具体实施方式
下面,我们参照所附各图描述本发明的各实施例。
[本发明第1方面]
我们首先描述本发明(第1方面)的原理。
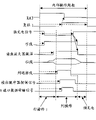
图1是用于解释本发明(第1方面)的原理的图。虽然图1表示用于解释2个端口情形中的原理的图,但是即便提供了两个以上的端口(N个端口)也可以得到相同的操作。
等效于内部电路(DRAM芯)操作的两个周期的时间跨度定义为外部指令周期的一个周期。即,芯操作周期是外部指令周期的速率的两倍。由内部存储器在两倍速率以指令越早到达就越早处理指令的这种次序对进入A端口和B端口的指令进行处理。然后将输出数据传送到每个端口。即,在一个芯操作周期中实施包括选择一条字线,放大数据,选择一条列线,读和写操作,预冲电操作的一系列操作,从而对相关的存储块完成一个存取操作。
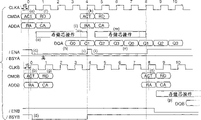
例如,在与图1的A端口有关的外部指令周期的定时C1,在A端口进入一个Read指令。进一步,在一个与B端口有关的外部指令周期的定时C1′,在B端口进入一个Read指令。因为A端口的Read指令的定时稍微早一些,所以这个Read指令在进入B端口的读指令之前被执行。这里,一个外部指令周期对应于4个时钟脉冲周期。如图1所示,在与1个芯操作周期对应的2个时钟脉冲周期中执行和完成每个Read指令。因此,响应在等效于一个外部指令周期的4个时钟脉冲周期的时间间隔中进入A端口和B端口的Read指令,能够实施读操作,而不会产生一个BUSY状态即便来自A端口的读存取和来自B端口的读存取都指向同一个存储块。这通过在2个时钟脉冲周期中执行和完成每个存取来实现。
在这种方式中,即便多个端口同时存取同一个存储块,因为内部存储器能够以两倍的速度进行相继的和连续的处理,所以也不会产生一个BUSY状态。
而且,当如图1所示从器件外部(例如在A端口)给出一个刷新指令时,在该器件内部能够实施刷新操作而不会影响来自另一个端口(即本例中的B端口)的存取。在这种情形中,可以选择多个端口中的一个(即图1例中的A端口)作为进行刷新管理的端口,总是从这个端口进入刷新指令。
而且,数据输出可以取来从多个列地址并行地读出数据和通过在输出时将并行数据变换成串行数据输出数据的脉冲串的形式。这增加了数据传输速率并使响应连续的Read指令连续地输出数据成为可能。
图2是表示当只有一个端口正在被使用时实施的刷新操作的图。
如图2所示,当提供2个端口,例如,A端口和B端口时,不需要让2个端口都操作。在器件内提供一个刷新定时器使内部产生刷新指令成为可能。
如图2所示,例如,当一个端口(例如,B端口)不在操作时能够内部产生刷新指令,从而执行刷新指令而不会影响在A端口的存取。
现在我们考虑一个例子,其中当进行刷新管理时,控制器A控制A端口,控制器B控制B端口。在这种情形中,如果存在一个如上述的内部刷新功能,则当只用A端口时B端口能够完全停止。这就能够减少由于下面的系统操作的改变引起的功率消耗。
图3A到3C是当2个端口,3个端口和N个端口时用于解释本发明原理的图。
如上面所描述的,本发明也可应用于有3个或更多端口的多端口存储器。图3A表示在如图1和图2所示的提供2个端口的情形中1个端口的操作。图3B表示在3个端口的情形中1个端口的操作,图3C表示N个端口的情形。如图3C所示,可以适当地将内部操作周期的长度设定在1/N与N个端口存储器的情形中的外部指令周期一样长。
下面,我们描述根据本发明的一个实施例的半导体存储器件。
图4是表示根据本发明的多端口存储器的第1实施例的方框图。在这个例子中,提供了具有2个端口,即A端口和B端口的配置。
图4的多端口存储器10包括A端口11,B端口12,自刷新电路13,DRAM芯14,判优器15,刷新指令寄存器16,指令寄存器A 17,指令寄存器B 18,刷新地址寄存器19,地址寄存器A 20,地址寄存器B 21,写数据寄存器A 22,写数据寄存器B 23,传输门A 24,和传输门B 25。
A端口11包括模寄存器31,CLK缓冲器32,数据I/O电路33,地址缓冲器34,和指令译码器35。进一步,B端口12包括模寄存器41,CLK缓冲器42,数据I/O电路43,地址缓冲器44,和指令译码器45。在A端口11和B端口12,分别与时钟信号CLKA和CLKB同步地独立地建立到外部总线的存取和来自外部总线的存取。模寄存器31和41能够在其中存储对于各端口的模式设定如数据等待时间和脉冲串长度。在这个实施例中,A端口11和B端口12两者都具有各自的模寄存器,使每个端口都能进行模式设定。然而,可以将模寄存器只安排在一个端口中,例如,使得对于2个端口的设置可以由对这一个端口的设置来实现。
自刷新电路13包括刷新定时器46和刷新指令发生器47。自刷新电路13在器件中产生刷新指令,分别从A端口11和B端口12接收信号CKEA1和CKEB1。信号CKEA1和CKEB1是分别用CLK缓冲器32和42对外部信号CKEA和CKEB进行缓冲得到的。用外部信号CKEA和CKEB暂停各端口的时钟缓冲器并使各端口去基活。如果使A端口11和B端口12中的一个进入去激活状态,则自刷新电路13开始它的操作。在模寄存器31和41中进行了设置,使得一个端口负责刷新管理的情形中,当负责刷新管理的的端口变得不操作时可以激活自刷新电路13。
进一步,DRAM芯包括存储器阵列51,译码器52,控制电路53,WriteAmp(写放大器)54和读出缓冲器55。存储器阵列51在其中存储被写和被读的数据,并包括DRAM存储单元,单元门晶体管,字线,位线,读出放大器,列线,列门等。译码器52对被存取的地址进行译码。控制电路53控制DRAM芯14的操作。WriteAmp 54放大写入存储器阵列51的数据。读出缓冲器55放大从存储器阵列51读出的数据。
将到A端口11的输入传输给地址寄存器A 20,刷新指令寄存器16,指令寄存器A 17和写数据寄存器A 22。进一步,将到B端口12的输入加到地址寄存器B 21,刷新指令寄存器16,指令寄存器B 18和写数据寄存器B 23。
判优器(判优电路)15确定指令进入的次序,以便确定将用于在A端口11和B端口12之间进行处理的优先权给予哪个指令。以确定的次序,判优器15将指令,地址和数据(在写操作的情形中)从各寄存器传输给DRAM芯14。DRAM芯14根据接收的数据进行操作。在Read指令的情形中,将从DRAM芯14读出的数据传输给输入相应指令的端口,然后将该数据从并行数据变换成串行数据,接着与这个端口的时钟同步地输出。
图5是与输入到判优器15的指令有关的电路的方框图;
指令译码器35包括输入缓冲器61,指令译码器62和(n-1)时钟延迟电路63。而且,指令译码器45包括输入缓冲器71,指令译码器72和(n-1)时钟延迟电路73。指令寄存器A 17包括读指令寄存器17-1和写指令寄存器17-2。而且,指令寄存器B 18包括读指令寄存器18-1和写指令寄存器18-2。
在Read指令的情形中,分别通过指令译码器62或72将输入到输入缓冲器61或71的指令传输给读指令寄存器17-1或18-1,而没有任何定时操作。在Write指令的情形中,由(n-1)时钟延迟电路63或73使进入的指令延迟(n-1)时钟,然后在当输入一系列要被写的脉冲串数据的第n个数据(即最后一个数据)时的定时将它传输给写指令寄存器17-2或18-2。
在刷新指令的情形中,将从A端口11,B端口12或刷新指令发生器47提供的刷新指令传输到刷新指令寄存器16。因为并不如此经常地出现刷新指令,所以不需要提供多个刷新指令寄存器。进一步,从模寄存器31和41提供输入到刷新指令发生器47的自刷新设置信息,该信息指出各端口中的哪一个负责刷新管理。
判优器15检测将指令传输到各指令寄存器的次序,并以这个次序将指令一个接着一个地传输到DRAM控制电路53。
当接收指令时(或当接近指令执行的结束时),DRAM控制电路53产生RESET1信号,让判优器15为下一个指令作好准备。在这个实施例的特定的配置中,当RESET1信号结束时DRAM控制电路53接收下一个指令。
接收RESET1信号时,判优器15将复位信号ResetRA,ResetWA,ResetRB,ResetWB和ResetREF中的一个加到指令寄存器A 17,指令寄存器B 18和刷新指令寄存器16中相应的一个。通过这个操作,使在其中存储了已经传输给DRAM芯14的指令的指令寄存器复位,在这个指令寄存器中准备接收下一个指令。
图6A和6B是表示判优器15的配置的电路图。
如图6A所示,判优器15包括比较器80-1到80-10,AND(“与”)电路81-1到81-5,AND电路82-1到82-5,AND电路83-1到83-5,延迟电路84-1到84-5,倒相器85到87,NAND(“与非”)电路88和倒相器89和90。比较器80-1到80-10每个都具有相同的电路配置,如图6B所示,包括NAND电路91和92和倒相器93和94。
将来自指令寄存器A 17的读指令信号RA2和写指令信号WA2,来自指令寄存器B 18的读指令信号RB2和写指令信号WB2,和来自刷新指令寄存器16的刷新指令REF2加到判优器15。对于由选择5个指令信号中的2个得到的全部10个组合,10个比较器80-1到80-10根据指令到达的定时确定哪一个指令比另一个早。
每个比较器比较2个指令的定时,将各输出中的一个设置在HIGH(高),它与在其它输入前已经接收了HIGH的输入相应。例如,比较器80-1到80-4中的每一个确定来自A端口11的读指令信号RA2或4个其它的指令中对应的一个中哪一个是较早的。如果读指令信号RA2比4个其它的指令中的任何一个早,则将从AND电路81-1输出的读指令信号RA31设置在HIGH。当RESET1信号是LOW(低)时,从判优器15将这个读指令信号RA31加到DRAM芯14作为读指令信号RA3。
当DRAM芯14接收指令时,DRAM芯14产生是HIGH的RESET1信号。由倒相器85到87,NAND电路88和倒相器89将这个RESET1信号变换成脉冲信号,并加到AND电路83-1到83-5。当Read指令信号RA31是HIGH时,例如,通过延迟电路84-1产生使其中具有接收到的指令的指令寄存器复位的信号。
图7是表示判优器15的操作的定时图。
具有图7中列举的名字的信号表示在图6A的各位置中。图7是表示当将Read指令加到A端口11和B端口12上时判优器15的操作。如图7所示,选择与A端口11对应的Read指令RA2作为具有优先权的指令,从而产生RA31,使得芯电路实施读操作READ-A。响应由此产生的复位信号RESET1,使读指令信号RA2复位。对应地,选择与B端口12对应的Read指令RB2,从而产生RB31。当复位信号RESET1变成LOW时,将读指令信号RB3加到芯电路,从而执行读操作READ-B。
图8是与输入到一个DRAM芯14的地址有关的电路方框图。
A端口11的地址缓冲器34包括输入缓冲器34-1,传输门34-2和OR(“或”)电路34-3。加入具有与从图5所示的指令译码器62输出的读指令信号RA1的前沿对应的脉冲的脉冲信号作为加到OR电路34-3的一个输入端的RA1P。进一步,加入具有与从图5所示的指令译码器62输出的写指令信号WA1的前沿对应的脉冲的脉冲信号作为加到OR电路34-3的另一个输入端的WA1P。下文中,在它的信号名称的未端具有字母“P”的信号代表具有从对应的信号名称的信号的前沿产生的脉冲的信号。
B端口12的地址缓冲器44包括输入缓冲器44-1,传输门44-2和OR电路44-3。
地址寄存器A 20包括地址锁存器101,传输门102,地址锁存器103,传输门104,传输门105,地址锁存器106,和传输门107。进一步,地址寄存器B 21包括地址锁存器111,传输门112,地址锁存器113,传输门114,传输门115,地址锁存器116,和传输门117。
刷新地址寄存器19包括刷新地址计数器/寄存器19-1,倒相器19-2,和传输门19-3。由刷新地址计数器/寄存器19-1产生和保持刷新地址。
通过上述电路配置的操作,当从器件外输入Read指令或Write指令时,将与指令一起进入的地址传输到地址锁存器101或111。在Read指令的情形中将地址传输到地址锁存器105或116而不需任何时间操作。在Write指令的情形中在取得一系列写数据的最后一个数据的定时将地址传输到地址锁存器103或113。
如图8的电路配置所示,响应与各从判优器15传输到DRAM芯14的指令信号RA3,WA3,RB3,WB3和REF3对应的脉冲信号RA3P,WA3P,RB3P,WB3P和REF3P,将地址信号从一个地址锁存器传输到DRAM芯14。
图9是与数据输出有关的电路方框图。
与数据I/O电路33的数据输出有关的部分包括数据锁存器121,传输门122,数据锁存器123,并行串行变换器124,输出缓冲器125和传输信号发生电路126。而且,与数据I/O电路43的数据输出有关的部分包括数据锁存器131,传输门132,数据锁存器133,并行串行变换器134,输出缓冲器135和传输信号发生电路136。
从存储器阵列51读出的数据被读出缓冲器55放大,分别通过传输门A 24或传输门B 25加到数据I/O电路33或数据I/O电路43。如果执行的指令与从A端口11的数据读出有关,则传输门A 24打开,而如果执行的的指令与从B端口12的数据读出有关,则传输门B 25打开。以这种方式提供的数据被数据锁存器121或131锁存和保持。
传输门122或132响应从传输信号发生电路126或136提供的传输信号在一个相应的端口接收读指令后打开预定等待时间。于是分别将数据锁存器121或131的数据传输到数据锁存器123或133。此后用并行串行变换器124或134将数据从并行数据变换到串行数据。然后将该数据传输给输出缓冲器125或135,并从那里输出。
图10是表示传输信号发生电路126或136的配置的电路图。
传输信号发生电路126或136包括触发器141到144和多路复用器145。将读指令信号RA1或RB1加到触发器141,并连续地与时钟信号CLKA1或CLKB1同步地从一个触发器传输到下一个。将等待时间信息A和B加到多路复用器145。这个等待时间信息例如用时钟周期的数目确定等待时间的长度。根据等待时间信息,多路复用器145选择一个相应的触发器的Q输出,并将它作为数据传输信号输出。
图11是与数据输入有关的电路方框图;
与数据I/O电路33的数据输入有关的部分包括数据输入缓冲器151,串行并行变换器152和数据传输装置153。与数据I/O电路43的数据输入有关的部分包括数据输入缓冲器154,串行并行变换器155和数据传输装置156。
分别用串行并行变换器152或155将串行地输入到数据输入缓冲器151或154的数据变换成并行数据。当输入最后一个数据时,将并行数据传输到写数据寄存器A 22或写数据寄存器B 23。当将Write指令从判优器15传输到DRAM芯14时,响应表示与Write指令到DRAM芯14的传输相应的定时的信号WA3P或WB3P,将写数据寄存器A 22或写数据寄存器B 23的数据传输到DRAM芯14。
图12是表示当连续进入Read指令时实施的操作的定时图。
A端口11和B端口12分别与具有不同频率的时钟信号CLKA和CLKB同步地操作。在这个例子中,A端口11用最大时钟频率操作,而B端口12用较低的时钟频率操作。
A端口11具有下列设置:读指令周期=4(CLKA),数据等待时间=4,和脉冲串长度=4。B端口12具有下列设置:读指令周期=2(CLKA),数据等待时间=2,和脉冲串长度=2。在每个端口的模寄存器中设置数据等待时间和脉冲串长度。
将由端口接收的指令存储在各指令寄存器中。将刷新指令存储在刷新指令寄存器中。判优器监视这些指令寄存器,并以接收指令的次序将指令传输给DRAM芯。当完成上一个指令的处理时传输下一个指令。
将从DRAM芯读出的数据从读出缓冲器传输到各端口数据锁存器(请参见图9)。以后将数据从并行变换成串行,作为脉冲串输出与外部时钟同步地输出。
虽然曾经从A端口输入刷新指令,但是不影响B端口的操作,如图12所示。
图13是表示当连续输入Write指令时实施的操作的定时图。
在写操作时从器件外部输入的数据取脉冲串输入的形式。Write指令存储在写指令寄存器中的定时是输入脉冲串输入的最后一个数据的定时。
如图13所示,从A端口提供的刷新指令不影响B端口的操作。
图14是表示当A端口和B端口两者都操作在最大时钟频率上时的定时图。
如图14所示,在这些端口的时钟信号之间可能存在相位差。两个端口具有下列设置:读指令周期=4,数据等待时间=4,和脉冲串长度=4。如从图可见的那样,甚至当两个端口都操作在最大时钟频率和连续输入Read指令时关于操作也没有问题。
图15是表示当A端口和B端口两者都操作在最大时钟频率上时的定时图。在图15中,两个端口连续地接收Write指令。
如图15所示,在这些端口的时钟信号之间可能存在相位差。两个端口具有下列设置:写指令周期=4,数据等待时间=4,和脉冲串长度=4。如从图可见的那样,甚至当两个端口都操作在最大时钟频率和连续输入Write指令时也能够进行适当的操作。
图16是表示当指令从Read指令改变到Write指令时的各操作的定时图;
如图16所示,当与“Write→Read”或“Read→Write”的指令间隔比较时指令传输“Write→Read”需要一个额外的指令间隔。这是因为我们传输Write指令以便在当进入脉冲串输入的最后一个数据时的定时对它进行处理。相反地,为了对它进行处理传输一个Read指令的定时定义为进入Read指令的定时,使得当相继的指令是“Write→Read”时需要提供一个额外的指令间隔。这样一个需要可以认为是将取脉冲串输入形式的输入数据变换成并行数据这个事实引起的。如果只输入一块数据而不是如脉冲串输入那样输入4块数据,则甚至当两个相继的指令都是“Write→Read”时也不需要提供一个额外的指令间隔。
在这种如对于一个Write写指令只输入一块数据那样的配置中,即便用与“Write→Write”或“Read→Read”的情形中相同的指令间隔,也能够对于“Write→Read”指令连续性适当地进行操作。
图17是表示当指令从“Read”改变到“Write”时输入刷新指令的定时图。
在图的顶部,表示出应该进入刷新指令的定时。在如说明的期间中在任何定时都能适当地进入刷新指令。例如,即便在图17所示的定时输入刷新指令,刷新指令只有当完成前一个Write写指令时才开始刷新操作,直到将刷新指令保存在备用状态时为止。因此,只要刷新指令落在与这个备用状态对应的期间内在任何定时都能适当地进入刷新指令。
图18是表示当使一个端口去激活时实施的操作的定时图;
如图18所示,当使一个端口(即,图18中的A端口)去激活时,根据刷新定时器内部产生刷新指令,从而执行刷新操作。
图19是表示当使两个端口去激活时实施的操作的定时图。
如图19所示,当使两个端口去激活时,根据刷新定时器内部产生刷新指令,从而执行刷新操作。
图20A和20B是表示DRAM芯操作的定时图。
图20A表示读操作的情形,图20B表示写操作的情形。在如图20A和20B所示的操作定时,在完成整个操作前通过字线选择,数据放大,写回,和预充电的相继操作发出进入的指令。
图21是表示当只使一个端口操作时实施的两倍速率操作的定时图;
通过使两个端口中的一个停止操作,可以将到操作端口的指令输入间隔缩短一半。当这种情形发生时,外部指令的最快周期和内部动作的最快周期彼此相同。在图21的例子中,缩短了指令间隔而没有改变时钟频率。在这个情形中,因为脉冲串长度也变得较短,所以数据传输速率与当用两个端口时的相同。
图22是表示当通过使时钟频率两倍高使数据传输速率两倍时两倍速率操作的定时图;
在图22中,当使两个端口中的一个停止操作时,将输入到操作端口时钟信号设置在高两倍的频率上。与此相关,指令输入的时间间隔缩短一半。在这个情形中,因为脉冲串长度与当用两个端口时的相同,所以数据传输速率为当用两个端口时的两倍那样快。
此外,因为只将外部时钟信号输入I/O电路装置,所以如果将该电路装置设计得能应付高速操作则实际上容易完成两倍速率操作。
图23是用于解释本发明的第2实施例的图;
一般,根据其用度扩大存储器。这同样应用于多端口存储器的情形,可能存在为了扩大存储空间提供多个多端口存储器的情形。
多端口存储器包括判优器,并检测哪一个指令较早进入各端口,接着以检测出的次序执行指令。甚至当在几乎相同的定时将指令输入各端口时,也为相继地执行指令确定一个次序。在图23所示的例子中,提供多个多端口存储器200-1到200-n,从A端口控制器201和B端口控制器202,将相同的指令加到多端口存储器200-1到200-n。即便同时将指令加到A端口和B端口,由于信号线有不同的长度和/或电源噪声的影响,指令到达每个多端口存储器的相对定时也可能稍有不同。在这个情形中,每个多端口存储器的判优器能够以从存储器到存储器不同的次序执行指令。
如果到A端口的指令和到B端口的指令指向不同的地址,则存储器件之间执行指令的不同次序可能不会成为一个问题。然而,当各指令是对于同一个地址时,就会发生问题。
例如,在当写存取同一个存储单元后读出数据时与当写存取同一个存储单元前读出数据时之间检索的数据是不同的。而且,当在写入A端口的数据后写入B端口的数据时B端口的数据保留在存储器中,而如果以相反的次序进行操作则A端口的数据保留在存储器中。
如果以上面描述的方式从存储器到存储器执行指令的次序不同,则关于数据的可靠性就存在严重的问题。
因此,当用多个多端口存储器时,需要使判优器作出的决定在存储器之间保持一致。为此,本发明的第2实施例指定多端口存储器中的一个为主器件200-1,并用其余的器件作为从器件200-2到200-n。从器件遵守由主器件的判优器作出的决定。
图24是表示根据本发明的多端口存储器的第2实施例的方框图。本例子的配置具有两个端口即A端口和B端口。
