KR20150130333A - 항체 약물 접합체 및 상응하는 항체 - Google Patents
항체 약물 접합체 및 상응하는 항체 Download PDFInfo
- Publication number
- KR20150130333A KR20150130333A KR1020157026812A KR20157026812A KR20150130333A KR 20150130333 A KR20150130333 A KR 20150130333A KR 1020157026812 A KR1020157026812 A KR 1020157026812A KR 20157026812 A KR20157026812 A KR 20157026812A KR 20150130333 A KR20150130333 A KR 20150130333A
- Authority
- KR
- South Korea
- Prior art keywords
- antibody
- antigen
- seq
- binding fragment
- fgfr2
- Prior art date
Links
- 239000000611 antibody drug conjugate Substances 0.000 title claims abstract description 143
- 229940049595 antibody-drug conjugate Drugs 0.000 title claims abstract description 143
- 206010028980 Neoplasm Diseases 0.000 claims abstract description 132
- 101000917134 Homo sapiens Fibroblast growth factor receptor 4 Proteins 0.000 claims abstract description 116
- 102100027844 Fibroblast growth factor receptor 4 Human genes 0.000 claims abstract description 96
- 201000011510 cancer Diseases 0.000 claims abstract description 96
- 238000011282 treatment Methods 0.000 claims abstract description 34
- 238000009739 binding Methods 0.000 claims description 240
- 230000027455 binding Effects 0.000 claims description 239
- 239000000427 antigen Substances 0.000 claims description 221
- 108091007433 antigens Proteins 0.000 claims description 220
- 102000036639 antigens Human genes 0.000 claims description 220
- 239000012634 fragment Substances 0.000 claims description 202
- 210000004027 cell Anatomy 0.000 claims description 176
- 239000003814 drug Substances 0.000 claims description 155
- 102100023600 Fibroblast growth factor receptor 2 Human genes 0.000 claims description 145
- 101710182389 Fibroblast growth factor receptor 2 Proteins 0.000 claims description 145
- 238000000034 method Methods 0.000 claims description 134
- 229940079593 drug Drugs 0.000 claims description 116
- 239000003112 inhibitor Substances 0.000 claims description 80
- ANZJBCHSOXCCRQ-FKUXLPTCSA-N mertansine Chemical compound CO[C@@H]([C@@]1(O)C[C@H](OC(=O)N1)[C@@H](C)[C@@H]1O[C@@]1(C)[C@@H](OC(=O)[C@H](C)N(C)C(=O)CCS)CC(=O)N1C)\C=C\C=C(C)\CC2=CC(OC)=C(Cl)C1=C2 ANZJBCHSOXCCRQ-FKUXLPTCSA-N 0.000 claims description 67
- -1 2,5-dioxo-2,5-dihydro-1H-pyrrol-1-yl Chemical group 0.000 claims description 58
- 102100035360 Cerebellar degeneration-related antigen 1 Human genes 0.000 claims description 57
- 150000007523 nucleic acids Chemical class 0.000 claims description 53
- 239000003431 cross linking reagent Substances 0.000 claims description 47
- 239000000562 conjugate Substances 0.000 claims description 44
- 241000282414 Homo sapiens Species 0.000 claims description 43
- JSHOVKSMJRQOGY-UHFFFAOYSA-N (2,5-dioxopyrrolidin-1-yl) 4-(pyridin-2-yldisulfanyl)butanoate Chemical compound O=C1CCC(=O)N1OC(=O)CCCSSC1=CC=CC=N1 JSHOVKSMJRQOGY-UHFFFAOYSA-N 0.000 claims description 40
- 229940127121 immunoconjugate Drugs 0.000 claims description 40
- 102000039446 nucleic acids Human genes 0.000 claims description 36
- 108020004707 nucleic acids Proteins 0.000 claims description 36
- 101000827688 Homo sapiens Fibroblast growth factor receptor 2 Proteins 0.000 claims description 35
- 102000055736 human FGFR2 Human genes 0.000 claims description 35
- 125000000539 amino acid group Chemical group 0.000 claims description 31
- 230000000694 effects Effects 0.000 claims description 29
- 239000013598 vector Substances 0.000 claims description 24
- 239000003153 chemical reaction reagent Substances 0.000 claims description 23
- 102000055699 human FGFR4 Human genes 0.000 claims description 22
- 239000008194 pharmaceutical composition Substances 0.000 claims description 22
- 239000003795 chemical substances by application Substances 0.000 claims description 19
- 229940121358 tyrosine kinase inhibitor Drugs 0.000 claims description 16
- 239000005483 tyrosine kinase inhibitor Substances 0.000 claims description 16
- 108020004414 DNA Proteins 0.000 claims description 14
- 150000003839 salts Chemical class 0.000 claims description 14
- JWDFQMWEFLOOED-UHFFFAOYSA-N (2,5-dioxopyrrolidin-1-yl) 3-(pyridin-2-yldisulfanyl)propanoate Chemical group O=C1CCC(=O)N1OC(=O)CCSSC1=CC=CC=N1 JWDFQMWEFLOOED-UHFFFAOYSA-N 0.000 claims description 13
- 101150029707 ERBB2 gene Proteins 0.000 claims description 13
- 229940127089 cytotoxic agent Drugs 0.000 claims description 13
- 231100000599 cytotoxic agent Toxicity 0.000 claims description 13
- 230000001965 increasing effect Effects 0.000 claims description 13
- 230000010056 antibody-dependent cellular cytotoxicity Effects 0.000 claims description 11
- 230000002285 radioactive effect Effects 0.000 claims description 11
- VRDGQQTWSGDXCU-UHFFFAOYSA-N (2,5-dioxopyrrolidin-1-yl) 2-iodoacetate Chemical compound ICC(=O)ON1C(=O)CCC1=O VRDGQQTWSGDXCU-UHFFFAOYSA-N 0.000 claims description 10
- BQWBEDSJTMWJAE-UHFFFAOYSA-N (2,5-dioxopyrrolidin-1-yl) 4-[(2-iodoacetyl)amino]benzoate Chemical compound C1=CC(NC(=O)CI)=CC=C1C(=O)ON1C(=O)CCC1=O BQWBEDSJTMWJAE-UHFFFAOYSA-N 0.000 claims description 10
- 206010006187 Breast cancer Diseases 0.000 claims description 10
- 150000004917 tyrosine kinase inhibitor derivatives Chemical class 0.000 claims description 10
- 208000026310 Breast neoplasm Diseases 0.000 claims description 9
- 101001034652 Homo sapiens Insulin-like growth factor 1 receptor Proteins 0.000 claims description 9
- 102100039688 Insulin-like growth factor 1 receptor Human genes 0.000 claims description 9
- NFGXHKASABOEEW-UHFFFAOYSA-N 1-methylethyl 11-methoxy-3,7,11-trimethyl-2,4-dodecadienoate Chemical compound COC(C)(C)CCCC(C)CC=CC(C)=CC(=O)OC(C)C NFGXHKASABOEEW-UHFFFAOYSA-N 0.000 claims description 8
- 229920001213 Polysorbate 20 Polymers 0.000 claims description 8
- 108010029485 Protein Isoforms Proteins 0.000 claims description 8
- 102000001708 Protein Isoforms Human genes 0.000 claims description 8
- 239000000256 polyoxyethylene sorbitan monolaurate Substances 0.000 claims description 8
- 235000010486 polyoxyethylene sorbitan monolaurate Nutrition 0.000 claims description 8
- 201000009410 rhabdomyosarcoma Diseases 0.000 claims description 8
- 239000012664 BCL-2-inhibitor Substances 0.000 claims description 7
- 229940123711 Bcl2 inhibitor Drugs 0.000 claims description 7
- 102100026539 Induced myeloid leukemia cell differentiation protein Mcl-1 Human genes 0.000 claims description 7
- 208000005718 Stomach Neoplasms Diseases 0.000 claims description 7
- 230000006907 apoptotic process Effects 0.000 claims description 7
- 239000002254 cytotoxic agent Substances 0.000 claims description 7
- 206010017758 gastric cancer Diseases 0.000 claims description 7
- 208000020816 lung neoplasm Diseases 0.000 claims description 7
- 201000011549 stomach cancer Diseases 0.000 claims description 7
- GTBCXYYVWHFQRS-UHFFFAOYSA-N (2,5-dioxopyrrolidin-1-yl) 4-(pyridin-2-yldisulfanyl)pentanoate Chemical compound C=1C=CC=NC=1SSC(C)CCC(=O)ON1C(=O)CCC1=O GTBCXYYVWHFQRS-UHFFFAOYSA-N 0.000 claims description 6
- FWMNVWWHGCHHJJ-SKKKGAJSSA-N 4-amino-1-[(2r)-6-amino-2-[[(2r)-2-[[(2r)-2-[[(2r)-2-amino-3-phenylpropanoyl]amino]-3-phenylpropanoyl]amino]-4-methylpentanoyl]amino]hexanoyl]piperidine-4-carboxylic acid Chemical compound C([C@H](C(=O)N[C@H](CC(C)C)C(=O)N[C@H](CCCCN)C(=O)N1CCC(N)(CC1)C(O)=O)NC(=O)[C@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 FWMNVWWHGCHHJJ-SKKKGAJSSA-N 0.000 claims description 6
- 206010009944 Colon cancer Diseases 0.000 claims description 6
- 101001056180 Homo sapiens Induced myeloid leukemia cell differentiation protein Mcl-1 Proteins 0.000 claims description 6
- 206010058467 Lung neoplasm malignant Diseases 0.000 claims description 6
- 102000029749 Microtubule Human genes 0.000 claims description 6
- 108091022875 Microtubule Proteins 0.000 claims description 6
- 238000004113 cell culture Methods 0.000 claims description 6
- 201000005202 lung cancer Diseases 0.000 claims description 6
- 210000004688 microtubule Anatomy 0.000 claims description 6
- 239000003381 stabilizer Substances 0.000 claims description 6
- 239000012624 DNA alkylating agent Substances 0.000 claims description 5
- 206010014733 Endometrial cancer Diseases 0.000 claims description 5
- 206010014759 Endometrial neoplasm Diseases 0.000 claims description 5
- 101710181812 Methionine aminopeptidase Proteins 0.000 claims description 5
- 208000029742 colonic neoplasm Diseases 0.000 claims description 5
- 201000007270 liver cancer Diseases 0.000 claims description 5
- 208000014018 liver neoplasm Diseases 0.000 claims description 5
- 102100024457 Cyclin-dependent kinase 9 Human genes 0.000 claims description 4
- 239000012623 DNA damaging agent Substances 0.000 claims description 4
- 102100024746 Dihydrofolate reductase Human genes 0.000 claims description 4
- 229940125831 FGFR2 inhibitor Drugs 0.000 claims description 4
- 101000980930 Homo sapiens Cyclin-dependent kinase 9 Proteins 0.000 claims description 4
- 101000684208 Homo sapiens Prolyl endopeptidase FAP Proteins 0.000 claims description 4
- PEEHTFAAVSWFBL-UHFFFAOYSA-N Maleimide Chemical compound O=C1NC(=O)C=C1 PEEHTFAAVSWFBL-UHFFFAOYSA-N 0.000 claims description 4
- 229940079156 Proteasome inhibitor Drugs 0.000 claims description 4
- 239000000362 adenosine triphosphatase inhibitor Substances 0.000 claims description 4
- 108010044540 auristatin Proteins 0.000 claims description 4
- 108020001096 dihydrofolate reductase Proteins 0.000 claims description 4
- 239000003937 drug carrier Substances 0.000 claims description 4
- 101150088071 fgfr2 gene Proteins 0.000 claims description 4
- 239000003481 heat shock protein 90 inhibitor Substances 0.000 claims description 4
- 239000003276 histone deacetylase inhibitor Substances 0.000 claims description 4
- 229940124302 mTOR inhibitor Drugs 0.000 claims description 4
- 239000003628 mammalian target of rapamycin inhibitor Substances 0.000 claims description 4
- 210000003470 mitochondria Anatomy 0.000 claims description 4
- 229940068977 polysorbate 20 Drugs 0.000 claims description 4
- 239000003207 proteasome inhibitor Substances 0.000 claims description 4
- 229940074404 sodium succinate Drugs 0.000 claims description 4
- ZDQYSKICYIVCPN-UHFFFAOYSA-L sodium succinate (anhydrous) Chemical compound [Na+].[Na+].[O-]C(=O)CCC([O-])=O ZDQYSKICYIVCPN-UHFFFAOYSA-L 0.000 claims description 4
- 238000006276 transfer reaction Methods 0.000 claims description 4
- FUHCFUVCWLZEDQ-UHFFFAOYSA-N 1-(2,5-dioxopyrrolidin-1-yl)oxy-1-oxo-4-(pyridin-2-yldisulfanyl)butane-2-sulfonic acid Chemical compound O=C1CCC(=O)N1OC(=O)C(S(=O)(=O)O)CCSSC1=CC=CC=N1 FUHCFUVCWLZEDQ-UHFFFAOYSA-N 0.000 claims description 3
- GWEVSJHKQHAKNW-UHFFFAOYSA-N 4-[[1-(2,5-dioxopyrrolidin-1-yl)-2h-pyridin-2-yl]disulfanyl]-2-sulfobutanoic acid Chemical compound OC(=O)C(S(O)(=O)=O)CCSSC1C=CC=CN1N1C(=O)CCC1=O GWEVSJHKQHAKNW-UHFFFAOYSA-N 0.000 claims description 3
- 229940121819 ATPase inhibitor Drugs 0.000 claims description 3
- 208000000461 Esophageal Neoplasms Diseases 0.000 claims description 3
- 206010030155 Oesophageal carcinoma Diseases 0.000 claims description 3
- 201000005188 adrenal gland cancer Diseases 0.000 claims description 3
- 208000024447 adrenal gland neoplasm Diseases 0.000 claims description 3
- 230000001268 conjugating effect Effects 0.000 claims description 3
- AMRJKAQTDDKMCE-UHFFFAOYSA-N dolastatin Chemical compound CC(C)C(N(C)C)C(=O)NC(C(C)C)C(=O)N(C)C(C(C)C)C(OC)CC(=O)N1CCCC1C(OC)C(C)C(=O)NC(C=1SC=CN=1)CC1=CC=CC=C1 AMRJKAQTDDKMCE-UHFFFAOYSA-N 0.000 claims description 3
- 229930188854 dolastatin Natural products 0.000 claims description 3
- 201000004101 esophageal cancer Diseases 0.000 claims description 3
- 229940043355 kinase inhibitor Drugs 0.000 claims description 3
- 229910021645 metal ion Inorganic materials 0.000 claims description 3
- 239000003757 phosphotransferase inhibitor Substances 0.000 claims description 3
- 101100004408 Arabidopsis thaliana BIG gene Proteins 0.000 claims description 2
- 102000000578 Cyclin-Dependent Kinase Inhibitor p21 Human genes 0.000 claims description 2
- 108010016788 Cyclin-Dependent Kinase Inhibitor p21 Proteins 0.000 claims description 2
- 229940126161 DNA alkylating agent Drugs 0.000 claims description 2
- 239000012625 DNA intercalator Substances 0.000 claims description 2
- 101100485279 Drosophila melanogaster emb gene Proteins 0.000 claims description 2
- 102100029095 Exportin-1 Human genes 0.000 claims description 2
- 229940124179 Kinesin inhibitor Drugs 0.000 claims description 2
- 229940123573 Protein synthesis inhibitor Drugs 0.000 claims description 2
- 101100485284 Saccharomyces cerevisiae (strain ATCC 204508 / S288c) CRM1 gene Proteins 0.000 claims description 2
- 101150094313 XPO1 gene Proteins 0.000 claims description 2
- 238000012258 culturing Methods 0.000 claims description 2
- 108700002148 exportin 1 Proteins 0.000 claims description 2
- 229940121372 histone deacetylase inhibitor Drugs 0.000 claims description 2
- 239000012216 imaging agent Substances 0.000 claims description 2
- 230000030147 nuclear export Effects 0.000 claims description 2
- 239000000007 protein synthesis inhibitor Substances 0.000 claims description 2
- 102100027670 Islet amyloid polypeptide Human genes 0.000 claims 2
- 102000052116 epidermal growth factor receptor activity proteins Human genes 0.000 claims 2
- 108700015053 epidermal growth factor receptor activity proteins Proteins 0.000 claims 2
- YOHYSYJDKVYCJI-UHFFFAOYSA-N n-[3-[[6-[3-(trifluoromethyl)anilino]pyrimidin-4-yl]amino]phenyl]cyclopropanecarboxamide Chemical group FC(F)(F)C1=CC=CC(NC=2N=CN=C(NC=3C=C(NC(=O)C4CC4)C=CC=3)C=2)=C1 YOHYSYJDKVYCJI-UHFFFAOYSA-N 0.000 claims 2
- 102100025012 Dipeptidyl peptidase 4 Human genes 0.000 claims 1
- LFGREXWGYUGZLY-UHFFFAOYSA-N phosphoryl Chemical group [P]=O LFGREXWGYUGZLY-UHFFFAOYSA-N 0.000 claims 1
- 102000008394 Immunoglobulin Fragments Human genes 0.000 abstract description 74
- 108010021625 Immunoglobulin Fragments Proteins 0.000 abstract description 74
- 229960005558 mertansine Drugs 0.000 description 95
- 125000005647 linker group Chemical group 0.000 description 93
- 239000000203 mixture Substances 0.000 description 72
- 206010057190 Respiratory tract infections Diseases 0.000 description 70
- 235000001014 amino acid Nutrition 0.000 description 65
- 229940024606 amino acid Drugs 0.000 description 64
- 150000001413 amino acids Chemical class 0.000 description 64
- 125000003275 alpha amino acid group Chemical group 0.000 description 58
- 108090000623 proteins and genes Proteins 0.000 description 50
- 108090000765 processed proteins & peptides Proteins 0.000 description 40
- 235000018102 proteins Nutrition 0.000 description 39
- 102000004169 proteins and genes Human genes 0.000 description 39
- 230000014509 gene expression Effects 0.000 description 37
- 238000004091 panning Methods 0.000 description 35
- 229940124597 therapeutic agent Drugs 0.000 description 34
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 description 33
- 102000004196 processed proteins & peptides Human genes 0.000 description 33
- 239000000243 solution Substances 0.000 description 30
- 229920001184 polypeptide Polymers 0.000 description 29
- 101100112922 Candida albicans CDR3 gene Proteins 0.000 description 25
- 238000006243 chemical reaction Methods 0.000 description 25
- 238000000746 purification Methods 0.000 description 25
- 239000011347 resin Substances 0.000 description 24
- 229920005989 resin Polymers 0.000 description 24
- 150000001875 compounds Chemical class 0.000 description 22
- 108010047041 Complementarity Determining Regions Proteins 0.000 description 20
- 108091033319 polynucleotide Proteins 0.000 description 20
- 102000040430 polynucleotide Human genes 0.000 description 20
- 239000002157 polynucleotide Substances 0.000 description 20
- 238000012360 testing method Methods 0.000 description 19
- KDXKERNSBIXSRK-YFKPBYRVSA-N L-lysine Chemical compound NCCCC[C@H](N)C(O)=O KDXKERNSBIXSRK-YFKPBYRVSA-N 0.000 description 18
- KDXKERNSBIXSRK-UHFFFAOYSA-N Lysine Natural products NCCCCC(N)C(O)=O KDXKERNSBIXSRK-UHFFFAOYSA-N 0.000 description 18
- 108020003175 receptors Proteins 0.000 description 18
- 238000002560 therapeutic procedure Methods 0.000 description 18
- 239000012099 Alexa Fluor family Substances 0.000 description 17
- 201000010099 disease Diseases 0.000 description 17
- 239000013604 expression vector Substances 0.000 description 17
- 238000010791 quenching Methods 0.000 description 17
- 102000005962 receptors Human genes 0.000 description 17
- DHMQDGOQFOQNFH-UHFFFAOYSA-N Glycine Chemical compound NCC(O)=O DHMQDGOQFOQNFH-UHFFFAOYSA-N 0.000 description 16
- 208000035475 disorder Diseases 0.000 description 16
- 230000000069 prophylactic effect Effects 0.000 description 16
- 239000000523 sample Substances 0.000 description 16
- 239000000126 substance Substances 0.000 description 15
- 238000013459 approach Methods 0.000 description 14
- 238000003556 assay Methods 0.000 description 14
- 210000001519 tissue Anatomy 0.000 description 14
- 102000018233 Fibroblast Growth Factor Human genes 0.000 description 13
- 108050007372 Fibroblast Growth Factor Proteins 0.000 description 13
- 239000002246 antineoplastic agent Substances 0.000 description 13
- 229940126864 fibroblast growth factor Drugs 0.000 description 13
- 230000013595 glycosylation Effects 0.000 description 13
- 238000006206 glycosylation reaction Methods 0.000 description 13
- 230000000171 quenching effect Effects 0.000 description 13
- 230000001225 therapeutic effect Effects 0.000 description 13
- STQGQHZAVUOBTE-UHFFFAOYSA-N 7-Cyan-hept-2t-en-4,6-diinsaeure Natural products C1=2C(O)=C3C(=O)C=4C(OC)=CC=CC=4C(=O)C3=C(O)C=2CC(O)(C(C)=O)CC1OC1CC(N)C(O)C(C)O1 STQGQHZAVUOBTE-UHFFFAOYSA-N 0.000 description 12
- 108091028043 Nucleic acid sequence Proteins 0.000 description 12
- 239000000872 buffer Substances 0.000 description 12
- 238000009295 crossflow filtration Methods 0.000 description 12
- LOKCTEFSRHRXRJ-UHFFFAOYSA-I dipotassium trisodium dihydrogen phosphate hydrogen phosphate dichloride Chemical compound P(=O)(O)(O)[O-].[K+].P(=O)(O)([O-])[O-].[Na+].[Na+].[Cl-].[K+].[Cl-].[Na+] LOKCTEFSRHRXRJ-UHFFFAOYSA-I 0.000 description 12
- 230000003993 interaction Effects 0.000 description 12
- 125000003729 nucleotide group Chemical group 0.000 description 12
- 239000002953 phosphate buffered saline Substances 0.000 description 12
- 208000016691 refractory malignant neoplasm Diseases 0.000 description 12
- 238000012216 screening Methods 0.000 description 12
- 108020004705 Codon Proteins 0.000 description 11
- 239000011230 binding agent Substances 0.000 description 11
- 238000002648 combination therapy Methods 0.000 description 11
- 230000000875 corresponding effect Effects 0.000 description 11
- 125000002496 methyl group Chemical group [H]C([H])([H])* 0.000 description 11
- 239000002773 nucleotide Substances 0.000 description 11
- 238000002965 ELISA Methods 0.000 description 10
- 230000000259 anti-tumor effect Effects 0.000 description 10
- 238000003776 cleavage reaction Methods 0.000 description 10
- 238000009472 formulation Methods 0.000 description 10
- 238000004519 manufacturing process Methods 0.000 description 10
- 230000002018 overexpression Effects 0.000 description 10
- 230000007017 scission Effects 0.000 description 10
- 239000007790 solid phase Substances 0.000 description 10
- IADUWZMNTKHTIN-MLSWMBHTSA-N (2,5-dioxopyrrolidin-1-yl) 4-[[3-[3-[[(2S)-1-[[(1S,2R,3S,5S,6S,16E,18E,20R,21S)-11-chloro-21-hydroxy-12,20-dimethoxy-2,5,9,16-tetramethyl-8,23-dioxo-4,24-dioxa-9,22-diazatetracyclo[19.3.1.110,14.03,5]hexacosa-10,12,14(26),16,18-pentaen-6-yl]oxy]-1-oxopropan-2-yl]-methylamino]-3-oxopropyl]sulfanyl-2,5-dioxopyrrolidin-1-yl]methyl]cyclohexane-1-carboxylate Chemical compound CO[C@@H]1\C=C\C=C(C)\Cc2cc(OC)c(Cl)c(c2)N(C)C(=O)C[C@H](OC(=O)[C@H](C)N(C)C(=O)CCSC2CC(=O)N(CC3CCC(CC3)C(=O)ON3C(=O)CCC3=O)C2=O)[C@]2(C)O[C@H]2[C@H](C)[C@@H]2C[C@@]1(O)NC(=O)O2 IADUWZMNTKHTIN-MLSWMBHTSA-N 0.000 description 9
- 239000004480 active ingredient Substances 0.000 description 9
- 238000007792 addition Methods 0.000 description 9
- 108020001507 fusion proteins Proteins 0.000 description 9
- 102000037865 fusion proteins Human genes 0.000 description 9
- 238000000338 in vitro Methods 0.000 description 9
- 238000002347 injection Methods 0.000 description 9
- 239000007924 injection Substances 0.000 description 9
- 230000004048 modification Effects 0.000 description 9
- 238000012986 modification Methods 0.000 description 9
- 230000035772 mutation Effects 0.000 description 9
- 230000035755 proliferation Effects 0.000 description 9
- 238000006467 substitution reaction Methods 0.000 description 9
- 239000000725 suspension Substances 0.000 description 9
- 102000003971 Fibroblast Growth Factor 1 Human genes 0.000 description 8
- 108090000386 Fibroblast Growth Factor 1 Proteins 0.000 description 8
- GHASVSINZRGABV-UHFFFAOYSA-N Fluorouracil Chemical compound FC1=CNC(=O)NC1=O GHASVSINZRGABV-UHFFFAOYSA-N 0.000 description 8
- 102100024319 Intestinal-type alkaline phosphatase Human genes 0.000 description 8
- 102000004022 Protein-Tyrosine Kinases Human genes 0.000 description 8
- 108090000412 Protein-Tyrosine Kinases Proteins 0.000 description 8
- 229920002684 Sepharose Polymers 0.000 description 8
- 239000002253 acid Substances 0.000 description 8
- 239000003623 enhancer Substances 0.000 description 8
- 238000001943 fluorescence-activated cell sorting Methods 0.000 description 8
- 238000003018 immunoassay Methods 0.000 description 8
- 239000003446 ligand Substances 0.000 description 8
- 239000000463 material Substances 0.000 description 8
- BASFCYQUMIYNBI-UHFFFAOYSA-N platinum Chemical compound [Pt] BASFCYQUMIYNBI-UHFFFAOYSA-N 0.000 description 8
- 229920000642 polymer Polymers 0.000 description 8
- 239000000843 powder Substances 0.000 description 8
- 125000002924 primary amino group Chemical group [H]N([H])* 0.000 description 8
- QADPYRIHXKWUSV-UHFFFAOYSA-N BGJ-398 Chemical compound C1CN(CC)CCN1C(C=C1)=CC=C1NC1=CC(N(C)C(=O)NC=2C(=C(OC)C=C(OC)C=2Cl)Cl)=NC=N1 QADPYRIHXKWUSV-UHFFFAOYSA-N 0.000 description 7
- AOJJSUZBOXZQNB-TZSSRYMLSA-N Doxorubicin Chemical compound O([C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(=O)CO)[C@H]1C[C@H](N)[C@H](O)[C@H](C)O1 AOJJSUZBOXZQNB-TZSSRYMLSA-N 0.000 description 7
- 108090000371 Esterases Proteins 0.000 description 7
- 102100023593 Fibroblast growth factor receptor 1 Human genes 0.000 description 7
- 101710182386 Fibroblast growth factor receptor 1 Proteins 0.000 description 7
- 239000004471 Glycine Substances 0.000 description 7
- 108010054477 Immunoglobulin Fab Fragments Proteins 0.000 description 7
- 102000001706 Immunoglobulin Fab Fragments Human genes 0.000 description 7
- 241001465754 Metazoa Species 0.000 description 7
- 108010090804 Streptavidin Proteins 0.000 description 7
- 229930006000 Sucrose Natural products 0.000 description 7
- CZMRCDWAGMRECN-UGDNZRGBSA-N Sucrose Chemical compound O[C@H]1[C@H](O)[C@@H](CO)O[C@@]1(CO)O[C@@H]1[C@H](O)[C@@H](O)[C@H](O)[C@@H](CO)O1 CZMRCDWAGMRECN-UGDNZRGBSA-N 0.000 description 7
- KZSNJWFQEVHDMF-UHFFFAOYSA-N Valine Chemical compound CC(C)C(N)C(O)=O KZSNJWFQEVHDMF-UHFFFAOYSA-N 0.000 description 7
- 230000000295 complement effect Effects 0.000 description 7
- 230000021615 conjugation Effects 0.000 description 7
- 239000012897 dilution medium Substances 0.000 description 7
- 239000002552 dosage form Substances 0.000 description 7
- 239000000839 emulsion Substances 0.000 description 7
- 150000002148 esters Chemical class 0.000 description 7
- 230000002401 inhibitory effect Effects 0.000 description 7
- 239000011159 matrix material Substances 0.000 description 7
- 239000005720 sucrose Substances 0.000 description 7
- YBJHBAHKTGYVGT-ZKWXMUAHSA-N (+)-Biotin Chemical compound N1C(=O)N[C@@H]2[C@H](CCCCC(=O)O)SC[C@@H]21 YBJHBAHKTGYVGT-ZKWXMUAHSA-N 0.000 description 6
- QTBSBXVTEAMEQO-UHFFFAOYSA-N Acetic acid Chemical compound CC(O)=O QTBSBXVTEAMEQO-UHFFFAOYSA-N 0.000 description 6
- ZEOWTGPWHLSLOG-UHFFFAOYSA-N Cc1ccc(cc1-c1ccc2c(n[nH]c2c1)-c1cnn(c1)C1CC1)C(=O)Nc1cccc(c1)C(F)(F)F Chemical compound Cc1ccc(cc1-c1ccc2c(n[nH]c2c1)-c1cnn(c1)C1CC1)C(=O)Nc1cccc(c1)C(F)(F)F ZEOWTGPWHLSLOG-UHFFFAOYSA-N 0.000 description 6
- 108090000695 Cytokines Proteins 0.000 description 6
- 102000004127 Cytokines Human genes 0.000 description 6
- KCXVZYZYPLLWCC-UHFFFAOYSA-N EDTA Chemical compound OC(=O)CN(CC(O)=O)CCN(CC(O)=O)CC(O)=O KCXVZYZYPLLWCC-UHFFFAOYSA-N 0.000 description 6
- 229940125497 HER2 kinase inhibitor Drugs 0.000 description 6
- HTTJABKRGRZYRN-UHFFFAOYSA-N Heparin Chemical compound OC1C(NC(=O)C)C(O)OC(COS(O)(=O)=O)C1OC1C(OS(O)(=O)=O)C(O)C(OC2C(C(OS(O)(=O)=O)C(OC3C(C(O)C(O)C(O3)C(O)=O)OS(O)(=O)=O)C(CO)O2)NS(O)(=O)=O)C(C(O)=O)O1 HTTJABKRGRZYRN-UHFFFAOYSA-N 0.000 description 6
- 108060003951 Immunoglobulin Proteins 0.000 description 6
- DCXYFEDJOCDNAF-REOHCLBHSA-N L-asparagine Chemical compound OC(=O)[C@@H](N)CC(N)=O DCXYFEDJOCDNAF-REOHCLBHSA-N 0.000 description 6
- 102000035195 Peptidases Human genes 0.000 description 6
- 108091005804 Peptidases Proteins 0.000 description 6
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 6
- 230000002378 acidificating effect Effects 0.000 description 6
- 230000000274 adsorptive effect Effects 0.000 description 6
- 125000000217 alkyl group Chemical group 0.000 description 6
- 229910052799 carbon Inorganic materials 0.000 description 6
- 230000004663 cell proliferation Effects 0.000 description 6
- 238000004587 chromatography analysis Methods 0.000 description 6
- 239000002619 cytotoxin Substances 0.000 description 6
- 230000007423 decrease Effects 0.000 description 6
- 238000010494 dissociation reaction Methods 0.000 description 6
- 230000005593 dissociations Effects 0.000 description 6
- 229940121647 egfr inhibitor Drugs 0.000 description 6
- 238000005516 engineering process Methods 0.000 description 6
- 229960002949 fluorouracil Drugs 0.000 description 6
- 230000012010 growth Effects 0.000 description 6
- 229920000669 heparin Polymers 0.000 description 6
- 229960002897 heparin Drugs 0.000 description 6
- 102000018358 immunoglobulin Human genes 0.000 description 6
- 238000001727 in vivo Methods 0.000 description 6
- 238000001990 intravenous administration Methods 0.000 description 6
- 238000004020 luminiscence type Methods 0.000 description 6
- 238000002360 preparation method Methods 0.000 description 6
- 235000019833 protease Nutrition 0.000 description 6
- 230000002829 reductive effect Effects 0.000 description 6
- 230000011664 signaling Effects 0.000 description 6
- 239000007787 solid Substances 0.000 description 6
- 241000894007 species Species 0.000 description 6
- DLGOEMSEDOSKAD-UHFFFAOYSA-N Carmustine Chemical compound ClCCNC(=O)N(N=O)CCCl DLGOEMSEDOSKAD-UHFFFAOYSA-N 0.000 description 5
- CMSMOCZEIVJLDB-UHFFFAOYSA-N Cyclophosphamide Chemical compound ClCCN(CCCl)P1(=O)NCCCO1 CMSMOCZEIVJLDB-UHFFFAOYSA-N 0.000 description 5
- UHDGCWIWMRVCDJ-CCXZUQQUSA-N Cytarabine Chemical compound O=C1N=C(N)C=CN1[C@H]1[C@@H](O)[C@H](O)[C@@H](CO)O1 UHDGCWIWMRVCDJ-CCXZUQQUSA-N 0.000 description 5
- BWGNESOTFCXPMA-UHFFFAOYSA-N Dihydrogen disulfide Chemical compound SS BWGNESOTFCXPMA-UHFFFAOYSA-N 0.000 description 5
- WHUUTDBJXJRKMK-UHFFFAOYSA-N Glutamic acid Natural products OC(=O)C(N)CCC(O)=O WHUUTDBJXJRKMK-UHFFFAOYSA-N 0.000 description 5
- OWXMKDGYPWMGEB-UHFFFAOYSA-N HEPPS Chemical compound OCCN1CCN(CCCS(O)(=O)=O)CC1 OWXMKDGYPWMGEB-UHFFFAOYSA-N 0.000 description 5
- 108010067060 Immunoglobulin Variable Region Proteins 0.000 description 5
- 102000017727 Immunoglobulin Variable Region Human genes 0.000 description 5
- 239000004472 Lysine Substances 0.000 description 5
- 229930126263 Maytansine Natural products 0.000 description 5
- 239000002033 PVDF binder Substances 0.000 description 5
- 108010076504 Protein Sorting Signals Proteins 0.000 description 5
- 206010038111 Recurrent cancer Diseases 0.000 description 5
- 239000000443 aerosol Substances 0.000 description 5
- 239000000556 agonist Substances 0.000 description 5
- 239000011324 bead Substances 0.000 description 5
- 239000012472 biological sample Substances 0.000 description 5
- 230000001186 cumulative effect Effects 0.000 description 5
- 238000001514 detection method Methods 0.000 description 5
- VHJLVAABSRFDPM-QWWZWVQMSA-N dithiothreitol Chemical compound SC[C@@H](O)[C@H](O)CS VHJLVAABSRFDPM-QWWZWVQMSA-N 0.000 description 5
- 238000011156 evaluation Methods 0.000 description 5
- 238000002474 experimental method Methods 0.000 description 5
- 238000001802 infusion Methods 0.000 description 5
- 239000002502 liposome Substances 0.000 description 5
- 235000018977 lysine Nutrition 0.000 description 5
- 239000012528 membrane Substances 0.000 description 5
- 239000000546 pharmaceutical excipient Substances 0.000 description 5
- 229920001223 polyethylene glycol Polymers 0.000 description 5
- 229920002981 polyvinylidene fluoride Polymers 0.000 description 5
- 238000011160 research Methods 0.000 description 5
- 238000013268 sustained release Methods 0.000 description 5
- 239000012730 sustained-release form Substances 0.000 description 5
- 208000024891 symptom Diseases 0.000 description 5
- 239000003053 toxin Substances 0.000 description 5
- 231100000765 toxin Toxicity 0.000 description 5
- 108700012359 toxins Proteins 0.000 description 5
- 229960000575 trastuzumab Drugs 0.000 description 5
- 238000005406 washing Methods 0.000 description 5
- 108091003079 Bovine Serum Albumin Proteins 0.000 description 4
- 102100021935 C-C motif chemokine 26 Human genes 0.000 description 4
- 108091026890 Coding region Proteins 0.000 description 4
- LFQSCWFLJHTTHZ-UHFFFAOYSA-N Ethanol Chemical compound CCO LFQSCWFLJHTTHZ-UHFFFAOYSA-N 0.000 description 4
- 101000897493 Homo sapiens C-C motif chemokine 26 Proteins 0.000 description 4
- FFEARJCKVFRZRR-BYPYZUCNSA-N L-methionine Chemical compound CSCC[C@H](N)C(O)=O FFEARJCKVFRZRR-BYPYZUCNSA-N 0.000 description 4
- 239000002136 L01XE07 - Lapatinib Substances 0.000 description 4
- 241000699666 Mus <mouse, genus> Species 0.000 description 4
- 206010035226 Plasma cell myeloma Diseases 0.000 description 4
- 241000700159 Rattus Species 0.000 description 4
- 101100331535 Saccharomyces cerevisiae (strain ATCC 204508 / S288c) DIB1 gene Proteins 0.000 description 4
- 229920005654 Sephadex Polymers 0.000 description 4
- 239000012507 Sephadex™ Substances 0.000 description 4
- RJURFGZVJUQBHK-UHFFFAOYSA-N actinomycin D Natural products CC1OC(=O)C(C(C)C)N(C)C(=O)CN(C)C(=O)C2CCCN2C(=O)C(C(C)C)NC(=O)C1NC(=O)C1=C(N)C(=O)C(C)=C2OC(C(C)=CC=C3C(=O)NC4C(=O)NC(C(N5CCCC5C(=O)N(C)CC(=O)N(C)C(C(C)C)C(=O)OC4C)=O)C(C)C)=C3N=C21 RJURFGZVJUQBHK-UHFFFAOYSA-N 0.000 description 4
- 239000013543 active substance Substances 0.000 description 4
- 230000001580 bacterial effect Effects 0.000 description 4
- 239000006227 byproduct Substances 0.000 description 4
- 210000004899 c-terminal region Anatomy 0.000 description 4
- 150000001720 carbohydrates Chemical class 0.000 description 4
- 229910002091 carbon monoxide Inorganic materials 0.000 description 4
- DQLATGHUWYMOKM-UHFFFAOYSA-L cisplatin Chemical compound N[Pt](N)(Cl)Cl DQLATGHUWYMOKM-UHFFFAOYSA-L 0.000 description 4
- 238000013270 controlled release Methods 0.000 description 4
- STQGQHZAVUOBTE-VGBVRHCVSA-N daunorubicin Chemical compound O([C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(C)=O)[C@H]1C[C@H](N)[C@H](O)[C@H](C)O1 STQGQHZAVUOBTE-VGBVRHCVSA-N 0.000 description 4
- 229940000406 drug candidate Drugs 0.000 description 4
- 238000010828 elution Methods 0.000 description 4
- GTTBEUCJPZQMDZ-UHFFFAOYSA-N erlotinib hydrochloride Chemical compound [H+].[Cl-].C=12C=C(OCCOC)C(OCCOC)=CC2=NC=NC=1NC1=CC=CC(C#C)=C1 GTTBEUCJPZQMDZ-UHFFFAOYSA-N 0.000 description 4
- 239000012091 fetal bovine serum Substances 0.000 description 4
- 239000001963 growth medium Substances 0.000 description 4
- 210000004408 hybridoma Anatomy 0.000 description 4
- 229910052588 hydroxylapatite Inorganic materials 0.000 description 4
- 238000011065 in-situ storage Methods 0.000 description 4
- 238000011534 incubation Methods 0.000 description 4
- 230000001939 inductive effect Effects 0.000 description 4
- 238000007918 intramuscular administration Methods 0.000 description 4
- BCFGMOOMADDAQU-UHFFFAOYSA-N lapatinib Chemical compound O1C(CNCCS(=O)(=O)C)=CC=C1C1=CC=C(N=CN=C2NC=3C=C(Cl)C(OCC=4C=C(F)C=CC=4)=CC=3)C2=C1 BCFGMOOMADDAQU-UHFFFAOYSA-N 0.000 description 4
- 239000007788 liquid Substances 0.000 description 4
- 210000004962 mammalian cell Anatomy 0.000 description 4
- 239000003550 marker Substances 0.000 description 4
- WKPWGQKGSOKKOO-RSFHAFMBSA-N maytansine Chemical compound CO[C@@H]([C@@]1(O)C[C@](OC(=O)N1)([C@H]([C@@H]1O[C@@]1(C)[C@@H](OC(=O)[C@H](C)N(C)C(C)=O)CC(=O)N1C)C)[H])\C=C\C=C(C)\CC2=CC(OC)=C(Cl)C1=C2 WKPWGQKGSOKKOO-RSFHAFMBSA-N 0.000 description 4
- 238000005259 measurement Methods 0.000 description 4
- GLVAUDGFNGKCSF-UHFFFAOYSA-N mercaptopurine Chemical compound S=C1NC=NC2=C1NC=N2 GLVAUDGFNGKCSF-UHFFFAOYSA-N 0.000 description 4
- 229930182817 methionine Natural products 0.000 description 4
- 125000000325 methylidene group Chemical group [H]C([H])=* 0.000 description 4
- 239000002245 particle Substances 0.000 description 4
- XYJRXVWERLGGKC-UHFFFAOYSA-D pentacalcium;hydroxide;triphosphate Chemical compound [OH-].[Ca+2].[Ca+2].[Ca+2].[Ca+2].[Ca+2].[O-]P([O-])([O-])=O.[O-]P([O-])([O-])=O.[O-]P([O-])([O-])=O XYJRXVWERLGGKC-UHFFFAOYSA-D 0.000 description 4
- 125000001997 phenyl group Chemical group [H]C1=C([H])C([H])=C(*)C([H])=C1[H] 0.000 description 4
- 239000013612 plasmid Substances 0.000 description 4
- 229910052697 platinum Inorganic materials 0.000 description 4
- 125000001436 propyl group Chemical group [H]C([*])([H])C([H])([H])C([H])([H])[H] 0.000 description 4
- 238000000159 protein binding assay Methods 0.000 description 4
- 239000011541 reaction mixture Substances 0.000 description 4
- 102000027426 receptor tyrosine kinases Human genes 0.000 description 4
- 108091008598 receptor tyrosine kinases Proteins 0.000 description 4
- 238000002415 sodium dodecyl sulfate polyacrylamide gel electrophoresis Methods 0.000 description 4
- 239000002904 solvent Substances 0.000 description 4
- 238000011301 standard therapy Methods 0.000 description 4
- 238000007920 subcutaneous administration Methods 0.000 description 4
- 125000000472 sulfonyl group Chemical group *S(*)(=O)=O 0.000 description 4
- SUVMJBTUFCVSAD-UHFFFAOYSA-N sulforaphane Chemical compound CS(=O)CCCCN=C=S SUVMJBTUFCVSAD-UHFFFAOYSA-N 0.000 description 4
- 229910052717 sulfur Inorganic materials 0.000 description 4
- 125000004434 sulfur atom Chemical group 0.000 description 4
- 239000006228 supernatant Substances 0.000 description 4
- 230000002195 synergetic effect Effects 0.000 description 4
- HVXKQKFEHMGHSL-QKDCVEJESA-N tesevatinib Chemical compound N1=CN=C2C=C(OC[C@@H]3C[C@@H]4CN(C)C[C@@H]4C3)C(OC)=CC2=C1NC1=CC=C(Cl)C(Cl)=C1F HVXKQKFEHMGHSL-QKDCVEJESA-N 0.000 description 4
- 150000003573 thiols Chemical class 0.000 description 4
- WYWHKKSPHMUBEB-UHFFFAOYSA-N tioguanine Chemical compound N1C(N)=NC(=S)C2=C1N=CN2 WYWHKKSPHMUBEB-UHFFFAOYSA-N 0.000 description 4
- 230000000699 topical effect Effects 0.000 description 4
- 230000009261 transgenic effect Effects 0.000 description 4
- 230000014616 translation Effects 0.000 description 4
- 230000004614 tumor growth Effects 0.000 description 4
- JXLYSJRDGCGARV-CFWMRBGOSA-N vinblastine Chemical compound C([C@H](C[C@]1(C(=O)OC)C=2C(=CC3=C([C@]45[C@H]([C@@]([C@H](OC(C)=O)[C@]6(CC)C=CCN([C@H]56)CC4)(O)C(=O)OC)N3C)C=2)OC)C[C@@](C2)(O)CC)N2CCC2=C1NC1=CC=CC=C21 JXLYSJRDGCGARV-CFWMRBGOSA-N 0.000 description 4
- OGWKCGZFUXNPDA-XQKSVPLYSA-N vincristine Chemical compound C([N@]1C[C@@H](C[C@]2(C(=O)OC)C=3C(=CC4=C([C@]56[C@H]([C@@]([C@H](OC(C)=O)[C@]7(CC)C=CCN([C@H]67)CC5)(O)C(=O)OC)N4C=O)C=3)OC)C[C@@](C1)(O)CC)CC1=C2NC2=CC=CC=C12 OGWKCGZFUXNPDA-XQKSVPLYSA-N 0.000 description 4
- 229960004528 vincristine Drugs 0.000 description 4
- OGWKCGZFUXNPDA-UHFFFAOYSA-N vincristine Natural products C1C(CC)(O)CC(CC2(C(=O)OC)C=3C(=CC4=C(C56C(C(C(OC(C)=O)C7(CC)C=CCN(C67)CC5)(O)C(=O)OC)N4C=O)C=3)OC)CN1CCC1=C2NC2=CC=CC=C12 OGWKCGZFUXNPDA-UHFFFAOYSA-N 0.000 description 4
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Chemical compound O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 4
- QWPXBEHQFHACTK-KZVYIGENSA-N (10e,12e)-86-chloro-12,14,4-trihydroxy-85,14-dimethoxy-33,2,7,10-tetramethyl-15,16-dihydro-14h-7-aza-1(6,4)-oxazina-3(2,3)-oxirana-8(1,3)-benzenacyclotetradecaphane-10,12-dien-6-one Chemical compound CN1C(=O)CC(O)C2(C)OC2C(C)C(OC(=O)N2)CC2(O)C(OC)\C=C\C=C(C)\CC2=CC(OC)=C(Cl)C1=C2 QWPXBEHQFHACTK-KZVYIGENSA-N 0.000 description 3
- QDITZBLZQQZVEE-YBEGLDIGSA-N (5z)-5-[(4-pyridin-4-ylquinolin-6-yl)methylidene]-1,3-thiazolidine-2,4-dione Chemical compound S1C(=O)NC(=O)\C1=C\C1=CC=C(N=CC=C2C=3C=CN=CC=3)C2=C1 QDITZBLZQQZVEE-YBEGLDIGSA-N 0.000 description 3
- JKMHFZQWWAIEOD-UHFFFAOYSA-N 2-[4-(2-hydroxyethyl)piperazin-1-yl]ethanesulfonic acid Chemical compound OCC[NH+]1CCN(CCS([O-])(=O)=O)CC1 JKMHFZQWWAIEOD-UHFFFAOYSA-N 0.000 description 3
- IAYGCINLNONXHY-LBPRGKRZSA-N 3-(carbamoylamino)-5-(3-fluorophenyl)-N-[(3S)-3-piperidinyl]-2-thiophenecarboxamide Chemical compound NC(=O)NC=1C=C(C=2C=C(F)C=CC=2)SC=1C(=O)N[C@H]1CCCNC1 IAYGCINLNONXHY-LBPRGKRZSA-N 0.000 description 3
- 206010069754 Acquired gene mutation Diseases 0.000 description 3
- ULXXDDBFHOBEHA-ONEGZZNKSA-N Afatinib Chemical compound N1=CN=C2C=C(OC3COCC3)C(NC(=O)/C=C/CN(C)C)=CC2=C1NC1=CC=C(F)C(Cl)=C1 ULXXDDBFHOBEHA-ONEGZZNKSA-N 0.000 description 3
- KXDAEFPNCMNJSK-UHFFFAOYSA-N Benzamide Chemical compound NC(=O)C1=CC=CC=C1 KXDAEFPNCMNJSK-UHFFFAOYSA-N 0.000 description 3
- 108010006654 Bleomycin Proteins 0.000 description 3
- COVZYZSDYWQREU-UHFFFAOYSA-N Busulfan Chemical compound CS(=O)(=O)OCCCCOS(C)(=O)=O COVZYZSDYWQREU-UHFFFAOYSA-N 0.000 description 3
- 101710112752 Cytotoxin Proteins 0.000 description 3
- 230000004544 DNA amplification Effects 0.000 description 3
- 108010092160 Dactinomycin Proteins 0.000 description 3
- 102000001301 EGF receptor Human genes 0.000 description 3
- 108060006698 EGF receptor Proteins 0.000 description 3
- 102000004190 Enzymes Human genes 0.000 description 3
- 108090000790 Enzymes Proteins 0.000 description 3
- 108010087819 Fc receptors Proteins 0.000 description 3
- 102000009109 Fc receptors Human genes 0.000 description 3
- 102100027842 Fibroblast growth factor receptor 3 Human genes 0.000 description 3
- 101710182396 Fibroblast growth factor receptor 3 Proteins 0.000 description 3
- QNAYBMKLOCPYGJ-REOHCLBHSA-N L-alanine Chemical compound C[C@H](N)C(O)=O QNAYBMKLOCPYGJ-REOHCLBHSA-N 0.000 description 3
- AGPKZVBTJJNPAG-WHFBIAKZSA-N L-isoleucine Chemical compound CC[C@H](C)[C@H](N)C(O)=O AGPKZVBTJJNPAG-WHFBIAKZSA-N 0.000 description 3
- FBOZXECLQNJBKD-ZDUSSCGKSA-N L-methotrexate Chemical compound C=1N=C2N=C(N)N=C(N)C2=NC=1CN(C)C1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 FBOZXECLQNJBKD-ZDUSSCGKSA-N 0.000 description 3
- QIVBCDIJIAJPQS-VIFPVBQESA-N L-tryptophane Chemical compound C1=CC=C2C(C[C@H](N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-VIFPVBQESA-N 0.000 description 3
- OUYCCCASQSFEME-QMMMGPOBSA-N L-tyrosine Chemical compound OC(=O)[C@@H](N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-QMMMGPOBSA-N 0.000 description 3
- CZQHHVNHHHRRDU-UHFFFAOYSA-N LY294002 Chemical compound C1=CC=C2C(=O)C=C(N3CCOCC3)OC2=C1C1=CC=CC=C1 CZQHHVNHHHRRDU-UHFFFAOYSA-N 0.000 description 3
- 241000124008 Mammalia Species 0.000 description 3
- QWPXBEHQFHACTK-UHFFFAOYSA-N Maytansinol Natural products CN1C(=O)CC(O)C2(C)OC2C(C)C(OC(=O)N2)CC2(O)C(OC)C=CC=C(C)CC2=CC(OC)=C(Cl)C1=C2 QWPXBEHQFHACTK-UHFFFAOYSA-N 0.000 description 3
- NWIBSHFKIJFRCO-WUDYKRTCSA-N Mytomycin Chemical compound C1N2C(C(C(C)=C(N)C3=O)=O)=C3[C@@H](COC(N)=O)[C@@]2(OC)[C@@H]2[C@H]1N2 NWIBSHFKIJFRCO-WUDYKRTCSA-N 0.000 description 3
- CXQHYVUVSFXTMY-UHFFFAOYSA-N N1'-[3-fluoro-4-[[6-methoxy-7-[3-(4-morpholinyl)propoxy]-4-quinolinyl]oxy]phenyl]-N1-(4-fluorophenyl)cyclopropane-1,1-dicarboxamide Chemical compound C1=CN=C2C=C(OCCCN3CCOCC3)C(OC)=CC2=C1OC(C(=C1)F)=CC=C1NC(=O)C1(C(=O)NC=2C=CC(F)=CC=2)CC1 CXQHYVUVSFXTMY-UHFFFAOYSA-N 0.000 description 3
- 108091007960 PI3Ks Proteins 0.000 description 3
- KDLHZDBZIXYQEI-UHFFFAOYSA-N Palladium Chemical compound [Pd] KDLHZDBZIXYQEI-UHFFFAOYSA-N 0.000 description 3
- 102000003993 Phosphatidylinositol 3-kinases Human genes 0.000 description 3
- 108090000430 Phosphatidylinositol 3-kinases Proteins 0.000 description 3
- 102000003867 Phospholipid Transfer Proteins Human genes 0.000 description 3
- 108090000216 Phospholipid Transfer Proteins Proteins 0.000 description 3
- 108091000080 Phosphotransferase Proteins 0.000 description 3
- 229920002873 Polyethylenimine Polymers 0.000 description 3
- 239000004793 Polystyrene Substances 0.000 description 3
- 102100023832 Prolyl endopeptidase FAP Human genes 0.000 description 3
- 102000007056 Recombinant Fusion Proteins Human genes 0.000 description 3
- 108010008281 Recombinant Fusion Proteins Proteins 0.000 description 3
- 206010039491 Sarcoma Diseases 0.000 description 3
- 108010088160 Staphylococcal Protein A Proteins 0.000 description 3
- 239000012505 Superdex™ Substances 0.000 description 3
- QIVBCDIJIAJPQS-UHFFFAOYSA-N Tryptophan Natural products C1=CC=C2C(CC(N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-UHFFFAOYSA-N 0.000 description 3
- JXLYSJRDGCGARV-WWYNWVTFSA-N Vinblastine Natural products O=C(O[C@H]1[C@](O)(C(=O)OC)[C@@H]2N(C)c3c(cc(c(OC)c3)[C@]3(C(=O)OC)c4[nH]c5c(c4CCN4C[C@](O)(CC)C[C@H](C3)C4)cccc5)[C@@]32[C@H]2[C@@]1(CC)C=CCN2CC3)C JXLYSJRDGCGARV-WWYNWVTFSA-N 0.000 description 3
- 241000700605 Viruses Species 0.000 description 3
- LUJZZYWHBDHDQX-QFIPXVFZSA-N [(3s)-morpholin-3-yl]methyl n-[4-[[1-[(3-fluorophenyl)methyl]indazol-5-yl]amino]-5-methylpyrrolo[2,1-f][1,2,4]triazin-6-yl]carbamate Chemical compound C=1N2N=CN=C(NC=3C=C4C=NN(CC=5C=C(F)C=CC=5)C4=CC=3)C2=C(C)C=1NC(=O)OC[C@@H]1COCCN1 LUJZZYWHBDHDQX-QFIPXVFZSA-N 0.000 description 3
- 230000002159 abnormal effect Effects 0.000 description 3
- 238000001042 affinity chromatography Methods 0.000 description 3
- 235000004279 alanine Nutrition 0.000 description 3
- 206010065867 alveolar rhabdomyosarcoma Diseases 0.000 description 3
- 150000001412 amines Chemical class 0.000 description 3
- 125000003277 amino group Chemical group 0.000 description 3
- 239000005557 antagonist Substances 0.000 description 3
- 239000003242 anti bacterial agent Substances 0.000 description 3
- 230000004071 biological effect Effects 0.000 description 3
- 229960002685 biotin Drugs 0.000 description 3
- 235000020958 biotin Nutrition 0.000 description 3
- 239000011616 biotin Substances 0.000 description 3
- 229930189065 blasticidin Natural products 0.000 description 3
- 210000004369 blood Anatomy 0.000 description 3
- 239000008280 blood Substances 0.000 description 3
- 230000008499 blood brain barrier function Effects 0.000 description 3
- 210000001218 blood-brain barrier Anatomy 0.000 description 3
- 230000037396 body weight Effects 0.000 description 3
- 239000002775 capsule Substances 0.000 description 3
- 235000014633 carbohydrates Nutrition 0.000 description 3
- 125000003178 carboxy group Chemical group [H]OC(*)=O 0.000 description 3
- 230000010261 cell growth Effects 0.000 description 3
- 238000012512 characterization method Methods 0.000 description 3
- 230000004540 complement-dependent cytotoxicity Effects 0.000 description 3
- KTEIFNKAUNYNJU-GFCCVEGCSA-N crizotinib Chemical compound O([C@H](C)C=1C(=C(F)C=CC=1Cl)Cl)C(C(=NC=1)N)=CC=1C(=C1)C=NN1C1CCNCC1 KTEIFNKAUNYNJU-GFCCVEGCSA-N 0.000 description 3
- 239000013078 crystal Substances 0.000 description 3
- 239000012228 culture supernatant Substances 0.000 description 3
- 229960004397 cyclophosphamide Drugs 0.000 description 3
- 229960000684 cytarabine Drugs 0.000 description 3
- 230000003111 delayed effect Effects 0.000 description 3
- 238000011161 development Methods 0.000 description 3
- 230000018109 developmental process Effects 0.000 description 3
- 239000000032 diagnostic agent Substances 0.000 description 3
- 229940039227 diagnostic agent Drugs 0.000 description 3
- 230000004069 differentiation Effects 0.000 description 3
- 239000000975 dye Substances 0.000 description 3
- 229940088598 enzyme Drugs 0.000 description 3
- 125000001495 ethyl group Chemical group [H]C([H])([H])C([H])([H])* 0.000 description 3
- 230000006870 function Effects 0.000 description 3
- XGALLCVXEZPNRQ-UHFFFAOYSA-N gefitinib Chemical compound C=12C=C(OCCCN3CCOCC3)C(OC)=CC2=NC=NC=1NC1=CC=C(F)C(Cl)=C1 XGALLCVXEZPNRQ-UHFFFAOYSA-N 0.000 description 3
- 230000002068 genetic effect Effects 0.000 description 3
- QBKSWRVVCFFDOT-UHFFFAOYSA-N gossypol Chemical compound CC(C)C1=C(O)C(O)=C(C=O)C2=C(O)C(C=3C(O)=C4C(C=O)=C(O)C(O)=C(C4=CC=3C)C(C)C)=C(C)C=C21 QBKSWRVVCFFDOT-UHFFFAOYSA-N 0.000 description 3
- 125000005179 haloacetyl group Chemical group 0.000 description 3
- 230000036541 health Effects 0.000 description 3
- 238000010438 heat treatment Methods 0.000 description 3
- 238000004191 hydrophobic interaction chromatography Methods 0.000 description 3
- 230000005847 immunogenicity Effects 0.000 description 3
- 230000005764 inhibitory process Effects 0.000 description 3
- 238000007912 intraperitoneal administration Methods 0.000 description 3
- 239000006166 lysate Substances 0.000 description 3
- 125000005439 maleimidyl group Chemical group C1(C=CC(N1*)=O)=O 0.000 description 3
- 239000011572 manganese Substances 0.000 description 3
- 239000002609 medium Substances 0.000 description 3
- MYWUZJCMWCOHBA-VIFPVBQESA-N methamphetamine Chemical compound CN[C@@H](C)CC1=CC=CC=C1 MYWUZJCMWCOHBA-VIFPVBQESA-N 0.000 description 3
- 125000000956 methoxy group Chemical group [H]C([H])([H])O* 0.000 description 3
- KKZJGLLVHKMTCM-UHFFFAOYSA-N mitoxantrone Chemical compound O=C1C2=C(O)C=CC(O)=C2C(=O)C2=C1C(NCCNCCO)=CC=C2NCCNCCO KKZJGLLVHKMTCM-UHFFFAOYSA-N 0.000 description 3
- 239000000178 monomer Substances 0.000 description 3
- 201000000050 myeloid neoplasm Diseases 0.000 description 3
- JLYAXFNOILIKPP-KXQOOQHDSA-N navitoclax Chemical compound C([C@@H](NC1=CC=C(C=C1S(=O)(=O)C(F)(F)F)S(=O)(=O)NC(=O)C1=CC=C(C=C1)N1CCN(CC1)CC1=C(CCC(C1)(C)C)C=1C=CC(Cl)=CC=1)CSC=1C=CC=CC=1)CN1CCOCC1 JLYAXFNOILIKPP-KXQOOQHDSA-N 0.000 description 3
- 239000012038 nucleophile Substances 0.000 description 3
- 239000002674 ointment Substances 0.000 description 3
- 239000012071 phase Substances 0.000 description 3
- 102000020233 phosphotransferase Human genes 0.000 description 3
- 229920002223 polystyrene Polymers 0.000 description 3
- 239000008057 potassium phosphate buffer Substances 0.000 description 3
- 230000002265 prevention Effects 0.000 description 3
- 230000009467 reduction Effects 0.000 description 3
- 230000022532 regulation of transcription, DNA-dependent Effects 0.000 description 3
- 238000012552 review Methods 0.000 description 3
- 238000002864 sequence alignment Methods 0.000 description 3
- 210000002966 serum Anatomy 0.000 description 3
- 239000011780 sodium chloride Substances 0.000 description 3
- 230000037439 somatic mutation Effects 0.000 description 3
- 238000001179 sorption measurement Methods 0.000 description 3
- 239000007921 spray Substances 0.000 description 3
- 206010041823 squamous cell carcinoma Diseases 0.000 description 3
- 239000008362 succinate buffer Substances 0.000 description 3
- KDYFGRWQOYBRFD-UHFFFAOYSA-L succinate(2-) Chemical compound [O-]C(=O)CCC([O-])=O KDYFGRWQOYBRFD-UHFFFAOYSA-L 0.000 description 3
- 230000004083 survival effect Effects 0.000 description 3
- 230000008685 targeting Effects 0.000 description 3
- 238000013518 transcription Methods 0.000 description 3
- 230000035897 transcription Effects 0.000 description 3
- 238000001890 transfection Methods 0.000 description 3
- 210000004881 tumor cell Anatomy 0.000 description 3
- 238000013413 tumor xenograft mouse model Methods 0.000 description 3
- OUYCCCASQSFEME-UHFFFAOYSA-N tyrosine Natural products OC(=O)C(N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-UHFFFAOYSA-N 0.000 description 3
- 238000000870 ultraviolet spectroscopy Methods 0.000 description 3
- UHTHHESEBZOYNR-UHFFFAOYSA-N vandetanib Chemical compound COC1=CC(C(/N=CN2)=N/C=3C(=CC(Br)=CC=3)F)=C2C=C1OCC1CCN(C)CC1 UHTHHESEBZOYNR-UHFFFAOYSA-N 0.000 description 3
- 229960003048 vinblastine Drugs 0.000 description 3
- 239000013603 viral vector Substances 0.000 description 3
- 230000003612 virological effect Effects 0.000 description 3
- 238000001262 western blot Methods 0.000 description 3
- NKUZQMZWTZAPSN-UHFFFAOYSA-N (2,5-dioxopyrrolidin-1-yl) 2-bromoacetate Chemical compound BrCC(=O)ON1C(=O)CCC1=O NKUZQMZWTZAPSN-UHFFFAOYSA-N 0.000 description 2
- WGMMKWFUXPMTRW-UHFFFAOYSA-N (2,5-dioxopyrrolidin-1-yl) 3-[(2-bromoacetyl)amino]propanoate Chemical compound BrCC(=O)NCCC(=O)ON1C(=O)CCC1=O WGMMKWFUXPMTRW-UHFFFAOYSA-N 0.000 description 2
- RKGUGSULMVQEIX-UHFFFAOYSA-N (2,5-dioxopyrrolidin-1-yl) 3-[2-[2-[6-(2,5-dioxopyrrol-1-yl)hexanoylamino]ethoxy]ethoxy]propanoate Chemical compound O=C1CCC(=O)N1OC(=O)CCOCCOCCNC(=O)CCCCCN1C(=O)C=CC1=O RKGUGSULMVQEIX-UHFFFAOYSA-N 0.000 description 2
- PVGATNRYUYNBHO-UHFFFAOYSA-N (2,5-dioxopyrrolidin-1-yl) 4-(2,5-dioxopyrrol-1-yl)butanoate Chemical compound O=C1CCC(=O)N1OC(=O)CCCN1C(=O)C=CC1=O PVGATNRYUYNBHO-UHFFFAOYSA-N 0.000 description 2
- DIGQNXIGRZPYDK-WKSCXVIASA-N (2R)-6-amino-2-[[2-[[(2S)-2-[[2-[[(2R)-2-[[(2S)-2-[[(2R,3S)-2-[[2-[[(2S)-2-[[2-[[(2S)-2-[[(2S)-2-[[(2R)-2-[[(2S,3S)-2-[[(2R)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[2-[[(2S)-2-[[(2R)-2-[[2-[[2-[[2-[(2-amino-1-hydroxyethylidene)amino]-3-carboxy-1-hydroxypropylidene]amino]-1-hydroxy-3-sulfanylpropylidene]amino]-1-hydroxyethylidene]amino]-1-hydroxy-3-sulfanylpropylidene]amino]-1,3-dihydroxypropylidene]amino]-1-hydroxyethylidene]amino]-1-hydroxypropylidene]amino]-1,3-dihydroxypropylidene]amino]-1,3-dihydroxypropylidene]amino]-1-hydroxy-3-sulfanylpropylidene]amino]-1,3-dihydroxybutylidene]amino]-1-hydroxy-3-sulfanylpropylidene]amino]-1-hydroxypropylidene]amino]-1,3-dihydroxypropylidene]amino]-1-hydroxyethylidene]amino]-1,5-dihydroxy-5-iminopentylidene]amino]-1-hydroxy-3-sulfanylpropylidene]amino]-1,3-dihydroxybutylidene]amino]-1-hydroxy-3-sulfanylpropylidene]amino]-1,3-dihydroxypropylidene]amino]-1-hydroxyethylidene]amino]-1-hydroxy-3-sulfanylpropylidene]amino]-1-hydroxyethylidene]amino]hexanoic acid Chemical compound C[C@@H]([C@@H](C(=N[C@@H](CS)C(=N[C@@H](C)C(=N[C@@H](CO)C(=NCC(=N[C@@H](CCC(=N)O)C(=NC(CS)C(=N[C@H]([C@H](C)O)C(=N[C@H](CS)C(=N[C@H](CO)C(=NCC(=N[C@H](CS)C(=NCC(=N[C@H](CCCCN)C(=O)O)O)O)O)O)O)O)O)O)O)O)O)O)O)N=C([C@H](CS)N=C([C@H](CO)N=C([C@H](CO)N=C([C@H](C)N=C(CN=C([C@H](CO)N=C([C@H](CS)N=C(CN=C(C(CS)N=C(C(CC(=O)O)N=C(CN)O)O)O)O)O)O)O)O)O)O)O)O DIGQNXIGRZPYDK-WKSCXVIASA-N 0.000 description 2
- SVNJBEMPMKWDCO-KCHLEUMXSA-N (2s)-2-[[(2s)-3-carboxy-2-[[2-[[(2s)-5-(diaminomethylideneamino)-2-[[4-oxo-4-[[4-(4-oxo-8-phenylchromen-2-yl)morpholin-4-ium-4-yl]methoxy]butanoyl]amino]pentanoyl]amino]acetyl]amino]propanoyl]amino]-3-hydroxypropanoate Chemical compound C=1C(=O)C2=CC=CC(C=3C=CC=CC=3)=C2OC=1[N+]1(COC(=O)CCC(=O)N[C@@H](CCCNC(=N)N)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C([O-])=O)CCOCC1 SVNJBEMPMKWDCO-KCHLEUMXSA-N 0.000 description 2
- CSGQVNMSRKWUSH-IAGOWNOFSA-N (3r,4r)-4-amino-1-[[4-(3-methoxyanilino)pyrrolo[2,1-f][1,2,4]triazin-5-yl]methyl]piperidin-3-ol Chemical compound COC1=CC=CC(NC=2C3=C(CN4C[C@@H](O)[C@H](N)CC4)C=CN3N=CN=2)=C1 CSGQVNMSRKWUSH-IAGOWNOFSA-N 0.000 description 2
- FDKXTQMXEQVLRF-ZHACJKMWSA-N (E)-dacarbazine Chemical compound CN(C)\N=N\c1[nH]cnc1C(N)=O FDKXTQMXEQVLRF-ZHACJKMWSA-N 0.000 description 2
- IAKHMKGGTNLKSZ-INIZCTEOSA-N (S)-colchicine Chemical compound C1([C@@H](NC(C)=O)CC2)=CC(=O)C(OC)=CC=C1C1=C2C=C(OC)C(OC)=C1OC IAKHMKGGTNLKSZ-INIZCTEOSA-N 0.000 description 2
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 2
- QFWCYNPOPKQOKV-UHFFFAOYSA-N 2-(2-amino-3-methoxyphenyl)chromen-4-one Chemical compound COC1=CC=CC(C=2OC3=CC=CC=C3C(=O)C=2)=C1N QFWCYNPOPKQOKV-UHFFFAOYSA-N 0.000 description 2
- GFMMXOIFOQCCGU-UHFFFAOYSA-N 2-(2-chloro-4-iodoanilino)-N-(cyclopropylmethoxy)-3,4-difluorobenzamide Chemical compound C=1C=C(I)C=C(Cl)C=1NC1=C(F)C(F)=CC=C1C(=O)NOCC1CC1 GFMMXOIFOQCCGU-UHFFFAOYSA-N 0.000 description 2
- PDMUGYOXRHVNMO-UHFFFAOYSA-N 2-[4-[3-(6-quinolinylmethyl)-5-triazolo[4,5-b]pyrazinyl]-1-pyrazolyl]ethanol Chemical compound C1=NN(CCO)C=C1C1=CN=C(N=NN2CC=3C=C4C=CC=NC4=CC=3)C2=N1 PDMUGYOXRHVNMO-UHFFFAOYSA-N 0.000 description 2
- XDLYKKIQACFMJG-UHFFFAOYSA-N 2-amino-8-[4-(2-hydroxyethoxy)cyclohexyl]-6-(6-methoxypyridin-3-yl)-4-methylpyrido[2,3-d]pyrimidin-7-one Chemical compound C1=NC(OC)=CC=C1C(C1=O)=CC2=C(C)N=C(N)N=C2N1C1CCC(OCCO)CC1 XDLYKKIQACFMJG-UHFFFAOYSA-N 0.000 description 2
- IUTPJBLLJJNPAJ-UHFFFAOYSA-N 3-(2,5-dioxopyrrol-1-yl)propanoic acid Chemical compound OC(=O)CCN1C(=O)C=CC1=O IUTPJBLLJJNPAJ-UHFFFAOYSA-N 0.000 description 2
- RCLQNICOARASSR-SECBINFHSA-N 3-[(2r)-2,3-dihydroxypropyl]-6-fluoro-5-(2-fluoro-4-iodoanilino)-8-methylpyrido[2,3-d]pyrimidine-4,7-dione Chemical compound FC=1C(=O)N(C)C=2N=CN(C[C@@H](O)CO)C(=O)C=2C=1NC1=CC=C(I)C=C1F RCLQNICOARASSR-SECBINFHSA-N 0.000 description 2
- WUIABRMSWOKTOF-OYALTWQYSA-N 3-[[2-[2-[2-[[(2s,3r)-2-[[(2s,3s,4r)-4-[[(2s,3r)-2-[[6-amino-2-[(1s)-3-amino-1-[[(2s)-2,3-diamino-3-oxopropyl]amino]-3-oxopropyl]-5-methylpyrimidine-4-carbonyl]amino]-3-[(2r,3s,4s,5s,6s)-3-[(2r,3s,4s,5r,6r)-4-carbamoyloxy-3,5-dihydroxy-6-(hydroxymethyl)ox Chemical compound OS([O-])(=O)=O.N([C@H](C(=O)N[C@H](C)[C@@H](O)[C@H](C)C(=O)N[C@@H]([C@H](O)C)C(=O)NCCC=1SC=C(N=1)C=1SC=C(N=1)C(=O)NCCC[S+](C)C)[C@@H](O[C@H]1[C@H]([C@@H](O)[C@H](O)[C@H](CO)O1)O[C@@H]1[C@H]([C@@H](OC(N)=O)[C@H](O)[C@@H](CO)O1)O)C=1NC=NC=1)C(=O)C1=NC([C@H](CC(N)=O)NC[C@H](N)C(N)=O)=NC(N)=C1C WUIABRMSWOKTOF-OYALTWQYSA-N 0.000 description 2
- QGZSANLMUAESBT-UHFFFAOYSA-N 3-piperazin-1-ylpropane-1-sulfonic acid Chemical compound OS(=O)(=O)CCCN1CCNCC1 QGZSANLMUAESBT-UHFFFAOYSA-N 0.000 description 2
- NCPQROHLJFARLL-UHFFFAOYSA-N 4-(2,5-dioxopyrrol-1-yl)butanoic acid Chemical compound OC(=O)CCCN1C(=O)C=CC1=O NCPQROHLJFARLL-UHFFFAOYSA-N 0.000 description 2
- SUVMJBTUFCVSAD-JTQLQIEISA-N 4-Methylsulfinylbutyl isothiocyanate Natural products C[S@](=O)CCCCN=C=S SUVMJBTUFCVSAD-JTQLQIEISA-N 0.000 description 2
- MOVBBVMDHIRCTG-LJQANCHMSA-N 4-[(3s)-1-azabicyclo[2.2.2]oct-3-ylamino]-3-(1h-benzimidazol-2-yl)-6-chloroquinolin-2(1h)-one Chemical compound C([N@](CC1)C2)C[C@@H]1[C@@H]2NC1=C(C=2NC3=CC=CC=C3N=2)C(=O)NC2=CC=C(Cl)C=C21 MOVBBVMDHIRCTG-LJQANCHMSA-N 0.000 description 2
- XRYJULCDUUATMC-CYBMUJFWSA-N 4-[4-[[(1r)-1-phenylethyl]amino]-7h-pyrrolo[2,3-d]pyrimidin-6-yl]phenol Chemical compound N([C@H](C)C=1C=CC=CC=1)C(C=1C=2)=NC=NC=1NC=2C1=CC=C(O)C=C1 XRYJULCDUUATMC-CYBMUJFWSA-N 0.000 description 2
- XXLPVQZYQCGXOV-UHFFFAOYSA-N 4-amino-5-fluoro-3-[6-(4-methylpiperazin-1-yl)-1H-benzimidazol-2-yl]-1H-quinolin-2-one 2-hydroxypropanoic acid Chemical compound CC(O)C(O)=O.CC(O)C(O)=O.CN1CCN(CC1)c1ccc2nc([nH]c2c1)-c1c(N)c2c(F)cccc2[nH]c1=O XXLPVQZYQCGXOV-UHFFFAOYSA-N 0.000 description 2
- JRWCBEOAFGHNNU-UHFFFAOYSA-N 6-[difluoro-[6-(1-methyl-4-pyrazolyl)-[1,2,4]triazolo[4,3-b]pyridazin-3-yl]methyl]quinoline Chemical compound C1=NN(C)C=C1C1=NN2C(C(F)(F)C=3C=C4C=CC=NC4=CC=3)=NN=C2C=C1 JRWCBEOAFGHNNU-UHFFFAOYSA-N 0.000 description 2
- GMIZZEXBPRLVIV-SECBINFHSA-N 6-bromo-3-(1-methylpyrazol-4-yl)-5-[(3r)-piperidin-3-yl]pyrazolo[1,5-a]pyrimidin-7-amine Chemical compound C1=NN(C)C=C1C1=C2N=C([C@H]3CNCCC3)C(Br)=C(N)N2N=C1 GMIZZEXBPRLVIV-SECBINFHSA-N 0.000 description 2
- HPLNQCPCUACXLM-PGUFJCEWSA-N ABT-737 Chemical compound C([C@@H](CCN(C)C)NC=1C(=CC(=CC=1)S(=O)(=O)NC(=O)C=1C=CC(=CC=1)N1CCN(CC=2C(=CC=CC=2)C=2C=CC(Cl)=CC=2)CC1)[N+]([O-])=O)SC1=CC=CC=C1 HPLNQCPCUACXLM-PGUFJCEWSA-N 0.000 description 2
- OONFNUWBHFSNBT-HXUWFJFHSA-N AEE788 Chemical compound C1CN(CC)CCN1CC1=CC=C(C=2NC3=NC=NC(N[C@H](C)C=4C=CC=CC=4)=C3C=2)C=C1 OONFNUWBHFSNBT-HXUWFJFHSA-N 0.000 description 2
- BUROJSBIWGDYCN-GAUTUEMISA-N AP 23573 Chemical compound C1C[C@@H](OP(C)(C)=O)[C@H](OC)C[C@@H]1C[C@@H](C)[C@H]1OC(=O)[C@@H]2CCCCN2C(=O)C(=O)[C@](O)(O2)[C@H](C)CC[C@H]2C[C@H](OC)/C(C)=C/C=C/C=C/[C@@H](C)C[C@@H](C)C(=O)[C@H](OC)[C@H](O)/C(C)=C/[C@@H](C)C(=O)C1 BUROJSBIWGDYCN-GAUTUEMISA-N 0.000 description 2
- 102000002260 Alkaline Phosphatase Human genes 0.000 description 2
- 108020004774 Alkaline Phosphatase Proteins 0.000 description 2
- 108010024976 Asparaginase Proteins 0.000 description 2
- MLDQJTXFUGDVEO-UHFFFAOYSA-N BAY-43-9006 Chemical compound C1=NC(C(=O)NC)=CC(OC=2C=CC(NC(=O)NC=3C=C(C(Cl)=CC=3)C(F)(F)F)=CC=2)=C1 MLDQJTXFUGDVEO-UHFFFAOYSA-N 0.000 description 2
- CWHUFRVAEUJCEF-UHFFFAOYSA-N BKM120 Chemical compound C1=NC(N)=CC(C(F)(F)F)=C1C1=CC(N2CCOCC2)=NC(N2CCOCC2)=N1 CWHUFRVAEUJCEF-UHFFFAOYSA-N 0.000 description 2
- 206010005003 Bladder cancer Diseases 0.000 description 2
- GAGWJHPBXLXJQN-UORFTKCHSA-N Capecitabine Chemical compound C1=C(F)C(NC(=O)OCCCCC)=NC(=O)N1[C@H]1[C@H](O)[C@H](O)[C@@H](C)O1 GAGWJHPBXLXJQN-UORFTKCHSA-N 0.000 description 2
- 241000283707 Capra Species 0.000 description 2
- OKTJSMMVPCPJKN-UHFFFAOYSA-N Carbon Chemical compound [C] OKTJSMMVPCPJKN-UHFFFAOYSA-N 0.000 description 2
- CURLTUGMZLYLDI-UHFFFAOYSA-N Carbon dioxide Chemical compound O=C=O CURLTUGMZLYLDI-UHFFFAOYSA-N 0.000 description 2
- 208000005623 Carcinogenesis Diseases 0.000 description 2
- 108090000397 Caspase 3 Proteins 0.000 description 2
- 102000003952 Caspase 3 Human genes 0.000 description 2
- PTOAARAWEBMLNO-KVQBGUIXSA-N Cladribine Chemical compound C1=NC=2C(N)=NC(Cl)=NC=2N1[C@H]1C[C@H](O)[C@@H](CO)O1 PTOAARAWEBMLNO-KVQBGUIXSA-N 0.000 description 2
- 241000699802 Cricetulus griseus Species 0.000 description 2
- 239000004971 Cross linker Substances 0.000 description 2
- 108010024986 Cyclin-Dependent Kinase 2 Proteins 0.000 description 2
- 102100036239 Cyclin-dependent kinase 2 Human genes 0.000 description 2
- ZBNZXTGUTAYRHI-UHFFFAOYSA-N Dasatinib Chemical compound C=1C(N2CCN(CCO)CC2)=NC(C)=NC=1NC(S1)=NC=C1C(=O)NC1=C(C)C=CC=C1Cl ZBNZXTGUTAYRHI-UHFFFAOYSA-N 0.000 description 2
- YZCKVEUIGOORGS-OUBTZVSYSA-N Deuterium Chemical group [2H] YZCKVEUIGOORGS-OUBTZVSYSA-N 0.000 description 2
- 241000588724 Escherichia coli Species 0.000 description 2
- HKVAMNSJSFKALM-GKUWKFKPSA-N Everolimus Chemical compound C1C[C@@H](OCCO)[C@H](OC)C[C@@H]1C[C@@H](C)[C@H]1OC(=O)[C@@H]2CCCCN2C(=O)C(=O)[C@](O)(O2)[C@H](C)CC[C@H]2C[C@H](OC)/C(C)=C/C=C/C=C/[C@@H](C)C[C@@H](C)C(=O)[C@H](OC)[C@H](O)/C(C)=C/[C@@H](C)C(=O)C1 HKVAMNSJSFKALM-GKUWKFKPSA-N 0.000 description 2
- 108091008794 FGF receptors Proteins 0.000 description 2
- AEMRFAOFKBGASW-UHFFFAOYSA-N Glycolic acid Polymers OCC(O)=O AEMRFAOFKBGASW-UHFFFAOYSA-N 0.000 description 2
- 239000007995 HEPES buffer Substances 0.000 description 2
- 101710154606 Hemagglutinin Proteins 0.000 description 2
- 241000238631 Hexapoda Species 0.000 description 2
- 108010093488 His-His-His-His-His-His Proteins 0.000 description 2
- 101001012157 Homo sapiens Receptor tyrosine-protein kinase erbB-2 Proteins 0.000 description 2
- VSNHCAURESNICA-UHFFFAOYSA-N Hydroxyurea Chemical compound NC(=O)NO VSNHCAURESNICA-UHFFFAOYSA-N 0.000 description 2
- 102000010638 Kinesin Human genes 0.000 description 2
- 108010063296 Kinesin Proteins 0.000 description 2
- LRQKBLKVPFOOQJ-YFKPBYRVSA-N L-norleucine Chemical compound CCCC[C@H]([NH3+])C([O-])=O LRQKBLKVPFOOQJ-YFKPBYRVSA-N 0.000 description 2
- 239000005517 L01XE01 - Imatinib Substances 0.000 description 2
- 239000005411 L01XE02 - Gefitinib Substances 0.000 description 2
- 239000005551 L01XE03 - Erlotinib Substances 0.000 description 2
- 239000005511 L01XE05 - Sorafenib Substances 0.000 description 2
- 239000002146 L01XE16 - Crizotinib Substances 0.000 description 2
- UCEQXRCJXIVODC-PMACEKPBSA-N LSM-1131 Chemical compound C1CCC2=CC=CC3=C2N1C=C3[C@@H]1C(=O)NC(=O)[C@H]1C1=CNC2=CC=CC=C12 UCEQXRCJXIVODC-PMACEKPBSA-N 0.000 description 2
- OTPNDVKVEAIXTI-UHFFFAOYSA-N LSM-1274 Chemical compound C12=C3C4=C5C=CC=C[C]5N3C(O3)CCC3N2C2=CC=C[CH]C2=C1C1=C4C(=O)NC1=O OTPNDVKVEAIXTI-UHFFFAOYSA-N 0.000 description 2
- GUBGYTABKSRVRQ-QKKXKWKRSA-N Lactose Natural products OC[C@H]1O[C@@H](O[C@H]2[C@H](O)[C@@H](O)C(O)O[C@@H]2CO)[C@H](O)[C@@H](O)[C@H]1O GUBGYTABKSRVRQ-QKKXKWKRSA-N 0.000 description 2
- 108090001090 Lectins Proteins 0.000 description 2
- 102000004856 Lectins Human genes 0.000 description 2
- NNJVILVZKWQKPM-UHFFFAOYSA-N Lidocaine Chemical compound CCN(CC)CC(=O)NC1=C(C)C=CC=C1C NNJVILVZKWQKPM-UHFFFAOYSA-N 0.000 description 2
- 102000043136 MAP kinase family Human genes 0.000 description 2
- 108091054455 MAP kinase family Proteins 0.000 description 2
- OFOBLEOULBTSOW-UHFFFAOYSA-N Malonic acid Chemical compound OC(=O)CC(O)=O OFOBLEOULBTSOW-UHFFFAOYSA-N 0.000 description 2
- PWHULOQIROXLJO-UHFFFAOYSA-N Manganese Chemical compound [Mn] PWHULOQIROXLJO-UHFFFAOYSA-N 0.000 description 2
- 102000003792 Metallothionein Human genes 0.000 description 2
- 108090000157 Metallothionein Proteins 0.000 description 2
- 206010027476 Metastases Diseases 0.000 description 2
- YNAVUWVOSKDBBP-UHFFFAOYSA-N Morpholine Chemical compound C1COCCN1 YNAVUWVOSKDBBP-UHFFFAOYSA-N 0.000 description 2
- 241000713333 Mouse mammary tumor virus Species 0.000 description 2
- 101150097381 Mtor gene Proteins 0.000 description 2
- VIUAUNHCRHHYNE-JTQLQIEISA-N N-[(2S)-2,3-dihydroxypropyl]-3-(2-fluoro-4-iodoanilino)-4-pyridinecarboxamide Chemical compound OC[C@@H](O)CNC(=O)C1=CC=NC=C1NC1=CC=C(I)C=C1F VIUAUNHCRHHYNE-JTQLQIEISA-N 0.000 description 2
- GCIKSSRWRFVXBI-UHFFFAOYSA-N N-[4-[[4-(4-methyl-1-piperazinyl)-6-[(5-methyl-1H-pyrazol-3-yl)amino]-2-pyrimidinyl]thio]phenyl]cyclopropanecarboxamide Chemical compound C1CN(C)CCN1C1=CC(NC2=NNC(C)=C2)=NC(SC=2C=CC(NC(=O)C3CC3)=CC=2)=N1 GCIKSSRWRFVXBI-UHFFFAOYSA-N 0.000 description 2
- JOCBASBOOFNAJA-UHFFFAOYSA-N N-tris(hydroxymethyl)methyl-2-aminoethanesulfonic acid Chemical compound OCC(CO)(CO)NCCS(O)(=O)=O JOCBASBOOFNAJA-UHFFFAOYSA-N 0.000 description 2
- 208000009905 Neurofibromatoses Diseases 0.000 description 2
- 108700020796 Oncogene Proteins 0.000 description 2
- 101710093908 Outer capsid protein VP4 Proteins 0.000 description 2
- 101710135467 Outer capsid protein sigma-1 Proteins 0.000 description 2
- 206010033128 Ovarian cancer Diseases 0.000 description 2
- 206010061535 Ovarian neoplasm Diseases 0.000 description 2
- DXCUKNQANPLTEJ-UHFFFAOYSA-N PD173074 Chemical compound CC(C)(C)NC(=O)NC1=NC2=NC(NCCCCN(CC)CC)=NC=C2C=C1C1=CC(OC)=CC(OC)=C1 DXCUKNQANPLTEJ-UHFFFAOYSA-N 0.000 description 2
- OYONTEXKYJZFHA-SSHUPFPWSA-N PHA-665752 Chemical compound CC=1C(C(=O)N2[C@H](CCC2)CN2CCCC2)=C(C)NC=1\C=C(C1=C2)/C(=O)NC1=CC=C2S(=O)(=O)CC1=C(Cl)C=CC=C1Cl OYONTEXKYJZFHA-SSHUPFPWSA-N 0.000 description 2
- QIUASFSNWYMDFS-NILGECQDSA-N PX-866 Chemical compound CC(=O)O[C@@H]1C[C@]2(C)C(=O)CC[C@H]2C2=C1[C@@]1(C)[C@@H](COC)OC(=O)\C(=C\N(CC=C)CC=C)C1=C(O)C2=O QIUASFSNWYMDFS-NILGECQDSA-N 0.000 description 2
- 108091093037 Peptide nucleic acid Proteins 0.000 description 2
- 239000002202 Polyethylene glycol Substances 0.000 description 2
- 229920000954 Polyglycolide Polymers 0.000 description 2
- 206010060862 Prostate cancer Diseases 0.000 description 2
- 208000000236 Prostatic Neoplasms Diseases 0.000 description 2
- 101710176177 Protein A56 Proteins 0.000 description 2
- 241000589516 Pseudomonas Species 0.000 description 2
- 102100030086 Receptor tyrosine-protein kinase erbB-2 Human genes 0.000 description 2
- 108091028664 Ribonucleotide Proteins 0.000 description 2
- 239000006146 Roswell Park Memorial Institute medium Substances 0.000 description 2
- BCZUAADEACICHN-UHFFFAOYSA-N SGX-523 Chemical compound C1=NN(C)C=C1C1=NN2C(SC=3C=C4C=CC=NC4=CC=3)=NN=C2C=C1 BCZUAADEACICHN-UHFFFAOYSA-N 0.000 description 2
- 240000004808 Saccharomyces cerevisiae Species 0.000 description 2
- 241000710961 Semliki Forest virus Species 0.000 description 2
- MTCFGRXMJLQNBG-UHFFFAOYSA-N Serine Natural products OCC(N)C(O)=O MTCFGRXMJLQNBG-UHFFFAOYSA-N 0.000 description 2
- 108010003723 Single-Domain Antibodies Proteins 0.000 description 2
- 208000021712 Soft tissue sarcoma Diseases 0.000 description 2
- 229940123237 Taxane Drugs 0.000 description 2
- VGQOVCHZGQWAOI-UHFFFAOYSA-N UNPD55612 Natural products N1C(O)C2CC(C=CC(N)=O)=CN2C(=O)C2=CC=C(C)C(O)=C12 VGQOVCHZGQWAOI-UHFFFAOYSA-N 0.000 description 2
- 208000007097 Urinary Bladder Neoplasms Diseases 0.000 description 2
- VWQVUPCCIRVNHF-OUBTZVSYSA-N Yttrium-90 Chemical compound [90Y] VWQVUPCCIRVNHF-OUBTZVSYSA-N 0.000 description 2
- CHKFLBOLYREYDO-SHYZEUOFSA-N [[(2s,4r,5r)-5-(4-amino-2-oxopyrimidin-1-yl)-4-hydroxyoxolan-2-yl]methoxy-hydroxyphosphoryl] phosphono hydrogen phosphate Chemical compound O=C1N=C(N)C=CN1[C@H]1[C@H](O)C[C@@H](COP(O)(=O)OP(O)(=O)OP(O)(O)=O)O1 CHKFLBOLYREYDO-SHYZEUOFSA-N 0.000 description 2
- 238000009825 accumulation Methods 0.000 description 2
- RJURFGZVJUQBHK-IIXSONLDSA-N actinomycin D Chemical compound C[C@H]1OC(=O)[C@H](C(C)C)N(C)C(=O)CN(C)C(=O)[C@@H]2CCCN2C(=O)[C@@H](C(C)C)NC(=O)[C@H]1NC(=O)C1=C(N)C(=O)C(C)=C2OC(C(C)=CC=C3C(=O)N[C@@H]4C(=O)N[C@@H](C(N5CCC[C@H]5C(=O)N(C)CC(=O)N(C)[C@@H](C(C)C)C(=O)O[C@@H]4C)=O)C(C)C)=C3N=C21 RJURFGZVJUQBHK-IIXSONLDSA-N 0.000 description 2
- 230000004913 activation Effects 0.000 description 2
- 208000020990 adrenal cortex carcinoma Diseases 0.000 description 2
- 238000005377 adsorption chromatography Methods 0.000 description 2
- 230000002411 adverse Effects 0.000 description 2
- 150000001408 amides Chemical class 0.000 description 2
- 230000003321 amplification Effects 0.000 description 2
- YBBLVLTVTVSKRW-UHFFFAOYSA-N anastrozole Chemical compound N#CC(C)(C)C1=CC(C(C)(C#N)C)=CC(CN2N=CN=C2)=C1 YBBLVLTVTVSKRW-UHFFFAOYSA-N 0.000 description 2
- 229940045799 anthracyclines and related substance Drugs 0.000 description 2
- VGQOVCHZGQWAOI-HYUHUPJXSA-N anthramycin Chemical compound N1[C@@H](O)[C@@H]2CC(\C=C\C(N)=O)=CN2C(=O)C2=CC=C(C)C(O)=C12 VGQOVCHZGQWAOI-HYUHUPJXSA-N 0.000 description 2
- 239000003429 antifungal agent Substances 0.000 description 2
- 229940121375 antifungal agent Drugs 0.000 description 2
- 229940045988 antineoplastic drug protein kinase inhibitors Drugs 0.000 description 2
- 230000001588 bifunctional effect Effects 0.000 description 2
- 239000003124 biologic agent Substances 0.000 description 2
- 230000008512 biological response Effects 0.000 description 2
- 210000001124 body fluid Anatomy 0.000 description 2
- 239000010839 body fluid Substances 0.000 description 2
- 229940112133 busulfex Drugs 0.000 description 2
- 125000000484 butyl group Chemical group [H]C([*])([H])C([H])([H])C([H])([H])C([H])([H])[H] 0.000 description 2
- 239000001506 calcium phosphate Substances 0.000 description 2
- 229910000389 calcium phosphate Inorganic materials 0.000 description 2
- 235000011010 calcium phosphates Nutrition 0.000 description 2
- 230000036952 cancer formation Effects 0.000 description 2
- 208000035269 cancer or benign tumor Diseases 0.000 description 2
- 125000004432 carbon atom Chemical group C* 0.000 description 2
- 231100000504 carcinogenesis Toxicity 0.000 description 2
- 229960005243 carmustine Drugs 0.000 description 2
- 239000000969 carrier Substances 0.000 description 2
- 230000012292 cell migration Effects 0.000 description 2
- 238000001516 cell proliferation assay Methods 0.000 description 2
- 239000006285 cell suspension Substances 0.000 description 2
- 239000000919 ceramic Substances 0.000 description 2
- 239000002738 chelating agent Substances 0.000 description 2
- 239000012539 chromatography resin Substances 0.000 description 2
- 229960004316 cisplatin Drugs 0.000 description 2
- 229960002436 cladribine Drugs 0.000 description 2
- 238000010367 cloning Methods 0.000 description 2
- 238000011260 co-administration Methods 0.000 description 2
- 229960002271 cobimetinib Drugs 0.000 description 2
- BSMCAPRUBJMWDF-KRWDZBQOSA-N cobimetinib Chemical compound C1C(O)([C@H]2NCCCC2)CN1C(=O)C1=CC=C(F)C(F)=C1NC1=CC=C(I)C=C1F BSMCAPRUBJMWDF-KRWDZBQOSA-N 0.000 description 2
- 230000008878 coupling Effects 0.000 description 2
- 238000010168 coupling process Methods 0.000 description 2
- 238000005859 coupling reaction Methods 0.000 description 2
- 239000006071 cream Substances 0.000 description 2
- 229960005061 crizotinib Drugs 0.000 description 2
- 230000009260 cross reactivity Effects 0.000 description 2
- 125000004122 cyclic group Chemical group 0.000 description 2
- NZNMSOFKMUBTKW-UHFFFAOYSA-M cyclohexanecarboxylate Chemical compound [O-]C(=O)C1CCCCC1 NZNMSOFKMUBTKW-UHFFFAOYSA-M 0.000 description 2
- 235000018417 cysteine Nutrition 0.000 description 2
- XUJNEKJLAYXESH-UHFFFAOYSA-N cysteine Natural products SCC(N)C(O)=O XUJNEKJLAYXESH-UHFFFAOYSA-N 0.000 description 2
- 125000000151 cysteine group Chemical group N[C@@H](CS)C(=O)* 0.000 description 2
- 231100000433 cytotoxic Toxicity 0.000 description 2
- 230000001472 cytotoxic effect Effects 0.000 description 2
- 229960000640 dactinomycin Drugs 0.000 description 2
- JOGKUKXHTYWRGZ-UHFFFAOYSA-N dactolisib Chemical compound O=C1N(C)C2=CN=C3C=CC(C=4C=C5C=CC=CC5=NC=4)=CC3=C2N1C1=CC=C(C(C)(C)C#N)C=C1 JOGKUKXHTYWRGZ-UHFFFAOYSA-N 0.000 description 2
- 229960000975 daunorubicin Drugs 0.000 description 2
- 230000001419 dependent effect Effects 0.000 description 2
- 230000002074 deregulated effect Effects 0.000 description 2
- 230000000368 destabilizing effect Effects 0.000 description 2
- 229910052805 deuterium Inorganic materials 0.000 description 2
- 238000003745 diagnosis Methods 0.000 description 2
- 238000006471 dimerization reaction Methods 0.000 description 2
- 230000006334 disulfide bridging Effects 0.000 description 2
- 125000002228 disulfide group Chemical group 0.000 description 2
- 230000007783 downstream signaling Effects 0.000 description 2
- 229960004679 doxorubicin Drugs 0.000 description 2
- 239000006196 drop Substances 0.000 description 2
- 239000012636 effector Substances 0.000 description 2
- 229960005073 erlotinib hydrochloride Drugs 0.000 description 2
- VJJPUSNTGOMMGY-MRVIYFEKSA-N etoposide Chemical compound COC1=C(O)C(OC)=CC([C@@H]2C3=CC=4OCOC=4C=C3[C@@H](O[C@H]3[C@@H]([C@@H](O)[C@@H]4O[C@H](C)OC[C@H]4O3)O)[C@@H]3[C@@H]2C(OC3)=O)=C1 VJJPUSNTGOMMGY-MRVIYFEKSA-N 0.000 description 2
- 238000001914 filtration Methods 0.000 description 2
- GNBHRKFJIUUOQI-UHFFFAOYSA-N fluorescein Chemical compound O1C(=O)C2=CC=CC=C2C21C1=CC=C(O)C=C1OC1=CC(O)=CC=C21 GNBHRKFJIUUOQI-UHFFFAOYSA-N 0.000 description 2
- 230000033581 fucosylation Effects 0.000 description 2
- 125000000524 functional group Chemical group 0.000 description 2
- 230000002538 fungal effect Effects 0.000 description 2
- 230000004927 fusion Effects 0.000 description 2
- 229960002584 gefitinib Drugs 0.000 description 2
- 239000000499 gel Substances 0.000 description 2
- 239000011521 glass Substances 0.000 description 2
- 239000003862 glucocorticoid Substances 0.000 description 2
- 108010038082 heparin proteoglycan Proteins 0.000 description 2
- 229940022353 herceptin Drugs 0.000 description 2
- 210000005260 human cell Anatomy 0.000 description 2
- 229910052739 hydrogen Inorganic materials 0.000 description 2
- 230000002209 hydrophobic effect Effects 0.000 description 2
- 238000003384 imaging method Methods 0.000 description 2
- KTUFNOKKBVMGRW-UHFFFAOYSA-N imatinib Chemical compound C1CN(C)CCN1CC1=CC=C(C(=O)NC=2C=C(NC=3N=C(C=CN=3)C=3C=NC=CC=3)C(C)=CC=2)C=C1 KTUFNOKKBVMGRW-UHFFFAOYSA-N 0.000 description 2
- 230000002998 immunogenetic effect Effects 0.000 description 2
- 229940072221 immunoglobulins Drugs 0.000 description 2
- 238000003364 immunohistochemistry Methods 0.000 description 2
- 239000002955 immunomodulating agent Substances 0.000 description 2
- 238000001114 immunoprecipitation Methods 0.000 description 2
- 239000007943 implant Substances 0.000 description 2
- APFVFJFRJDLVQX-AHCXROLUSA-N indium-111 Chemical compound [111In] APFVFJFRJDLVQX-AHCXROLUSA-N 0.000 description 2
- 230000006698 induction Effects 0.000 description 2
- 229940079322 interferon Drugs 0.000 description 2
- 230000003834 intracellular effect Effects 0.000 description 2
- 238000004255 ion exchange chromatography Methods 0.000 description 2
- UWKQSNNFCGGAFS-XIFFEERXSA-N irinotecan Chemical compound C1=C2C(CC)=C3CN(C(C4=C([C@@](C(=O)OC4)(O)CC)C=4)=O)C=4C3=NC2=CC=C1OC(=O)N(CC1)CCC1N1CCCCC1 UWKQSNNFCGGAFS-XIFFEERXSA-N 0.000 description 2
- JVTAAEKCZFNVCJ-UHFFFAOYSA-N lactic acid Chemical compound CC(O)C(O)=O JVTAAEKCZFNVCJ-UHFFFAOYSA-N 0.000 description 2
- 239000008101 lactose Substances 0.000 description 2
- 229960001320 lapatinib ditosylate Drugs 0.000 description 2
- 239000002523 lectin Substances 0.000 description 2
- 230000003902 lesion Effects 0.000 description 2
- 229960004194 lidocaine Drugs 0.000 description 2
- 239000006210 lotion Substances 0.000 description 2
- 229910052748 manganese Inorganic materials 0.000 description 2
- 238000013507 mapping Methods 0.000 description 2
- 230000035800 maturation Effects 0.000 description 2
- SGDBTWWWUNNDEQ-LBPRGKRZSA-N melphalan Chemical compound OC(=O)[C@@H](N)CC1=CC=C(N(CCCl)CCCl)C=C1 SGDBTWWWUNNDEQ-LBPRGKRZSA-N 0.000 description 2
- 229910052751 metal Inorganic materials 0.000 description 2
- 239000002184 metal Substances 0.000 description 2
- 229960000485 methotrexate Drugs 0.000 description 2
- 229960001156 mitoxantrone Drugs 0.000 description 2
- 238000002156 mixing Methods 0.000 description 2
- LBWFXVZLPYTWQI-IPOVEDGCSA-N n-[2-(diethylamino)ethyl]-5-[(z)-(5-fluoro-2-oxo-1h-indol-3-ylidene)methyl]-2,4-dimethyl-1h-pyrrole-3-carboxamide;(2s)-2-hydroxybutanedioic acid Chemical compound OC(=O)[C@@H](O)CC(O)=O.CCN(CC)CCNC(=O)C1=C(C)NC(\C=C/2C3=CC(F)=CC=C3NC\2=O)=C1C LBWFXVZLPYTWQI-IPOVEDGCSA-N 0.000 description 2
- 229950004847 navitoclax Drugs 0.000 description 2
- 239000006199 nebulizer Substances 0.000 description 2
- 230000001613 neoplastic effect Effects 0.000 description 2
- 201000004931 neurofibromatosis Diseases 0.000 description 2
- 230000007935 neutral effect Effects 0.000 description 2
- 229940080607 nexavar Drugs 0.000 description 2
- 238000003199 nucleic acid amplification method Methods 0.000 description 2
- 229960000435 oblimersen Drugs 0.000 description 2
- MIMNFCVQODTQDP-NDLVEFNKSA-N oblimersen Chemical compound O=C1NC(=O)C(C)=CN1[C@@H]1O[C@H](COP(S)(=O)O[C@@H]2[C@H](O[C@H](C2)N2C3=NC=NC(N)=C3N=C2)COP(O)(=S)O[C@@H]2[C@H](O[C@H](C2)N2C(N=C(N)C=C2)=O)COP(O)(=S)O[C@@H]2[C@H](O[C@H](C2)N2C(N=C(N)C=C2)=O)COP(O)(=S)O[C@@H]2[C@H](O[C@H](C2)N2C3=C(C(NC(N)=N3)=O)N=C2)COP(O)(=S)O[C@@H]2[C@H](O[C@H](C2)N2C(N=C(N)C=C2)=O)COP(O)(=S)O[C@@H]2[C@H](O[C@H](C2)N2C3=C(C(NC(N)=N3)=O)N=C2)COP(O)(=S)O[C@@H]2[C@H](O[C@H](C2)N2C(NC(=O)C(C)=C2)=O)COP(O)(=S)O[C@@H]2[C@H](O[C@H](C2)N2C3=C(C(NC(N)=N3)=O)N=C2)COP(O)(=S)O[C@@H]2[C@H](O[C@H](C2)N2C(N=C(N)C=C2)=O)COP(O)(=S)O[C@@H]2[C@H](O[C@H](C2)N2C3=C(C(NC(N)=N3)=O)N=C2)COP(O)(=S)O[C@@H]2[C@H](O[C@H](C2)N2C3=NC=NC(N)=C3N=C2)COP(O)(=S)O[C@@H]2[C@H](O[C@H](C2)N2C(N=C(N)C=C2)=O)COP(O)(=S)O[C@@H]2[C@H](O[C@H](C2)N2C(N=C(N)C=C2)=O)COP(O)(=S)O[C@@H]2[C@H](O[C@H](C2)N2C(N=C(N)C=C2)=O)COP(O)(=S)O[C@@H]2[C@H](O[C@H](C2)N2C(NC(=O)C(C)=C2)=O)COP(O)(=S)O[C@@H]2[C@H](O[C@H](C2)N2C(N=C(N)C=C2)=O)COP(O)(=S)O[C@@H]2[C@H](O[C@H](C2)N2C(NC(=O)C(C)=C2)=O)CO)[C@@H](O)C1 MIMNFCVQODTQDP-NDLVEFNKSA-N 0.000 description 2
- 238000011275 oncology therapy Methods 0.000 description 2
- 238000007911 parenteral administration Methods 0.000 description 2
- 239000008188 pellet Substances 0.000 description 2
- 230000026731 phosphorylation Effects 0.000 description 2
- 238000006366 phosphorylation reaction Methods 0.000 description 2
- 230000004962 physiological condition Effects 0.000 description 2
- BIWOSRSKDCZIFM-UHFFFAOYSA-N piperidin-3-ol Chemical compound OC1CCCNC1 BIWOSRSKDCZIFM-UHFFFAOYSA-N 0.000 description 2
- 229920000747 poly(lactic acid) Polymers 0.000 description 2
- 229920002401 polyacrylamide Polymers 0.000 description 2
- PHXJVRSECIGDHY-UHFFFAOYSA-N ponatinib Chemical compound C1CN(C)CCN1CC(C(=C1)C(F)(F)F)=CC=C1NC(=O)C1=CC=C(C)C(C#CC=2N3N=CC=CC3=NC=2)=C1 PHXJVRSECIGDHY-UHFFFAOYSA-N 0.000 description 2
- 150000003141 primary amines Chemical class 0.000 description 2
- 230000002062 proliferating effect Effects 0.000 description 2
- 230000000644 propagated effect Effects 0.000 description 2
- 239000003380 propellant Substances 0.000 description 2
- 238000011321 prophylaxis Methods 0.000 description 2
- AQHHHDLHHXJYJD-UHFFFAOYSA-N propranolol Chemical compound C1=CC=C2C(OCC(O)CNC(C)C)=CC=CC2=C1 AQHHHDLHHXJYJD-UHFFFAOYSA-N 0.000 description 2
- 239000003909 protein kinase inhibitor Substances 0.000 description 2
- RXWNCPJZOCPEPQ-NVWDDTSBSA-N puromycin Chemical compound C1=CC(OC)=CC=C1C[C@H](N)C(=O)N[C@H]1[C@@H](O)[C@H](N2C3=NC=NC(=C3N=C2)N(C)C)O[C@@H]1CO RXWNCPJZOCPEPQ-NVWDDTSBSA-N 0.000 description 2
- LISFMEBWQUVKPJ-UHFFFAOYSA-N quinolin-2-ol Chemical compound C1=CC=C2NC(=O)C=CC2=C1 LISFMEBWQUVKPJ-UHFFFAOYSA-N 0.000 description 2
- 230000003439 radiotherapeutic effect Effects 0.000 description 2
- 238000002708 random mutagenesis Methods 0.000 description 2
- 238000003259 recombinant expression Methods 0.000 description 2
- 238000007670 refining Methods 0.000 description 2
- 230000001105 regulatory effect Effects 0.000 description 2
- 230000010076 replication Effects 0.000 description 2
- 230000000717 retained effect Effects 0.000 description 2
- 239000002336 ribonucleotide Substances 0.000 description 2
- 230000035945 sensitivity Effects 0.000 description 2
- 238000013207 serial dilution Methods 0.000 description 2
- 229960002930 sirolimus Drugs 0.000 description 2
- QFJCIRLUMZQUOT-HPLJOQBZSA-N sirolimus Chemical compound C1C[C@@H](O)[C@H](OC)C[C@@H]1C[C@@H](C)[C@H]1OC(=O)[C@@H]2CCCCN2C(=O)C(=O)[C@](O)(O2)[C@H](C)CC[C@H]2C[C@H](OC)/C(C)=C/C=C/C=C/[C@@H](C)C[C@@H](C)C(=O)[C@H](OC)[C@H](O)/C(C)=C/[C@@H](C)C(=O)C1 QFJCIRLUMZQUOT-HPLJOQBZSA-N 0.000 description 2
- 238000002741 site-directed mutagenesis Methods 0.000 description 2
- 239000006104 solid solution Substances 0.000 description 2
- 230000009870 specific binding Effects 0.000 description 2
- 230000006641 stabilisation Effects 0.000 description 2
- 238000011105 stabilization Methods 0.000 description 2
- 238000010561 standard procedure Methods 0.000 description 2
- 238000011146 sterile filtration Methods 0.000 description 2
- 238000003860 storage Methods 0.000 description 2
- 239000004094 surface-active agent Substances 0.000 description 2
- 238000003786 synthesis reaction Methods 0.000 description 2
- 230000009885 systemic effect Effects 0.000 description 2
- 239000003826 tablet Substances 0.000 description 2
- FQZYTYWMLGAPFJ-OQKDUQJOSA-N tamoxifen citrate Chemical compound [H+].[H+].[H+].[O-]C(=O)CC(O)(CC([O-])=O)C([O-])=O.C=1C=CC=CC=1C(/CC)=C(C=1C=CC(OCCN(C)C)=CC=1)/C1=CC=CC=C1 FQZYTYWMLGAPFJ-OQKDUQJOSA-N 0.000 description 2
- 229940120982 tarceva Drugs 0.000 description 2
- XOAAWQZATWQOTB-UHFFFAOYSA-N taurine Chemical compound NCCS(O)(=O)=O XOAAWQZATWQOTB-UHFFFAOYSA-N 0.000 description 2
- 229950003046 tesevatinib Drugs 0.000 description 2
- 229960003087 tioguanine Drugs 0.000 description 2
- ORYDPOVDJJZGHQ-UHFFFAOYSA-N tirapazamine Chemical compound C1=CC=CC2=[N+]([O-])C(N)=N[N+]([O-])=C21 ORYDPOVDJJZGHQ-UHFFFAOYSA-N 0.000 description 2
- 238000004448 titration Methods 0.000 description 2
- 239000006208 topical dosage form Substances 0.000 description 2
- UCFGDBYHRUNTLO-QHCPKHFHSA-N topotecan Chemical compound C1=C(O)C(CN(C)C)=C2C=C(CN3C4=CC5=C(C3=O)COC(=O)[C@]5(O)CC)C4=NC2=C1 UCFGDBYHRUNTLO-QHCPKHFHSA-N 0.000 description 2
- 230000001988 toxicity Effects 0.000 description 2
- 231100000419 toxicity Toxicity 0.000 description 2
- 230000009466 transformation Effects 0.000 description 2
- 238000013519 translation Methods 0.000 description 2
