤린 백혈병 바이러스, 특히 몰로니(Moloney)(문헌[Gilboa, et al., 1988, Adv. Exp. Med. Biol. 241:29]) 또는 프렌드(Friend) FB29 균주(국제 특허 공개 제WO1995/01447호)에서 유래된 것들을 포함한다. 일반적으로, 레트로바이러스 벡터는 바이러스 유전자 gag, pol 및 env의 전부 또는 일부가 결실되고, 5' 및 3' LTR 및 캡슐화 서열을 보유한다. 이들 요소는 레트로바이러스 벡터의 발현 레벨 또는 안정성을 증가시키기 위해 변형될 수 있다. 이러한 변형에는 레트로바이러스 캡슐화 서열을 VL30과 같은 레트로트랜스포존 중 하나로 치환하는 것이 포함된다(예를 들어, 미국 특허 제5,747,323호 참조). 본 발명의 폴리뉴클레오티드는 예컨대, 레트로바이러스 게놈에 대해 반대 방향으로 캡슐화 서열의 하류에 삽입될 수 있다. 레트로바이러스 입자는 헬퍼 바이러스의 존재 하에 또는 레트로바이러스 벡터가 결함이 있는 레트로바이러스 유전자(예를 들어, gag/pol 및 env)를 게놈에 통합시켜 포함하는 적절한 상보성(패키징) 세포주에서 제조된다. 이러한 세포주는 종래 기술에 설명되어 있다(문헌[Miller and Rosman, 1989, BioTechniques 7: 980]; 문헌[Danos and Mulligan, 1988, Proc. Natl. Acad. Sci. USA 85: 6460]; 문헌[Markowitz, et al., 1988, Virol. 167: 400]). env 유전자의 산물은 표적 세포의 표면에 존재하는 바이러스 수용체에 대한 바이러스 입자의 결합에 관여하므로, 레트로바이러스 입자의 숙주 범위를 결정한다. 따라서, 양종성 엔벨로프(amphotropic envelope) 단백질을 함유하는 PA317 세포(ATCC CRL 9078) 또는 293EI6(WO97/35996)와 같은 패키징 세포주는 인간 및 다른 종의 표적 세포를 감염시키는데 사용될 수 있다. 레트로바이러스 입자는 배양 상청액으로부터 회수되고, 임의로 표준 기술(예를 들어, 크로마토그래피, 초원심분리)에 따라 추가로 정제될 수 있다.
조절 요소
본 발명의 폴리뉴클레오티드 또는 이종 폴리뉴클레오티드는 벡터 내의 하나 이상의 조절 요소에 작동가능하게 연결될 수 있다. 조절 요소는 프로모터, 인핸서, 폴리아데닐화 신호, 리프레서 등을 포함할 수 있다.
발현 벡터 및 바이러스 벡터에서 통상적으로 사용되는 인핸서 및 프로모터 서열 중 일부는 예를 들어, 인간 사이토메갈로바이러스(hCMV), 백시니아 P7.5 초기/후기 프로모터, CAG, SV40, 마우스 CMV(mCMV), EF-1 및 hPGK 프로모터이다. 강력하고 약 0.8 kB의 적당한 크기로 인해, hCMV 프로모터는 이들 프로모터 중 가장 일반적으로 사용되는 것 중 하나이다. hPGK 프로모터는 작은 크기(약 0.4 kB)가 특징이지만, hCMV 프로모터보다 덜 강력하다. 한편, 사이토메갈로바이러스 초기 인핸서 요소, 프로모터, 닭 베타-액틴 유전자의 첫 번째 엑손 및 인트론, 토끼 베타-글로빈 유전자의 스플라이스 수용체로 이루어진 CAG 프로모터는 hCMV 프로모터에 필적하는 매우 강력한 유전자 발현을 유도할 수 있지만, 이의 큰 크기로 공간 제약이 중요한 문제가 될 수 있는 바이러스 벡터, 예를 들어 아데노바이러스 벡터(AdV), 아데노 관련 바이러스 벡터(AAV) 또는 렌티바이러스 벡터(LV))에서 덜 적합하게 된다.
사용될 수 있는 추가의 프로모터는 국제 특허 공개 제WO2018/146205호에 기재된 아오틴(Aotine) 헤르페스바이러스 1 주요 전초기(immediate early) 프로모터(AoHV-1 프로모터)이다. 프로모터는 리프레서 단백질의 존재 하에서 프로모터의 발현을 억제하기 위해 리프레서 단백질이 결합할 수 있는 리프레서 오퍼레이터 서열에 작동가능하게 결합될 수 있다. 특정 실시 형태에서, 리프레서 오퍼레이터 서열은 TetO 서열 또는 CuO 서열이다(예를 들어, US9790256 참조).
특정 경우에, 동일한 벡터로부터 적어도 2개의 별개의 폴리펩티드를 발현하는 것이 바람직할 수 있다. 이러한 경우에, 각각의 폴리뉴클레오티드는 동일하거나 상이한 프로모터 및/또는 인핸서 서열에 작동가능하게 연결될 수 있거나, 예를 들어 뇌심근염 바이러스로부터의 내부 리보솜 침입 부위(IRES)를 이용함으로써 잘 알려진 2시스트론성 발현계가 사용될 수 있다. 대안적으로, hCMV-rhCMV 프로모터 및 국제 특허 공개 제WO2017/220499호에 기재된 다른 프로모터와 같은 양방향 합성 프로모터를 사용할 수 있다.
폴리아데닐화 신호는 SV40 또는 소 성장 호르몬(BGH)으로부터 유래될 수 있다.
본 발명의 벡터는 공지된 기술을 사용하여 생성될 수 있다.
벡터에 포함될 수 있는 예시적인 조절 요소는 백시니아 P7.5 초기/후기 프로모터(서열 번호 630), TetOCMV 프로모터(서열 번호 628), BGH 폴리 A 부위(서열 번호 629), T 세포 인핸서(서열 번호 546)를 포함한다.
본 발명은 또한 서열 번호 1, 3, 5, 7, 9, 11, 13, 15, 17, 19, 21, 23, 25, 27, 29, 31, 33, 35, 37, 39, 41, 43, 45, 47, 49, 51, 53, 55, 57, 59, 61, 63, 65, 67, 69, 71, 73, 75, 77, 79, 81, 83, 85, 87, 89, 91, 93, 95, 97, 99, 101, 103, 105, 107, 109, 111, 113, 115, 117, 119, 121, 123, 125, 127, 129, 131, 133, 135, 137, 139, 141, 143, 145, 147, 149, 151, 153, 155, 157, 159, 161, 163, 165, 167, 169, 171, 173, 175, 177, 179, 181, 183, 185, 187, 189, 191, 193, 195, 197, 199, 201, 203, 205, 207, 209, 211, 213, 215, 217, 219, 221, 223, 225, 227, 229, 231, 233, 235, 237, 239, 241, 243, 245, 247, 249, 251, 253, 255, 257, 259, 261, 263, 265, 267, 269, 271, 273, 275, 277, 279, 281, 283, 285, 287, 289, 291, 293, 295, 297, 299, 301, 303, 305, 307, 309, 311, 313, 315, 317, 319, 321, 323, 325, 327, 329, 331, 333, 335, 337, 339, 341, 343, 345, 347, 349, 351, 353, 355, 357, 359, 361, 363, 365, 367, 369, 371, 373, 375, 379, 381, 383, 385, 387, 388, 389, 390, 391, 392, 393, 394, 395, 396, 397, 398, 399, 400, 401, 402, 403, 404, 405, 406, 407, 408, 426, 427, 428, 429, 430, 431, 432, 433, 434, 435, 436, 437, 438, 439, 440, 441, 442, 443, 444, 445, 446 및 447로 이루어진 군으로부터 선택되는 2개 이상의 폴리펩티드 및 이들의 단편을 포함하는 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 단리된 바이러스 벡터를 제공한다.
일부 실시 형태에서, 바이러스 벡터는 서열 번호 2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26, 28, 30, 32, 34, 36, 38, 40, 42, 44, 46, 48, 50, 52, 54, 56, 58, 60, 62, 64, 66, 68, 70, 72, 74, 76, 78, 80, 82, 84, 86, 88, 90, 92, 94, 96, 98, 100, 102, 104, 106, 108, 110, 112, 114, 116, 118, 120, 122, 124, 126, 128, 130, 132, 134, 136, 138, 140, 142, 144, 146, 148, 150, 152, 154, 156, 158, 160, 162, 164, 166, 168, 170, 172, 174, 176, 178, 180, 182, 184, 186, 188, 190, 192, 194, 196, 198, 200, 202, 204, 206, 208, 210, 212, 214, 216, 218, 220, 222, 224, 226, 228, 230, 232, 234, 236, 238, 240, 242, 244, 246, 248, 250, 252, 254, 256, 258, 260, 262, 264, 266, 268, 270, 272, 274, 276, 278, 280, 282, 284, 286, 288, 290, 292, 294, 296, 298, 300, 302, 304, 306, 308, 310, 312, 314, 316, 318, 320, 322, 324, 326, 328, 330, 332, 334, 336, 338, 340, 342, 344, 346, 348, 350, 352, 354, 356, 358, 360, 362, 364, 366, 368, 370, 372, 374, 376, 380, 382, 384, 386, 448, 449, 450, 451, 452, 453, 454, 455, 456, 457 및 458로 이루어진 군으로부터 선택되는 2개 이상의 폴리뉴클레오티드 및 이들의 단편을 포함하는 이종 폴리뉴클레오티드를 포함한다.
본 발명은 또한 서열 번호 275, 381, 333, 337, 269, 253, 309, 325, 271, 305, 251, 245, 261, 265, 317, 255, 277, 297, 285, 437, 439, 442, 444, 379, 343, 211, 349, 213, 215, 221, 219, 225, 345, 353, 235, 223, 167, 171, 19, 23 및 177로 이루어진 군으로부터 선택되는 2개 이상의 폴리펩티드 및 이들의 단편을 포함하는 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 단리된 바이러스 벡터를 제공한다.
일부 실시 형태에서, 바이러스 벡터는 서열 번호 276, 382, 334, 338, 270, 254, 310, 326, 272, 306, 252, 246, 262, 266, 318, 256, 278, 298, 286, 448, 450, 453, 455, 380, 344, 212, 350, 214, 216, 222, 220, 226, 346, 354, 236, 224, 168, 172, 20, 24 및 178로 이루어진 군으로부터 선택되는 2개 이상의 폴리뉴클레오티드 및 이들의 단편을 포함하는 이종 폴리뉴클레오티드를 포함한다.
일부 실시 형태에서, 바이러스 벡터는 서열 번호 459, 460, 461, 462, 463, 464, 465, 466, 467, 468, 469, 470, 471, 472, 473, 474, 475, 476, 477, 478, 479, 480, 481, 482, 483, 484, 485, 486, 487, 488, 489, 490, 491, 492, 493, 494, 495, 496, 497, 498 및 499로 이루어진 군으로부터 선택되는 2개 이상의 폴리뉴클레오티드를 포함하는 이종 폴리뉴클레오티드를 포함한다.
일부 실시 형태에서, 바이러스 벡터는 서열 번호 500, 501, 461, 503, 504, 505, 506, 507, 508, 509, 510, 511, 512, 513, 514, 515, 516, 517, 477, 519, 520, 521, 522, 523, 524, 525, 485, 486, 528, 529, 530, 531, 532, 533, 534, 535, 536, 537, 538, 539 및 540으로 이루어진 군으로부터 선택되는 2개 이상의 폴리뉴클레오티드를 포함하는 이종 폴리뉴클레오티드를 포함한다.
일부 실시 형태에서, 바이러스 벡터는 아데노바이러스 벡터이다.
일부 실시 형태에서, 바이러스 벡터는 인간 아데노바이러스로부터 유래된다.
일부 실시 형태에서, 바이러스 벡터는 Ad26로부터 유래된다.
일부 실시 형태에서, 바이러스 벡터는 유인원 아데노바이러스로부터 유래된다.
일부 실시 형태에서, 바이러스 벡터는 GAd20로부터 유래된다.
일부 실시 형태에서, 바이러스 벡터는 ChAd20로부터 유래된다.
일부 실시 형태에서, 바이러스 벡터는 폭스바이러스 벡터이다.
일부 실시 형태에서, 바이러스 벡터는 변형된 백시니아 앙카라(MVA)로부터 유래된다.
일부 실시 형태에서, 바이러스 벡터는 GAd19으로부터 유래된다.
일부 실시 형태에서, 바이러스 벡터는 GAd21으로부터 유래된다.
일부 실시 형태에서, 바이러스 벡터는 GAd25로부터 유래된다.
일부 실시 형태에서, 바이러스 벡터는 GAd26로부터 유래된다.
일부 실시 형태에서, 바이러스 벡터는 GAd27으로부터 유래된다.
일부 실시 형태에서, 바이러스 벡터는 GAd28으로부터 유래된다.
일부 실시 형태에서, 바이러스 벡터는 GAd29으로부터 유래된다.
일부 실시 형태에서, 바이러스 벡터는 GAd30로부터 유래된다.
일부 실시 형태에서, 바이러스 벡터는 GAd31으로부터 유래된다.
본 발명은 또한 서열 번호 1, 3, 5, 7, 9, 11, 13, 15, 17, 19, 21, 23, 25, 27, 29, 31, 33, 35, 37, 39, 41, 43, 45, 47, 49, 51, 53, 55, 57, 59, 61, 63, 65, 67, 69, 71, 73, 75, 77, 79, 81, 83, 85, 87, 89, 91, 93, 95, 97, 99, 101, 103, 105, 107, 109, 111, 113, 115, 117, 119, 121, 123, 125, 127, 129, 131, 133, 135, 137, 139, 141, 143, 145, 147, 149, 151, 153, 155, 157, 159, 161, 163, 165, 167, 169, 171, 173, 175, 177, 179, 181, 183, 185, 187, 189, 191, 193, 195, 197, 199, 201, 203, 205, 207, 209, 211, 213, 215, 217, 219, 221, 223, 225, 227, 229, 231, 233, 235, 237, 239, 241, 243, 245, 247, 249, 251, 253, 255, 257, 259, 261, 263, 265, 267, 269, 271, 273, 275, 277, 279, 281, 283, 285, 287, 289, 291, 293, 295, 297, 299, 301, 303, 305, 307, 309, 311, 313, 315, 317, 319, 321, 323, 325, 327, 329, 331, 333, 335, 337, 339, 341, 343, 345, 347, 349, 351, 353, 355, 357, 359, 361, 363, 365, 367, 369, 371, 373, 375, 379, 381, 383, 385, 387, 388, 389, 390, 391, 392, 393, 394, 395, 396, 397, 398, 399, 400, 401, 402, 403, 404, 405, 406, 407, 408, 426, 427, 428, 429, 430, 431, 432, 433, 434, 435, 436, 437, 438, 439, 440, 441, 442, 443, 444, 445, 446 및 447로 이루어진 군으로부터 선택되는 2개 이상의 폴리펩티드 및 이들의 단편을 포함하는 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 바이러스 벡터를 포함하는 재조합 인간 아데노바이러스 혈청형 26(rAd26)을 제공한다.
일부 실시 형태에서, rAd26는 서열 번호 2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26, 28, 30, 32, 34, 36, 38, 40, 42, 44, 46, 48, 50, 52, 54, 56, 58, 60, 62, 64, 66, 68, 70, 72, 74, 76, 78, 80, 82, 84, 86, 88, 90, 92, 94, 96, 98, 100, 102, 104, 106, 108, 110, 112, 114, 116, 118, 120, 122, 124, 126, 128, 130, 132, 134, 136, 138, 140, 142, 144, 146, 148, 150, 152, 154, 156, 158, 160, 162, 164, 166, 168, 170, 172, 174, 176, 178, 180, 182, 184, 186, 188, 190, 192, 194, 196, 198, 200, 202, 204, 206, 208, 210, 212, 214, 216, 218, 220, 222, 224, 226, 228, 230, 232, 234, 236, 238, 240, 242, 244, 246, 248, 250, 252, 254, 256, 258, 260, 262, 264, 266, 268, 270, 272, 274, 276, 278, 280, 282, 284, 286, 288, 290, 292, 294, 296, 298, 300, 302, 304, 306, 308, 310, 312, 314, 316, 318, 320, 322, 324, 326, 328, 330, 332, 334, 336, 338, 340, 342, 344, 346, 348, 350, 352, 354, 356, 358, 360, 362, 364, 366, 368, 370, 372, 374, 376, 380, 382, 384, 386, 448, 449, 450, 451, 452, 453, 454, 455, 456, 457 및 458로 이루어진 군으로부터 선택되는 2개 이상의 폴리뉴클레오티드 및 이들의 단편을 포함하는 바이러스 벡터를 포함한다.
본 발명은 또한 서열 번호 275, 381, 333, 337, 269, 253, 309, 325, 271, 305, 251, 245, 261, 265, 317, 255, 277, 297, 285, 437, 439, 442, 444, 379, 343, 211, 349, 213, 215, 221, 219, 225, 345, 353, 235, 223, 167, 171, 19, 23 및 177로 이루어진 군으로부터 선택되는 2개 이상의 폴리펩티드 및 이들의 단편을 포함하는 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 rAd26를 제공한다.
일부 실시 형태에서, rAd26는 서열 번호 276, 382, 334, 338, 270, 254, 310, 326, 272, 306, 252, 246, 262, 266, 318, 256, 278, 298, 286, 448, 450, 453, 455, 380, 344, 212, 350, 214, 216, 222, 220, 226, 346, 354, 236, 224, 168, 172, 20, 24 및 178로 이루어진 군으로부터 선택되는 2개 이상의 폴리뉴클레오티드 및 이들의 단편을 포함하는 이종 폴리뉴클레오티드를 포함한다.
일부 실시 형태에서, rAd26는 서열 번호 459, 460, 461, 462, 463, 464, 465, 466, 467, 468, 469, 470, 471, 472, 473, 474, 475, 476, 477, 478, 479, 480, 481, 482, 483, 484, 485, 486, 487, 488, 489, 490, 491, 492, 493, 494, 495, 496, 497, 498 및 499로 이루어진 군으로부터 선택되는 2개 이상의 폴리뉴클레오티드 및 이들의 단편을 포함하는 이종 폴리뉴클레오티드를 포함한다.
일부 실시 형태에서, rAd26는 서열 번호 500, 501, 461, 503, 504, 505, 506, 507, 508, 509, 510, 511, 512, 513, 514, 515, 516, 517, 477, 519, 520, 521, 522, 523, 524, 525, 485, 486, 528, 529, 530, 531, 532, 533, 534, 535, 536, 537, 538, 539 및 540으로 이루어진 군으로부터 선택되는 2개 이상의 폴리뉴클레오티드 및 이들의 단편을 포함하는 이종 폴리뉴클레오티드를 포함한다.
본 발명은 또한 서열 번호 1, 3, 5, 7, 9, 11, 13, 15, 17, 19, 21, 23, 25, 27, 29, 31, 33, 35, 37, 39, 41, 43, 45, 47, 49, 51, 53, 55, 57, 59, 61, 63, 65, 67, 69, 71, 73, 75, 77, 79, 81, 83, 85, 87, 89, 91, 93, 95, 97, 99, 101, 103, 105, 107, 109, 111, 113, 115, 117, 119, 121, 123, 125, 127, 129, 131, 133, 135, 137, 139, 141, 143, 145, 147, 149, 151, 153, 155, 157, 159, 161, 163, 165, 167, 169, 171, 173, 175, 177, 179, 181, 183, 185, 187, 189, 191, 193, 195, 197, 199, 201, 203, 205, 207, 209, 211, 213, 215, 217, 219, 221, 223, 225, 227, 229, 231, 233, 235, 237, 239, 241, 243, 245, 247, 249, 251, 253, 255, 257, 259, 261, 263, 265, 267, 269, 271, 273, 275, 277, 279, 281, 283, 285, 287, 289, 291, 293, 295, 297, 299, 301, 303, 305, 307, 309, 311, 313, 315, 317, 319, 321, 323, 325, 327, 329, 331, 333, 335, 337, 339, 341, 343, 345, 347, 349, 351, 353, 355, 357, 359, 361, 363, 365, 367, 369, 371, 373, 375, 379, 381, 383, 385, 387, 388, 389, 390, 391, 392, 393, 394, 395, 396, 397, 398, 399, 400, 401, 402, 403, 404, 405, 406, 407, 408, 426, 427, 428, 429, 430, 431, 432, 433, 434, 435, 436, 437, 438, 439, 440, 441, 442, 443, 444, 445, 446 및 447로 이루어진 군으로부터 선택되는 2개 이상의 폴리펩티드 및 이들의 단편을 포함하는 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 바이러스 벡터를 포함하는 재조합 유인원 아데노바이러스(rGAd)를 제공한다.
일부 실시 형태에서, rGAd는 서열 번호 2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26, 28, 30, 32, 34, 36, 38, 40, 42, 44, 46, 48, 50, 52, 54, 56, 58, 60, 62, 64, 66, 68, 70, 72, 74, 76, 78, 80, 82, 84, 86, 88, 90, 92, 94, 96, 98, 100, 102, 104, 106, 108, 110, 112, 114, 116, 118, 120, 122, 124, 126, 128, 130, 132, 134, 136, 138, 140, 142, 144, 146, 148, 150, 152, 154, 156, 158, 160, 162, 164, 166, 168, 170, 172, 174, 176, 178, 180, 182, 184, 186, 188, 190, 192, 194, 196, 198, 200, 202, 204, 206, 208, 210, 212, 214, 216, 218, 220, 222, 224, 226, 228, 230, 232, 234, 236, 238, 240, 242, 244, 246, 248, 250, 252, 254, 256, 258, 260, 262, 264, 266, 268, 270, 272, 274, 276, 278, 280, 282, 284, 286, 288, 290, 292, 294, 296, 298, 300, 302, 304, 306, 308, 310, 312, 314, 316, 318, 320, 322, 324, 326, 328, 330, 332, 334, 336, 338, 340, 342, 344, 346, 348, 350, 352, 354, 356, 358, 360, 362, 364, 366, 368, 370, 372, 374, 376, 380, 382, 384, 386, 448, 449, 450, 451, 452, 453, 454, 455, 456, 457 및 458로 이루어진 군으로부터 선택되는 2개 이상의 폴리뉴클레오티드 및 이들의 단편을 포함하는 이종 폴리뉴클레오티드를 포함하는 바이러스 벡터를 포함한다.
본 발명은 또한 서열 번호 275, 381, 333, 337, 269, 253, 309, 325, 271, 305, 251, 245, 261, 265, 317, 255, 277, 297, 285, 437, 439, 442, 444, 379, 343, 211, 349, 213, 215, 221, 219, 225, 345, 353, 235, 223, 167, 171, 19, 23 및 177로 이루어진 군으로부터 선택되는 2개 이상의 폴리펩티드 및 이들의 단편을 포함하는 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 rGAd를 제공한다.
일부 실시 형태에서, rGAd는 서열 번호 276, 382, 334, 338, 270, 254, 310, 326, 272, 306, 252, 246, 262, 266, 318, 256, 278, 298, 286, 448, 450, 453, 455, 380, 344, 212, 350, 214, 216, 222, 220, 226, 346, 354, 236, 224, 168, 172, 20, 24 및 178로 이루어진 군으로부터 선택되는 2개 이상의 폴리뉴클레오티드 및 이들의 단편을 포함하는 이종 폴리뉴클레오티드를 포함한다.
일부 실시 형태에서, rGAd는 서열 번호 459, 460, 461, 462, 463, 464, 465, 466, 467, 468, 469, 470, 471, 472, 473, 474, 475, 476, 477, 478, 479, 480, 481, 482, 483, 484, 485, 486, 487, 488, 489, 490, 491, 492, 493, 494, 495, 496, 497, 498 및 499로 이루어진 군으로부터 선택되는 2개 이상의 폴리뉴클레오티드 및 이들의 단편을 포함하는 이종 폴리뉴클레오티드를 포함한다.
일부 실시 형태에서, rGAd는 서열 번호 500, 501, 461, 503, 504, 505, 506, 507, 508, 509, 510, 511, 512, 513, 514, 515, 516, 517, 477, 519, 520, 521, 522, 523, 524, 525, 485, 486, 528, 529, 530, 531, 532, 533, 534, 535, 536, 537, 538, 539 및 540으로 이루어진 군으로부터 선택되는 2개 이상의 폴리뉴클레오티드 및 이들의 단편을 포함하는 이종 폴리뉴클레오티드를 포함한다.
본 발명은 또한 서열 번호 1, 3, 5, 7, 9, 11, 13, 15, 17, 19, 21, 23, 25, 27, 29, 31, 33, 35, 37, 39, 41, 43, 45, 47, 49, 51, 53, 55, 57, 59, 61, 63, 65, 67, 69, 71, 73, 75, 77, 79, 81, 83, 85, 87, 89, 91, 93, 95, 97, 99, 101, 103, 105, 107, 109, 111, 113, 115, 117, 119, 121, 123, 125, 127, 129, 131, 133, 135, 137, 139, 141, 143, 145, 147, 149, 151, 153, 155, 157, 159, 161, 163, 165, 167, 169, 171, 173, 175, 177, 179, 181, 183, 185, 187, 189, 191, 193, 195, 197, 199, 201, 203, 205, 207, 209, 211, 213, 215, 217, 219, 221, 223, 225, 227, 229, 231, 233, 235, 237, 239, 241, 243, 245, 247, 249, 251, 253, 255, 257, 259, 261, 263, 265, 267, 269, 271, 273, 275, 277, 279, 281, 283, 285, 287, 289, 291, 293, 295, 297, 299, 301, 303, 305, 307, 309, 311, 313, 315, 317, 319, 321, 323, 325, 327, 329, 331, 333, 335, 337, 339, 341, 343, 345, 347, 349, 351, 353, 355, 357, 359, 361, 363, 365, 367, 369, 371, 373, 375, 379, 381, 383, 385, 387, 388, 389, 390, 391, 392, 393, 394, 395, 396, 397, 398, 399, 400, 401, 402, 403, 404, 405, 406, 407, 408, 426, 427, 428, 429, 430, 431, 432, 433, 434, 435, 436, 437, 438, 439, 440, 441, 442, 443, 444, 445, 446 및 447로 이루어진 군으로부터 선택되는 2개 이상의 폴리펩티드 및 이들의 단편을 포함하는 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 바이러스 벡터를 포함하는 재조합 변형된 백시니아 앙카라(rMVA)를 제공한다.
일부 실시 형태에서, rMVA는 서열 번호 2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26, 28, 30, 32, 34, 36, 38, 40, 42, 44, 46, 48, 50, 52, 54, 56, 58, 60, 62, 64, 66, 68, 70, 72, 74, 76, 78, 80, 82, 84, 86, 88, 90, 92, 94, 96, 98, 100, 102, 104, 106, 108, 110, 112, 114, 116, 118, 120, 122, 124, 126, 128, 130, 132, 134, 136, 138, 140, 142, 144, 146, 148, 150, 152, 154, 156, 158, 160, 162, 164, 166, 168, 170, 172, 174, 176, 178, 180, 182, 184, 186, 188, 190, 192, 194, 196, 198, 200, 202, 204, 206, 208, 210, 212, 214, 216, 218, 220, 222, 224, 226, 228, 230, 232, 234, 236, 238, 240, 242, 244, 246, 248, 250, 252, 254, 256, 258, 260, 262, 264, 266, 268, 270, 272, 274, 276, 278, 280, 282, 284, 286, 288, 290, 292, 294, 296, 298, 300, 302, 304, 306, 308, 310, 312, 314, 316, 318, 320, 322, 324, 326, 328, 330, 332, 334, 336, 338, 340, 342, 344, 346, 348, 350, 352, 354, 356, 358, 360, 362, 364, 366, 368, 370, 372, 374, 376, 380, 382, 384, 386, 448, 449, 450, 451, 452, 453, 454, 455, 456, 457 및 458로 이루어진 군으로부터 선택되는 2개 이상의 폴리뉴클레오티드 및 이들의 단편을 포함하는 이종 폴리펩티드를 포함하는 바이러스 벡터를 포함한다.
본 발명은 또한 서열 번호 275, 381, 333, 337, 269, 253, 309, 325, 271, 305, 251, 245, 261, 265, 317, 255, 277, 297, 285, 437, 439, 442, 444, 379, 343, 211, 349, 213, 215, 221, 219, 225, 345, 353, 235, 223, 167, 171, 19, 23 및 177로 이루어진 군으로부터 선택되는 2개 이상의 폴리펩티드 및 이들의 단편을 포함하는 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 rMVA를 제공한다.
일부 실시 형태에서, rMVA는 서열 번호 276, 382, 334, 338, 270, 254, 310, 326, 272, 306, 252, 246, 262, 266, 318, 256, 278, 298, 286, 448, 450, 453, 455, 380, 344, 212, 350, 214, 216, 222, 220, 226, 346, 354, 236, 224, 168, 172, 20, 24 및 178로 이루어진 군으로부터 선택되는 2개 이상의 폴리뉴클레오티드 및 이들의 단편을 포함하는 이종 폴리뉴클레오티드를 포함한다.
일부 실시 형태에서, rMVA는 서열 번호 459, 460, 461, 462, 463, 464, 465, 466, 467, 468, 469, 470, 471, 472, 473, 474, 475, 476, 477, 478, 479, 480, 481, 482, 483, 484, 485, 486, 487, 488, 489, 490, 491, 492, 493, 494, 495, 496, 497, 498 및 499로 이루어진 군으로부터 선택되는 2개 이상의 폴리뉴클레오티드 및 이들의 단편을 포함하는 이종 폴리뉴클레오티드를 포함한다.
일부 실시 형태에서, rMVA는 서열 번호 500, 501, 461, 503, 504, 505, 506, 507, 508, 509, 510, 511, 512, 513, 514, 515, 516, 517, 477, 519, 520, 521, 522, 523, 524, 525, 485, 486, 528, 529, 530, 531, 532, 533, 534, 535, 536, 537, 538, 539 및 540으로 이루어진 군으로부터 선택되는 2개 이상의 폴리뉴클레오티드 및 이들의 단편을 포함하는 이종 폴리뉴클레오티드를 포함한다.
본 발명의 세포
본 발명은 또한 하나 이상의 본 발명의 벡터 또는 하나 이상의 본 발명의 재조합 바이러스를 포함하거나 이로 형질도입된 세포를 제공한다. 일부 실시 형태에서, 상기 세포는 숙주 세포이다.
적절한 세포는 원핵세포 및 진핵세포, 예를 들어 포유류 세포, 효모, 진균 및 세균(예컨대, 대장균), 예컨대 Hek 293, CHO, PER.C6, PER.C6 TetO 또는 닭 배아 섬유아세포(CEF)를 포함한다. 세포는 시험관내에서, 예컨대 폴리펩티드 또는 바이러스의 연구 또는 생산을 위해 사용될 수 있거나, 세포는 생체내에서 사용될 수 있다. 일부 실시 형태에서, 세포는 근육 세포이다. 일부 실시 형태에서, 세포는 항원 제시 세포(APC)이다. 적절한 항원 제시 세포에는 수지상 세포, B 림프구, 단핵구 및 대식세포가 포함된다.
"형질도입된", "형질전환된" 또는 "트랜스펙션된"은 세포 내부에 본 발명의 폴리뉴클레오티드, 이종 폴리뉴클레오티드 또는 벡터를 도입하는 것을 지칭한다. 도입된 폴리뉴클레오티드는 세포의 게놈을 구성하는 염색체 DNA에 통합될 수 있거나 통합되지 않을 수 있다. "세포"는 기원 세포 및 기원 세포로부터 확립된 임의의 자손 또는 클론 세포주를 지칭한다.
본 발명의 폴리뉴클레오티드 또는 벡터로 트랜스펙션된 세포는 전형적으로 ATCC와 같은 세포 배양물 저장소를 통해 얻어질 수 있다. APC는 백혈구 성분채집술 및 "FICOLL/HYPAQUE" 밀도 구배 원심분리법(피콜 및 불연속적인 퍼콜 밀도 구배(Ficoll and discontinuous Percoll density gradient)를 통한 단계적 원심분리)를 사용하여 말초 혈액에서 얻을 수 있다. APC는 공지된 방법을 사용하여 단리되고, 배양되고, 조작될 수 있다. 예를 들어, 미성숙 및 성숙 수지상 세포는 공지된 방법을 사용하여 말초 혈액 단핵 세포(PBMC)로부터 생성될 수 있다. 예시적인 방법에서, 단리된 PBMC는 면역자기 기술에 의해 T 세포 및 B 세포를 고갈시키기 위해 전처리된다. 그 다음에 림프구 감소형 PBMC는 인간 혈장(바람직하게는 자가 혈장) 및 GM-CSF/IL-4가 보충된 RPMI 배지(예를 들어, 약 7일간)에서 배양되어 수지상 세포를 생성한다. 수지상 세포는 이의 단핵구 전구체와 비교하여 비접착성이다. 따라서, 약 7일째에, 비접착성 세포가 추가 처리를 위해 채취된다. GM-CSF 및 IL-4의 존재 하에서 PBMC로부터 유래된 수지상 세포는 이들이 비접착성을 상실하고, 사이토카인 자극이 배양물로부터 제거되면 대식세포의 운명으로 다시 되돌아갈 수 있다는 점에서 미성숙이다. 미성숙 상태의 수지상 세포는 MHC 클래스 II 제한 경로에 대한 천연 단백질 항원을 처리하는 데 효과적이다(문헌[Romani, et al., J. Exp. Med. 169: 1169, 1989]). 배양된 수지상 세포의 추가 성숙은 필요한 성숙 인자를 포함하는 대식세포 조절 배지(CM)에서 3일간 배양함으로써 달성된다. 성숙 수지상 세포는 제시를 위한 새로운 단백질을 포획할 수 없게 되지만, 휴지 T 세포(CD4 및 CD8 둘 다)가 성장 및 분화되는 것을 자극하는 데 훨씬 더 우수하다. 성숙 수지상 세포는 더욱 운동성이 있는 세포질 돌기의 형성과 같은 형태 변화에 의해, 비접착성에 의해, 다음 마커 CD83, CD68, HLA-DR 또는 CD86 중 적어도 하나의 존재에 의해, 또는 CD115와 같은 Fc 수용체의 손실에 의해 확인될 수 있다(문헌[Steinman, Annu. Rev. Immunol. 9: 271, 1991]에서 검토됨). 성숙 수지상 세포는 FACScan 및 FACStar와 같은 전형적인 세포 형광 분석 및 세포 분류 기술 및 장치를 사용하여 수집 및 분석될 수 있다. 유세포 분석에 사용되는 일차 항체는 성숙 수지상 세포의 세포 표면 항원에 특이적인 것이며, 시판되고 있다. 이차 항체는 비오틴화 Ig, 이어서 FITC- 또는 PE-접합된 스트렙타비딘일 수 있다. 본 발명의 벡터 및 재조합 바이러스는 트랜스펙션, 전기천공, 융합, 미량 주입(microinjection), 바이러스-기반 전달 또는 세포-기반 전달을 포함하나 이에 한정되지 않는 당업계에 공지된 방법을 사용하여 APC를 포함하는 세포에 도입될 수 있다.
본 발명의 백신 및 약제학적 조성물
폴리펩티드 또는 이종 폴리펩티드 또는 이들의 단편, 또는 이들을 인코딩하는 폴리뉴클레오티드는 대상에게 투여하기에 적합한 임의의 공지된 전달 비히클을 이용하여 대상에게 전달될 수 있다. 폴리펩티드, 이종 폴리펩티드 또는 이들의 단편은 사용되는 전달 비히클에 관계없이 대상에서 면역원성을 나타낼 것으로 예상된다. 다양한 바이러스 균주는 인간 대상에서 폴리펩티드 또는 이종 폴리펩티드의 전달을 매개하는 데 동등하게 효과적일 것이며, 따라서 상호교환가능할 수 있을 것으로 예상된다. 예를 들어, 본 명세서에 개시된 다양한 MVA 균주는 동일한 도입유전자 카세트에 의해 인코딩된 항원에 대한 면역반응을 촉진시키는데 동등하게 효과적일 것으로 예상된다. 유사하게, 다양한 아데노바이러스 균주는 동일한 도입유전자 카세트에 의해 인코딩된 항원에 대한 면역반응을 촉진시키는 능력의 변화가 전혀 없거나 최소한으로 상호교환가능할 것으로 예상된다. 폴리뉴클레오티드는 DNA 또는 RNA, 또는 이들의 유도체일 수 있다. RNA는 올리고뉴클레오티드 RNA, tRNA(전이 RNA), snRNA(핵내 저분자 RNA), rRNA(리보솜 RNA), mRNA(메신저 RNA), 안티센스 RNA, siRNA(저분자 간섭 RNA), 자기 복제 RNA, 리보자임, 키메라 서열 또는 이들 그룹의 유도체의 형태일 수 있다
본 발명은 또한 본 발명의 폴리뉴클레오티드를 포함하는 백신을 제공한다.
일부 실시 형태에서, 폴리뉴클레오티드는 DNA이다.
일부 실시 형태에서, 폴리뉴클레오티드는 RNA이다.
일부 실시 형태에서, RNA는 mRNA 또는 자기 복제 RNA이다.
일부 실시 형태에서, RNA는 자기 복제 RNA이다.
본 발명은 또한 본 발명의 이종 폴리뉴클레오티드를 포함하는 백신을 제공한다.
일부 실시 형태에서, 이종 폴리뉴클레오티드는 DNA이다.
일부 실시 형태에서, 이종 폴리뉴클레오티드는 RNA이다.
일부 실시 형태에서, RNA는 mRNA 또는 자기 복제 RNA이다.
일부 실시 형태에서, RNA는 자기 복제 RNA이다.
본 발명은 또한 본 발명의 폴리펩티드를 포함하는 백신을 제공한다.
본 발명은 또한 본 발명의 이종 폴리펩티드를 포함하는 백신을 제공한다.
본 발명은 또한 본 발명의 벡터를 포함하는 백신을 제공한다.
본 발명은 또한 본 발명의 rAd26를 포함하는 백신을 제공한다.
본 발명은 또한 본 발명의 rMVA를 포함하는 백신을 제공한다.
본 발명은 또한 본 발명의 rGAd를 포함하는 백신을 제공한다.
본 발명은 또한 본 발명의 rGAd20를 포함하는 백신을 제공한다.
본 발명은 또한 본 발명의 ChAd20를 포함하는 백신을 제공한다.
본 발명은 또한 본 발명의 세포를 포함하는 백신을 제공한다.
백신 조성물의 제법이 잘 알려져 있다. 백신은 백신 및 약제학적으로 허용가능한 부형제를 포함하는 약제학적 조성물을 포함하거나 이로 제제화될 수 있다. "약제학적으로 허용가능한"은 사용되는 투여량 및 농도에서 이들이 투여되는 대상에게 원치 않거나 유해한 영향을 미치지 않는 부형제를 지칭하며, 담체, 완충제, 안정제 또는 당업자에게 잘 알려진 다른 물질을 포함한다. 담체 또는 다른 물질의 정확한 성질은 투여 경로, 예를 들어 근육내, 피하, 경구, 정맥내, 피부, 점막내(예를 들어, 장), 비강내 또는 복막내 경로에 좌우될 수 있다. 물, 석유, 동물유 또는 식물유, 광유 또는 합성 오일과 같은 액체 담체가 포함될 수 있다. 생리식염수, 덱스트로스 또는 다른 당류 용액 또는 글리콜, 예컨대 에틸렌 글리콜, 프로필렌 글리콜 또는 폴리에틸렌 글리콜이 포함될 수 있다. 예시적인 바이러스 제제는 아데노바이러스 월드 스탠더드(Adenovirus World Standard)(문헌[Hoganson et al, 2002])이다: 20 mM 트리스(Tris) pH 8, 25 mM NaCl, 2.5% 글리세롤; 또는 20 mM 트리스, 2 mM MgCl2, 25 mM NaCl, 수크로스 10% w/v, 폴리소르베이트-80 0.02% w/v; 또는 10-25 mM 시트레이트 완충제 pH 5.9-6.2, 4-6% (w/w) 하이드록시프로필-베타-사이클로덱스트린(HBCD), 70-100 mM NaCl, 0.018-0.035% (w/w) 폴리소르베이트-80, 및 임의로 0.3-0.45% (w/w) 에탄올. 많은 다른 완충제가 사용될 수 있으며, 정제된 약제학적 제제의 보관 및 약제학적 투여에 적합한 제형의 예가 알려져 있다.
백신은 하나 이상의 애주번트를 포함할 수 있다. 적절한 애주번트는 QS-21, 디톡스(Detox)-PC, MPL- SE, MoGM-CSF, 타이터맥스(TiterMax)-G, CRL-1005, GERBU, 테라미드(TERamide), PSC97B, 아주머(Adjumer), PG-026, GSK-I, GcMAF, B-알레틴(alethine), MPC-026, 아주박스(Adjuvax), CpG ODN, 베타펙틴(Betafectin), 명반(Alum) 및 MF59을 포함한다. 사용될 수 있는 다른 애주번트는 렉틴, 성장 인자, 사이토카인 및 림포카인, 예컨대 알파-인터페론, 감마 인터페론, 혈소판 유래 성장 인자(PDGF), 과립구 콜로니 자극 인자(gCSF), 과립구 대식세포 콜로니 자극 인자(gMCSF), 종양 괴사 인자(TNF), 표피 성장 인자(EGF), IL-1, IL-2, IL-4, IL-6, IL-8, IL-10, IL-12 또는 TLR 작용제를 포함한다.
"애주번트" 및 "면역 자극제"는 본 명세서에서 상호교환가능하게 사용되며, 면역계의 자극을 일으키는 하나 이상의 물질로서 정의된다. 이와 관련하여, 애주번트는 본 명세서에 기재된 백신 또는 바이러스 벡터에 대한 면역반응을 증강시키는데 사용된다.
본 발명에 따른 약제학적 조성물은 특정 실시 형태에서 본 발명의 백신일 수 있다.
유사하게, 본 발명의 폴리뉴클레티드, 이종 폴리뉴클레오티드, 폴리펩티드 및 이종 폴리펩티드는 폴리뉴클레오티드, 이종 폴리뉴클레오티드, 폴리펩티드 및 이종 폴리펩티드 및 약제학적으로 허용가능한 부형제를 포함하는 약제학적 조성물로 제제화될 수 있다.
키트
본 발명은 또한 하나 이상의 본 발명의 백신을 포함하는 키트를 제공한다. 본 발명은 또한 하나 이상의 본 발명의 재조합 바이러스를 포함하는 키트를 제공한다. 키트는 본 명세서에 기재된 방법을 수행하는 것을 용이하게 하기 위해 사용될 수 있다. 일부 실시 형태에서, 키트는 본 발명의 백신의 세포, 예컨대 지질 기반 제제 또는 바이러스 패키징 물질 내로의 진입을 용이하게 하기 위한 시약을 추가로 포함한다.
일부 실시 형태에서, 키트는 본 발명의 rAd26를 포함한다. 일부 실시 형태에서, 키트는 본 발명의 rMVA를 포함한다. 일부 실시 형태에서, 키트는 본 발명의 rGAd를 포함한다. 일부 실시 형태에서, 키트는 본 발명의 rAd26 및 본 발명의 rMVA를 포함한다. 일부 실시 형태에서, 키트는 본 발명의 rGAd 및 본 발명의 rMVA를 포함한다. 일부 실시 형태에서, 키트는 본 발명의 rAd26 및 본 발명의 rGAd를 포함한다. 일부 실시 형태에서, 키트는 하나 이상의 본 발명의 폴리뉴클레오티드를 포함한다. 일부 실시 형태에서, 키트는 하나 이상의 본 발명의 이종 폴리뉴클레오티드를 포함한다. 일부 실시 형태에서, 키트는 하나 이상의 본 발명의 폴리펩티드를 포함한다. 일부 실시 형태에서, 키트는 하나 이상의 본 발명의 이종 폴리펩티드를 포함한다. 일부 실시 형태에서, 키트는 하나 이상의 본 발명의 벡터를 포함한다. 일부 실시 형태에서, 키트는 하나 이상의 본 발명의 세포를 포함한다.
비바이러스 전달 비히클
나노입자
폴리펩티드 또는 이종 폴리펩티드 또는 이들의 단편, 이들을 인코딩하는 폴리뉴클레오티드 또는 본 발명의 폴리뉴클레오티드를 포함하는 벡터는 대상으로의 전달을 위해 나노입자에 부착될 수 있다. 폴리펩티드 또는 이종 폴리펩티드 또는 이들의 단편, 이들을 인코딩하는 폴리뉴클레오티드 또는 폴리뉴클레오티드를 포함하는 벡터를 나노입자를 사용하여 전달함으로써, 백신 조성물에 바이러스 또는 애주번트를 포함할 필요성을 없앨 수 있다. 폴리뉴클레오티드는 DNA 또는 RNA일 수 있다. 나노입자는 펩티드에 대한 면역반응을 효과적으로 유도하는 데 도움이 되는 면역 위험 신호를 포함할 수 있다. 나노입자는 강력한 면역반응에 필요한 수지상 세포(DC) 활성화 및 성숙을 유도할 수 있다. 나노입자는 항원 제시 세포와 같은 세포에 의한 나노입자 및 따라서 펩티드의 흡수를 개선하는 비자기 성분을 함유할 수 있다.
나노입자는 전형적으로 직경이 약 1 nm 내지 약 100 nm, 예를 들어 약 20 nm 내지 약 40 nm이다. 평균 직경이 20 내지 40 nm인 나노입자는 사이토졸에 대한 나노입자의 흡수를 촉진시킬 수 있다(예를 들어, WO2019/135086 참조). 예시적인 나노입자는 폴리머 나노입자, 무기 나노입자, 리포좀, 지질 나노입자(LNP), 면역 자극 복합체(ISCOM), 바이러스 유사 입자(VLP) 또는 자기 조립 단백질이다. 나노입자는 인산칼슘 나노입자, 실리콘 나노입자 또는 금 나노입자일 수 있다. 폴리머 나노입자는 하나 이상의 합성 폴리머, 예컨대 폴리(d,l-락티드-코-글리콜라이드)(PLG), 폴리(d,l-락트산-코글리콜산)(PLGA), 폴리(g-글루탐산)(g-PGA)m 폴리(에틸렌 글리콜)(PEG), 또는 폴리스티렌 또는 하나 이상의 천연 폴리머, 예컨대 다당류, 예를 들어 풀루란, 알기네이트, 이눌린 및 키토산을 포함할 수 있다. 폴리머 나노입자의 사용은 나노입자에 포함될 수 있는 폴리머의 특성으로 인해 유리할 수 있다. 예를 들어, 상기에 언급된 천연 및 합성 폴리머는 양호한 생체적합성 및 생분해성, 비독성 특성 및/또는 원하는 형상 및 크기로 조작되는 능력을 가질 수 있다. 폴리머 나노입자는 하이드로젤 나노입자, 즉, 유연한 메시 크기, 다가 접합을 위한 큰 표면적, 높은 수분 함량 및 항원에 대한 높은 로딩 용량을 포함하는 유리한 특성을 갖는 친수성 3차원 폴리머 네트워크를 형성할 수 있다. 폴리(L-락트산)(PLA), PLGA, PEG 및 다당류와 같은 폴리머가 하이드로젤 나노입자를 형성하는데 적합하다. 무기 나노입자는 전형적으로 강성 구조를 가지며, 항원이 캡슐화된 셸 또는 항원이 공유결합될 수 있는 코어를 포함한다. 코어는 하나 이상의 원자, 예컨대 금(Au), 은(Ag), 구리(Cu) 원자, Au/Ag, Au/Cu, Au/Ag/Cu, Au/Pt, Au/Pd 또는 Au/Ag/Cu/Pd 또는 인산칼슘(CaP)을 포함할 수 있다.
나노입자는 리포솜일 수 있다. 리포솜은 전형적으로 생분해성 비독성 인지질로 형성되며, 수성 코어를 갖는 자기 조립 인지질 이중층 셸을 포함한다. 리포솜은 단일 인지질 이중층을 포함하는 단층 소포이거나, 수층에 의해 분리된 여러 동심 인지질 셸을 포함하는 다중층 소포일 수 있다. 결과적으로, 리포솜은 친수성 분자를 수성 코어에 통합하거나, 소수성 분자를 인지질 이중층 내에 통합하도록 맞춰질 수 있다. 리포솜은 전달을 위해 코어 내에 본 발명의 폴리펩티드 또는 이종 폴리펩티드 또는 이들의 단편과 같은 항원을 캡슐화할 수 있다. 리포솜 및 리포솜 제제는 표준 방법에 따라 제조할 수 있고, 당업계에 잘 알려져 있으며, 예를 들어 문헌[Remington's; Akimaru, 1995, Cytokines Mol. Ther. 1: 197-210]; 문헌[Alving, 1995, Immunol. Rev. 145: 5-31]; 문헌[Szoka, 1980, Ann. Rev. Biophys. Bioeng. 9: 467]; 미국 특허 제4,235,871호; 미국 특허 제4,501,728호; 및 미국 특허 제4,837,028호를 참조한다. 리포솜은 특정 세포형에 리포솜 복합체를 표적화하기 위한 표적화 분자를 포함할 수 있다. 표적화 분자는 표적 조직에서 발견되는 혈관 또는 세포의 표면 상의 생체분자(예를 들어, 수용체 또는 리간드)에 대한 결합 파트너(예를 들어, 리간드 또는 수용체)를 포함할 수 있다. 리포솜 전하는 혈액에서 리포좀 제거에 중요한 결정 인자이며, 음으로 하전된 리포솜은 세망내피계에 의해 더 빠르게 흡수되어(문헌[Juliano, 1975, Biochem. Biophys. Res. Commun. 63: 651]), 혈류에서 더 짧은 반감기를 갖는다. 포스파티딜에탄올아민 유도체의 혼입은 리포솜 응집을 방지하여 순환 시간을 향상시킨다. 예를 들어, N-(오메가-카르복시)아실아미도포스파티딜에탄올아민을 L-알파-다이스테아로일포스파티딜콜린의 큰 단층 소포에 혼입하면, 생체내 리포솜 순환 수명을 극적으로 증가시킨다(예를 들어, 문헌[Ahl, 1997, Biochim. Biophys. Acta 1329: 370-382]). 전형적으로, 리포솜은 약 5 내지 15 몰%의 음으로 하전된 인지질, 예컨대 포스파티딜글리세롤, 포스파티딜세린 또는 포스파티딜-이노시톨로 제조된다. 또한 포스파티딜글리세롤과 같은 음으로 하전된 인지질을 첨가하면, 자발적 리포솜 응집을 방지하여, 크기가 작은 리포솜 응집 형성의 위험을 최소화시킨다. 적어도 약 50몰% 농도의 막강성화제, 예컨대 스핑고미엘린 또는 포화 중성 인지질 및 5 내지 15 몰%의 모노시알릴강글리오시드(monosialylganglioside)는 또한 바람직하게는 강성과 같은 리포솜 특성을 부여할 수 있다(예를 들어, 미국 특허 제4,837,028호 참조). 게다가, 리포솜 현탁액은 저장 시의 자유 라디칼 및 지질 과산화 손상으로부터 지질을 보호하는 지질 보호제를 포함할 수 있다. 알파-토코페롤과 같은 친유성 자유 라디칼 소광제 및 페리옥사민과 같은 수용성 철 특이적 킬레이트제가 바람직하다.
나노입자는 지질 나노입자(LNP)일 수 있다. LNP는 리포솜과 유사하지만, 기능과 조성이 약간 다르다. LNP는 DNA, mRNA, siRNA 및 sRNA와 같은 폴리뉴클레오티드를 캡슐화하기 위해 설계된다. 전통적인 리포솜은 하나 이상의 지질 이중층으로 둘러싸인 수성 코어를 포함한다. LNP는 비수성 코어에 약물 분자를 캡슐화하는 미셀 유사 구조를 가정할 수 있다. LNP는 전형적으로 양이온성 지질, 비양이온성 지질 및 입자의 응집을 방지하는 지질(예를 들어, PEG-지질 접합체)을 포함한다. LNP는 정맥내(i.e.) 주사(즉) 후 연장된 순환 수명을 나타내며, 원위 부위(예를 들어, 투여 부위로부터 물리적으로 떨어져 있는 부위)에 축적되기 때문에, 전신 적용에 유용하다. LNP는 평균 직경이 약 50 nm 내지 약 150 nm, 예컨대 약 60 nm 내지 약 130 nm, 약 70 nm 내지 약 110 nm, 또는 약 70 nm 내지 약 90 nm 일 수 있으며, 실질적으로 비독성이다. 폴리뉴클레오티드 로딩된 LNP의 제조는 예를 들어, 미국 특허 제5,976,567호; 제5,981,501호; 제6,534,484호; 제6,586,410호; 제6,815,432호; 및 국제 특허 공개 제WO 96/40964호에 기재되어 있다. 폴리뉴클레오티드 함유 LNP는 예를 들어, WO2019/191780호에 기재되어 있다.
본 발명의 폴리뉴클레오티드, 이종 폴리뉴클레오티드, 폴리펩티드 및 이종 폴리펩티드는 불균질한 크기의 다중층 소포를 포함할 수 있다. 예를 들어, 소포 형성 지질은 적절한 유기 용매 또는 용매계에 용해되고 진공 또는 불활성 가스 하에서 건조되어 얇은 지질 박막을 형성할 수 있다. 필요에 따라, 지질 박막은 삼차 부탄올과 같은 적절한 용매 중에 재용해된 다음에, 동결건조되어 더욱 용이하게 수화된 분말 유사 형태인 더욱 균질한 지질 혼합물을 형성할 수 있다. 이러한 박막은 폴리펩티드 복합체의 수용액으로 덮고, 교반하면서 전형적으로 15 내지 60분간에 걸쳐 수화시킬 수 있다. 얻어진 다중층 소포의 크기 분포는 더욱 격렬한 교반 조건에서 지질을 수화하거나 데옥시콜레이트와 같은 가용화 세정제를 첨가하여 더욱 작은 크기로 전환될 수 있다. 수화 매질은 최종 리포솜 현탁액에서 리포솜의 내부 용적에 요구되는 농도로 핵산을 포함할 수 있다. 다중층 소포를 형성하는 데 사용될 수 있는 적절한 지질에는 DOTMA(문헌[Feigner, et al., 1987, Proc. Natl. Acad. Sci. USA 84: 7413-7417]), DOGS 또는 트랜스펙타인(Transfectain)™(문헌[Behr, et al., 1989, Proc. Natl. Acad. Sci. USA 86: 6982-6986]), DNERIE 또는 DORIE(문헌[Feigner, et al., Methods 5: 67-75]), DC-CHOL(문헌[Gao and Huang, 1991, BBRC 179: 280-285]), DOTAP™(문헌[McLachlan, et al., 1995, Gene Therapy 2: 674-622]), 리포펙타민(Lipofectamine)™ 및 글리세로지질 화합물(예를 들어, EP901463 및 W098/37916 참조)이 포함된다.
나노입자는 면역 자극 복합체(ISCOM)일 수 있다. ISCOM은 전형적으로 콜로이드상 사포닌 함유 미셸로 형성되는 케이지 유사 입자이다. ISCOM은 콜레스테롤, 인지질(예를 들어, 포스파티딜에탄올아민 또는 포스파티딜콜린) 및 사포닌(예를 들어, 퀼라야 사포나리아(Quillaia saponaria) 나무의 퀼(Quil) A)을 포함할 수 있다.
나노입자는 바이러스 유사 입자(VLP)일 수 있다. VLP는 생체적합성 캡시드 단백질의 자기 조립에 의해 형성되는, 감염성 핵산이 결여된 자기 조립 나노입자이다. VLP는 전형적으로 직경이 약 20 내지 약 150 nm, 예컨대 약 20 내지 약 40 nm, 약 30 내지 약 140 nm, 약 40 내지 약 130 nm, 약 50 내지 약 120 nm, 약 60 내지 약 110 nm, 약 70 내지 약 100 nm, 또는 약 80 내지 약 90 nm이다. VLP는 유리하게는, 면역계와의 상호작용에 자연적으로 최적화된 진화된 바이러스 구조의 파워를 이용한다. 자연적으로 최적화된 나노입자 크기와 반복적인 구조적 순서는 애주번트가 없는 경우에도 VLP가 강력한 면역반응을 유도한다는 것을 의미한다.
나노입자는 본 발명의 폴리펩티드 또는 이종 폴리펩티드를 인코딩하는 레플리콘을 함유할 수 있다. 레플리콘은 DNA 또는 RNA일 수 있다.
"레플리콘"은 그 자체의 카피의 생성을 유도할 수 있고, RNA뿐만 아니라 DNA를 포함하는 바이러스 핵산을 지칭한다. 예를 들어, 아테리바이러스(arterivirus) 게놈의 이중 가닥 DNA 버전은 아테리바이러스 레플리콘을 구성하는 단일 가닥 RNA 전사체를 생성하는 데 사용될 수 있다. 일반적으로, 바이러스 레플리콘은 바이러스의 완전 게놈을 포함한다. "서브게놈 레플리콘"은 바이러스 게놈의 유전자 및 다른 특징부의 완전 보체(full complement)보다 작은 것을 포함하는 바이러스 핵산을 지칭하지만, 여전히 그 자체의 카피의 생성을 유도할 수 있다. 예를 들어, 아테리바이러스의 서브게놈 레플리콘은 바이러스의 비구조적 단백질에 대한 대부분의 유전자를 포함할 수 있지만, 구조적 단백질을 코딩하는 유전자의 대부분은 결손되어 있다. 서브게놈 레플리콘은 바이러스 서브게놈의 복제(서브게놈 레플리콘의 복제)에 필요한 모든 바이러스 유전자의 발현을 바이러스 입자의 생성 없이 유도할 수 있다.
"RNA 레플리콘" (또는 "자기 복제 RNA")은 허용 세포 내에서 그 자체의 증폭 또는 자기 복제를 유도하는 데 필요한 모든 유전 정보를 포함하는 RNA를 지칭한다. 그 자체 복제를 유도하기 위해, RNA 분자는 1) RNA 증폭 과정을 촉매하기 위해 바이러스 또는 숙주 세포 유래 단백질, 핵산 또는 리보핵단백질과 상호작용할 수 있는 중합효소, 복제효소 또는 다른 단백질을 인코딩하고; 2) 레플리콘으로 인코딩된 RNA의 복제 및 전사에 필요한 시스 작용성 RNA 서열을 포함한다. 자기 복제 RNA는 전형적으로 양성 가닥 RNA 바이러스의 게놈으로부터 유래되며, 구조적 또는 비구조적 유전자를 인코딩하는 바이러스 서열을 치환하거나 구조적 또는 비구조적 유전자를 인코딩하는 서열의 외래 서열 5' 또는 3'을 삽입하여 숙주 세포에 외래 서열을 도입하는 기초로 사용될 수 있다. 외래 서열은 또한 알파바이러스의 서브게놈 영역에 도입될 수 있다. 자기 복제 RNA는 재조합 바이러스 입자, 예컨대 재조합 알파바이러스 입자로 패키징되거나, 대안적으로 지질 나노입자(LNP)를 사용하여 숙주에 전달될 수 있다. 자기 복제 RNA는 크기가 적어도 1 kb 또는 적어도 2 kb 또는 적어도 3 kb 또는 적어도 4 kb 또는 적어도 5 kb 또는 적어도 6 kb 또는 적어도 7 kb 또는 적어도 8 kb 또는 적어도 10 kb 또는 적어도 12 kb 또는 적어도 15 kb 또는 적어도 17 kb 또는 적어도 19 kb 또는 적어도 20 kb일 수 있거나, 100 bp 내지 8 kb 또는 500 bp 내지 8 kb 또는 500 bp 내지 7 kb 또는 1 내지 7 kb 또는 1 내지 8 kb 또는 2 내지 15 kb 또는 2 내지 20 kb 또는 5 내지 15 kb 또는 5 내지 20 kb 또는 7 내지 15 kb 또는 7 내지 18 kb 또는 7 내지 20 kb일 수 있다. 자기 복제 RNA는 예를 들어, WO2017/180770, WO2018/075235, WO2019143949A2에 기재되어 있다.
본 발명의 폴리뉴클레오티드, 이종 폴리뉴클레오티드, 폴리펩티드 및 이종 폴리펩티드와 복합체를 형성하기에 적합한 다른 분자는 양이온성 분자, 예를 들어 폴리아미도아민(문헌[Haensler and Szoka, 1993, Bioconjugate Chem. 4: 372-379]), 수지상 폴리라이신(국제 특허 공개 제WO1995/24221호), 폴리에틸렌 이리닌 또는 폴리프로필렌 h-닌(h-nine)(국제 특허 공개 제WO1996/02655호), 폴리라이신(미국 특허 제5,595,897호), 키토산(미국 특허 제5,744,166호), DNA-젤라틴 코아세르베이트(예를 들어, 미국 특허 제6,207,195호; 미국 특허 제6,025,337호; 미국 특허 제5,972,707호 참조) 또는 DEAE 덱스트란(문헌[Lopata, et al., 1984, Nucleic Acid Res. 12: 5707-5717]), 덴드리머(예를 들어, WO1996/19240호 참조) 또는 폴리에틸렌이민(PEI)(예를 들어, 문헌[Sun et al., 2014, Mol Med Rep. 10(5)2657-2662] 참조)을 포함한다.
전립선 신생항원/HLA 복합체
본 발명은 또한 전립선 신생항원 및 HLA를 포함하는 단백질 복합체를 제공한다. 본 발명은 또한 전립선 신생항원 및 HLA의 단편을 포함하는 단백질 복합체를 제공한다. 본 발명은 또한 전립선 신생항원 및 HLA의 변이체를 포함하는 단백질 복합체를 제공한다. 본 발명은 또한 전립선 신생항원 및 HLA의 단편의 변이체를 포함하는 단백질 복합체를 제공한다.
일부 실시 형태에서, 전립선 신생항원은 서열 번호 1, 3, 5, 7, 9, 11, 13, 15, 17, 19, 21, 23, 25, 27, 29, 31, 33, 35, 37, 39, 41, 43, 45, 47, 49, 51, 53, 55, 57, 59, 61, 63, 65, 67, 69, 71, 73, 75, 77, 79, 81, 83, 85, 87, 89, 91, 93, 95, 97, 99, 101, 103, 105, 107, 109, 111, 113, 115, 117, 119, 121, 123, 125, 127, 129, 131, 133, 135, 137, 139, 141, 143, 145, 147, 149, 151, 153, 155, 157, 159, 161, 163, 165, 167, 169, 171, 173, 175, 177, 179, 181, 183, 185, 187, 189, 191, 193, 195, 197, 199, 201, 203, 205, 207, 209, 211, 213, 215, 217, 219, 221, 223, 225, 227, 229, 231, 233, 235, 237, 239, 241, 243, 245, 247, 249, 251, 253, 255, 257, 259, 261, 263, 265, 267, 269, 271, 273, 275, 277, 279, 281, 283, 285, 287, 289, 291, 293, 295, 297, 299, 301, 303, 305, 307, 309, 311, 313, 315, 317, 319, 321, 323, 325, 327, 329, 331, 333, 335, 337, 339, 341, 343, 345, 347, 349, 351, 353, 355, 357, 359, 361, 363, 365, 367, 369, 371, 373, 375, 379, 381, 383, 385, 387, 388, 389, 390, 391, 392, 393, 394, 395, 396, 397, 398, 399, 400, 401, 402, 403, 404, 405, 406, 407, 408, 426, 427, 428, 429, 430, 431, 432, 433, 434, 435, 436, 437, 438, 439, 440, 441, 442, 443, 444, 445, 446 또는 447의 폴리펩티드를 포함한다.
일부 실시 형태에서, 전립선 신생항원의 단편은 서열 번호 387, 388, 389, 390, 391, 392, 393, 394, 395, 396, 397, 398, 399, 400, 401, 402, 403, 404, 405, 406, 407, 408, 560, 561, 562, 563, 564, 565, 566, 567, 568, 569, 570, 571, 572, 573, 574, 575, 576, 577, 578, 579, 580, 581, 582, 583, 584, 585, 586, 587, 588, 589, 590, 591, 592, 593, 594, 595, 596, 597, 598, 599, 600, 601, 602, 603, 604, 605, 606, 607, 608, 609, 610, 611, 612, 613, 614, 615, 616, 617, 618, 619, 620 및 621의 아미노산 서열을 포함한다.
일부 실시 형태에서, 전립선 신생항원의 단편은 서열 번호 377, 378, 415, 417, 418, 420, 502, 518, 526, 527, 714, 715, 716, 717, 718, 719, 720, 721, 722, 723, 724, 725, 726, 727, 728, 729, 730, 731, 732, 733, 734, 735, 736, 737, 738, 739, 740, 741, 742, 743, 744, 745, 746, 747, 748, 749, 750, 751, 752, 753, 74, 755, 756, 757, 758, 759, 760, 761, 762, 763, 764, 765, 766, 767, 768, 769, 770, 771, 772, 773, 774, 775, 776, 777, 778, 779, 780, 781, 782, 783, 784, 785, 786, 787, 788, 789, 790, 791, 792, 793, 794, 795, 796, 797, 798, 799, 800, 801, 802, 803, 804, 805, 806, 807, 808, 809, 810, 811, 812, 813, 814, 815, 816, 817, 818, 819, 820, 821, 822, 823, 824, 825, 826, 827, 828, 829, 830, 831, 832, 833, 834, 835, 836, 837, 838, 839, 840, 841, 842, 843, 844, 845, 846, 487, 848, 849, 850, 851, 852, 853, 854, 855, 856, 857, 858, 859, 860, 861, 862, 863, 864, 865, 866, 867, 868, 869, 870, 871, 872, 873, 874, 875, 876, 877, 878, 879, 880, 881, 882, 883, 884, 885, 886, 887, 888, 889, 890, 891, 892, 893, 894, 895, 896, 897, 898, 899, 900, 901, 902, 903, 904, 905, 906, 907, 908, 909, 910, 911, 912, 913, 914, 915, 916, 917, 918, 919, 920, 921, 922, 923, 924, 925, 926, 927, 928, 929, 930, 931, 932, 933, 934, 935, 936, 937, 938, 939, 940, 941, 942, 943, 944, 945, 946, 947, 948, 949, 950, 951, 952, 953, 954, 955, 956, 957, 958, 959, 960, 961, 962, 963, 964, 965, 966, 967, 968, 969, 970, 971, 972, 973, 974, 975, 976, 977, 978, 979, 980 또는 548의 아미노산 서열을 포함한다.
일부 실시 형태에서, HLA는 클래스 I HLA이다. 일부 실시 형태에서, HLA는 클래스 II HLA이다. 일부 실시 형태에서, HLA는 HLA-A이다. 일부 실시 형태에서, HLA는 HLA-B이다. 일부 실시 형태에서, HLA는 HLA-C이다. 일부 실시 형태에서, HLA는 HLA-DP이다. 일부 실시 형태에서, HLA는 HLA-DQ이다. 일부 실시 형태에서, HLA는 HLA-DR이다. 일부 실시 형태에서, HLA는 HLA-A*01:01, A*02:01, A*03:01, A*24:02, B*07:02 또는 B*08:01이다.
전립선 신생항원/HLA 복합체는 예를 들어, 시험관내 또는 생체내에서 동종 T 세포를 분리하는 데 사용될 수 있다. 전립선 신생항원/HLA 복합체는 또한 검출가능 표지에 접합될 수 있고, 동종 TCR 또는 동종 TCR을 발현하는 T 세포를 검출, 가시화 또는 분리하기 위한 검출제로 사용될 수 있다. 전립선 신생항원/HLA 복합체는 또한 세포독성제에 접합되어, 동종 TCR을 발현하는 세포의 수를 고갈시키거나 감소시키는 데 사용될 수 있다. 복합체는 이의 천연 형태일 수 있거나, 대안적으로 전립선 신생항원 및/또는 HLA가 조작될 수 있다.
조작 개념은 예를 들어, 절단할 수 있는 공유 링커를 사용하여 HLA에 펩티드를 공유 결합하는 것을 포함한다. 전립선 신생항원/HLA 복합체는 단량체 또는 다량체일 수 있다. 전립선 신생항원/HLA 복합체는 독소 또는 검출제에 결합될 수 있다. 다양한 조작 개념은 복합체를, 예를 들어 가용성 복합체로서, 공유결합 전립선 신생항원-β2-α2-α1-β1 사슬 또는 전립선 신생항원-β 사슬로서 복합체를 발현하는 것을 포함한다. 길이가 적어도 15개의 아미노산으로 된 링커가 전립선 신생항원과 HLA 사이에 사용될 수 있다. 대안적으로, 복합체는 공유결합된 전립선 신생항원-단일쇄 β1-α1으로 발현될 수 있다. 전립선 신생항원/HLA 복합체는 또한 전립선 신생항원이 α 사슬의 N 말단에 공유결합되거나, 대안적으로 전립선 신생항원이 비공유 상호작용을 통해 αβ 사슬과 관련된 전장 HLAαβ 사슬로서 발현될 수 있다. 다양한 발현 포맷이 US5976551, US5734023, US5820866, US7141656B2, US6270772B1 및 US7074905B2에 개시되어 있다. 게다가, HLA는 US8377447B2 및 US8828379B2에 기재된 바와 같이 α1 사슬에서 돌연변이되거나 α2 및 β2 도메인을 통한 다이설파이드 결합을 통해 안정화되는 단일쇄 구축물로 발현될 수 있다. 전립선 신생항원 또는 이의 단편은 US9079941B2에 기재된 바와 같이, 감광성 또는 과요오드산염 감수성 절단가능한 링커를 통해 HLA에 결합될 수 있다. 전립선 신생항원/HLA 복합체는 다량체 포맷으로 조작될 수 있다. 다량체 포맷은 US7074904B2에 기재된 바와 같이, 2개 이상의 전립선 신생항원/HLA 복합체의 가교결합을 용이하게 하기 위해 HLA α 또는 β 사슬의 C 말단에 반응성 측쇄를 도입함으로써 생성될 수 있다. 대안적으로, 비오틴화 인식 서열 BirA는 HLA α 또는 β 사슬의 C 말단에 도입될 수 있으며, 이는 이어서 비오틴화되고 다량체가 US563536에 기재된 바와 같이 아비딘/스트렙타비딘에 결합함으로써 형성된다. 다량체 전립선 신생항원/HLA 복합체는 US6197302B1, US6268411B1, US20150329617A1, EP1670823B1, EP1882700B1, EP2061807B1, US20120093934A1, US20130289253A1, US20170095544A1, US20170003288A1 및 WO2017015064A1에 기재된 바와 같이, Fc 융합을 이용하거나, 덱스트란 담체에서 전립선 신생항원/HLA 복합체를 커플링하거나, 비아 코일드(via coiled)-코일 도메인을 올리고머화하거나, 추가의 비오틴화 펩티드를 사용하거나, 전립선 신생항원/HLA 복합체를 나노입자 또는 킬레이트 담체에 접합하여 추가로 생성될 수 있다.
전립선 신생항원 또는 전립선 신생항원/HLA 복합체에 결합하는 단백질성 분자
본 발명은 또한 서열 번호 1, 3, 5, 7, 9, 11, 13, 15, 17, 19, 21, 23, 25, 27, 29, 31, 33, 35, 37, 39, 41, 43, 45, 47, 49, 51, 53, 55, 57, 59, 61, 63, 65, 67, 69, 71, 73, 75, 77, 79, 81, 83, 85, 87, 89, 91, 93, 95, 97, 99, 101, 103, 105, 107, 109, 111, 113, 115, 117, 119, 121, 123, 125, 127, 129, 131, 133, 135, 137, 139, 141, 143, 145, 147, 149, 151, 153, 155, 157, 159, 161, 163, 165, 167, 169, 171, 173, 175, 177, 179, 181, 183, 185, 187, 189, 191, 193, 195, 197, 199, 201, 203, 205, 207, 209, 211, 213, 215, 217, 219, 221, 223, 225, 227, 229, 231, 233, 235, 237, 239, 241, 243, 245, 247, 249, 251, 253, 255, 257, 259, 261, 263, 265, 267, 269, 271, 273, 275, 277, 279, 281, 283, 285, 287, 289, 291, 293, 295, 297, 299, 301, 303, 305, 307, 309, 311, 313, 315, 317, 319, 321, 323, 325, 327, 329, 331, 333, 335, 337, 339, 341, 343, 345, 347, 349, 351, 353, 355, 357, 359, 361, 363, 365, 367, 369, 371, 373, 375, 379, 381, 383, 385, 387, 388, 389, 390, 391, 392, 393, 394, 395, 396, 397, 398, 399, 400, 401, 402, 403, 404, 405, 406, 407, 408, 426, 427, 428, 429, 430, 431, 432, 433, 434, 435, 436, 437, 438, 439, 440, 441, 442, 443, 444, 445, 446 또는 447의 폴리펩티드 또는 이의 단편에 특이적으로 결합하는 항원 결합 도메인을 포함하는 단백질성 분자를 제공한다. 단백질성 분자는 신생항원이 유래된 야생형 단백질에 대해 불충분한 결합을 갖는다.
본 발명은 또한 전립선 신생항원/HLA 복합체에 특이적으로 결합하는 항원 결합 도메인을 포함하는 단백질성 분자를 제공하며, 여기서 전립선 신생항원은 서열 번호 1, 3, 5, 7, 9, 11, 13, 15, 17, 19, 21, 23, 25, 27, 29, 31, 33, 35, 37, 39, 41, 43, 45, 47, 49, 51, 53, 55, 57, 59, 61, 63, 65, 67, 69, 71, 73, 75, 77, 79, 81, 83, 85, 87, 89, 91, 93, 95, 97, 99, 101, 103, 105, 107, 109, 111, 113, 115, 117, 119, 121, 123, 125, 127, 129, 131, 133, 135, 137, 139, 141, 143, 145, 147, 149, 151, 153, 155, 157, 159, 161, 163, 165, 167, 169, 171, 173, 175, 177, 179, 181, 183, 185, 187, 189, 191, 193, 195, 197, 199, 201, 203, 205, 207, 209, 211, 213, 215, 217, 219, 221, 223, 225, 227, 229, 231, 233, 235, 237, 239, 241, 243, 245, 247, 249, 251, 253, 255, 257, 259, 261, 263, 265, 267, 269, 271, 273, 275, 277, 279, 281, 283, 285, 287, 289, 291, 293, 295, 297, 299, 301, 303, 305, 307, 309, 311, 313, 315, 317, 319, 321, 323, 325, 327, 329, 331, 333, 335, 337, 339, 341, 343, 345, 347, 349, 351, 353, 355, 357, 359, 361, 363, 365, 367, 369, 371, 373, 375, 379, 381, 383, 385, 387, 388, 389, 390, 391, 392, 393, 394, 395, 396, 397, 398, 399, 400, 401, 402, 403, 404, 405, 406, 407, 408, 426, 427, 428, 429, 430, 431, 432, 433, 434, 435, 436, 437, 438, 439, 440, 441, 442, 443, 444, 445, 446 또는 447의 폴리펩티드 또는 이의 단편을 포함한다.
예시적인 단편은 서열 번호 387, 388, 389, 390, 391, 392, 393, 394, 395, 396, 397, 398, 399, 400, 401, 402, 403, 404, 405, 406, 407, 408, 560, 561, 562, 563, 564, 565, 566, 567, 568, 569, 570, 571, 572, 573, 574, 575, 576, 577, 578, 579, 580, 581, 582, 583, 584, 585, 586, 587, 588, 589, 590, 591, 592, 593, 594, 595, 596, 597, 598, 599, 600, 601, 602, 603, 604, 605, 606, 607, 608, 609, 610, 611, 612, 613, 614, 615, 616, 617, 618, 619, 620 또는 621의 아미노산 서열을 포함한다.
다른 예시적인 단편은 서열 번호 377, 378, 415, 417, 418, 420, 502, 518, 526, 527, 714, 715, 716, 717, 718, 719, 720, 721, 722, 723, 724, 725, 726, 727, 728, 729, 730, 731, 732, 733, 734, 735, 736, 737, 738, 739, 740, 741, 742, 743, 744, 745, 746, 747, 748, 749, 750, 751, 752, 753, 74, 755, 756, 757, 758, 759, 760, 761, 762, 763, 764, 765, 766, 767, 768, 769, 770, 771, 772, 773, 774, 775, 776, 777, 778, 779, 780, 781, 782, 783, 784, 785, 786, 787, 788, 789, 790, 791, 792, 793, 794, 795, 796, 797, 798, 799, 800, 801, 802, 803, 804, 805, 806, 807, 808, 809, 810, 811, 812, 813, 814, 815, 816, 817, 818, 819, 820, 821, 822, 823, 824, 825, 826, 827, 828, 829, 830, 831, 832, 833, 834, 835, 836, 837, 838, 839, 840, 841, 842, 843, 844, 845, 846, 487, 848, 849, 850, 851, 852, 853, 854, 855, 856, 857, 858, 859, 860, 861, 862, 863, 864, 865, 866, 867, 868, 869, 870, 871, 872, 873, 874, 875, 876, 877, 878, 879, 880, 881, 882, 883, 884, 885, 886, 887, 888, 889, 890, 891, 892, 893, 894, 895, 896, 897, 898, 899, 900, 901, 902, 903, 904, 905, 906, 907, 908, 909, 910, 911, 912, 913, 914, 915, 916, 917, 918, 919, 920, 921, 922, 923, 924, 925, 926, 927, 928, 929, 930, 931, 932, 933, 934, 935, 936, 937, 938, 939, 940, 941, 942, 943, 944, 945, 946, 947, 948, 949, 950, 951, 952, 953, 954, 955, 956, 957, 958, 959, 960, 961, 962, 963, 964, 965, 966, 967, 968, 969, 970, 971, 972, 973, 974, 975, 976, 977, 978, 979, 980 또는 548의 아미노산 서열을 포함한다.
HLA는 클래스 I 또는 클래스 II를 포함할 수 있다.
HLA는 HLA-A, HLA-B 또는 HLA-C를 포함할 수 있다.
HLA는 HLA-DP, HLA-DQ 또는 HLA-DR을 포함할 수 있다.
HLA는 클래스 I 대립유전자 HLA-A*01:01, A*02:01, A*03:01, A*24:02, B*07:02 또는 B*08:01을 포함할 수 있다.
일부 실시 형태에서, 단백질성 분자는 항체의 항원 결합 단편이다.
일부 실시 형태에서, 단백질성 분자는 다중특이성 분자이다. 일부 실시 형태에서, 단백질성 분자는 이중특이성 분자이다. 일부 실시 형태에서, 단백질성 분자는 삼중특이성 분자이다. 일부 실시 형태에서, 다중특이성 분자는 2개 이상의 별개의 전립선 신생항원에 결합한다. 일부 실시 형태에서, 다중특이성 분자는 전립선 신생항원 및 T 세포 수용체(TCR) 복합체에 결합한다. 일부 실시 형태에서, 다중특이성 분자는 2개 이상의 별개의 전립선 신생항원 및 T 세포 수용체(TCR) 복합체에 결합한다.
일부 실시 형태에서, 단백질성 분자는 항체이다.
일부 실시 형태에서, 단백질성 분자는 다중특이성 항체이다. 일부 실시 형태에서, 단백질성 분자는 이중특이성 항체이다. 일부 실시 형태에서, 단백질성 분자는 삼중특이성 항체이다. 일부 실시 형태에서, 단백질성 분자는 T 세포 방향전환(redirecting) 분자이다.
본 발명의 전립선 신생항원이 단백질의 세포외 도메인의 일부인 경우에, 전립선 신생항원은 T 세포를 종양에 보충하거나 종양 세포 상의 전립선 신생항원에 선택적으로 결합하는 항원 결합 도메인을 이용하여 CAR-T 및 다른 세포 요법을 종양에 표적화하기 위한 종양 관련 항원으로서 사용될 수 있다.
전립선 신생항원이 세포내 도메인의 일부인 경우, 세포독성제 또는 치료제에 접합된 세포내 구획으로 전달되는 능력을 갖는 항원 결합 도메인이 치료제로서 사용될 수 있다. 대안적으로, 전립선 신생항원/HLA 복합체에 결합하는 동종 TCR을 발현하도록 조작된 세포가 치료제로서 사용될 수 있다.
일부 실시 형태에서, 단백질성 분자는 대체 스캐폴드이다.
일부 실시 형태에서, 단백질성 분자는 키메라 항원 수용체(CAR)이다.
일부 실시 형태에서, 단백질성 분자는 T 세포 수용체(TCR)이다.
본 발명의 전립선 신생항원 또는 전립선 신생항원/HLA 복합체에 대한 단백질성 분자의 결합은 임의의 적절한 방법을 사용하여 실험적으로 결정될 수 있다. 이러한 방법은 당업자에게 알려진 프로테온(ProteOn) XPR36, 비아코어(Biacore) 3000 또는 KinExA 기기, ELISA 또는 경쟁적 결합 분석을 사용할 수 있다. 측정된 결합은 상이한 조건(예를 들어, 오스몰 농도(osmolarity), pH) 하에 측정되는 경우에 변동될 수 있다. 따라서, 친화도 및 기타 결합 파라미터(예를 들어, KD, Kon, Koff)의 측정은 전형적으로 표준화된 조건 및 표준화된 완충액, 예컨대 본 명세서에 기재된 완충액을 사용하여 행해진다. 예를 들어, 비아코어 3000 또는 프로테온을 사용하는 친화도 측정에 대한 내부 오차(표준 편차, SD로서 측정됨)는 전형적인 검출 한계 내에서의 측정에 대해 전형적으로 5 내지 33% 이내일 수 있음을 당업자는 이해할 것이다. "불충분한"은 본 발명의 전립선 신생항원에 대한 단백질성 분자의 측정된 결합과 비교할 때 100배 미만인 결합을 지칭한다. 본 발명의 단백질성 분자는 공지된 방법 및 본 명세서에 기재된 것을 사용하여 이의 활성 및 기능, 예를 들어 전립선 신생항원 또는 전립선 신생항원/HLA 복합체를 발현하는 세포를 사멸시키는 단백질성 분자의 능력에 대해 추가로 특성화될 수 있다.
항체 및 항원 결합 도메인
전립선 신생항원 또는 전립선 신생항원/HLA 복합체에 특이적으로 결합하는 항체 및 항원 결합 도메인은 공지된 방법을 사용하여 생성될 수 있다. 이러한 항체는 모든 유형의 면역글로불린 분자(예를 들어, IgG, IgE, IgM, IgD, IgA 및 IgY), 클래스(예를 들어, IgG1, IgG2, IgG3, IgG4, IgA1 및 IgA2) 또는 서브클래스를 포함할 수 있다.
예를 들어, 문헌[Kohler and Milstein, Nature 256:495, 1975]의 하이브리도마 방법이 단일클론 항체를 생성하는 데 사용될 수 있다. 하이브리도마 방법에서, 마우스 또는 다른 숙주 동물, 예컨대 햄스터, 래트 또는 원숭이는 하나 이상의 전립선 신생항원 또는 전립선 신생항원/HLA 복합체로 면역화된 후에, 표준 방법을 사용하여 면역화된 동물의 비장 세포를 골수종 세포와 융합시켜 하이브리도마 세포를 형성한다(문헌[Goding, Monoclonal Antibodies: Principles and Practice, pp.59-103, Academic Press, 1986]). 단일 불멸화(immortalized) 하이브리도마 세포로부터 발생되는 콜로니를 원하는 특성, 예컨대 본 발명의 전립선 신생항원에 대한 결합 특이성 및 친화성을 갖는 항체의 생산을 위해 스크리닝한다.
다양한 숙주 동물을 사용하여 항체를 생성할 수 있다. 예를 들어, Balb/c 마우스, 래트 또는 닭을 사용하여 VH/VL 쌍을 포함하는 항체를 생성할 수 있고, 라마 및 알파카를 사용하여 표준 면역화 프로토콜을 사용하여 중쇄 전용(VHH) 항체를 생성할 수 있다. 비인간 동물에서 제조된 항체는 더욱 인간과 유사한 서열을 생성하기 위해 다양한 기술을 사용하여 인간화될 수 있다.
인간 수용자 프레임워크의 선택을 포함하는 예시적인 인간화 기술이 공지되어 있으며, CDR 이식(미국 특허 제5,225,539호), SDR 이식(미국 특허 제6,818,749호), 재표면화(resurfacing)(문헌[Padlan, (1991) Mol Immunol 28:489-499]), 특이성 결정 잔기 재표면화(미국 특허 공개 제2010/0261620호), 인간 프레임워크 적응화(미국 특허 제8,748,356호), 또는 초인간화(미국 특허 제7,709,226호)를 포함한다. 이들 방법에서는, 모 항체의 CDR을 인간 프레임워크 상에 전달하는데, 이러한 인간 프레임워크는 모 프레임워크에 대한 그의 전체 상동성에 기초하여, CDR 길이의 유사성에 기초하여, 또는 표준 구조 동일성에 기초하여, 또는 이들의 임의의 조합에 기초하여 선택될 수 있다.
인간화 항체는, 국제 특허 공개 WO1990/007861호 및 WO1992/22653호에 기재된 것들과 같은 기법들에 의해, 변경된 프레임워크 지지 잔기를 도입시켜 결합 친화도를 보존함으로써(복귀 돌연변이(backmutation)), 또는 CDR들 중 임의의 것에서 변이를 도입하여, 예를 들어 항체 친화성을 개선함으로써 원하는 항원에 대한 그의 선택성 또는 친화성을 개선하도록 추가로 최적화될 수 있다.
인간 면역글로불린(Ig) 유전자좌를 게놈에 보유하는 마우스 또는 래트와 같은 트랜스제닉 동물을 사용하여, 전립선 신생항원 또는 전립선 신생항원/HLA 복합체에 대한 인간 항체를 생성할 수 있으며, 예를 들어 미국 특허 제6,150,584호, 국제 특허 공개 WO99/45962호, 국제 특허 공개 WO2002/066630호, WO2002/43478호, WO2002/043478호 및 WO1990/04036호, 문헌[Lonberg et al (1994) Nature 368:856-9]; 문헌[Green et al (1994) Nature Genet. 7:13-21]; 문헌[Green & Jakobovits (1998) Exp . Med . 188:483-95]; 문헌[Lonberg and Huszar (1995) Int Rev Immunol 13:65-93]; 문헌[Bruggemann et al., (1991) Eur J Immunol 21:1323-1326]; 문헌[Fishwild et al., (1996) Nat Biotechnol 14:845-851]; 문헌[Mendez et al., (1997) Nat Genet 15:146-156]; 문헌[Green (1999) J Immunol Methods 231:11-23]; 문헌[Yang et al., (1999) Cancer Res 59:1236-1243]; 문헌[ and Taussig (1997) Curr Opin Biotechnol 8:455-458]에 기재되어 있다. 이러한 동물의 내인성 면역글로불린 유전자좌는 파괴되거나 결실될 수 있고, 상동적 또는 비상동적 재조합을 사용하거나, 도입염색체(transchromosome)를 사용하거나, 미니유전자(minigene)를 사용하여, 하나 이상의 완전하거나 부분적인 인간 면역글로불린 유전자좌를 동물의 게놈에 삽입할 수 있다. 레제네론(Regeneron) (http://_www_regeneron_com), 하버 안티바디스(Harbour Antibodies) (http://_www_harbourantibodies_com), 오픈 모노클로날 테크놀로지, 인코포레이티드(Open Monoclonal Technology, Inc.) (OMT) (http://_www_omtinc_net), 키맙(KyMab) (http://_www_kymab_com), 트리아니(Trianni) (http://_www.trianni_com) 및 아블렉시스(Ablexis) (http://_www_ablexis_com)와 같은 회사들이 상술한 바와 같은 기술을 사용하여 선택된 항원에 대한 인간 항체를 제공하는 데에 관여할 수 있다.
and Taussig (1997) Curr Opin Biotechnol 8:455-458]에 기재되어 있다. 이러한 동물의 내인성 면역글로불린 유전자좌는 파괴되거나 결실될 수 있고, 상동적 또는 비상동적 재조합을 사용하거나, 도입염색체(transchromosome)를 사용하거나, 미니유전자(minigene)를 사용하여, 하나 이상의 완전하거나 부분적인 인간 면역글로불린 유전자좌를 동물의 게놈에 삽입할 수 있다. 레제네론(Regeneron) (http://_www_regeneron_com), 하버 안티바디스(Harbour Antibodies) (http://_www_harbourantibodies_com), 오픈 모노클로날 테크놀로지, 인코포레이티드(Open Monoclonal Technology, Inc.) (OMT) (http://_www_omtinc_net), 키맙(KyMab) (http://_www_kymab_com), 트리아니(Trianni) (http://_www.trianni_com) 및 아블렉시스(Ablexis) (http://_www_ablexis_com)와 같은 회사들이 상술한 바와 같은 기술을 사용하여 선택된 항원에 대한 인간 항체를 제공하는 데에 관여할 수 있다.
인간 항체는 파지 디스플레이 라이브러리로부터 선택될 수 있으며, 여기서 파지는 인간 면역글로불린 또는 그의 일부, 예컨대 Fab, 단일쇄 항체(scFv), 도메인 항체 또는 쌍을 이루지 않거나 쌍을 이루는 항체 가변 영역을 발현시키도록 조작된다(문헌[Knappik et al., (2000) J Mol Biol 296:57-86]; 문헌[Krebs et al., (2001) J Immunol Meth 254:67-84]; 문헌[Vaughan et al., (1996) Nature Biotechnology 14:309-314]; 문헌[Sheets et al., (1998) PITAS (USA) 95:6157-6162]; 문헌[Hoogenboom and Winter (1991) J Mol Biol 227:381]; 문헌[Marks et al., (1991) J Mol Biol 222:581]). 본 발명의 항체는, 문헌[Shi et al., (2010) J Mol Biol 397:385-96] 및 국제 특허 공개 WO09/085462호에 기재된 바와 같이, 예를 들어 박테리오파지 pIX 외피 단백질과의 이종 폴리펩티드로서 항체 중쇄 및 경쇄 가변 영역을 발현시키는 파지 디스플레이 라이브러리로부터 단리될 수 있다. 라이브러리는 전립선 신생항원 또는 전립선 신생항원/HLA 복합체에 결합하는 파지에 대해 스크리닝될 수 있고, 얻어진 양성 클론은 추가로 특성화될 수 있으며, Fab는 클론 용해물로부터 단리되고, 전장 IgG로서 발현된다. 인간 항체를 단리하기 위한 이러한 파지 디스플레이 방법은, 예를 들어 미국 특허 제5,223,409호, 제5,403,484호, 제5,571,698호, 제5,427,908호, 제5,580,717호, 제5,969,108호, 제6,172,197호, 제5,885,793호; 제6,521,404호; 제6,544,731호; 제6,555,313호; 제6,582,915호 및 제6,593,081호에 기재되어 있다. 항체는 HLA/신생항원 복합체에 대한 결합 또는 신생항원 단독에 대한 결합에 대해 추가로 시험될 수 있다.
면역원성 항원의 제조 및 단일클론 항체 생산은 재조합 단백질 생산 또는 펩티드의 화학적 합성과 같은 임의의 적절한 기술을 사용하여 수행될 수 있다. 면역원성 항원을 정제된 단백질, 또는 전세포, 세포 또는 조직 추출물을 포함하는 단백질 혼합물의 형태로 동물에게 투여할 수 있거나, 항원은 상기 항원 또는 이의 부분을 인코딩하는 핵산으로부터 동물의 체내에 새로(de novo) 형성될 수 있다.
전립선 신생항원 또는 전립선 신생항원/HLA 복합체에 특이적으로 결합하는 항원 결합 도메인은 또한 본 명세서에 기재된 항체로부터 유래될 수 있다. 항원 결합 도메인은 단일쇄 항체, Fab 단편, Fv 단편, 단일쇄 Fv 단편 (scFv), VHH 도메인, VH, VL, 대체 스캐폴드(예를 들어, 비항체 항원 결합 도메인), 2가 항체 단편, 예컨대 (Fab)2'-단편, F(ab') 단편, 다이설파이드 결합 Fvs(sdFv), 인트라바디, 미니바디, 다이아바디, 트라이아바디 및 데카바디를 포함한다.
전립선 신생항원 또는 전립선 신생항원/HLA 복합체 및 제2 항원에 특이적으로 결합하는 이중특이성 및 다중특이성 항체는 공지된 방법을 사용하여 생성될 수 있다. 제2 항원은 T 세포 수용체 복합체(TCR 복합체)일 수 있다. 제2 항원은 TCR 복합체 내의 CD3일 수 있다. 본 발명의 전립선 신생항원 또는 전립선 신생항원/HLA 복합체 및 제2 항원에 특이적으로 결합하는 이중특이성 및 다중특이성 항체는 전립선 신생항원 또는 전립선 신생항원/HLA 복합체 및 제2 항원에 특이적으로 결합하는 임의의 공지된 항원 결합 도메인 포맷을 사용하여 임의의 다가 포맷으로 조작될 수 있다. 전립선 신생항원 또는 전립선 신생항원/HLA 복합체에 특이적으로 결합하는 항원 결합 도메인은 하나 이상의 Fc 도메인 또는 이의 단편, 또는 임의로 알부민, PEG 또는 트랜스페린을 포함하는 반감기 연장 부분과 같은 다른 스캐폴드에 접합될 수 있다.
2개 이상의 전립선 신생항원에 특이적으로 결합하는 다중특이성 항체는 전립선 신생항원을 발현하는 종양 세포를 표적화하는데 있어서 개선된 특이성 측면에서 이점을 제공할 수 있다.
전립선 신생항원 또는 전립선 신생항원/HLA 복합체에 특이적으로 결합하는 항원 결합 도메인은 Fab 아암 교환을 사용하여 생성되는 전장 다중특이성 항체로 조작될 수 있으며, 여기서 치환은 시험관내에서 Fab 아암 교환을 촉진하는 Ig 불변 영역 CH3 도메인 내의 2개의 단일특이성 2가 항체에 도입된다. 상기 방법에서, 2개의 단일특이성 2가 항체는 이종이량체 안정성을 촉진하는 CH3 도메인에서의 소정 치환을 갖도록 조작되며; 항체는 힌지 영역의 시스테인이 다이설파이드 결합 이성질화를 거치기에 충분한 환원 조건 하에서 함께 인큐베이션되어; Fab 아암 교환에 의해 이중특이성 항체를 생성한다. 인큐베이션 조건은 비환원성 상태로 최적으로 회복될 수 있다. 사용될 수 있는 예시적인 환원제는 2-메르캅토에틸아민(2-MEA), 다이티오트레이톨(DTT), 다이티오에리트리톨(DTE), 글루타티온, 트리스(2-카르복시에틸)포스핀(TCEP), L-시스테인 및 베타-메르캅토에탄올이며, 바람직하게는 환원제는 2-메르캅토에틸아민, 다이티오트레이톨 및 트리스(2-카르복시에틸)포스핀으로 이루어진 군으로부터 선택된다. 예를 들어, pH 5 내지 8에서, 예를 들어 pH 7.0에서 또는 pH 7.4에서 적어도 25 mM 2-MEA의 존재 하에서 또는 적어도 0.5 mM 다이티오트레이톨의 존재 하에서 20℃ 이상의 온도에서 90분 이상의 인큐베이션이 사용될 수 있다.
사용될 수 있는 CH3 돌연변이는 노브-인-홀(Knob-in-Hole) 돌연변이(Genentech), 정전기적으로 매칭된 돌연변이(Chugai, Amgen, NovoNordisk, Oncomed), SEEDbody(Strand Exchange Engineered Domain body) (EMD Serono), 듀오바디(Duobody)® 돌연변이(Genmab) 및 다른 비대칭 돌연변이(예를 들어, Zymeworks)와 같은 기술을 포함한다.
노브-인-홀 돌연변이는, 예를 들어 국제 특허 출원 공개 WO1996/027011호에 개시되어 있으며, CH3 영역의 계면 상의 돌연변이를 포함하는데, 여기서는 작은 측쇄(홀)를 갖는 아미노산이 제1 CH3 영역 내로 도입되고 큰 측쇄(노브)를 갖는 아미노산이 제2 CH3 영역 내로 도입되어, 그 결과 제1 CH3 영역과 제2 CH3 영역 사이의 우선적인 상호작용을 가져온다. 노브와 홀을 형성하는 예시적인 CH3 영역 돌연변이는 T366Y/F405A, T366W/F405W, F405W/Y407A, T394W/Y407T, T394S/Y407A, T366W/T394S, F405W/T394S 및 T366W/T366S_L368A_Y407V이다.
중쇄 이종이량체 형성은 미국 특허 출원 공개 제2010/0015133호, 미국 특허 출원 공개 제2009/0182127호, 미국 특허 출원 공개 제2010/028637호 또는 미국 특허 출원 공개 제2011/0123532호에 기재된 바와 같이 제1 CH3 영역 상에 양으로 하전된 잔기를 그리고 제2 CH3 영역 상에 음으로 하전된 잔기를 치환함으로써 정전기 상호작용을 사용함으로써 촉진될 수 있다.
중쇄 이종이량체화를 촉진하기 위해 사용될 수 있는 다른 비대칭 돌연변이는 미국 특허 출원 공개 제2012/0149876호 또는 미국 특허 출원 공개 제2013/0195849호에 기재된 바와 같은 L351Y_F405A_Y407V/T394W, T366I_K392M_T394W/F405A_Y407V, T366L_K392M_T394W/F405A_Y407V, L351Y_Y407A/T366A_K409F, L351Y_Y407A/T366V_K409F, Y407A/T366A_K409F, 또는 T350V_L351Y_F405A_Y407V/T350V_T366L_K392L_T394W(Zymeworks)이다.
SEEDbody 돌연변이는 미국 특허 출원 공개 제20070287170호에 기재된 바와 같이, 선택된 IgG 잔기를 IgA 잔기로 치환하여 중쇄 이종이량체화를 촉진하는 것을 수반한다.
사용될 수 있는 다른 예시적인 돌연변이는 국제 특허 출원 공개 WO2007/147901호, WO 2011/143545호, WO2013157954호, WO2013096291호 및 미국 특허 출원 공개 제2018/0118849호에 기재된 바와 같은 R409D_K370E/D399K_E357K, S354C_T366W/Y349C_T366S_L368A_Y407V, Y349C_T366W/S354C_T366S_L368A_Y407V, T366K/L351D, L351K/Y349E, L351K/Y349D, L351K/L368E, L351Y_Y407A/T366A_K409F, L351Y_Y407A/T366V_K409F, K392D/D399K, K392D/E356K, K253E_D282K_K322D/D239K_E240K_K292D, K392D_K409D/D356K_D399K이다.
듀오바디® 돌연변이(Genmab)는, 예를 들어 미국 특허 제9150663호 및 미국 특허 출원 공개 제2014/0303356호에 개시되어 있으며, 돌연변이 F405L/K409R, 야생형/F405L_R409K, T350I_K370T_F405L/K409R, K370W/K409R, D399AFGHILMNRSTVWY/K409R, T366ADEFGHILMQVY/K409R, L368ADEGHNRSTVQ/K409AGRH, D399FHKRQ/K409AGRH, F405IKLSTVW/K409AGRH 및 Y407LWQ/K409AGRH를 포함한다.
전립선 신생항원 또는 전립선 신생항원/HLA 복합체에 특이적으로 결합하는 항원 결합 도메인이 도입될 수 있는 추가의 이중특이성 또는 다중특이성 구조는 이중 가변 도메인 면역글로불린(Dual Variable Domain Immunoglobulin, DVD)(국제 특허 공개 제WO2009/134776호; DVD는 VH1-링커-VH2-CH 구조를 갖는 중쇄 및 VL1-링커-VL2-CL 구조를 갖는 경쇄를 포함하는 전장 항체(링커는 임의적임)), 류신 지퍼 또는 콜라겐 이량체화 도메인과 같은, 상이한 특이성을 갖는 2개의 항체 아암을 연결하는 다양한 이량체화 도메인을 포함하는 구조(국제 특허 공개 제WO2012/022811호, 미국 특허 제5,932,448호; 미국 특허 제6,833,441호), 함께 접합된 2개 이상의 도메인 항체(dAb), 다이아바디, 중쇄 전용 항체, 예컨대 낙타과 항체 및 조작된 낙타과 항체, 이중 표적화(DT)-Ig (GSK/Domantis), 투-인-원 항체(Two-in-one Antibody) (Genentech), 가교결합된(Cross-linked) Mab (Karmanos Cancer Center), mAb2 (F-Star) 및 CovX-body (CovX/Pfizer), IgG 유사 이중특이성 (InnClone/Eli Lilly), Ts2Ab (MedImmune/AZ) 및 BsAb (Zymogenetics), HERCULES (Biogen Idec) 및 TvAb (Roche), ScFv/Fc 융합체 (Academic Institution), SCORPION (Emergent BioSolutions/Trubion, Zymogenetics/BMS), 이중 친화성 재표적화 기술(Dual Affinity Retargeting Technology) (Fc-DART) (MacroGenics) 및 이중(Dual)(ScFv)2-Fab (National Research Center for Antibody Medicine--China), 이중 작용(Dual-Action) 또는 Bis-Fab (Genentech), 독-앤드-록(Dock-and-Lock)(DNL) (ImmunoMedics), 2가 이중특이성(Biotecnol) 및 Fab-Fv (UCB-Celltech)를 포함한다. ScFv-, 다이아바디-기반 및 도메인 항체는 이중특이성 T 세포 인게이저(BiTE) (Micromet), 탠덤 다이아바디(Tandab) (Affimed), 이중 친화성 재표적화 기술(DART) (MacroGenics), 단일쇄 다이아바디(Academic), TCR 유사 항체(AIT, ReceptorLogics), 인간 혈청 알부민 ScFv 융합체(Merrimack) 및 COMBODY(Epigen Biotech), 이중 표적화 나노바디(Ablynx), 이중 표적화 중쇄 전용 도메인 항체를 포함하지만 이로 한정되지 않는다.
대체 스캐폴드
전립선 신생항원 또는 전립선 신생항원/HLA 복합체에 특이적으로 결합하는 대체 스캐폴드(항체 모방체로도 지칭됨)는 당업계에 공지되고 본 명세서에 기재된 다양한 스캐폴드를 사용하여 생성될 수 있다. 대체 스캐폴드는 단백질 스캐폴드(미국 특허 제6,673,901호; 미국 특허 제6,348,584호)로서 피브로넥틴 또는 테나신의 피브로넥틴 III형 도메인(Fn3) 또는 미국 특허 공개 제2010/0216708호 및 미국 특허 공개 제2010/0255056호에 기재된 바와 같이 텐콘(tencon)과 같은 합성 FN3 도메인을 통합하도록 설계된 모노바디일 수 있다. 추가의 대체 스캐폴드는 아드넥틴(Adnectin)™, iMab, 안티칼린(Anticalin)®, EETI-II/AGRP, 쿠니츠(Kunitz) 도메인, 티오레독신 펩티드 앱타머, 애피바디(Affibody)®, DARPin, 아필린(Affilin), 테트라넥틴(Tetranectin), 파이노머(Fynomer) 및 아비머(Avimer)를 포함한다. 대안적인 스캐폴드는 가변 도메인 내에 삽입, 결실 또는 다른 치환을 허용하는 높은 입체형태 공차의 가변 도메인과 관련된 고도로 구조화된 코어를 포함유는 단일쇄 폴리펩티드 프레임워크이다. 다양성을 하나 이상의 가변 도메인에, 경우에 따라서는 구조화된 코어에 도입하는 라이브러리는 공지된 프로토콜을 사용하여 생성될 수 있고, 얻어진 라이브러리는 본 발명의 신생항원에 결합하기 위해 스크리닝될 수 있으며, 확인된 결합제는 공지된 방법을 사용하여 이의 특이성에 대해 추가로 특성화될 수 있다. 대체 스캐폴드는 단백질 A, 특히 이의 Z-도메인(어피바디), ImmE7(면역 단백질), BPTI/APPI(쿠니츠 도메인), Ras 결합 단백질 AF-6(PDZ-도메인), 카리브도톡신(전갈 독소), CTLA-4, Min-23(노틴(knottin)), 리포칼린(안티칼린(anticalin)), 네오카르지노스타틴(neokarzinostatin), 피브로넥틴 도메인, 안키린 공통 반복 도메인 또는 티오레독신으로부터 유래될 수 있다(문헌[Skerra, A., "Alternative Non-Antibody Scaffolds for Molecular Recognition," Curr . Opin . Biotechnol . 18:295-304 (2005)]; 문헌[Hosse et al., "A New Generation of Protein Display Scaffolds for Molecular Recognition," Protein Sci. 15:14-27 (2006)]; 문헌[Nicaise et al., "Affinity Transfer by CDR Grafting on a Nonimmunoglobulin Scaffold," Protein Sci . 13:1882-1891 (2004)]; 문헌[Nygren and Uhlen, "Scaffolds for Engineering Novel Binding Sites in Proteins," Curr. Opin. Struc. Biol. 7:463-469 (1997)].
키메라 항원 수용체(CAR)
전립선 신생항원 또는 전립선 신생항원/HLA 복합체에 특이적으로 결합하는 항원 결합 도메인을 CAR의 세포외 도메인에 도입함으로써, 전립선 신생항원 또는 전립선 신생항원/HLA 복합체에 결합하는 CAR이 생성될 수 있다. CAR은 유전자 조작된 수용체이다. 이들 유전자 조작된 수용체는 당업계에 알려진 기법에 따라 T 세포를 포함한 면역 세포에 용이하게 삽입되고 이에 의해 발현될 수 있다. CAR의 경우, 단일 수용체는 특정 항원을 인식하도록, 그리고 또한, 그 항원에 결합될 때 면역 세포를 활성화하여 그 항원을 보유하는 세포를 공격하고 파괴하도록 프로그래밍될 수 있다. 이들 항원이 종양 세포 상에 존재할 때, CAR을 발현하는 면역 세포는 종양 세포를 표적화하고 사멸시킬 수 있다.
CAR은 전형적으로 항원(예를 들어, 전립선 신생항원 또는 전립선 신생항원/HLA 복합체)에 결합하는 세포외 도메인, 선택적인 링커, 막관통 도메인, 및 공자극 도메인 및/또는 신호전달 도메인을 포함하는 세포질 도메인을 포함한다.
CAR의 세포외 도메인은 원하는 항원(예를 들어, 전립선 신생항원)에 특이적으로 결합하는 임의의 폴리펩티드를 포함할 수 있다. 세포외 도메인은 scFv, 항체의 일부 또는 대체 스캐폴드를 포함할 수 있다. CAR은 또한 직렬로 배열되고 링커 서열에 의해 분리될 수 있는 2개 이상의 원하는 항원에 결합하도록 조작될 수 있다. 예를 들어, 하나 이상의 도메인 항체, scFv, 라마 VHH 항체 또는 다른 VH 전용 항체 단편은 링커를 통해 직렬로 구성되어, CAR에 이중특이성 또는 다중특이성을 제공할 수 있다.
CAR의 막관통 도메인은 CD8, T 세포 수용체의 알파, 베타 또는 제타 사슬, CD28, CD3 엡실론, CD45, CD4, CD5, CD8, CD9, CD16, CD22, CD33, CD37, CD64, CD80, CD86, CD134, CD137, CD154, KIRDS2, OX40, CD2, CD27, LFA-1(CDI la, CD18), ICOS(CD278), 4-1 BB(CD137), 4-1 BBL, GITR, CD40, BAFFR, HVEM(LIGHTR), SLAMF7, NKp80(KLRFI), CD160, CD1 9, IL2R 베타, IL2R 감마, IL7R a, ITGA1, VLA1, CD49a, ITGA4, IA4, CD49D, ITGA6, VLA-6, CD49f, ITGAD, CDI Id, ITGAE, CD103, ITGAL, CDI la, LFA-1, ITGAM, CDI lb, ITGAX, CDI lc, ITGB1, CD29, ITGB2, CD1 8, LFA-1, ITGB7, TNFR2, DNAM1(CD226), SLAMF4(CD244, 2B4), CD84, CD96(Tactile), CEACAM1, CRT AM, Ly9(CD229), CD160(BY55), PSGL1, CD100(SEMA4D), SLAMF6(NTB-A, Lyl08), SLAM(SLAMF1, CD150, IPO-3), BLAME(SLAMF8), SELPLG(CD162), LTBR, PAG/Cbp, NKp44, NKp30, NKp46, NKG2D, 및/또는 NKG2C의 막관통 도메인으로부터 유래될 수 있다.
CAR의 세포내 공자극 도메인은 하나 이상의 공자극 분자의 세포내 도메인으로부터 유래될 수 있다. 공자극 분자는 항원에 결합 시에 T 림프구의 효율적인 활성화 및 기능에 필요한 제2 신호를 제공하는, 항원 수용체 또는 Fc 수용체 이외의 잘 알려진 세포 표면 분자이다. CAR에 사용될 수 있는 예시적인 공자극 도메인은 4-1BB, CD2, CD7, CD27, CD28, CD30, CD40, CD54 (ICAM), CD83, CD134 (OX40), CD150 (SLAMF1), CD152 (CTLA4), CD223 (LAG3), CD270 (HVEM), CD278 (ICOS), DAP10, LAT, NKD2C SLP76, TRIM, BTLA, GITR, CD226, HVEM, 및 ZAP70의 세포내 도메인이다.
CAR의 세포내 신호전달 도메인은 예를 들어, CD3ζ, CD3ε, CD22, CD79a, CD66d, CD39 DAP10, DAP12, Fc 엡실론 수용체 I 감마 사슬(FCER1G), FcR β, CD3δ, CD3γ, CD5, CD226 또는 CD79B의 신호전달 도메인으로부터 유래될 수 있다. "세포내 신호전달 도메인"은 표적 항원에 대한 효과적인 CAR 결합의 메시지를 면역 이펙터 세포의 내부로 전달하여 이펙터 세포 기능, 예를 들어 활성화, 사이토카인 생성, 증식 및 세포독성 활성 - CAR-결합된 표적 세포로의 세포독성 인자의 방출을 포함함 -, 또는 세포외 CAR 도메인에 대한 항원 결합 후에 유도되는 다른 세포 반응을 유도하는 데 참여하는 CAR 폴리펩티드의 일부를 지칭한다.
세포외 도메인과 막관통 도메인 사이에 위치된 CAR의 선택적인 링커는 약 2 내지 100개의 아미노산 길이의 폴리펩티드일 수 있다. 링커는 인접한 단백질 도메인들이 서로에 대해 자유롭게 이동하도록 글리신 및 세린과 같은 가요성 잔기를 포함하거나 이로 구성될 수 있다. 2개의 인접한 도메인이 서로 입체적으로 방해하지 않음을 보장하는 것이 바람직할 때에는 더 긴 링커가 사용될 수 있다. 링커는 절단성 또는 비절단성일 수 있다. 절단성 링커의 예에는 2A 링커(예를 들어, T2A), 2A-유사 링커 또는 이들의 기능적 등가물 및 이들의 조합이 포함된다. 링커는 또한 임의의 면역글로불린의 힌지 영역 또는 상기 힌지 영역의 일부분으로부터 유래될 수 있다. 링커의 비제한적인 예는 인간 CD8α 사슬의 일부, CD28의 부분 세포외 도메인, FcγRllla 수용체, IgG, IgM, IgA, IgD, IgE, Ig 힌지, 또는 이의 기능적 단편을 포함한다.
사용될 수 있는 예시적인 CAR은, 예를 들어 본 발명의 전립선 신생항원에 결합하는 세포외 도메인, CD8 막관통 도메인 및 CD3ζ 신호전달 도메인을 함유하는 CAR이다. 다른 예시적인 CAR은 본 발명의 전립선 신생항원에 결합하는 세포외 도메인, CD8 또는 CD28 막관통 도메인, CD28, 41BB 또는 OX40 공자극 도메인 및 CD3ζ 신호전달 도메인을 포함한다.
CAR은 표준 분자 생물학 기법에 의해 생성된다. 원하는 항원에 결합하는 세포외 도메인은 본 명세서에 기재된 기술을 사용하여 생성된 항체 또는 이의 항원 결합 단편으로부터 유래될 수 있다.
T 세포 수용체(TCR)
전립선 신생항원/HLA 복합체에 결합하는 TCR이 생성될 수 있다. TCR은 전립선 신생항원/HLA 복합체에 대한 T 세포 결합에 기초하여 확인되어, T 세포를 단리하고, T 세포에서 발현되는 TCR을 시퀀싱할 수 있다. 확인된 TCR은 αβ T 세포 또는 γδ T 세포로부터 확인될 수 있다. 확인된 TCR은 친화성, 안정성, 용해도 등을 개선하기 위해 추가로 조작될 수 있다. TCR은 친화성 성숙 면역글로불린에 사용된 것과 동일한 기술을 이용하여 친화성 성숙될 수 있다. TCR은 시스테인 안정화된 가용성 TCR로 발현될 수 있으며, 이는 α/β 상호작용 표면, 예를 들어 α 사슬 상의 G192R 및 β 사슬 상의 R208G에 돌연변이를 조작하여 안정화될 수 있다. TCR은 또한 US7329731, US7871817B2, US7569664, US9133264, US9624292, US20120252742A1, US2016/0130319, EP3215164A1, EP3286210A1, WO2017091905A1 또는 US9884075에 기재된 바와 같이, α 및 β 사슬 V 도메인, 막관통 도메인 또는 불변 도메인 간의 스왑을 포함하는 도메인 스왑을 사용하여, α 사슬의 위치 11, 13, 19, 21, 53, 76, 89, 91 또는 94와 같은 소수성 코어에 돌연변이를 도입함으로써, TCR 불변 도메인으로 다이설파이드 결합을 형성하는 시스테인 잔기를 조작함으로써 안정화될 수 있다.
본 발명의 CAR 또는 TCR을 발현하는 세포
본 발명의 전립선 신생항원 또는 본 발명의 전립선 신생항원/HLA 복합체에 특이적으로 결합하는 CAR 또는 TCR을 발현하는 세포는 본 발명의 범위 내에 있다. 본 발명은 또한 본 발명의 CAR 또는 본 발명의 TCR을 포함하는 단리된 세포를 제공한다. 일부 실시 형태에서, 단리된 세포는 본 발명의 CAR 또는 TCR로 형질도입되어, 세포의 표면 상에서 본 발명의 CAR 또는 TCR의 구성적 발현을 일으킨다. 본 발명의 CAR 또는 TCR을 발현하는 세포는 하나 이상의 공자극 분자를 발현하도록 추가로 조작될 수 있다. 예시적인 공자극 분자는 CD28, ICOS, LIGHT, GITR, 4-1BB 및 OX40이다. 본 발명의 CAR 또는 TCR을 발현하는 세포는 하나 이상의 사이토카인 또는 케모카인 또는 전염증성 메디에이터, 예컨대 TNFα, IFNγ, IL-2, IL-3, IL-6, IL-7, IL-11, IL-12, IL-15, IL-17 또는 IL-21을 생성하도록 추가로 조작될 수 있다. 세포는 공지된 유전자 편집 기술을 사용하여 불활성화된 내인성 TCR 유전자좌 및/또는 HLA 유전자좌를 가질 수 있다. 일부 실시 형태에서, 본 발명의 CAR 또는 TCR을 포함하는 세포는 T 세포, 자연 살해(NK) 세포, 세포독성 T 림프구(CTL), 조절 T 세포(Treg), 인간 배아 줄기 세포, 림프구 전구세포, T 세포 전구세포, 만능 줄기 세포, 또는 림프구 세포가 분화될 수 있는 유도 만능 줄기 세포(iPSC)이다.
일부 실시 형태에서, 본 발명의 CAR 또는 TCR을 포함하는 단리된 세포는 T 세포이다. T 세포는 배양된 T 세포, 예를 들어 일차 T 세포, 또는 배양된 T 세포주, 예를 들어 저캇(Jurkat), SupT1 등로부터의 T 세포, 또는 포유동물로부터 얻은 T 세포와 같은 임의의 T 세포일 수 있다. 포유동물로부터 얻은 경우, T 세포는 골수, 혈액, 림프절, 흉선, 또는 다른 조직 또는 체액을 비롯한 임의의 공급원으로부터 얻을 수 있다. T 세포는 또한 농축되거나 정제될 수 있다. T 세포는 인간 T 세포일 수 있다. T 세포는 인간으로부터 단리된 T 세포일 수 있다. T 세포는 임의의 유형의 T 세포일 수 있으며, CD4+CD8+ 이중 양성 T 세포, CD8+ T 세포(예를 들어, 세포독성 T 세포), CD4+ 헬퍼 T 세포, 예를 들어, Th1 및 Th2 세포, 말초 혈액 단핵 세포(PBMC), 말초 혈액 백혈구(PBL), 종양 침윤 세포, 기억 T 세포, 미감작 T 세포 등을 포함한 임의의 발달 단계일 수 있다. T 세포는 CD8+ T 세포 또는 CD4+ T 세포일 수 있다. T 세포는 αβ T 세포 또는 γδ T 세포일 수 있다.
일부 실시 형태에서, 본 발명의 CAR 또는 본 발명의 TCR을 포함하는 단리된 세포는 NK 세포이다.
일부 실시 형태에서, 본 발명의 CAR 또는 본 발명의 TCR을 포함하는 단리된 세포는 αβ T 세포이다.
일부 실시 형태에서, 본 발명의 CAR 또는 본 발명의 TCR을 포함하는 단리된 세포는 γδ T 세포이다.
일부 실시 형태에서, 본 발명의 CAR 또는 본 발명의 TCR을 포함하는 단리된 세포는 CD8+ 세포독성 T 림프구이다.
일부 실시 형태에서, 본 발명의 CAR 또는 본 발명의 TCR을 포함하는 단리된 세포는 인간 배아 줄기 세포이다.
일부 실시 형태에서, 본 발명의 CAR 또는 본 발명의 TCR을 포함하는 단리된 세포는 림프구 전구세포이다.
일부 실시 형태에서, 본 발명의 CAR 또는 본 발명의 TCR을 포함하는 단리된 세포는 만능 줄기 세포이다.
일부 실시 형태에서, 본 발명의 CAR 또는 본 발명의 TCR을 포함하는 단리된 세포는 유도 만능 줄기 세포(iPSC)이다.
본 발명의 세포는 공지된 방법을 사용하여 원하는 CAR 또는 TCR을 포함하는 렌티바이러스 벡터를 세포에 도입함으로써 생성될 수 있다. 본 발명의 세포는 생체내에서 복제하여 장기간 지속될 수 있고, 이는 지속적인 종양 제어로 이어질 수 있다.
세포독성제, 약물, 검출가능 표지 등과의 접합체
폴리펩티드, 이종 폴리펩티드 및 이들에 결합하는 단백질성 분자는 세포독성제, 치료제, 검출가능 표지 등에 접합될 수 있다. 이들 분자는 본 명세서에서 면역접합체로 지칭된다. 전립선 신생항원을 포함하는 면역접합체는 전립선 신생항원에 결합하는 HLA 분자를 발현하는 세포를 검출하거나, 페이로드(payload) 전달하거나, 사멸시키는데 사용될 수 있다. 전립선 신생항원 또는 전립선 신생항원/HLA 복합체에 특이적으로 결합하는 항체, 항원 결합 단편 또는 대체 스캐폴드를 포함하는 면역접합체는 더 큰 단백질과 관련하여, 또는 HLA와 복합체를 형성한 상태로 그 표면에 전립선 신생항원을 발현하는 세포를 검출하거나, 페이로드 전달하거나, 사멸시키거나, 세포 용해 후에 세포내 전립선 신생항원을 검출하는데 사용될 수 있다.
일부 실시 형태에서, 면역접합체는 검출가능 표지를 포함한다.
일부 실시 형태에서, 면역접합체는 세포독성제를 포함한다.
일부 실시 형태에서, 면역접합체는 치료제를 포함한다.
검출가능 표지는 분광학적, 광화학적, 생화학적, 면역화학적 또는 화학적 수단을 통해 가시화될 수 있는 조성물을 포함한다. 검출가능 표지는 또한 세포독성제를 포함할 수 있고, 세포독성제는 검출가능 표지를 포함할 수 있다.
예시적인 검출가능 표지에는 방사성 동위원소, 자성 비드, 금속 비드, 콜로이드 입자, 형광 염료, 고 전자밀도 시약(electron-dense reagent), 효소(예를 들어, ELISA에서 통상적으로 사용되는 것), 비오틴, 디곡시게닌, 합텐, 발광 분자, 화학발광 분자, 형광색소, 형광단, 형광 켄칭제(fluorescent quenching agent), 착색된 분자, 방사성 동위원소, 신틸레이트(scintillate), 아비딘, 스트렙타비딘, 단백질 A, 단백질 G, 항체 또는 이의 단편, 폴리히스티딘, Ni2+, Flag 태그, myc 태그, 중금속, 효소, 알칼리 포스파타제, 퍼옥시다제, 루시페라제, 전자 공여체/수용체, 아크리디늄 에스테르 및 발색 기질이 포함된다.
검출가능 표지는, 예컨대, 검출가능 표지가 방사성 동위원소인 경우, 신호를 자발적으로 방출할 수 있다. 다른 경우에는, 검출가능한 표지는 외부장(external field)에 의해 자극된 결과로서 신호를 방출한다.
예시적인 방사성 동위원소는 γ-방출, 오거(Auger)-방출, β-방출, 알파-방출 또는 양전자-방출 방사성 동위원소일 수 있다. 예시적인 방사성 동위원소는 3H, 11C, 13C, 15N, 18F, 19F, 55Co, 57Co, 60Co, 61Cu, 62Cu, 64Cu, 67Cu, 68Ga, 72As, 75Br, 86Y, 89Zr, 90Sr, 94mTc, 99mTc, 115In, 123I, 124I, 125I, 131I, 211At, 212Bi, 213Bi, 223Ra, 226Ra, 225Ac 및 227Ac를 포함한다.
예시적인 금속 원자는 원자번호가 20보다 큰 금속, 예컨대 칼슘 원자, 스칸듐 원자, 티타늄 원자, 바나듐 원자, 크롬 원자, 망간 원자, 철 원자, 코발트 원자, 니켈 원자, 구리 원자, 아연 원자, 갈륨 원자, 게르마늄 원자, 비소 원자, 셀레늄 원자, 브롬 원자, 크립톤 원자, 루비듐 원자, 스트론튬 원자, 이트륨 원자, 지르코늄 원자, 니오븀 원자, 몰리브덴 원자, 테크네튬 원자, 루테늄 원자, 로듐 원자, 팔라듐 원자, 은 원자, 카드뮴 원자, 인듐 원자, 주석 원자, 안티몬 원자, 텔루륨 원자, 요오드 원자, 제논 원자, 세슘 원자, 바륨 원자, 란타늄 원자, 하프늄 원자, 탄탈룸 원자, 텅스텐 원자, 레늄 원자, 오스뮴 원자, 이리듐 원자, 백금 원자, 금 원자, 수은 원자, 탈륨 원자, 납 원자, 비스무트 원자, 프란슘 원자, 라듐 원자, 악티늄 원자, 세륨 원자, 프라세오디뮴 원자, 네오디뮴 원자, 프로메튬 원자, 사마륨 원자, 유로퓸 원자, 가돌리늄 원자, 테르븀 원자, 디스프로슘 원자, 홀뮴 원자, 에르븀 원자, 툴륨 원자, 이터븀 원자, 루테튬 원자, 토륨 원자, 프로트악티늄 원자, 우라늄 원자, 넵투늄 원자, 플루토늄 원자, 아메리슘 원자, 퀴륨 원자, 버클륨 원자, 캘리포늄 원자, 아인슈타이늄 원자, 페르뮴 원자, 멘델레븀 원자, 노벨륨 원자 또는 로렌슘 원자이다.
일부 실시 형태에서, 금속 원자는 원자번호가 20보다 큰 알칼리 토금속일 수 있다.
일부 실시 형태에서, 금속 원자는 란탄족 원소일 수 있다.
일부 실시 형태에서, 금속 원자는 악티늄족 원소일 수 있다.
일부 실시 형태에서, 금속 원자는 전이 금속일 수 있다.
일부 실시 형태에서, 금속 원자는 전이후 금속(poor metal)일 수 있다.
일부 실시 형태에서, 금속 원자는 금 원자, 비스무트 원자, 탄탈룸 원자 및 가돌리늄 원자일 수 있다.
일부 실시 형태에서, 금속 원자는 원자번호가 53(즉, 요오드) 내지 83(즉, 비스무트)인 금속일 수 있다.
일부 실시 형태에서, 금속 원자는 자기 공명 영상에 적합한 원자일 수 있다.
금속 원자는 +1, +2 또는 +3 산화 상태의 형태의 금속 이온, 예컨대 Ba2 +, Bi3+, Cs+, Ca2 +, Cr2 +, Cr3 +, Cr6 +, Co2 +, Co3 +, Cu+, Cu2 +, Cu3 +, Ga3 +, Gd3 +, Au+, Au3 +, Fe2+, Fe3 +, F3+, Pb2 +, Mn2 +, Mn3 +, Mn4 +, Mn7 +, Hg2 +, Ni2 +, Ni3 +, Ag+, Sr2 +, Sn2 +, Sn4 + 및 Zn2+일 수 있다. 금속 원자는 금속 산화물, 예컨대 산화철, 산화망간 또는 산화가돌리늄을 포함할 수 있다.
적절한 염료는, 예를 들어 5(6)-카르복시플루오레세인, IRDye 680RD 말레이미드 또는 IRDye 800CW, 루테늄 폴리피리딜 염료 등과 같은 임의의 시판 염료를 포함한다.
적절한 형광단은 플루오레세인 아이소티오시아네이트(FITC), 플루오레세인 티오세미카르바지드, 로다민, 텍사스 레드(Texas Red), CyDye(예를 들어, Cy3, Cy5, Cy5.5), 알렉사 플루오르(Alexa Fluor; 예를 들어, 알렉사488, 알렉사555, 알렉사594; 알렉사647), 근적외선(NIR)(700 내지 900 nm) 형광 염료, 및 카르보시아닌 및 아미노스티릴 염료이다.
검출가능 표지를 포함하는 면역접합체는 조영제로서 사용될 수 있다.
일부 실시 형태에서, 세포독성제는 화학요법제, 약물, 성장 억제제, 독소(예를 들어, 세균, 진균, 식물 또는 동물 유래의 효소적으로 활성인 독소 또는 이의 단편) 또는 방사성 동위원소(즉, 방사성 접합체(radioconjugate))이다.
일부 실시 형태에서, 세포독성제는 다우노마이신, 독소루비신, 메토트렉세이트, 빈데신, 세균 독소, 예컨대 디프테리아 독소, 리신, 겔다나마이신, 메이탄시노이드 또는 칼리키아미신(calicheamicin)이다. 세포독성제는 튜불린 결합, DNA 결합 또는 토포아이소머라제 억제를 포함하는 메커니즘에 의해 이들의 세포독성 및 세포증식억제(cytostatic) 효과를 끌어낼 수 있다.
일부 실시 형태에서, 세포독성제는 효소적으로 활성인 독소, 예컨대 디프테리아 A 사슬, 디프테리아 독소의 비결합성 활성 단편, 외독소 A 사슬(슈도모나스 아에루기노사(Pseudomonas aeruginosa) 유래), 리신 A 사슬, 아브린 A 사슬, 모데신 A 사슬, 알파-사르신, 알레우리테스 포르디이(Aleurites fordii) 단백질, 디안틴 단백질, 피톨라카 아메리카나(Phytolaca americana) 단백질(PAPI, PAPII 및 PAP-S), 모모르디카 카란티아(Momordica charantia) 억제제, 쿠르신, 크로틴, 사파오나리아 오프피시날리스(Sapaonaria officinalis) 억제제, 겔로닌, 미토겔린, 레스트릭토신, 페노마이신, 에노마이신 및 트리코테센이다.
일부 실시 형태에서, 세포독성제는 방사성 핵종, 예컨대 212Bi, 131I, 131In, 90Y 및 186Re이다.
일부 실시 형태에서, 세포독성제는 돌라스타틴 또는 돌로스타틴 펩티드 유사체 및 유도체, 오리스타틴 또는 모노메틸 오리스타틴 페닐알라닌이다. 예시적인 분자가 미국 특허 제5,635,483호 및 제5,780,588호에 개시되어 있다. 돌라스타틴 및 오리스타틴은 미세소관의 동태, GTP 가수분해, 및 핵 및 세포 분열을 방해하고(문헌[Woyke et al (2001) Antimicrob Agents and Chemother. 45(12):3580-3584]), 항암 및 항진균 활성을 갖는 것으로 밝혀졌다. 돌라스타틴 또는 오리스타틴 약물 부분은 펩티드 약물 부분의 N(아미노) 말단 또는 C(카르복실) 말단을 통해(국제 특허 출원 공개 WO02/088172호), 또는 항체 내로 유전자 조작된 임의의 시스테인을 통해 본 발명의 항체에 부착될 수 있다.
면역접합체는 공지된 방법을 사용하여 제조될 수 있다.
일부 실시 형태에서, 검출가능 표지는 킬레이트제와 복합체를 형성한다.
검출가능 표지, 세포독성제 또는 치료제는 직접적으로, 또는 링커를 통해 간접적으로 폴리펩티드, 이종 폴리펩티드, 또는 폴리펩티드 또는 이종 폴리펩티드에 결합하는 단백질성 분자에 연결될 수 있다. 적절한 링커는 본 기술 분야에 알려져 있으며, 예를 들어, 보결분자족(prosthetic group), 비페놀계 링커(N-석신이미딜-벤조에이트의 유도체; 도데카보레이트), 마크로사이클릭 및 비환형 킬레이트제 둘 모두의 킬레이트 부분, 예컨대 1,4,7,10-테트라아자사이클로도데칸-1,4,7,10-테트라아세트산(DOTA)의 유도체, 다이에틸렌트라이아민펜타아세트산(DTPA)의 유도체, S-2-(4-아이소티오시아네이토벤질)-1,4,7-트라이아자사이클로노난-1,4,7-트라이아세트산(NOTA)의 유도체 및 1,4,8,11-테트라아자사이클로도데칸-1,4,8,11-테트라아세트산(TETA)의 유도체, N-석신이미딜-3-(2-피리딜다이티올) 프로피오네이트(SPDP), 이미노티올란(IT), 이미도에스테르의 2작용성 유도체(예컨대 다이메틸 아디피미데이트 HCl), 활성 에스테르(예컨대 다이석신이미딜 수베레이트), 알데하이드(예컨대 글루타르알데하이드), 비스-아지도 화합물(예컨대 비스(p-아지도벤조일)헥산다이아민), 비스-다이아조늄 유도체(예컨대 비스-(p-다이아조늄벤조일)-에틸렌다이아민), 다이아이소시아네이트(예컨대 톨루엔 2,6-다이아이소시아네이트), 및 비스-활성 불소 화합물(예컨대 1,5-다이플루오로-2,4-다이니트로벤젠) 및 다른 킬레이트 부분이 포함한다. 적절한 펩티드 링커가 잘 알려져 있다.
치료 방법, 용도 및 투여
본 발명의 전립선 신생항원을 대상에 도입하기 위해 사용될 수 있는 본 발명의 다양한 분자, 예를 들어 본 발명의 폴리뉴클레오티드, 이종 폴리뉴클레오티드, 폴리펩티드, 이종 폴리펩티드, 벡터, 재조합 바이러스 및 백신은 대상에서 전립선암을 치료하는데 사용될 수 있다. 본 발명의 전립선 신생항원을 대상에 도입하기 위해 사용될 수 있는 본 발명의 다양한 분자, 예를 들어 본 발명의 폴리뉴클레오티드, 이종 폴리뉴클레오티드, 폴리펩티드, 이종 폴리펩티드, 벡터, 재조합 바이러스 및 백신은 대상에서 전립선암을 예방하는데에도 사용될 수 있다. 본 발명의 전립선 신생항원 또는 본 발명의 전립선 신생항원/HLA 복합체에 특이적으로 결합하는 단백질성 분자는 대상에서 전립선암을 치료하거나 예방하는데 사용될 수 있다.
본 발명에서 확인된 전립선암 신생항원은 전립선암을 앓고 있는 대상 집단에서 적어도 약 1% 이상, 약 2% 이상, 약 3% 이상, 약 4% 이상, 약 5% 이상, 약 6% 이상, 약 7% 이상, 약 8% 이상, 약 9% 이상, 약 10% 이상, 약 11% 이상, 약 12% 이상, 약 13% 이상, 약 14% 이상, 약 15% 이상, 약 16% 이상, 약 17% 이상, 약 18% 이상, 약 19% 이상, 약 20% 이상, 약 21% 이상, 약 22% 이상, 약 23% 이상, 약 24% 이상, 약 25% 이상, 약 26% 이상, 약 27% 이상, 약 28% 이상, 약 29% 이상, 약 30% 이상, 약 35% 이상, 약 40% 이상, 약 45% 이상, 약 50% 이상, 약 55% 이상, 약 60% 이상, 약 65% 이상 또는 약 70% 이상의 빈도로 존재한다.
본 발명은 하나 이상의 본 발명의 백신의 치료적 유효량을 대상에게 투여하는 단계를 포함하는, 대상에서 전립선암을 치료하거나 예방하는 방법을 제공한다.
본 발명은 또한 전립선암을 치료하거나 예방하기 위한 의약의 제조를 위한 본 발명의 백신의 용도를 제공한다.
본 발명은 또한 전립선암을 치료하거나 예방하기 위한 약제학적 조성물의 제조를 위한 본 발명의 백신의 용도를 제공한다.
본 발명은 또한 전립선암을 치료하거나 예방하는데 사용하기 위한 본 발명의 백신을 제공한다.
본 발명은 또한 하나 이상의 본 발명의 약제학적 조성물의 치료적 유효량을 대상에게 투여하는 단계를 포함하는, 대상에서 전립선암을 치료하거나 예방하는 방법을 제공한다.
일부 실시 형태에서, 백신은 본 발명의 rAd26를 포함한다.
일부 실시 형태에서, 백신은 본 발명의 rMVA를 포함한다.
일부 실시 형태에서, 백신은 본 발명의 rGAd를 포함한다.
일부 실시 형태에서, 백신은 본 발명의 rGAd20를 포함한다.
일부 실시 형태에서, 백신은 본 발명의 rCh20를 포함한다.
일부 실시 형태에서, 백신은 본 발명의 rAd26 및 본 발명의 rMVA를 포함한다.
일부 실시 형태에서, 백신은 본 발명의 rGAd20 및 본 발명의 rMVA를 포함한다.
일부 실시 형태에서, 백신은 본 발명의 이종 폴리펩티드를 포함한다.
일부 실시 형태에서, 백신은 본 발명의 이종 폴리뉴클레오티드를 포함한다.
일부 실시 형태에서, 백신은 본 발명의 폴리뉴클레오티드를 포함한다.
일부 실시 형태에서, 백신은 본 발명의 폴리펩티드를 포함한다.
"전립선암"은 조직병리학적 유형 또는 침습성 병기에 관계없이, 전립선 또는 발암성 과정, 전이성 조직 또는 악성 형질전환된 세포, 조직 또는 기관 내의 모든 유형의 암성 종양을 포함하는 것을 의미한다.
일부 실시 형태에서, 전립선암은 선암이다.
일부 실시 형태에서, 전립선암은 전이성 전립선암이다. 일부 실시 형태에서, 전립선암은 직장, 림프절 또는 뼈, 또는 이들의 임의의 조합으로 전이되었다.
일부 실시 형태에서, 전립선암은 재발성 또는 불응성 전립선암이다.
일부 실시 형태에서, 전립선암은 거세저항성 전립선암이다.
일부 실시 형태에서, 전립선암은 안드로겐 차단요법에 민감하다.
일부 실시 형태에서, 전립선암은 안드로겐 차단요법에 둔감하다.
일부 실시 형태에서, 대상은 치료 경험이 없다(treatment  ).
).
일부 실시 형태에서, 대상은 안드로겐 차단요법을 받았다.
일부 실시 형태에서, 대상은 높은 전립선 특이항원(PSA) 레벨을 갖는다. PSA는 레벨이 전형적으로 약 ≥4.0 ng/mL일 때 대상에서 상승된다. 어떤 경우에는, 높은 PSA는 ≥3.0 ng/mL로 안정시키는 것을 지칭할 수 있다. PSA 레벨은 또한 안드로겐 차단요법 후의 레벨과 비교될 수 있다.
안드로겐 차단요법은 아비라테론(abiraterone), 케토코나졸(ketoconazole), 엔잘루타미드(enzalutamide), 갈레테론(galeterone), ARN-509 및 오르테로넬(orteronel; TAK-700) 또는 전립선 절제술을 포함한다.
본 발명은 또한 면역반응을 프라이밍하기 위해 본 발명의 rAd26를 포함하는 제1 백신의 치료적 유효량을 대상에게 투여하는 단계; 및 면역반응을 부스팅하기 위해 본 발명의 rMVA를 포함하는 제2 백신의 치료적 유효량을 대상에게 투여하여, 대상에서 전립선암을 치료하는 단계를 포함하는, 대상에서 전립선암을 치료하는 방법을 제공한다.
본 발명은 또한 면역반응을 프라이밍하기 위해 본 발명의 rGAd를 포함하는 제1 백신의 치료적 유효량을 대상에게 투여하는 단계; 및 면역반응을 부스팅하기 위해 본 발명의 rMVA를 포함하는 제2 백신의 치료적 유효량을 대상에게 투여하여, 대상에서 전립선암을 치료하는 단계를 포함하는, 대상에서 전립선암을 치료하는 방법을 제공한다.
본 발명은 또한 면역반응을 프라이밍하기 위해 본 발명의 rGAd20를 포함하는 제1 백신의 치료적 유효량을 대상에게 투여하는 단계; 및 면역반응을 부스팅하기 위해 본 발명의 rMVA를 포함하는 제2 백신의 치료적 유효량을 대상에게 투여하여, 대상에서 전립선암을 치료하는 단계를 포함하는, 대상에서 전립선암을 치료하는 방법을 제공한다.
본 발명은 또한 면역반응을 프라이밍하기 위해 본 발명의 rAd26를 포함하는 제1 백신의 치료적 유효량을 대상에게 투여하는 단계; 및 면역반응을 부스팅하기 위해 본 발명의 rMVA를 포함하는 제2 백신의 치료적 유효량을 대상에게 투여하여, 대상에서 전립선암을 예방하는 단계를 포함하는, 대상에서 전립선암을 예방하는 방법을 제공한다.
본 발명은 또한 면역반응을 프라이밍하기 위해 본 발명의 rGAd를 포함하는 제1 백신의 치료적 유효량을 대상에게 투여하는 단계; 및 면역반응을 부스팅하기 위해 본 발명의 rMVA를 포함하는 제2 백신의 치료적 유효량을 대상에게 투여하여, 대상에서 전립선암을 예방하는 단계를 포함하는, 대상에서 전립선암을 예방하는 방법을 제공한다.
본 발명은 또한 면역반응을 프라이밍하기 위해 본 발명의 rGAd20를 포함하는 제1 백신의 치료적 유효량을 대상에게 투여하는 단계; 및 면역반응을 부스팅하기 위해 본 발명의 rMVA를 포함하는 제2 백신의 치료적 유효량을 대상에게 투여하여, 대상에서 전립선암을 예방하는 단계를 포함하는, 대상에서 전립선암을 예방하는 방법을 제공한다.
본 발명은 또한 면역반응을 프라이밍하기 위해 본 발명의 rAd26를 포함하는 제1 백신의 면역학적 유효량을 대상에게 투여하는 단계; 및 면역반응을 부스팅하기 위해 본 발명의 rMVA를 포함하는 제2 백신의 면역학적 유효량을 대상에게 투여하여, 대상에서 면역반응을 증강시키는 단계를 포함하는, 대상에서 면역반응을 증강시키는 방법을 제공한다.
본 발명은 또한 면역반응을 프라이밍하기 위해 본 발명의 rGAd를 포함하는 제1 백신의 면역학적 유효량을 대상에게 투여하는 단계; 및 면역반응을 부스팅하기 위해 본 발명의 rMVA를 포함하는 제2 백신의 면역학적 유효량을 대상에게 투여하여, 대상에서 면역반응을 증강시키는 단계를 포함하는, 대상에서 면역반응을 증강시키는 방법을 제공한다.
본 발명은 또한 면역반응을 프라이밍하기 위해 본 발명의 rGAd20를 포함하는 제1 백신의 면역학적 유효량을 대상에게 투여하는 단계; 및 면역반응을 부스팅하기 위해 본 발명의 rMVA를 포함하는 제2 백신의 면역학적 유효량을 대상에게 투여하여, 대상에서 면역반응을 증강시키는 단계를 포함하는, 대상에서 면역반응을 증강시키는 방법을 제공한다.
본 발명은 또한 면역반응을 프라이밍하기 위해 본 발명의 rAd26를 포함하는 제1 백신의 치료적 유효량을 대상에게 투여하는 단계; 및 면역반응을 부스팅하기 위해 본 발명의 rMVA를 포함하는 제2 백신의 치료적 유효량을 대상에게 투여하여, 대상에서 전립선암을 치료하는 단계를 포함하며, 상기 rAd26 및 rMVA는 서열 번호 1, 3, 5, 7, 9, 11, 13, 15, 17, 19, 21, 23, 25, 27, 29, 31, 33, 35, 37, 39, 41, 43, 45, 47, 49, 51, 53, 55, 57, 59, 61, 63, 65, 67, 69, 71, 73, 75, 77, 79, 81, 83, 85, 87, 89, 91, 93, 95, 97, 99, 101, 103, 105, 107, 109, 111, 113, 115, 117, 119, 121, 123, 125, 127, 129, 131, 133, 135, 137, 139, 141, 143, 145, 147, 149, 151, 153, 155, 157, 159, 161, 163, 165, 167, 169, 171, 173, 175, 177, 179, 181, 183, 185, 187, 189, 191, 193, 195, 197, 199, 201, 203, 205, 207, 209, 211, 213, 215, 217, 219, 221, 223, 225, 227, 229, 231, 233, 235, 237, 239, 241, 243, 245, 247, 249, 251, 253, 255, 257, 259, 261, 263, 265, 267, 269, 271, 273, 275, 277, 279, 281, 283, 285, 287, 289, 291, 293, 295, 297, 299, 301, 303, 305, 307, 309, 311, 313, 315, 317, 319, 321, 323, 325, 327, 329, 331, 333, 335, 337, 339, 341, 343, 345, 347, 349, 351, 353, 355, 357, 359, 361, 363, 365, 367, 369, 371, 373, 375, 379, 381, 383, 385, 387, 388, 389, 390, 391, 392, 393, 394, 395, 396, 397, 398, 399, 400, 401, 402, 403, 404, 405, 406, 407, 408, 426, 427, 428, 429, 430, 431, 432, 433, 434, 435, 436, 437, 438, 439, 440, 441, 442, 443, 444, 445, 446 또는 447 중 하나 이상의 폴리펩티드 또는 이의 단편을 인코딩하는 이종 폴리뉴클레오티드를 포함하는, 대상에서 전립선암을 치료하는 방법을 제공한다.
본 발명은 또한 면역반응을 프라이밍하기 위해 본 발명의 rGAd를 포함하는 제1 백신의 치료적 유효량을 대상에게 투여하는 단계; 및 면역반응을 부스팅하기 위해 본 발명의 rMVA를 포함하는 제2 백신의 치료적 유효량을 대상에게 투여하여, 대상에서 전립선암을 치료하는 단계를 포함하며, 상기 rGAd 및 rMVA는 서열 번호 1, 3, 5, 7, 9, 11, 13, 15, 17, 19, 21, 23, 25, 27, 29, 31, 33, 35, 37, 39, 41, 43, 45, 47, 49, 51, 53, 55, 57, 59, 61, 63, 65, 67, 69, 71, 73, 75, 77, 79, 81, 83, 85, 87, 89, 91, 93, 95, 97, 99, 101, 103, 105, 107, 109, 111, 113, 115, 117, 119, 121, 123, 125, 127, 129, 131, 133, 135, 137, 139, 141, 143, 145, 147, 149, 151, 153, 155, 157, 159, 161, 163, 165, 167, 169, 171, 173, 175, 177, 179, 181, 183, 185, 187, 189, 191, 193, 195, 197, 199, 201, 203, 205, 207, 209, 211, 213, 215, 217, 219, 221, 223, 225, 227, 229, 231, 233, 235, 237, 239, 241, 243, 245, 247, 249, 251, 253, 255, 257, 259, 261, 263, 265, 267, 269, 271, 273, 275, 277, 279, 281, 283, 285, 287, 289, 291, 293, 295, 297, 299, 301, 303, 305, 307, 309, 311, 313, 315, 317, 319, 321, 323, 325, 327, 329, 331, 333, 335, 337, 339, 341, 343, 345, 347, 349, 351, 353, 355, 357, 359, 361, 363, 365, 367, 369, 371, 373, 375, 379, 381, 383, 385, 387, 388, 389, 390, 391, 392, 393, 394, 395, 396, 397, 398, 399, 400, 401, 402, 403, 404, 405, 406, 407, 408, 426, 427, 428, 429, 430, 431, 432, 433, 434, 435, 436, 437, 438, 439, 440, 441, 442, 443, 444, 445, 446 또는 447 중 하나 이상의 폴리펩티드 또는 이의 단편을 인코딩하는 이종 폴리뉴클레오티드를 포함하는, 대상에서 전립선암을 치료하는 방법을 제공한다.
본 발명은 또한 면역반응을 프라이밍하기 위해 본 발명의 rGAd20를 포함하는 제1 백신의 치료적 유효량을 대상에게 투여하는 단계; 및 면역반응을 부스팅하기 위해 본 발명의 rMVA를 포함하는 제2 백신의 치료적 유효량을 대상에게 투여하여, 대상에서 전립선암을 치료하는 단계를 포함하며, 상기 rGAd20 및 rMVA는 서열 번호 1, 3, 5, 7, 9, 11, 13, 15, 17, 19, 21, 23, 25, 27, 29, 31, 33, 35, 37, 39, 41, 43, 45, 47, 49, 51, 53, 55, 57, 59, 61, 63, 65, 67, 69, 71, 73, 75, 77, 79, 81, 83, 85, 87, 89, 91, 93, 95, 97, 99, 101, 103, 105, 107, 109, 111, 113, 115, 117, 119, 121, 123, 125, 127, 129, 131, 133, 135, 137, 139, 141, 143, 145, 147, 149, 151, 153, 155, 157, 159, 161, 163, 165, 167, 169, 171, 173, 175, 177, 179, 181, 183, 185, 187, 189, 191, 193, 195, 197, 199, 201, 203, 205, 207, 209, 211, 213, 215, 217, 219, 221, 223, 225, 227, 229, 231, 233, 235, 237, 239, 241, 243, 245, 247, 249, 251, 253, 255, 257, 259, 261, 263, 265, 267, 269, 271, 273, 275, 277, 279, 281, 283, 285, 287, 289, 291, 293, 295, 297, 299, 301, 303, 305, 307, 309, 311, 313, 315, 317, 319, 321, 323, 325, 327, 329, 331, 333, 335, 337, 339, 341, 343, 345, 347, 349, 351, 353, 355, 357, 359, 361, 363, 365, 367, 369, 371, 373, 375, 379, 381, 383, 385, 387, 388, 389, 390, 391, 392, 393, 394, 395, 396, 397, 398, 399, 400, 401, 402, 403, 404, 405, 406, 407, 408, 426, 427, 428, 429, 430, 431, 432, 433, 434, 435, 436, 437, 438, 439, 440, 441, 442, 443, 444, 445, 446 또는 447 중 하나 이상의 폴리펩티드 또는 이의 단편을 인코딩하는 이종 폴리뉴클레오티드를 포함하는, 대상에서 전립선암을 치료하는 방법을 제공한다.
본 발명은 또한 면역반응을 프라이밍하기 위해 본 발명의 rAd26를 포함하는 제1 백신의 치료적 유효량을 대상에게 투여하는 단계; 및 면역반응을 부스팅하기 위해 본 발명의 rMVA를 포함하는 제2 백신의 치료적 유효량을 대상에게 투여하여, 대상에서 전립선암을 예방하는 단계를 포함하며, 상기 rAd26 및 rMVA는 서열 번호 1, 3, 5, 7, 9, 11, 13, 15, 17, 19, 21, 23, 25, 27, 29, 31, 33, 35, 37, 39, 41, 43, 45, 47, 49, 51, 53, 55, 57, 59, 61, 63, 65, 67, 69, 71, 73, 75, 77, 79, 81, 83, 85, 87, 89, 91, 93, 95, 97, 99, 101, 103, 105, 107, 109, 111, 113, 115, 117, 119, 121, 123, 125, 127, 129, 131, 133, 135, 137, 139, 141, 143, 145, 147, 149, 151, 153, 155, 157, 159, 161, 163, 165, 167, 169, 171, 173, 175, 177, 179, 181, 183, 185, 187, 189, 191, 193, 195, 197, 199, 201, 203, 205, 207, 209, 211, 213, 215, 217, 219, 221, 223, 225, 227, 229, 231, 233, 235, 237, 239, 241, 243, 245, 247, 249, 251, 253, 255, 257, 259, 261, 263, 265, 267, 269, 271, 273, 275, 277, 279, 281, 283, 285, 287, 289, 291, 293, 295, 297, 299, 301, 303, 305, 307, 309, 311, 313, 315, 317, 319, 321, 323, 325, 327, 329, 331, 333, 335, 337, 339, 341, 343, 345, 347, 349, 351, 353, 355, 357, 359, 361, 363, 365, 367, 369, 371, 373, 375, 379, 381, 383, 385, 387, 388, 389, 390, 391, 392, 393, 394, 395, 396, 397, 398, 399, 400, 401, 402, 403, 404, 405, 406, 407, 408, 426, 427, 428, 429, 430, 431, 432, 433, 434, 435, 436, 437, 438, 439, 440, 441, 442, 443, 444, 445, 446 또는 447 중 하나 이상의 폴리펩티드 또는 이의 단편을 인코딩하는 이종 폴리뉴클레오티드를 포함하는, 대상에서 전립선암을 예방하는 방법을 제공한다.
본 발명은 또한 면역반응을 프라이밍하기 위해 본 발명의 rGAd를 포함하는 제1 백신의 치료적 유효량을 대상에게 투여하는 단계; 및 면역반응을 부스팅하기 위해 본 발명의 rMVA를 포함하는 제2 백신의 치료적 유효량을 대상에게 투여하여, 대상에서 전립선암을 예방하는 단계를 포함하며, 상기 rGAd 및 rMVA는 서열 번호 1, 3, 5, 7, 9, 11, 13, 15, 17, 19, 21, 23, 25, 27, 29, 31, 33, 35, 37, 39, 41, 43, 45, 47, 49, 51, 53, 55, 57, 59, 61, 63, 65, 67, 69, 71, 73, 75, 77, 79, 81, 83, 85, 87, 89, 91, 93, 95, 97, 99, 101, 103, 105, 107, 109, 111, 113, 115, 117, 119, 121, 123, 125, 127, 129, 131, 133, 135, 137, 139, 141, 143, 145, 147, 149, 151, 153, 155, 157, 159, 161, 163, 165, 167, 169, 171, 173, 175, 177, 179, 181, 183, 185, 187, 189, 191, 193, 195, 197, 199, 201, 203, 205, 207, 209, 211, 213, 215, 217, 219, 221, 223, 225, 227, 229, 231, 233, 235, 237, 239, 241, 243, 245, 247, 249, 251, 253, 255, 257, 259, 261, 263, 265, 267, 269, 271, 273, 275, 277, 279, 281, 283, 285, 287, 289, 291, 293, 295, 297, 299, 301, 303, 305, 307, 309, 311, 313, 315, 317, 319, 321, 323, 325, 327, 329, 331, 333, 335, 337, 339, 341, 343, 345, 347, 349, 351, 353, 355, 357, 359, 361, 363, 365, 367, 369, 371, 373, 375, 379, 381, 383, 385, 387, 388, 389, 390, 391, 392, 393, 394, 395, 396, 397, 398, 399, 400, 401, 402, 403, 404, 405, 406, 407, 408, 426, 427, 428, 429, 430, 431, 432, 433, 434, 435, 436, 437, 438, 439, 440, 441, 442, 443, 444, 445, 446 또는 447 중 하나 이상의 폴리펩티드 또는 이의 단편을 인코딩하는 이종 폴리뉴클레오티드를 포함하는, 대상에서 전립선암을 예방하는 방법을 제공한다.
본 발명은 또한 면역반응을 프라이밍하기 위해 본 발명의 rGAd20를 포함하는 제1 백신의 치료적 유효량을 대상에게 투여하는 단계; 및 면역반응을 부스팅하기 위해 본 발명의 rMVA를 포함하는 제2 백신의 치료적 유효량을 대상에게 투여하여, 대상에서 전립선암을 예방하는 단계를 포함하며, 상기 rGAd20 및 rMVA는 서열 번호 1, 3, 5, 7, 9, 11, 13, 15, 17, 19, 21, 23, 25, 27, 29, 31, 33, 35, 37, 39, 41, 43, 45, 47, 49, 51, 53, 55, 57, 59, 61, 63, 65, 67, 69, 71, 73, 75, 77, 79, 81, 83, 85, 87, 89, 91, 93, 95, 97, 99, 101, 103, 105, 107, 109, 111, 113, 115, 117, 119, 121, 123, 125, 127, 129, 131, 133, 135, 137, 139, 141, 143, 145, 147, 149, 151, 153, 155, 157, 159, 161, 163, 165, 167, 169, 171, 173, 175, 177, 179, 181, 183, 185, 187, 189, 191, 193, 195, 197, 199, 201, 203, 205, 207, 209, 211, 213, 215, 217, 219, 221, 223, 225, 227, 229, 231, 233, 235, 237, 239, 241, 243, 245, 247, 249, 251, 253, 255, 257, 259, 261, 263, 265, 267, 269, 271, 273, 275, 277, 279, 281, 283, 285, 287, 289, 291, 293, 295, 297, 299, 301, 303, 305, 307, 309, 311, 313, 315, 317, 319, 321, 323, 325, 327, 329, 331, 333, 335, 337, 339, 341, 343, 345, 347, 349, 351, 353, 355, 357, 359, 361, 363, 365, 367, 369, 371, 373, 375, 379, 381, 383, 385, 387, 388, 389, 390, 391, 392, 393, 394, 395, 396, 397, 398, 399, 400, 401, 402, 403, 404, 405, 406, 407, 408, 426, 427, 428, 429, 430, 431, 432, 433, 434, 435, 436, 437, 438, 439, 440, 441, 442, 443, 444, 445, 446 또는 447 중 하나 이상의 폴리펩티드 또는 이의 단편을 인코딩하는 이종 폴리뉴클레오티드를 포함하는, 대상에서 전립선암을 예방하는 방법을 제공한다.
본 발명은 또한 면역반응을 프라이밍하기 위해 본 발명의 rAd26를 포함하는 제1 백신의 면역학적 유효량을 대상에게 투여하는 단계; 및 면역반응을 부스팅하기 위해 본 발명의 rMVA를 포함하는 제2 백신의 면역학적 유효량을 대상에게 투여하여, 대상에서 면역반응을 증강시키는 단계를 포함하며, 상기 rAd26 및 rMVA는 서열 번호 1, 3, 5, 7, 9, 11, 13, 15, 17, 19, 21, 23, 25, 27, 29, 31, 33, 35, 37, 39, 41, 43, 45, 47, 49, 51, 53, 55, 57, 59, 61, 63, 65, 67, 69, 71, 73, 75, 77, 79, 81, 83, 85, 87, 89, 91, 93, 95, 97, 99, 101, 103, 105, 107, 109, 111, 113, 115, 117, 119, 121, 123, 125, 127, 129, 131, 133, 135, 137, 139, 141, 143, 145, 147, 149, 151, 153, 155, 157, 159, 161, 163, 165, 167, 169, 171, 173, 175, 177, 179, 181, 183, 185, 187, 189, 191, 193, 195, 197, 199, 201, 203, 205, 207, 209, 211, 213, 215, 217, 219, 221, 223, 225, 227, 229, 231, 233, 235, 237, 239, 241, 243, 245, 247, 249, 251, 253, 255, 257, 259, 261, 263, 265, 267, 269, 271, 273, 275, 277, 279, 281, 283, 285, 287, 289, 291, 293, 295, 297, 299, 301, 303, 305, 307, 309, 311, 313, 315, 317, 319, 321, 323, 325, 327, 329, 331, 333, 335, 337, 339, 341, 343, 345, 347, 349, 351, 353, 355, 357, 359, 361, 363, 365, 367, 369, 371, 373, 375, 379, 381, 383, 385, 387, 388, 389, 390, 391, 392, 393, 394, 395, 396, 397, 398, 399, 400, 401, 402, 403, 404, 405, 406, 407, 408, 426, 427, 428, 429, 430, 431, 432, 433, 434, 435, 436, 437, 438, 439, 440, 441, 442, 443, 444, 445, 446 또는 447 중 하나 이상의 폴리펩티드 또는 이의 단편을 인코딩하는 이종 폴리뉴클레오티드를 포함하는, 대상에서 면역반응을 증강시키는 방법을 제공한다.
본 발명은 또한 면역반응을 프라이밍하기 위해 본 발명의 rGAd를 포함하는 제1 백신의 면역학적 유효량을 대상에게 투여하는 단계; 및 면역반응을 부스팅하기 위해 본 발명의 rMVA를 포함하는 제2 백신의 면역학적 유효량을 대상에게 투여하여, 대상에서 면역반응을 증강시키는 단계를 포함하며, 상기 rGAd 및 rMVA는 서열 번호 1, 3, 5, 7, 9, 11, 13, 15, 17, 19, 21, 23, 25, 27, 29, 31, 33, 35, 37, 39, 41, 43, 45, 47, 49, 51, 53, 55, 57, 59, 61, 63, 65, 67, 69, 71, 73, 75, 77, 79, 81, 83, 85, 87, 89, 91, 93, 95, 97, 99, 101, 103, 105, 107, 109, 111, 113, 115, 117, 119, 121, 123, 125, 127, 129, 131, 133, 135, 137, 139, 141, 143, 145, 147, 149, 151, 153, 155, 157, 159, 161, 163, 165, 167, 169, 171, 173, 175, 177, 179, 181, 183, 185, 187, 189, 191, 193, 195, 197, 199, 201, 203, 205, 207, 209, 211, 213, 215, 217, 219, 221, 223, 225, 227, 229, 231, 233, 235, 237, 239, 241, 243, 245, 247, 249, 251, 253, 255, 257, 259, 261, 263, 265, 267, 269, 271, 273, 275, 277, 279, 281, 283, 285, 287, 289, 291, 293, 295, 297, 299, 301, 303, 305, 307, 309, 311, 313, 315, 317, 319, 321, 323, 325, 327, 329, 331, 333, 335, 337, 339, 341, 343, 345, 347, 349, 351, 353, 355, 357, 359, 361, 363, 365, 367, 369, 371, 373, 375, 379, 381, 383, 385, 387, 388, 389, 390, 391, 392, 393, 394, 395, 396, 397, 398, 399, 400, 401, 402, 403, 404, 405, 406, 407, 408, 426, 427, 428, 429, 430, 431, 432, 433, 434, 435, 436, 437, 438, 439, 440, 441, 442, 443, 444, 445, 446 또는 447 중 하나 이상의 폴리펩티드 또는 이의 단편을 인코딩하는 이종 폴리뉴클레오티드를 포함하는, 대상에서 면역반응을 증강시키는 방법을 제공한다.
본 발명은 또한 면역반응을 프라이밍하기 위해 본 발명의 rGAd20를 포함하는 제1 백신의 면역학적 유효량을 대상에게 투여하는 단계; 및 면역반응을 부스팅하기 위해 본 발명의 rMVA를 포함하는 제2 백신의 면역학적 유효량을 대상에게 투여하여, 대상에서 면역반응을 증강시키는 단계를 포함하며, 상기 rGAd20 및 rMVA는 서열 번호 1, 3, 5, 7, 9, 11, 13, 15, 17, 19, 21, 23, 25, 27, 29, 31, 33, 35, 37, 39, 41, 43, 45, 47, 49, 51, 53, 55, 57, 59, 61, 63, 65, 67, 69, 71, 73, 75, 77, 79, 81, 83, 85, 87, 89, 91, 93, 95, 97, 99, 101, 103, 105, 107, 109, 111, 113, 115, 117, 119, 121, 123, 125, 127, 129, 131, 133, 135, 137, 139, 141, 143, 145, 147, 149, 151, 153, 155, 157, 159, 161, 163, 165, 167, 169, 171, 173, 175, 177, 179, 181, 183, 185, 187, 189, 191, 193, 195, 197, 199, 201, 203, 205, 207, 209, 211, 213, 215, 217, 219, 221, 223, 225, 227, 229, 231, 233, 235, 237, 239, 241, 243, 245, 247, 249, 251, 253, 255, 257, 259, 261, 263, 265, 267, 269, 271, 273, 275, 277, 279, 281, 283, 285, 287, 289, 291, 293, 295, 297, 299, 301, 303, 305, 307, 309, 311, 313, 315, 317, 319, 321, 323, 325, 327, 329, 331, 333, 335, 337, 339, 341, 343, 345, 347, 349, 351, 353, 355, 357, 359, 361, 363, 365, 367, 369, 371, 373, 375, 379, 381, 383, 385, 387, 388, 389, 390, 391, 392, 393, 394, 395, 396, 397, 398, 399, 400, 401, 402, 403, 404, 405, 406, 407, 408, 426, 427, 428, 429, 430, 431, 432, 433, 434, 435, 436, 437, 438, 439, 440, 441, 442, 443, 444, 445, 446 또는 447 중 하나 이상의 폴리펩티드 또는 이의 단편을 인코딩하는 이종 폴리뉴클레오티드를 포함하는, 대상에서 면역반응을 증강시키는 방법을 제공한다.
일부 실시 형태에서, 대상은 전립선암을 앓고 있는 것으로 의심되거나, 발병할 것으로 의심된다.
본 발명의 백신은 전형적으로 근육내 또는 피하 주사에 의해 투여될 수 있다. 그러나, 정맥내, 피부, 피내 또는 비강내 투여와 같은 다른 투여 방법도 고려될 수 있다. 백신의 근육내 투여는 바늘을 사용하여 달성될 수 있다. 대안은 무침 주사기구를 사용하여 조성물(예를 들어, 바이오젝터(Biojector)TM를 사용함) 또는 백신을 함유하는 동결건조분말을 투여하는 것이다.
정맥내, 피부 또는 피하 주사, 또는 고통 부위에서의 주사의 경우, 벡터는 무발열성이고 적절한 pH, 등장성 및 안정성을 갖는 비경구적으로 허용되는 수용액의 형태일 수 있다. 당업자는, 예를 들어, 염화나트륨 주사액, 링거 주사액, 락트산 첨가 링거 주사액(Lactated Ringer's Injection)과 같은 등장성 비히클을 사용하여 적합한 용액을 충분히 제조할 수 있다. 방부제, 안정제, 완충제, 산화방지제 및/또는 다른 첨가제가 필요에 따라 포함될 수 있다. 서방성 제제도 사용될 수 있다.
전형적으로, 투여는 전립선암의 증상이 발현되기 전에 전립선 신생항원에 대한 면역반응을 일으키기 위한 예방적 목적을 가질 것이다.
본 발명의 백신은 대상에게 투여되어, 대상에서 면역반응을 일으킨다. 검출가능한 면역반응을 유도하기 위한 백신의 양은 "면역학적 유효량"으로 정의된다. 본 발명의 백신은 세포성 면역반응뿐만 아니라, 체액성 면역반응을 유도할 수 있다. 전형적인 실시 형태에서, 면역 반응은 방어 면역반응이다.
투여된 실제량, 및 투여 속도 및 투여의 경시 변화는 치료 대상의 특성 및 중증도에 따라 달라질 것이다. 치료의 처방, 예를 들어 용량 결정 등은 일반 개업의 및 다른 의사의 책임에 포함되며, 일반적으로 치료할 질환, 개별 환자의 상태, 전달 부위, 투여 방법 및 의사에게 알려진 다른 인자를 고려한다.
하나의 예시적인 요법에서, 아데노바이러스 벡터는 약 104 내지 1012개의 바이러스 입자/ml의 농도를 포함하는 약 100 μL 내지 약 10 ml 범위의 부피로 (예를 들어, 근육내) 투여된다. 아데노바이러스 벡터는 0.25 내지 1.0 ml의 범위의 부피로, 예컨대 0.5 ml의 부피로 투여될 수 있다.
아데노바이러스는 1회 투여 동안 인간 대상에게 약 109 내지 약 1012개의 바이러스 입자(vp)의 양으로, 더욱 전형적으로는 약 1010 내지 약 1012개의 vp의 양으로 투여될 수 있다.
하나의 예시적인 요법에서, 본 발명의 rMVA는 약 1x107 TCID50 내지 1x109 TCID50 (50% 조직 배양 감염량(Tissue Culture Infective Dose)) 또는 Inf.U.(감염 단위(Infectious Unit))의 용량을 함유하는 생리식염수 약 100 μl 내지 약 10 ml 범위의 부피로 (예를 들어, 근육내) 투여된다. rMVA는 0.25 내지 1.0 ml 범위의 부피로 투여될 수 있다.
부스팅 조성물은 프라이밍 조성물의 투여 후 2회 이상, 몇 주 또는 몇 개월 후에, 예를 들어 프라이밍 조성물의 투여 후 약 1주, 2주, 3주, 4주, 6주, 8주, 12주, 16주, 20주, 24주, 28주, 32주, 또는 1 내지 2년 후에 투여될 수 있다. 추가의 부스팅 조성물은 부스팅 단계(b) 후 6주 내지 5년 후에, 예를 들어 초기 부스팅 접종 후 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24 또는 25주, 또는 7, 8, 9, 10, 11 또는 12개월, 또는 2, 3, 4 또는 5년 후에 투여될 수 있다. 임의로, 추가의 부스팅 단계(c)는 필요에 따라 1회 이상 반복될 수 있다.
백신 요법을 위한 전립선 신생항원 조합
본 명세서에 기재된 확인된 신생항원은 만능 전립선암 백신에 포함시키기 위해 더욱 검증되고 우선순위화될 수 있다. 포함을 위한 고려사항은 예를 들어, 전립선암 조직 대 정상 전립선 조직 및 다른 정상 조직(예컨대, 간, 신장, 췌장, 난소, 전립선, 유선, 결장, 위, 골격근 및 폐)에서의 더욱 높은 발현 또는 정상 조직에서의 검출불가능한 발현, 공지된 분석에서 CD8+ T 세포의 활성화를 매개하는 신생항원 또는 이의 단편의 능력, HLA에 대한 결합, 신생항원으로부터 유래된 펩티드 단편의 생체내 처리 및 HLA로의 제시 입증 및 전립선암 대상의 충분한 유병률이다.
검증 과정을 통해, 41개의 신생항원(서열 번호 275, 381, 333, 337, 269, 253, 309, 325, 271, 305, 251, 245, 261, 265, 317, 255, 277, 297, 285, 437, 439, 442, 444, 379, 343, 211, 349, 213, 215, 221, 219, 225, 345, 353, 235, 223, 167, 171, 19, 23 및 177)은 이들의 발현 프로파일, 유병률 및 시험관내 면역원성에 기초하여 전립선암 백신에 포함시키기에 특히 유용한 것으로 확인되었다. 41개의 신생항원의 임의의 조합이 임의의 이용가능한 전달 비히클 및 이용가능한 임의의 형태, 예컨대 펩티드, DNA, RNA, 레플리콘을 이용하거나, 바이러스 전달을 사용하여 대상에게 전달될 수 있는 전립선암 백신을 생성하는데 이용될 수 있는 것으로 예상된다. 41개의 신생항원은 임의의 신생항원 순서로 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드로 조립될 수 있으며, 신생항원 순서는 다양한 전달 옵션 간에 상이할 수 있다. 일반적으로, 신생항원을 특정 순서로 조립하는 것은 공지된 알고리즘을 이용하여 최소한의 접합 에피토프를 생성하는 것에 기초할 수 있다. 신생항원의 예시적인 순서는 본 명세서에 기재되고 실시예 전체에 걸쳐 서열 번호 541, 550, 554, 555, 556, 623, 624, 543, 552, 557, 558, 559, 625 또는 626의 이종 폴리펩티드를 제공하는 순서이다.
본 발명은 서열 번호 275, 381, 333, 337, 269, 253, 309, 325, 271, 305, 251, 245, 261, 265, 317, 255, 277, 297, 285, 437, 439, 442, 444, 379, 343, 211, 349, 213, 215, 221, 219, 225, 345, 353, 235, 223, 167, 171, 19, 23 및 177로 이루어진 군으로부터 선택되는 2개 이상의 폴리펩티드 및 이들의 단편을 포함하는 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 백신을 제공한다.
본 발명은 또한 서열 번호 276, 382, 334, 338, 270, 254, 310, 326, 272, 306, 252, 246, 262, 266, 318, 256, 278, 298, 286, 448, 450, 453, 455, 380, 344, 212, 350, 214, 216, 222, 220, 226, 346, 354, 236, 224, 168, 172, 20, 24 및 178로 이루어진 군으로부터 선택되는 2개 이상의 폴리뉴클레오티드 및 이들의 단편을 포함하는 이종 폴리뉴클레오티드를 포함하는 백신을 제공한다.