与图4所示的第1实施例的不同包括A端口11A和B端口12A分别具有BUSY信号I/O装置36和46这个事实和提供地址比较器26比较A端口的地址和B端口的地址这个事实。如果地址比较器26检测出地址匹配,因此产生匹配信号,则判优器15A将转变DRAM芯的操作模式以便开始连续模式。
图25A和25B是用于解释连续模式的定时图。
如图(图20)表示的第1实施例的操作所示,将DRAM芯的操作分成ROW(行)操作和COLUMM(列)操作。在本发明中,进行ROW操作,COLUMM操作和预充电操作作为一系列的连续执行操作,这定义了单个内部操作周期。
在第2实施例中的连续模式与通常的DRAM的列存取操作相同,对于同一个存储单元反复执行一个指令。即,这个模式在ROW操作后多次执行COLUMM操作后进行预充电。当连续地加上对同一个存储单元地址的Write指令时,执行后面的指令而不执行前面的指令。这是因为即便相继地执行了这些Write指令,由前面的指令写入的数据将被后面的指令的数据覆盖。
如图25A所示,连续模式允许使操作缩短到比通常内部操作的2个周期短,从而提供额外的时间。将由这个额外时间得到的边边缘分配给在ROW操作和COLUMM操作之间的一个点(下文中将这个边缘称为Wait(等待)期间)。在这个Wait期间中,实施用于使主器件和从器件之间的指令执行次序一致的处理。
下面,我们说明用BUSY信号使主器件和从器件之间的操作一致的过程。
为了保证在主器件和从器件之间有相同的指令执行次序用BUSY信号。BUSY信号I/O装置36和46用作输出主器件200-1中的BUSY信号的BUSY输出电路,和用作在从器件200-2到200-n中接收BUSY信号的BUSY输入电路。将指示主器件标识或从器件标识的信息存储在模寄存器31或41中。
存储器件接收来自一个端口的指令,开始如图20A和20B所示的操作。
当从其它的端口输入指令,存取在ROW操作期间内的同一个地址时,地址比较器26产生一个匹配信号。在重复这个匹配信号时,判优器15A向DRAM芯14的控制电路53提供连续模式信号。响应连续模式信号,DRAM芯14转移到连续模式如图25B所示。
在Wait期间中,主器件200-1根据判优器15A作出的决定产生BUSY-A信号或BUSY-B信号。在这个例子中,对于一个被判优器15A识别的较早已经收到指令的端口产生BUSY信号。
类似地,在Wait期间中,从器件检测由主器件产生BUSY信号,改变由它自己的判优器15A作出的决定,以便如果它不同于BUSY信号的指示就遵从主器件。然后根据改变了的指令次序实施COLUMM操作。
图26是表示当对于A端口的Read指令和B端口的Write指令产生BUSY信号时实施的操作的定时图。
在这个实施例中,BUSY信号具有一个指示选择的逻辑级“L”。而且,优先地传输和非同步地接收BUSY信号。这是因为需要在有限的Wait期间内迅速地交换BUSY信号。
在图26的例子中,因为A端口的ReadA2比B端口的WriteB2早,所以主器件在Wait期间中产生指示A端口的BUSY信号。从器件接收这个BUSY信号,并依靠A端口的ReadA2比B端口的WriteB2早。然后,主器件和从器件以首先ReadA2然后WriteB2的次序执行在连续模式中的列操作。
图27是表示当对于A端口的Read指令和B端口的Write指令产生BUSY信号时实施的操作的定时图。而图26说明A端口的Read指令较早的情形。图27表示B端口的Write指令较早的情形。
图28是表示当对于A端口的Write指令和B端口的Write指令产生BUSY信号时实施的操作的定时图
图28所示的操作例子是关于A端口的Write指令比B端口的Write指令早的情形。即,因为A端口的WriteA2比B端口的WriteB2早,所以产生指示A端口的BUSY信号,并加到从器件上。在这种情形中,因为通过执行A端口的Write指令被写入的数据将立即被覆盖,所以只有B端口的写指令因为WriteB2因为它较后进入而被执行。
图29是表示当对于A端口的Write指令和B端口的Write指令产生BUSY信号时实施的操作的定时图。
图29所示的操作例子是关于B端口的Write指令比A端口的Write指令早的情形。在这种情形中,因为通过执行B端口的Write指令被写入的数据将立即被替代,所以只有A端口的写指令WriteA2被执行。在这个例子中,将A端口的时钟频率设置得稍低于B端口的时钟频率。虽然当比较指令WriteA2和WriteB2时对于A端口指令输入稍早,但是在接收最后一个数据输入时是B端口较早。因此,确定B端口的Write指令比A端口的Write指令早。
上面提供的描述还没有参考关于A端口的Read指令和B端口的Read指令的组合起来的情形。因为不管相对的定时如何,数据的可靠性不受影响,所以在这个情形中不需要产生BUSY信号。
图30是表示在能够处理由控制器发出的中断指令的配置中的操作的定时图。
“中断指令”是当开始BUSY信号时指令改变由主器件的判优器作出的决定的指示。造成中断的方法包括:
a)作为指令输入;
b)提供专用的端子销;
c)用特定的地址组合;和
d)用BUSY信号。
方法d)用控制器对与为其产生BUSY信号的端口不同的端口提供BUSY信号,并安排主存储器和从存储器对它进行检测。
在图30的例子中,当对于A端口的Write指令和B端口的Write指令发生BUSY信号时产生中断。如将图28和图29结合起来进行的描述那样,当Write和Write的组合产生BUSY信号时只有A端口的Write指令和B端口的Write指令中的一个被执行。结果,将失去较早进入的数据。
在图30中,A端口的WriteA2比B端口的WriteB2早,使产生指向A端口的BUSY信号。接收到主器件产生的BUSY信号后,控制器产生中断指令以便防止删除A端口的Write数据。
主器件和从器件从控制器接收中断指令,改变由判优器作出的决定,接着根据中断指令在等待期间结束后执行Write操作。即,判优器改变它们的决定指出A端口的指令WriteA2比B端口的指令WriteB2晚,实施与WriteA2有关的写操作。这能够防止A端口的写数据被删除。在Write→Write组合的情形中,全部需要只是执行写操作一次,使得可以分配比Read→Write组合或Write→Read组合的连续模式较长的等待期间。于是可以利用这个等待期间响应BUSY信号执行中断指令。
下面,我们描述用于实现上述操作的地址比较器,BUSY I/O系统和中断系统的配置。
图31是表示根据本发明的第2实施例的多端口存储器的地址比较器,BUSY I/O系统,和中断系统的配置的图。
地址比较器26比较存储在地址寄存器中的地址,并当A端口11的地址和B端口12的地址之间存在匹配时输出匹配信号。而且,为了指出哪两个地址是匹配地址,产生信号ARA,AWA,ARB和AWB。例如,当A端口的Write指令的地址和B端口的Write指令的地址显示匹配时,将AWA和AWB设置在“H”。NAND电路208到210每个都得到这些信号的一个逻辑NAND,使得N1,N2和N3中的一个变成“L”。
在图31左边(在地址比较器26的下面)提供了BUSY信号I/O装置36和46与中断电路。根据模寄存器31或41的设置,BUSY和I/O硬件控制装置211在主器件情形中响应匹配信号的检测产生激活信号(主),和在从器件情形中产生激活信号(从)。激活信号(主)激活BUSY输出电路212和213,而激活信号(从)激活BUSY输入电路214和215。
在判优器中,将选出的指令作为指令次序中的第一个输出到输出端RA3,WA3,RB3和WB3中的一个(即输出端中的一个是“H”)。在主器件情形中,RA3到WB3被锁存器216和217响应信号N4锁存起来,信号N4是由与匹配信号的前沿对应的脉冲组成的。根据锁存的数据输出BUSY-A信号和BUSY-B信号。
在从器件情形中,如果接收到是“L”的BUSY-A信号,则将从中断电路218输出的信号N10设置在“L”。如果接收到是“L”的BUSY-B信号,则将从中断电路219输出的信号N11设置在“L”。当信号N10和N11处于去激活状态时,它们是“H”,当检测出BUSY信号或中断指令时它们变成“L”。
中断检测装置220检测从控制器提供的中断指令,并输出中断信号A或B。给予中断信号对进入的BUSY信号的优先权,并将它们作为信号N10和N11传输出去。
图31底部所示的三个比较器80-3,80-5和80-6是判优器15A的比较电路的一部分(请参见图6A和图24)。这些比较器对于需要BUST确定的指令组合进行比较。
图32是表示一个主器件的操作的定时图。图33是表示一个从器件的操作的定时图。
这三个定时图说明A端口的Read指令的地址和B端口的Write指令的地址相互匹配的情形。图32的主器件决定A端口较早,图33的从器件决定B端口较早。在这种情形中,主器件的比较器80-3输出是“L”的N21和是“H”的N22。进一步,从器件的比较器80-3输出是“H”的N21和是“L”的N22。主器件产生BUSY-A信号,从器件在接收BUSY-A信号时将N10改变成“L”。因为在这个时间点N1是“L”,所以通过NOR(“或非”)电路221和倒相器222将N10的LOW信号加到从器件的比较器80-3上。对应地,从器件的比较器80-3的输出改变到是“L”的N21和是“H”的N22。在这种方式中,改变了由判优器作出的决定。
现在我考虑与上述情形相反的A端口的Write指令的地址和B端口的Read指令的地址相互匹配的情形。在这种情形中,从器件的比较器80-5输出被改变,从而改变在从器件中由判优器作出的决定。
比较WA2和WB2的比较器80-6具有一个不同于比较器80-3和80-5的外围电路配置。这是因为当响应Write和Write组合产生BUSY信号时,A端口的指令和B端口的指令中只有一个将被保留。
图34是表示当两个端口的写地址相同时实施的主器件的操作的定时图。图35是表示当两个端口的写地址相同时实施的从器件的操作的定时图。
现在我们考虑如图34所示主器件决定A端口较早,和如图35所示从器件决定B端口较早的情形。在地址比较器26刚刚产生一个匹配信号的瞬间,主器件的比较器80-6输出是“L”的N25和是“H”的N26,和从器件的比较器80-6输出是“H”的N25和是“L”的N26。主器件将RA3,WA3,RB3和WB3锁存在这个状态,并输出一个BUSY-A信号。
当如在本情形中那样在Write-Write组合中产生BUSY信号时,需要删除一个已较早进入的Write指令。为了这个目的,提供倒相器231,NOR电路232,NAND电路233和234,倒相器235和236。响应匹配信号,HIGH边沿脉冲电路230产生信号N4的“H”脉冲。通过某个逻辑操作将信号N4和信号N3组合起来,产生信号N31中的“H”脉冲。在这个例子中,N26对于主器件是“H”,使N33产生“H”脉冲,导致N25改变成“H”和N26改变成“L”。这里,延迟电路237和238用于提供一个能够用来在改变发生前产生BUSY信号的额外时间,并防止当将已经改变了的状态反馈回到NAND电路233和234时再次被改变。在从器件中,将N25改变成“L”,将N26改变成“H”。
如以前描述的那样,主器件产生BUSY-A信号,接收这个信号的从器件使它的N10改变成“L”。因为在这个特定瞬间N3是“L”,所以从器件的比较器80-6再次被反转,导致使N25改变成“H”,使N26改变成“L”。
延迟电路250接收信号N4,并使这个信号延迟一个预定时间长度,从而产生一个Wait期间。这里,当选择N1或N2时选择Delay(延迟)(t1),当选择N3时选择Delay(t2)。
提供NAND电路251和252与倒相器253和254用于当Wait期间结束时从指令寄存器清除被跳过的Write指令。例如,如果在Wait期间结束时N25是“L”和N26是“H”,则将执行A端口的Write指令。因此,为了从寄存器删除B端口的Write指令产生RESTWB2。因为在Wait期间中需要通过BUSY接收或中断改变决定,所以在这个期间指令寄存器中的指令被完整地保留下来。
图36是表示当两个端口的写地址相互匹配使控制器发出中断指令时主器件操作的定时图。图37是表示当两个端口的写地址相互匹配使控制器发出中断指令时从器件操作的定时图。
如图36所示,在主器件中的指令选择状态由于中断而反转,而且,如图37所示,在从器件中的指令选择状态由于BUSY信号而反转,然后进一步由于中断而反转。这里,由于中断而反转状态的操作与由于BUSY信号而反转状态的操作相同,我们将省略它的详细描述。
在上述第2实施例的操作中,设计从一个给定的指令到下一个接着的指令扩展的指令周期使它甚至在产生BUSY信号或中断指令后也不改变。
在图26中,例如,虽然响应ReadA2发生BUSY信号,ReadA2→ReadA3的指令间隔与ReadA1→ReadA2的指令间隔相同。要求在Wait期间处理BUSY信号和中断信号。因为这个原因,当由于长的系统总线,大量的从器件,控制器的慢响应等BUSY信号或中断信号的交换需要长时间时,就需要较长的Wait期间。
为了消除这个问题,当延迟跟随BUSY信号和中断信号的下一个指令输入时可以扩展Wait期间。即,当加长Wait期间时可以扩展ReadA2→ReadA3的指令间隔使它比在图26中的ReadA1→ReadA2的指令间隔长。
为了延迟一个指令输入,可以在设计书中说明指令输入的延迟,和可以设计控制器使它根据数据表进行操作。如图31所示通过加长延迟电路250的延迟时间达到Wait期间的扩展。如果根据用度需要调整Wait期间,则在延迟电路250中可以提供两条或多条延迟线,使通过一个模寄存器的设置改变延迟长度的设置成为可能。
当Wait期间以这种方式扩展时,除了响应Write-Write指令组合产生BUSY信号的情形外在其它情形中也能够提供长的Wait期间。考虑到这一点,甚至当响应Read-Write或Write-Read指令组合出现BUSY信号时控制器也可以发出一个中断指令。
在上面描述的本发明中,当指令进入N个端口时,在任何给定的端口的一个最小指令周期内一个接着一个地执行与N个端口对应的所有的N指令。因此,一个与任何给定端口有关的存取操作出现在器件外部中在最小指令周期内被实施。在这个情形中,只有当从多个端口存取同一个地址时才会发生BUSY信号。于是可以得到BUSY信号发生概率,该概率与SRAM型多端口存储器的BUSY信号发生概率一样低。
而且,在本发明的半导体存储器件中,内部电路包括一个存储单元阵列,该阵列由各动态型存储单元和一个定义存储单元被刷新的定时的刷新电路组成。在第1模式中,响应输入到在N个端口中的至少一个的刷新指令刷新存储单元,在第2模式中,在刷新电路确定的定时刷新存储单元。
即,上面描述的本发明具有第1操作模式,在该模式中响应来自一个外部端口的指令实施刷新操作,和第2操作模式,在该模式中响应内部刷新电路实施刷新操作。因为这个配置,允许一个外部端口作为一个用于刷新管理的端口进行操作,以便在恒定的间隔接收刷新指令,或者如果这个用于刷新管理的端口处在去激活状态则内部刷新电路实施刷新操作。这使根据系统配置以一种灵活的方式管理刷新操作成为可能。
[本发明的第2方面]
下面我们描述本发明的第2方面。
存在若干种多端口存储器。下文中,涉及具有多个端口的存储器,并允许从各端口相互独立地存取一个公共存储器阵列。例如,两个端口型的多端口存储器装备有一个A端口和一个B端口,并允许从与A端口链接的CPU-A和从与B端口链接的CPU-B独立地进行到公共存储器的读/写存取。
作为这类多端口存储器,具有SRAM存储器阵列的存储器是已知的,其中在复制的设置中提供各字线和各位线对,每个存储单元都与2组字线和位线对连接。然而,这种多端口存储器具有电路密度低的问题,其中需要提供字线和位线对的复制组。
为了消除这个问题,可以用与具有多个处理器配置的计算机所用的共用存储器相同的机构。共用存储器具有提供给公共存储器的多个端口。典型地,将SRAM用作存储器,并用离散的IC(集成电路)制成多个端口。当从多个端口同时进行存取时,因为存储器阵列是共用的,所以不能同时进行与多个端口相应的操作。防止这种问题发生的最简单的方法是对每个端口产生BUSY信号以便防止当从一个端口进行存取时到另一个端口的存取。然而,这引起限制存储器用度的问题。考虑到这一点,为公共存储器提供称为判优器的判优电路,判优电路确定多个端口接收的存取要求的优先权。构造存储器阵列的控制器,以优先权的次序执行与存取要求对应的操作。例如,以到达的次序即以将存取要求加到各端口的次序处理存取要求。
在这个情形中,存储器阵列最终随机地从多个端口被存取。因此,不能提供在同一个行地址连续地存取相继的列地址的列存取操作,而这样的列存取操作典型地可以在DRAM中得到。即,选择,为读/写操作存取和复位存储单元,响应单个存取实施所有这些操作。
当制成一个共用存储器时,一般地,按常规将SRAM用作存储器阵列。这是因为SRAM能够进行高速随机存取操作,并且因为不需要刷新操作所以能够容易地使用SRAM。然而,单块芯片的多端口存储器常规地具有以字线和位线对的复制组,在具有通常的SRAM配置的存储器阵列的基础上的单块芯片的多端口存储器还没有在实践中使用。
总结一下,多端口存储器和共用存储器是用SRAM制成的,而不用需要刷新操作的DRAM。
当系统不断地提供高性能时要被处理的数据量增加,并且多端口存储器也需要具有大的容量。可以用动态型存储单元(DRAM)阵列制成多端口存储器,DRAM阵列比SRAM具有较高的电路密度,从而以低的成本提供具有大存储容量的多端口存储器。然而,存储单元的刷新操作成为一个问题。
在常规的DRAM中,需要从器件外部以恒定间隔在读/写指令之间提供刷新指令。为此,在以DRAM为基础的系统中的控制器器件具有用于刷新管理的定时器和/或控制电路。然而,在用以SRAM为基础的多端口存储器的系统中不提供这样的电路。甚至在以DRAM为基础制成存储器的情形中,在这些系统中需要能以与常规的多端口存储器相同的方式使用这种存储器。即,具有由DRAM组成的存储器阵列的多端口存储器需要由它自己来进行刷新操作。
本发明的目的是提供具有由DRAM芯组成的存储器阵列,而且不需要考虑刷新操作就能使用的多端口存储器,从而以低的成本提供具有大存储容量并且容易使用的多端口存储器。
图38是用于解释本发明原理的图,表示当对于两个端口实施读操作时的情形。
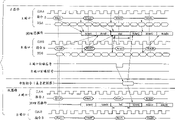
在能够实施3个内部操作周期的最小间隔上提供加到两个外部端口,A端口和B端口的指令。即,将一个外部指令周期设置在比3个内部操作周期需要的持续时间长的长度上。分别将时钟信号CLKA和CLKB输入到A端口和B端口,与时钟信号同步地进行在器件的一个外部装置和各外部端口之间的地址和数据的交换。使地址(图中未画出)与指令同时进入。当在最小外部指令周期上使读指令进入A端口和B端口时,判优电路通过将优先权给予首先到达的输入信号,控制芯的操作。如上所述在一个外部指令周期中能够实施3个内部操作,在这个外部指令周期中在存储器阵列上执行2个读操作,接着将读数据输出到A端口和B端口。A端口和B端口两者都保持检索的数据,并在下一个跟随的外部指令周期开始时,即与从输入读指令的第4个时钟信号同步地输出检索的数据。即,在这个情形中数据的等待时间是4。
提供刷新定时器作为内部电路,刷新定时器在它自己身上产生刷新指令。因为如上所述在一个外部指令周期中能够实施3个内部操作,所以当产生刷新指令时在单个外部指令周期中能够执行指令A,指令B和刷新指令。在下一个跟随的外部指令周期开始时输出读数据。在这个方式中,可以从器件外部存取多端口存储器而与刷新操作没有任何关系。
在图38的例子中,响应一个读指令输出一项读数据。即,脉冲串长度为1。所以,在一个时钟脉冲周期中完成读数据的输出后,在外部指令周期的3个余下的时钟周期中外部端口不输出任何数据,这导致无效的数据传输。可以通过加长脉冲串长度来消除这个问题。
图39是用于解释本发明原理的图,表示脉冲串长度为4的例子。在这个例子中,与上述情形相同,将2个外部端口的外部指令周期设置在能够供应3个内部操作周期的长度上。进一步,一个外部指令周期对应4个时钟周期。与时钟信号同步地在单个外部指令周期中从一个外部端口4次输出数据。所以,如果根据一个外部指令周期的时钟周期的数目设置脉冲串长度,则在两个端口都能实现无间隙的读操作,从而非常大地增加了数据传输速率。在这个情形中,要求与脉冲串长度一样多的数据项响应单个存取内部地输入存储器阵列或内部地从存储器阵列输出。例如,如果外部端口的数据输入/输出销的数目为4,和脉冲串长度为4,则需要保证由单个存取操作从存储器阵列输出16位数据或将16位数据输入存储器阵列。
我们应该注意到A端口和B端口不一定同步操作,并且只要将最小周期设置得等于3个内部操作周期需要的持续时间,就可以将各外部指令周期相互独立地设置在任何定时。
而且,外部端口的数目也可以是任何数目。如果将外部端口的数目设置为n,则将每个端口的外部指令周期设置在能够进行n+1个内部操作周期的最小周期上。如果满足这个要求,则甚至当刷新操作被执行时在一个外部指令周期中也可以实施各端口要求的所有操作,从而允许使用多端口存储器而与刷新操作没有任何关系。
图40和图41是表示当有2个,3个和n个端口时在一个最小外部指令周期和各内部操作周期之间的关系的图。
如这些图所示,如果端口的数目为2,则最小外部指令周期具有能够供应3个内部操作的长度,并且如果端口的数目为3,则最小外部指令周期是可以进行4个内部操作的时间长度。进一步,如果端口的数目为n,则最小外部指令周期等于可以执行n+1个内部操作的时间长度。
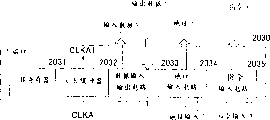
图42和图43A到43C是表示根据本发明的实施例的多端口存储器的配置的图。图42表示DRAM芯和它的相关电路,图43A表示A端口,图43B表示B端口。进一步,图43C表示刷新电路。图43A到43C所示的电路与图42的各部分连接。