- QORWJWZARLRLPR-UHFFFAOYSA-H tricalcium bis(phosphate) Chemical compound [Ca+2].[Ca+2].[Ca+2].[O-]P([O-])([O-])=O.[O-]P([O-])([O-])=O QORWJWZARLRLPR-UHFFFAOYSA-H 0.000 description 2
- LWIHDJKSTIGBAC-UHFFFAOYSA-K tripotassium phosphate Chemical compound [K+].[K+].[K+].[O-]P([O-])([O-])=O LWIHDJKSTIGBAC-UHFFFAOYSA-K 0.000 description 2
- 238000013414 tumor xenograft model Methods 0.000 description 2
- 229940094060 tykerb Drugs 0.000 description 2
- 241000701161 unidentified adenovirus Species 0.000 description 2
- 241001529453 unidentified herpesvirus Species 0.000 description 2
- 201000005112 urinary bladder cancer Diseases 0.000 description 2
- 229960000241 vandetanib Drugs 0.000 description 2
- GPXBXXGIAQBQNI-UHFFFAOYSA-N vemurafenib Chemical compound CCCS(=O)(=O)NC1=CC=C(F)C(C(=O)C=2C3=CC(=CN=C3NC=2)C=2C=CC(Cl)=CC=2)=C1F GPXBXXGIAQBQNI-UHFFFAOYSA-N 0.000 description 2
- 238000011179 visual inspection Methods 0.000 description 2
- PMJWDPGOWBRILU-UHFFFAOYSA-N (2,5-dioxopyrrolidin-1-yl) 4-[4-(2,5-dioxopyrrol-1-yl)phenyl]butanoate Chemical compound O=C1CCC(=O)N1OC(=O)CCCC(C=C1)=CC=C1N1C(=O)C=CC1=O PMJWDPGOWBRILU-UHFFFAOYSA-N 0.000 description 1
- WCWUXEGQKLTGDX-LLVKDONJSA-N (2R)-1-[[4-[(4-fluoro-2-methyl-1H-indol-5-yl)oxy]-5-methyl-6-pyrrolo[2,1-f][1,2,4]triazinyl]oxy]-2-propanol Chemical compound C1=C2NC(C)=CC2=C(F)C(OC2=NC=NN3C=C(C(=C32)C)OC[C@H](O)C)=C1 WCWUXEGQKLTGDX-LLVKDONJSA-N 0.000 description 1
- RXHGWONKWVQITK-AWEZNQCLSA-N (2r)-2-(dodecylamino)-3-sulfanylpropanoic acid Chemical compound CCCCCCCCCCCCN[C@@H](CS)C(O)=O RXHGWONKWVQITK-AWEZNQCLSA-N 0.000 description 1
- HSHPBORBOJIXSQ-HARLFGEKSA-N (2s)-1-[(2s)-2-cyclohexyl-2-[[(2s)-2-(methylamino)propanoyl]amino]acetyl]-n-[2-(1,3-oxazol-2-yl)-4-phenyl-1,3-thiazol-5-yl]pyrrolidine-2-carboxamide Chemical compound C1([C@H](NC(=O)[C@H](C)NC)C(=O)N2[C@@H](CCC2)C(=O)NC2=C(N=C(S2)C=2OC=CN=2)C=2C=CC=CC=2)CCCCC1 HSHPBORBOJIXSQ-HARLFGEKSA-N 0.000 description 1
- LGNCNVVZCUVPOT-FUVGGWJZSA-N (2s)-2-[[(2r,3r)-3-[(2s)-1-[(3r,4s,5s)-4-[[(2s)-2-[[(2s)-2-(dimethylamino)-3-methylbutanoyl]amino]-3-methylbutanoyl]-methylamino]-3-methoxy-5-methylheptanoyl]pyrrolidin-2-yl]-3-methoxy-2-methylpropanoyl]amino]-3-phenylpropanoic acid Chemical compound CC(C)[C@H](N(C)C)C(=O)N[C@@H](C(C)C)C(=O)N(C)[C@@H]([C@@H](C)CC)[C@H](OC)CC(=O)N1CCC[C@H]1[C@H](OC)[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 LGNCNVVZCUVPOT-FUVGGWJZSA-N 0.000 description 1
- WOWDZACBATWTAU-FEFUEGSOSA-N (2s)-2-[[(2s)-2-(dimethylamino)-3-methylbutanoyl]amino]-n-[(3r,4s,5s)-1-[(2s)-2-[(1r,2r)-3-[[(1s,2r)-1-hydroxy-1-phenylpropan-2-yl]amino]-1-methoxy-2-methyl-3-oxopropyl]pyrrolidin-1-yl]-3-methoxy-5-methyl-1-oxoheptan-4-yl]-n,3-dimethylbutanamide Chemical compound CC(C)[C@H](N(C)C)C(=O)N[C@@H](C(C)C)C(=O)N(C)[C@@H]([C@@H](C)CC)[C@H](OC)CC(=O)N1CCC[C@H]1[C@H](OC)[C@@H](C)C(=O)N[C@H](C)[C@@H](O)C1=CC=CC=C1 WOWDZACBATWTAU-FEFUEGSOSA-N 0.000 description 1
- MHFUWOIXNMZFIW-WNQIDUERSA-N (2s)-2-hydroxypropanoic acid;n-[4-[4-(4-methylpiperazin-1-yl)-6-[(5-methyl-1h-pyrazol-3-yl)amino]pyrimidin-2-yl]sulfanylphenyl]cyclopropanecarboxamide Chemical compound C[C@H](O)C(O)=O.C1CN(C)CCN1C1=CC(NC2=NNC(C)=C2)=NC(SC=2C=CC(NC(=O)C3CC3)=CC=2)=N1 MHFUWOIXNMZFIW-WNQIDUERSA-N 0.000 description 1
- UFPFGVNKHCLJJO-SSKFGXFMSA-N (2s)-n-[(1s)-1-cyclohexyl-2-[(2s)-2-[4-(4-fluorobenzoyl)-1,3-thiazol-2-yl]pyrrolidin-1-yl]-2-oxoethyl]-2-(methylamino)propanamide Chemical compound C1([C@H](NC(=O)[C@H](C)NC)C(=O)N2[C@@H](CCC2)C=2SC=C(N=2)C(=O)C=2C=CC(F)=CC=2)CCCCC1 UFPFGVNKHCLJJO-SSKFGXFMSA-N 0.000 description 1
- NAALWFYYHHJEFQ-ZASNTINBSA-N (2s,5r,6r)-6-[[(2r)-2-[[6-[4-[bis(2-hydroxyethyl)sulfamoyl]phenyl]-2-oxo-1h-pyridine-3-carbonyl]amino]-2-(4-hydroxyphenyl)acetyl]amino]-3,3-dimethyl-7-oxo-4-thia-1-azabicyclo[3.2.0]heptane-2-carboxylic acid Chemical compound N([C@@H](C(=O)N[C@H]1[C@H]2SC([C@@H](N2C1=O)C(O)=O)(C)C)C=1C=CC(O)=CC=1)C(=O)C(C(N1)=O)=CC=C1C1=CC=C(S(=O)(=O)N(CCO)CCO)C=C1 NAALWFYYHHJEFQ-ZASNTINBSA-N 0.000 description 1
- JXOCDHNKTVLZLD-ITYLOYPMSA-N (3z)-n-(3-chlorophenyl)-3-[[3,5-dimethyl-4-(3-morpholin-4-ylpropyl)-1h-pyrrol-2-yl]methylidene]-n-methyl-2-oxo-1h-indole-5-sulfonamide Chemical compound C=1C=C2NC(=O)\C(=C/C3=C(C(CCCN4CCOCC4)=C(C)N3)C)C2=CC=1S(=O)(=O)N(C)C1=CC=CC(Cl)=C1 JXOCDHNKTVLZLD-ITYLOYPMSA-N 0.000 description 1
- RPHHPHGATVNVCI-UHFFFAOYSA-N (5-methylpyridin-2-yl)urea Chemical compound CC1=CC=C(NC(N)=O)N=C1 RPHHPHGATVNVCI-UHFFFAOYSA-N 0.000 description 1
- VNTHYLVDGVBPOU-QQYBVWGSSA-N (7s,9s)-9-acetyl-7-[(2r,4s,5s,6s)-4-amino-5-hydroxy-6-methyloxan-2-yl]oxy-6,9,11-trihydroxy-4-methoxy-8,10-dihydro-7h-tetracene-5,12-dione;2-hydroxypropane-1,2,3-tricarboxylic acid Chemical compound OC(=O)CC(O)(C(O)=O)CC(O)=O.O([C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(C)=O)[C@H]1C[C@H](N)[C@H](O)[C@H](C)O1 VNTHYLVDGVBPOU-QQYBVWGSSA-N 0.000 description 1
- FPVKHBSQESCIEP-UHFFFAOYSA-N (8S)-3-(2-deoxy-beta-D-erythro-pentofuranosyl)-3,6,7,8-tetrahydroimidazo[4,5-d][1,3]diazepin-8-ol Natural products C1C(O)C(CO)OC1N1C(NC=NCC2O)=C2N=C1 FPVKHBSQESCIEP-UHFFFAOYSA-N 0.000 description 1
- LKJPYSCBVHEWIU-KRWDZBQOSA-N (R)-bicalutamide Chemical compound C([C@@](O)(C)C(=O)NC=1C=C(C(C#N)=CC=1)C(F)(F)F)S(=O)(=O)C1=CC=C(F)C=C1 LKJPYSCBVHEWIU-KRWDZBQOSA-N 0.000 description 1
- SUVMJBTUFCVSAD-SNVBAGLBSA-N (R)-sulforaphane Chemical compound C[S@@](=O)CCCCN=C=S SUVMJBTUFCVSAD-SNVBAGLBSA-N 0.000 description 1
- UKAUYVFTDYCKQA-UHFFFAOYSA-N -2-Amino-4-hydroxybutanoic acid Natural products OC(=O)C(N)CCO UKAUYVFTDYCKQA-UHFFFAOYSA-N 0.000 description 1
- DDMOUSALMHHKOS-UHFFFAOYSA-N 1,2-dichloro-1,1,2,2-tetrafluoroethane Chemical compound FC(F)(Cl)C(F)(F)Cl DDMOUSALMHHKOS-UHFFFAOYSA-N 0.000 description 1
- NKIJBSVPDYIEAT-UHFFFAOYSA-N 1,4,7,10-tetrazacyclododec-10-ene Chemical compound C1CNCCN=CCNCCN1 NKIJBSVPDYIEAT-UHFFFAOYSA-N 0.000 description 1
- KVXHTUDUVDTLLG-UHFFFAOYSA-N 1-(2-fluoro-5-methylphenyl)-3-phenylurea Chemical compound CC1=CC=C(F)C(NC(=O)NC=2C=CC=CC=2)=C1 KVXHTUDUVDTLLG-UHFFFAOYSA-N 0.000 description 1
- GLBZSOQDAOLMGC-UHFFFAOYSA-N 1-(2-hydroxy-2-methylpropyl)-n-[5-(7-methoxyquinolin-4-yl)oxypyridin-2-yl]-5-methyl-3-oxo-2-phenylpyrazole-4-carboxamide Chemical compound C=1C=NC2=CC(OC)=CC=C2C=1OC(C=N1)=CC=C1NC(=O)C(C1=O)=C(C)N(CC(C)(C)O)N1C1=CC=CC=C1 GLBZSOQDAOLMGC-UHFFFAOYSA-N 0.000 description 1
- FPKVOQKZMBDBKP-UHFFFAOYSA-N 1-[4-[(2,5-dioxopyrrol-1-yl)methyl]cyclohexanecarbonyl]oxy-2,5-dioxopyrrolidine-3-sulfonic acid Chemical compound O=C1C(S(=O)(=O)O)CC(=O)N1OC(=O)C1CCC(CN2C(C=CC2=O)=O)CC1 FPKVOQKZMBDBKP-UHFFFAOYSA-N 0.000 description 1
- 102100025573 1-alkyl-2-acetylglycerophosphocholine esterase Human genes 0.000 description 1
- PNDPGZBMCMUPRI-HVTJNCQCSA-N 10043-66-0 Chemical compound [131I][131I] PNDPGZBMCMUPRI-HVTJNCQCSA-N 0.000 description 1
- VGONTNSXDCQUGY-RRKCRQDMSA-N 2'-deoxyinosine Chemical group C1[C@H](O)[C@@H](CO)O[C@H]1N1C(N=CNC2=O)=C2N=C1 VGONTNSXDCQUGY-RRKCRQDMSA-N 0.000 description 1
- DVEXZJFMOKTQEZ-UHFFFAOYSA-N 2,3-bis[amino-[(2-aminophenyl)thio]methylidene]butanedinitrile Chemical compound C=1C=CC=C(N)C=1SC(N)=C(C#N)C(C#N)=C(N)SC1=CC=CC=C1N DVEXZJFMOKTQEZ-UHFFFAOYSA-N 0.000 description 1
- QPPUSXURIGJCFQ-UHFFFAOYSA-N 2-[(2-iodoacetyl)amino]propanoic acid Chemical compound OC(=O)C(C)NC(=O)CI QPPUSXURIGJCFQ-UHFFFAOYSA-N 0.000 description 1
- RTQWWZBSTRGEAV-PKHIMPSTSA-N 2-[[(2s)-2-[bis(carboxymethyl)amino]-3-[4-(methylcarbamoylamino)phenyl]propyl]-[2-[bis(carboxymethyl)amino]propyl]amino]acetic acid Chemical compound CNC(=O)NC1=CC=C(C[C@@H](CN(CC(C)N(CC(O)=O)CC(O)=O)CC(O)=O)N(CC(O)=O)CC(O)=O)C=C1 RTQWWZBSTRGEAV-PKHIMPSTSA-N 0.000 description 1
- FZDFGHZZPBUTGP-UHFFFAOYSA-N 2-[[2-[bis(carboxymethyl)amino]-3-(4-isothiocyanatophenyl)propyl]-[2-[bis(carboxymethyl)amino]propyl]amino]acetic acid Chemical compound OC(=O)CN(CC(O)=O)C(C)CN(CC(O)=O)CC(N(CC(O)=O)CC(O)=O)CC1=CC=C(N=C=S)C=C1 FZDFGHZZPBUTGP-UHFFFAOYSA-N 0.000 description 1
- 125000004179 3-chlorophenyl group Chemical group [H]C1=C([H])C(*)=C([H])C(Cl)=C1[H] 0.000 description 1
- GUPXYSSGJWIURR-UHFFFAOYSA-N 3-octoxypropane-1,2-diol Chemical compound CCCCCCCCOCC(O)CO GUPXYSSGJWIURR-UHFFFAOYSA-N 0.000 description 1
- ALUXPRDJABOEAG-UHFFFAOYSA-N 4-(2,4-dichloro-5-methoxyanilino)-6-methoxy-7-[3-(4-methylpiperazin-1-yl)propoxy]quinoline-2-carbonitrile Chemical compound C1=C(Cl)C(OC)=CC(NC=2C3=CC(OC)=C(OCCCN4CCN(C)CC4)C=C3N=C(C=2)C#N)=C1Cl ALUXPRDJABOEAG-UHFFFAOYSA-N 0.000 description 1
- YLUGQOCWOPDIMD-UHFFFAOYSA-N 4-(dimethylamino)but-2-enamide Chemical compound CN(C)CC=CC(N)=O YLUGQOCWOPDIMD-UHFFFAOYSA-N 0.000 description 1
- KIMHJNMVVCGYAX-VVHMCBODSA-N 4-amino-1-[(2R,3R,4S,5R)-2-(10,10-difluorodecoxy)-3,4-dihydroxy-5-(hydroxymethyl)oxolan-2-yl]pyrimidin-2-one Chemical compound FC(CCCCCCCCCO[C@@]1([C@H](O)[C@H](O)[C@@H](CO)O1)N1C(=O)N=C(N)C=C1)F KIMHJNMVVCGYAX-VVHMCBODSA-N 0.000 description 1
- ZRHDKBOBHHFLBW-UHFFFAOYSA-N 4-amino-5-fluoro-3-[6-(4-methylpiperazin-1-yl)-1H-benzimidazol-2-yl]-1H-quinolin-2-one 2-hydroxypropanoic acid Chemical compound CC(O)C(O)=O.C1CN(C)CCN1C1=CC=C(NC(=N2)C=3C(NC4=CC=CC(F)=C4C=3N)=O)C2=C1 ZRHDKBOBHHFLBW-UHFFFAOYSA-N 0.000 description 1
- 125000004195 4-methylpiperazin-1-yl group Chemical group [H]C([H])([H])N1C([H])([H])C([H])([H])N(*)C([H])([H])C1([H])[H] 0.000 description 1
- ALKJNCZNEOTEMP-UHFFFAOYSA-N 4-n-(5-cyclopropyl-1h-pyrazol-3-yl)-6-(4-methylpiperazin-1-yl)-2-n-[(3-propan-2-yl-1,2-oxazol-5-yl)methyl]pyrimidine-2,4-diamine Chemical compound O1N=C(C(C)C)C=C1CNC1=NC(NC=2NN=C(C=2)C2CC2)=CC(N2CCN(C)CC2)=N1 ALKJNCZNEOTEMP-UHFFFAOYSA-N 0.000 description 1
- DEZJGRPRBZSAKI-KMGSDFBDSA-N 565434-85-7 Chemical compound C([C@@H](N)C(=O)N[C@H](CO)C(=O)N[C@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@H](CO)C(=O)N[C@H](CC=1C(=C(F)C(F)=C(F)C=1F)F)C(=O)N[C@H](CC1CCCCC1)C(=O)N[C@H](CCCNC(N)=N)C(=O)N[C@H](CCCNC(N)=N)C(=O)N[C@H](CCCNC(N)=N)C(=O)N[C@H](CCC(N)=O)C(=O)N[C@H](CCCNC(N)=N)C(=O)N[C@H](CCCNC(N)=N)C(O)=O)C(C=C1)=CC=C1C(=O)C1=CC=CC=C1 DEZJGRPRBZSAKI-KMGSDFBDSA-N 0.000 description 1
- WOJKKJKETHYEAC-UHFFFAOYSA-N 6-Maleimidocaproic acid Chemical compound OC(=O)CCCCCN1C(=O)C=CC1=O WOJKKJKETHYEAC-UHFFFAOYSA-N 0.000 description 1
- YXHLJMWYDTXDHS-IRFLANFNSA-N 7-aminoactinomycin D Chemical compound C[C@H]1OC(=O)[C@H](C(C)C)N(C)C(=O)CN(C)C(=O)[C@@H]2CCCN2C(=O)[C@@H](C(C)C)NC(=O)[C@H]1NC(=O)C1=C(N)C(=O)C(C)=C2OC(C(C)=C(N)C=C3C(=O)N[C@@H]4C(=O)N[C@@H](C(N5CCC[C@H]5C(=O)N(C)CC(=O)N(C)[C@@H](C(C)C)C(=O)O[C@@H]4C)=O)C(C)C)=C3N=C21 YXHLJMWYDTXDHS-IRFLANFNSA-N 0.000 description 1
- 108700012813 7-aminoactinomycin D Proteins 0.000 description 1
- PBCZSGKMGDDXIJ-HQCWYSJUSA-N 7-hydroxystaurosporine Chemical compound N([C@H](O)C1=C2C3=CC=CC=C3N3C2=C24)C(=O)C1=C2C1=CC=CC=C1N4[C@H]1C[C@@H](NC)[C@@H](OC)[C@]3(C)O1 PBCZSGKMGDDXIJ-HQCWYSJUSA-N 0.000 description 1
- ZCYVEMRRCGMTRW-UHFFFAOYSA-N 7553-56-2 Chemical compound [I] ZCYVEMRRCGMTRW-UHFFFAOYSA-N 0.000 description 1
- PBCZSGKMGDDXIJ-UHFFFAOYSA-N 7beta-hydroxystaurosporine Natural products C12=C3N4C5=CC=CC=C5C3=C3C(O)NC(=O)C3=C2C2=CC=CC=C2N1C1CC(NC)C(OC)C4(C)O1 PBCZSGKMGDDXIJ-UHFFFAOYSA-N 0.000 description 1
- 108010022752 Acetylcholinesterase Proteins 0.000 description 1
- 102000012440 Acetylcholinesterase Human genes 0.000 description 1
- 208000031261 Acute myeloid leukaemia Diseases 0.000 description 1
- 206010052747 Adenocarcinoma pancreas Diseases 0.000 description 1
- 229920001817 Agar Polymers 0.000 description 1
- 108700028369 Alleles Proteins 0.000 description 1
- 229930182536 Antimycin Natural products 0.000 description 1
- 102100021569 Apoptosis regulator Bcl-2 Human genes 0.000 description 1
- 239000004475 Arginine Substances 0.000 description 1
- 102000015790 Asparaginase Human genes 0.000 description 1
- DCXYFEDJOCDNAF-UHFFFAOYSA-N Asparagine Natural products OC(=O)C(N)CC(N)=O DCXYFEDJOCDNAF-UHFFFAOYSA-N 0.000 description 1
- 206010003571 Astrocytoma Diseases 0.000 description 1
- 208000023275 Autoimmune disease Diseases 0.000 description 1
- 108090001008 Avidin Proteins 0.000 description 1
- 208000032791 BCR-ABL1 positive chronic myelogenous leukemia Diseases 0.000 description 1
- LQVXSNNAFNGRAH-QHCPKHFHSA-N BMS-754807 Chemical compound C([C@@]1(C)C(=O)NC=2C=NC(F)=CC=2)CCN1C(=NN1C=CC=C11)N=C1NC(=NN1)C=C1C1CC1 LQVXSNNAFNGRAH-QHCPKHFHSA-N 0.000 description 1
- 241000193830 Bacillus <bacterium> Species 0.000 description 1
- 244000063299 Bacillus subtilis Species 0.000 description 1
- 235000014469 Bacillus subtilis Nutrition 0.000 description 1
- 241000894006 Bacteria Species 0.000 description 1
- 208000035143 Bacterial infection Diseases 0.000 description 1
- 208000023514 Barrett esophagus Diseases 0.000 description 1
- 208000023665 Barrett oesophagus Diseases 0.000 description 1
- 108010079882 Bax protein (53-86) Proteins 0.000 description 1
- 101150017888 Bcl2 gene Proteins 0.000 description 1
- 206010004446 Benign prostatic hyperplasia Diseases 0.000 description 1
- 102100026189 Beta-galactosidase Human genes 0.000 description 1
- 102100023995 Beta-nerve growth factor Human genes 0.000 description 1
- PKWRMUKBEYJEIX-DXXQBUJASA-N Birinapant Chemical compound CN[C@@H](C)C(=O)N[C@@H](CC)C(=O)N1C[C@@H](O)C[C@H]1CC1=C(C2=C(C3=CC=C(F)C=C3N2)C[C@H]2N(C[C@@H](O)C2)C(=O)[C@H](CC)NC(=O)[C@H](C)NC)NC2=CC(F)=CC=C12 PKWRMUKBEYJEIX-DXXQBUJASA-N 0.000 description 1
- 206010005949 Bone cancer Diseases 0.000 description 1
- 208000018084 Bone neoplasm Diseases 0.000 description 1
- 241000283690 Bos taurus Species 0.000 description 1
- CPELXLSAUQHCOX-UHFFFAOYSA-M Bromide Chemical compound [Br-] CPELXLSAUQHCOX-UHFFFAOYSA-M 0.000 description 1
- 239000012619 Butyl Sepharose® Substances 0.000 description 1
- FERIUCNNQQJTOY-UHFFFAOYSA-M Butyrate Chemical compound CCCC([O-])=O FERIUCNNQQJTOY-UHFFFAOYSA-M 0.000 description 1
- KAJYHKRSEVHEGX-HCQSHQBASA-N C1[C@@]([N+]([O-])=O)(C)[C@@H](NC(=O)OC)[C@@H](C)O[C@H]1O[C@@H]1C(/C)=C/[C@@H]2[C@@H](O)CC(C=O)=CC2(C2=O)OC(O)=C2C(=O)[C@@]2(C)[C@@H]3[C@@H](C)C[C@H](C)[C@H](O[C@@H]4O[C@@H](C)[C@H](OC(C)=O)[C@H](O[C@@H]5O[C@@H](C)[C@H](O[C@@H]6O[C@@H](C)[C@H](O[C@@H]7O[C@@H](C)[C@H](O)CC7)[C@H](O)C6)CC5)C4)[C@H]3C=C[C@H]2\C(C)=C/C1 Chemical compound C1[C@@]([N+]([O-])=O)(C)[C@@H](NC(=O)OC)[C@@H](C)O[C@H]1O[C@@H]1C(/C)=C/[C@@H]2[C@@H](O)CC(C=O)=CC2(C2=O)OC(O)=C2C(=O)[C@@]2(C)[C@@H]3[C@@H](C)C[C@H](C)[C@H](O[C@@H]4O[C@@H](C)[C@H](OC(C)=O)[C@H](O[C@@H]5O[C@@H](C)[C@H](O[C@@H]6O[C@@H](C)[C@H](O[C@@H]7O[C@@H](C)[C@H](O)CC7)[C@H](O)C6)CC5)C4)[C@H]3C=C[C@H]2\C(C)=C/C1 KAJYHKRSEVHEGX-HCQSHQBASA-N 0.000 description 1
- UXVMQQNJUSDDNG-UHFFFAOYSA-L Calcium chloride Chemical compound [Cl-].[Cl-].[Ca+2] UXVMQQNJUSDDNG-UHFFFAOYSA-L 0.000 description 1
- 241000282472 Canis lupus familiaris Species 0.000 description 1
- GAGWJHPBXLXJQN-UHFFFAOYSA-N Capecitabine Natural products C1=C(F)C(NC(=O)OCCCCC)=NC(=O)N1C1C(O)C(O)C(C)O1 GAGWJHPBXLXJQN-UHFFFAOYSA-N 0.000 description 1
- 201000009030 Carcinoma Diseases 0.000 description 1
- 241000700199 Cavia porcellus Species 0.000 description 1
- 108010089388 Cdc25C phosphatase (211-221) Proteins 0.000 description 1
- 102000000844 Cell Surface Receptors Human genes 0.000 description 1
- 108010001857 Cell Surface Receptors Proteins 0.000 description 1
- 241000282693 Cercopithecidae Species 0.000 description 1
- VEXZGXHMUGYJMC-UHFFFAOYSA-M Chloride anion Chemical compound [Cl-] VEXZGXHMUGYJMC-UHFFFAOYSA-M 0.000 description 1
- 206010008631 Cholera Diseases 0.000 description 1
- VYZAMTAEIAYCRO-UHFFFAOYSA-N Chromium Chemical compound [Cr] VYZAMTAEIAYCRO-UHFFFAOYSA-N 0.000 description 1
- 208000010833 Chronic myeloid leukaemia Diseases 0.000 description 1
- 208000001333 Colorectal Neoplasms Diseases 0.000 description 1
- 241000759568 Corixa Species 0.000 description 1
- 241000938605 Crocodylia Species 0.000 description 1
- IGXWBGJHJZYPQS-SSDOTTSWSA-N D-Luciferin Chemical compound OC(=O)[C@H]1CSC(C=2SC3=CC=C(O)C=C3N=2)=N1 IGXWBGJHJZYPQS-SSDOTTSWSA-N 0.000 description 1
- SHZGCJCMOBCMKK-UHFFFAOYSA-N D-mannomethylose Natural products CC1OC(O)C(O)C(O)C1O SHZGCJCMOBCMKK-UHFFFAOYSA-N 0.000 description 1
- 230000006820 DNA synthesis Effects 0.000 description 1
- WEAHRLBPCANXCN-UHFFFAOYSA-N Daunomycin Natural products CCC1(O)CC(OC2CC(N)C(O)C(C)O2)c3cc4C(=O)c5c(OC)cccc5C(=O)c4c(O)c3C1 WEAHRLBPCANXCN-UHFFFAOYSA-N 0.000 description 1
- CYCGRDQQIOGCKX-UHFFFAOYSA-N Dehydro-luciferin Natural products OC(=O)C1=CSC(C=2SC3=CC(O)=CC=C3N=2)=N1 CYCGRDQQIOGCKX-UHFFFAOYSA-N 0.000 description 1
- 241000702421 Dependoparvovirus Species 0.000 description 1
- 239000004338 Dichlorodifluoromethane Substances 0.000 description 1
- QMMFVYPAHWMCMS-UHFFFAOYSA-N Dimethyl sulfide Chemical compound CSC QMMFVYPAHWMCMS-UHFFFAOYSA-N 0.000 description 1
- 108090000204 Dipeptidase 1 Proteins 0.000 description 1
- MWWSFMDVAYGXBV-RUELKSSGSA-N Doxorubicin hydrochloride Chemical compound Cl.O([C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(=O)CO)[C@H]1C[C@H](N)[C@H](O)[C@H](C)O1 MWWSFMDVAYGXBV-RUELKSSGSA-N 0.000 description 1
- 201000009051 Embryonal Carcinoma Diseases 0.000 description 1
- MBYXEBXZARTUSS-QLWBXOBMSA-N Emetamine Natural products O(C)c1c(OC)cc2c(c(C[C@@H]3[C@H](CC)CN4[C@H](c5c(cc(OC)c(OC)c5)CC4)C3)ncc2)c1 MBYXEBXZARTUSS-QLWBXOBMSA-N 0.000 description 1
- 201000009273 Endometriosis Diseases 0.000 description 1
- 241000588921 Enterobacteriaceae Species 0.000 description 1
- 241000701959 Escherichia virus Lambda Species 0.000 description 1
- 241000272185 Falco Species 0.000 description 1
- 108010008177 Fd immunoglobulins Proteins 0.000 description 1
- 102000044168 Fibroblast Growth Factor Receptor Human genes 0.000 description 1
- 101710182387 Fibroblast growth factor receptor 4 Proteins 0.000 description 1
- 102100021066 Fibroblast growth factor receptor substrate 2 Human genes 0.000 description 1
- 102100037362 Fibronectin Human genes 0.000 description 1
- 102000002090 Fibronectin type III Human genes 0.000 description 1
- 108050009401 Fibronectin type III Proteins 0.000 description 1
- 108010067306 Fibronectins Proteins 0.000 description 1
- BJGNCJDXODQBOB-UHFFFAOYSA-N Fivefly Luciferin Natural products OC(=O)C1CSC(C=2SC3=CC(O)=CC=C3N=2)=N1 BJGNCJDXODQBOB-UHFFFAOYSA-N 0.000 description 1
- PXGOKWXKJXAPGV-UHFFFAOYSA-N Fluorine Chemical compound FF PXGOKWXKJXAPGV-UHFFFAOYSA-N 0.000 description 1
- PNNNRSAQSRJVSB-SLPGGIOYSA-N Fucose Natural products C[C@H](O)[C@@H](O)[C@H](O)[C@H](O)C=O PNNNRSAQSRJVSB-SLPGGIOYSA-N 0.000 description 1
- 102000006471 Fucosyltransferases Human genes 0.000 description 1
- 108010019236 Fucosyltransferases Proteins 0.000 description 1
- 206010017533 Fungal infection Diseases 0.000 description 1
- GYHNNYVSQQEPJS-UHFFFAOYSA-N Gallium Chemical compound [Ga] GYHNNYVSQQEPJS-UHFFFAOYSA-N 0.000 description 1
- 241000287828 Gallus gallus Species 0.000 description 1
- 206010061968 Gastric neoplasm Diseases 0.000 description 1
- 201000003741 Gastrointestinal carcinoma Diseases 0.000 description 1
- 108010010803 Gelatin Proteins 0.000 description 1
- 108700028146 Genetic Enhancer Elements Proteins 0.000 description 1
- WQZGKKKJIJFFOK-GASJEMHNSA-N Glucose Natural products OC[C@H]1OC(O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-GASJEMHNSA-N 0.000 description 1
- 102000051366 Glycosyltransferases Human genes 0.000 description 1
- 108700023372 Glycosyltransferases Proteins 0.000 description 1
- 206010018612 Gonorrhoea Diseases 0.000 description 1
- 108010026389 Gramicidin Proteins 0.000 description 1
- 239000007996 HEPPS buffer Substances 0.000 description 1
- GIZQLVPDAOBAFN-UHFFFAOYSA-N HEPPSO Chemical group OCCN1CCN(CC(O)CS(O)(=O)=O)CC1 GIZQLVPDAOBAFN-UHFFFAOYSA-N 0.000 description 1
- 241001622557 Hesperia Species 0.000 description 1
- 241000282412 Homo Species 0.000 description 1
- 101100120051 Homo sapiens FGF1 gene Proteins 0.000 description 1
- 101000818410 Homo sapiens Fibroblast growth factor receptor substrate 2 Proteins 0.000 description 1
- 108010001336 Horseradish Peroxidase Proteins 0.000 description 1
- 241000701044 Human gammaherpesvirus 4 Species 0.000 description 1
- AVXURJPOCDRRFD-UHFFFAOYSA-N Hydroxylamine Chemical compound ON AVXURJPOCDRRFD-UHFFFAOYSA-N 0.000 description 1
- PMMYEEVYMWASQN-DMTCNVIQSA-N Hydroxyproline Chemical compound O[C@H]1CN[C@H](C(O)=O)C1 PMMYEEVYMWASQN-DMTCNVIQSA-N 0.000 description 1
- XDXDZDZNSLXDNA-TZNDIEGXSA-N Idarubicin Chemical compound C1[C@H](N)[C@H](O)[C@H](C)O[C@H]1O[C@@H]1C2=C(O)C(C(=O)C3=CC=CC=C3C3=O)=C3C(O)=C2C[C@@](O)(C(C)=O)C1 XDXDZDZNSLXDNA-TZNDIEGXSA-N 0.000 description 1
- 108010073807 IgG Receptors Proteins 0.000 description 1
- 102000009490 IgG Receptors Human genes 0.000 description 1
- 102100026120 IgG receptor FcRn large subunit p51 Human genes 0.000 description 1
- 101710177940 IgG receptor FcRn large subunit p51 Proteins 0.000 description 1
- 108700005091 Immunoglobulin Genes Proteins 0.000 description 1
- 206010061218 Inflammation Diseases 0.000 description 1
- 108010002386 Interleukin-3 Proteins 0.000 description 1
- 208000007766 Kaposi sarcoma Diseases 0.000 description 1
- CKLJMWTZIZZHCS-REOHCLBHSA-N L-aspartic acid Chemical compound OC(=O)[C@@H](N)CC(O)=O CKLJMWTZIZZHCS-REOHCLBHSA-N 0.000 description 1
- SHZGCJCMOBCMKK-DHVFOXMCSA-N L-fucopyranose Chemical compound C[C@@H]1OC(O)[C@@H](O)[C@H](O)[C@@H]1O SHZGCJCMOBCMKK-DHVFOXMCSA-N 0.000 description 1
- UKAUYVFTDYCKQA-VKHMYHEASA-N L-homoserine Chemical compound OC(=O)[C@@H](N)CCO UKAUYVFTDYCKQA-VKHMYHEASA-N 0.000 description 1
- ROHFNLRQFUQHCH-YFKPBYRVSA-N L-leucine Chemical compound CC(C)C[C@H](N)C(O)=O ROHFNLRQFUQHCH-YFKPBYRVSA-N 0.000 description 1
- QEFRNWWLZKMPFJ-ZXPFJRLXSA-N L-methionine (R)-S-oxide Chemical compound C[S@@](=O)CC[C@H]([NH3+])C([O-])=O QEFRNWWLZKMPFJ-ZXPFJRLXSA-N 0.000 description 1
- QEFRNWWLZKMPFJ-UHFFFAOYSA-N L-methionine sulphoxide Natural products CS(=O)CCC(N)C(O)=O QEFRNWWLZKMPFJ-UHFFFAOYSA-N 0.000 description 1
- COLNVLDHVKWLRT-QMMMGPOBSA-N L-phenylalanine Chemical compound OC(=O)[C@@H](N)CC1=CC=CC=C1 COLNVLDHVKWLRT-QMMMGPOBSA-N 0.000 description 1
- KZSNJWFQEVHDMF-BYPYZUCNSA-N L-valine Chemical compound CC(C)[C@H](N)C(O)=O KZSNJWFQEVHDMF-BYPYZUCNSA-N 0.000 description 1
- 239000002147 L01XE04 - Sunitinib Substances 0.000 description 1
- 239000002067 L01XE06 - Dasatinib Substances 0.000 description 1
- 239000003798 L01XE11 - Pazopanib Substances 0.000 description 1
- 239000002118 L01XE12 - Vandetanib Substances 0.000 description 1
- 239000002176 L01XE26 - Cabozantinib Substances 0.000 description 1
- 241000713666 Lentivirus Species 0.000 description 1
- ROHFNLRQFUQHCH-UHFFFAOYSA-N Leucine Natural products CC(C)CC(N)C(O)=O ROHFNLRQFUQHCH-UHFFFAOYSA-N 0.000 description 1
- 108060001084 Luciferase Proteins 0.000 description 1
- 239000005089 Luciferase Substances 0.000 description 1
- DDWFXDSYGUXRAY-UHFFFAOYSA-N Luciferin Natural products CCc1c(C)c(CC2NC(=O)C(=C2C=C)C)[nH]c1Cc3[nH]c4C(=C5/NC(CC(=O)O)C(C)C5CC(=O)O)CC(=O)c4c3C DDWFXDSYGUXRAY-UHFFFAOYSA-N 0.000 description 1
- 102000008072 Lymphokines Human genes 0.000 description 1
- 108010074338 Lymphokines Proteins 0.000 description 1
- 206010025323 Lymphomas Diseases 0.000 description 1
- 239000012515 MabSelect SuRe Substances 0.000 description 1
- 241001441512 Maytenus serrata Species 0.000 description 1
- VFKZTMPDYBFSTM-KVTDHHQDSA-N Mitobronitol Chemical compound BrC[C@@H](O)[C@@H](O)[C@H](O)[C@H](O)CBr VFKZTMPDYBFSTM-KVTDHHQDSA-N 0.000 description 1
- 239000004909 Moisturizer Substances 0.000 description 1
- ZOKXTWBITQBERF-AKLPVKDBSA-N Molybdenum Mo-99 Chemical compound [99Mo] ZOKXTWBITQBERF-AKLPVKDBSA-N 0.000 description 1
- 208000034578 Multiple myelomas Diseases 0.000 description 1
- 102000016943 Muramidase Human genes 0.000 description 1
- 108010014251 Muramidase Proteins 0.000 description 1
- 241001529936 Murinae Species 0.000 description 1
- 101000856426 Mus musculus Cullin-7 Proteins 0.000 description 1
- 241000699670 Mus sp. Species 0.000 description 1
- 208000031888 Mycoses Diseases 0.000 description 1
- 208000033761 Myelogenous Chronic BCR-ABL Positive Leukemia Diseases 0.000 description 1
- 208000033776 Myeloid Acute Leukemia Diseases 0.000 description 1
- 241001553014 Myrsine salicina Species 0.000 description 1
- 108010062010 N-Acetylmuramoyl-L-alanine Amidase Proteins 0.000 description 1
- LKJPYSCBVHEWIU-UHFFFAOYSA-N N-[4-cyano-3-(trifluoromethyl)phenyl]-3-[(4-fluorophenyl)sulfonyl]-2-hydroxy-2-methylpropanamide Chemical compound C=1C=C(C#N)C(C(F)(F)F)=CC=1NC(=O)C(O)(C)CS(=O)(=O)C1=CC=C(F)C=C1 LKJPYSCBVHEWIU-UHFFFAOYSA-N 0.000 description 1
- XKFTZKGMDDZMJI-HSZRJFAPSA-N N-[5-[(2R)-2-methoxy-1-oxo-2-phenylethyl]-4,6-dihydro-1H-pyrrolo[3,4-c]pyrazol-3-yl]-4-(4-methyl-1-piperazinyl)benzamide Chemical compound O=C([C@H](OC)C=1C=CC=CC=1)N(CC=12)CC=1NN=C2NC(=O)C(C=C1)=CC=C1N1CCN(C)CC1 XKFTZKGMDDZMJI-HSZRJFAPSA-N 0.000 description 1
- OVRNDRQMDRJTHS-RTRLPJTCSA-N N-acetyl-D-glucosamine Chemical group CC(=O)N[C@H]1C(O)O[C@H](CO)[C@@H](O)[C@@H]1O OVRNDRQMDRJTHS-RTRLPJTCSA-N 0.000 description 1
- ZDZOTLJHXYCWBA-VCVYQWHSSA-N N-debenzoyl-N-(tert-butoxycarbonyl)-10-deacetyltaxol Chemical compound O([C@H]1[C@H]2[C@@](C([C@H](O)C3=C(C)[C@@H](OC(=O)[C@H](O)[C@@H](NC(=O)OC(C)(C)C)C=4C=CC=CC=4)C[C@]1(O)C3(C)C)=O)(C)[C@@H](O)C[C@H]1OC[C@]12OC(=O)C)C(=O)C1=CC=CC=C1 ZDZOTLJHXYCWBA-VCVYQWHSSA-N 0.000 description 1
- GHAZCVNUKKZTLG-UHFFFAOYSA-N N-ethyl-succinimide Natural products CCN1C(=O)CCC1=O GHAZCVNUKKZTLG-UHFFFAOYSA-N 0.000 description 1
- HDFGOPSGAURCEO-UHFFFAOYSA-N N-ethylmaleimide Chemical compound CCN1C(=O)C=CC1=O HDFGOPSGAURCEO-UHFFFAOYSA-N 0.000 description 1
- 238000005481 NMR spectroscopy Methods 0.000 description 1
- 108091061960 Naked DNA Proteins 0.000 description 1
- 229920002274 Nalgene Polymers 0.000 description 1
- 206010061309 Neoplasm progression Diseases 0.000 description 1
- 206010029113 Neovascularisation Diseases 0.000 description 1
- 108010025020 Nerve Growth Factor Proteins 0.000 description 1
- 239000004677 Nylon Substances 0.000 description 1
- ARFQXMBWGFQFRG-UHFFFAOYSA-N O=C1CCC(=O)N1C(S(O)(=O)=O)(C(=O)O)CCSSC1=CC=CC=N1 Chemical compound O=C1CCC(=O)N1C(S(O)(=O)=O)(C(=O)O)CCSSC1=CC=CC=N1 ARFQXMBWGFQFRG-UHFFFAOYSA-N 0.000 description 1
- 229930012538 Paclitaxel Natural products 0.000 description 1
- 206010061902 Pancreatic neoplasm Diseases 0.000 description 1
- 241001631646 Papillomaviridae Species 0.000 description 1
- 208000030852 Parasitic disease Diseases 0.000 description 1
- 241001494479 Pecora Species 0.000 description 1
- 241000233805 Phoenix Species 0.000 description 1
- 241000235648 Pichia Species 0.000 description 1
- 108010001014 Plasminogen Activators Proteins 0.000 description 1
- 102000001938 Plasminogen Activators Human genes 0.000 description 1
- 229920001054 Poly(ethylene‐co‐vinyl acetate) Polymers 0.000 description 1
- 229920002732 Polyanhydride Polymers 0.000 description 1
- 239000004698 Polyethylene Substances 0.000 description 1
- 229920001710 Polyorthoester Polymers 0.000 description 1
- 239000004743 Polypropylene Substances 0.000 description 1
- 208000004403 Prostatic Hyperplasia Diseases 0.000 description 1
- 239000012614 Q-Sepharose Substances 0.000 description 1
- 108020005067 RNA Splice Sites Proteins 0.000 description 1
- 229940122277 RNA polymerase inhibitor Drugs 0.000 description 1
- 208000015634 Rectal Neoplasms Diseases 0.000 description 1
- 108020005091 Replication Origin Proteins 0.000 description 1
- AUVVAXYIELKVAI-UHFFFAOYSA-N SJ000285215 Natural products N1CCC2=CC(OC)=C(OC)C=C2C1CC1CC2C3=CC(OC)=C(OC)C=C3CCN2CC1CC AUVVAXYIELKVAI-UHFFFAOYSA-N 0.000 description 1
- 241000607142 Salmonella Species 0.000 description 1
- 239000012506 Sephacryl® Substances 0.000 description 1
- 238000012300 Sequence Analysis Methods 0.000 description 1
- 241000607720 Serratia Species 0.000 description 1
- 208000000453 Skin Neoplasms Diseases 0.000 description 1
- 206010041067 Small cell lung cancer Diseases 0.000 description 1
- 229920002125 Sokalan® Polymers 0.000 description 1
- 229920002472 Starch Polymers 0.000 description 1
- 108091081024 Start codon Proteins 0.000 description 1
- ZSJLQEPLLKMAKR-UHFFFAOYSA-N Streptozotocin Natural products O=NN(C)C(=O)NC1C(O)OC(CO)C(O)C1O ZSJLQEPLLKMAKR-UHFFFAOYSA-N 0.000 description 1
- NINIDFKCEFEMDL-UHFFFAOYSA-N Sulfur Chemical compound [S] NINIDFKCEFEMDL-UHFFFAOYSA-N 0.000 description 1
- 210000001744 T-lymphocyte Anatomy 0.000 description 1
- 101710192266 Tegument protein VP22 Proteins 0.000 description 1
- WDLRUFUQRNWCPK-UHFFFAOYSA-N Tetraxetan Chemical compound OC(=O)CN1CCN(CC(O)=O)CCN(CC(O)=O)CCN(CC(O)=O)CC1 WDLRUFUQRNWCPK-UHFFFAOYSA-N 0.000 description 1
- QHOPXUFELLHKAS-UHFFFAOYSA-N Thespesin Natural products CC(C)c1c(O)c(O)c2C(O)Oc3c(c(C)cc1c23)-c1c2OC(O)c3c(O)c(O)c(C(C)C)c(cc1C)c23 QHOPXUFELLHKAS-UHFFFAOYSA-N 0.000 description 1
- FOCVUCIESVLUNU-UHFFFAOYSA-N Thiotepa Chemical compound C1CN1P(N1CC1)(=S)N1CC1 FOCVUCIESVLUNU-UHFFFAOYSA-N 0.000 description 1
- AYFVYJQAPQTCCC-UHFFFAOYSA-N Threonine Natural products CC(O)C(N)C(O)=O AYFVYJQAPQTCCC-UHFFFAOYSA-N 0.000 description 1
- 239000004473 Threonine Substances 0.000 description 1
- 241000223259 Trichoderma Species 0.000 description 1
- 239000007983 Tris buffer Substances 0.000 description 1
- YZCKVEUIGOORGS-NJFSPNSNSA-N Tritium Chemical compound [3H] YZCKVEUIGOORGS-NJFSPNSNSA-N 0.000 description 1
- 108060008682 Tumor Necrosis Factor Proteins 0.000 description 1
- 102100033019 Tyrosine-protein phosphatase non-receptor type 11 Human genes 0.000 description 1
- 101710116241 Tyrosine-protein phosphatase non-receptor type 11 Proteins 0.000 description 1
- GBOGMAARMMDZGR-UHFFFAOYSA-N UNPD149280 Natural products N1C(=O)C23OC(=O)C=CC(O)CCCC(C)CC=CC3C(O)C(=C)C(C)C2C1CC1=CC=CC=C1 GBOGMAARMMDZGR-UHFFFAOYSA-N 0.000 description 1
- 208000002495 Uterine Neoplasms Diseases 0.000 description 1
- 241000700618 Vaccinia virus Species 0.000 description 1
- 241000251539 Vertebrata <Metazoa> Species 0.000 description 1
- 108010087302 Viral Structural Proteins Proteins 0.000 description 1
- 208000036142 Viral infection Diseases 0.000 description 1
- FHNFHKCVQCLJFQ-NJFSPNSNSA-N Xenon-133 Chemical compound [133Xe] FHNFHKCVQCLJFQ-NJFSPNSNSA-N 0.000 description 1
- CBPNZQVSJQDFBE-SREVRWKESA-N [(1S,2R,4S)-4-[(2R)-2-[(1R,9S,12S,15R,16E,18R,19R,21R,23S,24E,26E,28E,30S,32R,35R)-1,18-dihydroxy-19,30-dimethoxy-15,17,21,23,29,35-hexamethyl-2,3,10,14,20-pentaoxo-11,36-dioxa-4-azatricyclo[30.3.1.04,9]hexatriaconta-16,24,26,28-tetraen-12-yl]propyl]-2-methoxycyclohexyl] 3-hydroxy-2-(hydroxymethyl)-2-methylpropanoate Chemical group C[C@@H]1CC[C@@H]2C[C@@H](/C(=C/C=C/C=C/[C@H](C[C@H](C(=O)[C@@H]([C@@H](/C(=C/[C@H](C(=O)C[C@H](OC(=O)[C@@H]3CCCCN3C(=O)C(=O)[C@@]1(O2)O)[C@H](C)C[C@@H]4CC[C@@H]([C@@H](C4)OC)OC(=O)C(C)(CO)CO)C)/C)O)OC)C)C)/C)OC CBPNZQVSJQDFBE-SREVRWKESA-N 0.000 description 1
- LTEJRLHKIYCEOX-PUODRLBUSA-N [(2r)-1-[4-[(4-fluoro-2-methyl-1h-indol-5-yl)oxy]-5-methylpyrrolo[2,1-f][1,2,4]triazin-6-yl]oxypropan-2-yl] 2-aminopropanoate Chemical compound C1=C2NC(C)=CC2=C(F)C(OC2=NC=NN3C=C(C(=C32)C)OC[C@@H](C)OC(=O)C(C)N)=C1 LTEJRLHKIYCEOX-PUODRLBUSA-N 0.000 description 1
- BTKMJKKKZATLBU-UHFFFAOYSA-N [2-(1,3-benzothiazol-2-yl)-1,3-benzothiazol-6-yl] dihydrogen phosphate Chemical compound C1=CC=C2SC(C3=NC4=CC=C(C=C4S3)OP(O)(=O)O)=NC2=C1 BTKMJKKKZATLBU-UHFFFAOYSA-N 0.000 description 1
- 238000002835 absorbance Methods 0.000 description 1
- 238000010521 absorption reaction Methods 0.000 description 1
- 239000008351 acetate buffer Substances 0.000 description 1
- NIOHNDKHQHVLKA-UHFFFAOYSA-N acetic acid;7-(8-formyl-1,6,7-trihydroxy-3-methyl-5-propan-2-ylnaphthalen-2-yl)-2,3,8-trihydroxy-6-methyl-4-propan-2-ylnaphthalene-1-carbaldehyde Chemical compound CC(O)=O.CC(C)C1=C(O)C(O)=C(C=O)C2=C(O)C(C=3C(O)=C4C(C=O)=C(O)C(O)=C(C4=CC=3C)C(C)C)=C(C)C=C21 NIOHNDKHQHVLKA-UHFFFAOYSA-N 0.000 description 1
- 229940022698 acetylcholinesterase Drugs 0.000 description 1
- 125000003668 acetyloxy group Chemical group [H]C([H])([H])C(=O)O[*] 0.000 description 1
- 150000007513 acids Chemical class 0.000 description 1
- 229930183665 actinomycin Natural products 0.000 description 1
- 230000009471 action Effects 0.000 description 1
- 239000008186 active pharmaceutical agent Substances 0.000 description 1
- 230000006978 adaptation Effects 0.000 description 1
- 238000011374 additional therapy Methods 0.000 description 1
- 208000007128 adrenocortical carcinoma Diseases 0.000 description 1
- 229940009456 adriamycin Drugs 0.000 description 1
- 229940064305 adrucil Drugs 0.000 description 1
- ULXXDDBFHOBEHA-CWDCEQMOSA-N afatinib Chemical compound N1=CN=C2C=C(O[C@@H]3COCC3)C(NC(=O)/C=C/CN(C)C)=CC2=C1NC1=CC=C(F)C(Cl)=C1 ULXXDDBFHOBEHA-CWDCEQMOSA-N 0.000 description 1
- 229960001686 afatinib Drugs 0.000 description 1
- 229940042992 afinitor Drugs 0.000 description 1
- 239000008272 agar Substances 0.000 description 1
- QNAYBMKLOCPYGJ-UHFFFAOYSA-M alaninate Chemical compound CC(N)C([O-])=O QNAYBMKLOCPYGJ-UHFFFAOYSA-M 0.000 description 1
- 150000001298 alcohols Chemical class 0.000 description 1
- HAXFWIACAGNFHA-UHFFFAOYSA-N aldrithiol Chemical group C=1C=CC=NC=1SSC1=CC=CC=N1 HAXFWIACAGNFHA-UHFFFAOYSA-N 0.000 description 1
- 229940098174 alkeran Drugs 0.000 description 1
- 125000002947 alkylene group Chemical group 0.000 description 1
- HSFWRNGVRCDJHI-UHFFFAOYSA-N alpha-acetylene Natural products C#C HSFWRNGVRCDJHI-UHFFFAOYSA-N 0.000 description 1
- 150000001370 alpha-amino acid derivatives Chemical class 0.000 description 1
- 235000008206 alpha-amino acids Nutrition 0.000 description 1
- 125000003368 amide group Chemical group 0.000 description 1
- 229960002684 aminocaproic acid Drugs 0.000 description 1
- 210000004727 amygdala Anatomy 0.000 description 1
- 239000012491 analyte Substances 0.000 description 1
- 238000004458 analytical method Methods 0.000 description 1
- 238000012436 analytical size exclusion chromatography Methods 0.000 description 1
- 229960002932 anastrozole Drugs 0.000 description 1
- 230000033115 angiogenesis Effects 0.000 description 1
- 239000004037 angiogenesis inhibitor Substances 0.000 description 1
- 210000004102 animal cell Anatomy 0.000 description 1
- 230000001093 anti-cancer Effects 0.000 description 1
- 239000002260 anti-inflammatory agent Substances 0.000 description 1
- 229940121363 anti-inflammatory agent Drugs 0.000 description 1
- 230000000340 anti-metabolite Effects 0.000 description 1
- 230000001028 anti-proliverative effect Effects 0.000 description 1
- 239000000043 antiallergic agent Substances 0.000 description 1
- 229940088710 antibiotic agent Drugs 0.000 description 1
- 238000009175 antibody therapy Methods 0.000 description 1
- 230000000890 antigenic effect Effects 0.000 description 1
- 229940100197 antimetabolite Drugs 0.000 description 1
- 239000002256 antimetabolite Substances 0.000 description 1
- 239000003080 antimitotic agent Substances 0.000 description 1
- CQIUKKVOEOPUDV-IYSWYEEDSA-N antimycin Chemical compound OC1=C(C(O)=O)C(=O)C(C)=C2[C@H](C)[C@@H](C)OC=C21 CQIUKKVOEOPUDV-IYSWYEEDSA-N 0.000 description 1
- 239000003096 antiparasitic agent Substances 0.000 description 1
- 229940125687 antiparasitic agent Drugs 0.000 description 1
- 239000003443 antiviral agent Substances 0.000 description 1
- 239000012736 aqueous medium Substances 0.000 description 1
- 239000007864 aqueous solution Substances 0.000 description 1
- PYMYPHUHKUWMLA-WDCZJNDASA-N arabinose Chemical compound OC[C@@H](O)[C@@H](O)[C@H](O)C=O PYMYPHUHKUWMLA-WDCZJNDASA-N 0.000 description 1
- PYMYPHUHKUWMLA-UHFFFAOYSA-N arabinose Natural products OCC(O)C(O)C(O)C=O PYMYPHUHKUWMLA-UHFFFAOYSA-N 0.000 description 1
- ODKSFYDXXFIFQN-UHFFFAOYSA-N arginine Natural products OC(=O)C(N)CCCNC(N)=N ODKSFYDXXFIFQN-UHFFFAOYSA-N 0.000 description 1
- 229940078010 arimidex Drugs 0.000 description 1
- 206010003246 arthritis Diseases 0.000 description 1
- 235000009582 asparagine Nutrition 0.000 description 1
- 229960001230 asparagine Drugs 0.000 description 1
- 235000003704 aspartic acid Nutrition 0.000 description 1
- 230000001363 autoimmune Effects 0.000 description 1
- VSRXQHXAPYXROS-UHFFFAOYSA-N azanide;cyclobutane-1,1-dicarboxylic acid;platinum(2+) Chemical compound [NH2-].[NH2-].[Pt+2].OC(=O)C1(C(O)=O)CCC1 VSRXQHXAPYXROS-UHFFFAOYSA-N 0.000 description 1
- 210000003719 b-lymphocyte Anatomy 0.000 description 1
- 208000022362 bacterial infectious disease Diseases 0.000 description 1
- 230000009286 beneficial effect Effects 0.000 description 1
- 230000008901 benefit Effects 0.000 description 1
- SRBFZHDQGSBBOR-UHFFFAOYSA-N beta-D-Pyranose-Lyxose Natural products OC1COC(O)C(O)C1O SRBFZHDQGSBBOR-UHFFFAOYSA-N 0.000 description 1
- 108010005774 beta-Galactosidase Proteins 0.000 description 1
- OQFSQFPPLPISGP-UHFFFAOYSA-N beta-carboxyaspartic acid Natural products OC(=O)C(N)C(C(O)=O)C(O)=O OQFSQFPPLPISGP-UHFFFAOYSA-N 0.000 description 1
- 102000006635 beta-lactamase Human genes 0.000 description 1
- 229960000997 bicalutamide Drugs 0.000 description 1
- 229940108502 bicnu Drugs 0.000 description 1
- 238000004166 bioassay Methods 0.000 description 1
- 238000010256 biochemical assay Methods 0.000 description 1
- 230000003115 biocidal effect Effects 0.000 description 1
- 230000008033 biological extinction Effects 0.000 description 1
- 230000033228 biological regulation Effects 0.000 description 1
- 230000015572 biosynthetic process Effects 0.000 description 1
- 238000001815 biotherapy Methods 0.000 description 1
- 108091006004 biotinylated proteins Proteins 0.000 description 1
- 238000007413 biotinylation Methods 0.000 description 1
- 230000006287 biotinylation Effects 0.000 description 1
- 108010063132 birinapant Proteins 0.000 description 1
- 229960001561 bleomycin Drugs 0.000 description 1
- OYVAGSVQBOHSSS-UAPAGMARSA-O bleomycin A2 Chemical compound N([C@H](C(=O)N[C@H](C)[C@@H](O)[C@H](C)C(=O)N[C@@H]([C@H](O)C)C(=O)NCCC=1SC=C(N=1)C=1SC=C(N=1)C(=O)NCCC[S+](C)C)[C@@H](O[C@H]1[C@H]([C@@H](O)[C@H](O)[C@H](CO)O1)O[C@@H]1[C@H]([C@@H](OC(N)=O)[C@H](O)[C@@H](CO)O1)O)C=1N=CNC=1)C(=O)C1=NC([C@H](CC(N)=O)NC[C@H](N)C(N)=O)=NC(N)=C1C OYVAGSVQBOHSSS-UAPAGMARSA-O 0.000 description 1
- 229960004395 bleomycin sulfate Drugs 0.000 description 1
- 230000000903 blocking effect Effects 0.000 description 1
- 230000036765 blood level Effects 0.000 description 1
- RSIHSRDYCUFFLA-DYKIIFRCSA-N boldenone Chemical compound O=C1C=C[C@]2(C)[C@H]3CC[C@](C)([C@H](CC4)O)[C@@H]4[C@@H]3CCC2=C1 RSIHSRDYCUFFLA-DYKIIFRCSA-N 0.000 description 1
- 238000010504 bond cleavage reaction Methods 0.000 description 1
- 229960003736 bosutinib Drugs 0.000 description 1
- UBPYILGKFZZVDX-UHFFFAOYSA-N bosutinib Chemical compound C1=C(Cl)C(OC)=CC(NC=2C3=CC(OC)=C(OCCCN4CCN(C)CC4)C=C3N=CC=2C#N)=C1Cl UBPYILGKFZZVDX-UHFFFAOYSA-N 0.000 description 1
- 201000008275 breast carcinoma Diseases 0.000 description 1
- 239000006172 buffering agent Substances 0.000 description 1
- 244000309464 bull Species 0.000 description 1
- 229950003628 buparlisib Drugs 0.000 description 1
- 210000001217 buttock Anatomy 0.000 description 1
- 239000001110 calcium chloride Substances 0.000 description 1
- 229910001628 calcium chloride Inorganic materials 0.000 description 1
- KVUAALJSMIVURS-ZEDZUCNESA-L calcium folinate Chemical compound [Ca+2].C1NC=2NC(N)=NC(=O)C=2N(C=O)C1CNC1=CC=C(C(=O)N[C@@H](CCC([O-])=O)C([O-])=O)C=C1 KVUAALJSMIVURS-ZEDZUCNESA-L 0.000 description 1
- 235000008207 calcium folinate Nutrition 0.000 description 1
- 239000011687 calcium folinate Substances 0.000 description 1
- HXCHCVDVKSCDHU-LULTVBGHSA-N calicheamicin Chemical compound C1[C@H](OC)[C@@H](NCC)CO[C@H]1O[C@H]1[C@H](O[C@@H]2C\3=C(NC(=O)OC)C(=O)C[C@](C/3=C/CSSSC)(O)C#C\C=C/C#C2)O[C@H](C)[C@@H](NO[C@@H]2O[C@H](C)[C@@H](SC(=O)C=3C(=C(OC)C(O[C@H]4[C@@H]([C@H](OC)[C@@H](O)[C@H](C)O4)O)=C(I)C=3C)OC)[C@@H](O)C2)[C@@H]1O HXCHCVDVKSCDHU-LULTVBGHSA-N 0.000 description 1
- 229930195731 calicheamicin Natural products 0.000 description 1
- 229940088954 camptosar Drugs 0.000 description 1
- 229950002826 canertinib Drugs 0.000 description 1
- 229960004117 capecitabine Drugs 0.000 description 1
- 229940056434 caprelsa Drugs 0.000 description 1
- 239000001569 carbon dioxide Substances 0.000 description 1
- 229910002092 carbon dioxide Inorganic materials 0.000 description 1
- 229960004424 carbon dioxide Drugs 0.000 description 1
- 125000002915 carbonyl group Chemical group [*:2]C([*:1])=O 0.000 description 1
- 150000007942 carboxylates Chemical class 0.000 description 1
- 150000001732 carboxylic acid derivatives Chemical class 0.000 description 1
- 229940097647 casodex Drugs 0.000 description 1
- 239000006143 cell culture medium Substances 0.000 description 1
- 230000003915 cell function Effects 0.000 description 1
- 230000003833 cell viability Effects 0.000 description 1
- 238000003570 cell viability assay Methods 0.000 description 1
- 238000012054 celltiter-glo Methods 0.000 description 1
- 230000001413 cellular effect Effects 0.000 description 1
- 239000001913 cellulose Substances 0.000 description 1
- 229920002678 cellulose Polymers 0.000 description 1
- 238000005119 centrifugation Methods 0.000 description 1
- 229960005395 cetuximab Drugs 0.000 description 1
- NDAYQJDHGXTBJL-MWWSRJDJSA-N chembl557217 Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@@H](CC(C)C)NC(=O)[C@H](CC=3C4=CC=CC=C4NC=3)NC(=O)[C@@H](CC(C)C)NC(=O)[C@H](CC=3C4=CC=CC=C4NC=3)NC(=O)[C@@H](CC(C)C)NC(=O)[C@H](CC=3C4=CC=CC=C4NC=3)NC(=O)[C@@H](C(C)C)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](C(C)C)NC(=O)[C@H](C)NC(=O)[C@H](NC(=O)CNC(=O)[C@@H](NC=O)C(C)C)CC(C)C)C(=O)NCCO)=CNC2=C1 NDAYQJDHGXTBJL-MWWSRJDJSA-N 0.000 description 1
- 238000002512 chemotherapy Methods 0.000 description 1
- 235000013330 chicken meat Nutrition 0.000 description 1
- 210000004978 chinese hamster ovary cell Anatomy 0.000 description 1
- JCKYGMPEJWAADB-UHFFFAOYSA-N chlorambucil Chemical compound OC(=O)CCCC1=CC=C(N(CCCl)CCCl)C=C1 JCKYGMPEJWAADB-UHFFFAOYSA-N 0.000 description 1
- WIIZWVCIJKGZOK-RKDXNWHRSA-N chloramphenicol Chemical compound ClC(Cl)C(=O)N[C@H](CO)[C@H](O)C1=CC=C([N+]([O-])=O)C=C1 WIIZWVCIJKGZOK-RKDXNWHRSA-N 0.000 description 1
- 229960005091 chloramphenicol Drugs 0.000 description 1
- 230000004087 circulation Effects 0.000 description 1
- 239000007979 citrate buffer Substances 0.000 description 1
- 229950006647 cixutumumab Drugs 0.000 description 1
- 239000011248 coating agent Substances 0.000 description 1
- 238000000576 coating method Methods 0.000 description 1
- 229960001338 colchicine Drugs 0.000 description 1
- 230000004154 complement system Effects 0.000 description 1
- 239000002299 complementary DNA Substances 0.000 description 1
- 230000009918 complex formation Effects 0.000 description 1
- 238000009833 condensation Methods 0.000 description 1
- 230000005494 condensation Effects 0.000 description 1
- 238000012790 confirmation Methods 0.000 description 1
- 238000010276 construction Methods 0.000 description 1
- 239000000599 controlled substance Substances 0.000 description 1
- 238000007796 conventional method Methods 0.000 description 1
- ATDGTVJJHBUTRL-UHFFFAOYSA-N cyanogen bromide Chemical compound BrC#N ATDGTVJJHBUTRL-UHFFFAOYSA-N 0.000 description 1
- 125000000113 cyclohexyl group Chemical group [H]C1([H])C([H])([H])C([H])([H])C([H])(*)C([H])([H])C1([H])[H] 0.000 description 1
- GBOGMAARMMDZGR-TYHYBEHESA-N cytochalasin B Chemical compound C([C@H]1[C@@H]2[C@@H](C([C@@H](O)[C@@H]3/C=C/C[C@H](C)CCC[C@@H](O)/C=C/C(=O)O[C@@]23C(=O)N1)=C)C)C1=CC=CC=C1 GBOGMAARMMDZGR-TYHYBEHESA-N 0.000 description 1
- GBOGMAARMMDZGR-JREHFAHYSA-N cytochalasin B Natural products C[C@H]1CCC[C@@H](O)C=CC(=O)O[C@@]23[C@H](C=CC1)[C@H](O)C(=C)[C@@H](C)[C@@H]2[C@H](Cc4ccccc4)NC3=O GBOGMAARMMDZGR-JREHFAHYSA-N 0.000 description 1
- 230000001086 cytosolic effect Effects 0.000 description 1
- 229950006418 dactolisib Drugs 0.000 description 1
- 229960002448 dasatinib Drugs 0.000 description 1
- 229940052372 daunorubicin citrate liposome Drugs 0.000 description 1
- 229960003109 daunorubicin hydrochloride Drugs 0.000 description 1
- 229940107841 daunoxome Drugs 0.000 description 1
- 230000034994 death Effects 0.000 description 1
- 230000003247 decreasing effect Effects 0.000 description 1
- RSIHSRDYCUFFLA-UHFFFAOYSA-N dehydrotestosterone Natural products O=C1C=CC2(C)C3CCC(C)(C(CC4)O)C4C3CCC2=C1 RSIHSRDYCUFFLA-UHFFFAOYSA-N 0.000 description 1
- 238000012217 deletion Methods 0.000 description 1
- 230000037430 deletion Effects 0.000 description 1
- 239000005547 deoxyribonucleotide Substances 0.000 description 1
- 125000002637 deoxyribonucleotide group Chemical group 0.000 description 1
- 238000013461 design Methods 0.000 description 1
- 230000001627 detrimental effect Effects 0.000 description 1
- UREBDLICKHMUKA-CXSFZGCWSA-N dexamethasone Chemical compound C1CC2=CC(=O)C=C[C@]2(C)[C@]2(F)[C@@H]1[C@@H]1C[C@@H](C)[C@@](C(=O)CO)(O)[C@@]1(C)C[C@@H]2O UREBDLICKHMUKA-CXSFZGCWSA-N 0.000 description 1
- 229960003957 dexamethasone Drugs 0.000 description 1
- 239000008121 dextrose Substances 0.000 description 1
- PXBRQCKWGAHEHS-UHFFFAOYSA-N dichlorodifluoromethane Chemical compound FC(F)(Cl)Cl PXBRQCKWGAHEHS-UHFFFAOYSA-N 0.000 description 1
- 235000019404 dichlorodifluoromethane Nutrition 0.000 description 1
- 229940042935 dichlorodifluoromethane Drugs 0.000 description 1
- 229940087091 dichlorotetrafluoroethane Drugs 0.000 description 1
- 230000029087 digestion Effects 0.000 description 1
- 238000010790 dilution Methods 0.000 description 1
- 239000012895 dilution Substances 0.000 description 1
- 125000002147 dimethylamino group Chemical group [H]C([H])([H])N(*)C([H])([H])[H] 0.000 description 1
- 206010013023 diphtheria Diseases 0.000 description 1
- 238000009826 distribution Methods 0.000 description 1
- PMMYEEVYMWASQN-UHFFFAOYSA-N dl-hydroxyproline Natural products OC1C[NH2+]C(C([O-])=O)C1 PMMYEEVYMWASQN-UHFFFAOYSA-N 0.000 description 1
- 229960002918 doxorubicin hydrochloride Drugs 0.000 description 1
- 239000000890 drug combination Substances 0.000 description 1
- 238000012377 drug delivery Methods 0.000 description 1
- 229940126534 drug product Drugs 0.000 description 1
- 239000012893 effector ligand Substances 0.000 description 1
- 229940099302 efudex Drugs 0.000 description 1
- 238000001962 electrophoresis Methods 0.000 description 1
- 238000004520 electroporation Methods 0.000 description 1
- 229940073038 elspar Drugs 0.000 description 1
- 239000003480 eluent Substances 0.000 description 1
- 201000009409 embryonal rhabdomyosarcoma Diseases 0.000 description 1
- AUVVAXYIELKVAI-CKBKHPSWSA-N emetine Chemical compound N1CCC2=CC(OC)=C(OC)C=C2[C@H]1C[C@H]1C[C@H]2C3=CC(OC)=C(OC)C=C3CCN2C[C@@H]1CC AUVVAXYIELKVAI-CKBKHPSWSA-N 0.000 description 1
- 229960002694 emetine Drugs 0.000 description 1
- AUVVAXYIELKVAI-UWBTVBNJSA-N emetine Natural products N1CCC2=CC(OC)=C(OC)C=C2[C@H]1C[C@H]1C[C@H]2C3=CC(OC)=C(OC)C=C3CCN2C[C@H]1CC AUVVAXYIELKVAI-UWBTVBNJSA-N 0.000 description 1
- 210000001163 endosome Anatomy 0.000 description 1
- 230000006862 enzymatic digestion Effects 0.000 description 1
- 230000002255 enzymatic effect Effects 0.000 description 1
- 230000007705 epithelial mesenchymal transition Effects 0.000 description 1
- 229940082789 erbitux Drugs 0.000 description 1
- 125000000031 ethylamino group Chemical group [H]C([H])([H])C([H])([H])N([H])[*] 0.000 description 1
- LYCAIKOWRPUZTN-UHFFFAOYSA-N ethylene glycol Natural products OCCO LYCAIKOWRPUZTN-UHFFFAOYSA-N 0.000 description 1
- 125000002534 ethynyl group Chemical group [H]C#C* 0.000 description 1
- 229960005420 etoposide Drugs 0.000 description 1
- 210000003527 eukaryotic cell Anatomy 0.000 description 1
- 229960005167 everolimus Drugs 0.000 description 1
- 230000005284 excitation Effects 0.000 description 1
- 230000029142 excretion Effects 0.000 description 1
- 230000001747 exhibiting effect Effects 0.000 description 1
- 231100000776 exotoxin Toxicity 0.000 description 1
- 239000002095 exotoxin Substances 0.000 description 1
- 102000052178 fibroblast growth factor receptor activity proteins Human genes 0.000 description 1
- 229940125829 fibroblast growth factor receptor inhibitor Drugs 0.000 description 1
- GIUYCYHIANZCFB-FJFJXFQQSA-N fludarabine phosphate Chemical compound C1=NC=2C(N)=NC(F)=NC=2N1[C@@H]1O[C@H](COP(O)(O)=O)[C@@H](O)[C@@H]1O GIUYCYHIANZCFB-FJFJXFQQSA-N 0.000 description 1
- 229960005304 fludarabine phosphate Drugs 0.000 description 1
- 229910052587 fluorapatite Inorganic materials 0.000 description 1
- MHMNJMPURVTYEJ-UHFFFAOYSA-N fluorescein-5-isothiocyanate Chemical compound O1C(=O)C2=CC(N=C=S)=CC=C2C21C1=CC=C(O)C=C1OC1=CC(O)=CC=C21 MHMNJMPURVTYEJ-UHFFFAOYSA-N 0.000 description 1
- 229910052731 fluorine Inorganic materials 0.000 description 1
- 239000011737 fluorine Substances 0.000 description 1
- 125000001153 fluoro group Chemical group F* 0.000 description 1
- MKXKFYHWDHIYRV-UHFFFAOYSA-N flutamide Chemical compound CC(C)C(=O)NC1=CC=C([N+]([O-])=O)C(C(F)(F)F)=C1 MKXKFYHWDHIYRV-UHFFFAOYSA-N 0.000 description 1
- 229940014144 folate Drugs 0.000 description 1
- OVBPIULPVIDEAO-LBPRGKRZSA-N folic acid Chemical compound C=1N=C2NC(N)=NC(=O)C2=NC=1CNC1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 OVBPIULPVIDEAO-LBPRGKRZSA-N 0.000 description 1
- 235000019152 folic acid Nutrition 0.000 description 1
- 239000011724 folic acid Substances 0.000 description 1
- 238000007710 freezing Methods 0.000 description 1
- 230000008014 freezing Effects 0.000 description 1
- 125000002446 fucosyl group Chemical group C1([C@@H](O)[C@H](O)[C@H](O)[C@@H](O1)C)* 0.000 description 1
- 230000005714 functional activity Effects 0.000 description 1
- 101150023212 fut8 gene Proteins 0.000 description 1
- 229910052733 gallium Inorganic materials 0.000 description 1
- 239000007789 gas Substances 0.000 description 1
- 239000008273 gelatin Substances 0.000 description 1
- 229920000159 gelatin Polymers 0.000 description 1
- 235000019322 gelatine Nutrition 0.000 description 1
- 235000011852 gelatine desserts Nutrition 0.000 description 1
- 229960005277 gemcitabine Drugs 0.000 description 1
- SDUQYLNIPVEERB-QPPQHZFASA-N gemcitabine Chemical compound O=C1N=C(N)C=CN1[C@H]1C(F)(F)[C@H](O)[C@@H](CO)O1 SDUQYLNIPVEERB-QPPQHZFASA-N 0.000 description 1
- 239000003193 general anesthetic agent Substances 0.000 description 1
- 229940080856 gleevec Drugs 0.000 description 1
- 229940084910 gliadel Drugs 0.000 description 1
- 208000005017 glioblastoma Diseases 0.000 description 1
- 235000013922 glutamic acid Nutrition 0.000 description 1
- 239000004220 glutamic acid Substances 0.000 description 1
- ZDXPYRJPNDTMRX-UHFFFAOYSA-N glutamine Natural products OC(=O)C(N)CCC(N)=O ZDXPYRJPNDTMRX-UHFFFAOYSA-N 0.000 description 1
- 150000004676 glycans Chemical class 0.000 description 1
- 125000003827 glycol group Chemical group 0.000 description 1
- 208000001786 gonorrhea Diseases 0.000 description 1
- 229930000755 gossypol Natural products 0.000 description 1
- 229950005277 gossypol Drugs 0.000 description 1
- 230000005484 gravity Effects 0.000 description 1
- 239000003102 growth factor Substances 0.000 description 1
- 230000009036 growth inhibition Effects 0.000 description 1
- 201000000079 gynecomastia Diseases 0.000 description 1
- 239000000185 hemagglutinin Substances 0.000 description 1
- 230000011132 hemopoiesis Effects 0.000 description 1
- 206010073071 hepatocellular carcinoma Diseases 0.000 description 1
- 231100000844 hepatocellular carcinoma Toxicity 0.000 description 1
- 238000004128 high performance liquid chromatography Methods 0.000 description 1
- 238000013537 high throughput screening Methods 0.000 description 1
- 238000007825 histological assay Methods 0.000 description 1
- 210000000688 human artificial chromosome Anatomy 0.000 description 1
- 239000003906 humectant Substances 0.000 description 1
- 229940096120 hydrea Drugs 0.000 description 1
- 125000001183 hydrocarbyl group Chemical group 0.000 description 1
- 150000002431 hydrogen Chemical group 0.000 description 1
- 239000001257 hydrogen Substances 0.000 description 1
- 150000002433 hydrophilic molecules Chemical class 0.000 description 1
- 125000002887 hydroxy group Chemical group [H]O* 0.000 description 1
- WGCNASOHLSPBMP-UHFFFAOYSA-N hydroxyacetaldehyde Natural products OCC=O WGCNASOHLSPBMP-UHFFFAOYSA-N 0.000 description 1
- 229960001330 hydroxycarbamide Drugs 0.000 description 1
- 229960002591 hydroxyproline Drugs 0.000 description 1
- 229960001001 ibritumomab tiuxetan Drugs 0.000 description 1
- 229940099279 idamycin Drugs 0.000 description 1
- 229960002411 imatinib Drugs 0.000 description 1
- 229960003685 imatinib mesylate Drugs 0.000 description 1
- YLMAHDNUQAMNNX-UHFFFAOYSA-N imatinib methanesulfonate Chemical compound CS(O)(=O)=O.C1CN(C)CCN1CC1=CC=C(C(=O)NC=2C=C(NC=3N=C(C=CN=3)C=3C=NC=CC=3)C(C)=CC=2)C=C1 YLMAHDNUQAMNNX-UHFFFAOYSA-N 0.000 description 1
- 210000000987 immune system Anatomy 0.000 description 1
- 238000002649 immunization Methods 0.000 description 1
- 239000000367 immunologic factor Substances 0.000 description 1
- 229960003444 immunosuppressant agent Drugs 0.000 description 1
- 230000001861 immunosuppressant effect Effects 0.000 description 1
- 239000003018 immunosuppressive agent Substances 0.000 description 1
- 238000009169 immunotherapy Methods 0.000 description 1
- 230000001771 impaired effect Effects 0.000 description 1
- 230000001976 improved effect Effects 0.000 description 1
- 230000006872 improvement Effects 0.000 description 1
- 239000012535 impurity Substances 0.000 description 1
- 238000010348 incorporation Methods 0.000 description 1
- 229910052738 indium Inorganic materials 0.000 description 1
- APFVFJFRJDLVQX-UHFFFAOYSA-N indium atom Chemical compound [In] APFVFJFRJDLVQX-UHFFFAOYSA-N 0.000 description 1
- 229940055742 indium-111 Drugs 0.000 description 1
- 239000000411 inducer Substances 0.000 description 1
- 208000015181 infectious disease Diseases 0.000 description 1
- 230000002757 inflammatory effect Effects 0.000 description 1
- 230000004054 inflammatory process Effects 0.000 description 1
- 206010022000 influenza Diseases 0.000 description 1
- 239000004615 ingredient Substances 0.000 description 1
- 230000000977 initiatory effect Effects 0.000 description 1
- 238000003780 insertion Methods 0.000 description 1
- 230000037431 insertion Effects 0.000 description 1
- 239000000138 intercalating agent Substances 0.000 description 1
- 239000000543 intermediate Substances 0.000 description 1
- 201000002313 intestinal cancer Diseases 0.000 description 1
- 238000001361 intraarterial administration Methods 0.000 description 1
- 238000007917 intracranial administration Methods 0.000 description 1
- 238000007913 intrathecal administration Methods 0.000 description 1
- 229910052740 iodine Inorganic materials 0.000 description 1
- 239000011630 iodine Substances 0.000 description 1
- PGLTVOMIXTUURA-UHFFFAOYSA-N iodoacetamide Chemical compound NC(=O)CI PGLTVOMIXTUURA-UHFFFAOYSA-N 0.000 description 1
- 239000003456 ion exchange resin Substances 0.000 description 1
- 229920003303 ion-exchange polymer Polymers 0.000 description 1
- 150000002500 ions Chemical class 0.000 description 1
- 229940084651 iressa Drugs 0.000 description 1
- 229960004768 irinotecan Drugs 0.000 description 1
- 125000000959 isobutyl group Chemical group [H]C([H])([H])C([H])(C([H])([H])[H])C([H])([H])* 0.000 description 1
- 238000002955 isolation Methods 0.000 description 1
- 229960000310 isoleucine Drugs 0.000 description 1
- AGPKZVBTJJNPAG-UHFFFAOYSA-N isoleucine Natural products CCC(C)C(N)C(O)=O AGPKZVBTJJNPAG-UHFFFAOYSA-N 0.000 description 1
- 125000001449 isopropyl group Chemical group [H]C([H])([H])C([H])(*)C([H])([H])[H] 0.000 description 1
- 101150066555 lacZ gene Proteins 0.000 description 1
- 229960000448 lactic acid Drugs 0.000 description 1
- 229960004891 lapatinib Drugs 0.000 description 1
- 108010034897 lentil lectin Proteins 0.000 description 1
- 229960002293 leucovorin calcium Drugs 0.000 description 1
- 208000032839 leukemia Diseases 0.000 description 1
- 229940063725 leukeran Drugs 0.000 description 1
- 230000000670 limiting effect Effects 0.000 description 1
- MPVGZUGXCQEXTM-UHFFFAOYSA-N linifanib Chemical compound CC1=CC=C(F)C(NC(=O)NC=2C=CC(=CC=2)C=2C=3C(N)=NNC=3C=CC=2)=C1 MPVGZUGXCQEXTM-UHFFFAOYSA-N 0.000 description 1
- 229950001762 linsitinib Drugs 0.000 description 1
- PKCDDUHJAFVJJB-VLZXCDOPSA-N linsitinib Chemical compound C1[C@](C)(O)C[C@@H]1C1=NC(C=2C=C3N=C(C=CC3=CC=2)C=2C=CC=CC=2)=C2N1C=CN=C2N PKCDDUHJAFVJJB-VLZXCDOPSA-N 0.000 description 1
- 150000002632 lipids Chemical class 0.000 description 1
- 239000003589 local anesthetic agent Substances 0.000 description 1
- 229960005015 local anesthetics Drugs 0.000 description 1
- 230000033001 locomotion Effects 0.000 description 1
- 230000007774 longterm Effects 0.000 description 1
- HWYHZTIRURJOHG-UHFFFAOYSA-N luminol Chemical compound O=C1NNC(=O)C2=C1C(N)=CC=C2 HWYHZTIRURJOHG-UHFFFAOYSA-N 0.000 description 1
- 208000037841 lung tumor Diseases 0.000 description 1
- OHSVLFRHMCKCQY-NJFSPNSNSA-N lutetium-177 Chemical compound [177Lu] OHSVLFRHMCKCQY-NJFSPNSNSA-N 0.000 description 1
- 239000008176 lyophilized powder Substances 0.000 description 1
- 230000028744 lysogeny Effects 0.000 description 1
- 210000003712 lysosome Anatomy 0.000 description 1
- 230000001868 lysosomic effect Effects 0.000 description 1
- 229960000274 lysozyme Drugs 0.000 description 1
- 239000004325 lysozyme Substances 0.000 description 1
- 235000010335 lysozyme Nutrition 0.000 description 1
- 239000012516 mab select resin Substances 0.000 description 1
- 230000005291 magnetic effect Effects 0.000 description 1
- 239000006148 magnetic separator Substances 0.000 description 1
- 230000003211 malignant effect Effects 0.000 description 1
- 208000015486 malignant pancreatic neoplasm Diseases 0.000 description 1
- 210000001161 mammalian embryo Anatomy 0.000 description 1
- 229950001869 mapatumumab Drugs 0.000 description 1
- 229950008001 matuzumab Drugs 0.000 description 1
- 101150094281 mcl1 gene Proteins 0.000 description 1
- 230000001404 mediated effect Effects 0.000 description 1
- 238000002483 medication Methods 0.000 description 1
- 201000001441 melanoma Diseases 0.000 description 1
- 229960001924 melphalan Drugs 0.000 description 1
- 229960001428 mercaptopurine Drugs 0.000 description 1
- 108020004999 messenger RNA Proteins 0.000 description 1
- 230000009401 metastasis Effects 0.000 description 1
- 230000001394 metastastic effect Effects 0.000 description 1
- 125000004184 methoxymethyl group Chemical group [H]C([H])([H])OC([H])([H])* 0.000 description 1
- CPMDPSXJELVGJG-UHFFFAOYSA-N methyl 2-hydroxy-3-[N-[4-[methyl-[2-(4-methylpiperazin-1-yl)acetyl]amino]phenyl]-C-phenylcarbonimidoyl]-1H-indole-6-carboxylate Chemical compound OC=1NC2=CC(=CC=C2C=1C(=NC1=CC=C(C=C1)N(C(CN1CCN(CC1)C)=O)C)C1=CC=CC=C1)C(=O)OC CPMDPSXJELVGJG-UHFFFAOYSA-N 0.000 description 1
- YACKEPLHDIMKIO-UHFFFAOYSA-N methylphosphonic acid Chemical compound CP(O)(O)=O YACKEPLHDIMKIO-UHFFFAOYSA-N 0.000 description 1
- 125000004170 methylsulfonyl group Chemical group [H]C([H])([H])S(*)(=O)=O 0.000 description 1
- 230000000813 microbial effect Effects 0.000 description 1
- 244000005700 microbiome Species 0.000 description 1
- 238000000520 microinjection Methods 0.000 description 1
- 230000005012 migration Effects 0.000 description 1
- 238000013508 migration Methods 0.000 description 1
- 235000013336 milk Nutrition 0.000 description 1
- 239000008267 milk Substances 0.000 description 1
- 210000004080 milk Anatomy 0.000 description 1
- 231100000324 minimal toxicity Toxicity 0.000 description 1
- 239000003595 mist Substances 0.000 description 1
- CFCUWKMKBJTWLW-BKHRDMLASA-N mithramycin Chemical compound O([C@@H]1C[C@@H](O[C@H](C)[C@H]1O)OC=1C=C2C=C3C[C@H]([C@@H](C(=O)C3=C(O)C2=C(O)C=1C)O[C@@H]1O[C@H](C)[C@@H](O)[C@H](O[C@@H]2O[C@H](C)[C@H](O)[C@H](O[C@@H]3O[C@H](C)[C@@H](O)[C@@](C)(O)C3)C2)C1)[C@H](OC)C(=O)[C@@H](O)[C@@H](C)O)[C@H]1C[C@@H](O)[C@H](O)[C@@H](C)O1 CFCUWKMKBJTWLW-BKHRDMLASA-N 0.000 description 1
- 229960005485 mitobronitol Drugs 0.000 description 1
- 239000002829 mitogen activated protein kinase inhibitor Substances 0.000 description 1
- 229960004857 mitomycin Drugs 0.000 description 1
- 108091005601 modified peptides Proteins 0.000 description 1
- 230000001333 moisturizer Effects 0.000 description 1
- 230000004001 molecular interaction Effects 0.000 description 1
- 238000012544 monitoring process Methods 0.000 description 1
- ZTFBIUXIQYRUNT-MDWZMJQESA-N mubritinib Chemical compound C1=CC(C(F)(F)F)=CC=C1\C=C\C1=NC(COC=2C=CC(CCCCN3N=NC=C3)=CC=2)=CO1 ZTFBIUXIQYRUNT-MDWZMJQESA-N 0.000 description 1
- 238000002703 mutagenesis Methods 0.000 description 1
- 231100000350 mutagenesis Toxicity 0.000 description 1
- 229940090009 myleran Drugs 0.000 description 1
- ZTLGJPIZUOVDMT-UHFFFAOYSA-N n,n-dichlorotriazin-4-amine Chemical compound ClN(Cl)C1=CC=NN=N1 ZTLGJPIZUOVDMT-UHFFFAOYSA-N 0.000 description 1
- AZBFJBJXUQUQLF-UHFFFAOYSA-N n-(1,5-dimethylpyrrolidin-3-yl)pyrrolidine-1-carboxamide Chemical compound C1N(C)C(C)CC1NC(=O)N1CCCC1 AZBFJBJXUQUQLF-UHFFFAOYSA-N 0.000 description 1
- RDSACQWTXKSHJT-UHFFFAOYSA-N n-[3,4-difluoro-2-(2-fluoro-4-iodoanilino)-6-methoxyphenyl]-1-(2,3-dihydroxypropyl)cyclopropane-1-sulfonamide Chemical compound C1CC1(CC(O)CO)S(=O)(=O)NC=1C(OC)=CC(F)=C(F)C=1NC1=CC=C(I)C=C1F RDSACQWTXKSHJT-UHFFFAOYSA-N 0.000 description 1
- RDSACQWTXKSHJT-NSHDSACASA-N n-[3,4-difluoro-2-(2-fluoro-4-iodoanilino)-6-methoxyphenyl]-1-[(2s)-2,3-dihydroxypropyl]cyclopropane-1-sulfonamide Chemical compound C1CC1(C[C@H](O)CO)S(=O)(=O)NC=1C(OC)=CC(F)=C(F)C=1NC1=CC=C(I)C=C1F RDSACQWTXKSHJT-NSHDSACASA-N 0.000 description 1
- 125000004108 n-butyl group Chemical group [H]C([H])([H])C([H])([H])C([H])([H])C([H])([H])* 0.000 description 1
- 125000004123 n-propyl group Chemical group [H]C([H])([H])C([H])([H])C([H])([H])* 0.000 description 1
- 239000002105 nanoparticle Substances 0.000 description 1
- 229940086322 navelbine Drugs 0.000 description 1
- 229950008835 neratinib Drugs 0.000 description 1
- JWNPDZNEKVCWMY-VQHVLOKHSA-N neratinib Chemical compound C=12C=C(NC(=O)\C=C\CN(C)C)C(OCC)=CC2=NC=C(C#N)C=1NC(C=C1Cl)=CC=C1OCC1=CC=CC=N1 JWNPDZNEKVCWMY-VQHVLOKHSA-N 0.000 description 1
- 229940053128 nerve growth factor Drugs 0.000 description 1
- 108010087904 neutravidin Proteins 0.000 description 1
- 229960004378 nintedanib Drugs 0.000 description 1
- XZXHXSATPCNXJR-ZIADKAODSA-N nintedanib Chemical compound O=C1NC2=CC(C(=O)OC)=CC=C2\C1=C(C=1C=CC=CC=1)\NC(C=C1)=CC=C1N(C)C(=O)CN1CCN(C)CC1 XZXHXSATPCNXJR-ZIADKAODSA-N 0.000 description 1
- 229910052757 nitrogen Inorganic materials 0.000 description 1
- 229940085033 nolvadex Drugs 0.000 description 1
- 208000037916 non-allergic rhinitis Diseases 0.000 description 1
- 208000002154 non-small cell lung carcinoma Diseases 0.000 description 1
- 238000010899 nucleation Methods 0.000 description 1
- 229920001778 nylon Polymers 0.000 description 1
- 210000000056 organ Anatomy 0.000 description 1
- 201000008968 osteosarcoma Diseases 0.000 description 1
- 229940127084 other anti-cancer agent Drugs 0.000 description 1
- 210000001672 ovary Anatomy 0.000 description 1
- 229910052760 oxygen Inorganic materials 0.000 description 1
- 125000003854 p-chlorophenyl group Chemical group [H]C1=C([H])C(*)=C([H])C([H])=C1Cl 0.000 description 1
- 229960001592 paclitaxel Drugs 0.000 description 1
- 229910052763 palladium Inorganic materials 0.000 description 1
- 201000002094 pancreatic adenocarcinoma Diseases 0.000 description 1
- 201000002528 pancreatic cancer Diseases 0.000 description 1
- 208000008443 pancreatic carcinoma Diseases 0.000 description 1
- 229960001972 panitumumab Drugs 0.000 description 1
- 230000005298 paramagnetic effect Effects 0.000 description 1
- 230000037361 pathway Effects 0.000 description 1
- CUIHSIWYWATEQL-UHFFFAOYSA-N pazopanib Chemical compound C1=CC2=C(C)N(C)N=C2C=C1N(C)C(N=1)=CC=NC=1NC1=CC=C(C)C(S(N)(=O)=O)=C1 CUIHSIWYWATEQL-UHFFFAOYSA-N 0.000 description 1
- WVUNYSQLFKLYNI-AATRIKPKSA-N pelitinib Chemical compound C=12C=C(NC(=O)\C=C\CN(C)C)C(OCC)=CC2=NC=C(C#N)C=1NC1=CC=C(F)C(Cl)=C1 WVUNYSQLFKLYNI-AATRIKPKSA-N 0.000 description 1
- FPVKHBSQESCIEP-JQCXWYLXSA-N pentostatin Chemical compound C1[C@H](O)[C@@H](CO)O[C@H]1N1C(N=CNC[C@H]2O)=C2N=C1 FPVKHBSQESCIEP-JQCXWYLXSA-N 0.000 description 1
- 229960002340 pentostatin Drugs 0.000 description 1
- 230000002093 peripheral effect Effects 0.000 description 1
- 229960002087 pertuzumab Drugs 0.000 description 1
- 238000002823 phage display Methods 0.000 description 1
- 239000000825 pharmaceutical preparation Substances 0.000 description 1
- 230000000144 pharmacologic effect Effects 0.000 description 1
- 230000000079 pharmacotherapeutic effect Effects 0.000 description 1
- COLNVLDHVKWLRT-UHFFFAOYSA-N phenylalanine Natural products OC(=O)C(N)CC1=CC=CC=C1 COLNVLDHVKWLRT-UHFFFAOYSA-N 0.000 description 1
- 125000003356 phenylsulfanyl group Chemical group [*]SC1=C([H])C([H])=C([H])C([H])=C1[H] 0.000 description 1
- 239000008363 phosphate buffer Substances 0.000 description 1
- PTMHPRAIXMAOOB-UHFFFAOYSA-L phosphoramidate Chemical compound NP([O-])([O-])=O PTMHPRAIXMAOOB-UHFFFAOYSA-L 0.000 description 1
- 150000003013 phosphoric acid derivatives Chemical class 0.000 description 1
- BZQFBWGGLXLEPQ-REOHCLBHSA-N phosphoserine Chemical compound OC(=O)[C@@H](N)COP(O)(O)=O BZQFBWGGLXLEPQ-REOHCLBHSA-N 0.000 description 1
- 230000035790 physiological processes and functions Effects 0.000 description 1
- 230000006461 physiological response Effects 0.000 description 1
- YJGVMLPVUAXIQN-HAEOHBJNSA-N picropodophyllotoxin Chemical compound COC1=C(OC)C(OC)=CC([C@@H]2C3=CC=4OCOC=4C=C3[C@H](O)[C@@H]3[C@H]2C(OC3)=O)=C1 YJGVMLPVUAXIQN-HAEOHBJNSA-N 0.000 description 1
- LHNIIDJUOCFXAP-UHFFFAOYSA-N pictrelisib Chemical compound C1CN(S(=O)(=O)C)CCN1CC1=CC2=NC(C=3C=4C=NNC=4C=CC=3)=NC(N3CCOCC3)=C2S1 LHNIIDJUOCFXAP-UHFFFAOYSA-N 0.000 description 1
- 230000003169 placental effect Effects 0.000 description 1
- 210000002381 plasma Anatomy 0.000 description 1
- 230000036470 plasma concentration Effects 0.000 description 1
- 229940127126 plasminogen activator Drugs 0.000 description 1
- 238000007747 plating Methods 0.000 description 1
- 229940063179 platinol Drugs 0.000 description 1
- 229960003171 plicamycin Drugs 0.000 description 1
- 229920000191 poly(N-vinyl pyrrolidone) Polymers 0.000 description 1
- 229920001200 poly(ethylene-vinyl acetate) Polymers 0.000 description 1
- 229920003229 poly(methyl methacrylate) Polymers 0.000 description 1
- 230000008488 polyadenylation Effects 0.000 description 1
- 229920000573 polyethylene Polymers 0.000 description 1
- 229920002338 polyhydroxyethylmethacrylate Polymers 0.000 description 1
- 239000004926 polymethyl methacrylate Substances 0.000 description 1
- 229920001155 polypropylene Polymers 0.000 description 1
- 229920001282 polysaccharide Polymers 0.000 description 1
- 239000005017 polysaccharide Substances 0.000 description 1
- 229920002451 polyvinyl alcohol Polymers 0.000 description 1
- 239000004800 polyvinyl chloride Substances 0.000 description 1
- 229920000915 polyvinyl chloride Polymers 0.000 description 1
- 238000010837 poor prognosis Methods 0.000 description 1
- 239000011148 porous material Substances 0.000 description 1
- 230000035409 positive regulation of cell proliferation Effects 0.000 description 1
- 238000002600 positron emission tomography Methods 0.000 description 1
- 229910000160 potassium phosphate Inorganic materials 0.000 description 1
- 235000011009 potassium phosphates Nutrition 0.000 description 1
- 230000003389 potentiating effect Effects 0.000 description 1
- 238000001556 precipitation Methods 0.000 description 1
- 239000002243 precursor Substances 0.000 description 1
- 230000037452 priming Effects 0.000 description 1
- 229960004919 procaine Drugs 0.000 description 1
- MFDFERRIHVXMIY-UHFFFAOYSA-N procaine Chemical compound CCN(CC)CCOC(=O)C1=CC=C(N)C=C1 MFDFERRIHVXMIY-UHFFFAOYSA-N 0.000 description 1
- 238000012545 processing Methods 0.000 description 1
- 239000000047 product Substances 0.000 description 1
- 210000001236 prokaryotic cell Anatomy 0.000 description 1
- 230000001737 promoting effect Effects 0.000 description 1
- 229960003712 propranolol Drugs 0.000 description 1
- 238000000751 protein extraction Methods 0.000 description 1
- 239000003197 protein kinase B inhibitor Substances 0.000 description 1
- 238000001742 protein purification Methods 0.000 description 1
- 238000000455 protein structure prediction Methods 0.000 description 1
- 238000001243 protein synthesis Methods 0.000 description 1
- 230000002685 pulmonary effect Effects 0.000 description 1
- 229940117820 purinethol Drugs 0.000 description 1
- 229950010131 puromycin Drugs 0.000 description 1
- 125000004289 pyrazol-3-yl group Chemical group [H]N1N=C(*)C([H])=C1[H] 0.000 description 1
- 125000002206 pyridazin-3-yl group Chemical group [H]C1=C([H])C([H])=C(*)N=N1 0.000 description 1
- UDJFFSGCRRMVFH-UHFFFAOYSA-N pyrido[2,3-d]pyrimidine Chemical compound N1=CN=CC2=CC=CN=C21 UDJFFSGCRRMVFH-UHFFFAOYSA-N 0.000 description 1
- 125000004527 pyrimidin-4-yl group Chemical group N1=CN=C(C=C1)* 0.000 description 1
- 125000004943 pyrimidin-6-yl group Chemical group N1=CN=CC=C1* 0.000 description 1
- 239000002096 quantum dot Substances 0.000 description 1
- 125000004550 quinolin-6-yl group Chemical group N1=CC=CC2=CC(=CC=C12)* 0.000 description 1
- 230000005855 radiation Effects 0.000 description 1
- 238000003127 radioimmunoassay Methods 0.000 description 1
- 229940051022 radioimmunoconjugate Drugs 0.000 description 1
- 238000001959 radiotherapy Methods 0.000 description 1
- ZAHRKKWIAAJSAO-UHFFFAOYSA-N rapamycin Natural products COCC(O)C(=C/C(C)C(=O)CC(OC(=O)C1CCCCN1C(=O)C(=O)C2(O)OC(CC(OC)C(=CC=CC=CC(C)CC(C)C(=O)C)C)CCC2C)C(C)CC3CCC(O)C(C3)OC)C ZAHRKKWIAAJSAO-UHFFFAOYSA-N 0.000 description 1
- 239000011535 reaction buffer Substances 0.000 description 1
- 229940044601 receptor agonist Drugs 0.000 description 1
- 239000000018 receptor agonist Substances 0.000 description 1
- 230000006798 recombination Effects 0.000 description 1
- 238000005215 recombination Methods 0.000 description 1
- 238000011084 recovery Methods 0.000 description 1
- 206010038038 rectal cancer Diseases 0.000 description 1
- 201000001275 rectum cancer Diseases 0.000 description 1
- 230000000306 recurrent effect Effects 0.000 description 1
- 230000004044 response Effects 0.000 description 1
- 108091008146 restriction endonucleases Proteins 0.000 description 1
- 238000004366 reverse phase liquid chromatography Methods 0.000 description 1
- 238000004007 reversed phase HPLC Methods 0.000 description 1
- 230000002441 reversible effect Effects 0.000 description 1
- PYWVYCXTNDRMGF-UHFFFAOYSA-N rhodamine B Chemical compound [Cl-].C=12C=CC(=[N+](CC)CC)C=C2OC2=CC(N(CC)CC)=CC=C2C=1C1=CC=CC=C1C(O)=O PYWVYCXTNDRMGF-UHFFFAOYSA-N 0.000 description 1
- 125000002652 ribonucleotide group Chemical group 0.000 description 1
- 229960001302 ridaforolimus Drugs 0.000 description 1
- 229930195734 saturated hydrocarbon Natural products 0.000 description 1
- 238000009738 saturating Methods 0.000 description 1
- 125000002914 sec-butyl group Chemical group [H]C([H])([H])C([H])([H])C([H])(*)C([H])([H])[H] 0.000 description 1
- 230000003248 secreting effect Effects 0.000 description 1
- 230000028327 secretion Effects 0.000 description 1
- 238000010187 selection method Methods 0.000 description 1
- 239000006152 selective media Substances 0.000 description 1
- 238000012163 sequencing technique Methods 0.000 description 1
- 229950008834 seribantumab Drugs 0.000 description 1
- 239000012679 serum free medium Substances 0.000 description 1
- 230000001568 sexual effect Effects 0.000 description 1
- 239000002453 shampoo Substances 0.000 description 1
- 230000035939 shock Effects 0.000 description 1
- 238000003998 size exclusion chromatography high performance liquid chromatography Methods 0.000 description 1
- 238000001542 size-exclusion chromatography Methods 0.000 description 1
- 235000020183 skimmed milk Nutrition 0.000 description 1
- 201000000849 skin cancer Diseases 0.000 description 1
- 239000002002 slurry Substances 0.000 description 1
- 208000000587 small cell lung carcinoma Diseases 0.000 description 1
- 150000003384 small molecules Chemical class 0.000 description 1
- YCLWMUYXEGEIGD-UHFFFAOYSA-M sodium;2-hydroxy-3-[4-(2-hydroxyethyl)piperazin-1-yl]propane-1-sulfonate Chemical compound [Na+].OCCN1CCN(CC(O)CS([O-])(=O)=O)CC1 YCLWMUYXEGEIGD-UHFFFAOYSA-M 0.000 description 1
- 230000000087 stabilizing effect Effects 0.000 description 1
- 230000010473 stable expression Effects 0.000 description 1
- 239000008107 starch Substances 0.000 description 1
- 235000019698 starch Nutrition 0.000 description 1
- 238000007619 statistical method Methods 0.000 description 1
- 230000001954 sterilising effect Effects 0.000 description 1
- 238000004659 sterilization and disinfection Methods 0.000 description 1
- 150000003431 steroids Chemical class 0.000 description 1
- 239000011550 stock solution Substances 0.000 description 1
- 229960001052 streptozocin Drugs 0.000 description 1
- ZSJLQEPLLKMAKR-GKHCUFPYSA-N streptozocin Chemical compound O=NN(C)C(=O)N[C@H]1[C@@H](O)O[C@H](CO)[C@@H](O)[C@@H]1O ZSJLQEPLLKMAKR-GKHCUFPYSA-N 0.000 description 1
- 239000000758 substrate Substances 0.000 description 1
- 229960004793 sucrose Drugs 0.000 description 1
- NVBFHJWHLNUMCV-UHFFFAOYSA-N sulfamide Chemical compound NS(N)(=O)=O NVBFHJWHLNUMCV-UHFFFAOYSA-N 0.000 description 1
- 125000000446 sulfanediyl group Chemical group *S* 0.000 description 1
- 229960005559 sulforaphane Drugs 0.000 description 1
- 235000015487 sulforaphane Nutrition 0.000 description 1
- 239000011593 sulfur Substances 0.000 description 1
- 229910021653 sulphate ion Inorganic materials 0.000 description 1
- 229960002812 sunitinib malate Drugs 0.000 description 1
- 108010033090 surfactant protein A receptor Proteins 0.000 description 1
- 238000001356 surgical procedure Methods 0.000 description 1
- 238000004114 suspension culture Methods 0.000 description 1
- 229940034785 sutent Drugs 0.000 description 1
- 210000005222 synovial tissue Anatomy 0.000 description 1
- 230000001839 systemic circulation Effects 0.000 description 1
- 229940037128 systemic glucocorticoids Drugs 0.000 description 1
- 229960003454 tamoxifen citrate Drugs 0.000 description 1
- 229960003080 taurine Drugs 0.000 description 1
- RCINICONZNJXQF-MZXODVADSA-N taxol Chemical compound O([C@@H]1[C@@]2(C[C@@H](C(C)=C(C2(C)C)[C@H](C([C@]2(C)[C@@H](O)C[C@H]3OC[C@]3([C@H]21)OC(C)=O)=O)OC(=O)C)OC(=O)[C@H](O)[C@@H](NC(=O)C=1C=CC=CC=1)C=1C=CC=CC=1)O)C(=O)C1=CC=CC=C1 RCINICONZNJXQF-MZXODVADSA-N 0.000 description 1
- RCINICONZNJXQF-XAZOAEDWSA-N taxol® Chemical compound O([C@@H]1[C@@]2(CC(C(C)=C(C2(C)C)[C@H](C([C@]2(C)[C@@H](O)C[C@H]3OC[C@]3(C21)OC(C)=O)=O)OC(=O)C)OC(=O)[C@H](O)[C@@H](NC(=O)C=1C=CC=CC=1)C=1C=CC=CC=1)O)C(=O)C1=CC=CC=C1 RCINICONZNJXQF-XAZOAEDWSA-N 0.000 description 1
- 229940063683 taxotere Drugs 0.000 description 1
- 229910052713 technetium Inorganic materials 0.000 description 1
- GKLVYJBZJHMRIY-UHFFFAOYSA-N technetium atom Chemical compound [Tc] GKLVYJBZJHMRIY-UHFFFAOYSA-N 0.000 description 1
- 229960004556 tenofovir Drugs 0.000 description 1
- VCMJCVGFSROFHV-WZGZYPNHSA-N tenofovir disoproxil fumarate Chemical compound OC(=O)\C=C\C(O)=O.N1=CN=C2N(C[C@@H](C)OCP(=O)(OCOC(=O)OC(C)C)OCOC(=O)OC(C)C)C=NC2=C1N VCMJCVGFSROFHV-WZGZYPNHSA-N 0.000 description 1
- 125000000999 tert-butyl group Chemical group [H]C([H])([H])C(*)(C([H])([H])[H])C([H])([H])[H] 0.000 description 1
- 229960002372 tetracaine Drugs 0.000 description 1
- GKCBAIGFKIBETG-UHFFFAOYSA-N tetracaine Chemical compound CCCCNC1=CC=C(C(=O)OCCN(C)C)C=C1 GKCBAIGFKIBETG-UHFFFAOYSA-N 0.000 description 1
- 229910052716 thallium Inorganic materials 0.000 description 1
- BKVIYDNLLOSFOA-UHFFFAOYSA-N thallium Chemical compound [Tl] BKVIYDNLLOSFOA-UHFFFAOYSA-N 0.000 description 1
- 238000011285 therapeutic regimen Methods 0.000 description 1
- 230000004797 therapeutic response Effects 0.000 description 1
- 150000003568 thioethers Chemical class 0.000 description 1
- 125000003396 thiol group Chemical group [H]S* 0.000 description 1
- RYYWUUFWQRZTIU-UHFFFAOYSA-K thiophosphate Chemical compound [O-]P([O-])([O-])=S RYYWUUFWQRZTIU-UHFFFAOYSA-K 0.000 description 1
- 229960001196 thiotepa Drugs 0.000 description 1
- 229950002376 tirapazamine Drugs 0.000 description 1
- 238000012090 tissue culture technique Methods 0.000 description 1
- 230000017423 tissue regeneration Effects 0.000 description 1
- 230000008427 tissue turnover Effects 0.000 description 1
- 229950005976 tivantinib Drugs 0.000 description 1
- 238000011200 topical administration Methods 0.000 description 1
- 229960002190 topotecan hydrochloride Drugs 0.000 description 1
- 229960005267 tositumomab Drugs 0.000 description 1
- LIRYPHYGHXZJBZ-UHFFFAOYSA-N trametinib Chemical compound CC(=O)NC1=CC=CC(N2C(N(C3CC3)C(=O)C3=C(NC=4C(=CC(I)=CC=4)F)N(C)C(=O)C(C)=C32)=O)=C1 LIRYPHYGHXZJBZ-UHFFFAOYSA-N 0.000 description 1
- 229960001308 trametinib dimethyl sulfoxide Drugs 0.000 description 1
- OQUFJVRYDFIQBW-UHFFFAOYSA-N trametinib dimethyl sulfoxide Chemical compound CS(C)=O.CC(=O)NC1=CC=CC(N2C(N(C3CC3)C(=O)C3=C(NC=4C(=CC(I)=CC=4)F)N(C)C(=O)C(C)=C32)=O)=C1 OQUFJVRYDFIQBW-UHFFFAOYSA-N 0.000 description 1
- FGMPLJWBKKVCDB-UHFFFAOYSA-N trans-L-hydroxy-proline Natural products ON1CCCC1C(O)=O FGMPLJWBKKVCDB-UHFFFAOYSA-N 0.000 description 1
- 230000005030 transcription termination Effects 0.000 description 1
- 238000010361 transduction Methods 0.000 description 1
- 230000026683 transduction Effects 0.000 description 1
- 238000003146 transient transfection Methods 0.000 description 1
- 229960001612 trastuzumab emtansine Drugs 0.000 description 1
- 238000011269 treatment regimen Methods 0.000 description 1
- CYRMSUTZVYGINF-UHFFFAOYSA-N trichlorofluoromethane Chemical compound FC(Cl)(Cl)Cl CYRMSUTZVYGINF-UHFFFAOYSA-N 0.000 description 1
- 229940029284 trichlorofluoromethane Drugs 0.000 description 1
- 125000002023 trifluoromethyl group Chemical group FC(F)(F)* 0.000 description 1
- 229910052722 tritium Inorganic materials 0.000 description 1
- 102000003390 tumor necrosis factor Human genes 0.000 description 1
- 230000005751 tumor progression Effects 0.000 description 1
- 208000029729 tumor suppressor gene on chromosome 11 Diseases 0.000 description 1
- 231100000588 tumorigenic Toxicity 0.000 description 1
- 230000000381 tumorigenic effect Effects 0.000 description 1
- 241000701447 unidentified baculovirus Species 0.000 description 1
- 241001430294 unidentified retrovirus Species 0.000 description 1
- 206010046766 uterine cancer Diseases 0.000 description 1
- 239000004474 valine Substances 0.000 description 1
- 229960003862 vemurafenib Drugs 0.000 description 1
- GBABOYUKABKIAF-IELIFDKJSA-N vinorelbine Chemical compound C1N(CC=2C3=CC=CC=C3NC=22)CC(CC)=C[C@H]1C[C@]2(C(=O)OC)C1=CC([C@]23[C@H]([C@@]([C@H](OC(C)=O)[C@]4(CC)C=CCN([C@H]34)CC2)(O)C(=O)OC)N2C)=C2C=C1OC GBABOYUKABKIAF-IELIFDKJSA-N 0.000 description 1
- 229960002066 vinorelbine Drugs 0.000 description 1
- CILBMBUYJCWATM-PYGJLNRPSA-N vinorelbine ditartrate Chemical compound OC(=O)[C@H](O)[C@@H](O)C(O)=O.OC(=O)[C@H](O)[C@@H](O)C(O)=O.C1N(CC=2C3=CC=CC=C3NC=22)CC(CC)=C[C@H]1C[C@]2(C(=O)OC)C1=CC([C@]23[C@H]([C@@]([C@H](OC(C)=O)[C@]4(CC)C=CCN([C@H]34)CC2)(O)C(=O)OC)N2C)=C2C=C1OC CILBMBUYJCWATM-PYGJLNRPSA-N 0.000 description 1
- 210000002845 virion Anatomy 0.000 description 1
- 239000000277 virosome Substances 0.000 description 1
- 239000003039 volatile agent Substances 0.000 description 1
- 229940069559 votrient Drugs 0.000 description 1
- 239000008215 water for injection Substances 0.000 description 1
- 230000029663 wound healing Effects 0.000 description 1
- 238000002424 x-ray crystallography Methods 0.000 description 1
- 229940049068 xalkori Drugs 0.000 description 1
- 229940053867 xeloda Drugs 0.000 description 1
- 210000005253 yeast cell Anatomy 0.000 description 1
Images