일부 실시 형태에서, 상기 단편은 서열 번호 387, 388, 390, 392, 560, 561, 562, 563, 564, 565, 566, 567, 568, 569, 570, 571, 572, 573, 574, 575, 576, 577, 578, 579, 580, 581, 582, 583, 584, 585, 586, 587, 588, 589, 590, 591, 592, 593, 594, 595, 596, 597, 598, 599, 600, 601, 602, 603, 604, 605, 606, 607, 608, 609, 610, 611, 612, 613, 614, 615, 616, 617, 618, 619, 620, 621, 631, 632, 633, 634, 635, 636, 637, 638, 639, 640, 641, 642, 643, 644, 645, 646, 647, 648, 649, 650, 651, 652, 653, 654, 655, 656, 657, 658, 659, 660, 661, 662, 663, 664, 665, 666, 667, 668, 669, 670, 671, 672, 673, 674, 675, 676, 677, 678, 679, 680, 681, 682, 683, 684, 685, 686, 687, 688, 689, 690, 691, 692, 693, 694, 695, 696, 697, 698, 699, 700, 701, 702, 703, 704, 705, 706, 707, 708, 709, 710 또는 711의 폴리펩티드를 포함한다.
일부 실시 형태에서, 백신은 백신을 투여한 대상에서 세포성 면역반응을 유도할 수 있다.
일부 실시 형태에서, 세포성 면역반응은 서열 번호 275, 381, 333, 337, 269, 253, 309, 325, 271, 305, 251, 245, 261, 265, 317, 255, 277, 297, 285, 437, 439, 442, 444, 379, 343, 211, 349, 213, 215, 221, 219, 225, 345, 353, 235, 223, 167, 171, 19, 23 또는 177 중 하나 이상의 폴리펩티드의 단편에 대해 특이적이다.
일부 실시 형태에서, 세포성 면역반응은 백신 특이적 CD8+ T 세포, CD4+ T 세포, 또는 CD8+ T 세포 및 CD4+ T 세포의 활성화이며, 상기 활성화는 CD8+ T 세포, CD4+ T 세포, 또는 CD8+ T 세포 및 CD4+ T 세포에 의한 TNFα, IFNγ, 또는 TNFα 및 IFNγ의 생산 증가에 의해 평가된다.
일부 실시 형태에서, 이종 폴리뉴클레오티드는 프로모터, 인핸서, 폴리아데닐화 부위, 코작 서열(Kozak sequence), 정지 코돈, T 세포 인핸서(TCE) 또는 이들의 임의의 조합을 포함한다.
일부 실시 형태에서, 프로모터는 CMV 프로모터 또는 백시니아 P7.5 프로모터를 포함한다.
일부 실시 형태에서, TCE는 서열 번호 546의 폴리뉴클레오티드에 의해 인코딩되고, CMV 프로모터는 서열 번호 628의 폴리뉴클레오티드를 포함하며, 백시니아 P7.5 프로모터는 서열 번호 630의 폴리뉴클레오티드를 포함하고, 폴리아데닐화 부위는 서열 번호 629의 소 성장 호르몬 폴리아데닐화 부위를 포함한다.
일부 실시 형태에서, 이종 폴리펩티드는 서열 번호 541, 550, 554, 555, 556, 623 또는 624의 아미노산 서열을 포함한다.
일부 실시 형태에서, 이종 폴리뉴클레오티드는 서열 번호 542 또는 서열 번호 551의 폴리뉴클레오티드 서열을 포함한다.
일부 실시 형태에서, 이종 폴리펩티드는 서열 번호 543, 552, 557, 558, 559, 625 또는 626의 아미노산 서열을 포함한다.
일부 실시 형태에서, 이종 폴리뉴클레오티드는 서열 번호 544 또는 서열 번호 553의 폴리뉴클레오티드 서열을 포함한다.
일부 실시 형태에서, 이종 폴리뉴클레오티드는 DNA 또는 RNA이다.
일부 실시 형태에서, RNA는 mRNA 또는 자기 복제 RNA이다.
본 발명은 또한 서열 번호 541의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 백신을 제공한다.
본 발명은 또한 서열 번호 550의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 백신을 제공한다.
본 발명은 또한 서열 번호 554의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 백신을 제공한다.
본 발명은 또한 서열 번호 555의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 백신을 제공한다.
본 발명은 또한 서열 번호 556의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 백신을 제공한다.
본 발명은 또한 서열 번호 623의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 백신을 제공한다.
본 발명은 또한 서열 번호 624의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 백신을 제공한다.
본 발명은 또한 서열 번호 542의 이종 폴리뉴클레오티드를 포함하는 백신을 제공한다.
본 발명은 또한 서열 번호 551의 이종 폴리뉴클레오티드를 포함하는 백신을 제공한다.
본 발명은 또한 서열 번호 543의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 백신을 제공한다.
본 발명은 또한 서열 번호 552의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 백신을 제공한다.
본 발명은 또한 서열 번호 557의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 백신을 제공한다.
본 발명은 또한 서열 번호 558의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 백신을 제공한다.
본 발명은 또한 서열 번호 559의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 백신을 제공한다.
본 발명은 또한 서열 번호 625의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 백신을 제공한다.
본 발명은 또한 서열 번호 626의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 백신을 제공한다.
본 발명은 또한 서열 번호 544의 이종 폴리뉴클레오티드를 포함하는 백신을 제공한다.
본 발명은 또한 서열 번호 553의 이종 폴리뉴클레오티드를 포함하는 백신을 제공한다.
일부 실시 형태에서, 백신은 재조합 바이러스이다.
일부 실시 형태에서, 재조합 바이러스는 아데노바이러스(Ad), 폭스바이러스, 아데노 관련 바이러스(AAV) 또는 레트로바이러스로부터 유래된다.
일부 실시 형태에서, 재조합 바이러스는 hAd5, hAd7, hAd11, hAd26, hAd34, hAd35, hAd48, hAd49, hAd50, GAd20, GAd19, GAd21, GAd25, GAd26, GAd27, GAd28, GAd29, GAd30, GAd31, ChAd3, ChAd4, ChAd5, ChAd6, ChAd7, ChAd8, ChAd9, ChAd10, ChAd11, ChAd16, ChAd17, ChAd19, ChAd20, ChAd22, ChAd24, ChAd26, ChAd30, ChAd31, ChAd37, ChAd38, ChAd44, ChAd55, ChAd63, ChAd73, ChAd82, ChAd83, ChAd146, ChAd147, PanAd1, PanAd2, PanAd3, 코펜하겐 백시니아 바이러스(W), 뉴욕 약독화 백시니아 바이러스(NYVAC), ALVAC, TROVAC 또는 변형된 백시니아 앙카라(MVA)로부터 유래된다.
일부 실시 형태에서, 재조합 바이러스는 GAd20로부터 유래된다.
일부 실시 형태에서, GAd20로부터 유래된 재조합 바이러스는 서열 번호 713의 폴리뉴클레오티드 서열을 포함한다.
일부 실시 형태에서, 재조합 바이러스는 MVA로부터 유래된다.
일부 실시 형태에서, 재조합 바이러스는 hAd26로부터 유래된다.
본 발명은 또한 서열 번호 541의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 백신을 제공하며, 여기서 백신은 GAd20로부터 유래된 재조합 바이러스이다.
본 발명은 또한 서열 번호 550의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 백신을 제공하며, 여기서 백신은 GAd20로부터 유래된 재조합 바이러스이다.
본 발명은 또한 서열 번호 554의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 백신을 제공하며, 여기서 백신은 GAd20로부터 유래된 재조합 바이러스이다.
본 발명은 또한 서열 번호 555의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 백신을 제공하며, 여기서 백신은 GAd20로부터 유래된 재조합 바이러스이다.
본 발명은 또한 서열 번호 556의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 백신을 제공하며, 여기서 백신은 GAd20로부터 유래된 재조합 바이러스이다.
본 발명은 또한 서열 번호 623의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 백신을 제공하며, 여기서 백신은 GAd20로부터 유래된 재조합 바이러스이다.
본 발명은 또한 서열 번호 624의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 백신을 제공하며, 여기서 백신은 GAd20로부터 유래된 재조합 바이러스이다.
본 발명은 또한 서열 번호 713의 폴리뉴클레오티드 서열을 포함하는 백신을 제공하며, 여기서 백신은 GAd20로부터 유래된 재조합 바이러스이다.
본 발명은 또한 서열 번호 542의 이종 폴리뉴클레오티드를 포함하는 백신을 제공하며, 여기서 백신은 GAd20로부터 유래된 재조합 바이러스이다.
본 발명은 또한 서열 번호 551의 이종 폴리뉴클레오티드를 포함하는 백신을 제공하며, 여기서 백신은 GAd20로부터 유래된 재조합 바이러스이다.
본 발명은 또한 서열 번호 543의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 백신을 제공하며, 여기서 백신은 MVA로부터 유래된 재조합 바이러스이다.
본 발명은 또한 서열 번호 552의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 백신을 제공하며, 여기서 백신은 MVA로부터 유래된 재조합 바이러스이다.
본 발명은 또한 서열 번호 557의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 백신을 제공하며, 여기서 백신은 MVA로부터 유래된 재조합 바이러스이다.
본 발명은 또한 서열 번호 558의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 백신을 제공하며, 여기서 백신은 MVA로부터 유래된 재조합 바이러스이다.
본 발명은 또한 서열 번호 559의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 백신을 제공하며, 여기서 백신은 MVA로부터 유래된 재조합 바이러스이다.
본 발명은 또한 서열 번호 625의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 백신을 제공하며, 여기서 백신은 MVA로부터 유래된 재조합 바이러스이다.
본 발명은 또한 서열 번호 626의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 백신을 제공하며, 여기서 백신은 MVA로부터 유래된 재조합 바이러스이다.
본 발명은 또한 서열 번호 544의 이종 폴리뉴클레오티드를 포함하는 백신을 제공하며, 여기서 백신은 MVA로부터 유래된 재조합 바이러스이다.
본 발명은 또한 서열 번호 553의 이종 폴리뉴클레오티드를 포함하는 백신을 제공하며, 여기서 백신은 MVA로부터 유래된 재조합 바이러스이다.
본 발명은 또한 서열 번호 541, 550, 554, 555, 556, 623 또는 624의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 GAd20로부터 유래된 재조합 바이러스를 포함하는 백신의 치료적 유효량을 대상에게 투여하는 단계를 포함하는, 대상에서 전립선암을 치료하거나 예방하는 방법을 제공한다.
본 발명은 또한 서열 번호 541의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 GAd20로부터 유래된 재조합 바이러스를 포함하는 백신의 치료적 유효량을 대상에게 투여하는 단계를 포함하는, 대상에서 전립선암을 치료하거나 예방하는 방법을 제공한다.
본 발명은 또한 서열 번호 550의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 GAd20로부터 유래된 재조합 바이러스를 포함하는 백신의 치료적 유효량을 대상에게 투여하는 단계를 포함하는, 대상에서 전립선암을 치료하거나 예방하는 방법을 제공한다.
본 발명은 또한 서열 번호 554의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 GAd20로부터 유래된 재조합 바이러스를 포함하는 백신의 치료적 유효량을 대상에게 투여하는 단계를 포함하는, 대상에서 전립선암을 치료하거나 예방하는 방법을 제공한다.
본 발명은 또한 서열 번호 555의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 GAd20로부터 유래된 재조합 바이러스를 포함하는 백신의 치료적 유효량을 대상에게 투여하는 단계를 포함하는, 대상에서 전립선암을 치료하거나 예방하는 방법을 제공한다.
본 발명은 또한 서열 번호 556의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 GAd20로부터 유래된 재조합 바이러스를 포함하는 백신의 치료적 유효량을 대상에게 투여하는 단계를 포함하는, 대상에서 전립선암을 치료하거나 예방하는 방법을 제공한다.
본 발명은 또한 서열 번호 623의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 GAd20로부터 유래된 재조합 바이러스를 포함하는 백신의 치료적 유효량을 대상에게 투여하는 단계를 포함하는, 대상에서 전립선암을 치료하거나 예방하는 방법을 제공한다.
본 발명은 또한 서열 번호 624의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 GAd20로부터 유래된 재조합 바이러스를 포함하는 백신의 치료적 유효량을 대상에게 투여하는 단계를 포함하는, 대상에서 전립선암을 치료하거나 예방하는 방법을 제공한다.
본 발명은 또한 서열 번호 543, 552, 557, 558, 559, 625 또는 626의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 MVA로부터 유래된 재조합 바이러스를 포함하는 백신의 치료적 유효량을 대상에게 투여하는 단계를 포함하는, 대상에서 전립선암을 치료하거나 예방하는 방법을 제공한다.
본 발명은 또한 서열 번호 543의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 MVA로부터 유래된 재조합 바이러스를 포함하는 백신의 치료적 유효량을 대상에게 투여하는 단계를 포함하는, 대상에서 전립선암을 치료하거나 예방하는 방법을 제공한다.
본 발명은 또한 서열 번호 552의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 MVA로부터 유래된 재조합 바이러스를 포함하는 백신의 치료적 유효량을 대상에게 투여하는 단계를 포함하는, 대상에서 전립선암을 치료하거나 예방하는 방법을 제공한다.
본 발명은 또한 서열 번호 557의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 MVA로부터 유래된 재조합 바이러스를 포함하는 백신의 치료적 유효량을 대상에게 투여하는 단계를 포함하는, 대상에서 전립선암을 치료하거나 예방하는 방법을 제공한다.
본 발명은 또한 서열 번호 558의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 MVA로부터 유래된 재조합 바이러스를 포함하는 백신의 치료적 유효량을 대상에게 투여하는 단계를 포함하는, 대상에서 전립선암을 치료하거나 예방하는 방법을 제공한다.
본 발명은 또한 서열 번호 559의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 MVA로부터 유래된 재조합 바이러스를 포함하는 백신의 치료적 유효량을 대상에게 투여하는 단계를 포함하는, 대상에서 전립선암을 치료하거나 예방하는 방법을 제공한다.
본 발명은 또한 서열 번호 625의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 MVA로부터 유래된 재조합 바이러스를 포함하는 백신의 치료적 유효량을 대상에게 투여하는 단계를 포함하는, 대상에서 전립선암을 치료하거나 예방하는 방법을 제공한다.
본 발명은 또한 서열 번호 626의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 MVA로부터 유래된 재조합 바이러스를 포함하는 백신의 치료적 유효량을 대상에게 투여하는 단계를 포함하는, 대상에서 전립선암을 치료하거나 예방하는 방법을 제공한다.
본 발명은 또한 전립선암을 치료하거나 예방하기 위한 의약의 제조를 위한 서열 번호 541, 550, 554, 555, 556, 623 또는 624의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 GAd20로부터 유래된 재조합 바이러스를 포함하는 백신의 용도를 제공한다.
본 발명은 또한 전립선암을 치료하거나 예방하기 위한 의약의 제조를 위한 서열 번호 541의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 GAd20로부터 유래된 재조합 바이러스를 포함하는 백신의 용도를 제공한다.
본 발명은 또한 전립선암을 치료하거나 예방하기 위한 의약의 제조를 위한 서열 번호 550의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 GAd20로부터 유래된 재조합 바이러스를 포함하는 백신의 용도를 제공한다.
본 발명은 또한 전립선암을 치료하거나 예방하기 위한 의약의 제조를 위한 서열 번호 554의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 GAd20로부터 유래된 재조합 바이러스를 포함하는 백신의 용도를 제공한다.
본 발명은 또한 전립선암을 치료하거나 예방하기 위한 의약의 제조를 위한 서열 번호 555의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 GAd20로부터 유래된 재조합 바이러스를 포함하는 백신의 용도를 제공한다.
본 발명은 또한 전립선암을 치료하거나 예방하기 위한 의약의 제조를 위한 서열 번호 556의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 GAd20로부터 유래된 재조합 바이러스를 포함하는 백신의 용도를 제공한다.
본 발명은 또한 전립선암을 치료하거나 예방하기 위한 의약의 제조를 위한 서열 번호 623의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 GAd20로부터 유래된 재조합 바이러스를 포함하는 백신의 용도를 제공한다.
본 발명은 또한 전립선암을 치료하거나 예방하기 위한 의약의 제조를 위한 서열 번호 624의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 GAd20로부터 유래된 재조합 바이러스를 포함하는 백신의 용도를 제공한다.
본 발명은 또한 전립선암을 치료하거나 예방하기 위한 의약의 제조를 위한 서열 번호 543, 552, 557, 558, 559, 625 또는 626의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 MVA로부터 유래된 재조합 바이러스를 포함하는 백신의 용도를 제공한다.
본 발명은 또한 전립선암을 치료하거나 예방하기 위한 의약의 제조를 위한 서열 번호 543의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 MVA로부터 유래된 재조합 바이러스를 포함하는 백신의 용도를 제공한다.
본 발명은 또한 전립선암을 치료하거나 예방하기 위한 의약의 제조를 위한 서열 번호 552의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 MVA로부터 유래된 재조합 바이러스를 포함하는 백신의 용도를 제공한다.
본 발명은 또한 전립선암을 치료하거나 예방하기 위한 의약의 제조를 위한 서열 번호 557의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 MVA로부터 유래된 재조합 바이러스를 포함하는 백신의 용도를 제공한다.
본 발명은 또한 전립선암을 치료하거나 예방하기 위한 의약의 제조를 위한 서열 번호 558의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 MVA로부터 유래된 재조합 바이러스를 포함하는 백신의 용도를 제공한다.
본 발명은 또한 전립선암을 치료하거나 예방하기 위한 의약의 제조를 위한 서열 번호 559의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 MVA로부터 유래된 재조합 바이러스를 포함하는 백신의 용도를 제공한다.
본 발명은 또한 전립선암을 치료하거나 예방하기 위한 의약의 제조를 위한 서열 번호 625의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 MVA로부터 유래된 재조합 바이러스를 포함하는 백신의 용도를 제공한다.
본 발명은 또한 전립선암을 치료하거나 예방하기 위한 의약의 제조를 위한 서열 번호 626의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 MVA로부터 유래된 재조합 바이러스를 포함하는 백신의 용도를 제공한다.
본 발명은 또한 전립선암을 치료하거나 예방하는데 사용하기 위한 서열 번호 541, 550, 554, 555, 556, 623 또는 624의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 GAd20로부터 유래된 재조합 바이러스를 포함하는 백신을 제공한다.
본 발명은 또한 전립선암을 치료하거나 예방하는데 사용하기 위한 서열 번호 541의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 GAd20로부터 유래된 재조합 바이러스를 포함하는 백신을 제공한다.
본 발명은 또한 전립선암을 치료하거나 예방하는데 사용하기 위한 서열 번호 550의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 GAd20로부터 유래된 재조합 바이러스를 포함하는 백신을 제공한다.
본 발명은 또한 전립선암을 치료하거나 예방하는데 사용하기 위한 서열 번호 554의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 GAd20로부터 유래된 재조합 바이러스를 포함하는 백신을 제공한다.
본 발명은 또한 전립선암을 치료하거나 예방하는데 사용하기 위한 서열 번호 555의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 GAd20로부터 유래된 재조합 바이러스를 포함하는 백신을 제공한다.
본 발명은 또한 전립선암을 치료하거나 예방하는데 사용하기 위한 서열 번호 556의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 GAd20로부터 유래된 재조합 바이러스를 포함하는 백신을 제공한다.
본 발명은 또한 전립선암을 치료하거나 예방하는데 사용하기 위한 서열 번호 623의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 GAd20로부터 유래된 재조합 바이러스를 포함하는 백신을 제공한다.
본 발명은 또한 전립선암을 치료하거나 예방하는데 사용하기 위한 서열 번호 624의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 GAd20로부터 유래된 재조합 바이러스를 포함하는 백신을 제공한다.
본 발명은 또한 전립선암을 치료하거나 예방하는데 사용하기 위한 서열 번호 543, 552, 557, 558, 559, 625 또는 626의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 MVA로부터 유래된 재조합 바이러스를 포함하는 백신을 제공한다.
본 발명은 또한 전립선암을 치료하거나 예방하는데 사용하기 위한 서열 번호 543의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 MVA로부터 유래된 재조합 바이러스를 포함하는 백신을 제공한다.
본 발명은 또한 전립선암을 치료하거나 예방하는데 사용하기 위한 서열 번호 552의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 MVA로부터 유래된 재조합 바이러스를 포함하는 백신을 제공한다.
본 발명은 또한 전립선암을 치료하거나 예방하는데 사용하기 위한 서열 번호 557의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 MVA로부터 유래된 재조합 바이러스를 포함하는 백신을 제공한다.
본 발명은 또한 전립선암을 치료하거나 예방하는데 사용하기 위한 서열 번호 558의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 MVA로부터 유래된 재조합 바이러스를 포함하는 백신을 제공한다.
본 발명은 또한 전립선암을 치료하거나 예방하는데 사용하기 위한 서열 번호 559의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 MVA로부터 유래된 재조합 바이러스를 포함하는 백신을 제공한다.
본 발명은 또한 전립선암을 치료하거나 예방하는데 사용하기 위한 서열 번호 625의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 MVA로부터 유래된 재조합 바이러스를 포함하는 백신을 제공한다.
본 발명은 또한 전립선암을 치료하거나 예방하는데 사용하기 위한 서열 번호 626의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 MVA로부터 유래된 재조합 바이러스를 포함하는 백신을 제공한다.
일부 실시 형태에서, GAd20로부터 유래된 재조합 바이러스를 포함하는 백신은 프라임으로서 투여된다.
일부 실시 형태에서, MVA로부터 유래된 재조합 바이러스를 포함하는 백신은 부스트로서 투여된다.
일부 실시 형태에서, 서열 번호 541 또는 550의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드 서열을 포함하는 백신은 프라임으로서 투여된다.
일부 실시 형태에서, 서열 번호 543 또는 552의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드 서열을 포함하는 백신은 부스트로서 투여된다.
본 발명은 또한,
서열 번호 275, 381, 333, 337, 269, 253, 309, 325, 271, 305, 251, 245, 261, 265, 317, 255, 277, 297, 285, 437, 439, 442, 444, 379, 343, 211, 349, 213, 215, 221, 219, 225, 345, 353, 235, 223, 167, 171, 19, 23 및 177로 이루어진 군으로부터 선택되는 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40 또는 41개의 폴리펩티드 및 이들의 단편을 포함하는 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 백신의 치료적 유효량을 프라임으로서 대상에게 투여하는 단계; 및
서열 번호 275, 381, 333, 337, 269, 253, 309, 325, 271, 305, 251, 245, 261, 265, 317, 255, 277, 297, 285, 437, 439, 442, 444, 379, 343, 211, 349, 213, 215, 221, 219, 225, 345, 353, 235, 223, 167, 171, 19, 23 및 177로 이루어진 군으로부터 선택되는 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40 또는 41개의 폴리펩티드 및 이들의 단편을 포함하는 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 백신의 치료적 유효량을 부스트로서 대상에게 투여하여; 대상에서 전립선암을 치료하거나 예방하는 단계를 포함하는, 대상에서 전립선암을 치료하거나 예방하는 방법을 제공한다.
본 발명은 또한,
서열 번호 275, 381, 333, 337, 269, 253, 309, 325, 271, 305, 251, 245, 261, 265, 317, 255, 277, 297, 285, 437, 439, 442, 444, 379, 343, 211, 349, 213, 215, 221, 219, 225, 345, 353, 235, 223, 167, 171, 19, 23 및 177로 이루어진 군으로부터 선택되는 2개 이상의 폴리펩티드를 포함하는 제1 이종 폴리펩티드를 인코딩하는 제1 이종 폴리뉴클레오티드를 포함하는 제1 백신; 및
서열 번호 275, 381, 333, 337, 269, 253, 309, 325, 271, 305, 251, 245, 261, 265, 317, 255, 277, 297, 285, 437, 439, 442, 444, 379, 343, 211, 349, 213, 215, 221, 219, 225, 345, 353, 235, 223, 167, 171, 19, 23 및 177로 이루어진 군으로부터 선택되는 2개 이상의 폴리펩티드를 포함하는 제2 이종 폴리펩티드를 인코딩하는 제2 이종 폴리뉴클레오티드를 포함하는 제2 백신을 대상에게 투여하는 단계를 포함하는, 대상에서 전립선암을 치료하거나 예방하는 방법을 제공한다.
본 발명은 또한,
서열 번호 275, 381, 333, 337, 269, 253, 309, 325, 271, 305, 251, 245, 261, 265, 317, 255, 277, 297, 285, 437, 439, 442, 444, 379, 343, 211, 349, 213, 215, 221, 219, 225, 345, 353, 235, 223, 167, 171, 19, 23 및 177로 이루어진 군으로부터 선택되는 2개 이상의 폴리펩티드를 포함하는 제1 이종 폴리펩티드를 인코딩하는 제1 이종 폴리뉴클레오티드를 포함하는 제1 백신; 및
서열 번호 275, 381, 333, 337, 269, 253, 309, 325, 271, 305, 251, 245, 261, 265, 317, 255, 277, 297, 285, 437, 439, 442, 444, 379, 343, 211, 349, 213, 215, 221, 219, 225, 345, 353, 235, 223, 167, 171, 19, 23 및 177로 이루어진 군으로부터 선택되는 2개 이상의 폴리펩티드를 포함하는 제2 이종 폴리펩티드를 인코딩하는 제2 이종 폴리뉴클레오티드를 포함하는 제2 백신 - 상기 제1 이종 폴리펩티드 및 제2 이종 폴리펩티드는 별개의 아미노산 서열을 가짐 - 을 대상에게 투여하는 단계를 포함하는, 대상에서 전립선암을 치료하거나 예방하는 방법을 제공한다.
일부 실시 형태에서, 폴리펩티드는 1차 및 2차로 구성된다.
일부 실시 형태에서, 1차로 구성된 폴리펩티드는 서열 번호 541 또는 서열 번호 550의 이종 폴리펩티드를 포함한다.
일부 실시 형태에서, 2차로 구성된 폴리펩티드는 서열 번호 543 또는 서열 번호 552의 이종 폴리펩티드를 포함한다.
일부 실시 형태에서, 이종 폴리뉴클레오티드는 DNA 또는 RNA이다.
일부 실시 형태에서, RNA는 mRNA 또는 자기 복제 RNA이다.
일부 실시 형태에서, 백신은 재조합 바이러스이다.
일부 실시 형태에서, 재조합 바이러스는 아데노바이러스, 폭스바이러스, 아데노 관련 바이러스 또는 레트로바이러스로부터 유래된다.
일부 실시 형태에서, 1차로 구성된 폴리펩티드는 서열 번호 542 또는 서열 번호 551의 폴리뉴클레오티드에 의해 인코딩된다.
일부 실시 형태에서, 2차로 구성된 폴리펩티드는 서열 번호 544 또는 서열 번호 553의 폴리뉴클레오티드에 의해 인코딩된다.
일부 실시 형태에서, 프라임은 서열 번호 541 또는 서열 번호 550의 이종 폴리펩티드를 포함하는 GAd20로부터 유래된 재조합 바이러스를 포함한다.
일부 실시 형태에서, 부스트는 서열 번호 543 또는 서열 번호 552의 이종 폴리펩티드를 포함하는 MVA로부터 유래된 재조합 바이러스를 포함한다.
본 발명은 또한,
서열 번호 541, 550, 554, 555, 556, 623 또는 624의 아미노산 서열을 포함하는 제1 이종 폴리펩티드를 인코딩하는 제1 이종 폴리뉴클레오티드를 포함하는 제1 백신; 및
서열 번호 543, 552, 557, 558, 559, 625 또는 626의 아미노산 서열을 포함하는 제2 이종 폴리펩티드를 인코딩하는 제2 이종 폴리뉴클레오티드를 포함하는 제2 백신을 대상에게 투여하는 단계를 포함하는, 대상에서 전립선암을 치료하거나 예방하는 방법을 제공한다.
본 발명은 또한,
서열 번호 541의 아미노산 서열을 포함하는 제1 이종 폴리펩티드를 인코딩하는 제1 이종 폴리뉴클레오티드를 포함하는 제1 백신; 및
서열 번호 543의 아미노산 서열을 포함하는 제2 이종 폴리펩티드를 인코딩하는 제2 이종 폴리뉴클레오티드를 포함하는 제2 백신을 대상에게 투여하는 단계를 포함하는, 대상에서 전립선암을 치료하거나 예방하는 방법을 제공한다.
본 발명은 또한,
서열 번호 550의 아미노산 서열을 포함하는 제1 이종 폴리펩티드를 인코딩하는 제1 이종 폴리뉴클레오티드를 포함하는 제1 백신; 및
서열 번호 552의 아미노산 서열을 포함하는 제2 이종 폴리펩티드를 인코딩하는 제2 이종 폴리뉴클레오티드를 포함하는 제2 백신을 대상에게 투여하는 단계를 포함하는, 대상에서 전립선암을 치료하거나 예방하는 방법을 제공한다.
본 발명은 또한,
서열 번호 541의 아미노산 서열을 포함하는 제1 이종 폴리펩티드를 인코딩하는 제1 이종 폴리뉴클레오티드를 포함하는, 재조합 GAd20인 제1 백신; 및
서열 번호 543의 아미노산 서열을 포함하는 제2 이종 폴리펩티드를 인코딩하는 제2 이종 폴리뉴클레오티드를 포함하는, 재조합 MVA인 제2 백신을 대상에게 투여하는 단계를 포함하는, 대상에서 전립선암을 치료하거나 예방하는 방법을 제공한다.
본 발명은 또한,
서열 번호 550의 아미노산 서열을 포함하는 제1 이종 폴리펩티드를 인코딩하는 제1 이종 폴리뉴클레오티드를 포함하는, 재조합 GAd20인 제1 백신; 및
서열 번호 552의 아미노산 서열을 포함하는 제2 이종 폴리펩티드를 인코딩하는 제2 이종 폴리뉴클레오티드를 포함하는, 재조합 MVA인 제2 백신을 대상에게 투여하는 단계를 포함하는, 대상에서 전립선암을 치료하거나 예방하는 방법을 제공한다.
본 발명은 또한 서열 번호 541, 550, 554, 555, 556, 623 또는 624의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 GAd20로부터 유래된 재조합 바이러스를 포함하는 백신을 대상에게 투여하는 단계를 포함하는, 대상에서 면역반응을 유도하는 방법을 제공한다.
본 발명은 또한 서열 번호 541의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 GAd20로부터 유래된 재조합 바이러스를 포함하는 백신을 대상에게 투여하는 단계를 포함하는, 대상에서 면역반응을 유도하는 방법을 제공한다.
본 발명은 또한 서열 번호 550의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 GAd20로부터 유래된 재조합 바이러스를 포함하는 백신을 대상에게 투여하는 단계를 포함하는, 대상에서 면역반응을 유도하는 방법을 제공한다.
본 발명은 또한 서열 번호 554의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 GAd20로부터 유래된 재조합 바이러스를 포함하는 백신을 대상에게 투여하는 단계를 포함하는, 대상에서 면역반응을 유도하는 방법을 제공한다.
본 발명은 또한 서열 번호 555의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 GAd20로부터 유래된 재조합 바이러스를 포함하는 백신을 대상에게 투여하는 단계를 포함하는, 대상에서 면역반응을 유도하는 방법을 제공한다.
본 발명은 또한 서열 번호 556의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 GAd20로부터 유래된 재조합 바이러스를 포함하는 백신을 대상에게 투여하는 단계를 포함하는, 대상에서 면역반응을 유도하는 방법을 제공한다.
본 발명은 또한 서열 번호 623의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 GAd20로부터 유래된 재조합 바이러스를 포함하는 백신을 대상에게 투여하는 단계를 포함하는, 대상에서 면역반응을 유도하는 방법을 제공한다.
본 발명은 또한 서열 번호 624의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 GAd20로부터 유래된 재조합 바이러스를 포함하는 백신을 대상에게 투여하는 단계를 포함하는, 대상에서 면역반응을 유도하는 방법을 제공한다.
본 발명은 또한 서열 번호 543, 552, 557, 558, 559, 625 또는 626의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 MVA로부터 유래된 재조합 바이러스를 포함하는 백신을 대상에게 투여하는 단계를 포함하는, 대상에서 면역반응을 유도하는 방법을 제공한다.
본 발명은 또한 서열 번호 543의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 MVA로부터 유래된 재조합 바이러스를 포함하는 백신을 대상에게 투여하는 단계를 포함하는, 대상에서 면역반응을 유도하는 방법을 제공한다.
본 발명은 또한 서열 번호 552의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 MVA로부터 유래된 재조합 바이러스를 포함하는 백신을 대상에게 투여하는 단계를 포함하는, 대상에서 면역반응을 유도하는 방법을 제공한다.
본 발명은 또한 서열 번호 557의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 MVA로부터 유래된 재조합 바이러스를 포함하는 백신을 대상에게 투여하는 단계를 포함하는, 대상에서 면역반응을 유도하는 방법을 제공한다.
본 발명은 또한 서열 번호 558의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 MVA로부터 유래된 재조합 바이러스를 포함하는 백신을 대상에게 투여하는 단계를 포함하는, 대상에서 면역반응을 유도하는 방법을 제공한다.
본 발명은 또한 서열 번호 559의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 MVA로부터 유래된 재조합 바이러스를 포함하는 백신을 대상에게 투여하는 단계를 포함하는, 대상에서 면역반응을 유도하는 방법을 제공한다.
본 발명은 또한 서열 번호 625의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 MVA로부터 유래된 재조합 바이러스를 포함하는 백신을 대상에게 투여하는 단계를 포함하는, 대상에서 면역반응을 유도하는 방법을 제공한다.
본 발명은 또한 서열 번호 626의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 MVA로부터 유래된 재조합 바이러스를 포함하는 백신을 대상에게 투여하는 단계를 포함하는, 대상에서 면역반응을 유도하는 방법을 제공한다.
본 발명은 또한,
서열 번호 541, 550, 554, 555, 556, 623 또는 624의 아미노산 서열을 포함하는 제1 이종 폴리펩티드를 인코딩하는 제1 이종 폴리뉴클레오티드를 포함하는 제1 백신; 및
서열 번호 543, 552, 557, 558, 559, 625 또는 626의 아미노산 서열을 포함하는 제2 이종 폴리펩티드를 인코딩하는 제2 이종 폴리뉴클레오티드를 포함하는 제2 백신을 대상에게 투여하는 단계를 포함하는, 대상에서 면역반응을 유도하는 방법을 제공한다.
본 발명은 또한,
서열 번호 541의 아미노산 서열을 포함하는 제1 이종 폴리펩티드를 인코딩하는 제1 이종 폴리뉴클레오티드를 포함하는 제1 백신; 및
서열 번호 543의 아미노산 서열을 포함하는 제2 이종 폴리펩티드를 인코딩하는 제2 이종 폴리뉴클레오티드를 포함하는 제2 백신을 대상에게 투여하는 단계를 포함하는, 대상에서 면역반응을 유도하는 방법을 제공한다.
본 발명은 또한,
서열 번호 550의 아미노산 서열을 포함하는 제1 이종 폴리펩티드를 인코딩하는 제1 이종 폴리뉴클레오티드를 포함하는 제1 백신; 및
서열 번호 552의 아미노산 서열을 포함하는 제2 이종 폴리펩티드를 인코딩하는 제2 이종 폴리뉴클레오티드를 포함하는 제2 백신을 대상에게 투여하는 단계를 포함하는, 대상에서 면역반응을 유도하는 방법을 제공한다.
본 발명은 또한,
서열 번호 541의 아미노산 서열을 포함하는 제1 이종 폴리펩티드를 인코딩하는 제1 이종 폴리뉴클레오티드를 포함하는, 재조합 GAd20인 제1 백신; 및
서열 번호 543의 아미노산 서열을 포함하는 제2 이종 폴리펩티드를 인코딩하는 제2 이종 폴리뉴클레오티드를 포함하는, 재조합 MVA인 제2 백신을 대상에게 투여하는 단계를 포함하는, 대상에서 면역반응을 유도하는 방법을 제공한다.
본 발명은 또한,
서열 번호 550의 아미노산 서열을 포함하는 제1 이종 폴리펩티드를 인코딩하는 제1 이종 폴리뉴클레오티드를 포함하는, 재조합 GAd20인 제1 백신; 및
서열 번호 552의 아미노산 서열을 포함하는 제2 이종 폴리펩티드를 인코딩하는 제2 이종 폴리뉴클레오티드를 포함하는, 재조합 MVA인 제2 백신을 대상에게 투여하는 단계를 포함하는, 대상에서 면역반응을 유도하는 방법을 제공한다.
본 발명은 또한 전립선암을 치료하거나 예방하는데 사용하기 위한, 서열 번호 275, 381, 333, 337, 269, 253, 309, 325, 271, 305, 251, 245, 261, 265, 317, 255, 277, 297, 285, 437, 439, 442, 444, 379, 343, 211, 349, 213, 215, 221, 219, 225, 345, 353, 235, 223, 167, 171, 19, 23 및 177로 이루어진 군으로부터 선택되는 2개 이상의 폴리펩티드를 포함하는 제1 이종 폴리펩티드를 인코딩하는 제1 이종 폴리뉴클레오티드를 포함하는 제1 백신 및 서열 번호 275, 381, 333, 337, 269, 253, 309, 325, 271, 305, 251, 245, 261, 265, 317, 255, 277, 297, 285, 437, 439, 442, 444, 379, 343, 211, 349, 213, 215, 221, 219, 225, 345, 353, 235, 223, 167, 171, 19, 23 및 177로 이루어진 군으로부터 선택되는 2개 이상의 폴리펩티드를 포함하는 제2 이종 폴리펩티드를 인코딩하는 제2 이종 폴리뉴클레오티드를 포함하는 제2 백신을 제공한다.
본 발명은 또한 전립선암을 치료하거나 예방하는데 사용하기 위한, 서열 번호 541, 550, 554, 555, 556, 623 또는 624의 아미노산 서열을 포함하는 제1 이종 폴리펩티드를 인코딩하는 제1 이종 폴리뉴클레오티드를 포함하는 제1 백신 및 서열 번호 543, 552, 557, 558, 559, 625 또는 626의 아미노산 서열을 포함하는 제2 이종 폴리펩티드를 인코딩하는 제2 이종 폴리뉴클레오티드를 포함하는 제2 백신을 제공한다.
본 발명은 또한 전립선암을 치료하거나 예방하는데 사용하기 위한, 서열 번호 541의 아미노산 서열을 포함하는 제1 이종 폴리펩티드를 인코딩하는 제1 이종 폴리뉴클레오티드를 포함하는 제1 백신 및 서열 번호 543의 아미노산 서열을 포함하는 제2 이종 폴리펩티드를 인코딩하는 제2 이종 폴리뉴클레오티드를 포함하는 제2 백신을 제공한다.
본 발명은 또한 전립선암을 치료하거나 예방하는데 사용하기 위한, 서열 번호 550의 아미노산 서열을 포함하는 제1 이종 폴리펩티드를 인코딩하는 제1 이종 폴리뉴클레오티드를 포함하는 제1 백신 및 서열 번호 552의 아미노산 서열을 포함하는 제2 이종 폴리펩티드를 인코딩하는 제2 이종 폴리뉴클레오티드를 포함하는 제2 백신을 제공한다.
본 발명은 또한 전립선암을 치료하거나 예방하는데 사용하기 위한, 서열 번호 541의 아미노산 서열을 포함하는 제1 이종 폴리펩티드를 인코딩하는 제1 이종 폴리뉴클레오티드를 포함하는, 재조합 GAd20인 제1 백신; 및
서열 번호 543의 아미노산 서열을 포함하는 제2 이종 폴리펩티드를 인코딩하는 제2 이종 폴리뉴클레오티드를 포함하는, 재조합 MVA인 제2 백신을 제공한다.
본 발명은 또한 전립선암을 치료하거나 예방하는데 사용하기 위한, 서열 번호 550의 아미노산 서열을 포함하는 제1 이종 폴리펩티드를 인코딩하는 제1 이종 폴리뉴클레오티드를 포함하는, 재조합 GAd20인 제1 백신 및 서열 번호 552의 아미노산 서열을 포함하는 제2 이종 폴리펩티드를 인코딩하는 제2 이종 폴리뉴클레오티드를 포함하는, 재조합 MVA인 제2 백신을 제공한다.
본 발명은 또한 전립선암을 치료하거나 예방하는데 사용하기 위한 서열 번호 541, 550, 554, 555, 556, 623 또는 624의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 GAd20로부터 유래된 재조합 바이러스를 포함하는 백신을 제공한다.
본 발명은 또한 면역반응을 유도하는데 사용하기 위한 서열 번호 541의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 GAd20로부터 유래된 재조합 바이러스를 포함하는 백신을 제공한다.
본 발명은 또한 면역반응을 유도하는데 사용하기 위한 서열 번호 550의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 GAd20로부터 유래된 재조합 바이러스를 포함하는 백신을 제공한다.
본 발명은 또한 면역반응을 유도하는데 사용하기 위한 서열 번호 554의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 GAd20로부터 유래된 재조합 바이러스를 포함하는 백신을 제공한다.
본 발명은 또한 면역반응을 유도하는데 사용하기 위한 서열 번호 555의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 GAd20로부터 유래된 재조합 바이러스를 포함하는 백신을 제공한다.
본 발명은 또한 면역반응을 유도하는데 사용하기 위한 서열 번호 556의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 GAd20로부터 유래된 재조합 바이러스를 포함하는 백신을 제공한다.
본 발명은 또한 면역반응을 유도하는데 사용하기 위한 서열 번호 623의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 GAd20로부터 유래된 재조합 바이러스를 포함하는 백신을 제공한다.
본 발명은 또한 면역반응을 유도하는데 사용하기 위한 서열 번호 624의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 GAd20로부터 유래된 재조합 바이러스를 포함하는 백신을 제공한다.
본 발명은 또한 면역반응을 유도하는데 사용하기 위한 서열 번호 543, 552, 557, 558, 559, 625 또는 626의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 MVA로부터 유래된 재조합 바이러스를 포함하는 백신을 제공한다.
본 발명은 또한 면역반응을 유도하는데 사용하기 위한 서열 번호 543의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 MVA로부터 유래된 재조합 바이러스를 포함하는 백신을 제공한다.
본 발명은 또한 면역반응을 유도하는데 사용하기 위한 서열 번호 552의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 MVA로부터 유래된 재조합 바이러스를 포함하는 백신을 제공한다.
본 발명은 또한 면역반응을 유도하는데 사용하기 위한 서열 번호 557의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 MVA로부터 유래된 재조합 바이러스를 포함하는 백신을 제공한다.
본 발명은 또한 면역반응을 유도하는데 사용하기 위한 서열 번호 558의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 MVA로부터 유래된 재조합 바이러스를 포함하는 백신을 제공한다.
본 발명은 또한 면역반응을 유도하는데 사용하기 위한 서열 번호 559의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 MVA로부터 유래된 재조합 바이러스를 포함하는 백신을 제공한다.
본 발명은 또한 면역반응을 유도하는데 사용하기 위한 서열 번호 625의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 MVA로부터 유래된 재조합 바이러스를 포함하는 백신을 제공한다.
본 발명은 또한 면역반응을 유도하는데 사용하기 위한 서열 번호 626의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 MVA로부터 유래된 재조합 바이러스를 포함하는 백신을 제공한다.
본 발명은 또한 면역반응을 유도하는데 사용하기 위한, 서열 번호 541, 550, 554, 555, 556, 623 또는 624의 아미노산 서열을 포함하는 제1 이종 폴리펩티드를 인코딩하는 제1 이종 폴리뉴클레오티드를 포함하는 제1 백신 및 서열 번호 543, 552, 557, 558, 559, 625 또는 626의 아미노산 서열을 포함하는 제2 이종 폴리펩티드를 인코딩하는 제2 이종 폴리뉴클레오티드를 포함하는 제2 백신을 제공한다.
본 발명은 또한 면역반응을 유도하는데 사용하기 위한, 서열 번호 541의 아미노산 서열을 포함하는 제1 이종 폴리펩티드를 인코딩하는 제1 이종 폴리뉴클레오티드를 포함하는 제1 백신 및 서열 번호 543의 아미노산 서열을 포함하는 제2 이종 폴리펩티드를 인코딩하는 제2 이종 폴리뉴클레오티드를 포함하는 제2 백신을 제공한다.
본 발명은 또한 면역반응을 유도하는데 사용하기 위한, 서열 번호 550의 아미노산 서열을 포함하는 제1 이종 폴리펩티드를 인코딩하는 제1 이종 폴리뉴클레오티드를 포함하는 제1 백신 및 서열 번호 552의 아미노산 서열을 포함하는 제2 이종 폴리펩티드를 인코딩하는 제2 이종 폴리뉴클레오티드를 포함하는 제2 백신을 제공한다.
본 발명은 또한 면역반응을 유도하는데 사용하기 위한, 서열 번호 541의 아미노산 서열을 포함하는 제1 이종 폴리펩티드를 인코딩하는 제1 이종 폴리뉴클레오티드를 포함하는, 재조합 GAd20인 제1 백신 및 서열 번호 543의 아미노산 서열을 포함하는 제2 이종 폴리펩티드를 인코딩하는 제2 이종 폴리뉴클레오티드를 포함하는, 재조합 MVA인 제2 백신을 제공한다.
본 발명은 또한 면역반응을 유도하는데 사용하기 위한, 서열 번호 550의 아미노산 서열을 포함하는 제1 이종 폴리펩티드를 인코딩하는 제1 이종 폴리뉴클레오티드를 포함하는, 재조합 GAd20인 제1 백신, 및
서열 번호 552의 아미노산 서열을 포함하는 제2 이종 폴리펩티드를 인코딩하는 제2 이종 폴리뉴클레오티드를 포함하는, 재조합 MVA인 제2 백신을 제공한다.
일부 실시 형태에서, 대상은 전립선암을 앓고 있거나, 전립선암을 앓고 있는 것으로 의심되거나, 전립선암을 발병할 것으로 의심된다. 전립선암 진단은 면허가 있는 의사에 의해 행해진다.
일부 실시 형태에서, 전립선암은 재발성 전립선암, 불응성 전립선암, 전이성 전립선암 또는 거세저항성 전립선암, 또는 이들의 임의의 조합이다.
일부 실시 형태에서, 대상은 치료 경험이 없다.
일부 실시 형태에서, 대상은 안드로겐 차단요법을 받았다.
일부 실시 형태에서, 제1 백신은 대상에게 1회 이상 투여된다.
일부 실시 형태에서, 제2 백신은 대상에게 1회 이상 투여된다.
일부 실시 형태에서, 제1 백신은 제2 백신을 투여하기 약 1 내지 16주 전에 투여된다. 일부 실시 형태에서, 제1 백신은 제2 백신을 투여하기 약 1주 전에 투여된다. 일부 실시 형태에서, 제1 백신은 제2 백신을 투여하기 약 2주 전에 투여된다. 일부 실시 형태에서, 제1 백신은 제2 백신을 투여하기 약 3주 전에 투여된다. 일부 실시 형태에서, 제1 백신은 제2 백신을 투여하기 약 4주 전에 투여된다. 일부 실시 형태에서, 제1 백신은 제2 백신을 투여하기 약 5주 전에 투여된다. 일부 실시 형태에서, 제1 백신은 제2 백신을 투여하기 약 6주 전에 투여된다. 일부 실시 형태에서, 제1 백신은 제2 백신을 투여하기 약 7주 전에 투여된다. 일부 실시 형태에서, 제1 백신은 제2 백신을 투여하기 약 8주 전에 투여된다. 일부 실시 형태에서, 제1 백신은 제2 백신을 투여하기 약 9주 전에 투여된다. 일부 실시 형태에서, 제1 백신은 제2 백신을 투여하기 약 10주 전에 투여된다. 일부 실시 형태에서, 제1 백신은 제2 백신을 투여하기 약 11주 전에 투여된다. 일부 실시 형태에서, 제1 백신은 제2 백신을 투여하기 약 12주 전에 투여된다. 일부 실시 형태에서, 제1 백신은 제2 백신을 투여하기 약 13주 전에 투여된다. 일부 실시 형태에서, 제1 백신은 제2 백신을 투여하기 약 14주 전에 투여된다. 일부 실시 형태에서, 제1 백신은 제2 백신을 투여하기 약 16주 전에 투여된다.
일부 실시 형태에서, 전립선암은 재발성 전립선암, 불응성 전립선암, 전이성 전립선암 또는 거세저항성 전립선암, 또는 이들의 임의의 조합이다.
일부 실시 형태에서, 상기 방법은 추가의 암 치료제를 대상에게 추가로 투여하는 단계를 포함한다.
병용 요법
본 발명의 백신은 전립선암을 치료하기 위한 하나 이상의 추가의 암 치료제와 병용하여 사용될 수 있다.
상기 추가의 암 치료제는 수술, 화학요법, 안드로겐 차단요법, 방사선 요법, 표적요법 또는 체크포인트 억제제(checkpoint inhibitor), 또는 이들의 임의의 조합일 수 있다.
예시적인 화학요법제는 알킬화제; 니트로소우레아; 대사길항물질; 항종양 항생물질; 식물 알킬로이드; 탁산; 호르몬제; 및 기타 제제, 예를 들어, 부설판, 카르보플라틴, 클로람부실, 시스플라틴, 사이클로포스파미드, 다카르바진, 이포스파미드, 메클로레타민 하이드로클로라이드, 멜팔란, 프로카르바진, 티오테파, 우라실 머스터드, 5-플루오로우라실, 6-메르캅토푸린, 카페시타빈, 시토신 아라비노시드, 플록수리딘, 플루다라빈, 젬시타빈, 메토트렉세이트, 티오구아닌, 닥티노마이신, 다우노루비신, 독소루비신, 이다루비신, 미토마이신-C, 및 미톡산트론, 빈블라스틴, 빈크리스틴, 빈데신, 비노렐빈, 파클리탁셀, 도세탁셀이다.
예시적인 안드로겐 차단요법은 아비라테론 아세테이트, 케토코나졸, 엔잘루타미드, 갈레테론, ARN-509 및 오르테로넬(TAK-700) 및 고환의 외과적 제거를 포함한다.
방사선 요법은 외부-빔 요법, 내부 방사선 요법, 이식 방사선(implant radiation), 정위 방사선수술(stereotactic radiosurgery), 전신 방사선 요법, 방사선요법, 및 영구적이거나 일시적인 조직내 근접치료(interstitial brachytherapy)를 포함하는 다양한 방법을 사용하여 투여될 수 있다. 외부-빔 요법은 3 차원 입체조형 방사선 요법을 수반하며, 여기서 방사선의 조사야(field of radiation)는 국소 방사선(local radiation)(예를 들어, 사전 선택된 표적 또는 장기에 지향된 방사선), 또는 집속 방사선(focused radiation)으로 설계된다. 집속 방사선은 정위 방사선수술, 분할 정위 방사선수술, 또는 강도-변조 방사선 요법으로부터 선택될 수 있다. 집속 방사선은 방사선원으로서 입자 빔(양성자), 코발트-60(광자) 선형 가속기(x-선)를 가질 수 있다(예를 들어 WO 2012/177624호 참조). "근접치료"는 종양 또는 다른 증식성 조직 질병 부위 또는 그 주위에 신체 내로 삽입된 공간적으로 격리된 방사성 물질에 의해 전달되는 방사선 요법을 지칭하며, 방사성 동위원소(예를 들어, At-211, I-131, I-125, Y-90, Re-186, Re-188, Sm-153, Bi-212, P-32, 및 Lu의 방사성 동위원소)에 대한 노출을 포함한다. 세포 컨디셔너(cell conditioner)로 사용하기에 적합한 방사선원은 고체 및 액체 모두를 포함한다. 방사선원은 I-125, I-131, Yb-169, 고체 선원(solid source)으로서의 Ir-192, 고체 선원으로서의 I-125와 같은 방사성 핵종, 또는 광자, 베타 입자, 감마 방사선, 또는 다른 치료적 선을 발산하는 다른 방사성 핵종일 수 있다. 방사성 물질은 또한 임의의 방사성 핵종(들) 용액, 예를 들어, I-125 또는 I-131의 용액으로부터 제조된 유체일 수 있거나, 방사성 유체는 Au-198, Y-90과 같은 고체 방사성 핵종의 작은 입자를 함유하는 적합한 유체의 슬러리를 사용하여 생성될 수 있다. 방사성 핵종(들)은 겔 또는 방사성 미소구체에 함유될 수 있다.
표적 요법은 항안드로겐 요법, 혈관신생 억제제, 예컨대 베바시주맙, 항-PSA 또는 항-PSMA 항체, 또는 PSA 또는 PSMA에 대한 면역반응을 증강시키는 백신을 포함한다.
예시적인 체크포인트 억제제는 PD-1, PD-L1, PD-L2, VISTA, BTNL2, B7-H3, B7-H4, HVEM, HHLA2, CTLA-4, LAG-3, TIM-3, BTLA, CD160, CEACAM-1, LAIR1, TGFβ, IL-10, Siglec 패밀리 단백질, KIR, CD96, TIGIT, NKG2A, CD112, CD47, SIRPA 또는 CD244의 길항제이다. "길항제"는, 세포 단백질에 결합될 때, 단백질의 천연 리간드에 의해 유도되는 적어도 하나의 반응 또는 활성을 억제하는 분자를 지칭한다. 하나 이상의 반응 또는 활성이 길항제의 부재 하에(예를 들어, 음성 대조군) 억제되는 하나 이상의 반응 또는 활성보다 약 30%, 40%, 45%, 50%, 55%, 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%, 또는 100% 이상 만큼 더 크게 억제될 경우, 또는 그 억제가 길항제의 부재 하의 억제에 비교할 때 통계적으로 유의한 경우, 그 분자는 길항제이다. 길항제는 항체, 가용성 리간드, 소분자, DNA 또는 RNA, 예컨대 siRNA일 수 있다. 체크포인트 억제제의 예시적인 길항제는 미국 특허 공개 제2017/0121409호에 기재되어 있다.
일부 실시 형태에서, 하나 이상의 본 발명의 백신은 CTLA-4 항체, CTLA4 리간드, PD-1 축 억제제(PD-1 axis inhibitor), PD-L1 축 억제제, TLR 작용제, CD40 작용제, OX40 작용제, 하이드록시우레아, 룩솔리티닙(ruxolitinib), 페드라티닙(fedratinib), 41BB 작용제, CD28 작용제, STING 길항제, RIG-1 길항제, TCR-T 요법, CAR-T 요법, FLT3 리간드, 황산알루미늄, BTK 억제제, CD38 항체, CDK 억제제, CD33 항체, CD37 항체, CD25 항체, GM-CSF 억제제, IL-2, IL-15, IL-7, CD3 방향전환 분자(CD3 redirection molecule), 포말리밉(pomalimib), IFNγ, IFNα, TNFα, VEGF 항체, CD70 항체, CD27 항체, BCMA 항체 또는 GPRC5D 항체, 또는 이들의 임의의 조합과 병용하여 투여된다.
일부 실시 형태에서, 체크포인트 억제제는 이필리무맙(ipilimumab), 세트렐리맙(cetrelimab), 펨브롤리주맙(pembrolizumab), 니볼루맙(nivolumab), 신틸리맙(sintilimab), 세미플리맙(cemiplimab), 토리팔리맙(toripalimab), 캄렐리주맙(camrelizumab), 티슬렐리주맙(tislelizumab), 도스트랄리맙(dostralimab), 스파르탈리주맙(spartalizumab), 프롤골리맙(prolgolimab), AK-105, HLX-10, 발스틸리맙(balstilimab), MEDI-0680, HX-008, GLS-010, BI-754091, 제놀림주맙(genolimzumab), AK-104, MGA-012, F-520, 609A, LY-3434172, AMG-404, SL-279252, SCT-I10A, RO-7121661, ICTCAR-014, MEDI-5752, CS-1003, XmAb-23104, Sym-021, LZM-009, hAB21, BAT-1306, MGD-019, JTX-4014, 부디갈리맙(budigalimab), XmAb-20717, AK-103, MGD-013, IBI-318, 사산리맙(sasanlimab), CC-90006, 아벨루맙(avelumab), 아테졸리주맙(atezolizumab), 두르발루맙(durvalumab), CS-1001, 빈트라푸스프 알파(bintrafusp alpha), 엔바폴리맙(envafolimab), CX-072, GEN-1046, GS-4224, KL-A167, BGB-A333, SHR-1316, CBT-502, IL-103, KN-046, ZKAB-001, CA-170, TG-1501, LP-002, INCB-86550, ADG-104, SHR-1701, BCD-135, IMC-001, MSB-2311, FPT-155, FAZ-053, HLX-20, 아이오다폴리맙(iodapolimab), FS-118, BMS-986189, AK-106, MCLA-145, IBI-318 또는 CK-301, 또는 이들의 임의의 조합이다.
일부 실시 형태에서, 하나 이상의 본 발명의 백신은 이필리무맙, 세트렐리맙, 펨브롤리주맙, 니볼루맙, 신틸리맙, 세미플리맙, 토리팔리맙, 캄렐리주맙, 티슬렐리주맙, 도스트랄리맙, 스파르탈리주맙, 프롤골리맙, 발스틸리맙, 부디갈리맙, 사산리맙, 아벨루맙, 아테졸리주맙, 두르발루맙, 엔바폴리맙 또는 아이오다폴리맙, 또는 이들의 임의의 조합과 병용하여 투여된다.
키트
본 발명은 또한,
서열 번호 541, 550, 554, 555, 556, 623 또는 624의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 GAd20로부터 유래된 재조합 바이러스를 포함하는 제1 백신; 및
서열 번호 543, 552, 557, 558, 559, 625 또는 626의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 MVA로부터 유래된 재조합 바이러스를 포함하는 제2 백신을 포함하는 키트를 제공한다.
본 발명은 또한,
서열 번호 541의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 GAd20로부터 유래된 재조합 바이러스를 포함하는 제1 백신; 및
서열 번호 543의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 MVA로부터 유래된 재조합 바이러스를 포함하는 제2 백신을 포함하는 키트를 제공한다.
본 발명은 또한,
서열 번호 550의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 GAd20로부터 유래된 재조합 바이러스를 포함하는 제1 백신; 및
서열 번호 552의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 MVA로부터 유래된 재조합 바이러스를 포함하는 제2 백신을 포함하는 키트를 제공한다.
선택된 전립선 신생항원의 조합을 포함하는 이종 폴리펩티드 또는 인코딩하는 이종 폴리펩티드
본 발명은 또한,
아미노산 서열 WKFEMSYTVGGPPPHVHARPRHWKTDR (서열 번호 275)을 포함하는 AS18;
아미노산 서열 YEAGMTLGGKILFFLFLLLPLSPFSLIF (서열 번호 381)를 포함하는 P87;
아미노산 서열 DGHSYTSKVNCLLLQDGFHGCVSITGAAGRRNLSIFLFLMLCKLEFHAC (서열 번호 333)를 포함하는 AS55;
아미노산 서열 TGGKSTCSAPGPQSLPSTPFSTYPQWVILITEL (서열 번호 337)을 포함하는 AS57;
아미노산 서열 VLRFLDLKVRYLHS (서열 번호 269)를 포함하는 AS15;
아미노산 서열 DYWAQKEKGSSSFLRPSC (서열 번호 253)를 포함하는 AS7;
아미노산 서열 VPFRELKNVSVLEGLRQGRLGGPCSCHCPRPSQARLTPVDVAGPFLCLGDPGLFPPVKSSI (서열 번호 309)를 포함하는 AS43;
아미노산 서열 GMECTLGQVGAPSPRREEDGWRGGHSRFKADVPAPQGPCWGGQPGSAPSSAPPEQSLLD (서열 번호 325)를 포함하는 AS51;
아미노산 서열 GNTTLQQLGEASQAPSGSLIPLRLPLLWEVRG (서열 번호 271)를 포함하는 AS16;
아미노산 서열 EAFQRAAGEGGPGRGGARRGARVLQSPFCRAGAGEWLGHQSLR (서열 번호 305)을 포함하는 AS41;
아미노산 서열 DYWAQKEKISIPRTHLC (서열 번호 251)를 포함하는 AS6;
아미노산 서열 VAMMVPDRQVHYDFGL (서열 번호 245)을 포함하는 AS3;
아미노산 서열 VPFRELKNQRTAQGAPGIHHAASPVAANLCDPARHAQHTRIPCGAGQVRAGRGPEAGGGVLQPQRPAPEKPGCPCRRGQPRLHTVKMWRA (서열 번호 261)를 포함하는 AS11;
아미노산 서열 KRSFAVTERII (서열 번호 265)를 포함하는 AS13;
아미노산 서열 FKKFDGPCGERGGGRTARALWARGDSVLTPALDPQTPVRAPSLTRAAAAV (서열 번호 317)를 포함하는 AS47;
아미노산 서열 LVLGVLSGHSGSRL (서열 번호 255)을 포함하는 AS8;
아미노산 서열 QWQHYHRSGEAAGTPLWRPTRN (서열 번호 277)을 포함하는 AS19;
아미노산 서열 CHLFLQPQVGTPPPHTASARAPSGPPHPHESCPAGRRPARAAQTCARRQHGLPGCEEAGTARVPSLHLHLHQAALGAGRGRGWGEACAQVPPSRG (서열 번호 297)를 포함하는 AS37;
아미노산 서열 KIQNKNCPD (서열 번호 285)를 포함하는 AS23;
아미노산 서열 HYKLIQQPISLFSITDRLHKTFSQLPSVHLCSITFQWGHPPIFCSTNDICVTANFCISVTFLKPCFLLHEASASQ (서열 번호 437)를 포함하는 MS1;
아미노산 서열 RTALTHNQDFSIYRLCCKRGSLCHASQARSPAFPKPVRPLPAPITRITPQLGGQSDSSQPLLTTGRPQGWQDQALRHTQQASPASCATITIPIHSAALGDHSGDPGPAWDTCPPLPLTTLIPRAPPPYGDSTARSWPSRCGPLG (서열 번호 439)를 포함하는 MS3;
아미노산 서열 YAYKDFLWCFPFSLVFLQEIQICCHVSCLCCICCSTRICLGCLLELFLSRALRALHVLWNGFQLHCQ (서열 번호 442)를 포함하는 MS6;
아미노산 서열 TMPAILKLQKNCLLSL (서열 번호 444)을 포함하는 MS8; 및
아미노산 서열 YEAGMTLGEKFRVGNCKHLKMTRP (서열 번호 379)를 포함하는 P82로 이루어진 군으로부터 선택되는 2개 이상의 폴리펩티드 및 이들의 단편을 포함하는 단리된 이종 폴리펩티드를 제공한다.
일부 실시 형태에서, 단리된 이종 폴리펩티드는,
아미노산 서열 GVPGDSTRRAVRRMNTF (서열 번호 343)를 포함하는 P16;
아미노산 서열 CGASACDVSLIAMDSA (서열 번호 211)를 포함하는 FUS1;
아미노산 서열 SLYHREKQLIAMDSAI (서열 번호 349)를 포함하는 P22;
아미노산 서열 TEYNQKLQVNQFSESK (서열 번호 213)를 포함하는 FUS2;
아미노산 서열 TEISCCTLSSEENEYLPRPEWQLQ (서열 번호 215)를 포함하는 FUS3;
아미노산 서열 CEERGAAGSLISCE (서열 번호 221)를 포함하는 FUS6;
아미노산 서열 NSKMALNSEALSVVSE (서열 번호 219)를 포함하는 FUS5;
아미노산 서열 WGMELAASRRFSWDHHSAGGPPRVPSVRSGAAQVQPKDPLPLRTLAGCLARTAHLRPGAESLPQPQLHCT (서열 번호 225)를 포함하는 FUS8;
아미노산 서열 HVVGYGHLDTSGSSSSSSWP (서열 번호 345)를 포함하는 FUS15;
아미노산 서열 NSKMALNSLNSIDDAQLTRIAPPRSHCCFWEVNAP (서열 번호 353)를 포함하는 P35;
아미노산 서열 KMHFSLKEHPPPPCPP (서열 번호 235)를 포함하는 FUS19; 및
아미노산 서열 LWFQSSELSPTGAPWPSRRPTWRGTTVSPRTATSSARTCCGTKWPSSQEAALGLGSGLLRFSCGTAAIR (서열 번호 223)을 포함하는 FUS7으로 이루어진 군으로부터 선택되는 하나 이상의 폴리펩티드 및 이들의 단편을 추가로 포함한다.
본 발명은 또한,
아미노산 서열 GVPGDSTRRAVRRMNTF (서열 번호 343)를 포함하는 P16;
아미노산 서열 CGASACDVSLIAMDSA (서열 번호 211)를 포함하는 FUS1;
아미노산 서열 SLYHREKQLIAMDSAI (서열 번호 349)를 포함하는 P22;
아미노산 서열 TEYNQKLQVNQFSESK (서열 번호 213)를 포함하는 FUS2;
아미노산 서열 TEISCCTLSSEENEYLPRPEWQLQ (서열 번호 215)를 포함하는 FUS3;
아미노산 서열 CEERGAAGSLISCE (서열 번호 221)를 포함하는 FUS6;
아미노산 서열 NSKMALNSEALSVVSE (서열 번호 219)를 포함하는 FUS5;
아미노산 서열 WGMELAASRRFSWDHHSAGGPPRVPSVRSGAAQVQPKDPLPLRTLAGCLARTAHLRPGAESLPQPQLHCT (서열 번호 225)를 포함하는 FUS8;
아미노산 서열 HVVGYGHLDTSGSSSSSSWP (서열 번호 345)를 포함하는 FUS15;
아미노산 서열 NSKMALNSLNSIDDAQLTRIAPPRSHCCFWEVNAP (서열 번호 353)를 포함하는 P35;
아미노산 서열 KMHFSLKEHPPPPCPP (서열 번호 235)를 포함하는 FUS19; 및
아미노산 서열 LWFQSSELSPTGAPWPSRRPTWRGTTVSPRTATSSARTCCGTKWPSSQEAALGLGSGLLRFSCGTAAIR (서열 번호 223)을 포함하는 FUS7으로 이루어진 군으로부터 선택되는 하나 이상의 폴리펩티드 및 이들의 단편을 포함하는 단리된 이종 폴리펩티드를 제공한다.
일부 실시 형태에서, 단리된 이종 폴리펩티드는,
아미노산 서열 WKFEMSYTVGGPPPHVHARPRHWKTDR (서열 번호 275)을 포함하는 AS18;
아미노산 서열 YEAGMTLGGKILFFLFLLLPLSPFSLIF (서열 번호 381)를 포함하는 P87;
아미노산 서열 DGHSYTSKVNCLLLQDGFHGCVSITGAAGRRNLSIFLFLMLCKLEFHAC (서열 번호 333)를 포함하는 AS55;
아미노산 서열 TGGKSTCSAPGPQSLPSTPFSTYPQWVILITEL (서열 번호 337)을 포함하는 AS57;
아미노산 서열 VLRFLDLKVRYLHS (서열 번호 269)를 포함하는 AS15;
아미노산 서열 DYWAQKEKGSSSFLRPSC (서열 번호 253)를 포함하는 AS7;
아미노산 서열 VPFRELKNVSVLEGLRQGRLGGPCSCHCPRPSQARLTPVDVAGPFLCLGDPGLFPPVKSSI (서열 번호 309)를 포함하는 AS43;
아미노산 서열 GMECTLGQVGAPSPRREEDGWRGGHSRFKADVPAPQGPCWGGQPGSAPSSAPPEQSLLD (서열 번호 325)를 포함하는 AS51;
아미노산 서열 GNTTLQQLGEASQAPSGSLIPLRLPLLWEVRG (서열 번호 271)를 포함하는 AS16;
아미노산 서열 EAFQRAAGEGGPGRGGARRGARVLQSPFCRAGAGEWLGHQSLR (서열 번호 305)을 포함하는 AS41;
아미노산 서열 DYWAQKEKISIPRTHLC (서열 번호 251)를 포함하는 AS6;
아미노산 서열 VAMMVPDRQVHYDFGL (서열 번호 245)을 포함하는 AS3;
아미노산 서열 VPFRELKNQRTAQGAPGIHHAASPVAANLCDPARHAQHTRIPCGAGQVRAGRGPEAGGGVLQPQRPAPEKPGCPCRRGQPRLHTVKMWRA (서열 번호 261)를 포함하는 AS11;
아미노산 서열 KRSFAVTERII (서열 번호 265)를 포함하는 AS13;
아미노산 서열 FKKFDGPCGERGGGRTARALWARGDSVLTPALDPQTPVRAPSLTRAAAAV (서열 번호 317)를 포함하는 AS47;
아미노산 서열 LVLGVLSGHSGSRL (서열 번호 255)을 포함하는 AS8;
아미노산 서열 QWQHYHRSGEAAGTPLWRPTRN (서열 번호 277)을 포함하는 AS19;
아미노산 서열 CHLFLQPQVGTPPPHTASARAPSGPPHPHESCPAGRRPARAAQTCARRQHGLPGCEEAGTARVPSLHLHLHQAALGAGRGRGWGEACAQVPPSRG (서열 번호 297)를 포함하는 AS37;
아미노산 서열 KIQNKNCPD (서열 번호 285)를 포함하는 AS23;
아미노산 서열 HYKLIQQPISLFSITDRLHKTFSQLPSVHLCSITFQWGHPPIFCSTNDICVTANFCISVTFLKPCFLLHEASASQ (서열 번호 437)를 포함하는 MS1;
아미노산 서열 RTALTHNQDFSIYRLCCKRGSLCHASQARSPAFPKPVRPLPAPITRITPQLGGQSDSSQPLLTTGRPQGWQDQALRHTQQASPASCATITIPIHSAALGDHSGDPGPAWDTCPPLPLTTLIPRAPPPYGDSTARSWPSRCGPLG (서열 번호 439)를 포함하는 MS3;
아미노산 서열 YAYKDFLWCFPFSLVFLQEIQICCHVSCLCCICCSTRICLGCLLELFLSRALRALHVLWNGFQLHCQ (서열 번호 442)를 포함하는 MS6;
아미노산 서열 TMPAILKLQKNCLLSL (서열 번호 444)을 포함하는 MS8; 및
아미노산 서열 YEAGMTLGEKFRVGNCKHLKMTRP (서열 번호 379)를 포함하는 P82로 이루어진 군으로부터 선택되는 하나 이상의 폴리펩티드 및 이들의 단편을 추가로 포함한다.
일부 실시 형태에서, 단리된 이종 폴리펩티드는,
아미노산 서열 IARELHQFAFDLLIKSH (서열 번호 167)를 포함하는 M84;
아미노산 서열 QPDSFAALHSSLNELGE (서열 번호 171)를 포함하는 M86;
아미노산 서열 FVQGKDWGLKKFIRRDF (서열 번호 19)를 포함하는 M10;
아미노산 서열 FVQGKDWGVKKFIRRDF (서열 번호 23)를 포함하는 M12; 및
아미노산 서열 QNLQNGGGSRSSATLPGRRRRRWLRRRRQPISVAPAGPPRRPNQKPNPPGGARCVIMRPTWPGTSAFT (서열 번호 177)를 포함하는 FR1으로 이루어진 군으로부터 선택되는 하나 이상의 폴리펩티드 및 이들의 단편을 추가로 포함한다.
본 발명은 또한 서열 번호 275, 381, 333, 337, 269, 253, 309, 325, 271, 305, 251, 245, 261, 265, 317, 255, 277, 297, 285, 437, 439, 442, 444, 379, 343, 211, 349, 213, 215, 221, 219, 225, 345, 353, 235, 223, 167, 171, 19, 23 및 177로 이루어진 군으로부터 선택되는 2개 이상의 폴리펩티드 및 이들의 단편을 포함하는 이종 폴리펩티드를 제공한다.
본 발명은 또한,
TGGAAATTCGAGATGAGCTACACGGTGGGTGGCCCGCCTCCCCATGTTCATGCTAGACCCAGGCATTGGAAAACTGATAGA (서열 번호 276)의 폴리뉴클레오티드 서열 (AS18을 인코딩함);
TATGAAGCAGGGATGACTCTGGGAGGTAAGATACTTTTCTTTCTCTTCCTCCTCCTTCCTCTCTCCCCCTTCTCCCTCATTTTC (서열 번호 382)의 폴리뉴클레오티드 서열 (P87을 인코딩함);
GATGGCCACTCCTACACATCCAAGGTGAATTGTTTACTCCTTCAAGATGGGTTCCATGGCTGTGTGAGCATCACCGGGGCAGCTGGAAGAAGAAACCTGAGCATCTTCCTGTTCTTGATGCTGTGCAAATTGGAGTTCCATGCTTGT (서열 번호 334)의 폴리뉴클레오티드 서열 (AS55를 인코딩함);
ACAGGGGGCAAAAGCACCTGCTCGGCTCCTGGCCCTCAGTCTCTCCCCTCCACTCCATTCTCCACCTACCCACAGTGGGTCATTCTGATCACCGAACTG (서열 번호 338)의 폴리뉴클레오티드 서열 (AS57을 인코딩함);
GTGCTGCGCTTTCTGGACTTAAAGGTGAGATACCTGCACTCT (서열 번호 270)의 폴리뉴클레오티드 서열 (AS15을 인코딩함);
GACTACTGGGCTCAAAAGGAGAAGGGATCATCTTCATTCCTGCGACCATCCTGT (서열 번호 254)의 폴리뉴클레오티드 서열 (AS7을 인코딩함);
GTGCCCTTCCGGGAGCTCAAGAACGTGAGTGTCCTGGAGGGGCTCCGTCAAGGCCGGCTTGGGGGTCCCTGTTCATGTCACTGCCCAAGACCTTCCCAGGCCAGGCTCACGCCAGTGGATGTGGCAGGTCCCTTCTTGTGTCTGGGGGATCCTGGGCTGTTCCCCCCAGTCAAGAGCAGTATC (서열 번호 310)의 폴리뉴클레오티드 서열 (AS43를 인코딩함);
GGCATGGAGTGCACCCTGGGGCAGGTGGGTGCCCCGTCCCCTCGGAGGGAGGAGGACGGTTGGCGTGGGGGCCACAGCCGATTCAAGGCTGATGTACCAGCACCGCAGGGACCCTGCTGGGGTGGCCAACCTGGCTCTGCCCCCTCCTCAGCTCCTCCTGAACAGTCATTATTAGAT (서열 번호 326)의 폴리뉴클레오티드 서열 (AS51을 인코딩함);
GGCAACACCACCCTCCAGCAGCTGGGTGAGGCCTCCCAGGCGCCCTCAGGCTCCCTCATCCCTCTGAGGCTGCCTCTGCTCTGGGAAGTGAGGGGC (서열 번호 272)의 폴리뉴클레오티드 서열 (AS16을 인코딩함);
GAGGCCTTCCAGAGGGCCGCTGGTGAGGGCGGCCCGGGCCGCGGTGGGGCACGGCGCGGTGCCAGGGTGTTGCAGAGCCCCTTTTGCAGGGCAGGAGCTGGGGAGTGGTTAGGACATCAGTCCCTCAGG (서열 번호 306)의 폴리뉴클레오티드 서열 (AS41을 인코딩함);
GACTACTGGGCTCAAAAGGAGAAGATCAGCATCCCCAGAACACACCTGTGT (서열 번호 252)의 폴리뉴클레오티드 서열 (AS6를 인코딩함);
GTTGCTATGATGGTTCCTGATAGACAGGTTCATTATGACTTTGGATTG (서열 번호 246)의 폴리뉴클레오티드 서열 (AS3를 인코딩함);
GTGCCCTTCCGGGAGCTCAAGAACCAGAGAACAGCACAAGGGGCTCCTGGGATCCACCACGCGGCTTCCCCCGTTGCTGCCAACCTCTGCGACCCGGCGAGACACGCACAGCACACACGCATCCCCTGCGGCGCTGGCCAAGTGCGTGCTGGCCGAGGTCCCGAAGCAGGTGGTGGAGTACTACAGCCACAGAGGCCTGCCCCCGAGAAGCCTGGGTGTCCCTGCCGGAGAGGCCAGCCCAGGCTGCACACCGTGAAGATGTGGAGGGCG (서열 번호 262)의 폴리뉴클레오티드 서열 (AS11을 인코딩함);
AAGAGAAGTTTTGCTGTCACGGAGAGGATCATC (서열 번호 266)의 폴리뉴클레오티드 서열 (AS13을 인코딩함);
TTCAAGAAGTTCGACGGCCCTTGTGGTGAGCGCGGCGGCGGGCGCACGGCTCGAGCTCTGTGGGCGCGCGGCGACAGCGTCCTGACTCCTGCCCTCGACCCCCAGACCCCTGTCAGGGCGCCCTCCCTGACCCGAGCCGCAGCTGCCGTG (서열 번호 318)의 폴리뉴클레오티드 서열 (AS47을 인코딩함);
CTTGTACTTGGTGTATTGAGCGGGCACAGTGGCTCACGCCTA (서열 번호 256)의 폴리뉴클레오티드 서열 (AS8을 인코딩함);
CAGTGGCAGCACTACCACCGGTCAGGTGAGGCCGCAGGGACTCCCCTCTGGAGACCCACAAGAAAC (서열 번호 278)의 폴리뉴클레오티드 서열 (AS19을 인코딩함);
TGCCACCTCTTCCTGCAGCCCCAGGTTGGCACCCCCCCCCCCCACACTGCCAGTGCTCGAGCCCCCAGTGGTCCACCCCACCCTCATGAAAGTTGCCCTGCAGGGCGAAGACCTGCGAGAGCTGCGCAGACATGTGCACGCCGACAGCACGGACTTCCTGGCTGTGAAGAGGCTGGTACAGCGCGTGTTCCCAGCCTGCACCTGCACCTGCACCAGGCCGCCCTCGGAGCAGGAAGGGGCCGTGGGTGGGGAGAGGCCTGTGCCCAAGTACCCCCCTCAAGAGGC (서열 번호 298)의 폴리뉴클레오티드 서열 (AS37을 인코딩함);
AAAATTCAGAATAAAAATTGTCCAGAC (서열 번호 286)의 폴리뉴클레오티드 서열 (AS23를 인코딩함);
CACTACAAATTAATTCAACAACCCATATCCCTCTTCTCCATCACTGATAGGCTCCATAAGACGTTCAGTCAGCTGCCCTCGGTCCATCTCTGCTCAATCACCTTCCAGTGGGGACACCCGCCCATTTTCTGCTCAACAAATGATATCTGTGTCACGGCCAACTTCTGCATCTCGGTCACATTCCTTAAACCGTGCTTCCTCCTACATGAGGCATCTGCCTCACAG (서열 번호 448)의 폴리뉴클레오티드 서열 (MS1을 인코딩함);
AGGACCGCCCTGACACACAATCAGGACTTCTCTATCTACAGGCTCTGTTGCAAGAGGGGGTCCCTCTGCCACGCTTCCCAGGCCAGATCCCCGGCTTTCCCGAAGCCGGTCAGACCTCTTCCTGCCCCCATCACCAGAATCACCCCCCAACTGGGGGGACAATCTGACTCGAGTCAACCCCTTCTCACTACGGGAAGACCTCAGGGGTGGCAAGATCAAGCTCTTAGACACACCCAGCAAGCCAGTCCTGCCTCTTGTGCCACCATCACCATTCCCATCCACTCAGCTGCCCTTGGTGACCACTCCGGAGACCCTGGTCCAGCCTGGGACACCTGCCCGCCGCTGCCGCTCACTACCCTCATCCCCCGAGCTCCCCCGCCGTATGGAGACAGCACTGCCAGGTCCTGGCCCTCCCGCTGTGGGCCCCTCGGC (서열 번호 450)의 폴리뉴클레오티드 서열 (MS3를 인코딩함);
TATGCTTACAAGGACTTTCTCTGGTGTTTTCCTTTTTCTTTAGTTTTTCTCCAAGAGATTCAAATCTGCTGCCATGTTAGCTGTCTTTGCTGTATCTGCTGTAGTACACGAATATGCCTTGGCTGTTTGCTTGAGCTTTTTCTATCCCGTGCTCTTCGTGCTCTTCATGTTCTTTGGAATGGCTTTCAACTTCATTGTCAA (서열 번호 453)의 폴리뉴클레오티드 서열 (MS6를 인코딩함);
ACCATGCCTGCTATTTTAAAGTTACAGAAGAATTGTCTTCTCTCCTTA (서열 번호 455)의 폴리뉴클레오티드 서열 (MS8을 인코딩함); 및
TATGAAGCAGGGATGACTCTGGGAGAAAAATTCCGGGTTGGCAATTGCAAGCATCTCAAAATGACCAGACCC (서열 번호 380)의 폴리뉴클레오티드 서열 (P82를 인코딩함)로 이루어진 군으로부터 선택되는 2개 이상의 폴리뉴클레오티드 및 이들의 단편을 포함하는 단리된 이종 폴리뉴클레오티드를 제공한다.
일부 실시 형태에서, 단리된 이종 폴리뉴클레오티드는,
GGAGTTCCAGGAGATTCAACCAGGAGAGCAGTGAGGAGAATGAATACCTTC (서열 번호 344)의 폴리뉴클레오티드 서열 (P16을 인코딩함);
TGCGGGGCCTCTGCCTGTGATGTCTCCCTCATTGCTATGGACAGTGCT (서열 번호 212)의 폴리뉴클레오티드 서열 (FUS1을 인코딩함);
TCCCTCTACCACCGGGAGAAGCAGCTCATTGCTATGGACAGTGCTATC (서열 번호 350)의 폴리뉴클레오티드 서열 (P22를 인코딩함);
ACCGAATACAACCAGAAATTACAAGTGAATCAATTTAGTGAATCCAAA (서열 번호 214)의 폴리뉴클레오티드 서열 (FUS2를 인코딩함);
ACAGAAATTTCATGTTGCACCCTGAGCAGTGAGGAGAATGAATACCTTCCAAGACCAGAGTGGCAGCTCCAG (서열 번호 216)의 폴리뉴클레오티드 서열 (FUS3를 인코딩함);
TGTGAGGAGCGCGGCGCGGCAGGAAGCCTTATCAGTTGTGAG (서열 번호 222)의 폴리뉴클레오티드 서열 (FUS6를 인코딩함);
AACAGCAAGATGGCTTTGAACTCAGAAGCCTTATCAGTTGTGAGTGAG (서열 번호 220)의 폴리뉴클레오티드 서열 (FUS5를 인코딩함);
TGGGGGATGGAGTTGGCAGCGTCTCGGAGGTTCTCCTGGGACCACCACTCCGCCGGGGGGCCGCCCAGAGTGCCAAGCGTCCGATCCGGCGCCGCCCAAGTGCAGCCCAAGGACCCGCTCCCGCTCCGCACCCTGGCAGGCTGCCTAGCCAGGACTGCGCACCTGCGCCCTGGGGCGGAGTCCTTACCCCAACCCCAGCTTCACTGCACA (서열 번호 226)의 폴리뉴클레오티드 서열 (FUS8을 인코딩함);
CACGTGGTGGGCTATGGCCACCTTGATACTTCCGGGTCATCCTCCTCCTCCTCCTGGCCC (서열 번호 346)의 폴리뉴클레오티드 서열 (FUS15을 인코딩함);
AACAGCAAGATGGCTTTGAACTCATTAAACTCCATTGATGATGCACAGTTGACAAGAATTGCCCCTCCAAGATCTCATTGCTGTTTCTGGGAAGTAAACGCTCCT (서열 번호 354)의 폴리뉴클레오티드 서열 (P35를 인코딩함);
AAAATGCACTTCTCCCTCAAGGAGCACCCACCGCCCCCTTGCCCGCCT (서열 번호 236)의 폴리뉴클레오티드 서열 (FUS19을 인코딩함); 및
CTGTGGTTCCAGAGCAGTGAGCTGTCCCCGACGGGAGCGCCATGGCCCAGCCGCCGCCCGACGTGGAGGGGGACGACTGTCTCCCCGCGTACCGCCACCTCTTCTGCCCGGACCTGCTGCGGGACAAAGTGGCCTTCATCACAGGAGGCGGCTCTGGGATTGGGTTCCGGATTGCTGAGATTTTCATGCGGCACGGCTGCCATACGG (서열 번호 224)의 폴리뉴클레오티드 서열 (FUS7을 인코딩함)로 이루어진 군으로부터 선택되는 하나 이상의 폴리뉴클레오티드 및 이들의 단편을 추가로 포함한다.
본 발명은 또한,
GGAGTTCCAGGAGATTCAACCAGGAGAGCAGTGAGGAGAATGAATACCTTC (서열 번호 344)의 폴리뉴클레오티드 서열 (P16을 인코딩함);
TGCGGGGCCTCTGCCTGTGATGTCTCCCTCATTGCTATGGACAGTGCT (서열 번호 212)의 폴리뉴클레오티드 서열 (FUS1을 인코딩함);
TCCCTCTACCACCGGGAGAAGCAGCTCATTGCTATGGACAGTGCTATC (서열 번호 350)의 폴리뉴클레오티드 서열 (P22를 인코딩함);
ACCGAATACAACCAGAAATTACAAGTGAATCAATTTAGTGAATCCAAA (서열 번호 214)의 폴리뉴클레오티드 서열 (FUS2를 인코딩함);
ACAGAAATTTCATGTTGCACCCTGAGCAGTGAGGAGAATGAATACCTTCCAAGACCAGAGTGGCAGCTCCAG (서열 번호 216)의 폴리뉴클레오티드 서열 (FUS3를 인코딩함);
TGTGAGGAGCGCGGCGCGGCAGGAAGCCTTATCAGTTGTGAG (서열 번호 222)의 폴리뉴클레오티드 서열 (FUS6를 인코딩함);
AACAGCAAGATGGCTTTGAACTCAGAAGCCTTATCAGTTGTGAGTGAG (서열 번호 220)의 폴리뉴클레오티드 서열 (FUS5를 인코딩함);
TGGGGGATGGAGTTGGCAGCGTCTCGGAGGTTCTCCTGGGACCACCACTCCGCCGGGGGGCCGCCCAGAGTGCCAAGCGTCCGATCCGGCGCCGCCCAAGTGCAGCCCAAGGACCCGCTCCCGCTCCGCACCCTGGCAGGCTGCCTAGCCAGGACTGCGCACCTGCGCCCTGGGGCGGAGTCCTTACCCCAACCCCAGCTTCACTGCACA (서열 번호 226)의 폴리뉴클레오티드 서열 (FUS8을 인코딩함);
CACGTGGTGGGCTATGGCCACCTTGATACTTCCGGGTCATCCTCCTCCTCCTCCTGGCCC (서열 번호 346)의 폴리뉴클레오티드 서열 (FUS15을 인코딩함);
AACAGCAAGATGGCTTTGAACTCATTAAACTCCATTGATGATGCACAGTTGACAAGAATTGCCCCTCCAAGATCTCATTGCTGTTTCTGGGAAGTAAACGCTCCT (서열 번호 354)의 폴리뉴클레오티드 서열 (P35를 인코딩함);
AAAATGCACTTCTCCCTCAAGGAGCACCCACCGCCCCCTTGCCCGCCT (서열 번호 236)의 폴리뉴클레오티드 서열 (FUS19을 인코딩함); 및
CTGTGGTTCCAGAGCAGTGAGCTGTCCCCGACGGGAGCGCCATGGCCCAGCCGCCGCCCGACGTGGAGGGGGACGACTGTCTCCCCGCGTACCGCCACCTCTTCTGCCCGGACCTGCTGCGGGACAAAGTGGCCTTCATCACAGGAGGCGGCTCTGGGATTGGGTTCCGGATTGCTGAGATTTTCATGCGGCACGGCTGCCATACGG (서열 번호 224)의 폴리뉴클레오티드 서열 (FUS7을 인코딩함)로 이루어진 군으로부터 선택되는 2개 이상의 폴리뉴클레오티드를 포함하는 단리된 이종 폴리뉴클레오티드를 제공한다.
일부 실시 형태에서, 단리된 이종 폴리뉴클레오티드는 하나 이상의 폴리뉴클레오티드 또는 하나 이상의 폴리뉴클레오티드의, 길이가 24개 이상의 뉴클레오티드로 된 하나 이상의 인접 단편을 추가로 포함하며, 여기서 폴리뉴클레오티드는,
TGGAAATTCGAGATGAGCTACACGGTGGGTGGCCCGCCTCCCCATGTTCATGCTAGACCCAGGCATTGGAAAACTGATAGA (서열 번호 276)의 폴리뉴클레오티드 서열 (AS18을 인코딩함);
TATGAAGCAGGGATGACTCTGGGAGGTAAGATACTTTTCTTTCTCTTCCTCCTCCTTCCTCTCTCCCCCTTCTCCCTCATTTTC (서열 번호 382)의 폴리뉴클레오티드 서열 (P87을 인코딩함);
GATGGCCACTCCTACACATCCAAGGTGAATTGTTTACTCCTTCAAGATGGGTTCCATGGCTGTGTGAGCATCACCGGGGCAGCTGGAAGAAGAAACCTGAGCATCTTCCTGTTCTTGATGCTGTGCAAATTGGAGTTCCATGCTTGT (서열 번호 334)의 폴리뉴클레오티드 서열 (AS55를 인코딩함);
ACAGGGGGCAAAAGCACCTGCTCGGCTCCTGGCCCTCAGTCTCTCCCCTCCACTCCATTCTCCACCTACCCACAGTGGGTCATTCTGATCACCGAACTG (서열 번호 338)의 폴리뉴클레오티드 서열 (AS57을 인코딩함);
GTGCTGCGCTTTCTGGACTTAAAGGTGAGATACCTGCACTCT (서열 번호 270)의 폴리뉴클레오티드 서열 (AS15을 인코딩함);
GACTACTGGGCTCAAAAGGAGAAGGGATCATCTTCATTCCTGCGACCATCCTGT (서열 번호 254)의 폴리뉴클레오티드 서열 (AS7을 인코딩함);
GTGCCCTTCCGGGAGCTCAAGAACGTGAGTGTCCTGGAGGGGCTCCGTCAAGGCCGGCTTGGGGGTCCCTGTTCATGTCACTGCCCAAGACCTTCCCAGGCCAGGCTCACGCCAGTGGATGTGGCAGGTCCCTTCTTGTGTCTGGGGGATCCTGGGCTGTTCCCCCCAGTCAAGAGCAGTATC (서열 번호 310)의 폴리뉴클레오티드 서열 (AS43를 인코딩함);
GGCATGGAGTGCACCCTGGGGCAGGTGGGTGCCCCGTCCCCTCGGAGGGAGGAGGACGGTTGGCGTGGGGGCCACAGCCGATTCAAGGCTGATGTACCAGCACCGCAGGGACCCTGCTGGGGTGGCCAACCTGGCTCTGCCCCCTCCTCAGCTCCTCCTGAACAGTCATTATTAGAT (서열 번호 326)의 폴리뉴클레오티드 서열 (AS51을 인코딩함);
GGCAACACCACCCTCCAGCAGCTGGGTGAGGCCTCCCAGGCGCCCTCAGGCTCCCTCATCCCTCTGAGGCTGCCTCTGCTCTGGGAAGTGAGGGGC (서열 번호 272)의 폴리뉴클레오티드 서열 (AS16을 인코딩함);
GAGGCCTTCCAGAGGGCCGCTGGTGAGGGCGGCCCGGGCCGCGGTGGGGCACGGCGCGGTGCCAGGGTGTTGCAGAGCCCCTTTTGCAGGGCAGGAGCTGGGGAGTGGTTAGGACATCAGTCCCTCAGG (서열 번호 306)의 폴리뉴클레오티드 서열 (AS41을 인코딩함);
GACTACTGGGCTCAAAAGGAGAAGATCAGCATCCCCAGAACACACCTGTGT (서열 번호 252)의 폴리뉴클레오티드 서열 (AS6를 인코딩함);
GTTGCTATGATGGTTCCTGATAGACAGGTTCATTATGACTTTGGATTG (서열 번호 246)의 폴리뉴클레오티드 서열 (AS3를 인코딩함);
GTGCCCTTCCGGGAGCTCAAGAACCAGAGAACAGCACAAGGGGCTCCTGGGATCCACCACGCGGCTTCCCCCGTTGCTGCCAACCTCTGCGACCCGGCGAGACACGCACAGCACACACGCATCCCCTGCGGCGCTGGCCAAGTGCGTGCTGGCCGAGGTCCCGAAGCAGGTGGTGGAGTACTACAGCCACAGAGGCCTGCCCCCGAGAAGCCTGGGTGTCCCTGCCGGAGAGGCCAGCCCAGGCTGCACACCGTGAAGATGTGGAGGGCG (서열 번호 262)의 폴리뉴클레오티드 서열 (AS11을 인코딩함);
AAGAGAAGTTTTGCTGTCACGGAGAGGATCATC (서열 번호 266)의 폴리뉴클레오티드 서열 (AS13을 인코딩함);
TTCAAGAAGTTCGACGGCCCTTGTGGTGAGCGCGGCGGCGGGCGCACGGCTCGAGCTCTGTGGGCGCGCGGCGACAGCGTCCTGACTCCTGCCCTCGACCCCCAGACCCCTGTCAGGGCGCCCTCCCTGACCCGAGCCGCAGCTGCCGTG (서열 번호 318)의 폴리뉴클레오티드 서열 (AS47을 인코딩함);
CTTGTACTTGGTGTATTGAGCGGGCACAGTGGCTCACGCCTA (서열 번호 256)의 폴리뉴클레오티드 서열 (AS8을 인코딩함);
CAGTGGCAGCACTACCACCGGTCAGGTGAGGCCGCAGGGACTCCCCTCTGGAGACCCACAAGAAAC (서열 번호 278)의 폴리뉴클레오티드 서열 (AS19을 인코딩함);
TGCCACCTCTTCCTGCAGCCCCAGGTTGGCACCCCCCCCCCCCACACTGCCAGTGCTCGAGCCCCCAGTGGTCCACCCCACCCTCATGAAAGTTGCCCTGCAGGGCGAAGACCTGCGAGAGCTGCGCAGACATGTGCACGCCGACAGCACGGACTTCCTGGCTGTGAAGAGGCTGGTACAGCGCGTGTTCCCAGCCTGCACCTGCACCTGCACCAGGCCGCCCTCGGAGCAGGAAGGGGCCGTGGGTGGGGAGAGGCCTGTGCCCAAGTACCCCCCTCAAGAGGC (서열 번호 298)의 폴리뉴클레오티드 서열 (AS37을 인코딩함);
AAAATTCAGAATAAAAATTGTCCAGAC (서열 번호 286)의 폴리뉴클레오티드 서열 (AS23를 인코딩함);
CACTACAAATTAATTCAACAACCCATATCCCTCTTCTCCATCACTGATAGGCTCCATAAGACGTTCAGTCAGCTGCCCTCGGTCCATCTCTGCTCAATCACCTTCCAGTGGGGACACCCGCCCATTTTCTGCTCAACAAATGATATCTGTGTCACGGCCAACTTCTGCATCTCGGTCACATTCCTTAAACCGTGCTTCCTCCTACATGAGGCATCTGCCTCACAG (서열 번호 448)의 폴리뉴클레오티드 서열 (MS1을 인코딩함);
AGGACCGCCCTGACACACAATCAGGACTTCTCTATCTACAGGCTCTGTTGCAAGAGGGGGTCCCTCTGCCACGCTTCCCAGGCCAGATCCCCGGCTTTCCCGAAGCCGGTCAGACCTCTTCCTGCCCCCATCACCAGAATCACCCCCCAACTGGGGGGACAATCTGACTCGAGTCAACCCCTTCTCACTACGGGAAGACCTCAGGGGTGGCAAGATCAAGCTCTTAGACACACCCAGCAAGCCAGTCCTGCCTCTTGTGCCACCATCACCATTCCCATCCACTCAGCTGCCCTTGGTGACCACTCCGGAGACCCTGGTCCAGCCTGGGACACCTGCCCGCCGCTGCCGCTCACTACCCTCATCCCCCGAGCTCCCCCGCCGTATGGAGACAGCACTGCCAGGTCCTGGCCCTCCCGCTGTGGGCCCCTCGGC (서열 번호 450)의 폴리뉴클레오티드 서열 (MS3를 인코딩함);
TATGCTTACAAGGACTTTCTCTGGTGTTTTCCTTTTTCTTTAGTTTTTCTCCAAGAGATTCAAATCTGCTGCCATGTTAGCTGTCTTTGCTGTATCTGCTGTAGTACACGAATATGCCTTGGCTGTTTGCTTGAGCTTTTTCTATCCCGTGCTCTTCGTGCTCTTCATGTTCTTTGGAATGGCTTTCAACTTCATTGTCAA (서열 번호 453)의 폴리뉴클레오티드 서열 (MS6를 인코딩함);
ACCATGCCTGCTATTTTAAAGTTACAGAAGAATTGTCTTCTCTCCTTA (서열 번호 455)의 폴리뉴클레오티드 서열 (MS8을 인코딩함); 및
TATGAAGCAGGGATGACTCTGGGAGAAAAATTCCGGGTTGGCAATTGCAAGCATCTCAAAATGACCAGACCC (서열 번호 380)의 폴리뉴클레오티드 서열 (P82를 인코딩함), 및 이들의 단편을 포함한다.
일부 실시 형태에서, 단리된 이종 폴리뉴클레오티드는,
attgcgagagagctgcatcagttcGcttttgacctgctaatcaagtcacac (서열 번호 168)의 폴리뉴클레오티드 서열 (M84를 인코딩함);
cagcccgactcctttgcagccttgcActctagcctcaatgaactgggagag (서열 번호 172)의 폴리뉴클레오티드 서열 (M86를 인코딩함);
tttgtgcaaggcaaagactggggattAaagaaattcatccgtagagatttt (서열 번호 20)의 폴리뉴클레오티드 서열 (M10을 인코딩함);
tttgtgcaaggcaaagactggggaGtcaagaaattcatccgtagagatttt (서열 번호 24)의 폴리뉴클레오티드 서열 (M12를 인코딩함); 및
cagaacctgcagaatggaggggggagcaggtcttcagccacactgccggggcggcggcggcggcggtggctgcggcggcggcggcagccaatatcagtagctcctgcggggccccctcgccgaccaaaccaaaaaccaaacccacctggcggtgcgaggtgtgtgattatgagaccaacgtggccaggaacctccgcattcaca (서열 번호 178)의 폴리뉴클레오티드 서열 (FR1을 인코딩함)로 이루어진 군으로부터 선택되는 하나 이상의 폴리뉴클레오티드 및 이들의 단편을 추가로 포함한다.
본 발명은 또한 서열 번호 275, 381, 333, 337, 269, 253, 309, 325, 271, 305, 251, 245, 261, 265, 317, 255, 277, 297, 285, 437, 439, 442, 444, 379, 343, 211, 349, 213, 215, 221, 219, 225, 345, 353, 235, 223, 167, 171, 19, 23 및 177로 이루어진 군으로부터 선택되는 2개 이상의 폴리펩티드 및 이들의 단편을 인코딩하는 이종 폴리뉴클레오티드를 제공한다.
본 발명은 또한 서열 번호 276, 382, 334, 338, 270, 254, 310, 326, 272, 306, 252, 246, 262, 266, 318, 256, 278, 298, 286, 448, 450, 453, 455, 380, 344, 212, 350, 214, 216, 222, 220, 226, 346, 354, 236, 224, 168, 172, 20, 24 및 178로 이루어진 군으로부터 선택되는 2개 이상의 폴리뉴클레오티드 및 이들의 단편을 포함하는 이종 폴리뉴클레오티드를 제공한다.
본 발명은 또한 서열 번호 459, 460, 461, 462, 463, 464, 465, 466, 467, 468, 469, 470, 471, 472, 473, 474, 475, 476, 477, 478, 479, 480, 481, 482, 483, 484, 485, 486, 487, 488, 489, 490, 491, 492, 493, 494, 495, 496, 497, 498 및 499로 이루어진 군으로부터 선택되는 2개 이상의 폴리뉴클레오티드 및 이들의 단편을 포함하는 이종 폴리뉴클레오티드를 제공한다. 폴리뉴클레오티드는 아데노바이러스에서의 발현에 유용하다.
본 발명은 또한 서열 번호 500, 501, 461, 503, 504, 505, 506, 507, 508, 509, 510, 511, 512, 513, 514, 515, 516, 517, 477, 519, 520, 521, 522, 523, 524, 525, 485, 486, 528, 529, 530, 531, 532, 533, 534, 535, 536, 537, 538, 539 및 540으로 이루어진 군으로부터 선택되는 2개 이상의 폴리뉴클레오티드 및 이들의 단편을 포함하는 이종 폴리뉴클레오티드를 제공한다. 폴리뉴클레오티드는 MVA에서의 발현에 유용하다.
예를 들어, 서열 번호 541의 이종 폴리펩티드를 인코딩하는 서열 번호 542의 이종 폴리뉴클레오티드는 rGAd20에 기초한 것과 같은 아데노바이러스 기반 전립선암 백신을 생성하는데 사용될 수 있다. 대안적으로, 서열 번호 550, 554, 555, 556, 623 또는 624의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드는 또한 아데노바이러스 기반 백신에 사용될 수 있다. 41개의 신생항원의 조합을 인코딩하는 이종 폴리뉴클레오티드 이외에, 조절 서열, 태그 등과 같은 추가의 촉진자 요소가 이종 폴리뉴클레오티드의 5' 또는 3'에 포함될 수 있다. 예시적인 촉진자 요소는 CMV 프로모터, 백시니아 P7.5 프로모터, TetO 리프레서, 코작 서열, T 세포 인핸서(TCE)를 인코딩하는 폴리뉴클레오티드, 히스티딘 태그를 인코딩하는 폴리뉴클레오티드, 하나 이상의 정지 코돈, 폴리아데닐화 신호 또는 프로모터 서열을 포함한다. 촉진자 요소의 예시적인 폴리뉴클레오티드 서열은 서열 번호 628을 포함하는 CMVTetO 프로모터, 서열 번호 545를 포함하는 코작 서열, 서열 번호 546을 포함하는 TCE를 인코딩하는 폴리뉴클레오티드, 서열 번호 547을 포함하는 히스티딘 태그를 인코딩하는 폴리뉴클레오티드, 서열 번호 629를 포함하는 BGH 폴리아데닐화 부위, TAGTAA의 폴리뉴클레오티드 서열을 포함하는 하나 이상의 정지 코돈, 서열 번호 628의 폴리뉴클레오티드를 포함하는 CMV 프로모터 또는 서열 번호 630의 폴리뉴클레오티드를 포함하는 백시니아 P7.5 프로모터를 포함한다. 따라서, 하나 이상의 추가의 촉진자 서열을 포함하는 이종 폴리뉴클레오티드는 서열 번호 550의 폴리펩티드를 인코딩하는 서열 번호 551의 폴리뉴클레오티드 서열을 포함한다.
일부 실시 형태에서, 단리된 이종 폴리펩티드는 서열 번호 541의 아미노산 서열을 포함한다.
일부 실시 형태에서, 이종 폴리펩티드는 서열 번호 542의 이종 폴리뉴클레오티드에 의해 인코딩된다.
일부 실시 형태에서, 이종 폴리뉴클레오티드는 하나 이상의 촉진자 요소를 추가로 포함한다.
일부 실시 형태에서, 촉진자 요소는 프로모터, 인핸서, 폴리아데닐화 부위, 코작 서열, 정지 코돈, T 세포 인핸서(TCE) 또는 이들의 임의의 조합을 포함한다.
일부 실시 형태에서, 코작 서열은 서열 번호 545를 포함하고, TCE를 인코딩하는 폴리뉴클레오티드는 서열 번호 546을 포함하며, 히스티딘 태그를 인코딩하는 폴리뉴클레오티드는 서열 번호 547을 포함하고, 하나 이상의 정지 코돈은 TAGTAA의 폴리뉴클레오티드 서열을 포함한다.
일부 실시 형태에서, TCE는 서열 번호 546의 폴리뉴클레오티드에 의해 인코딩되고, CMV 프로모터는 서열 번호 628의 폴리뉴클레오티드를 포함하며, 백시니아 P7.5 프로모터는 서열 번호 630의 폴리뉴클레오티드를 포함하고, 폴리아데닐화 부위는 서열 번호 629의 소 성장 호르몬 폴리아데닐화 부위를 포함한다.
본 발명은 또한 서열 번호 550의 아미노산 서열을 포함하는 단리된 이종 폴리펩티드를 제공한다.
일부 실시 형태에서, 이종 폴리펩티드는 서열 번호 551의 이종 폴리뉴클레오티드에 의해 인코딩된다.
본 발명은 또한 서열 번호 554의 아미노산 서열을 포함하는 단리된 이종 폴리펩티드를 제공한다.
일부 실시 형태에서, 단리된 이종 폴리펩티드는 서열 번호 555의 아미노산 서열을 포함한다.
본 발명은 또한 서열 번호 556의 아미노산 서열을 포함하는 단리된 이종 폴리펩티드를 제공한다.
일부 실시 형태에서, 단리된 이종 폴리펩티드는 서열 번호 623의 아미노산 서열을 포함한다.
본 발명은 또한 서열 번호 624의 아미노산 서열을 포함하는 단리된 이종 폴리펩티드를 제공한다.
일부 실시 형태에서, 이종 폴리뉴클레오티드는 DNA이다. 일부 실시 형태에서, 이종 폴리뉴클레오티드는 RNA이다. 일부 실시 형태에서, 이종 폴리뉴클레오티드는 mRNA이다. 일부 실시 형태에서, 이종 폴리뉴클레오티드는 자기 복제 RNA이다.
서열 번호 543의 이종 폴리펩티드를 인코딩하는 서열 번호 544의 이종 폴리뉴클레오티드는 MVA 기반 전립선암 백신을 조작하는데 사용될 수 있다. 대안적으로, 서열 번호 557, 558, 559, 625 또는 626의 이종 폴리펩티드도 사용될 수 있다. 41개의 신생항원의 조합을 인코딩하는 이종 폴리뉴클레오티드 이외에, 조절 서열, 태그 등과 같은 추가의 촉진자 요소가 이종 폴리뉴클레오티드의 5' 또는 3'에 포함될 수 있다. 예시적인 촉진자 서열은 코작 서열, T 세포 인핸서(TCE)를 인코딩하는 폴리뉴클레오티드, 히스티딘 태그를 인코딩하는 폴리뉴클레오티드, 하나 이상의 정지 코돈, 폴리아데닐화 신호 또는 프로모터 서열을 포함한다. 예시적인 촉진자 요소의 폴리뉴클레오티드 서열은 서열 번호 545를 포함하는 코작 서열, 서열 번호 546을 포함하는 TCE를 인코딩하는 폴리뉴클레오티드, 서열 번호 547을 포함하는 히스티딘 태그를 인코딩하는 폴리뉴클레오티드 및 TAGTAA의 폴리뉴클레오티드 서열을 포함하는 하나 이상의 정지 코돈을 포함한다. 따라서, 하나 이상의 추가의 촉진자 요소를 포함하는 이종 폴리뉴클레오티드는 서열 번호 552의 폴리펩티드를 인코딩하는 서열 번호 553의 폴리뉴클레오티드 서열을 포함한다.
본 발명은 또한 서열 번호 543의 아미노산 서열을 포함하는 단리된 이종 폴리펩티드를 제공한다.
일부 실시 형태에서, 이종 폴리펩티드는 서열 번호 544의 이종 폴리뉴클레오티드에 의해 인코딩된다.
일부 실시 형태에서, 이종 폴리뉴클레오티드는 하나 이상의 촉진자 요소를 추가로 포함한다.
일부 실시 형태에서, 촉진자 요소는 프로모터, 인핸서, 폴리아데닐화 부위, 코작 서열, 정지 코돈, T 세포 인핸서(TCE) 또는 이들의 임의의 조합을 포함한다.
일부 실시 형태에서, 코작 서열은 서열 번호 545를 포함하고, TCE를 인코딩하는 폴리뉴클레오티드는 서열 번호 546을 포함하며, 히스티딘 태그를 인코딩하는 폴리뉴클레오티드는 서열 번호 547을 포함하고, 하나 이상의 정지 코돈은 TAGTAA의 폴리뉴클레오티드 서열을 포함한다.
일부 실시 형태에서, TCE는 서열 번호 546의 폴리뉴클레오티드에 의해 인코딩되고, CMV 프로모터는 서열 번호 628의 폴리뉴클레오티드를 포함하며, 백시니아 P7.5 프로모터는 서열 번호 630의 폴리뉴클레오티드를 포함하고, 폴리아데닐화 부위는 서열 번호 629의 소 성장 호르몬 폴리아데닐화 부위를 포함한다. 일부 실시 형태에서, 단리된 이종 폴리펩티드는 서열 번호 552의 아미노산 서열을 포함한다.
일부 실시 형태에서, 이종 폴리펩티드는 서열 번호 553의 이종 폴리뉴클레오티드에 의해 인코딩된다.
본 발명은 또한 서열 번호 557의 아미노산 서열을 포함하는 단리된 이종 폴리펩티드를 제공한다.
본 발명은 또한 서열 번호 558의 아미노산 서열을 포함하는 단리된 이종 폴리펩티드를 제공한다.
본 발명은 또한 서열 번호 559의 아미노산 서열을 포함하는 단리된 이종 폴리펩티드를 제공한다.
본 발명은 또한 서열 번호 625의 아미노산 서열을 포함하는 단리된 이종 폴리펩티드를 제공한다.
본 발명은 또한 서열 번호 626의 아미노산 서열을 포함하는 단리된 이종 폴리펩티드를 제공한다.
일부 실시 형태에서, 이종 폴리뉴클레오티드는 DNA이다. 일부 실시 형태에서, 이종 폴리뉴클레오티드는 RNA이다. 일부 실시 형태에서, 이종 폴리뉴클레오티드는 mRNA이다. 일부 실시 형태에서, 이종 폴리뉴클레오티드는 자기 복제 RNA이다.
41개의 전립선 신생항원(서열 번호 275, 381, 333, 337, 269, 253, 309, 325, 271, 305, 251, 245, 261, 265, 317, 255, 277, 297, 285, 437, 439, 442, 444, 379, 343, 211, 349, 213, 215, 221, 219, 225, 345, 353, 235, 223, 167, 171, 19, 23 및 177)의 하나 이상의 단편은 또한 하나 이상의 단편이 면역원성인 한, 전립선암 백신을 생성하는데 사용될 수 있다. 사용될 수 있는 예시적인 이러한 단편은 서열 번호 387, 388, 390, 392, 405, 406, 560, 561, 562, 563, 564, 565, 566, 567, 568, 569, 570, 571, 572, 573, 574, 575, 576, 577, 578, 579, 580, 581, 582, 583, 584, 585, 586, 587, 588, 589, 590, 591, 592, 593, 594, 595, 596, 597, 598, 599, 600, 601, 602, 603, 604, 605, 606, 607, 608, 609, 610, 611, 612, 613, 614, 615, 616, 617, 618, 619, 620, 621, 631, 632, 633, 634, 635, 636, 637, 638, 639, 640, 641, 642, 643, 644, 645, 646, 647, 648, 649, 650, 651, 652, 653, 654, 655, 656, 657, 658, 659, 660, 661, 662, 663, 664, 665, 666, 667, 668, 669, 670, 671, 672, 673, 674, 675, 676, 677, 678, 679, 680, 681, 682, 683, 684, 685, 686, 687, 688, 689, 690, 691, 692, 693, 694, 695, 696, 697, 698, 699, 700, 701, 702, 703, 704, 705, 706, 707, 708, 709의 폴리펩티드이다. 단편의 면역원성은 본 명세서에 기재된 분석을 사용하여 시험될 수 있다.
일부 실시 형태에서, 단편의 제1 N-말단 아미노산 잔기는 존재하지 않는다.
본 발명은 또한 본 발명의 이종 폴리펩티드를 인코딩하는 단리된 이종 폴리뉴클레오티드를 제공한다.
일부 실시 형태에서, 단편의 제1 5' 코돈은 존재하지 않는다.
본 발명은 또한 서열 번호 275, 381, 333, 337, 269, 253, 309, 325, 271, 305, 251, 245, 261, 265, 317, 255, 277, 297, 285, 437, 439, 442, 444, 379, 343, 211, 349, 213, 215, 221, 219, 225, 345, 353, 235, 223, 167, 171, 19, 23 및 177로 이루어진 군으로부터 선택되는 2개 이상의 폴리펩티드 및 이들의 단편을 인코딩하는 이종 폴리뉴클레오티드를 포함하는 벡터를 제공한다.
본 발명은 또한 서열 번호 276, 382, 334, 338, 270, 254, 310, 326, 272, 306, 252, 246, 262, 266, 318, 256, 278, 298, 286, 448, 450, 453, 455, 380, 344, 212, 350, 214, 216, 222, 220, 226, 346, 354, 236, 224, 168, 172, 20, 24 및 178로 이루어진 군으로부터 선택되는 2개 이상의 폴리뉴클레오티드 및 이들의 단편을 포함하는 이종 폴리뉴클레오티드를 포함하는 벡터를 제공한다.
본 발명은 또한 서열 번호 459, 460, 461, 462, 463, 464, 465, 466, 467, 468, 469, 470, 471, 472, 473, 474, 475, 476, 477, 478, 479, 480, 481, 482, 483, 484, 485, 486, 487, 488, 489, 490, 491, 492, 493, 494, 495, 496, 497, 498 및 499로 이루어진 군으로부터 선택되는 2개 이상의 폴리뉴클레오티드 및 이들의 단편을 포함하는 이종 폴리뉴클레오티드를 포함하는 벡터를 제공한다. 폴리뉴클레오티드는 아데노바이러스에서의 발현에 유용하다.
본 발명은 또한 서열 번호 541의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 벡터를 제공한다. 일부 실시 형태에서, 이종 폴리뉴클레오티드는 서열 번호 542의 폴리뉴클레오티드를 포함한다.
본 발명은 또한 서열 번호 542의 이종 폴리뉴클레오티드를 포함하는 벡터를 제공한다.
본 발명은 또한 서열 번호 550의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 벡터를 제공한다. 일부 실시 형태에서, 이종 폴리뉴클레오티드는 서열 번호 551의 폴리뉴클레오티드를 포함한다.
본 발명은 또한 서열 번호 551의 이종 폴리뉴클레오티드를 포함하는 벡터를 제공한다.
본 발명은 또한 서열 번호 554의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 벡터를 제공한다.
본 발명은 또한 서열 번호 555의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 벡터를 제공한다.
본 발명은 또한 서열 번호 556의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 벡터를 제공한다.
본 발명은 또한 서열 번호 623의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 벡터를 제공한다.
본 발명은 또한 서열 번호 624의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 벡터를 제공한다.
일부 실시 형태에서, 벡터는 바이러스 벡터이다.
일부 실시 형태에서, 바이러스 벡터는 아데노바이러스 벡터이다.
일부 실시 형태에서, 아데노바이러스 벡터는 인간 아데노바이러스, 임의로 Ad5, Ad7, Ad11, Ad26, Ad34, Ad35, Ad48, Ad49 또는 Ad50로부터 유래된다.
일부 실시 형태에서, 아데노바이러스 벡터는 Ad26로부터 유래된다.
일부 실시 형태에서, 아데노바이러스 벡터는 유인원 아데노바이러스, 임의로 GAd20, GAd19, GAd21, GAd25, GAd26, GAd27, GAd28, GAd29, GAd30, GAd31, ChAd3, ChAd4, ChAd5, ChAd6, ChAd7, ChAd8, ChAd9, ChAd10, ChAd1, ChAd16, ChAd17, ChAd19, ChAd20, ChAd22, ChAd24, ChAd26, ChAd30, ChAd31, ChAd37, ChAd38, ChAd44, ChAd55, ChAd63, ChAd73, ChAd82, ChAd83, ChAd146, ChAd147, PanAd1, PanAd2 또는 PanAd3로부터 유래된다.
일부 실시 형태에서, 아데노바이러스 벡터는 GAd20로부터 유래된다.
본 발명은 또한 서열 번호 275, 381, 333, 337, 269, 253, 309, 325, 271, 305, 251, 245, 261, 265, 317, 255, 277, 297, 285, 437, 439, 442, 444, 379, 343, 211, 349, 213, 215, 221, 219, 225, 345, 353, 235, 223, 167, 171, 19, 23 및 177로 이루어진 군으로부터 선택되는 2개 이상의 폴리펩티드 및 이들의 단편을 포함하는 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 rGAd20를 제공한다.
본 발명은 또한 서열 번호 276, 382, 334, 338, 270, 254, 310, 326, 272, 306, 252, 246, 262, 266, 318, 256, 278, 298, 286, 448, 450, 453, 455, 380, 344, 212, 350, 214, 216, 222, 220, 226, 346, 354, 236, 224, 168, 172, 20, 24 및 178로 이루어진 군으로부터 선택되는 2개 이상의 폴리뉴클레오티드 및 이들의 단편을 포함하는 이종 폴리뉴클레오티드를 포함하는 rGAd20를 제공한다.
본 발명은 또한 서열 번호 459, 460, 461, 462, 463, 464, 465, 466, 467, 468, 469, 470, 471, 472, 473, 474, 475, 476, 477, 478, 479, 480, 481, 482, 483, 484, 485, 486, 487, 488, 489, 490, 491, 492, 493, 494, 495, 496, 497, 498 및 499로 이루어진 군으로부터 선택되는 2개 이상의 폴리뉴클레오티드 및 이들의 단편을 포함하는 이종 폴리뉴클레오티드를 포함하는 rGAd20를 제공한다. 폴리뉴클레오티드는 아데노바이러스에서의 발현에 유용하다.
본 발명은 또한 서열 번호 541의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 rGAd20를 제공한다. 일부 실시 형태에서, 이종 폴리뉴클레오티드는 서열 번호 542를 포함한다.
본 발명은 또한 서열 번호 542의 이종 폴리뉴클레오티드를 포함하는 rGAd20를 제공한다.
본 발명은 또한 서열 번호 550의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 rGAd20를 제공한다. 일부 실시 형태에서, 이종 폴리뉴클레오티드는 서열 번호 551을 포함한다.
본 발명은 또한 서열 번호 551의 이종 폴리뉴클레오티드를 포함하는 rGAd20를 제공한다.
본 발명은 또한 서열 번호 554의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 rGAd20를 제공한다.
본 발명은 또한 서열 번호 555의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 rGAd20를 제공한다.
본 발명은 또한 서열 번호 556의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 rGAd20를 제공한다.
본 발명은 또한 서열 번호 623의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 rGAd20를 제공한다.
본 발명은 또한 서열 번호 624의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 rGAd20를 제공한다.
본 발명은 또한 rGAd20를 포함하거나 이로 형질도입된 세포를 제공하며, 여기서 rGAd20는,
서열 번호 275, 381, 333, 337, 269, 253, 309, 325, 271, 305, 251, 245, 261, 265, 317, 255, 277, 297, 285, 437, 439, 442, 444, 379, 343, 211, 349, 213, 215, 221, 219, 225, 345, 353, 235, 223, 167, 171, 19, 23 및 177로 이루어진 군으로부터 선택되는 2개 이상의 폴리펩티드 및 이들의 단편을 포함하는 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드;
서열 번호 459, 460, 461, 462, 463, 464, 465, 466, 467, 468, 469, 470, 471, 472, 473, 474, 475, 476, 477, 478, 479, 480, 481, 482, 483, 484, 485, 486, 487, 488, 489, 490, 491, 492, 493, 494, 495, 496, 497, 498 및 499로 이루어진 군으로부터 선택되는 2개 이상의 폴리뉴클레오티드 및 이들의 단편을 포함하는 이종 폴리뉴클레오티드;
서열 번호 541의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드;
서열 번호 542의 이종 폴리뉴클레오티드;
서열 번호 550의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드;
서열 번호 551의 이종 폴리뉴클레오티드;
서열 번호 554의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드;
서열 번호 555의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드;
서열 번호 556의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드;
서열 번호 623의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드; 또는
서열 번호 624의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함한다.
본 발명은 또한 rGAd20를 포함하는 백신을 제공하며, 여기서 rGAd20는,
서열 번호 275, 381, 333, 337, 269, 253, 309, 325, 271, 305, 251, 245, 261, 265, 317, 255, 277, 297, 285, 437, 439, 442, 444, 379, 343, 211, 349, 213, 215, 221, 219, 225, 345, 353, 235, 223, 167, 171, 19, 23 및 177로 이루어진 군으로부터 선택되는 2개 이상의 폴리펩티드 및 이들의 단편을 포함하는 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드;
서열 번호 459, 460, 461, 462, 463, 464, 465, 466, 467, 468, 469, 470, 471, 472, 473, 474, 475, 476, 477, 478, 479, 480, 481, 482, 483, 484, 485, 486, 487, 488, 489, 490, 491, 492, 493, 494, 495, 496, 497, 498 및 499로 이루어진 군으로부터 선택되는 2개 이상의 폴리뉴클레오티드 및 이들의 단편을 포함하는 이종 폴리뉴클레오티드;
서열 번호 541의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드;
서열 번호 542의 이종 폴리뉴클레오티드;
서열 번호 550의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드;
서열 번호 551의 이종 폴리뉴클레오티드;
서열 번호 554의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드;
서열 번호 555의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드;
서열 번호 556의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드;
서열 번호 623의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드; 또는
서열 번호 624의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함한다.
본 발명은 또한 서열 번호 276, 382, 334, 338, 270, 254, 310, 326, 272, 306, 252, 246, 262, 266, 318, 256, 278, 298, 286, 448, 450, 453, 455, 380, 344, 212, 350, 214, 216, 222, 220, 226, 346, 354, 236, 224, 168, 172, 20, 24 및 178로 이루어진 군으로부터 선택되는 2개 이상의 폴리뉴클레오티드 및 이들의 단편을 포함하는 이종 폴리뉴클레오티드를 포함하는 벡터를 제공한다.
본 발명은 또한 서열 번호 500, 501, 461, 503, 504, 505, 506, 507, 508, 509, 510, 511, 512, 513, 514, 515, 516, 517, 477, 519, 520, 521, 522, 523, 524, 525, 485, 486, 528, 529, 530, 531, 532, 533, 534, 535, 536, 537, 538, 539 및 540으로 이루어진 군으로부터 선택되는 2개 이상의 폴리뉴클레오티드 및 이들의 단편을 포함하는 이종 폴리뉴클레오티드를 포함하는 벡터를 제공한다. 폴리뉴클레오티드는 MVA에서의 발현에 유용하다.
본 발명은 또한 서열 번호 543의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 벡터를 제공한다. 일부 실시 형태에서, 이종 폴리뉴클레오티드는 서열 번호 544를 포함한다.
본 발명은 또한 서열 번호 544의 이종 폴리뉴클레오티드를 포함하는 벡터를 제공한다.
본 발명은 또한 서열 번호 552의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 벡터를 제공한다. 일부 실시 형태에서, 이종 폴리뉴클레오티드는 서열 번호 553을 포함한다.
본 발명은 또한 서열 번호 553의 이종 폴리뉴클레오티드를 포함하는 벡터를 제공한다.
본 발명은 또한 서열 번호 557의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 벡터를 제공한다.
본 발명은 또한 서열 번호 558의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 벡터를 제공한다.
본 발명은 또한 서열 번호 559의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 벡터를 제공한다.
본 발명은 또한 서열 번호 625의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 벡터를 제공한다.
본 발명은 또한 서열 번호 626의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 벡터를 제공한다.
일부 실시 형태에서, 벡터는 바이러스 벡터이다.
일부 실시 형태에서, 바이러스 벡터는 MVA이다.
일부 실시 형태에서, MVA 벡터는 MVA 476 MG/14/78, MVA-571, MVA-572, MVA-574, MVA-575 또는 MVA-BN으로부터 유래된다.
본 발명은 또한 서열 번호 275, 381, 333, 337, 269, 253, 309, 325, 271, 305, 251, 245, 261, 265, 317, 255, 277, 297, 285, 437, 439, 442, 444, 379, 343, 211, 349, 213, 215, 221, 219, 225, 345, 353, 235, 223, 167, 171, 19, 23 및 177로 이루어진 군으로부터 선택되는 2개 이상의 폴리펩티드 및 이들의 단편을 포함하는 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 rMVA를 제공한다.
본 발명은 또한 서열 번호 276, 382, 334, 338, 270, 254, 310, 326, 272, 306, 252, 246, 262, 266, 318, 256, 278, 298, 286, 448, 450, 453, 455, 380, 344, 212, 350, 214, 216, 222, 220, 226, 346, 354, 236, 224, 168, 172, 20, 24 및 178로 이루어진 군으로부터 선택되는 2개 이상의 폴리뉴클레오티드 및 이들의 단편을 포함하는 이종 폴리뉴클레오티드를 포함하는 rMVA를 제공한다.
본 발명은 또한 서열 번호 500, 501, 461, 503, 504, 505, 506, 507, 508, 509, 510, 511, 512, 513, 514, 515, 516, 517, 477, 519, 520, 521, 522, 523, 524, 525, 485, 486, 528, 529, 530, 531, 532, 533, 534, 535, 536, 537, 538, 539 및 540으로 이루어진 군으로부터 선택되는 2개 이상의 폴리뉴클레오티드 및 이들의 단편을 포함하는 이종 폴리뉴클레오티드를 포함하는 rMVA를 제공한다. 폴리뉴클레오티드는 MVA에서의 발현에 유용하다.
본 발명은 또한 서열 번호 543의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 rMVA를 제공한다. 일부 실시 형태에서, 이종 폴리뉴클레오티드는 서열 번호 544를 포함한다.
본 발명은 또한 서열 번호 544의 이종 폴리뉴클레오티드를 포함하는 rMVA를 제공한다.
본 발명은 또한 서열 번호 552의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 rMVA를 제공한다. 일부 실시 형태에서, 이종 폴리뉴클레오티드는 서열 번호 553을 포함한다.
본 발명은 또한 서열 번호 553의 이종 폴리뉴클레오티드를 포함하는 rMVA를 제공한다.
본 발명은 또한 서열 번호 557의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 rMVA를 제공한다.
본 발명은 또한 서열 번호 558의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 rMVA를 제공한다.
본 발명은 또한 서열 번호 559의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 rMVA를 제공한다.
본 발명은 또한 서열 번호 625의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 rMVA를 제공한다.
본 발명은 또한 서열 번호 626의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 rMVA를 제공한다.
본 발명은 또한 rMVA를 포함하거나 이로 형질도입된 세포를 제공하며, 여기서 rMVA는,
서열 번호 275, 381, 333, 337, 269, 253, 309, 325, 271, 305, 251, 245, 261, 265, 317, 255, 277, 297, 285, 437, 439, 442, 444, 379, 343, 211, 349, 213, 215, 221, 219, 225, 345, 353, 235, 223, 167, 171, 19, 23 및 177로 이루어진 군으로부터 선택되는 2개 이상의 폴리펩티드 및 이들의 단편을 포함하는 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드;
서열 번호 500, 501, 461, 503, 504, 505, 506, 507, 508, 509, 510, 511, 512, 513, 514, 515, 516, 517, 477, 519, 520, 521, 522, 523, 524, 525, 485, 486, 528, 529, 530, 531, 532, 533, 534, 535, 536, 537, 538, 539 및 540으로 이루어진 군으로부터 선택되는 2개 이상의 폴리뉴클레오티드를 포함하는 이종 폴리뉴클레오티드;
서열 번호 543의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드;
서열 번호 544의 이종 폴리뉴클레오티드;
서열 번호 552의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드;
서열 번호 553의 이종 폴리뉴클레오티드;
서열 번호 557의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드;
서열 번호 558의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드;
서열 번호 559의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드;
서열 번호 625의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드; 또는
서열 번호 626의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함한다.
본 발명은 또한 rMVA를 포함하는 백신을 제공하며, 여기서 rMVA는,
서열 번호 275, 381, 333, 337, 269, 253, 309, 325, 271, 305, 251, 245, 261, 265, 317, 255, 277, 297, 285, 437, 439, 442, 444, 379, 343, 211, 349, 213, 215, 221, 219, 225, 345, 353, 235, 223, 167, 171, 19, 23 및 177로 이루어진 군으로부터 선택되는 2개 이상의 폴리펩티드 및 이들의 단편을 포함하는 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드;
서열 번호 500, 501, 461, 503, 504, 505, 506, 507, 508, 509, 510, 511, 512, 513, 514, 515, 516, 517, 477, 519, 520, 521, 522, 523, 524, 525, 485, 486, 528, 529, 530, 531, 532, 533, 534, 535, 536, 537, 538, 539 및 540으로 이루어진 군으로부터 선택되는 2개 이상의 폴리뉴클레오티드를 포함하는 이종 폴리뉴클레오티드;
서열 번호 543의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드;
서열 번호 544의 이종 폴리뉴클레오티드;
서열 번호 552의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드;
서열 번호 553의 이종 폴리뉴클레오티드;
서열 번호 557의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드;
서열 번호 558의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드;
서열 번호 559의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드;
서열 번호 625의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드; 또는
서열 번호 626의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함한다.
본 발명은 또한 서열 번호 275, 381, 333, 337, 269, 253, 309, 325, 271, 305, 251, 245, 261, 265, 317, 255, 277, 297, 285, 437, 439, 442, 444, 379, 343, 211, 349, 213, 215, 221, 219, 225, 345, 353, 235, 223, 167, 171, 19, 23 및 177로 이루어진 군으로부터 선택되는 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40 또는 41개의 폴리펩티드 및 이들의 단편을 포함하는 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 백신을 제공한다.
일부 실시 형태에서, 이종 폴리뉴클레오티드는 서열 번호 276, 382, 334, 338, 270, 254, 310, 326, 272, 306, 252, 246, 262, 266, 318, 256, 278, 298, 286, 448, 450, 453, 455, 380, 344, 212, 350, 214, 216, 222, 220, 226, 346, 354, 236, 224, 168, 172, 20, 24 및 178로 이루어진 군으로부터 선택되는 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40 또는 41개의 폴리뉴클레오티드 및 이들의 단편을 포함한다.
일부 실시 형태에서, 단편은 서열 번호 387, 388, 390, 392, 560, 561, 562, 563, 564, 565, 566, 567, 568, 569, 570, 571, 572, 573, 574, 575, 576, 577, 578, 579, 580, 581, 582, 583, 584, 585, 586, 587, 588, 589, 590, 591, 592, 593, 594, 595, 596, 597, 598, 599, 600, 601, 602, 603, 604, 605, 606, 607, 608, 609, 610, 611, 612, 613, 614, 615, 616, 617, 618, 619, 620 또는 621의 펩티드를 포함한다.
일부 실시 형태에서, 이종 폴리펩티드는 서열 번호 541, 550, 554, 555, 556, 623 또는 624를 포함한다.
일부 실시 형태에서, 이종 폴리뉴클레오티드는 서열 번호 542 또는 서열 번호 551을 포함한다.
일부 실시 형태에서, 이종 폴리펩티드는 서열 번호 543, 552, 557, 558, 559, 625 또는 626을 포함한다.
일부 실시 형태에서, 이종 폴리뉴클레오티드는 서열 번호 544 또는 서열 번호 553을 포함한다.
일부 실시 형태에서, 이종 폴리뉴클레오티드는 DNA 또는 RNA이다.
일부 실시 형태에서, RNA는 mRNA 또는 자기 복제 RNA이다.
일부 실시 형태에서, 백신은 재조합 바이러스이다.
일부 실시 형태에서, 재조합 바이러스는 아데노바이러스, 폭스바이러스, 아데노 관련 바이러스 또는 레트로바이러스로부터 유래된다.
일부 실시 형태에서, 재조합 바이러스는 hAd5, hAd7, hAd11, hAd26, hAd34, hAd35, hAd48, hAd49, hAd50, GAd20, GAd19, GAd21, GAd25, GAd26, GAd27, GAd28, GAd29, GAd30, GAd31, ChAd3, ChAd4, ChAd5, ChAd6, ChAd7, ChAd8, ChAd9, ChAd10, ChAd11, ChAd16, ChAd17, ChAd19, ChAd20, ChAd22, ChAd24, ChAd26, ChAd30, ChAd31, ChAd37, ChAd38, ChAd44, ChAd55, ChAd63, ChAd73, ChAd82, ChAd83, ChAd146, ChAd147, PanAd1, PanAd2, PanAd3, 코펜하겐 백시니아 바이러스(W), 뉴욕 약독화 백시니아 바이러스(NYVAC), ALVAC, TROVAC 또는 변형된 백시니아 앙카라(MVA)로부터 유래된다.
일부 실시 형태에서, 재조합 바이러스는 GAd20로부터 유래된다.
일부 실시 형태에서, 재조합 바이러스는 MVA로부터 유래된다.
일부 실시 형태에서, 재조합 바이러스는 Ad26로부터 유래된다.
본 발명은 또한 서열 번호 541 또는 550의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드 서열을 포함하는 백신을 제공한다.
일부 실시 형태에서, 이종 폴리뉴클레오티드는 서열 번호 542 또는 551을 포함한다.
일부 실시 형태에서, 백신은 GAd20로부터 유래된 재조합 바이러스이다.
본 발명은 또한 서열 번호 543 또는 552의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드 서열을 포함하는 백신을 제공한다.
일부 실시 형태에서, 이종 폴리뉴클레오티드는 서열 번호 544 또는 553을 포함한다.
일부 실시 형태에서, 백신은 MVA로부터 유래된 재조합 바이러스이다.
하기 실시예는 본 명세서에 개시된 실시 형태들 중 일부를 더욱더 상세히 설명하기 위해 제공된다. 실시예는 개시된 실시 형태를 예시하고자 하는 것으로서, 이를 한정하고자 하는 것은 아니다.
실시예
1: 일반적 방법
펩티드 합성
펩티드를 >80% 순도로 뉴 잉글랜드 펩티드(New England Peptide)에 의해 합성하였다. 동결건조된 펩티드를 100% DMSO 중에 용해시켰다.
신생항원의 시험관내 면역원성 평가("환자 PBMC 재자극 분석")
전이성 거세저항성 전립선암에 걸린 인간 환자의 PBMC를 배지(글루타맥스, 10% HI FBS 및 1X 피루브산나트륨이 보충된 RPMI 1640)를 사용하여 해동시켰다. 세포를 계수하고, 250,000개의 생존 세포/웰의 농도로 96웰 둥근 바닥 마이크로플레이트에 플레이팅하였다. 동결건조된 펩티드를 100% DMSO에 용해시키고 배지에서 10 ㎍/mL로 희석하였다. 신생항원 펩티드를 5 ㎍/mL의 최종 농도를 위해 PBMC와 동일한 부피로 첨가하였다. CEF 펩티드 풀(Peptide Pool) "플러스(Plus)"(셀룰러 테크놀로지즈, 리미티드(Cellular Technologies, Ltd.))를 양성 대조군으로 사용하고, 실험 펩티드와 동일한 최종 농도의 DMSO를 음성 대조군으로 사용하였다. 인간 IL-15(페프로테크(Peprotech))을 10 ng/mL의 최종 농도로 모든 웰에 첨가하였다.
플레이트를 총 13일간 37℃(5% CO2)에서 인큐베이션하였다. 배지를 2일마다 IL-15(10 ng/mL 최종 농도) 및 IL-2(알앤디 시스템즈(R&D systems), 10 IU/mL 최종 농도)로 새로 채웠다. 12일째에, PBMC를 1일째의 펩티드 자극과 동일한 농도로, 동일한 실험 펩티드 또는 대조군으로 재자극하였다. 1시간 인큐베이션 후에, 단백질 억제제 칵테일(이바이오사이언스(eBioscience))을 모든 웰에 첨가하고, 플레이트를 밤새 인큐베이션하였다.
13일째에, 세포를 세포내 유세포 분석을 위해 염색하였다. 세포를 PBS로 세척하고, 라이브/데드 픽서블 아쿠아 데드 세포 염색제(Live/Dead Fixable Aqua Dead Cell stain(써모-피셔(Thermo-Fisher)))로 염색하였다. 라이브/데드 염색제에 이어서, 비오틴 미함유 Fc 수용체 차단제(Biotin-Free Fc Receptor Blocker)(아큐레이트 케미칼 앤드 사이언티픽 코포레이션(Accurate Chemical & Scientific Corp))를 사용하여 세포를 차단하였다. 세포외 세포 유동 패널(50 μL에서 웰당 1 μL/항체)은 CD3 PerCP-Cy5.5(바이오레전드(Biolegend)), CD4 BV421(바이오레전드) 및 CD8 APC-Cy7(바이오레전드)으로 구성되었다. 세포외 염색 후에, 세포를 Foxp3/전사인자 염색 완충액 세트(Transcription Factor Staining Buffer Set)(이바이오사이언스)를 사용하여 고정시키고, TNFα FITC(알앤디 시스템즈) 및 IFNγ BV785(바이오레전드)를 사용하여 세포내 단백질(1:50 희석)에 대해 염색하였다. 세포를 세척하고, 염색 완충액에 재현탁시키고, BD 첼레스타(Celesta) 유세포 분석기를 사용하여 분석하였다.
유세포 분석법에 의한 세포 염색 분석을 FlowJo v10을 사용하여 완료하였다. 세포를 살아있는 단일선 CD3+ 세포에 게이팅하였다. CD8+ T 세포를 TNFα/IFNγ 발현에 대해 분석하고, 이중 양성 TNFα/IFNγ CD8+ T 세포의 빈도를 기록하였다. 실험 펩티드에 의한 자극으로 인한 이중 양성 TNFα/IFNγ CD8+ T 세포의 빈도가 해당 환자에 대한 DMSO 단독 음성 대조군에 비해 2배 이상 증가할 때 반응은 양성으로 평가되었다. 펩티드를 1 내지 7개의 환자 샘플에서 분석하였다.
신생항원의 시험관내 면역원성 평가("외인성 자가 정상 공여자 재자극 분석")
인간 정상 PBMC로부터 단리된 CD1c+ 수지상 세포(DC)를 배지(글루타민, HEPES, 5% 인간 혈청(시그마(Sigma)) 및 1X Pen-Strep이 보충된 IMDM(집코(Gibco)))를 사용하여 해동시켰다. DC 세포를 IL-4(페프로테크, 80 ng/mL) 및 GM-CSF(집코, 80 ng/mL)가 보충된 배지에 재현탁시키고, 6웰 마이크로플레이트에 플레이팅하여, 37℃(5% CO2)에서 밤새 정치시켰다. 다음날에, DC 세포를 계수하고, 웰당 30,000개의 생존 세포의 농도로 96웰 둥근 바닥 마이크로플레이트에 플레이팅하였다. 동결건조된 펩티드(15량체 중첩 펩티드)를 100% DMSO 중에 용해시키고, 신생항원에 의해 5 mg/mL 내지 20 mg/mL로 풀링하였다. 신생항원 펩티드 풀을 DC에 2.5 ㎍/mL 내지 10 ㎍/mL의 최종 농도로 첨가하여, 37℃(5% CO2)에서 2시간 동안 정지시켰다. CEF 펩티드 풀 "플러스"(셀룰러 테크놀로지즈, 리미티드)를 양성 대조군으로 사용하고, 실험 펩티드와 동일한 최종 농도의 DMSO를 음성 대조군으로 사용하였다. 2시간 후에, DC 세포에 50 그레이의 이온화 방사선을 조사하였다. 인간 정상 PBMC로부터 단리된 자가 CD3+ Pan-T 세포를 배지를 사용하여 해동시켰다. 조사 후에, 자가 Pan-T 세포를 조사된 DC에 웰당 300,000개의 생존 세포로 첨가하였다. 인간 IL-15(페프로테크)을 10 ng/mL의 최종 농도로 모든 웰에 첨가하였다.
플레이트를 총 12일간 37℃(5% CO2)에서 인큐베이션하였다. 배지를 2 내지 3일마다 IL-15(10 ng/mL 최종 농도) 및 IL-2(알앤디 시스템즈, 10 IU/mL 최종 농도)로 새로 채웠다. 11일째에, 세포를 1일째의 펩티드 자극과 동일한 농도로, 동일한 실험 펩티드 풀 또는 대조군으로 재자극하였다. 단백질 억제제 칵테일(이바이오사이언스)을 모든 웰에 첨가하고, 플레이트를 37℃(5% CO2)에서 밤새 인큐베이션하였다.
12일째에, 세포를 세포내 유세포 분석을 위해 염색하였다. 세포를 PBS로 세척하고, 라이브/데드 픽서블 아쿠아 데드 세포 염색제(써모-피셔)로 염색하였다. 라이브/데드 염색제에 이어서, 비오틴 미함유 Fc 수용체 차단제(아큐레이트 케미칼 앤드 사이언티픽 코포레이션)를 사용하여 세포를 차단하였다. 세포외 세포 유동 패널(50 μL에서 웰당 1 μL/항체)은 CD3 PerCP-Cy5.5(바이오레전드), CD4 BV421(바이오레전드) 및 CD8 APC-Cy7(바이오레전드)으로 구성되었다. 세포외 염색 후에, 세포를 Foxp3/전사인자 염색 완충액 세트(이바이오사이언스)를 사용하여 고정시키고, TNFα FITC(알앤디 시스템즈) 및 IFNγ BV785(바이오레전드)를 사용하여 세포내 단백질(1:50 희석)에 대해 염색하였다. 세포를 세척하고, 염색 완충액에 재현탁시키고, BD 첼레스타 유세포 분석기를 사용하여 분석하였다.
유세포 분석법에 의한 세포 염색 분석을 FlowJo v10을 사용하여 완료하였다. 세포를 살아있는 단일선 CD3+ 세포에 게이팅하였다. CD8+ 및 CD4+ T 세포를 TNFα/IFNγ 발현에 대해 분석하고, 이중 양성 TNFα/IFNγ CD8+ T 세포의 빈도 및 이중 양성 TNFα/IFNγ CD4+ T 세포의 빈도를 기록하였다. 실험 펩티드 풀에 의한 자극으로 인한 이중 양성 TNFα/IFNγ CD8+ T 세포 또는 TNFα/IFNγ CD4+ T 세포의 빈도가 해당 공여자에 대한 DMSO 단독 음성 대조군에 비해 3배 이상 및 적어도 0.01% 증가할 때 반응은 양성으로 평가되었다.
신생항원의 시험관내 내인성 면역원성 평가("내인성 자가 정상 공여자 재자극 분석")
인간 정상 PBMC로부터 단리된 CD1c+ 수지상 세포(DC)를 배지(글루타민, HEPES, 5% 인간 혈청(시그마) 및 1X Pen-Strep이 보충된 IMDM(집코))를 사용하여 해동시켰다. DC 세포를 IL-4(페프로테크, 80 ng/mL) 및 GM-CSF(집코, 80 ng/mL)가 보충된 배지에 재현탁시키고, 6웰 마이크로플레이트에 플레이팅하여, 37℃(5% CO)에서 밤새 정지시켰다. 다음 날에, DC 세포를 계수하고, 웰당 30,000개의 생존 세포의 농도로 96웰 둥근 바닥 마이크로플레이트에 플레이팅하였다. Ad5 벡터(벡터 바이오랩스(Vector Biolabs))를 플라크 형성 단위(Plaque Forming Unit)에 기초한 5000의 MOI(감염의 다중도(Multiplicity Of Infection))로 배지에 희석시켰다. CEF 풀 및 "널(null)"에 대한 Ad5 벡터를 대조군으로 사용하였다. DC를 37℃(5% CO2)에서 밤새 Ad5 벡터로 형질도입하였다. 다음 날에, Ad5 벡터를 멸균 인산염 완충 식염수를 사용하여 3회의 순차적 원심분리/흡인 단계에 의해 플레이트로부터 세척하였다. 최종 세척 후에, 형질도입된 DC를 100 μL 배지에 재현탁시켰다. 인간 정상 PBMC로부터 단리된 자가 CD3+ Pan-T 세포를 배지를 사용하여 해동시켰다. Pan-T 세포를 조사된 DC에 웰당 300,000개의 생존 세포(100 μL/웰)로 첨가하였다. 인간 IL-15(페프로테크)을 10 ng/mL의 최종 농도로 모든 웰에 첨가하였다.
플레이트를 총 12일간 37℃(5% CO2)에서 인큐베이션하였다. 배지를 2 내지 3일마다 IL-15(10 ng/mL 최종 농도) 및 IL-2(알앤디 시스템즈, 10 IU/mL 최종 농도)로 새로 채웠다. 11일째에, 동결건조된 펩티드(15량체 중첩 펩티드)를 100% DMSO 중에 용해시키고, 신생항원에 의해 5 mg/mL 내지 20 mg/mL로 풀링하였다. 신생항원 펩티드 풀을 세포에 2.5 ㎍/mL 내지 10 ㎍/mL의 최종 농도로 첨가하였다. CEF 펩티드 풀 "플러스"(셀룰러 테크놀로지즈, 리미티드)를 양성 대조군으로 사용하고, 실험 펩티드와 동일한 최종 농도의 DMSO를 음성 대조군으로 사용하였다. 단백질 억제제 칵테일(이바이오사이언스)을 모든 웰에 첨가하고, 플레이트를 37℃(5% CO2)에서 밤새 인큐베이션하였다.
12일째에, 세포를 세포내 유세포 분석을 위해 염색하였다. 세포를 PBS로 세척하고, 라이브/데드 픽서블 아쿠아 데드 세포 염색제(써모-피셔)로 염색하였다. 라이브/데드 염색제에 이어서, 비오틴 미함유 Fc 수용체 차단제(아큐레이트 케미칼 앤드 사이언티픽 코포레이션)를 사용하여 세포를 차단하였다. 세포외 세포 유동 패널(50 μL에서 웰당 1 μL/항체)은 CD3 PerCP-Cy5.5(바이오레전드), CD4 BV421(바이오레전드) 및 CD8 APC-Cy7(바이오레전드)으로 구성되었다. 세포외 염색 후에, 세포를 Foxp3/전사인자 염색 완충액 세트(이바이오사이언스)를 사용하여 고정시키고, TNFα FITC(알앤디 시스템즈) 및 IFNγ BV785(바이오레전드)를 사용하여 세포내 단백질(1:50 희석)에 대해 염색하였다. 세포를 세척하고, 염색 완충액에 재현탁시키고, BD 첼레스타 유세포 분석기를 사용하여 분석하였다.
유세포 분석법에 의한 세포 염색 분석을 FlowJo v10을 사용하여 완료하였다. 세포를 살아있는 단일선 CD3+ 세포에 게이팅하였다. CD8+ 및 CD4+ T 세포를 TNFα/IFNγ 발현에 대해 분석하고, 이중 양성 TNFα/IFNγ CD8+ T 세포의 빈도 및 이중 양성 TNFα/IFNγ CD4+ T 세포의 빈도를 기록하였다. 실험 펩티드 풀에 의한 자극으로 인한 이중 양성 TNFα/IFNγ CD8+ T 세포 또는 TNFα/IFNγ CD4+ T 세포의 빈도가 해당 공여자에 대한 DMSO 단독 음성 대조군에 비해 3배 이상 및 적어도 0.01% 증가할 때 반응은 양성으로 평가되었다.
클래스 I MHC에 대한 신생항원의 시험관내 결합
생물정보학 분석에 의해 확인된 9량체 펩티드를 6개의 공통 HLA 클래스 I 대립유전자(HLA-A*01:01, A*02:01, A*03:01, A*24:02, B*07:02, B*08:01)에 대한 결합 성향에 대해 분석하였다. 본 방법의 원리는 하기에 간략하게 설명되어 있으며, 두 부분으로 구성되는데, 하나는 자외선(UV) 방사선에 의해 유도된 양성 대조군과 펩티드 교환을 포함하고, 다른 하나는 안정한 HLA-펩티드 및 비어있는 HLA 복합체를 검출하기 위한 효소 면역 측정법이다.
HLA 결합된 펩티드는 HLA 복합체의 안정성에 중요하다. 조건부 HLA 클래스 I 복합체를 각각의 HLA에 대해 상이한 펩티드(Pos)를 이용하여 UV에 불안정한 펩티드에 의해 안정화시켰다(Pos: HLA-A*01:01: CTELKLSDY(서열 번호 409), HLA-A*02:01: NLVPMVATV (서열 번호 410), HLA-A*03:01: LIYRRRLMK (서열 번호 411), HLA-A*24:02: LYSACFWWL (서열 번호 412), HLA-B*07:02: NPKASLLSL (서열 번호 413), HLA-B*08:01: ELRSRYWAI (서열 번호 414)(이는 HLA 분자에 결합될 때 UV 조사에 의해 절단될 수 있음). 절단 시에, 얻어진 펩티드 단편은 길이가 HLA에 안정적으로 결합하기에 불충분하기 때문에, HLA 클래스 I 복합체로부터 해리되었다. 펩티드 절단이 행해진 조건 하에서(중성 pH, 용융 얼음 상에서), 펩티드 비함유 HLA 복합체는 안정하게 유지되었다. 따라서, 선택된 다른 HLA 클래스 I 펩티드의 존재 하에 절단이 수행되었을 때, 이 반응은 절단된 UV에 불안정한 펩티드 Pos와 선택된 펩티드의 순 교환(net exchange)을 초래하였다(문헌[Rodenko, B et al. (2006) Nature Protocols 1: 1120-32], 문헌[Toebes, M et al. (2006) Nat Med 12: 246-51], 문헌[Bakker, AH et al. (2008) Proc Natl Acad Sci USA 105: 3825-30]).
관심 펩티드와 Pos 사이의 교환 효율을 HLA 클래스 I ELISA를사용하여 분석하였다. 복합 기술에 의해, 잠재적으로 면역원성인 관심 HLA 분자에 대한 리간드를 확인할 수 있게 되었다.
교환 대조군 펩티드 Pos는 관련 HLA 클래스 I 대립유전자에 대한 고친화성 결합제인 반면에, 교환 대조군 펩티드 Neg는 비결합제이었다. UV 대조군은 구제(rescue) 펩티드의 부재 하에서의 조건부 HLA 클래스 I 복합체의 UV 조사를 나타내었다. 교환 대조군 펩티드 Neg (HLA-A*01:01: NPKASLLSL (서열 번호 413), HLA-A*02-01: IVTDFSVIK (서열 번호 416), HLA-A*03:01: NPKASLLSL (서열 번호 413), HLA-A*24:02: NLVPMVATV (서열 번호 410), HLA-B*07:02: LIYRRRLMK (서열 번호 411), HLA-B*08:01: NLVPMVATV (서열 번호 410)) 및 모든 실험 펩티드의 결합을 교환 대조군 펩티드 Pos의 결합과 비교하여 평가하였다. 후자의 펩티드의 흡수를 100%로 설정하였다. 이러한 절차는 사용된 HLA 대립유전자에 대한 상이한 실험 펩티드의 친화성을 반영하는 다양한 상이한 교환율을 초래하였다.
HLA 클래스 I ELISA는 (펩티드 안정화된) HLA 클래스 I 복합체의 베타2-마이크로글로불린(B2M)의 검출에 기초한 효소 면역 측정법이다. 이를 위해 스트렙타비딘을 폴리스티렌 마이크로타이터 웰 상에 결합시켰다. 세척 및 차단 후에, 교환 반응 혼합물 또는 ELISA 대조군에 존재하는 HLA 복합체를 이의 비오틴화 중쇄를 통해 마이크로타이터 플레이트 상에서 스트렙타비딘에 의해 포획하였다. 비결합 물질을 세척에 의해 제거하였다. 이어서, 인간 B2M에 대한 서양고추냉이 퍼옥시다제(HRP) 접합 항체를 첨가하였다. HRP 접합 항체는 마이크로타이터 웰에 존재하는 온전한 HLA 복합체에만 결합하는데, 그 이유는 펩티드 교환이 실패하면 UV 조사 시에 원래의 UV 민감성 HLA 복합체가 분해되기 때문이다. 후자의 경우에, B2M을 세척 단계 동안에 제거하였다. 세척에 의해 비결합 HRP 접합체를 제거한 후에, 기질 용액을 웰에 첨가하였다. 샘플에 존재하는 온전한 HLA 복합체의 양에 비례하여 착색 생성물이 형성되었다. 정지액(stop solution)을 첨가하여 반응을 종료시킨 후에, 마이크로타이터 플레이트 리더(microtiter plate reader)로 흡광도를 측정하였다. 흡광도를 교환 대조군 펩티드의 흡광도(100%를 나타냄)에 대해 정규화하였다. HLA 클래스 I 분자에 대해 중간 내지 낮은 친화도를 갖는 펩티드의 차선의 HLA 결합이 또한 이러한 ELISA 기술로 검출될 수 있다(문헌[Rodenko, B et al. (2006) Nature Protocols 1: 1120-32]).
6개의 HLA 대립유전자 중 하나에서 10% 이상의 교환 효율을 갖는 펩티드를 추가의 면역원성 시험 및 분석을 위해 고려하였다.
실시예
2: 생물정보학에 의한 신생항원의 확인
유전자 융합 이벤트, 인트론 잔류(intron retention), 선택적 스플라이스에 의한(alternatively spliced) 변이체 및 발달상 침묵된(developmentally silenced) 유전자의 비정상적인 발현과 같은 비정상적인 전사 프로그램으로 인한 일반적인 전립선암 신생항원을 확인하기 위해 생물정보학 수단으로 다양한 전립선암 RNA-seq 데이터 세트를 분석하기 위해 컴퓨터에 의한 프레임워크를 개발하였다.
질의된(queried) 데이터 세트는 다음과 같았다:
분석 전에 원 데이터의 품질 관리(QC)를 수행하였다. 시퀀싱 리드는 먼저 일루미나(Illumina)의 어댑터 서열을 제거하기 위해 트리밍되었고 인간 tRNA 및 rRNA에 대한 리드 매핑은 다운스트림 분석으로부터 제거되었다. 리드는 또한 양측에서 불량한 염기 품질 점수(<10, PHRED 스케일, 10분의 1의 확률이 부정확한 염기를 나타냄)를 갖는 염기가 트리밍되었다. PHRED 품질 점수는 자동화된 DNA 시퀀싱 기기에서 생성된 염기의 확인 품질을 측정한다. 25 bp 미만의 트리밍된 리드를 데이터 세트로부터 제거하였다. 또한, 다음에 나오는 QC 단계를 고려하여, 불량한 품질의 리드를 제거하였다: 최대 염기 품질 PHRED 점수가 <15인 리드를 제거하고, 평균 염기 품질 PHRED 점수가 <10인 리드를 제거하고, polyATCG 비율이 >80%인 리드를 제거하고, 두 리드 중 하나가 실패한 RNA 서열을 제거하였다.
QC 기준을 통과한 리드를 ArrayStudio(https_//www_omicsoft_com/array-studio/) 플랫폼을 사용하여 인간 게놈 빌드(Human Genome Build) 38에 매핑하였다. Refseq 유전자 모델(출시일: 2017년 6월 6일)을 신규 RNA 특징의 주석에 사용하였다.
여기에 공개된 결과는 NCI 및 NHGRI가 관리하는 The Cancer Genome Atlas에서 생성한 데이터에 전체적으로 또는 부분적으로 기초한다. TCGA에 대한 정보는 http://_cancergenme_nih_gov에서 찾을 수 있다.
유전자 융합 이벤트의 확인
FusionMap 알고리즘(문헌[Ge H et al., Bioinformatics. 2011 Jul 15; 27(14):1922-8. doi: 10.1093/bioinformatics/btr310. Epub 2011 May 18])을 사용하여, 상술한 전립선암 데이터 세트에서 유전자 융합 이벤트를 확인하였다. FusionMap은 리드의 중간 영역의 융합 절단 위치를 포함하는 시드 리드(seed read)에 기초한 융합 접합부를 검출한다. 알고리즘은 시드 리드로부터의 매핑된 융합 접합부의 컨센서스(consensus)에 기초하여 의사 융합 전사체/서열 라이브러리를 동적으로 생성한다. 그 다음에, FusionMap은 매핑되지 않은 가능한 융합 리드를 의사 융합 기준에 정렬하여 구제된 리드를 추가로 확인한다. 이 프로그램은 검출된 융합 접합부의 목록, 지원 리드의 통계치, 융합 유전자쌍, 및 절단 및 접합 서열의 게놈 위치를 리포트하는데, 이는 염기쌍 해상도에서 포괄적으로 융합 유전자를 특징짓는다.
도 1에 나타낸 바와 같은 키메라 리드-스루 융합 및 도 2에 나타낸 바와 같은 염색체 변화에 의한 융합으로부터 유래하는 신생항원을 FusionMap을 사용하여 확인하였다. 신생항원은 하기 기준이 충족되었을 때 유전자 융합 이벤트로부터 유래하는 것으로 분류되었다: 융합 접합부가 게놈에서 매핑 위치가 상이한 2개 이상의 시드 리드, 접합부를 파싱(parsing)하는 4개 이상의 시퀀싱 리드(시드 및 구제 리드) 및 하나 이상의 접합 스패닝 리드(junction spanning read)에 의해 지원된 경우. 신생항원의 유병률을 상술한 데이터 세트를 사용하여 종양 조직 및 정상 조직에서 질의하였다. 신생항원은 유병률이 적어도 하나의 질병 코호트(TCGA 및 SU2C)에서 >10%이고, 정상 조직(49개의 정상 조직으로부터의 6137개의 RNA-seq 데이터세트)에서 <2%인 것으로 되었을 때, 흔한 것으로 확인되었다. 질병 코호트에서 유병률이 10% 미만인 유전자 융합 이벤트를, 이들이 신규 펩티드 서열의 긴 스트레치를 생성하거나 관심 유전자에 존재하는 경우에 포함시켰다.
스플라이스 변이체의 확인
대체 스플라이싱 이벤트로부터 발생하는 잠재적인 신생항원을 확인하기 위해, 커스텀 생물정보학 소프트웨어를 개발하여, 페어드 엔드(paired-end) RNA-seq 데이터를 분석하였다. 개발된 프로세스를 이용하여, 도 3에 도시된 바와 같은 대체 5' 또는 3' 스플라이스 부위, 보유된 인트론, 배제된 엑손, 대체 종결 또는 신규 카세트의 삽입(들)을 갖는 스플라이스 변이체를 확인하였다. 이 프로세스는 두 가지 주요 기능을 통해 RefSeq 유전자 모델에 존재하지 않는 스플라이스 변이체를 확인하였다: 1) 6 bp 이상의 갭과 갭의 각 측면에 정렬된 15 bp 이상의 서열이 있는 리드를 기반으로 하는 새로운 접합부의 확인(이하, 스플릿 매핑된(split-mapped) 리드라고 함). 5개 이상의 스플릿 매핑된 리드 및 각각의 단부 상의 접합부의 측면에 위치하는 하나의 메이트 쌍(mate pair)의 리드로 나타내었다면, 신규 접합부로 기록되었다. 2) 정렬된 리드의 아일랜드의 확인(이하, 커버리지 아일랜드라고 함). 아일랜드 경계를 결정하는데 사용되는 파라미터에 대한 상세사항은 후술된다. 도 4는 접근법의 카툰을 나타낸다.
게놈 DNA 및/또는 pre-mRNA 오염과는 대조적으로 진정한 스플라이싱 변이로 인해 인트론 영역에 대한 리드 매핑을 구별하기 위해, 200개의 고도로 발현된 하우스키핑 유전자 전반에 걸쳐 오염 분포를 규정하기 위해 2개의 파라미터를 개발하였다. 이어서, 이들 분포의 테일 엔드(tail end)를 관련이 있는 신규 스플라이스 변이체의 발견을 위한 컷-오프(cut-off)로서 사용하였다.
1.
인트론 커버리지 깊이(Intron depth of coverage, IDC): 모든 하우스키핑 인트론 염기에 대한 90번째 백분위수 커버리지 깊이. 특정 영역의 커버리지가 이 값 미만으로 떨어지면, 이것이 발생한 첫 번째 염기를 커버리지 아일랜드 경계로 정의하였다.
2.
인트론/엑손 커버리지 비(IECR): 모든 하우스키핑 유전자 인트론의 가장 가까운 상류 엑손의 중간 커버리지와 중간 인트론 커버리지 사이의 비의 90번째 백분위수
모든 보고된 스플라이스 변이체는 하기 기준을 충족하는 것이 요구되었다:
대체 3'/5'
스플라이스
부위 확인:
-
신규 스플라이스 부위는 5개 이상의 스플릿 매핑된 리드 및 접합부의 측면에 위치하는 하나의 메이트 쌍의 리드에 의해 지원되었다.
-
스플라이스 부위(해당하는 경우)를 사용하여 생성된 인트론 영역은 IECR을 초과하였고, 전체 영역은 IDC를 초과하였다.
신규 카세트 확인:
-
인트론 영역의 2개의 신규 스플라이스 부위는 5개 이상의 스플릿 매핑된 리드 및 접합부의 측면에 위치하는 하나의 메이트 쌍의 리드에 의해 지원되었다.
-
2개의 스플라이스 부위 사이의 영역은 IECR을 초과하였고, 전체 영역은 IDC를 초과하였다.
인트론 잔류 확인:
-
인트론 영역은 IECR을 초과하였고, 전체 영역은 IDC를 초과하였다.
-
5개 이상의 리드가 인트론-엑손 경계 둘 다에 걸쳐 있으며, 경계의 각 측면 상에 15개 이상의 bp가 정렬됨.
대체 종결 확인
-
3' 경계는 표준 엑손(canonical exon)의 3' 말단의 60 bp 내에 속하지 않는 커버리지 아일랜드의 에지로서 정의됨.
-
표준 엑손의 5' 말단과 3' 경계 사이의 임의의 인트론 영역은 IECR을 초과하였고, 전체 영역은 IDC를 초과하였다.
엑손 배제 확인:
-
신규 접합부는 5개 이상의 스플릿 매핑된 리드 및 하나 이상의 표준 엑손을 스키핑(skipping)한 접합부의 측면에 위치하는 하나의 메이트 쌍의 리드에 의해 지원되었다.
비정상적인 스플라이싱 이벤트로부터 유래된 신생항원은 발병률이 질병 코호트(TCGA 및 SU2C 데이터 세트)에서 약 >10%이고, 정상 조직(GTEx 컨소시엄 데이터 세트)에서 약 <1%인 것으로 확인되었을 때, 흔한 것으로 확인되었다.
DNA 돌연변이(점 및
프레임시프트
) 기반 신생항원의 확인
전립선암 환자의 엑솜 시퀀싱 데이터를 포함하는 상술한 TCGA, SU2C 및 통합 DFCI/슬로언 케터링(Sloane Kettering) 데이터 세트(통합 DFCI/슬로언 케터링 데이터 세트(문헌[Armenia et al., Nat Genet. 2018 May;50(5):645-651. doi: 10.1038/s41588-018-0078-z. Epub 2018 Apr 2]))를 조사하였다. 이러한 데이터 세트를 생성한 컨소시엄에서 게시한 돌연변이 콜(mutation call)을 다운로드하고, 환자 집단의 >10%에 존재하거나 전립선암을 유발하는 것으로 알려진 유전자(예컨대, AR)에 존재하는 유전자 돌연변이가 확인하였다. 선택된 각각의 단일 점 돌연변이에 대해, 중앙에 돌연변이된 아미노산이 있는 17량체 펩티드를 추가의 검증 연구를 위해 확인하였다.
스플라이싱 아이소형 예측
특정 경우에, 네오에피토프 서열에 선행하는 표준 펩티드 서열에 영향을 줄 수 있는, 확인된 스플라이싱 이벤트의 상류에 다수의 리딩 프레임 및 엑손이 있었다. 이들 유전자에서, 표준 엑손이 엑손 경계에 존재하는 스플릿 매핑된 리드에 기초하여 각각의 네오에피토프 특징부에 인접하는 것으로 측정되었다. 예측된 네오에피토프를 포함할 수 있는 이벤트의 가장 높은 유병률을 갖는 질병 코호트에서 가장 높은 평균 발현을 갖는 가장 고도로 발현된 아이소형을 상기 아이소형과 관련된 오픈 리딩 프레임의 선택에 의해 상응하는 단백질로의 번역을 위해 선택하였다. 단백질 서열의 네오에피토프 부분을 추출하였으며, 첫 번째 변경된 아미노산의 상류에 추가의 8개의 아미노산 잔기가 포함되어, 후속 검증 연구에 사용하였다. DNA 프레임시프트 변경으로부터 추정되는 면역원성 항원을 확인하기 위해 유사한 절차를 따랐다. 프레임시프트 결실 및 삽입 둘 다에 대해, 생성된 DNA 서열을 적절한 오픈 리딩 프레임의 선택에 의해 상응하는 단백질로 번역하고, 단백질 서열의 프레임시프트 변경된 부분을 추출하고, 첫 번째 변경된 아미노산의 상류에 추가의 8개의 아미노산 잔기가 포함되었다.
표 1은 단일 아미노산 돌연변이(M)를 갖는 확인된 신생항원의 유전자 기원, 특이적 돌연변이, 아미노산 서열 및 환자의 빈도를 나타낸다. 각각의 돌연변이는 표 1에서 볼드체로 표시되어 있다. 표 2는 이들의 상응하는 폴리뉴클레오티드 서열을 나타낸다. 돌연변이 서열은 표 2에 대문자로 표시되어 있다. 표 1의 환자 빈도(%)는 문헌[Armenia et al., Nat Genet 50(5): 645-651, 2018]에서 얻었다.
[표 1]


