ES2719406T3 - Antígenos recombinantes del VSR - Google Patents
Antígenos recombinantes del VSR Download PDFInfo
- Publication number
- ES2719406T3 ES2719406T3 ES16180926T ES16180926T ES2719406T3 ES 2719406 T3 ES2719406 T3 ES 2719406T3 ES 16180926 T ES16180926 T ES 16180926T ES 16180926 T ES16180926 T ES 16180926T ES 2719406 T3 ES2719406 T3 ES 2719406T3
- Authority
- ES
- Spain
- Prior art keywords
- protein
- antigen
- pref
- rsv
- domain
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 102000036639 antigens Human genes 0.000 title claims abstract description 295
- 108091007433 antigens Proteins 0.000 title claims abstract description 295
- 239000000427 antigen Substances 0.000 title claims abstract description 294
- 108090000765 processed proteins & peptides Proteins 0.000 claims abstract description 158
- 241000725643 Respiratory syncytial virus Species 0.000 claims abstract description 141
- 102000004196 processed proteins & peptides Human genes 0.000 claims abstract description 139
- 229920001184 polypeptide Polymers 0.000 claims abstract description 137
- 108010068327 4-hydroxyphenylpyruvate dioxygenase Proteins 0.000 claims abstract description 80
- 238000005829 trimerization reaction Methods 0.000 claims abstract description 21
- 101710160621 Fusion glycoprotein F0 Proteins 0.000 claims abstract description 20
- 210000004899 c-terminal region Anatomy 0.000 claims abstract description 15
- 239000013638 trimer Substances 0.000 claims abstract description 15
- 239000000203 mixture Substances 0.000 claims description 175
- 230000002163 immunogen Effects 0.000 claims description 116
- 150000007523 nucleic acids Chemical class 0.000 claims description 94
- 102000039446 nucleic acids Human genes 0.000 claims description 93
- 108020004707 nucleic acids Proteins 0.000 claims description 93
- 239000002671 adjuvant Substances 0.000 claims description 70
- 125000003275 alpha amino acid group Chemical group 0.000 claims description 56
- 201000010099 disease Diseases 0.000 claims description 29
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 claims description 29
- 238000002360 preparation method Methods 0.000 claims description 25
- 108010076504 Protein Sorting Signals Proteins 0.000 claims description 21
- 239000000546 pharmaceutical excipient Substances 0.000 claims description 14
- 206010061603 Respiratory syncytial virus infection Diseases 0.000 claims description 13
- 239000000839 emulsion Substances 0.000 claims description 10
- 230000002265 prevention Effects 0.000 claims description 10
- 239000003814 drug Substances 0.000 claims description 8
- 239000003937 drug carrier Substances 0.000 claims description 8
- 229940037003 alum Drugs 0.000 claims description 7
- 238000011282 treatment Methods 0.000 claims description 6
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 claims description 6
- 150000001413 amino acids Chemical class 0.000 abstract description 100
- 235000001014 amino acid Nutrition 0.000 description 123
- 229940024606 amino acid Drugs 0.000 description 104
- 210000004027 cell Anatomy 0.000 description 92
- 102000004169 proteins and genes Human genes 0.000 description 85
- 108090000623 proteins and genes Proteins 0.000 description 84
- 102000030782 GTP binding Human genes 0.000 description 82
- 108091000058 GTP-Binding Proteins 0.000 description 82
- 235000018102 proteins Nutrition 0.000 description 80
- 108091006027 G proteins Proteins 0.000 description 58
- 230000004044 response Effects 0.000 description 58
- 230000028993 immune response Effects 0.000 description 52
- 238000000034 method Methods 0.000 description 52
- 230000014509 gene expression Effects 0.000 description 44
- 239000000556 agonist Substances 0.000 description 36
- 239000013598 vector Substances 0.000 description 36
- 102000040430 polynucleotide Human genes 0.000 description 35
- 108091033319 polynucleotide Proteins 0.000 description 35
- 229960005486 vaccine Drugs 0.000 description 35
- 239000002157 polynucleotide Substances 0.000 description 34
- 244000052769 pathogen Species 0.000 description 26
- 238000006467 substitution reaction Methods 0.000 description 26
- 102000002689 Toll-like receptor Human genes 0.000 description 25
- 108020000411 Toll-like receptor Proteins 0.000 description 25
- 208000015181 infectious disease Diseases 0.000 description 25
- 238000007792 addition Methods 0.000 description 24
- 102000004961 Furin Human genes 0.000 description 22
- 108090001126 Furin Proteins 0.000 description 22
- 230000000875 corresponding effect Effects 0.000 description 22
- 239000012634 fragment Substances 0.000 description 22
- 230000004048 modification Effects 0.000 description 22
- 238000012986 modification Methods 0.000 description 22
- 241000700605 Viruses Species 0.000 description 21
- 238000004519 manufacturing process Methods 0.000 description 21
- 230000001717 pathogenic effect Effects 0.000 description 21
- 238000003776 cleavage reaction Methods 0.000 description 19
- 238000009472 formulation Methods 0.000 description 19
- 239000012528 membrane Substances 0.000 description 19
- 230000007017 scission Effects 0.000 description 19
- 230000011664 signaling Effects 0.000 description 19
- 230000006641 stabilisation Effects 0.000 description 19
- 238000011105 stabilization Methods 0.000 description 19
- 239000013604 expression vector Substances 0.000 description 18
- 230000002209 hydrophobic effect Effects 0.000 description 18
- 230000004927 fusion Effects 0.000 description 17
- 230000003612 virological effect Effects 0.000 description 17
- 210000001744 T-lymphocyte Anatomy 0.000 description 15
- 239000002158 endotoxin Substances 0.000 description 15
- 108020001507 fusion proteins Proteins 0.000 description 15
- 239000002243 precursor Substances 0.000 description 15
- 150000007949 saponins Chemical class 0.000 description 15
- 230000001580 bacterial effect Effects 0.000 description 14
- 239000000872 buffer Substances 0.000 description 14
- 102000037865 fusion proteins Human genes 0.000 description 14
- 229920006008 lipopolysaccharide Polymers 0.000 description 14
- 238000006386 neutralization reaction Methods 0.000 description 14
- 125000003729 nucleotide group Chemical group 0.000 description 14
- 229930182490 saponin Natural products 0.000 description 14
- 235000017709 saponins Nutrition 0.000 description 14
- FWMNVWWHGCHHJJ-SKKKGAJSSA-N 4-amino-1-[(2r)-6-amino-2-[[(2r)-2-[[(2r)-2-[[(2r)-2-amino-3-phenylpropanoyl]amino]-3-phenylpropanoyl]amino]-4-methylpentanoyl]amino]hexanoyl]piperidine-4-carboxylic acid Chemical compound C([C@H](C(=O)N[C@H](CC(C)C)C(=O)N[C@H](CCCCN)C(=O)N1CCC(N)(CC1)C(O)=O)NC(=O)[C@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 FWMNVWWHGCHHJJ-SKKKGAJSSA-N 0.000 description 13
- 239000003795 chemical substances by application Substances 0.000 description 13
- 238000012217 deletion Methods 0.000 description 13
- 230000037430 deletion Effects 0.000 description 13
- 239000002773 nucleotide Substances 0.000 description 13
- 238000000746 purification Methods 0.000 description 13
- 102100024365 Arf-GAP domain and FG repeat-containing protein 1 Human genes 0.000 description 12
- LOKCTEFSRHRXRJ-UHFFFAOYSA-I dipotassium trisodium dihydrogen phosphate hydrogen phosphate dichloride Chemical compound P(=O)(O)(O)[O-].[K+].P(=O)(O)([O-])[O-].[Na+].[Na+].[Cl-].[K+].[Cl-].[Na+] LOKCTEFSRHRXRJ-UHFFFAOYSA-I 0.000 description 12
- 239000002953 phosphate buffered saline Substances 0.000 description 12
- 230000001681 protective effect Effects 0.000 description 12
- 230000000638 stimulation Effects 0.000 description 12
- 238000013519 translation Methods 0.000 description 12
- GVJHHUAWPYXKBD-IEOSBIPESA-N α-tocopherol Chemical compound OC1=C(C)C(C)=C2O[C@@](CCC[C@H](C)CCC[C@H](C)CCCC(C)C)(C)CCC2=C1C GVJHHUAWPYXKBD-IEOSBIPESA-N 0.000 description 12
- 241001465754 Metazoa Species 0.000 description 11
- 230000000890 antigenic effect Effects 0.000 description 11
- 230000001965 increasing effect Effects 0.000 description 11
- 239000002609 medium Substances 0.000 description 11
- 241000238631 Hexapoda Species 0.000 description 10
- 101000669447 Homo sapiens Toll-like receptor 4 Proteins 0.000 description 10
- AGPKZVBTJJNPAG-WHFBIAKZSA-N L-isoleucine Chemical compound CC[C@H](C)[C@H](N)C(O)=O AGPKZVBTJJNPAG-WHFBIAKZSA-N 0.000 description 10
- 108091034117 Oligonucleotide Proteins 0.000 description 10
- 102100039360 Toll-like receptor 4 Human genes 0.000 description 10
- HVYWMOMLDIMFJA-DPAQBDIFSA-N cholesterol Chemical compound C1C=C2C[C@@H](O)CC[C@]2(C)[C@@H]2[C@@H]1[C@@H]1CC[C@H]([C@H](C)CCCC(C)C)[C@@]1(C)CC2 HVYWMOMLDIMFJA-DPAQBDIFSA-N 0.000 description 10
- 238000009396 hybridization Methods 0.000 description 10
- 229960000310 isoleucine Drugs 0.000 description 10
- AGPKZVBTJJNPAG-UHFFFAOYSA-N isoleucine Natural products CCC(C)C(N)C(O)=O AGPKZVBTJJNPAG-UHFFFAOYSA-N 0.000 description 10
- 241000894006 Bacteria Species 0.000 description 9
- 108020004414 DNA Proteins 0.000 description 9
- 240000004808 Saccharomyces cerevisiae Species 0.000 description 9
- 235000014680 Saccharomyces cerevisiae Nutrition 0.000 description 9
- JLCPHMBAVCMARE-UHFFFAOYSA-N [3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-hydroxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methyl [5-(6-aminopurin-9-yl)-2-(hydroxymethyl)oxolan-3-yl] hydrogen phosphate Polymers Cc1cn(C2CC(OP(O)(=O)OCC3OC(CC3OP(O)(=O)OCC3OC(CC3O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c3nc(N)[nH]c4=O)C(COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3CO)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cc(C)c(=O)[nH]c3=O)n3cc(C)c(=O)[nH]c3=O)n3ccc(N)nc3=O)n3cc(C)c(=O)[nH]c3=O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)O2)c(=O)[nH]c1=O JLCPHMBAVCMARE-UHFFFAOYSA-N 0.000 description 9
- 230000002349 favourable effect Effects 0.000 description 9
- -1 lysine Chemical class 0.000 description 9
- 239000007764 o/w emulsion Substances 0.000 description 9
- 230000004224 protection Effects 0.000 description 9
- 210000002966 serum Anatomy 0.000 description 9
- 241000196324 Embryophyta Species 0.000 description 8
- 241000588724 Escherichia coli Species 0.000 description 8
- 241000699670 Mus sp. Species 0.000 description 8
- 230000003308 immunostimulating effect Effects 0.000 description 8
- 239000002245 particle Substances 0.000 description 8
- 108010028921 Lipopeptides Proteins 0.000 description 7
- 206010024971 Lower respiratory tract infections Diseases 0.000 description 7
- KDXKERNSBIXSRK-UHFFFAOYSA-N Lysine Natural products NCCCCC(N)C(O)=O KDXKERNSBIXSRK-UHFFFAOYSA-N 0.000 description 7
- 239000004472 Lysine Substances 0.000 description 7
- 125000000539 amino acid group Chemical group 0.000 description 7
- 238000004113 cell culture Methods 0.000 description 7
- 210000004978 chinese hamster ovary cell Anatomy 0.000 description 7
- 230000000694 effects Effects 0.000 description 7
- 210000003979 eosinophil Anatomy 0.000 description 7
- 210000004962 mammalian cell Anatomy 0.000 description 7
- 230000001575 pathological effect Effects 0.000 description 7
- 239000013612 plasmid Substances 0.000 description 7
- 238000012545 processing Methods 0.000 description 7
- 230000009467 reduction Effects 0.000 description 7
- 208000024891 symptom Diseases 0.000 description 7
- YYGNTYWPHWGJRM-UHFFFAOYSA-N (6E,10E,14E,18E)-2,6,10,15,19,23-hexamethyltetracosa-2,6,10,14,18,22-hexaene Chemical compound CC(C)=CCCC(C)=CCCC(C)=CCCC=C(C)CCC=C(C)CCC=C(C)C YYGNTYWPHWGJRM-UHFFFAOYSA-N 0.000 description 6
- 108020004705 Codon Proteins 0.000 description 6
- SXRSQZLOMIGNAQ-UHFFFAOYSA-N Glutaraldehyde Chemical compound O=CCCCC=O SXRSQZLOMIGNAQ-UHFFFAOYSA-N 0.000 description 6
- 108091081024 Start codon Proteins 0.000 description 6
- BHEOSNUKNHRBNM-UHFFFAOYSA-N Tetramethylsqualene Natural products CC(=C)C(C)CCC(=C)C(C)CCC(C)=CCCC=C(C)CCC(C)C(=C)CCC(C)C(C)=C BHEOSNUKNHRBNM-UHFFFAOYSA-N 0.000 description 6
- 101710120037 Toxin CcdB Proteins 0.000 description 6
- 150000001875 compounds Chemical class 0.000 description 6
- 239000003599 detergent Substances 0.000 description 6
- PRAKJMSDJKAYCZ-UHFFFAOYSA-N dodecahydrosqualene Natural products CC(C)CCCC(C)CCCC(C)CCCCC(C)CCCC(C)CCCC(C)C PRAKJMSDJKAYCZ-UHFFFAOYSA-N 0.000 description 6
- 230000002068 genetic effect Effects 0.000 description 6
- 230000002480 immunoprotective effect Effects 0.000 description 6
- 239000002502 liposome Substances 0.000 description 6
- 230000007935 neutral effect Effects 0.000 description 6
- 229940031439 squalene Drugs 0.000 description 6
- TUHBEKDERLKLEC-UHFFFAOYSA-N squalene Natural products CC(=CCCC(=CCCC(=CCCC=C(/C)CCC=C(/C)CC=C(C)C)C)C)C TUHBEKDERLKLEC-UHFFFAOYSA-N 0.000 description 6
- 239000003981 vehicle Substances 0.000 description 6
- ROHFNLRQFUQHCH-UHFFFAOYSA-N Leucine Natural products CC(C)CC(N)C(O)=O ROHFNLRQFUQHCH-UHFFFAOYSA-N 0.000 description 5
- 108091005461 Nucleic proteins Proteins 0.000 description 5
- 239000002253 acid Substances 0.000 description 5
- 230000002411 adverse Effects 0.000 description 5
- 229940087168 alpha tocopherol Drugs 0.000 description 5
- WNROFYMDJYEPJX-UHFFFAOYSA-K aluminium hydroxide Chemical compound [OH-].[OH-].[OH-].[Al+3] WNROFYMDJYEPJX-UHFFFAOYSA-K 0.000 description 5
- 238000013459 approach Methods 0.000 description 5
- 210000003719 b-lymphocyte Anatomy 0.000 description 5
- 230000001413 cellular effect Effects 0.000 description 5
- 235000012000 cholesterol Nutrition 0.000 description 5
- 229940107161 cholesterol Drugs 0.000 description 5
- 230000007423 decrease Effects 0.000 description 5
- 238000001727 in vivo Methods 0.000 description 5
- 239000003446 ligand Substances 0.000 description 5
- 210000004072 lung Anatomy 0.000 description 5
- 239000000463 material Substances 0.000 description 5
- 238000000569 multi-angle light scattering Methods 0.000 description 5
- 231100000252 nontoxic Toxicity 0.000 description 5
- 230000003000 nontoxic effect Effects 0.000 description 5
- 235000010482 polyoxyethylene sorbitan monooleate Nutrition 0.000 description 5
- 229920000053 polysorbate 80 Polymers 0.000 description 5
- 239000000047 product Substances 0.000 description 5
- 235000004252 protein component Nutrition 0.000 description 5
- 238000012552 review Methods 0.000 description 5
- 210000001519 tissue Anatomy 0.000 description 5
- 229960000984 tocofersolan Drugs 0.000 description 5
- 241000701447 unidentified baculovirus Species 0.000 description 5
- 239000002076 α-tocopherol Substances 0.000 description 5
- 235000004835 α-tocopherol Nutrition 0.000 description 5
- 241000283707 Capra Species 0.000 description 4
- 208000034628 Celiac artery compression syndrome Diseases 0.000 description 4
- 108010001336 Horseradish Peroxidase Proteins 0.000 description 4
- 241000699666 Mus <mouse, genus> Species 0.000 description 4
- 241000588653 Neisseria Species 0.000 description 4
- ISWSIDIOOBJBQZ-UHFFFAOYSA-N Phenol Chemical compound OC1=CC=CC=C1 ISWSIDIOOBJBQZ-UHFFFAOYSA-N 0.000 description 4
- 102000017033 Porins Human genes 0.000 description 4
- 108010013381 Porins Proteins 0.000 description 4
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 4
- 238000004458 analytical method Methods 0.000 description 4
- 238000003556 assay Methods 0.000 description 4
- 238000004422 calculation algorithm Methods 0.000 description 4
- 210000000170 cell membrane Anatomy 0.000 description 4
- 238000011161 development Methods 0.000 description 4
- 230000018109 developmental process Effects 0.000 description 4
- 239000003623 enhancer Substances 0.000 description 4
- 210000003527 eukaryotic cell Anatomy 0.000 description 4
- 230000000799 fusogenic effect Effects 0.000 description 4
- ZDXPYRJPNDTMRX-UHFFFAOYSA-N glutamine Natural products OC(=O)C(N)CCC(N)=O ZDXPYRJPNDTMRX-UHFFFAOYSA-N 0.000 description 4
- 230000003053 immunization Effects 0.000 description 4
- 238000002649 immunization Methods 0.000 description 4
- 239000003022 immunostimulating agent Substances 0.000 description 4
- 206010022000 influenza Diseases 0.000 description 4
- 239000003112 inhibitor Substances 0.000 description 4
- 230000005764 inhibitory process Effects 0.000 description 4
- 238000007918 intramuscular administration Methods 0.000 description 4
- IZWSFJTYBVKZNK-UHFFFAOYSA-N lauryl sulfobetaine Chemical compound CCCCCCCCCCCC[N+](C)(C)CCCS([O-])(=O)=O IZWSFJTYBVKZNK-UHFFFAOYSA-N 0.000 description 4
- 125000001909 leucine group Chemical group [H]N(*)C(C(*)=O)C([H])([H])C(C([H])([H])[H])C([H])([H])[H] 0.000 description 4
- 230000000670 limiting effect Effects 0.000 description 4
- 239000003550 marker Substances 0.000 description 4
- 238000010369 molecular cloning Methods 0.000 description 4
- 125000002924 primary amino group Chemical group [H]N([H])* 0.000 description 4
- 230000008569 process Effects 0.000 description 4
- 150000003839 salts Chemical class 0.000 description 4
- 239000000523 sample Substances 0.000 description 4
- 238000002415 sodium dodecyl sulfate polyacrylamide gel electrophoresis Methods 0.000 description 4
- 238000004448 titration Methods 0.000 description 4
- 238000001890 transfection Methods 0.000 description 4
- DFUSDJMZWQVQSF-XLGIIRLISA-N (2r)-2-methyl-2-[(4r,8r)-4,8,12-trimethyltridecyl]-3,4-dihydrochromen-6-ol Chemical compound OC1=CC=C2O[C@@](CCC[C@H](C)CCC[C@H](C)CCCC(C)C)(C)CCC2=C1 DFUSDJMZWQVQSF-XLGIIRLISA-N 0.000 description 3
- 238000002965 ELISA Methods 0.000 description 3
- 241000991587 Enterovirus C Species 0.000 description 3
- LFQSCWFLJHTTHZ-UHFFFAOYSA-N Ethanol Chemical compound CCO LFQSCWFLJHTTHZ-UHFFFAOYSA-N 0.000 description 3
- PEDCQBHIVMGVHV-UHFFFAOYSA-N Glycerine Chemical compound OCC(O)CO PEDCQBHIVMGVHV-UHFFFAOYSA-N 0.000 description 3
- 241000282412 Homo Species 0.000 description 3
- 108010002350 Interleukin-2 Proteins 0.000 description 3
- 108090001030 Lipoproteins Proteins 0.000 description 3
- 102000004895 Lipoproteins Human genes 0.000 description 3
- 108010006035 Metalloproteases Proteins 0.000 description 3
- 102000005741 Metalloproteases Human genes 0.000 description 3
- 101100481584 Mus musculus Tlr1 gene Proteins 0.000 description 3
- 101710116435 Outer membrane protein Proteins 0.000 description 3
- 229910019142 PO4 Inorganic materials 0.000 description 3
- 229930040373 Paraformaldehyde Natural products 0.000 description 3
- 208000002606 Paramyxoviridae Infections Diseases 0.000 description 3
- 102000035195 Peptidases Human genes 0.000 description 3
- 108091005804 Peptidases Proteins 0.000 description 3
- 201000005702 Pertussis Diseases 0.000 description 3
- 102000007056 Recombinant Fusion Proteins Human genes 0.000 description 3
- 108010008281 Recombinant Fusion Proteins Proteins 0.000 description 3
- HEMHJVSKTPXQMS-UHFFFAOYSA-M Sodium hydroxide Chemical compound [OH-].[Na+] HEMHJVSKTPXQMS-UHFFFAOYSA-M 0.000 description 3
- 241000256251 Spodoptera frugiperda Species 0.000 description 3
- 206010043376 Tetanus Diseases 0.000 description 3
- UZQJVUCHXGYFLQ-AYDHOLPZSA-N [(2s,3r,4s,5r,6r)-4-[(2s,3r,4s,5r,6r)-4-[(2r,3r,4s,5r,6r)-4-[(2s,3r,4s,5r,6r)-3,5-dihydroxy-6-(hydroxymethyl)-4-[(2s,3r,4s,5s,6r)-3,4,5-trihydroxy-6-(hydroxymethyl)oxan-2-yl]oxyoxan-2-yl]oxy-3,5-dihydroxy-6-(hydroxymethyl)oxan-2-yl]oxy-3,5-dihydroxy-6-(hy Chemical compound O([C@H]1[C@H](O)[C@@H](CO)O[C@H]([C@@H]1O)O[C@H]1[C@H](O)[C@@H](CO)O[C@H]([C@@H]1O)O[C@H]1CC[C@]2(C)[C@H]3CC=C4[C@@]([C@@]3(CC[C@H]2[C@@]1(C=O)C)C)(C)CC(O)[C@]1(CCC(CC14)(C)C)C(=O)O[C@H]1[C@@H]([C@@H](O[C@H]2[C@@H]([C@@H](O[C@H]3[C@@H]([C@@H](O[C@H]4[C@@H]([C@@H](O[C@H]5[C@@H]([C@@H](O)[C@H](O)[C@@H](CO)O5)O)[C@H](O)[C@@H](CO)O4)O)[C@H](O)[C@@H](CO)O3)O)[C@H](O)[C@@H](CO)O2)O)[C@H](O)[C@@H](CO)O1)O)[C@@H]1O[C@H](CO)[C@@H](O)[C@H](O)[C@H]1O UZQJVUCHXGYFLQ-AYDHOLPZSA-N 0.000 description 3
- 235000004279 alanine Nutrition 0.000 description 3
- AZDRQVAHHNSJOQ-UHFFFAOYSA-N alumane Chemical class [AlH3] AZDRQVAHHNSJOQ-UHFFFAOYSA-N 0.000 description 3
- ILRRQNADMUWWFW-UHFFFAOYSA-K aluminium phosphate Chemical compound O1[Al]2OP1(=O)O2 ILRRQNADMUWWFW-UHFFFAOYSA-K 0.000 description 3
- 210000004102 animal cell Anatomy 0.000 description 3
- 238000010171 animal model Methods 0.000 description 3
- 238000002869 basic local alignment search tool Methods 0.000 description 3
- 229960000074 biopharmaceutical Drugs 0.000 description 3
- 230000015572 biosynthetic process Effects 0.000 description 3
- 230000000903 blocking effect Effects 0.000 description 3
- 239000001506 calcium phosphate Substances 0.000 description 3
- 229910000389 calcium phosphate Inorganic materials 0.000 description 3
- 235000011010 calcium phosphates Nutrition 0.000 description 3
- 238000004364 calculation method Methods 0.000 description 3
- 125000003178 carboxy group Chemical group [H]OC(*)=O 0.000 description 3
- 238000005119 centrifugation Methods 0.000 description 3
- 230000008859 change Effects 0.000 description 3
- 238000006243 chemical reaction Methods 0.000 description 3
- 238000004587 chromatography analysis Methods 0.000 description 3
- 230000034994 death Effects 0.000 description 3
- 231100000517 death Toxicity 0.000 description 3
- 238000013461 design Methods 0.000 description 3
- 206010013023 diphtheria Diseases 0.000 description 3
- 238000010828 elution Methods 0.000 description 3
- 210000002472 endoplasmic reticulum Anatomy 0.000 description 3
- 230000012010 growth Effects 0.000 description 3
- 210000002443 helper t lymphocyte Anatomy 0.000 description 3
- 230000002949 hemolytic effect Effects 0.000 description 3
- 230000001900 immune effect Effects 0.000 description 3
- 230000005847 immunogenicity Effects 0.000 description 3
- 230000006698 induction Effects 0.000 description 3
- 230000001939 inductive effect Effects 0.000 description 3
- 230000002458 infectious effect Effects 0.000 description 3
- 230000002401 inhibitory effect Effects 0.000 description 3
- 229910052500 inorganic mineral Inorganic materials 0.000 description 3
- 230000003993 interaction Effects 0.000 description 3
- GZQKNULLWNGMCW-PWQABINMSA-N lipid A (E. coli) Chemical class O1[C@H](CO)[C@@H](OP(O)(O)=O)[C@H](OC(=O)C[C@@H](CCCCCCCCCCC)OC(=O)CCCCCCCCCCCCC)[C@@H](NC(=O)C[C@@H](CCCCCCCCCCC)OC(=O)CCCCCCCCCCC)[C@@H]1OC[C@@H]1[C@@H](O)[C@H](OC(=O)C[C@H](O)CCCCCCCCCCC)[C@@H](NC(=O)C[C@H](O)CCCCCCCCCCC)[C@@H](OP(O)(O)=O)O1 GZQKNULLWNGMCW-PWQABINMSA-N 0.000 description 3
- 239000011159 matrix material Substances 0.000 description 3
- 230000034217 membrane fusion Effects 0.000 description 3
- 239000011707 mineral Substances 0.000 description 3
- NXFQHRVNIOXGAQ-YCRREMRBSA-N nitrofurantoin Chemical group O1C([N+](=O)[O-])=CC=C1\C=N\N1C(=O)NC(=O)C1 NXFQHRVNIOXGAQ-YCRREMRBSA-N 0.000 description 3
- 229920001542 oligosaccharide Polymers 0.000 description 3
- 229920002866 paraformaldehyde Polymers 0.000 description 3
- 229920002704 polyhistidine Polymers 0.000 description 3
- 238000001742 protein purification Methods 0.000 description 3
- 238000002708 random mutagenesis Methods 0.000 description 3
- 230000006798 recombination Effects 0.000 description 3
- 238000005215 recombination Methods 0.000 description 3
- 230000002829 reductive effect Effects 0.000 description 3
- 230000010076 replication Effects 0.000 description 3
- 230000028327 secretion Effects 0.000 description 3
- 238000000926 separation method Methods 0.000 description 3
- 238000002741 site-directed mutagenesis Methods 0.000 description 3
- 239000011734 sodium Substances 0.000 description 3
- 239000000243 solution Substances 0.000 description 3
- 241000894007 species Species 0.000 description 3
- 239000003381 stabilizer Substances 0.000 description 3
- 239000000126 substance Substances 0.000 description 3
- 239000006228 supernatant Substances 0.000 description 3
- 238000003786 synthesis reaction Methods 0.000 description 3
- QORWJWZARLRLPR-UHFFFAOYSA-H tricalcium bis(phosphate) Chemical compound [Ca+2].[Ca+2].[Ca+2].[O-]P([O-])([O-])=O.[O-]P([O-])([O-])=O QORWJWZARLRLPR-UHFFFAOYSA-H 0.000 description 3
- 210000003501 vero cell Anatomy 0.000 description 3
- HDTRYLNUVZCQOY-UHFFFAOYSA-N α-D-glucopyranosyl-α-D-glucopyranoside Natural products OC1C(O)C(O)C(CO)OC1OC1C(O)C(O)C(O)C(CO)O1 HDTRYLNUVZCQOY-UHFFFAOYSA-N 0.000 description 2
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 2
- 102000040650 (ribonucleotides)n+m Human genes 0.000 description 2
- 101150116940 AGPS gene Proteins 0.000 description 2
- 108010042708 Acetylmuramyl-Alanyl-Isoglutamine Proteins 0.000 description 2
- DCXYFEDJOCDNAF-UHFFFAOYSA-N Asparagine Natural products OC(=O)C(N)CC(N)=O DCXYFEDJOCDNAF-UHFFFAOYSA-N 0.000 description 2
- 241000201370 Autographa californica nucleopolyhedrovirus Species 0.000 description 2
- 102100026189 Beta-galactosidase Human genes 0.000 description 2
- 206010006448 Bronchiolitis Diseases 0.000 description 2
- 102000014914 Carrier Proteins Human genes 0.000 description 2
- 108091026890 Coding region Proteins 0.000 description 2
- 108091035707 Consensus sequence Proteins 0.000 description 2
- 241000255581 Drosophila <fruit fly, genus> Species 0.000 description 2
- 241000701867 Enterobacteria phage T7 Species 0.000 description 2
- WSFSSNUMVMOOMR-UHFFFAOYSA-N Formaldehyde Chemical compound O=C WSFSSNUMVMOOMR-UHFFFAOYSA-N 0.000 description 2
- 241000233866 Fungi Species 0.000 description 2
- 241001120659 Furina Species 0.000 description 2
- DHMQDGOQFOQNFH-UHFFFAOYSA-N Glycine Natural products NCC(O)=O DHMQDGOQFOQNFH-UHFFFAOYSA-N 0.000 description 2
- 239000004471 Glycine Substances 0.000 description 2
- 102000003886 Glycoproteins Human genes 0.000 description 2
- 108090000288 Glycoproteins Proteins 0.000 description 2
- 241000606768 Haemophilus influenzae Species 0.000 description 2
- 101000831567 Homo sapiens Toll-like receptor 2 Proteins 0.000 description 2
- 101000669402 Homo sapiens Toll-like receptor 7 Proteins 0.000 description 2
- 108090000978 Interleukin-4 Proteins 0.000 description 2
- 108010002616 Interleukin-5 Proteins 0.000 description 2
- 108091092195 Intron Proteins 0.000 description 2
- ONIBWKKTOPOVIA-BYPYZUCNSA-N L-Proline Chemical compound OC(=O)[C@@H]1CCCN1 ONIBWKKTOPOVIA-BYPYZUCNSA-N 0.000 description 2
- QNAYBMKLOCPYGJ-REOHCLBHSA-N L-alanine Chemical compound C[C@H](N)C(O)=O QNAYBMKLOCPYGJ-REOHCLBHSA-N 0.000 description 2
- DCXYFEDJOCDNAF-REOHCLBHSA-N L-asparagine Chemical compound OC(=O)[C@@H](N)CC(N)=O DCXYFEDJOCDNAF-REOHCLBHSA-N 0.000 description 2
- ROHFNLRQFUQHCH-YFKPBYRVSA-N L-leucine Chemical compound CC(C)C[C@H](N)C(O)=O ROHFNLRQFUQHCH-YFKPBYRVSA-N 0.000 description 2
- 201000005505 Measles Diseases 0.000 description 2
- 241001092142 Molina Species 0.000 description 2
- 108091028043 Nucleic acid sequence Proteins 0.000 description 2
- 108090001074 Nucleocapsid Proteins Proteins 0.000 description 2
- GLUUGHFHXGJENI-UHFFFAOYSA-N Piperazine Chemical compound C1CNCCN1 GLUUGHFHXGJENI-UHFFFAOYSA-N 0.000 description 2
- 206010035664 Pneumonia Diseases 0.000 description 2
- 239000002202 Polyethylene glycol Substances 0.000 description 2
- 241001454523 Quillaja saponaria Species 0.000 description 2
- 235000009001 Quillaja saponaria Nutrition 0.000 description 2
- 206010057190 Respiratory tract infections Diseases 0.000 description 2
- UIIMBOGNXHQVGW-UHFFFAOYSA-M Sodium bicarbonate Chemical compound [Na+].OC([O-])=O UIIMBOGNXHQVGW-UHFFFAOYSA-M 0.000 description 2
- PRXRUNOAOLTIEF-ADSICKODSA-N Sorbitan trioleate Chemical compound CCCCCCCC\C=C/CCCCCCCC(=O)OC[C@@H](OC(=O)CCCCCCC\C=C/CCCCCCCC)[C@H]1OC[C@H](O)[C@H]1OC(=O)CCCCCCC\C=C/CCCCCCCC PRXRUNOAOLTIEF-ADSICKODSA-N 0.000 description 2
- 230000029662 T-helper 1 type immune response Effects 0.000 description 2
- 229940124614 TLR 8 agonist Drugs 0.000 description 2
- 108010046722 Thrombospondin 1 Proteins 0.000 description 2
- 102100036034 Thrombospondin-1 Human genes 0.000 description 2
- 108010060818 Toll-Like Receptor 9 Proteins 0.000 description 2
- 102100024333 Toll-like receptor 2 Human genes 0.000 description 2
- 102100039390 Toll-like receptor 7 Human genes 0.000 description 2
- 102100033117 Toll-like receptor 9 Human genes 0.000 description 2
- HDTRYLNUVZCQOY-WSWWMNSNSA-N Trehalose Natural products O[C@@H]1[C@@H](O)[C@@H](O)[C@@H](CO)O[C@@H]1O[C@@H]1[C@H](O)[C@@H](O)[C@@H](O)[C@@H](CO)O1 HDTRYLNUVZCQOY-WSWWMNSNSA-N 0.000 description 2
- XSQUKJJJFZCRTK-UHFFFAOYSA-N Urea Chemical compound NC(N)=O XSQUKJJJFZCRTK-UHFFFAOYSA-N 0.000 description 2
- 241000251539 Vertebrata <Metazoa> Species 0.000 description 2
- 108020005202 Viral DNA Proteins 0.000 description 2
- 238000002835 absorbance Methods 0.000 description 2
- 150000007513 acids Chemical class 0.000 description 2
- 238000001042 affinity chromatography Methods 0.000 description 2
- 125000003295 alanine group Chemical group N[C@@H](C)C(=O)* 0.000 description 2
- HDTRYLNUVZCQOY-LIZSDCNHSA-N alpha,alpha-trehalose Chemical compound O[C@@H]1[C@@H](O)[C@H](O)[C@@H](CO)O[C@@H]1O[C@@H]1[C@H](O)[C@@H](O)[C@H](O)[C@@H](CO)O1 HDTRYLNUVZCQOY-LIZSDCNHSA-N 0.000 description 2
- 230000003321 amplification Effects 0.000 description 2
- 239000008135 aqueous vehicle Substances 0.000 description 2
- 229960001230 asparagine Drugs 0.000 description 2
- 235000009582 asparagine Nutrition 0.000 description 2
- 239000012298 atmosphere Substances 0.000 description 2
- 238000013320 baculovirus expression vector system Methods 0.000 description 2
- 108010005774 beta-Galactosidase Proteins 0.000 description 2
- 108091008324 binding proteins Proteins 0.000 description 2
- 230000021615 conjugation Effects 0.000 description 2
- 238000007796 conventional method Methods 0.000 description 2
- 230000002596 correlated effect Effects 0.000 description 2
- 239000012228 culture supernatant Substances 0.000 description 2
- GVJHHUAWPYXKBD-UHFFFAOYSA-N d-alpha-tocopherol Natural products OC1=C(C)C(C)=C2OC(CCCC(C)CCCC(C)CCCC(C)C)(C)CCC2=C1C GVJHHUAWPYXKBD-UHFFFAOYSA-N 0.000 description 2
- 238000001514 detection method Methods 0.000 description 2
- 238000000502 dialysis Methods 0.000 description 2
- 238000010790 dilution Methods 0.000 description 2
- 239000012895 dilution Substances 0.000 description 2
- 239000000539 dimer Substances 0.000 description 2
- NAGJZTKCGNOGPW-UHFFFAOYSA-K dioxido-sulfanylidene-sulfido-$l^{5}-phosphane Chemical group [O-]P([O-])([S-])=S NAGJZTKCGNOGPW-UHFFFAOYSA-K 0.000 description 2
- 150000002016 disaccharides Chemical class 0.000 description 2
- 238000004520 electroporation Methods 0.000 description 2
- 238000005538 encapsulation Methods 0.000 description 2
- 230000001973 epigenetic effect Effects 0.000 description 2
- 238000001825 field-flow fractionation Methods 0.000 description 2
- 238000001914 filtration Methods 0.000 description 2
- 239000012467 final product Substances 0.000 description 2
- 230000002538 fungal effect Effects 0.000 description 2
- 238000007499 fusion processing Methods 0.000 description 2
- 102000005396 glutamine synthetase Human genes 0.000 description 2
- 108020002326 glutamine synthetase Proteins 0.000 description 2
- 125000003630 glycyl group Chemical group [H]N([H])C([H])([H])C(*)=O 0.000 description 2
- 229940047650 haemophilus influenzae Drugs 0.000 description 2
- 208000002672 hepatitis B Diseases 0.000 description 2
- 238000004128 high performance liquid chromatography Methods 0.000 description 2
- 229940124669 imidazoquinoline Drugs 0.000 description 2
- 210000000987 immune system Anatomy 0.000 description 2
- 238000010166 immunofluorescence Methods 0.000 description 2
- 229960001438 immunostimulant agent Drugs 0.000 description 2
- 238000011534 incubation Methods 0.000 description 2
- 238000011081 inoculation Methods 0.000 description 2
- 210000000265 leukocyte Anatomy 0.000 description 2
- 230000029226 lipidation Effects 0.000 description 2
- 150000002632 lipids Chemical class 0.000 description 2
- 239000007788 liquid Substances 0.000 description 2
- 229920002521 macromolecule Polymers 0.000 description 2
- OVHQWOXKMOVDJP-UHFFFAOYSA-N melitin Chemical group OC1C(O)C(O)C(C)OC1OC1C(O)C(OC=2C=C3C(C(C(OC4C(C(O)C(O)C(COC5C(C(O)C(O)C(CO)O5)O)O4)O)=C(C=4C=CC(O)=CC=4)O3)=O)=C(O)C=2)OC(C)C1O OVHQWOXKMOVDJP-UHFFFAOYSA-N 0.000 description 2
- 229930182817 methionine Natural products 0.000 description 2
- 210000001616 monocyte Anatomy 0.000 description 2
- 229940035032 monophosphoryl lipid a Drugs 0.000 description 2
- BSOQXXWZTUDTEL-ZUYCGGNHSA-N muramyl dipeptide Chemical compound OC(=O)CC[C@H](C(N)=O)NC(=O)[C@H](C)NC(=O)[C@@H](C)O[C@H]1[C@H](O)[C@@H](CO)O[C@@H](O)[C@@H]1NC(C)=O BSOQXXWZTUDTEL-ZUYCGGNHSA-N 0.000 description 2
- 230000035772 mutation Effects 0.000 description 2
- 210000000440 neutrophil Anatomy 0.000 description 2
- 238000003199 nucleic acid amplification method Methods 0.000 description 2
- 210000003463 organelle Anatomy 0.000 description 2
- 229920001223 polyethylene glycol Polymers 0.000 description 2
- 230000003389 potentiating effect Effects 0.000 description 2
- 238000001556 precipitation Methods 0.000 description 2
- 210000001236 prokaryotic cell Anatomy 0.000 description 2
- 229960002429 proline Drugs 0.000 description 2
- 235000019833 protease Nutrition 0.000 description 2
- 239000001397 quillaja saponaria molina bark Substances 0.000 description 2
- 108020003175 receptors Proteins 0.000 description 2
- 102000005962 receptors Human genes 0.000 description 2
- 238000003259 recombinant expression Methods 0.000 description 2
- 238000011084 recovery Methods 0.000 description 2
- 230000022532 regulation of transcription, DNA-dependent Effects 0.000 description 2
- 230000001105 regulatory effect Effects 0.000 description 2
- BXNMTOQRYBFHNZ-UHFFFAOYSA-N resiquimod Chemical compound C1=CC=CC2=C(N(C(COCC)=N3)CC(C)(C)O)C3=C(N)N=C21 BXNMTOQRYBFHNZ-UHFFFAOYSA-N 0.000 description 2
- 230000000241 respiratory effect Effects 0.000 description 2
- 210000002345 respiratory system Anatomy 0.000 description 2
- 230000000717 retained effect Effects 0.000 description 2
- 230000003248 secreting effect Effects 0.000 description 2
- 238000013207 serial dilution Methods 0.000 description 2
- 150000003384 small molecules Chemical class 0.000 description 2
- 239000011780 sodium chloride Substances 0.000 description 2
- 230000003381 solubilizing effect Effects 0.000 description 2
- 239000002904 solvent Substances 0.000 description 2
- 230000009885 systemic effect Effects 0.000 description 2
- 229930003799 tocopherol Natural products 0.000 description 2
- 239000011732 tocopherol Substances 0.000 description 2
- 235000010384 tocopherol Nutrition 0.000 description 2
- 229960001295 tocopherol Drugs 0.000 description 2
- 238000013518 transcription Methods 0.000 description 2
- 230000035897 transcription Effects 0.000 description 2
- 238000012546 transfer Methods 0.000 description 2
- 108010087967 type I signal peptidase Proteins 0.000 description 2
- 241000701161 unidentified adenovirus Species 0.000 description 2
- 241000712461 unidentified influenza virus Species 0.000 description 2
- 238000002255 vaccination Methods 0.000 description 2
- 230000029812 viral genome replication Effects 0.000 description 2
- 238000005406 washing Methods 0.000 description 2
- OZFAFGSSMRRTDW-UHFFFAOYSA-N (2,4-dichlorophenyl) benzenesulfonate Chemical compound ClC1=CC(Cl)=CC=C1OS(=O)(=O)C1=CC=CC=C1 OZFAFGSSMRRTDW-UHFFFAOYSA-N 0.000 description 1
- MTCFGRXMJLQNBG-REOHCLBHSA-N (2S)-2-Amino-3-hydroxypropansäure Chemical compound OC[C@H](N)C(O)=O MTCFGRXMJLQNBG-REOHCLBHSA-N 0.000 description 1
- QPGLTHGSKVUPIB-DHIUTWEWSA-N (3R)-N-[(1R)-1,10-dihydroxydecyl]-3-hydroxytetradecanamide Chemical compound O[C@@H](CC(=O)N[C@@H](CCCCCCCCCO)O)CCCCCCCCCCC QPGLTHGSKVUPIB-DHIUTWEWSA-N 0.000 description 1
- PSBDWGZCVUAZQS-UHFFFAOYSA-N (dimethylsulfonio)acetate Chemical compound C[S+](C)CC([O-])=O PSBDWGZCVUAZQS-UHFFFAOYSA-N 0.000 description 1
- HTSGKJQDMSTCGS-UHFFFAOYSA-N 1,4-bis(4-chlorophenyl)-2-(4-methylphenyl)sulfonylbutane-1,4-dione Chemical compound C1=CC(C)=CC=C1S(=O)(=O)C(C(=O)C=1C=CC(Cl)=CC=1)CC(=O)C1=CC=C(Cl)C=C1 HTSGKJQDMSTCGS-UHFFFAOYSA-N 0.000 description 1
- IIZPXYDJLKNOIY-JXPKJXOSSA-N 1-palmitoyl-2-arachidonoyl-sn-glycero-3-phosphocholine Chemical compound CCCCCCCCCCCCCCCC(=O)OC[C@H](COP([O-])(=O)OCC[N+](C)(C)C)OC(=O)CCC\C=C/C\C=C/C\C=C/C\C=C/CCCCC IIZPXYDJLKNOIY-JXPKJXOSSA-N 0.000 description 1
- BZXMNFQDWOCVMU-UHFFFAOYSA-N 2-[dodecanoyl(methyl)amino]acetic acid;sodium Chemical compound [Na].CCCCCCCCCCCC(=O)N(C)CC(O)=O BZXMNFQDWOCVMU-UHFFFAOYSA-N 0.000 description 1
- BMYCCWYAFNPAQC-UHFFFAOYSA-N 2-[dodecyl(methyl)azaniumyl]acetate Chemical compound CCCCCCCCCCCCN(C)CC(O)=O BMYCCWYAFNPAQC-UHFFFAOYSA-N 0.000 description 1
- MSWZFWKMSRAUBD-IVMDWMLBSA-N 2-amino-2-deoxy-D-glucopyranose Chemical compound N[C@H]1C(O)O[C@H](CO)[C@@H](O)[C@@H]1O MSWZFWKMSRAUBD-IVMDWMLBSA-N 0.000 description 1
- VDCRFBBZFHHYGT-IOSLPCCCSA-N 2-amino-9-[(2r,3r,4s,5r)-3,4-dihydroxy-5-(hydroxymethyl)oxolan-2-yl]-7-prop-2-enyl-3h-purine-6,8-dione Chemical compound O=C1N(CC=C)C=2C(=O)NC(N)=NC=2N1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O VDCRFBBZFHHYGT-IOSLPCCCSA-N 0.000 description 1
- ASJSAQIRZKANQN-CRCLSJGQSA-N 2-deoxy-D-ribose Chemical group OC[C@@H](O)[C@@H](O)CC=O ASJSAQIRZKANQN-CRCLSJGQSA-N 0.000 description 1
- UMCMPZBLKLEWAF-BCTGSCMUSA-N 3-[(3-cholamidopropyl)dimethylammonio]propane-1-sulfonate Chemical compound C([C@H]1C[C@H]2O)[C@H](O)CC[C@]1(C)[C@@H]1[C@@H]2[C@@H]2CC[C@H]([C@@H](CCC(=O)NCCC[N+](C)(C)CCCS([O-])(=O)=O)C)[C@@]2(C)[C@@H](O)C1 UMCMPZBLKLEWAF-BCTGSCMUSA-N 0.000 description 1
- QZRAABPTWGFNIU-UHFFFAOYSA-N 3-[dimethyl(octyl)azaniumyl]propane-1-sulfonate Chemical compound CCCCCCCC[N+](C)(C)CCCS([O-])(=O)=O QZRAABPTWGFNIU-UHFFFAOYSA-N 0.000 description 1
- 102100031765 3-beta-hydroxysteroid-Delta(8),Delta(7)-isomerase Human genes 0.000 description 1
- SLXKOJJOQWFEFD-UHFFFAOYSA-N 6-aminohexanoic acid Chemical compound NCCCCCC(O)=O SLXKOJJOQWFEFD-UHFFFAOYSA-N 0.000 description 1
- 108010025188 Alcohol oxidase Proteins 0.000 description 1
- 101100107610 Arabidopsis thaliana ABCF4 gene Proteins 0.000 description 1
- 241000203069 Archaea Species 0.000 description 1
- 239000004475 Arginine Substances 0.000 description 1
- 208000002109 Argyria Diseases 0.000 description 1
- 241000271566 Aves Species 0.000 description 1
- 108091008875 B cell receptors Proteins 0.000 description 1
- 108020000946 Bacterial DNA Proteins 0.000 description 1
- 241000589969 Borreliella burgdorferi Species 0.000 description 1
- OYPRJOBELJOOCE-UHFFFAOYSA-N Calcium Chemical compound [Ca] OYPRJOBELJOOCE-UHFFFAOYSA-N 0.000 description 1
- OKTJSMMVPCPJKN-UHFFFAOYSA-N Carbon Chemical group [C] OKTJSMMVPCPJKN-UHFFFAOYSA-N 0.000 description 1
- LZZYPRNAOMGNLH-UHFFFAOYSA-M Cetrimonium bromide Chemical compound [Br-].CCCCCCCCCCCCCCCC[N+](C)(C)C LZZYPRNAOMGNLH-UHFFFAOYSA-M 0.000 description 1
- 108010077544 Chromatin Proteins 0.000 description 1
- 108091027551 Cointegrate Proteins 0.000 description 1
- 201000006306 Cor pulmonale Diseases 0.000 description 1
- 206010011409 Cross infection Diseases 0.000 description 1
- 241000195493 Cryptophyta Species 0.000 description 1
- 108090000695 Cytokines Proteins 0.000 description 1
- 102000004127 Cytokines Human genes 0.000 description 1
- 241000701022 Cytomegalovirus Species 0.000 description 1
- FBPFZTCFMRRESA-FSIIMWSLSA-N D-Glucitol Natural products OC[C@H](O)[C@H](O)[C@@H](O)[C@H](O)CO FBPFZTCFMRRESA-FSIIMWSLSA-N 0.000 description 1
- FBPFZTCFMRRESA-JGWLITMVSA-N D-glucitol Chemical compound OC[C@H](O)[C@@H](O)[C@H](O)[C@H](O)CO FBPFZTCFMRRESA-JGWLITMVSA-N 0.000 description 1
- HMFHBZSHGGEWLO-SOOFDHNKSA-N D-ribofuranose Chemical compound OC[C@H]1OC(O)[C@H](O)[C@@H]1O HMFHBZSHGGEWLO-SOOFDHNKSA-N 0.000 description 1
- 102100032881 DNA-binding protein SATB1 Human genes 0.000 description 1
- 241000702421 Dependoparvovirus Species 0.000 description 1
- BWGNESOTFCXPMA-UHFFFAOYSA-N Dihydrogen disulfide Chemical compound SS BWGNESOTFCXPMA-UHFFFAOYSA-N 0.000 description 1
- 239000012591 Dulbecco’s Phosphate Buffered Saline Substances 0.000 description 1
- 239000006144 Dulbecco’s modified Eagle's medium Substances 0.000 description 1
- 102000004190 Enzymes Human genes 0.000 description 1
- 108090000790 Enzymes Proteins 0.000 description 1
- 101000738180 Euglena gracilis Chaperonin CPN60, mitochondrial Proteins 0.000 description 1
- 206010015548 Euthanasia Diseases 0.000 description 1
- 108050001049 Extracellular proteins Proteins 0.000 description 1
- 102000008946 Fibrinogen Human genes 0.000 description 1
- 108010049003 Fibrinogen Proteins 0.000 description 1
- 108010067306 Fibronectins Proteins 0.000 description 1
- 102000016359 Fibronectins Human genes 0.000 description 1
- 241000287828 Gallus gallus Species 0.000 description 1
- 229930186217 Glycolipid Natural products 0.000 description 1
- NYHBQMYGNKIUIF-UUOKFMHZSA-N Guanosine Chemical group C1=NC=2C(=O)NC(N)=NC=2N1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O NYHBQMYGNKIUIF-UUOKFMHZSA-N 0.000 description 1
- 241001316290 Gypsophila Species 0.000 description 1
- 206010018910 Haemolysis Diseases 0.000 description 1
- 102100032606 Heat shock factor protein 1 Human genes 0.000 description 1
- 101710113864 Heat shock protein 90 Proteins 0.000 description 1
- 102100034051 Heat shock protein HSP 90-alpha Human genes 0.000 description 1
- 101710154606 Hemagglutinin Proteins 0.000 description 1
- 229920002971 Heparan sulfate Polymers 0.000 description 1
- 241000700721 Hepatitis B virus Species 0.000 description 1
- 101000866618 Homo sapiens 3-beta-hydroxysteroid-Delta(8),Delta(7)-isomerase Proteins 0.000 description 1
- 101000655234 Homo sapiens DNA-binding protein SATB1 Proteins 0.000 description 1
- 101000867525 Homo sapiens Heat shock factor protein 1 Proteins 0.000 description 1
- 101000582320 Homo sapiens Neurogenic differentiation factor 6 Proteins 0.000 description 1
- 101000831496 Homo sapiens Toll-like receptor 3 Proteins 0.000 description 1
- 101000669406 Homo sapiens Toll-like receptor 6 Proteins 0.000 description 1
- 101000800483 Homo sapiens Toll-like receptor 8 Proteins 0.000 description 1
- 241000711920 Human orthopneumovirus Species 0.000 description 1
- XQFRJNBWHJMXHO-RRKCRQDMSA-N IDUR Chemical compound C1[C@H](O)[C@@H](CO)O[C@H]1N1C(=O)NC(=O)C(I)=C1 XQFRJNBWHJMXHO-RRKCRQDMSA-N 0.000 description 1
- 108010050904 Interferons Proteins 0.000 description 1
- 102000014150 Interferons Human genes 0.000 description 1
- 108090000176 Interleukin-13 Proteins 0.000 description 1
- 241000235058 Komagataella pastoris Species 0.000 description 1
- ZDXPYRJPNDTMRX-VKHMYHEASA-N L-glutamine Chemical compound OC(=O)[C@@H](N)CCC(N)=O ZDXPYRJPNDTMRX-VKHMYHEASA-N 0.000 description 1
- FFEARJCKVFRZRR-BYPYZUCNSA-N L-methionine Chemical compound CSCC[C@H](N)C(O)=O FFEARJCKVFRZRR-BYPYZUCNSA-N 0.000 description 1
- 229930182821 L-proline Natural products 0.000 description 1