如这些图所示,这个实施例的多端口存储器包括DRAM芯2011,用于控制确定操作次序并保证以确定的次序实施操作的判优器2026,多组暂时存储指令,地址和数据的寄存器,2个由A端口2030和B端口2040组成的外部端口,和刷新电路2050。
A端口2030和B端口2040分别包括模寄存器2031和2041,CLK缓冲器2032和2042,数据I/O电路2033和2043,地址输入电路2034和2044,与指令输入装置2035和2045,它们根据从器件外部提供的各分开的时钟频率进行操作。将数据等待时间和脉冲串长度存储在模寄存器2031和2041中,使它们能被分别地设置。数据I/O电路2033和2043装备有根据脉冲串长度实施输出/输出数据的并行到串行变换和串行到并行变换的机构。
刷新电路2050包括刷新定时器2051和刷新指令发生器2052。刷新定时器2051在预定间隔上产生刷新开始信号,刷新指令发生器2052对应地产生刷新指令。
分别将加到A端口和B端口的指令,地址和写数据存储在寄存器中。也将刷新指令存储在刷新指令寄存器2027中,并将刷新地址存储在刷新地址计数器/寄存器2018中。
判优器2026根据指令到达的次序确定执行指令的次序,并以确定的次序将指令传输给DRAM芯2011的控制电路2014。进一步,判优器2026将传输信号传输给对应的地址寄存器和对应的数据寄存器(在写操作情形)。在DRAM芯2011中,控制电路2014响应提供的指令,控制译码器2013,写放大器(WriteAmp)2015,和读出缓冲器2016,从而实施对于存储器阵列2012的存取操作。在写操作的情形中,译码器2013为了进行写操作对存取的地址进行译码,以便激活在存储器阵列2012中的字线和列信号线,导致将存储在写数据寄存器A2022和B2023中的写数据通过WriteAmp 2015写入存储器阵列2012。在读操作的情形中,以类似的方式存取存储器阵列2012,导致通过传输门A 2024和B 2025将读数据从读出缓冲器2016传输到各端口的数据输出电路。根据DRAM芯2011的操作周期控制传输门的传输定时,并由控制电路2014确定传输定时。与对应的外部时钟信号同步地从每个端口的数据输出电路输出输出数据。
下面,我们描述与指令处理,地址处理和数据处理中的每一个有关的详细情形。
图44和图45是表示根据第1实施例与指令处理有关的装置配置的图。在与图42和图43A-43C中相同的部件上加上相同的参照数字。这也同样应用于其它的图。
如图44所示,A端口的指令输入装置2035包括输入缓冲器2036,指令译码器2037和(n-1)时钟延迟电路2038,B端口的指令输入装置2045包括输入缓冲器2046,指令译码器2047和(m-1)时钟延迟电路2048。这里,n和m是脉冲串长度。而且,如图45所示,指令寄存器A 2028包括Read指令寄存器AR和Write指令寄存器AW,指令寄存器B 2029包括Read指令寄存器BR和Write指令寄存器BW。
输入缓冲器2036和2046要求以与各时钟信号CLKA1和CLKB1同步地加上Read指令,指令译码器2037和2047进行译码处理。指令译码器2037和2047在读指令情形中分别产生RA1和RB1,而在写指令情形分别产生WA1和WB1。分别将信号RA1和RB1传输给Read指令寄存器AR和BR,不需要任何定时操作,而信号WA1和WB1分别被(n-1)时钟延迟电路2038和(m-1)时钟延迟电路2048延迟,直到输入脉冲串数据的最后一个数据项为止,接着被传输给Write指令寄存器AW和BW。而且,将由刷新电路2050产生的刷新指令REF1传输给刷新指令寄存器2027。
判优器2026检测将指令传输给这5个指令寄存器AR,AW,BR,BW和2027的次序,并以检测到的次序将这些指令一个接着一个地传输给DRAM控制电路2014。DRAM控制电路2014执行接收的指令,产生信号RESET1,要求判优器2026当指令执行结束或接近结束时发送下一个指令。响应RESET1信号,判优器使存储被执行指令的指令寄存器复位,并将下一个指令传输给DRAM控制电路2014。
图46是判优器2026的实施例。指令到达图45的5个指令寄存器的次序由比较器2053检测出来如该图46所示。每个比较器2053比较两个指令寄存器的定时,将它的输出在首先输入“H”的情形中改变成“H”。AND门2054通过检查相关的比较器2053的所有相关输出是否是“H”来确定给定的指令是否在所有4个其它指令前输入。如果一个响应的指令是最早的则响应各指令的信号RA3,WA3,RB3,WB3和REF变成“H”,并且将响应的指令的地址等被传输给DRAM芯2011,。当DRAM芯2011执行该指令时,从DRAM芯2011产生信号RESET1,并产生用于使被执行指令的指令寄存器复位的信号(ReasetRA,ReasetWA等)。当使被执行指令的指令寄存器复位时,接收这个被执行指令的比较器2053的输出改变,将在次序中的下一个指令传输给DRAM芯2011。在这个方式中,以指令输入的次序执行指令。
图47是表示根据第1实施例与地址处理有关的部分的配置的图。下文中,在它的信号名称的未端具有字母“P”的信号代表具有从对应的信号名称的信号的前沿产生的脉冲的信号。如图所示,地址输入电路2034和2044分别包括输入缓冲器2057A和2057B与传输门2058A和2058B。进一步,地址寄存器A 2019和地址寄存器B 2020分别包括地址锁存器A1和B1,传输门2060A和2060B,地址锁存器A2和B2,传输门2062A和2062B,与传输门2063A和2063B。通过地址总线2017将从传输门2062A,2062B,2063A和2063B提供的地址传输给DRAM芯2011。进一步,通过传输门2064和地址总线17将从刷新地址计数器/寄存器2018提供的刷新地址传输给DRAM芯2011。
当从器件外部输入Read指令或Write指令时,分别通过传输门2058A或2058B将加到输入缓冲器2057A或5027B的地址和输入指令同时传输给地址锁存器A1或B1。在Read指令的情形中,通过传输门2063A或2063B与到DRAM芯的指令传输同步地将地址传送给DRAM芯2011。在Write指令的情形中,进一步在上次数据采集的定时将地址传输给地址锁存器A2或B2,然后,与到DRAM芯的指令传输同步地通过传输门2062A或2062B传输给DRAM芯。进一步,刷新地址计数器/寄存器2018产生并在其中保存刷新地址,然后与到DRAM芯的刷新指令传输同步地通过传输门2064将该地址传输给DRAM芯2011。
图48是表示根据第1实施例与数据输出有关的部分的配置的图。图49是表示图48的传输信号发生电路的图。A端口2030和B端口2040的各数据I/O电路2033和2043分别包括为了输出数据的电路2065A和2065B与为了输入数据的电路2074A和2074B,我们将在后面描述它们。如图所示,将通过读出缓冲器2016从存储器阵列2012读出的数据通过数据总线2021和传输门2024或2025分别传输给为了输出数据的电路2065A或2065B。
为了输出数据的电路2065A和2065B分别包括数据锁存器A1或B1,传输信号发生电路2067A和2067B,传输门2069A或2069B,数据锁存器A2或B2,并行到串行变换器2070A和2070B,以及输出缓冲器2071A和2071B。
由DRAM芯2011的控制电路2014根据内部操作对传输门2024和2025进行控制。如果被执行的指令是Read-A(即,对于A端口的读操作),则传输门2024将打开。如果被执行的指令是Read-B,则传输门2025将打开。数据锁存器A1和B1在其中存储数据,然后在各端口中接收Read指令后的一个确定的等待时间,在这些端口通过传输门2068A或2068B引入这个等待时间,将数据传输给各数据锁存器A2或B2。然后,由并行到串行变换器2070A和2070B对数据进行变换,接着分别传输给输出缓冲器2071A和2071B,并从那里输出。
如图49所示,传输信号发生电路2067A和2067B采用一系列的触发器2072使各Read指令RA1和RB1延迟由等待时间设定确定的许多时间周期,从而产生数据传输信号2002。因为来自传输门2068A或2068B的读数据传输响应数据传输信号2002,所以读数据从读操作的定时开始被延迟与等待时间相当的许多周期后结束。
图50是表示根据第1实施例与数据输入有关的部分的配置的图。为了输入数据的电路2074A和2074B分别包括数据输入(Din)缓冲器2075A和2075B,串行到并行变换器2076A和2076B,以及数据传输装置2077A和2077B。分别通过Write数据寄存器2022和2023,数据传输装置2078A和2078B,以及数据总线21将来自数据传输装置2077A和2077B的写数据传送给WriteAmp 2015,并被写入存储器阵列2012。
根据脉冲串长度将串行输入数据从串行变换到并行,然后在输入最后一个数据项的定时传输给Write寄存器2022和2023。当从判优器2026将Write指令传输给DRAM芯2011时,通过数据传输门2078A和2078B也将对应的数据传输给DRAM芯2011。
图51到图58是表示第1实施例的多端口存储器操作的时间图。图51和图52,图54和图55与图57和图58是为了便于说明将单个时间图分成两部分的图,一个表示时间图的第一个一半,另一个表示时间图的第二个一半,它们之间存在一些重叠。
图51和图52表示当将Read指令相继地输入两个端口时实施的操作。A端口和B端口,它们分别具有有相互不同频率的时钟信号CLKA和CLKB,与接收的时钟信号同步地取得指令,地址和写数据,并与时钟信号同步地输出检索的数据。在这个例子中,A端口操作在最大时钟频率,而B端口操作在稍低的时钟频率。对于A端口,Read指令周期=4(CLKA),数据等待时间=4,和脉冲串长度=4。对于B端口,Read指令周期=2(CLKB),数据等待时间=2,和脉冲串长度=2。在各端口的模寄存器2031和2041中分别设置数据等待时间和脉冲串长度。在这个例子中,响应一个指令与时钟信号同步地实施数据的输入/输出4次,在输入读指令后的4个时钟信号中输出检索的数据。
分别将加到A端口和B端口的指令存储在指令寄存器2028和2029中。当刷新定时器2051产生信号时,刷新指令寄存器2027将刷新指令存储在它的里面。判优器2026监视这些指令寄存器,并以发出指令的次序将这些指令传输给DRAM芯2011。当完成上一个指令的处理后传输下一个指令。将从DRAM芯2011读出的数据从读出缓冲器2016传输到各端口的数据锁存器2069A和2069B,然后将数据从并行数据变换成串行数据,接着作为脉冲串数据与各外部时钟信号同步地输出。
如图所示,将指令Read-A2输入Read指令寄存器AR和将指令Read-B2输入Read指令寄存器BR。在此之前,发生一次刷新,并将刷新指令输入刷新指令寄存器。根据发出指令的次序,判优器2026以Read-A2→Ref→Read-B2的次序将这些指令传输给DRAM芯2011,然后由芯执行这些指令。甚至当在内部实施刷新操作时,从外部看来数据是在一个预定数据等待时间后输出的。这样,就不需要考虑任何刷新操作。
图53表示在与上述相同的条件下接连地输入Write指令的一个例子。也以脉冲串输入的形式给出在Write操作时间从器件外部输入的数据。在输入最后一块数据的定时将Write指令存储在Write指令寄存器AW中。在这个情形中,甚至当在内部产生和执行刷新指令时也不需要考虑任何刷新操作。
图54和图55表示当A端口和B端口两者都操作在最大时钟频率上进行Read操作时实施的操作。图56是表示当A端口和B端口两者操作在最大时钟频率上进行Write写操作时实施的操作的图。在这个情形中,在两个端口的时钟信号中可能存在相位差。对于两个端口,Read指令周期=4,Write指令周期=4,数据等待时间=4,和脉冲串长度=4。从图可见,在这个情形中也能够适当地实施操作。
图57和图58是表示当两个端口都操作在最高频率,并用内部产生的刷新指令从Write指令改变到Read指令时实施的操作的时间图。这是指令最拥挤的情形。
如图所示,DRAM芯2011以Ref→Write-A1→Write-B1→Read-A2→Read-B2的次序进行操作,在它们之间没有任何间隙。在这个例子中,在输入Write指令后的6个时钟脉冲输入Read-A2和Read-B2。即便这些定时超前2个时钟信号,也不可能超前DRAM芯的内部操作。由从输入Read指令开始的数据等待时间对读数据的输出定时进行控制。如果Read-A2和Read-B2的输入定时是超前的,则也需要将数据输出定时向前移动。在这个情形中响应Read-B2的数据输出定时太接近DRAM芯操作的开始时间,使得不能适当地执行Read-B2。因为这个原因,需要将Write→Read变迁的公共间隔设置得相当长如本例中的6个时钟脉冲。
关于Read→Write的公共间隔,因为除非完成了Read数据的输出,不能将Write数据输入DQ端子中,所以公共间隔不可避免地变长。
图59A和59B是表示DRAM芯2011操作的图。图59A表示Read操作,图59B表示Write操作。如这些图所示,响应单个指令以字线选择→数据放大→写回→预充电的次序实施一系列操作,从而完成整个操作。
如上所述,在第1实施例中从Write指令到Read指令的指令变迁的时间中指令间隔被加长。在第2实施例中对此进行了改进。当在第1实施例中一个相关的指令间隔是6个时钟脉冲周期时,第2实施例能将它缩短为5个时钟脉冲周期。
本发明的第2实施例的多端口存储器具有与第1实施例的多端口存储器类似的配置,不同之处只是刷新电路具有图60所示的配置。图61是表示第2刷新电路2083的配置的电路图。
如图60所示,第2实施例的刷新电路包括将图43C的刷新定时器2051和刷新指令发生器2052组合起来的定时器/刷新指令发生器2081,第2刷新指令寄存器2082和第2判优器2083,并将从第2判优器2083输出的刷新指令输入到刷新指令寄存器2027。与第1实施例相同将刷新指令寄存器2027的刷新指令REF2输入到判优器2026。在这个配置中,也将在完成刷新操作后从判优器2026输出到刷新指令寄存器2027的复位信号ResetREF加到第2刷新指令寄存器2082。
在第2实施例的刷新电路中,沿着刷新指令的路径提供第2判优器2083。如果我们预期如在Write指令→Read指令的指令变迁的情形中一样指令很拥挤,则第2判优器2083延迟刷新指令到刷新指令寄存器2027的传输。第2判优器2083检查是否用图61所示的电路配置发生从Write指令到Read指令的改变,并且如果检查出这样一个改变就延迟刷新指令从第2刷新指令寄存器2082到刷新指令寄存器2027的传输。
如图61所示,当各端口接到从器件外部转装置提供的Write指令时,使禁止REF传输的信号A和B去激活,在一个时钟脉冲周期后再被激活,接着在接到最后一个数据项后的若干个时钟脉冲周期(即,在本例中3个时钟脉冲)再被去激活。图61的3个CLK延迟装置2084A和2084B包括触发器等,并分别被WA1和WB1复位,这导致当通过延迟装置时WA1D和WB1D被复位。得到禁止REF传输的信号A和B的逻辑AND以便产生一个禁止REF传输的信号。因为只有当两个端口都经受从Write指令到Read指令的改变时在这个例子中才会出现问题,而当只有一个端口经受这种改变时不存在问题,所以得到这个逻辑AND。进一步,禁止REF传输的信号A和B在接到Write指令后只对一个时钟周期去激活的原因是这给出一个额外的时间以便完成在接收最后一个数据项前的刷新操作。进一步,提供延迟装置2086为了相对于时钟信号稍微延迟定时,以便增大在禁止REF指令传输的信号和从器件外部提供的指令之间的相关定时中的差别。
图62到图69是表示第2判优器的操作的定时图。图70到图72是表示第2实施例的多端口存储器操作的定时图。图62和图63,图64和图65,图66和图67,图68和图69,图70和图71是为了便于说明起见将单个时间图分成两半的图,一个表示时间图的第1个一半,另一个表示时间图的第2个一半,它们之间存在一些重叠。
图62和图63表示两个端口经受Write→Read指令改变,并当REF传输禁止期间发生刷新定时器事件的情形。在这个情形中,在完成Read-A2和Read-B2后实施刷新操作Ref。
图64和图65表示与上述情形相同两个端口经受Write→Read指令改变,但是在REF传输禁止期间前发生刷新定时器的情形。在这个情形中,在实施刷新操作Ref后实施Read操作。
图66和图67说明只有A端口经受Write→Read指令变迁,并在REF传输禁止期间中发生刷新定时器事件的情形。在这个情形中,在完成Write指令后实施刷新操作Ref,然后实施Read操作。
图68和图69显示在两个端口继续Write的情形。在这个情形中,一当在接着最后一个数据输入,输入Write指令后,就使3个CLK延迟装置2084A和2084B去激活。
图70和图71是表示与图57和图58所示的第1实施例的操作对应的第2实施例的操作的时间图。与第1实施例比较使Write→Read指令变迁的指令间隔从6个时钟脉冲缩短到5个时钟脉冲。
图72是表示与图56所示的第1实施例的操作对应的第2实施例的操作的时间图。虽然与第1实施例比较改变了关于刷新操作的指令执行次序,但是保持有次序的操作。
如上所述,第2实施例可以在任何条件下适当地实施操作,并能够将Write指令→Read指令变迁的指令间隔缩短到5个时钟脉冲周期。
如上所述,本发明允许当以DRAM芯为基础制成存储阵列时使用多端口存储器而不需要考虑任何刷新操作,从而以低成本提供具有大容量和容易使用的多端口存储器。
[本发明的第3方面]
下面我们描述本发明的第3方面。
存在若干种多端口存储器。下文中,涉及具有多个端口的存储器,并允许从各端口相互独立地存取一个公共存储器阵列。例如,两个端口型的多端口存储器装备有A端口和B端口,并允许从与A端口链接的CPU-A和从与B端口链接的CPU-B独立地进行到公共存储器的读/写存取。
作为这类多端口存储器,具有SRAM存储器阵列的存储器是已知的,其中在复制组中提供各字线和各位线对,每个存储单元都与2组字线和位线对连接。然而,这个多端口存储器具有电路密度低的问题,其中需要提供字线和位线对的复制组。
为了消除这个问题,可以用与具有多个处理器配置的计算机所用的共用存储器相同的机构。一个共用存储器具有提供给公共存储器的多个端口。典型地,将SRAM用作存储器,并用离散的IC制成多个端口。当从多个端口同时进行存取时,因为存储器阵列是共用的,所以不能同时进行与多个端口对应的操作。防止这种问题发生的最简单的方法是对每个端口产生一个BUSY信号以便防止当从一个端口作出存取时到另一个端口的存取。然而,这引起限制存储器用度的问题。考虑到这一点,为一个公共存储器提供一个称为判优器的判优电路,判优电路确定多个端口接收的存取要求的优先权。构造存储器阵列的控制器,以优先权的次序执行与存取要求相应的操作。例如,以到达的次序即以将存取要求加到各端口的次序处理存取要求。然而,这并不改变当另一个端口的指令正在被处理时不能执行新指令的情况。在这种情形中需要传输BUSY信号,存取存储器的器件需要具有处理BUSY信号的机构。
随机地从多个接口存取存储器阵列。因此,不提供在同一个行地址上连续地存取相继的列地址的列存取操作,但是在DRAM中典型地可以利用这种列存取操作。即,选择一个存储单元,为了读/写操作存取该存储单元,使该存储单元复位,所有这些操作都是在响应单个存取时被执行的。
当完成一个共用存储器时,一般,常规地将SRAM用作存储器阵列。这是因为SRAM能够进行高速随机存取操作,又,因为不需要刷新操作,所以很容易使用SRAM。而且,单块芯片的多端口存储器通常具有字线和位线对的复制组,但是在具有通常的SRAM配置的存储器阵列的基础上的单块芯片的多端口存储器还没有在实践中使用。
总结一下,多端口存储器和共用存储器是用SRAM制成的,而不用需要刷新操作的DRAM。
当系统不断地提供高性能时要被处理的数据量增加,并且多端口存储器也需要具有大的容量。可以用动态型存储单元(DRAM)阵列制成多端口存储器,DRAM比SRAM具有较高的电路密度,从而以低的成本提供具有大存储容量的多端口存储器。然而,存储单元的刷新操作成为一个问题。
在常规的DRAM中,需要从器件外部以恒定间隔在读/写指令之间提供刷新指令。为此,在以DRAM为基础的系统中的控制器器件具有用于刷新管理的定时器和/或控制电路。然而,在用以SRAM为基础的多端口存储器的系统中不提供这样一个电路。甚至在以DRAM为基础制成存储器的情形中,在这些系统中需要能以与常规的多端口存储器相同的方式使用这种存储器。即,具有由DRAM组成的存储器阵列的多端口存储器需要由它自己来进行刷新操作。
当判优器输出忙碌信号时,存在着如上所述使用存储器相当麻烦的问题。
本发明的目的是提供具有由DRAM芯组成的存储器阵列,而且不需要考虑刷新任何刷新操作就能使用的多端口存储器,从而以低的成本提供具有大存储容量并且容易使用的多端口存储器。
为了消除上述的问题,配置本发明的多端口半导体存储器件使它能够在长度为每个外部端口的最小输入周期m(m≥2)倍的时间周期中执行n个内部操作,其中满足mN<n<m(N+1)。
上述条件要求将N个端口的每一个的最小指令周期设置在允许N个内部操作周期的时间周期加比单个内部操作周期短的时间周期α上。例如当N=2时,将每个端口的最小外部指令周期设置在允许2个内部操作周期的时间周期加时间周期α上。这里,时间周期α比一个内部操作周期短。
本发明利用允许2个内部操作周期的时间周期以便消除由于判优器输出忙碌信号引起的存储器使用麻烦的问题,并利用时间周期α解决刷新操作问题。