[표 2]


표 3은 프레임시프트 이벤트로부터 발생한 확인된 신생항원의 유전자 기원, 특이적 프레임시프트 돌연변이(FR), 아미노산 서열 및 환자의 돌연변이 빈도를 나타낸다. 야생형 서열은 표 3에서 볼드체로 표시되며, 프레임시프트로 인한 신규 서열이 뒤따른다. 표 4는 이들의 상응하는 폴리뉴클레오티드 서열을 나타낸다. 돌연변이 서열은 표 4에 대문자로 표시되어 있다. 표 3의 환자 빈도(%)는 문헌[Armenia et al., Nat Genet 50(5): 645-651, 2018]에서 얻었다.
[표 3]

[표 4]

표 5는 유전자 융합(FUS) 이벤트로부터 발생한 확인된 신생항원의 유전자 기원 및 아미노산 서열을 나타낸다. 표 6은 이들의 상응하는 폴리뉴클레오티드 서열을 나타낸다. 표 7은 분석된 데이터베이스에서의 FUS 신생항원의 유병률을 나타낸다.
[표 5]

[표 6]

[표 7]

표 8은 대체 스플라이싱(AS) 이벤트로부터 발생한 확인된 신생항원의 유전자 기원 및 아미노산 서열을 나타낸다. 표 9는 이들의 상응하는 폴리뉴클레오티드 서열을 나타낸다. 표 10은 분석된 데이터베이스에서의 AS 신생항원의 유병률을 나타낸다.
[표 8]



[표 9]




[표 10]


실시예 3: 생물정보학을 이용한 추가의 신생항원의 확인
추가의 신생항원 서열을 실시예 2에 기재된 바와 같은 부가적 질의에 의해 확인하였다. 표 11은 추가의 신생항원의 아미노산 서열을 나타낸다. 표 12는 상응하는 폴리뉴클레오티드 서열을 나타낸다.
[표 11]

[표 12]


실시예 4: HLA 결합 예측
실시예 3에 기재된 바와 같은 다양한 접근법을 사용하여 확인된 신생항원의 아미노산 서열을 모든 가능한 고유한 인접한 9량체 아미노산 단편으로 분할하고, 6개의 공통 HLA 대립유전자(HLA-A*01:01, HLA-A*02:01, HLA-A*03:01, HLA-A*24:02, HLA-B*07:02, HLA-B*08:01)에 대한 HLA 결합 예측을 netMHCpan4.0을 사용하여 이러한 9량체 각각에 대해 행하였다. 시험된 HLA 대립유전자 중 하나 이상에 대한 결합 가능성 및 전립선암 환자에서의 유병률에 의한 순위에 기초하여 추가의 분석을 위해 몇몇 9량체 단편을 선택하였다.
표 13은 선택된 9량체 단편의 아미노산 서열 및 이의 신생항원 기원을 나타낸다. 표 14는 분석된 코호트에서의 신생항원의 유병률을 나타낸다.
[표 13]

[표 14]

실시예
5: 신생항원의 면역원성 평가
표 13에 나타낸 9량체 단편은 리드아웃(readout)으로서 CD8+ T 세포에 의한 TNFα 및 IFNγ 생산을 이용하여 실시예 1에 기재된 환자 PBMC 재자극 분석을 사용하여 T 세포를 활성화시키는 능력에 대해 평가되었다. 표 15에 나타낸 자기 항원도 분석에 사용하였다. 도 5a, 도 5b, 도 5c, 도 5d 및 도 5e는 무자극(DMSO 음성 대조군)(도 5a) 후, CEF 펩티드에 의한 자극(양성 대조군)(도 5b) 후, P16에 의한 자극(도 5c) 후, P98에 의한 자극(도 5d) 후 및 P3에 의한 자극(도 5e) 후에 PBMC 샘플에서의 TNFα+IFNγ+CD8+ T 세포 빈도를 나타내는 유세포 분석 도트 플롯을 나타낸다. 표 16은 TNFα+IFNγ+CD8+ T 세포의 최대 빈도 및 분석된 각 펩티드에서의 음성 대조군에 대한 최대 배수 변화를 나타내며, 이는 가장 높은 TNFα+IFNγ+CD8+ T 세포 빈도 및 펩티드에 대해 평가된 PBMC 공여자에 대해 얻어진 배수 변화를 나타낸다. 평가된 모든 신생항원은 CD8+ T 세포를 자극하는 것으로 밝혀졌다. 도 6은 PBMC 샘플이 특정 신생항원에 대해 양성 면역반응을 나타내는 전립선암 환자의 수를 나타낸다. 10명의 환자의 PBMC를 평가하였다.
[표 15]

[표 16]

실시예
6:
HLA에
대한 신생항원의 결합
HLA-A*01:01, HLA-A*02:01, HLA-A*03:01, HLA-A*24:02, HLA-B*07:02 및 HLA-B*08:01에 대한 선택된 네오에피토프의 결합을 실시예 1에 기재된 분석을 사용하여 평가하였다. 다양한 신생항원을 HLA에 결합시킨 결과가 표 17에 나타나 있다. 시험된 각각의 HLA 대립유전자는 관심 펩티드가 교환된 상응하는 양성 대조군(Pos) 및 음성 대조군(Neg) 펩티드를 가졌다. 따라서, Pos와의 교환율이 100%라는 것은 관심 펩티드가 양성 대조군 펩티드와 동일한 HLA 대립유전자에 대한 결합 친화성을 갖는다는 것을 의미한다. 추가의 평가에 대한 기준으로서, 본 발명자들은 6개의 HLA 대립유전자 중 적어도 하나에 대해 상응하는 Pos 펩티드와 적어도 10%의 교환율을 갖는 펩티드를 추가의 평가를 위해 고려하였다. 이와 같이 확인된 24개의 신생항원의 대립유전자 특이적 Pos 펩티드와의 교환율은 하기 표 17에 요약되어 있다. 더 높은 비율은 HLA 대립유전자에 대한 더 강한 결합에 해당한다.
[표 17]

실시예 7: 전립선암 조직의 MHC I-펩티드 복합체 프로파일링에 의한 전립선암의 고유한 MHC I-제시 펩티드의 확인
MHC I-펩티드 복합체를 11개의 인간 전립선암 샘플로부터 단리하고, MHC I에 의해 제시된 펩티드를 무작위 질량 분석을 사용하여 확인하였다. 채집 시에, 대상은 7등급 선암 또는 간질 육종으로 진단되었고, 2명의 대상은 침습성 선암을 앓고 있었다.
HLA-A*02:01, HLA-A*03:03, HLA-B*27:0 및 HLA-B*08:01 하플로타입을 갖는 동결 인간 전립선암 조직을 프로테아제 억제제를 포함하는 비이온성 세제에 기계적으로 파괴하고 가공처리하였다. pan-MHC 대립유전자 단일클론 항체를 사용하여, 샘플로부터의 MHC I-펩티드 복합체를 면역정제하였다. 산 용리 후에, MHC I-펩티드 복합체의 회수를 ELISA에 의해 평가하고, 회수된 펩티드를 탈염시키고 LC-MS/MS 분석을 행하였다.
전립선 종양의 원 LC-MS/MS 데이터 파일을 분석하여, 11개의 인간 전립선암 샘플로부터 얻어진 대응하는 RNAseq 데이터로부터 생성된 신생항원 데이터베이스를 검색하였다. 이들 펩티드는 모 이온(MS1)에 대한 이론적 질량 및 이론적 단편 이온(MS2) 목록을 갖고 있었다. MS2 스캔을 트리거링한 MS1 이온 목록을 이론적 펩티드 목록에 대해 검색하여, 질량별로 매칭시켰다. 이어서, 설정된 MS1 ppm 질량 정도(mass accuracy; 5 ppm) 내의 모든 이론적 펩티드는 그 모 이온(펩티드 스펙트럼 매치 또는 PSM)에 대한 실험적 MS2와 비교하여 인 실리코(in silico) MS2 스펙트럼을 가졌다. 실험적 스펙트럼이 이론적 스펙트럼과 얼마나 밀접하게 매칭되는지에 따라 점수를 계산하였다. 각각의 LC-MS/MS 실행(종양 샘플당 하나의 파일)은 수 천개의 PSM을 생성하였다. 그러나, 대부분의 이들 펩티드는 인간 참조 데이터베이스(스위스프로트(Swissprot))에서 발견된 표준 서열이었다. 이들을 걸러내고, 관심 펩티드(추정 신생항원)를 컴파일하였다. 이 목록으로부터, 양성으로 되기에 충분한 증거를 갖는 펩티드를 선택하였다.
표 18은 LC-MS/MS를 사용하여 MHC I과의 복합체로 확인된 펩티드의 아미노산 서열과 펩티드의 유전자 기원을 나타낸다.
표 19는 LC/MS/MS를 사용하여 MHC I과의 복합체로 확인된 펩티드의 상응하는 더 긴 신생항원의 아미노산 서열을 나타낸다.
표 20은 상응하는 더 긴 신생항원을 인코딩하는 폴리뉴클레오티드 서열을 나타낸다.
본 명세서에 기재된 MHC I 복합체 형성 펩티드에 의해, 전립선암 이상 유전자 변형에 특이적인 면역원성 에피토프의 발현, 처리 및 제시를 확인하였다. RNAseq 데이터베이스를 평가하여, 전립선암에 존재하는 더 긴 이상 전사체 내에서 확인된 MHC I 복합체 형성 펩티드를 매핑하였다. 따라서, 이러한 데이터로부터, 면역학적으로 관련되고 적응 T 세포 반응을 유도할 수 있는 하나 이상의 MHC 클래스 I 에피토프를 포함하는 전립선암 신생항원을 확인하였다.
[표 18]

[표 19]

[표 20]



실시예 8: 종양 및 정상 조직에서의 전립선 신생항원의 발현 프로파일링
확인된 전립선 신생항원을 전립선암(선암, 임상 병기 II 내지 IV기, 글리슨 스코어(Gleason score) 8 내지 9, 대상은 치료 경험이 없거나, 카소덱스(CASODEX)® (비칼루타마이드(bicalutamide)), 루프론 데포(LUPRON DEPOT)® (데포 현탁액(depot suspension)용 아세트산로이프롤라이드(leuprolide acetate)) 또는 피르마곤(FIRMAGON)® (데가렐릭스(degarelix))으로 치료됨) 및 간, 신장, 췌장, 난소, 전립선, 유선, 결장, 위, 골격근 및 폐를 포함한 정상 조직 패널의 약 90개 FFPE 조직 샘플에서, 건강한 대상으로부터 얻은 PBMC에서, 그리고 DU145-1, MDA-MB-436-1, LREX-1, 22RV1-1, H660-1을 포함한 전립선암 세포주 및 NCI-H2106-1, L-363-1, HCI-N87-1, OCI-AML5-1, MDA-PCa-2b-1 및 GDM-1-1을 포함한 다른 조직 세포주에서의 이의 발현에 대해 프로파일링하였다. 키트 프로토콜에 따라 CELLDATA의 RNAstorm-RNA 분리 키트를 사용하여 포르말린 고정 파라핀 포매 조직 샘플(formalin fixed paraffin embedded tissue sample)에서 총 RNA를 추출하였다. 배양된 세포주 및 PBMC의 RNA를 표준 방법을 이용하여 퀴아젠(Qiagen) RNA 단리 키트를 사용하여 분리하였다. 고용량 cDNA 역전사 키트(ABI) 및 표준 프로토콜을 사용하여 FFPE 샘플의 총 RNA 200 ng을 사용하여 cDNA를 제조하였다. 37.5 ng cDNA를 TaqMan 예비증폭 키트(써모피셔 사이언티픽)및 표준 프로토콜을 사용하여 15 μl 예비증폭 믹스에서 유전자 마커로 예비증폭시켰다. 다양한 샘플에서 확인된 신생항원의 유전자 발현을 시험하기 위해, 절단 서열에 걸쳐 있는 프라이머를 확인된 전립선 신생항원 각각에 대해 설계하고, 플루이다임 바이오마크(Fluidigm Biomark)™ HD를 사용하여 발현을 평가하였다. 발현 양성 FFPE 전립선암 샘플의 퍼센트(%)를 각각의 신생항원에 대해 기록하였으며, 이때 상대 평균 CT를 전립선암 샘플에서 계산하였다 선택된 신생항원의 발현 프로파일링의 결과가 표 21에 나타나 있다. TCGA, SU2C 및 GTEx 데이터베이스에서의 각각의 신생항원의 유병률은 표 22에 나타나 있다.
[표 21]

[표 22]


실시예
10: 확인된 신생항원을 인코딩하는 바이러스 벡터의 생성
확인된 신생항원을 만능 전립선암 백신에 포함시키기 위해 검증하고 우선순위화하였다. 41개의 확인된 신생항원을 전립선암 샘플 전반의 발현, 정상 조직에서의 낮은 발현, HLA에 대한 결합 및 면역원성에 기초하여 발현 카세트에 포함되도록 선택하였다. 선택된 41개의 신생항원이 표 21 및 표 22에 나타나 있으며, 다음을 포함한다:
AS18 (WKFEMSYTVGGPPPHVHARPRHWKTDR; 서열 번호 275),
P87 (YEAGMTLGGKILFFLFLLLPLSPFSLIF; 서열 번호 381),
AS55 (DGHSYTSKVNCLLLQDGFHGCVSITGAAGRRNLSIFLFLMLCKLEFHAC; 서열 번호 333),
AS57 (TGGKSTCSAPGPQSLPSTPFSTYPQWVILITEL; 서열 번호 337),
AS15 (VLRFLDLKVRYLHS; 서열 번호 269),
AS7 (DYWAQKEKGSSSFLRPSC; 서열 번호 253),
AS43 (VPFRELKNVSVLEGLRQGRLGGPCSCHCPRPSQARLTPVDVAGPFLCLGDPGLFPPVKSSI; 서열 번호 309),
AS51 (GMECTLGQVGAPSPRREEDGWRGGHSRFKADVPAPQGPCWGGQPGSAPSSAPPEQSLLD; 서열 번호 325),
AS16 (GNTTLQQLGEASQAPSGSLIPLRLPLLWEVRG; 서열 번호 271),
AS41 (EAFQRAAGEGGPGRGGARRGARVLQSPFCRAGAGEWLGHQSLR; 서열 번호 305),
AS6 (DYWAQKEKISIPRTHLC (서열 번호 251),
AS3 (VAMMVPDRQVHYDFGL (서열 번호 245),
AS11 (VPFRELKNQRTAQGAPGIHHAASPVAANLCDPARHAQHTRIPCGAGQVRAGRGPEAGGGVLQPQRPAPEKPGCPCRRGQPRLHTVKMWRA; 서열 번호 261),
AS13 (KRSFAVTERII; 서열 번호 265),
AS47 (FKKFDGPCGERGGGRTARALWARGDSVLTPALDPQTPVRAPSLTRAAAAV; 서열 번호 317),
AS8 (LVLGVLSGHSGSRL; 서열 번호 255),
AS19 (QWQHYHRSGEAAGTPLWRPTRN; 서열 번호 277),
AS37 (CHLFLQPQVGTPPPHTASARAPSGPPHPHESCPAGRRPARAAQTCARRQHGLPGCEEAGTARVPSLHLHLHQAALGAGRGRGWGEACAQVPPSRG; 서열 번호 297),
AS23 (KIQNKNCPD; 서열 번호 285),
MS1 (HYKLIQQPISLFSITDRLHKTFSQLPSVHLCSITFQWGHPPIFCSTNDICVTANFCISVTFLKPCFLLHEASASQ; 서열 번호 437),
MS3 (RTALTHNQDFSIYRLCCKRGSLCHASQARSPAFPKPVRPLPAPITRITPQLGGQSDSSQPLLTTGRPQGWQDQALRHTQQASPASCATITIPIHSAALGDHSGDPGPAWDTCPPLPLTTLIPRAPPPYGDSTARSWPSRCGPLG; 서열 번호 439),
MS6 (YAYKDFLWCFPFSLVFLQEIQICCHVSCLCCICCSTRICLGCLLELFLSRALRALHVLWNGFQLHCQ; 서열 번호 442),
MS8 (TMPAILKLQKNCLLSL; 서열 번호 444),
P82 (YEAGMTLGEKFRVGNCKHLKMTRP; 서열 번호 379).
P16 (GVPGDSTRRAVRRMNTF; 서열 번호 343),
FUS1 (CGASACDVSLIAMDSA; 서열 번호 211),
P22 (SLYHREKQLIAMDSAI; 서열 번호 349),
FUS2 (TEYNQKLQVNQFSESK; 서열 번호 213),
FUS3 (TEISCCTLSSEENEYLPRPEWQLQ; 서열 번호 215),
FUS6 (CEERGAAGSLISCE; 서열 번호 221),
FUS5 (NSKMALNSEALSVVSE; 서열 번호 219),
FUS8 (WGMELAASRRFSWDHHSAGGPPRVPSVRSGAAQVQPKDPLPLRTLAGCLARTAHLRPGAESLPQPQLHCT; 서열 번호 225),
FUS15 (HVVGYGHLDTSGSSSSSSWP; 서열 번호 345),
P35 (NSKMALNSLNSIDDAQLTRIAPPRSHCCFWEVNAP; 서열 번호 353),
FUS19 (KMHFSLKEHPPPPCPP; 서열 번호 235),
FUS7 (LWFQSSELSPTGAPWPSRRPTWRGTTVSPRTATSSARTCCGTKWPSSQEAALGLGSGLLRFSCGTAAIR; 서열 번호 223),
M84 (IARELHQFAFDLLIKSH; 서열 번호 167),
M86 (QPDSFAALHSSLNELGE; 서열 번호 171),
M10 (FVQGKDWGLKKFIRRDF; 서열 번호 19),
M12 (FVQGKDWGVKKFIRRDF; 서열 번호 23), 및
FR1 (QNLQNGGGSRSSATLPGRRRRRWLRRRRQPISVAPAGPPRRPNQKPNPPGGARCVIMRPTWPGTSAFT; 서열 번호 177).
발현 카세트는 어떠한 링커도 없이 41개의 신생항원 서열을 차례로 연결하여 바이러스 골격인 변형된 백시니아 앙카라(MVA) 및 유인원 아데노바이러스 20(GAd20)로 클로닝하기 위해 설계되었다. 각각의 신생항원 서열을 MVA 또는 GAd20 중 어느 하나에서의 발현을 위해 코돈 최적화하였다. 코돈 최적화된 폴리뉴클레오티드 서열은 GAd20 발현에 대해서는 표 23에, MVA 발현에 대해서는 표 24에 나타나 있다.
[표 23]




[표 24]




합성 유전자 설계
41개의 신생항원 아미노산 서열을 헤드에서 테일로 연결하였다. 신생항원 서열의 순서는 2개의 인접한 신생항원 펩티드의 병치에 의해 생성될 수 있는 예측된 접합 에피토프의 형성을 최소화하는 전략에 따라 결정되었다.
이를 위해 41개의 신생항원을 유사한 누적 길이의 4개의 더 작은 목록(하위 목록)으로 분할하고, 각 하위 목록에 대해 다른 신생항원 순서를 가진 합성 유전자의 200만 스크램블된 레이아웃을 생성하기 위해 커스텀 툴(custom tool)을 개발하였다. 커스텀 툴을 반복하여 진행하였다. 각각의 루프에서, 스크램블된 레이아웃을 생성하였고, 이미 생성된 레이아웃들과 비교하였다. 새로운 레이아웃의 예측된 접합 에피토프의 수가 이전에 최상의 레이아웃의 수보다 더 적으면, 새로운 레이아웃은 최상으로 간주되었다. 각 스크램블된 레이아웃은 IC50 <=1500 nM으로 9개의 클래스 I HLA 하플로타입의 서브세트 중 하나에 결합할 것으로 예상되는 잠재적 접합 에피토프의 수를 추정하여 분석되었다(IEDB 2.17 소프트웨어에 포함된 IEDB_추천 방법에 의해 예측된 9량체 에피토프만 고려하여). 9개의 클래스 I HLA 하플로타입은 1000개의 게놈 프로젝트의 대상에 대해 주석이 달린 하플로타입을 분석하여 추정한 세계 인구의 82%를 누적하여 포함한다. N 말단 T 세포 인핸서 또는 C 말단 TAG 서열을 갖는 예측된 접합부 에피토프를 형성한 신생항원을 갖는 스크램블된 레이아웃을 제외시켰다. 부가적 제약으로서, 각 레이아웃에서 인간 야생형 프로테옴에 주석이 달린 단백질과 일치하는 9량체 펩티드를 포함하는 접합부도 제외시켰다.
이어서, 4개의 하위목록 각각을 200만 번 스크램블링한 후에 얻은 최상의 레이아웃을 결합하여 41개의 신생항원을 모두 포함하는 전체 레이아웃을 생성하였다. 4개의 최상의 레이아웃의 모든 가능한 조합 중에서, 새로 형성된 접합부에 의해 형성된 예측된 에피토프의 수가 최소인 레이아웃을 선택하였다.
기재된 전체 절차를 독립적으로 2회 적용하여, GAd20 또는 MVA 벡터에 의해 선택적으로 인코딩되는 2개의 인공 유전자를 생성하였다. MVA 벡터의 경우, 스크램블된 레이아웃은 아데노바이러스 도입유전자에 대해 선택된 레이아웃에 이미 존재하는 예측된 접합 에피토프와의 접합을 피하는 부가적 제약으로 설계되었다.
GAd20에 대한 최적화 레이아웃의 아미노산 서열은 서열 번호 541에, MVA에 대해서는 서열 번호 543에 나타나 있다. 서열 번호 541의 GAd20 삽입물에서의 신생항원은 다음 순서로 되어 있다: FR1-AS13-AS7-AS6-AS8-P87-FUS3-AS43-AS57-AS51-AS18-AS55-AS23-AS47-MS1-AS37-AS15-AS19-AS11-AS3-P16-P82-FUS5-FUS1-M12-MS6-FUS2-P22-FUS6-MS8-MS3-AS16-M86-M84-M10-FUS8-FUS7-FUS19-AS41-FUS15-P35. 서열 번호 543의 MVA 삽입물에서의 신생항원은 다음 순서로 되었다: FR1-AS51-AS6-AS18-AS7-AS43-FUS3-P87-AS8-AS13-AS57-AS55-AS19-AS3-AS23-AS15-AS11-AS37-MS1-AS47-P16-FUS1-FUS6-P22-M12-MS8-FUS5-P82-FUS2-MS3-MS6-AS16-P35-M10-AS41-FUS8-M84-FUS19-FUS15-M86-FUS7
스크램블된 신생항원의 5개의 추가의 대체 최적화 레이아웃을 각각의 벡터에 대해 평가하였다. 5개의 대체 레이아웃은 서열 번호 541 및 서열 번호 543과 비교하여 동일한 수의 예측된 접합 에피토프를 가졌다. Gad20에 대한 5개의 대체 레이아웃은 서열 번호 554, 서열 번호 555, 서열 번호 556, 서열 번호 623 및 서열 번호 624에 나타나 있다. MVA에 대한 5개의 대체 레이아웃은 서열 번호 557, 서열 번호 558, 서열 번호 559, 서열 번호 625 및 서열 번호 626에 나타나 있다. 대체 최적화 레이아웃의 신생항원은 다음 순서로 되었다:
서열 번호 554: FR1-AS13-AS8-P87-FUS3-AS43-AS57-AS51-AS7-AS6-AS18-P16-P82-FUS5-FUS1-M12-MS6-FUS2-P22-FUS6-MS8-MS3-AS55-AS23-AS47-MS1-AS37-AS15-AS19-AS11-AS3-AS16-M86-M84-M10-FUS8-FUS7-FUS19-AS41-FUS15-P35
서열 번호 555: FR1-AS13-FUS3-P87-AS7-AS43-AS57-AS51-AS6-AS8-AS18-AS55-AS23-AS47-MS1-AS37-AS15-AS19-AS11-AS3-P16-P82-FUS5-FUS1-M12-MS6-FUS2-P22-FUS6-MS8-MS3-AS16-M86-M84-M10-FUS8-FUS7-FUS19-AS41-FUS15-P35
서열 번호 556: FR1-AS13-AS7-AS43-AS8-P87-FUS3-AS57-AS51-AS6-AS18-AS55-AS23-AS47-MS1-AS37-AS15-AS19-AS11-AS3-P16-P82-FUS5-FUS1-M12-MS6-FUS2-P22-FUS6-MS8-MS3-AS16-M86-M84-M10-FUS8-FUS7-FUS19-AS41-FUS15-P35
서열 번호 623: P16-P82-FUS5-FUS1-M12-MS6-FUS2-P22-FUS6-MS8-MS3-AS16-M86-M84-M10-FUS8-FUS7-FUS19-AS41-FUS15-P35-AS55-AS23-AS47-MS1-AS37-AS15-AS19-AS11-AS3-FR1-AS13-AS8-P87-FUS3-AS43-AS57-AS51-AS7-AS6-AS18
서열 번호 624: AS16-M86-M84-M10-FUS8-FUS7-FUS19-AS41-FUS15-P35-P16-P82-FUS5-FUS1-M12-MS6-FUS2-P22-FUS6-MS8-MS3-AS55-AS23-AS47-MS1-AS37-AS15-AS19-AS11-AS3-FR1-AS13-FUS3-P87-AS7-AS43-AS57-AS51-AS6-AS8-AS18
서열 번호 557: FR1-AS51-AS6-AS18-AS7-AS43-FUS3-P87-AS8-AS13-AS57-AS55-AS37-MS1-AS3-AS23-AS15-AS11-AS19-AS47-P16-FUS1-FUS6-P22-M12-MS8-FUS5-P82-FUS2-MS3-MS6-AS16-P35-M10-AS41-FUS8-M84-FUS19-FUS15-M86-FUS7
서열 번호 558: AS55-AS19-AS3-AS15-AS23-AS11-AS37-MS1-AS47-FR1-AS51-AS6-AS18-AS7-AS43-FUS3-P87-AS8-AS13-AS57-P16-FUS1-FUS6-P22-M12-MS8-FUS5-P82-FUS2-MS3-MS6-AS16-P35-M10-AS41-FUS8-M84-FUS19-FUS15-M86-FUS7
서열 번호: 559: AS16-P35-M10-AS41-FUS8-M84-FUS19-FUS15-M86-FUS7-AS55-AS19-AS3-AS23-AS15-AS11-AS37-MS1-AS47-P16-FUS1-FUS2-P82-MS8-FUS5-FUS6-P22-M12-MS3-MS6-FR1-AS51-AS6-AS18-AS7-AS43-FUS3-P87-AS8-AS13-AS57
서열 번호 625: AS16-P35-M10-AS41-FUS8-M84-FUS19-FUS15-M86-FUS7-FR1-AS51-AS6-AS18-AS7-AS43-FUS3-P87-AS8-AS13-AS57-AS55-AS19-AS3-AS15-AS23-AS11-AS37-MS1-AS47-P16-FUS1-FUS6-P22-M12-MS8-FUS5-P82-FUS2-MS3-MS6
서열 번호 626: AS55-AS11-AS19-AS23-AS3-AS15-AS37-MS1-AS47-FR1-AS51-AS6-AS18-AS7-AS43-FUS3-P87-AS8-AS13-AS57-AS16-P35-M10-AS41-FUS8-M84-FUS19-FUS15-M86-FUS7-P16-FUS1-FUS6-P22-M12-P82-MS8-FUS5-FUS2-MS3-MS6
T 세포 인핸서 및 TAG 서열의 삽입
쏘가리(mandarin fish) 불변 사슬로부터 28aa 길이의 작은 펩티드 단편(MGQKEQIHTLQKNSERMSKQLTRSSQAV; 서열 번호 549)을 41개의 신생항원을 인코딩하는 각각의 도입유전자의 N 말단에 배치하였다. 전임상 데이터는 이 서열이 바이러스 벡터의 면역학적 반응을 증가시키는 것으로 나타났다. 7개의 아미노산의 작은 세그먼트(TAG 서열; 서열: SHHHHHH; 서열 번호 627)를 인코딩된 도입유전자의 발현을 모니터링할 목적으로 도입유전자의 C 말단에 첨가하였다.
TCE 서열을 포함하고 태그 서열을 생략한 GAd20에 대한 최적화 레이아웃의 아미노산 서열은 서열 번호 550에, MVA에 대해서는 서열 번호 551에 나타나 있다.
뉴클레오티드 서열로의 변환 및 예측된 miRNA 결합 부위를 제거하기 위한 최적화
아미노산 서열에서 뉴클레오티드 서열로의 변환은 인간 코돈 사용 빈도에 따른 코돈 최적화를 이용하여 다음과 같은 특징을 최대한 피하기 위해 부가적 제약을 가하여 수행하였다.
이어서, EcoR1, BamH1 제한 부위 및 코작 서열을 최적화된 뉴클레오티드 서열의 상류에 첨가하였다. 2개의 정지 코돈, 이어서 Asc1 및 Not1 제한 부위를 최적화된 뉴클레오티드 서열의 하류에 첨가하였다.
그 다음에, 각각의 도입유전자의 최적화된 뉴클레오티드 서열을 PITA 및 미란다(miranda) 소프트웨어로 추가로 분석하여, 합성 도입유전자의 발현을 하향조절할 수도 있는 예측된 miRNA 표적 부위를 검출하였다. 두 방법에 의해 검출된 9개의 miRNA 결합 부위는 상응하는 코돈의 동의 치환(synonymous change)을 도입함으로써 miRNA "시드"에 결합하는 것으로 예측되는 영역의 뉴클레오티드 서열을 변형시켜 제거하였다. GAd20 및 MVA 도입유전자의 합성을 표준 방법을 사용하여 수행하였다.
서열 번호 541의 GAd20 신생항원 레이아웃을 인코딩하는 코돈 최적화된 폴리뉴클레오티드 서열은 서열 번호 542에 나타나 있다
서열 번호 543의 MVA(neoMVA) 신생항원 레이아웃을 인코딩하는 코돈 최적화된 폴리뉴클레오티드 서열은 서열 번호 544에 나타나 있다.
TCE 서열을 포함하고 TAG 서열을 제외한 서열 번호 550의 GAd20 신생항원 레이아웃을 인코딩하는 코돈 최적화된 폴리뉴클레오티드 서열은 서열 번호 551에 나타나 있다.
TCE 서열을 포함하고 TAG 서열을 제외한 서열 번호 552의 MVA 신생항원 레이아웃을 인코딩하는 코돈 최적화된 폴리뉴클레오티드 서열은 서열 번호 553에 나타나 있다.
코작 서열: CGCGACTTCGCCGCC; 서열 번호 545
TCE를 인코딩하는 폴리뉴클레오티드: ATGGGCCAGAAAGAGCAGATCCACACACTGCAGAAAAACAGCGAGCGGATGAGCAAGCAGCTGACCAGATCTTCTCAGGCCGTG; 서열 번호 546
세린-히스티딘 태그를 인코딩하는 폴리뉴클레오티드: AGCCATCACCATCACCACCAT; 서열 번호 547
2개의 정지 코돈(TAGTAA)
TCE의 폴리펩티드 서열: MGQKEQIHTLQKNSERMSKQLTRSSQAV; 서열 번호 549
바이러스 벡터 생산
GAd20 바이러스 벡터 생산
GAd20 도입유전자를 ECOR1-NOT1 제한 부위를 통해 2개의 TetO 반복체를 갖는 CMV 프로모터와 BGH 폴리A 사이의 셔틀 플라스미드에 서브클로닝하였다.
얻어진 발현 카세트를 적절한 대장균의 균주에서의 상동성 재조합에 의해 GAd20 게놈에 옮기고, CMV-도입유전자-BGH DNA 단편으로 형질전환시키고, GAd20 게놈을 지닌 구축물로 형질전환시켰다.
재조합은 E1 결실(도입유전자의 삽입 부위) 대신에 GAd20 구축물에 이미 존재하는 상동성 암으로서 CMV 및 BGH를 포함하였다. 이어서, 재조합 GAd20 벡터를 E1 상보적, TetR 발현 M9 세포의 트랜스펙션에 의해 구제하고, 새로운 M9 세포의 후속 재감염에 의해 증폭시켰다.
TetO 부위를 갖는 CMV 프로모터: 서열 번호 628
Ccattgcatacgttgtatccatatcataatatgtacatttatattggctcatgtccaacattaccgccatgttgacattgattattgactagttattaatagtaatcaattacggggtcattagttcatagcccatatatggagttccgcgttacataacttacggtaaatggcccgcctggctgaccgcccaacgacccccgcccattgacgtcaataatgacgtatgttcccatagtaacgccaatagggactttccattgacgtcaatgggtggagtatttacggtaaactgcccacttggcagtacatcaagtgtatcatatgccaagtacgccccctattgacgtcaatgacggtaaatggcccgcctggcattatgcccagtacatgaccttatgggactttcctacttggcagtacatctacgtattagtcatcgctattaccatggtgatgcggttttggcagtacatcaatgggcgtggatagcggtttgactcacggggatttccaagtctccaccccattgacgtcaatgggagtttgttttggcaccaaaatcaacgggactttccaaaatgtcgtaacaactccgccccattgacgcaaatgggcggtaggcgtgtacggtgggaggtctatataagcagagctctccctatcagtgatagagatctccctatcagtgatagagatcgtcgacgagctcgtttagtgaaccgtcagatcgcctggagacgccatccacgctgttttgacctccatagaagacaccgggaccgatccagcctccgcggccgggaacggtgcattggaacgcggattccccgtgccaagagtga
BGH 폴리A 서열 번호 629
ctgtgccttctagttgccagccatctgttgtttgcccctcccccgtgccttccttgaccctggaaggtgccactcccactgtcctttcctaataaaatgaggaaattgcatcgcattgtctgagtaggtgtcattctattctggggggtggggtggggcaggacagcaagggggaggattgggaagacaatagcaggcatgctggggatgcggtgggctctatggcc
MVA 바이러스 벡터 생산
MVA 도입유전자를 MVA의 결실 III 유전자좌(FlankIII-1 및 -2 영역)와 상동성인 서열 사이에서 백시니아 P7.5 초기/후기 프로모터(서열 번호 630)의 제어 하에 BAMH1-ASC1 제한 부위를 통해 p94 셔틀 플라스미드에 서브클로닝하였다. "Z"로 명명된 반복 서열이 양측에 있는 eGFP 단백질에 대한 추가의 발현 카세트가 플랭크 III 영역 사이의 p94 셔틀 플라스미드에 존재하였다.
재조합 백신 바이러스 생성에 사용되는 모 MVA 벡터는 결실 III 유전자좌에 HcRed1-1 형광 단백질 도입유전자를 가지며, MVA-RED 476 MG로 표시되었다.
결실 III 유전자좌에 도입유전자가 삽입된 재조합 MVA는 닭 배아 섬유아세포(CEF)에서 생체내 재조합의 두 가지 이벤트에 의해 생성되었다. 제1 재조합 이벤트는 MVA-RED 476 MG로 감염되고 p94 셔틀 플라스미드로 트랙스펙션된 세포에서 발생되고, HcRed 단백질 유전자가 도입유전자/eGFP 카세트로 치환되었다. MVA-녹색 중간체를 함유하는 감염 세포를 녹색 세포의 FACS 분류에 의해 단리하였다. 제1 재조합으로부터 생성된 중간체 재조합 MVA는 도입유전자 및 eGFP 카세트 둘 다를 갖고 있지만, 반복되는 Z 영역의 존재로 인해 불안정하였다. 따라서, Z 영역이 관여하는 자발적 제2 재조합 이벤트가 발생하고, eGFP 카세트를 제거하였다. 생성된 재조합 MVA는 무색이며, MVA-RED 476 MG의 결실 III 유전자좌(삽입 부위)에 도입유전자 카세트를 가졌다. 이것을 무색 감염 세포의 FACS 분류에 의해 단리하고, 신선한 CEF 세포의 재감염에 의해 증폭시켰다. 얻어진 용해물을 사용하여 Age1 세포를 감염시켜 연구용 배치(research batch)를 생산하였다.
P7.5 초기/후기 프로모터 서열 번호 630
gatcactaattccaaacccacccgctttttatagtaagtttttcacccataaataataaatacaataattaatttctcgtaaaagtagaaaatatattctaatttattgcacggtaaggaagtagaatcataaagaacagtgacGGATC
neoGAd20 단백질 서열 번호 541 (TCE 없음, HIS 태그 없음)
QNLQNGGGSRSSATLPGRRRRRWLRRRRQPISVAPAGPPRRPNQKPNPPGGARCVIMRPTWPGTSAFTKRSFAVTERIIDYWAQKEKGSSSFLRPSCDYWAQKEKISIPRTHLCLVLGVLSGHSGSRLYEAGMTLGGKILFFLFLLLPLSPFSLIFTEISCCTLSSEENEYLPRPEWQLQVPFRELKNVSVLEGLRQGRLGGPCSCHCPRPSQARLTPVDVAGPFLCLGDPGLFPPVKSSITGGKSTCSAPGPQSLPSTPFSTYPQWVILITELGMECTLGQVGAPSPRREEDGWRGGHSRFKADVPAPQGPCWGGQPGSAPSSAPPEQSLLDWKFEMSYTVGGPPPHVHARPRHWKTDRDGHSYTSKVNCLLLQDGFHGCVSITGAAGRRNLSIFLFLMLCKLEFHACKIQNKNCPDFKKFDGPCGERGGGRTARALWARGDSVLTPALDPQTPVRAPSLTRAAAAVHYKLIQQPISLFSITDRLHKTFSQLPSVHLCSITFQWGHPPIFCSTNDICVTANFCISVTFLKPCFLLHEASASQCHLFLQPQVGTPPPHTASARAPSGPPHPHESCPAGRRPARAAQTCARRQHGLPGCEEAGTARVPSLHLHLHQAALGAGRGRGWGEACAQVPPSRGVLRFLDLKVRYLHSQWQHYHRSGEAAGTPLWRPTRNVPFRELKNQRTAQGAPGIHHAASPVAANLCDPARHAQHTRIPCGAGQVRAGRGPEAGGGVLQPQRPAPEKPGCPCRRGQPRLHTVKMWRAVAMMVPDRQVHYDFGLGVPGDSTRRAVRRMNTFYEAGMTLGEKFRVGNCKHLKMTRPNSKMALNSEALSVVSECGASACDVSLIAMDSAFVQGKDWGVKKFIRRDFYAYKDFLWCFPFSLVFLQEIQICCHVSCLCCICCSTRICLGCLLELFLSRALRALHVLWNGFQLHCQTEYNQKLQVNQFSESKSLYHREKQLIAMDSAICEERGAAGSLISCETMPAILKLQKNCLLSLRTALTHNQDFSIYRLCCKRGSLCHASQARSPAFPKPVRPLPAPITRITPQLGGQSDSSQPLLTTGRPQGWQDQALRHTQQASPASCATITIPIHSAALGDHSGDPGPAWDTCPPLPLTTLIPRAPPPYGDSTARSWPSRCGPLGGNTTLQQLGEASQAPSGSLIPLRLPLLWEVRGQPDSFAALHSSLNELGEIARELHQFAFDLLIKSHFVQGKDWGLKKFIRRDFWGMELAASRRFSWDHHSAGGPPRVPSVRSGAAQVQPKDPLPLRTLAGCLARTAHLRPGAESLPQPQLHCTLWFQSSELSPTGAPWPSRRPTWRGTTVSPRTATSSARTCCGTKWPSSQEAALGLGSGLLRFSCGTAAIRKMHFSLKEHPPPPCPPEAFQRAAGEGGPGRGGARRGARVLQSPFCRAGAGEWLGHQSLRHVVGYGHLDTSGSSSSSSWPNSKMALNSLNSIDDAQLTRIAPPRSHCCFWEVNAP
neoGAd20 폴리뉴클레오티드 서열 번호 542 (TCE 없음, HIS 태그 없음)
CAGAACCTGCAGAACGGCGGAGGCTCTAGAAGCTCTGCTACACTTCCTGGCAGGCGGCGGAGAAGATGGCTGAGAAGAAGGCGGCAGCCTATCTCTGTGGCTCCTGCTGGACCTCCTAGACGGCCCAACCAGAAGCCTAATCCTCCTGGCGGAGCCAGATGCGTGATCATGAGGCCTACATGGCCTGGCACCAGCGCCTTCACCAAGAGAAGCTTTGCCGTGACCGAGCGGATCATCGACTATTGGGCTCAAAAAGAGAAGGGCAGCAGCAGCTTCCTGCGGCCTAGCTGTGATTATTGGGCCCAGAAAGAAAAGATCAGCATCCCCAGAACACACCTGTGCCTGGTGCTGGGAGTGCTGTCTGGACACTCTGGCAGCAGACTGTATGAGGCCGGCATGACACTCGGCGGCAAGATCCTGTTCTTCCTGTTCCTGCTGCTCCCTCTGAGCCCCTTCAGCCTGATCTTCACCGAGATCAGCTGCTGCACCCTGAGCAGCGAGGAAAACGAGTACCTGCCTAGACCTGAGTGGCAGCTGCAGGTCCCCTTCAGAGAGCTGAAGAACGTTTCCGTGCTGGAAGGCCTGAGACAGGGCAGACTTGGCGGCCCTTGTAGCTGTCACTGCCCCAGACCTAGTCAGGCCAGACTGACACCTGTGGATGTGGCCGGACCTTTCCTGTGTCTGGGAGATCCTGGCCTGTTTCCACCTGTGAAGTCCAGCATCACAGGCGGCAAGTCCACATGTTCTGCCCCTGGACCTCAGAGCCTGCCTAGCACACCCTTCAGCACATACCCTCAGTGGGTCATCCTGATCACCGAACTCGGCATGGAATGCACCCTGGGACAAGTGGGAGCCCCATCTCCTAGAAGAGAAGAGGATGGCTGGCGCGGAGGCCACTCTAGATTCAAAGCTGATGTGCCCGCTCCTCAGGGCCCTTGTTGGGGAGGACAACCTGGATCTGCCCCATCTTCTGCCCCACCTGAACAGTCCCTGCTGGATTGGAAGTTCGAGATGAGCTACACCGTCGGCGGACCTCCACCTCATGTTCATGCCAGACCTCGGCACTGGAAAACCGACAGAGATGGCCACAGCTACACCAGCAAAGTGAACTGCCTCCTGCTGCAGGATGGCTTCCACGGCTGTGTGTCTATTACTGGCGCCGCTGGCAGACGGAACCTGAGCATCTTTCTGTTTCTGATGCTGTGCAAGCTCGAGTTCCACGCCTGCAAGATCCAGAACAAGAACTGCCCCGACTTCAAGAAGTTCGACGGCCCTTGCGGAGAAAGAGGCGGAGGCAGAACAGCTAGAGCCCTTTGGGCTAGAGGCGACAGCGTTCTGACACCAGCTCTGGACCCTCAGACACCTGTTAGGGCCCCTAGCCTGACAAGAGCTGCCGCCGCTGTGCACTACAAGCTGATCCAGCAGCCAATCAGCCTGTTCAGCATCACCGACCGGCTGCACAAGACATTCAGCCAGCTGCCAAGCGTGCACCTGTGCTCCATCACCTTCCAGTGGGGACACCCTCCTATCTTTTGCTCCACCAACGACATCTGCGTGACCGCCAACTTCTGTATCAGCGTGACCTTCCTGAAGCCTTGCTTTCTGCTGCACGAGGCCAGCGCCTCTCAGTGCCACTTGTTTCTGCAGCCCCAAGTGGGCACACCTCCTCCACATACAGCCTCTGCTAGAGCACCTAGCGGCCCTCCACATCCTCACGAATCTTGTCCTGCCGGAAGAAGGCCTGCCAGAGCCGCTCAAACATGTGCCAGACGACAGCACGGACTGCCTGGATGTGAAGAGGCTGGAACAGCCAGAGTGCCTAGCCTGCACCTCCATCTGCATCAGGCTGCTCTTGGAGCCGGAAGAGGTAGAGGATGGGGCGAAGCTTGTGCTCAGGTGCCACCTTCTAGAGGCGTGCTGAGATTCCTGGACCTGAAAGTGCGCTACCTGCACAGCCAGTGGCAGCACTATCACAGATCTGGCGAAGCCGCCGGAACACCCCTTTGGAGGCCAACAAGAAACGTGCCCTTCCGGGAACTGAAGAACCAGAGAACAGCTCAGGGCGCTCCTGGAATCCACCATGCTGCTTCTCCAGTGGCCGCCAACCTGTGTGATCCTGCCAGACATGCCCAGCACACCAGGATTCCTTGTGGCGCTGGACAAGTGCGCGCTGGAAGAGGACCTGAAGCAGGCGGAGGTGTTCTGCAACCTCAAAGACCCGCTCCTGAGAAGCCTGGCTGCCCTTGCAGAAGAGGACAGCCTAGACTGCACACCGTGAAAATGTGGCGAGCCGTGGCCATGATGGTGCCCGATAGACAGGTCCACTACGACTTTGGACTGGGCGTGCCAGGCGATAGCACTCGGAGAGCCGTCAGACGGATGAACACCTTTTACGAAGCCGGGATGACCCTGGGCGAGAAGTTCAGAGTGGGCAACTGCAAGCACCTGAAGATGACCCGGCCTAACAGCAAGATGGCCCTGAATAGCGAGGCCCTGTCTGTGGTGTCTGAATGTGGCGCCTCTGCCTGTGACGTGTCCCTGATCGCTATGGACTCCGCCTTTGTGCAGGGCAAAGACTGGGGCGTGAAGAAGTTCATCCGGCGGGACTTCTACGCCTACAAGGACTTCCTGTGGTGCTTCCCCTTCTCTCTGGTGTTCCTGCAAGAGATCCAGATCTGCTGTCATGTGTCCTGCCTGTGCTGCATCTGCTGTAGCACCAGAATCTGCCTGGGCTGTCTGCTGGAACTGTTCCTGAGCAGAGCCCTGAGAGCACTGCACGTGCTGTGGAACGGATTCCAGCTGCACTGCCAGACCGAGTACAACCAGAAACTGCAAGTGAACCAGTTCAGCGAGAGCAAGAGCCTGTACCACCGGGAAAAGCAGCTCATTGCCATGGACAGCGCCATCTGCGAAGAGAGAGGCGCCGCAGGATCTCTGATCTCCTGCGAAACAATGCCCGCCATCCTGAAGCTGCAGAAGAATTGCCTCCTAAGCCTGCGAACCGCTCTGACACACAACCAGGACTTCAGCATCTACAGACTGTGTTGCAAGCGGGGCTCCCTGTGCCATGCAAGCCAAGCTAGAAGCCCCGCCTTTCCTAAACCTGTGCGACCTCTGCCAGCTCCAATCACCAGAATTACCCCTCAGCTCGGCGGCCAGAGCGATTCATCTCAACCTCTGCTGACCACCGGCAGACCTCAAGGCTGGCAAGACCAAGCTCTGAGACACACCCAGCAGGCTAGCCCTGCCTCTTGTGCCACCATCACAATCCCCATCCACTCTGCCGCTCTGGGCGATCATTCTGGCGATCCTGGACCAGCCTGGGACACATGTCCTCCACTGCCACTCACAACACTGATCCCTAGGGCTCCTCCACCTTACGGCGATTCTACCGCTAGAAGCTGGCCCAGCAGATGTGGACCACTCGGAGGCAACACAACCCTCCAGCAACTGGGAGAAGCCTCTCAGGCTCCTAGCGGCTCTCTGATCCCTCTCAGACTGCCTCTCCTGTGGGAAGTTCGGGGCCAGCCTGATTCTTTTGCCGCACTGCACAGCTCCCTGAACGAGCTGGGAGAGATCGCTAGAGAGCTGCACCAGTTCGCCTTCGACCTGCTGATCAAGAGCCACTTCGTGCAAGGCAAGGATTGGGGCCTCAAAAAGTTTATCCGCAGAGACTTCTGGGGCATGGAACTGGCCGCCAGCAGAAGATTCAGCTGGGATCATCATAGCGCAGGCGGCCCACCTAGAGTGCCATCTGTTAGAAGCGGAGCTGCCCAGGTGCAGCCTAAAGATCCTCTGCCACTGAGAACACTGGCCGGCTGCCTTGCTAGAACAGCCCATCTTAGACCTGGCGCCGAGTCTCTGCCTCAGCCACAACTGCACTGTACCCTGTGGTTCCAGTCCAGCGAGCTGTCTCCTACTGGTGCCCCTTGGCCATCTAGACGCCCTACTTGGAGAGGCACCACCGTGTCACCAAGAACCGCCACAAGCAGCGCCAGAACCTGTTGTGGCACAAAGTGGCCCTCCAGCCAAGAAGCCGCTCTCGGACTTGGAAGCGGACTGCTGAGGTTCTCTTGTGGAACCGCCGCCATTCGGAAGATGCACTTTAGCCTGAAAGAACACCCTCCACCACCTTGTCCTCCAGAGGCTTTCCAAAGAGCTGCTGGCGAAGGCGGACCTGGTAGAGGTGGTGCTAGAAGAGGTGCTAGGGTGCTGCAGAGCCCATTCTGTAGAGCAGGCGCAGGCGAATGGCTGGGCCATCAGAGTCTGAGACATGTCGTCGGCTACGGCCACCTGGATACAAGCGGAAGCAGCTCTAGCTCCAGCTGGCCTAACTCAAAAATGGCTCTGAACAGCCTGAACTCCATCGACGACGCCCAGCTGACAAGAATCGCCCCTCCTAGATCTCACTGCTGCTTTTGGGAAGTGAACGCCCCA
neoMVA 단백질 서열 번호 543 (TCE 없음, HIS 태그 없음)
QNLQNGGGSRSSATLPGRRRRRWLRRRRQPISVAPAGPPRRPNQKPNPPGGARCVIMRPTWPGTSAFTGMECTLGQVGAPSPRREEDGWRGGHSRFKADVPAPQGPCWGGQPGSAPSSAPPEQSLLDDYWAQKEKISIPRTHLCWKFEMSYTVGGPPPHVHARPRHWKTDRDYWAQKEKGSSSFLRPSCVPFRELKNVSVLEGLRQGRLGGPCSCHCPRPSQARLTPVDVAGPFLCLGDPGLFPPVKSSITEISCCTLSSEENEYLPRPEWQLQYEAGMTLGGKILFFLFLLLPLSPFSLIFLVLGVLSGHSGSRLKRSFAVTERIITGGKSTCSAPGPQSLPSTPFSTYPQWVILITELDGHSYTSKVNCLLLQDGFHGCVSITGAAGRRNLSIFLFLMLCKLEFHACQWQHYHRSGEAAGTPLWRPTRNVAMMVPDRQVHYDFGLKIQNKNCPDVLRFLDLKVRYLHSVPFRELKNQRTAQGAPGIHHAASPVAANLCDPARHAQHTRIPCGAGQVRAGRGPEAGGGVLQPQRPAPEKPGCPCRRGQPRLHTVKMWRACHLFLQPQVGTPPPHTASARAPSGPPHPHESCPAGRRPARAAQTCARRQHGLPGCEEAGTARVPSLHLHLHQAALGAGRGRGWGEACAQVPPSRGHYKLIQQPISLFSITDRLHKTFSQLPSVHLCSITFQWGHPPIFCSTNDICVTANFCISVTFLKPCFLLHEASASQFKKFDGPCGERGGGRTARALWARGDSVLTPALDPQTPVRAPSLTRAAAAVGVPGDSTRRAVRRMNTFCGASACDVSLIAMDSACEERGAAGSLISCESLYHREKQLIAMDSAIFVQGKDWGVKKFIRRDFTMPAILKLQKNCLLSLNSKMALNSEALSVVSEYEAGMTLGEKFRVGNCKHLKMTRPTEYNQKLQVNQFSESKRTALTHNQDFSIYRLCCKRGSLCHASQARSPAFPKPVRPLPAPITRITPQLGGQSDSSQPLLTTGRPQGWQDQALRHTQQASPASCATITIPIHSAALGDHSGDPGPAWDTCPPLPLTTLIPRAPPPYGDSTARSWPSRCGPLGYAYKDFLWCFPFSLVFLQEIQICCHVSCLCCICCSTRICLGCLLELFLSRALRALHVLWNGFQLHCQGNTTLQQLGEASQAPSGSLIPLRLPLLWEVRGNSKMALNSLNSIDDAQLTRIAPPRSHCCFWEVNAPFVQGKDWGLKKFIRRDFEAFQRAAGEGGPGRGGARRGARVLQSPFCRAGAGEWLGHQSLRWGMELAASRRFSWDHHSAGGPPRVPSVRSGAAQVQPKDPLPLRTLAGCLARTAHLRPGAESLPQPQLHCTIARELHQFAFDLLIKSHKMHFSLKEHPPPPCPPHVVGYGHLDTSGSSSSSSWPQPDSFAALHSSLNELGELWFQSSELSPTGAPWPSRRPTWRGTTVSPRTATSSARTCCGTKWPSSQEAALGLGSGLLRFSCGTAAIRS
neoMVA 폴리뉴클레오티드 서열 번호 544
CAGAACCTGCAGAACGGCGGAGGCTCTAGAAGCTCTGCTACACTTCCTGGCAGGCGGCGGAGAAGATGGCTGAGAAGAAGGCGGCAGCCTATCTCTGTGGCTCCTGCTGGACCTCCTAGACGGCCCAACCAGAAGCCTAATCCTCCTGGCGGAGCCAGATGCGTGATCATGAGGCCTACATGGCCTGGCACCAGCGCCTTTACCGGCATGGAATGTACACTGGGCCAAGTGGGAGCCCCATCTCCTAGAAGAGAAGAGGATGGCTGGCGCGGAGGCCACTCTAGATTCAAAGCTGATGTGCCCGCTCCTCAGGGCCCTTGTTGGGGAGGACAACCTGGATCTGCCCCATCTTCTGCCCCACCTGAACAGAGCCTGCTGGATGACTATTGGGCTCAAAAAGAGAAGATCAGCATCCCCAGAACACACCTGTGCTGGAAGTTCGAGATGAGCTACACCGTTGGCGGCCCTCCACCACATGTTCACGCCAGACCTAGACACTGGAAAACCGACAGAGATTATTGGGCCCAGAAAGAAAAGGGCAGCAGCAGCTTCCTGCGGCCTAGCTGTGTGCCCTTCCGGGAACTGAAGAACGTGTCCGTTCTGGAAGGCCTGAGGCAGGGCAGACTTGGCGGACCTTGTAGCTGCCACTGTCCTAGACCAAGCCAGGCCAGACTGACCCCTGTGGATGTGGCTGGCCCATTTCTGTGTCTGGGCGACCCTGGACTGTTCCCTCCAGTGAAGTCTAGCATCACCGAGATCAGCTGCTGCACCCTGAGCAGCGAGGAAAACGAGTACCTGCCTAGACCTGAATGGCAGCTGCAGTACGAGGCCGGCATGACACTCGGAGGCAAGATCCTGTTCTTCCTGTTCCTGCTGCTCCCTCTGAGCCCCTTCAGCCTGATCTTTCTGGTGCTGGGCGTGCTGTCTGGCCACTCTGGAAGCAGACTGAAGAGAAGCTTCGCCGTGACCGAGCGGATCATCACAGGCGGCAAGAGCACATGTTCTGCCCCTGGACCTCAGTCTCTGCCCAGCACACCCTTCAGCACATACCCTCAGTGGGTCATCCTGATCACCGAGCTGGATGGCCACAGCTACACCAGCAAAGTGAACTGCCTCCTGCTGCAGGATGGCTTCCACGGCTGTGTGTCTATTACTGGCGCCGCTGGCAGACGGAACCTGAGCATCTTTCTGTTTCTGATGCTGTGCAAGCTCGAGTTCCACGCCTGCCAATGGCAGCACTACCACAGATCTGGCGAAGCCGCTGGAACCCCACTTTGGAGGCCTACCAGAAACGTGGCCATGATGGTGCCCGACAGACAGGTGCACTACGACTTCGGCCTGAAGATCCAGAACAAGAACTGCCCCGACGTGCTGCGGTTCCTGGATCTCAAAGTGCGCTACCTGCACAGCGTGCCCTTCAGAGAGCTGAAAAACCAGAGAACAGCCCAGGGCGCTCCTGGAATCCATCATGCTGCTTCTCCAGTGGCCGCCAATCTGTGCGATCCTGCCAGACATGCCCAGCATACCAGGATTCCTTGTGGCGCTGGACAAGTGCGCGCTGGAAGAGGACCTGAAGCTGGTGGCGGAGTTCTGCAGCCTCAAAGACCTGCTCCTGAGAAGCCTGGCTGCCCCTGTAGAAGAGGACAGCCTAGACTGCACACCGTGAAGATGTGGCGGGCCTGCCACTTGTTTCTCCAGCCACAAGTGGGCACCCCTCCACCTCATACAGCCTCTGCTAGAGCACCTAGCGGCCCACCTCATCCTCACGAATCTTGTCCTGCCGGAAGAAGGCCTGCCAGAGCCGCTCAAACATGTGCCAGACGACAGCACGGACTGCCCGGATGTGAAGAAGCCGGAACAGCCAGAGTGCCTAGCCTGCACCTTCATCTGCATCAGGCCGCTCTTGGAGCCGGAAGAGGTAGAGGATGGGGAGAAGCTTGTGCCCAGGTGCCACCTTCTAGAGGCCACTACAAGCTGATCCAGCAGCCAATCAGCCTGTTCTCCATCACCGACCGGCTGCACAAGACATTCAGCCAGCTGCCTTCCGTGCATCTGTGCAGCATCACCTTCCAGTGGGGACACCCTCCTATCTTTTGCTCCACCAACGACATCTGCGTGACCGCCAACTTCTGTATCAGCGTGACCTTCCTGAAGCCTTGCTTTCTGCTGCACGAGGCCTCCGCCAGCCAGTTTAAGAAGTTTGACGGCCCCTGCGGCGAGAGAGGCGGAGGAAGAACTGCAAGAGCCCTTTGGGCCAGAGGCGACTCTGTTCTGACACCAGCTCTGGACCCTCAGACACCTGTTAGGGCCCCTAGCCTGACAAGAGCTGCCGCTGCTGTTGGAGTGCCTGGCGATTCTACTAGAAGGGCCGTGCGGCGGATGAACACCTTTTGTGGCGCATCTGCCTGCGACGTGTCCCTGATCGCTATGGATAGCGCCTGCGAGGAAAGAGGCGCAGCCGGATCTCTGATCTCTTGCGAGAGCCTGTACCACCGGGAAAAGCAGCTCATTGCCATGGACAGCGCCATCTTCGTGCAGGGCAAAGACTGGGGCGTGAAGAAGTTCATCCGGCGGGACTTTACCATGCCTGCCATTCTGAAGCTGCAGAAGAATTGTCTTCTAAGCCTGAACAGCAAGATGGCCCTGAATAGCGAGGCCCTGTCTGTGGTGTCCGAGTATGAGGCTGGAATGACCCTGGGCGAGAAGTTCAGAGTGGGCAACTGCAAGCACCTGAAGATGACCCGGCCTACCGAGTACAACCAGAAACTGCAAGTGAACCAGTTCAGCGAGAGCAAGCGGACCGCTCTGACCCACAACCAGGACTTCAGCATCTACCGGCTGTGCTGCAAGAGGGGCTCTCTGTGTCATGCTAGCCAGGCTAGAAGCCCCGCCTTTCCTAAGCCTGTCAGACCTCTGCCTGCTCCTATCACCAGAATCACCCCTCAGCTCGGCGGCCAGTCTGATTCATCTCAGCCACTGCTGACCACCGGCAGACCTCAAGGATGGCAAGACCAGGCTCTGAGACACACACAGCAGGCTAGCCCAGCCTCTTGCGCCACCATCACAATACCAATACATTCTGCCGCTCTGGGCGATCACAGCGGAGATCCTGGACCTGCCTGGGATACTTGTCCTCCTCTGCCCCTAACTACACTGATCCCTAGGGCTCCTCCACCTTACGGCGATAGCACAGCCAGATCCTGGCCTAGCAGATGTGGCCCTCTGGGCTACGCCTACAAGGACTTCCTGTGGTGCTTCCCCTTCTCTCTGGTGTTCCTGCAAGAAATCCAGATCTGCTGTCACGTGTCCTGCCTGTGCTGTATCTGCTGTAGCACCCGGATCTGTCTGGGCTGTCTGCTGGAACTGTTCCTGAGCAGAGCCCTGAGAGCACTGCACGTGCTGTGGAACGGATTCCAGCTGCACTGCCAGGGCAACACCACACTGCAACAGCTGGGAGAAGCCTCTCAGGCCCCAAGCGGTTCTCTGATCCCTCTCAGACTGCCCCTCCTGTGGGAAGTGCGGGGCAATTCTAAGATGGCTCTCAACAGCCTGAACTCCATCGACGACGCCCAGCTGACAAGAATCGCCCCTCCAAGAAGCCACTGTTGCTTTTGGGAAGTGAACGCCCCTTTTGTGCAGGGTAAAGATTGGGGCCTCAAAAAGTTTATCAGACGGGACTTCGAGGCTTTCCAGAGAGCAGCTGGCGAAGGCGGACCTGGCAGAGGTGGTGCTAGAAGAGGTGCTAGAGTGCTGCAGAGCCCATTCTGTAGAGCTGGCGCTGGCGAATGGCTGGGCCACCAATCTCTTAGATGGGGAATGGAACTGGCCGCTAGCAGGCGGTTTAGCTGGGATCATCATTCTGCCGGCGGACCTCCAAGAGTGCCAAGCGTTAGAAGCGGAGCAGCCCAGGTCCAGCCTAAAGATCCACTGCCACTGAGAACACTGGCCGGCTGCCTTGCCAGAACAGCTCATCTTAGACCTGGCGCCGAAAGCCTGCCTCAACCTCAGCTGCATTGCACAATCGCCAGAGAACTGCACCAGTTCGCCTTCGACCTGCTGATCAAGAGCCACAAGATGCACTTCTCACTGAAAGAGCACCCGCCACCGCCGTGCCCACCGCACGTTGTCGGCTATGGCCACCTGGATACAAGCGGCTCCTCTAGCAGTAGCTCCTGGCCTCAGCCTGACAGCTTTGCTGCCCTGCATAGCTCCCTGAATGAGCTGGGCGAACTGTGGTTCCAGTCCAGCGAACTGTCTCCTACTGGCGCTCCATGGCCAAGCAGAAGGCCTACTTGGAGAGGCACCACCGTGTCTCCAAGAACCGCTACAAGCAGCGCCAGAACCTGTTGCGGCACAAAATGGCCCTCCAGCCAAGAAGCTGCCCTCGGACTTGGAAGCGGACTGCTGAGATTCAGCTGTGGCACAGCCGCCATCAGA
neoGAd20 발현 카세트 단백질 서열 번호 550
MGQKEQIHTLQKNSERMSKQLTRSSQAVQNLQNGGGSRSSATLPGRRRRRWLRRRRQPISVAPAGPPRRPNQKPNPPGGARCVIMRPTWPGTSAFTKRSFAVTERIIDYWAQKEKGSSSFLRPSCDYWAQKEKISIPRTHLCLVLGVLSGHSGSRLYEAGMTLGGKILFFLFLLLPLSPFSLIFTEISCCTLSSEENEYLPRPEWQLQVPFRELKNVSVLEGLRQGRLGGPCSCHCPRPSQARLTPVDVAGPFLCLGDPGLFPPVKSSITGGKSTCSAPGPQSLPSTPFSTYPQWVILITELGMECTLGQVGAPSPRREEDGWRGGHSRFKADVPAPQGPCWGGQPGSAPSSAPPEQSLLDWKFEMSYTVGGPPPHVHARPRHWKTDRDGHSYTSKVNCLLLQDGFHGCVSITGAAGRRNLSIFLFLMLCKLEFHACKIQNKNCPDFKKFDGPCGERGGGRTARALWARGDSVLTPALDPQTPVRAPSLTRAAAAVHYKLIQQPISLFSITDRLHKTFSQLPSVHLCSITFQWGHPPIFCSTNDICVTANFCISVTFLKPCFLLHEASASQCHLFLQPQVGTPPPHTASARAPSGPPHPHESCPAGRRPARAAQTCARRQHGLPGCEEAGTARVPSLHLHLHQAALGAGRGRGWGEACAQVPPSRGVLRFLDLKVRYLHSQWQHYHRSGEAAGTPLWRPTRNVPFRELKNQRTAQGAPGIHHAASPVAANLCDPARHAQHTRIPCGAGQVRAGRGPEAGGGVLQPQRPAPEKPGCPCRRGQPRLHTVKMWRAVAMMVPDRQVHYDFGLGVPGDSTRRAVRRMNTFYEAGMTLGEKFRVGNCKHLKMTRPNSKMALNSEALSVVSECGASACDVSLIAMDSAFVQGKDWGVKKFIRRDFYAYKDFLWCFPFSLVFLQEIQICCHVSCLCCICCSTRICLGCLLELFLSRALRALHVLWNGFQLHCQTEYNQKLQVNQFSESKSLYHREKQLIAMDSAICEERGAAGSLISCETMPAILKLQKNCLLSLRTALTHNQDFSIYRLCCKRGSLCHASQARSPAFPKPVRPLPAPITRITPQLGGQSDSSQPLLTTGRPQGWQDQALRHTQQASPASCATITIPIHSAALGDHSGDPGPAWDTCPPLPLTTLIPRAPPPYGDSTARSWPSRCGPLGGNTTLQQLGEASQAPSGSLIPLRLPLLWEVRGQPDSFAALHSSLNELGEIARELHQFAFDLLIKSHFVQGKDWGLKKFIRRDFWGMELAASRRFSWDHHSAGGPPRVPSVRSGAAQVQPKDPLPLRTLAGCLARTAHLRPGAESLPQPQLHCTLWFQSSELSPTGAPWPSRRPTWRGTTVSPRTATSSARTCCGTKWPSSQEAALGLGSGLLRFSCGTAAIRKMHFSLKEHPPPPCPPEAFQRAAGEGGPGRGGARRGARVLQSPFCRAGAGEWLGHQSLRHVVGYGHLDTSGSSSSSSWPNSKMALNSLNSIDDAQLTRIAPPRSHCCFWEVNAP
neoGAd20 발현 카세트 폴리뉴클레오티드 서열 번호 551
CcattgcatacgttgtatccatatcataatatgtacatttatattggctcatgtccaacattaccgccatgttgacattgattattgactagttattaatagtaatcaattacggggtcattagttcatagcccatatatggagttccgcgttacataacttacggtaaatggcccgcctggctgaccgcccaacgacccccgcccattgacgtcaataatgacgtatgttcccatagtaacgccaatagggactttccattgacgtcaatgggtggagtatttacggtaaactgcccacttggcagtacatcaagtgtatcatatgccaagtacgccccctattgacgtcaatgacggtaaatggcccgcctggcattatgcccagtacatgaccttatgggactttcctacttggcagtacatctacgtattagtcatcgctattaccatggtgatgcggttttggcagtacatcaatgggcgtggatagcggtttgactcacggggatttccaagtctccaccccattgacgtcaatgggagtttgttttggcaccaaaatcaacgggactttccaaaatgtcgtaacaactccgccccattgacgcaaatgggcggtaggcgtgtacggtgggaggtctatataagcagagctctccctatcagtgatagagatctccctatcagtgatagagatcgtcgacgagctcgtttagtgaaccgtcagatcgcctggagacgccatccacgctgttttgacctccatagaagacaccgggaccgatccagcctccgcggccgggaacggtgcattggaacgcggattccccgtgccaagagtgagatcttccgtttatctaggtaccagatatcaGAATTCGGATCCCGCGACTTCGCCGCCATGGGCCAGAAAGAGCAGATCCACACACTGCAGAAAAACAGCGAGCGGATGAGCAAGCAGCTGACCAGATCTTCTCAGGCCGTGCAGAACCTGCAGAACGGCGGAGGCTCTAGAAGCTCTGCTACACTTCCTGGCAGGCGGCGGAGAAGATGGCTGAGAAGAAGGCGGCAGCCTATCTCTGTGGCTCCTGCTGGACCTCCTAGACGGCCCAACCAGAAGCCTAATCCTCCTGGCGGAGCCAGATGCGTGATCATGAGGCCTACATGGCCTGGCACCAGCGCCTTCACCAAGAGAAGCTTTGCCGTGACCGAGCGGATCATCGACTATTGGGCTCAAAAAGAGAAGGGCAGCAGCAGCTTCCTGCGGCCTAGCTGTGATTATTGGGCCCAGAAAGAAAAGATCAGCATCCCCAGAACACACCTGTGCCTGGTGCTGGGAGTGCTGTCTGGACACTCTGGCAGCAGACTGTATGAGGCCGGCATGACACTCGGCGGCAAGATCCTGTTCTTCCTGTTCCTGCTGCTCCCTCTGAGCCCCTTCAGCCTGATCTTCACCGAGATCAGCTGCTGCACCCTGAGCAGCGAGGAAAACGAGTACCTGCCTAGACCTGAGTGGCAGCTGCAGGTCCCCTTCAGAGAGCTGAAGAACGTTTCCGTGCTGGAAGGCCTGAGACAGGGCAGACTTGGCGGCCCTTGTAGCTGTCACTGCCCCAGACCTAGTCAGGCCAGACTGACACCTGTGGATGTGGCCGGACCTTTCCTGTGTCTGGGAGATCCTGGCCTGTTTCCACCTGTGAAGTCCAGCATCACAGGCGGCAAGTCCACATGTTCTGCCCCTGGACCTCAGAGCCTGCCTAGCACACCCTTCAGCACATACCCTCAGTGGGTCATCCTGATCACCGAACTCGGCATGGAATGCACCCTGGGACAAGTGGGAGCCCCATCTCCTAGAAGAGAAGAGGATGGCTGGCGCGGAGGCCACTCTAGATTCAAAGCTGATGTGCCCGCTCCTCAGGGCCCTTGTTGGGGAGGACAACCTGGATCTGCCCCATCTTCTGCCCCACCTGAACAGTCCCTGCTGGATTGGAAGTTCGAGATGAGCTACACCGTCGGCGGACCTCCACCTCATGTTCATGCCAGACCTCGGCACTGGAAAACCGACAGAGATGGCCACAGCTACACCAGCAAAGTGAACTGCCTCCTGCTGCAGGATGGCTTCCACGGCTGTGTGTCTATTACTGGCGCCGCTGGCAGACGGAACCTGAGCATCTTTCTGTTTCTGATGCTGTGCAAGCTCGAGTTCCACGCCTGCAAGATCCAGAACAAGAACTGCCCCGACTTCAAGAAGTTCGACGGCCCTTGCGGAGAAAGAGGCGGAGGCAGAACAGCTAGAGCCCTTTGGGCTAGAGGCGACAGCGTTCTGACACCAGCTCTGGACCCTCAGACACCTGTTAGGGCCCCTAGCCTGACAAGAGCTGCCGCCGCTGTGCACTACAAGCTGATCCAGCAGCCAATCAGCCTGTTCAGCATCACCGACCGGCTGCACAAGACATTCAGCCAGCTGCCAAGCGTGCACCTGTGCTCCATCACCTTCCAGTGGGGACACCCTCCTATCTTTTGCTCCACCAACGACATCTGCGTGACCGCCAACTTCTGTATCAGCGTGACCTTCCTGAAGCCTTGCTTTCTGCTGCACGAGGCCAGCGCCTCTCAGTGCCACTTGTTTCTGCAGCCCCAAGTGGGCACACCTCCTCCACATACAGCCTCTGCTAGAGCACCTAGCGGCCCTCCACATCCTCACGAATCTTGTCCTGCCGGAAGAAGGCCTGCCAGAGCCGCTCAAACATGTGCCAGACGACAGCACGGACTGCCTGGATGTGAAGAGGCTGGAACAGCCAGAGTGCCTAGCCTGCACCTCCATCTGCATCAGGCTGCTCTTGGAGCCGGAAGAGGTAGAGGATGGGGCGAAGCTTGTGCTCAGGTGCCACCTTCTAGAGGCGTGCTGAGATTCCTGGACCTGAAAGTGCGCTACCTGCACAGCCAGTGGCAGCACTATCACAGATCTGGCGAAGCCGCCGGAACACCCCTTTGGAGGCCAACAAGAAACGTGCCCTTCCGGGAACTGAAGAACCAGAGAACAGCTCAGGGCGCTCCTGGAATCCACCATGCTGCTTCTCCAGTGGCCGCCAACCTGTGTGATCCTGCCAGACATGCCCAGCACACCAGGATTCCTTGTGGCGCTGGACAAGTGCGCGCTGGAAGAGGACCTGAAGCAGGCGGAGGTGTTCTGCAACCTCAAAGACCCGCTCCTGAGAAGCCTGGCTGCCCTTGCAGAAGAGGACAGCCTAGACTGCACACCGTGAAAATGTGGCGAGCCGTGGCCATGATGGTGCCCGATAGACAGGTCCACTACGACTTTGGACTGGGCGTGCCAGGCGATAGCACTCGGAGAGCCGTCAGACGGATGAACACCTTTTACGAAGCCGGGATGACCCTGGGCGAGAAGTTCAGAGTGGGCAACTGCAAGCACCTGAAGATGACCCGGCCTAACAGCAAGATGGCCCTGAATAGCGAGGCCCTGTCTGTGGTGTCTGAATGTGGCGCCTCTGCCTGTGACGTGTCCCTGATCGCTATGGACTCCGCCTTTGTGCAGGGCAAAGACTGGGGCGTGAAGAAGTTCATCCGGCGGGACTTCTACGCCTACAAGGACTTCCTGTGGTGCTTCCCCTTCTCTCTGGTGTTCCTGCAAGAGATCCAGATCTGCTGTCATGTGTCCTGCCTGTGCTGCATCTGCTGTAGCACCAGAATCTGCCTGGGCTGTCTGCTGGAACTGTTCCTGAGCAGAGCCCTGAGAGCACTGCACGTGCTGTGGAACGGATTCCAGCTGCACTGCCAGACCGAGTACAACCAGAAACTGCAAGTGAACCAGTTCAGCGAGAGCAAGAGCCTGTACCACCGGGAAAAGCAGCTCATTGCCATGGACAGCGCCATCTGCGAAGAGAGAGGCGCCGCAGGATCTCTGATCTCCTGCGAAACAATGCCCGCCATCCTGAAGCTGCAGAAGAATTGCCTCCTAAGCCTGCGAACCGCTCTGACACACAACCAGGACTTCAGCATCTACAGACTGTGTTGCAAGCGGGGCTCCCTGTGCCATGCAAGCCAAGCTAGAAGCCCCGCCTTTCCTAAACCTGTGCGACCTCTGCCAGCTCCAATCACCAGAATTACCCCTCAGCTCGGCGGCCAGAGCGATTCATCTCAACCTCTGCTGACCACCGGCAGACCTCAAGGCTGGCAAGACCAAGCTCTGAGACACACCCAGCAGGCTAGCCCTGCCTCTTGTGCCACCATCACAATCCCCATCCACTCTGCCGCTCTGGGCGATCATTCTGGCGATCCTGGACCAGCCTGGGACACATGTCCTCCACTGCCACTCACAACACTGATCCCTAGGGCTCCTCCACCTTACGGCGATTCTACCGCTAGAAGCTGGCCCAGCAGATGTGGACCACTCGGAGGCAACACAACCCTCCAGCAACTGGGAGAAGCCTCTCAGGCTCCTAGCGGCTCTCTGATCCCTCTCAGACTGCCTCTCCTGTGGGAAGTTCGGGGCCAGCCTGATTCTTTTGCCGCACTGCACAGCTCCCTGAACGAGCTGGGAGAGATCGCTAGAGAGCTGCACCAGTTCGCCTTCGACCTGCTGATCAAGAGCCACTTCGTGCAAGGCAAGGATTGGGGCCTCAAAAAGTTTATCCGCAGAGACTTCTGGGGCATGGAACTGGCCGCCAGCAGAAGATTCAGCTGGGATCATCATAGCGCAGGCGGCCCACCTAGAGTGCCATCTGTTAGAAGCGGAGCTGCCCAGGTGCAGCCTAAAGATCCTCTGCCACTGAGAACACTGGCCGGCTGCCTTGCTAGAACAGCCCATCTTAGACCTGGCGCCGAGTCTCTGCCTCAGCCACAACTGCACTGTACCCTGTGGTTCCAGTCCAGCGAGCTGTCTCCTACTGGTGCCCCTTGGCCATCTAGACGCCCTACTTGGAGAGGCACCACCGTGTCACCAAGAACCGCCACAAGCAGCGCCAGAACCTGTTGTGGCACAAAGTGGCCCTCCAGCCAAGAAGCCGCTCTCGGACTTGGAAGCGGACTGCTGAGGTTCTCTTGTGGAACCGCCGCCATTCGGAAGATGCACTTTAGCCTGAAAGAACACCCTCCACCACCTTGTCCTCCAGAGGCTTTCCAAAGAGCTGCTGGCGAAGGCGGACCTGGTAGAGGTGGTGCTAGAAGAGGTGCTAGGGTGCTGCAGAGCCCATTCTGTAGAGCAGGCGCAGGCGAATGGCTGGGCCATCAGAGTCTGAGACATGTCGTCGGCTACGGCCACCTGGATACAAGCGGAAGCAGCTCTAGCTCCAGCTGGCCTAACTCAAAAATGGCTCTGAACAGCCTGAACTCCATCGACGACGCCCAGCTGACAAGAATCGCCCCTCCTAGATCTCACTGCTGCTTTTGGGAAGTGAACGCCCCAAGCCATCACCATCACCACCATTAGTAAAGGCGCGCCTAGCGGCCGCgatctgctgtgccttctagttgccagccatctgttgtttgcccctcccccgtgccttccttgaccctggaaggtgccactcccactgtcctttcctaataaaatgaggaaattgcatcgcattgtctgagtaggtgtcattctattctggggggtggggtggggcaggacagcaagggggaggattgggaagacaatagcaggcatgctggggatgcggtgggctctatggcc
neoMVA 발현 카세트 단백질 서열 번호 552
MGQKEQIHTLQKNSERMSKQLTRSSQAVQNLQNGGGSRSSATLPGRRRRRWLRRRRQPISVAPAGPPRRPNQKPNPPGGARCVIMRPTWPGTSAFTGMECTLGQVGAPSPRREEDGWRGGHSRFKADVPAPQGPCWGGQPGSAPSSAPPEQSLLDDYWAQKEKISIPRTHLCWKFEMSYTVGGPPPHVHARPRHWKTDRDYWAQKEKGSSSFLRPSCVPFRELKNVSVLEGLRQGRLGGPCSCHCPRPSQARLTPVDVAGPFLCLGDPGLFPPVKSSITEISCCTLSSEENEYLPRPEWQLQYEAGMTLGGKILFFLFLLLPLSPFSLIFLVLGVLSGHSGSRLKRSFAVTERIITGGKSTCSAPGPQSLPSTPFSTYPQWVILITELDGHSYTSKVNCLLLQDGFHGCVSITGAAGRRNLSIFLFLMLCKLEFHACQWQHYHRSGEAAGTPLWRPTRNVAMMVPDRQVHYDFGLKIQNKNCPDVLRFLDLKVRYLHSVPFRELKNQRTAQGAPGIHHAASPVAANLCDPARHAQHTRIPCGAGQVRAGRGPEAGGGVLQPQRPAPEKPGCPCRRGQPRLHTVKMWRACHLFLQPQVGTPPPHTASARAPSGPPHPHESCPAGRRPARAAQTCARRQHGLPGCEEAGTARVPSLHLHLHQAALGAGRGRGWGEACAQVPPSRGHYKLIQQPISLFSITDRLHKTFSQLPSVHLCSITFQWGHPPIFCSTNDICVTANFCISVTFLKPCFLLHEASASQFKKFDGPCGERGGGRTARALWARGDSVLTPALDPQTPVRAPSLTRAAAAVGVPGDSTRRAVRRMNTFCGASACDVSLIAMDSACEERGAAGSLISCESLYHREKQLIAMDSAIFVQGKDWGVKKFIRRDFTMPAILKLQKNCLLSLNSKMALNSEALSVVSEYEAGMTLGEKFRVGNCKHLKMTRPTEYNQKLQVNQFSESKRTALTHNQDFSIYRLCCKRGSLCHASQARSPAFPKPVRPLPAPITRITPQLGGQSDSSQPLLTTGRPQGWQDQALRHTQQASPASCATITIPIHSAALGDHSGDPGPAWDTCPPLPLTTLIPRAPPPYGDSTARSWPSRCGPLGYAYKDFLWCFPFSLVFLQEIQICCHVSCLCCICCSTRICLGCLLELFLSRALRALHVLWNGFQLHCQGNTTLQQLGEASQAPSGSLIPLRLPLLWEVRGNSKMALNSLNSIDDAQLTRIAPPRSHCCFWEVNAPFVQGKDWGLKKFIRRDFEAFQRAAGEGGPGRGGARRGARVLQSPFCRAGAGEWLGHQSLRWGMELAASRRFSWDHHSAGGPPRVPSVRSGAAQVQPKDPLPLRTLAGCLARTAHLRPGAESLPQPQLHCTIARELHQFAFDLLIKSHKMHFSLKEHPPPPCPPHVVGYGHLDTSGSSSSSSWPQPDSFAALHSSLNELGELWFQSSELSPTGAPWPSRRPTWRGTTVSPRTATSSARTCCGTKWPSSQEAALGLGSGLLRFSCGTAAIR
neoMVA 발현 카세트 폴리뉴클레오티드 서열 번호 553
gatcactaattccaaacccacccgctttttatagtaagtttttcacccataaataataaatacaataattaatttctcgtaaaagtagaaaatatattctaatttattgcacggtaaggaagtagaatcataaagaacagtgacGGATCCCGCGACTTCGCCGCCATGGGCCAGAAAGAGCAGATCCACACACTGCAGAAAAACAGCGAGCGGATGAGCAAGCAGCTGACCAGATCTTCTCAGGCCGTGCAGAACCTGCAGAACGGCGGAGGCTCTAGAAGCTCTGCTACACTTCCTGGCAGGCGGCGGAGAAGATGGCTGAGAAGAAGGCGGCAGCCTATCTCTGTGGCTCCTGCTGGACCTCCTAGACGGCCCAACCAGAAGCCTAATCCTCCTGGCGGAGCCAGATGCGTGATCATGAGGCCTACATGGCCTGGCACCAGCGCCTTTACCGGCATGGAATGTACACTGGGCCAAGTGGGAGCCCCATCTCCTAGAAGAGAAGAGGATGGCTGGCGCGGAGGCCACTCTAGATTCAAAGCTGATGTGCCCGCTCCTCAGGGCCCTTGTTGGGGAGGACAACCTGGATCTGCCCCATCTTCTGCCCCACCTGAACAGAGCCTGCTGGATGACTATTGGGCTCAAAAAGAGAAGATCAGCATCCCCAGAACACACCTGTGCTGGAAGTTCGAGATGAGCTACACCGTTGGCGGCCCTCCACCACATGTTCACGCCAGACCTAGACACTGGAAAACCGACAGAGATTATTGGGCCCAGAAAGAAAAGGGCAGCAGCAGCTTCCTGCGGCCTAGCTGTGTGCCCTTCCGGGAACTGAAGAACGTGTCCGTTCTGGAAGGCCTGAGGCAGGGCAGACTTGGCGGACCTTGTAGCTGCCACTGTCCTAGACCAAGCCAGGCCAGACTGACCCCTGTGGATGTGGCTGGCCCATTTCTGTGTCTGGGCGACCCTGGACTGTTCCCTCCAGTGAAGTCTAGCATCACCGAGATCAGCTGCTGCACCCTGAGCAGCGAGGAAAACGAGTACCTGCCTAGACCTGAATGGCAGCTGCAGTACGAGGCCGGCATGACACTCGGAGGCAAGATCCTGTTCTTCCTGTTCCTGCTGCTCCCTCTGAGCCCCTTCAGCCTGATCTTTCTGGTGCTGGGCGTGCTGTCTGGCCACTCTGGAAGCAGACTGAAGAGAAGCTTCGCCGTGACCGAGCGGATCATCACAGGCGGCAAGAGCACATGTTCTGCCCCTGGACCTCAGTCTCTGCCCAGCACACCCTTCAGCACATACCCTCAGTGGGTCATCCTGATCACCGAGCTGGATGGCCACAGCTACACCAGCAAAGTGAACTGCCTCCTGCTGCAGGATGGCTTCCACGGCTGTGTGTCTATTACTGGCGCCGCTGGCAGACGGAACCTGAGCATCTTTCTGTTTCTGATGCTGTGCAAGCTCGAGTTCCACGCCTGCCAATGGCAGCACTACCACAGATCTGGCGAAGCCGCTGGAACCCCACTTTGGAGGCCTACCAGAAACGTGGCCATGATGGTGCCCGACAGACAGGTGCACTACGACTTCGGCCTGAAGATCCAGAACAAGAACTGCCCCGACGTGCTGCGGTTCCTGGATCTCAAAGTGCGCTACCTGCACAGCGTGCCCTTCAGAGAGCTGAAAAACCAGAGAACAGCCCAGGGCGCTCCTGGAATCCATCATGCTGCTTCTCCAGTGGCCGCCAATCTGTGCGATCCTGCCAGACATGCCCAGCATACCAGGATTCCTTGTGGCGCTGGACAAGTGCGCGCTGGAAGAGGACCTGAAGCTGGTGGCGGAGTTCTGCAGCCTCAAAGACCTGCTCCTGAGAAGCCTGGCTGCCCCTGTAGAAGAGGACAGCCTAGACTGCACACCGTGAAGATGTGGCGGGCCTGCCACTTGTTTCTCCAGCCACAAGTGGGCACCCCTCCACCTCATACAGCCTCTGCTAGAGCACCTAGCGGCCCACCTCATCCTCACGAATCTTGTCCTGCCGGAAGAAGGCCTGCCAGAGCCGCTCAAACATGTGCCAGACGACAGCACGGACTGCCCGGATGTGAAGAAGCCGGAACAGCCAGAGTGCCTAGCCTGCACCTTCATCTGCATCAGGCCGCTCTTGGAGCCGGAAGAGGTAGAGGATGGGGAGAAGCTTGTGCCCAGGTGCCACCTTCTAGAGGCCACTACAAGCTGATCCAGCAGCCAATCAGCCTGTTCTCCATCACCGACCGGCTGCACAAGACATTCAGCCAGCTGCCTTCCGTGCATCTGTGCAGCATCACCTTCCAGTGGGGACACCCTCCTATCTTTTGCTCCACCAACGACATCTGCGTGACCGCCAACTTCTGTATCAGCGTGACCTTCCTGAAGCCTTGCTTTCTGCTGCACGAGGCCTCCGCCAGCCAGTTTAAGAAGTTTGACGGCCCCTGCGGCGAGAGAGGCGGAGGAAGAACTGCAAGAGCCCTTTGGGCCAGAGGCGACTCTGTTCTGACACCAGCTCTGGACCCTCAGACACCTGTTAGGGCCCCTAGCCTGACAAGAGCTGCCGCTGCTGTTGGAGTGCCTGGCGATTCTACTAGAAGGGCCGTGCGGCGGATGAACACCTTTTGTGGCGCATCTGCCTGCGACGTGTCCCTGATCGCTATGGATAGCGCCTGCGAGGAAAGAGGCGCAGCCGGATCTCTGATCTCTTGCGAGAGCCTGTACCACCGGGAAAAGCAGCTCATTGCCATGGACAGCGCCATCTTCGTGCAGGGCAAAGACTGGGGCGTGAAGAAGTTCATCCGGCGGGACTTTACCATGCCTGCCATTCTGAAGCTGCAGAAGAATTGTCTTCTAAGCCTGAACAGCAAGATGGCCCTGAATAGCGAGGCCCTGTCTGTGGTGTCCGAGTATGAGGCTGGAATGACCCTGGGCGAGAAGTTCAGAGTGGGCAACTGCAAGCACCTGAAGATGACCCGGCCTACCGAGTACAACCAGAAACTGCAAGTGAACCAGTTCAGCGAGAGCAAGCGGACCGCTCTGACCCACAACCAGGACTTCAGCATCTACCGGCTGTGCTGCAAGAGGGGCTCTCTGTGTCATGCTAGCCAGGCTAGAAGCCCCGCCTTTCCTAAGCCTGTCAGACCTCTGCCTGCTCCTATCACCAGAATCACCCCTCAGCTCGGCGGCCAGTCTGATTCATCTCAGCCACTGCTGACCACCGGCAGACCTCAAGGATGGCAAGACCAGGCTCTGAGACACACACAGCAGGCTAGCCCAGCCTCTTGCGCCACCATCACAATACCAATACATTCTGCCGCTCTGGGCGATCACAGCGGAGATCCTGGACCTGCCTGGGATACTTGTCCTCCTCTGCCCCTAACTACACTGATCCCTAGGGCTCCTCCACCTTACGGCGATAGCACAGCCAGATCCTGGCCTAGCAGATGTGGCCCTCTGGGCTACGCCTACAAGGACTTCCTGTGGTGCTTCCCCTTCTCTCTGGTGTTCCTGCAAGAAATCCAGATCTGCTGTCACGTGTCCTGCCTGTGCTGTATCTGCTGTAGCACCCGGATCTGTCTGGGCTGTCTGCTGGAACTGTTCCTGAGCAGAGCCCTGAGAGCACTGCACGTGCTGTGGAACGGATTCCAGCTGCACTGCCAGGGCAACACCACACTGCAACAGCTGGGAGAAGCCTCTCAGGCCCCAAGCGGTTCTCTGATCCCTCTCAGACTGCCCCTCCTGTGGGAAGTGCGGGGCAATTCTAAGATGGCTCTCAACAGCCTGAACTCCATCGACGACGCCCAGCTGACAAGAATCGCCCCTCCAAGAAGCCACTGTTGCTTTTGGGAAGTGAACGCCCCTTTTGTGCAGGGTAAAGATTGGGGCCTCAAAAAGTTTATCAGACGGGACTTCGAGGCTTTCCAGAGAGCAGCTGGCGAAGGCGGACCTGGCAGAGGTGGTGCTAGAAGAGGTGCTAGAGTGCTGCAGAGCCCATTCTGTAGAGCTGGCGCTGGCGAATGGCTGGGCCACCAATCTCTTAGATGGGGAATGGAACTGGCCGCTAGCAGGCGGTTTAGCTGGGATCATCATTCTGCCGGCGGACCTCCAAGAGTGCCAAGCGTTAGAAGCGGAGCAGCCCAGGTCCAGCCTAAAGATCCACTGCCACTGAGAACACTGGCCGGCTGCCTTGCCAGAACAGCTCATCTTAGACCTGGCGCCGAAAGCCTGCCTCAACCTCAGCTGCATTGCACAATCGCCAGAGAACTGCACCAGTTCGCCTTCGACCTGCTGATCAAGAGCCACAAGATGCACTTCTCACTGAAAGAGCACCCGCCACCGCCGTGCCCACCGCACGTTGTCGGCTATGGCCACCTGGATACAAGCGGCTCCTCTAGCAGTAGCTCCTGGCCTCAGCCTGACAGCTTTGCTGCCCTGCATAGCTCCCTGAATGAGCTGGGCGAACTGTGGTTCCAGTCCAGCGAACTGTCTCCTACTGGCGCTCCATGGCCAAGCAGAAGGCCTACTTGGAGAGGCACCACCGTGTCTCCAAGAACCGCTACAAGCAGCGCCAGAACCTGTTGCGGCACAAAATGGCCCTCCAGCCAAGAAGCTGCCCTCGGACTTGGAAGCGGACTGCTGAGATTCAGCTGTGGCACAGCCGCCATCAGAAGCCATCACCATCACCACCATTAGTAAAGGCGCGCC
GAd20 발현을 위한 추가의 5개의 신생항원 레이아웃의 아미노산 서열이 서열 번호 554, 555, 556, 623 및 624에 나타나 있다.
서열 번호 554
MGQKEQIHTLQKNSERMSKQLTRSSQAVQNLQNGGGSRSSATLPGRRRRRWLRRRRQPISVAPAGPPRRPNQKPNPPGGARCVIMRPTWPGTSAFTKRSFAVTERIILVLGVLSGHSGSRLYEAGMTLGGKILFFLFLLLPLSPFSLIFTEISCCTLSSEENEYLPRPEWQLQVPFRELKNVSVLEGLRQGRLGGPCSCHCPRPSQARLTPVDVAGPFLCLGDPGLFPPVKSSITGGKSTCSAPGPQSLPSTPFSTYPQWVILITELGMECTLGQVGAPSPRREEDGWRGGHSRFKADVPAPQGPCWGGQPGSAPSSAPPEQSLLDDYWAQKEKGSSSFLRPSCDYWAQKEKISIPRTHLCWKFEMSYTVGGPPPHVHARPRHWKTDRGVPGDSTRRAVRRMNTFYEAGMTLGEKFRVGNCKHLKMTRPNSKMALNSEALSVVSECGASACDVSLIAMDSAFVQGKDWGVKKFIRRDFYAYKDFLWCFPFSLVFLQEIQICCHVSCLCCICCSTRICLGCLLELFLSRALRALHVLWNGFQLHCQTEYNQKLQVNQFSESKSLYHREKQLIAMDSAICEERGAAGSLISCETMPAILKLQKNCLLSLRTALTHNQDFSIYRLCCKRGSLCHASQARSPAFPKPVRPLPAPITRITPQLGGQSDSSQPLLTTGRPQGWQDQALRHTQQASPASCATITIPIHSAALGDHSGDPGPAWDTCPPLPLTTLIPRAPPPYGDSTARSWPSRCGPLGDGHSYTSKVNCLLLQDGFHGCVSITGAAGRRNLSIFLFLMLCKLEFHACKIQNKNCPDFKKFDGPCGERGGGRTARALWARGDSVLTPALDPQTPVRAPSLTRAAAAVHYKLIQQPISLFSITDRLHKTFSQLPSVHLCSITFQWGHPPIFCSTNDICVTANFCISVTFLKPCFLLHEASASQCHLFLQPQVGTPPPHTASARAPSGPPHPHESCPAGRRPARAAQTCARRQHGLPGCEEAGTARVPSLHLHLHQAALGAGRGRGWGEACAQVPPSRGVLRFLDLKVRYLHSQWQHYHRSGEAAGTPLWRPTRNVPFRELKNQRTAQGAPGIHHAASPVAANLCDPARHAQHTRIPCGAGQVRAGRGPEAGGGVLQPQRPAPEKPGCPCRRGQPRLHTVKMWRAVAMMVPDRQVHYDFGLGNTTLQQLGEASQAPSGSLIPLRLPLLWEVRGQPDSFAALHSSLNELGEIARELHQFAFDLLIKSHFVQGKDWGLKKFIRRDFWGMELAASRRFSWDHHSAGGPPRVPSVRSGAAQVQPKDPLPLRTLAGCLARTAHLRPGAESLPQPQLHCTLWFQSSELSPTGAPWPSRRPTWRGTTVSPRTATSSARTCCGTKWPSSQEAALGLGSGLLRFSCGTAAIRKMHFSLKEHPPPPCPPEAFQRAAGEGGPGRGGARRGARVLQSPFCRAGAGEWLGHQSLRHVVGYGHLDTSGSSSSSSWPNSKMALNSLNSIDDAQLTRIAPPRSHCCFWEVNAP
서열 번호 555
MGQKEQIHTLQKNSERMSKQLTRSSQAVQNLQNGGGSRSSATLPGRRRRRWLRRRRQPISVAPAGPPRRPNQKPNPPGGARCVIMRPTWPGTSAFTKRSFAVTERIITEISCCTLSSEENEYLPRPEWQLQYEAGMTLGGKILFFLFLLLPLSPFSLIFDYWAQKEKGSSSFLRPSCVPFRELKNVSVLEGLRQGRLGGPCSCHCPRPSQARLTPVDVAGPFLCLGDPGLFPPVKSSITGGKSTCSAPGPQSLPSTPFSTYPQWVILITELGMECTLGQVGAPSPRREEDGWRGGHSRFKADVPAPQGPCWGGQPGSAPSSAPPEQSLLDDYWAQKEKISIPRTHLCLVLGVLSGHSGSRLWKFEMSYTVGGPPPHVHARPRHWKTDRDGHSYTSKVNCLLLQDGFHGCVSITGAAGRRNLSIFLFLMLCKLEFHACKIQNKNCPDFKKFDGPCGERGGGRTARALWARGDSVLTPALDPQTPVRAPSLTRAAAAVHYKLIQQPISLFSITDRLHKTFSQLPSVHLCSITFQWGHPPIFCSTNDICVTANFCISVTFLKPCFLLHEASASQCHLFLQPQVGTPPPHTASARAPSGPPHPHESCPAGRRPARAAQTCARRQHGLPGCEEAGTARVPSLHLHLHQAALGAGRGRGWGEACAQVPPSRGVLRFLDLKVRYLHSQWQHYHRSGEAAGTPLWRPTRNVPFRELKNQRTAQGAPGIHHAASPVAANLCDPARHAQHTRIPCGAGQVRAGRGPEAGGGVLQPQRPAPEKPGCPCRRGQPRLHTVKMWRAVAMMVPDRQVHYDFGLGVPGDSTRRAVRRMNTFYEAGMTLGEKFRVGNCKHLKMTRPNSKMALNSEALSVVSECGASACDVSLIAMDSAFVQGKDWGVKKFIRRDFYAYKDFLWCFPFSLVFLQEIQICCHVSCLCCICCSTRICLGCLLELFLSRALRALHVLWNGFQLHCQTEYNQKLQVNQFSESKSLYHREKQLIAMDSAICEERGAAGSLISCETMPAILKLQKNCLLSLRTALTHNQDFSIYRLCCKRGSLCHASQARSPAFPKPVRPLPAPITRITPQLGGQSDSSQPLLTTGRPQGWQDQALRHTQQASPASCATITIPIHSAALGDHSGDPGPAWDTCPPLPLTTLIPRAPPPYGDSTARSWPSRCGPLGGNTTLQQLGEASQAPSGSLIPLRLPLLWEVRGQPDSFAALHSSLNELGEIARELHQFAFDLLIKSHFVQGKDWGLKKFIRRDFWGMELAASRRFSWDHHSAGGPPRVPSVRSGAAQVQPKDPLPLRTLAGCLARTAHLRPGAESLPQPQLHCTLWFQSSELSPTGAPWPSRRPTWRGTTVSPRTATSSARTCCGTKWPSSQEAALGLGSGLLRFSCGTAAIRKMHFSLKEHPPPPCPPEAFQRAAGEGGPGRGGARRGARVLQSPFCRAGAGEWLGHQSLRHVVGYGHLDTSGSSSSSSWPNSKMALNSLNSIDDAQLTRIAPPRSHCCFWEVNAP
서열 번호 556
MGQKEQIHTLQKNSERMSKQLTRSSQAVQNLQNGGGSRSSATLPGRRRRRWLRRRRQPISVAPAGPPRRPNQKPNPPGGARCVIMRPTWPGTSAFTKRSFAVTERIIDYWAQKEKGSSSFLRPSCVPFRELKNVSVLEGLRQGRLGGPCSCHCPRPSQARLTPVDVAGPFLCLGDPGLFPPVKSSILVLGVLSGHSGSRLYEAGMTLGGKILFFLFLLLPLSPFSLIFTEISCCTLSSEENEYLPRPEWQLQTGGKSTCSAPGPQSLPSTPFSTYPQWVILITELGMECTLGQVGAPSPRREEDGWRGGHSRFKADVPAPQGPCWGGQPGSAPSSAPPEQSLLDDYWAQKEKISIPRTHLCWKFEMSYTVGGPPPHVHARPRHWKTDRDGHSYTSKVNCLLLQDGFHGCVSITGAAGRRNLSIFLFLMLCKLEFHACKIQNKNCPDFKKFDGPCGERGGGRTARALWARGDSVLTPALDPQTPVRAPSLTRAAAAVHYKLIQQPISLFSITDRLHKTFSQLPSVHLCSITFQWGHPPIFCSTNDICVTANFCISVTFLKPCFLLHEASASQCHLFLQPQVGTPPPHTASARAPSGPPHPHESCPAGRRPARAAQTCARRQHGLPGCEEAGTARVPSLHLHLHQAALGAGRGRGWGEACAQVPPSRGVLRFLDLKVRYLHSQWQHYHRSGEAAGTPLWRPTRNVPFRELKNQRTAQGAPGIHHAASPVAANLCDPARHAQHTRIPCGAGQVRAGRGPEAGGGVLQPQRPAPEKPGCPCRRGQPRLHTVKMWRAVAMMVPDRQVHYDFGLGVPGDSTRRAVRRMNTFYEAGMTLGEKFRVGNCKHLKMTRPNSKMALNSEALSVVSECGASACDVSLIAMDSAFVQGKDWGVKKFIRRDFYAYKDFLWCFPFSLVFLQEIQICCHVSCLCCICCSTRICLGCLLELFLSRALRALHVLWNGFQLHCQTEYNQKLQVNQFSESKSLYHREKQLIAMDSAICEERGAAGSLISCETMPAILKLQKNCLLSLRTALTHNQDFSIYRLCCKRGSLCHASQARSPAFPKPVRPLPAPITRITPQLGGQSDSSQPLLTTGRPQGWQDQALRHTQQASPASCATITIPIHSAALGDHSGDPGPAWDTCPPLPLTTLIPRAPPPYGDSTARSWPSRCGPLGGNTTLQQLGEASQAPSGSLIPLRLPLLWEVRGQPDSFAALHSSLNELGEIARELHQFAFDLLIKSHFVQGKDWGLKKFIRRDFWGMELAASRRFSWDHHSAGGPPRVPSVRSGAAQVQPKDPLPLRTLAGCLARTAHLRPGAESLPQPQLHCTLWFQSSELSPTGAPWPSRRPTWRGTTVSPRTATSSARTCCGTKWPSSQEAALGLGSGLLRFSCGTAAIRKMHFSLKEHPPPPCPPEAFQRAAGEGGPGRGGARRGARVLQSPFCRAGAGEWLGHQSLRHVVGYGHLDTSGSSSSSSWPNSKMALNSLNSIDDAQLTRIAPPRSHCCFWEVNAP
서열 번호 623
MGQKEQIHTLQKNSERMSKQLTRSSQAVGVPGDSTRRAVRRMNTFYEAGMTLGEKFRVGNCKHLKMTRPNSKMALNSEALSVVSECGASACDVSLIAMDSAFVQGKDWGVKKFIRRDFYAYKDFLWCFPFSLVFLQEIQICCHVSCLCCICCSTRICLGCLLELFLSRALRALHVLWNGFQLHCQTEYNQKLQVNQFSESKSLYHREKQLIAMDSAICEERGAAGSLISCETMPAILKLQKNCLLSLRTALTHNQDFSIYRLCCKRGSLCHASQARSPAFPKPVRPLPAPITRITPQLGGQSDSSQPLLTTGRPQGWQDQALRHTQQASPASCATITIPIHSAALGDHSGDPGPAWDTCPPLPLTTLIPRAPPPYGDSTARSWPSRCGPLGGNTTLQQLGEASQAPSGSLIPLRLPLLWEVRGQPDSFAALHSSLNELGEIARELHQFAFDLLIKSHFVQGKDWGLKKFIRRDFWGMELAASRRFSWDHHSAGGPPRVPSVRSGAAQVQPKDPLPLRTLAGCLARTAHLRPGAESLPQPQLHCTLWFQSSELSPTGAPWPSRRPTWRGTTVSPRTATSSARTCCGTKWPSSQEAALGLGSGLLRFSCGTAAIRKMHFSLKEHPPPPCPPEAFQRAAGEGGPGRGGARRGARVLQSPFCRAGAGEWLGHQSLRHVVGYGHLDTSGSSSSSSWPNSKMALNSLNSIDDAQLTRIAPPRSHCCFWEVNAPDGHSYTSKVNCLLLQDGFHGCVSITGAAGRRNLSIFLFLMLCKLEFHACKIQNKNCPDFKKFDGPCGERGGGRTARALWARGDSVLTPALDPQTPVRAPSLTRAAAAVHYKLIQQPISLFSITDRLHKTFSQLPSVHLCSITFQWGHPPIFCSTNDICVTANFCISVTFLKPCFLLHEASASQCHLFLQPQVGTPPPHTASARAPSGPPHPHESCPAGRRPARAAQTCARRQHGLPGCEEAGTARVPSLHLHLHQAALGAGRGRGWGEACAQVPPSRGVLRFLDLKVRYLHSQWQHYHRSGEAAGTPLWRPTRNVPFRELKNQRTAQGAPGIHHAASPVAANLCDPARHAQHTRIPCGAGQVRAGRGPEAGGGVLQPQRPAPEKPGCPCRRGQPRLHTVKMWRAVAMMVPDRQVHYDFGLQNLQNGGGSRSSATLPGRRRRRWLRRRRQPISVAPAGPPRRPNQKPNPPGGARCVIMRPTWPGTSAFTKRSFAVTERIILVLGVLSGHSGSRLYEAGMTLGGKILFFLFLLLPLSPFSLIFTEISCCTLSSEENEYLPRPEWQLQVPFRELKNVSVLEGLRQGRLGGPCSCHCPRPSQARLTPVDVAGPFLCLGDPGLFPPVKSSITGGKSTCSAPGPQSLPSTPFSTYPQWVILITELGMECTLGQVGAPSPRREEDGWRGGHSRFKADVPAPQGPCWGGQPGSAPSSAPPEQSLLDDYWAQKEKGSSSFLRPSCDYWAQKEKISIPRTHLCWKFEMSYTVGGPPPHVHARPRHWKTDR
서열 번호 624
MGQKEQIHTLQKNSERMSKQLTRSSQAVGNTTLQQLGEASQAPSGSLIPLRLPLLWEVRGQPDSFAALHSSLNELGEIARELHQFAFDLLIKSHFVQGKDWGLKKFIRRDFWGMELAASRRFSWDHHSAGGPPRVPSVRSGAAQVQPKDPLPLRTLAGCLARTAHLRPGAESLPQPQLHCTLWFQSSELSPTGAPWPSRRPTWRGTTVSPRTATSSARTCCGTKWPSSQEAALGLGSGLLRFSCGTAAIRKMHFSLKEHPPPPCPPEAFQRAAGEGGPGRGGARRGARVLQSPFCRAGAGEWLGHQSLRHVVGYGHLDTSGSSSSSSWPNSKMALNSLNSIDDAQLTRIAPPRSHCCFWEVNAPGVPGDSTRRAVRRMNTFYEAGMTLGEKFRVGNCKHLKMTRPNSKMALNSEALSVVSECGASACDVSLIAMDSAFVQGKDWGVKKFIRRDFYAYKDFLWCFPFSLVFLQEIQICCHVSCLCCICCSTRICLGCLLELFLSRALRALHVLWNGFQLHCQTEYNQKLQVNQFSESKSLYHREKQLIAMDSAICEERGAAGSLISCETMPAILKLQKNCLLSLRTALTHNQDFSIYRLCCKRGSLCHASQARSPAFPKPVRPLPAPITRITPQLGGQSDSSQPLLTTGRPQGWQDQALRHTQQASPASCATITIPIHSAALGDHSGDPGPAWDTCPPLPLTTLIPRAPPPYGDSTARSWPSRCGPLGDGHSYTSKVNCLLLQDGFHGCVSITGAAGRRNLSIFLFLMLCKLEFHACKIQNKNCPDFKKFDGPCGERGGGRTARALWARGDSVLTPALDPQTPVRAPSLTRAAAAVHYKLIQQPISLFSITDRLHKTFSQLPSVHLCSITFQWGHPPIFCSTNDICVTANFCISVTFLKPCFLLHEASASQCHLFLQPQVGTPPPHTASARAPSGPPHPHESCPAGRRPARAAQTCARRQHGLPGCEEAGTARVPSLHLHLHQAALGAGRGRGWGEACAQVPPSRGVLRFLDLKVRYLHSQWQHYHRSGEAAGTPLWRPTRNVPFRELKNQRTAQGAPGIHHAASPVAANLCDPARHAQHTRIPCGAGQVRAGRGPEAGGGVLQPQRPAPEKPGCPCRRGQPRLHTVKMWRAVAMMVPDRQVHYDFGLQNLQNGGGSRSSATLPGRRRRRWLRRRRQPISVAPAGPPRRPNQKPNPPGGARCVIMRPTWPGTSAFTKRSFAVTERIITEISCCTLSSEENEYLPRPEWQLQYEAGMTLGGKILFFLFLLLPLSPFSLIFDYWAQKEKGSSSFLRPSCVPFRELKNVSVLEGLRQGRLGGPCSCHCPRPSQARLTPVDVAGPFLCLGDPGLFPPVKSSITGGKSTCSAPGPQSLPSTPFSTYPQWVILITELGMECTLGQVGAPSPRREEDGWRGGHSRFKADVPAPQGPCWGGQPGSAPSSAPPEQSLLDDYWAQKEKISIPRTHLCLVLGVLSGHSGSRLWKFEMSYTVGGPPPHVHARPRHWKTDR
MVA 발현을 위한 추가의 5개의 신생항원 레이아웃의 아미노산 서열이 서열 번호 557, 558, 559, 625 및 626에 나타나 있다.
서열 번호 557
MGQKEQIHTLQKNSERMSKQLTRSSQAVQNLQNGGGSRSSATLPGRRRRRWLRRRRQPISVAPAGPPRRPNQKPNPPGGARCVIMRPTWPGTSAFTGMECTLGQVGAPSPRREEDGWRGGHSRFKADVPAPQGPCWGGQPGSAPSSAPPEQSLLDDYWAQKEKISIPRTHLCWKFEMSYTVGGPPPHVHARPRHWKTDRDYWAQKEKGSSSFLRPSCVPFRELKNVSVLEGLRQGRLGGPCSCHCPRPSQARLTPVDVAGPFLCLGDPGLFPPVKSSITEISCCTLSSEENEYLPRPEWQLQYEAGMTLGGKILFFLFLLLPLSPFSLIFLVLGVLSGHSGSRLKRSFAVTERIITGGKSTCSAPGPQSLPSTPFSTYPQWVILITELDGHSYTSKVNCLLLQDGFHGCVSITGAAGRRNLSIFLFLMLCKLEFHACCHLFLQPQVGTPPPHTASARAPSGPPHPHESCPAGRRPARAAQTCARRQHGLPGCEEAGTARVPSLHLHLHQAALGAGRGRGWGEACAQVPPSRGHYKLIQQPISLFSITDRLHKTFSQLPSVHLCSITFQWGHPPIFCSTNDICVTANFCISVTFLKPCFLLHEASASQVAMMVPDRQVHYDFGLKIQNKNCPDVLRFLDLKVRYLHSVPFRELKNQRTAQGAPGIHHAASPVAANLCDPARHAQHTRIPCGAGQVRAGRGPEAGGGVLQPQRPAPEKPGCPCRRGQPRLHTVKMWRAQWQHYHRSGEAAGTPLWRPTRNFKKFDGPCGERGGGRTARALWARGDSVLTPALDPQTPVRAPSLTRAAAAVGVPGDSTRRAVRRMNTFCGASACDVSLIAMDSACEERGAAGSLISCESLYHREKQLIAMDSAIFVQGKDWGVKKFIRRDFTMPAILKLQKNCLLSLNSKMALNSEALSVVSEYEAGMTLGEKFRVGNCKHLKMTRPTEYNQKLQVNQFSESKRTALTHNQDFSIYRLCCKRGSLCHASQARSPAFPKPVRPLPAPITRITPQLGGQSDSSQPLLTTGRPQGWQDQALRHTQQASPASCATITIPIHSAALGDHSGDPGPAWDTCPPLPLTTLIPRAPPPYGDSTARSWPSRCGPLGYAYKDFLWCFPFSLVFLQEIQICCHVSCLCCICCSTRICLGCLLELFLSRALRALHVLWNGFQLHCQGNTTLQQLGEASQAPSGSLIPLRLPLLWEVRGNSKMALNSLNSIDDAQLTRIAPPRSHCCFWEVNAPFVQGKDWGLKKFIRRDFEAFQRAAGEGGPGRGGARRGARVLQSPFCRAGAGEWLGHQSLRWGMELAASRRFSWDHHSAGGPPRVPSVRSGAAQVQPKDPLPLRTLAGCLARTAHLRPGAESLPQPQLHCTIARELHQFAFDLLIKSHKMHFSLKEHPPPPCPPHVVGYGHLDTSGSSSSSSWPQPDSFAALHSSLNELGELWFQSSELSPTGAPWPSRRPTWRGTTVSPRTATSSARTCCGTKWPSSQEAALGLGSGLLRFSCGTAAIR
서열 번호 558
MGQKEQIHTLQKNSERMSKQLTRSSQAVDGHSYTSKVNCLLLQDGFHGCVSITGAAGRRNLSIFLFLMLCKLEFHACQWQHYHRSGEAAGTPLWRPTRNVAMMVPDRQVHYDFGLVLRFLDLKVRYLHSKIQNKNCPDVPFRELKNQRTAQGAPGIHHAASPVAANLCDPARHAQHTRIPCGAGQVRAGRGPEAGGGVLQPQRPAPEKPGCPCRRGQPRLHTVKMWRACHLFLQPQVGTPPPHTASARAPSGPPHPHESCPAGRRPARAAQTCARRQHGLPGCEEAGTARVPSLHLHLHQAALGAGRGRGWGEACAQVPPSRGHYKLIQQPISLFSITDRLHKTFSQLPSVHLCSITFQWGHPPIFCSTNDICVTANFCISVTFLKPCFLLHEASASQFKKFDGPCGERGGGRTARALWARGDSVLTPALDPQTPVRAPSLTRAAAAVQNLQNGGGSRSSATLPGRRRRRWLRRRRQPISVAPAGPPRRPNQKPNPPGGARCVIMRPTWPGTSAFTGMECTLGQVGAPSPRREEDGWRGGHSRFKADVPAPQGPCWGGQPGSAPSSAPPEQSLLDDYWAQKEKISIPRTHLCWKFEMSYTVGGPPPHVHARPRHWKTDRDYWAQKEKGSSSFLRPSCVPFRELKNVSVLEGLRQGRLGGPCSCHCPRPSQARLTPVDVAGPFLCLGDPGLFPPVKSSITEISCCTLSSEENEYLPRPEWQLQYEAGMTLGGKILFFLFLLLPLSPFSLIFLVLGVLSGHSGSRLKRSFAVTERIITGGKSTCSAPGPQSLPSTPFSTYPQWVILITELGVPGDSTRRAVRRMNTFCGASACDVSLIAMDSACEERGAAGSLISCESLYHREKQLIAMDSAIFVQGKDWGVKKFIRRDFTMPAILKLQKNCLLSLNSKMALNSEALSVVSEYEAGMTLGEKFRVGNCKHLKMTRPTEYNQKLQVNQFSESKRTALTHNQDFSIYRLCCKRGSLCHASQARSPAFPKPVRPLPAPITRITPQLGGQSDSSQPLLTTGRPQGWQDQALRHTQQASPASCATITIPIHSAALGDHSGDPGPAWDTCPPLPLTTLIPRAPPPYGDSTARSWPSRCGPLGYAYKDFLWCFPFSLVFLQEIQICCHVSCLCCICCSTRICLGCLLELFLSRALRALHVLWNGFQLHCQGNTTLQQLGEASQAPSGSLIPLRLPLLWEVRGNSKMALNSLNSIDDAQLTRIAPPRSHCCFWEVNAPFVQGKDWGLKKFIRRDFEAFQRAAGEGGPGRGGARRGARVLQSPFCRAGAGEWLGHQSLRWGMELAASRRFSWDHHSAGGPPRVPSVRSGAAQVQPKDPLPLRTLAGCLARTAHLRPGAESLPQPQLHCTIARELHQFAFDLLIKSHKMHFSLKEHPPPPCPPHVVGYGHLDTSGSSSSSSWPQPDSFAALHSSLNELGELWFQSSELSPTGAPWPSRRPTWRGTTVSPRTATSSARTCCGTKWPSSQEAALGLGSGLLRFSCGTAAIR
서열 번호 559
MGQKEQIHTLQKNSERMSKQLTRSSQAVGNTTLQQLGEASQAPSGSLIPLRLPLLWEVRGNSKMALNSLNSIDDAQLTRIAPPRSHCCFWEVNAPFVQGKDWGLKKFIRRDFEAFQRAAGEGGPGRGGARRGARVLQSPFCRAGAGEWLGHQSLRWGMELAASRRFSWDHHSAGGPPRVPSVRSGAAQVQPKDPLPLRTLAGCLARTAHLRPGAESLPQPQLHCTIARELHQFAFDLLIKSHKMHFSLKEHPPPPCPPHVVGYGHLDTSGSSSSSSWPQPDSFAALHSSLNELGELWFQSSELSPTGAPWPSRRPTWRGTTVSPRTATSSARTCCGTKWPSSQEAALGLGSGLLRFSCGTAAIRDGHSYTSKVNCLLLQDGFHGCVSITGAAGRRNLSIFLFLMLCKLEFHACQWQHYHRSGEAAGTPLWRPTRNVAMMVPDRQVHYDFGLKIQNKNCPDVLRFLDLKVRYLHSVPFRELKNQRTAQGAPGIHHAASPVAANLCDPARHAQHTRIPCGAGQVRAGRGPEAGGGVLQPQRPAPEKPGCPCRRGQPRLHTVKMWRACHLFLQPQVGTPPPHTASARAPSGPPHPHESCPAGRRPARAAQTCARRQHGLPGCEEAGTARVPSLHLHLHQAALGAGRGRGWGEACAQVPPSRGHYKLIQQPISLFSITDRLHKTFSQLPSVHLCSITFQWGHPPIFCSTNDICVTANFCISVTFLKPCFLLHEASASQFKKFDGPCGERGGGRTARALWARGDSVLTPALDPQTPVRAPSLTRAAAAVGVPGDSTRRAVRRMNTFCGASACDVSLIAMDSATEYNQKLQVNQFSESKYEAGMTLGEKFRVGNCKHLKMTRPTMPAILKLQKNCLLSLNSKMALNSEALSVVSECEERGAAGSLISCESLYHREKQLIAMDSAIFVQGKDWGVKKFIRRDFRTALTHNQDFSIYRLCCKRGSLCHASQARSPAFPKPVRPLPAPITRITPQLGGQSDSSQPLLTTGRPQGWQDQALRHTQQASPASCATITIPIHSAALGDHSGDPGPAWDTCPPLPLTTLIPRAPPPYGDSTARSWPSRCGPLGYAYKDFLWCFPFSLVFLQEIQICCHVSCLCCICCSTRICLGCLLELFLSRALRALHVLWNGFQLHCQQNLQNGGGSRSSATLPGRRRRRWLRRRRQPISVAPAGPPRRPNQKPNPPGGARCVIMRPTWPGTSAFTGMECTLGQVGAPSPRREEDGWRGGHSRFKADVPAPQGPCWGGQPGSAPSSAPPEQSLLDDYWAQKEKISIPRTHLCWKFEMSYTVGGPPPHVHARPRHWKTDRDYWAQKEKGSSSFLRPSCVPFRELKNVSVLEGLRQGRLGGPCSCHCPRPSQARLTPVDVAGPFLCLGDPGLFPPVKSSITEISCCTLSSEENEYLPRPEWQLQYEAGMTLGGKILFFLFLLLPLSPFSLIFLVLGVLSGHSGSRLKRSFAVTERIITGGKSTCSAPGPQSLPSTPFSTYPQWVILITEL
서열 번호 625
MGQKEQIHTLQKNSERMSKQLTRSSQAVGNTTLQQLGEASQAPSGSLIPLRLPLLWEVRGNSKMALNSLNSIDDAQLTRIAPPRSHCCFWEVNAPFVQGKDWGLKKFIRRDFEAFQRAAGEGGPGRGGARRGARVLQSPFCRAGAGEWLGHQSLRWGMELAASRRFSWDHHSAGGPPRVPSVRSGAAQVQPKDPLPLRTLAGCLARTAHLRPGAESLPQPQLHCTIARELHQFAFDLLIKSHKMHFSLKEHPPPPCPPHVVGYGHLDTSGSSSSSSWPQPDSFAALHSSLNELGELWFQSSELSPTGAPWPSRRPTWRGTTVSPRTATSSARTCCGTKWPSSQEAALGLGSGLLRFSCGTAAIRQNLQNGGGSRSSATLPGRRRRRWLRRRRQPISVAPAGPPRRPNQKPNPPGGARCVIMRPTWPGTSAFTGMECTLGQVGAPSPRREEDGWRGGHSRFKADVPAPQGPCWGGQPGSAPSSAPPEQSLLDDYWAQKEKISIPRTHLCWKFEMSYTVGGPPPHVHARPRHWKTDRDYWAQKEKGSSSFLRPSCVPFRELKNVSVLEGLRQGRLGGPCSCHCPRPSQARLTPVDVAGPFLCLGDPGLFPPVKSSITEISCCTLSSEENEYLPRPEWQLQYEAGMTLGGKILFFLFLLLPLSPFSLIFLVLGVLSGHSGSRLKRSFAVTERIITGGKSTCSAPGPQSLPSTPFSTYPQWVILITELDGHSYTSKVNCLLLQDGFHGCVSITGAAGRRNLSIFLFLMLCKLEFHACQWQHYHRSGEAAGTPLWRPTRNVAMMVPDRQVHYDFGLVLRFLDLKVRYLHSKIQNKNCPDVPFRELKNQRTAQGAPGIHHAASPVAANLCDPARHAQHTRIPCGAGQVRAGRGPEAGGGVLQPQRPAPEKPGCPCRRGQPRLHTVKMWRACHLFLQPQVGTPPPHTASARAPSGPPHPHESCPAGRRPARAAQTCARRQHGLPGCEEAGTARVPSLHLHLHQAALGAGRGRGWGEACAQVPPSRGHYKLIQQPISLFSITDRLHKTFSQLPSVHLCSITFQWGHPPIFCSTNDICVTANFCISVTFLKPCFLLHEASASQFKKFDGPCGERGGGRTARALWARGDSVLTPALDPQTPVRAPSLTRAAAAVGVPGDSTRRAVRRMNTFCGASACDVSLIAMDSACEERGAAGSLISCESLYHREKQLIAMDSAIFVQGKDWGVKKFIRRDFTMPAILKLQKNCLLSLNSKMALNSEALSVVSEYEAGMTLGEKFRVGNCKHLKMTRPTEYNQKLQVNQFSESKRTALTHNQDFSIYRLCCKRGSLCHASQARSPAFPKPVRPLPAPITRITPQLGGQSDSSQPLLTTGRPQGWQDQALRHTQQASPASCATITIPIHSAALGDHSGDPGPAWDTCPPLPLTTLIPRAPPPYGDSTARSWPSRCGPLGYAYKDFLWCFPFSLVFLQEIQICCHVSCLCCICCSTRICLGCLLELFLSRALRALHVLWNGFQLHCQ
서열 번호 626
MGQKEQIHTLQKNSERMSKQLTRSSQAVDGHSYTSKVNCLLLQDGFHGCVSITGAAGRRNLSIFLFLMLCKLEFHACVPFRELKNQRTAQGAPGIHHAASPVAANLCDPARHAQHTRIPCGAGQVRAGRGPEAGGGVLQPQRPAPEKPGCPCRRGQPRLHTVKMWRAQWQHYHRSGEAAGTPLWRPTRNKIQNKNCPDVAMMVPDRQVHYDFGLVLRFLDLKVRYLHSCHLFLQPQVGTPPPHTASARAPSGPPHPHESCPAGRRPARAAQTCARRQHGLPGCEEAGTARVPSLHLHLHQAALGAGRGRGWGEACAQVPPSRGHYKLIQQPISLFSITDRLHKTFSQLPSVHLCSITFQWGHPPIFCSTNDICVTANFCISVTFLKPCFLLHEASASQFKKFDGPCGERGGGRTARALWARGDSVLTPALDPQTPVRAPSLTRAAAAVQNLQNGGGSRSSATLPGRRRRRWLRRRRQPISVAPAGPPRRPNQKPNPPGGARCVIMRPTWPGTSAFTGMECTLGQVGAPSPRREEDGWRGGHSRFKADVPAPQGPCWGGQPGSAPSSAPPEQSLLDDYWAQKEKISIPRTHLCWKFEMSYTVGGPPPHVHARPRHWKTDRDYWAQKEKGSSSFLRPSCVPFRELKNVSVLEGLRQGRLGGPCSCHCPRPSQARLTPVDVAGPFLCLGDPGLFPPVKSSITEISCCTLSSEENEYLPRPEWQLQYEAGMTLGGKILFFLFLLLPLSPFSLIFLVLGVLSGHSGSRLKRSFAVTERIITGGKSTCSAPGPQSLPSTPFSTYPQWVILITELGNTTLQQLGEASQAPSGSLIPLRLPLLWEVRGNSKMALNSLNSIDDAQLTRIAPPRSHCCFWEVNAPFVQGKDWGLKKFIRRDFEAFQRAAGEGGPGRGGARRGARVLQSPFCRAGAGEWLGHQSLRWGMELAASRRFSWDHHSAGGPPRVPSVRSGAAQVQPKDPLPLRTLAGCLARTAHLRPGAESLPQPQLHCTIARELHQFAFDLLIKSHKMHFSLKEHPPPPCPPHVVGYGHLDTSGSSSSSSWPQPDSFAALHSSLNELGELWFQSSELSPTGAPWPSRRPTWRGTTVSPRTATSSARTCCGTKWPSSQEAALGLGSGLLRFSCGTAAIRGVPGDSTRRAVRRMNTFCGASACDVSLIAMDSACEERGAAGSLISCESLYHREKQLIAMDSAIFVQGKDWGVKKFIRRDFYEAGMTLGEKFRVGNCKHLKMTRPTMPAILKLQKNCLLSLNSKMALNSEALSVVSETEYNQKLQVNQFSESKRTALTHNQDFSIYRLCCKRGSLCHASQARSPAFPKPVRPLPAPITRITPQLGGQSDSSQPLLTTGRPQGWQDQALRHTQQASPASCATITIPIHSAALGDHSGDPGPAWDTCPPLPLTTLIPRAPPPYGDSTARSWPSRCGPLGYAYKDFLWCFPFSLVFLQEIQICCHVSCLCCICCSTRICLGCLLELFLSRALRALHVLWNGFQLHCQ
서열 번호 713 GAd20 발현 카세트를 포함하는 전장 GAd20의 폴리뉴클레오티드 서열
catcatcaataatataccttattttggattgaggccaatatgataatgaggtgggcggggcgaggcggggcgggtgacgtaggacgcgcgagtagggttgggaggtgtggcggaagtgtggcatttgcaagtgggaggagctgacatgcaatcttccgtcgcggaaaatgtgacgtttttgatgagcgccgcctacctccggaagtgccaattttcgcgcgcttttcaccggatatcgtagtaattttgggcgggaccatgtaagatttggccattttcgcgcgaaaagtgaaacggggaagtgaaaactgaataatagggcgttagtcatagcgcgtaatatttaccgagggccgagggactttgaccgattacgtggaggactcgcccaggtgttttttacgtgaatttccgcgttccgggtcaaagtctccgtttttattgtcgccgtcatctgacgggccgccattgcatacgttgtatccatatcataatatgtacatttatattggctcatgtccaacattaccgccatgttgacattgattattgactagttattaatagtaatcaattacggggtcattagttcatagcccatatatggagttccgcgttacataacttacggtaaatggcccgcctggctgaccgcccaacgacccccgcccattgacgtcaataatgacgtatgttcccatagtaacgccaatagggactttccattgacgtcaatgggtggagtatttacggtaaactgcccacttggcagtacatcaagtgtatcatatgccaagtacgccccctattgacgtcaatgacggtaaatggcccgcctggcattatgcccagtacatgaccttatgggactttcctacttggcagtacatctacgtattagtcatcgctattaccatggtgatgcggttttggcagtacatcaatgggcgtggatagcggtttgactcacggggatttccaagtctccaccccattgacgtcaatgggagtttgttttggcaccaaaatcaacgggactttccaaaatgtcgtaacaactccgccccattgacgcaaatgggcggtaggcgtgtacggtgggaggtctatataagcagagctctccctatcagtgatagagatctccctatcagtgatagagatcgtcgacgagctcgtttagtgaaccgtcagatcgcctggagacgccatccacgctgttttgacctccatagaagacaccgggaccgatccagcctccgcggccgggaacggtgcattggaacgcggattccccgtgccaagagtgagatcttccgtttatctaggtaccagatatcagaattcggatcccgcgacttcgccgccatgggccagaaagagcagatccacacactgcagaaaaacagcgagcggatgagcaagcagctgaccagatcttctcaggccgtgcagaacctgcagaacggcggaggctctagaagctctgctacacttcctggcaggcggcggagaagatggctgagaagaaggcggcagcctatctctgtggctcctgctggacctcctagacggcccaaccagaagcctaatcctcctggcggagccagatgcgtgatcatgaggcctacatggcctggcaccagcgccttcaccaagagaagctttgccgtgaccgagcggatcatcgactattgggctcaaaaagagaagggcagcagcagcttcctgcggcctagctgtgattattgggcccagaaagaaaagatcagcatccccagaacacacctgtgcctggtgctgggagtgctgtctggacactctggcagcagactgtatgaggccggcatgacactcggcggcaagatcctgttcttcctgttcctgctgctccctctgagccccttcagcctgatcttcaccgagatcagctgctgcaccctgagcagcgaggaaaacgagtacctgcctagacctgagtggcagctgcaggtccccttcagagagctgaagaacgtttccgtgctggaaggcctgagacagggcagacttggcggcccttgtagctgtcactgccccagacctagtcaggccagactgacacctgtggatgtggccggacctttcctgtgtctgggagatcctggcctgtttccacctgtgaagtccagcatcacaggcggcaagtccacatgttctgcccctggacctcagagcctgcctagcacacccttcagcacataccctcagtgggtcatcctgatcaccgaactcggcatggaatgcaccctgggacaagtgggagccccatctcctagaagagaagaggatggctggcgcggaggccactctagattcaaagctgatgtgcccgctcctcagggcccttgttggggaggacaacctggatctgccccatcttctgccccacctgaacagtccctgctggattggaagttcgagatgagctacaccgtcggcggacctccacctcatgttcatgccagacctcggcactggaaaaccgacagagatggccacagctacaccagcaaagtgaactgcctcctgctgcaggatggcttccacggctgtgtgtctattactggcgccgctggcagacggaacctgagcatctttctgtttctgatgctgtgcaagctcgagttccacgcctgcaagatccagaacaagaactgccccgacttcaagaagttcgacggcccttgcggagaaagaggcggaggcagaacagctagagccctttgggctagaggcgacagcgttctgacaccagctctggaccctcagacacctgttagggcccctagcctgacaagagctgccgccgctgtgcactacaagctgatccagcagccaatcagcctgttcagcatcaccgaccggctgcacaagacattcagccagctgccaagcgtgcacctgtgctccatcaccttccagtggggacaccctcctatcttttgctccaccaacgacatctgcgtgaccgccaacttctgtatcagcgtgaccttcctgaagccttgctttctgctgcacgaggccagcgcctctcagtgccacttgtttctgcagccccaagtgggcacacctcctccacatacagcctctgctagagcacctagcggccctccacatcctcacgaatcttgtcctgccggaagaaggcctgccagagccgctcaaacatgtgccagacgacagcacggactgcctggatgtgaagaggctggaacagccagagtgcctagcctgcacctccatctgcatcaggctgctcttggagccggaagaggtagaggatggggcgaagcttgtgctcaggtgccaccttctagaggcgtgctgagattcctggacctgaaagtgcgctacctgcacagccagtggcagcactatcacagatctggcgaagccgccggaacacccctttggaggccaacaagaaacgtgcccttccgggaactgaagaaccagagaacagctcagggcgctcctggaatccaccatgctgcttctccagtggccgccaacctgtgtgatcctgccagacatgcccagcacaccaggattccttgtggcgctggacaagtgcgcgctggaagaggacctgaagcaggcggaggtgttctgcaacctcaaagacccgctcctgagaagcctggctgcccttgcagaagaggacagcctagactgcacaccgtgaaaatgtggcgagccgtggccatgatggtgcccgatagacaggtccactacgactttggactgggcgtgccaggcgatagcactcggagagccgtcagacggatgaacaccttttacgaagccgggatgaccctgggcgagaagttcagagtgggcaactgcaagcacctgaagatgacccggcctaacagcaagatggccctgaatagcgaggccctgtctgtggtgtctgaatgtggcgcctctgcctgtgacgtgtccctgatcgctatggactccgcctttgtgcagggcaaagactggggcgtgaagaagttcatccggcgggacttctacgcctacaaggacttcctgtggtgcttccccttctctctggtgttcctgcaagagatccagatctgctgtcatgtgtcctgcctgtgctgcatctgctgtagcaccagaatctgcctgggctgtctgctggaactgttcctgagcagagccctgagagcactgcacgtgctgtggaacggattccagctgcactgccagaccgagtacaaccagaaactgcaagtgaaccagttcagcgagagcaagagcctgtaccaccgggaaaagcagctcattgccatggacagcgccatctgcgaagagagaggcgccgcaggatctctgatctcctgcgaaacaatgcccgccatcctgaagctgcagaagaattgcctcctaagcctgcgaaccgctctgacacacaaccaggacttcagcatctacagactgtgttgcaagcggggctccctgtgccatgcaagccaagctagaagccccgcctttcctaaacctgtgcgacctctgccagctccaatcaccagaattacccctcagctcggcggccagagcgattcatctcaacctctgctgaccaccggcagacctcaaggctggcaagaccaagctctgagacacacccagcaggctagccctgcctcttgtgccaccatcacaatccccatccactctgccgctctgggcgatcattctggcgatcctggaccagcctgggacacatgtcctccactgccactcacaacactgatccctagggctcctccaccttacggcgattctaccgctagaagctggcccagcagatgtggaccactcggaggcaacacaaccctccagcaactgggagaagcctctcaggctcctagcggctctctgatccctctcagactgcctctcctgtgggaagttcggggccagcctgattcttttgccgcactgcacagctccctgaacgagctgggagagatcgctagagagctgcaccagttcgccttcgacctgctgatcaagagccacttcgtgcaaggcaaggattggggcctcaaaaagtttatccgcagagacttctggggcatggaactggccgccagcagaagattcagctgggatcatcatagcgcaggcggcccacctagagtgccatctgttagaagcggagctgcccaggtgcagcctaaagatcctctgccactgagaacactggccggctgccttgctagaacagcccatcttagacctggcgccgagtctctgcctcagccacaactgcactgtaccctgtggttccagtccagcgagctgtctcctactggtgccccttggccatctagacgccctacttggagaggcaccaccgtgtcaccaagaaccgccacaagcagcgccagaacctgttgtggcacaaagtggccctccagccaagaagccgctctcggacttggaagcggactgctgaggttctcttgtggaaccgccgccattcggaagatgcactttagcctgaaagaacaccctccaccaccttgtcctccagaggctttccaaagagctgctggcgaaggcggacctggtagaggtggtgctagaagaggtgctagggtgctgcagagcccattctgtagagcaggcgcaggcgaatggctgggccatcagagtctgagacatgtcgtcggctacggccacctggatacaagcggaagcagctctagctccagctggcctaactcaaaaatggctctgaacagcctgaactccatcgacgacgcccagctgacaagaatcgcccctcctagatctcactgctgcttttgggaagtgaacgccccaagccatcaccatcaccaccattagtaaaggcgcgcctagcggccgcgatctgctgtgccttctagttgccagccatctgttgtttgcccctcccccgtgccttccttgaccctggaaggtgccactcccactgtcctttcctaataaaatgaggaaattgcatcgcattgtctgagtaggtgtcattctattctggggggtggggtggggcaggacagcaagggggaggattgggaagacaatagcaggcatgctggggatgcggtgggctctatggccgggccgcgatcgcgcttaggcctgaccatctggtgctggcctgcaccagggccgagtttgggtctagcgatgaggataccgattgaggtgggtaaggtgggcgtggctagcagggtgggcgtgtataaattgggggtctaaggggtctctctgtttgtcttgcaacagccgccgccatgagcgacaccggcaacagctttgatggaagcatctttagtccctatctgacagtgcgcatgcctcactgggccggagtgcgtcagaatgtgatgggttccaacgtggatggacgtcccgttctgccttcaaattcgtctactatggcctacgcgaccgtgggaggaactccgctggacgccgcgacctccgccgccgcctccgccgccgccgcgaccgcgcgcagcatggctacggacctttacagctctttggtggcgagcagcgcggcctctcgcgcgtctgctcgggatgagaaactgactgctctgctgcttaaactggaagacttgacccgggagctgggtcaactgacccagcaggtttccagcttgcgtgagagcagccttgcctccccctaatggcccataatataaataaaagccagtctgtttggattaagcaagtgtatgttctttatttaactctccgcgcgcggtaagcccgggaccagcggtctcggtcgtttagggtgcggtggattttttccaacacgtggtacaggtggctctggatgtttagatacatgggcatgagtccatccctggggtggaggtagcaccactgcagagcttcgtgctcgggggtggtgttgtatatgatccagtcgtagcaggagcgctgggcgtggtgctgaaaaatgtccttaagcaagaggcttatagctagggggaggcccttggtgtaagtgtttacaaatctgcttagctgggaggggtgcatccggggggatatgatgtgcatcttggactggatttttaggttggctatgttcccgcccagatcccttctgggattcatgttgtgcaggaccaccagcacggtatatccagtgcacttgggaaatttatcgtggagcttagacgggaatgcatggaagaacttggagacgcccttgtggcctcccagattttccatacattcgtccatgatgatggcaatgggcccgtgggaagctgcctgagcaaaaacgtttctggcatcgctcacatcgtagttatgttccagggtgaggtcatcataggacatctttacgaatcgggggcgaagggtcccggactgggggatgatggtaccctcgggccccggggcgtagttcccctcacagatctgcatctcccaggctttcatttcagagggagggatcatatccacctgcggggcgatgaaaaagacagtttctggcgcaggggagattaactgggatgagagcaggtttctgagcagctgtgactttccacagccggtgggcccatatatcacgcctatcaccggctgcagctggtagttaagagagctgcagctgccgtcctcccggagcaggggggccacctcgttgagcatatccctgacgtggatgttctccctgaccagttccgccagaaggcgctcgccgcccagcgaaagcagctcttgcaaggaagcaaaatttttcagcggtttcaggccatcggccgtgggcatgtttttcagcgtctgggtcagcagctccagcctgtcccagagctcggtgatgtgctctacggcatctcgatccagcagatctcctcgtttcgcgggttggggcggctttcgctgtagggcaccagccgatgggcgtccagcggggccagagtcatgtccttccatgggcgcagggtcctcgtcagggtggtctgggtcacggtgaaggggtgcgctccgggttgggcactggccagggtgcgcttgaggctggttctgctggtgctgaatcgctgccgctcttcgccctgcgcgtcggccaggtagcatttgaccatggtctcgtagtcgagaccctcggcggcgtgccccttggcgcggagctttcccttggaggtggcgccgcacgaggggcactgcaggctcttcagggcgtagagcttgggagcgagaaacacggactctggggagtaggcgtccgcgccgcaggccgagcagaccgtctcgcattccaccagccaagtgagttccgggcggtcagggtcaaaaaccaggttgcccccatgctttttgatgcgtttcttaccttggctctccatgaggcggtgtcccttctcggtgacgaagaggctgtccgtgtccccgtagaccgacttcaggggcctgtcttccagcggagtgcctctgtcctcctcgtagagaaactctgaccactctgagacgaaggcccgcgtccaggccaggacgaaggaggccacgtgggaggggtagcggtcgttgtccactagcgggtccaccttctccagggtgtgcaggcacatgtccccctcctccgcgtccagaaaagtgattggcttgtaggtgtaggacacgtgaccgggggttcccaacgggggggtataaaagggggtgggtgccctttcatcttcactctcttccgcatcgctgtctgcgagagccagctgctggggtaagtattccctctcgaaggcgggcatgacctcagcgctcaggttgtcagtttctaaaaatgaggaggatttgatgttcacctgtccggaggtgatacctttgagggtacctgggtccatctggtcagaaaacactatttttttgttatcaagcttggtggcgaatgacccgtagagggcgttggagagcagcttggcgatggagcgcagggtctggtttttgtcgcggtcggctcgctccttggccgcgatgttgagttgcacgtactcgcgggccacgcacttccactcggggaacacggtggtgcgctcgtctgggatcaggcgcaccctccagccgcggttgtgcagggtgaccatgtcgacgctggtggcgacctcaccgcgcagacgctcgttggtccagcagaggcggccgcccttgcgcgagcagaaggggggtagggggtccagctggtcctcgtttggggggtccgcgtcgatggtaaagaccccggggagcaggcgcgggtcaaagtagtcgatcttgcaagcttgcatgtccagagcccgctgccattcgcgggcggcgagcgcgcgctcgtaggggttgaggggcgggccccagggcatggggtgggtgagcgcggaggcgtacatgccgcagatgtcatacacgtacaggggttccctgaggataccgaggtaggtggggtagcagcgccccccgcggatgctggcgcgcacgtagtcatagagctcgtgggagggggccagcatgttgggcccgaggttggtgcgctgggggcgctcggcgcggaagacgatctgcctgaagatggcgtgggagttggaggagatggtgggccgctggaagacgttgaagcttgcttcttgcaagcccacggagtccctgacgaaggaggcgtaggactcgcgcagcttgtgcaccagctcggcggtgacctggacgtcgagcgcacagtagtcgagggtctcgcggatgatgtcatacctatcctcccccttctttttccacagctcgcggttgaggacgaactcttcgcggtctttccagtactcttggaggggaaacccgtccgtgtccgaacggtaagagcctagcatgtagaactggttgacggcctggtaggggcagcagcccttctccacgggcagcgcgtaggcctgcgccgccttgcggagggaggtgtgggtgagggcgaaagtgtccctgaccatgactttgaggtattgatgtctgaagtctgtgtcatcgcagccgccctgttcccacagggtgtagtccgtgcgctttttggagcgcgggttgggcagggagaaggtgaggtcattgaagaggatcttccccgctcgaggcatgaagtttctggtgatgcgaaagggccctgggaccgaggagcggttgttgatgacctgggcggccaggacgatctcgtcaaagccgtttatgttgtgtcccacgatgtagagctccaggaagcggggctggcccttgatggaggggagctttttaagttcctcgtaggtaagctcctcgggcgattccaggccgtgctcctccagggcccagtcttgcaagtgagggttggccgccaggaaggatcgccagaggtcgcgggccatgagggtctgcaggcggtcgcggaaggttctgaactgccgccccacggccattttttcgggggtgatgcagtagaaggtgagggggtctttctcccaggggtcccatctgagctctcgggcgaggtcgcgcgcggcagcgaccagagcctcgtcgccccccagtttcatgaccagcatgaagggcacgagttgcttgccaaaggctcccatccaagtgtaggtttctacatcgtaggtgacaaagaggcgctccgtgcgaggatgagagccgattgggaagaactggatctcccgccaccagttggaggattggctgttgatgtggtgaaagtagaagtcccgtctgcgggccgagcactcgtgctggcttttgtaaaagcgaccgcagtactggcagcgctgcacgggttgtatatcttgcacgaggtgaacctggcgacctctgacgaggaagcgcagcgggaatctaagtcccccgcctggggtcccgtgtggctggtggtcttttactttggttgtctggccgccagcatctgtctcctggagggcgatggtggaacagaccaccacgccgcgagagccgcaggtccagatctcggcgctcggcgggcggagtttgatgacgacatcgcgcacattggagctgtccatggtctccagctcccgcggcggcaggtcagccgggagttccctggaggttcacctcgcagagacgggtcaaggcgcggacagtgttgagatggtatctgatttcaaggggcatgttggaggcggagtcgatggcttgcaggaggccgcagccccggggggccacgatggttccccgcggggcgcgaggggaggcggaagctgggggtgtgttcagaagcggtgacgcgggcgggcccccggaggtagggggggttccggccccacaggcatgggcggcaggggcacgtcttcgccgcgcgcgggcaggggctggtgctggctccgaagagcgcttgcgtgcgcgacgacgcgacggttggtgttcctgtatctggcgcctctgagtgaagaccacgggtcccgtgaccttgaacctgaaagagagttcgacagaatcaatctcggcatcgttgacagcggcctggcgcaggatctcctgcacgtcgcccgagttgtcctggtaggcgatttctgccatgaactgctcgatctcttcctcctggagatctcctcgtccggcgcgctccacggtggccgccaggtcgttggagatgcgacccatgagctgcgagaaggcgttgagtccgccctcgttccagacccggctgtagaccacgcccccctcggcgtcgcgggcgcgcatgaccacctgggccaggttgagctccacgtgtcgcgtgaagacggcgtagttgcgcaggcgctggaaaaggtagttcagggtggtggcggtgtgctcggcgacgaagaagtacatgacccagcgccgcaacgtggattcattgatgtcccccaaggcctccaggcgctccatggcctcgtagaagtccacggcgaagttgaaaaactgggagttgcgagcggacacggtcaactcctcctccagaagaacggatgagctcggcgacagtgtcgcgcacctcgcgctcgaaggccacggggggcgcttcttcctcttccacctcttcttccatgattgcttcttcttcttcctcagccgggacgggagggggcggcggcgggggaggggcgcggcggcggcggcggcgcaccgggaggcggtcgatgaagcgctcgatcatctccccccgcatgcggcgcatggtctcggtgacggcgcggccgttctcccgggggcgcagctcgaagacgccgcctctcatttcgccgcggggcgggcggccgtgaggtagcgagacggcgctgactatgcatcttaacaattgctgtgtaggtacgccgccaagggacctgattgagtccagatccaccggatccgaaaacctttggaggaaagcgtctatccagtcgcagtcgcaaggtaggctgagcaccgtggcgggcgggggcgggtcgggagagttcctggcggagatgctgctgatgatgtaattaaagtaggcggtcttgagaaggcggatggtggacaggagcaccatgtctttgggtccggcctgttggatgcggaggcggtcggccatgccccaggcctcgttctgacaccggcgcaggtctttgtagtaatcttgcatgagtctttccaccggcacttcttctccttcctcttcttcatctcgccggtggtttctcgcgccgcccatgcgcgtgaccccaaagcccctgagcggctgcagcagggccaggtcggcgaccacgcgctcggccaagatggcctgctgtacctgagtgagggtcctctcgaagtcatccatgtccacgaagcggtggtaggcacccgtgttgatggtgtaggtgcagttggccatgacggaccagttgacggtctggtgtcccggctgcgagagctccgtgtaccgcaggcgcgagaaggcgcgggaatcgaacacgtagtcgttgcaagtccgcaccagatactggtagcccaccaggaagtgcggcggaggttggcgatagaggggccagcgctgggtggcgggggcgccgggcgccaggtcttccagcatgaggcggtggtatccgtagatgtacctggacatccaggtgatgcctgcggcggtggtggtggcgcgcgcgtagtcgcggacccggttccagatgtttcgcaggggcgagaagtgttccatggtcggcacgctctggccggtgaggcgcgcgcagtcgttgacgctctatacacacacaaaaacgaaagcgtttacagggctttcgttctgtagcctggaggaaagtaaatgggttgggttgcggtgtgccccggttcgagaccaagctgagctcagccggctgaagccgcagctaacgtggtattggcagtcccgtctcgacccaggccctgtatcctccaggatacggtcgagagcccttttgctttcttggccaagcgcccgtggcgcgatctgggatagatggtcgcgatgagaggacaaaagcggctcgcttccgtagtctggagaaacaatcgccagggttgcgttgcggcgtaccccggttcgagcccctatggcggcttggatcggccggaaccgcggctaacgtgggctgtggcagccccgtcctcaggaccccgccagccgacttctccagttacgggagcgagccccttttgtttttttattttttagatgcatcccgtgctgcggcagatgcgcccctcgccccggcccgatcagcagcagcaacagcaggcatgcagacccccctctcctctccccgccccggtcaccacggccgcggcggccgtgtccggtgcggggggcgcgctggagtcagatgagccaccgcggcggcgacctaggcagtatctggacttggaagagggcgagggactggcgcggctgggggcgagctctccagagcgccacccgcgggtgcagttgaaaagggacgcgcgtgaggcgtacctgccgcggcaaaacctgtttcgcgaccgcgggggcgaggagcccgaggagatgcgggactgcaggttccaagcggggcgcgagctgcgccgcggcttggacagacagcgcctgctgcgcgaggaggactttgagcccgacacgcagacgggcatcagccccgcgcgcgcgcacgtggccgcggccgacctggtgaccgcctacgagcagacggtgaaccaggagcgcaacttccaaaaaagcttcaacaaccacgtgcgcacgctggtggcgcgcgaggaggtgaccctgggtctcatgcatctgtgggacctggtggaggcgatcgtgcagaaccccagcagcaagcccctgaccgcgcagctgttcctggtggtgcagcacagcagggacaacgaggccttcagggaggcgctgctgaacatcaccgagccggaggggcgctggctcctggacctgataaacatcctgcagagcatagtggtgcaggagcgcagcctgagcctggccgagaaggtggcggccattaactattctatgctgagcctgggcaagttctacgctcgcaagatctacaagaccccctacgtgcccatagacaaggaggtgaagatagacagcttctacatgcgcatggcgctgaaggtgctaaccctgagcgacgacctgggagtgtaccgcaacgagcgcatccacaaggccgtgagcgccagccggcggcgcgagctgagcgaccgcgaactgatgcacagtctgcagcgcgcgctgaccggcgcgggcgagggcgacagggaggtcgagtcctactttgacatgggggccgacctgcactggcagccgagccgccgcgccctggaagcggcgggggcgtacggcggccccctggcggccgatgacgaggaagaggaggactatgagctagaggagggcgagtacctggaggactgacctggctggtggtgttttggtatagatgcaagatccgaacgtggcggacccggcggtccgggcggcgctgcagagccagccgtccggcattaactcctctgacgactgggccgcggccatgggtcgcatcatggccctgaccgcgcgcaaccccgaggccttcaggcagcagcctcaggctaaccggctggcggccatcttggaagcggtagtgcccgcgcgctccaaccccacccacgagaaggtgctggccatagtcaacgcgctggcggagagcagggccatccgggcagacgaggccggactggtgtacgatgcgctgctgcagcgggtggcgcggtacaacagcggcaacgtgcagaccaacctggaccgcctggtgacggacgtgcgcgaggccgtggcgcagcgcgagcgcttgcatcaggacggcaacctgggctcgctggtggcgctaaacgccttccttagcacccagccggccaacgtaccgcgggggcaggaggactacaccaacttcttgagcgcgctgcggctgatggtgaccgaggtccctcagagcgaggtgtaccagtcggggcccgactacttcttccagaccagcagacagggcttgcaaaccgtgaacctgagccaggctttcaagaacctgcgggggctgtggggagtgaaggcgcccaccggcgaccgggctacggtgtccagcctgctaacccccaactcgcgcctgctgctgctgctgatcgcgcccttcacggacagcgggagcgtctcgcgggagacctatctgggccacctgctgacgctgtaccgcgaggccatcgggcaggcgcaggtggacgagcacaccttccaggagatcaccagcgtgagccacgcgctggggcaggaggacacgggcagcctgcaggcgaccctgaactacctgctgaccaacaggcggcagaagattcccacgctgcacagcctgacccaggaggaggagcgcatcttgcgctacgtgcagcagagcgtgagcctgaacctgatgcgcgacggcgtgacgcccagcgtggcgctggacatgaccgcgcgcaacatggaaccgggcatgtacgcttcccagcggccgttcatcaaccgcctgatggactacttgcatcgggcggcggccgtgaaccccgagtacttcaccaatgccattctgaatccccactggatgccccctccgggtttctacaacggggacttcgaggtgcctgaggtcaacgatgggttcctctgggatgacatggatgacagtgtgttctcccccaacccgctgcgcgccgcgtctctgcgattgaaggagggctctgacagggaaggaccaaggagtctggcctcctccctggctctgggggcggtgggcgccacgggcgcggcggcgcggggcagcagccccttccccagcctggcggactctctgaatagcgggcgggtgagcaggccccgcttgctaggcgaggaggagtatctgaacaactccctgctgcagcccgtgagggacaaaaacgctcagcggcagcagtttcccaacaatgggatagagagcctggtggacaagatgtccagatggaagacgtatgcgcaggagtacaaggagtgggaggaccgccagccgcggcccctgccgccccctagacagcgctggcagcggcgcgcgtccaaccgccgctggaggcaggggcccgaggacgatgatgactctgcagatgacagcagcgtgttggacctgggcgggagcgggaaccccttttcgcacctgcgcccacgcctgggcaagatgttttaaaagagaaaaataaaaactcaccaaggccatggcgacgagcgttggttttttgttcccttccttagtatgcggcgcgcggcgatgttcgaggaggggcctcccccctcttacgagagcgcgatgggaatttctcctgcggcgcccctgcagcctccctacgtgcctcctcggtacctgcaacctacaggggggagaaatagcatctgttactctgagctgcagcccctgtacgataccaccagactgtacctggtggacaacaagtccgcggacgtggcctccctgaactaccagaacgaccacagcgattttttgaccacggtgatccaaaacaacgacttcaccccaaccgaggccagtacccagaccataaacctggacaacaggtcgaactggggcggcgacctgaagactatcctgcacaccaatatgcccaacgtgaacgagttcatgttcaccaactcttttaaggcgcgggtgatggtggcgcgcgagcagggggaggcgaagtacgagtgggtggacttcacgctgcccgagggcaactactcagagaccatgactctcgacctgatgaacaatgcgatcgtggaacactatctgaaagtgggcaggcagaacggggtgaaggagagcgatatcggggtcaagtttgacaccagaaacttccgtctgggctgggaccctgtgaccgggctggtcatgccgggggtctacaccaacgaggcctttcatcccgatatagtgctcctgcccggctgtggggtggacttcacccagagccggctgagcaacctgctgggcgttcgcaagcggcaacctttccaggagggtttcaagatcacctatgaggatctggaggggggcaacattcccgcgctccttgatctggacgcctacgaggagagcttgaaacccgaggagagcgctggcgacagcggcgagagtggcgaggagcaagccggcggcggcggcagcgcgtcggtagaaaacgaaagtactcccgcagtggcggcggacgctgcggaggtcgagccggaggccatgcagcaggacgcagaggagggcgcgcaggaggacatgaacaatggggagatcaggggcgacactttcgccacccggggcgaagaaaaagaggcagaggcggcggcggcgacggcggaagccgaaaccgaggcagaggcagagcccgagaccgaagttatggaagacatgaatgatggagaacgtaggggtgacacgtttgccacccggggcgaagagaaggcggcggaggcagaagccgcggctgaggaggcggctgcggctgcggccaaggctgaggctgcggctgaggctaaggtcgaagccgatgttgcggttgaggctcaggctgaggaggaggcggcggctgaagcagttaaggaaaaggcccaggcagagcaggaagagaaaaaacctgtcattcaacctctaaaagaagatagcaaaaagcgcagttacaacgtcattgagggcagcacctttacccaataccgcagctggtacctggcttacaactacggcgacccggtcaagggggtgcgctcgtggaccctgctctgcacgccggacgtcacctgcggctccgagcagatgtactggtcgctgccaaacatgatgcaagacccggtgaccttccgttccacgcggcaggttagcaactttccggtggtgggcgccgaactgctgccagtacactccaagagtttttacaacgagcaggccgtctactcccagctgatccgccaggccacctctctgacccacgtgttcaatcgctttcccgagaaccagattttggcgcgcccgccggcccccaccatcaccaccgtcagtgaaaacgttcctgccctcacagatcacgggacgctaccgctgcgcaacagcatctcaggagtccagcgagtgaccattactgacgccagacgccggacctgcccctacgtttacaaggccttgggcatagtctcgccgcgcgtcctctccagtcgcactttttaaaacacatccacccacacgctccaaaatcatgtccgtactcatctcgcccagcaacaacaccggctgggggctgcgcgcacccagcaagatgtttggaggggcaaggaagcgctccgaccagcaccccgtgcgcgtgcgcggccactaccgcgcgccctggggtgcgcacaagcgcgggcgcacagggcgcaccactgtggatgatgtcattgactccgtagtggagcaggcgcgccactacacacccggcgcgccgaccgcctccgccgtgtccaccgtggaccaggcgatcgaaagcgtggtacagggggcgcggcactatgccaaccttaaaagtcgccgccgccgcgtggcgcgccgccatcgccggagaccccgggctactgccgccgcgcgccttaccaaggctctgctcaagcgcgccaggcgaactggccaccgggccgccatgagggccgcacggcgggctgccgctgccgcgagcgccgtggccccgcgggcacgaaggcgcgcggccgctgccgccgccgccgccatttccagcttggcctcgacgcggcgcggtaacatatactgggtgcgcgactcggtgagcggcacacgtgtgcccgtgcgctttcgccccccacggaattagcacaagacaacatacacactgagtctcctgctgttgtgtatcccagcggcgaccgtcagcagcggcgacatgtccaagcgcaaaattaaagaagagatgctccaggtcatcgcgccggagatctatgggcccccgaagaaggaggaggaggattacaagccccgcaagctaaagcgggtcaaaaagaaaaagaaagatgatgacgttgacgaggcggtggagtttgtccgccgcatggcgcccaggcgccctgtgcagtggaagggtcggcgcgtgcagcgagtcctgcgccccggcaccgcggtggtctttacgcccggcgagcgttccacgcgcactttcaagcgggtgtacgatgaggtgtacggcgacgaggatctgttggagcaggccaaccatcgatttggggagtttgcatatgggaaacggcctcgcgagagtctaaaagaggacctgctggcgctaccgctggacgagggcaatcccaccccgagtctgaagccggtgaccctgcaacaggtgctgcctttgagcgcgcccagcgagcagaagcgagggttaaagcgcgagggcggggacctggcacccaccgtgcagttgatggtgcccaagcggcagaagctggaggacgtgctggagaaaatgaaagtagagcccgggatccagcccgagatcaaggtccgccctatcaagcaggtggcgcccggcgtgggagtccagaccgtggacgttaggattcccacggaggagatggaaacccaaaccgccactccctcttcggcagcaagcgccaccaccggcgccgcttcggtagaggtgcagacggacccctggctacccgccgccactatcgccgtcgccgccgccccccgttcgcgcggacgcaagagaaattatccagcggccagcgcgcttatgccccagtatgcgctgcatccatccatcgcgcccacccccggctaccgcgggtactcgtaccgcccgcgcagatcagccggcactcgcggccgccgccgccgtgcgaccacaaccagccgccgccgtcgccgccgccgccagccagtgctgacccccgtgtctgtaaggaaggtggctcgctcggggagcacgctggtggtgcccagagcgcgctaccaccccagcatcgtttaaagccggtctctgtatggttcttgcagatatggccctcacttgtcgccttcgcttcccggtgccgggataccgaggaagaactcaccgccgcaggggcatggcgggcagcggtctccgcggcggccgtcgccatcgccggcgcgcaaagagcaggcgcatgcgcggcggtgtgttgcccctgctggtcccgctactcgccgcggcgatcggcgccgtgcccgggatcgcctccgtggccctgcaggcgtcccagaaacattgactcttgcaaccttgcaagcttgcatttttggaggaaaaaataaaaaagtctagactctcacgctcgcttggtcctgtgactattttgtagaaaaaagatggaagacatcaactttgcgtcgctggccccgcgtcacggctcgcgcccgttcatgggagactggacagatatcggcaccagcaatatgagcggtggcgccttcagctggggcagtctgtggagcggccttaaaaattttggttccaccattaagaactatggcaacaaagcgtggaacagcagcacgggtcagatgctgagagacaagttgaaagagcagaacttccaggagaaggtggcgcagggcctggcctctggcatcagcggggtggtggacatagctaaccaggccgtgcagaaaaagataaacagtcatctggacccccgccctcaggtggaggaaacgcctccagccatggagacggtgtctcccgagggcaaaggcgaaaagcgcccgcggcccgacagggaagagaccctggtgtcacacaccgaggagccgccctcttacgaggaggcagtcaaggccggcctgcccaccactcgccccatagctcccatggccaccggtgtggtgggtcacaggcaacacacccccgcaacactagatctgcccccgccgtccgagccgactcgccagccaaaggcggtgacggtgtccgctccctccacttccgccgccaacagagtgcctctgcgccgcgctgcgagcggcccccgggcctcgcgagtcagcggcaactggcagagcacactgaacagcatcgtgggcctgggagtgaggagtgtgaagcgccgccgttgctactgaatgagcaagctagctaacgtgttgtatgtgtgtatgcgtcctatgtcgccgccagaggagctgttgagccgccggcgccgtctgcactccagcgaatttcaagatggcgaccccatcgatgatgcctcagtggtcgtacatgcacatctcgggccaggacgcttcggagtacctgagccccgggctggtgcagttcgcccgcgccacagacacctacttcaacatgagtaacaagttcaggaaccccactgtggcgcccacccacgatgtgaccacggaccggtcgcagcgcctgacgctgcggttcatccccgtggatcgggaggacaccgcttactcttacaaggcgcggttcacgctggccgtgggcgacaaccgcgtgctggacatggcctccacttactttgacatccggggggtgctggacaggggccccacttttaagccctactcgggcactgcctacaaccccctggcccccaagggcgcccccaattcttgtgagtgggaacaagaggaaaatcaggtggtcgctgcagatgatgaacttgaagatgaagaagcgcaagcacaagaggaagcccctgtgaaaaaaattcatgtatatgctcaggcgcctctttctggcgaaaagatttccaaggatggtatccaaataggtactgaagtcgtaggagatacatctaaggacacttttgcagataaaacattccaacccgaacctcagataggcgagtctcagtggaacgaggctgatgccacagcagcaggaggtagagttttgaaaaagactacccctatgagaccttgctatggatcctatgccaggcctaccaatgccaacgggggtcaaggaattatggttgccaatgaacaaggagtgttggagtctaaagtagaaatgcaatttttctctaacaccacaacccttaatgcgcgggatggaaccggcaatcccgaaccaaaggtggtgttgtacagcgaagatgtccacttggaatctcccgatactcatctgtcttacaagcccaaaaaggatgatgttaatgccaaaatcatgttgggtcagcaagccatgcccaacagacccaacctcattggatttagagataatttcattgggcttatgttttacaacagcaccggtaacatgggagtgctggcgggtcaggcctctcagttgaatgctgtggtggacttgcaggatagaaacacagaactgtcatatcagcttctgcttgattcaattggggatagaaccagatacttctccatgtggaaccaggcagtggatagctatgatccagatgtcagaattattgaaaaccatgggactgaggatgaactgcccaactactgcttccctttgggcggcataggagttactgatacttatcaagggataaaaaataccaatggcaatggtcagtggaccaaagatgatcagttcgcggaccgcaacgaaataggggtgggaaacaacttcgccatggagatcaacatccaggccaacctttggagaaacttcctctatgcaaacgtggggctctacctgccagacaagctcaagtacaaccccaccaacgtggacatctctgacaaccccaacacctatgactacatgaacaagcgggtggtggcccctggcctggtggactgctttgtcaatgtgggagccaggtggtccctggactacatggacaacgtcaaccccttcaaccaccaccgcaatgcgggtctgcgctaccgctccatgatcctgggcaacgggcgctatgtgccctttcacatccaggtaccccagaagttctttgccatcaagaacctcctgctcctgcccggctcctacacctacgagtggaacttcaggaaggatgtgaacatggtcctacagagctctctgggcaatgaccttagggtggatggggccagcatcaagtttgacagcatcaccctctatgctacatttttccccatggcccacaacaccgcctccacgcttgaggccatgctgagaaacgacaccaacgaccagtcctttaatgactacctctctggggccaacatgctctacccaatcccagccaaggccaccaacgtgcccatctccatcccctctcgcaactgggccgcctttagaggctgggcctttacccgccttaagaccaaggagaccccctccctgggctcgggttttgatccctactttgtttactcgggatccatcccctacctggatggcaccttctacctcaaccacactttcaagaagatatccatcatgtatgactcctccgtcagctggccgggcaacgaccgcttgctcacccccaatgagttcgaggtcaagcgcgccgtggacggcgagggctacaacgtggcccagtgcaacatgaccaaggactggttcctggtgcagatgctggccaactacaacataggctaccagggcttttacatcccagagagctacaaggacaggatgtactccttcttcagaaatttccaacccatgagccgacaggtggtggacgagaccaattacaaggactatcaagccattggcatcacccaccagcacaacaactcgggtttcgtgggctacctggcgcccaccatgcgcgagggtcaggcctaccccgccaacttcccctaccccttgataggcaagaccgcggtcgacagcgtcacccagaaaaagttcctctgcgaccgcaccctctggcgcatccccttctctagcaacttcatgtccatgggtgcgctcacggacctgggccaaaacctgctttatgccaactctgcccatgcgctggacatgacttttgaggtggaccccatggacgagcccacccttctctatattgtgtttgaagtgttcgacgtggtcagagtgcaccagccgcaccgcggtgtcatcgagaccgtgtacctgcgtacgcccttctcagccggcaacgccaccacctaaggagacagcgccgccgccgcctgcatgacgggttccaccgagcaagagctcagggccattgccagagacctgggatgcggaccctattttttgggcacctatgacaaacgcttcccgggctttatctcccgagacaagctcgcctgcgccattgtcaacacggccgcgcgcgagaccgggggcgtgcactggctggcctttggctgggacccgcgctccaaaacttgctacctctttgacccctttggcttctccgatcagcgcctcaggcagatttatgagtttgagtacgaggggctgctgcgccgcagcgcgctcgcctcctcgcccgaccgctgcatcacccttgagaagtccaccgaaaccgtgcaggggccccactcggccgcctgcggtctcttctgttgcatgtttttgcacgcctttgtgcactggcctcagagtcccatggattgcaaccccaccatgaacttgctaaagggagtgcccaacgccatgctccagagcccccaggtccagcccaccctgcgccgcaaccaggaacagctttaccgcttcctggagcgccactccccctacttccgcagccacagcgcgcgcatccggggggccacctctttttgccacttgcaagaaaacatgcaagacggaaaatgatgtacagcatgcttttaataaatgtaaagactgtgcactttaattatacacgggctctttctggttatttattcaacaccgccgtcgccatttagaaatcgaaagggttctgccgtgcgtcgccgtgcgccacgggcagagacacgttgcgatactggaagcggctcgcccacttgaactcgggcaccaccatgcggggcagtggttcctcggggaagttctcgctccacagggtgcgggtcagctgcagcgcgctcaggaggtcgggagccgagatcttgaagtcgcagttggggccggaaccctgcgcgcgcgagttgcggtacacggggttgcagcactggaacaccagcagggccggattattcacgctggccagcaggctctcgtcgctgatcatgtcgctgtccagatcctccgcgttgctcagggcgaatggggtcatcttgcagacctgcctgcccaggaaaggcgggagcccaggcttgccgttgcagtcgcagcgcaggggcattagcaggtgcccacggcccgactgcgcctgcgggtacaacgcgcgcatgaaggcttcgatctgcctaaaagccacctgggtcttggctccctccgaaaagaacatcccacaggacttgctggagaactggttcgcgggacagctggcatcgtgcaggcagcagcgcgcgtcagtgttggcaatctgcaccacgttgcgaccccaccggtttttcactatcttggccttggaagcctgctcctttagcgcgcgctggccgttctcgctggtcacatccatctctatcacctgttccttgttgatcatgtttgtcccgtgcagacactttaggtcgccctccgtctgggtgcagcggtgctcccacagcgcgcaaccggtgggctcccaattcttgtgggtcacccccgcgtaggcctgcaggtaggcctgcaggaagcgccccatcatggtcataaaggtcttctggctcgtaaaggtcagctgcaggccgcgatgctcttcgttcagccaggtcttgcagatggcggccagcgcctcggtctgctcgggcagcatcttaaaatttgtcttcaggtcgttatccacgtggtacttgtccatcatggcacgcgccgcctccatgcccttctcccaggcggacaccatgggcaggcttagggggtttatcacttccagcggcgaggacaccgtactttcgatttcttcttcctccccctcttcccggcgcgcgcccccgctgttgcgcgctcttaccgcctgcaccaaggggtcgtcttcaggcaagcgccgcaccgagcgcttgccgcccttgacctgcttgatcagtaccggcgggttgctgaagcccaccatggtcagcgccgcctgctcttcttcgtcttcgctgtctaccactatttctggggaggggcttctccgctctgcggcaaaggcggcggatcgcttcttttttttcttgggagccgccgcgatggagtccgccacggcgaccgaggtcgagggcgtggggctgggggtgcgcggtaccagggcctcgtcgccctcggactcttcctctgactccaggcggcggcggagtcgcttctttgggggcgcgcgcgtcagcggcggcggagacggggacggggacggggacgggacgccctccacagggggtggtcttcgcgcagacccgcggccgcgctcgggggtcttctcgcgctggtcttggtcccgactggccattgtatcctcctcctcctaggcagagagacataaggagtctatcatgcaagtcgagaaggaggagagcttaaccaccccctcagagaccgccgatgcgcccgccgtcgccgtcgcccccgctaccgccgacgcgcccgccacaccgagcgacacccccacggacccccccgccgacgcacccctgttcgaggaagcggccgtggagcaggacccgggctttgtctcggcagaggaggatttgcaagaggaggagaataaggaggagaagccctcagtgccaaaagatcataaagagcaagacgagcacgacgcagacgcacaccagggtgaagtcgggcggggggacggagggcatggcggcgccgactacctagacgaaggaaacgacgtgctcttgaagcacctgcatcgtcagtgcgccatcgtctgcgacgctctgcaggagcgcagcgaggtgcccctcagcgtggcggaggtcagccgcgcctacgagctcagcctcttttccccccgggtgcccccccgccgccgcgaaaacggcacatgcgagcccaacccgcgcctcaacttctaccccgcctttgtggtgcccgaggtcctggccacctatcacatcttctttcaaaattgcaagatccccatctcgtgccgcgccaaccgtagccgcgccgataagatgctggccctgcgccagggcgaccacatacctgatatcgccgctttggaagatgtgccaaagatcttcgagggtctggggcgcaacgagaagcgggcagcaaactctctgcaacaggaaaacagcgaaaatgagagtcacactggagcgctggtggagctggagggcgacaacgcccgcctggcggtgctcaagcgcagcatcgaggtcacccactttgcctaccccgcgctcaacctgccccccaaagtcatgaacgcggtcatggacgggctgatcatgcgccgcggccggcccctcgctccagatgcaaacttgcatgaggagaccgaggacggtcagcccgtggtcagcgacgagcagctgacgcgctggctggagagcgcggaccccgccgaactggaggagcggcgcaagatgatgatggccgcggtgctggtcaccgtagagctggagtgtctgcagcgcttcttcggtgaccccgagatgcagagaaaggtcgaggagaccctacactacaccttccgccagggctacgtgcgccaggcttgcaagatctccaacgtggagctcagcaacctggtgtcctacctgggcatcttgcatgaaaaccgccttgggcagagcgtgctacactccaccctgcgcggggaggcgcgccgcgactacgtgcgcgactgcgtttacctcttcctctgctacacctggcagacggccatgggggtctggcagcagtgcctggaggagcgcaacctcaaggagctggagaagcttctgcagcgcgcgctcaaagacctctggacgggcttcaacgagcgctcggtggccgccgcgctagccgacctcatcttccccgagcgcctgctcaaaaccctccagcaggggctgcccgacttcaccagccaaagcatgttgcaaaattttaggaactttatcctggagcgttctggcatcctacccgccacctgctgcgccctgcccagcgactttgtccccctcgtgtaccgcgagtgccccccgccgctgtggggccactgctacctgttccaactggccaactacctgtcctaccacgcggacctcatggaggactccagcggcgaggggctcatggagtgccactgccgctgcaacctctgcacgccccaccgctccctggtctgcaacacccaactgctcagcgagagtcagattatcggtaccttcgagctacagggtccgtcctcctcagacgagaagtccgcggctccggggctaaaactcactccggggctgtggacttccgcctacctgcgcaaatttgtacctgaagactaccacgcccacgaaatcaggttttacgaggaccaatcccgcccgcccaaggcggagctgaccgcctgcgtcatcacccagggcgagatcctaggccaattgcaagccatccaaaaagcccgccaagagtttttgctgaagaggggtcggggggtgtatctggacccccagtcgggtgaggagctcaacccggttcccccgctgccaccgccgcgggaccttgcttcccaggataagcatcgccatggctcccagaaagaagcagcagcggccgccgctgccgccgccccacatgctggaggaagaggaggaatactgggacagtcaggcagaggaggtttcggacgaggaggagccggagacggagatggaagagtgggaggaggacagcttagacgaggaggcttccgaagccgaagaggcaggcgcaacaccgtcaccctcggccgcagccccctcgcaggcgcccccgaagtccgctcccagcatcagcagcaacagcagcgctataacctccgctcctccaccgccgcgacccacggccgaccgcagacccaaccgtagatgggacaccaccggaaccggggccggtaagtcctccgggagaggcaagcaagcgcagcgccaaggctaccgctcgtggcgcgctcacaagaacgccatagtcgcttgcttgcaagactgcggggggaacatctccttcgcccgccgcttcctgctcttccaccacggtgtggccttcccccgtaacgtcctgcattactaccgtcatctctacagcccctactgcggcggcagtgagccagaggcggccagcggcggcggcgcccgtttcggtgcctaggaagacccagggcaagacttcagccaagaaactcgcggcgaccgcggcgaacgcggtcgcgggggccctgcgcctgacggtgaacgaacccctgtcgacccgcgaactgaggaaccgaatcttccccactctctatgccatcttccagcagagcagagggcaggatcaggaactgaaagtaaaaaacaggtctctgcgctccctcacccgcagctgtctgtatcacaagagcgaagaccagcttcggcgcacgctggaggacgctgaggcactcttcagcaaatactgcgcgctcactcttaaggactagctccgcgcccttctcgaatttaggcgggaacgcctacgtcatcgcagcgccgccgtcatgagcaaggacattcccacgccatacatgtggagctatcagccgcagatgggactcgcggcgggcgcctcccaagactactccacccgcatgaactggctcagtgccggcccacacatgatctcacaggttaatgacatccgcacccatcgaaaccaaatattggtgaagcaggcggcaattaccaccacgccccgcaataatcccaaccccagggagtggcccgcgtccctggtgtatcaggaaattcccggccccaccaccgtactacttccgcgtgattcccaggccgaagtccaaatgactaactcaggggcacagctcgcgggcggctgtcgtcacagggtgcggcctcctcgccagggtataactcacctggagatccgaggcagaggtattcagctcaacgacgagtcggtgagctcctcgctcggtctcagacctgacgggaccttccagatagccggagccggccgatcttccttcacgccccgccaggcgtacctgactctgcagagctcgtcctcggcgccgcgctcgggcggcatcgggactctccagttcgtgcaggagtttgtgccctcggtctacttcaaccccttctcgggctctcccggtcgctacccggaccagtttatcccgaactttgacgccgcgagggactcggtggacggctacgactgaatgtcgggtggacccggtgcagagcaacttcgcctgaagcaccttgaccactgccgccgccctcagtgctttgcccgctgtcagaccggtgagttccagtacttttccctgcccgactcgcacccggacggcccggcgcacggggtgcgctttttcatcccgagtcaggtccgctctaccctaatcagggagttcaccgcccgtcccctactggcggagttggaaaaggggccttctatcctaaccattgcctgcatttgctctaaccctggattacaccaagatctttgctgtcatttgtgtgctgagtataataaaggctgagatcagaatctactcggaccttatccctttcaattgatcataactgtaatcaataaaaaatcacttacttgaaatctgatagcaagactctgtccaattttttcagcaacacttccttcccctcctcccaactctggtactctaggcgcctcctagctgcaaacttcctccacagtctgaagggaatgtcagattcctcctcctgtccctccgcacccacgatcttcatgttgttacagatgaaacgcgcgagatcgtctgacgagaccttcaaccccgtgtacccctacgataccgagatcgctccgacttctgtccctttccttacccctccctttgtatcatccgcaggaatgcaagaaaatccagctggggtgctgtccctgcacctgtcagagccccttaccacccacaatggggccctgactctaaaaatggggggcggcctgaccctggacaaggaagggaatctcacttcccaaaacatcaccagtgtcgatccccctctcaaaaaaagcaagaacaacatcagccttcagaccgccgcacccctcgccgtcagctccggggccctaaccctttttgccactccccccctagcggtcagtggcgacaaccttactgtgcagtctcaggcccctcttactttggaagactcaaaactaactctggccaccaaaggacccctaactgtgtccgaaggcaaacttgtcctagaaacagagcctcccctgcatgcaagtgacagcagtagcctgggccttagcgtcacggccccacttagcattaacaatgacagcctaggactagacatgcaagcgcccatcagctctcgagatggaaaactggctctaacagtggcggcccccctaactgtggccgagggtatcaatgctttggcagtagccacaggtaatggtattggactaaatgaaaccaacacacacctgcaggcaaaactggtcgcgcccctaggctttgataccaacggcaacattaagctaagcgtcgcaggaggcatgaggctaaacaataacacactgatactagatgtaaactacccatttgaggctcaaggccaactgagcctaagagtgggctcgggcccactatatgtagattctagtagtcataacctaaccattagatgccttaggggattgtatgtaacatcttctaacaaccaaaacggtctagaggccaacattaaactaacaaaaggccttgtgtatgacggaaatgccatagcagttaatgttggcaaagggctggaatacagccctactggcacaacagaaaaacctatacagactaaaataggtctaggcatggagtatgacactgagggagccatgatgacaaaactaggctctggactaagctttgacaattcaggagccattgtggtgggaaacaaaaatgatgacaggcttactttgtggaccacaccggacccatcgcccaactgtcagatttactctgaaaaagatgctaaactaaccttggtactgactaaatgtggcagtcaggttgtaggcacagtatctattgccgctcttaaaggtagccttgtgccaatcactagtgcaatcagtgtggttcagatatacctaaggtttgatgaaaatggggtgctgatgagtaactcttcacttaatggcgaatactggaattttagaaacggagactcaactaatggcacaccatatacaaacgcagtgggttttatgcctaatctactggcctatcctaaaggtcaaactacaactgcaaaaagtaacattgtcagccaggtctacatgaacggggacgatactaaacccatgacatttacaatcaacttcaatggccttagtgaaacaggggatacccctgtcagtaaatattccatgacattctcatggaggtggccaaatggaagctacatagggcacaattttgtaacaaactcctttactttctcctacatcgcccaagaataaagaaagcacagagatgcttgtttttgatttcaaaattgtgtgcttttatttattttcaagcttacagtatttccagtagtcattagaatagagcttaattaaactgcatgagaacccttccacatagcttaaatactagtggagaagtactcgcctacatgggggtagagtcataatcgtgcatcaggatagggcggtggtgctgcagcagcgcgcgaataaactgctgccgccgccgctccgtcctgcaggaatacaacatggcagtggtctcctcagcgatgattcgcaccgcccgcagcataaggcgccttgtcctccgggcacagcagcgcaccctgatctcacttaaatcagcacagtaactgcagcacagcaccacaatattgttcaaaatcccacagtgcaaggcgctgtatccaaagctcatggcggggaccacagaacccacgtggccatcataccacaagcgcaggtagattaagtggcgacccctcataaacacgctggacataaacattacctcttttggcatgttgtaattcaccacctcccggtaccatataaacctctgattaaacatggcgccatccaccaccatcctaaaccagctggccaaaacctgcccgccggctatacactgcagggaaccgggactggaacaatgacagtggagagcccaggactcgtaaccatggatcatcatgctcgtcatgatatcaatgttggcacaacacaggcacacgtgcatacacttcctcaggattacaagctcctcccgcgttagaaccatatcccagggaacaacccattcctgaatcagcgtaaatcccacactgcagggaagacctcgcacgtaactcacgttgtgcattgtcaaagtgttacattcgggcagcagcggatgatcctccagtatggtagcgcgggtttctgtctcaaaaggaggtagacgatccctactgtacggagtgcgccgagacaaccgagatcgtgttggtcgtagtgtcatgccaaatggaacgccggacgtagtcatatttcctgaagtcttcactctcacagcaccagcactaatcagagtgtgaagagggccaagtgccgaacgagtatatataggaattaaaaatgacgtaaatgtgtaaaggtcaaaaaacgcccagaaaaatacacagaccaacgcccgaaacgaaaacccgcgaaaaaatacccagaagttcctcaacaaccgccacttccgctttcccacgatacgtcacttcctcaaaaatagcaaactacatttcccacatgtacaaaaccaaaacccctccccttgtcaccgcccacaacttacataatcacaaacgtcaaagcctacgtcacccgccccgcctcgccccgcccacctcattatcatattggcctcaatccaaaataaggtatattattgatgatg
실시예 11: NeoGAd20 및 NeoMVA에 혼입된 신생항원은 시험관내에서 면역원성임
중첩 15량체 펩티드는 리드아웃으로서 CD8+ 및 CD4+ T 세포에 의한 TNFα 및 IFNγ 생산을 이용하여 풀로서 실시예 1에 기재된 외인성 자가 정상 공여자 재자극 분석을 사용하여 T 세포를 활성화시키는 능력을 평가하기 위해 NeoGAd20 및 NeoMVA에 통합된 각 신생항원에 미치도록 설계되었다. 표 25는 TNFα+IFNγ+CD8+ 및 TNFα+IFNγ+CD4+ T 세포의 최대 빈도 및 분석된 펩티드의 풀에서의 음성 대조군에 대한 최대 배수 변화를 나타내며, 이는 가장 높은 TNFα+IFNγ+CD8+ 및 TNFα+IFNγ+CD4+ T 세포 빈도 및 펩티드에 대해 평가된 정상 공여자에 대해 얻어진 배수 변화를 나타낸다. 표 26은 사용된 펩티드 서열을 나타낸다. 도 7은 선택된 신생항원에 대해 각각의 시험된 펩티드 풀에 대한 양성 CD8+ 반응을 보이는 환자의 수를 나타낸다. 도 8은 선택된 신생항원에 대해 각각의 시험된 펩티드 풀에 대한 양성 CD4+ 반응을 보이는 환자의 수를 나타낸다.
[표 25]