- QIVBCDIJIAJPQS-VIFPVBQESA-N L-tryptophane Chemical compound C1=CC=C2C(C[C@H](N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-VIFPVBQESA-N 0.000 description 1
- 102000004856 Lectins Human genes 0.000 description 1
- 108090001090 Lectins Proteins 0.000 description 1
- 238000003231 Lowry assay Methods 0.000 description 1
- 238000009013 Lowry's assay Methods 0.000 description 1
- 108010052285 Membrane Proteins Proteins 0.000 description 1
- 102000016943 Muramidase Human genes 0.000 description 1
- 108010014251 Muramidase Proteins 0.000 description 1
- MSFSPUZXLOGKHJ-UHFFFAOYSA-N Muraminsaeure Natural products OC(=O)C(C)OC1C(N)C(O)OC(CO)C1O MSFSPUZXLOGKHJ-UHFFFAOYSA-N 0.000 description 1
- 241000187479 Mycobacterium tuberculosis Species 0.000 description 1
- 108010062010 N-Acetylmuramoyl-L-alanine Amidase Proteins 0.000 description 1
- 108010084333 N-palmitoyl-S-(2,3-bis(palmitoyloxy)propyl)cysteinyl-seryl-lysyl-lysyl-lysyl-lysine Proteins 0.000 description 1
- 241000588650 Neisseria meningitidis Species 0.000 description 1
- 229930193140 Neomycin Natural products 0.000 description 1
- 102100030589 Neurogenic differentiation factor 6 Human genes 0.000 description 1
- 241000221961 Neurospora crassa Species 0.000 description 1
- 102000008297 Nuclear Matrix-Associated Proteins Human genes 0.000 description 1
- 108010035916 Nuclear Matrix-Associated Proteins Proteins 0.000 description 1
- 108020004711 Nucleic Acid Probes Proteins 0.000 description 1
- 108700020497 Nucleopolyhedrovirus polyhedrin Proteins 0.000 description 1
- 108700006640 OspA Proteins 0.000 description 1
- 208000005141 Otitis Diseases 0.000 description 1
- 101710093908 Outer capsid protein VP4 Proteins 0.000 description 1
- 101710135467 Outer capsid protein sigma-1 Proteins 0.000 description 1
- 241000711504 Paramyxoviridae Species 0.000 description 1
- 108010013639 Peptidoglycan Proteins 0.000 description 1
- 241000255969 Pieris brassicae Species 0.000 description 1
- 241000711904 Pneumoviridae Species 0.000 description 1
- 241000711902 Pneumovirus Species 0.000 description 1
- 101710182846 Polyhedrin Proteins 0.000 description 1
- 229920001213 Polysorbate 20 Polymers 0.000 description 1
- WCUXLLCKKVVCTQ-UHFFFAOYSA-M Potassium chloride Chemical compound [Cl-].[K+] WCUXLLCKKVVCTQ-UHFFFAOYSA-M 0.000 description 1
- 206010036590 Premature baby Diseases 0.000 description 1
- ONIBWKKTOPOVIA-UHFFFAOYSA-N Proline Natural products OC(=O)C1CCCN1 ONIBWKKTOPOVIA-UHFFFAOYSA-N 0.000 description 1
- 239000004365 Protease Substances 0.000 description 1
- 229940124158 Protease/peptidase inhibitor Drugs 0.000 description 1
- 102000004245 Proteasome Endopeptidase Complex Human genes 0.000 description 1
- 108090000708 Proteasome Endopeptidase Complex Proteins 0.000 description 1
- 101710176177 Protein A56 Proteins 0.000 description 1
- 102000007615 Pulmonary Surfactant-Associated Protein A Human genes 0.000 description 1
- 108010007100 Pulmonary Surfactant-Associated Protein A Proteins 0.000 description 1
- 239000012564 Q sepharose fast flow resin Substances 0.000 description 1
- 229940124679 RSV vaccine Drugs 0.000 description 1
- 108091028664 Ribonucleotide Proteins 0.000 description 1
- PYMYPHUHKUWMLA-LMVFSUKVSA-N Ribose Natural products OC[C@@H](O)[C@@H](O)[C@@H](O)C=O PYMYPHUHKUWMLA-LMVFSUKVSA-N 0.000 description 1
- 101100068078 Saccharomyces cerevisiae (strain ATCC 204508 / S288c) GCN4 gene Proteins 0.000 description 1
- 241000293869 Salmonella enterica subsp. enterica serovar Typhimurium Species 0.000 description 1
- 241000219287 Saponaria Species 0.000 description 1
- 108091058545 Secretory proteins Proteins 0.000 description 1
- 238000012300 Sequence Analysis Methods 0.000 description 1
- MTCFGRXMJLQNBG-UHFFFAOYSA-N Serine Natural products OCC(N)C(O)=O MTCFGRXMJLQNBG-UHFFFAOYSA-N 0.000 description 1
- 241000144290 Sigmodon hispidus Species 0.000 description 1
- BQCADISMDOOEFD-UHFFFAOYSA-N Silver Chemical compound [Ag] BQCADISMDOOEFD-UHFFFAOYSA-N 0.000 description 1
- DBMJMQXJHONAFJ-UHFFFAOYSA-M Sodium laurylsulphate Chemical compound [Na+].CCCCCCCCCCCCOS([O-])(=O)=O DBMJMQXJHONAFJ-UHFFFAOYSA-M 0.000 description 1
- 241000191967 Staphylococcus aureus Species 0.000 description 1
- 241000194017 Streptococcus Species 0.000 description 1
- 241000187747 Streptomyces Species 0.000 description 1
- 229930006000 Sucrose Natural products 0.000 description 1
- CZMRCDWAGMRECN-UGDNZRGBSA-N Sucrose Chemical compound O[C@H]1[C@H](O)[C@@H](CO)O[C@@]1(CO)O[C@@H]1[C@H](O)[C@@H](O)[C@H](O)[C@@H](CO)O1 CZMRCDWAGMRECN-UGDNZRGBSA-N 0.000 description 1
- 229940124615 TLR 7 agonist Drugs 0.000 description 1
- 108090000925 TNF receptor-associated factor 2 Proteins 0.000 description 1
- 102100034779 TRAF family member-associated NF-kappa-B activator Human genes 0.000 description 1
- 239000004098 Tetracycline Substances 0.000 description 1
- 102100036407 Thioredoxin Human genes 0.000 description 1
- 108010022394 Threonine synthase Proteins 0.000 description 1
- 102100024324 Toll-like receptor 3 Human genes 0.000 description 1
- 102100039387 Toll-like receptor 6 Human genes 0.000 description 1
- 102100033110 Toll-like receptor 8 Human genes 0.000 description 1
- 102100038896 Transmembrane protein domain Human genes 0.000 description 1
- 101710141239 Transmembrane protein domain Proteins 0.000 description 1
- 241000255993 Trichoplusia ni Species 0.000 description 1
- QIVBCDIJIAJPQS-UHFFFAOYSA-N Tryptophan Natural products C1=CC=C2C(CC(N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-UHFFFAOYSA-N 0.000 description 1
- 102000007537 Type II DNA Topoisomerases Human genes 0.000 description 1
- 108010046308 Type II DNA Topoisomerases Proteins 0.000 description 1
- 206010046865 Vaccinia virus infection Diseases 0.000 description 1
- 241000700647 Variola virus Species 0.000 description 1
- 108010003533 Viral Envelope Proteins Proteins 0.000 description 1
- 208000036142 Viral infection Diseases 0.000 description 1
- IXKSXJFAGXLQOQ-XISFHERQSA-N WHWLQLKPGQPMY Chemical compound C([C@@H](C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N1CCC[C@H]1C(=O)NCC(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)NC(=O)[C@@H](N)CC=1C2=CC=CC=C2NC=1)C1=CNC=N1 IXKSXJFAGXLQOQ-XISFHERQSA-N 0.000 description 1
- 108010046377 Whey Proteins Proteins 0.000 description 1
- 102000007544 Whey Proteins Human genes 0.000 description 1
- 229920000392 Zymosan Polymers 0.000 description 1
- 230000021736 acetylation Effects 0.000 description 1
- 238000006640 acetylation reaction Methods 0.000 description 1
- 230000004913 activation Effects 0.000 description 1
- 230000001154 acute effect Effects 0.000 description 1
- 230000010933 acylation Effects 0.000 description 1
- 238000005917 acylation reaction Methods 0.000 description 1
- 239000000654 additive Substances 0.000 description 1
- 238000000787 affinity precipitation Methods 0.000 description 1
- 238000001261 affinity purification Methods 0.000 description 1
- 125000000217 alkyl group Chemical group 0.000 description 1
- HMFHBZSHGGEWLO-UHFFFAOYSA-N alpha-D-Furanose-Ribose Natural products OCC1OC(O)C(O)C1O HMFHBZSHGGEWLO-UHFFFAOYSA-N 0.000 description 1
- XAGFODPZIPBFFR-UHFFFAOYSA-N aluminium Chemical compound [Al] XAGFODPZIPBFFR-UHFFFAOYSA-N 0.000 description 1
- 229910052782 aluminium Inorganic materials 0.000 description 1
- 230000006229 amino acid addition Effects 0.000 description 1
- BFNBIHQBYMNNAN-UHFFFAOYSA-N ammonium sulfate Chemical compound N.N.OS(O)(=O)=O BFNBIHQBYMNNAN-UHFFFAOYSA-N 0.000 description 1
- 229910052921 ammonium sulfate Inorganic materials 0.000 description 1
- 235000011130 ammonium sulphate Nutrition 0.000 description 1
- 229960000723 ampicillin Drugs 0.000 description 1
- AVKUERGKIZMTKX-NJBDSQKTSA-N ampicillin Chemical compound C1([C@@H](N)C(=O)N[C@H]2[C@H]3SC([C@@H](N3C2=O)C(O)=O)(C)C)=CC=CC=C1 AVKUERGKIZMTKX-NJBDSQKTSA-N 0.000 description 1
- 238000004873 anchoring Methods 0.000 description 1
- 125000000129 anionic group Chemical group 0.000 description 1
- 239000005557 antagonist Substances 0.000 description 1
- 230000000840 anti-viral effect Effects 0.000 description 1
- 230000005875 antibody response Effects 0.000 description 1
- ODKSFYDXXFIFQN-UHFFFAOYSA-N arginine Natural products OC(=O)C(N)CCCNC(N)=N ODKSFYDXXFIFQN-UHFFFAOYSA-N 0.000 description 1
- 125000000613 asparagine group Chemical group N[C@@H](CC(N)=O)C(=O)* 0.000 description 1
- 210000001224 bacterial fimbriae Anatomy 0.000 description 1
- MSWZFWKMSRAUBD-UHFFFAOYSA-N beta-D-galactosamine Natural products NC1C(O)OC(CO)C(O)C1O MSWZFWKMSRAUBD-UHFFFAOYSA-N 0.000 description 1
- 230000004071 biological effect Effects 0.000 description 1
- 230000005540 biological transmission Effects 0.000 description 1
- 210000004900 c-terminal fragment Anatomy 0.000 description 1
- 239000011575 calcium Substances 0.000 description 1
- 229910052791 calcium Inorganic materials 0.000 description 1
- 159000000007 calcium salts Chemical class 0.000 description 1
- 239000004202 carbamide Substances 0.000 description 1
- 229910052799 carbon Inorganic materials 0.000 description 1
- 230000021523 carboxylation Effects 0.000 description 1
- 238000006473 carboxylation reaction Methods 0.000 description 1
- 125000002091 cationic group Chemical group 0.000 description 1
- 150000001768 cations Chemical class 0.000 description 1
- 239000013592 cell lysate Substances 0.000 description 1
- 239000013553 cell monolayer Substances 0.000 description 1
- 238000012512 characterization method Methods 0.000 description 1
- 239000002738 chelating agent Substances 0.000 description 1
- SQQXRXKYTKFFSM-UHFFFAOYSA-N chembl1992147 Chemical compound OC1=C(OC)C(OC)=CC=C1C1=C(C)C(C(O)=O)=NC(C=2N=C3C4=NC(C)(C)N=C4C(OC)=C(O)C3=CC=2)=C1N SQQXRXKYTKFFSM-UHFFFAOYSA-N 0.000 description 1
- 208000029771 childhood onset asthma Diseases 0.000 description 1
- 210000003483 chromatin Anatomy 0.000 description 1
- 230000002759 chromosomal effect Effects 0.000 description 1
- 210000000349 chromosome Anatomy 0.000 description 1
- 238000005352 clarification Methods 0.000 description 1
- 238000010367 cloning Methods 0.000 description 1
- 238000010835 comparative analysis Methods 0.000 description 1
- 238000010276 construction Methods 0.000 description 1
- 238000002788 crimping Methods 0.000 description 1
- 238000004132 cross linking Methods 0.000 description 1
- 239000003431 cross linking reagent Substances 0.000 description 1
- 239000000287 crude extract Substances 0.000 description 1
- 238000002447 crystallographic data Methods 0.000 description 1
- 125000000151 cysteine group Chemical group N[C@@H](CS)C(=O)* 0.000 description 1
- OPTASPLRGRRNAP-UHFFFAOYSA-N cytosine Chemical class NC=1C=CNC(=O)N=1 OPTASPLRGRRNAP-UHFFFAOYSA-N 0.000 description 1
- 230000003247 decreasing effect Effects 0.000 description 1
- 229960003964 deoxycholic acid Drugs 0.000 description 1
- 239000005547 deoxyribonucleotide Substances 0.000 description 1
- 125000002637 deoxyribonucleotide group Chemical group 0.000 description 1
- 238000010612 desalination reaction Methods 0.000 description 1
- 238000011026 diafiltration Methods 0.000 description 1
- 238000002050 diffraction method Methods 0.000 description 1
- 102000004419 dihydrofolate reductase Human genes 0.000 description 1
- NBIIXXVUZAFLBC-UHFFFAOYSA-M dihydrogenphosphate Chemical compound OP(O)([O-])=O NBIIXXVUZAFLBC-UHFFFAOYSA-M 0.000 description 1
- 239000003085 diluting agent Substances 0.000 description 1
- 238000006073 displacement reaction Methods 0.000 description 1
- 238000009826 distribution Methods 0.000 description 1
- VHJLVAABSRFDPM-QWWZWVQMSA-N dithiothreitol Chemical compound SC[C@@H](O)[C@H](O)CS VHJLVAABSRFDPM-QWWZWVQMSA-N 0.000 description 1
- 230000009977 dual effect Effects 0.000 description 1
- 208000019258 ear infection Diseases 0.000 description 1
- 238000000635 electron micrograph Methods 0.000 description 1
- 239000003995 emulsifying agent Substances 0.000 description 1
- 239000006274 endogenous ligand Substances 0.000 description 1
- 230000007613 environmental effect Effects 0.000 description 1
- 230000002255 enzymatic effect Effects 0.000 description 1
- 229940088598 enzyme Drugs 0.000 description 1
- 210000003743 erythrocyte Anatomy 0.000 description 1
- NLFBCYMMUAKCPC-KQQUZDAGSA-N ethyl (e)-3-[3-amino-2-cyano-1-[(e)-3-ethoxy-3-oxoprop-1-enyl]sulfanyl-3-oxoprop-1-enyl]sulfanylprop-2-enoate Chemical compound CCOC(=O)\C=C\SC(=C(C#N)C(N)=O)S\C=C\C(=O)OCC NLFBCYMMUAKCPC-KQQUZDAGSA-N 0.000 description 1
- 238000011156 evaluation Methods 0.000 description 1
- 230000007717 exclusion Effects 0.000 description 1
- 239000006277 exogenous ligand Substances 0.000 description 1
- 238000000605 extraction Methods 0.000 description 1
- 229940012952 fibrinogen Drugs 0.000 description 1
- 239000013020 final formulation Substances 0.000 description 1
- MHMNJMPURVTYEJ-UHFFFAOYSA-N fluorescein-5-isothiocyanate Chemical compound O1C(=O)C2=CC(N=C=S)=CC=C2C21C1=CC=C(O)C=C1OC1=CC(O)=CC=C21 MHMNJMPURVTYEJ-UHFFFAOYSA-N 0.000 description 1
- 239000006260 foam Substances 0.000 description 1
- 238000010353 genetic engineering Methods 0.000 description 1
- 238000007496 glass forming Methods 0.000 description 1
- 229960002442 glucosamine Drugs 0.000 description 1
- 150000002333 glycines Chemical class 0.000 description 1
- 230000013595 glycosylation Effects 0.000 description 1
- 238000006206 glycosylation reaction Methods 0.000 description 1
- 239000001963 growth medium Substances 0.000 description 1
- 229960000789 guanidine hydrochloride Drugs 0.000 description 1
- PJJJBBJSCAKJQF-UHFFFAOYSA-N guanidinium chloride Chemical compound [Cl-].NC(N)=[NH2+] PJJJBBJSCAKJQF-UHFFFAOYSA-N 0.000 description 1
- UYTPUPDQBNUYGX-UHFFFAOYSA-N guanine Chemical class O=C1NC(N)=NC2=C1N=CN2 UYTPUPDQBNUYGX-UHFFFAOYSA-N 0.000 description 1
- 239000000185 hemagglutinin Substances 0.000 description 1
- 230000008588 hemolysis Effects 0.000 description 1
- 210000004458 heterochromatin Anatomy 0.000 description 1
- HNDVDQJCIGZPNO-UHFFFAOYSA-N histidine Natural products OC(=O)C(N)CC1=CN=CN1 HNDVDQJCIGZPNO-UHFFFAOYSA-N 0.000 description 1
- 238000002744 homologous recombination Methods 0.000 description 1
- 230000006801 homologous recombination Effects 0.000 description 1
- 230000005745 host immune response Effects 0.000 description 1
- 229940099552 hyaluronan Drugs 0.000 description 1
- 229920002674 hyaluronan Polymers 0.000 description 1
- 238000004191 hydrophobic interaction chromatography Methods 0.000 description 1
- 229910052588 hydroxylapatite Inorganic materials 0.000 description 1
- 238000012872 hydroxylapatite chromatography Methods 0.000 description 1
- 229960002751 imiquimod Drugs 0.000 description 1
- DOUYETYNHWVLEO-UHFFFAOYSA-N imiquimod Chemical group C1=CC=CC2=C3N(CC(C)C)C=NC3=C(N)N=C21 DOUYETYNHWVLEO-UHFFFAOYSA-N 0.000 description 1
- 230000036039 immunity Effects 0.000 description 1
- 230000016784 immunoglobulin production Effects 0.000 description 1
- 238000000338 in vitro Methods 0.000 description 1
- 238000010348 incorporation Methods 0.000 description 1
- 238000002347 injection Methods 0.000 description 1
- 239000007924 injection Substances 0.000 description 1
- 229940079322 interferon Drugs 0.000 description 1
- 238000005342 ion exchange Methods 0.000 description 1
- 238000004255 ion exchange chromatography Methods 0.000 description 1
- BPHPUYQFMNQIOC-NXRLNHOXSA-N isopropyl beta-D-thiogalactopyranoside Chemical compound CC(C)S[C@@H]1O[C@H](CO)[C@H](O)[C@H](O)[C@H]1O BPHPUYQFMNQIOC-NXRLNHOXSA-N 0.000 description 1
- 229960000318 kanamycin Drugs 0.000 description 1
- SBUJHOSQTJFQJX-NOAMYHISSA-N kanamycin Chemical compound O[C@@H]1[C@@H](O)[C@H](O)[C@@H](CN)O[C@@H]1O[C@H]1[C@H](O)[C@@H](O[C@@H]2[C@@H]([C@@H](N)[C@H](O)[C@@H](CO)O2)O)[C@H](N)C[C@@H]1N SBUJHOSQTJFQJX-NOAMYHISSA-N 0.000 description 1
- 229930027917 kanamycin Natural products 0.000 description 1
- 229930182823 kanamycin A Natural products 0.000 description 1
- 238000002372 labelling Methods 0.000 description 1
- 238000011005 laboratory method Methods 0.000 description 1
- 230000002045 lasting effect Effects 0.000 description 1
- 125000000400 lauroyl group Chemical group O=C([*])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])[H] 0.000 description 1
- 239000000787 lecithin Substances 0.000 description 1
- 229940067606 lecithin Drugs 0.000 description 1
- 235000010445 lecithin Nutrition 0.000 description 1
- 239000002523 lectin Substances 0.000 description 1
- 230000007774 longterm Effects 0.000 description 1
- 229950005634 loxoribine Drugs 0.000 description 1
- 210000004698 lymphocyte Anatomy 0.000 description 1
- 125000003588 lysine group Chemical group [H]N([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])(N([H])[H])C(*)=O 0.000 description 1
- 229960000274 lysozyme Drugs 0.000 description 1
- 239000004325 lysozyme Substances 0.000 description 1
- 235000010335 lysozyme Nutrition 0.000 description 1
- 210000002540 macrophage Anatomy 0.000 description 1
- 230000035800 maturation Effects 0.000 description 1
- 230000007246 mechanism Effects 0.000 description 1
- 230000001404 mediated effect Effects 0.000 description 1
- 201000001441 melanoma Diseases 0.000 description 1
- 238000002844 melting Methods 0.000 description 1
- 230000008018 melting Effects 0.000 description 1
- 210000004779 membrane envelope Anatomy 0.000 description 1
- 108020004999 messenger RNA Proteins 0.000 description 1
- 125000001360 methionine group Chemical group N[C@@H](CCSC)C(=O)* 0.000 description 1
- 230000000813 microbial effect Effects 0.000 description 1
- 230000002906 microbiologic effect Effects 0.000 description 1
- 244000005700 microbiome Species 0.000 description 1
- 235000013336 milk Nutrition 0.000 description 1
- 239000008267 milk Substances 0.000 description 1
- 210000004080 milk Anatomy 0.000 description 1
- 238000000302 molecular modelling Methods 0.000 description 1
- 239000000178 monomer Substances 0.000 description 1
- 150000002772 monosaccharides Chemical class 0.000 description 1
- 210000004877 mucosa Anatomy 0.000 description 1
- DVEKCXOJTLDBFE-UHFFFAOYSA-N n-dodecyl-n,n-dimethylglycinate Chemical compound CCCCCCCCCCCC[N+](C)(C)CC([O-])=O DVEKCXOJTLDBFE-UHFFFAOYSA-N 0.000 description 1
- 229960004927 neomycin Drugs 0.000 description 1
- 230000001537 neural effect Effects 0.000 description 1
- 230000003472 neutralizing effect Effects 0.000 description 1
- 210000000299 nuclear matrix Anatomy 0.000 description 1
- 230000006911 nucleation Effects 0.000 description 1
- 238000010899 nucleation Methods 0.000 description 1
- 238000007899 nucleic acid hybridization Methods 0.000 description 1
- 239000002853 nucleic acid probe Substances 0.000 description 1
- 230000000474 nursing effect Effects 0.000 description 1
- 235000015097 nutrients Nutrition 0.000 description 1
- 238000005457 optimization Methods 0.000 description 1
- 210000000056 organ Anatomy 0.000 description 1
- 229960005030 other vaccine in atc Drugs 0.000 description 1
- 101800002712 p27 Proteins 0.000 description 1
- 229960000402 palivizumab Drugs 0.000 description 1
- 230000008506 pathogenesis Effects 0.000 description 1
- 230000037361 pathway Effects 0.000 description 1
- XYJRXVWERLGGKC-UHFFFAOYSA-D pentacalcium;hydroxide;triphosphate Chemical compound [OH-].[Ca+2].[Ca+2].[Ca+2].[Ca+2].[Ca+2].[O-]P([O-])([O-])=O.[O-]P([O-])([O-])=O.[O-]P([O-])([O-])=O XYJRXVWERLGGKC-UHFFFAOYSA-D 0.000 description 1
- 239000000137 peptide hydrolase inhibitor Substances 0.000 description 1
- 230000000144 pharmacologic effect Effects 0.000 description 1
- 235000021317 phosphate Nutrition 0.000 description 1
- 239000008363 phosphate buffer Substances 0.000 description 1
- 239000008055 phosphate buffer solution Substances 0.000 description 1
- 229940080469 phosphocellulose Drugs 0.000 description 1
- 150000003013 phosphoric acid derivatives Chemical class 0.000 description 1
- 230000026731 phosphorylation Effects 0.000 description 1
- 238000006366 phosphorylation reaction Methods 0.000 description 1
- 230000007505 plaque formation Effects 0.000 description 1
- 238000002962 plaque-reduction assay Methods 0.000 description 1
- 229920000642 polymer Polymers 0.000 description 1
- 229920005862 polyol Polymers 0.000 description 1
- 150000003077 polyols Chemical class 0.000 description 1
- 235000010486 polyoxyethylene sorbitan monolaurate Nutrition 0.000 description 1
- 239000000256 polyoxyethylene sorbitan monolaurate Substances 0.000 description 1
- 239000000244 polyoxyethylene sorbitan monooleate Substances 0.000 description 1
- 229920000136 polysorbate Polymers 0.000 description 1
- 229940068968 polysorbate 80 Drugs 0.000 description 1
- 239000011148 porous material Substances 0.000 description 1
- 239000002244 precipitate Substances 0.000 description 1
- 230000035935 pregnancy Effects 0.000 description 1
- 230000000069 prophylactic effect Effects 0.000 description 1
- 238000011321 prophylaxis Methods 0.000 description 1
- 235000019419 proteases Nutrition 0.000 description 1
- 238000001814 protein method Methods 0.000 description 1
- 230000030788 protein refolding Effects 0.000 description 1
- 230000006337 proteolytic cleavage Effects 0.000 description 1
- 230000002685 pulmonary effect Effects 0.000 description 1
- 201000009732 pulmonary eosinophilia Diseases 0.000 description 1
- 239000008213 purified water Substances 0.000 description 1
- 230000009257 reactivity Effects 0.000 description 1
- 229940044601 receptor agonist Drugs 0.000 description 1
- 239000000018 receptor agonist Substances 0.000 description 1
- 230000007115 recruitment Effects 0.000 description 1
- 238000011160 research Methods 0.000 description 1
- 229950010550 resiquimod Drugs 0.000 description 1
- 210000003660 reticulum Anatomy 0.000 description 1
- 230000002441 reversible effect Effects 0.000 description 1
- 206010039083 rhinitis Diseases 0.000 description 1
- 239000002336 ribonucleotide Substances 0.000 description 1
- 125000002652 ribonucleotide group Chemical group 0.000 description 1
- 238000013515 script Methods 0.000 description 1
- 239000006152 selective media Substances 0.000 description 1
- 238000002864 sequence alignment Methods 0.000 description 1
- 239000012679 serum free medium Substances 0.000 description 1
- 101150091813 shfl gene Proteins 0.000 description 1
- 230000035939 shock Effects 0.000 description 1
- 230000019491 signal transduction Effects 0.000 description 1
- 229910052709 silver Inorganic materials 0.000 description 1
- 239000004332 silver Substances 0.000 description 1
- 238000001542 size-exclusion chromatography Methods 0.000 description 1
- 239000012279 sodium borohydride Substances 0.000 description 1
- 229910000033 sodium borohydride Inorganic materials 0.000 description 1
- FHHPUSMSKHSNKW-SMOYURAASA-M sodium deoxycholate Chemical compound [Na+].C([C@H]1CC2)[C@H](O)CC[C@]1(C)[C@@H]1[C@@H]2[C@@H]2CC[C@H]([C@@H](CCC([O-])=O)C)[C@@]2(C)[C@@H](O)C1 FHHPUSMSKHSNKW-SMOYURAASA-M 0.000 description 1
- 238000000527 sonication Methods 0.000 description 1
- 239000000600 sorbitol Substances 0.000 description 1
- 238000001228 spectrum Methods 0.000 description 1
- 238000009987 spinning Methods 0.000 description 1
- 230000000087 stabilizing effect Effects 0.000 description 1
- 230000010473 stable expression Effects 0.000 description 1
- 238000010186 staining Methods 0.000 description 1
- 150000003431 steroids Chemical class 0.000 description 1
- 239000000758 substrate Substances 0.000 description 1
- 239000005720 sucrose Substances 0.000 description 1
- QAOWNCQODCNURD-UHFFFAOYSA-L sulfate group Chemical group S(=O)(=O)([O-])[O-] QAOWNCQODCNURD-UHFFFAOYSA-L 0.000 description 1
- 229940117986 sulfobetaine Drugs 0.000 description 1
- 239000013589 supplement Substances 0.000 description 1
- 239000004094 surface-active agent Substances 0.000 description 1
- 239000000725 suspension Substances 0.000 description 1
- 238000007910 systemic administration Methods 0.000 description 1
- 238000012360 testing method Methods 0.000 description 1
- 229960002180 tetracycline Drugs 0.000 description 1
- 229930101283 tetracycline Natural products 0.000 description 1
- 235000019364 tetracycline Nutrition 0.000 description 1
- 150000003522 tetracyclines Chemical class 0.000 description 1
- 230000001225 therapeutic effect Effects 0.000 description 1
- RYYWUUFWQRZTIU-UHFFFAOYSA-K thiophosphate Chemical compound [O-]P([O-])([O-])=S RYYWUUFWQRZTIU-UHFFFAOYSA-K 0.000 description 1
- 108060008226 thioredoxin Proteins 0.000 description 1
- 229940094937 thioredoxin Drugs 0.000 description 1
- 238000012090 tissue culture technique Methods 0.000 description 1
- 238000010361 transduction Methods 0.000 description 1
- 230000026683 transduction Effects 0.000 description 1
- 239000012096 transfection reagent Substances 0.000 description 1
- 230000007704 transition Effects 0.000 description 1
- 229940121343 tricaprilin Drugs 0.000 description 1
- UYPYRKYUKCHHIB-UHFFFAOYSA-N trimethylamine N-oxide Chemical compound C[N+](C)(C)[O-] UYPYRKYUKCHHIB-UHFFFAOYSA-N 0.000 description 1
- VLPFTAMPNXLGLX-UHFFFAOYSA-N trioctanoin Chemical compound CCCCCCCC(=O)OCC(OC(=O)CCCCCCC)COC(=O)CCCCCCC VLPFTAMPNXLGLX-UHFFFAOYSA-N 0.000 description 1
- GPRLSGONYQIRFK-MNYXATJNSA-N triton Chemical compound [3H+] GPRLSGONYQIRFK-MNYXATJNSA-N 0.000 description 1
- 201000008827 tuberculosis Diseases 0.000 description 1
- 238000000108 ultra-filtration Methods 0.000 description 1
- 241001430294 unidentified retrovirus Species 0.000 description 1
- 229940045136 urea Drugs 0.000 description 1
- 208000007089 vaccinia Diseases 0.000 description 1
- 230000009385 viral infection Effects 0.000 description 1
- 210000002845 virion Anatomy 0.000 description 1
- 239000000304 virulence factor Substances 0.000 description 1
- 230000007923 virulence factor Effects 0.000 description 1
- 238000001262 western blot Methods 0.000 description 1
- 235000021119 whey protein Nutrition 0.000 description 1
- 238000004804 winding Methods 0.000 description 1
- 210000005253 yeast cell Anatomy 0.000 description 1
Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/005—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from viruses
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/12—Viral antigens
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/12—Viral antigens
- A61K39/155—Paramyxoviridae, e.g. parainfluenza virus
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P31/00—Antiinfectives, i.e. antibiotics, antiseptics, chemotherapeutics
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P31/00—Antiinfectives, i.e. antibiotics, antiseptics, chemotherapeutics
- A61P31/12—Antivirals
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P31/00—Antiinfectives, i.e. antibiotics, antiseptics, chemotherapeutics
- A61P31/12—Antivirals
- A61P31/14—Antivirals for RNA viruses
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P37/00—Drugs for immunological or allergic disorders
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P37/00—Drugs for immunological or allergic disorders
- A61P37/02—Immunomodulators
- A61P37/04—Immunostimulants
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/08—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from viruses
- C07K16/10—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from viruses from RNA viruses
- C07K16/1027—Paramyxoviridae, e.g. respiratory syncytial virus
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/555—Medicinal preparations containing antigens or antibodies characterised by a specific combination antigen/adjuvant
- A61K2039/55505—Inorganic adjuvants
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/555—Medicinal preparations containing antigens or antibodies characterised by a specific combination antigen/adjuvant
- A61K2039/55511—Organic adjuvants
- A61K2039/55572—Lipopolysaccharides; Lipid A; Monophosphoryl lipid A
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/555—Medicinal preparations containing antigens or antibodies characterised by a specific combination antigen/adjuvant
- A61K2039/55511—Organic adjuvants
- A61K2039/55577—Saponins; Quil A; QS21; ISCOMS
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/20—Immunoglobulins specific features characterized by taxonomic origin
- C07K2317/21—Immunoglobulins specific features characterized by taxonomic origin from primates, e.g. man
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/76—Antagonist effect on antigen, e.g. neutralization or inhibition of binding
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/70—Fusion polypeptide containing domain for protein-protein interaction
- C07K2319/73—Fusion polypeptide containing domain for protein-protein interaction containing coiled-coiled motif (leucine zippers)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2760/00—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA ssRNA viruses negative-sense
- C12N2760/00011—Details
- C12N2760/18011—Paramyxoviridae
- C12N2760/18511—Pneumovirus, e.g. human respiratory syncytial virus
- C12N2760/18522—New viral proteins or individual genes, new structural or functional aspects of known viral proteins or genes
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2760/00—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA ssRNA viruses negative-sense
- C12N2760/00011—Details
- C12N2760/18011—Paramyxoviridae
- C12N2760/18511—Pneumovirus, e.g. human respiratory syncytial virus
- C12N2760/18534—Use of virus or viral component as vaccine, e.g. live-attenuated or inactivated virus, VLP, viral protein
-
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y02—TECHNOLOGIES OR APPLICATIONS FOR MITIGATION OR ADAPTATION AGAINST CLIMATE CHANGE
- Y02A—TECHNOLOGIES FOR ADAPTATION TO CLIMATE CHANGE
- Y02A50/00—TECHNOLOGIES FOR ADAPTATION TO CLIMATE CHANGE in human health protection, e.g. against extreme weather
- Y02A50/30—Against vector-borne diseases, e.g. mosquito-borne, fly-borne, tick-borne or waterborne diseases whose impact is exacerbated by climate change
Landscapes
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Virology (AREA)
- General Health & Medical Sciences (AREA)
- Medicinal Chemistry (AREA)
- Organic Chemistry (AREA)
- Immunology (AREA)
- Pharmacology & Pharmacy (AREA)
- Veterinary Medicine (AREA)
- Public Health (AREA)
- Animal Behavior & Ethology (AREA)
- General Chemical & Material Sciences (AREA)
- Molecular Biology (AREA)
- Chemical Kinetics & Catalysis (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Pulmonology (AREA)
- Biochemistry (AREA)
- Biophysics (AREA)
- Genetics & Genomics (AREA)
- Mycology (AREA)
- Epidemiology (AREA)
- Microbiology (AREA)
- Communicable Diseases (AREA)
- Oncology (AREA)
- Engineering & Computer Science (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Gastroenterology & Hepatology (AREA)
- Medicines Containing Antibodies Or Antigens For Use As Internal Diagnostic Agents (AREA)
- Peptides Or Proteins (AREA)
- Medicines That Contain Protein Lipid Enzymes And Other Medicines (AREA)
- Pharmaceuticals Containing Other Organic And Inorganic Compounds (AREA)
- Micro-Organisms Or Cultivation Processes Thereof (AREA)
Abstract
Un antígeno del virus sincitial respiratorio recombinante (VSR) que se ensambla en un trímero, que comprende un polipéptido de la proteína F soluble que comprende un dominio F2 y un dominio F1 de un polipéptido de la proteína F del VSR y que comprende una secuencia de aminoácidos que comprende un dominio de trimerización heterólogo en posición C-terminal con respecto al dominio F1 que estabiliza la conformación de prefusión de la proteína F.
Description
DESCRIPCIÓN
Antígenos recombinantes del VSR
Antecedentes
La presente divulgación se refiere al campo de la inmunología. Más particularmente, la presente divulgación se refiere a composiciones y procedimientos para provocar una respuesta inmune específica para el Virus Sincitial Respiratorio (Vs R).
El Virus Sincitial Respiratorio (VSR) es la causa más común en todo el mundo de infecciones del tracto respiratorio inferior (LRI) en niños con menos de 6 meses de edad y bebés prematuros con un periodo de gestación inferior o igual a 35 semanas. El espectro de enfermedad por VSR incluye una amplia gama de síntomas respiratorios desde rinitis y otitis a neumonía y bronquiolitis, las últimas dos enfermedades estando asociadas con morbilidad y mortalidad considerables. Los seres humanos son el único reservorio conocido para el VSR. La propagación del virus a partir de secreciones nasales contaminadas se produce a través de gotitas respiratorias grandes, se necesita un contacto muy cercano con un individuo infectado o superficie contaminada para su transmisión. El VSR puede persistir durante varias horas en juguetes u otros objetos, lo que explica la tasa elevada de infecciones nosocomiales por VSR, en particular en salas de pediatría.
Se calcula que las cifras de mortalidad e infección anuales globales para el VSR son de 64 millones y 160.000 millones respectivamente. Solamente en Estados Unidos se calcula que el VSR es responsable de 18.000 a 75.000 hospitalizaciones y de 90 a 1.900 muertes al año. En climas templados, el VSR está bien documentado como una causa de epidemias anuales de comienzos del invierno de LRI agudas, incluyendo bronquiolitis y neumonía. En Estados Unidos, casi todos los niños han sido infectados con VSR hacia los dos años de edad. La tasa de incidencia de LRI asociada con VSR en niños por lo demás sanos se calculó como 37 de cada 1000 niños al año en los primeros dos años de vida (45 por cada 1000 niños al año en los lactantes menores de 6 meses de edad) y el riesgo de hospitalización como 6 de cada 1000 niños al año (por 1000 niños al año en los primeros seis meses de vida). La incidencia es mayor en los niños con enfermedad cardiopulmonar y en los que nacen de forma prematura, que constituyen casi la mitad de las hospitalizaciones relacionadas con el VSR en Estados Unidos. Los niños que experimentan una LRI más severa causada por el VSR más tarde tienen una mayor incidencia de asma infantil. Estos estudios demuestran una necesidad generalizada de vacunas para el VSR, así como el uso de las mismas, en países industrializados, en los que los costos del cuidado de los pacientes con LRI severa y sus secuelas son sustanciales. El VSR también se reconoce cada vez más como una causa importante de morbilidad enfermedades similares a la gripe en los ancianos.
Como se analiza, por ejemplo, en Van Drunen Littel-Van Den Hurk, S. y col., "Immunopathology of RSV infection: prospects for developing vaccines without this complication", Reviews in Medical Virology vol.17 (2007) pp5-34, el desarrollo de vacunas eficaces del VSR ha resultado ser una tarea difícil y se han intentado diversos enfoques en esfuerzos para producir una vacuna para el VSR segura y eficaz y que produzca respuestas inmunes duraderas y protectoras en poblaciones sanas y en riesgo se han intentado diversos enfoques. Sin embargo, ninguna de las candidatas evaluadas hasta la fecha ha demostrado ser segura ni eficaz como una vacuna para evitar la infección por el VSR y/o reducir o prevenir la enfermedad por el VSR, incluyendo infecciones del tracto respiratorio inferior (LRI).
Sumario
La presente invención se refiere a antígenos recombinantes del virus sincitial respiratorio (VSR). De forma más específica, la presente divulgación se refiere a antígenos que incluyen una proteína F recombinante que se ha modificado para estabilizar la conformación de prefusión trimérica. Los antígenos recombinantes desvelados muestran inmunogenicidad superior y se emplean de forma particularmente favorable como componentes de composiciones inmunogénicas (por ejemplo, vacunas) para la protección contra infección y/o enfermedad por VSR. También se desvelan ácidos nucleicos que codifican los antígenos recombinantes, composiciones inmunogénicas que contienen los antígenos y procedimientos para producir y usar los antígenos.
Específicamente, se proporciona un antígeno de virus sincitial respiratorio (VSR) recombinante que se ensambla en un trímero, que comprende un polipéptido de la proteína F soluble que comprende un dominio F2 y un dominio F1 de un polipéptido de la proteína F del VSR y que comprende una secuencia de aminoácidos que comprende un dominio de trimerización heterólogo situado en dirección C-terminal del dominio F1 que estabiliza la conformación de prefusión de la proteína F.
También se proporcionan un ácido nucleico recombinante que codifica el antígeno del VSR recombinante, una composición inmunogénica que comprende el antígeno del VSR recombinante y el uso del antígeno del VSR o el ácido nucleico recombinante en la preparación de un medicamente para tratar una infección por VSR.
Breve descripción de las figuras
La FIG. 1A es una ilustración esquemática que resalta las características estructurales de la proteína F del VSR.
La FIG. 1B es una ilustración esquemática de antígenos de Prefusión F (PreF) del VSR a modo de ejemplo. La FIG. 2 es un gráfico de líneas que ilustra resultados representativos de análisis de fraccionamiento de flujo de campo asimétrico (AFF-MALS) de PreF.
La FIG. 3 es un gráfico de barras que muestra la inhibición de neutralización de suero humano con antígeno PreF.
Las FIGS. 4A y B son gráficos de barras que muestran titulaciones de IgG en suero provocadas en ratones como respuesta al antígeno PreF.
Las FIGS. 5A y B son gráficos de barras que ilustran titulaciones de anticuerpos de neutralización específicos para el VSR provocados por el antígeno PreF.
Las FIGS. 6A y B son gráficos que indican protección frente a estimulación proporcionada por el antígeno PreF del VSR en ratones.
La FIG. 7 es un gráfico que evalúa leucocitos BAL después de en inmunización y estimulación.
Descripción detallada
INTRODUCCIÓN
El desarrollo de vacunas para prevenir la infección por el VSR se ha complicado por el hecho de que parece que algunas respuestas inmunes del hospedador desempeñan un papel en la patogénesis de la enfermedad. Algunos estudios iniciales en la década de 1960 mostraban que algunos niños vacunados con una vacuna de VSR inactivado con formalina padecían enfermedades más graves después de la exposición al virus en comparación con sujetos de control sin vacunar. Estos ensayos iniciales dieron como resultado la hospitalización de un 80 % de vacunados y dos muertes. El aumento de la gravedad de la enfermedad se ha reproducido en modelos animales y se cree que resulta de niveles inadecuados de anticuerpos de neutralización de suero, falta de inmunidad local, e inducción excesiva de una respuesta inmune similar a la de los linfocitos T auxiliares de tipo 2 (Th2) con eosinofilia pulmonar y aumento de la producción de citoquinas IL-4 e IL-5. Por el contrario, una vacuna satisfactoria que protege frente a la infección por el VSR induce una respuesta inmune desviada hacia Th1, caracterizada por la producción de IL-2 e interferón y (IFN).
La presente divulgación se refiere a antígenos del virus sincitial respiratorio (VSR) recombinantes que resuelven los problemas encontrados con antígenos del VSR usados anteriormente en vacunas, y mejoran las propiedades inmunológicas así como de fabricación del antígeno. Los antígenos del VSR recombinantes desvelados en el presente documento implican un análogo de la proteína Fusión (F) que incluye un polipéptido de la proteína F soluble, que se ha modificado para estabilizar la conformación de prefusión de la proteína F, es decir, la conformación de la proteína F ensamblada madura antes de la fusión con la membrana de la célula hospedadora. Estos análogos de la proteína F se denominan "PreF" o "antígenos PreF", por cuestiones de claridad y simplicidad. Los antígenos PreF desvelados en el presente documento se basan en el descubrimiento inesperado de que algunos análogos de la proteína F soluble que se han modificado por la incorporación de un dominio de trimerización heterólogo presentan características inmunogénicas mejoradas, y son seguros y altamente protectores cuando se administran a un sujeto in vivo.
En el presente documento se proporcionan algunos detalles de la estructura de la proteína F del VSR con referencia a terminología y denominaciones ampliamente aceptadas en la técnica, y se ilustran de forma esquemática en la FIG. 1A. Una ilustración esquemática de algunos antígenos PreF a modo de ejemplo se proporciona en la FIG. 1B. Los expertos en la materia entenderán que cualquier proteína F del VSR se puede modificar para estabilizar la conformación de prefusión de acuerdo con las enseñanzas proporcionadas en el presente documento. Por lo tanto, para facilitar la comprensión de los principios que guían la producción de antígenos PreF, algunos componentes estructurales individuales se indicarán con referencia a una proteína F a modo de ejemplo, cuyas secuencias de polinucleótidos y aminoácidos se proporcionan en las SEQ ID NOs: 1 y 2, respectivamente. De forma análoga, cuando sea aplicable, se describen antígenos de proteína G en referencia a una proteína G a modo de ejemplo, cuyas secuencias de polinucleótidos y aminoácidos se proporcionan en las SEQ ID NOs: 3 y 4, respectivamente. Con referencia a la secuencia de aminoácidos primaria del polipéptido de la proteína F (FIG. 1A), los siguientes términos se usan para describir características estructurales de los antígenos PreF.
El término F0 se refiere a un precursor de la proteína F traducido de longitud completa. El polipéptido F0 se puede subdividir en un dominio F2 y un dominio F1 separados por un péptido de intervención, denominado pep27. Durante la maduración, el polipéptido F0 se somete a escisión proteolítica en dos sitios de furina situados entre F2 y F1 y flanqueando a Pep27. Con fines de discusión que sigue a continuación, un dominio F2 incluye al menos una parte, y tanto como todos, de los aminoácidos 1-109, y una parte soluble de un dominio F1 incluye al menos una parte, y hasta todos, de los aminoácidos 137-526 de la proteína F. Como se ha indicado anteriormente, estos posiciones de los aminoácidos (y todas las posiciones de los aminoácidos posteriores mencionados en el presente documento) se
dan en referencia al polipéptido precursor de la proteína F a modo de ejemplo (Fo) de la SEQ ID NO: 2.