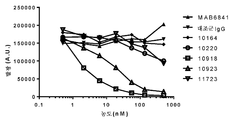
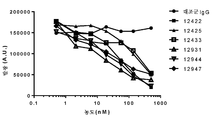
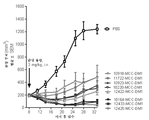

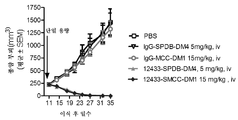



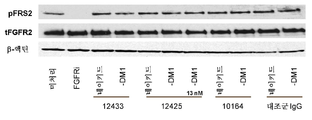




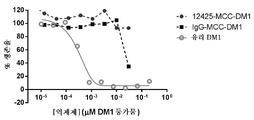

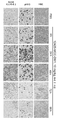
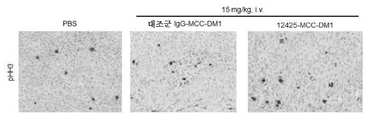
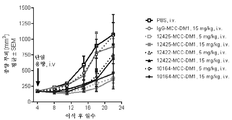
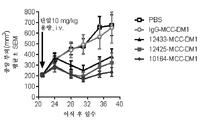

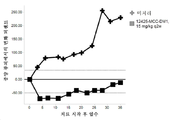
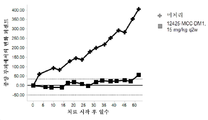
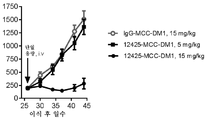

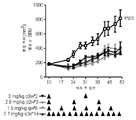
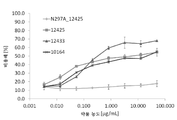
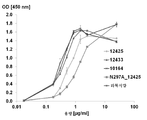
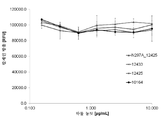
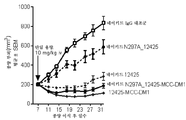



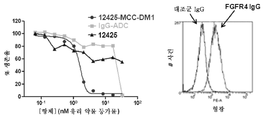
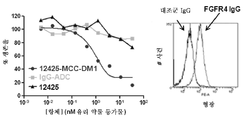

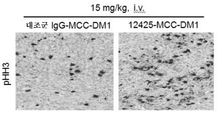


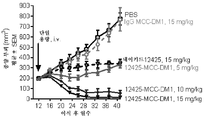
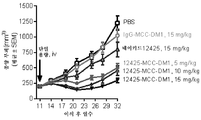




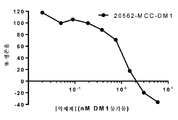

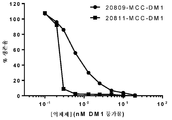





Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/30—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants from tumour cells
-
- A61K47/48384—
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K31/00—Medicinal preparations containing organic active ingredients
- A61K31/33—Heterocyclic compounds
- A61K31/395—Heterocyclic compounds having nitrogen as a ring hetero atom, e.g. guanethidine or rifamycins
- A61K31/495—Heterocyclic compounds having nitrogen as a ring hetero atom, e.g. guanethidine or rifamycins having six-membered rings with two or more nitrogen atoms as the only ring heteroatoms, e.g. piperazine or tetrazines
- A61K31/505—Pyrimidines; Hydrogenated pyrimidines, e.g. trimethoprim
- A61K31/506—Pyrimidines; Hydrogenated pyrimidines, e.g. trimethoprim not condensed and containing further heterocyclic rings
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K45/00—Medicinal preparations containing active ingredients not provided for in groups A61K31/00 - A61K41/00
- A61K45/06—Mixtures of active ingredients without chemical characterisation, e.g. antiphlogistics and cardiaca
-
- A61K47/48092—
-
- A61K47/48561—
-
- A61K47/48676—
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/50—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates
- A61K47/51—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent
- A61K47/54—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an organic compound
- A61K47/549—Sugars, nucleosides, nucleotides or nucleic acids
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/50—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates
- A61K47/51—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent
- A61K47/68—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment
- A61K47/6801—Drug-antibody or immunoglobulin conjugates defined by the pharmacologically or therapeutically active agent
- A61K47/6803—Drugs conjugated to an antibody or immunoglobulin, e.g. cisplatin-antibody conjugates
- A61K47/68033—Drugs conjugated to an antibody or immunoglobulin, e.g. cisplatin-antibody conjugates the drug being a maytansine
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/50—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates
- A61K47/51—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent
- A61K47/68—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment
- A61K47/6835—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment the modifying agent being an antibody or an immunoglobulin bearing at least one antigen-binding site
- A61K47/6849—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment the modifying agent being an antibody or an immunoglobulin bearing at least one antigen-binding site the antibody targeting a receptor, a cell surface antigen or a cell surface determinant
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/50—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates
- A61K47/51—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent
- A61K47/68—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment
- A61K47/6835—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment the modifying agent being an antibody or an immunoglobulin bearing at least one antigen-binding site
- A61K47/6875—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment the modifying agent being an antibody or an immunoglobulin bearing at least one antigen-binding site the antibody being a hybrid immunoglobulin
- A61K47/6879—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment the modifying agent being an antibody or an immunoglobulin bearing at least one antigen-binding site the antibody being a hybrid immunoglobulin the immunoglobulin having two or more different antigen-binding sites, e.g. bispecific or multispecific immunoglobulin
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K49/00—Preparations for testing in vivo
- A61K49/0004—Screening or testing of compounds for diagnosis of disorders, assessment of conditions, e.g. renal clearance, gastric emptying, testing for diabetes, allergy, rheuma, pancreas functions
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K51/00—Preparations containing radioactive substances for use in therapy or testing in vivo
- A61K51/02—Preparations containing radioactive substances for use in therapy or testing in vivo characterised by the carrier, i.e. characterised by the agent or material covalently linked or complexing the radioactive nucleus
- A61K51/04—Organic compounds
- A61K51/08—Peptides, e.g. proteins, carriers being peptides, polyamino acids, proteins
- A61K51/10—Antibodies or immunoglobulins; Fragments thereof, the carrier being an antibody, an immunoglobulin or a fragment thereof, e.g. a camelised human single domain antibody or the Fc fragment of an antibody
- A61K51/1027—Antibodies or immunoglobulins; Fragments thereof, the carrier being an antibody, an immunoglobulin or a fragment thereof, e.g. a camelised human single domain antibody or the Fc fragment of an antibody against receptors, cell-surface antigens or cell-surface determinants
- A61K51/103—Antibodies or immunoglobulins; Fragments thereof, the carrier being an antibody, an immunoglobulin or a fragment thereof, e.g. a camelised human single domain antibody or the Fc fragment of an antibody against receptors, cell-surface antigens or cell-surface determinants against receptors for growth factors or receptors for growth regulators
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P43/00—Drugs for specific purposes, not provided for in groups A61P1/00-A61P41/00
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2863—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against receptors for growth factors, growth regulators
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/30—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants from tumour cells
- C07K16/3015—Breast
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/30—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants from tumour cells
- C07K16/3023—Lung
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/30—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants from tumour cells
- C07K16/303—Liver or Pancreas
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/30—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants from tumour cells
- C07K16/3038—Kidney, bladder
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/30—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants from tumour cells
- C07K16/3046—Stomach, Intestines
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/30—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants from tumour cells
- C07K16/3069—Reproductive system, e.g. ovaria, uterus, testes, prostate
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/505—Medicinal preparations containing antigens or antibodies comprising antibodies
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/20—Immunoglobulins specific features characterized by taxonomic origin
- C07K2317/21—Immunoglobulins specific features characterized by taxonomic origin from primates, e.g. man
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/30—Immunoglobulins specific features characterized by aspects of specificity or valency
- C07K2317/31—Immunoglobulins specific features characterized by aspects of specificity or valency multispecific
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/30—Immunoglobulins specific features characterized by aspects of specificity or valency
- C07K2317/33—Crossreactivity, e.g. for species or epitope, or lack of said crossreactivity
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/30—Immunoglobulins specific features characterized by aspects of specificity or valency
- C07K2317/34—Identification of a linear epitope shorter than 20 amino acid residues or of a conformational epitope defined by amino acid residues
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/52—Constant or Fc region; Isotype
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/55—Fab or Fab'
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/56—Immunoglobulins specific features characterized by immunoglobulin fragments variable (Fv) region, i.e. VH and/or VL
- C07K2317/565—Complementarity determining region [CDR]
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/73—Inducing cell death, e.g. apoptosis, necrosis or inhibition of cell proliferation
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/73—Inducing cell death, e.g. apoptosis, necrosis or inhibition of cell proliferation
- C07K2317/732—Antibody-dependent cellular cytotoxicity [ADCC]
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/75—Agonist effect on antigen
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/76—Antagonist effect on antigen, e.g. neutralization or inhibition of binding
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/90—Immunoglobulins specific features characterized by (pharmaco)kinetic aspects or by stability of the immunoglobulin
- C07K2317/92—Affinity (KD), association rate (Ka), dissociation rate (Kd) or EC50 value
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
Landscapes
- Health & Medical Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Immunology (AREA)
- General Health & Medical Sciences (AREA)
- Medicinal Chemistry (AREA)
- Organic Chemistry (AREA)
- Engineering & Computer Science (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Animal Behavior & Ethology (AREA)
- Public Health (AREA)
- Veterinary Medicine (AREA)
- Pharmacology & Pharmacy (AREA)
- Molecular Biology (AREA)
- Biochemistry (AREA)
- Epidemiology (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Biophysics (AREA)
- Genetics & Genomics (AREA)
- Cell Biology (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- General Chemical & Material Sciences (AREA)
- Chemical Kinetics & Catalysis (AREA)
- Gastroenterology & Hepatology (AREA)
- Urology & Nephrology (AREA)
- Gynecology & Obstetrics (AREA)
- Pregnancy & Childbirth (AREA)
- Reproductive Health (AREA)
- Peptides Or Proteins (AREA)
- Medicines Containing Antibodies Or Antigens For Use As Internal Diagnostic Agents (AREA)
- Medicinal Preparation (AREA)
- Endocrinology (AREA)
- Physics & Mathematics (AREA)
- Optics & Photonics (AREA)
- Biomedical Technology (AREA)
- Diabetes (AREA)
- Pathology (AREA)
- Rheumatology (AREA)
- Toxicology (AREA)
- Medicines That Contain Protein Lipid Enzymes And Other Medicines (AREA)
Abstract
본 발명은 항-FGFR2 및 FGFR4 항체, 항체 단편, 항체 약물 접합체, 및 암의 치료를 위한 그의 용도에 관한 것이다.
Description
본 발명은 일반적으로 항-FGFR2 및 FGFR4 항체, 항체 단편, 항체 약물 접합체, 및 암의 치료를 위한 그의 용도에 관한 것이다.
섬유모세포 성장 인자 수용체
섬유모세포 성장 인자 (FGF) 수용체 (FGFR)를 통해 신호를 전달하는 섬유모세포 성장 인자 (FGF)는 근본적인 발생 경로를 조절하고, 폭 넓게 다양한 조직에서 발현된다. FGF는 증식, 세포 이동, 분화를 자극하고, 골격 및 사지 발생, 상처 치유, 조직 복구, 조혈, 혈관신생 및 종양발생에서 주요 역할을 한다 (예를 들어, 문헌 [Turner and Crose, Nature Reviews Cancer 10: 116 - 129 (2010)] 참조).
포유동물 FGF 패밀리는 4종의 고도로 보존된 막횡단 티로신 키나제 수용체인 FGFR1, FGFR2, FGFR3 및 FGFR4를 통해 그의 작용을 발휘하는 다수의 리간드를 포함한다. 전형적인 FGFR은 절단된 신호 펩티드, 3종의 이뮤노글로불린 (Ig)-유사 도메인 (Ig 도메인 I, II 및 III), 산성 박스, 막횡단 도메인 및 분할 티로신 키나제 도메인을 갖는다 (예를 들어, 문헌 [Ullrich and Schlessinger, Cell 61: 203 (1990); Johnson and Williams, Adv. Cancer Res. 60: 1-41 (1992)] 참조).
추가로, 전사된 수용체 유전자의 선택적 스플라이싱은 다양한 수용체 이소형, 예컨대 가용성의 분비된 FGFR, 말단절단된 COOH-말단 도메인을 갖는 FGFR, 2개 또는 3개의 Ig-유사 도메인을 갖는 FGFR을 생성하고, 뿐만 아니라 제3 Ig-유사 도메인의 선택적 스플라이싱을 통해 유발되는 FGFR 이소형은 단지 FGFR1, FGFR2 및 FGFR3에 대해서만 발생하고 제3 Ig-유사 도메인의 제2 절반을 구체화하여 수용체의 IIIb 또는 IIIc 이소형 중 어느 하나를 생성한다. 수용체의 제2 및 제3 Ig-유사 도메인은 리간드 결합을 위해 필요하고 이에 충분하지만, 제1 Ig-유사 도메인은 수용체 자가억제에 역할을 하는 것으로 여겨진다. 따라서, 다양한 수용체 및 그의 이소형은 리간드-결합 특이성을 나타낸다 (예를 들어, 문헌 [Haugsten et al., Mol. Cancer Res. 8:1439-1452 (2010)] 참조).
FGF는 또한 별개의 FGFR 및 그의 스플라이스 변이체에 결합하는 것 이외에도 헤파린 술페이트 프로테오글리칸 (HSPG)에 결합할 수 있다. 이에 따라 이량체 FGF-FGFR-HSPG 3원 복합체가 세포 표면 상에 형성된다. 3원 복합체는 복합체에 있는 상이한 성분 사이의 다중 상호작용에 의해 안정화된다. 2개의 FGF-결합 부위, 헤파린-결합 부위 및 수용체-수용체 상호작용 부위는 수용체의 Ig-유사 도메인 II 및 III 내에서 확인된 바 있다. (문헌 [Haugsten et al., 2010]).
FGFR에 대한 FGF의 결합은 수용체 이량체화를 유도하고, 이는 키나제 도메인의 활성화 루프에서 티로신의 인산전이를 가능하게 한다. 활성 FGFR은 다중 세포내 단백질, 예컨대 FRS2 및 PLCγ를 인산화하는 것으로 제시된 바 있다 (문헌 [Eswarakumar et al., Cytokine Growth Factor Rev 16:139-149 (2005)]). FGFR 신호전달은 다양한 세포 유형에서 별개의 생물학적 반응을 생성하며, 그 범위는 세포 증식 및 생존의 자극에서부터 성장 저지, 이동 및 분화에까지 이른다.
FGFR 및 암
FGF 신호전달은 효과의 강력한 조합을 매개한다: 성장/생존에서의 자급자족, 신혈관신생 및 종양 세포 이동. 따라서, FGF 신호전달은 그의 생리학적 기능에 대해 발휘된 엄격한 조절이 결여되는 경우에 강하게 종양원성이 되는 잠재력을 갖는다 (예를 들어 문헌 [Heinzle et al., Expert Opin. Ther. Targets 15(7):829-846 (2011)] 참조).
FGFR1, FGFR2 및 FGFR4의 유전자 증폭 및/또는 과다발현은 유방암에 연루되어 있다 (문헌 [Penault-Llorca et al., Int J Cancer 1995; Theillet et al., Genes Chrom. Cancer 1993; Adnane et al., Oncogene 1991; Jaakola et al., Int J Cancer 1993; Yamada et al., Neuro Res 2002]). FGFR1 및 FGFR4의 과다발현은 또한 췌장 선암종 및 성상세포종과 연관되어 있다 (문헌 [Kobrin et al., Cancer Research 1993; Yamanaka et al., Cancer Research 1993; Shah et al., Oncogene 2002; Yamaguchi et al., PNAS 1994; Yamada et al., Neuro Res 2002]). 전립선암은 또한 FGFR1 과다발현에 관련되어 있다 (문헌 [Giri et al., Clin Cancer Res 1999]). FGFR4 과다발현은 횡문근육종에 연루되어 있다 (문헌 [Khan et al., Nature Medicine 2001, Baird et al., Cancer Res 2005]). 폐포 횡문근육종의 하위세트는, FGFR4를 직접 전사적으로 활성화시키고 FGFR4 단백질 발현을 증가시키는 신규 융합 단백질을 생산하는 PAX3-FOXO 전위를 보유한다 (문헌 [Cao et al., Cancer Res 2010; Davicioni et al., Cancer Res 2006]).
일반적으로 FGFR2 및 FGFR1은 유전자 증폭에 의해 보다 흔히 탈조절된다. 위암에서, 증폭된 FGFR2 유전자는 불량한 예후와 연관되어 있다 (문헌 [Kunii et al., Cancer Res. 68:2340-2348 (2008)]). FGFR2-IIIb에서 IIIc로의 교체는 또한 방광암 및 전립선암에서 종양 진행, 상피-중간엽 전이 및 높은 침입성의 징후일 수 있다. 이러한 경우에 교체는 항종양발생 활성을 발휘하는 IIIb 수용체 변이체를 종양발생촉진 IIIc 수용체로 대체한 것이다 (예를 들어, 문헌 [Heinzle et al., 2011] 참조). 지금까지 FGFR2 돌연변이는 피부암, 자궁내막암, 난소암 및 폐암에 연루되었다. FGFR4 돌연변이는 횡문근육종, 폐암 및 유방암에 연루되었다 (예를 들어, 문헌 [Heinzle et al., 2011]).
항체 약물 접합체
항체 약물 접합체 ("ADC")는 암 치료에 있어서 세포독성제의 국부 전달에 사용되어 왔다 (예를 들어, 문헌 [Lambert, Curr. Opinion In Pharmacology 5:543-549, 2005] 참조). ADC는 최소 독성과 함께 최대 효능이 달성될 수 있는, 약물 모이어티의 표적화 전달을 허용한다. 더 많은 ADC가 유망한 임상 결과를 나타냄에 따라, 암 요법을 위한 새로운 치료제를 개발할 필요성이 증가한다.
본 발명은 화학식 Ab-(L-(D)m)n의 항체 약물 접합체 또는 그의 제약상 허용되는 염을 제공하고, 여기서 Ab는 인간 FGFR2 및 FGFR4 둘 다에 특이적으로 결합하는 항체 또는 그의 항원 결합 단편이고; L은 링커이고; D는 약물 모이어티이고; m은 1 내지 8의 정수이고; n은 1 내지 10의 정수이다. 일부 실시양태에서, m은 1이다. 일부 실시양태에서, n은 3 또는 4이다. 구체적 실시양태에서, m은 1이고, n은 3 또는 4이다.
본 발명은 인간 FGFR2 및 인간 FGFR4에 특이적으로 결합하는 항체 또는 그의 항원 결합 단편을 제공한다. 일부 실시양태에서, 본원에 기재된 항체 또는 항원 결합 단편은 인간 FGFR4 및 모든 이소형의 인간 FGFR2에 특이적으로 결합한다. 일부 실시양태에서, 본원에 기재된 항체 또는 항원 결합 단편은 서열 137의 아미노산 잔기 176 (Lys) 및 210 (Arg)을 포함하는 인간 FGFR2 상의 에피토프에 특이적으로 결합한다. 일부 실시양태에서, 본원에 기재된 항체 또는 항원 결합 단편은 서열 137의 아미노산 잔기 173 (Asn), 174 (Thr), 175 (Val), 176 (Lys), 178 (Arg), 208 (Lys), 209 (Val), 210 (Arg), 212 (Gln), 213 (His), 217 (Ile) 및 219 (Glu)에 특이적으로 결합한다. 본 발명은 추가로 본원에 기재된 항체 또는 항원 결합 단편을 포함하는 항체 약물 접합체를 제공한다.
일부 실시양태에서, 본원에 기재된 항체 또는 항원 결합 단편은 서열 136 또는 서열 141를 포함하거나 이들로 이루어진 인간 FGFR2의 에피토프에 특이적으로 결합한다. 본 발명은 추가로 본원에 기재된 항체 또는 항원 결합 단편을 포함하는 항체 약물 접합체를 제공한다.
본 발명의 항체, 항원 결합 단편 및 항체 약물 접합체는 또한 인간 FGFR4에 특이적으로 결합한다. 일부 실시양태에서, 이들은 인간 FGFR4의 D1 및 D2 도메인에 특이적으로 결합한다. 일부 실시양태에서, 이들은 인간 FGFR4의 D1 또는 D2 도메인에 특이적으로 결합한다. 일부 실시양태에서, 본원에 기재된 항체 또는 항원 결합 단편은 서열 142의 아미노산 잔기 169 (Lys) 및 203 (Arg)을 포함하는 인간 FGFR4 상의 에피토프에 특이적으로 결합한다. 일부 실시양태에서, 본원에 기재된 항체 또는 항원 결합 단편은 서열 142의 아미노산 잔기 150 (Thr), 151 (His), 154 (Arg), 157 (Lys), 160 (His), 166 (Asn), 167 (Thr), 168 (Val), 169 (Lys), 171 (Arg), 173 (Pro), 174 (Ala), 201 (Arg), 202 (Leu), 203 (Arg), 204 (His), 205 (Gln), 206 (His), 207 (Trp), 210 (Val) 및 212 (Glu)에 특이적으로 결합한다. 일부 실시양태에서, 본원에 기재된 항체 또는 항원 결합 단편은 서열 132 또는 서열 133을 포함하거나 이들로 이루어진 인간 FGFR4의 에피토프에 특이적으로 결합한다. 본 발명은 추가로 본원에 기재된 항체 또는 항원 결합 단편을 포함하는 항체 약물 접합체를 제공한다.
일부 실시양태에서, 본원에 기재된 항체 또는 항원 결합 단편은 서열 137의 아미노산 잔기 176 (Lys) 및 210 (Arg)을 포함하는 인간 FGFR2의 에피토프 및 서열 142의 아미노산 잔기 169 (Lys) 및 203 (Arg)을 포함하는 인간 FGFR4 상의 에피토프에 특이적으로 결합한다.
일부 실시양태에서, 본원에 기재된 항체 또는 항원 결합 단편은 서열 137의 아미노산 160-189 및/또는 서열 137의 아미노산 198-216을 포함하는 에피토프에 특이적으로 결합한다. 일부 실시양태에서, 본원에 기재된 항체 또는 항원 결합 단편은 서열 142의 아미노산 150-174 및/또는 서열 142의 아미노산 201-212를 포함하는 에피토프에 특이적으로 결합한다. 일부 실시양태에서, 본원에 기재된 항체 또는 항원 결합 단편은 서열 137의 아미노산 160-189 및/또는 서열 137의 아미노산 198-216을 포함하는 에피토프 및 서열 142의 아미노산 150-174 및/또는 서열 142의 아미노산 201-212를 포함하는 제2 에피토프에 특이적으로 결합한다.
일부 실시양태에서, 본 발명은 표 1에 기재된 항체, 그의 항원 결합 단편, 및 이러한 항체 또는 항원 결합 단편을 포함하는 항체 약물 접합체를 제공한다. 일부 실시양태에서, 본 발명은 (a) 서열 1의 VH CDR1, (b) 서열 2의 VH CDR2, 및 (c) 서열 3의 VH CDR3을 포함하는 중쇄 가변 영역을 포함하며, 여기서 CDR은 카바트(Kabat) 정의에 따라 규정된 것인 항체 및 항원 결합 단편을 제공한다. 일부 실시양태에서, 본 발명의 항체 또는 항원 결합 단편은 (a) 서열 1의 VH CDR1, (b) 서열 2의 VH CDR2, 및 (c) 서열 3의 VH CDR3을 포함하는 중쇄 가변 영역; 및 (a) 서열 11의 VL CDR1, (b) 서열 12의 VL CDR2, 및 (c) 서열 13의 VL CDR3을 포함하는 경쇄 가변 영역을 포함하며, 여기서 CDR은 카바트 정의에 따라 규정된다. 본 발명은 추가로 이러한 항체 또는 항원 결합 단편을 포함하는 항체 약물 접합체를 제공한다.
일부 실시양태에서, 본원에 기재된 항체 또는 항원 결합 단편은 서열 7의 VH 영역 및 서열 17의 VL 영역을 포함한다. 일부 실시양태에서, 본원에 기재된 항체는 서열 9의 중쇄 및 서열 19의 경쇄로 구성된다. 본 발명은 또한 상기 항체 또는 그의 항원 결합 단편을 포함하는 항체 약물 접합체를 제공한다.
일부 실시양태에서, 본원에 기재된 항체 또는 항원 결합 단편은 인간 FGFR2 및 FGFR4에의 결합에 대해 서열 9의 중쇄 및 서열 19의 경쇄로 이루어진 항체와 교차 경쟁하는 항체 또는 항원 결합 단편이다. 본 발명은 또한 이러한 항체 또는 항원 결합 단편을 포함하는 항체 약물 접합체를 제공한다.
일부 실시양태에서, 본원에 기재된 항체 또는 항원 결합 단편은 서열 9의 중쇄 및 서열 19의 경쇄로 이루어진 항체와 비교하여 증진된 ADCC 활성을 갖는다. 일부 실시양태에서, 본원에 기재된 항체 또는 항원 결합 단편은 서열 9의 중쇄 및 서열 19의 경쇄로 이루어진 항체와 비교하여 증진된 ADCC 활성을 갖지 않는다. 본 발명은 또한 이러한 항체 또는 항원 결합 단편을 포함하는 항체 약물 접합체를 제공한다.
일부 실시양태에서, 본원에 기재된 항체는 인간 또는 인간화 항체이다. 일부 실시양태에서, 본원에 기재된 항체는 모노클로날 항체이다. 일부 실시양태에서, 본원에 기재된 항체는 모노클로날 인간 또는 인간화 항체이다.
일부 실시양태에서, 본 발명은 본원에 기재된 항체 또는 항원 결합 단편 및 약물 모이어티를 포함하는 항체 약물 접합체를 제공하며, 여기서 약물 모이어티는 링커를 통해 항체 또는 항원 결합 단편에 연결되고, 여기서 상기 링커는 절단가능한 링커, 비-절단가능한 링커, 친수성 링커, 전구하전된 링커 및 디카르복실산계 링커로 이루어진 군으로부터 선택된다. 일부 실시양태에서, 링커는 N-숙신이미딜-3-(2-피리딜디티오)프로피오네이트 (SPDP), N-숙신이미딜 4-(2-피리딜디티오)펜타노에이트 (SPP), N-숙신이미딜 4-(2-피리딜디티오)부타노에이트 (SPDB), N-숙신이미딜-4-(2-피리딜디티오)-2-술포-부타노에이트 (술포-SPDB) , N-숙신이미딜 아이오도아세테이트 (SIA), N-숙신이미딜(4-아이오도아세틸)아미노벤조에이트 (SIAB), 말레이미드 PEG NHS, N-숙신이미딜 4-(말레이미도메틸) 시클로헥산카르복실레이트 (SMCC), N-술포숙신이미딜 4-(말레이미도메틸) 시클로헥산카르복실레이트 (술포-SMCC) 또는 2,5-디옥소피롤리딘-1-일 17-(2,5-디옥소-2,5-디히드로-1H-피롤-1-일)-5,8,11,14-테트라옥소-4,7,10,13-테트라아자헵타데칸-1-오에이트 (CX1-1)로 이루어진 군으로부터 선택된 가교 시약으로부터 유래된다. 구체적 실시양태에서, 링커는 가교 시약 N-숙신이미딜 4-(말레이미도메틸) 시클로헥산카르복실레이트 (SMCC)로부터 유래된다.
일부 실시양태에서, 본 발명은 본원에 기재된 항체 또는 항원 결합 단편, 및 약물 모이어티를 포함하는 항체 약물 접합체를 제공하며, 여기서 상기 약물 모이어티는 V-ATPase 억제제, 아폽토시스촉진제, Bcl2 억제제, MCL1 억제제, HSP90 억제제, IAP 억제제, mTor 억제제, 미세관 안정화제, 미세관 탈안정화제, 아우리스타틴, 돌라스타틴, 메이탄시노이드, MetAP (메티오닌 아미노펩티다제), 단백질 CRM1의 핵 유출의 억제제, DPPIV 억제제, 프로테아솜 억제제, 미토콘드리아에서의 포스포릴 전달 반응의 억제제, 단백질 합성 억제제, 키나제 억제제, CDK2 억제제, CDK9 억제제, 키네신 억제제, HDAC 억제제, DNA 손상 작용제, DNA 알킬화제, DNA 삽입제, DNA 작은 홈 결합제 및 DHFR 억제제로 이루어진 군으로부터 선택된다. 구체적 실시양태에서, 본 발명의 항체 약물 접합체의 약물 모이어티는 메이탄시노이드이다. 또 다른 구체적 실시양태에서, 본 발명의 항체 약물 접합체의 약물 모이어티는 N(2')-데아세틸-N(2')-(3-메르캅토-1-옥소프로필)-메이탄신 (DM1) 또는 N(2')-데아세틸-N2-(4-메르캅토-4-메틸-1-옥소펜틸)-메이탄신 (DM4)이다.
한 실시양태에서, 본 발명은 하기 화학식을 갖는 항체 약물 접합체 또는 그의 제약상 허용되는 염을 제공한다.

상기 식에서, Ab는 서열 1의 중쇄 CDR1, 서열 2의 중쇄 CDR2, 서열 3의 중쇄 CDR3, 및 서열 11의 경쇄 CDR1, 서열 12의 경쇄 CDR2, 서열 13의 경쇄 CDR3을 포함하며, 여기서 CDR은 카바트 정의에 따라 규정된 것인 항체 또는 그의 항원 결합 단편이고; n은 1 내지 10이다. 구체적 실시양태에서, n은 3 또는 4이다. 한 실시양태에서, Ab는 서열 7의 VH 영역 및 서열 17의 VL 영역을 포함하는 항체이다. 또 다른 실시양태에서, Ab는 서열 9의 중쇄 및 서열 19의 경쇄로 이루어진 항체이다.
본 발명은 또한 본원에 기재된 항체 약물 접합체 및 제약상 허용되는 담체를 포함하는 제약 조성물을 제공한다. 일부 실시양태에서, 본 발명의 제약 조성물은 동결건조물로서 제조된다. 일부 실시양태에서, 동결건조물은 본원에 기재된 항체 약물 접합체, 숙신산나트륨 및 폴리소르베이트 20을 포함한다.
본 발명은 FGFR2 양성 또는 FGFR4 양성 암의 치료를 필요로 하는 환자에게 본원에 기재된 항체 약물 접합체 또는 제약 조성물을 투여하는 것을 포함하는, 상기 환자에서 FGFR2 양성 또는 FGFR4 양성 암을 치료하는 방법을 제공한다. 일부 실시양태에서, 암은 위암, 유방암, 횡문근육종, 간암, 부신암, 폐암, 식도암, 결장암 및 자궁내막암으로 이루어진 군으로부터 선택된다. 특정 실시양태에서, 암은 폐포 횡문근육종 및 배아성 횡문근육종으로부터 선택된다. 일부 실시양태에서, 본원에 기재된 치료 방법은 상기 환자에게 티로신 키나제 억제제, IAP 억제제, Bcl2 억제제, MCL1 억제제 또는 또 다른 FGFR2 억제제를 투여하는 것을 추가로 포함한다. 구체적 실시양태에서, 치료 방법은 이를 필요로 하는 환자에게 본원에 기재된 항체 약물 접합체를 3-(2,6-디클로로-3,5-디메톡시-페닐)-1-{6-[4-(4-에틸-피페라진-1-일)-페닐아미노]-피리미딘-4-일}-1-메틸-우레아 또는 그의 제약상 허용되는 염, 예를 들어 그의 포스페이트 염과 조합하여 투여하는 것을 포함한다. 특정 측면에서 본 발명은 또한 티로신 키나제 억제제, 예컨대 이에 제한되지는 않지만, EGFR 억제제, Her2 억제제, Her3 억제제, IGFR 억제제 및 Met 억제제에 내성인 암을 치료하는 방법을 제공한다.
본 발명은 추가로 의약으로 사용하기 위한 본원에 기재된 항체 약물 접합체를 제공한다. 본 발명은 FGFR2 양성 또는 FGFR4 양성 암의 치료에 사용하기 위한 항체 약물 접합체 또는 제약 조성물을 제공한다. 본 발명은 내성 암, 예를 들어, 다른 티로신 키나제 억제제, EGFR 억제제, Her2 억제제, Her3 억제제, IGFR 억제제 및 Met 억제제에 내성인 암의 치료에 사용하기 위한 항체 약물 접합체 또는 제약 조성물을 제공한다.
일부 실시양태에서, 본원에 기재된 항체 또는 항원 결합 단편은 단일 쇄 항체 (scFv)이다.
본 발명은 또한 본원에 기재된 항체 또는 항원 결합 단편을 코딩하는 핵산을 제공한다. 일부 실시양태에서, 본 발명은 표 1에서 기재된 바와 같은 항체 또는 항원 결합 단편을 코딩하는 핵산을 제공한다. 본 발명은 본원에 기재된 핵산을 포함하는 벡터 및 이러한 벡터를 포함하는 숙주 세포를 추가로 제공한다.
본 발명은 본원에 기재된 숙주 세포를 배양하고 항체를 배양물로부터 회수하는 것을 포함하는, 항체 또는 항원 결합 단편을 생산하는 방법을 제공한다.
한 실시양태에서, 본 발명은 (a) SMCC를 약물 모이어티 DM-1에 화학적으로 연결하고; (b) 상기 링커-약물을 세포 배양물로부터 회수된 항체에 접합시키고; (c) 항체 약물 접합체를 정제하는 것을 포함하는, 상기 방법에 따라 제조된 항-FGFR2 및 FGFR4 항체 약물 접합체를 제조하는 방법을 제공한다. 일부 실시양태에서, 항체 약물 접합체는 UV 분광광도계로 측정 시에 약 3.5의 평균 DAR을 갖는다.
본 발명은 또한 본원에 기재된 항체 또는 항원 결합 단편, 또는 표지된 본원에 기재된 항체 약물 접합체를 포함하는 진단 시약을 제공한다. 일부 실시양태에서, 표지는 방사성표지, 형광단, 발색단, 영상화제 및 금속 이온으로 이루어진 군으로부터 선택된다.
정의
달리 언급되지 않는 한, 본원에 사용된 하기 용어 및 어구는 하기 의미를 갖는 것으로 의도된다.
용어 "알킬"은 명시된 개수의 탄소 원자를 갖는 1가 포화 탄화수소 쇄를 지칭한다. 예를 들어, C1-6 알킬은 1 내지 6개의 탄소 원자를 갖는 알킬 기를 지칭한다. 알킬 기는 직쇄형 또는 분지형일 수 있다. 대표적인 분지형 알킬 기는 1, 2 또는 3개의 분지를 갖는다. 알킬 기의 예는 메틸, 에틸, 프로필 (n-프로필 및 이소프로필), 부틸 (n-부틸, 이소부틸, sec-부틸 및 t-부틸), 펜틸 (n-펜틸, 이소펜틸 및 네오펜틸) 및 헥실을 포함하나, 이에 제한되지는 않는다.
본원에 사용된 용어 "항체"는 상응하는 항원에, 비-공유결합으로, 가역적으로, 및 특이적 방식으로 결합할 수 있는 이뮤노글로불린 패밀리의 폴리펩티드를 지칭한다. 예를 들어, 자연 발생 IgG 항체는 디술피드 결합에 의해 상호-연결된 적어도 2개의 중쇄 (H) 및 2개의 경쇄 (L)를 포함하는 사량체이다. 각각의 중쇄는 중쇄 가변 영역 (본원에서 VH로 약칭됨) 및 중쇄 불변 영역으로 구성된다. 중쇄 불변 영역은 3개의 도메인 CH1, CH2 및 CH3으로 구성된다. 각각의 경쇄는 경쇄 가변 영역 (본원에서 VL로 약칭됨) 및 경쇄 불변 영역으로 구성된다. 경쇄 불변 영역은 1개의 도메인 CL로 구성된다. VH 및 VL 영역은 프레임워크 영역 (FR)으로 불리는 보다 보존된 영역이 산재되어 있는 상보성 결정 영역 (CDR)으로 불리는 초가변성 영역으로 추가로 세분될 수 있다. 각각의 VH 및 VL은 아미노-말단에서 카르복시-말단까지 하기 순서로 정렬된 3개의 CDR 및 4개의 FR로 구성된다: FR1, CDR1, FR2, CDR2, FR3, CDR3 및 FR4. 중쇄 및 경쇄의 가변 영역은 항원과 상호작용하는 결합 도메인을 함유한다. 항체의 불변 영역은 면역계의 다양한 세포 (예를 들어, 이펙터 세포) 및 전형적 보체계의 제1 성분 (Clq)을 비롯한 숙주 조직 또는 인자에 대한 이뮤노글로불린의 결합을 매개할 수 있다.
용어 "항체"는 모노클로날 항체, 인간 항체, 인간화 항체, 키메라 항체 및 항-이디오타입 (항-Id) 항체 (예를 들어, 본 발명의 항체에 대한 항-Id 항체를 포함함)를 포함하나, 이에 제한되지는 않는다. 항체는 임의의 이소형/부류 (예를 들어, IgG, IgE, IgM, IgD, IgA 및 IgY), 또는 하위부류 (예를 들어, IgG1, IgG2, IgG3, IgG4, IgA1 및 IgA2)일 수 있다.
"상보성-결정 도메인" 또는 "상보성-결정 영역 ("CDR")은 상호교환적으로 VL 및 VH의 초가변 영역을 지칭한다. CDR은 항체 쇄의 표적 단백질-결합 부위이며, 이러한 표적 단백질에 대한 특이성을 보유한다. 각각의 인간 VL 또는 VH에는 3개의 CDR (N-말단으로부터 순차적으로 넘버링된 CDR1-3)이 존재하고, 이들은 가변 도메인의 약 15-20%를 구성한다. CDR은 표적 단백질의 에피토프에 대해 구조적으로 상보적이며, 따라서 결합 특이성의 직접적인 원인이 된다. VL 또는 VH의 나머지 스트레치(stretch), 소위 프레임워크 구역은 아미노산 서열의 보다 적은 변형을 보인다 (문헌 [Kuby, Immunology, 4th ed., Chapter 4. W.H. Freeman & Co., New York, 2000]).
CDR 및 프레임워크 영역의 위치는 관련 기술분야의 널리 공지된 다양한 정의, 예를 들어 카바트, 코티아(Chothia), 국제 이뮤노제네틱스(ImMunoGeneTics) 데이터베이스 (IMGT) (월드와이드 웹(worldwide web) 상의 imgt.cines.fr/에서) 및 AbM을 이용하여 결정될 수 있다 (예를 들어, 문헌 [Johnson et al., Nucleic Acids Res., 29:205-206 (2001); Chothia and Lesk, J. Mol. Biol., 196:901-917 (1987); Chothia et al., Nature, 342:877-883 (1989); Chothia et al., J. Mol. Biol., 227:799-817 (1992); Al-Lazikani et al., J.Mol.Biol., 273:927-748 (1997)]). 항원 결합 부위의 정의는 또한 하기에 기재되어 있다: 문헌 [Ruiz et al., Nucleic Acids Res., 28:219-221 (2000); 및 Lefranc, M.P., Nucleic Acids Res., 29:207-209 (2001); MacCallum et al., J. Mol. Biol., 262:732-745 (1996); 및 Martin et al., Proc. Natl. Acad. Sci. USA, 86:9268-9272 (1989); Martin et al., Methods Enzymol., 203:121-153 (1991); 및 Rees et al., In Sternberg M.J.E. (ed.), Protein Structure Prediction, Oxford University Press, Oxford, 141-172 (1996)].
경쇄 및 중쇄 둘 다는 구조적 및 기능적 상동성 영역으로 나눌 수 있다. 용어 "불변" 및 "가변"은 기능적으로 사용된다. 이와 관련하여, 경쇄 (VL) 및 중쇄 (VH) 부분 둘 다의 가변 도메인이 항원 인식 및 특이성을 결정하는 것으로 이해될 것이다. 이와 반대로, 경쇄의 불변 도메인 (CL) 및 중쇄의 불변 도메인 (CH1, CH2 또는 CH3)은 중요한 생물학적 특성, 예컨대 분비, 태반 경유 이동성, Fc 수용체 결합, 보체 결합 등을 부여한다. 관례적으로, 불변 영역 도메인의 넘버링은 항체의 항원 결합 부위 또는 아미노-말단에서 더욱 멀어질 경우에 증가한다. N-말단은 가변 영역이고, C-말단에 불변 영역이 있고; CH3 및 CL 도메인은 실제로 각각 중쇄 및 경쇄의 카르복시-말단 도메인을 구성한다.
본원에 사용된 용어 "항원 결합 단편"은 항원의 에피토프와 (예를 들어, 결합, 입체 장애, 안정화/탈안정화, 공간 분포에 의해) 특이적으로 상호작용하는 능력을 보유하는 항체의 하나 이상의 부분을 지칭한다. 결합 단편의 예는 단일 쇄 Fv (scFv), 낙타류 항체, 디술피드-연결된 Fv (sdFv), Fab 단편, F(ab') 단편, VL, VH, CL 및 CH1 도메인으로 이루어진 1가 단편; 힌지(hinge) 영역에서 디술피드 가교에 의해 연결된 2개의 Fab 단편을 포함하는 2가 단편인 F(ab)2 단편; VH 및 CH1 도메인으로 이루어진 Fd 단편; 항체의 1개의 아암의 VL 및 VH 도메인으로 이루어진 Fv 단편; VH 도메인으로 이루어진 dAb 단편 (문헌 [Ward et al., Nature 341:544-546, 1989]); 및 단리된 상보성 결정 영역 (CDR), 또는 항체의 기타 에피토프-결합 단편을 포함하나, 이에 제한되지는 않는다.
또한, Fv 단편의 2개의 도메인인 VL 및 VH가 별도의 유전자에 의해 코딩되지만, 이들은, VL 및 VH 영역이 쌍을 이루어 1가 분자를 형성하는 단일 단백질 쇄 (단일 쇄 Fv ("scFv")로 공지됨)로 만들어지도록 할 수 있는 합성 링커에 의해, 재조합 방법을 사용하여 연결될 수 있다 (예를 들어, 문헌 [Bird et al., Science 242:423-426, 1988; 및 Huston et al., Proc. Natl. Acad. Sci. 85:5879-5883, 1988] 참조). 이러한 단일 쇄 항체는 또한 용어 "항원 결합 단편" 내에 포함되도록 의도된다. 상기 항원 결합 단편은 관련 기술분야의 통상의 기술자에게 공지된 통상의 기술을 이용하여 획득되고, 단편은 무손상 항체와 동일한 방식으로 유용성에 대해 스크리닝된다.
항원 결합 단편이 단일 도메인 항체, 맥시바디, 미니바디, 나노바디, 인트라바디, 디아바디, 트리아바디, 테트라바디, v-NAR 및 비스-scFv 내로 또한 혼입될 수 있다 (예를 들어, 문헌 [Hollinger and Hudson, Nature Biotechnology 23:1126-1136, 2005] 참조). 항원 결합 단편이 피브로넥틴 제III형 (Fn3)과 같은 폴리펩티드를 기재로 하는 스캐폴드 내로 그라프팅될 수 있다 (피브로넥틴 폴리펩티드 모노바디가 기재되어 있는 미국 특허 번호 6,703,199 참조).
항원 결합 단편은 한 쌍의 직렬 Fv 절편 (VH-CH1-VH-CH1)을 포함하는 단일 쇄 분자 내로 혼입될 수 있고, 이는 상보적 경쇄 폴리펩티드와 함께 한 쌍의 항원 결합 영역을 형성한다 (문헌 [Zapata et al., Protein Eng. 8:1057-1062, 1995]; 및 미국 특허 번호 5,641,870 참조).
본원에 사용된 용어 "모노클로날 항체" 또는 "모노클로날 항체 조성물"은 동일한 아미노산 서열을 실질적으로 지니거나 또는 동일한 유전자원으로부터 유래된, 항체 및 항체 단편을 비롯한 폴리펩티드를 지칭한다. 또한, 이 용어는 단일 분자 조성의 항체 분자의 제제를 의미한다. 모노클로날 항체 조성물은 특정한 에피토프에 대해 단일 결합 특이성 및 친화도를 나타낸다.
본원에 사용된 용어 "인간 항체"는 프레임워크 및 CDR 영역이 둘 다 인간 기원의 서열로부터 유래된 것인 가변 영역을 갖는 항체를 포함한다. 또한, 항체가 불변 영역을 함유하면, 불변 영역은 또한 이러한 인간 서열, 예를 들어 인간 배선 서열, 또는 인간 배선 서열의 돌연변이된 형태, 또는 인간 프레임워크 서열 분석으로부터 유래된 컨센서스 프레임워크 서열을 함유하는 항체로부터 유래된다 (예를 들어, 문헌 [Knappik et al., J. Mol. Biol. 296:57-86, 2000]에 기재된 바와 같음).
본 발명의 인간 항체는 인간 서열에 의해 코딩되지 않는 아미노산 잔기 (예를 들어, 시험관내 무작위 또는 부위-특이적 돌연변이유발 또는 생체내 체세포 돌연변이에 의해 도입된 돌연변이, 또는 안정성 또는 제조를 용이하게 하기 위한 보존적 치환)를 포함할 수 있다.
본원에 사용된 용어 "친화도"는 단일 항원 부위에서 항체와 항원 사이의 상호작용의 강도를 지칭한다. 각각의 항원 부위 내에서, 항체 "아암"의 가변 영역은 다수의 부위에서 항원과 약한 비-공유 결합력을 통해 상호작용하고; 상호작용이 더 많을수록 친화도가 더 강해진다.
용어 "단리된 항체"는 항원 특이성이 상이한 다른 항체가 실질적으로 없는 항체를 지칭한다. 그러나, 하나의 항원에 특이적으로 결합하는 단리된 항체는 다른 항원에 대한 교차-반응성을 가질 수 있다. 더욱이, 단리된 항체는 다른 세포 물질 및/또는 화학물질을 실질적으로 함유하지 않을 수 있다.
용어 "상응하는 인간 배선 서열"은, 인간 배선 이뮤노글로불린 가변 영역 서열에 의해 코딩되는 모든 다른 공지된 가변 영역 아미노산 서열과 비교하여, 참조 가변 영역 아미노산 서열 또는 하위서열과 가장 높게 결정된 아미노산 서열 동일성을 공유하는 인간 가변 영역 아미노산 서열 또는 하위서열을 코딩하는 핵산 서열을 지칭한다. 상응하는 인간 배선 서열은 또한, 모든 다른 평가된 가변 영역 아미노산 서열과 비교하여, 참조 가변 영역 아미노산 서열 또는 하위서열과 가장 높은 아미노산 서열 동일성을 갖는 인간 가변 영역 아미노산 서열 또는 하위서열을 지칭할 수 있다. 상응하는 인간 배선 서열은 프레임워크 영역 단독, 상보성 결정 영역 단독, 프레임워크 및 상보성 결정 영역, 가변 절편 (상기 정의된 바와 같음), 또는 가변 영역을 포함하는 서열 또는 하위서열의 다른 조합일 수 있다. 서열 동일성은 본원에 기재된 방법을 이용하여, 예를 들어 BLAST, ALIGN, 또는 관련 기술분야에 공지된 또 다른 정렬 알고리즘을 이용하여 2개의 서열을 정렬시켜 결정될 수 있다. 상응하는 인간 배선 핵산 또는 아미노산 서열은 참조 가변 영역 핵산 또는 아미노산 서열과 적어도 약 90%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 100% 서열 동일성을 가질 수 있다. 상응하는 인간 배선 서열은, 예를 들어 공개적으로 이용가능한 국제 이뮤노제네틱스 데이터베이스 (IMGT) (월드와이드 웹 상의 imgt.cines.fr/에서) 및 V-베이스 (월드와이드 웹 상의 vbase.mrc-cpe.cam.ac.uk)를 통해 결정될 수 있다.
항원 (예를 들어, 단백질)과 항체, 항체 단편 또는 항체-유래 결합제 사이의 상호작용을 기재하는 문맥에 사용된 경우에, 어구 "특이적으로 결합하다" 또는 "선택적으로 결합하다"는, 예를 들어 생물학적 샘플, 예를 들어 혈액, 혈청, 혈장 또는 조직 샘플 중에서 단백질 및 다른 생물제제의 이종 집단 내 항원의 존재를 결정하는 결합 반응을 지칭한다. 따라서, 특정의 지정된 면역검정 조건 하에, 특정한 결합 특이성을 갖는 항체 또는 결합제는 특정한 항원에 배경의 적어도 2배로 결합하고, 샘플에 존재하는 다른 항원에 유의한 양으로 실질적으로 결합하지 않는다. 한 실시양태에서, 지정된 면역검정 조건 하에, 특정한 결합 특이성을 갖는 항체 또는 결합제는 특정한 항원에 배경의 적어도 10배로 결합하고, 샘플에 존재하는 다른 항원에 유의한 양으로 실질적으로 결합하지 않는다. 이러한 조건 하에서 항체 또는 결합제에 대한 특이적 결합은, 특정한 단백질에 대한 그의 특이성에 대해 항체 또는 결합제를 선택하는 것을 필요로 할 수 있다. 바람직하거나 적절한 바와 같이, 이러한 선택은 다른 종 (예를 들어, 마우스 또는 래트) 또는 다른 하위유형으로부터의 분자와 교차-반응하는 항체를 제외함으로써 달성될 수 있다. 대안적으로, 일부 실시양태에서, 항체 또는 항체 단편은 특정의 바람직한 분자와 교차-반응하는 것으로 선택된다.
용어 "특이적으로 결합하다"는, 에피토프 및 항체, 항체 단편 또는 항체-유래 결합제 사이의 상호작용을 기재하는 문맥에 사용되는 경우에, 항체 또는 그의 항원 결합 단편이 에피토프가 선형이든지 또는 입체형태이든지 그의 에피토프를 발견하고 이와 상호작용 (예를 들어, 결합)하는 것을 지칭한다. 용어 "에피토프"는 본 발명의 항체 또는 항원 결합 단편이 특이적으로 결합하는 항원 상의 부위를 지칭한다. 에피토프는 단백질의 3차 폴딩에 의해 병렬된 인접 아미노산 또는 비인접 아미노산 둘 다로부터 형성될 수 있다. 인접 아미노산으로부터 형성된 에피토프는 전형적으로 변성 용매에 대한 노출 시에 유지되는 반면, 3차 폴딩에 의해 형성된 에피토프는 전형적으로 변성 용매로의 처리 시에 손실된다. 에피토프는 전형적으로 적어도 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14 또는 15개의 아미노산을 특유한 공간 입체형태로 포함한다. 에피토프의 공간 형상을 결정하는 방법은 관련 기술분야의 기술, 예를 들어 X선 결정학 및 2-차원 핵 자기 공명을 포함한다 (예를 들어, 문헌 [Epitope Mapping Protocols in Methods in Molecular Biology, Vol. 66, G. E. Morris, Ed. (1996)] 참조).
다양한 면역검정 포맷을 이용하여 특정한 단백질과 특이적으로 면역반응성인 항체를 선택할 수 있다. 예를 들어, 단백질과 특이적으로 면역반응성인 항체를 선택하기 위해 고체-상 ELISA 면역검정이 통상적으로 이용된다 (특이적 면역반응성을 결정하는데 이용될 수 있는 면역검정 포맷 및 조건의 기재에 대해, 예를 들어 문헌 [Harlow & Lane, Using Antibodies, A Laboratory Manual (1998)] 참조). 전형적으로, 특이적 또는 선택적 결합 반응은 배경 신호에 대해 적어도 2배, 보다 전형적으로는 배경 신호에 대해 적어도 10 내지 100배의 신호를 생성할 것이다.
용어 "평형 해리 상수 (KD, M)"는 해리율 상수 (kd, 시간-1)를 회합률 상수 (ka, 시간-1, M-1)로 나눈 것을 지칭한다. 평형 해리 상수는 관련 기술분야에서 임의의 공지된 방법을 이용하여 측정될 수 있다. 본 발명의 항체는 일반적으로 약 10-7 또는 10-8 M 미만, 예를 들어, 약 10-9 M 또는 10-10 M 미만, 일부 실시양태에서, 약 10-11 M, 10-12 M 또는 10-13 M 미만의 평형 해리 상수를 가질 수 있다.
용어 "생체이용률"은 환자에게 투여된 소정량의 약물의 전신 이용률 (즉, 혈액/혈장 수준)을 지칭한다. 생체이용률은 투여된 투여 형태로부터 전신 순환계에 도달하는 약물의 시간 (속도) 및 총량 (정도) 둘 다의 측정치를 나타내는 절대적인 용어이다.
본원에 사용된 어구 "본질적으로 이루어진"은 방법 또는 조성물에 포함되는 활성 제약 작용제, 뿐만 아니라 방법 또는 조성물의 의도된 목적을 위한 불활성의 임의의 부형제의 속 또는 종을 지칭한다. 일부 실시양태에서, 어구 "본질적으로 이루어진"은 본 발명의 항체 약물 접합체 이외의 하나 이상의 추가의 활성제의 함유물을 분명히 제외한다. 일부 실시양태에서, 어구 "본질적으로 이루어진"은 본 발명의 항체 약물 접합체 및 제2 공투여된 작용제 이외의 하나 이상의 추가의 활성제의 함유물을 분명히 제외한다.
용어 "아미노산"은 자연 발생, 합성 및 비천연 아미노산, 뿐만 아니라 자연 발생 아미노산과 유사한 방식으로 기능하는 아미노산 유사체 및 아미노산 모방체를 지칭한다. 자연 발생 아미노산은 유전자 코드에 의해 코딩되는 것, 뿐만 아니라 이후에 변형된 아미노산, 예를 들어 히드록시프롤린, γ-카르복시글루타메이트 및 O-포스포세린이다. 아미노산 유사체는 자연 발생 아미노산과 동일한 기본 화학 구조, 즉, 수소, 카르복실 기, 아미노 기 및 R 기에 결합된 α-탄소를 갖는 화합물, 예를 들어 호모세린, 노르류신, 메티오닌 술폭시드, 메티오닌 메틸 술포늄을 지칭한다. 이러한 유사체는 변형된 R 기를 갖거나 (예를 들어, 노르류신) 또는 변형된 펩티드 백본을 갖지만, 자연 발생 아미노산과 동일한 기본 화학 구조를 보유한다. 아미노산 모방체는 아미노산의 일반 화학 구조와 상이한 구조를 갖지만, 자연 발생 아미노산과 유사한 방식으로 기능하는 화학적 화합물을 지칭한다.
용어 "보존적으로 변형된 변이체"는 아미노산 및 핵산 서열 둘 다에 적용된다. 특정한 핵산 서열과 관련하여, 보존적으로 변형된 변이체는 동일하거나 또는 본질적으로 동일한 아미노산 서열을 코딩하는 핵산을 지칭하거나, 또는 핵산이 아미노산 서열을 코딩하지 않는 경우에는 본질적으로 동일한 서열을 지칭한다. 유전자 코드의 축중성 때문에, 다수의 기능적으로 동일한 핵산이 임의의 주어진 단백질을 코딩한다. 예를 들어, 코돈 GCA, GCC, GCG 및 GCU는 모두 아미노산 알라닌을 코딩한다. 따라서, 코돈에 의해 알라닌이 지정되는 모든 위치에서, 코돈은 코딩되는 폴리펩티드를 변경하지 않으면서, 기재된 상응하는 코돈 중 임의의 것으로 변경될 수 있다. 이러한 핵산 변이는 보존적으로 변형된 변이의 일종인 "침묵 변이"이다. 폴리펩티드를 코딩하는 본원의 모든 핵산 서열은 또한 핵산의 모든 가능한 침묵 변이를 기재한다. 통상의 기술자는 핵산 내의 각각의 코돈 (통상적으로 메티오닌에 대한 유일한 코돈인 AUG, 및 통상적으로 트립토판에 대한 유일한 코돈인 TGG 제외)이 기능적으로 동일한 분자를 생성하도록 변형될 수 있음을 인식할 것이다. 따라서, 폴리펩티드를 코딩하는 핵산의 각각의 침묵 변이는 각각의 기재된 서열에 내포된다.
폴리펩티드 서열의 경우에, "보존적으로 변형된 변이체"는 아미노산의 화학적으로 유사한 아미노산으로의 치환을 생성하는, 폴리펩티드 서열에 대한 개개의 치환, 결실 또는 부가를 포함한다. 기능적으로 유사한 아미노산을 제공하는 보존적 치환 표는 관련 기술분야에 널리 공지되어 있다. 이러한 보존적으로 변형된 변이체는 본 발명의 다형성 변이체, 종간 상동체 및 대립유전자에 부가적인 것이고 이들을 배제하지 않는다. 하기 8개의 군은 서로에 대해 보존적 치환인 아미노산을 함유한다: 1) 알라닌 (A), 글리신 (G); 2) 아스파르트산 (D), 글루탐산 (E); 3) 아스파라긴 (N), 글루타민 (Q); 4) 아르기닌 (R), 리신 (K); 5) 이소류신 (I), 류신 (L), 메티오닌 (M), 발린 (V); 6) 페닐알라닌 (F), 티로신 (Y), 트립토판 (W); 7) 세린 (S), 트레오닌 (T); 및 8) 시스테인 (C), 메티오닌 (M) (예를 들어, [Creighton, Proteins (1984)] 참조). 일부 실시양태에서, 용어 "보존적 서열 변형"은 아미노산 서열을 함유하는 항체의 결합 특성에 유의하게 영향을 미치거나 이를 변경시키지 않는 아미노산 변형을 지칭하는데 사용된다.
본원에 사용된 용어 "최적화된"은 생산 세포 또는 유기체, 일반적으로는 진핵 세포, 예를 들어 효모 세포, 피키아(Pichia) 세포, 진균 세포, 트리코더마(Trichoderma) 세포, 차이니즈 햄스터 난소(Chinese Hamster Ovary) 세포 (CHO) 또는 인간 세포에서 선호되는 코돈을 사용하여 아미노산 서열을 코딩하도록 변경된 뉴클레오티드 서열을 지칭한다. 최적화된 뉴클레오티드 서열은, 또한 "모" 서열로도 공지되는 출발 뉴클레오티드 서열에 의해 본래 코딩되는 아미노산 서열을 완전하게 또는 가능한 한 많이 보유하도록 조작된다.
2개 이상의 핵산 또는 폴리펩티드 서열의 문맥에서의 용어 "동일한 퍼센트" 또는 "퍼센트 동일성"은 2개 이상의 서열 또는 하위서열이 동일한 정도를 지칭한다. 2개의 서열이 비교되는 영역에 걸쳐 동일한 서열의 아미노산 또는 뉴클레오티드를 갖는 경우에, 이들은 "동일하다". 하기 서열 비교 알고리즘 중 하나를 사용하거나 또는 수동 정렬 및 육안 검사에 의한 측정 시에 비교 윈도우 또는 지정된 영역에 걸쳐 최대한 상응하도록 비교 및 정렬했을 때, 2개의 서열이 동일한 아미노산 잔기 또는 뉴클레오티드의 명시된 백분율 (즉, 명시된 영역에 걸쳐, 또는 명시되지 않은 경우에는 전체 서열에 걸쳐 60% 동일성, 65%, 70%, 75%, 80%, 85%, 90%, 95% 또는 99% 동일성)을 갖는 경우에, 2개의 서열은 "실질적으로 동일하다". 임의로, 동일성은 적어도 약 30개 뉴클레오티드 (또는 10개 아미노산) 길이의 영역에 걸쳐, 또는 보다 바람직하게는 100 내지 500개 또는 1000개 또는 그 초과의 뉴클레오티드 (또는 20, 50, 200개 또는 그 초과의 아미노산) 길이에 걸쳐 존재한다.
서열 비교를 위해, 전형적으로 하나의 서열은 시험 서열과 비교되는 참조 서열로서 작용한다. 서열 비교 알고리즘을 사용하는 경우에, 시험 및 참조 서열을 컴퓨터에 입력하고, 필요한 경우에는 하위서열 좌표를 지정하고, 서열 알고리즘 프로그램 파라미터를 지정한다. 디폴트 프로그램 파라미터를 사용할 수 있거나, 또는 대안적 파라미터를 지정할 수 있다. 이어서, 서열 비교 알고리즘은 프로그램 파라미터에 기초하여 참조 서열에 대한 시험 서열의 퍼센트 서열 동일성을 계산한다.
본원에 사용된 "비교 윈도우"는 2개의 서열을 최적으로 정렬시킨 후 서열을 인접 위치의 동일한 수의 참조 서열과 비교할 수 있는, 20 내지 600개, 통상적으로는 약 50 내지 약 200개, 보다 통상적으로는 약 100 내지 약 150개로 이루어진 군으로부터 선택된 인접 위치의 개수 중 어느 하나의 절편에 대한 언급을 포함한다. 비교를 위한 서열 정렬 방법은 관련 기술분야에 널리 공지되어 있다. 비교를 위한 최적의 서열 정렬은, 예를 들어 문헌 [Smith and Waterman, Adv. Appl. Math. 2:482c (1970)]의 국소 상동성 알고리즘, 문헌 [Needleman and Wunsch, J. Mol. Biol. 48:443 (1970)]의 상동성 정렬 알고리즘, 문헌 [Pearson and Lipman, Proc. Natl. Acad. Sci. USA 85:2444 (1988)]의 유사성 검색 방법, 이러한 알고리즘들의 컴퓨터 실행 (위스콘신주 매디슨 사이언스 드라이브 575, 제네틱스 컴퓨터 그룹(Genetics Computer Group)의 위스콘신 제네틱스 소프트웨어 패키지(Wisconsin Genetics Software Package)의 GAP, BESTFIT, FASTA 및 TFASTA), 또는 수동 정렬 및 시각적 검사 (예를 들어, 문헌 [Brent et al., Current Protocols in Molecular Biology, 2003] 참조)에 의해 수행될 수 있다.
퍼센트 서열 동일성 및 서열 유사성을 결정하는데 적합한 알고리즘의 두가지 예는 BLAST 및 BLAST 2.0 알고리즘이고, 각각 문헌 [Altschul et al., Nuc. Acids Res. 25:3389-3402, 1977; 및 Altschul et al., J. Mol. Biol. 215:403-410, 1990]에 기재되어 있다. BLAST 분석을 수행하기 위한 소프트웨어는 미국 국립 생물 정보 센터(National Center for Biotechnology Information)를 통해 공개적으로 입수가능하다. 이러한 알고리즘은 먼저 데이터베이스 서열 내 동일한 길이의 워드와 정렬했을 때 어떠한 양의 값의 역치 점수 T에 매칭되거나 또는 이를 충족시키는, 질의 서열 내의 길이 W의 짧은 워드를 확인함으로써 높은 점수의 서열 쌍 (HSP)을 확인하는 것을 수반한다. T는 이웃 워드 점수 역치를 지칭한다 (상기 문헌 [Altschul et al.]). 이들 초기 이웃 워드 히트는 이것을 함유하는 보다 긴 HSP를 찾는 검색을 개시하기 위한 시드로서 작용한다. 워드 히트는 누적 정렬 점수가 증가될 수 있는 한, 각각의 서열을 따라 양쪽 방향으로 연장된다. 누적 점수는 뉴클레오티드 서열에 대해 파라미터 M (매칭 잔기의 쌍에 대한 보상 점수; 항상 > 0) 및 N (미스매칭 잔기에 대한 패널티 점수, 항상 < 0)을 사용하여 계산된다. 아미노산 서열의 경우에는 점수화 매트릭스를 사용하여 누적 점수를 계산한다. 누적 정렬 점수가 그의 최대 달성 값으로부터 X의 양만큼 하락하거나; 하나 이상의 음으로 점수화된 잔기 정렬의 축적으로 인해 누적 점수가 0 이하로 떨어지거나; 또는 어느 한쪽의 서열의 끝에 도달한 경우에, 각 방향으로의 워드 히트의 연장이 중단된다. BLAST 알고리즘 파라미터 W, T 및 X는 정렬의 감도 및 속도를 결정한다. BLASTN 프로그램 (뉴클레오티드 서열의 경우)은 디폴트로서 워드 길이 (W) 11, 기대값 (E) 또는 10, M=5, N=-4 및 양쪽 가닥의 비교를 사용한다. 아미노산 서열의 경우, BLASTP 프로그램은 디폴트로서 워드 길이 3, 및 예상값 (E) 10, 및 BLOSUM62 점수화 매트릭스 (문헌 [Henikoff and Henikoff, (1989) Proc. Natl. Acad. Sci. USA 89:10915] 참조) 정렬 (B) 50, 기대값 (E) 10, M=5, N=-4, 및 양쪽 가닥의 비교를 사용한다.
BLAST 알고리즘은 또한 2개의 서열 사이의 유사성에 대한 통계적 분석을 수행한다 (예를 들어, 문헌 [Karlin and Altschul, Proc. Natl. Acad. Sci. USA 90:5873-5787, 1993] 참조). BLAST 알고리즘에 의해 제공되는 유사성의 한 척도는 2개의 뉴클레오티드 또는 아미노산 서열 사이의 매칭이 우연히 발생할 확률의 지표를 제공하는 최소 합계 확률 (P(N))이다. 예를 들어, 핵산은 참조 핵산에 대한 시험 핵산의 비교에서 최소 합계 확률이 약 0.2 미만, 보다 바람직하게는 약 0.01 미만, 가장 바람직하게는 약 0.001 미만인 경우에 참조 서열과 유사한 것으로 간주된다.
PAM120 가중치 잔기 표, 갭 길이 페널티 12 및 캡 페널티 4를 사용하여 ALIGN 프로그램 (버젼 2.0) 내로 혼입된 문헌 [E. Meyers and W. Miller, Comput. Appl. Biosci. 4:11-17, 1988]의 알고리즘을 사용하여 2개의 아미노산 서열 간의 퍼센트 동일성이 또한 결정될 수 있다. 또한, 블라섬(Blossom) 62 매트릭스 또는 PAM250 매트릭스, 및 갭 가중치 16, 14, 12, 10, 8, 6 또는 4 및 길이 가중치 1, 2, 3, 4, 5 또는 6을 사용하여, GCG 소프트웨어 패키지 (www.gcg.com에서 입수가능함) 내의 GAP 프로그램 내로 혼입된 문헌 [Needleman and Wunsch, J. Mol. Biol. 48:444-453, 1970]의 알고리즘을 사용하여 2개의 아미노산 서열 간의 동일성 백분율이 결정될 수 있다.
상기 나타낸 서열 동일성의 백분율 이외에, 2개의 핵산 서열 또는 폴리펩티드가 실질적으로 동일하다는 또 다른 지표는, 제1 핵산에 의해 코딩된 폴리펩티드가 하기 기재된 바와 같이 제2 핵산에 의해 코딩된 폴리펩티드에 대해 생성된 항체와 면역학적으로 교차 반응성이라는 것이다. 따라서, 폴리펩티드는 전형적으로, 예를 들어 2개의 펩티드가 보존적 치환에 의해서만 상이한 경우에 제2 폴리펩티드와 실질적으로 동일하다. 2개의 핵산 서열이 실질적으로 동일하다는 또 다른 지표는, 2개의 분자 또는 그의 상보체가 하기 기재된 바와 같이 엄격한 조건 하에 서로 혼성화된다는 것이다. 2개의 핵산 서열이 실질적으로 동일하다는 또 다른 지표는 동일한 프라이머를 사용하여 서열을 증폭시킬 수 있다는 것이다.
용어 "핵산"은 본원에서 용어 "폴리뉴클레오티드"와 상호교환적으로 사용되고, 단일- 또는 이중-가닥 형태의 데옥시리보뉴클레오티드 또는 리보뉴클레오티드 및 그의 중합체를 지칭한다. 상기 용어는 합성, 자연 발생 및 비-자연 발생이고, 참조 핵산과 유사한 결합 특성을 갖고, 참조 뉴클레오티드와 유사한 방식으로 대사되는, 공지된 뉴클레오티드 유사체 또는 변형된 백본 잔기 또는 연결부를 함유하는 핵산을 포괄한다. 이러한 유사체의 예는 비제한적으로 포스포로티오에이트, 포스포르아미데이트, 메틸 포스포네이트, 키랄-메틸 포스포네이트, 2-O-메틸 리보뉴클레오티드, 펩티드-핵산 (PNA)을 포함한다.
달리 나타내지 않는 한, 특정한 핵산 서열은 또한 그의 보존적으로 변형된 변이체 (예를 들어, 축중성 코돈 치환) 및 상보적 서열, 뿐만 아니라 명시적으로 나타낸 서열을 함축적으로 포괄한다. 구체적으로, 하기 상세설명된 바와 같이, 축중성 코돈 치환은 1개 이상의 선택된 (또는 모든) 코돈의 제3 위치가 혼합-염기 및/또는 데옥시이노신 잔기로 치환된 서열을 생성함으로써 달성될 수 있다 (문헌 [Batzer et al., (1991) Nucleic Acid Res. 19:5081; Ohtsuka et al., (1985) J. Biol. Chem. 260:2605-2608; 및 Rossolini et al., (1994) Mol. Cell. Probes 8:91-98]).
핵산의 문맥에서의 용어 "작동적으로 연결된"은 2개 이상의 폴리뉴클레오티드 (예를 들어, DNA) 절편 간의 기능적 관계를 지칭한다. 전형적으로, 이는 전사되는 서열에 대한 전사 조절 서열의 기능적 관계를 지칭한다. 예를 들어, 프로모터 또는 인핸서 서열은 이들이 적절한 숙주 세포 또는 다른 발현 시스템 내에서 코딩 서열의 전사를 자극하거나 조절하는 경우에 코딩 서열에 작동가능하게 연결되어 있다. 일반적으로, 전사되는 서열에 작동가능하게 연결된 프로모터 전사 조절 서열은 전사되는 서열에 물리적으로 인접하며, 즉 이들은 시스-작용성이다. 그러나, 일부 전사 조절 서열, 예컨대 인핸서는 전사를 증진시키는 코딩 서열에 물리적으로 인접하거나 근접하여 위치할 필요가 없다.
용어 "폴리펩티드" 또는 "단백질"은 아미노산 잔기의 중합체를 지칭하기 위해 본원에서 상호교환적으로 사용된다. 상기 용어는 1개 이상의 아미노산 잔기가 상응하는 자연 발생 아미노산의 인공적인 화학적 모방체인 아미노산 중합체, 뿐만 아니라 자연 발생 아미노산 중합체 및 비-자연 발생 아미노산 중합체에도 적용된다. 달리 나타내지 않는 한, 특정한 폴리펩티드 서열은 또한 그의 보존적으로 변형된 변이체도 함축적으로 포괄한다.
본원에 사용된 용어 "면역접합체" 또는 "항체 약물 접합체" 또는 "접합체"는 항체 또는 그의 항원 결합 단편과 또 다른 작용제, 예컨대 화학요법제, 독소, 면역요법제, 영상화 프로브, 영상화 프로브 등과의 연결을 지칭한다. 이러한 연결은 공유 결합, 또는 비-공유 상호작용 예컨대 정전기력을 통한 상호작용일 수 있다. 관련 기술분야에 공지된 다양한 링커가 면역접합체를 형성하는데 사용될 수 있다. 추가로, 면역접합체는 면역접합체를 코딩하는 폴리뉴클레오티드로부터 발현될 수 있는 융합 단백질 형태로 제공될 수 있다. 본원에 사용되는 경우에, "융합 단백질"은 원래는 별도의 단백질들 (펩티드 및 폴리펩티드 포함)을 코딩하는 2개 이상의 유전자 또는 유전자 단편의 연결을 통해 생성된 단백질을 지칭한다. 융합 유전자의 번역은 원래의 단백질 각각으로부터 유래된 기능성 성질이 있는 단일 단백질을 생성한다.
용어 "염" 또는 "염들"은 화합물, 예를 들어 본 발명의 항체 약물 접합체와 조합하여 투여되는 또 다른 치료제인 화합물의 산 부가염 또는 염기 부가염을 지칭한다. "염"은 특히 "제약상 허용되는 염"을 포함한다. 용어 "제약상 허용되는 염"은, 화합물의 생물학적 유효성 및 특성을 보유하고 전형적으로 생물학적으로 또는 달리 바람직하지 않은 것이 아닌 염을 지칭한다. 다수의 경우에, 화합물은 아미노 및/또는 카르복실 기 또는 그와 유사한 기의 존재에 의해 산 및/또는 염기 염을 형성할 수 있다.
용어 "대상체"는 인간 및 비-인간 동물을 포함한다. 비-인간 동물은 모든 척추동물, 예를 들어 포유동물 및 비-포유동물, 비-인간 영장류, 양, 개, 소, 닭, 양서류 및 파충류를 포함한다. 언급되는 경우를 제외하고, 용어 "환자" 또는 "대상체"는 본원에서 상호교환적으로 사용된다.
본원에 사용된 용어 "세포독소" 또는 "세포독성제"는 세포의 성장 및 증식에 해롭고, 세포 또는 악성종양을 감소, 억제 또는 파괴하는 작용을 할 수 있는 임의의 작용제를 지칭한다.
본원에 사용된 용어 "항암제"는 세포독성제, 화학요법제, 방사선요법 및 방사선요법제, 표적화 항암제 및 면역요법제를 포함하지만 이에 제한되지 않는, 암과 같은 세포 증식성 장애를 치료하는데 사용될 수 있는 임의의 작용제를 지칭한다.
본원에 사용된 용어 "약물 모이어티" 또는 "페이로드"는 본 발명의 항체 또는 항원 결합 단편에 접합된 화학적 모이어티을 지칭하고, 임의의 치료제 또는 진단제, 예를 들어, 항암제, 항염증제, 항감염제 (예를 들어, 항진균제, 항박테리아제, 항기생충제, 항바이러스제) 또는 마취제를 포함할 수 있다. 예를 들어, 약물 모이어티는 항암제, 예컨대 세포독소일 수 있다. 특정 실시양태에서, 약물 모이어티는 V-ATPase 억제제, HSP90 억제제, IAP 억제제, mTor 억제제, 미세관 안정화제, 미세관 탈안정화제, 아우리스타틴, 돌라스타틴, 메이탄시노이드, MetAP (메티오닌 아미노펩티다제), 단백질 CRM1의 핵 유출의 억제제, DPPIV 억제제, 미토콘드리아에서의 포스포릴 전달 반응의 억제제, 단백질 합성 억제제, 키나제 억제제, CDK2 억제제, CDK9 억제제, 프로테아솜 억제제, 키네신 억제제, HDAC 억제제, DNA 손상 작용제, DNA 알킬화제, DNA 삽입제, DNA 작은 홈 결합제 및 DHFR 억제제로부터 선택된다. 이들 각각을 본 발명의 항체 및 방법과 상용성인 링커에 부착시키는 방법은 관련 기술분야에 공지되어 있다. 예를 들어, 문헌 [Singh et al., (2009) Therapeutic Antibodies: Methods and Protocols, vol. 525, 445-457]을 참조한다. 또한, 페이로드는 생물물리학적 프로브, 형광단, 스핀 표지, 적외선 프로브, 친화도 프로브, 킬레이트화제, 분광학적 프로브, 방사성 프로브, 지질 분자, 폴리에틸렌 글리콜, 중합체, 스핀 표지, DNA, RNA, 단백질, 펩티드, 표면, 항체, 항체 단편, 나노입자, 양자점, 리포솜, PLGA 입자, 사카라이드 또는 폴리사카라이드일 수 있다.
용어 "메이탄시노이드 약물 모이어티"는 메이탄시노이드 화합물의 구조를 갖는 항체-약물 접합체의 하위구조를 의미한다. 메이탄신은 동아프리카 관목 메이테누스 세라타(Maytenus serrata)로부터 처음 단리되었다 (미국 특허 번호 3,896,111). 후속적으로, 특정 미생물이 또한 메이탄시노이드, 예컨대 메이탄시놀 및 C-3 메이탄시놀 에스테르를 생산하는 것으로 발견되었다 (미국 특허 번호 4,151,042). 합성 메이탄시놀 및 메이탄시놀 유사체가 보고되어 있다. 미국 특허 번호 4,137,230; 4,248,870; 4,256,746; 4,260,608; 4,265,814; 4,294,757; 4,307,016; 4,308,268; 4,308,269; 4,309,428; 4,313,946; 4,315,929; 4,317,821; 4,322,348; 4,331,598; 4,361,650; 4,364,866; 4,424,219; 4,450,254; 4,362,663; 및 4,371,533; 및 문헌 [Kawai et al. (1984) Chem. Pharm. Bull. 3441-3451]을 참조하며, 이들 각각은 명확히 참조로 포함된다. 접합체에 유용한 특정 메이탄시노이드의 예는 DM1, DM3 및 DM4를 포함한다.
"종양"은 신생물성 세포 성장 및 증식 (악성이든 또는 양성이든), 및 모든 전암성 및 암성 세포 및 조직을 지칭한다.
용어 "항종양 활성"은 종양 세포 증식, 생존력, 또는 전이성 활성의 비율의 감소를 의미한다. 예를 들어, 항종양 활성은 요법이 없는 대조군과 비교하여, 요법 동안 발생하는 비정상 세포의 성장 속도에서의 저하, 또는 종양 크기 안정성 또는 감소, 또는 요법으로 인한 더 긴 생존에 의해 보여질 수 있다. 이러한 활성은 이종이식 모델, 동종이식편 모델, MMTV 모델, 및 항종양 활성을 조사하기 위한 관련 기술분야에 공지된 다른 모델을 포함하나 이에 제한되지는 않는, 승인된 시험관내 또는 생체내 종양 모델을 사용하여 평가될 수 있다.
용어 "악성종양"은 비-양성 종양 또는 암을 지칭한다. 본원에 사용된 용어 "암"은 탈조절되거나 비제어된 세포 성장을 특징으로 하는 악성종양을 포함한다. 예시적인 암은 암종, 육종, 백혈병 및 림프종을 포함한다.
용어 "암"은 원발성 악성 종양 (예를 들어, 그 세포가 대상체의 본래 종양의 부위 이외의 다른 신체 내의 부위로 이동하지 않은 종양) 및 속발성 악성 종양 (예를 들어, 전이, 즉 종양 세포가 본래 종양의 부위와 상이한 2차 부위로 이동함으로써 발생하는 종양)을 포함한다.
용어 "FGFR2"는 수용체 티로신 키나제 슈퍼패밀리의 구성원인 섬유모세포 성장 인자 수용체 2를 지칭한다. FGFR2의 핵산 및 아미노산 서열은 공지되어 있고, 진뱅크(GeneBank) 수탁 번호 NM_000141.4, NM_001144913.1, NM_001144914.1, NM_001144915.1, NM_001144916.1, NM_001144917.1, NM_001144918.1, NM_001144919.1, NM_022970.3, NM_023029.2에 공개되어 있다. 구조적으로, FGFR2 아미노산 서열은 절단되는 신호 펩티드, 적어도 1개 이상의 이뮤노글로불린 (Ig)-유사 도메인, 산성 박스, 막횡단 도메인 및 분할 티로신 키나제 도메인을 갖는 수용체 티로신 키나제 단백질이고, 진뱅크 수탁 번호 NM_000141.4, NM_001144913.1, NM_001144914.1, NM_001144915.1, NM_001144916.1, NM_001144917.1, NM_001144918.1, NM_001144919.1, NM_022970.3, NM_023029.2의 아미노산 서열과 그의 전장에 걸쳐 적어도 약 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 100% 서열 동일성을 갖는다. 구조적으로, FGFR2 핵산 서열은 진뱅크 수탁 번호 NM_000141.4, NM_001144913.1, NM_001144914.1, NM_001144915.1, NM_001144916.1, NM_001144917.1, NM_001144918.1, NM_001144919.1, NM_022970.3, NM_023029.2의 핵산 서열과 그의 전장에 걸쳐 적어도 약 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 100% 서열 동일성을 갖는다.
용어 "FGFR4"는 수용체 티로신 키나제 슈퍼패밀리의 구성원인 섬유모세포 성장 인자 수용체 4를 지칭한다. FGFR4의 핵산 및 아미노산 서열은 공지되어 있고, 진뱅크 수탁 번호 NM_002011.3, NM_022963.2, NM_213647.1로 공개되어 있다. 구조적으로, FGFR4 아미노산 서열은 절단되는 신호 펩티드, 3개의 이뮤노글로불린 (Ig)-유사 도메인, 산성 박스, 막횡단 도메인 및 분할 티로신 키나제 도메인을 갖는 수용체 티로신 키나제 단백질이고, 진뱅크 수탁 번호 NM_002011.3, NM_022963.2, NM_213647.1의 아미노산 서열과 그의 전장에 걸쳐 적어도 약 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 100% 서열 동일성을 갖는다. 구조적으로, FGFR4 핵산 서열은 진뱅크 수탁 번호 NM_002011.3, NM_022963.2, NM_213647.1의 핵산 서열과 그의 전장에 걸쳐 적여도 약 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 100% 서열 동일성을 갖는다.
용어 "FGFR2/4"는 FGFR2 및 FGFR4를 지칭하기 위해 본원에 사용된다. 예를 들어, FGFR2/4를 결합하는 항체는 FGFR2 및 FGFR4를 결합하는 항체를 지칭한다.
용어 "FGFR2 발현 암" 또는 "FGFR2 양성 암"은 암 세포의 표면 상에 FGFR2 또는 FGFR2의 돌연변이 형태를 발현하는 암을 지칭한다. 용어 "FGFR4 발현 암" 또는 "FGFR4 양성 암"은 암 세포의 표면 상에 FGFR4 또는 FGFR4의 돌연변이 형태를 발현하는 암을 지칭한다.
용어 "티로신 키나제 내성 암" 또는 "티로신 키나제 내성 종양"은, (1) 초기에 표준 치료 티로신 키나제 치료에 대해 반응하지 않아 "신생 내성"으로 지칭되는 암 또는 종양; 또는 (2) 표준 치료 티로신 키나제 치료에 대해 초기에 반응하고, 이후에 오래된 및/또는 새로운 병변의 재출현 또는 확산에 의해 결정되는 바에 따라 진행하는 암 또는 종양 (또한 이는 "속발성 내성" 또는 "재발성 암"으로서도 지칭됨)을 지칭한다.
용어 "Her2 내성 암" 또는 "Her2 내성 종양"은, (1) 초기에 표준 치료 Her2 치료에 대해 반응하지 않아 "신생 내성"으로 지칭되는 암 또는 종양; 또는 (2) 표준 치료 Her2 치료에 대해 초기에 반응하고, 이후에 오래된 및/또는 새로운 병변의 재출현 또는 확산에 의해 결정되는 바에 따라 진행하는 암 또는 종양 (또한 이는 "속발성 내성" 또는 "재발성 암"으로서도 지칭됨)을 지칭한다
본원에 사용된 바와 같은, 임의의 질환 또는 장애에 대한 용어 "치료하는" 또는 "치료"는, 한 실시양태에서, 질환 또는 장애의 개선 (즉, 질환 또는 그의 임상적 증상 중 하나 이상의 발달의 둔화 또는 저지 또는 감소)을 지칭한다. 또 다른 실시양태에서, "치료하다", "치료하는" 또는 "치료"는 환자에 의해 식별가능하지 않을 수 있는 것들을 비롯한 하나 이상의 물리적 파라미터의 완화 또는 개선을 지칭한다. 또 다른 실시양태에서, "치료하다", "치료하는" 또는 "치료"는 질환 또는 장애를, 물리적으로, (예를 들어, 식별가능한 증상의 안정화), 생리학적으로, (예를 들어, 물리적 파라미터의 안정화), 또는 이들 둘 다로 조절하는 것을 지칭한다. 또 다른 실시양태에서, "치료하다", "치료하는" 또는 "치료"는 질환 또는 장애의 발병 또는 발달 또는 진행의 예방 또는 지연을 지칭한다.
용어 "치료상 허용되는 양" 또는 "치료 유효 용량"은 목적하는 결과 (즉, 종양 크기의 감소, 종양 성장의 억제, 전이의 예방, 바이러스, 박테리아, 진균 또는 기생충 감염의 억제 또는 예방)를 유발하기에 충분한 양을 상호교환적으로 지칭한다. 일부 실시양태에서, 치료상 허용되는 양은 바람직하지 않은 부작용을 유발하거나 또는 그 원인이 되지 않는다. 일부 실시양태에서, 치료상 허용되는 양은 부작용, 그러나 단지 환자의 상태의 관점에서 건강관리 제공자에 의해 허용가능한 것들을 유도하거나 그의 원인이 된다. 치료상 허용되는 양은 먼저 저용량을 투여한 다음, 목적하는 효과가 달성될 때까지 그 용량을 점차 증가시킴으로써 결정될 수 있다. 본 발명의 분자의 "예방 유효 투여량" 및 "치료 유효 투여량"은 각각 질환 증상, 예컨대 암과 연관된 증상의 발병을 예방하거나, 또는 그의 중증도의 감소를 일으킬 수 있다.
용어 "공투여하다"는 개체의 혈액 중에 2종의 활성제의 존재를 지칭한다. 공투여된 활성제는 공동으로 또는 순차적으로 전달될 수 있다.
도 1은 재조합 인간 FGFR2 IIIb에 대한 항체의 패널에 대한 친화도 추정치를 보여준다.
도 2 (a) - (b)는 Baf-FGFR2 수용체 시스템에서 효능제로서 작용하는 항-FGFR 항체의 능력을 보여준다.
도 3 (a) - (b)는 Baf-FGFR2 수용체 시스템에서 길항제로서 작용하는 항-FGFR 항체의 능력을 보여준다.
도 4 (a) - (b)는 SNU16 종양 이종이식편 마우스 모델에서 항-FGFR2- 및 항-FGFR2/4-MCC-DM1 ADC의 항종양 활성을 보여주고; (c)는 SMCC-DM1 및 SPDB-DM4 링커-페이로드에 접합된 ADC로서 12433 항체의 항종양 활성을 보여주고; (d) - (e)는 항-FGFR2- 및 항-FGFR2/4-MCC-DM1 ADC의 약동학적 특성을 보여주고; (f)는 항-FGFR2- 및 항-FGFR2/4-MCC-DM1 ADC의 패널에 대한 ADC 클리어런스에 대한 항종양 활성을 보여준다.
도 5 (a) - (c)는 FGFR2-증폭된 세포주, SNU16에서 2시간 후 (a), 2-72시간에 (b) 또는 Kato-III 세포에서 (c) FGFR 신호전달 및 전체 수용체 발현을 조절하는 항-FGFR 항체 또는 ADC의 능력을 보여주는 웨스턴 블롯이다.
도 6 (a) - (d)는 IgG 및 유리 페이로드 대조군에 비해 SNU-16 (a), Kato-III (b) 또는 NUGC3 (c) 세포의 증식을 억제하는 12425-MCC-DM1의 능력을 보여주고; (d)는 비접합 항체, 12425가 임의의 인식가능한 항증식 효과를 갖지 않았음을 보여준다.
도 7 (a) - (b)는 pHH3 및 절단된 카스파제 3 발현의 평가를 보여주는, 12425-MCC-DM1로의 처리 후 SNU-16 (a) 또는 NUGC3 (b) 종양 이종이식편의 이미지이다.
도 8 (a) - (f)는 NCI-H716 (a), MFM223 (b), 인간 원발성 위 종양 제노그래프 (CHGA-010) (c), 인간 원발성 폐 종양 이종이식 모델 (HLUX1228) (d), 인간 원발성 유방암 이종이식 모델 (e) 및 인간 원발성 유방 관 암종 이종이식 모델 (f)에서 항-FGFR2- 및/또는 항-FGFR2/4-MCC-DM1 ADC의 항종양 활성을 보여준다.
도 9는 CHGA-119 종양 이종이식 모델에서 항 FGFR2/4 ADC, 12425-MCC-DM1의 단독으로의 및 FGFR 티로신 키나제 억제제, BGJ398와의 조합으로의 항종양 활성을 보여준다.
도 10은 SNU-16 종양 이종이식편 마우스 모델에서 다양한 용량 및 스케줄에서 항 FGFR2/4 ADC, 12425-MCC-DM1의 항종양 활성을 보여준다.
도 11 (a) - (c)는, Kato III 세포에서 시험관내 ADCC를 유도하고 (a), C1q에 결합하고 (b), Kato III 세포에서 CDC를 유도하는 (c), 항-FGFR2 항체의 능력의 평가를 보여준다. (d)는 생체내 비접합 항체 또는 MCC-DM1 접합 ADC로서 ADCC 고갈된 변이체의 효과를 보여준다.
도 12 (a) - (b)는 2시간 후 (a) 또는 시간 과정에 걸쳐 (b) FGFR4-발현 세포주인 MDA-MB453에서 FGFR 신호전달 및 전체 수용체 발현을 조절하는 항-FGFR 항체 또는 ADC의 능력을 보여주는 웨스턴 블롯이다.
도 13 (a) - (d)는 MDA-MB453 (a), RH4 (b), JR 세포 (c) 또는 암 세포주 패널 (d)에서 증식을 억제하는 FGFR2 또는 FGFR2/4 항체 (비접합 또는 MCC-DM1 ADC로서)의 능력을 보여준다.
도 14 (a) - (c)는 pHH3 및/또는 절단된 카스파제 3 발현의 평가를 보여주는, 12425-MCC-DM1로 치료 후 MDA-MB453 ((a) 및 (b)) 또는 RH4 (c) 종양 이종이식편의 이미지이다.
도 15 (a) - (b)는 MDA-MB453 (a) 및 RH4 (b) 종양 이종이식편 마우스 모델에서 항-FGFR2- 및 항-FGFR2/4-MCC-DM1 ADC의 항종양 활성을 보여준다.
도 16 (a) - (d)는 마우스 ((a) - (b)), 래트 (c) 또는 시노몰구스 원숭이 (d)에서 12425-MCC-DM1의 PK 프로파일을 보여준다.
도 17 (a) - (b)는 시험관내 (a) 및 생체내 (b) SNU-16 세포의 증식을 억제하는 조작된 12425 변이체 (20562-MCC-DM1)의 능력을 보여준다.
도 18 (a) - (b)는 시험관내 (a) 및 생체내 (b) SNU-16 세포의 증식을 억제하는 10164 (20809-MCC-DM1) 및 12425 (20811-MCC-DM1)의 친화성-성숙된 변이체의 능력을 보여준다.
도 19는 FGFR2에 대한 중수소 교환 실험의 결과를 나타낸다. (a)는 6종의 치료 mAb의 부재 (대조군) 및 존재 하에 FGFR2에 대한 절대 중수소 흡수를 보여준다. 막대의 높이는 3회 측정의 평균이고, 오차 막대는 하나의 표준 편차이고; (b)는 측정에서 표준 오차에 의해 나누어지는 결합 mAb 및 대조군 FGFR2 사이의 중수소 흡수에서의 차이를 보여주고; (c)는 FGFR2 IIIc: FGFR2 결정 구조 (PDB ID: 1EV2) 상에 맵핑된, FGFR2에 대한 mAb의 결합에 따른 고보호의 영역을 보여주고; (d)는 FGFR2 IIIb: FGFR1 결정 구조 (PDB ID: 3OJM) 상에 맵핑된, FGFR2에 대한 mAb의 결합에 따른 고보호의 영역을 보여준다.
도 20은 X선 결정학 에피토프 맵핑 연구로부터의 결과를 보여준다. (a)는 FGFR2에 결합하는 12425 Fab의 전체적 구조 (좌측 패널) 및 표지된 에피토프 잔기와 FGFR2에 대한 상세한 상호작용 표면 (우측 패널)을 보여주고; (b)는 FGFR4에 결합하는 12425 Fab의 전체적 구조 (좌측 패널) 및 표지된 에피토프 잔기와 FGFR4에 대한 상세한 상호작용 표면 (우측 패널)을 보여주고; (c)는 D2 도메인에서 인간 FGFR2 및 FGFR4의 서열 정렬을 보여준다. 완전 보존된 잔기는 암회색으로 어둡게 했으며, 부분적으로 보존된 잔기는 밝은 회색으로 어둡게 했다. 점선 박스는 FGFR4에서 그의 정렬된 대응부와 함께, 12425 Fab를 접촉하는 FGFR2 잔기이다.
도 21은 BGJ398 또는 게피티닙 (IC50 = 16.7 nM)에 대한 SNU 16 세포의 감수성 및 BGJ398 내성 SNU 16 세포의 감수성을 비교한 시험관내 증식 연구의 결과를 보여준다.
도 2 (a) - (b)는 Baf-FGFR2 수용체 시스템에서 효능제로서 작용하는 항-FGFR 항체의 능력을 보여준다.
도 3 (a) - (b)는 Baf-FGFR2 수용체 시스템에서 길항제로서 작용하는 항-FGFR 항체의 능력을 보여준다.
도 4 (a) - (b)는 SNU16 종양 이종이식편 마우스 모델에서 항-FGFR2- 및 항-FGFR2/4-MCC-DM1 ADC의 항종양 활성을 보여주고; (c)는 SMCC-DM1 및 SPDB-DM4 링커-페이로드에 접합된 ADC로서 12433 항체의 항종양 활성을 보여주고; (d) - (e)는 항-FGFR2- 및 항-FGFR2/4-MCC-DM1 ADC의 약동학적 특성을 보여주고; (f)는 항-FGFR2- 및 항-FGFR2/4-MCC-DM1 ADC의 패널에 대한 ADC 클리어런스에 대한 항종양 활성을 보여준다.
도 5 (a) - (c)는 FGFR2-증폭된 세포주, SNU16에서 2시간 후 (a), 2-72시간에 (b) 또는 Kato-III 세포에서 (c) FGFR 신호전달 및 전체 수용체 발현을 조절하는 항-FGFR 항체 또는 ADC의 능력을 보여주는 웨스턴 블롯이다.
도 6 (a) - (d)는 IgG 및 유리 페이로드 대조군에 비해 SNU-16 (a), Kato-III (b) 또는 NUGC3 (c) 세포의 증식을 억제하는 12425-MCC-DM1의 능력을 보여주고; (d)는 비접합 항체, 12425가 임의의 인식가능한 항증식 효과를 갖지 않았음을 보여준다.
도 7 (a) - (b)는 pHH3 및 절단된 카스파제 3 발현의 평가를 보여주는, 12425-MCC-DM1로의 처리 후 SNU-16 (a) 또는 NUGC3 (b) 종양 이종이식편의 이미지이다.
도 8 (a) - (f)는 NCI-H716 (a), MFM223 (b), 인간 원발성 위 종양 제노그래프 (CHGA-010) (c), 인간 원발성 폐 종양 이종이식 모델 (HLUX1228) (d), 인간 원발성 유방암 이종이식 모델 (e) 및 인간 원발성 유방 관 암종 이종이식 모델 (f)에서 항-FGFR2- 및/또는 항-FGFR2/4-MCC-DM1 ADC의 항종양 활성을 보여준다.
도 9는 CHGA-119 종양 이종이식 모델에서 항 FGFR2/4 ADC, 12425-MCC-DM1의 단독으로의 및 FGFR 티로신 키나제 억제제, BGJ398와의 조합으로의 항종양 활성을 보여준다.
도 10은 SNU-16 종양 이종이식편 마우스 모델에서 다양한 용량 및 스케줄에서 항 FGFR2/4 ADC, 12425-MCC-DM1의 항종양 활성을 보여준다.
도 11 (a) - (c)는, Kato III 세포에서 시험관내 ADCC를 유도하고 (a), C1q에 결합하고 (b), Kato III 세포에서 CDC를 유도하는 (c), 항-FGFR2 항체의 능력의 평가를 보여준다. (d)는 생체내 비접합 항체 또는 MCC-DM1 접합 ADC로서 ADCC 고갈된 변이체의 효과를 보여준다.
도 12 (a) - (b)는 2시간 후 (a) 또는 시간 과정에 걸쳐 (b) FGFR4-발현 세포주인 MDA-MB453에서 FGFR 신호전달 및 전체 수용체 발현을 조절하는 항-FGFR 항체 또는 ADC의 능력을 보여주는 웨스턴 블롯이다.
도 13 (a) - (d)는 MDA-MB453 (a), RH4 (b), JR 세포 (c) 또는 암 세포주 패널 (d)에서 증식을 억제하는 FGFR2 또는 FGFR2/4 항체 (비접합 또는 MCC-DM1 ADC로서)의 능력을 보여준다.
도 14 (a) - (c)는 pHH3 및/또는 절단된 카스파제 3 발현의 평가를 보여주는, 12425-MCC-DM1로 치료 후 MDA-MB453 ((a) 및 (b)) 또는 RH4 (c) 종양 이종이식편의 이미지이다.
도 15 (a) - (b)는 MDA-MB453 (a) 및 RH4 (b) 종양 이종이식편 마우스 모델에서 항-FGFR2- 및 항-FGFR2/4-MCC-DM1 ADC의 항종양 활성을 보여준다.
도 16 (a) - (d)는 마우스 ((a) - (b)), 래트 (c) 또는 시노몰구스 원숭이 (d)에서 12425-MCC-DM1의 PK 프로파일을 보여준다.
도 17 (a) - (b)는 시험관내 (a) 및 생체내 (b) SNU-16 세포의 증식을 억제하는 조작된 12425 변이체 (20562-MCC-DM1)의 능력을 보여준다.
도 18 (a) - (b)는 시험관내 (a) 및 생체내 (b) SNU-16 세포의 증식을 억제하는 10164 (20809-MCC-DM1) 및 12425 (20811-MCC-DM1)의 친화성-성숙된 변이체의 능력을 보여준다.
도 19는 FGFR2에 대한 중수소 교환 실험의 결과를 나타낸다. (a)는 6종의 치료 mAb의 부재 (대조군) 및 존재 하에 FGFR2에 대한 절대 중수소 흡수를 보여준다. 막대의 높이는 3회 측정의 평균이고, 오차 막대는 하나의 표준 편차이고; (b)는 측정에서 표준 오차에 의해 나누어지는 결합 mAb 및 대조군 FGFR2 사이의 중수소 흡수에서의 차이를 보여주고; (c)는 FGFR2 IIIc: FGFR2 결정 구조 (PDB ID: 1EV2) 상에 맵핑된, FGFR2에 대한 mAb의 결합에 따른 고보호의 영역을 보여주고; (d)는 FGFR2 IIIb: FGFR1 결정 구조 (PDB ID: 3OJM) 상에 맵핑된, FGFR2에 대한 mAb의 결합에 따른 고보호의 영역을 보여준다.
도 20은 X선 결정학 에피토프 맵핑 연구로부터의 결과를 보여준다. (a)는 FGFR2에 결합하는 12425 Fab의 전체적 구조 (좌측 패널) 및 표지된 에피토프 잔기와 FGFR2에 대한 상세한 상호작용 표면 (우측 패널)을 보여주고; (b)는 FGFR4에 결합하는 12425 Fab의 전체적 구조 (좌측 패널) 및 표지된 에피토프 잔기와 FGFR4에 대한 상세한 상호작용 표면 (우측 패널)을 보여주고; (c)는 D2 도메인에서 인간 FGFR2 및 FGFR4의 서열 정렬을 보여준다. 완전 보존된 잔기는 암회색으로 어둡게 했으며, 부분적으로 보존된 잔기는 밝은 회색으로 어둡게 했다. 점선 박스는 FGFR4에서 그의 정렬된 대응부와 함께, 12425 Fab를 접촉하는 FGFR2 잔기이다.
도 21은 BGJ398 또는 게피티닙 (IC50 = 16.7 nM)에 대한 SNU 16 세포의 감수성 및 BGJ398 내성 SNU 16 세포의 감수성을 비교한 시험관내 증식 연구의 결과를 보여준다.
본 발명은 FGFR2 및 FGFR4 둘 다 ("FGFR2/4")에 결합하는, 항체, 항체 단편 (예를 들어, 항원 결합 단편) 및 항체 약물 접합체를 제공한다. 특히, 본 발명은 FGFR2/4에 결합하고 이러한 결합에 따라 내재화하는 항체 및 항체 단편 (예를 들어, 항원 결합 단편)을 제공한다. 본 발명의 항체 및 항체 단편 (예를 들어, 항원 결합 단편)은 항체 약물 접합체를 제조하기 위해 사용될 수 있다. 또한, 본 발명은 바람직한 약동학적 특성 및 다른 바람직한 속성을 갖는 항체 약물 접합체를 제공하고, 따라서 FGFR2 및/또는 FGFR4를 발현하는 암, 예컨대 위암, 유방암, 횡문근육종 (예를 들어: 폐포 횡문근육종 또는 배아성 횡문근육종), 간암, 부신암, 폐암, 결장암 및 자궁내막암을 치료하는데 사용될 수 있다. 본 발명은 추가로 본 발명의 항체 약물 접합체를 포함하는 제약 조성물 및 암의 치료를 위한 이러한 제약 조성물의 제조 및 사용 방법을 제공한다.
항체 약물 접합체
본 발명은, FGFR2/4에 특이적으로 결합하는 항체, 항원 결합 단편 또는 그의 기능적 등가물이 약물 모이어티에 연결된 것인 항체 약물 접합체를 제공한다. 한 측면에서, 본 발명의 항체, 항원 결합 단편 또는 그의 기능적 등가물은 링커에 의한 공유 부착을 통해 항암제인 약물 모이어티에 연결된다. 본 발명의 항체 약물 접합체는 유효 용량의 항암제 (예를 들어, 세포독성제)를 FGFR2 및/또는 FGFR4를 발현하는 종양 조직에 선택적으로 전달할 수 있으며, 이에 따라 더 큰 선택성 (및 더 낮은 유효 용량)이 달성될 수 있다.
한 측면에서, 본 발명은 하기 화학식 I의 면역접합체를 제공한다.
Ab-(L-(D)m)n
상기 식에서, Ab는 본원에 기재된 FGFR2/4 결합 항체를 나타내고;
L은 링커이고;
D는 약물 모이어티이고;
m은 1 내지 8의 정수이고;
n은 1-20의 정수이다. 한 실시양태에서, n은 1 내지 10, 2 내지 8, 또는 2 내지 5의 정수이다. 구체적 실시양태에서, n은 2, 3 또는 4이다. 일부 실시양태에서, m은 1이고; 다른 실시양태에서 m은 2, 3 또는 4이다.
항체에 대한 약물 비가 특이적 접합체 분자에 대한 정확한 값 (예를 들어, 화학식 I에서 n 곱하기 m)을 갖는 경우에, 이러한 값은, 다수의 분자를 함유하는 샘플을 기재하기 위해 사용되는 경우에, 전형적으로 접합 단계와 연관된 어느 정도의 불균질성으로 인해 평균 값일 것으로 이해된다. 면역접합체의 샘플에 대한 평균 부하는 항체에 대한 약물 비 또는 "DAR"로 본원에 언급된다.
일부 실시양태에서, 약물이 메이탄시노이드인 경우에, 이는 "MAR"로 언급된다. 일부 실시양태에서, DAR은 약 1 내지 약 5이고, 전형적으로 약 3, 3.5, 4, 4.5 또는 5이다. 일부 실시양태에서, 샘플의 적어도 50 중량%는 평균 DAR 플러스 또는 마이너스 2를 갖는 화합물이고, 바람직하게는 샘플의 적어도 50%는 평균 DAR 플러스 또는 마이너스 1을 함유하는 접합체이다. 바람직한 실시양태는 DAR이 약 3.5인 면역접합체를 포함한다. 일부 실시양태에서, '약 n'의 DAR은 DAR에 대해 측정된 값이 n의 20% 내에 있는 것을 의미한다.
본 발명은 또한 약물 모이어티에 연결되거나 접합된, 본원에 개시된 바와 같은 항체, 항체 단편 (예를 들어, 항원 결합 단편) 및 그의 기능적 등가물을 포함하는 면역접합체에 관한 것이다. 한 실시양태에서, 약물 모이어티 D는 하기 구조를 갖는 것들을 비롯한 메이탄시노이드 약물 모이어티이다.

상기 식에서, 파상선은 항체 약물 접합체의 링커에 대한 메이탄시노이드의 황 원자의 공유 부착을 나타낸다. 각 경우에 R은 독립적으로 H 또는 C1-C6 알킬이다. 황 원자에 아미드 기를 부착시키는 알킬렌 쇄는 메타닐, 에타닐 또는 프로필일 수 있고, 즉, m은 1, 2 또는 3이다. (미국 특허 번호 633,410, 미국 특허 번호 5,208,020, 문헌 [Chari et al. (1992) Cancer Res. 52;127-131, Lui et al. (1996) Proc. Natl. Acad. Sci. 93:8618-8623]).
메이탄시노이드 약물 모이어티의 모든 입체 이성질체, 즉, 메이탄시노이드의 키랄 탄소에서 R 및 S 배위의 임의의 조합이 본 발명의 면역접합체에 고려된다. 한 실시양태에서 메이탄시노이드 약물 모이어티는 하기 입체화학을 갖는다.

한 실시양태에서, 메이탄시노이드 약물 모이어티는 N2'-데아세틸-N2'-(3-메르캅토-1-옥소프로필)-메이탄신 (또한 DM1로 공지됨)이다. DM1은 하기 구조 화학식에 의해 나타내어진다.

또 다른 실시양태에서 메이탄시노이드 약물 모이어티는 N2'-데아세틸-N2'-(4-메르캅토-1-옥소펜틸)-메이탄신 (또한 DM3으로 공지됨)이다. DM3은 하기 구조 화학식에 의해 나타내어진다.

또 다른 실시양태에서 메이탄시노이드 약물 모이어티는 N2'-데아세틸-N2'-(4-메틸-4-메르캅토-1-옥소펜틸)이다-메이탄신 (또한 DM4로 공지됨)이다. DM4는 하기 구조 화학식에 의해 나타내어진다.

약물 모이어티 D는 링커 L을 통해 항체 Ab에 연결될 수 있다. L은 공유 결합을 통해 약물 모이어티를 항체에 연결할 수 있는 임의의 화학적 모이어티이다. 가교 시약은 약물 모이어티 및 항체를 연결하여 항체 약물 접합체를 형성하는데 사용될 수 있는 이관능성 또는 다관능성 시약이다. 항체 약물 접합체는 약물 모이어티 및 항체 둘 다에 결합시킬 수 있는 반응성 관능기를 갖는 가교 시약을 사용하여 제조될 수 있다. 예를 들어, 시스테인, 티올 또는 아민, 예를 들어 N-말단 또는 아미노산 측쇄, 예컨대 항체의 리신은 가교 시약의 관능기와의 결합을 형성할 수 있다.
한 실시양태에서, L은 절단가능한 링커이다. 또 다른 실시양태에서, L은 비-절단가능한 링커이다. 일부 실시양태에서, L은 산-불안정성 링커, 광-불안정성 링커, 펩티다제 절단가능한 링커, 에스테라제 절단가능한 링커, 디술피드 결합 절단가능한 링커, 친수성 링커, 전구하전된 링커 또는 디카르복실산계 링커이다.
약물 모이어티, 예를 들어 메이탄시노이드와 항체 사이에 비-절단가능한 링커를 형성하는 적합한 가교 시약은 관련 기술분야에 널리 공지되어 있고, 황 원자를 포함하는 비-절단가능한 링커 (예컨대 SMCC) 또는 황 원자가 없는 비-절단가능한 링커를 형성할 수 있다. 약물 모이어티, 예를 들어 메이탄시노이드와 항체 사이에 비-절단가능한 링커를 형성하는 바람직한 가교 시약은 말레이미도계 또는 할로아세틸계 모이어티를 포함한다. 본 발명에 따르면, 이러한 비-절단가능한 링커는 말레이미도계 또는 할로아세틸계 모이어티로부터 유래된 것으로 언급된다.
말레이미도계 모이어티를 포함하는 가교 시약은 N-숙신이미딜-4-(말레이미도메틸)시클로헥산카르복실레이트 (SMCC), 술포숙신이미딜 4-(N-말레이미도메틸) 시클로헥산-1-카르복실레이트 (술포-SMCC), N-숙신이미딜-4-(말레이미도메틸)시클로헥산-1-카르복시-(6-아미노카프론산염) (이는 SMCC의 "장쇄" 유사체 (LC-SMCC)임), κ-말레이미도운데칸산 N-숙신이미딜 에스테르 (KMUA), γ-말레이미도부티르산 N-숙신이미딜 에스테르 (GMBS), ε-말레이미도카프로산 N-히드록시숙신이미딜 에스테르 (EMCS), m-말레이미도벤조일-N-히드록시숙신이미드 에스테르 (MBS), N-(α-말레이미도아세톡시)-숙신이미드 에스테르 (AMSA), 숙신이미딜-6-(β-말레이미도프로피온아미도)헥사노에이트 (SMPH), N-숙신이미딜-4-(p-말레이미도페닐)-부티레이트 (SMPB), N-(-p-말레이미도페닐)이소시아네이트 (PMIP), 및 폴리에텐 글리콜 스페이서를 함유하는 말레이미도계 가교 시약, 예컨대 MAL-PEG-NHS를 포함하나, 이에 제한되지는 않는다. 이러한 가교 시약은 말레이미도계 모이어티로부터 유래된 비-절단가능한 링커를 형성한다. 말레이미도계 가교 시약의 대표적인 구조는 하기에 나타낸다.