[표 26]



실시예 12: NeoGAd20 및 NeoMVA에 혼입된 신생항원은 시험관내에서 내인성 발현될 때 면역원성임
3개의 신생항원의 경우, Ad5 벡터를 설계하여 정상 수지상 세포를 신생항원으로 형질전환시켰다. 본 분석은 리드아웃으로서 CD8+ 및 CD4+ T 세포에 의한 TNFα 및 IFNγ 생산을 이용하여 실시예 1에 기재된 내인성 자가 정상 공여자 재자극 분석을 사용하여 중첩 15량체 펩티드 풀 재자극 후에 자가 T 세포를 활성화시키는 내인성 발현 및 제시된 신생항원의 능력을 평가하였다. 표 27은 TNFα+IFNγ+CD8+ 및 TNFα+IFNγ+CD4+ T 세포의 최대 빈도 및 분석된 펩티드의 풀에서의 음성 대조군에 대한 최대 배수 변화를 나타내며, 이는 가장 높은 TNFα+IFNγ+CD8+ 및 TNFα+IFNγ+CD4+ T 세포 빈도 및 펩티드에 대해 평가된 정상 공여자에 대해 얻어진 배수 변화를 나타낸다. 16명의 공여자를 사용하여 내인성 면역원성을 평가하였다.
[표 27]

실시예 13: 신생항원은 시험관내에서 면역원성임
다양한 추가의 확인된 신생항원의 면역원성을 평가하였다. 중첩 15량체 펩티드는 리드아웃으로서 CD8+ 및 CD4+ T 세포에 의한 TNFα 및 IFNγ 생산을 이용하여 풀로서 실시예 1에 기재된 외인성 자가 정상 공여자 재자극 분석을 사용하여 T 세포를 활성화시키는 능력을 평가하기 위해 실시예 11에서 행해진 것과 유사하게 각 신생항원에 미치도록 설계되었다. 표 28은 TNFα+IFNγ+CD8+ 및 TNFα+IFNγ+CD4+ T 세포의 최대 빈도 및 분석된 펩티드의 풀에서의 음성 대조군에 대한 최대 배수 변화를 나타내며, 이는 가장 높은 TNFα+IFNγ+CD8+ 및 TNFα+IFNγ+CD4+ T 세포 빈도 및 펩티드에 대해 평가된 정상 공여자에 대해 얻어진 배수 변화를 나타낸다. 표 29는 각각의 신생항원에 대한 분석에서 사용된 펩티드의 아미노산 서열을 나타낸다.
[표 28]

[표 29]