El antígeno de prefusión F (o "PreF") es un análogo de la proteína F soluble (es decir, no unido a la membrana) que incluye al menos una modificación que estabiliza la conformación de prefusión de la proteína F, de modo que el antígeno del VSR retiene al menos un epítopo inmunodominante de la conformación de prefusión de la protein F. El polipéptido de la proteína F soluble incluye un dominio F2 y un dominio F1 de la proteína F del VSR (pero no incluye un dominio transmembrana de la proteína F del VSR). En realizaciones a modo de ejemplo, el dominio F2 incluye aminoácidos 26-105 y el dominio F1 incluye los aminoácidos 137-516 de una proteína F. Sin embargo, también se pueden usar partes más pequeñas, siempre y cuando se mantenga la conformación tridimensional del antígeno de PreF estabilizado. De forma análoga, también se pueden usar los polipéptidos que incluyen componentes estructurales adicionales (por ejemplo, polipéptidos de fusión) en lugar de los dominios F2 y F1 a modo de ejemplo, siempre y cuando los componentes adicionales no alteren la conformación tridimensional, o de otro modo influyan de forma adversa en la estabilidad, producción o procesamiento, o disminución de la inmunogenicidad del antígeno. Los dominios F2 y F1 están situados en una orientación de N-terminal a C-terminal diseñada para replicar el plegamiento y ensamblaje del análogo de la proteína F en la conformación de prefusión madura. Para aumentar la producción, el dominio F2 puede ir precedido por un péptido señal secretor, tal como un péptido señal de la proteína F nativo o un péptido señal heterólogo elegido para aumentar la producción y secreción en las células hospedadoras en las que se va a expresar el antígeno de PreF recombinante.
Los antígenos de PreF se estabilizan (en la conformación de prefusión trimérica) mediante la introducción de una o más modificaciones, tales como la adición, deleción o sustitución de uno o más aminoácidos. Una modificación de estabilización de este tipo es la adición de una secuencia de aminoácidos que comprende un dominio de estabilización heterólogo. En realizaciones a modo de ejemplo, el dominio de estabilización heterólogo es un dominio de multimerización de proteína. Un ejemplo particularmente favorable de un dominio de multimerización de proteína de este tipo es un dominio de bucles superenrollados, tal como un dominio de cremallera de isoleucina que estimula la trimerización de múltiples polipéptidos que tienen un dominio de este tipo. Un dominio de cremallera de isoleucina a modo de ejemplo se representa en la SEQ ID NO: 11. Por lo general, el dominio de estabilización heterólogo está situado en posición C-terminal con respecto al dominio F1.
Opcionalmente, el dominio de multimerización está conectado con el dominio F1 a través de una secuencia de engarce de aminoácidos corta, tal como la secuencia GG. El engarce también puede ser un engarce más largo (por ejemplo, que incluye la secuencia GG, tal como la secuencia de aminoácidos: GGSGGSGGS; SEQ ID NO: 14). En la técnica se conocen numerosos engarces conformacionalmente neutros que se pueden usar en este contexto sin interrumpir la conformación del antígeno de PreF.
Otra modificación de estabilización es la eliminación de un sitio de reconocimiento y escisión de furina que está situado en los dominios F2 y F1 en la proteína F0 nativa. Uno o ambos sitios de reconocimiento de furina, situados en las posiciones 105-109 y en las posiciones 133-136 se pueden eliminar mediante deleción o sustitución de uno o más aminoácidos de los sitios de reconocimiento de furina, de modo que la proteasa es incapaz de escindir el polipéptido PreF en sus dominios componentes. Opcionalmente, el péptido pep27 de intervención también se puede retirar o sustituir, por ejemplo, mediante un péptido de engarce. Además, u opcionalmente, un sitio de escisión que no es furina (por ejemplo, un sitio de metaloproteinasa en las posiciones 112-113) en proximidad con el péptido de fusión se puede retirar o sustituir.
Otro ejemplo de mutación de estabilización es la adición o deleción de un aminoácido hidrófilo en un dominio hidrófobo de la proteína F. Por lo general, un aminoácido cargado, tal como lisina, se añadirá o sustituirá para un resto neutro, tal como leucina, en la región hidrófoba. Por ejemplo, un aminoácido hidrófilo se puede añadir a, o sustituir por, un aminoácido hidrófobo o neutro dentro del dominio de bucles superenrollados HRB del dominio extracelular de la proteína F. A modo de ejemplo, un resto de aminoácido cargado, tal como lisina, se puede sustituir por la leucina presente en la posición 512 de la proteína F. Como alternativa, o además, un aminoácido hidrófilo se puede añadir a, o sustituir por, un aminoácido hidrófobo o neutro dentro del dominio HRA de la proteína F. Por ejemplo, uno o más aminoácidos cargados, tales como lisina, se pueden insertar en o cerca de la posición 105-106 (por ejemplo, después del aminoácido que corresponde al resto 105 de la SEQ ID NO: 2 de referencia, tal como entre los aminoácidos 105 y 106) del antígeno de PreF). Opcionalmente, los aminoácidos hidrófilos se pueden añadir o sustituir en los dominios tanto HRA como HRB. Como alternativa, uno o más restos hidrófobos se pueden suprimir, siempre y cuando la conformación global del antígeno de PreF no se vea afectada de forma adversa. Cualquiera y/o todas las modificaciones de estabilización se pueden usar de forma individual y/o en combinación con cualquiera de las otras modificaciones de estabilización desveladas en el presente documento para producir un antígeno de PreF. En realizaciones ilustrativas, la proteína de PreF que comprende un polipéptido que comprende un dominio F2 y un dominio F1 sin sitio de escisión de furina de intervención entre el dominio F2 y el dominio F1, y con un dominio de estabilización heterólogo (por ejemplo, dominio de trimerización) situado en la posición C-terminal con respecto al dominio F1. En determinadas realizaciones, el antígeno de PreF también incluye una o más adiciones y/o sustituciones de un resto hidrófilo en un dominio HRA y/o HRB hidrófobo. Opcionalmente, el antígeno de PreF tiene una modificación de al menos un sitio de escisión que no es furina, tal como un sitio de metaloproteinasa.
Un antígeno de PreF puede incluir opcionalmente un componente de polipéptido adicional que incluye al menos una
parte inmunogénica de la proteína G del VSR. Es decir, en ciertas realizaciones, el antígeno de PreF es una proteína quimérica que incluye tanto un componente de la proteína F como de la proteína G. El componente de la proteína F puede ser cualquiera de los antígenos de PreF descritos anteriormente, y el componente de la proteína G se selecciona para que sea una parte inmunológicamente activa de la proteína G del VSR (hasta y/o incluyendo una proteína G de longitud completa). En realizaciones a modo de ejemplo, el polipéptido de la proteína G incluye los aminoácidos 149-229 de una proteína G (en la que las posiciones de los aminoácidos se designan con referencia a la secuencia de la proteína G representada en la SEQ ID NO: 4). Una persona con experiencia en la materia observará que se puede usar una parte o fragmento más pequeño de la proteína G, siempre y cuando la parte seleccionada mantenga las características inmunológicas dominantes del fragmento más grande de la proteína G. En particular, el fragmento seleccionado mantiene el epítopo inmunológicamente dominante entre aproximadamente las posiciones de los aminoácidos 184-198 (por ejemplo, los aminoácido 180-200), y es lo suficientemente largo como para plegarse y ensamblarse en una conformación estable que presenta el epítopo inmunodominante. También se pueden usar fragmentos más largos, por ejemplo, desde aproximadamente el aminoácido 128 a aproximadamente el aminoácido 229, hasta la proteína G de longitud completa. Siempre y cuando el fragmento seleccionado se pliegue en una conformación estable en el contexto de la proteína quimérica, y no interfiera con la producción, procesamiento o estabilidad cuando se produce de forma recombinante en células hospedadoras. Opcionalmente, el componente de la proteína G está conectado al componente de la proteína F a través de una secuencia de engarce de aminoácidos corta, tal como la secuencia GG. El engarce también puede ser un engarce más largo (tal como la secuencia de aminoácidos: GGSGGSGGS: SEQ ID NO: 14). En la técnica se conocen numerosos engarces conformacionalmente neutros que se pueden usar en este contexto sin alterar la conformación del antígeno de PreF.
Opcionalmente, el componente de la proteína G puede incluir una o más sustituciones de aminoácidos que reducen o previenen el aumento de la enfermedad viral en un modelo animal de enfermedad por VSR. Es decir, la proteína G puede incluir una sustitución de aminoácidos, de modo que cuando una composición inmunogénica que incluye el antígeno quimérico de PreF-G se administra a un sujeto seleccionado entre un modelo animal aceptado (por ejemplo, modelo de VSR de ratón), el sujeto presenta reducción o ningún síntoma de enfermedad vírica potenciada por vacuna (por ejemplo, eosinófilos, neutrófilos), en comparación con un animal de control que recibe una vacuna que incluyendo la que contiene una proteína G sin modificar. La reducción y/o prevención de enfermedad vírica potenciada por vacuna puede ser evidente cuando las composiciones inmunogénicas se administran en ausencia de adyuvante (pero no, por ejemplo, cuando los antígenos se administran en presencia de un adyuvante fuerte que induce Th1). Además, la sustitución de aminoácidos puede reducir o prevenir la enfermedad vírica potenciada por vacuna cuando se administra a un sujeto humano. Un ejemplo de una sustitución de aminoácidos adecuada es la sustitución de la asparagina en la posición 191 por una alanina (Asn ^ Ala en el aminoácido 191: N191A).
Opcionalmente, cualquier antígeno de PreF descrito anteriormente puede incluir una secuencia adicional que sirve como una ayuda en la purificación. Un ejemplo, es una etiqueta de polihistidina. Una etiqueta de este tipo se puede retirar del producto final si se desea.
Cuando se expresan, los antígenos de PreF se someten a plegamiento intramolecular y se ensamblan en proteína madura que incluye un multímero de polipéptidos. De forma favorable, los polipéptidos del antígeno de preF se ensamblan en un trímero que se parece a la conformación de prefusión de la proteína F del VSR, procesada, madura.
Cualquiera de los antígenos de PreF (incluyendo antígenos de PreF-G) desvelados en el presente documento se puede usar de forma favorable en composiciones inmunogénicas con el fin de provocar una respuesta inmune protectora frente al VSR. Tales composiciones inmunogénicas por lo general incluyen un vehículo y/o excipiente farmacéuticamente aceptable, tal como un tampón. Para mejorar la respuesta inmune producida después de la administración, la composición inmunogénica por lo general también incluye un adyuvante. En el caso de composiciones inmunogénicas para provocar una respuesta inmune frente al VSR (por ejemplo, vacunas), las composiciones favorables incluyen un adyuvante que predominantemente provoca una respuesta inmune a Th1 (un adyuvante de desviación hacia Th1). Por lo general, el adyuvante se selecciona para que sea adecuado para administración a la población diana a la que se va a administrar la composición. Por lo tanto, dependiendo de la aplicación, el adyuvante se selecciona para que sea adecuado para administración, por ejemplo, a neonatos con las personas de mayor edad.
Las composiciones inmunogénicas descritas en el presente documento se usan de forma favorable como vacunas para la reducción o prevención de infección con VSR, sin inducir una respuesta patológica (tal como enfermedad viral potenciada con vacuna) después de administración o exposición al VSR.
En algunas realizaciones, la composición inmunogénica incluye un antígeno de PreF (tal como la realización a modo de ejemplo ilustrada por la SEQ ID NO: 6) y un segundo polipéptido que incluye un componente de la proteína G. El componente de la proteína G por lo general incluye al menos los aminoácidos 149-229 de una proteína G. aunque se pueden usar partes más pequeñas de la proteína G, tales fragmentos deberían incluir, como mínimo, el epítopo dominante inmunológico de los aminoácidos 184-198. Como alternativa, la proteína G puede incluir una parte más grande de la proteína G, tal como los aminoácidos 128-229 o 130-230, opcionalmente como un elemento de una proteína más grande, tal como la proteína G de longitud completa, o un polipéptido quimérico.
En otras realizaciones, la composición inmunogénica incluye un antígeno de PreF que es una proteína quimérica que también incluye un componente de la proteína G (tal como las realizaciones a modo de ejemplo ilustradas por las SEQ ID NOs: 8 y 10). El componente de la proteína G de un antígeno de PreF quimérico (o PreF-G) de este tipo por lo general incluye al menos los aminoácidos 149-229 de una proteína G. Como se ha indicado anteriormente, también se pueden usar fragmentos más pequeños o más grandes (tales como los aminoácidos 129-229 o 130-230) de la proteína G, siempre y cuando se mantengan los epítopos inmunodominantes, y la conformación del antígeno de PreF-G no se vea influida de forma adversa.
Opcionalmente, las composiciones inmunogénicas también pueden incluir al menos un antígeno adicional de un organismo patógeno distinto del VSR. Por ejemplo, el organismo patógeno es un virus distinto del VSR, tal como virus de la Parainfluenza (PIV), sarampión, hepatitis B, poliovirus, o virus de la gripe. Como alternativa, el organismo patógeno puede ser una bacteria, tal como difteria, tétanos, pertussis, Haemophilus influenzae, y Pneumococcus. Los ácidos nucleicos recombinantes que codifican cualquiera de los antígenos de PreF (incluyendo antígenos de PreF-G) también son una característica de la presente divulgación. En algunas realizaciones, la secuencia de polinucleótidos del ácido nucleico que codifica el antígeno de PreF del ácido nucleico se optimiza para expresión en un hospedador seleccionado (tal como células CHO, otras células de mamífero, o células de insecto). Por consiguiente, los vectores, incluyendo vectores de expresión (que incluyen vectores de expresión procariotas y eucariotas) son una característica de la presente divulgación. De forma análoga, las células hospedadoras que incluyen tales ácidos nucleicos, y vectores, son una característica de la presente divulgación. Tales ácidos nucleicos también se pueden usar en el contexto de composiciones inmunogénica para administración a un sujeto para provocar una respuesta inmune específica para el VSR.
Los antígenos de PreF se usan de forma favorable para la prevención y/o tratamiento de infección por el VSR. Por lo tanto, otro aspecto de la presente divulgación se refiere a un procedimiento para provocar una respuesta inmune frente al VSR. El procedimiento implica la administración de una cantidad inmunológicamente eficaz de una composición que contiene un antígeno de PreF a un sujeto (tal como un sujeto humano o animal). La administración de una cantidad inmunológicamente eficaz de la composición provoca una respuesta inmune específica para epítopo presentes en el antígeno de PreF. Tal respuesta inmune puede incluir respuestas de linfocitos B (por ejemplo, la producción de anticuerpos de neutralización) y/o respuestas de linfocitos T (por ejemplo, la producción de citoquinas). De forma favorable, la respuesta inmune provocada por el antígeno de PreF incluye elementos que son específicos para al menos un epítopo conformacional presente en la conformación de prefusión de la proteína F del VSR Los antígenos y composiciones de PreF se pueden administrar a un sujeto sin aumentar una enfermedad viral después del contacto con el VSR De forma favorable, los antígenos de PreF desvelados en el presente documento y composiciones inmunogénicas formuladas de forma adecuada provocan una respuesta inmune desviada hacia Th1 que reduce o previene la infección con un VSR y/o reduce o previene una respuesta patológica después de infección con un VSR.
Las composiciones inmunogénicas se pueden administrar a través de una diversidad de vías, incluyendo vías tales como intranasal, que colocan directamente el antígeno de PreF en contacto con la mucosa del tracto respiratorio superior. Como alternativa, se pueden usar algunas vías de administración más tradicionales, tal como una vía de administración intramuscular.
Por lo tanto, también se contempla el uso de cualquiera de los antígenos del VSR (o ácidos nucleicos) desvelados en la preparación de un medicamento para el tratamiento de infección por VSR (por ejemplo, tratamiento de forma profiláctica o prevención de una infección por VSR). Por consiguiente, la presente divulgación proporciona los antígenos del VSR recombinantes desvelados o las composiciones inmunogénicas para uso en medicina, así como el uso de los mismos para la prevención o tratamiento de enfermedades asociadas con el VSR.
Algunos detalles adicionales con respecto a antígenos de PreF, y procedimientos para su uso, se presentan en la descripción y ejemplos que siguen a continuación.
TÉRMINOS
Para facilitar la revisión de las diversas realizaciones de la presente divulgación, se proporcionan las siguientes explicaciones de los términos. Algunos términos y explicaciones adicionales se pueden proporcionar en el contexto de la presente divulgación.
A menos que se explique de otro modo, todos los términos técnicos y científicos usados en el presente documento tienen el mismo significado que normalmente entiende un experto habitual en la materia a la que pertenece la presente divulgación. Algunas definiciones de términos comunes en biología molecular se pueden encontrar en Benjamin Lewin, Genes V, publicado por Oxford University Press, 1994 (ISBN 0-19-854287-9); Kendrew y col., (eds.), The Encyclopedia of Molecular Biology, publicado por Blackwell Science Ltd., 1994 (ISBN 0-632-02182-9); y Robert A. Meyers (ed.), Molecular Biology and Biotechnology: a Comprehensive Desk Reference, publicado por VCH Publishers, Inc., 1995 (ISBN 1-56081-569-8).
Los términos en singular "un", "uno", y "el" incluyen referentes en plural a menos que el contexto lo indique claramente de otro. De forma análoga, el término "o" pretende incluir "y" a menos que el contexto no indique
claramente de otro modo. El término "pluralidad" se refiere a dos o más. Se debe entender adicionalmente que todos los tamaños de bases o tamaños de aminoácidos, y todos los valores de pesos moleculares o masas moleculares, dados para ácidos nucleicos o polipéptido son aproximados, y se proporcionan para descripción. Además, se pretende que las limitaciones numéricas dadas con respecto a concentraciones o niveles de una sustancia, tal como un antígeno, sean aproximadas. Por lo tanto, cuando se indica que una concentración es al menos (por ejemplo) 200 pg, se pretende que se entienda que la concentración es al menos aproximadamente (o "aproximadamente" o "~") 200 pg.
Aunque en la práctica o ensayo de la presente divulgación se pueden usar algunos procedimientos y materiales similares o equivalentes a los descritos en el presente documento, a continuación se proporcionan algunos procedimientos y materiales adecuados. El término "comprende" se refiere a "incluye". Por lo tanto, a menos que el contexto lo requiera de otro modo, se entenderá que el término "comprende", y variaciones tales como "comprender" y "que comprende" implica la inclusión de un compuesto o composición indicados (por ejemplo, ácido nucleico, polipéptido, antígeno) o etapa, o grupo de compuestos o etapas, pero no la exclusión de cualquier otro compuesto, composición, etapa o grupo de los mismos. La abreviatura, "por ejemplo" se deriva del latín exempli gratia, y en el presente documento se usa para indicar un ejemplo no limitante. Por lo tanto, la abreviatura "e.g." es sinónima con el término "por ejemplo".
El virus sincitial respiratorio (VSR) es un virus patógeno de la familia Paramyxoviridae, subfamilia Pneumovirinae, género Pneumovirus. El genoma del VSR es una molécula de ARN de sentido negativo, que codifica 11 proteínas. Una asociación estrecha del genoma del ARN con la proteína N viral forma una nucleocápside encuentra dentro de la envoltura viral. Se han descrito dos grupos de cepas del VSR humano, los grupos A y B, basándose en las diferencias de antigenicidad de la glicoproteína G. Hasta la fecha se han aislado numerosas cepas del VSR. Algunas cepas a modo de ejemplo indicadas con número de referencia en GenBank y/o EMBL se pueden encontrar en el documento WO2008114149, que desvela las secuencias de ácidos nucleicos y polipéptidos de las proteínas F y G del VSR adecuadas para puso en antígenos PreF (incluyendo antígenos PreF-G quiméricos), y en combinaciones con antígenos PreF. Probablemente se van a aislar algunas cepas de VSR adicionales, y están incluidas dentro del género del VSR. De forma análoga, el género del VSR incluye variantes que se producen a partir de origen natural (por ejemplo, cepas identificadas previa o posteriormente) mediante deriva genética, o síntesis artificial y/o recombinación.
El término "proteína F" o "proteína de Fusión" o "polipéptido de la proteína F" o "polipéptido de proteína de Fusión" se refiere a un polipéptido o proteína que tiene toda o parte de una secuencia de aminoácidos de un polipéptido de proteína de Fusión del VSR. Del mismo modo, la expresión "proteína G" o "polipéptido de la proteína G" se refiere a un polipéptido o proteína que tienen toda o parte de una secuencia de aminoácidos de un polipéptido de proteínas de unión al VSR. Se han descrito numerosas proteínas de Fusión y Unión al VSR y son conocidas por los expertos en la materia. El documento WO2008114149 expone algunas variantes de la proteína F y G a modo de ejemplo (por ejemplo, variantes de origen natural) disponibles al público a partir de la fecha de presentación de la presente divulgación.
Una "variante" cuando se refiere a un ácido nucleico o un polipéptido (por ejemplo, un ácido nucleico o polipéptido de la proteína F o G del VSR, o un ácido nucleico o polipéptido PreF) es un ácido nucleico o un polipéptido que se diferencia de un ácido nucleico o polipéptido de referencia. Normalmente, la diferencia(s) entre el ácido nucleico o polipéptido variante y de referencia constituye un número de diferencias proporcionalmente pequeño en comparación con el referente.
Un "dominio" de un polipéptido o proteína es un elemento definido estructuralmente dentro del polipéptido o proteína. Por ejemplo, un "dominio de trimerización" es una secuencia de aminoácidos dentro de un polipéptido que estimula el ensamblaje del polipéptido en trímeros. Por ejemplo, un dominio de trimerización estimular el ensamblaje en trímeros mediante asociaciones con otros dominios de trimerización (de polipéptidos adicionales con la misma secuencia de aminoácidos o una diferente). El término también se usa para hacer referencia a un polinucleótido que codifica un péptido o polipéptido de este tipo.
Los términos "nativo" y "de origen natural" se refieren a un elemento, tal como una proteína, polipéptido o ácido nucleico, que está presente en el mismo estado que en el que se encuentra en la naturaleza. Es decir, el elemento no se ha modificado artificialmente. Se entenderá, que en el contexto de la presente divulgación, existen numerosas variantes nativas/de origen natural de proteínas o polipéptidos del VSR, por ejemplo, obtenidas a partir de diferentes cepas o aislados del VSR de origen natural.
El término "polipéptido" se refiere a un polímero en el que los monómeros son restos de aminoácidos que están unidos en conjunto a través de enlaces amida. Los términos "polipéptido" o "proteína" cómo se usan en el presente documento pretenden incluir cualquier secuencia de aminoácidos e incluyen secuencias modificadas tales como glicoproteínas. El término "polipéptido" pretende cubrir de forma específica proteínas de origen natural, así como las que se producen de forma recombinante o sintética. El término "fragmento", en referencia a un polipéptido, se refiere a una parte (es decir, una subsecuencia) de un polipéptido. La expresión "fragmento inmunogénico" se refiere a todos los fragmentos de un polipéptido que retienen al menos un epítopo inmunogénico predominante de la proteína polipéptido de referencia de longitud completa. La orientación dentro de un polipéptido se menciona por lo general
de una dirección N-terminal a C-terminal, definida por la orientación de los restos amino y carboxi de los aminoácidos individuales. Los polipéptido se traducen desde el extremo N o amino hacia el extremo C o carboxi. Un "péptido señal" es una secuencia corta de aminoácidos (por ejemplo, una longitud de aproximadamente 18-25 aminoácidos) que dirige proteínas secretoras o de membrana recién sintetizadas a y a través de membranas, por ejemplo, del retículo endo plasmático. Los péptidos señal se sitúan frecuentemente, pero no universalmente en el extremo N-terminal de un polipéptido, y frecuentemente se extinguen con peptidasas señal después de que la proteína haya atravesado la membrana. Las secuencias señal por lo general contienen tres características estructurales comunes: una región básica polar N-terminal (región n), un núcleo hidrófobo, y una región c hidrófila). Los términos "polinucleótido" y "secuencia de ácidos nucleicos" se refieren a una forma polimérica de nucleótidos con una longitud de al menos 10 bases. Los nucleótidos pueden ser ribonucleótidos, desoxirribonucleótidos, o formas modificadas de cualquier nucleótido. El término incluye formas individuales y dobles de ADN. Por "polinucleótido aislado" se hace referencia a un polinucleótido que no es inmediatamente contiguo con ambas secuencias de codificación con las que es inmediatamente contiguo (una en el extremo en la posición 5' y otra en el extremo en la posición 3') en el genoma de origen natural del organismo del que se deriva. En una realización, un polinucleótido codifica un polipéptido. La dirección en las posiciones 5' y 3' de un ácido nucleico se define por referencia a la conectividad de unidades de nucleótidos individuales, y se nombra de acuerdo con las posiciones del carbono del anillo de azúcar desoxirribosa (o ribosa). El contenido de información (codificación) de una secuencia de polinucleótidos se lee en una dirección desde la posición 5' a la posición 3'.
Un ácido nucleico "recombinante" es uno que tiene una secuencia que no tiene origen natural o tiene una secuencia que se fabrica mediante una combinación artificial de dos segmentos de secuencia separados de otro modo. Esta combinación artificial se puede realizar mediante síntesis química o, más comúnmente, mediante la manipulación artificial de segmentos aislados de ácidos nucleicos, por ejemplo, mediante técnicas de ingeniería genética. Una proteína "recombinante" es una que esta codificada por un ácido nucleico heterólogo (por ejemplo, recombinante), que se ha introducido en una célula hospedadora, tal como una célula bacteriana o eucariota. El ácido nucleico se puede introducir en un vector de expresión que tiene señales capaces de expresar la proteína codificada por el ácido nucleico introducido o el ácido nucleico se puede integrar en el cromosoma de la célula hospedadora.
El término "heterólogo" con respecto a un ácido nucleico, un polipéptido u otro componente celular, indica que el componente se produce cuando no se encuentra normalmente en la naturaleza y/o que se origina a partir de una fuente o especie diferentes.
El término "purificación" (por ejemplo, con respecto a un patógeno o una composición que contiene un patógeno) se refiere al procedimiento para retirar componentes de una composición, cuya presencia no se desea. Purificación es un término relativo, y no requiere que todas las trazas del componente no deseados se retiren de la composición. En el contexto de producción de vacunas, purificación incluye procedimientos tales como centrifugación, diálisis, cromatografía de intercambio iónico, y cromatografía de exclusión por tamaño, purificación por afinidad o precipitación. Por tanto, el término "purificado" no requiere una pobreza absoluta; en su lugar, se pretende como un término relativo. Por lo tanto, por ejemplo, una preparación de ácido nucleico purificado es una en la que la proteína especificada está más enriquecida de lo que el ácido nucleico lo está en su entorno generativo, por ejemplo, dentro de una célula o en una cámara de reacción bioquímica. Una preparación de ácido nucleico o proteína sustancialmente puros se debe purificar de modo que el ácido nucleico deseado represente al menos un 50 % del contenido total de ácido nucleico en la preparación. En determinadas realizaciones, un ácido nucleico sustancialmente puro representará al menos un 60 %, al menos un 70 %, al menos un 80 %, al menos un 85 %, al menos un 90 %, o al menos un 95 % o más del contenido total de ácido nucleico o proteína de la preparación.
Un componente biológico "aislado" (tal como una molécula de ácido nucleico, proteína u orgánulo) se ha separado o purificado sustancialmente de otros componentes biológicos en la célula del organismo en el que el componente se produce de forma natural, tal como, otro ADN y ARN cromosómico y extracromosómico, proteínas y orgánulos. Algunos ácidos nucleicos y proteínas que se han "aislado" incluyen ácidos nucleicos y proteínas purificados mediante procedimientos convencionales de purificación. El término también incluye ácidos nucleicos y proteínas preparados mediante expresión recombinante en una célula hospedadora así como ácidos nucleicos y proteínas sintetizados químicamente.
Un "antígeno" es un compuesto, composición o sustancia que puede estimular la producción de anticuerpos y/o una respuesta de linfocitos T en un animal, incluyendo composiciones que se inyectan, absorben o de otro modo se introducen en un animal. El término "antígeno" incluye todos los epítopos antigénicos relacionados. El término "epítopo" o "determinante antigénico" se refiere a un sitio en un antígeno a qué responden los linfocitos B y/o T. Los "epítopos antigénicos dominantes" o "epítopo dominante" son los epítopos a los que se fabrica una respuesta inmune al hospedador funcionalmente significativa, por ejemplo, una respuesta a anticuerpo o una respuesta a linfocitos T. Por lo tanto, con respecto a una respuesta inmune protectora frente a un patógeno, los epítopos antigénicos dominantes son esos restos antigénicos que cuando son reconocidos por el sistema inmune del hospedador dan como resultado protección de enfermedad causada por el patógeno. La expresión "epítopo de linfocitos T" se refiere a un epítopo que cuando se une a una molécula de MHC apropiada se une de forma específica mediante un linfocito T (mediante un receptor de linfocitos T). Un "epítopo de linfocitos B" es un epítopo
que se une de forma específica mediante un anticuerpo (o molécula receptora de linfocitos B).
Un "adyuvante" es un agente que aumenta la producción de una respuesta inmune de una manera no específica. Algunos adyuvantes comunes incluyen suspensiones de minerales (alumbre, hidróxido de aluminio, fosfato de aluminio) en el que se adsorbe el antígeno; emulsiones, incluyendo emulsiones de agua en aceite, y de aceite en agua (y variantes de las mismas, incluyendo emulsiones dobles y emulsiones reversibles), liposacáridos, lipopolisacáridos, ácidos nucleicos inmunoestimuladores (tales como oligonucleótidos CpG), liposomas, agonistas del receptor de tipo Toll (en particular, agonistas TLR2, TLR4, TLR7/8 y TLR9), y diversas combinaciones de tales componentes.
Una "composición inmunogénica" es una composición de materia adecuada para administración a un sujeto humano o animal (por ejemplo, en un entorno experimental) que es capaz de provocar una respuesta inmune específica, por ejemplo, frente a un patógeno, tal como VSR. Como tal, una composición inmunogénica incluye uno o más antígenos (por ejemplo, antígenos de polipéptido) o epítopos antigénicos. Una composición inmunogénica también puede incluir uno o más componentes adicionales capaces de provocar o aumentar una respuesta inmune, tal como un excipiente, vehículo y/o adyuvante. En ciertos casos, las composiciones inmunogénicas se administran para provocar una respuesta inmune que protege al sujeto frente a síntomas o afecciones inducidas por un patógeno. En algunos casos, los síntomas o enfermedad causados por un patógeno se previenen (o reducen o mejoran) inhibiendo la replicación del patógeno (por ejemplo, VSR) después de exposición del sujeto al patógeno. En el contexto de la presente divulgación, se entenderá que la expresión composición inmunogénica incluye composiciones que están destinadas a administración a un sujeto o población de sujetos con el fin de provocar una respuesta inmune protectora o paliativa frente al VSR (es decir, composiciones de vacuna o vacunas).
Una "respuesta inmune" es una respuesta de una célula del sistema inmune, tal como un linfocito B, linfocito T, o monocito, a un estímulo. Una respuesta inmune puede ser una respuesta de linfocitos B, que da como resultado la producción de anticuerpos específicos, tales como anticuerpos de neutralización específicos de antígeno. Una respuesta inmune también puede ser una respuesta de linfocitos T, tal como una respuesta de CD4+ o una respuesta de CD8+. En algunos casos, la respuesta es específica para un antígeno en particular (es decir, una "respuesta específica de antígeno"). Si el antígeno se deriva de un patógeno, la respuesta específica del antígeno es una " respuesta específica de patógeno". Una "respuesta inmune protectora" es una respuesta inmune que inhibe una función o actividad perjudicial de un patógeno, reduce la infección por un patógeno, o disminuye síntomas (incluyendo muerte) que resultan de la infección por el patógeno. Una respuesta inmune protectora se puede medir, por ejemplo, mediante la inhibición de la replicación viral o formación de placas en un ensayo de reducción de placas o ensayo de neutralización de ELISA, o midiendo la resistencia a estimulación de patógenos in vivo.
Una respuesta inmune desviada hacia "Th1" se caracteriza por la presencia de células auxiliares CD4+ T que producen IL-2 e IFN-y, y por lo tanto, mediante la secreción o presencia de IL-2 e IFN-y. Por el contrario, una respuesta inmune desviada hacia "Th2" se caracteriza por una preponderancia de células auxiliares CD4+ que producen IL-4, IL-5, e IL-13.
Una "cantidad inmunológicamente eficaz" es una cantidad de una composición (por lo general, una composición inmunogénica) usada para provocar una respuesta inmune en un sujeto a la composición o a un antígeno en la composición. Normalmente, el resultado deseado es la producción de una respuesta inmune específica de antígeno (por ejemplo, patógeno) si es capaz de o que contribuye a la protección del sujeto frente al patógeno. Sin embargo, para obtener una respuesta inmune protectora frente a un patógeno, se pueden necesitar múltiples administraciones de la composición inmunogénica. Por lo tanto, en el contexto de la presente divulgación, la expresión cantidad inmunológicamente eficaz incluye una dosis fraccionaria que contribuye, en combinación con administraciones previas o posteriores, a la obtención de una respuesta inmune protectora.
El adjetivo "farmacéuticamente aceptable" indica que el referente es adecuado para administración a un sujeto (por ejemplo, un sujeto humano o animal). Remington's Pharmaceutical Sciences, de E. W. Martin, Mack Publishing Co., Easton, PA, 15a Edición (1975), describe composiciones y formulaciones (incluyendo diluyentes) adecuadas para administración farmacéutica de composiciones terapéuticas y/o profilácticas, incluyendo composiciones inmunogénicas.
El término "modular" en referencia a una respuesta, tal como una respuesta inmune, significa alterado variar el inicio, magnitud, duración o características de la respuesta. Un agente que modula una respuesta inmune altera al menos uno del inicio, magnitud, duración o características de una respuesta inmune después de su administración, o que altera al menos uno del inicio, magnitud, duración característica en comparación con un agente de referencia.
El término "reduce" es un término relativo, de modo que un agente reduce una respuesta o afección si la respuesta o afección disminuye de forma cuantitativa después de la administración del agente, o si disminuye después de la administración del agente, en comparación con un agente de referencia. De forma análoga, el término "previene" no significa necesariamente que un agente elimine completamente la respuesta o afección, siempre y cuando se elimine al menos una característica de la respuesta o afección. Por lo tanto, una composición inmunogénica que renuncio previene una infección o una respuesta, tal como una respuesta patológica, por ejemplo, enfermedad viral potenciada por vacuna, puede, eliminar, pero no necesariamente de forma total, una infección o respuesta, siempre
y cuando la infección o respuesta sería disminuida de forma mensurable, por ejemplo, en al menos aproximadamente un 50 %, tal como en al menos aproximadamente un 70 %, o aproximadamente un 80 %, o incluso en aproximadamente un 90 % de (es decir, en un 10 % o inferior a) la infección o respuesta en ausencia del agente, o en comparación con un agente de referencia.
Un "sujeto" es un organismo vertebrado multicelular vivo. En el contexto de la presente divulgación, el sujeto puede ser un sujeto experimental, tal como un animal no humano, por ejemplo, un ratón, una rata del algodón, o un primate no humano. Como alternativa, el sujeto puede ser un sujeto humano.
ANTÍGENOS DE PreF
En la naturaleza, la proteína F del VSR se expresa como un solo precursor de polipéptido con una longitud de 574 aminoácidos, denominado F0. In vivo, F0 se oligomeriza en el retículo en lo plasmático y se procesa de forma proteolítica por una furina proteasa en dos secuencias consenso de furina conservadas (sitios de escisión de furina), RARR109 (SEQ ID NO: 15) y RKRR136 (SEQ ID NO: 16) para generar un oligómero que consiste en dos fragmentos unidos por disulfuro. El más pequeño de estos fragmentos se denomina F2 y se origina desde la parte N-terminal del precursor de F0. Los expertos en la materia reconocerán que las abreviaturas F0, F1 y F2 se denominan normalmente F0, F1 y F2 en la bibliografía científica. El fragmento F1 C-terminal más grande ancla la proteína F en la membrana a través de una secuencia de aminoácidos hidrófobos, que son adyacentes a una cola hito plasmática de 24 aminoácidos. Tres dímeros F2-F1 se asocian para formar una proteína F madura, que adopta una conformación prefusogénica ("prefusión") metaestable que se pone en funcionamiento para experimentar un cambio conformacional después de contacto con una membrana de célula diana. Este cambio conformacional expone a una secuencia hidrófoba, conocida como el péptido de fusión, que se asocia con la membrana de la célula hospedadora y estimula la fusión de la membrana del virus, o una célula infectada, con la membrana de la célula diana.
El fragmento F1 contiene al menos un dos dominios de repetición heptad, denominados HRA y HRB, y situados en proximidad a los dominios de ancla de péptido de fusión y transmembrana, respectivamente. En la conformación de prefusión, el dímero F2-F1 forma una estructura de cabeza y tallo globular, en la que los dominios HRA están en una conformación segmentada (extendida) en la cabeza globular. Por el contrario, los dominios HRB forman un tallo de bucles superenrollados de tres hebras que se extienden desde la región de la cabeza. Durante la transición de la prefusión a las conformaciones postfusión, los dominios HRA se colapsan y se ponen en proximidad con los HRB para formar un haz de seis hélices anti-paralelas. En el estado de postfusión, el péptido de fusión y dominios transmembrana se yuxtaponen para facilitar la fusión de la membrana.
Aunque la descripción conformacional proporcionada anteriormente se basa en el modelado molecular de datos cristalográficos, las distinciones estructurales entre las conformaciones de prefusión y postfusión se pueden controlar sin recurrir a la cristalografía. Por ejemplo, la micrografía electrónica se puede usar para distinguir entre las conformaciones de prefusión y postfusión (como alternativa denominadas prefusogénica y fusogénica), como se demuestra en Calder y col., Virology, 271: 122-131 (2000) y Morton y col., Virology, 311: 275-288. La conformación de prefusión también se puede distinguir de la conformación fusogénica (postfusión) mediante ensayos de asociación de liposomas como se describe en Connolly y col., Proc. Natl. Acad. Sci. USA, 103: 17903-17908 (2006). Además, las conformaciones de prefusión y fusogénica se pueden distinguir usando anticuerpos (por ejemplo, anticuerpos monoclonales) que reconocen de forma específica epítopos de conformación presentes en una o la otra de la forma de prefusión o fusogénica de la proteína F del VSR, pero no en la otra forma. Tales epítopos de conformación se pueden deber a la exposición preferente de un determinante antigénico en la superficie de la molécula. Como alternativa, los epítopos conformacionales pueden surgir de la yuxtaposición de aminoácidos que no son contiguos en el polipéptido lineal.
Los antígenos de PreF desvelados en el presente documento están diseñados para estabilizar y mantener la conformación de prefusión de la proteína F del VSR, tal como en una población de proteínas expresadas, una parte sustancial de la población de proteínas expresadas está en la conformación prefusogénica (prefusión) (por ejemplo, como se predice con el modelado estructural y/o termodinámico o como se evalúa con uno o más de los procedimientos desvelados anteriormente). Las modificaciones de estabilización se introducen en una proteína F nativa (o sintética), tal como la proteína F a modo de ejemplo de la SEQ ID NO: 2, de manera que los epítopos inmunogénicos principales de la conformación de prefusión de la proteína F se mantienen después de la introducción del antígeno PreF en un entorno celular o extracelular (por ejemplo, in vivo, por ejemplo, después de la administración a un sujeto).
En primer lugar, un dominio de estabilización heterólogo se puede colocar en el extremo C-terminal de la construcción para sustituir la membrana ese ancla al dominio del polipéptido F0. Este dominio de estabilización se predice para compensar la inestabilidad de HRB, para ayudar a estabilizar al confórmero de prefusión. En realizaciones a modo de ejemplo, el dominio de estabilización heterólogo es un dominio de multimerización de proteínas. Un ejemplo particularmente favorable de un dominio de multimerización de proteínas de este tipo es un dominio de trimerización. Algunos dominios de trimerización a modo de ejemplo se pliegan en bucles superenrollados que estimulan el ensamblaje en trímeros de múltiples polipéptidos que tienen tales dominios de bucles superenrollados. Un ejemplo favorable de un dominio de trimerización es una cremallera de isoleucina. Un dominio de cremallera de isoleucina a modo de ejemplo es la variante de isoleucina GCN4 de levadura modificada