图73是用于解释本发明(第3方面)原理的图,表示对于两个端口实施读操作的情形。
使到两个外部端口,A端口和B端口的指令在最小间隔进入,在该间隔中可以实施内部操作周期2.2次。即,内部操作周期的2.2倍等于最小外部指令周期,并将外部指令周期设置得比允许实施内部操作周期2.2次的时间周期长。分别将时钟脉冲CLKA和CLKB输入A端口和B端口,与对应的时钟脉冲同步地实施指令,地址和数据到外部端口的输入和从外部端口的输出。虽然未加说明,但是与指令同时输入地址。当在最小外部指令周期中将读指令加到A端口和B端口时,如图所示,判优电路对当实施芯操作时将优先权给予首先到达的指令进行控制。
DRAM芯实施两个读操作,在一个外部指令周期中从存储器阵列读出数据,并将数据输出到A端口和B端口。A端口和B端口分别保存检索的数据,并与各时钟脉冲信号的特定的时钟定时同步地输出检索的数据,这些时钟脉冲信号是从输入读指令开始的第6个时钟脉冲。即,在这个情形中数据等待时间是6。
提供刷新定时器作为内部电路,并在它自身上产生刷新指令。当不发生刷新操作时,器件的内部电路以例行程序的方式操作以便在一个外部指令周期中实施与指令A和B对应的两个操作。因为在一个外部指令周期中能够执行内部操作2.2次,所以DRAM芯将具有在完成两个内部操作后留下的一个额外时间tα。
当内部产生刷新指令时,器件的内部电路快速操作。这里,快速意味着执行操作而不产生额外时间tα。当产生刷新指令时,器件实施刷新操作。因为同时将指令输入A端口和B端口,所以要被处理的指令将积累起来。器件快速地一个接一个地执行指令而不提供额外时间tα。虽然将指令一个接一个地输入A端口和B端口,但是只有在比外部指令周期长的间隔发生刷新指令,只有指令A和指令B必须被执行直到产生下一个刷新指令。因为内部指令的处理速度较快,所以在结束时将不会有积累的指令。换句话说,内部处理将赶上外部指令的输入。此后,器件回到它的例行程序操作。通过考虑到外部端口的数目,内部操作周期的数目,刷新间隔等确定额外时间α。
因为当内部刷新指令和输入到另一个端口的指令立即在Read指令前发生时定时变得最坏,所以需要将与Read指令(RD)对应的数据输出的延迟时间(数据等待时间)设置在内部操作的3个周期中(在两个端口的情形中)。然而,因为稍长于两个内部操作周期的外部指令周期就是器件适当操作所需要的一切,所以数据传输速率是相当高的。
如上所述,本发明能够取消来自器件外部的刷新操作,并将外部指令周期设置得稍长于两个内部操作周期。不需要刷新来自外部装置的控制,甚至当在内部执行刷新操作时,这对外部装置是完全看不见的,并且不影响从外部装置看的器件操作的方式。因此,可以从每个外部端口进行到存储器的存取而不用考虑其它端口。
在这个方式中,本发明能够提供用DRAM存储单元的多端口存储器,它有大容量和快的数据传输速率,同时允许使用存储器而不用考虑任何刷新操作就像它在SRAM的基础上完成一样。
在图73的例子中,响应一个读指令与外部时钟脉冲同步地输出一项读数据。即,脉冲串长度为1。所以,在一个时钟脉冲周期中完成读数据的输出后,在外部指令周期的3个留下的时钟脉冲周期中外部端口不输出任何数据,这导致无效的数据传输。这个问题能够通过加长脉冲串长度来消除。
图74是用于解释本发明原理的图,表示脉冲串长度为4的例子。在这个例子中,如以前的情形那样,将两个外部端口的外部指令周期设置在能够提供2.2个内部操作周期的长度上。进一步,一个外部指令周期对应于4个时钟脉冲周期。与时钟脉冲同步地以提供数据等待时间为6的方式在单个外部指令周期中从一个外部端口输出数据4次。所以,如果根据一个外部指令周期的时钟脉冲周期的数目设置脉冲串长度,则在两个端口中都能够达到无间隙的读操作,从而非常大地促进了数据传输速率的提高。在这个情形中,需要响应单个存取将与脉冲串长度一样多的数据项内部地输入存储器阵列或从存储器阵列输出。例如,如果一个外部端口的数据输入/输出销数目为4和脉冲串长度为4,则需要保证通过单个存取操作将16位数据从存储器阵列输出或输入存储器阵列。
我们应该注意到A端口和B端口不一定同步地操作,只要设置最小周期等于对于N个内部操作周期加上比单个内部操作周期短的持续时间α需要的持续时间,就能够相互独立地将各外部指令周期设置在任何定时。
图75和图76是表示在2,3和N个端口的情形中在一个最小外部指令周期和各内部操作周期之间的关系的图。如图所示,如果端口数为2,则最小外部指令周期是允许2个内部操作的时间长度加上α,如果端口数为3,则最小外部指令周期是允许3个内部操作的时间长度加上α。进一步,如果端口数为N,则最小外部指令周期等于其间能执行N+1个内部操作的时间长度加上时间长度α。
图77和图78A到图78C是表示根据本发明的一个实施例的多端口存储器的配置的图。图77表示DRAM芯及其相关电路,图78A表示A端口,图78B表示B端口。进一步,图78C表示刷新电路。图78A到图78C所示的电路与图77的各部分连接。
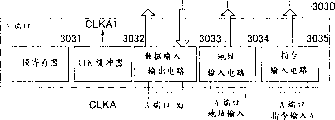
如这些图所示,本实施例的多端口存储器包括DRAM芯3011,用于控制确定操作次序并保证以确定的次序实施操作的判优器3026,指令寄存器3025,它暂时存储从判优器3026提供的指令,并将这些指令以接到它们的次序传输给DRAM芯3011的控制电路3014,暂时存储各端口的指令,地址和数据的多组寄存器,2个由A端口3030和B端口3040组成的外部端口,和刷新电路3050。
A端口3030和B端口3040分别包括模寄存器3031和3041,CLK缓冲器3032和3042,数据I/O电路3033和3043,地址输入电路3034和3044,与指令输入装置3035和3045,它们根据从器件外部提供的各分开的时钟频率进行操作。将数据等待时间和脉冲串长度存储在模寄存器3031和3041中,使它们能被分别地设置。数据I/O电路3033和3043装备有根据脉冲串长度实施输出/输出数据的并行到串行变换和串行到并行变换的机构。
刷新电路3050包括刷新定时器3051和刷新指令发生器3052。刷新定时器3051在预定间隔上产生刷新开始信号,和刷新指令发生器3052对应地产生刷新指令。
分别将加到A端口和B端口的指令存储在指令寄存器A 28A和指令寄存器B 28B中。分别将地址存储在地址寄存器A 19A和地址寄存器B19B中,分别将写入的数据存储在Write数据寄存器A 22A和Write数据寄存器B 22B中。进一步,将刷新指令存储在刷新指令寄存器3027中,并将刷新地址存储在刷新地址计数器/寄存器3018中。
判优器3026根据指令到达的次序确定执行指令的次序,并以确定的次序将指令传输给指令寄存器3025。指令寄存器3025以从判优器3026接到指令的次序将这些指令传送给DRAM芯3011的控制电路3014。当DRAM芯处理给定指令时,使控制电路3014处于能够接收下一个指令的状态。对应地,指令寄存器3025下一个指令传送给控制电路3014。同时将从判优器3026提供的指令暂时存储在指令寄存器3025中。进一步,指令寄存器3025除了将指令传输给DRAM芯3011的控制电路3014外也将传输信号传输给对应的地址寄存器和对应的数据寄存器(在写操作情形)。在DRAM芯3011中,控制电路3014响应提供的指令,控制译码器3013,写放大器(WriteAmp)3015,和读出缓冲器3016,从而对于存储器阵列3012实施存取操作。在写操作的情形中,译码器3013为了进行写操作对存取的地址进行译码,以便激活在存储器阵列3012中的字线和列信号线,导致将存储在Write数据寄存器A和B中的写数据通过WriteAmp 3015写入存储器阵列3012。在读操作的情形中,以类似的方式存取存储器阵列3012,导致分别通过标记为3024A和3024B的传输门A和B,将读数据从读出缓冲器3016传输到各端口的数据输出电路。根据DRAM芯3011的操作周期,控制传输门的传输定时,并由控制电路3014确定传输定时。与对应的外部时钟同步地从每个端口的数据输出电路输出输出数据。
下面,我们描述与每个指令处理,地址处理和数据处理有关的详细情形。
图79和图80是表示根据第1实施例与指令处理有关的装置的配置的图。在与图77和图78A-78C相同的部件上加上相同的参照数字。这也同样应用于其它的图。
如图79所示,A端口的指令输入装置3035包括输入缓冲器3036,指令译码器3037和(n-1)时钟延迟电路3038,B端口的指令输入装置3045包括输入缓冲器3046,指令译码器3047和(m-1)时钟延迟电路3048。这里,n和m是脉冲串长度。而且,如图80所示,指令寄存器A包括Read指令寄存器AR和Write指令寄存器AW,指令寄存器B包括Read指令寄存器BR和Write指令寄存器BW。
输入缓冲器3036和3046要求以与各时钟脉冲CLKA1和CLKB1同步地加上Read指令,指令译码器3037和3047进行译码处理。指令译码器3037和3047在Read指令情形分别产生RA1和RB1,而在Write指令情形分别产生WA1和WB1。分别将信号RA1和RB1传输给Read指令寄存器AR和BR,不需要任何定时操作,而信号WA1和WB1被(n-1)时钟延迟电路3038和(m-1)时钟延迟电路3048延迟,直到输入脉冲串数据的最后一个数据项为止,接着分别被传输给Write指令寄存器AW和BW。而且,将由刷新电路3050产生的刷新指令REF1传输给刷新指令寄存器3027。
判优器3026检测将指令传输给这5个指令寄存器AR,AW,BR,BW和3027的次序,并以检测到的次序一个接着一个地将这些指令传输给指令寄存器3025。在接到从判优器2026发出的指令时,指令寄存器3025将指令接收确认传输给判优器3026。响应指令接收确认,判优器3026将下一个指令发送给指令寄存器。
指令寄存器3025以从判优器3026接到指令的次序将指令一个接着一个地传输给DRAM芯3011的控制电路3014。DRAM芯的控制电路3014执行接到的指令,并当指令执行结束或接近结束时将准备好接收指令的信号传输给指令寄存器3025。响应准备好接收指令的信号,指令寄存器3025将下一个指令传输给控制电路3014。同时,将从判优器3026提供的指令暂时存储在指令寄存器3025中。
图81是判优器3026的实施例。指令到达图80的5个指令寄存器(Read指令寄存器AR,Write指令寄存器AW,Read指令寄存器BR,Write指令寄存器BW和刷新指令寄存器3027)的次序由比较器3053检测出来如该图所示。每个比较器3053比较两个指令寄存器的定时,并首先输入“H”时将它的输出改变成“H”。AND门3054通过检测相关比较器3053的所有相关输出是否是“H”来确定一个给定的指令是否在所有4个其它的指令前输入。如果一个对应的指令是最早的并且被传输给指令寄存器3025,则响应各指令,信号RA31,WA31,RB31,WB31和REF31变成“H”。如果RA2是RA2到REF2中最早的,则与RA2连接的比较器具有在与RA2连接的一边上为“H”的输出。在这个特定的瞬间,指令接收确认还没有产生(=“L”),使得N1=“H”,导致RA3为“H”。于是将指令发送给指令寄存器3025。
指令寄存器3025当接收指令时产生指令接收确认。当发生这种情况时,在节点N1产生“L”脉冲,导致RA3到REF3都为“L”。同时,将产生ResetRA到ResetREF中的一个。如果RA31为“H”,则产生ResetRA,从而使Read指令寄存器AR复位。对应地,RA2变成“L”,于是RA31到REF31中的一个变成“H”,指示中下一个在线的指令。当在“L”脉冲未端N1变成“H”时,将下一个在线的指令传输给指令寄存器3025。此后重复上述的操作。
图82和图83是表示指令寄存器3025的配置的图。将指令寄存器3025分成两半并表示在两个图中。
指令寄存器3025主要包括移位寄存器3092,移位寄存器3092在其中存储指令,将这些指令连续地输出到DRAM芯3011,并包括将从判优器3026接收的指令传输到移位寄存器3092的开关(SW1-SW3)3082-3084。在这个例子中,移位寄存器3092具有三级配置,并包括用于存储指令的寄存器3085-3087,指示寄存器3085-3087的存储状态的标志3088-3090,和使寄存器3085-3087的状态复位的复位数据装置3091。在没有指令存储在寄存器3085-3087的状态中,标志3088-3090都处于低的状态(FL1-FL3=“L”),使得开关3082(SW1)接上。通过SW1将第1指令存储在寄存器3085中,使得FL1变成“H”。当FL1变成“H”时,“H”边沿脉冲电路3093产生脉冲,将指令接收确认传输给判优器3026。
如果在这个特定的瞬间DRAM芯3011认定准备好接收指令的信号,则门3097打开将寄存器3085的指令传输给锁存器3098,然后将指令发送给DRAM芯3011的控制电路3014。同时,将对应于该指令的地址等传输给DRAM芯3011。DRAM芯3011当根据接到的指令开始操作时取消准备好接收指令的信号。于是门3097关闭。寄存器控制电路3096产生促使寄存器3086的数据移到寄存器3085和寄存器3087的数据移到寄存器3086的移位信号。如果在移位信号产生前寄存器3086中没有存储指令,则移位操作导致使寄存器3085复位和使FL1变成“L”。寄存器控制电路3096在产生移位信号同时产生禁止传输信号以便断开SW1-SW3,从而当移位操作时禁止将数据传送到移位寄存器3092。当通过SW1将第1指令(指令1)加到寄存器3085时,如果DRAM芯3011在执行前一个指令则将指令存储在寄存器3085中。FL1变成“H”,它断开SW1,并进一步在一个预定延迟后断开SW2。这里,预定延迟与从产生指令接收确认到使判优器输出复位的时间周期对应。如果在DRAM芯3011准备好接收指令前加上来自判优器3026的下一个指令(指令2),则通过SW2将指令存储在寄存器3086中。FL2变成“H”,它产生指令接收确认并断开SW2,接着在一个预定延迟时间后进一步断开SW3。当DRAM芯处在能接收指令的状态时,产生准备接收指令信号,打开门3097,使得将寄存器3085的指令1传输给锁存器3098,然后传输给DRAM芯3011。DRAM芯3011当根据指令1开始操作时取消准备接收指令信号。相应地,门3097关闭。寄存器控制电路3096产生移位信号,该移位信号将寄存器3086的指令2移到寄存器3085,和将寄存器3087的内容(复位状态)移到寄存器3086。寄存器3085结束指令2的存储,寄存器3086和3087终止在复位状态。因为FL1为“H”,FL2和FL3为“L”,所以接上SW2而断开SW1和SW3。
复位数据装置3091与在它左边的移位寄存器3092的寄存器连接。提供这个配置的目的是当在直到寄存器3087的整条路径上指令都被存储时,用接着的移位信号将寄存器3087的指令移到寄存器3086。在这个方式中,指令寄存器3025暂时积累从判优器3026发送的指令,检测DRAM芯3011的状态,接着一个又一个地传输指令。
将指令产生检测信号输入寄存器控制电路3096。当从判优器3026传输指令时产生指令产生检测信号。图84A和图84B表示寄存器控制电路3096的操作。当到寄存器控制电路3096的准备接收指令信号去激活时产生移位信号和禁止传输信号。然而,当就在准备接收指令信号去激活前立即从判优器3026传输指令时,优先的是只在将较早接收的指令传输给移位寄存器3092后才实施移位操作。因此,进行比较以便确定准备接收指令信号的后沿和指令产生检测信号的前沿中哪一个较早。如果前者较早,则响应前者的后沿产生移位信号和禁止传输信号,如果后者较早,则响应后者的后沿产生移位信号和禁止传输信号。
图85和图86是表示指令寄存器3025操作的图。这里对关于在表示输入指令最拥挤的定时条件的Write→Read指令传输的时间产生刷新指令的情形进行说明。图中所示的SW1到SW3的数目指出连接的SW,并说明了连接SW的持续时间。进一步,电阻1到3分别对应于寄存器3085到3087。
图87是表示根据第1实施例与地址处理有关的部分的配置的图。下文中,在它的信号名称的未端具有字母“P”的信号代表具有从对应的信号名称的信号的前沿产生的脉冲的信号。如图所示,地址输入电路3034和3044分别包括输入缓冲器3057A和3057B,传输门3058A和3058B。进一步,地址寄存器3019A和地址寄存器3019B分别包括地址锁存器A1到A4和B1到B4,传输门3059A到3063A和3059B到3063B。通过地址总线3017将从传输门3062A,3062B,3063A,3063B提供的地址传输到DRAM芯3011。进一步,通过传输门3064和地址总线3017将从刷新地址计数器/寄存器3018
提供的刷新地址传输到DRAM芯3011。
当从器件外部输入Read指令或Write指令时,分别通过传输门3058A或3058B将加到输入缓冲器3057A或3057B的地址和输入指令同时传输给地址锁存器A1或B1。在Read指令的情形中,通过传输门3061A和3063A或3061B和3063B和地址锁存器A4或B4与到DRAM芯的指令传输同步地将地址传送给DRAM芯3011。在Write指令的情形中,进一步在上次数据采集的定时将地址传输给地址锁存器A2或B2,然后,与到DRAM芯的指令传输同步地通过传输门3062A或3062B传输给DRAM芯3011。进一步,刷新地址计数器/寄存器3018产生并在其中保存刷新地址,然后与刷新指令到DRAM芯的传输同步地通过传输门3064将该地址传输给DRAM芯3011。
图88是表示根据第1实施例与数据输出有关的部分的配置的图。图89是表示图88的传输信号发生电路的图。A端口3030和B端口3040的各数据I/O电路3033和3043分别包括为了输出数据的电路3065A和3065B及为了输入数据的电路3074A和3074B。如图所示,将通过读出缓冲器3016从存储器阵列3012读出的数据通过数据总线3021和传输门3024A或3024B分别传输给为了输出数据的电路3065A或3065B。
为了输出数据的电路3065A和3065B分别包括数据锁存器A1或B1,传输信号发生电路3067A和3067B,传输门3068A或3068B,数据锁存器A2或B2,并行到串行变换器3070A和3070B,以及输出缓冲器3071A和3071B。
传输门3024A和3024B由DRAM芯3011的控制电路3014根据内部操作进行控制。如果执行的指令是Read-A(即,对于A端口的读操作),则传输门3024A将打开。如果执行的指令是Read-B,则传输门3024B将打开。数据锁存器A1或B1在其中存储数据,然后在通过传输门3068A和3068B引入等待时间的各端口中接收Read指令后的一个预定等待时间,将数据传输给各数据锁存器A2或B2。然后,由并行到串行变换器3070A和3070B对数据进行变换,接着分别传输给输出缓冲器3071A和3071B,并从那里输出。
如图89所示,传输信号发生电路3067(即3067A或2067B)采用一系列的触发器3072使各Read指令RA1或RB1延迟由等待时间设定确定的许多时钟脉冲周期,从而产生数据传输信号3002。因为响应数据传输信号3002,通过传输门3068A和3068B传输读数据,所以读数据从读操作的定时开始被延迟与等待时间设置相同的许多时钟脉冲周期后结束。
图90和图91是表示根据本实施例与数据输入有关的部分的配置的图。为了输入数据的电路3074A和3074B分别包括数据输入(Din)缓冲器3075A和3075B,串行到并行变换器3076A和3076B,以及数据传输装置3077A和3077B。分别通过第1个Write数据寄存器3078A和3078B,数据传输门3079A和3079B,第2个Write数据寄存器3080A和3080B,数据传输门3081A和3081B,以及数据总线3021将来自数据传输装置3077A和3077B的Write数据WDA和WDB传送给WriteAmp3015,然后被写入存储器阵列3012。
根据脉冲串长度将串行输入数据从串行变换到并行,然后在输入最后一个数据项的定时传输给第1个Write寄存器3078A和3078B。当从指令寄存器3025将Write指令传输给DRAM芯3011时,也将对应数据传输给DRAM芯3011。
图92到图99是表示第1实施例的多端口存储器的操作的定时图。图92和图93,图95和图96,图98和图99是为了便于说明起见将单个时间图分成两半的图,一个表示时间图的第1个一半,另一个表示时间图的第2个一半,它们之间存在一些重叠。
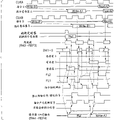
图92和图93表示当将Read指令相继输入两个端口时实施的操作。A端口和B端口,它们分别具有有相互不同频率的时钟信号CLKA和CLKB,与接收的时钟信号同步地取得指令,地址和写数据,并与时钟信号同步地输出检索的数据。在这个例子中,A端口操作在最大时钟频率,而B端口操作在稍低的时钟频率。对于A端口,Read指令周期=4(CLKA),数据等待时间=6(CLKA),和脉冲串长度=4。对于B端口,Read指令周期=2(CLKB),数据等待时间=3(CLKB),和脉冲串长度=2。在各端口的模寄存器3031和3041中分别设置数据等待时间和脉冲串长度。对于A端口,响应一个指令与时钟信号同步地实施数据的输入/输出4次,在输入读指令后的6个时钟脉冲周期输出检索的数据。对于B端口,响应一个指令与时钟信号同步地实施数据的输入/输出2次,在输入读指令后的3个时钟脉冲周期输出检索的数据。