SEQUENCE LISTING
<110> Janssen Biotech, Inc.
Bachman, Kurtis
Bhargava, Vipul
Davis, Darryl
Krishna, Vinod
Leoni, Guido
Pocalyko, David
Safabakhsh, Pegah
Sepulveda, Manuel
Siegel, Derick
<120> Prostate Neoantigens and their uses
<130> JBI6160WOPCT2
<140> To be assigned
<141> 2020-01-09
<150> 62/913,969
<151> 2019-10-11
<150> 62/883,786
<151> 2019-08-07
<150> 62/851,273
<151> 2019-05-22
<150> 62/790,673
<151> 2019-01-10
<160> 980
<170> PatentIn version 3.5
<210> 1
<211> 17
<212> PRT
<213> Homo sapiens
<400> 1
Ser Ser Cys Met Gly Gly Met Asn Gln Arg Pro Ile Leu Thr Ile Ile
1 5 10 15
Thr
<210> 2
<211> 51
<212> DNA
<213> Homo sapiens
<400> 2
agttcctgca tgggcggcat gaaccagagg cccatcctca ccatcatcac a 51
<210> 3
<211> 17
<212> PRT
<213> Homo sapiens
<400> 3
Ser Ser Cys Met Gly Gly Met Asn Trp Arg Pro Ile Leu Thr Ile Ile
1 5 10 15
Thr
<210> 4
<211> 51
<212> DNA
<213> Homo sapiens
<400> 4
agttcctgca tgggcggcat gaattggagg cccatcctca ccatcatcac a 51
<210> 5
<211> 17
<212> PRT
<213> Homo sapiens
<400> 5
Leu Gly Arg Asn Ser Phe Glu Val Cys Val Cys Ala Cys Pro Gly Arg
1 5 10 15
Asp
<210> 6
<211> 51
<212> DNA
<213> Homo sapiens
<400> 6
ctgggacgga acagctttga ggtgtgtgtt tgtgcctgtc ctgggagaga c 51
<210> 7
<211> 17
<212> PRT
<213> Homo sapiens
<400> 7
Leu Gly Arg Asn Ser Phe Glu Val Leu Val Cys Ala Cys Pro Gly Arg
1 5 10 15
Asp
<210> 8
<211> 51
<212> DNA
<213> Homo sapiens
<400> 8
ctgggacgga acagctttga ggtgcttgtt tgtgcctgtc ctgggagaga c 51
<210> 9
<211> 17
<212> PRT
<213> Homo sapiens
<400> 9
Met Cys Asn Ser Ser Cys Met Gly Ser Met Asn Arg Arg Pro Ile Leu
1 5 10 15
Thr
<210> 10
<211> 51
<212> DNA
<213> Homo sapiens
<400> 10
atgtgtaaca gttcctgcat gggcagcatg aaccggaggc ccatcctcac c 51
<210> 11
<211> 17
<212> PRT
<213> Homo sapiens
<400> 11
Phe Arg His Ser Val Val Val Pro Cys Glu Pro Pro Glu Val Gly Ser
1 5 10 15
Asp
<210> 12
<211> 51
<212> DNA
<213> Homo sapiens
<400> 12
tttcgacata gtgtggtggt gccctgtgag ccgcctgagg ttggctctga c 51
<210> 13
<211> 17
<212> PRT
<213> Homo sapiens
<400> 13
Val Cys Ala Cys Pro Gly Arg Asp Trp Arg Thr Glu Glu Glu Asn Leu
1 5 10 15
Arg
<210> 14
<211> 51
<212> DNA
<213> Homo sapiens
<400> 14
gtttgtgcct gtcctgggag agattggcgc acagaggaag agaatctccg c 51
<210> 15
<211> 17
<212> PRT
<213> Homo sapiens
<400> 15
Phe Val Gln Gly Lys Asp Trp Gly Cys Lys Lys Phe Ile Arg Arg Asp
1 5 10 15
Phe
<210> 16
<211> 51
<212> DNA
<213> Homo sapiens
<400> 16
tttgtgcaag gcaaagactg gggatgcaag aaattcatcc gtagagattt t 51
<210> 17
<211> 17
<212> PRT
<213> Homo sapiens
<400> 17
Phe Val Gln Gly Lys Asp Trp Gly Ile Lys Lys Phe Ile Arg Arg Asp
1 5 10 15
Phe
<210> 18
<211> 51
<212> DNA
<213> Homo sapiens
<400> 18
tttgtgcaag gcaaagactg gggaatcaag aaattcatcc gtagagattt t 51
<210> 19
<211> 17
<212> PRT
<213> Homo sapiens
<400> 19
Phe Val Gln Gly Lys Asp Trp Gly Leu Lys Lys Phe Ile Arg Arg Asp
1 5 10 15
Phe
<210> 20
<211> 51
<212> DNA
<213> Homo sapiens
<400> 20
tttgtgcaag gcaaagactg gggattaaag aaattcatcc gtagagattt t 51
<210> 21
<211> 17
<212> PRT
<213> Homo sapiens
<400> 21
Phe Val Gln Gly Lys Asp Trp Gly Ser Lys Lys Phe Ile Arg Arg Asp
1 5 10 15
Phe
<210> 22
<211> 51
<212> DNA
<213> Homo sapiens
<400> 22
tttgtgcaag gcaaagactg gggatccaag aaattcatcc gtagagattt t 51
<210> 23
<211> 17
<212> PRT
<213> Homo sapiens
<400> 23
Phe Val Gln Gly Lys Asp Trp Gly Val Lys Lys Phe Ile Arg Arg Asp
1 5 10 15
Phe
<210> 24
<211> 51
<212> DNA
<213> Homo sapiens
<400> 24
tttgtgcaag gcaaagactg gggagtcaag aaattcatcc gtagagattt t 51
<210> 25
<211> 17
<212> PRT
<213> Homo sapiens
<400> 25
Tyr Arg Phe Val Gln Gly Lys Asp Cys Gly Phe Lys Lys Phe Ile Arg
1 5 10 15
Arg
<210> 26
<211> 51
<212> DNA
<213> Homo sapiens
<400> 26
tataggtttg tgcaaggcaa agactgtgga ttcaagaaat tcatccgtag a 51
<210> 27
<211> 17
<212> PRT
<213> Homo sapiens
<400> 27
Tyr Arg Phe Val Gln Gly Lys Asp Gly Gly Phe Lys Lys Phe Ile Arg
1 5 10 15
Arg
<210> 28
<211> 51
<212> DNA
<213> Homo sapiens
<400> 28
tataggtttg tgcaaggcaa agacggggga ttcaagaaat tcatccgtag a 51
<210> 29
<211> 17
<212> PRT
<213> Homo sapiens
<400> 29
Tyr Arg Phe Val Gln Gly Lys Asp Leu Gly Phe Lys Lys Phe Ile Arg
1 5 10 15
Arg
<210> 30
<211> 51
<212> DNA
<213> Homo sapiens
<400> 30
tataggtttg tgcaaggcaa agactgggga ttcaagaaat tcatccgtag a 51
<210> 31
<211> 17
<212> PRT
<213> Homo sapiens
<400> 31
Tyr Arg Phe Val Gln Gly Lys Asp Arg Gly Phe Lys Lys Phe Ile Arg
1 5 10 15
Arg
<210> 32
<211> 51
<212> DNA
<213> Homo sapiens
<400> 32
tataggtttg tgcaaggcaa agaccgggga ttcaagaaat tcatccgtag a 51
<210> 33
<211> 17
<212> PRT
<213> Homo sapiens
<400> 33
Tyr Arg Phe Val Gln Gly Lys Asp Ser Gly Phe Lys Lys Phe Ile Arg
1 5 10 15
Arg
<210> 34
<211> 51
<212> DNA
<213> Homo sapiens
<400> 34
tataggtttg tgcaaggcaa agactcggga ttcaagaaat tcatccgtag a 51
<210> 35
<211> 17
<212> PRT
<213> Homo sapiens
<400> 35
Tyr Pro Val Gly Tyr Glu Ala Thr His Ile Tyr Trp Ser Leu Arg Thr
1 5 10 15
Asn
<210> 36
<211> 51
<212> DNA
<213> Homo sapiens
<400> 36
tatcccgtgg gctacgaggc cacgcacatc tattggagcc tccgcaccaa c 51
<210> 37
<211> 17
<212> PRT
<213> Homo sapiens
<400> 37
Met Phe Glu Asn Gly Cys Tyr Leu Cys Arg Gln Lys Arg Phe Lys Cys
1 5 10 15
Glu
<210> 38
<211> 51
<212> DNA
<213> Homo sapiens
<400> 38
atgttcgaga acggctgcta cttgtgccgc cagaagcgct tcaagtgcga g 51
<210> 39
<211> 17
<212> PRT
<213> Homo sapiens
<400> 39
Gly Lys Gly Ser Tyr Trp Thr Leu Gln Pro Asp Ser Gly Asn Met Phe
1 5 10 15
Glu
<210> 40
<211> 51
<212> DNA
<213> Homo sapiens
<400> 40
ggcaagggct cctactggac gctgcagccg gactccggca acatgttcga g 51
<210> 41
<211> 17
<212> PRT
<213> Homo sapiens
<400> 41
Gly Lys Gly Ser Tyr Trp Thr Leu Leu Pro Asp Ser Gly Asn Met Phe
1 5 10 15
Glu
<210> 42
<211> 51
<212> DNA
<213> Homo sapiens
<400> 42
ggcaagggct cctactggac gctgctcccg gactccggca acatgttcga g 51
<210> 43
<211> 17
<212> PRT
<213> Homo sapiens
<400> 43
Gly Lys Gly Ser Tyr Trp Thr Leu Asn Pro Asp Ser Gly Asn Met Phe
1 5 10 15
Glu
<210> 44
<211> 51
<212> DNA
<213> Homo sapiens
<400> 44
ggcaagggct cctactggac gctgaacccg gactccggca acatgttcga g 51
<210> 45
<211> 17
<212> PRT
<213> Homo sapiens
<400> 45
Gly Lys Gly Ser Tyr Trp Thr Leu Tyr Pro Asp Ser Gly Asn Met Phe
1 5 10 15
Glu
<210> 46
<211> 51
<212> DNA
<213> Homo sapiens
<400> 46
ggcaagggct cctactggac gctgtacccg gactccggca acatgttcga g 51
<210> 47
<211> 17
<212> PRT
<213> Homo sapiens
<400> 47
Cys Tyr Leu Arg Arg Gln Lys Arg Cys Lys Cys Glu Lys Gln Pro Gly
1 5 10 15
Ala
<210> 48
<211> 51
<212> DNA
<213> Homo sapiens
<400> 48
tgctacttgc gccgccagaa gcgctgcaag tgcgagaagc agccgggggc c 51
<210> 49
<211> 17
<212> PRT
<213> Homo sapiens
<400> 49
Cys Tyr Leu Arg Arg Gln Lys Arg Ser Lys Cys Glu Lys Gln Pro Gly
1 5 10 15
Ala
<210> 50
<211> 51
<212> DNA
<213> Homo sapiens
<400> 50
tgctacttgc gccgccagaa gcgctccaag tgcgagaagc agccgggggc c 51
<210> 51
<211> 17
<212> PRT
<213> Homo sapiens
<400> 51
Ile Arg His Ser Leu Ser Phe Asn Gly Cys Phe Val Lys Val Ala Arg
1 5 10 15
Ser
<210> 52
<211> 51
<212> DNA
<213> Homo sapiens
<400> 52
atccgccact cgctgtcctt caatggctgc ttcgtcaagg tggcacgctc c 51
<210> 53
<211> 17
<212> PRT
<213> Homo sapiens
<400> 53
Ile Arg His Ser Leu Ser Phe Asn Asn Cys Phe Val Lys Val Ala Arg
1 5 10 15
Ser
<210> 54
<211> 51
<212> DNA
<213> Homo sapiens
<400> 54
atccgccact cgctgtcctt caataactgc ttcgtcaagg tggcacgctc c 51
<210> 55
<211> 17
<212> PRT
<213> Homo sapiens
<400> 55
Gln Gln Arg Trp Gln Asn Ser Ile Cys His Ser Leu Ser Phe Asn Asp
1 5 10 15
Cys
<210> 56
<211> 51
<212> DNA
<213> Homo sapiens
<400> 56
cagcagcgct ggcagaactc catctgccac tcgctgtcct tcaatgactg c 51
<210> 57
<211> 17
<212> PRT
<213> Homo sapiens
<400> 57
Gln Gln Arg Trp Gln Asn Ser Ile Ser His Ser Leu Ser Phe Asn Asp
1 5 10 15
Cys
<210> 58
<211> 51
<212> DNA
<213> Homo sapiens
<400> 58
cagcagcgct ggcagaactc catcagccac tcgctgtcct tcaatgactg c 51
<210> 59
<211> 17
<212> PRT
<213> Homo sapiens
<400> 59
Thr Leu His Pro Asp Ser Gly Asn Lys Phe Glu Asn Gly Cys Tyr Leu
1 5 10 15
Arg
<210> 60
<211> 51
<212> DNA
<213> Homo sapiens
<400> 60
acgctgcacc cggactccgg caacaagttc gagaacggct gctacttgcg c 51
<210> 61
<211> 17
<212> PRT
<213> Homo sapiens
<400> 61
Thr Leu His Pro Asp Ser Gly Asn Arg Phe Glu Asn Gly Cys Tyr Leu
1 5 10 15
Arg
<210> 62
<211> 51
<212> DNA
<213> Homo sapiens
<400> 62
acgctgcacc cggactccgg caacaggttc gagaacggct gctacttgcg c 51
<210> 63
<211> 17
<212> PRT
<213> Homo sapiens
<400> 63
Cys His Lys Lys Asn Phe Leu His Trp Asp Ile Lys Cys Ser Asn Ile
1 5 10 15
Leu
<210> 64
<211> 51
<212> DNA
<213> Homo sapiens
<400> 64
tgtcacaaaa agaatttcct gcattgggat attaagtgtt ctaacatttt g 51
<210> 65
<211> 17
<212> PRT
<213> Homo sapiens
<400> 65
Ile His Cys Lys Ala Gly Lys Gly Gln Thr Gly Val Met Ile Cys Ala
1 5 10 15
Tyr
<210> 66
<211> 51
<212> DNA
<213> Homo sapiens
<400> 66
attcactgta aagctggaaa gggacaaact ggtgtaatga tatgtgcata t 51
<210> 67
<211> 17
<212> PRT
<213> Homo sapiens
<400> 67
Trp Leu Ser Glu Asp Asp Asn His Phe Ala Ala Ile His Cys Lys Ala
1 5 10 15
Gly
<210> 68
<211> 51
<212> DNA
<213> Homo sapiens
<400> 68
tggctaagtg aagatgacaa tcattttgca gcaattcact gtaaagctgg a 51
<210> 69
<211> 17
<212> PRT
<213> Homo sapiens
<400> 69
Gly Leu Gly Asp Arg His Val Gln Ser Ile Leu Ile Asn Glu Gln Ser
1 5 10 15
Ala
<210> 70
<211> 51
<212> DNA
<213> Homo sapiens
<400> 70
ggacttggtg atagacatgt acagagtatc ttgataaatg agcagtcagc a 51
<210> 71
<211> 17
<212> PRT
<213> Homo sapiens
<400> 71
Gly Leu Gly Asp Arg His Val Gln Lys Ile Leu Ile Asn Glu Gln Ser
1 5 10 15
Ala
<210> 72
<211> 51
<212> DNA
<213> Homo sapiens
<400> 72
ggacttggtg atagacatgt acagaaaatc ttgataaatg agcagtcagc a 51
<210> 73
<211> 17
<212> PRT
<213> Homo sapiens
<400> 73
Asn Ile Asn Ile Gly Pro Gly Asp Ser Glu Trp Phe Val Val Pro Glu
1 5 10 15
Gly
<210> 74
<211> 51
<212> DNA
<213> Homo sapiens
<400> 74
aacataaata ttggcccagg tgactctgaa tggtttgttg ttcctgaagg t 51
<210> 75
<211> 17
<212> PRT
<213> Homo sapiens
<400> 75
Asn Ile Asn Ile Gly Pro Gly Asp Tyr Glu Trp Phe Val Val Pro Glu
1 5 10 15
Gly
<210> 76
<211> 51
<212> DNA
<213> Homo sapiens
<400> 76
aacataaata ttggcccagg tgactatgaa tggtttgttg ttcctgaagg t 51
<210> 77
<211> 17
<212> PRT
<213> Homo sapiens
<400> 77
Phe Met Lys Gln Met Asn Asp Ala Arg His Gly Gly Trp Thr Thr Lys
1 5 10 15
Met
<210> 78
<211> 51
<212> DNA
<213> Homo sapiens
<400> 78
ttcatgaaac aaatgaatga tgcacgtcat ggtggctgga caacaaaaat g 51
<210> 79
<211> 17
<212> PRT
<213> Homo sapiens
<400> 79
Arg Asp Pro Leu Ser Glu Ile Thr Lys Gln Glu Lys Asp Phe Leu Trp
1 5 10 15
Ser
<210> 80
<211> 51
<212> DNA
<213> Homo sapiens
<400> 80
cgagatcctc tctctgaaat cactaagcag gagaaagatt ttctatggag t 51
<210> 81
<211> 17
<212> PRT
<213> Homo sapiens
<400> 81
Arg Asp Pro Leu Ser Glu Ile Thr Gly Gln Glu Lys Asp Phe Leu Trp
1 5 10 15
Ser
<210> 82
<211> 51
<212> DNA
<213> Homo sapiens
<400> 82
cgagatcctc tctctgaaat cactgggcag gagaaagatt ttctatggag t 51
<210> 83
<211> 17
<212> PRT
<213> Homo sapiens
<400> 83
Arg Asp Pro Leu Ser Glu Ile Thr Ala Gln Glu Lys Asp Phe Leu Trp
1 5 10 15
Ser
<210> 84
<211> 51
<212> DNA
<213> Homo sapiens
<400> 84
cgagatcctc tctctgaaat cactgcgcag gagaaagatt ttctatggag t 51
<210> 85
<211> 17
<212> PRT
<213> Homo sapiens
<400> 85
Ser Gly Ile His Ser Gly Ala Thr Ala Thr Ala Pro Ser Leu Ser Gly
1 5 10 15
Lys
<210> 86
<211> 51
<212> DNA
<213> Homo sapiens
<400> 86
tctggaatcc attctggtgc cactgccaca gctccttctc tgagtggtaa a 51
<210> 87
<211> 17
<212> PRT
<213> Homo sapiens
<400> 87
His Trp Gln Gln Gln Ser Tyr Leu Ala Ser Gly Ile His Ser Gly Ala
1 5 10 15
Thr
<210> 88
<211> 51
<212> DNA
<213> Homo sapiens
<400> 88
cactggcagc aacagtctta cctggcctct ggaatccatt ctggtgccac t 51
<210> 89
<211> 17
<212> PRT
<213> Homo sapiens
<400> 89
His Trp Gln Gln Gln Ser Tyr Leu His Ser Gly Ile His Ser Gly Ala
1 5 10 15
Thr
<210> 90
<211> 51
<212> DNA
<213> Homo sapiens
<400> 90
cactggcagc aacagtctta cctgcactct ggaatccatt ctggtgccac t 51
<210> 91
<211> 17
<212> PRT
<213> Homo sapiens
<400> 91
His Trp Gln Gln Gln Ser Tyr Leu Val Ser Gly Ile His Ser Gly Ala
1 5 10 15
Thr
<210> 92
<211> 51
<212> DNA
<213> Homo sapiens
<400> 92
cactggcagc aacagtctta cctggtctct ggaatccatt ctggtgccac t 51
<210> 93
<211> 17
<212> PRT
<213> Homo sapiens
<400> 93
His Trp Gln Gln Gln Ser Tyr Leu Tyr Ser Gly Ile His Ser Gly Ala
1 5 10 15
Thr
<210> 94
<211> 51
<212> DNA
<213> Homo sapiens
<400> 94
cactggcagc aacagtctta cctgtactct ggaatccatt ctggtgccac t 51
<210> 95
<211> 17
<212> PRT
<213> Homo sapiens
<400> 95
Ser Tyr Leu Asp Ser Gly Ile His Ala Gly Ala Thr Thr Thr Ala Pro
1 5 10 15
Ser
<210> 96
<211> 51
<212> DNA
<213> Homo sapiens
<400> 96
tcttacctgg actctggaat ccatgctggt gccactacca cagctccttc t 51
<210> 97
<211> 17
<212> PRT
<213> Homo sapiens
<400> 97
Ser Tyr Leu Asp Ser Gly Ile His Cys Gly Ala Thr Thr Thr Ala Pro
1 5 10 15
Ser
<210> 98
<211> 51
<212> DNA
<213> Homo sapiens
<400> 98
tcttacctgg actctggaat ccattgtggt gccactacca cagctccttc t 51
<210> 99
<211> 17
<212> PRT
<213> Homo sapiens
<400> 99
Ser Tyr Leu Asp Ser Gly Ile His Phe Gly Ala Thr Thr Thr Ala Pro
1 5 10 15
Ser
<210> 100
<211> 51
<212> DNA
<213> Homo sapiens
<400> 100
tcttacctgg actctggaat ccattttggt gccactacca cagctccttc t 51
<210> 101
<211> 17
<212> PRT
<213> Homo sapiens
<400> 101
Ser Tyr Leu Asp Ser Gly Ile His Tyr Gly Ala Thr Thr Thr Ala Pro
1 5 10 15
Ser
<210> 102
<211> 51
<212> DNA
<213> Homo sapiens
<400> 102
tcttacctgg actctggaat ccattatggt gccactacca cagctccttc t 51
<210> 103
<211> 17
<212> PRT
<213> Homo sapiens
<400> 103
Ser Gly Ala Thr Thr Thr Ala Pro Cys Leu Ser Gly Lys Gly Asn Pro
1 5 10 15
Glu
<210> 104
<211> 51
<212> DNA
<213> Homo sapiens
<400> 104
tctggtgcca ctaccacagc tccttgtctg agtggtaaag gcaatcctga g 51
<210> 105
<211> 17
<212> PRT
<213> Homo sapiens
<400> 105
Ser Gly Ala Thr Thr Thr Ala Pro Phe Leu Ser Gly Lys Gly Asn Pro
1 5 10 15
Glu
<210> 106
<211> 51
<212> DNA
<213> Homo sapiens
<400> 106
tctggtgcca ctaccacagc tccttttctg agtggtaaag gcaatcctga g 51
<210> 107
<211> 17
<212> PRT
<213> Homo sapiens
<400> 107
Ser Gly Ala Thr Thr Thr Ala Pro Pro Leu Ser Gly Lys Gly Asn Pro
1 5 10 15
Glu
<210> 108
<211> 51
<212> DNA
<213> Homo sapiens
<400> 108
tctggtgcca ctaccacagc tcctcctctg agtggtaaag gcaatcctga g 51
<210> 109
<211> 17
<212> PRT
<213> Homo sapiens
<400> 109
Tyr Val Pro Ser Glu Asp Tyr Tyr Lys Pro Ser Pro Tyr Asp Asp Leu
1 5 10 15
Thr
<210> 110
<211> 51
<212> DNA
<213> Homo sapiens
<400> 110
tacgtgccca gtgaggacta ctacaagccc tcaccgtatg atgacctcac c 51
<210> 111
<211> 17
<212> PRT
<213> Homo sapiens
<400> 111
Ile Arg Lys Arg Leu Lys Leu Cys Thr Asp Phe Lys Arg Thr Gly Met
1 5 10 15
Asp
<210> 112
<211> 51
<212> DNA
<213> Homo sapiens
<400> 112
atccggaaga ggctaaagct ctgcactgac ttcaaacgca cagggatgga t 51
<210> 113
<211> 17
<212> PRT
<213> Homo sapiens
<400> 113
Val Asp Gly Ala Val Phe Ala Val Phe Lys Ala Val Phe Val Leu Gly
1 5 10 15
Asp
<210> 114
<211> 51
<212> DNA
<213> Homo sapiens
<400> 114
gtggatggag ccgtgtttgc tgttttcaag gctgtgtttg tacttgggga t 51
<210> 115
<211> 17
<212> PRT
<213> Homo sapiens
<400> 115
Ile Val Asp Gly Ala Val Phe Ala Gly Leu Lys Ala Val Phe Val Leu
1 5 10 15
Gly
<210> 116
<211> 51
<212> DNA
<213> Homo sapiens
<400> 116
atcgtggatg gagccgtgtt tgctggtctc aaggctgtgt ttgtacttgg g 51
<210> 117
<211> 17
<212> PRT
<213> Homo sapiens
<400> 117
Ile Val Asp Gly Ala Val Phe Ala Leu Leu Lys Ala Val Phe Val Leu
1 5 10 15
Gly
<210> 118
<211> 51
<212> DNA
<213> Homo sapiens
<400> 118
atcgtggatg gagccgtgtt tgctcttctc aaggctgtgt ttgtacttgg g 51
<210> 119
<211> 17
<212> PRT
<213> Homo sapiens
<400> 119
Thr His Thr Ala Asn Glu Arg Arg Trp Arg Gly Glu Met Arg Asp Leu
1 5 10 15
Phe
<210> 120
<211> 51
<212> DNA
<213> Homo sapiens
<400> 120
acacacactg ccaatgagcg gcggtggcgt ggtgaaatga gggatctctt t 51
<210> 121
<211> 17
<212> PRT
<213> Homo sapiens
<400> 121
Gly Arg Phe Ser Lys Val Ser Ser Arg Ala Pro Met Glu Gly Gly Glu
1 5 10 15
Glu
<210> 122
<211> 51
<212> DNA
<213> Homo sapiens
<400> 122
gggaggttca gcaaggtgtc tagtcgagct cccatggagg gtggggaaga a 51
<210> 123
<211> 17
<212> PRT
<213> Homo sapiens
<400> 123
Gly Lys Thr Glu Asp Leu Gly Cys Arg Tyr Lys Leu Phe Ser Arg Val
1 5 10 15
Pro
<210> 124
<211> 51
<212> DNA
<213> Homo sapiens
<400> 124
ggaaagacag aagaccttgg ttgcaggtac aagttattta gtcgtgtgcc a 51
<210> 125
<211> 12
<212> PRT
<213> Homo sapiens
<400> 125
Met Asn His His Gln Gln Gln Gln Gln Gln Lys Ala
1 5 10
<210> 126
<211> 36
<212> DNA
<213> Homo sapiens
<400> 126
atgaaccacc accagcagca gcagcagcag aaagcg 36
<210> 127
<211> 17
<212> PRT
<213> Homo sapiens
<400> 127
His Gly Leu Val Asp Glu Gln Gln Glu Val Arg Thr Ile Ser Ala Leu
1 5 10 15
Ala
<210> 128
<211> 51
<212> DNA
<213> Homo sapiens
<400> 128
catggtcttg tggatgagca gcaggaagtt cggaccatca gtgctttggc c 51
<210> 129
<211> 17
<212> PRT
<213> Homo sapiens
<400> 129
Val Cys Arg His Gly Asp Arg Cys Phe Arg Leu His Asn Lys Pro Thr
1 5 10 15
Phe
<210> 130
<211> 51
<212> DNA
<213> Homo sapiens
<400> 130
gcatgtcgtc atggagacag gtgctttcgg ttgcacaata aaccgacgtt t 51
<210> 131
<211> 17
<212> PRT
<213> Homo sapiens
<400> 131
Ser Cys Thr Thr Pro Gln Cys Lys Cys Leu Leu Ala Lys Cys Cys Val
1 5 10 15
Asp
<210> 132
<211> 51
<212> DNA
<213> Homo sapiens
<400> 132
agttgtacta caccgcaatg caaatgcctg cttgcaaaat gttgtgttga t 51
<210> 133
<211> 17
<212> PRT
<213> Homo sapiens
<400> 133
Ser Ile Leu Ser Lys Gln Val Gln His Lys Pro Lys Thr Gly Arg Ser
1 5 10 15
Leu
<210> 134
<211> 51
<212> DNA
<213> Homo sapiens
<400> 134
tccatattat ctaaacaggt tcaacataaa ccaaaaactg gtcgaagttt a 51
<210> 135
<211> 17
<212> PRT
<213> Homo sapiens
<400> 135
Gln Arg Ile Gly Ser Gly Ser Phe Ala Thr Val Tyr Lys Gly Lys Trp
1 5 10 15
His
<210> 136
<211> 51
<212> DNA
<213> Homo sapiens
<400> 136
caaagaattg gatctggatc atttgcaaca gtctacaagg gaaagtggca t 51
<210> 137
<211> 17
<212> PRT
<213> Homo sapiens
<400> 137
Gly Asp Phe Gly Leu Ala Thr Val Glu Ser Arg Trp Ser Gly Ser His
1 5 10 15
Gln
<210> 138
<211> 51
<212> DNA
<213> Homo sapiens
<400> 138
ggtgattttg gtctagctac agtggaatct cgatggagtg ggtcccatca g 51
<210> 139
<211> 17
<212> PRT
<213> Homo sapiens
<400> 139
Gln Ala Asn Leu Arg His Leu Cys Cys Ile Cys Gly Asn Ser Phe Arg
1 5 10 15
Ala
<210> 140
<211> 51
<212> DNA
<213> Homo sapiens
<400> 140
caagccaacc ttcgacatct ctgctgcatc tgtgggaatt cttttagagc t 51
<210> 141
<211> 17
<212> PRT
<213> Homo sapiens
<400> 141
Gln Ala Asn Leu Arg His Leu Cys His Ile Cys Gly Asn Ser Phe Arg
1 5 10 15
Ala
<210> 142
<211> 51
<212> DNA
<213> Homo sapiens
<400> 142
caagccaacc ttcgacatct ctgccacatc tgtgggaatt cttttagagc t 51
<210> 143
<211> 17
<212> PRT
<213> Homo sapiens
<400> 143
Asp Arg Cys Leu Lys Lys Val Ser Lys Gly Val Glu Gln Phe Glu Asp
1 5 10 15
Ile
<210> 144
<211> 51
<212> DNA
<213> Homo sapiens
<400> 144
gatcgctgcc tcaagaaggt gtccaagggc gtggagcagt ttgaagatat t 51
<210> 145
<211> 17
<212> PRT
<213> Homo sapiens
<400> 145
Ile Lys Thr Trp Val Ala Ser Asn Lys Ile Lys Asp Lys Arg Gln Leu
1 5 10 15
Ile
<210> 146
<211> 51
<212> DNA
<213> Homo sapiens
<400> 146
atcaagacat gggtagcgtc caacaagatc aaggacaaga ggcagcttat a 51
<210> 147
<211> 17
<212> PRT
<213> Homo sapiens
<400> 147
Gln Lys Phe Asp Glu Ala Leu Arg Lys Ser Trp Thr Thr Lys Val Asn
1 5 10 15
Trp
<210> 148
<211> 51
<212> DNA
<213> Homo sapiens
<400> 148
caaaaatttg atgaggcgct caggaaaagc tggactacta aagtgaactg g 51
<210> 149
<211> 17
<212> PRT
<213> Homo sapiens
<400> 149
Trp Val Lys Pro Ile Ile Ile Gly Cys His Ala Tyr Gly Asp Gln Tyr
1 5 10 15
Arg
<210> 150
<211> 51
<212> DNA
<213> Homo sapiens
<400> 150
tgggtaaaac ctatcatcat aggttgtcat gcttatgggg atcaatacag a 51
<210> 151
<211> 17
<212> PRT
<213> Homo sapiens
<400> 151
Trp Val Lys Pro Ile Ile Ile Gly Gly His Ala Tyr Gly Asp Gln Tyr
1 5 10 15
Arg
<210> 152
<211> 51
<212> DNA
<213> Homo sapiens
<400> 152
tgggtaaaac ctatcatcat aggtggtcat gcttatgggg atcaatacag a 51
<210> 153
<211> 17
<212> PRT
<213> Homo sapiens
<400> 153
Trp Val Lys Pro Ile Ile Ile Gly His His Ala Tyr Gly Asp Gln Tyr
1 5 10 15
Arg
<210> 154
<211> 51
<212> DNA
<213> Homo sapiens
<400> 154
tgggtaaaac ctatcatcat aggtcatcat gcttatgggg atcaatacag a 51
<210> 155
<211> 17
<212> PRT
<213> Homo sapiens
<400> 155
Tyr Lys Leu Val Val Val Gly Ala Asp Gly Val Gly Lys Ser Ala Leu
1 5 10 15
Thr
<210> 156
<211> 51
<212> DNA
<213> Homo sapiens
<400> 156
tataagctgg tggtggtggg cgccgacggt gtgggcaaga gtgcgctgac c 51
<210> 157
<211> 17
<212> PRT
<213> Homo sapiens
<400> 157
Tyr Lys Leu Val Val Val Gly Ala Arg Gly Val Gly Lys Ser Ala Leu
1 5 10 15
Thr
<210> 158
<211> 51
<212> DNA
<213> Homo sapiens
<400> 158
tataagctgg tggtggtggg cgcccgcggt gtgggcaaga gtgcgctgac c 51
<210> 159
<211> 17
<212> PRT
<213> Homo sapiens
<400> 159
Leu Asp Ile Leu Asp Thr Ala Gly Lys Glu Glu Tyr Ser Ala Met Arg
1 5 10 15
Asp
<210> 160
<211> 51
<212> DNA
<213> Homo sapiens
<400> 160
ttggacatcc tggataccgc cggaaaggag gagtacagcg ccatgcggga c 51
<210> 161
<211> 17
<212> PRT
<213> Homo sapiens
<400> 161
Leu Asp Ile Leu Asp Thr Ala Gly Leu Glu Glu Tyr Ser Ala Met Arg
1 5 10 15
Asp
<210> 162
<211> 51
<212> DNA
<213> Homo sapiens
<400> 162
ttggacatcc tggataccgc cggcctggag gagtacagcg ccatgcggga c 51
<210> 163
<211> 17
<212> PRT
<213> Homo sapiens
<400> 163
Leu Asp Ile Leu Asp Thr Ala Gly Arg Glu Glu Tyr Ser Ala Met Arg
1 5 10 15
Asp
<210> 164
<211> 51
<212> DNA
<213> Homo sapiens
<400> 164
ttggacatcc tggataccgc cggccgggag gagtacagcg ccatgcggga c 51
<210> 165
<211> 17
<212> PRT
<213> Homo sapiens
<400> 165
Glu Gly Trp Leu His Lys Arg Gly Lys Tyr Ile Lys Thr Trp Arg Pro
1 5 10 15
Arg
<210> 166
<211> 51
<212> DNA
<213> Homo sapiens
<400> 166
gagggttggc tgcacaaacg agggaagtac atcaagacct ggcggccacg c 51
<210> 167
<211> 17
<212> PRT
<213> Homo sapiens
<400> 167
Ile Ala Arg Glu Leu His Gln Phe Ala Phe Asp Leu Leu Ile Lys Ser
1 5 10 15
His
<210> 168
<211> 51
<212> DNA
<213> Homo sapiens
<400> 168
attgcgagag agctgcatca gttcgctttt gacctgctaa tcaagtcaca c 51
<210> 169
<211> 17
<212> PRT
<213> Homo sapiens
<400> 169
Ile Ala Arg Glu Leu His Gln Phe Gly Phe Asp Leu Leu Ile Lys Ser
1 5 10 15
His
<210> 170
<211> 51
<212> DNA
<213> Homo sapiens
<400> 170
attgcgagag agctgcatca gttcggtttt gacctgctaa tcaagtcaca c 51
<210> 171
<211> 17
<212> PRT
<213> Homo sapiens
<400> 171
Gln Pro Asp Ser Phe Ala Ala Leu His Ser Ser Leu Asn Glu Leu Gly
1 5 10 15
Glu
<210> 172
<211> 51
<212> DNA
<213> Homo sapiens
<400> 172
cagcccgact cctttgcagc cttgcactct agcctcaatg aactgggaga g 51
<210> 173
<211> 17
<212> PRT
<213> Homo sapiens
<400> 173
Gln Met Ala Val Ile Gln Tyr Ser Leu Met Gly Leu Met Val Phe Ala
1 5 10 15
Met
<210> 174
<211> 51
<212> DNA
<213> Homo sapiens
<400> 174
cagatggctg tcattcagta ctccttgatg gggctcatgg tgtttgccat g 51
<210> 175
<211> 17
<212> PRT
<213> Homo sapiens
<400> 175
Gln Met Ala Val Ile Gln Tyr Ser Phe Met Gly Leu Met Val Phe Ala
1 5 10 15
Met
<210> 176
<211> 51
<212> DNA
<213> Homo sapiens
<400> 176
cagatggctg tcattcagta ctcctttatg gggctcatgg tgtttgccat g 51
<210> 177
<211> 68
<212> PRT
<213> Homo sapiens
<400> 177
Gln Asn Leu Gln Asn Gly Gly Gly Ser Arg Ser Ser Ala Thr Leu Pro
1 5 10 15
Gly Arg Arg Arg Arg Arg Trp Leu Arg Arg Arg Arg Gln Pro Ile Ser
20 25 30
Val Ala Pro Ala Gly Pro Pro Arg Arg Pro Asn Gln Lys Pro Asn Pro
35 40 45
Pro Gly Gly Ala Arg Cys Val Ile Met Arg Pro Thr Trp Pro Gly Thr
50 55 60
Ser Ala Phe Thr
65
<210> 178
<211> 204
<212> DNA
<213> Homo sapiens
<400> 178
cagaacctgc agaatggagg ggggagcagg tcttcagcca cactgccggg gcggcggcgg 60
cggcggtggc tgcggcggcg gcggcagcca atatcagtag ctcctgcggg gccccctcgc 120
cgaccaaacc aaaaaccaaa cccacctggc ggtgcgaggt gtgtgattat gagaccaacg 180
tggccaggaa cctccgcatt caca 204
<210> 179
<211> 33
<212> PRT
<213> Homo sapiens
<400> 179
Gln Asn Leu Gln Asn Gly Gly Gly Gly Ala Gly Leu Gln Pro His Cys
1 5 10 15
Arg Gly Gly Gly Gly Gly Gly Gly Cys Gly Gly Gly Gly Ser Gln Tyr
20 25 30
Gln
<210> 180
<211> 102
<212> DNA
<213> Homo sapiens
<400> 180
cagaacctgc agaatggagg ggggggagca ggtcttcagc cacactgccg gggcggcggc 60
ggcggcggtg gctgcggcgg cggcggcagc caatatcagt ag 102
<210> 181
<211> 10
<212> PRT
<213> Homo sapiens
<400> 181
Asn Gln Glu Lys Glu Ala Glu Lys Asn Tyr
1 5 10
<210> 182
<211> 33
<212> DNA
<213> Homo sapiens
<400> 182
aaccaagaga aagaggcaga aaaaaactat tga 33
<210> 183
<211> 40
<212> PRT
<213> Homo sapiens
<400> 183
Asp Ala Ala Val Ser Pro Arg Gly Leu Gln His Arg Gln Gly Arg Gly
1 5 10 15
Asn Leu Gly Trp Trp Gln Ser Pro Leu Arg Lys Val Arg Val Pro Lys
20 25 30
Arg Arg Met Val Tyr His Pro Ser
35 40
<210> 184
<211> 123
<212> DNA
<213> Homo sapiens
<400> 184
gatgctgctg tcagtcccag ggggctgcag cacaggcagg ggagagggaa tctggggtgg 60
tggcagtctc ccctgagaaa agtgagagtc cccaaaagga ggatggttta tcatcccagt 120
tga 123
<210> 185
<211> 33
<212> PRT
<213> Homo sapiens
<400> 185
Phe Val Val Ser Val Val Lys Lys Asn Arg Thr Cys Pro Phe Arg Leu
1 5 10 15
Phe Val Arg Arg Met Leu Gln Phe Thr Gly Asn Lys Val Leu Asp Arg
20 25 30
Pro
<210> 186
<211> 102
<212> DNA
<213> Homo sapiens
<400> 186
tttgtcgttt ctgttgtgaa aaaaaacagg acttgcccct ttcgtctatt tgtcagacga 60
atgttacaat ttactggcaa taaagttttg gatagacctt aa 102
<210> 187
<211> 9
<212> PRT
<213> Homo sapiens
<400> 187
Arg Ser Arg Arg Ser Ala Ile Lys Arg
1 5
<210> 188
<211> 32
<212> DNA
<213> Homo sapiens
<400> 188
agaagcagaa gatcggctat aaaaagataa tg 32
<210> 189
<211> 24
<212> PRT
<213> Homo sapiens
<400> 189
Ser Ile Ile Val Gln Glu Arg Glu Arg Ala Glu Arg Arg Val Arg Arg
1 5 10 15
Gly Gln Val Met Glu Ile Val Asp
20
<210> 190
<211> 75
<212> DNA
<213> Homo sapiens
<400> 190
agtataattg tacaagagag agagagagca gagagaaggg tcagaagagg ccaagtgatg 60
gaaatagtgg attaa 75
<210> 191
<211> 34
<212> PRT
<213> Homo sapiens
<400> 191
Asn Asn Leu Val Thr Glu Lys Lys His Arg Asn Val Gln Cys His Asp
1 5 10 15
Ala Val Glu Glu Asn Gly Gln Ser Ser Phe Ile Thr Ser Pro Ile Leu
20 25 30
His Ser
<210> 192
<211> 107
<212> DNA
<213> Homo sapiens
<400> 192
aataacttgg tcacagaaaa aaaacacaga aatgtgcaat gtcatgatgc agttgaggaa 60
aatggccaat catcctttat tacatcgcca atattacaca gctgaaa 107
<210> 193
<211> 48
<212> PRT
<213> Homo sapiens
<400> 193
His Pro Gln Arg Lys Arg Arg Gly Val Pro Pro Ser Pro Pro Leu Ala
1 5 10 15
Leu Gly Pro Arg Met Gln Leu Cys Thr Gln Leu Ala Arg Phe Phe Pro
20 25 30
Ile Thr Pro Pro Val Trp His Ile Leu Gly Pro Gln Arg His Thr Pro
35 40 45
<210> 194
<211> 149
<212> DNA
<213> Homo sapiens
<400> 194
cacccacaga ggaaaaggcg gggggtccct ccgagcccac ccctggctct cggccccagg 60
atgcaactgt gcacccagct tgccagattt ttccccatta cacccccagt gtggcatatc 120
cttggtcccc agaggcacac cccttgatc 149
<210> 195
<211> 31
<212> PRT
<213> Homo sapiens
<400> 195
Ala Ser Arg His His Leu Trp Gly Ala Thr Ala Gly Thr Pro Ala Pro
1 5 10 15
Pro Pro Val Pro Thr Cys Ser Pro Arg Thr Leu Arg Cys Leu Pro
20 25 30
<210> 196
<211> 98
<212> DNA
<213> Homo sapiens
<400> 196
gccagccggc accatctgtg gggggcaaca gcgggcaccc ccgcaccacc ccccgtgccc 60
acctgttcac ccaggaccct gcgatgcctc ccctgacc 98
<210> 197
<211> 13
<212> PRT
<213> Homo sapiens
<400> 197
Gly Pro Gly Glu Ala Gly Gly Pro Ser Pro Gln Gly Gly
1 5 10
<210> 198
<211> 44
<212> DNA
<213> Homo sapiens
<400> 198
gggcctgggg aggctggggg cccctcaccc caaggcgggt gagc 44
<210> 199
<211> 19
<212> PRT
<213> Homo sapiens
<400> 199
Gly Gly Gly Pro Ser Gly Ser Gly Glu Ala Pro Thr Ser Pro Ser Ala
1 5 10 15
Leu Arg Thr
<210> 200
<211> 62
<212> DNA
<213> Homo sapiens
<400> 200
ggcggggggc ccagcggctc aggggaggct cccacttctc cttcagccct gaggacatga 60
aa 62
<210> 201
<211> 23
<212> PRT
<213> Homo sapiens
<400> 201
Gly Asn Pro Asp Val Pro Pro Pro Val Leu Phe Lys Ala Asp Gln Ser
1 5 10 15
Glu Ser Ser Leu Ser Ser Gly
20
<210> 202
<211> 72
<212> DNA
<213> Homo sapiens
<400> 202
ggaaatccag atgtcccacc ccccgtcctc ttcaaggcag atcagagcga gagttctttg 60
tcaagtgggt ag 72
<210> 203
<211> 10
<212> PRT
<213> Homo sapiens
<400> 203
Ala Phe Cys Tyr Cys Gly Glu Lys Val Pro
1 5 10
<210> 204
<211> 35
<212> DNA
<213> Homo sapiens
<400> 204
gctttttgtt actgtgggga aaaagttcct tagga 35
<210> 205
<211> 16
<212> PRT
<213> Homo sapiens
<400> 205
Thr Leu His Pro Asp Ser Gly Asn Gly Cys Tyr Leu Arg Arg Gln Lys
1 5 10 15
<210> 206
<211> 50
<212> DNA
<213> Homo sapiens
<400> 206
acgctgcacc cggactccgg caacggctgc tacttgcgcc gccagaagcg 50
<210> 207
<211> 16
<212> PRT
<213> Homo sapiens
<400> 207
Leu His Pro Asp Ser Gly Asn Met Tyr Gly Cys Tyr Leu Arg Arg Gln
1 5 10 15
<210> 208
<211> 53
<212> DNA
<213> Homo sapiens
<400> 208
acgctgcacc cggactccgg caacatgtac ggctgctact tgcgccgcca gaa 53
<210> 209
<211> 17
<212> PRT
<213> Homo sapiens
<400> 209
Leu His Pro Asp Ser Gly Asn Met Cys Cys Tyr Leu Arg Arg Gln Lys
1 5 10 15
Arg
<210> 210
<211> 51
<212> DNA
<213> Homo sapiens
<400> 210
ctgcacccgg actccggcaa catgtgctgc tacttgcgcc gccagaagcg c 51
<210> 211
<211> 16
<212> PRT
<213> Homo sapiens
<400> 211
Cys Gly Ala Ser Ala Cys Asp Val Ser Leu Ile Ala Met Asp Ser Ala
1 5 10 15
<210> 212
<211> 48
<212> DNA
<213> Homo sapiens
<400> 212
tgcggggcct ctgcctgtga tgtctccctc attgctatgg acagtgct 48
<210> 213
<211> 16
<212> PRT
<213> Homo sapiens
<400> 213
Thr Glu Tyr Asn Gln Lys Leu Gln Val Asn Gln Phe Ser Glu Ser Lys
1 5 10 15
<210> 214
<211> 48
<212> DNA
<213> Homo sapiens
<400> 214
accgaataca accagaaatt acaagtgaat caatttagtg aatccaaa 48
<210> 215
<211> 24
<212> PRT
<213> Homo sapiens
<400> 215
Thr Glu Ile Ser Cys Cys Thr Leu Ser Ser Glu Glu Asn Glu Tyr Leu
1 5 10 15
Pro Arg Pro Glu Trp Gln Leu Gln
20
<210> 216
<211> 72
<212> DNA
<213> Homo sapiens
<400> 216
acagaaattt catgttgcac cctgagcagt gaggagaatg aataccttcc aagaccagag 60
tggcagctcc ag 72
<210> 217
<211> 16
<212> PRT
<213> Homo sapiens
<400> 217
Gly Leu Val Ser Phe Gly Glu His Phe Cys Leu Pro Cys Ala Leu Cys
1 5 10 15
<210> 218
<211> 50
<212> DNA
<213> Homo sapiens
<400> 218
gggctggtgt ccttcgggga gcacttttgt ctgccctgcg ccctctgcca 50
<210> 219
<211> 16
<212> PRT
<213> Homo sapiens
<400> 219
Asn Ser Lys Met Ala Leu Asn Ser Glu Ala Leu Ser Val Val Ser Glu
1 5 10 15
<210> 220
<211> 48
<212> DNA
<213> Homo sapiens
<400> 220
aacagcaaga tggctttgaa ctcagaagcc ttatcagttg tgagtgag 48
<210> 221
<211> 14
<212> PRT
<213> Homo sapiens
<400> 221
Cys Glu Glu Arg Gly Ala Ala Gly Ser Leu Ile Ser Cys Glu
1 5 10
<210> 222
<211> 42
<212> DNA
<213> Homo sapiens
<400> 222
tgtgaggagc gcggcgcggc aggaagcctt atcagttgtg ag 42
<210> 223
<211> 69
<212> PRT
<213> Homo sapiens
<400> 223
Leu Trp Phe Gln Ser Ser Glu Leu Ser Pro Thr Gly Ala Pro Trp Pro
1 5 10 15
Ser Arg Arg Pro Thr Trp Arg Gly Thr Thr Val Ser Pro Arg Thr Ala
20 25 30
Thr Ser Ser Ala Arg Thr Cys Cys Gly Thr Lys Trp Pro Ser Ser Gln
35 40 45
Glu Ala Ala Leu Gly Leu Gly Ser Gly Leu Leu Arg Phe Ser Cys Gly
50 55 60
Thr Ala Ala Ile Arg
65
<210> 224
<211> 207
<212> DNA
<213> Homo sapiens
<400> 224
ctgtggttcc agagcagtga gctgtccccg acgggagcgc catggcccag ccgccgcccg 60
acgtggaggg ggacgactgt ctccccgcgt accgccacct cttctgcccg gacctgctgc 120
gggacaaagt ggccttcatc acaggaggcg gctctgggat tgggttccgg attgctgaga 180
ttttcatgcg gcacggctgc catacgg 207
<210> 225
<211> 70
<212> PRT
<213> Homo sapiens
<400> 225
Trp Gly Met Glu Leu Ala Ala Ser Arg Arg Phe Ser Trp Asp His His
1 5 10 15
Ser Ala Gly Gly Pro Pro Arg Val Pro Ser Val Arg Ser Gly Ala Ala
20 25 30
Gln Val Gln Pro Lys Asp Pro Leu Pro Leu Arg Thr Leu Ala Gly Cys
35 40 45
Leu Ala Arg Thr Ala His Leu Arg Pro Gly Ala Glu Ser Leu Pro Gln
50 55 60
Pro Gln Leu His Cys Thr
65 70
<210> 226
<211> 210
<212> DNA
<213> Homo sapiens
<400> 226
tgggggatgg agttggcagc gtctcggagg ttctcctggg accaccactc cgccgggggg 60
ccgcccagag tgccaagcgt ccgatccggc gccgcccaag tgcagcccaa ggacccgctc 120
ccgctccgca ccctggcagg ctgcctagcc aggactgcgc acctgcgccc tggggcggag 180
tccttacccc aaccccagct tcactgcaca 210
<210> 227
<211> 28
<212> PRT
<213> Homo sapiens
<400> 227
Lys Glu Gln Ile Leu Ala Val Ala Ser Leu Val Ser Ser Gln Ser Ile
1 5 10 15
His Pro Ser Trp Gly Gln Ser Pro Leu Ser Arg Ile
20 25
<210> 228
<211> 84
<212> DNA
<213> Homo sapiens
<400> 228
aaggaacaga ttttagctgt ggccagtctc gtttcctctc agtccatcca cccttcatgg 60
ggccagagcc ctctctccag aatc 84
<210> 229
<211> 14
<212> PRT
<213> Homo sapiens
<400> 229
Leu Glu Leu Glu Leu Ser Glu Gly Val Cys Phe Arg Leu Arg
1 5 10
<210> 230
<211> 42
<212> DNA
<213> Homo sapiens
<400> 230
ctggagctgg agctgtcgga aggagtctgc ttcagattaa ga 42
<210> 231
<211> 17
<212> PRT
<213> Homo sapiens
<400> 231
Gln Gln Leu Arg Ile Phe Cys Ala Ala Met Ala Ser Asn Glu Asp Phe
1 5 10 15
Ser
<210> 232
<211> 52
<212> DNA
<213> Homo sapiens
<400> 232
cagcagctaa ggatattttg tgcagccatg gcctccaacg aagatttctc ca 52
<210> 233
<211> 31
<212> PRT
<213> Homo sapiens
<400> 233
Asp Gly Phe Ser Gly Ser Leu Phe Ala Val Val Thr Arg Arg Cys Tyr
1 5 10 15
Phe Leu Lys Trp Arg Thr Ile Phe Pro Gln Ser Leu Met Trp Leu
20 25 30
<210> 234
<211> 93
<212> DNA
<213> Homo sapiens
<400> 234
gacgggttta gcggcagcct cttcgcagtt gtcaccagac gctgttactt cctaaaatgg 60
cggacaatct tcccacagag tttgatgtgg tta 93
<210> 235
<211> 16
<212> PRT
<213> Homo sapiens
<400> 235
Lys Met His Phe Ser Leu Lys Glu His Pro Pro Pro Pro Cys Pro Pro
1 5 10 15
<210> 236
<211> 48
<212> DNA
<213> Homo sapiens
<400> 236
aaaatgcact tctccctcaa ggagcaccca ccgccccctt gcccgcct 48
<210> 237
<211> 31
<212> PRT
<213> Homo sapiens
<400> 237
Asp Leu Arg Arg Val Ala Thr Tyr Cys Ala Pro Leu Pro Ser Ser Trp
1 5 10 15
Arg Pro Gly Thr Gly Thr Thr Ile Pro Pro Arg Met Arg Ser Cys
20 25 30
<210> 238
<211> 93
<212> DNA
<213> Homo sapiens
<400> 238
gatctgcgcc gggtcgccac atactgcgct cctttaccct catcgtggag gcctgggact 60
gggacaacga taccaccccg aatgaggagc tgc 93
<210> 239
<211> 48
<212> PRT
<213> Homo sapiens
<400> 239
Leu Gln Glu Arg Met Glu Leu Leu Ala Cys Gly Ala Glu Arg Gly Ala
1 5 10 15
Gly Gly Trp Gly Gly Gly Gly Gly Gly Gly Gly Gly Asp Arg Arg Gly
20 25 30
Gly Gly Gly Ser Ala Pro Ala Leu Ala Asp Phe Ala Gly Gly Arg Gly
35 40 45
<210> 240
<211> 144
<212> DNA
<213> Homo sapiens
<400> 240
ttgcaggagc ggatggagtt gcttgcctgc ggagccgagc gcggggccgg cggctggggg 60
ggaggcggtg gcggcggcgg cggcgaccga agaggaggag gaggaagcgc gccagctctt 120
gcagactttg caggcggccg aggg 144
<210> 241
<211> 47
<212> PRT
<213> Homo sapiens
<400> 241
Leu Thr Phe Leu Asp Phe Ile Gln Val Thr Leu Arg Val Met Ser Gly
1 5 10 15
Ser Gln Met Glu Asn Gly Ser Ser Tyr Phe Phe Lys Pro Phe Ser Trp
20 25 30
Gly Leu Gly Val Gly Leu Ser Ala Trp Leu Cys Val Met Leu Thr
35 40 45
<210> 242
<211> 141
<212> DNA
<213> Homo sapiens
<400> 242
ctgacgtttt tagatttcat ccaggtaacg ttgagagtaa tgtcaggatc tcaaatggaa 60
aacggaagtt cctatttttt caagcccttt tcatggggtc tgggggtggg actctcggcc 120
tggctgtgtg taatgttaac t 141
<210> 243
<211> 51
<212> PRT
<213> Homo sapiens
<400> 243
Phe Met Ile Gly Glu Leu Val Gly Glu Leu Cys Cys Gln Leu Thr Phe
1 5 10 15
Arg Leu Pro Phe Leu Glu Ser Leu Cys Gln Ala Val Val Thr Gln Ala
20 25 30
Leu Arg Phe Asn Pro Ser Phe Gln Glu Val Cys Ile Tyr Gln Asp Thr
35 40 45
Asp Leu Met
50
<210> 244
<211> 153
<212> DNA
<213> Homo sapiens
<400> 244
ttcatgattg gagaacttgt aggtgagttg tgttgccaac tcactttccg tttacctttc 60
ctcgagagtc tttgtcaagc tgtagttaca caggctttga ggtttaaccc atcttttcag 120
gaagtttgta tttatcaaga cactgatctc atg 153
<210> 245
<211> 16
<212> PRT
<213> Homo sapiens
<400> 245
Val Ala Met Met Val Pro Asp Arg Gln Val His Tyr Asp Phe Gly Leu
1 5 10 15
<210> 246
<211> 48
<212> DNA
<213> Homo sapiens
<400> 246
gttgctatga tggttcctga tagacaggtt cattatgact ttggattg 48
<210> 247
<211> 24
<212> PRT
<213> Homo sapiens
<400> 247
Trp Cys Pro Leu Asp Leu Arg Leu Gly Ser Thr Gly Cys Leu Thr Cys
1 5 10 15
Arg His His Gln Thr Ser His Glu
20
<210> 248
<211> 72
<212> DNA
<213> Homo sapiens
<400> 248
tggtgtccgc tggatcttag actcggttcc actggatgtc tcacatgcag acatcatcaa 60
acgtcacatg ag 72
<210> 249
<211> 25
<212> PRT
<213> Homo sapiens
<400> 249
Val Val Gly Arg Arg His Glu Thr Ala Pro Gln Pro Leu Leu Val Pro
1 5 10 15
Asp Arg Ala Gly Gly Glu Gly Gly Ala
20 25
<210> 250
<211> 75
<212> DNA
<213> Homo sapiens
<400> 250
gtcgtgggaa ggcgtcatga aacagctcct caacccctgc tggtgcccga ccgagctggt 60
ggtgaagggg gagca 75
<210> 251
<211> 17
<212> PRT
<213> Homo sapiens
<400> 251
Asp Tyr Trp Ala Gln Lys Glu Lys Ile Ser Ile Pro Arg Thr His Leu
1 5 10 15
Cys
<210> 252
<211> 51
<212> DNA
<213> Homo sapiens
<400> 252
gactactggg ctcaaaagga gaagatcagc atccccagaa cacacctgtg t 51
<210> 253
<211> 18
<212> PRT
<213> Homo sapiens
<400> 253
Asp Tyr Trp Ala Gln Lys Glu Lys Gly Ser Ser Ser Phe Leu Arg Pro
1 5 10 15
Ser Cys
<210> 254
<211> 54
<212> DNA
<213> Homo sapiens
<400> 254
gactactggg ctcaaaagga gaagggatca tcttcattcc tgcgaccatc ctgt 54
<210> 255
<211> 14
<212> PRT
<213> Homo sapiens
<400> 255
Leu Val Leu Gly Val Leu Ser Gly His Ser Gly Ser Arg Leu
1 5 10
<210> 256
<211> 42
<212> DNA
<213> Homo sapiens
<400> 256
cttgtacttg gtgtattgag cgggcacagt ggctcacgcc ta 42
<210> 257
<211> 25
<212> PRT
<213> Homo sapiens
<400> 257
Pro Val Pro Thr Ala Thr Pro Gly Val Arg Ser Val Thr Ser Pro Gln
1 5 10 15
Gly Leu Gly Leu Phe Leu Lys Phe Ile
20 25
<210> 258
<211> 75
<212> DNA
<213> Homo sapiens
<400> 258
cctgtcccaa ctgctacacc tggggtaaga tcagtgacta gtccccaggg gctgggcctt 60
ttccttaagt ttatt 75
<210> 259
<211> 28
<212> PRT
<213> Homo sapiens
<400> 259
Lys Glu Asn Asp Val Arg Glu Val Cys Asp Val Tyr Leu Gln Met Gln
1 5 10 15
Ile Phe Phe His Phe Lys Phe Arg Ser Tyr Phe His
20 25
<210> 260
<211> 84
<212> DNA
<213> Homo sapiens
<400> 260
aaggaaaatg atgtccgtga ggtctgtgat gtgtatttac aaatgcagat cttcttccat 60
tttaagttca gaagttactt tcat 84
<210> 261
<211> 90
<212> PRT
<213> Homo sapiens
<400> 261
Val Pro Phe Arg Glu Leu Lys Asn Gln Arg Thr Ala Gln Gly Ala Pro
1 5 10 15
Gly Ile His His Ala Ala Ser Pro Val Ala Ala Asn Leu Cys Asp Pro
20 25 30
Ala Arg His Ala Gln His Thr Arg Ile Pro Cys Gly Ala Gly Gln Val
35 40 45
Arg Ala Gly Arg Gly Pro Glu Ala Gly Gly Gly Val Leu Gln Pro Gln
50 55 60
Arg Pro Ala Pro Glu Lys Pro Gly Cys Pro Cys Arg Arg Gly Gln Pro
65 70 75 80
Arg Leu His Thr Val Lys Met Trp Arg Ala
85 90
<210> 262
<211> 270
<212> DNA
<213> Homo sapiens
<400> 262
gtgcccttcc gggagctcaa gaaccagaga acagcacaag gggctcctgg gatccaccac 60
gcggcttccc ccgttgctgc caacctctgc gacccggcga gacacgcaca gcacacacgc 120
atcccctgcg gcgctggcca agtgcgtgct ggccgaggtc ccgaagcagg tggtggagta 180
ctacagccac agaggcctgc ccccgagaag cctgggtgtc cctgccggag aggccagccc 240
aggctgcaca ccgtgaagat gtggagggcg 270
<210> 263
<211> 22
<212> PRT
<213> Homo sapiens
<400> 263
Phe Ala Arg Lys Met Leu Glu Lys Val His Arg Gln His Leu Gln Leu
1 5 10 15
Ser His Asn Ser Gln Glu
20
<210> 264
<211> 66
<212> DNA
<213> Homo sapiens
<400> 264
tttgctagaa aaatgctgga gaaggtacac agacaacacc tacagctttc ccacaatagc 60
caggaa 66
<210> 265
<211> 11
<212> PRT
<213> Homo sapiens
<400> 265
Lys Arg Ser Phe Ala Val Thr Glu Arg Ile Ile
1 5 10
<210> 266
<211> 33
<212> DNA
<213> Homo sapiens
<400> 266
aagagaagtt ttgctgtcac ggagaggatc atc 33
<210> 267
<211> 17
<212> PRT
<213> Homo sapiens
<400> 267
Met Phe Leu Arg Lys Glu Gln Gln Val Gly Pro His Ser Phe Ser Met
1 5 10 15
Leu
<210> 268
<211> 51
<212> DNA
<213> Homo sapiens
<400> 268
atgttcctta gaaaggagca gcaggtgggt ccccacagct tttctatgct t 51
<210> 269
<211> 14
<212> PRT
<213> Homo sapiens
<400> 269
Val Leu Arg Phe Leu Asp Leu Lys Val Arg Tyr Leu His Ser
1 5 10
<210> 270
<211> 42
<212> DNA
<213> Homo sapiens
<400> 270
gtgctgcgct ttctggactt aaaggtgaga tacctgcact ct 42
<210> 271
<211> 32
<212> PRT
<213> Homo sapiens
<400> 271
Gly Asn Thr Thr Leu Gln Gln Leu Gly Glu Ala Ser Gln Ala Pro Ser
1 5 10 15
Gly Ser Leu Ile Pro Leu Arg Leu Pro Leu Leu Trp Glu Val Arg Gly
20 25 30
<210> 272
<211> 96
<212> DNA
<213> Homo sapiens
<400> 272
ggcaacacca ccctccagca gctgggtgag gcctcccagg cgccctcagg ctccctcatc 60
cctctgaggc tgcctctgct ctgggaagtg aggggc 96
<210> 273
<211> 25
<212> PRT
<213> Homo sapiens
<400> 273
Gly Leu Asn Leu Asn Thr Asp Arg Pro Gly Gly Tyr Ser Tyr Ser Ile
1 5 10 15
Trp Trp Lys Asn Asn Ala Lys Asn Arg
20 25
<210> 274
<211> 75
<212> DNA
<213> Homo sapiens
<400> 274
ggactgaact taaatactga tagaccaggt ggttacagct attcaatttg gtggaaaaac 60
aatgccaaga acaga 75
<210> 275
<211> 27
<212> PRT
<213> Homo sapiens
<400> 275
Trp Lys Phe Glu Met Ser Tyr Thr Val Gly Gly Pro Pro Pro His Val
1 5 10 15
His Ala Arg Pro Arg His Trp Lys Thr Asp Arg
20 25
<210> 276
<211> 81
<212> DNA
<213> Homo sapiens
<400> 276
tggaaattcg agatgagcta cacggtgggt ggcccgcctc cccatgttca tgctagaccc 60
aggcattgga aaactgatag a 81
<210> 277
<211> 22
<212> PRT
<213> Homo sapiens
<400> 277
Gln Trp Gln His Tyr His Arg Ser Gly Glu Ala Ala Gly Thr Pro Leu
1 5 10 15
Trp Arg Pro Thr Arg Asn
20
<210> 278
<211> 66
<212> DNA
<213> Homo sapiens
<400> 278
cagtggcagc actaccaccg gtcaggtgag gccgcaggga ctcccctctg gagacccaca 60
agaaac 66
<210> 279
<211> 29
<212> PRT
<213> Homo sapiens
<400> 279
Lys Val Leu Asn Glu Ile Asp Ala Val Val Thr Val Pro Pro Ser Leu
1 5 10 15
Ser Thr Ser Gln Ile Pro Gln Gly Cys Cys Ile Ile Leu
20 25
<210> 280
<211> 87
<212> DNA
<213> Homo sapiens
<400> 280
aaggtcctca acgagatcga tgcggtagtt accgtccctc cctccctgtc tacctcccag 60
ataccgcagg gctgctgcat catattg 87
<210> 281
<211> 18
<212> PRT
<213> Homo sapiens
<400> 281
Ala Asn Leu Lys Gly Thr Leu Gln Val Arg Ser Gly Gln Ala Val Ser
1 5 10 15
Pro Arg
<210> 282
<211> 54
<212> DNA
<213> Homo sapiens
<400> 282
gccaatctga aaggcaccct gcaggtgagg agtgggcagg cagtgagtcc acgc 54
<210> 283
<211> 70
<212> PRT
<213> Homo sapiens
<400> 283
Leu Gln Ala Ala Ala Ser Gly Gln Gly Lys Gln Gly Val Pro Cys Pro
1 5 10 15
Trp Gly Cys Cys Ala Tyr Ala Glu Ser Pro Arg Ala Leu Ile Ser Gly
20 25 30
Asp Ala Pro Ser Gln Val Glu Arg Glu Val Pro Gly Pro Cys Leu Asn
35 40 45
Thr His Ser Leu Ser His Arg Ser Pro Gln Leu Pro Gly Leu Pro His
50 55 60
Pro Lys Gln Pro Ser Val
65 70
<210> 284
<211> 210
<212> DNA
<213> Homo sapiens
<400> 284
ctccaggcgg ctgcctcggg ccaaggcaag cagggcgtcc cttgtccctg gggttgctgt 60
gcctacgctg agagtccccg ggccctgatt tcgggagatg ctccatcaca ggtggagcgg 120
gaggtgccgg gcccctgcct caacacgcat tctctctccc acagatcccc acagctccca 180
ggccttccac accccaagca gccttctgtt 210
<210> 285
<211> 9
<212> PRT
<213> Homo sapiens
<400> 285
Lys Ile Gln Asn Lys Asn Cys Pro Asp
1 5
<210> 286
<211> 27
<212> DNA
<213> Homo sapiens
<400> 286
aaaattcaga ataaaaattg tccagac 27
<210> 287
<211> 37
<212> PRT
<213> Homo sapiens
<400> 287
Gly Glu Val Glu Leu Ser Glu Gly Gly Glu Gly Gln Arg His Leu Ala
1 5 10 15
Phe Pro Trp Ala Cys Ser Gly Pro Gly Trp Arg Gly Val Cys Cys Ala
20 25 30
Ala Val Glu Pro Ala
35
<210> 288
<211> 111
<212> DNA
<213> Homo sapiens
<400> 288
ggcgaggtgg agctctcaga gggcggtgag ggccagcggc accttgcatt tccctgggcc 60
tgctctgggc cgggctggag aggggtgtgc tgtgctgctg tggagcctgc t 111
<210> 289
<211> 9
<212> PRT
<213> Homo sapiens
<400> 289
Ile Glu Met Lys Lys Leu Leu Lys Ser
1 5
<210> 290
<211> 27
<212> DNA
<213> Homo sapiens
<400> 290
attgaaatga aaaaactgtt aaaaagt 27
<210> 291
<211> 70
<212> PRT
<213> Homo sapiens
<400> 291
Lys Met Arg Ala Ile Gln Ala Glu Gly Gly His Gly Gln Ala Cys Cys
1 5 10 15
Gly Gly Ala Trp Gly Trp Ala Pro Gly Asp Gly Gly Pro Gln Gly Met
20 25 30
Leu Thr His Thr Leu Pro Thr Leu Gly Phe Gln Ser Ala Trp Thr Trp
35 40 45
Arg Arg Glu Asp Ala Asp Arg Ala Trp Arg Thr Pro Lys Ala Cys Ala
50 55 60
Ser Arg Arg Trp Ser Ile
65 70
<210> 292
<211> 210
<212> DNA
<213> Homo sapiens
<400> 292
aagatgcggg ccatccaggc cgagggtggg cacgggcagg cctgctgtgg aggggcctgg 60
ggatgggcac cgggggacgg gggcccccag gggatgctca cgcatactct gcccaccctg 120
ggcttccaga gcgcctggac atggagaaga gaagatgcag acagagcctg gaggactccg 180
aaagcctgcg catcaaggag gtggagcata 210
<210> 293
<211> 74
<212> PRT
<213> Homo sapiens
<400> 293
Leu Leu Glu Pro Phe Arg Arg Gly Glu Pro Gly Pro Arg Gly Leu Leu
1 5 10 15
Ser Gly Ser Ser Arg Gly Gly Glu Gly Pro Gly Arg Ser Ile Glu Ala
20 25 30
Ala Pro Ala Thr Pro Leu Pro Cys Cys Arg Lys Asn Pro Cys Arg Pro
35 40 45
Gln Pro Ser Arg Phe Leu Pro Pro Arg Val Leu Leu Val Ile Ile Leu
50 55 60
Pro Lys Leu Asp Cys Pro Lys Leu Gly Phe
65 70
<210> 294
<211> 222
<212> DNA
<213> Homo sapiens
<400> 294
ctgctggagc ccttccgccg cggtgagccc gggccccgcg ggctgctctc gggaagttcc 60
cgcggagggg aggggcctgg ccgttcgatc gaggctgcac ccgccacacc tttgccctgt 120
tgccgcaaga acccttgtcg gccccagcct tccagatttt tgcctcctag ggtattgtta 180
gtgatcattc ttcccaaact ggattgtcca aaacttgggt tc 222
<210> 295
<211> 65
<212> PRT
<213> Homo sapiens
<400> 295
Pro Ser Gly Arg Arg Thr Lys Arg Leu Val Thr Leu Arg Ser Gly Cys
1 5 10 15
Ala Ile Gln Cys Trp His Pro Arg Ala Gly Pro Val Pro Ser Ala Leu
20 25 30
Pro His Thr Glu Arg Pro Pro Arg Leu Val Arg Gly Ala Ala Asp Pro
35 40 45
Arg Thr Val Thr Leu Gly Arg Ser Pro Ala Val Met Pro Arg Ala Pro
50 55 60
Ala
65
<210> 296
<211> 195
<212> DNA
<213> Homo sapiens
<400> 296
ccctcggggc ggagaaccaa acggttagtt accctgcgtt ctggctgcgc catacaatgc 60
tggcatcctc gtgccggccc agttccctca gcgcttcctc acacagagag gcccccaagg 120
cttgtcaggg gagcagcaga tcccaggaca gtgaccctgg gacggagccc tgcagtcatg 180
cctcgggccc ctgcg 195
<210> 297
<211> 95
<212> PRT
<213> Homo sapiens
<400> 297
Cys His Leu Phe Leu Gln Pro Gln Val Gly Thr Pro Pro Pro His Thr
1 5 10 15
Ala Ser Ala Arg Ala Pro Ser Gly Pro Pro His Pro His Glu Ser Cys
20 25 30
Pro Ala Gly Arg Arg Pro Ala Arg Ala Ala Gln Thr Cys Ala Arg Arg
35 40 45
Gln His Gly Leu Pro Gly Cys Glu Glu Ala Gly Thr Ala Arg Val Pro
50 55 60
Ser Leu His Leu His Leu His Gln Ala Ala Leu Gly Ala Gly Arg Gly
65 70 75 80
Arg Gly Trp Gly Glu Ala Cys Ala Gln Val Pro Pro Ser Arg Gly
85 90 95
<210> 298
<211> 285
<212> DNA
<213> Homo sapiens
<400> 298
tgccacctct tcctgcagcc ccaggttggc accccccccc cccacactgc cagtgctcga 60
gcccccagtg gtccacccca ccctcatgaa agttgccctg cagggcgaag acctgcgaga 120
gctgcgcaga catgtgcacg ccgacagcac ggacttcctg gctgtgaaga ggctggtaca 180
gcgcgtgttc ccagcctgca cctgcacctg caccaggccg ccctcggagc aggaaggggc 240
cgtgggtggg gagaggcctg tgcccaagta cccccctcaa gaggc 285
<210> 299
<211> 45
<212> PRT
<213> Homo sapiens
<400> 299
Lys Glu Leu Lys Leu Glu Gln Gln Val Gly Gly Gln Gly Leu Arg Gly
1 5 10 15
Val Gly Gln Gly Val Arg Gly Gly Phe Val Thr Leu Thr Thr His Thr
20 25 30
Pro Phe Pro Ser Gln Glu Ala Ala Glu Arg Glu Ser Lys
35 40 45
<210> 300
<211> 135
<212> DNA
<213> Homo sapiens
<400> 300
aaggagctca agctggagca gcaggtgggt gggcagggct tgagaggggt gggccaaggg 60
gtgcgtggcg gcttcgtgac cctcactacc cataccccgt tcccctccca ggaagctgca 120
gagcgggagt ctaaa 135
<210> 301
<211> 175
<212> PRT
<213> Homo sapiens
<400> 301
Gly Glu Ile Ser Gln Glu Glu Val Pro Pro Ser Arg His Leu Gly Val
1 5 10 15
Ser Trp Gly Ala Gly Val Trp Ala Gly Leu Thr Leu Gly Ala Ser Ala
20 25 30
Pro Pro Asn Ser Ser Phe Pro Ser Gly Ala Glu Leu Gln Pro Val Val
35 40 45
Cys Cys Ile Arg Ser Asp Thr Arg Gln Pro Arg Pro Pro Asp Phe Pro
50 55 60
Gln His Arg Gly Asp Pro Arg Leu Pro Gln Leu Ser Leu Gly Ala Glu
65 70 75 80
Asn Gln Thr Val Ser Tyr Pro Ala Phe Trp Leu Arg His Thr Met Leu
85 90 95
Ala Ser Ser Cys Arg Pro Ser Ser Leu Ser Ala Ser Ser His Arg Glu
100 105 110
Ala Pro Lys Ala Cys Gln Gly Ser Ser Arg Ser Gln Asp Ser Asp Pro
115 120 125
Gly Thr Glu Pro Cys Ser His Ala Ser Gly Pro Cys Val Thr Ser Thr
130 135 140
Val Ser Ser Pro Gly Leu Leu Pro Gln Arg Leu Leu Pro Leu Ala Leu
145 150 155 160
Thr Gly Leu Pro Val Glu Glu Asp Gly Phe Glu His Ala Gly Ala
165 170 175
<210> 302
<211> 525
<212> DNA
<213> Homo sapiens
<400> 302
ggagaaatca gccaggaaga ggtgcctccc tcccgccacc tgggcgtctc atggggtgct 60
ggggtgtggg cgggcctcac cctcggggcc tctgcacccc ctaactctag cttcccctca 120
ggtgctgagc tacagccagt tgtgtgctgc attaggagtg acacaagaca gccccgaccc 180
cccgactttc ctcagcacag gggagatcca cgccttcctc agctctccct cggggcggag 240
aaccaaacgg ttagttaccc tgcgttctgg ctgcgccata caatgctggc atcctcgtgc 300
cggcccagtt ccctcagcgc ttcctcacac agagaggccc ccaaggcttg tcaggggagc 360
agcagatccc aggacagtga ccctgggacg gagccctgca gtcatgcctc gggcccctgc 420
gtaacctcca ctgtctccag cccaggtctc cttcctcaga ggctattgcc tctcgctctg 480
actgggctcc ctgtggagga agatggtttc gagcacgcgg gagcc 525
<210> 303
<211> 56
<212> PRT
<213> Homo sapiens
<400> 303
Asp Cys Met Leu Ser Glu Glu Gly Gly Gln Ala Arg Arg Gly Gly Ser
1 5 10 15
Leu Cys Ser Leu Ala Ala His Thr Ile Ala Ser Ala Ala Arg Gly Arg
20 25 30
Phe Leu Ser Arg Leu Ser Asn Phe Cys Ala Val Val Lys Ala Ser Arg
35 40 45
Gly Ala Pro Ser Cys Thr Trp Glu
50 55
<210> 304
<211> 168
<212> DNA
<213> Homo sapiens
<400> 304
gactgcatgc tcagcgagga aggtgggcag gcgcggcggg gtggatccct ctgctcctta 60
gctgcccaca ccattgcctc ggcagcccga ggtcgcttcc tctccaggct ctccaatttc 120
tgtgccgtag ttaaagcgag caggggcgcc ccttcctgca cctgggag 168
<210> 305
<211> 43
<212> PRT
<213> Homo sapiens
<400> 305
Glu Ala Phe Gln Arg Ala Ala Gly Glu Gly Gly Pro Gly Arg Gly Gly
1 5 10 15
Ala Arg Arg Gly Ala Arg Val Leu Gln Ser Pro Phe Cys Arg Ala Gly
20 25 30
Ala Gly Glu Trp Leu Gly His Gln Ser Leu Arg
35 40
<210> 306
<211> 129
<212> DNA
<213> Homo sapiens
<400> 306
gaggccttcc agagggccgc tggtgagggc ggcccgggcc gcggtggggc acggcgcggt 60
gccagggtgt tgcagagccc cttttgcagg gcaggagctg gggagtggtt aggacatcag 120
tccctcagg 129
<210> 307
<211> 35
<212> PRT
<213> Homo sapiens
<400> 307
Pro Glu Pro Arg Arg Leu Ser Pro Gly Glu Pro Arg Gly Arg Pro Arg
1 5 10 15
Lys Gly Trp Gly Ile Trp Gly Leu Cys Gly Ala Arg Val Gly Pro Lys
20 25 30
Ala Trp Arg
35
<210> 308
<211> 105
<212> DNA
<213> Homo sapiens
<400> 308
cctgagccca ggagactgag cccaggtgag cccagggggc gaccccggaa gggctggggg 60
atctggggtt tgtgtggagc gcgggtgggg cccaaggctt ggcgg 105
<210> 309
<211> 61
<212> PRT
<213> Homo sapiens
<400> 309
Val Pro Phe Arg Glu Leu Lys Asn Val Ser Val Leu Glu Gly Leu Arg
1 5 10 15
Gln Gly Arg Leu Gly Gly Pro Cys Ser Cys His Cys Pro Arg Pro Ser
20 25 30
Gln Ala Arg Leu Thr Pro Val Asp Val Ala Gly Pro Phe Leu Cys Leu
35 40 45
Gly Asp Pro Gly Leu Phe Pro Pro Val Lys Ser Ser Ile
50 55 60
<210> 310
<211> 183
<212> DNA
<213> Homo sapiens
<400> 310
gtgcccttcc gggagctcaa gaacgtgagt gtcctggagg ggctccgtca aggccggctt 60
gggggtccct gttcatgtca ctgcccaaga ccttcccagg ccaggctcac gccagtggat 120
gtggcaggtc ccttcttgtg tctgggggat cctgggctgt tccccccagt caagagcagt 180
atc 183
<210> 311
<211> 98
<212> PRT
<213> Homo sapiens
<400> 311
Phe Val Ser Leu Thr Ala Ile Gln Met Ala Ser Ser Ala Thr Pro Trp
1 5 10 15
Gly Arg Trp Pro Val Ala Thr Pro Thr Ala Ala Cys Pro Arg Arg Arg
20 25 30
Pro Ser Ser Leu Pro Thr Gly Gly Asp Ser Ala Ser Lys Lys Pro Ile
35 40 45
Ser Arg Arg Ala Pro Trp Gln Pro Trp Ala Cys Pro Gly Arg Ser Val
50 55 60
Asn Ser Ala Ala Pro Arg Ala Trp Cys Pro Pro Ala Thr Thr Pro Arg
65 70 75 80
Thr Gln Ser Pro Ser Arg Asp Leu Arg Pro Arg Cys Leu Ser Ser Trp
85 90 95
Ser Ser
<210> 312
<211> 294
<212> DNA
<213> Homo sapiens
<400> 312
tttgtgagcc tgactgccat ccagatggca tcgtcggcca ctccctgggg gaggtggcct 60
gtggctacgc cgacggctgc ctgtcccagg aggaggccgt cctcgctgcc tactggaggg 120
gacagtgcat caaagaagcc catctcccgc cgggcgccat ggcagccgtg ggcttgtcct 180
gggaggagtg taaacagcgc tgccccccgg gcgtggtgcc cgcctgccac aactccaagg 240
acacagtcac catctcggga cctcaggccc cggtgtttga gttcgtggag cagc 294
<210> 313
<211> 109
<212> PRT
<213> Homo sapiens
<400> 313
Pro Val Ala Ile Lys Pro Gly Thr Gly Pro Pro Asn Asn Ser Ser Ile
1 5 10 15
His Gly Gly Ser Lys Arg Ser Glu Asn Ser Tyr Cys Arg Asp Leu Arg
20 25 30
Gly Gln Leu Arg Ala Ile Cys Cys Ser Ser Tyr Ser His Asp Arg His
35 40 45
Thr Thr Glu Glu Arg Gly Ser Arg Gly Arg His Val Trp Arg Ile Arg
50 55 60
Arg Leu His Thr Ser Gly Leu Pro Cys Cys Cys His Ser Gly Pro His
65 70 75 80
Pro Arg Arg Leu Pro Asp Ile Leu Arg Leu Val Thr Ser Thr Lys Thr
85 90 95
Asp His Thr Asn Thr Thr Glu Gly Thr Leu Asp Tyr Leu
100 105
<210> 314
<211> 327
<212> DNA
<213> Homo sapiens
<400> 314
ccagttgcca ttaaacctgg tacagggccg cccaataact ccagtataca cggtggctcc 60
aaacgttcag agaattccta ctgccgggat ctacggggcc agttacgtgc catttgctgc 120
tccagctaca gccacgatcg ccacactaca gaagaacgcg gcagccgcgg ccgccatgta 180
tggaggatac gcaggctaca tacctcaggc cttccctgct gctgccattc aggtccccat 240
ccccgacgtc taccagacat actgaggctg gtgaccagca cgaagacaga ccacacaaac 300
accactgaag gaacgcttga ctattta 327
<210> 315
<211> 40
<212> PRT
<213> Homo sapiens
<400> 315
Lys Trp Asn Lys Asn Trp Thr Ala Thr Leu Gly Ala Leu Thr Ile Arg
1 5 10 15
Gly His Lys Leu Leu Cys His Leu Pro His Leu Leu Ser Ser Val Gln
20 25 30
Gln Thr Cys Arg Ser Ser Ser Arg
35 40
<210> 316
<211> 120
<212> DNA
<213> Homo sapiens
<400> 316
aagtggaaca agaactggac agccacactc ggggctctta caatcagggg tcataagctg 60
ctatgtcacc tacctcacct tctcagctct gtccagcaaa cctgcagaag tagttctaga 120
<210> 317
<211> 50
<212> PRT
<213> Homo sapiens
<400> 317
Phe Lys Lys Phe Asp Gly Pro Cys Gly Glu Arg Gly Gly Gly Arg Thr
1 5 10 15
Ala Arg Ala Leu Trp Ala Arg Gly Asp Ser Val Leu Thr Pro Ala Leu
20 25 30
Asp Pro Gln Thr Pro Val Arg Ala Pro Ser Leu Thr Arg Ala Ala Ala
35 40 45
Ala Val
50
<210> 318
<211> 150
<212> DNA
<213> Homo sapiens
<400> 318
ttcaagaagt tcgacggccc ttgtggtgag cgcggcggcg ggcgcacggc tcgagctctg 60
tgggcgcgcg gcgacagcgt cctgactcct gccctcgacc cccagacccc tgtcagggcg 120
ccctccctga cccgagccgc agctgccgtg 150
<210> 319
<211> 52
<212> PRT
<213> Homo sapiens
<400> 319
Glu Asn Ala Ser Leu Val Phe Thr Gly Ser Asn Ser Pro Ile Pro Ala
1 5 10 15
Cys Glu Leu Ser Ser His Pro Ala His Gly Ile Ser Pro Trp Ile Pro
20 25 30
Ser Pro Gly Asn Glu His Phe His Gly Ile Lys Lys Gln Val Lys Ala
35 40 45
Ile Lys Val Glu
50
<210> 320
<211> 156
<212> DNA
<213> Homo sapiens
<400> 320
gaaaatgcca gcctagtgtt tacaggatcc aacagcccca taccagcctg cgaactgagt 60
agtcacccag ctcatggtat cagtccttgg ataccctcac ctggaaatga acatttccat 120
ggcataaaga agcaagtaaa ggcaataaaa gtagaa 156
<210> 321
<211> 55
<212> PRT
<213> Homo sapiens
<400> 321
Arg Leu Thr Gln Arg Leu Val Gln Gly Trp Thr Pro Met Glu Asn Arg
1 5 10 15
Trp Cys Gly Arg Arg Ala Gly Gly Gln Pro Ala Ser Ser Ser Thr Arg
20 25 30
Trp Thr Thr Cys Arg Ala Ala Cys Leu Leu Thr Lys Trp Thr Ala Gly
35 40 45
Arg Ser Gln Thr Ser Ile Gly
50 55
<210> 322
<211> 165
<212> DNA
<213> Homo sapiens
<400> 322
cggctgacgc aacggctggt ccagggctgg accccaatgg agaacaggtg gtgtggcagg 60
cgagcgggtg ggcagcccgc atcatccagc acgagatgga ccacctgcag ggctgcctgt 120
ttattgacaa aatggacagc aggacgttca caaacgtcta ttgga 165
<210> 323
<211> 32
<212> PRT
<213> Homo sapiens
<400> 323
Glu Asn Ser Gly Asn Ala Ser Arg Trp Leu His Val Pro Ser Ser Ser
1 5 10 15
Asp Asp Trp Leu Gly Trp Lys Lys Ser Ser Ala Ile Thr Ser Asn Ser
20 25 30
<210> 324
<211> 96
<212> DNA
<213> Homo sapiens
<400> 324
gaaaattcag gcaacgcctc gcgttggctg catgtaccaa gtagttcaga cgattggctc 60
ggatggaaaa aatcttctgc aattacttcc aattcc 96
<210> 325
<211> 59
<212> PRT
<213> Homo sapiens
<400> 325
Gly Met Glu Cys Thr Leu Gly Gln Val Gly Ala Pro Ser Pro Arg Arg
1 5 10 15
Glu Glu Asp Gly Trp Arg Gly Gly His Ser Arg Phe Lys Ala Asp Val
20 25 30
Pro Ala Pro Gln Gly Pro Cys Trp Gly Gly Gln Pro Gly Ser Ala Pro
35 40 45
Ser Ser Ala Pro Pro Glu Gln Ser Leu Leu Asp
50 55
<210> 326
<211> 177
<212> DNA
<213> Homo sapiens
<400> 326
ggcatggagt gcaccctggg gcaggtgggt gccccgtccc ctcggaggga ggaggacggt 60
tggcgtgggg gccacagccg attcaaggct gatgtaccag caccgcaggg accctgctgg 120
ggtggccaac ctggctctgc cccctcctca gctcctcctg aacagtcatt attagat 177
<210> 327
<211> 110
<212> PRT
<213> Homo sapiens
<400> 327
Lys Gly Ser Val Glu Arg Arg Ser Val Ser Leu Gly His Pro Ala Glu
1 5 10 15
Gly Trp Ala Trp Ala Glu Arg Ser Leu Gln Pro Gly Met Thr Thr Ala
20 25 30
Asn Thr Gly Cys Leu Ser Phe His His Arg Gly Cys Leu Leu Pro Val
35 40 45
Leu Pro Lys Leu His Cys Gly Leu Gly Gly Leu Pro Leu Val Arg Ala
50 55 60
Lys Glu Ile Lys Arg Val Gln Arg Ala Gly Glu Ser Ser Leu Pro Val
65 70 75 80
Lys Gly Leu Leu Thr Val Ala Ser Ala Val Ile Ala Val Leu Trp Gly
85 90 95
Arg Pro Ser Glu Val Thr Gly Glu Asn Glu Ala Gln His Asp
100 105 110
<210> 328
<211> 330
<212> DNA
<213> Homo sapiens
<400> 328
aaagggagtg tggagaggcg ctcggtgagc ctggggcatc ctgctgaggg ttgggcatgg 60
gcagagagga gcctccagcc aggcatgacc acagccaaca caggctgcct ctcattccac 120
cacagagggt gcctcctccc tgttttgccc aaattacact gtgggctagg tggactacct 180
cttgtcagag ctaaagaaat caagcgagtg cagagggcag gggagagttc gctgcctgtg 240
aagggccttc tcaccgtcgc ttcggctgtc atcgcagtcc tgtggggtag gccaagcgag 300
gtcacaggag aaaatgaggc tcagcatgat 330
<210> 329
<211> 75
<212> PRT
<213> Homo sapiens
<400> 329
Phe Gly Leu Thr Thr Leu Ala Gly Arg Ser Ser His Gly Thr Ser Gly
1 5 10 15
Leu Arg Ala Ala Thr His Thr Lys Ser Gly Asp Gly Gly Gln Gly Ala
20 25 30
Ala Arg Gln Cys Glu Lys Leu Leu Glu Leu Ala Arg Ala Thr Arg Pro
35 40 45
Trp Gly Arg Ser Thr Ser Ala Ser Ser Arg Trp Thr His Arg Gly Tyr
50 55 60
Met Cys Pro Pro Arg Cys Ala Val Ala Cys Trp
65 70 75
<210> 330
<211> 225
<212> DNA
<213> Homo sapiens
<400> 330
tttggcctca ccacacttgc aggtagaagc tcccacggga cctcaggact gagggcagcc 60
acacacacca agtctgggga cggtggccag ggggctgcca ggcagtgtga gaagctcctg 120
gagctggccc gggctaccag accctggggg aggagtacgt cagcatcatc caggtggacc 180
catcgcggat acatgtgccc tcctcgctgc gccgtggcgt gctgg 225
<210> 331
<211> 29
<212> PRT
<213> Homo sapiens
<400> 331
Ile Ile Asp Ser Asp Lys Ile Met Ala Val Cys Met Gly Cys Leu Leu
1 5 10 15
Thr Arg His Val Gln Cys Gln Ala Met Glu Met Gln Gln
20 25
<210> 332
<211> 87
<212> DNA
<213> Homo sapiens
<400> 332
attattgaca gcgacaagat aatggcagtg tgcatggggt gcctgctcac acgtcatgtg 60
caatgccagg ccatggagat gcaacag 87
<210> 333
<211> 49
<212> PRT
<213> Homo sapiens
<400> 333
Asp Gly His Ser Tyr Thr Ser Lys Val Asn Cys Leu Leu Leu Gln Asp
1 5 10 15
Gly Phe His Gly Cys Val Ser Ile Thr Gly Ala Ala Gly Arg Arg Asn
20 25 30
Leu Ser Ile Phe Leu Phe Leu Met Leu Cys Lys Leu Glu Phe His Ala
35 40 45
Cys
<210> 334
<211> 147
<212> DNA
<213> Homo sapiens
<400> 334
gatggccact cctacacatc caaggtgaat tgtttactcc ttcaagatgg gttccatggc 60
tgtgtgagca tcaccggggc agctggaaga agaaacctga gcatcttcct gttcttgatg 120
ctgtgcaaat tggagttcca tgcttgt 147
<210> 335
<211> 70
<212> PRT
<213> Homo sapiens
<400> 335
Leu Leu Asn Ala Glu Asp Tyr Arg Cys Ala Ile His Ser Lys Glu Ile
1 5 10 15
Tyr Leu Leu Ser Pro Ser Pro His Gln Ala Met Asp Lys Phe Ser Leu
20 25 30
Cys Cys Ile Asn Cys Asn Leu Cys Leu His Val Phe Leu Leu Leu Leu
35 40 45
Phe Phe Gln Asn Lys Asp Val Trp Leu Ile Ser Asn Ile Ile Leu Leu
50 55 60
Trp Ile Tyr Gly Gly Ile
65 70
<210> 336
<211> 210
<212> DNA
<213> Homo sapiens
<400> 336
ctactaaatg cagaagatta ccggtgtgcc attcattcaa aagagattta tcttctttcc 60
ccctcccccc accaggcaat ggacaagttt tctctctgct gcatcaactg caatctatgt 120
ttacatgtat tccttttact actatttttt caaaacaaag atgtatggct tatttcaaac 180
atcattttac tttggatata tggcggtatt 210
<210> 337
<211> 33
<212> PRT
<213> Homo sapiens
<400> 337
Thr Gly Gly Lys Ser Thr Cys Ser Ala Pro Gly Pro Gln Ser Leu Pro
1 5 10 15
Ser Thr Pro Phe Ser Thr Tyr Pro Gln Trp Val Ile Leu Ile Thr Glu
20 25 30
Leu
<210> 338
<211> 99
<212> DNA
<213> Homo sapiens
<400> 338
acagggggca aaagcacctg ctcggctcct ggccctcagt ctctcccctc cactccattc 60
tccacctacc cacagtgggt cattctgatc accgaactg 99
<210> 339
<211> 28
<212> PRT
<213> Homo sapiens
<400> 339
Val Glu Thr Leu Glu Asn Ala Asn Ser Phe Ser Ser Gly Ile Gln Pro
1 5 10 15
Leu Leu Cys Ser Leu Ile Gly Leu Glu Asn Pro Thr
20 25
<210> 340
<211> 84
<212> DNA
<213> Homo sapiens
<400> 340
gtggagaccc tggagaatgc caacagcttc tccagcggga tccagccact cctctgttcc 60
ctgattggcc tggagaatcc cacc 84
<210> 341
<211> 38
<212> PRT
<213> Homo sapiens
<400> 341
Ala Gly Ala Gly Thr Ile Ser Glu Gly Ser Val Leu His Gly Gln Arg
1 5 10 15
Leu Glu Cys Asp Ala Arg Arg Phe Phe Gly Cys Gly Thr Thr Ile Leu
20 25 30
Ala Glu Trp Glu His His
35
<210> 342
<211> 114
<212> DNA
<213> Homo sapiens
<400> 342
gctggggctg gaacaatttc cgaaggtagt gttctccatg gtcagaggct ggagtgtgat 60
gccagacgtt tttttgggtg tgggactaca atactggcag agtgggagca ccat 114
<210> 343
<211> 17
<212> PRT
<213> Homo sapiens
<400> 343
Gly Val Pro Gly Asp Ser Thr Arg Arg Ala Val Arg Arg Met Asn Thr
1 5 10 15
Phe
<210> 344
<211> 51
<212> DNA
<213> Homo sapiens
<400> 344
ggagttccag gagattcaac caggagagca gtgaggagaa tgaatacctt c 51
<210> 345
<211> 20
<212> PRT
<213> Homo sapiens
<400> 345
His Val Val Gly Tyr Gly His Leu Asp Thr Ser Gly Ser Ser Ser Ser
1 5 10 15
Ser Ser Trp Pro
20
<210> 346
<211> 60
<212> DNA
<213> Homo sapiens
<400> 346
cacgtggtgg gctatggcca ccttgatact tccgggtcat cctcctcctc ctcctggccc 60
<210> 347
<211> 64
<212> PRT
<213> Homo sapiens
<400> 347
Trp Thr Pro Ile Pro Val Leu Thr Arg Trp Pro Leu Pro His Pro Pro
1 5 10 15
Pro Trp Arg Arg Ala Thr Ser Cys Arg Met Ala Arg Ser Ser Pro Ser
20 25 30
Ala Thr Ser Gly Ser Ser Val Arg Arg Arg Cys Ser Ser Leu Pro Ser
35 40 45
Trp Val Trp Asn Leu Ala Ala Ser Thr Arg Pro Arg Ser Thr Pro Ser
50 55 60
<210> 348
<211> 196
<212> DNA
<213> Homo sapiens
<400> 348
tggacgccca tcccggtgct cacgagatgg ccactaccac atcctcctcc ctggagaaga 60
gctacaagct gccggatggc caggtcatca ccatcagcaa caagcggttc cagtgtccgg 120
aggcgctgtt ccagccttcc ttcctgggta tggaatcttg cggcatccac gagaccacgt 180
tcaactccat catgaa 196
<210> 349
<211> 16
<212> PRT
<213> Homo sapiens
<400> 349
Ser Leu Tyr His Arg Glu Lys Gln Leu Ile Ala Met Asp Ser Ala Ile
1 5 10 15
<210> 350
<211> 48
<212> DNA
<213> Homo sapiens
<400> 350
tccctctacc accgggagaa gcagctcatt gctatggaca gtgctatc 48
<210> 351
<211> 43
<212> PRT
<213> Homo sapiens
<400> 351
Leu His Pro Gln Arg Glu Thr Phe Thr Pro Arg Trp Ser Gly Ala Asn
1 5 10 15
Tyr Trp Lys Leu Ala Phe Pro Val Gly Ala Glu Gly Thr Phe Pro Ala
20 25 30
Ala Ala Thr Gln Arg Gly Val Val Arg Pro Ala
35 40
<210> 352
<211> 131
<212> DNA
<213> Homo sapiens
<400> 352
cttcatcctc agagggaaac attcactccc cggtggtcgg gcgcgaatta ctggaaattg 60
gcttttcccg ttggggccga aggtaccttc cctgcggcgg cgactcagcg gggtgtcgtt 120
cggccggcgt g 131
<210> 353
<211> 35
<212> PRT
<213> Homo sapiens
<400> 353
Asn Ser Lys Met Ala Leu Asn Ser Leu Asn Ser Ile Asp Asp Ala Gln
1 5 10 15
Leu Thr Arg Ile Ala Pro Pro Arg Ser His Cys Cys Phe Trp Glu Val
20 25 30
Asn Ala Pro
35
<210> 354
<211> 105
<212> DNA
<213> Homo sapiens
<400> 354
aacagcaaga tggctttgaa ctcattaaac tccattgatg atgcacagtt gacaagaatt 60
gcccctccaa gatctcattg ctgtttctgg gaagtaaacg ctcct 105
<210> 355
<211> 50
<212> PRT
<213> Homo sapiens
<400> 355
Met Ala Gly Gly Val Leu Arg Arg Leu Leu Cys Arg Glu Pro Asp Arg
1 5 10 15
Asp Gly Asp Lys Gly Ala Ser Arg Glu Glu Thr Val Val Pro Leu His
20 25 30
Ile Gly Asp Pro Val Val Leu Pro Gly Ile Gly Gln Cys Tyr Ser Ala
35 40 45
Leu Phe
50
<210> 356
<211> 151
<212> DNA
<213> Homo sapiens
<400> 356
atggctggag gagtccttcg gcggctgttg tgtcgggagc ctgatcgcga tggggacaaa 60
ggcgcaagtc gagaggaaac tgttgtgcct cttcatattg gcgatcctgt tgtgctccct 120
ggcattgggc agtgttacag tgcactcttc t 151
<210> 357
<211> 39
<212> PRT
<213> Homo sapiens
<400> 357
Asp Asp Arg Asn Thr Phe Asp Ile Val Trp Trp Cys Pro Met Ser Arg
1 5 10 15
Leu Arg Leu Ala Leu Thr Val Pro Pro Ser Thr Thr Thr Thr Cys Val
20 25 30
Thr Val Pro Ala Trp Ala Ala
35
<210> 358
<211> 120
<212> DNA
<213> Homo sapiens
<400> 358
gatgacagaa acactttcga catagtgtgg tggtgcccta tgagccgcct gaggttggct 60
ctgactgtac caccatccac tacaactaca tgtgtaacag ttcctgcatg ggcggcatga 120
<210> 359
<211> 17
<212> PRT
<213> Homo sapiens
<400> 359
Val Gln Pro Ile Ala Arg Glu Leu Tyr Gln Phe Thr Phe Asp Leu Leu
1 5 10 15
Ile
<210> 360
<211> 51
<212> DNA
<213> Homo sapiens
<400> 360
gtgcagccta ttgcgagaga gctgcatcag ttcacttttg acctgctaat c 51
<210> 361
<211> 17
<212> PRT
<213> Homo sapiens
<400> 361
Gln Met Ala Val Ile Gln Tyr Ser Cys Met Gly Leu Met Val Phe Ala
1 5 10 15
Met
<210> 362
<211> 51
<212> DNA
<213> Homo sapiens
<400> 362
cagatggctg tcattcagta ctcctgcatg gggctcatgg tgtttgccat g 51
<210> 363
<211> 17
<212> PRT
<213> Homo sapiens
<400> 363
Pro Lys Ser Glu Val Arg Ala Lys Cys Lys Phe Ser Ile Leu Asn Ala
1 5 10 15
Lys
<210> 364
<211> 50
<212> DNA
<213> Homo sapiens
<400> 364
caaagagtga agttcgggca aaattcaaat gctccatcct gaatgccaag 50
<210> 365
<211> 17
<212> PRT
<213> Homo sapiens
<400> 365
Met Met Ala Glu Ile Ile Ser Val His Val Pro Lys Ile Leu Ser Gly
1 5 10 15
Lys
<210> 366
<211> 51
<212> DNA
<213> Homo sapiens
<400> 366
atgatggcag agatcatctc tgtgcacgtg cccaagatcc tttctgggaa a 51
<210> 367
<211> 17
<212> PRT
<213> Homo sapiens
<400> 367
Leu His Pro Asp Ser Gly Asn Met Val Glu Asn Gly Cys Tyr Leu Arg
1 5 10 15
Arg
<210> 368
<211> 51
<212> DNA
<213> Homo sapiens
<400> 368
ctgcacccgg actccggcaa catggtcgag aacggctgct acttgcgccg c 51
<210> 369
<211> 17
<212> PRT
<213> Homo sapiens
<400> 369
Cys Tyr Leu Arg Arg Gln Lys Arg Leu Lys Cys Glu Lys Gln Pro Gly
1 5 10 15
Ala
<210> 370
<211> 51
<212> DNA
<213> Homo sapiens
<400> 370
tgctacttgc gccgccagaa gcgcttgaag tgcgagaagc agccgggggc c 51
<210> 371
<211> 17
<212> PRT
<213> Homo sapiens
<400> 371
Met Phe Glu Asn Gly Cys Tyr Leu Gly Arg Gln Lys Arg Phe Lys Cys
1 5 10 15
Glu
<210> 372
<211> 51
<212> DNA
<213> Homo sapiens
<400> 372
atgttcgaga acggctgcta cttgggccgc cagaagcgct tcaagtgcga g 51
<210> 373
<211> 16
<212> PRT
<213> Homo sapiens
<400> 373
Asp Ser Ser Gly Asn Leu Leu Glu Arg Asn Ser Phe Glu Val Arg Val
1 5 10 15
<210> 374
<211> 48
<212> DNA
<213> Homo sapiens
<400> 374
gactccagtg gtaatctact ggaacggaac agctttgagg tgcgtgtt 48
<210> 375
<211> 61
<212> PRT
<213> Homo sapiens
<400> 375
Val Phe Phe Lys Arg Ala Ala Glu Gly Phe Phe Arg Met Asn Lys Leu
1 5 10 15
Lys Glu Ser Ser Asp Thr Asn Pro Lys Pro Tyr Cys Met Ala Ala Pro
20 25 30
Met Gly Leu Thr Glu Asn Asn Arg Asn Arg Lys Lys Ser Tyr Arg Glu
35 40 45
Thr Asn Leu Lys Ala Val Ser Trp Pro Leu Asn His Thr
50 55 60
<210> 376
<211> 183
<212> DNA
<213> Homo sapiens
<400> 376
gtcttcttca aaagagccgc tgaaggattt ttcagaatga acaaattaaa agaatcatca 60
gacactaacc ccaagccata ctgcatggca gcaccaatgg gactgacaga aaacaacaga 120
aataggaaga aatcctacag agaaacaaac ttgaaagctg tctcatggcc tttgaatcat 180
act 183
<210> 377
<211> 15
<212> PRT
<213> Homo sapiens
<400> 377
Leu Thr Phe Leu Asp Phe Ile Gln Val Thr Leu Arg Val Met Ser
1 5 10 15
<210> 378
<211> 15
<212> PRT
<213> Homo sapiens
<400> 378
Val Thr Leu Arg Val Met Ser Gly Ser Gln Met Glu Asn Gly Ser
1 5 10 15
<210> 379
<211> 24
<212> PRT
<213> Homo sapiens
<400> 379
Tyr Glu Ala Gly Met Thr Leu Gly Glu Lys Phe Arg Val Gly Asn Cys
1 5 10 15
Lys His Leu Lys Met Thr Arg Pro
20
<210> 380
<211> 72
<212> DNA
<213> Homo sapiens
<400> 380
tatgaagcag ggatgactct gggagaaaaa ttccgggttg gcaattgcaa gcatctcaaa 60
atgaccagac cc 72
<210> 381
<211> 28
<212> PRT
<213> Homo sapiens
<400> 381
Tyr Glu Ala Gly Met Thr Leu Gly Gly Lys Ile Leu Phe Phe Leu Phe
1 5 10 15
Leu Leu Leu Pro Leu Ser Pro Phe Ser Leu Ile Phe
20 25
<210> 382
<211> 84
<212> DNA
<213> Homo sapiens
<400> 382
tatgaagcag ggatgactct gggaggtaag atacttttct ttctcttcct cctccttcct 60
ctctccccct tctccctcat tttc 84
<210> 383
<211> 16
<212> PRT
<213> Homo sapiens
<400> 383
Gly Tyr Leu Arg Met Gln Gly Leu Met Ala Gln Arg Leu Leu Leu Arg
1 5 10 15
<210> 384
<211> 48
<212> DNA
<213> Homo sapiens
<400> 384
gggtacctga ggatgcaggg actcatggct cagcgacttc ttctgagg 48
<210> 385
<211> 48
<212> PRT
<213> Homo sapiens
<400> 385
Asp Gly His Ser Tyr Thr Ser Lys Val Asn Cys Leu Leu Leu Gln Asp
1 5 10 15
Gly Phe His Gly Cys Val Ser Ile Thr Gly Ala Ala Gly Arg Arg Asn
20 25 30
Leu Ser Ile Phe Leu Phe Leu Met Leu Cys Lys Leu Glu Phe His Ala
35 40 45
<210> 386
<211> 144
<212> DNA
<213> Homo sapiens
<400> 386
gatggccact cctacacatc caaggtgaat tgtttactcc ttcaagatgg gttccatggc 60
tgtgtgagca tcaccggggc agctggaaga agaaacctga gcatcttcct gttcttgatg 120
ctgtgcaaat tggagttcca tgct 144
<210> 387
<211> 9
<212> PRT
<213> Homo sapiens
<400> 387
Ser Thr Arg Arg Ala Val Arg Arg Met
1 5
<210> 388
<211> 9
<212> PRT
<213> Homo sapiens
<400> 388
Arg Ala Val Arg Arg Met Asn Thr Phe
1 5
<210> 389
<211> 9
<212> PRT
<213> Homo sapiens
<400> 389
Ile Pro Val Leu Thr Arg Trp Pro Leu
1 5
<210> 390
<211> 9
<212> PRT
<213> Homo sapiens
<400> 390
Gln Leu Ile Ala Met Asp Ser Ala Ile
1 5
<210> 391
<211> 9
<212> PRT
<213> Homo sapiens
<400> 391
Phe Pro Val Gly Ala Glu Gly Thr Phe
1 5
<210> 392
<211> 9
<212> PRT
<213> Homo sapiens
<400> 392
Asn Ser Lys Met Ala Leu Asn Ser Leu
1 5
<210> 393
<211> 9
<212> PRT
<213> Homo sapiens
<400> 393
Gly Val Leu Arg Arg Leu Leu Cys Arg
1 5
<210> 394
<211> 9
<212> PRT
<213> Homo sapiens
<400> 394
Cys Pro Met Ser Arg Leu Arg Leu Ala
1 5
<210> 395
<211> 9
<212> PRT
<213> Homo sapiens
<400> 395
Tyr Gln Phe Thr Phe Asp Leu Leu Ile
1 5
<210> 396
<211> 9
<212> PRT
<213> Homo sapiens
<400> 396
Ile Gln Tyr Ser Cys Met Gly Leu Met
1 5
<210> 397
<211> 9
<212> PRT
<213> Homo sapiens
<400> 397
Arg Ala Lys Cys Lys Phe Ser Ile Leu
1 5
<210> 398
<211> 9
<212> PRT
<213> Homo sapiens
<400> 398
His Val Pro Lys Ile Leu Ser Gly Lys
1 5
<210> 399
<211> 9
<212> PRT
<213> Homo sapiens
<400> 399
Asn Met Val Glu Asn Gly Cys Tyr Leu
1 5
<210> 400
<211> 9
<212> PRT
<213> Homo sapiens
<400> 400
Tyr Leu Arg Arg Gln Lys Arg Leu Lys
1 5
<210> 401
<211> 9
<212> PRT
<213> Homo sapiens
<400> 401
Cys Tyr Leu Gly Arg Gln Lys Arg Phe
1 5
<210> 402
<211> 9
<212> PRT
<213> Homo sapiens
<400> 402
Leu Leu Glu Arg Asn Ser Phe Glu Val
1 5
<210> 403
<211> 9
<212> PRT
<213> Homo sapiens
<400> 403
Tyr Cys Met Ala Ala Pro Met Gly Leu
1 5
<210> 404
<211> 9
<212> PRT
<213> Homo sapiens
<400> 404
Phe Phe Lys Arg Ala Ala Glu Gly Phe
1 5
<210> 405
<211> 9
<212> PRT
<213> Homo sapiens
<400> 405
Arg Val Gly Asn Cys Lys His Leu Lys
1 5
<210> 406
<211> 9
<212> PRT
<213> Homo sapiens
<400> 406
Phe Leu Phe Leu Leu Leu Pro Leu Ser
1 5
<210> 407
<211> 9
<212> PRT
<213> Homo sapiens
<400> 407
Leu Met Ala Gln Arg Leu Leu Leu Arg
1 5
<210> 408
<211> 9
<212> PRT
<213> Homo sapiens
<400> 408
Ile Val Trp Trp Cys Pro Met Ser Arg
1 5
<210> 409
<211> 9
<212> PRT
<213> Homo sapiens
<400> 409
Cys Thr Glu Leu Lys Leu Ser Asp Tyr
1 5
<210> 410
<211> 9
<212> PRT
<213> Homo sapiens
<400> 410
Asn Leu Val Pro Met Val Ala Thr Val
1 5
<210> 411
<211> 9
<212> PRT
<213> Homo sapiens
<400> 411
Leu Ile Tyr Arg Arg Arg Leu Met Lys
1 5
<210> 412
<211> 9
<212> PRT
<213> Homo sapiens
<400> 412
Leu Tyr Ser Ala Cys Phe Trp Trp Leu
1 5
<210> 413
<211> 9
<212> PRT
<213> Homo sapiens
<400> 413
Asn Pro Lys Ala Ser Leu Leu Ser Leu
1 5
<210> 414
<211> 9
<212> PRT
<213> Homo sapiens
<400> 414
Glu Leu Arg Ser Arg Tyr Trp Ala Ile
1 5
<210> 415
<211> 15
<212> PRT
<213> Homo sapiens
<400> 415
Ser Gln Met Glu Asn Gly Ser Ser Tyr Phe Phe Lys Pro Phe Ser
1 5 10 15
<210> 416
<211> 9
<212> PRT
<213> Homo sapiens
<400> 416
Ile Val Thr Asp Phe Ser Val Ile Lys
1 5
<210> 417
<211> 15
<212> PRT
<213> Homo sapiens
<400> 417
Tyr Phe Phe Lys Pro Phe Ser Trp Gly Leu Gly Val Gly Leu Ser
1 5 10 15
<210> 418
<211> 15
<212> PRT
<213> Homo sapiens
<400> 418
Phe Met Ile Gly Glu Leu Val Gly Glu Leu Cys Cys Gln Leu Thr
1 5 10 15
<210> 419
<211> 15
<212> PRT
<213> Homo sapiens
<400> 419
Glu Leu Cys Cys Gln Leu Thr Phe Arg Leu Pro Phe Leu Glu Ser
1 5 10 15
<210> 420
<211> 15
<212> PRT
<213> Homo sapiens
<400> 420
Arg Leu Pro Phe Leu Glu Ser Leu Cys Gln Ala Val Val Thr Gln
1 5 10 15
<210> 421
<211> 9
<212> PRT
<213> Homo sapiens
<400> 421
Lys Leu Ser Arg Ala Leu Arg Tyr Tyr
1 5
<210> 422
<211> 9
<212> PRT
<213> Homo sapiens
<400> 422
Met Val Phe Glu Leu Ala Asn Ser Ile
1 5
<210> 423
<211> 9
<212> PRT
<213> Homo sapiens
<400> 423
Ile Leu Phe Gln Asn Ile Asp Gly Lys
1 5
<210> 424
<211> 9
<212> PRT
<213> Homo sapiens
<400> 424
Lys Ile Val Ile Ala Arg Tyr Gly Lys
1 5
<210> 425
<211> 9
<212> PRT
<213> Homo sapiens
<400> 425
Phe Leu Leu Glu Leu Leu Ser Asp Ser
1 5
<210> 426
<211> 10
<212> PRT
<213> Homo sapiens
<400> 426
Val Thr Phe Leu Lys Pro Cys Phe Leu Leu
1 5 10
<210> 427
<211> 8
<212> PRT
<213> Homo sapiens
<400> 427
Thr Asp Ile Val Lys Gln Ser Val
1 5
<210> 428
<211> 10
<212> PRT
<213> Homo sapiens
<400> 428
Ser Pro Ala Phe Pro Lys Pro Val Arg Pro
1 5 10
<210> 429
<211> 12
<212> PRT
<213> Homo sapiens
<400> 429
Ser Tyr Phe Ser Leu Thr Asn Ile Phe Asn Phe Val
1 5 10
<210> 430
<211> 12
<212> PRT
<213> Homo sapiens
<400> 430
Glu Phe Ser Pro Glu Thr Cys Ala Phe Arg Leu Ser
1 5 10
<210> 431
<211> 9
<212> PRT
<213> Homo sapiens
<400> 431
Phe Leu Ser Arg Ala Leu Arg Ala Leu
1 5
<210> 432
<211> 8
<212> PRT
<213> Homo sapiens
<400> 432
Lys Lys Asp Leu Glu Leu Ile Leu
1 5
<210> 433
<211> 8
<212> PRT
<213> Homo sapiens
<400> 433
Lys Leu Gln Lys Asn Cys Leu Leu
1 5
<210> 434
<211> 9
<212> PRT
<213> Homo sapiens
<400> 434
Ser Ala Leu Ser Gly Asn Ser Trp Val
1 5
<210> 435
<211> 7
<212> PRT
<213> Homo sapiens
<400> 435
Thr Val Arg Ala Ile Leu Leu
1 5
<210> 436
<211> 10
<212> PRT
<213> Homo sapiens
<400> 436
Gly Ser Leu His Phe His Glu Val Leu Lys
1 5 10
<210> 437
<211> 75
<212> PRT
<213> Homo sapiens
<400> 437
His Tyr Lys Leu Ile Gln Gln Pro Ile Ser Leu Phe Ser Ile Thr Asp
1 5 10 15
Arg Leu His Lys Thr Phe Ser Gln Leu Pro Ser Val His Leu Cys Ser
20 25 30
Ile Thr Phe Gln Trp Gly His Pro Pro Ile Phe Cys Ser Thr Asn Asp
35 40 45
Ile Cys Val Thr Ala Asn Phe Cys Ile Ser Val Thr Phe Leu Lys Pro
50 55 60
Cys Phe Leu Leu His Glu Ala Ser Ala Ser Gln
65 70 75
<210> 438
<211> 40
<212> PRT
<213> Homo sapiens
<400> 438
Trp Thr Asp Ile Val Lys Gln Ser Val Ser Thr Asn Cys Ile Ser Ile
1 5 10 15
Lys Lys Gly Ser Tyr Thr Lys Leu Phe Ser Leu Val Phe Leu Ile Phe
20 25 30
Cys Trp Pro Leu Ile Ile Gln Leu
35 40
<210> 439
<211> 144
<212> PRT
<213> Homo sapiens
<400> 439
Arg Thr Ala Leu Thr His Asn Gln Asp Phe Ser Ile Tyr Arg Leu Cys
1 5 10 15
Cys Lys Arg Gly Ser Leu Cys His Ala Ser Gln Ala Arg Ser Pro Ala
20 25 30
Phe Pro Lys Pro Val Arg Pro Leu Pro Ala Pro Ile Thr Arg Ile Thr
35 40 45
Pro Gln Leu Gly Gly Gln Ser Asp Ser Ser Gln Pro Leu Leu Thr Thr
50 55 60
Gly Arg Pro Gln Gly Trp Gln Asp Gln Ala Leu Arg His Thr Gln Gln
65 70 75 80
Ala Ser Pro Ala Ser Cys Ala Thr Ile Thr Ile Pro Ile His Ser Ala
85 90 95
Ala Leu Gly Asp His Ser Gly Asp Pro Gly Pro Ala Trp Asp Thr Cys
100 105 110
Pro Pro Leu Pro Leu Thr Thr Leu Ile Pro Arg Ala Pro Pro Pro Tyr
115 120 125
Gly Asp Ser Thr Ala Arg Ser Trp Pro Ser Arg Cys Gly Pro Leu Gly
130 135 140
<210> 440
<211> 36
<212> PRT
<213> Homo sapiens
<400> 440
Leu Arg Tyr Gly Ala Leu Cys Asn Val Ser Arg Ile Ser Tyr Phe Ser
1 5 10 15
Leu Thr Asn Ile Phe Asn Phe Val Ile Lys Ser Leu Thr Ala Ile Phe
20 25 30
Thr Val Lys Phe
35
<210> 441
<211> 295
<212> PRT
<213> Homo sapiens
<400> 441
Arg Lys Glu Arg Asn Ile Arg Lys Ser Glu Ser Thr Leu Arg Leu Ser
1 5 10 15
Pro Phe Pro Thr Pro Ala Pro Ser Gly Ala Pro Ala Ala Ala Gln Gly
20 25 30
Lys Val Val Arg Val Pro Gly Pro Ala Gly Gly Leu Val Pro Arg Asp
35 40 45
Ala Gly Ala Arg Leu Leu Pro Pro Ala Gly Gly Pro Gly Gly Gly Ala
50 55 60
Ala Ala Gly Glu Gly Arg Ala Gly Arg Gly Arg Phe Pro Ser Ile Thr
65 70 75 80
Glu Pro Arg Pro Arg Asp Leu Pro Pro Arg Val Ala Thr Gly Arg Arg
85 90 95
Ala Gly Gly Arg Arg Lys Gly Ala Gly Gln Gly Val Arg Thr Arg Pro
100 105 110
Leu Pro Ala Ser Trp Pro Gly Gly Arg Gly Pro Phe Arg Lys Gly Pro
115 120 125
Arg Arg Leu Pro Leu Gly Ser Gly Pro Pro Ala Ala Gly Val Gln Arg
130 135 140
Leu Arg Cys Ser His Leu Ser Arg Gly Pro Arg Arg Arg Arg Gly Arg
145 150 155 160
Val Cys Gly Arg Ala Cys Val Ser Pro Pro Leu Pro Pro Arg Pro Pro
165 170 175
Pro Val Gly Leu Ser Ala Glu Asn Leu Ser Trp Leu Ser Ser Gly Leu
180 185 190
Pro Arg Ala Cys Ser Trp Arg Glu Phe Ser Pro Glu Thr Cys Ala Phe
195 200 205
Arg Leu Ser Gly Leu Asp Ser Lys Leu Ser Ala Arg Val Glu Arg Asp
210 215 220
Leu Gly Ala Leu Arg Ala Pro Gly Ser Arg Ala Ala Gln Gly Gly Gly
225 230 235 240
Arg Val Arg Gly Ser Arg Ser Glu Trp Lys Thr Arg Pro Trp Arg Pro
245 250 255
Pro Pro Ala Trp Pro Leu Thr Arg Ala Gly Gly Pro Leu Pro Lys Asn
260 265 270
Pro Phe Leu Glu Ser Cys Ser Glu Thr Ala Gln Arg Arg Arg Val Phe
275 280 285
Ser Phe Ser Thr Pro Leu Ser
290 295
<210> 442
<211> 67
<212> PRT
<213> Homo sapiens
<400> 442
Tyr Ala Tyr Lys Asp Phe Leu Trp Cys Phe Pro Phe Ser Leu Val Phe
1 5 10 15
Leu Gln Glu Ile Gln Ile Cys Cys His Val Ser Cys Leu Cys Cys Ile
20 25 30
Cys Cys Ser Thr Arg Ile Cys Leu Gly Cys Leu Leu Glu Leu Phe Leu
35 40 45
Ser Arg Ala Leu Arg Ala Leu His Val Leu Trp Asn Gly Phe Gln Leu
50 55 60
His Cys Gln
65
<210> 443
<211> 82
<212> PRT
<213> Homo sapiens
<400> 443
Ser Ile Asn Lys Ala Thr Ile Thr Gly Lys Lys Asp Leu Glu Leu Ile
1 5 10 15
Leu His Val Ser Arg Lys Lys Pro Phe Leu Pro Arg Val Asn Ile Thr
20 25 30
Pro Thr Pro Ile Ser Cys Cys Asn Leu Lys Met Leu Lys Lys Phe Phe
35 40 45
Leu Leu Tyr Ile Ile Ile Ser Ile Ile Asp Leu Thr Asn Cys Leu Ser
50 55 60
Cys Tyr Leu Glu His Phe Tyr Arg Phe Thr Phe Phe Thr Asp Val His
65 70 75 80
Tyr Phe
<210> 444
<211> 16
<212> PRT
<213> Homo sapiens
<400> 444
Thr Met Pro Ala Ile Leu Lys Leu Gln Lys Asn Cys Leu Leu Ser Leu
1 5 10 15
<210> 445
<211> 84
<212> PRT
<213> Homo sapiens
<400> 445
Pro Tyr Tyr Ser Ala Leu Ser Gly Asn Ser Trp Val Pro Ser Thr Leu
1 5 10 15
Glu Ser Asp Pro Phe Gly Tyr Val Phe Ser Pro Leu Ala Thr Arg Pro
20 25 30
Ala Leu Asn Asp Gln Glu Ser Ile Leu Trp Pro Thr Leu Thr Ser Val
35 40 45
Val Ser Cys Ala Leu Ser Cys Pro Ser Leu Asn Leu Pro Glu Asn Trp
50 55 60
Leu Thr Leu Ile Thr Gly Gly Met Lys Gly Gly Lys Lys Met Lys Phe
65 70 75 80
Thr Phe Arg His
<210> 446
<211> 46
<212> PRT
<213> Homo sapiens
<400> 446
Gly Leu Arg Asn Leu Gly Asn Thr Val Arg Ala Ile Leu Leu Ser Phe
1 5 10 15
Leu Ser Lys Arg Asn Val Lys Trp Cys Trp Gly Trp Gly Lys Pro Thr
20 25 30
Ser Leu Gly Lys Ala Cys Gly Arg Arg Ala Leu Lys Leu Phe
35 40 45
<210> 447
<211> 22
<212> PRT
<213> Homo sapiens
<400> 447
Met Glu Ala Glu Asn Ala Gly Ser Leu His Phe His Glu Val Leu Lys
1 5 10 15
Met Gly His Val Lys Phe
20
<210> 448
<211> 225
<212> DNA
<213> Homo sapiens
<400> 448
cactacaaat taattcaaca acccatatcc ctcttctcca tcactgatag gctccataag 60
acgttcagtc agctgccctc ggtccatctc tgctcaatca ccttccagtg gggacacccg 120
cccattttct gctcaacaaa tgatatctgt gtcacggcca acttctgcat ctcggtcaca 180
ttccttaaac cgtgcttcct cctacatgag gcatctgcct cacag 225
<210> 449
<211> 120
<212> DNA
<213> Homo sapiens
<400> 449
tggactgata tagttaagca gtctgtaagt acaaactgca tttctatcaa gaaaggtagc 60
tatacaaaac tgttttcctt agtctttctt attttctgtt ggccattaat tattcagttg 120
<210> 450
<211> 432
<212> DNA
<213> Homo sapiens
<400> 450
aggaccgccc tgacacacaa tcaggacttc tctatctaca ggctctgttg caagaggggg 60
tccctctgcc acgcttccca ggccagatcc ccggctttcc cgaagccggt cagacctctt 120
cctgccccca tcaccagaat caccccccaa ctggggggac aatctgactc gagtcaaccc 180
cttctcacta cgggaagacc tcaggggtgg caagatcaag ctcttagaca cacccagcaa 240
gccagtcctg cctcttgtgc caccatcacc attcccatcc actcagctgc ccttggtgac 300
cactccggag accctggtcc agcctgggac acctgcccgc cgctgccgct cactaccctc 360
atcccccgag ctcccccgcc gtatggagac agcactgcca ggtcctggcc ctcccgctgt 420
gggcccctcg gc 432
<210> 451
<211> 108
<212> DNA
<213> Homo sapiens
<400> 451
cttcgctatg gtgccttatg caatgtaagt agaataagtt atttcagtct aacaaatata 60
tttaattttg taattaaatc actaactgct atttttactg tgaaattt 108
<210> 452
<211> 885
<212> DNA
<213> Homo sapiens
<400> 452
cgaaaagaga gaaacatccg aaaaagtgag tccacgctgc gcctgtcccc gttccccacc 60
cccgccccgt cgggggcgcc cgcggccgcg caggggaaag ttgtccgggt ccccgggccg 120
gcgggcgggc tggtcccccg ggacgctggc gctcggctcc tgcccccggc gggcggcccg 180
gggggagggg cggcggcggg ggaggggcgc gcgggccgcg gccggttccc tagcatcacg 240
gagcctcgac cccgcgacct cccgccccgg gtcgccaccg gccggcgggc gggaggccgg 300
cggaaaggcg ccgggcaggg cgtgcgcacc cgtcccttgc ccgcgagctg gcccgggggt 360
cgcggccctt tccggaaggg gccccggcgt ctgccgctgg gctccggccc gcccgctgcg 420
ggagtgcagc ggctgcgttg ctcccacctg agccgcgggc cgaggaggcg gaggggccga 480
gtgtgcggga gggcgtgtgt ctcgcctccc cttcctcccc ggcccccgcc tgtcggcctt 540
tctgctgaga acctaagctg gttgtcaagt ggtttgcctc gggcgtgttc ctggcgcgag 600
ttcagccccg agacctgtgc gtttcggctc tcgggtttgg attcgaaact ttccgctcgg 660
gttgagcgtg acttgggtgc gctgcgggcg ccggggtcgc gggctgcgca gggcggtggg 720
cgtgtgcgcg ggagccggtc ggagtggaaa acgcgcccgt ggcggccacc tccagcctgg 780
ccgctcaccc gagcaggggg gccgctgccc aagaaccctt tcctggagag ctgctccgag 840
accgcacagc gccgccgcgt cttctccttt tccactcctc tctcc 885
<210> 453
<211> 201
<212> DNA
<213> Homo sapiens
<400> 453
tatgcttaca aggactttct ctggtgtttt cctttttctt tagtttttct ccaagagatt 60
caaatctgct gccatgttag ctgtctttgc tgtatctgct gtagtacacg aatatgcctt 120
ggctgtttgc ttgagctttt tctatcccgt gctcttcgtg ctcttcatgt tctttggaat 180
ggctttcaac ttcattgtca a 201
<210> 454
<211> 246
<212> DNA
<213> Homo sapiens
<400> 454
tccatcaaca aagccaccat aacaggtaag aaagatctgg agcttattct tcatgtgtct 60
aggaagaaac catttctgcc aagagtcaat ataacaccaa caccaatttc atgctgcaat 120
ttgaaaatgt taaagaaatt ctttcttctc tacattatca tttctatcat tgatctcaca 180
aattgtctaa gctgttattt ggaacatttt taccgattta cgttttttac tgatgtacat 240
tatttt 246
<210> 455
<211> 48
<212> DNA
<213> Homo sapiens
<400> 455
accatgcctg ctattttaaa gttacagaag aattgtcttc tctcctta 48
<210> 456
<211> 252
<212> DNA
<213> Homo sapiens
<400> 456
ccatactaca gcgcactgtc aggtaacagc tgggttccca gcaccctgga aagtgacccg 60
tttggctatg tttttagccc cttagcaaca cggccagctc tcaatgacca agagtccatc 120
ttgtggccga ccctgacttc tgtggtttcc tgtgctctat cctgcccatc tcttaactta 180
cctgagaatt ggctcactct catcacaggt ggaatgaaag ggggaaaaaa aatgaaattc 240
acattcagac ac 252
<210> 457
<211> 138
<212> DNA
<213> Homo sapiens
<400> 457
ggccttcgaa acctgggaaa cacggtgaga gctattctcc tatctttcct ctctaaaagg 60
aatgtgaaat ggtgctgggg gtggggaaaa cccacgagct tggggaaggc atgtggaagg 120
agagctctga agctcttc 138
<210> 458
<211> 66
<212> DNA
<213> Homo sapiens
<400> 458
atggaagcgg agaacgcggg cagtttgcat tttcatgaag tgctcaaaat gggacatgtg 60
aaattc 66
<210> 459
<211> 81
<212> DNA
<213> Artificial sequence
<220>
<223> Codon-optimized polynucleotide
<400> 459
tggaagttcg agatgagcta caccgtcggc ggacctccac ctcatgttca tgccagacct 60
cggcactgga aaaccgacag a 81
<210> 460
<211> 84
<212> DNA
<213> Artificial sequence
<220>
<223> Codon-optimized polynucleotide
<400> 460
tatgaggccg gcatgacact cggcggcaag atcctgttct tcctgttcct gctgctccct 60
ctgagcccct tcagcctgat cttc 84
<210> 461
<211> 147
<212> DNA
<213> Artificial sequence
<220>
<223> Codon-optimized polynucleotide
<400> 461
gatggccaca gctacaccag caaagtgaac tgcctcctgc tgcaggatgg cttccacggc 60
tgtgtgtcta ttactggcgc cgctggcaga cggaacctga gcatctttct gtttctgatg 120
ctgtgcaagc tcgagttcca cgcctgc 147
<210> 462
<211> 99
<212> DNA
<213> Artificial sequence
<220>
<223> Codon-optimized polynucleotide
<400> 462
acaggcggca agtccacatg ttctgcccct ggacctcaga gcctgcctag cacacccttc 60
agcacatacc ctcagtgggt catcctgatc accgaactc 99
<210> 463
<211> 42
<212> DNA
<213> Artificial sequence
<220>
<223> Codon-optimized polynucleotide
<400> 463
gtgctgagat tcctggacct gaaagtgcgc tacctgcaca gc 42
<210> 464
<211> 54
<212> DNA
<213> Artificial sequence
<220>
<223> Codon-optimized polynucleotide
<400> 464
gactattggg ctcaaaaaga gaagggcagc agcagcttcc tgcggcctag ctgt 54
<210> 465
<211> 183
<212> DNA
<213> Artificial sequence
<220>
<223> Codon-optimized polynucleotide
<400> 465
gtccccttca gagagctgaa gaacgtttcc gtgctggaag gcctgagaca gggcagactt 60
ggcggccctt gtagctgtca ctgccccaga cctagtcagg ccagactgac acctgtggat 120
gtggccggac ctttcctgtg tctgggagat cctggcctgt ttccacctgt gaagtccagc 180
atc 183
<210> 466
<211> 177
<212> DNA
<213> Artificial sequence
<220>
<223> Codon-optimized polynucleotide
<400> 466
ggcatggaat gcaccctggg acaagtggga gccccatctc ctagaagaga agaggatggc 60
tggcgcggag gccactctag attcaaagct gatgtgcccg ctcctcaggg cccttgttgg 120
ggaggacaac ctggatctgc cccatcttct gccccacctg aacagtccct gctggat 177
<210> 467
<211> 96
<212> DNA
<213> Artificial sequence
<220>
<223> Codon-optimized polynucleotide
<400> 467
ggcaacacaa ccctccagca actgggagaa gcctctcagg ctcctagcgg ctctctgatc 60
cctctcagac tgcctctcct gtgggaagtt cggggc 96
<210> 468
<211> 129
<212> DNA
<213> Artificial sequence
<220>
<223> Codon-optimized polynucleotide
<400> 468
gaggctttcc aaagagctgc tggcgaaggc ggacctggta gaggtggtgc tagaagaggt 60
gctagggtgc tgcagagccc attctgtaga gcaggcgcag gcgaatggct gggccatcag 120
agtctgaga 129
<210> 469
<211> 51
<212> DNA
<213> Artificial sequence
<220>
<223> Codon-optimized polynucleotide
<400> 469
gattattggg cccagaaaga aaagatcagc atccccagaa cacacctgtg c 51
<210> 470
<211> 48
<212> DNA
<213> Artificial sequence
<220>
<223> Codon-optimized polynucleotide
<400> 470
gtggccatga tggtgcccga tagacaggtc cactacgact ttggactg 48
<210> 471
<211> 270
<212> DNA
<213> Artificial sequence
<220>
<223> Codon-optimized polynucleotide
<400> 471
gtgcccttcc gggaactgaa gaaccagaga acagctcagg gcgctcctgg aatccaccat 60
gctgcttctc cagtggccgc caacctgtgt gatcctgcca gacatgccca gcacaccagg 120
attccttgtg gcgctggaca agtgcgcgct ggaagaggac ctgaagcagg cggaggtgtt 180
ctgcaacctc aaagacccgc tcctgagaag cctggctgcc cttgcagaag aggacagcct 240
agactgcaca ccgtgaaaat gtggcgagcc 270
<210> 472
<211> 33
<212> DNA
<213> Artificial sequence
<220>
<223> Codon-optimized polynucleotide
<400> 472
aagagaagct ttgccgtgac cgagcggatc atc 33
<210> 473
<211> 150
<212> DNA
<213> Artificial sequence
<220>
<223> Codon-optimized polynucleotide
<400> 473
ttcaagaagt tcgacggccc ttgcggagaa agaggcggag gcagaacagc tagagccctt 60
tgggctagag gcgacagcgt tctgacacca gctctggacc ctcagacacc tgttagggcc 120
cctagcctga caagagctgc cgccgctgtg 150
<210> 474
<211> 42
<212> DNA
<213> Artificial sequence
<220>
<223> Codon-optimized polynucleotide
<400> 474
ctggtgctgg gagtgctgtc tggacactct ggcagcagac tg 42
<210> 475
<211> 66
<212> DNA
<213> Artificial sequence
<220>
<223> Codon-optimized polynucleotide
<400> 475
cagtggcagc actatcacag atctggcgaa gccgccggaa cacccctttg gaggccaaca 60
agaaac 66
<210> 476
<211> 285
<212> DNA
<213> Artificial sequence
<220>
<223> Codon-optimized polynucleotide
<400> 476
tgccacttgt ttctgcagcc ccaagtgggc acacctcctc cacatacagc ctctgctaga 60
gcacctagcg gccctccaca tcctcacgaa tcttgtcctg ccggaagaag gcctgccaga 120
gccgctcaaa catgtgccag acgacagcac ggactgcctg gatgtgaaga ggctggaaca 180
gccagagtgc ctagcctgca cctccatctg catcaggctg ctcttggagc cggaagaggt 240
agaggatggg gcgaagcttg tgctcaggtg ccaccttcta gaggc 285
<210> 477
<211> 27
<212> DNA
<213> Artificial sequence
<220>
<223> Codon-optimized polynucleotide
<400> 477
aagatccaga acaagaactg ccccgac 27
<210> 478
<211> 225
<212> DNA
<213> Artificial sequence
<220>
<223> Codon-optimized polynucleotide
<400> 478
cactacaagc tgatccagca gccaatcagc ctgttcagca tcaccgaccg gctgcacaag 60
acattcagcc agctgccaag cgtgcacctg tgctccatca ccttccagtg gggacaccct 120
cctatctttt gctccaccaa cgacatctgc gtgaccgcca acttctgtat cagcgtgacc 180
ttcctgaagc cttgctttct gctgcacgag gccagcgcct ctcag 225
<210> 479
<211> 432
<212> DNA
<213> Artificial sequence
<220>
<223> Codon-optimized polynucleotide
<400> 479
cgaaccgctc tgacacacaa ccaggacttc agcatctaca gactgtgttg caagcggggc 60
tccctgtgcc atgcaagcca agctagaagc cccgcctttc ctaaacctgt gcgacctctg 120
ccagctccaa tcaccagaat tacccctcag ctcggcggcc agagcgattc atctcaacct 180
ctgctgacca ccggcagacc tcaaggctgg caagaccaag ctctgagaca cacccagcag 240
gctagccctg cctcttgtgc caccatcaca atccccatcc actctgccgc tctgggcgat 300
cattctggcg atcctggacc agcctgggac acatgtcctc cactgccact cacaacactg 360
atccctaggg ctcctccacc ttacggcgat tctaccgcta gaagctggcc cagcagatgt 420
ggaccactcg ga 432
<210> 480
<211> 201
<212> DNA
<213> Artificial sequence
<220>
<223> Codon-optimized polynucleotide
<400> 480
tacgcctaca aggacttcct gtggtgcttc cccttctctc tggtgttcct gcaagagatc 60
cagatctgct gtcatgtgtc ctgcctgtgc tgcatctgct gtagcaccag aatctgcctg 120
ggctgtctgc tggaactgtt cctgagcaga gccctgagag cactgcacgt gctgtggaac 180
ggattccagc tgcactgcca g 201
<210> 481
<211> 48
<212> DNA
<213> Artificial sequence
<220>
<223> Codon-optimized polynucleotide
<400> 481
acaatgcccg ccatcctgaa gctgcagaag aattgcctcc taagcctg 48
<210> 482
<211> 72
<212> DNA
<213> Artificial sequence
<220>
<223> Codon-optimized polynucleotide
<400> 482
tacgaagccg ggatgaccct gggcgagaag ttcagagtgg gcaactgcaa gcacctgaag 60
atgacccggc ct 72
<210> 483
<211> 51
<212> DNA
<213> Artificial sequence
<220>
<223> Codon-optimized polynucleotide
<400> 483
ggcgtgccag gcgatagcac tcggagagcc gtcagacgga tgaacacctt t 51
<210> 484
<211> 48
<212> DNA
<213> Artificial sequence
<220>
<223> Codon-optimized polynucleotide
<400> 484
tgtggcgcct ctgcctgtga cgtgtccctg atcgctatgg actccgcc 48
<210> 485
<211> 48
<212> DNA
<213> Artificial sequence
<220>
<223> Codon-optimized polynucleotide
<400> 485
agcctgtacc accgggaaaa gcagctcatt gccatggaca gcgccatc 48
<210> 486
<211> 48
<212> DNA
<213> Artificial sequence
<220>
<223> Codon-optimized polynucleotide
<400> 486
accgagtaca accagaaact gcaagtgaac cagttcagcg agagcaag 48
<210> 487
<211> 72
<212> DNA
<213> Artificial sequence
<220>
<223> Codon-optimized polynucleotide
<400> 487
accgagatca gctgctgcac cctgagcagc gaggaaaacg agtacctgcc tagacctgag 60
tggcagctgc ag 72
<210> 488
<211> 42
<212> DNA
<213> Artificial sequence
<220>
<223> Codon-optimized polynucleotide
<400> 488
tgcgaagaga gaggcgccgc aggatctctg atctcctgcg aa 42
<210> 489
<211> 48
<212> DNA
<213> Artificial sequence
<220>
<223> Codon-optimized polynucleotide
<400> 489
aacagcaaga tggccctgaa tagcgaggcc ctgtctgtgg tgtctgaa 48
<210> 490
<211> 210
<212> DNA
<213> Artificial sequence
<220>
<223> Codon-optimized polynucleotide
<400> 490
tggggcatgg aactggccgc cagcagaaga ttcagctggg atcatcatag cgcaggcggc 60
ccacctagag tgccatctgt tagaagcgga gctgcccagg tgcagcctaa agatcctctg 120
ccactgagaa cactggccgg ctgccttgct agaacagccc atcttagacc tggcgccgag 180
tctctgcctc agccacaact gcactgtacc 210
<210> 491
<211> 60
<212> DNA
<213> Artificial sequence
<220>
<223> Codon-optimized polynucleotide
<400> 491
catgtcgtcg gctacggcca cctggataca agcggaagca gctctagctc cagctggcct 60
<210> 492
<211> 105
<212> DNA
<213> Artificial sequence
<220>
<223> Codon-optimized polynucleotide
<400> 492
aactcaaaaa tggctctgaa cagcctgaac tccatcgacg acgcccagct gacaagaatc 60
gcccctccta gatctcactg ctgcttttgg gaagtgaacg cccca 105
<210> 493
<211> 48
<212> DNA
<213> Artificial sequence
<220>
<223> Codon-optimized polynucleotide
<400> 493
aagatgcact ttagcctgaa agaacaccct ccaccacctt gtcctcca 48
<210> 494
<211> 207
<212> DNA
<213> Artificial sequence
<220>
<223> Codon-optimized polynucleotide
<400> 494
ctgtggttcc agtccagcga gctgtctcct actggtgccc cttggccatc tagacgccct 60
acttggagag gcaccaccgt gtcaccaaga accgccacaa gcagcgccag aacctgttgt 120
ggcacaaagt ggccctccag ccaagaagcc gctctcggac ttggaagcgg actgctgagg 180
ttctcttgtg gaaccgccgc cattcgg 207
<210> 495
<211> 51
<212> DNA
<213> Artificial sequence
<220>
<223> Codon-optimized polynucleotide
<400> 495
atcgctagag agctgcacca gttcgccttc gacctgctga tcaagagcca c 51
<210> 496
<211> 51
<212> DNA
<213> Artificial sequence
<220>
<223> Codon-optimized polynucleotide
<400> 496
cagcctgatt cttttgccgc actgcacagc tccctgaacg agctgggaga g 51
<210> 497
<211> 51
<212> DNA
<213> Artificial sequence
<220>
<223> Codon-optimized polynucleotide
<400> 497
ttcgtgcaag gcaaggattg gggcctcaaa aagtttatcc gcagagactt c 51
<210> 498
<211> 51
<212> DNA
<213> Artificial sequence
<220>
<223> Codon-optimized polynucleotide
<400> 498
tttgtgcagg gcaaagactg gggcgtgaag aagttcatcc ggcgggactt c 51
<210> 499
<211> 204
<212> DNA
<213> Artificial sequence
<220>
<223> Codon-optimized polynucleotide
<400> 499
cagaacctgc agaacggcgg aggctctaga agctctgcta cacttcctgg caggcggcgg 60
agaagatggc tgagaagaag gcggcagcct atctctgtgg ctcctgctgg acctcctaga 120
cggcccaacc agaagcctaa tcctcctggc ggagccagat gcgtgatcat gaggcctaca 180
tggcctggca ccagcgcctt cacc 204
<210> 500
<211> 81
<212> DNA
<213> Artificial sequence
<220>
<223> Codon-optimized polynucleotide
<400> 500
tggaagttcg agatgagcta caccgttggc ggccctccac cacatgttca cgccagacct 60
agacactgga aaaccgacag a 81
<210> 501
<211> 84
<212> DNA
<213> Artificial sequence
<220>
<223> Codon-optimized polynucleotide
<400> 501
tacgaggccg gcatgacact cggaggcaag atcctgttct tcctgttcct gctgctccct 60
ctgagcccct tcagcctgat cttt 84
<210> 502
<211> 15
<212> PRT
<213> Homo sapiens
<400> 502
Cys Gln Ala Val Val Thr Gln Ala Leu Arg Phe Asn Pro Ser Phe
1 5 10 15
<210> 503
<211> 99
<212> DNA
<213> Artificial sequence
<220>
<223> Codon-optimized polynucleotide
<400> 503
acaggcggca agagcacatg ttctgcccct ggacctcagt ctctgcccag cacacccttc 60
agcacatacc ctcagtgggt catcctgatc accgagctg 99
<210> 504
<211> 42
<212> DNA
<213> Artificial sequence
<220>
<223> Codon-optimized polynucleotide
<400> 504
gtgctgcggt tcctggatct caaagtgcgc tacctgcaca gc 42
<210> 505
<211> 54
<212> DNA
<213> Artificial sequence
<220>
<223> Codon-optimized polynucleotide
<400> 505
gattattggg cccagaaaga aaagggcagc agcagcttcc tgcggcctag ctgt 54
<210> 506
<211> 183
<212> DNA
<213> Artificial sequence
<220>
<223> Codon-optimized polynucleotide
<400> 506
gtgcccttcc gggaactgaa gaacgtgtcc gttctggaag gcctgaggca gggcagactt 60
ggcggacctt gtagctgcca ctgtcctaga ccaagccagg ccagactgac ccctgtggat 120
gtggctggcc catttctgtg tctgggcgac cctggactgt tccctccagt gaagtctagc 180
atc 183
<210> 507
<211> 177
<212> DNA
<213> Artificial sequence
<220>
<223> Codon-optimized polynucleotide
<400> 507
ggcatggaat gtacactggg ccaagtggga gccccatctc ctagaagaga agaggatggc 60
tggcgcggag gccactctag attcaaagct gatgtgcccg ctcctcaggg cccttgttgg 120
ggaggacaac ctggatctgc cccatcttct gccccacctg aacagagcct gctggat 177
<210> 508
<211> 96
<212> DNA
<213> Artificial sequence
<220>
<223> Codon-optimized polynucleotide
<400> 508
ggcaacacca cactgcaaca gctgggagaa gcctctcagg ccccaagcgg ttctctgatc 60
cctctcagac tgcccctcct gtgggaagtg cggggc 96
<210> 509
<211> 129
<212> DNA
<213> Artificial sequence
<220>
<223> Codon-optimized polynucleotide
<400> 509
gaggctttcc agagagcagc tggcgaaggc ggacctggca gaggtggtgc tagaagaggt 60
gctagagtgc tgcagagccc attctgtaga gctggcgctg gcgaatggct gggccaccaa 120
tctcttaga 129
<210> 510
<211> 51
<212> DNA
<213> Artificial sequence
<220>
<223> Codon-optimized polynucleotide
<400> 510
gactattggg ctcaaaaaga gaagatcagc atccccagaa cacacctgtg c 51
<210> 511
<211> 48
<212> DNA
<213> Artificial sequence
<220>
<223> Codon-optimized polynucleotide
<400> 511
gtggccatga tggtgcccga cagacaggtg cactacgact tcggcctg 48
<210> 512
<211> 270
<212> DNA
<213> Artificial sequence
<220>
<223> Codon-optimized polynucleotide
<400> 512
gtgcccttca gagagctgaa aaaccagaga acagcccagg gcgctcctgg aatccatcat 60
gctgcttctc cagtggccgc caatctgtgc gatcctgcca gacatgccca gcataccagg 120
attccttgtg gcgctggaca agtgcgcgct ggaagaggac ctgaagctgg tggcggagtt 180
ctgcagcctc aaagacctgc tcctgagaag cctggctgcc cctgtagaag aggacagcct 240
agactgcaca ccgtgaagat gtggcgggcc 270
<210> 513
<211> 33
<212> DNA
<213> Artificial sequence
<220>
<223> Codon-optimized polynucleotide
<400> 513
aagagaagct tcgccgtgac cgagcggatc atc 33
<210> 514
<211> 150
<212> DNA
<213> Artificial sequence
<220>
<223> Codon-optimized polynucleotide
<400> 514
tttaagaagt ttgacggccc ctgcggcgag agaggcggag gaagaactgc aagagccctt 60
tgggccagag gcgactctgt tctgacacca gctctggacc ctcagacacc tgttagggcc 120
cctagcctga caagagctgc cgctgctgtt 150
<210> 515
<211> 42
<212> DNA
<213> Artificial sequence
<220>
<223> Codon-optimized polynucleotide
<400> 515
ctggtgctgg gcgtgctgtc tggccactct ggaagcagac tg 42
<210> 516
<211> 66
<212> DNA
<213> Artificial sequence
<220>
<223> Codon-optimized polynucleotide
<400> 516
caatggcagc actaccacag atctggcgaa gccgctggaa ccccactttg gaggcctacc 60
agaaac 66
<210> 517
<211> 285
<212> DNA
<213> Artificial sequence
<220>
<223> Codon-optimized polynucleotide
<400> 517
tgccacttgt ttctccagcc acaagtgggc acccctccac ctcatacagc ctctgctaga 60
gcacctagcg gcccacctca tcctcacgaa tcttgtcctg ccggaagaag gcctgccaga 120
gccgctcaaa catgtgccag acgacagcac ggactgcccg gatgtgaaga agccggaaca 180
gccagagtgc ctagcctgca ccttcatctg catcaggccg ctcttggagc cggaagaggt 240
agaggatggg gagaagcttg tgcccaggtg ccaccttcta gaggc 285
<210> 518
<211> 15
<212> PRT
<213> Homo sapiens
<400> 518
Leu Arg Phe Asn Pro Ser Phe Gln Glu Val Cys Ile Tyr Gln Asp
1 5 10 15
<210> 519
<211> 225
<212> DNA
<213> Artificial sequence
<220>
<223> Codon-optimized polynucleotide
<400> 519
cactacaagc tgatccagca gccaatcagc ctgttctcca tcaccgaccg gctgcacaag 60
acattcagcc agctgccttc cgtgcatctg tgcagcatca ccttccagtg gggacaccct 120
cctatctttt gctccaccaa cgacatctgc gtgaccgcca acttctgtat cagcgtgacc 180
ttcctgaagc cttgctttct gctgcacgag gcctccgcca gccag 225
<210> 520
<211> 432
<212> DNA
<213> Artificial sequence
<220>
<223> Codon-optimized polynucleotide
<400> 520
cggaccgctc tgacccacaa ccaggacttc agcatctacc ggctgtgctg caagaggggc 60
tctctgtgtc atgctagcca ggctagaagc cccgcctttc ctaagcctgt cagacctctg 120
cctgctccta tcaccagaat cacccctcag ctcggcggcc agtctgattc atctcagcca 180
ctgctgacca ccggcagacc tcaaggatgg caagaccagg ctctgagaca cacacagcag 240
gctagcccag cctcttgcgc caccatcaca ataccaatac attctgccgc tctgggcgat 300
cacagcggag atcctggacc tgcctgggat acttgtcctc ctctgcccct aactacactg 360
atccctaggg ctcctccacc ttacggcgat agcacagcca gatcctggcc tagcagatgt 420
ggccctctgg gc 432
<210> 521
<211> 201
<212> DNA
<213> Artificial sequence
<220>
<223> Codon-optimized polynucleotide
<400> 521
tacgcctaca aggacttcct gtggtgcttc cccttctctc tggtgttcct gcaagaaatc 60
cagatctgct gtcacgtgtc ctgcctgtgc tgtatctgct gtagcacccg gatctgtctg 120
ggctgtctgc tggaactgtt cctgagcaga gccctgagag cactgcacgt gctgtggaac 180
ggattccagc tgcactgcca g 201
<210> 522
<211> 48
<212> DNA
<213> Artificial sequence
<220>
<223> Codon-optimized polynucleotide
<400> 522
accatgcctg ccattctgaa gctgcagaag aattgtcttc taagcctg 48
<210> 523
<211> 72
<212> DNA
<213> Artificial sequence
<220>
<223> Codon-optimized polynucleotide
<400> 523
tatgaggctg gaatgaccct gggcgagaag ttcagagtgg gcaactgcaa gcacctgaag 60
atgacccggc ct 72
<210> 524
<211> 51
<212> DNA
<213> Artificial sequence
<220>
<223> Codon-optimized polynucleotide
<400> 524
ggagtgcctg gcgattctac tagaagggcc gtgcggcgga tgaacacctt t 51
<210> 525
<211> 48
<212> DNA
<213> Artificial sequence
<220>
<223> Codon-optimized polynucleotide
<400> 525
tgtggcgcat ctgcctgcga cgtgtccctg atcgctatgg atagcgcc 48
<210> 526
<211> 11
<212> PRT
<213> Homo sapiens
<400> 526
Glu Val Cys Ile Tyr Gln Asp Thr Asp Leu Met
1 5 10
<210> 527
<211> 15
<212> PRT
<213> Homo sapiens
<400> 527
Trp Cys Pro Leu Asp Leu Arg Leu Gly Ser Thr Gly Cys Leu Thr
1 5 10 15
<210> 528
<211> 72
<212> DNA
<213> Artificial sequence
<220>
<223> Codon-optimized polynucleotide
<400> 528
accgagatca gctgctgcac cctgagcagc gaggaaaacg agtacctgcc tagacctgaa 60
tggcagctgc ag 72
<210> 529
<211> 42
<212> DNA
<213> Artificial sequence
<220>
<223> Codon-optimized polynucleotide
<400> 529
tgcgaggaaa gaggcgcagc cggatctctg atctcttgcg ag 42
<210> 530
<211> 48
<212> DNA
<213> Artificial sequence
<220>
<223> Codon-optimized polynucleotide
<400> 530
aacagcaaga tggccctgaa tagcgaggcc ctgtctgtgg tgtccgag 48
<210> 531
<211> 210
<212> DNA
<213> Artificial sequence
<220>
<223> Codon-optimized polynucleotide
<400> 531
tggggaatgg aactggccgc tagcaggcgg tttagctggg atcatcattc tgccggcgga 60
cctccaagag tgccaagcgt tagaagcgga gcagcccagg tccagcctaa agatccactg 120
ccactgagaa cactggccgg ctgccttgcc agaacagctc atcttagacc tggcgccgaa 180
agcctgcctc aacctcagct gcattgcaca 210
<210> 532
<211> 60
<212> DNA
<213> Artificial sequence
<220>
<223> Codon-optimized polynucleotide
<400> 532
cacgttgtcg gctatggcca cctggataca agcggctcct ctagcagtag ctcctggcct 60
<210> 533
<211> 105
<212> DNA
<213> Artificial sequence
<220>
<223> Codon-optimized polynucleotide
<400> 533
aattctaaga tggctctcaa cagcctgaac tccatcgacg acgcccagct gacaagaatc 60
gcccctccaa gaagccactg ttgcttttgg gaagtgaacg cccct 105
<210> 534
<211> 48
<212> DNA
<213> Artificial sequence
<220>
<223> Codon-optimized polynucleotide
<400> 534
aagatgcact tctcactgaa agagcacccg ccaccgccgt gcccaccg 48
<210> 535
<211> 207
<212> DNA
<213> Artificial sequence
<220>
<223> Codon-optimized polynucleotide
<400> 535
ctgtggttcc agtccagcga actgtctcct actggcgctc catggccaag cagaaggcct 60
acttggagag gcaccaccgt gtctccaaga accgctacaa gcagcgccag aacctgttgc 120
ggcacaaaat ggccctccag ccaagaagct gccctcggac ttggaagcgg actgctgaga 180
ttcagctgtg gcacagccgc catcaga 207
<210> 536
<211> 51
<212> DNA
<213> Artificial sequence
<220>
<223> Codon-optimized polynucleotide
<400> 536
atcgccagag aactgcacca gttcgccttc gacctgctga tcaagagcca c 51
<210> 537
<211> 51
<212> DNA
<213> Artificial sequence
<220>
<223> Codon-optimized polynucleotide
<400> 537
cagcctgaca gctttgctgc cctgcatagc tccctgaatg agctgggcga a 51
<210> 538
<211> 51
<212> DNA
<213> Artificial sequence
<220>
<223> Codon-optimized polynucleotide
<400> 538
tttgtgcagg gtaaagattg gggcctcaaa aagtttatca gacgggactt c 51
<210> 539
<211> 51
<212> DNA
<213> Artificial sequence
<220>
<223> Codon-optimized polynucleotide
<400> 539
ttcgtgcagg gcaaagactg gggcgtgaag aagttcatcc ggcgggactt t 51
<210> 540
<211> 204
<212> DNA
<213> Artificial sequence
<220>
<223> Codon-optimized polynucleotide
<400> 540
cagaacctgc agaacggcgg aggctctaga agctctgcta cacttcctgg caggcggcgg 60
agaagatggc tgagaagaag gcggcagcct atctctgtgg ctcctgctgg acctcctaga 120
cggcccaacc agaagcctaa tcctcctggc ggagccagat gcgtgatcat gaggcctaca 180
tggcctggca ccagcgcctt tacc 204
<210> 541
<211> 1479
<212> PRT
<213> Artificial seqeunce
<220>
<223> Heterologous protein
<400> 541
Gln Asn Leu Gln Asn Gly Gly Gly Ser Arg Ser Ser Ala Thr Leu Pro
1 5 10 15
Gly Arg Arg Arg Arg Arg Trp Leu Arg Arg Arg Arg Gln Pro Ile Ser
20 25 30
Val Ala Pro Ala Gly Pro Pro Arg Arg Pro Asn Gln Lys Pro Asn Pro
35 40 45
Pro Gly Gly Ala Arg Cys Val Ile Met Arg Pro Thr Trp Pro Gly Thr
50 55 60
Ser Ala Phe Thr Lys Arg Ser Phe Ala Val Thr Glu Arg Ile Ile Asp
65 70 75 80
Tyr Trp Ala Gln Lys Glu Lys Gly Ser Ser Ser Phe Leu Arg Pro Ser
85 90 95
Cys Asp Tyr Trp Ala Gln Lys Glu Lys Ile Ser Ile Pro Arg Thr His
100 105 110
Leu Cys Leu Val Leu Gly Val Leu Ser Gly His Ser Gly Ser Arg Leu
115 120 125
Tyr Glu Ala Gly Met Thr Leu Gly Gly Lys Ile Leu Phe Phe Leu Phe
130 135 140
Leu Leu Leu Pro Leu Ser Pro Phe Ser Leu Ile Phe Thr Glu Ile Ser
145 150 155 160
Cys Cys Thr Leu Ser Ser Glu Glu Asn Glu Tyr Leu Pro Arg Pro Glu
165 170 175
Trp Gln Leu Gln Val Pro Phe Arg Glu Leu Lys Asn Val Ser Val Leu
180 185 190
Glu Gly Leu Arg Gln Gly Arg Leu Gly Gly Pro Cys Ser Cys His Cys
195 200 205
Pro Arg Pro Ser Gln Ala Arg Leu Thr Pro Val Asp Val Ala Gly Pro
210 215 220
Phe Leu Cys Leu Gly Asp Pro Gly Leu Phe Pro Pro Val Lys Ser Ser
225 230 235 240
Ile Thr Gly Gly Lys Ser Thr Cys Ser Ala Pro Gly Pro Gln Ser Leu
245 250 255
Pro Ser Thr Pro Phe Ser Thr Tyr Pro Gln Trp Val Ile Leu Ile Thr
260 265 270
Glu Leu Gly Met Glu Cys Thr Leu Gly Gln Val Gly Ala Pro Ser Pro
275 280 285
Arg Arg Glu Glu Asp Gly Trp Arg Gly Gly His Ser Arg Phe Lys Ala
290 295 300
Asp Val Pro Ala Pro Gln Gly Pro Cys Trp Gly Gly Gln Pro Gly Ser
305 310 315 320
Ala Pro Ser Ser Ala Pro Pro Glu Gln Ser Leu Leu Asp Trp Lys Phe
325 330 335
Glu Met Ser Tyr Thr Val Gly Gly Pro Pro Pro His Val His Ala Arg
340 345 350
Pro Arg His Trp Lys Thr Asp Arg Asp Gly His Ser Tyr Thr Ser Lys
355 360 365
Val Asn Cys Leu Leu Leu Gln Asp Gly Phe His Gly Cys Val Ser Ile
370 375 380
Thr Gly Ala Ala Gly Arg Arg Asn Leu Ser Ile Phe Leu Phe Leu Met
385 390 395 400
Leu Cys Lys Leu Glu Phe His Ala Cys Lys Ile Gln Asn Lys Asn Cys
405 410 415
Pro Asp Phe Lys Lys Phe Asp Gly Pro Cys Gly Glu Arg Gly Gly Gly
420 425 430
Arg Thr Ala Arg Ala Leu Trp Ala Arg Gly Asp Ser Val Leu Thr Pro
435 440 445
Ala Leu Asp Pro Gln Thr Pro Val Arg Ala Pro Ser Leu Thr Arg Ala
450 455 460
Ala Ala Ala Val His Tyr Lys Leu Ile Gln Gln Pro Ile Ser Leu Phe
465 470 475 480
Ser Ile Thr Asp Arg Leu His Lys Thr Phe Ser Gln Leu Pro Ser Val
485 490 495
His Leu Cys Ser Ile Thr Phe Gln Trp Gly His Pro Pro Ile Phe Cys
500 505 510
Ser Thr Asn Asp Ile Cys Val Thr Ala Asn Phe Cys Ile Ser Val Thr
515 520 525
Phe Leu Lys Pro Cys Phe Leu Leu His Glu Ala Ser Ala Ser Gln Cys
530 535 540
His Leu Phe Leu Gln Pro Gln Val Gly Thr Pro Pro Pro His Thr Ala
545 550 555 560
Ser Ala Arg Ala Pro Ser Gly Pro Pro His Pro His Glu Ser Cys Pro
565 570 575
Ala Gly Arg Arg Pro Ala Arg Ala Ala Gln Thr Cys Ala Arg Arg Gln
580 585 590
His Gly Leu Pro Gly Cys Glu Glu Ala Gly Thr Ala Arg Val Pro Ser
595 600 605
Leu His Leu His Leu His Gln Ala Ala Leu Gly Ala Gly Arg Gly Arg
610 615 620
Gly Trp Gly Glu Ala Cys Ala Gln Val Pro Pro Ser Arg Gly Val Leu
625 630 635 640
Arg Phe Leu Asp Leu Lys Val Arg Tyr Leu His Ser Gln Trp Gln His
645 650 655
Tyr His Arg Ser Gly Glu Ala Ala Gly Thr Pro Leu Trp Arg Pro Thr
660 665 670
Arg Asn Val Pro Phe Arg Glu Leu Lys Asn Gln Arg Thr Ala Gln Gly
675 680 685
Ala Pro Gly Ile His His Ala Ala Ser Pro Val Ala Ala Asn Leu Cys
690 695 700
Asp Pro Ala Arg His Ala Gln His Thr Arg Ile Pro Cys Gly Ala Gly
705 710 715 720
Gln Val Arg Ala Gly Arg Gly Pro Glu Ala Gly Gly Gly Val Leu Gln
725 730 735
Pro Gln Arg Pro Ala Pro Glu Lys Pro Gly Cys Pro Cys Arg Arg Gly
740 745 750
Gln Pro Arg Leu His Thr Val Lys Met Trp Arg Ala Val Ala Met Met
755 760 765
Val Pro Asp Arg Gln Val His Tyr Asp Phe Gly Leu Gly Val Pro Gly
770 775 780
Asp Ser Thr Arg Arg Ala Val Arg Arg Met Asn Thr Phe Tyr Glu Ala
785 790 795 800
Gly Met Thr Leu Gly Glu Lys Phe Arg Val Gly Asn Cys Lys His Leu
805 810 815
Lys Met Thr Arg Pro Asn Ser Lys Met Ala Leu Asn Ser Glu Ala Leu
820 825 830
Ser Val Val Ser Glu Cys Gly Ala Ser Ala Cys Asp Val Ser Leu Ile
835 840 845
Ala Met Asp Ser Ala Phe Val Gln Gly Lys Asp Trp Gly Val Lys Lys
850 855 860
Phe Ile Arg Arg Asp Phe Tyr Ala Tyr Lys Asp Phe Leu Trp Cys Phe
865 870 875 880
Pro Phe Ser Leu Val Phe Leu Gln Glu Ile Gln Ile Cys Cys His Val
885 890 895
Ser Cys Leu Cys Cys Ile Cys Cys Ser Thr Arg Ile Cys Leu Gly Cys
900 905 910
Leu Leu Glu Leu Phe Leu Ser Arg Ala Leu Arg Ala Leu His Val Leu
915 920 925
Trp Asn Gly Phe Gln Leu His Cys Gln Thr Glu Tyr Asn Gln Lys Leu
930 935 940
Gln Val Asn Gln Phe Ser Glu Ser Lys Ser Leu Tyr His Arg Glu Lys
945 950 955 960
Gln Leu Ile Ala Met Asp Ser Ala Ile Cys Glu Glu Arg Gly Ala Ala
965 970 975
Gly Ser Leu Ile Ser Cys Glu Thr Met Pro Ala Ile Leu Lys Leu Gln
980 985 990
Lys Asn Cys Leu Leu Ser Leu Arg Thr Ala Leu Thr His Asn Gln Asp
995 1000 1005
Phe Ser Ile Tyr Arg Leu Cys Cys Lys Arg Gly Ser Leu Cys His
1010 1015 1020
Ala Ser Gln Ala Arg Ser Pro Ala Phe Pro Lys Pro Val Arg Pro
1025 1030 1035
Leu Pro Ala Pro Ile Thr Arg Ile Thr Pro Gln Leu Gly Gly Gln
1040 1045 1050
Ser Asp Ser Ser Gln Pro Leu Leu Thr Thr Gly Arg Pro Gln Gly
1055 1060 1065
Trp Gln Asp Gln Ala Leu Arg His Thr Gln Gln Ala Ser Pro Ala
1070 1075 1080
Ser Cys Ala Thr Ile Thr Ile Pro Ile His Ser Ala Ala Leu Gly
1085 1090 1095
Asp His Ser Gly Asp Pro Gly Pro Ala Trp Asp Thr Cys Pro Pro
1100 1105 1110
Leu Pro Leu Thr Thr Leu Ile Pro Arg Ala Pro Pro Pro Tyr Gly
1115 1120 1125
Asp Ser Thr Ala Arg Ser Trp Pro Ser Arg Cys Gly Pro Leu Gly
1130 1135 1140
Gly Asn Thr Thr Leu Gln Gln Leu Gly Glu Ala Ser Gln Ala Pro
1145 1150 1155
Ser Gly Ser Leu Ile Pro Leu Arg Leu Pro Leu Leu Trp Glu Val
1160 1165 1170
Arg Gly Gln Pro Asp Ser Phe Ala Ala Leu His Ser Ser Leu Asn
1175 1180 1185
Glu Leu Gly Glu Ile Ala Arg Glu Leu His Gln Phe Ala Phe Asp
1190 1195 1200
Leu Leu Ile Lys Ser His Phe Val Gln Gly Lys Asp Trp Gly Leu
1205 1210 1215
Lys Lys Phe Ile Arg Arg Asp Phe Trp Gly Met Glu Leu Ala Ala
1220 1225 1230
Ser Arg Arg Phe Ser Trp Asp His His Ser Ala Gly Gly Pro Pro
1235 1240 1245
Arg Val Pro Ser Val Arg Ser Gly Ala Ala Gln Val Gln Pro Lys
1250 1255 1260
Asp Pro Leu Pro Leu Arg Thr Leu Ala Gly Cys Leu Ala Arg Thr
1265 1270 1275
Ala His Leu Arg Pro Gly Ala Glu Ser Leu Pro Gln Pro Gln Leu
1280 1285 1290
His Cys Thr Leu Trp Phe Gln Ser Ser Glu Leu Ser Pro Thr Gly
1295 1300 1305
Ala Pro Trp Pro Ser Arg Arg Pro Thr Trp Arg Gly Thr Thr Val
1310 1315 1320
Ser Pro Arg Thr Ala Thr Ser Ser Ala Arg Thr Cys Cys Gly Thr
1325 1330 1335
Lys Trp Pro Ser Ser Gln Glu Ala Ala Leu Gly Leu Gly Ser Gly
1340 1345 1350
Leu Leu Arg Phe Ser Cys Gly Thr Ala Ala Ile Arg Lys Met His
1355 1360 1365
Phe Ser Leu Lys Glu His Pro Pro Pro Pro Cys Pro Pro Glu Ala
1370 1375 1380
Phe Gln Arg Ala Ala Gly Glu Gly Gly Pro Gly Arg Gly Gly Ala
1385 1390 1395
Arg Arg Gly Ala Arg Val Leu Gln Ser Pro Phe Cys Arg Ala Gly
1400 1405 1410
Ala Gly Glu Trp Leu Gly His Gln Ser Leu Arg His Val Val Gly
1415 1420 1425
Tyr Gly His Leu Asp Thr Ser Gly Ser Ser Ser Ser Ser Ser Trp
1430 1435 1440
Pro Asn Ser Lys Met Ala Leu Asn Ser Leu Asn Ser Ile Asp Asp
1445 1450 1455
Ala Gln Leu Thr Arg Ile Ala Pro Pro Arg Ser His Cys Cys Phe
1460 1465 1470
Trp Glu Val Asn Ala Pro
1475
<210> 542
<211> 4437
<212> DNA
<213> Artificial seqeunce
<220>
<223> Heterologous polynucleotide
<400> 542
cagaacctgc agaacggcgg aggctctaga agctctgcta cacttcctgg caggcggcgg 60
agaagatggc tgagaagaag gcggcagcct atctctgtgg ctcctgctgg acctcctaga 120
cggcccaacc agaagcctaa tcctcctggc ggagccagat gcgtgatcat gaggcctaca 180
tggcctggca ccagcgcctt caccaagaga agctttgccg tgaccgagcg gatcatcgac 240
tattgggctc aaaaagagaa gggcagcagc agcttcctgc ggcctagctg tgattattgg 300
gcccagaaag aaaagatcag catccccaga acacacctgt gcctggtgct gggagtgctg 360
tctggacact ctggcagcag actgtatgag gccggcatga cactcggcgg caagatcctg 420
ttcttcctgt tcctgctgct ccctctgagc cccttcagcc tgatcttcac cgagatcagc 480
tgctgcaccc tgagcagcga ggaaaacgag tacctgccta gacctgagtg gcagctgcag 540
gtccccttca gagagctgaa gaacgtttcc gtgctggaag gcctgagaca gggcagactt 600
ggcggccctt gtagctgtca ctgccccaga cctagtcagg ccagactgac acctgtggat 660
gtggccggac ctttcctgtg tctgggagat cctggcctgt ttccacctgt gaagtccagc 720
atcacaggcg gcaagtccac atgttctgcc cctggacctc agagcctgcc tagcacaccc 780
ttcagcacat accctcagtg ggtcatcctg atcaccgaac tcggcatgga atgcaccctg 840
ggacaagtgg gagccccatc tcctagaaga gaagaggatg gctggcgcgg aggccactct 900
agattcaaag ctgatgtgcc cgctcctcag ggcccttgtt ggggaggaca acctggatct 960
gccccatctt ctgccccacc tgaacagtcc ctgctggatt ggaagttcga gatgagctac 1020
accgtcggcg gacctccacc tcatgttcat gccagacctc ggcactggaa aaccgacaga 1080
gatggccaca gctacaccag caaagtgaac tgcctcctgc tgcaggatgg cttccacggc 1140
tgtgtgtcta ttactggcgc cgctggcaga cggaacctga gcatctttct gtttctgatg 1200
ctgtgcaagc tcgagttcca cgcctgcaag atccagaaca agaactgccc cgacttcaag 1260
aagttcgacg gcccttgcgg agaaagaggc ggaggcagaa cagctagagc cctttgggct 1320
agaggcgaca gcgttctgac accagctctg gaccctcaga cacctgttag ggcccctagc 1380
ctgacaagag ctgccgccgc tgtgcactac aagctgatcc agcagccaat cagcctgttc 1440
agcatcaccg accggctgca caagacattc agccagctgc caagcgtgca cctgtgctcc 1500
atcaccttcc agtggggaca ccctcctatc ttttgctcca ccaacgacat ctgcgtgacc 1560
gccaacttct gtatcagcgt gaccttcctg aagccttgct ttctgctgca cgaggccagc 1620
gcctctcagt gccacttgtt tctgcagccc caagtgggca cacctcctcc acatacagcc 1680
tctgctagag cacctagcgg ccctccacat cctcacgaat cttgtcctgc cggaagaagg 1740
cctgccagag ccgctcaaac atgtgccaga cgacagcacg gactgcctgg atgtgaagag 1800
gctggaacag ccagagtgcc tagcctgcac ctccatctgc atcaggctgc tcttggagcc 1860
ggaagaggta gaggatgggg cgaagcttgt gctcaggtgc caccttctag aggcgtgctg 1920
agattcctgg acctgaaagt gcgctacctg cacagccagt ggcagcacta tcacagatct 1980
ggcgaagccg ccggaacacc cctttggagg ccaacaagaa acgtgccctt ccgggaactg 2040
aagaaccaga gaacagctca gggcgctcct ggaatccacc atgctgcttc tccagtggcc 2100
gccaacctgt gtgatcctgc cagacatgcc cagcacacca ggattccttg tggcgctgga 2160
caagtgcgcg ctggaagagg acctgaagca ggcggaggtg ttctgcaacc tcaaagaccc 2220
gctcctgaga agcctggctg cccttgcaga agaggacagc ctagactgca caccgtgaaa 2280
atgtggcgag ccgtggccat gatggtgccc gatagacagg tccactacga ctttggactg 2340
ggcgtgccag gcgatagcac tcggagagcc gtcagacgga tgaacacctt ttacgaagcc 2400
gggatgaccc tgggcgagaa gttcagagtg ggcaactgca agcacctgaa gatgacccgg 2460
cctaacagca agatggccct gaatagcgag gccctgtctg tggtgtctga atgtggcgcc 2520
tctgcctgtg acgtgtccct gatcgctatg gactccgcct ttgtgcaggg caaagactgg 2580
ggcgtgaaga agttcatccg gcgggacttc tacgcctaca aggacttcct gtggtgcttc 2640
cccttctctc tggtgttcct gcaagagatc cagatctgct gtcatgtgtc ctgcctgtgc 2700
tgcatctgct gtagcaccag aatctgcctg ggctgtctgc tggaactgtt cctgagcaga 2760
gccctgagag cactgcacgt gctgtggaac ggattccagc tgcactgcca gaccgagtac 2820
aaccagaaac tgcaagtgaa ccagttcagc gagagcaaga gcctgtacca ccgggaaaag 2880
cagctcattg ccatggacag cgccatctgc gaagagagag gcgccgcagg atctctgatc 2940
tcctgcgaaa caatgcccgc catcctgaag ctgcagaaga attgcctcct aagcctgcga 3000
accgctctga cacacaacca ggacttcagc atctacagac tgtgttgcaa gcggggctcc 3060
ctgtgccatg caagccaagc tagaagcccc gcctttccta aacctgtgcg acctctgcca 3120
gctccaatca ccagaattac ccctcagctc ggcggccaga gcgattcatc tcaacctctg 3180
ctgaccaccg gcagacctca aggctggcaa gaccaagctc tgagacacac ccagcaggct 3240
agccctgcct cttgtgccac catcacaatc cccatccact ctgccgctct gggcgatcat 3300
tctggcgatc ctggaccagc ctgggacaca tgtcctccac tgccactcac aacactgatc 3360
cctagggctc ctccacctta cggcgattct accgctagaa gctggcccag cagatgtgga 3420
ccactcggag gcaacacaac cctccagcaa ctgggagaag cctctcaggc tcctagcggc 3480
tctctgatcc ctctcagact gcctctcctg tgggaagttc ggggccagcc tgattctttt 3540
gccgcactgc acagctccct gaacgagctg ggagagatcg ctagagagct gcaccagttc 3600
gccttcgacc tgctgatcaa gagccacttc gtgcaaggca aggattgggg cctcaaaaag 3660
tttatccgca gagacttctg gggcatggaa ctggccgcca gcagaagatt cagctgggat 3720
catcatagcg caggcggccc acctagagtg ccatctgtta gaagcggagc tgcccaggtg 3780
cagcctaaag atcctctgcc actgagaaca ctggccggct gccttgctag aacagcccat 3840
cttagacctg gcgccgagtc tctgcctcag ccacaactgc actgtaccct gtggttccag 3900
tccagcgagc tgtctcctac tggtgcccct tggccatcta gacgccctac ttggagaggc 3960
accaccgtgt caccaagaac cgccacaagc agcgccagaa cctgttgtgg cacaaagtgg 4020
ccctccagcc aagaagccgc tctcggactt ggaagcggac tgctgaggtt ctcttgtgga 4080
accgccgcca ttcggaagat gcactttagc ctgaaagaac accctccacc accttgtcct 4140
ccagaggctt tccaaagagc tgctggcgaa ggcggacctg gtagaggtgg tgctagaaga 4200
ggtgctaggg tgctgcagag cccattctgt agagcaggcg caggcgaatg gctgggccat 4260
cagagtctga gacatgtcgt cggctacggc cacctggata caagcggaag cagctctagc 4320
tccagctggc ctaactcaaa aatggctctg aacagcctga actccatcga cgacgcccag 4380
ctgacaagaa tcgcccctcc tagatctcac tgctgctttt gggaagtgaa cgcccca 4437
<210> 543
<211> 1480
<212> PRT
<213> Artificial seqeunce
<220>
<223> Hetereologous protein
<400> 543
Gln Asn Leu Gln Asn Gly Gly Gly Ser Arg Ser Ser Ala Thr Leu Pro
1 5 10 15
Gly Arg Arg Arg Arg Arg Trp Leu Arg Arg Arg Arg Gln Pro Ile Ser
20 25 30
Val Ala Pro Ala Gly Pro Pro Arg Arg Pro Asn Gln Lys Pro Asn Pro
35 40 45
Pro Gly Gly Ala Arg Cys Val Ile Met Arg Pro Thr Trp Pro Gly Thr
50 55 60
Ser Ala Phe Thr Gly Met Glu Cys Thr Leu Gly Gln Val Gly Ala Pro
65 70 75 80
Ser Pro Arg Arg Glu Glu Asp Gly Trp Arg Gly Gly His Ser Arg Phe
85 90 95
Lys Ala Asp Val Pro Ala Pro Gln Gly Pro Cys Trp Gly Gly Gln Pro
100 105 110
Gly Ser Ala Pro Ser Ser Ala Pro Pro Glu Gln Ser Leu Leu Asp Asp
115 120 125
Tyr Trp Ala Gln Lys Glu Lys Ile Ser Ile Pro Arg Thr His Leu Cys
130 135 140
Trp Lys Phe Glu Met Ser Tyr Thr Val Gly Gly Pro Pro Pro His Val
145 150 155 160
His Ala Arg Pro Arg His Trp Lys Thr Asp Arg Asp Tyr Trp Ala Gln
165 170 175
Lys Glu Lys Gly Ser Ser Ser Phe Leu Arg Pro Ser Cys Val Pro Phe
180 185 190
Arg Glu Leu Lys Asn Val Ser Val Leu Glu Gly Leu Arg Gln Gly Arg
195 200 205
Leu Gly Gly Pro Cys Ser Cys His Cys Pro Arg Pro Ser Gln Ala Arg
210 215 220
Leu Thr Pro Val Asp Val Ala Gly Pro Phe Leu Cys Leu Gly Asp Pro
225 230 235 240
Gly Leu Phe Pro Pro Val Lys Ser Ser Ile Thr Glu Ile Ser Cys Cys
245 250 255
Thr Leu Ser Ser Glu Glu Asn Glu Tyr Leu Pro Arg Pro Glu Trp Gln
260 265 270
Leu Gln Tyr Glu Ala Gly Met Thr Leu Gly Gly Lys Ile Leu Phe Phe
275 280 285
Leu Phe Leu Leu Leu Pro Leu Ser Pro Phe Ser Leu Ile Phe Leu Val
290 295 300
Leu Gly Val Leu Ser Gly His Ser Gly Ser Arg Leu Lys Arg Ser Phe
305 310 315 320
Ala Val Thr Glu Arg Ile Ile Thr Gly Gly Lys Ser Thr Cys Ser Ala
325 330 335
Pro Gly Pro Gln Ser Leu Pro Ser Thr Pro Phe Ser Thr Tyr Pro Gln
340 345 350
Trp Val Ile Leu Ile Thr Glu Leu Asp Gly His Ser Tyr Thr Ser Lys
355 360 365
Val Asn Cys Leu Leu Leu Gln Asp Gly Phe His Gly Cys Val Ser Ile
370 375 380
Thr Gly Ala Ala Gly Arg Arg Asn Leu Ser Ile Phe Leu Phe Leu Met
385 390 395 400
Leu Cys Lys Leu Glu Phe His Ala Cys Gln Trp Gln His Tyr His Arg
405 410 415
Ser Gly Glu Ala Ala Gly Thr Pro Leu Trp Arg Pro Thr Arg Asn Val
420 425 430
Ala Met Met Val Pro Asp Arg Gln Val His Tyr Asp Phe Gly Leu Lys
435 440 445
Ile Gln Asn Lys Asn Cys Pro Asp Val Leu Arg Phe Leu Asp Leu Lys
450 455 460
Val Arg Tyr Leu His Ser Val Pro Phe Arg Glu Leu Lys Asn Gln Arg
465 470 475 480
Thr Ala Gln Gly Ala Pro Gly Ile His His Ala Ala Ser Pro Val Ala
485 490 495
Ala Asn Leu Cys Asp Pro Ala Arg His Ala Gln His Thr Arg Ile Pro
500 505 510
Cys Gly Ala Gly Gln Val Arg Ala Gly Arg Gly Pro Glu Ala Gly Gly
515 520 525
Gly Val Leu Gln Pro Gln Arg Pro Ala Pro Glu Lys Pro Gly Cys Pro
530 535 540
Cys Arg Arg Gly Gln Pro Arg Leu His Thr Val Lys Met Trp Arg Ala
545 550 555 560
Cys His Leu Phe Leu Gln Pro Gln Val Gly Thr Pro Pro Pro His Thr
565 570 575
Ala Ser Ala Arg Ala Pro Ser Gly Pro Pro His Pro His Glu Ser Cys
580 585 590
Pro Ala Gly Arg Arg Pro Ala Arg Ala Ala Gln Thr Cys Ala Arg Arg
595 600 605
Gln His Gly Leu Pro Gly Cys Glu Glu Ala Gly Thr Ala Arg Val Pro
610 615 620
Ser Leu His Leu His Leu His Gln Ala Ala Leu Gly Ala Gly Arg Gly
625 630 635 640
Arg Gly Trp Gly Glu Ala Cys Ala Gln Val Pro Pro Ser Arg Gly His
645 650 655
Tyr Lys Leu Ile Gln Gln Pro Ile Ser Leu Phe Ser Ile Thr Asp Arg
660 665 670
Leu His Lys Thr Phe Ser Gln Leu Pro Ser Val His Leu Cys Ser Ile
675 680 685
Thr Phe Gln Trp Gly His Pro Pro Ile Phe Cys Ser Thr Asn Asp Ile
690 695 700
Cys Val Thr Ala Asn Phe Cys Ile Ser Val Thr Phe Leu Lys Pro Cys
705 710 715 720
Phe Leu Leu His Glu Ala Ser Ala Ser Gln Phe Lys Lys Phe Asp Gly
725 730 735
Pro Cys Gly Glu Arg Gly Gly Gly Arg Thr Ala Arg Ala Leu Trp Ala
740 745 750
Arg Gly Asp Ser Val Leu Thr Pro Ala Leu Asp Pro Gln Thr Pro Val
755 760 765
Arg Ala Pro Ser Leu Thr Arg Ala Ala Ala Ala Val Gly Val Pro Gly
770 775 780
Asp Ser Thr Arg Arg Ala Val Arg Arg Met Asn Thr Phe Cys Gly Ala
785 790 795 800
Ser Ala Cys Asp Val Ser Leu Ile Ala Met Asp Ser Ala Cys Glu Glu
805 810 815
Arg Gly Ala Ala Gly Ser Leu Ile Ser Cys Glu Ser Leu Tyr His Arg
820 825 830
Glu Lys Gln Leu Ile Ala Met Asp Ser Ala Ile Phe Val Gln Gly Lys
835 840 845
Asp Trp Gly Val Lys Lys Phe Ile Arg Arg Asp Phe Thr Met Pro Ala
850 855 860
Ile Leu Lys Leu Gln Lys Asn Cys Leu Leu Ser Leu Asn Ser Lys Met
865 870 875 880
Ala Leu Asn Ser Glu Ala Leu Ser Val Val Ser Glu Tyr Glu Ala Gly
885 890 895
Met Thr Leu Gly Glu Lys Phe Arg Val Gly Asn Cys Lys His Leu Lys
900 905 910
Met Thr Arg Pro Thr Glu Tyr Asn Gln Lys Leu Gln Val Asn Gln Phe
915 920 925
Ser Glu Ser Lys Arg Thr Ala Leu Thr His Asn Gln Asp Phe Ser Ile
930 935 940
Tyr Arg Leu Cys Cys Lys Arg Gly Ser Leu Cys His Ala Ser Gln Ala
945 950 955 960
Arg Ser Pro Ala Phe Pro Lys Pro Val Arg Pro Leu Pro Ala Pro Ile
965 970 975
Thr Arg Ile Thr Pro Gln Leu Gly Gly Gln Ser Asp Ser Ser Gln Pro
980 985 990
Leu Leu Thr Thr Gly Arg Pro Gln Gly Trp Gln Asp Gln Ala Leu Arg
995 1000 1005
His Thr Gln Gln Ala Ser Pro Ala Ser Cys Ala Thr Ile Thr Ile
1010 1015 1020
Pro Ile His Ser Ala Ala Leu Gly Asp His Ser Gly Asp Pro Gly
1025 1030 1035
Pro Ala Trp Asp Thr Cys Pro Pro Leu Pro Leu Thr Thr Leu Ile
1040 1045 1050
Pro Arg Ala Pro Pro Pro Tyr Gly Asp Ser Thr Ala Arg Ser Trp
1055 1060 1065
Pro Ser Arg Cys Gly Pro Leu Gly Tyr Ala Tyr Lys Asp Phe Leu
1070 1075 1080
Trp Cys Phe Pro Phe Ser Leu Val Phe Leu Gln Glu Ile Gln Ile
1085 1090 1095
Cys Cys His Val Ser Cys Leu Cys Cys Ile Cys Cys Ser Thr Arg
1100 1105 1110
Ile Cys Leu Gly Cys Leu Leu Glu Leu Phe Leu Ser Arg Ala Leu
1115 1120 1125
Arg Ala Leu His Val Leu Trp Asn Gly Phe Gln Leu His Cys Gln
1130 1135 1140
Gly Asn Thr Thr Leu Gln Gln Leu Gly Glu Ala Ser Gln Ala Pro
1145 1150 1155
Ser Gly Ser Leu Ile Pro Leu Arg Leu Pro Leu Leu Trp Glu Val
1160 1165 1170
Arg Gly Asn Ser Lys Met Ala Leu Asn Ser Leu Asn Ser Ile Asp
1175 1180 1185
Asp Ala Gln Leu Thr Arg Ile Ala Pro Pro Arg Ser His Cys Cys
1190 1195 1200
Phe Trp Glu Val Asn Ala Pro Phe Val Gln Gly Lys Asp Trp Gly
1205 1210 1215
Leu Lys Lys Phe Ile Arg Arg Asp Phe Glu Ala Phe Gln Arg Ala
1220 1225 1230
Ala Gly Glu Gly Gly Pro Gly Arg Gly Gly Ala Arg Arg Gly Ala
1235 1240 1245
Arg Val Leu Gln Ser Pro Phe Cys Arg Ala Gly Ala Gly Glu Trp
1250 1255 1260
Leu Gly His Gln Ser Leu Arg Trp Gly Met Glu Leu Ala Ala Ser
1265 1270 1275
Arg Arg Phe Ser Trp Asp His His Ser Ala Gly Gly Pro Pro Arg
1280 1285 1290
Val Pro Ser Val Arg Ser Gly Ala Ala Gln Val Gln Pro Lys Asp
1295 1300 1305
Pro Leu Pro Leu Arg Thr Leu Ala Gly Cys Leu Ala Arg Thr Ala
1310 1315 1320
His Leu Arg Pro Gly Ala Glu Ser Leu Pro Gln Pro Gln Leu His
1325 1330 1335
Cys Thr Ile Ala Arg Glu Leu His Gln Phe Ala Phe Asp Leu Leu
1340 1345 1350
Ile Lys Ser His Lys Met His Phe Ser Leu Lys Glu His Pro Pro
1355 1360 1365
Pro Pro Cys Pro Pro His Val Val Gly Tyr Gly His Leu Asp Thr
1370 1375 1380
Ser Gly Ser Ser Ser Ser Ser Ser Trp Pro Gln Pro Asp Ser Phe
1385 1390 1395
Ala Ala Leu His Ser Ser Leu Asn Glu Leu Gly Glu Leu Trp Phe
1400 1405 1410
Gln Ser Ser Glu Leu Ser Pro Thr Gly Ala Pro Trp Pro Ser Arg
1415 1420 1425
Arg Pro Thr Trp Arg Gly Thr Thr Val Ser Pro Arg Thr Ala Thr
1430 1435 1440
Ser Ser Ala Arg Thr Cys Cys Gly Thr Lys Trp Pro Ser Ser Gln
1445 1450 1455
Glu Ala Ala Leu Gly Leu Gly Ser Gly Leu Leu Arg Phe Ser Cys
1460 1465 1470
Gly Thr Ala Ala Ile Arg Ser
1475 1480
<210> 544
<211> 4437
<212> DNA
<213> Artificial seqeunce
<220>
<223> Heterologous polynucleotide
<400> 544
cagaacctgc agaacggcgg aggctctaga agctctgcta cacttcctgg caggcggcgg 60
agaagatggc tgagaagaag gcggcagcct atctctgtgg ctcctgctgg acctcctaga 120
cggcccaacc agaagcctaa tcctcctggc ggagccagat gcgtgatcat gaggcctaca 180
tggcctggca ccagcgcctt taccggcatg gaatgtacac tgggccaagt gggagcccca 240
tctcctagaa gagaagagga tggctggcgc ggaggccact ctagattcaa agctgatgtg 300
cccgctcctc agggcccttg ttggggagga caacctggat ctgccccatc ttctgcccca 360
cctgaacaga gcctgctgga tgactattgg gctcaaaaag agaagatcag catccccaga 420
acacacctgt gctggaagtt cgagatgagc tacaccgttg gcggccctcc accacatgtt 480
cacgccagac ctagacactg gaaaaccgac agagattatt gggcccagaa agaaaagggc 540
agcagcagct tcctgcggcc tagctgtgtg cccttccggg aactgaagaa cgtgtccgtt 600
ctggaaggcc tgaggcaggg cagacttggc ggaccttgta gctgccactg tcctagacca 660
agccaggcca gactgacccc tgtggatgtg gctggcccat ttctgtgtct gggcgaccct 720
ggactgttcc ctccagtgaa gtctagcatc accgagatca gctgctgcac cctgagcagc 780
gaggaaaacg agtacctgcc tagacctgaa tggcagctgc agtacgaggc cggcatgaca 840
ctcggaggca agatcctgtt cttcctgttc ctgctgctcc ctctgagccc cttcagcctg 900
atctttctgg tgctgggcgt gctgtctggc cactctggaa gcagactgaa gagaagcttc 960
gccgtgaccg agcggatcat cacaggcggc aagagcacat gttctgcccc tggacctcag 1020
tctctgccca gcacaccctt cagcacatac cctcagtggg tcatcctgat caccgagctg 1080
gatggccaca gctacaccag caaagtgaac tgcctcctgc tgcaggatgg cttccacggc 1140
tgtgtgtcta ttactggcgc cgctggcaga cggaacctga gcatctttct gtttctgatg 1200
ctgtgcaagc tcgagttcca cgcctgccaa tggcagcact accacagatc tggcgaagcc 1260
gctggaaccc cactttggag gcctaccaga aacgtggcca tgatggtgcc cgacagacag 1320
gtgcactacg acttcggcct gaagatccag aacaagaact gccccgacgt gctgcggttc 1380
ctggatctca aagtgcgcta cctgcacagc gtgcccttca gagagctgaa aaaccagaga 1440
acagcccagg gcgctcctgg aatccatcat gctgcttctc cagtggccgc caatctgtgc 1500
gatcctgcca gacatgccca gcataccagg attccttgtg gcgctggaca agtgcgcgct 1560
ggaagaggac ctgaagctgg tggcggagtt ctgcagcctc aaagacctgc tcctgagaag 1620
cctggctgcc cctgtagaag aggacagcct agactgcaca ccgtgaagat gtggcgggcc 1680
tgccacttgt ttctccagcc acaagtgggc acccctccac ctcatacagc ctctgctaga 1740
gcacctagcg gcccacctca tcctcacgaa tcttgtcctg ccggaagaag gcctgccaga 1800
gccgctcaaa catgtgccag acgacagcac ggactgcccg gatgtgaaga agccggaaca 1860
gccagagtgc ctagcctgca ccttcatctg catcaggccg ctcttggagc cggaagaggt 1920
agaggatggg gagaagcttg tgcccaggtg ccaccttcta gaggccacta caagctgatc 1980
cagcagccaa tcagcctgtt ctccatcacc gaccggctgc acaagacatt cagccagctg 2040
ccttccgtgc atctgtgcag catcaccttc cagtggggac accctcctat cttttgctcc 2100
accaacgaca tctgcgtgac cgccaacttc tgtatcagcg tgaccttcct gaagccttgc 2160
tttctgctgc acgaggcctc cgccagccag tttaagaagt ttgacggccc ctgcggcgag 2220
agaggcggag gaagaactgc aagagccctt tgggccagag gcgactctgt tctgacacca 2280
gctctggacc ctcagacacc tgttagggcc cctagcctga caagagctgc cgctgctgtt 2340
ggagtgcctg gcgattctac tagaagggcc gtgcggcgga tgaacacctt ttgtggcgca 2400
tctgcctgcg acgtgtccct gatcgctatg gatagcgcct gcgaggaaag aggcgcagcc 2460
ggatctctga tctcttgcga gagcctgtac caccgggaaa agcagctcat tgccatggac 2520
agcgccatct tcgtgcaggg caaagactgg ggcgtgaaga agttcatccg gcgggacttt 2580
accatgcctg ccattctgaa gctgcagaag aattgtcttc taagcctgaa cagcaagatg 2640
gccctgaata gcgaggccct gtctgtggtg tccgagtatg aggctggaat gaccctgggc 2700
gagaagttca gagtgggcaa ctgcaagcac ctgaagatga cccggcctac cgagtacaac 2760
cagaaactgc aagtgaacca gttcagcgag agcaagcgga ccgctctgac ccacaaccag 2820
gacttcagca tctaccggct gtgctgcaag aggggctctc tgtgtcatgc tagccaggct 2880
agaagccccg cctttcctaa gcctgtcaga cctctgcctg ctcctatcac cagaatcacc 2940
cctcagctcg gcggccagtc tgattcatct cagccactgc tgaccaccgg cagacctcaa 3000
ggatggcaag accaggctct gagacacaca cagcaggcta gcccagcctc ttgcgccacc 3060
atcacaatac caatacattc tgccgctctg ggcgatcaca gcggagatcc tggacctgcc 3120
tgggatactt gtcctcctct gcccctaact acactgatcc ctagggctcc tccaccttac 3180
ggcgatagca cagccagatc ctggcctagc agatgtggcc ctctgggcta cgcctacaag 3240
gacttcctgt ggtgcttccc cttctctctg gtgttcctgc aagaaatcca gatctgctgt 3300
cacgtgtcct gcctgtgctg tatctgctgt agcacccgga tctgtctggg ctgtctgctg 3360
gaactgttcc tgagcagagc cctgagagca ctgcacgtgc tgtggaacgg attccagctg 3420
cactgccagg gcaacaccac actgcaacag ctgggagaag cctctcaggc cccaagcggt 3480
tctctgatcc ctctcagact gcccctcctg tgggaagtgc ggggcaattc taagatggct 3540
ctcaacagcc tgaactccat cgacgacgcc cagctgacaa gaatcgcccc tccaagaagc 3600
cactgttgct tttgggaagt gaacgcccct tttgtgcagg gtaaagattg gggcctcaaa 3660
aagtttatca gacgggactt cgaggctttc cagagagcag ctggcgaagg cggacctggc 3720
agaggtggtg ctagaagagg tgctagagtg ctgcagagcc cattctgtag agctggcgct 3780
ggcgaatggc tgggccacca atctcttaga tggggaatgg aactggccgc tagcaggcgg 3840
tttagctggg atcatcattc tgccggcgga cctccaagag tgccaagcgt tagaagcgga 3900
gcagcccagg tccagcctaa agatccactg ccactgagaa cactggccgg ctgccttgcc 3960
agaacagctc atcttagacc tggcgccgaa agcctgcctc aacctcagct gcattgcaca 4020
atcgccagag aactgcacca gttcgccttc gacctgctga tcaagagcca caagatgcac 4080
ttctcactga aagagcaccc gccaccgccg tgcccaccgc acgttgtcgg ctatggccac 4140
ctggatacaa gcggctcctc tagcagtagc tcctggcctc agcctgacag ctttgctgcc 4200
ctgcatagct ccctgaatga gctgggcgaa ctgtggttcc agtccagcga actgtctcct 4260
actggcgctc catggccaag cagaaggcct acttggagag gcaccaccgt gtctccaaga 4320
accgctacaa gcagcgccag aacctgttgc ggcacaaaat ggccctccag ccaagaagct 4380
gccctcggac ttggaagcgg actgctgaga ttcagctgtg gcacagccgc catcaga 4437
<210> 545
<211> 15
<212> DNA
<213> Homo sapiens
<400> 545
cgcgacttcg ccgcc 15
<210> 546
<211> 84
<212> DNA
<213> Artificial seqeunce
<220>
<223> T cell enhancer
<400> 546
atgggccaga aagagcagat ccacacactg cagaaaaaca gcgagcggat gagcaagcag 60
ctgaccagat cttctcaggc cgtg 84
<210> 547
<211> 21
<212> DNA
<213> Artificial seqeunce
<220>
<223> Tag seqeunce
<400> 547
agccatcacc atcaccacca t 21
<210> 548
<211> 12
<212> PRT
<213> Homo sapiens
<400> 548
Ile Lys Ser Leu Thr Ala Ile Phe Thr Val Lys Phe
1 5 10
<210> 549
<211> 28
<212> PRT
<213> Artificial sequence
<220>
<223> T cell enhancer
<400> 549
Met Gly Gln Lys Glu Gln Ile His Thr Leu Gln Lys Asn Ser Glu Arg
1 5 10 15
Met Ser Lys Gln Leu Thr Arg Ser Ser Gln Ala Val
20 25
<210> 550
<211> 1507
<212> PRT
<213> Artificial seqeunce
<220>
<223> Heterologous polypeptide
<400> 550
Met Gly Gln Lys Glu Gln Ile His Thr Leu Gln Lys Asn Ser Glu Arg
1 5 10 15
Met Ser Lys Gln Leu Thr Arg Ser Ser Gln Ala Val Gln Asn Leu Gln
20 25 30
Asn Gly Gly Gly Ser Arg Ser Ser Ala Thr Leu Pro Gly Arg Arg Arg
35 40 45
Arg Arg Trp Leu Arg Arg Arg Arg Gln Pro Ile Ser Val Ala Pro Ala
50 55 60
Gly Pro Pro Arg Arg Pro Asn Gln Lys Pro Asn Pro Pro Gly Gly Ala
65 70 75 80
Arg Cys Val Ile Met Arg Pro Thr Trp Pro Gly Thr Ser Ala Phe Thr
85 90 95
Lys Arg Ser Phe Ala Val Thr Glu Arg Ile Ile Asp Tyr Trp Ala Gln
100 105 110
Lys Glu Lys Gly Ser Ser Ser Phe Leu Arg Pro Ser Cys Asp Tyr Trp
115 120 125
Ala Gln Lys Glu Lys Ile Ser Ile Pro Arg Thr His Leu Cys Leu Val
130 135 140
Leu Gly Val Leu Ser Gly His Ser Gly Ser Arg Leu Tyr Glu Ala Gly
145 150 155 160
Met Thr Leu Gly Gly Lys Ile Leu Phe Phe Leu Phe Leu Leu Leu Pro
165 170 175
Leu Ser Pro Phe Ser Leu Ile Phe Thr Glu Ile Ser Cys Cys Thr Leu
180 185 190
Ser Ser Glu Glu Asn Glu Tyr Leu Pro Arg Pro Glu Trp Gln Leu Gln
195 200 205
Val Pro Phe Arg Glu Leu Lys Asn Val Ser Val Leu Glu Gly Leu Arg
210 215 220
Gln Gly Arg Leu Gly Gly Pro Cys Ser Cys His Cys Pro Arg Pro Ser
225 230 235 240
Gln Ala Arg Leu Thr Pro Val Asp Val Ala Gly Pro Phe Leu Cys Leu
245 250 255
Gly Asp Pro Gly Leu Phe Pro Pro Val Lys Ser Ser Ile Thr Gly Gly
260 265 270
Lys Ser Thr Cys Ser Ala Pro Gly Pro Gln Ser Leu Pro Ser Thr Pro
275 280 285
Phe Ser Thr Tyr Pro Gln Trp Val Ile Leu Ile Thr Glu Leu Gly Met
290 295 300
Glu Cys Thr Leu Gly Gln Val Gly Ala Pro Ser Pro Arg Arg Glu Glu
305 310 315 320
Asp Gly Trp Arg Gly Gly His Ser Arg Phe Lys Ala Asp Val Pro Ala
325 330 335
Pro Gln Gly Pro Cys Trp Gly Gly Gln Pro Gly Ser Ala Pro Ser Ser
340 345 350
Ala Pro Pro Glu Gln Ser Leu Leu Asp Trp Lys Phe Glu Met Ser Tyr
355 360 365
Thr Val Gly Gly Pro Pro Pro His Val His Ala Arg Pro Arg His Trp
370 375 380
Lys Thr Asp Arg Asp Gly His Ser Tyr Thr Ser Lys Val Asn Cys Leu
385 390 395 400
Leu Leu Gln Asp Gly Phe His Gly Cys Val Ser Ile Thr Gly Ala Ala
405 410 415
Gly Arg Arg Asn Leu Ser Ile Phe Leu Phe Leu Met Leu Cys Lys Leu
420 425 430
Glu Phe His Ala Cys Lys Ile Gln Asn Lys Asn Cys Pro Asp Phe Lys
435 440 445
Lys Phe Asp Gly Pro Cys Gly Glu Arg Gly Gly Gly Arg Thr Ala Arg
450 455 460
Ala Leu Trp Ala Arg Gly Asp Ser Val Leu Thr Pro Ala Leu Asp Pro
465 470 475 480
Gln Thr Pro Val Arg Ala Pro Ser Leu Thr Arg Ala Ala Ala Ala Val
485 490 495
His Tyr Lys Leu Ile Gln Gln Pro Ile Ser Leu Phe Ser Ile Thr Asp
500 505 510
Arg Leu His Lys Thr Phe Ser Gln Leu Pro Ser Val His Leu Cys Ser
515 520 525
Ile Thr Phe Gln Trp Gly His Pro Pro Ile Phe Cys Ser Thr Asn Asp
530 535 540
Ile Cys Val Thr Ala Asn Phe Cys Ile Ser Val Thr Phe Leu Lys Pro
545 550 555 560
Cys Phe Leu Leu His Glu Ala Ser Ala Ser Gln Cys His Leu Phe Leu
565 570 575
Gln Pro Gln Val Gly Thr Pro Pro Pro His Thr Ala Ser Ala Arg Ala
580 585 590
Pro Ser Gly Pro Pro His Pro His Glu Ser Cys Pro Ala Gly Arg Arg
595 600 605
Pro Ala Arg Ala Ala Gln Thr Cys Ala Arg Arg Gln His Gly Leu Pro
610 615 620
Gly Cys Glu Glu Ala Gly Thr Ala Arg Val Pro Ser Leu His Leu His
625 630 635 640
Leu His Gln Ala Ala Leu Gly Ala Gly Arg Gly Arg Gly Trp Gly Glu
645 650 655
Ala Cys Ala Gln Val Pro Pro Ser Arg Gly Val Leu Arg Phe Leu Asp
660 665 670
Leu Lys Val Arg Tyr Leu His Ser Gln Trp Gln His Tyr His Arg Ser
675 680 685
Gly Glu Ala Ala Gly Thr Pro Leu Trp Arg Pro Thr Arg Asn Val Pro
690 695 700
Phe Arg Glu Leu Lys Asn Gln Arg Thr Ala Gln Gly Ala Pro Gly Ile