por ingeniería descrita en Harbury y col., Science 262: 1401-1407 (1993). La secuencia de un dominio de cremallera de isoleucina adecuado se representa por la SEQ ID NO: 11, aunque algunas variantes de esta secuencia que retienen la capacidad para formar dominio de estabilización de bucles superenrollados son igualmente adecuadas. Algunos dominios de trimerización de bucles superenrollados de estabilización alternativos incluyen: TRAF2 (N.° de Referencia en GENBANK® Q12933 [gi:23503103]; aminoácidos 299-348); Thrombospondina 1 (N.° de Referencia PO7996 [gi:135717]; aminoácidos 291-314); Matrilina-4 (N.° de Referencia O95460 [gi:14548117]; aminoácidos 594 618; CMP (matrilina-1) (N.° de Referencia Np_002370 [gi:4505111]; aminoácidos 463-496; HSF1 (N.° de Referencia AAX42211 [gi:61362386]; aminoácidos 165-191; y Cubilina (N.° de Referencia NP_001072 [gi:4557503]; aminoácidos 104-138. Se espera que un dominio de trimerización adecuado dé como resultado el ensamblaje de una parte sustancial de la proteína expresada en trímeros. Por ejemplo, al menos un 50 % del polipéptido de PreF recombinante que tiene un dominio de trimerización se ensamblará en un trímero (por ejemplo, cómo se evalúa con AFF-MALS). Por lo general, al menos un 60 %, más favorablemente al menos un 70 %, y de forma más deseada al menos un aproximadamente un 75 % o más del polipéptido expresado existe como un trímero.
Para estabilizar HRB incluso más, el resto de leucina situado en la posición 512 (con respecto a la proteína F0 nativa) del PreF se puede sustituir con una lisina (L482K del polipéptido del antígeno de PreF a modo de ejemplo de la SEQ ID NO: 6). Esta sustitución mejora la periodicidad del resto hidrófobo de bucle superenrollado. De forma análoga, una lisina se puede añadir después del aminoácido en la posición 105.
En segundo lugar, pep27 se puede retirar. El análisis de un modelo estructural de la proteína F del VSR en el estado de prefusión sugiere que pep27 crea un bucle grande sin restricciones entre F1 y F2. Este bucle no contribuye a la estabilización del estado de prefusión, y se retira después de escisión de la proteína nativa por la furina.
En tercer lugar, una o ambos de los motivos de escisión de furina se pueden suprimir. Con este diseño, el péptido de fusión no se escinde de F2, evitando la liberación de la cabeza globular del confórmero de prefusión y la accesibilidad a membranas cercanas. Se predice que la interacción entre el péptido de fusión y la superficie de contacto de la membrana es una cuestión importante en la inestabilidad del estado de prefusión. Durante el proceso de fusión, la interacción entre el tejido de fusión y la membrana diana da como resultado la exposición del tejido de fusión desde dentro de la estructura de cabeza globular, aumentando la inestabilidad del estado de prefusión y plegándose en confórmero después de la fusión. Este cambio de conformación permite el proceso de fusión de membrana. Se predice que la retirada de uno o ambos de los sitios de escisión de furina evita la accesibilidad de la membrana a la parte N-terminal del péptido de fusión, estabilizando el estado de prefusión.
Opcionalmente, al menos un sitio de escisión que no es furina también se puede retirar, por ejemplo mediante sustitución de uno o más aminoácidos. Por ejemplo, las evidencias experimentales sugieren que en condiciones que conducen a escisión con ciertas metaloproteinasas, el antígeno de PreF se puede escindir en las proximidades de los aminoácidos 110-118 (por ejemplo, con la escisión produciéndose entre los aminoácidos 112 y 113 del antígeno de PreF; entre una leucina en la posición 142 y glicina en la posición 143 del polipéptido de la proteína F de referencia de la SEQ ID NO: 2). Por consiguiente, la modificación de uno o más aminoácidos dentro de esta región puede reducir la escisión del antígeno de PreF. Por ejemplo, la leucina en la posición 112 se puede sustituir con un aminoácido diferente, tal como isoleucina, glutamina o triptófano. Como alternativa o adicionalmente, la glicina en la posición 113 se puede sustituir con una serina o alanina.
El polipéptido de la proteína F nativa se puede seleccionar entre cualquier proteína de F de una cepa A del VSR o B del VSR, o de variantes de las mismas (como se ha definido anteriormente). En ciertas realizaciones a modo de ejemplo, el polipéptido de la proteína F es la proteína F representada por la SEQ ID NO: 2. Para facilitar la comprensión de la presente divulgación, todas las posiciones de los restos de aminoácidos, independientemente de la cepa, se proporcionan con respecto a (es decir, la posición del resto de aminoácido corresponden con) la posición del aminoácido de la proteína F a modo de ejemplo. Algunas posiciones del aminoácido comparables con cualquier otra cepa A o B del VSR las pueden determinar fácilmente los expertos habituales en la materia alineando las secuencias de aminoácidos de la cepa del VSR con la secuencia a modo de ejemplo usando algoritmos de alineamiento rápidamente disponibles y bien conocidos (tales como BLAST, por ejemplo, usando parámetros por defecto). Numerosos ejemplos adicionales de polipéptidos de la proteína F de diferentes cepas del v Sr se desvelan en el documento WO2008114149. Algunas variantes adicionales pueden surgir a través de deriva genética, o se pueden producir de forma artificial usando mutagénesis dirigida al sitio o aleatoria o mediante recombinación de dos o más variantes existentes previamente. Tales variantes adicionales también son adecuadas en el contexto de los antígenos de PreF desvelados en el presente documento.
En la selección de los dominios F2 y F1 de la proteína F, un experto en la materia reconocerá que no es estrictamente necesario incluir todo el dominio F2 y/o F1. Por lo general, las consideraciones conformacionales tienen importancia cuando se selecciona una subsecuencia (o fragmento) del dominio F2. Por lo tanto, el dominio F2 por lo general incluye una parte del dominio F2 que facilita el ensamblaje y la estabilidad del polipéptido. En ciertas variantes a modo de ejemplo, el dominio F2 incluye los aminoácidos 26-105. Sin embargo, también son posibles algunas variantes que tienen modificaciones menores de longitud (mediante adición, o deleción de uno o más aminoácidos).
Por lo general, al menos una subsecuencia (o fragmento) del dominio F1 se selecciona y diseña para mantener una
conformación estable que incluye epítopos inmunodominantes de la proteína F. Por ejemplo, por lo general es deseable seleccionar una subsecuencia del dominio del polipéptido F1 que incluya epítopos reconocidos por anticuerpos de neutralización en las regiones de los aminoácidos 262-275 (neutralización con palivizumab) y 423 436 (MAb ch101F de Centocor). Además, es deseable incluir epítopos de linfocitos T, por ejemplo, en la región de los aminoácidos 328-355. Lo más habitualmente, como una sola parte contigua de la subunidad F1 (por ejemplo, aminoácidos transmembrana 262-436) pero los epítopos se podrían retener en una secuencia sintética que incluyera estos epítopos inmunodominantes como elementos discontinuos ensamblados en una conformación estable. Por lo tanto, un polipéptido del dominio F1 comprende al menos aproximadamente los aminoácidos 262-436 de un polipéptido de la proteína F del VSR. En un ejemplo limitante proporcionado en el presente documento, el dominio F1 comprende los aminoácidos 137 a 516 de un polipéptido de la proteína F nativa. Un experto en la materia reconocerá que se pueden usar subsecuencias más cortas adicionales de acuerdo con el criterio del experto.
Cuando se selecciona una subsecuencia del dominio F2 o del dominio F1 (o como se discutirá a continuación con respecto al componente de la proteína G de ciertos antígenos de PreF-G), además de consideraciones conformacionales, puede ser deseable elegir secuencias (por ejemplo, variantes, subsecuencias, y similares) basándose en la inclusión de epítopos inmunogénicos adicionales. Por ejemplo, los epítopos de linfocitos T adicionales se pueden identificar usando motivos de ancla u otros procedimientos, tales como determinaciones de red neuronal o polinomiales, conocidos en la técnica, véase, por ejemplo RANKPEP (disponible en la world wide web en: mif.dfci.harvard.edu/Tools/rankpep.html); ProPredI (disponible en la world wide web en: imtech.res.in/raghava/propredI/index.html); Bimas (disponible en la world wide web en: wwwbimas.dcrt.nih.gov/molbi/hla bind/index.html); y SYFPEITH (disponible en la world wide web en: syfpeithi.bmiheidelberg.com/scripts/MHCServer.dll/home.htm). Por ejemplo, para determinar el "umbral de unión" de péptidos se usan algoritmos, y para seleccionar aquellos con puntuaciones que les dan una probabilidad elevada de unión a MHC o anticuerpo a una cierta afinidad. Los algoritmos se basan ya sea en los efectos en la unión a MHC de un aminoácido en particular en una posición en particular, los efectos en la unión anticuerpo de un aminoácido en particular en una posición en particular, o los efectos en la unión de una sustitución en particular en un péptido que contiene motivo. Dentro del contexto de un péptido inmunogénico, un "resto conservado" es uno que aparece con una frecuencia significativamente más elevada de lo que se podría esperar mediante distribución aleatoria en una posición en particular en un péptido. Los restos de ancla son restos conservados que proporcionan un punto de contacto con la molécula de MHC. Los epítopos de linfocitos T identificados con tales procedimientos predictivos can se pueden confirmar por medición de su unión a una proteína de MHC específica y por su capacidad para estimular los linfocitos T cuando se presentan en el contexto de la proteína de MHC.
De forma favorable, los antígenos de PreF (incluyendo antígenos de PreF-G como se discute a continuación) incluyen un péptido señal que corresponde al sistema de expresión, por ejemplo, un péptido señal de mamífero o viral, tal como una secuencia señal nativa de F0 del VSR (por ejemplo, los aminoácidos 1-25 de la SEQ ID NO: 2 o los aminoácidos 1-25 de la SEQ ID NO: 6). Por lo general, el péptido señal se selecciona para que sea compatible con las células seleccionadas para expresión recombinantes. Por ejemplo, un péptido señal (tal como un péptido señal de baculovirus, o el péptido señal de melitina, se puede sustituir para expresión, en células de insecto. En la técnica se conocen algunos péptidos señal vegetales, si se prefiere un sistema de expresión vegetal. En la técnica se conocen numerosos péptido señal a modo de ejemplo (véase, por ejemplo, Zhang y Henzel, Protein Sci., 13: 2819-2824 (2004), que describe numerosos péptidos señal humanos) y están catalogados, por ejemplo, en la base de datos de péptidos señal SPdb, que incluye secuencias señal de arqueas, procariotas y eucariotas (http://proline.bic.nus.edu.sg/spdb/). Opcionalmente, cualquiera de los antígenos precedentes puede incluir una secuencia o etiqueta adicional, tal como una etiqueta de His para facilitar la purificación.
Opcionalmente, el antígeno de PreF puede incluir componentes inmunogénicos adicionales. En ciertas realizaciones particularmente favorables, el antígeno de PreF incluye un componente antigénico de la proteína G del VSR. Las proteínas quiméricas a modo de ejemplo que tienen un componente de PreF y G incluyen las siguientes PreF_V1 (representadas por las SEQ ID NOs: 7 y 8) y PreF_V2 (representadas por las s Eq ID NOs: 9 y 10).
En los antígenos de PreF-G, una parte antigénica de la proteína G (por ejemplo, una proteína G truncada, tal como los restos de aminoácidos 149-229) se añade en el extremo C-terminal de la construcción. Por lo general, el componente de la proteína G se une al componente de la proteína F a través de una secuencia de engarce flexible. Por ejemplo, en el diseño de PreF_VI a modo de ejemplo, la proteína G se une al componente de PreF mediante un conector -GGSGGSGGS- (SEQ ID NO: 14). En el diseño de PreF_V2, el engarce es más corto. En lugar de tener el engarce -GGSGGSGGS- (SEQ ID NO: 14), PreF_V2 tiene 2 glicinas (-GG-) por engarce.
Cuando está presente, el dominio del polipéptido de la proteína G puede incluir toda o parte de una proteína G seleccionada entre cualquier cepa A del VSR o B del VSR. En ciertas realizaciones a modo de ejemplo, la proteína G es (o es idéntica en un 95 % a) la proteína G representada por la SEQ ID NO: 4. Algunos ejemplos adicionales de secuencias de la proteína G adecuadas se pueden encontrar en el documento WO2008114149.
El componente del polipéptido de la proteína G se selecciona para que incluya al menos una subsecuencia (o fragmento) de la proteína G que mantiene el epítopo(s) inmunodominante de linfocitos T, por ejemplo, en la región de los aminoácidos 183-197, tal como fragmentos de la proteína G que incluyen los aminoácidos 151-229, 149-229, o 128-229 de una proteína G nativa. En una realización a modo de ejemplo, el polipéptido de la proteína G es una
subsecuencia (o fragmento) de un polipéptido de la proteína G nativa que incluye todos o parte de los restos de aminoácidos 149 a 229 de un polipéptido de la proteína G nativa. Alguien con experiencia en la materia observará rápidamente que también se pueden usar partes más largas o más cortas de la proteína G, siempre y cuando la parte seleccionada no desestabilice o interrumpa de forma conformacional la expresión, plegamiento o procesamiento del antígeno de PreF-G. Opcionalmente, el dominio de la proteína G incluye una substitución de aminoácidos en la posición 191, que previamente se ha mostrado que está implicado en la reducción y/o prevención del aumento de enfermedades caracterizadas por eosinófilos asociados con vacunas del VSR inactivadas con formalina. Una descripción minuciosa de las características de las proteínas G de origen natural y sustituidas (N191A) se puede encontrar, por ejemplo, en la Publicación de Patente de Estados Unidos n.° 2005/0042230.
Por ejemplo, con respecto a la selección de secuencias correspondientes a cepas de origen natural, uno o más de los dominios puede corresponder, en secuencia, con una cepa A o B del VSR, tal como los aislados de laboratorio comunes denominados A2 o Largo, o cualquier otra cepa o aislado de origen natural (como se ha desvelado en el documento WO2008114149 mencionado anteriormente). Además de tales variantes de origen natural y aisladas, algunas variantes modificadas por ingeniería que comparten similitud de secuencias con las secuencias mencionadas anteriormente también se pueden usar en el contexto de antígenos de PreF (incluyendo PreF-G). Los expertos en la materia entenderán que la similitud entre el polipéptido del antígeno PreF (y secuencias de polinucleótidos como se describe a continuación), como para el polipéptido (y secuencias de nucleótidos en general), se puede expresar en términos de la similitud entre las secuencias, denominada de otro modo identidad de secuencias. La identidad de secuencia se mide frecuentemente en términos de porcentaje de identidad (o similitud); cuanto más elevado es el porcentaje, más similares son las estructuras primarias de las dos secuencias. En general, cuanto más similares son las estructuras primarias de dos secuencias de aminoácidos (o polinucleótidos), más similares son las estructuras de orden superior resultantes del plegamiento y ensamblaje. Algunas variantes de secuencias de polipéptido de PreF (y polinucleótidos) tienen por lo general una o un número más pequeño de deleciones, adiciones o sustituciones de aminoácidos pero sin embargo comparten un porcentaje muy elevado de sus secuencias de aminoácidos, y por lo general sus secuencias de polinucleótidos. De forma más importante, las variantes retienen los atributos estructurales, y por lo tanto, conformacionales de las secuencias de referencia desveladas en el presente documento.
Algunos procedimientos para determinar la identidad de secuencias se conocen bien en la técnica, y son aplicables a polipéptidos del antígeno de PreF, así como los ácidos nucleicos que los codifican (por ejemplo, como se describe a continuación). Diversos programas y algoritmos de alineamiento se describen en: Smith y Waterman, Adv. Appl. Math. 2: 482, 1981; Needleman y Wunsch, J. Mol. Biol. 48: 443, 1970; Higgins y Sharp, Gene 73: 237, 1988; Higgins y Sharp, CABIOS 5: 151, 1989; Corpet y col., Nucleic Acids Research 16: 10881, 1988; y Pearson y Lipman, Proc. Natl. Acad. Sci. USA 85: 2444, 1988. Altschul y col., Nature Genet. 6: 119, 1994, presenta una consideración detallada de procedimientos de alineamiento de secuencias y cálculos de homología. La Herramienta de Búsqueda de Alineamiento Local Básico del NCBI (BLAST) (Altschul y col., J. Mol. Biol. 215: 403, 1990) está disponible a partir de varias fuentes, incluyendo el National Center for Biotechnology Information (NCBI, Betesda, MD) y en internet, para uso en conexión con los programas de análisis de secuencias, blastp, blastn, blastx, tblastn y tblastx. Una descripción de cómo determinar la identidad de las secuencias usando este programa está disponible en la página web del NCBI en internet.
En algunos casos, los antígenos de PreF tienen una o más modificaciones de aminoácidos con respecto a la secuencia de aminoácidos de la cepa de origen natural a partir de la que se obtienen (por ejemplo, además de las modificaciones de estabilización mencionadas anteriormente). Tales diferencias pueden ser una adición, deleción o sustitución de uno o más aminoácidos. Una variante por lo general se diferencia en no más de aproximadamente un 1 %, o un 2%, o un 5%, o un 10%, o un 15%, o un 20% de los restos de aminoácidos. Por ejemplo, una secuencia de polipéptidos del antígeno de PreF variante (incluyendo PreF-G) puede incluir 1, o 2, o hasta 5, o hasta aproximadamente 10, o hasta aproximadamente 15, o hasta aproximadamente 50, o hasta aproximadamente 100 diferencias de aminoácidos en comparación con las secuencias de polipéptidos del antígeno de PreF a modo de ejemplo de las SEQ ID NOs: 6, 8, y/o 10. Por lo tanto, una variante en el contexto de una proteína F o G del VSR, o antígeno de PreF (incluyendo antígeno de PreF-G), por lo general comparte una identidad de secuencias de al menos un 80 %, o un 85 %, más comúnmente, al menos aproximadamente un 90 % o superior, tal como un 95 %, o incluso un 98 % o un 99 % con una proteína de referencia, por ejemplo, las secuencias de referencias ilustradas en las SEQ ID NO: 2, 4, 6, 8 y/o 10, o cualquiera de los antígenos de PreF a modo de ejemplo desvelados en el presente documento. Algunas variantes adicionales incluidas como una característica de la presente divulgación son antígenos de PreF (incluyendo antígenos de PreF-G) que incluyen todo o parte de una secuencia de nucleótidos o aminoácidos seleccionada entre las variantes de origen natural desveladas en el documento WO2008114149. Algunas variantes adicionales pueden surgir a través de deriva genética, o se pueden producir de forma artificial usando mutagénesis dirigida al sitio o aleatoria, o mediante recombinación de dos o más variantes existentes previamente. Tales variantes adicionales también son adecuadas en el contexto de los antígenos de PreF (y de PreF-G) desvelados en el presente documento. Por ejemplo, la modificación puede ser una sustitución de uno o más aminoácidos (tal como los aminoácidos, tres aminoácidos, cuatro aminoácidos, cinco aminoácidos, hasta aproximadamente diez aminoácidos, o más) que no altera los epítopos de conformación o inmunogénicos del antígeno de PreF resultante.
Como alternativa o adicionalmente, la modificación puede incluir una deleción de uno o más aminoácidos y/o una
adición de uno o más aminoácidos. De hecho, si se desea, uno o más dominios de polipéptido pueden ser un polipéptido sintético que no se corresponde con ninguna cepa individual, pero incluye subsecuencias componentes de múltiples cepas, o incluso de una secuencia consenso deducida por alineamiento de múltiples cepas de polipéptidos del virus VSR. En determinadas realizaciones, uno o más de los dominios del polipéptido se modifica mediante la adición de una secuencia de aminoácidos que constituye una etiqueta, que facilita procesamiento o purificación posteriores. Una etiqueta de este tipo puede ser una etiqueta antigénica o de epítopo, una etiqueta enzimática o una etiqueta de polihistidina. Por lo general, la etiqueta está situada en uno o en el otro extremo de la proteína, tal como en el extremo C-terminal o N-terminal del antígeno o proteína de fusión.
ÁCIDOS NUCLEICOS QUE CODIFICAN ANTÍGENOS DE PREF
Otro aspecto de la presente divulgación se refiere a ácidos nucleicos recombinantes que codifican antígenos de PreF como se ha descrito anteriormente. En ciertas realizaciones, los ácidos nucleicos recombinantes están optimizados por codón para su expresión en una célula hospedadora procariota o eucariota seleccionada. Por ejemplo, las SEQ ID NOs: 5 y 12 son dos ejemplos de secuencias no limitantes, ilustrativos diferentes que codifican un antígeno de PreF, que se han optimizado con codón para expresión en células de mamífero, por ejemplo células CHO. Para facilitar la replicación y la expresión, los ácidos nucleicos se pueden incorporar en un vector, tal como un vector de expresión procariota o eucariota. Algunas células hospedadoras que incluyen ácidos nucleicos que codifican antígeno de PreF recombinante también son una característica de presente divulgación. Algunas células hospedadoras favorables incluyen células hospedadoras procariotas (es decir, bacterianas), tales como E. coli, así como numerosas células hospedadoras eucariotas, incluyendo células de hongos (por ejemplo, levadura), células de insecto, y células de mamífero (tales como células CHO, VERO y HEK293).
Para facilitar la replicación y la expresión, los ácidos nucleicos se pueden incorporar en un vector, tal como un vector de expresión procariota o eucariota. Aunque los ácidos nucleicos desvelados en el presente documento se pueden incluir en una cualquiera de una diversidad de vectores (incluyendo, por ejemplo, plásmidos bacterianos; ADN de fago; baculovirus; plásmidos de levadura; vectores derivados de combinaciones de plásmidos y ADN de fago, ADN viral tal como vaccinia, adenovirus, virus de la viruela aviar, pseudorrabia, adenovirus, virus adeno-asociados virus, retrovirus y muchos otros), lo más habitualmente, el vector será un vector de expresión adecuado para generar productos de expresión de polipéptido. En un vector de expresión, el ácido nucleico que codifica el antígeno de PreF se coloca por lo general en proximidad y orientación con una secuencia de control de transcripción apropiada (promotor, y opcionalmente, uno o más potenciadores) para dirigir la síntesis del ARNm. Es decir, la secuencia de polinucleótidos de interés se une de forma operativa a una secuencia de control de transcripción apropiada. Algunos ejemplos de tales promotores incluyen: el promotor temprano inmediato del CMV, promotor de LTR o SV40, promotor de polihedrina de baculovirus, promotor lac o trp de E. coli, fago T7 y promotor de Pl lambda, y otros promotores conocidos por controlar la expresión de genes en células procariotas o eucariotas o sus virus. Por lo general, director de expresión también contiene un sitio de unión a ribosoma para el inicio de la traducción, y un terminador de la transcripción. El vector opcionalmente incluye secuencias apropiadas para la amplificación de la expresión. Además, los vectores de expresión comprenden opcionalmente uno o más genes marcadores seleccionables para proporcionar un rasgo fenotípico para selección de células hospedadoras transformadas, tal como dihidrofolato reductasa o resistencia a neomicina para cultivo de células eucariotas, o tal como resistencia a kanamicina, tetraciclina o ampicilina en E. coli.
El vector de expresión también puede incluir elementos de expresión adicionales, por ejemplo, para mejorar la eficacia de la traducción. Estas señales pueden incluir, por ejemplo, un codón de inicio de ATG y secuencias adyacentes. En algunos casos, por ejemplo, un codón de inicio de la traducción y elementos de la secuencia asociados se insertan en el vector de expresión apropiado de forma simultánea con la secuencia de polinucleótidos de interés (por ejemplo, un codón de inicio nativo). En tales casos, no son necesarias señales de control de la traducción adicionales. Sin embargo, en casos en los que solamente una secuencia que codifica polipéptido, o una parte de la misma, se inserta, se proporcionan señales de control de traducción exógenas, incluyendo un codón de inicio de ATG para la traducción del ácido nucleico que codifica para el antígeno de PreF. El codón de inicio se coloca en el marco de lectura correcto para asegurar la traducción de la secuencia de polinucleótidos de interés. Los elementos de transcripción exógenos y codones de inicio pueden ser de diversos orígenes, tanto naturales como sintéticos. Si se desea, la eficacia de la expresión se puede aumentar adicionalmente mediante la inclusión de potenciadores apropiados con respecto al sistema celular en uso (Scharf y col., (1994) Results Probl Cell Differ 20: 125-62; Bittery col., (1987) Methods in Enzymol 153: 516-544).
En algunos casos, el ácido nucleico (tal como un vector) que codifica el antígeno de PreF incluye uno o más elementos de la secuencia adicionales seleccionados para aumentar y/o optimizar la expresión del ácido nucleico que codifica PreF cuando se introduce en una célula hospedadora. Por ejemplo, en ciertas realizaciones, los ácidos nucleicos que codifican el antígeno de PreF incluyen una secuencia de intrón, tal como una secuencia de intrón de virus 5 del Herpes Human (véase, por ejemplo, SEQ ID NO: 13). De forma repetida se ha demostrado que algunos intrones aumentan la expresión de ácidos nucleicos homólogos y heterólogos cuando se colocan de forma apropiada en una construcción recombinante. Otra clase de secuencias de potenciación de la expresión incluye un elemento epigenético tal como una Región de Unión a Matriz (o MAR), o un elemento epigenético similar, por ejemplo, elementos STAR (por ejemplo, tales como los elementos STAR desvelados en Otte y col., Biotechnol. Prog.
23: 801-807, 2007). Sin quedar ligado por la teoría, se cree que los MAR median en el anclaje de una secuencia de
ADN diana a la matriz nuclear, generando dominios de bucle de cromatina que se extienden hacia fuera de los núcleos de la heterocromatina. Aunque las MAR no contiene ninguna secuencia consenso o reconocible evidente, parece que su característica más coherente es un contenido de A/T elevado global, y bases de C que predominan en una hebra. Parece que estas regiones forman estructuras secundarias plegadas que pueden ser propensas a separación de hebras, y pueden incluir un elemento de desplegamiento de núcleo (CUE) que puede servir como el punto de nucleación para separación de hebras. Varios motivos de secuencia ricos en AT sencillos se han asociado con secuencias de MAR: por ejemplo, la caja A, la caja T, motivos de desplegamiento de ADN, sitios de unión a SATB1 (caja H, A/T/C25) y sitios de Topoisomerasa II consenso para vertebrados o Drosophila. Algunas secuencias de MAR a modo de ejemplo se describen en la solicitud de Patente de Estados Unidos n.° 20070178469 publicada, y en la solicitud de patente internacional n.° WO02/074969. Algunas secuencias de MAR adicionales que se pueden usar para aumentar la expresión de un ácido nucleico que codifica un antígeno de PreF incluyen lisozima MAR de pollo, MARp1-42, MARp1-6, MARp1-68, y MARpx-29, descritas en Girod y col., Nature Methods, 4: 747-753, 2007 (desveladas en GenBank con los N.°s de Referencia EA423306, DI107030, DI106196, DI107561, y DI106512, respectivamente). Un experto en la materia observará que la expresión se puede modular adicionalmente mediante la selección de una MAR que produce un nivel intermedio de potenciación, como se informa para MAR 1-9. Si se desea, algunas secuencias de MAR alternativas para aumento de la expresión de un antígeno de PreF se pueden identificar mediante búsqueda en bases de datos de secuencias, por ejemplo, usando software tal como MAR-Finder (disponible en la web en futuresoft.org/MarFinder), SMARTest (disponible en la web en genomatix.de), o SMARScan I (Levitsky y col., Bioinformatics 15: 582-592, 1999). En determinadas realizaciones, la MAR se introduce (por ejemplo, se transfectar) en la célula hospedadora en el mismo ácido nucleico (por ejemplo, vector) que la secuencia que codifica antígeno de PreF. En una realización alternativa, la MAR se introduce en un ácido nucleico separado (por ejemplo, en trans) y se puede cointegrar opcionalmente con la secuencia de polinucleótidos que codifica antígeno de PreF.
Algunos procedimientos a modo de ejemplo suficientes para guiar a un experto habitual en la materia a través de la producción de ácidos nucleicos de antígeno PreF recombinante se pueden encontrar en Sambrook y col., Molecular Cloning: A Laboratory Manual, 2d ed., Cold Spring Harbor Laboratory Press, 1989; Sambrook y col., Molecular Cloning: Laboratory Manual, 3d ed., Cold Spring Harbor Press, 2001; Ausubel y col., Current Protocols in Molecular Biology, Greene Publishing Associates, 1992 (y Suplementos de 2003); y Ausubel y col., Short Protocols in Molecular Biology: A Compendium of Methods from Current Protocols in Molecular Biology, 4a ed., Wiley & Sons, 1999.
Algunos ácidos nucleicos a modo de ejemplo que codifican polipéptidos de antígeno de PreF se representan por las SEQ ID NOs: 5, 7, 9,12 y 13. Algunas variantes adicionales se pueden producir mediante ensamblaje de secuencias de polipéptidos de proteína F y G análogas seleccionadas entre cualquiera de las cepas descubiertas (o posteriormente) conocidas del v Sr , por ejemplo, como se desvela en el documento WO2008114149. Algunas variantes de secuencia adicionales que comparten identidad de secuencia con las variantes a modo de ejemplo las pueden producir los expertos en la materia. Por lo general, las variantes de ácido nucleico codificarán polipéptidos que se diferencian en no más de un 1 %, o un 2 %, o un 5 %, o un 10 %, o un 15 %, o un 20 % de los restos de aminoácidos. Es decir, los polipéptidos codificados comparten al menos una identidad de secuencias de un 80 %, o un 85 %, más comúnmente, al menos aproximadamente un 90 % o superior, tal como un 95 %, o incluso un 98 % o un 99 %. Los expertos en la materia entenderán inmediatamente que las secuencias de polinucleótido se codifican los polipéptidos de PreF, pueden compartir por sí mismas menos identidad de secuencias debido a la redundancia del código genético. En algunos casos, los antígenos de PreF tienen una o más modificaciones de aminoácidos con respecto a la secuencia de aminoácidos de la cepa de origen natural a partir de la que se obtienen (por ejemplo, además de las modificaciones de estabilización mencionadas anteriormente). Tales diferencias pueden ser una adición, deleción o sustitución de uno o más nucleótidos o aminoácidos, respectivamente. Una variante por lo general se diferencia en no más de aproximadamente un 1 %, o un 2 %, o un 5 %, o un 10 %, o un 15 %, o un 20 % de los restos de nucleótidos. Por ejemplo, un ácido nucleico del antígeno de PreF variante (incluyendo PreF-G) puede incluir 1, o 2, o hasta 5, o hasta aproximadamente 10, o hasta aproximadamente 15, o hasta aproximadamente 50, o hasta aproximadamente 100 diferencias de nucleótidos en comparación con los ácidos nucleicos del antígeno de PreF a modo de ejemplo de las SEQ ID NOs: 5, 7, 9, 12 y/o 13. Por lo tanto, una variante en el contexto de una proteína F o G del VSR, o ácido nucleico de antígeno de PreF (incluyendo antígeno de PreF-G), por lo general comparte una identidad de secuencias de al menos un 80 %, o un 85 %, más comúnmente, al menos aproximadamente un 90 % o superior, tal como un 95 %, o incluso un 98 % o un 99 % con una secuencia de referencia, por ejemplo, las secuencias de referencia ilustradas en las SEQ ID NO: 1, 3, 5, 7, 9, 12 o 13, o cualquiera de los otros ácidos nucleicos de antígeno de PreF a modo de ejemplo desvelados en el presente documento. Las variantes adicionales incluidas como una característica de la presente divulgación son antígenos de PreF (incluyendo antígenos de PreF-G) que incluyen toda o parte de una secuencia de nucleótidos seleccionada a partir de las variantes de origen natural desveladas en el documento WO2008114149. Las variantes adicionales pueden surgir a través de deriva genética, o se pueden producir de forma artificial usando mutagénesis dirigida al sitio o aleatoria, o mediante la combinación de dos o más variantes existentes previamente. Tales variantes adicionales también son adecuadas en el contexto de los antígenos de PreF (y PreF-G) desvelados en el presente documento.
Además de los ácidos nucleicos variantes descritos anteriormente, algunos ácidos nucleicos que se hibridan con uno o más de los ácidos nucleicos a modo de ejemplo representados por las SEQ ID NOs: 1, 3, 5, 7, 9, 12 y 13 también
se pueden usar para codificar antígenos de PreF. Un experto en la materia observará que además del % de la medida de identidad de secuencias discutida anteriormente, otro indicios de similitud de secuencias entre los ácidos nucleicos es la capacidad de hibridarse. Cuanto más similares son las secuencias de los dos ácidos nucleicos, más rigurosa son las condiciones en las que hibridarán. La rigurosidad de las condiciones de hibridación depende de la secuencia y son diferentes bajo diferentes parámetros ambientales. Por lo tanto, las condiciones de hibridación que dan como resultado grados de rigurosidad en particular variarán dependiendo de la naturaleza del procedimiento de hibridación de elección y la composición y longitud de las secuencias de ácidos nucleicos de hibridación. Por lo general, la temperatura de hibridación y la fuerza iónica (especialmente la concentración de Na+ y/o Mg++) del tampón de hibridación determinará la rigurosidad de la hibridación, aunque los tiempos de lavado también influyen en la rigurosidad. Por lo general, las condiciones rigurosas se seleccionan para que sean de aproximadamente 5 °C a 20 °C inferiores a las del punto de fusión térmica (Tm) para la secuencia específica a una fuerza iónica y pH definidos. La Tm es la temperatura (bajo la fuerza iónica y pH definidos) a la que un 50 % de la secuencia diana se hibridan a una sonda perfectamente emparejada. Las condiciones para la hibridación de ácidos nucleicos y el cálculo de las rigurosidades se puede encontrar, por ejemplo, en Sambrook y col., Molecular Cloning: A Laboratory Manual, Cold Spring Harbor Laboratory Press, Cold Spring Harbor, NY, 2001; Tijssen, Hybridization With Nucleic Acid Probes, Part I: Theory and Nucleic Acid Preparation Laboratory Techniques in Biochemistry and Molecular Biology, Elsevier Science Ltd., NY, NY, 1993. y Ausubel y col., Short Protocols in Molecular Biology, 4a ed., John Wiley & Sons, Inc., 1999.
Para fines de la presente divulgación, "condiciones rigurosas" incluye condiciones en las que la hibridación sólo se producirá si hay una falta de coincidencias inferior a un 25 % entre la molécula de hibridación y la secuencia diana. Las "condiciones rigurosas" pueden fracasar en niveles de rigurosidad en particular para definición más precisa. Por lo tanto, como se usa en el presente documento, las condiciones de "rigurosidad moderada" son aquéllas en las que las moléculas con una falta de coincidencias de secuencias de más de un 25 % no se hibridarán; las condiciones de "rigurosidad media" son aquellas en las que las moléculas con una falta de coincidencias de más de un 15 % no se hibridarán, y las condiciones de "rigurosidad elevada" son aquellas en las que las secuencias con una falta de coincidencias de más de un 10 % no se hibridarán. Las condiciones de "rigurosidad muy elevada" son aquellas en las que las secuencias con una falta de coincidencias de más de un 6 % no se hibridarán. Por el contrario, los ácidos nucleicos que se hibridan en condiciones de " baja rigurosidad” incluyen aquellos con una identidad de secuencias mucho menor, o con identidad de secuencias con respecto a solamente las subsecuencias cortas del ácido nucleico. Por lo tanto, se entenderá que las diversas variantes de ácidos nucleicos que están incluidas en la presente divulgación son capaces de hibridarse con al menos una de las SEQ ID NOs: 1, 3, 5, 7, 9 y/o 12 con respecto a sustancialmente toda su longitud.
PROCEDIMIENTOS PARA PRODUCIR POLIPÉPTIDOS ANTIGÉNICOS DEL VSR
Los antígenos de PreF (incluyendo antígenos de PreF-G, y también cuando sea aplicable, antígenos de G) desvelados en el presente documento se producen usando procedimientos bien establecidos para la expresión y purificación de proteínas recombinantes. Algunos procedimientos suficientes para guiar a un experto en la materia se pueden encontrar en las siguientes referencias: Sambrook y col., Molecular Cloning: A Laboratory Manual, Cold Spring Harbor Laboratory Press, Cold Spring Harbor, NY, 200; y Ausubel y col., Short Protocols in Molecular Biology, 4a ed., John Wiley & Sons, Inc., 999. En lo sucesivo en el presente documento se proporcionan algunos detalles adicionales y específicos.
Los ácidos nucleicos recombinantes que codifican los antígenos de PreF se introducen en células hospedadoras mediante cualquiera de una diversidad de procedimientos bien conocidos, tales como electroporación, transfección mediada por liposoma (por ejemplo, usando un reactivo de transfección liposomal disponible en el mercado, tal como LIPOFECTAMIn E™2000 o TRANSFECTIN™), precipitación con fosfato cálcico, infección, transfección y similares, dependiendo de la selección de vectores y células hospedadoras. Los ácidos nucleicos a modo de ejemplo que codifican antígenos de PreF (incluyendo antígenos de PreF-G) se proporcionan en las SEQ ID NOs: 5, 7, 9, 12 y 13. Un experto en la materia observará que las SEQ ID NOs: 5, 7, 9, 12 y 13 son ilustrativas y no pretenden ser limitantes. Por ejemplo, las secuencias de polinucleótidos que codifican las mismas proteínas que las SEQ ID NOs: 5, 7 y 9, (por ejemplo, representadas por las SEQ ID NOs: 6, 8 y 10), pero que se diferencian solamente en la redundancia del código genético (tal como mediante optimización de codón alternativa, como se muestra en la SEQ ID NO: 12), se pueden usar fácilmente en lugar de las secuencias a modo de ejemplo de las SEQ ID NOs: 5, 7, y 9. De forma análoga, se pueden usar secuencias de polinucleótidos que incluyen elementos de potenciación de la expresión, tales como intrones colocados internamente (o mediante la adición de promotor, potenciador, intrón u otros elementos similares), como se ilustra en la SEQ ID NO: 13. Un experto habitual en la materia reconocerá que algunas combinaciones de tales modificaciones son igualmente adecuadas. De forma análoga, las secuencias homólogas seleccionadas entre cualquier cepa de A del VSR o B del VSR, y/u otras secuencias que comparten identidad de secuencias sustancial, como se ha discutido anteriormente, también se pueden usar para expresar antígenos de PreF. De hecho, cualquiera de los ácidos nucleicos variantes desvelados anteriormente se pueden introducir de forma adecuada en células hospedadoras y usar para producir antígenos de PreF (incluyendo antígenos PreF-G) y cuando sea aplicable, polipéptidos G.
Las células hospedadoras que incluyen ácidos nucleicos que codifican antígeno de PreF recombinante son, por lo tanto, también una característica de la presente divulgación. Algunas células hospedadoras favorables incluyen
células hospedadoras procariotas (es decir, bacterianas), tales como E. coli, así como numerosas células hospedadoras eucariotas, incluyendo células de hongo (por ejemplo, células de levadura, tal como Saccharomyces cerevisiae y Picchia pastoris), células de insecto, células vegetales, y células de mamífero (tales como células CHO y HEK293). Los ácidos nucleicos de antígeno de PreF recombinantes se introducen (por ejemplo, transducidos, transformados o transfectados) en células hospedadoras, por ejemplo, a través de un vector, tal como un vector de expresión. Como se ha descrito anteriormente, de la forma más habitual el vector es un plásmido, pero tales vectores también pueden, por ejemplo, una partícula viral, un fago, etc. Algunos ejemplos de hospedador es de expresión apropiados incluyen: células bacterianas, tales como E. coli, Streptomyces, y Salmonella typhimurium; células de hongos, tales como Saccharomyces cerevisiae, Pichia pastoris, y Neurospora crassa; células de insecto tales como Drosophila y Spodoptera frugiperda; células de mamífero tales como 3T3, COS, CHO, BHK, HEK 293 o melanoma de Bowes; células vegetales, incluyendo células de algas, etc.
Las células hospedadoras se pueden cultivar en medio nutriente convencional modificado si fuera apropiado para activación de promotores, selección de transformantes, o amplificación de las secuencias de polinucleótidos insertadas. Las condiciones de cultivo, tales como temperatura, pH y similares, por lo general son las usadas anteriormente con la célula hospedadora seleccionada para expresión, y serán evidentes para los expertos en la materia y las referencias mencionadas en el presente documento, incluyendo, por ejemplo, Freshney (1994) Culture of Animal Cells, a Manual of Basic Technique, tercera edición, Wiley- Liss, New York y las referencias citadas en ese documento. Los productos de expresión que corresponden a los ácidos nucleicos de la divulgación también se pueden producir en células animales tales como plantas, levadura, hongo, bacterias y similares. Además de Sambrook, Berger y Ausubel, algunos detalles relacionados con el cultivo celular se pueden encontrar en Payne y col., (1992) Plant Cell and Tissue Culture in Liquid Systems John Wiley & Sons, Inc. New York, NY; Gamborg y Phillips (eds) (1995) Plant Cell. Tissue and Organ Culture; Fundamental Methods Springer Lab Manual, Springer-Verlag (Berlin Heidelberg New York) y Atlas y Parks (eds) The Handbook of Microbiological Media (1993) CRC Press, Boca Raton, FL.