分别将加到A端口和B端口的指令存储在指令寄存器3028A和3028B中。当刷新定时器3051产生信号时,刷新指令寄存器3027在其中存储刷新指令。判优器3026监视这些指令寄存器,并以发出指令的次序将这些指令传输给指令寄存器3025。指令寄存器3025暂时存储接收的指令,并以接到它们的次序将它们连续地传输给DRAM芯3011。即,在完成上一个传输指令的处理后传输下一个指令。
如图所示,将指令Read-A2输入Read指令寄存器AR和将指令Read-B2输入Read指令寄存器BR。在此之前,发生一次刷新,并将刷新指令输入刷新指令寄存器。根据发出指令的次序,判优器3026以Read-A2→Ref→Read-B2的次序将这些指令传输给DRAM芯3011,然后由芯执行这些指令。
由于芯的操作在Read-B1和Read-A2之间存在额外时间,并直到这个点都实施正常的和例行程序操作。当发生刷新时,在Read-A2后立即实施刷新而在其间没有任何时间间隙。此后,相继实施Read-B2,Read-A3等而没有任何时间间隙直到执行Read-A5。与正常的和例行程序操作相反,直到这个点都执行快速操作。
由于刷新指令的执行,内部操作相对于来自器件外部的指令输入显示出一些延迟。快速操作补偿该延迟,在执行指令Read-A5前赶上。在Read-A5和Read-B5之间再次存在额外时间,指出回到正常的和例行程序操作。将通过读出缓冲器3016从DRAM芯3011读出的数据通过传输门传输给接收对应的Read指令的端口的数据锁存器(数据锁存器A1或B1)。数据锁存器A1或B1为数据提供时间调整,然后将数据传输给数据锁存器A2或B2,并与对应端口的时钟信号同步地输出数据。
甚至当在内部实施刷新操作时,从外部看来数据是在一个预定数据等待时间后输出的。这样,就不需要考虑任何刷新操作。
图94表示当在与上述相同的条件下接连地输入Write指令时的例子。也以脉冲串输入的形式给出在Write操作时从器件外部输入的数据。在输入最后一个数据块的定时将Write指令存储在Write指令寄存器AW中。在这个情形中,甚至当在内部产生和执行刷新操作时也不需要考虑任何刷新操作。
图95和图96表示当A端口和B端口两者都操作在最大时钟频率上进行Read操作时实施的操作。图97是表示当A端口和B端口两者都操作在最大时钟频率上进行Write操作时实施的操作的图。在这个情形中,在这两个端口的时钟脉冲信号中可能存在相位差。对于两个端口,Read指令周期=4,Write指令周期=4,数据等待时间=6,和脉冲串长度=4。如从图可见的那样,在这个情形中也可以适当地实施操作。
图98和图99是表示当两个端口都操作在最高频率,并用内部产生的刷新指令经受从Write写指令到Read读指令的改变时实施的操作的时间图。这是指令最拥挤的情形。
如所说明的那样,DRAM芯3011以Ref→Write-A1→Write-B1→Read-A2→Read-B2的次序进行操作,在它们之间没有任何间隙。在这个例子中,在输入Write指令后6个时钟脉冲输入Read-A2和Read-B2。即便这些定时超前2个时钟脉冲,也不可能超前DRAM芯的内部操作。由从输入Read指令的数据等待时间对读数据的输出定时进行控制。如果Read-A2和Read-B2的输入定时是超前的,则也需要使数据输出定时是超前的。例如,如果在Write-B1后4个时钟脉冲输入Read-B2,则响应Read-B2的数据输出定时太接近DRAM芯操作的开始时间,使得不能适当地执行Read-B2。因为这个原因,需要将Write→Read变迁的指令间隔设置得相当长如本例中的6个时钟脉冲。
关于Read→Write的指令间隔,因为除非完成了Read数据的输出,不能将Write数据输入DQ端子中,所以指令间隔不可避免地变得很长。
图100A和100B是表示DRAM芯3011操作的定时图。图100A表示Read操作,图100B表示Write操作。如这些图所示,响应单个指令以字线选择→数据放大→写回→预充电的次序实施一系列操作,从而完成整个操作。当接到指令时DRAM芯3011使准备接收指令信号去激活,并当完成或接近结束指令的执行时产生准备接收指令信号。
如上所述,本发明允许当以DRAM芯为基础制成存储器阵列时使用多端口存储器而不需要考虑任何刷新操作,从而以低成本提供有大容量和容易使用的多端口存储器。
[本发明的第4方面]
下面我们描述本发明的第4方面。
多端口存储器,它们是装备有多个端口的半导体存储器,可以分成不同的类型。当下文中使用术语“多端口存储器”时,它指的是具有多端口的存储器,该存储器允许从任何一个端口独立地存取公共存储器阵列。这样一个存储器可以具有A端口和B端口,并允许对于公共存储器阵列从与A端口链接的CPU和从与B端口链接的CPU独立地进行读/写操作。
一个多端口存储器装备有称为判优器的判优电路。判优器确定从多个端口接收的存取要求的优先权,存储器阵列的控制电路根据确定的优先权一个接一个的进行存取操作。例如,存取要求越早到达端口,就会给予该存取要求越高的优先权。
在这种情形中,因为随机地从多个接口存取存储器阵列,所以在执行了读或写的存取操作后需要立即使存储器阵列复位,从而保证存储器阵列为下一次存取作好了准备。即,如果响应来自给定端口的存取要求使一条字线保持在选择状态,和如一般在DRAM中使用的列存取操作中那样连续地动移各列地址以便读出连续的数据,则当该操作期间来自另一个端口的存取要求将一直等待着。因此,在每次读或写操作后需要立即使存储器阵列复位。
常规地,已经典型地将SRAM用作多端口存储器的存储器阵列。这是因为SRAM允许高速随机存取,而且可以进行非破坏性读操作。
在具有两个端口的多端口存储器中,例如,一个SRAM存储单元具有两组字线和位线对。一个端口用一组字线和位线对实施读/写操作,另一个端口用另一组字线和位线对实施读/写操作。在这种方式中,能够从两个不同的端口独立地实施读/写操作。然而,因为当两个端口企图在同一时间将数据写入同一存储单元时不可能同时进行两个写操作,所以给予一个端口进行写操作的优先权,而给予另一个端口BUSY(忙碌)信号。这称为BUSY状态。
当开发系统使它有改善的性能时,由该系统处理的数据量也增加了。结果,多端口存储器需要很大的容量。然而,SRAM型多端口存储器具有存储单元的尺寸大的缺点。
为了消除这个缺点,在多端口存储器中采用DRAM阵列是可以理解的。为了得到比多端口SRAM高得非常多的电路密度,需要用于多端口存储器中一个DRAM存储单元以与典型的DRAM单元相同的方式只与一条字线和一条位线连接。如果以这样一种方式用DRAM元件制成存储块,如果一个端口正在对给定存储块执行读或写操作,则另一个端口不能存取该存储块。这是因为在DRAM存储单元中只可以有破坏性读操作。即,当读取信息时,不能选择在同一个存储块中的另一条字线直到这个信息被放大和存储在存储单元中,字线和位线被预先充电为止。
只有当多个端口同时对同一个存储单元提出写要求时,在常规的SRAM型多端口存储器中才会出现BUSY状态。因此,DRAM型多端口存储器需要具有一个独特的与常规的SRAM型多端口存储器不同的BUSY状态控制功能。
进一步,与SRAM型多端口存储器不同,DRAM型多端口存储器需要周期地实施刷新操作以便保持存储的信息,从而必须采取某种措施保证适当的刷新定时。
因此,本发明的目的是提供能够消除特别与DRAM有关的问题的DRAM型多端口存储器。
根据本发明,半导体存储器件包括多个N个外部端口,它们中的每一个都接收指令,多个与各外部端口对应的N条总线,多个与N条总线连接的存储块,比较由输入到N个各外部端口的指令存取的地址的地址比较器,和判优电路,它确定当地址比较电路根据地址比较检测出到同一个存储块的存取时,存取同一个存储块的各指令中的哪一个或哪几个要被执行,和存取同一个存储块的各指令中的哪一个或哪几个不被执行。
在上面描述的本发明中,如果从器件外部输入端口的指令企图存取同一个存储块时,判优电路确定各指令中的哪一个要被执行,和各指令中的哪一个不被执行。例如,比较指令定时,执行较早的指令,而不执行其它的一个或多个指令。当存在不被执行的指令时,产生BUSY信号等并输出到器件外部。这使得甚至当在以DRAM芯为基础的多端口存储器中指令存取相互发生冲突时也可以实施适当的存取操作并实现适当的BUSY控制。
根据本发明的一个方面,存储块包括在动态型存储单元的基础上制成的存储单元阵列,而半导体存储器件包括定义刷新存储单元的定时的刷新电路。在第一模式中,响应输入到N个外部端口中的至少一个端口的刷新指令刷新存储单元,在第二模式中,在刷新电路指出的定时刷新存储单元。
上面描述的本发明具有一个操作模式,其中响应来自器件外部的指令执行刷新操作的操作模式,和响应来自内部刷新电路的指令执行刷新操作的操作模式。这使在这样一种方式,即将预定外部端口指定作为一个用于在恒定的间隔接收刷新指令进行刷新管理的端口中用多端口存储器成为可能,或者使在这样一种方式,即当所有的外部环部端口都处于去激活状态时内部刷新电路开始刷新操作中用多端口存储器成为可能。因此,本发明为遵从系统要求的灵活的刷新管理提供了基础。
下面我们将参照所附各图描述本发明(第4方面)的实施例。
图101是表示根据本发明的多端口存储器的实施例的方框图。在这个例子中,配置是这样的,即提供两个端口,A端口和B端口。
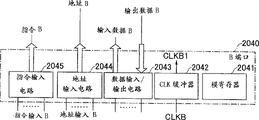
图101的多端口存储器4010包括A端口4011,B端口4012,自刷新电路4013,存储块4014-1到4014-n,判优器4015,刷新地址计数器4016,地址改变电路4017,地址改变电路4018,地址比较器4019,总线A 4020-1和总线B 4020-2。
A端口4011包括模寄存器4031,CLK缓冲器4032,数据I/O电路4033,指令译码寄存器4034,地址缓冲器/寄存器4035和BUSY信号I/O装置4036。进一步,B端口4012包括模寄存器4041,CLK缓冲器4042,数据I/O电路4043,指令译码寄存器4044,地址缓冲器/寄存器4045和BUSY信号I/O装置4046。在A端口4011和B端口4012,与各时钟信号CLKA和CLKB同步地独立地建立到外部总线的存取和来自外部总线的存取。模寄存器4031和4041能够在其中存储对于各端口的模式设定如数据等待时间和脉冲串长度。在这个实施例中,A端口4011和B端口4012两者都具有各自的模寄存器,使每个端口都能进行模式设定。然而,可以将模寄存器只安排在一个端口中,例如,使得对于2个端口的设置可以由对这一个端口的设置来实现。
自刷新电路4013包括刷新定时器4046和刷新指令发生器4047。自刷新电路4013在器件中产生刷新指令,分别从A端口4011和B端口4012接收信号CKEA1和CKEB1。信号CKEA1和CKEB1是分别用CLK缓冲器4032和4042对外部信号CKEA和CKEB进行缓冲得到的。用外部信号CKEA和CKEB暂停各端口的时钟缓冲器并使各端口去激活。如果使A端口4011和B端口4012两者都进入去激活状态,则自刷新电路4013开始它的操作。
存储块4014-1到4014-n每个都与内部总线A 4020-1和内部总线B4020-2连接。存在多个外部端口(即,A端口和B端口),其中A端口4011通过总线A 4020-1与存储块4014-1到4014-n中每一个接口,和B端口4012通过总线A 4020-2与存储块4014-1到4014-n中每一个接口。
如果在同一个时间输入来自A端口4011的存取要求和来自B端口4012的存取要求,则假定这些存取要求是指向不同的存储块的,存取存储块就对应于这些存取要求独立地实施它们的操作。
如果来自A端口4011的存取要求和来自B端口4012的存取要求是指向同一个存储块的,则判优器(判优电路)4015确定指令到达的次序,并执行第1个到达的指令而删除第2个到达的指令。当删除指令时,判优器4015产生BUSY信号以便通知外部控制器已经被删除第2个到达的指令的存取要求。
地址比较器4019确定进入两个端口的存取要求中是否指向同一个存储块。详细的说,地址比较器4019比较包含在进入两个端口的地址中的块选择地址。如果它们是相同的,则将匹配信号加到判优器4015。
当A端口4011或B端口4012处于激活状态时,从A端口4011和B端口4012输入刷新指令。
如果进入两个端口中的一个端口的刷新指令存取同一个存储块如输入到两个端口中的另一个端口的读指令或写指令所做的那样,则判优器4015确定指令到达的次序。如果刷新指令比其它指令晚,则取消刷新指令。在这个情形中,判优器4015产生BUSY信号,并将它加到器件外部。当检测出BUSY信号时,外部控制器在切断BUSY信号后再次向多端口存储器4010提供刷新指令。
如果刷新指令比其它指令早,或者从自刷新电路4013提供自刷新指令,则判优器4015产生计数信号,并将它加到刷新地址计数器4016。
刷新地址计数器4016响应计数信号对地址进行计数,从而产生刷新地址。需要从判优器4015提供计数信号的理由是因为如上所述刷新指令能够被取消,所以计数操作应该只响应从判优器4015实际发出的刷新指令进行。这里,在实施刷新操作后实施计数操作。
如果输入到A端口4011的指令是Read指令(读出指令)或Write指令(写入指令),则地址改变电路4017将从外部输入到A端口4011的地址传输给总线A 4020-1。如果输入到A端口4011的指令是刷新指令,则将由刷新地址计数器4016产生的地址传输给总线A 4020-1。
如果输入到B端口4012的指令是Read指令(读出指令)或Write指令(写入指令),则地址改变电路4018将从外部输入到B端口4012的地址传输给总线B 4020-2。另一方面,如果输入到B端口4012的指令是刷新指令,则将由刷新地址计数器4016产生的地址传输给总线B4020-2。
如上所述,如果A端口4011和B端口4012两者都处于去基活状态,则自刷新电路4013根据作为内部电路提供的刷新定时器4046的定时信号产生刷新指令。在这个实施例中,通过总线A 4020-1将自刷新指令和刷新地址传输给存储块4014-1到4014-n。因为自刷新不与A端口4011和B端口4012的指令冲突,所以不需要判优器4015确定优先权。然而,因为需要由判优器4015产生计数信号,所以也将自刷新指令提供给判优器4015。
图102是表示根据本发明的多端口存储器4010操作的一个例子的定时图。
指令Read-x是指向存储块4014-(x+1)的Read指令。首先将Read-0输入到A端口4011,然后将Read-3输入到B端口4012。在这个情形中,存取的存储块是不同的,使得存储块4014-1和存储块4014-4并行地操作。
此后,将Read-1输入到A端口4011,接着将Read-1输入到B端口4012。因为在这个情形中存取的存储块是相同的,所以产生匹配信号,取消输入到B端口4012的指令。而且,从B端口4012的BUSY信号I/O装置4046输出BUSY-B(负逻辑值)。
B端口4012的外部控制器检测BUSY-B,在切断这个信号后再次向多端口存储器4010提供Read-1。
图103是表示根据本发明的多端口存储器4010操作的另一个例子的定时图。
图103所示的操作直到将第2个指令Read-1输入A端口4011和B端口4012,产生BUSY-B为止都与图102的相同。在这个例子中,在响应输入到B端口4012的Read-1发生BUSY-B后,为了在BUSY-B结束前存取另一个存储块进入读指令Read-2。在这个方式中,只要下一个指令是指向另一个存储块的甚至在认定BUSY的周期中也能够输入下一个指令。
图104是表示根据本发明的多端口存储器4010操作的又一个例子的定时图。
图104的例子表示输入Write指令的情形。将Read指令输入A端口4011,接着将Write指令输入B端口4012。
在这个实施例中,输入/输出数据是脉冲串型的。即,通过从多个列地址读出并行数据,并当数据输出时在数据I/O电路4033和4043中将它变换成串行数据得到数据输出。串行地输入数据输入,然后在数据I/O电路4033和4043中将它变换成并行数据,接着将并行数据写入相关存储块的多个列地址中。使用这种脉冲串操作能够增加数据传输速率。在这个例子中,脉冲串长度为4,使连续地输出/输入4个数据项。
在Write操作的情形,除非输入所有的4个数据项,否则不能开始Write操作。所以,判优器4015能够确定Write操作的优先权的定时是给出一系列串行数据输入的最后一项的定时。
在图104中,A端口4011的第3个指令输入Read-3和B端口4012的第2个指令输入Write-3企图存取同一个存储块。虽然B端口4012的Write-3依据指令到各端口的输入定时在其它的指令输入前面,但是在写数据最后一项进入前给出了A端口4011的Read-3。因此,判优器4015确定A端口4011的指令在其它指令的前面,并取消B端口4012的指令。
如图101所示,A端口4011和B端口4012分别具有CLK缓冲器4032和4042,并从器件外部接收不同的时钟信号。各时钟信号可以具有相同或不同的相位和频率。
图105是表示指令译码器寄存器4034和4044的方框图。
指令译码器寄存器4034包括输入缓冲器4061,指令译码器4062和(n-1)时钟延迟电路4063。指令译码器寄存器4044包括输入缓冲器4071,指令译码器4072和(n-1)时钟延迟电路4073。
如果输入到输入缓冲器4061或4071的指令是Read指令(RA1,RB1)或刷新指令(REFA,REFB),通过指令译码器4062或4072将输入指令传输给判优器4015而不需要任何定时操作。在Write指令(WA1,WB1)的情形,输入指令被(n-1)时钟延迟电路4063或4073延迟(n-1)个时钟周期,在给出一系列脉冲串写输入的最后的第n个数据项的定时传输给判优器4015。
图106是根据本发明的实施例的判优器4015的方框图。
判优器4015包括寄存器4081,延迟电路4082,传输门4083,寄存器4084,寄存器4085,延迟电路4086,传输门4087,寄存器4088,NOR电路4091和4092,NAND电路4093到4096,倒相器4097到4101,与NOR电路4102和4103。
将从指令译码寄存器4034或4044传输过来的指令分别存储在寄存器4081或4085中。当将指令输入给予A端口4011时,在是倒相器4097的输出端的节点N1产生HIGH信号。当将指令输入给予B端口4012时,在是倒相器4100的输出端的节点N2产生HIGH信号。将N1的信号或N2的信号中较早的一个锁存在节点N3或N4中。
如果在A端口4011和B端口4012之间块选择地址不匹配,则地址比较器4019产生为LOW的匹配信号。所以,在这个情形中,将N5和N6设置在HIGH。响应这些HIGH信号,传输门A 4083和传输门B 4087两者都打开,无例外地将寄存器4081和4085的指令传输给寄存器4084和4088。
如果在A端口4011和B端口4012之间块选择地址匹配,则地址比较器4019产生为HIGH的匹配信号。所以,在这个情形中,在节点N5和N6的信号电平受到在节点N3和N4的信号电平的控制。如果A端口4011较早,则将N5设置在HIGH,将N6设置在LOW。响应N5的HIGH状态,传输门A 4083打开,将A端口4011的指令传输给寄存器4084。进一步,N6的LOW状态关闭传输门B 4087,不将B端口4012的指令传输给寄存器4088。
而且,根据N5和N6的信号电平,产生复位信号BUSY1-A和BUSY1-B,使各寄存器4081和4085复位。例如,如果选择A端口4011的指令,则产生BUSY1-B和使寄存器4085复位。
不需要确定自刷新指令的优先权,在寄存器4084的输出级使自刷新指令与A端口4011的刷新指令REFA组合起来。在这个方式中对于A端口4011产生的刷新指令信号REFA2与B端口4012的刷新指令信号REFB2组合起来以便产生计数信号。响应刷新指令的发生,从判优器4015将计数信号提供给刷新地址计数器4016。
图107是表示判优器4015操作的定时图。
图107表示在A端口4011和B端口4012之间块选择地址匹配,和A端口4011的Read指令RA1比B端口4012的Read指令RB1早的情形。在与上述相同的方式中,节点N5和N6的信号电平受到节点N3和N4的信号电平的控制,节点N3和N4的信号电平反应出节点N1和N2的信号电平,并从判优器4015传输出Read指令RA2。取消B端口4012的Read指令而不输出,并产生BUSY1-B信号。
图108是地址缓冲器/寄存器和地址改变电路的方框图。
在图108中,具有在信号名称(例如RA1)的未端加上字母“P”的信号名称(例如RA1P)的信号是通过在具有后一个信号名称(例如RA1)的信号的前沿定时产生脉冲而产生的。
A端口4011的地址缓冲器/寄存器4035包括输入缓冲器4035-1,传输门4035-2和OR电路4035-3。对于从图105所示的指令译码器4062输出的读指令信号RA1,将前沿转变为脉冲,产生脉冲信号RA1P,然后将它加到OR电路4035-3的一个输入端。对于从图105所示的指令译码器4062输出的写指令信号WA1,将前沿转变为脉冲,产生脉冲信号WA1P,然后将它加到OR电路4035-3的另一个输入端。将OR电路4035-3的输出加到传输门4035-2作为发出进行数据传输的指令的传输定向信号。
B端口4012的地址缓冲器/寄存器4045包括输入缓冲器4045-1,传输门4045-2和OR电路4045-3。对于B端口4012的地址缓冲器/寄存器4045的配置与对于A端口4011的地址缓冲器/寄存器4035的配置相同。
地址改变电路4017包括地址锁存器4017-1,传输门4017-2和4017-3,地址锁存器4017-4,与OR电路4017-5和4017-6。OR电路4017-5接收信号RA1P和WAD1P,并将它的输出加到传输门4017-2作为传输指示信号。OR电路4017-6接收信号REFAP和SR-AP,并将它的输出加到传输门4017-3作为传输指示信号。