705 710 715 720
His His Ala Ala Ser Pro Val Ala Ala Asn Leu Cys Asp Pro Ala Arg
725 730 735
His Ala Gln His Thr Arg Ile Pro Cys Gly Ala Gly Gln Val Arg Ala
740 745 750
Gly Arg Gly Pro Glu Ala Gly Gly Gly Val Leu Gln Pro Gln Arg Pro
755 760 765
Ala Pro Glu Lys Pro Gly Cys Pro Cys Arg Arg Gly Gln Pro Arg Leu
770 775 780
His Thr Val Lys Met Trp Arg Ala Val Ala Met Met Val Pro Asp Arg
785 790 795 800
Gln Val His Tyr Asp Phe Gly Leu Gly Val Pro Gly Asp Ser Thr Arg
805 810 815
Arg Ala Val Arg Arg Met Asn Thr Phe Tyr Glu Ala Gly Met Thr Leu
820 825 830
Gly Glu Lys Phe Arg Val Gly Asn Cys Lys His Leu Lys Met Thr Arg
835 840 845
Pro Asn Ser Lys Met Ala Leu Asn Ser Glu Ala Leu Ser Val Val Ser
850 855 860
Glu Cys Gly Ala Ser Ala Cys Asp Val Ser Leu Ile Ala Met Asp Ser
865 870 875 880
Ala Phe Val Gln Gly Lys Asp Trp Gly Val Lys Lys Phe Ile Arg Arg
885 890 895
Asp Phe Tyr Ala Tyr Lys Asp Phe Leu Trp Cys Phe Pro Phe Ser Leu
900 905 910
Val Phe Leu Gln Glu Ile Gln Ile Cys Cys His Val Ser Cys Leu Cys
915 920 925
Cys Ile Cys Cys Ser Thr Arg Ile Cys Leu Gly Cys Leu Leu Glu Leu
930 935 940
Phe Leu Ser Arg Ala Leu Arg Ala Leu His Val Leu Trp Asn Gly Phe
945 950 955 960
Gln Leu His Cys Gln Thr Glu Tyr Asn Gln Lys Leu Gln Val Asn Gln
965 970 975
Phe Ser Glu Ser Lys Ser Leu Tyr His Arg Glu Lys Gln Leu Ile Ala
980 985 990
Met Asp Ser Ala Ile Cys Glu Glu Arg Gly Ala Ala Gly Ser Leu Ile
995 1000 1005
Ser Cys Glu Thr Met Pro Ala Ile Leu Lys Leu Gln Lys Asn Cys
1010 1015 1020
Leu Leu Ser Leu Arg Thr Ala Leu Thr His Asn Gln Asp Phe Ser
1025 1030 1035
Ile Tyr Arg Leu Cys Cys Lys Arg Gly Ser Leu Cys His Ala Ser
1040 1045 1050
Gln Ala Arg Ser Pro Ala Phe Pro Lys Pro Val Arg Pro Leu Pro
1055 1060 1065
Ala Pro Ile Thr Arg Ile Thr Pro Gln Leu Gly Gly Gln Ser Asp
1070 1075 1080
Ser Ser Gln Pro Leu Leu Thr Thr Gly Arg Pro Gln Gly Trp Gln
1085 1090 1095
Asp Gln Ala Leu Arg His Thr Gln Gln Ala Ser Pro Ala Ser Cys
1100 1105 1110
Ala Thr Ile Thr Ile Pro Ile His Ser Ala Ala Leu Gly Asp His
1115 1120 1125
Ser Gly Asp Pro Gly Pro Ala Trp Asp Thr Cys Pro Pro Leu Pro
1130 1135 1140
Leu Thr Thr Leu Ile Pro Arg Ala Pro Pro Pro Tyr Gly Asp Ser
1145 1150 1155
Thr Ala Arg Ser Trp Pro Ser Arg Cys Gly Pro Leu Gly Gly Asn
1160 1165 1170
Thr Thr Leu Gln Gln Leu Gly Glu Ala Ser Gln Ala Pro Ser Gly
1175 1180 1185
Ser Leu Ile Pro Leu Arg Leu Pro Leu Leu Trp Glu Val Arg Gly
1190 1195 1200
Gln Pro Asp Ser Phe Ala Ala Leu His Ser Ser Leu Asn Glu Leu
1205 1210 1215
Gly Glu Ile Ala Arg Glu Leu His Gln Phe Ala Phe Asp Leu Leu
1220 1225 1230
Ile Lys Ser His Phe Val Gln Gly Lys Asp Trp Gly Leu Lys Lys
1235 1240 1245
Phe Ile Arg Arg Asp Phe Trp Gly Met Glu Leu Ala Ala Ser Arg
1250 1255 1260
Arg Phe Ser Trp Asp His His Ser Ala Gly Gly Pro Pro Arg Val
1265 1270 1275
Pro Ser Val Arg Ser Gly Ala Ala Gln Val Gln Pro Lys Asp Pro
1280 1285 1290
Leu Pro Leu Arg Thr Leu Ala Gly Cys Leu Ala Arg Thr Ala His
1295 1300 1305
Leu Arg Pro Gly Ala Glu Ser Leu Pro Gln Pro Gln Leu His Cys
1310 1315 1320
Thr Leu Trp Phe Gln Ser Ser Glu Leu Ser Pro Thr Gly Ala Pro
1325 1330 1335
Trp Pro Ser Arg Arg Pro Thr Trp Arg Gly Thr Thr Val Ser Pro
1340 1345 1350
Arg Thr Ala Thr Ser Ser Ala Arg Thr Cys Cys Gly Thr Lys Trp
1355 1360 1365
Pro Ser Ser Gln Glu Ala Ala Leu Gly Leu Gly Ser Gly Leu Leu
1370 1375 1380
Arg Phe Ser Cys Gly Thr Ala Ala Ile Arg Lys Met His Phe Ser
1385 1390 1395
Leu Lys Glu His Pro Pro Pro Pro Cys Pro Pro Glu Ala Phe Gln
1400 1405 1410
Arg Ala Ala Gly Glu Gly Gly Pro Gly Arg Gly Gly Ala Arg Arg
1415 1420 1425
Gly Ala Arg Val Leu Gln Ser Pro Phe Cys Arg Ala Gly Ala Gly
1430 1435 1440
Glu Trp Leu Gly His Gln Ser Leu Arg His Val Val Gly Tyr Gly
1445 1450 1455
His Leu Asp Thr Ser Gly Ser Ser Ser Ser Ser Ser Trp Pro Asn
1460 1465 1470
Ser Lys Met Ala Leu Asn Ser Leu Asn Ser Ile Asp Asp Ala Gln
1475 1480 1485
Leu Thr Arg Ile Ala Pro Pro Arg Ser His Cys Cys Phe Trp Glu
1490 1495 1500
Val Asn Ala Pro
1505
<210> 551
<211> 5703
<212> PRT
<213> Artificial seqeunce
<220>
<223> Heterologous polypeptide
<400> 551
Cys Cys Ala Thr Thr Gly Cys Ala Thr Ala Cys Gly Thr Thr Gly Thr
1 5 10 15
Ala Thr Cys Cys Ala Thr Ala Thr Cys Ala Thr Ala Ala Thr Ala Thr
20 25 30
Gly Thr Ala Cys Ala Thr Thr Thr Ala Thr Ala Thr Thr Gly Gly Cys
35 40 45
Thr Cys Ala Thr Gly Thr Cys Cys Ala Ala Cys Ala Thr Thr Ala Cys
50 55 60
Cys Gly Cys Cys Ala Thr Gly Thr Thr Gly Ala Cys Ala Thr Thr Gly
65 70 75 80
Ala Thr Thr Ala Thr Thr Gly Ala Cys Thr Ala Gly Thr Thr Ala Thr
85 90 95
Thr Ala Ala Thr Ala Gly Thr Ala Ala Thr Cys Ala Ala Thr Thr Ala
100 105 110
Cys Gly Gly Gly Gly Thr Cys Ala Thr Thr Ala Gly Thr Thr Cys Ala
115 120 125
Thr Ala Gly Cys Cys Cys Ala Thr Ala Thr Ala Thr Gly Gly Ala Gly
130 135 140
Thr Thr Cys Cys Gly Cys Gly Thr Thr Ala Cys Ala Thr Ala Ala Cys
145 150 155 160
Thr Thr Ala Cys Gly Gly Thr Ala Ala Ala Thr Gly Gly Cys Cys Cys
165 170 175
Gly Cys Cys Thr Gly Gly Cys Thr Gly Ala Cys Cys Gly Cys Cys Cys
180 185 190
Ala Ala Cys Gly Ala Cys Cys Cys Cys Cys Gly Cys Cys Cys Ala Thr
195 200 205
Thr Gly Ala Cys Gly Thr Cys Ala Ala Thr Ala Ala Thr Gly Ala Cys
210 215 220
Gly Thr Ala Thr Gly Thr Thr Cys Cys Cys Ala Thr Ala Gly Thr Ala
225 230 235 240
Ala Cys Gly Cys Cys Ala Ala Thr Ala Gly Gly Gly Ala Cys Thr Thr
245 250 255
Thr Cys Cys Ala Thr Thr Gly Ala Cys Gly Thr Cys Ala Ala Thr Gly
260 265 270
Gly Gly Thr Gly Gly Ala Gly Thr Ala Thr Thr Thr Ala Cys Gly Gly
275 280 285
Thr Ala Ala Ala Cys Thr Gly Cys Cys Cys Ala Cys Thr Thr Gly Gly
290 295 300
Cys Ala Gly Thr Ala Cys Ala Thr Cys Ala Ala Gly Thr Gly Thr Ala
305 310 315 320
Thr Cys Ala Thr Ala Thr Gly Cys Cys Ala Ala Gly Thr Ala Cys Gly
325 330 335
Cys Cys Cys Cys Cys Thr Ala Thr Thr Gly Ala Cys Gly Thr Cys Ala
340 345 350
Ala Thr Gly Ala Cys Gly Gly Thr Ala Ala Ala Thr Gly Gly Cys Cys
355 360 365
Cys Gly Cys Cys Thr Gly Gly Cys Ala Thr Thr Ala Thr Gly Cys Cys
370 375 380
Cys Ala Gly Thr Ala Cys Ala Thr Gly Ala Cys Cys Thr Thr Ala Thr
385 390 395 400
Gly Gly Gly Ala Cys Thr Thr Thr Cys Cys Thr Ala Cys Thr Thr Gly
405 410 415
Gly Cys Ala Gly Thr Ala Cys Ala Thr Cys Thr Ala Cys Gly Thr Ala
420 425 430
Thr Thr Ala Gly Thr Cys Ala Thr Cys Gly Cys Thr Ala Thr Thr Ala
435 440 445
Cys Cys Ala Thr Gly Gly Thr Gly Ala Thr Gly Cys Gly Gly Thr Thr
450 455 460
Thr Thr Gly Gly Cys Ala Gly Thr Ala Cys Ala Thr Cys Ala Ala Thr
465 470 475 480
Gly Gly Gly Cys Gly Thr Gly Gly Ala Thr Ala Gly Cys Gly Gly Thr
485 490 495
Thr Thr Gly Ala Cys Thr Cys Ala Cys Gly Gly Gly Gly Ala Thr Thr
500 505 510
Thr Cys Cys Ala Ala Gly Thr Cys Thr Cys Cys Ala Cys Cys Cys Cys
515 520 525
Ala Thr Thr Gly Ala Cys Gly Thr Cys Ala Ala Thr Gly Gly Gly Ala
530 535 540
Gly Thr Thr Thr Gly Thr Thr Thr Thr Gly Gly Cys Ala Cys Cys Ala
545 550 555 560
Ala Ala Ala Thr Cys Ala Ala Cys Gly Gly Gly Ala Cys Thr Thr Thr
565 570 575
Cys Cys Ala Ala Ala Ala Thr Gly Thr Cys Gly Thr Ala Ala Cys Ala
580 585 590
Ala Cys Thr Cys Cys Gly Cys Cys Cys Cys Ala Thr Thr Gly Ala Cys
595 600 605
Gly Cys Ala Ala Ala Thr Gly Gly Gly Cys Gly Gly Thr Ala Gly Gly
610 615 620
Cys Gly Thr Gly Thr Ala Cys Gly Gly Thr Gly Gly Gly Ala Gly Gly
625 630 635 640
Thr Cys Thr Ala Thr Ala Thr Ala Ala Gly Cys Ala Gly Ala Gly Cys
645 650 655
Thr Cys Thr Cys Cys Cys Thr Ala Thr Cys Ala Gly Thr Gly Ala Thr
660 665 670
Ala Gly Ala Gly Ala Thr Cys Thr Cys Cys Cys Thr Ala Thr Cys Ala
675 680 685
Gly Thr Gly Ala Thr Ala Gly Ala Gly Ala Thr Cys Gly Thr Cys Gly
690 695 700
Ala Cys Gly Ala Gly Cys Thr Cys Gly Thr Thr Thr Ala Gly Thr Gly
705 710 715 720
Ala Ala Cys Cys Gly Thr Cys Ala Gly Ala Thr Cys Gly Cys Cys Thr
725 730 735
Gly Gly Ala Gly Ala Cys Gly Cys Cys Ala Thr Cys Cys Ala Cys Gly
740 745 750
Cys Thr Gly Thr Thr Thr Thr Gly Ala Cys Cys Thr Cys Cys Ala Thr
755 760 765
Ala Gly Ala Ala Gly Ala Cys Ala Cys Cys Gly Gly Gly Ala Cys Cys
770 775 780
Gly Ala Thr Cys Cys Ala Gly Cys Cys Thr Cys Cys Gly Cys Gly Gly
785 790 795 800
Cys Cys Gly Gly Gly Ala Ala Cys Gly Gly Thr Gly Cys Ala Thr Thr
805 810 815
Gly Gly Ala Ala Cys Gly Cys Gly Gly Ala Thr Thr Cys Cys Cys Cys
820 825 830
Gly Thr Gly Cys Cys Ala Ala Gly Ala Gly Thr Gly Ala Gly Ala Thr
835 840 845
Cys Thr Thr Cys Cys Gly Thr Thr Thr Ala Thr Cys Thr Ala Gly Gly
850 855 860
Thr Ala Cys Cys Ala Gly Ala Thr Ala Thr Cys Ala Gly Ala Ala Thr
865 870 875 880
Thr Cys Gly Gly Ala Thr Cys Cys Cys Gly Cys Gly Ala Cys Thr Thr
885 890 895
Cys Gly Cys Cys Gly Cys Cys Ala Thr Gly Gly Gly Cys Cys Ala Gly
900 905 910
Ala Ala Ala Gly Ala Gly Cys Ala Gly Ala Thr Cys Cys Ala Cys Ala
915 920 925
Cys Ala Cys Thr Gly Cys Ala Gly Ala Ala Ala Ala Ala Cys Ala Gly
930 935 940
Cys Gly Ala Gly Cys Gly Gly Ala Thr Gly Ala Gly Cys Ala Ala Gly
945 950 955 960
Cys Ala Gly Cys Thr Gly Ala Cys Cys Ala Gly Ala Thr Cys Thr Thr
965 970 975
Cys Thr Cys Ala Gly Gly Cys Cys Gly Thr Gly Cys Ala Gly Ala Ala
980 985 990
Cys Cys Thr Gly Cys Ala Gly Ala Ala Cys Gly Gly Cys Gly Gly Ala
995 1000 1005
Gly Gly Cys Thr Cys Thr Ala Gly Ala Ala Gly Cys Thr Cys Thr
1010 1015 1020
Gly Cys Thr Ala Cys Ala Cys Thr Thr Cys Cys Thr Gly Gly Cys
1025 1030 1035
Ala Gly Gly Cys Gly Gly Cys Gly Gly Ala Gly Ala Ala Gly Ala
1040 1045 1050
Thr Gly Gly Cys Thr Gly Ala Gly Ala Ala Gly Ala Ala Gly Gly
1055 1060 1065
Cys Gly Gly Cys Ala Gly Cys Cys Thr Ala Thr Cys Thr Cys Thr
1070 1075 1080
Gly Thr Gly Gly Cys Thr Cys Cys Thr Gly Cys Thr Gly Gly Ala
1085 1090 1095
Cys Cys Thr Cys Cys Thr Ala Gly Ala Cys Gly Gly Cys Cys Cys
1100 1105 1110
Ala Ala Cys Cys Ala Gly Ala Ala Gly Cys Cys Thr Ala Ala Thr
1115 1120 1125
Cys Cys Thr Cys Cys Thr Gly Gly Cys Gly Gly Ala Gly Cys Cys
1130 1135 1140
Ala Gly Ala Thr Gly Cys Gly Thr Gly Ala Thr Cys Ala Thr Gly
1145 1150 1155
Ala Gly Gly Cys Cys Thr Ala Cys Ala Thr Gly Gly Cys Cys Thr
1160 1165 1170
Gly Gly Cys Ala Cys Cys Ala Gly Cys Gly Cys Cys Thr Thr Cys
1175 1180 1185
Ala Cys Cys Ala Ala Gly Ala Gly Ala Ala Gly Cys Thr Thr Thr
1190 1195 1200
Gly Cys Cys Gly Thr Gly Ala Cys Cys Gly Ala Gly Cys Gly Gly
1205 1210 1215
Ala Thr Cys Ala Thr Cys Gly Ala Cys Thr Ala Thr Thr Gly Gly
1220 1225 1230
Gly Cys Thr Cys Ala Ala Ala Ala Ala Gly Ala Gly Ala Ala Gly
1235 1240 1245
Gly Gly Cys Ala Gly Cys Ala Gly Cys Ala Gly Cys Thr Thr Cys
1250 1255 1260
Cys Thr Gly Cys Gly Gly Cys Cys Thr Ala Gly Cys Thr Gly Thr
1265 1270 1275
Gly Ala Thr Thr Ala Thr Thr Gly Gly Gly Cys Cys Cys Ala Gly
1280 1285 1290
Ala Ala Ala Gly Ala Ala Ala Ala Gly Ala Thr Cys Ala Gly Cys
1295 1300 1305
Ala Thr Cys Cys Cys Cys Ala Gly Ala Ala Cys Ala Cys Ala Cys
1310 1315 1320
Cys Thr Gly Thr Gly Cys Cys Thr Gly Gly Thr Gly Cys Thr Gly
1325 1330 1335
Gly Gly Ala Gly Thr Gly Cys Thr Gly Thr Cys Thr Gly Gly Ala
1340 1345 1350
Cys Ala Cys Thr Cys Thr Gly Gly Cys Ala Gly Cys Ala Gly Ala
1355 1360 1365
Cys Thr Gly Thr Ala Thr Gly Ala Gly Gly Cys Cys Gly Gly Cys
1370 1375 1380
Ala Thr Gly Ala Cys Ala Cys Thr Cys Gly Gly Cys Gly Gly Cys
1385 1390 1395
Ala Ala Gly Ala Thr Cys Cys Thr Gly Thr Thr Cys Thr Thr Cys
1400 1405 1410
Cys Thr Gly Thr Thr Cys Cys Thr Gly Cys Thr Gly Cys Thr Cys
1415 1420 1425
Cys Cys Thr Cys Thr Gly Ala Gly Cys Cys Cys Cys Thr Thr Cys
1430 1435 1440
Ala Gly Cys Cys Thr Gly Ala Thr Cys Thr Thr Cys Ala Cys Cys
1445 1450 1455
Gly Ala Gly Ala Thr Cys Ala Gly Cys Thr Gly Cys Thr Gly Cys
1460 1465 1470
Ala Cys Cys Cys Thr Gly Ala Gly Cys Ala Gly Cys Gly Ala Gly
1475 1480 1485
Gly Ala Ala Ala Ala Cys Gly Ala Gly Thr Ala Cys Cys Thr Gly
1490 1495 1500
Cys Cys Thr Ala Gly Ala Cys Cys Thr Gly Ala Gly Thr Gly Gly
1505 1510 1515
Cys Ala Gly Cys Thr Gly Cys Ala Gly Gly Thr Cys Cys Cys Cys
1520 1525 1530
Thr Thr Cys Ala Gly Ala Gly Ala Gly Cys Thr Gly Ala Ala Gly
1535 1540 1545
Ala Ala Cys Gly Thr Thr Thr Cys Cys Gly Thr Gly Cys Thr Gly
1550 1555 1560
Gly Ala Ala Gly Gly Cys Cys Thr Gly Ala Gly Ala Cys Ala Gly
1565 1570 1575
Gly Gly Cys Ala Gly Ala Cys Thr Thr Gly Gly Cys Gly Gly Cys
1580 1585 1590
Cys Cys Thr Thr Gly Thr Ala Gly Cys Thr Gly Thr Cys Ala Cys
1595 1600 1605
Thr Gly Cys Cys Cys Cys Ala Gly Ala Cys Cys Thr Ala Gly Thr
1610 1615 1620
Cys Ala Gly Gly Cys Cys Ala Gly Ala Cys Thr Gly Ala Cys Ala
1625 1630 1635
Cys Cys Thr Gly Thr Gly Gly Ala Thr Gly Thr Gly Gly Cys Cys
1640 1645 1650
Gly Gly Ala Cys Cys Thr Thr Thr Cys Cys Thr Gly Thr Gly Thr
1655 1660 1665
Cys Thr Gly Gly Gly Ala Gly Ala Thr Cys Cys Thr Gly Gly Cys
1670 1675 1680
Cys Thr Gly Thr Thr Thr Cys Cys Ala Cys Cys Thr Gly Thr Gly
1685 1690 1695
Ala Ala Gly Thr Cys Cys Ala Gly Cys Ala Thr Cys Ala Cys Ala
1700 1705 1710
Gly Gly Cys Gly Gly Cys Ala Ala Gly Thr Cys Cys Ala Cys Ala
1715 1720 1725
Thr Gly Thr Thr Cys Thr Gly Cys Cys Cys Cys Thr Gly Gly Ala
1730 1735 1740
Cys Cys Thr Cys Ala Gly Ala Gly Cys Cys Thr Gly Cys Cys Thr
1745 1750 1755
Ala Gly Cys Ala Cys Ala Cys Cys Cys Thr Thr Cys Ala Gly Cys
1760 1765 1770
Ala Cys Ala Thr Ala Cys Cys Cys Thr Cys Ala Gly Thr Gly Gly
1775 1780 1785
Gly Thr Cys Ala Thr Cys Cys Thr Gly Ala Thr Cys Ala Cys Cys
1790 1795 1800
Gly Ala Ala Cys Thr Cys Gly Gly Cys Ala Thr Gly Gly Ala Ala
1805 1810 1815
Thr Gly Cys Ala Cys Cys Cys Thr Gly Gly Gly Ala Cys Ala Ala
1820 1825 1830
Gly Thr Gly Gly Gly Ala Gly Cys Cys Cys Cys Ala Thr Cys Thr
1835 1840 1845
Cys Cys Thr Ala Gly Ala Ala Gly Ala Gly Ala Ala Gly Ala Gly
1850 1855 1860
Gly Ala Thr Gly Gly Cys Thr Gly Gly Cys Gly Cys Gly Gly Ala
1865 1870 1875
Gly Gly Cys Cys Ala Cys Thr Cys Thr Ala Gly Ala Thr Thr Cys
1880 1885 1890
Ala Ala Ala Gly Cys Thr Gly Ala Thr Gly Thr Gly Cys Cys Cys
1895 1900 1905
Gly Cys Thr Cys Cys Thr Cys Ala Gly Gly Gly Cys Cys Cys Thr
1910 1915 1920
Thr Gly Thr Thr Gly Gly Gly Gly Ala Gly Gly Ala Cys Ala Ala
1925 1930 1935
Cys Cys Thr Gly Gly Ala Thr Cys Thr Gly Cys Cys Cys Cys Ala
1940 1945 1950
Thr Cys Thr Thr Cys Thr Gly Cys Cys Cys Cys Ala Cys Cys Thr
1955 1960 1965
Gly Ala Ala Cys Ala Gly Thr Cys Cys Cys Thr Gly Cys Thr Gly
1970 1975 1980
Gly Ala Thr Thr Gly Gly Ala Ala Gly Thr Thr Cys Gly Ala Gly
1985 1990 1995
Ala Thr Gly Ala Gly Cys Thr Ala Cys Ala Cys Cys Gly Thr Cys
2000 2005 2010
Gly Gly Cys Gly Gly Ala Cys Cys Thr Cys Cys Ala Cys Cys Thr
2015 2020 2025
Cys Ala Thr Gly Thr Thr Cys Ala Thr Gly Cys Cys Ala Gly Ala
2030 2035 2040
Cys Cys Thr Cys Gly Gly Cys Ala Cys Thr Gly Gly Ala Ala Ala
2045 2050 2055
Ala Cys Cys Gly Ala Cys Ala Gly Ala Gly Ala Thr Gly Gly Cys
2060 2065 2070
Cys Ala Cys Ala Gly Cys Thr Ala Cys Ala Cys Cys Ala Gly Cys
2075 2080 2085
Ala Ala Ala Gly Thr Gly Ala Ala Cys Thr Gly Cys Cys Thr Cys
2090 2095 2100
Cys Thr Gly Cys Thr Gly Cys Ala Gly Gly Ala Thr Gly Gly Cys
2105 2110 2115
Thr Thr Cys Cys Ala Cys Gly Gly Cys Thr Gly Thr Gly Thr Gly
2120 2125 2130
Thr Cys Thr Ala Thr Thr Ala Cys Thr Gly Gly Cys Gly Cys Cys
2135 2140 2145
Gly Cys Thr Gly Gly Cys Ala Gly Ala Cys Gly Gly Ala Ala Cys
2150 2155 2160
Cys Thr Gly Ala Gly Cys Ala Thr Cys Thr Thr Thr Cys Thr Gly
2165 2170 2175
Thr Thr Thr Cys Thr Gly Ala Thr Gly Cys Thr Gly Thr Gly Cys
2180 2185 2190
Ala Ala Gly Cys Thr Cys Gly Ala Gly Thr Thr Cys Cys Ala Cys
2195 2200 2205
Gly Cys Cys Thr Gly Cys Ala Ala Gly Ala Thr Cys Cys Ala Gly
2210 2215 2220
Ala Ala Cys Ala Ala Gly Ala Ala Cys Thr Gly Cys Cys Cys Cys
2225 2230 2235
Gly Ala Cys Thr Thr Cys Ala Ala Gly Ala Ala Gly Thr Thr Cys
2240 2245 2250
Gly Ala Cys Gly Gly Cys Cys Cys Thr Thr Gly Cys Gly Gly Ala
2255 2260 2265
Gly Ala Ala Ala Gly Ala Gly Gly Cys Gly Gly Ala Gly Gly Cys
2270 2275 2280
Ala Gly Ala Ala Cys Ala Gly Cys Thr Ala Gly Ala Gly Cys Cys
2285 2290 2295
Cys Thr Thr Thr Gly Gly Gly Cys Thr Ala Gly Ala Gly Gly Cys
2300 2305 2310
Gly Ala Cys Ala Gly Cys Gly Thr Thr Cys Thr Gly Ala Cys Ala
2315 2320 2325
Cys Cys Ala Gly Cys Thr Cys Thr Gly Gly Ala Cys Cys Cys Thr
2330 2335 2340
Cys Ala Gly Ala Cys Ala Cys Cys Thr Gly Thr Thr Ala Gly Gly
2345 2350 2355
Gly Cys Cys Cys Cys Thr Ala Gly Cys Cys Thr Gly Ala Cys Ala
2360 2365 2370
Ala Gly Ala Gly Cys Thr Gly Cys Cys Gly Cys Cys Gly Cys Thr
2375 2380 2385
Gly Thr Gly Cys Ala Cys Thr Ala Cys Ala Ala Gly Cys Thr Gly
2390 2395 2400
Ala Thr Cys Cys Ala Gly Cys Ala Gly Cys Cys Ala Ala Thr Cys
2405 2410 2415
Ala Gly Cys Cys Thr Gly Thr Thr Cys Ala Gly Cys Ala Thr Cys
2420 2425 2430
Ala Cys Cys Gly Ala Cys Cys Gly Gly Cys Thr Gly Cys Ala Cys
2435 2440 2445
Ala Ala Gly Ala Cys Ala Thr Thr Cys Ala Gly Cys Cys Ala Gly
2450 2455 2460
Cys Thr Gly Cys Cys Ala Ala Gly Cys Gly Thr Gly Cys Ala Cys
2465 2470 2475
Cys Thr Gly Thr Gly Cys Thr Cys Cys Ala Thr Cys Ala Cys Cys
2480 2485 2490
Thr Thr Cys Cys Ala Gly Thr Gly Gly Gly Gly Ala Cys Ala Cys
2495 2500 2505
Cys Cys Thr Cys Cys Thr Ala Thr Cys Thr Thr Thr Thr Gly Cys
2510 2515 2520
Thr Cys Cys Ala Cys Cys Ala Ala Cys Gly Ala Cys Ala Thr Cys
2525 2530 2535
Thr Gly Cys Gly Thr Gly Ala Cys Cys Gly Cys Cys Ala Ala Cys
2540 2545 2550
Thr Thr Cys Thr Gly Thr Ala Thr Cys Ala Gly Cys Gly Thr Gly
2555 2560 2565
Ala Cys Cys Thr Thr Cys Cys Thr Gly Ala Ala Gly Cys Cys Thr
2570 2575 2580
Thr Gly Cys Thr Thr Thr Cys Thr Gly Cys Thr Gly Cys Ala Cys
2585 2590 2595
Gly Ala Gly Gly Cys Cys Ala Gly Cys Gly Cys Cys Thr Cys Thr
2600 2605 2610
Cys Ala Gly Thr Gly Cys Cys Ala Cys Thr Thr Gly Thr Thr Thr
2615 2620 2625
Cys Thr Gly Cys Ala Gly Cys Cys Cys Cys Ala Ala Gly Thr Gly
2630 2635 2640
Gly Gly Cys Ala Cys Ala Cys Cys Thr Cys Cys Thr Cys Cys Ala
2645 2650 2655
Cys Ala Thr Ala Cys Ala Gly Cys Cys Thr Cys Thr Gly Cys Thr
2660 2665 2670
Ala Gly Ala Gly Cys Ala Cys Cys Thr Ala Gly Cys Gly Gly Cys
2675 2680 2685
Cys Cys Thr Cys Cys Ala Cys Ala Thr Cys Cys Thr Cys Ala Cys
2690 2695 2700
Gly Ala Ala Thr Cys Thr Thr Gly Thr Cys Cys Thr Gly Cys Cys
2705 2710 2715
Gly Gly Ala Ala Gly Ala Ala Gly Gly Cys Cys Thr Gly Cys Cys
2720 2725 2730
Ala Gly Ala Gly Cys Cys Gly Cys Thr Cys Ala Ala Ala Cys Ala
2735 2740 2745
Thr Gly Thr Gly Cys Cys Ala Gly Ala Cys Gly Ala Cys Ala Gly
2750 2755 2760
Cys Ala Cys Gly Gly Ala Cys Thr Gly Cys Cys Thr Gly Gly Ala
2765 2770 2775
Thr Gly Thr Gly Ala Ala Gly Ala Gly Gly Cys Thr Gly Gly Ala
2780 2785 2790
Ala Cys Ala Gly Cys Cys Ala Gly Ala Gly Thr Gly Cys Cys Thr
2795 2800 2805
Ala Gly Cys Cys Thr Gly Cys Ala Cys Cys Thr Cys Cys Ala Thr
2810 2815 2820
Cys Thr Gly Cys Ala Thr Cys Ala Gly Gly Cys Thr Gly Cys Thr
2825 2830 2835
Cys Thr Thr Gly Gly Ala Gly Cys Cys Gly Gly Ala Ala Gly Ala
2840 2845 2850
Gly Gly Thr Ala Gly Ala Gly Gly Ala Thr Gly Gly Gly Gly Cys
2855 2860 2865
Gly Ala Ala Gly Cys Thr Thr Gly Thr Gly Cys Thr Cys Ala Gly
2870 2875 2880
Gly Thr Gly Cys Cys Ala Cys Cys Thr Thr Cys Thr Ala Gly Ala
2885 2890 2895
Gly Gly Cys Gly Thr Gly Cys Thr Gly Ala Gly Ala Thr Thr Cys
2900 2905 2910
Cys Thr Gly Gly Ala Cys Cys Thr Gly Ala Ala Ala Gly Thr Gly
2915 2920 2925
Cys Gly Cys Thr Ala Cys Cys Thr Gly Cys Ala Cys Ala Gly Cys
2930 2935 2940
Cys Ala Gly Thr Gly Gly Cys Ala Gly Cys Ala Cys Thr Ala Thr
2945 2950 2955
Cys Ala Cys Ala Gly Ala Thr Cys Thr Gly Gly Cys Gly Ala Ala
2960 2965 2970
Gly Cys Cys Gly Cys Cys Gly Gly Ala Ala Cys Ala Cys Cys Cys
2975 2980 2985
Cys Thr Thr Thr Gly Gly Ala Gly Gly Cys Cys Ala Ala Cys Ala
2990 2995 3000
Ala Gly Ala Ala Ala Cys Gly Thr Gly Cys Cys Cys Thr Thr Cys
3005 3010 3015
Cys Gly Gly Gly Ala Ala Cys Thr Gly Ala Ala Gly Ala Ala Cys
3020 3025 3030
Cys Ala Gly Ala Gly Ala Ala Cys Ala Gly Cys Thr Cys Ala Gly
3035 3040 3045
Gly Gly Cys Gly Cys Thr Cys Cys Thr Gly Gly Ala Ala Thr Cys
3050 3055 3060
Cys Ala Cys Cys Ala Thr Gly Cys Thr Gly Cys Thr Thr Cys Thr
3065 3070 3075
Cys Cys Ala Gly Thr Gly Gly Cys Cys Gly Cys Cys Ala Ala Cys
3080 3085 3090
Cys Thr Gly Thr Gly Thr Gly Ala Thr Cys Cys Thr Gly Cys Cys
3095 3100 3105
Ala Gly Ala Cys Ala Thr Gly Cys Cys Cys Ala Gly Cys Ala Cys
3110 3115 3120
Ala Cys Cys Ala Gly Gly Ala Thr Thr Cys Cys Thr Thr Gly Thr
3125 3130 3135
Gly Gly Cys Gly Cys Thr Gly Gly Ala Cys Ala Ala Gly Thr Gly
3140 3145 3150
Cys Gly Cys Gly Cys Thr Gly Gly Ala Ala Gly Ala Gly Gly Ala
3155 3160 3165
Cys Cys Thr Gly Ala Ala Gly Cys Ala Gly Gly Cys Gly Gly Ala
3170 3175 3180
Gly Gly Thr Gly Thr Thr Cys Thr Gly Cys Ala Ala Cys Cys Thr
3185 3190 3195
Cys Ala Ala Ala Gly Ala Cys Cys Cys Gly Cys Thr Cys Cys Thr
3200 3205 3210
Gly Ala Gly Ala Ala Gly Cys Cys Thr Gly Gly Cys Thr Gly Cys
3215 3220 3225
Cys Cys Thr Thr Gly Cys Ala Gly Ala Ala Gly Ala Gly Gly Ala
3230 3235 3240
Cys Ala Gly Cys Cys Thr Ala Gly Ala Cys Thr Gly Cys Ala Cys
3245 3250 3255
Ala Cys Cys Gly Thr Gly Ala Ala Ala Ala Thr Gly Thr Gly Gly
3260 3265 3270
Cys Gly Ala Gly Cys Cys Gly Thr Gly Gly Cys Cys Ala Thr Gly
3275 3280 3285
Ala Thr Gly Gly Thr Gly Cys Cys Cys Gly Ala Thr Ala Gly Ala
3290 3295 3300
Cys Ala Gly Gly Thr Cys Cys Ala Cys Thr Ala Cys Gly Ala Cys
3305 3310 3315
Thr Thr Thr Gly Gly Ala Cys Thr Gly Gly Gly Cys Gly Thr Gly
3320 3325 3330
Cys Cys Ala Gly Gly Cys Gly Ala Thr Ala Gly Cys Ala Cys Thr
3335 3340 3345
Cys Gly Gly Ala Gly Ala Gly Cys Cys Gly Thr Cys Ala Gly Ala
3350 3355 3360
Cys Gly Gly Ala Thr Gly Ala Ala Cys Ala Cys Cys Thr Thr Thr
3365 3370 3375
Thr Ala Cys Gly Ala Ala Gly Cys Cys Gly Gly Gly Ala Thr Gly
3380 3385 3390
Ala Cys Cys Cys Thr Gly Gly Gly Cys Gly Ala Gly Ala Ala Gly
3395 3400 3405
Thr Thr Cys Ala Gly Ala Gly Thr Gly Gly Gly Cys Ala Ala Cys
3410 3415 3420
Thr Gly Cys Ala Ala Gly Cys Ala Cys Cys Thr Gly Ala Ala Gly
3425 3430 3435
Ala Thr Gly Ala Cys Cys Cys Gly Gly Cys Cys Thr Ala Ala Cys
3440 3445 3450
Ala Gly Cys Ala Ala Gly Ala Thr Gly Gly Cys Cys Cys Thr Gly
3455 3460 3465
Ala Ala Thr Ala Gly Cys Gly Ala Gly Gly Cys Cys Cys Thr Gly
3470 3475 3480
Thr Cys Thr Gly Thr Gly Gly Thr Gly Thr Cys Thr Gly Ala Ala
3485 3490 3495
Thr Gly Thr Gly Gly Cys Gly Cys Cys Thr Cys Thr Gly Cys Cys
3500 3505 3510
Thr Gly Thr Gly Ala Cys Gly Thr Gly Thr Cys Cys Cys Thr Gly
3515 3520 3525
Ala Thr Cys Gly Cys Thr Ala Thr Gly Gly Ala Cys Thr Cys Cys
3530 3535 3540
Gly Cys Cys Thr Thr Thr Gly Thr Gly Cys Ala Gly Gly Gly Cys
3545 3550 3555
Ala Ala Ala Gly Ala Cys Thr Gly Gly Gly Gly Cys Gly Thr Gly
3560 3565 3570
Ala Ala Gly Ala Ala Gly Thr Thr Cys Ala Thr Cys Cys Gly Gly
3575 3580 3585
Cys Gly Gly Gly Ala Cys Thr Thr Cys Thr Ala Cys Gly Cys Cys
3590 3595 3600
Thr Ala Cys Ala Ala Gly Gly Ala Cys Thr Thr Cys Cys Thr Gly
3605 3610 3615
Thr Gly Gly Thr Gly Cys Thr Thr Cys Cys Cys Cys Thr Thr Cys
3620 3625 3630
Thr Cys Thr Cys Thr Gly Gly Thr Gly Thr Thr Cys Cys Thr Gly
3635 3640 3645
Cys Ala Ala Gly Ala Gly Ala Thr Cys Cys Ala Gly Ala Thr Cys
3650 3655 3660
Thr Gly Cys Thr Gly Thr Cys Ala Thr Gly Thr Gly Thr Cys Cys
3665 3670 3675
Thr Gly Cys Cys Thr Gly Thr Gly Cys Thr Gly Cys Ala Thr Cys
3680 3685 3690
Thr Gly Cys Thr Gly Thr Ala Gly Cys Ala Cys Cys Ala Gly Ala
3695 3700 3705
Ala Thr Cys Thr Gly Cys Cys Thr Gly Gly Gly Cys Thr Gly Thr
3710 3715 3720
Cys Thr Gly Cys Thr Gly Gly Ala Ala Cys Thr Gly Thr Thr Cys
3725 3730 3735
Cys Thr Gly Ala Gly Cys Ala Gly Ala Gly Cys Cys Cys Thr Gly
3740 3745 3750
Ala Gly Ala Gly Cys Ala Cys Thr Gly Cys Ala Cys Gly Thr Gly
3755 3760 3765
Cys Thr Gly Thr Gly Gly Ala Ala Cys Gly Gly Ala Thr Thr Cys
3770 3775 3780
Cys Ala Gly Cys Thr Gly Cys Ala Cys Thr Gly Cys Cys Ala Gly
3785 3790 3795
Ala Cys Cys Gly Ala Gly Thr Ala Cys Ala Ala Cys Cys Ala Gly
3800 3805 3810
Ala Ala Ala Cys Thr Gly Cys Ala Ala Gly Thr Gly Ala Ala Cys
3815 3820 3825
Cys Ala Gly Thr Thr Cys Ala Gly Cys Gly Ala Gly Ala Gly Cys
3830 3835 3840
Ala Ala Gly Ala Gly Cys Cys Thr Gly Thr Ala Cys Cys Ala Cys
3845 3850 3855
Cys Gly Gly Gly Ala Ala Ala Ala Gly Cys Ala Gly Cys Thr Cys
3860 3865 3870
Ala Thr Thr Gly Cys Cys Ala Thr Gly Gly Ala Cys Ala Gly Cys
3875 3880 3885
Gly Cys Cys Ala Thr Cys Thr Gly Cys Gly Ala Ala Gly Ala Gly
3890 3895 3900
Ala Gly Ala Gly Gly Cys Gly Cys Cys Gly Cys Ala Gly Gly Ala
3905 3910 3915
Thr Cys Thr Cys Thr Gly Ala Thr Cys Thr Cys Cys Thr Gly Cys
3920 3925 3930
Gly Ala Ala Ala Cys Ala Ala Thr Gly Cys Cys Cys Gly Cys Cys
3935 3940 3945
Ala Thr Cys Cys Thr Gly Ala Ala Gly Cys Thr Gly Cys Ala Gly
3950 3955 3960
Ala Ala Gly Ala Ala Thr Thr Gly Cys Cys Thr Cys Cys Thr Ala
3965 3970 3975
Ala Gly Cys Cys Thr Gly Cys Gly Ala Ala Cys Cys Gly Cys Thr
3980 3985 3990
Cys Thr Gly Ala Cys Ala Cys Ala Cys Ala Ala Cys Cys Ala Gly
3995 4000 4005
Gly Ala Cys Thr Thr Cys Ala Gly Cys Ala Thr Cys Thr Ala Cys
4010 4015 4020
Ala Gly Ala Cys Thr Gly Thr Gly Thr Thr Gly Cys Ala Ala Gly
4025 4030 4035
Cys Gly Gly Gly Gly Cys Thr Cys Cys Cys Thr Gly Thr Gly Cys
4040 4045 4050
Cys Ala Thr Gly Cys Ala Ala Gly Cys Cys Ala Ala Gly Cys Thr
4055 4060 4065
Ala Gly Ala Ala Gly Cys Cys Cys Cys Gly Cys Cys Thr Thr Thr
4070 4075 4080
Cys Cys Thr Ala Ala Ala Cys Cys Thr Gly Thr Gly Cys Gly Ala
4085 4090 4095
Cys Cys Thr Cys Thr Gly Cys Cys Ala Gly Cys Thr Cys Cys Ala
4100 4105 4110
Ala Thr Cys Ala Cys Cys Ala Gly Ala Ala Thr Thr Ala Cys Cys
4115 4120 4125
Cys Cys Thr Cys Ala Gly Cys Thr Cys Gly Gly Cys Gly Gly Cys
4130 4135 4140
Cys Ala Gly Ala Gly Cys Gly Ala Thr Thr Cys Ala Thr Cys Thr
4145 4150 4155
Cys Ala Ala Cys Cys Thr Cys Thr Gly Cys Thr Gly Ala Cys Cys
4160 4165 4170
Ala Cys Cys Gly Gly Cys Ala Gly Ala Cys Cys Thr Cys Ala Ala
4175 4180 4185
Gly Gly Cys Thr Gly Gly Cys Ala Ala Gly Ala Cys Cys Ala Ala
4190 4195 4200
Gly Cys Thr Cys Thr Gly Ala Gly Ala Cys Ala Cys Ala Cys Cys
4205 4210 4215
Cys Ala Gly Cys Ala Gly Gly Cys Thr Ala Gly Cys Cys Cys Thr
4220 4225 4230
Gly Cys Cys Thr Cys Thr Thr Gly Thr Gly Cys Cys Ala Cys Cys
4235 4240 4245
Ala Thr Cys Ala Cys Ala Ala Thr Cys Cys Cys Cys Ala Thr Cys
4250 4255 4260
Cys Ala Cys Thr Cys Thr Gly Cys Cys Gly Cys Thr Cys Thr Gly
4265 4270 4275
Gly Gly Cys Gly Ala Thr Cys Ala Thr Thr Cys Thr Gly Gly Cys
4280 4285 4290
Gly Ala Thr Cys Cys Thr Gly Gly Ala Cys Cys Ala Gly Cys Cys
4295 4300 4305
Thr Gly Gly Gly Ala Cys Ala Cys Ala Thr Gly Thr Cys Cys Thr
4310 4315 4320
Cys Cys Ala Cys Thr Gly Cys Cys Ala Cys Thr Cys Ala Cys Ala
4325 4330 4335
Ala Cys Ala Cys Thr Gly Ala Thr Cys Cys Cys Thr Ala Gly Gly
4340 4345 4350
Gly Cys Thr Cys Cys Thr Cys Cys Ala Cys Cys Thr Thr Ala Cys
4355 4360 4365
Gly Gly Cys Gly Ala Thr Thr Cys Thr Ala Cys Cys Gly Cys Thr
4370 4375 4380
Ala Gly Ala Ala Gly Cys Thr Gly Gly Cys Cys Cys Ala Gly Cys
4385 4390 4395
Ala Gly Ala Thr Gly Thr Gly Gly Ala Cys Cys Ala Cys Thr Cys
4400 4405 4410
Gly Gly Ala Gly Gly Cys Ala Ala Cys Ala Cys Ala Ala Cys Cys
4415 4420 4425
Cys Thr Cys Cys Ala Gly Cys Ala Ala Cys Thr Gly Gly Gly Ala
4430 4435 4440
Gly Ala Ala Gly Cys Cys Thr Cys Thr Cys Ala Gly Gly Cys Thr
4445 4450 4455
Cys Cys Thr Ala Gly Cys Gly Gly Cys Thr Cys Thr Cys Thr Gly
4460 4465 4470
Ala Thr Cys Cys Cys Thr Cys Thr Cys Ala Gly Ala Cys Thr Gly
4475 4480 4485
Cys Cys Thr Cys Thr Cys Cys Thr Gly Thr Gly Gly Gly Ala Ala
4490 4495 4500
Gly Thr Thr Cys Gly Gly Gly Gly Cys Cys Ala Gly Cys Cys Thr
4505 4510 4515
Gly Ala Thr Thr Cys Thr Thr Thr Thr Gly Cys Cys Gly Cys Ala
4520 4525 4530
Cys Thr Gly Cys Ala Cys Ala Gly Cys Thr Cys Cys Cys Thr Gly
4535 4540 4545
Ala Ala Cys Gly Ala Gly Cys Thr Gly Gly Gly Ala Gly Ala Gly
4550 4555 4560
Ala Thr Cys Gly Cys Thr Ala Gly Ala Gly Ala Gly Cys Thr Gly
4565 4570 4575
Cys Ala Cys Cys Ala Gly Thr Thr Cys Gly Cys Cys Thr Thr Cys
4580 4585 4590
Gly Ala Cys Cys Thr Gly Cys Thr Gly Ala Thr Cys Ala Ala Gly
4595 4600 4605
Ala Gly Cys Cys Ala Cys Thr Thr Cys Gly Thr Gly Cys Ala Ala
4610 4615 4620
Gly Gly Cys Ala Ala Gly Gly Ala Thr Thr Gly Gly Gly Gly Cys
4625 4630 4635
Cys Thr Cys Ala Ala Ala Ala Ala Gly Thr Thr Thr Ala Thr Cys
4640 4645 4650
Cys Gly Cys Ala Gly Ala Gly Ala Cys Thr Thr Cys Thr Gly Gly
4655 4660 4665
Gly Gly Cys Ala Thr Gly Gly Ala Ala Cys Thr Gly Gly Cys Cys
4670 4675 4680
Gly Cys Cys Ala Gly Cys Ala Gly Ala Ala Gly Ala Thr Thr Cys
4685 4690 4695
Ala Gly Cys Thr Gly Gly Gly Ala Thr Cys Ala Thr Cys Ala Thr
4700 4705 4710
Ala Gly Cys Gly Cys Ala Gly Gly Cys Gly Gly Cys Cys Cys Ala
4715 4720 4725
Cys Cys Thr Ala Gly Ala Gly Thr Gly Cys Cys Ala Thr Cys Thr
4730 4735 4740
Gly Thr Thr Ala Gly Ala Ala Gly Cys Gly Gly Ala Gly Cys Thr
4745 4750 4755
Gly Cys Cys Cys Ala Gly Gly Thr Gly Cys Ala Gly Cys Cys Thr
4760 4765 4770
Ala Ala Ala Gly Ala Thr Cys Cys Thr Cys Thr Gly Cys Cys Ala
4775 4780 4785
Cys Thr Gly Ala Gly Ala Ala Cys Ala Cys Thr Gly Gly Cys Cys
4790 4795 4800
Gly Gly Cys Thr Gly Cys Cys Thr Thr Gly Cys Thr Ala Gly Ala
4805 4810 4815
Ala Cys Ala Gly Cys Cys Cys Ala Thr Cys Thr Thr Ala Gly Ala
4820 4825 4830
Cys Cys Thr Gly Gly Cys Gly Cys Cys Gly Ala Gly Thr Cys Thr
4835 4840 4845
Cys Thr Gly Cys Cys Thr Cys Ala Gly Cys Cys Ala Cys Ala Ala
4850 4855 4860
Cys Thr Gly Cys Ala Cys Thr Gly Thr Ala Cys Cys Cys Thr Gly
4865 4870 4875
Thr Gly Gly Thr Thr Cys Cys Ala Gly Thr Cys Cys Ala Gly Cys
4880 4885 4890
Gly Ala Gly Cys Thr Gly Thr Cys Thr Cys Cys Thr Ala Cys Thr
4895 4900 4905
Gly Gly Thr Gly Cys Cys Cys Cys Thr Thr Gly Gly Cys Cys Ala
4910 4915 4920
Thr Cys Thr Ala Gly Ala Cys Gly Cys Cys Cys Thr Ala Cys Thr
4925 4930 4935
Thr Gly Gly Ala Gly Ala Gly Gly Cys Ala Cys Cys Ala Cys Cys
4940 4945 4950
Gly Thr Gly Thr Cys Ala Cys Cys Ala Ala Gly Ala Ala Cys Cys
4955 4960 4965
Gly Cys Cys Ala Cys Ala Ala Gly Cys Ala Gly Cys Gly Cys Cys
4970 4975 4980
Ala Gly Ala Ala Cys Cys Thr Gly Thr Thr Gly Thr Gly Gly Cys
4985 4990 4995
Ala Cys Ala Ala Ala Gly Thr Gly Gly Cys Cys Cys Thr Cys Cys
5000 5005 5010
Ala Gly Cys Cys Ala Ala Gly Ala Ala Gly Cys Cys Gly Cys Thr
5015 5020 5025
Cys Thr Cys Gly Gly Ala Cys Thr Thr Gly Gly Ala Ala Gly Cys
5030 5035 5040
Gly Gly Ala Cys Thr Gly Cys Thr Gly Ala Gly Gly Thr Thr Cys
5045 5050 5055
Thr Cys Thr Thr Gly Thr Gly Gly Ala Ala Cys Cys Gly Cys Cys
5060 5065 5070
Gly Cys Cys Ala Thr Thr Cys Gly Gly Ala Ala Gly Ala Thr Gly
5075 5080 5085
Cys Ala Cys Thr Thr Thr Ala Gly Cys Cys Thr Gly Ala Ala Ala
5090 5095 5100
Gly Ala Ala Cys Ala Cys Cys Cys Thr Cys Cys Ala Cys Cys Ala
5105 5110 5115
Cys Cys Thr Thr Gly Thr Cys Cys Thr Cys Cys Ala Gly Ala Gly
5120 5125 5130
Gly Cys Thr Thr Thr Cys Cys Ala Ala Ala Gly Ala Gly Cys Thr
5135 5140 5145
Gly Cys Thr Gly Gly Cys Gly Ala Ala Gly Gly Cys Gly Gly Ala
5150 5155 5160
Cys Cys Thr Gly Gly Thr Ala Gly Ala Gly Gly Thr Gly Gly Thr
5165 5170 5175
Gly Cys Thr Ala Gly Ala Ala Gly Ala Gly Gly Thr Gly Cys Thr
5180 5185 5190
Ala Gly Gly Gly Thr Gly Cys Thr Gly Cys Ala Gly Ala Gly Cys
5195 5200 5205
Cys Cys Ala Thr Thr Cys Thr Gly Thr Ala Gly Ala Gly Cys Ala
5210 5215 5220
Gly Gly Cys Gly Cys Ala Gly Gly Cys Gly Ala Ala Thr Gly Gly
5225 5230 5235
Cys Thr Gly Gly Gly Cys Cys Ala Thr Cys Ala Gly Ala Gly Thr
5240 5245 5250
Cys Thr Gly Ala Gly Ala Cys Ala Thr Gly Thr Cys Gly Thr Cys
5255 5260 5265
Gly Gly Cys Thr Ala Cys Gly Gly Cys Cys Ala Cys Cys Thr Gly
5270 5275 5280
Gly Ala Thr Ala Cys Ala Ala Gly Cys Gly Gly Ala Ala Gly Cys
5285 5290 5295
Ala Gly Cys Thr Cys Thr Ala Gly Cys Thr Cys Cys Ala Gly Cys
5300 5305 5310
Thr Gly Gly Cys Cys Thr Ala Ala Cys Thr Cys Ala Ala Ala Ala
5315 5320 5325
Ala Thr Gly Gly Cys Thr Cys Thr Gly Ala Ala Cys Ala Gly Cys
5330 5335 5340
Cys Thr Gly Ala Ala Cys Thr Cys Cys Ala Thr Cys Gly Ala Cys
5345 5350 5355
Gly Ala Cys Gly Cys Cys Cys Ala Gly Cys Thr Gly Ala Cys Ala
5360 5365 5370
Ala Gly Ala Ala Thr Cys Gly Cys Cys Cys Cys Thr Cys Cys Thr
5375 5380 5385
Ala Gly Ala Thr Cys Thr Cys Ala Cys Thr Gly Cys Thr Gly Cys
5390 5395 5400
Thr Thr Thr Thr Gly Gly Gly Ala Ala Gly Thr Gly Ala Ala Cys
5405 5410 5415
Gly Cys Cys Cys Cys Ala Ala Gly Cys Cys Ala Thr Cys Ala Cys
5420 5425 5430
Cys Ala Thr Cys Ala Cys Cys Ala Cys Cys Ala Thr Thr Ala Gly
5435 5440 5445
Thr Ala Ala Ala Gly Gly Cys Gly Cys Gly Cys Cys Thr Ala Gly
5450 5455 5460
Cys Gly Gly Cys Cys Gly Cys Gly Ala Thr Cys Thr Gly Cys Thr
5465 5470 5475
Gly Thr Gly Cys Cys Thr Thr Cys Thr Ala Gly Thr Thr Gly Cys
5480 5485 5490
Cys Ala Gly Cys Cys Ala Thr Cys Thr Gly Thr Thr Gly Thr Thr
5495 5500 5505
Thr Gly Cys Cys Cys Cys Thr Cys Cys Cys Cys Cys Gly Thr Gly
5510 5515 5520
Cys Cys Thr Thr Cys Cys Thr Thr Gly Ala Cys Cys Cys Thr Gly
5525 5530 5535
Gly Ala Ala Gly Gly Thr Gly Cys Cys Ala Cys Thr Cys Cys Cys
5540 5545 5550
Ala Cys Thr Gly Thr Cys Cys Thr Thr Thr Cys Cys Thr Ala Ala
5555 5560 5565
Thr Ala Ala Ala Ala Thr Gly Ala Gly Gly Ala Ala Ala Thr Thr
5570 5575 5580
Gly Cys Ala Thr Cys Gly Cys Ala Thr Thr Gly Thr Cys Thr Gly
5585 5590 5595
Ala Gly Thr Ala Gly Gly Thr Gly Thr Cys Ala Thr Thr Cys Thr
5600 5605 5610
Ala Thr Thr Cys Thr Gly Gly Gly Gly Gly Gly Thr Gly Gly Gly
5615 5620 5625
Gly Thr Gly Gly Gly Gly Cys Ala Gly Gly Ala Cys Ala Gly Cys
5630 5635 5640
Ala Ala Gly Gly Gly Gly Gly Ala Gly Gly Ala Thr Thr Gly Gly
5645 5650 5655
Gly Ala Ala Gly Ala Cys Ala Ala Thr Ala Gly Cys Ala Gly Gly
5660 5665 5670
Cys Ala Thr Gly Cys Thr Gly Gly Gly Gly Ala Thr Gly Cys Gly
5675 5680 5685
Gly Thr Gly Gly Gly Cys Thr Cys Thr Ala Thr Gly Gly Cys Cys
5690 5695 5700
<210> 552
<211> 1507
<212> PRT
<213> Artificial seqeunce
<220>
<223> Heterologous polypeptide
<400> 552
Met Gly Gln Lys Glu Gln Ile His Thr Leu Gln Lys Asn Ser Glu Arg
1 5 10 15
Met Ser Lys Gln Leu Thr Arg Ser Ser Gln Ala Val Gln Asn Leu Gln
20 25 30
Asn Gly Gly Gly Ser Arg Ser Ser Ala Thr Leu Pro Gly Arg Arg Arg
35 40 45
Arg Arg Trp Leu Arg Arg Arg Arg Gln Pro Ile Ser Val Ala Pro Ala
50 55 60
Gly Pro Pro Arg Arg Pro Asn Gln Lys Pro Asn Pro Pro Gly Gly Ala
65 70 75 80
Arg Cys Val Ile Met Arg Pro Thr Trp Pro Gly Thr Ser Ala Phe Thr
85 90 95
Gly Met Glu Cys Thr Leu Gly Gln Val Gly Ala Pro Ser Pro Arg Arg
100 105 110
Glu Glu Asp Gly Trp Arg Gly Gly His Ser Arg Phe Lys Ala Asp Val
115 120 125
Pro Ala Pro Gln Gly Pro Cys Trp Gly Gly Gln Pro Gly Ser Ala Pro
130 135 140
Ser Ser Ala Pro Pro Glu Gln Ser Leu Leu Asp Asp Tyr Trp Ala Gln
145 150 155 160
Lys Glu Lys Ile Ser Ile Pro Arg Thr His Leu Cys Trp Lys Phe Glu
165 170 175
Met Ser Tyr Thr Val Gly Gly Pro Pro Pro His Val His Ala Arg Pro
180 185 190
Arg His Trp Lys Thr Asp Arg Asp Tyr Trp Ala Gln Lys Glu Lys Gly
195 200 205
Ser Ser Ser Phe Leu Arg Pro Ser Cys Val Pro Phe Arg Glu Leu Lys
210 215 220
Asn Val Ser Val Leu Glu Gly Leu Arg Gln Gly Arg Leu Gly Gly Pro
225 230 235 240
Cys Ser Cys His Cys Pro Arg Pro Ser Gln Ala Arg Leu Thr Pro Val
245 250 255
Asp Val Ala Gly Pro Phe Leu Cys Leu Gly Asp Pro Gly Leu Phe Pro
260 265 270
Pro Val Lys Ser Ser Ile Thr Glu Ile Ser Cys Cys Thr Leu Ser Ser
275 280 285
Glu Glu Asn Glu Tyr Leu Pro Arg Pro Glu Trp Gln Leu Gln Tyr Glu
290 295 300
Ala Gly Met Thr Leu Gly Gly Lys Ile Leu Phe Phe Leu Phe Leu Leu
305 310 315 320
Leu Pro Leu Ser Pro Phe Ser Leu Ile Phe Leu Val Leu Gly Val Leu
325 330 335
Ser Gly His Ser Gly Ser Arg Leu Lys Arg Ser Phe Ala Val Thr Glu
340 345 350
Arg Ile Ile Thr Gly Gly Lys Ser Thr Cys Ser Ala Pro Gly Pro Gln
355 360 365
Ser Leu Pro Ser Thr Pro Phe Ser Thr Tyr Pro Gln Trp Val Ile Leu
370 375 380
Ile Thr Glu Leu Asp Gly His Ser Tyr Thr Ser Lys Val Asn Cys Leu
385 390 395 400
Leu Leu Gln Asp Gly Phe His Gly Cys Val Ser Ile Thr Gly Ala Ala
405 410 415
Gly Arg Arg Asn Leu Ser Ile Phe Leu Phe Leu Met Leu Cys Lys Leu
420 425 430
Glu Phe His Ala Cys Gln Trp Gln His Tyr His Arg Ser Gly Glu Ala
435 440 445
Ala Gly Thr Pro Leu Trp Arg Pro Thr Arg Asn Val Ala Met Met Val
450 455 460
Pro Asp Arg Gln Val His Tyr Asp Phe Gly Leu Lys Ile Gln Asn Lys
465 470 475 480
Asn Cys Pro Asp Val Leu Arg Phe Leu Asp Leu Lys Val Arg Tyr Leu
485 490 495
His Ser Val Pro Phe Arg Glu Leu Lys Asn Gln Arg Thr Ala Gln Gly
500 505 510
Ala Pro Gly Ile His His Ala Ala Ser Pro Val Ala Ala Asn Leu Cys
515 520 525
Asp Pro Ala Arg His Ala Gln His Thr Arg Ile Pro Cys Gly Ala Gly
530 535 540
Gln Val Arg Ala Gly Arg Gly Pro Glu Ala Gly Gly Gly Val Leu Gln
545 550 555 560
Pro Gln Arg Pro Ala Pro Glu Lys Pro Gly Cys Pro Cys Arg Arg Gly
565 570 575
Gln Pro Arg Leu His Thr Val Lys Met Trp Arg Ala Cys His Leu Phe
580 585 590
Leu Gln Pro Gln Val Gly Thr Pro Pro Pro His Thr Ala Ser Ala Arg
595 600 605
Ala Pro Ser Gly Pro Pro His Pro His Glu Ser Cys Pro Ala Gly Arg
610 615 620
Arg Pro Ala Arg Ala Ala Gln Thr Cys Ala Arg Arg Gln His Gly Leu
625 630 635 640
Pro Gly Cys Glu Glu Ala Gly Thr Ala Arg Val Pro Ser Leu His Leu
645 650 655
His Leu His Gln Ala Ala Leu Gly Ala Gly Arg Gly Arg Gly Trp Gly
660 665 670
Glu Ala Cys Ala Gln Val Pro Pro Ser Arg Gly His Tyr Lys Leu Ile
675 680 685
Gln Gln Pro Ile Ser Leu Phe Ser Ile Thr Asp Arg Leu His Lys Thr
690 695 700
Phe Ser Gln Leu Pro Ser Val His Leu Cys Ser Ile Thr Phe Gln Trp
705 710 715 720
Gly His Pro Pro Ile Phe Cys Ser Thr Asn Asp Ile Cys Val Thr Ala
725 730 735
Asn Phe Cys Ile Ser Val Thr Phe Leu Lys Pro Cys Phe Leu Leu His
740 745 750
Glu Ala Ser Ala Ser Gln Phe Lys Lys Phe Asp Gly Pro Cys Gly Glu
755 760 765
Arg Gly Gly Gly Arg Thr Ala Arg Ala Leu Trp Ala Arg Gly Asp Ser
770 775 780
Val Leu Thr Pro Ala Leu Asp Pro Gln Thr Pro Val Arg Ala Pro Ser
785 790 795 800
Leu Thr Arg Ala Ala Ala Ala Val Gly Val Pro Gly Asp Ser Thr Arg
805 810 815
Arg Ala Val Arg Arg Met Asn Thr Phe Cys Gly Ala Ser Ala Cys Asp
820 825 830
Val Ser Leu Ile Ala Met Asp Ser Ala Cys Glu Glu Arg Gly Ala Ala
835 840 845
Gly Ser Leu Ile Ser Cys Glu Ser Leu Tyr His Arg Glu Lys Gln Leu
850 855 860
Ile Ala Met Asp Ser Ala Ile Phe Val Gln Gly Lys Asp Trp Gly Val
865 870 875 880
Lys Lys Phe Ile Arg Arg Asp Phe Thr Met Pro Ala Ile Leu Lys Leu
885 890 895
Gln Lys Asn Cys Leu Leu Ser Leu Asn Ser Lys Met Ala Leu Asn Ser
900 905 910
Glu Ala Leu Ser Val Val Ser Glu Tyr Glu Ala Gly Met Thr Leu Gly
915 920 925
Glu Lys Phe Arg Val Gly Asn Cys Lys His Leu Lys Met Thr Arg Pro
930 935 940
Thr Glu Tyr Asn Gln Lys Leu Gln Val Asn Gln Phe Ser Glu Ser Lys
945 950 955 960
Arg Thr Ala Leu Thr His Asn Gln Asp Phe Ser Ile Tyr Arg Leu Cys
965 970 975
Cys Lys Arg Gly Ser Leu Cys His Ala Ser Gln Ala Arg Ser Pro Ala
980 985 990
Phe Pro Lys Pro Val Arg Pro Leu Pro Ala Pro Ile Thr Arg Ile Thr
995 1000 1005
Pro Gln Leu Gly Gly Gln Ser Asp Ser Ser Gln Pro Leu Leu Thr
1010 1015 1020
Thr Gly Arg Pro Gln Gly Trp Gln Asp Gln Ala Leu Arg His Thr
1025 1030 1035
Gln Gln Ala Ser Pro Ala Ser Cys Ala Thr Ile Thr Ile Pro Ile
1040 1045 1050
His Ser Ala Ala Leu Gly Asp His Ser Gly Asp Pro Gly Pro Ala
1055 1060 1065
Trp Asp Thr Cys Pro Pro Leu Pro Leu Thr Thr Leu Ile Pro Arg
1070 1075 1080
Ala Pro Pro Pro Tyr Gly Asp Ser Thr Ala Arg Ser Trp Pro Ser
1085 1090 1095
Arg Cys Gly Pro Leu Gly Tyr Ala Tyr Lys Asp Phe Leu Trp Cys
1100 1105 1110
Phe Pro Phe Ser Leu Val Phe Leu Gln Glu Ile Gln Ile Cys Cys
1115 1120 1125
His Val Ser Cys Leu Cys Cys Ile Cys Cys Ser Thr Arg Ile Cys
1130 1135 1140
Leu Gly Cys Leu Leu Glu Leu Phe Leu Ser Arg Ala Leu Arg Ala
1145 1150 1155
Leu His Val Leu Trp Asn Gly Phe Gln Leu His Cys Gln Gly Asn
1160 1165 1170
Thr Thr Leu Gln Gln Leu Gly Glu Ala Ser Gln Ala Pro Ser Gly
1175 1180 1185
Ser Leu Ile Pro Leu Arg Leu Pro Leu Leu Trp Glu Val Arg Gly
1190 1195 1200
Asn Ser Lys Met Ala Leu Asn Ser Leu Asn Ser Ile Asp Asp Ala
1205 1210 1215
Gln Leu Thr Arg Ile Ala Pro Pro Arg Ser His Cys Cys Phe Trp
1220 1225 1230
Glu Val Asn Ala Pro Phe Val Gln Gly Lys Asp Trp Gly Leu Lys
1235 1240 1245
Lys Phe Ile Arg Arg Asp Phe Glu Ala Phe Gln Arg Ala Ala Gly
1250 1255 1260
Glu Gly Gly Pro Gly Arg Gly Gly Ala Arg Arg Gly Ala Arg Val
1265 1270 1275
Leu Gln Ser Pro Phe Cys Arg Ala Gly Ala Gly Glu Trp Leu Gly
1280 1285 1290
His Gln Ser Leu Arg Trp Gly Met Glu Leu Ala Ala Ser Arg Arg
1295 1300 1305
Phe Ser Trp Asp His His Ser Ala Gly Gly Pro Pro Arg Val Pro
1310 1315 1320
Ser Val Arg Ser Gly Ala Ala Gln Val Gln Pro Lys Asp Pro Leu
1325 1330 1335
Pro Leu Arg Thr Leu Ala Gly Cys Leu Ala Arg Thr Ala His Leu
1340 1345 1350
Arg Pro Gly Ala Glu Ser Leu Pro Gln Pro Gln Leu His Cys Thr
1355 1360 1365
Ile Ala Arg Glu Leu His Gln Phe Ala Phe Asp Leu Leu Ile Lys
1370 1375 1380
Ser His Lys Met His Phe Ser Leu Lys Glu His Pro Pro Pro Pro
1385 1390 1395
Cys Pro Pro His Val Val Gly Tyr Gly His Leu Asp Thr Ser Gly
1400 1405 1410
Ser Ser Ser Ser Ser Ser Trp Pro Gln Pro Asp Ser Phe Ala Ala
1415 1420 1425
Leu His Ser Ser Leu Asn Glu Leu Gly Glu Leu Trp Phe Gln Ser
1430 1435 1440
Ser Glu Leu Ser Pro Thr Gly Ala Pro Trp Pro Ser Arg Arg Pro
1445 1450 1455
Thr Trp Arg Gly Thr Thr Val Ser Pro Arg Thr Ala Thr Ser Ser
1460 1465 1470
Ala Arg Thr Cys Cys Gly Thr Lys Trp Pro Ser Ser Gln Glu Ala
1475 1480 1485
Ala Leu Gly Leu Gly Ser Gly Leu Leu Arg Phe Ser Cys Gly Thr
1490 1495 1500
Ala Ala Ile Arg
1505
<210> 553
<211> 4722
<212> DNA
<213> Artificial seqeunce
<220>
<223> Heterologous polynucleotide
<400> 553
gatcactaat tccaaaccca cccgcttttt atagtaagtt tttcacccat aaataataaa 60
tacaataatt aatttctcgt aaaagtagaa aatatattct aatttattgc acggtaagga 120
agtagaatca taaagaacag tgacggatcc cgcgacttcg ccgccatggg ccagaaagag 180
cagatccaca cactgcagaa aaacagcgag cggatgagca agcagctgac cagatcttct 240
caggccgtgc agaacctgca gaacggcgga ggctctagaa gctctgctac acttcctggc 300
aggcggcgga gaagatggct gagaagaagg cggcagccta tctctgtggc tcctgctgga 360
cctcctagac ggcccaacca gaagcctaat cctcctggcg gagccagatg cgtgatcatg 420
aggcctacat ggcctggcac cagcgccttt accggcatgg aatgtacact gggccaagtg 480
ggagccccat ctcctagaag agaagaggat ggctggcgcg gaggccactc tagattcaaa 540
gctgatgtgc ccgctcctca gggcccttgt tggggaggac aacctggatc tgccccatct 600
tctgccccac ctgaacagag cctgctggat gactattggg ctcaaaaaga gaagatcagc 660
atccccagaa cacacctgtg ctggaagttc gagatgagct acaccgttgg cggccctcca 720
ccacatgttc acgccagacc tagacactgg aaaaccgaca gagattattg ggcccagaaa 780
gaaaagggca gcagcagctt cctgcggcct agctgtgtgc ccttccggga actgaagaac 840
gtgtccgttc tggaaggcct gaggcagggc agacttggcg gaccttgtag ctgccactgt 900
cctagaccaa gccaggccag actgacccct gtggatgtgg ctggcccatt tctgtgtctg 960
ggcgaccctg gactgttccc tccagtgaag tctagcatca ccgagatcag ctgctgcacc 1020
ctgagcagcg aggaaaacga gtacctgcct agacctgaat ggcagctgca gtacgaggcc 1080
ggcatgacac tcggaggcaa gatcctgttc ttcctgttcc tgctgctccc tctgagcccc 1140
ttcagcctga tctttctggt gctgggcgtg ctgtctggcc actctggaag cagactgaag 1200
agaagcttcg ccgtgaccga gcggatcatc acaggcggca agagcacatg ttctgcccct 1260
ggacctcagt ctctgcccag cacacccttc agcacatacc ctcagtgggt catcctgatc 1320
accgagctgg atggccacag ctacaccagc aaagtgaact gcctcctgct gcaggatggc 1380
ttccacggct gtgtgtctat tactggcgcc gctggcagac ggaacctgag catctttctg 1440
tttctgatgc tgtgcaagct cgagttccac gcctgccaat ggcagcacta ccacagatct 1500
ggcgaagccg ctggaacccc actttggagg cctaccagaa acgtggccat gatggtgccc 1560
gacagacagg tgcactacga cttcggcctg aagatccaga acaagaactg ccccgacgtg 1620
ctgcggttcc tggatctcaa agtgcgctac ctgcacagcg tgcccttcag agagctgaaa 1680
aaccagagaa cagcccaggg cgctcctgga atccatcatg ctgcttctcc agtggccgcc 1740
aatctgtgcg atcctgccag acatgcccag cataccagga ttccttgtgg cgctggacaa 1800
gtgcgcgctg gaagaggacc tgaagctggt ggcggagttc tgcagcctca aagacctgct 1860
cctgagaagc ctggctgccc ctgtagaaga ggacagccta gactgcacac cgtgaagatg 1920
tggcgggcct gccacttgtt tctccagcca caagtgggca cccctccacc tcatacagcc 1980
tctgctagag cacctagcgg cccacctcat cctcacgaat cttgtcctgc cggaagaagg 2040
cctgccagag ccgctcaaac atgtgccaga cgacagcacg gactgcccgg atgtgaagaa 2100
gccggaacag ccagagtgcc tagcctgcac cttcatctgc atcaggccgc tcttggagcc 2160
ggaagaggta gaggatgggg agaagcttgt gcccaggtgc caccttctag aggccactac 2220
aagctgatcc agcagccaat cagcctgttc tccatcaccg accggctgca caagacattc 2280
agccagctgc cttccgtgca tctgtgcagc atcaccttcc agtggggaca ccctcctatc 2340
ttttgctcca ccaacgacat ctgcgtgacc gccaacttct gtatcagcgt gaccttcctg 2400
aagccttgct ttctgctgca cgaggcctcc gccagccagt ttaagaagtt tgacggcccc 2460
tgcggcgaga gaggcggagg aagaactgca agagcccttt gggccagagg cgactctgtt 2520
ctgacaccag ctctggaccc tcagacacct gttagggccc ctagcctgac aagagctgcc 2580
gctgctgttg gagtgcctgg cgattctact agaagggccg tgcggcggat gaacaccttt 2640
tgtggcgcat ctgcctgcga cgtgtccctg atcgctatgg atagcgcctg cgaggaaaga 2700
ggcgcagccg gatctctgat ctcttgcgag agcctgtacc accgggaaaa gcagctcatt 2760
gccatggaca gcgccatctt cgtgcagggc aaagactggg gcgtgaagaa gttcatccgg 2820
cgggacttta ccatgcctgc cattctgaag ctgcagaaga attgtcttct aagcctgaac 2880
agcaagatgg ccctgaatag cgaggccctg tctgtggtgt ccgagtatga ggctggaatg 2940
accctgggcg agaagttcag agtgggcaac tgcaagcacc tgaagatgac ccggcctacc 3000
gagtacaacc agaaactgca agtgaaccag ttcagcgaga gcaagcggac cgctctgacc 3060
cacaaccagg acttcagcat ctaccggctg tgctgcaaga ggggctctct gtgtcatgct 3120
agccaggcta gaagccccgc ctttcctaag cctgtcagac ctctgcctgc tcctatcacc 3180
agaatcaccc ctcagctcgg cggccagtct gattcatctc agccactgct gaccaccggc 3240
agacctcaag gatggcaaga ccaggctctg agacacacac agcaggctag cccagcctct 3300
tgcgccacca tcacaatacc aatacattct gccgctctgg gcgatcacag cggagatcct 3360
ggacctgcct gggatacttg tcctcctctg cccctaacta cactgatccc tagggctcct 3420
ccaccttacg gcgatagcac agccagatcc tggcctagca gatgtggccc tctgggctac 3480
gcctacaagg acttcctgtg gtgcttcccc ttctctctgg tgttcctgca agaaatccag 3540
atctgctgtc acgtgtcctg cctgtgctgt atctgctgta gcacccggat ctgtctgggc 3600
tgtctgctgg aactgttcct gagcagagcc ctgagagcac tgcacgtgct gtggaacgga 3660
ttccagctgc actgccaggg caacaccaca ctgcaacagc tgggagaagc ctctcaggcc 3720
ccaagcggtt ctctgatccc tctcagactg cccctcctgt gggaagtgcg gggcaattct 3780
aagatggctc tcaacagcct gaactccatc gacgacgccc agctgacaag aatcgcccct 3840
ccaagaagcc actgttgctt ttgggaagtg aacgcccctt ttgtgcaggg taaagattgg 3900
ggcctcaaaa agtttatcag acgggacttc gaggctttcc agagagcagc tggcgaaggc 3960
ggacctggca gaggtggtgc tagaagaggt gctagagtgc tgcagagccc attctgtaga 4020
gctggcgctg gcgaatggct gggccaccaa tctcttagat ggggaatgga actggccgct 4080
agcaggcggt ttagctggga tcatcattct gccggcggac ctccaagagt gccaagcgtt 4140
agaagcggag cagcccaggt ccagcctaaa gatccactgc cactgagaac actggccggc 4200
tgccttgcca gaacagctca tcttagacct ggcgccgaaa gcctgcctca acctcagctg 4260
cattgcacaa tcgccagaga actgcaccag ttcgccttcg acctgctgat caagagccac 4320
aagatgcact tctcactgaa agagcacccg ccaccgccgt gcccaccgca cgttgtcggc 4380
tatggccacc tggatacaag cggctcctct agcagtagct cctggcctca gcctgacagc 4440
tttgctgccc tgcatagctc cctgaatgag ctgggcgaac tgtggttcca gtccagcgaa 4500
ctgtctccta ctggcgctcc atggccaagc agaaggccta cttggagagg caccaccgtg 4560
tctccaagaa ccgctacaag cagcgccaga acctgttgcg gcacaaaatg gccctccagc 4620
caagaagctg ccctcggact tggaagcgga ctgctgagat tcagctgtgg cacagccgcc 4680
atcagaagcc atcaccatca ccaccattag taaaggcgcg cc 4722
<210> 554
<211> 1507
<212> PRT
<213> Artificial seqeunce
<220>
<223> Heterologous polypeptide
<400> 554
Met Gly Gln Lys Glu Gln Ile His Thr Leu Gln Lys Asn Ser Glu Arg
1 5 10 15
Met Ser Lys Gln Leu Thr Arg Ser Ser Gln Ala Val Gln Asn Leu Gln
20 25 30
Asn Gly Gly Gly Ser Arg Ser Ser Ala Thr Leu Pro Gly Arg Arg Arg
35 40 45
Arg Arg Trp Leu Arg Arg Arg Arg Gln Pro Ile Ser Val Ala Pro Ala
50 55 60
Gly Pro Pro Arg Arg Pro Asn Gln Lys Pro Asn Pro Pro Gly Gly Ala
65 70 75 80
Arg Cys Val Ile Met Arg Pro Thr Trp Pro Gly Thr Ser Ala Phe Thr
85 90 95
Lys Arg Ser Phe Ala Val Thr Glu Arg Ile Ile Leu Val Leu Gly Val
100 105 110
Leu Ser Gly His Ser Gly Ser Arg Leu Tyr Glu Ala Gly Met Thr Leu
115 120 125
Gly Gly Lys Ile Leu Phe Phe Leu Phe Leu Leu Leu Pro Leu Ser Pro
130 135 140
Phe Ser Leu Ile Phe Thr Glu Ile Ser Cys Cys Thr Leu Ser Ser Glu
145 150 155 160
Glu Asn Glu Tyr Leu Pro Arg Pro Glu Trp Gln Leu Gln Val Pro Phe
165 170 175
Arg Glu Leu Lys Asn Val Ser Val Leu Glu Gly Leu Arg Gln Gly Arg
180 185 190
Leu Gly Gly Pro Cys Ser Cys His Cys Pro Arg Pro Ser Gln Ala Arg
195 200 205
Leu Thr Pro Val Asp Val Ala Gly Pro Phe Leu Cys Leu Gly Asp Pro
210 215 220
Gly Leu Phe Pro Pro Val Lys Ser Ser Ile Thr Gly Gly Lys Ser Thr
225 230 235 240
Cys Ser Ala Pro Gly Pro Gln Ser Leu Pro Ser Thr Pro Phe Ser Thr
245 250 255
Tyr Pro Gln Trp Val Ile Leu Ile Thr Glu Leu Gly Met Glu Cys Thr
260 265 270
Leu Gly Gln Val Gly Ala Pro Ser Pro Arg Arg Glu Glu Asp Gly Trp
275 280 285
Arg Gly Gly His Ser Arg Phe Lys Ala Asp Val Pro Ala Pro Gln Gly
290 295 300
Pro Cys Trp Gly Gly Gln Pro Gly Ser Ala Pro Ser Ser Ala Pro Pro
305 310 315 320
Glu Gln Ser Leu Leu Asp Asp Tyr Trp Ala Gln Lys Glu Lys Gly Ser
325 330 335
Ser Ser Phe Leu Arg Pro Ser Cys Asp Tyr Trp Ala Gln Lys Glu Lys
340 345 350
Ile Ser Ile Pro Arg Thr His Leu Cys Trp Lys Phe Glu Met Ser Tyr
355 360 365
Thr Val Gly Gly Pro Pro Pro His Val His Ala Arg Pro Arg His Trp
370 375 380
Lys Thr Asp Arg Gly Val Pro Gly Asp Ser Thr Arg Arg Ala Val Arg
385 390 395 400
Arg Met Asn Thr Phe Tyr Glu Ala Gly Met Thr Leu Gly Glu Lys Phe
405 410 415
Arg Val Gly Asn Cys Lys His Leu Lys Met Thr Arg Pro Asn Ser Lys
420 425 430
Met Ala Leu Asn Ser Glu Ala Leu Ser Val Val Ser Glu Cys Gly Ala
435 440 445
Ser Ala Cys Asp Val Ser Leu Ile Ala Met Asp Ser Ala Phe Val Gln
450 455 460
Gly Lys Asp Trp Gly Val Lys Lys Phe Ile Arg Arg Asp Phe Tyr Ala
465 470 475 480
Tyr Lys Asp Phe Leu Trp Cys Phe Pro Phe Ser Leu Val Phe Leu Gln
485 490 495
Glu Ile Gln Ile Cys Cys His Val Ser Cys Leu Cys Cys Ile Cys Cys
500 505 510
Ser Thr Arg Ile Cys Leu Gly Cys Leu Leu Glu Leu Phe Leu Ser Arg
515 520 525
Ala Leu Arg Ala Leu His Val Leu Trp Asn Gly Phe Gln Leu His Cys
530 535 540
Gln Thr Glu Tyr Asn Gln Lys Leu Gln Val Asn Gln Phe Ser Glu Ser
545 550 555 560
Lys Ser Leu Tyr His Arg Glu Lys Gln Leu Ile Ala Met Asp Ser Ala
565 570 575
Ile Cys Glu Glu Arg Gly Ala Ala Gly Ser Leu Ile Ser Cys Glu Thr
580 585 590
Met Pro Ala Ile Leu Lys Leu Gln Lys Asn Cys Leu Leu Ser Leu Arg
595 600 605
Thr Ala Leu Thr His Asn Gln Asp Phe Ser Ile Tyr Arg Leu Cys Cys
610 615 620
Lys Arg Gly Ser Leu Cys His Ala Ser Gln Ala Arg Ser Pro Ala Phe
625 630 635 640
Pro Lys Pro Val Arg Pro Leu Pro Ala Pro Ile Thr Arg Ile Thr Pro
645 650 655
Gln Leu Gly Gly Gln Ser Asp Ser Ser Gln Pro Leu Leu Thr Thr Gly
660 665 670
Arg Pro Gln Gly Trp Gln Asp Gln Ala Leu Arg His Thr Gln Gln Ala
675 680 685
Ser Pro Ala Ser Cys Ala Thr Ile Thr Ile Pro Ile His Ser Ala Ala
690 695 700
Leu Gly Asp His Ser Gly Asp Pro Gly Pro Ala Trp Asp Thr Cys Pro
705 710 715 720
Pro Leu Pro Leu Thr Thr Leu Ile Pro Arg Ala Pro Pro Pro Tyr Gly
725 730 735
Asp Ser Thr Ala Arg Ser Trp Pro Ser Arg Cys Gly Pro Leu Gly Asp
740 745 750
Gly His Ser Tyr Thr Ser Lys Val Asn Cys Leu Leu Leu Gln Asp Gly
755 760 765
Phe His Gly Cys Val Ser Ile Thr Gly Ala Ala Gly Arg Arg Asn Leu
770 775 780
Ser Ile Phe Leu Phe Leu Met Leu Cys Lys Leu Glu Phe His Ala Cys
785 790 795 800
Lys Ile Gln Asn Lys Asn Cys Pro Asp Phe Lys Lys Phe Asp Gly Pro
805 810 815
Cys Gly Glu Arg Gly Gly Gly Arg Thr Ala Arg Ala Leu Trp Ala Arg
820 825 830
Gly Asp Ser Val Leu Thr Pro Ala Leu Asp Pro Gln Thr Pro Val Arg
835 840 845
Ala Pro Ser Leu Thr Arg Ala Ala Ala Ala Val His Tyr Lys Leu Ile
850 855 860
Gln Gln Pro Ile Ser Leu Phe Ser Ile Thr Asp Arg Leu His Lys Thr
865 870 875 880
Phe Ser Gln Leu Pro Ser Val His Leu Cys Ser Ile Thr Phe Gln Trp
885 890 895
Gly His Pro Pro Ile Phe Cys Ser Thr Asn Asp Ile Cys Val Thr Ala
900 905 910
Asn Phe Cys Ile Ser Val Thr Phe Leu Lys Pro Cys Phe Leu Leu His
915 920 925
Glu Ala Ser Ala Ser Gln Cys His Leu Phe Leu Gln Pro Gln Val Gly
930 935 940
Thr Pro Pro Pro His Thr Ala Ser Ala Arg Ala Pro Ser Gly Pro Pro
945 950 955 960
His Pro His Glu Ser Cys Pro Ala Gly Arg Arg Pro Ala Arg Ala Ala
965 970 975
Gln Thr Cys Ala Arg Arg Gln His Gly Leu Pro Gly Cys Glu Glu Ala
980 985 990
Gly Thr Ala Arg Val Pro Ser Leu His Leu His Leu His Gln Ala Ala
995 1000 1005
Leu Gly Ala Gly Arg Gly Arg Gly Trp Gly Glu Ala Cys Ala Gln
1010 1015 1020
Val Pro Pro Ser Arg Gly Val Leu Arg Phe Leu Asp Leu Lys Val
1025 1030 1035
Arg Tyr Leu His Ser Gln Trp Gln His Tyr His Arg Ser Gly Glu
1040 1045 1050
Ala Ala Gly Thr Pro Leu Trp Arg Pro Thr Arg Asn Val Pro Phe
1055 1060 1065
Arg Glu Leu Lys Asn Gln Arg Thr Ala Gln Gly Ala Pro Gly Ile
1070 1075 1080
His His Ala Ala Ser Pro Val Ala Ala Asn Leu Cys Asp Pro Ala
1085 1090 1095
Arg His Ala Gln His Thr Arg Ile Pro Cys Gly Ala Gly Gln Val
1100 1105 1110
Arg Ala Gly Arg Gly Pro Glu Ala Gly Gly Gly Val Leu Gln Pro
1115 1120 1125
Gln Arg Pro Ala Pro Glu Lys Pro Gly Cys Pro Cys Arg Arg Gly
1130 1135 1140
Gln Pro Arg Leu His Thr Val Lys Met Trp Arg Ala Val Ala Met
1145 1150 1155
Met Val Pro Asp Arg Gln Val His Tyr Asp Phe Gly Leu Gly Asn
1160 1165 1170
Thr Thr Leu Gln Gln Leu Gly Glu Ala Ser Gln Ala Pro Ser Gly
1175 1180 1185
Ser Leu Ile Pro Leu Arg Leu Pro Leu Leu Trp Glu Val Arg Gly
1190 1195 1200
Gln Pro Asp Ser Phe Ala Ala Leu His Ser Ser Leu Asn Glu Leu
1205 1210 1215
Gly Glu Ile Ala Arg Glu Leu His Gln Phe Ala Phe Asp Leu Leu
1220 1225 1230
Ile Lys Ser His Phe Val Gln Gly Lys Asp Trp Gly Leu Lys Lys
1235 1240 1245
Phe Ile Arg Arg Asp Phe Trp Gly Met Glu Leu Ala Ala Ser Arg
1250 1255 1260
Arg Phe Ser Trp Asp His His Ser Ala Gly Gly Pro Pro Arg Val
1265 1270 1275
Pro Ser Val Arg Ser Gly Ala Ala Gln Val Gln Pro Lys Asp Pro
1280 1285 1290
Leu Pro Leu Arg Thr Leu Ala Gly Cys Leu Ala Arg Thr Ala His
1295 1300 1305
Leu Arg Pro Gly Ala Glu Ser Leu Pro Gln Pro Gln Leu His Cys
1310 1315 1320
Thr Leu Trp Phe Gln Ser Ser Glu Leu Ser Pro Thr Gly Ala Pro
1325 1330 1335
Trp Pro Ser Arg Arg Pro Thr Trp Arg Gly Thr Thr Val Ser Pro
1340 1345 1350
Arg Thr Ala Thr Ser Ser Ala Arg Thr Cys Cys Gly Thr Lys Trp
1355 1360 1365
Pro Ser Ser Gln Glu Ala Ala Leu Gly Leu Gly Ser Gly Leu Leu
1370 1375 1380
Arg Phe Ser Cys Gly Thr Ala Ala Ile Arg Lys Met His Phe Ser
1385 1390 1395
Leu Lys Glu His Pro Pro Pro Pro Cys Pro Pro Glu Ala Phe Gln
1400 1405 1410
Arg Ala Ala Gly Glu Gly Gly Pro Gly Arg Gly Gly Ala Arg Arg
1415 1420 1425
Gly Ala Arg Val Leu Gln Ser Pro Phe Cys Arg Ala Gly Ala Gly
1430 1435 1440
Glu Trp Leu Gly His Gln Ser Leu Arg His Val Val Gly Tyr Gly
1445 1450 1455
His Leu Asp Thr Ser Gly Ser Ser Ser Ser Ser Ser Trp Pro Asn
1460 1465 1470
Ser Lys Met Ala Leu Asn Ser Leu Asn Ser Ile Asp Asp Ala Gln
1475 1480 1485
Leu Thr Arg Ile Ala Pro Pro Arg Ser His Cys Cys Phe Trp Glu
1490 1495 1500
Val Asn Ala Pro
1505
<210> 555
<211> 1507
<212> PRT
<213> Artificial seqeunce
<220>
<223> Heterologous polypeptide
<400> 555
Met Gly Gln Lys Glu Gln Ile His Thr Leu Gln Lys Asn Ser Glu Arg
1 5 10 15
Met Ser Lys Gln Leu Thr Arg Ser Ser Gln Ala Val Gln Asn Leu Gln
20 25 30
Asn Gly Gly Gly Ser Arg Ser Ser Ala Thr Leu Pro Gly Arg Arg Arg
35 40 45
Arg Arg Trp Leu Arg Arg Arg Arg Gln Pro Ile Ser Val Ala Pro Ala
50 55 60
Gly Pro Pro Arg Arg Pro Asn Gln Lys Pro Asn Pro Pro Gly Gly Ala
65 70 75 80
Arg Cys Val Ile Met Arg Pro Thr Trp Pro Gly Thr Ser Ala Phe Thr
85 90 95
Lys Arg Ser Phe Ala Val Thr Glu Arg Ile Ile Thr Glu Ile Ser Cys
100 105 110
Cys Thr Leu Ser Ser Glu Glu Asn Glu Tyr Leu Pro Arg Pro Glu Trp
115 120 125
Gln Leu Gln Tyr Glu Ala Gly Met Thr Leu Gly Gly Lys Ile Leu Phe
130 135 140
Phe Leu Phe Leu Leu Leu Pro Leu Ser Pro Phe Ser Leu Ile Phe Asp
145 150 155 160
Tyr Trp Ala Gln Lys Glu Lys Gly Ser Ser Ser Phe Leu Arg Pro Ser
165 170 175
Cys Val Pro Phe Arg Glu Leu Lys Asn Val Ser Val Leu Glu Gly Leu
180 185 190
Arg Gln Gly Arg Leu Gly Gly Pro Cys Ser Cys His Cys Pro Arg Pro
195 200 205
Ser Gln Ala Arg Leu Thr Pro Val Asp Val Ala Gly Pro Phe Leu Cys
210 215 220
Leu Gly Asp Pro Gly Leu Phe Pro Pro Val Lys Ser Ser Ile Thr Gly
225 230 235 240
Gly Lys Ser Thr Cys Ser Ala Pro Gly Pro Gln Ser Leu Pro Ser Thr
245 250 255
Pro Phe Ser Thr Tyr Pro Gln Trp Val Ile Leu Ile Thr Glu Leu Gly
260 265 270
Met Glu Cys Thr Leu Gly Gln Val Gly Ala Pro Ser Pro Arg Arg Glu
275 280 285
Glu Asp Gly Trp Arg Gly Gly His Ser Arg Phe Lys Ala Asp Val Pro
290 295 300
Ala Pro Gln Gly Pro Cys Trp Gly Gly Gln Pro Gly Ser Ala Pro Ser
305 310 315 320
Ser Ala Pro Pro Glu Gln Ser Leu Leu Asp Asp Tyr Trp Ala Gln Lys
325 330 335
Glu Lys Ile Ser Ile Pro Arg Thr His Leu Cys Leu Val Leu Gly Val
340 345 350
Leu Ser Gly His Ser Gly Ser Arg Leu Trp Lys Phe Glu Met Ser Tyr
355 360 365
Thr Val Gly Gly Pro Pro Pro His Val His Ala Arg Pro Arg His Trp
370 375 380
Lys Thr Asp Arg Asp Gly His Ser Tyr Thr Ser Lys Val Asn Cys Leu
385 390 395 400
Leu Leu Gln Asp Gly Phe His Gly Cys Val Ser Ile Thr Gly Ala Ala
405 410 415
Gly Arg Arg Asn Leu Ser Ile Phe Leu Phe Leu Met Leu Cys Lys Leu
420 425 430
Glu Phe His Ala Cys Lys Ile Gln Asn Lys Asn Cys Pro Asp Phe Lys
435 440 445
Lys Phe Asp Gly Pro Cys Gly Glu Arg Gly Gly Gly Arg Thr Ala Arg
450 455 460
Ala Leu Trp Ala Arg Gly Asp Ser Val Leu Thr Pro Ala Leu Asp Pro
465 470 475 480
Gln Thr Pro Val Arg Ala Pro Ser Leu Thr Arg Ala Ala Ala Ala Val
485 490 495
His Tyr Lys Leu Ile Gln Gln Pro Ile Ser Leu Phe Ser Ile Thr Asp
500 505 510
Arg Leu His Lys Thr Phe Ser Gln Leu Pro Ser Val His Leu Cys Ser
515 520 525
Ile Thr Phe Gln Trp Gly His Pro Pro Ile Phe Cys Ser Thr Asn Asp
530 535 540
Ile Cys Val Thr Ala Asn Phe Cys Ile Ser Val Thr Phe Leu Lys Pro
545 550 555 560
Cys Phe Leu Leu His Glu Ala Ser Ala Ser Gln Cys His Leu Phe Leu
565 570 575
Gln Pro Gln Val Gly Thr Pro Pro Pro His Thr Ala Ser Ala Arg Ala
580 585 590
Pro Ser Gly Pro Pro His Pro His Glu Ser Cys Pro Ala Gly Arg Arg
595 600 605
Pro Ala Arg Ala Ala Gln Thr Cys Ala Arg Arg Gln His Gly Leu Pro
610 615 620
Gly Cys Glu Glu Ala Gly Thr Ala Arg Val Pro Ser Leu His Leu His
625 630 635 640
Leu His Gln Ala Ala Leu Gly Ala Gly Arg Gly Arg Gly Trp Gly Glu
645 650 655
Ala Cys Ala Gln Val Pro Pro Ser Arg Gly Val Leu Arg Phe Leu Asp
660 665 670
Leu Lys Val Arg Tyr Leu His Ser Gln Trp Gln His Tyr His Arg Ser
675 680 685
Gly Glu Ala Ala Gly Thr Pro Leu Trp Arg Pro Thr Arg Asn Val Pro
690 695 700
Phe Arg Glu Leu Lys Asn Gln Arg Thr Ala Gln Gly Ala Pro Gly Ile
705 710 715 720
His His Ala Ala Ser Pro Val Ala Ala Asn Leu Cys Asp Pro Ala Arg
725 730 735
His Ala Gln His Thr Arg Ile Pro Cys Gly Ala Gly Gln Val Arg Ala
740 745 750
Gly Arg Gly Pro Glu Ala Gly Gly Gly Val Leu Gln Pro Gln Arg Pro
755 760 765
Ala Pro Glu Lys Pro Gly Cys Pro Cys Arg Arg Gly Gln Pro Arg Leu
770 775 780
His Thr Val Lys Met Trp Arg Ala Val Ala Met Met Val Pro Asp Arg
785 790 795 800
Gln Val His Tyr Asp Phe Gly Leu Gly Val Pro Gly Asp Ser Thr Arg
805 810 815
Arg Ala Val Arg Arg Met Asn Thr Phe Tyr Glu Ala Gly Met Thr Leu
820 825 830
Gly Glu Lys Phe Arg Val Gly Asn Cys Lys His Leu Lys Met Thr Arg
835 840 845
Pro Asn Ser Lys Met Ala Leu Asn Ser Glu Ala Leu Ser Val Val Ser
850 855 860
Glu Cys Gly Ala Ser Ala Cys Asp Val Ser Leu Ile Ala Met Asp Ser
865 870 875 880
Ala Phe Val Gln Gly Lys Asp Trp Gly Val Lys Lys Phe Ile Arg Arg
885 890 895
Asp Phe Tyr Ala Tyr Lys Asp Phe Leu Trp Cys Phe Pro Phe Ser Leu
900 905 910
Val Phe Leu Gln Glu Ile Gln Ile Cys Cys His Val Ser Cys Leu Cys
915 920 925
Cys Ile Cys Cys Ser Thr Arg Ile Cys Leu Gly Cys Leu Leu Glu Leu
930 935 940
Phe Leu Ser Arg Ala Leu Arg Ala Leu His Val Leu Trp Asn Gly Phe
945 950 955 960
Gln Leu His Cys Gln Thr Glu Tyr Asn Gln Lys Leu Gln Val Asn Gln
965 970 975
Phe Ser Glu Ser Lys Ser Leu Tyr His Arg Glu Lys Gln Leu Ile Ala
980 985 990
Met Asp Ser Ala Ile Cys Glu Glu Arg Gly Ala Ala Gly Ser Leu Ile
995 1000 1005
Ser Cys Glu Thr Met Pro Ala Ile Leu Lys Leu Gln Lys Asn Cys
1010 1015 1020
Leu Leu Ser Leu Arg Thr Ala Leu Thr His Asn Gln Asp Phe Ser
1025 1030 1035
Ile Tyr Arg Leu Cys Cys Lys Arg Gly Ser Leu Cys His Ala Ser
1040 1045 1050
Gln Ala Arg Ser Pro Ala Phe Pro Lys Pro Val Arg Pro Leu Pro
1055 1060 1065
Ala Pro Ile Thr Arg Ile Thr Pro Gln Leu Gly Gly Gln Ser Asp
1070 1075 1080
Ser Ser Gln Pro Leu Leu Thr Thr Gly Arg Pro Gln Gly Trp Gln
1085 1090 1095
Asp Gln Ala Leu Arg His Thr Gln Gln Ala Ser Pro Ala Ser Cys
1100 1105 1110
Ala Thr Ile Thr Ile Pro Ile His Ser Ala Ala Leu Gly Asp His
1115 1120 1125
Ser Gly Asp Pro Gly Pro Ala Trp Asp Thr Cys Pro Pro Leu Pro
1130 1135 1140
Leu Thr Thr Leu Ile Pro Arg Ala Pro Pro Pro Tyr Gly Asp Ser
1145 1150 1155
Thr Ala Arg Ser Trp Pro Ser Arg Cys Gly Pro Leu Gly Gly Asn
1160 1165 1170
Thr Thr Leu Gln Gln Leu Gly Glu Ala Ser Gln Ala Pro Ser Gly
1175 1180 1185
Ser Leu Ile Pro Leu Arg Leu Pro Leu Leu Trp Glu Val Arg Gly
1190 1195 1200
Gln Pro Asp Ser Phe Ala Ala Leu His Ser Ser Leu Asn Glu Leu
1205 1210 1215
Gly Glu Ile Ala Arg Glu Leu His Gln Phe Ala Phe Asp Leu Leu
1220 1225 1230
Ile Lys Ser His Phe Val Gln Gly Lys Asp Trp Gly Leu Lys Lys
1235 1240 1245
Phe Ile Arg Arg Asp Phe Trp Gly Met Glu Leu Ala Ala Ser Arg
1250 1255 1260
Arg Phe Ser Trp Asp His His Ser Ala Gly Gly Pro Pro Arg Val
1265 1270 1275
Pro Ser Val Arg Ser Gly Ala Ala Gln Val Gln Pro Lys Asp Pro
1280 1285 1290
Leu Pro Leu Arg Thr Leu Ala Gly Cys Leu Ala Arg Thr Ala His
1295 1300 1305
Leu Arg Pro Gly Ala Glu Ser Leu Pro Gln Pro Gln Leu His Cys
1310 1315 1320
Thr Leu Trp Phe Gln Ser Ser Glu Leu Ser Pro Thr Gly Ala Pro
1325 1330 1335
Trp Pro Ser Arg Arg Pro Thr Trp Arg Gly Thr Thr Val Ser Pro
1340 1345 1350
Arg Thr Ala Thr Ser Ser Ala Arg Thr Cys Cys Gly Thr Lys Trp
1355 1360 1365
Pro Ser Ser Gln Glu Ala Ala Leu Gly Leu Gly Ser Gly Leu Leu
1370 1375 1380
Arg Phe Ser Cys Gly Thr Ala Ala Ile Arg Lys Met His Phe Ser
1385 1390 1395
Leu Lys Glu His Pro Pro Pro Pro Cys Pro Pro Glu Ala Phe Gln
1400 1405 1410
Arg Ala Ala Gly Glu Gly Gly Pro Gly Arg Gly Gly Ala Arg Arg
1415 1420 1425
Gly Ala Arg Val Leu Gln Ser Pro Phe Cys Arg Ala Gly Ala Gly
1430 1435 1440
Glu Trp Leu Gly His Gln Ser Leu Arg His Val Val Gly Tyr Gly
1445 1450 1455
His Leu Asp Thr Ser Gly Ser Ser Ser Ser Ser Ser Trp Pro Asn
1460 1465 1470
Ser Lys Met Ala Leu Asn Ser Leu Asn Ser Ile Asp Asp Ala Gln
1475 1480 1485
Leu Thr Arg Ile Ala Pro Pro Arg Ser His Cys Cys Phe Trp Glu
1490 1495 1500
Val Asn Ala Pro
1505
<210> 556
<211> 1507
<212> PRT
<213> Artificial seqeunce
<220>
<223> Heterologous polypeptide
<400> 556
Met Gly Gln Lys Glu Gln Ile His Thr Leu Gln Lys Asn Ser Glu Arg
1 5 10 15
Met Ser Lys Gln Leu Thr Arg Ser Ser Gln Ala Val Gln Asn Leu Gln
20 25 30
Asn Gly Gly Gly Ser Arg Ser Ser Ala Thr Leu Pro Gly Arg Arg Arg
35 40 45
Arg Arg Trp Leu Arg Arg Arg Arg Gln Pro Ile Ser Val Ala Pro Ala
50 55 60
Gly Pro Pro Arg Arg Pro Asn Gln Lys Pro Asn Pro Pro Gly Gly Ala
65 70 75 80
Arg Cys Val Ile Met Arg Pro Thr Trp Pro Gly Thr Ser Ala Phe Thr
85 90 95
Lys Arg Ser Phe Ala Val Thr Glu Arg Ile Ile Asp Tyr Trp Ala Gln
100 105 110
Lys Glu Lys Gly Ser Ser Ser Phe Leu Arg Pro Ser Cys Val Pro Phe
115 120 125
Arg Glu Leu Lys Asn Val Ser Val Leu Glu Gly Leu Arg Gln Gly Arg
130 135 140
Leu Gly Gly Pro Cys Ser Cys His Cys Pro Arg Pro Ser Gln Ala Arg
145 150 155 160
Leu Thr Pro Val Asp Val Ala Gly Pro Phe Leu Cys Leu Gly Asp Pro
165 170 175
Gly Leu Phe Pro Pro Val Lys Ser Ser Ile Leu Val Leu Gly Val Leu
180 185 190
Ser Gly His Ser Gly Ser Arg Leu Tyr Glu Ala Gly Met Thr Leu Gly
195 200 205
Gly Lys Ile Leu Phe Phe Leu Phe Leu Leu Leu Pro Leu Ser Pro Phe
210 215 220
Ser Leu Ile Phe Thr Glu Ile Ser Cys Cys Thr Leu Ser Ser Glu Glu
225 230 235 240
Asn Glu Tyr Leu Pro Arg Pro Glu Trp Gln Leu Gln Thr Gly Gly Lys
245 250 255
Ser Thr Cys Ser Ala Pro Gly Pro Gln Ser Leu Pro Ser Thr Pro Phe
260 265 270
Ser Thr Tyr Pro Gln Trp Val Ile Leu Ile Thr Glu Leu Gly Met Glu
275 280 285
Cys Thr Leu Gly Gln Val Gly Ala Pro Ser Pro Arg Arg Glu Glu Asp
290 295 300
Gly Trp Arg Gly Gly His Ser Arg Phe Lys Ala Asp Val Pro Ala Pro
305 310 315 320
Gln Gly Pro Cys Trp Gly Gly Gln Pro Gly Ser Ala Pro Ser Ser Ala
325 330 335
Pro Pro Glu Gln Ser Leu Leu Asp Asp Tyr Trp Ala Gln Lys Glu Lys
340 345 350
Ile Ser Ile Pro Arg Thr His Leu Cys Trp Lys Phe Glu Met Ser Tyr
355 360 365
Thr Val Gly Gly Pro Pro Pro His Val His Ala Arg Pro Arg His Trp
370 375 380
Lys Thr Asp Arg Asp Gly His Ser Tyr Thr Ser Lys Val Asn Cys Leu
385 390 395 400
Leu Leu Gln Asp Gly Phe His Gly Cys Val Ser Ile Thr Gly Ala Ala
405 410 415
Gly Arg Arg Asn Leu Ser Ile Phe Leu Phe Leu Met Leu Cys Lys Leu
420 425 430
Glu Phe His Ala Cys Lys Ile Gln Asn Lys Asn Cys Pro Asp Phe Lys
435 440 445
Lys Phe Asp Gly Pro Cys Gly Glu Arg Gly Gly Gly Arg Thr Ala Arg
450 455 460
Ala Leu Trp Ala Arg Gly Asp Ser Val Leu Thr Pro Ala Leu Asp Pro
465 470 475 480
Gln Thr Pro Val Arg Ala Pro Ser Leu Thr Arg Ala Ala Ala Ala Val
485 490 495
His Tyr Lys Leu Ile Gln Gln Pro Ile Ser Leu Phe Ser Ile Thr Asp
500 505 510
Arg Leu His Lys Thr Phe Ser Gln Leu Pro Ser Val His Leu Cys Ser
515 520 525
Ile Thr Phe Gln Trp Gly His Pro Pro Ile Phe Cys Ser Thr Asn Asp
530 535 540
Ile Cys Val Thr Ala Asn Phe Cys Ile Ser Val Thr Phe Leu Lys Pro
545 550 555 560
Cys Phe Leu Leu His Glu Ala Ser Ala Ser Gln Cys His Leu Phe Leu
565 570 575
Gln Pro Gln Val Gly Thr Pro Pro Pro His Thr Ala Ser Ala Arg Ala
580 585 590
Pro Ser Gly Pro Pro His Pro His Glu Ser Cys Pro Ala Gly Arg Arg
595 600 605
Pro Ala Arg Ala Ala Gln Thr Cys Ala Arg Arg Gln His Gly Leu Pro
610 615 620
Gly Cys Glu Glu Ala Gly Thr Ala Arg Val Pro Ser Leu His Leu His
625 630 635 640
Leu His Gln Ala Ala Leu Gly Ala Gly Arg Gly Arg Gly Trp Gly Glu
645 650 655
Ala Cys Ala Gln Val Pro Pro Ser Arg Gly Val Leu Arg Phe Leu Asp
660 665 670
Leu Lys Val Arg Tyr Leu His Ser Gln Trp Gln His Tyr His Arg Ser
675 680 685
Gly Glu Ala Ala Gly Thr Pro Leu Trp Arg Pro Thr Arg Asn Val Pro
690 695 700
Phe Arg Glu Leu Lys Asn Gln Arg Thr Ala Gln Gly Ala Pro Gly Ile
705 710 715 720
His His Ala Ala Ser Pro Val Ala Ala Asn Leu Cys Asp Pro Ala Arg
725 730 735
His Ala Gln His Thr Arg Ile Pro Cys Gly Ala Gly Gln Val Arg Ala
740 745 750
Gly Arg Gly Pro Glu Ala Gly Gly Gly Val Leu Gln Pro Gln Arg Pro
755 760 765
Ala Pro Glu Lys Pro Gly Cys Pro Cys Arg Arg Gly Gln Pro Arg Leu
770 775 780
His Thr Val Lys Met Trp Arg Ala Val Ala Met Met Val Pro Asp Arg
785 790 795 800
Gln Val His Tyr Asp Phe Gly Leu Gly Val Pro Gly Asp Ser Thr Arg
805 810 815
Arg Ala Val Arg Arg Met Asn Thr Phe Tyr Glu Ala Gly Met Thr Leu
820 825 830
Gly Glu Lys Phe Arg Val Gly Asn Cys Lys His Leu Lys Met Thr Arg
835 840 845
Pro Asn Ser Lys Met Ala Leu Asn Ser Glu Ala Leu Ser Val Val Ser
850 855 860
Glu Cys Gly Ala Ser Ala Cys Asp Val Ser Leu Ile Ala Met Asp Ser
865 870 875 880
Ala Phe Val Gln Gly Lys Asp Trp Gly Val Lys Lys Phe Ile Arg Arg
885 890 895
Asp Phe Tyr Ala Tyr Lys Asp Phe Leu Trp Cys Phe Pro Phe Ser Leu
900 905 910
Val Phe Leu Gln Glu Ile Gln Ile Cys Cys His Val Ser Cys Leu Cys
915 920 925
Cys Ile Cys Cys Ser Thr Arg Ile Cys Leu Gly Cys Leu Leu Glu Leu
930 935 940
Phe Leu Ser Arg Ala Leu Arg Ala Leu His Val Leu Trp Asn Gly Phe
945 950 955 960
Gln Leu His Cys Gln Thr Glu Tyr Asn Gln Lys Leu Gln Val Asn Gln
965 970 975
Phe Ser Glu Ser Lys Ser Leu Tyr His Arg Glu Lys Gln Leu Ile Ala
980 985 990
Met Asp Ser Ala Ile Cys Glu Glu Arg Gly Ala Ala Gly Ser Leu Ile
995 1000 1005
Ser Cys Glu Thr Met Pro Ala Ile Leu Lys Leu Gln Lys Asn Cys
1010 1015 1020
Leu Leu Ser Leu Arg Thr Ala Leu Thr His Asn Gln Asp Phe Ser
1025 1030 1035
Ile Tyr Arg Leu Cys Cys Lys Arg Gly Ser Leu Cys His Ala Ser
1040 1045 1050
Gln Ala Arg Ser Pro Ala Phe Pro Lys Pro Val Arg Pro Leu Pro
1055 1060 1065
Ala Pro Ile Thr Arg Ile Thr Pro Gln Leu Gly Gly Gln Ser Asp
1070 1075 1080
Ser Ser Gln Pro Leu Leu Thr Thr Gly Arg Pro Gln Gly Trp Gln
1085 1090 1095
Asp Gln Ala Leu Arg His Thr Gln Gln Ala Ser Pro Ala Ser Cys
1100 1105 1110
Ala Thr Ile Thr Ile Pro Ile His Ser Ala Ala Leu Gly Asp His
1115 1120 1125
Ser Gly Asp Pro Gly Pro Ala Trp Asp Thr Cys Pro Pro Leu Pro
1130 1135 1140
Leu Thr Thr Leu Ile Pro Arg Ala Pro Pro Pro Tyr Gly Asp Ser
1145 1150 1155
Thr Ala Arg Ser Trp Pro Ser Arg Cys Gly Pro Leu Gly Gly Asn
1160 1165 1170
Thr Thr Leu Gln Gln Leu Gly Glu Ala Ser Gln Ala Pro Ser Gly
1175 1180 1185
Ser Leu Ile Pro Leu Arg Leu Pro Leu Leu Trp Glu Val Arg Gly
1190 1195 1200
Gln Pro Asp Ser Phe Ala Ala Leu His Ser Ser Leu Asn Glu Leu
1205 1210 1215
Gly Glu Ile Ala Arg Glu Leu His Gln Phe Ala Phe Asp Leu Leu
1220 1225 1230
Ile Lys Ser His Phe Val Gln Gly Lys Asp Trp Gly Leu Lys Lys
1235 1240 1245
Phe Ile Arg Arg Asp Phe Trp Gly Met Glu Leu Ala Ala Ser Arg
1250 1255 1260
Arg Phe Ser Trp Asp His His Ser Ala Gly Gly Pro Pro Arg Val
1265 1270 1275
Pro Ser Val Arg Ser Gly Ala Ala Gln Val Gln Pro Lys Asp Pro
1280 1285 1290
Leu Pro Leu Arg Thr Leu Ala Gly Cys Leu Ala Arg Thr Ala His
1295 1300 1305
Leu Arg Pro Gly Ala Glu Ser Leu Pro Gln Pro Gln Leu His Cys
1310 1315 1320
Thr Leu Trp Phe Gln Ser Ser Glu Leu Ser Pro Thr Gly Ala Pro
1325 1330 1335
Trp Pro Ser Arg Arg Pro Thr Trp Arg Gly Thr Thr Val Ser Pro
1340 1345 1350
Arg Thr Ala Thr Ser Ser Ala Arg Thr Cys Cys Gly Thr Lys Trp
1355 1360 1365
Pro Ser Ser Gln Glu Ala Ala Leu Gly Leu Gly Ser Gly Leu Leu
1370 1375 1380
Arg Phe Ser Cys Gly Thr Ala Ala Ile Arg Lys Met His Phe Ser
1385 1390 1395
Leu Lys Glu His Pro Pro Pro Pro Cys Pro Pro Glu Ala Phe Gln
1400 1405 1410
Arg Ala Ala Gly Glu Gly Gly Pro Gly Arg Gly Gly Ala Arg Arg
1415 1420 1425
Gly Ala Arg Val Leu Gln Ser Pro Phe Cys Arg Ala Gly Ala Gly
1430 1435 1440
Glu Trp Leu Gly His Gln Ser Leu Arg His Val Val Gly Tyr Gly
1445 1450 1455
His Leu Asp Thr Ser Gly Ser Ser Ser Ser Ser Ser Trp Pro Asn
1460 1465 1470
Ser Lys Met Ala Leu Asn Ser Leu Asn Ser Ile Asp Asp Ala Gln
1475 1480 1485
Leu Thr Arg Ile Ala Pro Pro Arg Ser His Cys Cys Phe Trp Glu
1490 1495 1500
Val Asn Ala Pro
1505
<210> 557
<211> 1507
<212> PRT
<213> Artificial seqeunce
<220>
<223> Heterologous polypeptide
<400> 557
Met Gly Gln Lys Glu Gln Ile His Thr Leu Gln Lys Asn Ser Glu Arg
1 5 10 15
Met Ser Lys Gln Leu Thr Arg Ser Ser Gln Ala Val Gln Asn Leu Gln
20 25 30
Asn Gly Gly Gly Ser Arg Ser Ser Ala Thr Leu Pro Gly Arg Arg Arg
35 40 45
Arg Arg Trp Leu Arg Arg Arg Arg Gln Pro Ile Ser Val Ala Pro Ala
50 55 60
Gly Pro Pro Arg Arg Pro Asn Gln Lys Pro Asn Pro Pro Gly Gly Ala
65 70 75 80
Arg Cys Val Ile Met Arg Pro Thr Trp Pro Gly Thr Ser Ala Phe Thr
85 90 95
Gly Met Glu Cys Thr Leu Gly Gln Val Gly Ala Pro Ser Pro Arg Arg
100 105 110
Glu Glu Asp Gly Trp Arg Gly Gly His Ser Arg Phe Lys Ala Asp Val
115 120 125
Pro Ala Pro Gln Gly Pro Cys Trp Gly Gly Gln Pro Gly Ser Ala Pro
130 135 140
Ser Ser Ala Pro Pro Glu Gln Ser Leu Leu Asp Asp Tyr Trp Ala Gln
145 150 155 160
Lys Glu Lys Ile Ser Ile Pro Arg Thr His Leu Cys Trp Lys Phe Glu
165 170 175
Met Ser Tyr Thr Val Gly Gly Pro Pro Pro His Val His Ala Arg Pro
180 185 190
Arg His Trp Lys Thr Asp Arg Asp Tyr Trp Ala Gln Lys Glu Lys Gly
195 200 205
Ser Ser Ser Phe Leu Arg Pro Ser Cys Val Pro Phe Arg Glu Leu Lys
210 215 220
Asn Val Ser Val Leu Glu Gly Leu Arg Gln Gly Arg Leu Gly Gly Pro
225 230 235 240
Cys Ser Cys His Cys Pro Arg Pro Ser Gln Ala Arg Leu Thr Pro Val
245 250 255
Asp Val Ala Gly Pro Phe Leu Cys Leu Gly Asp Pro Gly Leu Phe Pro
260 265 270
Pro Val Lys Ser Ser Ile Thr Glu Ile Ser Cys Cys Thr Leu Ser Ser
275 280 285
Glu Glu Asn Glu Tyr Leu Pro Arg Pro Glu Trp Gln Leu Gln Tyr Glu
290 295 300
Ala Gly Met Thr Leu Gly Gly Lys Ile Leu Phe Phe Leu Phe Leu Leu
305 310 315 320
Leu Pro Leu Ser Pro Phe Ser Leu Ile Phe Leu Val Leu Gly Val Leu
325 330 335
Ser Gly His Ser Gly Ser Arg Leu Lys Arg Ser Phe Ala Val Thr Glu
340 345 350
Arg Ile Ile Thr Gly Gly Lys Ser Thr Cys Ser Ala Pro Gly Pro Gln
355 360 365
Ser Leu Pro Ser Thr Pro Phe Ser Thr Tyr Pro Gln Trp Val Ile Leu
370 375 380
Ile Thr Glu Leu Asp Gly His Ser Tyr Thr Ser Lys Val Asn Cys Leu
385 390 395 400
Leu Leu Gln Asp Gly Phe His Gly Cys Val Ser Ile Thr Gly Ala Ala
405 410 415
Gly Arg Arg Asn Leu Ser Ile Phe Leu Phe Leu Met Leu Cys Lys Leu
420 425 430
Glu Phe His Ala Cys Cys His Leu Phe Leu Gln Pro Gln Val Gly Thr
435 440 445
Pro Pro Pro His Thr Ala Ser Ala Arg Ala Pro Ser Gly Pro Pro His
450 455 460
Pro His Glu Ser Cys Pro Ala Gly Arg Arg Pro Ala Arg Ala Ala Gln
465 470 475 480
Thr Cys Ala Arg Arg Gln His Gly Leu Pro Gly Cys Glu Glu Ala Gly
485 490 495
Thr Ala Arg Val Pro Ser Leu His Leu His Leu His Gln Ala Ala Leu
500 505 510
Gly Ala Gly Arg Gly Arg Gly Trp Gly Glu Ala Cys Ala Gln Val Pro
515 520 525
Pro Ser Arg Gly His Tyr Lys Leu Ile Gln Gln Pro Ile Ser Leu Phe
530 535 540
Ser Ile Thr Asp Arg Leu His Lys Thr Phe Ser Gln Leu Pro Ser Val
545 550 555 560
His Leu Cys Ser Ile Thr Phe Gln Trp Gly His Pro Pro Ile Phe Cys
565 570 575
Ser Thr Asn Asp Ile Cys Val Thr Ala Asn Phe Cys Ile Ser Val Thr
580 585 590
Phe Leu Lys Pro Cys Phe Leu Leu His Glu Ala Ser Ala Ser Gln Val
595 600 605
Ala Met Met Val Pro Asp Arg Gln Val His Tyr Asp Phe Gly Leu Lys
610 615 620
Ile Gln Asn Lys Asn Cys Pro Asp Val Leu Arg Phe Leu Asp Leu Lys
625 630 635 640
Val Arg Tyr Leu His Ser Val Pro Phe Arg Glu Leu Lys Asn Gln Arg
645 650 655
Thr Ala Gln Gly Ala Pro Gly Ile His His Ala Ala Ser Pro Val Ala
660 665 670
Ala Asn Leu Cys Asp Pro Ala Arg His Ala Gln His Thr Arg Ile Pro
675 680 685
Cys Gly Ala Gly Gln Val Arg Ala Gly Arg Gly Pro Glu Ala Gly Gly
690 695 700
Gly Val Leu Gln Pro Gln Arg Pro Ala Pro Glu Lys Pro Gly Cys Pro
705 710 715 720
Cys Arg Arg Gly Gln Pro Arg Leu His Thr Val Lys Met Trp Arg Ala
725 730 735
Gln Trp Gln His Tyr His Arg Ser Gly Glu Ala Ala Gly Thr Pro Leu
740 745 750
Trp Arg Pro Thr Arg Asn Phe Lys Lys Phe Asp Gly Pro Cys Gly Glu
755 760 765
Arg Gly Gly Gly Arg Thr Ala Arg Ala Leu Trp Ala Arg Gly Asp Ser
770 775 780
Val Leu Thr Pro Ala Leu Asp Pro Gln Thr Pro Val Arg Ala Pro Ser
785 790 795 800
Leu Thr Arg Ala Ala Ala Ala Val Gly Val Pro Gly Asp Ser Thr Arg
805 810 815
Arg Ala Val Arg Arg Met Asn Thr Phe Cys Gly Ala Ser Ala Cys Asp
820 825 830
Val Ser Leu Ile Ala Met Asp Ser Ala Cys Glu Glu Arg Gly Ala Ala
835 840 845
Gly Ser Leu Ile Ser Cys Glu Ser Leu Tyr His Arg Glu Lys Gln Leu
850 855 860
Ile Ala Met Asp Ser Ala Ile Phe Val Gln Gly Lys Asp Trp Gly Val
865 870 875 880
Lys Lys Phe Ile Arg Arg Asp Phe Thr Met Pro Ala Ile Leu Lys Leu
885 890 895
Gln Lys Asn Cys Leu Leu Ser Leu Asn Ser Lys Met Ala Leu Asn Ser
900 905 910
Glu Ala Leu Ser Val Val Ser Glu Tyr Glu Ala Gly Met Thr Leu Gly
915 920 925
Glu Lys Phe Arg Val Gly Asn Cys Lys His Leu Lys Met Thr Arg Pro
930 935 940
Thr Glu Tyr Asn Gln Lys Leu Gln Val Asn Gln Phe Ser Glu Ser Lys
945 950 955 960
Arg Thr Ala Leu Thr His Asn Gln Asp Phe Ser Ile Tyr Arg Leu Cys
965 970 975
Cys Lys Arg Gly Ser Leu Cys His Ala Ser Gln Ala Arg Ser Pro Ala
980 985 990
Phe Pro Lys Pro Val Arg Pro Leu Pro Ala Pro Ile Thr Arg Ile Thr
995 1000 1005
Pro Gln Leu Gly Gly Gln Ser Asp Ser Ser Gln Pro Leu Leu Thr
1010 1015 1020
Thr Gly Arg Pro Gln Gly Trp Gln Asp Gln Ala Leu Arg His Thr
1025 1030 1035
Gln Gln Ala Ser Pro Ala Ser Cys Ala Thr Ile Thr Ile Pro Ile
1040 1045 1050
His Ser Ala Ala Leu Gly Asp His Ser Gly Asp Pro Gly Pro Ala
1055 1060 1065
Trp Asp Thr Cys Pro Pro Leu Pro Leu Thr Thr Leu Ile Pro Arg
1070 1075 1080
Ala Pro Pro Pro Tyr Gly Asp Ser Thr Ala Arg Ser Trp Pro Ser
1085 1090 1095
Arg Cys Gly Pro Leu Gly Tyr Ala Tyr Lys Asp Phe Leu Trp Cys
1100 1105 1110
Phe Pro Phe Ser Leu Val Phe Leu Gln Glu Ile Gln Ile Cys Cys
1115 1120 1125
His Val Ser Cys Leu Cys Cys Ile Cys Cys Ser Thr Arg Ile Cys
1130 1135 1140
Leu Gly Cys Leu Leu Glu Leu Phe Leu Ser Arg Ala Leu Arg Ala
1145 1150 1155
Leu His Val Leu Trp Asn Gly Phe Gln Leu His Cys Gln Gly Asn
1160 1165 1170
Thr Thr Leu Gln Gln Leu Gly Glu Ala Ser Gln Ala Pro Ser Gly
1175 1180 1185
Ser Leu Ile Pro Leu Arg Leu Pro Leu Leu Trp Glu Val Arg Gly
1190 1195 1200
Asn Ser Lys Met Ala Leu Asn Ser Leu Asn Ser Ile Asp Asp Ala
1205 1210 1215
Gln Leu Thr Arg Ile Ala Pro Pro Arg Ser His Cys Cys Phe Trp
1220 1225 1230
Glu Val Asn Ala Pro Phe Val Gln Gly Lys Asp Trp Gly Leu Lys
1235 1240 1245
Lys Phe Ile Arg Arg Asp Phe Glu Ala Phe Gln Arg Ala Ala Gly
1250 1255 1260
Glu Gly Gly Pro Gly Arg Gly Gly Ala Arg Arg Gly Ala Arg Val
1265 1270 1275
Leu Gln Ser Pro Phe Cys Arg Ala Gly Ala Gly Glu Trp Leu Gly
1280 1285 1290
His Gln Ser Leu Arg Trp Gly Met Glu Leu Ala Ala Ser Arg Arg
1295 1300 1305
Phe Ser Trp Asp His His Ser Ala Gly Gly Pro Pro Arg Val Pro
1310 1315 1320
Ser Val Arg Ser Gly Ala Ala Gln Val Gln Pro Lys Asp Pro Leu
1325 1330 1335
Pro Leu Arg Thr Leu Ala Gly Cys Leu Ala Arg Thr Ala His Leu
1340 1345 1350
Arg Pro Gly Ala Glu Ser Leu Pro Gln Pro Gln Leu His Cys Thr
1355 1360 1365
Ile Ala Arg Glu Leu His Gln Phe Ala Phe Asp Leu Leu Ile Lys
1370 1375 1380
Ser His Lys Met His Phe Ser Leu Lys Glu His Pro Pro Pro Pro
1385 1390 1395
Cys Pro Pro His Val Val Gly Tyr Gly His Leu Asp Thr Ser Gly
1400 1405 1410
Ser Ser Ser Ser Ser Ser Trp Pro Gln Pro Asp Ser Phe Ala Ala
1415 1420 1425
Leu His Ser Ser Leu Asn Glu Leu Gly Glu Leu Trp Phe Gln Ser
1430 1435 1440
Ser Glu Leu Ser Pro Thr Gly Ala Pro Trp Pro Ser Arg Arg Pro
1445 1450 1455
Thr Trp Arg Gly Thr Thr Val Ser Pro Arg Thr Ala Thr Ser Ser
1460 1465 1470
Ala Arg Thr Cys Cys Gly Thr Lys Trp Pro Ser Ser Gln Glu Ala
1475 1480 1485
Ala Leu Gly Leu Gly Ser Gly Leu Leu Arg Phe Ser Cys Gly Thr
1490 1495 1500
Ala Ala Ile Arg
1505
<210> 558
<211> 1507
<212> PRT
<213> Artificial seqeunce
<220>
<223> Heterologous polypeptide
<400> 558
Met Gly Gln Lys Glu Gln Ile His Thr Leu Gln Lys Asn Ser Glu Arg
1 5 10 15
Met Ser Lys Gln Leu Thr Arg Ser Ser Gln Ala Val Asp Gly His Ser
20 25 30
Tyr Thr Ser Lys Val Asn Cys Leu Leu Leu Gln Asp Gly Phe His Gly
35 40 45
Cys Val Ser Ile Thr Gly Ala Ala Gly Arg Arg Asn Leu Ser Ile Phe
50 55 60
Leu Phe Leu Met Leu Cys Lys Leu Glu Phe His Ala Cys Gln Trp Gln
65 70 75 80
His Tyr His Arg Ser Gly Glu Ala Ala Gly Thr Pro Leu Trp Arg Pro
85 90 95
Thr Arg Asn Val Ala Met Met Val Pro Asp Arg Gln Val His Tyr Asp
100 105 110
Phe Gly Leu Val Leu Arg Phe Leu Asp Leu Lys Val Arg Tyr Leu His
115 120 125
Ser Lys Ile Gln Asn Lys Asn Cys Pro Asp Val Pro Phe Arg Glu Leu
130 135 140
Lys Asn Gln Arg Thr Ala Gln Gly Ala Pro Gly Ile His His Ala Ala
145 150 155 160
Ser Pro Val Ala Ala Asn Leu Cys Asp Pro Ala Arg His Ala Gln His
165 170 175
Thr Arg Ile Pro Cys Gly Ala Gly Gln Val Arg Ala Gly Arg Gly Pro
180 185 190
Glu Ala Gly Gly Gly Val Leu Gln Pro Gln Arg Pro Ala Pro Glu Lys
195 200 205
Pro Gly Cys Pro Cys Arg Arg Gly Gln Pro Arg Leu His Thr Val Lys
210 215 220
Met Trp Arg Ala Cys His Leu Phe Leu Gln Pro Gln Val Gly Thr Pro
225 230 235 240
Pro Pro His Thr Ala Ser Ala Arg Ala Pro Ser Gly Pro Pro His Pro
245 250 255
His Glu Ser Cys Pro Ala Gly Arg Arg Pro Ala Arg Ala Ala Gln Thr
260 265 270
Cys Ala Arg Arg Gln His Gly Leu Pro Gly Cys Glu Glu Ala Gly Thr
275 280 285
Ala Arg Val Pro Ser Leu His Leu His Leu His Gln Ala Ala Leu Gly
290 295 300
Ala Gly Arg Gly Arg Gly Trp Gly Glu Ala Cys Ala Gln Val Pro Pro
305 310 315 320
Ser Arg Gly His Tyr Lys Leu Ile Gln Gln Pro Ile Ser Leu Phe Ser
325 330 335
Ile Thr Asp Arg Leu His Lys Thr Phe Ser Gln Leu Pro Ser Val His
340 345 350
Leu Cys Ser Ile Thr Phe Gln Trp Gly His Pro Pro Ile Phe Cys Ser
355 360 365
Thr Asn Asp Ile Cys Val Thr Ala Asn Phe Cys Ile Ser Val Thr Phe
370 375 380
Leu Lys Pro Cys Phe Leu Leu His Glu Ala Ser Ala Ser Gln Phe Lys
385 390 395 400
Lys Phe Asp Gly Pro Cys Gly Glu Arg Gly Gly Gly Arg Thr Ala Arg
405 410 415
Ala Leu Trp Ala Arg Gly Asp Ser Val Leu Thr Pro Ala Leu Asp Pro
420 425 430
Gln Thr Pro Val Arg Ala Pro Ser Leu Thr Arg Ala Ala Ala Ala Val
435 440 445
Gln Asn Leu Gln Asn Gly Gly Gly Ser Arg Ser Ser Ala Thr Leu Pro
450 455 460
Gly Arg Arg Arg Arg Arg Trp Leu Arg Arg Arg Arg Gln Pro Ile Ser
465 470 475 480
Val Ala Pro Ala Gly Pro Pro Arg Arg Pro Asn Gln Lys Pro Asn Pro
485 490 495
Pro Gly Gly Ala Arg Cys Val Ile Met Arg Pro Thr Trp Pro Gly Thr
500 505 510
Ser Ala Phe Thr Gly Met Glu Cys Thr Leu Gly Gln Val Gly Ala Pro
515 520 525
Ser Pro Arg Arg Glu Glu Asp Gly Trp Arg Gly Gly His Ser Arg Phe
530 535 540
Lys Ala Asp Val Pro Ala Pro Gln Gly Pro Cys Trp Gly Gly Gln Pro
545 550 555 560
Gly Ser Ala Pro Ser Ser Ala Pro Pro Glu Gln Ser Leu Leu Asp Asp
565 570 575
Tyr Trp Ala Gln Lys Glu Lys Ile Ser Ile Pro Arg Thr His Leu Cys
580 585 590
Trp Lys Phe Glu Met Ser Tyr Thr Val Gly Gly Pro Pro Pro His Val
595 600 605
His Ala Arg Pro Arg His Trp Lys Thr Asp Arg Asp Tyr Trp Ala Gln
610 615 620
Lys Glu Lys Gly Ser Ser Ser Phe Leu Arg Pro Ser Cys Val Pro Phe
625 630 635 640
Arg Glu Leu Lys Asn Val Ser Val Leu Glu Gly Leu Arg Gln Gly Arg
645 650 655
Leu Gly Gly Pro Cys Ser Cys His Cys Pro Arg Pro Ser Gln Ala Arg
660 665 670
Leu Thr Pro Val Asp Val Ala Gly Pro Phe Leu Cys Leu Gly Asp Pro
675 680 685
Gly Leu Phe Pro Pro Val Lys Ser Ser Ile Thr Glu Ile Ser Cys Cys
690 695 700
Thr Leu Ser Ser Glu Glu Asn Glu Tyr Leu Pro Arg Pro Glu Trp Gln
705 710 715 720
Leu Gln Tyr Glu Ala Gly Met Thr Leu Gly Gly Lys Ile Leu Phe Phe
725 730 735
Leu Phe Leu Leu Leu Pro Leu Ser Pro Phe Ser Leu Ile Phe Leu Val
740 745 750
Leu Gly Val Leu Ser Gly His Ser Gly Ser Arg Leu Lys Arg Ser Phe
755 760 765
Ala Val Thr Glu Arg Ile Ile Thr Gly Gly Lys Ser Thr Cys Ser Ala
770 775 780
Pro Gly Pro Gln Ser Leu Pro Ser Thr Pro Phe Ser Thr Tyr Pro Gln
785 790 795 800
Trp Val Ile Leu Ile Thr Glu Leu Gly Val Pro Gly Asp Ser Thr Arg
805 810 815
Arg Ala Val Arg Arg Met Asn Thr Phe Cys Gly Ala Ser Ala Cys Asp
820 825 830
Val Ser Leu Ile Ala Met Asp Ser Ala Cys Glu Glu Arg Gly Ala Ala
835 840 845
Gly Ser Leu Ile Ser Cys Glu Ser Leu Tyr His Arg Glu Lys Gln Leu
850 855 860
Ile Ala Met Asp Ser Ala Ile Phe Val Gln Gly Lys Asp Trp Gly Val
865 870 875 880
Lys Lys Phe Ile Arg Arg Asp Phe Thr Met Pro Ala Ile Leu Lys Leu
885 890 895
Gln Lys Asn Cys Leu Leu Ser Leu Asn Ser Lys Met Ala Leu Asn Ser
900 905 910
Glu Ala Leu Ser Val Val Ser Glu Tyr Glu Ala Gly Met Thr Leu Gly
915 920 925
Glu Lys Phe Arg Val Gly Asn Cys Lys His Leu Lys Met Thr Arg Pro
930 935 940
Thr Glu Tyr Asn Gln Lys Leu Gln Val Asn Gln Phe Ser Glu Ser Lys
945 950 955 960
Arg Thr Ala Leu Thr His Asn Gln Asp Phe Ser Ile Tyr Arg Leu Cys
965 970 975
Cys Lys Arg Gly Ser Leu Cys His Ala Ser Gln Ala Arg Ser Pro Ala
980 985 990
Phe Pro Lys Pro Val Arg Pro Leu Pro Ala Pro Ile Thr Arg Ile Thr
995 1000 1005
Pro Gln Leu Gly Gly Gln Ser Asp Ser Ser Gln Pro Leu Leu Thr
1010 1015 1020
Thr Gly Arg Pro Gln Gly Trp Gln Asp Gln Ala Leu Arg His Thr
1025 1030 1035
Gln Gln Ala Ser Pro Ala Ser Cys Ala Thr Ile Thr Ile Pro Ile
1040 1045 1050
His Ser Ala Ala Leu Gly Asp His Ser Gly Asp Pro Gly Pro Ala
1055 1060 1065
Trp Asp Thr Cys Pro Pro Leu Pro Leu Thr Thr Leu Ile Pro Arg
1070 1075 1080
Ala Pro Pro Pro Tyr Gly Asp Ser Thr Ala Arg Ser Trp Pro Ser
1085 1090 1095
Arg Cys Gly Pro Leu Gly Tyr Ala Tyr Lys Asp Phe Leu Trp Cys
1100 1105 1110
Phe Pro Phe Ser Leu Val Phe Leu Gln Glu Ile Gln Ile Cys Cys
1115 1120 1125
His Val Ser Cys Leu Cys Cys Ile Cys Cys Ser Thr Arg Ile Cys
1130 1135 1140
Leu Gly Cys Leu Leu Glu Leu Phe Leu Ser Arg Ala Leu Arg Ala
1145 1150 1155
Leu His Val Leu Trp Asn Gly Phe Gln Leu His Cys Gln Gly Asn
1160 1165 1170
Thr Thr Leu Gln Gln Leu Gly Glu Ala Ser Gln Ala Pro Ser Gly
1175 1180 1185
Ser Leu Ile Pro Leu Arg Leu Pro Leu Leu Trp Glu Val Arg Gly
1190 1195 1200
Asn Ser Lys Met Ala Leu Asn Ser Leu Asn Ser Ile Asp Asp Ala
1205 1210 1215
Gln Leu Thr Arg Ile Ala Pro Pro Arg Ser His Cys Cys Phe Trp
1220 1225 1230
Glu Val Asn Ala Pro Phe Val Gln Gly Lys Asp Trp Gly Leu Lys
1235 1240 1245
Lys Phe Ile Arg Arg Asp Phe Glu Ala Phe Gln Arg Ala Ala Gly
1250 1255 1260
Glu Gly Gly Pro Gly Arg Gly Gly Ala Arg Arg Gly Ala Arg Val
1265 1270 1275
Leu Gln Ser Pro Phe Cys Arg Ala Gly Ala Gly Glu Trp Leu Gly
1280 1285 1290
His Gln Ser Leu Arg Trp Gly Met Glu Leu Ala Ala Ser Arg Arg
1295 1300 1305
Phe Ser Trp Asp His His Ser Ala Gly Gly Pro Pro Arg Val Pro
1310 1315 1320
Ser Val Arg Ser Gly Ala Ala Gln Val Gln Pro Lys Asp Pro Leu
1325 1330 1335
Pro Leu Arg Thr Leu Ala Gly Cys Leu Ala Arg Thr Ala His Leu
1340 1345 1350
Arg Pro Gly Ala Glu Ser Leu Pro Gln Pro Gln Leu His Cys Thr
1355 1360 1365
Ile Ala Arg Glu Leu His Gln Phe Ala Phe Asp Leu Leu Ile Lys
1370 1375 1380
Ser His Lys Met His Phe Ser Leu Lys Glu His Pro Pro Pro Pro
1385 1390 1395
Cys Pro Pro His Val Val Gly Tyr Gly His Leu Asp Thr Ser Gly
1400 1405 1410
Ser Ser Ser Ser Ser Ser Trp Pro Gln Pro Asp Ser Phe Ala Ala
1415 1420 1425
Leu His Ser Ser Leu Asn Glu Leu Gly Glu Leu Trp Phe Gln Ser
1430 1435 1440
Ser Glu Leu Ser Pro Thr Gly Ala Pro Trp Pro Ser Arg Arg Pro
1445 1450 1455
Thr Trp Arg Gly Thr Thr Val Ser Pro Arg Thr Ala Thr Ser Ser
1460 1465 1470
Ala Arg Thr Cys Cys Gly Thr Lys Trp Pro Ser Ser Gln Glu Ala
1475 1480 1485
Ala Leu Gly Leu Gly Ser Gly Leu Leu Arg Phe Ser Cys Gly Thr
1490 1495 1500
Ala Ala Ile Arg
1505
<210> 559
<211> 1507
<212> PRT
<213> Artificial seqeunce
<220>
<223> Heterologous polypeptide
<400> 559
Met Gly Gln Lys Glu Gln Ile His Thr Leu Gln Lys Asn Ser Glu Arg
1 5 10 15
Met Ser Lys Gln Leu Thr Arg Ser Ser Gln Ala Val Gly Asn Thr Thr
20 25 30
Leu Gln Gln Leu Gly Glu Ala Ser Gln Ala Pro Ser Gly Ser Leu Ile
35 40 45
Pro Leu Arg Leu Pro Leu Leu Trp Glu Val Arg Gly Asn Ser Lys Met
50 55 60
Ala Leu Asn Ser Leu Asn Ser Ile Asp Asp Ala Gln Leu Thr Arg Ile
65 70 75 80
Ala Pro Pro Arg Ser His Cys Cys Phe Trp Glu Val Asn Ala Pro Phe
85 90 95
Val Gln Gly Lys Asp Trp Gly Leu Lys Lys Phe Ile Arg Arg Asp Phe
100 105 110
Glu Ala Phe Gln Arg Ala Ala Gly Glu Gly Gly Pro Gly Arg Gly Gly
115 120 125
Ala Arg Arg Gly Ala Arg Val Leu Gln Ser Pro Phe Cys Arg Ala Gly
130 135 140
Ala Gly Glu Trp Leu Gly His Gln Ser Leu Arg Trp Gly Met Glu Leu
145 150 155 160
Ala Ala Ser Arg Arg Phe Ser Trp Asp His His Ser Ala Gly Gly Pro
165 170 175
Pro Arg Val Pro Ser Val Arg Ser Gly Ala Ala Gln Val Gln Pro Lys
180 185 190
Asp Pro Leu Pro Leu Arg Thr Leu Ala Gly Cys Leu Ala Arg Thr Ala
195 200 205
His Leu Arg Pro Gly Ala Glu Ser Leu Pro Gln Pro Gln Leu His Cys
210 215 220
Thr Ile Ala Arg Glu Leu His Gln Phe Ala Phe Asp Leu Leu Ile Lys
225 230 235 240
Ser His Lys Met His Phe Ser Leu Lys Glu His Pro Pro Pro Pro Cys
245 250 255
Pro Pro His Val Val Gly Tyr Gly His Leu Asp Thr Ser Gly Ser Ser
260 265 270
Ser Ser Ser Ser Trp Pro Gln Pro Asp Ser Phe Ala Ala Leu His Ser
275 280 285
Ser Leu Asn Glu Leu Gly Glu Leu Trp Phe Gln Ser Ser Glu Leu Ser
290 295 300
Pro Thr Gly Ala Pro Trp Pro Ser Arg Arg Pro Thr Trp Arg Gly Thr
305 310 315 320
Thr Val Ser Pro Arg Thr Ala Thr Ser Ser Ala Arg Thr Cys Cys Gly
325 330 335
Thr Lys Trp Pro Ser Ser Gln Glu Ala Ala Leu Gly Leu Gly Ser Gly
340 345 350
Leu Leu Arg Phe Ser Cys Gly Thr Ala Ala Ile Arg Asp Gly His Ser
355 360 365
Tyr Thr Ser Lys Val Asn Cys Leu Leu Leu Gln Asp Gly Phe His Gly
370 375 380
Cys Val Ser Ile Thr Gly Ala Ala Gly Arg Arg Asn Leu Ser Ile Phe
385 390 395 400
Leu Phe Leu Met Leu Cys Lys Leu Glu Phe His Ala Cys Gln Trp Gln
405 410 415
His Tyr His Arg Ser Gly Glu Ala Ala Gly Thr Pro Leu Trp Arg Pro
420 425 430
Thr Arg Asn Val Ala Met Met Val Pro Asp Arg Gln Val His Tyr Asp
435 440 445
Phe Gly Leu Lys Ile Gln Asn Lys Asn Cys Pro Asp Val Leu Arg Phe
450 455 460
Leu Asp Leu Lys Val Arg Tyr Leu His Ser Val Pro Phe Arg Glu Leu
465 470 475 480
Lys Asn Gln Arg Thr Ala Gln Gly Ala Pro Gly Ile His His Ala Ala
485 490 495
Ser Pro Val Ala Ala Asn Leu Cys Asp Pro Ala Arg His Ala Gln His
500 505 510
Thr Arg Ile Pro Cys Gly Ala Gly Gln Val Arg Ala Gly Arg Gly Pro
515 520 525
Glu Ala Gly Gly Gly Val Leu Gln Pro Gln Arg Pro Ala Pro Glu Lys
530 535 540
Pro Gly Cys Pro Cys Arg Arg Gly Gln Pro Arg Leu His Thr Val Lys
545 550 555 560
Met Trp Arg Ala Cys His Leu Phe Leu Gln Pro Gln Val Gly Thr Pro
565 570 575
Pro Pro His Thr Ala Ser Ala Arg Ala Pro Ser Gly Pro Pro His Pro
580 585 590
His Glu Ser Cys Pro Ala Gly Arg Arg Pro Ala Arg Ala Ala Gln Thr
595 600 605
Cys Ala Arg Arg Gln His Gly Leu Pro Gly Cys Glu Glu Ala Gly Thr
610 615 620
Ala Arg Val Pro Ser Leu His Leu His Leu His Gln Ala Ala Leu Gly
625 630 635 640
Ala Gly Arg Gly Arg Gly Trp Gly Glu Ala Cys Ala Gln Val Pro Pro
645 650 655
Ser Arg Gly His Tyr Lys Leu Ile Gln Gln Pro Ile Ser Leu Phe Ser
660 665 670
Ile Thr Asp Arg Leu His Lys Thr Phe Ser Gln Leu Pro Ser Val His
675 680 685
Leu Cys Ser Ile Thr Phe Gln Trp Gly His Pro Pro Ile Phe Cys Ser
690 695 700
Thr Asn Asp Ile Cys Val Thr Ala Asn Phe Cys Ile Ser Val Thr Phe
705 710 715 720
Leu Lys Pro Cys Phe Leu Leu His Glu Ala Ser Ala Ser Gln Phe Lys
725 730 735
Lys Phe Asp Gly Pro Cys Gly Glu Arg Gly Gly Gly Arg Thr Ala Arg
740 745 750
Ala Leu Trp Ala Arg Gly Asp Ser Val Leu Thr Pro Ala Leu Asp Pro
755 760 765
Gln Thr Pro Val Arg Ala Pro Ser Leu Thr Arg Ala Ala Ala Ala Val
770 775 780
Gly Val Pro Gly Asp Ser Thr Arg Arg Ala Val Arg Arg Met Asn Thr
785 790 795 800
Phe Cys Gly Ala Ser Ala Cys Asp Val Ser Leu Ile Ala Met Asp Ser
805 810 815
Ala Thr Glu Tyr Asn Gln Lys Leu Gln Val Asn Gln Phe Ser Glu Ser
820 825 830
Lys Tyr Glu Ala Gly Met Thr Leu Gly Glu Lys Phe Arg Val Gly Asn
835 840 845
Cys Lys His Leu Lys Met Thr Arg Pro Thr Met Pro Ala Ile Leu Lys
850 855 860
Leu Gln Lys Asn Cys Leu Leu Ser Leu Asn Ser Lys Met Ala Leu Asn
865 870 875 880
Ser Glu Ala Leu Ser Val Val Ser Glu Cys Glu Glu Arg Gly Ala Ala
885 890 895
Gly Ser Leu Ile Ser Cys Glu Ser Leu Tyr His Arg Glu Lys Gln Leu
900 905 910
Ile Ala Met Asp Ser Ala Ile Phe Val Gln Gly Lys Asp Trp Gly Val
915 920 925
Lys Lys Phe Ile Arg Arg Asp Phe Arg Thr Ala Leu Thr His Asn Gln
930 935 940
Asp Phe Ser Ile Tyr Arg Leu Cys Cys Lys Arg Gly Ser Leu Cys His
945 950 955 960
Ala Ser Gln Ala Arg Ser Pro Ala Phe Pro Lys Pro Val Arg Pro Leu
965 970 975
Pro Ala Pro Ile Thr Arg Ile Thr Pro Gln Leu Gly Gly Gln Ser Asp
980 985 990
Ser Ser Gln Pro Leu Leu Thr Thr Gly Arg Pro Gln Gly Trp Gln Asp
995 1000 1005
Gln Ala Leu Arg His Thr Gln Gln Ala Ser Pro Ala Ser Cys Ala
1010 1015 1020
Thr Ile Thr Ile Pro Ile His Ser Ala Ala Leu Gly Asp His Ser
1025 1030 1035
Gly Asp Pro Gly Pro Ala Trp Asp Thr Cys Pro Pro Leu Pro Leu
1040 1045 1050
Thr Thr Leu Ile Pro Arg Ala Pro Pro Pro Tyr Gly Asp Ser Thr
1055 1060 1065
Ala Arg Ser Trp Pro Ser Arg Cys Gly Pro Leu Gly Tyr Ala Tyr
1070 1075 1080
Lys Asp Phe Leu Trp Cys Phe Pro Phe Ser Leu Val Phe Leu Gln
1085 1090 1095
Glu Ile Gln Ile Cys Cys His Val Ser Cys Leu Cys Cys Ile Cys
1100 1105 1110
Cys Ser Thr Arg Ile Cys Leu Gly Cys Leu Leu Glu Leu Phe Leu
1115 1120 1125
Ser Arg Ala Leu Arg Ala Leu His Val Leu Trp Asn Gly Phe Gln
1130 1135 1140
Leu His Cys Gln Gln Asn Leu Gln Asn Gly Gly Gly Ser Arg Ser
1145 1150 1155
Ser Ala Thr Leu Pro Gly Arg Arg Arg Arg Arg Trp Leu Arg Arg
1160 1165 1170
Arg Arg Gln Pro Ile Ser Val Ala Pro Ala Gly Pro Pro Arg Arg
1175 1180 1185
Pro Asn Gln Lys Pro Asn Pro Pro Gly Gly Ala Arg Cys Val Ile
1190 1195 1200
Met Arg Pro Thr Trp Pro Gly Thr Ser Ala Phe Thr Gly Met Glu
1205 1210 1215
Cys Thr Leu Gly Gln Val Gly Ala Pro Ser Pro Arg Arg Glu Glu
1220 1225 1230
Asp Gly Trp Arg Gly Gly His Ser Arg Phe Lys Ala Asp Val Pro
1235 1240 1245
Ala Pro Gln Gly Pro Cys Trp Gly Gly Gln Pro Gly Ser Ala Pro
1250 1255 1260
Ser Ser Ala Pro Pro Glu Gln Ser Leu Leu Asp Asp Tyr Trp Ala
1265 1270 1275
Gln Lys Glu Lys Ile Ser Ile Pro Arg Thr His Leu Cys Trp Lys
1280 1285 1290
Phe Glu Met Ser Tyr Thr Val Gly Gly Pro Pro Pro His Val His
1295 1300 1305
Ala Arg Pro Arg His Trp Lys Thr Asp Arg Asp Tyr Trp Ala Gln
1310 1315 1320
Lys Glu Lys Gly Ser Ser Ser Phe Leu Arg Pro Ser Cys Val Pro
1325 1330 1335
Phe Arg Glu Leu Lys Asn Val Ser Val Leu Glu Gly Leu Arg Gln
1340 1345 1350
Gly Arg Leu Gly Gly Pro Cys Ser Cys His Cys Pro Arg Pro Ser
1355 1360 1365
Gln Ala Arg Leu Thr Pro Val Asp Val Ala Gly Pro Phe Leu Cys
1370 1375 1380
Leu Gly Asp Pro Gly Leu Phe Pro Pro Val Lys Ser Ser Ile Thr
1385 1390 1395
Glu Ile Ser Cys Cys Thr Leu Ser Ser Glu Glu Asn Glu Tyr Leu
1400 1405 1410
Pro Arg Pro Glu Trp Gln Leu Gln Tyr Glu Ala Gly Met Thr Leu
1415 1420 1425
Gly Gly Lys Ile Leu Phe Phe Leu Phe Leu Leu Leu Pro Leu Ser
1430 1435 1440
Pro Phe Ser Leu Ile Phe Leu Val Leu Gly Val Leu Ser Gly His
1445 1450 1455
Ser Gly Ser Arg Leu Lys Arg Ser Phe Ala Val Thr Glu Arg Ile
1460 1465 1470
Ile Thr Gly Gly Lys Ser Thr Cys Ser Ala Pro Gly Pro Gln Ser
1475 1480 1485
Leu Pro Ser Thr Pro Phe Ser Thr Tyr Pro Gln Trp Val Ile Leu
1490 1495 1500
Ile Thr Glu Leu
1505
<210> 560
<211> 15
<212> PRT
<213> Homo sapiens
<400> 560
Trp Lys Phe Glu Met Ser Tyr Thr Val Gly Gly Pro Pro Pro His
1 5 10 15
<210> 561
<211> 15
<212> PRT
<213> Homo sapiens
<400> 561
Val Gly Gly Pro Pro Pro His Val His Ala Arg Pro Arg His Trp
1 5 10 15
<210> 562
<211> 14
<212> PRT
<213> Homo sapiens
<400> 562
Pro Pro His Val His Ala Arg Pro Arg His Trp Lys Thr Asp
1 5 10
<210> 563
<211> 15
<212> PRT
<213> Homo sapiens
<400> 563
Tyr Glu Ala Gly Met Thr Leu Gly Gly Lys Ile Leu Phe Phe Leu
1 5 10 15
<210> 564
<211> 15
<212> PRT
<213> Homo sapiens
<400> 564
Gly Lys Ile Leu Phe Phe Leu Phe Leu Leu Leu Pro Leu Ser Pro
1 5 10 15
<210> 565
<211> 16
<212> PRT
<213> Homo sapiens
<400> 565
Phe Phe Leu Phe Leu Leu Leu Pro Leu Ser Pro Phe Ser Leu Ile Phe
1 5 10 15
<210> 566
<211> 15
<212> PRT
<213> Homo sapiens
<400> 566
Asp Gly His Ser Tyr Thr Ser Lys Val Asn Cys Leu Leu Leu Gln
1 5 10 15
<210> 567
<211> 15
<212> PRT
<213> Homo sapiens
<400> 567
Val Asn Cys Leu Leu Leu Gln Asp Gly Phe His Gly Cys Val Ser
1 5 10 15
<210> 568
<211> 15
<212> PRT
<213> Homo sapiens
<400> 568
Gly Phe His Gly Cys Val Ser Ile Thr Gly Ala Ala Gly Arg Arg
1 5 10 15
<210> 569
<211> 15
<212> PRT
<213> Homo sapiens
<400> 569
Thr Gly Ala Ala Gly Arg Arg Asn Leu Ser Ile Phe Leu Phe Leu
1 5 10 15
<210> 570
<211> 15
<212> PRT
<213> Homo sapiens
<400> 570
Leu Ser Ile Phe Leu Phe Leu Met Leu Cys Lys Leu Glu Phe His
1 5 10 15
<210> 571
<211> 13
<212> PRT
<213> Homo sapiens
<400> 571
Leu Phe Leu Met Leu Cys Lys Leu Glu Phe His Ala Cys
1 5 10
<210> 572
<211> 15
<212> PRT
<213> Homo sapiens
<400> 572
Thr Gly Gly Lys Ser Thr Cys Ser Ala Pro Gly Pro Gln Ser Leu
1 5 10 15
<210> 573
<211> 15
<212> PRT
<213> Homo sapiens
<400> 573
Ala Pro Gly Pro Gln Ser Leu Pro Ser Thr Pro Phe Ser Thr Tyr
1 5 10 15
<210> 574
<211> 15
<212> PRT
<213> Homo sapiens
<400> 574
Ser Thr Pro Phe Ser Thr Tyr Pro Gln Trp Val Ile Leu Ile Thr
1 5 10 15
<210> 575
<211> 15
<212> PRT
<213> Homo sapiens
<400> 575
Ser Arg Ser Ser Ala Thr Leu Pro Gly Arg Arg Arg Arg Arg Trp
1 5 10 15
<210> 576
<211> 15
<212> PRT
<213> Homo sapiens
<400> 576
Asp Tyr Trp Ala Gln Lys Glu Lys Gly Ser Ser Ser Phe Leu Arg
1 5 10 15
<210> 577
<211> 14
<212> PRT
<213> Homo sapiens
<400> 577
Gln Lys Glu Lys Gly Ser Ser Ser Phe Leu Arg Pro Ser Cys
1 5 10
<210> 578
<211> 15
<212> PRT
<213> Homo sapiens
<400> 578
Val Pro Phe Arg Glu Leu Lys Asn Val Ser Val Leu Glu Gly Leu
1 5 10 15
<210> 579
<211> 15
<212> PRT
<213> Homo sapiens
<400> 579
Val Ser Val Leu Glu Gly Leu Arg Gln Gly Arg Leu Gly Gly Pro
1 5 10 15
<210> 580
<211> 15
<212> PRT
<213> Homo sapiens
<400> 580
Gln Gly Arg Leu Gly Gly Pro Cys Ser Cys His Cys Pro Arg Pro
1 5 10 15
<210> 581
<211> 15
<212> PRT
<213> Homo sapiens
<400> 581
Ser Cys His Cys Pro Arg Pro Ser Gln Ala Arg Leu Thr Pro Val
1 5 10 15
<210> 582
<211> 15
<212> PRT
<213> Homo sapiens
<400> 582
Gln Ala Arg Leu Thr Pro Val Asp Val Ala Gly Pro Phe Leu Cys
1 5 10 15
<210> 583
<211> 15
<212> PRT
<213> Homo sapiens
<400> 583
Val Ala Gly Pro Phe Leu Cys Leu Gly Asp Pro Gly Leu Phe Pro
1 5 10 15
<210> 584
<211> 13
<212> PRT
<213> Homo sapiens
<400> 584
Gly Asp Pro Gly Leu Phe Pro Pro Val Lys Ser Ser Ile
1 5 10
<210> 585
<211> 15
<212> PRT
<213> Homo sapiens
<400> 585
Gly Met Glu Cys Thr Leu Gly Gln Val Gly Ala Pro Ser Pro Arg
1 5 10 15
<210> 586
<211> 15
<212> PRT
<213> Homo sapiens
<400> 586
Val Gly Ala Pro Ser Pro Arg Arg Glu Glu Asp Gly Trp Arg Gly
1 5 10 15
<210> 587
<211> 15
<212> PRT
<213> Homo sapiens
<400> 587
Glu Glu Asp Gly Trp Arg Gly Gly His Ser Arg Phe Lys Ala Asp
1 5 10 15
<210> 588
<211> 15
<212> PRT
<213> Homo sapiens
<400> 588
His Ser Arg Phe Lys Ala Asp Val Pro Ala Pro Gln Gly Pro Cys
1 5 10 15
<210> 589
<211> 15
<212> PRT
<213> Homo sapiens
<400> 589
Pro Ala Pro Gln Gly Pro Cys Trp Gly Gly Gln Pro Gly Ser Ala
1 5 10 15
<210> 590
<211> 15
<212> PRT
<213> Homo sapiens
<400> 590
Gly Gly Gln Pro Gly Ser Ala Pro Ser Ser Ala Pro Pro Glu Gln
1 5 10 15
<210> 591
<211> 15
<212> PRT
<213> Homo sapiens
<400> 591
Gly Ser Ala Pro Ser Ser Ala Pro Pro Glu Gln Ser Leu Leu Asp
1 5 10 15
<210> 592
<211> 15
<212> PRT
<213> Homo sapiens
<400> 592
Gly Asn Thr Thr Leu Gln Gln Leu Gly Glu Ala Ser Gln Ala Pro
1 5 10 15
<210> 593
<211> 15
<212> PRT
<213> Homo sapiens
<400> 593
Gly Glu Ala Ser Gln Ala Pro Ser Gly Ser Leu Ile Pro Leu Arg
1 5 10 15
<210> 594
<211> 16
<212> PRT
<213> Homo sapiens
<400> 594
Gly Ser Leu Ile Pro Leu Arg Leu Pro Leu Leu Trp Glu Val Arg Gly
1 5 10 15
<210> 595
<211> 15
<212> PRT
<213> Homo sapiens
<400> 595
Glu Ala Phe Gln Arg Ala Ala Gly Glu Gly Gly Pro Gly Arg Gly
1 5 10 15
<210> 596
<211> 15
<212> PRT
<213> Homo sapiens
<400> 596
Glu Gly Gly Pro Gly Arg Gly Gly Ala Arg Arg Gly Ala Arg Val
1 5 10 15
<210> 597
<211> 15
<212> PRT
<213> Homo sapiens
<400> 597
Ala Arg Arg Gly Ala Arg Val Leu Gln Ser Pro Phe Cys Arg Ala
1 5 10 15
<210> 598
<211> 15
<212> PRT
<213> Homo sapiens
<400> 598
Gln Ser Pro Phe Cys Arg Ala Gly Ala Gly Glu Trp Leu Gly His
1 5 10 15
<210> 599
<211> 15
<212> PRT
<213> Homo sapiens
<400> 599
Cys Arg Ala Gly Ala Gly Glu Trp Leu Gly His Gln Ser Leu Arg
1 5 10 15
<210> 600
<211> 15
<212> PRT
<213> Homo sapiens
<400> 600
Asp Tyr Trp Ala Gln Lys Glu Lys Ile Ser Ile Pro Arg Thr His
1 5 10 15
<210> 601
<211> 13
<212> PRT
<213> Homo sapiens
<400> 601
Gln Lys Glu Lys Ile Ser Ile Pro Arg Thr His Leu Cys
1 5 10
<210> 602
<211> 15
<212> PRT
<213> Homo sapiens
<400> 602
Val Ala Met Met Val Pro Asp Arg Gln Val His Tyr Asp Phe Gly
1 5 10 15
<210> 603
<211> 13
<212> PRT
<213> Homo sapiens
<400> 603
Val Pro Asp Arg Gln Val His Tyr Asp Phe Gly Leu Arg
1 5 10
<210> 604
<211> 15
<212> PRT
<213> Homo sapiens
<400> 604
Phe Lys Lys Phe Asp Gly Pro Cys Gly Glu Arg Gly Gly Gly Arg
1 5 10 15
<210> 605
<211> 15
<212> PRT
<213> Homo sapiens
<400> 605
Gly Glu Arg Gly Gly Gly Arg Thr Ala Arg Ala Leu Trp Ala Arg
1 5 10 15
<210> 606
<211> 15
<212> PRT
<213> Homo sapiens
<400> 606
Ala Arg Ala Leu Trp Ala Arg Gly Asp Ser Val Leu Thr Pro Ala
1 5 10 15
<210> 607
<211> 15
<212> PRT
<213> Homo sapiens
<400> 607
Asp Ser Val Leu Thr Pro Ala Leu Asp Pro Gln Thr Pro Val Arg
1 5 10 15
<210> 608
<211> 15
<212> PRT
<213> Homo sapiens
<400> 608
Asp Pro Gln Thr Pro Val Arg Ala Pro Ser Leu Thr Arg Ala Ala
1 5 10 15
<210> 609
<211> 14
<212> PRT
<213> Homo sapiens
<400> 609
Pro Val Arg Ala Pro Ser Leu Thr Arg Ala Ala Ala Ala Val
1 5 10
<210> 610
<211> 15
<212> PRT
<213> Homo sapiens
<400> 610
Gly Arg Arg Arg Arg Arg Trp Leu Arg Arg Arg Arg Gln Pro Ile
1 5 10 15
<210> 611
<211> 15
<212> PRT
<213> Homo sapiens
<400> 611
Gly Val Pro Gly Asp Ser Thr Arg Arg Ala Val Arg Arg Met Asn
1 5 10 15
<210> 612
<211> 13
<212> PRT
<213> Homo sapiens
<400> 612
Asp Ser Thr Arg Arg Ala Val Arg Arg Met Asn Thr Phe
1 5 10
<210> 613
<211> 15
<212> PRT
<213> Homo sapiens
<400> 613
Arg Arg Arg Arg Gln Pro Ile Ser Val Ala Pro Ala Gly Pro Pro
1 5 10 15
<210> 614
<211> 15
<212> PRT
<213> Homo sapiens
<400> 614
Val Ala Pro Ala Gly Pro Pro Arg Arg Pro Asn Gln Lys Pro Asn
1 5 10 15
<210> 615
<211> 15
<212> PRT
<213> Homo sapiens
<400> 615
Thr Glu Ile Ser Cys Cys Thr Leu Ser Ser Glu Glu Asn Glu Tyr
1 5 10 15
<210> 616
<211> 16
<212> PRT
<213> Homo sapiens
<400> 616
Ser Ser Glu Glu Asn Glu Tyr Leu Pro Arg Pro Glu Trp Gln Leu Gln
1 5 10 15
<210> 617
<211> 15
<212> PRT
<213> Homo sapiens
<400> 617
Arg Pro Asn Gln Lys Pro Asn Pro Pro Gly Gly Ala Arg Cys Val
1 5 10 15
<210> 618
<211> 15
<212> PRT
<213> Homo sapiens
<400> 618
Pro Gly Gly Ala Arg Cys Val Ile Met Arg Pro Thr Trp Pro Gly
1 5 10 15
<210> 619
<211> 15
<212> PRT
<213> Homo sapiens
<400> 619
His Val Val Gly Tyr Gly His Leu Asp Thr Ser Gly Ser Ser Ser
1 5 10 15
<210> 620
<211> 16
<212> PRT
<213> Homo sapiens
<400> 620
Tyr Gly His Leu Asp Thr Ser Gly Ser Ser Ser Ser Ser Ser Trp Pro
1 5 10 15
<210> 621
<211> 12
<212> PRT
<213> Homo sapiens
<400> 621
Met Arg Pro Thr Trp Pro Gly Thr Ser Ala Phe Thr
1 5 10
<210> 622
<211> 32363
<212> DNA
<213> Artificial sequence
<220>
<223> GAd20
<400> 622
catcatcaat aatatacctt attttggatt gaggccaata tgataatgag gtgggcgggg 60
cgaggcgggg cgggtgacgt aggacgcgcg agtagggttg ggaggtgtgg cggaagtgtg 120
gcatttgcaa gtgggaggag ctgacatgca atcttccgtc gcggaaaatg tgacgttttt 180
gatgagcgcc gcctacctcc ggaagtgcca attttcgcgc gcttttcacc ggatatcgta 240
gtaattttgg gcgggaccat gtaagatttg gccattttcg cgcgaaaagt gaaacgggga 300
agtgaaaact gaataatagg gcgttagtca tagcgcgtaa tatttaccga gggccgaggg 360
actttgaccg attacgtgga ggactcgccc aggtgttttt tacgtgaatt tccgcgttcc 420
gggtcaaagt ctccgttttt attgtcgccg tcatctgacg cggagggtat ttaaacccgc 480
tgcgctccta aagaggccac tcttgagtgc cagcgagaag agttttctcc tccgctccgt 540
ttcggcgatc gaaaaatgag acatttagcc tgcactccgg gtcttttgtc cggccgggcg 600
gcgtccgagc ttttggacgc tttgctcaat gaggttctga gcgatgattt tccgtctact 660
acccacttta gcccacctac tcttcacgaa ctgtacgatc tggatgtact ggtggatgtg 720
aacgatccca acgaggaggc ggtttctacg ttttttcccg agtctgcgct tttggctgcc 780
caggagggat ttgacctaca cactccgccg ctgcctattt tagagtctcc gctgccggag 840
cccagtggta taccttatat gcctgaactg cttcccgaag tggtagacct gacctgccac 900
gagccgggct ttccgcccag cgacgatgag ggtgagcctt ttgctttaga ctatgctgag 960
atacctgggc tcggttgcag gtcttgtgca tatcatcaga gggttaccgg agaccccgag 1020
gttaagtgtt cgctgtgcta tatgaggctg acctcttcct ttatctacag taagtttttt 1080
tgtgtaggtg ggctttttgg gtaggtgggt tttgtggcag gacaggtgta aatgttgctt 1140
gtgttttttg tacctgcagg tccggtgtcc gagccagacc cggagcccga ccgcgatccc 1200
gagccggatc ccgagcctcc tcgcaggcca aggaaattac cttccatttt gtgcaagcct 1260
aagacacctg tgaggaccag cgaggcggac agcactgact ctggcacttc tacctctcct 1320
cctgaaattc acccagtggt tcctctgggt atacatagac ctgttgctgt tagagtttgc 1380
gggcgacgcc ctgcagtaga gtgcattgag gacttgctta acgatcccga gggacctttg 1440
gacttgagca ttaaacgccc taggcaataa accccaccta agtaataaac cccacctaag 1500
taataaactt taccgccctt ggttattgag atgacgccca atgtttgctt ttgaatgact 1560
tcatgtgtat aataaaagtg agtgtggtca taggtctctt gtttgtctgg gcggggttta 1620
agggtatata agtttctcgg ggctaaactt ggttacactt gaccccaatg gaggcgtggg 1680
ggtgcttgga ggagtttgcg gacgtgcgcc gtttgctgga cgagagctct agcaatacct 1740
atagtatttg gaggtatctg tggggctcta ctcaggccaa gttggtcttc agaattaagc 1800
aggattacaa gtgcgatttt gaagagcttt ttagttcctg tggtgagctt ttgcaatcct 1860
tgaatctggg ccaccaggct atcttccagg aaaaggttct ctcgactttg gatttttcca 1920
ctcccgggcg caccgccgct tgtgtggctt ttgtgtcttt tgtgcaagat aaatggagcg 1980
gggagaccca cctgagtcac ggctacgtgc tggatttcat ggcgatggct ctttggaggg 2040
cttacaacaa atggaagatt cagaaggaac tgtacggttc cgccctacgt cgtccacttc 2100
tgcagcggca ggggctgatg tttcccgacc atcgccagca tcagaatctg gaagacgagc 2160
gagcggagaa gatcagcttg agagccggcc tggaccctcc tcaggaggaa tgaatctccc 2220
gcaggtggtt gagctgtttc ccgaactgag acgggtcctg actatcaggg aggatggtca 2280
gtttgtgaag aagctgaaga gggatcgggg tgagggagat gatgaggcgg ctagcaattt 2340
agcttttagt ctgataactc gccaccgacc ggaatgtatt acctatcagc agattaagga 2400
gagttgtgcc aacgagctgg atcttttggg tcagaagtat agcatagaac agcttaccac 2460
ttactggctt cagcccgggg atgattggga agaggcgatt agggtgtatg caaaggtggc 2520
cctgcggccc gattgcaagt ataagattac taagttggtt aatattagaa actgctgcta 2580
tatttctgga aacggggccg aagtggagat agatactgag gacagggtgg ctattaggtg 2640
ttgcatgata aacatgtggc ccgggatact ggggatggat ggggtgatat ttatgaatgt 2700
gaggttcacg ggccccaact ttaatggtac ggtgttcatg ggcaacacca acttgctcct 2760
gcatggtgcg agtttctatg ggtttaacaa cacctgtata gaggcctgga ccgatgtaaa 2820
ggttcgaggt tgttcctttt atagctgttg gaaggcggtg gtgtgtcgcc ctaaaagcag 2880
gggttctgtg aagaaatgct tgtttgaaag gtgcacccta ggtatccttt ctgagggcaa 2940
ctccagggtg cgccataatg tggcttcgaa ctgcggttgc ttcatgcaag tgaagggggt 3000
gagcgttatc aagcataact cggtctgtgg aaactgcgag gatcgcgcct ctcagatgct 3060
gacctgcttt gatggcaact gtcacctgtt gaagaccatt catataagca gtcaccccag 3120
aaaggcctgg cccgtgtttg agcataacat tctgacccgc tgttccttgc atctgggggt 3180
caggaggggt atgttcctgc cttaccagtg taactttagc cacactaaaa tcctgctgga 3240
acccgagtgc atgactaagg tcagcctgaa tggtgtgttt gatgtgagtc tgaagatttg 3300
gaaggtgctg aggtatgatg agaccaggac caggtgccga ccctgcgagt gcggcggcaa 3360
gcacatgaga aatcagcctg tgatgttgga tgtgaccgag gagcttaggc ctgaccatct 3420
ggtgctggcc tgcaccaggg ccgagtttgg gtctagcgat gaggataccg attgaggtgg 3480
gtaaggtggg cgtggctagc agggtgggcg tgtataaatt gggggtctaa ggggtctctc 3540
tgtttgtctt gcaacagccg ccgccatgag cgacaccggc aacagctttg atggaagcat 3600
ctttagtccc tatctgacag tgcgcatgcc tcactgggcc ggagtgcgtc agaatgtgat 3660
gggttccaac gtggatggac gtcccgttct gccttcaaat tcgtctacta tggcctacgc 3720
gaccgtggga ggaactccgc tggacgccgc gacctccgcc gccgcctccg ccgccgccgc 3780
gaccgcgcgc agcatggcta cggaccttta cagctctttg gtggcgagca gcgcggcctc 3840
tcgcgcgtct gctcgggatg agaaactgac tgctctgctg cttaaactgg aagacttgac 3900
ccgggagctg ggtcaactga cccagcaggt ttccagcttg cgtgagagca gccttgcctc 3960
cccctaatgg cccataatat aaataaaagc cagtctgttt ggattaagca agtgtatgtt 4020
ctttatttaa ctctccgcgc gcggtaagcc cgggaccagc ggtctcggtc gtttagggtg 4080
cggtggattt tttccaacac gtggtacagg tggctctgga tgtttagata catgggcatg 4140
agtccatccc tggggtggag gtagcaccac tgcagagctt cgtgctcggg ggtggtgttg 4200
tatatgatcc agtcgtagca ggagcgctgg gcgtggtgct gaaaaatgtc cttaagcaag 4260
aggcttatag ctagggggag gcccttggtg taagtgttta caaatctgct tagctgggag 4320
gggtgcatcc ggggggatat gatgtgcatc ttggactgga tttttaggtt ggctatgttc 4380
ccgcccagat cccttctggg attcatgttg tgcaggacca ccagcacggt atatccagtg 4440
cacttgggaa atttatcgtg gagcttagac gggaatgcat ggaagaactt ggagacgccc 4500
ttgtggcctc ccagattttc catacattcg tccatgatga tggcaatggg cccgtgggaa 4560
gctgcctgag caaaaacgtt tctggcatcg ctcacatcgt agttatgttc cagggtgagg 4620
tcatcatagg acatctttac gaatcggggg cgaagggtcc cggactgggg gatgatggta 4680
ccctcgggcc ccggggcgta gttcccctca cagatctgca tctcccaggc tttcatttca 4740
gagggaggga tcatatccac ctgcggggcg atgaaaaaga cagtttctgg cgcaggggag 4800
attaactggg atgagagcag gtttctgagc agctgtgact ttccacagcc ggtgggccca 4860
tatatcacgc ctatcaccgg ctgcagctgg tagttaagag agctgcagct gccgtcctcc 4920
cggagcaggg gggccacctc gttgagcata tccctgacgt ggatgttctc cctgaccagt 4980
tccgccagaa ggcgctcgcc gcccagcgaa agcagctctt gcaaggaagc aaaatttttc 5040
agcggtttca ggccatcggc cgtgggcatg tttttcagcg tctgggtcag cagctccagc 5100
ctgtcccaga gctcggtgat gtgctctacg gcatctcgat ccagcagatc tcctcgtttc 5160
gcgggttggg gcggctttcg ctgtagggca ccagccgatg ggcgtccagc ggggccagag 5220
tcatgtcctt ccatgggcgc agggtcctcg tcagggtggt ctgggtcacg gtgaaggggt 5280
gcgctccggg ttgggcactg gccagggtgc gcttgaggct ggttctgctg gtgctgaatc 5340
gctgccgctc ttcgccctgc gcgtcggcca ggtagcattt gaccatggtc tcgtagtcga 5400
gaccctcggc ggcgtgcccc ttggcgcgga gctttccctt ggaggtggcg ccgcacgagg 5460
ggcactgcag gctcttcagg gcgtagagct tgggagcgag aaacacggac tctggggagt 5520
aggcgtccgc gccgcaggcc gagcagaccg tctcgcattc caccagccaa gtgagttccg 5580
ggcggtcagg gtcaaaaacc aggttgcccc catgcttttt gatgcgtttc ttaccttggc 5640
tctccatgag gcggtgtccc ttctcggtga cgaagaggct gtccgtgtcc ccgtagaccg 5700
acttcagggg cctgtcttcc agcggagtgc ctctgtcctc ctcgtagaga aactctgacc 5760
actctgagac gaaggcccgc gtccaggcca ggacgaagga ggccacgtgg gaggggtagc 5820
ggtcgttgtc cactagcggg tccaccttct ccagggtgtg caggcacatg tccccctcct 5880
ccgcgtccag aaaagtgatt ggcttgtagg tgtaggacac gtgaccgggg gttcccaacg 5940
ggggggtata aaagggggtg ggtgcccttt catcttcact ctcttccgca tcgctgtctg 6000
cgagagccag ctgctggggt aagtattccc tctcgaaggc gggcatgacc tcagcgctca 6060
ggttgtcagt ttctaaaaat gaggaggatt tgatgttcac ctgtccggag gtgatacctt 6120
tgagggtacc tgggtccatc tggtcagaaa acactatttt tttgttatca agcttggtgg 6180
cgaatgaccc gtagagggcg ttggagagca gcttggcgat ggagcgcagg gtctggtttt 6240
tgtcgcggtc ggctcgctcc ttggccgcga tgttgagttg cacgtactcg cgggccacgc 6300
acttccactc ggggaacacg gtggtgcgct cgtctgggat caggcgcacc ctccagccgc 6360
ggttgtgcag ggtgaccatg tcgacgctgg tggcgacctc accgcgcaga cgctcgttgg 6420
tccagcagag gcggccgccc ttgcgcgagc agaagggggg tagggggtcc agctggtcct 6480
cgtttggggg gtccgcgtcg atggtaaaga ccccggggag caggcgcggg tcaaagtagt 6540
cgatcttgca agcttgcatg tccagagccc gctgccattc gcgggcggcg agcgcgcgct 6600
cgtaggggtt gaggggcggg ccccagggca tggggtgggt gagcgcggag gcgtacatgc 6660
cgcagatgtc atacacgtac aggggttccc tgaggatacc gaggtaggtg gggtagcagc 6720
gccccccgcg gatgctggcg cgcacgtagt catagagctc gtgggagggg gccagcatgt 6780
tgggcccgag gttggtgcgc tgggggcgct cggcgcggaa gacgatctgc ctgaagatgg 6840
cgtgggagtt ggaggagatg gtgggccgct ggaagacgtt gaagcttgct tcttgcaagc 6900
ccacggagtc cctgacgaag gaggcgtagg actcgcgcag cttgtgcacc agctcggcgg 6960
tgacctggac gtcgagcgca cagtagtcga gggtctcgcg gatgatgtca tacctatcct 7020
cccccttctt tttccacagc tcgcggttga ggacgaactc ttcgcggtct ttccagtact 7080
cttggagggg aaacccgtcc gtgtccgaac ggtaagagcc tagcatgtag aactggttga 7140
cggcctggta ggggcagcag cccttctcca cgggcagcgc gtaggcctgc gccgccttgc 7200
ggagggaggt gtgggtgagg gcgaaagtgt ccctgaccat gactttgagg tattgatgtc 7260
tgaagtctgt gtcatcgcag ccgccctgtt cccacagggt gtagtccgtg cgctttttgg 7320
agcgcgggtt gggcagggag aaggtgaggt cattgaagag gatcttcccc gctcgaggca 7380
tgaagtttct ggtgatgcga aagggccctg ggaccgagga gcggttgttg atgacctggg 7440
cggccaggac gatctcgtca aagccgttta tgttgtgtcc cacgatgtag agctccagga 7500
agcggggctg gcccttgatg gaggggagct ttttaagttc ctcgtaggta agctcctcgg 7560
gcgattccag gccgtgctcc tccagggccc agtcttgcaa gtgagggttg gccgccagga 7620
aggatcgcca gaggtcgcgg gccatgaggg tctgcaggcg gtcgcggaag gttctgaact 7680
gccgccccac ggccattttt tcgggggtga tgcagtagaa ggtgaggggg tctttctccc 7740
aggggtccca tctgagctct cgggcgaggt cgcgcgcggc agcgaccaga gcctcgtcgc 7800
cccccagttt catgaccagc atgaagggca cgagttgctt gccaaaggct cccatccaag 7860
tgtaggtttc tacatcgtag gtgacaaaga ggcgctccgt gcgaggatga gagccgattg 7920
ggaagaactg gatctcccgc caccagttgg aggattggct gttgatgtgg tgaaagtaga 7980
agtcccgtct gcgggccgag cactcgtgct ggcttttgta aaagcgaccg cagtactggc 8040
agcgctgcac gggttgtata tcttgcacga ggtgaacctg gcgacctctg acgaggaagc 8100
gcagcgggaa tctaagtccc ccgcctgggg tcccgtgtgg ctggtggtct tttactttgg 8160
ttgtctggcc gccagcatct gtctcctgga gggcgatggt ggaacagacc accacgccgc 8220
gagagccgca ggtccagatc tcggcgctcg gcgggcggag tttgatgacg acatcgcgca 8280
cattggagct gtccatggtc tccagctccc gcggcggcag gtcagccggg agttcctgga 8340
ggttcacctc gcagagacgg gtcaaggcgc ggacagtgtt gagatggtat ctgatttcaa 8400
ggggcatgtt ggaggcggag tcgatggctt gcaggaggcc gcagccccgg ggggccacga 8460
tggttccccg cggggcgcga ggggaggcgg aagctggggg tgtgttcaga agcggtgacg 8520
cgggcgggcc cccggaggta gggggggttc cggccccaca ggcatgggcg gcaggggcac 8580
gtcttcgccg cgcgcgggca ggggctggtg ctggctccga agagcgcttg cgtgcgcgac 8640
gacgcgacgg ttggtgtcct gtatctggcg cctctgagtg aagaccacgg gtcccgtgac 8700
cttgaacctg aaagagagtt cgacagaatc aatctcggca tcgttgacag cggcctggcg 8760
caggatctcc tgcacgtcgc ccgagttgtc ctggtaggcg atttctgcca tgaactgctc 8820
gatctcttcc tcctggagat ctcctcgtcc ggcgcgctcc acggtggccg ccaggtcgtt 8880
ggagatgcga cccatgagct gcgagaaggc gttgagtccg ccctcgttcc agacccggct 8940
gtagaccacg cccccctcgg cgtcgcgggc gcgcatgacc acctgggcca ggttgagctc 9000
cacgtgtcgc gtgaagacgg cgtagttgcg caggcgctgg aaaaggtagt tcagggtggt 9060
ggcggtgtgc tcggcgacga agaagtacat gacccagcgc cgcaacgtgg attcattgat 9120
gtcccccaag gcctccaggc gctccatggc ctcgtagaag tccacggcga agttgaaaaa 9180
ctgggagttg cgagcggaca cggtcaactc ctcctccaga agacggatga gctcggcgac 9240
agtgtcgcgc acctcgcgct cgaaggccac ggggggcgct tcttcctctt ccacctcttc 9300
ttccatgatt gcttcttctt cttcctcagc cgggacggga gggggcggcg gcgggggagg 9360
ggcgcggcgg cggcggcggc gcaccgggag gcggtcgatg aagcgctcga tcatctcccc 9420
ccgcatgcgg cgcatggtct cggtgacggc gcggccgttc tcccgggggc gcagctcgaa 9480
gacgccgcct ctcatttcgc cgcggggcgg gcggccgtga ggtagcgaga cggcgctgac 9540
tatgcatctt aacaattgct gtgtaggtac gccgccaagg gacctgattg agtccagatc 9600
caccggatcc gaaaaccttt ggaggaaagc gtctatccag tcgcagtcgc aaggtaggct 9660
gagcaccgtg gcgggcgggg gcgggtcggg agagttcctg gcggagatgc tgctgatgat 9720
gtaattaaag taggcggtct tgagaaggcg gatggtggac aggagcacca tgtctttggg 9780
tccggcctgt tggatgcgga ggcggtcggc catgccccag gcctcgttct gacaccggcg 9840
caggtctttg tagtaatctt gcatgagtct ttccaccggc acttcttctc cttcctcttc 9900
ttcatctcgc cggtggtttc tcgcgccgcc catgcgcgtg accccaaagc ccctgagcgg 9960
ctgcagcagg gccaggtcgg cgaccacgcg ctcggccaag atggcctgct gtacctgagt 10020
gagggtcctc tcgaagtcat ccatgtccac gaagcggtgg taggcacccg tgttgatggt 10080
gtaggtgcag ttggccatga cggaccagtt gacggtctgg tgtcccggct gcgagagctc 10140
cgtgtaccgc aggcgcgaga aggcgcggga atcgaacacg tagtcgttgc aagtccgcac 10200
cagatactgg tagcccacca ggaagtgcgg cggaggttgg cgatagaggg gccagcgctg 10260
ggtggcgggg gcgccgggcg ccaggtcttc cagcatgagg cggtggtatc cgtagatgta 10320
cctggacatc caggtgatgc ctgcggcggt ggtggtggcg cgcgcgtagt cgcggacccg 10380
gttccagatg tttcgcaggg gcgagaagtg ttccatggtc ggcacgctct ggccggtgag 10440
gcgcgcgcag tcgttgacgc tctatacaca cacaaaaacg aaagcgttta cagggctttc 10500
gttctgtagc ctggaggaaa gtaaatgggt tgggttgcgg tgtgccccgg ttcgagacca 10560
agctgagctc agccggctga agccgcagct aacgtggtat tggcagtccc gtctcgaccc 10620
aggccctgta tcctccagga tacggtcgag agcccttttg ctttcttggc caagcgcccg 10680
tggcgcgatc tgggatagat ggtcgcgatg agaggacaaa agcggctcgc ttccgtagtc 10740
tggagaaaca atcgccaggg ttgcgttgcg gcgtaccccg gttcgagccc ctatggcggc 10800
ttggatcggc cggaaccgcg gctaacgtgg gctgtggcag ccccgtcctc aggaccccgc 10860
cagccgactt ctccagttac gggagcgagc cccttttgtt tttttatttt ttagatgcat 10920
cccgtgctgc ggcagatgcg cccctcgccc cggcccgatc agcagcagca acagcaggca 10980
tgcagacccc cctctcctct ccccgccccg gtcaccacgg ccgcggcggc cgtgtccggt 11040
gcggggggcg cgctggagtc agatgagcca ccgcggcggc gacctaggca gtatctggac 11100
ttggaagagg gcgagggact ggcgcggctg ggggcgagct ctccagagcg ccacccgcgg 11160
gtgcagttga aaagggacgc gcgtgaggcg tacctgccgc ggcaaaacct gtttcgcgac 11220
cgcgggggcg aggagcccga ggagatgcgg gactgcaggt tccaagcggg gcgcgagctg 11280
cgccgcggct tggacagaca gcgcctgctg cgcgaggagg actttgagcc cgacacgcag 11340
acgggcatca gccccgcgcg cgcgcacgtg gccgcggccg acctggtgac cgcctacgag 11400
cagacggtga accaggagcg caacttccaa aaaagcttca acaaccacgt gcgcacgctg 11460
gtggcgcgcg aggaggtgac cctgggtctc atgcatctgt gggacctggt ggaggcgatc 11520
gtgcagaacc ccagcagcaa gcccctgacc gcgcagctgt tcctggtggt gcagcacagc 11580
agggacaacg aggccttcag ggaggcgctg ctgaacatca ccgagccgga ggggcgctgg 11640
ctcctggacc tgataaacat cctgcagagc atagtggtgc aggagcgcag cctgagcctg 11700
gccgagaagg tggcggccat taactattct atgctgagcc tgggcaagtt ctacgctcgc 11760
aagatctaca agacccccta cgtgcccata gacaaggagg tgaagataga cagcttctac 11820
atgcgcatgg cgctgaaggt gctaaccctg agcgacgacc tgggagtgta ccgcaacgag 11880
cgcatccaca aggccgtgag cgccagccgg cggcgcgagc tgagcgaccg cgaactgatg 11940
cacagtctgc agcgcgcgct gaccggcgcg ggcgagggcg acagggaggt cgagtcctac 12000
tttgacatgg gggccgacct gcactggcag ccgagccgcc gcgccctgga agcggcgggg 12060
gcgtacggcg gccccctggc ggccgatgac gaggaagagg aggactatga gctagaggag 12120
ggcgagtacc tggaggactg acctggctgg tggtgttttg gtatagatgc aagatccgaa 12180
cgtggcggac ccggcggtcc gggcggcgct gcagagccag ccgtccggca ttaactcctc 12240
tgacgactgg gccgcggcca tgggtcgcat catggccctg accgcgcgca accccgaggc 12300
cttcaggcag cagcctcagg ctaaccggct ggcggccatc ttggaagcgg tagtgcccgc 12360
gcgctccaac cccacccacg agaaggtgct ggccatagtc aacgcgctgg cggagagcag 12420
ggccatccgg gcagacgagg ccggactggt gtacgatgcg ctgctgcagc gggtggcgcg 12480
gtacaacagc ggcaacgtgc agaccaacct ggaccgcctg gtgacggacg tgcgcgaggc 12540
cgtggcgcag cgcgagcgct tgcatcagga cggcaacctg ggctcgctgg tggcgctaaa 12600
cgccttcctt agcacccagc cggccaacgt accgcggggg caggaggact acaccaactt 12660
cttgagcgcg ctgcggctga tggtgaccga ggtccctcag agcgaggtgt accagtcggg 12720
gcccgactac ttcttccaga ccagcagaca gggcttgcaa accgtgaacc tgagccaggc 12780
tttcaagaac ctgcgggggc tgtggggagt gaaggcgccc accggcgacc gggctacggt 12840
gtccagcctg ctaaccccca actcgcgcct gctgctgctg ctgatcgcgc ccttcacgga 12900
cagcgggagc gtctcgcggg agacctatct gggccacctg ctgacgctgt accgcgaggc 12960
catcgggcag gcgcaggtgg acgagcacac cttccaggag atcaccagcg tgagccacgc 13020
gctggggcag gaggacacgg gcagcctgca ggcgaccctg aactacctgc tgaccaacag 13080
gcggcagaag attcccacgc tgcacagcct gacccaggag gaggagcgca tcttgcgcta 13140
cgtgcagcag agcgtgagcc tgaacctgat gcgcgacggc gtgacgccca gcgtggcgct 13200
ggacatgacc gcgcgcaaca tggaaccggg catgtacgct tcccagcggc cgttcatcaa 13260
ccgcctgatg gactacttgc atcgggcggc ggccgtgaac cccgagtact tcaccaatgc 13320
cattctgaat ccccactgga tgccccctcc gggtttctac aacggggact tcgaggtgcc 13380
tgaggtcaac gatgggttcc tctgggatga catggatgac agtgtgttct cccccaaccc 13440
gctgcgcgcc gcgtctctgc gattgaagga gggctctgac agggaaggac caaggagtct 13500
ggcctcctcc ctggctctgg gggcggtggg cgccacgggc gcggcggcgc ggggcagcag 13560
ccccttcccc agcctggcgg actctctgaa tagcgggcgg gtgagcaggc cccgcttgct 13620
aggcgaggag gagtatctga acaactccct gctgcagccc gtgagggaca aaaacgctca 13680
gcggcagcag tttcccaaca atgggataga gagcctggtg gacaagatgt ccagatggaa 13740
gacgtatgcg caggagtaca aggagtggga ggaccgccag ccgcggcccc tgccgccccc 13800
tagacagcgc tggcagcggc gcgcgtccaa ccgccgctgg aggcaggggc ccgaggacga 13860
tgatgactct gcagatgaca gcagcgtgtt ggacctgggc gggagcggga accccttttc 13920
gcacctgcgc ccacgcctgg gcaagatgtt ttaaaagaga aaaataaaaa ctcaccaagg 13980
ccatggcgac gagcgttggt tttttgttcc cttccttagt atgcggcgcg cggcgatgtt 14040
cgaggagggg cctcccccct cttacgagag cgcgatggga atttctcctg cggcgcccct 14100
gcagcctccc tacgtgcctc ctcggtacct gcaacctaca ggggggagaa atagcatctg 14160
ttactctgag ctgcagcccc tgtacgatac caccagactg tacctggtgg acaacaagtc 14220
cgcggacgtg gcctccctga actaccagaa cgaccacagc gattttttga ccacggtgat 14280
ccaaaacaac gacttcaccc caaccgaggc cagtacccag accataaacc tggacaacag 14340
gtcgaactgg ggcggcgacc tgaagactat cctgcacacc aatatgccca acgtgaacga 14400
gttcatgttc accaactctt ttaaggcgcg ggtgatggtg gcgcgcgagc agggggaggc 14460
gaagtacgag tgggtggact tcacgctgcc cgagggcaac tactcagaga ccatgactct 14520
cgacctgatg aacaatgcga tcgtggaaca ctatctgaaa gtgggcaggc agaacggggt 14580
gaaggagagc gatatcgggg tcaagtttga caccagaaac ttccgtctgg gctgggaccc 14640
tgtgaccggg ctggtcatgc cgggggtcta caccaacgag gcctttcatc ccgatatagt 14700
gctcctgccc ggctgtgggg tggacttcac ccagagccgg ctgagcaacc tgctgggcgt 14760
tcgcaagcgg caacctttcc aggagggttt caagatcacc tatgaggatc tggagggggg 14820
caacattccc gcgctccttg atctggacgc ctacgaggag agcttgaaac ccgaggagag 14880
cgctggcgac agcggcgaga gtggcgagga gcaagccggc ggcggcggca gcgcgtcggt 14940
agaaaacgaa agtactcccg cagtggcggc ggacgctgcg gaggtcgagc cggaggccat 15000
gcagcaggac gcagaggagg gcgcgcagga ggacatgaac aatggggaga tcaggggcga 15060
cactttcgcc acccggggcg aagaaaaaga ggcagaggcg gcggcggcga cggcggaagc 15120
cgaaaccgag gcagaggcag agcccgagac cgaagttatg gaagacatga atgatggaga 15180
acgtaggggt gacacgtttg ccacccgggg cgaagagaag gcggcggagg cagaagccgc 15240
ggctgaggag gcggctgcgg ctgcggccaa ggctgaggct gcggctgagg ctaaggtcga 15300
agccgatgtt gcggttgagg ctcaggctga ggaggaggcg gcggctgaag cagttaagga 15360
aaaggcccag gcagagcagg aagagaaaaa acctgtcatt caacctctaa aagaagatag 15420
caaaaagcgc agttacaacg tcattgaggg cagcaccttt acccaatacc gcagctggta 15480
cctggcttac aactacggcg acccggtcaa gggggtgcgc tcgtggaccc tgctctgcac 15540
gccggacgtc acctgcggct ccgagcagat gtactggtcg ctgccaaaca tgatgcaaga 15600
cccggtgacc ttccgttcca cgcggcaggt tagcaacttt ccggtggtgg gcgccgaact 15660
gctgccagta cactccaaga gtttttacaa cgagcaggcc gtctactccc agctgatccg 15720
ccaggccacc tctctgaccc acgtgttcaa tcgctttccc gagaaccaga ttttggcgcg 15780
cccgccggcc cccaccatca ccaccgtcag tgaaaacgtt cctgccctca cagatcacgg 15840
gacgctaccg ctgcgcaaca gcatctcagg agtccagcga gtgaccatta ctgacgccag 15900
acgccggacc tgcccctacg tttacaaggc cttgggcata gtctcgccgc gcgtcctctc 15960
cagtcgcact ttttaaaaca catccaccca cacgctccaa aatcatgtcc gtactcatct 16020
cgcccagcaa caacaccggc tgggggctgc gcgcacccag caagatgttt ggaggggcaa 16080
ggaagcgctc cgaccagcac cccgtgcgcg tgcgcggcca ctaccgcgcg ccctggggtg 16140
cgcacaagcg cgggcgcaca gggcgcacca ctgtggatga tgtcattgac tccgtagtgg 16200
agcaggcgcg ccactacaca cccggcgcgc cgaccgcctc cgccgtgtcc accgtggacc 16260
aggcgatcga aagcgtggta cagggggcgc ggcactatgc caaccttaaa agtcgccgcc 16320
gccgcgtggc gcgccgccat cgccggagac cccgggctac tgccgccgcg cgccttacca 16380
aggctctgct caagcgcgcc aggcgaactg gccaccgggc cgccatgagg gccgcacggc 16440
gggctgccgc tgccgcgagc gccgtggccc cgcgggcacg aaggcgcgcg gccgctgccg 16500
ccgccgccgc catttccagc ttggcctcga cgcggcgcgg taacatatac tgggtgcgcg 16560
actcggtgag cggcacacgt gtgcccgtgc gctttcgccc cccacggaat tagcacaaga 16620
caacatacac actgagtctc ctgctgttgt gtatcccagc ggcgaccgtc agcagcggcg 16680
acatgtccaa gcgcaaaatt aaagaagaga tgctccaggt catcgcgccg gagatctatg 16740
ggcccccgaa gaaggaggag gaggattaca agccccgcaa gctaaagcgg gtcaaaaaga 16800
aaaagaaaga tgatgacgtt gacgaggcgg tggagtttgt ccgccgcatg gcgcccaggc 16860
gccctgtgca gtggaagggt cggcgcgtgc agcgagtcct gcgccccggc accgcggtgg 16920
tctttacgcc cggcgagcgt tccacgcgca ctttcaagcg ggtgtacgat gaggtgtacg 16980
gcgacgagga tctgttggag caggccaacc atcgatttgg ggagtttgca tatgggaaac 17040
ggcctcgcga gagtctaaaa gaggacctgc tggcgctacc gctggacgag ggcaatccca 17100
ccccgagtct gaagccggtg accctgcaac aggtgctgcc tttgagcgcg cccagcgagc 17160
agaagcgagg gttaaagcgc gagggcgggg acctggcacc caccgtgcag ttgatggtgc 17220
ccaagcggca gaagctggag gacgtgctgg agaaaatgaa agtagagccc gggatccagc 17280
ccgagatcaa ggtccgccct atcaagcagg tggcgcccgg cgtgggagtc cagaccgtgg 17340
acgttaggat tcccacggag gagatggaaa cccaaaccgc cactccctct tcggcagcaa 17400
gcgccaccac cggcgccgct tcggtagagg tgcagacgga cccctggcta cccgccgcca 17460
ctatcgccgt cgccgccgcc ccccgttcgc gcggacgcaa gagaaattat ccagcggcca 17520
gcgcgcttat gccccagtat gcgctgcatc catccatcgc gcccaccccc ggctaccgcg 17580
ggtactcgta ccgcccgcgc agatcagccg gcactcgcgg ccgccgccgc cgtgcgacca 17640
caaccagccg ccgccgtcgc cgccgccgcc agccagtgct gacccccgtg tctgtaagga 17700
aggtggctcg ctcggggagc acgctggtgg tgcccagagc gcgctaccac cccagcatcg 17760
tttaaagccg gtctctgtat ggttcttgca gatatggccc tcacttgtcg ccttcgcttc 17820
ccggtgccgg gataccgagg aagaactcac cgccgcaggg gcatggcggg cagcggtctc 17880
cgcggcggcc gtcgccatcg ccggcgcgca aagagcaggc gcatgcgcgg cggtgtgttg 17940
cccctgctgg tcccgctact cgccgcggcg atcggcgccg tgcccgggat cgcctccgtg 18000
gccctgcagg cgtcccagaa acattgactc ttgcaacctt gcaagcttgc atttttggag 18060
gaaaaaataa aaaagtctag actctcacgc tcgcttggtc ctgtgactat tttgtagaaa 18120
aaagatggaa gacatcaact ttgcgtcgct ggccccgcgt cacggctcgc gcccgttcat 18180
gggagactgg acagatatcg gcaccagcaa tatgagcggt ggcgccttca gctggggcag 18240
tctgtggagc ggccttaaaa attttggttc caccattaag aactatggca acaaagcgtg 18300
gaacagcagc acgggtcaga tgctgagaga caagttgaaa gagcagaact tccaggagaa 18360
ggtggcgcag ggcctggcct ctggcatcag cggggtggtg gacatagcta accaggccgt 18420
gcagaaaaag ataaacagtc atctggaccc ccgccctcag gtggaggaaa cgcctccagc 18480
catggagacg gtgtctcccg agggcaaagg cgaaaagcgc ccgcggcccg acagggaaga 18540
gaccctggtg tcacacaccg aggagccgcc ctcttacgag gaggcagtca aggccggcct 18600
gcccaccact cgccccatag ctcccatggc caccggtgtg gtgggtcaca ggcaacacac 18660
ccccgcaaca ctagatctgc ccccgccgtc cgagccgact cgccagccaa aggcggtgac 18720
ggtgtccgct ccctccactt ccgccgccaa cagagtgcct ctgcgccgcg ctgcgagcgg 18780
cccccgggcc tcgcgagtca gcggcaactg gcagagcaca ctgaacagca tcgtgggcct 18840
gggagtgagg agtgtgaagc gccgccgttg ctactgaatg agcaagctag ctaacgtgtt 18900
gtatgtgtgt atgcgtccta tgtcgccgcc agaggagctg ttgagccgcc ggcgccgtct 18960
gcactccagc gaatttcaag atggcgaccc catcgatgat gcctcagtgg tcgtacatgc 19020
acatctcggg ccaggacgct tcggagtacc tgagccccgg gctggtgcag ttcgcccgcg 19080
ccacagacac ctacttcaac atgagtaaca agttcaggaa ccccactgtg gcgcccaccc 19140
acgatgtgac cacggaccgg tcgcagcgcc tgacgctgcg gttcatcccc gtggatcggg 19200
aggacaccgc ttactcttac aaggcgcggt tcacgctggc cgtgggcgac aaccgcgtgc 19260
tggacatggc ctccacttac tttgacatcc ggggggtgct ggacaggggc cccactttta 19320
agccctactc gggcactgcc tacaaccccc tggcccccaa gggcgccccc aattcttgtg 19380
agtgggaaca agaggaaaat caggtggtcg ctgcagatga tgaacttgaa gatgaagaag 19440
cgcaagcaca agaggaagcc cctgtgaaaa aaattcatgt atatgctcag gcgcctcttt 19500
ctggcgaaaa gatttccaag gatggtatcc aaataggtac tgaagtcgta ggagatacat 19560
ctaaggacac ttttgcagat aaaacattcc aacccgaacc tcagataggc gagtctcagt 19620
ggaacgaggc tgatgccaca gcagcaggag gtagagtttt gaaaaagact acccctatga 19680
gaccttgcta tggatcctat gccaggccta ccaatgccaa cgggggtcaa ggaattatgg 19740
ttgccaatga acaaggagtg ttggagtcta aagtagaaat gcaatttttc tctaacacca 19800
caacccttaa tgcgcgggat ggaaccggca atcccgaacc aaaggtggtg ttgtacagcg 19860
aagatgtcca cttggaatct cccgatactc atctgtctta caagcccaaa aaggatgatg 19920
ttaatgccaa aatcatgttg ggtcagcaag ccatgcccaa cagacccaac ctcattggat 19980
ttagagataa tttcattggg cttatgtttt acaacagcac cggtaacatg ggagtgctgg 20040
cgggtcaggc ctctcagttg aatgctgtgg tggacttgca ggatagaaac acagaactgt 20100
catatcagct tctgcttgat tcaattgggg atagaaccag atacttctcc atgtggaacc 20160
aggcagtgga tagctatgat ccagatgtca gaattattga aaaccatggg actgaggatg 20220
aactgcccaa ctactgcttc cctttgggcg gcataggagt tactgatact tatcaaggga 20280
taaaaaatac caatggcaat ggtcagtgga ccaaagatga tcagttcgcg gaccgcaacg 20340
aaataggggt gggaaacaac ttcgccatgg agatcaacat ccaggccaac ctttggagaa 20400
acttcctcta tgcaaacgtg gggctctacc tgccagacaa gctcaagtac aaccccacca 20460
acgtggacat ctctgacaac cccaacacct atgactacat gaacaagcgg gtggtggccc 20520
ctggcctggt ggactgcttt gtcaatgtgg gagccaggtg gtccctggac tacatggaca 20580
acgtcaaccc cttcaaccac caccgcaatg cgggtctgcg ctaccgctcc atgatcctgg 20640
gcaacgggcg ctatgtgccc tttcacatcc aggtacccca gaagttcttt gccatcaaga 20700
acctcctgct cctgcccggc tcctacacct acgagtggaa cttcaggaag gatgtgaaca 20760
tggtcctaca gagctctctg ggcaatgacc ttagggtgga tggggccagc atcaagtttg 20820
acagcatcac cctctatgct acatttttcc ccatggccca caacaccgcc tccacgcttg 20880
aggccatgct gagaaacgac accaacgacc agtcctttaa tgactacctc tctggggcca 20940
acatgctcta cccaatccca gccaaggcca ccaacgtgcc catctccatc ccctctcgca 21000
actgggccgc ctttagaggc tgggccttta cccgccttaa gaccaaggag accccctccc 21060
tgggctcggg ttttgatccc tactttgttt actcgggatc catcccctac ctggatggca 21120
ccttctacct caaccacact ttcaagaaga tatccatcat gtatgactcc tccgtcagct 21180
ggccgggcaa cgaccgcttg ctcaccccca atgagttcga ggtcaagcgc gccgtggacg 21240
gcgagggcta caacgtggcc cagtgcaaca tgaccaagga ctggttcctg gtgcagatgc 21300
tggccaacta caacataggc taccagggct tttacatccc agagagctac aaggacagga 21360
tgtactcctt cttcagaaat ttccaaccca tgagccgaca ggtggtggac gagaccaatt 21420
acaaggacta tcaagccatt ggcatcaccc accagcacaa caactcgggt ttcgtgggct 21480
acctggcgcc caccatgcgc gagggtcagg cctaccccgc caacttcccc taccccttga 21540
taggcaagac cgcggtcgac agcgtcaccc agaaaaagtt cctctgcgac cgcaccctct 21600
ggcgcatccc cttctctagc aacttcatgt ccatgggtgc gctcacggac ctgggccaaa 21660
acctgcttta tgccaactct gcccatgcgc tggacatgac ttttgaggtg gaccccatgg 21720
acgagcccac ccttctctat attgtgtttg aagtgttcga cgtggtcaga gtgcaccagc 21780
cgcaccgcgg tgtcatcgag accgtgtacc tgcgtacgcc cttctcagcc ggcaacgcca 21840
ccacctaagg agacagcgcc gccgccgcct gcatgacggg ttccaccgag caagagctca 21900
gggccattgc cagagacctg ggatgcggac cctatttttt gggcacctat gacaaacgct 21960
tcccgggctt tatctcccga gacaagctcg cctgcgccat tgtcaacacg gccgcgcgcg 22020
agaccggggg cgtgcactgg ctggcctttg gctgggaccc gcgctccaaa acttgctacc 22080
tctttgaccc ctttggcttc tccgatcagc gcctcaggca gatttatgag tttgagtacg 22140
aggggctgct gcgccgcagc gcgctcgcct cctcgcccga ccgctgcatc acccttgaga 22200
agtccaccga aaccgtgcag gggccccact cggccgcctg cggtctcttc tgttgcatgt 22260
ttttgcacgc ctttgtgcac tggcctcaga gtcccatgga ttgcaacccc accatgaact 22320
tgctaaaggg agtgcccaac gccatgctcc agagccccca ggtccagccc accctgcgcc 22380
gcaaccagga acagctttac cgcttcctgg agcgccactc cccctacttc cgcagccaca 22440
gcgcgcgcat ccggggggcc acctcttttt gccacttgca agaaaacatg caagacggaa 22500
aatgatgtac agcatgcttt taataaatgt aaagactgtg cactttaatt atacacgggc 22560
tctttctggt tatttattca acaccgccgt cgccatttag aaatcgaaag ggttctgccg 22620
tgcgtcgccg tgcgccacgg gcagagacac gttgcgatac tggaagcggc tcgcccactt 22680
gaactcgggc accaccatgc ggggcagtgg ttcctcgggg aagttctcgc tccacagggt 22740
gcgggtcagc tgcagcgcgc tcaggaggtc gggagccgag atcttgaagt cgcagttggg 22800
gccggaaccc tgcgcgcgcg agttgcggta cacggggttg cagcactgga acaccagcag 22860
ggccggatta ttcacgctgg ccagcaggct ctcgtcgctg atcatgtcgc tgtccagatc 22920
ctccgcgttg ctcagggcga atggggtcat cttgcagacc tgcctgccca ggaaaggcgg 22980
gagcccaggc ttgccgttgc agtcgcagcg caggggcatt agcaggtgcc cacggcccga 23040
ctgcgcctgc gggtacaacg cgcgcatgaa ggcttcgatc tgcctaaaag ccacctgggt 23100
cttggctccc tccgaaaaga acatcccaca ggacttgctg gagaactggt tcgcgggaca 23160
gctggcatcg tgcaggcagc agcgcgcgtc agtgttggca atctgcacca cgttgcgacc 23220
ccaccggttt ttcactatct tggccttgga agcctgctcc tttagcgcgc gctggccgtt 23280
ctcgctggtc acatccatct ctatcacctg ttccttgttg atcatgtttg tcccgtgcag 23340
acactttagg tcgccctccg tctgggtgca gcggtgctcc cacagcgcgc aaccggtggg 23400
ctcccaattc ttgtgggtca cccccgcgta ggcctgcagg taggcctgca ggaagcgccc 23460
catcatggtc ataaaggtct tctggctcgt aaaggtcagc tgcaggccgc gatgctcttc 23520
gttcagccag gtcttgcaga tggcggccag cgcctcggtc tgctcgggca gcatcttaaa 23580
atttgtcttc aggtcgttat ccacgtggta cttgtccatc atggcacgcg ccgcctccat 23640
gcccttctcc caggcggaca ccatgggcag gcttaggggg tttatcactt ccagcggcga 23700
ggacaccgta ctttcgattt cttcttcctc cccctcttcc cggcgcgcgc ccccgctgtt 23760
gcgcgctctt accgcctgca ccaaggggtc gtcttcaggc aagcgccgca ccgagcgctt 23820
gccgcccttg acctgcttga tcagtaccgg cgggttgctg aagcccacca tggtcagcgc 23880
cgcctgctct tcttcgtctt cgctgtctac cactatttct ggggaggggc ttctccgctc 23940
tgcggcaaag gcggcggatc gcttcttttt tttcttggga gccgccgcga tggagtccgc 24000
cacggcgacc gaggtcgagg gcgtggggct gggggtgcgc ggtaccaggg cctcgtcgcc 24060
ctcggactct tcctctgact ccaggcggcg gcggagtcgc ttctttgggg gcgcgcgcgt 24120
cagcggcggc ggagacgggg acggggacgg ggacgggacg ccctccacag ggggtggtct 24180
tcgcgcagac ccgcggccgc gctcgggggt cttctcgcgc tggtcttggt cccgactggc 24240
cattgtatcc tcctcctcct aggcagagag acataaggag tctatcatgc aagtcgagaa 24300
ggaggagagc ttaaccaccc cctcagagac cgccgatgcg cccgccgtcg ccgtcgcccc 24360
cgctaccgcc gacgcgcccg ccacaccgag cgacaccccc acggaccccc ccgccgacgc 24420
acccctgttc gaggaagcgg ccgtggagca ggacccgggc tttgtctcgg cagaggagga 24480
tttgcaagag gaggagaata aggaggagaa gccctcagtg ccaaaagatc ataaagagca 24540
agacgagcac gacgcagacg cacaccaggg tgaagtcggg cggggggacg gagggcatgg 24600
cggcgccgac tacctagacg aaggaaacga cgtgctcttg aagcacctgc atcgtcagtg 24660
cgccatcgtc tgcgacgctc tgcaggagcg cagcgaggtg cccctcagcg tggcggaggt 24720
cagccgcgcc tacgagctca gcctcttttc cccccgggtg cccccccgcc gccgcgaaaa 24780
cggcacatgc gagcccaacc cgcgcctcaa cttctacccc gcctttgtgg tgcccgaggt 24840
cctggccacc tatcacatct tctttcaaaa ttgcaagatc cccatctcgt gccgcgccaa 24900
ccgtagccgc gccgataaga tgctggccct gcgccagggc gaccacatac ctgatatcgc 24960
cgctttggaa gatgtgccaa agatcttcga gggtctgggg cgcaacgaga agcgggcagc 25020
aaactctctg caacaggaaa acagcgaaaa tgagagtcac actggagcgc tggtggagct 25080
ggagggcgac aacgcccgcc tggcggtgct caagcgcagc atcgaggtca cccactttgc 25140
ctaccccgcg ctcaacctgc cccccaaagt catgaacgcg gtcatggacg ggctgatcat 25200
gcgccgcggc cggcccctcg ctccagatgc aaacttgcat gaggagaccg aggacggtca 25260
gcccgtggtc agcgacgagc agctgacgcg ctggctggag agcgcggacc ccgccgaact 25320
ggaggagcgg cgcaagatga tgatggccgc ggtgctggtc accgtagagc tggagtgtct 25380
gcagcgcttc ttcggtgacc ccgagatgca gagaaaggtc gaggagaccc tacactacac 25440