En sistemas bacterianos, un número de vectores de expresión se puede seleccionar dependiendo del uso pretendido para el producto expresado. Por ejemplo, cuando se necesitan grandes cantidades de un polipéptido o fragmentos del mismo para la producción de anticuerpos, de forma favorable se usan vectores que dirigen un nivel de expresión elevado de proteínas de fusión que se purifican fácilmente. Tales vectores incluyen, pero no se limitan a, vectores de clonación y expresión de E. coli multifuncionales tales como BLUESCRIPT (Stratagene), en los que la secuencia de codificación de interés, por ejemplo, un polinucleótido de la invención como se ha descrito anteriormente, se puede ligar en el vector en marco con secuencias para la traducción amino-terminal comenzando en Metionina y los 7 restos posteriores de beta-galactosidasa que producen una proteína de fusión de beta galactosidasa catalíticamente activa; vectores de pIN (Van Heeke y Schuster (1989) J Biol Chem 264: 5503-5509); vectores de pET (Novagen, Madison WI), en los que la metionina amino-terminal está ligada en marco con una etiqueta de histidina; y similares.
De forma análoga, en levaduras, tal como Saccharomyces cerevisiae, un número de vectores que contienen promotores constitutivos o inducibles tales como factor alfa, alcohol oxidasa y PGH se pueden usar para producción de los productos de expresión deseados. Para revisiones, véase Berger, Ausubel, y, por ejemplo, Grant y col., (1987; Methods in Enzymology 153: 516-544). En células hospedadoras de mamífero, se puede usar un número de sistemas de expresión, incluyendo tanto plásmidos como sistemas basados en virus.
Una célula hospedadora se elige opcionalmente por su capacidad para modular la expresión de las secuencias insertadas o para procesar la proteína expresada de la forma deseada. Tales modificaciones de la proteína incluyen, pero no se limitan a, glicosilación, (así como, por ejemplo, acetilación, carboxilación, fosforilación, lipidación y acilación). El procesamiento después de la traducción que, por ejemplo, escinde una forma precursora en una forma madura de la proteína (por ejemplo, mediante una furina proteasa) se realiza opcionalmente en el contexto de la célula hospedadora. Algunas células hospedadoras diferentes tales como 3T3, c Os , CHO, HeLa, BHK, MDCK, 293, WI38, etc. tienen maquinaria celular y mecanismos característicos específicos para actividades después de la traducción de este tipo y se pueden elegir para asegurar la modificación y procesamiento correctos de la proteína extraña introducida.
Para producción con alto rendimiento, a largo plazo de antígenos de PreF recombinante desvelados en el presente documento, por lo general se usan sistemas de expresión estables. Por ejemplo, las líneas celulares que expresan de forma estable polipéptido de antígeno de PreF se introducen en la célula hospedadora usando vectores de expresión que contienen orígenes de replicación viral o elementos de expresión endógenos y un gen marcador seleccionable. Después de la introducción del vector, se permite que las células crezcan durante 1-2 días en un medio enriquecido antes de que se intercambie por medio selectivo. La finalidad del marcador seleccionables es conferir resistencia a la selección, y su presencia permite el crecimiento y la recuperación de células que expresan de forma satisfactoria las secuencias introducidas. Por ejemplo, algunos grupos o colonias existentes de células transformadas de forma estable pueden proliferar usando técnicas de cultivo tisular apropiadas para el tipo de célula. Las células hospedadoras transformadas con un ácido nucleico que codifica un antígeno de PreF se cultivan opcionalmente en condiciones adecuadas para la expresión y recuperación de la proteína codificada a partir del cultivo celular.
Después de la transducción de una línea de células hospedadoras adecuada y crecimiento de las células hospedadoras a una densidad celular apropiada, el promotor seleccionado se induce mediante medios apropiados (por ejemplo, desplazamiento de temperatura o inducción térmica) y las células se cultivan durante un periodo adicional. Opcionalmente, el medio incluye componentes y/o aditivos que disminuyen la declaración de proteínas expresadas por proteinasas. Por ejemplo, el medio usado para cultivar las células para producir el antígeno PreF pueden incluir un inhibidor de proteasa, tal como un agente de quelación o inhibidor de molécula pequeña (por ejemplo, AZ11557272, AS111793, etc.), para reducir o eliminar la escisión indeseada mediante proteinasas celulares, o extracelulares (por ejemplo, matriz).
El producto de polipéptido secretado se recupera a continuación del medio de cultivo. Como alternativa, las células se pueden cosechar mediante centrifugación, interrumpir mediante medios físicos o químicos, y el extracto en bruto resultante se puede retener para purificación adicional. Las células eucariotas o microbianos usadas en expresión de proteínas se pueden interrumpir mediante cualquier procedimiento conveniente, incluyendo ciclos de congelacióndescongelación, sonicación, interrupción mecánica, o uso de agentes de lisado celular, u otros procedimientos, que son bien conocidos por los expertos en la materia.
Los antígenos de PreF expresados se pueden recuperar y purificar a partir de cultivos de células recombinantes mediante cualquiera de un número de procedimientos bien conocidos en la técnica, incluyendo precipitación con sulfato de amonio o etanol, extracción con ácido, filtración, ultrafiltración, centrifugación, cromatografía de intercambio aniónico o catiónico, cromatografía de fosfocelulosa, cromatografía de interacción hidrófoba, cromatografía por afinidad (por ejemplo, usando cualquiera de los sistemas de etiquetados indicados en el presente documento), cromatografía de hidroxilapatita, y cromatografía de lectina. Se pueden usar etapas de replegamiento de proteínas, si se desea, para completar la configuración de la proteína madura. Por último, en las etapas de purificación final se puede usar cromatografía líquida de alto rendimiento (HPLC). Además de las referencias indicadas anteriormente, en la técnica se conoce bien una diversidad de procedimientos de purificación, incluyendo, por ejemplo, los que se exponen en Sandana (1997) Bioseparation of Proteins, Academic Press, Inc.; y Bollag y col., (1996) Protein Methods, 2a Edición Wiley-Liss, NY; Walquer (1996) The Protein Protocols Handbook Humana Press, NJ, Harris y Angal (1990) Protein Purification Applications: A Practical Approach IRL Press at Oxford, Oxford, U.K.; Scopes (1993) Protein Purification: Principles and Practice 3a Edición Springer Verlag, NY; Janson y Ryden (1998) Protein Purification: Principles High Resolution Methods and Applications, Segunda Edición Wiley-VCH, NY; y Walquer (1998) Protein Protocols on CD-ROM Humana Press, NJ.
En ciertos ejemplos, los ácidos nucleicos se introducen en células a través de vectores adecuados para introducción y expresión en células procariotas, por ejemplo, células de E. coli. Por ejemplo, un ácido nucleico que incluye una secuencia de polinucleótidos que codifica un antígeno de PreF se puede introducir en cualquiera de una diversidad de vectores disponibles en el mercado o patentados, tales como la serie pET de vectores de expresión (por ejemplo, pET9b y pET2d). La expresión de la secuencia de codificación se puede inducir con IPTG, dando como resultado niveles elevados de expresión de proteína. La secuencia de polinucleótidos que codifica el antígeno de PreF se transcribe bajo el promotor T7 de fago. También son adecuados algunos vectores alternativos, tales como pURV22 que incluyen un promotor lambda pL inducible por calor.
El vector de expresión se introduce (por ejemplo, mediante electroporación) en un hospedador bacteriano adecuado. Hay disponibilidad de numerosas cepas adecuadas de E. coli y las puede seleccionar un experto en la materia (por ejemplo, se ha demostrado que las cepas Rosetta y BL21 (DE3) son favorables para expresión de vectores recombinantes que contienen secuencias de polinucleótidos que codifican antígenos de PreF.
Más habitualmente, los polinucleótidos que codifican los antígenos de PreF se incorporan en vectores de expresión que son adecuados para la introducción y expresión en células eucariotas (por ejemplo, células de insecto o mamífero). De forma favorable, tales ácidos nucleicos están optimizados por codón para su expresión en el lector/célula hospedadora seleccionado (por ejemplo, las secuencias ilustradas en las SEQ ID NOs: 5, 7, 9 y 12 están optimizadas por codón para su expresión en células CHO). En una realización a modo de ejemplo, la secuencia de polinucleótidos que codifica el antígeno de PreF se introduce en un vector, tal como el vector pEE14 desarrollado por la firma Lonza Biologicals. El polipéptido se expresa en un promotor constitutivo, tal como el promotor de CMV (CitoMegaloVirus) temprano inmediato. La selección de las células transfectadas de forma estable que expresan el polipéptido se realiza basándose en la capacidad de las células transfectadas para crecer en ausencia de una fuente de glutamina. Las células que tienen integrado el vector pEE14 de forma satisfactoria son capaces de crecer en ausencia de glutamina exógena, porque el vector pEE14 expresa la enzima GS (Glutamina Sintetasa). Las células seleccionadas se pueden expandir de forma clonal y caracterizar para expresión del polipéptido de PreF deseado.
En otro ejemplo, la secuencia de polinucleótidos que codifica el antígeno de PreF se introduce en células de insecto usando un Sistema de Vector de Expresión de Baculovirus (BEVS). El baculovirus recombinante capaz de infectar células de insectos se puede generar usando vectores, kits y/o sistemas disponibles en el mercado, tal como el sistema BD BaculoGold de BD BioScience. En resumen, la secuencia de polinucleótidos que codifica el antígeno se inserta en el vector de transferencia pAcSG2. a continuación, las células hospedadoras SF9 (Spodoptera frugiperda) se cotransfectan mediante plásmido quimérico para pAcSG2 y BD BaculoGold, que contiene el ADN genómico linealizado del baculovirus del virus de poliedrosis nuclear de Autographa californica (AcNPV). Después de la
transfección, la recombinación homóloga se produce entre el plásmido de pACSG2 y el genoma del Baculovirus para generar el virus recombinante. En un ejemplo, el antígeno de PreF se expresa bajo el control regulador del promotor de polihedrina (pH). Se pueden producir vectores de transferencia similares usando otros promotores, tales como los promotores básicos (Ba) y p10. Del mismo modo, se pueden usar células de insecto alternativas, tal como SF21 que se relaciona en gran medida con Sf9, y la línea celular High Five obtenida a partir de un gusano gris de la col, Trichoplusia ni.
Después de transfección e inducción de expresión (de acuerdo con el promotor y/o potenciadores u otros elementos de regulación seleccionados), los polipéptidos expresados se recuperan ( por ejemplo, purificados o enriquecidos) y se vuelven a naturalizar para asegurar el plegamiento en una conformación de prefusión antigénicamente activa. COMPOSICIONES INMUNOGÉNICAS Y PROCEDIMIENTOS
También se proporcionan composiciones inmunogénicas que incluyen cualquiera de los antígenos de PreF desvelados anteriormente (tal como los proporcionados a modo de ejemplo con la SEQ ID NOs: 6, 8 y 10) y un vehículo o excipiente farmacéuticamente aceptable.
En ciertas realizaciones, por lo general, realizaciones en las que el antígeno de PreF no incluye un componente de la proteína G (tal como SEQ ID NO: 6), la composición inmunogénica puede incluir una proteína G aislada, recombinante y/o purificada. En la técnica se han descrito numerosas proteínas G adecuadas, e incluyen proteínas G recombinantes de longitud completa y proteínas quiméricas formadas por una parte de la proteína G (tal como los aminoácidos 128-229 o 130-230) y un compañero de fusión (tal como tiorredoxina), o una secuencia señal y/o directora, que facilitan la expresión y/o purificación. Algunas proteínas G a modo de ejemplo para uso en mezcla con un antígeno de PreF se pueden encontrar en el documento WO2008114149, Patente de Estados Unidos n.° 5.149.650, Patente de Estados Unidos n.° 6.113.911, Solicitud Publicada de Estados Unidos n.° 20080300382, y Patente de Estados Unidos n.° 7.368.537. Como se indica con respecto a las proteínas PreF-G quiméricas, un fragmento más pequeño de la proteína G, tal como la parte entre los aminoácidos 149-229, o la parte entre aproximadamente 128 y aproximadamente 229 se puede usar de forma favorable en el contexto de mezclas que implican un PreF (sin G) y G. Como se ha analizado anteriormente, la consideración importante es la presencia de epítopos inmunodominantes, por ejemplo, incluidos dentro de la región de los aminoácidos 183-197. Como alternativa, en tales composiciones se puede usar una proteína G de longitud completa.
Algunos vehículos y excipientes farmacéuticamente aceptables se conocen bien y los pueden seleccionar los expertos en la materia. Por ejemplo, el vehículo o excipiente puede incluir de forma favorable un tampón. Opcionalmente, el vehículo o excipiente también contiene al menos un componente que estabiliza la solubilidad y/o estabilidad. Algunos ejemplos de agentes solubilizantes/estabilizantes incluyen detergentes, por ejemplo, lauril sarcosina y/o tween. Algunos agentes solubilizantes/estabilizantes adecuados incluyen arginina, y polioles que forman vidrio (tales como sacarosa, trehalosa y similares). En la técnica se conocen numerosos vehículos farmacéuticamente aceptables y/o excipientes farmacéuticamente aceptables y se describen, por ejemplo, en Pharmaceutical Sciences de Remington, de E. W. Martin, Mack Publishing Co., Easton, PA, 5a Edición (975).
Por consiguiente, algunos excipientes y vehículos adecuados los pueden seleccionar los expertos en la materia para producir una formulación adecuada para administrar a un sujeto mediante una vía de administración seleccionada. Algunos excipientes adecuados incluyen, pero no se limitan a: glicerol, Polietilenglicol (PEG), Sorbitol, Trehalosa, San sódica de N-lauroilsarcosina, L-prolina, sulfobetaína no detergente, clorhidrato de Guanidina, Urea, óxido de Trimetilamina, KCl, Ca2+, Mg2+, Mn2+, Zn2+ y otras sales relacionadas con cationes divalentes, Ditiotreitol, Ditioeritrol, y p-mercaptoetanol. Otros excipientes pueden ser detergentes (incluyendo: Tween 80, Tween 20, Triton X-00, NP-40, Empigen BB, Octilglucósido Lauroil maltósido, Zwittergent 3-08, Zwittergent 3-0, Zwittergent 3-2, Zwittergent 3-4, Zwittergent 3-6, CHAPS, desoxicolato sódico, dodecil sulfato sódico, bromuro de Cetiltrimetilamonio).
Opcionalmente, las composiciones inmunogénicas también incluyen un adyuvante. En el contexto de una composición inmunogénica adecuada para administración a un sujeto con el fin de provocar una respuesta inmune protectora frente al VSR, el adyuvante se selecciona para provocar una respuesta inmune desviada hacia Th1. Por lo general el adyuvante se selecciona para que aumente una respuesta inmune desviada hacia Th1 en el sujeto, o población de sujetos, a los que se administra la composición. Por ejemplo, cuando la composición inmunogénica se va a administrar a un sujeto de un grupo de edades en particular susceptible a (o con un aumento del riesgo de) infección por VSR, el adyuvante se selecciona para que sea seguro y eficaz en el sujeto o población de sujetos. Por lo tanto, cuando se formula una composición inmunogénica que contiene un antígeno de PreF del VSR para administración en un sujeto de mayor edad (tal como un sujeto con una edad superior a 65 años de edad), el adyuvante se selecciona para que sea seguro y eficaz en sujetos de edades avanzadas. De forma análoga, cuando la composición inmunogénica que contiene el antígeno de PreF del VSR se pretende para administración en sujetos neonatales o infantiles (tales como sujetos entre el nacimiento y la edad de dos años), el adyuvante selecciona para que sea seguro y eficaz en neonatos y niños.
Además, el adyuvante por lo general se selecciona para que aumente una respuesta inmune de Th1 cuando se administra a través de la vía de administración, mediante la que se administra la composición inmunogénica. Por
ejemplo, cuando se formula una composición inmunogénica que contiene un antígeno de PreF para administración nasal, son favorables proteosoma y protolina son adyuvantes de desviación de Th1 favorables. Por el contrario, cuando la composición inmunogénica se formula para administración intramuscular, se seleccionan de forma favorable algunos adyuvantes que incluyen uno o más de 3D-MPL, escualeno (por ejemplo, QS21), liposomas, y/o emulsiones de aceite y agua.
Un adyuvante adecuado para uso en combinación con antígenos de PreF es un derivado de lipopolisacárido bacteriano no tóxico. Un ejemplo de un derivado no tóxico adecuado de lípido A, es el monofosforil lípido A o más particularmente el monofosforil lípido A 3-Desacilado (3D-MPL). El 3D-MPL se comercializa con el nombre MPL en GlaxoSmithKlina Biologicals N.A., y a través del documento se denomina MPL o 3D-MPL. Véanse, por ejemplo, las Patentes de Estados Unidos n.°s 4.436.727; 4.877.611; 4.866.034 y 4.912.094. El 3D-MPL estimula principalmente las respuestas de los linfocitos CD4+ T con un fenotipo de IFN-y (Th1). El 3D-MPL se prevé producir de acuerdo con los procedimientos que se desvelan en el documento GB2220211 A. Químicamente se trata de una mezcla de monofosforil lípido A 3-desacilado con 3, 4, 5 o 6 cadenas aciladas. En las composiciones de la presente invención, se puede usar 3D-MPL de partícula pequeña. El 3D-MPL de partícula pequeña tiene un tamaño de partícula de modo que se puede filtrar de forma estéril a través de un filtro de 0,22 pm. Tales preparaciones se describen en el documento WO94/21292.
Un lipopolisacárido, tal como 3D-MPL, se puede usar en cantidades entre 1 y 50 pg, por dosis humana de la composición inmunogénica. Tal 3D-MPL se puede usar a un nivel de aproximadamente 25 pg, por ejemplo entre 20 30 pg, de forma adecuada entre 21-29 pg o entre 22 y 28 pg o entre 23 y 27 pg o entre 24 y 26 pg, o 25 pg. En otra realización, la dosis humana de la composición inmunogénica comprende 3D-MPL a un nivel de aproximadamente 10 pg, por ejemplo entre 5 y 15 pg, adecuadamente entre 6 y 14 pg, por ejemplo entre 7 y 13 pg o entre 8 y 12 pg o entre 9 y 11 pg, o 10 pg. En una realización más, la dosis humana de la composición inmunogénica comprende 3D-MPL a un nivel de aproximadamente 5 pg, por ejemplo entre 1 y 9 pg, o entre 2 y 8 pg o de forma adecuada entre 3 y 7 pg o 4 y 6 pg, o 5 pg.
En otras realizaciones, el lipopolisacárido puede ser un disacárido (3(1-6) glucosamina, como se describe en la Patente de Estados Unidos n.° 6.005.099 y en el documento de Patente EP n.° 0729 473 B1. Un experto en la materia sería rápidamente capaz de producir diversos lipopolisacáridos, tal como 3D-MPL, basándose en las enseñanzas de estas referencias. Además de los agentes inmunoestimulantes mencionados anteriormente (que tienen una estructura similar a la de LPS o MPL o 3D-MPL), monosacárido acilado y derivados de disacárido que son una subparte de la estructura de MPL mencionada anteriormente también son adyuvantes adecuados. En otras realizaciones, el adyuvante es un derivado sintético del lípido A, algunos de los cuales se describen como agonistas de TLR-4, e incluyen, pero no se limitan a: OM174 (2-desoxi-6-o-[2-desoxi-2-[(R)-3-dodecanoiloxitetradecanoilamino]-4-o-fosfono-p-D-glucopiranosil]-2-[(R)-3-hidroxitetradecanoilamino]-a-D-glucopiranosildihidrogenfosfato), (documento w O 95/14026); OM 294 DP (3S,9R)-3--[(R)-dodecanoiloxitetradecanoilamino]-4-oxo-5-aza-9(R)-[(R)-3-hidroxitetradecanoilamino]decan-1,10-diol, 1,10-bis(dihidrogenofosfato) (documento WO 99/64301 y documento WO 00/0462); y OM 197 MP-Ac DP (3S-; 9R)-3-[(R)-dodecanoiloxitetradecanoilamino]-4-oxo-5-aza-9-[(R)-3-hidroxitetradecanoilamino]decan-1,10-diol, 1-dihidrogenofosfato 10-(6-aminohexanoato) (documento WO 01/46127).
Otros ligandos de TLR4 que se pueden usar son fosfatos de alquil Glucosamínido (AGP) tales como los desvelados en el documento WO 98/50399 o en la Patente de Estados Unidos n.° 6.303.347 (también se desvelan algunos procedimientos para la preparación de los AGP), de forma adecuada RC527 o RC529 o sales farmacéuticamente aceptables de los AGP como se desvela en Patente de Estados Unidos n.° 6.764.840. Algunos AGP son agonistas de TLR4 y algunos son antagonistas de TLR4. Se cree que ambos son útiles como adyuvantes.
Otros ligandos de TLR-4 adecuados, capaces de causar una respuesta de señalización a través de TLR-4 (Sabroe y col., JI 2003 p1630-5) son, por ejemplo, lipopolisacáridos de bacterias gram-negativas y sus derivados, o fragmentos de los mismos, en particular un derivado no tóxico de LPS (tal como 3D-MPL). Otros agonistas de TLR adecuados son: proteína de choque térmico (HSP) 10, 60, 65, 70, 75 o 90; Proteína A de tensioactivo, oligosacáridos de hialuronano, fragmentos de sulfato de heparano, fragmentos de fibronectina, péptidos de fibrinógeno y b-defensina-2, y dipéptido muramilo (MDP). En una realización, el agonista de TLR es HSP 60, 70 o 90. Otros ligandos de TLR-4 adecuados son los que se describen en el documento WO 2003/011223 y en el documento WO 2003/099195, tales como el compuesto I, compuesto II y compuesto III desvelados en las páginas 4-5 del documento WO2003/011223 o en las páginas 3-4 del documento WO2003/099195 y en particular los compuestos desvelados en el documento WO2003/011223 como ER803022, ER803058, ER803732, ER804053, ER804057, ER804058, ER804059, ER804442, ER804680, y ER804764. Por ejemplo, un ligando de TLR-4 adecuado es ER804057.
Algunos agonistas de TLR adicionales también son útiles como adyuvantes. La expresión "agonista de TLR" se refiere a un agente es capaz de causar una respuesta de señalización a través de una ruta de señalización de TLR, ya sea como un ligando directo o indirectamente a través de generación de ligando endógeno o exógeno. Tales agonistas de TLR naturales o sintéticos se pueden usar como adyuvantes alternativos o adicionales. Una breve revisión del papel de los TLR como receptores de adyuvante se proporcionan en Kaisho y Akira, Biochimica et Biophysica Acta 1589: 1-13, 2002. Estos adyuvantes potenciales incluyen, pero no se limitan a, agonistas para TLR2, TLR3, TLR7, TLR8 y TLR9. Por consiguiente, en una realización, el adyuvante y la composición
inmunogénica comprenden adicionalmente un adyuvante que se selecciona entre el grupo que consiste en: un agonista de TLR-1, un agonista de TLR-2, agonista de TLR-3, un agonista de TLR-4, un agonista de TLR-5, un agonista de TLR-6, agonista de TLR-7, un agonista de TLR-8, un agonista de TLR-9, o una combinación de los mismos.
En una realización de la presente invención, se usa un agonista de TLR que es capaz de causar una respuesta de señalización a través de TLR-1. De forma adecuada, el agonista de TLR que es capaz de causar una respuesta de señalización a través de TLR-1 se selecciona entre: lipopéptidos tri-acilados (LP); modulina soluble en fenol; LP de Mycobacterium tuberculosis; S-(2,3-bis(palmitoiloxi)-(2-RS)-propil)-N-palmitoil-(R)-Cys-(S)-Ser-(S)-Lys(4)-OH, triclorhidrato (Pam3Cys) LP que imita el extremo amino terminal acetilado de una lipoproteína bacteriana y OspA LP de Borrelia burgdorferi.
En una realización alternativa, se usa un agonista de TLR que es capaz de causar una respuesta de señalización a través de TLR-2. De forma adecuada, el agonista de TLR que es capaz de causar una respuesta de señalización a través de TLR-2 es uno o más de uno de una lipoproteína, un peptidoglicano, un lipopéptido bacteriano de M tuberculosis, B burgdorferi o T pallidum; peptidoglicanos de especies que incluyen Staphylococcus aureus; ácidos lipoteicoicos, ácidos manurónicos, porinas de Neisseria, fimbrias bacterianas, factores de virulencia de Yersina, viriones del CMV, hemaglutinina de sarampión, y zimosano de levadura.
En una realización alternativa, se usa un agonista de TLR que es capaz de causar una respuesta de señalización a través de TLR-3. De forma adecuada, el agonista de TLR que es capaz de causar una respuesta de señalización a través de TLR-3 es ARN bicatenario (ARNds), o ácido poliinosínico-policitidílico (Poly IC), un patrón de ácido nucleico molecular asociado con infección viral.
En una realización alternativa, se usa un agonista de TLR que es capaz de causar una respuesta de señalización a través de TLR-5. De forma adecuada, el agonista de TLR que es capaz de causar una respuesta de señalización a través de TLR-5 es flagelina bacteriana.
En una realización alternativa, se usa un agonista de TLR que es capaz de causar una respuesta de señalización a través de TLR-6. De forma adecuada, el agonista de TLR que es capaz de causar una respuesta de señalización a través de TLR-6 es lipoproteína micobacteriana, LP di-acilado, y modulina soluble en fenol. Algunos agonistas de TLR6 adicionales se describen en el documento WO 2003/043572.
En una realización alternativa, se usa un agonista de TLR que es capaz de causar una respuesta de señalización a través de TLR-7. De forma adecuada, el agonista de TLR que es capaz de causar una respuesta de señalización a través de TLR-7 es un ARN monocatenario (ARNss), loxoribina, un análogo de guanosina en las posiciones N7 y C8, o un compuesto de imidazoquinolina, o derivado del mismo. En una realización, el agonista de TLR es imiquimod. Algunos agonistas de t LR7 adicionales se describen en el documento WO 2002/085905.
En una realización alternativa, se usa un agonista de TLR que es capaz de causar una respuesta de señalización a través de TLR-8. De forma adecuada, el agonista de TLR que es capaz de causar una respuesta de señalización a través de TLR-8 es un ARN monocatenario (ARNss), una molécula de imidazoquinolina con actividad anti-viral, por ejemplo resiquimod (R848); el resiquimod también es capaz de reconocimiento mediante TLR-7. Otros agonistas de TLR-8 que se pueden usar incluyen los que se describen en el documento WO 2004/071459.
En una realización alternativa, se usa un agonista de TLR que es capaz de causar una respuesta de señalización a través de TLR-9. En una realización, el agonista de TLR capaz de causar una respuesta de señalización a través de TLR-9 es HSP90. Como alternativa, el agonista de TLR capaz de causar una respuesta de señalización a través de TLR-9 es ADN bacteriano o viral, ADN que contiene nucleótidos de CpG sin metilar, en contextos de secuencias en particular conocidos como motivos de CpG. Algunos oligonucleótidos que contienen CpG inducen una respuesta de Th1 predominantemente. Tales oligonucleótidos se conocen bien y se describen, por ejemplo, en el documento WO 96/02555, el documento WO 99/33488 y Patentes de Estados Unidos n.°s 6.008.200 y 5.856.462. De forma adecuada, los nucleótidos de CpG son oligonucleótidos de CpG. Algunos oligonucleótidos adecuados para uso en las composiciones inmunogénicas de la presente invención son oligonucleótidos que contienen CpG, opcionalmente que contienen dos o más motivos de CpG dinucleótidos separados por al menos tres, adecuadamente al menos seis o más nucleótidos. Un motivo de CpG es un nucleótido de Citosina seguido de un nucleótido de Guanina. Los oligonucleótidos de CpG de la presente invención son por lo general desoxinucleótidos. En una realización específica, el internucleótido en el oligonucleótido es fosforoditioato, o adecuadamente un enlace fosforotioato, aunque los enlaces fosfodiéster y otros enlaces internucleótido están dentro del alcance de la invención. Dentro del alcance de la invención también están incluidos oligonucleótidos con uniones internucleótido mixtas. Algunos procedimientos para producir oligonucleótidos de fosforotioato o fosforoditioato se describen en las Patentes de Estados Unidos n.°s 5.666.153, 5.278.302 y en el documento WO 95/26204.
Otros adyuvantes que se pueden usar en composiciones inmunogénicas con un antígeno PreF, por ejemplo, por sí mismos o en combinación con 3D-MPL, u otro adyuvante descrito en el presente documento, son las saponinas, tales como QS21.
Algunas saponinas se enseñan en: Lacaille-Dubois, M y Wagner H. (1996. A review of the biological and
pharmacological activities of saponins. Phytomedicine vol 2 pp 363-386). Las saponinas son glicósidos de esteroide o triterpeno ampliamente distribuidos en los reinos vegetales y animal marino. Las saponinas destacan por formar soluciones coloidales en agua que forman espuma cuando se agitan, y porque precipitan el colesterol. Cuando las saponinas están cerca de las membranas celulares, crean estructuras similares a poros en la membrana que hacen que la membrana estalle. La hemólisis de los eritrocitos es un ejemplo de este fenómeno, que es una propiedad de ciertas, pero no de todas, las saponinas.
Las saponinas se conocen como adyuvantes en vacunas para administración sistémica. La actividad de adyuvante y hemolítica de las saponinas individuales se ha estudiado extensamente en la técnica (Lacaille-Dubois y Wagner, mencionado anteriormente). Por ejemplo, Quil A (derivado de la corteza del árbol de América del Sur, Quillaja Saponaria Molina), y fracciones del mismo, se describen en la Patente de Estados Unidos n.° 5.057.540 y "Saponins as vaccina adjuvants", Kensil, C. R., Crit Rev Ther Drug Carrier Syst, 1996, 12 (1-2): 1-55; y documento de patente EP 0362279 B1. Algunas estructuras con partículas, denominadas Complejos de Estimulación Inmune (ISCOMS), que comprenden fracciones de Quil A son hemolíticas y se han usado en la fabricación de vacunas (Morein, B., documento EP 0 109 942 B1; documento WO 96/11711; documento WO 96/33739). Las saponinas hemolíticas QS21 y QS17 (fracciones purificadas por HPLC de Quil A) se han descrito como potentes adyuvantes sistémicos, y el procedimiento para su producción se desvela en la Patente de Estados Unidos n.° 5.057.540 y en el documento EP 0362279 B1. Otras saponinas que se han usado en estudios de vacunación sistémica incluyen las obtenidas a partir de otras especies vegetales tales como Gypsophila y Saponaria (Bomford y col., Vaccina, 10 (9): 572-577, 1992).
QS21 es una fracción no tóxica purificada de Hplc derivado de la corteza de Quillaja Saponaria Molina. Un procedimiento para producir QS21 se desvela en Patente de Estados Unidos n.° 5.057.540. Algunas formulaciones de adyuvante no reactogénicas que contienen QS21 se describen en el documento WO 96/33739. Dicha saponina inmunológicamente activa, tal como QS21, se puede usar en cantidades entre 1 y 50 |jg, por dosis humana de la composición inmunogénica. De forma ventajosa, QS21 se usa a un nivel de aproximadamente 25 jg, por ejemplo entre 20-30 jg, adecuadamente entre 21-29 jg o entre 22-28 jg o entre 23-27 jg o entre 24 -26 jg, o 25 jg. En otra realización, la dosis humana de la composición inmunogénica comprende QS21 a un nivel de aproximadamente 10 jg, por ejemplo entre 5 y 15 jg, adecuadamente entre 6 -14 jg, por ejemplo entre 7 -13 jg o entre 8 -12 jg o entre 9 -11 jg, o 10 jg. En una realización más, la dosis humana de la composición inmunogénica comprende QS21 a un nivel de aproximadamente 5 jg, por ejemplo entre 1-9 jg, o entre 2 -8 jg o adecuadamente entre 3-7 jg o 4 6 jg, o 5 jg. Se ha mostrado que tales formulaciones que comprenden QS21 y colesterol son adyuvantes de estimulación de Th1 satisfactorios fondos se formulan en conjunto con un agente. Por lo tanto, por ejemplo, algunos polipéptidos de PreF se pueden usar de forma favorable en composiciones inmunogénicas con un adyuvante que comprende una combinación de QS21 y colesterol.
Opcionalmente, el adyuvante también puede incluir sales minerales tales como sales de aluminio o calcio, en particular hidróxido de aluminio, fosfato de aluminio y fosfato cálcico. Por ejemplo, un adyuvante que contiene 3D-MPL en combinación con una sal de aluminio (por ejemplo, hidróxido de aluminio o "alumbre") es adecuado para formulación en una composición inmunogénica que contiene un antígeno de PreF para administración a un sujeto humano.
Otra clase de adyuvantes de desviación de Th1 adecuados para uso en formulaciones con antígenos de PreF incluye composiciones inmunoestimulantes a base de OMP. Las composiciones inmunoestimulantes a base de OMP son particularmente adecuadas como adyuvantes mucosales, por ejemplo, para administración intranasal. Las composiciones inmunoestimulantes a base de OMP son un género de preparaciones de proteínas de membrana externa (OMP, que incluyen algunas porinas) de bacterias Gram-negativas, tales como, pero no limitadas a, especies de Neisseria (véase, por ejemplo, Lowell y col., J. Exp. Med. 167: 658, 1988; Lowell y col., Science 240: 800, 1988; Lynch y col., Biophys. J. 45: 104, 1984; Lowell, en "New Generation Vaccines" 2a ed., Marcel Dekker, Inc., New York, Basilea, Hong Kong, página 193, 1997; Patente de Estados Unidos n.° 5.726.292; Patente de Estados Unidos n.° 4.707.543), que son útiles como un vehículo o en composiciones para inmunógeno, tales como antígenos bacterianos o virales. Algunas composiciones inmunoestimuladoras a base de OMP se pueden denominar "Proteosomas", que son hidrófobos y seguros para uso humano. Los proteosomas tienen la capacidad para autoensamblarse en vesículas o grupos de OMP similares a las vesículas de aproximadamente 20 nm a aproximadamente 800 nm, y para incorporar, coordinar, asociar (por ejemplo, preforma electrostática o hidrófoba), o de otro modo cooperar de forma no covalente con antígenos de proteína (Ags), en particular antígenos que tienen un resto hidrófobo. Cualquier procedimiento de preparación que dé como resultado el componente de la proteína de la membrana externa en forma vesicular o similar a vesícula, incluyendo estructuras membranoso las multi-moleculares o composiciones de OMP similares a glóbulos fundidos de una o más OMP, está incluido dentro de la definición de Proteosoma. Los proteosomas se pueden preparar, por ejemplo, como se describe en la técnica (véase, por ejemplo, Patente de Estados Unidos n.° 5.726.292 o Patente de Estados Unidos n.° 5.985.284). Los proteosomas también pueden contener un lipopolisacárido o lipooligosacárido endógeno (LPS o LOS, respectivamente) que se originan a partir de las bacterias usadas para producir las porinas de OMP (por ejemplo, especies de Neisseria), que por lo general serán menos de un 2 % de la preparación de la OMP total.
Los proteosomas están formados principalmente por proteínas de la membrana externa a extraídas de forma química (las OMP) de Neisseria menigitidis (principalmente las porinas A y B así como OMP de clase 4), mantenidas
en solución con detergente (Lowell GH. Proteosomes for Improved Nasal, Oral, or Injectable Vaccines. En: Levine MM, Woodrow GC, Kaper JB, Cobon GS, eds, New Generation Vaccines. New York: Marcel Dekker, Inc. 1997; 193 206). Los proteosomas se pueden formular con una diversidad de antígenos tales como proteínas purificadas o recombinantes derivadas de fuentes virales, incluyendo los polipéptidos de PreF desvelados en el presente documento, por ejemplo, mediante procedimientos tradicionales de diafiltración o de diálisis. La retirada gradual del detergente permite la formación de complejos hidrófobos de partículas de aproximadamente 100-200 nm de diámetro (Lowell GH. Proteosomes for Improved Nasal, Oral, or Injectable Vaccines. En: Levine MM, Woodrow GC, Kaper JB, Cobon GS, eds, New Generation Vaccines. New York: Marcel Dekker, Inc. 1997; 193-206).
"Proteosoma: LPS o Protolina", como se usa en el presente documento, se refiere a preparaciones de proteosomas mezcladas, por ejemplo, mediante la adición exógena, con al menos un tipo de lipo-polisacárido para proporcionar una composición de OMP-LPS (que puede funcionar como una composición inmunoestimulante). Por lo tanto, la composición de OMP-LPS puede estar formada por dos de los componentes básicos de la Protolina, que incluyen (1) una preparación de proteína de membrana externa de Proteosomas (por ejemplo, Projuvant) preparada a partir de bacterias Gram-negativas, tales como Neisseria meningitidis, y (2) una preparación de uno o más liposacáridos. Un lipo-oligosacárido puede ser endógeno (por ejemplo, contenido de forma natural con la preparación de Proteosoma de OMP), se puede mezclar o combinar con una preparación de OMP a partir de un lipo-oligosacárido preparado de forma exógena (por ejemplo, preparado a partir de un cultivo o microorganismo diferente de a la preparación de OMP), o puede ser una combinación de los mismos. Tales LPS añadidos de forma exógena pueden ser de la misma bacteria Gram-negativa a partir de la que se fabricó la preparación de OMP o de una bacteria Gramnegativa diferente. Se debería entender que la protolina incluye opcionalmente lípidos, glicolípidos, glicoproteínas, moléculas pequeñas, o similares, y combinaciones de los mismos. La Protolina se puede preparar, por ejemplo, como se describe en la Publicación de Solicitud de Patente de Estados Unidos n.° 2003/0044425.
Las combinaciones de diferentes adyuvantes, tales como las mencionadas anteriormente en el presente documento, también se pueden usar en composiciones con antígenos de PreF. Por ejemplo, como ya se ha indicado, QS21 se puede formular junto con 3D-MPL. La proporción de QS21 : 3D-MPL por lo general será del orden de 1:10 a 10:1; tal como de 1:5 a 5:1, y a menudo sustancialmente 1:1. Por lo general, la proporción está en el intervalo de 2,5:1 a 1:1 de 3D-MPL: QS21. Otra formulación de adyuvante de combinación incluye 3D-MPL y una sal de aluminio, tal como hidróxido de aluminio. Cuando se formula en combinación con esta combinación puede aumentar una respuesta inmune de Th1 específica de antígeno.
En algunos casos, la formulación de adyuvante incluye una emulsión de aceite en agua, o una sal mineral, tal como una sal de calcio o aluminio, por ejemplo fosfato cálcico, fosfato de aluminio o hidróxido de aluminio.
Un ejemplo de una emulsión de aceite en agua comprende un aceite metabolizable, tal como escualeno, un tocol tal como tocoferol, por ejemplo, alfa-tocoferol, y un tensioactivo, tal como polisorbato 80 o Tween 80, en un vehículo acuoso y no contiene ningún inmunoestimulante(s) adicional, en particular, no contiene un derivado del lípido A no tóxico, (tal como 3D-MPL), o una saponina, (tal como QS21). El vehículo acuoso puede ser, por ejemplo, solución salina tamponada con fosfato. Además, la emulsión de aceite en agua puede contener Span 85 y/o lecitina y/o tricaprilina.
En otra realización de la invención se proporciona una composición de vacuna que comprende un antígeno o composición de antígeno y una composición de adyuvante que comprende una emulsión de aceite en agua y opcionalmente uno o más agentes inmunoestimulantes, en la que dicha emulsión de aceite en agua comprende 0,5 10 mg de aceite metabolizable (adecuadamente escualeno), 0,5-11 mg de tocol (adecuadamente un tocoferol, tal como alfa-tocoferol) y 0,4-4 mg de agente emulgente.
En una realización específica, la formulación de adyuvante incluye 3D-MPL preparado en forma de una inclusión, tal como en forma de una emulsión de aceite en agua. En algunos casos, la emulsión tiene un tamaño de partícula pequeña inferior a 0,2 pm de diámetro, como se desvela en el documento WO 94/21292. Por ejemplo, las partículas de 3D-MPL pueden ser lo suficientemente pequeñas como para filtrarse de forma estéril a través de una membrana de 0,2 pm (como se describe en el número de Patente Europea 0689454). Como alternativa, el 3D-MPL se puede preparar en una formulación liposomal. Opcionalmente, el adyuvante que contiene 3D-MPL (o un derivado del mismo) también incluye un componente inmunoestimulante adicional.
Por ejemplo, cuando una composición inmunogénica con un antígeno de polipéptido de PreF se formula para su administración a un lactante, la dosificación de adyuvante se determina para que sea eficaz y relativamente no reactogénica en un sujeto lactante. Por lo general, la dosificación de adyuvante en una formulación para lactante es inferior a la usada en formulaciones designadas para su administración a adultos ( por ejemplo, adultos con edades de 65 o superiores). Por ejemplo, la cantidad de 3D-MPL por lo general está en el intervalo de 1 pg-200 pg, tal como 10-100 pg, o 10 pg-50 pg por dosis. Una dosis para lactante está por lo general en el extremo inferior de este intervalo, por ejemplo, de aproximadamente 1 pg a aproximadamente 50 pg, tal como de aproximadamente 2 pg, o aproximadamente 5 pg, o aproximadamente 10 pg, a aproximadamente 25 pg, o a aproximadamente 50 pg. por lo general, cuando se usa QS21 en la formulación, los intervalos son comparables (y están de acuerdo con las proporciones indicadas anteriormente). Para poblaciones de adultos y ancianos, las formulaciones incluyen por lo general más de un componente adyuvante que por lo general se encuentra en una formulación infantil. En
formulaciones en particular que usan una emulsión de aceite en agua, una emulsión de este tipo puede incluir componentes adicionales, por ejemplo, tal como colesterol, escualeno, alfa tocoferol, y/o un detergente, tal como Tween 80 o Span 85. En formulaciones a modo de ejemplo, tales componentes pueden estar presentes en las siguientes cantidades: de aproximadamente 1-50 mg de colesterol, de un 2 a un 10 % de escualeno, de un 2 a un 10 % de alfa tocoferol y de un 0,3 a un 3 % de Tween 80. Por lo general, la proporción de escualeno: alfa tocoferol es igual o inferior a 1 ya que ésta proporciona una emulsión más estable. En algunos casos, la formulación también puede contener un estabilizante. Cuando el alumbre está presente, por ejemplo, en combinación con 3D-MPL, la cantidad está por lo general entre aproximadamente 100 |jg y 1 mg, tal como de aproximadamente 100 |jg, o aproximadamente 200 jg aproximadamente 750 jg, tal como aproximadamente 500 jg por dosis.
Una composición inmunogénica por lo general contiene una cantidad inmunoprotectora (o una dosis fraccionaria de la misma) del antígeno y se puede preparar mediante técnicas convencionales. La preparación en composiciones inmunogénicas, incluyendo aquellas para administración o sujetos humanos, por lo general se describe en Pharmaceutical Biotechnology, Vol. 61 Vaccina Design-the subunit and adjuvant approach, editado por Powell y Newman, Plenum Press, 1995. New Trends and Developments in Vaccines, editado por Voller y col., University Park Press, Baltimore, Maryland, U.S.A. 1978. La encapsulación dentro de liposomas se describe, por ejemplo, en Fullerton, de Patente de Estados Unidos n.° 4.235.877. La conjugación de proteínas a macromoléculas se desvela, por ejemplo, en Likhite, Patente de Estados Unidos n.° 4.372,945 y en Armor y col., Patente de Estados Unidos n.° 4.474.757.