또 다른 실시양태에서, 링커 L은 N-숙신이미딜-4-(말레이미도메틸)시클로헥산카르복실레이트 (SMCC), 술포숙신이미딜 4-(N-말레이미도메틸) 시클로헥산-1-카르복실레이트 (술포-SMCC) 또는 MAL-PEG-NHS로부터 유래된다.
할로아세틸계 모이어티를 포함하는 가교 시약은 N-숙신이미딜 아이오도아세테이트 (SIA), N-숙신이미딜(4-아이오도아세틸)아미노벤조에이트 (SIAB), N-숙신이미딜 브로모아세테이트 (SBA) 및 N-숙신이미딜 3-(브로모아세트아미도)프로피오네이트 (SBAP)를 포함한다. 이러한 가교 시약은 할로아세틸계 모이어티로부터 유래된 비-절단가능한 링커를 형성한다. 할로아세틸계 가교 시약의 대표적인 구조는 하기에 나타낸다.

한 실시양태에서, 링커 L은 N-숙신이미딜 아이오도아세테이트 (SIA) 또는 N-숙신이미딜(4-아이오도아세틸)아미노벤조에이트 (SIAB)으로부터 유래된다.
약물 모이어티, 예를 들어 메이탄시노이드와 항체 사이에 절단가능한 링커를 형성하는 적합한 가교 시약은 관련 기술분야에 널리 공지되어 있다. 디술피드 함유 링커는 생리학적 조건 하에 발생할 수 있는 디술피드 교환을 통해 절단가능한 링커이다. 본 발명에 따르면, 이러한 절단가능한 링커는 디술피드계 모이어티로부터 유래되는 것으로 언급된다. 적합한 디술피드 가교 시약은 N-숙신이미딜-3-(2-피리딜디티오)프로피오네이트 (SPDP), N-숙신이미딜-4-(2-피리딜디티오)펜타노에이트 (SPP), N-숙신이미딜-4-(2-피리딜디티오)부타노에이트 (SPDB) 및 N-숙신이미딜-4-(2-피리딜디티오)-2-술포-부타노에이트 (술포-SPDB)를 포함하며, 그 구조는 하기에 나타낸다. 이러한 디술피드 가교 시약은 디술피드계 모이어티로부터 유래된 절단가능한 링커를 형성한다.

N-숙신이미딜-3-(2-피리딜디티오)프로피오네이트 (SPDP),

N-숙신이미딜-4-(2-피리딜디티오)펜타노에이트 (SPP),

N-숙신이미딜-4-(2-피리딜디티오)부타노에이트 (SPDB) 및

N-숙신이미딜-4-(2-피리딜디티오)-2-술포-부타노에이트 (술포-SPDB).
한 실시양태에서, 링커 L은 N-숙신이미딜-4-(2-피리딜디티오) 부타노에이트 (SPDB)로부터 유래된다.
약물 모이어티, 예를 들어 메이탄시노이드와 항체 사이에 하전된 링커를 형성하는 적합한 가교 시약은 전구하전된 가교 시약으로 공지되어 있다. 한 실시양태에서, 링커 L은 전구하전된 가교 시약 CX1-1로부터 유래된다. CX1-1의 구조는 하기와 같다.

2,5-디옥소피롤리딘-1-일 17-(2,5-디옥소-2,5-디히드로-1H-피롤-1-일)-5,8,11,14-테트라옥소-4,7,10,13-테트라아자헵타데칸-1-오에이트 (CX1-1)
상기 설명된 각각의 가교 시약은, 가교 시약의 한 말단에는 항체의 1급 아민과 반응하여 아미드 결합을 형성하는 NHS-에스테르, 및 다른 말단에는 메이탄시노이드 약물 모이어티의 술프히드릴과 반응하여 티오에테르 또는 디술피드 결합을 형성하는 말레이미드 기 또는 피리디닐디술피드 기를 함유한다.
한 실시양태에서, 본 발명의 접합체는 하기 구조 화학식 중 어느 하나에 의해 나타내어진다.



상기 식에서,
Ab는 인간 FGFR2 및 FGFR4 둘 다에 특이적으로 결합하는 항체 또는 그의 항원 결합 단편이고;
n은 Ab의 1급 아민과의 아미드 결합의 형성을 통해 Ab에 부착되는 D-L 기의 수를 나타내며, 1 내지 20의 정수이다. 한 실시양태에서, n은 1 내지 10, 2 내지 8 또는 2 내지 5의 정수이다. 구체적 실시양태에서, n은 3 또는 4이다.
한 실시양태에서, 접합체에서 항체에 대한 약물 (예를 들어, DM1 또는 DM4)의 평균 몰비 (즉, 평균 n 값, 또한 메이탄시노이드 항체 비 (MAR)로도 공지됨)는 약 1 내지 약 10, 약 2 내지 약 8 (예를 들어, 1.9, 2.0, 2.1, 2.2, 2.3, 2.4, 2.5, 2.6, 2.7, 2.8, 2.9, 3.0, 3.1, 3.2, 3.3, 3.4, 3.5, 3.6, 3.7, 3.8, 3.9, 4.0, 4.1, 4.2, 4.3, 4.4, 4.5, 4.6, 4.7, 4.8, 4.9, 5.0, 5.1, 5.2, 5.3, 5.4, 5.5, 5.6, 5.7, 5.8, 5.9, 6.0, 6.1, 6.2, 6.3, 6.4, 6.5, 6.6, 6.7, 6.8, 6.9, 7.0, 7.1, 7.2, 7.3, 7.4, 7.5, 7.6, 7.7, 7.8, 7.9, 8.0 또는 8.1), 약 2.5 내지 약 7, 약 3 내지 약 5, 약 2.5 내지 약 4.5 (예를 들어, 약 2.5, 약 2.6, 약 2.7, 약 2.8, 약 2.9, 약 3.0, 약 3.1, 약 3.3, 약 3.4, 약 3.5, 약 3.6, 약 3.7, 약 3.8, 약 3.9, 약 4.0, 약 4.1, 약 4.2, 약 4.3, 약 4.4, 약 4.5), 약 3.0 내지 약 4.0, 약 3.2 내지 약 4.2, 또는 약 4.5 내지 5.5 (예를 들어, 약 4.5, 약 4.6, 약 4.7, 약 4.8, 약 4.9, 약 5.0, 약 5.1, 약 5.2, 약 5.3, 약 5.4 또는 약 5.5)이다.
본 발명의 한 측면에서, 본 발명의 접합체는 실질적으로 고순도를 갖고, 하기 특징 중 하나 이상을 갖는다: (a) 약 90% 초과 (예를 들어, 약 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 100% 이상), 바람직하게는 약 95% 초과의 접합체 종이 단량체성임, (b) 접합체 제제 중 비접합 링커 수준이 약 10% 미만 (예를 들어, 약 9%, 8%, 7%, 6%, 5%, 4%, 3%, 2%, 1% 또는 0% 이하) (전체 링커에 대해)임, (c) 접합체 종의 10% 미만 (예를 들어, 약 9%, 8%, 7%, 6%, 5%, 4%, 3%, 2%, 1% 또는 0% 이하)이 가교됨, (d) 접합체 제제 중 유리 약물 (예를 들어, DM1 또는 DM4) 수준이 약 2% 미만 (예를 들어, 약 1.5%, 1.4%, 1.3%, 1.2%, 1.1%, 1.0%, 0.9%, 0.8%, 0.7%, 0.6%, 0.5%, 0.4%, 0.3%, 0.2%, 0.1% 또는 0% 이하) (전체 세포독성제에 대해 mol/mol)임, 및/또는 (e) 유리 약물 (예를 들어, DM1 또는 DM4)의 수준에서의 실질적인 증가가 저장 (예를 들어, 약 1주, 약 2 주, 약 3 주, 약 1개월, 약 2 개월, 약 3 개월, 약 4 개월, 약 5 개월, 약 6 개월, 약 1년, 약 2 년, 약 3 년, 약 4 년 또는 약 5 년 후) 시에는 발생하지 않음. 유리 약물 (예를 들어, DM1 또는 DM4)의 수준에서의 "실질적인 증가"는, 특정 저장 시간 (예를 들어, 약 1주, 약 2주, 약 3주, 약 1개월, 약 2개월, 약 3개월, 약 4개월, 약 5개월, 약 6개월, 약 1년, 약 2년, 약 3년, 약 4년 또는 약 5년) 후에, 유리 약물 (예를 들어, DM1 또는 DM4)의 수준에서의 증가가 약 0.1%, 약 0.2%, 약 0.3%, 약 0.4%, 약 0.5%, 약 0.6%, 약 0.7%, 약 0.8%, 약 0.9%, 약 1.0%, 약 1.1%, 약 1.2%, 약 1.3%, 약 1.4%, 약 1.5%, 약 1.6%, 약 1.7%, 약 1.8%, 약 1.9%, 약 2.0%, 약 2.2%, 약 2.5%, 약 2.7%, 약 3.0%, 약 3.2%, 약 3.5%, 약 3.7% 또는 약 4.0% 미만임을 의미한다.
본원에 사용된 용어 "비접합 링커"는 가교 시약 (예를 들어, SMCC, 술포-SMCC, SPDB, 술포-SPDB 또는 CX1-1)으로부터 유래된 링커와 공유적으로 연결된 항체를 지칭하며, 여기서 항체는 링커를 통해 약물 (예를 들어, DM1 또는 DM4)에 공유적으로 커플링되지 않는다 (즉, "비접합 링커"는 Ab-MCC, Ab-SPDB 또는 Ab-CX1-1에 의해 나타내어질 수 있음).
1. 약물 모이어티
본 발명은 FGFR2/4에 특이적으로 결합하는 면역접합체를 제공한다. 본 발명의 면역접합체는 약물 모이어티, 예를 들어, 항암제, 자가면역 치료제, 항염증제, 항진균제, 항박테리아제, 항기생충제, 항바이러스제 또는 마취제에 접합된, 항-FGFR2/4 항체, 항체 단편 (예를 들어, 항원 결합 단편) 또는 기능적 등가물을 포함한다. 본 발명의 항체, 항체 단편 (예를 들어, 항원 결합 단편) 또는 기능적 등가물은 관련 기술분야에 공지된 임의의 방법을 이용하여 여러 동일하거나 상이한 약물 모이어티에 접합될 수 있다.
특정 실시양태에서, 본 발명의 면역접합체의 약물 모이어티는 V-ATPase 억제제, 아폽토시스촉진제, Bcl2 억제제, MCL1 억제제, HSP90 억제제, IAP 억제제, mTor 억제제, 미세관 안정화제, 미세관 탈안정화제, 아우리스타틴, 돌라스타틴, 메이탄시노이드, MetAP (메티오닌 아미노펩티다제), 단백질 CRM1의 핵 유출의 억제제, DPPIV 억제제, 프로테아솜 억제제, 미토콘드리아에서의 포스포릴 전달 반응의 억제제, 단백질 합성 억제제, RNA 폴리머라제 억제제, 키나제 억제제, CDK2 억제제, CDK9 억제제, 키네신 억제제, HDAC 억제제, DNA 손상 작용제, DNA 알킬화제, DNA 삽입제, DNA 작은 홈 결합제 및 DHFR 억제제로 이루어진 군으로부터 선택된다.
한 실시양태에서, 본 발명의 면역접합체의 약물 모이어티는 메이탄시노이드 약물 모이어티, 예컨대 그러나 이에 제한되지는 않지만 DM1, DM3 또는 DM4이다.
또한, 본 발명의 항체, 항체 단편 (예를 들어, 항원 결합 단편) 또는 기능적 등가물은 주어진 생물학적 반응을 변형하는 약물 모이어티에 접합될 수 있다. 약물 모이어티는 전통적인 화학 치료제로 제한되는 것으로 간주되지 않는다. 예를 들어, 약물 모이어티는 목적하는 생물학적 활성을 보유하는 단백질, 펩티드 또는 폴리펩티드일 수 있다. 이러한 단백질은, 예를 들어 독소, 예컨대 아브린, 리신 A, 슈도모나스 외독소, 콜레라 독소 또는 디프테리아 독소, 단백질, 예컨대 종양 괴사 인자, α-인터페론, β-인터페론, 신경 성장 인자, 혈소판 유래 성장 인자, 조직 플라스미노겐 활성화제, 시토카인, 아폽토시스제, 항혈관신생제, 또는 생물학적 반응 조절제, 예컨대 림포카인을 포함할 수 있다.
한 실시양태에서, 본 발명의 항체, 항체 단편 (예를 들어, 항원 결합 단편) 또는 기능적 등가물은 약물 모이어티, 예컨대 세포독소, 약물 (예를 들어, 면역억제제) 또는 방사성독소에 접합된다. 세포독소의 예는 탁산 (예를 들어 국제 (PCT) 특허 출원 번호 WO 01/38318 및 PCT/US03/02675 참조), DNA-알킬화제 (예를 들어, CC-1065 유사체), 안트라시클린, 튜부리신 유사체, 두오카르마이신 유사체, 아우리스타틴 E, 아우리스타틴 F, 메이탄시노이드, 및 반응성 폴리에틸렌 글리콜 모이어티를 포함하는 세포독성제 (예를 들어, 문헌 [Sasse et al., J. Antibiot. (Tokyo), 53, 879-85 (2000), Suzawa et al., Bioorg. Med. Chem., 8, 2175-84 (2000), Ichimura et al., J. Antibiot. (Tokyo), 44, 1045-53 (1991), Francisco et al., Blood (2003)] (출판물 공개 이전의 전자 공개), 미국 특허 번호 5,475,092, 6,340,701, 6,372,738 및 6,436,931, 미국 특허 출원 공개 번호 2001/0036923 A1, 계류 미국 특허 출원 일련 번호 10/024,290 및 10/116,053, 및 국제 (PCT) 특허 출원 번호 WO 01/49698), 탁산, 시토칼라신 B, 그라미시딘 D, 브로민화에티듐, 에메틴, 미토마이신, 에토포시드, 테노포시드, 빈크리스틴, 빈블라스틴, t. 콜키신, 독소루비신, 다우노루비신, 디히드록시 안트라신 디온, 미톡산트론, 미트라마이신, 악티노마이신 D, 1-데히드로테스토스테론, 글루코코르티코이드, 프로카인, 테트라카인, 리도카인, 프로프라놀롤 및 퓨로마이신, 및 그의 유사체 또는 동족체를 포함하나, 이에 제한되지는 않는다. 치료제는, 또한 예를 들어 항대사물 (예를 들어, 메토트렉세이트, 6-메르캅토퓨린, 6-티오구아닌, 시타라빈, 5-플루오로우라실 데카르바진), 절제 작용제 (예를 들어, 메클로레타민, 티오테파 클로람부실, 멜팔란, 카르무스틴 (BSNU) 및 로무스틴 (CCNU), 시클로포스파미드, 부술판, 디브로모만니톨, 스트렙토조토신, 미토마이신 C 및 시스-디클로로디아민 백금 (II) (DDP) 시스플라틴, 안트라시클린 (예를 들어, 다우노루비신 (이전에는 다우노마이신) 및 독소루비신), 항생제 (예를 들어, 닥티노마이신 (이전에는 악티노마이신), 블레오마이신, 미트라마이신 및 안트라마이신 (AMC)), 및 항유사분열제 (예를 들어, 빈크리스틴 및 빈블라스틴)를 포함한다. (예를 들어, 시애틀 제네틱스(Seattle Genetics) US20090304721 참조).
본 발명의 항체, 항체 단편 (항원 결합 단편) 또는 기능적 등가물에 접합될 수 있는 세포독소의 다른 예는 두오카르마이신, 칼리케아미신, 메이탄신 및 아우리스타틴, 및 그의 유도체를 포함한다.
다양한 유형의 세포독소, 링커, 및 항체에 치료제를 접합시키는 방법은 관련 기술분야에 공지되어 있고, 예를 들어 문헌 [Saito et al., (2003) Adv. Drug Deliv. Rev. 55:199-215; Trail et al., (2003) Cancer Immunol. Immunother. 52:328-337; Payne, (2003) Cancer Cell 3:207-212; Allen, (2002) Nat. Rev. Cancer 2:750-763; Pastan and Kreitman, (2002) Curr. Opin. Investig. Drugs 3:1089-1091; Senter and Springer, (2001) Adv. Drug Deliv. Rev. 53:247-264]을 참조한다.
본 발명의 항체, 항체 단편 (예를 들어, 항원 결합 단편) 또는 기능적 등가물은 또한 방사성 동위원소에 접합되어 방사성면역접합체로 지칭되는 세포독성 방사성제약을 제조할 수 있다. 진단적으로 또는 치료적으로 사용하기 위해 항체에 접합될 수 있는 방사성 동위원소의 예는 아이오딘-131, 인듐-111, 이트륨-90 및 루테튬-177을 포함하나, 이에 제한되지는 않는다. 방사성면역접합체를 제조하는 방법은 관련 기술분야에 확립되어 있다. 제발린(Zevalin)® (덱 파마슈티칼스(DEC Pharmaceuticals)) 및 벡사르(Bexxar)® (코릭사 파마슈티칼스(Corixa Pharmaceuticals))를 비롯한 방사성면역접합체의 예가 상업적으로 입수가능하며, 본 발명의 항체를 사용하여 방사성면역접합체를 제조하기 위해 유사한 방법이 이용될 수 있다. 특정 실시양태에서, 마크로시클릭 킬레이트화제는 링커 분자를 통해 항체에 부착될 수 있는 1,4,7,10-테트라아자시클로도데칸-N,N',N",N"'-테트라아세트산 (DOTA)이다. 이러한 링커 분자는 관련 기술분야에 통상적으로 공지되어 있고, 문헌 [Denardo et al., (1998) Clin Cancer Res. 4(10):2483-90; Peterson et al., (1999) Bioconjug. Chem. 10(4):553-7; 및 Zimmerman et al., (1999) Nucl. Med. Biol. 26(8):943-50]에 기재되어 있으며, 이들 각각은 그의 전문이 본원에 참조로 포함된다.
본 발명의 항체, 항체 단편 (예를 들어, 항원 결합 단편) 또는 기능적 등가물은 또한 이종 단백질 또는 폴리펩티드 (또는 그의 단편, 바람직하게는 적어도 10, 적어도 20, 적어도 30, 적어도 40, 적어도 50, 적어도 60, 적어도 70, 적어도 80, 적어도 90 또는 적어도 100개 아미노산의 폴리펩티드)에 접합되어 융합 단백질을 생성할 수 있다. 특히, 본 발명은 본원에 기재된 항체 단편 (예를 들어, 항원 결합 단편) (예를 들어, Fab 단편, Fd 단편, Fv 단편, F(ab)2 단편, VH 도메인, VH CDR, VL 도메인 또는 VL CDR) 및 이종 단백질, 폴리펩티드 또는 펩티드를 포함하는 융합 단백질을 제공한다.
추가의 융합 단백질은 유전자-셔플링, 모티프-셔플링, 엑손-셔플링 및/또는 코돈-셔플링 ("DNA 셔플링"으로 총칭됨)의 기술을 통해 생성될 수 있다. DNA 셔플링은 본 발명의 항체 또는 그의 단편의 활성을 변경하기 위해 사용될 수 있다 (예를 들어, 보다 높은 친화도 및 보다 낮은 해리율을 갖는 항체 또는 그의 단편). 일반적으로, 미국 특허 번호 5,605,793, 5,811,238, 5,830,721, 5,834,252 및 5,837,458; 문헌 [Patten et al., (1997) Curr. Opinion Biotechnol. 8:724-33; Harayama, (1998) Trends Biotechnol. 16(2):76-82; Hansson et al., (1999) J. Mol. Biol. 287:265-76; 및 Lorenzo and Blasco, (1998) Biotechniques 24(2):308- 313]을 참조한다 (각각의 이들 특허 및 공보는 그 전문이 본원에 참고로 포함됨). 항체 또는 그의 단편, 또는 코딩된 항체 또는 그의 단편은 재조합 전에 오류-유발 PCR, 무작위 뉴클레오티드 삽입 또는 다른 방법에 의한 무작위 돌연변이유발에 의해 변경될 수 있다. 항원에 특이적으로 결합하는 항체 또는 그의 단편을 코딩하는 폴리뉴클레오티드가 하나 이상의 이종성 분자의 하나 이상의 성분, 모티프, 절편, 일부분, 도메인, 단편 등과 재조합될 수 있다.
더욱이, 본 발명의 항체, 항체 단편 (예를 들어, 항원 결합 단편) 또는 기능적 등가물은 마커 서열, 예컨대 펩티드에 접합되어 정제를 용이하게 할 수 있다. 바람직한 실시양태에서, 마커 아미노산 서열은 헥사-히스티딘 펩티드, 예컨대 특히 pQE 벡터 (퀴아젠®, 인크.(QIAGEN®, Inc.), 91311 캘리포니아주 채츠워스 에톤 애비뉴 9259)에서 제공되는 태그이며, 이 중 대부분은 상업적으로 입수가능하다. 예를 들어 문헌 [Gentz et al., (1989) Proc. Natl. Acad. Sci. USA 86:821-824]에 기재된 바와 같이, 헥사-히스티딘은 융합 단백질의 편리한 정제를 제공한다. 정제에 유용한 다른 펩티드 태그는 인플루엔자 헤마글루티닌 단백질로부터 유래된 에피토프에 상응하는 헤마글루티닌 ("HA") 태그 (문헌 [Wilson et al., (1984) Cell 37:767]) 및 "플래그(FLAG)®" 태그 (문헌 [A. Einhauer et al., J. Biochem. Biophys. Methods 49: 455-465, 2001])를 포함하나, 이에 제한되지는 않는다. 본 발명에 따르면, 항체 또는 항원 결합 단편이 또한 종양-투과 펩티드에 접합되어 그의 효능을 증진시킬 수 있다.
다른 실시양태에서, 본 발명의 항체, 항체 단편 (예를 들어, 항원 결합 단편) 또는 기능적 등가물은 진단제 또는 검출가능한 작용제에 접합된다. 이러한 면역접합체는 특정한 요법의 효능을 결정하는 것과 같은 임상 시험 절차의 일부로서 질환 또는 장애의 발병, 발달, 진행 및/또는 중증도를 모니터링하거나 예측하는데 유용할 수 있다. 이러한 진단 및 검출은 다양한 효소, 예컨대 이에 제한되지는 않지만, 양고추냉이 퍼옥시다제, 알칼리성 포스파타제, 베타-갈락토시다제 또는 아세틸콜린에스테라제; 보결분자단, 예컨대 이에 제한되지는 않지만, 스트렙타비딘/비오틴 및 아비딘/비오틴; 형광 물질, 예컨대 이에 제한되지는 않지만, 알렉사 플루오르(Alexa Fluor)® 350, 알렉사 플루오르® 405, 알렉사 플루오르® 430, 알렉사 플루오르® 488, 알렉사 플루오르® 500, 알렉사 플루오르® 514, 알렉사 플루오르® 532, 알렉사 플루오르® 546, 알렉사 플루오르® 555, 알렉사 플루오르® 568, 알렉사 플루오르® 594, 알렉사 플루오르® 610, 알렉사 플루오르® 633, 알렉사 플루오르® 647, 알렉사 플루오르® 660, 알렉사 플루오르® 680, 알렉사 플루오르® 700, 알렉사 플루오르® 750, 움벨리페론, 플루오레세인, 플루오레세인 이소티오시아네이트, 로다민, 디클로로트리아지닐아민 플루오레세인, 단실 클로라이드 또는 피코에리트린; 발광 물질, 예컨대 이에 제한되지는 않지만, 루미놀; 생물발광 물질, 예컨대 이에 제한되지는 않지만, 루시페라제, 루시페린 및 에쿼린; 방사성 물질, 예컨대 이에 제한되지는 않지만, 아이오딘 (131I, 125I, 123I 및 121I,), 탄소 (14C), 황 (35S), 삼중수소 (3H), 인듐 (115In, 113In, 112In 및 111In), 테크네튬 (99Tc), 탈륨 (201Ti), 갈륨 (68Ga, 67Ga), 팔라듐 (103Pd), 몰리브데넘 (99Mo), 크세논 (133Xe), 플루오린 (18F), 153Sm, 177Lu, 159Gd, 149Pm, 140La, 175Yb, 166Ho, 90Y, 47Sc, 186Re, 188Re, 142Pr, 105Rh, 97Ru, 68Ge, 57Co, 65Zn, 85Sr, 32P, 153Gd, 169Yb, 51Cr, 54Mn, 75Se, 64Cu, 113Sn 및 117Sn; 및 다양한 양전자 방출 단층촬영을 사용하는 양전자 발광 금속, 및 비-방사성 상자성 금속 이온을 포함하나 이에 제한되지 않는 검출가능한 물질에 항체를 커플링시킴으로써 달성될 수 있다.
본 발명의 항체, 항체 단편 (예를 들어, 항원 결합 단편) 또는 기능적 등가물은 또한 표적 항원의 면역검정 또는 정제에 특히 유용한 고체 지지체에 부착될 수 있다. 이러한 고체 지지체는 유리, 셀룰로스, 폴리아크릴아미드, 나일론, 폴리스티렌, 폴리비닐 클로라이드 또는 폴리프로필렌을 포함하나, 이에 제한되지는 않는다.
2. 링커
본원에 사용된 "링커"는 항체, 항체 단편 (예를 들어, 항원 결합 단편) 또는 기능적 등가물을 또 다른 모이어티, 예컨대 약물 모이어티에 연결할 수 있는 임의의 화학적 모이어티이다. 일부 경우에서, 링커의 일부는 메이탄시노이드로 제공된다. 예를 들어, 티올 함유 메이탄시노이드이 DM1은 천연 메이탄시노이드의 유도체이고, 링커의 일부를 제공한다. 메이탄신의 C-3 히드록실 기에서의 측쇄는 CO-CH3으로 종결되고, DM1의 측쇄는 CO-CH2-CH2-SH로 종결된다. 따라서 최종 링커는 2개 조각으로부터 조립되고, 가교 시약은 항체 및 DM1로부터의 측쇄에 도입된다. 링커는 화합물 또는 항체가 활성으로 남아있는 조건에서, 절단 (절단가능한 링커), 예컨대 산-유도된 절단, 광-유도된 절단, 펩티다제-유도된 절단, 에스테라제-유도된 절단 및 디술피드 결합 절단에 대해 영향받기 쉬울 수 있다. 대안적으로, 링커는 절단 (예를 들어, 안정한 링커 또는 비-절단가능한 링커)에 대해 실질적으로 내성일 수 있다. 일부 측면에서, 링커는 전구하전된 링커, 친수성 링커 또는 디카르복실산계 링커이다.
비-절단가능한 링커는 약물, 예컨대 메이탄시노이드를 항체에 안정한 공유 방식으로 연결할 수 있는 임의의 화학적 모이어티이고, 절단가능한 링커에 대해 상기 열거된 범주에 포함되지 않는다. 따라서, 비-절단가능한 링커는 산-유도된 절단, 광-유도된 절단, 펩티다제-유도된 절단, 에스테라제-유도된 절단 및 디술피드 결합 절단에 대해 실질적으로 내성이다. 또한, 비-절단가능한이란, 약물, 예컨대 메이탄시노이드 또는 항체가 그의 활성을 잃지 않는 조건에서, 디술피드 결합을 절단하는 산, 광불안정성-절단제, 펩티다제, 에스테라제 또는 화학 물질 또는 생리학적 화합물에 의해 유발되는 절단을 견디는 링커 내 화학 결합의 능력 또는 링커에 인접하는 능력을 지칭한다.
디술피드 함유 링커는 생리학적 조건 하에 발생할 수 있는 디술피드 교환을 통해 절단가능한 링커이다. 산-불안정성 링커는 산성 pH에서 절단가능한 링커이다. 예를 들어, 특정 세포내 구획, 예컨대 엔도솜 및 리소솜은 산성 pH (pH 4-5)를 가지고 있고, 산-불안정성 링커를 절단하기에 적합한 조건을 제공한다.
광-불안정성 링커는 광에 접근가능한 신체 표면에서 및 다수의 체강에서 유용한 링커이다. 또한, 적외선 광은 조직을 침투할 수 있다.
일부 링커는 펩티다제에 의해 절단될 수 있으며, 즉, 펩티다제 절단가능한 링커이다. 단지 특정 펩티드만이 세포 내부 또는 외부에서 용이하게 절단될 수 있고, 예를 들어 문헌 [Trout et al., 79 Proc. Natl. Acad.Sci. USA, 626-629 (1982) 및 Umemoto et al. 43 Int. J. Cancer, 677-684 (1989)]을 참조한다. 또한, 펩티드는 α-아미노산 및 펩티드성 결합으로 구성되고, 이는 화학적으로 1개의 아미노산의 카르복실레이트 및 제2 아미노산의 아미노 기 사이의 아미노 결합이다. 다른 아미드 결합, 예컨대 카르복실레이트와 리신의 ε-아미노 기 사이의 결합은 펩티드성 결합이 아닌 것으로 이해되고, 비-절단가능하다.
일부 링커는 에스테라제에 의해 절단가능할 수 있고, 즉, 에스테라제 절단가능한 링커이다. 다시, 단지 특정 에스테르만이 세포의 내부 또는 외부에 존재하는 에스테라제에 의해 절단될 수 있다. 에스테르는 카르복실산 및 알콜의 축합에 의해 형성된다. 단순 에스테르는 단순 알콜, 예컨대 지방족 알콜 및 작은 시클릭 및 작은 방향족 알콜과 함께 제조된 에스테르이다.
전구하전된 링커는 항체 약물 접합체 내로의 혼입 후에 그의 전하를 유지하는 하전된 가교 시약으로부터 유래된다. 전구하전된 링커의 예는 US 2009/0274713에서 발견될 수 있다.
한 측면에서, 본 발명에 사용된 링커는 가교 시약, 예컨대 N-숙신이미딜-3-(2-피리딜디티오)프로피오네이트 (SPDP), N-숙신이미딜 4-(2-피리딜디티오)펜타노에이트 (SPP), N-숙신이미딜 4-(2-피리딜디티오)부타노에이트 (SPDB), N-숙신이미딜-4-(2-피리딜디티오)-2-술포-부타노에이트 (술포-SPDB), N-숙신이미딜 아이오도아세테이트 (SIA), N-숙신이미딜(4-아이오도아세틸)아미노벤조에이트 (SIAB), 말레이미드 PEG NHS, N-숙신이미딜 4-(말레이미도메틸) 시클로헥산카르복실레이트 (SMCC), N-술포숙신이미딜 4-(말레이미도메틸) 시클로헥산카르복실레이트 (술포-SMCC) 또는 2,5-디옥소피롤리딘-1-일 17-(2,5-디옥소-2,5-디히드로-1H-피롤-1-일)-5,8,11,14-테트라옥소-4,7,10,13-테트라아자헵타데칸-1-오에이트 (CX1-1)로부터 유래된다. 또 다른 측면에서, 본 발명에 사용된 링커는 가교제, 예컨대 N-숙신이미딜-3-(2-피리딜디티오)프로피오네이트 (SPDP), N-숙신이미딜 4-(말레이미도메틸) 시클로헥산카르복실레이트 (SMCC), N-술포숙신이미딜 4-(말레이미도메틸) 시클로헥산카르복실레이트 (술포-SMCC), N-숙신이미딜-4-(2-피리딜디티오)-2-술포-부타노에이트 (술포-SPDB) 또는 2,5-디옥소피롤리딘-1-일 17-(2,5-디옥소-2,5-디히드로-1H-피롤-1-일)-5,8,11,14-테트라옥소-4,7,10,13-테트라아자헵타데칸-1-오에이트 (CX1-1)로부터 유래된다.
3. ADC의 접합 및 제조
본 발명의 접합체는 관련 기술분야에 공지된 임의의 방법, 예컨대 미국 특허 번호 7,811,572, 6,411,163, 7,368,565 및 8,163,888, 및 미국 출원 공개 2011/0003969, 2011/0166319, 2012/0253021 및 2012/0259100에 기재된 것에 의해 제조될 수 있다. 이러한 특허 및 특허 출원 공개의 전체 교시는 본원에 참조로 포함된다.
1-단계 방법
한 실시양태에서, 본 발명의 접합체는 1-단계 방법에 의해 제조될 수 있다. 상기 방법은 적합한 pH에서 하나 이상의 공-용매를 임의로 함유하는 실질적으로 수성 매질 중에서 항체, 약물 및 가교제를 배합하는 것을 포함한다. 한 실시양태에서, 상기 방법은 본 발명의 항체를 약물 (예를 들어, DM1 또는 DM4)과 접촉시켜 항체 및 약물을 포함하는 제1 혼합물을 형성하고, 이어서 항체 및 약물을 포함하는 제1 혼합물을 가교제 (예를 들어, SMCC, 술포-SMCC, SPDB, 술포-SPDB 또는 CX1-1)와 약 4 내지 약 9의 pH를 갖는 용액 중에서 접촉시켜 (i) 접합체 (예를 들어, Ab-MCC-DM1, Ab-SPDB-DM4 또는 Ab-CX1-1-DM1), (ii) 유리 약물 (예를 들어, DM1 또는 DM4), 및 (iii) 반응 부산물를 포함하는 혼합물을 제공하는 단계를 포함한다.
한 실시양태에서, 1-단계 방법은 항체를 약물 (예를 들어, DM1 또는 DM4) 및 이어서 가교제 (예를 들어, SMCC, 술포-SMCC, SPDB, 술포-SPDB 또는 CX1-1)와 약 6 이상 (예를 들어, 약 6 내지 약 9, 약 6 내지 약 7, 약 7 내지 약 9, 약 7 내지 약 8.5, 약 7.5 내지 약 8.5, 약 7.5 내지 약 8.0, 약 8.0 내지 약 9.0, 또는 약 8.5 내지 약 9.0)의 pH를 갖는 용액 중에서 접촉시키는 것을 포함한다. 예를 들어, 본 발명의 방법은 세포-결합제를 약물 (DM1 또는 DM4) 및 이어서 가교제 (예를 들어, SMCC, 술포-SMCC, SPDB, 술포-SPDB 또는 CX1-1)와 약 6.0, 약 6.1, 약 6.2, 약 6.3, 약 6.4, 약 6.5, 약 6.6, 약 6.7, 약 6.8, 약 6.9, 약 7.0, 약 7.1, 약 7.2, 약 7.3, 약 7.4, 약 7.5, 약 7.6, 약 7.7, 약 7.8, 약 7.9, 약 8.0, 약 8.1, 약 8.2, 약 8.3, 약 8.4, 약 8.5, 약 8.6, 약 8.7, 약 8.8, 약 8.9 또는 약 9.0의 pH를 갖는 용액 중에서 접촉시키는 것을 포함한다. 구체적 실시양태에서, 본 발명의 방법은 세포-결합제를 약물 (예를 들어, DM1 또는 DM4) 및 이어서 가교제 (예를 들어, SMCC, 술포-SMCC, SPDB, 술포-SPDB 또는 CX1-1)와 약 7.8의 pH (예를 들어, 7.6 내지 8.0의 pH 또는 7.7 내지 7.9의 pH)를 갖는 용액 중에서 접촉시키는 것을 포함한다.
1-단계 방법 (즉, 항체를 약물 (예를 들어, DM1 또는 DM4) 및 이어서 가교제 (예를 들어, SMCC, 술포-SMCC, SPDB, 술포-SPDB 또는 CX1-1과 접촉시킴)은 관련 기술분야에 공지된 임의의 적합한 온도에서 수행될 수 있다. 예를 들어, 1-단계 방법은 약 20℃ 이하 (예를 들어, 약 -10℃ (단, 예를 들어 세포독성제 및 이관능성 가교 시약을 용해시키는데 사용되는 유기 용매의 존재에 의해, 용액이 동결되는 것을 방지함) 내지 약 20℃, 약 0℃ 내지 약 18℃, 약 4℃ 내지 약 16℃)에서, 실온 (예를 들어, 약 20℃ 내지 약 30℃ 또는 약 20℃ 내지 약 25℃)에서, 또는 승온 (예를 들어, 약 30℃ 내지 약 37℃)에서 수행할 수 있다. 한 실시양태에서, 1-단계 방법은 약 16℃ 내지 약 24℃ (예를 들어, 약 16℃, 약 17℃, 약 18℃, 약 19℃, 약 20℃, 약 21℃, 약 22℃, 약 23℃, 약 24℃, 또는 약 25℃)의 온도에서 수행한다. 또 다른 실시양태에서, 1-단계 방법은 약 15℃ 이하 (예를 들어, 약 -10℃ 내지 약 15℃, 또는 약 0℃ 내지 약 15℃)의 온도에서 수행된다. 예를 들어, 상기 방법은 항체를 약물 (예를 들어, DM1 또는 DM4) 및 이어서 가교제 (예를 들어, SMCC, 술포-SMCC, SPDB, 술포-SPDB 또는 CX1-1)와 약 15℃, 약 14℃, 약 13℃, 약 12℃, 약 11℃, 약 10℃, 약 9℃, 약 8℃, 약 7℃, 약 6℃, 약 5℃, 약 4℃, 약 3℃, 약 2℃, 약 1℃, 약 0℃, 약 -1℃, 약 -2℃, 약 -3℃, 약 -4℃, 약 -5℃, 약 -6℃, 약 -7℃, 약 -8℃, 약 -9℃ 또는 약 -10℃의 온도에서 접촉시키는 것을 포함하며, 단 예를 들어 가교제 (예를 들어, SMCC, 술포-SMCC, 술포-SPDB SPDB 또는 CX1-1)를 용해시키는데 사용되는 유기 용매(들)의 존재에 의해, 용액이 동결되는 것을 방지한다. 한 실시양태에서, 상기 방법은 항체를 약물 (예를 들어, DM1 또는 DM4) 및 이어서 가교제 (예를 들어, SMCC, 술포-SMCC, SPDB, 술포-SPDB 또는 CX1-1)와 약 -10℃ 내지 약 15℃, 약 0℃ 내지 약 15℃, 약 0℃ 내지 약 10℃, 약 0℃ 내지 약 5℃, 약 5℃ 내지 약 15℃, 약 10℃ 내지 약 15℃, 또는 약 5℃ 내지 약 10℃의 온도에서 접촉시키는 것을 포함한다. 또 다른 실시양태에서, 상기 방법은 항체를 약물 (예를 들어, DM1 또는 DM4) 및 이어서 가교제 (예를 들어, SMCC, 술포-SMCC, SPDB, 술포-SPDB 또는 CX1-1)와 약 10℃의 온도 (예를 들어, 8℃ 내지 12℃의 온도 또는 9℃ 내지 11℃의 온도)에서 접촉시키는 것을 포함한다.
한 실시양태에서, 상기 기재된 접촉은, 항체를 제공하고, 이어서 항체를 약물 (예를 들어, DM1 또는 DM4)과 접촉시켜 항체 및 약물 (예를 들어, DM1 또는 DM4)을 포함하는 제1 혼합물을 형성하고, 이어서 항체 및 약물 (예를 들어, DM1 또는 DM4)을 포함하는 제1 혼합물을 가교제 (예를 들어, SMCC, 술포-SMCC, SPDB, 술포-SPDB 또는 CX1-1)와 접촉시킴으로써 달성된다. 예를 들어, 한 실시양태에서, 항체를 반응 용기에 제공하고, 약물 (예를 들어, DM1 또는 DM4)을 반응 용기에 첨가하고 (이에 따라 항체를 접촉시킴), 이어서 가교제 (예를 들어, SMCC, 술포-SMCC, SPDB, 술포-SPDB 또는 CX1-1)를 항체 및 약물 (예를 들어, DM1 또는 DM4)을 포함하는 혼합물에 첨가한다 (이에 따라 항체 및 약물을 포함하는 혼합물을 접촉시킴). 한 실시양태에서, 항체를 반응 용기에 제공하고, 항체를 용기에 제공한 직후에 약물 (예를 들어, DM1 또는 DM4)을 반응 용기에 첨가한다. 또 다른 실시양태에서, 항체를 반응 용기에 제공하고, 항체를 용기에 제공한 다음 소정의 시간 간격 (예를 들어, 세포-결합제를 공간에 제공한 후 약 5분, 약 10분, 약 20분, 약 30분, 약 40분, 약 50분, 약 1시간, 약 1일 또는 그 초과) 후에 약물 (예를 들어, DM1 또는 DM4)을 반응 용기에 첨가한다. 약물 (예를 들어, DM1 또는 DM4)을 신속하게 (즉, 짧은 시간 간격, 예컨대 약 5분, 약 10분 내에) 또는 천천히 (예컨대 펌프를 사용함으로써) 첨가할 수 있다.
이어서, 항체 및 약물 (예를 들어, DM1 또는 DM4)을 포함하는 혼합물은, 항체를 약물 (예를 들어, DM1 또는 DM4)과 접촉시킨 직후에 또는 항체를 약물 (예를 들어, DM1 또는 DM4)과 접촉시킨 후 약간의 후속 시점 (예를 들어, 약 5분 내지 약 8시간 또는 그 초과)에서, 가교제 (예를 들어, SMCC, 술포-SMCC, SPDB, 술포-SPDB 또는 CX1-1)와 접촉시킬 수 있다. 예를 들어, 한 실시양태에서, 가교제 (예를 들어, SMCC, 술포-SMCC, SPDB, 술포-SPDB 또는 CX1-1)는, 항체를 포함하는 반응 용기에 약물 (예를 들어, DM1 또는 DM4)을 첨가한 직후에, 항체 및 약물 (예를 들어, DM1 또는 DM4)을 포함하는 혼합물에 첨가한다. 대안적으로, 항체 및 약물 (예를 들어, DM1 또는 DM4)을 포함하는 혼합물은, 항체를 약물 (예를 들어, DM1 또는 DM4)과 접촉시킨 후 약 5분, 약 10분, 약 20분, 약 30분, 약 1시간, 약 2시간, 약 3시간, 약 4시간, 약 5시간, 약 6시간, 약 7시간, 약 8시간, 또는 그 초과에 가교제 (예를 들어, SMCC, 술포-SMCC, SPDB, 술포-SPDB 또는 CX1-1)와 접촉시킬 수 있다.
항체 및 약물 (예를 들어, DM1 또는 DM4)을 포함하는 혼합물을 가교제 (예를 들어, SMCC, 술포-SMCC, SPDB, 술포-SPDB 또는 CX1-1)와 접촉시킨 후, 반응이 약 1시간, 약 2시간, 약 3시간, 약 4시간, 약 5시간, 약 6시간, 약 7시간, 약 8시간, 약 9시간, 약 10시간, 약 11시간, 약 12시간, 약 13시간, 약 14시간, 약 15시간, 약 16시간, 약 17시간, 약 18시간, 약 19시간, 약 20시간, 약 21시간, 약 22시간, 약 23시간, 약 24시간, 또는 그 초과 (예를 들어, 약 30시간, 약 35시간, 약 40시간, 약 45시간 또는 약 48시간) 동안 진행하도록 한다.
한 실시양태에서, 1-단계 방법은 임의의 미반응 약물 (예를 들어, DM1 또는 DM4) 및/또는 미반응 가교제 (예를 들어, SMCC, 술포-SMCC, SPDB, 술포-SPDB 또는 CX1-1)를 켄칭하는 켄칭 단계를 추가로 포함한다. 켄칭 단계는 전형적으로 접합체의 정제 이전에 수행된다. 한 실시양태에서, 혼합물은 혼합물을 켄칭 시약과 접촉시킴으로써 켄칭시킨다. 본원에 사용된 "켄칭 시약"은 유리 약물 (예를 들어, DM1 또는 DM4) 및/또는 가교제 (예를 들어, SMCC, 술포-SMCC, SPDB, 술포-SPDB 또는 CX1-1)와 반응하는 시약을 지칭한다. 한 실시양태에서, 말레이미드 또는 할로아세트아미드 켄칭 시약, 예컨대 4-말레이미도부티르산, 3-말레이미도프로피온산, N-에틸말레이미드, 아이오도아세트아미드 또는 아이오도아세트아미도프로피온산은 약물 (예를 들어, DM1 또는 DM4)에서 임의의 미반응 기 (예컨대 티올)를 켄칭하는 것을 확실하게 하는데 사용될 수 있다. 켄칭 단계는 약물 (예를 들어, DM1)의 이량체화를 방지하는 것을 도울 수 있다. 이량체화된 DM1은 제거하기 어려울 수 있다. 극성의 하전된 티올-켄칭 시약 (예컨대 4-말레이미도부티르산 또는 3-말레이미도프로피온산)으로의 켄칭 시에, 과량의 미반응 DM1은 극성의 하전된 수가용성 부가물로 전환되며, 이는 정제 단계 동안 공유-연결된 접합체로부터 쉽게 분리될 수 있다. 비-극성 및 중성 티올-켄칭 시약으로의 켄칭이 또한 사용될 수 있다. 한 실시양태에서, 혼합물은 미반응 가교제 (예를 들어, SMCC, 술포-SMCC, SPDB, 술포-SPDB 또는 CX1-1)과 반응하는 켄칭 시약과 접촉시킴으로써 켄칭된다. 예를 들어, 친핵체를 혼합물에 첨가하여 임의의 미반응 SMCC를 켄칭할 수 있다. 친핵체는 바람직하게는 아미노 기 함유 친핵체, 예컨대 리신, 타우린 및 히드록실아민이다.
바람직한 실시양태에서, 반응 (즉, 항체를 약물 (예를 들어, DM1 또는 DM4) 및 이어서 가교제 (예를 들어, SMCC, 술포-SMCC, SPDB, 술포-SPDB 또는 CX1-1)와 접촉시키는 반응)은 혼합물을 켄칭 시약과 접촉시키기 이전에 완전히 진행되도록 한다. 이와 관련하여, 켄칭 시약은, 항체 및 약물 (예를 들어, DM1 또는 DM4)을 포함하는 혼합물을 가교제 (예를 들어, SMCC, 술포-SMCC, SPDB, 술포-SPDB 또는 CX1-1)와 접촉시킨 후 약 1시간 내지 약 48시간 (예를 들어, 약 1시간, 약 2시간, 약 3시간, 약 4시간, 약 5시간, 약 6시간, 약 7시간, 약 8시간, 약 9시간, 약 10시간, 약 11시간, 약 12시간, 약 13시간, 약 14시간, 약 15시간, 약 16시간, 약 17시간, 약 18시간, 약 19시간, 약 20시간, 약 21시간, 약 22시간, 약 23시간, 약 24시간, 또는 약 25시간 내지 약 48시간)에 혼합물에 첨가한다.
대안적으로, 혼합물은 혼합물의 pH를 약 5.0 (예를 들어, 4.8, 4.9, 5.0, 5.1 또는 5.2)로 저하시킴으로써 켄칭시킨다. 또 다른 실시양태에서, 혼합물은 pH를 6.0 미만, 5.5 미만, 5.0 미만, 4.8 미만, 4.6 미만, 4.4 미만, 4.2 미만, 4.0 미만으로 저하시킴으로써 켄칭시킨다. 대안적으로, pH는 약 4.0 (예를 들어, 3.8, 3.9, 4.0, 4.1 또는 4.2) 내지 약 6.0 (예를 들어, 5.8, 5.9, 6.0, 6.1 또는 6.2), 약 4.0 내지 약 5.0, 약 4.5 (예를 들어, 4.3, 4.4, 4.5, 4.6 또는 4.7) 내지 약 5.0로 저하시킨다. 한 실시양태에서, 혼합물은 혼합물의 pH를 4.8로 저하시킴으로써 켄칭시킨다. 또 다른 실시양태에서, 혼합물은 혼합물의 pH를 5.5로 저하시킴으로써 켄칭시킨다.
한 실시양태에서, 1-단계 방법은 추가로 불안정하게 결합된 링커를 항체로부터 방출시키는 홀딩 단계를 포함한다. 홀딩 단계는 접합체의 정제 이전에 (예를 들어, 반응 단계 후, 반응 단계와 켄칭 단계 사이, 또는 켄칭 단계 후) 혼합물을 홀딩하는 것을 포함한다. 예를 들어, 상기 방법은 (a) 항체를 약물 (예를 들어, DM1 또는 DM4)과 접촉시켜 항체 및 약물 (예를 들어, DM1 또는 DM4)을 포함하는 혼합물을 형성하고; 이어서 항체 및 약물 (예를 들어, DM1 또는 DM4)을 포함하는 혼합물을 가교제 (예를 들어, SMCC, 술포-SMCC, SPDB, 술포-SPDB 또는 CX1-1)와 약 4 내지 약 9의 pH를 갖는 용액 중에서 접촉시켜 (i) 접합체 (예를 들어, Ab-MCC-DM1, Ab-SPDB-DM4 또는 Ab-CX1-1-DM1), (ii) 유리 약물 (예를 들어, DM1 또는 DM4), 및 (iii) 반응 부산물을 포함하는 혼합물을 제공하는 단계, (b) 단계 (a)에서 제조된 혼합물을 홀딩하여 불안정하게 결합된 링커를 세포-결합제로부터 방출시키는 단계, 및 (c) 혼합물을 정제하여 정제된 접합체를 제공하는 단계를 포함한다.
또 다른 실시양태에서, 상기 방법은 (a) 항체를 약물 (예를 들어, DM1 또는 DM4)과 접촉시켜 항체 및 약물 (예를 들어, DM1 또는 DM4)을 포함하는 혼합물을 형성하고; 이어서 항체 및 약물 (예를 들어, DM1 또는 DM4)을 포함하는 혼합물을 가교제 (예를 들어, SMCC, 술포-SMCC, SPDB, 술포-SPDB 또는 CX1-1)와 약 4 내지 약 9의 pH를 갖는 용액 중에서 접촉시켜 (i) 접합체, (ii) 유리 약물 (예를 들어, DM1 또는 DM4), 및 (iii) 반응 부산물을 포함하는 혼합물을 제공하는 단계, (b) 단계 (a)에서 제조된 혼합물을 켄칭하여 임의의 미반응 약물 (예를 들어, DM1 또는 DM4) 및/또는 미반응 가교제 (예를 들어, SMCC, 술포-SMCC, SPDB, 술포-SPDB 또는 CX1-1)를 켄칭하는 단계, (c) 단계 (b)에서 제조된 혼합물을 홀딩하여 불안정하게 결합된 링커를 세포-결합제로부터 방출시키는 단계, 및 (d) 혼합물을 정제하여 정제된 접합체 (예를 들어, Ab-MCC-DM1, Ab-SPDB-DM4 또는 Ab-CX1-1-DM1)를 제공하는 단계를 포함한다.
대안적으로, 홀딩 단계는 접합체의 정제에 이은 추가 정제 단계 후에 수행될 수 있다.
바람직한 실시양태에서, 반응은 홀딩 단계 이전에 완전히 진행되도록 한다. 이와 관련하여, 홀딩 단계는, 항체 및 약물 (예를 들어, DM1 또는 DM4)을 포함하는 혼합물을 가교제 (예를 들어, SMCC, 술포-SMCC, SPDB, 술포-SPDB 또는 CX1-1)와 접촉시킨 후 약 1시간 내지 약 48시간 (예를 들어, 약 1시간, 약 2시간, 약 3시간, 약 4시간, 약 5시간, 약 6시간, 약 7시간, 약 8시간, 약 9시간, 약 10시간, 약 11시간, 약 12시간, 약 13시간, 약 14시간, 약 15시간, 약 16시간, 약 17시간, 약 18시간, 약 19시간, 약 20시간, 약 21시간, 약 22시간, 약 23시간, 약 24시간, 또는 약 24시간 내지 약 48시간)에 수행될 수 있다.
홀딩 단계는, 용액을 적합한 온도 (예를 들어, 약 0℃ 내지 약 37℃)에서 적합한 시간 기간 (예를 들어, 약 1시간 내지 약 1주, 약 1시간 내지 약 24시간, 약 1시간 내지 약 8시간, 또는 약 1시간 내지 약 4시간) 동안 유지하여, 안정하게 결합된 링커는 항체로부터 실질적으로 방출하지 않으면서 불안정하게 결합된 링커를 항체로부터 방출시키는 것을 포함한다. 한 실시양태에서, 홀딩 단계는, 용액을 약 20℃ 이하 (예를 들어, 약 0℃ 내지 약 18℃, 약 4℃ 내지 약 16℃)에서, 실온 (예를 들어, 약 20℃ 내지 약 30℃ 또는 약 20℃ 내지 약 25℃)에서, 또는 승온 (예를 들어, 약 30℃ 내지 약 37℃)에서 유지하는 것을 포함한다. 한 실시양태에서, 홀딩 단계는 용액을 약 16℃ 내지 약 24℃ (예를 들어, 약 15℃, 약 16℃, 약 17℃, 약 18℃, 약 19℃, 약 20℃, 약 21℃, 약 22℃, 약 23℃, 약 24℃, 또는 약 25℃)의 온도에서 유지하는 것을 포함한다. 또 다른 실시양태에서, 홀딩 단계는 용액을 약 2℃ 내지 약 8℃ (예를 들어, 약 0℃, 약 1℃, 약 2℃, 약 3℃, 약 4℃, 약 5℃, 약 6℃, 약 7℃, 약 8℃, 약 9℃, 또는 약 10℃)의 온도에서 유지하는 것을 포함한다. 또 다른 실시양태에서, 홀딩 단계는 용액을 약 37℃ (예를 들어, 약 34℃, 약 35℃, 약 36℃, 약 37℃, 약 38℃, 약 39℃ 또는 약 40℃)의 온도에서 유지하는 것을 포함한다.
홀딩 단계의 지속기간은, 홀딩 단계가 수행되는 온도 및 pH에 의존적이다. 예를 들어, 홀딩 단계의 지속기간은 홀딩 단계를 승온에서 수행함으로써 실질적으로 감소시킬 수 있으며, 여기서 최대 온도는 세포-결합제-세포독성제 접합체의 안정성에 의해 제한된다. 홀딩 단계는 용액을 약 1시간 내지 약 1일 (예를 들어, 약 1시간, 약 2시간, 약 3시간, 약 4시간, 약 5시간, 약 6시간, 약 7시간, 약 8시간, 약 9시간, 약 10시간, 약 12시간, 약 14시간, 약 16시간, 약 18시간, 약 20시간, 약 22시간, 또는 약 24시간), 약 10시간 내지 약 24시간, 약 12시간 내지 약 24시간, 약 14시간 내지 약 24시간, 약 16시간 내지 약 24시간, 약 18시간 내지 약 24시간, 약 20시간 내지 약 24시간, 약 5시간 내지 약 1주, 약 20시간 내지 약 1주, 약 12시간 내지 약 1주 (예를 들어, 약 12시간, 약 16시간, 약 20시간, 약 24시간, 약 2일, 약 3일, 약 4일, 약 5일, 약 6일 또는 약 7일), 또는 약 1일 내지 약 1주 동안 유지하는 것을 포함한다.
한 실시양태에서, 홀딩 단계는 용액을 약 2℃ 내지 약 8℃의 온도에서 적어도 약 12시간의 기간 동안 최대 1주 동안 유지하는 것을 포함한다. 또 다른 실시양태에서, 홀딩 단계는 용액을 약 2℃ 내지 약 8℃의 온도에서 밤새 (예를 들어, 약 12 내지 약 24시간, 바람직하게는 약 20시간) 유지하는 것을 포함한다.
홀딩 단계를 위한 pH 값은 바람직하게는 약 4 내지 약 10이다. 한 실시양태에서, 홀딩 단계를 위한 pH 값은 약 4 이상, 그러나 약 6 미만 (예를 들어, 4 내지 5.9) 또는 약 5 이상, 그러나 약 6 미만 (예를 들어, 5 내지 5.9)이다. 또 다른 실시양태에서, 홀딩 단계를 위한 pH 값은 약 6 내지 약 10 (예를 들어, 약 6.5 내지 약 9, 약 6 내지 약 8)의 범위이다. 예를 들어, 홀딩 단계를 위한 pH 값은 약 6, 약 6.5, 약 7, 약 7.5, 약 8, 약 8.5, 약 9, 약 9.5 또는 약 10일 수 있다.
구체적 실시양태에서, 홀딩 단계는, 혼합물을 25℃에서 약 6-7.5의 pH에서 약 12시간 내지 약 1주 동안 인큐베이션하거나, 혼합물을 4℃에서 약 4.5-5.9의 pH에서 약 5시간 내지 약 5일 동안 인큐베이션하거나, 또는 혼합물을 25℃에서 약 4.5-5.9의 pH에서 약 5시간 내지 약 1일 동안 인큐베이션하는 것을 포함할 수 있다.
1-단계 방법은 수크로스를 반응 단계에 첨가하여 접합체의 용해도 및 회수율을 증가시는 것을 임의로 포함할 수 있다. 바람직하게는, 수크로스는 약 0.1% (w/v) 내지 약 20% (w/v) (예를 들어, 약 0.1% (w/v), 1% (w/v), 5% (w/v), 10% (w/v), 15% (w/v), 또는 20% (w/v))의 농도로 첨가된다. 바람직하게는, 수크로스는 약 1% (w/v) 내지 약 10% (w/v) (예를 들어, 약 0.5% (w/v), 약 1% (w/v), 약 1.5% (w/v), 약 2% (w/v), 약 3% (w/v), 약 4% (w/v), 약 5% (w/v), 약 6% (w/v), 약 7% (w/v), 약 8% (w/v), 약 9% (w/v), 약 10% (w/v), 또는 약 11% (w/v))의 농도로 첨가한다. 추가로, 반응 단계는 또한 완충제의 첨가를 포함할 수 있다. 관련 기술분야에 공지된 임의의 적합한 완충제가 사용될 수 있다. 적합한 완충제는, 예를 들어, 시트레이트 완충제, 아세테이트 완충제, 숙시네이트 완충제 및 포스페이트 완충제를 포함한다. 한 실시양태에서, 완충제는 HEPPSO (N-(2-히드록시에틸)피페라진-N'-(2-히드록시프로판술폰산)), POPSO (피페라진-1,4-비스-(2-히드록시-프로판-술폰산) 탈수화물), HEPES (4-(2-히드록시에틸)피페라진-1-에탄술폰산), HEPPS (EPPS) (4-(2-히드록시에틸)피페라진-1-프로판술폰산), TES (N-[트리스(히드록시메틸)메틸]-2-아미노에탄술폰산), 및 그의 조합물로 이루어진 군으로부터 선택된다.
한 실시양태에서, 1-단계 방법은 혼합물을 정제하여 정제된 접합체 (예를 들어, Ab-MCC-DM1, Ab-SPDB-DM4 또는 Ab-CX1-1-DM1)를 제공하는 단계를 추가로 포함할 수 있다. 관련 기술분야에 공지된 임의의 정제 방법은 본 발명의 접합체를 정제하는데 사용될 수 있다. 한 실시양태에서, 본 발명의 접합체는 접선 흐름 여과 (TFF), 비-흡착성 크로마토그래피, 흡착성 크로마토그래피, 흡착성 여과, 선택적 침착, 또는 임의의 다른 적합한 정제 방법, 뿐만 아니라 그의 조합을 사용하여 정제된다. 또 다른 실시양태에서, 접합체를 상기 기재된 정제 방법에 적용하기 이전에, 접합체를 먼저 하나 이상의 PVDF 막을 통해 여과한다. 대안적으로, 접합체를 상기 기재된 정제 방법에 적용한 후에, 접합체를 하나 이상의 PVDF 막을 통해 여과한다. 예를 들어, 한 실시양태에서, 접합체는 하나 이상의 PVDF 막을 통해 여과시키고, 이어서 접선 흐름 여과를 사용하여 정제한다. 대안적으로, 접합체는 접선 흐름 여과를 사용하여 정제하고, 이어서 하나 이상의 PVDF 막을 통해 여과시킨다.
펠리콘(Pellicon)® 유형 시스템 (밀리포어(Millipore), 마이애미주 빌러리카), 사르토콘(Sartocon)® 카세트 시스템 (사토리우스 AG, 뉴욕주 엣지우드) 및 센트라셋(Centrasette)™ 유형 시스템 (팔 코포레이션(Pall Corp.), 뉴욕주 이스트 힐스)을 비롯한 임의의 적합한 TFF 시스템이 정제에 활용될 수 있다.
임의의 적합한 흡착성 크로마토그래피 수지가 정제에 활용될 수 있다. 바람직한 흡착성 크로마토그래피 수지는 히드록시아파타이트 크로마토그래피, 소수성 충전 유도 크로마토그래피 (HCIC), 소수성 상호작용 크로마토그래피 (HIC), 이온 교환 크로마토그래피, 혼합 모드 이온 교환 크로마토그래피, 고정된 금속 친화성 크로마토그래피 (IMAC), 염료 리간드 크로마토그래피, 친화성 크로마토그래피, 역상 크로마토그래피 및 그의 조합을 포함한다. 적합한 히드록시아파타이트 수지의 예는 세라믹 히드록시아파타이트 (CHT 유형 I 및 유형 II, 바이오-라드 래보러토리즈(Bio-Rad Laboratories), 캘리포니아주 허큘레스), HA 울트로겔(Ultrogel)® 히드록시아파타이트 (팔 코포레이션, 뉴욕주 이스트 힐스) 및 세라믹 플루오로아파타이트 (CFT 유형 I 및 유형 II, 바이오-라드 래보러토리즈, 캘리포니아주 허큘레스)를 포함한다. 적합한 HCIC 수지의 예는 MEP 하이퍼셀(Hypercel)™ 수지 (팔 코포레이션, 뉴욕주 이스트 힐스)이다. 적합한 HIC 수지의 예는 부틸-세파로스(Sepharose)®, 헥실-세파로스®, 페닐-세파로스® 및 옥틸 세파로스® 수지 (모두 지이 헬스케어(GE Healthcare), 뉴저지주 피스카타웨이로부터), 뿐만 아니라 매크로-정제용 메틸 및 매크로-정제용 t-부틸 수지 (바이오라드 래보러토리즈, 캘리포니아주 허큘레스)를 포함한다. 적합한 이온 교환 수지의 예는 SP-세파로스®, CM-세파로스® 및 Q-세파로스® 수지 (모두 지이 헬스케어, 뉴저지주 피스카타웨이로부터) 및 우노스페르(Unosphere)™ S 수지 (바이오-라드, 캘리포니아주 허큘레스)를 포함한다. 적합한 혼합 모드 이온 교환체의 예는 베이커본드(Bakerbond)® ABx 수지 (JT 베이커(JT Baker), 뉴저지주 필립스버그)를 포함한다. 적합한 IMAC 수지의 예는 킬레이팅 세파로스® 수지 (지이 헬스케어, 뉴저지주 피스카타웨이) 및 프로피니티(Profinity) IMAC 수지 (바이오-라드, 캘리포니아주 허큘레스)를 포함한다. 적합한 염료 리간드 수지의 예는 블루 세파로스® 수지 (지이 헬스케어, 뉴저지주 피스카타웨이) 및 아피-겔(Affi-gel)® 블루 수지 (바이오-라드 래보러토리즈, 캘리포니아주 허큘레스)를 포함한다. 적합한 친화도 수지의 예는 단백질 A 세파로스® 수지 (예를 들어, 맙셀렉트(MabSelect), 지이 헬스케어, 뉴저지주 피스카타웨이) 및 렉틴 친화도 수지, 예를 들어 렌틸 렉틴 세파로스(Lentil Lectin Sepharose)® 수지 (지이 헬스케어, 뉴저지주 피스카타웨이)를 포함하며, 여기서 항체는 적절한 렉틴 결합 부위를 보유한다. 적합한 역상 수지의 예는 C4, C8 및 C18 수지 (그레이스 비닥(Grace Vydac), 캘리포니아주 헤스페리아)를 포함한다.
임의의 적합한 비-흡착성 크로마토그래피 수지가 정제에 활용될 수 있다. 적합한 비-흡착성 크로마토그래피 수지의 예는 세파덱스(SEPHADEX)™ G-25, G-50, G-100, 세파크릴(SEPHACRYL)™ 수지 (예를 들어, S-200 및 S-300), 슈퍼덱스(SUPERDEX)™ 수지 (예를 들어, 슈퍼덱스™ 75 및 슈퍼덱스™ 200), 바이오-겔(BIO-GEL)® 수지 (예를 들어, P-6, P-10, P-30, P-60 및 P-100), 및 통상의 기술자에게 공지된 다른 것들을 포함하나, 이에 제한되지는 않는다.
2-단계 방법 및 원-포트 방법
한 실시양태에서, 본 발명의 접합체는 미국 특허 7,811,572 및 미국 특허 출원 공개 번호 2006/0182750에 기재된 바와 같이 제조될 수 있다. 상기 방법은 (a) 본 발명의 항체를 가교제 (예를 들어, SMCC, 술포-SMCC, SPDB, 술포-SPDB 또는 CX1-1)와 접촉시켜 링커 (즉, Ab-SMCC, Ab-SPDB 또는 Ab-CX1-1)를 항체에 공유 부착시키고, 이에 따라 링커가 결합되어 있는 항체를 포함하는 제1 혼합물을 제조하는 단계; (b) 제1 혼합물을 정제 방법에 임의로 적용하여 링커가 결합되어 있는 항체의 정제된 제1 혼합물을 제조하는 단계; (c) 링커가 결합되어 있는 항체를 약물 (예를 들어, DM1 또는 DM4)과 약 4 내지 약 9의 pH를 갖는 용액 중에서 반응시킴으로써 약물 (예를 들어, DM1 또는 DM4)을 링커가 결합되어 있는 항체와 제1 혼합물 중에서 접촉시켜 (i) 접합체 (예를 들어, Ab-MCC-DM1, Ab-SPDB-DM4 또는 Ab-CX1-1-DM1), (ii) 유리 약물 (예를 들어, DM1 또는 DM4); 및 (iii) 반응 부산물을 포함하는 제2 혼합물을 제조하는 단계; 및 (d) 제2 혼합물을 정제 방법에 적용하여 접합체를 제2 혼합물의 다른 성분으로부터 정제하는 단계를 포함한다. 대안적으로, 정제 단계 (b)는 생략될 수 있다. 본원에 기재된 임의의 정제 방법은 단계 (b) 및 (d)에 사용된다. 한 실시양태에서, TFF는 단계 (b) 및 (d)에 사용된다. 또 다른 실시양태에서, TFF는 단계 (b)에 대해 사용되고, 흡착성 크로마토그래피 (예를 들어, CHT)는 단계 (d)에 사용된다.
1-단계 시약 및 계내 방법
한 실시양태에서, 본 발명의 접합체는, 미국 특허 6,441,163 및 미국 특허 출원 공개 번호 2011/0003969 및 2008/0145374에 기재된 바와 같이, 사전-형성된 약물-링커 화합물 (예를 들어, SMCC-DM1, 술포-SMCC-DM1, SPDB-DM4 또는 CX1-1-DM1)을 본 발명의 항체에 접합시키고, 이어서 정제 단계에 의해 제조될 수 있다. 본원에 기재된 임의의 정제 방법이 사용될 수 있다. 약물-링커 화합물은 약물 (예를 들어, DM1 또는 DM4)을 가교제 (예를 들어, SMCC, 술포-SMCC, SPDB, 술포-SPDB 또는 CX1-1)와 반응시킴으로써 제조된다. 약물-링커 화합물 (예를 들어, SMCC-DM1, 술포-SMCC-DM1, SPDB-DM4 또는 CX1-1-DM1)은 항체에 접합되기 전에 정제에 임의로 적용된다.
4. 목적하는 항체 및 항체 약물 접합체의 특성화 및 선택
본 발명의 항체, 항체 단편 (예를 들어, 항원 결합 단편) 또는 항체 약물 접합체는 관련 기술분야에 공지된 다양한 검정에 의해 그의 물리적/화학적 특성 및/또는 생물학적 활성에 대해 특성화되고 선택될 수 있다.
예를 들어, 본 발명의 항체는 공지된 방법, 예컨대 ELISA, FACS, 비아코어(Biacore)® 또는 웨스턴 블롯에 의해 그의 항원 결합 활성에 대해 시험될 수 있다.
트랜스제닉 동물 및 세포주는 특히 종양-연관 항원 및 세포 표면 수용체의 암 과다발현의 예방적 또는 치료적 치료로서 잠재성을 갖는 항체 약물 접합체 (ADC)를 스크리닝하는데 유용하다. 유용한 ADC를 위한 스크리닝은, 소정 범위의 용량에 걸쳐 후보 ADC를 트랜스제닉 동물에게 투여하고, 평가할 질환 또는 장애에 대한 ADC의 효과(들)를 다양한 시점에 검정하는 것을 포함할 수 있다. 대안적으로 또는 추가로, 약물은 질환 유도자 (적용가능한 경우)에의 노출 전에 또는 그와 동시에 투여될 수 있다. 후보 ADC는 연속적으로 및 개별적으로, 또는 중간 처리량 또는 고처리량 스크리닝 포맷 하에 대등하게 스크리닝될 수 있다.
한 실시양태는 (a) FGFR2 또는 FGFR4를 발현하는 안정한 암 세포주 또는 인간 환자 종양으로부터의 세포 (예를 들어, 유방암 세포주 또는 종양 단편, 위암 세포주 또는 종양 단편)를 비-인간 동물 내로 이식하고, (b) ADC 약물 후보를 비-인간 동물에게 투여하고, (c) 이식된 세포주로부터의 종양 성장을 억제하는 후보의 능력을 결정하는 것을 포함하는 스크리닝 방법이다. 본 발명은 또한 (a) FGFR2 또는 FGFR4를 발현하는 안정한 암 세포주로부터의 세포를 약물 후보와 접촉시키고, (b) 안정한 세포주의 성장을 억제하는 ADC 후보의 능력을 평가하는 것을 포함하는, FGFR2 또는 FGFR4의 과다발현을 특징으로 하는 질환 또는 장애의 치료를 위한 ADC 후보를 스크리닝하는 방법을 포괄한다.
한 실시양태는 (a) FGFR2 또는 FGFR4를 발현하는 안정한 암 세포주로부터의 세포를 ADC 약물 후보와 접촉시키고, (b) FGFR2 또는 FGFR4의 리간드 활성화를 차단하는 ADC 후보의 능력을 평가하는 것을 포함하는 스크리닝 방법이다. 또 다른 실시양태에서 리간드-자극 티로신 인산화를 차단하는 ADC 후보의 능력이 평가된다.
또 다른 실시양태는 (a) FGFR2 또는 FGFR4를 발현하는 안정한 암 세포주로부터의 세포를 ADC 약물 후보와 접촉시키고, (b) 세포 사멸을 유도하는 ADC 후보의 능력을 평가하는 것을 포함하는 스크리닝 방법이다. 한 실시양태에서 아폽토시스를 유도하는 ADC 후보의 능력이 평가된다.
한 실시양태에서, 후보 ADC는, 트랜스제닉 동물에 소정 범위의 용량에 걸쳐 투여하고, 화합물에 대한 동물의 생리학적 반응을 시간에 따라 평가함으로써 스크리닝된다. 일부 경우에서, 화합물을 상기 화합물의 효능을 증진시키는 보조인자와 함께 투여하는 것이 적절할 수 있다. 대상체 트랜스제닉 동물로부터 유래된 세포주가 FGFR2 또는 FGFR4의 과다발현과 연관된다양한 장애를 치료하는데 유용한 ADC에 대한 스크리닝에 사용되는 경우에, 시험 ADC는 적절한 시간에 세포 배양 배지에 첨가되고, ADC에 대한 세포성 반응은 적절한 생화학적 및/또는 조직학적 검정을 사용하여 시간에 걸쳐 평가된다.
따라서, 본 발명은 FGFR2 및 FGFR4 둘 다 (종양 세포 상에서 이의 과다발현 및 증폭은 비정상적 세포 기능과 상관관계가 있음)를 특이적으로 표적화하고 이에 결합하는 ADC를 확인하는 검정을 제공한다. 한 실시양태에서, 본 발명은 하기 속성을 갖는 항-FGFR2/4 항체 또는 항체 단편 (예를 들어, 항원 결합 단편)을 포함하는 ADC를 제공한다: MCC-DM1 또는 SPDB-DM4에 대한 접합 후 인간 FGFR2에 대한 친화도 10 nM 미만, FGFR2/4 증폭 및/또는 과다발현 세포의 성장을 억제하는 능력 IC50 2 nM 미만 , 느린 클리어런스율, 예를 들어, 단일 3 mg/kg IV 용량 후 마우스에서 45 ml/d/kg 미만.
FGFR2/4 항체
본 발명은 인간 FGFR2 및 FGFR4 (FGFR2/4)에 특이적으로 결합하는 항체 또는 항체 단편 (예를 들어, 항원 결합 단편)을 제공한다. 본 발명의 항체 또는 항체 단편 (예를 들어, 항원 결합 단편)은 실시예 (하기 섹션 6 참조)에서 기재된 바와 같이 단리된 인간 모노클로날 항체 또는 단편을 포함하나, 이에 제한되지는 않는다.
본 발명은 특정 실시양태에서 FGFR2/4에 특이적으로 결합하는 항체 또는 항체 단편 (예를 들어, 항원 결합 단편)을 제공하고, 상기 항체 또는 항체 단편 (예를 들어, 항원 결합 단편)은 서열 7, 27, 47, 67, 87 또는 107의 아미노산 서열을 갖는 VH 도메인을 포함한다. 본 발명은 특정 실시양태에서 또한 FGFR2/4에 특이적으로 결합하는 항체 또는 항체 단편 (예를 들어, 항원 결합 단편)을 제공하고, 상기 항체 또는 항체 단편 (예를 들어, 항원 결합 단편)은 하기 표 1에 열거된 VH CDR 중 어느 하나의 아미노산 서열을 갖는 VH CDR을 포함한다. 특정한 실시양태에서, 본 발명은 FGFR2/4에 특이적으로 결합하는 항체 또는 항체 단편 (예를 들어, 항원 결합 단편)을 제공하고, 상기 항체는 하기 표 1에 열거된 VH CDR 중 어느 하나의 아미노산 서열을 갖는 1, 2, 3, 4, 5 또는 그 초과의 VH CDR을 포함한다 (또는 대안적으로 이것으로 이루어짐).
본 발명은 FGFR2/4에 특이적으로 결합하는 항체 또는 항체 단편 (예를 들어, 항원 결합 단편)을 제공하고, 상기 항체 또는 항체 단편 (예를 들어, 항원 결합 단편)은 서열 17, 37, 57, 77, 97 또는 117의 아미노산 서열을 갖는 VL 도메인을 포함한다. 본 발명은 또한 FGFR2/4에 특이적으로 결합하는 항체 또는 항체 단편 (예를 들어, 항원 결합 단편)을 제공하고, 상기 항체 또는 항체 단편 (예를 들어, 항원 결합 단편)은 하기 표 1에 열거된 VL CDR 중 어느 하나의 아미노산 서열을 갖는 VL CDR을 포함한다. 특히, 본 발명은 FGFR2/4에 특이적으로 결합하는 항체 또는 항체 단편 (예를 들어, 항원 결합 단편)을 제공하고, 상기 항체 또는 항체 단편 (예를 들어, 항원 결합 단편)은 하기 표 1에 열거된 VL CDR 중 어느 하나의 아미노산 서열을 갖는 1, 2, 3 또는 그 초과의 VL CDR을 포함한다 (또는 대안적으로 이것으로 이루어짐).
본 발명의 다른 항체 또는 항체 단편 (예를 들어, 항원 결합 단편)은, 돌연변이되었지만 CDR 영역에서 표 1에 기재된 서열에 도시된 CDR 영역과 적어도 60, 70, 80, 90 또는 95 퍼센트 동일성을 갖는 아미노산을 포함한다. 일부 실시양태에서, 이는 표 1에 기재된 서열에 도시된 CDR 영역과 비교 시에 1, 2, 3, 4 또는 5개 이하의 아미노산이 CDR 영역에서 돌연변이된 돌연변이체 아미노산 서열을 포함한다.
본 발명은 또한 FGFR2/4에 특이적으로 결합하는 항체의 VH, VL, 전장 중쇄 및 전장 경쇄를 코딩하는 핵산 서열을 제공한다. 이러한 핵산 서열은 포유동물 세포에서의 발현에 최적화될 수 있다.
<표 1> 본 발명의 항-FGFR2/4 항체의 예