地址改变电路4018包括地址锁存器4018-1,传输门4018-2和4018-3,地址锁存器4018-4,与OR电路4018-5。OR电路4018-5接收信号RB1P和WBD1P,并将它的输出加到传输门4018-3作为传输指示信号。又将信号REFBP加到传输门4018-2作为传输指示信号。
当从器件外部输入Read指令或Write指令时,将与指令一起输入的地址传输给地址改变电路4017或4018。在Read指令的情形中,将指令传输给地址锁存器4017-4或4018-4而不需要任何定时操作。在Write指令的情形中,在取得一系列写数据输入的最后一项的定时将指令传输给地址锁存器4017-4或4018-4。
在刷新指令的情形中,在信号REFA,REFB或ER-A的定时将由刷新地址计数器4016产生的刷新地址传输给地址锁存器4017-4或4018-4。
图109是存储块的方框图。
图109表示存储块4014-1作为存储块4014-1到4014-n的一个例子。存储块4014-1到4014-n具有相同的配置。
存储块4014-1包括存储器阵列4111,控制电路4112,总线选择器4113和4114,读出放大器缓冲器4115和写放大器4116。存储器阵列4111包括DRAM存储单元,存储单元门晶体管,字线,位线,读出放大器,列线,列门等,并存储用于读操作和写操作的数据。控制电路4112控制存储块4014-1的操作。写放大器4116放大写入存储器阵列4111的数据。读出缓冲器4115放大从存储器阵列4111读出的数据。
控制电路4112与总线A 4020-1和总线B 4020-2连接,并响应与它自己的存储块对应的相关的存储块选择地址被选出来。当选出时,控制电路4112从已经发出相关的存储块选择地址的一条总线取得指令。如果取得了总线A 4020-1指令,则控制总线选择器4113使它向存储器阵列4111发送总线A 4020-1的地址信号。进一步,控制总线选择器4114使它将读出缓冲器4115或写放大器4116与总线A 4020-1的数据线连接起来。如果取得了总线B 4020-2指令,则控制总线选择器4113使它向存储器阵列4111发送总线B 4020-2的地址信号。进一步,控制总线选择器4114使它将读出缓冲器4115或写放大器4116与总线B 4020-2的数据线连接起来。如果控制电路4112取得的指令是刷新指令,则总线选择器4114不需要操作。
如上所述选择一条总线,然后,作为一系列的连续操作,连续地实施字线选择,存储单元数据放大,或者Read,Write或者Refresh(刷新),和预充电操作。
图110A和110B是表示存储块操作的定时图。
图110A表示读操作的情形,图110B表示写操作的情形。在图110A和110B所示操作定时,响应单个指令实施字线选择,数据放大,或者读操作或者写操作,写回(数据恢复)操作和预充电操作,从而完成要求的操作。
在本发明(第4方面)中,如果从器件外部输入端口的指令企图存取同一个存储块,则判优电路确定各指令中的哪一个要被执行,和各指令中的哪一个不被执行。例如,比较指令定时,执行较早的指令,而不执行(各)其它的指令。当存在一个不被执行的指令时,产生BUSY信号等并输出到器件外部。这使得甚至当在以DRAM芯为基础的多端口存储器中指令存取相互发生冲突时也可以实施适当的存取操作并实现适当的BUSY控制。
进一步,本发明具有用于响应来自器件外部的指令实施刷新操作的操作模式,和用于响应来自内部刷新电路的指令实施刷新操作的操作模式。这使得在这样一种方式,即将预定外部端口指定作为用于在恒定的间隔接收刷新指令进行刷新管理的端口中用多端口存储器成为可能,或者使得在这样一种方式,即当所有的外部环部端口都处于去激活状态时内部刷新电路开始刷新操作中用多端口存储器成为可能。因此,本发明为遵从系统要求的灵活的刷新管理提供了基础。
[本发明的第5方面]
下面我们描述本发明的第5方面。
多端口存储器具有两组或多组输入/输出端子(即,多个输入/输出端口),并实施与接到的信号相应的存储操作。与普通的存储器不同,可以同时执行读操作和写操作。例如,如果系统中存在多条总线,如果多个控制器(CPU等)需要用各条总线,则通过将多端口存储器的输入/输出端口与各条总线连接起来能够制成该系统。这就消除了用特殊设计的控制逻辑电路(FIFO逻辑电路等)的需要。
而且,我们也将多个端口存储器开发成图象存储器(一般为双端口报告存储器)。图象存储器具有随机存取端口,通过这些端口能够实现到任何存储单元的存取,和与显示装置交换数据的串行存取端口。
这类多个端口存储器在存储单元区域中采用SRAM存储芯或DRAM存储芯。
然而,我们还必须开发这样的多端口存储器,它们接收在各输入/输出端口的不同时钟信号并与时钟信号同步地随机地存取一个存储单元区域。即,我们还不知道如何制成电路的详细情况和如何控制这种时钟同步的多端口存储器。
而且,常规的多端口存储器(具体地双端口存储器)具有分别对于各组输入/输出端口的位线和读出放大器。因为这个原因,存在存储器芯的布局尺寸变大,从而不希望地增大多端口存储器的芯片尺寸的问题。
因此,本发明的目的是提供允许能够进行随机存取的时钟同步的多端口存储器。
本发明的目的是进一步提供在各组输入/输出端口接收相互不同的时钟信号,并以可靠的方式进行操作的多端口存储器。
而且本发明的目的是提供能够通过与其它的输入/输出端口的状态无关地接收在任何时间的指令信号驱动存储芯的多端口存储器。
而且本发明的目的是提供具有减少的芯片尺寸的小的多端口存储器。
根据本发明(第5方面),多个存储芯中的一些在加到多个输入/输出端口的时钟信号和地址信号的基础上进行操作。每个输入/输出端口包括用于接收时钟信号的时钟端子,用于接收与时钟信号同步地提供的地址信号的地址端子,和用于输入/输出数据信号的数据输入/输出端口端子。为各存储芯提供控制电路。
如果地址信号指示将同一个存储芯加到两个或多个输入/输出端口,则控制电路使存储芯响应首先接到的地址信号进行操作。即,对于首先接收地址信号的输入/输出端口实施存储操作。可以如此定义存储芯,使它与各读出放大器区域相当,其中读出放大器区域是各读出放大器区域在其中一起操作的区域。由地址信号的上部分选择存储芯。由地址信号的下部分选择存储芯的存储单元。通过与首先接到的地址信号上部分对应的输入/输出端口输入或输出到与首先接到的地址信号上部分对应的输入/输出端口,将由地址信号的下部分选择的存储单元的数据信号输入到器件外部或从器件外部输出。
因为所要做的全部事情就是比较地址信号,所以能够将控制电路制成简单的电路。这使芯片尺寸减少。
因为每个输入/输出端口都具有时钟端子,所以对于每个输入/输出端口能够分别地控制时钟信号的频率。即,能够使具有不同操作频率的多个控制器与多端口存储器连接起来。
在本发明的多端口存储器中,在用于取得地址信号的时钟信号的特定边沿前的预定设置时间安排地址信号。控制电路用在时钟信号的这个特定边沿前安排的地址信号确定地址信号到达的次序。因此,能够用首先接收的时钟信号的边沿确定地址信号到达的次序。这使在存储芯开始操作前可以识别具有优先权的输入/输出端口,从而实现高速存储操作。因为在预定定时(即时钟信号的边沿)比较地址信号,所以能够防止与存储操作无关的地址信号的错误比较。
根据本发明,多个存储芯中的一些在加到多个输入/输出端口的时钟信号和地址信号的基础上进行操作。每个输入/输出端口包括用于接收时钟信号的时钟端子,用于接收与时钟信号同步地提供的地址信号的地址端子,和用于输入/输出数据信号的数据输入/输出端口端子。为各存储芯提供控制电路。
如果将指示同一个存储芯的地址信号加到两个或多个输入/输出端口,则控制电路使存储芯响应首先接到的地址信号进行操作。此后,控制电路使存储芯响应地址信号以接收地址信号的次序进行操作。由地址信号的上部分选择存储芯。由地址信号的下部分选择存储芯的存储单元。通过与各地址信号对应的输入/输出端口,连续地从器件外部输入由地址信号下部分选择的存储单元的数据信号或将由地址信号下部分选择的存储单元的数据信号输出到器件外部。因此,对于所有的接收存储操作要求的输入/输出端口没有例外地实施存储操作。
即,在所有时间中多端口存储器都处于备用状态。与多端口存储器连接的控制器不一定要检测多端口存储器的忙碌状态。这通过硬件和软件简化了控制器的操作。因为所要做的全部事情就是比较地址信号,所以能够将控制电路制成简单的电路。这使芯片尺寸减少。
因为每个输入/输出端口都具有时钟端子,所以对于每个输入/输出端口能够分别地控制时钟信号的频率。即,能够使具有不同操作频率的多个控制器与多端口存储器连接起来。
在本发明的多端口存储器中,每个输入/输出端口都具有指令端子,用于与控制存储芯操作的时钟信号同步地接收指令信号。在每个输入/输出端口中,在至少是读操作和写操作需要的存储芯的操作周期两倍长的间隔上,提供用于激活存储芯的指令信号。如果多端口存储器具有2个输入/输出端口或4个输入/输出端口,则可以分别将指令信号的间隔设置在操作周期的2倍或操作周期的4倍上。有了这些设置,多端口存储器处于响应外部控制器的备用状态。
如果在比预定间隔短的间隔上提供指令信号,则指令信号在防止故障方面是无效的。如果将指令信号提供给不同的输入/输出端口,则即便间隔不比预定间隔短也接收这些指令信号。
根据本发明,进一步,从存储单元读出或写入存储单元的数据通过缓冲器在数据输入/输出端口和存储单元之间传输。缓冲器在其中存储具有预定在数量上等于两个或多个存储单元的位数的数据。
在开始读操作和写操作时,例如,将具有预先确定数目的数据从存储单元传输到缓冲器。在读操作中,从缓冲器读出与各地址信号对应的数据,并从数据输入/输出端口输出到外部装置。在写操作中,将与各地址信号对应的数据存储在缓冲器中,并在写操作结束时立即将缓冲器的数据写入存储单元。
在这种方式中,容易实施页面操作。一般,当页面操作时存储芯(读出放大器等)必须保持在激活状态。如果不提供本发明的缓冲器,则当对于输入/输出端口实施的页面操作时不可能对于另一个输入/输出端口实施存储操作。在本发明中,在开始操作时将存储单元的数据传输给缓冲器,使得在这以后能够立即使存储芯去激活。结果,甚至当页面操作时与多端口存储器连接的控制器也不一定要检测多端口存储器的忙碌状态。
下面我们参照所附各图描述本发明(第5方面)的实施例。
图111表示根据本发明(第5方面)的多端口存储器的第1实施例。用CMOS工艺在硅基片上形成多端口存储器M。
多端口存储器M包括两个输入/输出端口PPRT-A和PORT-B,I/O电路5010,它向端口PPRT-A和PORT-B输出信号和从端口PPRT-A和PORT-B输入信号,和多个存储块MB。每个存储块MB都包括DRAM存储芯(包括存储单元,读出放大器线SA等),并进一步包括图中未画出的控制电路,译码器等。每个存储单元包括存储与数据信号值相应的电荷的电容器。根据通过端口PPRT-A和PORT-B提供的行地址信号选择一个存储芯。响应给定的存储芯的选择同时激活在给定的存储芯中的读出放大器线SA的所有读出放大器。即,响应激活指令ACT激活存储芯,我们将在后面对此进行描述,并选择在这个存储芯中的所有的存储单元区域。根据读出放大器激活后提供的列地址信号在存储芯上读出读数据或写入写数据。
图112表示多端口存储器M的I/O电路5010和存储块MB的详细情况。在图中,每条由粗线表示的信号线都由多条线组成。
I/O电路5010包括模寄存器5012a和5012b,时钟缓冲器5014a和5014b,数据输入/输出缓冲器5016a和5016b,地址缓冲器/寄存器5018a和5018b,指令缓冲器5020a和5020b,与忙碌缓冲器5022a和5022b,分别与输入/输出端口PPRT-A和PORT-B对应。模寄存器5012a和5012b是用于从器件外部设置多端口存储器M的操作模式的寄存器。
时钟缓冲器5014a,地址缓冲器/寄存器5018a,和指令缓冲器5020a分别将时钟信号CLKA,地址信号ADDA和指令信号CMDA加到存储块MB上,就如从器件外部加上一样。数据输入/输出缓冲器5016a用于从存储块MB输出数据信号DQA和将数据信号DQA输入存储块MB。忙碌缓冲器5022a向器件外部输出忙碌信号/BSYA。时钟缓冲器5014b,地址缓冲器/寄存器5018b,和指令缓冲器5020b分别将时钟信号CLKB,地址信号ADDB和指令信号CMDB加到存储块MB上,就如从器件外部加上一样。数据输入/输出缓冲器5016b用于从存储块MB输出数据信号DQB和将数据信号DQB输入存储块MB。忙碌缓冲器5022b向器件外部输出忙碌信号/BSYB。时钟信号CLKA和CLKB,地址信号ADDA和ADDB和指令信号CMDA和CMDB,数据信号DQA和DQB,与忙碌信号/BSYA和/BSYB分别通过时钟端子,地址端子,指令端子,数据输入/输出端子和忙碌端子进行传输。提供激活指令ACT和操作指令(例如读指令RD,写指令WR)等作为用于控制存储芯操作的指令信号CMDA和CMDB。
提供每个地址信号ADDA和ADDB作为相互分开的行地址信号RA和列地址信号CA。在输入/输出端口PPRT-A中,与时钟信号CLKA的前沿同步地提供行地址信号RA,列地址信号CA和指令信号CMDA。在输入/输出端口PPRT-B中,与时钟信号CLKB的前沿同步地提供行地址信号RB,列地址信号CB和指令信号CMDB。在这个方式中,多端口存储器M分别接收专门在输入/输出端口PPRT-A和PORT-B使用的时钟信号CLKA和CLKB,并与时钟信号CLKA和CLKB同步地进行操作。
存储块MB包括时钟缓冲器5024a和5024b,指令锁存器5026a和5026b,数据锁存器5028a和5028b,行地址锁存器5030a和5030b,列地址锁存器5031a和5031b,与列地址锁存器5032a和5032b,分别与输入/输出端口PPRT-A和PORT-B对应。存储块MB包括判优电路5034,控制信号锁存器5036,列地址计数器5038和存储芯5040,它们对于输入/输出端口PPRT-A和PORT-B是公用的。存储芯5040具有与时钟信号同步地取得指令信号RAS,CAS和WE,行地址信号RA和列地址信号CA的形式。
当激活从判优电路5034提供的启动信号/ENA时,与输入/输出端口PPRT-A对应的模寄存器5012a,时钟缓冲器5024a,指令锁存器5026a,数据锁存器5028a,行地址锁存器5031a,和列地址锁存器5032a进行操作。当激活从判优电路5034提供的启动信号/ENB时,与输入/输出端口PPRT-B对应的模寄存器5012b,时钟缓冲器5024b,指令锁存器5026b,数据锁存器5028b,行地址锁存器5031b,和列地址锁存器5032b进行操作。
即,在激活启动信号/ENA时,时钟缓冲器5024a向存储芯5040的时钟端子CLK提供时钟信号CLKA。进一步,指令锁存器5026a向控制信号锁存器5036提供锁存的指令信号CMDA,和行地址锁存器5031a向存储芯5040的行地址端子RA提供锁存的行地址信号RA(例如,与上地址位对应)。而且,列地址锁存器5032a向列地址计数器5038提供锁存的列地址信号CA(例如,与下地址位对应),和数据锁存器5028a与存储芯5040的数据输入/输出端子DQ和输入/输出缓冲器5016a交换数据信号。
类似地,在激活启动信号/ENB时,时钟缓冲器5024ba向存储芯5040的时钟端子CLK提供时钟信号CLKB。进一步,指令锁存器5026b向控制信号锁存器5036提供锁存的指令信号CMDB,和行地址锁存器5031b向存储芯5040的行地址端子RA提供锁存的列信号RA。而且,列地址锁存器5032b向列地址计数器5038提供锁存的列地址信号CA,和数据锁存器5028b与存储芯5040的数据输入/输出端子DQ和输入/输出缓冲器5016b交换数据信号。
控制信号锁存器5036根据接收的指令信号CMDA和CMDB产生用于使存储芯5040操作的行地址选通信号RAS,列地址选通信号CAS,和写启动信号WE,并将产生的信号加到存储芯5040上。而且,控制信号锁存器5036向判优电路5034提供指示读操作和写操作中的一个的读/写指令信号RWCMD。
列地址计数器5038根据关于从模寄存器5012a和5012b提供的脉冲串长度的信息以及地址信号ADDA和ADDB产生列地址信号CA,并向存储芯5040输出列地址信号。
判优电路5034包括地址比较电路5042和判优控制电路5044。地址比较电路5042比较在从输入/输出端口PPRT-A和PORT-B提供的地址信号ADDA和ADDB之间的行地址信号RA,并决定它们中哪一个较早到达。判优控制电路5044产生忙碌信号/BSYA和/BSYB与启动信号/ENA和/ENB,用于使内部电路根据地址比较电路5042的比较结果进行操作。
图113表示地址比较电路5042的详细情况。
地址比较电路5042包括两个地址匹配电路5042a和一个地址比较器5042b,地址比较器5042b检测地址到达的次序。地址匹配电路5042a包括多个EOR电路5042c,每个EOR电路5042c比较在地址信号ADDA和地址信号ADDB之间的行地址信号RA的对应位,并进一步包括多个nMOS晶体管5042d,它们与各EOR电路5042c对应。每个nMOS晶体管5042d的栅极都与对应的EOR电路5042c的输出端连接,它们的源极接地和它们的漏极相互连接。每个EOR电路5042c,当行地址信号RA的位值在输入/输出端口PPRT-A和PORT-B之间相互匹配时输出低电平信号,当行地址信号RA的位值不匹配时输出高电平信号。响应来自EOR电路5042c的低电平信号切断nMOS晶体管5042d,响应来自EOR电路5042c的高电平信号接通nMOS晶体管5042d。即,从地址匹配电路5042a输出的匹配信号/COIN1和/COIN2当行地址信号RA的所有的位在对应的位之间匹配时变成浮动的,并当行地址信号的至少一个位在对应的位之间不同时变成低电平信号。将两个地址匹配电路5042a分别安排在存储块MB的上端和下端如图111所示(即,安排得接近输入/输出电路5010)。地址匹配电路5042a接近输入/输出电路5010的安排可以缩短地址信号ADDA和ADDB到地址匹配电路5042a的整个路经上的传播延迟。因此,可以在较早的定时比较地址信号ADDA和ADDB,从而得到高速操作。
比较器5042b接收匹配信号/COIN1和/COIN2和时钟信号CLKA和CLKB,并输出首先到达信号/FSTA和/FSTB。
图114表示比较器5042b的详细情况。
比较器5042b包括脉冲发生器5042e,它们分别与时钟信号CLKA和CLKB的前沿同步地产生正脉冲PLSA和PLSB,并进一步包括触发器5042f,它在它的输入端子接收脉冲PLSA和PLSB。比较器5042b接收匹配信号/COIN1和/COIN2并输入到分别输出脉冲PLSA和PLSB的各倒相器。将在比较器5042b中产生各脉冲信号的NAND门制成小尺寸的电路元件,使得当从NAND门输出的信号具有与匹配信号/COIN1和/COIN2冲突的信号电平时将优先权给予匹配信号/COIN1和/COIN2。触发器5042f当接收脉冲PLSA时使首先到达信号/FSTA下降到低电平,当接收脉冲PLSB时使首先到达信号/FSTB下降到低电平。
图115表示当加到输入/输出端口PORT-A和PORT-B的行地址信号相互匹配时实施的比较器5042b的操作。在这个例子中,时钟信号CLKA和CLKB具有相同的周期。
图113所示的地址匹配电路5042a当行地址信号RA匹配时使匹配信号/COIN1和/COIN2处于浮动状态(Hi-z)。对应地,分别与时钟信号CLKA和CLKB的前沿同步地产生脉冲PLSA和PLSB(图115-(a))。图114所示的触发器5042f响应在其它信号之前接收的脉冲PLSA使首先到达信号/FSTA激活(图115-(b))。在使首先到达信号/FSTA去激活后使与以后接收的脉冲PLSB对应的首先到达信号/FSTB激活(图115-(c))。
图116表示当行地址信号RA在输入/输出端口PORT-A和PORT-B之间不匹配时比较器5042b的操作。在这个例子中,时钟信号CLKA和CLKB具有相同的周期。
地址匹配电路5042a当行地址信号RA甚至一个位都不匹配时使每个匹配信号/COIN1和/COIN2降到低电平(图116-(a))。对应地,图114所示的脉冲发生器5042e迫使脉冲信号PLSA和PLSB降到低电平而与时钟信号CLKA和CLKB无关(图116-(b))。因此,首先到达信号/FSTA和/FSTB保持在高电平(图115-(c))。
图117表示当加到输入/输出端口PORT-A和PORT-B的行地址信号RA在时钟信号CLKA具有一个与时钟信号CLKB的周期不同的周期的条件下匹配时比较器5042b的操作。在这个例子中,设置时钟信号CLKB的周期等于时钟信号CLKA的周期的两倍。分别与时钟信号CLKA和CLKB的前沿同步地取得行地址信号RA。在图中,实线表示的行地址信号RA说明加到输入/输出端口PORT-A和PORT-B的信号,虚线表示的行地址信号RA说明由图112所示的各行地址锁存器5030a和5030b锁存的信号。
当行地址信号RA匹配时,以与图115相同的方式使匹配信号/COIN1和/COIN2处于浮动状态(Hi-z)。当匹配信号/COIN1和/COIN2处于浮动状态(Hi-z)时,图114所示的脉冲发生器5042e发挥作用,使得分别与时钟信号CLKA和CLKB的前沿同步地产生脉冲信号PLSA和PLSB和首先到达信号/FSTA和/FSTB。
图118表示提供给图112所示的判优电路的判优控制电路5044。