Por lo general, la cantidad de proteína en cada dosis de la composición inmunogénica se selecciona como una cantidad que induce una respuesta inmunoprotectora sin efectos secundarios adversos significativos en el sujeto habitual. Inmunoprotector en este contexto no significa necesariamente que proteja completamente frente a la infección; significa protección frente a síntomas o enfermedad, en especial enfermedad grave asociada con el virus. La cantidad de antígeno puede variar dependiendo del inmunógeno específico que se use. Por lo general, se espera que cada dosis humana comprenda 1-1000 jg de proteína, tal como de aproximadamente 11 jg a aproximadamente 100 jg, por ejemplo, de aproximadamente 11 jg a aproximadamente 50 jg, tal como aproximadamente 1 jg, aproximadamente 2 jg, aproximadamente 5 jg, aproximadamente 10 jg, aproximadamente 15 jg, aproximadamente 20 jg, aproximadamente 25 jg, aproximadamente 30 jg, aproximadamente 40 jg, o aproximadamente 50 jg. La cantidad usada en una composición inmunogénica se selecciona basándose en la población de sujetos (por ejemplo, infantil o adulta). Una cantidad continua para una composición en particular se puede discernir con estudios convencionales que implican observación de titulaciones de anticuerpo y otras respuestas en sujetos. Después de una vacuna inicial, los sujetos pueden recibir un refuerzo en aproximadamente 4 semanas.
Se debería indicar que independientemente del adyuvante seleccionado, la concentración en la formulación final se calcula para que sea segura y eficaz en la población diana. Por ejemplo, algunas composiciones inmunogénicas para provocar una respuesta inmune frente al VSR en seres humanos se administra de forma favorable a bebés (por ejemplo, bebés entre el nacimiento y 1 años de edad, tal como entre 0 y 6 meses, a la edad de la dosis inicial). Algunas composiciones inmunogénicas para provocar una respuesta inmune frente al VSR también se administran de forma favorable a seres humanos adultos (por ejemplo, sola buen combinación con antígenos de otros patógenos asociados con EPOC). Se observará que la elección del adyuvante puede ser diferente en estas diferentes aplicaciones, y los expertos en la materia pueden determinar de forma empírica el adyuvante y concentración óptimos para cada situación.
En determinadas realizaciones, las composiciones inmunogénica son vacunas que reducen o previenen la infección con VSR. En algunas realizaciones, las composiciones inmunogénica son vacunas que reducen o previenen una respuesta patológica después de infección con VSR. Opcionalmente, las composiciones inmunogénicas que contienen un antígeno de PreF se formulan con al menos un antígeno adicional de un organismo patógeno distinto del VSR. Por ejemplo, el organismo patógeno puede ser un agente patógeno del tracto respiratorio (tal como un virus o bacteria que causa una infección respiratoria). En ciertos casos, la composición inmunogénica contiene un antígeno derivado del virus patógeno distinto del VSR, tal como un virus que causa una infección del tracto respiratorio, tal como gripe o parainfluenza. En otras realizaciones, los antígenos adicionales se seleccionan para facilitar la administración o reducir el número de inoculaciones necesarias para proteger a un sujeto frente a una pluralidad de organismos infecciosos. Por ejemplo, el antígeno se puede derivar de uno cualquiera o más de gripe, hepatitis B, difteria, tétanos, pertussis, Hemophilus influenza, poliovirus, Streptococcus o Pneumococcus, entre otros.
Por consiguiente, el uso de antígenos de PreF o ácidos nucleicos que los codifican en la preparación de un medicamento para tratar (ya sea de forma terapéutica después de o de forma profiláctica antes de) la exposición a una infección con el VSR también es una característica de la presente divulgación. De forma análoga, algunos procedimientos para provocar una respuesta inmune frente al VSR en un sujeto son una característica de la presente divulgación. Tales procedimientos incluyen la administración de una cantidad inmunológicamente eficaz de una composición que comprende un antígeno de PreF a un sujeto, tal como un sujeto humano. Normalmente, la composición incluye un adyuvante que provoca una respuesta inmune desviada hacia Th1. La composición se formula para provocar una respuesta inmune específica para el VSR sin aumentar la enfermedad viral después del contacto con el VSR. Es decir, la composición se formula para ir a como resultado una respuesta inmune desviada
hacia Th1 que reduce o previene la infección con un VSR y/o reduce o previene una respuesta patológica después de infección con un VSR. Aunque la composición se puede administrar mediante una diversidad de vías diferentes, lo más habitualmente, las composiciones inmunogénica se administran mediante una vía de administración intramuscular o intranasal.
Por lo general, una composición inmunogénica contiene una cantidad inmunoprotectora (o una dosis fraccionaria de la misma) del antígeno y se puede preparar mediante técnicas convencionales. La preparación de composiciones inmunogénicas, incluyendo las usadas para administración a sujetos humanos, por lo general se describe en Pharmaceutical Biotechnology, Vol. 61 Vaccina Design-the subunit and adjuvant approach, editado por Powell y Newman, Plenum Press, 1995. New Trends and Developments in Vaccines, editado por Voller y col., University Park Press, Baltimore, Maryland, U.S.A. 1978. La encapsulación dentro de liposomas se describe, por ejemplo, en Fullerton, Patente de Estados Unidos n.° 4.235.877. La conjugación de proteínas a macromoléculas se desvela, por ejemplo, en Likhite, Patente de Estados Unidos n.° 4.372.945 y en Armor y col., Patente de Estados Unidos n.° 4.474.757.
Por lo general, la cantidad de proteína en cada dosis de la composición inmunogénica se selecciona como una cantidad que induce una respuesta inmunoprotectora sin efectos secundarios adversos significativos en el sujeto habitual. En este contexto, inmunoprotector no significa necesariamente protección completamente frente a la infección; significa protección frente a síntomas o enfermedad, especialmente enfermedad grave asociada con el virus. La cantidad de antígeno puede variar dependiendo del inmunógeno específico que se esté usando. Por lo general, se espera que cada dosis humana comprenda 1-1000 |jg de proteína, tal como de aproximadamente 11 |jg a aproximadamente 100 jg, por ejemplo, de aproximadamente 11 jg a aproximadamente 50 jg, tal como aproximadamente 1 jg, aproximadamente 2 jg, aproximadamente 5 jg, aproximadamente 10 jg, aproximadamente 15 jg, aproximadamente 20 jg, aproximadamente 25 jg, aproximadamente 30 jg, aproximadamente 40 jg, o aproximadamente 50 jg. La cantidad usado en una composición inmunogénica se selecciona basándose en la población de sujetos (por ejemplo, niños o ancianos). Una cantidad óptima para una composición en particular se puede discernir con estudios convencionales que implican la observación de titulaciones de anticuerpo y otras respuestas en sujetos. Después de una vacuna inicial, los sujetos pueden recibir un refuerzo en aproximadamente 4 12 semanas. Por ejemplo, cuando se administra una composición inmunogénica que contiene un antígeno de PreF a un sujeto infantil, las inoculaciones iniciales y posteriores se pueden administrar para que coincidan con otras vacunas administradas durante este periodo.
Párrafos que desvelan adicionalmente aspectos de la invención:
1. Un antígeno del virus sincitial respiratorio (VSR) recombinante que comprende un polipéptido de la proteína F soluble que comprende al menos una modificación que estabiliza la conformación de prefusión de la proteína F.
2. Un antígeno del virus sincitial respiratorio (VSR) recombinante que comprende un polipéptido de la proteína F soluble, comprendiendo dicho polipéptido de la proteína F al menos una modificación seleccionada de:
(i) una adición de una secuencia de aminoácidos que comprende un dominio de trimerización heterólogo; (ii) una deleción de al menos un sitio de escisión de furina;
(iii) una deleción de al menos un sitio de escisión distinto de furina;
(iv) una deleción de uno o más aminoácidos del dominio pep27; y
(v) al menos una sustitución o adición de un aminoácido hidrófilo en un dominio hidrófobo del dominio extracelular de proteína F.
3. El antígeno de VSR recombinante del párrafo 1 o 2, en el que el polipéptido de la proteína F soluble comprende un dominio F2 y un dominio F1 de un polipéptido de la proteína F de VSR.
4. El antígeno de VSR recombinante de uno cualquiera de los párrafos 1-3, en el que la al menos una modificación comprende la adición de una secuencia de aminoácidos que comprende un dominio de trimerización heterólogo.
5. El antígeno de VSR recombinante del párrafo 4, en el que el dominio de trimerización heterólogo se sitúa en dirección C terminal del dominio F1.
6. El antígeno de VSR recombinante de uno cualquiera de los párrafos 1-5, que comprende un dominio F2 y un dominio F1 sin ningún sitio de escisión de furina intermedio.
7. Un análogo de proteína de Fusión (F) que comprende un dominio F2 y un dominio F1 de un polipéptido de la proteína F de VSR, en el que no hay ningún sitio de escisión de furina entre el dominio F2 y el dominio F1, y en el que el polipéptido comprende además un dominio de trimerización heterólogo situado en dirección C terminal del dominio F1.
8. El antígeno de VSR recombinante de uno cualquiera de los párrafos 1-7, en el que el antígeno de VSR se ensambla en un trímero.
9. El antígeno de VSR recombinante de uno cualquiera de los párrafos 3-8, en el que el dominio F2 comprende al menos una parte de un polipéptido de la proteína F de VSR correspondiente a los aminoácidos 26-105 del polipéptido precursor de proteína F de referencia F (Fo) de la SEQ ID. NO: 2.
10. El antígeno de VSR recombinante de uno cualquiera de los párrafos 3-9 y en el que el dominio F1 comprende al menos una parte de un polipéptido de la proteína F de VSR correspondiente a los aminoácidos 137-516 del polipéptido precursor de proteína F de referencia (Fo) de la SEQ ID NO: 2.
11. El antígeno de VSR recombinante de uno cualquiera de los párrafos 3-10, en el que el dominio F2 comprende un polipéptido de la proteína F de VSR correspondiente a los aminoácidos 26-105 y/o en el que el dominio F1 comprende un polipéptido de la proteína F de VSR correspondiente a los aminoácidos 137-516 del polipéptido precursor de proteína F de referencia (Fo) de la SEQ ID NO: 2.
12. El antígeno de VSR recombinante de uno cualquiera de los párrafos 9-11, en el que el antígeno de VSR se selecciona del grupo de:
a) un polipéptido que comprende la SEQ ID NO: 6;
b) un polipéptido que hibrida en condiciones rigurosas sobre sustancialmente su longitud completa con la SEQ ID NO: 6, comprendiendo dicho polipéptido una secuencia de aminoácidos correspondiente a una cepa de VSR de origen natural;
c) un polipéptido con al menos 95 % de identidad de secuencia con la SEQ ID NO: 6, comprendiendo dicho polipéptido una secuencia de aminoácidos que no corresponde a una cepa de VSR de origen natural.
13. El antígeno de VSR recombinante de uno cualquiera de los párrafos 1-12, que comprende además un péptido señal.
14. El antígeno de VSR recombinante de uno cualquiera de los párrafos 1-13, en el que el dominio F2 comprende los aminoácidos 1-105 del polipéptido de la proteína F de VSR.
15. El antígeno de VSR recombinante de uno cualquiera de los párrafos 3-14, en el que el dominio F2 y el dominio F1 se sitúan sin un dominio pep27 intermedio.
16. El antígeno de VSR recombinante de uno cualquiera de los párrafos 4-15, en el que el dominio de trimerización heterólogo comprende un dominio de bucles superenrollados.
17. El antígeno de VSR recombinante del párrafo 16, en el que el dominio de multimerización comprende una cremallera de isoleucina.
18. El antígeno de VSR recombinante del párrafo 17, en el que el dominio de cremallera de isoleucina comprende la secuencia de aminoácidos de la SEQ ID NO: 11.
19. El antígeno de VSR recombinante de uno cualquiera de los párrafos 1-18, en el que el antígeno de VSR comprende al menos una sustitución o adición de un aminoácido hidrófilo en un dominio hidrófobo del dominio extracelular de proteína F.
20. El antígeno de VSR recombinante del párrafo 19, en el que el dominio hidrófobo es el dominio de bucles superenrollados de HRB del dominio extracelular de proteína F.
21. El antígeno de VSR recombinante del párrafo 20, en el que el dominio de bucles superenrollados de HRB comprende la sustitución de un resto con carga en lugar de un resto neutro en la posición correspondiente al aminoácido 512 del precursor de proteína F de referencia (Fo) de la SEQ ID NO: 2.
22. El antígeno de VSR del párrafo 21, en el que el dominio de bucles superenrollados de HRB comprende una sustitución de leucina por lisina en la posición correspondiente al aminoácido 512 del precursor de proteína F de referencia (F0) de la s Eq ID NO: 2.
23. El antígeno de VSR recombinante del párrafo 19, en el que el dominio hidrófobo es el dominio de HRA del dominio extracelular de proteína F.
24. El antígeno de VSR recombinante del párrafo 23, en el que el dominio de HRA comprende la adición de un resto con carga tras la posición correspondiente al aminoácido 105 del precursor de proteína F de referencia (F0) de la SEQ ID NO: 2.
25. El antígeno de VSR recombinante del párrafo 24, en el que el dominio de HRA comprende la adición de una lisina tras la posición correspondiente al aminoácido 105 del precursor de proteína F de referencia (F0) de la SEQ ID NO: 2.
26. El antígeno de VSR recombinante de uno cualquiera de los párrafos 19-25, en el que el antígeno de VSR comprende al menos una primera sustitución o adición de un aminoácido hidrófilo en el dominio de HRA y al
menos una segunda sustitución o adición de un aminoácido hidrófilo en el dominio de HRB del dominio extracelular de proteína F.
27. El antígeno de VSR recombinante de uno cualquiera de los párrafos 1-26, en el que el antígeno de VSR comprende al menos una adición, deleción o sustitución de aminoácido que elimina un sitio de escisión de furina presente en un precursor de proteína F de origen natural (F0).
28. El antígeno de VSR recombinante de 27, en el que el antígeno de VSR comprende una adición, deleción o sustitución de aminoácidos que elimina un sitio de escisión de furina en una posición correspondiente a los aminoácidos 105-109, una posición correspondiente a los aminoácidos 133-136 o en ambas posiciones correspondientes a los aminoácidos 105-109 y 133-136 del precursor de proteína F de referencia (F0) de la SEQ ID NO: 2.
29. El antígeno de VSR recombinante de uno cualquiera de los párrafos 1-28, que comprende además un polipéptido de la proteína G que comprende las posiciones de aminoácidos 149 a 229 de un polipéptido de la proteína G de VSR.
30. El antígeno de VSR recombinante del párrafo 29, en el que el antígeno de VSR se selecciona del grupo de: a) un polipéptido que comprende las SEQ ID NO: 8 o SEQ ID NO: 10;
b) un polipéptido que hibrida en condiciones rigurosas sobre sustancialmente su longitud completa con al menos una de las SEQ ID NO: 8 y SEQ ID NO: 10, comprendiendo dicho polipéptido una secuencia de aminoácidos correspondiente a una cepa de VSR de origen natural;
c) un polipéptido con al menos 95 % de identidad de secuencia con al menos una de las SEQ ID NO: 8 y SEQ ID NO: 10, comprendiendo dicho polipéptido una secuencia de aminoácidos que no corresponde a una cepa de VSR de origen natural.
31. El antígeno de VSR recombinante del párrafo 29 o 30, en el que el polipéptido de la proteína G comprende una secuencia de aminoácidos correspondiente a las posiciones de aminoácidos 149 a 229 de la secuencia de proteína G de referencia de la SEQ ID NO: 4.
32. El antígeno de VSR recombinante del párrafo 31, en el que el polipéptido de la proteína G comprende los aminoácidos 149-229 de la SEQ ID NO: 4.
33. El antígeno de VSR recombinante del párrafo 29 o 30, en el que el polipéptido de la proteína G comprende al menos una sustitución de aminoácido en relación con un polipéptido de VSR de origen natural, correlacionándose dicha sustitución de aminoácido con la reducción o prevención de enfermedad vírica potenciada por vacuna.
34. El antígeno de VSR recombinante del párrafo 33, en el que la enfermedad vírica potenciada se reduce o previene cuando el antígeno de VSR se administra a un sujeto en ausencia de adyuvante.
35. El antígeno de VSR recombinante del párrafo 33, en el que la enfermedad vírica potenciada por vacuna se reduce o previene cuando el antígeno de VSR se administra a un sujeto humano.
36. El antígeno de VSR recombinante del párrafo 33, en el que el polipéptido de la proteína G comprende una sustitución de asparagina por alanina en la posición 191 (N191A) de la proteína G.
37. El antígeno de VSR recombinante de uno cualquiera de los párrafos 1-36, que comprende además un conector.
38. El antígeno de VSR recombinante del párrafo 37, en el que el conector comprende la secuencia de aminoácidos GG.
39. El antígeno de VSR recombinante del párrafo 38, en el que el conector comprende la secuencia de aminoácidos GGSGGSGGS.
40. El antígeno de VSR recombinante del párrafo 39, en el que el conector se selecciona del grupo de secuencias de aminoácidos que consiste en: GG y GGSGGSGGS.
41. El antígeno de VSR recombinante de uno cualquiera de los párrafos 1-40, en el que el polipéptido de la proteína F corresponde en secuencia a la cadena larga A de VSR.
42. El antígeno de VSR recombinante de uno cualquiera de los párrafos 1-41, en el que el polipéptido de la proteína F comprende además un marcador de polihistidina.
43. El antígeno de VSR recombinante de uno cualquiera de los párrafos 1-42, en el que el antígeno de VSR comprende un multímero de polipéptidos.
44. El antígeno de VSR recombinante de uno cualquiera de los párrafos 1-43, en el que el antígeno de VSR comprende un trímero de polipéptidos.
45. Una composición inmunogénica que comprende el antígeno de VSR recombinante de uno cualquiera de los párrafos 1-44, y un vehículo o excipiente farmacéuticamente aceptable.
46. La composición inmunogénica del párrafo 45, en la que el vehículo o excipiente comprende un tampón. 47. La composición inmunogénica del párrafo 45 o 46, que comprende además un adyuvante.
48. La composición inmunogénica del párrafo 47, en la que el adyuvante induce una respuesta inmunitaria desplazada hacia Th1.
49. La composición inmunogénica del párrafo 48, en la que el adyuvante comprende al menos uno de: 3D-MPL, QS21, una emulsión de aceite en agua y alumbre.
50. La composición inmunogénica del párrafo 49, en la que el adyuvante comprende una emulsión de aceite en agua.
51. La composición inmunogénica del párrafo 49 o 50, en la que la emulsión de aceite en agua comprende un tocol.
52. La composición inmunogénica de uno cualquiera de los párrafos 49-51, que comprende además 3D-MPL. 53. La composición inmunogénica del párrafo 49, en la que el adyuvante comprende 3D-MPL.
54. La composición inmunogénica del párrafo 53, que comprende además alumbre.
55. La composición inmunogénica del párrafo 53, que comprende además QS21.
56. La composición inmunogénica del párrafo 53, en la que el 3D-MPL y QS21 están en una formulación liposómica.
57. La composición inmunogénica del párrafo 47 o 48, en la que el adyuvante es adecuado para administración a un neonato.
58. La composición inmunogénica de uno cualquiera de los párrafos 45-57, en la que la composición inmunogénica reduce o previene la infección con Virus Sincitial Respiratorio (VSR).
59. La composición inmunogénica de uno cualquiera de los párrafos 45-58, en la que la composición inmunogénica reduce o previene una respuesta patológica después de infección con VSR.
60. La composición inmunogénica de uno cualquiera de los párrafos 45-59, en la que cuando la composición inmunogénica comprende el antígeno de VSR recombinante de uno cualquiera de los párrafos 1-28 la composición inmunogénica comprende además un polipéptido de la proteína G que comprende una secuencia de aminoácidos correspondiente a las posiciones de aminoácidos 149 a 229 de un polipéptido de la proteína G de VSR.
61. La composición inmunogénica del párrafo 60, en la que el polipéptido de la proteína G comprende una secuencia de aminoácidos correspondiente a las posiciones de aminoácidos 128-229 de un polipéptido de la proteína G de VSR.
62. La composición inmunogénica del párrafo 60 o 61, en la que el polipéptido de la proteína G comprende una secuencia de aminoácidos correspondiente a las posiciones de aminoácidos 149 a 229 de la secuencia de proteína G de referencia de la SEQ ID NO: 4.
63. La composición inmunogénica del párrafo 62, en la que el polipéptido de la proteína G comprende los aminoácidos 149-229 de la SEQ ID NO: 4.
64. La composición inmunogénica del párrafo 60 o 61, en la que el polipéptido de la proteína G comprende al menos una sustitución de aminoácido en relación con un polipéptido de VSR de origen natural, correlacionándose dicha sustitución de aminoácido con la reducción o prevención de enfermedad vírica potenciada por vacuna.
65. La composición inmunogénica del párrafo 60 o 64, en la que el polipéptido de la proteína G comprende un polipéptido de la proteína G de longitud completa o una proteína de fusión que comprende al menos una parte de un polipéptido de la proteína G.
66. La composición inmunogénica de uno cualquiera de los párrafos 45-65, que comprende además al menos un antígeno adicional de un organismo patógeno distinto de VSR.
67. La composición inmunogénica del párrafo 66, en la que el al menos un antígeno adicional es de un virus distinto de VSR.
68. La composición inmunogénica del párrafo 67, en la que el virus se selecciona de virus de la hepatitis B (VHB), virus paragripal (PIV), poliovirus y virus de la gripe.
69. La composición inmunogénica del párrafo 66, en la que el al menos un antígeno adicional se selecciona de: difteria, tétanos, tosferina, Haemophilus influenzae y Pneumococcus.
70. Un ácido nucleico recombinante que comprende una secuencia polinucleotídica que codifica el antígeno de VSR recombinante de uno cualquiera de los párrafos 1-44.
71. El ácido nucleico recombinante del párrafo 70, en el que la secuencia polinucleotídica que codifica el antígeno de VSR tiene codones optimizados para su expresión en una célula huésped seleccionada.
72. Un vector que comprende el ácido nucleico recombinante del párrafo 70 o 71.
73. El vector del párrafo 72, en el que el vector comprende un vector de expresión procariota o eucariota.
74. Una célula hospedadora que comprende el ácido nucleico del párrafo 70 o 71 o el vector del párrafo 72 o 73.
75. La célula hospedadora del párrafo 74, en la que la célula hospedadora se selecciona del grupo de: células bacterianas, células de insectos y células de mamíferos.
76. Una composición inmunogénica que comprende el ácido nucleico del párrafo 70 o 71, y un vehículo o excipiente farmacéuticamente aceptable.
77. El uso del antígeno de VSR de uno cualquiera de los párrafos 1-44 o el ácido nucleico del párrafo 70 o 71 en la preparación de un medicamento para tratar una infección por VSR.
78. El uso del antígeno de VSR o ácido nucleico del párrafo 76, en el que el medicamento se administra con el fin de tratar de forma profiláctica una infección por VSR.
79. Un método para inducir una respuesta inmunitaria contra Virus Sincitial Respiratorio (VSR), comprendiendo el método: administrar a un sujeto una composición que comprende el antígeno de VSR recombinante de uno cualquiera de los párrafos 1-44 o la composición inmunogénica de uno cualquiera de los párrafos 45-69.
80. El método del párrafo 79, en el que la administración de la composición que comprende el antígeno de VSR induce una respuesta inmunitaria específica para VSR sin potenciar la enfermedad vírica después del contacto con VSR.
81. El método del párrafo 79 u 80, en el que la respuesta inmunitaria comprende una respuesta inmunitaria desplazada hacia Th1.
82. El método de uno cualquiera de los párrafos 79-81, en el que la respuesta inmunitaria comprende una respuesta inmunitaria protectora que reduce o previene la infección con un VSR y/o reduce o previene una respuesta patológica tras infección con un VSR.
83. El método de uno cualquiera de los párrafos 79-82, en el que el sujeto es un sujeto humano.
84. El método de uno cualquiera de los párrafos 79-83, que comprende administrar la composición que comprende el antígeno de VSR comprende administrar mediante una vía intranasal.
85. El método de uno cualquiera de los párrafos 79-83, que comprende administrar la composición que comprende el antígeno de VSR comprende administrar mediante una vía intramuscular.
86. El antígeno de VSR recombinante de uno cualquiera de los párrafos 1-44 o la composición inmunogénica de uno cualquiera de los párrafos 45-69 para su uso en medicina.
87. El antígeno de VSR recombinante de uno cualquiera de los párrafos 1-44 o la composición inmunogénica de uno cualquiera de los párrafos 45-69 para la prevención o el tratamiento de enfermedades asociadas con VSR. Los siguientes ejemplos se proporcionan para ilustrar ciertas características y/o realizaciones en particular. No se debería interpretar que estos ejemplos limitan la invención a las características por realizaciones que se describen en particular.
Ejemplos
Ejemplo 1: Antígenos de PreF a modo de ejemplo
El antígeno de PreF se modificó en comparación con una proteína F del VSR nativa para estabilizar la proteína en su conformación de prefusión, basándose en la predicción de que una respuesta inmune generada en la conformación de prefusión de F incluiría preferentemente anticuerpos que evitarían la unión, desplazamiento de conformación y/o otros sucesos implicados en la fusión de la membrana, aumentando de ese modo la eficacia de la respuesta protectora.
La FIG. 1A y B ilustran de forma esquemática características de F0 del VSR y antígenos recombinantes de PreF a modo de ejemplo. La FIG. 1A es una representación de la proteína F0 del VSR. F0 es una proteína previa que consiste en 574 aminoácidos. La proteína previa F0 se procesa de forma proteolítica y se glicosilada después de la traducción. Un péptido señal, que posteriormente se retira con una peptidasa señal, dirige la traducción de la proteína previa F0 al retículo endoplasmático (RE). El péptido emergente en el RE se N-glicosila a continuación en múltiples sitios (representados por triángulos). La escisión de la furina de F0 genera dominios peptídicos F2 y F1, que se pliegan y ensamblan en conjunto como un trímero de heterodímeros F2-F1 (es decir, 3 veces F2-F1). En su estado nativo, la proteína F está anclada a la membrana mediante una hélice transmembrana helix en la región C-terminal. La adición de características del polipéptido F0 incluye, 15 restos de cisteína, 4 epítopos de neutralización caracterizados, 2 regiones de bucles superenrollados, y un motivo de lipidación. La FIG. 1B ilustra características de antígenos de PreF a modo de ejemplo. Para construir el antígeno de PreF, el polipéptido F0 se modificó para estabilizar la conformación de prefusión de la proteína F, reteniendo de este modo los epítopos inmunogénicos predominantes de la proteína F como se presenta con el virus del VSR antes de la unión a y fusión con células hospedadoras. Las siguientes mutaciones de estabilización se introdujeron en el antígeno de PreF con respecto al polipéptido F0. En primer lugar, un dominio bucles superenrollados de estabilización se puso en el extremo C-terminal del dominio extracelular del polipéptido de F0, reemplazando el dominio de anclaje a membrana de F0. En segundo lugar, el péptido pep27 (situado entre los dominios F2 y F1 en la proteína nativa) se retiró. En tercer lugar, ambos motivos de furina se eliminaron. En realizaciones alternativas (denominados PreF_V1 y PreF_V2), una parte inmunológicamente activa (por ejemplo, aminoácidos 149-229) de la proteína G del VSR se añadió al dominio C-terminal.
Ejemplo 2: Producción y purificación de proteína recombinante de PreF a partir de células CHO
Una secuencia de polinucleótidos recombinantes que codifica un antígeno de PreF a modo de ejemplo se introdujo en células CHO hospedadoras para la producción de antígeno de PreF. Las células hospedadoras transfectadas de forma transitoria o poblaciones estables expandidas que comprenden la secuencia de polinucleótidos introducida se cultivaron en medio y en condiciones adecuadas para el crecimiento en una escala aceptable para el fin deseado (por ejemplo, como se describe por lo general en Freshney (1994) Culture of Animal Cells, a Manual of Basic Technique, tercera edición, Wiley- Liss, New York y las referencias citadas en ese documento). Por lo general, las células se cultivaron en medio sin suero en matraces de agitación a 37 °C con CO2 al 5 % y se pasaron a intervalos de 2-3 días, o en biorreactores a 29 °C con pO2 mantenido a un 20 %.
Para recuperar antígeno de PreF recombinante, el cultivo celular se centrifugó y el sobrenadante cultivo celular se almacenó a -80 °C hasta su uso posterior. Para un análisis más detallado, se diluyeron alícuotas de 2 litros de sobrenadante de cultivo celular con agua purificada 2x y el pH se ajustó a pH 9,5 con NaOH. El sobrenadante se cargó a una tasa de 14 ml/min en una columna de intercambio iónicos Q Sepharose FF (60 ml, 11,3 cm), equilibrada en piperazina 20 mM a pH 9,5. Después de lavar la columna con el tampón de partida, la elución se realizó con un gradiente de NaCl de 0 a 0,5 M de NaCl en 20 volúmenes de columna (tamaño de la fracción 10 ml). Las fracciones se analizaron en gel de SDS PAGE mediante tinción con plata y transferencia de Western. Las fracciones que contenían la proteína PreF sustancial se combinaron a continuación antes del procesamiento adicional.
La elución combinada de la etapa Q (~ 130 ml) se sometió a intercambio de tampón en fosfato 10 mM, pH 7,0 usando el sistema TFF a escala experimental de Millipore con el casete de membrana Pelllicon XL PSE Biomax 100 (MWCO 10.000 Da). El material de Resultante tenía un pH de 7,0 y una conductividad de 1,8 mS/cm. Se cargaron 100 ml de esta muestra a 5 ml/min en 10 ml de un gel (XK 16, altura = 5 cm) de Hidroxiapatita de Tipo II (HA TII) equilibrada con tampón de PO4 (Na) 10 mM a pH 7,0. Después de lavar la columna con el tampón de partida, la elución se realizó con un gradiente de PO4 (Na) de 10 mM a 200 mM a pH 7,0 en 20 volúmenes de columna. Las fracciones se analizaron de nuevo en SDS PAGE con tinción de plata y azul de Coomassie y las fracciones positivas se combinaron.
Después de cromatografía de afinidad, las fracciones combinadas se concentraron y el tampón se intercambió en DPBS (pH ~ 7,4) usando una unidad concentradora Vivaspin 20, MWCO 10.000 Da. El producto final era de aproximadamente 13 ml. La concentración de la proteína fue de 195 pg/ml, evaluada con el ensayo de Lowry. La pureza era superior a un 95 %. Esta preparación de antígeno de PreF purificado se esterilizó por filtración y se almacenó a -20 °C antes de su uso.
Ejemplo 3: Caracterización de la proteína recombinante PreF producida en células CHO
La proteína recombinante PreF producida en células CHO se caracterizó mediante fraccionamiento de flujo de campo asimétrico (AFF-MALS) y se comparó con un antígeno quimérico que incluía componentes de las proteínas F y G del VRS. AFF-MALS permite la separación de especies de proteínas de acuerdo con su tamaño molecular en un
flujo de líquido con interacción de matriz mínima y análisis adicional mediante dispersión de luz multiángulo para la determinación exacta del peso molecular. La FIG. 2A muestra que más de un 65 % del material de FG purificado se encuentra en forma de oligómeros de alto peso molecular (1000-100000 KDa) en su tampón final de PBS, mientras que un 3 % permanece en forma monomérica.
La FIG. 2B muestra que la proteína PreF purificada se pliega en su forma trimérica hasta una proporción de un 73 % en tampón PBS. Un 10% del material se encuentra como oligómeros de 1000 a 20 000 kDa. Estos resultados indican que la proteína PreF recombinante expresada en células CHO se pliega como un trímero como se predijo para el estado nativo.
La proteína PreF purificada también se reticuló con glutaraldehído con la doble finalidad de confirmar la naturaleza soluble de la proteína en solución de tampón fosfato y para generar agregados para evaluación comparativa in vivo con proteína Fg (véase el Ejemplo 7 que sigue a continuación). La reticulación con glutaraldehído se conoce porque proporciona una buena evaluación de la estructura cuaternaria de una proteína, y se describe en (Biochemistry, 36: 10230-10239 (1997); Eur. J. Biochem., 271: 4284-4292 (2004)).
La proteína se incubó con un 1 %, 2 % y 5 % de agente de reticulación con glutaraldehído durante 4 horas a 4 °C y la reacción se bloqueó mediante la adición de NaBH4. El exceso de glutaraldehído se retiro por desalación de la columna en tampón PBS. La proteína resultante se cuantificó por absorbancia a 280 nm y se evaluó por SDS PAGE en condiciones de desnaturalización y reducción. Se determinó que la mayor parte del PreF recombinante purificado se determinó migraba como un trímero en solución de PBS. El aumento de la temperatura de incubación a 23 °C era necesario para convertir la mayor parte de la proteína trimérica en agregados de alto peso molecular, tal como se confirma por SDS PAGE.
Ejemplo 4: Neutralización de la inhibición in vitro con el antígeno de PreF
Los sueros humanos obtenidos de voluntarios se identificaron sistemáticamente para reactividad contra el VSR A con ELISA y se usó en el ensayo de inhibición de neutralización (NI) a dilución relevante basándose en la valoración del potencial de neutralización del VSR previa establecido para cada muestra de suero. En resumen, los sueros se mezclaron con proteínas inhibidoras (PreF o una proteína de control correspondiente esencialmente al FG quimérico desvelado en la Patente de Estados Unidos n.° 5.194,595, denominado RixFG) a concentraciones de 25 pg/ml en DMEM con medio 199-H al 50 %, con FBS al 0,5 %, glutamina 2 mM, 50 pg/ml de genamicina (todos de Invitrogen), y se incubó de 1,5 a 2 horas a 37 °C en una rueda giratoria. Se mezclaron 20 pl de las diluciones en serie de proteínas de suero y proteína en una placa de 96 pocillos de fondo redondo con un VSR A titulado para optimizar el rango de inhibición para cada muestra de suero. Las mezclas resultantes se incubaron durante 20 minutos a 33 °C en atmósfera de CO2 al 5 % para mantener el pH.
Las mezclas de sueros-inhibidor-virus se colocaron a continuación en placas de 96 pocillos de fondo plano sembradas previamente con células Vero, y se incubaron durante 2 horas a 33 °C antes de la adición de 160 pl de medio. Las placas se incubaron durante 5-6 días a 33 °C atmósfera de CO2 al 5 % hasta el ensayo de inmunofluorescencia para la detección de la titulación de NI. Después de la fijación durante 1 hora con paraformaldehído al 1 % en solución salina tamponada con fosfato (PBS), las placas se bloquearon con leche al 2 %/PBS y tampón de bloqueo. Se añadió anticuerpo de anti-VSR de cabra (Biodesign Internation; 1:400) a cada pocillo sin aclarar y se incubó durante 2 horas a temperatura ambiente (TA). Las muestras se lavaron 2x con PBS y se añadió IgG-FITC anti-cabra (Sigma, 1:400) en tampón de bloqueo a los pocillos. Las placas se incubaron de nuevo durante 2 horas a TA y se lavaron 2X como anteriormente antes de la lectura. Un pocillo se consideró positivo cuando se detectaba sincitio fluorescente > 1. Los cálculos de la dosis infecciosa de cultivo tisular al 50 % (TCID50) se realizaron usando el procedimiento de Spearman-Karber (SK) y los porcentajes de NI se calcularon como sigue a continuación: [(titulación de Neut de 0 pg/ml de inhibidor - titulación de Neut de 25 pg/ml de inhibidor)/titulación de Neut de 0 pg/ml de inhibidor] x 100. Los resultados a modo de ejemplo mostrados en la FIG. 3 indican que PreF es superior a FG en NI en 16/21 donantes sometidos a ensayo.
Ejemplo 5: El antígeno de PreF es inmunogénico
Para demostrar la inmunogenicidad del antígeno PreF, los ratones inmunizaron dos veces IM a intervalos de dos semanas con preF (6,5, 3,1, 0,63, 0,13, y 0,025 pg/ml) y un adyuvante de Th1 que contenía 3D MPL y QS21 a 1/20 de la dosis humana ("AS01E") o preF (1, 0,2 y 0,04 pg/ml) y un adyuvante de Th1 que contenía 3D m Pl y alumbre a 1/10 de la dosis humana ("AS04C") y el suero se recogió tres semanas más tarde.
Las titulaciones de anticuerpo de IgG específico de antígeno se determinaron en muestras de suero combinadas mediante ELISA de acuerdo con procedimientos convencionales. En resumen, las placas de 96 pocillos se revistieron con VSR A inactivado purificado, VSR B y proteína homóloga de preF y se incubaron durante una noche a 4 °C. Las muestras de suero se diluyeron en serie en tampón de bloqueo comenzando a una concentración inicial de 1:50, junto con IgG de ratón purificada (Sigma, ON) a concentraciones de partida de 200 ng/ml y se incubaron durante 2 h a temperatura ambiente. El anticuerpo unido se detectó con IgG anti-ratón conjugada con peroxidasa de rábano picante (HRP) (Sigma, ON). Como sustrato para HRP se usó 3,3A,5,5A-tetrametilbencidina (TMB, BD Opt EIATM, BD Biosciences, ON). Se añadieron 50 pl de H2SO41 M a cada pocillo para parar la reacción. Los valores de
absorbancia para cada pocilio se detectaron a 450 nm con un lector de microplacas de Molecular Devices (Molecular Devices, USA).
Los resultados representativos detallados en las FIGS. 4A y 4B muestran que algunas titulaciones fuertes se inducen tanto frente a VSR A como a VSR B después de inmunización con antígeno de preF.
Ejemplo 6: PreF induce anticuerpos de neutralización
La presencia y cantidad de anticuerpos de neutralización se evaluó en muestras de suero de ratones inmunizados como se ha descrito anteriormente en el Ejemplo 5. Los sueros combinados de animales inmunizados se diluyeron en serie desde una dilución de partida de 1:8 en medios de VSR en placas de 96 pocillos (20 pl/pocillos). Los pocillos de control contenían medio de VSR solamente, o anticuerpo anti-VSR de cabra a 1:50 (Biodesign international). Se añadieron 500-1000 dosis infecciosas de una cepa A o B del VSR representativa a los pocillos, y las placas se incubaron durante 20 minutos a 33 °C, CO2 al 5 %, antes de transferir la mezcla a placas de fondo plano de 96 pocillos sembradas previamente con 1 x 105 células/ml de células Vero. Las células se incubaron durante aproximadamente 2 horas a 33 °C, CO2 al 5 %, antes de incubación durante 5-6 días a la misma temperatura. Los sobrenadantes se retiraron; las placas se lavaron con PBS y las células de adherencia se fijaron con paraformaldehído al 1 % en PBS durante 1 hora, seguido de inmunofluorescencia indirecta (IFA) usando un anticuerpo primario anti VSR de cabra e IgG-FITC anti-cabra para detección.
Los resultados representativos mostrados en las FIGS 5A y 5B, respectivamente, demuestran que los anticuerpos de neutralización significativos frente a ambas cepas del v Sr se detectan en sueros de animales inmunizados con preF.
Ejemplo 7: PreF protege frente a la estimulación con VSR
Los ratones se inmunizaron dos veces IM a intervalos de dos semanas como se ha descrito anteriormente, y se estimularon tres semanas después de la segunda inyección con VSR A. La protección frente al VSR se evaluó mediante la medida del virus presente en los pulmones después de la estimulación. En resumen, los pulmones de animales inmunizados se extrajeron de forma aséptica después de eutanasia y se lavaron en medio de VSR usando 2 volúmenes de 10 ml/pulmón en tubos de 15 ml. A continuación, los pulmones se pesaron y homogeneizaron de forma individual en medio de VSR con un homogeneizador Potter automatizado (Fisher, Nepean ON), y se centrifugaron a 2655 x g durante 2 minutos a 4 °C. El virus presente en los sobrenadante se tituló mediante diluciones en serie (ocho replicados comenzando a 1:10) en una monocapa de células Vero (ATCC n.° CCL-81) sembradas previamente en placas de 96 pocillos y se incubó durante 6 días. El VSR se detectó mediante IFA indirecto después de fijación en paraformaldehído al 1 %/PBS a pH 7,2, con anticuerpo primario anti-VSR de cabra y anticuerpo secundario de IgG anti-cabra etiquetado con FITC.
Los resultados representativos mostrados en las FIGS. 6A y B demuestran que las dosis iguales o superiores a 0,04 pg cuando se administran en presencia de adyuvante provocan una fuerte protección frente al VSR.
Ejemplo 8: PreF no induce reclutamiento pulmonar de eosinófilos después de estimulación
Para evaluar el potencial del antígeno PreF para provocar enfermedad exacerbada después de inmunización y estimulación posterior, los grupos de ratones (5 ratones/grupo) se inmunizaron dos veces cada uno con (a) 10 pg de preF tratado con gluteraldehído, (b) 10 pg de preF o (c) 10 pg de FG sin adyuvante. Los ratones se estimularon con VSR A 3 semanas después de estimulación y el lavado broncoalveolar (BAL) se realizó 4 días después de la estimulación. Los infiltrados de leucocitos totales en BAL se enumeraron por ratón así como enumeraciones diferenciales (300 células) basándose en la morfología celular de macrófagos/monocitos, neutrófilos, eosinófilos y linfocitos.
Los números de células totales se multiplicaron mediante porcentajes diferenciales de eosinófilos para cada animal. Las medias geométricas se representan por grupo con límites de confianza de un 95 %. Los resultados representativos mostrados en la FIG. 7 demuestran que los eosinófilos no se reclutan a los pulmones después de inmunización con preF y estimulación. Además, estos resultados sugieren que la naturaleza soluble del antígeno preF, en comparación con una forma de preF agregada de forma deliberada (tratamiento con gluteraldehído) o antígeno de FG (agregado de forma natural) no favorece a los eosinófilos.
Listado de secuencias
SEQ ID NO: 1
Secuencia de nucleótidos que codifica la Cepa de proteína de Fusión de referencia del VSR con N.° de Referencia en GenBank U50362