본 발명의 다른 항체는 아미노산 또는 아미노산을 코딩하는 핵산이 돌연변이되었지만 표 1에 기재된 서열과 적어도 60, 70, 80, 90 또는 95 퍼센트 동일성을 갖는 것들을 포함한다. 일부 실시양태에서, 이것은 표 1에 기재된 서열에 도시된 가변 영역과 비교하였을 때 가변 영역에서 1, 2, 3, 4 또는 5개 이하의 아미노산이 돌연변이되고 실질적으로 동일한 치료 활성을 보유하는 돌연변이체 아미노산 서열을 포함한다.
각각의 이러한 항체는 FGFR2/4에 결합할 수 있기 때문에, VH, VL, 전장 경쇄 및 전장 중쇄 서열 (아미노산 서열 및 아미노산 서열을 코딩하는 뉴클레오티드 서열)은 "혼합 및 매칭"되어 본 발명의 다른 FGFR2/4-결합 항체를 생성할 수 있다. 이러한 "혼합 및 매칭"된 FGFR2/4-결합 항체는 관련 기술분야에 공지된 결합 검정 (예를 들어, ELISA, 및 실시예 섹션에 기재된 다른 검정)을 사용하여 시험할 수 있다. 이들 쇄가 혼합 및 매칭되는 경우에, 특정한 VH/VL 쌍으로부터의 VH 서열은 구조적으로 유사한 VH 서열로 대체되어야 한다. 마찬가지로, 특정한 전장 중쇄 / 전장 경쇄 쌍으로부터의 전장 중쇄 서열은 구조적으로 유사한 전장 중쇄 서열로 대체되어야 한다. 마찬가지로, 특정한 VH/VL 쌍으로부터의 VL 서열은 구조적으로 유사한 VL 서열로 대체되어야 한다. 마찬가지로, 특정한 전장 중쇄 / 전장 경쇄 쌍으로부터의 전장 경쇄 서열은 구조적으로 유사한 전장 경쇄 서열로 대체되어야 한다. 따라서, 한 측면에서, 본 발명은 서열 7, 27, 47, 67, 87 및 107로 이루어진 군으로부터 선택된 아미노산 서열을 포함하는 중쇄 가변 영역; 서열 17, 37, 57, 77, 97 및 117로 이루어진 군으로부터 선택된 아미노산 서열을 포함하는 경쇄 가변 영역을 가지며; 여기서 항체는 FGFR2/4에 특이적으로 결합하는 것인, 단리된 모노클로날 항체 또는 그의 항원 결합 영역을 제공한다.
또 다른 측면에서, 본 발명은 (i) 서열 9, 29, 49, 69, 89 및 109로 이루어진 군으로부터 선택된 포유동물 세포에서의 발현에 대해 최적화된 아미노산 서열을 포함하는 전장 중쇄; 및 서열 19, 39, 59, 79, 99 및 119로 이루어진 군으로부터 선택된 포유동물 세포에서의 발현에 대해 최적화된 아미노산 서열을 포함하는 전장 경쇄를 갖는 단리된 항체; 또는 (ii) 그의 항원 결합 부분을 포함하는 기능적 단백질을 제공한다.
또 다른 측면에서, 본 발명은 표 1에 기재된 바와 같은 중쇄 및 경쇄 CDR1, CDR2 및 CDR3, 또는 그의 조합을 포함하는 FGFR2/4-결합 항체를 제공한다. 항체의 VH CDR1의 아미노산 서열은 서열 1, 21, 41, 61, 81 및 101로 제시된다. 항체의 VH CDR2의 아미노산 서열은 서열 2, 22, 42, 62, 82 및 102로 제시된다. 항체의 VH CDR3의 아미노산 서열은 서열 3, 23, 43, 63, 83 및 103으로 제시된다. 항체의 VL CDR1의 아미노산 서열은 서열 11, 31, 51, 71, 91 및 111로 제시된다. 항체의 VL CDR2의 아미노산 서열은 서열 12, 32, 52, 72, 92 및 112로 제시된다. 항체의 VL CDR3의 아미노산 서열은 서열 13, 33, 53, 73, 93 및 113으로 제시된다.
각각의 이들 항체가 FGFR2/4에 결합할 수 있고 항원-결합 특이성이 주로 CDR1, 2 및 3 영역에 의해 제공됨을 고려하면, VH CDR1, 2 및 3 서열 및 VL CDR1, 2 및 3 서열은 "혼합 및 매칭"될 수 있지만 (즉, 상이한 항체로부터의 CDR이 혼합 및 매칭될 수 있지만), 각각의 항체는 본 발명의 다른 C5-결합 분자를 생성하기 위해 VH CDR1, 2 및 3 및 VL CDR1, 2 및 3을 함유한다. 이러한 "혼합 및 매치"된 FGFR2/4 결합 항체는 관련 기술분야 공지의 결합 검정 및 실시예에 기재된 방법 (예를 들어, ELISA)으로 시험할 수 있다. VH CDR 서열이 혼합 및 매칭되는 경우에, 특정한 VH 서열로부터의 CDR1, CDR2 및/또는 CDR3 서열은 구조적으로 유사한 CDR 서열(들)로 대체되어야 한다. 마찬가지로, VL CDR 서열이 혼합 및 매칭되는 경우에, 특정한 VL 서열로부터의 CDR1, CDR2 및/또는 CDR3 서열은 구조적으로 유사한 CDR 서열(들)로 대체되어야 한다. 1개 이상의 VH 및/또는 VL CDR 영역 서열을 본 발명의 모노클로날 항체에 대해 본원에 제시된 CDR 서열로부터의 구조적으로 유사한 서열로 치환함으로써 신규한 VH 및 VL 서열이 생성될 수 있음이 통상의 기술자에게 매우 명확할 것이다.
따라서, 본 발명은 서열 1, 21, 41, 61, 81 및 101로 이루어진 군으로부터 선택된 아미노산 서열을 포함하는 중쇄 CDR1; 서열 2, 22, 42, 62, 82 및 102로 이루어진 군으로부터 선택된 아미노산 서열을 포함하는 중쇄 CDR2; 서열 3, 23, 43, 63, 83 및 103으로 이루어진 군으로부터 선택된 아미노산 서열을 포함하는 중쇄 CDR3; 서열 11, 31, 51, 71, 91 및 111로 이루어진 군으로부터 선택된 아미노산 서열을 포함하는 경쇄 CDR1; 서열 12, 32, 52, 72, 92 및 112로 이루어진 군으로부터 선택된 아미노산 서열을 포함하는 경쇄 CDR2; 및 서열 13, 33, 53, 73, 93 및 113으로 이루어진 군으로부터 선택된 아미노산 서열을 포함하는 경쇄 CDR3을 포함하며; 여기서 항체는 FGFR2/4에 특이적으로 결합하는 것인, 단리된 모노클로날 항체 또는 그의 항원 결합 영역을 제공한다.
구체적 실시양태에서, FGFR2/4에 특이적으로 결합하는 항체 또는 항체 단편 (예를 들어, 항원 결합 단편)은 서열 1의 중쇄 CDR1, 서열 2의 중쇄 CDR2; 서열 3의 중쇄 CDR3; 서열 11의 경쇄 CDR1; 서열 12의 경쇄 CDR2; 및 서열 13의 경쇄 CDR3을 포함한다.
구체적 실시양태에서, FGFR2/4에 특이적으로 결합하는 항체 또는 항체 단편 (예를 들어, 항원 결합 단편)은 서열 21의 중쇄 CDR1, 서열 22의 중쇄 CDR2; 서열 23의 중쇄 CDR3; 서열 31의 경쇄 CDR1; 서열 32의 경쇄 CDR2; 및 서열 33의 경쇄 CDR3을 포함한다.
구체적 실시양태에서, FGFR2/4에 특이적으로 결합하는 항체 또는 항체 단편 (예를 들어, 항원 결합 단편)은 서열 41의 중쇄 CDR1, 서열 42의 중쇄 CDR2; 서열 43의 중쇄 CDR3; 서열 51의 경쇄 CDR1; 서열 52의 경쇄 CDR2; 및 서열 53의 경쇄 CDR3을 포함한다.
구체적 실시양태에서, FGFR2/4에 특이적으로 결합하는 항체 또는 항체 단편 (예를 들어, 항원 결합 단편)은 서열 61의 중쇄 CDR1, 서열 62의 중쇄 CDR2; 서열 63의 중쇄 CDR3; 서열 71의 경쇄 CDR1; 서열 72의 경쇄 CDR2; 및 서열 73의 경쇄 CDR3을 포함한다.
구체적 실시양태에서, FGFR2/4에 특이적으로 결합하는 항체 또는 항체 단편 (예를 들어, 항원 결합 단편)은 서열 81의 중쇄 CDR1, 서열 82의 중쇄 CDR2; 서열 83의 중쇄 CDR3; 서열 91의 경쇄 CDR1; 서열 92의 경쇄 CDR2; 및 서열 93의 경쇄 CDR3을 포함한다.
구체적 실시양태에서, FGFR2/4에 특이적으로 결합하는 항체 또는 항체 단편 (예를 들어, 항원 결합 단편)은 서열 101의 중쇄 CDR1, 서열 102의 중쇄 CDR2; 서열 103의 중쇄 CDR3; 서열 111의 경쇄 CDR1; 서열 112의 경쇄 CDR2; 및 서열 113의 경쇄 CDR3을 포함한다.
특정 실시양태에서, FGFR2/4에 특이적으로 결합하는 결합하는 항체는 표 1에서 기재된 항체 또는 항체 단편 (예를 들어, 항원 결합 단편)이다.
1. 에피토프 및 상기 에피토프에 결합하는 항체의 확인
한 실시양태에서, 본 발명은 서열 137의 아미노산 176 (Lys) 및 210 (Arg)을 포함하는 인간 FGFR2 상의 에피토프에 특이적으로 결합하는 항체 또는 항체 단편 (예를 들어, 항원 결합 단편)을 제공한다. 일부 측면에서, 본 발명은 서열 137에 나타낸 바와 같은 인간 FGFR2의 위치 173 (Asn), 174 (Thr), 175 (Val), 176 (Lys), 178 (Arg), 208 (Lys), 209 (Val), 210 (Arg), 212 (Gln), 213 (His), 217 (Ile), 219 (Glu)에서의 아미노산에 특이적으로 결합하는 항체 또는 항체 단편 (예를 들어, 항원 결합 단편)을 제공한다.
한 실시양태에서, 본 발명은 인간 FGFR2 (P21802-3에 따라 넘버링됨; 서열 137)의 아미노산 160-189 (KMEKRLHAVPAANTVKFRCPAGGNPMPTMR; 서열 136) 및/또는 아미노산 198-216 (KMEKRLHAVPAANTVKFRC; 서열 141)의 에피토프에 결합하는 항체 및 항체 단편 (예를 들어, 항원 결합 단편)을 제공한다.
한 실시양태에서, 본 발명은 서열 142의 아미노 169 (Lys) 및 203 (Arg)을 포함하는 인간 FGFR4 상의 에피토프에 특이적으로 결합하는 항체 또는 항체 단편 (예를 들어, 항원 결합 단편)을 제공한다. 일부 측면에서, 본 발명은 서열 142에 나타낸 바와 같은 인간 FGFR4의 위치 150 (Thr), 151 (His), 154 (Arg), 157 (Lys), 160 (His), 166 (Asn), 167 (Thr), 168 (Val), 169 (Lys), 171 (Arg), 173 (Pro), 174 (Ala), 201 (Arg), 202 (Leu), 203 (Arg), 204 (His), 205 (Gln), 206 (His), 207 (Trp), 210 (Val) 및 212 (Glu)에서의 아미노산에 특이적으로 결합하는 항체 또는 항체 단편 (예를 들어, 항원 결합 단편)을 제공한다.
한 실시양태에서, 본 발명은 인간 FGFR4 (P22455-1에 따라 넘버링됨; 서열 142)의 아미노산 150-174 (THPQRMEKKLHAVPAGNTVKFRCPA; 서열 132) 및/또는 아미노산 201-212 (RLRHQHWSLVME; 서열 133)의 에피토프에 결합하는 항체 및 항체 단편 (예를 들어, 항원 결합 단편)을 제공한다.
한 실시양태에서, 본 발명은 서열 137의 아미노산 176 (Lys) 및 210 (Arg)을 포함하는 인간 FGFR2 상의 에피토프 및 서열 142의 아미노산 169 (Lys) 및 203 (Arg)을 포함하는 인간 FGFR4 상의 에피토프에 특이적으로 결합하는 항체 또는 항체 단편 (예를 들어, 항원 결합 단편)을 제공한다.
한 실시양태에서, 본 발명은 인간 FGFR2 (P21802-3에 따라 넘버링됨; 서열 137)의 아미노산 160-189 (KMEKRLHAVPAANTVKFRCPAGGNPMPTMR; 서열 136) 및 아미노산 198-216 (KMEKRLHAVPAANTVKFRC; 서열 141)의 에피토프 및 인간 FGFR4 (P22455-1에 따라 넘버링됨; 서열 142)의 아미노산 150-174 (THPQRMEKKLHAVPAGNTVKFRCPA; 서열 132) 및 아미노산 201-212 (RLRHQHWSLVME; 서열 133)의 에피토프에 결합하는 항체 및 항체 단편 (예를 들어, 항원 결합 단편)을 제공한다.
본 발명은 또한 표 1에 기재된 항-FGFR2/4 항체가 그러하듯 동일한 에피토프에 특이적으로 결합하거나 또는 표 1에 기재된 항체와 교차 경쟁하는 항체 및 항체 단편 (예를 들어, 항원 결합 단편)을 제공한다. 따라서, 추가의 항체 및 항체 단편 (예를 들어, 항원 결합 단편)은 FGFR2 및/또는 FGFR4 결합 검정에서 본 발명의 다른 항체와 교차-경쟁하는 (예를 들어, 본 발명의 다른 항체의 결합을 통계적으로 유의한 방식으로 경쟁적으로 억제하는) 능력을 기반으로 하여 확인될 수 있다. 본 발명의 항체 및 항체 단편 (예를 들어, 항원 결합 단편)의 FGFR2 및/또는 FGFR4 단백질 (예를 들어, 인간 FGFR2 및/또는 FGFR4)에 대한 결합을 억제하는 시험 항체의 능력은 시험 항체가, FGFR2 및/또는 FGFR4에 결합하는 항체 또는 항체 단편 (예를 들어, 항원 결합 단편)과 경쟁할 수 있는 것을 입증하고; 이러한 항체는, 비제한적 이론에 따라, 이것이 경쟁하는 항체 또는 항체 단편 (예를 들어, 항원 결합 단편)와 동일하거나 관련이 있는 (예를 들어, 구조적으로 유사하거나 공간적으로 근접한), FGFR2 및/또는 FGFR4 단백질 상의 에피토프에 결합한다. 특정 실시양태에서, 표 1에 기재된 항체 또는 항체 단편 (예를 들어, 항원 결합 단편)과 동일한, FGFR2 및/또는 FGFR4 상의 에피토프에 결합하는 항체는 인간 또는 인간화 모노클로날 항체이다. 이러한 인간 또는 인간화 모노클로날 항체는 본원에 기재된 바와 같이 제조되고 단리될 수 있다.
2. Fc 영역의 프레임워크의 추가적 변경
본 발명의 면역접합체는, 예를 들어 항체의 특성을 개선하기 위해, VH 및/또는 VL 내의 프레임워크 잔기에 대한 변형을 추가로 포함하는 변형된 항체 또는 그의 항원 결합 단편을 포함할 수 있다. 일부 실시양태에서, 이러한 프레임워크 변형은 항체의 면역원성을 감소시키기 위해 이루어진다. 예를 들어, 한가지 접근법은 하나 이상의 프레임워크 잔기를 상응하는 배선 서열로 "역-돌연변이"시키는 것이다. 보다 구체적으로, 체세포 돌연변이가 일어난 항체는 항체가 유래된 배선 서열과는 상이한 프레임워크 잔기를 함유할 수 있다. 이러한 잔기는 항체 프레임워크 서열을 항체가 유래된 배선 서열과 비교함으로써 확인될 수 있다. 프레임워크 영역을 그의 배선 배위로 되돌리기 위해, 예를 들어 부위-지정 돌연변이유발에 의해, 체세포 돌연변이를 배선 서열로 "역-돌연변이"시킬 수 있다. 이러한 "역-돌연변이"된 항체 또한 본 발명에 포괄되도록 의도된다.
또 다른 유형의 프레임워크 변형은 프레임워크 영역 내의, 또는 심지어 하나 이상의 CDR 영역 내의 하나 이상의 잔기를 돌연변이시켜 T-세포 에피토프를 제거함으로써 항체의 잠재적인 면역원성을 감소시키는 것을 포함한다. 이러한 접근법은 또한 "탈면역화"로도 지칭되고, 미국 특허 공개 번호 20030153043 (Carr et al.)에 추가로 상세하게 기재되어 있다.
프레임워크 또는 CDR 영역 내에서 이루어진 변형에 더하여 또는 대안적으로, 본 발명의 항체는 전형적으로 항체의 하나 이상의 기능적 특성, 예컨대 혈청 반감기, 보체 고정, Fc 수용체 결합 및/또는 항원-의존성 세포성 세포독성을 변경하기 위해 Fc 영역 내에 변형을 포함하도록 조작될 수 있다. 또한, 본 발명의 항체는 항체의 하나 이상의 기능적 특성을 다시 변경하기 위해 화학적으로 변형될 수 있거나 (예를 들어, 하나 이상의 화학적 모이어티가 항체에 부착될 수 있음), 또는 그의 글리코실화를 변경하도록 변형될 수 있다. 각각의 이들 실시양태가 하기에 추가로 상세하게 기재된다.
한 실시양태에서, CH1의 힌지 영역은 힌지 영역 내의 시스테인 잔기의 수가 변경, 예를 들어 증가 또는 감소되도록 변형된다. 이러한 접근법은 미국 특허 번호 5,677,425 (Bodmer et al.)에 추가로 기재되어 있다. CH1의 힌지 영역 내의 시스테인 잔기의 수는, 예를 들어 경쇄 및 중쇄의 어셈블리를 용이하게 하거나 또는 항체의 안정성을 증가 또는 감소시키기 위해 변경된다.
또 다른 실시양태에서, 항체의 생물학적 반감기를 감소시키기 위해 항체의 Fc 힌지 영역이 돌연변이된다. 보다 구체적으로, 하나 이상의 아미노산 돌연변이가 Fc-힌지 단편의 CH2-CH3 도메인 계면 영역에 도입되어, 항체는 천연 Fc-힌지 도메인 스타필로코실 단백질 A (SpA) 결합에 비해 손상된 SpA 결합을 갖게 된다. 이러한 접근법은 미국 특허 번호 6,165,745 (Ward et al.)에 추가로 상세하게 기재되어 있다.
또 다른 실시양태에서, 항체의 이펙터 기능을 변경시키기 위해 Fc 영역은 적어도 하나의 아미노산 잔기를 상이한 아미노산 잔기로 대체하는 것에 의해 변경된다. 예를 들어, 항체가 이펙터 리간드에 대해 변경된 친화도를 갖지만 모 항체의 항원-결합 능력은 보유하도록 하나 이상의 아미노산이 상이한 아미노산 잔기로 대체될 수 있다. 친화도가 변경된 이펙터 리간드는, 예를 들어 Fc 수용체 또는 보체의 C1 성분일 수 있다. 미국 특허 번호 5,624,821 및 5,648,260 (둘 다 Winter et al.)에 이러한 접근법이 기재되어 있다.
또 다른 실시양태에서, 항체가 변경된 C1q 결합 및/또는 감소되거나 제거된 보체 의존성 세포독성 (CDC)을 갖도록 아미노산 잔기로부터 선택된 하나 이상의 아미노산을 상이한 아미노산 잔기로 대체할 수 있다. 예를 들어, 미국 특허 번호 6,194,551 (Idusogie et al.)에 이러한 접근법이 기재되어 있다.
또 다른 실시양태에서, 하나 이상의 아미노산 잔기를 변경함으로써 보체를 고정하는 항체의 능력을 변경한다. 예를 들어, PCT 공개 WO 94/29351 (Bodmer et al.)에 이러한 접근법이 기재되어 있다. 구체적 실시양태에서, 본 발명의 항체 또는 그의 단편의 하나 이상의 아미노산은 하나 이상의 동종이형 아미노산 잔기, 예컨대 IgG1 하위부류 및 카파 이소형에 대해 도 4에서 제시된 것들로 교체된다. 동종이형 아미노산 잔기는 또한 문헌 [Jefferis et al., MAbs. 1:332-338 (2009)]에 기재된 바와 같이 IgG1, IgG2, 및 IgG3 하위부류의 중쇄의 불변 영역, 뿐만 아니라 카파 이소형의 경쇄의 불변 영역을 또한 포함하나, 이에 제한되지는 않는다.
또 다른 실시양태에서, 하나 이상의 아미노산을 변형시킴으로써 항체 의존성 세포성 세포독성 (ADCC)을 매개하는 항체의 능력을 증가시키고/거나 Fcγ 수용체에 대한 항체의 친화도를 증가시키기 위해 Fc 영역이 변형된다. 예를 들어, PCT 공개 WO 00/42072 (Presta)에 이러한 접근법이 기재되어 있다. 또한, FcγRl, FcγRII, FcγRIII 및 FcRn에 대한 인간 IgG1 상의 결합 부위가 맵핑된 바 있고, 결합이 개선된 변이체들이 기재되어 있다 (문헌 [Shields et al., J. Biol. Chem. 276:6591-6604, 2001] 참조).
또 다른 실시양태에서, 항체의 글리코실화가 변형된다. 예를 들어, 비-글리코실화 항체가 제조될 수 있다 (즉, 항체에 글리코실화가 결여됨). 예를 들어, "항원"에 대한 항체의 친화도를 증가시키기 위해, 글리코실화가 변경될 수 있다. 이러한 탄수화물 변형은, 예를 들어 항체 서열 내의 하나 이상의 글리코실화 부위를 변경시킴으로써 달성될 수 있다. 예를 들어, 하나 이상의 가변 영역 프레임워크 글리코실화 부위를 제거하여 그 부위에서 글리코실화가 제거되도록, 하나 이상의 아미노산 치환이 이루어질 수 있다. 이러한 비-글리코실화는 항원에 대한 항체의 친화도를 증가시킬 수 있다. 예를 들어, 미국 특허 번호 5,714,350 및 6,350,861 (Co et al.)에 이러한 접근법이 기재되어 있다.
추가로 또는 대안적으로, 변경된 유형의 글리코실화를 갖는 항체, 예컨대 감소된 양의 푸코실 잔기를 갖는 저푸코실화 항체 또는 증가된 양분성 GlcNac 구조를 갖는 항체가 제조될 수 있다. 이러한 변경된 글리코실화 패턴은 항체의 ADCC 능력을 증가시키는 것으로 입증되었다. 이러한 탄수화물 변형은, 예를 들어 변경된 글리코실화 기구를 갖는 숙주 세포 내에서 항체를 발현시킴으로써 달성될 수 있다. 변경된 글리코실화 기구를 갖는 세포는 관련 기술분야에 기재되어 있고, 본 발명의 재조합 항체를 발현시켜 변경된 글리코실화를 갖는 항체를 생산하는 숙주 세포로서 사용될 수 있다. 예를 들어, EP 1,176,195 (Hang et al.)는 푸코실 트랜스퍼라제를 코딩하는, 기능적으로 파괴된 FUT8 유전자를 갖는 세포주를 기재하며, 이러한 세포주에서 발현된 항체는 저푸코실화를 나타낸다. PCT 공개 WO 03/035835 (Presta)는 Asn(297)-연결된 탄수화물에 푸코스를 부착시키는 능력이 감소되어 숙주 세포 내에서 발현된 항체에서 저푸코실화가 일어나는 변이체 CHO 세포주인 Lecl3 세포를 기재하고 있다 (또한, 문헌 [Shields et al., (2002) J. Biol. Chem. 277:26733-26740] 참조). PCT 공개 WO 99/54342 (Umana et al.)는 당단백질-변형된 글리코실 트랜스퍼라제 (예를 들어, 베타(1,4)-N 아세틸글루코스아미닐트랜스퍼라제 III (GnTIII))를 발현하도록 조작된 세포주를 기재하여, 이러한 조작된 세포주에서 발현된 항체는 증가된 양분성 GlcNac 구조를 나타내고, 이는 항체의 증가된 ADCC 활성을 유발한다 (또한 문헌 [Umana et al., Nat. Biotech. 17:176-180, 1999] 참조).
또 다른 실시양태에서, 항체는 그의 생물학적 반감기를 증가시키기 위해 변형된다. 다양한 접근법이 가능하다. 예를 들어, 하기 돌연변이 중 하나 이상이 도입될 수 있다: 미국 특허 번호 6,277,375 (Ward)에 기재된 바와 같은, T252L, T254S, T256F. 대안적으로, 생물학적 반감기를 증가시키기 위해, 항체는 미국 특허 번호 5,869,046 및 6,121,022 (Presta et al.)에 기재된 바와 같이 IgG의 Fc 영역의 CH2 도메인의 2개의 루프로부터 취해진 샐비지 수용체 결합 에피토프를 함유하도록 CH1 또는 CL 영역 내에서 변경될 수 있다.
3. FGFR2/4 항체의 생산
항-FGFR2/4 항체 및 그의 항체 단편 (예를 들어, 항원 결합 단편)은, 예컨대 이에 제한되지는 않지만, 재조합 발현, 화학적 합성, 및 항체 사량체의 효소적 소화를 비롯한 관련 기술분야에 공지된 임의의 수단으로 생산될 수 있는 반면, 전장 모노클로날 항체는, 예를 들어 하이브리도마 또는 재조합 생산에 의해 수득될 수 있다. 재조합 발현은 관련 기술분야에 공지된 임의의 적절한 숙주 세포, 예를 들어 포유동물 숙주 세포, 박테리아 숙주 세포, 효모 숙주 세포, 곤충 숙주 세포 등으로부터 일어날 수 있다.
본 발명은 본원에 기재된 항체를 코딩하는 폴리뉴클레오티드, 예를 들어 본원에 기재된 바와 같은 상보성 결정 영역을 포함하는 중쇄 또는 경쇄 가변 영역 또는 절편을 코딩하는 폴리뉴클레오티드를 추가로 제공한다. 일부 실시양태에서, 중쇄 가변 영역을 코딩하는 폴리뉴클레오티드는 서열 8, 28, 48, 68, 88 및 108로 이루어진 군으로부터 선택된 폴리뉴클레오티드와 적어도 85%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 100% 핵산 서열 동일성을 갖는다. 일부 실시양태에서, 경쇄 가변 영역을 코딩하는 폴리뉴클레오티드는 서열 18, 38, 58, 78, 98 및 118로 이루어진 군으로부터 선택된 폴리뉴클레오티드와 적어도 85%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 100% 핵산 서열 동일성을 갖는다.
일부 실시양태에서, 중쇄를 코딩하는 폴리뉴클레오티드는 서열 10, 30, 50, 70, 90 또는 110의 폴리뉴클레오티드와 적어도 85%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 100% 핵산 서열 동일성을 갖는다. 일부 실시양태에서, 경쇄를 코딩하는 폴리뉴클레오티드는 서열 20, 40, 60, 80, 100 또는 120의 폴리뉴클레오티드와 적어도 85%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 100% 핵산 서열 동일성을 갖는다.
본 발명의 폴리뉴클레오티드는 항-FGFR2/4 항체의 가변 영역 서열만을 코딩할 수 있다. 이들은 또한 항체의 가변 영역 및 불변 영역을 모두 코딩할 수 있다. 폴리뉴클레오티드 서열의 일부는 예시된 마우스 항-FGFR2 및/또는 FGFR4 항체 중 하나의 중쇄 및 경쇄 둘 다의 가변 영역을 포함하는 폴리펩티드를 코딩한다. 일부 다른 폴리뉴클레오티드는 각각 마우스 항체 중 하나의 중쇄 및 경쇄의 가변 영역에 실질적으로 동일한 2개의 폴리펩티드 절편을 코딩한다.
폴리뉴클레오티드 서열은 항-FGFR2/4 항체 또는 그의 결합 단편을 코딩하는 기존의 서열 (예를 들어, 하기 실시예에 기재된 바와 같은 서열)의 신생 고체-상 DNA 합성 또는 PCR 돌연변이유발에 의해 생산될 수 있다. 핵산의 직접적인 화학적 합성은 관련 기술분야에 공지된 방법, 예컨대 문헌 [Narang et al., Meth. Enzymol. 68:90, 1979]의 포스포트리에스테르 방법; 문헌 [Brown et al., Meth. Enzymol. 68:109, 1979]의 포스포디에스테르 방법; 문헌 [Beaucage et al., Tetra. Lett., 22:1859, 1981]의 디에틸포스포르아미다이트 방법; 및 미국 특허 번호 4,458,066의 고체 지지체 방법에 의해 달성될 수 있다. PCR에 의해 폴리뉴클레오티드 서열에 돌연변이를 도입하는 것은, 예를 들어 문헌 [PCR Technology: Principles and Applications for DNA Amplification, H.A. Erlich (Ed.), Freeman Press, NY, NY, 1992; PCR Protocols: A Guide to Methods and Applications, Innis et al. (Ed.), Academic Press, San Diego, CA, 1990; Mattila et al., Nucleic Acids Res. 19:967, 1991; 및 Eckert et al., PCR Methods and Applications 1:17, 1991]에 기재된 바와 같이 수행될 수 있다.
또한, 본 발명에서는 상기 기재된 항-FGFR2/4 항체를 생산하기 위한 발현 벡터 및 숙주 세포가 제공된다. 항-FGFR2/4 항체 쇄 또는 결합 단편을 코딩하는 폴리뉴클레오티드를 발현시키기 위해 다양한 발현 벡터를 사용할 수 있다. 포유동물 숙주 세포에서 항체를 생산하기 위해 바이러스-기반 및 비-바이러스 발현 벡터 둘 다 사용될 수 있다. 비-바이러스 벡터 및 시스템은 플라스미드, 에피솜 벡터 (전형적으로, 단백질 또는 RNA 발현을 위한 발현 카세트를 가짐), 및 인간 인공 염색체 (예를 들어, 문헌 [Harrington et al., Nat Genet 15:345, 1997] 참조)를 포함한다. 예를 들어, 포유동물 (예를 들어, 인간) 세포에서 항-FGFR2/4 폴리뉴클레오티드 및 폴리펩티드의 발현에 유용한 비-바이러스 벡터는 pThioHis A, B & C, pcDNATM3.1/His, pEBVHis A, B & C (인비트로젠(Invitrogen), 캘리포니아주 샌디에고), MPSV 벡터, 및 다른 단백질을 발현하기 위해 관련 기술분야에 공지된 수많은 다른 벡터를 포함한다. 유용한 바이러스 벡터는 레트로바이러스, 아데노바이러스, 아데노연관 바이러스, 헤르페스 바이러스를 기반으로 하는 벡터, SV40, 유두종 바이러스, HBP 엡스타인 바르(Epstein Barr) 바이러스를 기반으로 하는 벡터, 백시니아 바이러스 벡터 및 셈리키 포레스트(Semliki Forest) 바이러스 (SFV)를 포함한다. 문헌 [Brent et al., supra; Smith, Annu. Rev. Microbiol. 49:807, 1995; 및 Rosenfeld et al., Cell 68:143, 1992]을 참조한다.
발현 벡터의 선택은 벡터를 발현시키고자 의도되는 숙주 세포에 의존한다. 전형적으로, 발현 벡터는 항-FGFR2/4 항체 쇄 또는 단편을 코딩하는 폴리뉴클레오티드에 작동가능하게 연결된 프로모터 및 다른 조절 서열 (예를 들어, 인핸서)을 함유한다. 일부 실시양태에서, 유도성 프로모터는 유도 조건 하인 경우를 제외하고 삽입된 서열의 발현을 방지하기 위해 사용된다. 유도성 프로모터는 예를 들어 아라비노스, lacZ, 메탈로티오네인 프로모터 또는 열 쇼크 프로모터를 포함한다. 형질전환된 유기체의 배양물은, 발현 산물이 숙주 세포에 의해 보다 우수하게 허용되는 서열을 코딩하는 집단으로 편향되지 않으면서 비-유도 조건 하에서 증식될 수 있다. 프로모터 이외에도, 항-FGFR2/4 항체 쇄 또는 단편의 효율적인 발현을 위해 다른 조절 요소가 또한 요구되거나 바람직할 수 있다. 이들 요소는 전형적으로 ATG 개시 코돈 및 인접한 리보솜 결합 부위 또는 다른 서열을 포함한다. 또한, 발현 효율은 사용하는 세포 시스템에 적절한 인핸서를 포함시키는 것에 의해 증진될 수 있다 (예를 들어, 문헌 [Scharf et al., Results Probl. Cell Differ. 20:125, 1994; 및 Bittner et al., Meth. Enzymol., 153:516, 1987] 참조). 예를 들어, SV40 인핸서 또는 CMV 인핸서가 포유동물 숙주 세포에서의 발현을 증가시키기 위해 사용될 수 있다.
발현 벡터는 또한 삽입된 항-FGFR2/4 항체 서열에 의해 코딩되는 폴리펩티드와 융합 단백질을 형성하는 분비 신호 서열 위치를 제공할 수도 있다. 보다 흔히, 삽입된 항-FGFR2/4 항체 서열은 신호 서열에 연결된 후 벡터에 포함된다. 항-FGFR2/4 항체 경쇄 및 중쇄 가변 도메인을 코딩하는 서열을 수용하는데 사용되는 벡터는 때때로 또한 불변 영역 또는 그의 일부를 코딩한다. 이러한 벡터는 불변 영역과의 융합 단백질로서 가변 영역의 발현을 허용함으로써 무손상 항체 또는 그의 단편이 생산되게 한다. 전형적으로, 이러한 불변 영역은 인간의 것이다.
항-FGFR2/4 항체를 보유하고 발현하는 숙주 세포는 원핵 또는 진핵 세포일 수 있다. 이. 콜라이는 본 발명의 폴리뉴클레오티드를 클로닝하고 발현시키는데 유용한 하나의 원핵 숙주이다. 사용하기 적합한 다른 미생물 숙주는 바실루스, 예컨대 바실루스 서브틸리스(Bacillus subtilis), 및 다른 엔테로박테리아세아에, 예컨대 살모넬라(Salmonella), 세라티아(Serratia) 및 다양한 슈도모나스(Pseudomonas) 종을 포함한다. 이들 원핵 숙주에서, 전형적으로 숙주 세포와 상용가능한 발현 제어 서열 (예를 들어, 복제 기점)을 함유하는 발현 벡터를 또한 제조할 수 있다. 또한, 임의의 수의 다양한 널리 공지된 프로모터, 예컨대 락토스 프로모터 시스템, 트립토판 (trp) 프로모터 시스템, 베타-락타마제 프로모터 시스템, 또는 파지 람다로부터의 프로모터 시스템이 존재할 것이다. 프로모터는 임의로는 오퍼레이터 서열과 함께 전형적으로 발현을 제어하고, 전사 및 번역을 개시하고 완료하기 위한 리보솜 결합 부위 서열 등을 갖는다. 본 발명의 항-FGFR2/4 폴리펩티드를 발현시키기 위해 다른 미생물, 예컨대 효모가 또한 사용될 수 있다. 바큘로바이러스 벡터와 함께 곤충 세포가 또한 사용될 수 있다.
일부 바람직한 실시양태에서, 포유동물 숙주 세포가 본 발명의 항-FGFR2/4 폴리펩티드를 발현시키고 생산하는데 사용된다. 예를 들어, 이들은 내인성 이뮤노글로불린 유전자를 발현하는 하이브리도마 세포주 (예를 들어, 실시예에 기재된 바와 같은 골수종 하이브리도마 클론) 또는 외인성 발현 벡터를 내포하는 포유동물 세포주 (예를 들어, 하기 예시된 SP2/0 골수종 세포)일 수 있다. 이는 임의의 정상적인 사멸, 또는 정상적이거나 비정상적인 불멸 동물 또는 인간 세포를 포함한다. 예를 들어, CHO 세포주, 다양한 Cos 세포주, HeLa 세포, 골수종 세포주, 형질전환된 B-세포 및 하이브리도마를 비롯한, 무손상 이뮤노글로불린을 분비할 수 있는 많은 적합한 숙주 세포주가 개발되었다. 폴리펩티드를 발현시키기 위한 포유동물 조직 세포 배양의 사용은, 예를 들어 문헌 [Winnacker, From Genes to Clones, VCH Publishers, N.Y., N.Y., 1987]에서 일반적으로 논의된다. 포유동물 숙주 세포를 위한 발현 벡터는 발현 조절 서열, 예를 들어 복제 기점, 프로모터, 및 인핸서 (예를 들어, 문헌 [Queen, et al., Immunol. Rev. 89:49-68, 1986] 참조), 및 필요한 프로세싱 정보 부위, 예를 들어 리보솜 결합 부위, RNA 스플라이스 부위, 폴리아데닐화 부위, 및 전사 종결자 서열을 포함할 수 있다. 이들 발현 벡터는 통상적으로 포유동물 유전자 또는 포유동물 바이러스로부터 유래된 프로모터를 함유한다. 적합한 프로모터는 구성적, 세포 유형-특이적, 단계-특이적 및/또는 조정가능하거나 조절가능한 것일 수 있다. 유용한 프로모터는 메탈로티오네인 프로모터, 구성적 아데노바이러스 주요 후기 프로모터, 덱사메타손-유도성 MMTV 프로모터, SV40 프로모터, MRP polIII 프로모터, 구성적 MPSV 프로모터, 테트라시클린-유도성 CMV 프로모터 (예컨대, 인간 극초기 CMV 프로모터), 구성적 CMV 프로모터, 및 관련 기술분야에 공지된 프로모터-인핸서 조합을 포함하나, 이에 제한되지는 않는다.
관심 폴리뉴클레오티드 서열을 함유하는 발현 벡터를 도입하는 방법은 세포 숙주의 유형에 따라 달라진다. 예를 들어, 염화칼슘 형질감염은 통상적으로 원핵 세포에 대해 사용되는 반면, 인산칼슘 처리 또는 전기천공은 다른 세포 숙주에 대해 사용될 수 있다 (일반적으로 상기 문헌 [Sambrook, et al.] 참조). 다른 방법은, 예를 들어 전기천공, 인산칼슘 처리, 리포솜-매개 형질전환, 주사 및 미세주사, 탄도적 방법, 비로솜, 이뮤노리포솜, 다가양이온:핵산 접합체, 네이키드 DNA, 인공 비리온, 헤르페스 바이러스 구조 단백질 VP22에 대한 융합 (문헌 [Elliot and O'Hare, Cell 88:223, 1997]), 작용제-증진된 DNA 흡수, 및 생체외 형질도입을 포함한다. 재조합 단백질의 장기간 고수율 생산을 위해, 종종 안정적인 발현이 바람직할 것이다. 예를 들어, 항-FGFR2 및/또는 FGFR4 항체 쇄 또는 결합 단편을 안정하게 발현하는 세포주는, 바이러스 복제 기점 또는 내인성 발현 요소 및 선택가능한 마커 유전자를 함유하는 본 발명의 발현 벡터를 사용하여 제조될 수 있다. 벡터의 도입 후에, 세포를 1-2일 동안 농축 배지에서 성장시킨 후, 선택 배지로 전환시킬 수 있다. 선택 마커의 목적은 선택에 대한 내성을 부여하기 위한 것이고, 그의 존재는 도입된 서열을 성공적으로 발현하는 세포가 선택 배지에서 성장하게 한다. 안정적으로 형질감염된 내성 세포는 세포 유형에 적절한 조직 배양 기술을 사용하여 증식될 수 있다.
치료 및 진단 용도
본 발명의 항체, 항체 단편 (예를 들어, 항원 결합 단편) 및 항체 약물 접합체는 암, 예컨대 고형 암의 치료를 포함하나 이에 제한되지는 않는 다양한 적용에 유용하다. 특정 실시양태에서, 본 발명의 항체, 항체 단편 (예를 들어, 항원 결합 단편) 및 항체 약물 접합체는 종양 성장의 억제, 분화의 유도, 종양 부피의 감소, 및/또는 종양의 종양발생성의 감소에 유용하다. 사용 방법은 시험관내, 생체외 또는 생체내 방법일 수 있다.
한 측면에서, 본 발명의 항체, 항체 단편 (예를 들어, 항원 결합 단편) 및 항체 약물 접합체는 생물학적 샘플에서 FGFR2 또는 FGFR4의 존재를 검출하는데 유용하다. 본원에 사용된 용어 "검출하는"은 정량적 또는 정성적 검출을 포괄한다. 특정 실시양태에서, 생물학적 샘플은 세포 또는 조직을 포함한다. 특정 실시양태에서, 이러한 조직은 다른 조직과 관련하여 보다 높은 수준으로 FGFR2 또는 FGFR4를 발현하는 정상 및/또는 암성 조직을 포함한다.
한 측면에서, 본 발명은 생물학적 샘플에서 FGFR2 또는 FGFR4의 존재를 검출하는 방법을 제공한다. 특정 실시양태에서, 방법은 항원에 대한 항체의 결합을 허용하는 조건 하에 생물학적 샘플을 항-FGFR2/4 항체와 접촉시키고, 복합체가 항체와 항원 사이에 형성되는지 여부를 검출하는 것을 포함한다.
한 측면에서, 본 발명은 FGFR2 또는 FGFR4의 증가된 발현과 연관된 장애를 진단하는 방법을 제공한다. 특정 실시양태에서, 방법은 시험 세포를 항-FGFR2/4 항체와 접촉시키고; FGFR2 또는 FGFR4 항원에 대한 항-FGFR2/4 항체의 결합을 검출함으로써 시험 세포 상의 FGFR2 또는 FGFR4의 발현 수준 (정량적으로 또는 정성적으로)을 검출하고; 시험 세포에서의 FGFR2 또는 FGFR4의 발현 수준을 대조군 세포 (예를 들어, 시험 세포와 동일한 조직 기원의 정상 세포 또는 이러한 정상 세포에 필적하는 수준으로 FGFR2 또는 FGFR4를 발현하는 세포) 상에서의 FGFR2 또는 FGFR4의 발현 수준과 비교하는 것을 포함하며, 여기서 대조군 세포와 비교 시에 시험 세포 상의 FGFR2 또는 FGFR4의 보다 높은 발현 수준은 FGFR2 또는 FGFR4의 증가된 발현과 연관된 장애의 존재를 나타낸다. 특정 실시양태에서, 시험 세포는 FGFR2 또는 FGFR4의 증가된 발현과 연관된 장애를 갖는 것으로 의심되는 개체로부터 획득한다. 특정 실시양태에서, 장애는 세포 증식성 장애, 예컨대 암 또는 종양이다. 특정 실시양태에서, 방법은 시험 세포에서 FGFR2 유전자의 카피수를 측정하는 것을 포함한다. 특정 실시양태에서, 방법은 PAX-FOXO 전위 돌연변이를 검출하는 것을 포함한다. 유전자의 카피수 및/또는 전위 돌연변이는 관련 기술분야에 공지된 표준 방법, 예를 들어, PCR, RTPCR 등을 이용하여 검출될 수 있다.
특정 실시양태에서, 상기 기재된 바와 같은 진단 또는 검출의 방법은 세포 표면 상에서 또는 그의 표면 상에 FGFR2 또는 FGFR4를 발현하는 세포로부터 획득된 막 제제에서 발현된 FGFR2 또는 FGFR4에 대한 항-FGFR2/4 항체의 결합을 검출하는 것을 포함한다. 세포의 표면 상에서 발현된 FGFR2 또는 FGFR4에 대한 항- FGFR2/4 항체의 결합을 검출하기 위한 예시적인 검정은 "FACS" 검정이다.
특정의 다른 방법은 FGFR2 또는 FGFR4에 대한 항-FGFR2/4 항체의 결합을 검출하는데 사용될 수 있다. 상기 방법은 관련 기술분야에 공지된 항원 결합 검정, 예를 들어 웨스턴 블롯, 방사성면역검정, ELISA (효소 결합 면역흡착 검정), "샌드위치(sandwich)" 면역검정, 면역침전 검정, 형광 면역검정, 단백질 A 면역검정 및 면역조직화학 (IHC)을 포함하나, 이에 제한되지는 않는다.
특정 실시양태에서, 항-FGFR2/4 항체를 표지한다. 표지는 직접적으로 검출되는 표지 또는 모이어티 (예컨대, 형광, 발색, 전자-밀집, 화학발광 및 방사성 표지) 뿐만 아니라 간접적으로, 예를 들어 효소적 반응 또는 분자 상호작용을 통해 검출되는 모이어티, 예컨대 효소 또는 리간드를 포함하나, 이에 제한되지는 않는다.
특정 실시양태에서, 항-FGFR2/4 항체는 불용성 매트릭스 상에 고정된다. 고정화는 용액 중에서 유리되어 남아있는 임의의 FGFR2 또는 FGFR4 단백질로부터 항-FGFR2/4 항체를 분리하는 것을 수반한다. 이것은 통상적으로 검정 절차 전에 항-FGFR2/4 항체의 불용화에 의해, 수불용성 매트릭스 또는 표면에 대한 흡착에 의해 (미국 특허 번호 3,720,760 (Bennich et al.)), 또는 공유 커플링 (예를 들어, 글루타르알데히드 가교 사용)에 의해, 또는 예를 들어 면역침전에 의해 항-FGFR2/4 항체와 FGFR2 또는 FGFR4 단백질 사이의 복합체 형성 후에 항-FGFR2/4 항체의 불용화에 의해 달성된다.
진단 또는 검출의 임의의 상기 실시양태는 항-FGFR2/4 항체 대신에 또는 그에 추가로 본 발명의 면역접합체를 사용하여 수행할 수 있다.
한 실시양태에서, 본 발명은 본 발명의 항체, 항체 단편 (예를 들어, 항원 결합 단편) 또는 항체 약물 접합체를 환자에게 투여하는 것을 포함하는, 질환을 치료 또는 에방하는 방법을 제공한다. 특정 실시양태에서, 본 발명의 항체, 항체 단편 (예를 들어, 항원 결합 단편) 및 항체 약물 접합체로 치료되는 질환은 암이다. 치료 및/또는 예방될 수 있는 질환의 예는 부신피질 암종, 방광암, 골암, 유방암, 중추 신경계 비정형 기형양/횡문근양 종양, 결장암, 결장직장암, 배아성 종양, 자궁내막암, 위암, 두경부암, 간세포성암, 카포시 육종, 간암, 비소세포 폐암, 직장암, 횡문근육종, 소세포 폐암, 소장암, 연부 조직 육종, 편평 세포 암종, 편평 경부암, 위암, 자궁암, 질암, 외음부암을 포함하나, 이에 제한되지는 않는다. 특정 실시양태에서, 암은 본 발명의 항체, 항체 단편 (예를 들어, 항원 결합 단편) 및 항체 약물 접합체가 결합하는 FGFR2 또는 FGFR4 발현 세포를 특징으로 한다. 특정 실시양태에서, 암은 FGFR2 또는 FGFR4의 DNA 카피수의 증가를 특징으로 한다. 특정 실시양태에서, 암은, 예를 들어, 각각 FGFR2 또는 FGFR4 RNA에서의 증가에 의해 측정된 바와 같이, FGFR2 또는 FGFR4의 발현의 증가를 특징으로 한다. 본 발명은 치료 유효량의 본 발명의 항체, 항체 단편 (예를 들어, 항원 결합 단편) 또는 항체 약물 접합체를 투여하는 것을 포함하는, 암을 치료하는 방법을 제공한다. 특정 실시양태에서, 암은 고형 암이다. 특정 실시양태에서, 대상체는 인간이다. 특정 실시양태에서, 암은 내성 암 및/또는 재발성 암이다. 특정 측면에서, 예를 들어, 내성 암은 티로신 키나제 억제제, 예컨대 그러나 비제한적으로 EGFR 억제제, Her2 억제제, Her3 억제제, IGFR 억제제 및 Met 억제제에 내성이다. 특정 실시양태에서 암은 Her2 내성 암이다.
특정 실시양태에서, 본 발명은 대상체에게 치료 유효량의 본 발명의 항체, 항체 단편 (예를 들어, 항원 결합 단편) 또는 항체 약물 접합체를 투여하는 것을 포함하는, 종양 성장을 억제하는 방법을 제공한다. 특정 실시양태에서, 대상체는 인간이다. 특정 실시양태에서, 대상체는 종양을 가지고 있거나, 종양을 제거한 바 있다. 특정 실시양태에서, 종양은 다른 티로신 키나제 억제제, 예컨대 그러나 비제한적으로 EGFR 억제제, Her2 억제제, Her3 억제제, IGFR 억제제 및 Met 억제제에 대해 내성이다.
특정 실시양태에서, 종양은 항-FGFR2/4 항체가 결합하는 FGFR2 또는 FGFR4를 발현한다. 특정 실시양태에서, 종양은 인간 FGFR2 또는 FGFR4를 과다발현한다. 특정 실시양태에서, 종양은 FGFR2 유전자의 카피수 증가를 갖는다. 특정 실시양태에서, 종양은 FGFR4의 과다발현의 원인이 되는 PAX-FOXO 전위 돌연변이를 갖는다.
본 발명은 또한 치료 유효량의 본 발명의 항체, 항체 단편 (예를 들어, 항원 결합 단편) 또는 항체 약물 접합체를 투여하는 것을 포함하는, 상기 항체, 항체 단편 (예를 들어, 항원 결합 단편) 또는 항체 약물 접합체로의 치료를 위한 환자를 선택하는 방법을 제공한다. 특정 측면에서 방법은 티로신 키나제 억제제 내성 암을 갖는 환자를 선택하는 것을 포함한다. 특정 측면에서 티로신 키나제 억제제 내성 암은 EGFR 억제제, Her2 억제제, Her3 억제제, IGFR 억제제 및/또는 Met 억제제에 내성인 것으로 예상된다. 특정 측면에서 내성 암은 Her2 내성 암인 것으로 예상된다. 보다 구체적으로 Her2 내성 암은 트라스투주맙 또는 트라스투주맙 엠탄신에 반응하지 않을 것으로 예상된다. 특정 측면에서 암은 신생 내성 암인 것으로 예상되고, 여전히 다른 측면에서 암은 재발성 암, 예를 들어 Her2 재발성 암인 것으로 예상된다. 본 발명의 특정 측면에서 방법은 신생 내성 또는 재발성 암을 갖는 환자를 선택하고, FGFR2 및/또는 FGFR4의 발현을 측정하는 것을 포함한다. 특정 측면에서 재발성 암 또는 종양은 처음에는 FGFR2 또는 FGFR4 발현 암 또는 종양이 아니었지만, 티로신 키나제 억제제 (예를 들어, 트라스투주맙 또는 트라스투주맙 엠탄신)으로 치료한 후에 티로신 키나제 내성 또는 재발성 암 또는 종양인 FGFR2 및/또는 FGFR4 양성 암이 되는 것으로 예상된다.
질환의 치료를 위해, 본 발명의 항체, 항체 단편 (예를 들어, 항원 결합 단편) 또는 항체 약물 접합체의 적절한 투여량은 다양한 인자, 예컨대 치료할 질환의 유형, 질환의 중증도 및 경과, 질환의 반응성, 선행 요법, 환자의 임상 병력 등에 의존한다. 항체 또는 작용제는 한번에, 또는 수 일 내지 수 개월 동안 지속하는 일련의 치료에 걸쳐, 또는 치유되거나 질환 상태의 축소가 달성될 때까지 (예를 들어, 종양 크기의 감소) 투여될 수 있다. 최적의 투여 스케줄은 환자 신체에서의 약물 축적의 측정으로부터 계산될 수 있고, 개별 항체, 항체 단편 (예를 들어, 항원 결합 단편) 또는 항체 약물 접합체의 상대적 효능에 따라 달라질 것이다. 특정 실시양태에서, 투여량은 체중 kg 당 0.01mg 내지 10 mg (예를 들어, 0.01 mg, 0.05mg, 0.1mg, 0.5mg, 1mg, 2mg, 3mg, 4mg, 5mg, 7mg, 8mg, 9mg 또는 10mg)이고, 매일, 매주, 매월 또는 매년 1회 이상 제공될 수 있다. 특정 실시양태에서, 본 발명의 항체, 항체 단편 (예를 들어, 항원 결합 단편) 또는 항체 약물 접합체는 2주마다 1회 또는 3주마다 1회 제공된다. 치료의는 체액 또는 체조직 내에서의 약물의 측정된 체류 시간 및 농도에 기초하여 투여를 위한 반복 속도를 추정할 수 있다.
조합 요법
특정 경우에서, 본 발명의 항체, 항체 단편 (예를 들어, 항원 결합 단편) 또는 항체 약물 접합체는 다른 치료제, 예컨대 다른 항암제, 항알레르기제, 항오심제 (또는 항구토제), 통증 완화제, 세포 보호제 및 그의 조합물과 조합된다.
조합 요법에 사용하기 위해 고려된 일반적 화학요법제는 아나스트로졸 (아리미덱스(Arimidex)®), 비칼루타미드 (카소덱스(Casodex)®), 블레오마이신 술페이트 (블레녹산(Blenoxane)®), 부술판 (밀레란(Myleran)®), 부술판 주사 (부술펙스(Busulfex)®), 카페시타빈 (젤로다(Xeloda)®), N4-펜톡시카르보닐-5-데옥시-5-플루오로시티딘, 카르보플라틴 (파라플라틴(Paraplatin)®), 카르무스틴 (BiCNU®), 클로람부실 (류케란(Leukeran)®), 시스플라틴 (플라티놀(Platinol)®), 클라드리빈 (류스타틴(Leustatin)®), 시클로포스파미드 (시톡산(Cytoxan)® 또는 네오사르(Neosar)®), 시타라빈, 시토신 아라비노시드 (시토사르-유(Cytosar-U)®), 시타라빈 리포솜 주사 (DepoCyt®), 다카르바진 (DTIC-돔(Dome)®), 닥티노마이신 (악티노마이신(Actinomycin) D, 코스메간(Cosmegan)), 다우노루비신 히드로클로라이드 (세루비딘(Cerubidine)®), 다우노루비신 시트레이트 리포솜 주사 (다우노엑솜(DaunoXome)®), 덱사메타손, 도세탁셀 (탁소테레(Taxotere)®), 독소루비신 히드로클로라이드 (아드리아마이신(Adriamycin)®, 루벡스(Rubex)®), 에토포시드 (베페시드(Vepesid)®), 플루다라빈 포스페이트 (플루다라(Fludara)®), 5-플루오로우라실 (아드루실(Adrucil)®, 에푸덱스(Efudex)®), 플루타미드 (유렉신(Eulexin)®), 테자시티빈, 겜시타빈 (디플루오로데옥시시티딘), 히드록시우레아 (히드레아(Hydrea)®), 이다루비신 (이다마이신(Idamycin)®), 이포스파미드 (IFEX®), 이리노테칸 (캄프토사르(Camptosar)®), L-아스파라기나제 (엘스파르(ELSPAR)®), 류코보린 칼슘, 멜팔란 (알케란(Alkeran)®), 6-메르캅토퓨린 (퓨린톨(Purinethol)®), 메토트렉세이트 (폴렉스(Folex)®), 미톡산트론 (노반트론(Novantrone)®), 밀로타르그, 파클리탁셀 (탁솔(Taxol)®), 포에닉스 (이트륨90/MX-DTPA), 펜토스타틴, 카르무스틴 이식물을 갖는 폴리페프로산 20 (글리아델(Gliadel)®), 타목시펜 시트레이트 (놀바덱스(Nolvadex)®), 테니포시드 (부몬(Vumon)®), 6-티오구아닌, 티오테파, 티라파자민 (티라존(Tirazone)®), 주사용 토포테칸 히드로클로라이드 (하이캄틴(Hycamptin)®), 빈블라스틴 (벨반(Velban)®), 빈크리스틴 (온코빈(Oncovin)®) 및 비노렐빈 (나벨빈(Navelbine)®)을 포함한다.
한 실시양태에서, 본 발명의 항체, 항체 단편 (예를 들어, 항원 결합 단편) 또는 항체 약물 접합체는 제약 조합 제제에서 또는 조합 요법으로서의 투여 요법에서 항암 특성을 갖는 제2 화합물과 함께 조합된다. 제약 조합 제제 또는 투여 요법의 제2 화합물은 이들이 서로 악영향을 미치지 않도록 조합물의 항체 또는 면역접합체에 상보적 활성을 가질 수 있다. 예를 들어, 본 발명의 항체, 항체 단편 (예를 들어, 항원 결합 단편) 또는 항체 약물 접합체는, 이에 제한되지는 않지만, 화학요법제, 티로신 키나제 억제제, FGF 하류 신호전달 경로 억제제, IAP 억제제, Bcl2 억제제, Mcl1 억제제 및 다른 FGFR2 억제제와 조합하여 투여될 수 있다.
본원에 사용된 용어 "제약 조합물"은 하나의 투여 단위 형태로의 고정 조합물, 또는 비-고정 조합물 또는 조합 투여를 위한 부분들의 키트를 지칭하며, 여기서 2종 이상의 치료제는 동시에 독립적으로 또는 시간 간격을 두고 개별적으로 투여될 수 있고, 특히 여기서 이들 시간 간격은 조합 파트너가 협력적, 예를 들어 상승작용 효과를 나타내도록 한다.
용어 "조합 요법"은 본 개시내용에 기재된 치료 상태 또는 장애를 치료하기 위한 2종 이상의 치료제의 투여를 지칭한다. 이러한 투여는 이들 치료제의 실질적으로 동시 방식으로의, 예컨대 고정 비율의 활성 성분을 갖는 단일 캡슐로의 공투여를 포괄한다. 대안적으로, 이러한 투여는 각각의 활성 성분을 위한 다중 또는 개별 용기 (예를 들어, 캡슐, 분말 및 액체)로의 공투여를 포괄한다. 분말 및/또는 액체는 투여 전에 목적하는 용량으로 재구성 또는 희석될 수 있다. 추가로, 이러한 투여는 또한 각 유형의 치료제를 순차적 방식으로, 대략 동시에 또는 상이한 시간에 사용하는 것을 포괄한다. 각 경우에, 치료 요법은 본원에 기재된 상태 또는 장애를 치료하는데 있어서 약물 조합물의 유익한 효과를 제공할 것이다.
조합 요법은 "상승작용"을 제공하고 "상승작용적"을 입증할 수 있다 (즉, 활성 성분을 함께 사용할 경우에 달성되는 효과가 화합물을 개별적으로 사용함으로써 생성되는 효과의 합계보다 더 큼). 상승작용 효과는 활성 성분들이 (1) 공동-제제화되어 투여되거나 또는 조합된 단위 투여 제제로 동시에 전달되는 경우에; (2) 별개의 제제로서 교대로 또는 동시에 전달되는 경우에; 또는 (3) 일부 다른 요법에 의해 전달되는 경우에 달성될 수 있다. 대체 요법으로 전달되는 경우, 상승작용적 효과는 화합물이 순차적으로, 예를 들어, 개별 시린지로 상이한 주사에 의해 투여되거나 전달되는 경우에 달성될 수 있다. 일반적으로, 교대 요법 동안, 유효 투여량의 각각의 활성 성분이 순차적으로, 즉 연속적으로 투여되지만, 조합 요법에서는 유효 투여량의 2종 이상의 활성 성분이 함께 투여된다.
한 측면에서, 본 발명은 암의 치료를 필요로 하는 대상체에게 본 발명의 항체 약물 접합체를 하나 이상의 티로신 키나제 억제제, 예컨대 이에 제한되지는 않지만 EGFR 억제제, Her2 억제제, Her3 억제제, IGFR 억제제 및 Met 억제제와 조합하여 투여하는 것에 의해 암을 치료하는 방법을 제공한다.
예를 들어, 티로신 키나제 억제제는 에를로티닙 히드로클로라이드 (타르세바(Tarceva)®); 리니파닙 (N-[4-(3-아미노-1H-인다졸-4-일)페닐]-N'-(2-플루오로-5-메틸페닐)우레아, 또한 ABT 869로 공지되고, 제넨테크(Genentech)로부터 입수가능함); 수니티닙 말레이트 (수텐트(Sutent)®); 보수티닙 (4-[(2,4-디클로로-5-메톡시페닐)아미노]-6-메톡시-7-[3-(4-메틸피페라진-1-일)프로폭시]퀴놀린-3-카르보니트릴 (또한 SKI-606으로 공지되고, 미국 특허 번호 6,780,996에 기재됨); 다사티닙 (스프리셀(Sprycel)®); 파조파닙 (보트리엔트(Votrient)®); 소라페닙 (넥사바르(Nexavar)®); 작티마 (ZD6474); 및 이마티닙 또는 이마티닙 메실레이트 (길벡(Gilvec)® 및 글리벡(Gleevec)®)를 포함하나, 이에 제한되지는 않는다.
표피 성장 인자 수용체 (EGFR) 억제제는 에를로티닙 히드로클로라이드 (타르세바®), 게피티닙 (이레사(Iressa)®); N-[4-[(3-클로로-4-플루오로페닐)아미노]-7-[[(3"S")-테트라히드로-3-푸라닐]옥시]-6-퀴나졸리닐]-4(디메틸아미노)-2-부텐아미드, 토보크(Tovok)®); 반데타닙 (카프렐사(Caprelsa)®); 라파티닙 (타이커브(Tykerb)®); (3R,4R)-4-아미노-1-((4-((3-메톡시페닐)아미노)피롤로[2,1-f][1,2,4]트리아진-5-일)메틸)피페리딘-3-올 (BMS690514); 카네르티닙 디히드로클로라이드 (CI-1033); 6-[4-[(4-에틸-1-피페라지닐)메틸]페닐]-N-[(1R)-1-페닐에틸]- 7H-피롤로[2,3-d]피리미딘-4-아민 (AEE788, CAS 497839-62-0); 무브리티닙 (TAK165); 펠리티닙 (EKB569); 아파티닙 (BIBW2992); 네라티닙 (HKI-272); N-[4-[[1-[(3-플루오로페닐)메틸]-1H-인다졸-5-일]아미노]-5-메틸피롤로[2,1-f][1,2,4]트리아진-6-일]-카르밤산, (3S)-3-모르폴리닐메틸 에스테르 (BMS599626); N-(3,4-디클로로-2-플루오로페닐)-6-메톡시-7-[[(3aα,5β,6aα)-옥타히드로-2-메틸시클로펜타[c]피롤-5-일]메톡시]- 4-퀴나졸린아민 (XL647, CAS 781613-23-8); 및 4-[4-[[(1R)-1-페닐에틸]아미노]-7H-피롤로[2,3-d]피리미딘-6-일]-페놀 (PKI166, CAS 187724-61-4)을 포함하나, 이에 제한되지는 않는다.
EGFR 항체는 세툭시맙 (에르비툭스(Erbitux)®); 파니투무맙 (벡티빅스(Vectibix)®); 마투주맙 (EMD-72000); 트라스투주맙 (헤르셉틴(Herceptin)®); 니모투주맙 (hR3); 잘루투무맙; 테라(Thera)CIM h-R3; MDX0447 (CAS 339151-96-1); 및 ch806 (mAb-806, CAS 946414-09-1)을 포함하나, 이에 제한되지는 않는다.
인간 표피 성장 인자 수용체 2 (Her2 수용체) (또한 Neu, ErbB-2, CD340 또는 p185로 공지됨) 억제제는 트라스투주맙 (헤르셉틴(Herceptin)®); 페르투주맙 (옴니타르그(Omnitarg)®); 트라스투주맙 엠탄신 (카드실라(Kadcyla)®); 네라티닙 (HKI-272, (2E)-N-[4-[[3-클로로-4-[(피리딘-2-일)메톡시]페닐]아미노]-3-시아노-7-에톡시퀴놀린-6-일]-4-(디메틸아미노)부트-2-엔아미드, PCT 공개 번호 WO 05/028443에 기재됨); 라파티닙 또는 라파티닙 디토실레이트 (타이커브(Tykerb)®); (3R,4R)-4-아미노-1-((4-((3-메톡시페닐)아미노)피롤로[2,1-f][1,2,4]트리아진-5-일)메틸)피페리딘-3-올 (BMS690514); (2E)-N-[4-[(3-클로로-4-플루오로페닐)아미노]-7-[[(3S)-테트라히드로-3-푸라닐]옥시]-6-퀴나졸리닐]-4-(디메틸아미노)-2-부텐아미드 (BIBW-2992, CAS 850140-72-6); N-[4-[[1-[(3-플루오로페닐)메틸]-1H-인다졸-5-일]아미노]-5-메틸피롤로[2,1-f][1,2,4]트리아진-6-일]-카르밤산, (3S)-3-모르폴리닐메틸 에스테르 (BMS 599626, CAS 714971-09-2); 카네르티닙 디히드로클로라이드 (PD183805 또는 CI-1033); 및 N-(3,4-디클로로-2-플루오로페닐)-6-메톡시-7-[[(3aα,5β,6aα)-옥타히드로-2-메틸시클로펜타[c]피롤-5-일]메톡시]-4-퀴나졸린아민 (XL647, CAS 781613-23-8)을 포함하나, 이에 제한되지는 않는다.
Her3 억제제는 LJM716, MM-121, AMG-888, RG7116, REGN-1400, AV-203, MP-RM-1, MM-111 및 MEHD-7945A를 포함하나, 이에 제한되지는 않는다.
MET 억제제는 카보잔티닙 (XL184, CAS 849217-68-1); 포레티닙 (GSK1363089, 이전에 XL880, CAS 849217-64-7); 티반티닙 (ARQ197, CAS 1000873-98-2); 1-(2-히드록시-2-메틸프로필)-N-(5-(7-메톡시퀴놀린-4-일옥시)피리딘-2-일)-5-메틸-3-옥소-2-페닐-2,3-디히드로-1H-피라졸-4-카르복스아미드 (AMG 458); 크리조티닙 (크살코리(Xalkori)®, PF-02341066); (3Z)-5-(2,3-디히드로-1H-인돌-1-일술포닐)-3-({3,5-디메틸-4-[(4-메틸피페라진-1-일)카르보닐]-1H-피롤-2-일}메틸렌)-1,3-디히드로-2H-인돌-2-온 (SU11271); (3Z)-N-(3-클로로페닐)-3-({3,5-디메틸-4-[(4-메틸피페라진-1-일)카르보닐]-1H-피롤-2-일}메틸렌)-N-메틸-2-옥소인돌린-5-술폰아미드 (SU11274); (3Z)-N-(3-클로로페닐)-3-{[3,5-디메틸-4-(3-모르폴린-4-일프로필)-1H-피롤-2-일]메틸렌}-N-메틸-2-옥소인돌린-5-술폰아미드 (SU11606); 6-[디플루오로[6-(1-메틸-1H-피라졸-4-일)-1,2,4-트리아졸로[4,3-b]피리다진-3-일]메틸]-퀴놀린 (JNJ38877605, CAS 943540-75-8); 2-[4-[1-(퀴놀린-6-일메틸)-1H-[1,2,3]트리아졸로[4,5-b]피라진-6-일]-1H-피라졸-1-일]에탄올 (PF04217903, CAS 956905-27-4); N-((2R)-1,4-디옥산-2-일메틸)-N-메틸-N'-[3-(1-메틸-1H-피라졸-4-일)-5-옥소-5H-벤조[4,5]시클로헵타[1,2-b]피리딘-7-일]술파미드 (MK2461, CAS 917879-39-1); 6-[[6-(1-메틸-1H-피라졸-4-일)-1,2,4-트리아졸로[4,3-b]피리다진-3-일]티오]-퀴놀린 (SGX523, CAS 1022150-57-7); 및 (3Z)-5-[[(2,6-디클로로페닐)메틸]술포닐]-3-[[3,5-디메틸-4-[[(2R)-2-(1-피롤리디닐메틸)-1-피롤리디닐]카르보닐]-1H-피롤-2-일]메틸렌]-1,3-디히드로-2H-인돌-2-온 (PHA665752, CAS 477575-56-7)을 포함하나, 이에 제한되지는 않는다.
IGF1R 억제제는 BMS-754807, XL-228, OSI-906, GSK0904529A, A-928605, AXL1717, KW-2450, MK0646, AMG479, IMCA12, MEDI-573 및 BI836845를 포함하나, 이에 제한되지는 않는다. 검토를 위해, 예를 들어 문헌 [Yee, JNCI, 104; 975 (2012)]를 참조한다.
또 다른 측면에서, 본 발명은 암의 치료를 필요로 하는 대상체에게 본 발명의 항체 약물 접합체를 하나 이상의 FGF 하류 신호전달 경로 억제제, 예컨대 이에 제한되지는 않지만 MEK 억제제, Braf 억제제, PI3K/Akt 억제제, SHP2 억제제 및 또한 mTor와 조합하여 투여하는 것에 의해 암을 치료하는 방법을 제공한다.
예를 들어, 미토겐-활성화 단백질 키나제 (MEK) 억제제는 XL-518 (또한 GDC-0973로 공지됨, Cas 번호 1029872-29-4, ACC 코포레이션으로부터 입수가능함); 2-[(2-클로로-4-아이오도페닐)아미노]-N-(시클로프로필메톡시)-3,4-디플루오로-벤즈아미드 (또한 CI-1040 또는 PD184352로 공지되고, PCT 공개 번호 WO2000035436에 기재됨); N-[(2R)-2,3-디히드록시프로폭시]-3,4-디플루오로-2-[(2-플루오로-4-아이오도페닐)아미노]-벤즈아미드 (또한 PD0325901로 공지되고, PCT 공개 번호 WO2002006213에 기재됨); 2,3-비스[아미노[(2-아미노페닐)티오]메틸렌]-부탄디니트릴 (또한 U0126으로 공지되고, 미국 특허 번호 2,779,780에 기재됨); N-[3,4-디플루오로-2-[(2-플루오로-4-아이오도페닐)아미노]-6-메톡시페닐]-1-[(2R)-2,3-디히드록시프로필]-시클로프로판술폰아미드 (또한 RDEA119 또는 BAY869766으로 공지되고, PCT 공개 번호 WO2007014011에 기재됨); (3S,4R,5Z,8S,9S,11E)-14-(에틸아미노)-8,9,16-트리히드록시-3,4-디메틸-3,4,9,19-테트라히드로-1H-2-벤즈옥사시클로테트라데신-1,7(8H)-디온] (또한 E6201로 공지되고, PCT 공개 번호 WO2003076424에 기재됨); 2'-아미노-3'-메톡시플라본 (또한 PD98059로 공지되고, 비아핀 게엠베하 앤 코., 카케(Biaffin GmbH & Co., KG), 독일로부터 입수가능함); 베무라페닙 (PLX-4032, CAS 918504-65-1); (R)-3-(2,3-디히드록시프로필)-6-플루오로-5-(2-플루오로-4-아이오도페닐아미노)-8-메틸피리도[2,3-d]피리미딘-4,7(3H,8H)-디온 (TAK-733, CAS 1035555-63-5); 피마세르팁 (AS-703026, CAS 1204531-26-9); 및 트라메티닙 디메틸 술폭시드 (GSK-1120212, CAS 1204531-25-80)를 포함하나, 이에 제한되지는 않는다.
포스포이노시티드 3-키나제 (PI3K) 억제제는 4-[2-(1H-인다졸-4-일)-6-[[4-(메틸술포닐)피페라진-1-일]메틸]티에노[3,2-d]피리미딘-4-일]모르폴린 (또한 GDC 0941로 공지되고, PCT 공개 번호 WO 09/036082 및 WO 09/055730에 기재됨); 2-메틸-2-[4-[3-메틸-2-옥소-8-(퀴놀린-3-일)-2,3-디히드로이미다조[4,5-c]퀴놀린-1-일]페닐]프로피오니트릴 (또한 BEZ 235 또는 NVP-BEZ 235로 공지되고, PCT 공개 번호 WO 06/122806에 기재됨); 4-(트리플루오로메틸)-5-(2,6-디모르폴리노피리미딘-4-일)피리딘-2-아민 (또한 BKM120 또는 NVP-BKM120으로 공지되고, PCT 공개 번호 WO2007/084786에 기재됨); 토자세르팁 (VX680 또는 MK-0457, CAS 639089-54-6); (5Z)-5-[[4-(4-피리디닐)-6-퀴놀리닐]메틸렌]-2,4-티아졸리딘디온 (GSK1059615, CAS 958852-01-2); (1E,4S,4aR, 5R,6aS, 9aR)-5-(아세틸옥시)-1-[(디-2-프로페닐아미노)메틸렌]-4,4a,5,6,6a,8,9,9a-옥타히드로-11-히드록시-4-(메톡시메틸)-4a,6a-디메틸-시클로펜타[5,6]나프토[1,2-c]피란-2,7,10(1H)-트리온 (PX866, CAS 502632-66-8); 및 8-페닐-2-(모르폴린-4-일)-크로멘-4-온 (LY294002, CAS 154447-36-6)을 포함하나, 이에 제한되지는 않는다.
mTor은 템시롤리무스 (토리셀(Torisel)®); 리다포롤리무스 (이전에 데포롤리무스로 공지되고, (1R,2R,4S)-4-[(2R)-2 [(1R,9S,12S,15R,16E,18R,19R,21R, 23S,24E,26E,28Z,30S,32S,35R)-1,18-디히드록시-19,30-디메톡시-15,17,21,23,29,35-헥사메틸-2,3,10,14,20-펜타옥소-11,36-디옥사-4-아자트리시클로[30.3.1.04,9]헥사트리아콘타-16,24,26,28-테트라엔-12-일]프로필]-2-메톡시시클로헥실 디메틸포스피네이트 (또한 AP23573 및 MK8669로 공지되고, PCT 공개 번호 WO 03/064383에 기재됨); 에베롤리무스 (아피니토르(Afinitor)® 또는 RAD001); 라파마이신 (AY22989, 시롤리무스(Sirolimus)®); 시마피모드 (CAS 164301-51-3); (5-{2,4-비스[(3S)-3-메틸모르폴린-4-일]피리도[2,3-d]피리미딘-7-일}-2-메톡시페닐)메탄올 (AZD8055); 2-아미노-8-[트랜스-4-(2-히드록시에톡시)시클로헥실]-6-(6-메톡시-3-피리디닐)-4-메틸-피리도[2,3-d]피리미딘-7(8H)-온 (PF04691502, CAS 1013101-36-4); 및 N2-[1,4-디옥소-4-[[4-(4-옥소-8-페닐-4H-1-벤조피란-2-일)모르폴리늄-4-일]메톡시]부틸]-L-아르기닐글리실-L-α-아스파르틸L-세린-, 내부 염 (SF1126, CAS 936487-67-1)을 포함하나, 이에 제한되지는 않는다.
또 다른 측면에서, 본 발명은 암의 치료를 필요로 하는 대상체에게 본 발명의 항체 약물 접합체를 하나 이상의 아폽토시스촉진제, 예컨대 이에 제한되지는 않지만 IAP 억제제, Bcl2 억제제, MCl1 억제제, Trail 작용제, Chk 억제제와 조합하여 투여하는 것에 의해 암을 치료하는 방법을 제공한다.
예를 들어, IAP 억제제는 LCL161, GDC-0917, AEG-35156, AT406 및 TL32711을 포함하나, 이에 제한되지는 않는다. IAP 억제제의 다른 예는 WO04/005284, WO 04/007529, WO05/097791, WO 05/069894, WO 05/069888, WO 05/094818, US2006/0014700, US2006/0025347, WO 06/069063, WO 06/010118, WO 06/017295 및 WO08/134679에 개시된 것들을 포함하나 이에 제한되지는 않으며, 이들 모두는 본원에 참조로 포함된다.
BCL-2 억제제는 4-[4-[[2-(4-클로로페닐)-5,5-디메틸-1-시클로헥센-1-일]메틸]-1-피페라지닐]-N-[[4-[[(1R)-3-(4-모르폴리닐)-1-[(페닐티오)메틸]프로필]아미노]-3-[(트리플루오로메틸)술포닐]페닐]술포닐]벤즈아미드 (또한 ABT-263으로 공지되고, PCT 공개 번호 WO 09/155386에 기재됨); 테트로카르신 A; 안티마이신; 고시폴 ((-)BL-193); 오바토클락스; 에틸-2-아미노-6-시클로펜틸-4-(1-시아노-2-에톡시-2-옥소에틸)-4H크로몬-3-카르복실레이트 (HA14 - 1); 오블리메르센 (G3139, 게나센스(Genasense)®); Bak BH3 펩티드; (-)-고시폴 아세트산 (AT-101); 4-[4-[(4'-클로로[1,1'-비페닐]-2-일)메틸]-1-피페라지닐]-N-[[4-[[(1R)-3-(디메틸아미노)-1-[(페닐티오)메틸]프로필]아미노]-3-니트로페닐]술포닐]-벤즈아미드 (ABT-737, CAS 852808-04-9); 및 나비토클락 (ABT-263, CAS 923564-51-6)을 포함하나, 이에 제한되지는 않는다.
DR4 (TRAILR1) 및 DR5 (TRAILR2)을 비롯한 아폽토시스촉진 수용체 효능제 (PARA)는 둘라네르민 (AMG-951, RhApo2L/TRAIL); 마파투무맙 (HRS-ETR1, CAS 658052-09-6); 렉사투무맙 (HGS-ETR2, CAS 845816-02-6); 아포맙 (아포맙(Apomab)®); 코나투무맙 (AMG655, CAS 896731-82-1); 및 티가투주맙 (CS1008, CAS 946415-34-5, 다이이치 산쿄(Daiichi Sankyo)로부터 입수가능함)을 포함하나, 이에 제한되지는 않는다.
체크포인트 키나제 (CHK) 억제제는 7-히드록시스타우로스포린 (UCN-01); 6-브로모-3-(1-메틸-1H-피라졸-4-일)-5-(3R)-3-피페리디닐-피라졸로[1,5-a]피리미딘-7-아민 (SCH900776, CAS 891494-63-6); 5-(3-플루오로페닐)-3-우레이도티오펜-2-카르복실산 N-[(S)-피페리딘-3-일]아미드 (AZD7762, CAS 860352-01-8); 4-[((3S)-1-아자비시클로[2.2.2]옥트-3-일)아미노]-3-(1H-벤즈이미다졸-2-일)-6-클로로퀴놀린-2(1H)-온 (CHIR 124, CAS 405168-58-3); 7-아미노닥티노마이신 (7-AAD), 이소그라눌레이티미드, 데브로모히메니알디신; N-[5-브로모-4-메틸-2-[(2S)-2-모르폴리닐메톡시]-페닐]-N'-(5-메틸-2-피라지닐)우레아 (LY2603618, CAS 911222-45-2); 술포라판 (CAS 4478-93-7, 4-메틸술피닐부틸 이소티오시아네이트); 9,10,11,12-테트라히드로-9,12-에폭시-1H-디인돌로[1,2,3-fg:3',2',1'-kl]피롤로[3,4-i][1,6]벤조디아조신-1,3(2H)-디온 (SB-218078, CAS 135897-06-2); 및 TAT-S216A (YGRKKRRQRRRLYRSPAMPENL) 및 CBP501 ((d-Bpa)sws(d-Phe-F5)(d-Cha)rrrqrr)을 포함하나, 이에 제한되지는 않는다.
한 측면에서, 본 발명은 암의 치료를 필요로 하는 대상체에게 본 발명의 항체 약물 접합체를 하나 이상의 FGFR 억제제와 조합하여 투여하는 것에 의해 암을 치료하는 방법을 제공한다. 예를 들어, FGFR 억제제는 브리바닙 알라니네이트 (BMS-582664, (S)-((R)-1-(4-(4-플루오로-2-메틸-1H-인돌-5-일옥시)-5-메틸피롤로[2,1-f][1,2,4]트리아진-6-일옥시)프로판-2-일)2-아미노프로파노에이트); 바르가테프 (BIBF1120, CAS 928326-83-4); 도비티닙 디락트산 (TKI258, CAS 852433-84-2); 3-(2,6-디클로로-3,5-디메톡시-페닐)-1-{6-[4-(4-에틸-피페라진-1-일)-페닐아미노]-피리미딘-4-일}-1-메틸-우레아 (BGJ398, CAS 872511-34-7); 다우노세르팁 (PHA-739358); 및 N-[2-[[4-(디에틸아미노)부틸]아미노]-6-(3,5-디메톡시페닐)피리도[2,3-d]피리미딘-7-일]-N'-(1,1-디메틸에틸)-우레아 (PD173074, CAS 219580-11-7)를 포함하나, 이에 제한되지는 않는다. 구체적 실시양태에서, 본 발명은 암의 치료를 필요로 하는 대상체에게 본 발명의 항체 약물 접합체를 또 다른 FGFR2 억제제, 예컨대 3-(2,6-디클로로-3,5-디메톡시페닐)-1-(6((4-(4-에틸피페라진-1-일)페닐)아미노)피리미딘-4-일)-1-메틸우레아 (또한 BGJ-398로 공지됨); 또는 4-아미노-5-플루오로-3-(5-(4-메틸피페라진1-일)-1H-벤조[d]이미다졸-2-일)퀴놀린-2(1H)-온 (또한 도비티닙 또는 TKI-258로 공지됨)과 조합하여 투여하는 것에 의해 암을 치료하는 방법을 제공한다. AZD4547 (문헌 [Gavine et al., 2012, Cancer Research 72, 2045-56], N-[5-[2-(3,5-디메톡시페닐)에틸]-2H-피라졸-3-일]-4-(3R,5S)-디메틸피페라진-1-일)벤즈아미드), 포나티닙 (AP24534; 문헌 [Gozgit et al., 2012, Mol Cancer Ther., 11; 690-99]; 3-[2-(이미다조[1,2-b]피리다진-3-일)에티닐]-4-메틸-N-{4-[(4-메틸피페라진-1-일)메틸]-3-(트리플루오로메틸)페닐}벤즈아미드, CAS 943319-70-8).
제약 조성물
면역접합체를 포함하는 제약 또는 멸균 조성물을 제조하기 위해, 본 발명의 면역접합체는 제약상 허용되는 담체 또는 부형제와 혼합된다. 조성물은 추가로 암 (유방암, 결장직장암, 폐암, 다발성 골수종, 난소암, 간암, 위암, 췌장암, 급성 골수성 백혈병, 만성 골수성 백혈병, 골육종, 편평 세포 암종, 말초 신경초 종양 슈반세포종, 두경부암, 방광암, 식도암, 바렛 식도암, 교모세포종, 투명 세포 연부 조직 육종, 악성 중피종, 신경섬유종증, 신암, 흑색종, 전립선암, 양성 전립선 비대증 (BPH), 여성형유방증, 횡문근육종 및 자궁내막증)을 치료 또는 예방하는데 적합한 하나 이상의 다른 치료제를 함유할 수 있다.
치료제 및 진단제의 제제는 생리학상 허용되는 담체, 부형제 또는 안정화제와, 예를 들어 동결건조 분말, 슬러리, 수용액, 로션 또는 현탁액의 형태로 혼합함으로써 제조될 수 있다 (예를 들어, 문헌 [Hardman et al., Goodman and Gilman's The Pharmacological Basis of Therapeutics, McGraw-Hill, New York, N.Y., 2001; Gennaro, Remington: The Science and Practice of Pharmacy, Lippincott, Williams, and Wilkins, New York, N.Y., 2000; Avis, et al. (eds.), Pharmaceutical Dosage Forms: Parenteral Medications, Marcel Dekker, NY, 1993; Lieberman, et al. (eds.), Pharmaceutical Dosage Forms: Tablets, Marcel Dekker, NY, 1990; Lieberman, et al. (eds.) Pharmaceutical Dosage Forms: Disperse Systems, Marcel Dekker, NY, 1990; Weiner and Kotkoskie, Excipient Toxicity and Safety, Marcel Dekker, Inc., New York, N.Y., 2000] 참조).
구체적 실시양태에서, 본 발명의 항체 약물 접합체의 임상적 서비스 형태 (CSF)는 ADC, 숙신산나트륨 및 폴리소르베이트 20을 함유하는 바이알 내에 있는 동결건조물이다. 동결건조물은 주사용수로 재구성될 수 있고, 용액은 ADC, 숙신산나트륨, 수크로스 및 폴리소르베이트 20을 약 5.0의 pH에서 포함한다. 순차적 정맥내 투여를 위해, 수득된 용액은 보통 담체 용액 내로 추가로 희석될 것이다.
치료를 위한 투여 요법을 선택하는 것은 물질의 혈청 또는 조직 교체율, 증상 수준, 물질의 면역원성 및 생물학적 매트릭스에서의 표적 세포의 접근성을 비롯한 여러 요인에 따라 달라진다. 특정 실시양태에서, 투여 요법은 허용되는 부작용 수준에 부합하도록 환자에 전달되는 치료제의 양을 최대화한다. 따라서, 전달되는 생물제제의 양은 부분적으로는 특정 물질 및 치료되는 상태의 중증도에 따라 달라진다. 항체, 시토카인 및 소분자의 적합한 용량을 선택하는 것에서의 지침이 입수가능하다 (예를 들어, 문헌 [Wawrzynczak, Antibody Therapy, Bios Scientific Pub. Ltd, Oxfordshire, UK, 1996; Kresina (ed.), Monoclonal Antibodies, Cytokines and Arthritis, Marcel Dekker, New York, N.Y., 1991; Bach (ed.), Monoclonal Antibodies and Peptide Therapy in Autoimmune Diseases, Marcel Dekker, New York, N.Y., 1993; Baert et al., New Engl. J. Med. 348:601-608, 2003; Milgrom et al., New Engl. J. Med. 341:1966-1973, 1999; Slamon et al., New Engl. J. Med. 344:783-792, 2001; Beniaminovitz et al., New Engl. J. Med. 342:613-619, 2000; Ghosh et al., New Engl. J. Med. 348:24-32, 2003; Lipsky et al., New Engl. J. Med. 343:1594-1602, 2000] 참조).
적절한 용량은 예를 들어, 치료에 영향을 미치는 것으로 관련 기술분야에 공지되어 있거나 그러한 것으로 의심되거나, 또는 치료에 영향을 미칠 것으로 예측되는 파라미터 또는 인자를 사용하여 임상의에 의해 결정된다. 일반적으로, 용량은 최적 용량보다 다소 적은 양에서 시작하며, 그후 임의의 부정적 부작용에 비해 바람직하거나 최적인 효과가 달성될 때까지 소량 증분으로 증가시킨다. 중요한 진단 척도는, 예를 들어 염증의 증상 또는 생산된 염증성 시토카인의 수준을 포함한다.
본 발명의 제약 조성물 중 활성 성분의 실제 투여량 수준은 환자에게 독성이 없으면서 특정한 환자, 조성물 및 투여 방식에 대해 원하는 치료 반응을 달성하는데 효과적인 활성 성분의 양이 달성되도록 달라질 수 있다. 선택된 투여량 수준은 사용되는 본 발명의 특정한 조성물, 또는 그의 에스테르, 염 또는 아미드의 활성, 투여 경로, 투여 시간, 사용되는 특정한 화합물의 배출 속도, 치료 기간, 사용되는 특정한 조성물과 조합 사용되는 다른 약물, 화합물 및/또는 물질, 치료받는 환자의 연령, 성별, 체중, 상태, 전반적 건강 및 이전 병력 및 의료 분야에 공지된 다른 요인을 비롯한 다양한 약동학 요인에 따라 결정될 것이다.
본 발명의 항체 또는 그의 단편을 포함하는 조성물은 연속 주입에 의해 또는, 예를 들어 1일, 1주의 간격으로, 또는 주당 1-7회, 격주 1회, 3주마다 1회, 4주마다 1회, 5주마다 1회, 6주마다 1회, 7주마다 1회 또는 8주마다 1회의 용량으로 제공될 수 있다. 용량은 정맥내, 피하, 국부, 경구, 비강내, 직장, 근육내, 뇌내, 또는 흡입에 의해 제공될 수 있다. 특정 용량 프로토콜은 유의한 바람직하지 않은 부작용을 방지하는 최대 용량 또는 투여 빈도를 수반하는 것이다.
본 발명의 면역접합체에 대해, 환자에게 투여되는 투여량은 0.0001 mg/kg 내지 100 mg/kg (환자 체중)일 수 있다. 투여량은 0.0001 mg/kg 내지 20 mg/kg, 0.0001 mg/kg 내지 10 mg/kg, 0.0001 mg/kg 내지 5 mg/kg, 0.0001 내지 2 mg/kg, 0.0001 내지 1 mg/kg, 0.0001 mg/kg 내지 0.75 mg/kg, 0.0001 mg/kg 내지 0.5 mg/kg, 0.0001 mg/kg 내지 0.25 mg/kg, 0.0001 내지 0.15 mg/kg, 0.0001 내지 0.10 mg/kg, 0.001 내지 0.5 mg/kg, 0.01 내지 0.25 mg/kg 또는 0.01 내지 0.10 mg/kg (환자 체중)일 수 있다. 본 발명의 항체 또는 그의 단편의 투여량은 환자의 체중 (킬로그램 (kg))에 투여되는 용량 (mg/kg)을 곱하는 것을 이용하여 계산될 수 있다.
본 발명의 면역접합체의 투여가 반복될 수 있고, 투여는 적어도 1일, 2일, 3일, 5일, 10일, 15일, 30일, 45일, 2개월, 75일, 3개월, 또는 적어도 6개월 간격일 수 있다. 구체적 실시양태에서, 본 발명의 면역접합체의 투여는 3주마다 반복된다.
치료될 상태, 환자의 전반적인 건강, 투여 방법 경로 및 용량, 및 부작용의 중증도와 같은 요인들에 따라 특정한 환자에 대한 유효량이 변할 수 있다 (예를 들어, 문헌 [Maynard et al., A Handbook of SOPs for Good Clinical Practice, Interpharm Press, Boca Raton, Fla., 1996; Dent, Good Laboratory and Good Clinical Practice, Urch Publ., London, UK, 2001] 참조).
투여 경로는, 예를 들어 국소 또는 피부 적용에 의해, 정맥내, 복강내, 뇌내, 근육내, 안내, 동맥내, 뇌척수내, 병변내 주사 또는 주입에 의해, 또는 지속 방출 시스템 또는 이식물에 의해 이루어질 수 있다 (예를 들어, 문헌 [Sidman et al., Biopolymers 22:547-556, 1983; Langer et al., J. Biomed. Mater. Res. 15:167-277, 1981; Langer, Chem. Tech. 12:98-105, 1982; Epstein et al., Proc. Natl. Acad. Sci. USA 82:3688-3692, 1985; Hwang et al., Proc. Natl. Acad. Sci. USA 77:4030-4034, 1980]; 미국 특허 번호 6,350,466 및 6,316,024 참조). 필요한 경우에, 조성물은 또한 가용화제 및 국부 마취제, 예컨대 주사 부위의 통증을 완화하는 리도카인을 포함할 수 있다. 또한, 예를 들어 흡입기 또는 네뷸라이저의 사용, 및 에어로졸화제를 사용한 제제화에 의한 폐 투여도 사용될 수 있다. 예를 들어, 미국 특허 번호 6,019,968, 5,985,320, 5,985,309, 5,934,272, 5,874,064, 5,855,913, 5,290,540 및 4,880,078; 및 PCT 공개 번호 WO 92/19244, WO 97/32572, WO 97/44013, WO 98/31346 및 WO 99/66903을 참조하고, 이들 각각은 본원에 전문이 참조로 포함된다.
또한, 본 발명의 조성물은 관련 기술분야에 공지된 하나 이상의 다양한 방법을 사용하여 하나 이상의 투여 경로를 통해 투여될 수 있다. 통상의 기술자가 인지하는 바와 같이, 투여 경로 및/또는 방식은 원하는 결과에 따라 달라질 것이다. 본 발명의 면역접합체에 대한 선택된 투여 경로는 정맥내, 근육내, 피내, 복막내, 피하, 척수 또는 기타 비경구 투여 경로, 예를 들어 주사 또는 주입에 의한 것을 포함한다. 비경구 투여는 경장 및 국소 투여 이외의 다른, 통상적으로 주사에 의한 투여 방식을 나타내고, 정맥내, 근육내, 동맥내, 척수강내, 피막내, 안와내, 심장내, 피내, 복강내, 경기관, 피하, 표피하, 관절내, 피막하, 지주막하, 척수내, 경막외 및 흉골내 주사 및 주입을 포함하나, 이에 제한되지는 않는다. 대안적으로, 본 발명의 조성물은 비-비경구 경로를 통해, 예컨대 국소, 표피 또는 점막 투여 경로, 예를 들어, 비강내, 경구, 질, 직장, 설하 또는 국부 투여될 수 있다. 한 실시양태에서, 본 발명의 면역접합체는 주입에 의해 투여된다. 또 다른 실시양태에서, 본 발명의 면역접합체는 피하 투여된다.
본 발명의 면역접합체가 제어 방출 또는 지연 방출 시스템에서 투여되는 경우, 제어 또는 지연 방출을 달성하기 위해 펌프가 사용될 수 있다 (문헌 [Langer, supra; Sefton, CRC Crit. Ref Biomed. Eng. 14:20, 1987; Buchwald et al., Surgery 88:507, 1980; Saudek et al., N. Engl. J. Med. 321:574, 1989] 참조). 본 발명의 요법의 제어 또는 지속 방출을 달성하기 위해 중합체 물질이 사용될 수 있다 (예를 들어, 문헌 [Medical Applications of Controlled Release, Langer and Wise (eds.), CRC Pres., Boca Raton, Fla., 1974; Controlled Drug Bioavailability, Drug Product Design and Performance, Smolen and Ball (eds.), Wiley, New York, 1984; Ranger and Peppas, J. Macromol. Sci. Rev. Macromol. Chem. 23:61, 1983] 참조; 또한 문헌 [Levy et al., Science 228:190, 1985; During et al., Ann. Neurol. 25:351, 1989; Howard et al., J. Neurosurg. 7 1:105, 1989]; 미국 특허 번호 5,679,377; 미국 특허 번호 5,916,597; 미국 특허 번호 5,912,015; 미국 특허 번호 5,989,463; 미국 특허 번호 5,128,326; PCT 공개 번호 WO 99/15154; 및 PCT 공개 번호 WO 99/20253 참조). 지속 방출 제제에 사용된 중합체의 예는 폴리(2-히드록시 에틸 메타크릴레이트), 폴리(메틸 메타크릴레이트), 폴리(아크릴산), 폴리(에틸렌-코-비닐 아세테이트), 폴리(메타크릴산), 폴리글리콜리드 (PLG), 폴리무수물, 폴리(N-비닐 피롤리돈), 폴리(비닐 알콜), 폴리아크릴아미드, 폴리(에틸렌 글리콜), 폴리락티드 (PLA), 폴리(락티드-코-글리콜리드) (PLGA) 및 폴리오르토에스테르를 포함하나, 이에 제한되지는 않는다. 한 실시양태에서, 지속 방출 제제에 사용되는 중합체는 불활성이고, 여과가능한 불순물이 없고, 저장, 멸균 및 생분해성에 대해 안정하다. 제어 또는 지연 방출 시스템이 예방 또는 치료 표적에 인접하게 놓일 수 있고, 따라서 전신 용량의 일부만을 필요로 한다 (예를 들어, 문헌 [Goodson, in Medical Applications of Controlled Release, supra, vol. 2, pp. 115-138, 1984] 참조).
문헌 [Langer, Science 249:1527-1533, 1990]의 리뷰에서 제어 방출 시스템이 논의된다. 통상의 기술자에게 공지된 임의의 기술을 본 발명의 하나 이상의 면역접합체를 포함하는 지속 방출 제제를 생산하는데 사용할 수 있다. 예를 들어, 미국 특허 번호 4,526,938, PCT 공개 WO 91/05548, PCT 공개 WO 96/20698, 문헌 [Ning et al., Radiotherapy & Oncology 39:179-189, 1996; Song et al., PDA Journal of Pharmaceutical Science & Technology 50:372-397, 1995; Cleek et al., Pro. Int'l. Symp. Control. Rel. Bioact. Mater. 24:853-854, 1997; and Lam et al., Proc. Int'l. Symp. Control Rel. Bioact. Mater. 24:759-760, 1997]을 참조하고, 이들 각각은 본원에 전문이 참조로 포함된다.
본 발명의 면역접합체가 국소로 투여되는 경우에, 이는 연고, 크림, 경피 패치, 로션, 겔, 샴푸, 스프레이, 에어로졸, 용액, 에멀젼 형태, 또는 통상의 기술자에게 널리 공지된 다른 형태로 제제화될 수 있다. 예를 들어, 문헌 [Remington's Pharmaceutical Sciences and Introduction to Pharmaceutical Dosage Forms, 19th ed., Mack Pub. Co., Easton, Pa. (1995)]을 참조한다. 비-분무가능한 국소 투여 형태의 경우, 국소 적용에 적합한 담체 또는 하나 이상의 부형제를 포함하고 몇몇 경우에 물보다 큰 동적 점도를 갖는 점성 내지 반고체 또는 고체 형태가 일반적으로 사용된다. 적합한 제제는, 원하는 경우에 멸균되거나 예를 들어 삼투압과 같은 다양한 특성에 영향을 주는 보조제 (예를 들어, 보존제, 안정화제, 습윤제, 완충제, 또는 염)와 혼합되는 용액, 현탁액, 에멀젼, 크림, 연고, 분말, 도찰제, 살브 등을 포함하나, 이에 제한되지는 않는다. 다른 적합한 국소 투여 형태는 몇몇 경우에 활성 성분이 고체 또는 액체 불활성 담체와 조합되어 압축 휘발물질 (예를 들어, 기체상 추진제, 예컨대 프레온)의 혼합물에 또는 압착병에 충전되는 분무가능한 에어로졸 제제를 포함한다. 보습제 또는 함습제가 또한 원하는 경우에 제약 조성물 및 투여 형태에 첨가될 수 있다. 이러한 추가의 성분의 예는 관련 기술분야에 공지되어 있다.
면역접합체를 포함하는 조성물이 비강 내로 투여되는 경우, 이는 에어로졸 형태, 스프레이, 미스트 내에 또는 점적제의 형태로 제제화될 수 있다. 특히, 본 발명에 따라 사용하기 위한 예방제 또는 치료제는 적합한 추진제 (예를 들어, 디클로로디플루오로메탄, 트리클로로플루오로메탄, 디클로로테트라플루오로에탄, 이산화탄소 또는 다른 적합한 기체)를 사용하여 가압 팩 또는 연무기로부터 에어로졸 스프레이 제공 형태로 편리하게 전달될 수 있다. 가압 에어로졸의 경우에, 투여 단위는 계량된 양을 전달하기 위해 밸브를 제공함으로써 결정될 수 있다. 흡입기 또는 취입기에 사용하기 위한, 캡슐 및 카트리지 (예를 들어, 젤라틴으로 구성됨)는 화합물의 분말 혼합물 및 적합한 분말 기제, 예컨대 락토스 또는 전분을 함유하여 제제화될 수 있다.
제2 치료제, 예를 들어 시토카인, 스테로이드, 화학요법제, 항생제, 또는 방사선과 함께 공투여하거나 치료하기 위한 방법은 관련 기술분야에 공지되어 있다 (예를 들어, 문헌 [Hardman et al., (eds.) (2001) Goodman and Gilman's The Pharmacological Basis of Therapeutics, 10.sup.th ed., McGraw-Hill, New York, N.Y.; Poole and Peterson (eds.) (2001) Pharmacotherapeutics for Advanced Practice:A Practical Approach, Lippincott, Williams & Wilkins, Phila., Pa.; Chabner and Longo (eds.) (2001) Cancer Chemotherapy and Biotherapy, Lippincott, Williams & Wilkins, Phila., Pa.] 참조). 유효량의 치료제는 증상을 적어도 10%; 적어도 20%; 적어도 약 30%; 적어도 40%, 또는 적어도 50% 감소시킬 수 있다.
본 발명의 면역접합체와 조합되어 투여될 수 있는 추가적인 요법 (예를 들어, 예방제 또는 치료제)은 본 발명의 면역접합체와 5분 미만의 간격, 30분 미만의 간격, 1시간 간격, 약 1시간 간격, 약 1 내지 약 2시간 간격, 약 2시간 내지 약 3시간 간격, 약 3시간 내지 약 4시간 간격, 약 4시간 내지 약 5시간 간격, 약 5시간 내지 약 6시간 간격, 약 6시간 내지 약 7시간 간격, 약 7시간 내지 약 8시간 간격, 약 8시간 내지 약 9시간 간격, 약 9시간 내지 약 10시간 간격, 약 10시간 내지 약 11시간 간격, 약 11시간 내지 약 12시간 간격, 약 12시간 내지 18시간 간격, 18시간 내지 24시간 간격, 24시간 내지 36시간 간격, 36시간 내지 48시간 간격, 48시간 내지 52시간 간격, 52시간 내지 60시간 간격, 60시간 내지 72시간 간격, 72시간 내지 84시간 간격, 84시간 내지 96시간 간격, 또는 96시간 내지 120시간 간격으로 투여될 수 있다. 2종 이상의 요법제는 동일한 환자 방문 내에 투여될 수 있다.
특정 실시양태에서, 본 발명의 면역접합체는 생체내 적합한 분포를 확실히 하도록 제제제화될 수 있다. 예를 들어, 혈액-뇌 장벽 (BBB)은 다수의 고도의 친수성 화합물을 제외한다. 본 발명의 치료 화합물이 (원하는 경우에) BBB를 확실히 횡단하도록 하기 위해서는, 이들을 예를 들어 리포솜 내에 제제화할 수 있다. 리포솜 제조 방법에 대해서는, 예를 들어, 미국 특허 번호 4,522,811; 5,374,548; 및 5,399,331을 참조한다. 리포솜은 특정 세포 또는 기관 내로 선택적으로 수송되어 표적화 약물 전달을 증진시키는 하나 이상의 모이어티를 포함할 수 있다 (예를 들어, 문헌 [Ranade, (1989) J. Clin. Pharmacol. 29:685] 참조). 예시적인 표적화 모이어티는 폴레이트 또는 비오틴 (예를 들어, 미국 특허 번호 5,416,016 (Low et al.) 참조); 만노시드 (문헌 [Umezawa et al., (1988) Biochem. Biophys. Res. Commun. 153:1038]); 항체 (문헌 [Bloeman et al., (1995) FEBS Lett. 357:140; Owais et al., (1995) Antimicrob. Agents Chemother. 39:180]); 계면활성제 단백질 A 수용체 (문헌 [Briscoe et al., (1995) Am. J. Physiol. 1233:134); p 120 (문헌 [Schreier et al, (1994) J. Biol. Chem. 269:9090])를 포함하며; 또한 문헌 [also K. Keinanen; M. L. Laukkanen (1994) FEBS Lett. 346:123; J. J. Killion; I. J. Fidler (1994) Immunomethods 4:273]을 참조한다.
본 발명은 본 발명의 면역접합체를 포함하는 제약 조성물을 이를 필요로 하는 대상체에게 단독으로 또는 다른 요법과 조합하여 투여하기 위한 프로토콜을 제공한다. 본 발명의 조합 요법의 요법제 (예를 들어, 예방제 또는 치료제)는 대상체에게 공동으로 또는 순차적으로 투여될 수 있다. 본 발명의 조합 요법의 요법제 (예를 들어, 예방제 또는 치료제)는 또한 주기적으로 투여될 수 있다. 주기적 요법은 소정의 기간 동안의 제1 요법제 (예를 들어, 제1 예방제 또는 치료제)의 투여, 이어서 소정의 기간 동안의 제2 요법제 (예를 들어, 제2 예방제 또는 치료제)의 투여 및 상기 순차적인 투여의 반복, 즉 요법제 (예를 들어, 작용제) 중 하나에 대한 내성의 발생을 감소시키고/거나, 요법제 (예를 들어, 작용제) 중 하나의 부작용을 방지 또는 감소시키고/거나, 요법제의 효능을 개선시키기 위한 순환을 포함한다.
본 발명의 조합 요법의 요법제 (예를 들어, 예방제 또는 치료제)는 대상체에게 공동으로 투여할 수 있다.
"공동으로"라는 용어는 요법들 (예를 들어, 예방제 또는 치료제)을 정확히 동시에 투여하는 것에 한정되지 않고, 그보다는 본 발명의 항체 또는 그의 단편을 포함하는 제약 조성물이 대상체에게 순서대로, 및 본 발명의 항체가 다른 요법(들)과 함께 이들이 다르게 투여된 경우보다 증가된 이익을 제공하도록 작용할 수 있는 시간 간격으로 투여되는 것을 의미한다. 예를 들어, 각각의 요법제는 동시에 또는 상이한 시점에서 임의의 순서로 순차적으로 대상체에게 투여될 수 있지만; 동시에 투여되지 않을 경우에도, 이들은 목적하는 치료 또는 예방 효과를 제공하기 위해 충분히 가까운 시간 간격으로 투여되어야 한다. 각각의 요법제는 임의의 적절한 형태로 및 임의의 적합한 경로에 의해 대상체에게 개별 투여될 수 있다. 다양한 실시양태에서, 요법제 (예를 들어, 예방제 또는 치료제)는 대상체에게 15분 미만, 30분 미만, 1시간 미만, 약 1시간, 약 1 내지 약 2시간, 약 2시간 내지 약 3시간, 약 3시간 내지 약 4시간, 약 4시간 내지 약 5시간, 약 5시간 내지 약 6시간, 약 6시간 내지 약 7시간, 약 7시간 내지 약 8시간, 약 8시간 내지 약 9시간, 약 9시간 내지 약 10시간, 약 10시간 내지 약 11시간, 약 11시간 내지 약 12시간, 24시간, 48시간, 72시간, 또는 1주의 간격으로 투여될 수 있다. 다른 실시양태에서, 2종 이상의 요법제 (예를 들어, 예방제 또는 치료제)는 동일한 환자 방문 내에 투여된다.
조합 요법의 예방제 또는 치료제는 대상체에게 동일한 제약 조성물 내에서 투여될 수 있다. 대안적으로, 조합 요법의 예방제 또는 치료제는 대상체에게 개별 제약 조성물 내에서 공동으로 투여할 수 있다. 예방제 또는 치료제는 대상체에게 동일한 또는 상이한 투여 경로로 투여될 수 있다.
실시예
하기 실시예 및 중간체는 본 발명을 예시하기 위해 제공되며, 그 범주를 제한하지는 않는다.
실시예 1: 항-FGFR2/4 항체를 위한 스크리닝
세포주
Ba/F3 세포는 DSMZ로부터 구입하였고, KatoIII, SNU16, SNU5 및 HCI-H716 세포는 아메리칸 타입 컬쳐 콜렉션(American Type Culture Collection) (ATCC)으로부터 구입하였고, NUGC3 세포는 재팬 콜렉션 오브 리서치 바이오리소시스(Japanese Collection of Research Bioresources) (JCRB) 세포 은행으로부터 획득하였다. 모든 세포주는 통상적으로 그의 각 공급업체에 의해 권고된 바와 같이 태아 소 혈청 (FBS)으로 보충된 적절한 성장 배지 중에서 배양하였다.
재조합 인간, 시노, 마우스 및 래트 FGFR 벡터의 생성
인간, 마우스 및 래트 FGFR 세포외 도메인은 진뱅크(GenBank) 또는 유니프롯(Uniprot) 데이터베이스로부터의 아미노산 서열을 기준으로 하여 합성된 유전자였다 (표 2 참조). 시노몰구스 FGFR2 및 4 ECD cDNA 주형은 다양한 시노 조직으로부터의 mRNA를 사용하여 생성된 아미노산 서열 정보 (예를 들어 지아겐 래보러토리즈(Zyagen Laboratories); 표 3)를 기준으로 하여 합성된 유전자였다. 모든 합성된 DNA 단편은 정제를 감안하여 적절한 발현 벡터, 예를 들어 CMV 기반 벡터 또는 C-말단 태그를 갖는 pCDNA™3.1. 내로 클로닝하였다.
<표 2> FGFR 발현 벡터의 생성. 아미노산 넘버링은 하기 표에서 제공된 수탁 번호 또는 서열을 기준으로 함

<표 3> 시노몰구스 FGFR2 및 FGFR4 단백질의 서열

재조합 FGFR 단백질의 발현
목적하는 FGFR 재조합 단백질을 현탁액 배양물에 사전 적응시킨 HEK293 유래의 세포주 (293T)에서 발현시키고, 혈청-무함유 배지, L-글루타민이 없는 50% 하이클론(HyClone)™ SFM4Transfx-293 (하이클론™) 및 50% 프리스타일(FreeStyle)-293 (깁코(Gibco)®)의 믹스 중에 성장시켰다. 소규모 및 대규모 단백질 생산 둘 다는 일시적 형질감염을 통해 이루어지고, 다중 진탕기 플라스크 (날겐(Nalgene)®)에서 각각 최대 1 L로 플라스미드 운반체로서의 폴리에틸렌이민 (PEI, 25K, 알파에사르(AlfaAesar)®)과 함께 수행하였다. 비오티닐화 단백질이 C-말단 Avi 태그를 통해 발현될 수 있는 경우에, BirA 효소에 대한 유전자를 운반하는 플라스미드는 ECD 단백질 플라스미드에 대해 1:2의 비로 포함되었다. 전체 DNA 및 폴리에틸렌이민을 1:3 (w:w)의 비로 사용하였다. 배양물에 대한 DNA의 비는 1 mg/L였다. 세포 배양물 상청액을 형질감염 6일 후에 수확하고, 원심분리하고, 멸균 여과 후에 정제하였다.
태그부착된 단백질 정제
재조합 태그부착된 FGFR2 및 FGFR4 ECD 단백질 (예를 들어, APP-FGFR2 및 APP-FGFR4 ECD)을 세포 배양물 상청액을 수집함으로써 정제하였다. 항-APP 칼럼을 항-APP 모노클로날 항체를 CNBr 활성화된 세파로스®4B에 수지 mL 당 10 mg 항체의 최종 비로 커플링시킴으로써 준비하였다. 발현 상청액을 항-APP 칼럼에 1-2 mL/ 분의 유량으로 또는 중력 흐름에 의해 적용하였다. PBS를 사용한 기준 세척 후, 결합된 물질을 100 mM 글리신 (pH 2.7)으로 용리시키고, 즉시 PBS에 대해 밤새 투석시키고, 이어서 멸균 여과하였다. 단백질 농도를, 280 nm에서의 흡광도를 측정하고 개별 단백질의 아미노산 서열을 기준으로 하여 계산된 단백질 흡광 계수를 사용하여 전환시킴으로써 결정하였다. 이어서, 정제된 단백질을 SDS-PAGE, 분석용 크기 배제 크로마토그래피 (HPLC-SEC)에 의해 특성화하였다. 친화도 정제된 제제에서 >10% 초과의 응집체에 대해, 제2 단계 SEC 정제를 수행한 다음, 특성을 확인하였다.
Ba/F3 FGFR2 세포주의 생성
이러한 세포를 생성하기 위해, 인간 FRGR2-IIIb-C3 (NM_022970)을 pENTR™ 토포드(TOPOD)® 벡터 (인비트로젠 카탈로그 #K2400-20) 내로 및 이어서 pLenti6 데스트(DEST)™ 벡터 (인비트로젠 카탈로그 #V49610) 내로 CMV 프로모터 하에 클로닝하였다. 이어서, 바이러스를 패키징하고, Ba/F3 세포 (DSMZ 카탈로그 #ACC300)를 렌티바이러스로 회전 감염시킨 다음, 20 μg 블라스티시딘 (예를 들어 인비트로젠, 카탈로그 # A11139-03 또는 셀그로(Cellgro)®, 카탈로그 # 30-100-RB)으로 처리하고, IL3 (R&D 시스템스(R&D systems) 카탈로그 #403-ml-010)으로 5일 동안 조직 배양 인큐베이터 내 37℃ 및 5% CO2에서 선택하였다. 이어서, 생존 세포를 10% FBS (클론테크(Clontech) 카탈로그 #631101, 2 μg/ml 헤파린 (시그마(Sigma), 카탈로그 # H3149) 및 20 μg/ml 블라스티시딘 (예를 들어 인비트로젠, 카탈로그 # A11139-03 또는 셀그로®, 카탈로그 # 30-100-RB))으로 보충되었지만 IL3은 없는 배지 (RPMI (인비트로젠 카탈로그 #11875-093) 중에서 1개월 동안 성장시켰다. 이어서, 생존 세포를 희석 클로닝하여 클론 세포 집단을 생성하고, 이어서 이를 후속 연구에 사용하였다.
HuCAL 플라티눔(PLATINUM)® 패닝
인간 FGFR2를 인식하는 항체의 선택을 위해 다중 패닝 전략을 이용하였다. 인간 FGFR 단백질에 대한 치료 항체는 항체 변이체 단백질의 공급원으로서 상업적으로 입수가능한 파지 디스플레이 라이브러리인 모르포시스(MorphoSys) HuCAL 플라티눔® 라이브러리를 이용하여 FGFR2에 결합되어 있는 클론을 선택함으로써 생성하였다. 파지미드 라이브러리는 HuCAL® 개념을 기반으로 하고 (문헌 [Knappik et al., 2000, J Mol Biol 296: 57-86]), 파지 표면 상에 Fab를 디스플레이하기 위해 시스디스플레이(CysDisplay)™ 기술을 이용한다 (WO01/05950).
항-FGFR2 항체의 단리를 위해, 여러 다양한 패닝 전략을 활용하여 고체 상, 용액, 전세포 및 차등 전세포 접근법을 사용하였다.
재조합 FGFR2에 대한 고체 상 패닝
항원 선택 과정 이전에 코팅 체크 ELISA를 수행하여 항원에 대한 최적의 코팅 농도를 결정하였다. 수동 흡착을 통해 또는 항원의 각 태그를 표적화하는 포획 항체를 통해 맥시소르프(Maxisorp)™ 플레이트 (눈크(Nunc)®) 상에 코팅함으로써, 다양한 태그를 갖는 상이한 재조합 FGFR2 단백질을 고체 상 패닝 접근법에 사용하였다. 대안적으로 리액티-바인드(Reacti-Bind)™ 뉴트르아비딘(NeutrAvidin)™-코팅된 폴리스티렌 스트립 플레이트 (피어스(Pierce))를 비오티닐화 FGFR2 항원을 포획하는데 사용하였다. 96-웰 맥시소르프™ 플레이트 (눈크®)의 웰 중 적절한 개수 (서브-라이브러리 풀의 수에 따름)를 밤새 4℃에서 항원으로 코팅하였다. 코팅된 웰을 PBS (포스페이트 완충 염수)/5% 분유로 차단하였다. 각 패닝을 위해, 거의 HuCAL 플라티눔® 파지-항체를 차단하였다. 차단 절차 후에, 사전-차단된 파지 믹스를 코팅 및 잘 차단된 각 항원에 첨가하고, 2시간 (h) 동안 실온 (RT)에서 마이크로타이터 플레이트 (MTP) 진탕기 상에서 인큐베이션하였다. 그 후에, 비특이적 결합된 파지를 수회의 세척 단계로 세척해 냈다. 특이적으로 결합된 파지의 용리를 위해, 25 mM DTT (디티오트레이톨)를 10분 (min)동안 실온에서 첨가하였다. DTT 용리액을 이. 콜라이 (에스케리키아 콜라이(Escherichia coli)) TG-1 세포의 감염에 사용하였다. 감염 후에, 박테리아를 LB (리소제니 브로쓰(lysogeny broth))/Cam (클로람페니콜) 한천 플레이트 상에 플레이팅하고, 밤새 30℃에서 인큐베이션하였다. 콜로니를 플레이트에서 스크랩핑하여, 파지 구조, 선택된 클론의 폴리클로날 증폭, 및 파지 생산에 사용하였다. 각각의 FGFR2 고체 상 패닝 전략은 패닝의 개별 라운드로 구성되고, 특징적인 항원, 항원 농도, 완충제 조성물 및 세척 엄격도를 함유하였다.
스트렙타비딘-커플링된 자기 비드를 사용한 재조합 FGFR2 상의 용액 패닝
용액 패닝 접근법을 위한 전제조건은 항원의 비오티닐화, 및 비오티닐화 항원의 보유된 활성의 확인이었다. 용액 패닝 동안, Fab 디스플레이 파지 및 비오티닐화 항원을, 파지에 의한 항원의 접근성을 용이하게 하는 용액 중에서 인큐베이션하였다.
각각의 파지 풀을 위해, 스트렙타비딘 비드 (디나비즈(Dynabeads)® M-280 스트렙타비딘; 인비트로젠)를 1x 케미블로커(Chemiblocker)™ 중에서 차단하였다. 동시에, 각각의 패닝을 위해, 거의 HuCAL 플라티눔® 파지-항체를 동부피의 2x 케미블로커™/ 0.1% 트윈(Tween)20을 사용하여 차단하였다. 이어서, 특정 농도의 비오티닐화 항원 (예를 들어 100 nM)을 사전-흡착 및 차단된 파지 입자에 첨가하고, 회전기 상에서 1-2시간 동안 실온에서 인큐베이션하였다. 차단된 스트렙타비딘 비드를 사용하여 파지-항원 복합체를 포획하고, 스트렙타비딘 비드에 결합된 파지 입자를 자기 분리기를 사용하여 수집하였다. 비특이적 결합된 파지를 수회의 세척 단계에 의해 세척해 냈다. 특이적으로 결합된 파지의 스트렙타비딘 비드로부터의 용리를 위해, 25 mM DTT를 10분 동안 실온에서 첨가하였다. DTT 용리액을 고체 상 패닝에 대해 기재된 바와 같이 처리하였다.
각각의 FGFR2 용액 상 패닝 전략은 패닝의 개별 라운드로 구성되고, 특징적인 항원, 항원 농도 및 세척 엄격도를 함유하였다.
FGFR2 과다발현 세포에 대한 전세포 패닝
각 세포 패닝을 위해, HuCAL 플라티눔® 파지-항체를 PBS/FCS 중에서 사전-차단하였다. 동시에, FGFR2의 과다발현을 나타내는 파지 풀 (FGFR2로 안정하게 형질감염된 Ba/F3 세포, Kato-III, SNU16, H716) 당 0.5-1.0x107개의 표적 세포를 얼음 상의 PBS/FCS 중에 재현탁시켰다.
차단된 표적 세포를 회전 침강시키고, 사전 차단된 파지 입자 중에 재현탁시키고, 2시간 동안 4℃에서 회전기 상에서 인큐베이션하였다. 파지-세포 복합체를 PBS/FCS 중에서 세척하였다. 특이적으로 결합된 파지의 표적 세포로부터의 용리를 글리신 완충제, pH 2.2를 사용한 산성 용리에 의해 수행하였다. 원심분리 후, 비완충된 트리스를 첨가함으로써 상청액 (용리액)을 중화시켰다. 최종 파지 함유 상청액을 이. 콜라이 TG1 배양물의 감염에 사용하였다. 하기 단계를 섹션 고체 상 패닝 하에 기재된 바와 같이 수행하였다.
보다 상세하게, 각각의 패닝 라운드가 세포를 사용하여 수행되는 경우에는 전세포 패닝을 수행하거나, 또는 대안적으로, 세포 또는 재조합 단백질이 연속적 패닝 라운드에 사용된다는 것을 의미하는 차등 전세포 패닝을 수행하였다. 재조합 항원에 대한 선택 라운드는 고체 상 또는 용액 패닝에 대해 기재된 바와 같이 수행하였다.
성숙 패닝
상승된 친화도를 갖는 FGFR2 특이적 항체를 획득하기 위해, 성숙 패닝을 수행하였다 (문헌 [Prassler et al., 2009, Immunotherapy, 1: 571-583]). 이 목적을 위해, 표준 패닝 (고체 상 및 용액 상 패닝)는 상기 기재된 바와 같이 다양한 FGFR2 항원을 사용하여 수행하였다.
패닝 후에, 파지 파생된 pMORPH30® 벡터 DNA의 Fab-코딩 단편을 별개의 특이적 제한 효소에 의해 소화시켜 LCDR3 또는 HCDR2 성숙 라이브러리를 생성하였다. 삽입물을 트림(TRIM)™ 기술을 사용하여 대체하였다 (문헌 [Virnekas et al., 1994, Nucleic Acids Research 22: 5600-5607]).
생성된 라이브러리를 증폭시키고, 증가된 세척 엄격도 및 감소된 항원 농도를 갖는 패닝의 2회 추가 라운드에 적용하였다.
선택된 Fab 단편의 서브클로닝 및 미세발현
가용성 Fab의 빠른 발현을 용이하게 하기 위해, 선택된 HuCAL 플라티눔® 파지의 Fab 코딩 삽입물을 pMORPH®30 디스플레이 벡터로부터 pMORPH®x11 발현 벡터 pMORPH®x11_FH 내로 서브클로닝하였다.
이. 콜라이 TG1-F- 단일 클론의 형질전환 후에 HuCAL®-Fab 단편을 함유하는 주변세포질 추출물의 발현 및 제조를 상기 기재된 바와 같이 수행하였다 (문헌 [Rauchenberger et al., 2003 J Biol Chem 278: 38194-38205]).
ELISA 스크리닝
ELISA 스크리닝을 사용하여, 표적 항원에 대한 결합을 위해 단일 Fab 클론을 패닝 산출물로부터 확인하였다. Fab는 조 이. 콜라이 용해물을 함유하는 Fab를 사용하여 시험하였다.
맥시소르프™ (눈크®) 384웰 플레이트를 관심 FGFR 항원으로 (수동 흡착을 통해 또는 항원의 각 태그를 표적화하는 포획 항체를 통해) PBS 중에서 이들의 이전에 결정된 포화 농도로 코팅하였다. 대안적으로, 리액티-바인드™ 뉴트르아비딘™-코팅된 폴리스티렌 스트립 플레이트 (피어스)를 사용하여 비오티닐화 FGFR2 항원을 포획하였다.
플레이트를 PBS 중 5% 탈지유 분말로 차단시킨 후, Fab-함유 이. 콜라이 용해물을 첨가하였다. Fab의 결합은 아토포스(Attophos)® 형광 기질 (로슈(Roche), 카탈로그 #11681982001)을 사용하여 알칼리성 포스파타제 (1:5000 희석됨)에 접합된 F(ab)2 특이적 염소 항-인간 IgG 접합체에 의해 검출하였다. 535 nm에서의 형광 방출을 430 nm의 여기와 함께 기록하였다.
FACS 스크리닝 (형광 활성화 세포 분류)
FACS 스크리닝에서, 세포 표면 발현된 항원에 결합한 단일 Fab 클론을 패닝 산출물로부터 확인하였다. Fab는 Fab 함유 조 이. 콜라이 용해물을 사용하여 세포 결합에 대해 시험하였다.
이러한 연구에서, 100 μl의 세포-현탁액을 새로운 96-웰 플레이트에 옮겼다 (1x105개 세포/웰을 생성함). 표적 세포 현탁액이 담긴 플레이트를 원심분리하였고, 상청액을 경사분리하였다. 남아있는 세포 펠릿을 재현탁시키고, Fab 함유 박테리아 추출물 50 μl를 상응하는 웰에 첨가하였다.
대안적으로, 세포 펠릿을 재현탁시키고, 50 μl FACS 완충제 (PBS, 3% FCS) 및 동일 부피의 Fab 함유 박테리아 추출물을 상응하는 웰에 첨가하였다.
이어서, 세포-항체 현탁액을 얼음 상에서 1시간 동안 인큐베이션하였다. 인큐베이션에 이어서, 세포를 회전 침강시키고, 200 μl FACS 완충제로 3회 세척하였다. 각 세척 단계 후에, 세포를 원심분리하고, 조심스럽게 재현탁시켰다.
2차 검출 항체 (PE 접합된 염소 항 인간 IgG; 디아노바(Dianova))를 첨가하고, 샘플을 얼음 상에서 인큐베이션하고, 후속적으로 세척하고, Fab 인큐베이션에 따라 형광 강도를 FACS어레이(Array)™ 기기에서 결정하였다.
HuCAL® Fab 단편의 발현 및 정제
Fab 단편의 발현을 이. 콜라이 TG1 F- 세포에서 수행하였다. 이어서, 배양물을 30℃에서 18시간 동안 진탕시켰다. 세포를 수확하고, 리소자임 및 버그 부스터(Bug Buster)® 단백질 추출 시약 (노바젠(Novagen), 독일)의 조합을 사용하여 분쇄하였다. His6-태그부착된 Fab 단편을 IMAC (퀴아젠(Qiagen)®, 독일)를 통해 단리하고, 단백질 농도를 UV-분광광도측정법에 의해 결정하였다. 대표적으로 선택된 샘플의 순도를 변성, 환원 15% SDS-PAGE (소듐 도데실 술페이트 폴리아크릴아미드 겔 전기영동)에서 분석하였다.
Fab 제제의 균질성을 보정 표준을 갖는 크기 배제 크로마토그래피 (HP-SEC)에 의해 본래 상태에서 결정하였다.
IgG로의 전환 및 IgG 발현
전장 IgG를 발현시키기 위해, 중쇄 (VH) 및 경쇄 (VL)의 가변 도메인 단편을 Fab 발현 벡터로부터 인간 IgG1을 위한 적절한 pMorph®_hIg 벡터 내로 서브클로닝하였다. 대안적으로, 진핵 HKB11 세포를 pMORPH®4 발현 벡터 DNA로 형질감염시켰다. 세포 배양물 상청액을 형질감염 3 또는 7일 후에 수확하였다. 멸균 여과 후에, 용액을 단백질 A 친화성 크로마토그래피 (맙셀렉트 슈어(MabSelect SURE)™, 지이 헬스케어(GE Healthcare))에 액체 취급 스테이션을 사용하여 적용하였다. 달리 언급되지 않는 한, 완충제를 1x 둘베코(Dulbecco) PBS (pH 7.2, 인비트로젠)로 교환하고, 샘플을 멸균 여과하였다 (0.2 μm 기공 크기). 단백질 농도를 UV-분광광도측정법에 의해 결정하고, IgG의 순도를 캘리퍼(Caliper) 랩칩(Labchip)® 시스템 또는 SDS-PAGE에서 변성, 환원 조건 하에 분석하였다.
생물검정
상기 기재된 패닝 방법에 따라 수득된 항-FGFR 항체를 하기 예시된 검정에서 평가하였다:
BaF3/CMV-FGFRIIIB-C3 세포 증식 검정
FGF1-의존성 세포 증식을 억제하는 항-FGFR2 항체의 능력을 결정하기 위해, 증식 검정은, 각각의 키나제 도메인을 보유한 전장 FGFR2IIIb 수용체 ECD 및 FGFR1-세포내 도메인의 키메라로 안정하게 형질도입된 조작된 Ba/F3 세포주 (BaF3/CMV-FGFRIIIB-C3)를 사용하였다. 인간 FGF1의 첨가는 이러한 세포주에서 세포 증식을 촉진하였다.
세포를 완전-성장 배지 (RPMI + 10% FCS + 30ng/ml FGF1 + 2μg/ml 헤파린 + 20μg/ml 블라스티시딘) 중에 재현탁시키고, 평편-바닥 백색 96-웰 검정 플레이트 (코닝(Corning)® 코스타(Costar), #3903) 내에 80 μl 중 8x103개 세포/웰의 세포 밀도로 시딩하고, 37℃ 및 5% CO2에서 밤새 인큐베이션하였다.
다음날, HuCAL® 항체 (Fab 또는 IgG)를 완전-성장 배지 중에 목적하는 농도 (5배 농축됨)로 희석하였다. 20 μl의 항체 용액을 전날 시딩된 세포에 첨가하고, 세포를 72시간 동안 배양하였다. 72시간 후에, 100 μl 셀 타이터-글로(Cell Titer-Glo)™ 발광 세포 생존율 검정 시약 (#G7571; 프로메가(Promega))을 각 웰에 첨가하고, 조도계 (제니오스프로(GeniosPro), 테칸(Tecan))에서 발광을 후속 판독하면서 가볍게 진탕하면서 실온에서 15분 동안 인큐베이션하였다. 최대 억제 농도 절반 (IC50 값)을 결정하기 위해, Fab/IgG 적정을 수행하고, IC50를 그래프패드 프리즘(GraphPad Prism)을 사용하여 계산하였다.
HuCAL® IgG의 잠재적 효능작용 활성의 평가를 위해, 외인성 FGF1의 부재 하에, 조작된 BaF/3 세포의 증식을 촉진하는 항체의 능력에 의해 결정하기 때문에, 세포 및 IgG를 희석 배지 (FGF1 없는 완전-성장 배지) 중에 희석하였다. 세포의 시딩 및 IgG의 첨가는 동일한 날에 수행하였다.
친화도 결정
KD 결정을 위해, 항체 단백질의 단량체 분획을 사용하였다 (90% 이상의 단량체 함량, 분석용 SEC에 의해 분석됨; 각각, Fab에 대해서는 슈퍼덱스(Superdex)™75 (아머샴 파마시아(Amersham Pharmacia)), 또는 IgG에 대해서는 도소(Tosoh) G3000SWXL (도소 바이오사이언스(Tosoh Bioscience))).
(a) 섹터(Sector)® 이미저 6000 (메조스케일 디스커버리(Mesoscale discovery)®)를 사용하는 KD 결정을 위한 용액 평형 적정 (SET) 방법
용액 중에서의 친화도 결정은 기본적으로 문헌에 기재된 바와 같이 수행하였다 (문헌 [Friguet et al., 1985 J Immunol Methods 77: 305-319]). SET 방법의 감수성 및 정확도를 개선하기 위해, 고전적 ELISA로부터 ECL 기반 기술로 전환하였다 (문헌 [Haenel et al., 2005 Anal Biochem 339: 182-184]). HuCAL®_IgG의 KD 결정을 하기 시약을 사용하여 기재된 바와 같이 수행하였다: 비오티닐화 hFGFR2. 이를 PBS 중 0.5 μg/ml로 밤새 4℃에서 표준 MSD 플레이트 상에 코팅하였다.
MSD 플레이트를 세척하고 30 μl/웰 MSD 판독 완충제 T를 계면활성제와 함께 첨가한 후, 전기화학발광 신호를 섹터® 이미저 6000 (메조스케일 디스커버리®, 미국 매릴랜드주 게이더스버그)를 사용하여 검출하였다.
데이터는 주문제작된 적합화 모델을 적용하는 XLfit™ (IDBS) 소프트웨어를 사용하여 평가하였다. Fab 분자의 KD 결정을 위해, 하기 적합 모델을 사용하였다 (문헌 [Haenel et al., 2005 Anal Biochem 339: 182-184]에 따름).

[Fab]t: 적용된 전체 Fab 농도
x: 적용된 전체 가용성 항원 농도 (결합 부위)
Bmax: 항원이 없는 Fab의 최대 신호
KD: 친화도
IgG 분자의 KD 결정을 위해 IgG에 대한 하기 적합 모델을 사용하고 (문헌 [(Piehler et al., 1997 J Immunol Methods 201: 189-206)]에 따라 변형됨) 및 데이터 내용을 도 1에 제시하였다.