判优控制电路5044包括控制电路5044a和5044b,它们分别与输入/输出端口PPRT-A和PORT-B对应。控制电路5044a接收复位信号RESETA,延迟时钟信号DCLKA,有效指令信号ACTA,首先到达信号/FSTA,忙碌信号/BSYA,并输出启动信号/ENA和忙碌信号/BSYB。控制电路5044b接收复位信号RESETB,延迟时钟信号DCLKB,有效指令信号ACTB,首先到达信号/FSTB,忙碌信号/BSYB,并输出启动信号/ENB和忙碌信号/BSYA。
当完成与输入/输出端口PPRT-A和PORT-B对应的读或写操作时,在各预定周期中使复位信号RESETA和RESETB激活。延迟时钟信号DCLKA和DCLKB是分别通过使时钟信号CLKA和CLKB延迟得到的。当将有效指令ACT加到输入/输出端口PPRT-A和PORT-B时使有效指令信号ACTA和ACTB激活。
图119表示当加到输入/输出端口PORT-A和PORT-B的行地址信号匹配时实施的判优控制电路5044的操作。在这个例子中,时钟信号CLKA和CLKB的周期是相同的。与时钟信号CLKA同步地提供有效指令ACT,立即接着与时钟信号CLKB同步地提供有效指令ACT。
控制电路5044a与延迟时钟信号DCLKA的前沿同步地取得低电平的首先到达信号/FSTA,并使忙碌信号/BSYB激活(图119-(a))。响应有效指令信号ACTA的激活和忙碌信号/BSYA的去激活状态,控制电路5044a激活启动信号ENA(图119-(b))。因为控制电路5044b与延迟时钟信号DCLKB的前沿同步地取得高电平的首先到达信号/FSTB,所以不激活忙碌信号/BSYA(图119-(c))。虽然控制电路5044b接受激活状态的有效指令信号ACTB,但是因为激活了忙碌信号/BSYB,所以控制电路5044b不激活启动信号ENB(图119-(d))。
响应启动信号ENA的激活,将加到输入/输出端口PPRT-A的信号传输给存储芯5040。激活存储芯5040,根据加到输入/输出端口PPRT-A的读指令RD实施读操作。在完成读操作,控制电路5044a响应复位信号RESETA的激活使启动信号ENA和忙碌信号/BSYB去激活(图119-(e))。
下面,关于其操作进一步描述上述多端口存储器M。
图120表示当加到输入/输出PORT-A和PORT-B的行地址信号RA相互匹配时实施的操作。在这个例子中,时钟信号CLKA和CLKB具有相同的周期,时钟信号CLKA的相位稍微超前时钟信号CLKB的相位。通过各模寄存器5012a和5012b将输入/输出端口PORT-A和PORT-B的脉冲串长度两者都设置得等于4。这里,脉冲串长度是当写或读操作时输出和输入的数据项的数目。
与时钟信号CLKA的前沿同步地,输入/输出端口PORT-A接收有效指令ACT(指令信号CMDA)和行地址信号RA(地址信号ADDA)(图120-(a))。在输入/输出端口PORT-A接收信号后立即与时钟信号CLKB的前沿同步地,输入/输出端口PORT-B接收有效指令ACT(指令信号CMDB)和行地址信号RA(地址信号ADDB)(图120-(b))。这里,指令信号CMDA和CDMB与地址信号ADDA和ADDB在时钟信号CLKA和CLKB的各前沿前的一个预先设置时间ts(即按照定时说明)设置它们的信号电平。
因为加到端口PORT-B的行地址信号RA与加到端口PORT-A的行地址信号RA相同,所以一个接着一个地产生首先到达信号/FSTA和/FSTB如图115所示。判优控制电路5044如结合图119所描述的响应首先到达信号/FSTA和/FSTB激活启动信号ENA和忙碌信号/BSYB(图120-(c)和(d))。在这个方式中,通过用当设置时间ts时提供的行地址信号RA和通过利用具有较早相位的时钟信号(在本例中为CLKA)的前沿,确定两个地址信号中首先到达的一个。此后,与行地址信号RA对应的存储芯5040响应启动信号ENA的激活进行操作(图120-(e))。
响应忙碌信号/BSYB,控制器如与输入/输出端口PORT-B连接的CPU认定加到多端口存储器M的有效指令ACT是无效的。
输入/输出端口PORT-A与时钟信号CLKA的下一个前沿同步地,接收读指令RD(即指令信号CMDA)和列地址信号CA(地址信号ADDA)(图120-(f))。输入/输出端口PORT-B与时钟信号CLKB的前沿同步地接收读指令RD(指令信号CMDB)和列地址信号CA(地址信号ADDB)(图120-(g))。与各时钟信号CLKA和CLKB(根据定时说明)的下一个前沿同步地,在有效指令ACT后提供读指令RD(或写指令WR)。与忙碌信号/BUSY有关,输入/输出端口PORT-B连接的控制器可以不提供读指令RD和列地址信号CA。
存储块MB连续地输出数据作为数据信号DQA(Q0-Q3)(图120-(h))如它们是从与加到输入/输出端口PORT-A的列地址信号CA对应的存储单元读出的那样。在接收读指令RD后的2个时钟脉冲,输出数据信号DQA。在输出与脉冲串长度(=4)一样多的数据信号DQA后,存储芯5040实施预充电操作(图120-(i)),从而完成一个存储周期。响应读操作的完成使启动信号ENA去激活(图120-(j))。这里,预充电操作使用于将数据传输到存储单元和从存储单元传输出来的位线充电到预定电位,使与行地址操作有关的电路去激活。在每个存储操作中自动地实施预充电操作。根据存储在对应的模寄存器中的输入/输出端口PORT-A的脉冲串长度或输入/输出端口PORT-B的脉冲串长度中较长的一个确定预充电操作的定时。在这个实施例中,如果脉冲串长度为4,则存储周期(即单个读或写操作需要的时间周期)被固定在4个时钟周期。即,总是在接收到有效指令后的预定时间完成读操作和写操作。
与用于输出数据Q1的时钟信号CLKA同步地,将下一个有效指令ACT加到输入/输出端口PORT-A(图120-(k))。因为在这个特定的瞬间不将指令信号CMDB加到输入/输出端口PORT-B,所以用图113所示的地址比较电路5042比较行地址信号RA,产生指示不匹配的结果。因此,不激活忙碌信号/BSYA和/BSYB,只激活启动信号ENA(图120-(l))。将首先到达信号/FSTA和/FSTB保存在高电平,如图116所示。
存储芯5040根据加到输入/输出端口PORT-A的行地址信号RA进行操作,如前面描述的那样(图120-(m))。存储块MB根据与下面的时钟信号CLKA同步地提供的读指令RD和列地址信号CA一个接着一个地输出数据信号DQA(Q0-Q3)(图120-(n))。
在与输入/输出端口PORT-A对应的存储芯5040的操作完成后,将有效指令ACT和读指令RD连续地加到输入/输出端口PORT-B(图120-(o))。因为在这个特定的瞬间不将指令信号CMDA加到输入/输出端口PORT-A,所以存储芯5040对于输入/输出端口PORT-B进行操作,从而输出数据信号DQB(图120-(p))。
虽然在图中未画出,但是响应与时钟信号的前沿同步地提供的行地址信号RA和刷新指令实施恢复在存储单元的电容器中电荷的刷新操作,其中行地址信号RA确定存储芯5040要被刷新。或者通过输入/输出端口PORT-A或者通过输入/输出端口PORT-B能够要求刷新操作。在这个方式中,由一个存储芯5040的装置根据从器件外部提供的地址信号实施刷新操作。
图121表示当时钟信号CLKA和CLKB相同,时钟信号CLKA的相位超前时钟信号CLKB的相位多于半个周期时实施的操作。加到多端口存储器M的指令信号CMDA和CMDB与地址信号ADDA和ADDB与图120情形中的相同。
在这个例子中,当将有效指令ACT和行地址信号RA加到输入/输出端口PORT-A时(图121-(a)),还没有将指令信号CMDB与地址信号ADDB加到输入/输出端口PORT-B。因此,激活启动信号/ENA(图121-(b)),存储芯5040对于输入/输出端口PORT-A进行操作(图121-(c))。此后,将有效指令ACT和与输入/输出端口PORT-A相同的行地址信号RA加到输入/输出端口PORT-B(图121-(d))。
图118所示的控制电路5044b根据首先到达信号/FSTA的激活和启动信号/ENA的激活,激活忙碌信号/BSYB(图121-(e))。响应忙碌信号/BSYB,与输入/输出端口PORT-B连接的控制器如CPU认定加到多端口存储器M的有效指令ACT是无效的。以后的操作与上述图120的相同。
图122表示当几乎同时加到输入/输出端口PORT-A和PORT-B的行地址信号RA相互不同时的操作。时钟信号CKLA和CLKB具有相同的时钟周期,时钟信号CLKA的相位稍微超前时钟信号CLKB的相位。通过模寄存器5012对于输入/输出端口PORT-A和端口PORT-B两者都将脉冲串长度设置得等于4。
当行地址信号RA不同时,不同的存储芯5040进行操作。于是图114所示的比较器5042b使首先到达信号/FSTA和/FSTB两者去激活。即,不进行地址判优。判优控制电路5044对应首先到达信号/FSTA和/FSTB的去激活状态和有效指令信号ACTA和ACTB的激活,使启动信号/ENA和/ENB激活(图121-(a)和(b))。结果,相关的存储芯5040响应加到输入/输出端口PORT-A的有效指令ACT和行地址信号RA进行操作(图121-(c)),另一个存储芯5040响应加到输入/输出端口PORT-B的有效指令ACT和行地址信号RA进行操作(图121-(d))。即,输入/输出端口PORT-BA和PORT-B相互独立地进行操作。因为行地址信号RA相互不同,既不激活忙碌信号/BSYA也不激活忙碌信号/BSYB。
在上述的实施例中,当输入/输出端口PORT-A和PORT-B接收两个指示同一个存储芯5040分别与时钟信号CLKA和CLKB同步的行地址信号RA时,存储芯5040对于在两个行地址信号RA中首先到达的一个进行操作。即,这样我们就能够制成时钟同步型的多端口存储器M。
判优电路5034通过比较行地址信号RA满足对它预期的所有要求,于是能够通过简单的配置制成。因此,能够使多端口存储器M的芯片尺寸减小。
因为输入/输出端口PORT-A和PORT-B具有各自的时钟端子CLKA和CLKB,所以能够分别地对输入/输出端口PORT-A和PORT-B中的每一个设置时钟信号CLKA和CLKB的频率。即,操作在不同操作频率上的多个控制器能够与多端口存储器M连接。
进一步,用设置在时钟信号CLKA和CLKB的相关前沿前的行地址信号RA决定两个地址中首先到达的一个。即,利用地址信号的设置时间识别首先到达的一个。因此,在存储芯5040开始它的操作前能够识别将给予优先权的输入/输出端口,从而实现高速存储操作。进一步,因为根据具有较前相位的时钟信号CLKA(或CLKB)的前沿确定首先到达的一个,所以能够进一步提高存储操作速度。
在判优电路5034中,地址比较电路5042比较行地址信号RA,判优控制电路5044与用于取得有效指令ACT的时钟信号CLKA和CLKB同步地检查地址匹配。因为总是在预定定时(即在定时信号的边沿)相互比较行地址信号RA,所以可以防止由与存储操作无关的地址信号引起的存储芯5040的不正常操作。
图123表示多端口存储器的第2实施例和根据本发明(第5方面)控制多端口存储器的方法。用相同的数字标记与第1实施例相同的部件,并省略对它们的详细描述。
在这个实施例中,以第1实施例的四分之一大小形成存储块MB(在图中用粗线框表示)。即,同时被激活的读出放大器的数目是第1实施例的四分之一。除了存储块MB的大小外,配置与第1实施例相同。因为图123的多端口存储器M具有较少的同时被驱动的读出放大器,所以在存储操作时的功率消耗减少了。
这个实施例能够产生与上述第1实施例相同的优点。此外,在本实施例中能够降低功率消耗。
图124表示多端口存储器的第3实施例和根据本发明(第5方面)控制多端口存储器的方法。用相同的数字标记与第1实施例相同的部件,并省略对它们的详细描述。
在这个实施例中,在每个存储块MB中提供数据寄存器(缓冲器)5046a和5046b,它们暂时存储在数据锁存器5028和存储芯5040之间的各数据信号DQA和DQB。数据寄存器5046a和5046b与输入/输出端口PORT-A和PORT-B中的任何一个结合起来进行操作。而且,判优电路5034的判优控制电路5048不同于第1实施例的判优控制电路5044。判优控制电路5048不输出忙碌信号/BSYA和/BSYB,在I/O电路5010中不提供忙碌缓冲器。其它配置几乎与第1实施例相同。即,在输入/输出端口PORT-A和PORT-B中,分别通过时钟端子,地址端子,指令端子,和数据输入/输出端子,传输时钟信号CLKA和CLKB,地址信号ADDA和ADDB,指令信号CMDA和CMDB,与数据信号DQA和DQB。存储块MB包括DRAM存储芯5040,并进一步包括图中未画出的控制电路,译码器等。存储单元包括根据数据信号值存储电荷的电容器。
甚至当输入/输出端口PORT-A和PORT-B同时接收对于同一个地址信号RA进行存储操作的要求时,这个多端口存储器M也能够对输入/输出端口PORT-A和PORT-B两者实施存储操作,我们将在后面对此进行描述。因此,如第1实施例那样不需要向器件外部输出忙碌信号/BSYA和/BSYB。
在每个输入/输出端口PORT-A和PORT-B中,设置加上有效指令ACT间隔等于存储芯5040的操作周期的2倍以上(根据定时说明)。如果在同一个输入/输出端口PORT-A(或PORT-B)中有效指令ACT间隔小于上面确定的周期,则取消所加的有效指令ACT。加到不同的输入/输出端口的有效指令ACT的间隔不受限制。
如第1实施例那样与跟随用于接收有效指令ACT的定时的时钟信号的特定的定时同步地提供读指令RD和写指令WR。存储芯5040随着它的操作被自动地充电。在这个实施例中,例如,将时钟信号CLKA和CLKB的周期tCLK设置在10ns,将脉冲串长度BL设置在4,将数据等待时间DL设置在4。数据等待时间DL定义从输入读指令RD到输出数据的时钟周期的数目。在模寄存器5012a和5012b中设置脉冲串长度BL和数据等待时间DL。
图125表示判优控制电路5048的详细情况。
通过将控制电路5048a和5048b分别加到第1实施例的控制电路5044a和5044b构造判优控制电路5048。与输入/输出端口PORT-A对应的控制电路5048a从控制电路5044a接收复位信号RESETA和反向信号RVS以及启动信号/ENA0和忙碌信号/BSYB,并输出启动信号/ENA。与输入/输出端口PORT-B对应的控制电路5048b从控制电路5044b接收复位信号RESETB和反向信号RVS以及启动信号/ENB0和忙碌信号/BSYA,并输出启动信号/ENB。在与第1实施例的启动信号/ENA和/ENB相同的定时产生启动信号/ENA0和/ENB0
图126表示当加到输入/输出端口PORT-A和PORT-B的行地址信号相互匹配时实施的判优控制电路5048的操作。在这个例子中,时钟信号CLKA和CLKB的周期是相同的。与时钟信号CLKA同步地将有效指令ACT加到输入/输出端口PORT-A。此后立即与时钟信号CLKB同步地将有效指令ACT加到输入/输出端口PORT-B。与输入/输出端口PORT-A连接的控制器要求写操作,与输入/输出端口PORT-B连接的控制器要求读操作。
控制电路5044a和5044b的操作几乎与上述第1实施例的(图119)相同。控制电路5044a与延迟时钟信号DCLKA前沿同步地取得低电平的首先到达信号/FSTA,并激活忙碌信号/BSYB(图126-(a))。因为控制电路5044b与延迟时钟信号DCLKB前沿同步地取得高电平的首先到达信号/FSTB,不激活忙碌信号/BSYA(图126-(b))。控制电路5048a响应忙碌信号/BSYB的激活和反向信号RVS的低电平,激活启动信号/ENA(图126-(c))。控制电路5048b响应忙碌信号/BSYA的激活和反向信号RVS的低电平,使启动信号/ENB去激活(图126-(d))。
与时钟信号CLKA和CLKB的下一个定时同步地,分别提供写指令WR和读指令RD(图126-(e))。响应写指令WR和读指令RD,产生反向信号RVS的控制电路(图中未画出)激活反向信号RVS(图126-(f))。
控制电路5048a和5048b分别响应反向信号RVS的激活,切换启动信号/ENA和/ENB的电平(图126-(g))。然后,首先实施对于输入/输出端口PORT-B的读操作(图126-(h))。在完成读操作后,激活复位信号RESETB,并使反向信号RVS去激活(图126-(i))。控制电路5048a和5048b响应反向信号RVS的去激活,使启动信号/ENA和/ENB的电平回复到它们各自原来的电平(图126-(j))。然后,响应启动信号/FNA的激活实施对于输入/输出端口PORT-A的读操作(图126-(k))。
在完成读操作后,激活复位信号RESETA(图126-(l)),并使忙碌信号/BSYB去激活(图126-(m))。控制电路5048a响应忙碌信号/BSYB的去激活,使启动信号/ENA去激活(图126-(n))。在本实施例的这个方式中,当行地址信号RA相同时和当第1个到达的指令要求写操作,接着第2个到达的指令要求读操作时,如此控制存储芯5040使它首先实施读操作。在存储器LSI,如具有多端口存储器的DRAM中,通过在接收要写的数据后驱动存储芯执行写操作,和通过首先驱动存储芯然后输出数据实施读操作。因此,当在写操作后实施读操作时,全部操作周期通常变成等待时间。在这个实施例中,当写操作和读相互竞争时首先执行读操作,从而缩短全部操作周期和改善传输数据信号的数据总线的使用效率。
下面,我们描述根据第3实施例的多端口存储器M的操作。
图127表示当输入/输出端口PORT-A和PORT-B接收有效指令ACT和相同的行地址信号RA时实施读操作的方法。时钟信号CLKA的相位稍微超前时钟信号CLKB的相位。即,有效指令ACT到输入/输出端口PORT-A的输入稍微早于有效指令ACT进入输入/输出端口PORT-B。
对于输入/输出端口PORT-A,响应有效指令ACT实施读操作READ(图127-(a))。将从存储单元读出的数据存储在数据寄存器5046a(或5046b)中。然后,对于输入/输出端口PORT-B,响应有效指令ACT实施读操作READ(图127-(b))。在判优电路5034的控制下完成读操作READA后对于输入/输出端口PORT-B实施读操作READB(图127-(c))。将通过读操作READB从存储单元读出的数据存储在数据寄存器5046b(或5046a)中(图127-(d))。在这个方式中,甚至当将有效指令ACT和相同的行地址信号RA基本上同时加到输入/输出端口PORT-A和PORT-B时,也能够对于输入/输出端口PORT-A和PORT-B中的每一个连续地实施读操作(或写操作)。存储芯4050在完成读操作READA和READB中的每一个后自动地实施预充电操作,从而完成存储周期。
与图所示的第5到第8个时钟信号CLKA同步地输入读指令RD后,连续地输出存储在与输入/输出端口PORT-A对应的寄存器5046a中的检索数据作为输出数据Q1-Q3(图127-(e))。与图所示的第5到第8个时钟信号CLKB同步地输入读指令RD后,连续地输出存储在与输入/输出端口PORT-B对应的寄存器5046b中的检索数据作为输出数据Q1-Q3(图127-(f))。
输入/输出端口PORT-A和PORT-B两者在第1有效指令ACT后的4时钟脉冲,接收下一个有效指令ACT,进一步分别实施读操作READA和READB(图127-(g)和(h))。当在每4个时钟周期中加上有效指令ACT一次时,能够连续地输出检索的数据而没有任何间隙(即,无间隙读)。而且通过在每4个时钟周期中接收有效指令ACT一次得到随机存取操作。
图128表示当将有效指令ACT和相互不同的行地址信号RA加到输入/输出端口PORT-A和PORT-B时实施读操作的方法。
对于首先已经接收有效指令ACT和行地址信号RA的输入/输出端口PORT-A,响应有效指令ACT实施读操作READA(图128-(a))。将从存储单元读出的数据存储在数据寄存器5046a中(图128-(b))。然后,输入/输出端口PORT-B,响应有效指令ACT实施指向另一个与用于读操作READA的存储芯不同的存储芯5040的读操作READB(图128-(c))。即,相互独立地实施读操作READA和读操作READB。将通过读操作READB从存储单元读出的数据存储在数据寄存器5046b中(图128-(d))。
与图所示的第5到第8个时钟信号CLKA同步地输入读指令RD后,连续地输出存储在寄存器5046a中的检索数据作为输出数据Q0-Q3(图128-(e))。与图所示的第5到第8个时钟信号CLKB同步地输入读指令RD后,连续地输出存储在与输入/输出端口PORT-B对应的寄存器5046b中的检索数据作为输出数据Q0-Q3(图128-(f))。
输入/输出端口PORT-A和PORT-B两者在第1有效指令ACT后的4个时钟脉冲,接收下一个有效指令ACT,进一步分别实施读操作READA和READB(图128-(g)和(h))。
图129表示当输入/输出端口PORT-A和PORT-B接收有效指令ACT和相同的行地址信号RA时实施写操作的方法。
在输入/输出端口PORT-A和PORT-B中,与跟随用于接收有效指令ACT的前沿的下面的各时钟信号CLKA和CLKB的前沿同步地提供写指令WR,列地址信号CA和第1写数据Q0和Q0(图129-(a)和(b))。此后,与各时钟信号CLKA和CLKB同步地提供写数据Q1-Q3和Q0-Q3(图129-(c)和(d))。将写数据Q0-Q3和Q0-Q3分别存储在各数据寄存器5046a和5046b中(图129-(e)和(f))。对于首先接收有效指令ACT和行地址信号RA的输入/输出端口PORT-A,与取得写数据Q3的时钟信号CLKA的特定的定时同步地实施写操作WRITEA(图129-(g))。在完成写操作WRITEA后实施与输入/输出端口PORT-B对应的写操作WRITEB(图129-(h))。通过写操作WRITEA和WRITEB,将存储在各数据寄存器5046a和5046b中的写数据Q0-Q3和Q0-Q3写入与列地址信号CA对应的存储单元,从而完成写操作。