SEQ ID NO: 2
Secuencia de aminoácidos de la Cepa A2 de precursor F0 de la proteína F de referencia del VSR con N.° de Referencia en GenBank AAB86664

SEQ ID NO: 3
Secuencia de nucleótidos que codifica la Cepa Larga de la proteína G de referencia del VSR

SEQ ID NO: 4
Secuencia de aminoácidos de la proteína G de referencia del VSR

SEQ ID NO: 5
Secuencia de nucleótidos de análogo de PreF optimizado para CHO

SEQ ID NO: 6
Secuencia de aminoácidos de análogo de PreF

SEQ ID NO: 7
Secuencia de nucleótidos que codifica PreFG_V1 optimizado para CHO


SEQ ID NO: 8
Péptido PreFG_V1 para CHO

SEQ ID NO: 9
PreF_V2 para CHO

SEQ ID NO: 10
Péptido PreFG_V2 para CHO

SEQ ID NO: 11
Superenrollamiento a modo de ejemplo (cremallera de isoleucina) EDKIEEILSKIYHIENEIARIKKLIGEA
SEQ ID NO: 12
Polinucleótido CHO2 del antígeno PreF

SEQ ID NO: 13
Polinucleótido del antígeno PreF con intrón

SEQ ID NO: 14 Secuencia sintética de engarce
GGSGGSGGS SEQ ID NO: 15 Sitio de escisión de furina
RARR SEQ ID NO: 16 Sitio de escisión de furina
RKRR LISTADO DE SECUENCIAS
<110> GlaxoSmithKline Biologicals S.A. ID Corporación Biomédica de Quebec BAUDOUX, Guy J-M BLAIS, Normand Rheault, Patrick RUELLE, Jean-Louis
<120> Antígeno recombinante
<130>VU62788
<150> 61/016,524
<151 > 24-12-2007
<150> 61/056,206
<151 > 2008-05-27
<160> 16
<170> PatentIn versión 3.5
<210> 1
<211>1697
<212> ADN
<213> virus sincitial respiratorio
<400> 1

<210>2
<211> 574
<212> PRT
<213> virus sincitial respiratorio
Claims (9)
1. Un antígeno del virus sincitial respiratorio recombinante (VSR) que se ensambla en un trímero, que comprende un polipéptido de la proteína F soluble que comprende un dominio F2 y un dominio F1 de un polipéptido de la proteína F del VSR y que comprende una secuencia de aminoácidos que comprende un dominio de trimerización heterólogo en posición C-terminal con respecto al dominio F1 que estabiliza la conformación de prefusión de la proteína F.
2. El antígeno del VSR recombinante de la reivindicación 1, que comprende además un péptido señal.
3. El antígeno del VSR recombinante de una cualquiera de las reivindicaciones 1-2, en el que el dominio de trimerización heterólogo comprende un dominio de bucles superenrollados.
4. Un ácido nucleico recombinante que codifica el antígeno del VSR recombinante de una cualquiera de las reivindicaciones 1-3.
5. Una composición inmunogénica que comprende el antígeno del VSR recombinante de una cualquiera de las reivindicaciones 1-3, y un vehículo o excipiente farmacéuticamente aceptable.
6. La composición inmunogénica de la reivindicación 5 que comprende además un adyuvante.
7. La composición inmunogénica de la reivindicación 6, en la que el adyuvante comprende al menos uno de: 3D-MPL, QS21, una emulsión de aceite en agua y alumbre.
8. El uso del antígeno del VSR de una cualquiera de las reivindicaciones 1-3 o el ácido nucleico recombinante de la reivindicación 4 en la preparación de un medicamento para tratar una infección por VSR.
9. El antígeno del VSR recombinante de una cualquiera de las reivindicaciones 1-3 o la composición inmunogénica de una cualquiera de las reivindicaciones 5-7 para su uso en la prevención o tratamiento de enfermedades asociadas con el VSR.