[IgG]: 적용된 전체 IgG 농도
x: 적용된 전체 가용성 항원 농도 (결합 부위)
Bmax: 항원이 없는 IgG의 최대 신호
KD: 친화도
패닝 전략 및 스크리닝의 개요
전체적으로, 28가지 다양한 패닝 전략은 재조합 항원 물질 뿐만 아니라 상기 요약된 세포주를 사용하여 활용하였다. 상기 기재된 검정을 사용하여, 패닝 산출물을 특이성 및 교차-반응성에 대해 스크리닝하고, 935개 클론을 서열분석을 위해 선택하였다. 상기 기재된 스크리닝 방법에 따라, 하기 실시예에 기재된 추가 특성화를 위해 15종의 항체를 선택하였다. 이들 항체 중, 12433, 12947, 10846 및 12931은 FGFR2 IIIb 이소형 (유니프롯 수탁 # P21802-3)에 결합하는 것으로 밝혀졌고, 10164, 11725, 10220, 11723 및 12944는 인간 FGFR2 IIIb (유니프롯 수탁 # P21802-3) 및 IIIc 이소형 (유니프롯 수탁 # P21802-1) 둘 다에 결합하는 것으로 밝혀졌고, 12425, 12422, 12439, 10918, 10923 및 11722는 인간 FGFR2 IIIb (유니프롯 수탁 # P21802-3) 및 IIIc 이소형 (유니프롯 수탁 # P21802-1) 둘 다 및 또한 인간 FGFR4 (유니프롯 수탁 # P22455)에 결합하는 것으로 밝혀졌다.
실시예 2: 친화도 결정
FGFR2 종 오르토로그에 대한 및 또한 FGFR4에 대한 항체의 친화도는 비아코어(Biacore)® 기술을 사용하여 비아코어® T100 기기 (지이 시스템스(GE Systems)) 및 CM5 센서 칩으로 결정하였다.
간략하게, 0.5 mg/ml의 BSA 및 10 μg/ml 헤파린으로 보충된 HBS-EP+ (0.01 M HEPES, pH 7.4, 0.15 M NaCl, 0.005% 계면활성제 P20)를 모든 실험에 구동 완충제로서 사용하였다. 고정화 수준 및 분석물 상호작용을 반응 유닛 (RU)에 의해 측정하였다. 파일럿 실험은 항-인간 Fc 항체의 고정화 및 시험 항체의 포획의 실행가능성을 시험 및 확인하기 위해 수행하였다.
동역학적 측정을 위해, 항체를 센서 칩 표면에 고정시키고, 유리 용액 중에서 결합하는, 표 1에 열거된 상기 기재된 FGFR 단백질의 능력을 결정하는 실험을 수행하였다. 간략하게, 50 μg/ml의 항-인간 Fc 항체를 pH 4.75에서 CM5 센서 칩 상에 아민 커플링을 통해 10 μl/분의 유량으로 모든 4종의 유동 세포 상에 6000 RU에 도달하도록 고정하였다. 이어서, 3 μg/ml의 시험 항체를 10 μl/분으로 10초 동안 주입하였다. 항체의 고정화 수준을 일반적으로 250 RU 미만으로 유지하였다. 후속적으로, 2-배 시리즈로 희석된 0.078-100 nM의 FGFR 수용체를 참조 및 시험 유동 셀 둘 다에 대해 7분 동안 80 μl/분의 유량으로 주입하였다. 이어서, 결합의 해리가 0.5 mg/ml의 BSA 및 10 μg/ml 헤파린으로 보충된 HBS-EP+를 구동 완충제로서 사용하여 10분 동안 이어졌다. 각 주입 주기 후, 칩 표면을 10 mM 글리신 (pH 2.0)을 60 μl/분으로 70초 동안 사용하여 재생시켰다. 모든 실험은 25℃에서 수행하였고, 반응 데이터는 전적으로 간단한 1:1 상호작용 모델 (평가 소프트웨어 버전 1.1 (지이 시스템스) 사용)로 적합화하여 온-속도 (ka), 오프-속도 (kd) 및 친화도 (KD)의 추정치를 수득하였다.
FGFR2 IIIb 종 오르토로그 및 FGFR4에 대해 수득된 친화도 추정치의 개요는 표 4에 제시된다. 모든 항체가 평가된 FGFR2의 종 오르토로그에 결합하였고, 하위세트의 항체가 또한 인간 FGFR4에 결합한 것으로 밝혀졌다. 또한, 일부의 항체 (10846, 12433, 12931 및 12947)는 인간 FGFR2의 IIIc 이소형 (유니프롯 수탁 # P21802)에 결합할 수 없었다. 모든 항체는 FGFR2에 대해 특이적이거나 또는 FGFR2 및 FGFR4 둘 다에 결합하고, 어떠한 항체도 FGFR1 또는 FGFR3에 인식가능하게 결합하는 것으로 밝혀지지 않았다.
<표 4> FGFR2 IIIb 종 오르토로그 및 FGFR4에 대해 획득된 친화도 추정치

실시예 3: 항-FGFR 항체의 기능적 활성의 평가
FGFR2의 효능제 또는 길항제로서 작용하는 정제된 항체의 능력을 Baf 세포 시스템을 사용하여 평가하였고, 여기서 Baf 세포는 FGFR2를 과다별현하도록 형질도입되었다.
항체의 잠재적 효능제 특성을 평가하기 위해, Baf-FGFR2 세포를 PBS 중에 2회 세척하고, 희석 배지 (10% FBS, 2 μg/ml 헤파린 (시그마, 카탈로그 # H3149) 및 20 μg/ml 블라스티시딘 (예를 들어 인비트로젠, 카탈로그 # A11139-03 또는 셀그로®, 카탈로그 # 30-100-RB)이 보충된 RPMI) 중에 재현탁시킨 후, 96웰 플레이트 (코스타 카탈로그 # 3904)에 90 μl 희석 배지 중 8000개 세포/웰로 시딩하였다. 각 검정에서, 하나의 플레이트를 "제0일" 플레이트로 지정하고: 이들 플레이트의 각 웰에, 추가 10 μl의 희석 배지를 첨가하고, 이어서 80 μl/웰의 셀 타이터 글로® 시약 (프로메가 #G7573)을 첨가하였다. 검정 플레이트를 10분 동안 부드럽게 진탕시키고, 생성된 발광 강도를 퍼킨 엘머(Perkin Elmer) 엔비전(EnVision)® 2101 플레이트 판독기를 사용하여 측정하였다. 연속 희석물을 희석 배지 중에 10X 용액으로서 각 항체에 대해 제조하고, 10 μl를 적절한 웰에 첨가하였다. 또한 시험 항체에, FGF1 (페프로테크(Peprotech), 카탈로그 # 100-17A; 최종 검정 농도 0-30 nM), 상업적으로 입수가능한 항-FGFR2 항체 (R&D 시스템스, 카탈로그 # MAB6841) 및 비-FGFR2 결합 항체를 대조군 시약으로서 포함시켰다. 검정 플레이트를 3일 동안 37℃에서 5% CO2와 함께 인큐베이션하였다. 이러한 인큐베이션 후에, 상기 플레이트를 약 30분 동안 실온이 되게 하고, 80 μl/웰의 셀 타이터 글로® 시약 (프로메가 #G7573)을 첨가하였다. 이어서, 플레이트를 10분 동안 부드럽게 진탕시키고, 생성된 발광 강도를 퍼킨 엘머 엔비전® 2101 플레이트 판독기를 사용하여 측정하였다. 세포 증식에 대한 항체의 효과를 결정하기 위해, 원시 발광 값을 복제물에 대해 평균하였고, 제0일 대조군과 비교하였다. 10846, 11725 및 12439를 이러한 연구에서 평가하지는 않았지만, 시험된 다른 항체 중 어느 것도 FGF1을 대체하고 세포 성장을 유지하지는 못했다. 데이터 개요는 도 2 (a)/(b)에 제시된다.
또한, Baf 세포 시스템을 사용하여 FGFR2 수용체 신호전달의 길항제로서 작용하는 항체의 잠재성을 평가하였다. 이러한 연구에서, Baf-FGFR2 세포를 상기 효능 연구에 기재된 바와 같이 플레이팅하면서 30 μg/ml FGF1 (페프로테크, 카탈로그 # 100-17A)을 희석 배지에 첨가하였다. 연속 희석물을 30 μg/ml FGF1을 갖는 희석 배지 중에 4X 용액으로서 각 항체에 대해 제조하고, 25 μl를 적절한 웰에 첨가하였다. 시험 항체 이외에도, 상업적으로 입수가능한 항-FGFR2 항체 (R&D 시스템스, 카탈로그 # MAB6841) 및 비-FGFR2 결합 항체를 대조군 시약으로서 포함시켰다. 검정 플레이트를 3일 동안 37℃에서 5% CO2와 함께 인큐베이션하였다. 이러한 인큐베이션 후에, 플레이트를 약 30분 동안 실온이 되게 하고, 80 μl/웰의 셀 타이터 글로® 시약 (프로메가 #G7573)을 첨가하였다. 이어서, 플레이트를 10분 동안 부드럽게 진탕시키고, 생성된 발광 강도를 퍼킨 엘머 엔비전® 2101 플레이트 판독기를 사용하여 측정하였다. 상대적 세포 증식에 있어서 항체의 효과를 결정하기 위해, 원시 발광 값을 복제물에 대해 평균하였고, 비교하였다. 10846, 11725 및 12439는 이 연구에서 평가하지 않았다. 시험된 다른 항체의 효과는 도 3(a)/(b)에 제시되고, 클론 중 평가된 10918, 10923, 12931, 12944, 12947 및 12422가 조작된 Baf 세포의 증식을 100 nM 미만의 농도에서 50% 초과까지 억제한다는 것을 입증한다.
실시예 4: ADC의 제조
1-단계 방법에 의한 DM1 접합체의 제조
항체 12425를 반응 완충제 (15 mM 인산칼륨, 2 mM EDTA, pH 7.6) 내로 접선 흐름 여과 (TFF#1)를 통해 정용여과한 후에, 접합 반응을 시작하였다. 후속적으로, 항체 12425 (5.0 mg/mL)를 DM1 (항체의 양에 비해 5.6-배 몰 과량) 및 이어서 SMCC (항체의 양에 비해 4.7배 과량)와 혼합하였다. 반응을 20℃에서 2 mM EDTA 및 10% DMA를 함유한 15 mM 인산칼륨 완충제 (pH 7.6) 중에서 대략 16시간 동안 수행하였다. 1 M 아세트산을 첨가하여 pH를 5.50으로 조정함으로써 반응물을 켄칭하였다. pH 조정 후에, 반응 혼합물을 다중-층 (0.45/0.22 μm) PVDF 필터를 통해 여과하고, 8.22% 수크로스를 함유한 20 mM 숙시네이트 완충제 (pH 5.0) 내로 접선 흐름 여과 (TFF#2)을 사용하여 정제하고 정용여과하였다. 접선 흐름 여과를 위한 기기 파라미터는 하기 표 5에 열거되어 있다.
<표 5> 접선 흐름 여과를 위한 기기 파라미터

상기 기재된 방법으로부터 수득된 접합체를 분석하였다: 세포독성제 부하 (항체에 대한 메이탄시노이드 비, MAR)에 대해서는 UV 분광분석법; 접합체 단량체의 결정에 대해서는 SEC-HPLC; 및 유리 메이탄시노이드 백분율에 대해서는 역상 HPLC 또는 소수성 차폐된 상 (Hisep)-HPLC. 데이터를 표 6에 나타내었다.
<표 6> 12425-MCC-DM1의 특성

계내 방법에 의한 DM1 접합체의 제조
본 발명의 접합체는 또한 하기 절차에 따른 계내 방법에 의해 제조될 수 있다. 항체 (21개 클론)를 술포숙신이미딜 4-(N-말레이미도메틸) 시클로헥산-1-카르복실레이트 (술포-SMCC) 링커를 사용하여 DM1에 접합시켰다. DM1 및 술포-SMCC 이종이관능성 링커의 원액을 DMA 중에 제조하였다. 술포-SMCC 및 DM1 티올을 함께 혼합하여, 40% v/v의 수성 50 mM 숙시네이트 완충제, 2 mM EDTA, pH 5.0를 함유한 DMA 중에서, DM1 대 링커의 비 1.3:1 몰 당량 및 DM1의 최종 농도 1.95 mM에서 10분 동안 25℃에서 반응시켰다. 이어서, 항체를 반응 분취액과 반응시켜 50 mM EPPS, pH 8.0 및 10% DMA (v/v) 중 2.5 mg/mL의 Ab의 최종 접합 조건 하에 SMCC 대 Ab의 몰 당량 비 약 6.5:1을 수득하였다. 25℃에서 대략 18시간 후에, 접합 반응 혼합물을 10 mM 숙시네이트, 250 mM 글리신, 0.5% 수크로스, 0.01% 트윈 20, pH 5.5로 평형화된 세파덱스(SEPHADEX)™ G25 칼럼을 사용하여 정제하였다.
<표 7> DM1-접합된 항체의 특성

SPDB 링커를 갖는 ADC의 제조
항체 12422, 12425 및 12433 (8 mg/ml)을 50 mM NaCl, 2 mM EDTA 및 5% DMA를 함유한 50 mM 인산칼륨 완충제 (pH 7.5) 중에서 N-숙신이미딜 4-(2-피리딜디티오)부타노에이트 (SPDB, 각각 5.0, 5.5 및 4.9배 몰 과량)를 사용하여 120분 동안 25℃에서 변형시켰다. 변형된 Ab를 정제 없이 후속적으로 50 mM NaCl, 2 mM EDTA 및 5% DMA를 함유한 50 mM 인산칼륨 완충제 (pH 7.5) 중에서 4 mg/mL의 최종 변형된 항체 농도에서 18시간 동안 25℃에서 DM4 (미결합 링커에 비해 1.7배 몰 과량)에 접합시켰다. 접합 반응 혼합물을 10 mM 숙시네이트, 250 mM 글리신, 0.5% 수크로스, 0.01% 트윈 20, pH 5.5로 평형화 및 용리된 세파덱스(SEPHADEX)™ G25 칼럼을 사용하여 정제하였다.
<표 8> DM4-접합된 항체의 특성

CX1-1 링커를 갖는 ADC의 제조
항체 12425 (5.0 mg/mL)를 DM1 (항체의 양에 비해 7.15-배 몰 과량) 및 이어서 CX1-1 (항체의 양에 비해 5.5-배 과량)와 혼합하였다. 반응을 25℃에서 2 mM EDTA 및 5% DMA을 함유한 60 mM EPPS [4-(2-히드록시에틸)-1-피페라진프로판술폰산] 완충제 (pH 8.5) 중에서 대략 16시간 동안 수행하였다. 이어서, 반응 혼합물을 10 mM 숙시네이트, 250 mM 글리신, 0.5% 수크로스, 0.01% 트윈 20, pH 5.5로 평형화 및 용리되는 세파덱스™ G25 칼럼을 사용하여 정제하였다.
<표 9> CX1-1/DM1 접합된 12425의 특성

실시예 5: 모 항체 대비 ADC의 친화도
SMCC-DM1에 대한 접합 후의 FGFR2 및 FGFR4에 대한 항체의 친화도는 비아코어® 기술을 이용하여 비아코어® T100 기기 (지이 시스템스) 및 CM5 센서 칩을 사용하여 상기 실시예 2에 기재된 바와 유사한 방법론을 이용하여 결정하였다.
평가된 항체의 경우에, 인간 FGFR2 IIIb에 대한 결합을 위해 유사한 친화도 추정치가 모 비접합된 항체 대비 SMCC-DM1 접합된 항체에 대해 획득되며, 이는 접합이 항체 결합에 인식가능하게 영향을 미치지는 않음을 시사한다 (표 10).
<표 10> 비접합된 및 SMCC-DM1 접합된 항체에 대한 친화도 추정치

N.D. = 결정되지 않음
또한, FGFR2 및 FGFR4 종 오르토로그에 대한 몇몇 SMCC-DM1 접합된 항체의 친화도를 결정하였다. 이러한 연구에서, 친화도에서의 어떠한 인식가능한 차이도 접합된 및 비접합된 항체 사이에는 발견되지 않았다 (표 11).
<표 11> FGFR2 및 FGFR4 종 오르토로그에 대한 SMCC-DM1 접합된 항체의 친화도

N.D. = 결정되지 않음
실시예 6: SNU16 및 Kato-III 세포에서 ADC의 시험관내 활성
SMCC-DM1 링커-페이로드에 대한 접합 후에, FGFR2-증폭된 세포주, SNU16 (ATCC 카탈로그 #CRL-5974) 및 Kato-III (ATCC 카탈로그 # HTB-103)의 증식을 억제하는 항체 약물 접합체 (ADC)의 능력을 결정하였다. 간략하게, 세포를 조직 배양 인큐베이터 내 37℃에서 5% CO2와 함께 배양 배지 중에서 공급업체에 의해 권고되는 바와 같이 배양하였다. 검정 당일에, 세포를 PBS (론자(Lonza), 카탈로그 # 17516C)로 2회 세척한 후, 0.25% 트립신-EDTA (깁코® 카탈로그 # 25300)로 5분 동안 처리하고, 권고되는 배양 배지 중에 재현탁시켰다. 이어서, 세포를 카운팅하고, 96웰 플레이트 (코스타 카탈로그 # 3940 또는 코닝® 카탈로그 # 3340)에 100 μl의 세포 배양 배지 중 2600-3600개 세포/웰의 밀도로 시딩하였다. 2중 플레이트를 제0일 측정을 위해 준비하고, 모든 플레이트를 조직 배양 인큐베이터 내 37℃에서 5% CO2와 함께 밤새 인큐베이션하였다. 배지만 있는 웰을 또한 준비하여 음성 대조군으로 작용하게 하였다. 이러한 인큐베이션 후에, 50 μl/웰의 셀 타이터 글로® 시약 (프로메가 카탈로그 # G7573)을 제0일 플레이트에 첨가하고, 이어서 이를 10분 동안 부드럽게 진탕시키고, 생성된 발광 강도를 퍼킨 엘머 엔비전® 2101 플레이트 판독기를 사용하여 측정하였다. 시험 ADC를 적절한 세포 배양 배지 중 2X 원액으로 2중으로 연속 희석하고, 남아있는 검정 플레이트 각각으로부터 50 μl의 배지 제거에 이어서, 50 μl의 2X 연속 희석된 ADC를 첨가하고 (최종 검정 농도 0.2-50 nM DM1 등가물), 그 후 조직 배양 인큐베이터 내 37℃에서 5% CO2와 함께 5일 동안 인큐베이션하였다. 이 인큐베이션 기간 후에, 상대 세포 생존율을 상기 기재된 바와 같이 셀 타이터 글로® 시약의 첨가를 통해 결정하였다. 세포 증식에 대한 ADC의 효과를 하기에 따라 2중의 평균을 사용하여 계산하였다:
억제 % = (ADC 처리 - 미처리)/(미처리 - 제0일)*100
억제 % 데이터를 4-파라미터 로지스틱 방정식에 적합화하였고, IC50 값을 결정하였다. IgG 대조군 ADC와 달리, 시험된 ADC는 Kato-III 및 SNU16 세포 둘 다의 증식에 대해 3 nM 미만의 IC50을 갖는 강력한 억제제인 것으로 밝혀졌다 (표 12).
<표 12> MCC-DM1 ADC로서의 항체 효력

SPDB-DM4 링커-페이로드를 통해 접합된 몇몇 항-FGFR 항체의 능력을 또한 평가하였다. 상기 기재된 바와 같이 수행되는 이러한 연구는 평가되는 항체가 SPDB-DM4 ADC로서 세포 증식의 강력한 억제제임을 나타내었고, 이는 세포를 사멸시키는 페이로드를 성공적으로 전달하는 그의 능력이 MCC-DM1에 제한되지 않음을 시사한다. SNU16 세포주에 대한 데이터를 표 13에 요약하였다.
<표 13> SPDB-DM4 ADC로서의 항체 효력

실시예 7: 항-FGFR2/4 ADC의 생체내 활성의 평가
15종의 항-FGFR2 또는 항-FGFR2/FGFR4 교차-반응성 ADC의 항종양 활성은 위, FGFR2 증폭된 (CN = 31), FGFR2 IIIb 이소형 발현 SNU16 이종이식 종양 모델에서 평가하였다. 2가지 독립적인 연구에서, 암컷 누드 마우스에게 50% 페놀 레드-무함유 매트리겔(matrigel)™ (BD 바이오사이언시스(BD Biosciences))을 함유한 현탁액 중 10x106개 세포를 행크(Hank) 균형 염 용액 중에서 피하로 이식하였다. 현탁액 중 세포를 함유한 총 주사 부피는 200 μl였다. 마우스를 평균 종양 부피가 192.9 mm3인 이식 8일 후에 제1 연구에 등록하였다. 9개 군 중 하나에 무작위로 배정한 후에 (n = 8/군), 마우스에 PBS, 또는 하기 항체 약물 접합체 중 하나의 단일 3 mg/kg 정맥내 (i.v.) 주사를 투여하였다: 12433-MCC-DM1, 10164-MCC-DM1, 10220-MCC-DM1, 10918-MCC-DM1, 10923-MCC-DM1, 11722-MCC-DM1, 12422-MCC-DM1 또는 12425-MCC-DM1. 마우스를 평균 종양 부피가 223.4 mm3인 이식 7일 후에 제2 연구에 등록하였다. 9개 군 중 하나에 무작위로 배정한 후에 (n = 8/군), 마우스에 PBS, 또는 하기 항체 약물 접합체 중 하나의 단일 3 mg/kg i.v. 주사를 투여하였다: 12433-MCC-DM1, 12947-MCC-DM1, 12931-MCC-DM1, 12944-MCC-DM1, 12439-MCC-DM1, 10846-MCC-DM1, 11725-MCC-DM1, 또는 11723-MCC-DM1. 12433-MCC-DM1은 상기 연구 둘 다에서 항체 약물 접합체의 직접 비교를 용이하게 하기 위해 두 연구 사이의 가교로서 포함되었다. 종양을 주당 2회 캘리퍼로 측정하였다. 이러한 연구에서 평가되는 ADC는 투여 23 내지 24일 후에 광범위한 스펙트럼의 항종양 활성을 나타내었다 (33.2% T/C 내지 77.8% 범위의 퇴행) (도 4 (a) 및 (b)).
절단가능한 디술피드 링커 기반의 SPDB-DM4 FGFR2 ADC의 항종양 활성을 SNU16 이종이식 종양 모델에서 평가하였다. 이러한 연구에서, 암컷 누드 마우스에게 50% 페놀 레드-무함유 매트리겔™ (BD 바이오사이언시스)을 함유한 현탁액 중 10x106개 세포를 행크 균형 염 용액 중에서 피하로 이식하였다. 현탁액 중 세포를 함유한 총 주사 부피는 200 μl였다. 마우스를 평균 종양 부피가 223 mm3인 이식 11일 후에 연구에 등록하였다. 5개 군 중 하나에 무작위로 배정한 후에 (n = 7/군), 마우스에 PBS (10 ml/kg), 12433-MCC-DM1 또는 대조군 IgG-MCC-DM1의 단일 15 mg/kg 정맥내 주사, 또는 12433-SPDB-DM4 또는 IgG-SPDB-DM4의 단일 5 mg/kg 정맥내 주사를 투여하였다. 종양을 주당 2회 캘리퍼로 측정하였다. 어떠한 대조군 ADC도 이 연구에서 항종양 활성을 나타내지 않았다 (도 4(c)). 그러나, 반대로, 12433-MCC-DM1 및 12433-SPDB-DM4 둘 다는 투여된 용량에서 SNU16 이종이식 모델에 대해 고도로 활성이며, 이는 항-FGFR ADC의 항종양 효과가 다양한 링커를 사용하여 획득될 수 있음을 시사한다.
항-FGFR ADC의 약동학 (PK)은 3 mg/kg의 단일 IV 용량 후에 SNU16 종양-보유 마우스에서 평가하였다. PK 샘플을 투여 1시간, 24시간, 72시간, 168시간 및 336시간 후에 수집하였다. 모든 연구에서, "전체" 항체 및 "항체 약물 접합체 (ADC)" 둘 다의 혈청 농도는 모든 동물 종에서 유효 ELISA 방법을 사용하여 측정하였다. "전체" 분율은 접합된 DM1이 있는 또는 없는 항체의 측정을 지칭하며, 한편 ADC 분율은 DM1 접합된 항체만의 측정을 지칭한다 (≥ 1 DM1 분자). 모든 연구에서, 어떠한 인식가능한 차이도 ADC 및 전체 항체 분율의 클리어런스 사이에서 관찰되지 않았다. ADC의 PK 특성의 개요는 도 4 (d) - (e)에 제시된다. SNU16 종양 보유 마우스에서 단일 3 mg/kg 투여 후 ADC 클리어런스를 관찰된 항종양 효과와 비교하면, 가장 큰 항종양 활성 (> 40% 종양 퇴행)을 갖는 ADC가 45 ml/d/kg 미만의 속도로 깨끗해지는 것으로 밝혀졌다 (도 4 (F)).
실시예 8: FGFR2-증폭된 세포주를 사용하는 시험관내 비접합된 및 접합된 항체의 신호전달 활성의 평가
FGFR2-증폭된 세포주에서 FGFR 신호전달을 조절하는, 비접합된 및 SMCC-DM1 접합된 항-FGFR2 항체의 능력을 평가하였다. 초기 연구에서는, SNU16 (ATCC 카탈로그 #CRL-5974) 세포에서의 12433, 12425 및 10164 항체의 효과를 결정하였다. 간략하게, 세포를 10% FBS로 보충된 RPMI 중에서 12웰 셀바인드(CellBind)™ 플레이트 (코스타 카탈로그 #3336)에 시딩하고, 밤새 조직 배양 인큐베이터 내 37℃에서 5% CO2와 함께 인큐베이션하였다. 실험 당일에, 세포 배양 배지를 흡인하고, 시험 항체 또는 소분자 FGFR 억제제인 BGJ398로 대체하였으며, 이들 모두는 10% FBS로 보충된 RPMI 중에 최종 농도 (13-130 nM, 항체/ADC; 500 nM, BGJ398)로 희석하였다. 이어서, 세포를 조직 배양 인큐베이터 내 37℃에서 5% CO2와 함께 2시간 동안 인큐베이션하였다. 이러한 인큐베이션 후에, 세포를 차가운 PBS (론자, 카탈로그 # 17516C)로 2회 세척하고, 얼음 상에 놓고, 300 μl의 용해 완충제 (CST 카탈로그 # 9803 및 포스포스톱(PhosphoSTOP) 로슈 카탈로그 # 04 906237001)를 첨가하였다. 단백질 농도를 BCA 검정 (피어스 카탈로그 # 23228)에 의해 결정하였다. 이어서, 60 μg의 단백질을 SDS-PAGE에 의해 분해하고, 니트로셀룰로스 막 상에 옮기고, pFRS2 (셀 시그널링 테크놀로지(Cell Signaling Technology), 카탈로그 #3861), 전체 FGFR2 (예를 들어 산타 크루즈 바이오테크놀로지(Santa Cruz Biotechnology), 카탈로그 # SC-122 또는 R&D 시스템스 카탈로그 # 6841) 및 β-액틴 (베틸(Bethyl), 카탈로그 # A300-485A) 또는 시토케라틴 (다코(Dako) 카탈로그 # M3515)에 대해 항체로 프로빙하였다. 결과를 도 5 (a)에 제시하고, 비접합된 또는 MCC-DM1 ADC로서의 항체 중 어느 것도 2시간에서 pFRS2 신호를 조절할 수 없는 것으로 밝혀졌다. 추가 실험은 12425 항체 (4.3 nM) 및 12425-MCC-DM1 ADC (4.3 nM 항체, 13 nM DM1 등가물)을 사용하여 수행하였으며, 추가 시점 (4, 24 및 72시간)에 SNU16 및 또한 Kato-III (ATCC 카탈로그 # HTB-103) 세포 둘 다에서 평가하였다. 결과는 도 5 (b) (SNU16) 및 5 (c) (Kato-III)에 제시된다. 네이키드 항체 또는 ADC의 어떠한 효과도 SNU16 세포에서 최대 48시간 또는 Kato-III 세포에서 최대 72시간까지 관찰되지 않았다. 12425-MCC-DM1 처리 후에 시토케라틴에 비해 pFRS2 및 tFGFR2 신호 둘 다에서의 감소가 SNU16 세포에서 72시간에 관찰되었다. 하기 실시예 9에 기재된 바와 같이, 12425-MCC-DM1은 72시간 시점에서 SNU16 증식의 강력한 억제제이고, 이러한 감소는 SNU16 세포 집단에서 FGFR2 발현의 이질성을 반영하는 것으로 예상된다.
실시예 9: 세포성 증식에 대한 ADC 및 비접합된 항체의 평가
FGFR2-증폭된, 과다발현 및 눌(null) 세포주의 패널에서 증식을 억제하는 비접합된 및 SMCC-DM1 접합된 항-FGFR 항체의 능력을 평가하였다. 이러한 연구에서, 세포를 조직 배양 인큐베이터 내 37℃에서 5% CO2와 함께 배양 배지 중에서 공급업체에 의해 권고된 바와 같이 배양하였다. 검정 당일에, 세포를 PBS (론자, 카탈로그 # 17516C)로 2회 세척하고, 그 후에 0.25% 트립신-EDTA (깁코® 카탈로그 # 25300)로 5분 동안 처리하고, 권장 배양 배지 중에 재현탁시켰다. 이어서, 세포를 카운팅하고, 96 또는 384웰 플레이트 (예를 들어 코스타 카탈로그 # 3940, 코닝® 카탈로그 # 3340, 코스타 카탈로그 # 3707)에 세포 배양 배지 55-100 μl 중 800-3600개 세포/웰의 밀도로 시딩하였다. 2중 플레이트를 제0일 측정을 위해 준비하고, 모든 플레이트를 조직 배양 인큐베이터 내 37℃에서 5% CO2와 함께 밤새 인큐베이션하였다. 배지만 있는 웰을 또한 준비하여 음성 대조군으로서 작용하게 하였다. 이러한 인큐베이션 후에, 30-50 μl/웰의 셀 타이터 글로® 시약 (프로메가 카탈로그 # G7573)을 제0일 플레이트에 첨가하고, 이어서 이를 10분 동안 부드럽게 진탕시키고, 생성된 발광 강도를 퍼킨 엘머 엔비전® 2101 플레이트 판독기를 사용하여 측정하였다. 시험 ADC를 적절한 세포 배양 배지 중에 2X 또는 10X 원액으로 2중으로 연속 희석하였다. 2X ADC 원액을 사용하는 검정을 위해, 검정 배지의 절반을 제거하고, 동부피의 2X 연속 희석된 ADC로 대체하였다. 10X ADC 원액을 사용하는 경우에, 이를 검정 플레이트 내로 1:10 희석하고 (예를 들어 5 μl에서 55 μl로), 이후에 조직 배양 인큐베이터 내 37℃에서 5% CO2와 함께 5 또는 6일 동안 인큐베이션하였다. ADC의 최종 검정 농도는 0.005-100 nM DM1 등가물 범위이다. 이러한 인큐베이션 기간 후에, 상대 세포 생존율은 상기 기재된 바와 같이 셀 타이터 글로® 시약의 적가를 통해 결정하였다. 세포 증식에 대한 ADC의 효과를 하기에 따라 2중의 평균을 사용하여 계산하였다:
억제 % = (ADC 처리 - 미처리)/(미처리 - 제0일)*100
억제 % 데이터를 4-파라미터 로지스틱 방정식에 적합화하고, IC50 값을 결정하였다. 12425-MCC-DM1에 대한 대표적인 데이터는 도 6 (a)에 제시된다. 이 ADC는 SNU16 (도 6 (a)) 및 Kato-III FGFR2-증폭된 세포주 (도 6 (b)) 둘 다에서 세포 증식의 강력한 억제제인 것으로 밝혀졌다. 이들 세포주는 둘 다 메이탄시노이드 페이로드 (L-Me-DM1; 도 6 (a) - (c)에서 유리 DM1)에 대해 감수성이지만, SMCC-DM1를 통해 접합된 비-표적화 ADC (닭 리소자임에 지정됨)에 대해서는 유사한 메이탄시노이드 항체 비에서 감수성이 아닌 것으로 확인되었다. 12425-MCC-DM1은 또한, 인식가능한 FGFR2 발현은 없지만 메이탄시노이드 페이로드에 대해 감수성인 위암 세포주인 NUGC3에 대해서는 활성이 아니다 (도 6 (c)). 또한, 비접합된 항체인 12425는 SNU16 (도 6 (d)) 및 Kato-III 세포 (데이터는 나타내지 않음) 둘 다에서 항증식 활성이 결여된 것으로 밝혀졌다. FGFR2 증폭된 세포주, 예컨대 SNU16, Kato-III, SUM-52, MFM223 및 H716 세포 (문헌 [Kunii et al., 2008 Cancer Res 68: 2340-2348; Turner et al., 2010 29: 2013-2023; Mathur et al., 2010. Proceedings of the 101st Annual Meeting of the American Association for Cancer Research, poster # 284])에서의 몇몇 항-FGFR-MCC-DM1 ADC의 항증식 활성의 개요는 표 14에 제시된다. 또한, ADC 중 어느 것도 종양 세포주, 예컨대 AZ521, CAL-51, KYSE-150, TE-6, SNU-1041, TT, CHL-1, G401 및 HEC59의 패널에 대해 활성이 아닌 것으로 밝혀졌다.
<표 14> FGFR2 유전자 증폭된 & 비-증폭된 세포주에서 몇몇 항-FGFR-MCC-DM1 ADC의 항증식 활성

실시예 10: FGFR ADC의 생체내 PK-PD
연구는 생체내 약동학적 마커를 조절하는 12425-MCC-DM1의 능력을 평가하기 위해 수행하였다. 이러한 연구의 목적은 FGFR2 또는 FGFR4 발현 및 G2/M 세포 주기 정지 사이의 관계를 평가하기 위한 것이었다. pHH3 양성 핵의 축적은, 면역조직화학에 의해 평가된 바와 같이, G2/M 정지의 마커로서 사용하였다.
인간 히스톤 H3의 Ser10을 둘러싼 잔기에 상응하는 합성 포스포펩티드를 갖는 동물을 면역화시킴으로써 생산된 토끼 폴리클로날 항체는 셀 시그널링 테크놀로지 (마이애미주 단버스스)로부터 입수하였다. 간략하게, IHC 프로토콜은 가열 및 벤타나(Ventana) 세포 조건화 #1 항원 복원 시약에 대한 표준 노출을 포함하였다. 1차 항체를 1:100으로 희석하고, 37℃에서 60분 동안 인큐베이션하였다. 다음에, 벤타나 옴니맵(Ventana OmniMap) 사전-희석된 HRP-접합된 항-토끼 항체 (Cat # 760-4311)와의 인큐베이션을 4분 동안 수행하였다.
FGFR2 증폭된 SNU16 이종이식 모델에서 PD를 평가하기 위해, 암컷 누드 마우스에 50% 페놀 레드-무함유 매트리겔™ (BD 바이오사이언시스)을 함유한 현탁액 중 10x106개 세포를 행크 균형 염 용액 중에서 피하로 이식하였다. 현탁액 중 세포를 함유한 전체 주사 부피는 200 μl였다. 종양이 300 내지 500 mm3에 도달하면, 6마리 마우스를 12425-MCC-DM1 (10 mg/kg) 또는 PBS (10 ml/kg)의 i.v. 용량을 수여받도록 무작위로 배정하였다 (n=3/군). 메이탄시노이드 페이로드의 예상된 작용 메카니즘과 일치하도록, 12425-MCC-DM1은 PBS 처리 대조군에 비해 투여 24시간 후 핵 pHH3 확실성에 있어서 뚜렷한 시간-의존성 증가를 산출하였다 (도 7 (a)에 나타낸 대표적인 이미지). 절단된 카스파제 3에서의 시간 의존성 변화를 또한 평가하였다. 이러한 연구에서, 인간 카스파제-3에서 (Asp175)에 인접한 아미노-말단 잔기에 상응하는 합성 펩티드를 사용하여 동물을 면역화시킴으로써 생산된 토끼 폴리클로날 항체를 셀 시그널링 테크놀로지 (마이애미주 단버스)로부터 입수하였다. IHC 프로토콜은 가열 및 벤타나 세포 조건화 #1 항원 복원 시약에 대한 표준 노출을 포함하지 않았다. 1차 항체를 1:300로 희석하고, 60분 동안 실온에서 인큐베이션하였다. 후속적으로, 벤타나 옴니맵 사전희석된 HRP-접합된 항-토끼 항체 (Cat # 760-4311)와의 인큐베이션을 4분 동안 수행하였다. pHH3과 유사하게, 절단된 카스파제 3에서의 시간 의존성 변화가 또한 관찰되었다 (도 7(a)). 유사한 데이터를 또한 다른 항-FGFR2 ADC, 예를 들어 12433-MCC-DM1에 대해 획득하였다.
ADC 특이성을 평가하기 위해, PD를 FGFR2/FGFR4 음성 NUGC3 이종이식 모델에서 평가하였다. 이러한 연구에서, 암컷 누드 마우스에 50% 페놀 적색-무함유 매트리겔™ (BD 바이오사이언시스)을 함유한 현탁액 중 1x106개 세포를 행크 균형 염 용액 중에서 피하로 주사하였다. 현탁액 중 세포를 함유한 전체 주사 부피는 200 μl였다. 종양이 300 내지 500 mm3에 도달하면, 9마리 마우스를 단일 정맥내 15 mg/kg 용량의 12425-MCC-DM1, 대조군 IgG-MCC-DM1 또는 PBS (10 ml/kg)를 제공받도록 무작위로 배정하였다 (n=3/군). 12425-MCC-DM1은 FGFR2 및 FGFR4 음성 NUGC3 이종이식편에서 15 mg/kg i.v. 용량의 대조군 IgG-MCC-DM1에 비해 pHH3 수준을 조절하는 것을 실패하였다 (도 7(b)에 나타낸 대표적인 이미지). 유사한 데이터를 또한 다른 항-FGFR2 ADC, 예를 들어 12433-MCC-DM1에 대해 획득하였다.
종합해보면, 이러한 데이터는 12425-MCC-DM1이, FGFR2 또는 FGFR4 발현에 의존적이고 메이탄시노이드 페이로드의 작용 메카니즘과 일치하는 강건한 생체내 세포 PD 효과를 도출할 수 있음을 입증한다.
실시예 11: 항-FGFR ADC의 생체내 효능
항-FGFR2 및/또는 항-FGFR2/4 ADC의 항종양 활성을 여러 종양 이종이식 모델에서 평가하였다.
FGFR2 게놈 증폭을 갖는 이종이식 모델
모델 1: 3종의 항-FGFR2 또는 항-FGFR2/FGFR4 이중-표적화 ADC의 항종양 활성을 위, FGFR2 증폭된 (카피수 = 31, SNP6.0), FGFR2 IIIc 이소형 발현 NCI-H716 결장직장 이종이식 종양 모델에서 평가하였다. 암컷 누드 마우스에 50% 페놀 레드-무함유 매트리겔™ (BD 바이오사이언시스)를 함유한 5x106개 세포를 행크 균형 염 용액 중에서 피하로 이식하였다. 현탁액 중 세포를 함유한 전체 주사 부피는 200 μl였다.
마우스를 평균 종양 부피가 171.7 mm3인 이식 4일 후에 연구에 등록하였다 (도 8 (a)). 8개 군 중 하나에 무작위로 배정한 후에 (n = 6/군), 마우스에게 PBS (10 ml/kg), 단일 i.v. 용량의 대조군 IgG-MCC-DM1 (15 mg/kg), 12422-MCC-DM1 (5 또는 15 mg/kg), 12425-MCC-DM1 (5 또는 15 mg/kg) 또는 10164-MCC-DM1 (5 또는 15 mg/kg)을 투여하였다. 종양을 주당 2회 캘리퍼로 측정하였다. 대조군 IgG-MCC-DM1은 15 mg/kg에서 활성이 아니었다. 10164-MCC-DM1은 5 mg/kg에서 활성이 아니었다. 10164-MCC-DM1 (15 mg/kg), 12422-MCC-DM1 (5 및 15 mg/kg) 및 12425-MCC-DM1 (5 및 15 mg/kg)은 투여 후 14일에 걸쳐 유사한 활성을 나타냈다. 12425-MCC-DM1 (5 mg/kg 및 15 mg/kg) 및 10164-MCC-DM1 (15 mg/kg 단독)은 투여 후 18일에 걸쳐 가장 지속가능한 반응을 산출하였다 (각각 23, 21 및 31% T/C).
모델 2: 3종의 항-FGFR2 또는 항-FGFR2/FGFR4 ADC의 용량 반응 항종양 활성을 FGFR2 증폭된, FGFR2 IIIb 이소형 발현 MFM223 ER/PR/Her2 음성 유방 이종이식 종양 모델에서 평가하였다. MFM223 모델을 단편 기반 모델로서 확립하였다. 단편 이식 1일 전에, 암컷 누드 마우스에 0.72 mg의 60일 지속 방출 17β-에스트라디올 펠릿 (이노베이티브 리서치 오브 아메리카(Innovative Research of America))을 피하로 이식하여 혈청 에스트로겐 수준을 유지하였다. 17β-에스트라디올 펠릿 이식 1일 후에, 공여자 마우스로부터 수확된 이종이식편을 3 mm3 단편으로 3개로 잘라서, 수용자 누드 암컷 마우스 내로 피하로 이식하였다. 마우스를 평균 종양 부피가 208.4 mm3인 이식 21일 후에 연구에 등록하였다 (도 8 (b)). 5개 군 중 하나에 무작위로 배정한 후에 (n = 8/군), 마우스에게 PBS (10 ml/kg) 또는 단일 10 mg/kg i.v. 용량의 대조군 IgG-MCC-DM1, 12433-MCC-DM1, 10164-MCC-DM1, 또는 12425-MCC-DM1을 투여하였다. 종양을 주당 2회 캘리퍼로 측정하였다. IgG-MCC-DM1은 이 모델에서 활성이 아니었다. 단일 10 mg/kg i.v. 용량의 12433-MCC-DM1, 12425-MCC-DM1 및 10164-DM1은 투여 18일 후 37, 24 및 7% T/C를 산출하였다.
모델 3: 단일 작용제로서의 12425-MCC-DM1의 활성을 또한 FGFR2-증폭된 환자-유래 원발성 위 종양 이종이식 모델, CHGA-010 (FGFR2 카피수 = 48, (SNP6.0))에서 평가하였다. 이러한 연구에서, 암컷 nu/nu 무흉선 마우스에 3x3x3mm 종양 단편을 함유한, DMEM 중 50% 페놀 레드-무함유 매트리겔™ (BD 바이오사이언시스)을 피하로 이식하였다. 종양 유입율은 > 50%였고, 이식 4주 후에 대략 250 mm3에 도달하였다. 단일 용량의 10 mg/kg IV 12425-MCC-DM1 후에, 종양 정체가 투여 후 대략 16 내지 20일에 걸쳐 달성되었다 (도 8 (c)). 유사한 단일 용량 데이터를 또한 FGFR2 특이적 ADC인 12433-MCC-DM1에 대해 획득하였다 (데이터는 나타내지 않음). 또한, 10 mg/kg q3w*2 IV를 제공받은 군은 초기 투여 후 37일에 걸쳐 대략적으로 종양 정체를 유지하였고, 단일 10 mg/kg 용량을 제공받은 군에서의 종양은 초기 투여 후 37일까지 평균 1588 mm3이었다. 이들 데이터는 CHGA010 이종이식편이 제2 용량의 12425-MCC-DM1에 반응할 할 수 있음을 입증한다.
정상 FGFR2 및/또는 FGFR4 카피수를 갖는 이종이식 모델
12425-MCC-DM1의 항종양 활성을 또한 정상 FGFR2 카피수 및 FGFR2 및 FGFR4 mRNA 발현의 범위를 갖는 23개 인간 폐 원발성 종양 이종이식편 및 22개 인간 유방 원발성 종양 이종이식편에서 평가하였다. 인간 원발성 이종이식 모델은 인간 폐 원발성 종양 단편을 암컷 누드 마우스 내로 피하로 이식함으로써 확립되었다. 생성된 종양 이종이식편은 암컷 누드 마우스 내로 3 mm3 단편의 피하 이식에 의해 생체내 계대배양하였다. 동물에 종양 단편을 이식하고, 즉 종양이 대략 250 mm3에 도달하지만 종양 단편 이식 후 동일한 시기일 필요가 없는 경우에, 순환 등록을 통해 처리군 (미처리 또는 12425-MCC-DM1, 15 mg/kg i.v. q2w)에 배정하였다. 이종이식 모델 당 1마리 동물을 각각의 2개 치료 부문에 배정하였다. 종양을 주당 2회 캘리퍼로 측정하였고, 데이터를 종양 부피에서의 변화 퍼센트로서 분석하였다.
23가지 폐 원발성 종양 이종이식 모델 중 8가지 및 22가지 유방 원발성 종양 이종이식 모델 중 8가지가 12425-MCC-DM1에 반응하였다. 반응의 범위는 일시적 종양 성장 억제에서 종양 이종이식편의 완전 퇴행까지였다. 12425-MCC-DM1에 반응하는 하나의 폐 원발성 종양 이종이식 모델 및 하나의 유방 원발성 종양 이종이식 모델의 예는 각각 도 8(d) 및 8(e)에 나타낸다. 종합해보면, 데이터는 FGFR2 또는 FGFR4 mRNA의 상승된 발현을 갖는 인간 폐 및 유방 원발성 종양 이종이식편의 생체내 성장이 12425-MCC-DM1 처리에 의해 억제될 수 있음을 입증한다.
항종양 활성의 용량 반응을 위해, FGFR2를 발현하지만 유전자의 정상 카피수를 갖는 유방 이종이식 모델에서 항-FGFR2/FGFR4 ADC 12425-MCC-DM1을 또한 평가하였다. 관 암종을 갖는 52세 여성으로부터의 단편 기반의 이종이식 모델로서 모델을 확립하고, 암컷 누드 마우스에 확장시켰다. 공여자 마우스로부터 수확된 이종이식편을 3 mm3 단편으로 3개로 자르고, 수용자 누드 암컷 마우스 내로 피하로 이식하여, 0.0085mg/ml 17β-에스트라디올 풍부한 물을 보충하여 혈청 에스트로겐 수준을 유지하고, 이종이식편 성장을 지지하였다. 마우스를 평균 종양 부피가 198 mm3인 이식 26일 후에 연구에 등록하였다. 3개 군 중 하나에 무작위로 배정한 후에 (n = 6/군), 마우스에 단일 15 mg/kg i.v. 용량의 대조군 IgG-MCC-DM1 또는 단일 i.v. 용량의 12425-MCC-DM1을 15 또는 5 mg/kg로 투여하였다 (도 8(F)). 종양을 주당 2회 캘리퍼로 측정하였다. 단일 15 mg/kg i.v. 용량의 12425-MCC-DM1은 6.5% T/C를 산출하였지만, 5 mg/kg 용량은 불활성이었다. 이들 데이터는 유전자 증폭이 없는 FGFR2 발현 종양에서 12425-MCC-DM1의 유용성을 지지한다.
종합해보면, 이러한 모델은 FGFR2 유전자 증폭의 존재 또는 부재 하에 세포 표면에서 FGFR2를 발현하는 종양에서의 12425-MCC-DM1의 유용성을 지지한다.
실시예 12: 소분자 FGFR 억제제인 BGJ398 (또한 3-(2,6-디클로로-3,5-디메톡시-페닐)-1-{6-[4-(4-에틸-피페라진-1-일)-페닐아미노]-피리미딘-4-일}-1-메틸-우레아로도 공지됨)을 사용하는 FGFR ADC의 개선된 항종양 활성
FGFR2/4 항체 약물 접합체 12425-MCC-DM1의, 단독으로의 및 FGFR 소분자 티로신 키나제 억제제, 3-(2,6-디클로로-3,5-디메톡시-페닐)-1-{6-[4-(4-에틸-피페라진-1-일)-페닐아미노]-피리미딘-4-일}-1-메틸-우레아 (문헌 [Guagnano et al., 2011 J Med Chem 54: 7066-7083])과 조합으로의 항종양 활성을 FGFR2-증폭된 CHGA119 환자-유래의 원발성 위 종양 이종이식 모델에서 평가하였다 (FGFR2 카피수 = 22 (SNP6.0)). 이러한 연구에서, 크기 2mm x 2mm x 2mm의 CHGA119 종양 단편을 암컷 nu/nu 무흉선 마우스 내로 피하로 (s.c.) 이식하였다. 이식 40일 후, CHGA119 종양 수반 마우스 (n=8, 평균 251 mm3; 범위: 104-382 mm3)를 비히클 (아세트산/아세테이트 완충제 중 50% PEG300)을 위관영양을 통해 경구로 (pH4.6, 10 ml/kg, p.o., qd), 대조군 IgG-3207-DM1 (10 mg/kg, i.v., q2wk), 12425-MCC-DM1 (10 mg/kg, i.v., q2wk), 3-(2,6-디클로로-3,5-디메톡시-페닐)-1-{6-[4-(4-에틸-피페라진-1-일)-페닐아미노]-피리미딘-4-일}-1-메틸-우레아 포스페이트 (10 mg/kg, p.o., qd), 또는 12425-MCC-DM1과 3-(2,6-디클로로-3,5-디메톡시-페닐)-1-{6-[4-(4-에틸-피페라진-1-일)-페닐아미노]-피리미딘-4-일}-1-메틸-우레아 포스페이트의 조합물로 각각 처리하였다. 종양을 주 2회 캘리퍼로 측정하였다. 12425-MCC-DM1 및 3-(2,6-디클로로-3,5-디메톡시-페닐)-1-{6-[4-(4-에틸-피페라진-1-일)-페닐아미노]-피리미딘-4-일}-1-메틸-우레아 포스페이트 각각은 단일 작용제로서 종양 정체 또는 부분 반응을 생성하였지만 (각각 T/C=4% 또는 33%, p<0.05), 12425-MCC-DM1과 3-(2,6-디클로로-3,5-디메톡시-페닐)-1-{6-[4-(4-에틸-피페라진-1-일)-페닐아미노]-피리미딘-4-일}-1-메틸-우레아 포스페이트의 조합물로의 치료는 치료 5주 후 거의 완전한 종양 퇴행을 유도하였다 (퇴행=-94%, p<0.05) (도 9 및 표 15 참조). 10% 미만의 체중 손실이 단일 작용제 또는 조합물 치료 후에 관찰되었다 (표 15). 이들 데이터는 FGFR ADC를 FGFR 신호전달의 소분자 억제제 (예를 들어 3-(2,6-디클로로-3,5-디메톡시-페닐)-1-{6-[4-(4-에틸-피페라진-1-일)-페닐아미노]-피리미딘-4-일}-1-메틸-우레아 포스페이트, TKI258, 포나티닙, AZD4547)와 조합하는 것이 항종양 반응을 개선할 수 있음을 시사한다.
<표 15> CHGA119-종양 보유 마우스에서 종양 및 숙주 파라미터에 대한 항-FGFR 작용제의 효과

실시예 13: FGFR ADC의 생체내 효능에 대한 용량 분할의 효과
12425-MCC-DM1 Cmax (피크 노출) 또는 Cavg (투여 간격에 걸친 평균 노출)가 그의 항종양 활성에서 수행하는 역할을 더 잘 이해하기 위해, 시간-용량 분할 실험을 SNU16 이종이식 모델을 사용하여 수행하였다. 고정된 치료 지속기간에 걸친 예측된 고정된 전체 노출을 산출하는 투여 스케줄 간격 및 용량 수준의 범위를 연구하였다. 특정 용량 수준에서, FGFR2 ADC는 TMDD로 인해 비선형 PK를 나타낸다 (실시예 19 참조). 따라서, 모든 투여 스케줄 간격 및 용량 수준에 걸친 고정된 전체 노출을 유지하기 위해, PK 모델링은, 용량이 낮을수록 TMDD가 더 좋은 것으로 판단되기 때문에, 보다 낮게 보다 빈번한 투여 스케줄로 투여되는 경우에 보다 많은 전체 용량의 12425-MCC-DM1이 요구되는 것으로 예측되었다. PK 모델링은 3 mg/kg q3w*2, 2.5 mg/kg q2w*3, 1.5 mg/kg qw*6 및 0.7 mg/kg q3d*14로 투여된 12425-MCC-DM1이 유사한 전체 노출을 달성할 것으로 예측하였다.
암컷 누드 마우스에 50% 페놀 레드-무함유 매트리겔™ (BD 바이오사이언시스)을 함유한 현탁액 중 10x106개 세포를 행크 균형 염 용액 중에서 피하로 이식하였다. 현탁액 중 세포를 함유하는 전체 주사 부피는 200 μl였다. 마우스를 평균 종양 부피가 181.7 mm3인 이식 후 10일에 제1 연구에 등록하였다
PK 파라미터를 평가하기 위해, 혈청을 꼬리 닉 또는 후안와 출혈을 통해 수집하고, ELISA를 통해 분석하였다. 전체 항체 PK 검정은 전체 항체 농도를 DM1의 존재/부재 하에 비색 ELISA에 의해 측정하였다. 플레이트를 항-인간 IgG (Fc 특이적)로 코팅하고, 검출은 당나귀 항-인간 IgG-HRP를 사용하고, 그 후에 적절한 플레이트-판독기 상에서 판독하였다. 접합체 PK 검정은 적어도 1개 DM1 분자에 결합된 항체를 비색 ELISA에 의해 측정하였다. 이러한 포맷에서, 플레이트를 항-DM1 항체로 코팅하고, 당나귀 항-인간 IgG-HRP를 사용하여 검출하였다. 혈청을 초기 투여 후 하기 시점에서 수집하였다: 3 mg/kg q3w*2 (2, 6, 24, 48, 96, 168, 240, 336, 503시간); 2.5 mg/kg q2w*3 (2, 6, 24, 48, 96, 168, 240, 335, 503시간); 1.5 mg/kg qw*6 (2, 6, 24, 48, 96, 167, 335, 503, 671, 839시간); 0.7 mg/kg q3d*14 (2, 6, 24, 48, 71, 143, 215, 287, 359, 431, 503, 575, 647, 719, 791, 863, 935시간).
5개 군 중 하나에 무작위로 배정한 후에 (n = 7/군), 마우스에 PBS (10 ml/kg)를 투여하거나 또는 12425-MCC-DM1을 3 mg/kg q3w*2, 2.5 mg/kg q2w*3, 1.5 mg/kg qw*6 또는 0.7 mg/kg q3d*14로 i.v. 투여하였다. 예측된 바와 같이, Cmax는 치료 요법에 걸쳐 변하였지만, Cavg는 정적이었다 (표 16). 모든 치료 요법은 활성이고, 유사한 종양 성장 억제를 산출하였으며, 이는 12425-MCC-DM1의 평균 노출이 항종양 활성의 일차적인 구동인자임을 시사한다 (도 10). 이러한 발견은 다양한 투여 스케줄이 효능 절충 없이 클리닉에 사용될 수 있음을 나타낸다.
<표 16> SNU16 종양-보유 마우스에게 상이한 용량 및 스케줄의 12425-MCC-DM1의 투여 후 PK 파라미터

실시예 14: 시험관내 및 생체내 ADCC 활성의 평가
항체 의존성 세포성 세포독성 (ADCC)을 매개하는 비접합된 항-FGFR2 항체 (12433, 10164, 12425, N297A_12425 (ADCC-고갈 변이체 (문헌 [Bolt et al., 2003 Eur J Immunol 23: 403-411])))의 능력은 Kato-III 세포 (표적 세포; ATCC 카탈로그 # HTB-103)에 대해 NK3.3 세포 (킬러 세포 또는 이펙터 세포; 생 루이스 대학(San Louis University)으로부터 재키 코른블루쓰(Jacky Kornbluth)에 의해 친절하게 제공됨)와의 공동-인큐베이션에서 결정하였다. 간략하게, Kato-III 세포를 칼세인(Calcein) 아세톡시-메틸 에스테르 (칼세인-AM; 시그마-알드리치(Sigma-Aldrich) 카탈로그 # 17783-5MG)로 염색하고, 2회 세척하고, 96-웰 마이크로타이터플레이트 (96웰, U-바닥 투명 플라스틱; 코닝® 코스타, 카탈로그 # 650 160) 내로 5000개 세포/웰의 농도로 피페팅하고, 상기 언급된 항체 및 단백질의 연속 희석물 (50,000 내지 0.003μg/ml)과 함께 10분 동안 사전-인큐베이션한 후에, 이펙터 세포를 첨가하였다. 표적 세포의 항체 특이적 용해를 계산하기 위해, 항체 또는 이펙터 세포가 없는 표적 세포만의 병행 인큐베이션이 기준선 및 음성 대조군으로 작용하였지만, 양성 대조군 또는 최대 용해 또는 100 퍼센트 특이적 용해는 1% 트리톤(Triton)-X™ 100 용액을 사용한 표적 세포만의 용해에 의해 결정되었다. 표적 및 이펙터 세포을 1 대 5의 비로 공동-인큐베이션한 후에, 마이크로타이터플레이트를 원심분리하고, 상청액 유체의 분취액을 또 다른 마이크로타이터플레이트 (96웰, 평편-바닥, 투명 바닥의 흑색; 코닝® 코스타, 카탈로그 # 3904)에 옮기고, 용액 중 유리 칼세인의 농도를 형광 카운터 (빅터(Victor)™ 3 다중표지 카운터, 퍼킨 엘머)를 사용하여 결정하였다. 결과는 도 11 (a)에 제시되고, 모든 시험된 항체가 다양한 범위로 ADCC를 매개하는 것으로 관찰되었다. 항체의 Fc-부분에서 글리코실화를 수반하지 않고, 이에 따라 이펙터 세포의 CD16a 수용체에 대한 결합이 결여된 N297A_12425는 임의의 ADCC를 매개하지 않았고, 특이적 음성 대조군으로서 작용하였다. 표적 세포의 일정한 및 단백질-농도 의존성 사멸은 비특이적 배경, Kato-III 세포에 대한 NK3.3 세포의 천연 사멸 활성으로 인한 것이다. 항체 12433이 표적 세포의 약 60 퍼센트의 최고 비용해 (NK3.3 세포에 의한 Kato-III 세포의 배경 용해를 추정하는 신호)를 매개하는 반면, 항체 12425 및 10164는 약 55 퍼센트 (NK3.3 세포에 의한 Kato-III 세포의 배경 용해를 추정하는 신호)의 비용해에 도달하였다. 모든 3개 분자의 효력 (각각의 용량 반응 곡선의 최대 사멸 절반에서의 농도; 유효 농도 50, EC50)은 유사하였다. 유사한 일련의 실험에서, ADCC를 유도하는 네이키드 항체 12425의 능력을 12425-MCC-DM1과 비교하였다. 네이키드 12425 및 12425-MCC-DM1 사이의 차이는 관찰되지 않았고 (데이터는 나타내지 않음), 이는 DM1 접합이 ADCC를 유도하는 네이키드 항체의 능력을 인식가능하게 손상하지 않음을 시사한다.
추가 연구에서, 보체 인자 C1q에 결합하는 비접합된 항-FGFR2 항체의 능력을 평가하였다. 보체 인자 C1q의 결합은 보체 의존성 세포독성 (CDC) 및 생체내 세포 용해를 유도하는 초기 단계이다. 이러한 연구에서 96-웰 마이크로타이터플레이트 (눈크® ,맥시소르프®, 카탈로그 # 439454)의 웰의 표면을 항체 12433, 12425, N297A_12425 및 10164의 연속 희석물로 밤새 4℃에서 암실에서 코팅하였다 (모든 농도 범위는 25 내지 0.02 μg/ml임). 상업적으로 입수가능한 항체, 리툭시맙은 양성 대조군으로서 작용하였다. 마이크로타이터플레이트 상의 결합된 항체 분석물의 양을 모니터링하기 위해, 이러한 절차는 플레이트에 대한 분석물의 코팅 효능을 결정하기 위해 제2 희석 (3중으로)을 활용하여 플레이트당 2회 수행하였다. C1q 결합을 일정 농도의 C1q (시그마; 보체 성분 C1q 카탈로그 # C1740-1mg)를 첨가함으로써 정량화하고, 양고추냉이 퍼옥시다제 HRP에 접합된 폴리클로날 염소-항-인간 C1q 항체 (AbD 세로텍(Serotec); 양 항-인간 C1q:HRP; 카탈로그 번호 2221-5004P)를 사용하여 검출하였다. 코팅 효율 대조군은 퍼옥시다제-접합된 염소-항-인간 IgG 항체 단편 (잭슨 이뮤노리서치(Jackson ImmunoResearch); 카탈로그 # 109-036-003; 아피니퓨어(AffiniPure) F(ab'2) 단편 염소 항-인간 IgG (H+L))을 사용한 제2 희석 시리즈에서 결정하였다. 둘 다 TMB 기질 (TMB 퍼옥시다제 EIA 기질 키트; 바이오-라드(Bio-Rad); 카탈로그 #172-1067)을 사용하여 UV-Vis 분광분석법 (몰레큘라 디바이시스(Molecular Devices); 스펙트라맥스(Spectramax)®프로(Pro) 340)으로 450 nm에서의 광학 밀도의 후속 측정으로 가시화하였다. 결과는 도 11 (b)에 제시된다. 시험된 항체에 결합된 C1q 단백질의 최대량은 모든 분석물에 대해 동일하였다. 마이크로타이터플레이트에 결합되어 있는 항체의 양은 10164 항체 (이는 다른 분자의 단지 약 50%에 도달함)를 제외한 모든 분석물에 대해 동일하였다. 12433, 10164 및 리툭시맙의 효력 (각 용량 반응 곡선의 최대 결합의 절반에서의 농도; 유효 농도 50, EC50)은 대략 동일하였다. 12425 항체의 EC50은 3 더 높은 인자이고, N297A_12425의 EC50은 약 8 더 높은 인자였다. 10164가 다른 항체가 그러한 바와 같이 마이크로타이터플레이트에 동등하게 잘 코팅되지 않았다는 결과를 고려하면, C1q 결합에서 관찰된 결과는 C1q 단백질에 대한 결합에서 대략 두배 능력의 10164를 암시한다.
추가로 C1q 결합의 평가를 위해, 보체 의존성 세포독성 (CDC)을 촉발하는 비접합된 항-FGFR2 항체 12433, 10164 12425 및 N297A_12425의 능력을 평가하였다. Kato-III 세포 (표적 세포; ATCC 카탈로그 번호 HTB-103)를 96-웰 마이크로타이터플레이트 (코스타; 멸균, 백색, 96-웰 평편 바닥 세포 배양물 플레이트, 카탈로그 # 3610)의 웰 내로 10000개 세포/웰의 농도로 동등하게 분배하고, 상기 언급된 항체의 연속 희석물과 함께 10분 동안 예비-인큐베이션한 후에, 이펙터 시약을 첨가하였다. 이 연구에서 사용된 이펙터 시약은 토끼 보체 (펠프리즈(PelFreez); 카탈로그 # 31060-1)이며, 이를 Kato-III 세포 상에 1 내지 6의 최종 희석으로 피페팅하였다. 가습 세포 배양 인큐베이터 내 37℃에서 2시간 인큐베이션 후에, 마이크로타이터플레이트를 원심분리하고, 상청액을 경사분리하고, 세포 펠릿을 재구성된 셀타이터글로® (프로메가; 셀타이터글로® 발광 키트, 카탈로그 # G7572) 중에 용해시켰다. 발광을 다중표지 판독기 (퍼킨 엘머; 빅터™ 3)에서 정량화하였다. 모든 시험된 항체에 대한 결과는 도 11 (c)에 제시된다. 시험된 항체 (도 11 (c)) 또는 추가 대조군 (상업적으로 입수가능한 항체 에르비툭스® & 헤르셉틴®, 데이터는 나타내지 않음)에 대한 CDC의 증거는 관찰되지 않았다.
12425-MCC-DM1의 생체내 활성에서 ADCC의 역할을 평가하기 위해, 암컷 누드 마우스에 50% 페놀 레드-무함유 매트리겔™ (BD 바이오사이언시스)을 함유한 현탁액 중 10x106개 세포를 행크 균형 염 용액 중에서 피하로 이식하였다. 현탁액 중 세포를 함유한 전체 주사 부피는 200 μl였다. 마우스를 평균 종양 부피가 201.4 mm3인 이식 7일 후에 연구에 등록하였다. 5개 군 중 하나에 무작위로 배정한 후에 (n = 6/군), 마우스에 10 mg/kg i.v. 용량의 네이키드 대조군 IgG, 네이키드 N297A_12425, 네이키드 12425, N297A_12425-MCC-DM1 또는 12425-MCC-DM1을 제공하였다. 종양을 주당 2회 캘리퍼로 측정하였다 (도 11 (d)). 네이키드, ADCC-고갈 12425 변이체 (네이키드 N297A_12425)는 투여 25일 후에 ADCC 적격 모 12425보다 더 낮은 항종양 활성을 나타내었다 (각각 61 및 13% T/C). 이러한 데이터는 모 12425의 이펙터 세포 기능이 네이키드 항체의 생체내 항종양 활성에서 역할을 할 수 있음을 시사한다. ADCC 적격 12425-MCC-DM1 및 ADCC 고갈 N297A_12425-MCC-DM1은 투여 25일 후에 유사한 항종양 활성을 나타내었다 (각각 45 및 32% 퇴행). 이러한 데이터는 ADCC 활성이 소모가능한 경우에 메이탄시노이드 페이로드가 12425-MCC-DM1의 강건한 생체내 항종양 활성에 대해 필요하고 충분하다는 것을 시사한다.
실시예 15: FGFR4-과다발현 세포주에서 신호전달을 조절하는 항-FGFR 항체 및 ADC의 평가
FGFR4-과다발현 세포주에서 FGFR 신호전달을 조절하는 비접합된 및 접합된 항-FGFR 항체의 능력을 평가하였다. 초기 연구에서, MDA-MB453 (ATCC 카탈로그 # HTB-131) 세포에서 10164 (FGFR2 특이적), 12433 (FGFR2 특이적), 12425 (FGFR2/4 교차-반응성) 및 연관된 MCC-DM1 접합체의 효과를 결정하였다. 간략하게, 세포를 10% FBS로 보충된 RMPI 중에서 셀바인드™ 12웰 플레이트 (코스타, 카탈로그 # 3336) 내에 시딩하고, 밤새 조직 배양 인큐베이터 내 37℃에서 5% CO2와 함께 인큐베이션하였다. 실험 당일에, 세포 배양 배지를 흡인하고, 시험 항체 또는 소분자 FGFR 억제제인 BGJ398로 대체하였으며, 이들 모두를 10% FBS로 보충된 RPMI 중에 최종 농도 (13-130 nM, 항체/ADC; 500 nM, BGJ398)로 희석하였다. 이어서, 세포를 조직 배양 인큐베이터 내 37℃에서 5% CO2와 함께 2시간 동안 인큐베이션하였다. 이러한 인큐베이션 후에, 세포를 차가운 PBS (론자, 카탈로그 # 17516C)로 2회 세척하고, 얼음 상에 놓고, 300 μl의 용해 완충제 (셀 시그널링 테크놀로지, 카탈로그 # 9803)를 포스포스톱 (로슈, 카탈로그 # 04 906237001)과 함께 첨가하였다. 단백질 농도를 BCA 검정 (피어스, 카탈로그 # 23228)에 의해 결정하였다. 단백질 농도를 BCA 검정 (피어스)에 의해 결정하였다. 이어서, 60 μg의 단백질을 SDS-PAGE에 의해 분해하고, 니트로셀룰로스 막 상에 옮기고, pFRS2 (셀 시그널링 테크놀로지, 카탈로그 #3864), 전체 FGFR4 (R&D 시스템스, 카탈로그 #8652) 및 β-액틴 (베틸, 카탈로그 # A300-485A) 또는 시토케라틴 (다코, 카탈로그 # M3515)에 항체로 프로빙하였다. 결과는 도 12 (a)에 나타내고, 비접합된 또는 MCC-DM1 ADC로서의 항체 중 어느 것도 2시간에서 pFRS2 신호를 조절할 수 없었는 것으로 밝혀졌다. 추가 실험을 12425 항체 4.3 nM 및 12425-MCC-DM1 ADC (4.3 nM 항체, 13 nM DM1 등가물)를 사용하여 수행하였고, 이들을 추가 시점 (4, 24 및 72시간)에서 평가하였다. 결과는 도 12 (b)에 나타내었다. 유사한 데이터를 또한 RH4 횡문근육종 세포주에서 획득하였다.
실시예 16: FGFR4-과다발현 세포주에서 항-FGFR 항체 및 ADC의 항증식 효과의 평가
FGFR4 과다발현 세포주의 패널의 증식을 억제하는 비접합된 및 SMCC-DM1 접합된 항-FGFR 항체의 능력을 상기 기재된 실시예 9에 사용된 바와 유사한 방법론을 사용하여 평가하였다.
FGFR4에 대한 그의 교차-반응성과 일치하도록, 12425-MCC-DM1이 FGFR4의 구성적 활성 돌연변이체 형태를 과다발현하는 MDA-MB453 세포의 성장의 강력한 억제제인 것으로 밝혀졌다 (문헌 [Roidl et al., 2010, Oncogene, 29, 1543-1552]). FGFR4 발현을 항-FGFR4 항체 (바이오레전드(Biolegend) 카탈로그 # 324306; 도 13 (a))를 사용하는 FACS 분석에 의해 확인하였다. 12425는 MDA-MB453에서 뿐만 아니라 다른 FGFR4-과다발현 세포주 (데이터는 나타내지 않음)에서 바이오레전드 항체에 대한 유사한 결합 특성을 입증하였다. 이 효과는 비접합된 12425 항체가 불활성이기 때문에 ADC에 대해 특이적이다 (도 13 (a)). 추가로, 어떠한 활성도 FGFR2 특이적 항체 (10164) 또는 ADC (10164-MCC-DM1)의 투여 후에 관찰되지 않았으며, 이는 효과가 FGFR4 발현에 의해 구동됨을 시사한다 (도 13 (a)). 이는 FAC에 의해 평가된 바와 같이 이들 세포 상에서 검출가능한 FGFR2 발현의 부족과 일치한다 (데이터는 나타내지 않음). 12425-MCC-DM1 및 12425의 유사한 효과는 또한 FGFR4 과다발현 횡문근육종 세포주, RH4 (도 13 (b)) 및 JR (도 13 (c))에서 관찰되었다. 추가 세포주까지 확장되는 경우에, 12425-MCC-DM1의 활성은 FGFR4 과다발현 유방 및 횡문근육종 세포주의 서브세트에서 관찰되었다 (도 13 (d)).
실시예 17: FGFR4-과다발현 종양에서 FGFR ADC 및 비접합된 항체의 생체내 PK-PD
FGFR4 양성 MDA-MB-453 이종이식 모델에서 PD 조절을 평가하기 위해, 암컷 NSG 마우스를 활용하였다. 세포 이식 1일 전에, 암컷 NSG 마우스에 0.36 mg의 90일 지속 방출 17β-에스트라디올 펠릿 (이노베이티브 리서치 오브 아메리카)을 피하로 이식하였다. 17β-에스트라디올 펠릿 이식 1일 후, 50% 페놀 레드-무함유 매트리겔™ (BD 바이오사이언시스)을 함유한 현탁액 중 5 x106개 세포를 행크 균형 염 용액 중에서 피하로 이식하였다. 현탁액 중 세포를 함유한 전체 주사 부피는 200 μl였다. 종양이 300 내지 500 mm3에 도달하면, 6마리 마우스를 단일 정맥내 15 mg/kg 용량의 12425-MCC-DM1 또는 대조군 IgG-MCC-DM1를 제공받도록 무작위로 배정하였다 (n=3/군). 12425-MCC-DM1은 IgG-MCC-DM1를 투여받은 대조군 마우스에 비해 투여 96시간 후 핵 pHH3 확실성에 있어서 뚜렷한 증가를 산출하였다 (도 14 (a)에 나타낸 대표적인 이미지).
FGFR4 양성 MDA-MB-453 이종이식 모델에서 PD 조절의 시간 과정을 평가하기 위해, 암컷 NSG 마우스를 활용하였다. 세포 이식 1일 전에, 암컷 NSG 마우스에 0.36 mg의 90일 지속 방출 17β-에스트라디올 펠릿 (이노베이티브 리서치 오브 아메리카)을 피하로 이식하였다. 17β-에스트라디올 펠릿 이식 1일 후에, 50% 페놀 레드-무함유 매트리겔™ (BD 바이오사이언시스)을 함유한 현탁액 중 5 x106개 세포를 행크 균형 염 용액 중에서 피하로 주사하였다. 현탁액 중 세포를 함유한 전체 주사 부피는 200 μl였다. 마우스를 단일 정맥내 15 mg/kg 용량의 12425-MCC-DM1 (군당 3마리 마우스에서 치료 투여 24, 48, 72, 96 및 168시간 후에 수집함) 또는 PBS (10 ml/kg)를 제공받도록 무작위로 배정하였다. 종양 부피의 범위는 무작위화시에 300 내지 500 mm3였다. 메이탄시노이드 페이로드의 예상된 작동 메카니즘과 일치하도록, 12425-MCC-DM1은 PBS 처리 대조군에 비해 투여 약 72-96시간 후에 피크가 되는 핵 pHH3 확실성에 있어서 뚜렷한 시간-의존성 증가를 산출한다. 절단된 카스파제 3 면역반응성에서의 피크는 투여 약 96 및 168시간 후에 발생하였다. 대표적인 이미지는 도 14 (b)에 나타내었다.
RH4 세포주를 비롯한 폐포 횡문근육종의 일부는 상승된 FGFR4 mRNA 및 단백질 발현을 생성하는 Pax 3/7-FOXO1A 전위를 보유한다. RH4 이종이식 모델에서 PD 조절을 평가하기 위해, 암컷 누드 마우스에 50% 페놀 레드-무함유 매트리겔 (BD 바이오사이언시스)을 함유한 현탁액 중 10x106개 세포를 행크 균형 염 용액 중에서 피하로 이식하였다. 현탁액 중 세포를 함유한 전체 주사 부피는 200 μl였다. 종양이 500 내지 700 mm3에 도달하면, 6마리 마우스를 단일 정맥내 15 mg/kg 용량의 12425-MCC-DM1, 대조군 IgG-MCC-DM1, 또는 PBS (10 ml/kg)를 제공받도록 무작위로 배정하였다 (n=3/군). 12425-MCC-DM1은 IgG-MCC-DM1을 제공받은 대조군 마우스에 비해 투여 96시간 후에 핵 pHH3 확실성에 있어서 뚜렷한 증가를 산출하였다 (도 14 (c)에 나타낸 대표적인 이미지). 이러한 발견은 12425-MCC-DM1이 FGFR4 양성 이종이식 모델에서 G2/M 세포 주기 정지의 원인이 된다는 것을 입증한다.
실시예 18: FGFR4-과다발현 종양에서 항-FGFR ADC의 생체내 효능
12425-MCC-DM1의 용량 반응 항종양 활성을 FGFR4 양성 MDA-MB-453 유방 암 이종이식 모델에서 평가하였다. 세포 이식 1일 전에, 암컷 NSG 마우스에 0.36 mg의 90일 지속 방출 17β-에스트라디올 펠릿 (이노베이티브 리서치 오브 아메리카)을 피하로 이식하였다. 17β-에스트라디올 펠릿 이식 1일 후에, 50% 페놀 레드-무함유 매트리겔™ (BD 바이오사이언시스)을 함유한 현탁액 중 5 x106개 세포를 행크 균형 염 용액 중에서 피하로 주사하였다. 현탁액 중 세포를 함유한 전체 주사 부피는 200 μl였다. 마우스를 평균 종양 부피가 197.9 mm3인 이식 12일 후에 연구에 등록하였다. 5개 군 중 하나에 무작위로 배정한 후에 (n = 5/군), 마우스에 PBS (10 ml/kg), 대조군 IgG-MCC-DM1 (15 mg/kg), 비접합된 12425 IgG (15 mg/kg) 또는 12425-MCC-DM1 (5, 10 또는 15 mg/kg)을 i.v. 투여하였다 (도 15 (a)). 대조군 IgG-MCC-DM1이 모델에서 활성이 아니었다. 단일 용량의 15 mg/kg 네이키드 IgG 12425 또는 5 mg/kg 12425-MCC-DM1은 투여 29일 후에 유사한 활성을 나타내었다 (각각 25 및 24% T/C). 12425-MCC-DM1은 10 및 15 mg/kg 둘 다로 투여되어 종양 퇴행을 산출하였다 (각각 72 및 92% 퇴행).
12425-MCC-DM1의 용량 반응 항종양 활성을 FGFR4 양성, Pax 3/7-FOXO1A 양성 RH4 이종이식 모델에서 평가하였다. 암컷 누드 마우스에 50% 페놀 레드-무함유 매트리겔™ (BD 바이오사이언시스)을 함유한 현탁액 중 10x106개 세포를 행크 균형 염 용액 중에서 피하로 이식하였다. 현탁액 중 세포를 함유한 전체 주사 부피는 200 μl였다. 마우스를 평균 종양 부피가 200.8 mm3인 이식 11일 후에 연구에 등록하였다 (도 15 (b)). 5개 군 중 하나에 무작위로 배정한 후에 (n = 8/군), 마우스에 PBS (10 ml/kg), 대조군 IgG-MCC-DM1 (15 mg/kg), 비접합된 12425 IgG (15 mg/kg) 또는 12425-MCC-DM1 (5, 10, 또는 15 mg/kg)을 i.v. 투여하였다. 대조군 IgG-MCC-DM1이 모델에서 활성이 아니었다. 유사하게, 단일 15 mg/kg 용량의 네이키드 IgG 12425는 제한된 활성을 나타내었다. 12425-MCC-DM1은 단일 용량의 5, 10 및 15 mg/kg으로서 항종양 활성을 나타내었다 (각각 36, 24, 26% T/C). 이러한 발견은 Pax 3/7-FOXO1A 전위가 RH4 세포주가 12425-MCC-DM1에 대해 감수성이 되게 하여 충분한 FGFR4 발현을 생성한다는 것을 확인한다. 따라서, 12425-MCC-DM1은 Pax 3/7-FOXO1A 전위 양성 횡문근육종을 갖는 환자를 치료하는데 사용될 수 있다.
실시예 19: 마우스, 래트 및 시노몰구스 원숭이의 항-FGFR ADC의 약동학의 평가
항-FGFR ADC의 약동학 (PK)을 종양- 및 비-종양-보유 마우스에서 1-15 mg/kg 범위의 몇몇 용량 수준으로, 비-종양 보유 래트에서 1, 5 및 45 mg/kg으로 및 시노몰구스 원숭이에서 30 mg/kg으로 평가하였다. 모든 연구에서, "전체" 항체 및 "항체 약물 접합체 (ADC)" 둘 다의 혈청 농도를 유효 ELISA 방법을 사용하여 모든 동물 종에서 측정하였다. "전체" 분율은 접합된 DM1이 있는 또는 없는 항체의 측정을 지칭하지만, ADC 분율은 DM1 접합된 항체만의 측정을 지칭한다 (≥ 1 DM1 분자). 모든 연구에서, 어떠한 인식가능한 차이도 ADC 및 전체 항체 분율의 클리어런스 사이에서 관찰되지 않았다.
12425-MCC-DM1 PK를 단일 IV 용량의 3 mg/kg 후에 SNU16 종양-보유 마우스에서 조사하였다. PK 샘플을 투여 1시간, 24시간, 72시간, 168시간 및 336시간 후에 수집하고, 전체 및 ADC 분율의 혈청 농도는 이 용량에서 중첩가능하였다 (도 16 (a)). 12425-MCC-DM1 반감기는 SNU16 이종이식편의 존재 하에 약 1.5일이었다.
12425-MCC-DM1 PK를 또한 단일 IV 용량의 1, 5, 10 또는 15 mg/kg 후에 비-종양 보유 마우스에서 조사하였다. PK 샘플을 투여 1시간, 6시간, 24시간, 72시간, 96시간, 168시간, 240시간, 336시간 및 540시간 후에 수집하였다. 전체 및 ADC 분율의 혈청 농도는 이 용량에서 중첩가능하였고 (도 16 (b)), PK 특성은 종양 보유 동물에 비해 비-종양 보유 동물에서 유사한 것으로 나타났다.
SNU16 종양-보유 마우스에서 12433-MCC-DM1 및 10164-MCC-DM1의 PK를 또한 결정하였다. 이들 ADC의 전체적인 PK 프로파일은 12425-MCC-DM1의 것과 유사하였고, 획득된 데이터를 표 17에 요약한다.
<표 17> 마우스에서 3 mg/kg 용량으로의 12433-, 12425- 및 10164-MCC-DM1의 약동학적 특성

12425-MCC-DM1 PK를 비-종양 보유 래트에서 IV 투여되는 2가지 용량 수준; 1 및 5 mg/kg에서 연구하였다. PK 샘플을 0.5시간, 1시간, 2시간, 6시간, 8시간 및 제1일, 제2일, 제4일, 제8일, 제11일, 제14일, 제21일 및 제35일에 수집하였다. "전체" 및 "ADC" 종에 대한 농도-시간 프로파일은 용량 수준 둘 다에서 거의 중첩가능하였다 (도 16 (c)). 말기 제거기는 1 mg/kg 용량 군에서 다소 더 급경사이고, 이는 후기 시점에서 표적-매개 약물 배치 (TMD)의 결과로서 존재할 수 있다. 유사하게, 전체 및 ADC 분율에 대한 클리어런스 값은 1 mg/kg 용량에서 각각 0.757 ± 0.088 mL/h/kg 및 0.813 ± 0.041 mL/h/kg이지만, 각각 다소 더 낮은 값 0.623 ± 0.027 mL/h/kg 및 0.607 ± 0.019 mL/h/kg이 5 mg/kg 용량에서 언급된다. 12425-MCC-DM1 ADC 종은 5 mg/kg 용량 수준에서 약 3.9일의 말단 반감기를 갖는다. 추가 연구에서, 래트 PK를 또한 5 mg/kg 및 45mg/kg 용량 수준에서 결정하였다. 5 mg/kg 용량에서의 반감기는 상기 언급된 값과 유사하였지만, 45 mg/kg 용량에서의 반감기는 전체 및 ADC 분율에 대해 각각 163.9시간, 121.3시간 (~5일)이었고, 이러한 값은 비-FGFR2/4 교차-반응성 대조군 ADC에 대한 관찰과 유사하였으며, 이는 임의의 가능한 TMD 클리어런스 경로의 포화를 시사한다.
12433-MCC-DM1 및 10164-MCC-DM1 PK를 또한 유사한 연구에서 결정하였고, 획득된 PK 파라미터는 표 18에 나타낸다. 사용된 용량 수준에서, 전체 및 ADC 반감기 및 클리어런스의 유사한 추정치는 처리된 모든 3종의 ADC에 대해 획득하였다.
<표 18> 래트에서 12433-, 12425- 및 10164-MCC-DM1의 약동학적 특성

12425-MCC-DM1 PK를 일군의 3마리 시노몰구스 원숭이 (1마리 수컷, 2마리 암컷)에게 단일 30 mg/kg IV 용량의 투여 후에 조사하였다. 혈청 샘플을 제1일 - 0시간 (투여 이전), 및 투여 후 0.25시간, 2시간, 4시간, 6시간, 24시간, 48시간, 72시간, 168시간 및 240시간에 수집하였다. 12425-MCC-DM1에 대한 최대 노출이 IV 주사 직후, 즉 제1 샘플링 시점인 0.25시간에 관찰되었다. 시간 과정은 긴 제거기를 특징으로 하였고, 전체 및 ADC 분율에 대한 프로파일은 샘플링 시간 과정에 걸쳐 중첩가능하였다 (도 16 (d)). 말단 반감기는 약 6-7일이었다.
10164-MCC-DM1 PK를 또한 일군의 3마리 시노몰구스 원숭이에게 단일 30 mg/kg IV 용량의 투여 후에 조사하였다. 이러한 시약에 대한 시간 과정은 긴 제거기를 특징으로 하였고 (말단 반감기 6-7일), 10164-MCC-DM1 및 12425-MCC-DM1 둘 다에 대한 PK 파라미터는 표 19에 나타내었다.
<표 19> 30 mg/kg IV 용량 후 시노몰구스 원숭이에서 12425- 및 10164-MCC-DM1의 약동학적 특성

실시예 20: 서열-변형된 항-FGFR 항체 및 ADC의 활성의 시험관내 및 생체내 평가
잠재적 구조적 불안정성이, 최종 단백질의 이질성에 영향을 미칠 수 있고 예를 들어 항체 제조성 및 면역원성에 충격을 줄 수 있는, 치료 항체의 서열에 존재할 수 있는 것으로 인지된다. 이러한 불안정성은 글리코실화 부위, 쌍형성되지 않은 시스테인, 잠재적 탈아미드화 부위 등을 포함할 수 있다. 이러한 잠재적 불안정성의 위험을 감소시키기 위해, 돌연변이가 도입되어 하나 이상의 이들 불안전성을 제거할 수 있다. 예를 들어, 잠재적 탈아미드화 부위는 단독으로 또는 다른 구조 변화와 함께 대체될 수 있다. 잠재적 탈아미드화 부위의 예는 10164 및 12425의 중쇄 CDR2에 있는 DG를 포함한다 (표 1 참조). 이들 잔기는 다른 적절한 아미노산으로 돌연변이될 수 있다. 비제한적 예에 의해, 10164 HCDR2에서의 아스파르트산 (D)은 글루탐산 (E) 또는 트레오닌 (T)으로 돌연변이될 수 있다. 12425에서, HCDR2 글리신 (G)은 또 다른 아미노산, 예컨대 알라닌 (A)으로 돌연변이될 수 있다.
항체가 아미노산 수준에서의 그의 각 배선 서열과 상이한 경우에, 항체가 그의 배선 서열로 역돌연변이될 수 있음이 또한 인지되어야 한다. 이러한 교정 돌연변이는 하나 이상의 위치에서 발생하고, 표준 분자 생물학 기술을 사용하여 또는 유전자 합성에 의해 생성될 수 있다. 비제한적 예로서, 12425 중쇄의 중쇄 서열 (서열 9, 표 1 참조)은 위치 1에서의 Q에 대해 E에 의해 상응하는 배선 서열과 상이하고, 경쇄 (서열 17)는 위치 85에서의 V에 대해 T에 의해 상응하는 배선과 상이하다. 따라서 12425에서의 아미노산은 이들 부위 중 임의의 곳 또는 모두에서 변형될 수 있다.
본 출원에 기재된 항체 약물 접합체를 생성하는데 사용된 화학은 항체 서열에서 리신 (K) 잔기에 대한 접합에 의존적이다. 이들 리신 잔기가, 예를 들어, CDR 영역에서 에피토프 인식에 포함되는 영역 내에 존재하는 경우에, 유의한 접합이 이들 부위에 발생한다면, 항체 약물 접합체가 그의 의도하는 표적에 결합하는 능력이 변경될 수 있다. 이러한 잠재적 위험을 완화시키기 위해, 이러한 리신 잔기는 대체의 적절한 아미노산, 예컨대 아르기닌, 아스파라긴 또는 글루타민으로 돌연변이될 수 있다. 1개의 리신은 12425의 중쇄 CDR2 및 CDR3 영역 둘 다에 존재한다. 이들 리신 중 1개 이상이 대체 잔기, 예컨대 아르기닌, 아스파라긴 또는 글루타민으로 돌연변이될 수 있다.
상기 기재된 몇몇 변화가 12425 항체 내로 도입되어 항체 20562를 생성하였다 (표 1). 이 항체를, FGFR2에 결합하는 그의 능력, FGFR2-증폭된 세포주, 예컨대 SNU16의 증식을 억제하고 SNU16 세포에 대한 생체내 항종양 효과를 유발하는 그의 능력에 대해 12425와 비교하였다. 인간 FGFR2 IIIb 및 FGFR4에 대한 20562의 친화도는 유사한 검정 조건 하에 12425의 친화도와 유사한 것으로 밝혀졌다 (20562 FGFR2 IIIb 친화도 추정치: 9 nM; 인간 FGFR4 친화도 추정치: 3.3 nM). 실시예 6에 기재된 방법론을 사용하여, 12425-MCC-DM1과 유사하게, 20562-MCC-DM1은 또한 SNU16 세포의 시험관내 증식의 강력한 억제제였다 (도 17 (a)). 20437-MCC-DM1의 생체내 효력을 평가하기 위해, 암컷 누드 마우스에 50% 페놀 레드-무함유 매트리겔™ (BD 바이오사이언시스)을 함유한 현탁액 중 10x106개 세포를 행크 균형 염 용액 중에서 피하로 이식하였다. 현탁액 중 세포를 함유한 전체 주사 부피는 200 μl였다. 마우스를 평균 종양 부피가 217.1 mm3인 이식 7일 후에 연구에 등록하였다. 5개 군 중 하나에 무작위로 배정한 후에 (n = 6/군), 마우스는 PBS (10 ml/kg) 또는 3 mg/kg i.v. 용량의 12425-MCC-DM1 또는 20562-MCC-DM1을 제공받았다. 종양을 주당 2회 캘리퍼로 측정하였다 (도 17(b)). 12425-MCC-DM1 및 그의 변이체 20562-MCC-DM1 둘 다는 FGFR2 증폭된 SNU16 이종이식편에 대해 생체내 유사한 활성을 가졌다. 이러한 데이터는 ADC로서의 생체내 활성에 충격 없이 모 항체의 DG 부위를 제거하는 것이 가능함을 시사한다.
실시예 21: 친화도 성숙 FGFR ADC의 생성 및 특성화
선택된 항-FGFR 항체의 생물학적 활성에 대한 친화도의 효과를 평가하기 위해, 친화도 최적화를 12433, 10164 및 12425 클론에 대해 수행하였다. 이러한 연구에서, L-CDR3 및 H-CDR2 영역을 카세트 돌연변이유발에 의해 트리뉴클레오티드 지정 돌연변이유발을 사용하여 동시에 최적화시키면서 (문헌 [Virnekas et al., 1994 Nucleic Acids Research 22: 5600-5607]), 프레임워크 영역을 불변하게 유지하였다. 친화도 성숙을 위한 클로닝 이전에, 모 Fab 단편을 상응하는 발현 벡터 pM®x11로부터 시스디스플레이(CysDisplay)™ 벡터 pMORPH®30 내로 XbaI/EcoRI를 통해 전달하였다.
모 Fab 단편의 L-CDR3을 최적화하기 위해, 결합제의 L-CDR3을 제거하고, 다양화된 L-CDR3의 레퍼토리에 의해 대체하였다. 각각의 모 Fab에 대해, 다양화된 H-CDR2를 갖는 제2 라이브러리 세트를 생성하였다. 각각의 돌연변이 라이브러리 (LCDR3 및 HCDR2)에 대해, 항체-다스플레이 파지를 준비하고, 파지 역가를 스팟-적정에 의해 결정하였다. 라이브러리의 증폭을 다르게 기재된 바와 같이 수행하였다 (문헌 [Rauchenberger et al., 2003 J Biol Chem 278: 38194-38205]). 품질 관리를 위해, 단일 클론을 무작위로 선택하고 서열분석하였다.
친화도의 선택을 위해, 성숙 라이브러리로부터 유래된 개선된 결합제 파지를 비오티닐화 인간 FGFR2를 사용하는 용액 패닝의 3개 라운드에 적용하였다. 엄격도를 각 패닝 라운드에서 항원 농도를 저하시킴으로써 증가시켰다 (문헌 [Low et al., 1996 J Mol Biol 260(3): 359-368]). 항원 감소 이외에도, 오프-속도 선택 (문헌 [Hawkins et al., 1992 J Mol Biol 226: 889-896])을 수행하였다. 이는 실온에서 지속 세척 단계와 합쳐진다. 일반적인 패닝 절차는 상기 기재된 바와 같이 수행하였다 (용액 패닝).
선택된 하위코드를 위해, 실시된 H-CDR2 친화도 성숙 패닝의 제2 라운드 패닝 산출물을 L-CDR3에서 추가로 다양화하였다. 라이브러리 생성은 상기 기재된 바와 같이 정확하게 수행하였다. 개선된 결합제의 선택을 위해, 새로 생성된 라이브러리를 용액 패닝의 2회 추가 라운드에 적용하였다.
확인된 서열 유일 클론을 IgG로서 발현시키고, 인간 FGFR2에 대한 친화도를 실시예 1 및 2에 기재된 바와 유사한 SET 또는 비아코어® 방법론을 사용하여 결정하였다. 80개 초과 클론을 3개 모 항체로부터 평가하였으며, 3-6배의 친화도 개선을 12433 항체로부터 유래된 클론에 대해, 27-배의 친화도 개선을 10164 유래 클론에 대해 및 68-배의 친화도 개선을 12425 유래 항체에 대해 획득하였다. 10164로부터 유래된 최고 친화도 클론을 20809로 지정하였고, 인간 FGFR2에 대한 그의 친화도는 450 pM인 것으로 결정되었다. 흥미롭게도, 이러한 항체는 또한 7.4 nM의 친화도 추정치로 인간 FGFR4에 결합하였다. 12425로부터 유래된 최고 친화도 항체를 20811로 지정하였고 (표 1), 인간 FGFR2에 대한 그의 친화도는 110 pM인 것으로 결정되었다. FGFR4에 대한 이러한 항체의 친화도는 75 pM인 것으로 결정되었다.
추가 연구에서, 20809 및 20811 둘 다는 SMCC-DM1에 직접 접합되어 20809-MCC-DM1 및 20811-MCC-DM1을 산출하였다. SNU16 세포의 성장을 억제하는 이들 ADC의 능력은 도 18 (a)에 나타내었다. 생체내 항종양 활성에 대한 친화도의 영향을 FGFR2 증폭된 SNU16 이종이식 모델에서 평가하였다. 암컷 누드 마우스에 50% 페놀 레드-무함유 매트리겔™ (BD 바이오사이언시스)을 함유한 현탁액 중 10x106개 세포를 행크 균형 염 용액 중에서 피하로 이식하였다. 현탁액 중 세포를 함유한 전체 주사 부피는 200 μl였다. 마우스를 평균 종양 부피가 217.6 mm3인 이식 7일 후에 연구에 등록하였다. 5개 군 중 하나에 무작위로 배정한 후에 (n = 6/군), 마우스는 PBS (10 ml/kg) 또는 3 mg/kg i.v. 용량의 12425-MCC-DM1, 20811-MCC-DM1, 10164-MCC-DM1 또는 20809-MCC-DM1을 제공받았다. 종양을 주당 2회 캘리퍼로 측정하였다 (도 18 (b)). 10164-MCC-DM1 및 그의 친화도 성숙 변이체 20809-MCC-DM1은 SNU16 이종이식편에 대해 유사한 활성을 입증하였다. 12425-MCC-DM1은 항종양 활성과 관련하여 그의 친화도 성숙 변이체 20811-MCC-DM1에 비해 우월성을 입증하였다. 이러한 데이터는 친화도 성숙이 MCC-DM1 ADC로서의 개선된 생체내 활성을 산출하지 않음을 시사한다.
실시예 22: 중수소 교환 질량 분광측정법 (HDx-MS)에 의한 FGFR2 및 그의 항체 복합체의 에피토프 맵핑
중수소 교환 질량 분광측정법 (HDx-MS)은 단백질의 아미드 백본 상의 중수소 흡수를 측정한다. 이러한 측정은 아미드의 용매 접근성 및 백본 아미드의 수소 결합 네트워크에서의 변화에 민감하다. HDx-MS는 종종 2가지 상이한 상태의 단백질, 예컨대 아포 및 리간드-결합 단백질을 비교하는데 사용되고, 펩신을 사용한 신속한 소화와 커플링된다. 이러한 실험에서, 전형적으로 10 내지 15 아미노산의 영역을 위치시킬 수 있고, 이는 2가지 상이한 상태 사이의 차등 중수소 흡수를 나타낸다. 보호된 영역은 리간드 결합에 직접 포함되거나 또는 리간드의 결합에 의해 알로스테릭하게 영향을 받는다.
이들 실험에서, 이. 콜라이 유래의 FGFR2 D2-D3 단백질 (서열 135, 하기 참조)의 중수소 흡수는 3가지 치료 항체: 12425, 10164 및 12433의 부재 및 존재 하에 측정하였다. 항체의 결합에 따라 중수소 흡수에서의 감소를 나타내는 FGFR2 내 영역이 에피토프에 포함될 가능성이 있지만; 그러나, 측정의 성질로 인해, 직접 결합 부위로부터 원격인 변화 (알로스테릭 효과)를 검출하는 것이 또한 가능하다. 보통, 최대 보호량을 갖는 영역이 직접 결합에 포함되지만, 이는 항상 그러한 경우는 아닐 수 있다. 알로스테릭 효과로부터 직접 결합 사건을 설명하기 위해 직각 측정 (예를 들어 X선 결정학, 알라닌 돌연변이유발)이 필요하다.
<표 20> FGFR2 D2-D3 구축물

이 실시예에 기재된 에피토프 맵핑 실험을 리프(LEAP) 오토샘플러, 나노액퀴티(nanoACQUITY) UPLC 시스템 및 시냅트(Synapt) G2 질량 분광계를 포함하는 워터스 HDx-MS 플랫폼 상에서 수행하였다. 상기 연구는 리프쉘(LeapShell) 소프트웨어에 의해 작동되는 리프 오토샘플러에 의해 자동화되었으며, 이는 수소 교환 반응의 개시, 반응 시간 제어, 반응 켄칭, UPLC 시스템 상의 주입 및 소화 시간 제어를 수행하였다. HDx 반응을 위해 25℃에서 유지되고 단백질의 저장 및 용액 켄칭을 위해 2℃에서 유지되는 각각의 2개의 온도 제어된 스택을 리프 오토샘플러에 장착하였다. 3중 대조군 실험을 25분의 중수소 교환 시간으로 항원에 대해 수행하였다. HDX를 켄칭 완충제 (6 M 우레아 및 1 M TCEP pH = 2.5)로 켄칭하였다. 켄칭 후에, 항원을 UPLC 시스템 내로 주입하고, 여기서 이를 12℃에서 온-라인 펩신 소화에 적용하고, 이어서 워터스 BEH C18 1 x 100 mm 칼럼 (1℃에서 유지됨) 상에서 40 μL/분의 유량으로 신속한 8분 2에서 35% 아세토니트릴 구배에 적용하였다. 3중 실험을 대조군 실험과 같이 항원-mAb 복합체에 대해 수행하지만, 단 이 실험에서는 항원을 항체와 함께 25℃에서 30분 동안 인큐베이션한 후에 중수소 교환하였다.
이러한 측정의 결과는 도 19 (a) 및 도 19 (b)에 요약된다. 도 19 (a)에서, mAb의 부재 (대조군) 및 존재 하에 FGFR2 펩티드에 대한 평균 중수소 흡수를 나타내었다. 이 도면에서, 2가지 차이를 검토하는 것이 유용하다: 대조군 및 mAb 사이의 차이 및 mAb 군 사이의 차이. 도 19 (b)에서, mAb 및 대조군 샘플 사이의 중수소 흡수에서의 차이는 측정에서의 표준 오차에 의해 나누어진다. 차이가 절대 척도에서 0.5 Da 초과인 경우에 (도 19 (a)) 및 표준 오차에 의해 나누어진 차이의 비가 -3.0 이하인 경우에 (도 19 (b)) 그 차이가 유의한 것으로 여겨진다. 이러한 분석으로부터 본 발명자들은 보호된 FGFR2의 영역을 mAb 결합에 따라 고, 중 및 저 보호량의 카테로리 내로 순위를 매길 수 있다. 고보호의 FGFR2 영역은 특이적 항체와 함께 에피토프의 형성에 잠재적으로 포함되지만, 보다 덜 보호된 영역에 대한 다른 기여도를 배제할 수는 없다.
10164의 FGFR2에 대한 결합에 따라, 본 발명자들은 FGFR2의 하기 2개 영역에서 고보호량을 관찰하였다: 서열 137의 잔기 174-189 및 198-216. 이러한 영역은 βB에서 βC의 N-말단 측면 및 βC' 루프에서 βE로 구체적으로 이루어진 D2 도메인에 위치한다 (도 19 (c) 및 (d)). 영역 222-231에서 발견되는 저보호의 한 영역이 존재한다. 그러나, 이 영역은 모든 연구된 항체의 결합 시에 보호되고; 이러한 관찰은 이 영역이 자연에서 비특이적 및 알로스테릭일 수 있는 그의 국부 수소 결합 네트워크의 안정화를 겪는다는 것을 시사한다. 항체 12425의 FGFR2에 대한 결합은 또한 서열 137의 잔기 174-189 및 198-216의 영역에서 고보호량의 원인이 된다. 또한, 12425 패밀리와 함께 서열 137의 잔기 160-173의 영역에서의 고보호량 (도 19 (a) 및 (b))이 또한 관찰되었다. 이러한 영역은 공개된 결정학 데이터로부터 FGF2 및 FGF1와 상호작용하는 것으로 공지된 FGFR2의 영역을 포함한다 (문헌 [Plotnikov et al., M. Cell 2000, 101, 413-424; Beenken et al., M. J. Biol. Chem. 2012, 287, 3067-3078]). 이 영역에서의 보호는 12425 패밀리 항체에 대해 유일하다. 연구된 항체 중에서, 12433은 FGFR2의 IIIb 이소형을 FGFR2의 D3 도메인과의 상호작용을 통해 특이적으로 표적화한다는 점에서 유일하다. 12433에 대하여 펩티드 338-354에서는 고보호량 (~2 Da), 및 338-345의 보다 짧은 N-말단 단편에서는 유의하지 않은 보호량이 관찰되었다. 이러한 관찰은 12433 결합 시에 보호된 338-354 펩티드의 일부가 영역 346-354인 것을 시사한다 (도 19 (a) 및 (b)). 영역 346 내지 354는 IIIc 이소형에 비해 IIIb 이소형에 대해 특이적인 4개의 잔기를 함유하고; 이들 잔기는 Q348, A349, N350 및 Q351을 포함한다. 추가 연구에서, 10164 및 12425의 친화도 성숙 버전 (하기 실시예 23 참조)을 평가하였고, 관찰된 보호된 영역의 관점에서 각 모 항체와 유사한 것으로 밝혀졌다.
추가로, 유사한 방법을 사용하여 FGFR2/4 교차-반응성 항체 12425의 존재 하에 FGFR4의 보호를 검사하는 중수소 교환 연구를 수행하였다. FGFR4 D1-D3 구축물 (서열 124, 하기 참조)을 사용하는 예비 분석은 12425의 결합이 D3 영역에서 임의의 보호를 유발하지 않음을 시사하였다. 보호는 D1 및 D2 도메인 내에 있는 영역에 제한되는 것으로 나타난다.
<표 21> FGFR4 D1-D3 구축물

실시예 23: 인간 FGFR2 / 12425 Fab 및 FGFR4 / 12425 Fab 복합체의 X선 결정학적 구조 결정
12425의 Fab 단편에 결합된 인간 FGFR2 ECD 단편 (FGFR2 도메인 2, 또는 FGFR2 D2, 서열 138, 표 22) 또는 인간 FGFR4 ECD 단편 (FGFR4 도메인 2, 또는 FGFR4 D2, 서열 143, 표 22)의 결정 구조 (표 22)를 결정하였다. 하기 상세설명된 바와 같이, FGFR2 D2 또는 FGFR4 D2를 발현시키고, 정제하고, 12425 Fab와 혼합하여 복합체를 형성하였다. 이어서, 단백질 결정학을 이용하여 12425 Fab에 결합된 FGFR2 D2 또는 FGFR4 D2에 대한 원자 해상도 데이터를 생성하여 에피토프를 정의하였다. FGFR2의 결정학적 에피토프를, 결정적 에피토프 잔기를 돌연변이시키고 돌연변이체 FGFR2의 12425에 대한 결합을 표면 플라즈몬 공명 (SPR) 기술을 이용하여 측정함으로써 추가로 유효화하였다.
결정학 및 SPR을 위한 단백질 생산
결정학 및 SPR를 위해 생산된 단백질의 서열은 표 22에 나타낸다. FGFR2 D2의 구축물은 인간 FGFR2의 잔기 146 내지 249 (밑줄) (유니프롯 식별자 P21802-3, 서열 137)을 재조합 발현 벡터로부터의 N- 및 C-말단 잔기 (소문자로 나타냄, 서열 137)와 함께 포함한다. FGFR4 D2의 구축물 (서열 143)은 인간 FGFR4의 잔기 140 내지 242 (밑줄) (유니프롯 식별자 P22455-1, 서열 142)를 재조합 발현 벡터로부터의 N- 및 C-말단 잔기 (소문자로 나타냄)와 함께 포함한다. FGFR2 도메인 2부터 도메인 3의 구축물 (D2D3)은 잔기 140 내지 369 (서열 137에서의 이탤릭체)를 포함한다. 야생형 (WT) 및 K176A/R201A 이중 돌연변이체 버전의 FGFR2 D2D3은 SPR에 의한 에피토프 확인을 위해 생산된다 (각각 서열 144 및 145; 소문자는 재조합 발현 벡터로부터의 N- 및 C-말단 잔기임). 12425 Fab에 대하여, 중쇄 및 경쇄의 서열을 나타낸다 (각각 서열 139 및 140).
<표 22> 결정학 및 SPR에 사용된 단백질의 서열



FGFR2 D2를 이. 콜라이 BL21 (DE3) (노바젠R, EMD 밀리포어(Millipore))에서 발현시켰다. IPTG를 사용하여 밤새 18℃에서 유도시킨 후, 세포를 수확하고, -80℃에서 동결시키고, 용해시켰다. 봉입체를 20 mM 인산나트륨 pH 7.5, 300 mM NaCl 및 8M 우레아를 사용하여 추출하고, 동일한 완충제 중에 사전-평형화된 Ni-NTA 칼럼 상에 로딩하였다. 칼럼을 20 mM 인산나트륨 pH 7.5, 300 mM NaCl, 50 mM 황산암모늄 및 20mM 이미다졸을 사용하여 세척하고, 이어서 20 mM 인산나트륨 pH 7.5, 300mM NaCl, 50mM 황산암모늄 및 300mM 이미다졸로 용리시켰다. 이어서, 용리된 단백질을 20 mM 인산나트륨 pH 6.5 (완충제 A)으로 12-배 희석하고, 완충제 A 플러스 2%의 20mM 인산나트륨 pH 6.5, 1.5M NaCl, 50mM 황산암모늄 (완충제 B)로 사전-평형화된 하이트랩(HiTrap) S HP 칼럼 (지이 헬스케어) 상에 로딩하였다. S 칼럼을 완충제 A 플러스 2% - 100% 완충제 B의 구배에 의해 용리시켰다. FGFR2 D2를 함유한 주요 피크를 수집하고, 농축시키고, 20mM Hepes pH 7.5, 150mM NaCl로 평형화된 하이로드(HiLoad)® 16/60 슈퍼덱스™ 75 (지이 헬스케어) 상에 로딩하였다. 피크 분획을 SDS-PAGE 및 LCMS에 의해 분석하고, 이어서 모아서 12425 Fab와의 복합체를 형성하였다.
FGFR4 D2를 이. 콜라이 계통 셔플(Shuffle)® T7 익스프레스(Express) (뉴잉글랜드 바이오랩스(New England BioLabs)R)에서 발현시켰다. IPTG를 사용하여 밤새 18℃에서 유도시킨 후, 세포를 수확하고, 50 mM 인산나트륨 pH 7.5, 300 mM NaCl 플러스 소 췌장으로부터의 0.1 mg/ml 데옥시리보뉴클레아제 I (시그마®) 및 용해 완충제 50ml당 완전 프로테아제 억제제 칵테일 정제 (로슈®) 1개 정제 중에 용해시켰다. 1시간 동안 15,000 rpm으로 원심분리에 의해 용해를 명확하게 하고; 이어서 탈론(Talon)R 수지 (클론테크®)를 밤새 4℃에서의 배치 결합을 위해 상청액에 첨가하였다. 다음날, 수지를 칼럼에 패킹하고, 50 mM 인산나트륨 pH 7.5, 300 mM NaCl, 20 mM 이미다졸로 세척하고, 50 mM 인산나트륨 pH 7.5, 300 mM NaCl, 300 mM 이미다졸로 용리시켰다. 이어서, 용리된 단백질을 50mM 인산나트륨 pH 7.5 (완충제 C)로 12배 희석하고, 완충제 C 플러스 2%의 50mM 인산나트륨 pH 7.5, 1M NaCl (완충제 D)로 사전-평형화시킨 하이트랩 S HP 칼럼 (지이 헬스케어) 상에 로딩하였다. S 칼럼을 완충제 C 플러스 2% - 100% 완충제 D의 구배에 의해 용리시켰다. FGFR4 D2를 함유한 주요 피크를 수집하고, 농축시키고, 20mM Hepes pH 7.5, 150mM NaCl로 평형화된 하이로드® 16/60 슈퍼덱스™ 75 (지이 헬스케어) 상에 로딩하였다. 피크 분획을 SDS-PAGE 및 LCMS에 의해 분석하고, 이어서 모아서 12425 Fab와의 복합체를 형성하였다.
12425 Fab를 전장 12425 IgG을 고정된 파파인 (피어스)을 사용하여 절단함으로써 생산하였다. 20 mM 인산나트륨 pH 7.0 및 10 mM EDTA 중 20 mg/ml의 12425 IgG를 고정된 파파인과 80:1의 중량비로 혼합하였다. 혼합물을 15 ml 튜브 내에서 37℃에서 밤새 회전시켰다. 다음날 고정된 파파인을 중력 흐름 칼럼에 의해 제거하고; Fab 및 Fc 절편 둘 다를 함유하는 통과액을 수집하고, 하이트랩™ 맙셀렉트 슈어™ 칼럼 (지이 헬스케어) 상에 로딩하여 Fc 절편을 제거하였다. Fab 단편만을 함유한 이 단계로부터의 통과액을 농축시키고, 20mM Hepes pH 7.5, 150mM NaCl 중에 평형화시킨 하이로드® 16/60 슈퍼덱스™ 75 (지이 헬스케어) 상에 로딩하였다. 피크 분획을 SDS-PAGE 및 LCMS에 의해 분석하고, 이어서 모아서 FGFR2 D2 또는 FGFR4 D2와의 복합체를 형성하였다.
FGFR2 D2/12425 및 FGFR4 D2/12425 Fab 복합체의 결정화 및 구조 결정
FGFR2 D2 또는 FGFR4 D2와 12425 Fab와의 복합체를, 정제된 FGFR2 D2 또는 FGFR4 D2를 12425 Fab와 2:1 몰비 (LCUV를 통해 측정된 농도)로 혼합하고, 얼음 상에서 30분 동안 인큐베이션하고, 20mM Hepes pH 7.5, 150mM NaCl 중에 평형화시킨 복합체를 하이로드® 16/60 슈퍼덱스™ 75 (지이 헬스케어) 상에 로딩함으로써 정제하였다. 피크 분획을 SDS-PAGE 및 LCMS에 의해 분석하였다.
FGFR2 D2/12425 Fab 복합체를 결정화하기 위해, 복합체 함유 분획을 모으고, 약 30 mg/ml로 농축시켰다. 트립신 (1 mM HCl 및 2 mM CaCl2 중에 1 mg/ml로 용해시킴)을 복합체 내로 1:100의 부피비로 첨가하여 결정화를 용이하게 하였다 (문헌 [Wernimont et al., (2009) Plos One 4:e5095]). FGFR2 D2/12425 Fab/트립신 혼합물을 즉시 원심분리하고, 결정화를 위해 스크리닝하였다.
결정을 시팅 점적 증기 확산에 의해 성장시켰다. 자세하게는, 0.1 μl의 단백질을, 0.1 M 시트르산삼나트륨 2수화물 pH 5.0, 20% (w/v) PEG6000을 함유한 0.1 μl의 저장 용액과 혼합하고; 점적을 45 μl의 동일한 저장 용액에 대해 4℃에서 평형화시켰다.
FGFR4 D2/12425 Fab 복합체를 결정화하기 위해, 복합체를 함유한 크기 배제 분획을 모으고, 20mg/ml로 농축시키고, 원심분리하고, 결정화를 위해 스크리닝하였다. 결정을 FGFR2 D2/12425 Fab 복합체 (상기 기재됨)와 동일한 방식으로 성장시키며, 단 저장 용액은 0.2 M 포름산마그네슘, 20% (w/v) PEG3350을 함유하였고, 결정을 20℃에서 성장시켰다.
데이터 수집 전에, FGFR2 D2/12425 Fab 및 FGFR4 D2/12425 Fab 결정 둘 다를 추가의 22.5% 글리세롤을 함유한 저장 용액에 옮기고, 액체 질소 중에서 새로 냉각시켰다.
회절 데이터를 어드밴스드 포톤 소스(Advanced Photon Source) (아르곤 국립 연구소(Argonne National Laboratory), 미국)에서 빔라인 17-ID에 수집하였다. 데이터를 가공하고, HKL2000 (HKL 리써치(HKL Research))를 사용하여 2.8Å에서 점수화하였다. FGFR2 D2 구조 (PDB ID: 3DAR) 및 인-하우스 Fab 구조를 탐색 모델로서 갖는 페이저(Phaser)를 사용한 분자 대체 (문헌 [McCoy et al., (2007) J. Appl. Cryst. 40:658-674])에 의해 두 구조 모두를 해결하였다. 최종 모델을 COOT에서 구축하고 (문헌 [Emsley & Cowtan (2004) Acta Cryst. 60:2126-2132]), 부스터(Buster) (글로벌 페이징, 리미티드(Global Phasing, LTD))로 정밀화하였다. 12425 Fab에서 5 Å의 임의의 분자 내에 원자를 함유하는 FGFR2 D2 또는 FGFR4 D2의 잔기를 PyMOL (슈레딩거, 엘엘씨(Schroedinger, LLC))에 의해 확인하고, 표 23 및 24에 열거하였다.
FGFR2 및 SPR 검정의 돌연변이유발
K176A/R210A 이중 돌연변이를 퀵체인지(Quikchange)R 부위-지정 돌연변이 유발 키트 (애질런트 테크놀로지스(Agilent Technologies))에 의해 FGFR2 D2D3 구축물 내로 도입하였다. WT 및 돌연변이체 FGFR2 D2D3 단백질 둘 다를 FGFR4 D2 단백질에 대해서와 동일한 절차를 사용하여 생산하였다.
SPR 검정에 사용되는 시약에 있어서, 친화도 순수한 F(ab)' 단편 항-인간 IgG Fcγ 단편 (109-006-098)을 잭슨 이뮤노 리서치 래버로토리(Jackson Immuno Research Laboratory)로부터 구입하였다. 센서 칩 CM5 (BR-1006-068), 글리신 pH 2.0 (BR-1003-55) 및 HBS-EP+ 완충제 (BR-1006-69)를 지이 헬스케어로부터 주문하였다. BSA를 깁코® (15260)로부터, 헤파린을 시그마R (H3149-100KU)로부터 구입하였다.
모든 SPR 작업을 비아코어® T100을 평가 소프트웨어 버전 1.1 및 CM5 센서 칩과 함께 사용하여 수행하였다. HBS-EP+를 0.5 mg/ml의 BSA 및 10 μg/ml 헤파린과 함께 모든 실험에서 구동 완충제로서 사용하였다. 고정화 수준 및 분석물 상호작용을 반응 유닛 (RU)에 의해 측정하였다. 파일럿 실험을 수행하여 항-인간 Fc 항체의 고정화 및 12425 IgG의 하위서열 포획의 실행가능성을 시험하고 확인하였다.
12425 동역학 측정을 위해, 항체를 칩 상에 포획하고, 이어서 WT 또는 돌연변이체 FGFR2 D2D3 단백질을 그 위에 유동시켰다. 간략하게, 50 μg/ml의 항-인간 Fc 항체 (pH 4.75)를 CM5 칩 상에 아민 커플링을 통해 10 μl/분의 유량으로 고정시켜 모든 4종의 유동 세포가 6000 RU에 도달하도록 하였다. 3 μg/ml의 12425를 10 μl/분으로 10초 동안 시험 유동 셀 상에 주사하였다. 0.078 -100 nM의 FGFR2 D2D3 단백질을 2배 희석으로 80 μl/분으로 7분 동안 모든 참조 유동 세포 및 시험 유동 셀 위에 주사하였다. 이어서, HBS-EP+ + BSA + 헤파린 완충제를 10분 동안 유동시켜 결합된 12425를 해리시켰다. 각 주사 주기 후에, 칩 표면을 10 mM 글리신 pH 2를 60 μl/분로 70초 동안 사용하여 재생시켰다. 모든 동역학 측정을 25℃에서 수행하였다.
12425에 대한 FGFR2 에피토프
FGFR2 D2/12425 Fab 복합체의 결정 구조를 사용하여 12425에 대한 FGFR2 에피토프를 확인하였다. 6 카피의 FGFR2 D2/12425 Fab 복합체가 비대칭 유닛의 결정에 존재한다 (비대칭 유닛은 전체 결정을 재생하는데 필요한 모든 구조 정보를 함유함). 모든 6 카피는 12425 Fab와의 접촉에서 거의 동일한 잔기를 공유하지만, 단 결정 패킹으로 인한 작은 변이가 있다. 모든 6 카피에 의해 공유되는 유일한 12425-접촉 FGFR2 잔기를 사용하여 에피토프를 정의하였다.
12425 Fab에 의한 FGFR2 D2 상의 상호작용 표면은 불연속적 (즉, 비연속적) 서열: 즉 표 23 및 24에 상세설명된 바와 같은 잔기 173 내지 176, 잔기 178, 잔기 208 내지 210, 및 잔기 212, 213, 217 및 219에 의해 형성된다. 이러한 잔기는 12425 Fab에 의해 결합되는 3차원 표면을 형성한다 (도 20 (a)). 결정학에 의해 정의된 이러한 에피토프는 중수소 교환 질량 분광측정법 (HDx-MS)에 의해 정의된 것과 양호하게 일치하고, 이는 잔기 160-173, 174-189 및 198-216을 포함한다.
<표 23> 인간 FGFR2 D2 및 12425 Fab 중쇄 (H) 사이의 상호작용. FGFR2 잔기는 P21802-3 (서열 137)을 기준으로 하여 넘버링된다. Fab 중쇄 잔기는 그의 선형 아미노산 서열 (서열 139)을 기준으로 하여 넘버링된다. 나타낸 FGFR2 잔기는 잠재적 물 매개 상호작용을 설명하기 위해 12425 Fab에서 원자의 5 Å 내의 적어도 1개 분자를 갖는다.

<표 24> 인간 FGFR D2 및 12425 Fab 경쇄 (L) 사이의 상호작용. FGFR2 잔기는 P21802-3 (서열 137)을 기준으로 하여 넘버링된다. Fab 경쇄 잔기는 그의 선형 아미노산 서열 (서열 140)을 기준으로 하여 넘버링된다. 나타낸 FGFR2 잔기는 잠재적 물 매개 상호작용을 설명하기 위해 12425 Fab에서 원자의 5 Å 내의 적어도 1개 분자를 갖는다.

FGFR2 D2/12425 Fab 구조로부터, FGFR2 상의 잠재적 N-연결된 글리코실화 부위, 즉 Asn241 및 Asn288 (문헌 [Duchesne et al., (2006) J. Biol. Chem 281:27178-27189])는 12425 에피토프로부터 떨어진 단백질의 반대 표면 상에 있고 (도 20 (a)), 이는 FGFR2에 결합하는 12425가 글리코실화에 독립적임을 나타낸다. 이는 12425 항체가 이. 콜라이-생산 (글리코실화 없음) 및 포유동물 세포-생산 (글리코실화) FGFR2 D2-D3에 유사한 친화도로 결합한다는 발견과 일치한다 (데이터는 나타내지 않음).
FGFR2 D2의 Lys176 및 Arg210은 각각 12425 Fab 경쇄 및 중쇄와 대부분 접촉하는 2개의 에피토프 잔기이다. 흥미롭게도, Arg210은 헤파린에 결합하는 것으로 입증되었으며 (문헌 [Pellegrini et al., (2000) Nature 407:1029-1034]), 이는 FGF에 대한 FGFR2 결합 및 후속 이량체화 및 신호전달을 증진시킬 수 있다. 한편, Lys176은 또한 헤파린 결합 포켓에 있는 것으로 가정된다 (문헌 [Pellegrini et al., (2000) Nature 407:1029-1034]). 이들 2개 잔기의 알라닌으로의 돌연변이는 SPR 검정 (SPR 방법에 대해 상기 참조)에서 FGFR2의 12425 IgG에 대한 결합을 완전히 파기하며, 이는 12425 결합에서의 중요한 역할을 확인하였고, 결정 구조에서 관찰된 에피토프를 유효화하였다.
12425에 대한 FGFR4 에피토프
FGFR4 D2/12425 Fab 복합체의 결정 구조를 사용하여 12425에 대한 FGFR4 에피토프를 확인하였다. 4 카피의 FGFR4 D2/12425 Fab 복합체가 결정의 비대칭 유닛에 존재하였다. 모든 4 카피는 12425 Fab와의 접촉에서 거의 동일한 잔기를 공유하지만, 단 결정 패킹으로 인한 작은 변이가 있다. 모든 4 카피에 의해 공유되는 유일한 12425-접촉 FGFR4 잔기를 사용하여 에피토프를 정의하였다.
12425 Fab에 의한 FGFR4 D2 상의 상호작용 표면은 불연속적 (즉, 비연속적) 서열: 즉 표 25에 상세설명된 바와 같은 잔기 150-151, 154, 157, 160, 166-169, 171, 173-174, 201-207, 210 및 212에 의해 형성된다. 이러한 잔기는 12425 Fab에 의해 결합되는 3차원 표면을 형성한다 (도 20 (b)).
<표 25> 인간 FGFR4 D2 및 12425 Fab 중쇄 (H) 및 경쇄 (L) 사이의 상호작용. FGFR4 잔기는 P22455-1 (서열 142)을 기준으로 하여 넘버링된다. Fab 잔기는 그의 선형 아미노산 서열 (서열 139 및 140)을 기준으로 하여 넘버링된다. 나타낸 FGFR4 잔기는 잠재적 물 매개 상호작용을 설명하기 위해 12425 Fab에서 원자의 5 Å 내의 적어도 1개 분자를 갖는다.