在写操作中,在每4个时钟周期中提供一组写数据一次,使得写数据能够连续地进入而没有任何间隙(即,无间隙写)。
图130表示对于输入/输出端口PORT-A连续地实施写操作和读操作,和对于输入/输出端口PORT-B相继地实施指向与输入/输出端口PORT-A的写操作的行地址信号RA相同的行地址信号RA的写操作,和指向与输入/输出端口PORT-A的读操作的行地址信号RA相同的行地址信号RA的写操作的情形。第1写操作的定时与图127相同,并省略对它的说明。
在输入/输出端口PORT-B,在与图127相同的定时提供与第2写操作对应的有效指令ACT(图130-(a))。因为不将指令信号加到输入/输出端口PORT-A,所以在取得写数据Q0-Q3后立即实施写操作WRITEB(图130-(b))。
在输入/输出端口PORT-A,与图所示的第7个时钟信号CLKA同步地提供下一个有效指令ACT(图130-(c))。虽然在图中未画出,但是在这个特定的瞬间激活对于输入/输出端口PORT-B的启动信号/ENB。结果,在完成写操作WRITEB后实施读操作READA(图130-(d))。因为多端口存储器M以接收各指令的次序执行写操作WRITEB和读操作READA,所以在完成写操作前被读的存储单元的数据不变。
此外,因为输入/输出端口PORT-A能够输出存储在与输入/输出端口PORT-B对应的数据寄存器5046b中数据作为检索数据,所以可以在输入/输出端口PORT-B的写操作WRITEB前实施输入/输出端口PORT-A的读操作READA。
图131表示对于输入/输出端口PORT-A连续地实施写操作和读操作,和对于输入/输出端口PORT-B相继地实施指向与输入/输出端口PORT-A的写操作的行地址信号RA相同的行地址信号RA的读操作和指向与输入/输出端口PORT-A的读操作的行地址信号RA相同的行地址信号RA的写操作的情形。对于输入/输出端口PORT-A的第1写操作的定时和对于输入/输出端口PORT-B的第1读操作的定时分别与图129的写操作和图128的读操作相同。
在输入/输出端口PORT-A,与图所示的第7和第8时钟信号CLKA同步地提供有效指令ACT和读指令(图131-(a))。因为在这个特定的瞬间不将有效指令ACT加到输入/输出端口PORT-B,所以实施对于输入/输出端口PORT-A的读操作READA(图131-(b))。
下面,在输入/输出端口PORT-B,与图所示的第8和第9时钟信号CLKB同步地提供有效指令ACT和写指令WR(图131-(c))。在接收数据Q0-Q3后,实施对于输入/输出端口PORT-B的写操作(图中未画出)。
图132表示在时钟信号CLKA和CLKB具有不同的时钟周期的情形中当加到输入/输出端口PORT-A和PORT-B的行地址信号相互匹配时实施的操作。在这个例子中,时钟信号CLKB的周期长度等于时钟信号CLKA的周期长度的两倍。
在输入/输出端口PORT-A,当在每4个时钟周期中加上一组有效指令ACT和读指令RD一次,以与图127相同的方式实施读操作。在输入/输出端口PORT-B,也当在每4个时钟周期中加上一组有效指令ACT和读指令RD一次。向输入/输出端口PORT-B输入第1有效指令ACT的时间比向输入/输出端口PORT-A输入第1有效指令ACT的时间晚一些(图132-(a))。因此,与图127的情形相同在读操作READA后实施读操作READB(图132-(b))。在两个读操作READA之间执行与输入/输出端口PORT-B的跟随的有效指令ACT对应的下一个读操作READB(图132-(c))。
本实施例能够提供与上述的第1实施例相同的优点。此外,在每个输入/输出端口PORT-A和PORT-B中,本实施例用等于存储芯5040的操作周期的2倍以上的有效指令ACT的间隔(按照定时说明)。因此,甚至当加到输入/输出端口PORT-A和PORT-B的行地址信号RA相同,也肯定能够对于每个端口实施读操作和写操作。因此,控制多端口存储器M的控制器不需要检测多端口存储器M的忙碌状态。这样就简化了控制器的控制(藉助硬件和软件)。
图133表示多端口存储器的第4实施例和根据本发明(第5方面)控制多端口存储器的方法。用相同的数字标记与第1和第3实施例相同的部件,并省略对它们的详细描述。
在这个实施例中,提供页面缓冲器5050a和5050b代替上述第3实施例的数据寄存器5046a和5046b。页面缓冲器5050a和5050b与输入/输出端口PORT-A和PORT-B中的至少一个结合起来进行操作。其它配置几乎与第3实施例完全相同。
每个页面缓冲器5050a和5050b都包括锁存器,其中存储在存储芯5040中的所有存储单元的数据。在开始读操作和写操作时,将存储在选出的存储芯5040的存储单元中的数据读出到页面缓冲器5050a(或5050b)。在读操作中,响应列地址信号CA输出锁存在页面缓冲器5050a中的数据作为数据信号。在写操作中,首先根据列地址信号CA将数据信号写入页面缓冲器5050a。此后,在完成写操作时将页面缓冲器5050a的数据写入存储单元。
下面,我们描述第4实施例多端口存储器M的操作。
图134表示当输入/输出端口PORT-A和PORT-B接收有效指令ACT和相同的行地址信号RA时实施读操作的方法。时钟信号CLKA的相位稍微超前时钟信号CLKB的相位。即,输入到输入/输出PORT-A的有效指令ACT比输入到输入/输出PORT-B的有效指令ACT稍微早一些。
在输入/输出端口PORT-A,响应有效指令ACT实施读操作READA(图134-(a))。从由读操作READA选出的存储芯5040的所有存储单元读出数据,并将检索数据存储在页面缓冲器5050a(或5050b)中的一个(图134-(b))。另一方面,在输入/输出端口PORT-B,行地址信号RA与加到输入/输出端口PORT-A的相同,所以不实施与有效指令ACT相应的读操作。
在输入/输出端口PORT-A,与如图所示的第1和第5时钟信号CLKA同步地加上读指令RD(图134-(c)和(d))。在接收各读指令RD后与第5到第12时钟信号CLKA同步地连续输出存储在页面缓冲器5050a中的数据作为输出数据Q0-Q7(图134-(e))。即,实施页面读操作。
由于同样的原因,在输入/输出端口PORT-B,与如图所示的第1和第5时钟信号CLKB同步地加上读指令RD(图134-(f)和(g))。在接收各读指令RD后与第5到第12时钟信号CLKB同步地连续输出存储在页面缓冲器5050a中的数据作为输出数据Q0-Q7(图134-(h))。在这个方式中,如果行地址信号RA是相同的,则输入/输出端口PORT-A和PORT-B共用一个页面缓冲器5050a(或5050b)。
输入/输出端口PORT-A和PORT-B两者都在第1有效指令ACT后的8个时钟周期,接收下一个有效指令ACT(图134-(i)和(j))。因为行地址信号RA是相同的,所以只实施读操作READA(图134-(k))。不实施对于输入/输出端口PORT-B的读操作READB。通过在每4个时钟周期中加上读指令RD一次能够连续地输出读数据而没有任何间隙(即,无间隙读)。
图135表示当将有效指令ACT和不同的行地址信号RA加到输入/输出端口PORT-A和PORT-B时实施读操作的方法。与输入/输出端口PORT-A对应的读操作的定时和图134相同。
在首先接收有效指令ACT和行地址信号RA的输入/输出端口PORT-A,响应有效指令ACT实施读操作READA(图135-(a))。将从存储芯5040的所有存储单元读出的数据存储在页面缓冲器5050a中(图135-(b))。在输入/输出端口PORT-B,响应有效指令ACT对于与读操作READA的不同的存储芯5040实施读操作READB(图135-(c))。即,将由读操作READB从存储芯5040的所有存储单元读出的数据存储在页面缓冲器5050b中(图135-(d))。此后,以与结合图134描述的相同方式实施读操作。在这个方式中,当行地址信号RA相互不同时,独立的实施读操作READA和读操作READB,分别将检索数据存储在各页面缓冲器5050a和5050b中。
图136表示将有效指令ACT和相同的行地址信号RA加到输入/输出端口PORT-A和PORT-B,并实施写操作,接着加上有效指令ACT和不同的行地址信号RA,导致实施写操作的情形。
在输入/输出端口PORT-A和PORT-B,与时钟信号CLKA和CLKB的各前沿同步地加上有效指令ACT和相同的行地址信号RA。图133所示的判优电路5034认定输入/输出端口PORT-A首先接收有效指令ACT,并实施读操作READA(图136-(a)),以便将数据从存储单元传输到页面缓冲器5050a(或5050b)。
从由读操作READA选出的存储芯5040的所有存储单元读出数据,并存储在页面缓冲器5050a(或5050b)中(图136-(b))。另一方面,在输入/输出端口PORT-B,因为行地址信号RA与加到输入/输出端口PORT-A的相同,所以响应有效指令ACT不实施读操作。
此后,在输入/输出端口PORT-A,与如图所示的第1和第5时钟信号CLKA同步地加上写指令WD和列地址信号CA(图136-(c)和(d))。将与钟信号CLKA同步地连续加上的写数据Q0-Q7写入页面缓冲器5050a中(图134-(e))。即,实施页面写操作。
在输入/输出端口PORT-B,与如图所示的第1和第5时钟信号CLKB同步地加上写指令WR和列地址信号CA(图136-(f)和(g))。将与时钟信号CLKB同步地一个接一个地加上的写数据Q0-Q7写入共用的列页面缓冲器5050a中(图134-(h))。在这个方式中,如果行地址信号RA相同,则在写操作中输入/输出端口PORT-A和PORT-B共用同一个页面缓冲器5050a(或5050b)。
在首先接收有效指令ACT的输入/输出端口PORT-A,与取得写数据Q7的时钟信号CLKA的特定定时同步地实施写操作WRITEA(图136-(i))。在完成写操作WRITEA后实施与输入/输出端口PORT-B对应的写操作WRITEB(图136-(j))。
此后,在输入/输出端口PORT-A和PORT-B,与时钟信号CLKA和CLKB的各前沿同步地加上有效指令ACT和相互不同的行地址信号RA。图133所示的判优电路5034认定首先将有效指令ACT加到输入/输出端口PORT-A,并一个接着一个地实施读操作READA和READB(图136-(k)和(l))。
从由读操作READA选出的存储芯5040的所有存储单元读出数据,并存储在页面缓冲器5050a(或5050b)中(图136-(m))。进一步,从由读操作READB选出的存储芯5040的所有存储单元读出数据,并存储在另一个页面缓冲器5050b(或5050a)中(图136-(n))。
在输入/输出端口PORT-A,与如图所示的第13和第17时钟信号CLKA同步地加上读指令RD和列地址信号CA(图136-(o)和(p))。将与钟信号CLKA同步地一个接着一个加上的写数据Q0-Q7存储在页面缓冲器5050a中(图136-(q))。
类似地,在输入/输出端口PORT-B,与如图所示的第13和第17时钟信号CLKB同步地加上写指令WR和列地址信号CA(图136-(r)和(s))。将与钟信号CLKB同步地一个接着一个加上的写数据Q0-Q7写入页面缓冲器5050b中(图136-(t))。在这个方式中,当行地址信号RA不同时用页面缓冲器5050a和5050b。
在首先接收有效指令ACT和行地址信号RA的输入/输出端口PORT-A,与取得写数据Q7的时钟信号CLKA的特定定时同步地实施写操作WRITEA(图136-(u))。在完成写操作WRITEA后实施与输入/输出端口PORT-B对应的写操作WRITEB(图136-(v))。通过写操作WRITEA和WRITEB,分别将存储器在页面缓冲器5050a和5050b中的写数据Q0-Q7写入与列地址信号CA对应的存储单元,从而完成写操作。
图137表示将有效指令ACT和相同的行地址信号RA加到输入/输出端口PORT-A和PORT-B,实施写操作,接着加上有效指令ACT和相同的行地址信号RA,导致在输入/输出端口PORT-A实施读操作和在输入/输出端口PORT-B实施写操作的情形。第1写操作的定时与图137相同,我们将省略对它的描述。
在输入/输出端口PORT-A和PORT-B,与图所示的第12时钟信号CLKA和CLKB的各前沿同步地提供有效指令ACT和相同的行地址信号RA(图137-(a)和(b))。图133所示的判优电路5034认定首先将有效指令ACT加到输入/输出端口PORT-A,并实施读操作READA(图137-(c))。从由读操作READA选出的存储芯5040的所有存储单元读出数据,并存储在页面缓冲器5050a(或5050b)中(图137-(d))。在输入/输出端口PORT-B,因为行地址信号RA与加到输入/输出端口PORT-A的信号相同,所以不实施与有效指令ACT对应的写操作。
此后,在输入/输出端口PORT-A,与如图所示的第13和第17时钟信号CLKA同步地加上读指令RD(图137-(e)和(f))。在接收各读指令RD后与如图所示的第17到第24时钟信号CLKA同步地连续输出存储在页面缓冲器5050a中的数据(图137-(g))。
在输入/输出端口PORT-B,与如图所示的第13和第17时钟信号CLKB同步地加上写指令WR(图137-(h)和(i))。将与钟信号CLKB同步地连续加上的写数据Q0-Q7存储在共用的页面缓冲器5050a中(图137-(j))。
此后,在输入/输出端口PORT-B,与取得写数据Q7的时钟信号CLKB的特定定时同步地实施写操作WRITEB(图137-(k))。
图138表示将有效指令ACT和相同的行地址信号RA加到输入/输出端口PORT-A和PORT-B,实施写操作和读操作,接着加上有效指令ACT和不同的行地址信号RA,导致实施写操作和读操作的情形。
在输入/输出端口PORT-A和PORT-B,与时钟信号CLKA和CLKB的前沿同步地提供有效指令ACT和相同的行地址信号RA(图138-(a)和(b))。判优电路5034确定首先将有效指令ACT加到输入/输出端口PORT-A,并实施读操作READA(图138-(c))。从由读操作READA选出的存储芯5040的所有存储单元读出数据,并将读出数据存储在页面缓冲器5050a(或5050b)中(图137-(d))。另一方面,在输入/输出端口PORT-B,行地址信号RA与加到输入/输出端口PORT-A的那些相同,所以不实施与有效指令ACT对应的读操作。
此后,在输入/输出端口PORT-A,与第1和第5时钟信号CLKA同步地加上写指令WR(图138-(e)和(f))。将与时钟信号CLKA同步地连续加上的写数据Q0-Q7存储在页面缓冲器5050a中(图137-(g))。
在输入/输出端口PORT-B,与第1和第5时钟信号CLKB同步地加上读指令RD(图138-(h)和(i))。在接收各读指令RD后与第5到第12时钟信号CLKB的定时同步地一个接着一个地输出存储在页面缓冲器5050a中的数据作为输出数据Q0-Q7(图138-(j))。在输入/输出端口PORT-A,与取得写数据Q7的时钟信号CLKA的特定定时同步地实施写操作WRITEA(图138-(k))。
然后,在输入/输出端口PORT-A和PORT-B,与时钟信号CLKA和CLKB的前沿同步地提供有效指令ACT和相互不同的行地址信号RA(图138-(l)和(m))。判优电路5034认定首先将有效指令ACT加到输入/输出端口PORT-A,并连续实施读操作READA和READB(图138-(n)和(o))。从由读操作READA选出的存储芯5040的所有存储单元读出数据,并将读出的数据存储在页面缓冲器5050a(或5050b)中的一个(图138-(p))。进一步,从由读操作READB选出的存储芯5040的所有存储单元读出数据,并将读出的数据存储在页面缓冲器5050b(或5050a)中的另一个(图138-(q))。
在输入/输出端口PORT-A,与时钟信号CLKA的第13和第17定时同步地加上写指令WR(图138-(r)和(s))。将与时钟信号CLKA同步地一个接着一个加上的写数据Q0-Q7写入页面缓冲器5050a中(图138-(t))。
类似地,在输入/输出端口PORT-B,与时钟信号CLKA的第13和第17定时同步地加上写指令WR(图138-(u)和(v))。将与时钟信号CLKB同步地一个接着一个加上的写数据Q0-Q7写入页面缓冲器5050b中(图138-(w))。
本实施例能够提供与上述的第3实施例相同的优点。进一步,在本实施例中,用作对于存储芯5040的所有存储单元的暂时数据存储的页面缓冲器5050a和5050b位于数据锁存器5028和存储芯5040之间。这使多端口存储器M能够实施页面读操作和页面写操作。
当将相同的行地址信号RA加到输入/输出端口PORT-A和PORT-B时,共用同一个页面缓冲器5050a。这防止写入存储单元的数据通过覆盖操作被破坏。
当将相同的行地址信号RA加到输入/输出端口PORT-A和PORT-B时,响应一个端口只实施读操作。因此,与对于两个端口实施的各读操作的情形比较能够减少操作时的功率消耗。使用页面缓冲器5050a和5050b甚至当实施页面操作时也消除了对于控制多端口存储器M,检测多端口存储器M的忙碌状态的控制器的需要。因此,控制器等的控制(藉助硬件和软件)变得较容易了。
图139表示根据多端口存储器的第5实施例的多端口存储器的操作和控制本发明的多端口存储器的方法。用相同的数字标记与第4实施例相同的部件,并省略对它们的详细描述。
这个实施例具有用于通常的脉冲串操作的读指令RD和写指令WR两者与用于页面操作的读指令PRD和写指令PWR两者。多端口存储器M的电路配置基本上与第4实施例相同。
在图139中,将有效指令ACT和相同的行地址信号RA加到输入/输出端口PORT-A和PORT-B(图139-(a)和(b))。与时钟信号CLKA和CLKB的下一个周期同步地,加上读指令PRD(图139-(c)和(d)),实施页面读操作(图139-(e))。页面读操作的定时与图134相同,并省略对它的详细描述。
此后,将有效指令ACT和相同的行地址信号RA加到输入/输出端口PORT-A和PORT-B(图139-(f)和(g))。与时钟信号CLKA和CLKB的下一个周期同步地,加上读指令RD(图139-(h)和(i))。对于各输入/输出端口PORT-A和PORT-B连续实施读操作READA和READB(图139-(j)和(k))。即完成通常的读操作(即脉冲串读操作)。
这个本实施例能够提供与上述的第4实施例相同的优点。因为这个实施例准备了用于页面操作的读指令PRD和PWR以及用于通常操作的读指令RD和WR,所以多端口存储器M响应所加的指令信号不仅能够实施页面操作而且能够实施通常操作。
上述实施例已经指向一个将本发明用于多路复用地址信号的地址多路复用型的多端口存储器的例子。但是本发明不限于这些特定的实施例。例如,也可以将本发明用于同时接收地址信号的地址非多路复用型的多端口存储器。
上述实施例已经指向一个将本发明用于具有两个输入/输出端口PORT-A和PORT-B的多端口存储器M的例子。但是本发明不限于这些实施例。例如,也可以将本发明用于具有4个输入/输出端口的多端口存储器。在这个情形中,将所加的有效指令ACT的间隔(按照定时说明)设置得等于或大于存储芯的操作周期的4倍。
在上述实施例中,对将本发明用于具有同步DRAM存储芯的多端口存储器的例子进行了描述。但是本发明不限于这种形式的实施例。例如,也可以将本发明用于具有同步SRAM存储芯的多端口存储器。
进一步,在上述的多端口存储器中,可以将对于存储芯操作的要求作为指令信号输入。将这样的指令信号与时钟信号同步地加到一个输入/输出端口的指令端子。可以将该指令信号分成一个用于激活存储块的一个特定存储区域的有效指令和一个指示在这个存储区域中或者实施读操作或者实施写操作的动作指令,并且可以连续地加上这些指令。由于同样的原因,也可以在时分基础上一个接着一个地加上地址信号。通过在加上有效指令后的预定时钟周期上加上动作指令将读操作周期和写操作周期固定在恒定的周期上。
如果存储块的存储单元由DRAM单元构成则需要刷新操作。对于由加在任何一个输入/输出端口上的地址信号指示的刷新地址实施刷新操作。这个配置能够使在多端口存储器中的控制电路的尺寸减到最小,从而能够减小芯片尺寸。
在读操作和写操作后自动地实施将与存储单元连接的位线复位到预定电位的预充电操作。这使从开始各操作的预定时间周期内完成读操作和写操作成为可能。即,能够将读周期时间和写周期时间固定为恒定的。
而且,可以为每个输入/输出端口提供忙碌端子以便输出忙碌信号。当加到一个输入/输出端口的地址信号与加到另一个输入/输出端口的地址信号相同时和当对于后一个输入/输出端口执行存储操作时,输出忙碌信号。用这种配置,与多端口存储器连接的控制器很容易知道还没有实施所要求的操作。
进一步,本发明不限于这些实施例,而且可以作出不同的变化和修改而没有偏离本发明的范围。
例如,我们已经参考为了同步只用一个前沿或一个后沿的配置描述了本发明的第1到第5方面。然而对于那些熟练的技术人员来说显然能够容易地改变上述任何一个配置,使它与为了同步用前沿和后沿两者的DDR(双数据速率)操作匹配。我们有意使这样一个明显的改变处在本发明的范围内。
本申请基于向日本专利局提出的日本优先权专利申请2000年12月20日递交的No.2000-387891,2001年2月9日递交的No.2001-034361,2001年2月14日递交的No.2000-037547,2000年12月27日递交的No.2000-398893和2000年12月27日递交的No.2000-399052,这里我们将这些专利申请的全部内容作为参考。