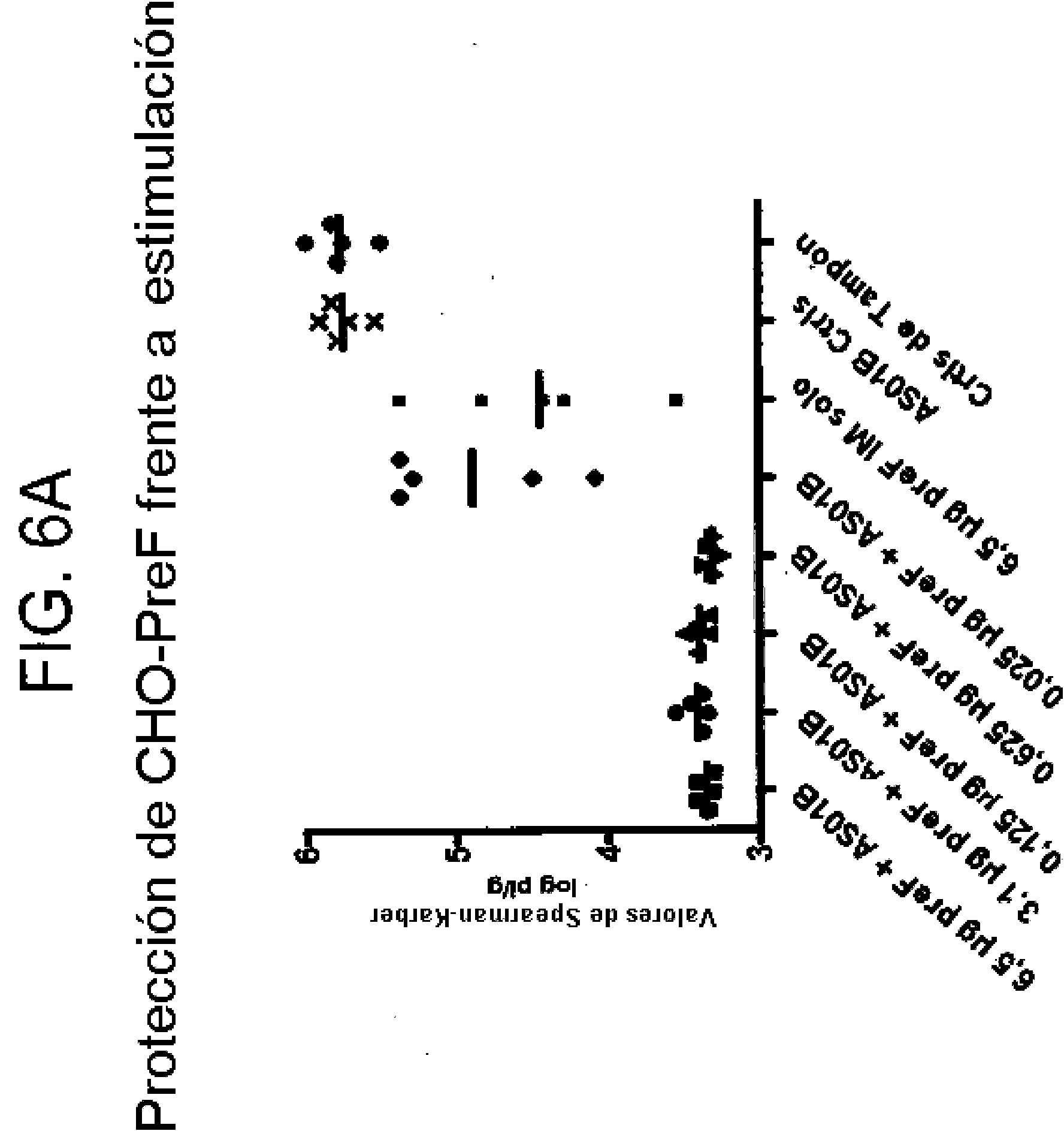


Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US1652407P | 2007-12-24 | 2007-12-24 | |
| US5620608P | 2008-05-27 | 2008-05-27 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| ES2719406T3 true ES2719406T3 (es) | 2019-07-10 |
Family
ID=40800629
Family Applications (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| ES16180926T Active ES2719406T3 (es) | 2007-12-24 | 2008-12-23 | Antígenos recombinantes del VSR |
| ES08864495.0T Active ES2597439T3 (es) | 2007-12-24 | 2008-12-23 | Antígenos recombinantes del VSR |
Family Applications After (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| ES08864495.0T Active ES2597439T3 (es) | 2007-12-24 | 2008-12-23 | Antígenos recombinantes del VSR |
Country Status (23)
| Country | Link |
|---|---|
| US (1) | US8563002B2 (es) |
| EP (7) | EP4108687A1 (es) |
| JP (1) | JP5711972B2 (es) |
| KR (1) | KR101617895B1 (es) |
| CN (1) | CN101952321B (es) |
| AU (1) | AU2008340949A1 (es) |
| BR (1) | BRPI0821532A2 (es) |
| CA (1) | CA2710600C (es) |
| CY (1) | CY1118090T1 (es) |
| DK (1) | DK2222710T3 (es) |
| EA (1) | EA021393B1 (es) |
| ES (2) | ES2719406T3 (es) |
| HR (1) | HRP20161353T1 (es) |
| HU (1) | HUE029258T2 (es) |
| LT (1) | LT2222710T (es) |
| MX (1) | MX2010007107A (es) |
| PL (1) | PL2222710T3 (es) |
| PT (1) | PT2222710T (es) |
| RS (1) | RS55162B1 (es) |
| SG (1) | SG188813A1 (es) |
| SI (1) | SI2222710T1 (es) |
| WO (1) | WO2009079796A1 (es) |
| ZA (1) | ZA201004289B (es) |
Families Citing this family (78)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP2425854A1 (en) | 2005-04-08 | 2012-03-07 | Wyeth LLC | Multivalent pneumococcal polysaccharide-protein conjugate composition |
| BRPI0821532A2 (pt) | 2007-12-24 | 2015-06-16 | Id Biomedical Corp Quebec | Antígenos de rsv recombinantes |
| MX2011000668A (es) * | 2008-07-18 | 2011-07-29 | Id Biomedical Corp Quebec | Antigenos quimericos polipeptidicos del virus sincitial respiratorio. |
| US11446374B2 (en) | 2008-12-09 | 2022-09-20 | Novavax, Inc. | Modified RSV F proteins and methods of their use |
| SG172022A1 (en) | 2008-12-09 | 2011-07-28 | Novavax Inc | Modified rsv f proteins and methods of their use |
| US8858952B2 (en) * | 2009-02-19 | 2014-10-14 | Mayo Foundation For Medical Education And Research | Methods and materials for generating T cells |
| MX2012000036A (es) | 2009-06-24 | 2012-02-28 | Glaxosmithkline Biolog Sa | Vacuna. |
| SI2445526T1 (sl) | 2009-06-24 | 2016-08-31 | Glaxosmithkline Biologicals S.A. | Rekombinantni RSV antigeni |
| WO2011008974A2 (en) * | 2009-07-15 | 2011-01-20 | Novartis Ag | Rsv f protein compositions and methods for making same |
| CN102481309B (zh) * | 2009-07-17 | 2014-06-18 | 翰林大学校产学协力团 | 包含脂质体包胶的寡核苷酸和表位的免疫刺激性组合物 |
| US20120315270A1 (en) * | 2009-10-21 | 2012-12-13 | The United States Of America, As Represented By The | Rsv immunogens, antibodies and compositions thereof |
| US9718862B2 (en) | 2010-10-06 | 2017-08-01 | University Of Washington Through Its Center For Commercialization | Polypeptides and their use in treating and limiting respiratory syncytial virus infection |
| EP2667892B1 (en) | 2011-01-26 | 2019-03-27 | GlaxoSmithKline Biologicals SA | Rsv immunization regimen |
| WO2012116715A1 (en) * | 2011-03-02 | 2012-09-07 | Curevac Gmbh | Vaccination in newborns and infants |
| WO2012116714A1 (en) | 2011-03-02 | 2012-09-07 | Curevac Gmbh | Vaccination in elderly patients |
| US9585953B2 (en) * | 2011-03-22 | 2017-03-07 | Mucosis B.V. | Immunogenic compositions in particulate form and methods for producing the same |
| LT3275892T (lt) | 2011-05-13 | 2020-04-10 | Glaxosmithkline Biologicals S.A. | Struktūros prieš suliejimą rsv f antigenai |
| US11058762B2 (en) | 2011-07-06 | 2021-07-13 | Glaxosmithkline Biologicals Sa | Immunogenic compositions and uses thereof |
| CN102294027A (zh) * | 2011-07-26 | 2011-12-28 | 昆明理工大学 | 一种呼吸道合胞病毒f2蛋白亚单位疫苗及其制备方法 |
| JP6085886B2 (ja) | 2011-08-29 | 2017-03-01 | 国立大学法人徳島大学 | Rsv粘膜ワクチン |
| WO2013049342A1 (en) * | 2011-09-30 | 2013-04-04 | Novavax, Inc. | Recombinant nanoparticle rsv f vaccine for respiratory syncytial virus |
| US9701720B2 (en) | 2012-04-05 | 2017-07-11 | University Of Washington Through Its Center For Commercialization | Epitope-scaffold immunogens against respiratory syncytial virus (RSV) |
| US9241988B2 (en) * | 2012-04-12 | 2016-01-26 | Avanti Polar Lipids, Inc. | Disaccharide synthetic lipid compounds and uses thereof |
| RU2518277C2 (ru) * | 2012-07-09 | 2014-06-10 | Федеральное государственное бюджетное учреждение "Научно-исследовательский институт гриппа" Министерства здравоохранения и социального развития Российской Федерации | Способ лечения гриппа и гриппоподобных заболеваний, осложненных пневмонией |
| US9480738B2 (en) | 2012-08-01 | 2016-11-01 | Bavarian Nordic A/S | Recombinant modified vaccinia virus ankara (MVA) respiratory syncytial virus (RSV) vaccine |
| EP2922570A1 (en) * | 2012-11-20 | 2015-09-30 | GlaxoSmithKline Biologicals SA | Rsv f prefusion trimers |
| US9738689B2 (en) | 2013-03-13 | 2017-08-22 | The United States Of America, As Represented By The Secretary, Department Of Health And Human Services | Prefusion RSV F proteins and their use |
| KR20220139415A (ko) | 2013-03-13 | 2022-10-14 | 더 유나이티드 스테이츠 오브 어메리카, 애즈 리프리젠티드 바이 더 세크러테리, 디파트먼트 오브 헬쓰 앤드 휴먼 서비씨즈 | 선융합(prefusion) RSV F 단백질 및 이의 용도 |
| EP2983708A4 (en) * | 2013-04-08 | 2016-10-05 | Medimmune Llc | VACCINE COMPOSITION AND METHOD OF USE |
| AU2014259474B2 (en) | 2013-04-25 | 2018-09-13 | Janssen Vaccines & Prevention B.V. | Stabilized soluble prefusion RSV F polypeptides |
| MY171210A (en) | 2013-06-17 | 2019-10-02 | Janssen Vaccines & Prevention Bv | Stabilized soluble pre-fusion rsv f polypeptides |
| JP6685903B2 (ja) | 2013-07-25 | 2020-04-22 | アバター・メディカル・エルエルシー | 立体構造的に安定化されたrsv融合前fタンパク質 |
| US20150110825A1 (en) * | 2013-09-24 | 2015-04-23 | Massachusetts Institute Of Technology | Self-assembled nanoparticle vaccines |
| US20150166610A1 (en) * | 2013-10-14 | 2015-06-18 | Glaxosmithkline Biologicals, S.A. | Recombinant rsv antigens |
| US11571472B2 (en) | 2014-06-13 | 2023-02-07 | Glaxosmithkline Biologicals Sa | Immunogenic combinations |
| US9630994B2 (en) | 2014-11-03 | 2017-04-25 | University Of Washington | Polypeptides for use in self-assembling protein nanostructures |
| CN108472343B (zh) * | 2015-06-18 | 2021-12-10 | 非营利性组织佛兰芒综合大学生物技术研究所 | 抗rsv融合前f蛋白的免疫球蛋白单可变结构域抗体 |
| EP3124042A1 (en) * | 2015-07-28 | 2017-02-01 | VIB, vzw | Immunoglobulin single variable domain antibody against rsv prefusion f protein |
| WO2017005844A1 (en) | 2015-07-07 | 2017-01-12 | Janssen Vaccines & Prevention B.V. | Vaccine against rsv |
| CN107847581B (zh) | 2015-07-07 | 2022-03-22 | 扬森疫苗与预防公司 | 稳定化的可溶性融合前rsv f多肽 |
| RU2730625C2 (ru) | 2015-09-03 | 2020-08-24 | Новавакс, Инк. | Вакцинные композиции, характеризующиеся улучшенной стабильностью и иммуногенностью |
| KR102136678B1 (ko) | 2015-12-23 | 2020-07-22 | 화이자 인코포레이티드 | Rsv f 단백질 돌연변이체 |
| EP3436064A1 (en) * | 2016-03-29 | 2019-02-06 | The U.S.A. As Represented By The Secretary, Department Of Health And Human Services | Substitutions-modified prefusion rsv f proteins and their use |
| WO2017174564A1 (en) | 2016-04-05 | 2017-10-12 | Janssen Vaccines & Prevention B.V. | Vaccine against rsv |
| IL262108B2 (en) | 2016-04-05 | 2023-04-01 | Janssen Vaccines Prevention B V | Soluble pre-fusion rsv f proteins are stabilized |
| WO2017207477A1 (en) | 2016-05-30 | 2017-12-07 | Janssen Vaccines & Prevention B.V. | Stabilized pre-fusion rsv f proteins |
| WO2017207480A1 (en) | 2016-05-30 | 2017-12-07 | Janssen Vaccines & Prevention B.V. | Stabilized pre-fusion rsv f proteins |
| GB201621686D0 (en) | 2016-12-20 | 2017-02-01 | Glaxosmithkline Biologicals Sa | Novel methods for inducing an immune response |
| CN108300705B (zh) * | 2017-01-12 | 2021-10-22 | 厦门大学 | 稳定呼吸道合胞病毒融合蛋白的方法 |
| WO2018175518A1 (en) * | 2017-03-22 | 2018-09-27 | The Scripps Research Institute | Mini-protein immunogens displayng neutralization epitopes for respiratory syncytial virus (rsv) |
| US11192926B2 (en) | 2017-04-04 | 2021-12-07 | University Of Washington | Self-assembling protein nanostructures displaying paramyxovirus and/or pneumovirus F proteins and their use |
| AU2018269319A1 (en) | 2017-05-15 | 2019-11-07 | Janssen Vaccines & Prevention B.V. | Stable virus-containing composition |
| EP3624845A1 (en) | 2017-05-15 | 2020-03-25 | Janssen Vaccines & Prevention B.V. | Stable virus-containing composition |
| JP2020519663A (ja) * | 2017-05-17 | 2020-07-02 | ヤンセン ファッシンズ アンド プリベンション ベーフェーJanssen Vaccines & Prevention B.V. | Rsv感染に対する防御免疫を誘導するための方法及び組成物 |
| EP3630176A1 (en) | 2017-05-30 | 2020-04-08 | GlaxoSmithKline Biologicals S.A. | Methods for manufacturing an adjuvant |
| CN116813720A (zh) * | 2017-07-07 | 2023-09-29 | 浙江海隆生物科技有限公司 | 猪伪狂犬病毒gD蛋白的制备方法及猪伪狂犬病毒亚单位疫苗和应用 |
| CN111148509A (zh) | 2017-07-24 | 2020-05-12 | 诺瓦瓦克斯股份有限公司 | 治疗呼吸系统疾病的方法和组合物 |
| AU2018313000A1 (en) | 2017-08-07 | 2020-02-27 | Calder Biosciences Inc. | Conformationally stabilized RSV pre-fusion F proteins |
| MX2020002876A (es) | 2017-09-15 | 2020-07-22 | Janssen Vaccines & Prevention Bv | Metodo para la induccion segura de inmunidad contra el vsr. |
| US11591364B2 (en) | 2017-12-01 | 2023-02-28 | Glaxosmithkline Biologicals Sa | Saponin purification |
| EP3758747A1 (en) | 2018-02-28 | 2021-01-06 | University of Washington | Self-asssembling nanostructure vaccines |
| IL305911B1 (en) | 2018-03-19 | 2024-09-01 | Novavax Inc | Multifunctional nanoparticle vaccines for influenza |
| CN112512567A (zh) | 2018-04-03 | 2021-03-16 | 赛诺菲 | 抗原性呼吸道合胞病毒多肽 |
| KR20210013571A (ko) | 2018-05-04 | 2021-02-04 | 스파이바이오테크 리미티드 | 백신 조성물 |
| BR112021000965A2 (pt) | 2018-08-07 | 2021-04-27 | Glaxosmithkline Biologicals S.A. | processos e vacinas |
| EA202191355A1 (ru) | 2018-11-13 | 2021-09-20 | Янссен Вэксинс Энд Превеншн Б.В. | Стабилизированные f-белки rsv до слияния |
| CN109851678A (zh) * | 2019-03-07 | 2019-06-07 | 苏州宇之波生物科技有限公司 | 一种改良的亚稳定态牛呼吸道合胞病毒融合前体f蛋白质及编码的dna分子和其应用 |
| CA3142300A1 (en) | 2019-06-05 | 2020-12-10 | Glaxosmithkline Biologicals Sa | Saponin purification |
| CN112220921B (zh) * | 2020-08-25 | 2022-08-16 | 北京交通大学 | 一种针对呼吸道合胞病毒感染的组合疫苗 |
| JP2022060169A (ja) | 2020-10-02 | 2022-04-14 | ファイザー・インク | Rsv fタンパク質生産のための細胞培養工程 |
| CN114685627A (zh) * | 2020-12-28 | 2022-07-01 | 广州更新生物医药科技有限公司 | 一种预防呼吸道合胞病毒的rAAV载体疫苗 |
| JP2024509756A (ja) | 2021-02-19 | 2024-03-05 | ヤンセン ファッシンズ アンド プリベンション ベーフェー | 安定化された融合前rsv fb抗原 |
| EP4169513A1 (en) | 2021-10-19 | 2023-04-26 | GlaxoSmithKline Biologicals S.A. | Adjuvant composition comprising sting agonists |
| WO2024069420A2 (en) | 2022-09-29 | 2024-04-04 | Pfizer Inc. | Immunogenic compositions comprising an rsv f protein trimer |
| TW202424187A (zh) | 2022-10-27 | 2024-06-16 | 美商輝瑞大藥廠 | Rna分子 |
| WO2024089634A1 (en) | 2022-10-27 | 2024-05-02 | Pfizer Inc. | Immunogenic compositions against influenza and rsv |
| WO2024127181A1 (en) | 2022-12-11 | 2024-06-20 | Pfizer Inc. | Immunogenic compositions against influenza and rsv |
| WO2024154048A1 (en) | 2023-01-18 | 2024-07-25 | Pfizer Inc. | Vaccines against respiratory diseases |
Family Cites Families (60)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US1652407A (en) | 1924-04-28 | 1927-12-13 | Hastings H Johnson | Wire-measuring device |
| US4235877A (en) | 1979-06-27 | 1980-11-25 | Merck & Co., Inc. | Liposome particle containing viral or bacterial antigenic subunit |
| US4372945A (en) | 1979-11-13 | 1983-02-08 | Likhite Vilas V | Antigen compounds |
| IL61904A (en) | 1981-01-13 | 1985-07-31 | Yeda Res & Dev | Synthetic vaccine against influenza virus infections comprising a synthetic peptide and process for producing same |
| US4436727A (en) * | 1982-05-26 | 1984-03-13 | Ribi Immunochem Research, Inc. | Refined detoxified endotoxin product |
| US4866034A (en) | 1982-05-26 | 1989-09-12 | Ribi Immunochem Research Inc. | Refined detoxified endotoxin |
| SE8205892D0 (sv) | 1982-10-18 | 1982-10-18 | Bror Morein | Immunogent membranproteinkomplex, sett for framstellning och anvendning derav som immunstimulerande medel och sasom vaccin |
| US4707543A (en) | 1985-09-17 | 1987-11-17 | The United States Of America As Represented By The Secretary Of The Army | Process for the preparation of detoxified polysaccharide-outer membrane protein complexes, and their use as antibacterial vaccines |
| US5149650A (en) * | 1986-01-14 | 1992-09-22 | University Of North Carolina At Chapel Hill | Vaccines for human respiratory virus |
| US4877611A (en) | 1986-04-15 | 1989-10-31 | Ribi Immunochem Research Inc. | Vaccine containing tumor antigens and adjuvants |
| CA1331443C (en) | 1987-05-29 | 1994-08-16 | Charlotte A. Kensil | Saponin adjuvant |
| US5057540A (en) | 1987-05-29 | 1991-10-15 | Cambridge Biotech Corporation | Saponin adjuvant |
| US5726292A (en) | 1987-06-23 | 1998-03-10 | Lowell; George H. | Immuno-potentiating systems for preparation of immunogenic materials |
| WO1989005823A1 (en) | 1987-12-23 | 1989-06-29 | The Upjohn Company | Chimeric glycoproteins containing immunogenic segments of the glycoproteins of human respiratory syncytial virus |
| US5278302A (en) | 1988-05-26 | 1994-01-11 | University Patents, Inc. | Polynucleotide phosphorodithioates |
| US4912094B1 (en) | 1988-06-29 | 1994-02-15 | Ribi Immunochem Research Inc. | Modified lipopolysaccharides and process of preparation |
| UA40597C2 (uk) * | 1992-06-25 | 2001-08-15 | Смітклайн Бічем Байолоджікалс С.А. | Вакцинна композиція,спосіб лікування ссавців, що страждають або сприйнятливі до інфекції, спосіб лікування ссавців, що страждають на рак, спосіб одержання вакцинної композиції, композиція ад'ювантів |
| AU5955294A (en) | 1993-01-08 | 1994-08-15 | Upjohn Company, The | Process for the purification and refolding of human respiratory syncytial virus fg glycoprotein |
| ES2162139T5 (es) * | 1993-03-23 | 2008-05-16 | Smithkline Beecham Biologicals S.A. | Composiciones de vacuna que contienen monofosforil-lipido a 3-o-desacilado. |
| US5961970A (en) | 1993-10-29 | 1999-10-05 | Pharmos Corporation | Submicron emulsions as vaccine adjuvants |
| WO1995014026A1 (en) | 1993-11-17 | 1995-05-26 | Laboratoires Om S.A. | Glucosamine disaccharides, method for their preparation, pharmaceutical composition comprising same, and their use |
| WO1995026204A1 (en) | 1994-03-25 | 1995-10-05 | Isis Pharmaceuticals, Inc. | Immune stimulation by phosphorothioate oligonucleotide analogs |
| FR2718452B1 (fr) | 1994-04-06 | 1996-06-28 | Pf Medicament | Elément d'immunogène, agent immunogène, composition pharmaceutique et procédé de préparation. |
| CA2194761C (en) | 1994-07-15 | 2006-12-19 | Arthur M. Krieg | Immunomodulatory oligonucleotides |
| AUPM873294A0 (en) | 1994-10-12 | 1994-11-03 | Csl Limited | Saponin preparations and use thereof in iscoms |
| UA56132C2 (uk) | 1995-04-25 | 2003-05-15 | Смітклайн Бічем Байолоджікалс С.А. | Композиція вакцини (варіанти), спосіб стабілізації qs21 відносно гідролізу (варіанти), спосіб приготування композиції вакцини |
| US5620608A (en) | 1995-06-07 | 1997-04-15 | Cobe Laboratories, Inc. | Information entry validation system and method for a dialysis machine |
| US5666153A (en) | 1995-10-03 | 1997-09-09 | Virtual Shopping, Inc. | Retractable teleconferencing apparatus |
| US5856462A (en) | 1996-09-10 | 1999-01-05 | Hybridon Incorporated | Oligonucleotides having modified CpG dinucleosides |
| US6764840B2 (en) | 1997-05-08 | 2004-07-20 | Corixa Corporation | Aminoalkyl glucosaminide phosphate compounds and their use as adjuvants and immunoeffectors |
| US6303347B1 (en) | 1997-05-08 | 2001-10-16 | Corixa Corporation | Aminoalkyl glucosaminide phosphate compounds and their use as adjuvants and immunoeffectors |
| US6113918A (en) | 1997-05-08 | 2000-09-05 | Ribi Immunochem Research, Inc. | Aminoalkyl glucosamine phosphate compounds and their use as adjuvants and immunoeffectors |
| ATE287957T1 (de) | 1997-09-19 | 2005-02-15 | Wyeth Corp | Peptide abgeleitet vom bindungs (g) protein des respiratorisches synzytialvirus |
| GB9727262D0 (en) | 1997-12-24 | 1998-02-25 | Smithkline Beecham Biolog | Vaccine |
| EP1089913A1 (fr) | 1998-06-08 | 2001-04-11 | SCA Emballage France | Emballage a remise a plat rapide |
| BR9911329A (pt) | 1998-06-30 | 2001-10-16 | Om Pharma | Novos pseudodipeptìdeos de acila, processo de preparação e composições farmacêuticas contendo os mesmos |
| US7357936B1 (en) * | 1998-10-16 | 2008-04-15 | Smithkline Beecham Biologicals, Sa | Adjuvant systems and vaccines |
| US6551600B2 (en) | 1999-02-01 | 2003-04-22 | Eisai Co., Ltd. | Immunological adjuvant compounds compositions and methods of use thereof |
| US20040006242A1 (en) | 1999-02-01 | 2004-01-08 | Hawkins Lynn D. | Immunomodulatory compounds and method of use thereof |
| WO2001046127A1 (fr) | 1999-12-22 | 2001-06-28 | Om Pharma | Pseudodipeptides acyles porteurs d'un bras auxiliaire fonctionnalise |
| WO2002042326A1 (en) | 2000-11-22 | 2002-05-30 | Biota Scientific Management Pty Ltd | A method of expression and agents identified thereby |
| JP4307079B2 (ja) | 2001-01-26 | 2009-08-05 | セレキス エスアー | マトリックス付着領域およびその使用方法 |
| DE60238471D1 (de) | 2001-03-09 | 2011-01-13 | Id Biomedical Corp Quebec | Proteosom-liposaccharid-vakzine-adjuvans |
| US7157465B2 (en) | 2001-04-17 | 2007-01-02 | Dainippon Simitomo Pharma Co., Ltd. | Adenine derivatives |
| AU2002343728A1 (en) | 2001-11-16 | 2003-06-10 | 3M Innovative Properties Company | Methods and compositions related to irm compounds and toll-like receptor pathways |
| WO2004071459A2 (en) | 2003-02-13 | 2004-08-26 | 3M Innovative Properties Company | Methods and compositions related to irm compounds and toll-like receptor 8 |
| US7368537B2 (en) | 2003-07-15 | 2008-05-06 | Id Biomedical Corporation Of Quebec | Subunit vaccine against respiratory syncytial virus infection |
| KR101269656B1 (ko) | 2003-10-24 | 2013-05-30 | 셀렉시스 에스. 에이. | Mar 서열의 복합 트랜스펙션 방법에 의한 포유동물 세포에서의 고효율 유전자 전달 및 발현 |
| KR100599454B1 (ko) * | 2004-04-27 | 2006-07-12 | 재단법인서울대학교산학협력재단 | 종양 억제자로 작용하는 aim3의 신규 용도 |
| FR2873378A1 (fr) | 2004-07-23 | 2006-01-27 | Pierre Fabre Medicament Sa | Complexes immunogenes, leur procede de preparation et leur utilisation dans des compositions pharmaceutiques |
| GB0422439D0 (en) | 2004-10-08 | 2004-11-10 | European Molecular Biology Lab Embl | Inhibitors of infection |
| WO2006042156A2 (en) * | 2004-10-08 | 2006-04-20 | THE GOVERNMENT OF THE UNITED STATES OF AMERICA AS represneted by THE SECRETARY OF THE DEPARTMENT OF HEALTH AND HUMAN SERVICES, CENTERS FOR DISEASE CONTROL AND PREVENTION | Modulation of replicative fitness by using less frequently used synonymous codons |
| TWI457133B (zh) * | 2005-12-13 | 2014-10-21 | Glaxosmithkline Biolog Sa | 新穎組合物 |
| WO2008114149A2 (en) | 2007-03-21 | 2008-09-25 | Id Biomedical Corporation Of Quebec | Chimeric antigens |
| WO2008154456A2 (en) * | 2007-06-06 | 2008-12-18 | Nationwide Children's Hospital, Inc. | Methods and compositions relating to viral fusion proteins |
| BRPI0821532A2 (pt) | 2007-12-24 | 2015-06-16 | Id Biomedical Corp Quebec | Antígenos de rsv recombinantes |
| MX2011000668A (es) * | 2008-07-18 | 2011-07-29 | Id Biomedical Corp Quebec | Antigenos quimericos polipeptidicos del virus sincitial respiratorio. |
| SI2445526T1 (sl) | 2009-06-24 | 2016-08-31 | Glaxosmithkline Biologicals S.A. | Rekombinantni RSV antigeni |
| MX2012000036A (es) * | 2009-06-24 | 2012-02-28 | Glaxosmithkline Biolog Sa | Vacuna. |
| JP7291398B2 (ja) * | 2017-03-30 | 2023-06-15 | ザ ユニバーシティー オブ クイーンズランド | キメラ分子およびその使用 |
-
2008
- 2008-12-23 BR BRPI0821532-4A patent/BRPI0821532A2/pt not_active Application Discontinuation
- 2008-12-23 US US12/810,196 patent/US8563002B2/en active Active
- 2008-12-23 SG SG2013014287A patent/SG188813A1/en unknown
- 2008-12-23 CA CA2710600A patent/CA2710600C/en active Active
- 2008-12-23 RS RS20160792A patent/RS55162B1/sr unknown
- 2008-12-23 EP EP22181398.3A patent/EP4108687A1/en not_active Withdrawn
- 2008-12-23 SI SI200831685A patent/SI2222710T1/sl unknown
- 2008-12-23 EP EP23150323.6A patent/EP4219566A3/en active Pending
- 2008-12-23 AU AU2008340949A patent/AU2008340949A1/en not_active Abandoned
- 2008-12-23 ES ES16180926T patent/ES2719406T3/es active Active
- 2008-12-23 JP JP2010539977A patent/JP5711972B2/ja active Active
- 2008-12-23 WO PCT/CA2008/002277 patent/WO2009079796A1/en active Application Filing
- 2008-12-23 HU HUE08864495A patent/HUE029258T2/en unknown
- 2008-12-23 MX MX2010007107A patent/MX2010007107A/es active IP Right Grant
- 2008-12-23 EP EP16180926.4A patent/EP3109258B1/en not_active Revoked
- 2008-12-23 EP EP22211934.9A patent/EP4206231A1/en active Pending
- 2008-12-23 PL PL08864495T patent/PL2222710T3/pl unknown
- 2008-12-23 EP EP19152924.7A patent/EP3508505A1/en active Pending
- 2008-12-23 EP EP22181399.1A patent/EP4108688A1/en active Pending
- 2008-12-23 EA EA201070794A patent/EA021393B1/ru not_active IP Right Cessation
- 2008-12-23 EP EP08864495.0A patent/EP2222710B8/en active Active
- 2008-12-23 CN CN200880127407.3A patent/CN101952321B/zh active Active
- 2008-12-23 KR KR1020107016541A patent/KR101617895B1/ko active IP Right Grant
- 2008-12-23 ES ES08864495.0T patent/ES2597439T3/es active Active
- 2008-12-23 LT LTEP08864495.0T patent/LT2222710T/lt unknown
- 2008-12-23 PT PT88644950T patent/PT2222710T/pt unknown
- 2008-12-23 DK DK08864495.0T patent/DK2222710T3/en active
-
2010
- 2010-06-17 ZA ZA2010/04289A patent/ZA201004289B/en unknown
-
2016
- 2016-10-11 CY CY20161101010T patent/CY1118090T1/el unknown
- 2016-10-17 HR HRP20161353TT patent/HRP20161353T1/hr unknown
Also Published As
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| ES2719406T3 (es) | Antígenos recombinantes del VSR | |
| US9492531B2 (en) | Recombinant RSV vaccines | |
| US8889146B2 (en) | Vaccine | |
| US20100203071A1 (en) | Chimeric antigens | |
| US20160122398A1 (en) | Recombinant rsv antigens | |
| JP2011528222A (ja) | キメラ呼吸器合胞体ウイルスポリペプチド抗原 | |
| AU2013201836B2 (en) | Recombinant RSV antigens |