FGFR2 및 FGFR4 상의 12425 에피토프의 비교
FGFR2 및 FGFR4 상의 12425 에피토프는 서열 및 입체형태 둘 다에 있어 매우 유사하다. 서열 정렬에 나타낸 바와 같이 (도 20 (c)), FGFR2 상의 모든 에피토프 잔기 (점선 박스 내)는 FGFR4에 의해 공유되고 보존된다. 또한, 2개의 복합체 구조가 12425의 가변 도메인 상에 중첩되는 경우에, 2개 항원의 구조는 매우 잘 겹치고, 이는 FGFR2 및 FGFR4에 결합하는 12425의 입체형태가 매우 유사함을 나타낸다. 이는 수용체 둘 다에 대한 12425의 교차-반응성에 대한 구조적 설명을 제공한다.
12425 결합 및 FGFR 이량체화
2종의 모델, 즉 2:2:2 모델 (FGFR:FGF:헤파린)(문헌 [Schlessinger et al., (2000) Mol. Cell 6:743-750]) 및 2:2:1 모델 (FGFR:FGF:헤파린)(문헌 [Pellegrini et al., (2000) Nature 407:1029-1034])은 FGFR-FGF-헤파린 복합체가 세포 표면 상에 이량체화되어 하류 신호전달을 활성화시키는 방법에 대해 보고되었다. FGFR2 D2/12425 Fab 복합체의 결정 구조를 기준으로 하여, 12425의 FGFR2 및/또는 FGFR4에 대한 결합은 이량체화 모델 둘 다와 충돌하고 따라서 이들을 차단할 수 있다.
실시예 24. 제제
ADC의 임상 서비스 형태 (CSF)는 50 mg 12425-MCC-DM1, 16.2 mg 숙신산나트륨, 410.8 mg 수크로스 및 1 mg 폴리소르베이트 20 (표준 함량의 철회에 대해 허용되는 10 % 과다충전을 고려하지 않음)를 함유한 바이알 내 동결건조물이다. 5 mL 주사용수를 사용한 동결건조물의 재구성 후에, 10 mg/mL 12425-MCC-DM1, 20 mM 숙신산나트륨, 240 mM 수크로스 및 0.02 % 폴리소르페이트 20 (pH 5.0)을 함유한 용액을 획득한다.
후속 정맥내 투여를 위해, 획득된 용액은 보통, 주입을 위한 즉시-사용 ADC 용액으로 담체 용액 내로 추가로 희석할 것이다.
CSF를 위해, 10 mg/ml의 ADC 농도는 예비 안정성 시험을 기준으로 하여 선택되었다. 240 mM의 수크로스 농도는, 등장성 제제를 만들고 무정형 동결건조물 케이크 구조를 유지하고 단백질 안정화를 제공하기 위해 선택되었다.
가장 안정한 제제를 선택하기 위한 중요한 안정성-표시 분석 방법은 특히 크기-배제 크로마토그래피를 포괄하여 응집 수준, 가시영역미만 미립자 물질 시험, 유리 독소 결정 및 효력 시험을 결정하였다.
사전-스크리닝 연구는 농도 0.02 %의 폴리소르페이트 20가 기계적 스트레스에 대해 충분한 안정화를 제공하는 것을 나타내었다. 실시간 및 가속화 안정성 조건 (25℃ 및 40℃)에서의 액체 및 동결건조 안정성 연구는 숙시네이트 pH 5.0 제제가 총괄적으로 최선의 저장 안정성을 제공한다는 것을 입증하였다. 가장 두드러지게는 이 제제에서 유리 독소의 응집 및 방출 사이의 모든 시험된 제제의 최선의 균형이 충족될 수 있다. 40℃에서 3개월 후에 분해 산물에서의 주목할만한 상승이 결정되지 않을 수 있다.
실시예 25. 종양 내성 메카니즘 및 조합 요법의 사용
기존의 이종성은 다양한 암의 공통 특징이다. 임상적으로 유의한 종양 (및 이들로부터 유래된 세포주)은 이들의 초기 종양원성 사건으로부터 많은 세대가 지난 것이다. 이들은 유전학적으로 다양한 하위-집단을 획득하기에 충분한 시간을 가지며 (문헌 [Nowell, Science 194: 23-28 (1976)]), 이는 생존을 위한 공통 유전 구동인자 병변에 반드시 의존적이지는 않을 것이다. 이러한 하위-집단이 각 환자에서 단일 클론 종양을 치료하는 것보다 연속적인 세대에 따라 수반되기에 충분히 적합한 경우에, 본 발명자들은 실제로 복합 집단을 치료하고 있다. 따라서, 종양유전자 또는 종양 억제자의 상이한 증폭을 갖는 클론 집단의 존재는 단일 요법에 대한 감수성 또는 내성을 설명하고, 표적화된 조합 요법을 필요로 할 수 있다.
FGFR2 발현은 FGFR2 증폭된 SNU 16 세포에서 및 FGFR2 증폭된 인간 종양에서 이종성임
FGFR2 발현은 SNU16 세포에서 면역조직화학 (IHC), 유동 세포측정법 및/또는 형광 계내 혼성화에 의해, 관련 기술분야에 공지되고 본원에 기재된 방법을 사용하여 측정하였다. 모 SNU 16 파라핀 포매 세포 펠릿의 IHC 염색은 FGFR2 염색 강도의 범위를 드러냈다. 또한, 배양물 중 번식된 SNU 16 세포 상의 FGFR2 표면 발현은 또한 유동 세포측정법에 의해 측정된 바와 같이 FGFR2에 대한 발현 값 범위를 보여주었다. 흥미롭게도, 세포 집단이 EGFR에 대해 동시염색된 경우에, EGFR 양성 세포의 하위-집단이 존재하는 것으로 나타났다. 집단이 qPCR에 의해 검사되는 경우에, 저수준의 발현 가능성으로 인해 EGFR 증폭이 치료 전 집단에서 검출될 수 없었지만, 산란된 EGFR 증폭된 세포 (<5%)는 또한 예비처리 세포 차단 제제에서 FISH에 의해 분명해졌다.
296개의 인간 위 종양 샘플을 qPCR에 의해 평가하였고, 7개 (2.4%)는 FGFR2 카피수가 증가된 것으로 밝혀졌다 (예를 들어, 유전자 카피수 대략 4). 최고 FGFR2 카피수를 나타내는 각 샘플을 갖는 세트로부터의 9개 샘플에 대한 IHC 염색은 FGFR2 발현에 대해 양성인 종양 영역 및 음성인 영역을 가졌다. 면역반응성은 임의의 특이적 종양 형태학과 상관관계가 없었다. 종양 샘플을 연속 절편 상의 마스크로서 FGFR2 면역반응성을 사용하여 미세-절제하는 경우에, 이들 FGFR2 양성 및 음성 영역으로부터의 DNA는 모든 9가지 경우에 각각 FGFR2 유전자 증폭 또는 비-증폭과 상관관계가 있었다. FGFR2의 과다발현 및 증폭의 상관관계는 하기 기재된 바와 같이 집중 서열분석에 의해 확인되었다.
EGFR은 BGJ398에 대해 내성인 SNU 16 세포에서 과다발현 및 증폭되고, FGFR2 발현 및 증폭은 손실됨
SNU 16 세포 (ACCT CRL-5974)를 0.5 μM의 BGJ398 함유 RPMI-1640 배지 + 10% FBS (ATCC 카탈로그 # 30-2001) 중에서, 이어서 BGJ398 농도를 0.5 μM에서 1.0 μM에서 2.5 μM에서 5.0 μM로 증가시키면서 배양하였다. 배지를 변경하고, 신선한 BGJ398 (5μM)을 6주 동안 주당 1회 첨가하였다. 세포를 회수용 세포 배양물 동결 배지 (깁코® #12648-101) 중에서 동결시키고, RPMI-1640+10% FBS 중에 재구성하였다. 내성 세포주의 해동 계대 배양은 후속적으로 1μM BGJ398 선택 하에 유지하였다. BGJ398로의 선택 하에 배양물 중 유지된 SNU 16 세포는 IC50을 1.7 nM에서 2.4 μM (각각 감수성에서 내성 세포)로 증가시키면서 성장 억제에 대해 점차 덜 민감해졌다.
BGJ398 내성 SNU 16 세포의 웨스턴 블롯 분석은, 내성 세포 집단이 FGFR2의 발현을 손실하였고 p-FRS2를 통해 더 이상 신호전달되지 않음을 보여주며, 이는 FGFR2 신호전달 경로가 더 이상 활성이 아님을 나타낸다. 내성 집단은 높은 수준의 EGFR 및 pEGFR을 대신 발현하였고, 이는 세포가 EGFR 경로를 통해 대신 신호전달되었음을 나타낸다. BGJ398 내성 SNU 16 세포는 또한 qPCR에 의해 측정 시에 EGFR DNA 카피수에서의 증가를 나타내고, 이는 사전처리된 SNU16 세포와 비교하여 단백질 발현에서의 증가와 상관관계가 있다. BGJ398 내성 세포는 계속 성장하지만, 모 SNU 16 세포에 대한 36시간에 비해 125시간의 배가 시간으로 모 (미처리) 세포주보다 더 느린 성장 속도로 계속 성장하였다.
SNU 16 세포에서 BGJ398 내성의 개시는 EGFR 억제제 게피티닙에 대한 후천성 감수성을 결과로 한다 (도 21). SNU 16 모 및 BGJ398 내성 세포에 대해 수행된 세포 성장 검정은 게피티닙 IC50을 각각 > 10 uM에서 16.7 nM로의 이동을 나타냈으며, 이는 FGFR2에서 EGFR로 종양유전자 의존성의 스위칭을 확인한다.
본 발명자들은 형질전환 종양유전자인 FGFR2가 증폭된 세포주가 제2 종양유전자인 EGFR이 증폭되고 이에 의존적인 기존의 세포를 함유한다는 것을 제시한다. FGFR2 증폭된 세포주 SNU 16이 FGFR 키나제 억제제에 의한 압박 하에 놓인 경우에, 한 집단은 제거되고, 하위-집단은 우세해졌으며; 본 발명자들은 이종 종양이 선택적 압박, 예컨대 표적화된 요법 하에 놓인 경우에, 하위-집단의 성장이 임상 내성에 대해 유리해지고 이를 유도할 수 있다는 것을 예측한다.
집중 서열분석이 인간 위암 시편에서 기존의 추가 종양원성 병변을 밝힘
FGFR2 과다발현 종양 영역 및 FGFR2 과다발현이 없는 종양 영역으로부터 취한 한쌍의 종양 샘플의 미세절개된 영역의 집중 서열분석은 FGFR2 증폭과의 상관관계를 보여주었다. FGFR2 과다발현이 있는 모든 종양 영역은 카피수에서의 FGFR2 증폭 (예를 들어: 카피수 6 -16)을 나타내었지만, FGFR2 과다발현이 없는 종양 영역은 FGFR2 카피수 증폭을 나타내지 않았다. 상기 기재된 SNU 16에서의 발견과 일치하게, 한 종양은 비-FGFR2 증폭된 영역에서만 EGFR 증폭을 나타내었다. EGFR 증폭은 이 시편에서 kras 증폭과 동시-발생하였다. 이러한 관찰은 kras 증폭이 항-EGFR 요법으로 치료된 암에서의 내성 메카니즘을 시사한다는 이전 보고와 일치한다 (문헌 [Valtorta, et al., IJC (2013) 133:1259-1266; Misale, et al., Nature (2012) 486:532-538]).
다른 종양은 대체 수용체 티로신 키나제의 증폭을 나타내었다. 예를 들어, 하나의 종양 쌍은 FGFR2 증폭된 및 FGFR2 비-증폭된 영역 둘 다에서 증폭된 Her2를 가졌고, 반면 추가의 종양은 비-FGFR2 증폭된 영역에서만 확인된 IGF1R 증폭을 가졌다. 모든 종양에서 모든 영역은 p53에 돌연변이를 갖는 것으로 나타났다. 몇몇 추가의 돌연변이가 확인되었지만, 샘플 세트 전체에서 일치하게 발견되는 것은 아니었다. 초기 비-만연성 수용체 티로신 키나제가 증폭된 이들 소형의 기존 집단은 선택적 압박, 예컨대 표적화된 요법 (예를 들어: 항-FGFR2 요법)이 적용되는 경우에 내성 세포의 공급원이 될 수 있다.
본 발명자들은 또한, FGFR2 증폭을 갖는 원발성 인간 종양이 다른 티로신 키나제의 증폭을 갖는 하위-집단을 함유하고, 이 하위-집단 증폭이 때때로 FGFR2 증폭이 없는 종양 영역에서 발생함을 입증하였다. 다른 연구 (문헌 [Snuderl, et al. (2011) Cancer Cell 20: 810-817])를 연상하면, 모든 종양 영역이 또한 공통 돌연변이, 이 경우에 p53에서의 돌연변이를 함유하였고, 이는 전체적으로 종양에 대한 공통 조상을 시사한다.
Her2 발현 종양에서 내성 메카니즘으로서의 FGFR2
FGFR2의 증폭은 라파티닙으로의 치료 후 유방 암 세포에서의 내성 메카니즘으로서 제안되었으며 (문헌 [Azuma, et al. (2011) Biochem Biophys Res Comm, 407:219-224]), FGFR2 발현은 라파티닙에 대해 불량한 반응을 갖는 유방 암 환자에서 과다발현되는 것으로 보였다. 본 발명자들은 인간 Her2 증폭된 위 종양 샘플이 FGFR2 증폭된 세포의 기존 하위집단을 갖는다는 것을 집중 서열분석에 의해 입증하였다 (문헌 [Deeds et al.,. United States and Canadian Academy of Pathology, March 2014: Abstract no: 453290]). 이는 FGFR2 증폭이 항-Her2 요법 후 다른 Her2 증폭된 종양에서의 내성 메카니즘을 나타냄을 시사한다. 따라서, FGFR2 요법, 예를 들어 본원에 기재된 FGFR2 항체 및 ADC와 조합된 Her2 요법의 치료는 Her2 발현 및/또는 Her2 내성 암의 치료에 유용할 것이다.
이러한 데이터는 FGFR2 요법, 예를 들어 본원에 기재된 FGFR2 ADC가 암 치료를 위한 다른 티로신 키나제 억제제와의 조합에 유용할 수 있음을 시사한다. 또한, 본원에 기재된 FGFR2 ADC는 다른 암 요법, 예컨대 다른 티로신 키나제 억제제 (예를 들어: Her2 억제제, Her3 억제제, EGFR 억제제, Met 억제제 및 IGFR 억제제)에 대해 내성인 환자 집단의 치료에 유용할 수 있다.
본원에 기재된 실시예 및 실시양태는 단지 예시적 목적을 위한 것이며, 이에 비추어 다양한 변형 또는 변화가 통상의 기술자에게 제안될 것이고, 본원의 취지 및 범위, 및 첨부된 특허청구범위의 범주 내에 포함되어야 하는 것으로 이해된다.
SEQUENCE LISTING
<110> NOVARTIS AG
<120> ANTIBODY DRUG CONJUGATES
<130> PAT055642-WO-PCT
<140> PCT/US2014/025944
<141> 2014-03-13
<150> 61/780,299
<151> 2013-03-13
<160> 150
<170> PatentIn version 3.5
<210> 1
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 1
Asp Tyr Ala Met Ser
1 5
<210> 2
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 2
Val Ile Glu Gly Asp Gly Ser Tyr Thr His Tyr Ala Asp Ser Val Lys
1 5 10 15
Gly
<210> 3
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 3
Glu Lys Thr Tyr Ser Ser Ala Phe Asp Tyr
1 5 10
<210> 4
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 4
Gly Phe Thr Phe Ser Asp Tyr
1 5
<210> 5
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 5
Glu Gly Asp Gly Ser Tyr
1 5
<210> 6
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 6
Glu Lys Thr Tyr Ser Ser Ala Phe Asp Tyr
1 5 10
<210> 7
<211> 119
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 7
Gln Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Asp Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Val Ile Glu Gly Asp Gly Ser Tyr Thr His Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Glu Lys Thr Tyr Ser Ser Ala Phe Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 8
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 8
caggtgcagc tgctggaatc aggcggcgga ctggtgcagc ctggcggtag cctgagactg 60
agctgtgccg cctccggctt cacctttagc gactacgcta tgagctgggt ccgacaggcc 120
cctggcaagg gactggaatg ggtgtcagtg atcgagggcg acggtagcta cactcactac 180
gccgatagcg tgaagggccg gttcactatc tctagggaca actctaagaa caccctgtac 240
ctgcagatga actcactgag agccgaggac accgccgtct actactgcgc tagagaaaag 300
acctactcta gcgccttcga ctactggggc cagggcaccc tggtcaccgt gtcatca 357
<210> 9
<211> 449
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 9
Gln Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Asp Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Val Ile Glu Gly Asp Gly Ser Tyr Thr His Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Glu Lys Thr Tyr Ser Ser Ala Phe Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe
115 120 125
Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu
130 135 140
Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp
145 150 155 160
Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu
165 170 175
Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser
180 185 190
Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro
195 200 205
Ser Asn Thr Lys Val Asp Lys Arg Val Glu Pro Lys Ser Cys Asp Lys
210 215 220
Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro
225 230 235 240
Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser
245 250 255
Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp
260 265 270
Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn
275 280 285
Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val
290 295 300
Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu
305 310 315 320
Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys
325 330 335
Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr
340 345 350
Leu Pro Pro Ser Arg Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr
355 360 365
Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu
370 375 380
Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu
385 390 395 400
Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys
405 410 415
Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu
420 425 430
Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly
435 440 445
Lys
<210> 10
<211> 1347
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 10
caggtgcagc tgctggaatc aggcggcgga ctggtgcagc ctggcggtag cctgagactg 60
agctgtgccg cctccggctt cacctttagc gactacgcta tgagctgggt ccgacaggcc 120
cctggcaagg gactggaatg ggtgtcagtg atcgagggcg acggtagcta cactcactac 180
gccgatagcg tgaagggccg gttcactatc tctagggaca actctaagaa caccctgtac 240
ctgcagatga actcactgag agccgaggac accgccgtct actactgcgc tagagaaaag 300
acctactcta gcgccttcga ctactggggc cagggcaccc tggtcaccgt gtcatcagct 360
agcactaagg gcccaagtgt gtttcccctg gcccccagca gcaagtctac ttccggcgga 420
actgctgccc tgggttgcct ggtgaaggac tacttccccg agcccgtgac agtgtcctgg 480
aactctgggg ctctgacttc cggcgtgcac accttccccg ccgtgctgca gagcagcggc 540
ctgtacagcc tgagcagcgt ggtgacagtg ccctccagct ctctgggaac ccagacctat 600
atctgcaacg tgaaccacaa gcccagcaac accaaggtgg acaagagagt ggagcccaag 660
agctgcgaca agacccacac ctgccccccc tgcccagctc cagaactgct gggagggcct 720
tccgtgttcc tgttcccccc caagcccaag gacaccctga tgatcagcag gacccccgag 780
gtgacctgcg tggtggtgga cgtgtcccac gaggacccag aggtgaagtt caactggtac 840
gtggacggcg tggaggtgca caacgccaag accaagccca gagaggagca gtacaacagc 900
acctacaggg tggtgtccgt gctgaccgtg ctgcaccagg actggctgaa cggcaaagaa 960
tacaagtgca aagtctccaa caaggccctg ccagccccaa tcgaaaagac aatcagcaag 1020
gccaagggcc agccacggga gccccaggtg tacaccctgc cccccagccg ggaggagatg 1080
accaagaacc aggtgtccct gacctgtctg gtgaagggct tctaccccag cgatatcgcc 1140
gtggagtggg agagcaacgg ccagcccgag aacaactaca agaccacccc cccagtgctg 1200
gacagcgacg gcagcttctt cctgtacagc aagctgaccg tggacaagtc caggtggcag 1260
cagggcaacg tgttcagctg cagcgtgatg cacgaggccc tgcacaacca ctacacccag 1320
aagtccctga gcctgagccc cggcaag 1347
<210> 11
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 11
Arg Ala Ser Gln Asp Ile Ser Ser Asp Leu Asn
1 5 10
<210> 12
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 12
Asp Ala Ser Asn Leu Gln Ser
1 5
<210> 13
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 13
Gln Gln His Tyr Ser Pro Ser His Thr
1 5
<210> 14
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 14
Ser Gln Asp Ile Ser Ser Asp
1 5
<210> 15
<211> 3
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 15
Asp Ala Ser
1
<210> 16
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 16
His Tyr Ser Pro Ser His
1 5
<210> 17
<211> 107
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 17
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Asp Ile Ser Ser Asp
20 25 30
Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Asp Ala Ser Asn Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln His Tyr Ser Pro Ser His
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys
100 105
<210> 18
<211> 321
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 18
gatattcaga tgactcagtc acctagtagc ctgagcgcct cagtgggcga tagagtgact 60
atcacctgta gagcctctca ggacatctct agcgacctga actggtatca gcagaagccc 120
ggcaaggccc ctaagctgct gatctacgac gcctctaacc tgcagagcgg cgtgccctct 180
aggtttagcg gtagcggctc aggcaccgac tttaccctga ctatctctag cctgcagccc 240
gaggacttcg ccgtctacta ctgtcagcag cactatagcc ctagtcacac cttcggccag 300
ggcactaagg tcgagattaa g 321
<210> 19
<211> 214
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 19
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Asp Ile Ser Ser Asp
20 25 30
Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Asp Ala Ser Asn Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln His Tyr Ser Pro Ser His
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 20
<211> 642
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 20
gatattcaga tgactcagtc acctagtagc ctgagcgcct cagtgggcga tagagtgact 60
atcacctgta gagcctctca ggacatctct agcgacctga actggtatca gcagaagccc 120
ggcaaggccc ctaagctgct gatctacgac gcctctaacc tgcagagcgg cgtgccctct 180
aggtttagcg gtagcggctc aggcaccgac tttaccctga ctatctctag cctgcagccc 240
gaggacttcg ccgtctacta ctgtcagcag cactatagcc ctagtcacac cttcggccag 300
ggcactaagg tcgagattaa gcgtacggtg gccgctccca gcgtgttcat cttccccccc 360
agcgacgagc agctgaagag cggcaccgcc agcgtggtgt gcctgctgaa caacttctac 420
ccccgggagg ccaaggtgca gtggaaggtg gacaacgccc tgcagagcgg caacagccag 480
gagagcgtca ccgagcagga cagcaaggac tccacctaca gcctgagcag caccctgacc 540
ctgagcaagg ccgactacga gaagcataag gtgtacgcct gcgaggtgac ccaccagggc 600
ctgtccagcc ccgtgaccaa gagcttcaac aggggcgagt gc 642
<210> 21
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 21
Ser Tyr Ala Ile Ser
1 5
<210> 22
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 22
Tyr Ile Ser Pro Tyr Met Gly Glu Thr His Tyr Ala Gln Arg Phe Gln
1 5 10 15
Gly
<210> 23
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 23
Glu Ser Tyr Glu Tyr Phe Asp Ile
1 5
<210> 24
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 24
Gly Gly Thr Phe Ser Ser Tyr
1 5
<210> 25
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 25
Ser Pro Tyr Met Gly Glu
1 5
<210> 26
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 26
Glu Ser Tyr Glu Tyr Phe Asp Ile
1 5
<210> 27
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 27
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ser
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Gly Thr Phe Ser Ser Tyr
20 25 30
Ala Ile Ser Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Tyr Ile Ser Pro Tyr Met Gly Glu Thr His Tyr Ala Gln Arg Phe
50 55 60
Gln Gly Arg Val Thr Ile Thr Ala Asp Glu Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Glu Ser Tyr Glu Tyr Phe Asp Ile Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 28
<211> 351
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 28
caggtgcagc tggtgcagtc aggcgccgaa gtgaagaaac ccggctctag cgtgaaggtg 60
tcctgtaaag cctccggcgg caccttctct agctacgcta ttagctgggt ccgacaggcc 120
ccaggacagg gcctggaatg gatgggctat attagcccct atatgggcga gactcactac 180
gctcagcggt ttcagggtag agtgactatc accgccgacg agtctactag caccgcctat 240
atggaactgt ctagcctgag atcagaggac accgccgtct actactgcgc tagagagtcc 300
tacgagtact tcgatatctg gggccagggc accctggtca ccgtgtcatc a 351
<210> 29
<211> 447
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 29
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ser
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Gly Thr Phe Ser Ser Tyr
20 25 30
Ala Ile Ser Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Tyr Ile Ser Pro Tyr Met Gly Glu Thr His Tyr Ala Gln Arg Phe
50 55 60
Gln Gly Arg Val Thr Ile Thr Ala Asp Glu Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Glu Ser Tyr Glu Tyr Phe Asp Ile Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu
115 120 125
Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys
130 135 140
Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser
145 150 155 160
Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser
165 170 175
Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser
180 185 190
Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn
195 200 205
Thr Lys Val Asp Lys Arg Val Glu Pro Lys Ser Cys Asp Lys Thr His
210 215 220
Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val
225 230 235 240
Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr
245 250 255
Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu
260 265 270
Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys
275 280 285
Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser
290 295 300
Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys
305 310 315 320
Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile
325 330 335
Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro
340 345 350
Pro Ser Arg Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu
355 360 365
Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn
370 375 380
Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser
385 390 395 400
Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg
405 410 415
Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu
420 425 430
His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
435 440 445
<210> 30
<211> 1341
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 30
caggtgcagc tggtgcagtc aggcgccgaa gtgaagaaac ccggctctag cgtgaaggtg 60
tcctgtaaag cctccggcgg caccttctct agctacgcta ttagctgggt ccgacaggcc 120
ccaggacagg gcctggaatg gatgggctat attagcccct atatgggcga gactcactac 180
gctcagcggt ttcagggtag agtgactatc accgccgacg agtctactag caccgcctat 240
atggaactgt ctagcctgag atcagaggac accgccgtct actactgcgc tagagagtcc 300
tacgagtact tcgatatctg gggccagggc accctggtca ccgtgtcatc agctagcact 360
aagggcccaa gtgtgtttcc cctggccccc agcagcaagt ctacttccgg cggaactgct 420
gccctgggtt gcctggtgaa ggactacttc cccgagcccg tgacagtgtc ctggaactct 480
ggggctctga cttccggcgt gcacaccttc cccgccgtgc tgcagagcag cggcctgtac 540
agcctgagca gcgtggtgac agtgccctcc agctctctgg gaacccagac ctatatctgc 600
aacgtgaacc acaagcccag caacaccaag gtggacaaga gagtggagcc caagagctgc 660
gacaagaccc acacctgccc cccctgccca gctccagaac tgctgggagg gccttccgtg 720
ttcctgttcc cccccaagcc caaggacacc ctgatgatca gcaggacccc cgaggtgacc 780
tgcgtggtgg tggacgtgtc ccacgaggac ccagaggtga agttcaactg gtacgtggac 840
ggcgtggagg tgcacaacgc caagaccaag cccagagagg agcagtacaa cagcacctac 900
agggtggtgt ccgtgctgac cgtgctgcac caggactggc tgaacggcaa agaatacaag 960
tgcaaagtct ccaacaaggc cctgccagcc ccaatcgaaa agacaatcag caaggccaag 1020
ggccagccac gggagcccca ggtgtacacc ctgcccccca gccgggagga gatgaccaag 1080
aaccaggtgt ccctgacctg tctggtgaag ggcttctacc ccagcgatat cgccgtggag 1140
tgggagagca acggccagcc cgagaacaac tacaagacca cccccccagt gctggacagc 1200
gacggcagct tcttcctgta cagcaagctg accgtggaca agtccaggtg gcagcagggc 1260
aacgtgttca gctgcagcgt gatgcacgag gccctgcaca accactacac ccagaagtcc 1320
ctgagcctga gccccggcaa g 1341
<210> 31
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 31
Arg Ala Ser Gln Ser Ile Ser Asn Asp Leu Ala
1 5 10
<210> 32
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 32
Ala Thr Ser Ile Leu Gln Ser
1 5
<210> 33
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 33
Leu Gln Tyr Tyr Asp Tyr Ser Tyr Thr
1 5
<210> 34
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 34
Ser Gln Ser Ile Ser Asn Asp
1 5
<210> 35
<211> 3
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 35
Ala Thr Ser
1
<210> 36
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 36
Tyr Tyr Asp Tyr Ser Tyr
1 5
<210> 37
<211> 107
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 37
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Ser Ile Ser Asn Asp
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Ala Thr Ser Ile Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln Tyr Tyr Asp Tyr Ser Tyr
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys
100 105
<210> 38
<211> 321
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 38
gatattcaga tgactcagtc acctagtagc ctgagcgcct cagtgggcga tagagtgact 60
atcacctgta gagcctccca gtctatctct aacgacctgg cctggtatca gcagaagccc 120
ggcaaggccc ctaagctgct gatctacgct acctctatcc tgcagagcgg cgtgccctct 180
aggtttagcg gtagcggctc aggcaccgac tttaccctga ctatctctag cctgcagccc 240
gaggacttcg ctacctacta ctgcctgcag tactacgact actcctacac cttcggccag 300
ggcactaagg tcgagattaa g 321
<210> 39
<211> 214
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 39
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Ser Ile Ser Asn Asp
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Ala Thr Ser Ile Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln Tyr Tyr Asp Tyr Ser Tyr
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 40
<211> 642
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 40
gatattcaga tgactcagtc acctagtagc ctgagcgcct cagtgggcga tagagtgact 60
atcacctgta gagcctccca gtctatctct aacgacctgg cctggtatca gcagaagccc 120
ggcaaggccc ctaagctgct gatctacgct acctctatcc tgcagagcgg cgtgccctct 180
aggtttagcg gtagcggctc aggcaccgac tttaccctga ctatctctag cctgcagccc 240
gaggacttcg ctacctacta ctgcctgcag tactacgact actcctacac cttcggccag 300
ggcactaagg tcgagattaa gcgtacggtg gccgctccca gcgtgttcat cttccccccc 360
agcgacgagc agctgaagag cggcaccgcc agcgtggtgt gcctgctgaa caacttctac 420
ccccgggagg ccaaggtgca gtggaaggtg gacaacgccc tgcagagcgg caacagccag 480
gagagcgtca ccgagcagga cagcaaggac tccacctaca gcctgagcag caccctgacc 540
ctgagcaagg ccgactacga gaagcataag gtgtacgcct gcgaggtgac ccaccagggc 600
ctgtccagcc ccgtgaccaa gagcttcaac aggggcgagt gc 642
<210> 41
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 41
Asp Tyr Ala Met Ser
1 5
<210> 42
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 42
Val Ile Glu Gly Asp Ala Ser Tyr Thr His Tyr Ala Asp Ser Val Arg
1 5 10 15
Gly
<210> 43
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 43
Glu Arg Thr Tyr Ser Ser Ala Phe Asp Tyr
1 5 10
<210> 44
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 44
Gly Phe Thr Phe Ser Asp Tyr
1 5
<210> 45
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 45
Glu Gly Asp Ala Ser Tyr
1 5
<210> 46
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 46
Glu Arg Thr Tyr Ser Ser Ala Phe Asp Tyr
1 5 10
<210> 47
<211> 119
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 47
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Asp Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Val Ile Glu Gly Asp Ala Ser Tyr Thr His Tyr Ala Asp Ser Val
50 55 60
Arg Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Glu Arg Thr Tyr Ser Ser Ala Phe Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 48
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 48
gaggtgcagc tgctggaatc aggcggcgga ctggtgcagc ctggcggtag cctgagactg 60
agctgcgctg ctagtggctt cacctttagc gactacgcta tgagctgggt cagacaggcc 120
cctggtaaag gcctggagtg ggtcagcgtg atcgagggcg acgctagtta cactcactac 180
gccgatagcg tcagaggccg gttcactatc tctagggata actctaagaa caccctgtac 240
ctgcagatga atagcctgag agccgaggac accgccgtct actactgcgc tagagagcgg 300
acctactcta gcgccttcga ctactggggt cagggcaccc tggtcaccgt gtctagc 357
<210> 49
<211> 449
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 49
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Asp Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Val Ile Glu Gly Asp Ala Ser Tyr Thr His Tyr Ala Asp Ser Val
50 55 60
Arg Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Glu Arg Thr Tyr Ser Ser Ala Phe Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe
115 120 125
Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu
130 135 140
Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp
145 150 155 160
Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu
165 170 175
Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser
180 185 190
Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro
195 200 205
Ser Asn Thr Lys Val Asp Lys Arg Val Glu Pro Lys Ser Cys Asp Lys
210 215 220
Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro
225 230 235 240
Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser
245 250 255
Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp
260 265 270
Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn
275 280 285
Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val
290 295 300
Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu
305 310 315 320
Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys
325 330 335
Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr
340 345 350
Leu Pro Pro Ser Arg Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr
355 360 365
Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu
370 375 380
Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu
385 390 395 400
Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys
405 410 415
Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu
420 425 430
Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly
435 440 445
Lys
<210> 50
<211> 1347
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 50
gaggtgcagc tgctggaatc aggcggcgga ctggtgcagc ctggcggtag cctgagactg 60
agctgcgctg ctagtggctt cacctttagc gactacgcta tgagctgggt cagacaggcc 120
cctggtaaag gcctggagtg ggtcagcgtg atcgagggcg acgctagtta cactcactac 180
gccgatagcg tcagaggccg gttcactatc tctagggata actctaagaa caccctgtac 240
ctgcagatga atagcctgag agccgaggac accgccgtct actactgcgc tagagagcgg 300
acctactcta gcgccttcga ctactggggt cagggcaccc tggtcaccgt gtctagcgct 360
agcactaagg gcccaagtgt gtttcccctg gcccccagca gcaagtctac ttccggcgga 420
actgctgccc tgggttgcct ggtgaaggac tacttccccg agcccgtgac agtgtcctgg 480
aactctgggg ctctgacttc cggcgtgcac accttccccg ccgtgctgca gagcagcggc 540
ctgtacagcc tgagcagcgt ggtgacagtg ccctccagct ctctgggaac ccagacctat 600
atctgcaacg tgaaccacaa gcccagcaac accaaggtgg acaagagagt ggagcccaag 660
agctgcgaca agacccacac ctgccccccc tgcccagctc cagaactgct gggagggcct 720
tccgtgttcc tgttcccccc caagcccaag gacaccctga tgatcagcag gacccccgag 780
gtgacctgcg tggtggtgga cgtgtcccac gaggacccag aggtgaagtt caactggtac 840
gtggacggcg tggaggtgca caacgccaag accaagccca gagaggagca gtacaacagc 900
acctacaggg tggtgtccgt gctgaccgtg ctgcaccagg actggctgaa cggcaaagaa 960
tacaagtgca aagtctccaa caaggccctg ccagccccaa tcgaaaagac aatcagcaag 1020
gccaagggcc agccacggga gccccaggtg tacaccctgc cccccagccg ggaggagatg 1080
accaagaacc aggtgtccct gacctgtctg gtgaagggct tctaccccag cgatatcgcc 1140
gtggagtggg agagcaacgg ccagcccgag aacaactaca agaccacccc cccagtgctg 1200
gacagcgacg gcagcttctt cctgtacagc aagctgaccg tggacaagtc caggtggcag 1260
cagggcaacg tgttcagctg cagcgtgatg cacgaggccc tgcacaacca ctacacccag 1320
aagtccctga gcctgagccc cggcaag 1347
<210> 51
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 51
Arg Ala Ser Gln Asp Ile Ser Ser Asp Leu Asn
1 5 10
<210> 52
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 52
Asp Ala Ser Asn Leu Gln Ser
1 5
<210> 53
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 53
Gln Gln His Tyr Ser Pro Ser His Thr
1 5
<210> 54
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 54
Ser Gln Asp Ile Ser Ser Asp
1 5
<210> 55
<211> 3
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 55
Asp Ala Ser
1
<210> 56
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 56
His Tyr Ser Pro Ser His
1 5
<210> 57
<211> 107
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 57
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Asp Ile Ser Ser Asp
20 25 30
Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Asp Ala Ser Asn Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln His Tyr Ser Pro Ser His
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys
100 105
<210> 58
<211> 321
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 58
gatattcaga tgactcagtc acctagtagc ctgagcgcta gtgtgggcga tagagtgact 60
atcacctgta gagcctctca ggatatctct agcgacctga actggtatca gcagaagccc 120
ggtaaagccc ctaagctgct gatctacgac gcctctaacc tgcagtcagg cgtgccctct 180
aggtttagcg gtagcggtag tggcaccgac ttcaccctga ctatctctag cctgcagccc 240
gaggacttcg ctacctacta ctgtcagcag cactatagcc ctagtcacac cttcggtcag 300
ggcactaagg tcgagattaa g 321
<210> 59
<211> 214
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 59
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Asp Ile Ser Ser Asp
20 25 30
Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Asp Ala Ser Asn Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln His Tyr Ser Pro Ser His
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 60
<211> 642
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 60
gatattcaga tgactcagtc acctagtagc ctgagcgcta gtgtgggcga tagagtgact 60
atcacctgta gagcctctca ggatatctct agcgacctga actggtatca gcagaagccc 120
ggtaaagccc ctaagctgct gatctacgac gcctctaacc tgcagtcagg cgtgccctct 180
aggtttagcg gtagcggtag tggcaccgac ttcaccctga ctatctctag cctgcagccc 240
gaggacttcg ctacctacta ctgtcagcag cactatagcc ctagtcacac cttcggtcag 300
ggcactaagg tcgagattaa gcgtacggtg gccgctccca gcgtgttcat cttccccccc 360
agcgacgagc agctgaagag cggcaccgcc agcgtggtgt gcctgctgaa caacttctac 420
ccccgggagg ccaaggtgca gtggaaggtg gacaacgccc tgcagagcgg caacagccag 480
gagagcgtca ccgagcagga cagcaaggac tccacctaca gcctgagcag caccctgacc 540
ctgagcaagg ccgactacga gaagcataag gtgtacgcct gcgaggtgac ccaccagggc 600
ctgtccagcc ccgtgaccaa gagcttcaac aggggcgagt gc 642
<210> 61
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 61
Asp Tyr Ala Met Ser
1 5
<210> 62
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 62
Thr Ile Glu Gly Asp Ser Asn Tyr Ile Glu Tyr Ala Asp Ser Val Lys
1 5 10 15
Gly
<210> 63
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 63
Glu Arg Thr Tyr Ser Ser Ala Phe Asp Tyr
1 5 10
<210> 64
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 64
Gly Phe Thr Phe Ser Asp Tyr
1 5
<210> 65
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 65
Glu Gly Asp Ser Asn Tyr
1 5
<210> 66
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 66
Glu Arg Thr Tyr Ser Ser Ala Phe Asp Tyr
1 5 10
<210> 67
<211> 119
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 67
Gln Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Asp Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Thr Ile Glu Gly Asp Ser Asn Tyr Ile Glu Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Glu Arg Thr Tyr Ser Ser Ala Phe Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 68
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 68
caggtgcaat tgctggaaag cggcggtggc ctggtgcagc cgggtggcag cctgcgtctg 60
agctgcgcgg cgtccggatt caccttttct gactacgcta tgtcttgggt gcgccaggcc 120
ccgggcaaag gtctcgagtg ggtttccact atcgaaggtg acagcaacta catcgaatat 180
gcggatagcg tgaaaggccg ctttaccatc agccgcgata attcgaaaaa caccctgtat 240
ctgcaaatga acagcctgcg tgcggaagat acggccgtgt attattgcgc gcgtgaacgt 300
acttactctt ctgctttcga ttactggggc caaggcaccc tggtgactgt tagctca 357
<210> 69
<211> 449
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 69
Gln Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Asp Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Thr Ile Glu Gly Asp Ser Asn Tyr Ile Glu Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Glu Arg Thr Tyr Ser Ser Ala Phe Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe
115 120 125
Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu
130 135 140
Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp
145 150 155 160
Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu
165 170 175
Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser
180 185 190
Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro
195 200 205
Ser Asn Thr Lys Val Asp Lys Arg Val Glu Pro Lys Ser Cys Asp Lys
210 215 220
Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro
225 230 235 240
Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser
245 250 255
Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp
260 265 270
Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn
275 280 285
Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val
290 295 300
Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu
305 310 315 320
Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys
325 330 335
Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr
340 345 350
Leu Pro Pro Ser Arg Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr
355 360 365
Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu
370 375 380
Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu
385 390 395 400
Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys
405 410 415
Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu
420 425 430
Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly
435 440 445
Lys
<210> 70
<211> 1347
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 70
caggtgcaat tgctggaaag cggcggtggc ctggtgcagc cgggtggcag cctgcgtctg 60
agctgcgcgg cgtccggatt caccttttct gactacgcta tgtcttgggt gcgccaggcc 120
ccgggcaaag gtctcgagtg ggtttccact atcgaaggtg acagcaacta catcgaatat 180
gcggatagcg tgaaaggccg ctttaccatc agccgcgata attcgaaaaa caccctgtat 240
ctgcaaatga acagcctgcg tgcggaagat acggccgtgt attattgcgc gcgtgaacgt 300
acttactctt ctgctttcga ttactggggc caaggcaccc tggtgactgt tagctcagcc 360
tccaccaagg gtccatcggt cttccccctg gcaccctcct ccaagagcac ctctgggggc 420
acagcggccc tgggctgcct ggtcaaggac tacttccccg aaccggtgac ggtgtcgtgg 480
aactcaggcg ccctgaccag cggcgtgcac accttcccgg ctgtcctaca gtcctcagga 540
ctctactccc tcagcagcgt ggtgaccgtg ccctccagca gcttgggcac ccagacctac 600
atctgcaacg tgaatcacaa gcccagcaac accaaggtgg acaagagagt tgagcccaaa 660
tcttgtgaca aaactcacac atgcccaccg tgcccagcac ctgaactcct ggggggaccg 720
tcagtcttcc tcttcccccc aaaacccaag gacaccctca tgatctcccg gacccctgag 780
gtcacatgcg tggtggtgga cgtgagccac gaagaccctg aggtcaagtt caactggtac 840
gtggacggcg tggaggtgca taatgccaag acaaagccgc gggaggagca gtacaacagc 900
acgtaccggg tggtcagcgt cctcaccgtc ctgcaccagg actggctgaa tggcaaggag 960
tacaagtgca aggtctccaa caaagccctc ccagccccca tcgagaaaac catctccaaa 1020
gccaaagggc agccccgaga accacaggtg tacaccctgc ccccatcccg ggaggagatg 1080
accaagaacc aggtcagcct gacctgcctg gtcaaaggct tctatcccag cgacatcgcc 1140
gtggagtggg agagcaatgg gcagccggag aacaactaca agaccacgcc tcccgtgctg 1200
gactccgacg gctccttctt cctctacagc aagctcaccg tggacaagag caggtggcag 1260
caggggaacg tcttctcatg ctccgtgatg catgaggctc tgcacaacca ctacacgcag 1320
aagagcctct ccctgtctcc gggtaaa 1347
<210> 71
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 71
Arg Ala Ser Gln Asp Ile Ser Ser Asp Leu Asn
1 5 10
<210> 72
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 72
Asp Ala Ser Asn Leu Gln Ser
1 5
<210> 73
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 73
His Gln Trp Tyr Ser Thr Leu Tyr Thr
1 5
<210> 74
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 74
Ser Gln Asp Ile Ser Ser Asp
1 5
<210> 75
<211> 3
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 75
Asp Ala Ser
1
<210> 76
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 76
Trp Tyr Ser Thr Leu Tyr
1 5
<210> 77
<211> 107
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 77
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Asp Ile Ser Ser Asp
20 25 30
Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Asp Ala Ser Asn Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys His Gln Trp Tyr Ser Thr Leu Tyr
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys
100 105
<210> 78
<211> 321
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 78
gatatccaga tgacccagag cccgagcagc ctgagcgcca gcgtgggcga tcgcgtgacc 60
attacctgca gagccagcca ggacatttct tctgacctga actggtacca gcagaaaccg 120
ggcaaagcgc cgaaactatt aatctacgac gcttctaacc tgcaaagcgg cgtgccgagc 180
cgctttagcg gcagcggatc cggcaccgat ttcaccctga ccattagctc tctgcaaccg 240
gaagactttg cgacctatta ttgccatcag tggtactcta ctctgtacac ctttggccag 300
ggcacgaaag ttgaaattaa a 321
<210> 79
<211> 214
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 79
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Asp Ile Ser Ser Asp
20 25 30
Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Asp Ala Ser Asn Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys His Gln Trp Tyr Ser Thr Leu Tyr
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 80
<211> 642
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 80
gatatccaga tgacccagag cccgagcagc ctgagcgcca gcgtgggcga tcgcgtgacc 60
attacctgca gagccagcca ggacatttct tctgacctga actggtacca gcagaaaccg 120
ggcaaagcgc cgaaactatt aatctacgac gcttctaacc tgcaaagcgg cgtgccgagc 180
cgctttagcg gcagcggatc cggcaccgat ttcaccctga ccattagctc tctgcaaccg 240
gaagactttg cgacctatta ttgccatcag tggtactcta ctctgtacac ctttggccag 300
ggcacgaaag ttgaaattaa acgtacggtg gccgctccca gcgtgttcat cttccccccc 360
agcgacgagc agctgaagag cggcaccgcc agcgtggtgt gcctgctgaa caacttctac 420
ccccgggagg ccaaggtgca gtggaaggtg gacaacgccc tgcagagcgg caacagccag 480
gaaagcgtca ccgagcagga cagcaaggac tccacctaca gcctgagcag caccctgacc 540
ctgagcaagg ccgactacga gaagcacaag gtgtacgcct gcgaggtgac ccaccagggc 600
ctgtccagcc ccgtgaccaa gagcttcaac cggggcgagt gt 642
<210> 81
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 81
Ser Tyr Ala Ile Ser
1 5
<210> 82
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 82
Tyr Ile Ser Pro Tyr Met Gly Glu Thr His Tyr Ala Gln Lys Phe Gln
1 5 10 15
Gly
<210> 83
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 83
Glu Ser Tyr Glu Tyr Phe Asp Ile
1 5
<210> 84
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 84
Gly Gly Thr Phe Ser Ser Tyr
1 5
<210> 85
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 85
Ser Pro Tyr Met Gly Glu
1 5
<210> 86
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 86
Glu Ser Tyr Glu Tyr Phe Asp Ile
1 5
<210> 87
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 87
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ser
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Gly Thr Phe Ser Ser Tyr
20 25 30
Ala Ile Ser Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Tyr Ile Ser Pro Tyr Met Gly Glu Thr His Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Ile Thr Ala Asp Glu Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Glu Ser Tyr Glu Tyr Phe Asp Ile Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 88
<211> 351
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 88
caggtgcaat tggtgcagag cggtgccgaa gtgaaaaaac cgggcagcag cgtgaaagtt 60
agctgcaaag catccggagg gacgtttagc agctatgcga ttagctgggt gcgccaggcc 120
ccgggccagg gcctcgagtg gatgggctac atctctccgt acatgggcga aactcattac 180
gcccagaaat ttcagggccg ggtgaccatt accgccgatg aaagcaccag caccgcctat 240
atggaactga gcagcctgcg cagcgaagat acggccgtgt attattgcgc gcgtgaatct 300
tacgaatact tcgacatctg gggccaaggc accctggtga ctgttagctc a 351
<210> 89
<211> 447
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 89
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ser
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Gly Thr Phe Ser Ser Tyr
20 25 30
Ala Ile Ser Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Tyr Ile Ser Pro Tyr Met Gly Glu Thr His Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Ile Thr Ala Asp Glu Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Glu Ser Tyr Glu Tyr Phe Asp Ile Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu
115 120 125
Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys
130 135 140
Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser
145 150 155 160
Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser
165 170 175
Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser
180 185 190
Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn
195 200 205
Thr Lys Val Asp Lys Arg Val Glu Pro Lys Ser Cys Asp Lys Thr His
210 215 220
Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val
225 230 235 240
Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr
245 250 255
Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu
260 265 270
Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys
275 280 285
Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser
290 295 300
Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys
305 310 315 320
Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile
325 330 335
Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro
340 345 350
Pro Ser Arg Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu
355 360 365
Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn
370 375 380
Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser
385 390 395 400
Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg
405 410 415
Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu
420 425 430
His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
435 440 445
<210> 90
<211> 1341
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 90
caggtgcaat tggtgcagag cggtgccgaa gtgaaaaaac cgggcagcag cgtgaaagtt 60
agctgcaaag catccggagg gacgtttagc agctatgcga ttagctgggt gcgccaggcc 120
ccgggccagg gcctcgagtg gatgggctac atctctccgt acatgggcga aactcattac 180
gcccagaaat ttcagggccg ggtgaccatt accgccgatg aaagcaccag caccgcctat 240
atggaactga gcagcctgcg cagcgaagat acggccgtgt attattgcgc gcgtgaatct 300
tacgaatact tcgacatctg gggccaaggc accctggtga ctgttagctc agcctccacc 360
aagggtccat cggtcttccc cctggcaccc tcctccaaga gcacctctgg gggcacagcg 420
gccctgggct gcctggtcaa ggactacttc cccgaaccgg tgacggtgtc gtggaactca 480
ggcgccctga ccagcggcgt gcacaccttc ccggctgtcc tacagtcctc aggactctac 540
tccctcagca gcgtggtgac cgtgccctcc agcagcttgg gcacccagac ctacatctgc 600
aacgtgaatc acaagcccag caacaccaag gtggacaaga gagttgagcc caaatcttgt 660
gacaaaactc acacatgccc accgtgccca gcacctgaac tcctgggggg accgtcagtc 720
ttcctcttcc ccccaaaacc caaggacacc ctcatgatct cccggacccc tgaggtcaca 780
tgcgtggtgg tggacgtgag ccacgaagac cctgaggtca agttcaactg gtacgtggac 840
ggcgtggagg tgcataatgc caagacaaag ccgcgggagg agcagtacaa cagcacgtac 900
cgggtggtca gcgtcctcac cgtcctgcac caggactggc tgaatggcaa ggagtacaag 960
tgcaaggtct ccaacaaagc cctcccagcc cccatcgaga aaaccatctc caaagccaaa 1020
gggcagcccc gagaaccaca ggtgtacacc ctgcccccat cccgggagga gatgaccaag 1080
aaccaggtca gcctgacctg cctggtcaaa ggcttctatc ccagcgacat cgccgtggag 1140
tgggagagca atgggcagcc ggagaacaac tacaagacca cgcctcccgt gctggactcc 1200
gacggctcct tcttcctcta cagcaagctc accgtggaca agagcaggtg gcagcagggg 1260
aacgtcttct catgctccgt gatgcatgag gctctgcaca accactacac gcagaagagc 1320
ctctccctgt ctccgggtaa a 1341
<210> 91
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 91
Arg Ala Ser Gln Ser Ile Ser Asn Asp Leu Ala
1 5 10
<210> 92
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 92
Ala Thr Ser Ile Leu Gln Ser
1 5
<210> 93
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 93
Leu Gln Tyr Tyr Asp Tyr Ser Tyr Thr
1 5
<210> 94
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 94
Ser Gln Ser Ile Ser Asn Asp
1 5
<210> 95
<211> 3
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 95
Ala Thr Ser
1
<210> 96
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 96
Tyr Tyr Asp Tyr Ser Tyr
1 5
<210> 97
<211> 107
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 97
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Ser Ile Ser Asn Asp
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Ala Thr Ser Ile Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln Tyr Tyr Asp Tyr Ser Tyr
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys
100 105
<210> 98
<211> 321
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 98
gatatccaga tgacccagag cccgagcagc ctgagcgcca gcgtgggcga tcgcgtgacc 60
attacctgca gagccagcca gtctatttct aacgacctgg cttggtacca gcagaaaccg 120
ggcaaagcgc cgaaactatt aatctacgct acttctatcc tgcaaagcgg cgtgccgagc 180
cgctttagcg gcagcggatc cggcaccgat ttcaccctga ccattagctc tctgcaaccg 240
gaagactttg cgacctatta ttgcctgcag tactacgact actcttacac ctttggccag 300
ggcacgaaag ttgaaattaa a 321
<210> 99
<211> 214
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 99
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Ser Ile Ser Asn Asp
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Ala Thr Ser Ile Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln Tyr Tyr Asp Tyr Ser Tyr
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 100
<211> 642
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 100
gatatccaga tgacccagag cccgagcagc ctgagcgcca gcgtgggcga tcgcgtgacc 60
attacctgca gagccagcca gtctatttct aacgacctgg cttggtacca gcagaaaccg 120
ggcaaagcgc cgaaactatt aatctacgct acttctatcc tgcaaagcgg cgtgccgagc 180
cgctttagcg gcagcggatc cggcaccgat ttcaccctga ccattagctc tctgcaaccg 240
gaagactttg cgacctatta ttgcctgcag tactacgact actcttacac ctttggccag 300
ggcacgaaag ttgaaattaa acgtacggtg gccgctccca gcgtgttcat cttccccccc 360
agcgacgagc agctgaagag cggcaccgcc agcgtggtgt gcctgctgaa caacttctac 420
ccccgggagg ccaaggtgca gtggaaggtg gacaacgccc tgcagagcgg caacagccag 480
gaaagcgtca ccgagcagga cagcaaggac tccacctaca gcctgagcag caccctgacc 540
ctgagcaagg ccgactacga gaagcacaag gtgtacgcct gcgaggtgac ccaccagggc 600
ctgtccagcc ccgtgaccaa gagcttcaac cggggcgagt gt 642
<210> 101
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 101
Ser Tyr Asp Ile Ser
1 5
<210> 102
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 102
Trp Ile Asn Pro Tyr Asn Gly Gly Thr Asn Tyr Ala Gln Lys Phe Gln
1 5 10 15
Gly
<210> 103
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 103
Glu Gly Ser Gly Met Ile Val Tyr Pro Gly Trp Ser Tyr Ala Phe Asp
1 5 10 15
Tyr
<210> 104
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 104
Gly Tyr Thr Phe Thr Ser Tyr
1 5
<210> 105
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 105
Asn Pro Tyr Asn Gly Gly
1 5
<210> 106
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 106
Glu Gly Ser Gly Met Ile Val Tyr Pro Gly Trp Ser Tyr Ala Phe Asp
1 5 10 15
Tyr
<210> 107
<211> 126
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 107
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr
20 25 30
Asp Ile Ser Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Trp Ile Asn Pro Tyr Asn Gly Gly Thr Asn Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Met Thr Arg Asp Thr Ser Ile Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Arg Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Glu Gly Ser Gly Met Ile Val Tyr Pro Gly Trp Ser Tyr Ala
100 105 110
Phe Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120 125
<210> 108
<211> 378
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 108
caggtgcaat tggtgcagag cggtgcggaa gtgaaaaaac cgggtgccag cgtgaaagtt 60
agctgcaaag cgtccggata taccttcact tcttacgaca tctcttgggt gcgccaggcc 120
ccgggccagg gcctcgagtg gatgggctgg atcaacccgt acaacggcgg tacgaactac 180
gcgcagaaat ttcagggccg ggtgaccatg acccgtgata ccagcattag caccgcgtat 240
atggaactga gccgtctgcg tagcgaagat acggccgtgt attattgcgc gcgtgaaggt 300
tctggtatga tcgtttaccc gggttggtct tacgctttcg attactgggg ccaaggcacc 360
ctggtgactg ttagctca 378
<210> 109
<211> 456
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 109
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr
20 25 30
Asp Ile Ser Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Trp Ile Asn Pro Tyr Asn Gly Gly Thr Asn Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Met Thr Arg Asp Thr Ser Ile Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Arg Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Glu Gly Ser Gly Met Ile Val Tyr Pro Gly Trp Ser Tyr Ala
100 105 110
Phe Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ala Ser
115 120 125
Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr
130 135 140
Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro
145 150 155 160
Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val
165 170 175
His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser
180 185 190
Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile
195 200 205
Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Arg Val
210 215 220
Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala
225 230 235 240
Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro
245 250 255
Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val
260 265 270
Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val
275 280 285
Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln
290 295 300
Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln
305 310 315 320
Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala
325 330 335
Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro
340 345 350
Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Glu Glu Met Thr
355 360 365
Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser
370 375 380
Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr
385 390 395 400
Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr
405 410 415
Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe
420 425 430
Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys
435 440 445
Ser Leu Ser Leu Ser Pro Gly Lys
450 455
<210> 110
<211> 1368
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 110
caggtgcaat tggtgcagag cggtgcggaa gtgaaaaaac cgggtgccag cgtgaaagtt 60
agctgcaaag cgtccggata taccttcact tcttacgaca tctcttgggt gcgccaggcc 120
ccgggccagg gcctcgagtg gatgggctgg atcaacccgt acaacggcgg tacgaactac 180
gcgcagaaat ttcagggccg ggtgaccatg acccgtgata ccagcattag caccgcgtat 240
atggaactga gccgtctgcg tagcgaagat acggccgtgt attattgcgc gcgtgaaggt 300
tctggtatga tcgtttaccc gggttggtct tacgctttcg attactgggg ccaaggcacc 360
ctggtgactg ttagctcagc ctccaccaag ggtccatcgg tcttccccct ggcaccctcc 420
tccaagagca cctctggggg cacagcggcc ctgggctgcc tggtcaagga ctacttcccc 480
gaaccggtga cggtgtcgtg gaactcaggc gccctgacca gcggcgtgca caccttcccg 540
gctgtcctac agtcctcagg actctactcc ctcagcagcg tggtgaccgt gccctccagc 600
agcttgggca cccagaccta catctgcaac gtgaatcaca agcccagcaa caccaaggtg 660
gacaagagag ttgagcccaa atcttgtgac aaaactcaca catgcccacc gtgcccagca 720
cctgaactcc tggggggacc gtcagtcttc ctcttccccc caaaacccaa ggacaccctc 780
atgatctccc ggacccctga ggtcacatgc gtggtggtgg acgtgagcca cgaagaccct 840
gaggtcaagt tcaactggta cgtggacggc gtggaggtgc ataatgccaa gacaaagccg 900
cgggaggagc agtacaacag cacgtaccgg gtggtcagcg tcctcaccgt cctgcaccag 960
gactggctga atggcaagga gtacaagtgc aaggtctcca acaaagccct cccagccccc 1020
atcgagaaaa ccatctccaa agccaaaggg cagccccgag aaccacaggt gtacaccctg 1080
cccccatccc gggaggagat gaccaagaac caggtcagcc tgacctgcct ggtcaaaggc 1140
ttctatccca gcgacatcgc cgtggagtgg gagagcaatg ggcagccgga gaacaactac 1200
aagaccacgc ctcccgtgct ggactccgac ggctccttct tcctctacag caagctcacc 1260
gtggacaaga gcaggtggca gcaggggaac gtcttctcat gctccgtgat gcatgaggct 1320
ctgcacaacc actacacgca gaagagcctc tccctgtctc cgggtaaa 1368
<210> 111
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 111
Arg Ala Ser Gln Asp Ile Ser Asn Asp Leu Gly
1 5 10
<210> 112
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 112
Ala Ala Ser Ser Leu Gln Ser
1 5
<210> 113
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 113
Gln Gln His Tyr His Thr Pro Asn Thr
1 5
<210> 114
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 114
Ser Gln Asp Ile Ser Asn Asp
1 5
<210> 115
<211> 3
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 115
Ala Ala Ser
1
<210> 116
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 116
His Tyr His Thr Pro Asn
1 5
<210> 117
<211> 107
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 117
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Asp Ile Ser Asn Asp
20 25 30
Leu Gly Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Ala Ala Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln His Tyr His Thr Pro Asn
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys
100 105
<210> 118
<211> 321
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 118
gatatccaga tgacccagag cccgagcagc ctgagcgcca gcgtgggcga tcgcgtgacc 60
attacctgca gagccagcca ggacatttct aacgacctgg gttggtacca gcagaaaccg 120
ggcaaagcgc cgaaactatt aatctacgct gcttcttctc tgcaaagcgg cgtgccgagc 180
cgctttagcg gcagcggatc cggcaccgat ttcaccctga ccattagctc tctgcaaccg 240
gaagactttg cgacctatta ttgccagcag cattaccata ctccgaacac ctttggccag 300
ggcacgaaag ttgaaattaa a 321
<210> 119
<211> 214
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 119
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Asp Ile Ser Asn Asp
20 25 30
Leu Gly Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Ala Ala Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln His Tyr His Thr Pro Asn
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 120
<211> 642
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 120
gatatccaga tgacccagag cccgagcagc ctgagcgcca gcgtgggcga tcgcgtgacc 60
attacctgca gagccagcca ggacatttct aacgacctgg gttggtacca gcagaaaccg 120
ggcaaagcgc cgaaactatt aatctacgct gcttcttctc tgcaaagcgg cgtgccgagc 180
cgctttagcg gcagcggatc cggcaccgat ttcaccctga ccattagctc tctgcaaccg 240
gaagactttg cgacctatta ttgccagcag cattaccata ctccgaacac ctttggccag 300
ggcacgaaag ttgaaattaa acgtacggtg gccgctccca gcgtgttcat cttccccccc 360
agcgacgagc agctgaagag cggcaccgcc agcgtggtgt gcctgctgaa caacttctac 420
ccccgggagg ccaaggtgca gtggaaggtg gacaacgccc tgcagagcgg caacagccag 480
gaaagcgtca ccgagcagga cagcaaggac tccacctaca gcctgagcag caccctgacc 540
ctgagcaagg ccgactacga gaagcacaag gtgtacgcct gcgaggtgac ccaccagggc 600
ctgtccagcc ccgtgaccaa gagcttcaac cggggcgagt gt 642
<210> 121
<211> 5911
<212> DNA
<213> Homo sapiens
<400> 121
agatgcaggg gcgcaaacgc caaaggagac caggctgtag gaagagaagg gcagagcgcc 60
ggacagctcg gcccgctccc cgtcctttgg ggccgcggct ggggaactac aaggcccagc 120
aggcagctgc agggggcgga ggcggaggag ggaccagcgc gggtgggagt gagagagcga 180
gccctcgcgc cccgccggcg catagcgctc ggagcgctct tgcggccaca ggcgcggcgt 240
cctcggcggc gggcggcagc tagcgggagc cgggacgccg gtgcagccgc agcgcgcgga 300
ggaacccggg tgtgccggga gctgggcggc cacgtccgga cgggaccgag acccctcgta 360
gcgcattgcg gcgacctcgc cttccccggc cgcgagcgcg ccgctgcttg aaaagccgcg 420
gaacccaagg acttttctcc ggtccgagct cggggcgccc cgcagggcgc acggtacccg 480
tgctgcagtc gggcacgccg cggcgccggg gcctccgcag ggcgatggag cccggtctgc 540
aaggaaagtg aggcgccgcc gctgcgttct ggaggagggg ggcacaaggt ctggagaccc 600
cgggtggcgg acgggagccc tccccccgcc ccgcctccgg ggcaccagct ccggctccat 660
tgttcccgcc cgggctggag gcgccgagca ccgagcgccg ccgggagtcg agcgccggcc 720
gcggagctct tgcgaccccg ccaggacccg aacagagccc gggggcggcg ggccggagcc 780
ggggacgcgg gcacacgccc gctcgcacaa gccacggcgg actctcccga ggcggaacct 840
ccacgccgag cgagggtcag tttgaaaagg aggatcgagc tcactgtgga gtatccatgg 900
agatgtggag ccttgtcacc aacctctaac tgcagaactg ggatgtggag ctggaagtgc 960
ctcctcttct gggctgtgct ggtcacagcc acactctgca ccgctaggcc gtccccgacc 1020
ttgcctgaac aagcccagcc ctggggagcc cctgtggaag tggagtcctt cctggtccac 1080
cccggtgacc tgctgcagct tcgctgtcgg ctgcgggacg atgtgcagag catcaactgg 1140
ctgcgggacg gggtgcagct ggcggaaagc aaccgcaccc gcatcacagg ggaggaggtg 1200
gaggtgcagg actccgtgcc cgcagactcc ggcctctatg cttgcgtaac cagcagcccc 1260
tcgggcagtg acaccaccta cttctccgtc aatgtttcag atgctctccc ctcctcggag 1320
gatgatgatg atgatgatga ctcctcttca gaggagaaag aaacagataa caccaaacca 1380
aaccccgtag ctccatattg gacatcccca gaaaagatgg aaaagaaatt gcatgcagtg 1440
ccggctgcca agacagtgaa gttcaaatgc ccttccagtg ggaccccaaa ccccacactg 1500
cgctggttga aaaatggcaa agaattcaaa cctgaccaca gaattggagg ctacaaggtc 1560
cgttatgcca cctggagcat cataatggac tctgtggtgc cctctgacaa gggcaactac 1620
acctgcattg tggagaatga gtacggcagc atcaaccaca cataccagct ggatgtcgtg 1680
gagcggtccc ctcaccggcc catcctgcaa gcagggttgc ccgccaacaa aacagtggcc 1740
ctgggtagca acgtggagtt catgtgtaag gtgtacagtg acccgcagcc gcacatccag 1800
tggctaaagc acatcgaggt gaatgggagc aagattggcc cagacaacct gccttatgtc 1860
cagatcttga agactgctgg agttaatacc accgacaaag agatggaggt gcttcactta 1920
agaaatgtct cctttgagga cgcaggggag tatacgtgct tggcgggtaa ctctatcgga 1980
ctctcccatc actctgcatg gttgaccgtt ctggaagccc tggaagagag gccggcagtg 2040
atgacctcgc ccctgtacct ggagatcatc atctattgca caggggcctt cctcatctcc 2100
tgcatggtgg ggtcggtcat cgtctacaag atgaagagtg gtaccaagaa gagtgacttc 2160
cacagccaga tggctgtgca caagctggcc aagagcatcc ctctgcgcag acaggtaaca 2220
gtgtctgctg actccagtgc atccatgaac tctggggttc ttctggttcg gccatcacgg 2280
ctctcctcca gtgggactcc catgctagca ggggtctctg agtatgagct tcccgaagac 2340
cctcgctggg agctgcctcg ggacagactg gtcttaggca aacccctggg agagggctgc 2400
tttgggcagg tggtgttggc agaggctatc gggctggaca aggacaaacc caaccgtgtg 2460
accaaagtgg ctgtgaagat gttgaagtcg gacgcaacag agaaagactt gtcagacctg 2520
atctcagaaa tggagatgat gaagatgatc gggaagcata agaatatcat caacctgctg 2580
ggggcctgca cgcaggatgg tcccttgtat gtcatcgtgg agtatgcctc caagggcaac 2640
ctgcgggagt acctgcaggc ccggaggccc ccagggctgg aatactgcta caaccccagc 2700
cacaacccag aggagcagct ctcctccaag gacctggtgt cctgcgccta ccaggtggcc 2760
cgaggcatgg agtatctggc ctccaagaag tgcatacacc gagacctggc agccaggaat 2820
gtcctggtga cagaggacaa tgtgatgaag atagcagact ttggcctcgc acgggacatt 2880
caccacatcg actactataa aaagacaacc aacggccgac tgcctgtgaa gtggatggca 2940
cccgaggcat tatttgaccg gatctacacc caccagagtg atgtgtggtc tttcggggtg 3000
ctcctgtggg agatcttcac tctgggcggc tccccatacc ccggtgtgcc tgtggaggaa 3060
cttttcaagc tgctgaagga gggtcaccgc atggacaagc ccagtaactg caccaacgag 3120
ctgtacatga tgatgcggga ctgctggcat gcagtgccct cacagagacc caccttcaag 3180
cagctggtgg aagacctgga ccgcatcgtg gccttgacct ccaaccagga gtacctggac 3240
ctgtccatgc ccctggacca gtactccccc agctttcccg acacccggag ctctacgtgc 3300
tcctcagggg aggattccgt cttctctcat gagccgctgc ccgaggagcc ctgcctgccc 3360
cgacacccag cccagcttgc caatggcgga ctcaaacgcc gctgactgcc acccacacgc 3420
cctccccaga ctccaccgtc agctgtaacc ctcacccaca gcccctgctg ggcccaccac 3480
ctgtccgtcc ctgtcccctt tcctgctggc aggagccggc tgcctaccag gggccttcct 3540
gtgtggcctg ccttcacccc actcagctca cctctccctc cacctcctct ccacctgctg 3600
gtgagaggtg caaagaggca gatctttgct gccagccact tcatcccctc ccagatgttg 3660
gaccaacacc cctccctgcc accaggcact gcctggaggg cagggagtgg gagccaatga 3720
acaggcatgc aagtgagagc ttcctgagct ttctcctgtc ggtttggtct gttttgcctt 3780
cacccataag cccctcgcac tctggtggca ggtgccttgt cctcagggct acagcagtag 3840
ggaggtcagt gcttcgtgcc tcgattgaag gtgacctctg ccccagatag gtggtgccag 3900
tggcttatta attccgatac tagtttgctt tgctgaccaa atgcctggta ccagaggatg 3960
gtgaggcgaa ggccaggttg ggggcagtgt tgtggccctg gggcccagcc ccaaactggg 4020
ggctctgtat atagctatga agaaaacaca aagtgtataa atctgagtat atatttacat 4080
gtctttttaa aagggtcgtt accagagatt tacccatcgg gtaagatgct cctggtggct 4140
gggaggcatc agttgctata tattaaaaac aaaaaagaaa aaaaaggaaa atgtttttaa 4200
aaaggtcata tattttttgc tacttttgct gttttatttt tttaaattat gttctaaacc 4260
tattttcagt ttaggtccct caataaaaat tgctgctgct tcatttatct atgggctgta 4320
tgaaaagggt gggaatgtcc actggaaaga agggacaccc acgggccctg gggctaggtc 4380
tgtcccgagg gcaccgcatg ctcccggcgc aggttccttg taacctcttc ttcctaggtc 4440
ctgcacccag acctcacgac gcacctcctg cctctccgct gcttttggaa agtcagaaaa 4500
agaagatgtc tgcttcgagg gcaggaaccc catccatgca gtagaggcgc tgggcagaga 4560
gtcaaggccc agcagccatc gaccatggat ggtttcctcc aaggaaaccg gtggggttgg 4620
gctggggagg gggcacctac ctaggaatag ccacggggta gagctacagt gattaagagg 4680
aaagcaaggg cgcggttgct cacgcctgta atcccagcac tttgggacac cgaggtgggc 4740
agatcacttc aggtcaggag tttgagacca gcctggccaa cttagtgaaa ccccatctct 4800
actaaaaatg caaaaattat ccaggcatgg tggcacacgc ctgtaatccc agctccacag 4860
gaggctgagg cagaatccct tgaagctggg aggcggaggt tgcagtgagc cgagattgcg 4920
ccattgcact ccagcctggg caacagagaa aacaaaaagg aaaacaaatg atgaaggtct 4980
gcagaaactg aaacccagac atgtgtctgc cccctctatg tgggcatggt tttgccagtg 5040
cttctaagtg caggagaaca tgtcacctga ggctagtttt gcattcaggt ccctggcttc 5100
gtttcttgtt ggtatgcctc cccagatcgt ccttcctgta tccatgtgac cagactgtat 5160
ttgttgggac tgtcgcagat cttggcttct tacagttctt cctgtccaaa ctccatcctg 5220
tccctcagga acggggggaa aattctccga atgtttttgg ttttttggct gcttggaatt 5280
tacttctgcc acctgctggt catcactgtc ctcactaagt ggattctggc tcccccgtac 5340
ctcatggctc aaactaccac tcctcagtcg ctatattaaa gcttatattt tgctggatta 5400
ctgctaaata caaaagaaag ttcaatatgt tttcatttct gtagggaaaa tgggattgct 5460
gctttaaatt tctgagctag ggattttttg gcagctgcag tgttggcgac tattgtaaaa 5520
ttctctttgt ttctctctgt aaatagcacc tgctaacatt acaatttgta tttatgttta 5580
aagaaggcat catttggtga acagaactag gaaatgaatt tttagctctt aaaagcattt 5640
gctttgagac cgcacaggag tgtctttcct tgtaaaacag tgatgataat ttctgccttg 5700
gccctacctt gaagcaatgt tgtgtgaagg gatgaagaat ctaaaagtct tcataagtcc 5760
ttgggagagg tgctagaaaa atataaggca ctatcataat tacagtgatg tccttgctgt 5820
tactactcaa atcacccaca aatttcccca aagactgcgc tagctgtcaa ataaaagaca 5880
gtgaaattga cctgaaaaaa aaaaaaaaaa a 5911
<210> 122
<211> 4657
<212> DNA
<213> Homo sapiens
<400> 122
ggcggcggct ggaggagagc gcggtggaga gccgagcggg cgggcggcgg gtgcggagcg 60
ggcgagggag cgcgcgcggc cgccacaaag ctcgggcgcc gcggggctgc atgcggcgta 120
cctggcccgg cgcggcgact gctctccggg ctggcggggg ccggccgcga gccccggggg 180
ccccgaggcc gcagcttgcc tgcgcgctct gagccttcgc aactcgcgag caaagtttgg 240
tggaggcaac gccaagcctg agtcctttct tcctctcgtt ccccaaatcc gagggcagcc 300
cgcgggcgtc atgcccgcgc tcctccgcag cctggggtac gcgtgaagcc cgggaggctt 360
ggcgccggcg aagacccaag gaccactctt ctgcgtttgg agttgctccc cgcaaccccg 420
ggctcgtcgc tttctccatc ccgacccacg cggggcgcgg ggacaacaca ggtcgcggag 480
gagcgttgcc attcaagtga ctgcagcagc agcggcagcg cctcggttcc tgagcccacc 540
gcaggctgaa ggcattgcgc gtagtccatg cccgtagagg aagtgtgcag atgggattaa 600
cgtccacatg gagatatgga agaggaccgg ggattggtac cgtaaccatg gtcagctggg 660
gtcgtttcat ctgcctggtc gtggtcacca tggcaacctt gtccctggcc cggccctcct 720
tcagtttagt tgaggatacc acattagagc cagaagagcc accaaccaaa taccaaatct 780
ctcaaccaga agtgtacgtg gctgcgccag gggagtcgct agaggtgcgc tgcctgttga 840
aagatgccgc cgtgatcagt tggactaagg atggggtgca cttggggccc aacaatagga 900
cagtgcttat tggggagtac ttgcagataa agggcgccac gcctagagac tccggcctct 960
atgcttgtac tgccagtagg actgtagaca gtgaaacttg gtacttcatg gtgaatgtca 1020
cagatgccat ctcatccgga gatgatgagg atgacaccga tggtgcggaa gattttgtca 1080
gtgagaacag taacaacaag agagcaccat actggaccaa cacagaaaag atggaaaagc 1140
ggctccatgc tgtgcctgcg gccaacactg tcaagtttcg ctgcccagcc ggggggaacc 1200
caatgccaac catgcggtgg ctgaaaaacg ggaaggagtt taagcaggag catcgcattg 1260
gaggctacaa ggtacgaaac cagcactgga gcctcattat ggaaagtgtg gtcccatctg 1320
acaagggaaa ttatacctgt gtagtggaga atgaatacgg gtccatcaat cacacgtacc 1380
acctggatgt tgtggagcga tcgcctcacc ggcccatcct ccaagccgga ctgccggcaa 1440
atgcctccac agtggtcgga ggagacgtag agtttgtctg caaggtttac agtgatgccc 1500
agccccacat ccagtggatc aagcacgtgg aaaagaacgg cagtaaatac gggcccgacg 1560
ggctgcccta cctcaaggtt ctcaagcact cggggataaa tagttccaat gcagaagtgc 1620
tggctctgtt caatgtgacc gaggcggatg ctggggaata tatatgtaag gtctccaatt 1680
atatagggca ggccaaccag tctgcctggc tcactgtcct gccaaaacag caagcgcctg 1740
gaagagaaaa ggagattaca gcttccccag actacctgga gatagccatt tactgcatag 1800
gggtcttctt aatcgcctgt atggtggtaa cagtcatcct gtgccgaatg aagaacacga 1860
ccaagaagcc agacttcagc agccagccgg ctgtgcacaa gctgaccaaa cgtatccccc 1920
tgcggagaca ggtaacagtt tcggctgagt ccagctcctc catgaactcc aacaccccgc 1980
tggtgaggat aacaacacgc ctctcttcaa cggcagacac ccccatgctg gcaggggtct 2040
ccgagtatga acttccagag gacccaaaat gggagtttcc aagagataag ctgacactgg 2100
gcaagcccct gggagaaggt tgctttgggc aagtggtcat ggcggaagca gtgggaattg 2160
acaaagacaa gcccaaggag gcggtcaccg tggccgtgaa gatgttgaaa gatgatgcca 2220
cagagaaaga cctttctgat ctggtgtcag agatggagat gatgaagatg attgggaaac 2280
acaagaatat cataaatctt cttggagcct gcacacagga tgggcctctc tatgtcatag 2340
ttgagtatgc ctctaaaggc aacctccgag aatacctccg agcccggagg ccacccggga 2400
tggagtactc ctatgacatt aaccgtgttc ctgaggagca gatgaccttc aaggacttgg 2460
tgtcatgcac ctaccagctg gccagaggca tggagtactt ggcttcccaa aaatgtattc 2520
atcgagattt agcagccaga aatgttttgg taacagaaaa caatgtgatg aaaatagcag 2580
actttggact cgccagagat atcaacaata tagactatta caaaaagacc accaatgggc 2640
ggcttccagt caagtggatg gctccagaag ccctgtttga tagagtatac actcatcaga 2700
gtgatgtctg gtccttcggg gtgttaatgt gggagatctt cactttaggg ggctcgccct 2760
acccagggat tcccgtggag gaacttttta agctgctgaa ggaaggacac agaatggata 2820
agccagccaa ctgcaccaac gaactgtaca tgatgatgag ggactgttgg catgcagtgc 2880
cctcccagag accaacgttc aagcagttgg tagaagactt ggatcgaatt ctcactctca 2940
caaccaatga ggaatacttg gacctcagcc aacctctcga acagtattca cctagttacc 3000
ctgacacaag aagttcttgt tcttcaggag atgattctgt tttttctcca gaccccatgc 3060
cttacgaacc atgccttcct cagtatccac acataaacgg cagtgttaaa acatgaatga 3120
ctgtgtctgc ctgtccccaa acaggacagc actgggaacc tagctacact gagcagggag 3180
accatgcctc ccagagcttg ttgtctccac ttgtatatat ggatcagagg agtaaataat 3240
tggaaaagta atcagcatat gtgtaaagat ttatacagtt gaaaacttgt aatcttcccc 3300
aggaggagaa gaaggtttct ggagcagtgg actgccacaa gccaccatgt aacccctctc 3360
acctgccgtg cgtactggct gtggaccagt aggactcaag gtggacgtgc gttctgcctt 3420
ccttgttaat tttgtaataa ttggagaaga tttatgtcag cacacactta cagagcacaa 3480
atgcagtata taggtgctgg atgtatgtaa atatattcaa attatgtata aatatatatt 3540
atatatttac aaggagttat tttttgtatt gattttaaat ggatgtccca atgcacctag 3600
aaaattggtc tctctttttt taatagctat ttgctaaatg ctgttcttac acataatttc 3660
ttaattttca ccgagcagag gtggaaaaat acttttgctt tcagggaaaa tggtataacg 3720
ttaatttatt aataaattgg taatatacaa aacaattaat catttatagt tttttttgta 3780
atttaagtgg catttctatg caggcagcac agcagactag ttaatctatt gcttggactt 3840
aactagttat cagatccttt gaaaagagaa tatttacaat atatgactaa tttggggaaa 3900
atgaagtttt gatttatttg tgtttaaatg ctgctgtcag acgattgttc ttagacctcc 3960
taaatgcccc atattaaaag aactcattca taggaaggtg tttcattttg gtgtgcaacc 4020
ctgtcattac gtcaacgcaa cgtctaactg gacttcccaa gataaatggt accagcgtcc 4080
tcttaaaaga tgccttaatc cattccttga ggacagacct tagttgaaat gatagcagaa 4140
tgtgcttctc tctggcagct ggccttctgc ttctgagttg cacattaatc agattagcct 4200
gtattctctt cagtgaattt tgataatggc ttccagactc tttggcgttg gagacgcctg 4260
ttaggatctt caagtcccat catagaaaat tgaaacacag agttgttctg ctgatagttt 4320
tggggatacg tccatctttt taagggattg ctttcatcta attctggcag gacctcacca 4380
aaagatccag cctcatacct acatcagaca aaatatcgcc gttgttcctt ctgtactaaa 4440
gtattgtgtt ttgctttgga aacacccact cactttgcaa tagccgtgca agatgaatgc 4500
agattacact gatcttatgt gttacaaaat tggagaaagt atttaataaa acctgttaat 4560
ttttatactg acaataaaaa tgtttctaca gatattaatg ttaacaagac aaaataaatg 4620
tcacgcaact tattttttta ataaaaaaaa aaaaaaa 4657
<210> 123
<211> 4304
<212> DNA
<213> Homo sapiens
<400> 123
gtcgcgggca gctggcgccg cgcggtcctg ctctgccggt cgcacggacg caccggcggg 60
ccgccggccg gagggacggg gcgggagctg ggcccgcgga cagcgagccg gagcgggagc 120
cgcgcgtagc gagccgggct ccggcgctcg ccagtctccc gagcggcgcc cgcctcccgc 180
cggtgcccgc gccgggccgt ggggggcagc atgcccgcgc gcgctgcctg aggacgccgc 240
ggcccccgcc cccgccatgg gcgcccctgc ctgcgccctc gcgctctgcg tggccgtggc 300
catcgtggcc ggcgcctcct cggagtcctt ggggacggag cagcgcgtcg tggggcgagc 360
ggcagaagtc ccgggcccag agcccggcca gcaggagcag ttggtcttcg gcagcgggga 420
tgctgtggag ctgagctgtc ccccgcccgg gggtggtccc atggggccca ctgtctgggt 480
caaggatggc acagggctgg tgccctcgga gcgtgtcctg gtggggcccc agcggctgca 540
ggtgctgaat gcctcccacg aggactccgg ggcctacagc tgccggcagc ggctcacgca 600
gcgcgtactg tgccacttca gtgtgcgggt gacagacgct ccatcctcgg gagatgacga 660
agacggggag gacgaggctg aggacacagg tgtggacaca ggggcccctt actggacacg 720
gcccgagcgg atggacaaga agctgctggc cgtgccggcc gccaacaccg tccgcttccg 780
ctgcccagcc gctggcaacc ccactccctc catctcctgg ctgaagaacg gcagggagtt 840
ccgcggcgag caccgcattg gaggcatcaa gctgcggcat cagcagtgga gcctggtcat 900
ggaaagcgtg gtgccctcgg accgcggcaa ctacacctgc gtcgtggaga acaagtttgg 960
cagcatccgg cagacgtaca cgctggacgt gctggagcgc tccccgcacc ggcccatcct 1020
gcaggcgggg ctgccggcca accagacggc ggtgctgggc agcgacgtgg agttccactg 1080
caaggtgtac agtgacgcac agccccacat ccagtggctc aagcacgtgg aggtgaatgg 1140
cagcaaggtg ggcccggacg gcacacccta cgttaccgtg ctcaagacgg cgggcgctaa 1200
caccaccgac aaggagctag aggttctctc cttgcacaac gtcacctttg aggacgccgg 1260
ggagtacacc tgcctggcgg gcaattctat tgggttttct catcactctg cgtggctggt 1320
ggtgctgcca gccgaggagg agctggtgga ggctgacgag gcgggcagtg tgtatgcagg 1380
catcctcagc tacggggtgg gcttcttcct gttcatcctg gtggtggcgg ctgtgacgct 1440
ctgccgcctg cgcagccccc ccaagaaagg cctgggctcc cccaccgtgc acaagatctc 1500
ccgcttcccg ctcaagcgac aggtgtccct ggagtccaac gcgtccatga gctccaacac 1560
accactggtg cgcatcgcaa ggctgtcctc aggggagggc cccacgctgg ccaatgtctc 1620
cgagctcgag ctgcctgccg accccaaatg ggagctgtct cgggcccggc tgaccctggg 1680
caagcccctt ggggagggct gcttcggcca ggtggtcatg gcggaggcca tcggcattga 1740
caaggaccgg gccgccaagc ctgtcaccgt agccgtgaag atgctgaaag acgatgccac 1800
tgacaaggac ctgtcggacc tggtgtctga gatggagatg atgaagatga tcgggaaaca 1860
caaaaacatc atcaacctgc tgggcgcctg cacgcagggc gggcccctgt acgtgctggt 1920
ggagtacgcg gccaagggta acctgcggga gtttctgcgg gcgcggcggc ccccgggcct 1980
ggactactcc ttcgacacct gcaagccgcc cgaggagcag ctcaccttca aggacctggt 2040
gtcctgtgcc taccaggtgg cccggggcat ggagtacttg gcctcccaga agtgcatcca 2100
cagggacctg gctgcccgca atgtgctggt gaccgaggac aacgtgatga agatcgcaga 2160
cttcgggctg gcccgggacg tgcacaacct cgactactac aagaagacaa ccaacggccg 2220
gctgcccgtg aagtggatgg cgcctgaggc cttgtttgac cgagtctaca ctcaccagag 2280
tgacgtctgg tcctttgggg tcctgctctg ggagatcttc acgctggggg gctccccgta 2340
ccccggcatc cctgtggagg agctcttcaa gctgctgaag gagggccacc gcatggacaa 2400
gcccgccaac tgcacacacg acctgtacat gatcatgcgg gagtgctggc atgccgcgcc 2460
ctcccagagg cccaccttca agcagctggt ggaggacctg gaccgtgtcc ttaccgtgac 2520
gtccaccgac gagtacctgg acctgtcggc gcctttcgag cagtactccc cgggtggcca 2580
ggacaccccc agctccagct cctcagggga cgactccgtg tttgcccacg acctgctgcc 2640
cccggcccca cccagcagtg ggggctcgcg gacgtgaagg gccactggtc cccaacaatg 2700
tgaggggtcc ctagcagccc accctgctgc tggtgcacag ccactccccg gcatgagact 2760
cagtgcagat ggagagacag ctacacagag ctttggtctg tgtgtgtgtg tgtgcgtgtg 2820
tgtgtgtgtg tgtgcacatc cgcgtgtgcc tgtgtgcgtg cgcatcttgc ctccaggtgc 2880
agaggtaccc tgggtgtccc cgctgctgtg caacggtctc ctgactggtg ctgcagcacc 2940
gaggggcctt tgttctgggg ggacccagtg cagaatgtaa gtgggcccac ccggtgggac 3000
ccccgtgggg cagggagctg ggcccgacat ggctccggcc tctgcctttg caccacggga 3060
catcacaggg tgggcctcgg cccctcccac acccaaagct gagcctgcag ggaagcccca 3120
catgtccagc accttgtgcc tggggtgtta gtggcaccgc ctccccacct ccaggctttc 3180
ccacttccca ccctgcccct cagagactga aattacgggt acctgaagat gggagccttt 3240
accttttatg caaaaggttt attccggaaa ctagtgtaca tttctataaa tagatgctgt 3300
gtatatggta tatatacata tatatatata acatatatgg aagaggaaaa ggctggtaca 3360
acggaggcct gcgaccctgg gggcacagga ggcaggcatg gccctgggcg gggcgtgggg 3420
gggcgtggag ggaggcccca gggggtctca cccatgcaag cagaggacca gggccttttc 3480
tggcaccgca gttttgtttt aaaactggac ctgtatattt gtaaagctat ttatgggccc 3540
ctggcactct tgttcccaca ccccaacact tccagcattt agctggccac atggcggaga 3600
gttttaattt ttaacttatt gacaaccgag aaggtttatc ccgccgatag agggacggcc 3660
aagaatgtac gtccagcctg ccccggagct ggaggatccc ctccaagcct aaaaggttgt 3720
taatagttgg aggtgattcc agtgaagata ttttatttcc tttgtccttt ttcaggagaa 3780
ttagatttct ataggatttt tctttaggag atttattttt tggacttcaa agcaagctgg 3840
tattttcata caaattcttc taattgctgt gtgtcccagg cagggagacg gtttccaggg 3900
aggggccggc cctgtgtgca ggttccgatg ttattagatg ttacaagttt atatatatct 3960
atatatataa tttattgagt ttttacaaga tgtatttgtt gtagacttaa cacttcttac 4020
gcaatgcttc tagagtttta tagcctggac tgctaccttt caaagcttgg agggaagccg 4080
tgaattcagt tggttcgttc tgtactgtta ctgggccctg agtctgggca gctgtccctt 4140
gcttgcctgc agggccatgg ctcagggtgg tctcttcttg gggcccagtg catggtggcc 4200
agaggtgtca cccaaaccgg caggtgcgat tttgttaacc cagcgacgaa ctttccgaaa 4260
aataaagaca cctggttgct aacctggaaa aaaaaaaaaa aaaa 4304
<210> 124
<211> 371
<212> PRT
<213> Homo sapiens
<400> 124
Leu Glu Ala Ser Glu Glu Val Glu Leu Glu Pro Cys Leu Ala Pro Ser
1 5 10 15
Leu Glu Gln Gln Glu Gln Glu Leu Thr Val Ala Leu Gly Gln Pro Val
20 25 30
Arg Leu Cys Cys Gly Arg Ala Glu Arg Gly Gly His Trp Tyr Lys Glu
35 40 45
Gly Ser Arg Leu Ala Pro Ala Gly Arg Val Arg Gly Trp Arg Gly Arg
50 55 60
Leu Glu Ile Ala Ser Phe Leu Pro Glu Asp Ala Gly Arg Tyr Leu Cys
65 70 75 80
Leu Ala Arg Gly Ser Met Ile Val Leu Gln Asn Leu Thr Leu Ile Thr
85 90 95
Gly Asp Ser Leu Thr Ser Ser Asn Asp Asp Glu Asp Pro Lys Ser His
100 105 110
Arg Asp Pro Ser Asn Arg His Ser Tyr Pro Gln Gln Ala Pro Tyr Trp
115 120 125
Thr His Pro Gln Arg Met Glu Lys Lys Leu His Ala Val Pro Ala Gly
130 135 140
Asn Thr Val Lys Phe Arg Cys Pro Ala Ala Gly Asn Pro Thr Pro Thr
145 150 155 160
Ile Arg Trp Leu Lys Asp Gly Gln Ala Phe His Gly Glu Asn Arg Ile
165 170 175
Gly Gly Ile Arg Leu Arg His Gln His Trp Ser Leu Val Met Glu Ser
180 185 190
Val Val Pro Ser Asp Arg Gly Thr Tyr Thr Cys Leu Val Glu Asn Ala
195 200 205
Val Gly Ser Ile Arg Tyr Asn Tyr Leu Leu Asp Val Leu Glu Arg Ser
210 215 220
Pro His Arg Pro Ile Leu Gln Ala Gly Leu Pro Ala Asn Thr Thr Ala
225 230 235 240
Val Val Gly Ser Asp Val Glu Leu Leu Cys Lys Val Tyr Ser Asp Ala
245 250 255
Gln Pro His Ile Gln Trp Leu Lys His Ile Val Ile Asn Gly Ser Ser
260 265 270
Phe Gly Ala Asp Gly Phe Pro Tyr Val Gln Val Leu Lys Thr Ala Asp
275 280 285
Ile Asn Ser Ser Glu Val Glu Val Leu Tyr Leu Arg Asn Val Ser Ala
290 295 300
Glu Asp Ala Gly Glu Tyr Thr Cys Leu Ala Gly Asn Ser Ile Gly Leu
305 310 315 320
Ser Tyr Gln Ser Ala Trp Leu Thr Val Leu Pro Glu Glu Asp Pro Thr
325 330 335
Trp Thr Ala Ala Ala Pro Glu Ala Arg Tyr Thr Asp Lys Leu Glu Phe
340 345 350
Arg His Asp Ser Gly Leu Asn Asp Ile Phe Glu Ala Gln Lys Ile Glu
355 360 365
Trp His Glu
370
<210> 125
<211> 4657
<212> DNA
<213> Homo sapiens
<400> 125
ggcggcggct ggaggagagc gcggtggaga gccgagcggg cgggcggcgg gtgcggagcg 60
ggcgagggag cgcgcgcggc cgccacaaag ctcgggcgcc gcggggctgc atgcggcgta 120
cctggcccgg cgcggcgact gctctccggg ctggcggggg ccggccgcga gccccggggg 180
ccccgaggcc gcagcttgcc tgcgcgctct gagccttcgc aactcgcgag caaagtttgg 240
tggaggcaac gccaagcctg agtcctttct tcctctcgtt ccccaaatcc gagggcagcc 300
cgcgggcgtc atgcccgcgc tcctccgcag cctggggtac gcgtgaagcc cgggaggctt 360
ggcgccggcg aagacccaag gaccactctt ctgcgtttgg agttgctccc cgcaaccccg 420
ggctcgtcgc tttctccatc ccgacccacg cggggcgcgg ggacaacaca ggtcgcggag 480
gagcgttgcc attcaagtga ctgcagcagc agcggcagcg cctcggttcc tgagcccacc 540
gcaggctgaa ggcattgcgc gtagtccatg cccgtagagg aagtgtgcag atgggattaa 600
cgtccacatg gagatatgga agaggaccgg ggattggtac cgtaaccatg gtcagctggg 660
gtcgtttcat ctgcctggtc gtggtcacca tggcaacctt gtccctggcc cggccctcct 720
tcagtttagt tgaggatacc acattagagc cagaagagcc accaaccaaa taccaaatct 780
ctcaaccaga agtgtacgtg gctgcgccag gggagtcgct agaggtgcgc tgcctgttga 840
aagatgccgc cgtgatcagt tggactaagg atggggtgca cttggggccc aacaatagga 900
cagtgcttat tggggagtac ttgcagataa agggcgccac gcctagagac tccggcctct 960
atgcttgtac tgccagtagg actgtagaca gtgaaacttg gtacttcatg gtgaatgtca 1020
cagatgccat ctcatccgga gatgatgagg atgacaccga tggtgcggaa gattttgtca 1080
gtgagaacag taacaacaag agagcaccat actggaccaa cacagaaaag atggaaaagc 1140
ggctccatgc tgtgcctgcg gccaacactg tcaagtttcg ctgcccagcc ggggggaacc 1200
caatgccaac catgcggtgg ctgaaaaacg ggaaggagtt taagcaggag catcgcattg 1260
gaggctacaa ggtacgaaac cagcactgga gcctcattat ggaaagtgtg gtcccatctg 1320
acaagggaaa ttatacctgt gtagtggaga atgaatacgg gtccatcaat cacacgtacc 1380
acctggatgt tgtggagcga tcgcctcacc ggcccatcct ccaagccgga ctgccggcaa 1440
atgcctccac agtggtcgga ggagacgtag agtttgtctg caaggtttac agtgatgccc 1500
agccccacat ccagtggatc aagcacgtgg aaaagaacgg cagtaaatac gggcccgacg 1560
ggctgcccta cctcaaggtt ctcaagcact cggggataaa tagttccaat gcagaagtgc 1620
tggctctgtt caatgtgacc gaggcggatg ctggggaata tatatgtaag gtctccaatt 1680
atatagggca ggccaaccag tctgcctggc tcactgtcct gccaaaacag caagcgcctg 1740
gaagagaaaa ggagattaca gcttccccag actacctgga gatagccatt tactgcatag 1800
gggtcttctt aatcgcctgt atggtggtaa cagtcatcct gtgccgaatg aagaacacga 1860
ccaagaagcc agacttcagc agccagccgg ctgtgcacaa gctgaccaaa cgtatccccc 1920
tgcggagaca ggtaacagtt tcggctgagt ccagctcctc catgaactcc aacaccccgc 1980
tggtgaggat aacaacacgc ctctcttcaa cggcagacac ccccatgctg gcaggggtct 2040
ccgagtatga acttccagag gacccaaaat gggagtttcc aagagataag ctgacactgg 2100
gcaagcccct gggagaaggt tgctttgggc aagtggtcat ggcggaagca gtgggaattg 2160
acaaagacaa gcccaaggag gcggtcaccg tggccgtgaa gatgttgaaa gatgatgcca 2220
cagagaaaga cctttctgat ctggtgtcag agatggagat gatgaagatg attgggaaac 2280
acaagaatat cataaatctt cttggagcct gcacacagga tgggcctctc tatgtcatag 2340
ttgagtatgc ctctaaaggc aacctccgag aatacctccg agcccggagg ccacccggga 2400
tggagtactc ctatgacatt aaccgtgttc ctgaggagca gatgaccttc aaggacttgg 2460
tgtcatgcac ctaccagctg gccagaggca tggagtactt ggcttcccaa aaatgtattc 2520
atcgagattt agcagccaga aatgttttgg taacagaaaa caatgtgatg aaaatagcag 2580
actttggact cgccagagat atcaacaata tagactatta caaaaagacc accaatgggc 2640
ggcttccagt caagtggatg gctccagaag ccctgtttga tagagtatac actcatcaga 2700
gtgatgtctg gtccttcggg gtgttaatgt gggagatctt cactttaggg ggctcgccct 2760
acccagggat tcccgtggag gaacttttta agctgctgaa ggaaggacac agaatggata 2820
agccagccaa ctgcaccaac gaactgtaca tgatgatgag ggactgttgg catgcagtgc 2880
cctcccagag accaacgttc aagcagttgg tagaagactt ggatcgaatt ctcactctca 2940
caaccaatga ggaatacttg gacctcagcc aacctctcga acagtattca cctagttacc 3000
ctgacacaag aagttcttgt tcttcaggag atgattctgt tttttctcca gaccccatgc 3060
cttacgaacc atgccttcct cagtatccac acataaacgg cagtgttaaa acatgaatga 3120
ctgtgtctgc ctgtccccaa acaggacagc actgggaacc tagctacact gagcagggag 3180
accatgcctc ccagagcttg ttgtctccac ttgtatatat ggatcagagg agtaaataat 3240
tggaaaagta atcagcatat gtgtaaagat ttatacagtt gaaaacttgt aatcttcccc 3300
aggaggagaa gaaggtttct ggagcagtgg actgccacaa gccaccatgt aacccctctc 3360
acctgccgtg cgtactggct gtggaccagt aggactcaag gtggacgtgc gttctgcctt 3420
ccttgttaat tttgtaataa ttggagaaga tttatgtcag cacacactta cagagcacaa 3480
atgcagtata taggtgctgg atgtatgtaa atatattcaa attatgtata aatatatatt 3540
atatatttac aaggagttat tttttgtatt gattttaaat ggatgtccca atgcacctag 3600
aaaattggtc tctctttttt taatagctat ttgctaaatg ctgttcttac acataatttc 3660
ttaattttca ccgagcagag gtggaaaaat acttttgctt tcagggaaaa tggtataacg 3720
ttaatttatt aataaattgg taatatacaa aacaattaat catttatagt tttttttgta 3780
atttaagtgg catttctatg caggcagcac agcagactag ttaatctatt gcttggactt 3840
aactagttat cagatccttt gaaaagagaa tatttacaat atatgactaa tttggggaaa 3900
atgaagtttt gatttatttg tgtttaaatg ctgctgtcag acgattgttc ttagacctcc 3960
taaatgcccc atattaaaag aactcattca taggaaggtg tttcattttg gtgtgcaacc 4020
ctgtcattac gtcaacgcaa cgtctaactg gacttcccaa gataaatggt accagcgtcc 4080
tcttaaaaga tgccttaatc cattccttga ggacagacct tagttgaaat gatagcagaa 4140
tgtgcttctc tctggcagct ggccttctgc ttctgagttg cacattaatc agattagcct 4200
gtattctctt cagtgaattt tgataatggc ttccagactc tttggcgttg gagacgcctg 4260
ttaggatctt caagtcccat catagaaaat tgaaacacag agttgttctg ctgatagttt 4320
tggggatacg tccatctttt taagggattg ctttcatcta attctggcag gacctcacca 4380
aaagatccag cctcatacct acatcagaca aaatatcgcc gttgttcctt ctgtactaaa 4440
gtattgtgtt ttgctttgga aacacccact cactttgcaa tagccgtgca agatgaatgc 4500
agattacact gatcttatgt gttacaaaat tggagaaagt atttaataaa acctgttaat 4560
ttttatactg acaataaaaa tgtttctaca gatattaatg ttaacaagac aaaataaatg 4620
tcacgcaact tattttttta ataaaaaaaa aaaaaaa 4657
<210> 126
<211> 400
<212> PRT
<213> Macaca fascicularis
<400> 126
Met Glu Thr Asp Thr Leu Leu Leu Trp Val Leu Leu Leu Trp Val Pro
1 5 10 15
Gly Ser Thr Gly Arg Pro Ser Phe Ser Leu Val Glu Asp Thr Thr Leu
20 25 30
Glu Pro Glu Glu Pro Pro Thr Lys Tyr Gln Ile Ser Gln Pro Glu Val
35 40 45
Tyr Val Ala Ala Pro Gly Glu Ser Leu Glu Val Arg Cys Leu Leu Lys
50 55 60
Asp Ala Ala Val Ile Ser Trp Thr Lys Asp Gly Val His Leu Gly Pro
65 70 75 80
Asn Asn Arg Thr Val Leu Ile Gly Glu Tyr Leu Gln Ile Lys Gly Ala
85 90 95
Thr Pro Arg Asp Ser Gly Leu Tyr Ala Cys Thr Ala Thr Arg Thr Val
100 105 110
Asp Ser Glu Thr Trp Tyr Phe Met Val Asn Val Thr Asp Ala Ile Ser
115 120 125
Ser Gly Asp Asp Glu Asp Asp Thr Asp Gly Ala Glu Asp Phe Val Ser
130 135 140
Glu Asn Gly Asn Asn Lys Arg Ala Pro Tyr Trp Thr Asn Thr Glu Lys
145 150 155 160
Met Glu Lys Arg Leu His Ala Val Pro Ala Ala Asn Thr Val Lys Phe
165 170 175
Arg Cys Pro Ala Gly Gly Asn Pro Thr Pro Thr Met Arg Trp Leu Lys
180 185 190
Asn Gly Lys Glu Phe Lys Gln Glu His Arg Ile Gly Gly Tyr Lys Val
195 200 205
Arg Asn Gln His Trp Ser Leu Ile Met Glu Ser Val Val Pro Ser Asp
210 215 220
Lys Gly Asn Tyr Thr Cys Val Val Glu Asn Glu Tyr Gly Ser Ile Asn
225 230 235 240
His Thr Tyr His Leu Asp Val Val Glu Arg Ser Pro His Arg Pro Ile
245 250 255
Leu Gln Ala Gly Leu Pro Ala Asn Ala Ser Thr Val Val Gly Gly Asp
260 265 270
Val Glu Phe Val Cys Lys Val Tyr Ser Asp Ala Gln Pro His Ile Gln
275 280 285
Trp Ile Lys His Val Glu Lys Asn Gly Ser Lys Tyr Gly Pro Asp Gly
290 295 300
Leu Pro Tyr Leu Lys Val Leu Lys His Ser Gly Ile Asn Ser Ser Asn
305 310 315 320
Ala Glu Val Leu Ala Leu Phe Asn Val Thr Glu Ala Asp Ala Gly Glu
325 330 335
Tyr Ile Cys Lys Val Ser Asn Tyr Ile Gly Gln Ala Asn Gln Ser Ala
340 345 350
Trp Leu Thr Val Leu Pro Lys Gln Gln Ala Pro Gly Arg Glu Lys Glu
355 360 365
Ile Thr Ala Ser Pro Asp Tyr Leu Glu Lys Leu Glu Phe Arg His Asp
370 375 380
Ser Gly Leu Asn Asp Ile Phe Glu Ala Gln Lys Ile Glu Trp His Glu
385 390 395 400
<210> 127
<211> 5223
<212> DNA
<213> Mus musculus
<400> 127
gatgtgcgga taagtacaat tacctattca cgtgttccct tcctaaagga gggtttccca 60
aacactcgtc ccctgtctat tgttcagagg aacaagacaa cgcaacatct cccacgaaca 120
tccgctgctt ccaccctcaa agcttcatga catgaaatgt ctggccccag tatgctgcag 180
acctattcta aggtgtctga agttgcacag cattctgtca tttgtttcct aacttgacat 240
aaaacaacgt aacgcatcca ctgtgcacca aagctggcta ggaactgggg cagtggcgta 300
cagaggccgt tcaccaacag ggttccgaga ggtcatctgt gcacccctgc gggcagcgcg 360
gcggggcccc tcgcctgcct ggcgggtgtc tctttgcggc tgctaggctt cgggggcagc 420
gcggggctcg ggactgcccc agcgcgaggc gctgattggc agagcgggcg ccgccgtcca 480
ggaaacggct cgggtttcag cggggggcgt gacccgcccg aggaggctgc ggcggcggcg 540
cgggcggcga ggggagagag ccgggagagg cgagcggcgg cggcggcagg cgcggaacgg 600
gcgcacggac gatcgaacgc gcggccgcca gagctccggc gcgggggctg cctgtgtgtt 660
cctggcccgg cgtggcgact gctctccggg ctggcggggg ccgggcgtga gcccccgggc 720
ctcagcgttc ctgagcgctg cgagtgttca ctactcgcca gcaaagtttg gagtaggcaa 780
cgccaagctc cagtcctttc ttctgctgct gcccagatcc gagagcagct ccggtgtcat 840
gtcctagctg ttctgcgatc cccggcgcgc gtgaagcctc ggaaccttgg cgccggctgc 900
tacccaagga atcgttctct ttttggagtt ttcctccgag atcatcgcct gctccatccc 960
gatccactct gggctccggc gcagcaccga gcgcagagga gcgctgccat tcaagtggca 1020
gccacagcag cagcagcagc agcagtggga gcaggaacag cagtaacaac agcaacagca 1080
gcacagccgc ctcagagctt tggctcctga gccccctgtg ggctgaaggc attgcaggta 1140
gcccatggtc tcagaagaag tgtgcagatg ggattaccgt ccacgtggag atatggaaga 1200
ggaccaggga ttggcactgt gaccatggtc agctgggggc gcttcatctg cctggtcttg 1260
gtcaccatgg caaccttgtc cctggcccgg ccctccttca gtttagttga ggataccact 1320
ttagaaccag aagagccacc aaccaaatac caaatctccc aaccagaagc gtacgtggtt 1380
gcccccgggg aatcgctaga gttgcagtgc atgttgaaag atgccgccgt gatcagttgg 1440
actaaggatg gggtgcactt ggggcccaac aataggacag tgcttattgg ggagtatctc 1500
cagataaaag gtgccacacc tagagactcc ggcctctatg cttgtactgc agctaggacg 1560
gtagacagtg aaacttggta cttcatggtg aatgtcacag atgccatctc atctggagat 1620
gatgaggacg acacagatag ctccgaagac gttgtcagtg agaacaggag caaccagaga 1680
gcaccgtact ggaccaacac cgagaagatg gagaagcggc tccacgctgt ccctgccgcc 1740
aacactgtga agttccgctg tccggctggg gggaatccaa cgcccacaat gaggtggtta 1800
aaaaacggga aggagtttaa gcaggagcat cgcattggag gctataaggt acgaaaccag 1860
cactggagcc ttattatgga aagtgtggtc ccgtcagaca aaggcaacta cacctgcctg 1920
gtggagaatg aatacgggtc catcaaccac acctaccacc tcgatgtcgt tgaacggtca 1980
ccacaccggc ccatcctcca agctggactg cctgcaaatg cctccacggt ggtcggaggg 2040
gatgtggagt ttgtctgcaa ggtttacagc gatgcccagc cccacatcca gtggatcaag 2100
cacgtggaaa agaacggcag taaatacggg cctgatgggc tgccctacct caaggtcctg 2160
aaggccgccg gtgttaacac cacggacaaa gagattgagg ttctctatat tcggaatgta 2220
acttttgagg atgctgggga atatacgtgc ttggcgggta attctatcgg gatatccttt 2280
cactctgcat ggttgacagt tctgccagcg cctgtgagag agaaggagat cacggcttcc 2340
ccagattatc tggagatagc tatttactgc ataggggtct tcttaatcgc ctgcatggtg 2400
gtgacagtca tcttttgccg aatgaagacc acgaccaaga agccagactt cagcagccag 2460
ccagctgtgc acaagctgac caagcgcatc cccctgcgga gacaggtaac agtttcggcc 2520
gagtccagct cctccatgaa ctccaacacc ccgctggtga ggataacaac gcgtctgtcc 2580
tcaacagcgg acaccccgat gctagcaggg gtctccgagt atgagttgcc agaggatcca 2640
aagtgggaat tccccagaga taagctgacg ctgggcaaac ccctggggga aggttgcttc 2700
gggcaagtag tcatggctga agcagtggga atcgataaag acaaacccaa ggaggcggtc 2760
accgtggcag tgaagatgtt gaaagatgat gccacagaga aggacctgtc tgatctggta 2820
tcagagatgg agatgatgaa gatgattggg aaacataaga acattatcaa cctcctgggg 2880
gcctgcacgc aggatggacc tctctacgtc atagttgaat atgcatcgaa aggcaacctc 2940
cgggaatacc tccgagcccg gaggccacct ggcatggagt actcctatga cattaaccgt 3000
gtccccgagg agcagatgac cttcaaggac ttggtgtcct gcacctacca gctggctaga 3060
ggcatggagt acttggcttc ccaaaaatgt atccatcgag atttggctgc cagaaacgtg 3120
ttggtaacag aaaacaatgt gatgaagata gcagactttg gcctggccag ggatatcaac 3180
aacatagact actataaaaa gaccacaaat gggcgacttc cagtcaagtg gatggctcct 3240
gaagcccttt ttgatagagt ttacactcat cagagcgatg tctggtcctt cggggtgtta 3300
atgtgggaga tctttacttt agggggctca ccctacccag ggattcccgt ggaggaactt 3360
tttaagctgc tcaaagaggg acacaggatg gacaagccca ccaactgcac caatgaactg 3420
tacatgatga tgagggattg ctggcatgct gtaccctcac agagacccac attcaagcag 3480
ttggtcgaag acttggatcg aattctgact ctcacaacca atgaggaata cttggatctc 3540
acccagcctc tcgaacagta ttctcctagt taccccgaca caaggagctc ttgttcttca 3600
ggggacgatt ctgtgttttc tccagacccc atgccttatg aaccctgtct gcctcagtat 3660
ccacacataa acggcagtgt taaaacatga gtgaatgtgt cttcctgtcc ccaaacagga 3720
cagcaccagg aacctactta cactgagcag agaggctgtg cctccagagc ctgtgacacg 3780
cctccacttg tatatatgga tcagaggagt aaatagtggg aagcatattt gtcacgtgtg 3840
taaagattta tacagttgga aacatgttac ctaaccagga aaggaagact gtttcctgat 3900
aagtggacag ccgcaagcca ccatgccacc ctctctgacc caccatgtat gctggctgtg 3960
ccccagttgg actcaaggca gacaggtgtt ctgccttcct tgttaatttt gtaataattg 4020
gagaagatat atgtcagcac acacttacag agcacaaacg cagtatatag gtgctggatg 4080
tatgtaaata tattcaaatt atgtataaat atatattata tatttacaag gaattatttt 4140
ttgtattgat tttaaatgga tgtcctgatg cacctagaaa attggtctct ctttttttta 4200
aatagatatt tgctaaatgc tgttcttaga gtttcttaat tttcaccgag cagaggtggg 4260
aaaatacttt tgctttcagg gaaaatggtg tcacattaat ttattaacga attggtaata 4320
tacgaaacga ttaatcatct atagtttttt tttttttgta atttaagtgg catttctatg 4380
caggcagcac ggaggactag ttaatctatt gcttggactt aactggttat tggatccttt 4440
gagaagagaa atatttacga tatatgacta atttgggggg aaatggtgtt ttgatttatt 4500
tgtgtttcaa ctctgctgtc cgatgagcat gtctagacac cctaatgccc atgtttcaag 4560
aaacctgtta aactctgtca ccccagggta acaattaacc agacttccca agacaaatgg 4620
taccagcatc ctcatcccaa gatgccttaa tccacttctc tggagaacag acttccatgg 4680
gaatgatagc agggtcctct cgtccggcag ctggccttct gcccgggtta cacattcatc 4740
acgtttgcct tgcttctcag tgagttttaa taacagcttc agattcttca gcaccaagag 4800
ccctttgggg aatctccatc ctctcgaagg atggcaaaag cccagcatca ttcggttgag 4860
agtctgggac ctccttccat cttcttaagg gtttgcttct ggcttctacc cacttctgac 4920
aagacctcac ctcacaaaaa gatctggcct aatagctaca tccgacaaga taacgcttat 4980
tgttgatttc cgtattcaag tattgttttg ctttggatac gcccactcac tttgctacag 5040
tcatgcgaca tgtatgcaga ttacactgat tttatgtgtt ttggaattgg agaaagtatt 5100
taataaaacc tgttaatttt tatactgaca ataaaaatgt ttctacagat attaatgtta 5160
acaagacaaa ataaatgtca cgcagcttat ttttttaaaa aaaaaaaaaa aaaaaaaaaa 5220
aaa 5223
<210> 128
<211> 4277
<212> DNA
<213> Rattus norvegicus
<400> 128
gcggccgcag cagcagcagc agcgacagca gcagcaacaa cagcctgagc aagccacagc 60
agcgccctgg ctcctgagcc ccccgtgggc tgaaggcatt gcaggtagcc catggtccct 120
gaagaagtgt gcagatggga ttaccgtcca catggagata tggaacagga ccagggattg 180
gcaccgtgac catggtcagc tgggggcgct tcatctgcct ggtcttggtc accatggcaa 240
ccttgtccct ggcccggccc tccttcagtt tagttgaaga taccacttta gaaccagaag 300
agccaccaac caaataccaa atctcccaac cagaagcgtg cgtggttgcc cccggggagt 360
cgctagagtt gcgctgcatg ttgaaagatg ccgccgtgat cagttggact aaggatgggg 420
tgcacttggg gcccaacaat aggacagtgc ttattgggga gtacctccag ataaaaggtg 480
ccacacctag agactccggc ctctatgctt gtgctgcagc taggacggta gacagtgaaa 540
ctttgtactt catggtgaat gtcacagatg ccatctcatc tggagatgac gaggacgaca 600
cagatagctc cgaagacttt gtcagtgaga acaggagcaa ccagagagca ccgtactgga 660
ccaacaccga aaagatggag aagcggctcc atgctgtccc tgccgccaac actgtgaagt 720
tccgctgtcc agccgggggg aatccaacac ccacaatgag gtggctaaaa aacgggaagg 780
agtttaagca ggagcatcgc atcggaggct ataaggtacg aaaccagcac tggagcctta 840
ttatggaaag tgtggtccca tcagacaaag gcaattacac ctgcctggtg gagaatgaat 900
acgggtccat caaccacacc taccaccttg atgttgttga gcgatcacca caccggccca 960
tcctccaagc tggactgcct gcaaatgcct ccacggtggt cggaggggac gtagaatttg 1020
tctgcaaggt ttatagtgat gcccagcccc atatccagtg gatcaaacat gtggaaaaga 1080
acggcagtaa atatggacct gatgggctgc cctacctcaa ggtcctgaag gtgagaaagg 1140
ccgccggtgt taacaccacg gacaaagaaa ttgaggttct ctatattcgg aatgtaactt 1200
ttgaggatgc tggggaatat acgtgcttgg cgggtaattc tatcgggata tcctttcact 1260
ctgcatggtt gacagttctg ccagcacctg tgagagagaa ggagatcaca gcttccccag 1320
attacctgga gatagctatt tactgcatag gggtcttctt aatcgcctgc atggtggtga 1380
cagtcatctt ttgccgaatg aagaccacga ccaagaagcc agacttcagc agccagccag 1440
ctgtgcacaa gctgaccaag cgcatccccc tgcggagaca ggtttcggcc gagtccagct 1500
cgtccatgaa ctccaacacc ccactggtga ggataacgac acgtctgtcc tcaacggcgg 1560
acaccccgat gctagcaggg gtctctgagt acgagttgcc agaggatcca aagtgggaat 1620
tccccagaga taagctgacg ctgggcaaac ccctggggga aggctgcttc gggcaagtag 1680
tcatggctga agcggtggga atcgataagg acagacccaa ggaggcagtc accgtggcgg 1740
tgaagatgtt gaaagatgac gccacagaga aggacctgtc tgacctggtg tcagagatgg 1800
agatgatgaa gatgattggt aaacataaga acatcatcaa cctcctgggg gcctgcaccc 1860
aggatggacc cctctatgtc atagtcgaat acgcatcgaa aggcaacctc cgggaatacc 1920
tccgggcccg gaggccacct ggcatggagt actcctatga cattaaccga gttcccgagg 1980
agcagatgac cttcaaggac ttggtgtcct gcacctacca gctggcgaga ggcatggagt 2040
acttggcttc ccaaaaatgt atccatcgag acttggcagc cagaaatgtg ctggtaacag 2100
aaaacaacgt gatgaagata gcagactttg gcctggccag ggatatcaac aacatagact 2160
attacaaaaa gaccacgaat gggcgacttc cagtcaagtg gatggctcct gaagcccttt 2220
ttgatagagt ttacactcat cagagtgatg tctggtcctt cggggtgtta atgtgggaga 2280
tcttcacttt agggggttca ccctacccag ggattcccgt ggaggaactt tttaagctgc 2340
tcaaagaggg ccacaggatg gacaagccca ccaactgcac caatgaactg tacatgatga 2400
tgagggactg ctggcatgct gtaccctcac agaggcccac gtttaagcag ttggtggaag 2460
acttggatcg aattctgact ctcacaacca atgaggaata cttggacctc agtcagcctc 2520
tcgaaccgta ttcaccttgt tatcctgacc caaggtgaaa taaaacgtct ctcttccctt 2580
cttgcaggaa tacttggacc tcacccagcc tctcgaacag tattctccta gttaccccga 2640
cacaaggagc tcttgttctt caggggacga ttctgtgttt tctccagacc ccatgcctta 2700
tgacccctgc ctgcctcagt atccacacat aaacggcagt gttaaaacat gagcgggtgt 2760
gtcttcctgt ccccaaacag gacagcacca ggaacctact tacactgagc agagaggctg 2820
tgcccccaaa gcgtgtggca tgcctccaca tgtatatatg gatcagagga gtaaatagtg 2880
ggaagagtat ttgtcacgtg tgtgaagatt tatacagttg gaaacatgtt actttcccag 2940
gaaaggaaga ctgtttcctg ataagtggac agccgcaagc caccgccacc ctctctgacc 3000
taccatgtat gctggctgtg ccccagttgg actcaaggca gaccgctgtt ctgccttcct 3060
tgttaatttt gtaataattg gagaagatat atgtcagcac atacttacag agcacaaatg 3120
cagtatatag gtgctggatg tatgtaaata tattcaaatt atgtataaat atatattata 3180
tatttacaag gaattatttt ttgtattgat cttaaatgga tgtcctgatg cacctagaaa 3240
attggtctct ccattttttt taaatagata tttgctaaat gctgttctta gaatttctta 3300
attttcaccg agcagaggtg ggaaaatact tttgctttca gggaaaatgg tgtcacatta 3360
atttattaat gaattggtaa tatacgaaac aattaatcat ctatagtttg tttttttttt 3420
tttgtaattt aagtggcatt tctatgcaga cagcacagag gactagttaa tctattgctt 3480
ggacttaact ggttattgga tcctttgaga agagaaatat ttacgatata tgactaattt 3540
ggggggaaat gatgtcttga tttatttgtg tttcaactct gctgtccgat gattatgtct 3600
aaacacctca atgcccacct ttcaagaaac cttttaaact ctgtcacccc agtgtaacaa 3660
ttaaccagac ttcccatgac aaatggtacc agagtcctca tcccaagatg ccttaatcct 3720
cttctctgga gaacagactc ccatcggaga cggcagggtg ggtcttgtct ggcagctggc 3780
cttctgcctg agttacacac ccgtcacatt cgccttgctc cctctccgtg agttttgata 3840
acagcttcag attcttcagc atcaaaaact ctttggggac tctccatcct ctcggagaat 3900
agtgaaagcc cagggttatt ctgtcgagag tttgggacct ccttccatct tctgcagggt 3960
ttgcttctgg cttccaccca cttctgacaa gacctctcct cactaaaaga tctggcccga 4020
gagctacacc cgacaagaga acgcttacca ttgatttccg tgttcaagtc ttgtgctttg 4080
ctttggacac gcccactcac cttgctaccg tcatgtgaca ggagtgcaga ctacactgat 4140
tttatgtgtt ttgaaattgg agaaagtatt taataaaacc tgttaatttt tatactgaca 4200
ataaaaatgt ttctacagat attaatgtta acgagacaaa aataaatgtc gcgcagctta 4260
tttttttaat actcgtg 4277
<210> 129
<211> 3164
<212> DNA
<213> Rattus norvegicus
<400> 129
ctgtagttgc agggacattc ctggctcttc ggcccggggc ggaggagctc caggcgggtg 60
agtgtgccag ccctgccggg atcgtgaccc ccgagcacgg gaaccgggtg gcggaggagc 120
caggaaggtg gtcagcggga agtctggcct gggtcccgag aacagctgga aggaaatgtg 180
gctgctgttg gctttgttga gcatctttca ggagacacca gccttctccc ttgaggcctc 240
tgaggaaatg gaacaggagc cctgcccagc cccaatctcg gagcagcaag agcaggtgtt 300
gactgtggcc cttgggcagc ctgtgcggct atgctgtggc cgcactgagc gtggtcgtca 360
ttggtacaag gagggcagcc gtttagcatc tgctgggaga gtacggggct ggagaggccg 420
cctggagatc gccagcttcc ttcctgagga tgctggccgg tacctctgcc tggcccgtgg 480
ctccatgact gtcgtacaca atcttacttt gattatggat gactccttac cctccatcaa 540
taacgaggac cccaagaccc tcagcagctc ctcgagtggg cactcctacc tgcagcaagc 600
accttactgg acacaccccc aacgcatgga gaagaaactg cacgcggtac ctgccgggaa 660
cactgtcaaa ttccgctgtc cagctgcagg gaaccccatg cccaccatcc actggctcaa 720
gaacggacag gccttccacg gagagaatcg tatcggaggc attcggctgc gtcaccaaca 780
ctggagcctc gtgatggaga gcgtggtgcc ctcagaccgt ggcacgtaca cgtgtcttgt 840
ggagaactct ctgggtagca ttcgctacag ctatctgctg gatgtgctgg agcggtcccc 900
gcaccggccc atcctgcagg cgggactccc agccaacacc acggctgtgg ttggcagcaa 960
cgtggagctg ctgtgcaagg tgtacagtga cgcccagccg cacatccagt ggctgaagca 1020
catcgttatc aacggcagca gtttcggcgc tgatggtttc ccctacgtac aagtcctgaa 1080
gacaacagac atcaatagct cagaggtgga ggtgctgtat ctgaggaacg tgtcggctga 1140
ggatgcaggg gagtacacct gcctggcggg caactccatc ggcctctcct accagtcagc 1200
gtggctcaca gtgctacccg cagaggaaga agacctcgcg tggacaacag caacatcgga 1260
ggccagatat acagatatta tcctatatgt atctggctca ctggctttgg ttttgctcct 1320
gctgctggcc ggggtgtatc accgacaagc aatccacggc caccactctc gacagcctgt 1380
cactgtacag aagctgtccc ggttcccttt ggcccggcag ttctccttgg agtcgaggtc 1440
ctctggcaag tcaagtttgt ccctggtgcg aggtgtccgg ctctcctcca gtggcccgcc 1500
cttgctcacg ggccttgtga gtctagacct acctctcgat ccactttggg agttcccccg 1560
ggacaggctg gtgctcggaa agcccctggg tgagggctgc tttgggcaag tggttcgtgc 1620
agaagccctt ggcatggatt cctcccggcc agaccaaacc agcaccgtgg ctgtgaagat 1680
gctgaaagac aatgcctccg acaaggattt ggcagacctg atctctgaga tggagatgat 1740
gaagctaatc ggaagacaca agaacatcat taacctgctg ggtgtctgca ctcaggaagg 1800
gcccctgtat gtgattgtgg aatatgcggc caagggaaac cttcgggaat tcctccgtgc 1860
ccggcgtccc ccaggccctg atctcagccc tgatgggcct cggagcagcg aaggaccgct 1920
ctccttcccg gccctggtct cctgtgccta ccaggtggcc cgaggcatgc agtatctgga 1980
gtctcggaag tgcatccacc gggacctggc tgcccgaaac gtgctggtga ccgaggatga 2040
cgtgatgaag atcgctgact ttggtctggc ccgtggtgtc caccacatcg actactataa 2100
gaaaaccagc aatggccgcc tgccagtcaa gtggatggct cctgaggcgt tgtttgaccg 2160
tgtatacaca caccagagtg acgtgtggtc cttcgggatc ctgctgtggg aaatcttcac 2220
cctcgggggc tccccatacc ccggcatccc agtggaggag ctgttctcac tgctgcgaga 2280
ggggcacagg atggagcggc ccccaaactg cccctcagag ctgtatgggc taatgaggga 2340
gtgttggcac gcagctcctt ctcagaggcc gacttttaag cagctggtgg aagctctgga 2400
caaggtcctg ctggctgtct ctgaagagta ccttgacctc cgcctgacct ttggacccta 2460
ttcccccaac aatggggatg ccagcagcac gtgctcctcc agcgactcgg ttttcagcca 2520
cgaccctttg cccctcgagc caagcccctt cccatttcct gaggcgcaga ccacatgagc 2580
ctgggaacga tgttgcatgg gctcgtaggc ccgtggccgt gggactccaa cctgtttcat 2640
cagcatttga cgttggcact gtcatcaggc ctctgactcg aggctactgc tggcccagat 2700
cctctctctg gccctgtttt ggggaggccc attcttggtc ttggggttca cagttgaggc 2760
cttctgttcc aaacttatgt tcccagctca gagttcaact cctcgtctca agatcatggt 2820
cgtgcccttg gactcatcct caaaggagcg aagcattaag gccttgacac ttagcctcca 2880
ccccaggggc tctccgggcc tgactgcaaa tctttggtcc taaacatttc tagctcccca 2940
aacaacctag aggcctcggg acttcactgc acccccgccc ccgcagccca caagcctcgc 3000
caccctggtc cccaactccc cactgcttgt tctagcatct tgttgaagga gcctcagctc 3060
tggtgtcctt gagagacgag aagcctgtgg aaaagacaga agaacaaggc attttataaa 3120
ttattattat tttttgaaat aaaaaaaaaa aaaaaaaaaa aaaa 3164
<210> 130
<211> 391
<212> PRT
<213> Macaca fascicularis
<400> 130
Met Glu Thr Asp Thr Leu Leu Leu Trp Val Leu Leu Leu Trp Val Pro
1 5 10 15
Gly Ser Thr Gly Leu Glu Ala Ser Glu Glu Val Glu Leu Glu Pro Cys
20 25 30
Leu Ala Pro Ser Met Glu Gln Gln Glu Gln Glu Leu Thr Val Ala Leu
35 40 45
Gly Gln Pro Val Arg Leu Cys Cys Gly Arg Ala Glu Arg Gly Gly His
50 55 60
Trp Tyr Lys Glu Gly Ser Arg Leu Ala Pro Ala Gly Arg Val Arg Gly
65 70 75 80
Trp Arg Gly Arg Leu Glu Ile Ala Ser Phe Leu Pro Glu Asp Ala Gly
85 90 95
Arg Tyr Leu Cys Leu Ala Arg Ala Ser Met Ile Val Leu Gln Asn Val
100 105 110
Thr Leu Thr Ile Asp Asp Ser Leu Thr Ser Ser Asn Asp Asp Glu Asp
115 120 125
Pro Gln Ser His Arg Asp Ser Ser Asn Gly His Ile Tyr Pro Gln Gln
130 135 140
Ala Pro Tyr Trp Thr His Pro Gln Arg Met Glu Lys Lys Leu His Ala
145 150 155 160
Val Pro Ala Gly Asn Thr Val Lys Phe Arg Cys Pro Ala Ala Gly Asn
165 170 175
Pro Thr Pro Thr Ile Arg Trp Leu Lys Asp Gly Gln Ala Phe His Gly
180 185 190
Glu Asn Arg Ile Gly Gly Ile Arg Leu Arg His Gln His Trp Ser Leu
195 200 205
Val Met Glu Ser Val Val Pro Ser Asp Arg Gly Thr Tyr Thr Cys Leu
210 215 220
Val Glu Asn Ala Val Gly Ser Ile Arg Tyr Asn Tyr Leu Leu Asp Val
225 230 235 240
Leu Glu Arg Ser Pro His Arg Pro Ile Leu Gln Ala Gly Leu Pro Ala
245 250 255
Asn Thr Thr Ala Val Val Gly Ser Asp Val Glu Leu Leu Cys Lys Val
260 265 270
Tyr Ser Asp Ala Gln Pro His Ile Gln Trp Leu Lys His Ile Val Ile
275 280 285
Asn Gly Ser Ser Phe Gly Ala Asp Gly Phe Pro Tyr Val Gln Val Leu
290 295 300
Lys Thr Ala Asp Ile Asn Ser Ser Glu Val Glu Val Leu Tyr Leu Arg
305 310 315 320
Asn Val Ser Ala Glu Asp Ala Gly Glu Tyr Thr Cys Leu Ala Gly Asn
325 330 335
Ser Ile Gly Leu Ser Tyr Gln Ser Ala Trp Leu Thr Val Leu Pro Glu
340 345 350
Glu Asp Leu Thr Trp Thr Ala Ala Thr Pro Glu Ala Arg Tyr Thr Asp
355 360 365
Lys Leu Glu Phe Arg His Asp Ser Gly Leu Asn Asp Ile Phe Glu Ala
370 375 380
Gln Lys Ile Glu Trp His Glu
385 390
<210> 131
<211> 3146
<212> DNA
<213> Mus musculus
<400> 131
gacattcctg gctcttcggc ccggggcgga ggagctccgg gcgggtgagt gtgccagccc 60
tgccgggatc gtgacccgcg cgcgcgggag ccgggcggcg gaggagccag gaaggtggtc 120
agtgggaagt ctggccctga tcctgagatc agctggaagg aaatgtggct gctcttggcc 180
ctgttgagca tctttcaggg gacaccagct ttgtcccttg aggcctctga ggaaatggag 240
caggagccct gcctagcccc aatcctggag cagcaagagc aggtgttgac ggtggccctg 300
gggcagcctg tgaggctgtg ctgtgggcgc accgagcgtg gtcgtcactg gtacaaagag 360
ggcagccgcc tagcatctgc tgggcgagta cggggttgga gaggccgcct ggagatcgcc 420
agcttccttc ctgaggatgc tggccgatac ctctgcctgg cccgtggctc catgaccgtc 480
gtacacaatc ttacgttgct tatggatgac tccttaacct ccatcagtaa tgatgaagac 540
cccaagacac tcagcagctc ctcgagtggt catgtctacc cacagcaagc accctactgg 600
acacaccccc aacgcatgga gaagaaactg catgcagtgc ctgccgggaa tactgtcaaa 660
ttccgctgtc cagctgcagg gaaccccatg cctaccatcc actggctcaa ggatggacag 720
gccttccacg gggagaatcg tattggaggc attcggctgc gccaccaaca ctggagcctg 780
gtgatggaaa gtgtggtacc ctcggaccgt ggcacataca catgccttgt ggagaactct 840
ctgggtagca ttcgctacag ctatctcctg gatgtgctgg agcggtcccc gcaccggccc 900
atcctgcagg cggggctccc agccaacacc acagctgtgg ttggcagcga tgtggagcta 960
ctctgcaagg tgtacagcga cgcccagccc cacatacagt ggctgaaaca cgtcgtcatc 1020
aacggcagca gcttcggcgc cgacggtttc ccctacgtac aagtcctgaa gacaacagac 1080
atcaatagct cggaggtaga ggtcttgtat ctgaggaacg tgtccgctga ggatgcagga 1140
gagtatacct gtctggcggg caactccatc ggcctttcct accagtcagc gtggctcacg 1200
gtgctgccag aggaagacct cacgtggaca acagcaaccc ctgaggccag atacacagat 1260
atcatcctgt atgtatcagg ctcactggtt ctgcttgtgc tcctgctgct ggccggggtg 1320
tatcatcggc aagtcatccg tggccactac tctcgccagc ctgtcactat acaaaagctg 1380
tcccgtttcc ctttggcccg acagttctct ttggagtcga ggtcctctgg caagtcaagt 1440
ttgtccctgg tgcgaggtgt ccgtctctcc tccagcggcc cgcccttgct cacgggcctt 1500
gtgaatctag acctgcctct cgatccgctt tgggaattcc cccgggacag gttggtgctc 1560
ggaaagcccc tgggtgaggg ctgctttggg caagtggttc gtgcagaggc ctttggtatg 1620
gatccctccc ggcccgacca aaccagcacc gtggctgtga agatgctgaa agacaatgcc 1680
tccgacaagg atttggcaga cctggtctcc gagatggagg tgatgaagct aatcggaaga 1740
cacaagaaca tcatcaacct gctgggtgtc tgcactcagg aagggcccct gtacgtgatt 1800
gtggaatgtg ccgccaaggg aaaccttcgg gaattcctcc gtgcccggcg ccccccaggc 1860
cctgatctca gccctgatgg acctcggagc agcgaaggac cactctcctt cccggcccta 1920
gtctcctgtg cctaccaggt ggcccgaggc atgcagtatc tggagtctcg gaagtgcatc 1980
caccgggacc tggctgcccg aaatgtgctg gtgaccgagg atgatgtgat gaagatcgct 2040
gactttgggc tggcacgtgg tgtccaccac attgactact ataagaaaac cagcaacggc 2100
cgcctgccag tcaaatggat ggctccagag gcattgttcg accgcgtgta cacacaccag 2160
agtgacgtgt ggtctttcgg gatcctgctg tgggaaatct tcaccctcgg gggctcccca 2220
taccctggca ttccggtgga ggagctcttc tcactgctgc gagaggggca caggatggag 2280
cggcccccaa actgcccctc agagctgtat gggctaatga gggagtgctg gcacgcagcc 2340
ccatctcaga ggcctacttt taagcagctg gtggaagctc tggacaaggt cctgctggct 2400
gtctctgaag agtaccttga cctccgcctg acctttggac ccttttctcc ctccaatggg 2460
gatgccagca gcacctgctc ctccagtgac tcggttttca gccacgaccc tttgcccctc 2520
gagccaagcc ccttcccttt ctctgactcg cagacgacat gagccgggga gcagcaatgt 2580
tgtatgggct acgcggccca tggccgtggg tctcctcgct gagctgcaac ctgatgcatc 2640
gacatttaat gttggcagtg tcaggcctct gacttgagac tactgctgtc gcagatcctc 2700
tctctggccc tgttttgggg agggccattc ttggtcctaa ggttcatagt tgaggccttc 2760
tgttccagcc ttatgctccc atctcagagt tcaactctca tctcaagatc atggccttgc 2820
ccttggactc atcctcagag aagttaagca ttaaggcctt ggcacgcagc ctccgtctcc 2880
ggggctctcc gggactagct gcaaaactta tgctctaaac atttctagtt cccccaaaca 2940
acctagaggc cttgggactt cacatccccc agcacacaag cctcaccacc ccctgccatc 3000
ccccctccat tgcttgttcc agcatcttgg tgaaaggggc atcagctctg gtgtccctga 3060
gagacgagaa gcctgtggga acgacagaag aacatggcat ttttataaat tatttttttg 3120
aaataaatct ctgtgtgcct ggtggc 3146
<210> 132
<211> 25
<212> PRT
<213> Homo sapiens
<400> 132
Thr His Pro Gln Arg Met Glu Lys Lys Leu His Ala Val Pro Ala Gly
1 5 10 15
Asn Thr Val Lys Phe Arg Cys Pro Ala
20 25
<210> 133
<211> 12
<212> PRT
<213> Homo sapiens
<400> 133
Arg Leu Arg His Gln His Trp Ser Leu Val Met Glu
1 5 10
<210> 134
<400> 134
000
<210> 135
<211> 237
<212> PRT
<213> Homo sapiens
<400> 135
Met Ala Glu Asp Phe Val Ser Glu Asn Ser Asn Asn Lys Arg Ala Pro
1 5 10 15
Tyr Trp Thr Asn Thr Glu Lys Met Glu Lys Arg Leu His Ala Val Pro
20 25 30
Ala Ala Asn Thr Val Lys Phe Arg Cys Pro Ala Gly Gly Asn Pro Met
35 40 45
Pro Thr Met Arg Trp Leu Lys Asn Gly Lys Glu Phe Lys Gln Glu His
50 55 60
Arg Ile Gly Gly Tyr Lys Val Arg Asn Gln His Trp Ser Leu Ile Met
65 70 75 80
Glu Ser Val Val Pro Ser Asp Lys Gly Asn Tyr Thr Cys Val Val Glu
85 90 95
Asn Glu Tyr Gly Ser Ile Asn His Thr Tyr His Leu Asp Val Val Glu
100 105 110
Arg Ser Pro His Arg Pro Ile Leu Gln Ala Gly Leu Pro Ala Asn Ala
115 120 125
Ser Thr Val Val Gly Gly Asp Val Glu Phe Val Cys Lys Val Tyr Ser
130 135 140
Asp Ala Gln Pro His Ile Gln Trp Ile Lys His Val Glu Lys Asn Gly
145 150 155 160
Ser Lys Tyr Gly Pro Asp Gly Leu Pro Tyr Leu Lys Val Leu Lys His
165 170 175
Ser Gly Ile Asn Ser Ser Asn Ala Glu Val Leu Ala Leu Phe Asn Val
180 185 190
Thr Glu Ala Asp Ala Gly Glu Tyr Ile Cys Lys Val Ser Asn Tyr Ile
195 200 205
Gly Gln Ala Asn Gln Ser Ala Trp Leu Thr Val Leu Pro Lys Gln Gln
210 215 220
Ala Pro Gly Arg Glu Lys Glu His His His His His His
225 230 235
<210> 136
<211> 30
<212> PRT
<213> Homo sapiens
<400> 136
Lys Met Glu Lys Arg Leu His Ala Val Pro Ala Ala Asn Thr Val Lys
1 5 10 15
Phe Arg Cys Pro Ala Gly Gly Asn Pro Met Pro Thr Met Arg
20 25 30
<210> 137
<211> 822
<212> PRT
<213> Homo sapiens
<400> 137
Met Val Ser Trp Gly Arg Phe Ile Cys Leu Val Val Val Thr Met Ala
1 5 10 15
Thr Leu Ser Leu Ala Arg Pro Ser Phe Ser Leu Val Glu Asp Thr Thr
20 25 30
Leu Glu Pro Glu Glu Pro Pro Thr Lys Tyr Gln Ile Ser Gln Pro Glu
35 40 45
Val Tyr Val Ala Ala Pro Gly Glu Ser Leu Glu Val Arg Cys Leu Leu
50 55 60
Lys Asp Ala Ala Val Ile Ser Trp Thr Lys Asp Gly Val His Leu Gly
65 70 75 80
Pro Asn Asn Arg Thr Val Leu Ile Gly Glu Tyr Leu Gln Ile Lys Gly
85 90 95
Ala Thr Pro Arg Asp Ser Gly Leu Tyr Ala Cys Thr Ala Ser Arg Thr
100 105 110
Val Asp Ser Glu Thr Trp Tyr Phe Met Val Asn Val Thr Asp Ala Ile
115 120 125
Ser Ser Gly Asp Asp Glu Asp Asp Thr Asp Gly Ala Glu Asp Phe Val
130 135 140
Ser Glu Asn Ser Asn Asn Lys Arg Ala Pro Tyr Trp Thr Asn Thr Glu
145 150 155 160
Lys Met Glu Lys Arg Leu His Ala Val Pro Ala Ala Asn Thr Val Lys
165 170 175
Phe Arg Cys Pro Ala Gly Gly Asn Pro Met Pro Thr Met Arg Trp Leu
180 185 190
Lys Asn Gly Lys Glu Phe Lys Gln Glu His Arg Ile Gly Gly Tyr Lys
195 200 205
Val Arg Asn Gln His Trp Ser Leu Ile Met Glu Ser Val Val Pro Ser
210 215 220
Asp Lys Gly Asn Tyr Thr Cys Val Val Glu Asn Glu Tyr Gly Ser Ile
225 230 235 240
Asn His Thr Tyr His Leu Asp Val Val Glu Arg Ser Pro His Arg Pro
245 250 255
Ile Leu Gln Ala Gly Leu Pro Ala Asn Ala Ser Thr Val Val Gly Gly
260 265 270
Asp Val Glu Phe Val Cys Lys Val Tyr Ser Asp Ala Gln Pro His Ile
275 280 285
Gln Trp Ile Lys His Val Glu Lys Asn Gly Ser Lys Tyr Gly Pro Asp
290 295 300
Gly Leu Pro Tyr Leu Lys Val Leu Lys His Ser Gly Ile Asn Ser Ser
305 310 315 320
Asn Ala Glu Val Leu Ala Leu Phe Asn Val Thr Glu Ala Asp Ala Gly
325 330 335
Glu Tyr Ile Cys Lys Val Ser Asn Tyr Ile Gly Gln Ala Asn Gln Ser
340 345 350
Ala Trp Leu Thr Val Leu Pro Lys Gln Gln Ala Pro Gly Arg Glu Lys
355 360 365
Glu Ile Thr Ala Ser Pro Asp Tyr Leu Glu Ile Ala Ile Tyr Cys Ile
370 375 380
Gly Val Phe Leu Ile Ala Cys Met Val Val Thr Val Ile Leu Cys Arg
385 390 395 400
Met Lys Asn Thr Thr Lys Lys Pro Asp Phe Ser Ser Gln Pro Ala Val
405 410 415
His Lys Leu Thr Lys Arg Ile Pro Leu Arg Arg Gln Val Thr Val Ser
420 425 430
Ala Glu Ser Ser Ser Ser Met Asn Ser Asn Thr Pro Leu Val Arg Ile
435 440 445
Thr Thr Arg Leu Ser Ser Thr Ala Asp Thr Pro Met Leu Ala Gly Val
450 455 460
Ser Glu Tyr Glu Leu Pro Glu Asp Pro Lys Trp Glu Phe Pro Arg Asp
465 470 475 480
Lys Leu Thr Leu Gly Lys Pro Leu Gly Glu Gly Cys Phe Gly Gln Val
485 490 495
Val Met Ala Glu Ala Val Gly Ile Asp Lys Asp Lys Pro Lys Glu Ala
500 505 510
Val Thr Val Ala Val Lys Met Leu Lys Asp Asp Ala Thr Glu Lys Asp
515 520 525
Leu Ser Asp Leu Val Ser Glu Met Glu Met Met Lys Met Ile Gly Lys
530 535 540
His Lys Asn Ile Ile Asn Leu Leu Gly Ala Cys Thr Gln Asp Gly Pro
545 550 555 560
Leu Tyr Val Ile Val Glu Tyr Ala Ser Lys Gly Asn Leu Arg Glu Tyr
565 570 575
Leu Arg Ala Arg Arg Pro Pro Gly Met Glu Tyr Ser Tyr Asp Ile Asn
580 585 590
Arg Val Pro Glu Glu Gln Met Thr Phe Lys Asp Leu Val Ser Cys Thr
595 600 605
Tyr Gln Leu Ala Arg Gly Met Glu Tyr Leu Ala Ser Gln Lys Cys Ile
610 615 620
His Arg Asp Leu Ala Ala Arg Asn Val Leu Val Thr Glu Asn Asn Val
625 630 635 640
Met Lys Ile Ala Asp Phe Gly Leu Ala Arg Asp Ile Asn Asn Ile Asp
645 650 655
Tyr Tyr Lys Lys Thr Thr Asn Gly Arg Leu Pro Val Lys Trp Met Ala
660 665 670
Pro Glu Ala Leu Phe Asp Arg Val Tyr Thr His Gln Ser Asp Val Trp
675 680 685
Ser Phe Gly Val Leu Met Trp Glu Ile Phe Thr Leu Gly Gly Ser Pro
690 695 700
Tyr Pro Gly Ile Pro Val Glu Glu Leu Phe Lys Leu Leu Lys Glu Gly
705 710 715 720
His Arg Met Asp Lys Pro Ala Asn Cys Thr Asn Glu Leu Tyr Met Met
725 730 735
Met Arg Asp Cys Trp His Ala Val Pro Ser Gln Arg Pro Thr Phe Lys
740 745 750
Gln Leu Val Glu Asp Leu Asp Arg Ile Leu Thr Leu Thr Thr Asn Glu
755 760 765
Glu Tyr Leu Asp Leu Ser Gln Pro Leu Glu Gln Tyr Ser Pro Ser Tyr
770 775 780
Pro Asp Thr Arg Ser Ser Cys Ser Ser Gly Asp Asp Ser Val Phe Ser
785 790 795 800
Pro Asp Pro Met Pro Tyr Glu Pro Cys Leu Pro Gln Tyr Pro His Ile
805 810 815
Asn Gly Ser Val Lys Thr
820
<210> 138
<211> 118
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 138
Met Asn Ser Asn Asn Lys Arg Ala Pro Tyr Trp Thr Asn Thr Glu Lys
1 5 10 15
Met Glu Lys Arg Leu His Ala Val Pro Ala Ala Asn Thr Val Lys Phe
20 25 30
Arg Cys Pro Ala Gly Gly Asn Pro Met Pro Thr Met Arg Trp Leu Lys
35 40 45
Asn Gly Lys Glu Phe Lys Gln Glu His Arg Ile Gly Gly Tyr Lys Val
50 55 60
Arg Asn Gln His Trp Ser Leu Ile Met Glu Ser Val Val Pro Ser Asp
65 70 75 80
Lys Gly Asn Tyr Thr Cys Val Val Glu Asn Glu Tyr Gly Ser Ile Asn
85 90 95
His Thr Tyr His Leu Asp Val Val Leu Val Pro Arg Gly Ser Leu Glu
100 105 110
His His His His His His
115
<210> 139
<211> 226
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 139
Gln Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Asp Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Val Ile Glu Gly Asp Gly Ser Tyr Thr His Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Glu Lys Thr Tyr Ser Ser Ala Phe Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe
115 120 125
Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu
130 135 140
Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp
145 150 155 160
Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu
165 170 175
Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser
180 185 190
Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro
195 200 205
Ser Asn Thr Lys Val Asp Lys Arg Val Glu Pro Lys Ser Cys Asp Lys
210 215 220
Thr His
225
<210> 140
<211> 214
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 140
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Asp Ile Ser Ser Asp
20 25 30
Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Asp Ala Ser Asn Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln His Tyr Ser Pro Ser His
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 141
<211> 19
<212> PRT
<213> Homo sapiens
<400> 141
Lys Met Glu Lys Arg Leu His Ala Val Pro Ala Ala Asn Thr Val Lys
1 5 10 15
Phe Arg Cys
<210> 142
<211> 802
<212> PRT
<213> Homo sapiens
<400> 142
Met Arg Leu Leu Leu Ala Leu Leu Gly Val Leu Leu Ser Val Pro Gly
1 5 10 15
Pro Pro Val Leu Ser Leu Glu Ala Ser Glu Glu Val Glu Leu Glu Pro
20 25 30
Cys Leu Ala Pro Ser Leu Glu Gln Gln Glu Gln Glu Leu Thr Val Ala
35 40 45
Leu Gly Gln Pro Val Arg Leu Cys Cys Gly Arg Ala Glu Arg Gly Gly
50 55 60
His Trp Tyr Lys Glu Gly Ser Arg Leu Ala Pro Ala Gly Arg Val Arg
65 70 75 80
Gly Trp Arg Gly Arg Leu Glu Ile Ala Ser Phe Leu Pro Glu Asp Ala
85 90 95
Gly Arg Tyr Leu Cys Leu Ala Arg Gly Ser Met Ile Val Leu Gln Asn
100 105 110
Leu Thr Leu Ile Thr Gly Asp Ser Leu Thr Ser Ser Asn Asp Asp Glu
115 120 125
Asp Pro Lys Ser His Arg Asp Pro Ser Asn Arg His Ser Tyr Pro Gln
130 135 140
Gln Ala Pro Tyr Trp Thr His Pro Gln Arg Met Glu Lys Lys Leu His
145 150 155 160
Ala Val Pro Ala Gly Asn Thr Val Lys Phe Arg Cys Pro Ala Ala Gly
165 170 175
Asn Pro Thr Pro Thr Ile Arg Trp Leu Lys Asp Gly Gln Ala Phe His
180 185 190
Gly Glu Asn Arg Ile Gly Gly Ile Arg Leu Arg His Gln His Trp Ser
195 200 205
Leu Val Met Glu Ser Val Val Pro Ser Asp Arg Gly Thr Tyr Thr Cys
210 215 220
Leu Val Glu Asn Ala Val Gly Ser Ile Arg Tyr Asn Tyr Leu Leu Asp
225 230 235 240
Val Leu Glu Arg Ser Pro His Arg Pro Ile Leu Gln Ala Gly Leu Pro
245 250 255
Ala Asn Thr Thr Ala Val Val Gly Ser Asp Val Glu Leu Leu Cys Lys
260 265 270
Val Tyr Ser Asp Ala Gln Pro His Ile Gln Trp Leu Lys His Ile Val
275 280 285
Ile Asn Gly Ser Ser Phe Gly Ala Asp Gly Phe Pro Tyr Val Gln Val
290 295 300
Leu Lys Thr Ala Asp Ile Asn Ser Ser Glu Val Glu Val Leu Tyr Leu
305 310 315 320
Arg Asn Val Ser Ala Glu Asp Ala Gly Glu Tyr Thr Cys Leu Ala Gly
325 330 335
Asn Ser Ile Gly Leu Ser Tyr Gln Ser Ala Trp Leu Thr Val Leu Pro
340 345 350
Glu Glu Asp Pro Thr Trp Thr Ala Ala Ala Pro Glu Ala Arg Tyr Thr
355 360 365
Asp Ile Ile Leu Tyr Ala Ser Gly Ser Leu Ala Leu Ala Val Leu Leu
370 375 380
Leu Leu Ala Gly Leu Tyr Arg Gly Gln Ala Leu His Gly Arg His Pro
385 390 395 400
Arg Pro Pro Ala Thr Val Gln Lys Leu Ser Arg Phe Pro Leu Ala Arg
405 410 415
Gln Phe Ser Leu Glu Ser Gly Ser Ser Gly Lys Ser Ser Ser Ser Leu
420 425 430
Val Arg Gly Val Arg Leu Ser Ser Ser Gly Pro Ala Leu Leu Ala Gly
435 440 445
Leu Val Ser Leu Asp Leu Pro Leu Asp Pro Leu Trp Glu Phe Pro Arg
450 455 460
Asp Arg Leu Val Leu Gly Lys Pro Leu Gly Glu Gly Cys Phe Gly Gln
465 470 475 480
Val Val Arg Ala Glu Ala Phe Gly Met Asp Pro Ala Arg Pro Asp Gln
485 490 495
Ala Ser Thr Val Ala Val Lys Met Leu Lys Asp Asn Ala Ser Asp Lys
500 505 510
Asp Leu Ala Asp Leu Val Ser Glu Met Glu Val Met Lys Leu Ile Gly
515 520 525
Arg His Lys Asn Ile Ile Asn Leu Leu Gly Val Cys Thr Gln Glu Gly
530 535 540
Pro Leu Tyr Val Ile Val Glu Cys Ala Ala Lys Gly Asn Leu Arg Glu
545 550 555 560
Phe Leu Arg Ala Arg Arg Pro Pro Gly Pro Asp Leu Ser Pro Asp Gly
565 570 575
Pro Arg Ser Ser Glu Gly Pro Leu Ser Phe Pro Val Leu Val Ser Cys
580 585 590
Ala Tyr Gln Val Ala Arg Gly Met Gln Tyr Leu Glu Ser Arg Lys Cys
595 600 605
Ile His Arg Asp Leu Ala Ala Arg Asn Val Leu Val Thr Glu Asp Asn
610 615 620
Val Met Lys Ile Ala Asp Phe Gly Leu Ala Arg Gly Val His His Ile
625 630 635 640
Asp Tyr Tyr Lys Lys Thr Ser Asn Gly Arg Leu Pro Val Lys Trp Met
645 650 655
Ala Pro Glu Ala Leu Phe Asp Arg Val Tyr Thr His Gln Ser Asp Val
660 665 670
Trp Ser Phe Gly Ile Leu Leu Trp Glu Ile Phe Thr Leu Gly Gly Ser
675 680 685
Pro Tyr Pro Gly Ile Pro Val Glu Glu Leu Phe Ser Leu Leu Arg Glu
690 695 700
Gly His Arg Met Asp Arg Pro Pro His Cys Pro Pro Glu Leu Tyr Gly
705 710 715 720
Leu Met Arg Glu Cys Trp His Ala Ala Pro Ser Gln Arg Pro Thr Phe
725 730 735
Lys Gln Leu Val Glu Ala Leu Asp Lys Val Leu Leu Ala Val Ser Glu
740 745 750
Glu Tyr Leu Asp Leu Arg Leu Thr Phe Gly Pro Tyr Ser Pro Ser Gly
755 760 765
Gly Asp Ala Ser Ser Thr Cys Ser Ser Ser Asp Ser Val Phe Ser His
770 775 780
Asp Pro Leu Pro Leu Gly Ser Ser Ser Phe Pro Phe Gly Ser Gly Val
785 790 795 800
Gln Thr
<210> 143
<211> 118
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 143
Met His Ser Tyr Pro Gln Gln Ala Pro Tyr Trp Thr His Pro Gln Arg
1 5 10 15
Met Glu Lys Lys Leu His Ala Val Pro Ala Gly Asn Thr Val Lys Phe
20 25 30
Arg Cys Pro Ala Ala Gly Asn Pro Thr Pro Thr Ile Arg Trp Leu Lys
35 40 45
Asp Gly Gln Ala Phe His Gly Glu Asn Arg Ile Gly Gly Ile Arg Leu
50 55 60
Arg His Gln His Trp Ser Leu Val Met Glu Ser Val Val Pro Ser Asp
65 70 75 80
Arg Gly Thr Tyr Thr Cys Leu Val Glu Asn Ala Val Gly Ser Ile Arg
85 90 95
Tyr Asn Tyr Leu Leu Asp Val Leu Leu Val Pro Arg Gly Ser Leu Glu
100 105 110
His His His His His His
115
<210> 144
<211> 237
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 144
Met Ala Glu Asp Phe Val Ser Glu Asn Ser Asn Asn Lys Arg Ala Pro
1 5 10 15
Tyr Trp Thr Asn Thr Glu Lys Met Glu Lys Arg Leu His Ala Val Pro
20 25 30
Ala Ala Asn Thr Val Lys Phe Arg Cys Pro Ala Gly Gly Asn Pro Met
35 40 45
Pro Thr Met Arg Trp Leu Lys Asn Gly Lys Glu Phe Lys Gln Glu His
50 55 60
Arg Ile Gly Gly Tyr Lys Val Arg Asn Gln His Trp Ser Leu Ile Met
65 70 75 80
Glu Ser Val Val Pro Ser Asp Lys Gly Asn Tyr Thr Cys Val Val Glu
85 90 95
Asn Glu Tyr Gly Ser Ile Asn His Thr Tyr His Leu Asp Val Val Glu
100 105 110
Arg Ser Pro His Arg Pro Ile Leu Gln Ala Gly Leu Pro Ala Asn Ala
115 120 125
Ser Thr Val Val Gly Gly Asp Val Glu Phe Val Cys Lys Val Tyr Ser
130 135 140
Asp Ala Gln Pro His Ile Gln Trp Ile Lys His Val Glu Lys Asn Gly
145 150 155 160
Ser Lys Tyr Gly Pro Asp Gly Leu Pro Tyr Leu Lys Val Leu Lys His
165 170 175
Ser Gly Ile Asn Ser Ser Asn Ala Glu Val Leu Ala Leu Phe Asn Val
180 185 190
Thr Glu Ala Asp Ala Gly Glu Tyr Ile Cys Lys Val Ser Asn Tyr Ile
195 200 205
Gly Gln Ala Asn Gln Ser Ala Trp Leu Thr Val Leu Pro Lys Gln Gln
210 215 220
Ala Pro Gly Arg Glu Lys Glu His His His His His His
225 230 235
<210> 145
<211> 237
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 145
Met Ala Glu Asp Phe Val Ser Glu Asn Ser Asn Asn Lys Arg Ala Pro
1 5 10 15
Tyr Trp Thr Asn Thr Glu Lys Met Glu Lys Arg Leu His Ala Val Pro
20 25 30
Ala Ala Asn Thr Val Ala Phe Arg Cys Pro Ala Gly Gly Asn Pro Met
35 40 45
Pro Thr Met Arg Trp Leu Lys Asn Gly Lys Glu Phe Lys Gln Glu His
50 55 60
Arg Ile Gly Gly Tyr Lys Val Ala Asn Gln His Trp Ser Leu Ile Met
65 70 75 80
Glu Ser Val Val Pro Ser Asp Lys Gly Asn Tyr Thr Cys Val Val Glu
85 90 95
Asn Glu Tyr Gly Ser Ile Asn His Thr Tyr His Leu Asp Val Val Glu
100 105 110
Arg Ser Pro His Arg Pro Ile Leu Gln Ala Gly Leu Pro Ala Asn Ala
115 120 125
Ser Thr Val Val Gly Gly Asp Val Glu Phe Val Cys Lys Val Tyr Ser
130 135 140
Asp Ala Gln Pro His Ile Gln Trp Ile Lys His Val Glu Lys Asn Gly
145 150 155 160
Ser Lys Tyr Gly Pro Asp Gly Leu Pro Tyr Leu Lys Val Leu Lys His
165 170 175
Ser Gly Ile Asn Ser Ser Asn Ala Glu Val Leu Ala Leu Phe Asn Val
180 185 190
Thr Glu Ala Asp Ala Gly Glu Tyr Ile Cys Lys Val Ser Asn Tyr Ile
195 200 205
Gly Gln Ala Asn Gln Ser Ala Trp Leu Thr Val Leu Pro Lys Gln Gln
210 215 220
Ala Pro Gly Arg Glu Lys Glu His His His His His His
225 230 235
<210> 146
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
6xHis tag"
<400> 146
His His His His His His
1 5
<210> 147
<211> 22
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 147
Tyr Gly Arg Lys Lys Arg Arg Gln Arg Arg Arg Leu Tyr Arg Ser Pro
1 5 10 15
Ala Met Pro Glu Asn Leu
20
<210> 148
<211> 3040
<212> DNA
<213> Homo sapiens
<400> 148
ctcgctcccg gccgaggagc gctcgggctg tctgcggacc ctgccgcgtg caggggtcgc 60
ggccggctgg agctgggagt gaggcggcgg aggagccagg tgaggaggag ccaggaaggc 120
agttggtggg aagtccagct tgggtccctg agagctgtga gaaggagatg cggctgctgc 180
tggccctgtt gggggtcctg ctgagtgtgc ctgggcctcc agtcttgtcc ctggaggcct 240
ctgaggaagt ggagcttgag ccctgcctgg ctcccagcct ggagcagcaa gagcaggagc 300
tgacagtagc ccttgggcag cctgtgcgtc tgtgctgtgg gcgggctgag cgtggtggcc 360
actggtacaa ggagggcagt cgcctggcac ctgctggccg tgtacggggc tggaggggcc 420
gcctagagat tgccagcttc ctacctgagg atgctggccg ctacctctgc ctggcacgag 480
gctccatgat cgtcctgcag aatctcacct tgattacagg tgactccttg acctccagca 540
acgatgatga ggaccccaag tcccataggg acccctcgaa taggcacagt tacccccagc 600
aagcacccta ctggacacac ccccagcgca tggagaagaa actgcatgca gtacctgcgg 660
ggaacaccgt caagttccgc tgtccagctg caggcaaccc cacgcccacc atccgctggc 720
ttaaggatgg acaggccttt catggggaga accgcattgg aggcattcgg ctgcgccatc 780
agcactggag tctcgtgatg gagagcgtgg tgccctcgga ccgcggcaca tacacctgcc 840
tggtagagaa cgctgtgggc agcatccgct ataactacct gctagatgtg ctggagcggt 900
ccccgcaccg gcccatcctg caggccgggc tcccggccaa caccacagcc gtggtgggca 960
gcgacgtgga gctgctgtgc aaggtgtaca gcgatgccca gccccacatc cagtggctga 1020
agcacatcgt catcaacggc agcagcttcg gagccgacgg tttcccctat gtgcaagtcc 1080
taaagactgc agacatcaat agctcagagg tggaggtcct gtacctgcgg aacgtgtcag 1140
ccgaggacgc aggcgagtac acctgcctcg caggcaattc catcggcctc tcctaccagt 1200
ctgcctggct cacggtgctg ccagaggagg accccacatg gaccgcagca gcgcccgagg 1260
ccaggtatac ggacatcatc ctgtacgcgt cgggctccct ggccttggct gtgctcctgc 1320
tgctggccgg gctgtatcga gggcaggcgc tccacggccg gcacccccgc ccgcccgcca 1380
ctgtgcagaa gctctcccgc ttccctctgg cccgacagtt ctccctggag tcaggctctt 1440
ccggcaagtc aagctcatcc ctggtacgag gcgtgcgtct ctcctccagc ggccccgcct 1500
tgctcgccgg cctcgtgagt ctagatctac ctctcgaccc actatgggag ttcccccggg 1560
acaggctggt gcttgggaag cccctaggcg agggctgctt tggccaggta gtacgtgcag 1620
aggcctttgg catggaccct gcccggcctg accaagccag cactgtggcc gtcaagatgc 1680
tcaaagacaa cgcctctgac aaggacctgg ccgacctggt ctcggagatg gaggtgatga 1740
agctgatcgg ccgacacaag aacatcatca acctgcttgg tgtctgcacc caggaagggc 1800
ccctgtacgt gatcgtggag tgcgccgcca agggaaacct gcgggagttc ctgcgggccc 1860
ggcgcccccc aggccccgac ctcagccccg acggtcctcg gagcagtgag gggccgctct 1920
ccttcccagt cctggtctcc tgcgcctacc aggtggcccg aggcatgcag tatctggagt 1980
cccggaagtg tatccaccgg gacctggctg cccgcaatgt gctggtgact gaggacaatg 2040
tgatgaagat tgctgacttt gggctggccc gcggcgtcca ccacattgac tactataaga 2100
aaaccagcaa cggccgcctg cctgtgaagt ggatggcgcc cgaggccttg tttgaccggg 2160
tgtacacaca ccagagtgac gtgtggtctt ttgggatcct gctatgggag atcttcaccc 2220
tcgggggctc cccgtatcct ggcatcccgg tggaggagct gttctcgctg ctgcgggagg 2280
gacatcggat ggaccgaccc ccacactgcc ccccagagct gtacgggctg atgcgtgagt 2340
gctggcacgc agcgccctcc cagaggccta ccttcaagca gctggtggag gcgctggaca 2400
aggtcctgct ggccgtctct gaggagtacc tcgacctccg cctgaccttc ggaccctatt 2460
ccccctctgg tggggacgcc agcagcacct gctcctccag cgattctgtc ttcagccacg 2520
accccctgcc attgggatcc agctccttcc ccttcgggtc tggggtgcag acatgagcaa 2580
ggctcaaggc tgtgcaggca cataggctgg tggccttggg ccttggggct cagccacagc 2640
ctgacacagt gctcgacctt gatagcatgg ggcccctggc ccagagttgc tgtgccgtgt 2700
ccaagggccg tgcccttgcc cttggagctg ccgtgcctgt gtcctgatgg cccaaatgtc 2760
agggttctgc tcggcttctt ggaccttggc gcttagtccc catcccgggt ttggctgagc 2820
ctggctggag agctgctatg ctaaacctcc tgcctcccaa taccagcagg aggttctggg 2880
cctctgaacc ccctttcccc acacctcccc ctgctgctgc tgccccagcg tcttgacggg 2940
agcattggcc cctgagccca gagaagctgg aagcctgccg aaaacaggag caaatggcgt 3000
tttataaatt atttttttga aataaaaaaa aaaaaaaaaa 3040
<210> 149
<211> 103
<212> PRT
<213> Homo sapiens
<400> 149
Asn Ser Asn Asn Lys Arg Ala Pro Tyr Trp Thr Asn Thr Glu Lys Met
1 5 10 15
Glu Lys Arg Leu His Ala Val Pro Ala Ala Asn Thr Val Lys Phe Arg
20 25 30
Cys Pro Ala Gly Gly Asn Pro Met Pro Thr Met Arg Trp Leu Lys Asn
35 40 45
Gly Lys Glu Phe Lys Gln Glu His Arg Ile Gly Gly Tyr Lys Val Arg
50 55 60
Asn Gln His Trp Ser Leu Ile Met Glu Ser Val Val Pro Ser Asp Lys
65 70 75 80
Gly Asn Tyr Thr Cys Val Val Glu Asn Glu Tyr Gly Ser Ile Asn His
85 90 95
Thr Tyr His Leu Asp Val Val
100
<210> 150
<211> 103
<212> PRT
<213> Homo sapiens
<400> 150
His Ser Tyr Pro Gln Gln Ala Pro Tyr Trp Thr His Pro Gln Arg Met
1 5 10 15
Glu Lys Lys Leu His Ala Val Pro Ala Gly Asn Thr Val Lys Phe Arg
20 25 30
Cys Pro Ala Ala Gly Asn Pro Thr Pro Thr Ile Arg Trp Leu Lys Asp
35 40 45
Gly Gln Ala Phe His Gly Glu Asn Arg Ile Gly Gly Ile Arg Leu Arg
50 55 60
His Gln His Trp Ser Leu Val Met Glu Ser Val Val Pro Ser Asp Arg
65 70 75 80
Gly Thr Tyr Thr Cys Leu Val Glu Asn Ala Val Gly Ser Ile Arg Tyr
85 90 95
Asn Tyr Leu Leu Asp Val Leu
100
Claims (70)
- 하기 화학식의 항체 약물 접합체.
Ab-(L-(D)m)n
상기 식에서,
Ab는 인간 FGFR2 및 FGFR4 둘 다에 특이적으로 결합하는 항체 또는 그의 항원 결합 단편이고;
L은 링커이고;
D는 약물 모이어티이고;
m은 1 내지 8의 정수이고;
n은 1 내지 10의 정수이다. - 제1항에 있어서, 상기 m이 1인 항체 약물 접합체.
- 제1항 또는 제2항에 있어서, 상기 n이 3 또는 4인 항체 약물 접합체.
- 제1항 내지 제3항 중 어느 한 항에 있어서, 상기 항체 또는 항원 결합 단편이 인간 FGFR2의 모든 이소형에 특이적으로 결합하는 것인 항체 약물 접합체.
- 제1항 내지 제4항 중 어느 한 항에 있어서, 상기 항체 또는 항원 결합 단편이 서열 137의 아미노산 잔기 176 (Lys) 및 210 (Arg)을 포함하는 인간 FGFR2 상의 에피토프에 특이적으로 결합하는 것인 항체 약물 접합체.
- 제1항 내지 제5항 중 어느 한 항에 있어서, 상기 항체 또는 항원 결합 단편이 서열 137의 아미노산 잔기 173 (Asn), 174 (Thr), 175 (Val), 176 (Lys), 178 (Arg), 208 (Lys), 209 (Val), 210 (Arg), 212 (Gln), 213 (His), 217 (Ile) 및 219 (Glu)에 특이적으로 결합하는 것인 항체 약물 접합체.
- 제1항 내지 제6항 중 어느 한 항에 있어서, 상기 항체 또는 항원 결합 단편이 서열 136 또는 서열 141을 포함하는 인간 FGFR2의 에피토프에 특이적으로 결합하는 것인 항체 약물 접합체.
- 제1항 내지 제6항 중 어느 한 항에 있어서, 상기 항체 또는 항원 결합 단편이 서열 136 또는 서열 141로 이루어진 인간 FGFR2의 에피토프에 특이적으로 결합하는 것인 항체 약물 접합체.
- 제1항 내지 제8항 중 어느 한 항에 있어서, 상기 항체 또는 항원 결합 단편이 서열 142의 아미노산 잔기 169 (Lys) 및 203 (Arg)을 포함하는 인간 FGFR4의 에피토프에 특이적으로 결합하는 것인 항체 약물 접합체.
- 제1항 내지 제9항 중 어느 한 항에 있어서, 상기 항체 또는 항원 결합 단편이 서열 137의 아미노산 잔기 176 (Lys) 및 210 (Arg)을 포함하는 인간 FGFR2의 에피토프 및 서열 142의 아미노산 잔기 169 (Lys) 및 203 (Arg)을 포함하는 인간 FGFR4의 에피토프에 특이적으로 결합하는 것인 항체 약물 접합체.
- 제1항 내지 제10항 중 어느 한 항에 있어서, 상기 항체 또는 항원 결합 단편이 서열 142의 인간 FGFR4의 아미노산 잔기 150 (Thr), 151 (His), 154 (Arg), 157 (Lys), 160 (His), 166 (Asn), 167 (Thr), 168 (Val), 169 (Lys), 171 (Arg), 173 (Pro), 174 (Ala), 201 (Arg), 202 (Leu), 203 (Arg), 204 (His), 205 (Gln), 206 (His), 207 (Trp), 210 (Val) 및 212 (Glu)에 특이적으로 결합하는 것인 항체 약물 접합체.
- 제1항 내지 제11항 중 어느 한 항에 있어서, 상기 항체 또는 항원 결합 단편이 서열 132 또는 133을 포함하는 인간 FGFR4의 에피토프에 특이적으로 결합하는 것인 항체 약물 접합체.
- 제1항 내지 제11항 중 어느 한 항에 있어서, 상기 항체 또는 항원 결합 단편이 서열 132 또는 133으로 이루어진 인간 FGFR4의 에피토프에 특이적으로 결합하는 것인 항체 약물 접합체.
- 제1항 내지 제13항 중 어느 한 항에 있어서, 상기 항체 또는 그의 항원 결합 단편이 (a) 서열 1, 21, 41, 61, 81 또는 101의 VH CDR1, (b) 서열 2, 22, 42, 62, 82 또는 102의 VH CDR2 및 (c) 서열 3, 23, 43, 63, 83 또는 103의 VH CDR3을 포함하는 중쇄 가변 영역을 포함하며, 여기서 CDR은 카바트(Kabat) 정의에 따라 규정된 것인 항체 약물 접합체.
- 제14항에 있어서, 상기 항체 또는 그의 항원 결합 단편이 (a)서열 11, 31, 51, 71, 91 또는 111의 VL CDR1, (b) 서열 12, 32, 52, 72, 92 또는 112의 VL CDR2 및 (c) 서열 13, 33, 53, 73, 93 또는 113의 VL CDR3을 포함하는 경쇄 가변 영역을 추가로 포함하며, 여기서 CDR은 카바트 정의에 따라 규정된 것인 항체 약물 접합체.
- 제15항에 있어서, 상기 항체 또는 그의 항원 결합 단편이 서열 7, 27, 47, 67, 87 또는 107의 VH 영역 및 서열 17, 37, 57, 77, 97 또는 117의 VL 영역을 포함하는 것인 항체 약물 접합체.
- 제16항에 있어서, 상기 항체가 서열 9, 29, 49, 69, 89 또는 109의 중쇄 및 서열 19, 39, 59, 79, 99 또는 119의 경쇄로 이루어진 것인 항체 약물 접합체.
- 제1항에 있어서, 상기 항체 또는 항원 결합 단편이 인간 FGFR2 및 FGFR4에의 결합에 대해 서열 9, 29, 49, 69, 89 또는 109의 중쇄 및 서열 19의 경쇄로 이루어진 항체와 교차 경쟁하는 것인 항체 약물 접합체.
- 제1항에 있어서, 상기 항체 또는 항원 결합 단편이 서열 9, 29, 49, 69, 89 또는 109의 중쇄 및 서열 19, 39, 59, 79, 99 또는 119의 경쇄로 이루어진 항체와 비교하여 증진된 ADCC 활성을 갖는 것인 항체 약물 접합체.
- 제1항에 있어서, 상기 항체 또는 항원 결합 단편이 서열 9, 29, 49, 69, 89 또는 109의 중쇄 및 서열 19, 39, 59, 79, 99 또는 119의 경쇄로 이루어진 항체와 비교하여 증진된 ADCC 활성을 갖지 않는 것인 항체 약물 접합체.
- 제1항 내지 제20항 중 어느 한 항에 있어서, 상기 항체가 인간 항체인 항체 약물 접합체.
- 제1항 내지 제21항 중 어느 한 항에 있어서, 상기 항체가 모노클로날 항체인 항체 약물 접합체.
- 제1항 내지 제22항 중 어느 한 항에 있어서, 상기 링커가 절단가능한 링커, 비-절단가능한 링커, 친수성 링커, 전구하전된 링커 및 디카르복실산계 링커로 이루어진 군으로부터 선택된 것인 항체 약물 접합체.
- 제23항에 있어서, 링커가 N-숙신이미딜-3-(2-피리딜디티오)프로피오네이트 (SPDP), N-숙신이미딜 4-(2-피리딜디티오)펜타노에이트 (SPP), N-숙신이미딜 4-(2-피리딜디티오)부타노에이트 (SPDB), N-숙신이미딜-4-(2-피리딜디티오)-2-술포-부타노에이트 (술포-SPDB), N-숙신이미딜 아이오도아세테이트 (SIA), N-숙신이미딜(4-아이오도아세틸)아미노벤조에이트 (SIAB), 말레이미드 PEG NHS, N-숙신이미딜 4-(말레이미도메틸) 시클로헥산카르복실레이트 (SMCC), N-술포숙신이미딜 4-(말레이미도메틸) 시클로헥산카르복실레이트 (술포-SMCC) 또는 2,5-디옥소피롤리딘-1-일 17-(2,5-디옥소-2,5-디히드로-1H-피롤-1-일)-5,8,11,14-테트라옥소-4,7,10,13-테트라아자헵타데칸-1-오에이트 (CX1-1)로 이루어진 군으로부터 선택된 가교 시약으로부터 유래된 것인 항체 약물 접합체.
- 제24항에 있어서, 상기 링커가 가교 시약 N-숙신이미딜 4-(말레이미도메틸) 시클로헥산카르복실레이트 (SMCC)로부터 유래된 것인 항체 약물 접합체.
- 제1항 내지 제25항 중 어느 한 항에 있어서, 상기 약물 모이어티가 V-ATPase 억제제, 아폽토시스촉진제, Bcl2 억제제, MCL1 억제제, HSP90 억제제, IAP 억제제, mTor 억제제, 미세관 안정화제, 미세관 탈안정화제, 아우리스타틴, 돌라스타틴, 메이탄시노이드, MetAP (메티오닌 아미노펩티다제), 단백질 CRM1의 핵 유출의 억제제, DPPIV 억제제, 프로테아솜 억제제, 미토콘드리아에서의 포스포릴 전달 반응의 억제제, 단백질 합성 억제제, 키나제 억제제, CDK2 억제제, CDK9 억제제, 키네신 억제제, HDAC 억제제, DNA 손상 작용제, DNA 알킬화제, DNA 삽입제, DNA 작은 홈 결합제 및 DHFR 억제제로 이루어진 군으로부터 선택된 것인 항체 약물 접합체.
- 제26항에 있어서, 세포독성제가 메이탄시노이드인 항체 약물 접합체.
- 제27항에 있어서, 메이탄시노이드가 N(2')-데아세틸-N(2')-(3-메르캅토-1-옥소프로필)-메이탄신 (DM1) 또는 N(2')-데아세틸-N2-(4-메르캅토-4-메틸-1-옥소펜틸)-메이탄신 (DM4)인 항체 약물 접합체.
- 제1항에 있어서, 하기 화학식을 갖는 항체 약물 접합체.