cttccgccag ggctacgtgc gccaggcttg caagatctcc aacgtggagc tcagcaacct 25500
ggtgtcctac ctgggcatct tgcatgaaaa ccgccttggg cagagcgtgc tacactccac 25560
cctgcgcggg gaggcgcgcc gcgactacgt gcgcgactgc gtttacctct tcctctgcta 25620
cacctggcag acggccatgg gggtctggca gcagtgcctg gaggagcgca acctcaagga 25680
gctggagaag cttctgcagc gcgcgctcaa agacctctgg acgggcttca acgagcgctc 25740
ggtggccgcc gcgctagccg acctcatctt ccccgagcgc ctgctcaaaa ccctccagca 25800
ggggctgccc gacttcacca gccaaagcat gttgcaaaat tttaggaact ttatcctgga 25860
gcgttctggc atcctacccg ccacctgctg cgccctgccc agcgactttg tccccctcgt 25920
gtaccgcgag tgccccccgc cgctgtgggg ccactgctac ctgttccaac tggccaacta 25980
cctgtcctac cacgcggacc tcatggagga ctccagcggc gaggggctca tggagtgcca 26040
ctgccgctgc aacctctgca cgccccaccg ctccctggtc tgcaacaccc aactgctcag 26100
cgagagtcag attatcggta ccttcgagct acagggtccg tcctcctcag acgagaagtc 26160
cgcggctccg gggctaaaac tcactccggg gctgtggact tccgcctacc tgcgcaaatt 26220
tgtacctgaa gactaccacg cccacgaaat caggttttac gaggaccaat cccgcccgcc 26280
caaggcggag ctgaccgcct gcgtcatcac ccagggcgag atcctaggcc aattgcaagc 26340
catccaaaaa gcccgccaag agtttttgct gaagaggggt cggggggtgt atctggaccc 26400
ccagtcgggt gaggagctca acccggttcc cccgctgcca ccgccgcggg accttgcttc 26460
ccaggataag catcgccatg gctcccagaa agaagcagca gcggccgccg ctgccgccgc 26520
cccacatgct ggaggaagag gaggaatact gggacagtca ggcagaggag gtttcggacg 26580
aggaggagcc ggagacggag atggaagagt gggaggagga cagcttagac gaggaggctt 26640
ccgaagccga agaggcaggc gcaacaccgt caccctcggc cgcagccccc tcgcaggcgc 26700
ccccgaagtc cgctcccagc atcagcagca acagcagcgc tataacctcc gctcctccac 26760
cgccgcgacc cacggccgac cgcagaccca accgtagatg ggacaccacc ggaaccgggg 26820
ccggtaagtc ctccgggaga ggcaagcaag cgcagcgcca aggctaccgc tcgtggcgcg 26880
ctcacaagaa cgccatagtc gcttgcttgc aagactgcgg ggggaacatc tccttcgccc 26940
gccgcttcct gctcttccac cacggtgtgg ccttcccccg taacgtcctg cattactacc 27000
gtcatctcta cagcccctac tgcggcggca gtgagccaga ggcggccagc ggcggcggcg 27060
cccgtttcgg tgcctaggaa gacccagggc aagacttcag ccaagaaact cgcggcgacc 27120
gcggcgaacg cggtcgcggg ggccctgcgc ctgacggtga acgaacccct gtcgacccgc 27180
gaactgagga accgaatctt ccccactctc tatgccatct tccagcagag cagagggcag 27240
gatcaggaac tgaaagtaaa aaacaggtct ctgcgctccc tcacccgcag ctgtctgtat 27300
cacaagagcg aagaccagct tcggcgcacg ctggaggacg ctgaggcact cttcagcaaa 27360
tactgcgcgc tcactcttaa ggactagctc cgcgcccttc tcgaatttag gcgggaacgc 27420
ctacgtcatc gcagcgccgc cgtcatgagc aaggacattc ccacgccata catgtggagc 27480
tatcagccgc agatgggact cgcggcgggc gcctcccaag actactccac ccgcatgaac 27540
tggctcagtg ccggcccaca catgatctca caggttaatg acatccgcac ccatcgaaac 27600
caaatattgg tgaagcaggc ggcaattacc accacgcccc gcaataatcc caaccccagg 27660
gagtggcccg cgtccctggt gtatcaggaa attcccggcc ccaccaccgt actacttccg 27720
cgtgattccc aggccgaagt ccaaatgact aactcagggg cacagctcgc gggcggctgt 27780
cgtcacaggg tgcggcctcc tcgccagggt ataactcacc tggagatccg aggcagaggt 27840
attcagctca acgacgagtc ggtgagctcc tcgctcggtc tcagacctga cgggaccttc 27900
cagatagccg gagccggccg atcttccttc acgccccgcc aggcgtacct gactctgcag 27960
agctcgtcct cggcgccgcg ctcgggcggc atcgggactc tccagttcgt gcaggagttt 28020
gtgccctcgg tctacttcaa ccccttctcg ggctctcccg gtcgctaccc ggaccagttt 28080
atcccgaact ttgacgccgc gagggactcg gtggacggct acgactgaat gtcgggtgga 28140
cccggtgcag agcaacttcg cctgaagcac cttgaccact gccgccgccc tcagtgcttt 28200
gcccgctgtc agaccggtga gttccagtac ttttccctgc ccgactcgca cccggacggc 28260
ccggcgcacg gggtgcgctt tttcatcccg agtcaggtcc gctctaccct aatcagggag 28320
ttcaccgccc gtcccctact ggcggagttg gaaaaggggc cttctatcct aaccattgcc 28380
tgcatttgct ctaaccctgg attacaccaa gatctttgct gtcatttgtg tgctgagtat 28440
aataaaggct gagatcagaa tctactcggg ctcctgtcgc catcctgtca acgccaccgt 28500
ccaagcccgg cccgatcagc ccgaggtgaa cctcacctgt ggtctgcacc ggcgcctgag 28560
gaaataccta gcttggtact acaacagcac tccctttgtg gtttacaaca gctttgacca 28620
ggacggggtc tcactgaggg ataacctctc gaacctgagc tactccatca ggaagaacaa 28680
caccctcgag ctacttcctc cttacctgcc cgggacttac cagtgtgtca ccggcccctg 28740
cacccacacc cacctgttga tcgtaaacga ctctcttccg agaacagacc tcaataactc 28800
ctctccgcag ttccccagaa caggaggtga gctcaggaaa ccccgggtaa agaagggtgg 28860
acaagagtta acacttgtgg ggtttctggt atatgtgacg ctggtggtgg ctcttttgat 28920
taaggctttt ccttccatgt ctgaactatc cctcttcttt tatgaacaac tcgactagtg 28980
ctaacgggac cctacccaac gaatcgggat tgaatatcgg taaccaggtt gcagtttcac 29040
ttttgattac cttcatagtc ctcttcctgc tagtgctgtc gcttctgtgc ctgcggatcg 29100
ggggctgctg catccacgtt tatatctggt gctggctgtt tagaaggttc ggagaccacc 29160
gcaggtagaa taatgctgct taccctcttt gtcctggcgc tggctgccag ctgccaagcc 29220
ttttccgagg ctgacttcat agagccccag tgcaatatca cttataaatc tgaacgtgcc 29280
atctgtacta ttctaatcaa atgtgttact caacacgata aggtgactgt taaatacaaa 29340
gatcaattaa aaaaagacgc actttacagc agctggcaac caggagatga tcaaaaatac 29400
aatgtaaccg tcttccaggg caaactctcc aaaacttaca attacaattt cccatttgag 29460
cagatgtgtg actttgtcat gtacatggaa aagcagtaca agctgtggcc tccaactccc 29520
cagggctgtg tggaaaatcc aggctctttc tgtatgatct ctctctgtgt aactgtgctg 29580
gcactaatac tcacgcttct gtatctcaga tttaaatcaa ggcaaagctt cattgatgaa 29640
aagaaaatgc cataatcgct caacgcttga ttgctaacac cgggttttta tccgcagaat 29700
gattggaatc accctactaa tcacctccct ccttgcgatt gcccatgggt tggaacgaat 29760
cgaagtccct gtgggggcca atgttaccct ggtggggcct gtcggcaatg ctacattaat 29820
gtgggaaaaa tatactaaaa atcaatgggt ttcttactgc actaacaaaa acagccacaa 29880
gcccagagcc atctgcgatg ggcaaaatct aaccttgatt gatgttcaat tgctggatgc 29940
gggctactat tatgggcagc tgggtacaat gattaattac tggagacccc acagagatta 30000
catgcttcac gtagtaaagg gtcccattag cagcccaacc accacctcta ccacacccac 30060
taccaccact actcccacca ccagcactgc cgcccagcct cctcatagca gaacaaccac 30120
ttttatcaat tccaagtccc actcccccca cattgccggc gggccctccg cctcagactc 30180
cgagaccacc gagatctgct tctgcaaatg ctctgacgcc attgcccagg atttggaaga 30240
tcacgaggaa gatgagcatg actacgcaga tgcatgccag gcatcagagg cagaagcgct 30300
accggtggcc ctaaaacagt atgcagactc ccacaccacc cccaaccttc ctccaccttc 30360
ccagaagcca agtttcctgg gggaaaatga aactctgcct ctttccatac tagctctgac 30420
atctgttgct attttggccg ctctgctggt gcttctatgc tctatatgct acctgatctg 30480
ctgcagaaag aaaaaatctc acggccatgc tcaccagccc ctcatgcact tcccttaccc 30540
tccagagctg ggcgaccaca aactttaagt ctgcagtagc tatctgccca tcccttgtca 30600
gtcgacagcg atgagcccca ctaatctaac agcctctgga cttacaacat tgtctcttaa 30660
tgagaccacc gctcctcaag acctgtacga tggtgtctcc gcgctggtta accagtggga 30720
tcacctgggc atatggtggc tcctcatagg agcagtgacc ctgtgcctaa tcctggtctg 30780
gatcatctgc tgcatcaaaa gcagaagacc caggcggcgg cccatctaca ggcccttcgt 30840
catcacacct gaagataatg atgatgatga caccacctcc aggctgcaga gcctaaagca 30900
gctactcttc tcttttacag catggtaaat tgaatcatgc cccgcatttt catctacttg 30960
cttctccttc cactttttct gggctcctct acattggcca ctgtgtccca catcgaggta 31020
gactgcctca cgcccttcac agtctacctg cttttcggct ttgtcatctg cacctttgtc 31080
tgcagcgtta tcactgtagt gatctgcttc atacagtgca tcgactacat ctgtgtgcgg 31140
gtggcctact ttagacacca cccccagtat cgcaacaggg acatagcggc tctcctaaga 31200
cttgtttaaa tcatggccaa attacctgtg attggtcttc tgattatctg ctgcgtccta 31260
gccgcgattg ggactcaacc taataccacc accagcgctc ccagaaagag acatgtatcc 31320
tgcagcttca agcgtccctg gaatataccc caatgcttta ctgatgaacc tgaaatctct 31380
ttggcttggt acttcagcgt caccgccctt ctcatcttct gcagtacggt tattgctctt 31440
gccatctacc cttcccttaa cctgggctgg aatgctgtca actctatgga atatcccacc 31500
ttcccagaac cagacctgcc agacctggtt gttctaaacg cgtttcctcc tcctccagtt 31560
caaaatcagt ttcgccctcc gtcccctacg cccactgagg tcagctactt taatctaaca 31620
ggcggagatg actgaaaacc tagacctaga aatggacggt ctctgcagcg agcaacgcac 31680
actagagagg cgccggcaaa aagcagagct cgagcgtctt aaacaagagc tccaagacgc 31740
cgtggccata caccagtgca aaaaagggct cttctgtctg gtaaaacagg ccacgctcac 31800
ctatgaaaaa acaggtgaca cccaccgcct aggatacaag ctgcccacac agcgccaaaa 31860
gtttgccctt atgataggtg aacaacccat caccgtcacc cagcactccg tggagacaga 31920
aggctgcatt catgctccct gcaggggcgc tgactgcctc tacaccttga tcaaaaccct 31980
ctgcggtctc agagacctta tccctttcaa ttgatcataa ctgtaatcaa taaaaaatca 32040
cttacttgaa atctgatagc aagactctgt ccaatttttt cagcaacact tccttcccct 32100
cctcccaact ctggtactct aggcgcctcc tagctgcaaa cttcctccac agtctgaagg 32160
gaatgtcaga ttcctcctcc tgtccctccg cacccacgat cttcatgttg ttacagatga 32220
aacgcgcgag atcgtctgac gagaccttca accccgtgta cccctacgat accgagatcg 32280
ctccgacttc tgtccctttc cttacccctc cctttgtatc atccgcagga atgcaagaaa 32340
atccagctgg ggtgctgtcc ctg 32363
<210> 623
<211> 1507
<212> PRT
<213> Artificial seqeunce
<220>
<223> Heterologous polypeptide
<400> 623
Met Gly Gln Lys Glu Gln Ile His Thr Leu Gln Lys Asn Ser Glu Arg
1 5 10 15
Met Ser Lys Gln Leu Thr Arg Ser Ser Gln Ala Val Gly Val Pro Gly
20 25 30
Asp Ser Thr Arg Arg Ala Val Arg Arg Met Asn Thr Phe Tyr Glu Ala
35 40 45
Gly Met Thr Leu Gly Glu Lys Phe Arg Val Gly Asn Cys Lys His Leu
50 55 60
Lys Met Thr Arg Pro Asn Ser Lys Met Ala Leu Asn Ser Glu Ala Leu
65 70 75 80
Ser Val Val Ser Glu Cys Gly Ala Ser Ala Cys Asp Val Ser Leu Ile
85 90 95
Ala Met Asp Ser Ala Phe Val Gln Gly Lys Asp Trp Gly Val Lys Lys
100 105 110
Phe Ile Arg Arg Asp Phe Tyr Ala Tyr Lys Asp Phe Leu Trp Cys Phe
115 120 125
Pro Phe Ser Leu Val Phe Leu Gln Glu Ile Gln Ile Cys Cys His Val
130 135 140
Ser Cys Leu Cys Cys Ile Cys Cys Ser Thr Arg Ile Cys Leu Gly Cys
145 150 155 160
Leu Leu Glu Leu Phe Leu Ser Arg Ala Leu Arg Ala Leu His Val Leu
165 170 175
Trp Asn Gly Phe Gln Leu His Cys Gln Thr Glu Tyr Asn Gln Lys Leu
180 185 190
Gln Val Asn Gln Phe Ser Glu Ser Lys Ser Leu Tyr His Arg Glu Lys
195 200 205
Gln Leu Ile Ala Met Asp Ser Ala Ile Cys Glu Glu Arg Gly Ala Ala
210 215 220
Gly Ser Leu Ile Ser Cys Glu Thr Met Pro Ala Ile Leu Lys Leu Gln
225 230 235 240
Lys Asn Cys Leu Leu Ser Leu Arg Thr Ala Leu Thr His Asn Gln Asp
245 250 255
Phe Ser Ile Tyr Arg Leu Cys Cys Lys Arg Gly Ser Leu Cys His Ala
260 265 270
Ser Gln Ala Arg Ser Pro Ala Phe Pro Lys Pro Val Arg Pro Leu Pro
275 280 285
Ala Pro Ile Thr Arg Ile Thr Pro Gln Leu Gly Gly Gln Ser Asp Ser
290 295 300
Ser Gln Pro Leu Leu Thr Thr Gly Arg Pro Gln Gly Trp Gln Asp Gln
305 310 315 320
Ala Leu Arg His Thr Gln Gln Ala Ser Pro Ala Ser Cys Ala Thr Ile
325 330 335
Thr Ile Pro Ile His Ser Ala Ala Leu Gly Asp His Ser Gly Asp Pro
340 345 350
Gly Pro Ala Trp Asp Thr Cys Pro Pro Leu Pro Leu Thr Thr Leu Ile
355 360 365
Pro Arg Ala Pro Pro Pro Tyr Gly Asp Ser Thr Ala Arg Ser Trp Pro
370 375 380
Ser Arg Cys Gly Pro Leu Gly Gly Asn Thr Thr Leu Gln Gln Leu Gly
385 390 395 400
Glu Ala Ser Gln Ala Pro Ser Gly Ser Leu Ile Pro Leu Arg Leu Pro
405 410 415
Leu Leu Trp Glu Val Arg Gly Gln Pro Asp Ser Phe Ala Ala Leu His
420 425 430
Ser Ser Leu Asn Glu Leu Gly Glu Ile Ala Arg Glu Leu His Gln Phe
435 440 445
Ala Phe Asp Leu Leu Ile Lys Ser His Phe Val Gln Gly Lys Asp Trp
450 455 460
Gly Leu Lys Lys Phe Ile Arg Arg Asp Phe Trp Gly Met Glu Leu Ala
465 470 475 480
Ala Ser Arg Arg Phe Ser Trp Asp His His Ser Ala Gly Gly Pro Pro
485 490 495
Arg Val Pro Ser Val Arg Ser Gly Ala Ala Gln Val Gln Pro Lys Asp
500 505 510
Pro Leu Pro Leu Arg Thr Leu Ala Gly Cys Leu Ala Arg Thr Ala His
515 520 525
Leu Arg Pro Gly Ala Glu Ser Leu Pro Gln Pro Gln Leu His Cys Thr
530 535 540
Leu Trp Phe Gln Ser Ser Glu Leu Ser Pro Thr Gly Ala Pro Trp Pro
545 550 555 560
Ser Arg Arg Pro Thr Trp Arg Gly Thr Thr Val Ser Pro Arg Thr Ala
565 570 575
Thr Ser Ser Ala Arg Thr Cys Cys Gly Thr Lys Trp Pro Ser Ser Gln
580 585 590
Glu Ala Ala Leu Gly Leu Gly Ser Gly Leu Leu Arg Phe Ser Cys Gly
595 600 605
Thr Ala Ala Ile Arg Lys Met His Phe Ser Leu Lys Glu His Pro Pro
610 615 620
Pro Pro Cys Pro Pro Glu Ala Phe Gln Arg Ala Ala Gly Glu Gly Gly
625 630 635 640
Pro Gly Arg Gly Gly Ala Arg Arg Gly Ala Arg Val Leu Gln Ser Pro
645 650 655
Phe Cys Arg Ala Gly Ala Gly Glu Trp Leu Gly His Gln Ser Leu Arg
660 665 670
His Val Val Gly Tyr Gly His Leu Asp Thr Ser Gly Ser Ser Ser Ser
675 680 685
Ser Ser Trp Pro Asn Ser Lys Met Ala Leu Asn Ser Leu Asn Ser Ile
690 695 700
Asp Asp Ala Gln Leu Thr Arg Ile Ala Pro Pro Arg Ser His Cys Cys
705 710 715 720
Phe Trp Glu Val Asn Ala Pro Asp Gly His Ser Tyr Thr Ser Lys Val
725 730 735
Asn Cys Leu Leu Leu Gln Asp Gly Phe His Gly Cys Val Ser Ile Thr
740 745 750
Gly Ala Ala Gly Arg Arg Asn Leu Ser Ile Phe Leu Phe Leu Met Leu
755 760 765
Cys Lys Leu Glu Phe His Ala Cys Lys Ile Gln Asn Lys Asn Cys Pro
770 775 780
Asp Phe Lys Lys Phe Asp Gly Pro Cys Gly Glu Arg Gly Gly Gly Arg
785 790 795 800
Thr Ala Arg Ala Leu Trp Ala Arg Gly Asp Ser Val Leu Thr Pro Ala
805 810 815
Leu Asp Pro Gln Thr Pro Val Arg Ala Pro Ser Leu Thr Arg Ala Ala
820 825 830
Ala Ala Val His Tyr Lys Leu Ile Gln Gln Pro Ile Ser Leu Phe Ser
835 840 845
Ile Thr Asp Arg Leu His Lys Thr Phe Ser Gln Leu Pro Ser Val His
850 855 860
Leu Cys Ser Ile Thr Phe Gln Trp Gly His Pro Pro Ile Phe Cys Ser
865 870 875 880
Thr Asn Asp Ile Cys Val Thr Ala Asn Phe Cys Ile Ser Val Thr Phe
885 890 895
Leu Lys Pro Cys Phe Leu Leu His Glu Ala Ser Ala Ser Gln Cys His
900 905 910
Leu Phe Leu Gln Pro Gln Val Gly Thr Pro Pro Pro His Thr Ala Ser
915 920 925
Ala Arg Ala Pro Ser Gly Pro Pro His Pro His Glu Ser Cys Pro Ala
930 935 940
Gly Arg Arg Pro Ala Arg Ala Ala Gln Thr Cys Ala Arg Arg Gln His
945 950 955 960
Gly Leu Pro Gly Cys Glu Glu Ala Gly Thr Ala Arg Val Pro Ser Leu
965 970 975
His Leu His Leu His Gln Ala Ala Leu Gly Ala Gly Arg Gly Arg Gly
980 985 990
Trp Gly Glu Ala Cys Ala Gln Val Pro Pro Ser Arg Gly Val Leu Arg
995 1000 1005
Phe Leu Asp Leu Lys Val Arg Tyr Leu His Ser Gln Trp Gln His
1010 1015 1020
Tyr His Arg Ser Gly Glu Ala Ala Gly Thr Pro Leu Trp Arg Pro
1025 1030 1035
Thr Arg Asn Val Pro Phe Arg Glu Leu Lys Asn Gln Arg Thr Ala
1040 1045 1050
Gln Gly Ala Pro Gly Ile His His Ala Ala Ser Pro Val Ala Ala
1055 1060 1065
Asn Leu Cys Asp Pro Ala Arg His Ala Gln His Thr Arg Ile Pro
1070 1075 1080
Cys Gly Ala Gly Gln Val Arg Ala Gly Arg Gly Pro Glu Ala Gly
1085 1090 1095
Gly Gly Val Leu Gln Pro Gln Arg Pro Ala Pro Glu Lys Pro Gly
1100 1105 1110
Cys Pro Cys Arg Arg Gly Gln Pro Arg Leu His Thr Val Lys Met
1115 1120 1125
Trp Arg Ala Val Ala Met Met Val Pro Asp Arg Gln Val His Tyr
1130 1135 1140
Asp Phe Gly Leu Gln Asn Leu Gln Asn Gly Gly Gly Ser Arg Ser
1145 1150 1155
Ser Ala Thr Leu Pro Gly Arg Arg Arg Arg Arg Trp Leu Arg Arg
1160 1165 1170
Arg Arg Gln Pro Ile Ser Val Ala Pro Ala Gly Pro Pro Arg Arg
1175 1180 1185
Pro Asn Gln Lys Pro Asn Pro Pro Gly Gly Ala Arg Cys Val Ile
1190 1195 1200
Met Arg Pro Thr Trp Pro Gly Thr Ser Ala Phe Thr Lys Arg Ser
1205 1210 1215
Phe Ala Val Thr Glu Arg Ile Ile Leu Val Leu Gly Val Leu Ser
1220 1225 1230
Gly His Ser Gly Ser Arg Leu Tyr Glu Ala Gly Met Thr Leu Gly
1235 1240 1245
Gly Lys Ile Leu Phe Phe Leu Phe Leu Leu Leu Pro Leu Ser Pro
1250 1255 1260
Phe Ser Leu Ile Phe Thr Glu Ile Ser Cys Cys Thr Leu Ser Ser
1265 1270 1275
Glu Glu Asn Glu Tyr Leu Pro Arg Pro Glu Trp Gln Leu Gln Val
1280 1285 1290
Pro Phe Arg Glu Leu Lys Asn Val Ser Val Leu Glu Gly Leu Arg
1295 1300 1305
Gln Gly Arg Leu Gly Gly Pro Cys Ser Cys His Cys Pro Arg Pro
1310 1315 1320
Ser Gln Ala Arg Leu Thr Pro Val Asp Val Ala Gly Pro Phe Leu
1325 1330 1335
Cys Leu Gly Asp Pro Gly Leu Phe Pro Pro Val Lys Ser Ser Ile
1340 1345 1350
Thr Gly Gly Lys Ser Thr Cys Ser Ala Pro Gly Pro Gln Ser Leu
1355 1360 1365
Pro Ser Thr Pro Phe Ser Thr Tyr Pro Gln Trp Val Ile Leu Ile
1370 1375 1380
Thr Glu Leu Gly Met Glu Cys Thr Leu Gly Gln Val Gly Ala Pro
1385 1390 1395
Ser Pro Arg Arg Glu Glu Asp Gly Trp Arg Gly Gly His Ser Arg
1400 1405 1410
Phe Lys Ala Asp Val Pro Ala Pro Gln Gly Pro Cys Trp Gly Gly
1415 1420 1425
Gln Pro Gly Ser Ala Pro Ser Ser Ala Pro Pro Glu Gln Ser Leu
1430 1435 1440
Leu Asp Asp Tyr Trp Ala Gln Lys Glu Lys Gly Ser Ser Ser Phe
1445 1450 1455
Leu Arg Pro Ser Cys Asp Tyr Trp Ala Gln Lys Glu Lys Ile Ser
1460 1465 1470
Ile Pro Arg Thr His Leu Cys Trp Lys Phe Glu Met Ser Tyr Thr
1475 1480 1485
Val Gly Gly Pro Pro Pro His Val His Ala Arg Pro Arg His Trp
1490 1495 1500
Lys Thr Asp Arg
1505
<210> 624
<211> 1507
<212> PRT
<213> Artificial seqeunce
<220>
<223> Heterologous polypeptide
<400> 624
Met Gly Gln Lys Glu Gln Ile His Thr Leu Gln Lys Asn Ser Glu Arg
1 5 10 15
Met Ser Lys Gln Leu Thr Arg Ser Ser Gln Ala Val Gly Asn Thr Thr
20 25 30
Leu Gln Gln Leu Gly Glu Ala Ser Gln Ala Pro Ser Gly Ser Leu Ile
35 40 45
Pro Leu Arg Leu Pro Leu Leu Trp Glu Val Arg Gly Gln Pro Asp Ser
50 55 60
Phe Ala Ala Leu His Ser Ser Leu Asn Glu Leu Gly Glu Ile Ala Arg
65 70 75 80
Glu Leu His Gln Phe Ala Phe Asp Leu Leu Ile Lys Ser His Phe Val
85 90 95
Gln Gly Lys Asp Trp Gly Leu Lys Lys Phe Ile Arg Arg Asp Phe Trp
100 105 110
Gly Met Glu Leu Ala Ala Ser Arg Arg Phe Ser Trp Asp His His Ser
115 120 125
Ala Gly Gly Pro Pro Arg Val Pro Ser Val Arg Ser Gly Ala Ala Gln
130 135 140
Val Gln Pro Lys Asp Pro Leu Pro Leu Arg Thr Leu Ala Gly Cys Leu
145 150 155 160
Ala Arg Thr Ala His Leu Arg Pro Gly Ala Glu Ser Leu Pro Gln Pro
165 170 175
Gln Leu His Cys Thr Leu Trp Phe Gln Ser Ser Glu Leu Ser Pro Thr
180 185 190
Gly Ala Pro Trp Pro Ser Arg Arg Pro Thr Trp Arg Gly Thr Thr Val
195 200 205
Ser Pro Arg Thr Ala Thr Ser Ser Ala Arg Thr Cys Cys Gly Thr Lys
210 215 220
Trp Pro Ser Ser Gln Glu Ala Ala Leu Gly Leu Gly Ser Gly Leu Leu
225 230 235 240
Arg Phe Ser Cys Gly Thr Ala Ala Ile Arg Lys Met His Phe Ser Leu
245 250 255
Lys Glu His Pro Pro Pro Pro Cys Pro Pro Glu Ala Phe Gln Arg Ala
260 265 270
Ala Gly Glu Gly Gly Pro Gly Arg Gly Gly Ala Arg Arg Gly Ala Arg
275 280 285
Val Leu Gln Ser Pro Phe Cys Arg Ala Gly Ala Gly Glu Trp Leu Gly
290 295 300
His Gln Ser Leu Arg His Val Val Gly Tyr Gly His Leu Asp Thr Ser
305 310 315 320
Gly Ser Ser Ser Ser Ser Ser Trp Pro Asn Ser Lys Met Ala Leu Asn
325 330 335
Ser Leu Asn Ser Ile Asp Asp Ala Gln Leu Thr Arg Ile Ala Pro Pro
340 345 350
Arg Ser His Cys Cys Phe Trp Glu Val Asn Ala Pro Gly Val Pro Gly
355 360 365
Asp Ser Thr Arg Arg Ala Val Arg Arg Met Asn Thr Phe Tyr Glu Ala
370 375 380
Gly Met Thr Leu Gly Glu Lys Phe Arg Val Gly Asn Cys Lys His Leu
385 390 395 400
Lys Met Thr Arg Pro Asn Ser Lys Met Ala Leu Asn Ser Glu Ala Leu
405 410 415
Ser Val Val Ser Glu Cys Gly Ala Ser Ala Cys Asp Val Ser Leu Ile
420 425 430
Ala Met Asp Ser Ala Phe Val Gln Gly Lys Asp Trp Gly Val Lys Lys
435 440 445
Phe Ile Arg Arg Asp Phe Tyr Ala Tyr Lys Asp Phe Leu Trp Cys Phe
450 455 460
Pro Phe Ser Leu Val Phe Leu Gln Glu Ile Gln Ile Cys Cys His Val
465 470 475 480
Ser Cys Leu Cys Cys Ile Cys Cys Ser Thr Arg Ile Cys Leu Gly Cys
485 490 495
Leu Leu Glu Leu Phe Leu Ser Arg Ala Leu Arg Ala Leu His Val Leu
500 505 510
Trp Asn Gly Phe Gln Leu His Cys Gln Thr Glu Tyr Asn Gln Lys Leu
515 520 525
Gln Val Asn Gln Phe Ser Glu Ser Lys Ser Leu Tyr His Arg Glu Lys
530 535 540
Gln Leu Ile Ala Met Asp Ser Ala Ile Cys Glu Glu Arg Gly Ala Ala
545 550 555 560
Gly Ser Leu Ile Ser Cys Glu Thr Met Pro Ala Ile Leu Lys Leu Gln
565 570 575
Lys Asn Cys Leu Leu Ser Leu Arg Thr Ala Leu Thr His Asn Gln Asp
580 585 590
Phe Ser Ile Tyr Arg Leu Cys Cys Lys Arg Gly Ser Leu Cys His Ala
595 600 605
Ser Gln Ala Arg Ser Pro Ala Phe Pro Lys Pro Val Arg Pro Leu Pro
610 615 620
Ala Pro Ile Thr Arg Ile Thr Pro Gln Leu Gly Gly Gln Ser Asp Ser
625 630 635 640
Ser Gln Pro Leu Leu Thr Thr Gly Arg Pro Gln Gly Trp Gln Asp Gln
645 650 655
Ala Leu Arg His Thr Gln Gln Ala Ser Pro Ala Ser Cys Ala Thr Ile
660 665 670
Thr Ile Pro Ile His Ser Ala Ala Leu Gly Asp His Ser Gly Asp Pro
675 680 685
Gly Pro Ala Trp Asp Thr Cys Pro Pro Leu Pro Leu Thr Thr Leu Ile
690 695 700
Pro Arg Ala Pro Pro Pro Tyr Gly Asp Ser Thr Ala Arg Ser Trp Pro
705 710 715 720
Ser Arg Cys Gly Pro Leu Gly Asp Gly His Ser Tyr Thr Ser Lys Val
725 730 735
Asn Cys Leu Leu Leu Gln Asp Gly Phe His Gly Cys Val Ser Ile Thr
740 745 750
Gly Ala Ala Gly Arg Arg Asn Leu Ser Ile Phe Leu Phe Leu Met Leu
755 760 765
Cys Lys Leu Glu Phe His Ala Cys Lys Ile Gln Asn Lys Asn Cys Pro
770 775 780
Asp Phe Lys Lys Phe Asp Gly Pro Cys Gly Glu Arg Gly Gly Gly Arg
785 790 795 800
Thr Ala Arg Ala Leu Trp Ala Arg Gly Asp Ser Val Leu Thr Pro Ala
805 810 815
Leu Asp Pro Gln Thr Pro Val Arg Ala Pro Ser Leu Thr Arg Ala Ala
820 825 830
Ala Ala Val His Tyr Lys Leu Ile Gln Gln Pro Ile Ser Leu Phe Ser
835 840 845
Ile Thr Asp Arg Leu His Lys Thr Phe Ser Gln Leu Pro Ser Val His
850 855 860
Leu Cys Ser Ile Thr Phe Gln Trp Gly His Pro Pro Ile Phe Cys Ser
865 870 875 880
Thr Asn Asp Ile Cys Val Thr Ala Asn Phe Cys Ile Ser Val Thr Phe
885 890 895
Leu Lys Pro Cys Phe Leu Leu His Glu Ala Ser Ala Ser Gln Cys His
900 905 910
Leu Phe Leu Gln Pro Gln Val Gly Thr Pro Pro Pro His Thr Ala Ser
915 920 925
Ala Arg Ala Pro Ser Gly Pro Pro His Pro His Glu Ser Cys Pro Ala
930 935 940
Gly Arg Arg Pro Ala Arg Ala Ala Gln Thr Cys Ala Arg Arg Gln His
945 950 955 960
Gly Leu Pro Gly Cys Glu Glu Ala Gly Thr Ala Arg Val Pro Ser Leu
965 970 975
His Leu His Leu His Gln Ala Ala Leu Gly Ala Gly Arg Gly Arg Gly
980 985 990
Trp Gly Glu Ala Cys Ala Gln Val Pro Pro Ser Arg Gly Val Leu Arg
995 1000 1005
Phe Leu Asp Leu Lys Val Arg Tyr Leu His Ser Gln Trp Gln His
1010 1015 1020
Tyr His Arg Ser Gly Glu Ala Ala Gly Thr Pro Leu Trp Arg Pro
1025 1030 1035
Thr Arg Asn Val Pro Phe Arg Glu Leu Lys Asn Gln Arg Thr Ala
1040 1045 1050
Gln Gly Ala Pro Gly Ile His His Ala Ala Ser Pro Val Ala Ala
1055 1060 1065
Asn Leu Cys Asp Pro Ala Arg His Ala Gln His Thr Arg Ile Pro
1070 1075 1080
Cys Gly Ala Gly Gln Val Arg Ala Gly Arg Gly Pro Glu Ala Gly
1085 1090 1095
Gly Gly Val Leu Gln Pro Gln Arg Pro Ala Pro Glu Lys Pro Gly
1100 1105 1110
Cys Pro Cys Arg Arg Gly Gln Pro Arg Leu His Thr Val Lys Met
1115 1120 1125
Trp Arg Ala Val Ala Met Met Val Pro Asp Arg Gln Val His Tyr
1130 1135 1140
Asp Phe Gly Leu Gln Asn Leu Gln Asn Gly Gly Gly Ser Arg Ser
1145 1150 1155
Ser Ala Thr Leu Pro Gly Arg Arg Arg Arg Arg Trp Leu Arg Arg
1160 1165 1170
Arg Arg Gln Pro Ile Ser Val Ala Pro Ala Gly Pro Pro Arg Arg
1175 1180 1185
Pro Asn Gln Lys Pro Asn Pro Pro Gly Gly Ala Arg Cys Val Ile
1190 1195 1200
Met Arg Pro Thr Trp Pro Gly Thr Ser Ala Phe Thr Lys Arg Ser
1205 1210 1215
Phe Ala Val Thr Glu Arg Ile Ile Thr Glu Ile Ser Cys Cys Thr
1220 1225 1230
Leu Ser Ser Glu Glu Asn Glu Tyr Leu Pro Arg Pro Glu Trp Gln
1235 1240 1245
Leu Gln Tyr Glu Ala Gly Met Thr Leu Gly Gly Lys Ile Leu Phe
1250 1255 1260
Phe Leu Phe Leu Leu Leu Pro Leu Ser Pro Phe Ser Leu Ile Phe
1265 1270 1275
Asp Tyr Trp Ala Gln Lys Glu Lys Gly Ser Ser Ser Phe Leu Arg
1280 1285 1290
Pro Ser Cys Val Pro Phe Arg Glu Leu Lys Asn Val Ser Val Leu
1295 1300 1305
Glu Gly Leu Arg Gln Gly Arg Leu Gly Gly Pro Cys Ser Cys His
1310 1315 1320
Cys Pro Arg Pro Ser Gln Ala Arg Leu Thr Pro Val Asp Val Ala
1325 1330 1335
Gly Pro Phe Leu Cys Leu Gly Asp Pro Gly Leu Phe Pro Pro Val
1340 1345 1350
Lys Ser Ser Ile Thr Gly Gly Lys Ser Thr Cys Ser Ala Pro Gly
1355 1360 1365
Pro Gln Ser Leu Pro Ser Thr Pro Phe Ser Thr Tyr Pro Gln Trp
1370 1375 1380
Val Ile Leu Ile Thr Glu Leu Gly Met Glu Cys Thr Leu Gly Gln
1385 1390 1395
Val Gly Ala Pro Ser Pro Arg Arg Glu Glu Asp Gly Trp Arg Gly
1400 1405 1410
Gly His Ser Arg Phe Lys Ala Asp Val Pro Ala Pro Gln Gly Pro
1415 1420 1425
Cys Trp Gly Gly Gln Pro Gly Ser Ala Pro Ser Ser Ala Pro Pro
1430 1435 1440
Glu Gln Ser Leu Leu Asp Asp Tyr Trp Ala Gln Lys Glu Lys Ile
1445 1450 1455
Ser Ile Pro Arg Thr His Leu Cys Leu Val Leu Gly Val Leu Ser
1460 1465 1470
Gly His Ser Gly Ser Arg Leu Trp Lys Phe Glu Met Ser Tyr Thr
1475 1480 1485
Val Gly Gly Pro Pro Pro His Val His Ala Arg Pro Arg His Trp
1490 1495 1500
Lys Thr Asp Arg
1505
<210> 625
<211> 1507
<212> PRT
<213> Artificial seqeunce
<220>
<223> Heterologous polypeptide
<400> 625
Met Gly Gln Lys Glu Gln Ile His Thr Leu Gln Lys Asn Ser Glu Arg
1 5 10 15
Met Ser Lys Gln Leu Thr Arg Ser Ser Gln Ala Val Gly Asn Thr Thr
20 25 30
Leu Gln Gln Leu Gly Glu Ala Ser Gln Ala Pro Ser Gly Ser Leu Ile
35 40 45
Pro Leu Arg Leu Pro Leu Leu Trp Glu Val Arg Gly Asn Ser Lys Met
50 55 60
Ala Leu Asn Ser Leu Asn Ser Ile Asp Asp Ala Gln Leu Thr Arg Ile
65 70 75 80
Ala Pro Pro Arg Ser His Cys Cys Phe Trp Glu Val Asn Ala Pro Phe
85 90 95
Val Gln Gly Lys Asp Trp Gly Leu Lys Lys Phe Ile Arg Arg Asp Phe
100 105 110
Glu Ala Phe Gln Arg Ala Ala Gly Glu Gly Gly Pro Gly Arg Gly Gly
115 120 125
Ala Arg Arg Gly Ala Arg Val Leu Gln Ser Pro Phe Cys Arg Ala Gly
130 135 140
Ala Gly Glu Trp Leu Gly His Gln Ser Leu Arg Trp Gly Met Glu Leu
145 150 155 160
Ala Ala Ser Arg Arg Phe Ser Trp Asp His His Ser Ala Gly Gly Pro
165 170 175
Pro Arg Val Pro Ser Val Arg Ser Gly Ala Ala Gln Val Gln Pro Lys
180 185 190
Asp Pro Leu Pro Leu Arg Thr Leu Ala Gly Cys Leu Ala Arg Thr Ala
195 200 205
His Leu Arg Pro Gly Ala Glu Ser Leu Pro Gln Pro Gln Leu His Cys
210 215 220
Thr Ile Ala Arg Glu Leu His Gln Phe Ala Phe Asp Leu Leu Ile Lys
225 230 235 240
Ser His Lys Met His Phe Ser Leu Lys Glu His Pro Pro Pro Pro Cys
245 250 255
Pro Pro His Val Val Gly Tyr Gly His Leu Asp Thr Ser Gly Ser Ser
260 265 270
Ser Ser Ser Ser Trp Pro Gln Pro Asp Ser Phe Ala Ala Leu His Ser
275 280 285
Ser Leu Asn Glu Leu Gly Glu Leu Trp Phe Gln Ser Ser Glu Leu Ser
290 295 300
Pro Thr Gly Ala Pro Trp Pro Ser Arg Arg Pro Thr Trp Arg Gly Thr
305 310 315 320
Thr Val Ser Pro Arg Thr Ala Thr Ser Ser Ala Arg Thr Cys Cys Gly
325 330 335
Thr Lys Trp Pro Ser Ser Gln Glu Ala Ala Leu Gly Leu Gly Ser Gly
340 345 350
Leu Leu Arg Phe Ser Cys Gly Thr Ala Ala Ile Arg Gln Asn Leu Gln
355 360 365
Asn Gly Gly Gly Ser Arg Ser Ser Ala Thr Leu Pro Gly Arg Arg Arg
370 375 380
Arg Arg Trp Leu Arg Arg Arg Arg Gln Pro Ile Ser Val Ala Pro Ala
385 390 395 400
Gly Pro Pro Arg Arg Pro Asn Gln Lys Pro Asn Pro Pro Gly Gly Ala
405 410 415
Arg Cys Val Ile Met Arg Pro Thr Trp Pro Gly Thr Ser Ala Phe Thr
420 425 430
Gly Met Glu Cys Thr Leu Gly Gln Val Gly Ala Pro Ser Pro Arg Arg
435 440 445
Glu Glu Asp Gly Trp Arg Gly Gly His Ser Arg Phe Lys Ala Asp Val
450 455 460
Pro Ala Pro Gln Gly Pro Cys Trp Gly Gly Gln Pro Gly Ser Ala Pro
465 470 475 480
Ser Ser Ala Pro Pro Glu Gln Ser Leu Leu Asp Asp Tyr Trp Ala Gln
485 490 495
Lys Glu Lys Ile Ser Ile Pro Arg Thr His Leu Cys Trp Lys Phe Glu
500 505 510
Met Ser Tyr Thr Val Gly Gly Pro Pro Pro His Val His Ala Arg Pro
515 520 525
Arg His Trp Lys Thr Asp Arg Asp Tyr Trp Ala Gln Lys Glu Lys Gly
530 535 540
Ser Ser Ser Phe Leu Arg Pro Ser Cys Val Pro Phe Arg Glu Leu Lys
545 550 555 560
Asn Val Ser Val Leu Glu Gly Leu Arg Gln Gly Arg Leu Gly Gly Pro
565 570 575
Cys Ser Cys His Cys Pro Arg Pro Ser Gln Ala Arg Leu Thr Pro Val
580 585 590
Asp Val Ala Gly Pro Phe Leu Cys Leu Gly Asp Pro Gly Leu Phe Pro
595 600 605
Pro Val Lys Ser Ser Ile Thr Glu Ile Ser Cys Cys Thr Leu Ser Ser
610 615 620
Glu Glu Asn Glu Tyr Leu Pro Arg Pro Glu Trp Gln Leu Gln Tyr Glu
625 630 635 640
Ala Gly Met Thr Leu Gly Gly Lys Ile Leu Phe Phe Leu Phe Leu Leu
645 650 655
Leu Pro Leu Ser Pro Phe Ser Leu Ile Phe Leu Val Leu Gly Val Leu
660 665 670
Ser Gly His Ser Gly Ser Arg Leu Lys Arg Ser Phe Ala Val Thr Glu
675 680 685
Arg Ile Ile Thr Gly Gly Lys Ser Thr Cys Ser Ala Pro Gly Pro Gln
690 695 700
Ser Leu Pro Ser Thr Pro Phe Ser Thr Tyr Pro Gln Trp Val Ile Leu
705 710 715 720
Ile Thr Glu Leu Asp Gly His Ser Tyr Thr Ser Lys Val Asn Cys Leu
725 730 735
Leu Leu Gln Asp Gly Phe His Gly Cys Val Ser Ile Thr Gly Ala Ala
740 745 750
Gly Arg Arg Asn Leu Ser Ile Phe Leu Phe Leu Met Leu Cys Lys Leu
755 760 765
Glu Phe His Ala Cys Gln Trp Gln His Tyr His Arg Ser Gly Glu Ala
770 775 780
Ala Gly Thr Pro Leu Trp Arg Pro Thr Arg Asn Val Ala Met Met Val
785 790 795 800
Pro Asp Arg Gln Val His Tyr Asp Phe Gly Leu Val Leu Arg Phe Leu
805 810 815
Asp Leu Lys Val Arg Tyr Leu His Ser Lys Ile Gln Asn Lys Asn Cys
820 825 830
Pro Asp Val Pro Phe Arg Glu Leu Lys Asn Gln Arg Thr Ala Gln Gly
835 840 845
Ala Pro Gly Ile His His Ala Ala Ser Pro Val Ala Ala Asn Leu Cys
850 855 860
Asp Pro Ala Arg His Ala Gln His Thr Arg Ile Pro Cys Gly Ala Gly
865 870 875 880
Gln Val Arg Ala Gly Arg Gly Pro Glu Ala Gly Gly Gly Val Leu Gln
885 890 895
Pro Gln Arg Pro Ala Pro Glu Lys Pro Gly Cys Pro Cys Arg Arg Gly
900 905 910
Gln Pro Arg Leu His Thr Val Lys Met Trp Arg Ala Cys His Leu Phe
915 920 925
Leu Gln Pro Gln Val Gly Thr Pro Pro Pro His Thr Ala Ser Ala Arg
930 935 940
Ala Pro Ser Gly Pro Pro His Pro His Glu Ser Cys Pro Ala Gly Arg
945 950 955 960
Arg Pro Ala Arg Ala Ala Gln Thr Cys Ala Arg Arg Gln His Gly Leu
965 970 975
Pro Gly Cys Glu Glu Ala Gly Thr Ala Arg Val Pro Ser Leu His Leu
980 985 990
His Leu His Gln Ala Ala Leu Gly Ala Gly Arg Gly Arg Gly Trp Gly
995 1000 1005
Glu Ala Cys Ala Gln Val Pro Pro Ser Arg Gly His Tyr Lys Leu
1010 1015 1020
Ile Gln Gln Pro Ile Ser Leu Phe Ser Ile Thr Asp Arg Leu His
1025 1030 1035
Lys Thr Phe Ser Gln Leu Pro Ser Val His Leu Cys Ser Ile Thr
1040 1045 1050
Phe Gln Trp Gly His Pro Pro Ile Phe Cys Ser Thr Asn Asp Ile
1055 1060 1065
Cys Val Thr Ala Asn Phe Cys Ile Ser Val Thr Phe Leu Lys Pro
1070 1075 1080
Cys Phe Leu Leu His Glu Ala Ser Ala Ser Gln Phe Lys Lys Phe
1085 1090 1095
Asp Gly Pro Cys Gly Glu Arg Gly Gly Gly Arg Thr Ala Arg Ala
1100 1105 1110
Leu Trp Ala Arg Gly Asp Ser Val Leu Thr Pro Ala Leu Asp Pro
1115 1120 1125
Gln Thr Pro Val Arg Ala Pro Ser Leu Thr Arg Ala Ala Ala Ala
1130 1135 1140
Val Gly Val Pro Gly Asp Ser Thr Arg Arg Ala Val Arg Arg Met
1145 1150 1155
Asn Thr Phe Cys Gly Ala Ser Ala Cys Asp Val Ser Leu Ile Ala
1160 1165 1170
Met Asp Ser Ala Cys Glu Glu Arg Gly Ala Ala Gly Ser Leu Ile
1175 1180 1185
Ser Cys Glu Ser Leu Tyr His Arg Glu Lys Gln Leu Ile Ala Met
1190 1195 1200
Asp Ser Ala Ile Phe Val Gln Gly Lys Asp Trp Gly Val Lys Lys
1205 1210 1215
Phe Ile Arg Arg Asp Phe Thr Met Pro Ala Ile Leu Lys Leu Gln
1220 1225 1230
Lys Asn Cys Leu Leu Ser Leu Asn Ser Lys Met Ala Leu Asn Ser
1235 1240 1245
Glu Ala Leu Ser Val Val Ser Glu Tyr Glu Ala Gly Met Thr Leu
1250 1255 1260
Gly Glu Lys Phe Arg Val Gly Asn Cys Lys His Leu Lys Met Thr
1265 1270 1275
Arg Pro Thr Glu Tyr Asn Gln Lys Leu Gln Val Asn Gln Phe Ser
1280 1285 1290
Glu Ser Lys Arg Thr Ala Leu Thr His Asn Gln Asp Phe Ser Ile
1295 1300 1305
Tyr Arg Leu Cys Cys Lys Arg Gly Ser Leu Cys His Ala Ser Gln
1310 1315 1320
Ala Arg Ser Pro Ala Phe Pro Lys Pro Val Arg Pro Leu Pro Ala
1325 1330 1335
Pro Ile Thr Arg Ile Thr Pro Gln Leu Gly Gly Gln Ser Asp Ser
1340 1345 1350
Ser Gln Pro Leu Leu Thr Thr Gly Arg Pro Gln Gly Trp Gln Asp
1355 1360 1365
Gln Ala Leu Arg His Thr Gln Gln Ala Ser Pro Ala Ser Cys Ala
1370 1375 1380
Thr Ile Thr Ile Pro Ile His Ser Ala Ala Leu Gly Asp His Ser
1385 1390 1395
Gly Asp Pro Gly Pro Ala Trp Asp Thr Cys Pro Pro Leu Pro Leu
1400 1405 1410
Thr Thr Leu Ile Pro Arg Ala Pro Pro Pro Tyr Gly Asp Ser Thr
1415 1420 1425
Ala Arg Ser Trp Pro Ser Arg Cys Gly Pro Leu Gly Tyr Ala Tyr
1430 1435 1440
Lys Asp Phe Leu Trp Cys Phe Pro Phe Ser Leu Val Phe Leu Gln
1445 1450 1455
Glu Ile Gln Ile Cys Cys His Val Ser Cys Leu Cys Cys Ile Cys
1460 1465 1470
Cys Ser Thr Arg Ile Cys Leu Gly Cys Leu Leu Glu Leu Phe Leu
1475 1480 1485
Ser Arg Ala Leu Arg Ala Leu His Val Leu Trp Asn Gly Phe Gln
1490 1495 1500
Leu His Cys Gln
1505
<210> 626
<211> 1507
<212> PRT
<213> Artificial seqeunce
<220>
<223> Heterologous polypeptide
<400> 626
Met Gly Gln Lys Glu Gln Ile His Thr Leu Gln Lys Asn Ser Glu Arg
1 5 10 15
Met Ser Lys Gln Leu Thr Arg Ser Ser Gln Ala Val Asp Gly His Ser
20 25 30
Tyr Thr Ser Lys Val Asn Cys Leu Leu Leu Gln Asp Gly Phe His Gly
35 40 45
Cys Val Ser Ile Thr Gly Ala Ala Gly Arg Arg Asn Leu Ser Ile Phe
50 55 60
Leu Phe Leu Met Leu Cys Lys Leu Glu Phe His Ala Cys Val Pro Phe
65 70 75 80
Arg Glu Leu Lys Asn Gln Arg Thr Ala Gln Gly Ala Pro Gly Ile His
85 90 95
His Ala Ala Ser Pro Val Ala Ala Asn Leu Cys Asp Pro Ala Arg His
100 105 110
Ala Gln His Thr Arg Ile Pro Cys Gly Ala Gly Gln Val Arg Ala Gly
115 120 125
Arg Gly Pro Glu Ala Gly Gly Gly Val Leu Gln Pro Gln Arg Pro Ala
130 135 140
Pro Glu Lys Pro Gly Cys Pro Cys Arg Arg Gly Gln Pro Arg Leu His
145 150 155 160
Thr Val Lys Met Trp Arg Ala Gln Trp Gln His Tyr His Arg Ser Gly
165 170 175
Glu Ala Ala Gly Thr Pro Leu Trp Arg Pro Thr Arg Asn Lys Ile Gln
180 185 190
Asn Lys Asn Cys Pro Asp Val Ala Met Met Val Pro Asp Arg Gln Val
195 200 205
His Tyr Asp Phe Gly Leu Val Leu Arg Phe Leu Asp Leu Lys Val Arg
210 215 220
Tyr Leu His Ser Cys His Leu Phe Leu Gln Pro Gln Val Gly Thr Pro
225 230 235 240
Pro Pro His Thr Ala Ser Ala Arg Ala Pro Ser Gly Pro Pro His Pro
245 250 255
His Glu Ser Cys Pro Ala Gly Arg Arg Pro Ala Arg Ala Ala Gln Thr
260 265 270
Cys Ala Arg Arg Gln His Gly Leu Pro Gly Cys Glu Glu Ala Gly Thr
275 280 285
Ala Arg Val Pro Ser Leu His Leu His Leu His Gln Ala Ala Leu Gly
290 295 300
Ala Gly Arg Gly Arg Gly Trp Gly Glu Ala Cys Ala Gln Val Pro Pro
305 310 315 320
Ser Arg Gly His Tyr Lys Leu Ile Gln Gln Pro Ile Ser Leu Phe Ser
325 330 335
Ile Thr Asp Arg Leu His Lys Thr Phe Ser Gln Leu Pro Ser Val His
340 345 350
Leu Cys Ser Ile Thr Phe Gln Trp Gly His Pro Pro Ile Phe Cys Ser
355 360 365
Thr Asn Asp Ile Cys Val Thr Ala Asn Phe Cys Ile Ser Val Thr Phe
370 375 380
Leu Lys Pro Cys Phe Leu Leu His Glu Ala Ser Ala Ser Gln Phe Lys
385 390 395 400
Lys Phe Asp Gly Pro Cys Gly Glu Arg Gly Gly Gly Arg Thr Ala Arg
405 410 415
Ala Leu Trp Ala Arg Gly Asp Ser Val Leu Thr Pro Ala Leu Asp Pro
420 425 430
Gln Thr Pro Val Arg Ala Pro Ser Leu Thr Arg Ala Ala Ala Ala Val
435 440 445
Gln Asn Leu Gln Asn Gly Gly Gly Ser Arg Ser Ser Ala Thr Leu Pro
450 455 460
Gly Arg Arg Arg Arg Arg Trp Leu Arg Arg Arg Arg Gln Pro Ile Ser
465 470 475 480
Val Ala Pro Ala Gly Pro Pro Arg Arg Pro Asn Gln Lys Pro Asn Pro
485 490 495
Pro Gly Gly Ala Arg Cys Val Ile Met Arg Pro Thr Trp Pro Gly Thr
500 505 510
Ser Ala Phe Thr Gly Met Glu Cys Thr Leu Gly Gln Val Gly Ala Pro
515 520 525
Ser Pro Arg Arg Glu Glu Asp Gly Trp Arg Gly Gly His Ser Arg Phe
530 535 540
Lys Ala Asp Val Pro Ala Pro Gln Gly Pro Cys Trp Gly Gly Gln Pro
545 550 555 560
Gly Ser Ala Pro Ser Ser Ala Pro Pro Glu Gln Ser Leu Leu Asp Asp
565 570 575
Tyr Trp Ala Gln Lys Glu Lys Ile Ser Ile Pro Arg Thr His Leu Cys
580 585 590
Trp Lys Phe Glu Met Ser Tyr Thr Val Gly Gly Pro Pro Pro His Val
595 600 605
His Ala Arg Pro Arg His Trp Lys Thr Asp Arg Asp Tyr Trp Ala Gln
610 615 620
Lys Glu Lys Gly Ser Ser Ser Phe Leu Arg Pro Ser Cys Val Pro Phe
625 630 635 640
Arg Glu Leu Lys Asn Val Ser Val Leu Glu Gly Leu Arg Gln Gly Arg
645 650 655
Leu Gly Gly Pro Cys Ser Cys His Cys Pro Arg Pro Ser Gln Ala Arg
660 665 670
Leu Thr Pro Val Asp Val Ala Gly Pro Phe Leu Cys Leu Gly Asp Pro
675 680 685
Gly Leu Phe Pro Pro Val Lys Ser Ser Ile Thr Glu Ile Ser Cys Cys
690 695 700
Thr Leu Ser Ser Glu Glu Asn Glu Tyr Leu Pro Arg Pro Glu Trp Gln
705 710 715 720
Leu Gln Tyr Glu Ala Gly Met Thr Leu Gly Gly Lys Ile Leu Phe Phe
725 730 735
Leu Phe Leu Leu Leu Pro Leu Ser Pro Phe Ser Leu Ile Phe Leu Val
740 745 750
Leu Gly Val Leu Ser Gly His Ser Gly Ser Arg Leu Lys Arg Ser Phe
755 760 765
Ala Val Thr Glu Arg Ile Ile Thr Gly Gly Lys Ser Thr Cys Ser Ala
770 775 780
Pro Gly Pro Gln Ser Leu Pro Ser Thr Pro Phe Ser Thr Tyr Pro Gln
785 790 795 800
Trp Val Ile Leu Ile Thr Glu Leu Gly Asn Thr Thr Leu Gln Gln Leu
805 810 815
Gly Glu Ala Ser Gln Ala Pro Ser Gly Ser Leu Ile Pro Leu Arg Leu
820 825 830
Pro Leu Leu Trp Glu Val Arg Gly Asn Ser Lys Met Ala Leu Asn Ser
835 840 845
Leu Asn Ser Ile Asp Asp Ala Gln Leu Thr Arg Ile Ala Pro Pro Arg
850 855 860
Ser His Cys Cys Phe Trp Glu Val Asn Ala Pro Phe Val Gln Gly Lys
865 870 875 880
Asp Trp Gly Leu Lys Lys Phe Ile Arg Arg Asp Phe Glu Ala Phe Gln
885 890 895
Arg Ala Ala Gly Glu Gly Gly Pro Gly Arg Gly Gly Ala Arg Arg Gly
900 905 910
Ala Arg Val Leu Gln Ser Pro Phe Cys Arg Ala Gly Ala Gly Glu Trp
915 920 925
Leu Gly His Gln Ser Leu Arg Trp Gly Met Glu Leu Ala Ala Ser Arg
930 935 940
Arg Phe Ser Trp Asp His His Ser Ala Gly Gly Pro Pro Arg Val Pro
945 950 955 960
Ser Val Arg Ser Gly Ala Ala Gln Val Gln Pro Lys Asp Pro Leu Pro
965 970 975
Leu Arg Thr Leu Ala Gly Cys Leu Ala Arg Thr Ala His Leu Arg Pro
980 985 990
Gly Ala Glu Ser Leu Pro Gln Pro Gln Leu His Cys Thr Ile Ala Arg
995 1000 1005
Glu Leu His Gln Phe Ala Phe Asp Leu Leu Ile Lys Ser His Lys
1010 1015 1020
Met His Phe Ser Leu Lys Glu His Pro Pro Pro Pro Cys Pro Pro
1025 1030 1035
His Val Val Gly Tyr Gly His Leu Asp Thr Ser Gly Ser Ser Ser
1040 1045 1050
Ser Ser Ser Trp Pro Gln Pro Asp Ser Phe Ala Ala Leu His Ser
1055 1060 1065
Ser Leu Asn Glu Leu Gly Glu Leu Trp Phe Gln Ser Ser Glu Leu
1070 1075 1080
Ser Pro Thr Gly Ala Pro Trp Pro Ser Arg Arg Pro Thr Trp Arg
1085 1090 1095
Gly Thr Thr Val Ser Pro Arg Thr Ala Thr Ser Ser Ala Arg Thr
1100 1105 1110
Cys Cys Gly Thr Lys Trp Pro Ser Ser Gln Glu Ala Ala Leu Gly
1115 1120 1125
Leu Gly Ser Gly Leu Leu Arg Phe Ser Cys Gly Thr Ala Ala Ile
1130 1135 1140
Arg Gly Val Pro Gly Asp Ser Thr Arg Arg Ala Val Arg Arg Met
1145 1150 1155
Asn Thr Phe Cys Gly Ala Ser Ala Cys Asp Val Ser Leu Ile Ala
1160 1165 1170
Met Asp Ser Ala Cys Glu Glu Arg Gly Ala Ala Gly Ser Leu Ile
1175 1180 1185
Ser Cys Glu Ser Leu Tyr His Arg Glu Lys Gln Leu Ile Ala Met
1190 1195 1200
Asp Ser Ala Ile Phe Val Gln Gly Lys Asp Trp Gly Val Lys Lys
1205 1210 1215
Phe Ile Arg Arg Asp Phe Tyr Glu Ala Gly Met Thr Leu Gly Glu
1220 1225 1230
Lys Phe Arg Val Gly Asn Cys Lys His Leu Lys Met Thr Arg Pro
1235 1240 1245
Thr Met Pro Ala Ile Leu Lys Leu Gln Lys Asn Cys Leu Leu Ser
1250 1255 1260
Leu Asn Ser Lys Met Ala Leu Asn Ser Glu Ala Leu Ser Val Val
1265 1270 1275
Ser Glu Thr Glu Tyr Asn Gln Lys Leu Gln Val Asn Gln Phe Ser
1280 1285 1290
Glu Ser Lys Arg Thr Ala Leu Thr His Asn Gln Asp Phe Ser Ile
1295 1300 1305
Tyr Arg Leu Cys Cys Lys Arg Gly Ser Leu Cys His Ala Ser Gln
1310 1315 1320
Ala Arg Ser Pro Ala Phe Pro Lys Pro Val Arg Pro Leu Pro Ala
1325 1330 1335
Pro Ile Thr Arg Ile Thr Pro Gln Leu Gly Gly Gln Ser Asp Ser
1340 1345 1350
Ser Gln Pro Leu Leu Thr Thr Gly Arg Pro Gln Gly Trp Gln Asp
1355 1360 1365
Gln Ala Leu Arg His Thr Gln Gln Ala Ser Pro Ala Ser Cys Ala
1370 1375 1380
Thr Ile Thr Ile Pro Ile His Ser Ala Ala Leu Gly Asp His Ser
1385 1390 1395
Gly Asp Pro Gly Pro Ala Trp Asp Thr Cys Pro Pro Leu Pro Leu
1400 1405 1410
Thr Thr Leu Ile Pro Arg Ala Pro Pro Pro Tyr Gly Asp Ser Thr
1415 1420 1425
Ala Arg Ser Trp Pro Ser Arg Cys Gly Pro Leu Gly Tyr Ala Tyr
1430 1435 1440
Lys Asp Phe Leu Trp Cys Phe Pro Phe Ser Leu Val Phe Leu Gln
1445 1450 1455
Glu Ile Gln Ile Cys Cys His Val Ser Cys Leu Cys Cys Ile Cys
1460 1465 1470
Cys Ser Thr Arg Ile Cys Leu Gly Cys Leu Leu Glu Leu Phe Leu
1475 1480 1485
Ser Arg Ala Leu Arg Ala Leu His Val Leu Trp Asn Gly Phe Gln
1490 1495 1500
Leu His Cys Gln
1505
<210> 627
<211> 7
<212> PRT
<213> Artificial seqeunce
<220>
<223> protein tag
<400> 627
Ser His His His His His His
1 5
<210> 628
<211> 845
<212> DNA
<213> Artificial sequence
<220>
<223> Promoter
<400> 628
ccattgcata cgttgtatcc atatcataat atgtacattt atattggctc atgtccaaca 60
ttaccgccat gttgacattg attattgact agttattaat agtaatcaat tacggggtca 120
ttagttcata gcccatatat ggagttccgc gttacataac ttacggtaaa tggcccgcct 180
ggctgaccgc ccaacgaccc ccgcccattg acgtcaataa tgacgtatgt tcccatagta 240
acgccaatag ggactttcca ttgacgtcaa tgggtggagt atttacggta aactgcccac 300
ttggcagtac atcaagtgta tcatatgcca agtacgcccc ctattgacgt caatgacggt 360
aaatggcccg cctggcatta tgcccagtac atgaccttat gggactttcc tacttggcag 420
tacatctacg tattagtcat cgctattacc atggtgatgc ggttttggca gtacatcaat 480
gggcgtggat agcggtttga ctcacgggga tttccaagtc tccaccccat tgacgtcaat 540
gggagtttgt tttggcacca aaatcaacgg gactttccaa aatgtcgtaa caactccgcc 600
ccattgacgc aaatgggcgg taggcgtgta cggtgggagg tctatataag cagagctctc 660
cctatcagtg atagagatct ccctatcagt gatagagatc gtcgacgagc tcgtttagtg 720
aaccgtcaga tcgcctggag acgccatcca cgctgttttg acctccatag aagacaccgg 780
gaccgatcca gcctccgcgg ccgggaacgg tgcattggaa cgcggattcc ccgtgccaag 840
agtga 845
<210> 629
<211> 227
<212> DNA
<213> Artificial sequence
<220>
<223> polyA site
<400> 629
ctgtgccttc tagttgccag ccatctgttg tttgcccctc ccccgtgcct tccttgaccc 60
tggaaggtgc cactcccact gtcctttcct aataaaatga ggaaattgca tcgcattgtc 120
tgagtaggtg tcattctatt ctggggggtg gggtggggca ggacagcaag ggggaggatt 180
gggaagacaa tagcaggcat gctggggatg cggtgggctc tatggcc 227
<210> 630
<211> 149
<212> DNA
<213> Artificial sequence
<220>
<223> Promoter
<400> 630
gatcactaat tccaaaccca cccgcttttt atagtaagtt tttcacccat aaataataaa 60
tacaataatt aatttctcgt aaaagtagaa aatatattct aatttattgc acggtaagga 120
agtagaatca taaagaacag tgacggatc 149
<210> 631
<211> 15
<212> PRT
<213> Homo sapiens
<400> 631
Val Pro Phe Arg Glu Leu Lys Asn Gln Arg Thr Ala Gln Gly Ala
1 5 10 15
<210> 632
<211> 15
<212> PRT
<213> Homo sapiens
<400> 632
Gln Arg Thr Ala Gln Gly Ala Pro Gly Ile His His Ala Ala Ser
1 5 10 15
<210> 633
<211> 15
<212> PRT
<213> Homo sapiens
<400> 633
Gly Ile His His Ala Ala Ser Pro Val Ala Ala Asn Leu Cys Asp
1 5 10 15
<210> 634
<211> 15
<212> PRT
<213> Homo sapiens
<400> 634
Val Ala Ala Asn Leu Cys Asp Pro Ala Arg His Ala Gln His Thr
1 5 10 15
<210> 635
<211> 15
<212> PRT
<213> Homo sapiens
<400> 635
Ala Arg His Ala Gln His Thr Arg Ile Pro Cys Gly Ala Gly Gln
1 5 10 15
<210> 636
<211> 15
<212> PRT
<213> Homo sapiens
<400> 636
Ile Pro Cys Gly Ala Gly Gln Val Arg Ala Gly Arg Gly Pro Glu
1 5 10 15
<210> 637
<211> 15
<212> PRT
<213> Homo sapiens
<400> 637
Arg Ala Gly Arg Gly Pro Glu Ala Gly Gly Gly Val Leu Gln Pro
1 5 10 15
<210> 638
<211> 15
<212> PRT
<213> Homo sapiens
<400> 638
Gly Gly Gly Val Leu Gln Pro Gln Arg Pro Ala Pro Glu Lys Pro
1 5 10 15
<210> 639
<211> 15
<212> PRT
<213> Homo sapiens
<400> 639
Arg Pro Ala Pro Glu Lys Pro Gly Cys Pro Cys Arg Arg Gly Gln
1 5 10 15
<210> 640
<211> 15
<212> PRT
<213> Homo sapiens
<400> 640
Cys Pro Cys Arg Arg Gly Gln Pro Arg Leu His Thr Val Lys Met
1 5 10 15
<210> 641
<211> 14
<212> PRT
<213> Homo sapiens
<400> 641
Arg Gly Gln Pro Arg Leu His Thr Val Lys Met Trp Arg Ala
1 5 10
<210> 642
<211> 15
<212> PRT
<213> Homo sapiens
<400> 642
Cys His Leu Phe Leu Gln Pro Gln Val Gly Thr Pro Pro Pro His
1 5 10 15
<210> 643
<211> 15
<212> PRT
<213> Homo sapiens
<400> 643
Val Gly Thr Pro Pro Pro His Thr Ala Ser Ala Arg Ala Pro Ser
1 5 10 15
<210> 644
<211> 15
<212> PRT
<213> Homo sapiens
<400> 644
Ala Ser Ala Arg Ala Pro Ser Gly Pro Pro His Pro His Glu Ser
1 5 10 15
<210> 645
<211> 15
<212> PRT
<213> Homo sapiens
<400> 645
Pro Pro His Pro His Glu Ser Cys Pro Ala Gly Arg Arg Pro Ala
1 5 10 15
<210> 646
<211> 15
<212> PRT
<213> Homo sapiens
<400> 646
Pro Ala Gly Arg Arg Pro Ala Arg Ala Ala Gln Thr Cys Ala Arg
1 5 10 15
<210> 647
<211> 15
<212> PRT
<213> Homo sapiens
<400> 647
Ala Ala Gln Thr Cys Ala Arg Arg Gln His Gly Leu Pro Gly Cys
1 5 10 15
<210> 648
<211> 15
<212> PRT
<213> Homo sapiens
<400> 648
Gln His Gly Leu Pro Gly Cys Glu Glu Ala Gly Thr Ala Arg Val
1 5 10 15
<210> 649
<211> 15
<212> PRT
<213> Homo sapiens
<400> 649
Glu Ala Gly Thr Ala Arg Val Pro Ser Leu His Leu His Leu His
1 5 10 15
<210> 650
<211> 15
<212> PRT
<213> Homo sapiens
<400> 650
Ser Leu His Leu His Leu His Gln Ala Ala Leu Gly Ala Gly Arg
1 5 10 15
<210> 651
<211> 15
<212> PRT
<213> Homo sapiens
<400> 651
Ala Ala Leu Gly Ala Gly Arg Gly Arg Gly Trp Gly Glu Ala Cys
1 5 10 15
<210> 652
<211> 15
<212> PRT
<213> Homo sapiens
<400> 652
Arg Gly Trp Gly Glu Ala Cys Ala Gln Val Pro Pro Ser Arg Gly
1 5 10 15
<210> 653
<211> 15
<212> PRT
<213> Homo sapiens
<400> 653
His Tyr Lys Leu Ile Gln Gln Pro Ile Ser Leu Phe Ser Ile Thr
1 5 10 15
<210> 654
<211> 15
<212> PRT
<213> Homo sapiens
<400> 654
Ile Ser Leu Phe Ser Ile Thr Asp Arg Leu His Lys Thr Phe Ser
1 5 10 15
<210> 655
<211> 15
<212> PRT
<213> Homo sapiens
<400> 655
Arg Leu His Lys Thr Phe Ser Gln Leu Pro Ser Val His Leu Cys
1 5 10 15
<210> 656
<211> 15
<212> PRT
<213> Homo sapiens
<400> 656
Leu Pro Ser Val His Leu Cys Ser Ile Thr Phe Gln Trp Gly His
1 5 10 15
<210> 657
<211> 15
<212> PRT
<213> Homo sapiens
<400> 657
Ile Thr Phe Gln Trp Gly His Pro Pro Ile Phe Cys Ser Thr Asn
1 5 10 15
<210> 658
<211> 15
<212> PRT
<213> Homo sapiens
<400> 658
Pro Ile Phe Cys Ser Thr Asn Asp Ile Cys Val Thr Ala Asn Phe
1 5 10 15
<210> 659
<211> 15
<212> PRT
<213> Homo sapiens
<400> 659
Ile Cys Val Thr Ala Asn Phe Cys Ile Ser Val Thr Phe Leu Lys
1 5 10 15
<210> 660
<211> 15
<212> PRT
<213> Homo sapiens
<400> 660
Ile Ser Val Thr Phe Leu Lys Pro Cys Phe Leu Leu His Glu Ala
1 5 10 15
<210> 661
<211> 11
<212> PRT
<213> Homo sapiens
<400> 661
Cys Phe Leu Leu His Glu Ala Ser Ala Ser Gln
1 5 10
<210> 662
<211> 15
<212> PRT
<213> Homo sapiens
<400> 662
Arg Thr Ala Leu Thr His Asn Gln Asp Phe Ser Ile Tyr Arg Leu
1 5 10 15
<210> 663
<211> 15
<212> PRT
<213> Homo sapiens
<400> 663
Asp Phe Ser Ile Tyr Arg Leu Cys Cys Lys Arg Gly Ser Leu Cys
1 5 10 15
<210> 664
<211> 15
<212> PRT
<213> Homo sapiens
<400> 664
Cys Lys Arg Gly Ser Leu Cys His Ala Ser Gln Ala Arg Ser Pro
1 5 10 15
<210> 665
<211> 15
<212> PRT
<213> Homo sapiens
<400> 665
Ala Ser Gln Ala Arg Ser Pro Ala Phe Pro Lys Pro Val Arg Pro
1 5 10 15
<210> 666
<211> 15
<212> PRT
<213> Homo sapiens
<400> 666
Phe Pro Lys Pro Val Arg Pro Leu Pro Ala Pro Ile Thr Arg Ile
1 5 10 15
<210> 667
<211> 15
<212> PRT
<213> Homo sapiens
<400> 667
Pro Ala Pro Ile Thr Arg Ile Thr Pro Gln Leu Gly Gly Gln Ser
1 5 10 15
<210> 668
<211> 15
<212> PRT
<213> Homo sapiens
<400> 668
Pro Gln Leu Gly Gly Gln Ser Asp Ser Ser Gln Pro Leu Leu Thr
1 5 10 15
<210> 669
<211> 15
<212> PRT
<213> Homo sapiens
<400> 669
Ser Ser Gln Pro Leu Leu Thr Thr Gly Arg Pro Gln Gly Trp Gln
1 5 10 15
<210> 670
<211> 15
<212> PRT
<213> Homo sapiens
<400> 670
Gly Arg Pro Gln Gly Trp Gln Asp Gln Ala Leu Arg His Thr Gln
1 5 10 15
<210> 671
<211> 15
<212> PRT
<213> Homo sapiens
<400> 671
Gln Ala Leu Arg His Thr Gln Gln Ala Ser Pro Ala Ser Cys Ala
1 5 10 15
<210> 672
<211> 15
<212> PRT
<213> Homo sapiens
<400> 672
Ala Ser Pro Ala Ser Cys Ala Thr Ile Thr Ile Pro Ile His Ser
1 5 10 15
<210> 673
<211> 15
<212> PRT
<213> Homo sapiens
<400> 673
Ile Thr Ile Pro Ile His Ser Ala Ala Leu Gly Asp His Ser Gly
1 5 10 15
<210> 674
<211> 15
<212> PRT
<213> Homo sapiens
<400> 674
Ala Leu Gly Asp His Ser Gly Asp Pro Gly Pro Ala Trp Asp Thr
1 5 10 15
<210> 675
<211> 15
<212> PRT
<213> Homo sapiens
<400> 675
Pro Gly Pro Ala Trp Asp Thr Cys Pro Pro Leu Pro Leu Thr Thr
1 5 10 15
<210> 676
<211> 15
<212> PRT
<213> Homo sapiens
<400> 676
Pro Pro Leu Pro Leu Thr Thr Leu Ile Pro Arg Ala Pro Pro Pro
1 5 10 15
<210> 677
<211> 15
<212> PRT
<213> Homo sapiens
<400> 677
Ile Pro Arg Ala Pro Pro Pro Tyr Gly Asp Ser Thr Ala Arg Ser
1 5 10 15
<210> 678
<211> 16
<212> PRT
<213> Homo sapiens
<400> 678
Gly Asp Ser Thr Ala Arg Ser Trp Pro Ser Arg Cys Gly Pro Leu Gly
1 5 10 15
<210> 679
<211> 15
<212> PRT
<213> Homo sapiens
<400> 679
Tyr Ala Tyr Lys Asp Phe Leu Trp Cys Phe Pro Phe Ser Leu Val
1 5 10 15
<210> 680
<211> 15
<212> PRT
<213> Homo sapiens
<400> 680
Cys Phe Pro Phe Ser Leu Val Phe Leu Gln Glu Ile Gln Ile Cys
1 5 10 15
<210> 681
<211> 15
<212> PRT
<213> Homo sapiens
<400> 681
Leu Gln Glu Ile Gln Ile Cys Cys His Val Ser Cys Leu Cys Cys
1 5 10 15
<210> 682
<211> 15
<212> PRT
<213> Homo sapiens
<400> 682
His Val Ser Cys Leu Cys Cys Ile Cys Cys Ser Thr Arg Ile Cys
1 5 10 15
<210> 683
<211> 15
<212> PRT
<213> Homo sapiens
<400> 683
Cys Cys Ser Thr Arg Ile Cys Leu Gly Cys Leu Leu Glu Leu Phe
1 5 10 15
<210> 684
<211> 15
<212> PRT
<213> Homo sapiens
<400> 684
Gly Cys Leu Leu Glu Leu Phe Leu Ser Arg Ala Leu Arg Ala Leu
1 5 10 15
<210> 685
<211> 15
<212> PRT
<213> Homo sapiens
<400> 685
Ser Arg Ala Leu Arg Ala Leu His Val Leu Trp Asn Gly Phe Gln
1 5 10 15
<210> 686
<211> 11
<212> PRT
<213> Homo sapiens
<400> 686
Val Leu Trp Asn Gly Phe Gln Leu His Cys Gln
1 5 10
<210> 687
<211> 15
<212> PRT
<213> Homo sapiens
<400> 687
Tyr Glu Ala Gly Met Thr Leu Gly Glu Lys Phe Arg Val Gly Asn
1 5 10 15
<210> 688
<211> 16
<212> PRT
<213> Homo sapiens
<400> 688
Glu Lys Phe Arg Val Gly Asn Cys Lys His Leu Lys Met Thr Arg Pro
1 5 10 15
<210> 689
<211> 15
<212> PRT
<213> Homo sapiens
<400> 689
Trp Gly Met Glu Leu Ala Ala Ser Arg Arg Phe Ser Trp Asp His
1 5 10 15
<210> 690
<211> 15
<212> PRT
<213> Homo sapiens
<400> 690
Arg Arg Phe Ser Trp Asp His His Ser Ala Gly Gly Pro Pro Arg
1 5 10 15
<210> 691
<211> 15
<212> PRT
<213> Homo sapiens
<400> 691
Ser Ala Gly Gly Pro Pro Arg Val Pro Ser Val Arg Ser Gly Ala
1 5 10 15
<210> 692
<211> 15
<212> PRT
<213> Homo sapiens
<400> 692
Pro Ser Val Arg Ser Gly Ala Ala Gln Val Gln Pro Lys Asp Pro
1 5 10 15
<210> 693
<211> 15
<212> PRT
<213> Homo sapiens
<400> 693
Gln Val Gln Pro Lys Asp Pro Leu Pro Leu Arg Thr Leu Ala Gly
1 5 10 15
<210> 694
<211> 15
<212> PRT
<213> Homo sapiens
<400> 694
Pro Leu Arg Thr Leu Ala Gly Cys Leu Ala Arg Thr Ala His Leu
1 5 10 15
<210> 695
<211> 15
<212> PRT
<213> Homo sapiens
<400> 695
Leu Ala Arg Thr Ala His Leu Arg Pro Gly Ala Glu Ser Leu Pro
1 5 10 15
<210> 696
<211> 14
<212> PRT
<213> Homo sapiens
<400> 696
Pro Gly Ala Glu Ser Leu Pro Gln Pro Gln Leu His Cys Thr
1 5 10
<210> 697
<211> 15
<212> PRT
<213> Homo sapiens
<400> 697
Asn Ser Lys Met Ala Leu Asn Ser Leu Asn Ser Ile Asp Asp Ala
1 5 10 15
<210> 698
<211> 15
<212> PRT
<213> Homo sapiens
<400> 698
Leu Asn Ser Ile Asp Asp Ala Gln Leu Thr Arg Ile Ala Pro Pro
1 5 10 15
<210> 699
<211> 15
<212> PRT
<213> Homo sapiens
<400> 699
Leu Thr Arg Ile Ala Pro Pro Arg Ser His Cys Cys Phe Trp Glu
1 5 10 15
<210> 700
<211> 15
<212> PRT
<213> Homo sapiens
<400> 700
Ala Pro Pro Arg Ser His Cys Cys Phe Trp Glu Val Asn Ala Pro
1 5 10 15
<210> 701
<211> 15
<212> PRT
<213> Homo sapiens
<400> 701
Leu Trp Phe Gln Ser Ser Glu Leu Ser Pro Thr Gly Ala Pro Trp
1 5 10 15
<210> 702
<211> 15
<212> PRT
<213> Homo sapiens
<400> 702
Ser Pro Thr Gly Ala Pro Trp Pro Ser Arg Arg Pro Thr Trp Arg
1 5 10 15
<210> 703
<211> 15
<212> PRT
<213> Homo sapiens
<400> 703
Ser Arg Arg Pro Thr Trp Arg Gly Thr Thr Val Ser Pro Arg Thr
1 5 10 15
<210> 704
<211> 15
<212> PRT
<213> Homo sapiens
<400> 704
Thr Thr Val Ser Pro Arg Thr Ala Thr Ser Ser Ala Arg Thr Cys
1 5 10 15
<210> 705
<211> 15
<212> PRT
<213> Homo sapiens
<400> 705
Thr Ser Ser Ala Arg Thr Cys Cys Gly Thr Lys Trp Pro Ser Ser
1 5 10 15
<210> 706
<211> 15
<212> PRT
<213> Homo sapiens
<400> 706
Gly Thr Lys Trp Pro Ser Ser Gln Glu Ala Ala Leu Gly Leu Gly
1 5 10 15
<210> 707
<211> 15
<212> PRT
<213> Homo sapiens
<400> 707
Glu Ala Ala Leu Gly Leu Gly Ser Gly Leu Leu Arg Phe Ser Cys
1 5 10 15
<210> 708
<211> 13
<212> PRT
<213> Homo sapiens
<400> 708
Gly Leu Leu Arg Phe Ser Cys Gly Thr Ala Ala Ile Arg
1 5 10
<210> 709
<211> 15
<212> PRT
<213> Homo sapiens
<400> 709
Gln Asn Leu Gln Asn Gly Gly Gly Ser Arg Ser Ser Ala Thr Leu
1 5 10 15
<210> 710
<211> 15
<212> PRT
<213> Homo sapiens
<400> 710
Gln Trp Gln His Tyr His Arg Ser Gly Glu Ala Ala Gly Thr Pro
1 5 10 15
<210> 711
<211> 14
<212> PRT
<213> Homo sapiens
<400> 711
Gly Glu Ala Ala Gly Thr Pro Leu Trp Arg Pro Thr Arg Asn
1 5 10
<210> 712
<211> 16
<212> PRT
<213> Homo sapiens
<400> 712
Thr Glu Tyr Asn Gln Lys Leu Gln Val Asn Gln Phe Ser Glu Ser Lys
1 5 10 15
<210> 713
<211> 32767
<212> DNA
<213> Artificial sequence
<220>
<223> recombinant GAd20
<400> 713
catcatcaat aatatacctt attttggatt gaggccaata tgataatgag gtgggcgggg 60
cgaggcgggg cgggtgacgt aggacgcgcg agtagggttg ggaggtgtgg cggaagtgtg 120
gcatttgcaa gtgggaggag ctgacatgca atcttccgtc gcggaaaatg tgacgttttt 180
gatgagcgcc gcctacctcc ggaagtgcca attttcgcgc gcttttcacc ggatatcgta 240
gtaattttgg gcgggaccat gtaagatttg gccattttcg cgcgaaaagt gaaacgggga 300
agtgaaaact gaataatagg gcgttagtca tagcgcgtaa tatttaccga gggccgaggg 360
actttgaccg attacgtgga ggactcgccc aggtgttttt tacgtgaatt tccgcgttcc 420
gggtcaaagt ctccgttttt attgtcgccg tcatctgacg ggccgccatt gcatacgttg 480
tatccatatc ataatatgta catttatatt ggctcatgtc caacattacc gccatgttga 540
cattgattat tgactagtta ttaatagtaa tcaattacgg ggtcattagt tcatagccca 600
tatatggagt tccgcgttac ataacttacg gtaaatggcc cgcctggctg accgcccaac 660
gacccccgcc cattgacgtc aataatgacg tatgttccca tagtaacgcc aatagggact 720
ttccattgac gtcaatgggt ggagtattta cggtaaactg cccacttggc agtacatcaa 780
gtgtatcata tgccaagtac gccccctatt gacgtcaatg acggtaaatg gcccgcctgg 840
cattatgccc agtacatgac cttatgggac tttcctactt ggcagtacat ctacgtatta 900
gtcatcgcta ttaccatggt gatgcggttt tggcagtaca tcaatgggcg tggatagcgg 960
tttgactcac ggggatttcc aagtctccac cccattgacg tcaatgggag tttgttttgg 1020
caccaaaatc aacgggactt tccaaaatgt cgtaacaact ccgccccatt gacgcaaatg 1080
ggcggtaggc gtgtacggtg ggaggtctat ataagcagag ctctccctat cagtgataga 1140
gatctcccta tcagtgatag agatcgtcga cgagctcgtt tagtgaaccg tcagatcgcc 1200
tggagacgcc atccacgctg ttttgacctc catagaagac accgggaccg atccagcctc 1260
cgcggccggg aacggtgcat tggaacgcgg attccccgtg ccaagagtga gatcttccgt 1320
ttatctaggt accagatatc agaattcgga tcccgcgact tcgccgccat gggccagaaa 1380
gagcagatcc acacactgca gaaaaacagc gagcggatga gcaagcagct gaccagatct 1440
tctcaggccg tgcagaacct gcagaacggc ggaggctcta gaagctctgc tacacttcct 1500
ggcaggcggc ggagaagatg gctgagaaga aggcggcagc ctatctctgt ggctcctgct 1560
ggacctccta gacggcccaa ccagaagcct aatcctcctg gcggagccag atgcgtgatc 1620
atgaggccta catggcctgg caccagcgcc ttcaccaaga gaagctttgc cgtgaccgag 1680
cggatcatcg actattgggc tcaaaaagag aagggcagca gcagcttcct gcggcctagc 1740
tgtgattatt gggcccagaa agaaaagatc agcatcccca gaacacacct gtgcctggtg 1800
ctgggagtgc tgtctggaca ctctggcagc agactgtatg aggccggcat gacactcggc 1860
ggcaagatcc tgttcttcct gttcctgctg ctccctctga gccccttcag cctgatcttc 1920
accgagatca gctgctgcac cctgagcagc gaggaaaacg agtacctgcc tagacctgag 1980
tggcagctgc aggtcccctt cagagagctg aagaacgttt ccgtgctgga aggcctgaga 2040
cagggcagac ttggcggccc ttgtagctgt cactgcccca gacctagtca ggccagactg 2100
acacctgtgg atgtggccgg acctttcctg tgtctgggag atcctggcct gtttccacct 2160
gtgaagtcca gcatcacagg cggcaagtcc acatgttctg cccctggacc tcagagcctg 2220
cctagcacac ccttcagcac ataccctcag tgggtcatcc tgatcaccga actcggcatg 2280
gaatgcaccc tgggacaagt gggagcccca tctcctagaa gagaagagga tggctggcgc 2340
ggaggccact ctagattcaa agctgatgtg cccgctcctc agggcccttg ttggggagga 2400
caacctggat ctgccccatc ttctgcccca cctgaacagt ccctgctgga ttggaagttc 2460
gagatgagct acaccgtcgg cggacctcca cctcatgttc atgccagacc tcggcactgg 2520
aaaaccgaca gagatggcca cagctacacc agcaaagtga actgcctcct gctgcaggat 2580
ggcttccacg gctgtgtgtc tattactggc gccgctggca gacggaacct gagcatcttt 2640
ctgtttctga tgctgtgcaa gctcgagttc cacgcctgca agatccagaa caagaactgc 2700
cccgacttca agaagttcga cggcccttgc ggagaaagag gcggaggcag aacagctaga 2760
gccctttggg ctagaggcga cagcgttctg acaccagctc tggaccctca gacacctgtt 2820
agggccccta gcctgacaag agctgccgcc gctgtgcact acaagctgat ccagcagcca 2880
atcagcctgt tcagcatcac cgaccggctg cacaagacat tcagccagct gccaagcgtg 2940
cacctgtgct ccatcacctt ccagtgggga caccctccta tcttttgctc caccaacgac 3000
atctgcgtga ccgccaactt ctgtatcagc gtgaccttcc tgaagccttg ctttctgctg 3060
cacgaggcca gcgcctctca gtgccacttg tttctgcagc cccaagtggg cacacctcct 3120
ccacatacag cctctgctag agcacctagc ggccctccac atcctcacga atcttgtcct 3180
gccggaagaa ggcctgccag agccgctcaa acatgtgcca gacgacagca cggactgcct 3240
ggatgtgaag aggctggaac agccagagtg cctagcctgc acctccatct gcatcaggct 3300
gctcttggag ccggaagagg tagaggatgg ggcgaagctt gtgctcaggt gccaccttct 3360
agaggcgtgc tgagattcct ggacctgaaa gtgcgctacc tgcacagcca gtggcagcac 3420
tatcacagat ctggcgaagc cgccggaaca cccctttgga ggccaacaag aaacgtgccc 3480
ttccgggaac tgaagaacca gagaacagct cagggcgctc ctggaatcca ccatgctgct 3540
tctccagtgg ccgccaacct gtgtgatcct gccagacatg cccagcacac caggattcct 3600
tgtggcgctg gacaagtgcg cgctggaaga ggacctgaag caggcggagg tgttctgcaa 3660
cctcaaagac ccgctcctga gaagcctggc tgcccttgca gaagaggaca gcctagactg 3720
cacaccgtga aaatgtggcg agccgtggcc atgatggtgc ccgatagaca ggtccactac 3780
gactttggac tgggcgtgcc aggcgatagc actcggagag ccgtcagacg gatgaacacc 3840
ttttacgaag ccgggatgac cctgggcgag aagttcagag tgggcaactg caagcacctg 3900
aagatgaccc ggcctaacag caagatggcc ctgaatagcg aggccctgtc tgtggtgtct 3960
gaatgtggcg cctctgcctg tgacgtgtcc ctgatcgcta tggactccgc ctttgtgcag 4020
ggcaaagact ggggcgtgaa gaagttcatc cggcgggact tctacgccta caaggacttc 4080
ctgtggtgct tccccttctc tctggtgttc ctgcaagaga tccagatctg ctgtcatgtg 4140
tcctgcctgt gctgcatctg ctgtagcacc agaatctgcc tgggctgtct gctggaactg 4200
ttcctgagca gagccctgag agcactgcac gtgctgtgga acggattcca gctgcactgc 4260
cagaccgagt acaaccagaa actgcaagtg aaccagttca gcgagagcaa gagcctgtac 4320
caccgggaaa agcagctcat tgccatggac agcgccatct gcgaagagag aggcgccgca 4380
ggatctctga tctcctgcga aacaatgccc gccatcctga agctgcagaa gaattgcctc 4440
ctaagcctgc gaaccgctct gacacacaac caggacttca gcatctacag actgtgttgc 4500
aagcggggct ccctgtgcca tgcaagccaa gctagaagcc ccgcctttcc taaacctgtg 4560
cgacctctgc cagctccaat caccagaatt acccctcagc tcggcggcca gagcgattca 4620
tctcaacctc tgctgaccac cggcagacct caaggctggc aagaccaagc tctgagacac 4680
acccagcagg ctagccctgc ctcttgtgcc accatcacaa tccccatcca ctctgccgct 4740
ctgggcgatc attctggcga tcctggacca gcctgggaca catgtcctcc actgccactc 4800
acaacactga tccctagggc tcctccacct tacggcgatt ctaccgctag aagctggccc 4860
agcagatgtg gaccactcgg aggcaacaca accctccagc aactgggaga agcctctcag 4920
gctcctagcg gctctctgat ccctctcaga ctgcctctcc tgtgggaagt tcggggccag 4980
cctgattctt ttgccgcact gcacagctcc ctgaacgagc tgggagagat cgctagagag 5040
ctgcaccagt tcgccttcga cctgctgatc aagagccact tcgtgcaagg caaggattgg 5100
ggcctcaaaa agtttatccg cagagacttc tggggcatgg aactggccgc cagcagaaga 5160
ttcagctggg atcatcatag cgcaggcggc ccacctagag tgccatctgt tagaagcgga 5220
gctgcccagg tgcagcctaa agatcctctg ccactgagaa cactggccgg ctgccttgct 5280
agaacagccc atcttagacc tggcgccgag tctctgcctc agccacaact gcactgtacc 5340
ctgtggttcc agtccagcga gctgtctcct actggtgccc cttggccatc tagacgccct 5400
acttggagag gcaccaccgt gtcaccaaga accgccacaa gcagcgccag aacctgttgt 5460
ggcacaaagt ggccctccag ccaagaagcc gctctcggac ttggaagcgg actgctgagg 5520
ttctcttgtg gaaccgccgc cattcggaag atgcacttta gcctgaaaga acaccctcca 5580
ccaccttgtc ctccagaggc tttccaaaga gctgctggcg aaggcggacc tggtagaggt 5640
ggtgctagaa gaggtgctag ggtgctgcag agcccattct gtagagcagg cgcaggcgaa 5700
tggctgggcc atcagagtct gagacatgtc gtcggctacg gccacctgga tacaagcgga 5760
agcagctcta gctccagctg gcctaactca aaaatggctc tgaacagcct gaactccatc 5820
gacgacgccc agctgacaag aatcgcccct cctagatctc actgctgctt ttgggaagtg 5880
aacgccccaa gccatcacca tcaccaccat tagtaaaggc gcgcctagcg gccgcgatct 5940
gctgtgcctt ctagttgcca gccatctgtt gtttgcccct cccccgtgcc ttccttgacc 6000
ctggaaggtg ccactcccac tgtcctttcc taataaaatg aggaaattgc atcgcattgt 6060
ctgagtaggt gtcattctat tctggggggt ggggtggggc aggacagcaa gggggaggat 6120
tgggaagaca atagcaggca tgctggggat gcggtgggct ctatggccgg gccgcgatcg 6180
cgcttaggcc tgaccatctg gtgctggcct gcaccagggc cgagtttggg tctagcgatg 6240
aggataccga ttgaggtggg taaggtgggc gtggctagca gggtgggcgt gtataaattg 6300
ggggtctaag gggtctctct gtttgtcttg caacagccgc cgccatgagc gacaccggca 6360
acagctttga tggaagcatc tttagtccct atctgacagt gcgcatgcct cactgggccg 6420
gagtgcgtca gaatgtgatg ggttccaacg tggatggacg tcccgttctg ccttcaaatt 6480
cgtctactat ggcctacgcg accgtgggag gaactccgct ggacgccgcg acctccgccg 6540
ccgcctccgc cgccgccgcg accgcgcgca gcatggctac ggacctttac agctctttgg 6600
tggcgagcag cgcggcctct cgcgcgtctg ctcgggatga gaaactgact gctctgctgc 6660
ttaaactgga agacttgacc cgggagctgg gtcaactgac ccagcaggtt tccagcttgc 6720
gtgagagcag ccttgcctcc ccctaatggc ccataatata aataaaagcc agtctgtttg 6780
gattaagcaa gtgtatgttc tttatttaac tctccgcgcg cggtaagccc gggaccagcg 6840
gtctcggtcg tttagggtgc ggtggatttt ttccaacacg tggtacaggt ggctctggat 6900
gtttagatac atgggcatga gtccatccct ggggtggagg tagcaccact gcagagcttc 6960
gtgctcgggg gtggtgttgt atatgatcca gtcgtagcag gagcgctggg cgtggtgctg 7020
aaaaatgtcc ttaagcaaga ggcttatagc tagggggagg cccttggtgt aagtgtttac 7080
aaatctgctt agctgggagg ggtgcatccg gggggatatg atgtgcatct tggactggat 7140
ttttaggttg gctatgttcc cgcccagatc ccttctggga ttcatgttgt gcaggaccac 7200
cagcacggta tatccagtgc acttgggaaa tttatcgtgg agcttagacg ggaatgcatg 7260
gaagaacttg gagacgccct tgtggcctcc cagattttcc atacattcgt ccatgatgat 7320
ggcaatgggc ccgtgggaag ctgcctgagc aaaaacgttt ctggcatcgc tcacatcgta 7380
gttatgttcc agggtgaggt catcatagga catctttacg aatcgggggc gaagggtccc 7440
ggactggggg atgatggtac cctcgggccc cggggcgtag ttcccctcac agatctgcat 7500
ctcccaggct ttcatttcag agggagggat catatccacc tgcggggcga tgaaaaagac 7560
agtttctggc gcaggggaga ttaactggga tgagagcagg tttctgagca gctgtgactt 7620
tccacagccg gtgggcccat atatcacgcc tatcaccggc tgcagctggt agttaagaga 7680
gctgcagctg ccgtcctccc ggagcagggg ggccacctcg ttgagcatat ccctgacgtg 7740
gatgttctcc ctgaccagtt ccgccagaag gcgctcgccg cccagcgaaa gcagctcttg 7800
caaggaagca aaatttttca gcggtttcag gccatcggcc gtgggcatgt ttttcagcgt 7860
ctgggtcagc agctccagcc tgtcccagag ctcggtgatg tgctctacgg catctcgatc 7920
cagcagatct cctcgtttcg cgggttgggg cggctttcgc tgtagggcac cagccgatgg 7980
gcgtccagcg gggccagagt catgtccttc catgggcgca gggtcctcgt cagggtggtc 8040
tgggtcacgg tgaaggggtg cgctccgggt tgggcactgg ccagggtgcg cttgaggctg 8100
gttctgctgg tgctgaatcg ctgccgctct tcgccctgcg cgtcggccag gtagcatttg 8160
accatggtct cgtagtcgag accctcggcg gcgtgcccct tggcgcggag ctttcccttg 8220
gaggtggcgc cgcacgaggg gcactgcagg ctcttcaggg cgtagagctt gggagcgaga 8280
aacacggact ctggggagta ggcgtccgcg ccgcaggccg agcagaccgt ctcgcattcc 8340
accagccaag tgagttccgg gcggtcaggg tcaaaaacca ggttgccccc atgctttttg 8400
atgcgtttct taccttggct ctccatgagg cggtgtccct tctcggtgac gaagaggctg 8460
tccgtgtccc cgtagaccga cttcaggggc ctgtcttcca gcggagtgcc tctgtcctcc 8520
tcgtagagaa actctgacca ctctgagacg aaggcccgcg tccaggccag gacgaaggag 8580
gccacgtggg aggggtagcg gtcgttgtcc actagcgggt ccaccttctc cagggtgtgc 8640
aggcacatgt ccccctcctc cgcgtccaga aaagtgattg gcttgtaggt gtaggacacg 8700
tgaccggggg ttcccaacgg gggggtataa aagggggtgg gtgccctttc atcttcactc 8760
tcttccgcat cgctgtctgc gagagccagc tgctggggta agtattccct ctcgaaggcg 8820
ggcatgacct cagcgctcag gttgtcagtt tctaaaaatg aggaggattt gatgttcacc 8880
tgtccggagg tgataccttt gagggtacct gggtccatct ggtcagaaaa cactattttt 8940
ttgttatcaa gcttggtggc gaatgacccg tagagggcgt tggagagcag cttggcgatg 9000
gagcgcaggg tctggttttt gtcgcggtcg gctcgctcct tggccgcgat gttgagttgc 9060
acgtactcgc gggccacgca cttccactcg gggaacacgg tggtgcgctc gtctgggatc 9120
aggcgcaccc tccagccgcg gttgtgcagg gtgaccatgt cgacgctggt ggcgacctca 9180
ccgcgcagac gctcgttggt ccagcagagg cggccgccct tgcgcgagca gaaggggggt 9240
agggggtcca gctggtcctc gtttgggggg tccgcgtcga tggtaaagac cccggggagc 9300
aggcgcgggt caaagtagtc gatcttgcaa gcttgcatgt ccagagcccg ctgccattcg 9360
cgggcggcga gcgcgcgctc gtaggggttg aggggcgggc cccagggcat ggggtgggtg 9420
agcgcggagg cgtacatgcc gcagatgtca tacacgtaca ggggttccct gaggataccg 9480
aggtaggtgg ggtagcagcg ccccccgcgg atgctggcgc gcacgtagtc atagagctcg 9540
tgggaggggg ccagcatgtt gggcccgagg ttggtgcgct gggggcgctc ggcgcggaag 9600
acgatctgcc tgaagatggc gtgggagttg gaggagatgg tgggccgctg gaagacgttg 9660
aagcttgctt cttgcaagcc cacggagtcc ctgacgaagg aggcgtagga ctcgcgcagc 9720
ttgtgcacca gctcggcggt gacctggacg tcgagcgcac agtagtcgag ggtctcgcgg 9780
atgatgtcat acctatcctc ccccttcttt ttccacagct cgcggttgag gacgaactct 9840
tcgcggtctt tccagtactc ttggagggga aacccgtccg tgtccgaacg gtaagagcct 9900
agcatgtaga actggttgac ggcctggtag gggcagcagc ccttctccac gggcagcgcg 9960
taggcctgcg ccgccttgcg gagggaggtg tgggtgaggg cgaaagtgtc cctgaccatg 10020
actttgaggt attgatgtct gaagtctgtg tcatcgcagc cgccctgttc ccacagggtg 10080
tagtccgtgc gctttttgga gcgcgggttg ggcagggaga aggtgaggtc attgaagagg 10140
atcttccccg ctcgaggcat gaagtttctg gtgatgcgaa agggccctgg gaccgaggag 10200
cggttgttga tgacctgggc ggccaggacg atctcgtcaa agccgtttat gttgtgtccc 10260
acgatgtaga gctccaggaa gcggggctgg cccttgatgg aggggagctt tttaagttcc 10320
tcgtaggtaa gctcctcggg cgattccagg ccgtgctcct ccagggccca gtcttgcaag 10380
tgagggttgg ccgccaggaa ggatcgccag aggtcgcggg ccatgagggt ctgcaggcgg 10440
tcgcggaagg ttctgaactg ccgccccacg gccatttttt cgggggtgat gcagtagaag 10500
gtgagggggt ctttctccca ggggtcccat ctgagctctc gggcgaggtc gcgcgcggca 10560
gcgaccagag cctcgtcgcc ccccagtttc atgaccagca tgaagggcac gagttgcttg 10620
ccaaaggctc ccatccaagt gtaggtttct acatcgtagg tgacaaagag gcgctccgtg 10680
cgaggatgag agccgattgg gaagaactgg atctcccgcc accagttgga ggattggctg 10740
ttgatgtggt gaaagtagaa gtcccgtctg cgggccgagc actcgtgctg gcttttgtaa 10800
aagcgaccgc agtactggca gcgctgcacg ggttgtatat cttgcacgag gtgaacctgg 10860
cgacctctga cgaggaagcg cagcgggaat ctaagtcccc cgcctggggt cccgtgtggc 10920
tggtggtctt ttactttggt tgtctggccg ccagcatctg tctcctggag ggcgatggtg 10980
gaacagacca ccacgccgcg agagccgcag gtccagatct cggcgctcgg cgggcggagt 11040
ttgatgacga catcgcgcac attggagctg tccatggtct ccagctcccg cggcggcagg 11100
tcagccggga gttccctgga ggttcacctc gcagagacgg gtcaaggcgc ggacagtgtt 11160
gagatggtat ctgatttcaa ggggcatgtt ggaggcggag tcgatggctt gcaggaggcc 11220
gcagccccgg ggggccacga tggttccccg cggggcgcga ggggaggcgg aagctggggg 11280
tgtgttcaga agcggtgacg cgggcgggcc cccggaggta gggggggttc cggccccaca 11340
ggcatgggcg gcaggggcac gtcttcgccg cgcgcgggca ggggctggtg ctggctccga 11400
agagcgcttg cgtgcgcgac gacgcgacgg ttggtgttcc tgtatctggc gcctctgagt 11460
gaagaccacg ggtcccgtga ccttgaacct gaaagagagt tcgacagaat caatctcggc 11520
atcgttgaca gcggcctggc gcaggatctc ctgcacgtcg cccgagttgt cctggtaggc 11580
gatttctgcc atgaactgct cgatctcttc ctcctggaga tctcctcgtc cggcgcgctc 11640
cacggtggcc gccaggtcgt tggagatgcg acccatgagc tgcgagaagg cgttgagtcc 11700
gccctcgttc cagacccggc tgtagaccac gcccccctcg gcgtcgcggg cgcgcatgac 11760
cacctgggcc aggttgagct ccacgtgtcg cgtgaagacg gcgtagttgc gcaggcgctg 11820
gaaaaggtag ttcagggtgg tggcggtgtg ctcggcgacg aagaagtaca tgacccagcg 11880
ccgcaacgtg gattcattga tgtcccccaa ggcctccagg cgctccatgg cctcgtagaa 11940
gtccacggcg aagttgaaaa actgggagtt gcgagcggac acggtcaact cctcctccag 12000
aagaacggat gagctcggcg acagtgtcgc gcacctcgcg ctcgaaggcc acggggggcg 12060
cttcttcctc ttccacctct tcttccatga ttgcttcttc ttcttcctca gccgggacgg 12120
gagggggcgg cggcggggga ggggcgcggc ggcggcggcg gcgcaccggg aggcggtcga 12180
tgaagcgctc gatcatctcc ccccgcatgc ggcgcatggt ctcggtgacg gcgcggccgt 12240
tctcccgggg gcgcagctcg aagacgccgc ctctcatttc gccgcggggc gggcggccgt 12300
gaggtagcga gacggcgctg actatgcatc ttaacaattg ctgtgtaggt acgccgccaa 12360
gggacctgat tgagtccaga tccaccggat ccgaaaacct ttggaggaaa gcgtctatcc 12420
agtcgcagtc gcaaggtagg ctgagcaccg tggcgggcgg gggcgggtcg ggagagttcc 12480
tggcggagat gctgctgatg atgtaattaa agtaggcggt cttgagaagg cggatggtgg 12540
acaggagcac catgtctttg ggtccggcct gttggatgcg gaggcggtcg gccatgcccc 12600
aggcctcgtt ctgacaccgg cgcaggtctt tgtagtaatc ttgcatgagt ctttccaccg 12660
gcacttcttc tccttcctct tcttcatctc gccggtggtt tctcgcgccg cccatgcgcg 12720
tgaccccaaa gcccctgagc ggctgcagca gggccaggtc ggcgaccacg cgctcggcca 12780
agatggcctg ctgtacctga gtgagggtcc tctcgaagtc atccatgtcc acgaagcggt 12840
ggtaggcacc cgtgttgatg gtgtaggtgc agttggccat gacggaccag ttgacggtct 12900
ggtgtcccgg ctgcgagagc tccgtgtacc gcaggcgcga gaaggcgcgg gaatcgaaca 12960
cgtagtcgtt gcaagtccgc accagatact ggtagcccac caggaagtgc ggcggaggtt 13020
ggcgatagag gggccagcgc tgggtggcgg gggcgccggg cgccaggtct tccagcatga 13080
ggcggtggta tccgtagatg tacctggaca tccaggtgat gcctgcggcg gtggtggtgg 13140
cgcgcgcgta gtcgcggacc cggttccaga tgtttcgcag gggcgagaag tgttccatgg 13200
tcggcacgct ctggccggtg aggcgcgcgc agtcgttgac gctctataca cacacaaaaa 13260
cgaaagcgtt tacagggctt tcgttctgta gcctggagga aagtaaatgg gttgggttgc 13320
ggtgtgcccc ggttcgagac caagctgagc tcagccggct gaagccgcag ctaacgtggt 13380
attggcagtc ccgtctcgac ccaggccctg tatcctccag gatacggtcg agagcccttt 13440
tgctttcttg gccaagcgcc cgtggcgcga tctgggatag atggtcgcga tgagaggaca 13500
aaagcggctc gcttccgtag tctggagaaa caatcgccag ggttgcgttg cggcgtaccc 13560
cggttcgagc ccctatggcg gcttggatcg gccggaaccg cggctaacgt gggctgtggc 13620
agccccgtcc tcaggacccc gccagccgac ttctccagtt acgggagcga gccccttttg 13680
tttttttatt ttttagatgc atcccgtgct gcggcagatg cgcccctcgc cccggcccga 13740
tcagcagcag caacagcagg catgcagacc cccctctcct ctccccgccc cggtcaccac 13800
ggccgcggcg gccgtgtccg gtgcgggggg cgcgctggag tcagatgagc caccgcggcg 13860
gcgacctagg cagtatctgg acttggaaga gggcgaggga ctggcgcggc tgggggcgag 13920
ctctccagag cgccacccgc gggtgcagtt gaaaagggac gcgcgtgagg cgtacctgcc 13980
gcggcaaaac ctgtttcgcg accgcggggg cgaggagccc gaggagatgc gggactgcag 14040
gttccaagcg gggcgcgagc tgcgccgcgg cttggacaga cagcgcctgc tgcgcgagga 14100
ggactttgag cccgacacgc agacgggcat cagccccgcg cgcgcgcacg tggccgcggc 14160
cgacctggtg accgcctacg agcagacggt gaaccaggag cgcaacttcc aaaaaagctt 14220
caacaaccac gtgcgcacgc tggtggcgcg cgaggaggtg accctgggtc tcatgcatct 14280
gtgggacctg gtggaggcga tcgtgcagaa ccccagcagc aagcccctga ccgcgcagct 14340
gttcctggtg gtgcagcaca gcagggacaa cgaggccttc agggaggcgc tgctgaacat 14400
caccgagccg gaggggcgct ggctcctgga cctgataaac atcctgcaga gcatagtggt 14460
gcaggagcgc agcctgagcc tggccgagaa ggtggcggcc attaactatt ctatgctgag 14520
cctgggcaag ttctacgctc gcaagatcta caagaccccc tacgtgccca tagacaagga 14580
ggtgaagata gacagcttct acatgcgcat ggcgctgaag gtgctaaccc tgagcgacga 14640
cctgggagtg taccgcaacg agcgcatcca caaggccgtg agcgccagcc ggcggcgcga 14700
gctgagcgac cgcgaactga tgcacagtct gcagcgcgcg ctgaccggcg cgggcgaggg 14760
cgacagggag gtcgagtcct actttgacat gggggccgac ctgcactggc agccgagccg 14820
ccgcgccctg gaagcggcgg gggcgtacgg cggccccctg gcggccgatg acgaggaaga 14880
ggaggactat gagctagagg agggcgagta cctggaggac tgacctggct ggtggtgttt 14940
tggtatagat gcaagatccg aacgtggcgg acccggcggt ccgggcggcg ctgcagagcc 15000
agccgtccgg cattaactcc tctgacgact gggccgcggc catgggtcgc atcatggccc 15060
tgaccgcgcg caaccccgag gccttcaggc agcagcctca ggctaaccgg ctggcggcca 15120
tcttggaagc ggtagtgccc gcgcgctcca accccaccca cgagaaggtg ctggccatag 15180
tcaacgcgct ggcggagagc agggccatcc gggcagacga ggccggactg gtgtacgatg 15240
cgctgctgca gcgggtggcg cggtacaaca gcggcaacgt gcagaccaac ctggaccgcc 15300
tggtgacgga cgtgcgcgag gccgtggcgc agcgcgagcg cttgcatcag gacggcaacc 15360
tgggctcgct ggtggcgcta aacgccttcc ttagcaccca gccggccaac gtaccgcggg 15420
ggcaggagga ctacaccaac ttcttgagcg cgctgcggct gatggtgacc gaggtccctc 15480
agagcgaggt gtaccagtcg gggcccgact acttcttcca gaccagcaga cagggcttgc 15540
aaaccgtgaa cctgagccag gctttcaaga acctgcgggg gctgtgggga gtgaaggcgc 15600
ccaccggcga ccgggctacg gtgtccagcc tgctaacccc caactcgcgc ctgctgctgc 15660
tgctgatcgc gcccttcacg gacagcggga gcgtctcgcg ggagacctat ctgggccacc 15720
tgctgacgct gtaccgcgag gccatcgggc aggcgcaggt ggacgagcac accttccagg 15780
agatcaccag cgtgagccac gcgctggggc aggaggacac gggcagcctg caggcgaccc 15840
tgaactacct gctgaccaac aggcggcaga agattcccac gctgcacagc ctgacccagg 15900
aggaggagcg catcttgcgc tacgtgcagc agagcgtgag cctgaacctg atgcgcgacg 15960
gcgtgacgcc cagcgtggcg ctggacatga ccgcgcgcaa catggaaccg ggcatgtacg 16020
cttcccagcg gccgttcatc aaccgcctga tggactactt gcatcgggcg gcggccgtga 16080
accccgagta cttcaccaat gccattctga atccccactg gatgccccct ccgggtttct 16140
acaacgggga cttcgaggtg cctgaggtca acgatgggtt cctctgggat gacatggatg 16200
acagtgtgtt ctcccccaac ccgctgcgcg ccgcgtctct gcgattgaag gagggctctg 16260
acagggaagg accaaggagt ctggcctcct ccctggctct gggggcggtg ggcgccacgg 16320
gcgcggcggc gcggggcagc agccccttcc ccagcctggc ggactctctg aatagcgggc 16380
gggtgagcag gccccgcttg ctaggcgagg aggagtatct gaacaactcc ctgctgcagc 16440
ccgtgaggga caaaaacgct cagcggcagc agtttcccaa caatgggata gagagcctgg 16500
tggacaagat gtccagatgg aagacgtatg cgcaggagta caaggagtgg gaggaccgcc 16560
agccgcggcc cctgccgccc cctagacagc gctggcagcg gcgcgcgtcc aaccgccgct 16620
ggaggcaggg gcccgaggac gatgatgact ctgcagatga cagcagcgtg ttggacctgg 16680
gcgggagcgg gaaccccttt tcgcacctgc gcccacgcct gggcaagatg ttttaaaaga 16740
gaaaaataaa aactcaccaa ggccatggcg acgagcgttg gttttttgtt cccttcctta 16800
gtatgcggcg cgcggcgatg ttcgaggagg ggcctccccc ctcttacgag agcgcgatgg 16860
gaatttctcc tgcggcgccc ctgcagcctc cctacgtgcc tcctcggtac ctgcaaccta 16920
caggggggag aaatagcatc tgttactctg agctgcagcc cctgtacgat accaccagac 16980
tgtacctggt ggacaacaag tccgcggacg tggcctccct gaactaccag aacgaccaca 17040
gcgatttttt gaccacggtg atccaaaaca acgacttcac cccaaccgag gccagtaccc 17100
agaccataaa cctggacaac aggtcgaact ggggcggcga cctgaagact atcctgcaca 17160
ccaatatgcc caacgtgaac gagttcatgt tcaccaactc ttttaaggcg cgggtgatgg 17220
tggcgcgcga gcagggggag gcgaagtacg agtgggtgga cttcacgctg cccgagggca 17280
actactcaga gaccatgact ctcgacctga tgaacaatgc gatcgtggaa cactatctga 17340
aagtgggcag gcagaacggg gtgaaggaga gcgatatcgg ggtcaagttt gacaccagaa 17400
acttccgtct gggctgggac cctgtgaccg ggctggtcat gccgggggtc tacaccaacg 17460
aggcctttca tcccgatata gtgctcctgc ccggctgtgg ggtggacttc acccagagcc 17520
ggctgagcaa cctgctgggc gttcgcaagc ggcaaccttt ccaggagggt ttcaagatca 17580
cctatgagga tctggagggg ggcaacattc ccgcgctcct tgatctggac gcctacgagg 17640
agagcttgaa acccgaggag agcgctggcg acagcggcga gagtggcgag gagcaagccg 17700
gcggcggcgg cagcgcgtcg gtagaaaacg aaagtactcc cgcagtggcg gcggacgctg 17760
cggaggtcga gccggaggcc atgcagcagg acgcagagga gggcgcgcag gaggacatga 17820
acaatgggga gatcaggggc gacactttcg ccacccgggg cgaagaaaaa gaggcagagg 17880
cggcggcggc gacggcggaa gccgaaaccg aggcagaggc agagcccgag accgaagtta 17940
tggaagacat gaatgatgga gaacgtaggg gtgacacgtt tgccacccgg ggcgaagaga 18000
aggcggcgga ggcagaagcc gcggctgagg aggcggctgc ggctgcggcc aaggctgagg 18060
ctgcggctga ggctaaggtc gaagccgatg ttgcggttga ggctcaggct gaggaggagg 18120
cggcggctga agcagttaag gaaaaggccc aggcagagca ggaagagaaa aaacctgtca 18180
ttcaacctct aaaagaagat agcaaaaagc gcagttacaa cgtcattgag ggcagcacct 18240
ttacccaata ccgcagctgg tacctggctt acaactacgg cgacccggtc aagggggtgc 18300
gctcgtggac cctgctctgc acgccggacg tcacctgcgg ctccgagcag atgtactggt 18360
cgctgccaaa catgatgcaa gacccggtga ccttccgttc cacgcggcag gttagcaact 18420
ttccggtggt gggcgccgaa ctgctgccag tacactccaa gagtttttac aacgagcagg 18480
ccgtctactc ccagctgatc cgccaggcca cctctctgac ccacgtgttc aatcgctttc 18540
ccgagaacca gattttggcg cgcccgccgg cccccaccat caccaccgtc agtgaaaacg 18600
ttcctgccct cacagatcac gggacgctac cgctgcgcaa cagcatctca ggagtccagc 18660
gagtgaccat tactgacgcc agacgccgga cctgccccta cgtttacaag gccttgggca 18720
tagtctcgcc gcgcgtcctc tccagtcgca ctttttaaaa cacatccacc cacacgctcc 18780
aaaatcatgt ccgtactcat ctcgcccagc aacaacaccg gctgggggct gcgcgcaccc 18840
agcaagatgt ttggaggggc aaggaagcgc tccgaccagc accccgtgcg cgtgcgcggc 18900
cactaccgcg cgccctgggg tgcgcacaag cgcgggcgca cagggcgcac cactgtggat 18960
gatgtcattg actccgtagt ggagcaggcg cgccactaca cacccggcgc gccgaccgcc 19020
tccgccgtgt ccaccgtgga ccaggcgatc gaaagcgtgg tacagggggc gcggcactat 19080
gccaacctta aaagtcgccg ccgccgcgtg gcgcgccgcc atcgccggag accccgggct 19140
actgccgccg cgcgccttac caaggctctg ctcaagcgcg ccaggcgaac tggccaccgg 19200
gccgccatga gggccgcacg gcgggctgcc gctgccgcga gcgccgtggc cccgcgggca 19260
cgaaggcgcg cggccgctgc cgccgccgcc gccatttcca gcttggcctc gacgcggcgc 19320
ggtaacatat actgggtgcg cgactcggtg agcggcacac gtgtgcccgt gcgctttcgc 19380
cccccacgga attagcacaa gacaacatac acactgagtc tcctgctgtt gtgtatccca 19440
gcggcgaccg tcagcagcgg cgacatgtcc aagcgcaaaa ttaaagaaga gatgctccag 19500
gtcatcgcgc cggagatcta tgggcccccg aagaaggagg aggaggatta caagccccgc 19560
aagctaaagc gggtcaaaaa gaaaaagaaa gatgatgacg ttgacgaggc ggtggagttt 19620
gtccgccgca tggcgcccag gcgccctgtg cagtggaagg gtcggcgcgt gcagcgagtc 19680
ctgcgccccg gcaccgcggt ggtctttacg cccggcgagc gttccacgcg cactttcaag 19740
cgggtgtacg atgaggtgta cggcgacgag gatctgttgg agcaggccaa ccatcgattt 19800
ggggagtttg catatgggaa acggcctcgc gagagtctaa aagaggacct gctggcgcta 19860
ccgctggacg agggcaatcc caccccgagt ctgaagccgg tgaccctgca acaggtgctg 19920
cctttgagcg cgcccagcga gcagaagcga gggttaaagc gcgagggcgg ggacctggca 19980
cccaccgtgc agttgatggt gcccaagcgg cagaagctgg aggacgtgct ggagaaaatg 20040
aaagtagagc ccgggatcca gcccgagatc aaggtccgcc ctatcaagca ggtggcgccc 20100
ggcgtgggag tccagaccgt ggacgttagg attcccacgg aggagatgga aacccaaacc 20160
gccactccct cttcggcagc aagcgccacc accggcgccg cttcggtaga ggtgcagacg 20220
gacccctggc tacccgccgc cactatcgcc gtcgccgccg ccccccgttc gcgcggacgc 20280
aagagaaatt atccagcggc cagcgcgctt atgccccagt atgcgctgca tccatccatc 20340
gcgcccaccc ccggctaccg cgggtactcg taccgcccgc gcagatcagc cggcactcgc 20400
ggccgccgcc gccgtgcgac cacaaccagc cgccgccgtc gccgccgccg ccagccagtg 20460
ctgacccccg tgtctgtaag gaaggtggct cgctcgggga gcacgctggt ggtgcccaga 20520
gcgcgctacc accccagcat cgtttaaagc cggtctctgt atggttcttg cagatatggc 20580
cctcacttgt cgccttcgct tcccggtgcc gggataccga ggaagaactc accgccgcag 20640
gggcatggcg ggcagcggtc tccgcggcgg ccgtcgccat cgccggcgcg caaagagcag 20700
gcgcatgcgc ggcggtgtgt tgcccctgct ggtcccgcta ctcgccgcgg cgatcggcgc 20760
cgtgcccggg atcgcctccg tggccctgca ggcgtcccag aaacattgac tcttgcaacc 20820
ttgcaagctt gcatttttgg aggaaaaaat aaaaaagtct agactctcac gctcgcttgg 20880
tcctgtgact attttgtaga aaaaagatgg aagacatcaa ctttgcgtcg ctggccccgc 20940
gtcacggctc gcgcccgttc atgggagact ggacagatat cggcaccagc aatatgagcg 21000
gtggcgcctt cagctggggc agtctgtgga gcggccttaa aaattttggt tccaccatta 21060
agaactatgg caacaaagcg tggaacagca gcacgggtca gatgctgaga gacaagttga 21120
aagagcagaa cttccaggag aaggtggcgc agggcctggc ctctggcatc agcggggtgg 21180
tggacatagc taaccaggcc gtgcagaaaa agataaacag tcatctggac ccccgccctc 21240
aggtggagga aacgcctcca gccatggaga cggtgtctcc cgagggcaaa ggcgaaaagc 21300
gcccgcggcc cgacagggaa gagaccctgg tgtcacacac cgaggagccg ccctcttacg 21360
aggaggcagt caaggccggc ctgcccacca ctcgccccat agctcccatg gccaccggtg 21420
tggtgggtca caggcaacac acccccgcaa cactagatct gcccccgccg tccgagccga 21480
ctcgccagcc aaaggcggtg acggtgtccg ctccctccac ttccgccgcc aacagagtgc 21540
ctctgcgccg cgctgcgagc ggcccccggg cctcgcgagt cagcggcaac tggcagagca 21600
cactgaacag catcgtgggc ctgggagtga ggagtgtgaa gcgccgccgt tgctactgaa 21660
tgagcaagct agctaacgtg ttgtatgtgt gtatgcgtcc tatgtcgccg ccagaggagc 21720
tgttgagccg ccggcgccgt ctgcactcca gcgaatttca agatggcgac cccatcgatg 21780
atgcctcagt ggtcgtacat gcacatctcg ggccaggacg cttcggagta cctgagcccc 21840
gggctggtgc agttcgcccg cgccacagac acctacttca acatgagtaa caagttcagg 21900
aaccccactg tggcgcccac ccacgatgtg accacggacc ggtcgcagcg cctgacgctg 21960
cggttcatcc ccgtggatcg ggaggacacc gcttactctt acaaggcgcg gttcacgctg 22020
gccgtgggcg acaaccgcgt gctggacatg gcctccactt actttgacat ccggggggtg 22080
ctggacaggg gccccacttt taagccctac tcgggcactg cctacaaccc cctggccccc 22140
aagggcgccc ccaattcttg tgagtgggaa caagaggaaa atcaggtggt cgctgcagat 22200
gatgaacttg aagatgaaga agcgcaagca caagaggaag cccctgtgaa aaaaattcat 22260
gtatatgctc aggcgcctct ttctggcgaa aagatttcca aggatggtat ccaaataggt 22320
actgaagtcg taggagatac atctaaggac acttttgcag ataaaacatt ccaacccgaa 22380
cctcagatag gcgagtctca gtggaacgag gctgatgcca cagcagcagg aggtagagtt 22440
ttgaaaaaga ctacccctat gagaccttgc tatggatcct atgccaggcc taccaatgcc 22500
aacgggggtc aaggaattat ggttgccaat gaacaaggag tgttggagtc taaagtagaa 22560
atgcaatttt tctctaacac cacaaccctt aatgcgcggg atggaaccgg caatcccgaa 22620
ccaaaggtgg tgttgtacag cgaagatgtc cacttggaat ctcccgatac tcatctgtct 22680
tacaagccca aaaaggatga tgttaatgcc aaaatcatgt tgggtcagca agccatgccc 22740
aacagaccca acctcattgg atttagagat aatttcattg ggcttatgtt ttacaacagc 22800
accggtaaca tgggagtgct ggcgggtcag gcctctcagt tgaatgctgt ggtggacttg 22860
caggatagaa acacagaact gtcatatcag cttctgcttg attcaattgg ggatagaacc 22920
agatacttct ccatgtggaa ccaggcagtg gatagctatg atccagatgt cagaattatt 22980
gaaaaccatg ggactgagga tgaactgccc aactactgct tccctttggg cggcatagga 23040
gttactgata cttatcaagg gataaaaaat accaatggca atggtcagtg gaccaaagat 23100
gatcagttcg cggaccgcaa cgaaataggg gtgggaaaca acttcgccat ggagatcaac 23160
atccaggcca acctttggag aaacttcctc tatgcaaacg tggggctcta cctgccagac 23220
aagctcaagt acaaccccac caacgtggac atctctgaca accccaacac ctatgactac 23280
atgaacaagc gggtggtggc ccctggcctg gtggactgct ttgtcaatgt gggagccagg 23340
tggtccctgg actacatgga caacgtcaac cccttcaacc accaccgcaa tgcgggtctg 23400
cgctaccgct ccatgatcct gggcaacggg cgctatgtgc cctttcacat ccaggtaccc 23460
cagaagttct ttgccatcaa gaacctcctg ctcctgcccg gctcctacac ctacgagtgg 23520
aacttcagga aggatgtgaa catggtccta cagagctctc tgggcaatga ccttagggtg 23580
gatggggcca gcatcaagtt tgacagcatc accctctatg ctacattttt ccccatggcc 23640
cacaacaccg cctccacgct tgaggccatg ctgagaaacg acaccaacga ccagtccttt 23700
aatgactacc tctctggggc caacatgctc tacccaatcc cagccaaggc caccaacgtg 23760
cccatctcca tcccctctcg caactgggcc gcctttagag gctgggcctt tacccgcctt 23820
aagaccaagg agaccccctc cctgggctcg ggttttgatc cctactttgt ttactcggga 23880
tccatcccct acctggatgg caccttctac ctcaaccaca ctttcaagaa gatatccatc 23940
atgtatgact cctccgtcag ctggccgggc aacgaccgct tgctcacccc caatgagttc 24000
gaggtcaagc gcgccgtgga cggcgagggc tacaacgtgg cccagtgcaa catgaccaag 24060
gactggttcc tggtgcagat gctggccaac tacaacatag gctaccaggg cttttacatc 24120
ccagagagct acaaggacag gatgtactcc ttcttcagaa atttccaacc catgagccga 24180
caggtggtgg acgagaccaa ttacaaggac tatcaagcca ttggcatcac ccaccagcac 24240
aacaactcgg gtttcgtggg ctacctggcg cccaccatgc gcgagggtca ggcctacccc 24300
gccaacttcc cctacccctt gataggcaag accgcggtcg acagcgtcac ccagaaaaag 24360
ttcctctgcg accgcaccct ctggcgcatc cccttctcta gcaacttcat gtccatgggt 24420
gcgctcacgg acctgggcca aaacctgctt tatgccaact ctgcccatgc gctggacatg 24480
acttttgagg tggaccccat ggacgagccc acccttctct atattgtgtt tgaagtgttc 24540
gacgtggtca gagtgcacca gccgcaccgc ggtgtcatcg agaccgtgta cctgcgtacg 24600
cccttctcag ccggcaacgc caccacctaa ggagacagcg ccgccgccgc ctgcatgacg 24660
ggttccaccg agcaagagct cagggccatt gccagagacc tgggatgcgg accctatttt 24720
ttgggcacct atgacaaacg cttcccgggc tttatctccc gagacaagct cgcctgcgcc 24780
attgtcaaca cggccgcgcg cgagaccggg ggcgtgcact ggctggcctt tggctgggac 24840
ccgcgctcca aaacttgcta cctctttgac ccctttggct tctccgatca gcgcctcagg 24900
cagatttatg agtttgagta cgaggggctg ctgcgccgca gcgcgctcgc ctcctcgccc 24960
gaccgctgca tcacccttga gaagtccacc gaaaccgtgc aggggcccca ctcggccgcc 25020
tgcggtctct tctgttgcat gtttttgcac gcctttgtgc actggcctca gagtcccatg 25080
gattgcaacc ccaccatgaa cttgctaaag ggagtgccca acgccatgct ccagagcccc 25140
caggtccagc ccaccctgcg ccgcaaccag gaacagcttt accgcttcct ggagcgccac 25200
tccccctact tccgcagcca cagcgcgcgc atccgggggg ccacctcttt ttgccacttg 25260
caagaaaaca tgcaagacgg aaaatgatgt acagcatgct tttaataaat gtaaagactg 25320
tgcactttaa ttatacacgg gctctttctg gttatttatt caacaccgcc gtcgccattt 25380
agaaatcgaa agggttctgc cgtgcgtcgc cgtgcgccac gggcagagac acgttgcgat 25440
actggaagcg gctcgcccac ttgaactcgg gcaccaccat gcggggcagt ggttcctcgg 25500
ggaagttctc gctccacagg gtgcgggtca gctgcagcgc gctcaggagg tcgggagccg 25560
agatcttgaa gtcgcagttg gggccggaac cctgcgcgcg cgagttgcgg tacacggggt 25620
tgcagcactg gaacaccagc agggccggat tattcacgct ggccagcagg ctctcgtcgc 25680
tgatcatgtc gctgtccaga tcctccgcgt tgctcagggc gaatggggtc atcttgcaga 25740
cctgcctgcc caggaaaggc gggagcccag gcttgccgtt gcagtcgcag cgcaggggca 25800
ttagcaggtg cccacggccc gactgcgcct gcgggtacaa cgcgcgcatg aaggcttcga 25860
tctgcctaaa agccacctgg gtcttggctc cctccgaaaa gaacatccca caggacttgc 25920
tggagaactg gttcgcggga cagctggcat cgtgcaggca gcagcgcgcg tcagtgttgg 25980
caatctgcac cacgttgcga ccccaccggt ttttcactat cttggccttg gaagcctgct 26040
cctttagcgc gcgctggccg ttctcgctgg tcacatccat ctctatcacc tgttccttgt 26100
tgatcatgtt tgtcccgtgc agacacttta ggtcgccctc cgtctgggtg cagcggtgct 26160
cccacagcgc gcaaccggtg ggctcccaat tcttgtgggt cacccccgcg taggcctgca 26220
ggtaggcctg caggaagcgc cccatcatgg tcataaaggt cttctggctc gtaaaggtca 26280
gctgcaggcc gcgatgctct tcgttcagcc aggtcttgca gatggcggcc agcgcctcgg 26340
tctgctcggg cagcatctta aaatttgtct tcaggtcgtt atccacgtgg tacttgtcca 26400
tcatggcacg cgccgcctcc atgcccttct cccaggcgga caccatgggc aggcttaggg 26460
ggtttatcac ttccagcggc gaggacaccg tactttcgat ttcttcttcc tccccctctt 26520
cccggcgcgc gcccccgctg ttgcgcgctc ttaccgcctg caccaagggg tcgtcttcag 26580
gcaagcgccg caccgagcgc ttgccgccct tgacctgctt gatcagtacc ggcgggttgc 26640
tgaagcccac catggtcagc gccgcctgct cttcttcgtc ttcgctgtct accactattt 26700
ctggggaggg gcttctccgc tctgcggcaa aggcggcgga tcgcttcttt tttttcttgg 26760
gagccgccgc gatggagtcc gccacggcga ccgaggtcga gggcgtgggg ctgggggtgc 26820
gcggtaccag ggcctcgtcg ccctcggact cttcctctga ctccaggcgg cggcggagtc 26880
gcttctttgg gggcgcgcgc gtcagcggcg gcggagacgg ggacggggac ggggacggga 26940
cgccctccac agggggtggt cttcgcgcag acccgcggcc gcgctcgggg gtcttctcgc 27000
gctggtcttg gtcccgactg gccattgtat cctcctcctc ctaggcagag agacataagg 27060
agtctatcat gcaagtcgag aaggaggaga gcttaaccac cccctcagag accgccgatg 27120
cgcccgccgt cgccgtcgcc cccgctaccg ccgacgcgcc cgccacaccg agcgacaccc 27180
ccacggaccc ccccgccgac gcacccctgt tcgaggaagc ggccgtggag caggacccgg 27240
gctttgtctc ggcagaggag gatttgcaag aggaggagaa taaggaggag aagccctcag 27300
tgccaaaaga tcataaagag caagacgagc acgacgcaga cgcacaccag ggtgaagtcg 27360
ggcgggggga cggagggcat ggcggcgccg actacctaga cgaaggaaac gacgtgctct 27420
tgaagcacct gcatcgtcag tgcgccatcg tctgcgacgc tctgcaggag cgcagcgagg 27480
tgcccctcag cgtggcggag gtcagccgcg cctacgagct cagcctcttt tccccccggg 27540
tgcccccccg ccgccgcgaa aacggcacat gcgagcccaa cccgcgcctc aacttctacc 27600
ccgcctttgt ggtgcccgag gtcctggcca cctatcacat cttctttcaa aattgcaaga 27660
tccccatctc gtgccgcgcc aaccgtagcc gcgccgataa gatgctggcc ctgcgccagg 27720
gcgaccacat acctgatatc gccgctttgg aagatgtgcc aaagatcttc gagggtctgg 27780
ggcgcaacga gaagcgggca gcaaactctc tgcaacagga aaacagcgaa aatgagagtc 27840
acactggagc gctggtggag ctggagggcg acaacgcccg cctggcggtg ctcaagcgca 27900
gcatcgaggt cacccacttt gcctaccccg cgctcaacct gccccccaaa gtcatgaacg 27960
cggtcatgga cgggctgatc atgcgccgcg gccggcccct cgctccagat gcaaacttgc 28020
atgaggagac cgaggacggt cagcccgtgg tcagcgacga gcagctgacg cgctggctgg 28080
agagcgcgga ccccgccgaa ctggaggagc ggcgcaagat gatgatggcc gcggtgctgg 28140
tcaccgtaga gctggagtgt ctgcagcgct tcttcggtga ccccgagatg cagagaaagg 28200
tcgaggagac cctacactac accttccgcc agggctacgt gcgccaggct tgcaagatct 28260
ccaacgtgga gctcagcaac ctggtgtcct acctgggcat cttgcatgaa aaccgccttg 28320
ggcagagcgt gctacactcc accctgcgcg gggaggcgcg ccgcgactac gtgcgcgact 28380
gcgtttacct cttcctctgc tacacctggc agacggccat gggggtctgg cagcagtgcc 28440
tggaggagcg caacctcaag gagctggaga agcttctgca gcgcgcgctc aaagacctct 28500
ggacgggctt caacgagcgc tcggtggccg ccgcgctagc cgacctcatc ttccccgagc 28560
gcctgctcaa aaccctccag caggggctgc ccgacttcac cagccaaagc atgttgcaaa 28620
attttaggaa ctttatcctg gagcgttctg gcatcctacc cgccacctgc tgcgccctgc 28680
ccagcgactt tgtccccctc gtgtaccgcg agtgcccccc gccgctgtgg ggccactgct 28740
acctgttcca actggccaac tacctgtcct accacgcgga cctcatggag gactccagcg 28800
gcgaggggct catggagtgc cactgccgct gcaacctctg cacgccccac cgctccctgg 28860
tctgcaacac ccaactgctc agcgagagtc agattatcgg taccttcgag ctacagggtc 28920
cgtcctcctc agacgagaag tccgcggctc cggggctaaa actcactccg gggctgtgga 28980
cttccgccta cctgcgcaaa tttgtacctg aagactacca cgcccacgaa atcaggtttt 29040
acgaggacca atcccgcccg cccaaggcgg agctgaccgc ctgcgtcatc acccagggcg 29100
agatcctagg ccaattgcaa gccatccaaa aagcccgcca agagtttttg ctgaagaggg 29160
gtcggggggt gtatctggac ccccagtcgg gtgaggagct caacccggtt cccccgctgc 29220
caccgccgcg ggaccttgct tcccaggata agcatcgcca tggctcccag aaagaagcag 29280
cagcggccgc cgctgccgcc gccccacatg ctggaggaag aggaggaata ctgggacagt 29340
caggcagagg aggtttcgga cgaggaggag ccggagacgg agatggaaga gtgggaggag 29400
gacagcttag acgaggaggc ttccgaagcc gaagaggcag gcgcaacacc gtcaccctcg 29460
gccgcagccc cctcgcaggc gcccccgaag tccgctccca gcatcagcag caacagcagc 29520
gctataacct ccgctcctcc accgccgcga cccacggccg accgcagacc caaccgtaga 29580
tgggacacca ccggaaccgg ggccggtaag tcctccggga gaggcaagca agcgcagcgc 29640
caaggctacc gctcgtggcg cgctcacaag aacgccatag tcgcttgctt gcaagactgc 29700
ggggggaaca tctccttcgc ccgccgcttc ctgctcttcc accacggtgt ggccttcccc 29760
cgtaacgtcc tgcattacta ccgtcatctc tacagcccct actgcggcgg cagtgagcca 29820
gaggcggcca gcggcggcgg cgcccgtttc ggtgcctagg aagacccagg gcaagacttc 29880
agccaagaaa ctcgcggcga ccgcggcgaa cgcggtcgcg ggggccctgc gcctgacggt 29940
gaacgaaccc ctgtcgaccc gcgaactgag gaaccgaatc ttccccactc tctatgccat 30000
cttccagcag agcagagggc aggatcagga actgaaagta aaaaacaggt ctctgcgctc 30060
cctcacccgc agctgtctgt atcacaagag cgaagaccag cttcggcgca cgctggagga 30120
cgctgaggca ctcttcagca aatactgcgc gctcactctt aaggactagc tccgcgccct 30180
tctcgaattt aggcgggaac gcctacgtca tcgcagcgcc gccgtcatga gcaaggacat 30240
tcccacgcca tacatgtgga gctatcagcc gcagatggga ctcgcggcgg gcgcctccca 30300
agactactcc acccgcatga actggctcag tgccggccca cacatgatct cacaggttaa 30360
tgacatccgc acccatcgaa accaaatatt ggtgaagcag gcggcaatta ccaccacgcc 30420
ccgcaataat cccaacccca gggagtggcc cgcgtccctg gtgtatcagg aaattcccgg 30480
ccccaccacc gtactacttc cgcgtgattc ccaggccgaa gtccaaatga ctaactcagg 30540
ggcacagctc gcgggcggct gtcgtcacag ggtgcggcct cctcgccagg gtataactca 30600
cctggagatc cgaggcagag gtattcagct caacgacgag tcggtgagct cctcgctcgg 30660
tctcagacct gacgggacct tccagatagc cggagccggc cgatcttcct tcacgccccg 30720
ccaggcgtac ctgactctgc agagctcgtc ctcggcgccg cgctcgggcg gcatcgggac 30780
tctccagttc gtgcaggagt ttgtgccctc ggtctacttc aaccccttct cgggctctcc 30840
cggtcgctac ccggaccagt ttatcccgaa ctttgacgcc gcgagggact cggtggacgg 30900
ctacgactga atgtcgggtg gacccggtgc agagcaactt cgcctgaagc accttgacca 30960
ctgccgccgc cctcagtgct ttgcccgctg tcagaccggt gagttccagt acttttccct 31020
gcccgactcg cacccggacg gcccggcgca cggggtgcgc tttttcatcc cgagtcaggt 31080
ccgctctacc ctaatcaggg agttcaccgc ccgtccccta ctggcggagt tggaaaaggg 31140
gccttctatc ctaaccattg cctgcatttg ctctaaccct ggattacacc aagatctttg 31200
ctgtcatttg tgtgctgagt ataataaagg ctgagatcag aatctactcg gaccttatcc 31260
ctttcaattg atcataactg taatcaataa aaaatcactt acttgaaatc tgatagcaag 31320
actctgtcca attttttcag caacacttcc ttcccctcct cccaactctg gtactctagg 31380
cgcctcctag ctgcaaactt cctccacagt ctgaagggaa tgtcagattc ctcctcctgt 31440
ccctccgcac ccacgatctt catgttgtta cagatgaaac gcgcgagatc gtctgacgag 31500
accttcaacc ccgtgtaccc ctacgatacc gagatcgctc cgacttctgt ccctttcctt 31560
acccctccct ttgtatcatc cgcaggaatg caagaaaatc cagctggggt gctgtccctg 31620
cacctgtcag agccccttac cacccacaat ggggccctga ctctaaaaat ggggggcggc 31680
ctgaccctgg acaaggaagg gaatctcact tcccaaaaca tcaccagtgt cgatccccct 31740
ctcaaaaaaa gcaagaacaa catcagcctt cagaccgccg cacccctcgc cgtcagctcc 31800
ggggccctaa ccctttttgc cactcccccc ctagcggtca gtggcgacaa ccttactgtg 31860
cagtctcagg cccctcttac tttggaagac tcaaaactaa ctctggccac caaaggaccc 31920
ctaactgtgt ccgaaggcaa acttgtccta gaaacagagc ctcccctgca tgcaagtgac 31980
agcagtagcc tgggccttag cgtcacggcc ccacttagca ttaacaatga cagcctagga 32040
ctagacatgc aagcgcccat cagctctcga gatggaaaac tggctctaac agtggcggcc 32100
cccctaactg tggccgaggg tatcaatgct ttggcagtag ccacaggtaa tggtattgga 32160
ctaaatgaaa ccaacacaca cctgcaggca aaactggtcg cgcccctagg ctttgatacc 32220
aacggcaaca ttaagctaag cgtcgcagga ggcatgaggc taaacaataa cacactgata 32280
ctagatgtaa actacccatt tgaggctcaa ggccaactga gcctaagagt gggctcgggc 32340
ccactatatg tagattctag tagtcataac ctaaccatta gatgccttag gggattgtat 32400
gtaacatctt ctaacaacca aaacggtcta gaggccaaca ttaaactaac aaaaggcctt 32460
gtgtatgacg gaaatgccat agcagttaat gttggcaaag ggctggaata cagccctact 32520
ggcacaacag aaaaacctat acagactaaa ataggtctag gcatggagta tgacactgag 32580
ggagccatga tgacaaaact aggctctgga ctaagctttg acaattcagg agccattgtg 32640
gtgggaaaca aaaatgatga caggcttact ttgtggacca caccggaccc atcgcccaac 32700
tgtcagattt actctgaaaa agatgctaaa ctaaccttgg tactgactaa atgtggcagt 32760
caggttg 32767
<210> 714
<211> 16
<212> PRT
<213> Homo sapiens
<400> 714
Gly Ser Thr Gly Cys Leu Thr Cys Arg His His Gln Thr Ser His Glu
1 5 10 15
<210> 715
<211> 15
<212> PRT
<213> Homo sapiens
<400> 715
Val Val Gly Arg Arg His Glu Thr Ala Pro Gln Pro Leu Leu Val
1 5 10 15
<210> 716
<211> 15
<212> PRT
<213> Homo sapiens
<400> 716
Ala Pro Gln Pro Leu Leu Val Pro Asp Arg Ala Gly Gly Glu Gly
1 5 10 15
<210> 717
<211> 9
<212> PRT
<213> Homo sapiens
<400> 717
Asp Arg Ala Gly Gly Glu Gly Gly Ala
1 5
<210> 718
<211> 15
<212> PRT
<213> Homo sapiens
<400> 718
Pro Val Pro Thr Ala Thr Pro Gly Val Arg Ser Val Thr Ser Pro
1 5 10 15
<210> 719
<211> 15
<212> PRT
<213> Homo sapiens
<400> 719
Val Arg Ser Val Thr Ser Pro Gln Gly Leu Gly Leu Phe Leu Lys
1 5 10 15
<210> 720
<211> 9
<212> PRT
<213> Homo sapiens
<400> 720
Gly Leu Gly Leu Phe Leu Lys Phe Ile
1 5
<210> 721
<211> 15
<212> PRT
<213> Homo sapiens
<400> 721
Lys Glu Asn Asp Val Arg Glu Val Cys Asp Val Tyr Leu Gln Met
1 5 10 15
<210> 722
<211> 15
<212> PRT
<213> Homo sapiens
<400> 722
Cys Asp Val Tyr Leu Gln Met Gln Ile Phe Phe His Phe Lys Phe
1 5 10 15
<210> 723
<211> 12
<212> PRT
<213> Homo sapiens
<400> 723
Ile Phe Phe His Phe Lys Phe Arg Ser Tyr Phe His
1 5 10
<210> 724
<211> 15
<212> PRT
<213> Homo sapiens
<400> 724
Phe Ala Arg Lys Met Leu Glu Lys Val His Arg Gln His Leu Gln
1 5 10 15
<210> 725
<211> 14
<212> PRT
<213> Homo sapiens
<400> 725
Val His Arg Gln His Leu Gln Leu Ser His Asn Ser Gln Glu
1 5 10
<210> 726
<211> 15
<212> PRT
<213> Homo sapiens
<400> 726
Met Phe Leu Arg Lys Glu Gln Gln Val Gly Pro His Ser Phe Ser
1 5 10 15
<210> 727
<211> 9
<212> PRT
<213> Homo sapiens
<400> 727
Val Gly Pro His Ser Phe Ser Met Leu
1 5
<210> 728
<211> 15
<212> PRT
<213> Homo sapiens
<400> 728
Gly Leu Asn Leu Asn Thr Asp Arg Pro Gly Gly Tyr Ser Tyr Ser
1 5 10 15
<210> 729
<211> 15
<212> PRT
<213> Homo sapiens
<400> 729
Pro Gly Gly Tyr Ser Tyr Ser Ile Trp Trp Lys Asn Asn Ala Lys
1 5 10 15
<210> 730
<211> 9
<212> PRT
<213> Homo sapiens
<400> 730
Trp Trp Lys Asn Asn Ala Lys Asn Arg
1 5
<210> 731
<211> 15
<212> PRT
<213> Homo sapiens
<400> 731
Lys Val Leu Asn Glu Ile Asp Ala Val Val Thr Val Pro Pro Ser
1 5 10 15
<210> 732
<211> 15
<212> PRT
<213> Homo sapiens
<400> 732
Val Val Thr Val Pro Pro Ser Leu Ser Thr Ser Gln Ile Pro Gln
1 5 10 15
<210> 733
<211> 13
<212> PRT
<213> Homo sapiens
<400> 733
Ser Thr Ser Gln Ile Pro Gln Gly Cys Cys Ile Ile Leu
1 5 10
<210> 734
<211> 15
<212> PRT
<213> Homo sapiens
<400> 734
Ala Asn Leu Lys Gly Thr Leu Gln Val Arg Ser Gly Gln Ala Val
1 5 10 15
<210> 735
<211> 10
<212> PRT
<213> Homo sapiens
<400> 735
Val Arg Ser Gly Gln Ala Val Ser Pro Arg
1 5 10
<210> 736
<211> 15
<212> PRT
<213> Homo sapiens
<400> 736
Leu Gln Ala Ala Ala Ser Gly Gln Gly Lys Gln Gly Val Pro Cys
1 5 10 15
<210> 737
<211> 15
<212> PRT
<213> Homo sapiens
<400> 737
Gly Lys Gln Gly Val Pro Cys Pro Trp Gly Cys Cys Ala Tyr Ala
1 5 10 15
<210> 738
<211> 15
<212> PRT
<213> Homo sapiens
<400> 738
Trp Gly Cys Cys Ala Tyr Ala Glu Ser Pro Arg Ala Leu Ile Ser
1 5 10 15
<210> 739
<211> 15
<212> PRT
<213> Homo sapiens
<400> 739
Ser Pro Arg Ala Leu Ile Ser Gly Asp Ala Pro Ser Gln Val Glu
1 5 10 15
<210> 740
<211> 15
<212> PRT
<213> Homo sapiens
<400> 740
Asp Ala Pro Ser Gln Val Glu Arg Glu Val Pro Gly Pro Cys Leu
1 5 10 15
<210> 741
<211> 15
<212> PRT
<213> Homo sapiens
<400> 741
Glu Val Pro Gly Pro Cys Leu Asn Thr His Ser Leu Ser His Arg
1 5 10 15
<210> 742
<211> 15
<212> PRT
<213> Homo sapiens
<400> 742
Thr His Ser Leu Ser His Arg Ser Pro Gln Leu Pro Gly Leu Pro
1 5 10 15
<210> 743
<211> 14
<212> PRT
<213> Homo sapiens
<400> 743
Pro Gln Leu Pro Gly Leu Pro His Pro Lys Gln Pro Ser Val
1 5 10
<210> 744
<211> 15
<212> PRT
<213> Homo sapiens
<400> 744
Gly Glu Val Glu Leu Ser Glu Gly Gly Glu Gly Gln Arg His Leu
1 5 10 15
<210> 745
<211> 15
<212> PRT
<213> Homo sapiens
<400> 745
Gly Glu Gly Gln Arg His Leu Ala Phe Pro Trp Ala Cys Ser Gly
1 5 10 15
<210> 746
<211> 15
<212> PRT
<213> Homo sapiens
<400> 746
Phe Pro Trp Ala Cys Ser Gly Pro Gly Trp Arg Gly Val Cys Cys
1 5 10 15
<210> 747
<211> 15
<212> PRT
<213> Homo sapiens
<400> 747
Lys Met Arg Ala Ile Gln Ala Glu Gly Gly His Gly Gln Ala Cys
1 5 10 15
<210> 748
<211> 15
<212> PRT
<213> Homo sapiens
<400> 748
Gly Gly His Gly Gln Ala Cys Cys Gly Gly Ala Trp Gly Trp Ala
1 5 10 15
<210> 749
<211> 15
<212> PRT
<213> Homo sapiens
<400> 749
Gly Gly Ala Trp Gly Trp Ala Pro Gly Asp Gly Gly Pro Gln Gly
1 5 10 15
<210> 750
<211> 15
<212> PRT
<213> Homo sapiens
<400> 750
Gly Asp Gly Gly Pro Gln Gly Met Leu Thr His Thr Leu Pro Thr
1 5 10 15
<210> 751
<211> 15
<212> PRT
<213> Homo sapiens
<400> 751
Leu Thr His Thr Leu Pro Thr Leu Gly Phe Gln Ser Ala Trp Thr
1 5 10 15
<210> 752
<211> 15
<212> PRT
<213> Homo sapiens
<400> 752
Gly Phe Gln Ser Ala Trp Thr Trp Arg Arg Glu Asp Ala Asp Arg
1 5 10 15
<210> 753
<211> 15
<212> PRT
<213> Homo sapiens
<400> 753
Arg Arg Glu Asp Ala Asp Arg Ala Trp Arg Thr Pro Lys Ala Cys
1 5 10 15
<210> 754
<211> 14
<212> PRT
<213> Homo sapiens
<400> 754
Trp Arg Thr Pro Lys Ala Cys Ala Ser Arg Arg Trp Ser Ile
1 5 10
<210> 755
<211> 15
<212> PRT
<213> Homo sapiens
<400> 755
Leu Leu Glu Pro Phe Arg Arg Gly Glu Pro Gly Pro Arg Gly Leu
1 5 10 15
<210> 756
<211> 15
<212> PRT
<213> Homo sapiens
<400> 756
Glu Pro Gly Pro Arg Gly Leu Leu Ser Gly Ser Ser Arg Gly Gly
1 5 10 15
<210> 757
<211> 15
<212> PRT
<213> Homo sapiens
<400> 757
Ser Gly Ser Ser Arg Gly Gly Glu Gly Pro Gly Arg Ser Ile Glu
1 5 10 15
<210> 758
<211> 15
<212> PRT
<213> Homo sapiens
<400> 758
Gly Pro Gly Arg Ser Ile Glu Ala Ala Pro Ala Thr Pro Leu Pro
1 5 10 15
<210> 759
<211> 15
<212> PRT
<213> Homo sapiens
<400> 759
Ala Pro Ala Thr Pro Leu Pro Cys Cys Arg Lys Asn Pro Cys Arg
1 5 10 15
<210> 760
<211> 15
<212> PRT
<213> Homo sapiens
<400> 760
Cys Arg Lys Asn Pro Cys Arg Pro Gln Pro Ser Arg Phe Leu Pro
1 5 10 15
<210> 761
<211> 15
<212> PRT
<213> Homo sapiens
<400> 761
Gln Pro Ser Arg Phe Leu Pro Pro Arg Val Leu Leu Val Ile Ile
1 5 10 15
<210> 762
<211> 15
<212> PRT
<213> Homo sapiens
<400> 762
Arg Val Leu Leu Val Ile Ile Leu Pro Lys Leu Asp Cys Pro Lys
1 5 10 15
<210> 763
<211> 10
<212> PRT
<213> Homo sapiens
<400> 763
Pro Lys Leu Asp Cys Pro Lys Leu Gly Phe
1 5 10
<210> 764
<211> 15
<212> PRT
<213> Homo sapiens
<400> 764
Pro Ser Gly Arg Arg Thr Lys Arg Leu Val Thr Leu Arg Ser Gly
1 5 10 15
<210> 765
<211> 15
<212> PRT
<213> Homo sapiens
<400> 765
Leu Val Thr Leu Arg Ser Gly Cys Ala Ile Gln Cys Trp His Pro
1 5 10 15
<210> 766
<211> 15
<212> PRT
<213> Homo sapiens
<400> 766
Ala Ile Gln Cys Trp His Pro Arg Ala Gly Pro Val Pro Ser Ala
1 5 10 15
<210> 767
<211> 15
<212> PRT
<213> Homo sapiens
<400> 767
Ala Gly Pro Val Pro Ser Ala Leu Pro His Thr Glu Arg Pro Pro
1 5 10 15
<210> 768
<211> 15
<212> PRT
<213> Homo sapiens
<400> 768
Pro His Thr Glu Arg Pro Pro Arg Leu Val Arg Gly Ala Ala Asp
1 5 10 15
<210> 769
<211> 15
<212> PRT
<213> Homo sapiens
<400> 769
Leu Val Arg Gly Ala Ala Asp Pro Arg Thr Val Thr Leu Gly Arg
1 5 10 15
<210> 770
<211> 15
<212> PRT
<213> Homo sapiens
<400> 770
Arg Thr Val Thr Leu Gly Arg Ser Pro Ala Val Met Pro Arg Ala
1 5 10 15
<210> 771
<211> 9
<212> PRT
<213> Homo sapiens
<400> 771
Pro Ala Val Met Pro Arg Ala Pro Ala
1 5
<210> 772
<211> 15
<212> PRT
<213> Homo sapiens
<400> 772
Asp Cys Met Leu Ser Glu Glu Gly Gly Gln Ala Arg Arg Gly Gly
1 5 10 15
<210> 773
<211> 15
<212> PRT
<213> Homo sapiens
<400> 773
Gly Gln Ala Arg Arg Gly Gly Ser Leu Cys Ser Leu Ala Ala His
1 5 10 15
<210> 774
<211> 15
<212> PRT
<213> Homo sapiens
<400> 774
Leu Cys Ser Leu Ala Ala His Thr Ile Ala Ser Ala Ala Arg Gly
1 5 10 15
<210> 775
<211> 15
<212> PRT
<213> Homo sapiens
<400> 775
Ile Ala Ser Ala Ala Arg Gly Arg Phe Leu Ser Arg Leu Ser Asn
1 5 10 15
<210> 776
<211> 15
<212> PRT
<213> Homo sapiens
<400> 776
Phe Leu Ser Arg Leu Ser Asn Phe Cys Ala Val Val Lys Ala Ser
1 5 10 15
<210> 777
<211> 16
<212> PRT
<213> Homo sapiens
<400> 777
Cys Ala Val Val Lys Ala Ser Arg Gly Ala Pro Ser Cys Thr Trp Glu
1 5 10 15
<210> 778
<211> 15
<212> PRT
<213> Homo sapiens
<400> 778
Pro Glu Pro Arg Arg Leu Ser Pro Gly Glu Pro Arg Gly Arg Pro
1 5 10 15
<210> 779
<211> 15
<212> PRT
<213> Homo sapiens
<400> 779
Gly Glu Pro Arg Gly Arg Pro Arg Lys Gly Trp Gly Ile Trp Gly
1 5 10 15
<210> 780
<211> 15
<212> PRT
<213> Homo sapiens
<400> 780
Lys Gly Trp Gly Ile Trp Gly Leu Cys Gly Ala Arg Val Gly Pro
1 5 10 15
<210> 781
<211> 11
<212> PRT
<213> Homo sapiens
<400> 781
Cys Gly Ala Arg Val Gly Pro Lys Ala Trp Arg
1 5 10
<210> 782
<211> 15
<212> PRT
<213> Homo sapiens
<400> 782
Phe Val Ser Leu Thr Ala Ile Gln Met Ala Ser Ser Ala Thr Pro
1 5 10 15
<210> 783
<211> 15
<212> PRT
<213> Homo sapiens
<400> 783
Met Ala Ser Ser Ala Thr Pro Trp Gly Arg Trp Pro Val Ala Thr
1 5 10 15
<210> 784
<211> 15
<212> PRT
<213> Homo sapiens
<400> 784
Gly Arg Trp Pro Val Ala Thr Pro Thr Ala Ala Cys Pro Arg Arg
1 5 10 15
<210> 785
<211> 15
<212> PRT
<213> Homo sapiens
<400> 785
Thr Ala Ala Cys Pro Arg Arg Arg Pro Ser Ser Leu Pro Thr Gly
1 5 10 15
<210> 786
<211> 15
<212> PRT
<213> Homo sapiens
<400> 786
Pro Ser Ser Leu Pro Thr Gly Gly Asp Ser Ala Ser Lys Lys Pro
1 5 10 15
<210> 787
<211> 15
<212> PRT
<213> Homo sapiens
<400> 787
Asp Ser Ala Ser Lys Lys Pro Ile Ser Arg Arg Ala Pro Trp Gln
1 5 10 15
<210> 788
<211> 15
<212> PRT
<213> Homo sapiens
<400> 788
Ser Arg Arg Ala Pro Trp Gln Pro Trp Ala Cys Pro Gly Arg Ser
1 5 10 15
<210> 789
<211> 15
<212> PRT
<213> Homo sapiens
<400> 789
Trp Ala Cys Pro Gly Arg Ser Val Asn Ser Ala Ala Pro Arg Ala
1 5 10 15
<210> 790
<211> 15
<212> PRT
<213> Homo sapiens
<400> 790
Asn Ser Ala Ala Pro Arg Ala Trp Cys Pro Pro Ala Thr Thr Pro
1 5 10 15
<210> 791
<211> 15
<212> PRT
<213> Homo sapiens
<400> 791
Cys Pro Pro Ala Thr Thr Pro Arg Thr Gln Ser Pro Ser Arg Asp
1 5 10 15
<210> 792
<211> 15
<212> PRT
<213> Homo sapiens
<400> 792
Thr Gln Ser Pro Ser Arg Asp Leu Arg Pro Arg Cys Leu Ser Ser
1 5 10 15
<210> 793
<211> 10
<212> PRT
<213> Homo sapiens
<400> 793
Arg Pro Arg Cys Leu Ser Ser Trp Ser Ser
1 5 10
<210> 794
<211> 15
<212> PRT
<213> Homo sapiens
<400> 794
Pro Val Ala Ile Lys Pro Gly Thr Gly Pro Pro Asn Asn Ser Ser
1 5 10 15
<210> 795
<211> 15
<212> PRT
<213> Homo sapiens
<400> 795
Gly Pro Pro Asn Asn Ser Ser Ile His Gly Gly Ser Lys Arg Ser
1 5 10 15
<210> 796
<211> 15
<212> PRT
<213> Homo sapiens
<400> 796
His Gly Gly Ser Lys Arg Ser Glu Asn Ser Tyr Cys Arg Asp Leu
1 5 10 15
<210> 797
<211> 15
<212> PRT
<213> Homo sapiens
<400> 797
Asn Ser Tyr Cys Arg Asp Leu Arg Gly Gln Leu Arg Ala Ile Cys
1 5 10 15
<210> 798
<211> 15
<212> PRT
<213> Homo sapiens
<400> 798
Gly Gln Leu Arg Ala Ile Cys Cys Ser Ser Tyr Ser His Asp Arg
1 5 10 15
<210> 799
<211> 15
<212> PRT
<213> Homo sapiens
<400> 799
Ser Ser Tyr Ser His Asp Arg His Thr Thr Glu Glu Arg Gly Ser
1 5 10 15
<210> 800
<211> 15
<212> PRT
<213> Homo sapiens
<400> 800
Thr Thr Glu Glu Arg Gly Ser Arg Gly Arg His Val Trp Arg Ile
1 5 10 15
<210> 801
<211> 15
<212> PRT
<213> Homo sapiens
<400> 801
Gly Arg His Val Trp Arg Ile Arg Arg Leu His Thr Ser Gly Leu
1 5 10 15
<210> 802
<211> 15
<212> PRT
<213> Homo sapiens
<400> 802
Arg Leu His Thr Ser Gly Leu Pro Cys Cys Cys His Ser Gly Pro
1 5 10 15
<210> 803
<211> 15
<212> PRT
<213> Homo sapiens
<400> 803
Cys Cys Cys His Ser Gly Pro His Pro Arg Arg Leu Pro Asp Ile
1 5 10 15
<210> 804
<211> 15
<212> PRT
<213> Homo sapiens
<400> 804
Pro Arg Arg Leu Pro Asp Ile Leu Arg Leu Val Thr Ser Thr Lys
1 5 10 15
<210> 805
<211> 15
<212> PRT
<213> Homo sapiens
<400> 805
Arg Leu Val Thr Ser Thr Lys Thr Asp His Thr Asn Thr Thr Glu
1 5 10 15
<210> 806
<211> 13
<212> PRT
<213> Homo sapiens
<400> 806
Asp His Thr Asn Thr Thr Glu Gly Thr Leu Asp Tyr Leu
1 5 10
<210> 807
<211> 15
<212> PRT
<213> Homo sapiens
<400> 807
Lys Trp Asn Lys Asn Trp Thr Ala Thr Leu Gly Ala Leu Thr Ile
1 5 10 15
<210> 808
<211> 15
<212> PRT
<213> Homo sapiens
<400> 808
Thr Leu Gly Ala Leu Thr Ile Arg Gly His Lys Leu Leu Cys His
1 5 10 15
<210> 809
<211> 15
<212> PRT
<213> Homo sapiens
<400> 809
Gly His Lys Leu Leu Cys His Leu Pro His Leu Leu Ser Ser Val
1 5 10 15
<210> 810
<211> 16
<212> PRT
<213> Homo sapiens
<400> 810
Pro His Leu Leu Ser Ser Val Gln Gln Thr Cys Arg Ser Ser Ser Arg
1 5 10 15
<210> 811
<211> 15
<212> PRT
<213> Homo sapiens
<400> 811
Glu Asn Ala Ser Leu Val Phe Thr Gly Ser Asn Ser Pro Ile Pro
1 5 10 15
<210> 812
<211> 15
<212> PRT
<213> Homo sapiens
<400> 812
Gly Ser Asn Ser Pro Ile Pro Ala Cys Glu Leu Ser Ser His Pro
1 5 10 15
<210> 813
<211> 15
<212> PRT
<213> Homo sapiens
<400> 813
Cys Glu Leu Ser Ser His Pro Ala His Gly Ile Ser Pro Trp Ile
1 5 10 15
<210> 814
<211> 15
<212> PRT
<213> Homo sapiens
<400> 814
His Gly Ile Ser Pro Trp Ile Pro Ser Pro Gly Asn Glu His Phe
1 5 10 15
<210> 815
<211> 15
<212> PRT
<213> Homo sapiens
<400> 815
Ser Pro Gly Asn Glu His Phe His Gly Ile Lys Lys Gln Val Lys
1 5 10 15
<210> 816
<211> 12
<212> PRT
<213> Homo sapiens
<400> 816
Gly Ile Lys Lys Gln Val Lys Ala Ile Lys Val Glu
1 5 10
<210> 817
<211> 15
<212> PRT
<213> Homo sapiens
<400> 817
Arg Leu Thr Gln Arg Leu Val Gln Gly Trp Thr Pro Met Glu Asn
1 5 10 15
<210> 818
<211> 15
<212> PRT
<213> Homo sapiens
<400> 818
Gly Trp Thr Pro Met Glu Asn Arg Trp Cys Gly Arg Arg Ala Gly
1 5 10 15
<210> 819
<211> 15
<212> PRT
<213> Homo sapiens
<400> 819
Trp Cys Gly Arg Arg Ala Gly Gly Gln Pro Ala Ser Ser Ser Thr
1 5 10 15
<210> 820
<211> 15
<212> PRT
<213> Homo sapiens
<400> 820
Gln Pro Ala Ser Ser Ser Thr Arg Trp Thr Thr Cys Arg Ala Ala
1 5 10 15
<210> 821
<211> 15
<212> PRT
<213> Homo sapiens
<400> 821
Trp Thr Thr Cys Arg Ala Ala Cys Leu Leu Thr Lys Trp Thr Ala
1 5 10 15
<210> 822
<211> 15
<212> PRT
<213> Homo sapiens
<400> 822
Leu Leu Thr Lys Trp Thr Ala Gly Arg Ser Gln Thr Ser Ile Gly
1 5 10 15
<210> 823
<211> 15
<212> PRT
<213> Homo sapiens
<400> 823
Glu Asn Ser Gly Asn Ala Ser Arg Trp Leu His Val Pro Ser Ser
1 5 10 15
<210> 824
<211> 15
<212> PRT
<213> Homo sapiens
<400> 824
Trp Leu His Val Pro Ser Ser Ser Asp Asp Trp Leu Gly Trp Lys
1 5 10 15
<210> 825
<211> 16
<212> PRT
<213> Homo sapiens
<400> 825
Asp Asp Trp Leu Gly Trp Lys Lys Ser Ser Ala Ile Thr Ser Asn Ser
1 5 10 15
<210> 826
<211> 15
<212> PRT
<213> Homo sapiens
<400> 826
Lys Gly Ser Val Glu Arg Arg Ser Val Ser Leu Gly His Pro Ala
1 5 10 15
<210> 827
<211> 15
<212> PRT
<213> Homo sapiens
<400> 827
Val Ser Leu Gly His Pro Ala Glu Gly Trp Ala Trp Ala Glu Arg
1 5 10 15
<210> 828
<211> 15
<212> PRT
<213> Homo sapiens
<400> 828
Gly Trp Ala Trp Ala Glu Arg Ser Leu Gln Pro Gly Met Thr Thr
1 5 10 15
<210> 829
<211> 15
<212> PRT
<213> Homo sapiens
<400> 829
Leu Gln Pro Gly Met Thr Thr Ala Asn Thr Gly Cys Leu Ser Phe
1 5 10 15
<210> 830
<211> 15
<212> PRT
<213> Homo sapiens
<400> 830
Asn Thr Gly Cys Leu Ser Phe His His Arg Gly Cys Leu Leu Pro
1 5 10 15
<210> 831
<211> 15
<212> PRT
<213> Homo sapiens
<400> 831
His Arg Gly Cys Leu Leu Pro Val Leu Pro Lys Leu His Cys Gly
1 5 10 15
<210> 832
<211> 15
<212> PRT
<213> Homo sapiens
<400> 832
Leu Pro Lys Leu His Cys Gly Leu Gly Gly Leu Pro Leu Val Arg
1 5 10 15
<210> 833
<211> 15
<212> PRT
<213> Homo sapiens
<400> 833
Gly Gly Leu Pro Leu Val Arg Ala Lys Glu Ile Lys Arg Val Gln
1 5 10 15
<210> 834
<211> 15
<212> PRT
<213> Homo sapiens
<400> 834
Lys Glu Ile Lys Arg Val Gln Arg Ala Gly Glu Ser Ser Leu Pro
1 5 10 15
<210> 835
<211> 15
<212> PRT
<213> Homo sapiens
<400> 835
Ala Gly Glu Ser Ser Leu Pro Val Lys Gly Leu Leu Thr Val Ala
1 5 10 15
<210> 836
<211> 15
<212> PRT
<213> Homo sapiens
<400> 836
Lys Gly Leu Leu Thr Val Ala Ser Ala Val Ile Ala Val Leu Trp
1 5 10 15
<210> 837
<211> 15
<212> PRT
<213> Homo sapiens
<400> 837
Ala Val Ile Ala Val Leu Trp Gly Arg Pro Ser Glu Val Thr Gly
1 5 10 15
<210> 838
<211> 14
<212> PRT
<213> Homo sapiens
<400> 838
Arg Pro Ser Glu Val Thr Gly Glu Asn Glu Ala Gln His Asp
1 5 10
<210> 839
<211> 15
<212> PRT
<213> Homo sapiens
<400> 839
Phe Gly Leu Thr Thr Leu Ala Gly Arg Ser Ser His Gly Thr Ser
1 5 10 15
<210> 840
<211> 15
<212> PRT
<213> Homo sapiens
<400> 840
Arg Ser Ser His Gly Thr Ser Gly Leu Arg Ala Ala Thr His Thr
1 5 10 15
<210> 841
<211> 15
<212> PRT
<213> Homo sapiens
<400> 841
Leu Arg Ala Ala Thr His Thr Lys Ser Gly Asp Gly Gly Gln Gly
1 5 10 15
<210> 842
<211> 15
<212> PRT
<213> Homo sapiens
<400> 842
Ser Gly Asp Gly Gly Gln Gly Ala Ala Arg Gln Cys Glu Lys Leu
1 5 10 15
<210> 843
<211> 15
<212> PRT
<213> Homo sapiens
<400> 843
Ala Arg Gln Cys Glu Lys Leu Leu Glu Leu Ala Arg Ala Thr Arg
1 5 10 15
<210> 844
<211> 15
<212> PRT
<213> Homo sapiens
<400> 844
Glu Leu Ala Arg Ala Thr Arg Pro Trp Gly Arg Ser Thr Ser Ala
1 5 10 15
<210> 845
<211> 15
<212> PRT
<213> Homo sapiens
<400> 845
Trp Gly Arg Ser Thr Ser Ala Ser Ser Arg Trp Thr His Arg Gly
1 5 10 15
<210> 846
<211> 15
<212> PRT
<213> Homo sapiens
<400> 846
Ser Arg Trp Thr His Arg Gly Tyr Met Cys Pro Pro Arg Cys Ala
1 5 10 15
<210> 847
<211> 11
<212> PRT
<213> Homo sapiens
<400> 847
Met Cys Pro Pro Arg Cys Ala Val Ala Cys Trp
1 5 10
<210> 848
<211> 15
<212> PRT
<213> Homo sapiens
<400> 848
Ile Ile Asp Ser Asp Lys Ile Met Ala Val Cys Met Gly Cys Leu
1 5 10 15
<210> 849
<211> 15
<212> PRT
<213> Homo sapiens
<400> 849
Asp Lys Ile Met Ala Val Cys Met Gly Cys Leu Leu Thr Arg His
1 5 10 15
<210> 850
<211> 15
<212> PRT
<213> Homo sapiens
<400> 850
Ala Val Cys Met Gly Cys Leu Leu Thr Arg His Val Gln Cys Gln
1 5 10 15
<210> 851
<211> 15
<212> PRT
<213> Homo sapiens
<400> 851
Gly Cys Leu Leu Thr Arg His Val Gln Cys Gln Ala Met Glu Met
1 5 10 15
<210> 852
<211> 13
<212> PRT
<213> Homo sapiens
<400> 852
Thr Arg His Val Gln Cys Gln Ala Met Glu Met Gln Gln
1 5 10
<210> 853
<211> 16
<212> PRT
<213> Homo sapiens
<400> 853
Leu Ser Ile Phe Leu Phe Leu Met Leu Cys Lys Leu Glu Phe His Ala
1 5 10 15
<210> 854
<211> 15
<212> PRT
<213> Homo sapiens
<400> 854
Leu Leu Asn Ala Glu Asp Tyr Arg Cys Ala Ile His Ser Lys Glu
1 5 10 15
<210> 855
<211> 15
<212> PRT
<213> Homo sapiens
<400> 855
Cys Ala Ile His Ser Lys Glu Ile Tyr Leu Leu Ser Pro Ser Pro
1 5 10 15
<210> 856
<211> 15
<212> PRT
<213> Homo sapiens
<400> 856
Tyr Leu Leu Ser Pro Ser Pro His Gln Ala Met Asp Lys Phe Ser
1 5 10 15
<210> 857
<211> 15
<212> PRT
<213> Homo sapiens
<400> 857
Gln Ala Met Asp Lys Phe Ser Leu Cys Cys Ile Asn Cys Asn Leu
1 5 10 15
<210> 858
<211> 15
<212> PRT
<213> Homo sapiens
<400> 858
Cys Cys Ile Asn Cys Asn Leu Cys Leu His Val Phe Leu Leu Leu
1 5 10 15
<210> 859
<211> 15
<212> PRT
<213> Homo sapiens
<400> 859
Leu His Val Phe Leu Leu Leu Leu Phe Phe Gln Asn Lys Asp Val
1 5 10 15
<210> 860
<211> 15
<212> PRT
<213> Homo sapiens
<400> 860
Phe Phe Gln Asn Lys Asp Val Trp Leu Ile Ser Asn Ile Ile Leu
1 5 10 15
<210> 861
<211> 14
<212> PRT
<213> Homo sapiens
<400> 861
Leu Ile Ser Asn Ile Ile Leu Leu Trp Ile Tyr Gly Gly Ile
1 5 10
<210> 862
<211> 15
<212> PRT
<213> Homo sapiens
<400> 862
Val Glu Thr Leu Glu Asn Ala Asn Ser Phe Ser Ser Gly Ile Gln
1 5 10 15
<210> 863
<211> 15
<212> PRT
<213> Homo sapiens
<400> 863
Ser Phe Ser Ser Gly Ile Gln Pro Leu Leu Cys Ser Leu Ile Gly
1 5 10 15
<210> 864
<211> 12
<212> PRT
<213> Homo sapiens
<400> 864
Leu Leu Cys Ser Leu Ile Gly Leu Glu Asn Pro Thr
1 5 10
<210> 865
<211> 15
<212> PRT
<213> Homo sapiens
<400> 865
Ala Gly Ala Gly Thr Ile Ser Glu Gly Ser Val Leu His Gly Gln
1 5 10 15
<210> 866
<211> 15
<212> PRT
<213> Homo sapiens
<400> 866
Gly Ser Val Leu His Gly Gln Arg Leu Glu Cys Asp Ala Arg Arg
1 5 10 15
<210> 867
<211> 15
<212> PRT
<213> Homo sapiens
<400> 867
Leu Glu Cys Asp Ala Arg Arg Phe Phe Gly Cys Gly Thr Thr Ile
1 5 10 15
<210> 868
<211> 14
<212> PRT
<213> Homo sapiens
<400> 868
Phe Gly Cys Gly Thr Thr Ile Leu Ala Glu Trp Glu His His
1 5 10
<210> 869
<211> 15
<212> PRT
<213> Homo sapiens
<400> 869
Lys Glu Gln Ile Leu Ala Val Ala Ser Leu Val Ser Ser Gln Ser
1 5 10 15
<210> 870
<211> 15
<212> PRT
<213> Homo sapiens
<400> 870
Ser Leu Val Ser Ser Gln Ser Ile His Pro Ser Trp Gly Gln Ser
1 5 10 15
<210> 871
<211> 12
<212> PRT
<213> Homo sapiens
<400> 871
His Pro Ser Trp Gly Gln Ser Pro Leu Ser Arg Ile
1 5 10
<210> 872
<211> 15
<212> PRT
<213> Homo sapiens
<400> 872
Gln Gln Leu Arg Ile Phe Cys Ala Ala Met Ala Ser Asn Glu Asp
1 5 10 15
<210> 873
<211> 9
<212> PRT
<213> Homo sapiens
<400> 873
Ala Met Ala Ser Asn Glu Asp Phe Ser
1 5
<210> 874
<211> 15
<212> PRT
<213> Homo sapiens
<400> 874
Asp Gly Phe Ser Gly Ser Leu Phe Ala Val Val Thr Arg Arg Cys
1 5 10 15
<210> 875
<211> 15
<212> PRT
<213> Homo sapiens
<400> 875
Ala Val Val Thr Arg Arg Cys Tyr Phe Leu Lys Trp Arg Thr Ile
1 5 10 15
<210> 876
<211> 15
<212> PRT
<213> Homo sapiens
<400> 876
Phe Leu Lys Trp Arg Thr Ile Phe Pro Gln Ser Leu Met Trp Leu
1 5 10 15
<210> 877
<211> 15
<212> PRT
<213> Homo sapiens
<400> 877
Asp Leu Arg Arg Val Ala Thr Tyr Cys Ala Pro Leu Pro Ser Ser
1 5 10 15
<210> 878
<211> 15
<212> PRT
<213> Homo sapiens
<400> 878
Cys Ala Pro Leu Pro Ser Ser Trp Arg Pro Gly Thr Gly Thr Thr
1 5 10 15
<210> 879
<211> 15
<212> PRT
<213> Homo sapiens
<400> 879
Arg Pro Gly Thr Gly Thr Thr Ile Pro Pro Arg Met Arg Ser Cys
1 5 10 15
<210> 880
<211> 15
<212> PRT
<213> Homo sapiens
<400> 880
Leu Gln Glu Arg Met Glu Leu Leu Ala Cys Gly Ala Glu Arg Gly
1 5 10 15
<210> 881
<211> 15
<212> PRT
<213> Homo sapiens
<400> 881
Ala Cys Gly Ala Glu Arg Gly Ala Gly Gly Trp Gly Gly Gly Gly
1 5 10 15
<210> 882
<211> 15
<212> PRT
<213> Homo sapiens
<400> 882
Gly Gly Trp Gly Gly Gly Gly Gly Gly Gly Gly Gly Asp Arg Arg
1 5 10 15
<210> 883
<211> 15
<212> PRT
<213> Homo sapiens
<400> 883
Gly Gly Gly Gly Asp Arg Arg Gly Gly Gly Gly Ser Ala Pro Ala
1 5 10 15
<210> 884
<211> 16
<212> PRT
<213> Homo sapiens
<400> 884
Gly Gly Gly Ser Ala Pro Ala Leu Ala Asp Phe Ala Gly Gly Arg Gly
1 5 10 15
<210> 885
<211> 15
<212> PRT
<213> Homo sapiens
<400> 885
Trp Thr Asp Ile Val Lys Gln Ser Val Ser Thr Asn Cys Ile Ser
1 5 10 15
<210> 886
<211> 15
<212> PRT
<213> Homo sapiens
<400> 886
Val Ser Thr Asn Cys Ile Ser Ile Lys Lys Gly Ser Tyr Thr Lys
1 5 10 15
<210> 887
<211> 15
<212> PRT
<213> Homo sapiens
<400> 887
Lys Lys Gly Ser Tyr Thr Lys Leu Phe Ser Leu Val Phe Leu Ile
1 5 10 15
<210> 888
<211> 16
<212> PRT
<213> Homo sapiens
<400> 888
Phe Ser Leu Val Phe Leu Ile Phe Cys Trp Pro Leu Ile Ile Gln Leu
1 5 10 15
<210> 889
<211> 15
<212> PRT
<213> Homo sapiens
<400> 889
Leu Arg Tyr Gly Ala Leu Cys Asn Val Ser Arg Ile Ser Tyr Phe
1 5 10 15
<210> 890
<211> 15
<212> PRT
<213> Homo sapiens
<400> 890
Val Ser Arg Ile Ser Tyr Phe Ser Leu Thr Asn Ile Phe Asn Phe
1 5 10 15
<210> 891
<211> 15
<212> PRT
<213> Homo sapiens
<400> 891
Leu Thr Asn Ile Phe Asn Phe Val Ile Lys Ser Leu Thr Ala Ile
1 5 10 15
<210> 892
<211> 15
<212> PRT
<213> Homo sapiens
<400> 892
Arg Lys Glu Arg Asn Ile Arg Lys Ser Glu Ser Thr Leu Arg Leu
1 5 10 15
<210> 893
<211> 15
<212> PRT
<213> Homo sapiens
<400> 893
Ser Glu Ser Thr Leu Arg Leu Ser Pro Phe Pro Thr Pro Ala Pro
1 5 10 15
<210> 894
<211> 15
<212> PRT
<213> Homo sapiens
<400> 894
Pro Phe Pro Thr Pro Ala Pro Ser Gly Ala Pro Ala Ala Ala Gln
1 5 10 15
<210> 895
<211> 15
<212> PRT
<213> Homo sapiens
<400> 895
Gly Ala Pro Ala Ala Ala Gln Gly Lys Val Val Arg Val Pro Gly
1 5 10 15
<210> 896
<211> 15
<212> PRT
<213> Homo sapiens
<400> 896
Lys Val Val Arg Val Pro Gly Pro Ala Gly Gly Leu Val Pro Arg
1 5 10 15
<210> 897
<211> 15
<212> PRT
<213> Homo sapiens
<400> 897
Ala Gly Gly Leu Val Pro Arg Asp Ala Gly Ala Arg Leu Leu Pro
1 5 10 15
<210> 898
<211> 15
<212> PRT
<213> Homo sapiens
<400> 898
Ala Gly Ala Arg Leu Leu Pro Pro Ala Gly Gly Pro Gly Gly Gly
1 5 10 15
<210> 899
<211> 15
<212> PRT
<213> Homo sapiens
<400> 899
Ala Gly Gly Pro Gly Gly Gly Ala Ala Ala Gly Glu Gly Arg Ala
1 5 10 15
<210> 900
<211> 15
<212> PRT
<213> Homo sapiens
<400> 900
Ala Ala Gly Glu Gly Arg Ala Gly Arg Gly Arg Phe Pro Ser Ile
1 5 10 15
<210> 901
<211> 15
<212> PRT
<213> Homo sapiens
<400> 901
Arg Gly Arg Phe Pro Ser Ile Thr Glu Pro Arg Pro Arg Asp Leu
1 5 10 15
<210> 902
<211> 15
<212> PRT
<213> Homo sapiens
<400> 902
Glu Pro Arg Pro Arg Asp Leu Pro Pro Arg Val Ala Thr Gly Arg
1 5 10 15
<210> 903
<211> 15
<212> PRT
<213> Homo sapiens
<400> 903
Pro Arg Val Ala Thr Gly Arg Arg Ala Gly Gly Arg Arg Lys Gly
1 5 10 15
<210> 904
<211> 15
<212> PRT
<213> Homo sapiens
<400> 904
Ala Gly Gly Arg Arg Lys Gly Ala Gly Gln Gly Val Arg Thr Arg
1 5 10 15
<210> 905
<211> 15
<212> PRT
<213> Homo sapiens
<400> 905
Gly Gln Gly Val Arg Thr Arg Pro Leu Pro Ala Ser Trp Pro Gly
1 5 10 15
<210> 906
<211> 15
<212> PRT
<213> Homo sapiens
<400> 906
Leu Pro Ala Ser Trp Pro Gly Gly Arg Gly Pro Phe Arg Lys Gly
1 5 10 15
<210> 907
<211> 15
<212> PRT
<213> Homo sapiens
<400> 907
Arg Gly Pro Phe Arg Lys Gly Pro Arg Arg Leu Pro Leu Gly Ser
1 5 10 15
<210> 908
<211> 15
<212> PRT
<213> Homo sapiens
<400> 908
Arg Arg Leu Pro Leu Gly Ser Gly Pro Pro Ala Ala Gly Val Gln
1 5 10 15
<210> 909
<211> 15
<212> PRT
<213> Homo sapiens
<400> 909
Pro Pro Ala Ala Gly Val Gln Arg Leu Arg Cys Ser His Leu Ser
1 5 10 15
<210> 910
<211> 15
<212> PRT
<213> Homo sapiens
<400> 910
Leu Arg Cys Ser His Leu Ser Arg Gly Pro Arg Arg Arg Arg Gly
1 5 10 15
<210> 911
<211> 15
<212> PRT
<213> Homo sapiens
<400> 911
Gly Pro Arg Arg Arg Arg Gly Arg Val Cys Gly Arg Ala Cys Val
1 5 10 15
<210> 912
<211> 15
<212> PRT
<213> Homo sapiens
<400> 912
Val Cys Gly Arg Ala Cys Val Ser Pro Pro Leu Pro Pro Arg Pro
1 5 10 15
<210> 913
<211> 15
<212> PRT
<213> Homo sapiens
<400> 913
Pro Pro Leu Pro Pro Arg Pro Pro Pro Val Gly Leu Ser Ala Glu
1 5 10 15
<210> 914
<211> 15
<212> PRT
<213> Homo sapiens
<400> 914
Pro Val Gly Leu Ser Ala Glu Asn Leu Ser Trp Leu Ser Ser Gly
1 5 10 15
<210> 915
<211> 15
<212> PRT
<213> Homo sapiens
<400> 915
Leu Ser Trp Leu Ser Ser Gly Leu Pro Arg Ala Cys Ser Trp Arg
1 5 10 15
<210> 916
<211> 15
<212> PRT
<213> Homo sapiens
<400> 916
Pro Arg Ala Cys Ser Trp Arg Glu Phe Ser Pro Glu Thr Cys Ala
1 5 10 15
<210> 917
<211> 15
<212> PRT
<213> Homo sapiens
<400> 917
Phe Ser Pro Glu Thr Cys Ala Phe Arg Leu Ser Gly Leu Asp Ser
1 5 10 15
<210> 918
<211> 15
<212> PRT
<213> Homo sapiens
<400> 918
Arg Leu Ser Gly Leu Asp Ser Lys Leu Ser Ala Arg Val Glu Arg
1 5 10 15
<210> 919
<211> 15
<212> PRT
<213> Homo sapiens
<400> 919
Leu Ser Ala Arg Val Glu Arg Asp Leu Gly Ala Leu Arg Ala Pro
1 5 10 15
<210> 920
<211> 15
<212> PRT
<213> Homo sapiens
<400> 920
Leu Gly Ala Leu Arg Ala Pro Gly Ser Arg Ala Ala Gln Gly Gly
1 5 10 15
<210> 921
<211> 15
<212> PRT
<213> Homo sapiens
<400> 921
Ser Arg Ala Ala Gln Gly Gly Gly Arg Val Arg Gly Ser Arg Ser
1 5 10 15
<210> 922
<211> 15
<212> PRT
<213> Homo sapiens
<400> 922
Arg Val Arg Gly Ser Arg Ser Glu Trp Lys Thr Arg Pro Trp Arg
1 5 10 15
<210> 923
<211> 15
<212> PRT
<213> Homo sapiens
<400> 923
Trp Lys Thr Arg Pro Trp Arg Pro Pro Pro Ala Trp Pro Leu Thr
1 5 10 15
<210> 924
<211> 15
<212> PRT
<213> Homo sapiens
<400> 924
Pro Pro Ala Trp Pro Leu Thr Arg Ala Gly Gly Pro Leu Pro Lys
1 5 10 15
<210> 925
<211> 15
<212> PRT
<213> Homo sapiens
<400> 925
Ala Gly Gly Pro Leu Pro Lys Asn Pro Phe Leu Glu Ser Cys Ser
1 5 10 15
<210> 926
<211> 15
<212> PRT
<213> Homo sapiens
<400> 926
Pro Phe Leu Glu Ser Cys Ser Glu Thr Ala Gln Arg Arg Arg Val
1 5 10 15
<210> 927
<211> 15
<212> PRT
<213> Homo sapiens
<400> 927
Thr Ala Gln Arg Arg Arg Val Phe Ser Phe Ser Thr Pro Leu Ser
1 5 10 15
<210> 928
<211> 15
<212> PRT
<213> Homo sapiens
<400> 928
Ser Ile Asn Lys Ala Thr Ile Thr Gly Lys Lys Asp Leu Glu Leu
1 5 10 15
<210> 929
<211> 15
<212> PRT
<213> Homo sapiens
<400> 929
Gly Lys Lys Asp Leu Glu Leu Ile Leu His Val Ser Arg Lys Lys
1 5 10 15
<210> 930
<211> 15
<212> PRT
<213> Homo sapiens
<400> 930
Leu His Val Ser Arg Lys Lys Pro Phe Leu Pro Arg Val Asn Ile
1 5 10 15
<210> 931
<211> 15
<212> PRT
<213> Homo sapiens
<400> 931
Phe Leu Pro Arg Val Asn Ile Thr Pro Thr Pro Ile Ser Cys Cys
1 5 10 15
<210> 932
<211> 15
<212> PRT
<213> Homo sapiens
<400> 932
Pro Thr Pro Ile Ser Cys Cys Asn Leu Lys Met Leu Lys Lys Phe
1 5 10 15
<210> 933
<211> 15
<212> PRT
<213> Homo sapiens
<400> 933
Leu Lys Met Leu Lys Lys Phe Phe Leu Leu Tyr Ile Ile Ile Ser
1 5 10 15
<210> 934
<211> 15
<212> PRT
<213> Homo sapiens
<400> 934
Leu Leu Tyr Ile Ile Ile Ser Ile Ile Asp Leu Thr Asn Cys Leu
1 5 10 15
<210> 935
<211> 15
<212> PRT
<213> Homo sapiens
<400> 935
Ile Asp Leu Thr Asn Cys Leu Ser Cys Tyr Leu Glu His Phe Tyr
1 5 10 15
<210> 936
<211> 15
<212> PRT
<213> Homo sapiens
<400> 936
Cys Tyr Leu Glu His Phe Tyr Arg Phe Thr Phe Phe Thr Asp Val
1 5 10 15
<210> 937
<211> 10
<212> PRT
<213> Homo sapiens
<400> 937
Phe Thr Phe Phe Thr Asp Val His Tyr Phe
1 5 10
<210> 938
<211> 15
<212> PRT
<213> Homo sapiens
<400> 938
Pro Tyr Tyr Ser Ala Leu Ser Gly Asn Ser Trp Val Pro Ser Thr
1 5 10 15
<210> 939
<211> 15
<212> PRT
<213> Homo sapiens
<400> 939
Asn Ser Trp Val Pro Ser Thr Leu Glu Ser Asp Pro Phe Gly Tyr
1 5 10 15
<210> 940
<211> 15
<212> PRT
<213> Homo sapiens
<400> 940
Glu Ser Asp Pro Phe Gly Tyr Val Phe Ser Pro Leu Ala Thr Arg
1 5 10 15
<210> 941
<211> 15
<212> PRT
<213> Homo sapiens
<400> 941
Phe Ser Pro Leu Ala Thr Arg Pro Ala Leu Asn Asp Gln Glu Ser
1 5 10 15
<210> 942
<211> 15
<212> PRT
<213> Homo sapiens
<400> 942
Ala Leu Asn Asp Gln Glu Ser Ile Leu Trp Pro Thr Leu Thr Ser
1 5 10 15
<210> 943
<211> 15
<212> PRT
<213> Homo sapiens
<400> 943
Leu Trp Pro Thr Leu Thr Ser Val Val Ser Cys Ala Leu Ser Cys
1 5 10 15
<210> 944
<211> 15
<212> PRT
<213> Homo sapiens
<400> 944
Val Ser Cys Ala Leu Ser Cys Pro Ser Leu Asn Leu Pro Glu Asn
1 5 10 15
<210> 945
<211> 15
<212> PRT
<213> Homo sapiens
<400> 945
Ser Leu Asn Leu Pro Glu Asn Trp Leu Thr Leu Ile Thr Gly Gly
1 5 10 15
<210> 946
<211> 15
<212> PRT
<213> Homo sapiens
<400> 946
Leu Thr Leu Ile Thr Gly Gly Met Lys Gly Gly Lys Lys Met Lys
1 5 10 15
<210> 947
<211> 12
<212> PRT
<213> Homo sapiens
<400> 947
Lys Gly Gly Lys Lys Met Lys Phe Thr Phe Arg His
1 5 10
<210> 948
<211> 15
<212> PRT
<213> Homo sapiens
<400> 948
Gly Leu Arg Asn Leu Gly Asn Thr Val Arg Ala Ile Leu Leu Ser
1 5 10 15
<210> 949
<211> 15
<212> PRT
<213> Homo sapiens
<400> 949
Val Arg Ala Ile Leu Leu Ser Phe Leu Ser Lys Arg Asn Val Lys
1 5 10 15
<210> 950
<211> 15
<212> PRT
<213> Homo sapiens
<400> 950
Leu Ser Lys Arg Asn Val Lys Trp Cys Trp Gly Trp Gly Lys Pro
1 5 10 15
<210> 951
<211> 15
<212> PRT
<213> Homo sapiens
<400> 951
Cys Trp Gly Trp Gly Lys Pro Thr Ser Leu Gly Lys Ala Cys Gly
1 5 10 15
<210> 952
<211> 14
<212> PRT
<213> Homo sapiens
<400> 952
Ser Leu Gly Lys Ala Cys Gly Arg Arg Ala Leu Lys Leu Phe
1 5 10
<210> 953
<211> 15
<212> PRT
<213> Homo sapiens
<400> 953
Met Glu Ala Glu Asn Ala Gly Ser Leu His Phe His Glu Val Leu
1 5 10 15
<210> 954
<211> 14
<212> PRT
<213> Homo sapiens
<400> 954
Leu His Phe His Glu Val Leu Lys Met Gly His Val Lys Phe
1 5 10
<210> 955
<211> 15
<212> PRT
<213> Homo sapiens
<400> 955
Trp Thr Pro Ile Pro Val Leu Thr Arg Trp Pro Leu Pro His Pro
1 5 10 15
<210> 956
<211> 15
<212> PRT
<213> Homo sapiens
<400> 956
Arg Trp Pro Leu Pro His Pro Pro Pro Trp Arg Arg Ala Thr Ser
1 5 10 15
<210> 957
<211> 15
<212> PRT
<213> Homo sapiens
<400> 957
Pro Trp Arg Arg Ala Thr Ser Cys Arg Met Ala Arg Ser Ser Pro
1 5 10 15
<210> 958
<211> 15
<212> PRT
<213> Homo sapiens
<400> 958
Arg Met Ala Arg Ser Ser Pro Ser Ala Thr Ser Gly Ser Ser Val
1 5 10 15
<210> 959
<211> 15
<212> PRT
<213> Homo sapiens
<400> 959
Ala Thr Ser Gly Ser Ser Val Arg Arg Arg Cys Ser Ser Leu Pro
1 5 10 15
<210> 960
<211> 15
<212> PRT
<213> Homo sapiens
<400> 960
Arg Arg Cys Ser Ser Leu Pro Ser Trp Val Trp Asn Leu Ala Ala
1 5 10 15
<210> 961
<211> 16
<212> PRT
<213> Homo sapiens
<400> 961
Trp Val Trp Asn Leu Ala Ala Ser Thr Arg Pro Arg Ser Thr Pro Ser
1 5 10 15
<210> 962
<211> 15
<212> PRT
<213> Homo sapiens
<400> 962
Leu His Pro Gln Arg Glu Thr Phe Thr Pro Arg Trp Ser Gly Ala
1 5 10 15
<210> 963
<211> 15
<212> PRT
<213> Homo sapiens
<400> 963
Thr Pro Arg Trp Ser Gly Ala Asn Tyr Trp Lys Leu Ala Phe Pro
1 5 10 15
<210> 964
<211> 15
<212> PRT
<213> Homo sapiens
<400> 964
Tyr Trp Lys Leu Ala Phe Pro Val Gly Ala Glu Gly Thr Phe Pro
1 5 10 15
<210> 965
<211> 15
<212> PRT
<213> Homo sapiens
<400> 965
Gly Ala Glu Gly Thr Phe Pro Ala Ala Ala Thr Gln Arg Gly Val
1 5 10 15
<210> 966
<211> 11
<212> PRT
<213> Homo sapiens
<400> 966
Ala Ala Thr Gln Arg Gly Val Val Arg Pro Ala
1 5 10
<210> 967
<211> 15
<212> PRT
<213> Homo sapiens
<400> 967
Met Ala Gly Gly Val Leu Arg Arg Leu Leu Cys Arg Glu Pro Asp
1 5 10 15
<210> 968
<211> 15
<212> PRT
<213> Homo sapiens
<400> 968
Leu Leu Cys Arg Glu Pro Asp Arg Asp Gly Asp Lys Gly Ala Ser
1 5 10 15
<210> 969
<211> 15
<212> PRT
<213> Homo sapiens
<400> 969
Asp Gly Asp Lys Gly Ala Ser Arg Glu Glu Thr Val Val Pro Leu
1 5 10 15
<210> 970
<211> 15
<212> PRT
<213> Homo sapiens
<400> 970
Glu Glu Thr Val Val Pro Leu His Ile Gly Asp Pro Val Val Leu
1 5 10 15
<210> 971
<211> 15
<212> PRT
<213> Homo sapiens
<400> 971
Ile Gly Asp Pro Val Val Leu Pro Gly Ile Gly Gln Cys Tyr Ser
1 5 10 15
<210> 972
<211> 10
<212> PRT
<213> Homo sapiens
<400> 972
Gly Ile Gly Gln Cys Tyr Ser Ala Leu Phe
1 5 10
<210> 973
<211> 15
<212> PRT
<213> Homo sapiens
<400> 973
Val Phe Phe Lys Arg Ala Ala Glu Gly Phe Phe Arg Met Asn Lys
1 5 10 15
<210> 974
<211> 15
<212> PRT
<213> Homo sapiens
<400> 974
Gly Phe Phe Arg Met Asn Lys Leu Lys Glu Ser Ser Asp Thr Asn
1 5 10 15
<210> 975
<211> 15
<212> PRT
<213> Homo sapiens
<400> 975
Lys Glu Ser Ser Asp Thr Asn Pro Lys Pro Tyr Cys Met Ala Ala
1 5 10 15
<210> 976
<211> 15
<212> PRT
<213> Homo sapiens
<400> 976
Lys Pro Tyr Cys Met Ala Ala Pro Met Gly Leu Thr Glu Asn Asn
1 5 10 15
<210> 977
<211> 15
<212> PRT
<213> Homo sapiens
<400> 977
Met Gly Leu Thr Glu Asn Asn Arg Asn Arg Lys Lys Ser Tyr Arg
1 5 10 15
<210> 978
<211> 15
<212> PRT
<213> Homo sapiens
<400> 978
Asn Arg Lys Lys Ser Tyr Arg Glu Thr Asn Leu Lys Ala Val Ser
1 5 10 15
<210> 979
<211> 13
<212> PRT
<213> Homo sapiens
<400> 979
Thr Asn Leu Lys Ala Val Ser Trp Pro Leu Asn His Thr
1 5 10
<210> 980
<211> 13
<212> PRT
<213> Homo sapiens
<400> 980
Gly Trp Arg Gly Val Cys Cys Ala Ala Val Glu Pro Ala
1 5 10
Claims (147)
- 서열 번호 275, 381, 333, 337, 269, 253, 309, 325, 271, 305, 251, 245, 261, 265, 317, 255, 277, 297, 285, 437, 439, 442, 444, 379, 343, 211, 349, 213, 215, 221, 219, 225, 345, 353, 235, 223, 167, 171, 19, 23 및 177로 이루어진 군으로부터 선택되는 2개 이상의 폴리펩티드 및 이들의 단편을 포함하는 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 백신.
- 제1항에 있어서, 상기 이종 폴리뉴클레오티드는,
a) 서열 번호 276, 382, 334, 338, 270, 254, 310, 326, 272, 306, 252, 246, 262, 266, 318, 256, 278, 298, 286, 448, 450, 453, 455, 380, 344, 212, 350, 214, 216, 222, 220, 226, 346, 354, 236, 224, 168, 172, 20, 24 및 178로 이루어진 군으로부터 선택되는 2개 이상의 폴리뉴클레오티드 및 이들의 단편;
b) 서열 번호 459, 460, 461, 462, 463, 464, 465, 466, 467, 468, 469, 470, 471, 472, 473, 474, 475, 476, 477, 478, 479, 480, 481, 482, 483, 484, 485, 486, 487, 488, 489, 490, 491, 492, 493, 494, 495, 496, 497, 498 및 499로 이루어진 군으로부터 선택되는 2개 이상의 폴리뉴클레오티드 및 이들의 단편; 또는
c) 서열 번호 500, 501, 461, 503, 504, 505, 506, 507, 508, 509, 510, 511, 512, 513, 514, 515, 516, 517, 477, 519, 520, 521, 522, 523, 524, 525, 485, 486, 528, 529, 530, 531, 532, 533, 534, 535, 536, 537, 538, 539 및 540으로 이루어진 군으로부터 선택되는 2개 이상의 폴리뉴클레오티드 및 이들의 단편을 포함하는 백신. - 제1항에 있어서, 상기 단편은 서열 번호 387, 388, 390, 392, 560, 561, 562, 563, 564, 565, 566, 567, 568, 569, 570, 571, 572, 573, 574, 575, 576, 577, 578, 579, 580, 581, 582, 583, 584, 585, 586, 587, 588, 589, 590, 591, 592, 593, 594, 595, 596, 597, 598, 599, 600, 601, 602, 603, 604, 605, 606, 607, 608, 609, 610, 611, 612, 613, 614, 615, 616, 617, 618, 619, 620, 621, 631, 632, 633, 634, 635, 636, 637, 638, 639, 640, 641, 642, 643, 644, 645, 646, 647, 648, 649, 650, 651, 652, 653, 654, 655, 656, 657, 658, 659, 660, 661, 662, 663, 664, 665, 666, 667, 668, 669, 670, 671, 672, 673, 674, 675, 676, 677, 678, 679, 680, 681, 682, 683, 684, 685, 686, 687, 688, 689, 690, 691, 692, 693, 694, 695, 696, 697, 698, 699, 700, 701, 702, 703, 704, 705, 706, 707, 708, 709, 710, 711 또는 712의 폴리펩티드를 포함하는 백신.
- 제1항 내지 제3항 중 어느 한 항에 있어서, 백신을 투여한 대상에서 세포성 면역반응을 유도할 수 있는 백신.
- 제4항에 있어서, 상기 세포성 면역반응은 서열 번호 275, 381, 333, 337, 269, 253, 309, 325, 271, 305, 251, 245, 261, 265, 317, 255, 277, 297, 285, 437, 439, 442, 444, 379, 343, 211, 349, 213, 215, 221, 219, 225, 345, 353, 235, 223, 167, 171, 19, 23 또는 177 중 하나 이상의 폴리펩티드의 단편에 대해 특이적인 백신.
- 제4항 또는 제5항에 있어서, 상기 세포성 면역반응은 백신 특이적 CD8+ T 세포, CD4+ T 세포, 또는 CD8+ T 세포 및 CD4+ T 세포의 활성화이며, 상기 활성화는 CD8+ T 세포, CD4+ T 세포, 또는 CD8+ T 세포 및 CD4+ T 세포에 의한 TNFα, IFNγ, 또는 TNFα 및 IFNγ의 생산 증가에 의해 평가되는 백신.
- 제1항 내지 제6항 중 어느 한 항에 있어서, 상기 이종 폴리뉴클레오티드는 프로모터, 인핸서, 폴리아데닐화 부위, 코작 서열(Kozak sequence), 정지 코돈, T 세포 인핸서(TCE) 또는 이들의 임의의 조합을 포함하는 백신.
- 제7항에 있어서, 상기 프로모터는 CMV 프로모터 또는 백시니아(vaccinia) P7.5 프로모터를 포함하는 백신.
- 제7항 또는 제8항에 있어서, 상기 TCE는 서열 번호 546의 폴리뉴클레오티드에 의해 인코딩되고, 상기 CMV 프로모터는 서열 번호 628의 폴리뉴클레오티드를 포함하며, 상기 백시니아 P7.5 프로모터는 서열 번호 630의 폴리뉴클레오티드를 포함하고, 상기 폴리아데닐화 부위는 서열 번호 629의 소 성장 호르몬 폴리아데닐화 부위를 포함하는 백신.
- 제1항 내지 제9항 중 어느 한 항에 있어서, 상기 이종 폴리펩티드는 서열 번호 541, 550, 554, 555, 556, 623 또는 624의 아미노산 서열을 포함하는 백신.
- 제10항에 있어서, 상기 이종 폴리뉴클레오티드는 서열 번호 542 또는 서열 번호 551의 폴리뉴클레오티드 서열을 포함하는 백신.
- 제1항 내지 제9항 중 어느 한 항에 있어서, 상기 이종 폴리펩티드는 서열 번호 543, 552, 557, 558, 559, 625 또는 626의 아미노산 서열을 포함하는 백신.
- 제12항에 있어서, 상기 이종 폴리뉴클레오티드는 서열 번호 544 또는 서열 번호 553의 폴리뉴클레오티드 서열을 포함하는 백신.
- 제1항 내지 제13항 중 어느 한 항에 있어서, 상기 이종 폴리뉴클레오티드는 DNA 또는 RNA인 백신.
- 제14항에 있어서, 상기 RNA는 mRNA 또는 자기 복제 RNA인 백신.
- 제1항 내지 제14항 중 어느 한 항에 있어서, 재조합 바이러스인 백신.
- 제16항에 있어서, 상기 재조합 바이러스는 아데노바이러스(Ad), 폭스바이러스, 아데노 관련 바이러스(AAV) 또는 레트로바이러스로부터 유래되는 백신.
- 제17항에 있어서, 상기 재조합 바이러스는 hAd5, hAd7, hAd11, hAd26, hAd34, hAd35, hAd48, hAd49, hAd50, GAd20, GAd19, GAd21, GAd25, GAd26, GAd27, GAd28, GAd29, GAd30, GAd31, ChAd3, ChAd4, ChAd5, ChAd6, ChAd7, ChAd8, ChAd9, ChAd10, ChAd11, ChAd16, ChAd17, ChAd19, ChAd20, ChAd22, ChAd24, ChAd26, ChAd30, ChAd31, ChAd37, ChAd38, ChAd44, ChAd55, ChAd63, ChAd73, ChAd82, ChAd83, ChAd146, ChAd147, PanAd1, PanAd2, PanAd3, 코펜하겐 백시니아 바이러스(Copenhagen vaccinia virus; W), 뉴욕 약독화 백시니아 바이러스(New York Attenuated Vaccinia Virus; NYVAC), ALVAC, TROVAC 또는 변형된 백시니아 앙카라(modified vaccinia Ankara; MVA)로부터 유래되는 백신.
- 제16항 내지 제18항 중 어느 한 항에 있어서, 상기 재조합 바이러스는 GAd20로부터 유래되는 백신.
- 제16항 내지 제18항 중 어느 한 항에 있어서, 상기 재조합 바이러스는 MVA로부터 유래되는 백신.
- 제16항 내지 제18항 중 어느 한 항에 있어서, 상기 재조합 바이러스는 hAd26로부터 유래되는 백신.
- 서열 번호 541, 550, 554, 555, 556, 623 또는 624의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 백신.
- 제22항에 있어서, 상기 이종 폴리뉴클레오티드는 서열 번호 542 또는 551의 폴리뉴클레오티드 서열을 포함하는 백신.
- 제22항 또는 제23항에 있어서, GAd20로부터 유래된 재조합 바이러스인 백신.
- 서열 번호 543, 552, 557, 558, 559, 625 또는 626의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 백신.
- 제25항에 있어서, 상기 이종 폴리뉴클레오티드는 서열 번호 544 또는 553의 폴리뉴클레오티드 서열을 포함하는 백신.
- 제25항 또는 제26항에 있어서, MVA로부터 유래된 재조합 바이러스인 백신.
- 제1항 내지 제27항 중 어느 한 항의 하나 이상의 백신의 치료적 유효량을 대상에게 투여하는 단계를 포함하는, 대상에서 전립선암을 치료하거나 예방하는 방법.
- 제1항 내지 제27항 중 어느 한 항의 하나 이상의 백신을 대상에게 투여하는 단계를 포함하는, 대상에서 면역반응을 유도하는 방법.
- 제28항 또는 제29항에 있어서, 상기 대상은 전립선암을 앓고 있거나, 전립선암을 앓고 있는 것으로 의심되거나, 전립선암을 발병할 것으로 의심되는 방법.
- 제28항 내지 제30항 중 어느 한 항에 있어서, 상기 전립선암은 재발성 전립선암, 불응성 전립선암, 전이성 전립선암 또는 거세저항성(castration resistant) 전립선암, 또는 이들의 임의의 조합인 방법.
- 제28항 내지 제31항 중 어느 한 항에 있어서, 상기 대상은 치료 경험이 없는(treatment) 방법.