상기 식에서, Ab는 서열 1, 21, 41, 61, 81 또는 101의 중쇄 CDR1, 서열 2, 22, 42, 62, 82 또는 102의 중쇄 CDR2, 서열 3, 23, 43, 63, 83 또는 103의 중쇄 CDR3 및 서열 11, 31, 51, 71, 91 또는 111의 경쇄 CDR1, 서열 12, 32, 52, 72, 92 또는 112의 경쇄 CDR2, 서열 13, 33, 53, 73, 93 또는 113의 경쇄 CDR3을 포함하며, 여기서 CDR은 카바트 정의에 따라 규정된 것인 항체 또는 그의 항원 결합 단편이고;
n은 1 내지 10이다. - 제1항 내지 제29항 중 어느 한 항의 항체 약물 접합체 및 제약상 허용되는 담체를 포함하는 제약 조성물.
- 제30항에 있어서, 동결건조물로서 제조된 제약 조성물.
- 제31항에 있어서, 상기 동결건조물이 상기 항체 약물 접합체, 숙신산나트륨 및 폴리소르베이트 20을 포함하는 것인 제약 조성물.
- FGFR2 양성 및/또는 FGFR4 양성 암의 치료를 필요로 하는 환자에게 제1항 내지 제30항 중 어느 한 항의 항체 약물 접합체, 또는 제30항 내지 제32항 중 어느 한 항의 제약 조성물을 투여하는 것을 포함하는, 상기 환자에서 FGFR2 양성 및/또는 FGFR4 양성 암을 치료하는 방법.
- 제29항에 있어서, 암이 FGFR2 유전자 카피수의 증가 또는 PAX3-FOXO 전위를 갖는 것인 방법.
- 제33항에 있어서, 상기 암이 위암, 유방암, 횡문근육종, 간암, 부신암, 폐암, 식도암, 결장암 및 자궁내막암으로 이루어진 군으로부터 선택된 것인 방법.
- 제33항 또는 제34항에 있어서, 상기 환자에게 티로신 키나제 억제제, IAP 억제제, Bcl2 억제제, MCL1 억제제 또는 또 다른 FGFR2 억제제를 투여하는 것을 추가로 포함하는 방법.
- 제36항에 있어서, 상기 또 다른 FGFR2 억제제가 3-(2,6-디클로로-3,5-디메톡시-페닐)-1-{6-[4-(4-에틸-피페라진-1-일)-페닐아미노]-피리미딘-4-일}-1-메틸-우레아 또는 그의 제약상 허용되는 염인 방법.
- 제33항 또는 제35항에 있어서, 암이 티로신 키나제 억제제에 내성인 방법.
- 제38항에 있어서, 티로신 키나제 억제제가 EGFR, Her2, Her3, IGFR 또는 Met 억제제인 방법.
- Her2 억제제에 내성인 암의 치료를 필요로 하는 환자에게 제1항 내지 제29항 중 어느 한 항의 항체 약물 접합체, 또는 제30항 내지 제32항 중 어느 한 항의 제약 조성물을 투여하는 것을 포함하는, 상기 환자에서 Her2 억제제에 내성인 암을 치료하는 방법.
- 제1항 내지 제29항 중 어느 한 항에 있어서, 의약으로 사용하기 위한 항체 약물 접합체.
- 제1항 내지 제29항 및 제31항 내지 제33항 중 어느 한 항에 있어서, FGFR2 양성 또는 FGFR4 양성 암의 치료에 사용하기 위한 항체 약물 접합체 또는 제약 조성물.
- 제1항 내지 제29항 및 제31항 내지 제33항 중 어느 한 항에 있어서, 티로신 키나제 억제제에 내성인 암의 치료에 사용하기 위한 항체 약물 접합체 또는 제약 조성물.
- 제1항 내지 제32항 중 어느 한 항에 있어서, EGFR, Her2, Her3, IGFR 또는 Met 억제제에 내성인 암의 치료에 사용하기 위한 항체 약물 접합체 또는 제약 조성물.
- FGFR2 및 FGFR4에 특이적으로 결합하는 항체 또는 그의 항원 결합 단편.
- 제45항에 있어서, 서열 137의 아미노산 잔기 176 (Lys) 및 210 (Arg)을 포함하는 인간 FGFR2 상의 에피토프에 특이적으로 결합하는 항체 또는 항원 결합 단편.
- 제46항에 있어서, 서열 137의 아미노산 잔기 173 (Asn), 174 (Thr), 175 (Val), 176 (Lys), 178 (Arg), 208 (Lys), 209 (Val), 210 (Arg), 212 (Gln), 213 (His), 217 (Ile) 및 219 (Glu)에 특이적으로 결합하는 항체 또는 항원 결합 단편.
- 제47항에 있어서, 서열 136 또는 서열 141을 포함하는 인간 FGFR2의 에피토프에 특이적으로 결합하는 항체 또는 항원 결합 단편.
- 제46항 내지 제48항 중 어느 한 항에 있어서, 서열 142의 아미노산 잔기 169 (Lys) 및 203 (Arg)을 포함하는 인간 FGFR4의 에피토프에 특이적으로 결합하는 항체 또는 항원 결합 단편.
- 제45항에 있어서, 서열 137의 아미노산 잔기 176 (Lys) 및 210 (Arg)을 포함하는 인간 FGFR2의 에피토프 및 서열 142의 아미노산 잔기 169 (Lys) 및 203 (Arg)을 포함하는 인간 FGFR4의 에피토프에 특이적으로 결합하는 항체 또는 항원 결합 단편.
- 제45항 내지 제50항 중 어느 한 항에 있어서, 서열 142의 아미노산 잔기 150 (Thr), 151 (His), 154 (Arg), 157 (Lys), 160 (His), 166 (Asn), 167 (Thr), 168 (Val), 169 (Lys), 171 (Arg), 173 (Pro), 174 (Ala), 201 (Arg), 202 (Leu), 203 (Arg), 204 (His), 205 (Gln), 206 (His), 207 (Trp), 210 (Val) 및 212 (Glu)에 특이적으로 결합하는 항체 또는 항원 결합 단편.
- 제45항 내지 제51항 중 어느 한 항에 있어서, 서열 132 또는 133을 포함하는 인간 FGFR4의 에피토프에 특이적으로 결합하는 항체 또는 항원 결합 단편.
- 제45항 내지 제51항 중 어느 한 항에 있어서, 서열 132 또는 133으로 이루어진 인간 FGFR4의 에피토프에 특이적으로 결합하는 항체 또는 항원 결합 단편.
- 제45항 내지 제53항 중 어느 한 항에 있어서, (a) 서열 1, 21, 41, 61, 81 또는 101의 VH CDR1, (b) 서열 2, 22, 42, 62, 82 또는 102의 VH CDR2 및 (c) 서열 3, 23, 43, 63, 83 또는 103의 VH CDR3을 포함하는 중쇄 가변 영역을 포함하며, 여기서 CDR은 카바트 정의에 따라 규정된 것인 항체 또는 항원 결합 단편.
- 제54항에 있어서, (a) 서열 11, 31, 51, 71, 91 또는 111의 VL CDR1, (b) 서열 12, 32, 52, 72, 92 또는 112의 VL CDR2 및 (c) 서열 13, 33, 53, 73, 93 또는 113의 VL CDR3을 포함하는 경쇄 가변 영역을 포함하며, 여기서 CDR은 카바트 정의에 따라 규정된 것인 항체 또는 항원 결합 단편.
- 제55항에 있어서, 서열 7, 27, 47, 67, 87 또는 107의 VH 영역 및 서열 17, 37, 57, 77, 97 또는 117의 VL 영역을 포함하는 항체 또는 항원 결합 단편.
- 제56항에 있어서, 서열 9, 29, 49, 69, 89 또는 109의 중쇄 및 서열 19, 39, 59, 79, 99 또는 119의 경쇄로 이루어진 항체.
- 제45항에 있어서, 인간 FGFR2 및 FGFR4에의 결합에 대해 제57항의 항체 또는 항체 결합 단편과 교차 경쟁하는 항체 또는 항원 결합 단편.
- 제45항에 있어서, 제59항의 항체와 비교하여 증진된 ADCC 활성을 갖는 항체 또는 항원 결합 단편.
- 제45항 내지 제59항 중 어느 한 항에 있어서, 인간 항체인 항체 또는 항원 결합 단편.
- 제45항 내지 제60항 중 어느 한 항에 있어서, 모노클로날 항체인 항체 또는 항원 결합 단편.
- 제45항 내지 제61항 중 어느 한 항에 있어서, 단일 쇄 항체 (scFv)인 항체 또는 항원 결합 단편.
- 제45항 내지 제62항 중 어느 한 항의 항체 또는 항원 결합 단편을 코딩하는 핵산.
- 제63항의 핵산을 포함하는 벡터.
- 제64항에 따른 벡터를 포함하는 숙주 세포.
- 제65항의 숙주 세포를 배양하고 항체를 배양물로부터 회수하는 것을 포함하는, 항체 또는 항원 결합 단편을 생산하는 방법.
- (a) SMCC를 약물 모이어티 DM-1에 화학적으로 연결하고;
(b) 상기 링커-약물을 제66항의 세포 배양물로부터 회수된 항체에 접합시키고;
(c) 항체 약물 접합체를 정제하는 것
을 포함하는, 항-FGFR2 및 FGFR4 항체 약물 접합체를 제조하는 방법. - UV 분광광도계로 측정 시에 약 3.5의 평균 DAR을 갖는, 제67항에 따라 제조된 항체 약물 접합체.
- 제45항 내지 제62항 중 어느 한 항의 항체 또는 그의 항원 결합 단편 또는 표지된 제1항 내지 제29항 중 어느 한 항의 항체 약물 접합체를 포함하는 진단 시약.
- 제69항에 있어서, 표지가 방사성표지, 형광단, 발색단, 영상화제 및 금속 이온으로 이루어진 군으로부터 선택된 것인 진단 시약.
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201361780299P | 2013-03-13 | 2013-03-13 | |
| US61/780,299 | 2013-03-13 | ||
| PCT/US2014/025944 WO2014160160A2 (en) | 2013-03-13 | 2014-03-13 | Antibody drug conjugates |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20150130333A true KR20150130333A (ko) | 2015-11-23 |
Family
ID=50897870
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020157026812A KR20150130333A (ko) | 2013-03-13 | 2014-03-13 | 항체 약물 접합체 및 상응하는 항체 |
Country Status (14)
| Country | Link |
|---|---|
| US (2) | US9498532B2 (ko) |
| EP (1) | EP2968592A2 (ko) |
| JP (2) | JP2016518332A (ko) |
| KR (1) | KR20150130333A (ko) |
| CN (1) | CN105188763B (ko) |
| AR (1) | AR096015A1 (ko) |
| AU (2) | AU2014244060B2 (ko) |
| BR (1) | BR112015023418A8 (ko) |
| CA (1) | CA2904090A1 (ko) |
| EA (1) | EA201591611A1 (ko) |
| MX (1) | MX2015012122A (ko) |
| TW (1) | TW201444574A (ko) |
| UY (1) | UY35399A (ko) |
| WO (1) | WO2014160160A2 (ko) |
Families Citing this family (71)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2012088266A2 (en) | 2010-12-22 | 2012-06-28 | Incyte Corporation | Substituted imidazopyridazines and benzimidazoles as inhibitors of fgfr3 |
| US9714298B2 (en) | 2012-04-09 | 2017-07-25 | Daiichi Sankyo Company, Limited | Anti-FGFR2 antibodies and methods of use thereof for treating cancer |
| CN107652289B (zh) | 2012-06-13 | 2020-07-21 | 因塞特控股公司 | 作为fgfr抑制剂的取代的三环化合物 |
| WO2014026125A1 (en) | 2012-08-10 | 2014-02-13 | Incyte Corporation | Pyrazine derivatives as fgfr inhibitors |
| US9266892B2 (en) | 2012-12-19 | 2016-02-23 | Incyte Holdings Corporation | Fused pyrazoles as FGFR inhibitors |
| US9415118B2 (en) * | 2013-03-13 | 2016-08-16 | Novartis Ag | Antibody drug conjugates |
| JP6449244B2 (ja) | 2013-04-19 | 2019-01-09 | インサイト・ホールディングス・コーポレイションIncyte Holdings Corporation | Fgfr抑制剤としての二環式複素環 |
| PL3027651T3 (pl) * | 2013-08-01 | 2019-08-30 | Five Prime Therapeutics, Inc. | Afukozylowane przeciwciała anty-fgfr2iiib |
| TWI541022B (zh) * | 2013-12-18 | 2016-07-11 | 應克隆公司 | 針對纖維母細胞生長因子受體-3(fgfr3)之化合物及治療方法 |
| CA2974651A1 (en) | 2014-01-24 | 2015-07-30 | Children's Hospital Of Eastern Ontario Research Institute Inc. | Smc combination therapy for the treatment of cancer |
| JOP20200094A1 (ar) | 2014-01-24 | 2017-06-16 | Dana Farber Cancer Inst Inc | جزيئات جسم مضاد لـ pd-1 واستخداماتها |
| JOP20200096A1 (ar) | 2014-01-31 | 2017-06-16 | Children’S Medical Center Corp | جزيئات جسم مضاد لـ tim-3 واستخداماتها |
| CU24481B1 (es) | 2014-03-14 | 2020-03-04 | Immutep Sas | Moléculas de anticuerpo que se unen a lag-3 |
| MA41044A (fr) | 2014-10-08 | 2017-08-15 | Novartis Ag | Compositions et procédés d'utilisation pour une réponse immunitaire accrue et traitement contre le cancer |
| CR20170143A (es) | 2014-10-14 | 2017-06-19 | Dana Farber Cancer Inst Inc | Moléculas de anticuerpo que se unen a pd-l1 y usos de las mismas |
| US10851105B2 (en) | 2014-10-22 | 2020-12-01 | Incyte Corporation | Bicyclic heterocycles as FGFR4 inhibitors |
| EP3212668B1 (en) * | 2014-10-31 | 2020-10-14 | AbbVie Biotherapeutics Inc. | Anti-cs1 antibodies and antibody drug conjugates |
| SG11201703599VA (en) * | 2014-11-19 | 2017-06-29 | Immunogen Inc | Process for preparing cell-binding agent-cytotoxic agent conjugates |
| WO2016100882A1 (en) | 2014-12-19 | 2016-06-23 | Novartis Ag | Combination therapies |
| MA41551A (fr) | 2015-02-20 | 2017-12-26 | Incyte Corp | Hétérocycles bicycliques utilisés en tant qu'inhibiteurs de fgfr4 |
| US9580423B2 (en) | 2015-02-20 | 2017-02-28 | Incyte Corporation | Bicyclic heterocycles as FGFR4 inhibitors |
| WO2016134320A1 (en) | 2015-02-20 | 2016-08-25 | Incyte Corporation | Bicyclic heterocycles as fgfr inhibitors |
| TN2017000375A1 (en) | 2015-03-10 | 2019-01-16 | Aduro Biotech Inc | Compositions and methods for activating "stimulator of interferon gene" -dependent signalling |
| US10881734B2 (en) | 2015-04-20 | 2021-01-05 | Daiichi Sankyo Company, Limited | Monoclonal antibodies to human fibroblast growth factor receptor 2 (HFGFR2) and methods of use thereof |
| EP3095465A1 (en) | 2015-05-19 | 2016-11-23 | U3 Pharma GmbH | Combination of fgfr4-inhibitor and bile acid sequestrant |
| JP6768011B2 (ja) * | 2015-06-23 | 2020-10-14 | バイエル ファーマ アクチエンゲゼルシャフト | キネシンスピンドルタンパク質(ksp)阻害剤の抗cd123抗体との抗体薬物複合体 |
| PT3317301T (pt) | 2015-07-29 | 2021-07-09 | Novartis Ag | Terapias de associação compreendendo moléculas de anticorpo contra lag-3 |
| WO2017019896A1 (en) | 2015-07-29 | 2017-02-02 | Novartis Ag | Combination therapies comprising antibody molecules to pd-1 |
| US20180207273A1 (en) | 2015-07-29 | 2018-07-26 | Novartis Ag | Combination therapies comprising antibody molecules to tim-3 |
| WO2017060322A2 (en) * | 2015-10-10 | 2017-04-13 | Bayer Pharma Aktiengesellschaft | Ptefb-inhibitor-adc |
| SG11201803520PA (en) | 2015-11-03 | 2018-05-30 | Janssen Biotech Inc | Antibodies specifically binding pd-1 and their uses |
| CN106699889A (zh) | 2015-11-18 | 2017-05-24 | 礼进生物医药科技(上海)有限公司 | 抗pd-1抗体及其治疗用途 |
| EP3380523A1 (en) | 2015-11-23 | 2018-10-03 | Five Prime Therapeutics, Inc. | Fgfr2 inhibitors alone or in combination with immune stimulating agents in cancer treatment |
| AU2016369537B2 (en) | 2015-12-17 | 2024-03-14 | Novartis Ag | Antibody molecules to PD-1 and uses thereof |
| WO2017127468A1 (en) | 2016-01-22 | 2017-07-27 | Merck Sharp & Dohme Corp. | Anti-coagulation factor xi antibodies |
| EP3411077A1 (en) | 2016-02-05 | 2018-12-12 | ImmunoGen, Inc. | Efficient process for preparing cell-binding agent-cytotoxic agent conjugates |
| CN109071659B (zh) * | 2016-02-10 | 2022-06-10 | 生物发明国际股份公司 | 人抗fgfr4抗体和索拉非尼的组合 |
| EP3448874A4 (en) | 2016-04-29 | 2020-04-22 | Voyager Therapeutics, Inc. | COMPOSITIONS FOR TREATING A DISEASE |
| US11299751B2 (en) | 2016-04-29 | 2022-04-12 | Voyager Therapeutics, Inc. | Compositions for the treatment of disease |
| CA3025869A1 (en) | 2016-06-14 | 2017-12-21 | Merck Sharp & Dohme Corp. | Anti-coagulation factor xi antibodies |
| CN109310781B (zh) | 2016-06-15 | 2024-06-18 | 拜耳制药股份公司 | 具有ksp抑制剂和抗-cd123-抗体的特异性抗体-药物-缀合物(adc) |
| WO2018009466A1 (en) | 2016-07-05 | 2018-01-11 | Aduro Biotech, Inc. | Locked nucleic acid cyclic dinucleotide compounds and uses thereof |
| JP7066714B2 (ja) | 2016-12-21 | 2022-05-13 | バイエル・ファルマ・アクティエンゲゼルシャフト | 酵素的に切断可能な基を有する抗体薬物コンジュゲート(adc) |
| EP3558387B1 (de) | 2016-12-21 | 2021-10-20 | Bayer Pharma Aktiengesellschaft | Spezifische antikörper-wirkstoff-konjugate (adcs) mit ksp-inhibitoren |
| UY37695A (es) | 2017-04-28 | 2018-11-30 | Novartis Ag | Compuesto dinucleótido cíclico bis 2’-5’-rr-(3’f-a)(3’f-a) y usos del mismo |
| SG10202112636SA (en) | 2017-05-16 | 2021-12-30 | Five Prime Therapeutics Inc | Anti-fgfr2 antibodies in combination with chemotherapy agents in cancer treatment |
| AR111960A1 (es) | 2017-05-26 | 2019-09-04 | Incyte Corp | Formas cristalinas de un inhibidor de fgfr y procesos para su preparación |
| WO2018237173A1 (en) | 2017-06-22 | 2018-12-27 | Novartis Ag | ANTIBODY MOLECULES DIRECTED AGAINST CD73 AND CORRESPONDING USES |
| EP3444275A1 (en) | 2017-08-16 | 2019-02-20 | Exiris S.r.l. | Monoclonal antibody anti-fgfr4 |
| US11773132B2 (en) | 2017-08-30 | 2023-10-03 | Beijing Xuanyi Pharmasciences Co., Ltd. | Cyclic di-nucleotides as stimulator of interferon genes modulators |
| SG11202010882XA (en) | 2018-05-04 | 2020-11-27 | Incyte Corp | Salts of an fgfr inhibitor |
| DK3788047T3 (da) | 2018-05-04 | 2024-09-16 | Incyte Corp | Faste former af en FGFR-inhibitor og fremgangsmåder til fremstilling deraf |
| AR126019A1 (es) | 2018-05-30 | 2023-09-06 | Novartis Ag | Anticuerpos frente a entpd2, terapias de combinación y métodos de uso de los anticuerpos y las terapias de combinación |
| WO2019246571A1 (en) * | 2018-06-22 | 2019-12-26 | Children's Medical Center Corporation | Compositions and methods for treating adrenocortical carcinoma |
| WO2019246572A1 (en) * | 2018-06-22 | 2019-12-26 | Children's Medical Center Corporation | Compositions and methods for treating primary aldosteonism |
| CN116063513A (zh) | 2018-12-21 | 2023-05-05 | Ose免疫疗法公司 | 人源化的抗人pd-1抗体 |
| US11628162B2 (en) | 2019-03-08 | 2023-04-18 | Incyte Corporation | Methods of treating cancer with an FGFR inhibitor |
| WO2021007269A1 (en) | 2019-07-09 | 2021-01-14 | Incyte Corporation | Bicyclic heterocycles as fgfr inhibitors |
| EP4031578A1 (en) | 2019-09-18 | 2022-07-27 | Novartis AG | Entpd2 antibodies, combination therapies, and methods of using the antibodies and combination therapies |
| MX2022004513A (es) | 2019-10-14 | 2022-07-19 | Incyte Corp | Heterociclos biciclicos como inhibidores de los receptores del factor de crecimiento de fibroblastos (fgfr). |
| WO2021076728A1 (en) | 2019-10-16 | 2021-04-22 | Incyte Corporation | Bicyclic heterocycles as fgfr inhibitors |
| JP2023505258A (ja) | 2019-12-04 | 2023-02-08 | インサイト・コーポレイション | Fgfr阻害剤としての三環式複素環 |
| BR112022010664A2 (pt) | 2019-12-04 | 2022-08-16 | Incyte Corp | Derivados de um inibidor de fgfr |
| JP6949343B1 (ja) * | 2019-12-18 | 2021-10-13 | 国立大学法人 岡山大学 | 抗体薬物コンジュゲート及び抗体の薬物送達のための使用 |
| US12012409B2 (en) | 2020-01-15 | 2024-06-18 | Incyte Corporation | Bicyclic heterocycles as FGFR inhibitors |
| KR20230042753A (ko) | 2020-08-05 | 2023-03-29 | 드래곤플라이 쎄라퓨틱스, 인크. | Egfr을 표적화하는 항체 및 그의 용도 |
| EP4323405A1 (en) | 2021-04-12 | 2024-02-21 | Incyte Corporation | Combination therapy comprising an fgfr inhibitor and a nectin-4 targeting agent |
| CA3220274A1 (en) | 2021-06-09 | 2022-12-15 | Incyte Corporation | Tricyclic heterocycles as fgfr inhibitors |
| US20230220106A1 (en) | 2021-12-08 | 2023-07-13 | Dragonfly Therapeutics, Inc. | Antibodies targeting 5t4 and uses thereof |
| WO2023235727A1 (en) * | 2022-06-01 | 2023-12-07 | Cornell University | Cancer immunotherapies to promote hyperacute rejection |
| CN115645526B (zh) * | 2022-12-27 | 2023-03-21 | 中国人民解放军军事科学院军事医学研究院 | 溶菌酶c特异性抗体在制备治疗肝癌的药物中的应用 |
Family Cites Families (127)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US633410A (en) | 1898-09-22 | 1899-09-19 | George A Ames | Ice-cutter. |
| US2429001A (en) | 1946-12-28 | 1947-10-14 | Axel H Stone | Artificial hand |
| US2779780A (en) | 1955-03-01 | 1957-01-29 | Du Pont | 1, 4-diamino-2, 3-dicyano-1, 4-bis (substituted mercapto) butadienes and their preparation |
| US3720760A (en) | 1968-09-06 | 1973-03-13 | Pharmacia Ab | Method for determining the presence of reagin-immunoglobulins(reagin-ig)directed against certain allergens,in aqueous samples |
| US3896111A (en) | 1973-02-20 | 1975-07-22 | Research Corp | Ansa macrolides |
| US4151042A (en) | 1977-03-31 | 1979-04-24 | Takeda Chemical Industries, Ltd. | Method for producing maytansinol and its derivatives |
| US4137230A (en) | 1977-11-14 | 1979-01-30 | Takeda Chemical Industries, Ltd. | Method for the production of maytansinoids |
| US4307016A (en) | 1978-03-24 | 1981-12-22 | Takeda Chemical Industries, Ltd. | Demethyl maytansinoids |
| US4265814A (en) | 1978-03-24 | 1981-05-05 | Takeda Chemical Industries | Matansinol 3-n-hexadecanoate |
| JPS5562090A (en) | 1978-10-27 | 1980-05-10 | Takeda Chem Ind Ltd | Novel maytansinoid compound and its preparation |
| US4256746A (en) | 1978-11-14 | 1981-03-17 | Takeda Chemical Industries | Dechloromaytansinoids, their pharmaceutical compositions and method of use |
| JPS55164687A (en) | 1979-06-11 | 1980-12-22 | Takeda Chem Ind Ltd | Novel maytansinoid compound and its preparation |
| JPS5566585A (en) | 1978-11-14 | 1980-05-20 | Takeda Chem Ind Ltd | Novel maytansinoid compound and its preparation |
| JPS55102583A (en) | 1979-01-31 | 1980-08-05 | Takeda Chem Ind Ltd | 20-acyloxy-20-demethylmaytansinoid compound |
| JPS55162791A (en) | 1979-06-05 | 1980-12-18 | Takeda Chem Ind Ltd | Antibiotic c-15003pnd and its preparation |
| JPS55164685A (en) | 1979-06-08 | 1980-12-22 | Takeda Chem Ind Ltd | Novel maytansinoid compound and its preparation |
| JPS55164686A (en) | 1979-06-11 | 1980-12-22 | Takeda Chem Ind Ltd | Novel maytansinoid compound and its preparation |
| US4309428A (en) | 1979-07-30 | 1982-01-05 | Takeda Chemical Industries, Ltd. | Maytansinoids |
| JPS5645483A (en) | 1979-09-19 | 1981-04-25 | Takeda Chem Ind Ltd | C-15003phm and its preparation |
| JPS5645485A (en) | 1979-09-21 | 1981-04-25 | Takeda Chem Ind Ltd | Production of c-15003pnd |
| EP0028683A1 (en) | 1979-09-21 | 1981-05-20 | Takeda Chemical Industries, Ltd. | Antibiotic C-15003 PHO and production thereof |
| US4458066A (en) | 1980-02-29 | 1984-07-03 | University Patents, Inc. | Process for preparing polynucleotides |
| WO1982001188A1 (en) | 1980-10-08 | 1982-04-15 | Takeda Chemical Industries Ltd | 4,5-deoxymaytansinoide compounds and process for preparing same |
| US4450254A (en) | 1980-11-03 | 1984-05-22 | Standard Oil Company | Impact improvement of high nitrile resins |
| US4313946A (en) | 1981-01-27 | 1982-02-02 | The United States Of America As Represented By The Secretary Of Agriculture | Chemotherapeutically active maytansinoids from Trewia nudiflora |
| US4315929A (en) | 1981-01-27 | 1982-02-16 | The United States Of America As Represented By The Secretary Of Agriculture | Method of controlling the European corn borer with trewiasine |
| JPS57192389A (en) | 1981-05-20 | 1982-11-26 | Takeda Chem Ind Ltd | Novel maytansinoid |
| ATE37983T1 (de) | 1982-04-22 | 1988-11-15 | Ici Plc | Mittel mit verzoegerter freigabe. |
| US4522811A (en) | 1982-07-08 | 1985-06-11 | Syntex (U.S.A.) Inc. | Serial injection of muramyldipeptides and liposomes enhances the anti-infective activity of muramyldipeptides |
| US5128326A (en) | 1984-12-06 | 1992-07-07 | Biomatrix, Inc. | Drug delivery systems based on hyaluronans derivatives thereof and their salts and methods of producing same |
| US5374548A (en) | 1986-05-02 | 1994-12-20 | Genentech, Inc. | Methods and compositions for the attachment of proteins to liposomes using a glycophospholipid anchor |
| MX9203291A (es) | 1985-06-26 | 1992-08-01 | Liposome Co Inc | Metodo para acoplamiento de liposomas. |
| WO1988007089A1 (en) | 1987-03-18 | 1988-09-22 | Medical Research Council | Altered antibodies |
| US4880078A (en) | 1987-06-29 | 1989-11-14 | Honda Giken Kogyo Kabushiki Kaisha | Exhaust muffler |
| US5677425A (en) | 1987-09-04 | 1997-10-14 | Celltech Therapeutics Limited | Recombinant antibody |
| US5108921A (en) | 1989-04-03 | 1992-04-28 | Purdue Research Foundation | Method for enhanced transmembrane transport of exogenous molecules |
| WO1991005548A1 (en) | 1989-10-10 | 1991-05-02 | Pitman-Moore, Inc. | Sustained release composition for macromolecular proteins |
| US5208020A (en) | 1989-10-25 | 1993-05-04 | Immunogen Inc. | Cytotoxic agents comprising maytansinoids and their therapeutic use |
| AU642932B2 (en) | 1989-11-06 | 1993-11-04 | Alkermes Controlled Therapeutics, Inc. | Protein microspheres and methods of using them |
| ES2181673T3 (es) | 1991-05-01 | 2003-03-01 | Jackson H M Found Military Med | Procedimiento de tratamiento de las enfermedades respiratorias infecciosas. |
| US5714350A (en) | 1992-03-09 | 1998-02-03 | Protein Design Labs, Inc. | Increasing antibody affinity by altering glycosylation in the immunoglobulin variable region |
| US5912015A (en) | 1992-03-12 | 1999-06-15 | Alkermes Controlled Therapeutics, Inc. | Modulated release from biocompatible polymers |
| EP0563475B1 (en) | 1992-03-25 | 2000-05-31 | Immunogen Inc | Cell binding agent conjugates of derivatives of CC-1065 |
| AU4116793A (en) | 1992-04-24 | 1993-11-29 | Board Of Regents, The University Of Texas System | Recombinant production of immunoglobulin-like domains in prokaryotic cells |
| US5934272A (en) | 1993-01-29 | 1999-08-10 | Aradigm Corporation | Device and method of creating aerosolized mist of respiratory drug |
| CA2163345A1 (en) | 1993-06-16 | 1994-12-22 | Susan Adrienne Morgan | Antibodies |
| US5834252A (en) | 1995-04-18 | 1998-11-10 | Glaxo Group Limited | End-complementary polymerase reaction |
| US5605793A (en) | 1994-02-17 | 1997-02-25 | Affymax Technologies N.V. | Methods for in vitro recombination |
| US5837458A (en) | 1994-02-17 | 1998-11-17 | Maxygen, Inc. | Methods and compositions for cellular and metabolic engineering |
| US6132764A (en) | 1994-08-05 | 2000-10-17 | Targesome, Inc. | Targeted polymerized liposome diagnostic and treatment agents |
| ATE252894T1 (de) | 1995-01-05 | 2003-11-15 | Univ Michigan | Oberflächen-modifizierte nanopartikel und verfahren für ihre herstellung und verwendung |
| US5641870A (en) | 1995-04-20 | 1997-06-24 | Genentech, Inc. | Low pH hydrophobic interaction chromatography for antibody purification |
| US6121022A (en) | 1995-04-14 | 2000-09-19 | Genentech, Inc. | Altered polypeptides with increased half-life |
| US6019968A (en) | 1995-04-14 | 2000-02-01 | Inhale Therapeutic Systems, Inc. | Dispersible antibody compositions and methods for their preparation and use |
| US5869046A (en) | 1995-04-14 | 1999-02-09 | Genentech, Inc. | Altered polypeptides with increased half-life |
| AU710347B2 (en) | 1995-08-31 | 1999-09-16 | Alkermes Controlled Therapeutics, Inc. | Composition for sustained release of an agent |
| PT885002E (pt) | 1996-03-04 | 2011-07-14 | Massachusetts Inst Technology | Materiais e métodos para aumento da internalização celular |
| US5874064A (en) | 1996-05-24 | 1999-02-23 | Massachusetts Institute Of Technology | Aerodynamically light particles for pulmonary drug delivery |
| US5855913A (en) | 1997-01-16 | 1999-01-05 | Massachusetts Instite Of Technology | Particles incorporating surfactants for pulmonary drug delivery |
| US5985309A (en) | 1996-05-24 | 1999-11-16 | Massachusetts Institute Of Technology | Preparation of particles for inhalation |
| US6056973A (en) | 1996-10-11 | 2000-05-02 | Sequus Pharmaceuticals, Inc. | Therapeutic liposome composition and method of preparation |
| ATE287257T1 (de) | 1997-01-16 | 2005-02-15 | Massachusetts Inst Technology | Zubereitung von partikelhaltigen arzneimitteln zur inhalation |
| US6277375B1 (en) | 1997-03-03 | 2001-08-21 | Board Of Regents, The University Of Texas System | Immunoglobulin-like domains with increased half-lives |
| JP2002512624A (ja) | 1997-05-21 | 2002-04-23 | バイオベーション リミテッド | 非免疫原性タンパク質の製造方法 |
| CA2293632C (en) | 1997-06-12 | 2011-11-29 | Research Corporation Technologies, Inc. | Artificial antibody polypeptides |
| US5989463A (en) | 1997-09-24 | 1999-11-23 | Alkermes Controlled Therapeutics, Inc. | Methods for fabricating polymer-based controlled release devices |
| SE512663C2 (sv) | 1997-10-23 | 2000-04-17 | Biogram Ab | Inkapslingsförfarande för aktiv substans i en bionedbrytbar polymer |
| US6194551B1 (en) | 1998-04-02 | 2001-02-27 | Genentech, Inc. | Polypeptide variants |
| DK2180007T4 (da) | 1998-04-20 | 2017-11-27 | Roche Glycart Ag | Glycosyleringsteknik for antistoffer til forbedring af antistofafhængig cellecytotoxicitet |
| AU747231B2 (en) | 1998-06-24 | 2002-05-09 | Alkermes, Inc. | Large porous particles emitted from an inhaler |
| IL143236A0 (en) | 1998-12-16 | 2002-04-21 | Warner Lambert Co | Treatment of arthritis with mek inhibitors |
| KR20060067983A (ko) | 1999-01-15 | 2006-06-20 | 제넨테크, 인크. | 효과기 기능이 변화된 폴리펩티드 변이체 |
| EP2275541B1 (en) | 1999-04-09 | 2016-03-23 | Kyowa Hakko Kirin Co., Ltd. | Method for controlling the activity of immunologically functional molecule |
| ATE349438T1 (de) | 1999-11-24 | 2007-01-15 | Immunogen Inc | Cytotoxische wirkstoffe enthaltend taxane und deren therapeutische anwendung |
| DE60031793T2 (de) | 1999-12-29 | 2007-08-23 | Immunogen Inc., Cambridge | Doxorubicin- und daunorubicin-enthaltende, zytotoxische mittel und deren therapeutische anwendung |
| ES2461854T3 (es) | 2000-07-19 | 2014-05-21 | Warner-Lambert Company Llc | Ésteres oxigenados de ácidos 4-yodofenilamino-benzhidroxámicos |
| US6411163B1 (en) | 2000-08-14 | 2002-06-25 | Intersil Americas Inc. | Transconductance amplifier circuit |
| US6441163B1 (en) | 2001-05-31 | 2002-08-27 | Immunogen, Inc. | Methods for preparation of cytotoxic conjugates of maytansinoids and cell binding agents |
| AU2002337935B2 (en) | 2001-10-25 | 2008-05-01 | Genentech, Inc. | Glycoprotein compositions |
| PL216224B1 (pl) | 2002-02-01 | 2014-03-31 | Ariad Pharmaceuticals | Pochodne rapamycyny zawierające fosfor, kompozycja je zawierająca oraz ich zastosowanie |
| WO2003076424A1 (en) | 2002-03-08 | 2003-09-18 | Eisai Co. Ltd. | Macrocyclic compounds useful as pharmaceuticals |
| TWI275390B (en) | 2002-04-30 | 2007-03-11 | Wyeth Corp | Process for the preparation of 7-substituted-3- quinolinecarbonitriles |
| GB0215823D0 (en) | 2002-07-09 | 2002-08-14 | Astrazeneca Ab | Quinazoline derivatives |
| ES2318167T3 (es) | 2002-07-15 | 2009-05-01 | The Trustees Of Princeton University | Compuestos de union a iap. |
| US8088387B2 (en) | 2003-10-10 | 2012-01-03 | Immunogen Inc. | Method of targeting specific cell populations using cell-binding agent maytansinoid conjugates linked via a non-cleavable linker, said conjugates, and methods of making said conjugates |
| US7399865B2 (en) | 2003-09-15 | 2008-07-15 | Wyeth | Protein tyrosine kinase enzyme inhibitors |
| ZA200601182B (en) * | 2003-10-10 | 2007-04-25 | Immunogen Inc | Method of targeting specific cell populations using cell-binding agent maytansinoid conjugates linked via a non-cleavable linker, said conjugates, and methods of making said conjugates |
| WO2005066211A2 (en) | 2003-12-19 | 2005-07-21 | Five Prime Therapeutics, Inc. | Fibroblast growth factor receptors 1, 2, 3, and 4 as targets for therapeutic intervention |
| CA2553874A1 (en) | 2004-01-16 | 2005-08-04 | The Regents Of The University Of Michigan | Conformationally constrained smac mimetics and the uses thereof |
| US20100093645A1 (en) | 2004-01-16 | 2010-04-15 | Shaomeng Wang | SMAC Peptidomimetics and the Uses Thereof |
| JP5122275B2 (ja) | 2004-03-23 | 2013-01-16 | ジェネンテック, インコーポレイテッド | Iapのアザビシクロ−オクタンインヒビター |
| KR20080083220A (ko) | 2004-04-07 | 2008-09-16 | 노파르티스 아게 | Iap 억제제 |
| WO2006014361A1 (en) | 2004-07-02 | 2006-02-09 | Genentech, Inc. | Inhibitors of iap |
| WO2006010118A2 (en) | 2004-07-09 | 2006-01-26 | The Regents Of The University Of Michigan | Conformationally constrained smac mimetics and the uses thereof |
| EA200700225A1 (ru) | 2004-07-12 | 2008-02-28 | Айдан Фармасьютикалз, Инк. | Аналоги тетрапептида |
| EP1773766B1 (en) | 2004-07-15 | 2014-04-02 | Tetralogic Pharmaceuticals Corporation | Iap binding compounds |
| ES2349110T5 (es) | 2004-12-20 | 2013-11-27 | Genentech, Inc. | Inhibidores de IAP derivados de pirrolidina |
| US20110166319A1 (en) | 2005-02-11 | 2011-07-07 | Immunogen, Inc. | Process for preparing purified drug conjugates |
| ES2503719T3 (es) | 2005-02-11 | 2014-10-07 | Immunogen, Inc. | Procedimiento para preparar conjugados de anticuerpos y de maitansinoides |
| MX2007012817A (es) | 2005-04-15 | 2007-12-12 | Immunogen Inc | Eliminacion de poblacion celular heterogenea o mezclada en tumores. |
| WO2006124451A2 (en) | 2005-05-11 | 2006-11-23 | Centocor, Inc. | Anti-il-13 antibodies, compositions, methods and uses |
| GB0510390D0 (en) | 2005-05-20 | 2005-06-29 | Novartis Ag | Organic compounds |
| SI1904104T1 (sl) | 2005-07-08 | 2013-12-31 | Biogen Idec Ma Inc. | Protitelesa SP35 in njihova uporaba |
| PL1912636T3 (pl) | 2005-07-21 | 2015-02-27 | Ardea Biosciences Inc | N-(aryloamino)sulfonamidowe inhibitory mek |
| SI1928503T1 (sl) | 2005-08-24 | 2012-11-30 | Immunogen Inc | Postopek za pripravo konjugatov majtansinoid protitelo |
| JP2009506790A (ja) | 2005-09-07 | 2009-02-19 | メディミューン,エルエルシー | 毒素とコンジュゲートしたeph受容体抗体 |
| JO2660B1 (en) | 2006-01-20 | 2012-06-17 | نوفارتيس ايه جي | Pi-3 inhibitors and methods of use |
| EP2018442A2 (en) | 2006-05-12 | 2009-01-28 | Genentech, Inc. | Methods and compositions for the diagnosis and treatment of cancer |
| TWI432212B (zh) | 2007-04-30 | 2014-04-01 | Genentech Inc | Iap抑制劑 |
| ES2537352T3 (es) | 2007-09-12 | 2015-06-05 | Genentech, Inc. | Combinaciones de compuestos inhibidores de fosfoinositida 3-cinasa y agentes quimioterapéuticos, y metodos para su uso |
| WO2009055730A1 (en) | 2007-10-25 | 2009-04-30 | Genentech, Inc. | Process for making thienopyrimidine compounds |
| WO2009100105A2 (en) | 2008-02-04 | 2009-08-13 | Attogen Inc. | Inhibitors of oncogenic isoforms and uses thereof |
| WO2012021841A2 (en) | 2010-08-12 | 2012-02-16 | Attogen Inc. | Antibody molecules to oncogenic isoforms of fibroblast growth factor receptor-2 and uses thereof |
| US8236319B2 (en) | 2008-04-30 | 2012-08-07 | Immunogen, Inc. | Cross-linkers and their uses |
| US8101725B2 (en) * | 2008-05-29 | 2012-01-24 | Galaxy Biotech, Llc | Monoclonal antibodies to basic fibroblast growth factor |
| US8168784B2 (en) | 2008-06-20 | 2012-05-01 | Abbott Laboratories | Processes to make apoptosis promoters |
| PE20120878A1 (es) * | 2009-04-01 | 2012-08-06 | Genentech Inc | ANTICUERPOS ANTI-FcRH5 E INMUNOCONJUGADOS |
| CN104984360A (zh) | 2009-06-03 | 2015-10-21 | 伊缪诺金公司 | 轭合方法 |
| IN2012DN02780A (ko) * | 2009-10-06 | 2015-09-18 | Immunogen Inc | |
| TWI507524B (zh) * | 2009-11-30 | 2015-11-11 | Genentech Inc | 診斷及治療腫瘤之組合物及方法 |
| US9145462B2 (en) | 2010-06-30 | 2015-09-29 | The Regents Of The University Of California | Glioblastoma multiforme-reactive antibodies and methods of use thereof |
| ES2544608T3 (es) | 2010-11-17 | 2015-09-02 | Genentech, Inc. | Conjugados de anticuerpo y de alaninil-maitansinol |
| EP2691117A2 (en) | 2011-03-29 | 2014-02-05 | Immunogen, Inc. | Process for manufacturing conjugates of improved homogeneity |
| KR102272828B1 (ko) | 2011-03-29 | 2021-07-05 | 이뮤노젠 아이엔씨 | 일-단계 방법에 의한 메이탄시노이드 항체 접합체의 제조 |
| WO2014089193A1 (en) | 2012-12-04 | 2014-06-12 | Aveo Pharmaceuticals, Inc. | Anti-fgfr2 antibodies |
| US9415118B2 (en) | 2013-03-13 | 2016-08-16 | Novartis Ag | Antibody drug conjugates |
| US11605302B2 (en) | 2020-11-10 | 2023-03-14 | Rockwell Collins, Inc. | Time-critical obstacle avoidance path planning in uncertain environments |
-
2014
- 2014-03-11 US US14/203,997 patent/US9498532B2/en active Active
- 2014-03-12 TW TW103108773A patent/TW201444574A/zh unknown
- 2014-03-12 UY UY0001035399A patent/UY35399A/es not_active Application Discontinuation
- 2014-03-13 CN CN201480021393.2A patent/CN105188763B/zh not_active Expired - Fee Related
- 2014-03-13 MX MX2015012122A patent/MX2015012122A/es unknown
- 2014-03-13 BR BR112015023418A patent/BR112015023418A8/pt not_active Application Discontinuation
- 2014-03-13 WO PCT/US2014/025944 patent/WO2014160160A2/en active Application Filing
- 2014-03-13 EA EA201591611A patent/EA201591611A1/ru unknown
- 2014-03-13 KR KR1020157026812A patent/KR20150130333A/ko not_active Application Discontinuation
- 2014-03-13 JP JP2016502005A patent/JP2016518332A/ja active Pending
- 2014-03-13 AR ARP140100924A patent/AR096015A1/es unknown
- 2014-03-13 EP EP14729099.3A patent/EP2968592A2/en not_active Withdrawn
- 2014-03-13 AU AU2014244060A patent/AU2014244060B2/en not_active Ceased
- 2014-03-13 CA CA2904090A patent/CA2904090A1/en not_active Abandoned
-
2016
- 2016-10-11 US US15/291,024 patent/US20170106095A1/en not_active Abandoned
-
2017
- 2017-03-31 AU AU2017202150A patent/AU2017202150B2/en not_active Ceased
-
2019
- 2019-04-18 JP JP2019079590A patent/JP2019193626A/ja active Pending
Also Published As
| Publication number | Publication date |
|---|---|
| US20170106095A1 (en) | 2017-04-20 |
| EP2968592A2 (en) | 2016-01-20 |
| US9498532B2 (en) | 2016-11-22 |
| AU2017202150B2 (en) | 2018-12-20 |
| BR112015023418A8 (pt) | 2018-01-23 |
| CA2904090A1 (en) | 2014-10-02 |
| AU2014244060A1 (en) | 2015-10-01 |
| WO2014160160A3 (en) | 2015-01-08 |
| JP2016518332A (ja) | 2016-06-23 |
| JP2019193626A (ja) | 2019-11-07 |
| BR112015023418A2 (pt) | 2017-11-28 |
| US20140301946A1 (en) | 2014-10-09 |
| AU2014244060B2 (en) | 2017-04-20 |
| AR096015A1 (es) | 2015-12-02 |
| CN105188763A (zh) | 2015-12-23 |
| EA201591611A1 (ru) | 2016-03-31 |
| CN105188763B (zh) | 2019-02-19 |
| MX2015012122A (es) | 2016-11-08 |
| AU2017202150A1 (en) | 2017-04-20 |
| WO2014160160A2 (en) | 2014-10-02 |
| TW201444574A (zh) | 2014-12-01 |
| UY35399A (es) | 2014-10-31 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR20150130333A (ko) | 항체 약물 접합체 및 상응하는 항체 | |
| US9125896B2 (en) | EGFR-binding molecules and immunoconjugates thereof | |
| AU2015302959B2 (en) | Anti-CDH6 antibody drug conjugates | |
| US9238690B2 (en) | Non-antagonistic EGFR-binding molecules and immunoconjugates thereof | |
| KR20150131173A (ko) | 항체 약물 접합체 | |
| EP2968600A2 (en) | Antibody drug conjugates | |
| US20240189439A1 (en) | Antibodies to pmel17 and conjugates thereof | |
| TW202430573A (zh) | 針對pmel17之抗體及其軛合物 | |
| KR20230002910A (ko) | 암 치료를 위한 ccr7 항체 약물 접합체 | |
| AU2015252047A1 (en) | Novel EGFR-Binding Molecules and Immunoconjugates Thereof |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| E902 | Notification of reason for refusal | ||
| E601 | Decision to refuse application |