- 제28항 내지 제31항 중 어느 한 항에 있어서, 상기 대상은 안드로겐 차단요법(androgen deprivation therapy)을 받은 적이 있는 방법.
- 제28항 내지 제33항 중 어느 한 항에 있어서, 상기 대상은 높은 전립선 특이항원(PSA) 레벨을 갖는 방법.
- 제28항 내지 제34항 중 어느 한 항에 있어서, 상기 백신은 서열 번호 541, 550, 554, 555, 556, 623 또는 624의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 GAd20로부터 유래된 재조합 바이러스인 방법.
- 제28항 내지 제35항 중 어느 한 항에 있어서, 상기 백신은 서열 번호 543, 552, 557, 558, 559, 625 또는 626의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 MVA로부터 유래된 재조합 바이러스인 방법.
- 제28항 내지 제36항 중 어느 한 항에 있어서, 추가의 암 치료제를 대상에게 투여하는 단계를 포함하는 방법.
- 제37항에 있어서, 상기 추가의 암 치료제는 수술, 화학요법, 안드로겐 차단요법, 방사선, 체크포인트 억제제(checkpoint inhibitor), 표적요법 또는 이들의 임의의 조합인 방법.
- 제38항에 있어서, 상기 추가의 암 치료제는 CTLA-4 항체, CTLA4 리간드, PD-1 축 억제제(PD-1 axis inhibitor), PD-L1 축 억제제, TLR 작용제, CD40 작용제, OX40 작용제, 하이드록시우레아, 룩솔리티닙(ruxolitinib), 페드라티닙(fedratinib), 41BB 작용제, CD28 작용제, STING 길항제, RIG-1 길항제, TCR-T 요법, CAR-T 요법, FLT3 리간드, 황산알루미늄, BTK 억제제, CD38 항체, CDK 억제제, CD33 항체, CD37 항체, CD25 항체, GM-CSF 억제제, IL-2, IL-15, IL-7, CD3 방향전환 분자(CD3 redirection molecule), 포말리밉(pomalimib), IFNγ, IFNα, TNFα, VEGF 항체, CD70 항체, CD27 항체, BCMA 항체 또는 GPRC5D 항체, 또는 이들의 임의의 조합인 방법.
- 제38항에 있어서, 상기 체크포인트 억제제는 이필리무맙(ipilimumab), 세트렐리맙(cetrelimab), 펨브롤리주맙(pembrolizumab), 니볼루맙(nivolumab), 신틸리맙(sintilimab), 세미플리맙(cemiplimab), 토리팔리맙(toripalimab), 캄렐리주맙(camrelizumab), 티슬렐리주맙(tislelizumab), 도스트랄리맙(dostralimab), 스파르탈리주맙(spartalizumab), 프롤골리맙(prolgolimab), 발스틸리맙(balstilimab), 부디갈리맙(budigalimab), 사산리맙(sasanlimab), 아벨루맙(avelumab), 아테졸리주맙(atezolizumab), 두르발루맙(durvalumab), 엔바폴리맙(envafolimab) 또는 아이오다폴리맙(iodapolimab), 또는 이들의 임의의 조합인 방법.
- a) 서열 번호 275, 381, 333, 337, 269, 253, 309, 325, 271, 305, 251, 245, 261, 265, 317, 255, 277, 297, 285, 437, 439, 442, 444, 379, 343, 211, 349, 213, 215, 221, 219, 225, 345, 353, 235, 223, 167, 171, 19, 23 및 177로 이루어진 군으로부터 선택되는 2개 이상의 폴리펩티드를 포함하는 제1 이종 폴리펩티드를 인코딩하는 제1 이종 폴리뉴클레오티드를 포함하는 제1 백신; 및
b) 서열 번호 275, 381, 333, 337, 269, 253, 309, 325, 271, 305, 251, 245, 261, 265, 317, 255, 277, 297, 285, 437, 439, 442, 444, 379, 343, 211, 349, 213, 215, 221, 219, 225, 345, 353, 235, 223, 167, 171, 19, 23 및 177로 이루어진 군으로부터 선택되는 2개 이상의 폴리펩티드를 포함하는 제2 이종 폴리펩티드를 인코딩하는 제2 이종 폴리뉴클레오티드를 포함하는 제2 백신을 대상에게 투여하는 단계를 포함하는, 대상에서 전립선암을 치료하거나 예방하는 방법. - a) 서열 번호 275, 381, 333, 337, 269, 253, 309, 325, 271, 305, 251, 245, 261, 265, 317, 255, 277, 297, 285, 437, 439, 442, 444, 379, 343, 211, 349, 213, 215, 221, 219, 225, 345, 353, 235, 223, 167, 171, 19, 23 및 177로 이루어진 군으로부터 선택되는 2개 이상의 폴리펩티드를 포함하는 제1 이종 폴리펩티드를 인코딩하는 제1 이종 폴리뉴클레오티드를 포함하는 제1 백신; 및
b) 서열 번호 275, 381, 333, 337, 269, 253, 309, 325, 271, 305, 251, 245, 261, 265, 317, 255, 277, 297, 285, 437, 439, 442, 444, 379, 343, 211, 349, 213, 215, 221, 219, 225, 345, 353, 235, 223, 167, 171, 19, 23 및 177로 이루어진 군으로부터 선택되는 2개 이상의 폴리펩티드를 포함하는 제2 이종 폴리펩티드를 인코딩하는 제2 이종 폴리뉴클레오티드를 포함하는 제2 백신을 대상에게 투여하는 단계를 포함하는, 대상에서 면역반응을 유도하는 방법. - 제41항 또는 제42항에 있어서, 상기 제1 이종 폴리펩티드 및 상기 제2 이종 폴리펩티드는 별개의 아미노산 서열을 갖는 방법.
- 제41항 내지 제43항 중 어느 한 항에 있어서, 상기 대상은 전립선암을 앓고 있거나, 전립선암을 앓고 있는 것으로 의심되거나, 전립선암을 발병할 것으로 의심되는 방법.
- 제41항 내지 제44항 중 어느 한 항에 있어서, 상기 제1 이종 폴리뉴클레오티드 및 상기 제2 이종 폴리뉴클레오티드는 프로모터, 인핸서, 폴리아데닐화 부위, 코작 서열, 정지 코돈, TCE 또는 이들의 임의의 조합을 포함하는 방법.
- 제41항 내지 제45항 중 어느 한 항에 있어서, 상기 제1 이종 폴리펩티드는 서열 번호 541, 550, 554, 555, 556, 623 또는 624의 아미노산 서열을 포함하는 방법.
- 제41항 내지 제46항 중 어느 한 항에 있어서, 상기 제2 이종 폴리펩티드는 서열 번호 543, 552, 557, 558, 559, 625 또는 626의 아미노산 서열을 포함하는 방법.
- 제41항 내지 제47항 중 어느 한 항에 있어서, 상기 제1 백신 및 제2 백신은 상기 제1 백신 및 제2 백신을 투여한 대상에서 세포성 면역반응을 유도할 수 있는 방법.
- 제48항에 있어서, 상기 세포성 면역반응은 서열 번호 275, 381, 333, 337, 269, 253, 309, 325, 271, 305, 251, 245, 261, 265, 317, 255, 277, 297, 285, 437, 439, 442, 444, 379, 343, 211, 349, 213, 215, 221, 219, 225, 345, 353, 235, 223, 167, 171, 19, 23 또는 177, 또는 이들의 임의의 조합의 폴리펩티드의 하나 이상의 단편에 대해 특이적인 방법.
- 제48항 또는 제49항에 있어서, 상기 세포성 면역반응은 백신 특이적 CD8+ T 세포, CD4+ T 세포, 또는 CD8+ T 세포 및 CD4+ T 세포의 활성화이며, 상기 활성화는 CD8+ T 세포, CD4+ T 세포, 또는 CD8+ T 세포 및 CD4+ T 세포에 의한 TNFα, IFNγ, 또는 TNFα 및 IFNγ의 생산 증가에 의해 평가되는 방법.
- 제41항 내지 제50항 중 어느 한 항에 있어서, 상기 제1 백신, 상기 제2 백신, 또는 상기 제1 백신 및 상기 제2 백신 둘 다는 DNA 백신인 방법.
- 제41항 내지 제50항 중 어느 한 항에 있어서, 상기 제1 백신, 상기 제2 백신, 또는 상기 제1 백신 및 상기 제2 백신 둘 다는 RNA 백신인 방법.
- 제41항 내지 제50항 중 어느 한 항에 있어서, 상기 제1 백신, 상기 제2 백신, 또는 상기 제1 백신 및 상기 제2 백신 둘 다는 재조합 바이러스인 방법.
- 제53항에 있어서, 상기 재조합 바이러스는 Ad, 폭스바이러스, AAV 또는 레트로바이러스로부터 유래되는 방법.
- 제54항에 있어서, 상기 재조합 바이러스는 hAd5, hAd7, hAd11, hAd26, hAd34, hAd35, hAd48, hAd49, hAd50, GAd20, GAd19, GAd21, GAd25, GAd26, GAd27, GAd28, GAd29, GAd30, GAd31, ChAd3, ChAd4, ChAd5, ChAd6, ChAd7, ChAd8, ChAd9, ChAd10, ChAd11, ChAd16, ChAd17, ChAdI9, ChAd20, ChAd22, ChAd24, ChAd26, ChAd30, ChAd31, ChAd37, ChAd38, ChAd44, ChAd55, ChAd63, ChAd73, ChAd82, ChAd83, ChAd146, ChAd147, PanAd1, PanAd2, PanAd3, 코펜하겐 백시니아 바이러스(W), 뉴욕 약독화 백시니아 바이러스(NYVAC), ALVAC, TROVAC 또는 MVA로부터 유래되는 방법.
- 제55항에 있어서, 상기 재조합 바이러스는 GAd20로부터 유래되는 방법.
- 제55항에 있어서, 상기 재조합 바이러스는 MVA로부터 유래되는 방법.
- 제41항 내지 제57항 중 어느 한 항에 있어서, 상기 전립선암은 재발성 전립선암, 불응성 전립선암, 전이성 전립선암 또는 거세저항성 전립선암, 또는 이들의 임의의 조합인 방법.
- 제41항 내지 제58항 중 어느 한 항에 있어서, 상기 대상은 치료 경험이 없는 방법.
- 제41항 내지 제58항 중 어느 한 항에 있어서, 상기 대상은 안드로겐 차단요법을 받은 적이 있는 방법.
- 제41항 내지 제60항 중 어느 한 항에 있어서, 상기 대상은 높은 PSA 레벨을 갖는 방법.
- 제41항 내지 제61항 중 어느 한 항에 있어서, 상기 제1 백신은 서열 번호 541, 550, 554, 555, 556, 623 또는 624의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 GAd20로부터 유래된 재조합 바이러스인 방법.
- 제41항 내지 제62항 중 어느 한 항에 있어서, 상기 제2 백신은 서열 번호 543, 552, 557, 558, 559, 625 또는 626의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 MVA로부터 유래된 재조합 바이러스인 방법.
- 제41항 내지 제63항 중 어느 한 항에 있어서, 추가의 암 치료제를 대상에게 투여하는 단계를 포함하는 방법.
- 제64항에 있어서, 상기 추가의 암 치료제는 수술, 화학요법, 안드로겐 차단요법, 방사선, 체크포인트 억제제, 표적요법 또는 이들의 임의의 조합인 방법.
- 제64항에 있어서, 상기 추가의 암 치료제는 CTLA-4 항체, CTLA4 리간드, PD-1 축 억제제, PD-L1 축 억제제, TLR 작용제, CD40 작용제, OX40 작용제, 하이드록시우레아, 룩솔리티닙, 페드라티닙, 41BB 작용제, CD28 작용제, STING 길항제, RIG-1 길항제, TCR-T 요법, CAR-T 요법, FLT3 리간드, 황산알루미늄, BTK 억제제, CD38 항체, CDK 억제제, CD33 항체, CD37 항체, CD25 항체, GM-CSF 억제제, IL-2, IL-15, IL-7, CD3 방향전환 분자, 포말리밉, IFNγ, IFNα, TNFα, VEGF 항체, CD70 항체, CD27 항체, BCMA 항체 또는 GPRC5D 항체, 또는 이들의 임의의 조합인 방법.
- 제65항에 있어서, 상기 체크포인트 억제제는 이필리무맙, 세트렐리맙, 펨브롤리주맙, 니볼루맙, 신틸리맙, 세미플리맙, 토리팔리맙, 캄렐리주맙, 티슬렐리주맙, 도스트랄리맙, 스파르탈리주맙, 프롤골리맙, 발스틸리맙, 부디갈리맙, 사산리맙, 아벨루맙, 아테졸리주맙, 두르발루맙, 엔바폴리맙 또는 아이오다폴리맙, 또는 이들의 임의의 조합인 방법.
- 제41항 내지 제67항 중 어느 한 항에 있어서, 상기 제1 백신을 대상에게 1회 이상 투여하는 방법.
- 제41항 내지 제68항 중 어느 한 항에 있어서, 상기 제2 백신을 대상에게 1회 이상 투여하는 방법.
- 제41항 내지 제69항 중 어느 한 항에 있어서, 상기 제1 백신을 상기 제2 백신을 투여하기 약 1 내지 16주 전에 투여하는 방법.
- a) 서열 번호 541, 550, 554, 555, 556, 623 또는 624의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 GAd20로부터 유래된 재조합 바이러스를 포함하는 제1 백신; 및
b) 서열 번호 543, 552, 557, 558, 559, 625 또는 626의 이종 폴리펩티드를 인코딩하는 이종 폴리뉴클레오티드를 포함하는 MVA로부터 유래된 재조합 바이러스를 포함하는 제2 백신을 포함하는 키트. - 서열 번호 275, 381, 333, 337, 269, 253, 309, 325, 271, 305, 251, 245, 261, 265, 317, 255, 277, 297, 285, 437, 439, 442, 444, 379, 343, 211, 349, 213, 215, 221, 219, 225, 345, 353, 235, 223, 167, 171, 19, 23 및 177로 이루어진 군으로부터 선택되는 2개 이상의 폴리펩티드 및 이들의 단편을 인코딩하는 단리된 이종 폴리뉴클레오티드.
- 제72항에 있어서, 서열 번호 276, 382, 334, 338, 270, 254, 310, 326, 272, 306, 252, 246, 262, 266, 318, 256, 278, 298, 286, 448, 450, 453, 455, 380, 344, 212, 350, 214, 216, 222, 220, 226, 346, 354, 236, 224, 168, 172, 20, 24 및 178로 이루어진 군으로부터 선택되는 2개 이상의 폴리뉴클레오티드 및 이들의 단편을 포함하는 단리된 이종 폴리뉴클레오티드.
- 제72항 또는 제73항에 있어서, 서열 번호 541, 550, 554, 555, 556, 623 또는 624의 폴리펩티드를 인코딩하는 단리된 이종 폴리뉴클레오티드.
- 제74항에 있어서, 서열 번호 542 또는 서열 번호 551의 폴리뉴클레오티드 서열을 포함하는 단리된 이종 폴리뉴클레오티드.
- 제72항 또는 제73항에 있어서, 서열 번호 543, 552, 557, 558, 559, 625 또는 626의 폴리펩티드를 인코딩하는 단리된 이종 폴리뉴클레오티드.
- 제76항에 있어서, 서열 번호 544 또는 서열 번호 553의 폴리뉴클레오티드 서열을 포함하는 단리된 이종 폴리뉴클레오티드.
- 제71항 내지 제77항 중 어느 한 항의 이종 폴리뉴클레오티드를 포함하는 벡터.
- 제78항에 있어서, 발현 벡터인 벡터.
- 제78항에 있어서, 재조합 바이러스 벡터인 벡터.
- 제80항에 있어서, 상기 재조합 바이러스 벡터는 Ad, 폭스바이러스, AAV 또는 레트로바이러스로부터 유래되는 벡터.
- 제81항에 있어서, 상기 재조합 바이러스 벡터는 hAd5, hAd7, hAd11, hAd26, hAd34, hAd35, hAd48, hAd49, hAd50, GAd20, GAd19, GAd21, GAd25, GAd26, GAd27, GAd28, GAd29, GAd30, GAd31, ChAd3, ChAd4, ChAd5, ChAd6, ChAd7, ChAd8, ChAd9, ChAd10, ChAd11, ChAdI6, ChAdI7, ChAdI9, ChAd20, ChAd22, ChAd24, ChAd26, ChAd30, ChAd31, ChAd37, ChAd38, ChAd44, ChAd55, ChAd63, ChAd73, ChAd82, ChAd83, ChAd146, ChAd147, PanAd1, PanAd2, PanAd3, 코펜하겐 백시니아 바이러스(W), 뉴욕 약독화 백시니아 바이러스(NYVAC), ALVAC, TROVAC 또는 MVA로부터 유래되는 벡터.
- 제80항 내지 제82항 중 어느 한 항에 있어서, 상기 재조합 바이러스는 GAd20로부터 유래되는 벡터.
- 제80항 내지 제82항 중 어느 한 항에 있어서, 상기 재조합 바이러스는 MVA로부터 유래되는 벡터.
- 제72항 내지 제77항 중 어느 한 항의 이종 폴리뉴클레오티드 또는 제78항 내지 제84항 중 어느 한 항의 벡터를 포함하는 숙주 세포.
- 제85항에 있어서, 원핵세포 또는 진핵세포인 숙주 세포.
- 제86항에 있어서, PER.C6, PER.C6 TetO, 닭 배아 섬유아세포(CEF), CHO, HEK 또는 Age1 세포인 숙주 세포.
- a) 서열 번호 275, 381, 333, 337, 269, 253, 309, 325, 271, 305, 251, 245, 261, 265, 317, 255, 277, 297, 285, 437, 439, 442, 444, 379, 343, 211, 349, 213, 215, 221, 219, 225, 345, 353, 235, 223, 167, 171, 19, 23 및 177로 이루어진 군으로부터 선택되는 2개 이상의 폴리펩티드 및 이들의 단편; 또는
b) 서열 번호 541, 550, 554, 555, 556, 623, 624, 543, 552, 557, 558, 559, 625 또는 626의 아미노산 서열을 포함하는 단리된 이종 폴리펩티드. - 제88항의 이종 폴리펩티드를 포함하는 백신.
- 이종 폴리펩티드가 발현되는 조건에서 제85항 내지 제87항 중 어느 한 항의 숙주 세포를 배양하는 단계 및 이종 폴리펩티드를 정제하는 단계를 포함하는, 제88항의 이종 폴리펩티드의 제조 방법.
- 제88항의 이종 폴리펩티드에 특이적으로 결합하는 단리된 단백질성 분자.
- 제91항에 있어서, 항체, 대체 스캐폴드(alternative scaffold), 키메라 항원 수용체(CAR) 또는 T 세포 수용체(TCR)인 단리된 단백질성 분자.
- 제92항의 CAR 또는 TCR을 포함하는 단리된 세포.
- 제88항의 이종 폴리펩티드, 제89항의 백신, 제91항의 단백질성 분자 또는 제93항의 세포를 대상에게 투여하는 단계를 포함하는, 대상에서 전립선암을 치료하거나 예방하는 방법.
- 서열 번호 541, 550, 554, 555, 556, 623, 624, 543, 552, 557, 558, 559, 625 또는 626의 폴리펩티드의 단편 및 HLA를 포함하는 단백질 복합체.
- 제95항에 있어서,
a) 상기 단편은 길이가 약 6 내지 25개의 아미노산이거나;
b) 상기 단편은 서열 번호 387, 388, 390, 392, 560, 561, 562, 563, 564, 565, 566, 567, 568, 569, 570, 571, 572, 573, 574, 575, 576, 577, 578, 579, 580, 581, 582, 583, 584, 585, 586, 587, 588, 589, 590, 591, 592, 593, 594, 595, 596, 597, 598, 599, 600, 601, 602, 603, 604, 605, 606, 607, 608, 609, 610, 611, 612, 613, 614, 615, 616, 617, 618, 619, 620, 621, 631, 632, 633, 634, 635, 636, 637, 638, 639, 640, 641, 642, 643, 644, 645, 646, 647, 648, 649, 650, 651, 652, 653, 654, 655, 656, 657, 658, 659, 660, 661, 662, 663, 664, 665, 666, 667, 668, 669, 670, 671, 672, 673, 674, 675, 676, 677, 678, 679, 680, 681, 682, 683, 684, 685, 686, 687, 688, 689, 690, 691, 692, 693, 694, 695, 696, 697, 698, 699, 700, 701, 702, 703, 704, 705, 706, 707, 708, 709, 710, 711 또는 712의 폴리펩티드를 포함하는 단백질 복합체. - 제95항 또는 제96항에 있어서, 상기 단편은 하나 이상의 돌연변이, 역 펩티드 결합, 아미노산의 D 이성질체 또는 화학적 변형, 또는 이들의 임의의 조합을 포함하는 단백질 복합체.
- 제95항 내지 제97항 중 어느 한 항에 있어서, 상기 HLA는 클래스 I HLA 또는 클래스 II HLA인 단백질 복합체.
- 제95항 내지 제98항 중 어느 한 항에 있어서, 검출가능 표지 또는 세포독성제에 추가로 접합되는 단백질 복합체.
- 제95항 내지 제99항 중 어느 한 항의 단백질 복합체에 특이적으로 결합하는 단리된 단백질성 분자.
- 제100항에 있어서, 항체, 항원 결합 단편, 대체 스캐폴드, CAR 또는 TCR인 단리된 단백질성 분자.
- 제95항 내지 제99항 중 어느 한 항의 단백질 복합체 또는 제100항 또는 제101항의 단백질성 분자를 대상에게 투여하는 단계를 포함하는, 대상에서 전립선암을 치료하거나 예방하는 방법.
- a) 서열 번호 1, 3, 5, 7, 9, 11, 13, 15, 17, 19, 21, 23, 25, 27, 29, 31, 33, 35, 37, 39, 41, 43, 45, 47, 49, 51, 53, 55, 57, 59, 61, 63, 65, 67, 69, 71, 73, 75, 77, 79, 81, 83, 85, 87, 89, 91, 93, 95, 97, 99, 101, 103, 105, 107, 109, 111, 113, 115, 117, 119, 121, 123, 125, 127, 129, 131, 133, 135, 137, 139, 141, 143, 145, 147, 149, 151, 153, 155, 157, 159, 161, 163, 165, 167, 169, 171, 173, 175, 177, 179, 181, 183, 185, 187, 189, 191, 193, 195, 197, 199, 201, 203, 205, 207, 209, 211, 213, 215, 217, 219, 221, 223, 225, 227, 229, 231, 233, 235, 237, 239, 241, 243, 245, 247, 249, 251, 253, 255, 257, 259, 261, 263, 265, 267, 269, 271, 273, 275, 277, 279, 281, 283, 285, 287, 289, 291, 293, 295, 297, 299, 301, 303, 305, 307, 309, 311, 313, 315, 317, 319, 321, 323, 325, 327, 329, 331, 333, 335, 337, 339, 341, 343, 345, 347, 349, 351, 353, 355, 357, 359, 361, 363, 365, 367, 369, 371, 373, 375, 379, 381, 383, 385, 387, 388, 389, 390, 391, 392, 393, 394, 395, 396, 397, 398, 399, 400, 401, 402, 403, 404, 405, 406, 407, 408, 426, 427, 428, 429, 430, 431, 432, 433, 434, 435, 436, 437, 438, 439, 440, 441, 442, 443, 444, 445, 446 또는 447의 폴리펩티드 또는 이의 단편을 인코딩하거나;
b) 서열 번호 1, 3, 5, 7, 9, 11, 13, 15, 17, 19, 21, 23, 25, 27, 29, 31, 33, 35, 37, 39, 41, 43, 45, 47, 49, 51, 53, 55, 57, 59, 61, 63, 65, 67, 69, 71, 73, 75, 77, 79, 81, 83, 85, 87, 89, 91, 93, 95, 97, 99, 101, 103, 105, 107, 109, 111, 113, 115, 117, 119, 121, 123, 125, 127, 129, 131, 133, 135, 137, 139, 141, 143, 145, 147, 149, 151, 153, 155, 157, 159, 161, 163, 165, 167, 169, 171, 173, 175, 177, 179, 181, 183, 185, 187, 189, 191, 193, 195, 197, 199, 201, 203, 205, 207, 209, 211, 213, 215, 217, 219, 221, 223, 225, 227, 229, 231, 233, 235, 237, 239, 241, 243, 245, 247, 249, 251, 253, 255, 257, 259, 261, 263, 265, 267, 269, 271, 273, 275, 277, 279, 281, 283, 285, 287, 289, 291, 293, 295, 297, 299, 301, 303, 305, 307, 309, 311, 313, 315, 317, 319, 321, 323, 325, 327, 329, 331, 333, 335, 337, 339, 341, 343, 345, 347, 349, 351, 353, 355, 357, 359, 361, 363, 365, 367, 369, 371, 373, 375, 379, 381, 383, 385, 387, 388, 389, 390, 391, 392, 393, 394, 395, 396, 397, 398, 399, 400, 401, 402, 403, 404, 405, 406, 407, 408, 426, 427, 428, 429, 430, 431, 432, 433, 434, 435, 436, 437, 438, 439, 440, 441, 442, 443, 444, 445, 446 또는 447의 폴리펩티드와 적어도 90% 동일한 폴리펩티드 또는 이의 단편을 인코딩하거나;
c) 서열 번호 2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26, 28, 30, 32, 34, 36, 38, 40, 42, 44, 46, 48, 50, 52, 54, 56, 58, 60, 62, 64, 66, 68, 70, 72, 74, 76, 78, 80, 82, 84, 86, 88, 90, 92, 94, 96, 98, 100, 102, 104, 106, 108, 110, 112, 114, 116, 118, 120, 122, 124, 126, 128, 130, 132, 134, 136, 138, 140, 142, 144, 146, 148, 150, 152, 154, 156, 158, 160, 162, 164, 166, 168, 170, 172, 174, 176, 178, 180, 182, 184, 186, 188, 190, 192, 194, 196, 198, 200, 202, 204, 206, 208, 210, 212, 214, 216, 218, 220, 222, 224, 226, 228, 230, 232, 234, 236, 238, 240, 242, 244, 246, 248, 250, 252, 254, 256, 258, 260, 262, 264, 266, 268, 270, 272, 274, 276, 278, 280, 282, 284, 286, 288, 290, 292, 294, 296, 298, 300, 302, 304, 306, 308, 310, 312, 314, 316, 318, 320, 322, 324, 326, 328, 330, 332, 334, 336, 338, 340, 342, 344, 346, 348, 350, 352, 354, 356, 358, 360, 362, 364, 366, 368, 370, 372, 374, 376, 380, 382, 384, 386, 448, 449, 450, 451, 452, 453, 454, 455, 456, 457, 458, 459, 460, 461, 462, 463, 464, 465, 466, 467, 468, 469, 470, 471, 472, 473, 474, 475, 476, 477, 478, 479, 480, 481, 482, 483, 484, 485, 486, 487, 488, 489, 490, 491, 492, 493, 494, 495, 496, 497, 498, 499, 500, 501, 503, 504, 505, 506, 507, 508, 509, 510, 511, 512, 513, 514, 515, 516, 517, 519, 520, 521, 522, 523, 524, 525, 528, 529, 530, 531, 532, 533, 534, 535, 536, 537, 538, 539 또는 540의 폴리뉴클레오티드 서열 또는 이의 단편을 포함하거나;
d) 서열 번호 2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26, 28, 30, 32, 34, 36, 38, 40, 42, 44, 46, 48, 50, 52, 54, 56, 58, 60, 62, 64, 66, 68, 70, 72, 74, 76, 78, 80, 82, 84, 86, 88, 90, 92, 94, 96, 98, 100, 102, 104, 106, 108, 110, 112, 114, 116, 118, 120, 122, 124, 126, 128, 130, 132, 134, 136, 138, 140, 142, 144, 146, 148, 150, 152, 154, 156, 158, 160, 162, 164, 166, 168, 170, 172, 174, 176, 178, 180, 182, 184, 186, 188, 190, 192, 194, 196, 198, 200, 202, 204, 206, 208, 210, 212, 214, 216, 218, 220, 222, 224, 226, 228, 230, 232, 234, 236, 238, 240, 242, 244, 246, 248, 250, 252, 254, 256, 258, 260, 262, 264, 266, 268, 270, 272, 274, 276, 278, 280, 282, 284, 286, 288, 290, 292, 294, 296, 298, 300, 302, 304, 306, 308, 310, 312, 314, 316, 318, 320, 322, 324, 326, 328, 330, 332, 334, 336, 338, 340, 342, 344, 346, 348, 350, 352, 354, 356, 358, 360, 362, 364, 366, 368, 370, 372, 374, 376, 380, 382, 384, 386, 448, 449, 450, 451, 452, 453, 454, 455, 456, 457, 458, 459, 460, 461, 462, 463, 464, 465, 466, 467, 468, 469, 470, 471, 472, 473, 474, 475, 476, 477, 478, 479, 480, 481, 482, 483, 484, 485, 486, 487, 488, 489, 490, 491, 492, 493, 494, 495, 496, 497, 498, 499, 500, 501, 503, 504, 505, 506, 507, 508, 509, 510, 511, 512, 513, 514, 515, 516, 517, 519, 520, 521, 522, 523, 524, 525, 528, 529, 530, 531, 532, 533, 534, 535, 536, 537, 538, 539 또는 540의 폴리뉴클레오티드 서열과 적어도 90% 동일한 폴리뉴클레오티드 서열 또는 이의 단편을 포함하는 단리된 폴리뉴클레오티드. - 제103항의 폴리뉴클레오티드를 포함하는 벡터.
- 제104항에 있어서, 발현 벡터인 벡터.
- 제104항에 있어서, 바이러스 벡터인 벡터.
- 제103항 내지 제105항 중 어느 한 항의 벡터를 포함하는 숙주 세포.
- a) 서열 번호 1, 3, 5, 7, 9, 11, 13, 15, 17, 19, 21, 23, 25, 27, 29, 31, 33, 35, 37, 39, 41, 43, 45, 47, 49, 51, 53, 55, 57, 59, 61, 63, 65, 67, 69, 71, 73, 75, 77, 79, 81, 83, 85, 87, 89, 91, 93, 95, 97, 99, 101, 103, 105, 107, 109, 111, 113, 115, 117, 119, 121, 123, 125, 127, 129, 131, 133, 135, 137, 139, 141, 143, 145, 147, 149, 151, 153, 155, 157, 159, 161, 163, 165, 167, 169, 171, 173, 175, 177, 179, 181, 183, 185, 187, 189, 191, 193, 195, 197, 199, 201, 203, 205, 207, 209, 211, 213, 215, 217, 219, 221, 223, 225, 227, 229, 231, 233, 235, 237, 239, 241, 243, 245, 247, 249, 251, 253, 255, 257, 259, 261, 263, 265, 267, 269, 271, 273, 275, 277, 279, 281, 283, 285, 287, 289, 291, 293, 295, 297, 299, 301, 303, 305, 307, 309, 311, 313, 315, 317, 319, 321, 323, 325, 327, 329, 331, 333, 335, 337, 339, 341, 343, 345, 347, 349, 351, 353, 355, 357, 359, 361, 363, 365, 367, 369, 371, 373, 375, 379, 381, 383, 385, 387, 388, 389, 390, 391, 392, 393, 394, 395, 396, 397, 398, 399, 400, 401, 402, 403, 404, 405, 406, 407, 408, 426, 427, 428, 429, 430, 431, 432, 433, 434, 435, 436, 437, 438, 439, 440, 441, 442, 443, 444, 445, 446 및 447로 이루어진 군으로부터 선택되는 2개 이상의 폴리펩티드 및 이들의 단편을 포함하는 이종 폴리펩티드를 인코딩하거나;
b) 서열 번호 2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26, 28, 30, 32, 34, 36, 38, 40, 42, 44, 46, 48, 50, 52, 54, 56, 58, 60, 62, 64, 66, 68, 70, 72, 74, 76, 78, 80, 82, 84, 86, 88, 90, 92, 94, 96, 98, 100, 102, 104, 106, 108, 110, 112, 114, 116, 118, 120, 122, 124, 126, 128, 130, 132, 134, 136, 138, 140, 142, 144, 146, 148, 150, 152, 154, 156, 158, 160, 162, 164, 166, 168, 170, 172, 174, 176, 178, 180, 182, 184, 186, 188, 190, 192, 194, 196, 198, 200, 202, 204, 206, 208, 210, 212, 214, 216, 218, 220, 222, 224, 226, 228, 230, 232, 234, 236, 238, 240, 242, 244, 246, 248, 250, 252, 254, 256, 258, 260, 262, 264, 266, 268, 270, 272, 274, 276, 278, 280, 282, 284, 286, 288, 290, 292, 294, 296, 298, 300, 302, 304, 306, 308, 310, 312, 314, 316, 318, 320, 322, 324, 326, 328, 330, 332, 334, 336, 338, 340, 342, 344, 346, 348, 350, 352, 354, 356, 358, 360, 362, 364, 366, 368, 370, 372, 374, 376, 380, 382, 384, 386, 448, 449, 450, 451, 452, 453, 454, 455, 456, 457, 458, 459, 460, 461, 462, 463, 464, 465, 466, 467, 468, 469, 470, 471, 472, 473, 474, 475, 476, 477, 478, 479, 480, 481, 482, 483, 484, 485, 486, 487, 488, 489, 490, 491, 492, 493, 494, 495, 496, 497, 498, 499, 500, 501, 503, 504, 505, 506, 507, 508, 509, 510, 511, 512, 513, 514, 515, 516, 517, 519, 520, 521, 522, 523, 524, 525, 528, 529, 530, 531, 532, 533, 534, 535, 536, 537, 538, 539 및 540으로 이루어진 군으로부터 선택되는 2개 이상의 폴리뉴클레오티드 및 이들의 단편을 포함하는 단리된 이종 폴리뉴클레오티드. - 제108항의 이종 폴리뉴클레오티드를 포함하는 벡터.
- 제109항에 있어서, 바이러스 벡터인 벡터.
- 제110항에 있어서, 상기 바이러스 벡터는 Ad 벡터, AAV 벡터, 폭스바이러스 벡터, 백시니아 벡터 또는 MVA 벡터인 벡터.
- 제111항에 있어서, 아데노바이러스 벡터는 인간 아데노바이러스, 임의로 hAd26, hAd5, hAd7, hAd11, hAd34, hAd35, hAd48, hAd49 또는 hAd50로부터 유래되는 벡터.
- 제112항에 있어서, 상기 아데노바이러스 벡터는 유인원 아데노바이러스, 임의로 GAd20, GAd19, GAd21, GAd25, GAd26, GAd27, GAd28, GAd29, GAd30, GAd31, ChAd3, ChAd4, ChAd5, ChAd6, ChAd7, ChAd8, ChAd9, ChAd10, ChAd11, ChAd16, ChAd17, ChAd19, ChAd20, ChAd22, ChAd24, ChAd26, ChAd30, ChAd31, ChAd37, ChAd38, ChAd44, ChAd55, ChAd63, ChAd73, ChAd82, ChAd83, ChAd146, ChAd147, PanAd1, PanAd2 또는 PanAd3로부터 유래되는 벡터.
- 제113항에 있어서, 상기 MVA 벡터는 MVA 476 MG/14/78, MVA-571, MVA-572, MVA-574, MVA-575 또는 MVA-BN으로부터 유래되는 벡터.
- 제109항 내지 제114항 중 어느 한 항의 벡터를 포함하는 숙주 세포.
- 서열 번호 1, 3, 5, 7, 9, 11, 13, 15, 17, 19, 21, 23, 25, 27, 29, 31, 33, 35, 37, 39, 41, 43, 45, 47, 49, 51, 53, 55, 57, 59, 61, 63, 65, 67, 69, 71, 73, 75, 77, 79, 81, 83, 85, 87, 89, 91, 93, 95, 97, 99, 101, 103, 105, 107, 109, 111, 113, 115, 117, 119, 121, 123, 125, 127, 129, 131, 133, 135, 137, 139, 141, 143, 145, 147, 149, 151, 153, 155, 157, 159, 161, 163, 165, 167, 169, 171, 173, 175, 177, 179, 181, 183, 185, 187, 189, 191, 193, 195, 197, 199, 201, 203, 205, 207, 209, 211, 213, 215, 217, 219, 221, 223, 225, 227, 229, 231, 233, 235, 237, 239, 241, 243, 245, 247, 249, 251, 253, 255, 257, 259, 261, 263, 265, 267, 269, 271, 273, 275, 277, 279, 281, 283, 285, 287, 289, 291, 293, 295, 297, 299, 301, 303, 305, 307, 309, 311, 313, 315, 317, 319, 321, 323, 325, 327, 329, 331, 333, 335, 337, 339, 341, 343, 345, 347, 349, 351, 353, 355, 357, 359, 361, 363, 365, 367, 369, 371, 373, 375, 379, 381, 383, 385, 387, 388, 389, 390, 391, 392, 393, 394, 395, 396, 397, 398, 399, 400, 401, 402, 403, 404, 405, 406, 407, 408, 426, 427, 428, 429, 430, 431, 432, 433, 434, 435, 436, 437, 438, 439, 440, 441, 442, 443, 444, 445, 446 또는 447의 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드.
- 서열 번호 1, 3, 5, 7, 9, 11, 13, 15, 17, 19, 21, 23, 25, 27, 29, 31, 33, 35, 37, 39, 41, 43, 45, 47, 49, 51, 53, 55, 57, 59, 61, 63, 65, 67, 69, 71, 73, 75, 77, 79, 81, 83, 85, 87, 89, 91, 93, 95, 97, 99, 101, 103, 105, 107, 109, 111, 113, 115, 117, 119, 121, 123, 125, 127, 129, 131, 133, 135, 137, 139, 141, 143, 145, 147, 149, 151, 153, 155, 157, 159, 161, 163, 165, 167, 169, 171, 173, 175, 177, 179, 181, 183, 185, 187, 189, 191, 193, 195, 197, 199, 201, 203, 205, 207, 209, 211, 213, 215, 217, 219, 221, 223, 225, 227, 229, 231, 233, 235, 237, 239, 241, 243, 245, 247, 249, 251, 253, 255, 257, 259, 261, 263, 265, 267, 269, 271, 273, 275, 277, 279, 281, 283, 285, 287, 289, 291, 293, 295, 297, 299, 301, 303, 305, 307, 309, 311, 313, 315, 317, 319, 321, 323, 325, 327, 329, 331, 333, 335, 337, 339, 341, 343, 345, 347, 349, 351, 353, 355, 357, 359, 361, 363, 365, 367, 369, 371, 373, 375, 379, 381, 383, 385, 387, 388, 389, 390, 391, 392, 393, 394, 395, 396, 397, 398, 399, 400, 401, 402, 403, 404, 405, 406, 407, 408, 426, 427, 428, 429, 430, 431, 432, 433, 434, 435, 436, 437, 438, 439, 440, 441, 442, 443, 444, 445, 446 또는 447의 폴리펩티드와 적어도 90% 동일한 아미노산 서열 또는 이의 단편을 포함하는 단리된 폴리펩티드.
- 서열 번호 387, 388, 389, 390, 391, 392, 393, 394, 395, 396, 397, 398, 399, 400, 401, 402, 403, 404, 405, 406, 407, 408, 560, 561, 562, 563, 564, 565, 566, 567, 568, 569, 570, 571, 572, 573, 574, 575, 576, 577, 578, 579, 580, 581, 582, 583, 584, 585, 586, 587, 588, 589, 590, 591, 592, 593, 594, 595, 596, 597, 598, 599, 600, 601, 602, 603, 604, 605, 606, 607, 608, 609, 610, 611, 612, 613, 614, 615, 616, 617, 618, 619, 620, 621, 377, 378, 415, 417, 418, 420, 502, 518, 526, 527, 714, 715, 716, 717, 718, 719, 720, 721, 722, 723, 724, 725, 726, 727, 728, 729, 730, 731, 732, 733, 734, 735, 736, 737, 738, 739, 740, 741, 742, 743, 744, 745, 746, 747, 748, 749, 750, 751, 752, 753, 74, 755, 756, 757, 758, 759, 760, 761, 762, 763, 764, 765, 766, 767, 768, 769, 770, 771, 772, 773, 774, 775, 776, 777, 778, 779, 780, 781, 782, 783, 784, 785, 786, 787, 788, 789, 790, 791, 792, 793, 794, 795, 796, 797, 798, 799, 800, 801, 802, 803, 804, 805, 806, 807, 808, 809, 810, 811, 812, 813, 814, 815, 816, 817, 818, 819, 820, 821, 822, 823, 824, 825, 826, 827, 828, 829, 830, 831, 832, 833, 834, 835, 836, 837, 838, 839, 840, 841, 842, 843, 844, 845, 846, 487, 848, 849, 850, 851, 852, 853, 854, 855, 856, 857, 858, 859, 860, 861, 862, 863, 864, 865, 866, 867, 868, 869, 870, 871, 872, 873, 874, 875, 876, 877, 878, 879, 880, 881, 882, 883, 884, 885, 886, 887, 888, 889, 890, 891, 892, 893, 894, 895, 896, 897, 898, 899, 900, 901, 902, 903, 904, 905, 906, 907, 908, 909, 910, 911, 912, 913, 914, 915, 916, 917, 918, 919, 920, 921, 922, 923, 924, 925, 926, 927, 928, 929, 930, 931, 932, 933, 934, 935, 936, 937, 938, 939, 940, 941, 942, 943, 944, 945, 946, 947, 948, 949, 950, 951, 952, 953, 954, 955, 956, 957, 958, 959, 960, 961, 962, 963, 964, 965, 966, 967, 968, 969, 970, 971, 972, 973, 974, 975, 976, 977, 978, 979, 980 또는 548의 아미노산 서열을 포함하는 단리된 폴리펩티드.
- 서열 번호 387, 388, 389, 390, 391, 392, 393, 394, 395, 396, 397, 398, 399, 400, 401, 402, 403, 404, 405, 406, 407, 408, 560, 561, 562, 563, 564, 565, 566, 567, 568, 569, 570, 571, 572, 573, 574, 575, 576, 577, 578, 579, 580, 581, 582, 583, 584, 585, 586, 587, 588, 589, 590, 591, 592, 593, 594, 595, 596, 597, 598, 599, 600, 601, 602, 603, 604, 605, 606, 607, 608, 609, 610, 611, 612, 613, 614, 615, 616, 617, 618, 619, 620, 621, 377, 378, 415, 417, 418, 420, 502, 518, 526, 527, 714, 715, 716, 717, 718, 719, 720, 721, 722, 723, 724, 725, 726, 727, 728, 729, 730, 731, 732, 733, 734, 735, 736, 737, 738, 739, 740, 741, 742, 743, 744, 745, 746, 747, 748, 749, 750, 751, 752, 753, 74, 755, 756, 757, 758, 759, 760, 761, 762, 763, 764, 765, 766, 767, 768, 769, 770, 771, 772, 773, 774, 775, 776, 777, 778, 779, 780, 781, 782, 783, 784, 785, 786, 787, 788, 789, 790, 791, 792, 793, 794, 795, 796, 797, 798, 799, 800, 801, 802, 803, 804, 805, 806, 807, 808, 809, 810, 811, 812, 813, 814, 815, 816, 817, 818, 819, 820, 821, 822, 823, 824, 825, 826, 827, 828, 829, 830, 831, 832, 833, 834, 835, 836, 837, 838, 839, 840, 841, 842, 843, 844, 845, 846, 487, 848, 849, 850, 851, 852, 853, 854, 855, 856, 857, 858, 859, 860, 861, 862, 863, 864, 865, 866, 867, 868, 869, 870, 871, 872, 873, 874, 875, 876, 877, 878, 879, 880, 881, 882, 883, 884, 885, 886, 887, 888, 889, 890, 891, 892, 893, 894, 895, 896, 897, 898, 899, 900, 901, 902, 903, 904, 905, 906, 907, 908, 909, 910, 911, 912, 913, 914, 915, 916, 917, 918, 919, 920, 921, 922, 923, 924, 925, 926, 927, 928, 929, 930, 931, 932, 933, 934, 935, 936, 937, 938, 939, 940, 941, 942, 943, 944, 945, 946, 947, 948, 949, 950, 951, 952, 953, 954, 955, 956, 957, 958, 959, 960, 961, 962, 963, 964, 965, 966, 967, 968, 969, 970, 971, 972, 973, 974, 975, 976, 977, 978, 979, 980 또는 548의 아미노산 서열과 적어도 90% 동일한 아미노산 서열을 포함하는 단리된 폴리펩티드.
- 제116항 내지 제119항 중 어느 한 항에 있어서, 하나 이상의 역 펩티드 결합, 아미노산의 D 이성질체 또는 화학적 변형, 또는 이들의 임의의 조합을 포함하는 단리된 폴리펩티드.
- 서열 번호 1, 3, 5, 7, 9, 11, 13, 15, 17, 19, 21, 23, 25, 27, 29, 31, 33, 35, 37, 39, 41, 43, 45, 47, 49, 51, 53, 55, 57, 59, 61, 63, 65, 67, 69, 71, 73, 75, 77, 79, 81, 83, 85, 87, 89, 91, 93, 95, 97, 99, 101, 103, 105, 107, 109, 111, 113, 115, 117, 119, 121, 123, 125, 127, 129, 131, 133, 135, 137, 139, 141, 143, 145, 147, 149, 151, 153, 155, 157, 159, 161, 163, 165, 167, 169, 171, 173, 175, 177, 179, 181, 183, 185, 187, 189, 191, 193, 195, 197, 199, 201, 203, 205, 207, 209, 211, 213, 215, 217, 219, 221, 223, 225, 227, 229, 231, 233, 235, 237, 239, 241, 243, 245, 247, 249, 251, 253, 255, 257, 259, 261, 263, 265, 267, 269, 271, 273, 275, 277, 279, 281, 283, 285, 287, 289, 291, 293, 295, 297, 299, 301, 303, 305, 307, 309, 311, 313, 315, 317, 319, 321, 323, 325, 327, 329, 331, 333, 335, 337, 339, 341, 343, 345, 347, 349, 351, 353, 355, 357, 359, 361, 363, 365, 367, 369, 371, 373, 375, 379, 381, 383, 385, 387, 388, 389, 390, 391, 392, 393, 394, 395, 396, 397, 398, 399, 400, 401, 402, 403, 404, 405, 406, 407, 408, 426, 427, 428, 429, 430, 431, 432, 433, 434, 435, 436, 437, 438, 439, 440, 441, 442, 443, 444, 445, 446 및 447로 이루어진 군으로부터 선택되는 2개 이상의 폴리펩티드 및 이들의 단편을 포함하는 단리된 이종 폴리펩티드.
- 서열 번호 387, 388, 389, 390, 391, 392, 393, 394, 395, 396, 397, 398, 399, 400, 401, 402, 403, 404, 405, 406, 407, 408, 560, 561, 562, 563, 564, 565, 566, 567, 568, 569, 570, 571, 572, 573, 574, 575, 576, 577, 578, 579, 580, 581, 582, 583, 584, 585, 586, 587, 588, 589, 590, 591, 592, 593, 594, 595, 596, 597, 598, 599, 600, 601, 602, 603, 604, 605, 606, 607, 608, 609, 610, 611, 612, 613, 614, 615, 616, 617, 618, 619, 620, 621, 377, 378, 415, 417, 418, 420, 502, 518, 526, 527, 714, 715, 716, 717, 718, 719, 720, 721, 722, 723, 724, 725, 726, 727, 728, 729, 730, 731, 732, 733, 734, 735, 736, 737, 738, 739, 740, 741, 742, 743, 744, 745, 746, 747, 748, 749, 750, 751, 752, 753, 74, 755, 756, 757, 758, 759, 760, 761, 762, 763, 764, 765, 766, 767, 768, 769, 770, 771, 772, 773, 774, 775, 776, 777, 778, 779, 780, 781, 782, 783, 784, 785, 786, 787, 788, 789, 790, 791, 792, 793, 794, 795, 796, 797, 798, 799, 800, 801, 802, 803, 804, 805, 806, 807, 808, 809, 810, 811, 812, 813, 814, 815, 816, 817, 818, 819, 820, 821, 822, 823, 824, 825, 826, 827, 828, 829, 830, 831, 832, 833, 834, 835, 836, 837, 838, 839, 840, 841, 842, 843, 844, 845, 846, 487, 848, 849, 850, 851, 852, 853, 854, 855, 856, 857, 858, 859, 860, 861, 862, 863, 864, 865, 866, 867, 868, 869, 870, 871, 872, 873, 874, 875, 876, 877, 878, 879, 880, 881, 882, 883, 884, 885, 886, 887, 888, 889, 890, 891, 892, 893, 894, 895, 896, 897, 898, 899, 900, 901, 902, 903, 904, 905, 906, 907, 908, 909, 910, 911, 912, 913, 914, 915, 916, 917, 918, 919, 920, 921, 922, 923, 924, 925, 926, 927, 928, 929, 930, 931, 932, 933, 934, 935, 936, 937, 938, 939, 940, 941, 942, 943, 944, 945, 946, 947, 948, 949, 950, 951, 952, 953, 954, 955, 956, 957, 958, 959, 960, 961, 962, 963, 964, 965, 966, 967, 968, 969, 970, 971, 972, 973, 974, 975, 976, 977, 978, 979, 980 및 548로 이루어진 군으로부터 선택되는 2개 이상의 폴리펩티드를 포함하는 단리된 이종 폴리펩티드.
- 제121항 또는 제122항에 있어서, 하나 이상의 역 펩티드 결합, 아미노산의 D 이성질체 또는 화학적 변형, 또는 이들의 임의의 조합을 포함하는 단리된 이종 폴리펩티드.
- 제116항 내지 제120항 중 어느 한 항의 폴리펩티드 또는 제121항 내지 제123항 중 어느 한 항의 이종 폴리펩티드에 특이적으로 결합하는 단리된 단백질성 분자.
- 제124항에 있어서, 항체, 대체 스캐폴드, CAR 또는 TCR인 단리된 단백질성 분자.
- 제125항의 CAR 또는 TCR을 포함하는 단리된 세포.
- 제116항 내지 제120항 중 어느 한 항의 폴리펩티드, 제121항 내지 제123항 중 어느 한 항의 이종 폴리펩티드, 제124항 또는 제125항의 단백질성 분자, 또는 제126항의 세포를 대상에게 투여하는 단계를 포함하는, 대상에서 면역반응을 유도하는 방법.
- 제116항 내지 제120항 중 어느 한 항의 폴리펩티드, 제121항 내지 제123항 중 어느 한 항의 이종 폴리펩티드, 제124항 또는 제125항의 단백질성 분자, 또는 제126항의 세포를 대상에게 투여하는 단계를 포함하는, 대상에서 전립선암을 치료하거나 예방하는 방법.
- 서열 번호 1, 3, 5, 7, 9, 11, 13, 15, 17, 19, 21, 23, 25, 27, 29, 31, 33, 35, 37, 39, 41, 43, 45, 47, 49, 51, 53, 55, 57, 59, 61, 63, 65, 67, 69, 71, 73, 75, 77, 79, 81, 3, 85, 87, 89, 91, 93, 95, 97, 99, 101, 103, 105, 107, 109, 111, 113, 115, 117, 119, 121, 123, 125, 127, 129, 131, 133, 135, 137, 139, 141, 143, 145, 147, 149, 151, 153, 155, 157, 159, 161, 163, 165, 167, 169, 171, 173, 175, 177, 179, 181, 183, 185, 187, 189, 191, 193, 195, 197, 199, 201, 203, 205, 207, 209, 211, 213, 215, 217, 219, 221, 223, 225, 227, 229, 231, 233, 235, 237, 239, 241, 243, 245, 247, 249, 251, 253, 255, 257, 259, 261, 263, 265, 267, 269, 271, 273, 275, 277, 279, 281, 283, 285, 287, 289, 291, 293, 295, 297, 299, 301, 303, 305, 307, 309, 311, 313, 315, 317, 319, 321, 323, 325, 327, 329, 331, 333, 335, 337, 339, 341, 343, 345, 347, 349, 351, 353, 355, 357, 359, 361, 363, 365, 367, 369, 371, 373, 375, 379, 381, 383 또는 385의 폴리펩티드 또는 이의 단편, 및 HLA를 포함하는 단백질 복합체.
- 제129항에 있어서,
a) 상기 단편은 길이가 약 6 내지 25개의 아미노산이거나;
b) 상기 단편은 서열 번호 387, 388, 389, 390, 391, 392, 393, 394, 395, 396, 397, 398, 399, 400, 401, 402, 403, 404, 405, 406, 407, 408, 560, 561, 562, 563, 564, 565, 566, 567, 568, 569, 570, 571, 572, 573, 574, 575, 576, 577, 578, 579, 580, 581, 582, 583, 584, 585, 586, 587, 588, 589, 590, 591, 592, 593, 594, 595, 596, 597, 598, 599, 600, 601, 602, 603, 604, 605, 606, 607, 608, 609, 610, 611, 612, 613, 614, 615, 616, 617, 618, 619, 620, 621, 377, 378, 415, 417, 418, 420, 502, 518, 526, 527, 714, 715, 716, 717, 718, 719, 720, 721, 722, 723, 724, 725, 726, 727, 728, 729, 730, 731, 732, 733, 734, 735, 736, 737, 738, 739, 740, 741, 742, 743, 744, 745, 746, 747, 748, 749, 750, 751, 752, 753, 74, 755, 756, 757, 758, 759, 760, 761, 762, 763, 764, 765, 766, 767, 768, 769, 770, 771, 772, 773, 774, 775, 776, 777, 778, 779, 780, 781, 782, 783, 784, 785, 786, 787, 788, 789, 790, 791, 792, 793, 794, 795, 796, 797, 798, 799, 800, 801, 802, 803, 804, 805, 806, 807, 808, 809, 810, 811, 812, 813, 814, 815, 816, 817, 818, 819, 820, 821, 822, 823, 824, 825, 826, 827, 828, 829, 830, 831, 832, 833, 834, 835, 836, 837, 838, 839, 840, 841, 842, 843, 844, 845, 846, 487, 848, 849, 850, 851, 852, 853, 854, 855, 856, 857, 858, 859, 860, 861, 862, 863, 864, 865, 866, 867, 868, 869, 870, 871, 872, 873, 874, 875, 876, 877, 878, 879, 880, 881, 882, 883, 884, 885, 886, 887, 888, 889, 890, 891, 892, 893, 894, 895, 896, 897, 898, 899, 900, 901, 902, 903, 904, 905, 906, 907, 908, 909, 910, 911, 912, 913, 914, 915, 916, 917, 918, 919, 920, 921, 922, 923, 924, 925, 926, 927, 928, 929, 930, 931, 932, 933, 934, 935, 936, 937, 938, 939, 940, 941, 942, 943, 944, 945, 946, 947, 948, 949, 950, 951, 952, 953, 954, 955, 956, 957, 958, 959, 960, 961, 962, 963, 964, 965, 966, 967, 968, 969, 970, 971, 972, 973, 974, 975, 976, 977, 978, 979, 980 또는 548의 폴리펩티드를 포함하는 단백질 복합체. - 제129항 또는 제130항에 있어서, 상기 단편은 하나 이상의 돌연변이, 역 펩티드 결합, 아미노산의 D 이성질체 또는 화학적 변형, 또는 이들의 임의의 조합을 포함하는 단백질 복합체.
- 제129항 내지 제131항 중 어느 한 항에 있어서, 상기 HLA는 클래스 I HLA 또는 클래스 II HLA인 단백질 복합체.
- 제129항 내지 제132항 중 어느 한 항에 있어서, 검출가능 표지 또는 세포독성제에 추가로 접합되는 단백질 복합체.
- 제129항 내지 제133항 중 어느 한 항의 단백질 복합체에 특이적으로 결합하는 단리된 단백질성 분자.
- 제134항에 있어서, 항체, 항원 결합 단편, 대체 스캐폴드, CAR 또는 TCR인 단리된 단백질성 분자.
- 제129항 내지 제133항 중 어느 한 항의 단백질 복합체 또는 제134항 또는 제135항의 단백질성 분자를 대상에게 투여하는 단계를 포함하는, 대상에서 전립선암을 치료하거나 예방하는 방법.
- a) 서열 번호 1, 3, 5, 7, 9, 11, 13, 15, 17, 19, 21, 23, 25, 27, 29, 31, 33, 35, 37, 39, 41, 43, 45, 47, 49, 51, 53, 55, 57, 59, 61, 63, 65, 67, 69, 71, 73, 75, 77, 79, 81, 83, 85, 87, 89, 91, 93, 95, 97, 99, 101, 103, 105, 107, 109, 111, 113, 115, 117, 119, 121, 123, 125, 127, 129, 131, 133, 135, 137, 139, 141, 143, 145, 147, 149, 151, 153, 155, 157, 159, 161, 163, 165, 167, 169, 171, 173, 175, 177, 179, 181, 183, 185, 187, 189, 191, 193, 195, 197, 199, 201, 203, 205, 207, 209, 211, 213, 215, 217, 219, 221, 223, 225, 227, 229, 231, 233, 235, 237, 239, 241, 243, 245, 247, 249, 251, 253, 255, 257, 259, 261, 263, 265, 267, 269, 271, 273, 275, 277, 279, 281, 283, 285, 287, 289, 291, 293, 295, 297, 299, 301, 303, 305, 307, 309, 311, 313, 315, 317, 319, 321, 323, 325, 327, 329, 331, 333, 335, 337, 339, 341, 343, 345, 347, 349, 351, 353, 355, 357, 359, 361, 363, 365, 367, 369, 371, 373, 375, 379, 381, 383, 385, 387, 388, 389, 390, 391, 392, 393, 394, 395, 396, 397, 398, 399, 400, 401, 402, 403, 404, 405, 406, 407, 408, 426, 427, 428, 429, 430, 431, 432, 433, 434, 435, 436, 437, 438, 439, 440, 441, 442, 443, 444, 445, 446 또는 447의 폴리펩티드와 적어도 90% 동일한 폴리펩티드 또는 이의 단편을 인코딩하는 단리된 폴리뉴클레오티드;
b) 서열 번호 2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26, 28, 30, 32, 34, 36, 38, 40, 42, 44, 46, 48, 50, 52, 54, 56, 58, 60, 62, 64, 66, 68, 70, 72, 74, 76, 78, 80, 82, 84, 86, 88, 90, 92, 94, 96, 98, 100, 102, 104, 106, 108, 110, 112, 114, 116, 118, 120, 122, 124, 126, 128, 130, 132, 134, 136, 138, 140, 142, 144, 146, 148, 150, 152, 154, 156, 158, 160, 162, 164, 166, 168, 170, 172, 174, 176, 178, 180, 182, 184, 186, 188, 190, 192, 194, 196, 198, 200, 202, 204, 206, 208, 210, 212, 214, 216, 218, 220, 222, 224, 226, 228, 230, 232, 234, 236, 238, 240, 242, 244, 246, 248, 250, 252, 254, 256, 258, 260, 262, 264, 266, 268, 270, 272, 274, 276, 278, 280, 282, 284, 286, 288, 290, 292, 294, 296, 298, 300, 302, 304, 306, 308, 310, 312, 314, 316, 318, 320, 322, 324, 326, 328, 330, 332, 334, 336, 338, 340, 342, 344, 346, 348, 350, 352, 354, 356, 358, 360, 362, 364, 366, 368, 370, 372, 374, 376, 380, 382, 384, 386, 448, 449, 450, 451, 452, 453, 454, 455, 456, 457, 458, 459, 460, 461, 462, 463, 464, 465, 466, 467, 468, 469, 470, 471, 472, 473, 474, 475, 476, 477, 478, 479, 480, 481, 482, 483, 484, 485, 486, 487, 488, 489, 490, 491, 492, 493, 494, 495, 496, 497, 498, 499, 500, 501, 503, 504, 505, 506, 507, 508, 509, 510, 511, 512, 513, 514, 515, 516, 517, 519, 520, 521, 522, 523, 524, 525, 528, 529, 530, 531, 532, 533, 534, 535, 536, 537, 538, 539 또는 540의 폴리뉴클레오티드 서열과 적어도 90% 동일한 폴리뉴클레오티드 서열 또는 이의 단편을 포함하는 단리된 폴리뉴클레오티드;
c) 서열 번호 1, 3, 5, 7, 9, 11, 13, 15, 17, 19, 21, 23, 25, 27, 29, 31, 33, 35, 37, 39, 41, 43, 45, 47, 49, 51, 53, 55, 57, 59, 61, 63, 65, 67, 69, 71, 73, 75, 77, 79, 81, 83, 85, 87, 89, 91, 93, 95, 97, 99, 101, 103, 105, 107, 109, 111, 113, 115, 117, 119, 121, 123, 125, 127, 129, 131, 133, 135, 137, 139, 141, 143, 145, 147, 149, 151, 153, 155, 157, 159, 161, 163, 165, 167, 169, 171, 173, 175, 177, 179, 181, 183, 185, 187, 189, 191, 193, 195, 197, 199, 201, 203, 205, 207, 209, 211, 213, 215, 217, 219, 221, 223, 225, 227, 229, 231, 233, 235, 237, 239, 241, 243, 245, 247, 249, 251, 253, 255, 257, 259, 261, 263, 265, 267, 269, 271, 273, 275, 277, 279, 281, 283, 285, 287, 289, 291, 293, 295, 297, 299, 301, 303, 305, 307, 309, 311, 313, 315, 317, 319, 321, 323, 325, 327, 329, 331, 333, 335, 337, 339, 341, 343, 345, 347, 349, 351, 353, 355, 357, 359, 361, 363, 365, 367, 369, 371, 373, 375, 379, 381, 383, 385, 387, 388, 389, 390, 391, 392, 393, 394, 395, 396, 397, 398, 399, 400, 401, 402, 403, 404, 405, 406, 407, 408, 426, 427, 428, 429, 430, 431, 432, 433, 434, 435, 436, 437, 438, 439, 440, 441, 442, 443, 444, 445, 446 및 447로 이루어진 군으로부터 선택되는 2개 이상의 폴리펩티드 및 이들의 단편을 포함하는 이종 폴리펩티드를 인코딩하는 단리된 이종 폴리뉴클레오티드; 또는
d) 서열 번호 2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26, 28, 30, 32, 34, 36, 38, 40, 42, 44, 46, 48, 50, 52, 54, 56, 58, 60, 62, 64, 66, 68, 70, 72, 74, 76, 78, 80, 82, 84, 86, 88, 90, 92, 94, 96, 98, 100, 102, 104, 106, 108, 110, 112, 114, 116, 118, 120, 122, 124, 126, 128, 130, 132, 134, 136, 138, 140, 142, 144, 146, 148, 150, 152, 154, 156, 158, 160, 162, 164, 166, 168, 170, 172, 174, 176, 178, 180, 182, 184, 186, 188, 190, 192, 194, 196, 198, 200, 202, 204, 206, 208, 210, 212, 214, 216, 218, 220, 222, 224, 226, 228, 230, 232, 234, 236, 238, 240, 242, 244, 246, 248, 250, 252, 254, 256, 258, 260, 262, 264, 266, 268, 270, 272, 274, 276, 278, 280, 282, 284, 286, 288, 290, 292, 294, 296, 298, 300, 302, 304, 306, 308, 310, 312, 314, 316, 318, 320, 322, 324, 326, 328, 330, 332, 334, 336, 338, 340, 342, 344, 346, 348, 350, 352, 354, 356, 358, 360, 362, 364, 366, 368, 370, 372, 374, 376, 380, 382, 384, 386, 448, 449, 450, 451, 452, 453, 454, 455, 456, 457, 458, 459, 460, 461, 462, 463, 464, 465, 466, 467, 468, 469, 470, 471, 472, 473, 474, 475, 476, 477, 478, 479, 480, 481, 482, 483, 484, 485, 486, 487, 488, 489, 490, 491, 492, 493, 494, 495, 496, 497, 498, 499, 500, 501, 503, 504, 505, 506, 507, 508, 509, 510, 511, 512, 513, 514, 515, 516, 517, 519, 520, 521, 522, 523, 524, 525, 528, 529, 530, 531, 532, 533, 534, 535, 536, 537, 538, 539 및 540으로 이루어진 군으로부터 선택되는 2개 이상의 폴리뉴클레오티드 및 이들의 단편을 포함하는 단리된 이종 폴리뉴클레오티드를 포함하는 백신. - 제137항에 있어서, 상기 폴리뉴클레오티드 또는 이종 폴리뉴클레오티드는 RNA 또는 DNA인 백신.
- 제138항에 있어서, 상기 RNA는 mRNA 또는 자기 복제 RNA인 백신.
- 제138항에 있어서, 재조합 바이러스인 백신.
- 제140항에 있어서, 상기 재조합 바이러스는 Ad, 폭스바이러스, AAV 또는 레트로바이러스로부터 유래되는 백신.
- 제141항에 있어서, 상기 재조합 바이러스는 hAd5, hAd7, hAd11, hAd26, hAd34, hAd35, hAd48, hAd49, hAd50, GAd20, GAd19, GAd21, GAd25, GAd26, GAd27, GAd28, GAd29, GAd30, GAd31, ChAd3, ChAd4, ChAd5, ChAd6, ChAd7, ChAd8, ChAd9, ChAd10, ChAd11, ChAd16, ChAd17, ChAd19, ChAd20, ChAd22, ChAd24, ChAd26, ChAd30, ChAd31, ChAd37, ChAd38, ChAd44, ChAd55, ChAd63, ChAd73, ChAd82, ChAd83, ChAd146, ChAd147, PanAd1, PanAd2, PanAd3, 코펜하겐 백시니아 바이러스(W), 뉴욕 약독화 백시니아 바이러스(NYVAC), ALVAC, TROVAC 또는 MVA로부터 유래되는 백신.
- 제137항 내지 제142항 중 어느 한 항의 백신 및 약제학적으로 허용가능한 담체 또는 애주번트를 포함하는 약제학적 조성물.
- 제137항 내지 제142항 중 어느 한 항의 백신 또는 제143항의 약제학적 조성물의 치료적 유효량을 대상에게 투여하는 단계를 포함하는, 대상에서 전립선암을 치료하거나 예방하는 방법.
- 제137항 내지 제142항 중 어느 한 항의 백신 또는 제143항의 약제학적 조성물을 대상에게 투여하는 단계를 포함하는, 대상에서 제116항의 폴리펩티드에 대한 면역반응을 유도하는 방법.
- 제144항 또는 제145항에 있어서, 상기 대상은 하나 이상의 제116항의 폴리펩티드를 발현하거나 발현하는 것으로 의심되는 방법.
- 제146항에 있어서, 상기 하나 이상의 제116항의 폴리펩티드는 전립선암을 앓고 있는 대상 집단에서 적어도 약 1% 이상, 약 2% 이상, 약 3% 이상, 약 4% 이상, 약 5% 이상, 약 6% 이상, 약 7% 이상, 약 8% 이상, 약 9% 이상, 약 10% 이상, 약 11% 이상, 약 12% 이상, 약 13% 이상, 약 14% 이상, 약 15% 이상, 약 16% 이상, 약 17% 이상, 약 18% 이상, 약 19% 이상, 약 20% 이상, 약 21% 이상, 약 22% 이상, 약 23% 이상, 약 24% 이상, 약 25% 이상, 약 26% 이상, 약 27% 이상, 약 28% 이상, 약 29% 이상, 약 30% 이상, 약 35% 이상, 약 40% 이상, 약 45% 이상, 약 50% 이상, 약 55% 이상, 약 60% 이상, 약 65% 이상 또는 약 70% 이상의 빈도로 존재하는 방법.
Applications Claiming Priority (9)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201962790673P | 2019-01-10 | 2019-01-10 | |
| US62/790,673 | 2019-01-10 | ||
| US201962851273P | 2019-05-22 | 2019-05-22 | |
| US62/851,273 | 2019-05-22 | ||
| US201962883786P | 2019-08-07 | 2019-08-07 | |
| US62/883,786 | 2019-08-07 | ||
| US201962913969P | 2019-10-11 | 2019-10-11 | |
| US62/913,969 | 2019-10-11 | ||
| PCT/IB2020/050145 WO2020144615A1 (en) | 2019-01-10 | 2020-01-09 | Prostate neoantigens and their uses |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20210113655A true KR20210113655A (ko) | 2021-09-16 |
Family
ID=69191089
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020217025212A KR20210113655A (ko) | 2019-01-10 | 2020-01-09 | 전립선 신생항원 및 이의 용도 |
Country Status (21)
| Country | Link |
|---|---|
| US (2) | US11793843B2 (ko) |
| EP (1) | EP3908311A1 (ko) |
| JP (1) | JP2022516770A (ko) |
| KR (1) | KR20210113655A (ko) |
| CN (1) | CN113573729A (ko) |
| AU (1) | AU2020207641A1 (ko) |
| BR (1) | BR112021013507A2 (ko) |
| CA (1) | CA3126462A1 (ko) |
| CL (2) | CL2021001835A1 (ko) |
| CO (1) | CO2021010006A2 (ko) |
| CR (1) | CR20210370A (ko) |
| EC (1) | ECSP21056536A (ko) |
| IL (1) | IL284561A (ko) |
| JO (1) | JOP20210186A1 (ko) |
| MA (1) | MA54693A (ko) |
| MX (1) | MX2021008392A (ko) |
| PE (1) | PE20211660A1 (ko) |
| SG (1) | SG11202107274VA (ko) |
| TW (1) | TW202043256A (ko) |
| UY (1) | UY38542A (ko) |
| WO (2) | WO2020144615A1 (ko) |
Families Citing this family (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| TW202043256A (zh) | 2019-01-10 | 2020-12-01 | 美商健生生物科技公司 | 前列腺新抗原及其用途 |
| TW202144388A (zh) * | 2020-02-14 | 2021-12-01 | 美商健生生物科技公司 | 在卵巢癌中表現之新抗原及其用途 |
| US20230035403A1 (en) * | 2020-07-06 | 2023-02-02 | Janssen Biotech, Inc. | Method For Determining Responsiveness To Prostate Cancer Treatment |
| WO2022009052A2 (en) * | 2020-07-06 | 2022-01-13 | Janssen Biotech, Inc. | Prostate neoantigens and their uses |
| CN117377683A (zh) * | 2021-02-25 | 2024-01-09 | 西湖生物医药科技(杭州)有限公司 | 新抗原肽及其在治疗braf基因突变相关疾病中的用途 |
| US20230190903A1 (en) * | 2021-12-16 | 2023-06-22 | Janssen Biotech, Inc. | Prostate cancer vaccines and uses thereof |
Family Cites Families (320)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US563536A (en) | 1896-07-07 | Bracket for swinging stages | ||
| US914623A (en) | 1908-08-19 | 1909-03-09 | Henry H Williams | Process in the manufacture of generating-plates for x-ray machines. |
| US1051266A (en) | 1910-09-26 | 1913-01-21 | George I Rockwood | Apparatus for operating alarms or other devices. |
| US4235871A (en) | 1978-02-24 | 1980-11-25 | Papahadjopoulos Demetrios P | Method of encapsulating biologically active materials in lipid vesicles |
| US4603112A (en) | 1981-12-24 | 1986-07-29 | Health Research, Incorporated | Modified vaccinia virus |
| US4769330A (en) | 1981-12-24 | 1988-09-06 | Health Research, Incorporated | Modified vaccinia virus and methods for making and using the same |
| US4501728A (en) | 1983-01-06 | 1985-02-26 | Technology Unlimited, Inc. | Masking of liposomes from RES recognition |
| US5225539A (en) | 1986-03-27 | 1993-07-06 | Medical Research Council | Recombinant altered antibodies and methods of making altered antibodies |
| US4897445A (en) | 1986-06-27 | 1990-01-30 | The Administrators Of The Tulane Educational Fund | Method for synthesizing a peptide containing a non-peptide bond |
| EP0281604B1 (en) | 1986-09-02 | 1993-03-31 | Enzon Labs Inc. | Single polypeptide chain binding molecules |
| DE3642912A1 (de) | 1986-12-16 | 1988-06-30 | Leybold Ag | Messeinrichtung fuer paramagnetische messgeraete mit einer messkammer |
| US4837028A (en) | 1986-12-24 | 1989-06-06 | Liposome Technology, Inc. | Liposomes with enhanced circulation time |
| CA1341245C (en) | 1988-01-12 | 2001-06-05 | F. Hoffmann-La Roche Ag | Recombinant vaccinia virus mva |
| US5223409A (en) | 1988-09-02 | 1993-06-29 | Protein Engineering Corp. | Directed evolution of novel binding proteins |
| GB8823869D0 (en) | 1988-10-12 | 1988-11-16 | Medical Res Council | Production of antibodies |
| IL162181A (en) | 1988-12-28 | 2006-04-10 | Pdl Biopharma Inc | A method of producing humanized immunoglubulin, and polynucleotides encoding the same |
| US5744166A (en) | 1989-02-25 | 1998-04-28 | Danbiosyst Uk Limited | Drug delivery compositions |
| US5100587A (en) | 1989-11-13 | 1992-03-31 | The United States Of America As Represented By The Department Of Energy | Solid-state radioluminescent zeolite-containing composition and light sources |
| US6150584A (en) | 1990-01-12 | 2000-11-21 | Abgenix, Inc. | Human antibodies derived from immunized xenomice |
| US5427908A (en) | 1990-05-01 | 1995-06-27 | Affymax Technologies N.V. | Recombinant library screening methods |
| GB9015198D0 (en) | 1990-07-10 | 1990-08-29 | Brien Caroline J O | Binding substance |
| US6172197B1 (en) | 1991-07-10 | 2001-01-09 | Medical Research Council | Methods for producing members of specific binding pairs |
| US6255458B1 (en) | 1990-08-29 | 2001-07-03 | Genpharm International | High affinity human antibodies and human antibodies against digoxin |
| US5179993A (en) | 1991-03-26 | 1993-01-19 | Hughes Aircraft Company | Method of fabricating anisometric metal needles and birefringent suspension thereof in dielectric fluid |
| US6407213B1 (en) | 1991-06-14 | 2002-06-18 | Genentech, Inc. | Method for making humanized antibodies |
| US5976551A (en) | 1991-11-15 | 1999-11-02 | Institut Pasteur And Institut Nationale De La Sante Et De La Recherche Medicale | Altered major histocompatibility complex (MHC) determinant and method of using the determinant |
| US5734023A (en) | 1991-11-19 | 1998-03-31 | Anergen Inc. | MHC class II β chain/peptide complexes useful in ameliorating deleterious immune responses |
| US5932448A (en) | 1991-11-29 | 1999-08-03 | Protein Design Labs., Inc. | Bispecific antibody heterodimers |
| DE69233782D1 (de) | 1991-12-02 | 2010-05-20 | Medical Res Council | Herstellung von Autoantikörpern auf Phagenoberflächen ausgehend von Antikörpersegmentbibliotheken |
| US5635483A (en) | 1992-12-03 | 1997-06-03 | Arizona Board Of Regents Acting On Behalf Of Arizona State University | Tumor inhibiting tetrapeptide bearing modified phenethyl amides |
| ATE199392T1 (de) | 1992-12-04 | 2001-03-15 | Medical Res Council | Multivalente und multispezifische bindungsproteine, deren herstellung und verwendung |
| US5747323A (en) | 1992-12-31 | 1998-05-05 | Institut National De La Sante Et De La Recherche Medicale (Inserm) | Retroviral vectors comprising a VL30-derived psi region |
| US5780588A (en) | 1993-01-26 | 1998-07-14 | Arizona Board Of Regents | Elucidation and synthesis of selected pentapeptides |
| FR2705686B1 (fr) | 1993-05-28 | 1995-08-18 | Transgene Sa | Nouveaux adénovirus défectifs et lignées de complémentation correspondantes. |
| FR2707091B1 (fr) | 1993-06-30 | 1997-04-04 | Cohen Haguenauer Odile | Vecteur rétroviral pour le transfert et l'expression de gènes dans des cellules eucaryotes. |
| US5820866A (en) | 1994-03-04 | 1998-10-13 | National Jewish Center For Immunology And Respiratory Medicine | Product and process for T cell regulation |
| JPH08510761A (ja) | 1994-03-07 | 1996-11-12 | ザ・ダウ・ケミカル・カンパニー | 生物活性及び/又はターゲテッドデンドリマー複合体 |
| FR2719316B1 (fr) | 1994-04-28 | 1996-05-31 | Idm | Nouveaux complexes d'acide nucléique et de polymère, leur procédé de préparation et leur utilisation pour la transfection de cellules. |
| US5851806A (en) | 1994-06-10 | 1998-12-22 | Genvec, Inc. | Complementary adenoviral systems and cell lines |
| EP1548118A2 (en) | 1994-06-10 | 2005-06-29 | Genvec, Inc. | Complementary adenoviral vector systems and cell lines |
| EP0769063A1 (en) | 1994-06-27 | 1997-04-23 | The Johns Hopkins University | Targeted gene delivery system |
| US5972707A (en) | 1994-06-27 | 1999-10-26 | The Johns Hopkins University | Gene delivery system |
| FR2722506B1 (fr) | 1994-07-13 | 1996-08-14 | Rhone Poulenc Rorer Sa | Composition contenant des acides nucleiques, preparation et utilisations |
| US7074904B2 (en) | 1994-07-29 | 2006-07-11 | Altor Bioscience Corporation | MHC complexes and uses thereof |
| US5965541A (en) | 1995-11-28 | 1999-10-12 | Genvec, Inc. | Vectors and methods for gene transfer to cells |
| US5559099A (en) | 1994-09-08 | 1996-09-24 | Genvec, Inc. | Penton base protein and methods of using same |
| US5846782A (en) | 1995-11-28 | 1998-12-08 | Genvec, Inc. | Targeting adenovirus with use of constrained peptide motifs |
| FR2727689A1 (fr) | 1994-12-01 | 1996-06-07 | Transgene Sa | Nouveau procede de preparation d'un vecteur viral |
| AU4344696A (en) | 1994-12-21 | 1996-07-10 | Novartis Ag | Oligonucleotide-dendrimer conjugates |
| US5635363A (en) | 1995-02-28 | 1997-06-03 | The Board Of Trustees Of The Leland Stanford Junior University | Compositions and methods for the detection, quantitation and purification of antigen-specific T cells |
| US5731168A (en) | 1995-03-01 | 1998-03-24 | Genentech, Inc. | Method for making heteromultimeric polypeptides |
| US5837520A (en) | 1995-03-07 | 1998-11-17 | Canji, Inc. | Method of purification of viral vectors |
| AUPO591797A0 (en) | 1997-03-27 | 1997-04-24 | Commonwealth Scientific And Industrial Research Organisation | High avidity polyvalent and polyspecific reagents |
| US7422902B1 (en) | 1995-06-07 | 2008-09-09 | The University Of British Columbia | Lipid-nucleic acid particles prepared via a hydrophobic lipid-nucleic acid complex intermediate and use for gene transfer |
| US5981501A (en) | 1995-06-07 | 1999-11-09 | Inex Pharmaceuticals Corp. | Methods for encapsulating plasmids in lipid bilayers |
| ATE285477T1 (de) | 1995-06-07 | 2005-01-15 | Inex Pharmaceutical Corp | Herstellung von lipid-nukleinsäure partikeln duch ein hydrophobische lipid-nukleinsäuree komplexe zwischenprodukt und zur verwendung in der gentransfer |
| ATE278794T1 (de) | 1995-06-15 | 2004-10-15 | Crucell Holland Bv | Verpackungssysteme für humane, menschliche adenoviren, zur verwendung in die gentherapie |
| FR2737222B1 (fr) | 1995-07-24 | 1997-10-17 | Transgene Sa | Nouveaux vecteurs viraux et lignee pour la therapie genique |
| US5837511A (en) | 1995-10-02 | 1998-11-17 | Cornell Research Foundation, Inc. | Non-group C adenoviral vectors |
| US5869270A (en) | 1996-01-31 | 1999-02-09 | Sunol Molecular Corporation | Single chain MHC complexes and uses thereof |
| WO1997035996A1 (en) | 1996-03-25 | 1997-10-02 | Transgene S.A. | Packaging cell line based on human 293 cells |
| CA2177085C (en) | 1996-04-26 | 2007-08-14 | National Research Council Of Canada | Adenovirus e1-complementing cell lines |
| WO1998000524A1 (fr) | 1996-07-01 | 1998-01-08 | Rhone-Poulenc Rorer S.A. | Procede de production d'adenovirus recombinants |
| US6211342B1 (en) | 1996-07-18 | 2001-04-03 | Children's Hospital Medical Center | Multivalent MHC complex peptide fusion protein complex for stimulating specific T cell function |
| US6348584B1 (en) | 1996-10-17 | 2002-02-19 | John Edward Hodgson | Fibronectin binding protein compounds |
| DE69739961D1 (de) | 1996-12-13 | 2010-09-23 | Schering Corp | Methoden zur Virus-Reinigung |
| FR2759382A1 (fr) | 1997-02-10 | 1998-08-14 | Transgene Sa | Nouveaux composes et compositions les contenant utilisables pour le transfert d'au moins une substance therapeutiquement active, notamment un polynucleotide, dans une cellule cible et utilisation en therapie genique |
| FR2760193B1 (fr) | 1997-02-28 | 1999-05-28 | Transgene Sa | Lipides et complexes de lipides cationiques et de substances actives, notamment pour la transfection de cellules |
| WO1998039411A1 (en) | 1997-03-04 | 1998-09-11 | Baxter International Inc. | Adenovirus e1-complementing cell lines |
| US6268411B1 (en) | 1997-09-11 | 2001-07-31 | The Johns Hopkins University | Use of multivalent chimeric peptide-loaded, MHC/ig molecules to detect, activate or suppress antigen-specific T cell-dependent immune responses |
| US6020191A (en) | 1997-04-14 | 2000-02-01 | Genzyme Corporation | Adenoviral vectors capable of facilitating increased persistence of transgene expression |
| ES2301198T3 (es) | 1997-06-12 | 2008-06-16 | Novartis International Pharmaceutical Ltd. | Polipeptidos artificiales de anticuerpos. |
| WO1998056370A2 (en) | 1997-06-13 | 1998-12-17 | Johns Hopkins University School Of Medicine | Therapeutic nanospheres |
| AU741130B2 (en) | 1997-09-16 | 2001-11-22 | Oregon Health Sciences University | Recombinant MHC molecules useful for manipulation of antigen-specific T-cells |
| US6232445B1 (en) | 1997-10-29 | 2001-05-15 | Sunol Molecular Corporation | Soluble MHC complexes and methods of use thereof |
| US5981225A (en) | 1998-04-16 | 1999-11-09 | Baylor College Of Medicine | Gene transfer vector, recombinant adenovirus particles containing the same, method for producing the same and method of use of the same |
| US6113913A (en) | 1998-06-26 | 2000-09-05 | Genvec, Inc. | Recombinant adenovirus |
| US6440442B1 (en) | 1998-06-29 | 2002-08-27 | Hydromer, Inc. | Hydrophilic polymer blends used for dry cow therapy |
| US6818749B1 (en) | 1998-10-31 | 2004-11-16 | The United States Of America As Represented By The Department Of Health And Human Services | Variants of humanized anti carcinoma monoclonal antibody cc49 |
| US7264958B1 (en) | 1999-02-22 | 2007-09-04 | Transgene, S.A. | Method for obtaining a purified viral preparation |
| NZ515582A (en) | 1999-05-17 | 2003-11-28 | Crucell Holland B | Adenovirus derived gene delivery vehicles comprising at least one element of adenovirus type 35 |
| US6913922B1 (en) | 1999-05-18 | 2005-07-05 | Crucell Holland B.V. | Serotype of adenovirus and uses thereof |
| AU1013601A (en) | 1999-10-22 | 2001-05-08 | Aventis Pasteur Limited | Method of inducing and/or enhancing an immune response to tumor antigens |
| DE19955558C2 (de) | 1999-11-18 | 2003-03-20 | Stefan Kochanek | Permanente Amniozyten-Zelllinie, ihre Herstellung und Verwendung zur Herstellung von Gentransfervektoren |
| US20030198953A1 (en) | 2000-03-30 | 2003-10-23 | Spytek Kimberly A. | Novel proteins and nucleic acids encoding same |
| US20020192763A1 (en) * | 2000-04-17 | 2002-12-19 | Jiangchun Xu | Compositions and methods for the therapy and diagnosis of prostate cancer |
| US6596541B2 (en) | 2000-10-31 | 2003-07-22 | Regeneron Pharmaceuticals, Inc. | Methods of modifying eukaryotic cells |
| CN100537773C (zh) | 2000-11-23 | 2009-09-09 | 巴法里安诺迪克有限公司 | 改良安卡拉痘苗病毒变体 |
| CA2430013C (en) | 2000-11-30 | 2011-11-22 | Medarex, Inc. | Transgenic transchromosomal rodents for making human antibodies |
| US20150329617A1 (en) | 2001-03-14 | 2015-11-19 | Dynal Biotech Asa | Novel MHC molecule constructs, and methods of employing these constructs for diagnosis and therapy, and uses of MHC molecules |
| US6884869B2 (en) | 2001-04-30 | 2005-04-26 | Seattle Genetics, Inc. | Pentapeptide compounds and uses related thereto |
| WO2004006955A1 (en) | 2001-07-12 | 2004-01-22 | Jefferson Foote | Super humanized antibodies |
| US6833441B2 (en) | 2001-08-01 | 2004-12-21 | Abmaxis, Inc. | Compositions and methods for generating chimeric heteromultimers |
| PL208712B1 (pl) | 2001-08-31 | 2011-05-31 | Avidex Ltd | Rozpuszczalny receptor komórek T (sTCR), rozpuszczalna αβ-postać receptora komórek T (sTCR), wielowartościowy kompleks receptora komórek T (TCR), sposób wykrywania kompleksów MHC-peptyd, środek farmaceutyczny zawierający sTCR i/lub wielowartościowy kompleks TCR, cząsteczka kwasu nukleinowego, wektor, komórka gospodarz, sposób otrzymywania całości lub części łańcucha α TCR albo całości lub części łańcucha β TCR, sposób otrzymywania rozpuszczalnego receptora komórek T (sTCR), sposób otrzymywania rozpuszczalnej αβ-postaci receptora komórek T (sTCR) oraz sposób wykrywania kompleksów MHC-peptyd |
| AU2003242820A1 (en) | 2002-03-14 | 2003-09-22 | Exonhit Therapeutics S.A. | Variants of human kallikrein-2 and kallikrein-3 and uses thereof |
| ES2288609T5 (es) | 2002-04-19 | 2017-11-13 | Bavarian Nordic A/S | Virus vaccinia ankara modificado para la vacunación de neonatos |
| DE10244457A1 (de) | 2002-09-24 | 2004-04-01 | Johannes-Gutenberg-Universität Mainz | Verfahren zur rationalen Mutagenese von alpha/beta T-Zell Rezeptoren und entsprechend mutierte MDM2-Protein spezifische alpha/beta T-Zell Rezeptoren |
| AU2003271904B2 (en) | 2002-10-09 | 2009-03-05 | Adaptimmune Limited | Single chain recombinant T cell receptors |
| CA2509980C (en) | 2002-11-12 | 2012-12-18 | Albert B. Deisseroth | Adenoviral vector vaccine |
| JP5052893B2 (ja) | 2003-02-20 | 2012-10-17 | アメリカ合衆国 | ポックスベクターにおける新規の挿入部位 |
| WO2004113571A2 (en) | 2003-06-26 | 2004-12-29 | Exonhit Therapeutics Sa | Prostate specific genes and the use thereof as targets for prostate cancer therapy and diagnosis |
| CA2537759C (en) | 2003-09-05 | 2015-03-24 | Oregon Health & Science University | Monomeric recombinant mhc molecules useful for manipulation of antigen-specific t cells |
| GB2408507B (en) | 2003-10-06 | 2005-12-14 | Proimmune Ltd | Chimeric MHC protein and oligomer thereof for specific targeting |
| EP1687033A4 (en) | 2003-11-12 | 2008-06-11 | Us Navy | STRENGTHENING IMMUNE RESPONSE INDUCED BY A VACCINE AND HETEROLOGOUS AMPLIFICATION PROTECTION WITH ALPHAVIRUS REPLICON VACCINES |
| EP1687334B1 (en) | 2003-11-24 | 2014-01-08 | MicroVAX, LLC | Mucin antigen vaccine |
| US20050244851A1 (en) | 2004-01-13 | 2005-11-03 | Affymetrix, Inc. | Methods of analysis of alternative splicing in human |
| PL1711518T3 (pl) | 2004-01-23 | 2010-06-30 | St Di Richerche Di Biologia Molecolare P Angeletti S P A | Nośniki szczepionek pochodzące od szympansich adenowirusów |
| WO2006056766A2 (en) | 2004-11-24 | 2006-06-01 | St George's Enterprises Limited | Diagnosis of prostate cancer |
| EP1683808A1 (en) | 2005-01-25 | 2006-07-26 | Het Nederlands Kanker Instituut | Means and methods for breaking noncovalent binding interactions between molecules |
| AU2006232287B2 (en) | 2005-03-31 | 2011-10-06 | Chugai Seiyaku Kabushiki Kaisha | Methods for producing polypeptides by regulating polypeptide association |
| DE102005028778A1 (de) | 2005-06-22 | 2006-12-28 | SUNJÜT Deutschland GmbH | Mehrlagige Folie mit einer Barriere- und einer antistatischen Lage |
| AU2006291054B2 (en) | 2005-09-12 | 2011-10-13 | The Brigham And Women's Hospital, Inc. | Recurrent gene fusions in prostate cancer |
| US9732131B2 (en) | 2006-02-27 | 2017-08-15 | Calviri, Inc. | Identification and use of novopeptides for the treatment of cancer |
| WO2007104792A2 (en) | 2006-03-16 | 2007-09-20 | Crucell Holland B.V. | Recombinant adenoviruses based on serotype 26 and 48, and use thereof |
| PL1999154T3 (pl) | 2006-03-24 | 2013-03-29 | Merck Patent Gmbh | Skonstruowane metodami inżynierii heterodimeryczne domeny białkowe |
| EP2035456A1 (en) | 2006-06-22 | 2009-03-18 | Novo Nordisk A/S | Production of bispecific antibodies |
| EP1878744A1 (en) | 2006-07-13 | 2008-01-16 | Max-Delbrück-Centrum für Molekulare Medizin (MDC) | Epitope-tag for surface-expressed T-cell receptor proteins, uses thereof and method of selecting host cells expressing them |
| GB2442048B (en) | 2006-07-25 | 2009-09-30 | Proimmune Ltd | Biotinylated MHC complexes and their uses |
| GB2440529B (en) | 2006-08-03 | 2009-05-13 | Proimmune Ltd | MHC Oligomer, Components Therof, And Methods Of Making The Same |
| US7910565B2 (en) | 2006-09-01 | 2011-03-22 | Wisconsin Alumni Research Foundation | Prostate cancer vaccine |
| NZ575388A (en) | 2006-10-06 | 2012-03-30 | Bn Immunotherapeutics Inc | Recombinant modified vaccinia ankara encoding a her-2 antigen and a taxane for use in treating cancer |
| WO2008106615A1 (en) | 2007-02-28 | 2008-09-04 | Numenta, Inc. | Spatio-temporal learning algorithms in hierarchical temporal networks |
| EP3061462B1 (en) | 2007-07-02 | 2019-02-27 | Etubics Corporation | Methods and compositions for producing an adenovirus vector for use with multiple vaccinations |
| CA2702586C (en) | 2007-10-18 | 2017-08-01 | Bn Immunotherapeutics Inc. | Use of mva to treat prostate cancer |
| US8748356B2 (en) | 2007-10-19 | 2014-06-10 | Janssen Biotech, Inc. | Methods for use in human-adapting monoclonal antibodies |
| ES2567564T3 (es) | 2007-11-19 | 2016-04-25 | Transgene Sa | Vectores oncolíticos de poxvirus |
| ES2564523T3 (es) | 2007-12-19 | 2016-03-23 | Janssen Biotech, Inc. | Diseño y generación de bibliotecas de presentación en fago por pIX de novo humanas mediante fusión con pIX o pVII, vectores, anticuerpos y métodos |
| PL2235064T3 (pl) | 2008-01-07 | 2016-06-30 | Amgen Inc | Sposób otrzymywania cząsteczek przeciwciał z heterodimerycznymi fc z zastosowaniem kierujących efektów elektrostatycznych |
| WO2009111738A2 (en) | 2008-03-06 | 2009-09-11 | Mayo Foundation For Medical Education And Research | Single cycle replicating adenovirus vectors |
| WO2009127060A1 (en) | 2008-04-15 | 2009-10-22 | Protiva Biotherapeutics, Inc. | Novel lipid formulations for nucleic acid delivery |
| US9146238B2 (en) | 2008-04-16 | 2015-09-29 | The Johns Hopkins University | Compositions and methods for treating or preventing prostate cancer and for detecting androgen receptor variants |
| CN102076355B (zh) | 2008-04-29 | 2014-05-07 | Abbvie公司 | 双重可变结构域免疫球蛋白及其用途 |
| WO2010028099A1 (en) | 2008-09-03 | 2010-03-11 | The Johns Hopkins University | Genetic alterations in isocitrate dehydrogenase and other genes in malignant glioma |
| US8133724B2 (en) | 2008-09-17 | 2012-03-13 | University Of Maryland, Baltimore | Human androgen receptor alternative splice variants as biomarkers and therapeutic targets |
| JP2012505654A (ja) | 2008-10-14 | 2012-03-08 | ヤンセン バイオテツク,インコーポレーテツド | 抗体をヒト化及び親和性成熟する方法 |
| JP5809978B2 (ja) | 2008-10-31 | 2015-11-11 | ザ・トラステイーズ・オブ・ザ・ユニバーシテイ・オブ・ペンシルベニア | サルアデノウイルスSAdV−43、−45、−46、−47、−48、−49および−50ならびにそれらの用途 |
| CN102307896B (zh) | 2008-10-31 | 2016-10-12 | 森托科尔奥索生物科技公司 | 基于iii型纤连蛋白结构域的支架组合物、方法及用途 |
| KR20110111474A (ko) | 2009-01-09 | 2011-10-11 | 더 리젠츠 오브 더 유니버시티 오브 미시간 | 암에서의 반복적 유전자 융합체 |
| BRPI1008018A2 (pt) | 2009-02-02 | 2016-03-15 | Okairos Ag | ácidos nucleicos de adenovírus símio e sequências de aminoácidos, vetores contendo os mesmos e uso dos mesmos |
| JP5873335B2 (ja) | 2009-02-12 | 2016-03-01 | ヤンセン バイオテツク,インコーポレーテツド | フィブロネクチンiii型ドメインに基づくスカフォールド組成物、方法及び使用 |
| US8394385B2 (en) | 2009-03-13 | 2013-03-12 | Bavarian Nordic A/S | Optimized early-late promoter combined with repeated vaccination favors cytotoxic T cell response against recombinant antigen in MVA vaccines |
| EP2424567B1 (en) | 2009-04-27 | 2018-11-21 | OncoMed Pharmaceuticals, Inc. | Method for making heteromultimeric molecules |
| US9539320B2 (en) | 2009-05-15 | 2017-01-10 | Irx Therapeutics, Inc. | Vaccine immunotherapy |
| US20110300205A1 (en) | 2009-07-06 | 2011-12-08 | Novartis Ag | Self replicating rna molecules and uses thereof |
| CA2777053A1 (en) | 2009-10-06 | 2011-04-14 | The Board Of Trustees Of The University Of Illinois | Human single-chain t cell receptors |
| ES2713852T3 (es) | 2009-12-01 | 2019-05-24 | Translate Bio Inc | Derivado de esteroides para la administración de ARNm en enfermedades genéticas humanas |
| GB201002730D0 (en) | 2010-02-18 | 2010-04-07 | Uni I Oslo | Product |
| US20170039314A1 (en) | 2010-03-23 | 2017-02-09 | Iogenetics, Llc | Bioinformatic processes for determination of peptide binding |
| WO2011119484A1 (en) | 2010-03-23 | 2011-09-29 | Iogenetics, Llc | Bioinformatic processes for determination of peptide binding |
| TWI688395B (zh) | 2010-03-23 | 2020-03-21 | 英翠克頌公司 | 條件性表現治療性蛋白質之載體、包含該載體之宿主細胞及彼等之用途 |
| BR112012026766B1 (pt) | 2010-04-20 | 2021-11-03 | Genmab A/S | Métodos in vitro para gerar um anticorpo igg heterodimérico, para a seleção de um anticorpo biespecífico, vetor de expressão, anticorpo igg heterodimérico, composição farmacêutica, e, uso de um anticorpo igg heterodimérico |
| CA2797981C (en) | 2010-05-14 | 2019-04-23 | Rinat Neuroscience Corporation | Heterodimeric proteins and methods for producing and purifying them |
| PT2591114T (pt) | 2010-07-06 | 2016-08-02 | Glaxosmithkline Biologicals Sa | Imunização de mamíferos de grande porte com doses baixas de arn |
| US9770463B2 (en) | 2010-07-06 | 2017-09-26 | Glaxosmithkline Biologicals Sa | Delivery of RNA to different cell types |
| EP2590670B1 (en) | 2010-07-06 | 2017-08-23 | GlaxoSmithKline Biologicals SA | Methods of raising an immune response by delivery of rna |
| RS54489B1 (en) | 2010-07-06 | 2016-06-30 | Glaxosmithkline Biologicals Sa | LIPOSOMS WITH LIPIDS THAT HAVE IMPROVED PKA VALUE FOR RNA RELEASE |
| LT2590676T (lt) | 2010-07-06 | 2016-10-25 | Glaxosmithkline Biologicals Sa | Viriono tipo išnešiojančios dalelės, skirtos besireplikuojančioms rnr molekulėms |
| EP2420253A1 (en) | 2010-08-20 | 2012-02-22 | Leadartis, S.L. | Engineering multifunctional and multivalent molecules with collagen XV trimerization domain |
| ES2935542T3 (es) | 2010-08-31 | 2023-03-07 | Glaxosmithkline Biologicals Sa | Liposomas pequeños para la administración de ARN que codifica para inmunógeno |
| PL3970742T3 (pl) | 2010-08-31 | 2022-09-19 | Glaxosmithkline Biologicals S.A. | Pegylowane liposomy do dostarczania rna kodującego immunogen |
| WO2012041968A1 (en) | 2010-09-29 | 2012-04-05 | Uti Limited Partnership | Methods for treating autoimmune disease using biocompatible bioabsorbable nanospheres |
| WO2012044999A2 (en) | 2010-10-01 | 2012-04-05 | Ludwig Institute For Cancer Research Ltd. | Reversible protein multimers, methods for their production and use |
| CN103429620B (zh) | 2010-11-05 | 2018-03-06 | 酵活有限公司 | 在Fc结构域中具有突变的稳定异源二聚的抗体设计 |
| WO2012089225A1 (en) | 2010-12-29 | 2012-07-05 | Curevac Gmbh | Combination of vaccination and inhibition of mhc class i restricted antigen presentation |
| EP2502934B1 (en) | 2011-03-24 | 2018-01-17 | Universitätsmedizin der Johannes Gutenberg-Universität Mainz | Single chain antigen recognizing constructs (scARCs) stabilized by the introduction of novel disulfide bonds |
| CN103874706B (zh) | 2011-04-28 | 2016-06-08 | 贝勒医学院 | 在人类前列腺癌富集的作为生物标记物的再生嵌合rna |
| GB201108879D0 (en) | 2011-05-25 | 2011-07-06 | Isis Innovation | Vector |
| CN103796680A (zh) | 2011-06-21 | 2014-05-14 | 约翰霍普金斯大学 | 用于增强针对赘生物的基于免疫的治疗的聚焦放射 |
| EP2729126B1 (en) | 2011-07-06 | 2020-12-23 | GlaxoSmithKline Biologicals SA | Liposomes having useful n:p ratio for delivery of rna molecules |
| US11896636B2 (en) | 2011-07-06 | 2024-02-13 | Glaxosmithkline Biologicals Sa | Immunogenic combination compositions and uses thereof |
| JP2014520807A (ja) | 2011-07-06 | 2014-08-25 | ノバルティス アーゲー | 免疫原性組成物およびその使用 |
| SG11201400250UA (en) | 2011-08-31 | 2014-03-28 | Novartis Ag | Pegylated liposomes for delivery of immunogen-encoding rna |
| CN107574154A (zh) | 2011-10-05 | 2018-01-12 | 金维克有限公司 | 猴(大猩猩)腺病毒或腺病毒载体及其使用方法 |
| RU2014118727A (ru) | 2011-10-11 | 2015-11-20 | Новартис Аг | Рекомбинантные самореплицирующиеся полицистронные молекулы рнк |
| US10344050B2 (en) | 2011-10-27 | 2019-07-09 | Genmab A/S | Production of heterodimeric proteins |
| KR102052774B1 (ko) | 2011-11-04 | 2019-12-04 | 자임워크스 인코포레이티드 | Fc 도메인 내의 돌연변이를 갖는 안정한 이종이합체 항체 설계 |
| LT2794905T (lt) | 2011-12-20 | 2020-07-10 | Medimmune, Llc | Modifikuoti polipeptidai, skirti bispecifinių antikūnų karkasams |
| AU2013214776B2 (en) | 2012-02-02 | 2017-11-09 | Board Of Regents, The University Of Texas System | Adenoviruses expressing heterologous tumor-associated antigens |
| US20160078168A1 (en) | 2012-02-13 | 2016-03-17 | Splicingcodes.Com | Fusion transcript detection methods and fusion transcripts identified thereby |
| US10501513B2 (en) | 2012-04-02 | 2019-12-10 | Modernatx, Inc. | Modified polynucleotides for the production of oncology-related proteins and peptides |
| AU2013243953A1 (en) | 2012-04-02 | 2014-10-30 | Modernatx, Inc. | Modified polynucleotides for the production of nuclear proteins |
| PT2838917T (pt) | 2012-04-20 | 2019-09-12 | Merus Nv | Métodos e meios para a produção de moléculas similares a ig heterodiméricas |
| PE20150336A1 (es) * | 2012-05-25 | 2015-03-25 | Univ California | Metodos y composiciones para la modificacion de adn objetivo dirigida por arn y para la modulacion de la transcripcion dirigida por arn |
| KR20150038066A (ko) | 2012-07-30 | 2015-04-08 | 알렉스 와 힌 영 | 종양 세포, 암세포파괴 바이러스 벡터 및 면역 체크포인트 조절인자를 갖는 암 백신 시스템 |
| EP3639851A1 (en) | 2012-09-04 | 2020-04-22 | Bavarian Nordic A/S | Methods and compositions for enhancing vaccine immune responses |
| EP2925348B1 (en) | 2012-11-28 | 2019-03-06 | BioNTech RNA Pharmaceuticals GmbH | Individualized vaccines for cancer |
| SG11201506052PA (en) | 2013-02-22 | 2015-09-29 | Curevac Gmbh | Combination of vaccination and inhibition of the pd-1 pathway |
| MX2016000231A (es) | 2013-06-26 | 2016-10-05 | Guangzhou Xiangxue Pharmaceutical Co Ltd | Receptor de celulas t de la alta estabilidad y metodo de preparacion y aplicacion del mismo. |
| US10350275B2 (en) | 2013-09-21 | 2019-07-16 | Advantagene, Inc. | Methods of cytotoxic gene therapy to treat tumors |
| EP3412304A3 (en) | 2013-10-23 | 2019-03-20 | The United States of America, as represented by The Secretary, Department of Health and Human Services | Hla-a24 agonist epitopes of muc1-c oncoprotein and compositions and methods of use |
| AU2014347004B2 (en) | 2013-11-05 | 2019-08-08 | Bavarian Nordic A/S | Combination therapy for treating cancer with a poxvirus expressing a tumor antigen and an antagonist and/or agonist of an immune checkpoint inhibitor |
| BR112016010224A2 (pt) | 2013-11-05 | 2018-05-02 | Cognate Bioservices, Inc. | combinações de inibidores do ponto de verificação e produtos terapêuticos para tratar o câncer. |
| CN105873902B (zh) | 2013-11-18 | 2019-03-08 | 阿克丘勒斯治疗公司 | 用于rna递送的可电离的阳离子脂质 |
| DK3071697T3 (da) | 2013-11-22 | 2020-01-27 | Dnatrix Inc | Adenovirus der udtrykker immuncelle-stimulatorisk(e) receptor agonist(er) |
| JP6641276B2 (ja) | 2013-11-28 | 2020-02-05 | バヴァリアン・ノルディック・アクティーゼルスカブ | ポックスウイルスベクターを用いて増強された免疫応答を誘導するための組成物及び方法ベクター |
| US20170106065A1 (en) | 2013-12-31 | 2017-04-20 | Bavarian Nordic A/S | Combination Therapy for Treating Cancer with a Poxvirus Expressing a Tumor Antigen and an Antagonist of TIM-3 |
| US9884075B2 (en) | 2014-01-16 | 2018-02-06 | California Institute Of Technology | Domain-swap T cell receptors |
| CA2939093A1 (en) | 2014-02-14 | 2015-08-20 | Immune Design Corp. | Immunotherapy of cancer through combination of local and systemic immune stimulation |
| JP2017507672A (ja) | 2014-02-28 | 2017-03-23 | ヤンセン ファッシンズ アンド プリベンション ベーフェーJanssen Vaccines & Prevention B.V. | 複製型組み換えアデノウイルスベクター、組成物およびこれらの使用方法 |
| WO2015143221A1 (en) | 2014-03-19 | 2015-09-24 | Mayo Foundation For Medical Education And Research | Methods and materials for treating cancer |
| EP4023249A1 (en) | 2014-04-23 | 2022-07-06 | ModernaTX, Inc. | Nucleic acid vaccines |
| KR102499737B1 (ko) | 2014-05-13 | 2023-02-13 | 버베리안 노딕 에이/에스 | 종양 항원을 발현하는 재조합 폭스바이러스 및 면역 체크포인트 분자 길항제 또는 효현제로 암을 치료하기 위한 복합 요법 |
| JP2017515841A (ja) | 2014-05-13 | 2017-06-15 | バヴァリアン・ノルディック・アクティーゼルスカブ | 腫瘍抗原を発現するポックスウイルス及びtim−3に対するモノクローナル抗体を用いた癌治療のための併用療法 |
| US20170158776A1 (en) | 2014-05-15 | 2017-06-08 | Bristol-Myers Squibb Company | Treatment of lung cancer using a combination of an anti-pd-1 antibody and another anti-cancer agent |
| WO2015192068A1 (en) | 2014-06-12 | 2015-12-17 | The Johns Hopkins University | Combinatorial immunotherapy for pancreatic cancer treatment |
| JP2017530114A (ja) | 2014-09-26 | 2017-10-12 | バヴァリアン・ノルディック・アクティーゼルスカブ | フラジェリンをコードする組み換えmvaによる鼻腔内免疫のための方法と組成物 |
| EP3215164A1 (en) | 2014-11-03 | 2017-09-13 | Immures S.r.l. | T cell receptors |
| EP3256156A1 (en) | 2015-02-13 | 2017-12-20 | Transgene SA | Immunotherapeutic vaccine and antibody combination therapy |
| KR20180006916A (ko) | 2015-04-17 | 2018-01-19 | 메모리얼 슬로안-케터링 캔서 센터 | 고형 종양에 대한 면역치료제로서 mva 또는 mva델타e3l의 용도 |
| GB201506642D0 (en) | 2015-04-20 | 2015-06-03 | Ucl Business Plc | T cell receptor |
| DK3326641T3 (da) | 2015-04-22 | 2019-09-30 | Curevac Ag | Rna-holdig sammensætning til behandling af tumorsygdomme |
| AU2016253145B2 (en) | 2015-04-23 | 2020-07-02 | Nant Holdings Ip, Llc | Cancer neoepitopes |
| US20190060484A1 (en) | 2015-05-06 | 2019-02-28 | Uti Limited Partnership | Nanoparticle compositions for sustained therapy |
| US11559570B2 (en) | 2015-05-15 | 2023-01-24 | CureVac SE | Prime-boost regimens involving administration of at least one mRNA construct |
| TWI806815B (zh) | 2015-05-20 | 2023-07-01 | 美商博德研究所有限公司 | 共有之gata3相關之腫瘤特異性新抗原 |
| JP6752231B2 (ja) | 2015-06-01 | 2020-09-09 | カリフォルニア インスティテュート オブ テクノロジー | 抗原を用いて特異的集団に関してt細胞をスクリーニングするための組成物および方法 |
| CN106714836A (zh) | 2015-06-05 | 2017-05-24 | H·李·莫菲特癌症中心研究有限公司 | Gm‑csf/cd40l疫苗和检查点抑制剂联合治疗 |
| WO2016203025A1 (en) | 2015-06-17 | 2016-12-22 | Curevac Ag | Vaccine composition |
| CN107847544B (zh) | 2015-07-20 | 2021-10-15 | 小利兰·斯坦福大学董事会 | 用多聚体结合试剂检测细胞表型和定量 |
| GB201513176D0 (en) * | 2015-07-27 | 2015-09-09 | Glaxosmithkline Biolog Sa | Novel methods for inducing an immune response |
| EP3328394A4 (en) * | 2015-07-30 | 2019-03-13 | ModernaTX, Inc. | PEPTIDE CONCATEMERIC EPITAOPE RNA |
| EA037295B1 (ru) | 2015-08-20 | 2021-03-05 | Янссен Вэксинс Энд Превеншн Б.В. | Терапевтические вакцины против hpv18 |
| WO2017070110A1 (en) | 2015-10-19 | 2017-04-27 | Cold Genesys, Inc. | Methods of treating solid or lymphatic tumors by combination therapy |
| CN114404581A (zh) | 2015-10-22 | 2022-04-29 | 摩登纳特斯有限公司 | 癌症疫苗 |
| WO2017075440A1 (en) | 2015-10-30 | 2017-05-04 | The United States Of America, As Represented By The Secretary, Department Of Health And Human Services | Targeted cancer therapy |
| AU2016348391A1 (en) | 2015-11-03 | 2018-05-17 | Janssen Biotech, Inc. | Antibodies specifically binding TIM-3 and their uses |
| US20190255186A1 (en) | 2015-12-02 | 2019-08-22 | Innovative Targeting Solutions Inc. | Single variable domain t-cell receptors |
| CA3015650A1 (en) | 2016-02-25 | 2017-08-31 | Memorial Sloan Kettering Cancer Center | Replication competent attenuated vaccinia viruses with deletion of thymidine kinase with and without the expression of human flt3l or gm-csf for cancer immunotherapy |
| MX2018010231A (es) | 2016-02-25 | 2019-06-06 | Memorial Sloan Kettering Cancer Center | Mva recombinante o mvadele3l que expresa el flt3l humano y uso de los mismos como agentes inmunoterapéuticos contra tumores sólidos. |
| BR112018067565A2 (pt) | 2016-03-04 | 2019-02-05 | Univ New York | vetores de vírus que expressam múltiplos epítopos de antígenos associados a tumor para induzir imunidade antitumor |
| WO2017162266A1 (en) | 2016-03-21 | 2017-09-28 | Biontech Rna Pharmaceuticals Gmbh | Rna replicon for versatile and efficient gene expression |
| BR112018070183A2 (pt) | 2016-03-31 | 2019-04-16 | Neon Therapeutics, Inc. | neoantígenos e métodos de seu uso |
| CA3056212A1 (en) | 2016-04-07 | 2017-10-12 | Bostongene Corporation | Construction and methods of use of a therapeutic cancer vaccine library comprising fusion-specific vaccines |
| US11446398B2 (en) | 2016-04-11 | 2022-09-20 | Obsidian Therapeutics, Inc. | Regulated biocircuit systems |
| US10538786B2 (en) | 2016-04-13 | 2020-01-21 | Janssen Pharmaceuticals, Inc. | Recombinant arterivirus replicon systems and uses thereof |
| US20180126003A1 (en) | 2016-05-04 | 2018-05-10 | Curevac Ag | New targets for rna therapeutics |
| ES2941411T3 (es) | 2016-05-18 | 2023-05-22 | Modernatx Inc | Polinucleótidos que codifican interleucina-12 (IL12) y usos de los mismos |
| AU2017266929B2 (en) | 2016-05-18 | 2023-05-11 | Modernatx, Inc. | Combinations of mRNAs encoding immune modulating polypeptides and uses thereof |
| EP3458092A1 (en) | 2016-05-18 | 2019-03-27 | Modernatx, Inc. | Mrna combination therapy for the treatment of cancer |
| EP3463440A4 (en) | 2016-05-27 | 2020-04-15 | Etubics Corporation | NEOEPITOP VACCINE COMPOSITIONS AND METHOD FOR USE THEREOF |
| US11427625B2 (en) | 2016-06-14 | 2022-08-30 | University of Pittsburgh—of the Commonwealth System of Higher Education | Expression of NKG2D activating ligand proteins for sensitizing cancer cells to attack by cytotoxic immune cells |
| EP3472327B1 (en) | 2016-06-20 | 2020-08-19 | Janssen Vaccines & Prevention B.V. | Potent and balanced bidirectional promoter |
| WO2018033254A2 (en) | 2016-08-19 | 2018-02-22 | Curevac Ag | Rna for cancer therapy |
| TW202304970A (zh) | 2016-08-26 | 2023-02-01 | 德商英麥提克生物技術股份有限公司 | 用於頭頸鱗狀細胞癌和其他癌症免疫治療的新型肽和支架 |
| CN110494159A (zh) | 2016-09-02 | 2019-11-22 | 扬森疫苗与预防公司 | 在接受抗逆转录病毒治疗的对象中诱导针对人类免疫缺陷病毒感染的免疫应答的方法 |
| HUE053236T2 (hu) | 2016-09-12 | 2021-06-28 | Targovax Oy | Adenovírus és ellenõrzõpont-gátlók kombinálása rák kezelésére |
| JP7062003B2 (ja) | 2016-09-28 | 2022-05-02 | バヴァリアン・ノルディック・アクティーゼルスカブ | ポックスウイルス内における導入遺伝子の安定性を向上させるための組成物及び方法 |
| JP7022123B2 (ja) | 2016-09-30 | 2022-02-17 | エフ・ホフマン-ラ・ロシュ・アクチェンゲゼルシャフト | Cd3に対する二重特異性抗体 |
| KR20190082226A (ko) | 2016-10-17 | 2019-07-09 | 신테틱 제노믹스, 인코포레이티드. | 재조합 바이러스 레플리콘 시스템 및 그의 용도 |
| EP3532103A1 (en) | 2016-10-26 | 2019-09-04 | Acuitas Therapeutics, Inc. | Lipid nanoparticle formulations |
| JP2020500847A (ja) | 2016-11-16 | 2020-01-16 | プライムヴァックス イミュノ−オンコロジー,インク. | 癌の処置のための併用免疫療法 |
| BR112019010565A2 (pt) * | 2016-11-23 | 2019-09-17 | Gritstone Oncology Inc | aplicação viral de neoantígenos |
| KR20190082850A (ko) | 2016-11-30 | 2019-07-10 | 어드박시스, 인크. | 반복되는 암 돌연변이를 표적화하는 면역원 조성물 및 그것의 사용 방법 |
| WO2018102585A1 (en) | 2016-11-30 | 2018-06-07 | Advaxis, Inc. | Personalized immunotherapy in combination with immunotherapy targeting recurrent cancer mutations |
| BR112019011661A2 (pt) | 2016-12-05 | 2020-01-07 | Synthetic Genomics, Inc. | Composições e métodos para aumentar expressão de gene |
| WO2018107011A1 (en) | 2016-12-08 | 2018-06-14 | City Of Hope | P53-targeting vaccines and pd-1 pathway inhibitors and methods of use thereof |
| US10459372B2 (en) | 2017-01-31 | 2019-10-29 | Hewlett-Packard Development Company, L.P. | Binary ink developer (BID) assembly for liquid electrophotography (LEP) printing device |
| NZ755780A (en) | 2017-02-01 | 2023-10-27 | Modernatx Inc | Rna cancer vaccines |
| US11229668B2 (en) | 2017-02-07 | 2022-01-25 | Nantcell, Inc. | Maximizing T-cell memory and compositions and methods therefor |
| KR102111244B1 (ko) | 2017-02-09 | 2020-05-15 | 얀센 백신스 앤드 프리벤션 비.브이. | 이종 유전자의 발현을 위한 강력한 짧은 프로모터 |
| MX2019009612A (es) | 2017-02-10 | 2019-11-12 | Univ Rockefeller | Metodos de elaboracion de perfiles especificos al tipo celular para identificar objetivos de farmacos. |
| WO2018161092A1 (en) | 2017-03-03 | 2018-09-07 | New York University | Induction and enhancement of antitumor immunity involving virus vectors expressing multiple epitopes of tumor associated antigens and immune checkpoint inhibitors or proteins |
| EP3595715A1 (en) | 2017-03-17 | 2020-01-22 | CureVac AG | Rna vaccine and immune checkpoint inhibitors for combined anticancer therapy |
| US20230241207A1 (en) | 2017-04-03 | 2023-08-03 | Neon Therapeutics, Inc. | Protein antigens and uses thereof |
| US20200121774A1 (en) | 2017-04-19 | 2020-04-23 | University Of Iowa Research Foundation | Cancer vaccines and methods of producing and using same |
| CA3062591A1 (en) | 2017-05-08 | 2018-11-15 | Gritstone Oncology, Inc. | Alphavirus neoantigen vectors |
| CN111107872A (zh) | 2017-05-12 | 2020-05-05 | 纪念斯隆-凯特林癌症中心 | 有用于癌症免疫疗法的牛痘病毒突变体 |
| US20200188496A1 (en) | 2017-06-02 | 2020-06-18 | Arizona Board Of Regents On Behalf Of Arizona State University | Universal cancer vaccines and methods of making and using same |
| JP7334124B2 (ja) | 2017-06-21 | 2023-08-28 | トランジェーヌ | 個別化ワクチン |
| CN111108192B (zh) | 2017-07-05 | 2023-12-15 | Nouscom股份公司 | 非人类人猿腺病毒核酸序列和氨基酸序列、含有其的载体及其用途 |
| IL271965B2 (en) | 2017-07-12 | 2023-03-01 | Nouscom Ag | Preparations containing a neoantigenic vaccine for the treatment of cancer |
| SG11202000250PA (en) * | 2017-07-12 | 2020-02-27 | Nouscom Ag | A universal vaccine based on shared tumor neoantigens for prevention and treatment of micro satellite instable (msi) cancers |
| WO2019023566A1 (en) | 2017-07-28 | 2019-01-31 | Janssen Vaccines & Prevention B.V. | METHODS AND COMPOSITIONS FOR PROVIDING IMMUNIZATION AGAINST Heterologous ARNREP |
| GB201713163D0 (en) * | 2017-08-16 | 2017-09-27 | Univ Oxford Innovation Ltd | HPV vaccine |
| JP7202362B2 (ja) | 2017-08-24 | 2023-01-11 | バヴァリアン・ノルディック・アクティーゼルスカブ | 組み換えmva及び抗体の静脈内投与を用いた、がん治療のための併用療法 |
| US11839655B2 (en) | 2017-09-01 | 2023-12-12 | Microvax, Llc | Combination cancer therapy |
| AU2018333530B2 (en) | 2017-09-13 | 2024-05-30 | Biontech Cell & Gene Therapies Gmbh | RNA replicon for expressing a T cell receptor or an artificial T cell receptor |
| KR20200076696A (ko) | 2017-11-03 | 2020-06-29 | 노우스콤 아게 | 백신 t 세포 인핸서 |
| WO2019094396A1 (en) | 2017-11-07 | 2019-05-16 | Nektar Therapeutics | Immunotherapeutic combination for treating cancer |
| GB201721068D0 (en) | 2017-12-15 | 2018-01-31 | Glaxosmithkline Biologicals Sa | Hepatitis B immunisation regimen and compositions |
| JP7312412B2 (ja) | 2018-01-05 | 2023-07-21 | オタワ ホスピタル リサーチ インスティチュート | 改変オルトポックスウイルスベクター |
| AU2019205627B2 (en) | 2018-01-06 | 2024-05-09 | Emergex Vaccines Holding Limited | MHC class I associated peptides for prevention and treatment of multiple flavi virus |
| JP2021516660A (ja) | 2018-01-11 | 2021-07-08 | バイオンテック エールエヌアー ファーマシューティカルズ ゲーエムベーハー | Rnaの投与のための配合物 |
| WO2019143949A2 (en) | 2018-01-19 | 2019-07-25 | Synthetic Genomics, Inc. | Induce and enhance immune responses using recombinant replicon systems |
| EP3743084A4 (en) | 2018-01-24 | 2021-12-08 | Virogin Biotech Canada Ltd | RECOMBINANT ANTIVIRAL VACCINES |
| CN111655845A (zh) | 2018-01-26 | 2020-09-11 | 联邦高等教育系统匹兹堡大学 | 代谢调节剂在肿瘤微环境中的表达以改善肿瘤的治疗 |
| WO2019152922A1 (en) | 2018-02-05 | 2019-08-08 | Nant Holdings Ip, Llc | Calreticulin and fusion proteins |
| US11376290B2 (en) | 2018-03-14 | 2022-07-05 | Wuhan Boweid Biotechnology Co., Ltd. | Recombinant oncolytic virus, synthetic DNA sequence, and application thereof |
| US20210015878A1 (en) | 2018-03-28 | 2021-01-21 | Epicentrx, Inc. | Personalized cancer vaccines |
| EP3773476A1 (en) | 2018-03-30 | 2021-02-17 | Arcturus Therapeutics, Inc. | Lipid particles for nucleic acid delivery |
| TWI787500B (zh) | 2018-04-23 | 2022-12-21 | 美商南特細胞公司 | 新抗原表位疫苗及免疫刺激組合物及方法 |
| GB201807932D0 (en) | 2018-05-16 | 2018-06-27 | Redchenko Irina | Compositions and methods for inducing an immune response |
| EP3796927A4 (en) | 2018-05-23 | 2022-04-20 | Gritstone bio, Inc. | SHARED ANTIGENS |
| CN112351793A (zh) | 2018-05-23 | 2021-02-09 | 磨石肿瘤生物技术公司 | 免疫检查点抑制剂共表达载体 |
| CN112384205B (zh) | 2018-05-30 | 2024-05-03 | 川斯勒佰尔公司 | 信使rna疫苗及其用途 |
| WO2019238023A1 (en) * | 2018-06-11 | 2019-12-19 | Chineo Medical Technology Co., Ltd. | Neoantigen vaccines and uses thereof |
| EP3587581A1 (en) | 2018-06-26 | 2020-01-01 | GlaxoSmithKline Biologicals S.A. | Formulations for simian adenoviral vectors having enhanced storage stability |
| WO2020014539A1 (en) | 2018-07-11 | 2020-01-16 | Epicentrx, Inc. | Methods and compositions for targeting cancer cells for treatment |
| WO2020022897A1 (en) | 2018-07-26 | 2020-01-30 | Frame Pharmaceuticals B.V. | Method of preparing subject-specific immunogenic compositions based on a neo open-reading-frame peptide database |
| GB201812647D0 (en) | 2018-08-03 | 2018-09-19 | Chancellor Masters And Scholars Of The Univ Of Oxford | Viral vectors and methods for the prevention or treatment of cancer |
| EP3850103A4 (en) | 2018-09-15 | 2022-06-22 | Memorial Sloan Kettering Cancer Center | RECOMBINANT POXVIRUS FOR CANCER IMMUNOTHERAPY |
| US20210393757A1 (en) | 2018-10-01 | 2021-12-23 | The Wistar Institute | Melanoma Canine Vaccine Compositions and Methods of Use Thereof |
| JP2022512595A (ja) | 2018-10-05 | 2022-02-07 | バヴァリアン・ノルディック・アクティーゼルスカブ | 組み換えmva、及び免疫チェックポイントアンタゴニストまたは免疫チェックポイントアゴニストの静脈内投与によって、がんを治療する併用療法 |
| WO2020073045A1 (en) | 2018-10-05 | 2020-04-09 | Nantcell, Inc. | Cd40 and cd40l combo in an adenovirus vaccine vehicle |
| KR20210081325A (ko) | 2018-10-19 | 2021-07-01 | 노우스콤 아게 | 경골어류 불변 사슬 암 백신 |
| JP2022506839A (ja) | 2018-11-07 | 2022-01-17 | モデルナティエックス インコーポレイテッド | Rnaがんワクチン |
| AU2019374874A1 (en) | 2018-11-07 | 2021-06-10 | Gritstone Bio, Inc. | Alphavirus neoantigen vectors and interferon inhibitors |
| JP7477888B2 (ja) | 2018-11-15 | 2024-05-02 | ノイスコム アーゲー | 個別化された癌ワクチンの作製のための癌変異の選択 |
| EP3883599A1 (en) | 2018-11-20 | 2021-09-29 | Bavarian Nordic A/S | Therapy for treating cancer with an intratumoral and/or intravenous administration of a recombinant mva encoding 4-1bbl (cd137l) and/or cd40l |
| WO2020123912A1 (en) | 2018-12-13 | 2020-06-18 | Rhode Island Hospital | Inhibition of asph expressing tumor growth and progression |
| CA3121430A1 (en) | 2018-12-14 | 2020-06-18 | Glaxosmithkline Biologicals Sa | Heterologous prime boost vaccine compositions and methods |
| US20220062394A1 (en) | 2018-12-17 | 2022-03-03 | The Broad Institute, Inc. | Methods for identifying neoantigens |
| CN109806390A (zh) | 2019-01-07 | 2019-05-28 | 康希诺生物股份公司 | 一种SamRNA疫苗及其制备方法 |
| TW202043256A (zh) | 2019-01-10 | 2020-12-01 | 美商健生生物科技公司 | 前列腺新抗原及其用途 |
| JP2022518399A (ja) | 2019-01-14 | 2022-03-15 | ジェネンテック, インコーポレイテッド | Pd-1軸結合アンタゴニスト及びrnaワクチンを用いてがんを処置する方法 |
| KR20210118870A (ko) | 2019-01-21 | 2021-10-01 | 사노피 | 진행성 단계의 고형 종양 암에 대한 치료용 rna 및 항-pd1 항체 |
| TW202102543A (zh) | 2019-03-29 | 2021-01-16 | 美商安進公司 | 溶瘤病毒在癌症新輔助療法中之用途 |
| EP3721899A1 (en) | 2019-04-08 | 2020-10-14 | China Medical University | Combination therapies comprising dendritic cells-based vaccine and immune checkpoint inhibitor |
| KR20220016137A (ko) | 2019-05-30 | 2022-02-08 | 그릿스톤 바이오, 인코포레이티드 | 변형된 아데노바이러스 |
| WO2020247547A1 (en) | 2019-06-03 | 2020-12-10 | Geovax, Inc. | Cancer vaccine compositions and methods for use thereof |
-
2020
- 2020-01-08 TW TW109100544A patent/TW202043256A/zh unknown
- 2020-01-09 CN CN202080020511.3A patent/CN113573729A/zh active Pending
- 2020-01-09 BR BR112021013507A patent/BR112021013507A2/pt unknown
- 2020-01-09 SG SG11202107274VA patent/SG11202107274VA/en unknown
- 2020-01-09 WO PCT/IB2020/050145 patent/WO2020144615A1/en unknown
- 2020-01-09 US US16/737,950 patent/US11793843B2/en active Active
- 2020-01-09 MX MX2021008392A patent/MX2021008392A/es unknown
- 2020-01-09 EP EP20701888.8A patent/EP3908311A1/en active Pending
- 2020-01-09 KR KR1020217025212A patent/KR20210113655A/ko active Search and Examination
- 2020-01-09 AU AU2020207641A patent/AU2020207641A1/en active Pending
- 2020-01-09 CA CA3126462A patent/CA3126462A1/en active Pending
- 2020-01-09 WO PCT/IB2020/050144 patent/WO2020144614A1/en active Application Filing
- 2020-01-09 JP JP2021539906A patent/JP2022516770A/ja active Pending
- 2020-01-09 PE PE2021001152A patent/PE20211660A1/es unknown
- 2020-01-09 JO JOP/2021/0186A patent/JOP20210186A1/ar unknown
- 2020-01-09 MA MA054693A patent/MA54693A/fr unknown
- 2020-01-09 CR CR20210370A patent/CR20210370A/es unknown
- 2020-01-10 UY UY0001038542A patent/UY38542A/es unknown
-
2021
- 2021-07-01 IL IL284561A patent/IL284561A/en unknown
- 2021-07-08 CL CL2021001835A patent/CL2021001835A1/es unknown
- 2021-07-28 CO CONC2021/0010006A patent/CO2021010006A2/es unknown
- 2021-07-30 EC ECSENADI202156536A patent/ECSP21056536A/es unknown
-
2022
- 2022-02-15 CL CL2022000373A patent/CL2022000373A1/es unknown
-
2023
- 2023-06-27 US US18/342,322 patent/US20240139265A1/en active Pending
Also Published As
| Publication number | Publication date |
|---|---|
| CA3126462A1 (en) | 2020-07-16 |
| EP3908311A1 (en) | 2021-11-17 |
| US11793843B2 (en) | 2023-10-24 |
| CR20210370A (es) | 2021-09-09 |
| CL2021001835A1 (es) | 2022-01-21 |
| JP2022516770A (ja) | 2022-03-02 |
| BR112021013507A2 (pt) | 2021-11-16 |
| CN113573729A (zh) | 2021-10-29 |
| MA54693A (fr) | 2021-11-17 |
| JOP20210186A1 (ar) | 2023-01-30 |
| AU2020207641A1 (en) | 2021-07-22 |
| CL2022000373A1 (es) | 2022-10-28 |
| SG11202107274VA (en) | 2021-07-29 |
| IL284561A (en) | 2021-08-31 |
| US20200222478A1 (en) | 2020-07-16 |
| CO2021010006A2 (es) | 2021-08-30 |
| ECSP21056536A (es) | 2023-02-28 |
| US20240139265A1 (en) | 2024-05-02 |
| WO2020144615A1 (en) | 2020-07-16 |
| TW202043256A (zh) | 2020-12-01 |
| UY38542A (es) | 2020-07-31 |
| MX2021008392A (es) | 2021-10-26 |
| WO2020144614A1 (en) | 2020-07-16 |
| PE20211660A1 (es) | 2021-08-26 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR20210113655A (ko) | 전립선 신생항원 및 이의 용도 | |
| CN112088008B (zh) | 修饰细胞的扩增及其用途 | |
| KR102272932B1 (ko) | 이종 유전자로 무장된 종양살상 아데노바이러스 | |
| AU2013295647B2 (en) | Multimeric fusion protein vaccine and immunotherapeutic | |
| KR20200104284A (ko) | Hpv-특이적 결합 분자 | |
| TW202333779A (zh) | 阿爾法病毒新抗原載體 | |
| CN113227144A (zh) | 用于生成car-t细胞的两类基因载体及其用途 | |
| KR20220038362A (ko) | 재조합 ad35 벡터 및 관련 유전자 요법 개선 | |
| KR20210013589A (ko) | 면역 체크포인트 억제제 공동-발현 벡터 | |
| KR20230014694A (ko) | 항원-코딩 카세트 | |
| AU2020387646A1 (en) | Recombinant MVA viruses for intratumoral and/or intravenous administration for treating cancer | |
| US20210261636A1 (en) | Neoantigens expressed in multiple myeloma and their uses | |
| US11945881B2 (en) | Neoantigens expressed in ovarian cancer and their uses | |
| RU2804664C2 (ru) | Hpv-специфические связывающие молекулы | |
| JP2024073576A (ja) | 改変アデノウイルス | |
| CN116997565A (zh) | 用于产生表达抗cd19嵌合抗原受体的细胞的慢病毒 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A201 | Request for examination |